












































































































































































































































































































































































































Author: Максфилд К.
Tags: блоки обработки данных процессоры радиоаппаратура (радиоэлектронная аппаратура) микросхемы программирование проектирование
ISBN: 978-5-94120-147-1
Year: 2007




Text
СЕРИЯ
/ОАЭ К А ПРОГРАММИРУЕМЫЕ СИСТЕМЫ
www. dodeca ru
—Mentor
Г^З
Архитектура, средства и методы
EMBEDDED TECHNOLOGY
SERIES
The Design Warrior’s
Guide to FPGA’s
Clive «Мах» Maxfield
Newnes
'**3^ An imprint of Elsevier Science
СЕРИЯ
ПРОГРАММИРУЕМЫЕ СИСТЕМЫ
Клайв Максфилд
Проектирование на ПЛИС
Архитектура, средства
и методы
Курс молодого бойца
Перевод с английского
А Москва
~ т_ . Издательский дом «Додэка-ХХ1»
ЭКА 2007
УДК 004.312
ББК 32.844-1
М17
Максфилд К.
М17 Проектирование на ПЛИС. Курс молодого бойца. — М.: Издательский дом
«Додэка-ХХ1», 2007. — 408 с.: илл. (Серия «Программируемые системы»).
ISBN 978-5-94120-147-1
Эта книга является не только пособием по проектированию устройств на основе ПЛИС (FPGA),
но и содержит поистине энциклопедические сведения. Кроме архитектурных особенностей послед-
них поколений микросхем ПЛИС, здесь рассматриваются различные методы и средства проектирова-
ния. Проводится обзор и анализ схемотехнических подходов к проектированию (которые всё ещё на-
ходят применение), HDL-моделирования и логического синтеза, а так же современных технологий
проектирования, основанных на использовании языка C/C++. Рассматриваются специализирован-
ные вопросы, такие как совместное проектирование программно-аппаратных систем и разработка
систем цифровой обработки сигналов (ЦОС). Обсуждаются и технические новинки, например про-
граммируемые пользователем массивы узлов (FPNA).
Написанная в непринуждённом, увлекательном стиле, книга будет хорошим пособием и для на-
чинающих, и для опытных инженеров, разрабатывающих устройства на основе ПЛИС. Книга послу-
жит весьма ценным источником информации и для специалистов, разрабатывающих устройства на
основе заказных микросхем и переходящих на использование ПЛИС. А также, несомненно, привле-
чет внимание широкого круга читателей, в том числе технических аналитиков, студентов и продавцов
технической продукции.
УДК 004.312
ББК 32.844-1
Максфилд Клайв
Проектирование на ПЛИС. Архитектура, средства и методы
Курс молодого бойца
Переводчик В. М. Барская
Главный редактор В. М. Халикеев
Ответственный редактор И. А. Корабельникова
Научный редактор В. Н. Немцев
Технический редактор А. И. Михалченков
График Л. Н. Клочков, И. С. Каинова
Верстальщик И. С. Каинова
Подписано в печать 15.03.2007. Формат 70x100/16. Бумага офсетная № 1.
Гарнитура «NewtonC». Печать офсетная. Объем 25,5 п.л. Уел. печ. л. 33,1 + вкл. 0,125
Тираж 2000 экз. Код FPGA. Заказ № 625.
Издательский дом «Додэка-ХХ1»
ОКП 95 3000
105318 Москва, а/я 70.
Тел./факс: (495) 366-24-29, 366-09-22
E-mail: boor@dodccfaru; red@dodeca.ru
Отпечатано с готовых диапозитивов в ОАО «Московская типография № 6»
115088 Москва, Южнопортовая ул., 24
Настоящее издание «Проектирование на ПЛИС: архитектура, средства и методы. Курс молодого бойца»
Клайва Максфилда выполнено по договору с Elsevier Inc., 200 Wheeler Road, 6th Floor, Burlington, MA01803,
USA.
ISBN 978-5-94120-147-1 (pyc.)
ISBN 0-7506-7604-3 (англ.)
© Издательский дом «Додэка-XXI», 2007
® Серия «Программируемые системы»
ОГЛАВЛЕНИЕ
Благодарности.......................................................................15
Предисловие ........................................................................16
Глава 1. Введение...................................................................18
Что такое ПЛИС...................................................................18
Чем интересны ПЛИС...............................................................18
Как можно использовать ПЛИС......................................................20
Что есть в этой книге............................................................21
Чего нет в этой книге............................................................22
Кому предназначается эта книга...................................................23
Глава!. Основные понятия ...........................................................24
Особенность микросхем ПЛИС ......................................................24
Простая программируемая функция .................................................24
Метод плавких перемычек..........................................................25
Метод наращиваемых перемычек.....................................................26
Устройства, программируемые фотошаблоном ........................................28
ППЗУ.............................................................................29
СППЗУ............................................................................30
ЭСППЗУ ..........................................................................32
Flash-технология ................................................................32
Статическое ОЗУ..................................................................33
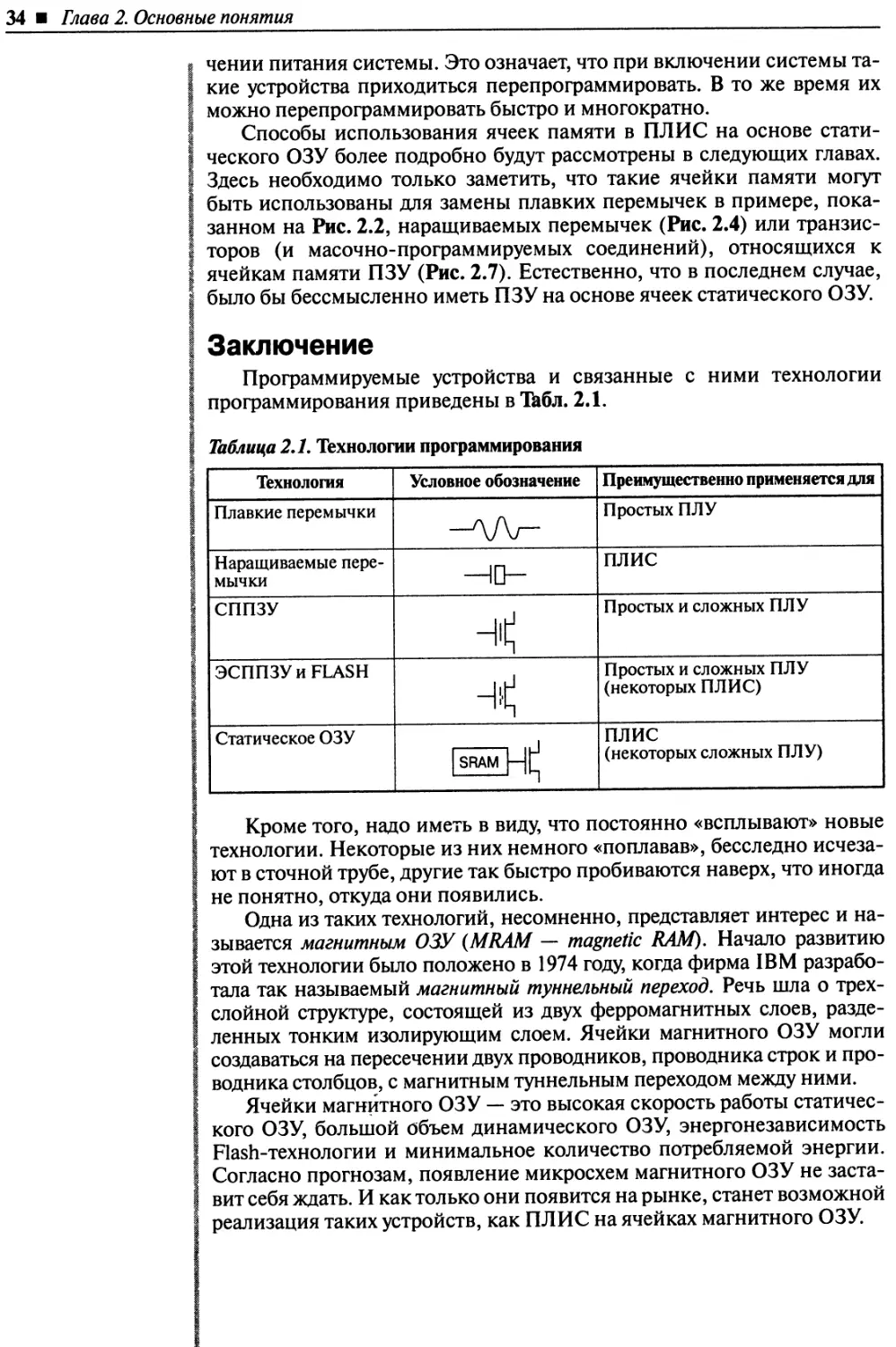
Заключение.......................................................................34
Глава 3. История развития ПЛИС......................................................35
Родственные технологии...........................................................35
Транзисторы......................................................................35
Интегральные микросхемы .........................................................36
Статическое и динамическое ОЗУ, микропроцессоры..................................37
Простые и сложные ПЛУ............................................................37
ППЗУ..........................................................................38
Программируемые логические матрицы (ПЛМ)......................................41
Программируемые матрицы PAL и GAL.............................................43
Дополнительные программируемые опции .........................................43
Сложные ПЛУ...................................................................44
Программные средства ABEL, CLJPL, PALASM, JEDEC и другие......................46
Заказные интегральные схемы — ASIC ..............................................47
Заказные интегральные микросхемы..............................................48
Микроматрица и микромозаика...................................................49
Вентильные матрицы ...........................................................49
Схемы на стандартных элементах................................................51
Структурированные специализированные микросхемы и структурированные ASIC .....52
ПЛИС.............................................................................53
ПЛ ИС-платформа...............................................................56
Гибриды вида ПЛИС — заказные интеральные схемы................................57
Как создают ПЛИС..............................................................58
6 Оглавление
Глава 4. Архитектура ПЛИС ............................................................60
Предупреждение.....................................................................60
Небольшое введение ................................................................60
Наращиваемые перемычки, статическое ОЗУ и прочее...................................61
Устройства на основе статического ОЗУ...........................................61
Защита интеллектуальной собственности в устройствах на основе статического ОЗУ...62
Устройства на основе наращиваемых перемычек.....................................63
Устройства на основе СППЗУ......................................................65
Устройства на основе ЭСППЗУ и Flash.............................................65
Гибридные устройства на ячейках Flash и статического ОЗУ........................66
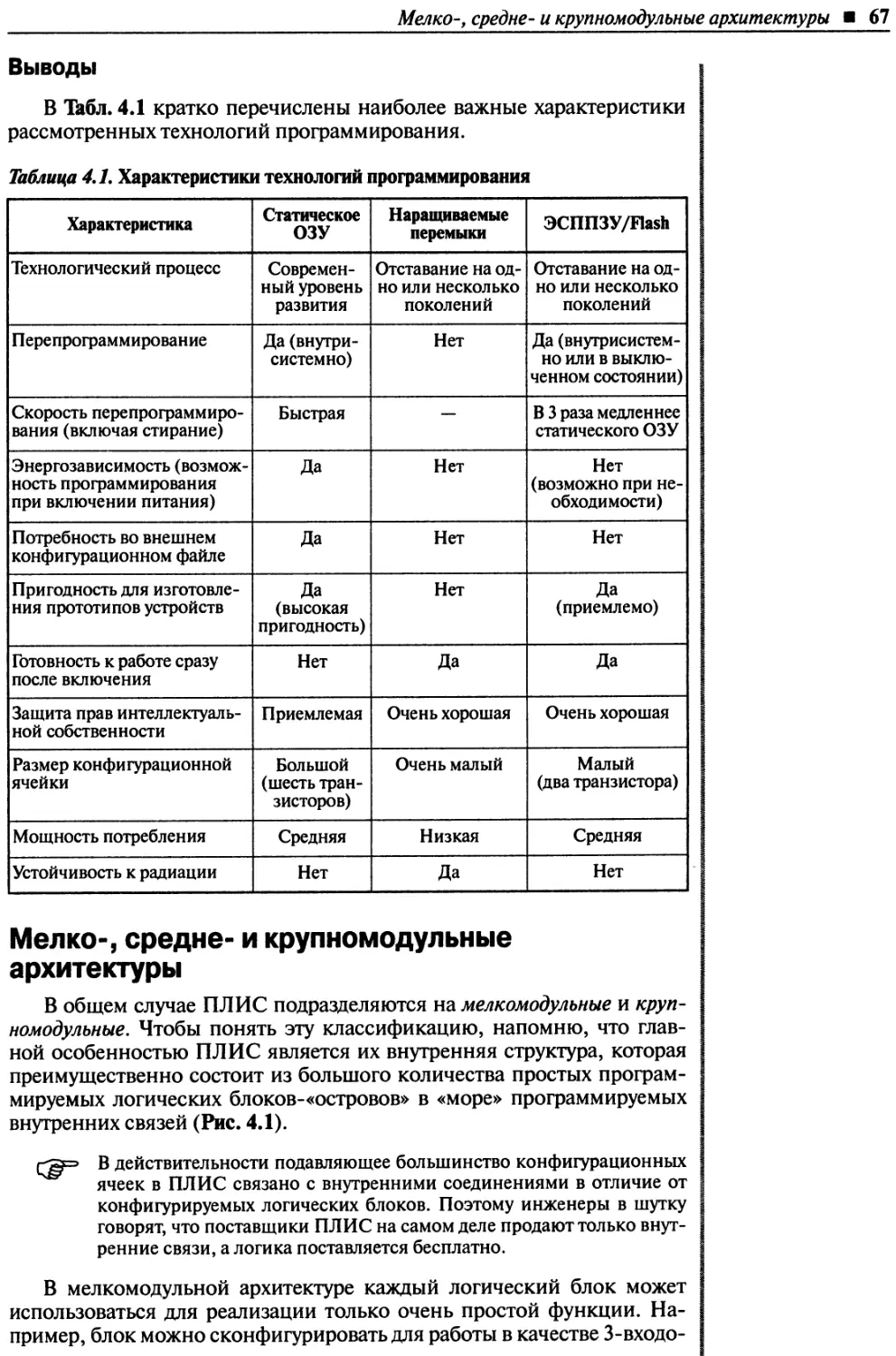
Выводы .........................................................................67
Мелко-, средне- и крупномодульные архитектуры .....................................67
Логические блоки на мультиплексорах и таблицах соответствия........................69
Устройства на основе мультиплексоров ...........................................69
Устройства на основе таблиц соответствия .......................................69
Мультиплексоры или таблицы соответствия? .......................................71
3-, 4-, 5- или 6-входовые таблицы соответствия .................................71
Таблицы соответствия, распределенное ОЗУ, сдвиговые регистры....................72
Конфигурируемые логические блоки, блоки логических массивов, секции................73
Логические ячейки фирмы Xilinx..................................................73
Логические элементы компании Altera.............................................74
Секции и логические ячейки......................................................74
Конфигурируемые логические блоки CLB и блоки логических массивов LAB............75
Распределенное ОЗУ и сдвиговые регистры.........................................76
Схемы ускоренного переноса.........................................................76
Встроенные блоки ОЗУ...............................................................77
Встроенные умножители, сумматоры, блоки умножения с накоплением и др...............77
Аппаратные и программные встроенные микропроцессорные ядра ........................79
Аппаратные микропроцессорные ядра...............................................79
Программные микропроцессорные ядра .............................................81
Дерево синхронизации и диспетчеры синхронизации ...................................81
Дерево синхронизации............................................................81
Диспетчер синхронизации.........................................................82
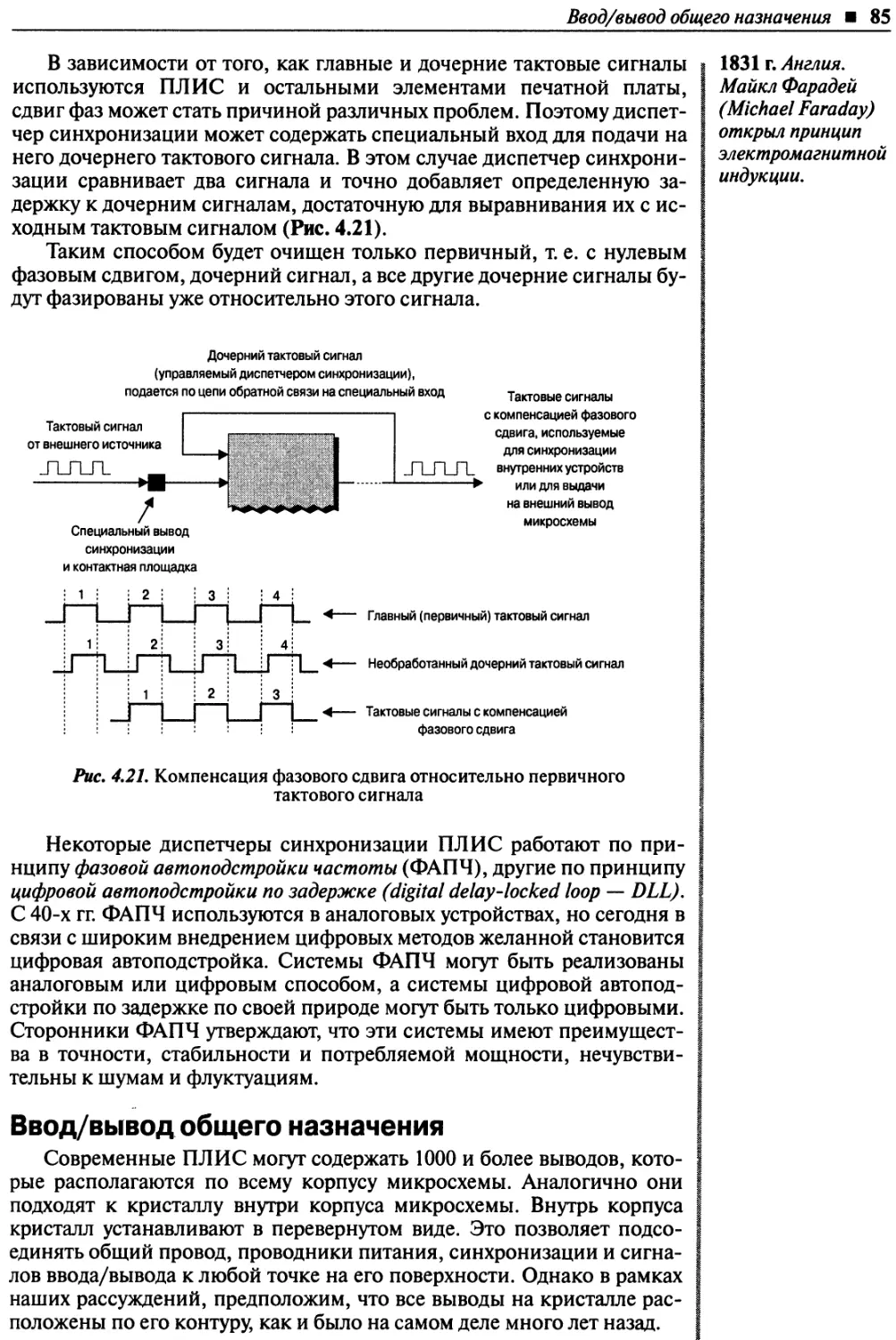
Ввод/вывод общего назначения ......................................................85
Конфигурируемые стандарты ввода/вывода .........................................86
Согласование ввода/вывода ......................................................86
Напряжение ядра и напряжение ввода/вывода.......................................87
Гигабитные приёмопередатчики.......................................................87
IP — блоки аппаратной, программной и микропрограммной интеллектуальной собственности .... 88
Системный вентиль и реальный вентиль...............................................90
Возраст ПЛИС ......................................................................92
Глава 5. Программирование или конфигурирование ПЛИС...................................93
Ласковые слова.....................................................................93
Конфигурационные файлы и прочее....................................................93
Конфигурационные ячейки............................................................93
ПЛИС на наращиваемых перемычках .. ................................................95
ПЛИС на ячейках статического ОЗУ ..................................................95
Ловкость рук и никакого мошенства...............................................96
Программирование встроенных блоков ОЗУ, распределенного ОЗУ и других ОЗУ........97
Мультипрограммирование конфигурационных цепочек.................................98
Быстрая реинициализация устройства .............................................98
Конфигурационный порт..............................................................98
Последовательная загрузка, ПЛИС в режиме ведущий ...............................99
Параллельная загрузка, ПЛИС в режиме ведущий....................................100
Параллельная загрузка, ПЛИС в режиме ведомый....................................102
Последовательная загрузка, ПЛИС в режиме ведомый................................102
Оглавление 7
JTAG-порт.........................................................................103
Встроенные процессоры.............................................................104
Глава 6. Ведущие производители.......................................................106
Введение..........................................................................106
Поставщики FPGА и FPAA............................................................106
Поставщики устройств FPNА ........................................................107
Поставщики САПР для полного цикла разработки ПЛИС ................................107
Специалисты по ПЛИС и независимые разработчики САПР...............................108
Консультанты по разработке ПЛИС и их средства проектирования .....................109
Открытые, недорогие и бесплатные системы проектирования...........................109
Глава 7. Различные подходы к проектированию систем на основе ПЛИС к заказных микросхем 111
Введение .........................................................................111
Подходы к проектированию..........................................................111
Конвейеры и уровни логики ........................................................112
Что такое конвейер.............................................................112
Конвейер в электронных системах................................................112
Логические уровни .............................................................114
Метод асинхронного проектирования.................................................115
Асинхронные элементы...........................................................115
Комбинационные петли...........................................................115
Элементы задержки..............................................................115
Анализ систем синхронизации ......................................................115
Зоны синхронизации ............................................................115
Выравнивание тактовых сигналов.................................................116
Стробирование и разрешение тактовых сигналов...................................116
ФАПЧ и схема согласования тактовых сигналов....................................116
Достоверность передачи данных через разные зоны синхронизации .................117
Регистры и защелки................................................................117
Защелки........................................................................117
Триггеры с входами установки и сброса .........................................117
Общий сброс и исходное состояние...............................................117
Разделение ресурсов или разделение по времени.....................................117
Использовать или потерять! ....................................................118
Подождите, ещё не вечер! ......................................................118
Кодирование конечных автоматов....................................................119
Методики тестирования ............................................................119
Глава 8. Схемотехническое проектирование ............................................120
Давным-давно......................................................................120
Развитие САПР электронных систем..................................................121
Начальный этап проектирования. Логическое моделирование .......................121
Завершающий этап проектирования. Компоновка....................................125
САПР электронных систем........................................................126
Простой метод схемотехнического проектирования заказных ИС........................126
Простой метод схемотехнического проектирования ПЛИС ..............................128
Сопоставление..................................................................129
Компоновка.....................................................................129
Размещение и разводка .........................................................130
Временной анализ и повторное моделирование ....................................131
Одноуровневые и иерархические принципиальные схемы ...............................132
Одноуровневые принципиальные схемы ............................................132
Иерархические принципиальные схемы.............................................133
Современная последовательность схемотехнического проектирования ПЛИС .............134
Глава 9. Проектирование на основе языков описания аппаратных средств.................136
Закат схемотехнического проектирования ...........................................136
История развития HDL-проектирования ..............................................136
8 Оглавление
Уровни абстракции...............................................................136
Простые HDL-методы проектирования заказных микросхем ...........................138
Простые HDL-методы проектирования ПЛИС..........................................140
Архитектурное проектирование ПЛИС...............................................141
Логический и физический синтез..................................................141
Средства графического ввода продолжают жить .......................................142
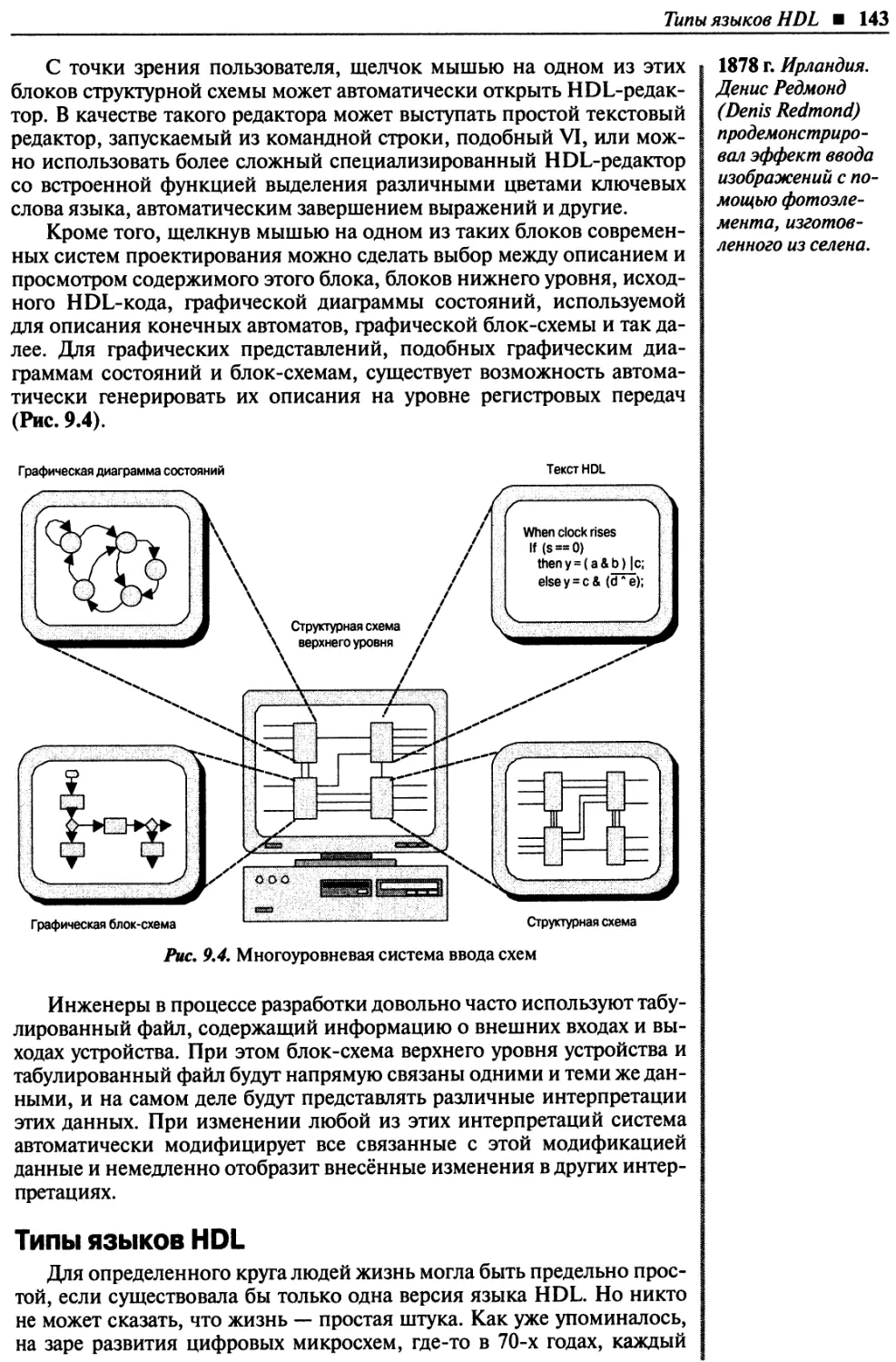
Типы языков HDL....................................................................143
Verilog HDL.....................................................................144
VHDLhVITAL......................................................................146
Проектирование с применением нескольких языков..................................148
LJDL/I .........................................................................148
Superlog и System Verilog.......................................................148
SystemC.........................................................................149
Информация к размышлению...........................................................150
Ужасы проектирования ...........................................................150
Последовательные и параллельные мультиплексоры..................................150
Остерегайтесь защёлок! .........................................................151
Рационально используйте константы ..............................................152
Распределение ресурсов..........................................................152
Последнее, но не менее важное ..................................................153
Глава 10. Виртуальное макетирование ПЛИС..............................................154
Общие сведения о виртуальном макетировании.........................................154
Применение виртуальных прототипов при проектировании заказных микросхем............154
Виртуальные прототипы на уровне вентилей. Быстрый и грубый синтез...............155
Виртуальные прототипы на уровне вентилей. Синтез, оптимизированный по быстродействию 156
Виртуальные прототипы на уровне кластеров.......................................157
Виртуальные прототипы на основе RTL ............................................158
Виртуальные прототипы ПЛИС ........................................................160
Интерактивная правка............................................................161
Поэтапные размещение и разводка.................................................162
Виртуальные прототипы ПЛИС уровня регистровых передач ..........................163
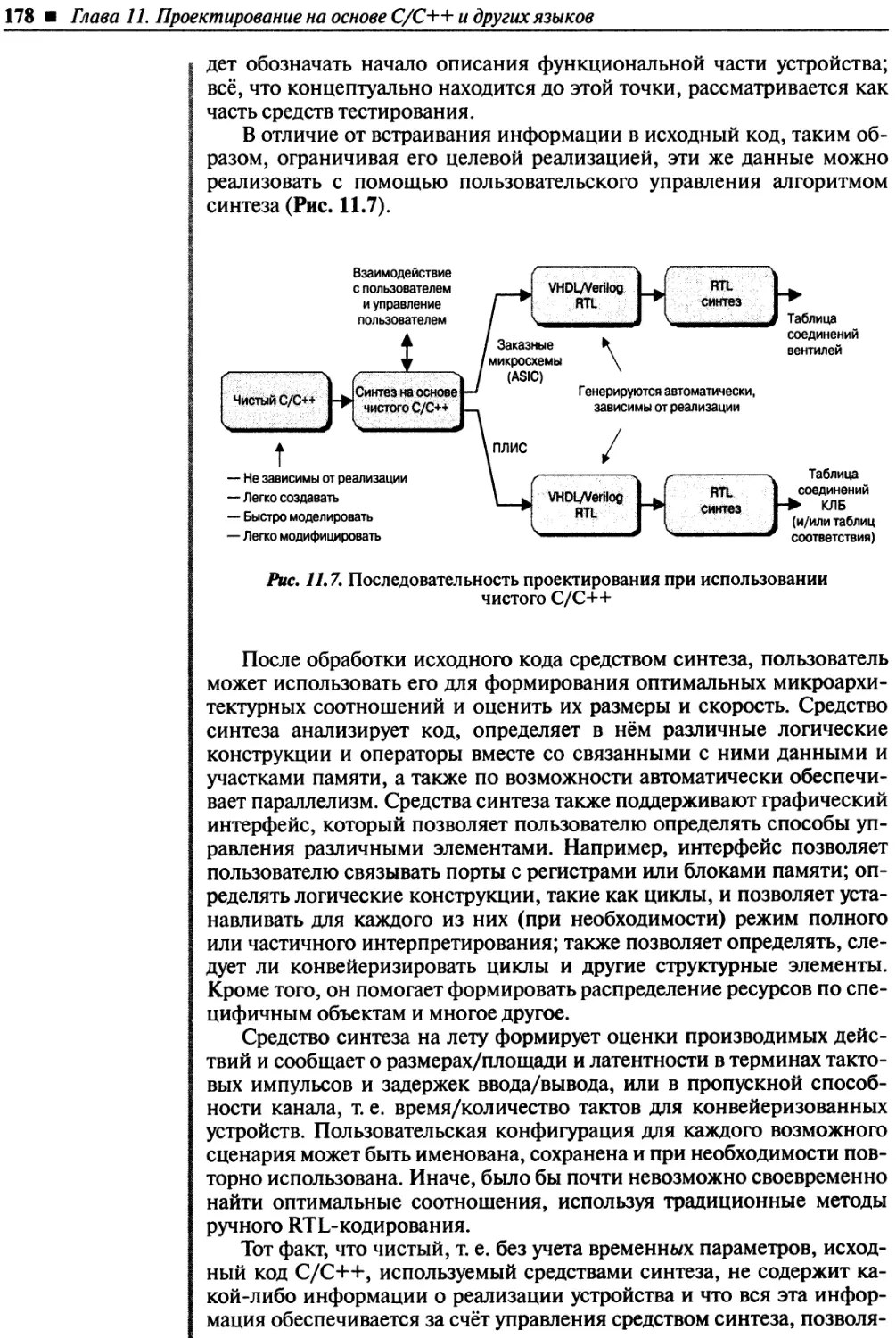
Глава 11. Проектирование на основе C/C++ и других языков..............................164
Проблемы использования HDL-языков..................................................164
С, C++ и другие версии ............................................................166
Проектирование на языке SystemC....................................................167
Что такое SystemC и его история ................................................167
SystemC 1.0.....................................................................168
SystemC 2.0.....................................................................168
Уровни абстракции...............................................................170
Альтернативные методы проектирования на основе языка SystemC....................170
Принять иль не принять..........................................................172
Проектирование на расширенном C/C++................................................173
Что такое расширенный C/C++.....................................................173
Расширенный стандарт языка C/C++................................................175
Проектирование на немодифицированном C/C++.........................................176
Уровни абстракций синтеза..........................................................179
Системы мультиязычного проектирование м тестирования ..............................180
Глава 12. Проектирование средств цифровой обработки сигналов ..........................182
Введение в ЦОС......................................................................182
Альтернативы реализации ЦОС ........................................................182
Выбрать любое устройство, но мне его не показывать...............................182
Оценки системного уровня и алгоритмическая верификация ..........................183
Работа программного обеспечения на ядре ЦСП ......................................184
Специализированное аппаратное обеспечение ЦОС....................................185
Другие встраиваемые в ПЛИС ресурсы ЦОС...........................................187
Оглавление 9
Разработка ПЛИС для ЦОС .........................................................188
Специализированные языки.........................................................188
Системы проектирования и моделирования на системном уровне.......................190
Модели с фиксированной и плавающей точкой .......................................190
Перевод из системного/алгоритмического уровня к RTL. Ручной способ...............191
Перевод из системного/алгоритмического уровня к RTL. Автоматический способ.......192
Перевод из системного/алгоритмического уровня в код C/C++ и другие...............194
Блоки интеллектуальной собственности.............................................195
Не забудьте о средствах тестирования! ...........................................196
Смешанные системы проектирования: ЦОС и VHDL/Verilog ...............................196
Глава 13. Проектирование устройств со встроенными микропроцессорами....................198
Введение ...........................................................................198
Аппаратные и программные ядра.......................................................200
Аппаратные ядра..................................................................200
Программные микропроцессорные ядра ..............................................201
Разделение устройства на аппаратные и программные компоненты........................203
Аппаратное и программное мировоззрение .............................................204
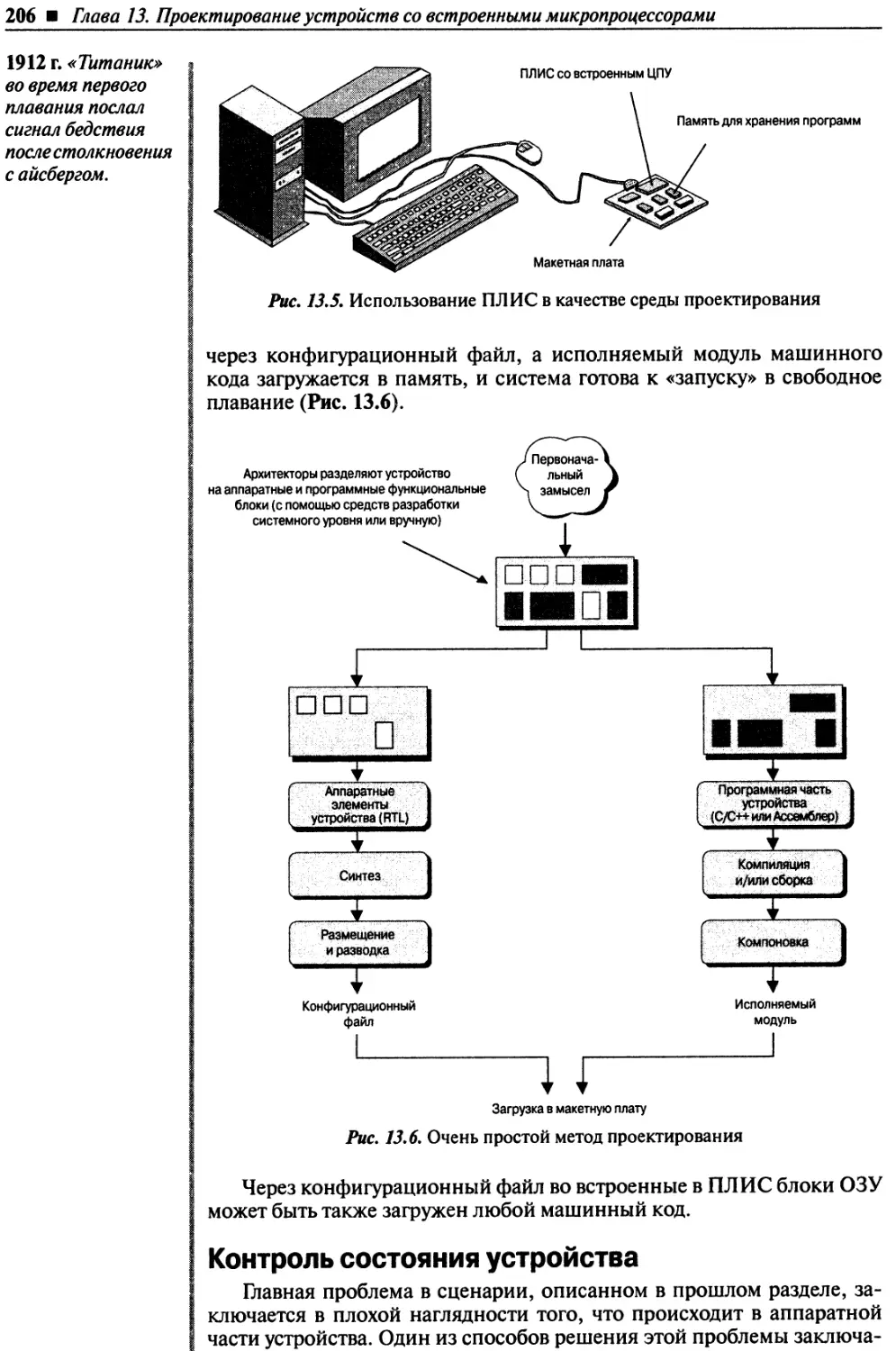
ПЛИС как среда проектирования.......................................................205
Контроль состояния устройства ......................................................206
Некоторые альтернативные методы совместной проверки ................................207
RTL-описания: VHDL или Verilog...................................................208
C/C++, SystemC и т. д............................................................208
Реальные микросхемы в аппаратных устройствах моделирования ......................209
Эмулятор машинных команд ........................................................209
Очень интересная среда проектирования ..............................................211
Глава 14. Модульное и пошаговое проектирование.........................................213
Работа с одним целым................................................................213
Разбиение на меньшие блоки..........................................................214
Модульное проектирование ........................................................215
Пошаговое проектирование ........................................................216
Отрицательные стороны............................................................216
Всегда есть выход...................................................................217
Глава 15. Быстродействующие схемы и некоторые соображения по поводу печатных плат......218
Предисловие.........................................................................218
Когда мы были молодыми .............................................................218
Время перемен ......................................................................219
FPGAXchange.........................................................................221
Другие элементы проектирования .....................................................221
Быстродействующие схемы..........................................................221
Анализ искажений сигналов........................................................222
SPICE и IBIS ....................................................................222
Стартовая мощность потребления...................................................223
Применение внутренней согласованной нагрузки.....................................223
Параллельная и последовательная передача данных .................................224
Глава 16. Отслеживание состояния внутренних точек схемы в ПЛИС.........................225
Отсутствие наглядности..............................................................225
Мультиплексирование ................................................................226
Специальные цепи отладки ...........................................................227
Виртуальный логический анализатор...................................................227
VirtualWires........................................................................228
Проблема ........................................................................229
Решение VirtualWire .............................................................230
Глава 17. Блоки интеллектуальной собственности ........................................232
Источники блоков интеллектуальной собственности.....................................232
Ручная работа ......................................................................232
10 Оглавление
Незашифрованные RTL-описания ...................................................232
Шифрованные RTL-описания........................................................233
Таблица соединений до размещения и разводки.....................................233
Таблица соединений после размещения и разводки..................................234
Генераторы ядер IP ................................................................234
Разное.............................................................................235
Глава 18. Переход от заказных микросхем к ПЛИС и наоборот.............................236
Сценарии проектирования............................................................236
Только ПЛИС ....................................................................236
От ПЛИС к ПЛИС .................................................................236
От ПЛИС к заказной микросхеме ..................................................237
От заказной микросхемы к ПЛИС...................................................239
Глава 19. Средства моделирования, синтеза, верификации и реализации ..................241
Введение ..........................................................................241
Типы моделирования.................................................................241
Событийное моделирование .......................................................241
Краткий обзор систем событийного моделирования .................................243
Логические величины и системы логических величин................................245
Моделирование с использованием разных языков....................................245
Альтернативные форматы описания задержек........................................246
Системы циклового моделирования.................................................251
Выбор оптимальной системы логического моделирования!............................251
Средства синтеза. Логический/HDL и физический синтез ..............................253
Технология логического/НВЬ-синтеза..............................................253
Технология физического синтеза..................................................253
Коррекция временных параметров, репликация и повторный синтез ..................254
Выбор оптимального средства синтеза!............................................256
Временной анализ. Статический и динамический.......................................256
Статический временной анализ....................................................256
Статистический статический временной анализ.....................................257
Динамический временной анализ ..................................................258
Общая верификация .................................................................259
Верификация блоков интеллектуальной собственности ..............................259
Среда верификации и разработка тестов...........................................261
Анализ результатов моделирования................................................262
Формальная верификация ............................................................262
Особенности формальной верификации .............................................263
Что такое формальная верификация, и чем она хороша .............................263
Термины и определения...........................................................265
Альтернативные методы описания утверждений/свойств..............................266
Статическая и динамическая формальная верификация...............................268
Обзор других языков.............................................................268
Разное.............................................................................270
Преобразование из HDL в С.......................................................270
Кодовое покрытие................................................................271
Анализ производительности..........,............................................272
Глава 20. Выбор правильного устройства ...............................................273
Такой широкий выбор................................................................273
Главное, чтобы инструмент был .....................................................273
Технология изготовления............................................................274
Основные ресурсы и корпус..........................................................275
Интерфейсы ввода/вывода общего назначения..........................................276
Встроенные умножители, блоки ОЗУ и т. д............................................276
Встроенные микропроцессорные ядра..................................................276
Возможности гигабитного ввода/вывода...............................................277
Оглавление 11
Блоки интеллектуальной собственности...............................................277
Скоростные показатели .............................................................278
На оптимистической ноте ...........................................................278
Глава 21. Гигабитные приёмопередатчики ...............................................279
Введение ..........................................................................279
Дифференциальные пары..............................................................280
Многообразие стандартов............................................................282
8- и 10-битное кодирование.........................................................283
Погружение в приёмопередатчики.....................................................284
Соединение нескольких приёмопередающих блоков......................................286
Конфигурируемые параметры..........................................................286
Определение разделителей .......................................................287
Амплитуда выходного сигнала ....................................................287
Внутрикристальные согласующие резисторы ........................................288
Внесение предыскажений .........................................................288
Компенсация.....................................................................289
Восстановление синхронизации, флуктуация и глазковые диаграммы.....................289
Восстановление синхронизации....................................................289
Флуктуация и глазковые диаграммы................................................291
Глава 22. Системы с перестраиваемой архитектурой .....................................293
Динамически реконфигурируемая логика...............................................293
Динамически реконфигурируемые внутренние соединения................................294
Системы с перестраиваемой архитектурой ............................................294
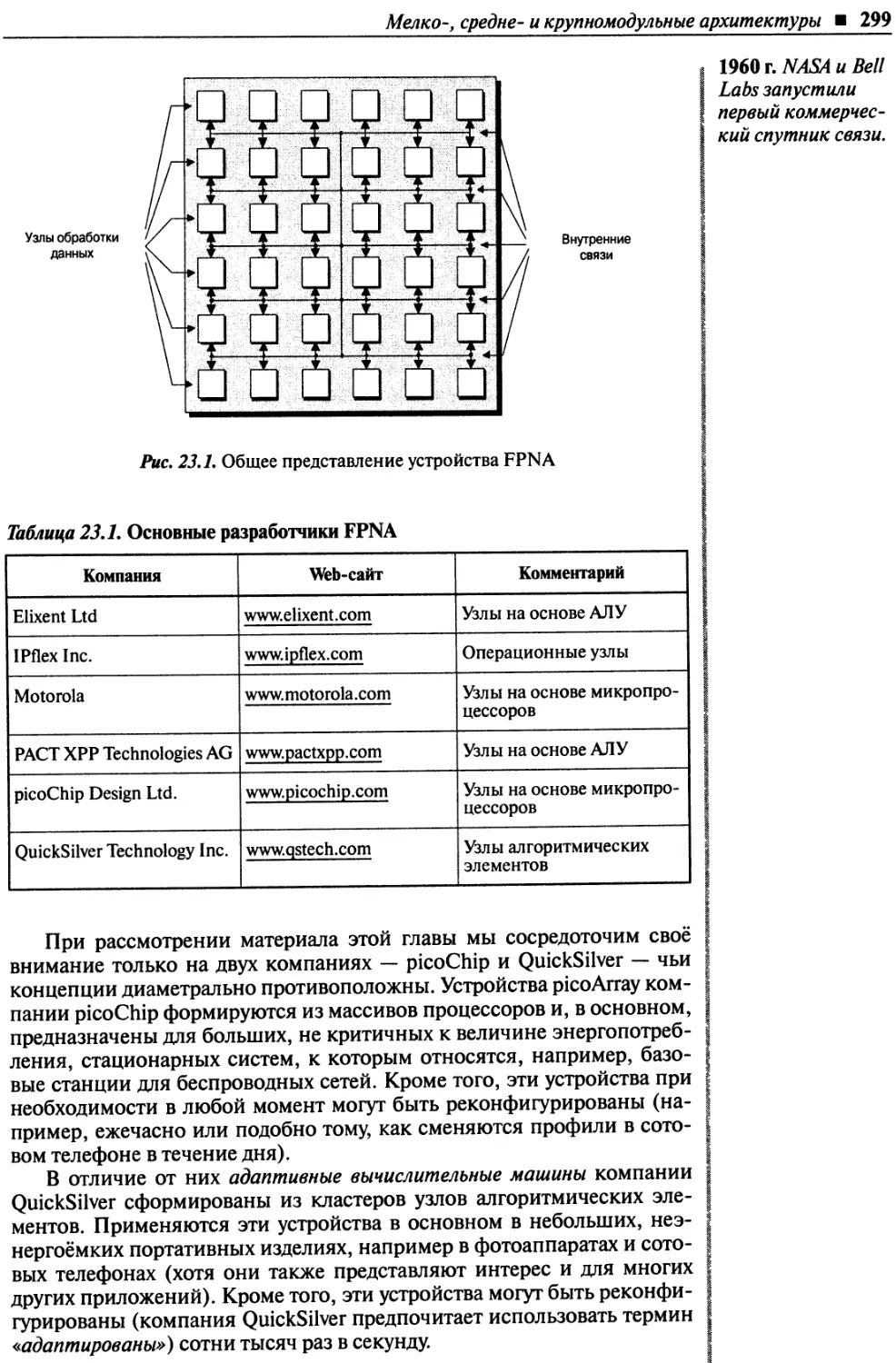
Глава 23. FPNA — программируемый пользователем массив узлов...........................298
Введение...........................................................................298
Мелко-, средне- и крупномодульные архитектуры .....................................298
Алгоритмическая оценка ............................................................300
Технология picoArray компании picoChip.............................................301
Идеальные приложения для picoArray: беспроводные базовые станции................301
Среда проектирования picoArray .................................................302
Технология адаптивных вычислительных машин компании Quicksilver....................303
Конфигурирование состава узлов..................................................305
Разновидности узлов.............................................................305
Пространственная и временная сегментация........................................306
Создание и выполнение приложений на АВМ.........................................307
Подождите, ещё не вечер.........................................................308
Это кристалл, Джим, но не такой, каким мы его знаем!...............................308
Глава 24. Средства проектирования независимых разработчиков...........................309
Введение ..........................................................................309
ParaCore Architect.................................................................309
Реализация модулей для обработки данных с плавающей точкой......................310
Реализация функций БПФ .........................................................310
Web-интерфейс ..................................................................312
Язык проектирования системы Confluence.............................................312
Простой пример..................................................................313
Но подождите, есть кое-что ещё..................................................315
Бесплатная копия ...............................................................316
У вас есть средство?...............................................................316
Глава 25. Проектирование с использованием открытого программного обеспечения..........317
Как открыть магазин по продаже устройств на основе ПЛИС без крупных вложений.......317
Базовая платформа: Linux...........................................................317
Приобретение ОС Linux...........................................................320
Среда верификации..................................................................320
Icarus Verilog..................................................................320
Dinotrace и GTKWave.............................................................321
12 Оглавление
Covered .........................................................................321
Verilator........................................................................321
Python ..........................................................................322
Формальная верификация .............................................................322
Верификация модели ..............................................................323
Автоматизированная формулировка логических выводов...............................323
В чём заключается проблема?......................................................324
Доступ к общим блокам интеллектуальной собственности................................324
OpenCores........................................................................325
OVL .............................................................................325
Средства синтеза и реализации.......................................................325
Макетная плата......................................................................325
Другие необходимые средства и утилиты...............................................326
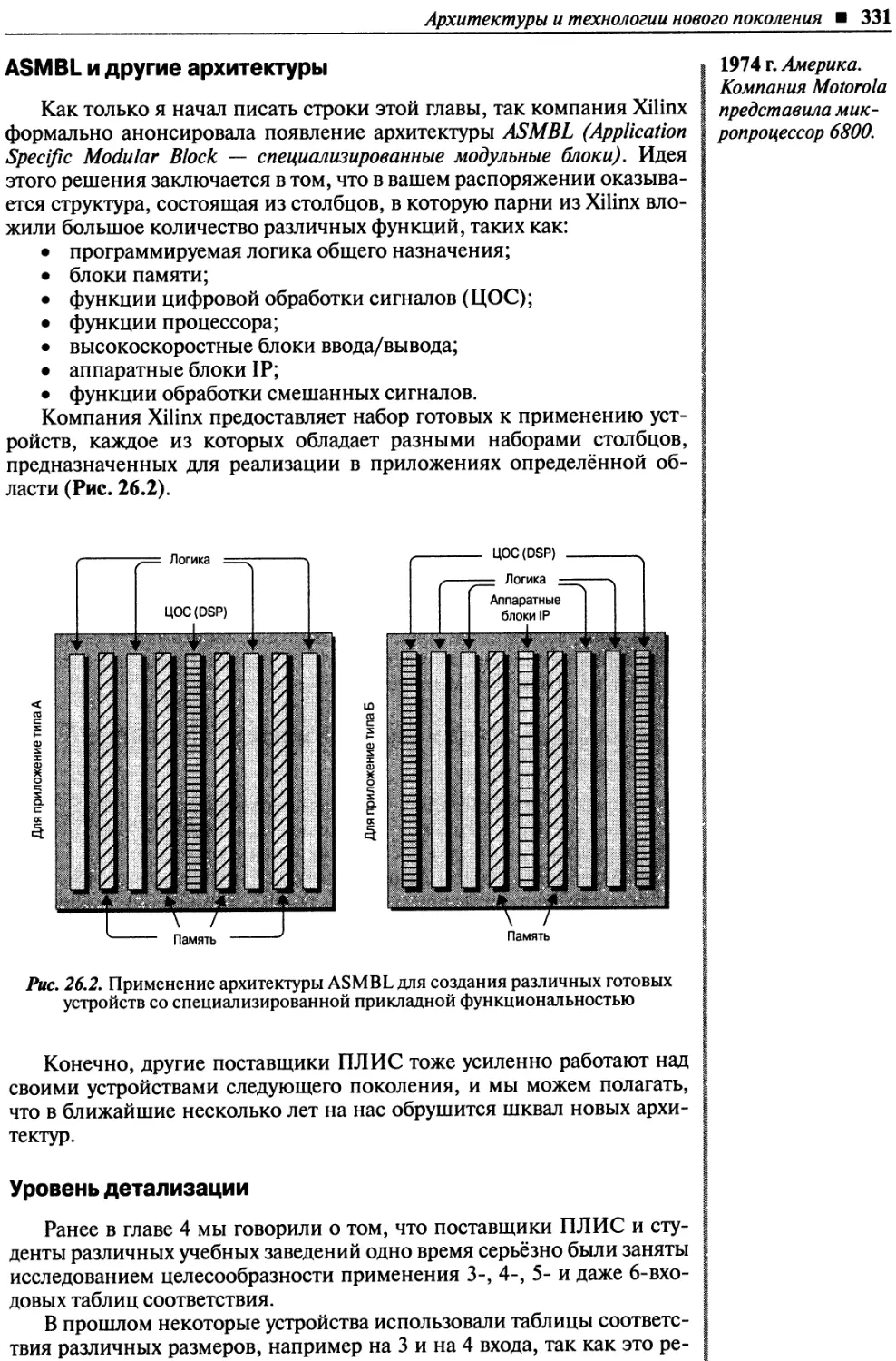
Глава 26. Перспективы развития ПЛИС ...................................................327
Ужасы проектирования................................................................327
Архитектуры и технологии нового поколения ..........................................328
Устройства с миллиардами транзисторов............................................328
Сверхбыстрые устройства ввода/вывода.............................................328
Сверхскоростное конфигурирование ................................................328
Увеличение количества аппаратных блоков интеллектуальной собственности ..........330
Аналоговые и комбинированные устройства..........................................330
ASMBL и другие архитектуры.......................................................331
Уровень детализации .............................................................331
Включение ядер ПЛИС в заказные микросхемы........................................332
Включение ядер FPNA в заказные микросхемы и ПЛИС и наоборот......................332
Устройства на основе магнитного ОЗУ..............................................332
Не забывайте о средствах проектирования ............................................332
Ожидание неожиданного ..............................................................333
Приложение А. Целостность сигнала......................................................334
Вступление..........................................................................334
Ёмкостное и индуктивное взаимодействие..............................................334
Эффекты на уровне кристалла.........................................................336
Резистивно-ёмкостные эффекты на уровне кристалла.................................336
Увеличение ёмкостной связи боковых стенок........................................337
Выбросы, вызванные перекрестными наводками ......................................338
Задержки распространения сигнала.................................................339
Воздействие нескольких проводников-«агрессоров»..................................340
И не надо забывать про эффект Миллера............................................341
Эффекты на уровне печатной платы....................................................342
Эффекты индуктивно-ёмкостного характера на уровне печатной платы ................342
Разные способы представления проблемы............................................342
Эффекты взаимной ёмкости и индуктивности ........................................342
Эффект Миллера наоборот..........................................................343
Эффекты линии передачи ..........................................................344
Как можно облегчить себе жизнь...................................................344
Приложение Б. Эффекты задержки в технологии глубокого субмикрона.......................345
Введение ......................................................................... 345
Развитие спецификаций задержки .....................................................345
Набор определений ..................................................................346
Крутизна импульса................................................................346
Входной порог срабатывания ......................................................347
Внутренние и внешние задержки....................................................347
Задержки вывод-вывод и точка-точка...............................................348
Зависимость от состояния и зависимость от крутизны ..............................349
Альтернативные модели внутренних соединений ........................................349
Оглавление 13
Модель с сосредоточенной нагрузкой..............................................349
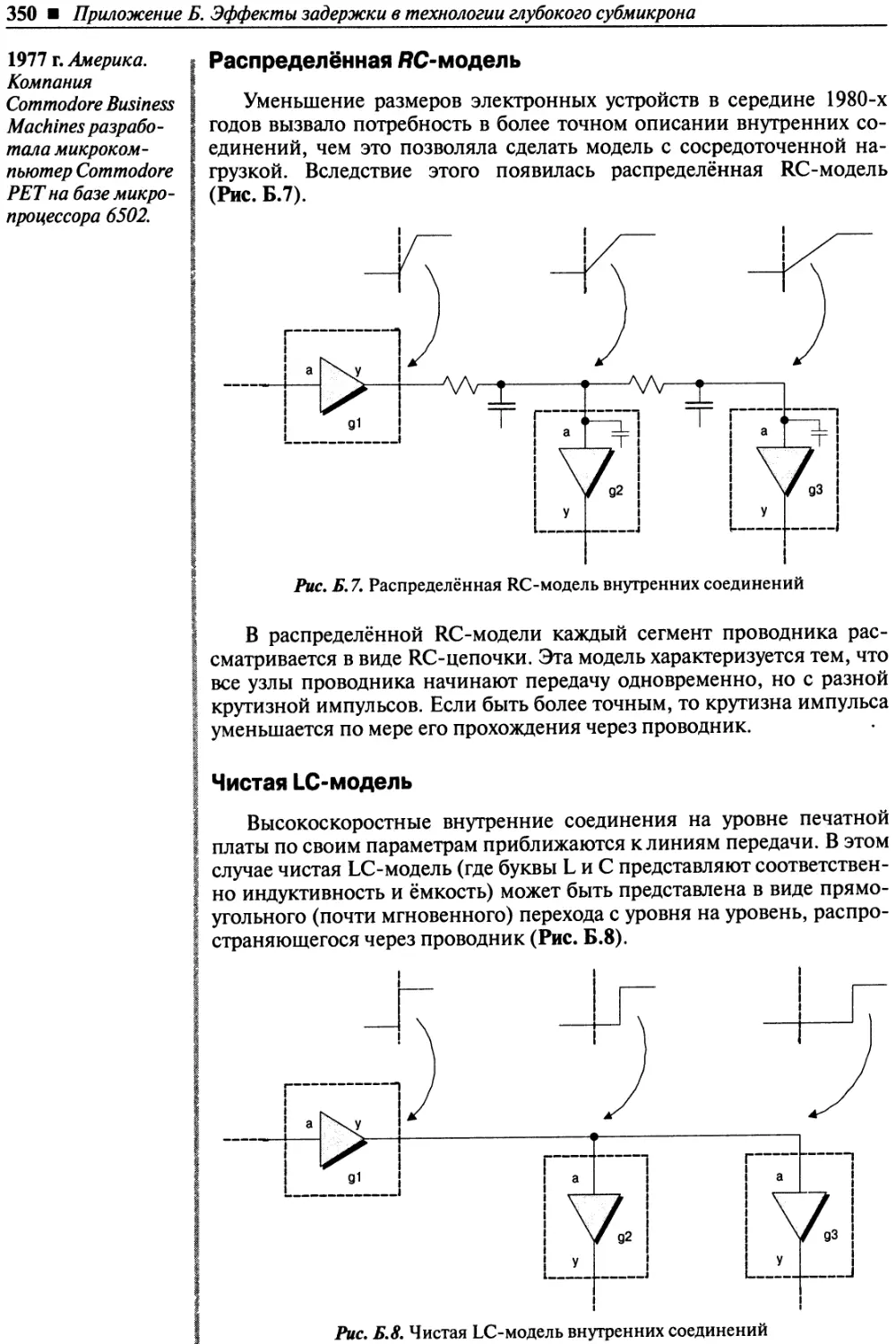
Распределённая RC-модель........................................................350
Чистая LC-модель................................................................350
RLC-модель .....................................................................351
Эффекты задержки глубокого субмикрона..............................................351
Зависимость задержки вывод-вывод от пути прохождения сигнала ...................351
Зависимость задержки вывод-вывод от порога срабатывания ........................352
Зависимость задержки вывод-вывод от крутизны фронта входного сигнала............353
Зависимость задержки вывод-вывод от состояния вентиля ..........................354
Зависимость выходной характеристики от пути прохождения сигнала.................355
Зависимость выходной характеристики от крутизны входного сигнала................356
Зависимость выходной характеристики вентиля от его состояния ...................356
Зависимость порога срабатывания вентиля от его состояния........................357
Зависимость величины паразитных элементов вентиля от его состояния .............357
Влияние изменения нескольких сигналов на задержку вывод-вывод...................358
Влияние изменения нескольких сигналов на выходную характеристику................359
Паразитное отражение............................................................360
Выводы.............................................................................360
Приложение В. Линейный сдвиговый регистр с обратной связью............................361
Ауроборос ........................................................................ 361
Реализация вида «многие к одному»..................................................361
Множество отводов..................................................................363
Реализация вида «один ко многим» ..................................................365
Инициализация LFSR.................................................................366
Очереди FIFO.......................................................................367
Модификация LFSR для формирования последовательностей длиной 2п....................368
Доступ к предыдущему значению......................................................369
Шифрование и дешифровка ...........................................................370
Контроль с помощью циклических избыточных кодов....................................371
Сжатие данных......................................................................372
Встроенное самотестирование........................................................373
Генераторы псевдослучайных последовательностей.....................................374
И последнее, но не менее важное ...................................................375
Об авторе ............................................................................376
Словарь...............................................................................377
Предметный указатель..................................................................397
Моей жене Джине, которая по-
добно радуге, украшает и услаждает
мою жизнь.
Также моим приемному сыну
Джозефу и внукам Уиллоу, Тайгу, Ки-
гану и Карму, восторг которых будет
беспределен при виде своих имен
в книге для взрослых!
Благодарности
Я давно хотел написать книгу по программируемым логическим
интегральным схемам, и был несказанно рад, когда мой издатель, Кэ-
рол Льюис из научного отдела компании Elsevier (как мне сообщили,
это самый крупный мировой англоязычный издательский дом) предо-
ставил мне такую возможность.
Была только одна небольшая проблема. Дело в том, что почти в те-
чение 10 лет я работал все дни напролет, а вечера и выходные посвя-
щал написанию книг. При этом меня посещали мысли о том, что было
бы совсем неплохо проводить хотя бы какое-то время в кругу семьи и
друзей. Поэтому я страшно обрадовался, когда представители компа-
ний Mentor Graphics и Xilinx предложили свои услуги в качестве спон-
соров и, тем самым, дали мне возможность работать над книгой днем и
иметь свободные вечера и выходные.
Дальше — больше. Будучи по профессии инженером, я ненавижу
иметь дело с книгой, которая по своему содержанию претендует быть
сугубо технической, но каким-то непостижимым образом «ухитряет-
ся» превратиться в глашатая маркетинга, что меня совершенно не ин-
тересует. Поэтому моему восторгу не было предела, когда оба моих
спонсора дали понять, что моя книга не должна быть ориентирована
ни на компанию Mentor, ни на компанию Xilinx и может содержать
любую информацию в любой форме, которая, по моему мнению, будет
уместной, причем я должен делать это без страха и экивоков.
Эта книга никогда не увидела бы свет, если бы не помощь множес-
тва людей. Число их так велико, что не представляется возможным на-
звать всех. Тем не менее, я выражаю свою глубокую признательность
всем представителям компаний Mentor и Xilinx, которые уделили мне
массу времени и предоставили кучу информации. Я также благодарен
Гэри Смиту и Дайу Надамуни (компания Gartner DataQuest) и Ричарду
Гоэрингу (компания EETimes), у которых находилось время читать
мои животрепещущие электронные письма, как правило, содержащие
просьбу ответить на «всего лишь еще один маленький вопрос...».
Не могу не упомянуть представителей компаний О-In, AccelChip,
Actel, Aldec, Altera, Altium, Axis, Cadence, Carbon, Celoxica, Elanix, In
Time, Magma, picoChip, Quick-Logic, Quicksilver, Synopsys, Synplicity,
The Math Works, Hier Design и Verisity, которые оказали мне неоцени-
мую поддержку, а также Тома Хокинса (компания Launchbird Design
Systems), который предельно ответственно относился к своим обязан-
ностям по обеспечению меня потрясающими обзорами конструкторс-
ких утилит с открытым кодом. Хочу также поблагодарить доктора Эри-
ка Богатина (компания GigaTest Labs) за любезно предоставленную мне
информацию по эффектам интеграции сигналов на печатных платах.
И, конечно, самые искренние слова благодарности в адрес моего
издателя Кэрола Льюиса за возможность включить в эту книгу Прило-
жение В («Designus Maximus Unleashed», ISBN 0-7506-9089-5) и При-
ложение С («Bebop to the Boogie», второе издание (ISBN 0-7506-7543-
8) из книг, авторами которых я являюсь.
Прошу прощения, если кого-то забыл упомянуть (непременно сооб-
щите мне об этом, и я обязательно исправлюсь в следующем издании).
Предисловие
Как автор, я беру на себя смелость утверждать, что эта книга может
быть отнесена к разряду любопытного и нестандартного произведе-
ния, написанного в жанре технической прозы. Подобное утверждение
преследует вполне определенную цель: привлечь к книге внимание
широкого круга читателей. С одной стороны, это могут быть опытные
инженеры, которые либо уже занимаются разработками систем с при-
менением ПЛИС (FPGA) — программируемых логических интеграль-
ных схем, либо планируют заняться этим в ближайшем будущем.
Именно им адресованы главы по созданию устройств на основе
ПЛИС. В них рассматриваются стадии проектирования, инструмента-
рий и методики с огромным количеством замысловатых технических
тонкостей, которые способен оценить только инженер. С другой сто-
роны, такие главы, как «Основные понятия», доступны читателям са-
мого разного уровня подготовки.
Подобная «двуликость» продиктована огромной популярностью
программируемых логических интегральных схем, особенно среди тех,
кто никогда не имел с ними дело. Первые ПЛИС содержали сравни-
тельно небольшое количество эквивалентов логических вентилей, к
тому же производительность микросхем была невысокая. Поэтому
раньше серьезные устройства создавались на базе заказных интеграль-
ные схем (ASIC — application specific integrated circuit и/или ASSP —
application specific standard parts ). Но проектирование и изготовление
заказных интегральных схем было довольно трудоемким и дорогостоя-
щим занятием, к тому же модифицировать схему, которая представля-
ла собой «идею, уже воплощенную в кремнии» практически невоз-
можно без создания новой версии интегральной схемы.
Результаты сравнительного анализа свидетельствуют о том, что
создание ПЛИС намного дешевле, чем заказных аналогов (ASIC или
ASSP). Кроме того, в ПЛИС проще вносить изменения и сроки выхо-
да этих устройств на рынок значительно сокращаются. Особого вни-
мания заслуживает и тот факт, что современные программируемые
логические интегральные схемы (ПЛИС — FPGA) содержат милли-
оны эквивалентов логических вентилей, встроенные процессоры и
современные высокоскоростные интерфейсы. Все это позволяет ис-
пользовать ПЛИС в приложениях, которые до настоящего времени
могли быть реализованы только с помощью заказных микросхем
(ASIC и ASSP).
Разработка ПЛИС со встроенными микропроцессорами требует
совместных усилий разработчиков как аппаратного, так и програм-
много обеспечения. Часто программисты плохо представляют себе
тонкости, связанные с аппаратным обеспечением устройства. Поэто-
му книга будет интересна не только разработчикам аппаратных
средств, но и той части славного братства программистов, которые
занимаются разработкой встроенных приложений для таких уст-
ройств.
Предисловие 17
Еще одна группа читателей, которая может быть частью целевой
аудитории данной книги, — это студенты колледжей и университе-
тов по специальности «Электроника», продавцы и все люди, работа-
ющие в компаниях, чья сфера деятельности связана с САПР элект-
ронных устройств и программируемыми логическими интегральны-
ми схемами; а также аналитики и редакторы соответствующих
журналов. Многие из этих читателей оценят доступность техничес-
кого материала во вступительной части и изящество стиля изложе-
ния в приложениях.
И последнее, но очень важное замечание: я стремился написать
книгу, которую мне самому было бы интересно читать. Честно говоря,
сам я редко читаю техническую литературу, так как это нудное и уто-
мительное занятие. Именно поэтому в своей книге я попытался соче-
тать сложные темы и базовые понятия, «как это появилось» и «почему
это надо делать именно так, а не иначе», с россыпью удивительных по
своей красоте мелочей. Одно из преимуществ такого изложения состо-
ит в том, что, перечитывая страницы этой книги на закате лет, когда
мой разум начнет бродить по закоулкам памяти, я буду приятно удив-
лен, и это придаст мне силы (всегда приятно знать, что впереди тебя
ждет что-то удивительное).
Клайв Максфилд (Макс), июнь 2003 — январь 2004.
ГЛАВА 1
ВВЕДЕНИЕ
Что такое ПЛИС
FPGA (field programmable gate arrays), или ПЛИС (программируемые
логические интегральные схемы), представляют собой цифровые интег-
ральные микросхемы (ИС), состоящие из программируемых логических
блоков и программируемых соединений между этими блоками. Воз-
можность конфигурировать эти устройства позволяет инженерам-раз-
работчикам решать множество различных задач.
В зависимости от способа изготовления ПЛИС могут программи-
роваться либо один раз, либо многократно. Устройства, которые могут
программироваться только один раз, называются однократно програм-
мируемыми.
Словосочетание «field programmable», содержащееся в расшифров-
ке аббревиатуры FPGA, означает, что программирование FPGA-уст-
ройств выполняется на месте, «в полевых условиях» (в отличие от уст-
ройств, внутренняя функциональность которых жестко прописана
производителем). Оно может также означать, что FPGA-устройства
(ПЛИС) конфигурируются в лабораторных условиях, или свидетельс-
твовать о том, что речь идет о возможности модификации функций ус-
тройства, встроенного в электронную систему, которая уже как-то ис-
пользуется. Если устройство может быть запрограммировано, остава-
ясь в составе системы более высокого уровня, оно называется
внутрисистемно программируемым.
Чем интересны ПЛИС
Существует множество различных типов цифровых микросхем, в
том числе и такие как «рассыпная логика» (небольшие компоненты, со-
держащие несколько простых фиксированных логических функций),
устройства памяти и микропроцессоры. В данном случае интерес
представляют программируемые логические устройства (ПЛУ), специа-
лизированные заказные интегральные микросхемы (ASIC — application
specific integrated circuit, специализированная интегральная схема и
ASSP — application specific standard parts, специализированная стандарт-
ная схема f)7 и, естественно, ПЛИС. Причем термин ПЛУ объединяет
два типа устройств: простые программируемые логические устройства
(простые ПЛУ) и сложные программируемые логические устройства
(сложные ПЛУ)* 2\
° В советской (российской) технической литературе ASIC принято называть
«заказными интегральными схемами (микросхемами)» хотя сегодня часто ASIC
называют «специализированными интегральными схемами». Часто делается
уточнение и микросхемы делят на «заказные» и «полузаказные». — Прим. ред.
2) Более подробная информация о ПЛУ, и заказных микросхемах (ASIS и
ASSP) содержится в главах 2 и 3. (Если не указано иное, примечание сделано ав-
тором.)
Чем интересны ПЛИС 19
Внутренняя архитектура ПЛУ определена производителем, таким
образом, что они могут быть сконфигурированы (перепрограммирова-
ны) «на месте» для выполнения самых различных функций. В отличие
от ПЛИС эти устройства содержат меньшее количество вентилей и ис-
пользуются для решения небольших и достаточно простых задач.
Вместе с тем, существуют заказные интегральные схемы ASIC и
ASSP, которые содержат сотни миллионов логических вентилей и могут
выполнять невероятно большие и сложные функций. В основе ASIC и
ASSP лежат одни и те же конструкторские решения, и у них одна и та же
технология производства. Оба типа устройств разрабатываются для ис-
пользования в составе специальных приложений, но при этом ASIC
разрабатываются и производятся по заказу специализированных ком-
паний, a ASSP предназначаются массовому пользователю0.
Несмотря на то, что предлагаемые пользователю заказные микро-
схемы отличаются высокой степенью интеграции, уровнем сложности
решаемых задач и производительностью, их разработка и производс-
тво довольно длительный и дорогостоящий процесс. К тому же, окон-
чательный вариант схемы «замораживается в кремнии», и для ее моди-
фикации требуется создание новой версии.
Таким образом, ПЛИС занимают промежуточное положение меж-
ду ПЛУ и заказными интегральными схемами. С одной стороны, их
функциональность может быть задана непосредственно на месте в со-
ответствии с требованиями заказчика-пользователя. С другой сторо-
ны, они могут содержать миллионы логических вентилей и, следова-
тельно, реализовывать чрезвычайно большие и сложные функции, ко-
торые изначально могли быть реализованы только с помощью
заказных интегральных схем.
Что касается стоимости ПЛИС, то она намного ниже стоимости
заказных интегральных схем (хотя окончательная версия заказной
микросхемы при массовом производстве оказывается более дешевой).
К тому же, в случае использования ПЛИС внесение изменений в уст-
ройство не вызывает особых затруднений и существенно сокращаются
сроки выхода таких устройств на рынок. Все это делает ПЛИС привле-
кательными не только для крупных разработчиков, но и для неболь-
ших новаторских конструкторских бюро, которые благодаря способ-
ности ПЛИС создать «рай в шалаше» остаются жизнеспособными.
Другими словами, «аппаратные» или «программные» идеи отдельных
инженеров или небольших групп инженеров могут быть реализованы в
виде испытательных стендов на основе ПЛИС без больших единовре-
менных затрат на проектирование или закупку дорогостоящей оснаст-
ки, необходимой для разработки заказных микросхем. Именно этим
объясняется тот факт, что в 2003 году, было начато почти 450000 разра-
боток, предусматривающих использование ПЛИС, всего 5000 разрабо-
ток с использованием заказных микросхем ASSP и только от 1500 до
4000 разработок с использованием заказных микросхем ASIC, причем
эти цифры стремительно падают из года в год.
Трудно назвать эти цифры достоверными, потому что пока нет чет-
кого представления о том, что следует называть началом разработки.
В случаях с заказными микросхемами, например, не ясно, какие
разработки надо учитывать: только те, которые были доведены до
В ПЛИС понятие
«логический вен-
тиль» приобретает
иной оттенок. Эта
тема подробно бу-
дет рассмотрена в
главе 4.
° В дальнейшем термин «заказная интегральная схема» (заказная микросхе-
ма) будет использоваться и по отношению к ASIC и по отношению к ASSP, при ус-
ловии, что в тексте не указано иное или такая интерпретация не противоречит
контексту.
20 Глава 1. Введение
Термин «связующая
логика» подразуме-
вает сравнительно
небольшое количес-
тво простых логи-
ческих элементов,
которые использу-
ются для соединения
(«склеивания»), и в
качестве интерфей-
са, между большими
логическими блока-
ми, функциями или
устройствами.
конца, или и те, которые были закрыты на полпути. Ситуация еще
больше усложняется, когда речь заходит о реконфигурируемости
ПЛИС. В качестве убедительного доказательства существующего
положения дел можно привести слова представителя поставщиков
ПЛИС, который, порекомендовав мне использовать данные анали-
тиков на Web-сайте ПЛИС производителей, заметил: «Но там при-
водятся не очень-то точные данные». А на мой вопрос о причине по-
явления таких данных, он, усмехаясь, ответил: «Главным образом
потому, что именно такие данные они получают от нас». Эти цифры
весьма относительны, поскольку зависят от того, кто проводил оп-
рос. Не удивительно, что поставщики ПЛИС стремятся занизить
число разработок с применением заказных микросхем по сравнению
с оценкой из других источников.
Как можно использовать ПЛИС
Первые ПЛИС появились в середине 80-х годов. В то время они
использовались преимущественно для создания связующей логики, для
реализации конечных автоматов средней сложности и для решения
некоторых задач обработки данных. По мере усложнения и увеличе-
ния размеров ПЛИС начинают пользоваться большим спросом. В на-
чале 90-х прошлого века самый большой объем продаж отмечался в
области сетей и телекоммуникаций, в которых предусматривались об-
работка и передача больших потоков информации. К концу 90-х спрос
на ПЛИС резко возрос в потребительской, автомобильной и произ-
водственной сферах.
ПЛИС, как правило, использовались для создания прототипов
заказных микросхем или для создания испытательных стендов, на
которых проверяется физическая реализуемость новых алгоритмов.
Однако благодаря низким затратам на производство и малым срокам
выхода на рынок эти микросхемы всё чаще используются как конеч-
ный продукт. У некоторых крупных поставщиков ПЛИС есть уст-
ройства, которые составляют прямую конкуренцию заказным мик-
росхемам.
К началу второго тысячелетия появились высокопроизводитель-
ные ПЛИС, которые содержат миллионы вентилей. Некоторые из них
содержат встроенные микропроцессорные ядра, высокоскоростные
интерфейсы ввода/вывода и другие устройства. Современные ПЛИС
находят применение практически в любой сфере, включая устройства
связи и программируемые радиостанции. ПЛИС применяют в радио-
локации, обработке изображений и в других приложениях цифровой
обработки сигналов (ЦОС). ПЛИС используют повсюду, в том числе и в
однокристальных системахх\ содержащих программные и аппаратные
модули.
Если быть более точным, в настоящее время ПЛИС заполняют че-
тыре крупных сегмента рынка: заказные интегральные схемы, цифро-
вая обработка сигналов, системы на основе встраиваемых микроконт-
роллеров и микросхемы, обеспечивающие физический уровень пере-
дачи данных. Кроме того, с появлением ПЛИС возник новый сектор
рынка — системы с перестраиваемой архитектурой, или reconfigurable
computing (RC).
° Хотя понятие «однокристальной системы» подразумевает целостную элект-
ронную систему в одном устройстве, в реальности для их функционирования тре-
буются дополнительные комплектующие. Поэтому более корректным будет на-
звание «однокристальная подсистема» или «часть однокристальной системы».
Что есть в этой книге 21
• Заказные интегральные схемы. Как уже отмечалось, современ-
ные ПЛИС используются для создания устройств такого уров-
ня, который до этого могли обеспечить только заказные микро-
схемы.
• Цифровая обработка сигналов. Высокоскоростная цифровая об-
работка сигналов традиционно производилась с помощью спе-
циально разработанных микропроцессоров, называемых цифро-
вые сигнальные процессоры (ЦСП) или digital signal processors
(DSP). Однако современные ПЛИС содержат встроенные умно-
жители, схемы арифметического переноса и большой объем
оперативной памяти внутри кристалла. Все это в сочетании с
высокой степенью параллелизма ПЛИС обеспечивает превос-
ходство ПЛИС над самыми быстрыми сигнальными процессо-
рами в 500 и более раз.
• Встраиваемые микроконтроллеры. Несложные задачи управле-
ния обычно выполняются встраиваемыми процессорами спе-
циального назначения, которые называются микроконтроллера-
ми. Эти недорогие устройства содержат встроенную программу,
память команд, таймеры, интерфейсы ввода/вывода, располо-
женные рядом с ядром на одном кристалле. Цены на ПЛИС па-
дают, к тому же, даже самые простые из них можно использо-
вать для реализации программного микропроцессорного ядра с
необходимыми функциями ввода/вывода. В результате ПЛИС
становятся все более привлекательными устройствами для реа-
лизации функций микроконтроллеров.
• Физический уровень передачи данных. ПЛИС уже давно исполь-
зуются в качестве связующей логики, выполняющей функцию
интерфейса между микросхемами, реализующими физический
уровень передачи данных, и высшими уровнями сетевых прото-
колов. Тот факт, что современные ПЛИС могут содержать мно-
жество высокоскоростных передатчиков, означает, что сетевые
и коммуникационные функции могут быть реализованы в од-
ном устройстве.
• Системы с перестраиваемой архитектурой. Можно использовать
«аппаратное ускорение» программных алгоритмов, основыва-
ясь на таких свойствах программируемых логических интег-
ральных схем (ПЛИС), как параллелизм и перенастраивае-
мость. В настоящее время различные компании заняты
созданием огромных перенастраиваемых вычислительных ма-
шин на основе ПЛИС. Такие системы могут использоваться для
выполнения широкого спектра задач — от моделирования аппа-
ратуры до криптографического анализа или создания новых ле-
карств. ,
Что есть в этой книге
Каждый, кто имеет дело с разработкой электронных устройств и
использует системы автоматизированного проектирования электрон-
ных устройств (САПР электронных устройств или EDA — electronic
design automation) знает, что и электронные компоненты, и системы
проектирования с каждым годом становятся сложнее. Не являются
исключением и ПЛИС, а также связанные с ними системы проекти-
рования.
22 Глава 1. Введение
Когда ПЛИС только заявили о себе, где-то в середине 80-х, все
было относительно просто. Первые устройства содержали всего не-
сколько тысяч логических вентилей, точнее их эквивалентов. Про-
цесс проектирования электронных компонентов в основном сводил-
ся к вводу описания электрической схемы, был понятным и доступ-
ным для освоения и использования. По сравнению с ними
современные ПЛИС представляют собой невероятно сложные уст-
ройства, а средств и методов проектирования стало больше, чем мо-
жет понадобиться пользователю.
Изложение материала в книге начинается с рассмотрения основ-
ных понятий и архитектурных изысков ПЛИС. Затем дань отдается
множеству средств, методов и этапов проектирования, которые могут
быть использованы инженерами в зависимости от поставленной цели.
При этом книга позволяет заглянуть во «внутренний мир» ПЛИС.
Кроме того, в ней рассматривается интегрирование устройств на осно-
ве ПЛИС, а также содержится информация по гигабитным интерфей-
сам, которые появились совсем недавно.
И последнее, что необходимо иметь в виду. Книга буквально на-
шпигована аббревиатурами, которые шутки ради можно назвать со-
кращениями из трех букв или акронимами. Если в разговоре со специ-
алистом кто-то начнет называть вещи не своими именами, он сразу
окажется чужаком, т. е. лицом, не принадлежащим к данному кругу
(одним из «тех», но не из «наших»). Поэтому при вводе нового акрони-
ма, или аббревиатуры, с большим количеством символов, в книге да-
ется его «расшифровка».
Чего нет в этой книге
В этой книге не отдается предпочтение какому-либо постав-
щику ПЛИС или какому-то конкретному виду ПЛИС. Объясняет-
ся это тем, что новые функциональные возможности и чипы появ-
ляются настолько быстро, что вся содержащаяся в книге информа-
ция может оказаться устаревшей прежде, чем она станет
бестселлером (иногда, прежде чем автор успеет закончить данное
высказывание).
По этой же причине в книге не приводятся названия отдельных
фирм-поставщиков САПР электронных устройств и не содержатся
ссылки на их продукты, потому что фирмы-поставщики постоянно
трансформируются, меняя при этом свои названия или названия сво-
их продуктов. Ввиду интенсивного развития данной сферы полно-
стью теряют смысл такие выражения, как: «Средство А обладает дан-
ной характеристикой, а средство Б не обладает». Поскольку не ис-
ключено, что спустя несколько месяцев средство Б будет
пользоваться повышенным спросом, а средство А будет вынуждено
покинуть рынок.
Поэтому данная книга посвящена главным образом рассмотрению
различных особенностей ПЛИС и многообразию средств и методов
проектирования. При этом читателю предоставляется возможность са-
мому выбрать поставщика микросхем, чьи ПЛИС поддерживают тре-
буемую архитектуру, и поставщика САПР, чьи инструментальные
средства обеспечат требуемую функциональность (полезные Web-
ссылки представлены в гл. 6).
Кому предназначается эта книга 23
Кому предназначается эта книга
Книга рассчитана на широкий круг читателей, в который могут
входить:
• специалисты небольших консалтинговых фирм;
• специалисты по разработке аппаратного и программного обес-
печения крупных компаний;
• разработчики заказных микросхем, только еще начинающие ра-
ботать с ПЛИС;
• разработчики устройств цифровой обработки сигналов, начина-
ющие использовать ПЛИС в своей работе;
• студенты колледжей и университетов;
• молодежь из отделов сбыта, маркетинга и других подразделений
компаний, сфера деятельности которых связана с САПР элект-
ронных устройств и ПЛИС;
• аналитики и редакторы журналов.
ГЛАВА 2
ОСНОВНЫЕ ПОНЯТИЯ
Особенность микросхем ПЛИС
Основное отличие ПЛИС (FPGA) от заказных микросхем (ASIC),
которое, по сути, является причиной их существования, заключается
в... их названии, т. е.
программируемая логическая интегральная схема
(field programmable gate array)
А теперь — шутки в сторону. Дело в том, что для программирова-
ния необходим механизм, который позволял бы конфигурировать
(программировать) подготовленный кремниевый кристалл.
Простая программируемая функция
В качестве основы для дальнейших рассуждений давайте рассмот-
рим пример очень простой программируемой функции с двумя входа-
ми а и b и одним выходом у (Рис. 2.1).
Рис. 2.1. Простая программируемая функция
На входах присутствуют инверторы (операция НЕ), следовательно,
каждый вход может быть представлен либо в прямой, т. е. истинной,
либо в измененной, т. е. инвертированной, форме.
Особого внимания заслуживает расположение предполагаемых пе-
ремычек. При отсутствии перемычек на все входы логического эле-
мента И через нагрузочные резисторы будет подана логическая 1. Это
значит, что выход у данного устройства всегда будет находиться в со-
стоянии логической 1, что делает эту схему весьма неинтересной в её
текущем состоянии. Чтобы сделать простую программируемую функ-
цию более привлекательной, необходим некий механизм, который
позволял бы устанавливать одну или несколько перемычек.
Метод плавких перемычек 25
Метод плавких перемычек
Одним из первых методов, позволявший пользователям програм-
мировать собственные устройства, был и до сих пор существует так на-
зываемый метод плавких перемычек. При использовании этого метода
устройство изготавливается со всеми возможными соединениями,
каждое из которых представляет собой плавкую перемычку (Рис. 2.2).
Рис. 2.2. Заполнение устройства ^запрограммированными
плавкими перемычками
25000 лет до н. э.
Первые бумеранги
использовались
людьми, прожива-
ющими на терри-
тории нынешней
Польши. Самому
старому австра-
лийскому бумеран-
гу «всего лишь»
13000лет.
Принцип действия этих перемычек аналогичен принципу дейс-
твия предохранителей, которые используются в бытовой технике, на-
пример в телевизорах. Если в силу непредвиденных обстоятельств те-
левизор начинает потреблять слишком большую мощность, это при-
ведет к перегоранию предохранителя. В результате произойдет
разрыв цепи (разрыв проводника), который защитит устройство от
повреждения.
Плавкие перемычки имеют микроскопические размеры, посколь-
ку при их изготовлении на кремниевом кристалле используются те же
технологии что при изготовлении транзисторов и проводников.
Когда инженер приобретает новое программируемое устройств на
основе плавких перемычек все перемычки в устройстве изначально це-
лые. Это означает, что в незапрограммированном состоянии на выходе
функции, которая рассматривается здесь в качестве примера, всегда
будет находиться уровень логического 0. Наличие уровня логического
0 хотя бы на одном из входов вентиля И приведет к установке 0 на вы-
ходе. Так, если на входе а установлен 0, на выходе вентиля И также бу-
дет 0. Аналогично, если на входе а установлена логическая 1, выход
вентиля НЕ, который будем обозначать как а9 будет установлен в 0, и,
следовательно, на выходе вентиля И будет 0. Такая же ситуация имеет
место при использовании входа Ь.
Вся суть заключается в том, что разработчики могут выборочно
удалять ненужные плавкие перемычки, подавая на входы устройства
импульсы относительно высокого напряжения и большого тока. Рас-
смотрим, например, что произойдет, если удалить плавкие перемычки
Faf и Fbt (Рис. 2.3).
Удаление этих перемычек приведет к отсоединению инвертирован-
ного входа а и прямого входа b от логического элемента И (через на-
26 Глава 2. Основные понятия
2500 лет до н. э.
В Месопотамии
изобретена пайка,
ее использовали для
соединения листов
золота.
Рис. 2.3. Плавкие перемычки после программирования
Символ «&» ис-
пользуется для
обозначения логи-
ческой функции И,
а символ « » для
обозначения функ-
ции НЕ.
грузочные резисторы на этих входах устанавливается значение логи-
ческой 1). Это обстоятельство вынуждает устройство формировать но-
вую функцию у = а & b (см. главу 3).
Такой процесс удаления плавких перемычек обычно называется
процессом программирования устройства, но может также называться
пережиганием перемычек или прожиганием устройства.
Устройства, конфигурирование которых основано на методе плав-
ких перемычек, являются однократно программируемыми устройствами
(OTP - one-time programmable), так как после пережига плавкая пере-
мычка не может быть заменена или возвращена в первоначальное со-
стояние.
Для разных ПЛИС используются разные методы программирова-
ния, но метод плавких перемычек к современным ПЛИС не применя-
ют. Поводом для его упоминания в данной книге явилось то, что он
позволяет читателю понять материал, представленный в следующем
разделе, и, кроме того, о нем достаточно подробно говориться в гл. 3,
где рассматривается история развития технологии производства
ПЛИС.
Метод наращиваемых перемычек
Данный метод прямо противоположен методу плавких перемычек.
В этом случае каждое конфигурируемое соединение имеет линию свя-
зи, называемую наращиваемой перемычкой. В ^запрограммирован-
ном состоянии наращиваемая перемычка имеет столь высокое сопро-
тивление, что её можно рассматривать как разомкнутую цепь (разрыв
проводника, Рис. 2.4, а).
В таком виде устройство находится в момент его приобретения.
Однако перемычки могут выборочно «наращиваться» (программиро-
ваться) с помощью подаваемых на входы устройства импульсов отно-
сительно высокого напряжения и большого тока. Например, если до-
бавить наращиваемые перемычки в цепь инвертированного входа а и
прямого входа Ь, устройство реализует функцию у = а & b (Рис. 2.5, а).
Наращиваемая перемычка начинает свою жизнь как микроскопи-
ческий столбец аморфного (некристаллического) кремния, связываю-
щего два металлических проводника. В таком «незапрограммирован-
Метод наращиваемых перемычек 27
НЕ
Рис, 2,4, Наращиваемые перемычки до программирования
Рис, 2,5, Наращиваемые перемычки после программирования
ном» состоянии аморфный кремний ведет себя как диэлектрик с со-
противлением, достигающем миллиарда ом (Рис. 2.6, а).
Процесс программирования отдельного элемента заключается в
выращивании связи, называемой соединением, и осуществляется пу-
тем преобразования аморфного кремния-изолятора в токопроводя-
щий поликристаллический кремний (Рис. 2.6, б).
Столбик аморфного кремния
а) До программирования
Металл
Металл
Соединение
<4— Оксид кремния —►
◄----- Подложка -----►
из поликристаллического кремния
б) После программирования
Рис, 2,6, Выращивание перемычки
28 Глава 2. Основные понятия
260 лет до н. э. Ар-
химед разработал
принцип рычага.
К сожалению, устройства, конфигурирование которых основано
на методе наращиваемых перемычек, являются однократно программи-
руемыми, так как однажды выращенная перемычка не может быть раз-
рушена или возвращена в исходное состояние.
Устройства, программируемые фотошаблоном
Прежде чем продолжить наши рассуждения, давайте совершим не-
большой экскурс в область терминологии, которой будем придержи-
ваться в дальнейшем. Электронные системы в общем и компьютеры в
частности используют два типа запоминающих устройств: постоянное
запоминающее устройство (ПЗУ) и оперативное запоминающее уст-
ройство (ОЗУ).
ПЗУ называют энергонезависимыми устройствами, так как хранимая
в них информация не разрушается при отключении питания системы.
Другие компоненты системы могут считывать информацию из уст-
ройств ПЗУ, но не могут записывать в них новые данные. В отличие от
ПЗУ, в ОЗУ данные могут как записываться, так и считываться. Такие
устройства являются энергозависимыми, так как при отключении пита-
ния вся информация, хранимая в ОЗУ, будет потеряна.
Типовые микросхемы ПЗУ также называются программируемыми
фотошаблоном, или масочно-программируемыми, поскольку любые со-
держащиеся в них данные жестко прошиваются в процессе производс-
тва с помощью фотошаблона^. Фотошаблоны используются для созда-
ния транзисторов и соединяющих их на кремниевом кристалле метал-
лических проводников, которые также называют слоями металлизации.
Рассмотрим, например, транзисторную ячейку ПЗУ, которая может
хранить один битР данных (Рис. 2.7). Стандартное устройство ПЗУ со-
стоит из некоторого количества строк (адреса) и столбцов (данные), ко-
торые вместе образуют массив данных. К каждому столбцу подключен
один нагрузочный резистор, который позволяет поддерживать на выво-
де столбца уровень логической 1, а в каждом пересечении строки и
столбца присутствует транзистор и, при необходимости, перемычка.
Наличие/отсутствие перемычки задается фотошаблоном.
Большинство микросхем ПЗУ изначально конфигурируют для
массового пользователя. Когда необходимо сконфигурировать уст-
ройство в соответствии с особенными требованиями используется ин-
дивидуально изготовленный фотошаблон, с помощью которого опре-
деляются ячейки с перемычками и ячейки без перемычек.
Давайте проанализируем ситуацию, которая возникает при подаче
активного сигнала на проводник строк, т. е. когда эта строка пытается
перевести все подключенные к ней транзисторы в открытое состояние.
В случае, когда ячейка содержит запрограммированное по фотошабло-
ну соединение, активирующийся транзистор этой ячейки будет соеди-
нять проводник столбца с уровнем логического 0, устанавливая, таким
образом, значение выхода в 0. И наоборот: если в ячейке нет запрог-
раммированного соединения, транзистор не будет привносить какого-
либо действия и через нагрузочный резистор, подсоединённый к стол-
бцу, будет поддерживать на выходе микросхемы уровень логической 1.
° Концепция фотошаблона и способы создания кремниевых кристаллов бо-
лее детально описаны в книге «Bebop to the Boolean Boogie (An Unconventional
Guide to Electronics)», ISBN 0-7506-7543-8.
2) Термин «бит», что значит двоичная цифра, «изобрел» в 1940 году Джон Таки
(John Wilder Tukey), американский химик и специалист в области топологии и ста-
тистики.
ППЗУ 29
Программируемое
фотошаблоном
соединение
Логический О
Проводник столбца
(данные)
Рис. 2.7. Транзисторная ячейка ПЗУ, программируемая фотошаблоном
ППЗУ
Недостаток масочно-программируемых устройств состоит в том,
что их производство является весьма дорогостоящим удовольствием,
если только не предполагается их производство в очень больших коли-
чествах. Кроме того, они весьма редко используются при разработке
аппаратуры, когда возникает необходимость часто менять состав ком-
понентов.
Первые программируемые постоянные запоминающие устройства
(ППЗУ) были разработаны в 1970 году фирмой Harris Semiconductor.
Для создания этих устройств использовался метод плавких перемычек
из нихрома.
В качестве примера рассмотрим упрощенную схему ячейки ППЗУ
на основе транзистора с плавкой перемычкой (Рис. 2.8).
Рис. 2.8. Ячейка ППЗУ на основе транзистора с плавкой перемычкой
Микросхема, поступившая от изготовителя, находится в незапрог-
раммированном состоянии, но при этом она содержит все предусмот-
ренные конструкцией плавкие перемычки. В этом случае при переводе
строки в активное состояние будут включаться все транзисторы, под-
30 Глава 2. Основные понятия
15 год до н. э. В Ки-
тае изобрели ре-
менную передачу.
соединенные к этой строке, вынуждая, таким образом, все столбцы
понижать уровень выходного напряжения до логического 0 через соот-
ветствующие им транзисторы. Инженер-разработчик может по своему
усмотрению выборочно удалять ненужные плавкие перемычки, пода-
вая на вход устройства импульсы относительно высокого напряжения
и большого тока. При удалении плавкой перемычки на выходе ячейки
будет формироваться уровень логической 1.
Эти микросхемы изначально предназначались для использования
в качестве устройств памяти, т. е. для хранения компьютерных про-
грамм и значений постоянных величин (отсюда аббревиатура ПЗУ).
Однако разработчики нашли им полезное применение при реализации
простых логических функций, таких как таблицы соответствия и ко-
нечные автоматы. Тот факт, что микросхемы ППЗУ имели низкую сто-
имость, позволяет предположить, что эти устройства могли использо-
ваться для устранения неисправностей или тестирования новых разра-
боток посредством простого прожига новой микросхемы и помещения
её в систему.
Со временем появились различные ПЛУ общего назначения, осно-
ванные на методах прожигаемых и наращиваемых перемычек (см. гл. 3).
СППЗУ
Как уже отмечалось, устройства на основе прожигаемых или нара-
щиваемых перемычек могут быть запрограммированы только один
раз, однократно. Поэтому внесение в систему каких-либо изменений
после пережигания, или наращивания, перемычки требует больших
затрат времени. В некоторых случаях можно увеличить модифицируе-
мость устройства путем прожига или наращивания ещё не модифици-
рованных исходных перемычек, но возможность воспользоваться
этим свойством выпадает крайне редко. В связи с этим возникла идея
создания таких устройств, которые можно было бы программировать,
стирать и вновь программировать, т. е. перепрограммировать.
Одним из вариантов реализации этой идеи явилось стираемое про-
i граммируемое постоянное запоминающее устройство (СППЗУ). Первое
такое устройство было разработано в 1971 году компанией Intel, кото-
рая присвоилаему название 1702.
СППЗУ-транзистор имеет такую же структуру, как стандартный
МОП-транзистор, но с дополнительным (вторым) плавающим затво-
ром из поликристаллического кремния, изолированного слоями окси-
да кремния (Рис. 2.9).
Контакт Контакт Контакт
истока затвора стока
Контакт Контакт Контакт
истока затвора стока
а) Стандартный МОП-транзистор
б) СППЗУ-транзистор
Рис. 2.9. Сравнение МОП- и СППЗУ-транзисторов
СППЗУ 31
В незапрограммированном состоянии плавающий затвор не заря-
жен и не влияет на работу обычного затвора. Чтобы запрограммировать
транзистор, необходимо приложить к контактам затвора и стока поле-
вого транзистора относительно высокое напряжение, около 12 вольт.
При этом транзистор резко включается, и быстрые электроны преодо-
левают слой оксида кремния, направляясь в плавающий затвор. Этот
процесс известен как инжекция горячих, или высокоэнергетичных, элек-
тронов. После снятия сигнала программирования, отрицательно заря-
женные частицы остаются в плавающем затворе. Их заряд стабилен и
при соблюдении правил эксплуатации не рассеивается на протяжении
более 10 лет. Накопленные на плавающем затворе заряды блокируют
нормальную работу обычного затвора, и, таким образом, позволяют
различать запрограммированные ячейки от незапрограммированных.
Благодаря этому свойству такие транзисторы можно использовать для
формирования ячеек памяти (Рис. 2.10).
Рис. 2.10. Ячейка памяти на основе СППЗУ-транзистора
Такая ячейка памяти больше не нуждается в плавких перемычках,
наращиваемых перемычках или программируемых фотошаблоном со-
единениях. В незапрограммированном состоянии, которое обеспечи-
вается производителем, все плавающие затворы в СППЗУ-транзисто-
рах будут не заряжены. В этом случае при переводе проводника строк в
активное состояние будут включаться все транзисторы, подсоединен-
ные к этой строке, заставляя все проводники столбцов сбрасывать сиг-
нал на выходе до уровня логического 0 через соответствующие тран-
зисторы. Для программирования инженеры могут использовать входы
устройства для заряда плавающих затворов выбранных транзисторов,
тем самым, блокируя их работу. В этих случаях в ячейках памяти будут
храниться логические 1.
С точки зрения расположения на кремниевом кристалле ячейки
памяти СППЗУ более эффективны, так как их размеры существенно
меньше, чем размеры их аналогов на плавких перемычках. Однако
предметом их гордости является возможность быть стёртыми и пере-
программируемыми. Стирание ячеек памяти есть не что иное, как
«вытекание» электронов из плавающего затвора. Энергия, необходи-
мая для вытекания электронов, обеспечивается с помощью источника
ультрафиолетового (УФ) излучения. Микросхемы СППЗУ поставля-
ются в керамическом или пластиковом корпусе, наверху которого
32 Глава 2. Основные понятия
имеется небольшое кварцевое окно. Это окно обычно закрыто кусоч-
ком непрозрачной клейкой ленты. Чтобы стереть микросхему, сначала
надо извлечь её из монтажной платы, открыть кварцевое окно, и затем
поместить в закрывающийся контейнер с мощным УФ-источником.
Главными недостатками СППЗУ является их дорогостоящий кор-
пус с кварцевым окном и время, необходимое для их очистки, которое
составляет примерно 20 минут. Проблема, которую придется решать в
ближайшее время, как это не парадоксально, связана с усовершенс-
твованием технологического процесса, который позволит выполнять
транзисторы меньшего размера. Наряду с тем, что полупроводниковые
структуры становятся меньше и их плотность, т. е. количество тран-
зисторов и соединений, увеличивается, большой процент поверхности
кристалла оказывается покрытым металлом. Это затрудняет поглоще-
ние УФ-излучения ячейками СППЗУ и увеличивает время экспози-
ции, требуемое для стирания.
Эти микросхемы изначально предназначались для использования
в качестве программируемых постоянных запоминающих устройств, и
это нашло отражение в их названии — ППЗУ. Позднее эта технология
стала применяться в более универсальных ПЛУ, которые получили на-
звание стираемые ПЛУ.
ЭСППЗУ
Следующая ступенька технологической лестницы представляла
собой электрически стираемое программируемое постоянное запомина-
ющее устройство (ЭСППЗУ). Ячейка ЭСППЗУ приблизительно в 2.5
раза больше, чем эквивалентная ей ячейка СППЗУ, так как она состо-
ит из двух отстоящих друг от друга транзисторов (Рис. 2.11).
Обычный
МОП-транзистор
ЭСППЗУ-
транзистор
Ячейка памяти ЭСППЗУ
Рис. 2.11. Ячейка памяти ЭСППЗУ
Flash — вспышка,
миг, мгновение.
Подобно ЭСППЗУ-транзистору, СППЗУ-транзистор имеет плава-
ющий затвор, но этот затвор окружен очень тонким изолирующим
слоем оксида кремния. Второй транзистор может использоваться для
стирания ячейки памяти электрическим способом.
На заре своего существования ЭСППЗУ-микросхемы использова-
лись в качестве компьютерной памяти. Эта же технология была впос-
ледствии применена к устройствам ПЛУ, которые стали называться
электрически стираемыми ПЛУ (ЭСПЛУ) или программируемыми логи-
ческими интегральными схемами (ПЛИС).
Flash-технология
Технология, известная как Flash, ведет свою родословную от техно-
логии изготовления как СППЗУ, так и ЭСППЗУ. Первоначально на-
звание Flash было присвоено устройствам, выполненным по этой тех-
Статическое ОЗУ 33
нологии, чтобы отразить характерное для них чрезвычайно малое вре-
мя стирания по сравнению с устройствами СППЗУ. Компоненты,
выполненные по Flash-технологии, могут быть реализованы во мно-
жестве архитектур. Одни устройства могут иметь ячейки памяти, вы-
полненные на одном транзисторе с плавающим затвором такой же
площади, как в ячейках СППЗУ, но с гораздо более тонкими изолиру-
ющими слоями оксида кремния. Такие устройства могут стираться
электрическим способом, но при этом только путём очистки всего уст-
ройства или большей его части. Другие типы устройств построены на
двухтранзисторных ячейках памяти подобно микросхемам ЭСППЗУ,
что позволяет стирать или перепрограммировать информацию пос-
ловно.
Первые версии Flash-устройств могли хранить только один бит ин-
формации на ячейку. Но уже к началу 2002 года технологи выполнили
ряд экспериментов по увеличению ёмкости ячеек. Оказалось, что со-
гласно одному методу запоминание двух битов в одной ячейке возмож-
но благодаря хранению различных уровней зарядов в плавающих за-
творах Flash-транзисторов, а согласно другому методу — благодаря со-
зданию двух дискретных запоминающих узлов в слое под затвором.
Статическое ОЗУ
Существуют два основных типа полупроводниковых устройств
оперативной памяти: динамическое ОЗУ и статическое ОЗУ. В случае
динамического ОЗУ каждая ячейка памяти формируется с помощью
пары транзистор-конденсатор, которая занимает мало места на повер-
хности кремниевого кристалла. Определение «динамическое» отража-
ет тот факт, что с течением времени конденсатор теряет свой заряд, т. е.
для сохранности данных каждая ячейка должна периодически переза-
ряжаться. Эта операция называется регенерацией. Она является отно-
сительно сложной и требует значительного количества дополнитель-
ных схемных решений. Применение этих микросхем оказывается оп-
равданным, если «стоимость» цепей регенерации покрывается
десятками миллионов бит в одной микросхеме динамического ОЗУ.
Однако с точки зрения программируемой логики технология динами-
ческого ОЗУ не представляет большого интереса.
Определение «статическое» в назва-
нии статического ОЗУ отражает тот
факт, что однажды записанное в ячейку
памяти значение будет оставаться в ней
неизменным до тех пор, пока не будет
специально изменено или система не бу-
дет обесточена. Обозначение ячейки па-
мяти на основе статического ОЗУ приве-
дено на Рис. 2Л2.
Ячейка памяти содержит мультит-
ранзисторный элемент статического ОЗУ, выход которого подключен
к дополнительному управляющему транзистору. В зависимости от со-
держимого (логический 0 или логическая 1) элемента памяти управля-
ющий транзистор будет закрыт (т. е. отключен) или отрыт (т. е. вклю-
чен). Один из недостатков программируемых устройств на основе яче-
ек памяти статического ОЗУ состоит в том, что каждая ячейка
занимает значительную площадь на поверхности кремниевого крис-
талла, так как состоит из четырех или шести транзисторов, сконфигу-
рированных в виде регистра-защелки. Другим недостатком является
то, что данные о конфигурации устройства будут потеряны при отклю-
Статическое
ОЗУ
Рис. 2.12. Программируемая
ячейка памяти на основе
статического ОЗУ
34 Глава 2. Основные понятия
чении питания системы. Это означает, что при включении системы та-
кие устройства приходиться перепрограммировать. В то же время их
можно перепрограммировать быстро и многократно.
Способы использования ячеек памяти в ПЛИС на основе стати-
ческого ОЗУ более подробно будут рассмотрены в следующих главах.
Здесь необходимо только заметить, что такие ячейки памяти могут
быть использованы для замены плавких перемычек в примере, пока-
занном на Рис. 2.2, наращиваемых перемычек (Рис. 2.4) или транзис-
торов (и масочно-программируемых соединений), относящихся к
ячейкам памяти ПЗУ (Рис. 2.7). Естественно, что в последнем случае,
было бы бессмысленно иметь ПЗУ на основе ячеек статического ОЗУ
Заключение
Программируемые устройства и связанные с ними технологии
программирования приведены в Табл. 2.1.
Таблица 2.1, Технологии программирования
Технология Условное обозначение Преимущественно применяется для
Плавкие перемычки —Л/Х/— Простых ПЛУ
Наращиваемые пере- мычки —ID— ПЛИС
СППЗУ Простых и сложных ПЛУ
ЭСППЗУиРЬАЗН Простых и сложных ПЛУ (некоторых ПЛИС)
Статическое ОЗУ SRAM ПЛИС (некоторых сложных ПЛУ)
Кроме того, надо иметь в виду, что постоянно «всплывают» новые
технологии. Некоторые из них немного «поплавав», бесследно исчеза-
ют в сточной трубе, другие так быстро пробиваются наверх, что иногда
не понятно, откуда они появились.
Одна из таких технологий, несомненно, представляет интерес и на-
зывается магнитным ОЗУ (MRAM — magnetic RAM). Начало развитию
этой технологии было положено в 1974 году, когда фирма IBM разрабо-
тала так называемый магнитный туннельный переход. Речь шла о трех-
слойной структуре, состоящей из двух ферромагнитных слоев, разде-
ленных тонким изолирующим слоем. Ячейки магнитного ОЗУ могли
создаваться на пересечении двух проводников, проводника строк и про-
водника столбцов, с магнитным туннельным переходом между ними.
Ячейки магнитного ОЗУ — это высокая скорость работы статичес-
кого ОЗУ, большой объем динамического ОЗУ, энергонезависимость
Flash-технологии и минимальное количество потребляемой энергии.
Согласно прогнозам, появление микросхем магнитного ОЗУ не заста-
вит себя ждать. И как только они появится на рынке, станет возможной
реализация таких устройств, как ПЛИС на ячейках магнитного ОЗУ.
ГЛАВА 3
ИСТОРИЯ РАЗВИТИЯ плис
Родственные технологии
Чтобы проследить историю развития ПЛИС и выявить причины,
по которым они заняли лидирующее положение в этой области, рас-
смотрим родственные ей технологии (Рис. 3.1).
1945 1950 1955 1960 1965 1970 1975 1980 1985 1990 1995 2000
Транзисторы------
ИС (общего назначения)---------
Статические ________
и динамические ОЗУ
Микропроцессоры ---------
Простые ПЛУ
Сложные ПЛУ---------
Заказные микросхемы---------
ПЛИС (FPGA)---------
Рис, 3,1, Диаграмма развития технологий (даты указаны приблизительно)
Белые области на полосах диаграммы свидетельствуют о том, что,
не смотря на возможность более раннего воплощения в жизнь, эти
технологии по той или иной причине в то время не вызвали большого
восторга у инженеров. Так, фирма Xilinx еще в 1984 году продемонс-
трировала миру первую микросхему ПЛИС. Однако эти маленькие
штучки не произвели должного впечатления на инженеров и не поль-
зовались особой популярностью вплоть до начала 90-х прошлого века.
Транзисторы
23 декабря 1947 года физики Вильям Шокли (William Shockley),
Вальтер Брэттин (Walter Brattain) и Джон Бардин (John Bardeen) (Ис-
следовательский центр компании Bell Laboratories, США), создали
первый транзистор — точечное устройство на основе германия (символ
химического элемента — Ge).
1950-й год стал свидетелем появления более сложного устройства —
биполярного транзистора. Производство этих транзисторов было доста-
точно простым и дешевым и, кроме того, налицо было неоспоримое
преимущество — более высокая надежность. Однако к концу 50-х гер-
маний, несмотря на определенные преимущества в части электричес-
ких характеристик, уступил место кремнию (символ химического эле-
мента — Si). Низкая стоимость кремния и легкость его обработки при-
вели к тому, что транзисторы стали производить чаще из кремния, чем
из германия.
36 Глава 3. История развития ПЛИС
Если соединить биполярные транзисторы определенным образом,
получим базовый логический элемент или логический вентиль тран-
зисторно-транзисторной логики (ТТЛ). Соединив те же транзисторы по
другому, получим логический вентиль эмиттерно-связанной логики
(ЭСЛ). Логические вентили ТТЛ обладают высокой скоростью пере-
ключения, но при этом потребляют относительно большой ток. Логи-
ческие вентили ЭСЛ потенциально быстрее ТТЛ-вентилей, но потреб-
ляют еще больший ток.
В 1962 году Стивен Хофстайн (Steven Hofstein) и Фридрих Хейман
(Fredric Heiman) из Исследовательской лаборатории RCA, Прингстон,
шт. Нью-Джерси разработали новое семейство устройств — металл-
оксид-полупроводниковые полевые транзисторы (metal-oxide
semiconductor field-effect transistors —- MOSFET). Для краткости их часто
называют просто полевыми транзисторами или МОП-транзисторами.
В целом полевые транзисторы несколько медленнее, чем их биполяр-
ные родственники, но они дешевле, меньшего размера и потребляют
существенно меньше энергии.
Существуют два основных типа полевых транзисторов, а именно 72-
типа, или л-МОП, и p-типа, или p-МОП. Логические элементы, пост-
роенные из соединенных вместе л-МОП и p-МОП транзисторов, на-
зываются комплементарным металл-оксид полупроводниковым элемен-
том (КМОП). КМОП-вентили, если и были несколько медленнее сво-
их ТТЛ родственников, в настоящее время практически догнали их по
скоростным характеристикам. Однако преимущество КМОП венти-
лей состоит в том, что в статическом (некоммутируемом) режиме их
мощность потребления чрезвычайно мала.
Интегральные микросхемы
Первые транзисторы поставлялись в виде отдельных компонентов,
заключенных в небольшие металлические корпуса. Спустя некоторое
время возникла идея выполнить всю электрическую схему целиком на
одном куске полупроводника. Впервые эта идея была «озвучена» в ста-
тье, опубликованной в 1952 году, автором который был британский эк-
сперт в области радиолокации Дж. Даммер (G.W.A. Dummer). Обсуж-
дение этой идеи и возможности ее реализации продолжались до тех
пор, пока летом 1958 года Джеку Килби (Jack Kilby) из компании Texas
Instruments не удалось создать генератор с фазовым сдвигом, состоя-
щего из пяти компонентов, расположенных на одном куске полупро-
водника.
Почти в это же время, пока Д. Килби работал над своим генерато-
ром, два основателя компании Fairchild Semiconductor, швейцарский
физик Джин Хорни (Jean Hoerni) и американский физик Роберт Нойс
(Robert Noyce), разработали основы технологии оптической литогра-
фии, которая в настоящее время используется для создания транзисто-
ров, изолирующих слоёв и межэлементных соединений в современных
микросхемах.
В середине 60-х Texas Instruments представила большое семейс-
тво базовых микросхем 54-й и 74-й серий, которые предназнача-
лись соответственно для военных и коммерческих целей. Эти уст-
ройства-«конфетки», размером 3/4 дюйма (1.89 см) в длину и
3/8 дюйма (0.95 см) в ширину, имели 14 или 16 выводов и содержа-
ли небольшой набор простой логики (для особо педантичных чита-
телей следует заметить, что некоторые из них были длиннее, шире
и имели большее количество выводов). Например, микросхема 7400
содержала четыре элемента 2-входового И-НЕ, микросхема 7402 —
Статическое и динамическое ОЗУ, микропроцессоры 37
четыре элемента 2-входового ИЛИ-HE, микросхема 7404 состояла
их шести инвертирующих (НЕ) логических элементов.
54-я и 74-я серии микросхем компании Texas Instruments изготав-
ливались по технологии ТТЛ. Но уже в 1968 году компания RCA анон-
сировала практически эквивалентный набор КМОП микросхем, на-
званный серией 4000.
Статическое и динамическое ОЗУ,
микропроцессоры
Конец 60-х и начало 70-х оказались урожайными на разработки в
области интегральных микросхем. Так, в 1970 году компания Intel
анонсирует первую 1024-битную микросхему динамического ОЗУ (мо-
дель 1103), а компания Fairchild представляет первую 256-битную мик-
росхему статического ОЗУ (модель 4100).
Год спустя, т. е. в 1971, Intel демонстрирует первый в мире микро-
процессор (МП), так называемую модель 4004, создателями которой
были Марсиан Хофф, известный как Тэд (Marcian «Ted» Hoff), Стэн
Мазор (Stan Mazor) и Федерико Фэггин (Federico Faggin). Микропро-
цессор 4004 представлял собой «компьютер-на-кристалле», содержал
всего лишь около 2300 транзисторов и мог выполнять 60000 операций
в секунду.
Несмотря на то что 4004-й часто упоминается как первый микро-
процессор, на это звание претендовали многие. Так, в феврале 1968 года
компания International Research Corporation представила разработку ус-
тройства, относящуюся к классу «компьютер-на-кристалле». В 1970-м,
за год до того, как микропроцессор 4004 увидел свет, некий Гилберт
Хайатт (Gilbert Hyatt) подал заявку на патент под названием «Принцип
построения однокристального компьютера» (споры относительно этого
патента продолжаются и по сей день). Но что никем и никогда не оспа-
ривалось и не оспаривается, так это то, что микропроцессор 4004 был
первым физически исполненным, серийно выпускаемым микропро-
цессором, который действительно был способен выполнять некие по-
лезные функции.
Микропроцессоры и микросхемы статического ОЗУ заслуживают
особого внимания, поскольку большинство современных ПЛИС ос-
нованы на ячейках статического ОЗУ, а некоторые их современные
высокотехнологичные представители содержат встроенные микропро-
цессорные ядра (см. гл. 4).
Простые и сложные ПЛУ
Первые программируемые интегральные микросхемы можно от-
нести к программируемым логическим устройствам (ПЛУ). Они появи-
лись в 70-м в виде микросхем ППЗУ и были довольно примитивными,
но из вежливости к их авторам все предпочитали об этом помалкивать.
Только к концу 70-х появились более сложные версии этих устройств.
Чтобы отличить их от менее сложных предшественников, которые все
еще находят применение в наши дни, эти устройства стали называть
сложными ПЛУ (CPLD — complex programmable logic devices). Естествен-
но, что впоследствии менее сложные устройства стали называться про-
стыми ПЛУ (SPLD — simple programmable logic devices).
В результате возникла некоторая путаница, причем одни воспри-
нимают понятия простые и сложные ПЛУ как синонимы, в то время
как другие считают, что термин ЯЛУ включает в себя как простые, так
и сложные устройства.
38 Глава 3. История развития ПЛИС
1500 г. Италия.
Леонардо да Винчи
нарисовал детали
простого механи-
ческого калькуля-
тора.
Ситуация осложняется еще и тем, что инженеры часто используют
один акроним (аббревиатуру, сокращение) для обозначения разных
понятий, либо разные акронимы для обозначения одного и того же по-
нятия (самые стойкие могут впасть в истерику, слушая гогот инжене-
ров, которые потчуют друг друга изысками во время своих бесед). На-
пример, в случае простых ПЛУ существует множество производных
архитектур, многие из которых обозначаются аббревиатурами из раз-
личных комбинаций тех же трех или четырех букв (Рис. 3.2).
ПЛУ(РЦЭ)
Простые ПЛУ
(SPLD)
Сложные ПЛУ |
(SPLD) I
ППЗУ
(PROM)
(програм мируемые
логические
матрицы)
Рис, 3,2, Изобилие архитектур ПЛУ
Конечно, существуют и стираемые ПЛУ, и электрически стираемые
ПЛУ, и Flash-версии различных устройств, например СППЗУ и ЭСП-
ПЗУ (см. гл. 2). На Рис. 3.2 они отсутствуют с целью его упрощения.
ППЗУ
Первыми представителями простых ПЛУ были ППЗУ-микросхе-
мы, которые появились в 70-м. Чтобы понять какие чудеса происходят
внутри этих устройств, лучше всего представить их состоящими из
фиксированного массива логических функций И, подсоединенного к
программируемому массиву логических функций ИЛИ.
Для примера рассмотрим работу ППЗУ с тремя входами и тремя
выходами (Рис. 3.3).
В качестве программируемых связей в массиве элементов ИЛИ мо-
гут применяться плавкие перемычки, либо СППЗУ-транзисторы или
ячейки ЭСППЗУ, соответственно для микросхем СППЗУ или ЭСП-
ПЗУ. Рис. 3.3 дает лишь общее представление о принципе действия
рассматриваемого устройства и не отображает реальную диаграмму со-
единений. В.действительности каждая функция И предопределенного
массива имеет три входа, которые подсоединены к истинным или ин-
вертированным входам а, b или с устройства. Аналогично каждая фун-
кция ИЛИ программируемого массива имеет восемь входов, которые
подсоединены к выходам массива функций И.
Как уже отмечалось, микросхемы ППЗУ изначально предназнача-
лись для хранения программных инструкций и значений констант, т. е.
для выполнения функций компьютерной памяти. Однако разработчи-
ки используют их также для реализации простых логических функций,
таких как таблицы соответствия или конечные автоматы. В действи-
Простые и сложные ПЛУ 39
Рис, 3,3, Незапрограммированная микросхема ППЗУ
тельности микросхемы ППЗУ могут использоваться для реализации
любого блока комбинационной логики0, или комбинационного уст-
ройства, при условии, что он имеет небольшое количество входов и
выходов. Например, простое ППЗУ с тремя входами и тремя выхода-
ми, показанное на Рис. 3.3, может использоваться для синтеза любой
комбинационной функции с не более чем тремя входными и тремя вы-
ходными параметрами. Чтобы понять, как оно работает, рассмотрим
небольшой логический блок, показанный на Рис. 3.4. Следует иметь в
виду, что эта схема имеет смысл только для данного примера.
а b с W X У
0 0 0 0 1 0
0 0 1 0 1 1
0 1 0 0 1 0
0 1 1 0 1 1
1 0 0 0 1 0
1 0 1 0 1 1
1 1 0 1 0 1
1 1 1 1 0 0
Рис, 3,4, Небольшой блок комбинационной логики
Логический блок (Рис. 3.4) может быть заменен микросхемой
ППЗУ с тремя входами и тремя выходами. Для этого надо всего лишь
запрограммировать соответствующие связи в массиве логических эле-
ментов ИЛИ (Рис. 3.5).
В выражениях на этом рисунке использованы следующие обозна-
чения: «&» — операция И (AND), «|» — операция ИЛИ (OR), «л» —
операция ИСКЛЮЧАЮЩЕЕ ИЛИ (XOR), «"» - операция НЕ (NOT).
Комбинационную логику часто называют комбинаторной логикой.
40 Глава 3. История развития ПЛИС
На ранних этапах развития ПЛУ имел широкое хождение другой син-
таксис: вместо символа « » использовался символ «!», так как с его по-
мощью можно было легко и сжато записать логическое выражение в
текстовый файл, используя стандартные символы клавиатуры.
Рассмотренная выше микросхема ППЗУ является очень простой. В
действительности микросхемы ППЗУ имеют значительно больше вхо-
дов и выходов и могут использоваться для реализации больших блоков
комбинационной логики. С середины 60-х и до середины 80-х (или да-
же позже) комбинационная логика в общем случае реализовывалась с
помощью микросхем-«конфеток», таких как 74-ая серия компании
Texas Instruments.
Тот факт, что довольно большое число таких микросхем можно за-
менить одной микросхемой ППЗУ, означает, что монтажную плату
можно сделать меньше, проще, дешевле и менее подверженной сбоям
(каждое паяное соединение на монтажной плате — потенциально
сбойный узел). Кроме того, если в этой части системы обнаружится
логическая ошибка, например разработчик ошибочно использовал
функцию И вместо И?НЕ, она может быть легко исправлена путем
прошивки новой ППЗУ-микросхемы или посредством очистки и пе-
репрограммирования СППЗУ либо ЭСППЗУ-микросхем. Этот способ
предпочтительнее, чем обнаружение ошибок на печатной плате, вы-
полненной на основе отдельных микросхем. В подобной ситуации на
печатную плату приходится добавлять новые микросхемы, перерезать
скальпелем существующие дорожки и с помощью дополнительных
проводов вручную подсоединять новые микросхемы к требуемому
месту на плате.
Простые и сложные ПЛУ 41
В логических выражениях оператор И («&») называется логичес-
ким умножением или произведением, а оператор ИЛИ («|») логичес-
ким сложением или суммой. Тем не менее, когда речь идет о логичес-
ком выражении вида
у = (а & b & с) | (а & b & с) | (а & b & с) | (а & b & с),
понятие литерал означает либо истинную, либо инвертированную пе-
ременную (a, a, b, b и т. д.), а группа литералов, связанная оператором
«&», называется произведением. Таким образом, произведение
(а & b & с) состоит из трех литералов, а именно а, b и с, и приведенное
выше уравнение будет суммой произведений.
Суть заключается в том, что когда эти выражения используются
для реализации комбинационной логики (Рис. 3.4 и 3.5), ППЗУ удоб-
но использовать для выражений с большим количеством произведе-
ний, но небольшим количеством входов, так как все входные комби-
нации жестко зашиты в матрице И и всегда декодируются.
1600 г. Джон Непер
(John Napier) раз-
работал простую
таблицу умноже-
ния, которую на-
звали «Кости Не-
пера» (Napier's
Bones).
1614 г. Джон Непер
(John Napier) изоб-
рёл логарифмы.
Программируемые логические матрицы (ПЛМ)
Следующая ступень развития ПЛУ — решение проблем, связанных
с ограничениями, свойственными архитектуре ППЗУ.
Первые программируемые логические матрицы (ПЛМ) появились
примерно в 1975 году. Большинство пользователей использовали их
как простые ПЛУ, так как оба массива, т. е. и массив функций И, и
массив функций ИЛИ, были программируемыми.
Если взять простую ПЛМ с тремя входами и тремя выходами в не-
запрограммированном состоянии (Рис. 3.6), в отличие от ППЗУ коли-
чество функций И в одноименном массиве не зависит от количества
входов матрицы. При этом дополнительные функции И могут быть
сформированы путем простого добавления в массиве строк.
Аналогично количество функций ИЛИ в одноименном массиве не
зависит от количества входов матрицы и от размера массива функций
И. Дополнительные функции ИЛИ могут быть сформированы путем
простого добавления в этом массиве столбцов.
Рис. 3.6. Незапрограммированная ПЛМ
Предположим, что ПЛМ должна реализовать следующие три урав-
нения:
w = (а & с) | (Ь & с), х = (а & b & с) | (Ь & с) и у = (а & b & с).
Решить эту задачу можно путем программирования соответствую-
щих связей, как показано на Рис. 3.7.
42 Глава 3. История развития ПЛИС
w = (a&c)|(b&c’)-----------1 |
х = ( а & b & с ) | ( b & с*) -*
у=(а&Ь&с ) ----------------------
Рис. 3.7. Запрограммированная ПЛМ
Ц
i 2
1!
И
Судьба распорядилась таким образом, что ПЛМ никогда не зани-
мали существенной доли рынка, но при этом время от времени неко-
торым поставщикам удавалось поразить рынок какими-нибудь изю-
минками своих устройств. Так, в ПЛМ нет жесткой необходимости
подключать массив функций ИЛИ к выходу массива функций И. Поэ-
тому некоторые альтернативные конфигурации, например массив
функций И, подключенный к входу массива ИЛИ-HE, иногда показы-
вал неплохие результаты. Однако, несмотря на теоретическую возмож-
ность реализации на практике, функции ИЛИ-И, И-НЕ-ИЛИ, И-НЕ-
ИЛИ-НЕ относительно редко встречались или просто не существова-
ли. Одной из причин, по которой ПЛМ продолжают работать с архи-
тектурой И-ИЛИ0 (и И-ИЛИ-НЕ), стало то, что выражение сумма-
произведений наиболее часто используется в логических уравнениях.
Другие типы уравнений, такие как произведение-сумм, приводятся к
ним с помощью стандартных алгебраических методов. Такое преобра-
зование обычно выполняется с помощью программ, которые, условно
говоря, могут сделать эту работу и со связанными руками.
Микросхемы ПЛМ рекламировались как весьма полезные уст-
ройства для больших схем, логические уравнения которых характери-
зовались большим количеством одинаковых произведений. Напри-
мер, произведение вида (Ь & с) используется дважды: для вычисления
выхода w и для вычисления входах (Рис. 3.7). Это свойство называется
распределением произведений.
Вместе с тем для прохождения через программируемые связи сиг-
налам требуется намного больше времени, чем при прохождении через
их предопределенные аналоги. Поэтому ПЛМ работает медленнее чем
ППЗУ, так как оба массива и функций И, и функций ИЛИ являются
программируемыми.
° Действительно, как-то один разработчик сказал мне, что его команда созда-
ла архитектуру НЕ-ИЛИ-НЕ-ИЛИ-НЕ-НЕ, которая имеет незначительное пре-
имущество в скорости, но своих покупателей они заверили в том, что это архитек-
тура И-ИЛИ, так как «именно этого желали покупатели». И в наше время, если
производители говорят, что они что-то сделали, это отнюдь не значит, что они сде-
лали именно то, о чем говорят.
Простые и сложные ПЛУ 43
Программируемые матрицы PAL и GAL
Для того чтобы решить проблему скорости, свойственной про-
граммируемым логическим матрицам, в конце 1970-х появился новый
класс устройств, называемый программируемый массив логики (ПМЛ
или PAL — Programmable Array Logic). На понятийном уровне устройс-
тва PAL почти полностью противоположны микросхемам ППЗУ, так
как состоят из программируемого массива логических функций И и
предопределенного массива функций ИЛИ. Устройства GAL (Generic
Array Logic — изменяемый массив логики), разработанные в 1983 году
компанией Lattice Semiconductor Corporation, представляют собой бо-
лее сложные электрически стираемые КМОП-разновидности идеоло-
гии PAL.
В качестве примера рассмотрим простое PAL-устройство с тремя
входами и тремя выходами (Рис. 3.8). Преимуществом микросхем PAL
(по сравнению с программируемыми логическими матрицами) являет-
ся более высокая скорость, так как из двух массивов у них только один
программируемый.
PAL — зарегистриро-
ванная торговая
марка компании
Monolithic Memories,
Inc.
а b
Программируемый
массив элементов И
Рис. 3.8. Незапрограммированное устройство PAL
-4- Предопределенная связь
Программируемая связь
У
§
са
2
о
5
>х
3
I
1
Вместе с тем программируемый массив логики более ограничен по
функциональности, так как он позволял складывать только ограни-
ченное количество произведений. Но инженеры люди изобретатель-
ные: у них всегда имеется в запасе много разных уловок, помогающих
обойти все эти трудности.
Дополнительные программируемые опции
Рассмотренные выше в качестве примеров ПЛМ и PAL на самом
деле очень большие, с множеством входов, выходов и с внутренними
сигналами. В них могут быть предусмотрены различные дополнитель-
ные программируемые опции, такие как возможность инвертировать
выходы, либо иметь выходы с тремя состояниями, либо и то, и другое.
Кроме того, некоторые из них поддерживают регистровые выходы,
т. е. выходы с защелкой, аналогично программируемым мультиплексо-
44 Глава 3. История развития ПЛИС
1621 г. Вильям От-
ped (William
Oughtred) на основе
логарифмов Джо-
на Непера разрабо-
тал логарифмичес-
кую линейку.
Понятие «software»
(в переводе с англ. —
программное
обеспечение) также
«изобрел» Джон
Таки (John Wilder
Tukey).
рам, которые позволяют пользователю устанавливать поочередно для
каждого вывода, какую версию выхода использовать — регистровую
или нерегистровую. Некоторые устройства позволяют конфигуриро-
вать определенные выводы в качестве либо выходов, либо дополни-
тельных входов. И это далеко не все опции, и список можно продол-
жать и продолжать.
Проблема заключается в том, что различные устройства могут
обеспечивать разные наборы опций, что затрудняет выбор оптималь-
ного устройства для конкретного приложения. В подобных случаях
инженеры либо ограничивают себя в выборе устройств и подгоняют
свою конструкцию под эти устройства, либо используют компьютер-
ные программы, с помощью которых выбирают устройство макси-
мально удовлетворяющее их требованиям.
Сложные ПЛУ
Типичное для электроники явление — вечный поиск способа, как
сделать устройство больше, в смысле функциональности, меньше, в
смысле физических размеров, быстрее, производительнее и дешевле.
Я бы сказал, довольно скромненькие требования. Не правда ли? В свя-
зи с этим в конце 70-х — начале 80-х появились более сложные про-
граммируемые логические устройства, так называемые сложные ПЛУ
(CPLD — complex PLD).
Лидерами были изобретатели оригинальных устройств PAL — раз-
работчики компании Monolithic Memories (MMI), которые представи-
ли компонент под названием Мега-PAL (Mega-PAL). Это устройство с
84 выводами по существу включало в себя 4 PAL-устройства и соеди-
нения между ними. К сожалению, Мега-PAL потребляла непропорци-
ональное много энергии, и давала небольшое преимущество по срав-
нению с использованием четырех отдельных устройств.
Существенный прорыв пришелся на 1984 год, когда только что об-
разованная компания Altera представила сложное ПЛУ, основанное на
сочетании КМОП- и СППЗУ-технологий. Использование КМОП
позволило компании Altera достичь невероятной функциональной
плотности и сложности при сравнительно небольшом потреблении
энергии. Основой для программирования этих устройств были ячейки
СППЗУ, и именно это сделало их идеальными для использования при
разработке и создании прототипов оборудования.
Компания Altera заслужила свою славу не только благодаря комби-
нации технологий КМОП и СППЗУ. При наращивании архитектуры
простых ПЛУ до уровня больших устройств, подобных Мега-PAL, ин-
женеры полагали, что центральный коммутационный массив, извест-
ный так же как программируемая коммутационная матрица, и связыва-
ющий индивидуальные блоки простых ПЛУ, должен на 100% соеди-
няться со всем входам и выходам блоков. В результате это приводило к
существенному сйижению скорости, повышению рассеиваемой мощ-
ности и увеличению стоимости компонентов.
Altera удалось совершить технологический прорыв, используя цен-
тральный коммутационный массив с количеством соединений с вхо-
дами/выходами блоков менее 100% (подробнее на Рис. 3.10). Это ус-
ложнило программное обеспечение для проектирования ПЛУ, но ско-
рость, потребляемая мощность и стоимость этих устройств были
вполне приемлемыми.
Несмотря на то что каждый производитель сложных ПЛУ реализо-
вывал свои уникальные технологии, в общем случае устройство состо-
Простые и сложные ПЛУ 45
яло из нескольких блоков простых ПЛУ, обычно PAL, объединенных ।
общей программируемой коммутационной матрицей (Рис. 3.9). Поми-
мо отдельных блоков простых ПЛУ можно было также запрограмми-
ровать соединения между ними с помощью программируемой комму-
тационной матрицы.
На Рис. 3.9 не показаны различные дополнительные компоненты,
и он дает лишь поверхностное представление о работе сложного ПЛУ.
В действительности все структуры устройства сформированы на одном
куске кремния. Например, программируемая коммутационная матри-
ца может содержать большое количество проводников, скажем 100. Но
это больше, чем может быть подключено к блоку простого ПЛУ, кото-
рый способен работать только с ограниченным количеством сигналов,
скажем 30. Блоки простых ПЛУ связаны с коммутационной матрицей
своего рода программируемыми мультиплексорами (Рис. 3.10).
Рис. 3.10. Использование программируемого мультиплексора
В зависимости от производителя и от типа устройства программи-
руемые переключатели сложных ПЛУ могут быть выполнены на ячей-
ках памяти типа СППЗУ, ЭСППЗУ, Flash или на статическом ОЗУ.
При использовании статического ОЗУ появляется возможность уве-
личить универсальность этой памяти, используя её в качестве про-
граммируемых переключателей и в качестве фактической оператив-
ной памяти.
46 Глава 3. История развития ПЛИС
Средневековье от-
носится к периоду
истории от класси-
ческой античности
до итальянского
Ренессанса, эпоха
Возрождения. Раз-
личные источники
определяют дату на-
чала средневековья
с точностью до не-
скольких сотен лет.
Программные средства ABEL, CUPL, PALASM, JEDEC и другие
Для инженеров первые дни существования микросхем ПЛУ во
многом напоминали времена средневековья.
Спецификация на новые устройства обычно представляла собой
принципиальную схему или схему конечного автомата. Эти схемы со-
здавались с помощью бумаги и карандаша, так как в то время не су-
ществовало автоматизированных систем описания принципиальных
схем в том виде, в котором они известны нам.
Однажды конструкция устройства, представленная в графическом
виде, была вручную преобразована в табличный эквивалент и затем
введена в текстовый файл. Этот текстовый файл, кроме всего прочего,
определял, какие плавкие перемычки должны быть подвержены пере-
жиганию или какие наращиваемые перемычки должны быть созданы.
В те незапамятные дни текстовый файл напрямую вводился в специ-
альное устройство, называемое программатором, который использо-
вался для программирования микросхем. Однако со временем файл
начали создавать на компьютере, с помощью которого производилась
загрузка и управление программатором (Рис. 3.11).
Рис. 3.11. Программирование микросхем ПЛУ
При создании файла от инженера требовались знание внутренних
связей устройства и формата файла, записываемого в программатор.
Исключительно ради развлечения каждый производитель ПЛУ разви-
вал собственные форматы файлов, которые обычно работали со свои-
ми типами устройств. Всем заинтересованным было очевидно, что та-
кой порядок проектирования был трудоемким, чреват ошибками и, к
тому же, затруднял их поиск и исправление.
В 1980 году комиссия Объединенного инженерного совета по элек-
тронным устройствам (JEDEC), подразделение Ассоциации электрон-
ной промышленности США, предложила стандарт форматов тексто-
вых файлов для программирования устройств ПЛУ. Это случилось не-
задолго до того, как программисты электронных устройств уже были
готовы принять этот формат.
Примерно в это же время Джон Беркнер (John Birkner), человек ко-
торый разработал первые устройства PAL и стоял во главе их дальней-
шего развития, создал PAL Ассемблер (PALASM). PAL Ассемблер соче-
тает в себе язык описания аппаратных средств (HDL — Hardware
Description Language) и прикладное программное обеспечение. Как
язык описания аппаратных средств PAL Ассемблер позволяет инжене-
рам-разработчикам точно описать функции принципиальной схемы в
Заказные интегральные схемы — ASIC 47
текстовом файле с исходными кодами. Файл состоял из булевых урав-
нений, записанных в формате «сумма-произведений». Как приклад-
ная программа, которая на языке программирования Фортран0 зани-
мала всего лишь 6 страниц (сегодня мы назвали бы ее САПР электрон-
ных устройств) PALASM читал текстовый файл с исходными кодами и
автоматически генерировал текстовый программный файл, пригод-
ный для программирования устройства.
Появление PALASM, несомненно, было эпохальным событием для
того времени, но его первоначальные версии поддерживали только ус-
тройства компании MMI (Monolithic Memories Inc), и не поддержива-
ли какие-либо виды минимизации или оптимизации. Для решения
этих проблем в 1983 году компания Data I/O представила язык ABEL
(Advanced Boolean Expression Language — расширенный язык логических
выражений). Примерно в это же время компания Assisted Technology
обнародовала пакет CUPL (Common Universal tool for Programmable Logic
— Общие универсальные средства проектирования для программируемой
логики). Оба продукта сочетали в себе язык HDL и программные при-
ложения. Кроме того, что они поддерживали конструкции конечных
автоматов и алгоритмы автоматической минимизации логики, они
позволяли работать с многочисленными типами ПЛУ устройств раз-
ных производителей.
Кроме PALASM, ABEL и CUPL, которые были, несомненно, луч-
шими из ранних версий языка HDL, существовало много других вер-
сий, таких как AMAZE (Automated Map and Zap of Equation — автомати-
ческое преобразование и исправление выражений) компании Signetics.
Эти простые языки и сопутствующие им средства проектирования
прокладывали путь для высокоуровневых версий языка HDL, таких
как Verilog или VHDL, и средств проектирования, таких как логичес-
кий синтез, которые в настоящее время используются для проектиро-
вания современных заказных микросхем и устройств с использовани-
ем ПЛИС.
Заказные интегральные схемы — ASIC
Во время написания этой книги существовало четыре основных
класса специализированных заказных интегральных микросхем (ASIC —
application specific integrated circuit), заслуживающих внимания. В поряд-
ке увеличения сложности такими устройствами были вентильные мат-
рицы, структурированные ASIC, схемы на стандартных элементах и
полностью заказные микросхемы (Рис. 3.12).
Типы специализированных микросхем можно рассмотреть и в по-
рядке возрастания их сложности, как показано на Рис. 3.12. Однако
имеет смысл описать их в той последовательности, в какой они появи-
лись на свет, Т. е. заказные микросхемы одновременно с вентильными
матрицами* 2*, затем микросхемы на стандартных элементах и, наконец,
структурированные специализированные интегральные схемы, или
структурированные специализированные ИС. Вопрос, какое из уст-
0 Разработанный компанией IBM в 1950 году язык Фортран (FORTRAN —
FORmula TRANslator — транслятор формул) стал первым компьютерным языком
программирования, уровень которого был выше, чем уровень Ассемблера.
2) Для вентильной матрицы часто можно встретить другой термин — базовый
матричный кристалл (БМК). — Прим. ред.
48 Глава 3. История развития ПЛИС
Специализированные заказные ИС
Возрастание сложности
Рис, 3,12, Различные типы специализированных заказных ИС
ройств, структурированная специализированная ИС или вентильная
матрица, является более сложным, довольно спорный0.
Заказные интегральные микросхемы
На заре появления цифровых микросхем существовало только два
типа устройств, кроме, естественно, микросхем памяти. К первому
типу относились относительно простые блоки, которые производи-
лись такими компаниями, как Texas Instruments или Fairchild, и про-
давались как стандартные компоненты для всех желающих. Ко второ-
му типу принадлежали заказные специализированные микросхемы,
такие как микропроцессоры, которые разрабатывались и производи-
лись по заказу.
При создании заказных устройств разработка маски для каждого
слоя микросхемы была прерогативой инженеров — разработчиков ко-
нечного устройства. Поставщики специализированных микросхем
предварительно не создавали никаких компонентов на кремниевом
кристалле заводским способом и не поставляли библиотек предопре-
деленных логических вентилей или функций.
Используя соответствующие средства проектирования инженеры
задавали размеры отдельных транзисторов и на их основе создавали
высокоуровневые функции. Например, при необходимости слегка
увеличить скорость логического вентиля они могли изменить размеры
транзисторов, используемых для построения вентилей. Средства про-
ектирования, используемые для разработки заказных устройств, часто
создавались инженерами фирм-разработчиков.
Разработка заказных устройств является очень сложным и трудо-
емким процессом, но созданные таким способом микросхемы содер-
жат необходимое количество вентилей с минимальными потерями
свободного места на кремниевом кристалле.
° Наиболее въедливые читатели могут предложить альтернативную термино-
логию. Например, специализированные микросхемы (ASIC) логичнее назвать по-
лузаказными, а специализированные схемы (Full Custom) — уже по-настоящему
заказными микросхемами. Пожалуй, они тоже правы... — Прим. ред.
Заказные интегральные схемы — ASIC 49
Микроматрица и микромозаика
В середине 60-х компания Fairchild Semiconductor представила но-
вое устройство под названием микроматрица (Micromatrix). Это устройс-
тво состояло из небольшого количества, около 100, ни к чему не под-
ключенных транзисторов. Для того чтобы это устройство могло выпол-
нять полезные функции, разработчики вручную вычерчивали на двух
пластиковых листах слои металлизации для соединения транзисторов.
На первом листе с помощью зеленого карандаша изображались
проводники по оси Y, т. е. сверху вниз, с помощью которых изготавли-
вался первый слой металлизации. На втором листе, но уже с помощью
красного карандаша, изображались проводники по оси X, т. е. слева
направо, для изготовления второго слоя металлизации. Кроме того,
использовались дополнительные листы для изображения переходных
отверстий, соединяющих первый слой металлизации с транзисторами
и для переходных отверстий, соединяющих первый и второй слои ме-
таллизации.
Изготовление устройства таким способом было крайне трудоем-
ким занятием и способствовало возникновению ошибок, но, так или
иначе, дорогостоящая и по настоящему трудоемкая работа по созда-
нию транзисторов выполнялась. Другими словами, микроматрица
позволяла разработчикам создавать заказные устройства, приемлемые
по стоимости (хотя все же дорогие), и срокам изготовления (хотя и не
очень быстро).
По прошествии нескольких лет, а точнее в 1967 году, компания
Fairchild представила новое устройство, получившее название микро-
мозаики (Micromosaic). На этот раз устройство содержало несколько со-
тен отдельных транзисторов, которые могли соединяться вместе, обра-
зуя около 150 логических элементов И, ИЛИ и НЕ. Уникальность мик-
ромозаики заключалась в том, что разработчики могли задавать
функции заказного устройства, используя логические выражения в
виде текстового файла, с помощью которого компьютерная программа
определяла необходимые межтранзисторные соединения и изготавли-
вала фотошаблон, по которому уже создавалось устройство. Такой
подход был настоящей революцией для того времени, и сегодня мик-
ромозаика считается предтечей современных вентильных матриц как
разновидности специализированных заказных микросхем и первым
настоящим приложением средств автоматизированного проектирова-
ния (САПР).
Вентильные матрицы
Идея создания матриц логических элементов, или вентильных
матриц, витала еще в конце 60-х в компаниях IBM, Fujitsu и др. Одна-
ко первые устройства использовались только для внутреннего потреб-
ления, и только в середине 70-х вентильные матрицы, изготовленные
по технологии КМОП, вышли на широкую дорогу и стали доступны
широкому кругу потребителей. Первые вентильные матрицы называ-
лись нескоммутированная логическая матрица (ULA — uncommitted logic
array). Со временем этот термин перестал употребляться.
Основу вентильных матриц составляет базисная ячейка, состоящая
из набора несоединённых транзисторов и резисторов. Каждый постав-
щик заказных микросхем самостоятельно определяет оптимальный
набор компонентов, входящих в состав отдельной базисной ячейки
(Рис. 3.13).
1642 г. Блез Пас-
каль (Blaise Pascal)
построил первый
механический каль-
кулятор, так на-
зываемую арифме-
тическую машину.
50 Глава 3. История развития ПЛИС
а) Однородная КМОП
базисная ячейка
Рис. 3.13. Примеры простых базисных ячеек вентильной матрицы
б) Смешанная биполярная —
КМОП базисная ячейка
Поставщики заказных микросхем начинали свою работу с изготов-
ления заводским способом кремниевого кристалла, содержащего мас-
сив базисных ячеек. В случае канальной матрицы базисные ячейки, как
правило, располагались в виде одностолбцовых или двухстолбцовых
массивов, причем между столбцами имелись свободные области, так
называемые каналы (Рис. 3.14).
Рис. 3.14. Архитектура канальных логических матриц
При отсутствии каналов на матрице ячейки располагались в виде
одного большого массива. Поверхность такого устройства была пок-
рыта большим количеством ячеек и не имела выделенных каналов для
внутренних соединений. Такие матрицы назывались бесканалъными.
Разработчики могут использовать определяемый поставщиком
микросхем набор логических функций, таких как простые логические
вентили, мультиплексоры и регистры. Каждая из этих функций-бло-
ков рассматривается как отдельный элемент или ячейка. Не путать с
базисной ячейкой! Набор таких функций, поддерживаемый поставщи-
ком, называется библиотекой элементов.
Средства, с помощью которых создаются заказные микросхемы,
здесь не рассматриваются. Достаточно сказать, что разработчики в ко-
нечном итоге получают таблицу соединений на уровне вентилей, кото-
рая описывает, какие вентили будут использоваться, и какие между
ними будут соединения. Чтобы установить соответствие логических
вентилей и базисных ячеек и определить, как эти ячейки будут связы-
ваться между собой, используются специальные программы определе-
ния соответствий, программы расстановки, трассировки и другие.
Заказные интегральные схемы — ASIC 51
На основе полученных результатов изготовляются фотошаблоны, с
помощью которых создаются слои металлизации. Эти слои будут свя-
зывать компоненты внутри базисной ячейки, а также ячейки между
собой, с входами и выходами устройства.
Вентильные матрицы имеют разумную цену, так как транзисторы и
другие компоненты производятся заводским способом, а по заказу из-
готавливаются только слои металлизации. Большинство таких уст-
ройств не использует всех внутренних ресурсов. Кроме того, расположе-
ние вентилей жестко определено, а трассировка внутренних соедине-
ний далека от оптимальной. Все эти недостатки отрицательно сказались
на производительности и потребляемой мощности этих устройств.
1671 г. Барон Гот-
фрид фон Лейбниц
(Gottfried von
Leibniz) построил
первый механичес-
кий калькулятор.
Схемы на стандартных элементах
Решение проблем, свойственных вентильным матрицам стало воз-
можным с появлением в начале 90-х схем на стандартных элементах.
Эти компоненты имели много общего с вентильными матрицами.
Итак, еще раз: поставщик специализированной заказной (ASIC)
микросхемы составляет библиотеку элементов, и этой библиотекой
могут пользоваться разработчики. Поставщик также поддерживает
библиотеки аппаратных и программных макроопределений, которые
включают такие элементы, как процессоры, функции связи, ОЗУ или
ПЗУ. Наконец последнее, но не менее важное, разработчики могут ис-
пользовать ранее созданные функции или приобрести блоки интеллек-
туальной собственности.
Когда команда инженеров конструирует сложную микросхему, дабы
не изобретать велосипеда, она может принять решение о покупке
уже готового, т. е. кем-то разработанного, проекта одного или не-
скольких функциональных блоков. Проект таких функциональных
блоков называется интеллектуальной собственностью или IP
(intellectual property). Средства интеллектуальной собственности мо-
гут охватывать любые функциональные блоки, в том числе функции
связи и микропроцессоры. Наиболее сложные функции, такие как
микропроцессоры, могут называться ядрами.
Тем или иным способом, в наши дни с помощью сложных систем
автоматизированного проектирования, разработчики завершают свою
работу созданием таблицы соединений на уровне вентилей. Такая таб-
лица описывает, какие вентили используются и как они соединены
между собой.
В отличие от вентильных матриц схемы на стандартных элементах
не используют концепцию базисных ячеек, и компоненты на кремни-
евом кристалле не изготовляются заводским способом. Для индивиду-
ального расположения каждого вентиля в таблице соединений и для
оптимальной разводки соединений между ними используются специ-
альные средства автоматизированного проектирования. Полученные
результаты используются для создания заказных фотошаблонов для
каждого слоя микросхемы.
Концепция схем на стандартных элементах позволяет создавать ло-
гические функции, используя минимальное количество транзисторов
без какой-либо избыточности компонентов; сами функции могут реа-
лизовываться таким образом, чтобы сделать менее трудоемким создание
внутренних связей между ними. Именно поэтому схемы на стандартных
элементах обеспечивают почти оптимальное использование поверхнос-
ти кремниевого кристалла по сравнению с вентильными матрицами.
52 Глава 3. История развития ПЛИС
1746 г. Голландия. В
Лейденском уни-
верситете изобре-
тена лейденская
банка.
Структурированные специализированные микросхемы
и структурированные ASIC
С появлением схем на стандартных элементах эксперты предска-
зывали конец вентильным матрицам. Но, несмотря на то что, согласно
пословице «ничто не вечно под луной», они продолжают занимать
свою нишу на рынке, а несколько лет назад даже пережили свое второе
рождение.
Структурированные специализированные микросхемы, кстати
вначале они назывались иначе, появились на свет примерно в начале
90-х и прослонявшись без дела некоторое время, вернулись в преис-
поднюю, откуда собственно и пришли. Спустя 10 лет, примерно где-то
в 2001-2002 году, некоторые производители приступили к изучению
способов снижения затрат на проектирование специализированных
микросхем и сокращения продолжительности их разработки. Всех пу-
гал тот факт, что новые устройства ассоциировались с традиционными
вентильными матрицами. Поэтому, когда примерно в 2003 году появи-
лось название структурированные специализированные микросхемы
(structured ASIC), оно сразу пришлось всем по душе.
Конечно же, как обычно, у каждого поставщика собственная архи-
тектура устройства. В связи с этим будут рассмотрены только общие
черты этих устройств. Каждое устройство начинается с фундаменталь-
ного элемента, который одни называют модуль, а другие элемент моза-
ики. Такой элемент может содержать изготовленный заводским спосо-
бом набор общей логики, выполненной в виде логических вентилей,
мультиплексоров или таблиц соответствия, одного или нескольких ре-
гистров, и, возможно, небольшого локального ОЗУ (Рис. 3.15).
б) Модуль содержит таблицы
соответствия (LUT) и триггеры
а) Модуль содержит вентили,
мультиплексоры и триггеры
Рис. 3.15. Примеры модулей структурированных специализированных ИС
Массив таких элементов изготавливается заводским способом по
всей поверхности кристалла. Некоторые альтернативные архитектуры
начинаются с базисной ячейки или базисного модуля, или базисного эле-
мента мозаики, или др., в состав которой входят только элементы об-
щей логики в форме изготовленных заводским способом вентилей,
мультиплексоров или таблиц соответствия. Массив таких базисных
единиц (говорят 4x4, 8x8 или 16x16) в соединении с некоторыми спе-
циальными модулями, содержащими регистры, небольшие элементы
памяти и другую логику, образует базовую ячейку или базовый модуль,
или базовый элемент мозаики, или др. Этот массив изготавливается за-
водским способом по всей поверхности кристалла.
ПЛИС 53
Заводским способом также изготавливаются, обычно по контуру
кристалла, некоторые дополнительные функции, например блоки
ОЗУ, тактовые генераторы, логика периферийного сканирования и
другие функции (Рис. 3.16).
1752 г. Америка.
Бенджамин Фран-
клин, проведя опыт
с воздушным змеем,
доказал, что мол-
ния представляет
из себя электричес-
кий разряд.
1775 г. Италия.
Алессандро Вольта
изобрел генератор
статического
электричества,
так называемую
электростатичес-
кую индукционную
машину.
Дело в том, что при выполнении устройства по заказу изготавлива-
ются только слои металлизации, как и в случае стандартных вентиль-
ных матриц. Отличие кроется в том, что вследствие большей сложнос-
ти модулей структурированных специализированных ИС большинс-
тво слоев металлизации уже предопределено. Таким образом, при
изготовлении многих структурированных микросхем по заказу их ар-
хитектура нуждается всего лишь в двух или трех слоях металлизации, а
в некоторых случаях требуется изготовить только один слой с переход-
ными отверстиями. В результате значительно снижается стоимость и
сокращается время изготовления оставшихся фотошаблонов, необхо-
димых для создания устройства.
Определить точное значение параметров довольно сложно, однако
предопределенная и изготовленная заводским способом логика струк-
турированных микросхем, по сравнению со схемами на стандартных
элементах, потребляет большую мощность, обладает большей произ-
водительностью и занимает больше места на кристалле. Для выполне-
ния одних и тех же функций структурированные микросхемы в сред-
нем требуют в три раза больше места на кристалле и потребляют в два-
три раза больше энергии, чем схемы на стандартных элементах. На
практике эти параметры существенно зависят от типа устройства и его
архитектуры. К сожалению, в то время, когда писалась эта книга, не
существовало каких-либо оценок параметров, основанных на про-
мышленных стандартах.
плис
В начале 80-х стало ясно, что в сфере цифровых микросхем образо-
вался пробел. С одной стороны, существовали программируемые уст-
ройства, подобные простым и сложным ПЛУ, которые отличались вы-
сокой конфигурируемостью и малым временем изготовления и моди-
фикации. Но эти устройства не были способны поддерживать большие
и сложные функции.
54 Глава 3. История развития ПЛИС
С другой стороны, существовали заказные специализированные
интегральные микросхемы. Они поддерживали чрезвычайно большие
и сложные функции, но также были чрезвычайно дорогими, и для их
изготовления требовалось значительное время. Кроме того, оконча-
тельный вариант заказной микросхемы «замораживался в кремнии»
(Рис. 3.17).
Специализированные
ИС (ASIC)
Структурированные
специализированные ИС '|
ИС на стандартных
элементах
Полностью заказные ИС
1 ) В начале 1980-х не существовали.
Рис. 3.17. Пробел между ПЛУ и заказными ИС
Чтобы заполнить этот пробел, фирма Xilinx разработала новый
класс микросхем FPGA (Field programmable gate arrays), или ПЛИС
(программируемые логические интегральные схемы), которые появи-
лись в продаже в 1984 году. Различные типы существующих ПЛИС бо-
лее подробно рассматриваются в гл. 4, а здесь необходимо только уточ-
нить, что ПЛИС изготавливались по КМОП-технологии и для хране-
ния конфигурации использовали статическое ОЗУ. Несмотря на то что
первые версии этих устройств были сравнительно простыми и содер-
жали, по сегодняшним меркам, относительно мало вентилей или их
эквивалентов, многие представления, лежащие в основе их архитекту-
ры, используются и в наши дни.
Основу первых ПЛИС составляла концепция программируемых
логических блоков, которые включали в себя 3-х входовую таблицу со-
ответствия (LUT — lookup table), регистр, выполняющий функцию
триггера или защелки, мультиплексор, а также некоторые другие эле-
менты, не представляющие в данном контексте особого интереса. На
Рис. 3.18 показан очень простой программируемый логический блок.
Как будет показано в гл. 4, логический блок современной ПЛИС мо-
жет быть чрезвычайно сложным.
Каждая ПЛИС содержит большое количество таких программиру-
емых блоков. Путем программирования соответствующих ячеек стати-
ческого ОЗУ каждый логический блок устройства может быть сконфи-
гурирован для выполнения различных функций. В процессе конфигу-
рирования в каждый регистр записывается его начальное значение в
виде логического 0 или логической 1, а также определяется, будет ли
регистр выполнять функцию триггера или защелки (Рис. 3.18). В пер-
вом случае также определяется, по какому фронту тактового сигнала,
положительному или отрицательному, будет производиться переклю-
чение. Тактовые сигналы являются общими для всех логических бло-
ков. Мультиплексор, подключенный к входу триггера, может конфигу-
рироваться на передачу сигналов с выхода таблицы соответствия или с
ПЛИС 55
1777 г. Чарлъз
Стэнхоп (Charles
Stanhope) разрабо-
тал механическую
счётную машину.
отдельного входа логического блока. Таблица соответствия может про-
граммироваться на работу в качестве любой логической функции с
тремя входами и одним выходом.
Допустим, что таблице соответствия необходимо сформировать
функцию
у = (а & Ь) | с.
Для этого в таблицу соответствия необходимо загрузить соответс-
твующие выходные значения этой функции (Рис. 3.19).
Рис. 3.19. Конфигурирование таблицы соответствия
Таблица,соответствия с мультиплексором 8:1, представленная на
Рис. 3.19, является упрощенным вариантом существующих таблиц со-
ответствия (см. гл. 4 и гл. 5).
ПЛИС состоит из большого числа программируемых логических
блоков, или «островов», окруженных «морем» программируемых внут-
ренних соединений (Рис. 3.20).
Как обычно, упрощенная схема является всего лишь весьма при-
ближенным представлением архитектуры ПЛИС. В действительности
все транзисторы и внутренние соединения выполняются на одном
кристалле кремния с помощью стандартных технологий изготовления
интегральных микросхем.
56 Глава 3. История развития ПЛИС
Конец 1700-х гг.
Чарльз Стэнхоп
(Charles Stanhope)
разработал логи-
ческую машину, на-
званную демонс-
тратор Стенхопа.
Программируемые
внутренние
соединения
Программируемые
логические блоки
Рис, 3,20, Упрощенная архитектура ПЛИС
Кроме локальных внутренних связей, показанных на Рис. 3.20, су-
ществуют глобальные, или высокоскоростные, соединения, которые
передают сигналы через кристалл без участия многочисленных ло-
кальных переключающих элементов.
Устройство также содержит контактные площадки и ножки для
ввода/вывода данных (на рисунке не показаны). С помощью ячеек па-
мяти статического ОЗУ внутренние соединения программируются та-
ким образом, чтобы входы микросхемы соединялись с входами одного
или нескольких программируемых логических блоков, а выходы этих
блоков подключались к входам другим блоков и/или подавались на
выходы микросхемы.
В конечном итоге, ПЛИС успешно справились с ролью моста
между ПЛУ и заказными специализированными микросхемами. С
одной стороны, они обладают высокой степенью конфигурируемости
и малым временем изготовления и модификации, как и ПЛУ. С дру-
гой стороны, они могут использоваться для реализации невероятно
больших и сложных функций, которые раньше реализовывались
только с помощью заказных микросхем. Специализированные заказ-
ные микросхемы предназначались для действительно больших, слож-
ных и высокотехнологичных систем. Однако на место, отведенное
этим микросхемам в сфере программируемой логики, посягают
ПЛИС, которые по мере совершенствования начали постепенно их
вытеснять.
ПЛИС-платформа
Принцип разработки по образцу, или разработки платформы, дли-
тельное время использовался на уровне печатных плат. Согласно этому
принципу на основе базовой конфигурации может быть реализовано
множество производных продуктов.
Современные высокотехнологичные ПЛИС, помимо громадней-
шего количества программируемой логики, содержат встроенные
блоки ОЗУ, встроенные процессорные ядра, высокоскоростные бло-
ки ввода/вывода и многое другое. Кроме того, разработчики имеют
доступ к большому набору блоков интеллектуальной собственности.
Все это способствовало развитию концепции ПЛИС-платформы. Суть
её заключается в том, что любая компания может использовать уже
ПЛИС 57
спроектированную ПЛИС-платформу для многочисленных изделий
внутреннего пользования либо предложить исходные проекты дру-
гим компаниям для изготовления заказных устройств или для их ви-
доизменения.
1800 г. Италия.
Алессандро Вольта
изобрел первую ба-
тарейку.
Гибриды вида ПЛИС — заказные интеральные схемы
Очевидно, что нет никакого смысла встраивать компоненты заказ-
ных интегральных схем внутри ПЛИС, поскольку полученная интег-
ральная схема будет источником классических проблем, которые
свойственны технологии создания заказных микросхем: высокие рас-
ходы на проектирование и производство, продолжительные сроки вы-
хода на рынок и другие. Однако существует ряд случаев, когда один
или несколько компонентов ПЛИС используются как часть заказных
микросхем на стандартных элементах.
Одна из причин встраивания компонентов ПЛИС внутрь заказ-
ных микросхем — сделать как можно проще принцип разработки
платформы. В этом случае платформа будет принадлежать к классу
заказных микросхем, но встроенные компоненты ПЛИС будут обес-
печивать один из механизмов, используемых для адаптации и моди-
фикации изделия.
Другая причинная связана с тем, что последние несколько лет на-
блюдается расширение сферы применения ПЛИС, в частности они
могут использоваться для придания дополнительных свойств издели-
ям на заказных микросхемах. В этом случае большие и сложные спе-
циализированные микросхемы соединяются с ПЛИС, расположенны-
ми на одной печатной плате в непосредственной близости друг от дру-
га (Рис. 3.21).
К другим микросхемам
на печатной плате
Рис. 3.21. Применение ПЛИС для придания дополнительных свойств изделиям
на заказных микросхемах
Применение этой схемы оправданно большой трудоёмкостью и
дороговизной операций по устранению ошибок и изменению функци-
ональности системы при использовании заказных микросхем. Даже
если изделие на заказных микросхемах не содержит ошибок, примене-
ние ПЛИС можно использовать для выполнения низкоуровневых мо-
58 Глава 3. История развития ПЛИС
1801 г. Франция.
Жозеф Жаккар
(Joseph Jacquard)
разработал ткац-
кий станок, управ-
ляемый перфокар-
тами.
1820 г. Франция.
Андре Ампер (Andre
Ampere) исследовал
силу электрическо-
го тока в магнит-
ном поле.
дификаций и модернизации системы. Недостатком такой технологии
является длительность прохождения сигналов от заказной микросхе-
мы к ПЛИС и обратно. Устранить этот недостаток можно, встроив яд-
ро ПЛИС внутрь заказной микросхемы. В результате получим гибрид:
ПЛИС — заказная интегральная схема (FPGA-ASIC).
При этом, однако, надо иметь в виду, что системы автоматизиро-
ванного проектирования и методы проектирования заказных микро-
схем и ПЛИС существенно различаются. Например, про заказные
микросхемы можно сказать, что они мелкомодульные, поскольку в ос-
новном они создаются на уровне простейших логических элементов.
Это значит, что традиционные методы проектирования, такие как ло-
гический синтез, традиционные методы размещения элементов и
трассировки соединений также применимы к проектированию мелко-
модульных заказных интегральных схем.
Что касается ПЛИС, то про них можно сказать, что они являются
среднемодульными (или крупномодульными в зависимости от того, кто
об этом говорит, поскольку физически они реализуются с использова-
нием высокоуровневых блоков, таких как программируемые логичес-
кие блоки, ранее рассмотренные в этой главе). В этом случае для про-
ектирования лучше использовать специфичные для ПЛИС методы
синтеза, размещения элементов и трассировки соединений, посколь-
ку данные методы «воспринимают мир» в терминах высокоуровне-
вых блоков.
Областью применения гибридов вида ПЛИС — заказная микро-
схема являются структурированные специализированные микросхе-
мы, или структурированные ASIC, поскольку они также соответству-
ют принципам блочного построения. Когда поставщики структуриро-
ванных специализированных микросхем выбирают средства
проектирования, они чаще общаются с поставщиками ПЛИС—ориен-
тированных средств синтеза, технологий размещения элементов и
трассировки соединений, чем с их коллегами, предлагающими тради-
ционные средства. Таким образом, для проектирования гибридов вида
ПЛИС-заказная микросхема, основанных на структурированной
ASIC, автоматически можно пользоваться едиными средствами разра-
ботки, так как одни и те же методы блочного синтеза, размещения и
трассировки могут использоваться для изготовления как «заказной»,
так и «ПЛИС»-части микросхемы.
Как создают ПЛИС
Вопрос, который часто задают, но ответ на который вряд ли можно
найти в книге о ПЛИС. Действительно, каким же образом поставщики
ПЛИС проектируют новые поколения устройств?
Приходится ли им вручную разрабатывать каждый транзистор и
проводник? Придерживаются ли они при этом порядка проектирова-
ния, принятого при изготовлении заказных микросхем? Или же они
создают описание уровня регистровых передач, преобразуют его в
список соединений логических элементов и затем используют про-
граммное обеспечение для размещения элементов и трассировки со-
единений. Другими словами, используют методы, аналогичные тем,
которые используются при построении классических заказных мик-
росхем, т. е. вентильных матриц или схем на стандартных элементах
(см. гл. 2).
Если ответить на все эти вопросы кратко, ответом будет да! Развер-
нутый ответ будет выглядеть приблизительно так:
ПЛИС 59
Некоторые части устройств подобны программируемым логичес-
ким блокам и базовым соединительным структурам, и в этом случае
поставщики борются за каждый квадратный микрон и каждую частич-
ку наносекунды. Такими частями устройств являются транзисторы и
проводники, изготавливаемыми вручную по технологии заказных
микросхем. Утешает в этом случае то, что эти части устройства являют-
ся относительно малыми и часто повторяющимися, т. е. будучи один
раз созданы, они могут тысячи раз воспроизводятся на поверхности
кристалла.
Существуют и вспомогательные части устройств, такие как кон-
фигурируемые схемы управления, которые встречаются в единич-
ном экземпляре и к которым не предъявляются жестких требований
по размерам и производительности. Эти части изготавливаются ме-
тодами, которые используются для создания схем на стандартных
элементах.
ГЛАВА 4
АРХИТЕКТУРА ПЛИС
Предупреждение
Данная глава посвящена особенностям построения ПЛИС. При
этом часть вопросов, таких, например, как сравнение технологий на
основе метода наращиваемых перемычек или на основе ячеек памяти
статического ОЗУ, в явном виде не рассматривается. Некоторые пос-
тавщики ПЛИС специализируются на одной из упомянутых техноло-
гий, другие предлагают различные семейства устройств, основанные
на обеих технологиях. Большинство рассуждений в этой главе отно-
сится к устройствам на основе ячеек статического ОЗУ.
При использовании в составе ПЛИС встраиваемых блоков, таких
как мультиплексоры, сумматоры, память и микропроцессорные ядра,
каждый поставщик предлагает свое «меню» этих блоков с различным
«составом» ингредиентов. Аналогично различным сортам печенья с
шоколадной крошкой, которые отличаются количеством шоколадных
крошек, разные ПЛИС будут содержать большие/лучшие/худшие
встроенные блоки ОЗУ или будут отличаться параметрами умножите-
лей либо поддерживаемыми стандартами ввода/вывода, либо чем-ни-
будь ещё.
Проблема заключается в том, что характеристики, поддерживае-
мые каждым производителем и каждым семейством устройств, меня-
ются едва ли не каждый день. Это значит, что при выборе микросхемы
по определенным параметрам необходимо провести небольшое иссле-
дование, чтобы выяснить, устройства каких поставщиков, максималь-
но удовлетворяют вашим запросам.
Небольшое введение
Перед тем как погрузиться в эту главу, уточним определения неко-
торых терминов, чтобы убедиться в том, что мы говорим на одном и
том же языке. Например, рассмотрим термин структура, который
встречается в этой книге. Если этот термин используется в контексте
описания кремниевого кристалла, это значит, что он имеет отношение
к основной структуре устройства (например, как в выражении «струк-
тура цивилизованного общества»).
Когда кто-то впервые слышит этот термин, произнесенный в дан-
ном контексте, возможно, он покажется несколько вычурным или да-
же высокопарным. Между прочим, некоторые инженеры действитель-
но считают, что это не что иное, как очередной рекламный трюк. Дру-
гими словами, они считают, что таким образом поставщики
специализированных микросхем и ПЛИС раскручивают свои устройс-
тва, создавая им имидж более сложных, чем они есть на самом деле.
Наращиваемые перемычки, статическое ОЗУ и прочее... 61
Но стоит только привыкнуть к этому термину, как сразу понимаешь,
что он даже очень полезный.
Когда речь идет о проектных нормах микросхем, подразумеваются
размеры конкретных структур, сформированных на кристалле, — ана-
логично тому, как под словом канал мы понимаем часть полевого тран-
зистора. Эти структуры невероятно малы. В начале и середине 80-х ус-
тройства основывались на 3-х микронной геометрии, т. е. их наимень-
шие структуры составляли по размеру 3 мкм (три микрометра = три
миллионных части метра = три микрона). Звучать это будет так: «Эта
микросхема выполнена по трехмикронной технологии».
Разработку каждых новых проектных норм называют технологи-
ческим процессом. К 90-м стали появляться устройства, основанные
на 1-микронной технологии, и на протяжении последующих 10 лет
характеристики размеров продолжали падать. С наступлением 21-го
века появились высокопроизводительные ИС, выполненные по
технологии менее 0.18 мкм. К 2002 году этот показатель сократился
до 0.13 мкм, и в 2003 году появятся устройства с технологией
0.09 мкм.
Технологический процесс менее чем примерно 0.5 мкм, называет-
ся глубоким субмикронном (DSM — deep submicron). С некоторого мо-
мента, а именно с какого точно не определено, поскольку существует
несколько определений в зависимости от того, о чём идет речь, мы пе-
ремещаемся в область сверхглубокого субмикрона (USMC — ultra deep
submicron).
Возникает некомфортная ситуация: когда показатели конфигура-
ции опускаются ниже 1 мкм, приходится выговаривать что-то вроде
«ноль целых тринадцать сотых микрона». По этой причине общепри-
нятым стало употреблять приставку «нано». Один нано, сокращение от
«нанометр», соответствует одной тысячной микрона, что, в свою оче-
редь, соответствует одной тысячной от одной миллионной метра. Поэ-
тому вместо того чтобы бормотать «ноль целых девять сотых микрона»
(0.09 мкм), можно просто четко произнести «девяносто нанометров» и
покончить с этим. Естественно, оба выражения имеют одинаковый
смысл, но если захочется пообщаться с друзьями на эту тему, лучше го-
ворить на общепринятом языке и показать себя знающим и ультрасов-
ременным, чем стариком минувшего тысячелетия.
Наращиваемые перемычки, статическое ОЗУ
и прочее...
Устройства на основе статического ОЗУ
Большинство ПЛИС использует для хранения конфигурации
ячейки памяти статического ОЗУ, которые могут быть многократно
перепрограммируемы. Главным преимуществом этой технологии яв-
ляется то, что они позволяют легко и быстро реализовать и протести-
ровать все новые идеи, относительно легко подстраиваясь под новые
стандарты и протоколы. Кроме того, при включении системы такая
ПЛИС может быть изначально запрограммирована для выполнения
определенных функций, например, самотестирования или тестирова-
ния всей системы, а затем может быть перепрограммирована для вы-
полнения своей главной задачи.
62 Глава 4. Архитектура ПЛИС
Другое существенное преимущество использования ячеек ста-
тического ОЗУ заключается в том, что эта технология является пе-
редовой. На поставщиков ПЛИС также действует тот факт, что
многие компании, специализирующиеся на устройствах памяти,
расходуют огромные ресурсы на исследование и развитие ячеек
статического ОЗУ. Более того, эти ячейки памяти создаются по та-
кой же КМОП-технологии, как и остальные части ПЛИС, т. е. для
создания этих компонентов не требуются какие-то специальные
технологии.
Раньше для апробирования производства микросхем по новым
технологиям часто использовались микросхемы памяти. В последнее
время совокупность таких характеристик, как размер, сложность и
бесперебойность последних поколений ПЛИС сделали возможным их
применение для решения и этих задач. В отличие от устройств памяти
ПЛИС позволяют легко идентифицировать и обнаруживать дефекты
структуры, т. е. установить факт ошибки и даже определить, что и где
произошло. Например, когда компании IBM и UMC внедряли техно-
логию 0.09 мкм (90 нм), ПЛИС фирмы Xilinx стали первыми устройс-
твами, изготовленными по такой технологии.
К сожалению, ничего не дается даром, за все надо платить. Недо-
статком устройств на основе статического ОЗУ является то, что их
нужно переконфигурировать каждый раз при включении системы.
Для этого приходится использовать специальную внешнюю память,
что увеличивает стоимость системы и требует места на печатной плате,
или использовать встроенный микропроцессор, или реализовать ка-
кие-то другие варианты (см. гл. 5).
Защита интеллектуальной собственности в устройствах
на основе статического ОЗУ
При использовании ячеек статического ОЗУ может оказаться до-
вольно сложно защитить интеллектуальную собственность, реализо-
ванную в данном устройстве. Это обусловлено тем, что конфигураци-
онный файл, используемый для программирования устройства, в том
или ином виде хранится во внешней памяти.
В настоящее время существуют некоммерческие инструменты, с
помощью которых можно прочитать содержимое конфигурационного
файла и сгенерировать соответствующую схему или таблицу соедине-
ний. Говоря об этом следует иметь в виду, что понимание и извлечение
логики из конфигурационного файла пока не является тривиальной
задачей, но и не находится выше предела следующей суммы: сообрази-
тельность человека + мощность современного компьютера.
Давайте не будем забывать, что по всему миру существуют компа-
нии обратного проектирования, которые специализируются на вскры-
тии «средств интеллектуальной собственности». Правительства неко-
торых стран закрывают глаза на воровство интеллектуальной собс-
твенности, получая от этого немалые доходы. Надеюсь, все понимают,
кого я имею в виду. Если изделие приносит большие доходы, готов
поспорить, что найдутся такие ребята, которые будут стремиться пов-
торить его у вас за спиной.
В действительности проблема связана не с личностью, ворующего
интеллектуальную собственность с помощью содержимого конфигу-
рационного файла. Все зависит от его способности клонировать уст-
ройство независимо от понимания принципов его работы. Используя
Наращиваемые перемычки, статическое ОЗУ и прочее... 63
легко доступные технологии, любой может взять печатную плату, по-
ложить её на испытательную установку с матрицей подпружиненных
игольчатых контактов и быстро получить полную таблицу соединений
на плате. Такая таблица может быть использована для воспроизводства
печатной платы. Теперь единственное, что остается сделать этому
гнусному подонку — скопировать конфигурационный файл из загру-
зочного ППЗУ (или СППЗУ, ЭСППЗУ и так далее), и... он получает
дубликат всего устройства.
Радует то, что некоторые современные ПЛИС на основе статичес-
кого ОЗУ поддерживают концепцию побитного поточного шифрования.
В этом случае окончательная версия конфигурационных данных шиф-
руется перед сохранением в устройство внешней памяти. Ключ шиф-
рования загружается в специальный регистр на ячейках статического
ОЗУ в ПЛИС через порт JTAG (см. гл. 5). Совместно с небольшим ко-
личеством логики этот ключ позволяет дешифровать входящий за-
шифрованный конфигурационный поток битов во время загрузки уст-
ройства.
Процесс загрузки зашифрованного потока автоматически делает
невозможным считывание записанной в ПЛИС информации. Это зна-
чит, что обычно можно использовать незашифрованные конфигура-
ционные данные в процессе разработки (когда необходимо использо-
вать считывание записанной информации), а в процессе производства
просто перейти к использованию зашифрованных потоков. Разработ-
чик может в любое время загрузить незашифрованный поток. Следо-
вательно, сначала можно загрузить тестовую конфигурацию, а затем
перегрузить зашифрованную версию.
Недостатком этой схемы является то, что для её работоспособнос-
ти на печатной плате необходимо использовать батарею резервного
питания, и таким образом сохранить содержимое регистра ключа
шифрования, когда ПЛИС будет обесточена. Эта батарея будет иметь
продолжительное время жизни, исчисляемое годами или десятилетия-
ми, так как необходимо поддерживать работу только одного регистра в
устройстве. Однако её присутствие приводит к увеличению размеров,
веса, сложности и стоимости печатной платы.
Устройства на основе наращиваемых перемычек
В отличие от устройств, основанных на ячейках статического ОЗУ,
которые программируются при включении системы, устройства на ос-
нове наращиваемых перемычек программируются в выключенном со-
стоянии с помощью так называемого программатора.
Сторонники ПЛИС на основе наращиваемых перемычек гордят-
ся разнообразием их преимуществ. Во-первых, эти устройства энер-
гонезависимы, т. е. их конфигурационные данные не стираются при
отключении, питания системы. Это значит, что они готовы к работе
сразу после включения системы. Будучи энергонезависимыми, эти
устройства не требуют дополнительной микросхемы внешней памя-
ти для хранения конфигурационных данных. Это позволяет умень-
шить стоимость всей системы и сохранить свободное место на печат-
ной плате.
Одно из преимуществ ПЛИС на основе наращиваемых перемычек
заслуживает особого внимания: структура их внутренних соединений
является действительно «сверхжесткой», и значит, такие устройства
относительно устойчивы к радиации. Это свойство перемычек может
представлять определенный интерес для военных и космических при-
64 Глава 4. Архитектура ПЛИС
ложений. Состояние конфигурационных ячеек компонентов стати-
ческого ОЗУ может быть «переключено» в произвольное состояние,
если эти ячейки будут поражены радиацией, которой так много в кос-
мосе. В сравнении с ними, однажды запрограммированная наращива-
емая перемычка не может быть изменена таким способом. При этом,
следует иметь в виду, что любые триггеры в этом устройстве остаются
чувствительными к воздействию радиации, поэтому микросхемы,
предназначенные для работы в условиях радиационного воздействия,
должны иметь защиту триггеров в виде системы тройного резервирова-
ния. Другими словами, в системе должно быть три копии каждого ре-
гистра, и решение о значении выходного сигнала принимается боль-
шинством голосов. В идеальном случае все три регистра будут содер-
жать одинаковое значение, но если один из регистров
«переключается» так, что два из них содержат 0, а третий — 1, выход-
ным значением будет 0, и наоборот, если два регистра содержат 1, а
третий 0, выходным значением будет считаться 1.
Радиация может проявляться в виде гамма-лучей (высокоэнергети-
ческих фотонов), бета-частиц (высокоэнергетических электронов) и
альфа-частиц. Следует заметить, что устойчивые к радиации уст-
ройства не ограничены только технологией наращиваемых перемы-
чек. Такими свойствами обладают и другие компоненты, в том числе
на основе ячеек статического ОЗУ, но в специальных радиационно-
устойчивых корпусах и с поддержкой рассмотренной системы трой-
ного резервирования.
Но, возможно, самым важным преимуществом ПЛИС на основе
наращиваемых перемычек является то, что их конфигурационные
данные скрыты глубоко внутри. По определению программатор мо-
жет прочитать эти данные, поскольку это часть его работы. После на-
ращивания каждой перемычки программатор должен провести тести-
рование, чтобы убедиться, что элемент успешно запрограммирован, и
лишь затем перейти к следующей перемычке. Кроме того, программа-
тор может использовать автоматическую проверку успешного конфи-
гурирования устройства. Такой подход оправдан в случае устройства,
содержащего 50 миллионов элементов не считая программируемых.
Чтобы это сделать, программатору потребуется произвести чтение со-
стояния наращиваемых перемычек и полученные результаты срав-
нить с требуемым состоянием, которое определяется в конфигураци-
онном файле.
После программирования устройства следует воспользоваться воз-
можностью наращивать специальную защиту перемычек, и, таким об-
разом, обеспечить защиту от считывания любых запрограммирован-
ных данных из устройства (в форме наличия или отсутствия перемы-
чек). Даже если устройство будет вскрыто, запрограммированные и
незапрограммированные перемычки остаются идентичными, к тому
же тот факт, что наращиваемые перемычки утоплены во внутренних
слоях металлизации, делает конструкцию недоступной для обратного
проектирования.
Поставщики ПЛИС на основе наращиваемых перемычек могут
рекламировать и два других преимуществ, связанных с мощностью
потребления и скоростью, и, если при этом вы не будете очень до-
тошным, не исключено, что ваш собственный выбор вас разочарует.
Например, поставщики могут завлекать вас тем, что устройства на
наращиваемых перемычках потребляют в режиме покоя, примерно,
всего лишь 20% мощности по сравнению с аналогичными устройства-
Наращиваемые перемычки, статическое ОЗУ и прочее... 65
ми на статическом ОЗУ, что их рабочая мощность потребления также
существенно ниже, а задержка на внутренних соединениях меньше.
Они могут также ненароком упомянуть, что наращиваемые перемыч-
ки очень маленькие и, таким образом, занимают значительно мень-
ше места на кристалле, чем эквивалентные им ячейки памяти стати-
ческого ОЗУ. При этом они могут игнорировать тот факт, что устройс-
тво на наращиваемых перемычках требуют внешних
программируемых цепей, включая большие корпусные транзисторы.
Они будут продолжать, утверждая, что, если ваше устройство содер-
жит десятки миллионов конфигурируемых элементов, использование
наращиваемых перемычек позволит сделать устройство более ком-
пактным. Это, в свою очередь, позволяет уменьшить задержки на
внутренних соединениях, делая устройство быстрее, чем его аналоги
на статическом ОЗУ.
И оба этих утверждения будут справедливыми... при сравнении
двух устройств, выполненных по одной технологии. Но это невозмож-
но, так как технология наращиваемых перемычек требует использова-
ния приблизительно трех дополнительных технологических шагов
после завершения основного технологического процесса. В силу этих,
а также других причин устройства на наращиваемых перемычках всег-
да отстают на одно, а обычно на несколько поколений технологичес-
ких процессов от компонентов на статическом ОЗУ, которые обладают
преимуществами в скорости и потребляемой мощности по сравнению
с другими микросхемами.
Устройства на наращиваемых перемычках являются однократно
программируемыми, и это их главный недостаток, так как, если эта
маленькая штучка уже была однажды запрограммирована, изменить её
конфигурацию уже невозможно.
1821 год. Англия.
Майкл Фарадей
(Michael Faraday)
изобрел первый
электрический
двигатель.
Следует заметить, что когда появятся устройства, основанные на
ячейках магнитного ОЗУ, о которых говорилось в гл. 2, то положе-
ние среди ПЛИС может существенно измениться. Причиной тому
может быть то, что перемычки магнитного ОЗУ будут намного мень-
ше, чем ячейки статического ОЗУ, что приведёт к увеличению плот-
ности элементов на кристалле и уменьшению задержек, при этом та-
кие устройства будут потреблять меньше энергии. Более того,
устройства на магнитном ОЗУ могут быть предварительно запрог-
раммированы, подобно микросхемам на наращиваемых перемыч-
ках, и впоследствии перепрограммированы, как устройства на ячей-
ках статического ОЗУ.
Устройства на основе СППЗУ
Этот предельно короткий и чрезвычайно приятный раздел, пос-
кольку в настоящее время никто не делает и даже не планирует делать
ПЛИС на основе СППЗУ.
Устройства на основе ЭСППЗУ и Flash
Конфигурационные ячейки ПЛИС на основе ЭСППЗУ или Flash-
памяти так же, как и ячейки памяти статического ОЗУ, образуют
длинную цепочку подобно сдвиговому регистру. Эти устройства мо-
гут программироваться в отключенном состоянии с помощью про-
грамматора. Некоторые версии устройств можно программировать не
66 Глава 4. Архитектура ПЛИС
1821 г. Англия.
Майкл Фарадей на-
рисовал магнитное
поле вокруг провод-
ника.
выключая питание, но при этом время их программирования пример-
но в три раза превышает время программирования устройств на ста-
тическом ОЗУ.
После программирования содержащиеся в устройствах данные бу-
дут энергонезависимы, т. е. эти устройства будут сразу готовы к работе
после подачи напряжения на систему. Что касается защиты, то некото-
рые из этих устройств используют принцип мультибитного ключа, раз-
мер которого приблизительно от 50 до нескольких сотен бит. После
программирования устройства можно загрузить в него личный ключ,
т. е. битовую комбинацию, для защиты конфигурационных данных.
Дело в том, что, если загрузить ключ, прочитать данные из устройства
или записать в него новые данные можно будет только, загрузив ко-
пию ключа через JTAG-порт (гл. 5). Если при этом учесть, что JTAG
порт современных устройств работает на частоте 20 МГц, взлом ключа
методом изнурительного перебора каждого возможного значения зай-
мет миллионы лет.
Двухтранзисторные ЭСППЗУ- и Flash-ячейки памяти приблизи-
тельно в два с половиной раза больше по размеру своих однотранзис-
торных СППЗУ братьев, но они существенно меньше, чем ячейки ста-
тического ОЗУ. Это значит, что устройство может быть выполнено бо-
лее компактным, с меньшими задержками на внутренних
соединениях.
Вместе с тем эти устройства требуют примерно пять дополни-
тельных технологических шагов после завершения стандартного тех-
нологического цикла КМОП. Именно в этом кроется причина их
отставания от устройств на статическом ОЗУ на одно или несколько
поколений технологических процессов. И последнее, но, как обыч-
но, не менее важное. Эти устройства имеют тенденцию сохранять
относительно высокую мощность потребления в статическом режи-
ме из-за содержащегося в них большого количества нагрузочных ре-
зисторов.
Гибридные устройства на ячейках Flash и статического ОЗУ
Так уж повелось в этой жизни, что всегда найдется желающий до-
бавить еще какие-нибудь ингредиенты в котелок с супом. Примени-
тельно к ПЛИС некоторые производители часто предлагают весьма
экзотические комбинации технологий программирования. Рассмот-
рим, например, устройство, каждый конфигурационный элемент ко-
торого представляет собой комбинацию Flash- (или ЭСППЗУ-) ячей-
ки памяти и связанной с ней ячейки памяти статического ОЗУ.
В этом случае Flash-элементы могут быть предварительно запрог-
раммированы. Затем, после включения системы, содержимое Flash-
ячеек памяти массово параллельно копируется в соответствующие им
ячейки памяти статического ОЗУ. Такая технология обеспечивает
энергонезависимость, присущую устройствам на основе наращивае-
мых перемычек, и это значит, что устройство будет немедленно готово
к работе после включения системы. Но, в отличие от устройств на ос-
нове наращиваемых перемычек, ячейки памяти статического ОЗУ
можно использовать для перепрограммирования устройства во вклю-
ченном состоянии. Аналогично можно перепрограммировать Flash-
ячейки памяти устройства, не снимая напряжения питания, либо вы-
полнить процедуру перепрограммирования с помощью программато-
ра после выключения системы.
Мелко-, средне- и крупномодульные архитектуры 67
Выводы
В Табл. 4.1 кратко перечислены наиболее важные характеристики
рассмотренных технологий программирования.
Таблица 4.1. Характеристики технологий программирования
Характеристика Статическое ОЗУ Наращиваемые перемыки ЭСППЗУ/Hash
Технологический процесс Современ- ный уровень развития Отставание на од- но или несколько поколений Отставание на од- но или несколько поколений
Перепрограммирование Да (внутри- системно) Нет Да (внутрисистем- но или в выклю- ченном состоянии)
Скорость перепрограммиро- вания (включая стирание) Быстрая — В 3 раза медленнее статического ОЗУ
Энергозависимость (возмож- ность программирования при включении питания) Да Нет Нет (возможно при не- обходимости)
Потребность во внешнем конфигурационном файле Да Нет Нет
Пригодность для изготовле- ния прототипов устройств Да (высокая пригодность) Нет Да (приемлемо)
Готовность к работе сразу после включения Нет Да Да
Защита прав интеллектуаль- ной собственности Приемлемая Очень хорошая Очень хорошая
Размер конфигурационной ячейки Большой (шесть тран- зисторов) Очень малый Малый (два транзистора)
Мощность потребления Средняя Низкая Средняя
Устойчивость к радиации Нет Да Нет
Мелко-, средне- и крупномодульные
архитектуры
В общем случае ПЛИС подразделяются на мелкомодульные и круп-
номодульные. Чтобы понять эту классификацию, напомню, что глав-
ной особенностью ПЛИС является их внутренняя структура, которая
преимущественно состоит из большого количества простых програм-
мируемых логических блоков-«островов» в «море» программируемых
внутренних связей (Рис. 4.1).
qgR В действительности подавляющее большинство конфигурационных
ячеек в ПЛИС связано с внутренними соединениями в отличие от
конфигурируемых логических блоков. Поэтому инженеры в шутку
говорят, что поставщики ПЛИС на самом деле продают только внут-
ренние связи, а логика поставляется бесплатно.
В мелкомодульной архитектуре каждый логический блок может
использоваться для реализации только очень простой функции. На-
пример, блок можно сконфигурировать для работы в качестве 3-входо-
68 Глава 4. Архитектура ПЛИС
1821 год. Англия.
Чарльз Уитстон
(Sir Charles
Wheatstone) впер-
вые воспроизвёл
звук.
вого простого логического элемента (И, ИЛИ, И-НЕ и так далее) или
элемента памяти (триггер D-типа, защелка D-типа и так далее).
Мелкомодульные структуры используются при реализации связу-
ющей логики и неоднородных структур, подобных конечным автома-
там. Мелкомодульные структуры также эффективны при реализации
систолических алгоритмов (функции, которые чрезвычайно эффектив-
ны за счет реализации массового параллелизма). Эти структуры обла-
дают определённым преимуществом при использовании технологии
традиционного логического синтеза, которая базируется на мелкомо-
дульной архитектуре заказных микросхем.
Пик интереса к мелкомодульной архитектуре ПЛИС был отмечен в
середине 90-х. Однако со временем подавляющее большинство пред-
ставителей этого семейства канули в лету, и на плаву остались лишь
представители крупномодульной архитектуры. В подобной архитекту-
ре каждый логический блок содержит относительно большое количес-
тво логики по сравнению с мелкомодульными представителями. Так,
например, логический блок может содержать четыре 4-входовых таб-
лицы соответствия, четыре мультиплексора, четыре D-триггера, и не-
которое количество логики быстрого переноса.
Для «мелкомодульных» ПЛИС характерно большое количество со-
единений внутри блоков и между ними. По мере увеличения модуль-
ности устройств до среднемодульных и выше количество соединений в
блоках уменьшается. Это важное свойство, так как внутренние связи
определяют величину подавляющего большинства задержек, связан-
ных с прохождением сигналов через ПЛИС.
Своеобразной ложкой дегтя в бочке классификации ПЛИС было
появление компаний, создающих крупномодульные устройства. Эти
устройства содержат массивы узлов, где каждый узел представляет со-
бой сложный элемент, реализующий алгоритмические функции, на-
пример быстрое преобразование Фурье (БПФ), или даже ядро микро-
процессора общего назначения (см. гл. 6 и 23). Суть заключается в том,
что на самом деле эти устройства мутят воду, поскольку не классифи-
цируются как ПЛИС. По этой причине архитектуру ПЛИС на основе
таблиц соответствия (LUT) часто классифицируют как среднемодуль-
ную, тем самым, освобождая термин крупномодулъный для обозначения
таких устройств, как устройства на основе узлов.
Логические блоки на мультиплексорах и таблицах соответствия 69
Логические блоки на мультиплексорах
и таблицах соответствия
Существуют два основных способа реализации программируемых
логических блоков, используемых для формирования среднемодуль-
ных устройств на основе мультиплексоров (MUX — от multiplexer) и на
основе таблиц соответствия (LUT — от lookup table).
Устройства на основе мультиплексоров
В качестве примера реализации устройств на основе мультиплексо-
ров рассмотрим 3-входовую функцию у = (а & Ь) | с, реализованную с
помощью блока, содержащего только мультиплексоры (Рис. 4.2).
и
Рис. 4.2. Логический блок на мультиплексорах
Устройство может быть запрограммировано таким образом, что на
каждый его вход может подаваться логический 0 либо логическая 1, ли-
бо истинное, либо инверсное значение входного сигнала (в нашем слу-
чае а, b или с), приходящего с другого блока или с входа микросхемы.
Такой подход позволяет для каждого блока создавать огромнейшее ко-
личество вариантов конфигурирования для выполнения разнообраз-
нейших функций (х на входе центрального мультиплексора на Рис. 4.2
обозначает, что на вход можно подавать любой сигнал — 0 или 1).
Устройства на основе таблиц соответствия
Основная концепция таблиц соответствия относительно проста. В
таких микросхемах группа входных сигналов используется в качестве
индекса (указателя, или адреса ячейки) таблицы соответствия. Содер-
жимое этой таблицы организовано таким образом, что ячейки, указы-
ваемые каждой входной комбинацией, содержат требуемое выходное
значение. Допустим, что требуется реализовать функцию у = (а & Ь) | с,
см. Рис. 4.3.
70 Глава 4. Архитектура ПЛИС
Рис. 4.3. Требуемая функция и соответствующая ей таблица истинности
Таблица истинности
qgp* Если взять группу логических вентилей глубиной в несколько слоёв,
таблица соответствия может быть весьма эффективной с точки зре-
ния использования ресурсов и задержки распространения сигнала.
Здесь под «глубиной» подразумевается количество логических эле-
ментов между входом и выходом цепочки, так на Рис. 4.3 глубина со-
ставляет два слоя. Однако недостатком архитектуры на таблицах со-
ответствия является то, что если с их помощью реализовать
небольшую функцию, например 2-входовый логический элемент И,
для этого придётся использовать всю таблицу. Результирующая за-
держка для такой простой функции окажется весьма большой.
Для этого надо загрузить 3-входовую таблицу соответствующими
значениями. А теперь допустим, что таблица соответствий формирует-
ся из ячеек памяти статического ОЗУ. Она может также быть сформи-
рована наращиваемыми перемычками, ЭСППЗУ- или Flash-ячейками
памяти. Для выбора требуемой ячейки ОЗУ с помощью каскада пере-
даточных вентилей используются входные сигналы, как показано на
Рис. 4.4. При этом ячейки памяти статического ОЗУ для загрузки кон-
фигурационных данных должны быть соединены в длинную цепочку,
но эти цепи на Рис. 4.4 не показаны с целью его упрощения.
с Ь а
Рис. 4.4. Таблица соответствия на основе передаточных вентилей
На схеме открытый, или активный, передаточный вентиль пропус-
кает сигнал с входа на выход. Закрытый вентиль электрически отклю-
чает свой выход от проводника, к которому он подсоединен.
Логические блоки на мультиплексорах и таблицах соответствия 71
Передаточные вентили, на обозначениях которых изображен не-
большой «кружок», активируются при подаче на управляющий вход
логического 0. И наоборот, вентили, на обозначениях которых нет
кружка, активируются при подаче на управляющий вход уровня логи-
ческой 1. Основываясь на этом, легко проследить, как различные
входные комбинации могут использоваться для выбора содержимого
требуемой ячейки памяти.
Мультиплексоры или таблицы соответствия?
До появления современных систем автоматизированного проекти-
рования, когда инженеры вручную изготавливали схемы, некоторые
утверждали, что применение архитектуры на основе мультиплексоров
позволяет достичь лучших результатов. К сожалению, они, как прави-
ло, не удосуживались пояснить, почему эти результаты лучше. По сути
дела ответ на этот вопрос перекладывался на плечи других. Говорят
также, что мультиплексорные архитектуры имеют преимущество при
разработке управляющей логики в стиле «если этот вход имеет значе-
ние истина, а этот вход имеет значение ложь, то на выходе будет исти-
на...»^. Однако некоторые из этих архитектур не обеспечивают работу
высокоскоростных цепочек логического переноса. Их аналоги на таб-
лицах соответствия остаются лидерами во всех приложениях, в кото-
рых предусмотрены арифметические действия.
qgp* В сравнении с таблицами соответствия, при использовании мульти-
плексорной архитектуры, содержащей смесь мультиплексоров и ло-
гических вентилей, часто удаётся получить доступ к промежуточным
значениям сигналов, проходящих между логическими элементами и
мультиплексорами. В этом случае при реализации небольших функ-
ций ненужные (лишние) логические блоки могут быть отключены.
Следовательно, мультиплексорная архитектура может иметь пре-
имущества с точки зрения производительности и использования ре-
сурсов кристалла при реализации устройств, содержащих большое
количество простых независимых логических функций.
В 90-х ПЛИС получили широкое применение в области сетей пе-
редачи данных и связи. Обе сферы подразумевают передачу больших
потоков данных, в которых архитектуры на основе таблиц соответс-
твия зарекомендовали себя очень хорошо. По мере того как устройства
и их пропускная способность становились больше, и технология син-
теза микросхем становилась сложнее, ручное изготовление схем вмес-
те с мультиплексорной архитектурой постепенно уходили со сцены. В
итоге, как будет показано, большинство современных архитектур
ПЛИС основывается на таблицах соответствия.
3-, 4-, 5- или 6-входовые таблицы соответствия
Важной особенностью многовходовой таблицы соответствия явля-
ется то, что она может реализовать любую л-входовую комбинацион-
ную, или комбинаторную* 2*, логическую функцию. С помощью боль-
0 Некоторые мультиплексорные архитектуры, такие как выпускаемые компа-
нией QuickLogic (www.quicklogic.com), состоят из логических блоков с множест-
вом мультиплексоров, к выходам которых подключены простые логические вен-
тили, например реализующие функцию И. Такая схема обеспечивает большую на-
грузочную способность, что дает преимущество в приложениях декодирования
адреса и в конечных автоматах.
2) Как уже упоминалось в гл. 3, некоторые называют комбинационную логику
комбинаторной.
72 Глава 4. Архитектура ПЛИС
1822 г. Англия.
Чарльз Бэббидж
(Charles Babbage)
приступил к пост-
роению механичес-
кой вычислитель-
ной машины, так
называемой разно-
стной машины.
шего количества входов можно реализовать более сложные функции,
но при этом следует учитывать, что добавление каждого нового входа
сопровождается удвоением количества ячеек статического ОЗУ.
Первые ПЛИС основывались на 3-входовых таблицах соответс-
твия. Впоследствии поставщики ПЛИС и студенты некоторых учеб-
ных заведений провели анализ сравнительных эксплуатационных ха-
рактеристик 3-, 4-, 5- и даже 6-входовых таблиц соответствия (чем бы
вы ни занимались, никогда не ввязывайтесь в разговоры проектиров-
щиков ПЛИС). Результаты исследований показали, что оптимальному
равновесию всех «за» и «против» отвечают 4-входовые таблицы соот-
ветствия.
В прошлом некоторые поставщики использовали в своих устройс-
твах таблицы соответствия разных размеров, например, на три и на че-
тыре входа, так как они сулили наиболее оптимальное использование
устройства. Однако это решение не пришлось по душе большинству
инженеров, которые предпочли использовать программы синтеза
схем. Поэтому в настоящее время все действительно удачные архитек-
туры основываются только на 4-входовых таблицах соответствия. Это
вовсе не означает, что архитектуры на смешанных по размеру таблицах
соответствия не появятся вновь, так как программное обеспечение
систем проектирования продолжает усложняться.
Таблицы соответствия, распределенное ОЗУ, сдвиговые
регистры
Ядро таблицы соответствия в устройстве на статическом ОЗУ ис-
пользует для своей работы несколько ячеек памяти. Это позволяет ис-
пользовать некоторые интересные возможности. Помимо основного
назначения, т. е. формирования таблицы соответствия, устройства не-
которых поставщиков позволяют использовать ячейки, формирующие
таблицу, в качестве небольших блоков оперативной памяти. Напри-
мер, 16 ячеек памяти, формирующих 4-входовую таблицу, могут вы-
ступать в роли блока ОЗУ 16x1. Такие участки памяти называются рас-
пределенным ОЗУ, так как, во-первых, таблицы соответствия разброса-
ны (распределены) по всей поверхности кристалла, а во-вторых, это
название отличает их от больших блоков ОЗУ.
Другой вариант альтернативного использования таблиц основан на
том, что все конфигурационные ячейки, включая и те, которые фор-
мируют таблицу соответствия, эффективно связаны вместе в одну
длинную цепочку (Рис. 4.5).
К следующей ячейке
в цепочке
Рис. 4.5. Конфигурационные ячейки, связанные в цепочку
Ячейки
статического
ОЗУ
Конфигурируемые логические блоки, блоки логических массивов, секции 73
Дело в том, что в некоторых устройствах ячейки памяти, формиру- ।
ющие таблицу соответствия, после программирования могут рассмат- I
риваться независимо от главной структуры цепочки и использоваться |
в качестве сдвигового регистра. Таким образом, каждую таблицу соот-
ветствия можно рассматривать как многофункциональный компонент
(Рис. 4.6).
16-битный
сдвиговый регистр
1822 г. Франция.
Андре Ампер (Andre
Ampere) открыл,
что два проводни-
ка, по которым те-
чет электрический
ток, притягива-
ются друг к другу.
ОЗУ 16x1
4-входовая
таблица
соответствия
Рис. 4.6. Многофункциональная таблица соответствия
Конфигурируемые логические блоки, блоки
логических массивов, секции
«Человек не может жить только таблицами соответствия», непре-
менно сказал бы Шекспир, будь он разработчиком ПЛИС. И действи-
тельно, помимо одной или нескольких таблиц соответствия логичес-
кий блок может содержать другие элементы, такие как мультиплексо-
ры и регистры. Но перед тем как мы начнем копаться в этом разделе,
нам необходимо настроить наши мозги на некоторую терминологию.
Логические ячейки фирмы Xilinx
Это может быть показаться странным, но каждый производитель
ПЛИС дает им собственное название. Начнем с того, что блоки, из ко-
торых состоит современная ПЛИС фирмы Xilinx, называются логичес-
кими ячейками (logic cell). Кроме всего прочего, логическая ячейка со-
держит 4-входовую таблицу соответствия, которая может работать как
ОЗУ 16x1 или как 16-битный сдвигающий регистр, а также мульти-
плексор и регистр (Рис. 4.7).
Рис. 4.7. Упрощенный вид логической ячейки Xilinx
74 Глава 4. Архитектура ПЛИС
1827 г. Англия.
Чарльз Уитстон
(Sir Charles
Wheatstone) разра-
ботал микрофон.
Схема, представленная на Рис. 4.7, сильно упрощена, но, тем не
менее, она удовлетворяет контексту рассматриваемого материала. Ре-
гистр может быть сконфигурирован для работы в качестве триггера
(Рис. 4.7) или в качестве защелки. Полярность тактового сигнала (ре-
акция триггера на фронт или спад синхроимпульса) может задаваться
программно, так же как полярность сигналов «тактовый сигнал разре-
шен» и «установка/сброс» (активный высокий или низкий уровень).
Кроме таблиц соответствия, мультиплексоров и регистров, логи-
ческие ячейки содержат небольшое количество других элементов,
включая специальную логику быстрого переноса для использования в
арифметических действиях.
Логические элементы компании Altera
Блоки, из которых состоят ПЛИС компании Altera, называются
логическими элементами (logic element). Между логическими ячейками
Xilinx и логическими элементами Altera существует ряд отличий, но в
целом их концепции очень похожи.
Секции и логические ячейки
Следующей ступенью в иерархии построения микросхем програм-
мируемой логики является так называемая, по определению фирмы
Xilinx, секция (slice). Компания Altera и другие поставщики, по-види-
мому, называют эту ступень как-то иначе, используя собственные оп-
ределения. Почему же секция! Ну, хорошо, надо же было как-то на-
звать эту ступень. Так почему же, не назвать его секцией, тем более что
бы там не говорили, а секция — именно то, что нужно. Во время напи-
сания этой книги, секция содержала две логические ячейки (Рис. 4.8).
I ОЗУ 16х
4-входовая
таблица
соответствия
Таблица соответствия Мультиплексор Регистр
Рис. 4.8. Секция, содержащая две логических ячейки
Приходится использовать слова «во время написания», так как эти
определения не только могут меняться, но и меняются с каждым сезо-
ном. На Рис. 4.8 для его упрощения не показаны внутренние связи, так-
Конфигурируемые логические блоки, блоки логических массивов, секции 75
же необходимо заметить, что хотя таблицы соответствия, мультиплексо-
ры и регистры каждой логической ячейки имеют собственные входы и
выходы данных. Секция имеет общие тактовые сигналы, разрешения
тактовых сигналов и установки/сброса для обеих логических ячеек.
Конфигурируемые логические блоки CLB и блоки логических
массивов LAB
1827 г. Германия.
Георг Ом (Georg
Ohm) исследовал
электрическое со-
противление и
сформулировал за-
кон Ома.
Поднимаясь по иерархической лестнице, мы достигаем уровня,
который компания Xilinx называет конфигурируемый логический блок
КЛБ или (CLB — configurable logic block). Компания Altera, в свою оче-
редь, называет его блоком логических массивов или LAB (LAB — logic
array block). Другие поставщики ПЛИС, очевидно, дают им свои экви-
валентные названия, которые представляют интерес только в случае,
когда пользователь имеет дело именно с такими устройствами.
(^=э Определение конфигурируемого логического блока (КЛБ) меняется
с каждым годом. На заре своего существования КЛБ содержали две
3-входовых таблицы соответствия и один регистр. Позже в них стали
включать две 4-входовых таблицы соответствия и два регистра. Те-
перь каждый блок содержит две или четыре секции, каждая из кото-
рых состоит из двух 4-входовых таблиц соответствия и двух регист-
ров, а в недалёком будущем...
Используя конфигурационные логические блоки в качестве при-
мера, заметим, что некоторые ПЛИС фирмы Xilinx содержат по две
секции в каждом блоке, другие устройства по четыре секции в каждом
блоке. Во время написания этой книги логические блоки визуально
можно было представить в виде «островов» программируемой логики в
«море» программируемых соединений (Рис. 4.9).
Г
Рис. 4.9. Конфигурируемый логический блок, содержащий четыре секции
(количество секций зависит от семейства ПЛИС)
Конфигурируемый логический блок (КЛБ)
Внутри логического блока находятся быстрые программируемые
внутренние соединения. Эти проводники используются для соедине-
ния соседних секций (на Рис. 4.9 для простоты изложения они не по-
казаны).
Причина существования такой логико-блочной иерархии, т. е. ло-
гическая ячейка-» секция с двумя логическими ячейками-» конфигу-
рируемый логический блок с четырьмя секциями, заключается в том,
что она дополняется эквивалентной иерархией внутренних соедине-
76 Глава 4. Архитектура ПЛИС
ний. Другими словами, существуют быстрые внутренние соединения
между логическими ячейками внутри секции, затем менее быстрые
соединения между секциями внутри логического блока и соединения
между блоками. Подобная иерархия отражает пошаговое достижени
оптимального компромисса между простотой соединения внутрен-
них структур и чрезмерными задержками сигнала на внутренних со-
единениях.
Распределенное ОЗУ и сдвиговые регистры
Как уже отмечалось, каждая 4-входовая таблица соответствия мо-
жет использоваться в качестве блока ОЗУ 16x1. Если взять за основу
четырёхсекционный конфигурируемый логический блок, показанный
на Рис. 4.9, все таблицы соответствия внутри этого блока могут быть
сконфигурированы для реализации следующих функций:
• Однопортовый блок ОЗУ 16x8 бит.
• Однопортовый блок ОЗУ 32x4 бита.
• Однопортовый блок ОЗУ 64x2 бита.
• Однопортовый блок ОЗУ 128x1 бит.
• Двухпортовый блок ОЗУ 16x4 бита.
• Двухпортовый блок ОЗУ 32x2 бита.
• Двухпортовый блок ОЗУ 64x1 бит.
(^=э Набор сигналов управления и данных, рассматриваемых как единое
целое, обычно называют портом. В однопортовом ОЗУ данные запи-
сываются и считываются из ячейки через общую шину данных. В
двухпортовом ОЗУ данные записываются и считываются через раз-
личные шины (порты). На практике в этом случае операции чтения
и записи, как правило, работают со своими адресными шинами (ис-
пользуемыми для указания необходимой ячейки внутри ОЗУ), т. е.
операции чтения и записи в двухпортовом ОЗУ могут выполняться
одновременно.
Аналогично, каждая 4-битная таблица соответствий может исполь-
зоваться в качестве 16-битного сдвигового регистра. Для этого сущест-
вуют специальные соединения между логическими ячейками внутри
секции и между секциями, которые позволяют соединить последний
бит одного сдвигового регистра с первым битом другого регистра без
привлечения к этому процессу выходных сигналов таблиц соответствия.
Последние также могут использоваться для просмотра содержимого оп-
ределенного бита в 16-битном регистре. Это позволяет при необходи-
мости соединить вместе таблицы соответствия внутри одного логичес-
кого блока и реализовать сдвиговый регистр величиной до 128 бит.
Схемы ускоренного переноса
Ключевой особенностью современных ПЛИС является то, что они
содержат специальную логику и внутренние соединения, необходи-
мые для реализации схем ускоренного переноса. В контексте програм-
мируемых логических блоков, рассмотренных в предыдущем разделе,
следует упомянуть о том, что каждая логическая ячейка содержит спе-
циальную логику переноса. Эта логика дополняется специальными
внутренними соединениями между двумя логическими ячейками в
пределах каждой секции, между секциями в рамках каждого логичес-
кого блока и между блоками.
Специальная логика быстрого переноса и выделенная маршрути-
зация способствуют выполнению логических функций, таких как
Встроенные блоки ОЗУ 77
счетчики, и арифметических функций, таких как сумматоры. Возмож-
ности схем ускоренного переноса совместно с возможностями других
средств, аналогичных сдвиговым регистрам на основе таблиц соот-
ветствия, встроенным умножителям и другим блокам обеспечивают
необходимый набор средств для использования ПЛИС в приложениях
цифровой обработки сигналов (ЦОС).
Встроенные блоки ОЗУ
В процессе реализации большинства приложений возникает необ-
ходимость использовать ячейки памяти, поэтому современные ПЛИС
содержат довольно большие блоки встроенной памяти, называемые
блоками встроенного ОЗУ. В зависимости от архитектуры микросхемы
эти блоки могут быть расположены по периметру кристалла, разброса-
ны по его поверхности и относительно изолированы друг от друга или
организованы в столбцы, как показано на Рис. 4.10.
Рис. 4.10. Вид на кристалл со столбцами встроенных блоков ОЗУ
В зависимости от устройства размер блоков ОЗУ может меняться
от нескольких тысяч до нескольких десятков тысяч бит. Каждая мик-
росхема может содержать от нескольких десятков до нескольких сотен
таких блоков. Таким образом, полная ёмкость простирается от не-
скольких сотен тысяч бит до нескольких миллионов бит.
Каждый блок ОЗУ может использоваться либо как независимое за-
поминающее устройство, либо находиться в связке с несколькими
блоками для реализации массивов памяти большого объема. Блоки
могут использоваться для различных целях, например, как стандарт-
ные одно- и двух-портовые блоки ОЗУ, очереди FIFO (first-in first-out —
первый пришёл, первый вышел), конечные автоматы и так далее.
Встроенные умножители, сумматоры, блоки
умножения с накоплением и др.
Некоторые типы функций, например умножители, по своей сути
являются довольно медленными, если их реализовывать с помощью
большого количества программируемых логических блоков соединен-
ных вместе. Поскольку эти функции используются в многочисленных
78 Глава 4. Архитектура ПЛИС
приложениях, многие ПЛИС содержат специальные аппаратные бло-
ки умножения. Эти блоки обычно расположены в непосредственной
близости от блоков встроенного ОЗУ, которые рассматривались в пре-
дыдущем разделе, так как они часто используются вместе (Рис. 4.11).
Рис. 4.11. Вид на кристалл со столбцами встроенных умножителей и блоков ОЗУ
Некоторые производители ПЛИС также предлагают выделенные
сумматоры. В то же время, одной из самых распространенных опера-
ций, применяемых в приложениях цифровой обработки сигналов, яв-
ляется умножение с накоплением (multiply-and-accumulate или МАС),
Рис. 4.12. Как подсказывает название, эта функция перемножает два
числа и суммирует результат с текущим числом, сохранённым в акку-
муляторе.
А[п:0]
В[п:0]
Умножитель
Умножение с накоплением (МАС)
Рис. 4.12. Функции, формирующие операцию умножения с накоплением
При работе с ПЛИС, которая содержит только встроенные умножи-
тели, для реализации этой функции необходимо соединить умножи-
тель с сумматором, сформированным из нескольких программируе-
мых логических блоков. Результат будет сохраняться в триггерах логи-
Аппаратные и программные встроенные микропроцессорные ядра 79
ческих блоков, либо в блоках встроенного ОЗУ, либо в
распределенном ОЗУ. Жизнь становится проще, когда ПЛИС уже со-
держат встроенные сумматоры, а отдельные их виды даже поддержива-
ют встроенные умножители с накоплением.
Аппаратные и программные встроенные
микропроцессорные ядра
Важной особенностью ПЛИС является то, что в них почти все час-
ти электронного устройства могут быть реализованы аппаратно (с ис-
пользованием логических вентилей, регистров и т. д.) или программно
(в виде инструкций микропроцессора). Одним из главных частных
критериев выбора между аппаратной и программной реализацией
функции является время, за которое эта функция должна выполнять
свои задачи:
• Пикосекундная и наносекундная логика — должна работать без-
умно быстро и реализуется аппаратно (в структуре ПЛИС).
• Микросекундная логика — умеренно быстрая и может реализо-
вываться как аппаратно, так и программно. Тип логики, при ко-
тором основная масса времени тратится на определение того,
каким путём пойти.
• Миллисекундная логика — используется при реализации интер-
фейсов, таких как опрос состояния переключателей или зажига-
ние светодиодов. Основные усилия будут направлены на замед-
ление аппаратной части при реализации этих функций;
например, используя громаднейшие счетчики для генерации за-
держек. Таким образом, зачастую такие задачи лучше реализо-
вывать в микропроцессорном коде, так как процессор позволя-
ет снизить скорость по сравнению с аппаратной частью, но при
этом задача может оказаться очень сложной.
Фактически большинство устройств в той или иной форме исполь-
зуют микропроцессоры. До последнего времени микропроцессоры
представляли собой дискретные элементы, располагаемые на печат-
ной плате. В последнее время появились высокотехнологичные
ПЛИС, которые содержат один или несколько встроенных микропро-
цессоров, которые обычно называются микропроцессорными ядрами.
При применении таких микросхем часто имеет смысл переложить все
задачи, выполняемые внешним микропроцессором, на «плечи» встро-
енного ядра. Такой подход обеспечивает ряд преимуществ, не послед-
ними из которых будут снижение стоимости, устранение большого ко-
личества дорожек, посадочных мест и выводов на печатной плате, а
также уменьшение размера и веса печатной платы.
Аппаратные микропроцессорные ядра
Аппаратные микропроцессорные ядра изготавливаются как отде-
льные предопределённые блоки. Существует два способа интеграции
таких ядер в ПЛИС. Первый предусматривает расположение ядра в ви-
де полосы (полоса — stripe) вдоль одной из сторон главной части, или
главной структуры ПЛИС (Рис. 4.13).
При таком подходе все компоненты обычно формируются на од-
ном кремниевом кристалле, хотя они могут быть выполнены и на двух
кристаллах и размещены в виде многокристалъного модуля (Multichip
module — МСМ). Птавная часть ПЛИС также включает встроенные бло-
ки ОЗУ, умножители и другие рассмотренные выше блоки, которые на
этом рисунке не показаны с целью его упрощения.
1829 г. Англия.
Чарльз Уитстон
(Sir Charles
Wheatstone) разра-
ботал концертино
— шестигранную
гармонику.
80 Глава 4. Архитектура ПЛИС
1831 г. Англия.
Майкл Фарадей
(Michael Faraday)
создал первую элек-
трическую динамо-
машину.
Микропроцес-
сорное ядро,
специальное ОЗУ,
интерфейсы
ввода/вывода,
и так далее
Рис. 4.13. Вид на кристалл со встроенным ядром, находящимся
за пределами главной части
Преимущество такой реализации проявляется в главной части
(структуре) ПЛИС, которая получается идентичной для устройств со
I встроенным и без встроенного микропроцессорного ядра. Это может
существенно упростить работу инженеров со средствами разработки.
Другое преимущество заключается в том, что поставщики ПЛИС мо-
гут связать все дополнительные функции, такие как память, устройс-
тва ввода-вывода и другие, в одну полосу для дополнения микропро-
цессорного ядра.
Одним из возможных решений является встраивание одного или
более микропроцессорных ядер прямо в главную часть ПЛИС. Во вре-
мя написания этих строк существовали микросхемы с одним, двумя и
даже четырьмя ядрами (Рис. 4.14).
Хочу повториться и повторяюсь, главная часть ПЛИС включает
встроенные блоки ОЗУ, умножители, и другие рассмотренные выше
блоки, которые на этом рисунке не показаны с целью его упрощения.
а) Одно встроенное ядро б) Четыре встроенных ядра
Рис. 4.14. Вид на кристаллы с ядрами, встроенными внутрь главной части
Дерево синхронизации и диспетчеры синхронизации 81
При использовании этого способа используемые средства проек-
тирования должны учитывать присутствие микропроцессоров в струк-
туре микросхемы. Память, используемая ядром, формируется из
встроенных блоков ОЗУ, а любые функции сопряжения реализуются с
помощью групп программируемых логических блоков общего назна-
чения. Сторонники этой схемы утверждают, что размещение микро-
процессорного ядра в непосредственной близости к главной части
(структуре) ПЛИС обеспечивает ей преимущество в скорости.
Программные микропроцессорные ядра
Кроме физического встраивания микропроцессора в структуру
кристалла, можно сконфигурировать группу программируемых логи-
ческих блоков для работы в качестве микропроцессора. Такую группу
блоков обычно называют программным ядром, но более точно они мо-
гут быть классифицированы как программные и микропрограммные в
зависимости от способа, с помощью которого функциональность мик-
ропроцессора реализована логическими блоками. Программные ядра
проще и медленнее, чем их аппаратные аналоги. Однако у них есть од-
но преимущество — при необходимости можно реализовать ядро или
несколько ядер в том объеме, который можно достичь пока не будут
исчерпаны все ресурсы в виде программируемых логических блоков.
Дерево синхронизации и диспетчеры
синхронизации
Все синхронные элементы внутри ПЛИС, например регистры
внутри программируемого логического блока, сконфигурированные
для работы в виде триггеров, необходимо синхронизировать с помо-
щью тактового сигнала. Тактовые сигналы обычно вырабатываются за
пределами микросхемы и поступают в неё через специальные входы
синхронизации, а затем распределяются через специальные устройс-
тва и подаются на соответствующие регистры.
Дерево синхронизации
Рассмотрим упрощенное изображение дерева синхронизации
(Рис. 4.15, программируемые логические блоки не показаны).
Название дерево синхронизации возникло потому, что главный син-
хросигнал разветвляется подобно ветвям дерева, при этом триггеры
могут рассматриваться как «листья» на концах веток. Такая структура
вселяет уверенность в том, что все триггеры увидят свои тактовые сиг-
налы одновременно, на сколько это возможно. Если бы тактовые сиг-
налы распространялись по одному длинному проводнику, синхрони-
зируя все триггеры поочередно, триггер, расположенный ближе к вы-
воду синхронизации микросхемы увидел бы синхроимпульс намного
раньше, чем последние триггеры в этой цепочке. Подобная ситуация
называется фазовым сдвигом, и она порождает целый ряд проблем. Да-
же при использовании дерева синхронизации может возникнуть неко-
торый сдвиг фаз между регистрами, находящимися на одной ветви, а
также между ветвями.
Дерево синхронизации реализуется с помощью специальных про-
водников, которые отделены от внутренних соединений общего на-
значения. Принцип действия, рассмотренный выше, на самом деле
сильно упрощен. На практике в микросхемах существуют множество
1831 г. Англия,
Майкл Фарадей
(Michael Faraday)
создал первый элек-
трический транс-
форматор.
Скорость работы
программного ядра
обычно составляет
30...50% от скоро-
сти аппаратного
ядра.
82 Глава 4. Архитектура ПЛИС
1831 г. Англия.
Майкл Фарадей
(Michael Faraday)
открыл силовые
линии магнитного
поля.
Рис. 4.15. Простое дерево синхронизации
выводов синхронизации (неиспользуемые выводы синхронизации мо-
гут быть использованы как выводы общего назначения), а внутри уст-
ройства имеются множественные домены синхронизации (деревья
синхронизации).
Устройство управле-
ния синхронизацией
(диспетчер синхрони-
зации) по терминоло-
гии компании Xilinx
называется DCM
(digital clock manager).
Диспетчер синхронизации
Вывод синхронизации микросхемы может быть подключен к дере-
ву синхронизации. Однако, как правило, этот вывод подключают не
напрямую к дереву синхронизации, а к входу устройства (или блока)
управления синхронизацией, называемого диспетчером синхронизации.
который генерирует дочерние тактовые сигналы (Рис. 4.16).
Дочерние тактовые
сигналы, используемые
для управления
внутренними деревьями
синхронизации или
для выдачи
на внешний вывод
микросхемы
Рис. 4.16. Диспетчер синхронизации, генерирующий дочерние тактовые сигналы
Дочерние тактовые сигналы могут использоваться для управления
внутренними деревьями (доменами) синхронизации или для выдачи
сигналов на внешние выводы микросхемы, которые, в свою очередь,
можно использовать для синхронизации других устройств, располо-
женных на печатной плате. Каждое семейство микросхем ПЛИС рас-
полагает собственным типом диспетчера синхронизации, и в одном
устройстве могут находиться множество модулей диспетчера синхро-
низации. Различные диспетчеры синхронизации могут поддерживать
все или только некоторые из следующих свойств.
Дерево синхронизации и диспетчеры синхронизации 83
Устранение флуктуаций. Для упрощения примера допустим, что
сигнал синхронизации имеет частоту 1 МГц. На практике, конечно же,
эта частота во много-много раз выше. В идеальном случае каждый
фронт тактового сигнала от внешней системы синхронизации прихо-
дит ровно через одну миллионную долю секунды после предыдущего.
Однако в реальной жизни фронт импульса может прийти немного
раньше или немного позже.
Для визуализации этого эффекта, называемого флуктуацией, изоб-
разим фронты импульсов один под другим, чтобы получить их супер-
позицию; в результате может получиться смазанный тактовый сигнал
(Рис. 4.17).
Рис. 4.17. Флуктуация как результат смазывания тактового сигнала
Единица измерения
герц (Гц) названа в
честь Генриха Герца
(Heinrich Hertz), не-
мецкого физика из
университета Карл-
сруэ (Karlsruhe) в
Германии, который
впервые в 1888 г. осу-
ществил передачу и
приём радиоволн в
лабораторных усло-
виях. Один герц
(1 Гц) равен одному
колебанию в секун-
ду, 1 мегагерц
(1 МГц) равен одно-
му миллиону Герц.
Диспетчер синхронизации ПЛИС может использоваться для обна-
ружения и коррекции подобных флуктуаций и обеспечивать очистку
дочерних тактовых сигналов для их использования внутри устройства
(Рис. 4.18).
«Очищенный» дочерний
тактовый сигнал,
используемый для
управления деревьями
синхронизации или
для выдачи на внешний
вывод микросхемы
Рис. 4.18. Диспетчер синхронизации может убрать флуктуацию тактового сигнала
Частотный синтез. Может случиться так, что частота тактового
сигнала, поступающего на ПЛИС от внешнего источника синхрониза-
ции, не соответствует частоте, необходимой для решения поставлен-
ных задач. В этом случае диспетчер синхронизации может генериро-
вать дочерние тактовые сигналы, частота которых является производ-
ной величиной от исходного сигнала и получается путем его деления
или умножения.
84 Глава 4. Архитектура ПЛИС
В качестве простого примера рассмотрим три дочерних тактовых
сигнала: первый с частотой, эквивалентной исходной частоте тактово-
го сигнала, второй с частотой, равной частоте исходной последова-
тельности умноженной на два, и третий с частотой, равной половине
частоты исходного сигнала (Рис. 4.19).
1.0 х исходная частота тактового сигнала
2.0 х исходная частота тактового сигнала
0.5 х исходная частота тактового сигнала
Рис. 4.19. Использование диспетчера синхронизации для частотного синтеза
И еще раз повторюсь, что на Рис. 4.19 представлен очень простой
пример. На практике ПЛИС могут синтезировать все типы внутренних
тактовых сигналов, например четыре пятых от частоты первоначаль-
ной последовательности тактового сигнала.
Фазовый сдвиг. Некоторые изделия требуют использования такто-
вых сигналов, фаза в которых сдвинута (задержана) относительно друг
друга. Некоторые диспетчеры синхронизации позволяют выбирать об-
щие фиксированные значения фазовых сдвигов, например 120° и 240°
для трехфазной системы синхронизации или 90°, 180° и 270° для четы-
рёхфазной системе синхронизации. Другие диспетчеры позволяют
конфигурировать точное значение фазового сдвига по требованию
пользователя для каждого дочернего тактового сигнала.
Предположим, что мы получаем четыре внутренних тактовых сиг-
нала из главной последовательности тактовых сигналов, где первый
находится в фазе с исходным сигналом, второй сдвинут по фазе на 90°,
третий на 180° и т. д. (Рис. 4.20).
Фазовый сдвиг 0*
Фазовый сдвиг 90*
Фазовый сдвиг 180*
Фазовый сдвиг 270*
Рис. 4.20. Использование диспетчера синхронизации для фазового
сдвига дочерних тактовых сигналов
Автокоррекция сдвига фаз. В целях упрощения предположим, что
речь идет о дочерних тактовых сигналах, сформированных на той же
частоте и с той же фазой, что и главный тактовый сигнал, приходящий
на вход ПЛИС. Однако диспетчер синхронизации, по определению,
будет добавлять к сигналам некоторую задержку. Кроме того, еще
большие задержки добавляют логические вентили и внутренние со-
единения, используемые в распределении тактовых сигналов. Итак,
если не предпринять корректирующих мер, дочерние тактовые сигна-
лы будут отставать от входных тактовых сигналов на некоторую вели-
чину. Напомню, что разница между фазами двух сигналов называется
фазовым сдвигом.
Ввод/вывод общего назначения 85
В зависимости от того, как главные и дочерние тактовые сигналы
используются ПЛИС и остальными элементами печатной платы,
сдвиг фаз может стать причиной различных проблем. Поэтому диспет-
чер синхронизации может содержать специальный вход для подачи на
него дочернего тактового сигнала. В этом случае диспетчер синхрони-
зации сравнивает два сигнала и точно добавляет определенную за-
держку к дочерним сигналам, достаточную для выравнивания их с ис-
ходным тактовым сигналом (Рис. 4.21).
Таким способом будет очищен только первичный, т. е. с нулевым
фазовым сдвигом, дочерний сигнал, а все другие дочерние сигналы бу-
дут фазированы уже относительно этого сигнала.
1831 г. Англия.
Майкл Фарадей
(Michael Faraday)
открыл принцип
электромагнитной
индукции.
Дочерний тактовый сигнал
(управляемый диспетчером синхронизации),
подается по цепи обратной связи на специальный вход Тактовые сигналы
Тактовый сигнал
от внешнего источника
Специальный вывод
с компенсацией фазового
сдвига, используемые
для синхронизации
_П_П_П_ внутренних устройств
-----------► или для выдачи
на внешний вывод
микросхемы
синхронизации
и контактная площадка
◄---- Главный (первичный) тактовый сигнал
◄---- Необработанный дочерний тактовый сигнал
◄---- Тактовые сигналы с компенсацией
фазового сдвига
Рис. 4.21. Компенсация фазового сдвига относительно первичного
тактового сигнала
Некоторые диспетчеры синхронизации ПЛИС работают по при-
нципу фазовой автоподстройки частоты (ФАПЧ), другие по принципу
цифровой автоподстройки по задержке (digital delay-locked loop — DLL).
С 40-х гг. ФАПЧ используются в аналоговых устройствах, но сегодня в
связи с широким внедрением цифровых методов желанной становится
цифровая автоподстройка. Системы ФАПЧ могут быть реализованы
аналоговым или цифровым способом, а системы цифровой автопод-
стройки по задержке по своей природе могут быть только цифровыми.
Сторонники ФАПЧ утверждают, что эти системы имеют преимущест-
ва в точности, стабильности и потребляемой мощности, нечувстви-
тельны к шумам и флуктуациям.
Ввод/вывод общего назначения
Современные ПЛИС могут содержать 1000 и более выводов, кото-
рые располагаются по всему корпусу микросхемы. Аналогично они
подходят к кристаллу внутри корпуса микросхемы. Внутрь корпуса
кристалл устанавливают в перевернутом виде. Это позволяет подсо-
единять общий провод, проводники питания, синхронизации и сигна-
лов ввода/вывода к любой точке на его поверхности. Однако в рамках
наших рассуждений, предположим, что все выводы на кристалле рас-
положены по его контуру, как и было на самом деле много лет назад.
86 Глава 4. Архитектура ПЛИС
1831 г. Англия.
Майкл Фарадей
(Michael Faraday)
открыл, что пере-
менное магнитное
поле вызывает
электрический
ток.
Конфигурируемые стандарты ввода/вывода
Давайте посмотрим на электронное устройство с точки зрения ин-
женеров, разрабатывающих печатную плату. В зависимости от того что
они делают, от типов используемых устройств, от окружающей среды,
в которой будет работать плата и так далее, разработчики будут выби-
рать определенный стандарт передачи данных. (В этом контексте по-
нятие «стандарт» относится к электрическим параметрам сигналов, та-
ким как уровень логического 0 или логической 1 в вольтах.)
Проблема в том, что существует большое разнообразие стандартов,
и было бы трудно создавать специальные ПЛИС для поддержки каж-
дого варианта. По этой причине ввод/вывод общего назначения ПЛИС
может быть сконфигурирован для приема и передачи сигналов, соот-
ветствующих любому стандарту. Эти сигналы ввода/вывода разделя-
ются на несколько банков. Будем полагать, что существует восемь бан-
ков, пронумерованных от 0 до 7 (Рис. 4.22).
Банки ввода/вывода
общего назначения
(с 0-го по 7-й)
Рис. 4.22. Вид на кристалл с банками ввода/вывода
Интересно, что каждый банк может быть индивидуально сконфи-
гурирован для поддержки определенных стандартов ввода/вывода. Та-
ким образом, мало того, что ПЛИС имеет возможность работать с уст-
ройствами, используя многочисленные стандарты ввода/вывода, эти
микросхемы могут служить интерфейсом между различными стандар-
тами ввода/вывода, а также осуществлять связь между различными
протоколами, которые могут основываться на частных электрических
стандартах.
Согласование ввода/вывода
Сигналы в современных печатных платах часто обладают быстрым
временем переключения. Имеется в виду время, которое необходимо
сигналу для переключения с одного логического уровня на другой.
Чтобы предотвратить отражение сигналов, приводящее к возникнове-
нию пульсаций, к выводам микросхемы, т. е. к входу или выходу, необ-
ходимо подключить соответствующие согласующие резисторы, т. е.
терминаторы.
В прошлом эти резисторы применялись как отдельные компонен-
ты, которые размещались на печатной плате за пределами ПЛИС. Од-
нако такой подход становился всё более проблематичным, поскольку
Гигабитные приёмопередатчики 87
количество выводов у микросхемы увеличивалось, а шаг, т. е. расстоя-
ние между ними, уменьшался. В связи с этим современные ПЛИС
позволяют использовать внутренние согласующие резисторы, или
внутренние терминаторы, сопротивление которых может задаваться
пользователем, для согласования различного оборудования на печат-
ной плате и различных стандартов ввода/вывода.
Напряжение ядра и напряжение ввода/вывода
В былые времена, где-то с 1965 по 1995 год, большинство цифро-
вых микросхем использовало напряжение земли О В и напряжение пи-
тания +5 В. Кроме того, сигналы ввода/вывода переключались между
уровнями О В (логический 0) и +5 В (логическая 1), что значительно
упрощало жизнь.
Со временем размеры структур на кремниевых кристаллах стано-
вились меньше, поскольку транзисторы меньших размеров были де-
шевле, а также быстрее и потребляли меньше энергии. Однако для
этого требовалось понизить напряжения питания. Напряжение пита-
ния продолжало падать с каждым годом (Табл. 4.2).
1832 г. Англия.
Чарльз Бэббидж
(Charles Babbage)
создал первый ме-
ханический ком-
пьютер, так назы-
ваемую аналити-
ческую машину.
Таблица 4.2. Зависимость напряжения питания от технологического процесса
Год Источник питания (напряжение ядра) [В] Технологический процесс [нм]
1998 3.3 350
1999 2.5 250
2000 1.8 180
2001 1.5 150
2003 1.2 130
Источник питания, указанный в таблице, используется для питания
внутренней логики ПЛИС, поэтому это напряжение называется напря-
жением ядра (на самом деле для подключения питания и «земли» задейс-
твуются несколько выводов микросхемы). Различные стандарты вво-
да/вывода используют сигналы с напряжениями, уровни которых значи-
тельно отличаются от напряжения ядра, поэтому каждый банк
ввода/вывода данных может иметь свой дополнительный вывод питания.
Интересно, что, начиная с 350 нм процесса, напряжение ядра из-
менялось прямо пропорционально технологическому процессу. Одна-
ко существуют физические причины, не позволяющие опуститься зна-
чительно ниже 1 вольта (эти причины основаны на технологических
аспектах, таких как входной порог переключения транзисторов и пе-
репад напряжений), поэтому эта «лестница напряжений» в недалеком
будущем может закончиться.
Гигабитные приёмопередатчики
Традиционный способ передачи больших объемов данных предус-
матривает использование шины, которая представляет собой набор
сигналов, передающих данные и выполняющие некоторые общие
функции (Рис. 4.23).
Примерно с 1975 г. для передачи информации в микропроцессор-
ных системах стали использоваться 8-битные шины. С ростом потреб-
ности в передачи большего объема данных и увеличении скорости их
88 Глава 4, Архитектура ПЛИС
1832 г. Англия.
Джозеф Генри
(Joseph Henry) от-
крыл явление само-
индукции, или ин-
дуктивности.
Рис. 4.23. Использование шины для связи устройств
передачи разрядность шин выросла до 16 бит, затем до 32 бит, затем до
64 бит и так далее. Проблема заключается в том, что такой рост требо-
вал большого количества выводов в микросхеме и большого количест-
ва дорожек на печатной плате для соединения компонентов. Проклад-
ка дорожек таким образом, чтобы дорожки были одинаковой длины и
имели одно и то же сопротивление, становится всё более трудной зада-
чей по мере роста сложности печатных плат. Кроме того, усложнялось
управление параметрами целостности сигналов, такими, как чувстви-
тельность к шумам, особенно при наличии большого количества про-
водников в шине
По этой причине современные высокотехнологичные ПЛИС снаб-
жены встроенными блоками гигабитных приёмопередатчиков. Эти
блоки используют одну пару дифференциальных сигналов для передачи
(ТХ) и вторую пару для приема (RX) данных (Рис. 4.24). Это значит, что
пара сигналов всегда несет противоположные логические значения.
Рис. 4.24. Использование высокоскоростных приёмопередатчиков
для связи устройств
Эти приёмопередатчики работают на невероятно высоких скоро-
стях, которые позволяют им передавать и принимать миллиарды бит
данных в секунду. Кроме того, каждый блок практически поддержива-
ет несколько, скажем четыре, таких передатчиков, и каждая ПЛИС
может содержать несколько таких передающих блоков.
IP — блоки аппаратной, программной
и микропрограммной интеллектуальной
собственности
Каждый поставщик ПЛИС предлагает собственный набор аппа-
ратных, микропрограммных и программных блоков интеллектуальной
собственности (IP — intellectual property). Аппаратные блоки интеллек-
туальной собственности (аппаратные IP) представляют собой уже реа-
IP — блоки аппаратной, программной и микропрограммной интеллектуальной собственности 89
лизованные блоки, такие как микропроцессорные ядра, гигабитные
интерфейсы, умножители, сумматоры, функции умножения с накоп-
лением и им подобные. Эти блоки разрабатываются так, чтобы они
были максимально эффективны и с точки зрения потребляемой мощ-
ности, и с точки зрения производительности, и с точки зрения площа-
ди, занимаемой на кристалле. Для каждого семейства ПЛИС характер-
ны различные комбинации и различное количество таких блоков.
Программные блоки интеллектуальной собственности (програм-
мные IP) представляют собой библиотеки исходных кодов высокоу-
ровневых функций, которые могут использовать разработчики конеч-
ных устройств. Эти функции выражаются языком описания аппарат-
ных средств HDL (HDL — hardware description language), таким как
Verilog или VHDL, терминами уровня регистровых передач (RTL —
register transfer level). Все функции программных блоков интеллектуаль-
ной собственности, используемые инженерами, являются частью ос-
новного устройства, которое также описывается в терминах RTL, и за-
тем синтезируется в группу программируемых логических блоков, воз-
можно в комбинации с некоторыми аппаратными блоками
интеллектуальной собственности, такими как умножители и другими.
Среднее положение между аппаратными и программными занима-
ют микропрограммные блоки интеллектуальной собственности (микро-
программные IP — firm IP), которые также реализуются в виде библи-
отеки высокоуровневых функций. В отличие от своих программных
эквивалентов эти функции уже оптимально преобразованы, размеще-
ны и объединены в группы программируемых логических блоков (воз-
можно в комбинации с некоторыми аппаратными блоками интеллек-
туальной собственности, такими как, например, умножители). При
необходимости, в конструкцию микросхемы могут быть включены не-
сколько предопределенных блоков микропрограммной IP.
Проблема состоит в том, что довольно трудно провести границу
между функциями, которые лучше реализовывать в виде аппаратных
IP, и функциями, которые следует реализовывать как программные
или микропрограммные блоки интеллектуальной собственности, ис-
пользуя набор программируемых логических блоков общего назначе-
ния. Что касается умножителей, сумматоров, и функций умножения
с накоплением, которые уже рассматривались в этой главе, они ис-
пользуются в большинстве практических приложений и будут всегда
востребованы. Вместе с тем, некоторые ПЛИС содержат специализи-
рованные блоки для управления специфичными интерфейсными
протоколами, например, стандарт PCI. Это, конечно, может сущест-
венно облегчить жизнь пользователя, но при условии, что на печат-
ной плате найдется интерфейс, с которым он пожелаете соединить
своё устройство. При необходимости использовать другой интер-
фейс специализированный PCI-блок окажется только растратой сво-
бодного места, и будет затруднять передачу данных и бездумно пот-
реблять энергию.
Поэтому, если поставщики ПЛИС добавляют в свои микросхе-
мы подобные специфичные функции, это свидетельствует о том, что
они уже определили для этого компонента его нишу. Иногда потре-
бители вынуждены использовать подобные функции для достиже-
ния желаемых показателей или параметров разрабатываемых сис-
тем, что является классической проблемой, так как следующее по-
коление устройств очень часто способно достигать необходимых
показателей в своей главной (программируемой) структуре без спе-
цифичных блоков.
1833 г. Англия.
Майкл Фарадей
(Michael Faraday)
сформулировал за-
коны электролиза.
90 Глава 4. Архитектура ПЛИС
Системный вентиль и реальный вентиль
Одним из показателей, используемых для измерения размера уст-
ройства в мире заказных микросхем, является эквивалентный вентиль.
Дело в том, что различные поставщики предоставляют различные биб-
лиотеки своих функций, причем реализация каждой функции требует
различного количества транзисторов. Это затрудняет сравнение отно-
сительной ёмкости и сложности двух устройств.
Решение заключается в назначении каждой функции устройства
эквивалентного количества вентилей по принципу: «Функция А счи-
тается равной пяти эквивалентным вентилям; функция Б считается
равной трем эквивалентным вентилям...». На следующем этапе необ-
ходимо подсчитать количество экземпляров каждой функции, преоб-
разовать его в значение в эквивалентных вентилях, суммировать все
значения вместе и с гордостью заявить: «Моя микросхема содержит 10
миллионов эквивалентных вентилей, что существенно больше, чем в
вашей микросхеме!»
К сожалению, не всё так просто, так как определение, что действи-
тельно представляет собой эквивалентный вентиль, существенно за-
висит от того, кто об этом говорит. Имеется договоренность, согласно
которой 2-входовая функция И-НЕ представляется собой один экви-
валентный вентиль. Между тем, некоторые поставщики эквивалент-
ный вентиль приравнивают к некоторому количеству транзисторов. И
ещё более специфичная договоренность, понятная только посвящен-
ным, определяет эквивалентный вентиль эмиттерно-связанной логи-
ки: «одна одиннадцатая минимального количества логики, требуемого
для реализации полного однобитного сумматора» (кому же это при-
шло в голову?). В подобной ситуации перед реализацией каких-либо
планов за кровно заработанные деньги следует убедиться, что все вкла-
дывают один и тот же смысл в обсуждаемые понятия.
Вернемся к ПЛИС. Проблема, с которой постоянно сталкивают-
ся поставщики ПЛИС, возникает при попытке сравнить их устройс-
тво с заказной интегральной микросхемой. Например, кто-то распо-
лагает устройством на заказной микросхеме с 500000 эквивалентных
вентилей и желает перенести его на микросхему ПЛИС. Как в этом
случае определить, можно ли эту разработку реализовать на конкрет-
ной ПЛИС? Тот факт, что каждая 4-входовая таблица соответствия
может использоваться в виде блока, содержащего от одного до 20 и
более 2-входовых примитивных вентилей, делает такое сравнение до-
вольно сложным.
Чтобы устранить эти разногласия, в начале 90-х поставщики
ПЛИС начали поговаривать о системном вентиле. Некоторые расце-
нивают это как благородное желание использовать терминологию,
понятную разработчикам заказных микросхем, другие утверждают,
что это был маркетинговый ход, не нашедший соответствующей под-
держки.
К сожалению, как оказалось, в то время не существовало точного
определения системного вентиля. Ситуация осложнялась тем, что тог-
да ПЛИС в основном состояли из программируемой логики общего
назначения в форме таблиц соответствия и регистров. Даже нельзя бы-
ло получить ответ на такой вопрос, как: «Можно ли впихнуть функци-
ональность, реализованную на определенной заказной микросхеме,
содержащей х эквивалентных вентилей, в некоторую ПЛИС, содержа-
щую у системных вентилей?». Проблема состояла в том, что некоторые
устройства на заказных микросхемах были, как правило, комбинаци-
онными, в то же время как на других устройствах было довольно тяже-
Системный вентиль и реальный вентиль 91
ло использовать регистры. И в том, и в другом случае перенос устройс-
тва на ПЛИС не был в полной мере оптимальным.
Проблема обострилась, когда ПЛИС стали содержать встроенные
блоки ОЗУ, так как некоторые функции могли быть более эффективно
реализованы в памяти, чем с помощью логики общего назначения. А
тот факт, что таблица соответствия могла работать как распределённое
ОЗУ, ещё больше замутил воду. Так, например, по утверждению одного
из поставщиков: «Предположительно, от 20 до 30% таблиц соответс-
твия используется в качестве распределенных ОЗУ». При рассмотре-
нии ПЛИС со встроенными процессорными ядрами и подобными
функциями ситуация усугубляется до такой степени, что некоторые
поставщики говорят: «Количество системных вентилей для этих уст-
ройств не определено».
Существуют ли какие-нибудь практические приемы для перевода
системных вентилей в эквивалентные вентили и наоборот? Конечно
таких способов очень много. Некоторые говорят, если вы оптимист,
вам следует разделить количество системных вентилей на 3. В этом
случае, например, 3 000000 системных вентилей ПЛИС-устройств бу-
дут соответствовать 1 000000 эквивалентных вентилей заказных интег-
ральных микросхем. Если же вы скорее пессимист, чем оптимист, мо-
жете разделить количество системных вентилей на 5. В этом случае
3 000000 системных вентилей будут соответствовать 600000 эквивален-
тных вентилей.
Однако кое-кто может сказать, что изложенное выше справедливо,
если допустить, что число системных логических элементов включает
все возможные функции, которые могут быть реализованы при ис-
пользовании как программируемой логики общего назначения, так и
блоков ОЗУ. Этот же кое-кто будет утверждать, что при удалении из
расчетов блоков ОЗУ, следует делить число системных вентилей на 10.
В этом случае 3 000000 миллионам системных вентилей будут соот-
ветствовать всего лишь 300000 эквивалентных вентилей), но в этом
случае блок ОЗУ по-прежнему будет играть свою роль... Брррррррррр!
В конечном счете, эта тема становится сложной настолько, что да-
же поставщики ПЛИС отчаянно пытаются не заводить разговоров о
системных вентилях. Когда ПЛИС только появились, дискомфорта по
отношению к эквивалентным вентилям не существовало, чего нельзя
сказать о таблицах соответствия, секциях и тому подобному. Однако
спустя годы, широкое распространение ПЛИС привело к тому, что се-
годня разработчики более свободно ориентируются и в этих понятиях.
По этой причине я предпочел бы определять и сравнивать ПЛИС по
таким показателям:
• количество логических ячеек или логических элементов или
других элементов (которые эквивалентны 4-входовым таблицам
соответствия и связанными с ними триггерами/защелками);
• количество (и размер) встроенных блоков ОЗУ;
• количество (и размер) встроенных умножителей;
• количество (и размер) встроенных сумматоров;
• количество (и размер) встроенных блоков операций умножения
с накоплением;
• и т. д.
Почему же все так сложно? На самом деле было бы очень полезно
взять другой набор реально существующих заказных интегральных
микросхем и определить значения эквивалентных вентилей с учетом
триггеров или защёлок, примитивных логических элементов и других
более сложных функций. Затем соотнести каждое из этих устройств с
1837 г. Америка.
Самуил Финли Бриз
Морзе (Samuel
Finley Breese Morse)
изобрёл электроме-
ханический теле-
графный аппарат.
92 Глава 4, Архитектура ПЛИС
1837 г. Англия.
Чарльз Уитстон
(Sir Charles
Wheatstone) сов-
местно с Вильямом
Куком (Sir William
Fothergill Cooke) за-
патентовали 5-
стрелочный элект-
рический телеграф.
1842 г. Англия.
Джозеф Генри
(Joseph Henry) от-
крыл явление, со-
гласно которому
электрическая иск-
ра между двумя
проводниками вы-
зывает намагничи-
вание стальных
игл. Этот эффект
обнаруживался на
расстоянии
30 метров.
1842 г. Шотлан-
дия. Александр
Бейл (Alexander
Bail) продемонс-
трировал первое
электромеханичес-
кое средство, поз-
воляющее вводить,
передавать и вос-
производить изоб-
ражения.
количеством таблиц соответствия, триггеров/защелок, необходимых
для реализации эквивалентного устройства на базе ПЛИС с учетом ко-
личества встроенных блоков памяти ОЗУ и ряда других встроенных
функций.
Конечно, это далеко не идеальное решение, поскольку общая тен-
денция в проектировании имеет различные подходы для ПЛИС и за-
казных интегральных микросхем, но, по крайней мере, надо же с чего-
то начать.
Возраст ПЛИС
Все мы знаем, что один год жизни собаки соответствует семи годам
человеческой жизни. Следовательно, 10-летняя дворняга, в пересчете
на человеческий возраст, это 70-летний человек. Это, разумеется, ни-
чего не меняет. Но, тем не менее, этот пример демонстрирует прекрас-
ную систему отсчета. Так, если во время продолжительной прогулки
гончая не будет поспевать за хозяином, вполне справедливо будет ска-
зать: «Этого стоило ожидать, ведь тебе, дружище, уже почти 100 лет».
Или что-то в этом роде.
В случае с ПЛИС рассмотренная ситуация может натолкнуть на
мысль, что один год для этих устройств соответствует 15 годам челове-
ческой жизни. Поэтому, если пользователь имеет дело с микросхемой,
которая появилась на рынке в прошлом году, её можно сравнивать с
подростком. Если имеются большие виды на будущее, возможно, в бу-
дущем он или она станет лауреатом Нобелевской премии мира или
займет пост президента Соединенных Штатов Америки. Или же объ-
ект вашей любви будет, как обычно, обладать некоторыми капризами,
к которым придется привыкать и учиться их использовать.
Если ПЛИС присутствует на рынке в течение 2-х лет, что соответс-
твует 30 годам в пересчете на человеческий возраст, можно восприни-
мать ее как достаточно зрелого и всесторонне одаренного человека,
который находится в самом расцвете сил. После трехлетнего возраста
(45 лет) ПЛИС становится уравновешенным человеком средних лет, а
через четыре года (60-летний возраст) следует относиться к ней с ува-
жением, а не как к ломовой лошади!
ГЛАВА 5
ПРОГРАММИРОВАНИЕ
ИЛИ КОНФИГУРИРОВАНИЕ ПЛИС
Ласковые слова
Перед тем как полностью погрузиться в эту тему, вероятно, име-
ет смысл в качестве небольшого вступления сказать несколько
«ласковых слов». В этой связи на ум приходить поговорка: «Орел па-
рит в небе, а ласка вряд ли попадёт в струю реактивного двигателя
на высоте 10000 футов». (Рожденный ползать, летать не может. —
Прим, перев.)
Дело в том, что у каждого производителя ПЛИС своя терминоло-
гия, свои методы, средства работы. Чтобы жизнь не стояла на месте,
механизмы программирования ПЛИС должны существенно меняться
от семейства к семейству. Поэтому последующие рассуждения будут
посвящены исключительно общим вопросам программирования мик-
росхем.
Конфигурационные файлы и прочее
Вторая часть этой книги посвящена описанию множества инстру-
ментов и подходов, которые могут быть использованы для проектиро-
вания принципиальных схем и реализации ПЛИС-систем. С помощью
этих средств разработчики получают конфигурационный, или битовый,
файл, который содержит информацию, предназначенную для загрузки
в микросхему, т. е. для её программирования с целью выполнения оп-
ределенных функций.
Если микросхема использует для хранения своей конфигурации
ячейки статического ОЗУ, конфигурационный файл содержит некото-
рую совокупность конфигурационных данных, или биты, используемые
для определения состояния элементов программируемой логики и
конфигурационных команд, т. е. инструкций, говорящих устройству, что
ему необходимо делать с конфигурационными данными. При загрузке
конфигурационного файла в устройство передаваемую информацию
называют конфигурационным двоичным потоком.
Устройства на ячейках памяти ЭСППЗУ или Flash-памяти про-
граммируются аналогично своим родственникам на ячейках статичес-
кого ОЗУ В отличие от них в устройствах основанных на методе нара-
щиваемых перемычек конфигурационный файл содержит только кон-
фигурационные данные, которые будут использоваться для
наращивания перемычек.
Конфигурационные ячейки
Основная концепция программирования ПЛИС относительно
проста и представляет собой загрузку в устройство конфигурационно-
го файла. Поскольку это довольно-таки сложный процесс, и чтобы он
94 Глава 5. Программирование или конфигурирование ПЛИС
1843 г. Англия. Ав-
густа Ада Лавлейс
(Augusta Ada
Lovelace) опублико-
вала свои труды,
посвященные рас-
смотрению концеп-
ции компьютера.
был понятен, начнем с основ. Для начала рассмотрим элементарное
устройство, состоящее из массива очень простых программируемых
логических блоков, окруженных программируемыми внутренними со-
единениями (Рис. 5.1).
Рис. 5.1. Простая ПЛИС-архитекгура (вид сверху)
Все возможности программируемых устройств реализуются с по-
мощью специальных конфигурационных ячеек. Большинство ПЛИС ис-
пользуют ячейки статического ОЗУ, другие используют ЭСППЗУ или
ячейки Flash-памяти, третьи основываются на наращиваемых пере-
мычках.
Независимо от базовой технологии внутренние соединения уст-
ройства содержат большое количество связующих (соединительных)
ячеек, которые можно использовать для его конфигурирования, чтобы
соединить входы и выходы микросхемы с программируемыми логи-
ческими блоками, а также блоки между собой. Все блоки ввода/выво-
да, которые не показаны на Рис. 5.1, располагают несколькими соеди-
нительными ячейками, которые используются для их конфигурирова-
ния в соответствии с определенными стандартами интерфейсов
ввода/вывода или другими параметрами.
Предположим, что каждый программируемый логический блок со-
держит всего лишь 4-входовую таблицу соответствия, мультиплексор
и регистр (Рис. 5.2). Мультиплексор нуждается в соединительной кон-
фигурационной ячейке, чтобы определить вход, сигнал с которого бу-
дет передаваться на его выход. Регистр нуждается в соединительных
конфигурационных ячейках, чтобы определить будет ли он:
• выступать в роли триггера (как показано на Рис. 5.2) или в роли
защелки;
• переключаться по фронту или по спаду синхроимпульса (при
работе в режиме триггера) либо переключаться высоким или
низким уровнем сигнала (в режиме защелки);
• инициализироваться логическим 0 или логической 1.
В свою очередь, 4-входовая таблица соответствия содержит 16 кон-
фигурационных ячеек.
ПЛИС на наращиваемых перемычках 95
Рис. 5.2. Очень простой программируемый логический блок
ПЛИС на наращиваемых перемычках
В микросхемах на наращиваемых перемычках конфигурационные
ячейки, как правило, распределены по всей поверхности устройства
по определённым ключевым направлениям. Для программирования
микросхема помещается в специальный программатор, в который из
управляющего компьютера загружается конфигурационный или бито-
вый файл. Этот файл используется программатором в качестве руко-
водства по выдачи импульсов относительно высокого напряжения и
большого тока на определенные выводы микросхемы, вследствие чего
происходит поочерёдное наращивание перемычек.
Чтобы лучше понять процесс программирования, представим, что
каждая наращиваемая перемычка имеет виртуальные х-у координаты
на поверхности кристалла и эти х-у значения представляются в виде
чисел. Далее вообразим, что одна группа контактов ввода/вывода мик-
росхемы предназначена для представления значения х, а другая группа
контактов предназначена для представления значения у. В реальной
жизни всё выглядит намного сложнее, но этот пример позволяет по-
нять процесс, не напрягая мозги.
После наращивания всех перемычек микросхема извлекается из
программатора и помещается на печатную плату. Конечно же, уст-
ройства на наращиваемых перемычках являются однократно програм-
мируемыми. и с началом процесса программирования что-либо поме-
нять в конфигурации устройства будет невозможно, как говорится, по-
езд ушел.
ПЛИС на ячейках статического ОЗУ
Рассмотрим ПЛИС-структуру на основе ячеек статического ОЗУ.
Напомню, что эти устройства являются энергозависимыми. Это зна-
чит, что они программируются внутрисистемно, т. е. на печатной пла-
те, причём программируются каждый раз после включения системы.
Все конфигурационные ячейки статического ОЗУ можно предста-
вить в виде одного длинного сдвигового регистра. Давайте рассмотрим
простой рисунок поверхности кристалла, на котором изображены
только контакты ввода/вывода и конфигурационные ячейки статичес-
кого ОЗУ (Рис. 5.3).
Будем полагать, что начало и окончание, т. е. вход и выход, этой
регистровой цепочки напрямую подключены к внешним контактам
микросхемы. Однако при этом следует иметь в виду, что это возможно
96 Глава 5. Программирование или конфигурирование ПЛИС
Рис. 5.3. Представление ячеек статического ОЗУ в форме большого
сдвигового регистра
только в том случае, когда программирование осуществляется с помо-
щью конфигурационного порта в режиме последовательной загрузки.
Как будет показано, при последовательной загрузке ПЛИС может на-
ходиться в двух режимах: ведущий (master) и ведомый (slave).
Также следует иметь в виду, что выходные контакты и выходные
сигналы конфигурационных данных, показанные на Рис. 5.3, исполь-
зуются только в том случае, когда несколько ПЛИС сконфигурирова-
ны для работы в режиме каскадирования, т. е. последовательного оп-
роса, или если по тем или иным причинам из устройства требуется
прочитать конфигурационные данные.
Устройства на основе ячеек памяти Flash (и ЭСППЗУ) обычно про-
граммируются таким же способом, каким и микросхемы на основе
статического ОЗУ, но при этом являются энергонезависимыми. Это
свойство позволяет Flash-устройствам сохранять конфигурацион-
ную информацию при отключении питания системы. Другими сло-
вами, такие устройства не надо перепрограммировать при включе-
нии системы, хотя при необходимости такая процедура может быть
выполнена. ПЛИС на основе Flash-элементов могут программиро-
ваться внутрисистемно, т. е. на печатной плате, или внесистемно с
помощью отдельного программатора.
Ловкость рук и никакого мошенства
Вниманию читателя предлагается необязательный для чтения раз-
дел. Если он торопится, может перейти к следующей теме. Но мне этот
материал представляется очень интересным, и я надеюсь, что многим
он придется по душе.
Как показано на Рис. 5.3, самый простой способ понять внутрен-
нюю структуру программируемых ячеек статического ОЗУ заключает-
ся в представлении их в виде длинного сдвигового регистра. Так было
бы в том случае, когда каждая ячейка была бы реализована в виде триг-
гера, все триггеры были бы соединены в цепочку и управлялись общим
синхросигналом.
Проблема заключается в том, что ПЛИС может содержать огром-
ное количество конфигурационных ячеек. Уже к 2003-му году высоко-
технологичные устройства могли запросто содержать 25 миллионов та-
ких ячеек! Здесь необходимо заметить, что для реализации триггера
ПЛИС на ячейках статического ОЗУ 97
требуется восемь транзисторов, а для защелки всего лишь четыре. Поэ-
тому конфигурационные ячейки в устройствах на статическом ОЗУ
выполняются на защелках. Так, в устройстве с 25 миллионами конфи-
гурационных ячеек такой подход позволяет сэкономить 100 милли-
онов транзисторов, что тоже немало.
Проблема кроется в том, что нельзя создать такой большой сдвиго-
вый регистр из защелок. Ну, хорошо, хорошо. Ну, можно создать такой
регистр, но, разумеется, не длиною в 25 миллионов ячеек. Поставщики
ПЛИС обходят эту проблему с помощью группы триггеров, скажем из
1024-х, объединенных общим синхросигналом и конфигурируемых как
классический сдвиговый регистр. Такую группу называют фреймом.
25 миллионов конфигурационных ячеек-защёлок в устройстве из
нашего примера также разбивались на фреймы, при этом длина каж-
дого равнялась длине специального триггерного фрейма. Внешне про-
цесс представлял собой простую загрузку 25 миллионов бит конфигу-
рационных данных в устройство. Однако внутри устройства, как толь-
ко первые 1024 бита последовательно загружались в триггерный
фрейм, специальная внутренняя схема автоматически параллельно ко-
пировала эти данные в первый фрейм защёлок. Затем следующие 1024
бита загружались в триггерный фрейм и автоматически параллельно
копировались во второй фрейм защёлок и так далее до полного запол-
нения устройства. При чтении данных из устройства процесс протекал
в обратном порядке.
(^=> Программирование ПЛИС может занимать значительное время. Ес-
ли рассматривать высокотехнологичную микросхему, содержащую
25 миллионов ячеек статического ОЗУ, конфигурирование такого
устройства в последовательном режиме с тактовой частотой 25 МГц
займёт одну секунду. Это не очень плохой результат в случае, когда
программирование производится при включении питания, но вряд
ли пользователь захочет воспользоваться возможностью такой ре-
конфигурации в процессе работы системы.
Программирование встроенных блоков ОЗУ,
распределенного ОЗУ и других ОЗУ
Если ПЛИС содержит большие встроенные блоки ОЗУ, то ядра
этих блоков выполняются из защелок на основе ячеек статической па-
мяти. Каждая защелка, в свою очередь, является конфигурационной
ячейкой, которая формирует часть воображаемой регистровой цепоч-
ки, которая рассматривалась в предыдущем разделе.
Интерес представляет тот факт, что каждая 4-входовая таблица со-
ответствия (см. Рис. 5.2) может конфигурироваться для работы в ка-
честве собственно таблицы соответствия либо в качестве небольшого
блока (16x1) распределенного ОЗУ, либо в качестве 16-битного сдвиго-
вого регистра. Все эти конфигурации используют для своей работы
группу из 16 защелок на основе статического ОЗУ, причем каждая за-
щелка является конфигурационной ячейкой из состава рассмотренной
нами регистровой цепочки.
«Ну и что следует из этого перевоплощения 16-битного сдвигового
регистра? — спросит читатель. — Разве в этом случае не надо использо-
вать настоящие триггеры?» А вот это уже хороший вопрос, и я рад, что
он прозвучал. Вся хитрость схемы заключается в том, что в этом случае
используется концепция ёмкостных защёлок, которые по многим па-
раметрам превосходят классические защёлки. Очень похожим спосо-
бом разработчики делали внешние триггеры из дискретных транзисто-
ров, резисторов и конденсаторов в начале 60-х прошлого века.
98 Глава 5. Программирование или конфигурирование ПЛИС
1843 г. Англия.
Чарльз Уитстон
(Sir Charles
Wheatstone) сов-
местно с Вильямом
Куком (Sir William
Fothergill Cooke)
запатентовали
2-стрелочный элек-
трический теле-
граф.
1844 г. Америка.
Телеграф Морзе
соединил города
Вашингтон и Бал-
тимор.
Мультипрограммирование конфигурационных цепочек
На Рис. 5.3 показаны конфигурационные ячейки в виде одной
программируемой цепочки. Поскольку количество конфигурацион-
ных ячеек может достигать нескольких десятков миллионов, цепочка
действительно может оказаться очень длинной. В некоторых микро-
схемах цепочка разбивается на части, и отдельные участки этой цепи
подключаются к конфигурационному порту. Такой подход позволяет
конфигурировать отдельные части устройства и упрощает реализацию
различных концепций, таких как модульное и пошаговое проектиро-
вание.
Быстрая реинициализация устройства
Как уже отмечалось, регистры программируемых логических бло-
ков соединены с конфигурационными ячейками, в которых содержит-
ся его исходное значение: логический 0 или логическая 1. Каждое се-
мейство ПЛИС обычно поддерживает некоторый механизм, напри-
мер, вывод инициализации, который при активации даёт команду
регистрам вернуться к исходным значениям. Такой механизм не ини-
циализирует встроенные блоки памяти или распределенное ОЗУ.
Конфигурационный порт
В своё время первые ПЛИС использовали инструмент, называе-
мый конфигурационным портом. Даже сегодня, когда доступны более
сложные методы, подобные JTAG-интерфейсу, конфигурационный
порт все еще находит широкое применение, так как представляет со-
бой довольно простой инструмент, и к тому же к нему с пониманием
относятся его сторонки в сообществе ПЛИС.
Начнем рассмотрение с небольшой группы специальных контак-
тов, или выводов, режима конфигурации, которые используются для
установки режима конфигурации устройства. В первых ПЛИС для
этих целей использовались только два вывода, которые позволяли за-
давать четыре режима конфигурации (Табл. 5.1).
Таблица 5.1. Четыре первичных режима конфигурации
Выводы установки режима Наименование режима
00 Последовательная загрузка, ПЛИС в режиме ведущий
01 Последовательная загрузка, ПЛИС в режиме ведомый
10 Параллельная загрузка, ПЛИС в режиме ведущий
11 Параллельная загрузка, ПЛИС в режиме ведомый
Следует иметь в виду, что названия режимов, а также соответствие
кода на выводах установки режима и названием режима приведены
только в качестве примера. Настоящие коды и названия режимов у
каждого поставщика свои.
Выводы, или контакты, установки режима обычно подключаются
к требуемым значениям логического 0 или логической 1 на печатной
плате. Эти выводы могут подключаться к другим логическим устройс-
твам, которые позволяют изменять режим программирования, но та-
кая схема редко встречается на практике.
Конфигурационный порт 99
Кроме выводов установки режима, используется дополнительный
вывод для информирования ПЛИС о начале процесса конфигурирова-
ния, и еще один вывод для выдачи сигнала, свидетельствующего об
окончании процесса конфигурирования. Существуют также сигналы
для определения ошибок, возникающих в ходе конфигурирования.
Помимо конфигурирования ПЛИС при включении системы, при не-
обходимости она может быть реинициализирована и возвращена к
первоначальным конфигурационным данным.
Конфигурационный порт также использует дополнительные выво-
ды микросхемы для управления загрузкой данных и для их ввода. Как
будет показано, количество этих выводов зависит от выбранного ре-
жима конфигурации. Важное значение имеет тот факт, что при завер-
шении конфигурирования большинство этих выводов могут использо-
ваться в качестве входов/выходов общего назначения.
1845 г. Англия.
Майкл Фарадей
(Michael Faraday)
открыл явление
вращения поляри-
зации света при
воздействии маг-
нитного поля.
Последовательная загрузка, ПЛИС в режиме ведущий
Вероятно, этот режим является самым простым из всех режимов
программирования. Раньше для работы в этом режиме использовались
внешние микросхемы ППЗУ. Впоследствии их заменили СППЗУ, за-
тем ЭСППЗУ и теперь, как правило, используются устройства на
ячейках flash-памяти. Эти компоненты специальной памяти содержат
один вывод для выхода данных, который подсоединяется к выводу вво-
да конфигурационных данных ПЛИС (Рис. 5.4).
данных
Рис. 5.4. Последовательная загрузка, ПЛИС в режиме ведущий
ПЛИС также использует несколько сигналов для управления вне-
шней памятью. К ним относится сигнал сброса, который выдается
ПЛИС при готовности ею начать чтение данных, а также синхросигнал,
предназначенный для синхронизации конфигурационных данных.
В этом режиме ПЛИС не нуждается во внешней памяти с последо-
вательной адресацией. При таком режиме используются простые им-
пульсы сигнала сброса для передачи сигнала готовности начать чтение
данных с начала конфигурационной последовательности, а затем при-
меняется последовательность синхроимпульсов для синхронизации
выдачи конфигурационных данных из памяти.
При необходимости выходной сигнал из ПЛИС может использо-
ваться для чтения конфигурационных данных устройства. Такой под-
ход имеет место при использовании нескольких микросхем ПЛИС на
100 Глава 5. Программирование или конфигурирование ПЛИС
1845 г. Англия.
Электрический те-
леграф впервые ис-
пользуется в качес-
тве вспомогатель-
ного средства при
раскрытии пре-
ступлений.
одной печатной плате. В этом случае каждая микросхема может иметь
собственное выделенное устройство внешней памяти и конфигуриро-
ваться по отдельности, как показано на Рис. 5.4. Согласно другому
подходу, ПЛИС могут соединяться каскадом, т. е. по схеме последова-
тельного опроса, и использовать совместно одно устройство внешней
памяти (Рис. 5.5).
Рис. 5.5. Последовательное включение микросхем FPGA
Группы из четырёх
битов в общем случае
называются ниблом
или полубайтом. Как
это не удивительно,
но два полубайта со-
ставляют один байт.
Это ещё раз доказы-
вает, что у инженеров
с чувством юмора всё
в порядке.
На заре компьютер-
ной эры каждый же-
лающий самостоя-
тельно вводил в об-
ращение свои
собственные опреде-
ления, и поначалу по
разным версиям байт
состоял из 5,6, 7, 8 и
даже 9 битов. Спустя
некоторое время все
заи нтересованные
лица пришли к кон-
сенсусу, и байты ста-
ли 8-битными. После
этого все стали до-
вольными и счастли-
выми. Правда и на
этот раз не обошлось
без недовольных, но
на них никто не об-
ращал внимания.
В схеме, показанной на Рис. 5.5, первая ПЛИС в цепочке (она со-
единена напрямую с внешней памятью) будет конфигурироваться для
работы в последовательном режиме как ведущий (master). Все последу-
ющие ПЛИС в этой цепочке должны быть сконфигурированы для ра-
боты в последовательном режиме как ведомые (slave).
Параллельная загрузка, ПЛИС в режиме ведущий
Во многих отношениях этот режим подобен предыдущему, но при
этом данные читаются 8-битными кусками из памяти, которая содер-
жит также восемь выводов данных. Группы из восьми бит довольно
широко распространены и называются байтом.
Кроме обеспечения управляющих сигналов, ПЛИС формирует для
внешней памяти сигналы адреса, которые используются для указания
байта конфигурационных данных, который будет загружаться на сле-
дующем такте (Рис. 5.6).
Подобная схема работает при условии, что ПЛИС содержит внут-
ренний счетчик, который используется для генерации адреса для вне-
шней памяти. Первые ПЛИС содержали 24-битные счетчики, которые
позволяли им адресовать 16 миллионов байт данных. В начале конфи-
гурационной последовательности счетчик сбрасывался в ноль. После
того, как байта данных счетчика адреса будет считан, содержимое
счетчика увеличивается для адресации следующего байта. Это процесс
продолжался до тех пор, пока конфигурационные данные полностью
не загрузятся в микросхему.
Казалось бы, что такой метод параллельной загрузки имеет пре-
имущество в скорости по сравнению с рассмотренным ранее последо-
вательным способом. Однако вначале это было не так. В первых мик-
росхемах, как только байт данных считывался ПЛИС, он по-прежнему
последовательно передавался во внутренний конфигурационный
сдвиговый регистр. К счастью, эта ситуация была исправлена в более
современных устройствах. Хотя восемь выводов микросхемы после за-
грузки конфигурационных данных могут использоваться как выводы
Конфигурационный порт 101
Рис. 5.6. Параллельная загрузка, ПЛИС в режиме ведущий (первый способ)
входа-выхода общего назначения, в реальных системах это свойство
сопряжено с рядом трудностей. Вызваны они тем, что эти выводы жес-
тко соединены с проводниками, соединяющими их с устройством вне-
шней памяти, что может стать причиной проблем, связанных с интег-
рацией различных сигналов.
Действительная причина популярности этих микросхем заклю-
чалась в том, что специальные устройства памяти, используемые
для последовательной загрузки конфигурационных данных в режи-
ме ведущий, были довольно дорогими. По сравнению с ними парал-
лельный метод позволял разработчикам использовать серийно вы-
пускаемые устройства памяти, которые отличались низкой стои-
мостью.
Специальные устройства памяти, создаваемые для использования
совместно с ПЛИС в настоящее время, являются относительно недо-
рогими и изготавливаются по Flash-технологии, т. е. являются уст-
ройствами многократного использования. Современные ПЛИС ис-
пользуют новые варианты параллельной загрузки. В этих случаях вне-
шняя память является специальным устройством, которое не требует
внешней адресации, т. е. ПЛИС больше не нуждается во внутреннем
счетчике для этих целей (Рис. 5.7).
Рис. 5.7. Параллельная загрузка, ПЛИС в режиме ведущий
(современная реализация)
102 Глава 5. Программирование или конфигурирование ПЛИС
1845 г. Англия и
Франция. Через
Ла-Манш проло-
жен первый теле-
графный кабель.
1846 г. Германия.
Густав Кирхгоф
(Gustav Kirchhoff)
сформулировал за-
коны Кирхгофа для
электрических
цепей.
В этом случае так же, как и в последовательном режиме, ПЛИС
просто выдает сигнал сброса внешней памяти для обозначения того,
что она готова начать чтение данных с начала конфигурационной пос-
ледовательности, и затем выдает синхроимпульсы для синхронизации
конфигурационных данных, поступающих из внешней памяти.
Параллельная загрузка, ПЛИС в режиме ведомый
Рассмотренные выше режимы конфигурирования, в которых
ПЛИС выступала в роли ведущей (master) довольно привлекательны
благодаря своей простоте и непритязательности, так как для работы
требуется только ПЛИС и одна микросхема внешней памяти.
Однако на многих печатных платах содержатся микропроцессоры,
которые обычно используются для выполнения разнообразных внут-
ренних задач. В этом случае разработчики могут решить использовать
микропроцессоры для загрузки конфигурационных данных в ПЛИС
(Рис. 5.8).
Рис. 5.8. Параллельная загрузка, ПЛИС в режиме ведомый
Идея заключается в том, что микропроцессор является управляю-
щим устройством. В этом режиме микропроцессор сообщает ПЛИС,
что он готов начать процесс конфигурирования, после этого произво-
дит чтение байта конфигурационных данных с определенного уст-
ройства памяти или с внешнего устройства, или ещё откуда-то, запи-
сывает эти данные в ПЛИС, считывает следующий байт данных из па-
мяти, записывает его в ПЛИС и так до окончания процесса
конфигурирования.
Такой подход обладает рядом преимуществ, не последним из кото-
рых является то, что микропроцессор может использоваться для за-
проса оборудования, принадлежащее соседней системе, и выбирать по
определенному признаку конфигурационные данные для загрузки в
ПЛИС.
Последовательная загрузка, ПЛИС в режиме ведомый
Этот режим аналогичен своему параллельному родственнику, но
при этом для загрузки данных в ПЛИС используется только один бит.
Микропроцессор по-прежнему производит чтение одного байта дан-
ных из устройства памяти и затем преобразует этот байт в последова-
тельность битов для записи в ПЛИС.
JTAG-порт 103
Главным преимуществом такого подхода является то, что его реа-
лизация требует меньшее количество выводов, задействованных у
ПЛИС. Другими словами, в процессе конфигурирования используется
только один контакт ввода/вывода, который с помощью дополнитель-
ного проводника подключается к шине данных микропроцессора.
JTAG-порт
Многие современные устройства, в том числе и ПЛИС, оборудова-
ны специальным интерфейсом, который называется JTAG-nopm. Этот
порт, поддерживаемый Объединенной рабочей группой по автоматиза-
ции тестирования (Joint Test Automation Group, JTAG) и известный как
стандарт IEEE 1149.1, изначально разрабатывался для реализации ме-
тода периферийного сканирования, который применялся для тестирова-
ния печатных плат и цифровых микросхем.
Детальное описание порта JTAG и метода периферийного скани-
рования выходит за рамки этой книги. В данном контексте важно, что
ПЛИС имеет некоторое количество выводов-контактов, которые ис-
пользуются в качестве JTAG-порта. При этом один из этих выводов
используется для ввода данных, другой для вывода, а остальные для
связи с последовательно соединенными JTAG-регистрами или тригге-
рами (Рис. 5.9).
Выход данных JTAG Вход данных JTAG
Рис. 5.9. JTAG-регистры последовательного сканирования
Идея последовательного сканирования состоит в следующем: че-
рез JTAG-порт можно последовательно передавать данные в JTAG-ре-
гистры, которые связаны с входными выводами микросхемы. В ре-
зультате устройство, в данном случае ПЛИС, получает возможность
работать с этими данными, сохранять результаты этой работы в JTAG-
регистрах, связанных с выходными выводами микросхемы, и последо-
вательно выдавать эти результаты обратно в JTAG-порт.
JTAG-устройства содержат различную дополнительную управляю-
щую логику. В случае ПЛИС JTAG-порт, кроме операций последова-
тельного сканирования, может выполнять и другие функции. Напри-
мер, возможно выдавать специальные команды, которые загружаются
в специальный командный JTAG-регистр (он не показан на Рис. 5.9)
через вход JTAG-порта. Одна такая команда указывает ПЛИС подсо-
единить свой внутренний конфигурационный сдвиговый регистр к
104 Глава 5. Программирование или конфигурирование ПЛИС
1847 г. Англия.
Джордж Буль
(George Boole) опуб-
ликовал первые
идеи символичес-
кой логики.
сканирующей цепочке JTAG-порта. В этом случае JTAG-порт может
использоваться для программирования ПЛИС. Таким образом, совре-
менные ПЛИС поддерживают пять различных режимов программиро-
вания, и, следовательно, для определения того, какой из них будет ис-
пользоваться, потребуется уже три вывода, как показано на Табл. 5.2
(в будущем также могут появиться и дополнительные режимы).
Таблица 5.2. Пять современных конфигурационных режимов
Выводы установки режима Наименование режима
ООО Последовательная загрузка, ПЛИС в режиме ведущий
001 Последовательная загрузка, ПЛИС в режиме ведомый
010 Параллельная загрузка, ПЛИС в режиме ведущий
011 Параллельная загрузка, ПЛИС в режиме ведомый
1хх Используется только JTAG-порт
Заметим, что JTAG-порт всегда доступен к использованию, то есть
устройство может быть сначала сконфигурировано через обычный
конфигурационный порт, используя один из стандартных конфигура-
ционных режимов, а затем, при необходимости, может быть реконфи-
гурировано при помощи JTAG-порта. Также устройство может про-
граммироваться с помощью только JTAG-порта.
Встроенные процессоры
Но и это ещё не всё! В гл. 4 говорилось о том, что некоторые ПЛИС
содержат встроенные процессорные ядра, причем каждое ядро имеет
свою специфичную JTAG-цепочку последовательного сканирования.
Рассмотрим ПЛИС, содержащую только один встроенный процессор
(Рис. 5.10).
Рис. 5.10. Цепочка последовательного сканирования встроенного процессора
Встроенные процессоры 105
В этом случае ПЛИС будет содержать только один внешний JTAG-
порт. При необходимости через этот порт можно загрузить команду,
которая даст указание процессорной JTAG-цепочке связаться с глав-
ной JTAG-цепочкой устройства. Если, в зависимости от поставщика,
обе цепочки могут быть соединены вместе по определению, то для их
разделения будет использоваться добавочная команда.
Идея состоит в том, что JTAG-порт может использоваться для ини-
циализации внутреннего микропроцессорного ядра и связанной с ним
периферии до некоторого состояния, после которого процессор само-
стоятельно загружает основную часть конфигурационных данных. В
некоторых случаях процессорное ядро может использоваться для вы-
полнения запросов во внешнюю среду и выбора конфигурационных
данных, предназначенных для загрузки в ПЛИС.
1850 г. Англия.
Френсис Галътон
(Francis Galton)
изобрёл телетайп.
ГЛАВА 6
ВЕДУЩИЕ ПРОИЗВОДИТЕЛИ
Введение
Как отмечалось в гл. 1, в этой книге не отдается предпочтение ка-
кому-то конкретному производителю или какой-то определенной
ПЛИС, поскольку характеристики микросхем постоянно улучшаются,
и, следовательно, появляются все новые и новые. По возможности, в
этой книге также отсутствуют ссылки на конкретных поставщиков
САПР электронных устройств и не приводятся названия их систем
проектирования, так как и эта область настолько быстро развивается,
что названия и характеристики этих инструментов могут меняться с
каждым днём.
Сказав это, заметим, что в данной главе рассматриваются основ-
ные производители ПЛИС и САПР, связанных с ПЛИС или смежны-
ми областями.
Поставщики FPGA и FPAA
Основная часть этой книги посвящена рассмотрению цифровых
устройств — ПЛИС (FPGA). Между тем существуют и такие устройс-
тва, как программируемые аналоговые интегральные схемы или ПАИС
(FPAA - field-programmable analog arrays — программируемые пользова-
телем аналоговые матрицы). Кроме того, некоторые компании специа-
лизируются на разработке блоков интеллектуальной собственности на
основе ядер ПЛИС, которые используются как часть заказной микро-
схемы на стандартных элементах или структурированной специализи-
рованной микросхемы, т. е. структурированной ASIC.
Таблица 6.L Основные поставщики ПЛИС
Компания Web-сайт Комментарий
Actel Corp. www.actel.com ПЛИС
Altera Corp. www.altera.com ПЛИС
Anadigm Inc. www.anadigm.com ПЛИС
Atmel Corp. www.atmel.com ПЛИС
Lattice Semiconductor Corp. www.latticesemi.com ПЛИС
Leopard Logic Inc. www.leopardlogic.com Встраиваемые ПЛИС-ядра
QuickLogic Corp. www.quicklogic.com ПЛИС
Xilinx Inc. www.xilinx.com ПЛИС
Поставщики устройств FPNA 107
Поставщики устройств FPNA
FPNA (fieldprogrammable nodal arrays) — несколько сложная, но не
лишенная смысла аббревиатура. Название программируемый пользова-
телем массив узлов было «изобретено» автором непосредственно перед
тем, как написать эти слова. Ну, как?
Все дело заключается в том, что все эти устройства построены по
крупномодульной архитектуре и представляют собой массив узлов.
Каждый узел, в свою очередь, является сложным элементом обработки
данных и выполняет функции от арифметико-логического устройства
(АЛУ) до быстрого преобразования Фурье (БПФ), обеспечивая пол-
ный набор средств микропроцессорного ядра общего назначения.
Эти устройства не классифицируются как ПЛИС в классическом
смысле. Однако границы определения, что является, и что не является
программируемой логической интегральной схемой, постоянно рас-
ширяются, и, по правде говоря, современные ПЛИС со встроенными
блоками ОЗУ, процессорами и гигабитными передатчиками не явля-
ются ПЛИС в классическом смысле. Что касается устройств FPNA,
они являются одновременно и цифровыми, и программируемыми
пользователем, поэтому заслуживают некоторого внимания в рамках
данной главы.
Во время написания этой книги от 30 до 50 компаний проводили
серьёзные эксперименты с различными типами FPNA-устройств; пе-
речень наиболее интересных фирм из их числа представлен в Табл. 6.2
(см. также гл. 23).
Таблица 6.2. Основные разработчики FPNA
Компания Web-сайт Комментарий
Elixent Ltd. www.elixent.com Узлы на основе АЛУ
IPflex Inc. www.ipflex.com Операционные узлы
Motorola www.motorola.com Узлы на основе микропроцессоров
PACT XPP Technologies AG www.pactxpp.com Узлы на основе АЛУ
picoChip Design Ltd. www.picochip.com Узлы на основе микропроцессоров
Quicksilver Technology Inc. www.qstech.com Узлы алгоритмических элементов
Поставщики САПР для полного цикла разработки
ПЛИС
Каждый поставщик ПЛИС (FPGA), ПАИС (FPAA) и FPNA уст-
ройств предоставляет набор средств проектирования для пользова-
тельских микросхем. В случае ПЛИС этот набор неизменно содержит
модули для размещения элементов и трассировки соединений. Пос-
тавщики ПЛИС могут также предложить OEM-версии САПР, так на-
зываемые легкие или «1йе»-версии сторонних разработчиков. В дан-
ном контексте «ОЕМ» значит следующее: поставщики ПЛИС лицен-
зируют программное обеспечение стороннего разработчика, и затем
поставляют его как часть собственной среды проектирования.
Первым делом рассмотрим крупные корпорации-поставщиков
программных комплексов САПР электронных систем, которые предо-
ставляют полный набор средств проектирования всех уровней
(Табл. 6.3). В ряде случаях эти решения могут включать ОЕМ-версии
продуктов от отдельных поставщиков САПР, рассматриваемых в сле-
дующем разделе.
108 Глава 6. Ведущие производители
1850 г. Изобретён
бумажный пакет.
Таблица 6.3. Разработчики САПР электронных систем
Компания Web-сайт Комментарий
Altium Ltd. www.altium.com Аппаратно-программные средства про- ектирования систем на основе ПЛИС
Cadence Design Systems www.cadence.com Средства описания и моделирования ПЛИС
Mentor Graphics Corp. www.mentor.com Системы описания, моделирования и синтеза ПЛИС
Synopsys Inc. www.synopsys.com Системы описания, моделирования и синтеза ПЛИС
Не всё так просто в этой жизни! Может показаться странным со-
седство относительно небольшой компании, такой как Altium, с кор-
поративными гигантами «большой тройки». Однако что касается
ПЛИС, компания Altium предоставляет полную программно-аппарат-
ную среду разработки для проектирования систем на основе ПЛИС. В
ее состав входят системы описания схемотехнических изображений,
моделирования, синтеза, компиляции и сборки, комплексные средс-
тва отладки и макетная плата, совместимая со многими ПЛИС других
поставщиков.
Специалисты по ПЛИС и независимые
разработчики САПР
Некоторые команды разработчиков предпочитают не покупать го-
товые решения, а создавать собственную среду разработки, приобре-
тая отдельные ее компоненты у разных поставщиков САПР. Во многих
случаях стоимость этих систем ниже, чем у их аналогов от производи-
телей полных систем, но они могут быть менее сложными и менее
мощными (Табл. 6.4). В то же время небольшие компании-поставщи-
ки иногда предлагают невероятно удобные и оригинальные решения,
к тому же они более «дружественно» настроены к своим клиентам. Как
говорится: «Кто платит, тот и выбирает».
Таблица 6.4. Независимые разработчики САПР
Компания Web-сайт Комментарий
О-In Design Automation www.0-in.com Системы проверки на основе утвержде- ний
AccelChip Inc. www.accelchip.com Системы цифровой обработки сигна- лов на основе ПЛИС
Aldec Inc. www.aldec.com Мультиязычные системы моделирова- ния
Celoxica Ltd. www.celoxica.com Проектирование и синтез ПЛИС-сис- тем
Elanix Inc. www.elanix.com Системы цифровой обработки сигна- лов и алгоритмической проверки
Fintronic USA Inc. www.fintronic.com Системы моделирования
First Silicon Solutions Inc. www.fs2.com Встраиваемые средства контроля и сис- темы отладки для логики ПЛИС и встроенных микропроцессоров
Консультанты по разработке ПЛИС и их средства проектирования 109
(продолжение)
Компания Web-сайт Комментарий
Green Hills Software Inc. www.ghs.com Специалисты в области систем реаль- ного времени и встраиваемых програм- мных модулей
Hier Design Inc. www.hierdesign.com Виртуальные прототипы на основе ПЛИС
Novas Software Inc. www.novas.com Анализ результатов тестирования
Simucad Inc. www.simucad.com Системы моделирования
Synplicity Inc. www.synplicity.com Синтез ПЛИС
The MathWbrks Inc. www.mathworks.com Системное проектирование и алгорит- мическая проверка
TransEDA PLC www.transeda.com Проверка блоков интеллектуальной собственности
Xferisity Design Inc. www.verisity.com Среды и языки тестирования систем
Wind River Systems Inc. www.windriver.com Специалисты в области систем реаль- ного времени и встраиваемых програм- мных модулей
Консультанты по разработке ПЛИС и их средства
проектирования
Существуют несколько небольших конструкторских компаний,
специализирующихся на разработке ПЛИС-систем. Некоторые из них
гордятся своими хитроумными средствами проектирования, которые
действительно стоят того, чтобы о них упомянуть.
Таблица 6.5. САПР от небольших консалтинговых компаний
Компания Web-сайт Комментарий
Dillon Engineering Inc. www.dilloneng.com Система разработки «ParaCore Architect»
Launchbird Inc. www.launchbird.com Компилятор и язык конструирования систем Confluence
Открытые, недорогие и бесплатные системы
проектирования
Предположим, что кто-то решил создать небольшую команду раз-
работчиков или стать консультантом по созданию систем на базе
ПЛИС. Но на данный момент не располагает необходимыми для этого
средствами. Можете поверить, что кому, как не мне очень хорошо зна-
кома такая ситуация! В этом случае можно использовать различные
недорогие или бесплатные системы или системы с открытым исход-
ным кодом. При этом затраты будут связаны только с приобретением
средств проектирования.
110 Глава 6. Ведущие производители
1853 г. Шотлан-
дия/Ирландия.
Чарльз Тильстон
Брайт (Sir Charles
Tilston Bright) про-
ложил первый под-
водный кабель
между Шотланди-
ей и Ирландией,
Таблица 6.6. Бесплатные и недорогие средства проектирования
Компания Web-сайт Комментарий
Altera Corp. www.altera.com Средства синтеза, размещения и разводки
Gentoo www.gentoo.com Система разработки для ОС Linux
Icarus http://icarus.com/eda/verilog Система моделирования для языка Wrilog
Xilinx Inc. www.xilinx.com Средства синтеза, размещения и разводки
— www.cs.man.ac.uk/apt/tools/gtkwave/ Просмотрщик формы сигнала «GTKWave»
— www.opencores.org Аппаратные ядра и системы проектирования с открытым кодом
— www.opencollector.org База данных аппаратных ядер и систем проектирования с от- крытым кодом
— www.python.org Язык программирования Python (для заказных средств и систем цифровой обработки сигналов)
— www.veripool.com/dinotrace Просмотрщик формы сигнала «Dinotrace»
— www.veripool.com/verilator.html Xferilator — транслятор из языка \ferilog в язык С
Что касается использования операционной системы Linux как
платформы для разработки, то два главных поставщика ПЛИС, ком-
пании Xilinx и Altera, в настоящее время занимаются совместимостью
собственных средств проектирования с этой системой. Эти компании
также предлагают бесплатные версии систем ISE и Quartus-II для раз-
работки устройств на основе ПЛИС. Даже полные версии этих систем
проектирования вполне по карману большинству новых фирм.
ГЛАВА 7
РАЗЛИЧНЫЕ ПОДХОДЫ
К ПРОЕКТИРОВАНИЮ СИСТЕМ
НА ОСНОВЕ ПЛИС И ЗАКАЗНЫХ
МИКРОСХЕМ
Введение
Моя мама очень гордится тем, что её сын стал инженером в облас-
ти электронных систем. И эта гордость зиждется на абсолютно непо-
колебимой уверенности в том, что я могу все: создать, понять и отре-
монтировать любое электронное устройство, какой бы эпохе оно ни
принадлежало и где бы оно ни находилось на нашей планете. В реаль-
ности, конечно, дела обстоят намного скромнее, так как очень немно-
гие из нас становятся асами во всех областях науки электроники^.
В то время как одни тратят свои лучшие годы на разработку, по
всей видимости бесконечной, серии заказных микросхем, другие из-
нывают в своих офисах, постигая тайны области применения ПЛИС.
Проблема становится очевидной, когда инженер, владеющий в совер-
шенстве одной из этих технологий, неожиданно вынужден все бросить
и освоить другие технологические процессы. Типичная картина для
наших дней, когда разработчики, которых буквально распирает от гор-
дости и уверенности, что они знают всё о микросхемах, вдруг получа-
ют задание создать устройство, реализованное на основе ПЛИС.
Это довольно трудная глава ввиду многогранности обсуждаемых в
ней проблем. Самое оптимальное, что можно сделать в подобной ситу-
ации, — ограничиться обзором наиболее важных отличий подходов к
проектированию систем на основе ПЛИС и систем на основе заказных
микросхемах (ASIC).
Подходы к проектированию
Когда дело доходит до представления устройства с помощью одно-
го из языков описания аппаратных средств (см. гл. 9), инженеры, рабо-
тающие с заказными микросхемами, предпочитают написать порта-
тивный код на языке VHDL или Verilog и свести к минимуму конкре-
тизацию ячеек.
В отличие от них разработчики ПЛИС-систем предпочитают рабо-
тать с конкретными ячейками. Если разработчиков ПЛИС-систем, на-
пример, не устраивают результаты работы средств синтеза, создающих
нечто вроде мультиплексора, они могут вручную создать собственную
версию и включить её в состав кода. Искушенные разработчики сис-
тем на основе ПЛИС применяют, как правило, более или менее техно-
логически зависимые решения при синтезе, чем их коллеги, работаю-
щие с заказными микросхемами.
° Совсем недавно мне пришлось столкнуться со старым Wjrtsel Grinder
Mark 4, у которого был ажурный корпус и зеркальная зигзагообразная панель. Я и
понятия не имел, с какой стороны к нему подступиться. Даже трудно представить,
насколько беспомощным я казался себе.
112 Глава 7. Различные подходы к проектированию систем на основе ПЛИС и заказных микросхем
1854 г. Крым.
В крымской войне
используется теле-
граф.
Конвейеры и уровни логики
Что такое конвейер
Слово «конвейер» довольно часто употребляется. Однако очень ред-
ко можно встретить его определение. Несомненно, инженеры прекрас-
но знают, что значит этот термин, но поскольку эта книга рассчитана на
широкий круг читателей, уделим этому вопросу некоторое время, что-
бы быть уверенными, что все танцуют степ в одном и том же ритме1).
Предположим, что мы строим нечто вроде автомобиля и все части это-
го автомобиля находятся у нас под руками. Предположим также, что
весь процесс сборки состоит из следующих пяти этапов:
1. Присоединение колес к шасси.
2. Присоединение двигателя к шасси.
3. Присоединение сидений к шасси.
4. Присоединение кузова к шасси.
5. Покраска.
Да... знаю, знаю. Инженеры сразу начнут упрекать меня в том, что
в этом списке отсутствует рулевое управление, освещение и много дру-
гое. Но, господа, это же всего лишь пример!
Допустим, что для выполнения каждой из перечисленных опера-
ций потребуется один специалист. Один из способов выполнения
сборки заключается в том, чтобы рассадить всех специалистов в круг
для игры в карты. Первый парень (или девушка, так как любая дискри-
минация исключается)2) встает, присоединяет колёса к шасси и воз-
вращается к игре. После его (или её) возвращения второй парень вста-
ет, устанавливает двигатель и возвращается к игре. Теперь третий па-
рень встает прогуляться, чтобы присоединить сиденья к шасси. После
его возвращения четвертый парень подходит к шасси, чтобы устано-
вить на него кузов и так далее. После того как машина будет собрана,
начинается всё сначала.
Очевидно, что это очень нерациональный подход. Если, например,
каждая операция занимает один час, весь процесс будет длиться пять
часов. Кроме того, в течение каждого часа только один человек будет
работать, в то время как четверо других будут слоняться без дела. Оче-
видно, что более эффективной будет сборка одновременно пяти авто-
мобилей на сборочной линии. Тогда, как только первый парень присо-
единит колеса к первому шасси, второй парень начнет устанавливать
двигатель на это шасси, а в это время первый парень начнет устанавли-
вать колеса на второе шасси. Следовательно, сборочная линия будет
полностью заполнена, и каждый работник будет занять все рабочее
время, и новые автомобили будут сходить с конвейера каждый час.
Конвейер в электронных системах
Дело в том, что схему конвейера можно применить во многих элек-
тронных системах. Предположим, например, что имеется устройство,
или функциональный блок устройства, которое может быть реализо-
0 В молодости, перед Второй мировой войной, мой отец со своим братом ис-
полняли чечётку в варьете-холлах Англии. Держу пари, они не ожидали найти
упоминание об этом факте в книге по электронике, написанной в 21-м веке.
2) Женщины сейчас очень эмансипированы и при описании любого процесса
о них нельзя не упоминать, исключая ситуации, когда такая трактовка противоре-
чит правилам грамматики.
Конвейеры и уровни логики 113
вано в виде последовательно соединенных блоков комбинационной,
или комбинаторной, логики (Рис. 7.1),
Предположим также, что каждый блок требует Y наносекунд для
выполнения своей задачи. Допусти, что имеется пять таких блоков (на
Рис. 7.1 показано только три). В этом случае понадобится 5xY наносе-
кунд для передачи слова данных через эту функцию, начиная с дости-
жения им входов первого блока и кончая его уходом с выходов послед-
него блока.
Комбинаторная
Комбинаторная
логика логика
Комбинаторная
логика
Рис, 7,1, Функция, реализованная с помощью комбинаторной логики
1855 г. Англия.
Джеймс Клерк
Максвелл (James
Clerk Maxwell) ма-
тематически опи-
сал открытые Фа-
радеем силовые ли-
нии поля.
В такой ситуации не хотелось бы выставлять новые данные на вхо-
ды блока до тех пор, пока не будет сохранен результат, относящийся к
первому слову данных. Это значит, что возникает та же ситуация, ко-
торая имела место при неэффективной сборке автомобиля. Другими
словами, потребуется много времени для обработки каждого слова
данных, и большинство «рабочих», т. е. логических блоков, основную
часть времени будут простаивать без работы. Проблема решается мето-
дом конвейерной обработки, в котором «острова» комбинационной
логики чередуются с блоками регистров (Рис. 7.2).
Существует метод
волнового конвейе-
ра, когда через логи-
ку одновременно
проходят несколько
«волн» данных.
Однако их рассмот-
рение выходит
за рамки этой кни-
ги, и, к тому же,
этот метод не при-
меняется в ПЛИС.
Все регистры синхронизируются с помощью общего тактового сиг-
нала. С приходом каждого синхроимпульса результаты с предыдущего
блока загружаются в регистры, подключенные к входам логических
блоков. Эти значения затем передаются через этот логический блок на
его выходы, где они будут готовы для загрузки в следующий регистр на
следующем такте.
При такой схеме, после того как «насос будет запущен» и конвейер
полностью заполнен, новые слова данных могут поступать через каж-
дые Y наносекунд.
114 Глава 7. Различные подходы к проектированию систем на основе ПЛИС и заказных микросхем
1858 г. Америка.
Агенты судоходной
компании Cunard
послали первую
коммерческую те-
леграмму о столк-
новении двух паро-
ходов.
Логические уровни
Всё вышесказанное сводится к тому, что инженерам следует соб-
людать определённый баланс. Разделение комбинационной логики на
меньшие блоки и увеличение количества регистров приведет к росту
производительности устройства и одновременно к увеличению пот-
ребления ресурсов микросхемы, в том числе и места на кристалле, что
увеличит задержку, или латентность, устройства.
В электронных системах термин «латентность» означает время,
(или количество тактовых импульсов) необходимое для прохожде-
ния блока данных через функцию, устройство или систему.
Чтобы лучше понять, что такое латентность, рассмотрим еще раз
пример конвейерной сборки автомобиля. В этом случае пропускная
способность системы может составлять один автомобиль в минуту, а
латентность системы может составлять 8 часов, в течение которых
выполняются сотни операций по сборке автомобиля (каждая такая
операция соответствует одному регистру в конвейерной цепочке).
Рассмотрим концепцию логического уровня, т. е. количество логи-
ческих элементов между входами и выходами логического блока. Так,
например, на Рис. 7.3 показано три логически уровня, так как перед
тем как достичь выхода сигнал, в наихудшем случае, пройдет через три
логических элемента.
От предыдущего
регистра
К следующему
регистру
При использовании заказных микросхем логические элементы,
как показано на Рис. 7.3, могут быть размещены в непосредственной
близости друг к другу, т. е. задержка сигнала на проводниках между ни-
ми будет минимальной. Следовательно, если позволяет устройство,
разработчики заказных микросхем могут иногда позволить себе неко-
торую фривольность с задачами подобно рода. Однако она не заста-
вить себя долго ждать и сразу проявится, если сигналу предстоит прой-
ти путь через, скажем, 15 и более логических уровней.
При реализации этого устройства на ПЛИС, в которых каждый ло-
гический вентиль реализуется в виде отдельной таблицы соответствия
(LUT), сигнал будет двигаться с черепашьей скоростью, так как за-
держка на проводниках в ПЛИС существенно больше, чем у заказных
микросхем. Конечно, на практике таблица соответствия может объ-
единять несколько логических блоков (функция, показанная на
Рис. 7.3, может быть реализована в одной 4-входовой таблице соот-
ветствия), так что ситуация не столь ужасна, как это могло показаться
на первый взгляд.
Чтобы поднять, или удержать, производительность устройств на
основе ПЛИС, они должны быть более конвейеризованы, чем их ана-
логи на заказных микросхемах. Задача облегчается тем, что каждая ло-
гическая ячейка в ПЛИС содержит таблицу соответствия и регистр.
Метод асинхронного проектирования 115
Метод асинхронного проектирования
Асинхронные элементы
При решении некоторых задач разработчики заказных микросхем,
иногда добавляют в свои схемы асинхронные элементы, полагаясь на
относительную задержку распространения сигналов. Этот подход не
работает по отношению к ПЛИС, так как разводка и связанные с ней
задержки сигналов могут сильно изменяться после каждого нового
прогона трассировщика.
Комбинационные петли
Этот подраздел в какой-то мере связан с предыдущим. Комбина-
ционные петли возникают в схемах, в которых сигнал формируется с
помощью цепей обратной связи, проходящих через один или более ло-
гический вентиль1). Они являются главным источником так называе-
мых критических состояний гонки, при которых логические значения
зависят от задержек, определяемых разводкой элементов внутри мик-
росхемы. Хотя подобный подход осуждается в некоторых кругах, но в
случае заказных микросхемах разработчики могут себе позволить по-
добную вольность, поскольку они в состоянии точно определить мар-
шрут дорожки между элементами и, соответственно, связанную с ним
задержку. В случае ПЛИС это невозможно, так как такие цепи обрат-
ной связи должны содержать регистры.
Элементы задержки
Для создания элементов задержки в заказных микросхемах инже-
неры используют последовательность буферов или инвертирующих
вентилей. Эти элементы могут использоваться в различных целях, на-
пример для определения состояния гонки в асинхронных блоках уст-
ройства. При использовании таких элементов в ПЛИС довольно труд-
но прогнозировать величину задержки, к тому же, эти элементы уве-
личивают чувствительность устройства к условиям эксплуатации,
уменьшают её надежность и могут стать источником проблем при пе-
реходе на другую архитектуру или технологию реализации.
Анализ систем синхронизации
Зоны синхронизации
Заказные микросхемы могут использовать огромное количество
синхросигналов. Кто-то слышал, что существуют даже устройства с
более чем 300 различными зонами (доменами) синхронизации. Одна-
ко на этот счет у ПЛИС существует ограничения: разработчикам на-
стоятельно не рекомендуется выходить за рамки ресурсов, выделенных
для каждого конкретного устройства на обеспечение синхронизации.
Другими словами, не надо использовать выводы общего назначения
для подачи на микросхему пользовательских тактовых сигналов.
1858 г. Атлантика.
Проложен первый
трансатлантичес-
кий телеграфный
кабель. Впоследс-
твии он вышел из
строя.
° Конечно, каждая защёлка содержит цепь внутренней обратной связи, и
каждый триггер формируется из двух защёлок. Но эти обратные связи очень жес-
тко контролируются производителем микросхем.
116 Глава 7. Различные подходы к проектированию систем на основе ПЛИС и заказных микросхем
1858 г. Королева
Виктория отпра-
вила трансатлан-
тическую теле-
грамму президенту
СШАДжеймсу
Бьюкенену.
Некоторые ПЛИС позволяют разделять свои деревья синхрониза-
ции на сегменты. Если такая возможность поддерживается используе-
мой технологией, следует определить сегменты синхронизации и выде-
лить их соответственно под внешние и внутренние тактовые сигналы.
Выравнивание тактовых сигналов
В устройствах на заказных микросхемах необходимо использовать
специальные методы для выравнивания задержек тактовых сигналов,
распространяющихся по всему устройству. В отличие от заказных мик-
росхем, ПЛИС обладают небольшим фазовым сдвигам по всей поверх-
ности кристалла. Другими словами, нет необходимости выравнивать
тактовые сигналы, поскольку производители ПЛИС уже позаботились
об этом.
Стробирование и разрешение тактовых сигналов
В устройствах на заказных микросхемах часто используется кон-
цепция стробирования тактовых сигналов, что позволяет уменьшить
рассеиваемую мощность (Рис. 7.4, а). Однако при подобных подходах
устройство приобретает асинхронные свойства и становится чувстви-
тельным к выбросам импульсов, которые возникают при переключе-
нии входов, расположенных рядом с логикой стробирования.
В отличие от заказных микросхем (ASIC) разработчики ПЛИС ис-
пользуют концепцию разрешения тактовых сигналов. Раньше разреше-
ние реализовывалось с помощью отдельного мультиплексора
(Рис. 7.4, б), теперь в регистрах ПЛИС почти любой архитектуры пре-
дусмотрен отдельный специальный вход разрешения тактовых сигна-
лов (Рис. 7.4, в).
Данные
Синхроимпульс (СИ)
Строб
Регистр
а) Стробирование синхроимпульсов
б) Разрешение тактовых сигналов в) Разрешение тактовых сигналов
(старый вариант) (новый вариант)
Рис. 7.4. Стробирование и разрешение тактовых сигналов
ФАПЧ и схема согласования тактовых сигналов
ПЛИС обычно содержат схемы фазовой автоподстройки частоты
(ФАПЧ) или схемы автоматической подстройки по задержке: одну для
каждого встроенного общего тактового сигнала (см. гл. 4). Если эти
схемы используются для генерации тактовых сигналов внутри микро-
схемы, её конструкция должна предусматривать некий механизм от-
ключения или шунтирования функций автоподстройки в режимах тес-
тирования или отладки.
Регистры и защелки 117
Достоверность передачи данных через разные зоны
синхронизации
Вопрос достоверности передачи данных имеет отношение как к за-
казным микросхемам, так и к ПЛИС. Дело в том, что обмен данными
между двумя независимыми зонами синхронизации должен выпол-
няться предельно аккуратно, чтобы исключить потерю или искажение
информации. Плохая синхронизация может привести к нестабильным
результатам и проблемам при временном анализе. Для достижения на-
дежной передачи данных через зоны с различной синхронизацией ре-
комендуется использовать квитирование, буферизацию или асинхрон-
ные очереди.
Регистры и защелки
Защелки
В устройствах на основе заказных микросхем инженеры часто ис-
пользуют защёлки. Основываясь на опыте проб и ошибок, могу ска-
зать, что если речь идет о проектировании системы на основе ПЛИС с
использованием защелок — не делайте этого!
Триггеры с входами установки и сброса
Многие библиотеки заказных микросхем (ASIC) содержат различ-
ные триггеры, в том числе с входами установки (set) и сброса (reset).
Обычно доступны как синхронные, так и асинхронные варианты.
В отличие от ASIC в ПЛИС триггеры могут быть сконфигурирова-
ны с одним входом: либо для установки, либо для сброса. В этом слу-
чае реализация одновременно двух входов потребует использования
таблицы соответствия. Часто разработчики, пытаясь решить эту про-
блему, предлагают свои альтернативные решения.
Общий сброс и исходное состояние
Каждый регистр ПЛИС программируется определенным началь-
ным состоянием: либо логическим 0, либо логической 1. Кроме того,
ПЛИС обычно имеют сигнал общего сброса, который применяется для
возвращения всех регистров, но не блоков встроенного ОЗУ, в исход-
ное состояние. Разработчики, использующие заказные микросхемы,
обычно не используют подобную возможность.
Разделение ресурсов или разделение
по времени
Разделение ресурсов — метод оптимизации, позволяющий исполь-
зовать один функциональный блок, например сумматор или компара-
тор, для реализации нескольких операций. Например, умножитель
сначала может использоваться для обработки двух чисел, скажем А и Б.
Затем тот же умножитель может использоваться для обработки двух
других чисел, скажем ВиГ. Хороший пример разделение ресурсов рас-
сматривается в гл. 12.
Разделение ресурсов также называют разделением, или распределе-
нием, по времени либо мультиплексированием по времени. В ПЛИС ко-
личество ресурсов более ограничено, чем в ASIC, поэтому разработчи-
1859 г. Германия.
Гитторф и Паккер
изобрели трубку на
катодных лучах.
118 Глава 7. Различные подходы к проектированию систем на основе ПЛИС и заказных микросхем
ки ПЛИС в отличие от своих коллег, работающих с заказными микро-
схемами, вынуждены затрачивать определённые усилия на
реализацию распределения ресурсов.
В области связи понятие «мультиплексирование по времени» озна-
чает объединение нескольких медленных потоков данных в один
скоростной поток путём выделения каждому медленному потоку не-
продолжительного временного интервала для передачи своих дан-
ных.
В области разделения ресурсов временное мультиплексирование от-
носится к общему использованию ресурсов, например, умножителя,
входы которого переключаются и позволяют в различные моменты
времени обрабатывать разные данные.
Использовать или потерять!
На самом деле в случае ПЛИС всё обстоит немного сложнее, чем
описывалось выше, так как существует фундаментальная дилемма «ис-
пользовать или потерять», относящаяся к аппаратным ресурсам мик-
росхемы. Это значит, что ПЛИС поставляются только с фиксирован-
ным набором элементов. Другими словами, если пользователю не под-
ходит микросхема меньшего размера, он может использовать любую
доступную ему большего размера, при этом реализовав только часть её
ресурсов.
Допустим, что речь идет о разработке устройства, для которого тре-
буется два встроенных аппаратных процессорных ядер. В этом случае
возможно решение, согласно которому для функционирования систе-
мы с помощью разделения ресурсов с учетом имеющихся двух процес-
соров можно обойтись 10-ю умножителями и 2-я мегабайтами опера-
тивной памяти. Но, если ПЛИС с двумя процессорами содержит 50
умножителей и 10 мегабайт памяти, придется оплатить их полную сто-
имость. При этом избыточные средства в виде дополнительных умно-
жителей и блоков памяти, в которых на данный момент нет необходи-
мости, могут быть использованы для повышения функциональности
системы.
Подождите, ещё не вечер!
В ПЛИС обмен данными между таблицами соответствия (или ло-
гическими блоками) и специальными компонентами, такими как ум-
ножители, обычно является более дорогостоящим (из-за связности),
чем соединение с другой таблицей соответствия (или логическим бло-
ком). Процедура разделения ресурсов увеличивает значения связнос-
ти, поэтому этот процесс следует держать под контролем.
Распределение ресурсов оправдано не только в случае таких боль-
ших компонентов, как умножители или функции умножения с накоп-
лением, но и в случае, например, сумматоров. Интересно, что при тех-
нологии с использованием схем переноса, которые реализуются в уст-
ройствах компаний Altera и Xilinx, стоимость построения сумматора, в
первом приближении, почти эквивалента стоимости построения ши-
ны данных с разделяемой логикой. Например, реализация двух сумма-
торов с полностью независимыми входами и выходами будет стоить
двух сумматоров, при этом не потребуется реализация ресурсоразделя-
ющих мультиплексоров. При разделении ресурсов получим один сум-
матор и два мультиплексора, по одному для каждого набора входов.
Кодирование конечных автоматов 119
В случае ПЛИС это будет более дорогой вариант; в случае ASIC стои-
мость мультиплексора намного меньше стоимости сумматора.
На практике соотношение между дилеммой «использовать или по-
терять» и стоимостью соединений зависит от технологии и конкрет-
ной ситуации, при этом также следует иметь в виду, что устройства
компании Altera отличаются от устройств компании Xilinx.
Кодирование конечных автоматов
Схема кодирования конечных автоматов является примером об-
ласти, которая очень хорошо реализуется с помощью заказных микро-
схем, а решение на основе ПЛИС может оказаться не вполне удачным.
Однако конечные автоматы с успехом могут быть реализованы и на
ПЛИС. Как известно, каждая таблица соответствия в ПЛИС снабжа-
ется триггером, т. е. в устройстве имеется некоторое количество триг-
геров, находящихся в ожидании и готовых к каким-либо действиям.
Следовательно, во многих случаях для реализации конечных автома-
тов на основе ПЛИС наилучшим образом подходит схема прямого ко-
дирования, особенно если активность в различных состояниях автома-
та действительно независима.
Методики тестирования
При создании устройств на заказных микросхемах у разработчиков
масса времени уходит на работу со средствами автоматизированного
проектирования, с помощью которых выполняют формирование це-
почек сканирования и автоматическую генерацию тестовых комбина-
ций. Для реализации функций встроенного самоконтроля они могут
включать в свои устройства дополнительную логику. Немало усилий
требует тестирование устройства на предмет производственных дефек-
тов. В случае ПЛИС разработчики, как правило, не беспокоятся по по-
воду такой формы проверки, поскольку все устройства предваритель-
но тестируются поставщиком.
Разработчики, использующие заказные микросхемы, обычно тра-
тят много усилий на формирование JTAG-ячеек, последовательное
сканирование и проверку своих конструкций. В отличие от заказных
микросхем, средства последовательного сканирования, предусмотрен-
ные в ПЛИС, встраиваются в микросхему в процессе производства.
Прямое кодирова-
ние — представле-
ние каждого состоя-
ния конечного авто-
мата только одним
его активным триг-
гером, причем
в каждый момент
времени может быть
активен только один
триггер.
ГЛАВА 8
СХЕМОТЕХНИЧЕСКОЕ
ПРОЕКТИРОВАНИЕ
Давным-давно
Для начала рассмотрим способы проектирования цифровых микро-
схем, которые использовались давным-давно, т. е. в начале 60-х. Эта ин-
формация будет интересна читателю нетехнического склада ума, а также
начинающим инженерам, которые достаточно хорошо разбираются в
современных средствах и методах проектирования, но не знакомы с ис-
торией их возникновения и развития. Кроме того, все, о чем говорится
здесь, помогает лучше понять суть и возможности современных методов
проектирования, которые будут рассмотрены в последующих главах.
Давным-давно электронные схемы создавались вручную. Электри-
ческие схемы или принципиальные схемы, или просто схемы, вычерчи-
вались вручную с помощью карандаша и трафарета, а иногда для этих
целей использовалась скатерть, если это происходило в ресторане. На
схемы наносились обозначения применяемых в устройстве логических
вентилей и функций и изображались соединения между ними.
Соединения между логическими элементами внутри микросхемы
могут называться проводниками, дорожками или внутренними соеди-
нениями, причём эти термины могут употребляться как синонимы. В
некоторых случаях в этом же значении может использоваться тер-
мин металлизация, поскольку проводники в микросхемах преиму-
щественно формируются в виде слоёв металлизации.
В каждой команде разработчиков был хотя бы один человек, пре-
восходно выполняющий процедуры логической минимизации и опти-
мизации, которые сводились к замене одной группы логических эле-
ментов другой, выполняющей те же задачи, но быстрее или с исполь-
зованием меньшего пространства на кремниевом кристалле.
Проверка функционирования конструкции на соответствие требу-
емому алгоритму работы, т. е. функциональная проверка, обычно выпол-
нялась группой инженеров, которые сидели за столом и проверяли
схему, приговаривая: «Да, вроде все правильно». Аналогично, верифи-
кация временных параметров, т. е. проверка на соответствие задержки
сигнала от входов до выходов устройства и на внутренних блоках тре-
буемым значениям, а также проверка на отсутствие нарушения вре-
менных ограничений, таких как время готовности и время занятости
устройства, которые могут быть вызваны нарушением работы одного
из внутренних регистров, выполнялась с помощью карандаша и листа
бумаги. При этом в распоряжении самых удачливых были механичес-
кие или электромеханические калькуляторы.
Затем вручную выполнялся набор чертежей, на которых были
представлены элементы, используемые для формирования логических
вентилей или, если быть более точным, транзисторы, формирующие
логические вентили, и внутренние соединения между ними. Такие
чертежи, состоящие из групп квадратов и прямоугольников, использо-
вались для создания фотошаблонов, применяемых при изготовлении
кремниевых кристаллов.
Развитие САПР электронных систем 121
Развитие САПР электронных систем
Начальный этап проектирования. Логическое
моделирование
Неудивительно, что процесс разработки систем вручную, который
рассматривался выше, был трудоемким и способствовал возникнове-
нию ошибок. В связи с этим необходимо было предпринять какие-то
меры, и многие компании и университеты начали активно работать в
различных направлениях. Так, например, для проведения функцио-
нальной верификации в конце 60-х — начале 70-х годов появились
специальные программы в виде элементарных систем логического мо-
делирования.
Чтобы понять принцип действия такой системы, представим, что в
нашем распоряжении находится простое устройство на логических вен-
тилях, принципиальная схема которого выполнена вручную на листе
бумаги (Рис. 8.1).
Под устройством на логических вентилях подразумевается устройс-
тво, выполненное в виде набора логических вентилей и функций и со-
единений между ними. Чтобы использовать логическое моделирова-
ние, инженерам для начала необходимо было создать текстовое описа-
ние принципиальной схемы, которое называлось таблицей соединения
вентилей (gate-level netlist). Давным-давно разработчики обычно ис-
пользовали мейнфраймы, т. е. большие ЭВМ общего назначения, и
таблицы соединений, которые вводились с помощью набора перфо-
карт. Такой набор называли колодой. (Колода карт... Понятно, что к че-
му?) С внедрением персональных компьютеров вместе с устройствами
хранения данных, таких как жесткие диски, таблицы соединений ста-
ли записывать в виде текстовых файлов (Рис. 8.2).
1865 г. Англия.
Джеймс Клерк
Максвелл (James
Clerk Maxwell)
предсказал сущес-
твование электро-
магнитных волн,
которые распро-
страняются так
же, как и свет.
Рис. 8.1. Простая принципиальная схема, выполненная на бумаге
Существовала также возможность каждому вентилю сопоставить
некоторую задержку распространения сигнала. Эти задержки, в при-
мере они опущены для простоты изложения, обычно представлялись в
виде чисел, кратных некоторой единице времени системы моделиро-
вания (см. гл. 19).
Форма представления таблицы соединений, показанная на
Рис. 8.2, приведена исключительно в качестве примера. Она выполне-
на в духе того времени, когда, давным-давно исключительно ради под-
122 Глава 8. Схемотехническое проектирование
BEGIN CIRCUIT=TEST
INPUT SET.A, SET-B, DATA, CLOCK, CLEAR.A, CLEAR_B;
OUTPUT Q, N_Q;
WIRE SET, N.DATA, CLEAR;
GATE G1=NAND (IN1=SET_A, IN2=SET„B, OUT1=SET);
GATE G2=NOT (IN 1= DATA, OUT1=N_DATA);
GATE G3=OR (iN1=CLEAR_A, IN2=CLEARJ3, OUTKLEAR);
GATE G4=DFF (IN1=SET, IN2=N_DATA, IN3=CLOCK,
IN4=CLEAR, OUT1=Q, OUT2=N_Q);
END CIRCUIT=TEST;
Puc. 8.2. Простая таблица соединений вентилей — текстовый файл
держания хорошего настроения каждый разработчик системам моде-
лирования стремился разработать собственный язык описания табли-
цы соединений.
Первые системы логического моделирования содержали в себе
описания только примитивных вентилей, таких как И, И-НЕ, ИЛИ,
ИЛИ-HE и др. Такие инструменты назывались простейшими система-
ми моделирования. Позже некоторые системы стали поддерживать опи-
сания более сложных логических функций, таких как D-триггеры. В
этом случае функция G4 = DFF, представленная на Рис. 8.2, реализу-
ется с помощью собственного внутреннего описания.
В качестве альтернативного подхода можно было бы создать под-
схему, назвать её DDF, описать её функциональность с помощью таб-
лицы соединений примитивных логических вентилей И, И-НЕ и др. В
этом случае функция G4 = DFF, представленная на Рис. 8.2, может
быть реализована в системе моделирования в виде вызова обработчика
описания этой подсхемы
На следующем этапе пользователи создавали набор тестовых век-
торов, или задающих или внешних воздействий (stimulus), в виде набо-
ров значений логических 0 и 1, которые предназначались для подачи
на входы схемы. Эти тестовые векторы в текстовой форме и обычно
представляли собой таблицу, (Рис. 8.3), причем любая информация
после символа «;» воспринималась как комментарий.
При описании задающего воздействия в левой колонке указыва-
лось его время действия. Для экономии места названия входных сиг-
налов указывались вертикально.
Как следует из Рис. 8.1 и 8.2, между входом схемы DATA и D-триг-
гером установлен инвертирующий логический элемент НЕ (NOT). Та-
ким образом, в начальный момент времени на вход DATA подается ло-
гическая 1, которая затем инвертируется в логический 0, и это значе-
ние загружается в регистр по фронту синхроимпульса, т. е. при его
переходе из 0 в 1, в момент времени 500. Аналогично в момент време-
ни 1500 на вход DATA подается логический 0, который инвертором
преобразуется в 1 и при значении времени 2000 по фронту синхроим-
пульса загружается в регистр.
В современной терминологии файл с тестовыми векторами, пока-
занный на Рис. 8.3, представляет собой упрощенный тестовый стенд.
Ещё раз повторюсь: значения времени обычно представлялись в виде
чисел, кратных некоторой единице времени в системе моделирования.
Развитие САПР электронных систем 123
С С
L L
S S С Е Е
Е Е D L А А
Т Т А 0 R R
Т С
TIME А В А К А В
0 1 110 0 0 ; Установка начальных значений
500 1 1110 0. ; Фронт синхроимпульса (загрузка 0)
1000 1 110 0 0 ; Спад синхроимпульса
1500 1 1 0 0 0 0 ; Установка данных в 0 (N_data « 1)
2000 1 10 10 0 ; Фронт синхроимпульса (загрузка 1)
2500 1 10 10 1 ; Очистка значения В (загрузка 0)
и так далее
Рис, 8,3, Простой набор тестовых векторов — текстовый файл
После этого инженеры запускали систему логического моделиро-
вания, которая считывала таблицу соединений вентилей и строила
виртуальное представление принципиальной схемы в памяти компью-
тера. Затем система моделирования считывала первый тестовый век-
тор (первую строку из файла внешних воздействий), выставляла за-
данные значения на виртуальных входах и транслировала их через схе-
му. Подобным образом процедура повторялась для каждого
последующего тестового вектора, и, таким образом, формировалась
работа тестового стенда (Рис. 8.4).
Текстовая таблица соединений
логических элементов
Текстовые (табличные)
внешние воздействия
Система
логического
моделирования
Текстовый (табличный) файл
с результатами моделирования
(внешние воздействия
и выходные значения)
Рис. 8.4. Работа системы логического моделирования
Система моделирования может также использовать один или не-
сколько управляющих файлов (или интерактивных команд) для обоз-
начения внутренних узлов (проводников) и выходов схемы, которые
подвергаются мониторингу в процессе моделирования, а также для
124 Глава 8. Схемотехническое проектирование
обозначения длительности процесса моделирования и установки дру-
гих параметров. Результаты моделирования вместе с исходными воз-
действиями сохраняются в форме таблицы в текстовом файле.
Представим себе, что совершаем путешествие в прошлое и там за-
пускаем одну из старых систем моделирования, используя описания
схемы, изображённые на Рис. 8.1 и 8.2 вместе с воздействиями, пока-
занными на Рис. 8.3. Допустим, что инвертирующему логическому
вентилю соответствует задержка сигнала величиной в пять временных
единиц системы моделирования. Это значит, что после подачи сигнала
на вход этого логического элемента, соответствующее ему значение на
выходе появиться только через пять отсчётов времени. Аналогично,
допустим, что логические элементы И-НЕ и ИЛИ имеют задержку в 10
временных единиц, а D-триггер задерживает сигнал на 20 отсчётов.
Если система моделирования была настроена на мониторинг всех
внутренних узлов и выходных сигналов, выходной файл будет содер-
жать результаты моделирования в виде, как показано на Рис. 8.5.
с с
S Е Т S Е D L L С Е Е L А А N _ с D L S А Е N
Т А Т 0 R С _ R
Е Т А
TIME А В А К А В Т А R Q Q
0111000 XXX XX ; Установка начальных значений
5111000 ХОХ XX
10 111000 000 XX
500 111100 000 XX ; Фронт синхроимпульса
520 111100 000 01
1000 111000 000 01 ; Спад синхроимпульса
1500 110000 000 01 ; Установка данных в 0
1505 11000001001
2000 110100 010 01 ; Фронт синхроимпульса
2020 110100 010 10
2500 110101 010 10 ; Активный сигнал С1еаг_В
2510 110101 011 10
2530 110101 011 01
и так далее
Рис, 8,5, Результаты моделирования (текстовый файл)
Для улучшения восприятия нашего примера все изменения значе-
ний сигналов на рисунке выделены жирным шрифтом, хотя на прак-
тике этот прием не применялся.
Начальные значения воздействия подаются на входы схемы в мо-
мент времени 0. В этот момент времени состояния всех внутренних уз-
лов и выходов в таблице обозначены значением X, что означает неоп-
ределённое состояние. По прошествии пяти единиц времени, началь-
ное значение логической 1, которое было подано на вход DATA,
проходит через инвертирующий логический элемент НЕ и преобразу-
ется в логический 0 на внутреннем узле N_DATA. Аналогично по про-
Развитие САПР электронных систем 125
шествии 10 единиц времени, начальные значения, которые были пред-
ставлены на входы схемы SET_A и SET_B, проходят через логический
элемент И-НЕ на внутренний узел SET. Одновременно сигналы, по-
данные на входы CLEAR_A и CLEAR_B, проходят через логический
элемент ИЛИ на внутренний узел CLEAR.
В момент времени 500 по фронту синхроимпульса на входе CLOCK
D-триггер загружает значение, находящееся в этот момент на внутрен-
нем узле N_DATA. Спустя 20 временных единиц это значение появля-
ется на выходах Q и N_Q триггера. И так далее.
Пустые строки в выходном файле, такие как между записями, со-
ответствующие значениям времени 10 и 500, используются для обоз-
начения родственных групп действий. Например, установка началь-
ных значений в момент времени 0 является причиной изменения сиг-
налов в моменты времени 5 и 10. Затем фронт синхроимпульса на
входе CLOCK в момент времени 500 вызывает изменение сигналов
при достижении временной отметки 520. Так как эти две группы дейс-
твий абсолютно не зависят друг от друга, то они разделяются пустой
строкой.
Всё вышесказанное происходило незадолго до того, как инженеры
начали работать со схемами, содержащими тысячи вентилей и узлов,
моделирование которых проводилось на протяжении нескольких ты-
сяч временных шагов (тактов). Да, я часами просиживал, анализируя
файлы, подобные только что рассмотренным, пытаясь понять, работа-
ет ли система так, как ей положено, и отчаянно пытаясь найти ошибку,
если что-то было не так.
1865 г. Атланти-
ческий кабель свя-
зал Валенсию (Ир-
ландия) и Тринити
Бей (Ньюфаунд-
ленд).
1866 г. Ирлан-
дия/США. Проло-
жен первый долго-
временный транс-
атлантический
кабель.
1869 г. Вильям
Стэнли Джеванс
(William Stenly
Jevans) изобрёл «ло-
гическое пианино».
1872 г. Осущест-
влена первая одно-
временная переда-
ча с двух концов
телеграфного про-
вода.
Завершающий этап проектирования. Компоновка
Инструменты, подобные системам логического моделирования,
были призваны помочь инженерам определить функциональность
микросхемы и печатной платы. В то же время некоторые компании со-
средоточили свои усилия на создании средств проектирования, кото-
рые помогали бы выполнять компоновку внутренних узлов микросхе-
мы. В этом контексте термин компоновка имеет отношение и к распо-
ложению вентилей (на самом деле транзисторов, из которых состоит
вентиль) на поверхности кристалла, и к тому, как прокладывать соеди-
нения, связывающие их между собой.
В начале 70-х такие компании, как Calma, ComputerVision и
Applicon создали специальные компьютерные программы, которые
позволяли сотрудникам конструкторских отделов переводить разрабо-
танные вручную схемы в цифровой вид. Для этого схема устройства
помещалась на широкий цифровой планшет графического ввода. За-
тем с помощью устройства, напоминающего компьютерную мышку,
выполняясь оцифровка границ фигур, т. е. многоугольников, исполь-
зуемых для определения транзисторов и внутренних соединений.
Цифровые файлы, созданные таким способом, использовались для со-
здания фотошаблонов, которые, в свою очередь, применялись при
производстве кремниевых кристаллов.
Спустя некоторое время эти первые компьютерные инструменты
для конструкторов развились до уровня интерактивных программ, на-
зываемых редакторами многоугольников, которые позволяли пользова-
телям рисовать многоугольники непосредственно на экране компью-
тера. Потомки этих программ со временем получили возможность ис-
пользовать применяемые в системах моделирования таблицы
соединений логических элементов, по которым автоматически выпол-
нялись задачи разводки микросхем.
126 Глава 8. Схемотехническое проектирование
Термин САПР также
используется во мно-
гих других областях,
например в машино-
строительном конс-
труировании и архи-
тектуре.
САПР электронных систем
Средства проектирования, такие как системы логического модели-
рования, которые использовались на первых этапах проектирования,
т. е. на этапах описания принципиальной схемы и функциональной
проверки, изначально имели общее название системы автоматизиро-
ванной разработки (моделирования) — САЕ (computer-aided engineering).
А инструменты компоновки, т. е. размещения элементов и трассиров-
ки, использующиеся на завершающих, или физических, этапах, изна-
чально имели общее название системы автоматизированного проекти-
рования (конструирования) — CAD (computer-aided design).
Исторически сложилось так, что, в основном основываясь на
определении понятий систем автоматического конструирования и
проектирования, термин проектировщик, или просто инженер,
обычно относился к человеку, занятому на первых этапах разработ-
ки, т. е. выполняющему задачи по составлению и описанию, или
вводу, функциональности микросхемы, т. е. что она делает и как
она это делает. В свою очередь, понятие инженер-конструктор, или
просто конструктор, в общем случае относилось к человеку, кото-
рый работает на завершающем этапе проектирования, т. е. на этапе
конструирования, и выполняет задачи по разводке узлов микросхе-
мы, определения расположения логических элементов и их связи
между собой.
В 80-х все системы автоматизированного конструирования и про-
ектирования электронных компонентов и систем получили одно на-
звание — системы автоматизации проектирования электронных прибо-
ров и устройств, или сокращенно САПР электронных устройств
(EDA — electronic design automation). Таким решением, казалось, доволь-
ны были все. Однако были, все-таки, недовольные, но никто не обра-
щал внимания на их недовольные выкрики...
Простой метод схемотехнического
проектирования заказных ИС
В конце 70-х и начале 80-х компании Daisy, Mentor и Valid выпус-
тили первые программы графического описания схем, которые позволя-
ли инженерам интерактивно создавать принципиальные схемы непос-
редственно на компьютере. С помощью компьютерной мышки инже-
нер мог выбрать из специальной библиотеки элементов графическое
обозначение различных элементов, например контакты ввода/вывода,
логические вентили или функциональные узлы, и поместить их в нуж-
ном месте на экране компьютера. Позже у инженеров появилась воз-
можность с помощью мышки чертить линии или проводники, соеди-
няя вместе различные элементы.
После ввода в компьютер описания принципиальной схемы про-
грамма по указанию пользователя могла генерировать соответствую-
щую таблицу соединений логических элементов. Эта таблица могла
быть использована, во-первых, в качестве исходных данных для систе-
мы логического моделирования, т. е. для проверки функциональности
устройства, и, во-вторых, для работы программного обеспечения по
размещению элементов и трассировки соединений (Рис. 8.6).
Программа производила оценку всех временных параметров, кото-
рые в начале использовались системой логического моделирования.
Особое внимание уделялось внутренним проводникам, так как воз-
можность провести точный временной анализ появлялась только пос-
Простой метод схемотехнического проектирования заказных ИС 127
Ввод принципиальной Таблица соединений
схемы
логических вентилей
Рис, 8,6, Простой цикл схемотехнического проектирования заказных микросхем
1873 г. Англия,
Джеймс Клерк
Максвелл (James
Clerk Maxwell) опи-
сал электромаг-
нитную природу
света и опублико-
вал свою теорию
электромагнит -
ных волн.
ле размещения всех логических элементов и разводки внутренних свя-
зей между ними. Другими словами, после процедуры размещения эле-
ментов и их разводки специальная программа извлекала, т. е.
выделяла, и рассчитывала величины паразитных сопротивлений и ём-
костей, связанных с элементами, формирующими схему: сегментами
проводников, переходными отверстиями транзисторами и так далее.
Затем эти данные использовались программой временного анализа
для создания отчёта о временных параметрах устройства. В некоторых
системах проектирования эта временная информация также возвра-
щалась в подсистему логического моделирования для проведения бо-
лее точного моделирования.
Особого внимания заслуживает тот факт, что при создании схемы
устройства пользователю через условные обозначения были доступны
логические вентили и функции из специальной библиотеки, которая
связана с определённой технологией изготовления специализирован-
ных микросхем0. Также система моделирования могла быть настроена
на использование определенной библиотеки моделей с требуемой ло-
гической функциональностью* 2) и временными параметрами, соот-
Существуют различные способы построения библиотек. Например, некото-
рые их виды основаны на концепции использования наборов элементов общего
назначения, которые входят в состав большинства библиотек заказных ИС. В
этом случае таблица соединений, сгенерированная после создания принципиаль-
ной схемы устройства, пропускалась через транслятор, который производил пре-
образование наименований из библиотеки общего назначения в эквиваленты, ис-
пользуемые библиотекой конкретной заказной микросхемы.
2) Что касается функциональности, то для многих она ассоциируется с про-
стейшим логическим объектом, например 2-входовым элементом И, который
функционирует одинаково на большинстве платформ. Конечно, такая однознач-
ность будет только в том случае, когда на входы этих элементов подаются «пра-
вильные» значения (логические 0 и 1), ситуация сильно меняется, если на входы
подаётся высокоимпедансное состояние «Z» или неизвестное значение «X». Даже
при подаче на входы логических 0 и 1, более сложные функции, такие, как защел-
ки и триггеры, могут вести себя непредсказуемо в необычных ситуациях, напри-
мер при одновременной активации входов «установка» и «сброс».
128 Глава 8. Схемотехническое проектирование
1874 г. Америка.
Александр Белл
(Alexander Graham
Bell) разработал
идею телефона.
1875 г. Америка.
Эдисон изобрёл ми-
меограф.
ветствующими определенной технологии изготовления заказных мик-
росхем. В результате работы рассмотренных систем получалась табли-
ца соединений, которая передавалась компоновщику-трассировщику
для размещения и разводки. Таблица однозначно определяла структу-
ру построения логических вентилей и функций на поверхности крис-
талла. В этом и заключается небольшое отличие в подходах к проекти-
рованию ASIC и ПЛИС.
Простой метод схемотехнического
проектирования ПЛИС
С появлением первых ПЛИС в 1984 году по вполне естественным
причинам их технологии проектирования были основаны на сущест-
вующих схематических подходах проектирования заказных микро-
схем. Несомненно, сходство первых этапов проектирования заключа-
лось в том, что программный блок описания схемотехнических изоб-
ражений использовался для представления устройства в виде набора
простейших логических вентилей и функций, а также для создания со-
ответствующей таблицы соединений. Как и раньше, эта таблица ис-
пользовалась системой моделирования для функциональной верифи-
кации устройства.
Различие начиналось на этапе реализации устройства, так как
структура ПЛИС состояла из массива конфигурируемых логических бло-
ков (КЛБ), каждый из которых формировался с помощью таблиц соот-
ветствия и регистров. Это потребовало введения в процесс проектиро-
вания некоторых дополнительных шагов, названных сопоставлением и
компоновкой (Рис. 8.7).
Ввод описания
Таблица соединений
принципиальной схемы логических элементов
Таблица соединений
конфигурируемых
логических блоков
Временной анализ и
временной отчёт
Таблица соединений
логических вентилей
для моделирования
Временная информация
для моделирования (SDF)
Рис. 8.7. Простой цикл схемотехнического проектирования ПЛИС
Простой метод схемотехнического проектирования ПЛИС 129
Сопоставление
В контексте рассматриваемого материала сопоставление означает
процесс установки соответствия между объектами, например между
логическими функциями из таблицы соединений логических венти-
лей и таблицами соответствия ПЛИС. Конечно, речь не идёт о сопос-
тавлении по принципу один к одному, так как каждая таблица соот-
ветствия может использоваться для представления нескольких логи-
ческих элементов (Рис. 8.8).
1875 г. Англия.
Джеймс Максвелл
(James Clerk
Maxwell) устано-
вил, что атомы
должны иметь оп-
ределённую струк-
туру.
Фрагмент таблицы соединений
логических вентилей
Исключающее
Рис. 8.8. Сопоставление логических вентилей с таблицей соответствия
Содержимое 3-входовой
таблицы соответствия
Сопоставление проводится и в наше время, но, как будет показано,
на другом этапе проектирования ПЛИС, и является нетривиальной за-
дачей, поскольку имеется много вариантов разбиения вентилей, фор-
мирующих таблицы соединений, на небольшие группы для их после-
дующей реализации с помощью таблиц соответствия. Например, логи-
ческий вентиль НЕ, показанный на Рис. 8.8, может реализовываться
не в представленной таблице соответствия, а в предыдущей, к выходу
которой подключается вход с.
Компоновка
После завершения этапа сопоставления наступает очередь этапа
компоновки, в процессе которого таблицы соответствия и регистры
распределяются по конфигурируемым логическим блокам (КЛБ).
Процесс компоновки (который проводится и в наши дни, но, как бу-
дет показано, на другом этапе проектирования ПЛИС) также нетриви-
альная задача, поскольку имеется множество вариантов перестановок
и сочетаний элементов логических ячеек по логическим блокам. В ка-
честве примера рассмотрим простейшее устройство, состоящее из не-
скольких логических вентилей, которые на предыдущем этапе были
сопоставлены с четырьмя 3-входовыми таблицами соответствия, обоз-
наченными символами А, В, С и D. Допустим, что необходимо реали-
зовать устройство на ПЛИС, в котором каждый конфигурируемый ло-
гический блок состоит из двух 3-входовых таблиц соответствия. В этом
случае нам потребуется два логических блока (назовём их 1 и 2). На
первый взгляд, существует 4! (факториал четырёх = 4x3x2x1 = 24)
различных способа распределения наших таблиц по двум логическим
блокам (Рис. 8.9).
130 Глава 8. Схемотехническое проектирование
Функциональные эквиваленты
Варианты перестановок
Рис, 8,9, Разбивка таблиц соответствия по логическим блокам
На Рис. 8.9 показаны только 12 из 24 возможных перестановок (чи-
тателю предлагается потренироваться и дописать недостающие вари-
анты). На самом деле существует только 12 вариантов перестановок,
имеющих практический смысл. Объясняется это тем, что существуют
так называемые «зеркальные» перестановки, которые функционально
эквивалентны, например пары АС-BD и BD-АС, показанные на
Рис. 8.9. Эквивалентность этих пар связана с работой системы разме-
щения и разводки, которая позволяет менять расположение двух логи-
ческих блоков между собой.
Размещение и разводка
Двигаясь дальше, приходим к этапу размещения элементов и развод-
ки или трассировки соединений. Вернемся к только что рассмотренному
примеру и предположим, что два логических блока необходимо соеди-
нить вместе, но применительно к нашему случаю, они могут быть рас-
положены только так, чтобы один из них являлся смежным по гори-
зонтали или по вертикали с другим блоком. С учётом этих ограниче-
ний конфигурируемые логические блоки могут быть расположены по
одному из четырёх вариантов (Рис. 8.10).
Вариант 1 Вариант 2
Вариант 3
Вариант 4
Варианты расположения блоков
Рис, 8,10, Расположение конфигурируемых логических блоков
Если КЛБ 1 содержит таблицы соответствия Ли С, а КЛБ 2 табли-
цы соответствия BviD, можно получить эквивалентное расположение.
Для этого надо чтобы блоки поменялись местами и обменялись своим
содержимым.
Простой метод схемотехнического проектирования ПЛИС 131
При работе с двумя логическими блоками (Рис. 8.10) довольно
просто определить их оптимальное расположение относительно друг
друга, т. е. выбрать наиболее оптимальный вариант из четырех воз-
можных, а также относительно других элементов на кристалле.
На практике размещение элементов является куда более сложной
задачей, чем рассматривалось в примере, поскольку реальные микро-
схемы могут содержать чрезвычайно большое количество конфигури-
руемых логических блоков: от нескольких сотен, на заре своего разви-
тия, и до нескольких сотен тысяч по состоянию на 2004 год. Соединен-
ные вместе логические блоки 1 и 2 также могут подключаться к другим
блокам. Например, КЛБ 1 может подключаться к КЛБ 3, 5 и 8, а КЛБ 2
может подключаться к КЛБ 4, 6, 7 и 8. Кроме того, эти блоки могут со-
единяться друг с другом и с другими блоками. Другими словами, хотя
расположение КЛБ 1 и КЛБ 2 в непосредственной близости друг к дру-
гу может оказаться очень эффективным с точки зрения разводки со-
единений между ними, но с учётом их взаимосвязи с другими блоками
такая расстановка может быть нежелательной. В некоторых случаях
наиболее оптимальным может оказаться расположение, при котором
КЛБ 1 и КЛБ 2 находятся на некотором расстоянии один от другого.
Если и размещение логических блоков является довольно сложной
процедурой, оптимальная разводка соединений между этими блоками
оказывается куда более сложной задачи. Сложность этих операций на-
столько огромна, что здесь лучше предоставить слово ребятам, безу-
словно, очень умным людям, которые заняты разработкой алгоритмов
расположения элементов и разводки соединений, а мы перейдём к
рассмотрению других вопросов.
Ещё до появления микросхем ПЛИС в мире ПЛУ такой же функцио-
нальностью, как и у утилит размещения и разводки, обладали прило-
жения под названием «сборщики». С появлением ПЛИС название
«сборщик» (fitter) также перешло и в эту сферу, однако со временем
оно вытиснилось понятием «размещение и разводка» (place-and-
route), которое более точно отражало суть выполняемых им действий.
(^=э В начале 90-х гг. некоторые поставщики вместо символической биб-
лиотеки простейших логических элементов и регистров стали ис-
пользовать символические библиотеки более сложных функций, ко-
торых насчитывалось около 70. После разработки схемы
формировалась таблица соединений функциональных блоков, кото-
рые, как правило, уже были сопоставлены таблицам соответствия и
скомпонованы в КЛБ. Этот подход позволял лучше реализовать
идею считать уровни логики между регистрами, но ограничивал воз-
можности по оптимизации и замене элементов.
Временной анализ и повторное моделирование
Результатом процедуры размещения и разводки элементов являет-
ся полная таблица физических соединений (на уровне КЛБ), как пока-
зано на Рис. 8.7. С помощью утилиты статического временного анали-
за (STA — static timing analysis) выполняется расчет значений всех вре-
менных задержек как на внутренних участках, так и при прохождении
сигнала от входа до выхода микросхемы, а также проверка всех вре-
менных параметров, т. е. времени готовности, времени занятости и
других, связанных с работой регистров.
Интересная ситуация складывается, когда разработчики решают
произвести повторное моделирование своего устройства с учётом точ-
ной, т. е. полученной после процедуры размещения и разводки эле-
ментов, временной информации. В этом случае они используют комп-
132 и Глава 8. Схемотехническое проектирование
1876 г. Америка.
10-е марта. Алек-
сандр Белл
(Alexander Graham
Bell) впервые осу-
ществил телефон-
ную связь.
лект ПЛИС-утилит для создания новой таблицы соединений логичес-
ких вентилей (с учётом временной информации) в виде файла
промышленного формата, называемого, как это не удивительно, фор-
матом стандартных задержек (SDF— standard delay format). Необходи-
мость создания этого файла обусловлена тем, что при обратном пере-
ходе от таблицы соединения, приведенной к уровню конфигурируе-
мых логических блоков (КЛБ), к исходной таблице соединения
логических вентилей просто невозможно соотнести новую и получен-
ную ранее временную информацию.
Одноуровневые и иерархические
принципиальные схемы
Одноуровневые принципиальные схемы
Первые программы ввода и принципиальных схем позволяли опи-
сывать огромные одноуровневые принципиальные схемы посредством
их разделения на некоторое количество «страниц». Допустим, вы хоти-
те нарисовать на листе бумаги принципиальную схему, состоящую из
1000 логических вентилей. Для полного изображения этой схемы пот-
ребуется огромный лист бумаги (около одного квадратного метра). На
левой стороне листа будут отображены входы схемы, справа выходы, а
между ними сама схема.
В таком виде схему крайне неудобно переносить для демонстрации
из одного места в другое. Но можно разрезать на несколько страниц,
которые будут храниться вместе в одной папке. В этом случае следует
произвести разделение схемы таким образом, чтобы каждая страница
содержала логические вентили, относящиеся к определенной функ-
ции системы. Также следует использовать межстраничные соедине-
ния, подобные входам и выходам, для прохождения сигналов между
различными страницами.
По такому же принципу работали первые программы ввода при-
нципиальных схем. Разработчики создавали одноуровневую принци-
пиальную схему на нескольких страницах, связанных вместе с помо-
щью межстраничных связей. Их названия указывали системе на поря-
док соединения страниц. Рассмотрим подобную простую схему,
выполненную на листе бумаги (Рис. 8.11).
Рис. 8.11. Простая принципиальная схема, выполненная на листе бумаги
Допустим, что логические вентили в левой части схемы представ-
ляют собой некую схему управления, а в правой части четыре регист-
ра реализуют 4-битный сдвиговый регистр. Очевидно, что это очень
простой пример, реальные принципиальные схемы состоят из гораз-
Одноуровневые и иерархические принципиальные схемы 133
до большего количества логических вентилей. Данный пример — это
всего лишь попытка продемонстрировать принцип, согласно которо-
му принципиальную схему при её описании можно разбить на две
части (Рис. 8.12).
1876 г. Александр
Белл получил па-
тент на телефон.
Иерархические принципиальные схемы
При использовании одноуровневых принципиальных схем, осо-
бенно если эта схема занимает более 50-ти страниц, возникали следу-
ющие проблемы:
• Было трудно визуально представить все устройство как единое
целое.
• Довольно сложно было повторно использовать части устройства
в новых проектах.
• Если какая-либо часть схемы встречалась в устройстве несколь-
ко раз, что, кстати, случалось нередко, копию приходилось пе-
рерисовывать на нескольких страницах. Проблема усугублялась
при необходимости внести некоторые изменения в эту часть
схемы, т. е. приходилось перерисовывать все копии.
Решение этих проблем предусматривало расширение пакета про-
грамм ввода и описания принципиальных схем, в результате чего по-
являлась возможность реализации иерархической концепции. Напри-
мер, при реализации рассмотренной выше схемы сдвигового регистра
создается базовая страница, на которой будут изображены два блока:
управления и сдвига. Каждый блок должен быть оснащен необходи-
мыми входными и выходными контактами. Эти блоки должны соеди-
няться межу собой, а также с входами и выходами устройства.
Затем можно перейти к блоку управления, при выборе которого
откроется новая страница для ввода принципиальной схемы. Если по-
везёт, система автоматически разместит на этой странице условные
обозначения входных и выходных соединений в соответствии с распо-
ложением контактов на базовой странице и присвоит им определен-
ные названия. После этого можно приступать к созданию принципи-
альной схемы этого блока (Рис. 8.13).
На практике каждый блок может содержать вложенные блоки бо-
лее низкого уровня или схему на логических вентилях, или (очень час-
то) их совокупность. Такие иерархические принципиальные схемы
позволяют устранить недостатки, присущие одноуровневым схемам, а
именно:
134 Глава 8. Схемотехническое проектирование
1877 г. Начала ра-
боту первая ком-
мерческая теле-
фонная сеть.
• Облегчают наглядное представление облика устройства и упро-
щают работу со схемой.
• Упрощают повторное использование блоков в последующих
проектах.
• Если часть схемы встречается в конструкции несколько раз,
следует реализовать её в виде отдельного блока и при необходи-
мости использовать, т. е. вызывать. Такой подход существенно
упрощает работу в случаях, когда в схему блока требуется внести
какие-либо изменения. При этом модифицировать придется
содержимое только одного блока.
Рис, 8.13. Простая иерархическая принципиальная схема
Современная последовательность
схемотехнического проектирования ПЛИС
Раньше каждый поставщик ПЛИС разрабатывал собственное про-
граммное обеспечение для ввода и описания принципиальных схем,
сопоставления, компоновки, размещения и разводки элементов. Од-
нако, как показала практика, одна и та же компания может преуспеть
только в одной сфере — либо в разработке САПР электронных уст-
ройств, либо в создании ПЛИС, но не в нескольких областях одновре-
менно.
Другая сторона этой проблемы заключалась в том, что изначально
средства проектирования заказных микросхем (ASIC) были слишком
дорогими (даже утилиты для ввода принципиальных схем, которые в
наши дни расценивают как продукт широкого потребления). В то же
время поставщики ПЛИС всегда продавали свои средства разработки
по очень низкой цене (достаточно крупным покупателям полный на-
бор компонентов для системы проектирования доставался бесплатно),
так как все свои усилия данные компании направляли на продажу
микросхем. Конечно, это предложение было очень привлекательно
для потребителей, но со стороны поставщиков ПЛИС этот шаг был не
очень удачным, так как они делали огромные вложения в системы
проектирования, которые приносили слишком маленькую прибыль.
Со временем сторонние создатели САПР электронных устройств
стали поставлять программные продукты, начиная со средств описа-
ния схемы и кончая утилитами расстановки компонентов, включая и
средства логического синтеза (гл. 9 и 19). Производители ПЛИС по-
прежнему поставляют менее сложные (если сравнивать с современ-
ным уровнем развития) средства проектирования, подобные програм-
мам ввода схем, которые входят в состав их базового набора САПР, а
также поддерживают средства размещения и разводки элементов.
Современная последовательность схемотехнического проектирования ПЛИС 135
Однако в наши дни многие инженеры уже давно не начинают про-
цесс создания устройства со схематического описания, выполняемого
на уровне логических вентилей. В некоторых случаях поставщики
ПЛИС всё же предлагают незначительную поддержку для реализации
схематического подхода применительно к современным устройствам,
но в основном ограничиваются предоставлением схемотехнических
библиотек только для устройств предшествующих поколений. Тем не
менее, схематическое описание принципиальных схем всё ещё нахо-
дит применение у старшего поколения инженеров, а также при необ-
ходимости внесения несущественных изменений в действующие уст-
ройства. Более того, графические механизмы, которые применялись в
ранних программах ввода принципиальных схем, по-прежнему нахо-
дят применение и на современных этапах проектирования, как будет
описано в следующей главе.
1877 г. Америка. То-
мас Ватсон (Thomas
Watson) разработал
телефонный звонок
для вызова пользова-
теля.
1878 г. Америка.
Начала работу
первая междуго-
родняя телефонная
линия между горо-
дами Бостон и
Провиденс.
ГЛАВА 9
ПРОЕКТИРОВАНИЕ НА ОСНОВЕ
ЯЗЫКОВ ОПИСАНИЯ АППАРАТНЫХ
СРЕДСТВ
Закат схемотехнического проектирования
С увеличением размеров и сложности заказных микросхем к концу
80-х наметился спад интереса к схемотехническим подходам проекти-
рования. Визуализация, ввод, отладка, поддержка устройства на уров-
не вентилей стали трудным и неэффективным занятием, если в уст-
ройстве используется более 5000 логических вентилей, размещенных
на нескольких страниц.
Кроме того, ввод схемы большого устройства на уровне вентилей
часто приводил к ошибкам и являлся чрезвычайно трудоемким делом.
Поэтому некоторые поставщики САПР электронных систем присту-
пили к разработке средств и методов проектирования, основанных на
языках описания аппаратных средств или HDL (Hardware Description
Language).
История развития HDL-проектирования
Идея, положенная в основу языков описания аппаратных средств,
как это не удивительно, заключается в том, что с их помощью можно
описать работу аппаратных средств. В более широком понимании,
термин «аппаратный» используется для описания любых физических
узлов и компонентов электронной системы, включая микросхемы, пе-
чатные платы, системные блоки, кабели, и даже гайки и болты, с по-
мощью которых собрано изделие. Однако в контексте языков HDL по-
нятие «аппаратный» имеет отношение только к электронным узлам,
т. е. компонентам и проводникам, микросхем и печатных плат. HDL
может также использоваться для ограниченного представления кабе-
лей и соединителей, связывающих вместе печатные платы.
На заре развития электроники почти каждый разработчик САПР
изобретал свою версию языка HDL. Одни из них представляли собой
аналоговые версии HDL, так как описывали работу аналоговых сис-
тем, в то время как другие концентрировали своё внимание на описа-
нии цифровой функциональности. Нас интересуют только версии
HDL, которые применяются в процессе проектирования ПЛИС и за-
казных микросхем.
Уровни абстракции
Наиболее известные версии «цифровых» языков HDL будут рас-
смотрены в этой главе, но не сейчас. А сейчас давайте сосредоточимся
на том, как некий абстрактный «цифровой» язык описания аппарат-
ных средств (HDL) используется в проектировании цифровых микро-
схем. В первую очередь следует обратить внимание на то, что функци-
ональные возможности цифровых микросхем могут быть представле-
ны на различных уровнях абстракции. Эти уровни в большей или
меньшей степени поддерживаются различными версиями HDL
(Рис. 9.1).
История развития HDL-проектирования 137
Самым низким уровнем абстракции цифровых HDL является уро-
вень транзисторных ключей, который определяется способностью опи-
сывать схему в виде таблицы соединений транзисторных ключей. Вы-
ше него находится уровень вентилей, который описывает схему в виде
таблицы соединений простых логических вентилей и функций. Поэто-
му первые версии форматов таблиц соединений логических вентилей,
формируемые с помощью программ ввода принципиальных схем, о
которых говорилось в предыдущей главе, представляли собой, по су-
ществу простейшие версии языков описания аппаратных средств.
Оба уровня, транзисторных ключей и логических вентилей, можно
отнести к структурному представлению устройства. Однако следует
обратить внимание на то, что слово «структурный» имеет несколько
значений, так как оно может также относиться к иерархической табли-
це соединений блоков устройства, где содержание каждого блока оп-
ределено на любом уровне абстракции, изображенном на Рис. 9.1.
Следующий, более сложный уровень HDL, определяется способ-
ностью поддерживать функциональные представления устройства, ко-
торые включают в себя набор конструктивов. Нижняя граница этого
уровня определяется способностью описывать функцию с помощью
булевых (логических) выражений. Например, если представить, что
имеется набор сигналов, которые называются Y, SELECT, DATA-A и
DATA-B, то можно описать функциональность простого 2:1 мульти-
плексора с помощью следующего булевого выражения:
Y = (SELECT & DATA-A) I (!SELECT & DATA-B);
Это выражение записано с помощью обычного синтаксиса, который
не поддерживается ни одной конкретной версией HDL и используется
только в качестве примера. Как уже отмечалось, символ «&» представля-
ет собой логическую функцию И, символ «|» соответствует логической
функции ИЛИ, а символ « » отображает функцию НЕ (см. гл. 3).
Функциональный уровень абстракции включает в себя представле-
ния уровня регистровых передач (RTL — register transfer level). Термин
RTL подразумевает большое количество различных проявлений. Са-
138 Глава 9. Проектирование на основе языков описания аппаратных средств
1847 и 1854 гг. Са-
моучка Джордж
Буль (George Boole)
внес значительный
вклад в ряд облас-
тей математики,
но был увековечен
благодаря двум сво-
им работам, в ко-
торых он предста-
вил логические вы-
ражения в мате-
матической фор-
ме. Теперь эта
форма называется
булевой алгеброй.
В1938 году Клод
Шеннон (Claude
Shannon) опублико-
вал статью, в ко-
торой показал, как
булевы концепции
могут быть ис-
пользованы для реа-
лизации функций
переключения в
электронных це-
пях.
мый простой способ понять его основную концепцию — представить
устройство в виде совокупности регистров, связанных между собой
элементами комбинационной логики. Эти регистры часто управляют-
ся с помощью общего синхросигнала. Допустим, что мы располагаем
двумя сигналами, называемыми CLOCK и CONTROL, а также набо-
ром регистров, обозначенных как REGA, REGB, REGC и REGD. Тог-
да выражение RTL может иметь следующий вид:
when CLOCK rises
if CONTROL == "1"
then REGA = REGB & REGC;
else REGA = REGB I REGD;
end if;
end when;
В этом случае команды when, rises, if, then, else и им подобные явля-
ются ключевыми словами, семантика которых определяется версией
языка HDL. Этот пример записан с помощью обычного синтаксиса,
который не поддерживается ни одной конкретной версией HDL и ис-
пользуется только в качестве примера.
Высшим уровнем абстракции считается поведенческий, который
поддерживается современными версиями HDL и обозначает возмож-
ность описывать поведение схемы, используя абстрактные логические
структуры, например циклы и процессы. Этот уровень также подразу-
мевает использование в выражениях алгоритмических элементов, та-
ких как сумматоры и умножители. Например:
Y = (DATA-A + DATA-B) * DATA-C;
Имеется еще и системный уровень абстракций (он не показан на
Рис. 9.1), который характеризует конструктивы, предназначенные для
приложений системного уровня проектирования, но о них мы погово-
рим немного позже.
Многие ранние цифровые версии HDL понимали только структур-
ные описания устройств в форме таблиц соединений вентилей или
транзисторных ключей. Другие представители этого семейства язы-
ков, например ABEL, CUPL или PALASM, использовались для описа-
ния функциональности программируемых логических устройств
(ПЛУ). Эти языки поддерживали различные уровни функционального
уровня абстракции, такие как булевы выражения, текстовые таблицы
истинности, текстовые описания конечных автоматов (см. гл. 3).
Следующее поколение языков HDL, которые изначально предна-
значались для систем логического моделирования, поддерживало бо-
лее сложные уровни абстракции, например RTL и некоторые поведен-
ческие конструкции (имеются в виду языковые конструкции, описы-
вающие поведенческие аспекты системы или устройства). Как будет
показано ниже, эти версии языков описания аппаратных средств стали
основой для первых по-настоящему HDL-ориентированных техноло-
гий проектирования.
Простые HDL-методы проектирования заказных микросхем
Ключевой особенностью HDL-проектирования заказных микро-
схем является использование в технологическом цикле проектирова-
ния методов логического синтеза, средства автоматизации которых
начали появляться на рынке в середине 80-х годов. Эти средства могли
воспринимать RTL-описания устройств вместе с набором временных
История развития HDL-проектирования 139
ограничений. Временные ограничения описывались в файле, который
содержал выражения, описывающие работу устройства, дополненные
строками вида «максимальная задержка распространения сигнала от
входа Л до выхода должна быть не больше, чем N наносекунд». На са-
мом деле формат этой строки выглядел более сжато и скучно.
Средства логического синтеза автоматически конвертировали
RTL-описания устройств в набор регистров и булевых выражений, по-
путно реализуя различные процедуры минимизации и оптимизации, в
том числе оптимизацию по временным задержкам и по площади ис-
пользуемого места на кристалле. После этого средства синтеза генери-
ровали таблицы соединений вентилей, которые должны были соот-
ветствовать, и соответствовали, начальным временным ограничениям
(Рис. 9.2).
Уровень регистровых Таблица соединений
передач логических элементов
Рис. 9.2. Цикл HDL-проектирования заказных микросхем (простой)
Подход обладал рядом преимуществ. Во-первых, существенно по-
высилась производительность труда разработчиков, так как стало на-
много проще определять, понимать, обсуждать и отлаживать функци-
ональность устройств, описание которых выполнено на уровне регист-
ровых передач, чего нельзя было осуществить, работая с пачкой
чертежей принципиальных схем. Во-вторых, средства логического мо-
делирования работали с RTL-моделями намного быстрее, чем со схе-
мами соединений вентилей.
Незначительная проблема возникала при использовании систем
логического моделирования и заключалась в том, что хотя эти средства
и позволяли работать с моделями, описанными на высоких уровнях
абстракции, с использованием поведенческих конструкций, но пер-
вые версии средств синтеза воспринимали описание функциональ-
ности устройства только до уровня регистровых передач. Вследствие
этого инженеры были вынуждены выбирать для работы «синтезопри-
годные» подмножества HDL.
После генерации средствами синтеза таблицы соединений венти-
лей дальнейшая процедура проектирования повторяла схемотехничес-
кие методы, рассмотренные в предыдущей главе. Таблица соединений
140 Глава 9. Проектирование на основе языков описания аппаратных средств
вновь подвергалась процедуре моделирования, чтобы убедиться в её
функциональной достоверности, а также применялась для формиро-
вания результатов временного анализа, основанного на значениях па-
раметров проводников и других элементов схемы. Затем таблица со-
единений использовалась в качестве исходных данных для работы ути-
лит размещения и разводки элементов, после которого выполнялся
более точный временной анализ с использованием полученных значе-
ний сопротивлений и ёмкостей.
Простые HDL-методы проектирования ПЛИС
Потребовалось какое-то время, прежде чем HDL-проектирование
расцвело пышным цветом среди поклонников заказных микросхем. В
те времена разработчики всё ещё только осваивали принципы ПЛИС.
В связи с этим лишь только в начале 90-х в мир ПЛИС пришли техно-
логии HDL-проектирования, в частности средства логического синте-
за (Рис. 9.3).
Уровень регистровых Таблица соединений
передач логических элементов
Рис. 9.3. Цикл HDL-проектирования ПЛИС (простой)
Аналогично случаю с заказными микросхемами после генерации
таблицы соединений вентилей средствами синтеза, технология проек-
тирования сильно напоминала схемотехнические методы создания
ПЛИС, описанные в гл. 8. Таблица соединений вновь подвергалась
процедуре моделирования, чтобы убедиться в её функциональной до-
стоверности, а затем подвергалась временному анализу на основе оце-
нок параметров проводников и других элементов схемы. После этого
таблица соединений обрабатывалась средствами сопоставления, ком-
поновки, размещения и разводки, и вновь проводился более точный
временной анализ, основанный на реальных, т. е. физических, пара-
метрах устройства.
История развития HDL-проектирования 141
Архитектурное проектирование ПЛИС
Главная проблема ранних подходов к проектированию ПЛИС за-
ключалась в том, что их средства логического синтеза вышли из мира
заказных микросхем. Другими словами, эти средства «мыслили» в по-
нятиях простейших вентилей и регистров. Это значит, что они форми-
ровали таблицу соединения вентилей и передавали её программным
модулям поставщиков ПЛИС для выполнения операций сопоставле-
ния, компоновки, размещения и разводки.
Примерно в 1994 году средства синтеза «вооружились знаниями» о
различных принципах построения (архитектурах) ПЛИС. Это позво-
лило им самостоятельно выполнять операции сопоставления и, в не-
которой степени, компоновки, а также формировать таблицу соедине-
ний логических блоков и таблиц соответствия. Впоследствии эта таб-
лица соединений могла использоваться средствами размещения и
разводки из инструментария, предоставляемого поставщиками
ПЛИС. Главное преимущество этого метода заключалось в том, что
средства синтеза располагали лучшими методами оценки временных
параметров и занимаемой площади, что обеспечивало более высокое
качество результатов. На практике проектирование ПЛИС с помощью
архитектурных методов синтеза производилось на 15...20% быстрее,
чем при использовании традиционных (на уровне вентилей) средств
синтеза.
Логический и физический синтез
Здесь мы несколько опережаем события, так как именно сейчас
как нельзя уместно упомянуть о содержимом данной части книги.
Первые версии программ логического синтеза, которые появились в
середине 80-х годов, предназначались для проектирования заказных
микросхем. В этих устройствах задержка на вентилях, намного превы-
шала задержку, вносимую проводниками, соединяющими эти венти-
ли. Кроме того, количество этих вентилей было относительно мало (по
современным меркам), а для их управления применялась относитель-
но низкая тактовая частота. Поэтому первые версии программ логи-
ческого синтеза могли использовать относительно простые алгоритмы
для оценки задержки сигнала на проводниках. При этом полученные
оценки несущественно отличались от действительных значений, полу-
чаемых после размещения и разводки элементов.
Спустя годы, сложность и размеры (выраженные в количестве вен-
тилей) заказных микросхем значительно увеличились. Одновременно
с этим размеры структур на кремниевом кристалле уменьшались, что
привело к следующим последствиям:
• эффекты, вызванные задержками, в общем случае становилось
более сложными;
• задержки, на проводниках, начали перевешивать задержки на
вентилях.
К середине 90-х, в связи с ростом размеров заказных микросхем,
также существенно усложнились эффекты, вызванные задержкой.
Сложность этих эффектов существенно превышала уровень, на кото-
рый рассчитывались первые средства логического синтеза. В результа-
те это привело к тому, что оценки задержек, полученных с помощью
средств логического синтеза, очень плохо соотносились с данными,
полученными после размещения и разводки элементов. В свою оче-
редь это значит, что достижение состояния временного соответствия
1878 г. Англия.
Джозеф Сван (Sir
Joseph Wilson Swan)
изобрел электри-
ческую лампу нака-
ливания.
142 Глава 9. Проектирование на основе языков описания аппаратных средств
1878 г. Англия. Ви-
льям Крукс
(William Crookes)
разработал элект-
ронную «трубку
Крукса».
(доводка устройства для достижения заданных временных характерис-
тик) становилась всё более трудной и длительной задачей.
Поэтому, примерно в 1996 году, в процессе проектирования специ-
ализированных микросхем начали применять средства физического
синтеза. Способы работы физического синтеза более подробно будут
рассмотрены в гл. 19. Здесь лишь заметим, что в процессе, физического
синтеза производится начальное размещение логических вентилей и
функций. Основываясь на результатах размещениях, средства времен-
ного анализа позволяют получить более точные временные оценки.
В конечном счете, средства физического синтеза формировали
таблицу соединений размещенных (но не разведенных) вентилей.
Средства физической реализации (размещения и разводки) заказных
микросхем использовали эту начальную информацию о размещении в
качестве стартовой точки, от которой выполнялась локальная (точная)
оптимизация размещения, после чего производилась разводка элемен-
тов. В результате применения средств физического синтеза существен-
но повысилась точность оценок задержек. В свою очередь это значило,
что достижение временного соответствия стало менее дорогостоящим.
Ну, а что там с ПЛИС? Размеры и сложность этих устройств также
увеличивались на протяжении 90-х годов. К концу прошлого тысячеле-
тия проектировщики ПЛИС столкнулись со значительными проблема-
ми, связанными с временным соответствием. Поэтому, примерно в 2000
году, поставщики САПР электронных устройств начали предлагать
ПЛИС-ориентированные средства физического синтеза, которые мог-
ли выдавать сопоставленную, скомпонованную и размещенную табли-
цу соединений КЛБ и таблиц соответствия (LUT/CLB-level netlist). В
этом случае средства физической реализации ПЛИС (модули размеще-
ния и разводки — place-and-route) используют эту информацию о на-
чальном размещении в качестве стартовой точки, от которой выполня-
ется процедура локальной (точной) оптимизации размещения, после
чего производится детальная разводка элементов устройства.
Средства графического ввода продолжают жить
Когда появились первые методы проектирования, основанные на
языках описания аппаратных средств (HDL), многие предрекали
средствам графического ввода и визуализации незавидную участь: в
скором времени они должны были исчезнуть навсегда. И правда, одно
время многих инженеров прямо распирало от гордости при мысли, что
они используют текстовые редакторы, подобные К/0 (сокращенно от
Visual Interface) или EMACS, в качестве единственного средства описа-
ния принципиальной схемы.
Но, как говорится, лучше один раз увидеть, чем сто раз услышать.
Другими словами, одна картинка может заменить тысячи слов, и средс-
тва графического ввода и визуализации остались популярными на мно-
гих этапах проектирования. Например, редакторы схем широко приме-
няются для ввода структурных схем, представляющих собой совокуп-
ность соединенных вместе блоков высокого уровня. На основании
этой схемы система может автоматически создать скелет текстового
HDL-описания с объявленными названиями блоков, входов и выхо-
дов. И наоборот, пользователь может самостоятельно создать скелет
текстового HDL-описания устройства, а затем система на основе этого
описания автоматически построит структурную схему устройства.
1)
Редактор VI — чрезвычайно мощный, но трудный для понимания редактор.
Типы языков HDL 143
С точки зрения пользователя, щелчок мышью на одном из этих
блоков структурной схемы может автоматически открыть HDL-редак-
тор. В качестве такого редактора может выступать простой текстовый
редактор, запускаемый из командной строки, подобный VI, или мож-
но использовать более сложный специализированный HDL-редактор
со встроенной функцией выделения различными цветами ключевых
слова языка, автоматическим завершением выражений и другие.
Кроме того, щелкнув мышью на одном из таких блоков современ-
ных систем проектирования можно сделать выбор между описанием и
просмотром содержимого этого блока, блоков нижнего уровня, исход-
ного HDL-кода, графической диаграммы состояний, используемой
для описания конечных автоматов, графической блок-схемы и так да-
лее. Для графических представлений, подобных графическим диа-
граммам состояний и блок-схемам, существует возможность автома-
тически генерировать их описания на уровне регистровых передач
(Рис. 9.4).
1878 г. Ирландия,
Денис Редмонд
(Denis Redmond)
продемонстриро-
вал эффект ввода
изображений с по-
мощью фотоэле-
мента, изготов-
ленного из селена.
Рис. 9.4. Многоуровневая система ввода схем
Инженеры в процессе разработки довольно часто используют табу-
лированный файл, содержащий информацию о внешних входах и вы-
ходах устройства. При этом блок-схема верхнего уровня устройства и
табулированный файл будут напрямую связаны одними и теми же дан-
ными, и на самом деле будут представлять различные интерпретации
этих данных. При изменении любой из этих интерпретаций система
автоматически модифицирует все связанные с этой модификацией
данные и немедленно отобразит внесённые изменения в других интер-
претациях.
Типы языков HDL
Для определенного круга людей жизнь могла быть предельно прос-
той, если существовала бы только одна версия языка HDL. Но никто
не может сказать, что жизнь — простая штука. Как уже упоминалось,
на заре развития цифровых микросхем, где-то в 70-х годах, каждый
144 Глава 9. Проектирование на основе языков описания аппаратных средств
разработчик HDL-средств проектирования обычно испытывал непре-
одолимое желание заодно создать собственный язык описания аппа-
ратных средств. И не удивительно, что в результате в этой области воз-
никла такая неразбериха. Даже невозможно себе вообразить весь ужас
этой ситуации. Решением проблемы мог бы стать промышленный
стандарт языка HDL, но где же его было взять?
Verilog HDL
В середине 80-х Фил Морби (Phil Moorby), один из создателей зна-
менитой системы логического моделирования HILO, разработал но-
вую версию языка HDL под названием Verilog. В 1985 году компания
Gateway Design Automation, в которой работал Фил Морби, выпустила
этот язык на рынок вместе с сопутствующей его системой логического
моделирования, называемой Verilog-XL.
Verilog и Verilog-XL поддерживали весьма прогрессивную концеп-
цию, называемую интерфейсом языка программирования или PLI Verilog
(Programming Language Interface). В общем виде эта концепция известна
как интерфейс прикладного программирования или API (Application
Programming Interface). API представляет собой библиотеку програм-
мных функций, которая позволяет внешнему программному обеспече-
нию передавать данные в приложение и получать из него выходные ре-
зультаты. Другими словами, функции API Verilog позволили пользова-
телям расширить функциональность этого языка и поставляемого с
ним пакета логического моделирования.
В качестве простого примера рассмотрим ситуацию, когда инже-
нер разрабатывает схему, в которой должен использоваться существу-
ющий модуль, выполняющий математические функции, например
быстрое преобразование Фурье (БПФ). Представление этой функции,
выполненное на языке Verilog, потребует довольно много времени для
работы системы моделирования, что может вызвать задержку разра-
ботки последующих модулей устройства. В таком случае разработчики
системы могут создать модель этой функции на языке программирова-
ния С, которая будет моделироваться примерно в 1000 раз быстрее,
чем её Verilog-эквивалент. Такая модель должна содержать структуры
PLI, через которые осуществляется связь со средой моделирования.
Впоследствии подобные модели могут вызываться из Verilogoпиcaния
других модулей устройства при помощи обращения к соответствую-
щим функциям PLI, которые обеспечивают двунаправленную переда-
чу данных между главной схемой (представленной в коде Verilog) и
БПФ (описанным на языке С).
Другая, действительно полезная особенность, связанная с Verilog и
Verilog-XL, заключалась в возможности получать информацию о вре-
менных параметрах устройства из внешнего текстового файла, сфор-
мированного в SDF-формате (Standart Delay Format — формат стан-
дартных задержек). Это свойство позволяло некоторым средствам, на-
пример приложению, выполняющему временной анализ после
процедуры размещения и разводки, создавать SDF-файл, который за-
тем мог быть использован средствами моделирования для обеспечения
более точных результатов.
Как язык программирования, Verilog обладал достаточной мощью
при работе на структурном (вентили и ключи) уровне абстракции (осо-
бенно в отношении моделирования задержек), отличался большой мо-
щью на функциональном (булевы выражения и RTL) уровне абстрак-
ции и поддерживал некоторые поведенческие (алгоритмические)
конструкции (Рис. 9.5).
Типы языков HDL 145
Системный
Поведенческий
(алгоритмический)
1879 г. Америка.
Томас Эдисон
(Thomas Alva
Edison) разрабо-
тал лампу накали-
вания (на год поз-
же, чем Джозеф
Сван из Англии).
Функциональный
(булевый, RTL)
Структурный
(логические
элементы,
ключи)
Рис. 9.5. Уровни абстракции (Verilog)
В 1989 году компания Cadence Design Systems приобрела компанию
Gateway Design Automation и заодно язык Verilog, а также систему мо-
делирования Verilog-XL. По наиболее вероятному сценарию того вре-
мени в результате этой процедуры язык Verilog должен был просто сме-
нить своего владельца. Однако неожиданно для всех в 1990 году ком-
пания Cadence представила спецификации VerilogHDL, VerilogPLI и
VbrilogSDF для открытого использования.
Это было довольно смелое решение, так как после этого любой же-
лающий мог развивать средства моделирования, основанные на языке
Verilog, тем самым становясь потенциальным конкурентом Cadence.
Причина такой щедрости этой компании заключалась в растущей по-
пулярности языка VHDL. Другой причиной открытия Verilog для пуб-
личного использования было то, что огромное количество компаний,
развивающих средства проектирования на основе HDL, такие как
средства логического синтеза, теперь ощутили достоинства использо-
вания языка Verilog.
С появлением единого представителя, который мог быть использо-
ван средствами моделирования, синтеза и так далее, для многих разра-
ботчиков жизнь значительно упростилась. Однако не стоит забывать,
что Verilog изначально разрабатывался совместно со средствами моде-
лирования, а средства синтеза при этом находились в стороне. Это
значило, что при создании устройства, инженеры были вынуждены
использовать подкласс средств синтеза используемого ими языка, ко-
торый примерно можно было определить, как некую совокупность
языковых конструкций, понятную и поддерживаемую приложением
синтеза, выбранным пользователем.
Официальные выпуски \brilog включали в себя документы, назы-
ваемые справочным руководством по языку или LRM (Language Reference
Manual), которые описывали синтаксис и семантику языка. В данном
случае термин синтаксис относится к грамматике языка и определяет
порядок слов и символов в выражениях, а семантика определяет
смысл этих слов и символов, и отношения между понятиями, которые
они описывают.
146 Глава 9. Проектирование на основе языков описания аппаратных средств
1879 г. Англия. Ви-
льям Крукс
(William Crookes)
установил, что ка-
тодные лучи в
трубке могут быть
отрицательно за-
ряженными части-
цами.
В идеале справочные страницы LRM должны довольно строго оп-
ределять понятия языка, исключая какие-либо неверные или двусмыс-
ленные толкования. В действительности, однако, Verilog LRM допус-
кает некоторую неопределенность. Эти неопределенности возникали в
выражениях вида «если управляющий сигнал на триггере переходит в
неактивное состояние, а в это же время происходит переключение
синхросигнала, то какой из этих сигналов сработает первым?» Это
приводило к тому, что в различных версиях средств моделирования
могли генерироваться различные результаты, что зачастую и приводи-
ло пользователя в замешательство.
Verilog быстро стал весьма популярным. Отдельные компании на-
чали развивать язык в разных направлениях, что привело к определен-
ным сложностям. В связи с этим в 1991 году была создана некоммер-
ческая организация Open Verilog International (OVI), которая выполня-
ла функции координации и стандартизации Verilog HDL и Verilog PLI и
пользовалась поддержкой ведущих поставщиков САПР электронных
систем.
После этого популярность языка Verilog стала возрастать по экспо-
ненте, и в конечном итоге OVI подала запрос в Институт инженеров по
электротехнике и радиоэлектроники (IEEE) о создании группы подде-
ржки языка Verilog. Такой комитет был сформирован в 1993 году и стал
известным под названием IEEE 1364. Май 1995 года оказался свидете-
лем первого официального выпуска IEEE Vferilog, официальное назва-
ние которого звучит так: 1364-1995, а неофициальное так: Verilog 95.
В 2001 году в этот стандарт были внесены некоторые изменения,
поэтому новую версию часто называют Verilog 2001 (или Verilog 2К1).
Во время написания этой книги комитет IEEE 1364 усиленно работал
над следующей версией Verilog 2005, а весь конструкторский мир, зата-
ив дыхание, ожидал выхода нового релиза.
VHDL и VITAL
В 1980 году Министерство обороны США приступило к разработке
программы сверхбыстрых схем с высоким уровнем интеграции или
VHSIC (Very High Speed Integrated Circuit). Эта программа предназнача-
лась для развития современных технологий изготовления цифровых
микросхем. Программа предназначалась также для решения проблемы
воспроизведения микросхем и печатных плат военного оборудования,
которое длительное время находилось в эксплуатации. Эта проблема
возникла в связи с отсутствием подробной документации на составные
части данного оборудования.
Кроме того, различные части системы зачастую разрабатывались и
тестировались с помощью разнотипных и несовместимых средств раз-
работки и моделирования.
Для решения этих проблем в ходе реализации проекта, в 1981 году,
был разработан новый язык аппаратных средств, названный VHSIC
HDL, или кратко VHDL. Примечательно, что на ранних стадиях разра-
ботки этого языка в процесс были вовлечены промышленные компа-
нии. В 1983 году ряд компаний-производителей, включая Intermetrics,
IBM и Texas Instruments получили контракт на развитие языка VHDL,
первая версия которого вышла в 1985 году.
Чтобы получить признание промышленности, в 1986 году Минис-
терство обороны передало права на язык VHDL Институту инженеров
по электротехнике и радиоэлектроники (IEEE). После выполнения
некоторых модификаций, предназначенных для решения ряда про-
Типы языков HDL 147
блем, в 1987 году VHDL вышел в качестве официального стандарта
IEEE 1076. Последующие модифицированные версии этого языка вы-
ходили в 1993 и 1999 годах.
Язык VHDL отличался большой мощностью на функциональном
(булевы выражения и RTL) и поведенческом (алгоритмическом) уров-
нях абстракции, а также поддерживал некоторые конструкции систем-
ного уровня. Однако он не оправдал своих возможностей при работе
на структурном (вентили и ключи) уровне абстракции, особенно в час-
ти моделирования задержек.
— Относительно легкий для изучения
— Фиксированные типы данных
— Использует интерпретатор
— Хорошо просчитывает задержки
на уровне вентилей
— Ограничение при повторном
использование проекта
— Ограничение в управлении проектом
— Не поддерживает репликацию структур
— Относительно сложный для изучения
— Абстрактные типы данных
— Использует компилятор
— Просчитывает задержки на уровне вентилей
— Возможность повторного использования проекта
— Хорошее управление проектом
— Поддерживает репликацию структур
Изначально язык
VHDL не поддержи-
вал библиотеку, ана-
логичную Verilog
PLI. Современные
системы моделиро-
вания располагают
собственными мето-
дами обмена данны-
ми, например, таки-
ми как ModelSim
foreign language
interface или FLI
(инородный языко-
вый интерфейс). Бу-
дем надеяться, что
подобные средства,
в конечном счете,
станут стандартом.
Рис. 9.6. Уровни абстракции: \ferilog и VHDL
Очень скоро стало очевидно, что VHDL обладает недостаточ-
ной временной точностью для использования в качестве завершаю-
щего моделирующего средства. По этой причине в 1992 году на
конференции по САПР электронных систем была представлена
VHDL-библиотека начального уровня для заказных микросхем или
VITAL (VHDL Initiative toward ASIC Libraries). Библиотека VITAL яв-
лялась попыткой повышения возможностей языка VHDL для при-
менения его в системах временного моделирования при проектиро-
вании ПЛИС и заказных микросхем. В итоге в её состав вошла биб-
лиотека простых функций, используемых в ПЛИС и заказных
микросхемах, и модуль обратной корректировки информации о за-
держке. Механизм задержки основывался на тех же форматах, что и
язык Verilog (Рис. 9.6).
148 и Глава 9. Проектирование на основе языков описания аппаратных средств
1880 г. Америка.
Александр Белл за-
патентовал опти-
ческую телефонную
систему, названную
фотофоном.
Закон Мэрфи гласит:
если неприятность
может случиться, она
обязательно случает-
ся. Капитан и инже-
нер Эдварду Мэрфи
(Edward Murphy) ра-
ботал на авиабазе Эд-
вардс в 1949 г.
Проектирование с применением нескольких языков
Давным-давно для описания целого устройства, как правило, ис-
пользовался один язык описания аппаратных средств: Verilog или
VHDL. По мере увеличения размеров и сложности устройств для разра-
ботки различных частей устройства стали привлекаться разные коман-
ды разработчиков. Эти команды могли быть из разных компаний или
даже проживать в разных странах. Не удивительно, что в процессе раз-
работки разные группы использовали разные языки проектирования.
Вместе с тем, все чаще используются уже готовые блоки или блоки
интеллектуальной собственности, приобретенные у сторонних разра-
ботчиков. И очень часто, как по законам Мэрфи, если в процессе раз-
работки использовался один язык, приобретённый блок интеллекту-
альной собственности наверняка оказывался написанным на другом
языке.
В начале 90-х началась так называемая война HDL, когда сторон-
ники одного языка Verilog или VHDL предсказывали неминуемую кон-
чину другого языка... Но годы идут, а оба языка по-прежнему сущест-
вуют и развиваются. В конечном итоге поставщики САПР электрон-
ных устройств стали поддерживать многоязычные программные
продукты, в число которых входили модули логического моделирова-
ния, синтеза и другие средства, которые могли работать с устройства-
ми, состоящими из блоков, описанных с помощью и VHDL, и Verilog.
UDL/I
Как уже отмечалось, язык Verilog изначально создавался для реше-
ния задач моделирования. Аналогично VHDL создавался как язык
описания с учетом необходимости моделирования. В результате оба
этих языка можно было использовать для описания и последующего
моделирования систем, но они не были предназначены для синтеза.
Для решения этих проблем в 1990 году Японская ассоциация раз-
вития электронной промышленности (JEIDA) представила собствен-
ную версию языка HDL, которая называлась унифицированный язык
разработки интегральных микросхем (или UDL/I — Unified design
language for integrated circuits).
Главным преимуществом этого языка являлось то, что он изна-
чально создавался как для обеспечения моделирования, так и для
обеспечения синтеза. Окружение UDL/I включало в себя системы мо-
делирования и синтеза, к тому же он распространялся бесплатно (в
том числе и с исходными кодами). Однако когда UDL/I вышел в свет,
языки Verilog и VHDL уже стали настолько популярными, что UDL/I
не вызвал особого интереса у инженеров за пределами Японии.
Superlog и SystemVerilog
В 1997 году с появлением компании Со-Design Automation ситуа-
ция в сфере языков описания аппаратных средств стала накаляться.
Разработчики компании усердно корпели над созданием продукта
под названием Verilog on steroids, который впоследствии назвали
Superlog.
Superlog был забавной штукой, сочетающий простоту языка Verilog
и мощь языка программирования С. Он содержал такие вещи, как вре-
менная логика, возможность верификации сложных схем, динамичес-
кие библиотеки API и концепцию утверждений — ключевое понятие
Типы языков HDL 149
стратегии формальной верификации, известной также как model
checking (проверка модели). (VHDL также поддерживал простые струк-
туры утверждений, но оригинальная версия языка Verilog не могла
этим похвастаться.)
У Superlog было две проблемы, во-первых, он был совершенно
обособленным языком, во-вторых, он был намного сложнее, чем
Verilog 95 и Verilog 2001. Это потребовало от поставщиков САПР элект-
ронных систем дополнительных усилий для его поддержки.
Тем временем, пока многие пребывали в раздумьях о том, что их
ожидает в будущем, группа OVI наладила отношения с аналогичной
организацией по поддержке языка VHDL, которая называлась VHDL
International, чтобы сформировать новую ассоциацию, которая теперь
называется Accellera. Функциями этой организации были: определе-
ние новых форматов и стандартов, их развитие, поддержка новых ме-
тодов проектирования, основанных на этих форматах и стандартах.
Летом 2002 года Accellera представила спецификацию на новый
гибридный язык, названный SystemVerilog 3.0. (Только не спрашивай-
те меня о версиях 1.0 и 2.0.) Новый язык отличался большими возмож-
ностями, чем существующие версии Verilog, и превзошел нашумевшую
когда-то реализацию языка Superlog. Действительно, SystemVerilog 3.0
поддерживал большинство форматов и структуру языка Superlog, пре-
доставленных компанией Со-Design Automation. Кроме того, он под-
держивал утверждения и возможности расширенного синтеза. Нако-
нец-то свершилось то, о чем все давно мечтали. SystemVerilog 3.0 яв-
лялся также стандартом компании Accellera, что способствовало его
быстрому и широкому распространению.
В 2002 году Со-Design Automation была приобретена компанией
Synopsys, которая продолжила политику передачи логической структу-
ры языка Superlog в SystemVerilog, но теперь уже никто не говорил, что
Superlog — независимый язык. После некоторых раздумий все основ-
ные поставщики САПР электронных систем официально приняли
SystemVerilog и расширили свои продукты для поддержки этого языка
в той или иной степени в зависимости от области применения и
предъявленных требований. Летом 2003 года появился SystemVerilog
3.1, и вслед за ним, в начале 2004 года, вышла следующая версия 3.1а, в
которую было добавлено несколько дополнительных возможностей и
исправлены некоторые ошибки. Тем временем, Институт инженеров
по электротехнике и радиоэлектроники (IEEE) начал работу над но-
вой версией Verilog 2005. Для предотвращения раскола между Verilog
2005 и SystemVerilog. компания Accellera обещала к лету 2004 передать
свои права на SystemVerilog институту IEEE.
SystemC
Давайте рассмотрим язык SystemC, к которому одни разработчики
относятся с большой любовью, а другие просто терпеть не могут. Язык
SystemC можно использовать для описания схем устройств на уровне
абстракции RTL (см. гл. 11). Моделирование этих описаний может
быть выполнено в 5... 10 раз быстрее, чем моделирование эквивалент-
ных описаний на Verilog или VHDL, а средства синтеза способны пре-
образовывать SystemC RTL в таблицы соединений вентилей.
Весомым аргументом в пользу языка SystemC является то, что
SystemC обеспечивает более естественную среду для совместного про-
граммно-аппаратного проектирования и проверки. В качестве аргу-
мента против SystemC выступал тот факт, что большинство разработ-
1880 г. Франция.
Пьер и Жак Кюри
(Pierre Currie,
Jacques Currie) от-
крыли пьезоэлект-
ричество.
SystemC может под-
держивать более вы-
сокие уровни абс-
тракции, чем RTL,
но их рассмотрение
выходит за рамки
этой главы; более
подробно они будут
описаны в гл. 11.
150 Глава 9. Проектирование на основе языков описания аппаратных средств
1881 г. Алан Мар-
куонд (Alan
Marquand) изобрёл
графический ме-
тод представле-
ния логических
проблем.
чиков хоть и были хорошо знакомы с языками Verilog или VHDL, но
очень плохо разбирались в объектно-ориентированных особенностях
языка SystemC. Кроме того, в большинстве современных средств син-
теза реализованы многолетние инженерные наработки по переводу
текстов Verilog или VHDL в таблицы соединений вентилей. В отличие
от них средства синтеза на основе языка SystemC намного проще, чем
традиционные методы.
В действительности SystemC больше подходит для проектирования
на системном уровне, чем на уровне регистровых передач (RTL). Пос-
кольку SystemC становится популярным в странах Азии и Европы,
споры между SystemC, SystemVerilog и VHDL будут продолжаться еще
очень долго.
Информация к размышлению
Ужасы проектирования
У большинства программистов опускаются руки при виде кода, на-
писанного другим программистом. При этом они начинают ворчать по
поводу комментариев, логики и других вещей, и нельзя сказать, что
они пребывают от этого занятия в восторге.
Они просто не ведают, как им повезло, что они не видели RTL-кода,
который описывает работу какого-либо устройства. Печально, но боль-
шинство схем, описанных на RTL, почти не понятны для других инже-
неров. В идеале RTL-описание схемы устройства можно было бы читать
как книгу, начиная с «оглавления» в виде описания структуры устройс-
тва, переходя к содержанию в виде логического описания, разбитого на
«главы», т. е. логические блоки устройства, и большого количества «ком-
ментариев», поясняющих структуру и принцип действия устройства.
Следует иметь в виду, что стиль кодирования может повлиять на
производительность устройства. Обычно это замечание относится в
большей степени к ПЛИС, чем к заказным микросхемам. Причина за-
ключается в том, что логически эквивалентные, но разные RTL-onepa-
торы могут выдать различные результаты, разные результаты могут по-
лучиться также при использовании разных средств проектирования.
Поставщики ПЛИС и САПР по возможности снабжают своих кли-
ентов большим количеством документации рекомендательного харак-
тера по стилям кодирования, ориентированным соответственно на
собственные чипы и средства разработки. Ниже вниманию читателя
предлагается ряд общих положений, которые могут оказаться полез-
ными в большинстве ситуаций, возникающих в процессе разработки
устройств.
Последовательные и параллельные мультиплексоры
При создании RTL-кода полезно иметь представление, как будут
вести себя средства синтеза в определённых ситуациях. Например,
оператор if-then-else (если-то-иначе), как правило, реализуется с помо-
щью мультиплексоров вида 2:1. Самое интересное начинается при ис-
пользовании нескольких, вложенных друг в друга операторов if-then-
else, которые средствами синтеза будут реализованы в виде структуры с
приоритетом. Допустим, что ранее мы уже описали сигналы Y, А, В, С,
D и SEL (сигнал выбора) и используем их в многоуровневом операторе
if-then-else (Рис. 9.7).
Информация к размышлению 151
if SEL == 00" then Y = А;
elseif SEL == 01" then Y = В;
elseif SEL == 10" then Y = C;
else Y = D;
1883 г. Вильям
Хаммер (William
Hammer) и Томас
Эдисон (Thomas
Alva Edison) от-
крыли эффект
Эдисона.
Puc, 9,7, Синтез вложенных операторов if-then-else
Как и раньше, использованный в этом случае синтаксис является
общим и не принадлежит ни к одному из описываемых в этой книге
языков (Рис. 9.7). В рассмотренном примере самый первый оператор
if-then-else будет выполняться быстрее, чем все остальные, а самый
последний может не уложиться в отведенный временной бюджет. Не-
смотря на это, в некоторых ПЛИС время прохождения сигналов через
подобную структуру будет меньше, чем при использовании оператора
case (оператор выбора). Реализация рассмотренного примера с помо-
щью оператора case потребует использования мультиплексора вида 4:1,
в котором время распространения сигналов от всех входов до выхода
будет примерно одинаково (Рис. 9.8).
case SEL of;
00": Y = A;
01": Y = B;
10": Y = C;
otherwise: Y = D;
end case;
4:1 MUX
SEL
Puc, 9,8, Синтез оператора case
Остерегайтесь защёлок!
В инженерной практике настоятельно рекомендуется избегать ис-
пользования защёлок в ПЛИС, кроме случаев, когда они действитель-
но необходимы. Также следует остерегаться случаев, когда при исполь-
зовании операторов if-then-else вы пренебрегаете конструкцией «else»,
так как большинство средств синтеза в этом месте будут вставлять за-
щёлку.
152 Глава 9. Проектирование на основе языков описания аппаратных средств
1884 г. Германия.
Пол Нипков (Paul
Gottleib Nipkow) ис-
пользовал вращаю-
щийся диск для ска-
нирования, переда-
чи и воспроизведе-
ния изображений.
Рационально используйте константы
В обычных схемах из всех сложных операторов наиболее часто ис-
пользуются сумматоры. В некоторых случаях разработчики устройств
на основе заказных микросхем используют комбинации полусуммато-
ров и полных сумматоров. Этот подход весьма эффективен в устройс-
твах, например, представляющих собой массив вентилей, но, как пра-
вило, плохо подходит для ПЛИС.
При использовании сумматоров с константами можно провести
некоторую модификацию кода, которая позволит более эффективно
расходовать ресурсы устройства. Например, выражение «А + 2» может
быть реализовано более эффективно в виде «А + 1 с переносом», а вы-
ражение «А - 2» как «А - 1 с переносом».
Аналогично, при использовании умножителей выражение «А х 2»
более эффективно может быть реализовано в виде выражения
«А SHL 1» (что значит «А сдвигается влево на один бит»), а выражение
«А х 3» лучше будет представить в виде «(A SHL 1) + А».
В самом деле, небольшие преобразования могут иметь большое
значение при реализации ПЛИС. Например, замена «А х 9» выраже-
нием «(A SHL 3) + А» в итоге сократит занимаемую этим выражением
площадь на кристалле на 40%.
Распределение ресурсов
Распределение ресурсов представляет собой метод оптимизации, ко-
торый позволяет использовать один функциональный блок, например
сумматор или компаратор, для реализации нескольких операторов.
Если распределение ресурсов не используется, каждая RTL-опера-
ция реализуется с помощью собственной логики. Такой подход спо-
собствует повышению производительности устройства, но требует ис-
пользования большего количества вентилей, т. е. потребляет больше
места на кремниевом кристалле. Если же используется распределение
ресурсов, то сокращается количество требуемых вентилей, но, как
правило, это приводит к снижению производительности. Рассмотрим,
например, выражение, приведенное на Рис. 9.9.
qgR Для читателей нетехнического склада ума заметим, что знак «>»
обозначает компаратор, т. е. устройство, которое сравнивает два чис-
ла и определяет, какое из них больше; знак «+» обозначает сумматор,
а клиновидный блок представляет собой мультиплексор 2:1, кото-
рый на выход пропускает одно из двух значений в зависимости от
состояния на выходе компаратора.
Значения частот, указанных на Рис. 9.9, представляют интерес
только для сравнительного анализа, так как эти значения будут зави-
сеть от типа архитектуры ПЛИС, а также от технологии изготовления
микросхем.
Перечисленные ниже операторы могут быть объединены вместе с
такими же операторами или с другими однотипными, записанными с
ними в одной строке:
*
+ -
Например, оператор «+» может быть объединен с другими опера-
торами «+» или с операторами «-», а оператор «х» может быть объеди-
нен только с такими же операторами «х».
Информация к размышлению 153
if (В > С)
then Y = А + В ;
elseY = A + C;
end if;
Использовано таблиц соответствия — 32
Тактовая частота =87.7 МГц
Использовано таблиц соответствия — 64
Тактовая частота = 133.3 МГц (+52%!)
Рис. 9.9. Распределение ресурсов
1886 г. Льюис Кэр-
рол (Lewis Carrol)
опубликовал рабо-
ту, в которой изло-
жил диаграммные
методы логических
представлений в
Теории Игр.
Также необходимо проверить, разрешено или запрещено по-умол-
чанию использование распределения ресурсов в вашем приложении
синтеза. И в завершение: распределение ресурсов может существенно
упростить разводку элементов в заказных микросхемах, а в случае
ПЛИС, напротив, может привести к возникновению ряда проблем
при разводке.
Последнее, но не менее важное
Внутренние шины с тремя состояниями обычно работают доволь-
но медленно, и в большинстве ПЛИС следует избегать их использова-
ния, если только нет полной уверенности в их необходимости. По воз-
можности используйте буферы с тремя состояниями исключительно
на верхнем уровне устройства. Если все-таки они будут использовать-
ся, а применяемая ПЛИС не поддерживает вентили с тремя состояни-
ями, большинство современных средств синтеза обеспечивают авто-
матическую реализацию третьего состояния с помощью мультиплек-
соров. В основном производятся преобразования буферов с тремя
состояниями, описанными с помощью RTL-кода, в соответствующую
логику на основе таблиц соответствия.
Причиной проблем синхронизации также могут быть двунаправ-
ленные буферы, поэтому при их использовании следует быть предель-
но осторожными.
ГЛАВА 1 О
ВИРТУАЛЬНОЕ МАКЕТИРОВАНИЕ ПЛИС
Общие сведения о виртуальном макетировании
Перед тем как перейти к рассмотрению принципов виртуального
макетирования ПЛИС, имеет смысл вспомнить, как развивалась кон-
цепция виртуальных макетов (прототипов) кристалла (SVP — silicon
virtual prototype) в среде заказных микросхем. Подобный экскурс поз-
волит проследить миграцию некоторых проявлений виртуального ма-
кетирования из мира заказных микросхем в мир ПЛИС, а также вы-
явить проблемы, связанные с этими проявлениями.
Среди заказных микросхем (ASIC) существуют высокотехнологич-
ные устройства, содержащие десятки миллионов вентилей. Размеры и
сложность систем на подобных мегаустройствах фактически привели к
тому, что средства проектирования в определённом смысле перестали
соответствовать требуемому уровню.
Проблема заключалась в том, что при традиционных методах про-
ектирования многие ошибки невозможно было выявить до проведе-
ния временного анализа, основанного на реальных физических значе-
ниях ёмкостей, сопротивлений и иногда индуктивностей, которые бы-
ли получены на этапе размещения и разводки элементов. Для
проведения подобного анализа разработчикам приходилось преодоле-
вать весь путь проектирования от начала до конца, включая синтез,
размещение и разводку элементов, и лишь только потом появлялась
возможность выявить ошибки. Очевидно, что процедуру выявления и
локализации ошибок желательно производить на ранних этапах про-
ектирования.
Описанная ситуация зачастую приводила к многочисленным ите-
рациям процесса проектирования и существенно задерживала выход
систем на базе заказных микросхем на рынок. А как показала практи-
ка, как правило, на рынке место есть только победителю, второе место
отсутствует!
Одно из решений описанной проблемы заключается в разработке
виртуальных прототипов, которые являются макетами устройств, мо-
гут относительно быстро генерироваться, и, будем надеяться, содержат
достаточно информации, чтобы позволить разработчикам идентифи-
цировать и решать большую часть потенциальных проблем, не прибе-
гая к трудоёмким этапам проектирования. Теоретически, чтобы повто-
рить устройство обычным способом, нужно несколько дней или не-
дель, а если использовать виртуальный прототип — несколько часов.
Применение виртуальных прототипов
при проектировании заказных микросхем
В предыдущей главе мы рассмотрели ряд положений, согласно ко-
торым роль логического синтеза заключается в обработке описания
устройства на уровне регистровых передач RTL вместе с набором вре-
Применение виртуальных прототипов при проектировании заказных микросхем 155
менных ограничений. Средства логического синтеза автоматически
конвертируют RTL-описание устройства в совокупность регистров и
булевых (логических) выражений, одновременно выполняя различные
процедуры минимизации и оптимизации, включая оптимизацию по
площади, занимаемой на кристалле, и по быстродействию. После это-
го они генерируют таблицу соединений вентилей, которая, будем на-
деяться, удовлетворяет заданным временным ограничениям.
Большинство обычных приложений логического синтеза опериру-
ют размерами вентиля, а не величиной задержки на нем. Другими сло-
вами, эти приложения постоянно ищут компромисс между размерами
вентиля и связанной с ними задержкой. В соответствии со своим при-
нципом действия эти приложения производят огромное количество
трудоемких и ресурсоемких вычислений. Кроме того, некоторые опти-
мизационные решения, сформированные средствами логического
синтеза, приводят к бессмыслице, когда дело доходит до физической
реализации устройства, т. е. до размещения и разводки элементов.
1887 г. Англия. Дж.
Томсон открыл
электрон.
Виртуальные прототипы на уровне вентилей.
Быстрый и грубый синтез
Ключевая особенность виртуальных прототипов заключается в
том, что они могут создаваться достаточно быстро и просто. Боль-
шинство современных виртуальных прототипов заказных микросхем
основаны на использовании таблицы соединений вентилей, которая
впоследствии разводится с помощью временного алгоритма. К сожа-
лению, применяемые здесь средства традиционного синтеза потребля-
ют слишком большое количество времени и вычислительных ресурсов
в связи с необходимостью соответствия заданным временным ограни-
чениям. Поэтому для создания некоторых виртуальных прототипов за-
казных микросхем используют так называемый метод быстрого и гру-
бого синтеза (Рис. 10.1).
Виртуальное макетирование
Физическая реализация
Рис. 10.1. Виртуальное макетирование, на основе алгоритма быстрого
и грубого синтеза
Метод быстрого и грубого синтеза обычно основывается на алго-
ритмах, совершенно отличных от тех, которые применяются в процес-
се создания реального экземпляра устройства. Это может быть, напри-
мер, алгоритм прямого отображения RTL-кода. Следовательно, гене-
156 Глава 10. Виртуальное макетирование ПЛИС
1887 г. Англия. Ви-
льям Крукс
(William Crookes)
продемонстриро-
вал прямолинейное
распространение
катодных лучей.
1887 г. Германия.
Генрих Герц
(Heinrich Hertz)
продемонстриро-
вал эффекты пере-
дачи, приёма и от-
ражения радио-
волн.
рируемая таблица соединений вентилей, используемая для
формирования описания уровня регистровых передач, может отли-
чаться от точного образа окончательного варианта устройства.
Это значит, что, используя виртуальный прототип для выверки
RTL-описания и временного анализа, разработчики по-прежнему
применяют совершенно другие методы для создания реальной табли-
цы соединений, которая затем поступает на этап физической реализа-
ции устройства, т. е. передается средствам размещения и разводки.
Другими словами, проблема, и довольно сложная, реализации рас-
сматриваемого подхода применения виртуального прототипа состоит
в том что средства макетирования и их методики никак не связаны и
существенно отличаются от средств практической, реальной реализа-
ции. Это приводит к несоответствию прототипа и реального устройс-
тва, то есть к плохой корреляции между ними, что может стать причи-
ной длительных по времени итераций, тем самым, сводя на нет все
преимущества использования виртуальных прототипов.
Виртуальные прототипы на уровне вентилей.
Синтез, оптимизированный по быстродействию
В отличие от обычного логического синтеза, который основывает-
ся на поиске компромисса между размерами и задержкой вентилей, в
основе так называемого синтеза, оптимизированного по быстродейс-
твию^ (gain-based synthesis), лежит концепция логической работы^.
В этом алгоритме концепция логической работы используется для
установки фиксированных временных параметров, которые средства
физической реализации устройства будут использовать для размеще-
ния и разводки элементов. Это значит, что по окончании этапа синтеза
будет завершена временная оптимизация, а также определены и за-
фиксированы все задержки на участках схемы. На этапе размещения
элементов используется алгоритм изменений размера, который, под-
страиваясь под жестко определённые временные параметры, произво-
дит изменение размера логической ячейки. Затем очередь за алгорит-
мом разводки, который для поддержки начальных временных ограни-
чений и сохранения целостности сигнала производит подстройку
ширины проводников и расстояний между ними.
Этот метод требует существенно меньшего количества памяти и
вычислительных ресурсов, чем обычный синтез. Другими словами,
этот метод синтеза, оптимизированного по быстродействию (gain-
based synthesis), по своим возможностям превосходит обычные алго-
ритмы.
Интересно, что методы синтеза, оптимизированного по быстро-
действию (gain-based synthesis), используют все имеющиеся резервы по
задержке сигнала. Это значит, что каждый вентиль будет иметь мини-
мально допустимый размер, удовлетворяющий временным ограниче-
ниям. Вследствие этого итоговая реализация устройства будет зани-
0 Во время написания этой книги главным сторонником синтеза, оптимизи-
рованного по расширению, выступала компания Magma Design Automation
(www.magma-da.com).
2) Концепция логической работы была разработана в 1999 году и подробно рас-
смотрена в книге «Логическая работа: разработка быстрых КМОП-схем» («Logical
Effort:Designing Fast CMOS Ciecuits», авторами которой были Иван Сюзерланд
(Ivan Sutherland), Боб Спрул (Bob Sproull) и Дэвид Харрис (David Harris).
Иван Сюзерланд приобрёл мировую известность благодаря исследованиям в
области логического проектирования.
Применение виртуальных прототипов при проектировании заказных микросхем 157
мать наименьшую площадь на поверхности кристалла, что позволит
существенно снизить перегрузки устройства, мощность потребления и
уровень шумов.
«Но позвольте, — скажет читатель, — причем здесь виртуальные
прототипы?» Да притом, что скорость и производительность, присущие
такому синтезу, позволяют одно и то же программное ядро использовать
как для макетирования, так и для физической реализации (Рис. 10.2).
1888 г. Америка.
Начал работу пер-
вый общественный
таксофон.
Рис. 10.2. Виртуальное макетирование, на основе синтеза оптимизированного
по быстродействию
Использование одинаковых алгоритмов, средств и технологий, как
при макетировании, так и при физической реализации, позволяет до-
стичь высокой корреляции между прототипом и реальным устройс-
твом, а также значительно уменьшить время на повторные итерации в
процессе разработки.
Виртуальные прототипы на уровне кластеров
Как обсуждалось ранее, большинство современных виртуальных
прототипов основаны на таблицах соединений вентилей. Даже если
эти таблицы генерируются путем быстрого-и-грубого синтеза, они по-
прежнему могут содержать миллионы вентилей. В свою очередь, ог-
ромное количество вентилей существенно замедляет процесс разме-
щения и разводки виртуального прототипа.
Одно из решений этой проблемы заключается в использовании
принципа кластеризации в качестве основы для размещения в вирту-
альном прототипе и оценке задержки сигналов. В этом случае ячейки,
т. е. вентили и регистры, сгенерированные путем быстрого-и-грубого
синтеза или синтеза, оптимизированного по быстродействию, автома-
тически собираются в группы, называемые кластерами. Каждый клас-
тер может состоять из нескольких десятков или нескольких сотен яче-
ек, т. е. имеет достаточно малые размеры, чтобы сохранить качество
размещения компонентов на поверхности кристалла, но в то же время
количество кластеров существенно меньше количества ячеек, что
весьма существенно сказывается на времени выполнения алгоритма
размещения.
В действительности, от кластера к кластеру число ячеек может ме-
няться, при этом площадь, занимаемая кластером, поддерживается, по
158 Глава 10. Виртуальное макетирование ПЛИС
1889 г. Америка.
Алмон Строуджер
(Almon Brown
Strowger) изобрёл
первую шаговую
АТС.
возможности, на одном уровне. Чтобы сделать вычисления не такими
сложными, а требования по производительности не столь жесткими,
все процедуры оптимизации и анализа выполняются применительно к
кластерам, а не к вентилям. Кроме того, если два кластера связаны
между собой большим количеством проводников, как и бывает в боль-
шинстве случаев, для предварительной оценки разводки, влияющей на
итоговое расположение кластеров, эта совокупность проводников рас-
сматривается как один «утяжелённый» проводник.
Виртуальные прототипы на основе RTL
В инженерной практике существует эмпирическое правило, кото-
рое гласит: обнаружение и исправление проблем на любой из стадий
проектирования, реализации и внедрения обходится в 10 раз дороже,
чем обнаружение и устранение тех же проблем на предыдущем этапе.
В области проектирования устройств на цифровых микросхемах су-
ществует три главные контрольные точки, в которых можно провести
анализ занимаемой площади на кристалле, временных параметров и
так далее (Рис. 10.3).
Относительная стоимость
временного анализа и отладки
синтезом) оптимизации) разводки)
Уровень абстракции
схемы (устройства)
Рис. 10.3. Контрольные точки для проведения анализа занимаемой площади,
временных и других параметров
При анализе схемы или архитектуры устройства, процесс обнару-
жения проблемных, с точки зрения временных параметров, участков
цепи и внесения в них исправлений называется поиском временного
соответствия (timing closure). Независимо от этапа применения уста-
новление временного соответствия является итеративным процессом,
т. е. для устранения ошибок в устройстве необходимо несколько раз
провести операции в цикле анализ-обнаружение-коррекция.
Что касается уровней абстракции, показанных на Рис. 10.3, несом-
ненно, источником самых точных данных будет временной анализ,
выполняемый после разводки элементов. Однако результаты этого
анализа будут чрезвычайно дорогими, и чтобы их получить, потребует-
ся много времени. Процесс итерации на этом этапе, как правило, яв-
ляется тяжелой процедурой, поэтому разработчик всеми правдами и
неправдами стараются избежать внесения изменений в устройство на
этом этапе разработки.
Применение виртуальных прототипов при проектировании заказных микросхем 159
При обычном подходе к проектированию устройств первая конт-
рольная точка, пригодная для проведения относительно точного вре-
менного анализа, располагается после синтеза вентилей и локальной
оптимизации^.
Проблема заключается в том, что при типовой последовательности
проектирования на этом этапе потребуется использование алгоритма
физического синтеза для создания таблицы соединений вентилей. По-
этому этот подход является чрезвычайно сложным и длительным, и в
случае больших блоков может потребоваться несколько дней на про-
хождение полного цикла синтеза и временного анализа. Такой подход
не только затягивает процессы разработки и достижение состояния
временного соответствия, но и требует использования дорогих средств
разработки, которые должны использоваться в большей степени для
реализации кристалла, чем для временного анализа.
Возможным решением является использование виртуального про-
тотипа, но при этом следует иметь в виду, что данному решению при-
сущи собственные недостатки, включая требование использовать не-
которые виды сложного и достаточно продолжительного синтеза и та-
ких же средств размещения элементов.
Еще один подход заключается в использовании виртуального про-
тотипа на уровне регистровых передач* 2*. Это позволит инженерам
быстро обнаруживать и исправлять участки схемы, которые могут ока-
заться потенциальными причинами проблем. Чтобы понять принцип
этого подхода, сначала необходимо отметить, что существуют родс-
твенные приложения, которые из файлов логических (LEF) и физичес-
ких (DEF) определений, связанных с библиотекой логических элемен-
тов ASIC, генерируют соответствующую базу данных наборов конс-
труктивных компонентов, которая затем используется в виртуальном
прототипе на уровне регистровых передач (RTL), см. Рис. 10.4.
LEF
DEF
Набор
конструктивных
компонентов
Рис. 10.4. Создание набора конструктивных компонентов
Важно, что такой набор конструктивных компонентов не является
библиотекой типовых логических элементов, но служит набором ти-
повых логических функций (таких как: счетчики, элементы ИСКЛЮ-
ЧАЮЩЕЕ ИЛИ и так далее). В ходе создания набора компонентов ге-
нератор описывает режим работы этих функций, в том числе времен-
ные параметры и параметры расположения на поверхности кристалла.
Генератор виртуального прототипа уровня регистровых передач и
подсистема анализа обрабатывают RTL-код устройства, заданные уст-
ройству временные ограничения (в промышленном стандарте SDF) и
набор конструктивных компонентов, связанный с целевой библиоте-
Файл LEF (logical
exchange format —
формат логического
обмена) детализирует
логическую функци-
ональность ячеек в
библиотеке.
DEF-файл (design
exchange format —
формат конструктив-
ного обмена) детали-
зирует физические
аспекты ячеек, на-
пример значения их
сопротивлений и ём-
костей, а также фи-
зические размеры.
° Локальная оптимизация подразумевает, что после работы алгоритма разме-
щения во время первого прохода можно произвести некоторые «настройки» (вы-
полнить оптимизацию). Например, можно изменить размер ячеек, основываясь
на уточнённых оценках длин проводников.
2) Во время написания этой книги ведущим сторонником применения вирту-
альных прототипов на уровне регистровых передач (RTL) являлась компания
InTime Software (www.intimesw.com).
160 Глава 10. Виртуальное макетирование ПЛИС
1890 г. Америка.
Входе переписи на-
селения использова-
лись 80-колонные
перфокарты Гер-
мана Холлерита
(Herman Hollerith)
и машины для ав-
томатического со-
ставления таблиц.
кой. Генератор виртуального прототипа воспринимает данные в RTL-
коде и преобразует его в таблицу соединений модулей, называемых ра-
бочими функциями. Каждая рабочая функция представляет собой не-
кую абстракцию, которая затем напрямую отображается на эквивален-
тную функцию в наборе конструктивных компонентов.
Преобразовав RTL-код в таблицу соединений рабочих функций,
генератор виртуального прототипа формирует идентичные логические
операции, которые обычно реализуются на уровне вентилей. В их чис-
ло входят общие подвыражения исключений, константы распростра-
нения, развертывающиеся циклы, средства удаления излишних функ-
циональных вычислений и так далее.
Генератор виртуального прототипа и подсистема анализа исполь-
зуют сформированную минимальную неизбыточную сеть рабочих
функций для формирования их «виртуального размещения». Затем это
размещение используется для создания оценок площади, занимаемой
элементами на поверхности кристалла, которые, в свою очередь, будут
использоваться для генерации точных временных параметров. Набор
конструктивных компонентов, генератор виртуального прототипа и
алгоритм анализа оценивают, каким образом различные методы син-
теза будут определять значимость различных факторов, и затем произ-
водят модификацию стратегии их реализации. Эта процедура необхо-
дима для соответствия результата синтеза заданным временным огра-
ничениям. Все эти факторы учитываются в процессе работы
подсистемы анализа.
Сторонники виртуальных прототипов, основанных на уровне ре-
гистровых передач, говорят о 40-кратном скоростном преимуществе
по сравнению с использованием таблицы соединений вентилей после
этапа локальной оптимизации и перед этапом размещения и разводки.
Например, в 2003 году в случае устройства, состоящего из 4.5 милли-
она логических элементов, для создания и анализа виртуального про-
тотипа на основе RTL потребовалось итерация длительностью 2.5 ча-
са. В то же время для генерации и анализа таблицы соединения венти-
лей после этапа локальной оптимизации потребовалось 99 часов.
Конечно, остается еще получить ответ на главный вопрос: на
сколько точно виртуальное макетирование на основе RTL? Сторонни-
ки этой формы виртуального макетирования утверждают, что резуль-
таты временного анализа обычно отличаются от данных, полученных
из анализа таблицы соединений, не более чем на 20%, в худшем случае
ошибка может составлять до 30%. Несмотря на то что это значение мо-
жет показаться чрезмерно большим, замечу, что последние поколения
средств синтеза дают погрешность временных параметров на уровне
20...30%. Но и такое значение не вызывает каких-либо проблем. Сле-
довательно, виртуальное макетирование на основе RTL являются до-
статочно точным, чтобы позволить разработчикам создавать описание
RTL, которое может быть использовано для реализации этапов низко-
уровневого синтеза и разводки элементов.
Знаю, знаю, мы снова отвлеклись. Но согласитесь, что этот мате-
риал весьма интересен. Ну а теперь давайте вернемся к размышлениям
о ПЛИС.
Виртуальные прототипы ПЛИС
Не удивительно, что ПЛИС, содержащие миллионы вентилей,
сталкиваются с теми же проблемами, что и заказные микросхемы, в
том числе и с длительностью этапов размещения, разводки, временно-
го анализа и другими.
Виртуальные прототипы ПЛИС 161
Неприятной особенностью этого процесса является то, что хотя
изначально представление уровня регистровых передач, как правило,
является иерархическим, средства размещения и разводки ПЛИС
обычно преобразуют его в плоское, или одноуровневое, представление
устройства. Это значит, что если произвести незначительные измене-
ния в одном из блоков RTL-кода и пересинтезировать только этот
блок, всё равно придётся вернуться и произвести повторный синтез
всего устройства. Ещё это значит, что вы можете стать седым и старым
прежде, чем дождетесь достижения временного соответствия для дан-
ного устройства.
Чтобы решить эти проблемы, некоторые поставщики САПР элект-
ронных устройств стали создавать средства, поддерживающие концеп-
цию виртуального макетирования ПЛИС и обеспечивающие планиро-
вание компоновки кристалла и предварительный, т. е. до размещения и
разводки, временной анализ. Подобный подход позволяет выполнять
размещение и разводку индивидуально для каждого блока устройства,
что значительно повышает скорость процесса его реализации0.
Эта форма виртуального макетирования начинается с просмотра
графического представления ПЛИС, на котором отображаются все
внутренние логические ресурсы (таблицы соответствия, регистры,
слои, логические блоки, встроенные ОЗУ, умножители и так далее).
Затем последует процедура логического синтеза, которая будет вы-
полняться по выбранному алгоритму, и после этого генератор вирту-
ального прототипа осуществит загрузку иерархической таблицы со-
единений, выполненной на уровне таблиц соответствия или логичес-
ких блоков, а также временных и конструктивных ограничений. На
основе полученных данных генератор формирует начальный компоно-
вочный план в виде квадратов и прямоугольников, каждый из которых
соответствует модулю из верхнего уровня иерархии устройства. Если
какой-то из этих модулей включает в себя один или несколько субмо-
дулей нижнего уровня, эти субмодули отображаются на плане в виде
встроенных блоков. И так далее вниз по иерархии.
Генератор виртуального прототипа формирует собственное началь-
ное размещение ресурсов, т. е. таблиц соответствия, регистров, блоков
ОЗУ, умножителей и других ресурсов, используемых каждым блоком.
Эти ресурсы также отображаются на детальном плане устройства вмес-
те с графическим представлением ресурсов, требуемых для связи раз-
личных блоков между собой.
Интерактивная правка
Предварительное размещение элементов устройства в виртуальном
прототипе позволяет получить точные временные оценки на уровне
блоков до их размещения и разводки. При обнаружении какой-либо
проблемы можно интерактивно изменить компоновочный план уст-
ройства и оперативно исправить сбойный участок схемы.
Простейший способ интерактивной обработки заключается в из-
менении границ прямоугольников на компоновочном плане устройс-
тва, чтобы сделать их выше, тоньше, ниже или толще. Вместе с тем,
также можно создать более сложные фигуры, например «L», «и» или
1890-е и.Джон
Венн (John Venn)
предложил пред-
ставление логичес-
ких величин (диа-
граммы Венна)
в виде окружнос-
тей и эллипсов.
Под иерархическим
мы подразумеваем,
что верхний уровень
устройства обычно
формируется
из ряда функцио-
нальных модулей,
которые могут
состоять из субмоду-
лей и так далее.
Во время написания этой книги, ведущим сторонником описываемой здесь
формы виртуального макетирования ПЛИС являлась компания Hier Design
(www.hierdesign.com).
162 Глава 10. Виртуальное макетирование ПЛИС
1892 г. Америка.
Начал работу пер-
вый автоматичес-
кий телефонный
коммутатор.
«Т»-образные; из квадратов и прямоугольников можно получить боль-
шое количество разнообразных форм.
При интерактивной правке можно передвигать блоки с одного
места на другое. При захвате блока и перетаскивании его через изобра-
жение поверхности устройства система будет автоматически произво-
дить графическую индикацию, уточняя, имеется ли в данном положе-
нии необходимое количество ресурсов для реализации перетаскивае-
мого блока; при этом блок можно перетащить только в ту область, где
имеется необходимое количество свободных ресурсов. По мере внесе-
ния изменений в компоновочный план устройства путём изменения
формы или перетаскивания прямоугольников система будет динами-
чески отображать расход ресурсов, т. е. таблиц соответствия, регист-
ров, блоков ОЗУ, умножителей и так далее, выделенных на текущий
блок, по отношению к общему количеству всех ресурсов устройства.
Имеющиеся блоки также можно разделить на два или более суб-
блоков, с которыми впоследствии сможно произвести независимую
правку. Можно также соединить несколько блоков в один. Иногда воз-
никает необходимость вытащить один или несколько субблоков за
пределы родительских блоков и перевести их на высший уровень ие-
рархии устройства, где можно их перетаскивать, менять форму, соеди-
нять вместе и так далее.
Многое из рассмотренных аспектов интерактивной правки отра-
жает различие подходов к применению одноуровневых виртуальных
прототипов, используемых среди заказных микросхем. Например, в
случае заказной микросхемы при наличии двух блоков с большим
количеством соединений между ними, естественно разместить их бок
о бок. В случае же ПЛИС эти блоки целесообразно соединить вмес-
те, тем самым позволяя средствам размещения и разводки произвес-
ти более эффективную работу по оптимизации распределения ло-
кальных и глобальных ресурсов, что обеспечит более эффективное
решение.
Кроме того, правка блоков не ограничивается только в пределах
первоначального описания иерархии уровня регистровых передач, и у
вас есть возможность манипулировать индивидуальными ресурсами
ПЛИС, такими как таблицы соответствия, регистры, секции, логичес-
кие блоки и так далее. Этот процесс подразумевает изменение их мес-
тоположения в пределах текущего иерархического блока, перемеще-
ние их из одного блока в другой, создание новых блоков и перемеще-
ние групп таблиц соответствия из одного или нескольких блоков во
вновь созданный и так далее.
Самое «забавное» начинается при внесении изменений в первона-
чальный RTL-код и повторном синтезе этих модулей. В этом случае
при повторном импорте результирующей таблицы соединений КЛБ (и
таблиц соответствия), генератор виртуального прототипа производит
сортировку и загрузку необходимой логики в соответствующие ском-
понованные блоки. Я не представляю, как это происходит!
Поэтапные размещение и разводка
Итак, если вы готовы станцевать рок-н-ролл, можете выбрать один
или несколько скомпонованных блоков и выкинуть программы разме-
щения и разводки, полученные от поставщика вашей ПЛИС. Каждый
блок воспринимается как отдельная единица, и после его формирова-
ния он будет оставаться неизменным до тех пор, пока вы не решитесь
его изменить.
Виртуальные прототипы ПЛИС 163
Этот подход имеет ряд преимуществ. Во-первых, время работы
процедуры размещения и разводки для отдельного блока чрезвычайно
мало по сравнению с разводкой многомиллионного устройства.
Во-вторых, если сложить время работы средств размещения и раз-
водки для всех отдельно взятых блоков, полученное общее время всё
равно будет существенно меньше, чем при работе аналогичных
средств для всей схемы целиком. Объяснить это можно тем, что с воз-
растанием сложности устройства по мере увеличения размеров блока
время работы по размещению и разводке увеличивается нелинейно.
Кроме того, при размещении и разводке всех блоков можно внести из-
менения в некоторые из них и повторить процедуру разводки только
для изменённых блоков, не затрагивая остальные части кристалла.
Еще одно преимущество виртуальных прототипов состоит в том,
что они могут применяться для создания и сохранения блоков интел-
лектуальной собственности. Другими словами, после размещения и
разводки блока его можно закрыть и экспортировать как новую струк-
турную таблицу соединений уровня КЛБ и таблиц соответствия вместе
с соответствующими физическими и временными ограничениями.
Впоследствии этот блок может быть использован в других устройствах.
Как уже отмечалось, расположение этого блока является относитель-
ным, т. е. он может быть перемещён в другую часть кристалла.
1894 г. Германия.
Генрих Герц
(Heinrich Hertz) от-
крыл, что радио-
волны распростра-
няются со скоро-
стью света и могут
отражаться и по-
ляризоваться.
1894 г. Италия. Гу-
льельмо Маркони
(Guglielmo Marconi)
изобрел беспровод-
ной телеграф.
Виртуальные прототипы ПЛИС уровня регистровых передач
Естественно, было бы очень удобно работать с виртуальными про-
тотипами ПЛИС, функционирующими на уровне регистровых пере-
дач (RTL). Некоторые поставщики ПЛИС и САПР электронных уст-
ройств представляют на рынке такие RTL-средства компоновки раз-
личной степени сложности. Тем не менее, на момент написания этой
книги в мире не существовало виртуальных прототипов ПЛИС, кото-
рые соответствовали бы современному уровню развития виртуальных
прототипов заказных микросхем, работающих на уровне регистровых
передач. Но, несомненно, они появятся в недалеком будущем.
ГЛАВА 1 1
ПРОЕКТИРОВАНИЕ НА ОСНОВЕ С/С++
И ДРУГИХ ЯЗЫКОВ
При реализации
ПЛИС таблица со-
единений конфигу-
рируемых логичес-
ких блоков/таблиц
соответствия может
быть представлена
bEDIF,VHDL или
Vferilog-версиях
в зависимости от
поставщика микро-
схем.
Проблемы использования HDL-языков
В этой главе рассматриваются только общие вопросы проектиро-
вания с применением языков C/C++. Рассмотрение других вопросов,
например, связанных с квантованием (замена числа с плавающей точ-
кой на число с фиксированной точкой), более подробно рассматрива-
ются в гл.12.
При использовании традиционных методов проектирования
ПЛИС, основанных на HDL-языках, которые были рассмотрены в гл. 9,
создание устройства начинается с того, что архитекторы совместно
с разработчиками создают концепцию и определяют функции системы.
На этом уровне вырабатываются макроархитектурные определения, на-
пример разделение устройства на программные и аппаратные компо-
ненты (см. гл. 13).
Итоговая спецификация передаётся разработчикам аппаратных
модулей системы, которые начинают, свою часть процесса с решения
задач микроархитектурных определений, например детализации управ-
ляющих структур, шин и элементов тракта передачи данных. Эти мик-
роархитектурные определения, которые зачастую появляются на бе-
лой доске во время совещания инженеров в результате мозговой атаки,
могут включать формирование определённых операций в параллель-
ных и последовательных, конвейерных и неконвейерных частях уст-
ройства с использованием общих ресурсов, например две операции
выполняются на одном умножителе и используют выделенные ресур-
сы, и без таковых.
В конечном итоге все функции устройства описываются термина-
ми уровня регистровых передач (RTL) на VHDL или Verilog. После
проверки устройства с помощью средств моделирования RTL-пред-
ставление трансформируется в структурную таблицу соединений, при-
годную для промышленных средств размещения и разводки элементов
устройства (Рис. ПЛ).
Рис. 11.1. Традиционное проектирование на основе HDL-языков (упрощенно)
Виртуальные прототипы ПЛИС 165
Во время написания этой книги около 95% всех методов проекти-
рования заказных микросхем или ПЛИС основывались на языках про-
граммирования VHDL или Verilog. Однако при работе с этими языка-
ми возникает ряд проблем:
• Большие временные затраты на описание RTL — несмотря на то
что языки VHDL и Verilog предназначены для представления
аппаратного обеспечения, описание функциональности уст-
ройства с их помощью занимает много времени.
• Большие временные затраты на проверку RTL — использование
моделирования для проверки больших устройств, представлен-
ных в виде ЮТ-кода, требует больших вычислительных и вре-
менных затрат.
• Трудности с оценкой альтернативных реализаций — для выпол-
нения ряда оценок альтернативных микроархитектурных реали-
заций используют модификацию и повторную проверку RTL,
выполнение которых является весьма затруднительным и тру-
доемким. Это означает, что команда разработчиков ограничена
в количестве оценок различных вариантов устройства, что мо-
жет стать результатом не вполне оптимальной реализации.
• Трудности внесения изменений в спецификацию устройства — ес-
ли в ходе реализации проекта потребуется внести изменения в
технические требования к устройству, то свертывание этих из-
менений в RTL и выполнение необходимых перепроверок мо-
жет оказаться весьма неприятным и трудоемким процессом.
Для некоторых прикладных областей это замечание является
существенным, например, для сферы беспроводной передачи
данных, что связано с постоянным развитием и изменением
стандартов и протоколов передачи данных.
• Особенности реализации RTL — реализация устройства на ПЛИС
обычно требует иного стиля кодирования RTL, чем при исполь-
зовании заказных микросхем (смотри также главы 7, 9 и 18).
Другими словами, может оказаться чрезвычайно трудно пере-
нести сложную схему, представленную в RTL-коде, из одной
технологии в другую. Это замечание относится к случаям пере-
носа существующих устройств, выполненных на заказных мик-
росхемах, в их эквиваленты на основе ПЛИС, или к случаям ре-
ализации устройств в ПЛИС в качестве прототипов для
последующей реализации устройств на заказных микросхемах.
Чтобы прояснить ситуацию, скажу, что информация о реализа-
ции устройства жестко зашита в RTL, который вследствие этого
становится зависимым от реализации конкретного устройства.
Важно понять, что эта особенность выходит за рамки грубого
сравнения заказных микросхем и ПЛИС, согласно которому
RTL-код, предназначенный для ПЛИС устройства, не подходит
для оптимальной реализации заказной микросхемы, и наобо-
рот. Даже в устройствах, предназначенных для решения одних и
тех же задач, набор алгоритмов, используемых для обработки
данных, может потребовать ряд различных микроархитектур-
ных реализаций в зависимости от целевого назначения устройс-
тва. Если пойти до конца, скажу, что одни и те же RTL могут ис-
пользоваться для реализации как заказных микросхем, так и
ПЛИС. Этот подход применяется для предотвращения функци-
ональных ошибок в RTL при переносе кода из одной области в
другую, но за это приходится платить. Это значит что, если код,
изначально предназначенный для ПЛИС, используется для реа-
166 Глава 11. Проектирование на основе C/C++ и других языков
1895 г. Америка.
Абонентские теле-
фоны начали ис-
пользоваться в зда-
нии городского со-
вета города Милу-
оки.
Системы реально-
го времени работа-
ют по принципу не
только что выпол-
нить, но и когда это
должно быть вы-
полнено.
лизации заказной микросхемы ASIC, в результате такого пере-
носа заказная микросхема обычно будет занимать больше места
на кристалле и будет потреблять энергии больше, чем устройс-
тво, изначально разработанное для ASIC. Аналогично, если код,
изначально предназначенный для ASIC применяется для реали-
зации ПЛИС, конечное устройство, как правило, потребует су-
щественно больше ресурсов, чем при использовании RTL, со-
зданного специально для FPGA.
• RTL не является идеальным средством для аппаратно-програм-
много проектирования — к однокристальным устройствам, как
правило, относят такие, которые содержат микропроцессорные
ядра. Независимо от способа реализации этих устройств, т. е. с
помощью заказной микросхемы или ПЛИС, современные одно-
кристальные системы тяготеют к увеличению доли програм-
мных компонентов. Кроме того, в связи с участившимися случа-
ями повторного использования аппаратной части таких
устройств, как правило, требуется одновременно проверять про-
граммные и аппаратные части, чтобы полностью подтвердить
достоверность таких компонентов, как системная диагностика,
операционная система реального времени, драйверы устройств,
встроенные программные приложения. В общем случае доволь-
но-таки сложно проверить (промоделировать) аппаратную
часть, описываемую языком VHDL или Verilog, вместе с про-
граммной частью, написанной на языке C/C++ или ассемблера.
Один из методов решения описанных выше проблем заключается в
первоначальном описании устройства на более высоком уровне абс-
тракции, чем тот, которого можно достичь при использовании языка
VHDL или Verilog. Первый такой уровень достигается при использова-
нии какой-либо формы записи языка C/C++, и, следовательно, вновь
возникает не простая ситуация, поскольку имеются различные версии
этого языка, например, SystemC, расширенный C/C++ и немодифи-
цированный (чистый) C/C++.
С, C++ и другие версии
Прежде всего необходимо рассмотреть несколько понятий, чтобы
убедиться, что все мы говорим на одном и том же языке. Во-первых,
существует огромное количество языков программирования, но, за ис-
ключением специальных областей, наиболее часто используется тра-
диционный язык С и его объектно-ориентированный потомок C++. В
своем повествовании я буду ссылаться на них, пользуясь общим назва-
нием C/C++.
Во-вторых, и это очень важно, по определению операторы в язы-
ках, подобных C/C++, выполняются последовательно. Например, до-
пустим, что мы уже описали три переменных целого типа, обозначен-
ных как а, Ь, с. Тогда нижеприведенные операторы
а = 6; /* Оператор в программе C/C++ */
b = 2; /* Оператор в программе C/C++ */
с = 9; /* Оператор в программе C/C++ */
будут выполняться, как и полагается, один за другим. Однако такая
последовательность имеет определенные последствия. Например, ес-
ли предположить, что в программе появятся операторы вида
а = Ь; /* Оператор в программе C/C++ */
Ь = а; /* Оператор в программе C/C++ */
Проектирование на языке SystemC 167
то переменной а, которой изначально было присвоено значение 6, будет
присвоено значение, которое в настоящее время хранится в переменной
Ь, т. е. 2.; переменной Ь, которой в начале было присвоено значение 2,
будет присвоено значение, которое в настоящее время хранится в пере-
менной а, т. е. 2. Другими словами, в результате выполнения этих выра-
жений переменным а и b будет присвоено одинаковое значение.
Последовательное выполнение команд в языках программирова-
ния отражает ход мысли разработчиков программного обеспечения.
Однако разработчики аппаратных средств смотрят на мир по-другому.
Допустим, что в аппаратной части устройства содержится два регистра
а и Ь, на которые подается общий тактовый сигнал. Предположим, что
в эти регистры изначально загружены значениями соответственно 6 и
2 и в некоторой части HDL-кода находятся следующие операторы:
а = Ь; /* Выражение в коде VHDL или Verilog */
Ь = а; /* Выражение в коде VHDL или Verilog */
Как обычно, приведенный здесь синтаксис не соответствует язы-
кам VHDL или Verilog: эта общепринятая форма записи приведена
здесь только для наглядности рассматриваемого примера. При этом
разработчики аппаратных средств ожидают, что оба этих оператора бу-
дут выполняться одновременно. Это значит, что в регистр а, в который
изначально было записано число 6, будет загружено значение, которое
в настоящее время хранится в регистре Ь, т. е. 2, и одновременно в ре-
гистр Ь, в который изначально было записано число 2, будет загружено
значение, которое в настоящее время хранится в регистре а, т. е. 6. В
результате выполнения этих операторов регистры а и b обменяются
своим содержанием.
Как обычно, всё наши рассуждения несколько упрощены по срав-
нению с практикой. Справедливо будет заметить, что HDL-операторы
будут выполняться одновременно по умолчанию. Однако это правило
можно отменить с помощью некоторых методов, например, метода
блокирующего присваивания. Таким образом, по определению под-
система моделирования на основе RTL будет выполнять приведённые
выше операторы одновременно; аналогично средства синтеза на осно-
ве RTL буду синтезировать аппаратную часть устройства, которая так-
же будет выполнять эти два действия одновременно. В отличии от них,
если явно не задано иное, операторы языка C/C++ будут выполняться
последовательно.
Проектирование на языке SystemC
Что такое SystemC и его история
Перед тем, как приступить к обсуждению методов проектирова-
ния, основанных на языке SystemC, целесообразно кратко рассмот-
реть, что собой представляет этот язык, поскольку при обсуждении
этого вопроса обычно возникает некоторая неразбериха, в том числе и
у автора.
Язык SystemC находится под покровительством независимой неком-
мерческой организации OSCI (Open SystemC Initiative), которая объ-
единяет различные компании, университеты и независимых разра-
ботчиков и продвигает SystemC как стандарт с открытым исходным
кодом, предназначенный для проектирования на системном уровне.
Код SystemC вместе со встроенной системой моделирования и сре-
дой проектирования можно найти на сайте www.systemc.oig.
1895 г. Германия.
Вильгельм Конрад
Рентген (Wilhelm
Kohnrad Roentgen)
отрыл рентгеновс-
кие лучи.
168 и Глава 11. Проектирование на основе C/C++ и других языков
1895 г. Россия.
Александр Попов
сконструировал
приёмник природ-
ных электромаг-
нитных волн, пред-
назначенный для
предупреждений
о грозе.
SystemC 1.0
Основная концепция языка SystemC заключается в том, что он яв-
ляется программным продуктом с открытым кодом, в который любой
желающий может внести свой вклад. В качестве аналогичного приме-
ра можно привести операционную систему Linux, которая в самом на-
чале своего развития ничего особенного собой не представляла. Одна-
ко, основываясь на открытом коде и заручившись поддержкой многих
людей, Linux в конечном итоге стала настоящей операционной систе-
мой (ОС), обладающей достаточным потенциалом, чтобы бросить вы-
зов компании Microsoft.
Относительно недокументированный открытый программный
продукт SystemC пустился в свободное плавание где-то в 2000 году. Это
был объектно-ориентированный язык программирования, который
поддерживал библиотеки классов, что упрощало реализацию парал-
лельных процессов (ситуации, когда несколько операций обрабатыва-
ются параллельно), синхронизации и выводов входа/выхода. Исполь-
зуя библиотеку классов, инженеры могли описывать устройства с по-
мощью абстракций, выполненных на уровне регистровых передач.
Реализация подходов с использованием языка SystemC давала ин-
женерам ряд преимуществ. Одно из них заключалось в том, что приме-
нение этих методов сделало возможным создание среды программно-
аппаратного кодирования. Другое преимущество состояло в том, что
моделирование устройства, описание которого было реализовано с по-
мощью абстракций уровня регистровых передач на языке SystemC,
могло быть выполнено в 5... 10 раз быстрее, чем при использовании
языков VHDL или Verilog1*. В то же время использование этого языка
имело ряд неудобств и в частности требовало существенно больше вре-
мени и сил для создания RTL-описания устройства. Кроме того, ощу-
щалась нехватка программных средств, позволяющих синтезировать
таблицу соединений элементов устройства из кода, написанного на
SystemC.
SystemC 2.0
В 2002 году появилась следующая версия языка — SystemC 2.0. Эта
версия отличалась от предыдущей наличием некоторых высокоуровне-
вых схем, предназначенных для моделирования, например — очереди
FIFO. Это устройство представляет собой форму памяти, которая мо-
жет принимать и впоследствии выдавать в обработку последователь-
ность слов данных по принципу «первым пришел, первым вышел».
Версия 2.0 также поддерживала ряд поведенческих, алгоритмичес-
ких и моделирующих возможностей, например концепции транзакций
и каналов (которые используются для абстрактного описания процес-
са передачи данных между блоками). Чтобы представить перспективу
применения этих нововведений, давайте сначала рассмотрим исполь-
зование первоначальной версии языка SystemC 1.0 на простом приме-
ре. Допустим, что имеются две функции f(x) и g(x), которые требуется
связать между собой (Рис. 11.2).
В случае схемы, представленной на Рис. 11.2 интерфейс между
блоками должен быть определен на физическом уровне, т. е. на уровне
Это значение существенно зависит от схемы устройства; в действительнос-
ти, некоторые модели, созданные с помощью языка SystemC, обрабатываются не
быстрее, чем их HDL-аналоги.
Проектирование на языке SystemC 169
Две функции, описанные
на высоком уровне
с помощью языка C/C++
проводников
Рис. 11.2. Связь двух функций с помощью SystemC 1.0
1897 г. Англия.
Гульельмо Маркони
(Guglielmo Marconi)
передал сообщение
в коде Морзе через
Бристольский
канал.
проводников, связывающих их между собой. Проблемы, связанные с
этим методом, дают о себе знать на первых стадиях проектирования,
так как на этом этапе уже должны быть определены все детали реали-
зации, в частности ширина шины. Это усложняло процедуру внесения
изменений в схему при попытке попробовать различные варианты ар-
хитектуры устройства. Однако эта проблема перестала существовать с
приходом SystemC 2.0, который позволил выделить в явном виде абс-
трактные интерфейсы между этими блоками (Рис. 11.3).
Две функции, описанные
на высоком уровне
с помощью языка C/C++ Ч
Интерфейсы
Рис. 11.3. Связь двух функций в SystemC 2.0
Теперь связь между блоками можно было описать с помощью абс-
трактных записей, и на ранних стадиях проектирования устройства не
заботиться о том, каким образом данные из точки а передаются в точку б,
а лишь ограничиться констатацией факта такой передачи.
Абстрактные интерфейсы облегчают формирование архитектур-
ных оценок на ранних этапах проектирования. Начало формирования
архитектуры можно совместить с началом процесса усовершенствова-
ния интерфейсов путем применения высокоуровневых устройств, та-
ких как очереди FIFO. При использовании таких очередей должны
быть установлены параметры, как, например, ширина и глубина оче-
реди, а также ряд характеристик, таких как «блокирующая запись»,
«неблокирующее чтение», и порядок работы при опустошении и пол-
170 Глава 11. Проектирование на основе C/C++ и других языков
1897 г. Англия.
Г. Маркони уста-
новил первую стан-
цию Маркони на
острове Уайт и пе-
редал сигнал через
22 км на побе-
режье Англии.
ном заполнении очереди. На последующих этапах логические интер-
фейсы могут быть полностью заменены специализированными интер-
фейсами, позволяющими связать функциональные блоки на физичес-
ком уровне.
Уровни абстракции
К сожалению, определение уровней абстракции несколько рас-
плывчатое, размытое. Очевидно, это связано с тем, что каждый стре-
мится внести свою лепту в это определение и придать этому определе-
нию только ему понятный смысл. Для начала рассмотрим описание
различных уровней абстракции языка SystemC (Рис. 11.4).
Неразбериха возникает из-за того, что в процессе проектирования
язык SystemC может использоваться по-разному. Так, например, он
может «замещать» языки VHDL/Verilog, когда речь идет об описания
уровня регистровых передач. В другом случае он может оказаться
единственным языком, который можно использовать для описания
устройства на системном уровне, для алгоритмического и архитектур-
ного анализа, поведенческого проектирования и создания испыта-
тельных стендов с целью верификации.
Примером неразберихи и недоразумений может служить поведен-
ческий синтез, в котором, безусловно, проявляются аспекты как алго-
ритмического, так и транзакционного уровней. В последнем случае
следует быть аккуратным при определении транзакций.
Альтернативные методы проектирования на основе языка
SystemC
Это достаточно сложная тема, поскольку она имеет много различ-
ных аспектов. Например, многие современные устройства начинают
свою жизнь в виде набора сложных алгоритмов. В этом случае разра-
ботку устройства можно начать с реализации этих алгоритмов на языке
C/C++ и полученный код скомпилировать в форму, которая может
быть использована для проверки работоспособности алгоритмов. При
Проектирование на языке SystemC 171
этом моделирование может выполняться в тысячи раз быстрее, чем
аналогичная проверка, выполненная на уровне регистровых передач.
В случае использования HDL-методов проектирования, рассмот-
ренных в гл. 9, представление алгоритмов с языка C/C++ может быть
экспортировано в RTL-код языка VHDL/Verilog. При этом код языка
C/C++ обычно продолжают использовать в качестве золотой модели,
которая может быть связана с системой моделирования RTL и рабо-
тать параллельно с RTL-моделью. Результаты работы обеих моделей
затем сравниваются для того, чтобы гарантировать их функциональ-
ную эквивалентность.
Еще один способ применения языка SystemC для проектирования
устройств заключается в постепенной модификации первоначального
кода C/C++ путем добавления в него возможностей для обеспечения
параллелизма, синхронизации, определения контактов и так далее,
т. е. для модификации кода до уровня, когда он может быть подвержен
поведенческому синтезу.
А можно пойти и по такому пути, как создание первоначального
описания устройства с помощью конструкций системного, алгоритми-
ческого уровня или уровня транзакций языка SystemC, которые могут
быть использованы для верификации устройства на высоком уровне
абстракций. Это описание может быть постепенно модифицировано и
переведено на более низкий уровень регистровых передач SystemC или
уровень поведенческого синтеза.
Не зависимо от того, какой из описанных выше способов форми-
рования кода используется, допустим, что имеется описание устройс-
тва на языке C/C++, которое подходит для RTL или поведенческого
синтеза на основе SystemC. В этом случае существует два подхода к
последовательному проектированию. Первый из них состоит в ис-
пользовании средств синтеза языка SystemC для непосредственной ге-
нерации таблицы соединений. Второй подход заключается в автомати-
ческой трансляции из SystemC в RTL VHDL/Verilog и последующем
использовании традиционных средств RTL-синтеза.
Поклонники первого подхода утверждают, что прямой синтез таб-
лицы соединений средствами SystemC предлагает более быстрое, на-
глядное и эффективное решение. Приверженцы второго подхода на-
стаивают на том, что лучше транслировать исходный код C/C++ в RTL
VHDL/Verilog. Кроме того, RTL предоставляет разработчикам визуали-
зацию кода устройства, также на этом уровне легко проводить интегра-
цию различных блоков, в том числе блоков интеллектуальной собс-
твенности сторонних разработчиков. Не говоря уже о том, что средства
синтеза VHDL/Verilog отличаются мощностью и глубиной проработки
по сравнению со средствами SystemC. Но я вновь отвлекся.
Оба подхода могут быть с успехом применены как для ПЛИС, так и
для заказных микросхем (Рис. 11.5).
Первые версии программ синтеза на основе кода SystemC преиму-
щественно использовались для заказных микросхем, так как эти
средства довольно неэффективно работали со специфичными для
ПЛИС блоками, такими как: встроенное ОЗУ, встроенные умножите-
ли, и другими. Последние версии этих программ намного лучше
справляются с блоками ПЛИС, но их уровень сложности постоянно
меняется, и продвинутому пользователю я настоятельно рекомендую
до оформления заказа провести тщательный анализ этих средств.
На Рис. 11.5 показано использование зависимого от реализации
кода SystemC в процессе проектирования ПЛИС и заказных микро-
схем. Как только начнется процесс кодирования на уровне регистро-
1901 г. Хьюберт
Бут (Hubert Booth)
изобрёл пылесос.
172 Глава 11. Проектирование на основе C/C++и других языков
1901 г. Г. Маркони
послал радиосигнал
через Атлантику.
Рис, 11,5, Последовательность проектирования на основе языка SystemC
вых передач и будет добавлено понятие синхронизации, независимо от
используемого языка программирования, будь-то VHDL, Verilog или
C/C++, для достижения оптимальной реализации устройства код дол-
жен зависеть от специфики архитектурной реализации.
В этом случае один и тот же код SystemC может использоваться как
при построении ПЛИС, так и при построении заказных микросхем
(ASIC), но за такую универсальность придётся платить. Если такой код
SystemC изначально предназначался для создания ПЛИС, а использо-
вался для реализации заказной микросхемы, изготовленная таким
способом схема будет занимать больше места на поверхности кристал-
ла и потреблять энергии больше, чем устройство, изготовленное с ис-
пользованием кода, ориентированного на заказную микросхему. Ана-
логично, если код, изначально предназначенный для реализации за-
казных микросхем, использовался для создания ПЛИС,
изготовленное таким образом устройство будет потреблять значитель-
но больше ресурсов, чем устройство, изготовленное по коду, ориенти-
рованному на ПЛИС. Все описанные здесь накладные расходы при
нецелевом использовании кода возникают вследствие жесткого аппа-
ратного кодирования микроархитектурных определений на уровне ис-
ходного кода.
Принять иль не принять
Разработчики, занимающиеся созданием ПЛИС, делятся на две
группы: на сторонников и противников языка SystemC. Большинство
специалистов утверждают, что SystemC 2.0 весьма перспективен и об-
ладает непревзойдёнными возможностями проектирования. Эти воз-
можности уже реализованы в языке System Verilog, но еще далеко не
все. Также нужно отметить, что SystemC может быть очень полезен для
верификации и высокоуровневого системного моделирования, но в
полной мере эти возможности пока не востребованы реальными мето-
дами проектирования.
Большинство специалистов, занимающихся проектированием уст-
ройств, на достаточно хорошем уровне владеют навыками написания
кода на языке С, но многие из них имеют весьма смутное представле-
ние об объектно-ориентированных аспектах C++. Следовательно,
требуя от некоторых разработчиков, чтобы они пользовались языком
Проектирование на расширенном C/C++ 173
SystemC, мы, с одной стороны, стремимся вручить им мощное средс-
тво, а с другой стороны, толкаем в мир, который им, мягко говоря, не
симпатичен или не совсем понятен.
Некоторые инженеры говорят, что хотя SystemC относительно тя-
жело использовать для написания кода вручную и также тяжело про-
изводить синтез устройства (что делает его отчасти грубым языком
спецификаций), но он предоставляет мощную основу для моделирова-
ния на разных уровнях абстракции с применением различных языков.
В то время, когда я писал эту книгу, среди компаний, занимающих-
ся поддержкой и развитием языка SystemC в Соединённых Штатах,
наметился некий спад продвижения своих продуктов. Однако этот
язык нашёл своих приверженцев в Европе и Азии. Что ожидает
SystemC в будущем? Поживем, увидим.
Проектирование на расширенном C/C++
Что такое расширенный C/C++
В стандартной версии языка C/C++ существует два способа рас-
ширения его функциональности. Первый из них заключается во вклю-
чении в «чистый» C/C++ код специальных комментариев, которые
называют комментированными директивами или псевдокомментариями
(прагмами). Эти комментарии распознаются и интерпретируются про-
граммами синтаксического анализа или парсерами, препроцессорами,
компиляторами и другими средствами, а затем используются в процес-
се создания кода или изменения метода его построения0. Существен-
ным недостатком этого метода является тот факт, что системы модели-
рования, построенные на основе C/C++, требуют использования
собственных компиляторов. Это обстоятельство ограничивает набор
применяемых для расширения опций, реализация которых возможно
лишь в том случае, когда поставщики САПР электронных систем под-
держивают стандарты расширения языка.
Еще один способ расширения возможностей языка C/C++ заклю-
чается в добавлении в язык специальных ключевых слов и выражений.
Этот метод пользуется большой популярностью, и в настоящее время
во всем мире существует огромное количество различных вариантов
языковых модификаций C/C++ для разных сфер применения. Глав-
ным недостатком этого расширения, так же как и в предыдущем мето-
де, является то, что средства моделирования для своей работы требуют
применения собственных компиляторов, и если в исходном коде будут
содержаться непонятные для них конструкции, это приведет к краху
системы моделирования. Общее решение этих проблем заключается в
том, что новые ключевые слова и выражения заключаются в стандарт-
ные директивы препроцессора #ifdef. Таким образом, препроцессор
при необходимости может пропускать непонятные для него новые
конструкции. Этот метод не отличается элегантностью, но он работает.
При описании аппаратной функциональности для ПЛИС и заказ-
ных микросхем часто возникает необходимость расширить стандарт-
ные возможности языка C/C++ для поддержки таких понятий, как
1902 г. Америка.
Миллар Хутчинсон
(Millar Hutchinson)
изобрёл электри-
ческий слуховой
аппарат.
Примером такой формы расширения языка C/C++ может служить техноло-
гия проверки условий компании О-In Design Automation (www.0in.com). В качестве
другого примера можно упомянуть компанию Future Design Automation
(www.future-da.com), которая использует упомянутые здесь методы в системах
RTL-синтеза.
174 Глава 11. Проектирование на основе C/C++ и других языков
1902 г. Роберт Бош
(Robert Bosch)
изобрёл свечу
зажигания.
синхронизация, тактовый сигнал, выводы, параллелизм, и общие (выде-
ленные) ресурсы^.
Допустим, что мы располагаем начальной моделью системы, опи-
санной на чистом C/C++. Первым делом необходимо расширить её,
добавив выражения, описывающие систему формирования синхроим-
пульсов, а также описать с помощью выражений интерфейсы для оп-
ределения контактов ввода/вывода. После этого с помощью соответс-
твующего средства синтеза вы можете создать реализацию своего уст-
ройства. Поскольку C/C++ по своей природе является языком
последовательного выполнения, полученная в результате процедуры
синтеза аппаратная реализация может оказаться чрезвычайно медлен-
ной и неэффективной, если только в ней не будут реализованы при-
нципы параллелизма.
Допустим, например, что в описании устройства, выполненного с
помощью языка C/C++, находятся следующие операторы:
а = 6; /* Стандартный оператор C/C++ */
b = 2; /* Стандартный оператор C/C++ */
с = 9; /* Стандартный оператор C/C++ */
d = а + Ь; /* Стандартный оператор C/C++ */
и так далее
По умолчанию каждый символ «=» рассматривается средствами
синтеза как один период тактового сигнала. Следовательно, если при-
веденный выше код рассматривать в том виде, как он приведён, систе-
ма синтеза будет генерировать аппаратное обеспечение следующим
образом: на первом такте в регистр а будет загружаться число 6, на сле-
дующем такте в регистр b будет загружено число 2, на следующем такте
в регистр с загрузится число 9 и так далее. Другими словами, с точки
зрения стандартов аппаратного обеспечения, такое устройство будет
чрезвычайно медленным.
Конечно, большинство средств синтеза поддерживают реализацию
параллелизма в виде, приемлемом для реализации рассмотренного вы-
ше примера, но и они могут не справиться с более сложными задача-
ми. В этом случае в процесс синтеза необходимо вмешательство чело-
века для проведения некоторого анализа сложившейся ситуации. Не-
смотря на простоту рассмотренного примера, будем работать с ним в
пределах этой главы. Расширенная версия языка C/C++ должна под-
держивать ключевые слова «parallel», или «раг» (параллельный), и
«sequential», или «seq» (последовательный), для формирования инс-
трукций средствам синтеза на последовательную или параллельную
реализацию операторов. Например:
parallel; /* Оператор расширенной версии C/C++ */
а = 6; /* Оператор стандартной версии C/C++ */
b = 2; /* Оператор стандартной версии C/C++ */
с = 9; /* Оператор стандартной версии C/C++ */
sequential; /* Оператор расширенной версии C/C++ */
d = а + b; /* Оператор стандартной версии C/C++ */
и так далее
° Ярым приверженцем подобной формы расширения языка C/C++ для
ПЛИС и заказных микросхем является компания Celoxica (www.celoxica.com),
поставляющая на рынок средства ввода описания схемы, моделирования и синте-
за на основе языка Handel-C.
Проектирование на расширенном C/C++ 175
В этом случае ключевое слово «parallel» указывает средствам синте-
за, что следующие за ним выражения могут выполняться одновремен-
но, а ключевое слово «sequential» подразумевает, что последующие вы-
ражения должны реализовываться поочередно. Конечно, эти выраже-
ния размещаются в соответствии с потребностями.
Гораздо более сложная задача возникает при необходимости реали-
зации циклов, причём уровень сложности зависит от способа реализа-
ции цикла. Если рассмотреть цикл вида «для i = 1 до Юс шагом увеличе-
ния 1 выполнить операции хххх, уууу и zzzz», то в некоторых случаях его
можно просто заменить выражениями параллельного или последова-
тельного выполнения. Если же потребуется реализация более изыс-
канных задач, инженеры, вероятно, будут вынуждены полностью пе-
реписать этот участок кода.
Возможно также, что необходимо будет добавить в код конструк-
ции «share», чтобы обеспечить общий доступ к ресурсам, выражение
«channel», чтобы обеспечить совместное использование сигналов меж-
ду выражениями, а также другие ключевые слова.
Как отмечалось ранее, средства моделирования и другие утилиты
проектирования, не поддерживающие новых ключевых слов и выра-
жений, прекращают свою работу, если встречают их в исходном ко-
де. Одно из решений заключается в охвате этих выражений с помо-
щью директив #ifdef, которые позволяют при необходимости
отказаться от их использования. Однако это значит, что средства
синтеза и моделирования будут по-разному смотреть на схему, что не
очень хорошо. Другое решение заключается в использовании патен-
тованных систем моделирования, но они могут быть менее мощны-
ми или несовместимыми с имеющимися у пользователя технология-
ми моделирования.
Расширенный стандарт языка C/C++
Очевидно, что во многих областях один и тот же результат может
быть достигнут разными способами. Если жизненный путь устройства
начинается с разработки набора алгоритмов, описывающих его работу,
процесс создания устройства целесообразно начать с составления опи-
сания этих алгоритмов на языке С или C++. После необходимых про-
верок написанная на языке C/C++ модель может постепенно допол-
няться выражениями, реализующими тактовые сигналы, интерфейсы
ввода-вывода, параллелизм, систему синхронизации и общий доступ к
ресурсам, тем самым доводя её до уровня, приемлемого для работы
средств синтеза. Можно пойти другим путём, изначально реализовав
описание устройства с помощью расширенной версии языка C/C++.
Независимо от типа используемого варианта допустим, что мы уже
располагаем описанием устройства на расширенной версии языка
C/C++ на уровне, пригодном для использования средствами синтеза.
В этом случае, снова повторюсь, существую два основных метода син-
теза устройств. Один из них заключается в автоматическом переводе
кода, выполненного на расширенном C/C++, на языки \ferilog или
VHDL на уровне абстракций регистровых передач с последующем
применением обычных средств RTL синтеза. Второй метод предусмат-
ривает использование собственных средств синтеза на основе расши-
ренной версии языка C/C++.
И ещё раз повторюсь: некоторые утверждают, что прямой синтез из
кода C/C++ в таблицу соединений элементов предлагает более про-
стое и эффективное решение. В то же время существует другое мнение,
1902 г. Кабель, про-
ложенный через
Тихий океан, связал
Канаду и Австра-
лию,
176 Глава 11. Проектирование на основе C/C++ и других языков
1902 г. На корабли
Военно-морских
сил (ВМС) США ус-
тановили радиоте-
лефоны.
1904 г. Джон Фле-
минг (John Ambrose
Fleming) изобрёл
вакуумный диодный
детектор.
1904 г. Разработа-
на первая фото-
электрическая
ячейка.
согласно которому уровень регистровых передач языков Verilog/VHDL
наиболее адаптирован для интеграции различных устройств, к тому же
современные технологии RTL-синтеза отличаются мощностью и глу-
биной проработки.
Оба подхода находят своё применение при реализации как ПЛИС,
так и заказных микросхем (Рис. 11.6). Первые приложения синтеза на
основе расширенной версии языка C/C++ использовались преиму-
щественно при проектировании заказных микросхем (ASIC). Объяс-
нить это обстоятельство можно тем, что ранние версии программного
обеспечения не могли эффективно работать с ПЛИС-модулями, таки-
ми как встроенные блоки ОЗУ, встроенные умножители, и другими.
Последние версии этих утилит намного лучше справляются с постав-
ленной задачей, но, как обычно, будущему пользователю настоятель-
но рекомендую тщательно проверить и оценить то или иное средство,
прежде чем оплатить счет.
Заказные микросхемы
(ASIC)
Расширенный
C/C++
f
Исходный код,
зависимый
Автоматическая
'трансляция в RTL
Синтез на основе
расширенного C/C++
RTL
синтез
Таблица
соединений
вентилей
от реализации
4
Автоматическая
’ трансляция в RTL
VHDL/Verilog
RTL
RTL
синтез
Расширенный
C/C++
ПЛИС
Синтез на основе
расширенного C/C++
Таблица
соединений
f КЛБ
(и/или таблиц
соответствия)
Рис. 11.6. Последовательность проектирования, на основе расширенной версии
языка C/C++
Рис. 11.6 демонстрирует использование зависимого от реализации
кода при проектировании ПЛИС и заказных микросхем (ASIC), что
требуется для реализации оптимального устройства. На практике один
и тот же код может использоваться как для построения ПЛИС, так и
для создания заказной микросхемы, но, как обычно, при нецелевом
использовании кода придётся расплачиваться эффективностью пост-
роения устройства.
Проектирование на немодифицированном C/C++
И в завершении этой главы рассмотрим методы проектирования,
связанные с применением ^модифицированного языка1) C/C++. На
самом деле термин ^модифицированный, или чистый, относится к про-
мышленному стандарту языка C/C++, который минимально расширен
типами данных, подобных применяемым в SystemC. Это позволяет зада-
вать количество битов данных, отводимых для переменных и констант.
° Во время написания этой книги, возможно, самым лучшим примером ис-
пользования немодифицированного C/C++ в средствах проектирования стал
программный продукт «Precision С Synthesis» компании Mentor (www.mentor.com).
Также интересный программный комплекс SPARKC-to-VHDL synthesis разработан
в Центре встроенных компьютерных систем Университета Калифорнии
(www.cecs.uci.edu/~spark).
Проектирование на ^модифицированном C/C++ 177
Несмотря на то что методы проектирования с применением ^мо-
дифицированной версии языка C/C++ используются сравнительно
недавно, их использование, как правило, имеет ряд преимуществ по
сравнению с применением других С-подобных или традиционных
Verilog/VHDL подходов:
• Создать код на чистом C/C++ можно быстро и эффективно: при
использовании немодифицированного C/C++ для составле-
ния описания устройства полученный код не учитывает вре-
менных параметров и получается более компактным и прос-
тым для понимания, чем выполненные с помощью языков
SystemC или расширенного C/C++, хотя и они на один-два по-
рядка меньше, чем их аналоги, выполненные на уровне регист-
ровых передач.
• Верифицировать C/C++ код можно быстро и эффективно: про-
верка модели без учета временных параметров, описанной на
чистом C/C++, будет производиться намного быстрее, чем ана-
логичная процедура с моделью, реализованной с помощью
SystemC или с помощью расширенного C/C++, и в 100... 10000
раз быстрее, чем при использовании RTL-кода. В настоящее
время модели, описанные на чистом C/C++ очень широко ис-
пользуются системными разработчиками для проверки досто-
верности алгоритмов и систем.
• Оценить альтернативные варианты устройства можно быстро и
эффективно: при использовании моделей без учета временных
параметров, созданных на чистом C/C++, очень удобно прово-
дить модификацию и повторную проверку устройства, что явля-
ется необходимым условием для оценки альтернативных мик-
роархитектурных реализаций. Такое свойство облегчает
команде разработчиков поиск наилучшего микроархитектурно-
го решения. Это в свою очередь позволяет синтезировать более
быстрые и компактные устройства, чем при использовании тра-
диционных методов ручного RTL-кодирования.
• Относительно просто вносить изменения в спецификации: если в
ходе проектирования в исходную спецификацию на устройс-
тво внесены некоторые изменения, то при использовании мо-
делей без учета временных параметров, описанных с помо-
щью чистого C/C++, можно достаточно просто реализовать и
оценить влияние этих изменений на работу устройства, и за-
тем продублировать изменения при окончательной его реали-
зации.
Как уже упоминалось в этой главе, наиболее существенная пробле-
ма проектирования, основанного на языках SystemC и расширенном
C/C++, заключается в том, что информация о реализации устройства
жестко прописывается в модели. Вследствие чего модель становится
зависимой от способа реализации.
Ключевым аспектом, разработки устройств на основе чистой, т. е.
без учета временных параметров, версии языка C/C++ является то,
что код, представляемый средствам синтеза, может быть написан
людьми, заранее не представляющими себе способ аппаратной реали-
зации или архитектуру устройства. Это значит, что С/С++-код, кото-
рый системные инженеры создают сегодня, является идеальным ис-
точником для такой формы синтеза. Единственная модификация, ко-
торая обычно требуется для того чтобы модель, описанная на чистом
C/C++, стала пригодной для средств синтеза, заключается в добавле-
нии в исходный код простого специального комментария, который бу-
178 Глава 11. Проектирование на основе C/C++ и других языков
дет обозначать начало описания функциональной части устройства;
всё, что концептуально находится до этой точки, рассматривается как
часть средств тестирования.
В отличие от встраивания информации в исходный код, таким об-
разом, ограничивая его целевой реализацией, эти же данные можно
реализовать с помощью пользовательского управления алгоритмом
синтеза (Рис. 11.7).
г /г 4.x Синтез на основе
Чистый С/С« > чистогоС/с++
Взаимодействие
с пользователем
и управление
пользователем
Заказные
микросхемы
(ASIC)
VHDL/Verilog
RTL
RTL
синтез
/ Таблица
соединений
вентилей
— Не зависимы от реализации
— Легко создавать
— Быстро моделировать
— Легко модифицировать
VHDL/Verilog
RTL
Генерируются автоматически,
зависимы от реализации
RTL
синтез
Таблица
соединений
► КЛБ
(и/или таблиц
соответствия)
Рис, 11,7, Последовательность проектирования при использовании
чистого C/C++
После обработки исходного кода средством синтеза, пользователь
может использовать его для формирования оптимальных микроархи-
тектурных соотношений и оценить их размеры и скорость. Средство
синтеза анализирует код, определяет в нём различные логические
конструкции и операторы вместе со связанными с ними данными и
участками памяти, а также по возможности автоматически обеспечи-
вает параллелизм. Средства синтеза также поддерживают графический
интерфейс, который позволяет пользователю определять способы уп-
равления различными элементами. Например, интерфейс позволяет
пользователю связывать порты с регистрами или блоками памяти; оп-
ределять логические конструкции, такие как циклы, и позволяет уста-
навливать для каждого из них (при необходимости) режим полного
или частичного интерпретирования; также позволяет определять, сле-
дует ли конвейеризировать циклы и другие структурные элементы.
Кроме того, он помогает формировать распределение ресурсов по спе-
цифичным объектам и многое другое.
Средство синтеза на лету формирует оценки производимых дейс-
твий и сообщает о размерах/площади и латентности в терминах такто-
вых импульсов и задержек ввода/вывода, или в пропускной способ-
ности канала, т. е. время/количество тактов для конвейеризованных
устройств. Пользовательская конфигурация для каждого возможного
сценария может быть именована, сохранена и при необходимости пов-
торно использована. Иначе, было бы почти невозможно своевременно
найти оптимальные соотношения, используя традиционные методы
ручного RTL-кодирования.
Тот факт, что чистый, т. е. без учета временных параметров, исход-
ный код C/C++, используемый средствами синтеза, не содержит ка-
кой-либо информации о реализации устройства и что вся эта инфор-
мация обеспечивается за счёт управления средством синтеза, позволя-
Уровни абстракций синтеза 179
ет легко перенастраивать исходный код на разные микроархитектуры
и разные технологии реализации.
Как только пользовательские оценки будут сформированы, при
нажатии кнопки Go («Начать») средство синтеза сгенерирует соответс-
твующий RTL VHDL код. Этот код может быть использован средства-
ми традиционного логического синтеза или приложениями физичес-
кого синтеза для генерирования таблицы соединений, используемой
средствами реализации (размещения и разводки).
Можно также синтезировать таблицу соединений вентилей непос-
редственно из исходного С/С++-кода (этот метод не показан на
Рис. 11.7). Однако промежуточный RTL-код предоставляет разработ-
чикам определенную зону комфорта, так как на этом этапе можно
провести проверки и убедиться в правильности результатов, достигну-
тых в ходе трансляции из C/C++ в RTL.
Создание промежуточного RTL весьма полезно и с той точки зре-
ния, что на этом уровне абстракции разработчики аппаратуры произ-
водят соединение различных функциональных блоков, из которых со-
стоит устройство. Большая часть модулей современных устройств
обычно представлена в виде отдельных блоков интеллектуальной
собственности, выполненных на уровне регистровых передач. Это зна-
чит, что промежуточный RTL-код весьма полезен при разработке, так
как позволяет производить интеграцию и проверку всей аппаратной
части системы Рис. 11.7. Разработчики также могут воспользоваться
всеми преимуществами существующих средств RTL-синтеза, которые
очень хорошо продуманны, устойчивы к ошибкам и понятны пользо-
вателю.
Уровни абстракций синтеза
Фундаментальное отличие различных подходов проектирования,
основанных на языке C/C++ и рассматриваемых в этой главе, опреде-
ляется уровнями абстракций, которые они поддерживают. Так, хотя
SystemC предусматривает возможность моделирования на системном,
алгоритмическом и транзакционном уровнях, его средства синтеза ра-
ботают на относительно низком уровне абстракции. Аналогично, хотя
описания на расширенном C/C++ более близки к чистому C/C++,
чем SystemC, и их моделирование выполняется быстрее, их «синте-
зопригодность» далека от идеала.
Этот недостаток абстрактности синтеза становится причиной того,
что описания устройств, проектируемых на SystemC и расширенном
C/C++, т. е. описания с учетом временных параметров, зависят от спо-
соба реализации. Это, в свою очередь; усложняет разработку и моди-
фикацию устройств, а также значительно снижает их гибкость в оцен-
ке возможных вариантов реализации и перенастройки их на другие
технологии (Рис. 11.8).
В отличие от них последнее поколение средств синтеза на основе
чистого C/C++ поддерживает высокий уровень абстракции. Не зави-
сящие от конкретной реализации модели C/C++ являются очень ком-
пактными, быстро и легко создаются и модифицируются. Используя
само по себе средство синтеза, пользователь может легко и быстро
формировать оценки возможных вариантов и перестраивать схему уст-
ройства на другие технологии реализации. В итоге проектирование на
основе чистого C/C++ может значительно повысить скорость реали-
зации и увеличить гибкость процесса проектирования по сравнению с
проектированием на основе других версий языка C/C++.
1904 г. Разработа-
на первая ультра-
фиолетовая лампа.
1904 г. Разработан
телефонный авто-
ответчик.
180 Глава 11. Проектирование на основе C/C++ и других языков
Область применения
языка С без учета
временных параметров
(Untimed С)
(Не зависит от конкретной
реализации)
Область применения
языка С с учетом
временных параметров
(Timed С)
(Зависит от конкретной
реализации)
Уровень регистровых
передач (RTL)
(Зависит от конкретной
реализации)
Больше абстракции,
меньше зависимость
от реалиции
Меньше абстракции,
больше зависимость
от реализации
Рис. 11.8. Уровни абстракции синтеза языка C/C++
Системы мультиязычного проектирование
и тестирования
Подводя итог, необходимо заметить, что ряд поставщиков САПР
электронных систем выпускают системы многоязычного проектиро-
вания и тестирования, которые могут выполнять совместное модели-
рование устройств, описанных на разных уровнях абстракции.
В ряде случаев этот процесс может представлять собой вызов
средствами моделирования Verilog связанных C/C++ моделей через
его интерфейс языка программирования (PLI — Programming Language
Interface) либо вызов из средств моделирования VHDL таких же функ-
ций через интерфейс незнакомых слов (FLI— Foreign Language Interface).
Аналогично, вы можете найти окружение для языка SystemC с воз-
можностью работать с блоками, представленными в виде кода Verilog
или VHDL.
Существуют очень сложные программные продукты, которые в
графическом блочном редакторе отображают главные функциональ-
ные узлы устройства, при этом каждый узел может быть представлен с
помощью языков:
• VHDL;
• Verilog;
• SystemVerilog;
• SystemC;
• Handel-C;
• Чистый C/C++.
Верхний уровень схемы может быть представлен традиционным
кодом HDL, который вызывает другие модули, описанные на различ-
ных версиях HDL или на версия C/C++ (одной или нескольких). Вер-
хний уровень схемы может быть также представлен одной из разно-
видностей языка C/C++, из которой происходит вызов субмодулей,
написанных на других языках.
При таком подходе работа с описаниями модулей, написанных на
языках VHDL, Verilog и SystemVerilog, обычно выполняется с помощью
Системы мулътиязычного проектирование и тестирования 181
одноядерного алгоритма моделирования. Затем этот алгоритм вместе с
другим соответствующим алгоритмом одной из разновидностей языка
C/C++ производит моделирование всего устройства. Кроме того, та-
кие системы проектирования содержат встроенные отладчики исход-
ного кода, который поддерживает различные версии языка C/C++;
позволяют создавать тестирующие стенды, используя любой язык;
поддерживают средства, такие как графический экран формы сигнала,
или осциллограф, который способен отображать сигналы и перемен-
ные, связанные с любым из блоков вне зависимости от используемого
языка0.
В действительности, состав различных мультиязычных систем про-
ектирования и тестирования меняется почти каждую неделю, поэтому
перед выбором той или иной системы (среды) проектирования вам не-
обходимо провести определённый анализ.
Всем противникам языка SystemC по секрету признаюсь, что этот
язык рассматривается только применительно к проектированию
ПЛИС. В этой сфере набор средств SystemC, используемых для полу-
чения действительной реализации устройств, пока не отличается силь-
ной проработкой и сложностью. Однако приложения проверки и мо-
делирования на системном уровне языка SystemC отличаются высокой
эффективностью. Многие эксперты используют связку SystemC-
SystemVerilog, при которой на системном уровне работают с SystemC, а
затем с помощью SystemVerilog «конкретизируют» содержимое уровня
реализации.
При разработке представления схемы с помощью одной из рассмот-
ренных здесь версий языка C/C++ довольно часто на этом же языке
создаются и наборы тестов. Эти тесты, как правило, используют
языковые конструкции, которые не понятны многим низкоуровне-
вым средствам, таким как преобразователь кода из C/C++ в RTL. В
этом случае, как и раньше, придётся вручную переносить тестовые
воздействия из C/C++ в VHDL/Verilog, с тем чтобы запустить их на
системе моделирования RTL. Одним из преимуществ смешанных
систем проектирования и тестирования заключается в том, что мож-
но использовать тестовые воздействия языка C/C++ при работе
средств моделирования на уровнях абстракции RTL и вентилей. Не
исключено, что кое-что придётся подкорректировать, но это всё же
намного легче, чем начинать всё с нуля.
Для программиста,
который по тем или
иным причинам пе-
рестает заниматься
своим делом, т. е.
разработкой про-
граммного обеспече-
ния, и начинает за-
ниматься разработ-
кой программных
модулей или аппа-
ратно-программным
проектированием и
тестированием, язык
SystemC является
своеобразной палоч-
кой-выручалочкой.
° Хорошим примером мультиязычных средств моделирования и контроля для
ПЛИС и в меньшей степени для специализированных микросхем — могут слу-
жить продукты компании Aldec Inc. (www.aldec.com). Другим хорошим представи-
телем средств этого класса может выступать пакет ModelSim® компании Mentor,
который включает собственный модуль поддержки языка SystemC, таким обра-
зом, позволяя одноядерной системе моделирования работать с модулями VHDL,
Verilog и SystemC.
ГЛАВА 1 2
ПРОЕКТИРОВАНИЕ СРЕДСТВ
ЦИФРОВОЙ ОБРАБОТКИ СИГНАЛОВ
Введение в ЦОС
Понятие цифровая обработка сигналов, или ЦОС, относится к об-
ласти электроники, предметом которой является представление и об-
работка сигналов в цифровой форме. Такая обработка включает в себя
сжатие, распаковку, модуляцию, коррекцию ошибок, фильтрацию и
другие действия с аудио- (голос, музыка и так далее) и видеосигнала-
ми, изображениями и другими данными для связи, локации и обработ-
ки изображений, включая рентгеновские изображения.
Во многих случаях до начала обработки сигналы находятся в реаль-
ной, или аналоговой, форме. Аналоговый сигнал периодически диск-
ретизируется и каждый отсчёт преобразуется в цифровую форму путем
аналогово-цифрового преобразователя (АЦП), Рис. 12.1.
Цифровая часть
Аналоговая часть
Аналоговая часть
выходные
отсчёты
входные
отсчёты
выходной
сигнал
входной
сигнал
Рис. 12.1. Что такое цифровая обработка сигналов
Затем эти отсчёты обрабатываются в цифровой части системы. Во
многих случаях обработанные цифровые данные вновь преобразуются в
аналоговую форму с помощью цифро-аналогового преобразователя (ЦАП).
Цифровая обработка сигналов применяется во всех сотовых теле-
фонах и телефонных системах, в CD, DVD и МРЗ-плеерах, настольных
кабельных системах, в средствах беспроводной связи, медицинском
оборудовании, электронных системах видеонаблюдения... Этот спи-
сок можно продолжить. Другими словами, рынок применения ЦОС
просто огромен, и по некоторым оценкам его оборот в 2003 году пре-
высил 10 миллиардов долларов США!
Альтернативы реализации ЦОС
Выбрать любое устройство, но мне его не показывать
И опять не всё так просто, как мечтается, поскольку задачи цифро-
вой обработки могут быть решены разными способами и с помощью
различных средств:
• Микропроцессоры общего назначения (МП) — центральные про-
цессоры (ЦП) или микропроцессорные устройства (МПУ), ко-
Альтернативы реализации ЦОС 183
торые могут производить цифровую обработку сигнала с помо-
щью соответствующего алгоритма ЦОС.
• Цифровой сигнальный процессор, ЦСП (DSP — Digital Signal
processor) — микропроцессорный кристалл, или ядро, специаль-
но разработанный для более быстрого и эффективного выпол-
нения задач цифровой обработки сигналов, чем при использо-
вании микропроцессоров общего назначения.
• Специализированные системы на основе заказных микросхем — в
рамках этого раздела будем полагать, что это название относит-
ся к изготовленному по заказу устройству на заказных микро-
схемах, которое выполняет задачи цифровой обработки сигна-
лов. Однако необходимо иметь в виду, что задачи цифровой
обработки могут быть реализованы программно путем включе-
ния в состав заказной микросхемы микропроцессорного ядра
или ядра ЦСП.
• Специализированные системы на основе ПЛИС — в рамках этого
раздела будем полагать, что это название относится к изготов-
ленному по заказу устройству на основе ПЛИС, которое выпол-
няет задачи цифровой обработки сигналов. Здесь также необхо-
димо иметь в виду, что задачи цифровой обработки могут быть
реализованы программно посредством встраивания микропро-
цессорного ядра в ПЛИС. Во время написания этой книги сре-
ди ПЛИС не существовало заказных аппаратных ядер цифровой
обработки сигналов.
Оценки системного уровня и алгоритмическая верификация
Независимо от технологии реализации, т. е. использования микро-
процессора, ЦСП (DSP), заказной микросхемы или ПЛИС, при созда-
нии системы с реализацией алгоритмов цифровой обработки в общем
случае на первом этапе проектирования с помощью соответствующих
программных средств выполняется оценка устройства на системном
уровне и его алгоритмическая проверка или верификация.
В этой книге я пытался по мере сил и возможностей не акцентиро-
вать внимания на определённых компаниях или продуктах, но было
бы весьма некорректно не упомянуть, что во время ее написания де-
факто промышленным стандартом алгоритмической проверки систем
ЦОС являлся программный комплекс MATLAB®0 компании The
MathWorks (www.mathworks.com)* 2).
Поэтому в рамках данной главы я при необходимости буду ссылать-
ся на MATLAB. При этом замечу, что инженеры располагают некоторы-
ми другими очень мощными средствами. К числу таких средств отно-
сятся, например, Simulink от компании The MathWorks, которое очень
популярно, особенно в области телекоммуникации, программа Signal
Processing Worksystem (SPW) компании CoWare3) (www.coware.com), a
также программные продукты компании Elanix (www.elanix.com).
° MATLAB и Simulink являются зарегистрированными торговыми марками
компании The MathWorks Inc.
2) Следует заметить, что MATLAB и Simulink могут быть использованы для
широкого круга задач, включая разработку и анализ систем управления, финансо-
вое моделирование и так далее.
3) Область САПР электронных систем довольно быстро меняется. Например,
программа SPW в то время, когда я начинал писать эту главу, находилась под пок-
ровительством компании Cadence, а когда я написал пол главы, она перешла к
компании Coware!
184 Глава 12. Проектирование средств цифровой обработки сигналов
1906 г. Америка.
Начала вещание
радиопрограмма,
передающая голос
и музыку.
Работа программного обеспечения на ядре ЦСП
Допустим, что алгоритм цифровой обработки сигналов должен
быть реализован с помощью микропроцессора или цифрового сиг-
нального процессора (ЦСП). В этом случае методика реализации мо-
жет выглядеть так, как показано на Рис. 12.2.
Рис. 12.2. Простой метод проектирования программного ЦСП
Процесс начинается с того, что у кого-то возникает идея нового
алгоритма или совокупности алгоритмов. Эта новая концепция обыч-
но подвергается проверке с помощью специальных средств, таких как
MATLAB. В некоторых случаях можно перейти непосредственно от
концепции к ручной разработке кода на языке C/C++ или на языке
Ассемблера.
После проверки алгоритмы должны быть переведены в код языка
C/C++ или языка Ассемблера. MATLAB может автоматически генери-
ровать код C/C++ специально для ядер цифровой обработки сигна-
лов. Однако в некоторых случаях разработчики предпочитают выпол-
нять эту операцию пошагово и вручную, поскольку полагают, что мо-
гут достичь более оптимального представления. Существуют и другие
методы создания кода. Например, можно сначала автоматически сге-
нерировать С/С ++ код из окружения алгоритмической проверки,
проанализировать и спрофилировать его для определения узких мест в
производительности устройства и затем вручную перекодировать на-
иболее критичные узлы. Это хороший пример старого правила 80:20,
которое гласит, что 80% рабочего времени тратится на наиболее кри-
тичные 20% устройства.
После создания представления устройства в виде кода на языке
C/C++ или языке Ассемблера этот код должен быть скомпилирован,
или транслирован, в машинный код, который будет выполняться мик-
ропроцессором и ядром ЦСП.
Этот подход является очень гибким, так как позволяет относитель-
но просто и быстро производить необходимые изменения в устройстве
путем простой модификации и перекомпилирования исходного кода.
Однако подобный подход приводит к медленной работе алгоритма
ЦОС, так как микропроцессор и кристалл ЦСП попадают под опреде-
ление машины Тьюринга (Turing machines). Это значит, что их первич-
ная роль заключается в выполнении инструкций, поэтому оба этих ус-
тройства работают по следующей схеме:
I • Выборка команды.
• Декодирование команды.
• Выборка блока данных.
• Выполнение операции с данными.
• Сохранение результатов.
• Выборка другой инструкции и повтор всех операций.
Альтернативы реализации ЦОС 185
Конечно, алгоритм цифровой обработки действительно реализует-
ся на аппаратном обеспечении, выполненном в виде микропроцессора
или ЦСП. Но здесь он рассматривается в качестве программной реа-
лизации, поскольку действительное, или физическое, воплощение ал-
горитма представляет собой программу, которая выполняется на крис-
талле.
Специализированное аппаратное обеспечение ЦОС
Существует множество способов реализации алгоритмов цифро-
вой обработки на основе заказной микросхемы и ПЛИС. Данная глава
посвящена самым последним достижениям в этой области. Но перед
тем как окунуться в эту сложную тему, давайте сначала рассмотрим,
как различные архитектуры могут влиять на скорость и размеры, с точ-
ки зрения места на кристалле, разрабатываемого устройства.
Алгоритмы цифровой обработки обычно требуют выполнения ог-
ромного количества операций умножения и сложения. В качестве
очень простого примера возьмем алгоритм цифровой обработки, кото-
рый содержит выражение вида Y = (А * В) + (С * D) + (Е * F) + (G * Н).
По традиции этот синтаксис не соответствует ни одному конкрет-
ному HDL-языку и используется только в наших рассуждениях. Естес-
твенно, это мизерный элемент чрезвычайно сложного алгоритма. Но,
в конце-то концов, алгоритмы цифровой обработки обычно содержат
огромное количество выражений подобного типа.
В 1937 г. Еще буду-
чи студентом, экс-
центричный анг-
лийский гений Алан
Тюринг написал ра-
боту «Теория логи-
ческих вычисляю-
щих машин». Не
имея доступа к ре-
альным компьюте-
рам, поскольку они
в то время просто
не существовали,
он разработал
собственный метод
«вычислений на бу-
маге». Позже эту
теоретическую
модель назвали ма-
шиной Тюринга.
q^=> Для читателей нетехнического круга следует заметить, что перемен-
ные А, В, С и D в вышеприведённом выражении используются для
представления шины (группы) двоичных сигналов. При умножении
двух двоичных чисел одинаковой ширины, ширина результата будет
в два раза шире, чем у аргументов (так если А и В занимают по 16
бит, то результат получится шириной 32 бита).
Суть заключается в том, что мы можем использовать параллелизм,
свойственный аппаратным решениям, для более быстрого выполне-
ния функций ЦОС, чем можно было бы достичь с помощью програм-
много подхода. Допустим, например, что все операции умножения бы-
ли выполнены параллельно, одновременно, а затем последовали две
стадии сложения (Рис. 12.3).
Несмотря на то что сумматоры и особенно умножители являются
относительно большими и сложными модулями, всё же можно пред-
положить, что эта реализация будет очень быстрой, но в то же время
будет потреблять большое количество ресурсов.
Вместе с тем, можно использовать распределение ресурсов (распре-
деляя некоторые умножители и сумматоры между операциями умно-
жения) и выбрать решение, которое будет являться смесью параллель-
ного и последовательного соединения (Рис. 12.4).
Это решение потребует дополнительно четырёх мультиплексоров
вида 2:1 и одного регистра, причем каждый из них должен иметь ту же
разрядность, что и используемые сигналы. Однако мультиплексоры и
регистр занимают намного меньше места на кристалле, чем два умно-
жителя и сумматор, которые, между прочим, уже не требуются в теку-
щей реализации.
Этот метод медленнее предыдущего, поскольку сначала надо: про-
извести умножения (А * В) и (С * D), сложить результаты вместе, сло-
жить получившуюся сумму с текущим содержимым регистра, который
в начале будет содержать значение 0, и записать результат в регистр.
186 Глава 12. Проектирование средств цифровой обработки сигналов
Рис. 12.3. Параллельная реализация функции
2:1
Затем выполнить умножения (Е * F) и (G * Н), просуммировать ре-
зультаты вместе, сложить полученную сумму с текущим содержимым
регистра, который теперь содержит результаты первой части умноже-
ний и сложений, и сохранить результат в регистр.
Альтернативы реализации ЦОС 187
А можно поступить иначе, т. е. последовательное решение
(Рис. 12.5).
1906 г. Разработа-
на первая лампа
накаливания
с вольфрамовой
нитью.
Последняя реализация очень эффективна с точки зрения занимае-
мого на кристалле места, так как для этого потребуется только один
умножитель и один сумматор. Однако это довольно медленная реали-
зация, поскольку сначала надо выполнить умножение (А * В), сложить
результаты с текущим значением регистра, который в начальный мо-
мент времени будет содержать значение 0, и записать результат в ре-
гистр. Затем надо выполнить умножение (С * D), сложить результат с
содержимым регистра и записать новую сумму в регистр. И так далее
со всеми оставшимися операциями умножения. Замечу, что когда мы
говорим «это медленная реализация», мы говорим это по сравнению с
другими аппаратными решениями, но самое медленное аппаратное
решение может оказаться намного быстрее программной реализации
на микропроцессоров или ЦСП.
Другие встраиваемые в ПЛИС ресурсы ЦОС
Как уже обсуждалось в гл. 4, некоторые функции, например, умно-
жители, по своей сути являются довольно медленными, если они реа-
лизованы с помощью большого количества соединённых вместе про-
граммируемых логических блоков. Поскольку эти функции востребо-
ваны большим количеством приложений, многие устройства ПЛИС
содержат встроенные аппаратные умножители. Эти блоки обычно рас-
полагаются в непосредственной близости к встроенным блоками ОЗУ,
так как эти функции очень часто используются вместе.
Некоторые ПЛИС содержат специализированные блоки суммато-
ров. В приложениях цифровой обработки сигналов довольно часто ис-
пользуется операция, называемая умножение с накоплением. Как следу-
ет из названия, эта операция сводится к умножению двух чисел и сло-
жению результата с текущим значением аккумулятора, или регистра.
Для обозначения этой операции используется аббревиатура МАС
(multiply-and-accumulate), которая подразумевает умножение, сложе-
ние и накопление (Рис. 12.6).
188 Глава 12. Проектирование средств цифровой обработки сигналов
1907 г. Америка. Ли
де Форест (Lee de
Forest) разработал
усилитель на лам-
пе с тремя элект-
родами (триод).
МАС
Рис. 12.6. Формирование функции МАС
Последовательно расположенные умножитель, сумматор и ре-
гистр, как показано на Рис. 12.5, представляют собой классический
пример функции умножения с накоплением. Если ПЛИС содержит
| только встроенные умножители, эту функцию необходимо реализовы-
вать с помощью комбинации умножителя с сумматором, сформиро-
ванным из нескольких логических блоков, при этом результат будет
сохраняться в блоке ОЗУ или в нескольких ячейках распределённого
ОЗУ. Реализовать такую функцию будет намного проще, если ПЛИС
содержит встроенные сумматоры, а некоторые из этих устройств пре-
доставляют полностью готовые встроенные функции умножения с на-
коплением.
Разработка ПЛИС для ЦОС
Меня просто бросало в дрожь, когда я писал эти слова. Это могло
быть от предвкушения, а может быть от предчувствия. Дело в том, что
в то время, когда писалась эта книга, идея использовать ПЛИС для
цифровой обработки сигналов была сравнительно новой. Это означа-
ло отсутствие устоявшихся технологий проектирования устройств на
основе ПЛИС. Такая ситуация способствовала тому, что каждый стре-
мился разработать собственный подход, и поэтому, какой бы подход не
выбрал пользователь, он мог тут же обнаружить еще один.
Специализированные языки
Размеры и сложность электронных систем увеличиваются с каж-
дым днём. Чтобы отслеживать эту проблему и поддерживать или, в
большинстве случаев, увеличивать производительность, необходимо
сохранить тенденцию повышения уровня абстракции для описания
функциональности устройства и его проверки.
По этой причине схемотехнические методы проектирования, опи-
санные в гл. 8, были вытеснены RTL-описаниями, выполненными на
языках VHDL или Verilog (гл. 9). Аналогично методы проектирования
Альтернативы реализации ЦОС 189
на основе языка С, которые рассматривались в гл. 11, больше подходят *
для быстрого и простого описания устройств, а также упрощают архи-
тектурный анализ и исследование возможных вариантов устройств.
Специалисты из области цифровой обработки сигналов, систем-
ные инженеры и инженеры-разработчики могут значительно повы-
сить производительность своей работы с помощью специализированных
языков, которые обеспечивают более быстрые способы представления
специфических задач, чем языки общего назначения, такие как
C/C++ или SystemC.
Примером такого языка может служить MATLAB, который позво-
ляет инженерам цифровой обработки сигналов описывать функции
преобразования сигнала, такие как быстрое преобразование Фурье
(БПФ), которые потенциально могут занимать всю микросхему
ПЛИС с помощью одной строки кода0 вида
у = ffx( х );
Название MATLAB относится как к языку, так и к средствам моде-
лирования алгоритмического уровня. Чтобы избежать путаницы, в об-
щем случае различают М-код, что значит MATLAB-код и М-файл* 2\
т. е. файл, содержащий код MATLAB. Некоторые разработчики иногда
употребляют сокращенно — М-язык, но этот термин не поддержива-
ется сотрудниками компании The MathWorks.
Кроме сложных операторов преобразования, таких как БПФ, так-
же существуют менее сложные, например сумматоры, блоки вычита-
ния, умножители, логические операторы, матричные вычисления и
другие. При необходимости из этих простых операторов могут форми-
роваться более сложные операторы преобразования сигналов, напри-
мер БПФ. Результат работы каждой функции преобразования сигнала
может быть использован как аргумент, т. е. входное значение, для од-
ной или нескольких последующих функций преобразования и так да-
лее до тех пор, пока вся система не будет представлена на высшем
уровне абстракции.
Важное значение имеет тот факт, что такие представления на
системном уровне изначально не предполагают способа реализации
устройства. Так, например, при использовании ядра цифрового сиг-
нального процессора (ЦСП) это может значить, что вся функция ре-
ализуется программно. Разработчики системы могут разделить уст-
ройство и таким образом, что одни функции будут реализоваться
программно, а другие, критичные по производительности, аппарат-
но, используя заказные микросхемы или ПЛИС структуры. В этом
случае инженерам необходим доступ к системам проектирования
как аппаратуры, так и программного обеспечения (см. гл. 13). Но в
рамках этой главы мы будем рассматривать только аппаратные реа-
лизации.
Входные воздейс-
твия для системы
моделирования
MATLAB могут
поступать из одной
или нескольких ма-
тематических функ-
ций, таких как гене-
ратор синусоиды,
или формироваться
из реальных дан-
ных в виде аудио-
ил и видеофайла.
В этом примере точка с запятой не является обязательной. Она используется
при необходимости подавить вывод на дисплей.
2) М-файлы могут содержать сценарии либо преобразования, либо и то и дру-
гое. Кроме того, одни М-файлы могут иерархически включать другие М-файлы.
Первичный (наивысшего уровня) М-файл обычно содержит сценарий, который
определяет процесс моделирования. Этот сценарий может дать пользователю
только общую информацию об используемых коэффициентах фильтрации, име-
нах файлов с входными воздействиями и так далее, а затем вызывать другие М-
файлы для определения других необходимых параметров.
190 Глава 12, Проектирование средств цифровой обработки сигналов
Разработанный
в 1962 году язык
Фортран (Fortran),
что в переводе озна-
чает транслятор
формул, был одним
из первых высокоу-
ровневых языков
программирования.
Системы проектирования и моделирования
на системном уровне
Средства проектирования и моделирования системного уровня
концептуально находятся на более высоком уровне, чем специализи-
рованные языки. Прекрасным примером среды проектирования и мо-
делирования такого рода может служить пакет Simulink компании The
MathWorks. Порой может казаться, что Simulink является просто гра-
фическим пользовательским интерфейсом к пакету MATLAB. На са-
мом деле Simulink является независимым приложением динамическо-
го моделирования, которое работает с программой MATLAB.
При использовании Simulink процесс разработки начинается
обычно с создания графической структурной схемы системы, на ко-
торой схематически изображаются функциональные блоки и соеди-
нения между ними. При этом каждый блок может быть определён
пользователем или может находиться в одной из библиотек, постав-
ляемых вместе с Simulink. Эти библиотеки включают наборы для
цифровой обработки сигналов, телекоммуникации, управления. При
работе с определяемыми пользователем блоками, можно щёлкнуть
мышью на этом блоке и отобразить его содержимое в виде новой
структурной схемы. Можно создавать блоки, содержащие функции
MATLAB, М-код, C/C++, FORTRAN... Этот список может быть
продолжен.
После описания принципа действия устройства для моделирова-
ния и проверки функциональности можно использовать средства
Simulink. Так же как и при использовании пакета MATLAB, задающее
воздействие для модели в Simulink может генерироваться одной или
несколькими математическими функциями, например генераторами
синусоиды, или могут использоваться реальные данные в виде аудио
или видеофайлов. Во многих случаях используются оба вида воздейс-
твий, например реальные данные могут дополняться псевдослучайны-
ми шумами, генерируемыми стандартным блоком из библиотеки
Simulink.
Необходимо иметь в виду, что на этом этапе не существует правила
«все сразу и побыстрее». Одни инженеры предпочитают использовать
MATLAB в качестве средства начальной разработки, другие выбирают
Simulink, что бывает крайне редко. Кое-кто считает, что это предпоч-
тение зависит от опыта пользователя, т. е. занимался ли он разработ-
кой программных средств ЦОС или разработкой заказных микросхем
и ПЛИС. Однако есть и такие, которые считают, что все это чушь. На
самом деле опыт в данном случае не причем. Но даже если и причем,
причины, по которым пользователи делают свой выбор, просто ничто
по сравнению с тем, что их ожидает.
Модели с фиксированной и плавающей точкой
Независимо от того, какое из средств будет выбрано, Simulink или
MATLAB, или подобный продукт другого производителя, на началь-
ной стадии проектирования, первая версия модели системы почти
всегда использует числа с плавающей точкой. В десятичной системе
счисления это соответствует числам вида 1.235х103 (другими словами
дробное число, умноженное на 10 в некоторой степени). В таких при-
ложениях, как MATLAB, эквивалентное для этой дроби двоичное зна-
чение представляется внутри компьютера в виде стандарта IEEE для
чисел с плавающей точкой двойной точности.
Альтернативы реализации ЦОС 191
Этот тип чисел с плавающей точкой обладает определенными пре-
имуществами, так как обеспечивает высокую точность в огромном ди-
намическом диапазоне. Однако реализация вычислений с плавающей
точкой этого типа данных в специализированных устройствах на базе
ПЛИС или заказных микросхем требует огромного количества ресур-
сов и по меркам аппаратного обеспечения является чрезвычайно мед-
ленной. Поэтому на некоторой стадии проектирования устройство
должно быть переведено на использование чисел с фиксированной точ-
кой, т. е. числа с фиксированным количеством битов для представле-
ния целой и дробной частей. Этот процесс обычно называется кванто-
ванием.
Процесс квантования целиком и полностью зависит от типа систе-
мы и алгоритма, и может потребоваться немалое количество экспери-
ментов для определения оптимального баланса между использованием
наименьшего количества битов для представления чисел тем самым,
уменьшая количество требуемых ресурсов и увеличивая скорость вы-
числения, и сохранением точности вычислений. Это может натолк-
нуть на мысль о компромиссной величине погрешности, которую раз-
работчик допускает для данного количества битов. В некоторых случа-
ях конструкторы могут провести несколько дней, решая: «Следует ли
использовать 14, 15 или 16 бит для представления этих данных?». И
специально для поднятия настроения можно попробовать использо-
вать различное количество битов для представления данных на разных
участках алгоритма или системы.
Ещё больше «удовольствия» можно получить при переходе от чи-
сел с плавающей точкой к данным с фиксированной точкой на более
высоком системном или алгоритмическом уровне проектирования,
или на более низком уровне кода C/C++.
При работе в окружении MATLAB эти преобразования могут быть
выполнены путем прогона сигналов с плавающей точкой через специ-
альные преобразовательные функции, называемые дискретизаторами.
Аналогично при работе в окружении Simulink преобразования могут
быть выполнены путем прогона сигналов с плавающей точкой через
специальные блоки с фиксированной точкой.
Перевод из системного/алгоритмического уровня к RTL.
Ручной способ
Во времена, когда писалась эта книга, многие инженеры, занятые в
сфере проектирования устройств цифровой обработки сигналов, на-
чинали работу в среде MATLAB или аналогичной с проверки алгорит-
мов и оценки на системном уровне параметров устройства, используя
числа с плавающей точкой. Часто описание устройства включало и
промежуточные этапы, на которых создавались модели на языке
C/C++ с фиксированной точкой для использования в средствах быст-
рого моделирования или проверки. На этом этапе многие конструкто-
ры переходили напрямую к созданию вручную кода RTL с фиксиро-
ванной точкой, используя при этом языки VHDL или \ferilog
(Рис. 12.7, а). Однако разработчики могли сначала перейти от плаваю-
щей точки к числам с фиксированной точкой на системном (алгорит-
мическом) уровне и лишь только после этого переходить к написанию
кода на VHDL или \ferilog (Рис. 12.7, б).
Конечно, при такой последовательности возникает ряд проблем,
так как налицо существенное концептуальное и представительское
различие между работой инженеров-системщиков на системном (ал-
1907 г. Ли де Фо-
рест (Lee de Forest)
начал постоянное
вещание музыкаль-
ной радиостанции.
192 Глава 12. Проектирование средств цифровой обработки сигналов
1908 г. Чарльз
Фредрик Кросс
(Charles Fredrick
Cross) изобрёл
целофан.
1909 г. Дженерал
Электрик пред-
ставила миру пер-
вый тостер.
К стандартному RTL
моделированию и синтезу
Рис. 12.7. Ручное создание RTL-кода
горитмическом) уровне и работой инженеров-проектировщиков на
уровне регистровых передач в среде VHDL или Verilog.
Поскольку системный (алгоритмический) уровень и уровень регис-
тровых передач (RTL) существенно отличаются, ручной перенос кода
из одной области в другую занимает массу времени и имеет такие неже-
лательные последствия, как наличие ошибок. Итоговое RTL-представ-
ление устройства зависит также от конкретной реализации, поскольку
создание оптимального устройства на ПЛИС требует иного стиля про-
граммирования, чем при использовании заказной микросхемы.
Что же касается модификации вручную и перепроверки RTL-кода
для формирования ряда оценок возможных вариантов микроархитек-
турных реализаций, то они требует чрезвычайно много времени. Кста-
ти, такие оценки могут включать формирование определённых опера-
ций в параллельном и последовательном режимах: с применением и
без применения канала передачи данных, с распределёнными ресурса-
ми, например две операции используют один умножитель, и со специ-
ализированными средствами и т. д.
Аналогично, если в ходе проектирования в начальный замысел бы-
ли внесены некоторые изменения, их можно довольно просто реали-
зовать и оценить на системном (алгоритмическом) уровне представле-
ния, но последующая ручная свёртка этих изменений в RTL-код мо-
жет оказаться трудоёмкой и потребовать много времени.
После создания RTL-представления устройства можно воспользо-
ваться низкоуровневыми средствами логического синтеза, которые
были рассмотрены в гл. 9.
Перевод из системного/алгоритмического уровня к RTL.
Автоматический способ
Как отмечалось в прошлом подразделе, ручная трансляция из сис-
темного (алгоритмического) уровня в RTL код требует много времени
и способствует возникновению ошибок. Существуют альтернативные
методы, в частности некоторые средства проектирования системного
Альтернативы реализации ЦОС 193
(алгоритмического) уровня позволяют производить непосредственную
трансляцию в код VHDL или Verilog (Рис. 12.8).
Как обычно, проектирование на системном (алгоритмическом)
уровне начинается с описания устройства с применением чисел с пла-
вающей точкой. Согласно одному из подходов к проектированию,
система (среда) проектирования используется также для перевода этих
представлений в их эквиваленты с фиксированной точкой, а затем вы-
полняется автоматическая генерация эквивалентного RTL кода на
языке VHDL или Verilog0 (Рис. 12.8, а).
1909 г. Лео Баке-
ланд (Leo Baekeland)
запатентовал ис-
кусственный плас-
тик и назвал его
Бакелит.
К стандартному моделированию
и синтезу RTL
Рис, 12,8, Прямой переход к RTL
В процессе проектирования можно также использовать среду раз-
работки сторонних поставщиков для представления устройства на сис-
темном уровне с использованием чисел с плавающей точкой, автома-
тического перевода их в числа с фиксированной точкой и автомати-
ческого создания эквивалентного RTL кода на языке VHDL или
Verilog (Рис. 12.8, б)* 2).
Как и раньше, после создания RTL-представления устройства
можно воспользоваться низкоуровневыми средствами логического
синтеза, которые были рассмотрены в гл. 9.
° Хороший пример такой среды конструирования предлагает компания
Elanix Inc. (www.elanix.com).
2) Хороший пример такой среды проектирования предлагает компания
AccellChip Inc. (www.accelchop.com). Программный пакет этой компании прини-
мает М-файлы с плавающей точкой среды MATLAB, формирует их эквиваленты с
фиксированной точкой для верификации, и затем использует эти файлы для авто-
матического создания RTL-кода.
194 и Глава 12. Проектирование средств цифровой обработки сигналов
Перевод из системного/алгоритмического уровня
в код C/C++ и другие
В последнее время наметилась тенденция использовать для реше-
ния проблем, связанных с анализом устройства на уровне регистровых
передач (RTL), так называемый метод ступенек. Этот метод подразу-
мевает преобразование из системного (алгоритмического) представле-
ния устройства в некоторое представление кода C/C++, которое затем
переводится в код RTL. Одна из причин такого двойного перехода за-
ключается в том, что большинство разработчиков, проектирующих
системы цифровой обработки сигналов, используют представления на
языке C/C++ в качестве золотой, т. е. эталонной, модели, причём та-
кие модели являются бесплатными, в чём весьма заинтересованы раз-
работчики, работающие с RTL.
Разумеется, сначала необходимо принять решение, где и когда в
процессе проектирования перейти от моделей с плавающей точкой к
описаниям с фиксированной точкой (Рис. 12.9).
Напрямую к средствам синтеза чистого C/C++
или ручное преобразование в код Handel-C
и последующий Handel-C синтез, или ручное преобразование
в код SystemC и последующий SystemC синтез, или...
Рис. 12.9. Переход от представления с плавающей точкой к представлению
с фиксированной точкой
Такой переход выглядит устрашающе и это притом, что на Рис. 12.9
представлена только часть возможных вариантов. Например, при ко-
дировании вручную вместо первого этапа разработки кода на C/C++ и
постепенного его перевода в Handel-C или SystemC можно сразу при-
ступать к разработке кода на этих языках. Но при этом следует пом-
нить, что после того, как будет получено описание устройства с фик-
сированной точкой в одной из версий языка C/C++, можно использо-
вать один из низкоуровневых методов C/C++ проектирования,
которые были описаны в гл. 11. Особый интерес вызывает версия чис-
того, без учета временных параметров, C/C++, используемого паке-
том Precision С компании Mentor.
Альтернативы реализации ЦОС 195
qgF3 Иногда довольно трудно классифицировать другие методы преобра-
зования кода. На практике может встречаться один из следующих
подходов:
а) Можно довольно легко вручную перевести код из MATLAB в
C/C++, потратив на это от нескольких часов до нескольких дней.
Автоматическая трансляция, как правило, используется только для
систем моделирования или кода ЦОС в зависимости от того, на-
сколько критичны требования к производительности.
б) Довольно просто можно осуществить ручное исследование про-
цесса квантования, особенно для инженеров-системщиков (автома-
тическое квантование применяется не так часто). Многие разработ-
чики рассчитывают также на результаты анализа шумов, который
может помочь в управлении процессом квантования.
в) Ручное преобразование из кода MATLAB или C/C++ в код RTL
представляет собой довольно сложную задачу, которая может затя-
нуться на недели или месяцы. Автоматизация в этой области играет
огромную роль при условии достижения качественного результата.
г) Средства проектирования, основанные на пакетах
MATLAB/Simulink, обычно плохо справляются с задачей примене-
ния ядер-блоков интеллектуальной собственности (ядер IP) при не-
обходимости реализовать действительно оригинальную концепцию.
Блоки интеллектуальной собственности
Не всё так просто устроено в этом мире, так как во всяком деле
найдётся ещё один или несколько вариантов его реализации. Напри-
мер, можно создать библиотеку функциональных блоков ЦОС на сис-
темном (алгоритмическом) уровне абстракции совместно с такой же
эквивалентной библиотекой RTL для языков VHDL или Verilog.
Идея заключается в том, что можно описать и проверить устройс-
тво, используя иерархию функциональных блоков на системном (ал-
горитмическом) уровне абстракции. Насладившись вдоволь получен-
ным устройством, можно создать таблицу соединений RTL-блоков и
использовать её для передачи средствам низкоуровневого моделирова-
ния и синтеза. Эти блоки должны быть параметризованы на всех уров-
нях абстракции, в первую очередь для того, чтобы позволить точно оп-
ределить такие параметры, как, например, ширину шины и другие.
Возможно и другое решение, которое заключается в том, что круп-
ные поставщики ПЛИС обычно предлагают генераторы ядер интел-
лектуальной собственности (IP). В данном контексте понятие ядро
обозначает блоки, которые выполняют специфичные логические фун-
кции; этот термин не относится к микропроцессорным или ЦСП яд-
рам. В некоторых случаях эти генераторы ядер могут быть интегриро-
ваны в среду системного (алгоритмического) уровня проектирования.
Это значит, что можно создать устройство, состоящее из этих блоков в
среде системного (алгоритмического) уровня проектирования, опре-
делить все параметры этих блоков и произвести системную (алгорит-
мическую) проверку (верификацию).
Позже, когда уже можно будет танцевать рок-н-ролл, генератор ядер
автоматически сгенерирует аппаратные модели каждого блока0. Причем
модели системного (алгоритмического) уровня и аппаратные модели,
° Хорошим примером реализации такого подхода может служить интеграция
в Simulink утилиты System Generator компании Xilinx (www.xilinx.com).
196 и Глава 12. Проектирование средств цифровой обработки сигналов
1909 г. Маркони
получил Нобелевс-
кую премию по фи-
зике за вклад в раз-
витие телеграфии.
сформированные генераторами ядер, абсолютно идентичны по всем па-
раметрам. В некоторых случаях аппаратные блоки будут генерироваться
как синтезируемые на RTL в формате VHDL или \ferilog. Они могут быть
представлены также как ядра на уровне таблиц соответствия/КЛБ, тем
самым максимально используя ресурсы выбранной ПЛИС.
Существенный недостаток, присущий этому методу, заключается в
том, что по своей сути блоки интеллектуальной собственности основа-
ны на аппаратной микроархитектуре. Это значит, что возможность со-
здания устройства, предназначенного для решения узкоспецифичных
задач, будет до некоторой степени ограничена. Поэтому, разрабатывая
что-либо с использованием блоков интеллектуальной собственности,
можно достичь стадии реализации быстрее и с меньшим риском, но, в
то же время результат может оказаться не вполне оптимальным с точки
зрения занимаемой площади, производительности и потребляемой
мощности по сравнению с заказным вариантом.
Не забудьте о средствах тестирования!
При продаже средств проектирования систем цифровой обработ-
ки сигналов продавцы часто забывают упомянуть о средствах тести-
рования. Например, допустим, что метод проектирования предпола-
гает ручной перевод их системных (алгоритмических) описаний уст-
ройства в код RTL. В этом случае этот же подход используется и для
средств тестирования. Во многих случаях это может оказаться нетри-
виальной задачей, реализация которой может занять несколько дней
или недель.
Или, скажем, метод проектирования предполагает ручной перевод
системного (алгоритмического) описания устройтства с плавающей
точкой в код C/C++ также с плавающей точкой, после чего при жела-
нии может быть выполнена проверка этого нового описания устройс-
тва. Затем можно взять этот C/C++ код с плавающей точкой и вруч-
ную перевести его в C/C++ код с фиксированной точкой и в этом мес-
те вновь произвести тестирование устройства. После этого можно
взять полученный C/C++ код с фиксированной точкой и (будем наде-
яться) автоматически синтезировать эквивалентное RTL представле-
ние, и в этом месте... ну... смысл ясен0.
Проблема заключается в том, что на каждом этапе будут произво-
диться одни и те же действия с наборами тестов* 2) (если только не дела-
ется что-то хитроумное, как описано в следующем (и последнем —
ура!) разделе.
Смешанные системы проектирования: ЦОС
и VHDL/Verilog
В предыдущей главе мы упомянули о том, что ряд компаний, спе-
циализирующихся на САПР электронных систем, могут предоставлять
системы проектирования и проверки устройств смешанного уровня,
которые могут поддерживать совместное моделирование модулей,
° Не надо смеяться, потому что я знаю одну очень крупную компанию, кото-
рая поступает именно таким образом!
2) Что касается процесса перевода кода C/C++ на уровень RTL, даже если вы
располагаете алгоритмом синтеза RTL из C/C++, ваш набор тестов, как правило,
будет содержать языковые конструкции, неподдающиеся синтезу, т. е. придётся
вернуться назад и выполнить эти операции вручную.
Смешанные системы проектирования: ЦОС и VHDL/Verilog 197
описанных на разных уровнях абстракции. Например, можно начать
проектирование в графическом блочном редакторе, который отобра-
жает основные функциональные модули устройства, где содержимое
каждого блока может быть описано с помощью языков:
• VHDL;
• \ferilog;
• SystemVerilog;
• SystemC;
• Handel-C;
• Чистый C/C++.
В этом случае на верхнем уровне устройство может быть описано с
помощью традиционного HDL, который вызывает субмодули, опи-
санные в различных версиях языка HDL и в одной или нескольких
разновидностях языка C/C++. На верхнем уровне устройство может
быть также описано одной из разновидностей языка C/C++, который
вызывает субмодули, написанные на других языках.
Недавно появились системы проектирования, объединяющие сис-
темный (алгоритмический) уровень и уровень реализации. Принцип
работы таких систем зависит от того, кто на них работает и чего он хо-
чет добиться. Например, разработчики, проектируя на системном (ал-
горитмическом) уровне, т. е. в MATLAB, могут решить заменить один
или несколько блоков эквивалентными реализациями, выполненны-
ми в VHDL или Verilog на уровне регистровых передач. Или наоборот,
инженеры, работая в VHDL или Verilog на уровне абстракции RTL, мо-
гут решить вызвать один или несколько блоков, описанных на систем-
ном (алгоритмическом) уровне.
Оба этих случая требуют совместного моделирования в среде раз-
работки как системного уровня, так и VHDL/Verilog. Главное отличие
заключается в том, кто кого вызывает. Конечно, это звучит просто,
особенно если произнести всё быстро, но существует огромное коли-
чество факторов, которые необходимо учитывать. Например, синхро-
низация времени между двумя представлениями или определение, как
различные типы сигналов переходят из одного представления в другое
и обратно.
Это именно тот случай, когда следует рассматривать любые заранее
подготовленные демонстрации с определенной долей недоверия. Если
вы планируете реализовать подобные задачи, необходимо сесть вместе
с инженером компании-поставщика и проработать свой собственный
пример от корки до корки, т. е. от начала до конца. Можете назвать ме-
ня старым циником, но я бы посоветовал вам позволить инженеру
компании поучить вас, при этом вы должны твёрдо держать клавиату-
ру и мышку в своих руках. Уверяю вас, вы будете потрясены тем, как
много может произойти за несколько секунд, стоит вам только отвер-
нуться от монитора в ответ на старую уловку: «Какое несчастье! Вы ви-
дели, что случилось за окном?»
1909 г. Радиосигнал
бедствия (SOS)
спас 1900 жизней
после крушения
двух кораблей.
1910 г. Америка.
На почтовых лини-
ях связи между
Нью-Йорком и Бос-
тоном установле-
ны телетайпы.
ГЛАВА 1 3
ПРОЕКТИРОВАНИЕ УСТРОЙСТВ
СО ВСТРОЕННЫМИ
МИКРОПРОЦЕССОРАМИ
Введение
В этой книге рассматриваются только электронные системы, кото-
рые на печатной плате содержат одну или несколько ПЛИС. Огром-
ное количество таких систем используют также микропроцессоры об-
щего назначения (МП) для формирования различных приложений уп-
равления и обработки данных0. Их часто называют центральными
процессорами (ЦП) или микропроцессорными устройствами (МПУ).
До недавнего времени микропроцессоры и периферийные уст-
ройства обычно реализовывались в виде отдельных микросхем на пе-
чатной плате. Существует почти бесконечное множество возможных
вариантов соединения этих элементов, но в двух основных из них мик-
ропроцессор соединён с памятью (Рис. 13.1).
а) Память соединена
с процесором через общую шину
б) Жестко связанная память
соединена с процессором
через выделенную шину
Рис, 13,1, Два варианта расположения элементов на уровне печатной платы
В вариантах, показанных на Рис. 13.1, микропроцессор соединён с
ПЛИС и другими устройствами через шину общего назначения. Под
«дополнительными устройствами» преимущественно подразумевают-
ся периферийные устройства, такие как таймеры, контроллеры преры-
ваний, устройства связи и другие.
В некоторых случаях блок памяти будет соединён также с процес-
сором с помощью главной процессорной шины, как показано на
Рис. 13.1, а. На самом деле это соединение будет выполняться через
специальный периферийный блок, называемый контроллером памя-
ти, но он для простоты изложения не показан на этом рисунке. Кроме
того, память может соединяться с процессором напрямую с помощью
выделенной шины памяти, как показано на Рис. 13.1, б.
Также можно использовать микроконтроллеры, которые сочетают в себе
микропроцессорное ядро с некоторой периферией и специализированными вхо-
дами и выходами.
Введение 199
Суть вопроса состоит в том, что представление микропроцессора и ।
его различных периферийных устройств в виде выделенной микросхем
на печатной плате требует финансовых затрат и места на печатной
плате. Кроме того, это влияет на надежность платы, поскольку каждое
паяное соединение, т. е. точка подсоединения, является потенциаль-
ным сбойным механизмом.
Альтернативное решение заключается во встраивании микропро-
цессора вместе с некоторой его периферией внутрь ПЛИС1*
(Рис. 13.2).
1910 г. Разработа-
на первая электри-
ческая стиральная
машина.
а) Память соединена
с процесором через общую шину
Встроенный ц
микропроцессор
Печатная плата
Специализированная
шина памяти
Жестко
связанная
память
Дополни-
тельные
устройства
Встроенные
дополнительные
устройства
ПЛИС
Процессорная
шина
б) Память с жесткой связью
соединена с процессором через
специализированную шину
Рис. 13.2. Два варианта расположения элементов на уровне ПЛИС
Довольно часто, если микропроцессор использует сравнительно
небольшое количество памяти, и она тоже включается в состав ПЛИС.
Во время написания этой книги очень редко вся память микропроцес-
сора встраивалась внутрь ПЛИС.
Создание ПЛИС такого типа сразу породило огромное множество
новых проблем. Во-первых, разработчики системы должны были ре-
шить, какие функции должны быть реализованы программно, т. е. в
виде инструкций для выполнения микропроцессором, а какие подле-
жат аппаратной реализации (используя главную структуру ПЛИС).
Во-вторых, среда разработки должна была поддерживать концепцию
совместной проверки, при которой аппаратная и встроенная програм-
мная части устройства должны подвергаться совместной верифика-
ции, чтобы убедиться, что всё работает как следует.
qgp* Кроме микропроцессоров, каждый поставщик ПЛИС поддерживает
соответствующую процессорную шину. Например, компании Altera
и Quicklogic поддерживают шину АМВА компании ARM (открытая
спецификация, которая может быть бесплатно загружена с сайта
www.arm.com для последующих модификаций). Xilinx для своих ядер
использует шину CoreConnect компании IBM. CoreConnect существу-
ет в двух вариантах. Главный из них представляет собой 64-битную
шину под названием PLB (processor local bus — локальная процессорная
шина). Она может использоваться вместе с одной или несколькими
32-битными шинами ОРВ (on-chip peripheral busses — внутрикрис-
тальная периферийная шина).
° Ещё одно возможное решение может заключаться во встраивании микро-
процессорного ядра в заказную микросхему ASIC, но это уже другая песня!
200 Глава 13. Проектирование устройств со встроенными микропроцессорами
1910 г. Франция.
Джордж Клод
(George Claude)
изобрёл неоновую
лампу.
Аппаратные и программные ядра
Аппаратные ядра
Аппаратные микропроцессорные ядра представляют собой специ-
ализированные, предопределённые, т. е. аппаратно-реализованные,
блоки, которые представляют собой ядра, доступные только в опреде-
лённых семействах устройств. Все ведущие поставщики предпочитают
реализовывать в своих устройствах некоторые определённые типы
процессоров. Например, Altera предлагает встроенные ARM процессо-
ры, QuickLogic предпочитает решения на основе MIPS-процессоров, а
Xilinx встраивает ядра PowerPC.
Конечно, каждый поставщик с превеликим удовольствием пустит-
ся в пространные рассуждения о том, почему именно эта реализация
превосходит любые другие. Проблема принятия решения, какая из ре-
ализаций будет действительно лучше других, довольно многогранна, и
осложняется только тем, что разные процессоры лучше подходят для
решения разных задач.
Как обсуждалось в гл. 4, существует два главных подхода к интегра-
ции таких ядер внутри ПЛИС. Один из них предполагает расположение
их в виде отдельной полосы вдоль стороны главной ПЛИС-структуры
(Рис. 13.3). При таком подходе все компоненты обычно формируются
на одном кремниевом кристалле, хотя могут быть реализованы и на
двух кристаллах и упакованы в виде многокристалъного модуля (МКМ).
Микропроцессорное
ядро, специальное ОЗУ,
интерфейсы
ввода/вывода
и так далее
Рис. 13.3. Вид на кристалл со встроенным микропроцессорным ядром
за пределами главной структуры
Одно из преимуществ такой реализации заключается в том, что
главная структура ПЛИС получается идентичной для устройств как со
встроенным микропроцессорным ядром, так и без него, что может уп-
ростить средства проектирования, используемые разработчиками.
Другое преимущество заключается в том, что поставщики ПЛИС мо-
гут связать все дополнительные функции, такие как память, устройс-
тва ввода/вывода и другие, в одну полосу для дополнения микропро-
цессорного ядра0.
!) Этот метод используется такими поставщиками, как Altera (www.altera.com)
и QuickLogic (www.quicklogic.com).
Аппаратные и программные ядра 201
Альтернативным решением является встраивание одного или не-
скольких микропроцессорных ядер прямо в главную структуру ПЛИС.
Во время написания этих строк существовали микросхемы с одним,
двумя и даже четырьмя ядрами (Рис. 13.4).
а) Одно встроенное ядро б) Четыре встроенных ядра
Рис, 13,4, Вид на кристаллы с микропроцессорными ядрами встроенными
внутрь главной структуры
В этом случае средства проектирования должны учитывать при-
сутствие микропроцессоров в структуре микросхемы. Память, исполь-
зуемая ядром, формируется из встроенных блоков ОЗУ, и любые функ-
ции сопряжения реализуются с помощью групп программируемых ло-
гических блоков общего назначения. Сторонники этой схемы
утверждают, что размещение микропроцессорного ядра в непосредс-
твенной близости к главной структуре ПЛИС дает ей преимущество в
скорости0.
Программные микропроцессорные ядра
Кроме физического встраивания микропроцессора в структуру
кристалла, можно сконфигурировать группу программируемых логи-
ческих блоков для работы в качестве микропроцессора. Такую группу
блоков обычно называют программным ядром, но более точно они мо-
гут быть классифицированы как программные (soft) и микропрограм-
мные (flrm) в зависимости от способа реализации функциональности
микропроцессора с помощью логических блоков. Например, если яд-
ро реализовано в форме таблицы соединений RTL, которая будет син-
тезирована вместе с другой логикой, это будет действительно програм-
мная реализация. Если же ядро реализовано в виде размещенных и
разведенных конфигурируемых логических блоков (КЛБ) или таблиц
соответствия, такая реализация обычно считается микропрограммной.
В обоих случаях все периферийные устройства, такие как таймеры,
контроллеры прерываний, контроллеры памяти, функции связи и дру-
гие, также реализуются в виде программных или микропрограммных
° Этот метод использует компания Xilinx (www.xilinx.com), которая также ре-
ализует множественные функции сопряжения в виде программных блоков интел-
лектуальной собственности.
202 Глава 13. Проектирование устройств со встроенными микропроцессорами
Ядра Nios основаны
на архитектуре
SPARC, использую-
щей концепцию ре-
гистровых окон,а
MicroBlaze построе-
ны на классичес-
кой RISC-архитек-
туре.
ядер. Причем поставщики ПЛИС обычно предлагают большие библи-
отеки таких ядер.
Программные ядра медленнее и проще, чем их аппаратные анало-
ги, хотя, они невероятно быстрые в человеческом понимании. Кроме
невысокой цены у них есть одно преимущество, которое заключается в
том, что при необходимости можно реализовывать ядро или ядра до
тех пор, пока не будут исчерпаны все ресурсы в виде программируемых
логических блоков.
Как и прежде, все ведущие поставщики ПЛИС предпочитают реа-
лизовывать определённые типы процессоров в своих программных яд-
рах. Например, Altera предлагает ядра Nios, a Xilinx предпочитает
MicroBlaze. Ядра Nios существуют в 16-битных и 32-битных вариантах
архитектуры, которые соответственно работают с 16-битными и 32-
битными блоками данных. Оба варианта используют одну и ту же сис-
тему 16-битных команд. В отличие от них, Micro Blaze является полно-
стью 32-битным процессором, т. е. он поддерживает 32-битные коман-
ды и работает с 32-битными блоками данных. Снова повторюсь, что
каждый поставщик с большой радостью поведает о том, почему его
программное ядро является лучшим и почему конкурирующие пред-
ложения обречены на провал. Сожалею, но делать выбор вам, чита-
тель, придется самостоятельно.
Хочу вас обрадовать: интегрированная среда разработки (IDE —
integrated development environment) компании Xilinx одинаково восприни-
мает аппаратные ядра PowerPC и программные ядра MicroBlaze. Эта
среда включает в себя оба процессора, которые основаны на одной и той
же процессорной шине CoreConnect, и использует для сопряжения об-
щие программные ядра интеллектуальной собственности. Это позволя-
ет относительно легко перейти от одного микропроцессора к другому.
Интерес представляет и тот факт, что Xilinx предлагает небольшие
8-битные программные ядра, называемые PicoBlaze, которые могут
быть реализованы с помощью всего лишь (примерно) 150 логических
ячеек. В отличие от них MicroBlaze использует примерно 1000 логичес-
ких ячеек. Это0 вполне приемлемо для реализации 32-битного про-
цессора, особенно когда кое-кто использует ПЛИС, содержащие
70000^ или более таких ячеек.
Особый интерес представляет программное ядро LisaTek компании
CoWare Inc. (www.coware.com). С помощью специального языка в
этом ядре можно определить требуемый набор команд и микроархи-
тектуру (ресурсы, конвейеры, тактовые частоты). Затем LisaTek по
этим определениям генерирует требуемый RTL-код программного
ядра вместе с соответствующими программными средствами, таки-
ми как компилятор языка С, ассемблер, компоновщик и система
моделирования.
Компания QuickLogic предлагает 9-битные программные микрокон-
троллеры, которые обозначаются как Q90Clxx (9-битные слова дан-
ных могут быть полезны для некоторых функций в телекоммуника-
ции).
° В рамках рассматриваемого материала предположим, что логическая ячейка
содержит 4-входовую таблицу соответствия, регистр и другие блоки, такие как
мультиплексоры и цепи быстрого переноса.
2) Эти 70000 соответствовали истине сегодня утром, когда я завтракал, но это
значение, несомненно, увеличится к тому времени, когда вы будете читать эту
книгу.
Разделение устройства на аппаратные и программные компоненты 203
Разделение устройства на аппаратные
и программные компоненты
Как уже упоминалось в гл. 4, почти все части электронного устройс-
тва могут быть реализованы аппаратно (с использованием логических
вентилей, регистров и прочим) или программно (в виде инструкций
микропроцессора)0. Одним из главных частных критериев выбора
между аппаратной и программной реализацией функции является вре-
мя, за которое эта функция должна выполнять такие задачи, как:
• Пикосекундная и наносекундная логика — эта логика должна ра-
ботать безумно быстро и реализовываться аппаратно в структу-
рах ПЛИС.
• Микросекундная логика — умеренно быстрая логика. Может вы-
полняться как аппаратно, так и программно. Тип логики, при
котором основная масса времени уходит на определение того,
каким путём пойти.
• Миллисекундная логика — эта логика используется при реализа-
ции интерфейсов, таких как опрос состояния переключателей
или зажигание светодиодов. Основные усилия будут направле-
ны на замедление аппаратной части при реализации таких фун-
кций; например, используя громаднейшие счетчики для генера-
ции задержек. Часто такие задачи лучше реализовывать в
микропроцессорном коде, поскольку процессор позволяет по-
лучить низкую скорость (в сравнении с аппаратной реализаци-
ей), но следует учитывать тот факт, что задача может оказаться
очень сложной.
Вся хитрость состоит в том, чтобы решить все проблемы наиболее
экономичным способом. Определённые функции должны реализовы-
ваться аппаратно, другие должны быть выполнены программно, а не-
которые их них могут быть реализованы и тем, и другим способом в за-
висимости от предположений, как лучше использовать доступные ре-
сурсы (ресурсы на кристалле и работу инженеров-разработчиков и
программистов).
Давайте рассмотрим «идеальную» среду разработки системного
уровня, в которой архитекторы системы вначале описывают устройство
с помощью графического интерфейса в виде совокупности соединён-
ных вместе функциональных блоков. Каждый из этих блоков может
быть описан на системном (алгоритмическом) уровне, например, с по-
мощью SystemC. После этого все устройство целиком может быть про-
верено на функциональность, прежде чем будет принято решение, ка-
кую часть следует реализовывать аппаратным, а какую программным
путём.
Когда дойдёт очередь до разделения устройства, можем предста-
вить себе, что существует возможность выделять каждый логический
блок мышкой и выбирать для него опцию аппаратной или програм-
мной реализации. После того как эта операция будет проведена со все-
ми блоками, можно было бы нажать кнопку Пуск, и среда разработки
позаботилась бы о синтезе аппаратного обеспечения, компиляции
программного кода и произвела бы сборку всей конструкции.
° Некоторые циники могут сказать, что части устройства, которые изначаль-
но всем понятны и не будут подвержены изменению, как правило, реализуются
аппаратно, ну, а те части, в отношении которых на момент начала проектирования
системы есть какие-то сомнения, наверняка, будут реализованы программно, так
как программные модули могут быть «настроены в последнюю минуту».
204 Глава 13. Проектирование устройств со встроенными микропроцессорами
Системы реального
времени работают
по принципу не
только что выпол-
нить, но и когда это
должно быть выпол-
нено.
А теперь с оглушительным треском возвращаемся в реальный мир.
На самом деле ряд перспективных средств разработки подают некото-
рые надежды, а новые инструменты и технологии появляются почти
ежедневно. Однако во время написания этой книги системные инже-
неры обычно разделяли устройство на аппаратные и программные час-
ти вручную, затем передавали эти высокоуровневые функции соот-
ветствующим инженерам и надеялись на лучшее.
Что касается программной части устройства, здесь всё выглядит
немного проще, примерно как конечный автомат, используемый для
управления интерфейсом оператора (чтение состояния переключате-
лей и управление устройством отображения). Хотя конечный автомат
сам по себе может быть довольно сложным, но подобный уровень про-
граммного обеспечения далёк от ракетной техники. Вместе с тем, эта
часть устройства может иметь невероятно сложные программные тре-
бования и должна содержать:
• подпрограммы инициализации системы и уровень аппаратной
абстракции (HAL — hardware abstraction layer);
• набор тестов аппаратной диагностики;
• операционную систему реального времени (ОС РВ)\
• драйверы устройств ОС РВ;
• другие встроенные приложения.
Этот код обычно описывается с помощью языка C/C++ и затем
компилируется в машинный код, который будет выполняться микро-
процессорным ядром. В экстремальных ситуациях можно попытаться
выжать последнюю каплю производительности устройства, написав
вручную точные подпрограммы на языке Ассемблера.
А в это время разработчики аппаратуры описывают свою часть уст-
ройства обычно на RTL-уровне абстракции, используя язык VHDL
или Verilog, или System Verilog.
Современное проектирование систем является настолько слож-
ным, что их аппаратные и программные части следует проверять сов-
местно. К сожалению, выбор среди множества альтернативных
средств совместной проверки и их сложность могут расстроить и вы-
вести из себя даже взрослого, в том числе и меня.
Аппаратное и программное мировоззрение
Одна из самых больших проблем, с которой приходится сталки-
ваться при совместной проверке аппаратных и программных частей
устройства, заключается в совершенно различном мировоззрении их
разработчиков.
Разработчики аппаратуры обычно представляют свои части уст-
ройства в виде RTL-блоков, которые состоят из таких компонентов,
как регистры, логические функции и проводники, соединяющих всё
вместе. При отладке своих частей разработчики аппаратуры мыслят
категориями редактора исходного кода, системы моделирования, и
графического дисплея, отображающего форму сигналов и изменение
переменных с привязкой ко времени. В типичной среде разработки
аппаратного обеспечения щелчок мышкой при определённом собы-
тии на графическом дисплее автоматически укажет соответствующую
строку RTL-кода, которая вызвала это событие.
В отличие от разработчиков аппаратуры программисты оперируют
понятиями исходного кода языка C/C++, регистров процессора
(и внешних устройств) и содержимым различных участков памяти.
При отладке программы они часто предпочитают проходить через код
в пошаговом режиме и отслеживать при этом изменения в различных
ПЛИС как среда проектирования 205
регистрах. Они, возможно, также захотят установить одну или не-
сколько точек останова, которые представляют собой метки на специ-
фичных участках кода, запустить программу и ждать её выполнения до
тех пор, пока она не достигнет этих точек, и затем в режиме паузы пос-
мотреть текущие результаты моделирования. Кроме того, программис-
ты могут задать определённые состояния, например, когда регистр бу-
дет содержать определённое значение, затем запустить программу и
ожидать этого состояния, и затем в режиме паузы просмотреть что
произошло во время выполнения.
Когда программисты пишут код приложений, например компью-
терной игры, они определённо уверены в том, что аппаратная часть,
скажем домашний компьютер, исправна и устойчива к ошибкам. Од-
нако всё обстоит по-иному, когда речь идет об инженерах-програм-
мистах, создающих встраиваемые приложения, которые предназна-
ченные для работы на аппаратном обеспечении, разрабатываемом в
это же время. Когда обнаруживается какая-то проблема, определить, в
чьей зоне ответственности, аппаратной или программной, находится
ошибка, может оказаться чрезвычайно сложно. Классической шуткой
стал разговор между двумя представителями:
Инженер-программист: «Я думаю, что обнаружил аппаратную про-
блему во время работы моего встроенного приложения».
Разработчик аппаратуры: «В какой момент произошла ошибка?
Можете ли вы дать мне контрольный пример, который поможет лока-
лизовать проблему?»
Инженер-программист: «Ошибка произошла сегодня утром в 9:30,
контрольным примером может служить моё приложение».
В современных средствах совместной проверки аппаратный и про-
граммный миры тесно связаны. Это значит, что если программисты
обнаруживают потенциальный аппаратный сбой, они определяют вы-
полняемую строку кода, которая непосредственно укажет разработчи-
кам аппаратуры на соответствующий моделированию интервал време-
ни на графическом дисплее. Аналогично, если разработчики аппарат-
ной части обнаруживают потенциальную программную ошибку
(например, код, запрашивающий недопустимую аппаратную транзак-
цию), они могут использовать свой интерфейс для указания програм-
мистам соответствующей строки исходного кода. К сожалению, по-
добные средства разработки могут оказаться весьма дорогими, поэто-
му иногда приходится выбирать менее сложные решения.
ПЛИС как среда проектирования
Возможно, проще всего начать разговор на эту тему с описания об-
ластей, в которых ПЛИС применяются в качестве средства разработ-
ки. Идея заключается в том, что ПЛИС на основе ячеек статического
ОЗУ со встроенным процессором (аппаратным или программным)
располагается на макетной плате, которая соединена с компьютером
пользователем. Кроме ПЛИС, на этой плате также установлена па-
мять, в которой будут храниться программы, выполняемые встроен-
ным микропроцессором (Рис. 13.5).
После того как системные инженеры (архитекторы) определили,
какие части устройства должны быть реализованы аппаратно, а какие
программно, разработчик аппаратуры начинают описывать свои RTL-
блоки и функции и синтезировать из них таблицу соединений
КЛБ/таблиц соответствия. Тем временем программисты начинают со-
здавать на языке C/C++ программы и подпрограммы и компилируют
их в машинный код. В итоге таблица соединений загружается в ПЛИС
1911 г. Датский
физик Хейке Кам-
мерлинг-Оннс
(Heike Kamerlingh
Onnes) открыл яв-
ление сверхпрово-
димости.
1912 г. Америка.
Сидней Рассел (Dr.
Sidney Russell)
изобрёл одеяло с
электрообогревом.
1912 г. Радиопри-
ёмники начали ос-
нащать обратны-
ми связями и стро-
ить по гетеродин-
ной схеме.
206 Глава 13. Проектирование устройств со встроенными микропроцессорами
1912 г. «Титаник»
во время первого
плавания послал
сигнал бедствия
после столкновения
с айсбергом.
Рис. 13.5. Использование ПЛИС в качестве среды проектирования
через конфигурационный файл, а исполняемый модуль машинного
кода загружается в память, и система готова к «запуску» в свободное
плавание (Рис. 13.6).
Конфигурационный Исполняемый
файл модуль
Загрузка в макетную плату
Рис. 13.6. Очень простой метод проектирования
Через конфигурационный файл во встроенные в ПЛИС блоки ОЗУ
может быть также загружен любой машинный код.
Контроль состояния устройства
Главная проблема в сценарии, описанном в прошлом разделе, за-
ключается в плохой наглядности того, что происходит в аппаратной
части устройства. Один из способов решения этой проблемы заключа-
Некоторые альтернативные методы совместной проверки 207
ется в использовании виртуального логического анализатора, который
позволяет наблюдать за событиями внутри аппаратной части конс-
трукции (этот способ более детально рассматривается в гл. 16).
Ситуация осложняется при попытке определить, что происходит в
программной части. Но при этом следует иметь в виду, что встроенное
микропроцессорное ядро содержит свою собственную специализиро-
ванную JTAG цепочку последовательного сканирования, как было по-
казано в гл. 5 (Рис. 13.7).
Рис, 13,7, Цепочка последовательного сканирования ПЛИС
со встроенным процессором
1913 г. Вильям Ку-
лидж (William
D. Coolidge) изоб-
рёл рентгеновскую
трубку с термока-
тодом из тонкой
вольфрамовой спи-
рали. Трубка Ку-
лиджа стала
стандартным ге-
нератором рентге-
новских лучей для
медицины.
Это справедливо как для аппаратных ядер, так и для большинства
сложных программных ядер. В этом случае средства совместной про-
верки могут использовать цепочки сканирования для наблюдения за
активностью шин и сигналов управления, соединяющих микропро-
цессор с остальной частью системы. Через порт JTAG также могут
быть доступны внутренние регистры микропроцессора, что позволяет
внешнему отладчику управлять устройством, реализовывать пошаго-
вый режим, устанавливать точки останова и так далее.
Некоторые альтернативные методы совместной
проверки
Один из способов получить представление о том, что же в действи-
тельности происходит в аппаратной части устройства — использовать
логическое моделирование. В этом случае большинство систем долж-
ны быть сконструированы и промоделированы средствами языка
VHDL, Verilog и SystemXferilog на RTL-уровне абстракции. Однако
микропроцессорное ядро может быть представлено несколькими спо-
собами (Рис. 13.8).
Независимо от типа модели, используемой для представления
микропроцессора, встроенные программные части устройства (ма-
шинный код) будут загружены в какую-либо память — во встроенную
память внутри ПЛИС или во внешнюю память системы — после чего
микропроцессор сможет выполнить эти машинные команды.
208 Глава 13. Проектирование устройств со встроенными микропроцессорами
1914 г. Америка.
В Кливленде,
шт. Огайо, впер-
вые установлен
светофор.
Модель VHDL/Verilog
C/C++, SystemC
и другие модели
Физический кристалл
в аппаратном устройстве
моделирования
Эмулятор машинных
команд
Рис, 13,8. Альтернативные представления микропроцессора
На Рис. 13.8 показано только высокоуровневое представление со-
держимого ПЛИС. Если машинный код сохранён во внешней памяти
устройства, это устройство также должно быть частью системы моде-
лирования. На практике, если программное обеспечение взаимодейс-
твует с каким-то объектом, то этот объект должен быть частью систе-
мы совместной проверки.
RTL-описания: VHDL или Verilog
Возможно, что наличие RTL-описания микропроцессора обеспе-
чит самый простой вариант проверки, так как в этом случае все дейс-
твия выполняются в системе логического моделирования. Одним из
недостатков этого метода является то, что для реализации простейших
задач микропроцессор выполняет огромное количество внутренних
операций. Другими словами, работа системы моделирования будет
чрезвычайно медленной. Читатель, вы будете безмерно счастливы, ес-
ли удастся смоделировать 10...20 системных тактов за секунду реально-
го времени.
Другой недостаток заключается в отсутствии наглядности, т. е.: что
же там выполняет программное обеспечение на уровне исходного ко-
да. Всё, что можно сделать в этом случае — проанализировать измене-
ния логических значений на проводниках и внутри регистров.
К тому же, следует учесть, что независимо от того, кто продал вам
микропроцессор, он не будет заинтересован в том, чтобы пользователь
знал, как работает его устройство. Это связано с тем, возможно, что
поставщик использует запатентованные приёмы и желает сохранить в
тайне свою интеллектуальную собственность. В этом случае будет до-
вольно сложно понять работу RTL-модели микропроцессора.
C/C++, SystemC и т. д.
В качестве противовеса RTL-модели в обычной практике исполь-
зуются некоторые C/C++ модели микропроцессоров. (Сторонники
языка SystemC мечтают о моделях микропроцессоров и основных пе-
риферийных устройств, описанных на этом языке, как о стандарте при
работе в своей среде проектирования.)
Откомпилированная версия этой модели микропроцессора может
быть связана с системой моделирования через интерфейс языка про-
Некоторые альтернативные методы совместной проверки 209
граммирования (PLI — Programming Language Interface), в случае Verilog-
моделирования, либо через интерфейс незнакомых слов (FLI — Foreign
language interface) или его эквивалент, в случае VHDL-моделирования.
Данные модели имеют ряд преимуществ: они могут выполняться
намного быстрее, чем их RTL-аналоги; могут поставляться в откомпи-
лированном виде, тем самым, скрывая различные секреты, представ-
ляющие собой интеллектуальную собственность поставщика; и, по
крайней мере, для ПЛИС, обычно являются бесплатными (поставщи-
ки ПЛИС продают кристаллы, но не модели).
Недостаток этого подхода состоит в том, что модели C/C++ не
обеспечивают на 100% точное потактовое описание работы реального
микропроцессора, что может стать причиной различных проблем при
неаккуратной работе. Но, вновь повторюсь: всё же главный недостаток
таких моделей заключается в том, что они представляют собой про-
грамму в машинном коде, т. е. пользователь не может просмотреть ра-
боту программного обеспечения на уровне исходного кода. Всё, что
можно сделать — это проследить изменение логических значений на
проводниках и внутри регистров.
(^=> Когда-то давно компания Logic Modeling Corporation (LMC), кото-
рая впоследствии была приобретена компанией Synopsys, определи-
ла интерфейс связи между поведенческими моделями аппаратных
блоков с системами логического моделирования, который называл-
ся SWIFT. Модели, такие как микропроцессоры, которые подде-
рживали эту спецификацию, назывались SWIFT-моделями.
Реальные микросхемы в аппаратных устройствах
моделирования
Однако существует и другой способ описать для моделирования
аппаратное микропроцессорное ядро. Например, при использовании
ядра PowerPC в ПЛИС фирмы Xilinx можете легко взять настоящий
микропроцессор PowerPC. Этот микропроцессор можно установить в
так называемое аппаратное устройство моделирования, которое может
быть включено в систему логического моделирования.
Преимущество этого метода заключается в том, что физическая
модель с максимальной эффективностью стремится функционально
соответствовать аппаратному ядру. К недостаткам метода можно от-
нести некоторые трудности, связанные с большой стоимостью и слож-
ностью таких аппаратных устройств моделирования.
Большинство аппаратных решений, основанных на устройствах
моделирования, не поддерживают работу средств отладки совместно с
исходным кодом. Другими словами, невозможно проследить работу
программного обеспечения на уровне исходного кода0. Всё, что мож-
но сделать — это проследить изменение логических значений на про-
водниках и внутри регистров.
Эмулятор машинных команд
Как уже отмечалось, в некоторых случаях роль программной части
ПЛИС может быть отчасти ограничена. Например, программное обес-
печение может быть использовано в качестве конечного автомата для
1914 г. Для изго-
товления радио-
приёмников начали
использоваться
лампы-триоды.
На самом деле некоторые устройства моделирования предоставляют неко-
торые возможности отладки на уровне исходного кода, например, интересные ре-
шения предлагает компания Simpod Inc. (www.simpod.com).
210 Глава 13. Проектирование устройств со встроенными микропроцессорами
1914 г. Осущест-
влён первый транс-
континентальный
телефонный зво-
нок.
управления некоторым интерфейсом. Программы могут также приме-
няться для инициализации некоторых средств аппаратной части уст-
ройства, а после этого переходить в ждущий режим и контролировать
работу аппаратуры. Такие C/C++ модели или физические модели, ве-
роятно, будут достаточно полными, по крайней мере в том объеме, как
полагают разработчики.
В некоторых случаях аппаратная часть устройства может в основ-
ном выполнять функции сопряжения с внешним миром. Например,
аппаратура может считывать из внешнего источника блок данных и
сохранять его в памяти ПЛИС. После этого микропроцессор может
выполнить огромное количество сложных преобразований с этими
данными. В этом и в других подобных случаях программистам необхо-
димо иметь возможность проводить отладку своих программ на уровне
исходного кода. Это, в свою очередь, потребует использования эмуля-
тора машинных команд (ЭМК), который обеспечивает виртуальное
представление микропроцессора.
Хотя ЭМК почти всегда создаётся с помощью языка C/C++, тем
не менее, он будет существенно сильно отличаться от C/C++ моделей
микропроцессоров, которые были рассмотрены в этой главе. Причина
такого отличия заключается в очень высоком уровне абстракции, на
котором описывается ЭМК. Кроме того, он оперирует терминами
транзакций, например «дайте мне слово данных, расположенное по
адресу х в памяти» и не заботится о мелких деталях, например, как сиг-
налы будут вести себя в реальном мире. Наиболее просто объяснить
принцип действия такого метода можно с помощью Рис. 13.9.
Компилятор
Файл исходного с опцией -d Файл
кода C/C++ (debug — отладка) машинного кода
в действие систему
моделирования
Рис. 13.9. Применение ЭМК
Во-первых, программисты описывают свои программы на языке
C/C++. Затем производят компиляцию исходного кода, используя оп-
цию -d компилятора (debug — режим отладки), вследствие чего сов-
местно с исполняемым кодом генерируется таблица символов и другая
отладочная информация.
Очень интересная среда проектирования 211
Когда дело доходит до совместной проверки устройства, то про-
цесс разделяется на несколько ветвей. С одной стороны находится от-
ладчик исходного кода, чей интерфейс используется программистами
для взаимодействия с оборудованием, а с другой стороны расположена
система логического моделирования, которая работает с описаниями
устройств памяти, внешних периферийных устройств, логики общего
назначения и так далее (для простоты рисунка предположим, что вся
память программ находится внутри ПЛИС).
При использовании микропроцессоров система логического моде-
лирования очень тщательно анализирует место расположения этой
функции. Если быть более точным, система моделирования обрабаты-
вает набор входов и выходов, соответствующих микропроцессору. Эти
входы и выходы, объединённые в одно целое, называются моделью ин-
терфейсной шины или МИШ (BIM — bus interface model), которая дейс-
твует как транслятор между системой моделирования и ЭМК.
Далее в отладчик исходного кода загружается исходный код и ис-
полняемый двоичный модуль вместе с таблицей символов и другой от-
ладочной информацией. В это же время модуль двоичного исполняе-
мого кода загружается в память ПЛИС. Когда пользователь указывает
отладчику выполнить в пошаговом режиме строку кода, он выдаёт ко-
манду ЭМК. В свою очередь, эмулятор начнёт выполнять высокоуров-
невую транзакцию, например извлечение команды или чтение/запись
памяти, или команду ввода/вывода. Эта транзакция проходит в блок
МИШ, который с помощью соответствующих выводов ПЛИС приво-
дит в действие систему моделирования.
Аналогично, когда какой-нибудь из блоков, подсоединённых к
процессорной шине внутри ПЛИС, попытается взаимодействовать с
процессором, этот процесс «расшевелит» систему МИШ, которая пе-
реведёт низкоуровневые действия в высокоуровневые транзакции, пе-
редаст их в ЭМК, который, в свою очередь, проинформирует отладчик
исходного кода о происходящих событиях. После этого отладчик отоб-
разит состояние программных переменных, регистров микропроцес-
сора и другую подобную информацию.
На рынке существуют различные, невероятно сложные, часто от-
пугивающие дороговизной системы проектирования данного типа1}.
Каждая из них обладает своими хитрыми приёмами и возможностями.
Некоторые в большей степени подходят для заказных микросхем, чем
для ПЛИС, другие наоборот. Как обычно, все стремительно меняется
и развивается, поэтому необходимо тщательно проанализировать каж-
дое предложение, перед тем как выложить свои кровно заработанные
деньги за тот или иной продукт.
Очень интересная среда проектирования
Насколько возможно (в разумной степени), в этой книге не акцен-
тируется внимание на отдельных компаниях и их продукции. Но из
всякого правила есть исключения, в том числе и из этого. В данном
случае исключением является компания Altium Ltd. (www.altium.com),
предложившая весьма интересную среду проектирования ПЛИС под
названием Nexar, которая заслуживает, чтобы о ней упомянули в этой
главе.
1914 г. Осущест-
влена передача ра-
диосообщения с
земли на аэроплан.
° Например, среда разработки Seamless компании Mentor (www.mentor.com),
среда разработки Incisive компании Cadence (www.cadence.com) и ХоС компании
Axis Systems (www.axissystems.com).
212 Глава 13. Проектирование устройств со встроенными микропроцессорами
1915 г. Осуществлён
первый трансат-
лантический радио-
телефонный разго-
вор.
Я даже не знаю с чего начать. Ну, давайте начнём с того, что пого-
ворим о полном наборе средств аппаратного и программного проекти-
рования и тестирования для ПЛИС стоимостью примерно 7995 долла-
ров США1*. Эта среда проектирования предназначается инженерам,
разрабатывающим небольшие системы, например простые контролле-
ры для бытовой техники, скажем, для стиральных машин, и основным
их достоинством является доступность. Это значит, что пользователь
может купить микросхему ПЛИС, содержащую более 1 миллиона сис-
темных логических элементов, примерно за 20 долларов США* 2).
Среда разработки Nexar включает макетную плату, которая под-
ключается к персональному компьютеру. Эта макетная плата оснащена
двумя дочерними картами: на одной из них установлена ПЛИС фирмы
Xilinx, а другая оснащена устройством компании Altera. Среда Nexar ха-
рактеризуется также набором программных микропроцессорных ядер,
имитирующих функциональность стандартных промышленных 8-бит-
ных устройств, таких как 8051, Z80, и PIC-микроконтроллеров (в буду-
щем планируется поддержка 16-битных и 32-битных процессорных и
ЦСП (В8Р)-ядер). В состав пакета также входит библиотека перифе-
рийных устройств и библиотека из примерно 1500 компонентов, от
простых вентилей до более сложных функций, таких как счётчики, а
также операционная система реального времени (ОС РВ).
С помощью интерфейса графического описания схемы пользова-
тель размещает блоки, представляющие собой процессоры, перифе-
рию, различные логические функции, и связывает их проводниками
между собой. Все поддерживаемые средой Nexar блоки являются бес-
платными, и не требуют выплаты авторского гонорара. Эти блоки про-
шли предварительную процедуру синтеза, поэтому на соответствую-
щем этапе проектирования они могут быть загружены в ПЛИС на ма-
кетной плате. При необходимости можно создать собственные блоки и
описать их содержимое на уровне регистровых передач. Впоследствии
эти блоки будут обработаны средством синтеза из состава пакета Nexar.
Чтобы ввести исходный код программы на языке C/C++, которая
должна выполняться этим процессором, надо щелкнуть мышью на
блоке процессора. После ввода код будет откомпилирован одним из
компиляторов, входящих в состав пакета Nexar.
Идея такого подхода заключается в том, что все части разрабатыва-
емого устройства — и аппаратные, и программные — будут загружены в
ПЛИС на макетной плате. Чтобы увидеть, что же происходит внутри
аппаратной части устройства, можно включить в схему различные вир-
туальные блоки инструментов, в том числе логический анализатор, ге-
нераторы частот и прочее. Для контроля программной части в состав
Nexar входит отладчик исходного кода, позволяющий формировать все
стандартные задачи отладки, например установку точек останова, оп-
ределение просматриваемых выражений, пошаговый режим и другие.
Что могу сказать лично я? Я действительно видел своими глазами
эту штуковину в действии и был поражён. Мне очень понравилось, что
в данном случае предлагается решение «под ключ», т. е. законченное
решение, размеры которого не превышают размеров коробки из-под
обуви, не считая, разумеется, дорогих достоинств. Что касается уровня
разработки, я думаю, что такую блестящую работу как Nexar в ближай-
шее время вряд ли кто-то в силах повторить.
° Эта цена была действительна в ноябре 2003 года.
2) Опять же, это количество элементов и цена были действительны в ноябре
2003 года.
ГЛАВА 1 4
МОДУЛЬНОЕ И ПОШАГОВОЕ
ПРОЕКТИРОВАНИЕ
Работа с одним целым
Для того чтобы подготовиться к разговору на эту тему, давайте рас-
смотрим структуру ПЛИС как набор столбцов, каждый из которых со-
держит большое количество программируемых логических блоков
вместе с блоками ОЗУ и другими аппаратными элементами, например
умножителями с накоплением (МАС), см. Рис. 14.1.
Рис. 14.1. Архитектура в виде столбцов
Конечно, этот рисунок сильно упрощен, так как современные уст-
ройства могут содержать больше столбцов, чем можно себе вообра-
зить, и каждый столбец может состоять из огромного множества про-
граммируемой логики, и так далее.
При рассмотрении программирования ПЛИС на основе ячеек ста-
тического ОЗУ, было установлено, что все конфигурационные ячейки
памяти можно рассматривать как один большой сдвиговый регистр
(см. гл. 5). Рассмотрим, например, простое изображение поверхности
кристалла, на котором показаны только контакты ввода/вывода и кон-
фигурационные ячейки ОЗУ (Рис. 14.2).
Снова повторюсь: мы рассматриваем конфигурационные ячейки
как совокупность столбцов, каждый из которых соответствует столбцу
программируемой логики, как показано на Рис. 14.1. Такое представ-
ление является существенно упрощенным, так как ПЛИС может со-
держать десятки миллионов таких конфигурационных ячеек, но оно
позволяет сделать более доступным для восприятия и понимания со-
214 и Глава 14, Модульное и пошаговое проектирование
1917 г. Кларенс
Бердзай (Clarence
Birdseye) стал хра-
нить продукты при
помощи заморозки.
ЕЗ = Контакты ввода/вывода
= Конфигурационные
ш ячейки СОЗУ
Рис. 14.2. Конфигурационные ячейки статического ОЗУ, представленные
как один большой сдвиговый регистр
держание этой главы. Способы доступа к двум концам регистровой це-
почки зависят от выбранного режима программирования.
На заре проектирования ПЛИС, примерно во второй половине 80-х,
устройства были относительно небольшими, если говорить об этом тер-
минами их логической ёмкости. Вследствие этого одному инженеру, как
правило, было под силу создать RTL-описание всего устройства. Затем
RTL-описания проходили процедуру синтеза, после чего синтезирован-
ная таблица соединений подвергалась операции размещения и развод-
ки, которая и завершала процедуру проектирования устройства. В ре-
зультате получался монолитный конфигурационный файл, который оп-
ределял функциональность всего устройства и мог быть загружен в
микросхему одним большим куском. Такая схема очень хорошо работа-
ла с конфигурационными ячейками, представленными в виде большого
сдвигового регистра, и все были счастливы.
Разбиение на меньшие блоки
ПЛИС не стояли на месте: они непрерывно расширялись и совер-
шенствовались, в результате чего стали стремительно расти их разме-
ры и сложность. В связи с этим все устройство стали разбивать на отде-
льные функциональные блоки, и за каждым блоком закреплялся один
или несколько инженеров. В этом случае каждый блок мог быть синте-
зирован самостоятельно, но все таблицы соединений, связанные с
каждым блоком, перед операцией размещения и разводки собирались
вместе. Снова повторюсь, что размещение и разводка обычно выпол-
нялись для всего устройства, и выполнение этих операций могло за-
нять всю ночь, если речь шла об устройстве с миллионами логических
элементов.
Начиная где-то с 2002, года некоторые поставщики ПЛИС начали
предлагать большие устройства, в которых конфигурационные ячейки
на основе статического ОЗУ представлялись как множество относи-
тельно коротких сдвиговых регистров (Рис. 14.3).
Идея представления устройства с множеством цепочек возникла в
связи с концепцией модульного и пошагового проектирования. Не ис-
ключено, что причина появления представления в виде множества цепо-
Разбиение на меньшие блоки 215
Рис, 14.3, Конфигурационные ячейки статического ОЗУ, представленные
в виде множества относительно небольших сдвиговых регистров
1917 г. Франк Кон-
рад (Frank Conrad)
построил радио-
станцию, которая
затем стала назы-
ваться KDKA
(этот позывной ис-
пользуется и в на-
ши дни).
чек была более приземлённой и имела аппаратный характер, и вообще
все могло произойти примерно так — какой-то умник сказал: «Постойте-
постойте, теперь, когда у нас есть множество цепочек, почему бы нам не
поддержать концепцию модульного и пошагового проектирования?»
Если б я был любителем заключать пари, вероятнее всего, поставил
бы на последний вариант. Но, будем терпимыми и предположим, что
кто-то когда-то все-таки понимал, что он или она делает (могло же так
быть). Тем не менее, это уже случившийся факт, и в результате эта архи-
тектура вместе с соответствующим программным обеспечением может
поддерживать концепцию модульного и пошагового проектирования.
Модульное проектирование
В этом разделе мы рассмотрим так называемую командную разра-
ботку. В этом случае большое устройство разбивается на функцио-
нальные блоки и за каждым блоком закрепляется отдельный разработ-
чик или группа разработчиков, которые проектируют его с учётом всех
временных ограничений. Для каждого блока индивидуально создаётся
и синтезируется RTL-код, и после завершения блочной разработки все
полученные физические таблицы соединений передаются системному
интегратору.
В конечном счете, каждому блоку (или небольшой группе блоков)
будет назначено определённое место в устройстве. Системный интег-
ратор несет ответственность за «стыковку» всех этих блоков вместе.
По-другому это представление можно сравнить с разделённой на мно-
гие устройства ПЛИС с той лишь разницей, что в данном случае все
устройства реализованы в одной микросхеме.
Главное преимущество этого метода заключается в том, что табли-
ца соединений для каждой проектируемой области может быть инди-
видуально подвержена обработке приложением размещения и развод-
ки. Это значит, что каждый член команды может заканчивать свою ра-
боту над устройством с полной уверенностью, что его блок будет
соответствовать временным ограничениям не только после синтеза, но
и после реализации устройства.
Термин «блочное про-
ектирование» иног-
да может относить-
ся к модульному
проектированию.
216 Глава 14. Модульное и пошаговое проектирование
1918 г. Осущест-
влена радиосвязь
между Великобри-
танией и Австра-
лией.
Пошаговое проектирование
Пошаговое проектирование предусматривает наличие интерфейса
между блоками или столбцами и в этом случае позволяет модифици-
ровать RTL какого-либо отдельного блока, затем пересинтезировать
этот блок и локально запустить приложение размещения и разводки
для этого блока. Это намного быстрее, чем перезапуск приложения
размещения и разводки для всего устройства.
На самом деле понятие «локально», возможно, не совсем точно
отражает то, что имеет место в действительности. Очевидно, следова-
ло бы сказать, что пошаговое проектирование «замораживает» все не-
изменённые блоки на своих местах, а переделывает только модифи-
цированный блок или блоки в контексте всего устройства. Этот под-
ход обладает преимуществом над модульными методами
проектирования, в которых другие блоки не участвуют в этой проце-
дуре. При этом данные методы можно использовать в сочетании од-
ного с другим.
Отрицательные стороны
Одна из проблем, присущих описанным в этой главе методам, за-
ключается в том, что их использование может привести к большой
растрате ресурсов, так как во время написания этой книги, наилучшее
разрешение, свойственное этим методам, составляло величину одного
целого столбца. Другими словами, если какой-то функциональный
блок занимает, скажем, 75% логики этого столбца, остальные 25% бу-
дут неиспользованными. Поставщики ПЛИС, поддерживающие по-
добные архитектуры, говорят о некотором механизме, который в буду-
щем позволит поддерживать лучшее разрешение.
Другая проблема заключается в том, что описанные здесь методы
почти обрекают каждый логический блок на реализацию в виде «высо-
кий-и-тонкий», так как они могут состоять только из одного или не-
скольких вертикальных столбцов. Это особенно огорчительно, когда
речь идет о функциональных блоках, которые больше подходят для ре-
ализации в виде «низкий-и-широкий», т. е. при необходимости ис-
пользования небольших частей из нескольких, находящихся рядом
столбцов.
Но, пожалуй, наиболее существенным недостатком первых вер-
сий средств и методов, использующих рассматриваемую архитектуру
для реализации концепции модульного и пошагового проектирова-
ния, является то, что кто-то, скажем системный интегратор, вынуж-
ден вручную создавать компоновочный план устройства. Этому бедо-
лаге предстоит также определить и разместить специальные интер-
фейсные блоки, называемые шинными макроячейками, для связи шин
и передачи индивидуальных сигналов из одного блока в другой
(Рис. 14.4).
Первые версии средств разработки компоновочного плана, оп-
ределения и размещения шинных макроячеек были, мягко гово-
ря, неудобными. Ходят слухи, что в недалёком будущем произой-
дёт замена программного обеспечения, вследствие чего выпол-
нять эти операции станет существенно проще. Хуже, чем есть, не
будет.
Всегда есть выход 217
1919 г. У абонентов
телефонных стан-
ций появилась воз-
можность само-
стоятельно наби-
рать телефонные
номера.
1919 г. Открыт ко-
ротковолновый ра-
диодиапазон.
Всегда есть выход
В главе 10 была рассмотрена концепция виртуальных макетов (про-
тотипов) кристалла. При этом было отмечено, что некоторые постав-
щики САПР электронных систем приступили к поставкам средства,
которые поддерживали концепцию виртуальных прототипов для
ПЛИС посредством планирования компоновки и предварительного,
перед процедурой размещения и разводки, временного анализа. Эти
средства в сочетании с возможностью выполнять операцию размеще-
ния и разводки для индивидуальных блоков устройства, существенно
сокращают время создания устройства1 \
Дело в том, что если вернуться к 10-й главе и перечитать ее, можно
обнаружить, что описанные там средства виртуального макетирования
ПЛИС полностью поддерживают концепцию модульного и пошагово-
го проектирования, причём без недостатков, присущих методам, опи-
санных в этой главе. Проблема заключается только в том, что, будучи
более сложными, средства САПР электронных систем окажутся су-
щественно дороже, чем решения, предлагаемые поставщиками
ПЛИС. Как всегда, действует принцип «кто платит, тот и выбирает».
° Во время написания этой книги ведущим сторонником виртуального маке-
тирования ПЛИС в форме, описываемой в этой книге, являлась компания Hier
Design (www.hierdesign.com).
ГЛАВА 1 5
Примерно с 90-х гг.,
ПЛИС в корпусах
PGA выпускались в
основном для воен-
ных нужд; для ком-
мерческих приложе-
ний использовался
плоский квадрат-
ный пластиковый
корпус PQFR, в ко-
тором контакты рас-
полагались по пери-
метру устройства.
БЫСТРОДЕЙСТВУЮЩИЕ СХЕМЫ
И НЕКОТОРЫЕ СООБРАЖЕНИЯ
ПО ПОВОДУ ПЕЧАТНЫХ ПЛАТ
Предисловие
Читатель, если вы ищете информацию о ПЛИС со встроенными
гигабитными передатчиками последовательного ввода/вывода, это
глава не для вас: вам нужна гл. 21.
Когда мы были молодыми
В недалёком прошлом, где-то в 1990 году, жизнь разработчиков
ПЛИС во многих отношениях была намного проще, чем у наших сов-
ременников. В те безмятежные дни никто и не задумывался о том, до
какой степени проектировщики были озадачены разработкой печат-
ных плат.
Давайте проследим, как развивались события. В те далёкие времена
даже самые мощные ПЛИС содержали всего лишь около 200 выводов,
что ничтожно мало по сегодняшним меркам. Если эти выводы распола-
гались в виде матрицы штырьковых выводов (или PGA — Pin GridArray)'\
то расстояние между ними составляло примерно 1/10 дюйма (2.5 мм),
что по сегодняшним меркам является чудовищно огромным. К тому же,
задержка сигналов при прохождении через подобные ПЛИС, была на-
много больше, чем при прохождении через проводники печатной пла-
ты. Все эти факторы способствовали тому, что методы проектирования
отличались простотой и наглядностью.
Процесс проектирования устройств начинался с работы системных
инженеров, которые вручную, на белой доске или на листе бумаги, со-
здавали приблизительный компоновочный план печатной платы. На
самом деле понятие «компоновочный план» — слишком громкое на-
звание, так как в действительности он представлял собой эскиз, на ко-
тором были изображены основные компоненты и основные соедине-
ния между ними (Рис. 15.1).
Взяв за основу этот компоновочный план, системные инженеры
долго размахивали руками, делали всяческие умные предположения,
и, в конечном итоге, высасывали из пальца некоторые временные ог-
раничения на распространение сигнала от входа до выхода. Вооружив-
шись этими временными ограничениями и спецификациями функций
ПЛИС, системщик, а в то время, как правило, одним устройством за-
нимался только один человек, уходил в подполье для осуществления
своих махинаций.
Вообще говоря, системные инженеры довольно редко заботились о
распределении выводов ПЛИС. Обычно они оставляли это на совести
PGA представляет собой массив выводов, расположенных на нижней по-
верхности корпуса устройства. Печатная плата под такой корпус изготавливалась
с соответствующим набором отверстий. Корпус к плате крепился путём вставки
всех выводов в соответствующие отверстия на печатной плате.
Время перемен 219
Рис. 15.1. Примерный компоновочный план устройства
1919 г. Разработа-
ны принципы триг-
герных схем (уст-
ройств памяти).
программы размещения и разводки, позволяя ей самостоятельно вы-
полнять все операции, и с радостью принимали любое выданное ею
решение.
По завершении проектирования устройства на основе ПЛИС,
включая процедуру распределения выводов, кому-то из разработчиков
поручалось задание по созданию графического обозначения устройс-
тва, которое затем использовалось при разработке принципиальной
схемы. Кроме того, необходимо было создать шаблон микросхемы для
разводки печатной платы. На этих обозначениях указывались наиме-
нования всех физических контактов микросхемы и их физическое рас-
положение для процедуры разводки.
Тем временем разработчики печатной платы продолжали свою ра-
боту, размещая на плате другие устройства и, насколько это было воз-
можно, производили их разводку. После завершения работ по созда-
нию ПЛИС, в том числе после создания графических обозначений,
она интегрировалась на печатную плату и проводилась разводка всей
системы. В итоге нелегкая задача по обеспечению функциональности
всей конструкции ложилась на плечи разработчика печатной платы.
Теперь о грустном. Обычно после «финализации» микросхемы
(ПЛИС) все искренне надеятся, что работа над ней уже завершена. В
действительности, фактически во всех без исключения случаях, как
только разработчик печатной платы заканчивал разводку последнего
проводника, разработчики ПЛИС тут же приступали к переделке того,
что они уже произвели. Реализация этих переделок очень часто приво-
дила к изменению распределения выводов ПЛИС, что до некоторой
степени огорчало разработчиков печатных плат. Нетрудно догадаться,
какие слова они при этом употребляли.
Время перемен
Как это не чудовищно, но эта примитивная последовательность
проектирования, о которой только что шла речь, просуществовала
большую часть 90-х годов. Ее кончина была предрешена размерами и
сложностью современных ПЛИС, поскольку старые методы просто
перестали справляться с нагрузкой.
В то время, когда я работал над этой книгой, ходили слухи о су-
ществовании высокотехнологичной ПЛИС, содержащей 1700 выво-
дов, выполненной в корпусе BGA (Ball Grid Array)^ с расстоянием
между выводами всего лишь 1 мм. Кроме того, современные микро-
220 Глава 15. Быстродействующие схемы и некоторые соображения по поводу печатных плат
1919 г. Вальтер
Шоттки (Walter
Schottky)
разработал
тетрод — первую
многосеточную
вакуумную лампу.
схемы, включая ПЛИС, стали настолько быстрыми по сравнению со
своими предшественниками, что задержка распространения сигнала в
таких микросхемах становится меньше, чем задержка на проводни-
ках печатной платы.
На практике это значит, что системные инженеры больше не могут
назначать временные ограничения ПЛИС произвольным образом и
переадресовывают эту задачу проектировщикам печатных плат, чтобы
в нужный момент всё заработало как надо. Не надо было быть семи пя-
ди во лбу, чтобы понять — этот сценарий также не бог весть что, пос-
кольку не отличался высокой скоростью работы. Теперь процесс раз-
работки необходимо начинать на уровне печатной платы, где ПЛИС
будет рассматриваться как «чёрный ящик» (Рис. 15.2).
Рис. 15.2. Разработчики печатной платы выполняют предварительное
размещение элементов
При этом разработчик печатной платы формирует временные па-
раметры на уровне печатной платы на основе предварительного распо-
ложения элементов. Затем эта информация используется для вычисле-
ния реальных временных ограничений, которые передаются разработ-
чикам ПЛИС. В современных устройствах насчитываются тысячи
таких временных ограничений, и процесс их определения и расстанов-
ки по приоритетам был бы просто невозможным без анализа на уровне
печатной платы.
Не стоит спешить, это только начало. Для уверенности в том, что
разводка микросхемы (ПЛИС) может быть успешно завершена, разра-
ботчик платы должен выполнить начальное распределение сигналов
по контактам ввода/вывода микросхемы. Для выполнения этих задач
для проектировщиков плат стали разрабатывать специальные про-
граммы. Эти средства обеспечивают графическое представление фи-
зических шаблонов микросхем вместе с интерактивным интерфейсом,
° BGA представляет собой массив токопроводящих площадок, расположен-
ный на нижней поверхности корпуса микросхемы. Под него на поверхности пе-
чатной платы изготавливался соответствующий массив токопроводящих площа-
док. На каждой площадке корпуса специальным образом наращивался шарик
припоя. После её правильного расположения над соответствующими площадка-
ми на плате микросхема крепилась к плате путём расплавки припоя, при этом так-
же соединялись между собой площадки на плате и на корпусе.
FPGAXchange 221
который позволяет пользователю объявлять наименования сигналов и
связывать их с определенными контактами устройства0.
Эти программные продукты также обеспечивают автоматическое
создание графических обозначений микросхемы. Если устройство со-
держит 1000 и более выводов, программа разбивает графическое обоз-
начение устройства на несколько частей. Признаком для разбиения
служат банки ввода/вывода ПЛИС или разбиение можно производить-
ся вручную на основе группировки отдельных контактов ввода/вывода.
После того как разработчики печатной платы выполнили эту пред-
варительную работу, возникает необходимость в некотором механиз-
ме, с помощью которого можно передать сформированное ими рас-
пределение выводов микросхемы разработчикам ПЛИС. Это является
физическим ограничением для управления процессом размещения и
разводки. В реальном мире всё ещё возможны итерации, если разра-
ботчикам необходимо выполнить некоторые модификации в первона-
чальном распределении выводов, но такие приёмы встречаются всё ре-
же в сравнении с ужасами прошлых лет, которые были нами только что
рассмотрены.
FPGAXchange
До недавнего времени передача данных между разработчиками пе-
чатных плат и разработчиками ПЛИС обычно включала в себя огромное
количество пользовательских данных. Ситуация изменилась с появле-
нием нового ASCII-формата файла под названием FPGAXchange, кото-
рый был разработан компанией Mentor совместно с другими компания-
ми-поставщиками ПЛИС (FPGA), такими как Altera, Xilinx и другие.
Этот формат позволял использовать для двух средств проектирова-
ния общие определения различных аспектов устройства, таких как,
например, названия сигналов, соответствующих физическим выводам
ПЛИС. Это дает возможность разработчикам ПЛИС легко и быстро
обмениваться данными.
Например, разработчик печатной платы может создать начальное
распределение выводов и, используя FPGAXchange файл, передать их
в качестве ограничений для приложения размещения и разводки
ПЛИС. После этого приступает к разводке печатной платы.
Тем временем разработчик ПЛИС может модифицировать распо-
ложение некоторых выводов микросхемы. Эти изменения будут вклю-
чены в первоначальный FPGAXchange файл, который затем использу-
ется средствами разводки печатной платы для удаления проводников,
связанных с модифицированными выводами. Затем эти проводники
могут быть автоматически или интерактивно переразведены.
Другие элементы проектирования
Быстродействующие схемы
Одно заблуждение относительно термина быстродействие объяс-
няется тем, что под ним подразумевают высокую частоту тактовых им-
пульсов. На самом деле, эффект быстродействия связан с крутизной
фронтов и спадов импульсов. Другими словами, этот процесс опреде-
Во время написания этой книги хорошим примером такого современного
средства был программный продукт BoardLink от компании Mentor
(www.mentor.com).
222 Глава 15. Быстродействующие схемы и некоторые соображения по поводу печатных плат
1921 г. Альберт
Халл (Albert Hull)
изобрёл магнетрон
(микроволновый ге-
нератор).
ляется скоростью перехода импульсов с 0 в 1 и наоборот. При увеличе-
нии крутизны импульсов в большей степени начинают проявлять себя
различные паразитные явления, например, увеличивается уровень шу-
мов, появляются перекрёстные помехи и т. д. Увеличение тактовой
частоты системы также всегда сопровождается увеличением крутизны
фронтов и спадов импульсов. Но многих проблем можно избежать, ес-
ли при тактовой частоте даже в один мегагерц устройство будет харак-
теризоваться высокой скоростью перехода из одного состояния в дру-
гое. В наши дни подавляющее большинство сигналов отличается вы-
сокой крутизной фронтов и спадов.
Анализ искажений сигналов
Большинство поставщиков ПЛИС уже оснащают свои устройства
некоторыми средствами для работы с основными видами искажения
сигналов. Однако в наши дни также возникает необходимость анализа
искажений сигналов на уровне печатной платы. Стоимость лучших
средств такой проверки весьма высока, но они позволяют создавать
работоспособные платы. Поэтому у пользователя есть выбор — или
выполнить анализ искажений сигналов, или просто понадеяться на
удачу.
SPICE и IBIS
Для анализа искажений сигнала на уровне печатной платы можно
использовать так называемые модели SPICE0, но этот процесс может
занять очень много времени. В начале 90-х годов компания Intel разра-
ботала и стала продвигать на рынок пакет IBIS (Input/output buffer
information specification — Спецификация информации о буферах ввода/вы-
вода), который представлял собой формат моделирования, описываю-
щий аналоговые характеристики передающих и приемных узлов.
Причина такой щедрости компании Intel заключалась в нежелании
предоставлять своим покупателям детальные SPICE-модели, так как
они реализовывались на транзисторно-резисторно-конденсаторном
уровне и могли содержать большой объем информации, которую пос-
тавщик компонентов не желал делать достоянием своих конкурентов.
Модели IBIS по своей природе являются поведенческими и скры-
вают от пользователя всю низкоуровневую информацию. Однако они
довольно точны до некоторой максимальной частоты, значение кото-
рой находится в диапазоне от 500 мегагерц до 1 гигагерца. При работе
на более высоких частотах приходится использовать более точные мо-
дели, такие как SPICE.
Еще одна проблема кроется в том, что применяемый язык описа-
ния аппаратных средств должен включать дополнительные расшире-
ния для поддержки новой технологии. Например, IBIS не поддержива-
ет механизм моделирования коррекции предискажений (см. гл. 21). К
тому же, синтаксис IBIS по своей природе не позволяет дополнять его
новыми возможностями, а расширение этого языка с помощью раз-
личных открытых форумов может оказаться длительным и скучным
SPICE (simulation program with integrated circuit emphasis) представляет со-
бой набор программ моделирования для интегральных микросхем. Эти програм-
мы аналогового моделирования развивались в Университете в Беркли, в Калифор-
нии, и стали доступны для широкого использования в начале 70-х.
Другие элементы проектирования 223
процессом. Пока будет найдено решение одной проблемы, новые тех-
нологии породят несколько новых.
В конце 2002 года для расширения IBIS-стандарта был сформули-
рован ряд предложений, которые получили название BIRD75 (при-
ставка BIRD — аббревиатура buffer information resolution document, что
означает документ о буферной информации). Эти предложения позволи-
ли бы вызывать внешние модели для каждого используемого вывода. В
случае принятия этого документа IBIS получит возможность наращи-
вания своих возможностей, так как внешние модели могут быть напи-
саны на языках SPICE, VHDL-AMS, Verilog-A и других.
Стартовая мощность потребления
Некоторые ПЛИС могут предъявлять существенные требования к
источнику питания из-за кратковременного высокого тока потребле-
ния, возникающего в момент включения устройства. Разработчикам
печатной платы необходимо согласовать эти требования с разработчи-
ками ПЛИС, чтобы быть уверенным в способности печатной платы
выдержать необходимую мощность. Это позволит избежать некоторых
проблем.
Применение внутренней согласованной нагрузки
Почти все современные стандарты высокоскоростных систем вво-
да/вывода требуют, чтобы дорожки на печатной плате имели строго
определённое полное (волновое) сопротивление и предусматривали
наличие согласующих резисторов — терминаторов. Правильные зна-
чения полного сопротивления проводников устраняют эффекты отра-
жения и «эха», которые приводят к искажению сигналов и уменьше-
нию производительности системы.
Применение согласующих резисторов, которые являются вне-
шними по отношению к ПЛИС, может потребовать дополнительных
слоёв на печатной плате, что, в свою очередь, приведёт к удорожа-
нию устройства и увеличению времени её разработки. При использо-
вании ПЛИС с сотнями или тысячами выводов задача размещения
такого количества резисторов в непосредственной близости к корпу-
су становится почти невыполнимой (расстояние большее, чем 1 см
от вывода, может стать причиной определённых проблем). Для реше-
ния этой задачи поставщики ПЛИС включают в некоторые микро-
схемы цифровое управления импедансом (DCI — digitally controlled
impedance).
Система управления импедансом устанавливается на входах и вы-
ходах микросхемы и может быть сконфигурирована для поддержки па-
раллельной или последовательной схемы согласования. Значения со-
противлений внутрикристальных резисторов этой системы полностью
определяются пользователем, а их цифровая реализация подразумева-
ет, что величина сопротивления не будет зависеть от изменений темпе-
ратуры или нестабильности источника питания.
На практике существует простое правило, которое гласит: для лю-
бых сигналов с длительностью фронта или спада менее 500 пикосекунд
применение внешних согласующих резисторов вызывает неоднород-
ности в этих сигналах, и в этих случаях для согласования необходимо
использовать внутрикристальные компоненты.
224 Глава 15. Быстродействующие схемы и некоторые соображения по поводу печатных плат
1921 г. Канада-
Америка. Джон
Ларсон (John
Augustus Larson)
изобрёл детектор
лжи.
Параллельная и последовательная передача данных
В электронных системах принято группы бит, которые называются
словами, обрабатывать параллельно, при этом ширина слова зависит
от типа системы. Например, при использовании 8-битного микропро-
цессора или 8-битного микроконтроллера, ширина слова, как это не
удивительно, равна 8 битам.
В прошлом, когда производители сражались за каждый дополни-
тельный вывод на корпусе микросхемы, очень часто в их состав вклю-
чалась функция, называемая универсальным асинхронным приёмопере-
датчиком — УАПП (universal asynchronous receiver transmitter — UART).
При работе с 8-битными словами, если устройство собиралось пере-
дать информацию во внешний мир, УАПП преобразовывал 8-битные
данные внутренней шины в последовательность импульсов для пере-
дачи. Аналогично, если устройству было необходимо произвести чте-
ние внешней информации, УАПП принимал последовательность им-
пульсов, собирал их в 8-битное слово, и выкладывал на внутреннюю
шину. Таким образом, для реализации такого метода в микросхеме тре-
бовалось только 2 вывода — для передачи данных (TXD) и для приема
данных (RXD).
По мере совершенствования технологии изготовления корпусов
увеличение количества выводов стало не таким уж трудным делом, и
для обмена данными всё чаще стали применять целые слова. Для 8-
битной системы в этом случае требовалось восемь проводников на пе-
чатной плате и восемь выводов на каждой микросхеме, подключенной
к этой шине.
Со временем стали повышаться требования к скорости и объему
передаваемой информации. Вследствие этого стала расти ширина ши-
ны: сначала до 16-ти бит, потом до 32-х, потом до 64-х и так далее. В
это же время увеличилась скорость передачи данных: сначала были
единицы мегагерц, потом десятки, затем сотни и тысячи.
С ростом частоты системной шины становилось всё сложнее про-
изводить разводку широких шин на печатной плате с надеждой полу-
чить требуемую информацию с нужного места, в нужное время, и без
искажений сигналов в виде шумов и перекрёстных помех. Таким обра-
зом, в случае проектирования высокоскоростных приложениях разра-
ботчики вернулись к последовательной передаче данных, реализуемой
в виде гигабитных передатчиков, которые более детально будут рас-
сматриваться в гл. 21.
ГЛАВА 1 6
ОТСЛЕЖИВАНИЕ СОСТОЯНИЯ
ВНУТРЕННИХ ТОЧЕК СХЕМЫ В ПЛИС
Отсутствие наглядности
Одна из проблем, связанных с отладкой устройств на программи-
руемых цифровых микросхемах, будь то заказные микросхемы или
ПЛИС, заключается в отсутствии возможности увидеть воочию, что
же происходит внутри устройства. Давайте рассмотрим простую схему
конвейера, состоящую из нескольких регистров и вентилей (Рис. 16.1).
/----- Вход конвейера
Выход конвейера
Рис. 16.1. Схема очень простого конвейера
Очевидно, что в некоторой степени эта схема лишена смысла. Чи-
татель, возможно, будет поражен тем, насколько сложными могут
быть схемы реальных конвейеров и насколько тяжело бывает изло-
жить их в доступном виде. Поэтому схема, изображенная на Рис. 16.1,
удобна для рассмотрения материала этой главы.
Проблема заключается в том, что мы имеем доступ только к входам
и выходам конвейера и не можем увидеть, что происходит у него внут-
ри. В этом и нет необходимости, если разработка устройства заверше-
на и проведены все его испытания. Однако отсутствие наглядности
происходящего внутри конвейера может вызвать головную боль, если
мы пытаемся произвести отладку устройства, чтобы определить, поче-
му оно не выполняет тех функций, которые от него ожидают.
Очевидное решение может быть реализовано путем соединения
внутренних точек схемы с внешними выводами устройства, вследствие
чего обеспечивается доступ к их содержимому (Рис. 16.2).
Трудности реализации этого подхода заключаются в ограниченном
количестве доступных выводов у большинства микросхем. На практи-
ке, у многих ПЛИС-устройств остается незадействованной куча внут-
ренних ресурсов, поскольку, как правило, не хватает свободных выво-
дов, необходимых для передачи сигналов управления и данных в уст-
ройство и из него, даже если мы не будем использовать какие-либо
выводы для доступа к внутренним точкам.
226 Глава 16. Отслеживание состояния внутренних точек схемы в ПЛИС
1921 г. Чешский
писатель Карел
Чапек (Karal
Capek) придумал
понятие робот для
своей пьесы «РУР
— Россумские уни-
версальные
роботы».
1921 г.Для стаби-
лизации частоты
начали применять
кварцевые крис-
таллы.
Рис. 16.2. Подсоединение внутренних точек схемы к внешними выводам
RAO
RA1
RA2
RA3
RBO
RB1
RB2
RB3
RCO
RC1
RC2
RC3
Мультиплексирование
Простое решение описанной выше проблемы заключается в муль-
типлексировании внешних выходов конвейера с внутренними сигна-
лами и в последующей их передаче через одни и те же внешние выводы
(Рис. 16.3).
Внутренние
сигналы
Выходы
конвейера
Сигнал управления
Мультиплексор
Рис. 16.3. Мультиплексирование сигналов
Внешние
выводы
Разумеется, для сигналов управления мультиплексорами потребу-
ются отдельные выводы. В нашем примере два сигнала управления на-
прямую соединены с внешним миром, и для этого потребуется два вы-
вода. Однако можно использовать несколько вентилей для реализации
простого конечного автомата, который потребует только одного выво-
да для переключения состояний мультиплексора, причем каждому со-
стоянию будет соответствовать определенный набор сигналов.
Специальные цепи отладки 227
Основное преимущество этой схемы заключается в большой степе-
ни наглядности и относительно высокой скорости работы. Недостат-
ком является отсутствие гибкости и трудоёмкость реализации, так как
если поменять точку наблюдения, придётся модифицировать исход-
ный код устройства и произвести повторный синтез. Аналогично, если
изменить режим переключения триггера(ов), используемый в конеч-
ном автомате для определения наборов сигналов, выбираемых мульти-
плексором в определенное время, также придётся изменить исходный
код устройства.
Другой недостаток заключается в том, что, если после отладки уст-
ройства удалить тестовые структуры из исходного кода, могут возник-
нуть новые проблемы, например может измениться разводка элемен-
тов ПЛИС и, как следствие, величина задержек сигналов.
Специальные цепи отладки
Некоторые ПЛИС содержат специальные цепи отладки, позволя-
ющие вести наблюдение за внутренними точками. Например, микро-
схема фирмы Actel содержит два специальных вывода, называемых
PRA («Probe А» — «пробник А») и PRB («Probe В» — «пробник В»). С
помощью встроенной отладочной цепи вместе со специальным отла-
дочным программным обеспечением0 на эти выводы можно подать
любые внутренние сигналы и провести анализ состояния в различных
точках схемы устройства.
Основное преимущество такого подхода заключается в том, что ис-
ключается необходимость изменять исходный код устройства. Однако
двух тестовых выводов не достаточно для полноценных исследований,
так как анализу порой должны быть подвергнуты сотни тысяч внут-
ренних сигналов.
Виртуальный логический анализатор
Кроме рассмотренной выше весьма полезной схемы, довольно час-
то возникает необходимость в средствах обширного логического ана-
лиза, позволяющих отслеживать и производить отладку групп внут-
ренних сигналов, производить анализ одних сигналов относительно
других или относительно определённых событий. В этом случае ре-
шить проблему можно с помощью внутрикристальных инструменталь-
ных средств (OCI — On-chip instrumentation), которые упрощают логи-
ческую отладку устройства, позволяя пользователю встраивать диа-
гностические блоки интеллектуальной собственности в свои
устройства, например, можно встроить виртуальный логический ана-
лизатор. Идея заключается в использовании некоторого количества
ресурсов ПЛИС для реализации одного или нескольких блоков вирту-
ального логического анализа, фиксирующих активность заданных сиг-
налов. Эти данные могут быть сохранены в одном или нескольких бло-
ках встроенного ОЗУ ПЛИС, доступ к содержимому которых может
быть получен с помощью внешнего программного обеспечения через
JTAG-порт устройства (Рис. 16.4).
Часть виртуального логического анализатора используется для оп-
ределения состояния специальных управляющих сигналов, с помо-
1922 г. Начало ра-
боты коммерческо-
го радиовещания
(по цене 100$ за 10-
минутный репор-
таж).
1923 г. Появилась
первая неоновая
рекламная вывеска.
0 Это программное обеспечение раньше называлось Actionprobe®. Затем поя-
вилась «новая и улучшенная» версия Silicon Explorer. Во время написания этой
книги наибольшей популярностью пользовалась версия Silicon Explorerll.
228 Глава 16. Отслеживание состояния внутренних точек схемы в ПЛИС
1923 г. Разработа-
на первая фото-
электрическая
ячейка.
1923 г. Осущест-
влен первый сеанс
радиосвязи ко-
рабль-корабль.
Состояния
старт/стоп
на триггерах
JTAG (от внешней программы
виртуального логического анализа
Наблюдаемые
сигналы
Рис. 16.4. Виртуальный логический анализатор
щью которых производится включение и выключение режима захвата
данных с наблюдаемых сигналов.
В зависимости от типа используемого виртуального логического
анализатора, либо придётся, либо не придётся модифицировать исход-
ный код устройства для включения этой функциональности. Сущест-
венное преимущество схемы данного типа заключается в том, что даже
при включении специальных макросов в исходный код системы реа-
лизация чрезвычайно сложных возможностей отладки не вызовет ка-
ких-либо трудностей.
В некоторых случаях поставщики ПЛИС сами предлагают такие
возможности отладки. Хорошим примером средств этого типа могут
служить продукты Chipscope™ Pro компании Xilinx (www.xilinx.com) и
SignalTap® II компании Altera (www.altera.com). Вместе с тем, при ра-
боте с устройством, не содержащим встроенных возможностей отлад-
ки, можно обратиться к сторонним разработчикам, например к компа-
нии First Silicon Solutions Inc. (www.fs2.com), которая специализирует-
ся на внутрикристальных инструментальных средствах и средствах
отладки для ПЛИС-логики и встраиваемых процессоров.
В качестве виртуальных логических анализаторов, используемых
для трассировки, анализа и отладки внутренних сигналов ПЛИС, ком-
пания First Silicon Solutions предлагает конфигурируемые модули логи-
ческого анализатора (CLAM — configurable logic analyzer module). Эти ма-
ленькие штучки состоят из блоков внутрикристальных инструмен-
тальных средств, описанных на языках Verilog или VHDL, которые
конфигурируются и синтезируются как часть устройства. Этот блок
(или блоки, если использовать несколько штук) используется совмест-
но с программным обеспечением управления, тестирования и отобра-
жения информации, установленном на персональном компьютере.
VirtualWires
В начале 90-х компания Virtual Machine Works обнародовала свою
новую технологию под названием VirtualWire™. Изначально представ-
ленная как технология производства больших устройств, для реализа-
VirtualWires 229
ции которых приходится использовать несколько ПЛИС, VirtualWire
подготовила почву для различных эмуляторов на основе ПЛИС. Одна
из причин, по которой данная технология упоминается в этой главе,
заключается в том, что она представляет собой некое подобие рассмот-
ренному ранее методу мультиплексирования. Еще одна причина кро-
ется в том, что это действительно очень хорошее решение.
Проблема
Технология VirtualWire применяется в больших устройствах, размер
которых не позволяет разместить их в одной ПЛИС, и поэтому реали-
зацию столь больших устройств приходится разделять на несколько
микросхем. В качестве простого примера рассмотрим устройство, ко-
торое эквивалентно некоторому количеству системных логических
элементов, но наибольшая из ПЛИС содержит только половину требу-
емого количества таких элементов. Очевидно, что в этом случае уст-
ройство будет состоять из двух микросхем (Рис. 16.5).
1925 г. Америка.
Учёный, инженер
и политик Ваневар
Буш (Vannevar
Bush) сконструиро-
вал аналоговый
компьютер, на-
званный Product
Intergraph.
1925 г. На терри-
тории США начал
работать коммер-
ческий сервис по
передаче изобра-
жений/факсов
по радиоканалу.
Рис. 16.5. У микросхем не хватает выводов, если мы пытаемся разделить
конструкцию на два устройства
На Рис. 16.5 логика показана в виде нескольких субблоков, обозна-
ченных латинскими буквами от Адо Н. Такое обозначение использо-
вано исключительно для наглядности метода разбиения устройства.
Недостатком такой реализации является то, что микросхемы обыч-
но не располагают требуемым количеством выводов для удовлетворе-
ния потребностей во внешних входах и выходах схемы, а также для
связи между различными блоками устройства. Методы, предшествую-
щие технологии VirtualWire или аналогичные предусматривали разбие-
ние конструкции на большее количество частей (Рис. 16.6).
В этом случае возникает очередная проблема, связанная с тем, что
огромная часть логических ресурсов ПЛИС остается не задействован-
ной, и в результате для реализации требуемой функциональности уст-
ройства потребуется довольно много микросхем.
230 Глава 16. Отслеживание состояния внутренних точек схемы в ПЛИС
1926 г. Америка.
Джулиус Лилиен-
филд (Dr. Julius
Edgar Lilienfield) из
Нью-Йорка полу-
чил патент, со-
гласно которому
теперь нам необхо-
димо получать раз-
решение на приме-
нение п-р-п-тран-
зистора в качест-
ве усилителя.
Внешние входы
схемы
Внешние входы
схемы
К ПЛИС
(микросхемам)
5,6,7, и 8
Рис. 16.6. Неиспользованные ресурсы ПЛИС при разбиении устройства на части
Решение VirtualWire
Чтобы понять, как VirtualWire способна решить эту проблему, рас-
смотрим сначала экзотический случай, когда имеются очень странные
микросхемы всего лишь с тремя выводами, из которых 2 вывода — это
входы, причём один используется для синхронизации, а третий — это
выход. В этом случае, по всей видимости, в каждой микросхеме можно
использовать незначительное количество логических ресурсов
(Рис. 16.7).
ПЛИС (п) ПЛИС (п + 1)
Рис. 16.7. ПЛИС с тремя выводами
Идея, заложенная в основе технологии VirtualWire, заключается в
следующем: поскольку огромное количество внутренних ресурсов уст-
ройства тратится в пустую, часть из них можно было использовать для
реализации специальных цепей. Эти цепи позволят переключать
единственный вход микросхемы между несколькими регистрами, каж-
дый из которых подключен к определённому логическому блоку. Вы-
ходы этих логических блоков могут быть также мультиплексированы, а
выходное значение сохранено в регистре (Рис. 16.8).
В схеме на Рис. 16.8 тактовые сигналы заменены виртуальными так-
товыми сигналами, при этом один системный такт делится на несколь-
ко виртуальных тактов. Кроме того, внутри каждой ПЛИС реализован
VirtualWires 231
ПЛИС (п)
ПЛИС (п + 1)
Системные
Виртуальные
тактовые сигналы
Рис, 16,8, Простой пример технологии VirtualWire
конечный автомат, который используется для включения/выключения
регистров, управления мультиплексорами и для других целей. Разумеет-
ся, Рис. 16.8 приведён не в масштабе: конечные автоматы и другие
структуры VirtualWire на самом деле потребляют относительно неболь-
шое количество логических ресурсов в каждой микросхеме по сравне-
нию с логическими блоками, которые выполняют основные задачи.
С поступлением каждого виртуального тактового сигнала конеч-
ные автоматы внутри всех ПЛ ТС включают определённые регистры,
выход которых подключен к входу соответствующих логических бло-
ков. Вследствие этого данные с входа микросхемы записываются в эти
регистры и передаются в соответствующие логические блоки. В это же
время конечный автомат выдаёт команды мультиплексору, который
подключает выход одного из логических блоков к выходному регистру
и сохраняет в нём результаты работы. Выход регистра подключен к вы-
ходу микросхемы, который, в свою очередь, подключен к входу другой
ПЛИС и так далее по цепочке.
Конечно же, в реальном мире ПЛИС имеют сотни или даже тыся-
чи выводов. Следовательно, каждый вход может быть подключен к не-
скольким логическим блокам, и к каждому физическому выходу с по-
мощью мультиплексора VirtualWire также могут быть подключены не-
сколько логических блоков. Не будем продолжать эту длинную
историю, в завершении лишь заметим, что рассмотренные методы
стремительно развиваются и усложняются, но принципы, заложенные
в их основу, остаются неизменными.
И последнее, но не менее важное. Ключевым элементом концеп-
ции VirtualWire является компилятор, который берёт начальное описа-
ние устройства в виде таблицы соединения вентилей, разбивает её на
несколько ПЛИС, автоматически формирует конечные автоматы и
другие структуры VirtualWire, после чего генерирует конфигурацион-
ные файлы, предназначенные для загрузки в каждую ПЛИС.
1926 г. Америка.
Разработан пер-
вый тостер.
1926 г. Произведе-
на передача первого
факсимильного со-
общения по радио-
каналу через Ат-
лантику.
1926 г. Джон Лоу-
ган Бэрд (John
Logie Baird) проде-
монстрировал ра-
боту электромеха-
нической телевизи-
онной системы.
1927 г. Изобретена
пятиэлектродная
вакуумная лампа
(пентод).
ГЛАВА 1 7
БЛОКИ ИНТЕЛЛЕКТУАЛЬНОЙ
СОБСТВЕННОСТИ
Источники блоков интеллектуальной
собственности
Не секрет, что современные ПЛИС настолько большие и сложные,
что было бы весьма непрактично создавать каждую часть устройства с
чистого листа. Одно из решений этого вопроса, дабы не изобретать ве-
лосипед, заключается в использовании в новом устройстве уже кем-то
созданных и существующих функциональных блоков общего назначе-
ния. При этом основную массу времени и ресурсов можно потратить
на разработку новых изысканных частей нового устройства, которые
будут составлять некую «неожиданную изюминку» и выгодно отличать
собственное устройство от предложений конкурентов.
Существующие функциональные блоки представляют собой, как пра-
вило, блоки интеллектуальной собственности (IP). Эти блоки можно: со-
здать самим на основе ранее разработанных устройств, использовать гото-
вые решения поставщиков ПЛИС или использовать наработки сторонних
разработчиков. В этой главе будут рассматриваться два последних решения.
Ручная работа
Блоки интеллектуальной собственности могут создаваться и рас-
пространяться по-разному. Один из вариантов заключается в том, что
поставщик IP может создавать их вручную и распространять в виде
RTL-описания. В этом случае существует несколько способов, с помо-
щью которых конечный пользователь может купить и использовать
эти блоки (Рис. 17.1). Как будет показано, поставщик этих блоков так-
же может использовать специальные приложения, генерирующие бло-
ки или ядра интеллектуальной собственности.
Незашифрованные RTL-описания
В некоторых случаях разработчики устройств на основе ПЛИС мо-
гут купить блоки интеллектуальной собственности в виде блоков неза-
шифрованного исходного кода уровня регистровых передач (исходно-
го RTL-кода). Эти блоки впоследствии могут быть интегрированы в
RTL-код разрабатываемого устройства (Рис. 17.1, а). Перед тем как
продать исходные коды своих блоков IP поставщик IP производит их
моделирование, синтез и верификацию.
Как правило, это весьма дорогой вариант, поскольку поставщики
блоков интеллектуальной собственности обычно не хотят, чтобы кто-
то видел исходный код их решений. Со своей стороны, поставщики
ПЛИС в большинстве случаев неохотно предоставляют незашифро-
ванный RTL, так как они не хотят, чтобы чья-либо модификация их
кода лила воду на мельницу конкурента. Поэтому, если пойти таким
путем, надо быть готовым к тому, что, во-первых, любой из поставщи-
ков непременно заломит цену, и, во-вторых, придется подписать все
виды лицензий и соглашений о конфиденциальности.
Ручная работа 233
Разработчик
Поставщик IP
Создание RTL-описания
для блока IP
Разработка RTL-описания
устройства
на основе ПЛИС
- ........I....... .
Встраивание
блока(ов)1Р
____ 4 .
Таблица соединений
до размещения
и Разводки л
Синтез
Таблица соединений
доразмещения
ираэдодки
Встраивание
блока(ов) IP
“Т—
Рис, 17,1, Варианты приобретения блоков интеллектуальной собственности
Обладание незашифрованной версии RTL-кода какого-то блока
интеллектуальной собственности имеет одно важное преимущество,
такое как возможность его модификации, чтобы удалить из него не-
нужные функции или, при необходимости, добавить новые. Можно ку-
пить код блока IP у стороннего разработчика, а не у поставщика ПЛИС.
В этом случае его можно просто и быстро изменить и приспособить для
различных устройств, причём от разных поставщиков. Существенный
недостаток этого метода заключается в том, что итоговая реализация
устройства обычно менее эффективна с точки зрения потребляемых
ресурсов и производительности, чем при использовании оптимизиро-
ванных версий, представленных на уровне таблиц соединений.
Шифрованные RTL-описания
К сожалению, во время написания этой книги не существовало ме-
тодов стандартного промышленного шифрования для RTL-описаний,
которые пользовались бы широкой популярностью. Поэтому такие
компании, как Altera и Xilinx, разработали свои собственные схемы и
средства шифрования. Не удивительно, что эти средства работали со
средствами синтеза только одного и того же разработчика (также иног-
да с пакетом синтеза стороннего разработчика, который предоставлял-
ся в виде OEM-версии поставщиком ПЛИС).
Таблица соединений до размещения и разводки
Возможно, наиболее часто разработчики ПЛИС-устройств поку-
пают средства интеллектуальной собственности в виде таблиц соеди-
нений КЛБ/таблиц соответствия, выполненных до этапа размещения
и разводки элементов (Рис. 17.1, б). Такие таблицы обычно поставля-
ются в зашифрованном виде в EDIF-формате (electronic data
interchange format — формат электронного обмена данными) либо в
формате поставщика ПЛИС.
234 Глава 17. Блоки интеллектуальной собственности
В этом случае поставщик IP может также предоставлять своим
пользователям откомпилированные потактные (cycle-accurate) C/C++
модели для функциональной верификации, так как их моделирование
будет выполняться намного быстрее, чем это делают их аналоги, вы-
полненные на уровне таблиц соединений КЛБ/таблиц соответствия.
К преимуществам рассмотренного подхода можно отнести то, что
поставщик блоков интеллектуальной собственности часто выполняет
огромное количество настроек средств синтеза, а некоторые блоки
функций разрабатывает вручную, чтобы достичь оптимальной реали-
зации с точки зрения использования ресурсов и производительности.
К недостаткам этих методов можно отнести отсутствие возможности
для разработчиков ПЛИС-устройств убрать из кода неиспользуемые
функции. К тому же, такие блоки IP привязаны к устройствам опреде-
лённого семейства конкретного поставщика ПЛИС.
Таблица соединений после размещения и разводки
В некоторых случаях разработчики ПЛИС-устройств могут приоб-
рести блоки интеллектуальной собственности в виде таблиц соедине-
ний КЛБ/таблиц соответствия, прошедшие процедуру размещения и
разводки (Рис. 17.1, в). Повторюсь, такие таблицы обычно поставля-
ются в зашифрованном виде в EDIF-формате либо в формате постав-
щика ПЛИС.
Блоки, прошедшие процедуру размещения и разводки достигают
наивысшего уровня производительности. В некоторых случаях разме-
щение элементов в этих решениях может быть относительным. Други-
ми словами, расположение всех таблиц соответствия, конфигурируе-
мых логических блоков и других элементов, формирующих блок ин-
теллектуальной собственности, является фиксированным только по
отношению друг к другу, но сам блок как единое целое может быть рас-
положен внутри ПЛИС в любом доступном месте. В некоторых случа-
ях для блоков IP, например, реализующих функции протоколов связи
или шинного обмена со специфическими требованиями к контактам
ввода/вывода, может понадобиться абсолютное расположение на по-
верхности кристалла, которое уже невозможно изменить.
Снова повторюсь, поставщики блоков IP также могут предостав-
лять своим пользователям откомпилированные потактные C/C++ мо-
дели, используемые для функциональной верификации, так как их мо-
делирование будет выполняться намного быстрее, чем аналогов, вы-
полненных на уровне таблиц соединений КЛБ/таблиц соответствия.
Генераторы ядер IP
На практике поставщики ПЛИС (и иногда поставщики САПР,
блоков IP и даже небольшие независимые разработчики) обычно
предлагают специальные средства, которые функционируют как гене-
раторы блоков или ядер интеллектуальной собственности. Эти, как
правило, параметризируемые приложения позволяет задавать различ-
ные параметры генерируемых блоков, например, разрядность шин и
функциональных элементов.
Сначала необходимо выбрать из списка нужные блоки (или ядра) и
для каждого блока задать все параметры. Для отдельных блоков гене-
ратор может позволить выбрать из списка функциональные элементы,
которые желательно включить или, напротив, исключить из состава
окончательной версии. Например, для коммуникационных блоков
можно включить или исключить логические элементы, используемые
Разное 235
для проверки ошибок. Для микропроцессорного ядра можно отклю-
чить использование некоторых команд или режимов адресации. Эти
возможности позволят генераторам создавать более эффективные бло-
ки IP с точки зрения потребления ресурсов и производительности.
В зависимости от типа приложения-генератора (или от типа лицен-
зии, которую вы подписали) блоки интеллектуальной собственности мо-
гут формироваться в виде зашифрованного или нешифрованного RTL-
кода, в виде таблицы соединений, не прошедшей процедуру размещения
и разводки или таблицы соединений, прошедшей процедуру размеще-
ния и разводки. В некоторых случаях генератор может также создавать
потактную C/C++ модель для средств моделирования (Рис. 17.2).
1927 г. Впервые
осуществлена пуб-
личная демонстра-
ция удалённого те-
левизионного веща-
ния с помощью
диска Нипкова.
Разное
В последнее время ведущие поставщики ПЛИС начали продвигать
на рынок специальные утилиты — генераторы систем. Эти средства по
существу представляют собой наборы блоков интеллектуальной собс-
твенности, которые позволяют пользователю быстро построить очень
сложные устройства, используя различные блоки IP определённого
поставщика ПЛИС.
Утилиты системной разработки формируют таблицу соединений
системы в некоторой абстрактной форме (в отличие от создания де-
тального RTL кода конечным пользователем). Эти средства стремятся
изменить модель ПЛИС-устройства путем создания парадигм на сис-
темном уровне, в дополнении стандартным этапам RTL-проектирова-
ния. Эта концепция представляет интерес для разработчиков, которые
не разрабатывают RTL-код или работают на более высоких уровнях
абстракции (смотрите также главу 12).
Помимо проектирования генераторов систем поставщики ПЛИС
работают над упрощением использования блоков интеллектуальной
собственности и встраивают поддержку проектирования на основе ис-
пользования блоков интеллектуальной собственности в свои интегри-
рованные среды разработки (IDE — Integrated Development Environment).
Некоторые блоки IP, которые раньше были «программными» бло-
ками, теперь воплощаются в виде аппаратных структур. Например,
большинство представителей современных ПЛИС содержат аппарат-
ные процессорные ядра, системы синхронизации, контроллеры
Ethernet, гигабитные блоки ввода/вывода и так далее. Эти средства
позволяют перенести высокотехнологичные функции, реализованные
на заказных микросхемах, в область ПЛИС. Вероятно, со временем в
ПЛИС также появятся и другие высокотехнологичные функции.
ГЛАВА 1 8
ПЕРЕХОД ОТ ЗАКАЗНЫХ МИКРОСХЕМ
К ПЛИС И НАОБОРОТ
Сценарии проектирования
Существует несколько сценариев проектирования электронных
систем с применением ПЛИС (Рис. 18.1).
Рис, 18,1, Сценарии проектирования
Только ПЛИС
Этот сценарий относится к устройствам, предназначенным для ре-
ализации только на основе ПЛИС. В этом случае могут быть использо-
ваны любые, упоминаемые в этой книге, методы и средства проекти-
рования.
ОтПЛИСкПЛИС
Такой подход подразумевает переход от уже существующего уст-
ройства на основе ПЛИС к ПЛИС, изготовленной по новой техноло-
гии. Новая технология очень часто выступает в форме нового семейс-
тва микросхем от того же поставщика, что и существующая микросхе-
ма, но также можно перейти и к микросхемам другого производителя.
При развитии событий по такому сценарию довольно редко имеет
место переход от одного устройства к другому по принципу 1:1, т. е.
просто взять содержимое одного компонента и реализовывать его в
другом. Наиболее часто такой переход осуществляется в виде перехода
от нескольких ПЛИС к одному новому. Также можно собрать функци-
ональность одной или нескольких существующих ПЛИС, добавить к
ней окружающую дискретную логику и реализовать всё в одном новом
устройстве.
В подобных случаях обычно собирают в одно целое RTL-описания
всех существующих устройств и дискретной логики, настраивают по-
лученный код для улучшения отдельных характеристик схемы, и затем
его вновь синтезируют в одно новое устройство.
Разное 237
От ПЛИС к заказной микросхеме
Под переходом от ПЛИС к заказной микросхеме (ASIC) обычно
понимают использование одной или нескольких ПЛИС в качестве
прототипа устройства на основе заказной микросхемы. При этом, если
пользователь работает не с малыми или средними заказными микро-
схемами, часто возникает необходимость разделить устройство на не-
сколько ПЛИС. Некоторые поставщики ПЛИС и САПР электронных
систем предлагают (или предлагали) приложения, которые выполняют
такое разбиение автоматически!), но эти средства появляются и исче-
зают с завидной регулярностью. Их характеристики, возможности и
качество работы также меняются почти каждую неделю (другими сло-
вами, вам придётся самостоятельно оценить предлагаемые решения и
сделать свой выбор).
Некоторые функции, такие как очереди FIFO или блоки двухпор-
товой памяти, имеют довольно-таки специфичную реализацию, если
они формируются из блоков ОЗУ, встроенных в ПЛИС. Способы реа-
лизации этих функций обычно отличаются от тех, которые использу-
ются при реализации заказных микросхем, что может послужить при-
чиной некоторых проблем. Решение этого вопроса заключается в со-
здании своей собственной RTL-библиотеки функций заказных
микросхем, таких как умножители, компараторы, блоки памяти и так
далее, которые будут полностью соответствовать своим ПЛИС-анало-
гам. К сожалению, такой подход подразумевает реализацию этих эле-
ментов в пользовательском устройстве в виде отдельного RTL-кода,
вместо того чтобы взять универсальный RTL-код всего устройства и
позволить все сделать алгоритму синтеза. Своего рода уравновешива-
ющее действие, как и многие другие, используемые в проектировании.
Как уже отмечалось в гл. 7, устройство, предназначенное для реа-
лизации с помощью ПЛИС, обычно содержит меньшее количество
уровней логики (последовательно соединенных логических вентилей)
между регистрами, чем при реализации на основе заказной микросхе-
мы. В некоторых случаях целесообразно создать RTL-код устройства,
предназначенный для реализации на основе заказной микросхемы и
пойти на уменьшение производительности ПЛИС-прототипа.
Можно также сгенерировать два варианта RTL-кода, один для ис-
пользования в ПЛИС-прототипе, а другой для конечного устройства
на основе ASIC. Но, как правило, это решение может стать причиной
многих проблем, так как в двух представлениях довольно легко поте-
рять синхронизацию и прийти в итоге к двум совершенно разным ре-
зультатам.
В этом случае могут использоваться средства, основанные на чис-
той версии языка C/C++, которые были рассмотрены в гл. 11. Напом-
ню, что идея состоит в том, чтобы не вручную добавлять информацию
о реализации в исходный RTL-код (таким образом делая его зависи-
мым от конкретной реализации), а все информацию формировать
(синтезировать) с помощью управляемой пользователем C/C++ ма-
шиной (алгоритмом) синтеза (Рис. 18.2).
После обработки исходного кода средствами синтеза, его можно
использовать для формирования микроархитектурных компромиссов
и затем оценить их с точки зрения размеров и скорости. Пользователь-
ская конфигурация для каждого возможного сценария может быть
Хорошим примером приложения, которое предлагает подобную функцио-
нальность, является пакет Certify® от компании Synplicity (www.synplicity.com).
238 Глава 18. Переход от заказных микросхем к ПЛИС и наоборот
Взаимодействие
с пользователем
и управление пользователем
Чистый C/C++ ->
Синтез
на основе
чистого C/C++
— Не зависим от реализации
— Легко создавать
— Быстро моделировать
— Легко модифицировать
RTL Verilog/
VHDL
Verilog/
VHDL RTL
RTL
синтез
. соединений КЛБ/
* таблиц
соответствия
Генерируются автоматически,
зависимые от реализации
RTL
синтез
Таблица
вентилей
Рис. 18.2. Проектирование на основе «чистой» версии языка C/C++
именована, сохранена и, при необходимости, повторно использована.
Следовательно, сначала можно создать конфигурацию для ПЛИС-
прототипа и после проверки создать второй её вариант для оконча-
тельной реализации в ASIC. Суть состоит в том, что один и тот же ис-
ходный код C/C++ может использоваться в обеих цепочках проекти-
рования.
Следующая особенность заключается в том, что современные за-
казные микросхемы могут содержать невообразимо большое количес-
тво зон (доменов) и подзон синхронизации (речь идёт о сотнях таких
зон и подзон). В отличие от них, количество зон первичной синхрони-
зации в ПЛИС ограничено (около 10). Это значит, что при использова-
нии одной или нескольких микросхем ПЛИС для создания прототипа
заказной микросхемы, надо хорошенько продумать организацию сис-
темы синхронизации.
И в завершении замечу, что существует интересный Европейский
патент под номером ЕР0437491 (В 1), при чтении которого — о, ужас,
какой он нудный — кажется, что возможность использования не-
скольких программируемых устройств, таких как ПЛИС, для реализа-
ции прототипов ASIC, сильно преувеличена. В действительности, как
я думаю, этот патент, вероятно, описывал применение ПЛИС для со-
здания логического эмулятора, но был сформулирован таким образом,
что стал препятствовать использованию нескольких ПЛИС в качестве
прототипа заказной микросхемы.
qgF3 Когда данная книга уже буквально была готова к изданию, компа-
ния Synopsys (www.synopsys.com) заявила о создании ПЛИС-опти-
мизированной версии Design Compiler FPGA (DC FPGA), в основе ко-
торой лежал хорошо известный алгоритм синтеза заказных
микросхем Design Compiler® (DC ASIC). Кроме того, этот компиля-
тор поддерживал весьма интересные нововведения, которые назвали
Adaptive Optimization™ Technology. Главное его достоинство состояло
в том, что DC ASIC и DC FPGA могут использовать один и тот же
исходный RTL-код для создания одного и того же устройства с по-
мощью и ПЛИС и заказных микросхем. Каждое программное ядро
может быть настроено на использование различных микроархитек-
турных схем, таких как распределение ресурсов и конвейерная обра-
ботка. Кроме того, компилятор для ПЛИС может выполнять автома-
тическое преобразование любых, ориентированных на заказные
микросхемы, встроенных функций в код RTL. Поэтому DC FPGA и
DC ASIC знаменуют собой значительное событие в контексте ис-
пользования ПЛИС как прототипов устройств на основе заказных
микросхем.
Разное 239
От заказной микросхемы к ПЛИС
Этот сценарий подразумевается перевод устройства, реализованно-
го на основе заказной микросхемы, к реализации на основе ПЛИС.
Причин для этого может быть много, но очень часто преследуется цель
усовершенствовать существующую функциональность устройства на
основе заказной микросхемы без существенных финансовых затрат.
Иногда первоначальная технология, по которой изготавливалась ASIC,
может устареть, но устройства, в которых используется данная микро-
схема, всё ещё востребованы для поддержки текущих контрактов (осо-
бенно часто это встречается в военной сфере). Интересно, что послед-
нее поколение ПЛИС обычно настолько далеко вырывается вперёд, что
в одной такой микросхеме возможно разместить целиком все устройс-
тво, использующее заказную микросхему, разработанную несколько лет
назад (при разбиении устройств на несколько ПЛИС можно воспользо-
ваться некоторыми средствами автоматизации, облегчающими эту зада-
чу, как описывалось в подразделе «От ПЛИС к заказной микросхеме»).
Прежде всего, необходимо тщательно просмотреть RTL-код, что-
бы удалить или, по крайней мере, оценить, всю асинхронную логику,
комбинационные петли, цепи задержки и другие подобные им блоки
(см. гл. 7). Если в устройстве используются триггеры с входами как ус-
тановки, так и сброса, можно изменить их и использовать только один
из этих входов (см. гл. 7). Необходимо также найти все защёлки и пере-
делать схемы под использование триггеров. Кроме того, следует про-
анализировать выражение вида if-then-else, в которых отсутствует
конструкция else, так как в этом случае средства синтеза будут встав-
лять в описание устройства защёлку (см. гл. 9).
Что касается средств синхронизации, необходимо убедиться, что
выбранная ПЛИС поддерживает достаточное количество зон синхро-
низации, чтобы удовлетворить требования заказной микросхемы, в
противном случае придётся переделать имеющиеся цепи синхрониза-
ции. Кроме того, если заказная микросхема использует методы стро-
бирования тактовых сигналов, следует исключить их из нового уст-
ройства и, по возможности, заменить средствами разрешения такто-
вых сигналов (см. гл. 7). Повторюсь, что некоторые поставщики
ПЛИС и САПР электронных систем предоставляют средства синтеза,
которые могут автоматически преобразовывать устройства на основе
ASIC, использующие методы стробирования тактовых сигналов, в их
ПЛИС-эквиваленты, использующие разрешение тактовых сигналов0.
При использовании сложных функциональных элементов, напри-
мер блоков памяти (очередей FIFO и двухпортовых блоков ОЗУ), ве-
роятно, вам придётся подстроить RTL-код под особенности ПЛИС. В
некоторых случаях придётся заменить некоторые стандартные опера-
торы RTL-кода (которые будут обрабатываться алгоритмом синтеза)
на вызовы специфичных фрагментов схем или элементов ПЛИС.
И в завершении замечу, что конвейеры, реализованные в заказной
микросхеме, вероятно, имеют большее число уровней логики между
регистрами, чем при реализации на ПЛИС, если желательно сохра-
нить её производительность. Большинство современных средств логи-
ческого и физического синтеза поддерживают возможности восста-
новления синхронизации, которые позволяют им передвигать логику
1927 г. Харолд
Стивен Блэк
(Harold Stephen
Black) предложил
идею использования
отрицательной об-
ратной связи, бла-
годаря которой
стало возможным
создание усилите-
ля Hi-Fi класса.
Хорошим примером приложения, которое обеспечивает решение задач это-
го рода, может служить пакет Amplify® от компании Synplicity
(www.synplicity.com).
240 Глава 18. Переход от заказных микросхем к ПЛИС и наоборот
1927 г. Америка.
Фило Фарнзуэрт
(Philo Farnsworth)
собрал полную элек-
тронную телевизи-
онную систему.
вперёд и назад по конвейеру через регистровые границы для достиже-
ния лучших временных показателей. С этой работой обычно лучше
справляется алгоритм физического синтеза (см. гл. 19).
Наверняка не ошибусь, если скажу, что современная ПЛИС, веро-
ятно, изготовлена с использованием более современной технологии
(например, изготовлена по технологии 130 нм), чем заказная микро-
схема в существующем устройстве (например, изготовлена по техноло-
гии 250 нм). Это даёт ПЛИС определённые преимущества в скорости,
что компенсирует более существенную задержку сигнала на проводни-
ках. И в завершении заметим, что, возможно, все равно, придётся до-
водить настройку кода вручную, чтобы добавить в конвейер дополни-
тельный элемент.
ГЛАВА 1 9
СРЕДСТВА МОДЕЛИРОВАНИЯ,
СИНТЕЗА, ВЕРИФИКАЦИИ
И РЕАЛИЗАЦИИ
Введение
Для ввода, верификации, синтеза и реализации своих проектов ин-
женерам-разработчикам обычно приходится использовать огромное
количество разнообразных средств. Даже краткое описание всех этих
средств вылилось бы не в одну книгу1 \ Поэтому мы ограничимся рас-
смотрением лишь наиболее важных из них в контексте разработки уст-
ройств на основе ПЛИС, включая:
• средства моделирования на основе циклов, событий и другие;
• средства синтеза логического/HDL и физического;
• средства общей верификации;
• средства формальной верификации;
• другие средства.
Типы моделирования
Событийное моделирование
Сегодня логическое моделирование является одним из главных инс-
трументов проверки, или верификации, в арсенале инженера. Наиболее
распространенной формой логического моделирования является собы-
тийное (event-driven) моделирование. Средства событийного моделиро-
вания воспринимают окружающий мир как последовательность диск-
ретных событий. В качестве примера рассмотрим очень простую схему,
показанную на Рис. 19.1. Как следует из рисунка, схема включает вен-
тиль ИЛИ, буферный вентиль BUF пару инверторов НЕ; сигнал с вен-
тиля ИЛИ поступает на буферный вентиль BUE Давайте посмотрим,
что произойдет в схеме при изменении сигнала на одном из ее входов.
Рис. 19.1. Пример простой схемы
Я был бы безмерно счастлив написать такую книгу, если бы нашел спонсора.
242 и Глава 19. Средства моделирования, синтеза, верификации и реализации
Для упрощения примера допустим, что вентили НЕ имеют задерж-
ку 5 пикосекунд, буферный логический элемент 10 пикосекунд, а ло-
гический элемент ИЛИ 15 пикосекунд (Рис. 19.2).
Рис, 19.2. Результаты событийного моделирования
Внутри системы моделирования находится так называемое собы-
тийное колесо, или колесо событий, на которое помещаются события,
которые будут «происходить» в будуящем. Когда на входе вход 1 имеет
место первое событие в период времени система моделирования от-
слеживает, с чем соединен этот вход: в данном случае он соединён с ло-
гическим элементом ИЛИ. Затем система моделирования с учётом ин-
формации о задержке этого элемента планирует соответствующее со-
бытие на его выходе, а именно: через 15 пикосекунд в момент времени
t2 на шине wl состоится переход с уровня логического 0 на уровень 1.
После этого система моделирования проверяет, нужно ли выпол-
нять ещё какие-либо действия в текущий момент времени и обра-
щается к колесу событий, чтобы выяснить, что должно произойти
дальше. В нашем примере следующим событием оказалось как раз то,
что мы только что запланировали на время t2i т. е. фронт импульса, или
переход с уровня 0 на уровень 1, на шине wl. Во время выполнения
этого действия система моделирования также отслеживает, с чем со-
единена шина wl: в нашем случае к этой шине подсоединены буфер-
ный элемент BUF, обозначенный как g2, и инвертирующий логичес-
кий элемент НЕ, обозначенный как#3.
Так как логический элемент НЕ (g3) имеет задержку 5 пикосекунд,
система моделирования планирует на выходе этого элемента, т. е. на
шине w2, на момент времени t3 (через 5 пикосекунд) спад импульса
(переход с уровня логической 1 на уровень 0). Аналогично, поскольку
буферный элемент BUF (g2) имеет задержку 10 пикосекунд, система
моделирования планирует фронт импульса (переход с уровня 0 на уро-
вень 1) на выходе выход 1 на время /4 (через 10 пикосекунд). И так да-
лее, пока не будут выполнены все события, запущенные фронтом им-
пульса на входе 1.
Преимущество такого событийного подхода состоит в том, что
системы моделирования на его основе могут использоваться для пред-
Типы моделирования 243
ставления почти всех видов устройств, включая синхронные и асинх-
ронные схемы, комбинаторные цепи обратной связи и другие. Эти
системы моделирования обеспечивают хорошую визуализацию, упро-
щая тем самым процесс отладки, и могут оценивать влияние запазды-
вающих коротких импульсов и выбросов, которые трудно выявить с
помощью других методов. Существенным недостатком этих систем
моделирования является то, что они требуют значительных вычисли-
тельных ресурсов и, соответственно, отличаются медлительностью.
Краткий обзор систем событийного моделирования
Как уже обсуждалось в гл. 8, первые цифровые системы событий-
ного моделирования (конец 60-х — начало 70-х) основывались на кон-
цепции базовых элементов моделирования. Как минимум, эти базовые
элементы включали логические вентили, такие как буферы, НЕ, И, И-
НЕ, ИЛИ, ИСКЛЮЧАЮЩЕЕ HE-ИЛИ, а также некоторые типы бу-
ферных элементов с тремя состояниями. Одни системы моделирова-
ния в качестве базовых элементов содержали набор регистров и защё-
лок, другие для реализации этих же функций предусматривали созда-
ние подсхем из набора более примитивных логических вентилей.
В то время функциональность устройств обычно описывалась с по-
мощью стандартных текстовых редакторов в виде таблицы соединений
вентилей. Аналогично сами тесты описывались в виде текстовых (таб-
личных) файлов задающих воздействий. Система моделирования вос-
принимала для обработки таблицу соединений и таблицу задающих
воздействий, а также управляющие файлы и команды из командной
строки. По таблице соединений вентилей в памяти компьютера созда-
валась модель устройства, затем к этой моделям прикладывались зада-
ющие воздействия из соответствующего файла, и в конце формирова-
лись результаты в виде текстового (табличного) файла (Рис. 19.3).
1928 г.Джон Байрд
(John Logie Baird)
продемонстриро-
вал работу элект-
ронной системы
цветного телеви-
дения.
1928 г.Джон Байрд
разработал видео-
диск для записи те-
левизионных про-
грамм.
ВЮ ©RCUIT"TEST:
Текстовая таблица
соединений вентилей
Текстовый (табличный)
файл задающих воздействий
Текстовый (табличный) файл результатов
моделирования (задающих воздействия
и отклики на них)
Рис. 19.3. Работа системы логического моделирования
244 Глава 19. Средства моделирования, синтеза, верификации и реализации
1929 г. Джозеф
Шик (Joseph
Schick) разработал
электрическую
бритву.
Со временем всё стало несколько сложнее. Сначала для создания
таблицы соединений вентилей стали использоваться средства ввода
принципиальных схем. Затем использовались специальные средства,
которые считывали готовые текстовые файлы и представляли полу-
ченную информацию в графическом виде. В некоторых случаях эти
средства использовались также для описания в графическом виде зада-
ющих воздействий и последующей генерации соответствующего таб-
личного файла.
После этого разработчики цифровых систем моделирования взя-
лись за более сложные языки, которые могли бы описывать логичес-
кие функции на более высоких уровнях абстракции, таких как уровень
регистровых передач (RTL — register transfer level). Хорошим примером
такого языка был GHDL (GenRad Hardware Description Language — язык
описания аппаратных средств GenRad), используемый системой моде-
лирования System HILO.
Получили также развитие и более сложные языки описания испы-
тательных стендов, как, например GWDL (GenRad WaveformDescription
Language — язык описания формы сигнала GenRad). Языки этого типа
могли поддерживать сложные структуры, такие как циклы, а также
имели доступ к текущему состоянию схемы и, соответственно, могли
изменять наборы тестов по принципу: «Если на этом выходе находится
уровень логического нуля, приступайте к тесту Б, в противном случае
начинайте тест В».
Эти языки в какой-то степени опережали свое время. Например,
полезное свойство языка GWDL заключалось в том, что кроме опреде-
ления входного сигнала, например «вход А = 0», можно было опреде-
лять ожидаемый выходной отклик, например «выходY== 1». При
этом наличие одного знака равенства означало подачу воздействия на
вход системы, а пара знаков равенства соответствовала ожидаемому
отклику. Если после этого использовался специальный оператор
STROBE, имитатор проверял, совпадает или нет реальный отклик (со
схемы) с ожидаемым откликом (заданным формой сигнала) и выдавал
предупреждение, если эти сигналы отличались.
Шло время, и начали появляться промышленные стандарты язы-
ков HDL, такие как Verilog и VHDL. Их преимущество заключалось в
том, что один и тот же язык мог использоваться для описания и функ-
циональности схемы, и испытательных стендов0.
Стали появляться и форматы стандартных файлов для вывода ре-
зультатов моделирования, например VCD-формат (Value Change Dump
— дамп изменения значений). Эти форматы помогали сторонним ком-
паниям САПР электронных систем создавать сложные графические
средства наблюдения за формой сигнала, а также средства анализа, ко-
торые могли работать с выходными данными многочисленных систем
моделирования. Следует упомянуть и новый FSDB-формат (Fast Signal
Database™ — база данных быстрых сигналов) компании Novas Software
(www.novas.com), который создаёт файлы гораздо меньших размеров,
чем VCD, и в то же время позволяет осуществлять быстрый поиск ин-
формации.
Были и другие инновации, например SDF-формат (standard delay
format — формат стандартных задержек), который помогал сторонним
компаниям САПР разрабатывать сложные средства временного ана-
лиза. Эти средства были способны производить оценку схемы, созда-
0 Главный разработчик языка Verilog Фил Морби (Phil Moorby) был также од-
ним из разработчиков первой версии языка и среды моделирования HILO.
Типы моделирования 245
вать временные отчеты, выделять потенциальные проблемы и выво-
дить SDF-файлы, которые могли быть использованы для проведения
более точного временного моделирования
Логические величины и системы логических величин
Подавляющее большинство современных цифровых электронных
систем основываются на двоичной логике, которая использует цифры,
называемыми битами. Другими словами, логические элементы ис-
пользуют два разных напряжения для представления двоичных значе-
ний 0 и 1 или логических (булевых) значений вида true и false (соот-
ветственно истина и ложь). Были проведены некоторые эксперименты
по использованию троичной логики, основанной на трех различных ло-
гических уровнях, значения которых называются тритами. Однако до
сих пор эта технология не нашла коммерческого и промышленного
применения. Чему я несказанно рад.
Опять я отвлекся. Минимальный набор логических значений, не-
обходимых для описания работы двоичного логического элемента, со-
стоит из чисел 0 и 1. Затем, чтобы как-то представить неизвестные ве-
личины, для их обозначения обычно используется символ «X». Эти не-
известные величины могут использоваться для представления разных
состояний, например для обозначения содержания неинициализиро-
ванного регистра или для выделения конфликта, возникающего, когда
два логических элемента управляют одной и той же шиной с противо-
положными логическими значениями. Для обозначения высокоимпе-
дансного состояния, которое может появиться на выходах логических
элементов с тремя состояниями, обычно используется символ «Z».
В языках описания аппаратных средств вместо символа «X» обычно
используются обозначения «?» или «—». Неопределённое значение
не может быть установлено на выходе в качестве входных воздейс-
твий для других входов. Вместо этого используется форма записи, в
которой описывается, как входы реагируют на различные комбина-
ции сигналов.
Но состояния 0, 1, X и Z — только верхушка айсберга. Более про-
двинутые логические системы моделирования могут связывать раз-
личные воздействия с выходами разных логических элементов. Они
могут также содержать средства разрешения и описания ситуаций, в
которых несколько логических элементов управляются одним и тем
же проводником с различными логическими значениями разных воз-
действий. Ну, разумеется, исключительно ради разнообразия, языки
VHDL и Verilog работают с такими ситуациями по-разному.
Моделирование с использованием разных языков
При существовании двух стандартных промышленных языков, на-
пример, VHDL и Verilog, рано или поздно возникнет проблема, смысл
которой в том, что через некоторое время у пользователя окажутся две
части устройства, описанные на разных языках. Вероятно, все собс-
твенные разработки компании будут написаны на том языке, которо-
му она отдает предпочтение. Тем не менее, проблема может возник-
нуть, если компания захочет использовать рабочий код, написанный
на другом языке. Та же ситуация может повториться, если компания
примет решение о приобретении блоков интеллектуальной собствен-
ности у стороннего разработчика, который может работать только с
Цифровые системы
логического модели-
рования, такие как
векторное произведе-
ние и метод интер-
вальных значений, и
различные аспекты
неизвестной пере-
менной Xболее де-
тально рассмотрены
в моей книге Designus
Maximus Unleashed
(Banned in Alabama),
ISBN 0-7506-9089-5.
246 Глава 19. Средства моделирования, синтеза, верификации и реализации
тем языком, который компания в текущий момент не использует. Воз-
можна также ситуация, когда одна компания объединится с другой для
совместного проекта, причем обе компании давно занимаются проек-
тными разработками и используют несопоставимые языки.
Подобная ситуация приводит к необходимости прибегнуть к помо-
щи концепции моделирования на разных языках, которая исторически
имеет несколько разновидностей. Одна из первых методик заключа-
лась в переводе исходного кода с «чужого» языка на «свой». Но этот
подход отличался низкой эффективностью, так как разные языки под-
держивали разные логические состояния и разные языковые конс-
трукции, и даже похожие операторы языка имели разную семантику. В
результате при моделировании переведенный с другого языка проект
редко вел себя так, как ожидалось, поэтому этот метод нечасто исполь-
зуется в наши дни.
Другая методика подразумевала наличие двух систем моделирова-
ния — для языка VHDL и для Verilog и предполагала совместное моде-
лирование двух подсистем с помощью двуядерной системы. В этом
случае производительность моделирования, к сожалению, находилась
на низком уровне, так как одна из подсистем останавливалась, дожи-
даясь, пока другая закончит свою работу. Поэтому и этот метод редко
используется в наши дни.
Оптимальное решение описанной проблемы предполагает одно-
ядерную систему моделирования, которая поддерживает описания ус-
тройств, представленных в виде комбинации (или смеси) блоков на
языках VHDL и Verilog. Все компании САПР электронных систем рас-
полагают собственными версиями таких средств, а некоторые из них
переходят границы всех смелых предположений, сделанных в про-
шлом, поддерживая множество языков, например: VHDL, Verilog,
SystemVerilog, SystemC и PSL°.
Альтернативные форматы описания задержек
В моделях, которые разрабатываются для использования в системе
событийного моделирования, выбор формата представления задержек
зависит от возможностей моделирования задержек самой системой
моделирования и от выбора места (и средств) в процессе разработки, в
котором будет выполняться временной анализ.
Очень часто статический временной анализ (или STA — static timing
analysis) выполняется отдельно от моделирования (подробно обсужда-
ется позже в этой главе). В этом случае логические вентили и более
сложные операторы могут быть промоделированы с нулевой задерж-
кой, т. е. масштаб времени — 0 или с единичной задержкой, т. е. масш-
таб времени — 1. Здесь термин масштаб времени относится к наимень-
шему сегменту времени, распознаваемому системой моделирования.
В другом случае можно связать более сложные типы задержек с ло-
гическими вентилями и с другими более сложными операторами для
использования в системе моделирования. При этом сначала необходи-
мо отделить задержку фронта импульса от задержки спада на выходе
логического вентиля или другого оператора. Исторически сложилось
так, что задержка фронта импульса (при переходе с 0 в 1) часто обозна-
чается как LH (сокращенно от low-to-high — от низкого к высокому
° Хорошим примером одноядерного решения такого типа может служить
программный продукт ModelSim® от компании Mentor Graphics
(www.mentor.com).
Типы моделирования 247
уровню). Соответственно задержка спада (при переходе с 1 в 0) обозна-
чается как HL (high-to-low — от высокого к низкому уровню).
Рассмотрим, например, что произойдет, если подать 12-пикосе-
кундный (12 пс) положительный (0-1-0) импульс на вход простого бу-
ферного логического элемента с задержкой LH = 5 пс и HL = 8 пс
(Рис. 19.4).
1929 г. В Британии
заработала техно-
логическая линия
по производству
механических те-
левизионных сис-
тем.
вход 1
LH = 5 пс
HL= 8 пс
BUF
вход 1
выход 1
Рис, 19,4, Различные LH- и HL-задержки
Не удивительно, что напряжение на выходе логического элемента
возрастает через 5 пс после приложения к входу фронта импульса, и
падает через 8 пс после снятия импульса на входе. Интересно, что из-
за несбалансированных задержек 12-пикосекундный импульс увели-
чился до 15 пс на выходе логического элемента, причем дополнитель-
ные 3 пс отражают разницу между значениями LH и HL. Аналогично,
если отрицательный импульс длительностью 12 пс (1-0-1) будет подан
на вход этого логического элемента, соответствующий импульс на вы-
ходе уменьшится до 9 пс. Читатель, попробуйте самостоятельно изоб-
разить этот процесс на листе бумаге.
Кроме задержек LH и HL, системы моделирования поддерживают
минимальные, номинальные и максимальные (мин:ном:макс) значе-
ния для каждой задержки. Рассмотрим, например, положительный
импульс длительностью 16 пс, который подается на вход буферного
логического элемента с задержками фронта и спада соответственно,
6:8:10 пс и 7:9:11 пс (Рис. 19.5).
Диапазон величин задаётся для работы в разных рабочих условиях,
например при перепадах окружающей температуры или напряжения
питания. Таким же образом охватывают изменения в производствен-
ном процессе, так как некоторые микросхемы могут работать немного
быстрее или медленнее, чем другие того же класса. Аналогично логи-
ческие вентили микросхем из одной области (например, в заказных
микросхемах или в ПЛИС) могут включаться быстрее или медленнее,
чем идентичные логические вентили из другой области.
248 и Глава 19. Средства моделирования, синтеза, верификации и реализации
ТТЛ-логика реализу-
ется с помощью
соединённых опре-
делённым образом
биполярных тран-
зисторов.
LH = 6:8:10 пс
HL = 7:9:11 пс
вход 1
BUF
Рис. 19.5. Поддержка формата описания задержек
вида мин:ном:макс
Раньше все задержки распространения сигнала от входа до выхо-
да микросхемы у многовходовых вентилей были одинаковыми. На-
пример, в случае 3-входового вентиля И с входами а, b и с, и выходом
у любые задержки вида LH и HL при прохождении по пути а-у, b-у и
с-у были одинаковыми. Изначально это обстоятельство не вызывало
никаких проблем, поскольку таким же способом задержки описыва-
лись и в соответствующих справочниках. Однако со временем в спра-
вочниках стали определять задержки индивидуально для каждого пу-
ти прохождения сигнала, и в результате возникла необходимость мо-
дернизировать системы моделирования для поддержки этих
возможностей.
Давайте рассмотрим, что произойдет, если к входу логического
вентиля (или более сложной функции) приложить короткий им-
пульс. Под «коротким» мы будем подразумевать импульс, длитель-
ность которого меньше времени задержки прохождения сигнала че-
рез вентиль. Следует заметить, что первые логические элементы в ос-
новном использовались в простых микросхемах транзисторно-
транзисторной логики (TTL), которые располагались на печатной пла-
те. Эти микросхемы имели свойство поглощать (или отбрасывать)
поступающие на них короткие импульсы, что и имитировали систе-
мы моделирования. Описания этих процессов стали называть моде-
лью инерционной задержки. В качестве простого примера давайте рас-
смотрим два положительных импульса длительностью 8 пс и 4 пс,
приложенных к буферному логическому элементу, у которого время
задержки по фронту и по спаду в форме мин:ном:макс равно 6 пс
(Рис. 19.6).
Типы моделирования 249
BUF
выход 1
1929 г. Начало
экспериментов по
изучению цветного
электронного
телевидения.
Рис. 19.6. Модель инерционной задержки отбрасывает импульс, длительность
которого меньше, чем время задержки вентиля
ВХ0Д1 1^^
В отличие от рассмотренного примера вентили, реализованные с
помощью более поздних технологий, таких как эмиттерно-связанная
логика (или ECL — emitter-coupled logic)}\ пропускали импульсы, дли-
тельность которых была меньше задержки прохождения через них сиг-
нала. Для работы с такими элементами некоторые системы моделиро-
вания могли функционировать в режиме, названном моделью транс-
портной задержки. Давайте ещё раз рассмотрим два положительных
импульса длительностью 8 пс и 4 пс, приложенных к буферному логи-
ческому элементу, у которого время задержки по фронту и по спаду в
форме мин:ном:макс равно 6 пс (Рис. 19.7).
В случае моделей инерционной и транспортной задержки возника-
ет проблема, связанная с тем, что они могут применяться лишь в экс-
тремальных ситуациях. В связи с этим разработчики некоторых систем
моделирования начали проводить эксперименты с более сложными
короткоимпульсными методиками, такими как модель трёхдиапазон-
ной задержки* 2^. В этом случае каждая задержка может определяться
двумя значениями, скажем г для описания отбрасывания сигнала и р
для описания пропускания сигнала, которые задаются в процентах от
общей задержки. Например, рассмотрим буферный вентиль, у которо-
го все задержки в форме мин:ном:макс равны 6 пс, а значения г и р со-
ответственно 33% и 66% (Рис. 19.8).
Любые, поданные на вход вентиля импульсы, длительность кото-
рых больше или равна значению р, будут пропускаться этим вентилем;
все импульсы, длительность которых меньше, чем значение г, будут
° ЭСЛ-логика также реализуется с помощью биполярных транзисторов, но
соединённых подругой схеме, чем ТТЛ. Логические элементы ЭСЛ работают быс-
трее своих ТТЛ-аналогов, но и потребляют больше энергии (следовательно, выде-
ляют больше тепла).
2) Система моделирования System HILO компании GenRad начала использо-
вать модель 3-диапазонной задержки незадолго до ее исчезновения с лица Земли.
250 Глава 19. Средства моделирования, синтеза, верификации и реализации
1929 г. Начали ра-
боту первые ком-
мерческие службы
связи (для пасса-
жиров) между ко-
раблями и берегом.
LH = 6:6:6 пс
HL = 6:6:6 пс
вход 1
BUF
выход 1
Рис. 19.7. Модель транспортной задержки пропускает импульсы
любой длительности
LH = 6:6:6 пс (33:66%)
HL = 6:6:6 пс (33:66%)
вход 1
BUF
-<^J| выход!
Рис. 19.8. Модель инерционной задержки отбрасывает импульс, длительность
которого меньше, чем время задержки вентиля
полностью отбрасываться (поглощаться); импульсы, длительность ко-
торых находится между этими двумя экстремумами, будут пропускать-
ся, как импульсы с неизвестными величинами Xс тем, чтобы показать,
что их состояние неопределенно, так как мы не знаем, будут ли они
пропущены через логический элемент при работе в реальном устройс-
тве. (Установка значений г и р на уровень 100% эквивалентна исполь-
зованию модели инерционной задержки, а их установка на уровень 0%
приводит к модели транспортной задержки.)
Типы моделирования 251
Системы циклового моделирования
Кроме событийного моделирования, возможно также цикловое
(cycle-based) моделирование. Оно очень хорошо подходит для модели-
рования конвейерных устройств, в которых «островки» комбинацион-
ной логики расположены между блоками регистров (Рис. 19.9).
Рис. 19.9. Простое конвейерное устройство
В этом случае система циклового моделирования будет выдавать
любую временную информацию, связанную с вентилями комбинаци-
онной логики, а также будет преобразовывать эту логику в последова-
тельность логических (булевых) операций, которые могут быть реали-
зованы с помощью микропроцессорных команд.
При наличии схемы, которая работает соответствующим образом,
системы циклового моделирования демонстрируют лучшее быстро-
действие по сравнению со своими событийными аналогами. Недоста-
ток таких систем заключается в том, что они обычно работают лишь с
логическими величинами 0 и 1 (значения X, Z и другие выражения не
поддерживаются). Кроме того, эти системы не могут моделировать ра-
боту асинхронных логических устройств или комбинационных цепей
обратной связи.
В наше время цикловые системы моделирования в чистом виде
почти не используются. Однако путем определённых расширений не-
которые системы событийного моделирования приобрели смешанные
свойства. В этом случае, если дать указание такой системе работать в
режиме максимальной производительности, а не в режиме максималь-
ной временной точности, она автоматически обработает некоторые
части схемы с помощью методов событийного моделирования, а ос-
тавшуюся часть с помощью методов циклового моделирования.
Выбор оптимальной системы логического моделирования!
Выбор системы моделирования, как и всего остального при разра-
ботке чего-то нового, это выбор сбалансированного решения. Если вы
работаете в небольшой начинающей компании, для которой при вы-
боре средств разработки решающим является их стоимость, переходи-
те сразу к гл. 25, в которой описаны методы разработки с использова-
нием средств с открытым исходным кодом.
Первым делом необходимо определиться, нужно ли вам исполь-
зовать нескольких языков в пределах одного устройства. Если у вас
небольшая начинающая фирма, можно ограничиться только одним
языком, но помните, что какие-нибудь блоки интеллектуальной
252 Глава 19, Средства моделирования, синтеза, верификации и реализации
1929 г. Германия,
Осуществлена за-
пись звука на плас-
тиковую ленту с
магнитным покры-
тием.
собственности, которые вы решите приобрести в будущем, возмож-
но, не смогут работать с этим языком. Неплохо было бы начать ра-
ботать с языками VHDL, Verilog или SystemVerilog, а, если возмож-
но, еще и оперировать с SystemC вместе с одним или несколькими
языками формальной верификации. Тогда, по всей видимости, ва-
ша позиция будет достаточно сильной в течение определённого
времени.
В общем случае, наиболее важным критерием для большинства
является производительность. Возникает вопрос: как наиболее точ-
но определить производительность? Пожалуй, единственный спо-
соб заключается в разработке собственного тестового устройства и
его моделировании на нескольких системах. Создание хорошего
теста — нетривиальная задача, но этот способ лучше, чем использо-
вать разработку, предлагаемую производителем САПР. Подобный
проект будет реализован так, чтобы в наилучшем свете продемонс-
трировать решение своего разработчика и поставить подножку кон-
курентам.
Однако, кроме производительности, есть еще не менее важные по-
казатели. Вам также понадобится хорошее интерактивное средство от-
ладки, чтобы после обнаружения проблемы можно было бы остано-
вить моделирование и проверить свое устройство. В этом отношении
не все системы моделирования одинаковы и разные средства имеют
разные уровни возможностей. В некоторых случаях, даже если имита-
тор позволяет выполнить задуманное, для этого иногда приходится
встать на уши. Поэтому целесообразно воспользоваться некоторой
уловкой, которая заключается в следующем: после прохождения собс-
твенного образцового теста создать такую же схему, но с заложенным в
неё заранее известным дефектом и посмотреть, насколько легко и
быстро будет обнаружен и локализован заложенный дефект. На самом
деле, некоторые системы моделирования, которые обладают необхо-
димой производительностью, настолько плохо справляются с подоб-
ным заданием, что придётся воспользоваться средствами сторонних
разработчиков для проведения дополнительного анализа после завер-
шения моделирования1).
Внимания заслуживает и разрядность системы моделирования.
Средства, поставляемые большими компаниями САПР, как правило,
не имеют ограничений по разрядности, а вот системы моделирования
небольших разработчиков могут основываться на 32-битном коде. Ес-
тественно, если вы собираетесь работать с небольшими проектами,
скажем не более 500000 вентилей, то, вероятно, подойдут системы мо-
делирования, поставляемые производителями ПЛИС. Обычно это уп-
рощенные версии средств от крупных разработчиков САПР.
Разумеется, кроме вышеперечисленных, у вас будут собствен-
ные критерии оценки средств моделирования, например по качест-
ву кодового покрытия или анализу производительности. Когда-то
эти возможности были в компетенции специализированных
средств сторонних разработчиков, но теперь большинство мощных
систем моделирования позволяют оценить на некотором уровне ко-
довое покрытие и провести анализ производительности непосредс-
твенно в среде моделирования. При этом разные системы модели-
рования предлагают различные наборы дополнительных функцио-
нальных возможностей.
!) Лидирующее положение в этой области занимает компания Novas Software
Inc. (www.novas.com) со своими средствам анализа Debussy® и Verdi™.
Средства синтеза. Логический/HDL и физический синтез 253
Средства синтеза.
Логический/HDL и физический синтез
Технология логического/НОЬсинтеза
Традиционные средства логического синтеза появились примерно в
первой половине 80-х. В наши дни эти средства иногда называют тех-
нологией HDL-синтеза.
Роль первых средств логического/НВЬ-синтеза заключалась в
формировании таблицы соединений вентилей на основе заранее со-
ставленного RTL описания заказной микросхемы и соответствующих
временных ограничений. Во время этого процесса приложение синте-
за выполняло различные процедуры минимизации и оптимизации,
включая оптимизацию по быстродействию и по площади, занимаемой
на поверхности кристалла.
В середине 90-х средства синтеза были расширены для поддержки
архитектуры устройств ПЛИС. Такие приложения могли формировать
таблицу соединений КЛБ/таблиц соответствия, которая затем переда-
валась программному обеспечению размещения и разводки, предо-
ставляемому поставщиком ПЛИС (Рис. 19.10).
1929 г. На автомо-
биль впервые уста-
новлен радиоприём-
ник.
Архитектурный логический
HDL-синтез
RTL
Размещение и разводка
(поставщик ПЛИС)
Рис. 19.10. Традиционный логический/НВЬ-синтез
На практике, устройства, на основе ПЛИС, созданные средствами
архитектурного синтеза, были на 15...20% быстрее, чем их аналоги, со-
зданные с использованием средств традиционного синтеза на уровне
вентилей.
Технология физического синтеза
У традиционного логического/НВЬ-синтеза была одна проблема,
которая заключалась в том, что он был разработан в то время, когда за-
держка распространения сигнала в основном определялась задержкой
вентилей, а задержки на проводниках были сравнительно малыми. Это
значит, что средства синтеза могли использовать простые модели на-
грузки на шину для оценки влияния задержек на проводниках. Такие
модели включали параметры ненагруженной шины, ёмкость шины
при нагрузке в виде одного логического элемента — х пикофарад (пФ),
ёмкость шины при нагрузке двумя логическими элементами — у пФ и
т. д. По этим данным средства синтеза могли оценивать задержку, свя-
занную с каждым проводником, как функцию её загрузки и сопротив-
ления вентиля, подключенного к этому проводнику.
254 Глава 19. Средства моделирования, синтеза, верификации и реализации
1930 г. Ваневар
Буш (Vannevar
Bush) сконструиро-
вал аналоговый
компьютер, на-
званный Differential
Analizer (диффе-
ренциальный ана-
лизатор).
1933 г. Эдвин Арм-
стронг (Edwin
Howard Armstrong)
разработал новую
систему радиосвя-
зи: широкополос-
ную частотную
модуляцию.
Эта методика соответствовала уровню изготовления устройств того
времени, которые реализовывались по мультимикронным технологи-
ям и содержали, по сегодняшним меркам, относительно небольшое
количество вентилей. В сравнении с ними, современные устройства
могут содержать десятки миллионов вентилей, и размеры этих элемен-
тов уходят в область глубокого субмикронна. Другими словами, за-
держки сигнала на проводниках теперь могут составлять до 80% пол-
ной задержки. Следовательно, использование традиционных средств
| логического/НОЬ-синтеза для оценки временных параметров совре-
менных устройств может привести к таким данным, которые будут
иметь мало общего с действительностью. При этом достичь состояния
временного соответствия будет почти невозможно.
По этой причине при разработке заказных интегральных микро-
схем (ASIC), примерно с 1996 года стали использовать физический
синтез, который в 2000 или 2001 году стал применяться и для ПЛИС.
Конечно, существует множество различных определений в отношении
того, что именно обозначает термин физический синтез. Основная идея
состоит в том, чтобы до начала синтеза использовать физическую ин-
формацию об устройстве, но что это означает на самом деле? Напри-
мер, некоторые компании добавили возможности интерактивного
планирования компоновки в качестве первого этапа алгоритма синте-
за, и классифицировали это как физический синтез. Однако для боль-
шинства инженеров физический синтез означает получение информа-
ции связанной с физическим расположением различных логических
элементов в схеме, использование этой информации для точной оцен-
ки задержек на проводниках, использование этих задержек для уточ-
ненного размещения элементов и выполнения других оптимизаций.
Интересно заметить, что физический синтез начинается с выполнения
первого этапа, в котором используется алгоритм традиционного логи-
ческого/НОЬ-синтеза (Рис. 19.11).
Архитектурный Размещение элементов Физический
логический/НОЬ-синтез (поставщик ПЛИС) синтез
Размещение и разводка
(поставщик FPGA)
Таблица соединений
логических блоков
до размещения
и разводки
Таблица соединений
КЛБ после размещения
элементов
Таблица соединений КЛБ
после размещения
и оптимизации
Таблица соединений
логических блоков
после размещения
и разводки
Рис. 19.11. Физический синтез
Коррекция временных параметров, репликация и повторный
синтез
В инженерной практике существует ряд терминов, которые можно
услышать, когда речь о физическом синтезе, например коррекция вре-
менных параметров, репликация, повторный синтез^. Коррекция вре-
менных параметров основана на концепции балансировки между по-
ложительным и отрицательным резервом времени в масштабах всего
устройства. Под положительным резервом будем подразумевать неко-
1} Эти термины могут применяться в традиционном логическом/НВЬ-синтезе,
но они более действенны, когда используются в контексте физического синтеза.
Средства синтеза. Логический/HDL и физический синтез 255
торую величину задержки, которая остается в запасе, а под отрицатель-
ным некоторую задержку, которая превышает допустимое значение.
Рассмотрим конвейер, у которого тактовая частота выбрана таким
образом, что максимальная задержка между регистрами составляет ве-
личину 15 пикосекунд. Допустим, что для этого устройства сложилась
ситуация, которая показана на Рис. 19.12, а. В этом случае максималь-
ное время распространения сигнала в первом логическом блоке соста-
вит 10 пс. Другими словами, положительный резерв времени составит
5 пс, а во втором логическом блоке максимальное время прохождения
сигнала будет равно 20 пс, т. е. величина отрицательного резерва со-
ставит величину 5 пс.
1934 г. Половина
домов в США осна-
щены радиоприём-
никами.
б) После коррекции
временных параметров
Рис. 19.12. Коррекция временных параметров
После расчёта значений временных параметров логических бло-
ков, в том числе с учётом задержки, вызванной разводкой элементов,
часть логики перебрасывается через регистровый порог, тем самым,
изымая резервы времени из первого блока и передавая их во второй
(Рис. 19.12, б). Коррекция временных параметров очень часто исполь-
зуется при проектировании устройств на основе ПЛИС, поскольку в
них реализовано очень большое количество регистров.
Процедура репликации аналогична коррекции временных пара-
метров с той лишь разницей, что в этом случае производится разрыв
длинных внутренних соединений. Например, имеется регистр с поло-
жительным резервом времени 4 пс. Допустим, что к выходу этого ре-
гистра подключено три блока, каждый из которых имеет отрицатель-
ный временной резерв (Рис. 19.13, а).
С помощью репликации регистра и расположения его копий в не-
посредственной близости к их нагрузке, можно перераспределить вре-
менные резервы и сделать все части устройства рабочими
(Рис. 19.13, б).
256 Глава 19. Средства моделирования, синтеза, верификации и реализации
1935 г. Разрабо-
тан полностью
электронный теле-
визор метрового
диапазона волн.
а) Перед репликацией
Рис. 19.13. Репликация
И в завершении замечу, что концепция повторного синтеза основа-
на на большом разнообразии способов реализации и размещения раз-
личных функций. При повторном синтезе используется информация о
физическом размещении элементов, после чего выполняется локаль-
ная оптимизация на критических участках устройства с помощью опе-
раций логической реструктуризации, повторной кластеризации, и,
возможно, путем исключения вентилей и проводников.
Выбор оптимального средства синтеза!
Неужели вы надеетесь получить здесь ответ на этот вопрос? В ре-
альном мире возможности различных машин синтеза вместе со свя-
занными с ними особенностями, такими как автоинтерактивное ком-
поновочное планирование, меняются почти ежедневно, и разные про-
изводители постоянно обходят друг друга в этой гонке.
Существует также мнение, что разные системы работают лучше
или хуже с разными архитектурами ПЛИС от разных производителей.
Одним из критериев поиска системы синтеза является способность
(или отсутствие таковой) автоматически выполнять из исходного кода
логический синтез некоторых узлов, например элементов системы
синхронизации и встроенных функций, или обеспечивать целостность
файлов без необходимости создавать соответствующие описания в яв-
ном виде. Однако, в конце концов, придется самому сделать свой вы-
бор, когда наступит время оценивать и сортировать различные предло-
жения. Пожалуйста, не стесняйтесь и сообщите мне о своем решении
по адресу max@techbites.com.
Временной анализ. Статический и динамический
Статический временной анализ
В наши дни наиболее распространенной формой временного ана-
лиза является статический анализ. Концептуально этот метод доволь-
но прост, хотя на практике, как обычно, все оказывается гораздо слож-
нее, чем казалось на первый взгляд.
По существу, временной анализатор суммирует значения задержек
всех логических элементов и проводников и формирует общие значе-
ния задержек от входа до выхода микросхемы для каждого канала про-
хождения сигнала. В устройствах, в которых используются конвейеры,
анализатор подсчитывает значение задержек между соседними груп-
пами регистров.
Временной анализ. Статический и динамический 257
Перед размещением элементов и разводкой соединений времен-
ной анализатор может оценивать значения задержек, вызванных про-
водниками устройства. После размещения и разводки для достижения
более точных результатов анализатор также будет использовать полу-
ченные значения паразитных параметров, т. е. сопротивлений и ём-
костей физических проводников. В результате будет сформирован от-
чёт с указанием всех путей прохождения сигнала, задержка на которых
не соответствует заданным временным ограничениям, а также с пре-
дупреждениями о потенциальных временных проблемах, например о
нарушении режимов установки и хранения данных, связанных с сиг-
налами, поступающими на вход регистров и защёлок.
Статический временной анализ хорошо подходит для классичес-
ких синхронизированных схем и конвейерных архитектур. Главное
преимущество такого анализа состоит в том, что он достаточно быст-
рый, для него не требуются дополнительные средства тестирования, и
он тщательно проверяет каждый возможный путь прохождения сигна-
ла. Вместе с тем, статические временные анализаторы жульничают
при обнаружении ложных путей распространения сигнала, которые
никогда не будут использованы в процессе штатной работы устройс-
тва. Кроме того, эти средства плохо работают со схемами, в которых
используются защёлки, асинхронные цепи и комбинационные обрат-
ные связи.
Статистический статический временной анализ
Статический временной анализ составляет основу современных
методов проектирования устройств на основе ПЛИС и заказных мик-
росхем (ASIC). Однако при работе с устройствами, изготовленными с
помощью последних технологических процессов, в работе этого мето-
да стали возникать некоторые проблемы. Во время написания этой
книги для изготовления микросхем использовался технологический
процесс 90-нм, а к 2007-му году ожидается переход к 45-нм процессу.
Как уже упоминалось, при использовании современных кремние-
вых кристаллов, задержка, вызванная распространением сигнала через
внутренние соединения, преобладает над задержкой вентилей, осо-
бенно в ПЛИС. В свою очередь, задержки внутренних соединений за-
висят от значений паразитных ёмкостей, сопротивлений и индуктив-
ностей, которые определяются топологией и формой используемых
проводников.
Проблема заключается в том, что при реализации современных
технологических процессов фотолитографическим способом практи-
чески невозможно обеспечить точную форму проводника. Поэтому
вместо квадратов и прямоугольников приходится использовать окруж-
ности и эллипсоиды. Размеры проводников, например их ширина, те-
перь настолько малы, что даже небольшие изменения в процессе трав-
ления вызывают отклонения, которые хоть и невелики, но достаточно
существенны по сравнению с шириной проводника. Эти изменения
становятся ещё более значимыми, так как в высокочастотных устройс-
твах вступает в силу так называемый поверхностный эффект, смысл
которого заключается в том, что высокочастотные сигналы передают-
ся только через внешнюю поверхность проводника. Кроме того, су-
ществуют отклонения в вертикальной плоскости поперечного сечения
дорожки, обусловленные процессами химико-механического полирова-
ния или другими подобными процедурами.
258 Глава 19. Средства моделирования, синтеза, верификации и реализации
В конечном счете, все эти особенности существенно затрудняют
определение точных значений временных задержек на внутренних со-
единениях. Конечно, можно воспользоваться традиционным инже-
нерным методом резервирования параметров, используя наихудшие
оценки, но практика чрезмерного консерватизма в сфере проектиро-
вания приводит к значительному снижению производительности
кристалла и, как следствие, является не очень удачным выбором в ус-
ловиях жесткой конкуренции на рынке. В реальной жизни разброс
геометрических размеров может привести к значительному расшире-
нию распределения вероятности ошибки, и в наихудшем случае уст-
ройство может оказаться более медленным, чем при использовании
даже более ранних технологических процессов!
Потенциальным решением этого вопроса может быть концепция
статистического статического временного анализатора (или SSTA —
statistical static timing analyzer). Этот метод основан на формировании
функции вероятности задержки для каждого сигнала каждого сегмента
проводника, затем, на основе которых, формируются общие функции
распределения задержки сигналов, проходящих через все части уст-
ройства. Во время написания этой книги не существовало коммерчес-
ких средств статистического статического временного анализа, но не-
которые компании — разработчики САПР и ряд учебных заведений
занимаются проработкой этого вопроса.
Динамический временной анализ
Другая форма контроля временных параметров, известная как ди-
намический временной анализ, или DTA — dynamic timing analysis, в наши
дни не очень-то популярна и упомянута здесь для полноты обзора рас-
сматриваемых средств. Эта форма проверки основана на использова-
нии системы событийного моделирования, и в процессе работы ис-
пользует набор тестов. В отличие от стандартной системы событийно-
го моделирования, которая использует одно из значений задержки,
т. е. минимальное (мин), номинальное (ном) или максимальное
(макс), для каждого пути прохождения сигнала, динамический анали-
затор работает с парой значений задержки, т. е. мин:ном, ном:макс или
мин:макс). Например, рассмотрим, как две системы моделирования
оценят работу простого буферного вентиля (Рис. 19.14).
В случае стандартной системы моделирования изменение сигнала
на входе вентиля вызовет событие, которое должно быть спланирова-
но на некоторое время в будущем, а случае временного анализатора,
использующего пару мингмакс, изменение сигнала на выходе логичес-
кого элемента начнёт происходить после истечения времени мини-
мальной задержки и закончится только после достижения значения
максимальной задержки.
Неопределенность между этими двумя значениями отличается от
неизвестного состояния X, так как известно, что будет происходить пе-
реход с уровня 0 на уровень 1 или с 1 в 0, но при этом неизвестно время
перехода. В связи с этим вводятся два новых состояния, называемых
«перешёл в 1, но не знаю когда» и «перешёл в 0, но не знаю когда»
Динамический временной анализ позволяет обнаруживать неоче-
видные потенциальные проблемы, которые почти невозможно опре-
0 Динамический временной анализ более подробно описан в моей книге
«Designus Maximus Unleashed (Banned in Alabama)», ISBN 0-7506-9089.
Общая верификация 259
LH = 3:5:7 пс
Обычная система
моделирования,
использующая типичное
значение задержки
Динамический
временной анализатор,
использующий
пару мин:макс значений
задержки
Рис. 19.14. Стандартная система событийного моделирования и динамический
временной анализатор
делить другими формами временного анализа. К сожалению, эти
средства настолько переполнены вычислениями, что в наши дни они
не очень популярны, но кто знает, что день грядущий нам готовит?
Общая верификация
Верификация блоков интеллектуальной собственности
С увеличением сложности устройств все больше ресурсов и време-
ни уходит на проверку их функциональности. Такая проверка включа-
ет в себя реализацию проверочной среды, создание набора тестов, вы-
полнение логического моделирования, анализ результатов для выявле-
ния и выделения проблем и так далее. На практике, на контроль
современных высокотехнологичных однокристальных устройств,
ASIC и ПЛИС, может потребоваться свыше 70% времени, потрачен-
ного с момента разработки начальной концепции и до окончательной
реализации.
Помочь в решении этой проблемы может верификация блоков ин-
теллектуальной собственности (верификация IP). Идея состоит в том,
что устройство, которое на этапе верификации называют проверяемым
устройством, обычно взаимодействует с окружающим миром, исполь-
зуя стандартные интерфейсы и протоколы. Кроме того, проверяемое
устройство обычно общается с микропроцессорами, арбитрами, конт-
роллерами, периферийными устройствами и т. д.
В большинстве случае для функциональной проверки использует-
ся стандартная система событийного моделирования. Один из спосо-
бов тестирования проверяемого устройства заключается в создании
набора тестов, которые точно описывают сигналы на уровне битовых
значений, поступающих на вход устройства и появляющихся на его
выходах. Однако в связи со сложностью современных протоколов,
применяемых при работе интерфейсов и шин, разработать подобные
тесты для большинства устройств просто невозможно.
260 и Глава 19. Средства моделирования, синтеза, верификации и реализации
Другой метод тестирования предполагает использование RTL-mo-
делей всех внешних устройств, формирующих систему. Однако многие
из этих устройств запатентованы, и их RTL-модели могут быть недо-
ступны для использования. Более того, моделирование всей системы с
использованием полнофункциональных моделей всех процессоров и
устройств ввода/вывода может потребовать значительных временных
и вычислительных ресурсов.
В качестве решения проблемы можно применить верификацию
блоков IP в форме функциональных моделей шины ФМШ, или BFM (bus
functional model), для представления процессоров и блоков ввода/выво-
да, формирующих тестируемую систему (Рис. 19.15) °.
Функциональные модели шин
(ФМШ) процессоров,
систем ввода/вывода и так далее
Высокоуровневые
транзакции,
поступающие
из «испытательного
стенда» или
среды проверки
Сложные сигналы,
описанные на уровне
«битового
жонглирования»
одна и та же ФШМ
Высокоуровневые
транзакции,
поступающие
в «испытательный
стенд» или в
среду проверки
Рис. 19.15. Применение проверки IP в форме ФМШ
Функциональная модель шины не копирует полную функциональ-
ность представляемого устройства, вместо этого она эмулирует способ
его работы на уровне интерфейса шины путем генерации и приёма
транзакций. В контексте рассматриваемого материала термин транзак-
ция относится к высокоуровневому событию на шине, например к вы-
полнению цикла чтения или записи. Среда проверки, или испытатель-
ный стенд, могут выдавать команды для ФМШ на выполнение тран-
закций, например чтения содержимого памяти. После этого ФМШ
генерирует сложный сигнал, состоящий из битов («битовое жонглиро-
вание»^), поступающий на интерфейс проверяемого устройства.
Аналогично, когда проверяемое устройство отвечает на задающее
воздействие каким-либо сложным сигналом, другая ФМШ, или это
может быть та же модель, интерпретирует эти сигналы и переводит их
в соответствующую высокоуровневую транзакцию.
Хотя ФМШ намного меньше и проще, и, следовательно, проце-
дура моделирования выполняется намного быстрее, чем полнофунк-
циональные модели представляемых ими устройств, они отнюдь не
тривиальны. Например, сложные ФМШ, которые часто создаются в
виде потактных, побитовых C/C++ моделей, могут включать в себя
внутреннюю кэш-память (вместе с возможностью её инициализа-
!) Примером очень сложного средства верификации блоков IP может служить
TransEDA PLC (www.transeda.com).
2) Битовое жонглирование — программирование на уровне машинных кодов с
манипулированием битами, флагами, полубайтами и прочими элементами дан-
ных, размером меньше одного байта. — Прим. пер.
Общая верификация 261
ции), внутренние буферы, конфигурационные регистры, очереди с
отложенной записью и т. д. ФМШ могут также обеспечивать огром-
ный набор параметров, которые позволяют производить низкоуров-
невое управление такими элементами, как адресная синхрониза-
ция, состояния ожидания данных для различных устройств памяти и
другими.
Среда верификации и разработка тестов
Когда я в молодости начинал работу с системами моделирования,
мы разрабатывали для них тестовые вектора, задающие воздействия и
реакции на них, в виде табличных текстовых ASCII-файлов, содержа-
щих логические значения 0 и 1 (или шестнадцатеричные значения, ес-
ли повезёт). В то время устройства, которые мы пытались тестировать,
были существенно проще, чем современные монстры. В переводе на
человеческий язык эти тесты могли бы быть представлены в виде сле-
дующих строк:
• При значении времени 1000 переведите сигнал сброса в актив-
ное состояние.
• При значении времени 2000 переведите сигнал сброса в неак-
тивное состояние.
• При значении времени 2500 удостоверьтесь, что на 8-битной
шине данных установлено значение 00000000.
• При значении времени ... и так далее.
Со временем устройства усложнялись, и с появлением языков вы-
сокого уровня средства их верификации стали более сложными. Язы-
ки высокого уровня использовались в системах моделирования для
формирования задающих воздействий и ожидаемых откликов, а также
для поддержки различных особенностей, таких как циклы и возмож-
ности переключать тесты в зависимости от состояния выходов. (На-
пример, если на шине состояния установлено значение 010, тогда пе-
реходим к тесту ху.) На определённом этапе инженеры начали назы-
вать эти тесты испытательным стендом,
В настоящее время многие современные устройства настолько
сложны, что почти невозможно создать адекватный тест вручную. Это
обстоятельство послужило поводом для применения сложных сред
тестирования и языков высокого уровня. Возможно, самым сложным
из языков, известных как языки верификации аппаратного обеспечения
(HVL — hardware verification language), является специализированный
продукт под названием е от компании Verisity Design
(www.verisity.com)1 \
Возможно, что вас удивило это название. На самом деле е ничего
не обозначает, хотя поначалу у разработчиков было намерение отра-
зить идею его подобия английскому (english) языку. При желании мож-
но использовать е для написания специализированных тестов, но
обычно в таком качестве он применяется только в особых случаях.
Вместо этого концепция е, которую можно рассматривать как смесь
языков С, Verilog и отчасти Pascal, больше подходит для описания до-
пустимых диапазонов и порядка следования входных значений, а так-
1935 г. В продажу
поступила звукоза-
писывающая лента.
Если быть более
точным, понятие
«испытательный
стенд» на самом де-
ле относится к ин-
фраструктуре, под-
держивающей вы-
полнение этих
тестов.
0 Поскольку промышленность с большим подозрением относится ко всем па-
тентованным языкам, компания Verisity Design работает с институтом IEEE над
тем, чтобы сделать е стандартным промышленным языком. Во время написания
этой книги институтом IEEE была образована рабочая группа Р1647 и издано
справочное руководство по этому языку.
262 Глава 19. Средства моделирования, синтеза, верификации и реализации
же стратегий верификации высокого уровня. Эти описания восприни-
маются средой моделирования для управления непосредственно про-
цессом моделирования.
Необходимо отметить, что первой и единственной во время напи-
сания этой книги средой верификации, полностью использующей
мощь языка е, являлся пакет Specman Elite® компании Verisity. Это па-
кет можно рассматривать как совокупность компилятора и системы
событийного моделирования, которая связывает и управляет исполь-
зуемые вами стандартные событийные HDL-системы моделирования.
Пакет Specman с помощью программ на языке е на лету генерирует за-
дающие воздействия, и затем подаёт их на вход устройства через ис-
пользуемую HDL-систему моделирования. Пакет производит также
наблюдение за результатами и функциональным покрытием модели-
рования, и по результатам этого наблюдения динамически перестраи-
вает последующие задающие воздействия для тестирования неохва-
ченных участков устройства.
В вопросах класси-
ческого анализа фор-
мы сигнала, средств
отладки и отображе-
ния информации од-
ним из наиболее из-
вестных производи-
телей является
компания Novas
Software Inc.
(www.novas.com) со
своим пакетом
Debussy®. Другое,
заслуживающее вни-
мания средство под
названием \ferdi™
поддерживает чрез-
вычайно прогрес-
сивные и мощные
методы выделения,
визуализации, ана-
лиза и отладки уст-
ройств в течение
большого количества
тактовых импульсов.
Анализ результатов моделирования
Почти все современные системы моделирования оснащены средс-
твами графического просмотра сигнала, которые могут быть использо-
ваны для интерактивного отображения результатов моделирования во
время работы системы моделирования или для последующего про-
смотра этих результатов, сохранённых в файлах VCD-формата (value
change dump — дамп изменения значений). Грустно признавать, но не-
которые из этих средств не настолько эффективны, как хотелось бы,
когда дело доходит до анализа полученной информации и выявления
проблем. В этом случае, возможно, следовало бы воспользоваться
средствами сторонних разработчиков.
Формальная верификация
Несмотря на то что большие компьютерные компании и произво-
дители микросхем, такие как IBM, Intel и Motorola, десятилетиями
разрабатывают и используют свои средства формальной верификации
(примерно с середины 80-х), для большинства людей эта область тес-
тирования всё же является новой. Особенно это касается ПЛИС, где
применение формальной верификации отстаёт от заказных микро-
схем. Следует заметить, что формальная верификация может быть на-
столько мощным средством, что всё больше и больше людей начинают
воспринимать её всерьез.
Основная проблема формальной верификации состоит в том, что она
ещё не вышла на уровень повсеместного использования, поэтому нахо-
дится много желающих, которые с радостью бросаются в эту область и
теряются в массе различных направлений. Кроме отсутствия стандартов,
здесь существует множество предложений, от которых просто голова
идёт кругом. При этом почти каждый пытается внести свою лепту в су-
ществующую неразбериху, тем самым ещё больше осложняя ситуацию.
Например, если попросить 20 поставщиков САПР дать определение тер-
минам «утверждение» и «свойство» и указать их отличия, вы сойдете с
ума из-за диаметрально противоположных ответов1).
Попытка распутать этот клубок окажется трудноразрешимой зада-
чей, если вообще разрешимой. Однако, как любил говаривать мой дед,
Я убедился в этом на собственном горьком опыте.
Формальная верификация 263
у страха глаза велики, поэтому давайте ещё раз попытаемся приотк-
рыть завесу и описать формальную верификацию понятным для всех
способом.
qgR Средства формальной верификации изначально разрабатывались
большими компьютерными компаниями и производителями мик-
росхем для своего внутреннего пользования. Одним из первых ком-
мерческих средств такого типа был программный пакет проверки на
эквивалентность Design VERIFYer, разработанный в 1993 г. компа-
нией Chrysalis Symbolic Design Inc. Средства проверки на эквивален-
тность изначально разрабатывались большими компаниями для
своего внутреннего применения и первая коммерческая утилита
проверки моделей также была разработана компанией Chrysalis в
1996 и получила название Design inSIGHT.
Особенности формальной верификации
Еще совсем недавно большинство разработчиков рассматривали
термин формальная верификация как синоним проверки на эквивалент-
ность. В рамках рассматриваемого материала проверка на эквивалент-
ность представляет собой средство, использующее формальные, стро-
гие математические методы сравнения двух разных представлений уст-
ройства, скажем RTL-описания и таблицы соединений вентилей.
Такая проверка проводится для определения, имеют эти представле-
ния одинаковую функциональность от входов до выходов или нет.
В сущности, проверка на эквивалентность может рассматриваться
как подвид формальной верификации, называемый верификация моде-
ли (Modelchecking)^. Эта проверка относится к методам, используемым
для анализа пространственного состояния системы с целью проверки
достоверности её определенных характеристик, которые обычно опи-
сываются в виде утверждений.
И в завершении этих рассуждений уточню: под формальной вери-
фикацией мы будем понимать именно верификацию модели. Также
замечу, что существует и другая категория формальной верификации,
известная как автоматизированные рассуждения, которые для тестиро-
вания устройств используют логику, больше напоминающую формаль-
ное математическое доказательство, и применение этого вида тестиро-
вания имеет свои характерные особенности.
Что такое формальная верификация, и чем она хороша
Предположим, что имеется устройство, состоящее из нескольких
блоков, и в текущий момент мы работаем с одним из этих блоков, ко-
торый выполняет некоторую специфичную функцию. Кроме RTL-
представления, определяющего функциональность этого блока, с ним
можно связать одно или несколько утверждений или свойств. Эти ут-
верждения/свойства могут быть связаны с сигналами интерфейса это-
го блока либо с сигналами или регистрами внутри блока.
Очень простое утверждение/свойство может соответствовать
строкам вида: «Сигналы А и Б никогда не будут активными одновре-
!) Термин Model Checking (проверка модели или верификация модели) полу-
чил широкое распространение в 90-х годах двадцатого столетия и обозначает про-
верку систем алгоритмическими методами на формальное соответствие специфи-
кации. Книга, целиком посвященная этой концепции, была переведена и издана
на русском языке в 2002 г. (Кларк Э.М. и др. «Верификация моделей программ:
Model Checking»). — Прим. ред.
264 и Глава 19. Средства моделирования, синтеза, верификации и реализации
1935 г. Англия. Де-
монстрация перво-
го радара.
1936 г. Эксперт в
области эффек-
тивности Август
Дворак (August
Dvorak) изобрёл но-
вый тип клавиату-
ры, названной кла-
виатурой Дворака,
в которой символы
располагались по
частоте их встре-
чаемости.
менно». Но эти выражения могут также расширяться до чрезвычай-
но сложных конструкций уровня транзакций, например: «При полу-
чении команды на запись от шины PCI соответствующая команда за-
писи в память вида хххх должна быть выдана в течение от 5 до 36
тактов».
Таким образом, утверждения/свойства позволяют описывать поведе-
ние контролируемой по времени системы в формальной и строгой фор-
ме. Это обеспечивает точное и всестороннее представление о предназна-
чении устройства. (А теперь попробуйте повторить это скороговоркой.)
Кроме того, утверждения/свойства могут использоваться для описания
как ожидаемых, так и запрещенных сценариев поведения устройства.
Тот факт, что утверждения/свойства могут читать как человек, так
и машина, делает их идеальными для описания выполняемых специ-
фикаций, но на этом их применение не ограничивается.
Давайте вернемся к рассмотрению очень простого утвержде-
ния/свойства вида: «Сигналы А и Б никогда не будут активными одно-
временно». Здесь должен «прозвучать» термин верификация на основе
утверждений, который постоянно присутствует в разговорах о модели-
ровании, статической формальной верификации и динамической
формальной верификации. При статической формальной верифика-
ции соответствующее средство считывает функциональное описание
устройства, обычно на уровне абстракции регистровых передач (RTL),
и затем полностью анализирует его логику, чтобы гарантировать, что
именно это частное условие никогда не наступит. При динамической
формальной верификации соответствующим образом расширенная сис-
тема логического моделирования будет работать до определенного мо-
мента, затем прервется и автоматически запустит соответствующее
средство формальной верификации.
Разумеется, утверждения и свойства могут быть связаны с устройс-
твом на любом уровне, т. е. могут относиться к отдельным блокам, к
нескольким соединённым по какому-либо интерфейсу блокам или ко
всей системе. Эта особенность предусматривает важную процедуру,
которая называется повторная верификация. До появления формаль-
ной верификации повторная верификация использовалась довольно
редко. Например, при продаже ядро IP обычно снабжается соответс-
твующими средствами тестирования, которые анализируют сигналы
ввода/вывода непосредственно на его входах и выходах. Эти средства
позволяют проверять отдельное ядро, но как только ядро будет интег-
рировано в устройство, поставляемые с ним средства тестирования
становятся бесполезными.
Теперь рассмотрим ядро IP, которое оснащено набором предопре-
делённых утверждений/свойств вида: «Сигнал А никогда не будет осу-
ществлять переход из 0 в 1 в течение трех тактов после активации сиг-
нала Б». Эти утверждения и свойства обеспечивают прекрасный меха-
низм взаимодействия от разработчика IP до конечного пользователя.
Более того, утверждения и свойства остаются в силе и могут быть вос-
приняты средствами проверки даже после встраивания ядра IP в раз-
рабатываемое устройство.
Что касается утверждений и свойств, связанных с внешними вхо-
дами и выходами системы, среда верификации может использовать их
для автоматической генерации задающих воздействий, подаваемых на
вход системы. Кроме того, можно использовать утверждения и свойс-
тва для анализа расширенного кода и функционально покрытия, что-
бы гарантировать выполнение характерной последовательности дейс-
твий или выполнения ряда условий.
Формальная верификация 265
Термины и определения
Получив общее представление о верификации модели (Model
checking), можно поговорить о терминах и определениях. Честно гово-
ря, эти понятия пока представляют собой мало исследованную область
и были тщательно отобраны в процессе общения со многими людьми.
Другими словами, была сделана попытка отделить зерна от плевел.
• Свойства и утверждения — термин свойство пришел из облас-
ти верификации модели (Model checking) и означает характер-
ное функциональное поведение устройства, которое желатель-
но (формально) проверить, например: «После запроса мы
ожидаем ответа в течение 10 тактов».
Термин утверждение пришел из области моделирования и оз-
начает специфическое функциональное поведение устройс-
тва, которое желательно наблюдать в процессе моделирова-
ния, и сигнализирует об ошибке, если такое утверждение
«срабатывает».
В наши дни при использовании формальных методов и
средств моделирования в унифицированных средах термины
«свойство» и «утверждение» взаимозаменяемые, т. е. свойство
может выступать в качестве утверждения и наоборот. В общем
случае под понятием «свойство/утверждение» мы понимаем
формулирование специфических атрибутов, связанных с до-
пустимым устройством или объектом. Таким образом, свойс-
тва/утверждения могут использоваться в качестве средств про-
верки и (или) наблюдения или в качестве объектов
формальных доказательств, а часто для выявления и локализа-
ции недопустимого поведения устройства.
• Ограничения — термин пришел из области верификации модели
(Model checking). В процессе формальной верификации модели
устройства рассматриваются все возможные допустимые вход-
ные комбинации. Следовательно, часто возникает необходи-
мость ограничивать входные воздействия по каким-либо при-
знакам, в противном случае средства проверки будут
сигнализировать об ошибочных отказах и нарушениях свойств
устройства, которые обычно не возникают в реальных устройс-
твах. Как и свойства, ограничения также могут быть простыми и
сложными. В некоторых случаях ограничения могут быть ин-
терпретированы как свойства, которые подлежат доказательс-
тву. Например, входное ограничение первого модуля может
быть также свойством выходного сигнала второго модуля, при
этом выход второго модуля подключен к входу первого. Поэто-
му свойства и ограничения могут иметь двойственную природу.
Термин ограничение также используется в системах ограничен-
ного стохастического моделирования, и в этом случае ограниче-
ние обычно применяется для обозначения диапазона значений,
которые могут быть использованы для управления шиной.
• События — отчасти напоминают утверждения и свойства, и в
общем случае могут рассматриваться как подмножество ут-
верждений или свойств. Однако если утверждения и свойства
обычно используются для выделения недопустимого поведе-
ния устройства, события могут использоваться для определе-
ния требуемого поведения устройства в целях обеспечения ана-
лиза функционального охвата. В некоторых случаях
утверждения/ свойства могут состоять из последовательности
266 Глава 19. Средства моделирования, синтеза, верификации и реализации
1936 г. Америка.
Психолог Бенджа-
мин Бурак
(Benjamin Burack)
сконструировал
первую электричес-
кую логическую ма-
шину (но информа-
цию о ней не публи-
ковал вплоть
до 1949 г.).
1936 г. Осущест-
влён первый элект-
ронный синтез речи.
событий. События могут также использоваться для определе-
ния интервала, внутри которого должно проверяться утвержде-
ние/свойство. Например, «после а, б, в мы предполагаем г, по-
ка не произошло д», где а, б, в и д — события, а г — поведение
устройства, которое надо контролировать. Отслеживание име-
ющих место событий и утверждений/свойств позволяет полу-
чать количественные данные о том, какие «тупиковые» ситуа-
ции и другие характерные состояния устройства были
проверены. Статистика по событиям и утверждениям/свойс-
твам может быть использована для определения функциональ-
ного охвата показателей устройства.
• Процедурный — этот термин употребляется по отношению к ут-
верждениям, свойствам, событиям и ограничениям, описанным
в контексте исполняемого процесса или набора последователь-
ных выражений, например, в виде процесса VHDL или блока
языка Verilog (поэтому их иногда называют внутриконтекстны-
ми свойствами/утверждениями). В этом случае утвержде-
ние/свойство является встроенным в логику устройства, и в
дальнейшем будет оцениваться исходя из образа действия набо-
ра последовательных операторов.
• Декларативный — относится к утверждениям/свойствам, собы-
тиям и ограничениям, которые существуют в структурном кон-
тексте устройства и оцениваются вместе со всеми другими
структурными элементами. Например, это может быть модуль,
принимающий формы структурного элемента. Вместе с тем, де-
кларативные утверждения/свойства всегда «активны/включе-
ны», а их процедурные аналоги активируются только при вы-
полнении определённой части HDL-кода.
• Прагмы — сокращение словосочетания «прагматическая ин-
формация»; относится к специальным директивам в виде псев-
докомментариев, которые могут интерпретироваться и исполь-
зоваться различными анализаторами, компиляторами и
другими средствами. (Это универсальный термин, и прагма-
методы широко используются не только при формальной вери-
фикации.)
Альтернативные методы описания утверждений/свойств
Вот с этого места и начинается полная неразбериха, потому что,
как будет показано, существует множество способов реализации ут-
верждений/свойств, описывающих устройство.
• Специальные языки — в этом случае используются формальные
языки, которые разработаны специально для максимально эф-
фективного описания утверждений/свойств. Языки этого ти-
па, к которым относятся Sugar, PSL и OVA, отличаются широ-
кими возможностями при создании сложных регулярных и
временных выражений, и с помощью очень компактного кода
позволяют описывать сложные поведенческие алгоритмы. Эти
языки часто используются для определения утвержде-
ний/свойств, которые располагаются в отдельных файлах и не
входят в главное HDL-описание устройства. Файлы могут быть
доступными в процессе компилирования, а также реализовы-
ваться в описательной форме. Кроме того, анализаторы кода,
компиляторы и системы моделирования могут быть дополне-
ны возможностями поддержки выражений, написанных на
Формальная верификация 267
специальных языках. Это позволяет напрямую встраивать их в
строки HDL-кода или в прагмы (определение «прагмы» смот-
рите в предыдущем подразделе). В подобных случаях выраже-
ния могут быть реализованы в декларативной или процедур-
ной форме.
• Специальные операторы языка HDL — изначально язык VHDL
поддерживал простые операторы контроля, которые проверя-
ли значения булевых выражений и отображали определённые
пользователем текстовые строки, если выражение принимало
значение false (ложь). Изначально Verilog не поддерживал опе-
раторов проверки, но его последующая реализация
SystemVerilog была дополнена такой возможностью. Недоста-
ток данного подхода заключается в относительной простоте
операторов контроля (в сравнении со специальными языками
утверждений/свойств). Кроме того, эти операторы плохо под-
ходят для описания сложных временных последовательностей
(хотя для этих целей SystemVerilog в некоторой степени превос-
ходит VHDL).
• Модели, написанные на HDL и вызываемые из HDL — эта концеп-
ция основана на доступе к библиотекам внутренних и внешних
моделей. Эти модели представляют собой утверждения/свойс-
тва, использующие стандартные выражения языка HDL, и мо-
гут быть представлены в устройстве как любые другие блоки.
Однако эти блоки будут свернуты прагмами синтеза вида
«Вкл/Выкл», чтобы быть уверенным, что они не будут реализо-
ваны физически. Хорошим примером этого метода может слу-
жить открытая библиотека средств проверки (OVL), разработан-
ная компанией Accellera (www.accellera.org).
• Модели, созданные на HDL с доступом через прагмы — эта кон-
цепция аналогична концепции предыдущего метода, так как
включает библиотеки моделей, представляющие собой утверж-
дения и свойства, использующие стандартные HDL-выраже-
ния. Однако вместо того чтобы вызывать эти модели напрямую
из главного кода устройства, обращение к ним производится с
помощью прагм. Хорошим примером этой методики является
библиотека CheckerWare® компании О-In Design Automation
(www.0-In.com). Например, рассмотрим устройство, содержа-
щую строку кода Verilog:
reg [5:0] STATE_VAR; //Oin one_hot.
Левая часть этого выражения объявляет 6-битный регистр, на-
званный STATE_VAR, который, допустим, будет использовать-
ся для хранения переменных состояния, используемых в конеч-
ных автоматах. Тем временем, правая часть, которая обозначена
как «Oin one_hot», является прагмой. Большинство средств бу-
дут воспринимать эту прагму как комментарий, и игнорировать
её, но средства компании О-In будут использовать её для вызова
соответствующей «one_hot» модели (которая является схемой
прямого кодирования) свойств/утверждений из библиотеки
CheckerWare. Замечу, что при использовании данного выраже-
ния не требуется определять переменную, тактовый сигнал или
ширину шины этого утверждений, так как информация такого
рода собирается автоматически. Кроме того, в зависимости от
положения прагмы в коде, она может реализовываться в декла-
ративной или процедурной форме.
1936 г. Начато
применение люми-
несцентного
освещения.
1936 г. Олимпиада
в Мюнхене впервые
транслировалась
по телевидению.
268 и Глава 19. Средства моделирования, синтеза, верификации и реализации
1937 г. Джордж
Стибиц (George
Robert Stibitz) со-
трудник лаборато-
рии Bell Labs,
сконструировал
простой, работаю-
щий на реле, циф-
ровой калькулятор
под названием
«Model К».
Статическая и динамическая формальная верификация
Данная тема может оказаться несколько трудной для восприятия,
поэтому будем погружаться в нее постепенно. Во-первых, в среде мо-
делирования можно использовать утверждения/свойства. В том слу-
чае, когда эти свойства и утверждения означают, что «сигналы А и В
никогда не будут активными одновременно», и когда такая недопусти-
мая ситуация всё-таки имеет место во время моделирования, на экра-
не появится соответствующее предупреждение и данное событие будет
зарегистрировано в журнале.
Альтернативой системам моделирования может служить статичес-
кая формальная верификация. Эти средства отличаются высокой точ-
ностью и позволяют проверять всё пространство состояний устройства
без применения систем моделирования. Их недостаток кроется в том,
что обычно они могут использоваться только для небольших частей ус-
тройства, так как пространство состояний с увеличением сложности
возрастает по экспоненте и можно очень быстро дойти до так называе-
мого разрыва пространства состояний. В отличие от статической фор-
мальной верификации системы логического моделирования, которые
также могут быть использованы для проверки утверждений, могут ох-
ватывать огромные устройства, но для их работы требуются задающие
воздействия и применять их можно не в каждой ситуации.
Например, можно использовать моделирование до тех пор, пока не
будет достигнуто определённое тупиковое состояние, затем сделать па-
узу и автоматически вызвать алгоритм статической формальной вери-
фикации для более тщательного обследования этого состояния. В кон-
тексте рассматриваемого материала понятия «тупиковое» состояние и
тупиковая ситуация характеризуют трудновыполнимые и труднодо-
ступные функциональные состояния устройства. После оценки «тупи-
кового» состояния управление автоматически вернётся к системе мо-
делирования для выполнения дальнейшей работы. Эта комбинация
системы моделирования и традиционной статической формальной ве-
рификации называется динамической формальной верификацией .
В качестве простого примера применения динамической формаль-
ной верификации рассмотрим память типа FIFO (очередь вида «пер-
вым пришёл, первым вышел»), в которой состояния «заполнена» и
«пустая» могут считаться тупиковыми ситуациями. Для заполнения та-
кой очереди потребуется много тактов, поэтому состояния «заполне-
на» можно достичь с помощью системы моделирования. Но точная
оценка утверждений/свойств, связанных с этими тупиковыми ситуа-
циями, например факт того, что в память FIFO невозможно записать
какие-либо данные, пока не освободится место, лучше всего достига-
ется с помощью статических методов.
И еще хороший пример такого средства динамического верифика-
ции предоставляет компания О-In. Библиотека моделей CheckerWare
содержит подробные описания тупиковых ситуаций. Если в процессе
моделирования достигается положение тупикового состояния, систе-
ма останавливается, и для детального анализа этого случая использует-
ся средство статической верификации.
Обзор других языков
Содержимое этого подраздела при неаккуратном подходе может
вызвать некоторую путаницу, поэтому давайте будем аккуратными.
Начнём обзор с продукта под названием Vera®, который появился на
Формальная верификация 269
свет в компании Sun Microsystems в начале 90-х. Впоследствии, где-то
в середине 90-х, он был предоставлен компании Systems Science
Corporation, которая в 1998 году была приобретена компанией
Synopsys.
По сути Vera есть не что иное, как среда полной верификации, по-
хожая, но, возможно, не такая сложная, как язык или среда верифика-
ции под названием е. Среда Vera поддерживает возможности формиро-
вания наборов тестов и утверждений, и компания Synopsys продвигает
ее как функционально законченный продукт с интеграцией в свою
систему логического моделирования. Позже, по заявкам пользовате-
лей, Synopsys открыла свой продукт для стороннего использования
под марками OpenVera™ и OpenVera Assertions (или OVA0).
Примерно в это же время язык SystemVerilog после очередной мо-
дификации обзавелся оператором assert (утвеждение). Тем временем,
благодаря возрастающему интересу к технологии формальной верифи-
кации один из комитетов по стандартам компании Acceller занялся по-
иском языка формальной верификации, который можно было бы при-
нять в качестве производственного стандарта. При этом рассматрива-
лись несколько вариантов, включая OVA, но в 2002 году комитет,
наконец, отдал предпочтение языку Sugar от IBM. Забавно, что через
какое-то время компания Synopsys подарила OVA одному из комитетов
Accellera, ответственному за язык SystemVerilog (это была другая ко-
миссия, которая оценивала формальные свойства языков).
Кроме того, одному из комитетов компании Accellera удалось стать
ответственным за так называемую библиотеку открытой проверки (или
OVL — open verification liblary), которая является библиотекой моделей
утверждений и свойств для языков VHDL и Verilog 2К1.
В связи с упомянутыми событиями, теперь операторы assert под-
держиваются языками VHDL и SystemVerilog, библиотекой моделей
OVL, языком утверждений OVA и специализированным языком опи-
сания свойств PSL (property specification language), который представ-
ляет собой версию языка Sugar компании IBM, переработанную ком-
панией Accellera (Рис. 19.16)* 2). Преимущество языка PSL заключает-
ся в том, что он достаточно самостоятельный и может
использоваться независимо от языков, применяемых для представле-
ния функциональности устройства. К его недостаткам можно отнес-
ти то, что он не похож на языки описания аппаратных средств, к
примеру, на VHDL, Verilog, C/C++ и другие, с которыми хорошо
знакомы разработчики. Необходимо также упомянуть о появлении
различных версий языка PSL, таких как Verilog PSL, VHDL PSL,
SystemC PSL и других. В этих версиях его синтаксис отличается от
оригинала и соответствует целевому языку, а вот семантика идентич-
на исходной версии.
Изначально пакет OVA был позаимствован из технологии моделирования
компании Synopsys. Позже было принято решение о его расширении для подде-
ржки средств формальной верификации на основе свойств. Поэтому Synopsys на-
чала сотрудничать с компанией Intel, чтобы воспользоваться опытом её сотрудни-
ков в сфере формальной верификации, работавших с языком внутреннего ис-
пользования на основе утверждений под названием ForSpec. В результате
появился пакет OVA 2.0, который объединил в себе мощные модули статической и
динамической формальной верификации.
2) Не следует считать, что PSL и Sugar — это один комбинированный язык.
Есть язык PSL, а есть Sugar, и это не одно и то же. PSL представляет собой стандарт
компании Accellera, a Sugar — язык, используемый компанией IBM.
270 Глава 19. Средства моделирования, синтеза, верификации и реализации
1937 г. Разработа-
ны принципы им-
пульсно-кодовой
модуляции (ИКМ)
для цифровой ра-
диопередачи
сигналов.
1938 г. Американец
Клод Шеннон
(Claude Е. Shannon)
опубликовал ста-
тью, основанную
на его работах в
Массачусетском
технологическом
институте,
в которой описы-
вались принципы
построения цифро-
вых схем на основе
булевой алгебры.
Подход к верификации
(как проверяемый объкт воспринимается «системой» верификации)
Рис. 19.16 отражает только одну точку зрения, и не каждый с ней
согласится: кто-то будет считать его блестящим разрешением излишне
запутанной ситуации, а кто-то в лучшем случае посчитает его грубым
упрощением или в худшем — полной чепухой.
Разное
Преобразование из HDL в С
Как уже обсуждалось в гл. 11, в наши дни наблюдается тенденция
описывать устройства на высших уровнях абстракции, например, с по-
мощью языка C/C++. Кроме более лёгких архитектурных исследова-
ний, высокоуровневые (поведенческие и (или) алгоритмические) мо-
дели, описанные на языке C/C++ могут моделироваться в сотни и ты-
сячи раз быстрее, чем их аналоги, созданные в HDL-коде.
Несмотря на всё вышесказанное, многие инженеры продолжают
работать с привычными для них RTL-описаниями. При этом надо
иметь в виду, что в случае моделирования однокристальной системы со
встроенным микропроцессорным ядром, памятью, периферией и дру-
гой логикой, описанной на уровне регистровых передач, пользователю
крупно повезет, если скорость моделирования будет составлять пару
герц (что составляет пару тактов системы синхронизации за каждую
секунду реального времени).
Чтобы решить эту проблему, некоторые компании САПР элект-
ронных устройств начали предлагать способы преобразования пользо-
вательских «эталонных» RTL-моделей в высокоскоростные аналоги,
которые могут достичь скорости моделирования в несколько кило-
Разное «271
герц1*. Этого достаточно, чтобы программные модули выполнялись на
представленном (виртуальном) аппаратном обеспечении за единицы
миллисекунд реального времени. В свою очередь, это обстоятельство
позволяет тестировать критичное базовое программное обеспечение,
например драйверы, модули диагностики, встроенные микрокоды,
вследствие чего проверка системы будет выполняться быстрее, чем
при использовании традиционных методов.
Кодовое покрытие
Не так давно средства оценки кодового покрытия, или анализа
структуры кода, разрабатывались сторонними производителями
САПР электронных систем. Однако сегодня эта возможность считает-
ся настолько важной, что все большие компании встраивают средства
оценки кодового покрытия в свои среды верификации/моделирова-
ния, но, естественно, набор возможностей у таких средств сильно ме-
няется в зависимости от предложения.
Не удивляйтесь, если узнаете о существовании разновидностей ко-
дового покрытия. Их типы в порядке возрастания сложности приведе-
ны в нижеследующем списке:
• Базовое кодовое покрытие (Basic code coverage) — просто анализ
строк исходного кода, т. е. сколько раз каждая строка исходного
кода выполнялась.
• Покрытие ветвей исходного кода (Brunch coverage) — анализиру-
ются выражения, подобные оператору if-then-else\ сколько раз
выполнялась часть then, и сколько раз else.
• Покрытие условий (Condition coverage) — относится к операторам
условий, записанных в виде «if (a OR b == TRUE) then...». В этом
случае речь идет о том, сколько раз выполнялся оператор then
вследствие того, что переменной а было присвоено значение
TRUE, и сколько раз из-за того, что это значение соответствова-
ло переменной Ь.
• Покрытие выражений (Expression coverage) — в этом случае име-
ем выражения вида «а = (b AND с) ORd»,& именно, речь идет обо
всех возможных комбинациях входных значений, какие из них
инициируют изменение выходного сигнала и какие переменные
не были протестированы.
• Покрытие состояний (State coverage) — означает анализ конеч-
ных автоматов и определение, какие состояния были ими за-
действованы, а какие нет, также какие защитные условия и пути
между этими состояниями были задействованы, а какие нет и
так далее. Вы можете получить эту информацию из анализа
структуры строк, но должны читать «между строк».
• Функциональное покрытие (Functional coverage) — анализу под-
вергаются события на уровне транзакций (например, транзак-
ции чтения или записи в память) и особые комбинации и пере-
становки этих событий.
• Покрытие утверждений/свойств (Assertion/property coverage) —
относится к среде верификации, которая может собирать, орга-
низовывать и делать доступными для анализа результаты рабо-
1938 г. Аргентина.
Выходец из Болга-
рии Лазро Биро
(Lazro Biro) разра-
ботал и получил
патент на первую
шариковую ручку.
1938 г. Германия.
Конрад Зюс
(Konrad Zuse)
сконструировал
первый работаю-
щий механический
цифровой компью-
тер, названный ZI.
1938 г. Джон Байрд
(John Logie Baird)
продемонстриро-
вал работу цветно-
го телевидения.
1938 г. Америка.
Трансляция радио-
спектакля «Война
миров» стала при-
чиной распростра-
нившейся паники.
° Интересным решением является транслятор VTOC™ (из языка Verilog в С)
от компании Tenison Technology Ltd. (www.tenison.com). Также интересны продук-
ты SPEEDCompiler™ и DesignPlayer™ компании Carbon Design Systems Inc.
(www.carbondesignsystems.com).
272 Глава 19. Средства моделирования, синтеза, верификации и реализации
1938 г. Телевизион-
ный сигнал может
быть записан на
пленку и подвержен
редактированию.
1938 г. Вальтер
Шоттки (Walter
Schottky) открыл
существование ды-
рок в зонной струк-
туре полупровод-
ников и объяснил
принципы построе-
ния диодов на осно-
ве технологии ме-
талл -полупровод-
ник.
ты различных событийных, формальных статических и динами-
ческих машин верификации на основе свойств и утверждений.
Эта форма анализа на самом деле может быть разделена на две
части: анализ на уровне спецификации и анализ на уровне реализа-
ции. В данном контексте, анализ на уровне спецификации изме-
ряет активность средств верификации по отношению к элемен-
там высокоуровневым функциональным или макроархитектур-
ным определениям. К ним относятся поведение систем
ввода/вывода устройства, типы допустимых транзакций (вклю-
чая взаимоотношение между собой транзакций разного типа) и
требуемые преобразования данных. Для сравнения, анализ на
уровне реализации измеряет активность средств верификации
по отношению к микроархитектурным деталям реального воп-
лощения. К ним относятся инженерные решения, встроенные в
RTL, которые являются результатом специфичных тупиковых
ситуаций, например, ситуации, связанные с опустошением и
переполнением буфера FIFO. Подобные детали реализации
редко видны на уровне спецификации.
Анализ производительности
И последней, важной характеристикой современных систем вери-
фикации является возможность выполнять анализ производительнос-
ти. Это свойство относится к некому анализу и формированию отчё-
тов о том, где и сколько времени система моделирования затратила на
свою работу. Сформированный таким образом отчёт позволяет сфоку-
сироваться на высокоактивных областях устройства и, следовательно,
достичь высоких показателей производительности системы.
ГЛАВА 20
ВЫБОР ПРАВИЛЬНОГО УСТРОЙСТВА
Такой широкий выбор
Наша жизнь была бы намного проще, если бы не приходилось пос-
тоянно что-нибудь выбирать. Например, заказывая обычный воскрес-
ный американский завтрак, состоящий из яиц, бекона, жареной кар-
тошки и тоста, можно потратить уйму времени из-за большого коли-
чества альтернатив.
Во-первых, официантка спросит, как именно яйца вам пригото-
вить (глазунью, слабо прожарить, средне прожарить, сильно прожа-
рить, болтунью, омлет, яйцо-пашот, вкрутую и так далее). Затем вас
спросят, желаете ли вы американский или канадский бекон, подать ли
вам картофель с луком, томатом, сыром, ветчиной, чили или сразу с
несколькими из этих продуктов; хотите ли вы, чтобы хлеб для тоста
был белый, ржаной, пшеничный, приготовленный из муки грубого
помола, на опаре...
Самое ужасное, что сложность выбора завтрака меркнет по сравне-
нию с выбором ПЛИС, так как в мире существует огромное множество
семейств этих устройств от разных производителей. Линейки и се-
мейства изделий одного и того же производителя частично совпадают,
а изделия от разных производителей могут как совпадать, так и иметь
разные особенности и возможности. И эта ситуация с завидным пос-
тоянством меняется почти ежедневно.
Главное, чтобы инструмент был
Прежде, чем приступить к обсуждению этой темы, стоит отметить,
что размер — это еще не самое главное в мире ПЛИС. На самом деле
при выборе устройства нужно руководствоваться и такими требовани-
ями к нему, как количество контактов ввода/вывода, наличие логичес-
ких ресурсов, специальных функциональных блоков и так далее.
Вместе с тем, следует учитывать, имели ли вы прежде дело с каким-
либо определённым производителем или семейством ПЛИС, или
столкнулись с ними впервые. Если у вас уже есть опыт работы с каким-
либо поставщиком и вы уже знакомы с использованием его компонен-
тов, инструментов и методов проектирования, тогда стоит сотрудни-
чать с ним и в дальнейшем, пока не появится веская причина, чтобы
перейти к продукции другого производителя.
Однако в нашем случае давайте предположим, что мы начинаем с
самого начала и, следовательно, не можем отдать предпочтение како-
му-либо поставщику. В подобной ситуации выбор оптимального уст-
ройства для конкретного проекта будет представлять собой довольно
сложную задачу.
Знакомство с архитектурой, ресурсами и возможностями различ-
ных семейств компонентов от разных производителей ПЛИС требует
много времени и усилий. В современном мире время выхода нового
товара на рынок настолько ограничено, что разработчики могут про-
274 Глава 20. Выбор правильного устройства
В 1939 г., в Амери-
ке, Джордж Сти-
биц (George Stibitz)
разработал цифро-
вой калькулятор,
способный склады-
вать комплексные
числа и выполнять
другие алгебраичес-
кие вычисления.
Это устройство
назвали калькуля-
тором комплекс-
ных чисел (Complex
Number Calculator).
1939 г. Америка.
Джон Атанасов
(John Atanasoff) и
Клиффорд Берри
(Clifford Berry) соб-
рали первый специ-
альный цифровой
компьютер, кото-
рый должен был
производить вы-
числения с помо-
щью электронных
ламп. Его назвали
ABC (Atanasoff-
Berry Computer).
Работы по доводке
компьютера про-
должались до 1942
года.
В 1939 г. компания
Bell Labs присту-
пила к тестирова-
нию высокочас-
тотного радара.
В том же 1939 го-
ду Мессере Бай
(Messers Вау) и Бе-
ла Сигети (Szigeti)
запатентовали
светодиод.
извести лишь поверхностную оценку всего многообразия существую-
щих устройств, прежде чем остановиться на определённой модели, се-
рии и производителе. Таким образом, выбранная ПЛИС почти навер-
няка не является оптимальным компонентом для устройства, но
такова жизнь.
В процессе выбора хотелось бы получить доступ к какому-нибудь
своего рода мастеру, желательно Web-приложению, позволяющему
осуществлять выбор ПЛИС по определённым признакам. Эта про-
грамма позволила бы нам подобрать конкретного производителя, сде-
лать подборку производителей или произвести открытый поиск по
производителям
Мастер запросил бы у нас значения таких параметров, как коли-
чество эквивалентных вентилей заказной микросхемы (ASIC) или ко-
личество системных вентилей ПЛИС (при условии, что существуют
хорошие определения этих понятий, см. гл. 4), а также требования к
контактам и интерфейсам ввода/вывода, допустимые варианты корпу-
са и т. д.
Для больших схем мастер выдал бы запрос о необходимости ис-
пользования гигабитных передатчиков или встроенных функций, на-
пример, умножителей, сумматоров, операций умножения с накопле-
нием, блоков ОЗУ (как встроенного, так и распределённого ОЗУ) и
т. д. Мастер также позволил бы нам определить, нужен ли доступ к
встроенным микропроцессорным ядрам (аппаратным или програм-
мным) с выбором соответствующей периферии.
И еще, не менее важное, было бы здорово, если бы мастер мог под-
сказать, какие потребуются блоки интеллектуальной собственности.
Коль мечтать, так мечтать! И в завершении, после нажатия кнопки Го-
тово создавался бы подробный отчет, содержащий допустимые вариан-
ты, их возможности и расценки.
Спустившись на грешную Землю, мы обнаруживаем, что на самом-
то деле таких программ пока нет в природе0, поэтому нам придётся
производить все эти оценки вручную. Ну, разве это не чудесно?
Разумеется, создание такого приложения не было бы тривиальной
задачей, и его поддержка потребовала бы определённых временных за-
трат, но я уверен, что проектные организации или инженеры-разра-
ботчики готовы выложить кругленькую сумму за такую услугу, если бы
кто-то рискнул принять вызов и справился бы с этой задачей.
Технология изготовления
Прежде всего, нам предстоит выбрать технологию, на основе кото-
рой будут построены ПЛИС. Имеются следующие варианты для выбора:
• На основе ячеек статического ОЗУ — несмотря на то, что уст-
ройства, изготовленные по такой технологии, отличаются чрез-
вычайной гибкостью, для их работы потребуется внешнее кон-
фигурационное устройство (как правило, микросхема памяти),
а сам процесс конфигурирования после включения системы мо-
жет занять несколько секунд. Первые версии этих устройств
могли потреблять большой ток из-за больших кратковременных
токов переключения, но эта проблема уже решена в современ-
ных устройствах. Основное преимущество этого варианта за-
ключается в том, что он основан на стандартной КМОП-техно-
0 В своё время существовали средства, подобные описанным здесь, которые
помогали выбирать программируемые логические устройства (ПЛУ), но работали
они со значительно менее сложным пространством решений.
Основные ресурсы и корпус 275
логии и не требует никаких дополнительных шагов в процессе
производства. Это значит, что ПЛИС на основе ячеек статичес-
кого ОЗУ изготавливаются с использованием самых современ-
ных технологических процессов.
• На основе наращиваемых перемычек — эта технология предлагает
наилучшую защиту для блоков интеллектуальной собственности
(IP), а также обеспечивает низкое энергопотребление, мгновен-
ную готовность к работе, и не нуждается во внешних конфигура-
ционных устройствах (что позволяет сократить стоимость, разме-
ры и вес печатной платы). Устройства на основе наращиваемых
перемычек, в отличие от всех других технологий, отличаются по-
вышенной радиационной стойкостью, что представляет интерес
для авиакосмических приложений. К сожалению, эти устройства
не подходят для применения в качестве прототипов, так как яв-
ляются однократно программируемыми. Также устройства на ос-
нове наращиваемых перемычек отстают на одно или несколько
поколений от текущего уровня технологического процесса, так
как в отличие от КМОП-устройств при их производстве необхо-
димо задействовать дополнительные технологические этапы.
• На основе технологии Flash — хотя эти устройства обладают боль-
шей степенью защиты, чем при использовании ячеек статичес-
кого ОЗУ, но, применительно к блокам IP, они всё же уступают
по этому показателю устройствам на основе наращиваемых пе-
ремычек. ПЛИС-компоненты на основе технологии Flash не
требуют для своей работы внешних конфигурационных уст-
ройств и при необходимости могут быть перепрограммируемы
внутрисистемно. Также как и компоненты на основе наращива-
емых перемычек, Flash-устройства мгновенно готовы к работе
сразу после включения, но и они отстают на одно или несколько
поколений от текущего уровня технологического процесса, так
как в отличие от КМОП-устройств при их производстве необхо-
димо задействовать дополнительные технологические этапы. К
тому же эти устройства обычно содержат гораздо меньшее коли-
чество вентилей, чем их аналоги на статическом ОЗУ.
Основные ресурсы и корпус
После выбора технологии изготовления микросхем надо опреде-
лить, какие устройства будут удовлетворять вашим потребностям в ре-
сурсах, и в каком корпусе они могут быть реализованы. Что касается
основных ресурсов, в большинстве случаев ограничивающим факто-
ром является количество выводов микросхемы, только при создании
устройств, требующих обработки сложных алгоритмов (например,
преобразование цветового пространства), вы столкнетесь с ограниче-
ниями по количеству логических элементов. Итак, независимо от типа
устройства нам необходимо принять решение о количестве требуемых
контактов ввода/вывода, и определить приблизительно количество ос-
новных логических элементов (таблиц соответствия и регистров).
Как уже обсуждалось в гл. 4, сочетание таблиц соответствия, регис-
тров и связующей логики одни называют логическими элементами, а
другие — логическими ячейками. В общем случае предпочтительнее
пользоваться именно этими категориями, чем структурами более вы-
сокого уровня — секциями, конфигурируемыми логическими блоками
(КЛБ или CLB — configurable logic block) или блоками логических масси-
вов (LAB — logic array bloc), так как определение этих более сложных
структур может меняться в зависимости от семейства устройств.
В 1939 году в Анг-
лии началось регу-
лярное телевеща-
ние.
1939 г. Америка.
Джордж Стибиц
(George Stibitz) про-
демонстрировал
первый пример уда-
лённых вычислений
между Нью-Йор-
ком и Нью-Гемп-
широм.
276 и Глава 20. Выбор правильного устройства
В 1940 г. Bell Labs
приступила к раз-
работке техноло-
гии сотовой связи
(но до рыночного
уровня эта техно-
логия доводилась
почти ЗОлет).
В 1941 г. осущест-
влена первая ко-
ротковолновая пе-
редача.
Далее надо определить, какие компоненты содержат достаточное
количество зон синхронизации, систем ФАПЧ, систем автоматичес-
кой подстройки по задержке или цифровых диспетчеров синхронизации
(DCM— digital clock manager).
И напоследок, при наличии собственных конкретных требований
к корпусу было бы хорошо, чтобы устройства, которые привлекли на-
ше внимание, находились в требуемом корпусе. Я знаю, это кажется
само собой разумеющимся, но готовы ли вы побиться об заклад, что до
вас никто не споткнулся на этом?
Интерфейсы ввода/вывода общего назначения
Следующий пункт для обдумывания заключается в выборе микро-
схем, которые располагают конфигурируемыми блоками ввода/вывода
общего назначения, поддерживающие стандарты и технологии пере-
дачи данных, необходимые для связи с другими компонентами на пе-
чатной плате.
Предположим, что в начале процесса проектирования разработчи-
ки системы выбрали один или несколько стандартов ввода/вывода для
обмена между устройствами на печатной плате. Вам повезёт, если
удастся найти такую ПЛИС, которая поддерживает все требуемые
стандарты, а также предоставляет другие необходимые возможности.
В противном случае можно:
• выбрать другое семейство, может быть, от другого поставщика —
если в результате первоначального отбора ПЛИС не удовлетво-
ряет некоторым обязательным общим требованиям или требова-
ниям к функциональным возможностям;
• если изначально выбранный ПЛИС-компонент только час-
тично удовлетворяет предъявляемым требованиям, то вы мо-
жете использовать дополнительные внешние навесные эле-
менты (подобное решение приведет к повышению стоимости
устройства и уменьшению свободного места на печатной
плате). В качестве альтернативы, совместно с командой раз-
работчиков системы вы можете изменить архитектуру печат-
ной платы. Это решение может оказаться довольно дорогим,
если разработка системы уже достигла некоторого высокого
уровня.
Встроенные умножители, блоки ОЗУ и т. д.
На некотором этапе выбора устройства вам необходимо произвес-
ти оценку требуемого объема распределенной оперативной памяти
(распределенного ОЗУ) и количества встраиваемых блоков ОЗУ (с учё-
том требуемой разрядности).
Аналогично, необходимо подумать о количестве специальных
встраиваемых функций, таких как умножители и сумматоры, а также об
их разрядности и возможностях. В случае разработки системы для циф-
ровой обработки сигналов (ЦОС) некоторые ПЛИС могут содержать
встроенные функции, подобные операциям вида «умножение с накоп-
лением» (МАС), которые будут крайне полезны для решения этих задач
и могут помочь принять верное решение при выборе компонентов.
Встроенные микропроцессорные ядра
При желании использовать в своём проекте встроенные процес-
сорные ядра придется принять решение, будет ли программное ядро
достаточным для решения поставленных задач (такие ядра могут быть
Возможности гигабитного ввода/вывода 277
реализованы в микросхемах многих семейств) или лучше применить
аппаратное ядро (см. гл. 13).
В случае выбора программного ядра можно принять решение об
использовании наработок, предлагаемых производителем ПЛИС. В
этом случае вы ограничиваете себя продукцией только выбранного
производителя, поэтому необходимо произвести тщательный анализ
всех возможных вариантов до принятия окончательного решения. В
качестве альтернативы можно использовать программные ядра сто-
ронних разработчиков, которые могут быть реализованы на устройс-
твах от разных поставщиков1'.
При использовании аппаратного ядра возникнут проблемы, свя-
занные с ограниченным выбором микросхем, и, в конечном итоге,
вы окажетесь жестко привязанными к продукции одного конкретно-
го производителя. На процесс принятия решения может оказать вли-
яние личный опыт работы с различными типами процессоров. Если,
например, вы обладаете «черным поясом» в вопросах построения
систем на основе платформы PowerPC, то наверняка пожелаете вло-
жить свои капиталы в средства разработки и технологии для этой
платформы. Таким образом, решение, вероятнее всего, будет в поль-
зу ПЛИС фирмы Xilinx, поскольку они поддерживают платформу
PowerPC. Однако если вы «гуру» в отношении процессоров ARM или
MIPS, то наверняка предпочтёте продукцию компаний Altera или
QuickLogic.
Возможности гигабитного ввода/вывода
Если в системе необходимо использовать гигабитные приемопере-
датчики, то предметом обсуждения должно стать число таких блоков в
устройстве и конкретный стандарт передачи, выбранный разработчи-
ками системы (см. гл. 21).
Блоки интеллектуальной собственности
Каждый поставщик ПЛИС имеет свой набор блоков, представля-
ющих интеллектуальную собственность (блоки IP). Часто эти средс-
тва у разных поставщиков во многом схожи, но какие-то важные
скрытые функции могут быть реализованы только устройствами кон-
кретного производителя, что может существенно ограничить выбор
компонентов.
Альтернативой может стать приобретение права на интеллектуаль-
ную собственность у стороннего поставщика. В этом случае блоки ин-
теллектуальной собственности могут быть использованы примени-
тельно ко многим ПЛИС от разных поставщиков или только к ограни-
ченному числу (или к определённому подмножеству микросхем от
этих поставщиков).
Необходимо заметить, что, в общем, под термином блок IP мы под-
разумеваем аппаратную реализацию некоторых функций, но какие-то
блоки интеллектуальной собственности могут быть реализованы так-
же в форме программных решений2*. В качестве примера рассмотрим
функцию связи, которая может быть реализована аппаратно в составе
° Примером решения такого типа может служить продукт под названием
Nexar компании Altium Ltd. (www.altium.com), который рассматривался нами в
главе 13.
2) Существуют также средства тестирования, представляющие собой интел-
лектуальную собственность, которые мы рассматривали в главе 19.
В 1941 г. появились
первые кнопочные
телефоны с то-
нальным вызовом
(которые были
слишком дорогими
для массового ис-
пользования).
В период 1942-1946
гг. в Германии Кон-
рад Зюс (Konrad
Zuse) разрабаты-
вает идею высоко-
уровневого компью-
терного языка про-
граммирования, ко-
торый получил на-
звание Plankakul.
1943 г. Германия.
Конрад Зюс
(Konrad Zuse) на-
чал работу над сво-
им компьютером
общего назначения
под название Z4,
который работал
на электромехани-
ческих реле.
1944 г. Америка.
Говард Айкен
(Howard Aiken) и
его команда завер-
шили построение
электромеханичес-
кого компьютера
под названием
Harvard Mark I
(который также
известен как
IBMASCC).
В 1945 году венгер-
ский и американс-
кий математик
Джон фон Нейман
(John Von
Neumann) опубли-
ковал статью под
названием «Пред-
варительный до-
клад о машине
EDVAC».
278 Глава 20. Выбор правильного устройства
В 1946 году Перси
Спенсор (Percy
Spensor) изобрел
микроволновую
печь (первые прода-
жи которой состо-
ялись в 1947году).
1945 г., научный
фантаст Артур
Кларк (Arthur
Clark) выдвинул ги-
потезу о геостаци-
онарных спутни-
ках связи.
1946 г. Америка.
Джон Моучли
(John Mauchly) и
Преспер Эккерт
(Presper Eckert)
совместно с коман-
дой разработчиков
завершили постро-
ение электронного
компьютера обще-
го назначения под
названием ENIAC.
1946 г., автомо-
бильный радиоте-
лефон был подклю-
чен к телефонной
сети.
23 декабря 1947 г.
американские фи-
зики Уильям Шок-
ли (William
Shockley), Вальтер
Браттейн (Walter
Brattain) и Джон
Бардин (John
Bardeen) создали
первый в мире то-
чечный германие-
вый транзистор.
структуры ПЛИС, либо может представлять собой программу, которая
будет выполняться встроенным процессором. В последнем случае вы
можете принять решение о покупке такой программы у стороннего
разработчика, тогда фактически вы приобретёте программное средс-
тво интеллектуальной собственности.
Скоростные показатели
После выбора ПЛИС для своего устройства необходимо опреде-
литься со скоростью его работы. Поставщики ПЛИС обычно при оп-
ределении стоимости своих устройств в качестве главного критерия
рассматривают его производительность (скорость работы).
Увеличение скорости работы устройства, в результате которого
производительность возрастет на 12... 15%, приводит к увеличению его
стоимости на 20...30%. И наоборот, если вы можете с помощью изме-
нения архитектуры вашего устройства улучшить его производитель-
ность на 12...15% (скажем, с помощью увеличения длины конвейера),
тогда это позволит снизить скорость его работы и сэкономить на каж-
дой микросхеме от 20 до 30% её стоимости.
Если вы намереваетесь создать только одно устройство в качестве
прототипа какой-либо системы, тогда скорость его работы не будет яв-
ляться для вас существенным фактором. С другой стороны, если вы
собираетесь покупать сотни или тысячи этих маленьких штучек, тогда
вам предстоит очень серьёзно подумать, насколько медленными уст-
ройствами вы можете обойтись.
Вся проблема заключается в том, что модификация и перепроверка
RTL-описания для выполнения ряда оценок вида «что-если» разных
альтернативных реализаций одного и того же устройства требует много
времени и больших усилий. (Выполнение таких оценок может вклю-
чать формирование некоторых операций в параллельном и последова-
тельном режимах, с применением конвейера и без него, с распределе-
нием ресурсов и так далее.) Это значит, что команда разработчиков
может быть ограничена в анализе возможных реализаций устройства,
что в конечном итоге, может привести к неоптимальному решению.
Как рассматривалось в гл. 11, в качестве альтернативы можно ис-
пользовать методы проектирования на основе чистой (стандартной)
версии языка С. Такое проектирование подразумевает использование
C/C++ анализа и синтеза, которые позволяют приходить к микроархи-
тектурным компромиссным решениям, а также оценивать их эффек-
тивность по размеру (или площади) и частоте шины (скорости работы)
устройства. Это позволяет повысить производительность устройства,
и, тем самым, снизить требуемую скорость работы системы.
На оптимистической ноте
Мой друг Том Диллон (Tom Dillon) сказал, что после того, как я за-
стращал всех описанными выше сложностями, я должен закончить
свой рассказ на оптимистической ноте. Поэтому с радостью могу со-
общить, что после того, как команда разработчиков остановила свой
выбор на каком-либо из поставщиков ПЛИС и освоила работу с его
линейкой продуктов, в течение некоторого времени это существенно
облегчит выбор нового устройства для последующих проектов.
ГЛАВА 21
ГИГАБИТНЫЕ ПРИЁМОПЕРЕДАТЧИКИ
Введение
Как уже обсуждалось в гл. 4, в общем случае большие массивы дан-
ных между двумя (или несколькими) устройствами в пределах одной
печатной платы передаются с помощью шины, которая представляет
собой набор сигналов, передающих схожие данные и выполняющий
общие функции (Рис. 21Л).
Рис. 21.1. Использование шины для связи между устройствами
Примерно с 1975 года первые микропроцессорные системы ис-
пользовали для передачи данных 8-битные шины. С ростом потреб-
ности в передаче большего объема данных и увеличения скорости их
передачи шины выросли сначала до 16 бит, потом до 32 бит, затем до 64
бит и т. д. Однако такой подход требует большого количества выводов
в микросхеме и большого количества проводников для соединения ус-
тройств. С ростом сложности печатной платы прокладка этих провод-
ников таким образом, чтобы они имели одинаковую длину и сопро-
тивление, становится всё более сложной задачей. Более того, с боль-
шим количеством шинных проводников становится сложнее
обеспечивать целостность сигналов из-за чувствительности к шумам и
перекрёстных помех.
По этой причине современные высокотехнологичные ПЛИС снаб-
жаются блоками гигабитных приёмопередатчиков. Эти высокоскорос-
тные последовательные интерфейсы используют одну пару дифферен-
циальных сигналов для передачи (ТХ), и одну пару для приема (RX) дан-
ных (Рис. 21.2).
Следует заметить, что в отличие от традиционных шин данных, к
которым можно подключать большое количество устройств, эти высо-
коскоростные последовательные интерфейсы поддерживают соедине-
ния типа точка-точка, другими словами каждый передающий блок
может общаться только с одним таким же блоком, установленном на
другом устройстве.
Во время написания этой книги эти высокоскоростные последова-
тельные интерфейсы использовались сравнительно небольшим коли-
чеством моделей. Однако будем полагать, что их число заметно увели-
чится в ближайшие несколько лет. Использование гигабитных приё-
мопередатчиков сродни искусству, но каждый поставщик ПЛИС
280 Глава 21. Гигабитные приёмопередатчики
В 1948 году в США
с помощью самолё-
та была осущест-
влена ретрансля-
ция телевизионно-
го сигнала на де-
вять штатов.
Рис, 21,2. Использование высокоскоростных приёмопередатчиков
для связи между устройствами
снабжает свои продукты подробными руководствами пользователя и
особенностями применения устройств в конкретных условиях.
Трудность работы с этими интерфейсами заключается в существо-
вании такого большого количества обычных, но практически важных
деталей, что можно совершенно запутаться. В этой книге представле-
ны лишь основные концепции гигабитных интерфейсов, так как неос-
торожное предоставление более полной информации может оказаться
опасным!
Дифференциальные пары
Причина использования дифференциальных пар, т. е. пары доро-
жек на печатной плате, всегда передающих комплементарные логичес-
кие уровни, состоит в том, что эти проводники менее чувствительны к
помехам от внешних источников. Помехи могут быть вызваны интер-
ференцией радиосигналов или другими, переключающимися с одного
логического уровня на другой, сигналами, проводники которых нахо-
дятся в непосредственной близости от этих дорожек. Чтобы проде-
монстрировать описанный процесс, создадим одинаковые помехи для
одиночного провода и для дифференциальной пары (Рис. 21.3).
Рис. 21.3. Использование высокоскоростных приёмопередатчиков
для связи между устройствами
При стандартном подходе у микросхемы имеется вывод «Вход»,
который подключен к входу буферного логического элемента. В этом
примере первый выброс (а) не представляет для нас какого-либо инте-
реса, а вот второй (б) может стать причиной определённых проблем.
Дифференциальные пары 281
Если этот выброс перешагнёт через входное пороговое значение пере-
ключения буферного вентиля, то это приведёт к появлению всплеска
(импульса) на выходе вентиля. В свою очередь, этот всплеск может вы-
звать внутри ПЛИС нежелательные процессы (например, спровоциру-
ет загрузку неверных данных в регистры).
Совсем еще недавно эти проблемы были не столь актуальны, пос-
кольку разница напряжений между логическим 0 и логической 1 со-
ставляла 5 В, и в этом случае выброс, скажем амплитудой 1 В, не поро-
дил бы каких-либо проблем. Но прошло время, и в зависимости от
стандарта ввода/вывода разница между логическим нулем и логичес-
кой единицей теперь составляет величину всего 1.8 В, 1.5 В или даже
меньше. В этом случае выброс даже гораздо меньший чем 1 В может
нарушить работу устройства1*.
Теперь рассмотрим дифференциальную пару, сигналы в которой ге-
нерируются специальным формирующим вентилем в передающем уст-
ройстве (Рис. 21.4). Специально для пуристов2*, если среди читателей
таковые имеются, заметим, что положительные проводники диффе-
ренциальных пар (RXP и ТХР на Рис. 21.3 и 21.4 соответственно) обыч-
но изображаются сверху, а отрицательные (инверсные или комплемен-
тарные) с кружочками на обозначениях обычно изображаются внизу.
Причина, по которой мы нарисовали их наоборот, состоит в том, чтобы
сделать сигнал RXP аналогичным сигналу «Вход» на Рис. 21.3, тем са-
мым, сделав материал более доступным для понимания.
1948 г. в Америке
начались разработ-
ки первого коммер-
ческого компьюте-
ра UNIVAC-1.
Рис. 21.4. Формирование дифференциальных пар
Напомню, что два сигнала в дифференциальной паре всегда несут
комплементарные логические значения. Так, если сигнал RXP
(Рис. 21.3) находится в состоянии логического нуля, то на RXN будет
логическая единица, и наоборот. Как следует из Рис. 21.3, две дорож-
ки, формирующие дифференциальную пару, разведены очень близко
друг с другом. Это означает, что любые всплески помех одинаково пов-
лияют на сигналы обеих дорожек. Входной буферный вентиль на са-
мом деле рассматривает лишь разницу напряжений между двумя вход-
ными сигналами, а это значит, что дифференциальные пары гораздо
менее восприимчивы к влиянию помех, чем соединения, сформиро-
ванные из отдельных проводников.
° У одного стандарта, использующего дифференциальные пары, разница
между напряжением 0 и 1 составляет всего 0.175 В (175 мВ)!
2) Пуристами называют консервативных приверженцев чрезмерной строгости
в соблюдении всех правил. — Прим. ред.
282 Глава 21. Гигабитные приёмопередатчики
1948 г. Разработа-
ны первые атомные
часы.
1949 г. Америка.
Массачусетский
технологический
институт запус-
тил первый ком-
пьютер реального
времени под назва-
нием Whirlwind.
И в завершении, допустим, что печатная плата разработана надле-
жащим образом, тогда эти приёмопередатчики могут работать с неве-
роятно большими скоростями. Кроме того, каждая микросхема
(ПЛИС) может содержать несколько таких блоков и, как мы еще убе-
димся, несколько блоков могут быть соединены вместе для достиже-
ния более высоких скоростей передачи данных.
Многообразие стандартов
Конечно, электроника не была бы электроникой, если бы не су-
ществовало большого разнообразия стандартов гигабитной передачи
данных. Каждый стандарт определяет параметры протоколов от вы-
сшего до физического уровня. В число самых распространенных стан-
дартов входят:
• Fibre Channel (оптоволоконная архитектура);
• InifiniBand®;
• PCI Express (разработанный компанией Intel Corporation);
• RapidlO™;
• SkyRail™ (от Mindspeed Technologies™);
• 10-гигабайтный Ethernet.
Ситуация осложняется тем, что при использовании некоторых из
этих стандартов, например PCI Express или SkyRail, производители
могут использовать одинаковые базовые концепции, но выпускать их
под собственными названиями и использовать свою терминологию.
Кроме того, реализация некоторых стандартов требует использования
нескольких передающих блоков.
Предположим, что речь идет о разработке печатной платы с ис-
пользованием высокоскоростного последовательного интерфейса. В
этом случае разработчики системы определяют, какой стандарт дол-
жен использоваться. Каждый из гигабитных передающих блоков внут-
ри ПЛИС может быть сконфигурирован для поддержки нескольких
различных стандартов, но, как правило, не всех. Это значит, что сис-
темные инженеры отдадут предпочтение стандарту, который подде-
рживается используемой ими ПЛИС, или им придётся выбрать ПЛИС
другого типа, поддерживающую выбранный интерфейс.
Если рассматриваемая система подразумевает разработку одной
или нескольких заказных микросхем, ASIC, предпочтительнее, конеч-
но же, использовать стандартный компонент по собственному выбору
или приобрести подходящий блок IP у стороннего производителя. Од-
нако имеющиеся в наличии микросхемы (заказные микросхемы ASSP)
обычно поддерживают лишь один или несколько из вышеперечислен-
ных стандартов. В этом случае ПЛИС может быть использована как ин-
терфейс между двумя (или несколькими) стандартами (Рис. 21.5).
Рис. 21.5. Использование ПЛИС в качестве интерфейса между
различными стандартами
8- и 10-битное кодирование 283
8- и 10-битное кодирование
Одна из проблем передачи данных со скоростями несколько гига-
бит в секунду заключается в том, что печатная плата и ее дорожки пог-
лощают существенную часть высокочастотного сигнала, вследствие
чего приемник получает лишь его ослабленную версию.
К сожалению, это явление трудно объяснить словами, поэтому
рассмотрим несколько наглядных (визуальных) примеров. Сначала
предположим, что идеальный сигнал меняет своё состояние между
уровнями логического 0 и логической 1 (Рис. 21.6).
1949 г. Америка.
Начало работы се-
тевого телевиде-
ния.
10 10 10 10 1
Сигнал,
переданный
передатчиком
Сигнал
на входе
приёмника
Рис. 21.6. Идеальный сигнал
Опытные инженеры непременно найдут несколько неточностей в
этом рисунке. Например, сигнал, образованный передатчиком, пока-
зан в виде чистых цифровых прямоугольных импульсов: на самом деле
такой сигнал имел бы ярко выраженные аналоговые черты. На практи-
ке лучшее, что можно было бы сказать при работе на этих частотах, так
это то, что сигнал устрашающей формы выходит с передающего уст-
ройства и в ещё худшем виде поступает на приёмное устройство. Кроме
того, сигнал, полученный приемником, будет сдвинут по фазе относи-
тельно сигнала, показанного на Рис. 21.6. Но мы синхронизировали
оба сигнала и, следовательно, можем видеть, как биты на передающей
и приемной сторонах дорожки взаимосвязаны друг с другом.
Как следует из рисунка, сигнал на приемной стороне сильно ос-
лаблен, но все еще колеблется около некоторого среднего уровня. Это
позволит приёмнику отдетектировать его, и извлечь из него полезную
информацию. Теперь рассмотрим, что произошло бы, если мы моди-
фицировали бы предыдущую последовательность таким образом, что-
бы она начиналась с передачи трех последовательных логических еди-
ниц (Рис. 21.7).
В этом случае сигнал, полученный приемником, нарастает в тече-
ние времени, длительность которого соответствует первым трём би-
там. (Не будем забывать, что этот пессимистический сценарий рас-
сматривается лишь в качестве примера!) Это обстоятельство увеличи-
вает величину сигнала по сравнению со средним значением,
вследствие чего, когда сигнал на входе опять возвращается к первона-
чальному виду 010101..., приемник будет продолжать принимать его
как последовательность логических 1.
В контексте передачи данных отдельные двоичные цифры (или
иногда слова, сформированные из нескольких цифр) называются сим-
волами. Рассеивание, или размазывание, символов, когда энергия од-
ного символа воздействует на другой, может привести к неправильной
284 Глава 21. Гигабитные приёмопередатчики
Сигнал,
переданный
передатчиком
Сигнал
на входе
приёмника
Рис. 21.7. Эффект при передаче последовательности идентичных
битовых значений
интерпретации принятого сигнала. Такое явление называется межсим-
вольной интерференцией (ISI — intersymbol interference).
Другой термин, который часто звучит в разговорах на эту тему, на-
зывается последовательными идентичными цифрами (CID — consecutive
identical digits) и относится к ситуациям, похожим на рассмотренный
случай с тремя логическими единицами (Рис. 21.7). Как уже было ска-
зано, пример, изображенный на Рис. 21.7, чрезмерно пессимистич-
ный. Чтобы избежать сбойной ситуации, достаточно убедиться, что
мы не отправляем больше пяти идентичных битов подряд. Следова-
тельно, блоки высокоскоростных передатчиков должны включать не-
которые формы кодирования, например стандарт 8 бит/10 бит (обоз-
начается аббревиатурой 8Ь/10Ь или 8В/10В), когда каждая 8-битная
порция данных содержит два дополнительных бита, чтобы нельзя бы-
ло отправить больше пяти 0 или пяти 1 подряд. Кроме того, этот стан-
дарт гарантирует, что передаваемый сигнал будет всегда сбалансирован
по постоянному току, т. е. будет иметь одинаковое значение энергии
импульсов выше и ниже среднего значения в течение последователь-
ности из 20 бит (два слова).
Существуют также альтернативные кодирующие схемы, в том чис-
ле 64b/66b или SONET Scrambling (шифрование синхронной сети оп-
тической связи). Слово «Scrambling» (шифрование) в названии ис-
пользуется для отображения того факта, что этот стандарт перемеши-
вает (шифрует) 0 и 1 в передаваемом сигнале, чтобы не допустить
длинных цепочек, состоящих из одних 0 или 1.
И напоследок, я скажу, что одна из основных причин использова-
ния этих кодирующих схем обусловлена стремлением упростить задачу
восстановления тактовых синхроимпульсов из потока данных.
Погружение в приёмопередатчики
Теперь, после знакомства с концепцией кодирования 8Ь/10Ь, мож-
но вплотную приступить к рассмотрению основных элементов блока
приёмопередатчика (Рис. 21.8).
Как обычно, эта схема представляет собой очень упрощенное
представление, на котором опущено много функциональных частей,
но, тем не менее, она подходит для рассмотрения материала этого раз-
дела. Что касается «предыскажений» и «коррекции», более подробно
эти процессы будут обсуждаться несколько позднее.
Погружение в приёмопередатчики 285
Кодер
WWb
8-битная
шина из
основной
части ПЛИС
Прообразе* последоватвльнь1й
аателькода
Передатчик
К другому
устройству
В этом месте
производится
внесение
предыскажений
1949 г. Англия.
Компьютер EDSAC
использует первый
язык ассемблера
под названием
Initial Orders.
Декодер Преобразо-
8Ь/10Ь ватель кода
8-битная
шина из
основной
части ПЛИС
Очередь
FIFO
I
Параллельно-
последовательный
преобразователь
В этом месте
производится
компенсация
сигнала
RXP \
I---- I От другого
।____ ^устройства
RXN /
Приемник
Приёмопередатчик
ПЛИС
Рис. 21.8. Структурная схема приёмопередатчика
На передающей стороне байты данных поступают на передатчик от
пользовательской логики основной части ПЛИС через 8-битную ши-
ну. После этого данные проходят через кодер 8Ь/1ОЬ и передаются в бу-
фер FIFO (очередь данных, работающая по принципу «первый пришёл
— первый вышел»), который используется для временного хранения
информации при большой загрузке шины. Выходной сигнал из очере-
ди FIFO поступает на преобразователь кода, который может использо-
ваться для передачи ^модифицированных данных, либо может пере-
брасывать каждый бит из 0 в 1 и наоборот (преобразование данных
возможно только в том случае, если приёмное устройство готово полу-
чать их в преобразованном виде). В свою очередь, выходной сигнал с
преобразователя кода подается на параллельно-последовательный
преобразователь, который преобразует параллельные входные данные
в последовательный поток битов. Этот последовательный поток пере-
дается на специальный выходной буфер, который и генерирует диффе-
ренциальную сигнальную пару.
Соответственно, на приёмной стороне последовательный поток
данных представлен в виде пары дифференциальных сигналов, посту-
пающей через специальный входной буфер в последовательно-парал-
лельный преобразователь, который преобразует последовательные
данные в 10-битные слова. Эти слова передаются в преобразователь
кода, который может использоваться для передачи немодифицирован-
ных данных или преобразовывать каждый бит из 0 в 1 и наоборот (пре-
образование кода потребуется лишь только в том случае, когда уст-
ройство, с которого мы получаем данные, отправляет их в преобразо-
ванном виде). Выходной сигнал с преобразователя кода передается в
286 Глава 21. Гигабитные приёмопередатчики
1950 г. Америка.
Джей Форрестер
изобрёл магнитное
запоминающее
устройство.
декодер 8Ь/10Ь, который декодирует поступающие данные. В результа-
те 8-битные слова передаются через очередь FIFO в основную часть
ПЛИС, где они могут быть обработаны логическими устройствами.
Следует отметить, что в зависимости от технологии используемой
для создания ПЛИС, некоторые блоки приёмопередатчиков могут
поддерживать различные стандарты кодирования, такие как 8Ь/10Ь,
64b/66b, SONET Scrambling и так далее. Другие устройства могут под-
держивать только отдельные стандарты, например 8Ь/10Ь, но в этом
случае можно отключить эти блоки и при необходимости реализовать
собственный алгоритм кодирования в основной части ПЛИС.
i Соединение нескольких приёмопередающих
блоков
Термин скорость передачи по последовательному каналу (baud rate)
показывает, сколько раз сигнал в канале связи меняется (или может
поменяться) за одну секунду времени. В зависимости от используемых
методов техники кодирования с каждым тактом канал связи может пе-
редать один бит данных либо больше, либо меньше, либо это значение
может меняться.
Во время написания этой книги все каналы приёмопередатчиков
могли принимать и передавать закодированные алгоритмом 8Ь/10Ь
данные со скоростью передачи 3.125 гигабит в секунду (Гбит/с)0. На
самом деле, если отбросить дополнительные биты, добавленные при
[ кодировании 8Ь/10Ь, то скорость передачи необработанных данных
составит величину 2.5 Гбит/с (реальная скорость 2.5 Гбит/с образуется
путём деления 3.125 Гбит/с на 10 бит и умножения на 8 бит).
Проблема заключается в том, что, по определению, некоторые
I стандарты, например 10-гигабитный Ethernet, передают данные со
скоростью 10 Гбит/с. В связи с этим на практике используются допол-
нительные стандарты, например 10-гигабитный интерфейс соединён-
ных устройств (10-gigfbit attachment unit interface — ХАШ), который поз-
{ воляет достичь скорости передачи данных 10 Гбит/с с помощью четы-
рех дифференциальных пар в каждом направлении (Рис. 21.9).
В этом случае четыре блока приёмопередатчиков соединены между
собой с помощью специального канала связи управляющих сигналов,
причём соединение установлено таким образом, что каждый блок зна-
ет, что и когда надо делать.
В будущем, под воздействием высокоскоростных последователь-
ных интерфейсов для обмена данными на уровне печатной платы весь-
ма вероятно, что некоторые функции, которые в настоящее время реа-
лизуются во внешних интерфейсных микросхемах, будут встроены
внутрь ПЛИС. Это позволит непосредственно передавать и получать
оптические сигналы (см. гл. 26).
Конфигурируемые параметры
Блоки, встраиваемых в ПЛИС гигабитных приёмопередатчиков,
обычно имеют ряд конфигурируемых (программируемых) параметров.
Разные производители и разные семейства этих устройств могут под-
держивать различные наборы этих параметров. Здесь мы рассмотрим
только основные конфигурируемые параметры.
° После превышения скорости 3.175 Гбит/с сильно увеличиваются затраты на
кодирование информации по схеме 8Ь/10Ь, вследствие чего приходится приме-
нять другие алгоритмы, например 64b/66b.
Конфигурируемые параметры 287
Рис. 21.9. Соединение нескольких приёмопередатчиков
1950 г. Америка.
Физик Уильям
Шокли (William
Shockley) изобрёл
первый биполярный
плоскостной преоб-
разователь.
Определение разделителей
Схемы кодирования, работающие по принципу 8Ь/10Ь (и другие
алгоритмы) используют специальные символы-разделители (comma
characters). Такие символы-разделители представляют собой нулевые
символы, которые могут передаваться для поддержки линии в актив-
ном состоянии или могут инициировать передачу данных с помощью
передачи сообщения приемнику, что процесс в состоянии готовности
и необходимо пробудиться и подготовиться к приему
Вместе с тем, высокоскоростные последовательные интерфейсы
по своей природе являются асинхронными, т. е. синхроимпульсы
встраиваются в сигнал данных. Следовательно, когда передатчик будет
готов инициировать передачу данных, то он отправит серию символь-
ных разделителей (несколько сотен бит), для того чтобы приемник на
другом конце линии смог засинхронизироваться. Как уже упомина-
лось в предыдущем разделе, символы-разделители также используют-
ся при синхронизации нескольких двоичных потоков.
Некоторые блоки приёмопередатчиков позволяют конфигуриро-
вать вид отправляемых и принимаемых ими символов-разделителей,
которые теперь могут представлять собой любое 10-битное значение,
тем самым, позволяя приёмопередатчику поддерживать разные ком-
муникационные протоколы.
Амплитуда выходного сигнала
Разные стандарты передачи данных поддерживают различные пе-
репады напряжений выходных дифференциальных сигналов, которые
определяются разницей между амплитудами значений логического 0 и
логической 1. Поэтому блоки приёмопередатчиков, как правило, поз-
воляют производить конфигурацию амплитуд выходного сигнала в
пределах рабочего диапазона с тем, чтобы поддерживать совмести-
мость с разными уровнями напряжения систем последовательной пе-
редачи данных.
288 Глава 21. Гигабитные приёмопередатчики
В 1950 году Морис
Карно (Maurice
Karnaugh) разрабо-
тал карту Карно,
которая чрезвы-
чайно быстро ста-
ла главным инстру-
ментом инженера-
проектировщика.
Внутрикристальные согласующие резисторы
Скорость передачи данных, поддерживаемая высокоскоростными
последовательными интерфейсами, подразумевает, что использова-
ние внешних согласующих резисторов (терминаторов) может привес-
ти к неоднородности сигналов, поэтому обычно рекомендуется ис-
пользовать внутрикристальные согласующие резисторы, предустанов-
ленные в ПЛИС. Значения этих внутрикристальных согласующих
резисторов, как правило, могут конфигурироваться (и обычно может
составлять 50 или 75 Ом) для поддержки разных интерфейсов и компо-
нентов печатной платы.
Внесение предыскажений
Как уже отмечалось во время обсуждения Рис. 21.6, сигналы, про-
ходящие через высокоскоростной последовательный интерфейс к
приёмному устройству, сильно искажаются, так как печатная плата и
её проводники поглощают большую часть высокочастотной составля-
ющей сигнала, оставляя в основном только его низкочастотные (мед-
ленно меняющиеся) составляющие.
Для решения этой проблемы можно использовать метод внесения
предыскажений, который заключается в том, что первому 0 из последо-
вательности логических 0 и первой 1 из последовательности логичес-
ких 1 придаётся небольшое добавочное напряжение. (В этом контекс-
те термин «последовательность» мы будем использовать применитель-
но к одному или нескольким битам.) В этом случае можно
представить, что мы прикладываем собственные искажения сигнала,
действия которых направлены в обратную сторону от искажений пе-
чатной платы (Рис. 21.10).
Рис. 21.10. Внесение предыскажений
Ещё раз повторюсь, что на этом рисунке показан идеальный пере-
дающий сигнал (с крутыми фронтами и спадами), но в реальности та-
кой сигнал имел бы ярко выраженные аналоговые черты.
Амплитуда применяемых предыскажений обычно реконфигуриру-
ется, чтобы интерфейс можно было построить под разные устройства
на печатной плате. Кроме того, амплитуда предыскажений для конк-
ретного высокоскоростного соединения является функцией положе-
ния микросхемы от положения других компонентов (т. е. зависит от
длины дорожек), различных характеристик печатной платы и типа
применяемого стандарта передачи. Амплитуда предыскажений может
быть определена с помощью системы моделирования или с помощью
эмпирических правил.
Восстановление синхронизации, флуктуация и глазковые диаграммы 289
Компенсация
Компенсация применяется в тех же случаях, что и внесение пре-
дыскажений, но при этом производится на приёмной стороне высо-
коскоростного интерфейса связи (Рис. 21.11).
Коррекция
Рис. 21.11. Применение компенсации
В 1950 году разра-
ботанный Конра-
дом Зюсом (Konrad
Zuse) компьютер
Z4 начал свою «ка-
рьеру» в коммерчес-
ком банке в Цюрихе
(Швейцария), та-
ким образом, став
первым коммерчес-
ки используемым
компьютером.
1951 г. Америка.
Продан первый
компьютер серии
UNIVAC1.
Компенсация относится к специальному этапу усиления сигнала,
при котором высокие частоты усиливаются сильнее, чем низкие. Как и
в случае предыскажений можно представить, что мы применяем свои
собственные искажения сигнала, действия которых направлены в об-
ратную сторону от искажений печатной платы.
Величина применяемой компенсации обычно реконфигурируется,
чтобы интерфейс можно было подстроить под разные устройства на
печатной плате. В каждом конкретном случае можно использовать ли-
бо предыскажения, либо компенсацию, либо одновременно и то и
другое.
Если дорожки высокоскоростного интерфейса действительно
длинные (скажем, около 1 метра и более), возможно, лучше отказаться
от внутренней компенсации и использовать внешнее компенсацион-
ное устройство, так как качество компенсации в специальных анало-
говых устройствах обычно лучше, чем в микросхемах (ПЛИС). В отно-
шении компенсации искажений сигнала ПЛИС постоянно совер-
шенствуются, и разные поставщики постоянно обгоняют друг друга по
различным показателям. Следовательно, на выбор устройства для схе-
мы может оказать влияние и такой фактор, как качество внутрикрис-
тальной компенсации.
Восстановление синхронизации, флуктуация
и глазковые диаграммы
Восстановление синхронизации
Высокоскоростные последовательные интерфейсы по своей при-
роде являются асинхронными, другими словами, в процессе их работы
синхронизация встраивается в сигнал данных. Следовательно, приём-
ная часть приёмопередатчика (трансивера) должна включать в себя
290 Глава 21. Гигабитные приёмопередатчики
1952 г. Америка.
Джон Моучли
(John Mauchly) и
Перепер Эккерт
(Persper Eckert) с
командой разра-
ботчиков закончи-
ли построение
электронного ком-
пьютера общего
назначения под на-
званием EDVAC.
1952 г. Англия.
Первые публичные
обсуждения кон-
цепции интеграль-
ных микросхем, ко-
торую выдвинул
британский экс-
перт в области ра-
даров Дж. Даммер
(G. РИ. A. Dummer).
схему восстановления и синхронизации данных (CDR — clock and data
recovery), которая игнорирует перепады уровня сигнала, соответствую-
щие собственно передаче данных и автоматически выделяет сигналы
синхронизации. Очевидно, не надо было бы прилагать больших уси-
лий, если бы входной сигнал представлял собой последовательность
чередующихся значений логического 0 и логической 1, причем в этом
случае синхронизация и данные были бы действительно идентичны
(Рис. 21.12, а).
На самом деле ситуация меняется с ростом сложности сигнала
(Рис. 21.12, б). Например, если входной сигнал начинается с трех 1, за
которыми следуют три 0, можно было бы предположить, что частота
синхронизации, выделяемая схемой восстановления, составляет лишь
1/3 своего истинного значения. С ростом количества поступающих
данных схема восстановления синхронизации автоматически скоррек-
тирует свои показания для достижения правильного значения частоты.
а) Простой сигнал
Реальные фронты
(перепады) синхросигнала
Мнимые фронты Реальные фронты
(перепады) синхросигнала (перепады) синхросигнала
б) Сложный сигнал
Рис. 21.12. Восстановление синхросигнала
После захвата сигнала приемник производит выборку каждого би-
та в центральной точке из входного потока данных, чтобы определить
является ли этот бит логическим 0 или логической 1 (Рис. 21.13).
Точки (моменты) выборки битов
Мнимые фронты (перепады)
Реальные фронты (перепады)
Рис. 21.13. Оценивание входящего сигнала
Восстановление синхронизации, флуктуация и глазковые диаграммы 291
Необходимость этой операции обусловлена тем, что как уже упо-
миналось, передача данных будет начата с нескольких сотен симво-
лов-разделителей, чтобы позволить приемнику захватить синхросиг-
нал и подготовиться к приему данных.
Схема восстановления синхронизации будет продолжать отслежи-
вать перепады (фронты) поступающих импульсов и постоянно под-
страивать синхронизацию для корректировки незначительных откло-
нений, вызванных некоторыми внешними факторами, например из-
менением температуры и напряжения питания.
Флуктуация и глазковые диаграммы
Термин флуктуация означает кратковременный сдвиг сигнала от
его идеального положения во времени. Например, если взять входной
сигнал, который представляет собой последовательность чередующих-
ся логических 0 и 1 (Рис. 21.14, а, б), и наложить на него данные, свя-
занные с каждым тактом в предыдущих циклах, наблюдалась бы неко-
торая размытость фронтов и спадов импульсов (Рис. 21.14, в-е).
Такт 1
Такт 2 ТактЗ Такт 4
а) Идеальный
сигнал
i— б) Сигнал
с флуктуациями
Ji в) Такт 1
| j | д) Такты 1,2 и 3
| [ е) Такты 1,2,3 и 4
ж) «Итог»
Рис. 21.14. Флуктуация
Можно пойти дальше, и мысленно разделить каждый такт попо-
лам, наложив положительные импульсы вида 0-1-0 первой половины с
отрицательными импульсами 1-0-1 второй половины (Рис. 21.14, ж).
Напомню еще раз, что форма сигналов, показанных на Рис. 21.14,
идеализирована, так как изображенные сигналы имеют правильную
прямоугольную форму. Реальный же сигнал будет иметь чётко выра-
женные аналоговые черты, и если можно было бы увидеть результат
наложения сигналов на осциллографе, картинка бы выглядела при-
мерно так, как на Рис. 21.15.
В результате получилась диаграмма, центр которой напоминает че-
ловеческий глаз, и неудивительно, называется глазковой диаграммой. С
ростом флуктуаций, затухания сигнала и других искажений зрачок
глаза будет всё больше и больше закрываться, поэтому многие харак-
теристики геометрической формы сигнала могут характеризоваться
именно глазковой маской. Эта маска, которая может быть четырех-
1952 г. Компания
Sony представила
первый миниатюр-
ный транзистор-
ный радиоприём-
ник, который пос-
тупил в продажу в
1954 году.
1953 г. Компания
Swanson Company
приступила к реа-
лизации первых
обедов из заморо-
женных полуфаб-
рикатов (продаю-
щихся в алюминие-
вой фольге).
1954 г. В США за-
пущен гигантский
аэростат «Echo 1»
для обеспечения
телефонных пере-
говоров по терри-
тории США.
1954 г. Изготовлен
первый кремние-
вый транзистор.
1955 г. Запатенто-
вана застёжка -
«липучка».
1956 г.Джон Бэкус
(John Backus) с ко-
мандой разработ-
чиков представил
первый, широко ис-
пользуемый ком-
пьютерный язык
программирования
высокого уровня —
FORTRAN.
292 Глава 21. Гигабитные приёмопередатчики
1956 г. Америка.
Джон Маккартни
(John McCarthy)
разработал ком-
пьютерный язык
LISP для приложе-
ний искусственно-
го интеллекта.
1956 г. Америка.
Для компьютера
MANIAC 1 появи-
лась первая ком-
пьютерная игра
(простая версия
шахмат).
1956 г. Начал рабо-
ту первый транс-
атлантический те-
лефонный кабель.
угольной или шестиугольной, как показано на рисунке, представляет
собой окно достоверности данных. Работа высокоскоростного интер-
фейса возможна лишь только в том случае, когда все кривые остаются
за пределами этого окна.
Если вы собираетесь использовать высокоскоростные последова-
тельные интерфейсы, необходимо удостовериться в том, что имеется
доступ к средствам анализа целостности сигнала, которые поддержи-
вают концепцию глазковых диаграмм.
ГЛАВА 22
СИСТЕМЫ С ПЕРЕСТРАИВАЕМОЙ
АРХИТЕКТУРОЙ
Динамически реконфигурируемая логика
С развитием ПЛИС на основе ячеек статического ОЗУ в электро-
нике появились новые возможности, связанные с динамически рекон-
фигурируемой логикой. Имеются в виду устройства, которые могут ре-
конфигурироваться на лету в процессе работы системы.
Напомню, что ПЛИС содержит большое количество программиру-
емых логических элементов и регистров, которые могут быть соедине-
ны разными способами для реализации различных функций. Приме-
чательно, что компоненты на базе ячеек статического ОЗУ позволяют
системе загружать в устройство новые конфигурационные данные. Хо-
тя все логические вентили, регистры и ячейки статической памяти, из
которых состоит ПЛИС, созданы на поверхности одного кремниевого
кристалла, иногда полезно рассматривать это устройство как состоя-
щее из двух отдельных частей — логических вентилей (и регистров) и
программируемых конфигурационных ячеек статического ОЗУ
(Рис. 22.1).
Неинициализированные
ячейки статического ОЗУ
Ячейки статического ОЗУ,
загруженные 0-ми и 1 -ми
а) Несконфигуриованная ПЛИС б) Сконфигурированная ПЛИС
Рис, 22.1. Динамически реконфигурируемая логика: ПЛИС на основе
ячеек статического ОЗУ
Гибкость реконфигурируемых устройств открывает поистине ши-
рокие возможности. Например, при включении питания ПЛИС может
быть сконфигурирована для тестирования системы или самотестиро-
вания. Как только система завершает тестирование, ПЛИС вновь мо-
жет быть переконфигурирована для выполнения своих основных фун-
кций.
294 Глава 22. Системы с перестраиваемой архитектурой
1957 г. Америка.
Гордон Голд (Gordon
Gould) сформулиро-
ван принципы рабо-
ты лазера.
1957 г. Америка.
Создан первый ком-
пьютер серии IBM
610.
1957 г. В России за-
пущен первый ис-
кусственный спут-
ник Земли.
Динамически реконфигурируемые внутренние
соединения
Безусловно, возможность переконфигурировать функции отдельных
устройств на печатной плате предоставляет дополнительные удобства
для инженеров, но иногда им необходимо создавать целые системы, ко-
торые могут быть переконфигурированы на уровне печатной платы для
выполнения различных, радикально отличающихся, функций.
Для решения этой задачи необходимо динамически конфигуриро-
вать соединения между устройствами на уровне печатной платы.
Справиться с поставленной задачей могут так называемые программи-
руемые пользователем устройства внутренних соединений (или FPID —
field-programmable interconnect devices), которые также известны как про-
граммируемые пользователем кристаллы внутренних соединений (или
FPIC — field-programmable interconnect chips)x\ Эти микросхемы, приме-
няемые для соединения логических устройств, могут быть динамичес-
ки переконфигурированы таким же образом, как и стандартные
ПЛИС на основе ячеек статического ОЗУ. Так как каждая микросхема
FPID может содержать более 1000 контактов, для соединения компо-
нентов на печатной плате может понадобиться всего лишь несколько
таких микросхем (Рис. 22.2).
Рис, 22,2, Динамически реконфигурируемые соединения:
FPID на основе ячеек статического ОЗУ
Интересно, что описанный подход не ограничивается только при-
менением на уровне печатных плат. Любой из вышеописанных подхо-
дов потенциально может быть использован и в гибридных микросхе-
мах, и в многокристальных модулях, и в однокристальных устройствах.
Системы с перестраиваемой архитектурой
Как часто бывает в электронике, термин перестраиваемая архитек-
тура (Reconfigurable Computing) может иметь разные значения для раз-
ных людей. Одни это понятие относят к микропроцессорам, набор ко-
манд которых можно изменять или расширять на лету. Однако в на-
шем случае под перестраиваемой архитектурой (системой с
перестраиваемой архитектурой) лучше понимать часть аппаратного
обеспечения общего назначения — такого как ПЛИС (какая неожи-
0 FPIC — торговая марка компании Aptix Corporation (www.aptix.com).
Системы с перестраиваемой архитектурой 295
данность!) — которое может быть сконфигурировано для выполнения
каких-либо задач, но при необходимости его конфигурацию можно
изменить.
Одним из ограничивающих факторов для большинства ПЛИС на
основе ячеек статического ОЗУ является необходимость затрачивать
определенное время на переконфигурацию. Эта особенность вызвана
тем, что ПЛИС обычно программируется с помощью последователь-
ной загрузки данных (или параллельного загрузки данных шириной
всего лишь 8 бит). Когда речь идет о высокотехнологичных устройс-
твах с десятками миллионов конфигураций ячеек статической памяти,
на перепрограммирование может уйти несколько секунд. Существует
некоторые типы ПЛИС, которые решают эту проблему путем исполь-
зования большого количества контактов ввода/вывода общего назна-
чения, которые в процессе программирования образуют широкую ши-
ну конфигурации (скажем, 256 бит), а после конфигурирования воз-
вращаются к выполнению своих основных функций (см. гл. 26). Кроме
того, некоторые типы программируемых пользователем массивов узлов
(FPNA — field programmable node array) также используют широкие ши-
ны конфигурации (см. гл. 23).
Другой недостаток ПЛИС традиционной архитектуры состоит в
том, что при необходимости внести самые незначительные изменения
в конфигурацию приходится перепрограммировать целиком всё уст-
ройство. Некоторые последние ПЛИС позволяют переконфигуриро-
вать их по столбцам (см. гл. 14), но и в этом случае обеспечивается
весьма грубый уровень структурирования. Кроме того, на время ре-
конфигурирования обычно приходится приостанавливать работу всей
печатной платы. Также при программировании безвозвратно теряется
содержимое всех регистров ПЛИС.
Для решения этих проблем, примерно в 1994 году компания Atmel
Corporation (www.atmel.com) предложила ряд интересных ПЛИС. Кро-
ме поддержки динамической реконфигурации выбранных элементов
внутренней логики, эти устройства характеризуются тем, что:
• не нарушается работа входов и выходов устройства;
• не нарушается работа средств синхронизации системы;
• любые части устройства, не подверженные реконфигурации,
могут продолжать свою работу;
• не теряется информация внутренних регистров, даже тех, кото-
рые находятся в области реконфигурирования.
Интерес представляет последний пункт этого списка, так как поз-
воляет одной реализации функции передавать данные для другой. На-
пример, группа регистров изначально может быть запрограммирована
для работы в качестве двоичного счетчика. Затем в какой-то момент
времени, определяемый главной системой, те же регистры могут быть
переконфигурированы для работы в качестве линейного сдвигового ре-
гистра с обратной связъю'\ начальное значение которого определяется
последним содержимым счётчика до реконфигурирования.
Хотя эти устройства стали очередным эволюционным шагом в тех-
нологическом плане, с точки зрения их потенциальных возможностей
шаг оказался поистине революционным. Для оценки этих возможнос-
тей были введены такие новые термины, как виртуальное аппаратное
обеспечение и кэш-логика* 2\
1958 г. Америка.
Осуществлена пе-
редача компьютер-
ных данных через
телефонные кана-
лы связи.
1958 г. Америка.
Джеку Килби (Jack
Kilby) в то время,
когда он работал в
компании Texas
Instruments, удалось
изготовить не-
сколько компонен-
тов на одном полу-
проводниковом
кристалле (первая
интегральная мик-
росхема).
Более подробно эти регистры описаны в Приложении В.
2) Термин кэш-логика (Cache Logic) является торговой маркой компании Atmel
Corporation, Сан-Хосе, Канада, США.
296 Глава 22. Системы с перестраиваемой архитектурой
1959 г. Америка.
Разработан ком-
пьютерный язык
COBOL.
1959 г. Америка.
Роберт Нойс
(Robert Noyce) раз-
работал техноло-
гию создания мик-
роскопических
алюминиевых про-
водников на крем-
ниевом кристалле,
которые продол-
жают использо-
ваться для изго-
товления современ-
ных интегральных
микросхем.
Понятие виртуальное аппаратное обеспечение возникло по анало-
гии с его программным эквивалентом — виртуальной памяти; оба этих
термина используются для представления предметов, которые на са-
мом деле не существуют. В случае виртуальной памяти компьютерная
операционная система делает вид, что ей доступно больше оператив-
ной памяти, чем есть на самом деле. Например, программе, выполня-
ющейся на компьютере, может потребоваться 500 мегабайт памяти для
хранения данных, а в компьютере установлено только 128 мегабайт.
Чтобы решить эту проблему, каждый раз, когда программа пытается
получить доступ к ячейкам памяти, которых физически не существует,
операционная система хитрит и меняет часть данных, находящихся в
памяти, с данными, расположенными на жестком диске. Хотя эта про-
цедура, известная как свопинг, замедляет процесс обработки данных,
но в то же время позволяет программе выполнять свои задачи не дожи-
даясь, пока кто-нибудь сбегает в магазин за дополнительными модуля-
ми памяти.
Аналогично термин кэш-логика произошел от родственного ему
понятия кэш-память, которая представляет собой высокоскоростную
дорогостоящую статическую память для хранения текущих активных
данных, в то время как основная часть данных помещается в более
медленную недорогую память, например, динамическую (DRAM). В
данном контексте, к «текущим активным данным» относятся данные
или инструкции, которые в настоящее время используются програм-
мой или будут, по требованию операционной системы, использованы
в ближайшем будущем.
На самом деле концепцию виртуального аппаратного обеспечения
довольно легко понять. Каждая большая макрофункция в устройстве
обычно формируется из комбинации нескольких меньших микрофун-
кций, таких как счетчики, сдвиговые регистры, мультиплексоры. При
разделении нескольких макрофункций на ряд соответствующих мик-
рофункций становится очевидным, что:
во-первых, перекрывается функциональность, и такой элемент,
как счетчик может использоваться несколько раз в разных местах, и
во-вторых, появляется большое значение функциональной латент-
ности, т. е. в любой момент времени активна только часть микрофунк-
ций. Также в течение каждого такта системы используется сравнитель-
но мало микрофункций. Следовательно, с помощью динамической ре-
конфигурации отдельных частей виртуального аппаратного
обеспечения различные макрофункции можно реализовать относи-
тельно небольшим количеством логики.
Отслеживая местоположение и обращение к каждой микрофунк-
ции, а также объединяя функциональность и исключая избыточность,
устройства с виртуальной аппаратной частью могут выполнять гораздо
более сложные задачи, чем устройства, построенные по классической
схеме. Например, в сложных функциях, требующих 100000 эквивален-
тных вентилей, в отдельный момент времени из них могут быть актив-
ны только 10000. Следовательно, с помощью сохранения или кэширо-
вания можно реализовать функций ещё на 90000 логических элемен-
тов. Тем самым небольшое и недорогое устройство со 10000
логическими элементами может заменить большее и дорогое с 100000
элементами (Рис. 22.3).
Теоретически также возможно в реальном масштабе времени ком-
пилировать новые варианты устройств, которые могут быть использо-
ваны как динамически создаваемые аппаратные подпрограммы.
Системы с перестраиваемой архитектурой 297
Функция А
Функция Б
Функция В
Рис, 22,3, Виртуальное аппаратное обеспечение
Во второй половине 90-х идея перестраиваемой архитектуры наде-
лала много шума, и до сих пор встречаются ярые приверженцы-фана-
ты этих систем, которые размахивают символикой и носят майки с со-
ответствующими надписями. Грустно признавать, но ничего эпохаль-
ного из этого не вышло, за исключением сугубо специализированных
приложений. Основная проблема кроется в том, что структура тради-
ционной ПЛИС слишком «мелкомодульная», поэтому их реконфигу-
рирование занимает чрезвычайно много времени (по компьютерным
меркам). Чтобы поддерживать перестраиваемую архитектуру, необхо-
димы устройства, которые можно переконфигурировать сотни тысяч
раз в секунду. Собака может быть зарыта в крупномодульной архитек-
туре, используемой устройствами FPNA (см. гл. 23).
1959 г. Швейцарс-
кий физик Джин
Герни (Jean Hoemi)
разработал пла-
нарную техноло-
гию, в которой для
создания транзис-
торов использова-
лись оптические
литографические
методы.
1960 г. Америка.
Теодор Мэйман
(Theodore Maiman)
создал первый лазер.
1960 г. Америка.
Управление перс-
пективного плани-
рования оборонных
научно-исследова -
тельских работ
(или DARPA —
Defense Advanced
Research Projects
Agency) заложило
основы, благодаря
которым появи-
лась сеть Интер-
нет.
ГЛАВА 23
FPNA - ПРОГРАММИРУЕМЫЙ
ПОЛЬЗОВАТЕЛЕМ МАССИВ УЗЛОВ
Введение
Прежде, чем перейти к рассмотрению этой темы, справедливости
ради следует заметить, что термин программируемый пользователем
массив узлов (или FPNA — field-programmable node array) введен автором
и не относится к стандартной промышленной терминологии. Пока не
относится.
Мелко-, средне- и крупномодульные
архитектуры
Когда дело доходит до классификации структур различных интег-
ральных микросхем, заказные интегральные микросхемы (ASIC), как
правило, относят к мелкомодульным, так как инженеры-разработчики
могут точно задавать их функциональность вплоть до уровня отде-
льных логических вентилей. По сравнению с ними, большинство сов-
ременных ПЛИС могут классифицироваться как среднемодульные,
поскольку они состоят из небольших блоков («островков») програм-
мируемой логики (где каждый логический блок состоит из нескольких
логических вентилей и регистров) в «море» программируемых внут-
ренних соединений. Такая классификация справедлива даже в том
случае, когда ПЛИС включают в себя микропроцессорные ядра, блоки
памяти и встроенные функции, такие как умножители.
По-правде говоря, многие инженеры на самом деле склонны отно-
сить ПЛИС к крупномодульным устройствам, но при рассмотрении уст-
ройства FPNA гораздо больше смысла имеет классификация ПЛИС
как среднемодульных, поскольку FPNA построены по настоящей круп-
номодульной архитектуре. Основополагающая концепция этих уст-
ройств состоит в том, что они сформированы из массива узлов, каждый
из которых является сложным элементом обработки данных
(Рис. 23.1).
Разумеется, на Рис. 23.1 показано довольно упрощенное представ-
ление FPNA-устройства, не только потому что на нём не приведены
элементы ввода/вывода и показано небольшое количество узлов обра-
ботки, хотя потенциально такое устройство может содержать сотни
или тысячи подобных узлов. В зависимости от поставщика FPNA каж-
дый узел может представлять собой арифметико-логическое устройс-
тво АЛУ, целый микропроцессор или элемент алгоритмической обра-
ботки (последний из них более подробно будет описан в этой главе).
Во время написания этой книги от 30 до 50 компаний проводили серь-
ёзные эксперименты с различными типами устройств FPNA; перечень
наиболее интересных из них представлен в Табл. 23.1.
Мелко-, средне- и крупномодулъные архитектуры 299
Рис, 23,1. Общее представление устройства FPNA
1960 г. NASA и Bell
Labs запустили
первый коммерчес-
кий спутник связи.
Таблица 23.1, Основные разработчики FPNA
Компания Web-сайт Комментарий
Elixent Ltd www.elixent.com Узлы на основе АЛУ
IPflex Inc. www.ipflex.com Операционные узлы
Motorola www.motorola.com Узлы на основе микропро- цессоров
PACT XPP Technologies AG www.pactxpp.com Узлы на основе АЛУ
picoChip Design Ltd. www.picochip.com Узлы на основе микропро- цессоров
Quicksilver Technology Inc. www.qstech.com Узлы алгоритмических элементов
При рассмотрении материала этой главы мы сосредоточим своё
внимание только на двух компаниях — picoChip и Quicksilver — чьи
концепции диаметрально противоположны. Устройства picoArray ком-
пании picoChip формируются из массивов процессоров и, в основном,
предназначены для больших, не критичных к величине энергопотреб-
ления, стационарных систем, к которым относятся, например, базо-
вые станции для беспроводных сетей. Кроме того, эти устройства при
необходимости в любой момент могут быть реконфигурированы (на-
пример, ежечасно или подобно тому, как сменяются профили в сото-
вом телефоне в течение дня).
В отличие от них адаптивные вычислительные машины компании
Quicksilver сформированы из кластеров узлов алгоритмических эле-
ментов. Применяются эти устройства в основном в небольших, неэ-
нергоёмких портативных изделиях, например в фотоаппаратах и сото-
вых телефонах (хотя они также представляют интерес и для многих
других приложений). Кроме того, эти устройства могут быть реконфи-
гурированы (компания Quicksilver предпочитает использовать термин
«адаптированы») сотни тысяч раз в секунду.
300 Глава 23. FPNA — программируемый пользователем массив узлов
1961 г. Разработан
метод вычислений
с разделением вре-
мени.
Алгоритмическая оценка
Устройства FPNA главным образом предназначены для реализа-
ции сложных алгоритмов, требующих значительных вычислительных
ресурсов. Поэтому, прежде чем двинуться дальше, давайте уделим не-
много времени технологиям, использующим эти алгоритмы, чтобы
подготовить почву для восприятия последующего материала.
С одной стороны, существуют технологии, использующие алгорит-
мы пословной обработки, к числу которых, например, относится ме-
тод множественного доступа с разделением по времени (или TDMA —
time division multiple access), применяемый в системах беспроводной
цифровой передачи данных. Варианты этой технологии, такие как
Sirius, ХМ Radio, EDGE и другие, образуют подгруппу, использующую
TDMA. Неудивительно, что архитектура, которая способна подде-
ржать высокотехнологичные стандарты, использующие метод мно-
жественного доступа с разделением по времени (TDMA), также спра-
вится и с менее сложными своими собратьями (Рис. 23.2).
Рис. 23.2. Общее представление устройства FPNA
С другой стороны, существуют технологии, использующие алго-
ритмы побитовой обработки, такие как метод широкополосного мно-
жественного доступа с кодовым разделением каналов (или W-CDMA —
Wideband Code Division Multiple Access) и его подвиды CDMA2000, IS-
95А и другие. (W-CDMA используется в широкополосной цифровой
радиосвязи, применяемой для передачи данных сети Интернет, муль-
тимедийных, видео и других приложений с изменяемой пропускной
способностью канала связи.)
Существуют также технологии, использующие алгоритмы, пред-
ставляющие смесь пословной и побитовой обработки данных, напри-
мер, различные виды MPEG, сжатие речи, музыки и так далее.
При оценке этих технологий быстро осознаешь, что традиционный
подход к системам с перестраиваемой архитектурой не в состоянии ре-
шить проблему на должном уровне (концепция систем с перестраивае-
мой архитектурой была изложена в гл. 22). Например, некоторые из
концепций пытаются рассмотреть системы с перестраиваемой архи-
Технология picoArray компании picoChip 301
тектурой и работают на очень низком уровне, а именно на уровне от-
дельных логических вентилей или блоков ПЛИС. В сочетании с ог-
ромнейшей сложностью программирования, этот подход в результате
приводит к большим временным затратам на переконфигурирование,
что делает его непригодным для некоторых приложений. В отличие от
него, другие подходы решают проблему на слишком высоком уровне,
например на уровне целых приложений или алгоритмов, что приводит
к неэффективному использованию ресурсов.
Неудивительно, если в скором времени выясниться, что эти техно-
логии являются гетерогенными (разнородными) по своей природе,
т. е. их разновидности будут существенно отличаться по своему соста-
ву. Исходя из этого, очевидно, что для реализации гетерогенных техно-
логий необходимо использовать и гетерогенные структуры. Но что они
собой представляют?
Технология picoArray компании picoChip
Для удовлетворения требований к обработке описанных выше ал-
горитмов, компания picoChip использует устройство под названием
picoArray. Его гетерогенная узловая архитектура представляет собой
матрицу различных 16-битных RISC (Reduced Instruction Set
Computing — технология вычислений с сокращённым набором ко-
манд) микропроцессоров, каждый тип которых оптимизирован для ре-
ализации определенных вычислений. Например, один из них может
содержать много памяти, а другой будет поддерживать специальные
алгоритмические команды типа «расширение» и «сужение» для бес-
проводного стандарта CDMA, используя для этого один такт (в отли-
чие от 40 тактов при использовании универсального процессора).
В первых версиях этих устройств каждый процессорный узел был
приблизительно эквивалентен (по производительности, но не по архи-
тектуре) процессорам ARM9 для функций управления, и TI С54хх для
цифровой обработки сигналов (ЦОС). Учитывая тот факт, что каждое
устройство picoArray может содержать сотни таких узлов, в результате
его применения можно получить огромную вычислительную мощность.
Например, где-то в декабре 2002 года, когда я впервые узнал о тех-
нологии picoArray, лидирующее положение в мире цифровой обработ-
ки сигналов занимали микросхемы TMS320C6415 компании Texas
Instruments. Эти устройства обеспечивали огромный объем вычисле-
ний с такой скоростью, что глаза начинали слезиться. Однако picoChip
заявила, что один picoArray, работающий на частоте лишь 160 МГц, мо-
жет достичь вычислительной мощности почти в 20 раз больше (по по-
казателям для 16-битного АЛУ), чем TMS320C6415, работающий при
600 МГц. Вот это да!
Идеальные приложения для picoArray: беспроводные
базовые станции
Операторы сотовой связи тратят миллиарды долларов ежегодно на
развитие своих беспроводных инфраструктур, причём большая часть
этих сумм уходит на разработку новых модулей цифровой обработки,
устанавливаемых на базовых станциях. В зависимости от расположе-
ния каждая базовая станция должна предусматривать обработку десят-
ков или сотен каналов одновременно.
Поэтому неудивительно, что у всех заинтересованных лиц есть ог-
ромное желание уменьшить стоимость реализации каждого канала.
Так как один picoArray может заменить несколько традиционных за-
1962 г. Америка.
Стив Хофштейн
(Steve Hofstein) и
Фредерик Хайман
(Fredric Heiman)
разработали пер-
вый полевой тран-
зистор.
302 Глава 23. FPNA — программируемый пользователем массив узлов
1962 г. Америка.
Компания
Unimation предста-
вила первый про-
мышленный робот.
казных микросхем, ПЛИС и процессоров ЦОС (DSP), его использова-
ние как раз и позволит существенно снизить цену канала базовой
станции.
Одна из проблем, связанных с использованием традиционных ре-
шений заключается в том, что для них требуется, по крайней мере, три
среды проектирования: для заказных микросхем (ASIC) и (или)
ПЛИС, процессоров ЦОС (DSP) и RISC (последняя из них относится
к функциональности микропроцессора). При этом все сложности раз-
работки и тестирования, к сожалению, замедляют выход таких базо-
вых станций на рынок (Рис. 23.3, а). Вследствие этого значительным
преимуществом устройств picoArray является возможность создать за-
конченное изделие в одной среде проектирования. (Рис. 23.3, б).
а) Традиционный способ б) С применением picoArray
Рис. 23.3. Применение традиционных устройств и picoArray
При обычном подходе заказные микросхемы позволяют достичь
очень высокой производительности, но они отличаются высокой сто-
имостью и длительными сроками разработки. К тому же алгоритмы,
реализованные в заказных микросхемах, жестко прошиваются в схему.
Это, пожалуй, самая главная проблема заказных микросхем, так как
стандарты беспроводной связи меняются настолько быстро, что к мо-
менту завершения разработки заказной микросхемы она уже может ус-
тареть. Между нами говоря, подобное явление происходит гораздо ча-
ще, чем можно себе представить.
В отличие от заказных микросхем у picoArray каждый микропро-
цессорный узел полностью программируем, а это значит, что каждый
канал может быть легко реконфигурирован для адаптации к ежечас-
ным изменениям пользовательских профилей, к еженедельным рас-
ширениям и исправлениям ошибок, и к ежемесячным этапам разви-
тия беспроводных протоколов. Следовательно, базовая станция, пост-
роенная по технологии picoArray, будет иметь более долгий срок
эксплуатации, что позволит снизить затраты на работу системы связи.
Среда проектирования picoArray
Функциональность микропроцессорных узлов устройства
picoArray описывается на чистой версии языка С или на Ассемблере.
Как уже отмечалось в гл. 11, язык С относится к классу последователь-
ных языков, поэтому нам необходимо каким-либо образом описывать
Технология адаптивных вычислительных машин компании Quicksilver 303
все параллельные вычисления. В отличие от использования одного из
методов расширений языка C/C++, рассмотренного в гл. 11, инжене-
ры компании picoChip пошли другим путём. Они используют язык
VHDL для описания структур устройства, в том числе и блоков парал-
лельной обработки, а также для объединения модулей на блочном
уровне. После этого с помощью языка С или Ассемблера производится
описание внутренней структуры каждого блока.
Интересно заметить, что компания picoChip поставляет полную
библиотеку программируемых/реконфигурированных модулей, кото-
рые могут быть соединены вместе для реализации полнофункциональ-
ной базовой станции (пользователи также могут подстроить отдельные
модули для реализации своих собственных алгоритмов). Примерно в
мае 2003 года компания picoChip заявила о своём лидерстве, реализо-
вав с помощью этой библиотеки базовую станцию стандарта 3GPP и
произведя с неё первый звонок! С тех пор picoChip продолжает актив-
но развиваться, поэтому чтобы быть в курсе текущего положения дел,
лучше посетить её сайт по адресу www.picochip.com.
Технология адаптивных вычислительных машин
компании Quicksilver
В течение нескольких последних лет сотрудники компании
Quicksilver в режиме повышенной секретности работали над своей вер-
сией устройств FPNA. Представляю себе, как они начнут кряхтеть, ус-
лышав это название. Исходя из того, что я знаю (а это больше, чем они
думают что я знаю ..., по крайней мере, мне так кажется), можно ут-
верждать, что технология компании Quicksilver, которую они называ-
ют адаптивной вычислительной машиной (АВМ), может похвастаться в
полном смысле этого слова революционной гетерогенной узловой ар-
хитектурой и структурой внутренних соединений (Рис. 23.4).
1962 г. Начал рабо-
тать первый ком-
мерческий спут-
ник связи Telstar.
Q Узел алгоритмических элементов
Матрица внутренних соединений
Кластер 3 уровня
Рис. 23.4. Архитектура адаптивной вычислительной машины
304 Глава 23. FPNA — программируемый пользователем массив узлов
1962 г. Начала ра-
боту первая ком-
мерческая теле-
фонная система с
тоновым набором
номера.
На самом нижнем уровне находится узел алгоритмических элемен-
тов. Четыре таких узла, составляющих квадрант, соединённый матри-
цей внутренних соединений, формируют структуру, которую можно на-
звать кластером первого уровня. Четыре таких кластера первого уров-
ня могут быть сгруппированы в кластер второго уровня и так далее.
Во время написания этой книги существовало много разных типов
алгоритмических узлов (несколько позже мы поговорим о том, какие
из них формируют квадрант). Я не буду рассматривать во всех подроб-
ностях все узлы, но важно понимать, что каждый их них выполняет за-
дачи на уровне целых алгоритмических элементов. Например, ариф-
метический узел может применяться для реализации различных ли-
нейных арифметических функций, например фильтров с конечной
импульсной характеристикой (КИХ-фильтров), дискретного косинус-
ного преобразования (ДКП), быстрого преобразования Фурье (БПФ)
и т. д. Также такой узел может применяться для реализации нелиней-
ных арифметических функций, таких как (1/sin А)-(1/х) и полученное
произведение возвести в 13 степень.
Аналогично узел обработки битов может применяться для реализа-
ции различных функций побитной обработки, например линейного
сдвигового регистра с обратной связью, кодового генератора Уолша, гене-
ратора кода общей диагностики, дешифратора TCP/IP-пакетов и т. д.
Каждый узел окружен оболочкой, которая позволяет со стороны
внешнего мира рассматривать все узлы совершенно одинаковыми. Эта
оболочка принимает входящие пакеты информации (команды, необ-
работанные данные, конфигурационные данные и т. д.) из внешнего
мира, распаковывает их, распределяет по узлу, управляет задачами об-
работки, собирает результаты и возвращает их во внешний мир.
Особый интерес представляет концепция оболочки, позволяющая
унифицировать внешние интерфейсы узлов и отделить их от внешнего
мира, особенно тогда, когда мы понимаем, что каждый узел представ-
ляет собой «множество Тьюринга». Это означает, что перед любым уз-
лом, например перед арифметическим узлом побитной обработки,
можно поставить любую задачу, и этот узел решит её, хотя и менее эф-
фективно, чем это мог бы сделать узел специализированного типа.
Кроме того, компания Quicksilver также позволяет создавать свои
собственные типы узлов, в которых вы определяете их начинку и окру-
жаете её оболочкой Quicksilver.
Какие страсти, ужас! Попытка выбрать наилучший путь решения
задачи вызвала у меня головную боль. Один из ключевых моментов
технологии АВМ заключается в том, что любая часть устройства, от
нескольких узлов до целой микросхемы, может быть быстро адапти-
рована для решения определённой задачи в большинстве случаев за
один такт. Также любопытно, что примерно 75% каждого узла реали-
зуется в локальной памяти. Эти особенности позволяют вносить ра-
дикальные изменения в методы реализации алгоритмов. В отличие от
обычного способа передачи данных от функции к функции при та-
ком подходе данные могут оставаться в узле, в то время как функция
узла может меняться с каждым тактом. Это также значит, что в отли-
чие от заказных микросхем, в которых для каждого алгоритма требу-
ется отдельный кристалл, возможность адаптировать АВМ десятки
или сотни тысяч раз в секунду подразумевает, что только те части ал-
горитма, которые действительно выполняются, должны оставаться в
устройстве в текущий момент времени. Этот подход позволяет сущес-
твенно снизить величину потребляемой мощности и занимаемое на
кристалле место.
Технология адаптивных вычислительных машин компании Quicksilver 305
Конфигурирование состава узлов
Я точно не знаю, когда наступит время этой темы, поэтому рас-
смотрим её прямо сейчас. Итак, мы уже знаем, что существуют раз-
ные типы алгоритмических узлов, и что каждый кластер состоит из
квадранта этих узлов, соединённых вместе матрицей внутренних
соединений. Исходя из этого, я уверен, читателю интересно будет
узнать, каким образом разные типы узлов распределяются по клас-
терам.
Все дело в том, что компания Quicksilver сама не производит и не
продает микросхемы, не считая, конечно, опытно-эксперименталь-
ных образцов и средств тестирования. Она предоставляет лицензии
на использование своих технологий адаптивных вычислительных ма-
шин (АВМ) всем желающим, тем самым, позволяя конечному поль-
зователю самому определить оптимальный состав узлов для требуемо-
го конкретного приложения и получить готовые микросхемы, изго-
товленные в соответствии с его спецификацией. Поскольку все узлы
оснащены оболочками, которые позволяют рассматривать их как
идентичные блоки, у пользователя появляется возможность легко
производить замену одного типа узла другим!
1963 г. Америка. В
Массачусетском
технологическом
институте разра-
ботан компьютер
LINC.
Разновидности узлов
В дополнение к структуре, изображенной на Рис. 23.4, любая адап-
тивная вычислительная машина включает в себя группу узлов специ-
ального назначения, таких как системный контроллер, контроллер
внешней и контроллер внутренней памяти, а также узлы ввода/выво-
да. Каждый узел ввода/вывода может использоваться для реализации
задач ввода/вывода данных в форме универсального асинхронного
приёмопередатчика (УАПП) или в виде шинного интерфейса, напри-
мер, PCI, USB, Firewire и им подобных (как и алгоритмические узлы,
узлы ввода/вывода при необходимости могут быть реконфигурирова-
ны в течение одного такта). Кроме того, эти узлы используются для
импорта конфигурационных данных, так как при необходимости у
каждой адаптивной машины ширина шины конфигурации может быть
равна количеству входных контактов.
Теперь рассмотрим кратко процесс разработки и выполнения при-
ложений на АВМ. В данном случае необходимо отметить, что почти
все трудности, возникающие при использовании других технологий,
ложатся на плечи разработчика АВМ. Например, каждая АВМ содер-
жит встроенную операционную систему ОС, которая распределена по
узлу системного контроллера и оболочкам, связанных с каждым алго-
ритмическим узлом. Алгоритмические узлы также планируют свои за-
дачи и все межузловые соединения. Это позволяет разгрузить работу
узла системного контроллера, основная обязанность которого заклю-
чается в отслеживании свободных в текущий момент узлов и распреде-
лении между ними новых заданий.
Из Рис. 23.4 следует, что ядро архитектуры АВМ может легко мас-
штабироваться. При этом желательно, чтобы установленные на пе-
чатной плате микросхемы различных АВМ взаимодействовали меж-
ду собой и с остальной частью схемы на уровне операционных сис-
тем. В этом случае их работу можно рассматривать как работу
отдельных устройств.
306 Глава 23. FPNA — программируемый пользователем массив узлов
1963 г. Начал рабо-
ту первый популяр-
ный компьютер се-
рии PDP-8.
Пространственная и временная сегментация
Наиболее важной особенностью архитектуры АВМ является воз-
можность реконфигурировать её сотни тысяч раз в секунду, затрачивая
на это минимум энергии. Это достоинство позволяет АВМ поддержи-
вать концепцию пространственной и временной сегментации.
Во многих случаях различные алгоритмы и даже разные части од-
ного и того же алгоритма могут выполняться в разные периоды време-
ни. Концепция пространственной и временной сегментации относит-
ся к процессу реконфигурирования динамических аппаратных средств
для быстрого выполнения различных частей алгоритма в разные мо-
менты времени и на разных узлах АВМ.
Рассмотрим простой пример. Предположим, что в беспроводном
телефоне некоторые операции являются модальными, то есть они
должны выполняться в течение некоторого отрезка времени. При этом
существует три основных режима работы — обнаружение, ожидание и
обмен данными. Режим обнаружения относится к сотовым телефонам и
подразумевает обнаружение ближайшей базовой станции. В режиме
ожидания телефон следит за базовой станцией и за каналом персо-
нального вызова, отслеживая сигнал, который скажет: «Проснись и
слушай, тебе звонят». Режим обмена делится на два варианта: прием и
передача. Хотя нам может показаться, что мы говорим и слушаем од-
новременно, но на самом деле, в конкретный момент времени теле-
фон работает только в одном из этих режимов.
В том случае, когда телефон реализован на основе обычных микро-
схем, то каждая из рассмотренных выше функций обработки полезно-
го сигнала потребует своего собственного кремниевого кристалла или
некоторой области на общем кристалле. Это значит, что даже если
функция не востребована, она все равно будет занимать место, что от-
разится в виде высокой стоимости телефона и высокого энергопотреб-
ления, а это в свою очередь приведет к быстрому разряду аккумулято-
ра. Если же телефон будет изготовлен на базе технологии АВМ, для
этих функций потребуется только один кристалл, который при необ-
ходимости можно будет в процессе работы телефона адаптировать для
выполнения определённой функции.
Но это лишь начало. Во многих случаях каждая из этих основных
функций состоит из набора алгоритмов, которые могут выполняться в
разные моменты времени. Например, рассмотрим сильно упрощенное
представление беспроводного телефона, принимающего и обрабаты-
вающего сигнал (Рис. 23.5).
Входящий сигнал состоит из последовательности сильно сжатых
блоков данных, передача каждого такого блока занимает крошечный
отрезок времени. Затем эта информация проходит через ряд алгорит-
мов, каждый из которых выполняет некоторую обработку данных и
переводит их на более низкую частоту.
Основная особенность этого процесса заключается в том, что каж-
дый алгоритм выполняется в разные моменты времени. При традици-
онном использовании заказных микросхем каждая функция занимает
свой собственный кристалл или часть кристалла на общем устройстве.
Поскольку в отдельные моменты времени выполняется только огра-
ниченное количество функций, то в результате подобный подход при-
водит к значительным потерям доступных ресурсов (затрачивается
время и потребляется лишняя энергия).
Еще раз подчеркну, что решение этих проблем заключается в ис-
пользовании адаптивных вычислительных машин, которые при необ-
Технология адаптивных вычислительных машин компании Quicksilver 307
Время —► Время —► Время —► Время —►
Один фрейм
Рис. 23.5. Сильно упрощенное представление сотового телефона,
принимающего и обрабатывающего сигнал
1963 г. Компания
Philips представи-
ла первую аудио-
кассету.
1965 г. Джон Кеме-
ни (John Кетепу) и
Томас Курц
(Thomas Kurtz) раз-
работали язык про-
граммирования
Бейсик (BASIC).
ходимости на лету могут быть адаптированы для выполнения любого
алгоритма. Предоставление аппаратного обеспечения по запросу приво-
дит в результате к наиболее эффективному использованию аппаратной
части в смысле стоимости, размера, производительности и потребле-
ния энергии (АВМ обещает увеличить производительность в десятки,
сотни и более раз по сравнению с аналогичными решениями, потреб-
ляя при этом в 2...20 раз меньше энергии).
Создание и выполнение приложений на АВМ
Разумеется, правомерен следующий вопрос: как создать приложе-
ния, которые могли бы работать на этих маленьких штучках? Ну, во
общем-то, средства проектирования компании Quicksilver представля-
ют собой С-подобный язык, названный SilverC. Концепция этого язы-
ка аналогична расширениям языка C/C++ (гл. 11).
SilverC сохраняет традиционный синтаксис и структуры управле-
ния языка С. Это упрощает С-программистам и проектировщиками
систем ЦОС использовать и преобразовывать существующий С-код.
SilverC также поддерживает специальные ключевые слова, например
module (модуль), pipe (канал) и process (обработка), которые способс-
твуют представлению потока данных и поддерживают параллельное
программирование. Более того, SilverC поддерживает специальные
расширения для цифровой обработки сигналов, например циркуляр-
ный указатель для эффективного использования ресурсов ориентиро-
ванного ациклического графа, целые числа с фиксированной шири-
ной и фиксированной точкой и так далее.
Представления на языке SilverC могут описываться и моделиро-
ваться гораздо быстрее, чем при использовании языка описания аппа-
ратных средств (Verilog или VHDL), которые применяются при тради-
ционном проектировании систем на основе заказных микросхем и
308 Глава 23. FPNA — программируемый пользователем массив узлов
1967 г. Америка.
Компания Fairchild
разработала ин-
тегральную микро-
схему под названи-
ем Micromosaic, ко-
торая стала пред-
шественницей сов-
ременных заказных
и полузаказных
микросхем.
1967 г. Разработа-
на система шумо-
подавления Долби
(Dolby).
ПЛИС. После моделирования и проверки SilverC-представления про-
изводится его компиляция в исполняемое (двоичное) приложение
Silverware. Внутренняя операционная система АВМ при необходимос-
ти лишь загружает его определённые части, и в текущий момент вре-
мени на АВМ может работать множество таких приложений.
Важно, что при разработке приложения Silverware нет необходи-
мости знать тип кристалла используемой АВМ, включая состав узлов и
так далее, или сколько ABM-устройств доступно на плате. Внутренняя
операционная система АВМ сама распределяет все необходимые зада-
чи по соответствующим узлам.
Подождите, ещё не вечер
В процессе обсуждения средств разработки для устройств цифро-
вой обработки сигналов (гл. 12) мы рассмотрели концепцию проекти-
рования на системном уровне и среду моделирования Simulink компа-
нии MathWorks (www.mathworks.com). Это популярное средство подде-
рживает потоковое проектирование и прекрасно подходит для
архитектуры АВМ.
Сотрудники Quicksilver усердно поработали над интеграцией язы-
ка SilverC в Simulink. На простейшем уровне можно использовать
Simulink для описания различных блоков и потоков данных между ни-
ми, и автоматически получить структуру, скелет, всего устройства, со-
стоящую из модулей и соединяющих их вместе каналов. Затем можно
снова уйти «внутрь скелета» и вручную создавать код на SilverC.
Также Quicksilver разработала библиотеку SilverC-модулей, кото-
рые могут загружаться в существующие Simulink-блоки. Эта библиоте-
ка включает в себя широко используемые компоненты цифровой об-
работки сигналов, фильтры, шифраторы, дешифраторы, манипулято-
ры битов и кодовых групп. Эти модули используются для
функционального и потактного моделирования и после компиляции в
двоичный Silverware-код могут быть напрямую загружены в АВМ.
Это кристалл, Джим, но не такой, каким мы его
знаем!
Как вы, вероятно, догадались, возможности FPNA, вообще, и
предложения компании Quicksilver в частности произвели на меня не-
изгладимое впечатление! Итак, означает ли это конец заказным интег-
ральным микросхемам и ПЛИС? Конечно же, нет!
FPNA очень хорошо подходят для разных областей, но нет такой
универсальной структуры кристалла, которая хорошо бы подходила
для всех случаев, а еще бы и кофе варила. На практике микросхемы
FPNA представляют собой лишь одно из средств в арсенале системно-
го разработчика.
С одной стороны, учитывая вышесказанное, я не очень бы удивил-
ся, если в недалёком будущем появились бы заказные микросхемы и
ПЛИС со встроенными ядрами FPNA. С другой стороны, как уже бы-
ло сказано, компания Quicksilver позволяет создавать свои собствен-
ные типы узлов и окружать их оболочками этой же компании. Поэто-
му в качестве альтернативы можно использовать главную АВМ-струк-
туру, как рекомендует Quicksilver, но включить в неё еще и несколько
узлов в виде ПЛИС.
И если однажды это вдруг случиться, ставлю против Ваших, чита-
тель, хлопчатобумажных носков, что я непременно буду в самой гуще
событий, яростно жестикулируя и восклицая: «Я же говорил вам!»
ГЛАВА 24
СРЕДСТВА ПРОЕКТИРОВАНИЯ
НЕЗАВИСИМЫХ РАЗРАБОТЧИКОВ
Введение
Когда дело доходит до средств проектирования — систем логичес-
кого моделирования, средств синтеза и так далее, мы обычно обраща-
емся к большим компаниям, разрабатывающим полный набор САПР
электронных систем, а также к небольшим фирмам, специализирую-
щимся на средствах для отдельных этапов проектирования, или к про-
изводителям самих ПЛИС.
Однако не следует забывать о тех, кто работает с продуктами с от-
крытым исходным кодом (смотрите также гл. 25). Более того, неболь-
шие консалтинговые компании часто тратят довольно много времени
и усилий на создание собственных средств, предназначенных для их
внутренних проектов. Порой эти инструменты становятся настолько
полезными, что они становятся доступны всему миру. В этой главе мы
кратко рассмотрим такие средства.
ParaCore Architect
Компания Dillon Engineering (www.dilloneng.com) предлагает раз-
нообразные услуги по разработке определяемых заказчиком алгорит-
мов ЦОС на основе ПЛИС, а также приложений по широкополосной
цифровой обработке сигналов и изображений в реальном масштабе
времени.
К концу 90-х инженеры этой компании осознали, что они посто-
янно заново изобретают и реализовывают такие средства, как библио-
теки функций с плавающей точкой, ядра свёртки, процессоры БПФ и
так далее. Поэтому для облегчения своей жизни они разработали
средство под названием ParaCore Architect™, которое представляет со-
бой набор блоков интеллектуальной собственности.
Процесс проектирования начинается с написания на языке про-
граммирования Python исходных файлов, содержащих высоко пара-
метризованные описания устройства на очень высоком уровне абс-
тракции (более подробно язык Python будет рассматриваться в гл. 25).
ParaCore Architect обрабатывает это описание, комбинирует его со зна-
чениями пользовательских параметров, и затем генерирует эквивален-
тное представление устройства на языке HDL, потактную C/C++ мо-
дель для ускорения процесса моделирования, и соответствующий на-
бор тестов (Рис. 24.1).
Полученный таким образом RTL-код гарантировано подойдет для
использования в любой среде моделирования или средствах синтеза,
поэтому нет необходимости запускать какую-либо программу для его
проверки. Вся прелесть этого высокопараметризованного описания
заключается в том, что его чрезвычайно легко использовать в новых
приложениях или других устройствах.
310 Глава 24. Средства проектирования независимых разработчиков
1967 г. Америка.
Джек Килби (Jack
Kilby), работая в
компании Texas
Instruments, изоб-
рёл первый ручной
электронный каль-
кулятор.
Рис. 24.1. ParaCore Architect генерирует C/C++ и RTL-представления,
а также набор тестов
Реализация модулей для обработки данных с плавающей
точкой
В качестве простого примера использования ParaCore Architect
можно рассмотреть некоторые ПЛИС, в которые встраивают микро-
процессорные ядра. К сожалению, эти ядра, как правило, не комплек-
туются соответствующим модулем для выполнения операций с плава-
ющей точкой. Это означает, что если проектировщики захотят выпол-
нять операции с плавающей точкой в соответствующем проекте, то
сделать это они смогут программным (что довольно медленно) или ап-
паратным путём. В последнем случае на реализацию подобного реше-
ния понадобится затратить много усилий, которые лучше было бы
потратить на разработку хорошей функциональной части устройства.
Для решения этой проблемы можно использовать одно из конс-
труктивных описаний ParaCore Architect, которое позволит сгенериро-
вать соответствующее ядро обработки данных с плавающей точкой.
При этом могут использоваться различные параметры для определе-
ния необходимой точности порядка и мантиссы чисел, количества
ступеней используемого конвейера, необходимости обработки особых
случаев чисел с плавающей точкой, например, бесконечности (для не-
которых приложений эти особые случаи не требуются), типа использу-
емого микропроцессорного ядра и т. д.
Реализация функций БПФ
Хорошим примером демонстрации мощности пакета РагаСоге
Architect может служить его использование для генерации ядра, вы-
полняющего функции быстрого преобразования Фурье (БПФ). На-
именьший вычислительный элемент, используемый для создания
функций БПФ, называется «бабочка», который состоит из комплекс-
ного умножения, комплексного сложения и комплексного вычитания
(Рис. 24.2).
В свою очередь, операция комплексного умножения требует четы-
рех простых умножителей и двух простых сумматоров, а комплексное
сложение и комплексное вычитание требуют по два простых суммато-
ра. Таким образом, для реализации каждой «бабочки» потребуется че-
тыре простых умножителя и шесть простых сумматоров.
Одно реальное приложение обработки изображений, использую-
щее подобное ядро, должно обрабатывать двухмерный массив разме-
ром 2048x2048 точек БПФ, обновляющийся с частотой 120 кадров в
ParaCore Architect 311
Рис. 24.2. «Бабочка» — наименьший вычислительный элемент БПФ
секунду. Для обработки одного столбца из 2048 пикселей понадобится
11256 «бабочек», организованных в одиннадцать рангов, где выходы
«бабочек» первого ранга поступают на вход второго ранга и т. д. Таким
образом, для обработки одного столбца потребуется 45025 простых ум-
ножителей и 67536 простых сумматоров. Чтобы произвести БПФ для
всего кадра размером 2048x2048 точек, необходимо повторить этот
процесс для каждого из 2048 рядов, формирующих кадр. Это значит,
что для достижения частоты обновления в 120 кадров в секунду обра-
ботка каждого ряда должна завершаться за 4 микросекунды. (Это зна-
чит, что на каждое простое умножение отводится 90 пикосекунд, а на
каждое простое сложение — 60 пикосекунд.)
Давайте рассмотрим работу 11256 «бабочек», требуемых для обра-
ботки 2048 точек БПФ. Если бы время выполнения этой операции не
было бы решающим фактором, то для её решения можно было бы ис-
пользовать сравнительно небольшие ПЛИС, например Xilinx Virtex-II
XC2V40 с четырьмя блоками умножения для создания одной «бабоч-
ки» (четыре простых умножителя и шесть простых сумматоров), и за-
тем выполнить все операции «бабочки» с помощью этой функции. В
итоге для обработки каждых 2048 точек БПФ уходило бы 90 микросе-
кунд. Хотя это очень хорошее значение, но оно не подходит для при-
ложения обработки изображений, в котором на эту операцию отводит-
ся всего 4 микросекунды.
Самый легкий способ увеличения скорости работы этого алгоритма
заключается в увеличении количества «бабочек» в аппаратной части и в
выполнении большего количества параллельных вычислений. При ис-
пользовании микросхемы Xilinx XC2V6000, которая содержит шесть
миллионов системных логических элементов, 144 18-битных умножи-
теля и 144 блока оперативной памяти объёмом 18 килобит, можно об-
рабатывать все 2048x2048 точек со скоростью 120 кадров в секунду.
Всё дело заключается в том, чтобы получить все эти устройства
потребуется установить только один параметр в пакете РагаСоге
Architect, который определяет количество «бабочек», подлежащих реа-
лизации в аппаратной части устройства.
В другом примере, если мы решили изменить длину БПФ с 2048 на
1024 точки, тогда нам необходимо поменять значение только одного
параметра, который вызовет реконфигурацию всех необходимых
312 Глава 24. Средства проектирования независимых разработчиков
1969 г. «Человек на
Луне» передал пер-
вый радиосигнал.
структур, в том числе произведёт изменение размеров оперативной па-
мяти, используемой для хранения внутренних результатов. Также мо-
жет использоваться ещё один параметр для выбора формата представ-
ления чисел — с фиксированной точкой или с плавающей точкой (в
последнем случае задействуются ещё два параметра для определения
размера экспоненты и мантиссы).
В начале 2002 сотрудники Dillon Engineering использовали пакет
ParaCore Architect для создания, возможно, самого быстрого в мире (на
тот момент) процессора БПФ. Этот процессор впоследствии нашел
применение во многих областях, например, в программе SETI для по-
иска внеземных цивилизаций, где он использовался для обработки ог-
ромного количества данных, поступающих с радиотелескопов!
Web-интерфейс
Пожалуй, самым приятным моментом является то, что компания
Dillon Engineering открыла для своих клиентов доступ к пакету
ParaCore Architect через сеть Интернет. При разработке функций, та-
ких как БПФ и ей подобных, часто хочется достичь какого-либо комп-
ромисса, например, узнать, сколько надо сохранить бит для одной
точки. Теперь клиенты компании Dillon Engineering могут посетить
сайт www.dilloneng.com, выбрать интересующий их тип ядра, задать па-
раметры и нажать кнопку «Go» для создания эквивалентных C/C++ и
HDL-моделей, а также набора соответствующих тестов.
Язык проектирования системы Confluence
Как и большинство разработчиков, меня бросает в дрожь, когда я
сталкиваюсь с ещё одним языком программирования или разработки
аппаратных средств, но компания Launchbird Design Systems
(www.launchbird.com) предложила свой язык проектирования систем
под названием Confluence, а также соответствующий компилятор
Confluence Compiler, который стоит рассмотреть более подробно.
Трудно охватить вниманием все многочисленные грани языка
Confluence, но мы все же попытаемся это сделать. Во-первых,
Confluence является невероятно компактным языком, который может
использоваться для создания описаний как аппаратных средств, так и
встраиваемого программного обеспечения. При работе с аппаратной
частью эти описания обрабатываются компилятором Confluence, ко-
торый генерирует соответствующее RTL-описание на языках VHDL
или Verilog (Рис. 24.3).
— Легко модифицировать
Рис. 24.3. Использование компилятора языка Confluence
Чтобы лучше понять этот процесс, можно представить, что один из
языков HDL (например, VHDL или Verilog) используется для описа-
Язык проектирования системы Confluence 313
ния отдельных схем, а язык Confluence — для описания алгоритмов,
которые могут сгенерировать целый класс схем. Смысл такого подхода
заключается в том, что с помощью Confluence вы можете выразить
больше, затрачивая на это существенно меньше строк кода (таким об-
разом можно уменьшить исходный код от 3-х до 10-ти раз, что сокра-
тит время, затрачиваемое на разработку и верификацию устройства).
Также, в результате работы компилятора получится «гарантированно
чистый» RTL-код, который не содержит ошибок и некорректных
схемных решений.
Если рассуждать, оперируя терминами программирования, язык
Confluence поддерживает рекурсию, типы данных высшего порядка,
лексический анализ и прозрачность ссылок (более чем достаточно,
чтобы привести в восторг любого разработчика).
Простой пример
В качестве простого примера давайте рассмотрим компонент язы-
ка Confluence, который позволяет описать последовательное (каскад-
ное) соединение любого количества любых элементов с одним входом
и одним выходом:
component Cascade +Stages +SisoComp +Input -Output
is
if Stages <= 0
Output <- Input
else
Output <- {Cascade (Stages - 1) SisoComp
{SisoComp Input $} $}
end
end
Хотя люди, не связанные с программированием, могут отнестись к
этому тексту с опаской, но на самом деле ничего страшного здесь нет.
В первой строке описывается новый компонент, который мы решили
назвать Cascade, с которым связано четыре параметра: Stages (количес-
тво необходимых стадий, т. е. количество элементов в последователь-
ной цепочке), SisoComp (название элемента, из которого вы решили
создать последовательную цепочку), Input (название входного сигнала
или сигналов, если используется шина) и Output (название выходного
сигнала или сигналов, если используется шина).
Заметим, что к ключевым словам языка в этой строке относятся
только «component» и «is», а выражения «Stages», «SisoComp», «Input» и
«Output» являются определяемыми пользователем именами перемен-
ных. Знаки «+» и «—» в этой строке отображают связь пользователь-
ских переменных с портами ввода и вывода соответственно.
Более того, когда мы говорили, что этот компонент описывает пос-
ледовательное соединение любых элементов с одним входом и одним
выходом, то на самом деле имелось в виду, что переменные Input и
Output могут представлять собой многобитные шины. Фактически,
эти сигналы даже не должны быть двоичными векторами, они могут
быть списками битовых векторов или списками списков битовых век-
торов (или любым другим подобным типом данных).
В качестве простого примера использования нашего нового ком-
понента под названием Cascade давайте, допустим, что нам по какой-
то причине необходимо связать вместе 1024 вентиля НЕ (не спраши-
1970 г. Америка.
Боб Меткалф (Bob
Metcalf) и Дэвид
Боггс (David Boggs)
в исследователь-
ском центре в Па-
ло-Альто разрабо-
тали описание
Ethernet.
1970 г. Америка.
Компания Fairchild
представила пер-
вую 256-битную
микросхему ста-
тического ОЗУ, ко-
торая получила на-
звание 4100.
314 Глава 24. Средства проектирования независимых разработчиков
вайте зачем) таким образом, чтобы выходной сигнал с первого вентиля
поступал на вход второго, со второго на третий и т. д. В этом случае мы
могли бы эту процедуру описать с помощью одной строки, которая
вызывает наш компонент Cascade и передает ему соответствующие па-
раметры:
{Cascade 1024 Input Output}
В этом случае компилятор языка Confluence понимает, что символ
«~» обозначает простейший логический элемент отрицания (НЕ).
В качестве более интересного примера давайте рассмотрим ситуа-
цию, когда мы хотим организовать каскад из шестнадцати 8-битных
регистров, в котором выходы первого регистра соединялись бы с вхо-
дами второго, выходы второго — с входами третьего и т. д. В этом слу-
чае нам необходимо сначала описать компонент под названием, на-
пример, Reg8, представляющий собой 8-битный регистр, а затем ис-
пользовать компонент Cascade, который и будет 16 раз тиражировать
этот регистр:
component Reg8 +А -X is
{VectorReg 8 A X}
end
{Cascade 16 Reg8 Input Output}
Здорово, да? Но будет ещё лучше! А как насчет возведения в квад-
рат значений сигналов, и так четыре раза подряд, да ещё с конвейер-
ным регистром между соседними стадиями? Мы можем легко и быст-
ро представить эту процедуру следующим образом:
component RegisteredPowerOfTwo +А -X is
{Delay 1 (A A) X}
end
{Cascade 4 RegisteredPowerOfTwo Input Output}
Как мы можем увидеть, наш компонент Cascade представляет хо-
роший пример рекурсии и использования типов данных высокого
уровня, что составляет две основные характеристики функционально-
го программирования, обеспечивающие высокие уровни абстракции и
повышающие возможность повторного использования ранее разрабо-
танного кода.
Очень радует тот факт, что переменная-элемент SisoComp не под-
разумевает, что порты ввода и вывода должны быть одинаковой шири-
ны. Фактически эта переменная может быть связана с любой опреде-
ляемой пользователем функцией, и даже может получать на входе опи-
сание компонент, а после обработки выводить другой компонент, или
она может получить на входе систему, и затем выводить другую систе-
му. Не существует никаких ограничений, чтобы элемент SisoComp ра-
ботал не только с двоичными векторами, но также и с целыми числа-
ми, переменными, списками, компонентами, системами или любыми
другими типами данных языка Confluence.
И в завершающем примере элемент SisoComp может использовать-
ся для соединения двоичного вектора с самим собой, тем самым, удва-
ивая количество бит. Для того, чтобы проиллюстрировать этот про-
цесс, давайте допустим, что мы создаем новый компонент под назва-
нием SelfConcat:
Язык проектирования системы Confluence 315
component SelfConcat +А -X is
X = A '++' A
end
где «++» обозначает оператор соединения (конкатенации). Когда
SelfConcat используется вместе с компонентом Cascade, тогда двоич-
ный вектор возрастает в два раза на каждом этапе. Например, допус-
тим, что мы начинаем с 2-битного вектора, установленного в значение
01 и помещаем SelfConcat в Cascade:
1970 г. Америка.
Компания Intel
анонсировала пер-
вую 1024-битную
микросхему дина-
мического ОЗУ, ко-
торая получила на-
звание 1103.
{Cascade 4 SelfConcat '01' Output}
В этом случае на выходе мы получим 32-битный вектор со значе-
нием 01010101010101010101010101010101.
Безусловно, язык VHDL всегда поддерживал операторы генериро-
вания, такая же возможность была добавлена в Verilog, начиная с вер-
сии 2К1, но из языка Confluence эти операторы словно ветром сдуло.
Но подождите, есть кое-что ещё
Как было сказано раньше, трудно охватить вниманием все возмож-
ности языка Confluence. Возможно, лучше всего это сделать с помо-
щью наглядного примера (Рис. 24.4).
RTL-описание,
используемое
для средств синтеза
заказных микросхем
и/или ПЛИС
Аппаратная модель
или программный код
Формальная
верификация
Рис. 24.4. Более полное представление возможностей компилятора
языка Confluence
Компилятор может принимать для обработки исходные тексты
языка Confluence, описывающие аппаратные элементы схемы уст-
ройства, или фрагменты встроенного программного обеспечения уст-
ройства, написанные на этом же языке. Если источником является
описаниие аппаратных элементов, нужно дать команду компилятору
Confluence генерировать RTL-код на языке VHDL или Verilog, чтобы
впоследствии использовать его для моделирования и синтеза.
Также можно использовать компилятор Confluence для создания
эквивалентных исходных текстов на языках ANSI С, Python или Java
(более подробно о языке Python см. гл. 25). Если при этом ваш исход-
ный текст описывает работу аппаратного обеспечения, тогда получен-
ные выходные описания могут выступать в качестве потактных или
битовых высокопроизводительных моделей, которые можно включить
в собственную среду верификации. Аналогично, если исходный текст
представляет собой встроенное программное обеспечение, то на выхо-
де получим исполняемый код для использования в среде совместной
верификации аппаратного и программного обеспечения.
316 Глава 24. Средства проектирования независимых разработчиков
1970 г. Для хране-
ния компьютерных
данных начали при-
меняться флоппи-
диски (8.5 дюймов).
1970 г. Исследова-
ния компании
Coming Glass приве-
ли к появлению пер-
вого коммерчески-
используемого оп-
тического кабеля.
И последнее, но не менее важное, компилятор языка Confluence
может создавать описания на языках PROMELA или NuSMV, которые
используются в средствах формальной верификации SPIN и NuSMV
соответственно (формальная верификация рассматривалась нами в
гл. 19, a PROMELA, SPIN и NuSMV будут рассмотрены в гл. 25).
Бесплатная копия
Если вы посетите сайт компании Launchbird (www.launchbird.com),
то там вы найдете большое количество примеров исходного текста, на-
писанных на языке Confluence. Особенно приятно то, что каждый мо-
жет загрузить с этого сайта и использовать совершенно бесплатно одну
неограниченную лицензию. За последующие лицензии придется вы-
ложить определённую сумму (версии для учебных заведений выпуска-
ются бесплатно), но цены часто меняются, поэтому последнюю ин-
формацию по этому вопросу лучше узнать непосредственно у компа-
нии Launchbird.
Но действительно радует то, что вы остаетесь полноправным собс-
твенником всех своих разработок, выполненных на одной бесплатной
лицензии (под которую попадают все исходные коды на языке
Confluence и полученные из них тексты на языках VHDL, С или
Verilog) и можете делать с ними всё, что пожелаете, в том числе их мож-
но и продать.
У вас есть средство?
Если вам приходилось сталкиваться с полезными средствами или
утилитами для проектирования от небольших фирм-разработчиков,
или если вы сами создаёте средства такого типа, то, пожалуйста, не
стесняйтесь и свяжитесь со мной по электронной почте
max@techbites.com, и, возможно, информация о таких средствах поя-
вится в следующих изданиях этой книги или в выходящем раз в два ме-
сяца разделе «Мах Bytes» на сайте www.eedesign.com.
ГЛАВА 25
ПРОЕКТИРОВАНИЕ
С ИСПОЛЬЗОВАНИЕМ ОТКРЫТОГО
ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ
Как открыть магазин по продаже устройств
на основе ПЛИС без крупных вложений
Уверен, что вам не часто приходилось сталкиваться с проектными
компаниями, организованными по принципу «два парня в гараже»,
которые занимались бы проектированием заказных микросхем. И это
не удивительно, так как стоимость средств проектирования, необходи-
мых для разработки устройств этого класса, ужасающе высокая и со-
ставляет от 100 000$ и выше. Непреодолимым препятствием также яв-
ляется тот факт, что для организации производства микросхем объем
необходимых инвестиций достигает миллионов долларов.
Хочу заметить, что моя задача не сводится к пропаганде менее под-
держиваемых средств. Для бюджетных проектов предпочтительнее
использовать недорогие средства проектирования от поставщиков
ПЛИС. Мощные средства от крупных или специализированных
поставщиков САПР будут предпочтительны для использования в
больших по размеру и сложности устройствах. Однако если вы пыта-
етесь создать «мастерскую» по производству и продаже устройств на
основе ПЛИС на дому без крупных капиталовложений (или вовсе
без вложений), то в этом случае, я думаю, представленные здесь
средства с открытым кодом, будут для вас весьма интересными.
В отличие от заказных микросхем, сочетание современной ПЛИС,
а также последние достижения в области открытых САПР электронно-
го проектирования и блоков интеллектуальной собственности сводит
стоимость стартового набора для проектирования устройств на основе
ПЛИС почти к нулю. Именно поэтому «магазин» по продаже уст-
ройств на основе ПЛИС могут открыть как выпускники колледжа, так
и профессионалы.
Чтобы проектная компания была успешной, кроме наличия знаний
в области проектирования цифровых логических устройств, требуется
ряд других фундаментальных составляющих, в число которых входят:
• базовая платформа;
• среда верификации (тестирования);
• средства формальной верификации (необязательная составляющая);
• доступ к блокам интеллектуальной собственности общего на-
значения;
• средства синтеза и реализации;
• макетная плата (необязательная составляющая).
Базовая платформа: Linux
Созданная шведским инженером Линусом Торвальдсом (Linus
Torvalds) в начале 1990-х годов, операционная система Linux очень
быстро стала основной платформой для проектирования устройств на
основе ПЛИС и заказных микросхем. Несмотря на то что болыиинс-
318 Глава 25. Проектирование с использованием открытого программного обеспечения
Официально аббре-
виатура LISP про-
изошла от слов List
Processor (язык об-
работки списков),
хотя критики ут-
верждают, что LISP
следует расшифро-
вывать как «Lots of
Irritating, Superfluous
Parentheses» (мно-
жество идиотских
ненужных скобок).
тво средств синтеза и реализации ПЛИС изначально работали под уп-
равлением операционной системы Microsoft Windows®, большинство
из них переносятся или уже перенесены под Linux.
Linux и GNU (GNU — проект свободного распространения про-
граммного обеспечения. — Прим, пер.) поддерживают многочислен-
ные средства аппаратной и программной разработки. Некоторые, на-
иболее распространённые из них (не в порядке по какому-то правилу,
а так как расположил их автор) кратко рассмотрены ниже:
• gcc. Язык С остаётся наиболее быстрым языком моделирования
и верификации устройств. Если ваше устройство является на-
столько большим, что средства моделирования HDL (Verilog
или VHDL) с ним не справляются, то вы можете попробовать
создать потактную модель на языке С и откомпилировать её с
помощью компилятора с открытым исходным кодом gcc (аббре-
виатура от GNU С Compiler).
• make. Утилита make используется для автоматизации процесса
построения. В контексте аппаратного обеспечения понятие
«построение» может относиться к моделированию, созданию
RTL-кода или логическому синтезу. Для того чтобы запустить
утилиту таке и начать процесс построения кода, вы должны в
специальном файле, который называется makefile, описать все
участвующие в проекте файлы, их зависимость от других фай-
лов, а также взаимоотношения между собой.
• gvim. Самым распространённым текстовым редактором для опе-
рационной системы Unix, пожалуй, является VI, название кото-
рого образовано от слов «visual interface», что значит «визуальный
интерфейс». Утилита под названием vim представляет собой рас-
ширенную версию vi, а её аналог с графическим интерфейсом
называется gvim. В gvim встроены средства расширения редакто-
ра vi, которые позволяют графически выделять (подсвечивать)
названия функций и макросов. Также в этот редактор встроена
поддержка языков Verilog или VHDL, что делает его сверхбыст-
рым и мощным средством описания электронных систем.
• EMACS (от «Editing MACroS» — редактирование макросов) заду-
мывался сообществом хакеров1' как совершенный редактор, и
представляет собой программируемый текстовый редактор со
встроенным интерпретатором языка LISP. Отличается большей
мощностью и сложностью, чем VI, а также содержит модули
позволяющие использовать его для создания Verilog или VHDL-
описаний.
• cvs. Система CVS (Concurrent Version System — система согласова-
ния версий) является основным средством контроля версий про-
граммного обеспечения с открытым исходным кодом (открыто-
го программного обеспечения), которую могут использовать все
желающие — от индивидуальных разработчиков до больших
дистрибьюторских компаний. CVS поддерживает ветвление,
многопользовательский режим и удалённое взаимодействие, а
также сохраняет историю всех изменений, произведенных в
В программистском сообществе этот термин возник в конце 50-х годов про-
шлого века и обозначал людей, поддерживающих принципы открытого обмена
программами и проектирования аппаратуры. В это сообщество входил и Ричард
Столман (Richard Stallman), написавший редактор EMACS. Позже, после выхода
в 1983 г. фильма «War Games», слово «хакер» стало ассоциироваться со словом
«кракер» (cracker) и людьми, злонамеренно взламывающими программы и прони-
кающими в чужие компьютеры. — Прим. пер.
Базовая платформа: Linux 319
подконтрольных ему папках (дереве каталогов) и файлах. Ис-
пользуя эту историю, CVS может восстанавливать прошлые со-
стояния дерева каталогов и показывать, кто, когда и какие из-
менения в него вносил. Таким образом, если вы случайно
испортили свой RTL-код или намерены пересинтезировать вер-
сию вашего устройства трёхмесячной давности, то CVS поможет
легко решить эти вопросы.
• PERL. Языки сценариев очень часто используются для реализа-
ции одноразовых программных задач и для создания прототи-
пов. В области разработки электронных устройств они также
применяются для связывания отдельных операций в процессе
проектирования друг с другом при помощи управления режима-
ми работы отдельных средств проектирования и организации
передачи данных между ними. Язык PERL (Practical Extraction
and Report Language — практический язык отчётов и извлечений)
исторически является одним из наиболее широко используемых
языков сценариев. Разработанный Ларри Уоллом (Larry Wall)
PERL в шутку называют «швейцарским армейским ножом»
(универсальным языком) для программирования под ОС Unix
(и Linux), и многие отдельные операции при проектировании
аппаратуры склеиваются в единую технологическую цепочку с
помощью сценариев, написанных на языке PERL.
• Python. Возможно, более мощный, чем PERL, язык Python является
«всеобъемлющим» языком сценариев, который перерос во вполне
законченный язык программирования. Язык Python разработал
Гвидо ван Россум (Guido Van Rossum) в 1990 году и назвал его в
честь Монти Пайтона (Monty Python), поклонником которого он
являлся0. Python может использоваться для решения разнообраз-
ных задач, начиная от склейки между собой отдельных этапов про-
ектирования, и до высокоуровневого моделирования, верифика-
ции и создания пользовательских средств САПР (см. также
дополнительное обсуждение языка Python ниже в этой главе).
• diff. Относительно простая, но чрезвычайно полезная утилита
diff используется для быстрого сравнения файлов исходного ко-
да, обнаружения отличий между ними и формирования отчёта
об этих отличиях.
• grep. Поддерживая глобальный поиск по регулярным выражениям и
отображая строки, которые им соответствуют, утилита grep
используется для быстрого поиска файла или группы файлов по
запросу в виде отдельной текстовой строки или в виде шаблона.
• OpenSSL. Независимо от того, являетесь ли вы большой или ма-
лой компанией, вам следует обеспечить сохранность ваших бло-
ков интеллектуальной собственности (IP). Вопросы сохраннос-
ти возникают, когда вы собираетесь передавать IP через
локальную сеть или через Интернет своим сотрудникам или по-
купателям. В этом случае предварительно необходимо зашиф-
ровать передаваемые данные, для чего можно воспользоваться
открытым программным обеспечением под названием OpenSSL.
Этот пакет осуществляет полноценную поддержку протоколов
SSL (Secure Sockets Layer — протокол безопасных соединений) и
TLS (Transport Layer Security — защита транспортного уровня),
° Гвидо ван Россум был поклонником комедийного сериала ВВС «Воздуш-
ный цирк Монти Пайтона», в честь которого он и назвал свой язык (а не в честь
подсемейства змей семейства ложноногих — питонов). — Прим. пер.
320 Глава 25. Проектирование с использованием открытого программного обеспечения
1971 г. Америка.
Тед Хофф (Ted
Hoff) разработал (а
компания Intel реа-
лизовала) первый
компьютер-на-
кристалле, извест-
ный как микропро-
цессор 4004.
1971 г. Америка.
Компания СТС со-
здаёт компьютер
Datapoint 2200.
причём качество его работы не уступает специализированным
промышленным криптографическим библиотекам.
• OpenSSH. Как быть, если ваша команда разработчиков разбро-
сана по всему миру? В этом случае поможет утилита ssh (Secure
SHell — защищенная оболочка), которая представляет собой про-
грамму, предназначенную для регистрации на удалённой маши-
не (компьютере) и выполнения на ней различных команд. При
этом используются защищённое зашифрованное соединение
между двумя хостами без установления доверительных отноше-
ний через открытую сеть. Утилита OpenSSH представляет собой
открытое программное обеспечение, и позволяет шифровать
весь трафик (включая пароли) для предотвращения перехвата
данных и других сетевых атак. Также OpenSSH поддерживает
различные аутентификационные методы и возможности уста-
новления защищённых туннелей.
• tar, gzip, bzip2. Эти утилиты используются для сжатия и архиви-
рования информации.
Приобретение ОС Linux
До недавнего времени лидерами по распространению ОС Linux
были компании Red Hat (www.redhat.com) и MandrakeSoft
(www.mandrakesoft.com). Однако в наши дни большой популярностью
пользуется дистрибутив компании Gentoo Linux™ (www.gentoo.org). В
Gentoo встроена уникальная система распределения пакетов, которая
автоматически скачивает, компилирует и устанавливает пакеты на
Linux машины. Хотите установить Icarus Verilog? Тогда просто введите
$ emerge iverilog
и через несколько минут вы обнаружите Icarus в своей системе полно-
стью готовым к работе!
Среда верификации
Вы можете придерживаться другой точки зрения, но многие инже-
неры считают средства верификации (тестирования) наиболее важной
частью в проектировании электронных устройств. Можно усердно ра-
ботать за клавиатурой и разрабатывать HDL-код, но именно тестиро-
вание предоставляет проектировщику обратную связь, с помощью ко-
торой он может довести устройство до правильной реализации.
Icarus Verilog
Наиболее широко распространённым открытым средством вери-
фикации является компилятор языка Verilog под названием Icarus
(http://icarus.com/eda/verilog). В начальном виде Icarus компилирует
исходный код устройсва, написанный на языке Verilog, в исполняемый
код, который применяется в качестве модели устройства. Честно гово-
ря, Icarus изначально использовался в качестве системы событийного
моделирования, но он также поддерживает основы логического синте-
за для ПЛИС компании Xilinx.
Несмотря на то что Verilog является сложным языком, Стивен Уи-
льямс (автор пакета Icarus) выполнил блестящую работу по его реали-
зации. Язык Icarus Verilog по распространению и производительности
фактически превзошёл некоторые коммерческие системы моделиро-
вания.
Среда верификации 321
Dinotrace и GTKWave
Icarus Verilog, рассмотренный выше, полностью является средс-
твом командной строки. (Средства командной строки широко распро-
странены в ОС Unix и Linux, так как они легко взаимодействуют с по-
мощью make-файла.)
Icarus не поддерживает графический пользовательский интерфейс
(GUI) для отображения результатов моделирования. Вместо этого он
может формировать файлы в промышленном формате VCD (value
change dump — дамп изменения значений), которые впоследствии мо-
гут быть использованы отдельными приложениями для просмотра
формы сигнала.
В отличие от Icarus, Dinotrace и GTKWave поддерживают гра-
фический пользовательский интерфейс (GUI) и могут исполь-
зоваться для отображения результатов моделирования, представлен-
ных в формате VCD. Оба этих просмотрщика формы сигнала могут
наблюдать за процессом моделирования, отслеживать отдельные эле-
менты и осуществлять поиск по шаблону. Утилита Dinotrace
(www.veripool.com/dinotrace) представляет собой законченную про-
грамму, но с ограниченной функциональностью. Для сравнения от-
метим, что GTKWave (www.cs.man.ac.uk/apt/tools/gtkwave) в начале
своего развития представлял собой довольно сырой продукт, но в
последнее время активно развивается.
1971 г. Америка.
Компания СТС со-
здаёт компьютер
Kenbak-1.
Covered
При верификации устройства очень важно знать уровень кодового
покрытия, чтобы быть уверенным, что ваши тестовые задающие воз-
действия (ваш тестовый вектор) охватывают все «тупиковые ситуации»
в устройстве.
Утилита Covered (http://covered.sourceforge.net) осуществляет про-
верку кодового покрытия, написанного на языке Verilog, и применяет-
ся для оценки работы систем моделирования. Если быть более точ-
ным, то Covered для определения полноты функционального покры-
тия анализирует исходный код языка Verilog и файлы формата VCD,
созданные системой моделирования Icarus Verilog.
В настоящее время Covered выполняет четыре типа измерений:
анализ строк исходного кода, анализ переключения логических значе-
ний, комбинационный анализ и анализ конечных автоматов.
Verilator
В наши дни весьма актуальным стал вопрос о том, как управлять
однокристальными системами, в которых аппаратная и программная
составляющие встраиваются в один кристалл. Многие ПЛИС также
содержат в своём составе аппаратные процессорные ядра или позволя-
ют реализовывать программные микропроцессоры (см. также гл. 13).
Настоящие чудеса приходится творить при верификации аппарат-
ных и программных частей однокристальных систем. Например, про-
грамма Verilator (www.veripool.com/verilator.html) преобразует код языка
Verilog в потактную модель C/C++. Следует заметить, что возможность
автоматически генерировать модели на языке C/C++ из RTL кода
представляет собой довольно мощное средство отладки, которое поз-
Компания Tenison
EDA разработала
другой очень полез-
ный инструмент под
названием VTOC,
который создаёт мо-
дели на языках C++
или SystemC
из RTL-кода.
322 Глава 25. Проектирование с использованием открытого программного обеспечения
1971 г. Первое пря-
мое телефонное со-
единение Америки с
Европой.
воляет программной части системы интегрироваться с этой моделью
для выполнения процедуры моделирования.
В дополнение к аппаратно-программной верификации системы,
Verilator также используется для Verilog моделирования, так как моде-
лирование с использованием потактных моделей языка С требует го-
раздо меньше времени, чем событийное HDL-моделирование. Всё,
что вам для этого потребуется — это откомпилировать файл с С-кодом
с помощью компилятора gcc (смотрите также раздел «Базовая плат-
форма: Linux» выше в этой главе) и запустить его на выполнение^.
Python
Python (www.python.org) является очень удобным высокоуровневым
языком программирования и создания сценариев, также приобрел ми-
ровую известность благодаря своим возможностям быстрого достиже-
ния результатов. Разумеется, Python развивается как мощное средство
для инженеров, проектирующих и тестирующих электронные устройс-
тва, в частности для решения задач системного моделирования, разра-
ботки тестовых устройств и общего управления устройством.
На практике многие проектные организации открыли для себя, что
модели описания разрабатываемых ими устройств гораздо легче и быс-
трее создавать с помощью языка Python, чем использовать для этого
языки Verilog или VHDL. Поэтому многие компании сначала разраба-
тывают модель устройства на Python’e, проверяют её с помощью сис-
темы моделирования и, затем, создают RTL-код, постоянно сравнивая
его с этой «эталонной» моделью.
Для языка Python разработана специальная среда высокоуровнево-
го системного моделирования под названием MyHDL
(www.jandecaluwe.com/Tools/MyHDL/Overview.html), которая исполь-
зует новые дополнения для этого языка (генераторы), предназначен-
ные для эмуляции процесса параллельных вычислений. MyHDL также
может соединяться с компилятором Icarus Verilog для создания сме-
шанной среды моделирования Python/Verilog.
Формальная верификация
Как однажды сказал голландский математик и основатель многих
компьютерных концепций Эдсгер Дейкстра (Edsger Wybe Dijkstra):
«Тестирование программ может использоваться только для того, чтобы
показать наличие ошибок в коде, но не для того, чтобы показать их от-
сутствие».
Хотя аппаратное моделирование по-прежнему остаётся основным
способом системной проверки, убедиться в правильности работы уст-
ройства вы можете только с помощью средств формальной верифика-
ции (см. также гл. 19). В отличие от средств моделирования, формаль-
ная верификация математически доказывает, что реализация системы
соответствует некоторой спецификации.
Существуют два основных типа формальной верификации — авто-
матизированная формулировка логических выводов и верификация моде-
ли. Верификация модели представляет собой метод анализа про-
странства состояния системы для проверки некоторых свойств, обыч-
но называемых «утверждениями». Одной из разновидностей
верификации моделей является проверка на эквивалентность, которая
° Заметим, что компилятор Icarus также поддерживает возможности генери-
рования кода на языке С.
Формальная верификация 323
сравнивает два представления системы (например, RTL и таблицу со-
единений вентилей). Для сравнения отметим, что автоматизированная
формулировка логических выводов использует логику для доказатель-
ства того, что реализация соответствует исходной спецификации (по-
добно формальному математическому доказательству).
Верификация модели
Наиболее широко распространённой открытой системой верифи-
кации моделей является программный пакет SPIN
(http://spinroot.com), который почти 20 лет развивался Джерардом
Холзманом (Dr. Gerard J. Holzmann) из лаборатории Bell Labs. Весьма
знаменательно то, что SPIN недавно получил весьма почётную награду
(Software and System Award) от Ассоциации по вычислительной технике
/или АСМ—Association for Computing Machinery), которую до этого полу-
чали Unix, SmallTalk, TCP/IP и World Wide Web.
SPIN обрабатывает исходную спецификацию с интегрированной
моделью системы, используя для этого язык PROMELA1). С помощью
этого языка пользователи могут создавать сложные утверждения, оп-
ределяющие события, которые никогда не должны происходить в сис-
теме. В представленной модели и спецификации SPIN осуществляет
поиск пространства состояний ошибок.
Главный недостаток системы SPIN заключается в том, что она из-
начально предназначена для проверки асинхронного программного
обеспечения, то есть использует методы явной проверки. Хотя явная
проверка идеально подходит для тестирования программных протоко-
лов, эти методы могут оказаться неэффективными для больших аппа-
ратных устройств.
Для средних по размеру устройств лучше всего подходит так назы-
ваемая символическая система проверки модели. В отличие от явной
проверки, она использует диаграммы двоичного выбора и алгоритмы вы-
сказываемой выполнимости (или SAT)1} для того, чтобы удержать про-
блемы и, по возможности, избежать расширения пространства состоя-
ний. Эти функции выполняет высококачественная система проверки с
открытым исходным кодом под названием NuSMV
(http://nusmv.irst.itc.it).
Автоматизированная формулировка логических выводов
Преимущество рассмотренного в предыдущем разделе метода ве-
рификации модели заключается в том, что этот процесс выполняется
автоматически — нажимаем на кнопку и ждём результат. Однако вам,
возможно, придётся довольно долго ждать окончания проверки.
Хотя символическое представление, используемое пакетом
NuSMV, является более совершенным, чем явная проверка модели,
для него всё же существует угроза расширения пространства состоя-
ний. Очень скоро наступит ситуация, когда рост размеров системы
превысит практические ограничения, присущие системе верификации
моделей. Другая проблема заключается в том, что некоторые сложные
утверждения просто не могут быть описаны в среде верификации мо-
1971 г. Никлаус
Вирт (Niclaus Wirth)
разработал язык
программирования
PASCAL (назван
в честь Блеза
Паскаля).
Название PROMELA образовано от PROcess MEta LAnguage — язык метаоб-
работки. — Прим. пер.
2) Название SAT образовано от первых трёх букв слова «satisfiability», что озна-
чает выполнимость.
324 и Глава 25. Проектирование с использованием открытого программного обеспечения
1972 г. Америка.
Компания Intel
представила мик-
ропроцессор 8008.
делей. Для решения этих проблем существуют средства автоматизиро-
ванной формулировки логических выводов, или, как их ещё называют,
средства автоматизированного доказательства теорем.
Для автоматизированной формулировки не свойственны ограни-
чения, присущие верификации моделей. Например, размеры системы
не играют столь большого значения, так как автоматизированная фор-
мулировка не производит поиск пространства состояний. Кроме того,
она поддерживает более высокий уровень выражений для точного мо-
делирования сложных спецификаций.
К сожалению, то, что достигнуто в одних областях, уже утеряно в
других. Несмотря на название, автоматизированная формулировка не
выполняется в автоматическом режиме. На практике, при проверке
устройства разработчики проводят доказательства с помощью опреде-
ленных средств. Более того, для эффективного использования этих
средств инженерам необходимо хорошо владеть стратегией доказа-
тельств, математической логикой и другими приёмами. Всё это требует
нестандартных знаний, но если вы желаете потратить время и силы, то
автоматизированная формулировка логических выводов, вероятно,
будет наиболее мощным средством верификации ваших систем.
В отличие от средств верификации моделей, где приложения с от-
крытым исходным кодом соперничают с коммерческими приложени-
ями, в области автоматизированных формулировок открытые средства
являются наиболее проработанными. Самыми популярными продук-
тами этого класса являются пакеты
• HOL (http://hol.source-forge.net);
• TPS (http://gtps.math.cmu.edu/tps.html);
• MetaPRL (http://cvs.metaprl.org: 12000/metaprl/default.html).
В чём заключается проблема?
Качества формальной верификации определяются тем, как инже-
неры её используют, что, впрочем, справедливо для всех средств. Фак-
тически формальная верификация может ответить только на один
вопрос — насколько моя реализация соответствует спецификации? Но
появляется другой вопрос — насколько корректно составлена сама
спецификация?
Оценка современных методов проектирования показывает, что
большинство системных ошибок по существу не зависят от процесса
реализации. Даже без использования средств формальной верифика-
ции, как правило, реализация устройства чаще выполняется коррект-
но. Основная причина большинства ошибок обычно связана с теми
требованиями, которые предъявляются к устройству или схеме.
Лучше всего обеспечить корректность составления спецификации
можно в процессе открытого общения и сотрудничества, и во время
написания этой книги единственным инструментом для решения .этой
проблемы была кора головного мозга.
Доступ к общим блокам интеллектуальной
собственности
Полезное практическое правило для малых (и даже для больших)
проектных организаций гласит, что не стоит изобретать велосипед. Со
временем у каждой организации или компании собирается библиотека
часто используемых компонентов, которые повышают скорость про-
ектирования. Возможности проектной организации иногда оценива-
ются по её набору блоков интеллектуальной собственности (IP).
Средства синтеза и реализации 325
OpenCores
К счастью, у разработчиков есть доступ к большой библиотеке бло-
ков интеллектуальной собственности в виде проекта OpenCores
(www.opencores.org). OpenCores представляет собой основное хранили-
ще промышленных аппаратных блоков интеллектуальной собствен-
ности (IP) с открытым исходным кодом, в котором собраны проекты
ядер арифметических модулей, контроллеров связи, сопроцессоров,
ЦСП, средств прямого исправления ошибок и встраиваемых микро-
процессоров. Более того, OpenCores осуществляет поддержку стандар-
та Wishbone, который применяется в однокристальных устройствах в
качестве протокола общей шины.
OVL
Разработчики электронных систем могут потратить до 70 процен-
тов времени, выделенного на разработку устройства, на выполнение
операций проверки. В связи с этим возникла необходимость доступа к
библиотеке IP, предназначенных для тестирования устройств. Чтобы
удовлетворить эти потребности, компания Accellera (www.accellera.org)
начала развитие Библиотеки открытых средств проверки (или OVL —
Open Verification Library)
Средства синтеза и реализации
Синтез (логический и физический) является одним из основных
этапов в процессе проектирования устройств на основе ПЛИС, кото-
рый нельзя реализовать в полном объёме только с помощью средств с
открытым исходным кодом. К сожалению, эта ситуация вряд ли изме-
ниться в ближайшем будущем из-за сложности ПЛИС-синтеза.
В то время, когда я работал над этой книгой, компилятор Icarus
(см. также раздел «Среда верификации» выше в этой главе) был
единственным открытым средством, способным синтезировать про-
тотипы ПЛИС из HDL кода. Недорогие средства синтеза предлагали
только поставщики ПЛИС (как правило, их выбирали для недорогих
решений).
Однако когда ваше устройство приближается к ёмкости самых
мощных ПЛИС, то средства синтеза от поставщика ПЛИС не могут
решить поставленную перед ними задачу. Это значит, что для проекти-
рования больших и сложных устройств вам придётся раскошелиться и
купить мощное средство синтеза.
Макетная плата
Если проектная организация решит заняться физической реализа-
цией аппаратуры на основе ПЛИС, то обязательно потребуется макет-
ная плата ПЛИС.
Проект OpenCores (см. также раздел «Доступ к общим блокам ин-
теллектуальной собственности» выше в этой главе) предлагает не-
сколько вариантов макетных плат ПЛИС, но большинство разработ-
чиков предпочитают покупать профессиональные платы.
С другой стороны деньги, потраченные на плату, могут быть сэко-
номлены в других областях. Например, умные инженеры могут пре-
вратить небольшую макетную плату ПЛИС в логический анализатор с
большими возможностями (да, это звучит как потенциальный проект
OpenCores).
1973 г. Америка.
Компания Selbi
Computer Consulting
Company предста-
вила микрокомпью-
терный набор для
самостоятельной
сборки под назва-
нием Selbi-8H.
326 Глава 25. Проектирование с использованием открытого программного обеспечения
1973 г. Америка.
Разработан ком-
пьютер Xerox Alto.
1973 г., май, Фран-
ция. Разработан
компьютер Micral
на базе микропро-
цессора 8008.
Другие необходимые средства и утилиты
В нижеследующем списке представлены Интернет-сайты, на кото-
рых можно найти заслуживающие внимание средства и утилиты:
• www.easics.be
На странице этого сайта щёлкните на ссылке «WebTools» для то-
го, чтобы найти утилиты создания контрольных сумм (CRC),
которые позволят вам выбрать стандартную или полиномиаль-
ную проверку и сгенерировать соответствующие Verilog или
VHDL-модули.
• www.linuxeda.com
Здесь находятся средства САПР для ОС Linux.
• http://gedaweul.org
На этом сайте можно найти коллекцию открытых САПР для
проектирования электроники.
• www.veripool.com
Здесь можно найти набор средств языка Verilog (домашняя стра-
ница пакетов Dinotrace и Verilator).
• http://ghdl.free.fr
На этом сайте находится клиентская часть открытого языка
VHDL для компилятора gcc.
• http://asics.ws
На этом сайте находятся некоторые блоки интеллектуальной
собственности с открытым кодом.
Во время путешествия по страницам Интернета можно встретить
большое количество проектов с открытым исходным кодом, относя-
щихся к ПЛИС или САПР электронных устройств. К сожалению,
большинство из них не работают или заброшены на этапе, когда они
ещё не достигли какого-либо полезного уровня функциональности.
Поэтому, если вы встретите или сами создадите что-нибудь полезное,
то, пожалуйста, свяжитесь со мной по адресу max@techbites.com, что-
бы я, по-возможности, смог поместить этот материал в следующем из-
дании этой книги.
ГЛАВА 26
ПЕРСПЕКТИВЫ РАЗВИТИЯ ПЛИС
Ужасы проектирования
Это ужасная глава, так как по прошлому опыту могу сказать, что
иногда что-то новое кажется многообещающим, но потом понимаешь,
что это всего лишь жалкое подобие того, что появляется незаметно, и
затем неожиданно приобретает широкую популярность именно в тот
момент, когда этого не ожидаешь.
Вы, должно быть, помните, что когда я в далёком 1980 году начи-
нал свою карьеру, разрабатывая микропроцессоры для мэйнфреймов
(что, в принципе, было не так уж и давно), у нас не было доступа к тем
технологиям и средствам проектирования, которые применяются в
наши дни. У нас не было даже программ для разработки схем, и поль-
зовались мы только карандашом и бумагой, с помощью которых рисо-
вали принципиальные схемы, состоящие из многих логических эле-
ментов. У нас не было систем логического моделирования (в то время
уже появились их первые версии, но доступны они были не для всех),
поэтому свои конструкции мы проверяли с помощью экспертной
оценки, которая сводилась к тому, что другие инженеры смотрели на
вашу схему и приговаривали: «По-моему, всё хорошо».
Сложные языки семейства HDL, такие как Verilog и VHDL, появи-
лись намного позже, хотя, возможно, что в то время уже существовали
средства логического синтеза, но нам они не встречались. Когда дело
доходило до логической оптимизации и минимизации, то эта задача
поручалась одному китайцу из нашей команды, который был в этом
деле непревзойденным мастером, он брал нашу схему и возвращал че-
рез несколько дней её оптимизированную версию. Для выполнения
временного анализа мы снова брались за карандаш и бумагу и вручную
вычисляли значение задержек для каждого пути прохождения сигнала
(в то время никто не мог себе позволить даже простейший электрон-
ный калькулятор).
Мы работали с заказными микросхемами, изготовленными по
мультимикронной технологии, которые содержали всего лишь не-
сколько тысяч логических элементов (ПЛИС в то время ещё не были
изобретены). Если бы тогда мне кто-то сказал, что к 2003 году мы бу-
дем заниматься разработкой заказных микросхем и однокристальных
систем, изготовленных по 90-нм технологии, которые будут содержать
десятки и сотни миллионов логических элементов, и что у нас будут
реконфигурируемые устройства, такие как ПЛИС на основе ячеек ста-
тического ОЗУ, то я бы просто покатился со смеху. Также если бы вы
мне тогда сказали, что когда-нибудь у меня на столе будет стоять пер-
сональный компьютер с сотнями мегабайт ОЗУ и тактовой частотой
более 2 ГГц, объёмом жесткого диска 60 Гбайт, и в моём распоряжении
будут средства САПР электронных систем, то я, изображая на лице ус-
328 Глава 26. Перспективы развития ПЛИС
покаивающую улыбку, всерьёз бы призадумался над тем, как бы пос-
корее от вас улизнуть1*.
Сфера электроники развивается настолько быстрыми темпами, что
все наши прогнозы по поводу её будущего можно свести к словам:
«Что день грядущий нам готовит?... В глубокой тьме таится он». Но
всё-таки давайте отложим в сторону все шуточки, бросим игральные
кости и посмотрим, что же ждёт нас в будущем.
Архитектуры и технологии нового поколения
Устройства с миллиардами транзисторов
Одно моё предсказание, в котором я абсолютно уверен, заключает-
ся в том, что следующее поколение ПЛИС будет содержать миллиарды
транзисторов, а может даже и больше (причиной моей самоувереннос-
ти послужил тот факт, что компания Xilinx недавно анонсировала уст-
ройства этого типа). Эти кристаллы будут изготовлены по 90-нм тех-
нологии, вслед за ними последуют устройства с технологией изготов-
ления 65 и 70 нм.
Сверхбыстрые устройства ввода/вывода
Многие современные высокотехнологичные ПЛИС оснащаются
одним или несколькими блоками гигабитных передатчиков, описыва-
емых ранее в гл. 21. Каждый такой передатчик может поддерживать
несколько каналов. В свою очередь, каждый канал может работать с
потоком 2.5 Гбит/с, следовательно, четыре канала могут одновремен-
но передавать данные со скоростью 10 Гбит/с. Кроме того, с микросхе-
мами могут применяться дополнительные внешние устройства, с по-
мощью которых входной оптический сигнал можно преобразовать в
четыре электрических канала и передать их в ПЛИС. И наоборот, эти
устройства могут объединять четыре электрических канала, приходя-
щих от ПЛИС, и преобразовывать их в один оптический сигнал. Во
время написания этой книги появилась информация, что некоторые
ПЛИС могут самостоятельно принимать и генерировать оптические
сигналы со скоростью 10 Гбит/с.
В недалёком будущем могут появиться другие технологии, позво-
ляющие осуществлять беспроводную или подобную беспроводной
связь между кристаллами по типу ПЛИС-ПЛИС или ПЛИС-заказная
микросхема. Что касается упомянутого здесь понятия «подобные бес-
проводной», то я имею в виду методы, аналогичные проводящимся
сейчас экспериментальным работам компании Sun Microsystems по
межкристальному обмену на основе чрезвычайно быстрых и мало-
мощных ёмкостных связей. В этом случае требуется, чтобы кристаллы
были установлены очень (ОЧЕНЬ) близко друг к другу на печатной
плате, но скорость межкристального обмена при этом возрастает в 60
раз по сравнению с самыми быстрыми на сегодняшний день техноло-
гиями связи между компонентами на печатной плате.
Сверхскоростное конфигурирование
Большинство современных ПЛИС конфигурируются с помощью
последовательного битового, либо параллельного 8-битного потока.
Это обстоятельство сильно ограничивает применение устройств
1)
Первые компьютеры IBM PC появились только в 1981 году.
Архитектуры и технологии нового поколения 329
ПЛИС в системах с перестраиваемой архитектурой. Некоторое время
назад (примерно в середине 1990-х годов) команда Pilkington
Microelectronics (PMEL) из Соединённого Королевства представила
оригинальную архитектуру ПЛИС, в которой контакты ввода/вывода
микросхемы также использовались для загрузки конфигурационных
данных. Такое решение обеспечило сверхширокую шину (256 бит и
более), с помощью которой устройство программировалось в один
миг (jiffy)0.
(^=э Компания Pilkington, основанная в 1826 году, является одним из
крупнейших мировых производителей стеклянных изделий, а также
мировым лидером в разработке технологий изготовления стекла.
Так, в 1952 году господин Аластэр Пилкингтон разработал флоат-
процесс, при котором стекломасса температурой около 1000°С не-
прерывно выливается из печи в ванну с растопленным оловом.
Стекломасса растекается по олову, благодаря чему приобретает неве-
роятную гладкость, одновременно она охлаждается и затвердевает,
образуя в итоге непрерывную ленту.
Не понимаю, почему Пилкингтон решил заняться микроэлектрони-
кой.
Такие устройства, например, могут использоваться при работе с
разнообразными алгоритмами сжатия и распаковки данных (кодека-
ми), которые применяются при обработке аудио- и видеоданных. Если
ваша система должна распаковывать файлы, которые были сжаты с
помощью различных алгоритмов, тогда вам необходимо поддерживать
различные наборы кодеков.
Допустим, вы решили аппаратно выполнять распаковку с помо-
щью устройства, реализованного на основе ПЛИС, тогда при исполь-
зовании традиционных устройств вам необходимо реализовать каж-
дый кодек в своей микросхеме или в отдельных областях одного боль-
шого устройства. Перепрограммирование ПЛИС для «горячей» смены
кодека в большом устройстве потребует от 1 до 2.5 с, что может не уст-
роить конечного пользователя (в наши дни всё должно выполняться
мгновенно). В отличие от этих методов, при использовании архитекту-
ры PMEL, реконфигурационные данные могут быть загружены в
ПЛИС перед поступлением файла, подлежащего обработке
(Рис. 26.1).
Идея заключается в том, что конфигурационные данные могут
загружаться через широкую шину, программировать устройство за
долю секунды и сразу же приступать к распаковке следующего за ни-
ми аудио- или видеофайла. Если следующий файл, подлежащий об-
работке, требует другого кодека, тогда соответствующий конфигура-
ционный файл должен предварительно перепрограммировать уст-
ройство.
CODEC — как со-
кращение от слов
COmpressor/DECom
pressor или КОдер-
ДЕКодер
Официальное определение понятия «jiffy» («миг») может означать «корот-
кий отрезок времени», «момент», «мгновение». Инженеры используют понятие
«jiffy» для обозначения длительности одного периода частоты синхронизации
компьютера. Также это понятие может обозначать длительность периода сетевого
источника питания, который составляет 1/60 секунды в США и Канаде, или 1/50
секунды в Англии и многих других странах. Не так давно в общем случае под по-
нятием «jiffy» стали понимать 1/100 долю секунды. И только ради развлечения,
физики иногда под понятием «jiffy» подразумевают время, за которое луч света в
вакууме преодолевает расстояние в один фут (на это потребуется примерно 1 на-
носекунда).
330 Глава 26. Перспективы развития ПЛИС
Июнь 1973 г. В пе-
чати впервые поя-
вилось слово «мик-
рокомпьютер», ко-
торое относилось к
микрокомп ьютеру
Micral на базе мик-
ропроцессора 8008.
1974 г. Америка.
Компания Intel вы-
пускает микропро-
цессор 8080, кото-
рый стал поистине
первым микропро-
цессором общего
назначения.
Файлы, содержащие конфигурационные данные
для различных кодеков
Аудио- и видеофайлы,
сжатые с помощью различных кодеков
Рис. 26.1. Широкая конфигурационная шина
Эта концепция применима для большого числа приложений. К со-
жалению, первые воплощения этой технологии потерпели неудачу, но,
вероятно, в недалёком будущем подобные устройства появятся снова1*.
Увеличение количества аппаратных блоков
интеллектуальной собственности
При изготовлении микросхем по 90-нм (и ниже) технологии, на
одном кристалле можно расположить так много транзисторов, что это
почти наверняка вызовет увеличение количества аппаратных блоков
интеллектуальной собственности для функций связи, специальной об-
работки, микропроцессорной периферии и так далее.
Аналоговые и комбинированные устройства
Поставщики традиционных цифровых микросхем ПЛИС стремят-
ся захватить как можно больше функций, находящихся на печатной
плате и перенести их в свои устройства. Другими словами, в ПЛИС на-
чали включать аппаратные блоки IP с аналоговыми составляющими,
такими как АЦП (аналогово-цифровые преобразователи) и ЦАП (циф-
ро-аналоговые преобразователи). Эти блоки могут программироваться
на определённое количество уровней квантования (разрешение ЦАП
и АЦП) и динамический диапазон поддерживаемого аналогового сиг-
нала. Также такие устройства могут включать в свой состав усилители
и некоторые функции фильтрации и преобразования сигналов.
Более того, уже несколько лет ряд компаний производят програм-
мируемые пользователем аналоговые матрицы (или FPAA — field-
programmable analog arrays)2*. Таким образом, с большой вероятностью
можно утверждать, что изначально цифровые ПЛИС начнут включать
реальные программируемые аналоговые блоки, подобно тому, как это
делается в микросхемах FPAA.
° Схема широкой конфигурационной шины используется в некоторых уст-
ройствах FPNA (программируемых пользователем массивом узлов), рассмотренных в
главе 23.
2) Например, компания Anadigm (www.anadigm.com) предлагает некоторые
интересные устройства этого вида.
Архитектуры и технологии нового поколения 331
ASMBL и другие архитектуры
Как только я начал писать строки этой главы, так компания Xilinx
формально анонсировала появление архитектуры ASMBL (Application
Specific Modular Block — специализированные модульные блоки). Идея
этого решения заключается в том, что в вашем распоряжении оказыва-
ется структура, состоящая из столбцов, в которую парни из Xilinx вло-
жили большое количество различных функций, таких как:
• программируемая логика общего назначения;
• блоки памяти;
• функции цифровой обработки сигналов (ЦОС);
• функции процессора;
• высокоскоростные блоки ввода/вывода;
• аппаратные блоки IP;
• функции обработки смешанных сигналов.
Компания Xilinx предоставляет набор готовых к применению уст-
ройств, каждое из которых обладает разными наборами столбцов,
предназначенных для реализации в приложениях определённой об-
ласти (Рис. 26.2).
1974 г. Америка.
Компания Motorola
представила мик-
ропроцессор 6800.
Рис. 26.2. Применение архитектуры ASMBL для создания различных готовых
устройств со специализированной прикладной функциональностью
Конечно, другие поставщики ПЛИС тоже усиленно работают над
своими устройствами следующего поколения, и мы можем полагать,
что в ближайшие несколько лет на нас обрушится шквал новых архи-
тектур.
Уровень детализации
Ранее в главе 4 мы говорили о том, что поставщики ПЛИС и сту-
денты различных учебных заведений одно время серьёзно были заняты
исследованием целесообразности применения 3-, 4-, 5- и даже 6-вхо-
довых таблиц соответствия.
В прошлом некоторые устройства использовали таблицы соответс-
твия различных размеров, например на 3 и на 4 входа, так как это ре-
332 Глава 26. Перспективы развития ПЛИС
1974 г. Америка. В
журнале «Radio
Electronic» опубли-
кована статья
Джонатана Тай-
туса (Jonathon
Tytus) о разработке
микрокомпьютера
Mark-8 на базе
микропроцессора
8008.
шение сулило оптимальное использование ресурсов устройства. В си-
лу различных причин большинство современных ПЛИС используют
только 4-входовые таблицы соответствия, однако не исключено, что в
будущем часть из них снова начнёт применять блоки с разным коли-
чеством входов.
Включение ядер ПЛИС в заказные микросхемы
Стоимость разработки современных 90-нм заказных микросхем все-
ляет ужас. Эта проблема усугубляется тем фактом, что после разработки
устройства и создания микросхемы ваш алгоритм и все функции оказы-
ваются «зашитыми в кремний». Это значит, что если после этого внести
некоторые изменения, то вам придётся заново генерировать все уст-
ройство, создавать новый набор фотошаблонов (стоимостью примерно
1 миллион долларов США) и заново создавать новую микросхему.
Для решения этой проблемы некоторые пользователи заинтересова-
ны в создании заказных микросхем со встроенными в их структуру яд-
рами ПЛИС. Если быть кратким, то это значит, что можно использовать
одни и те же устройства для многих приложений без создания новых на-
боров фотошаблонов. Во время написания этой книги, последним воп-
лощением этой технологии была архитектура XBlue, представленная
компаниями IBM и Xilinx. Появление подобных устройств, изготовлен-
ных по 90-нм технологии, ожидается в самом ближайшем будущем.
Я думаю, что мы также станем свидетелями увеличения примене-
ния структурированных заказных специализированных микросхем,
которые будут использовать встроенные ядра ПЛИС, так как методы и
средства их проектирования содержат много общего.
Включение ядер FPNA в заказные микросхемы и ПЛИС
и наоборот
В главе 23 мы рассматривали концепцию встраивания ядер FPNA в
структуру ПЛИС и заказных микросхем, или наоборот, включение
ПЛИС-узлов в структуру FPNA. Также вполне возможно, что в неда-
лёком будущем мы будем разрабатывать устройство на основе заказ-
ных микросхем со встроенным ядром ПЛИС, которое будет включать
встроенное ядро FPNA, которое, в свою очередь, будет включать узлы
ПЛИС. Потрясающе!
Устройства на основе магнитного ОЗУ
В главе 2 мы рассматривали концепцию магнитного ОЗУ. Ячейки
этого типа памяти потенциально сочетают в себе скорость работы ста-
тического ОЗУ, большой объём динамического ОЗУ, энергонезависи-
мость технологии Flash и потребляют чрезвычайно мало энергии.
Микросхемы памяти на основе ячеек магнитного ОЗУ должны по-
явиться в ближайшем будущем. После выхода на рынок этих модулей
памяти начнётся развитие и других устройств на их основе, таких как
ПЛИС на основе ячеек магнитного ОЗУ
Не забывайте о средствах проектирования
Как мы уже заметили выше, следующее поколение ПЛИС будет
содержать более 1 миллиарда транзисторов. Существующие методы
проектирования, основанные на HDL, в которых устройство описыва-
ется на уровне абстракции регистровых передач, уже начинают споты-
Ожидание неожиданного 333
каться при работе с современными устройствами, и в скором времени
просто перестанут справляться со своей задачей.
Решением этой проблемы может послужить переход на более вы-
сокий уровень абстракции устройства при помощи использования ме-
тодов проектирования, основанных на использовании чистой версии
языка C/C++, рассмотренных нами в главе 11. Однако на практике
требуются также средства проектирования системного уровня, кото-
рые помогут пользователю управлять пространством параметров раз-
работки на чрезвычайно высоком уровне абстракции. В дополнение к
средствам алгоритмического моделирования и верификации, эти ок-
ружения должны также помогать пользователю разделять устройство
на аппаратную и программную части.
Также эти средства системного уровня должны поддерживать воз-
можности анализа производительности, с тем, чтобы помочь пользо-
вателю оценить какие программные блоки работают слишком медлен-
но, и, таким образом, перевести их на аппаратную реализацию, и ка-
кие аппаратные блоки можно реализовать программно, дабы
оптимизировать использование ресурсов микросхемы.
О подобных инструментах люди говорят целую вечность, и различ-
ные окружения и средства проектирования уже решают эти задачи.
Однако на практике они проходят длинный путь, прежде чем достиг-
нут соответствующих возможностей и простоты использования.
Ожидание неожиданного
Вот и всё, конец этой главы и конец этой книги. Фу! Но перед тем
как закончить, я ещё раз повторюсь, что все мои и ваши предположе-
ния в будущем могут оказаться лишь слабым отражением того, что
произойдёт на самом деле. В мире существует ряд технологий и
средств проектирования, которые пока ещё только развиваются, и ког-
да они всё-таки появятся на сцене (с учётом прошлого опыта, это слу-
чится раньше, чем мы полагаем), мы все воскликнем «Ух ты! Какая хо-
рошая идея!» и «Почему я сам до этого не додумался?». О Боже, я
ЛЮБЛЮ электронику!
1975 г. Америка.
На рынке Америки
появился микро-
компьютерный на-
бор для самостоя-
тельной сборки.
Приложение А.
ЦЕЛОСТНОСТЬ СИГНАЛА
Величина, которая
характеризует про-
тивостояние вещес-
тва электрическому
току, называется со-
противлением и
обозначается бук-
вой R, измеряется в
Омах (1 Ом). Едини-
ца измерения «Ом»
(иногда обозначает-
ся буквой греческо-
го алфавита О) на-
звана в честь немец-
кого ученого Георга
Симона Ома, кото-
рый в 1827 году оп-
ределил отношения
между напряжени-
ем, током и сопро-
тивлением.
Вступление
Перед тем как погрузиться в эту тему, необходимо заметить, что це-
лостность сигнала представляет собой весьма сложное понятие, и в
итоге может довести вас до слёз и головной боли, если отнестись к его
рассмотрению небрежно. Поэтому задача этого приложения заключа-
ется в том, чтобы дать только общее представление о концепции це-
лостности сигнала. Если же вы хотите узнать об этом явлении больше,
то очень рекомендую вам книгу, написанную экспертом в этой сфере,
доктором Эриком Богатином (Eric Bogatin), «Signal Integrity —
Simplified», ISBN: 0130669466, и книгу Говарда Джонсона (Howard
Johnson) «High Speed Signal Propagation: Advanced Black Magic» ISBN:
013084408X.
Понятие целостности сигнала включает в себя ряд различных ас-
пектов, в том числе явление изменения «формы» сигнала при его про-
хождении через проводник, а также явление отражения сигнала от
конца несогласованного проводника (подобно тому, как отскакивает
от стены брошенный по коридору мячик). Однако в данном разделе
мы будем рассматривать только те явления интегральной целостности,
которые можно объединить одним общим понятием — перекрёстные
помехи.
Шумы (выбросы) и задержки сигнала, спровоцированные пере-
крёстными помехами, чаще происходят на уровне кремниевого крис-
талла, чем на уровне печатной платы. Поэтому сначала мы рассмотрим
причины возникновения подобных явлений, а затем перейдём к их
анализу на уровне кристалла и на уровне печатной платы.
Ёмкостное и индуктивное взаимодействие
Давайте рассмотрим два сигнальных проводника, мы назовём их
Проводник 1 и Проводник 2, причем каждый из которых одним концом
подключен к выходу запитывающего его отдельного вентиля (источ-
нику сигнала), а другим — к согласованной нагрузке. В идеальных ус-
ловиях (в упрощенном виде) оба проводника будут совершенно пря-
мыми, без изгибов и разрывов (то есть однородными), и каждый из
них может быть представлен с помощью последовательно включенно-
го резистора, последовательно включенной индуктивности, и конден-
сатора (Рис. АЛ).
В этом простом примере конденсаторы CW1 и CW2 мы рассматрива-
ем относительно «земли». В таком случае конденсатор состоит из двух
металлических пластин, разделенных с помощью изоляционного слоя,
который называется диэлектриком. Это значит, что если наши сиг-
нальные проводники находятся в непосредственной близости относи-
тельно друг друга, то их можно будет рассматривать в качестве про-
Ёмкостное и индуктивное взаимодействие 335
Приёмник
Источник сигнала (нагрузка)
Рис. А.1. Два сигнальных проводника (упрощенное представление)
стейшего конденсатора. На принципиальной схеме это явление можно
представить с помощью добавления символа См, который обозначает
взаимную ёмкость (Рис. А.2).
Два проводника связаны взаимной ёмкостью
Рис. А.2. Два проводника, находящиеся в непосредственной близости,
связаны взаимной ёмкостью
Когда сигнал в одном из проводников переходит с одного логичес-
кого уровня на другой, то часть протекающих через него зарядов через
взаимную ёмкость перетекают в другой проводник и провоцируют там
возникновение шумов (выбросов) и задержку сигнала, о которых мы
ещё поговорим немного позже.
Как мы уже заметили, каждый проводник обладает некоторой
собственной индуктивностью. В первом приближении, индуктивность
представляет собой свойство проводников, которое заключается в том,
что при изменении тока, проходящего через первый проводник, созда-
ётся магнитное поле, окружающее оба проводника. Следовательно,
любые изменения магнитного поля вокруг первого проводника вызо-
вут реакцию во втором проводнике.
Свойство проводни-
ка, которое характе-
ризует его способ-
ность хранить элек-
трический заряд,
называют ёмкостью
и обозначают бук-
вой С, единица из-
мерения фарада (Ф).
Единица измерения
«фарада» названа в
честь английского
учёного Майкла Фа-
радея, который в
1821 году сконстру-
ировал первый элек-
трический мотор.
В 1831 году английс-
кий учёный Майкл
Фарадей обнаружил,
что изменения элек-
тромагнитного поля
оказывают воздейс-
твие на ток в сосед-
нем проводнике.
Впоследствии это
явление назвали ин-
дукцией.
Индуктивность
обозначается заглав-
ной буквой L в честь
русского физика
Эмилия Кристиано-
вича Ленца, кото-
рый в 1833 году оп-
ределил отношения
между силой,напря-
жением и током при
электромагнитной
индукции.
336 Приложение А. Целостность сигнала
Индуктивность изме-
ряется в генри (Гн).
Единица измерения
«генри» названа в
честь американско-
го учёного Джозефа
Генри, который от-
крыл явление ин-
дуктивности при-
мерно в то же время,
что и Фарадей.
Это значит, что переход сигнала от одного логического значения к
другому в одном из сигнальных проводников сопровождается изменени-
ем значения протекающего через него тока, который в сочетании с ин-
дуктивностью этого проводника способствует возникновению окружаю-
щего магнитного поля. Поле, по мере своего распространения, начинает
взаимодействовать с индуктивностью других проводников, находящих-
ся в непосредственной близости, что, в свою очередь, может вызывать
помехи и задержки сигнала, которые мы рассмотрим немного позже. На
рисунке взаимоиндукция обозначена с помощью точки, добавленной к
каждому символу, обозначающему индуктивность (Рис. А.З).
До 1925 года в Аме-
рике существовало
два варианта напи-
сания слова алюми-
ний «aluminium» и
«aluminum». Затем
члены Американс-
кого Химического
Общества приняли
официальное реше-
ние об использова-
нии в своих публи-
кациях варианта
«aluminum».
Медь представляет
собой один из самых
древних металлов, ис-
пользуемых челове-
ком (более 10000 лет).
У большинства жи-
вых существ, обита-
ющих на земле,
кровь красного цве-
та, это обусловлено
наличием железосо-
держащего пигмен-
та — гемоглобина.
Но у некоторых
примитивных жи-
вых организмов ос-
новой кровяного
пигмента(купро-
глобина) является
медь, и поэтому
цвет их крови зеле-
ный.
Приёмник
(нагрузка)
Рис. А.З. Два проводника, находящиеся в непосредственной близости,
связаны взаимной индуктивностью
Эффекты на уровне кристалла
Резистивно-ёмкостные эффекты на уровне кристалла
В первых интегральных микросхемах дорожки изготавливались из
алюминия (химическое обозначение А1), который обладает сравни-
тельно высоким сопротивлением.
С появлением каждого нового технологического процесса изготов-
ления микросхем размеры устройств становились всё меньше и мень-
ше, и сопротивление алюминиевых дорожек уже не соответствовало
новым требованиям.
Производители интегральных микросхем давно размышляли над
изготовлением дорожек из меди (химическое обозначение Си), так как
медь является одним из лучших, из известных человечеству, проводни-
ков, особенно на высоких частотах. Однако медь обладает рядом недо-
статков, например, она может легко диффузировать в кремниевый
кристалл, что приводит устройство в негодность. Проблема оставалась
нерешенной до 1990-х, пока компания IBM не разрешила эту задачу с
помощью специальных запирающих слоёв.
Хотя сопротивление меди намного меньше сопротивления алюми-
ния, из-за чрезвычайно малых поперечных размеров сигнальных про-
водников в интегральных микросхемах, их сопротивление всё же оста-
ётся довольно существенным. Поэтому задержки, связанные с распро-
странением сигналов по дорожкам микросхемы, доминируют над
задержками печатной платы из-за свойственных им параметров собс-
твенных сопротивлений и ёмкости (то есть RC-характеристик).
Эффекты на уровне кристалла 337
Здесь мы не учитываем индуктивность в сигнальных проводниках,
и рассматриваться она будет только относительно сети проводников
питания. В этих цепях питания обычно используют более широкие
проводники со сравнительно меньшим сопротивлением, поэтому в та-
ких случаях следует учитывать все упомянутые характеристики — со-
противление, индуктивность и ёмкость.
Увеличение ёмкостной связи боковых стенок
На заре развития технологий производства интегральных микро-
схем соотношение размеров дорожек было таковым, что их ширина
значительно превосходила высоту (Рис. А.4, а). Уменьшение размеров
устройств сказалось на процессах их производства, а это, в свою оче-
редь, привело к изменению соотношений размеров дорожек — теперь
высота стала больше ширины (Рис. А.4, б).
Поперечный разрез
схемы соединений
Боковая ёмкостная
связь (CS1DE)
а) 1 мкм в 1990 году
(малое значение Cside)
б) 0.13 мкм в 2003 году
(большое значение Cside)
Рис. А.4. Увеличение явлений боковой ёмкости с уменьшением размеров
устройства (масштаб не учтён, показано только соотношение размеров)
В результате этих изменений значительно увеличилось значение
ёмкости (Cside) между боковыми стенками соседних дорожек по срав-
нению с ёмкостью между основанием проводника и подложкой крис-
талла CAREA и ёмкостью между боковой стенкой проводника и под-
ложкой CFR|NGE. Более того, высокая степень интеграции современ-
ных устройств, которые могут поддерживать восемь и более слоёв
металлизации, приводит к появлению существенной по величине ём-
костной связи между соседними слоями, которая на Рис. А.5 обозначе-
на как CCROssover-
Рис. А.5. Ёмкостные явления, связанные с внутренними проводниками
338 Приложение А. Целостность сигнала
Совокупность всех этих факторов приводит к повышению уровня
сложности перекрёстных помех и изменению временных параметров,
которые будут рассматриваться ниже.
Выбросы, вызванные перекрестными наводками
Английское слово
«glitch» (выброс),
возможно, произош-
ло от еврейского сло-
ва «glitsh» (ошибка,
упущение).
При изменении логических уровней сигналов, протекающих в рас-
положенных рядом проводниках, ёмкостная связь между дорожками
внутри микросхем приводит к тому, что часть зарядов перетекает из
одного проводника в другой. В зависимости от скорости изменения
уровней сигналов (крутизны фронтов и спадов) и величины паразит-
ной взаимной ёмкости (См), на соседних проводниках могут возни-
кать значительные выбросы, вызванные перекрёстными наводками
(Рис. А.6).
Проводник-«жертва»
Приёмник
(нагрузка)
Изменение уровня сигнала
на проводнике-«агрессоре»
вызывает выброс
на проводнике-«жертве»
Приёмник
(нагрузка)
Потенциальная
логическая
ошибка
Рис, А, 6, Выброс
Из данного примера мы видим, что изменение уровня сигнала в
быстродействующей цепи проводника-«агрессора» провоцирует вы-
брос напряжения на входе приёмника, подключенного к проводнику-
«жертве». Конечно, этот рисунок даёт нам лишь упрощенное пред-
ставление всех протекающих процессов. В действительности каждая
дорожка может состоять из множества сегментов, расположенных на
разных слоях металлизации. Таким образом, сопротивления (RW1 и
RW2) и ёмкости (CW1 и CW2) каждого проводника будут состоять из
множества элементов, связанных с различными сегментами. Паразит-
ная взаимная ёмкость (См) может также состоять из нескольких эле-
ментов.
Пример выброса, показанный на Рис. А.6, представляет собой
только одну из четырёх возможных форм искажений, проявление ко-
торых основанно на том факте, что фронт или спад импульса в провод-
нике-«агрессоре» может происходить при разных логических значени-
ях проводника-«жертвы» (Рис. А.7).
Эффекты на уровне кристалла 339
Логическая 1
Логический О
Логическая 1
Логический О
Рис, А, 7. Виды выбросов
1975 г. Америка.
Разработан микро-
компьютер KIM-1
на базе процессора
6502, изготовлен-
ного с помощью
МОП-технологии.
Если возникающие в проводнике-«жертве» выбросы или провалы
пересекают входной порог срабатывания приёмного устройства, то
это может привести к функциональной ошибке. В некоторых случаях
эта ошибка проявляется в виде неправильных значений, которые
впоследствии загружаются в регистр или защёлку. Иногда ошибка за-
ставляет защёлку выполнить непредусмотренную загрузку, установку
или сброс. Высокоуровневые выбросы и низкоуровневые провалы на
проводнике-«жертве» также могут вызывать нежелательный перенос
носителей заряда в транзисторах, формирующих логические элемен-
ты, вследствие чего работоспособность схемы может быть нарушена.
Хотя эти явления (их ещё называют эффектами горячих электронов)
не являются главной угрозой в контексте рассматриваемой нами тех-
нологии реализации цифровых микросхем с увеличением размеров
устройств, реализованных с помощью глубокого и сверхглубокого суб-
микрона, проблемы, связанные с данными явлениями выйдут на пер-
вое место.
Задержки распространения сигнала
Ситуация становится ещё более сложной, когда одновременно на
двух проводниках — на «агрессоре» и на «жертве» — происходит пере-
ключение сигнала. Например, при противоположных переключениях
сигнал на проводнике-«жертве» может быть задержан во времени
(Рис. А.8).
Если бы сигнал на проводнике-«жертве» распространялся изоли-
рованно (без учёта действия других проводников), то для преодоления
порога срабатывания приёмника понадобилось бы некоторое время
(примерно 50 процентов от общего времени переключения из 1 в 0).
Однако выброс, спровоцированный выполняющимся в это же время
переключением сигнала из 0 в 1 на проводнике-«агрессоре», задержи-
вает сигнал на проводнике-«жертве» выше порога срабатывания в те-
чение ещё некоторого времени. Это явление может привести к нару-
шению установки данных в системе.
Обратная ситуация может произойти, когда сигналы на обоих про-
водниках одновременно переключаются в одном и том же направле-
нии, в этом случае скорость изменения уровня сигнала на проводни-
ке-«жертве» может увеличиться (Рис. А.9).
Технологический
процесс менее
0.5 мкм называется
глубоким субмикро-
ном.
С некоторого мо-
мента, значение ко-
торого точно не оп-
ределено (или зави-
сит от того, кто об
этом говорит), мы
погружаемся в об-
ласть сверхглубокого
субмикрона.
340 Приложение А. Целостность сигнала
Уровень сигнала
на проводнике-«жертве» переходит с 1 в 0
(без учёта действия проводника-«агрессора»)
В это же время уровень сигнала
в проводнике-«агрессоре» переходит с 0 в 1
Время, через которое уровень сигнала
на проводнике достигнет порога
срабатывания, увеличивается на величину
задержки, из-за выброса,
вызванного перекрёстной наводкой
Рис, Л.8. Увеличение задержки сигнала, вызванное перекрестной наводкой
Порог
срабатывания
Порог
срабатывания
Уровень сигнала на проводнике-«жертве»
переходит с 0 в 1 (без учёта действия
проводника-«агрессора»)
В это же время уровнь сигнала
в проводнике-«агрессоре» тоже меняется с 0 на 1
Время, в течение которого уровень сигнала
на проводнике-«жертве» достинает порога
срабатывания, уменьшается из-за выброса,
вызванного перекрёстной наводкой
Рис, А,9, Уменьшение задержки сигнала, вызванное перекрёстной наводкой
В этом случае выброс, вызванный одновременным переключением
сигналов на обоих проводниках в одинаковом направлении, приводит
к тому, что уровень сигнала в проводнике-«жертве» достигает порога
срабатывания приёмника раньше, чем ожидалось. Это явление может
привести к потере данных системы.
Воздействие нескольких проводников-«агрессоров»
Следует заметить, что практически все рассмотренные выше при-
меры сильно упрощены. В реальных схемах каждый проводник-«жерт-
ва» подвержен влиянию множества проводников-«агрессоров»
(Рис. АЛО).
Точный анализ современных схем требует, чтобы влияния каждо-
го проводника-агрессора было проанализировано и учтено индивиду-
ально.
Эффекты на уровне кристалла 341
Рис. А. 10. Воздействие нескольких проводников-«агрессоров»
1975 г. Америка.
Компания Sphere
Corporation пред-
ставила микроком-
пьютер Sphere 1 на
базе процессора
6800.
И не надо забывать про эффект Миллера
Эффект Миллера, который приобретает особое значение на уровне
кристалла, заключается в том, что одновременное изменение сигнала
на обеих обкладках конденсатора приводит к изменению его эффек-
тивной ёмкости.
На практике такие условия можно встретить, например, если мы
рассмотрим сигнал, который распространяется по проводнику находя-
щемуся в середине шины0. Если на одном или нескольких ближайших
проводниках в шине одновременно произойдет переключение сигнала
в том же направлении, что и на рассматриваемом проводнике, то свя-
занная с этими проводниками взаимная ёмкость будет уменьшаться,
что приведёт к уменьшению задержки переключения сигнала (в допол-
нение к эффекту уменьшения задержки вызванному выбросом, возни-
кающему из-за перекрёстных наводок, как рассматривалось выше).
И наоборот, если на одном или нескольких ближайших проводни-
ках в шине одновременно произойдет переключение сигнала в проти-
воположных относительно рассматриваемого проводника направле-
ниях, то это приведёт к увеличению взаимной ёмкости и увеличению
задержки переключения сигнала.
Причина, по которой мы начали рассматривать явления искаже-
ний на уровне кристалла, заключается в том, что эти эффекты более
близки и понятны разработчикам цифровых микросхем. Однако на
практике явления нарушающие целостность сигнала (за исключением
явлений, связанных с корпусом микросхемы) не представляют какого-
либо интереса для инженеров, использующих ПЛИС, так как эти про-
блемы решаются изготовителями микросхем, чего нельзя сказать про
искажения сигнала на уровне печатной платы, которые проявляются
при установке на неё различных ПЛИС.
° При рассмотрении электронных систем термином «шина» обозначают сово-
купность сигналов, выполняющих одинаковые функции и передающие данные
одного типа.
342 Приложение А. Целостность сигнала
1975 г. Америка.
Билл Гейтс (Bill
Gates) и Пол Аллен
(Paul Allen) основа-
ли компанию
Microsoft.
В большинстве слу-
чаев для изготовле-
ния печатных плат
используется мате-
риал FR4 (аббревиа-
тура образована от
слов «flame retardant»
— огнезащитный со-
став). (У нас этот
материал называют
текстолит или стек-
лотекстолит. —
Прим, ред.)
Эффекты на уровне печатной платы
Эффекты индуктивно-ёмкостного характера на уровне
печатной платы
При рассмотрении явлений, происходящих на печатной плате,
следует заметить, что влияние сопротивления медных дорожек на ис-
кажения сигналов весьма незначительно в сравнении с действием дру-
гих эффектов. Обусловлено это тем, что дорожки на плате имеют ши-
рину примерно 125 микрон и толщину 18 микрон, вследствие чего их
поперечное сечение намного больше, чем у проводников на кристалле
(чем больше поперечное сечение проводника, тем меньше его сопро-
тивление). Но, с другой стороны, в этом случае наиболее сильно про-
являют себя эффекты взаимной ёмкости и индуктивности. Поэтому
при анализе сигналов на печатной плате рассматриваются их индук-
тивно-ёмкостные связи (LC-связи).
Разные способы представления проблемы
В современных быстродействующих высокотехнологичных печат-
ных платах, почти все без исключения проводники работают подобно
линиям передачи сигналов. Это значит, что мы можем изобразить
фронт (или спад) сигнала в виде волны, распространяющейся через
проводник с течением времени (Рис. А. 11).
Время Время Т2 Время Т3 Время Т4
Рис. А. 11. Фронт сигнала, распространяющийся по проводнику
с течением времени
Приёмник (нагрузка)
Что касается линий передачи, в которых задержка распростране-
ния сигнала больше длительности его распространения, то все возни-
кающие при этом значения взаимных ёмкостей и индуктивностей за-
висят от текущего положения движущегося фронта. Это значит, что
мы должны рассматривать проводник в виде последовательности не-
больших RLC-сегментов, которые на рисунке с целью его упрощения
не показаны.
Эффекты взаимной ёмкости и индуктивности
Самое интересное в анализе искажений сигналов начинается тог-
да, когда мы рассматриваем две дорожки печатной платы, находящих-
ся в непосредственной близости друг к другу. Допустим, что по одному
из таких проводников, который мы назовём «агрессором», движется
фронт импульса. Этот проводник в свою очередь связан индуктивной
и ёмкостной связью с соседним проводником-«жертвой» (Рис. А. 12).
Наличие ёмкостной связи приведёт к тому, что движущийся по
проводнику-«агрессору» фронт импульса вне зависимости от направ-
ления своего движения вызовет положительный импульс тока в про-
воднике-«жертве». В отличие от него, индуктивная связь вызовет в
проводнике-«жертве» отрицательный импульс тока при движении
Эффекты на уровне печатной платы 343
Рис. А.12. Эффекты взаимной индуктивности и ёмкости
фронта по «агрессору» в прямом направлении, и положительный им-
пульс — при движении в обратном направлении.
Это значит, что взаимные ёмкостные и индуктивные связи могут
усиливать друг друга при распространении сигнала в начале проводни-
ка (в области подключения проводника к источнику сигнала). И наобо-
рот, они могут компенсировать друг друга при прохождении сигнала в
конце проводника (в месте подключения приёмника сигнала). Други-
ми словами, можно надеяться, что в лучшем случае одинаковые по ам-
плитуде перекрёстные импульсы сложатся в противофазе и устранят
друг друга. К сожалению, такое явление может произойти только слу-
чайно, если диэлектрический (изолирующий) слой вокруг проводни-
ков будет однородным. В реальном мире диэлектрик под дорожками в
силу различных факторов будет неоднороден. Поэтому величина вза-
имной индукции остаётся неизменной, а значение взаимной ёмкости
будет уменьшаться. Вследствие этого произойдёт увеличение влияния
индуктивной составляющей, что вызовёт повышение уровня шумов на
входе приёмника. В реальных печатных платах индуктивные шумы мо-
гут от двух до четырёх раз превышать уровень ёмкостных шумов.
Если по каким-либо причинам характеристики обратной цепи
ухудшится, то индуктивная составляющая может в 10...30 раз превы-
сить уровень ёмкостной помехи. В таком режиме, когда перекрёстные
помехи в основном определяются индуктивными составляющими,
возникающие при этом выбросы мы называем коммутационными шу-
мами. В случаях, когда несколько сигналов используют одну и ту же
обратную цепь (общий, «земляной» провод), коммутационные шумы
проходят через общий провод и называются шумами общего провода.
Эффект Миллера наоборот
При анализе искажений сигнала на уровне кристалла мы рассмот-
рели так называемый эффект Миллера, суть которого заключается в
том, что если один или несколько сигналов переключается с одинако-
вой полярностью (переходят с одного уровня на другой в одном на-
правлении) вместе с рассматриваемым сигналом, то значение их вза-
имной ёмкости будет уменьшаться, что приведёт и к уменьшению за-
держки распространения.
Однако, как упоминалось ранее, задержка распространения сигна-
лов на уровне кристалла в основном носит резистивно-ёмкостной ха-
рактер, а на печатной плате — определяется значением индуктивно-
ёмкостных параметров. Это значит, что если один или несколько сиг-
344 Приложение А. Целостность сигнала
1975 г. Америка.
Эд Робертс (Ed
Roberts) вместе с
сотрудниками
Массачусетского
технологического
института разра-
ботали микроком-
пьютер Altair 8800
на базе одноимён-
ного процессора
(8800).
1975 г. Англия.
Впервые в цифро-
вых часах и кальку-
ляторах стали
применяться жид-
кокристалличес-
кие индикаторы
(ЖКИ).
налов на печатной плате переключаются в одном и том же направле-
нии с находящимся в непосредственной близости рассматриваемым
проводником, то значение взаимной индукции между этими провод-
никами увеличится. В неоднородном диэлектрике доля индуктивных
искажений больше, чем ёмкостных, поэтому увеличение индуктив-
ности сигнальных проводников приведёт к увеличению задержки рас-
пространения.
И наоборот, если один или несколько сигналов переключаются в
противоположном с рассматриваемым проводником направлении, то
это приведёт к уменьшению задержки распространения.
Эффекты линии передачи
В дополнение к рассмотренным выше процессам, конечно же, не-
маловажную роль играют и классические эффекты линии передачи,
связанные с согласованием. В частности это относится к использова-
нию последовательно включенных согласующих резисторов на выходе
и параллельных резисторов на входе линии, но эти явления хорошо
описаны во многих книгах, и нами рассматриваться не будут.
Как можно облегчить себе жизнь
К сожалению, на 70...80% проблема обеспечения целостности сиг-
налов на печатной плате связана не с самой платой, а с корпусом мик-
росхемы (ПЛИС).
В идеале микросхема должна иметь большое количество пар выво-
дов вида питание-общий провод, и эти пары должны быть равномерно
распределены по всей поверхности её корпуса с тем, чтобы обеспечить
все сигнальные выводы индивидуальными, находящейся по соседству,
цепями обратной передачи. На практике же выводы питания и общего
провода в микросхемах обычно располагаются группами отдельно от
сигнальных выводов (контактов ввода/вывода).
Вы можете сильно упростить себе жизнь, если будете использовать
на практике несложные правила, а именно для элементов ввода/выво-
да, особенно для шин и высокоскоростных соединений, лучше ис-
пользовать дифференциальные пары, чем отдельные проводники. Ко-
нечно, это сразу же увеличит в 2 раза количество требуемых контактов
на корпусе микросхемы, необходимых для организации процесса вво-
да/вывода, но всё-таки стоит потратить на это время, если, конечно,
вы можете себе позволить дополнительные расходы на реализацию до-
полнительных контактов.
Другая рекомендация относится к внутренним программируемым
согласующим резисторам, которыми комплектуются устройства неко-
торых поставщиков. Их использование необязательно, и вместо них
можно применить внешние дискретные компоненты. Внутренние со-
гласующие резисторы изначально предназначались для уменьшения
количества внешних элементов на печатной плате, тем самым, позво-
ляя её разгрузить, но они также могут применяться для решения про-
блем целостности сигналов. Для этого существует эмпирическое пра-
вило, которое гласит, что для любых сигналов со временем фронта или
спада 500 пикосекунд или менее, применение внешних согласующих
элементов может разрушить сигнал, и в этом случае необходимо ис-
пользовать внутрикристальные элементы.
Приложение Б.
ЭФФЕКТЫ ЗАДЕРЖКИ В ТЕХНОЛОГИИ
ГЛУБОКОГО СУБМИКРОНА
Введение
При проектировании систем, основанных на использовании заказ-
ных микросхем (ASIC) или специализированных стандартных блоков
(ASSP), расчет необходимых временных параметров и эффектов пред-
ставляет собой довольно сложную задачу. С появлением каждого нового
уровня технологического процесса анализ временных эффектов стано-
вится всё более устрашающим. С некоторого момента, значение которо-
го точно не определено (или разными людьми определяется по-разно-
му), но находится на уровне примерно 0.5-микронного (500 наномет-
ров) технологического процесса, мы погружаемся в область, которой
свойственны так называемые эффекты задержки глубокого субмикрона.
Конечно же, что касается ПЛИС, то их разработчики решают мно-
жество проблем, связанных с проявлением этих задержек, тем самым,
скрывая их от конечного пользователя (то есть от проектировщика ус-
тройств на основе ПЛИС). Основываясь на этом, можно сказать, что у
нас нет необходимости обсуждать эти явления в контексте ПЛИС. С
другой стороны, разговоры об этих задержках ведутся постоянно, но я
ни разу не встречал их полного и понятного любому человеку описа-
ния. Именно поэтому нижеследующее описание представлено здесь
для вашего удовольствия и наслаждения.
Содержимое этого
приложения взято
из моей книги
«Designus Maximus
Unleashed»
(ISBN 0-7506-9089-5)
с любезного разре-
шения издателя.
Развитие спецификаций задержки
Давным-давно, в былые времена, где-то после Юрского периода,
когда Землю населяли динозавры — скажем, в конце 1970-х или начале
1980-х годов — жизнь инженеров, разрабатывающих системы на осно-
ве заказных специализировнных микросхем, была куда проще, чем у
наших современников. Спецификация задержек для ранних (мульти-
микронных) технологий была элементарной во всех отношениях. Да-
вайте рассмотрим простой 2-входовый вентиль И, для которого за-
держка прохождения данных от входа до выхода изначально была оди-
наковой для фронтов и спадов поступающих на вход импульсов
(Рис. Б.1, а).
а)
б)
а
b
г)
а,Ь -> у (LH, HL) » ?нс + ?нс/пф | I Конец 1970-х
I
а,Ь -> у (LH) - ?нс + ?нс/пФ а,Ь -> у (HL) = ?нс + ?нс/пФ + Увеличение сложности
а -> у (LH) - ?нс + ?нс/пФ i а -> у (HL) = ?нс ♦ ?нс/пф b -> у (LH) ® ?нс + ?нс/пФ b -> у (HL) - ?нс + ?нс/пФ спецификаций задержки 1
I Начало 2000-х
Рис. Б.1. Увеличение сложности спецификации задержек с течением времени
346 Приложение Б. Эффекты задержки в технологии глубокого субмикрона
1975 г. Разработан
микропроцессор
6502 с использова-
нием МОП-техно -
логии.
Однако уменьшение геометрических размеров устройств сопро-
вождалось увеличением сложности спецификаций задержек. На сле-
дующем этапе задержки стали различаться для фронтов (возрастание
сигнала) и спадов (спад сигнала) поступающих импульсов
(Рис. БЛ, б), а затем появилось отличие в задержках для разных входов
элементов (Рис. БЛ, в).
В прежние времена задержки обычно описывались в виде записи
?нс + ?нс/пФ. В этом представлении первая часть (?нс) отображает
фиксированную задержку в наносекундах0 для всего логического эле-
мента. К ней добавляется некоторая дополнительная задержка, изме-
ряемая в наносекундах на пикофарад ёмкости нагрузки* 2) (?нс/пФ). Ра-
зумеется, эта форма записи просто не может описывать явления за-
держки в субмикронных технологиях, хотя бы вследствие того, что в
этой области, как будет показано ниже, задержка определяется RLC-
параметрами.
Набор определений
Перед тем, как с головой погрузиться в пучину субмикронных за-
держек, сначала необходимо рассмотреть ряд определений, которые
представлены ниже.
Крутизна импульса
Крутизна (или наклон) импульса представляет собой скорость из-
менения сигнала при его переходе с уровня логического 0 на уровень
логической 1 и наоборот. При мгновенном переходе, который не мо-
жет быть достигнут в реальном мире, обеспечивается максимально
возможное значение крутизны (Рис. Б.2).
Рис, Б.2. Крутизна сигнала характеризует время, необходимое для перехода
сигнала с уровня на уровень
Крутизна импульса представляет собой одну из выходных харак-
теристик источника сигнала совместно с параметрами внутренних
соединений (проводников) и входных характеристик нагрузки (вен-
тилей).
° Современные устройства работают намного быстрее, их задержка может из-
меряться в пикосекундах.
2) Основной единицей измерения ёмкости служит Фарада в честь британского
учёного Майкла Фарадея (Michael Faraday), который в 1821 году сконструировал
первый электромотор.
Набор определений 347
Входной порог срабатывания
Порог срабатывания представляет собой точку на входной характе-
ристике нагрузки (то есть логического элемента — вентиля), и харак-
теризует собой уровень напряжения, пересечение которого входным
сигналом будет означать, что на входе элемента логическое состояние
сменилось на противоположное. Входной порог срабатывания обычно
описывается в процентах от величины разности напряжений между
уровнями логического 0 и логической 1, и каждый вход может иметь
различные пороги срабатывания для фронтов и спадов (Рис. Б.З).
1975 г. Америка.
Компания Microsoft
разработала язык
Basic 2.0 для мик-
рокомпьютера
Altair 8800.
Рис. Б.З. Входной порог срабатывания может иметь различные значения
для фронтов и спадов
Внутренние и внешние задержки
Внутренними называют задержки, которые свойственны внутрен-
ней архитектуре логических функций, соответственно внешние за-
держки относятся к внутренним (межблочным) соединениям
(Рис. Б.4).
Во времена ранних мультимикронных технологий внутренние за-
держки преобладали над внешними. Например, в 2-микронной техно-
логии внутренние задержки составляли величину порядка двух третей
от общей задержки (Рис. Б.4, а). Но с уменьшением геометрических
размеров элементов микросхем внешняя задержка стала расти. Так в 1-
микронной технологии соотношение внутренних и внешних задержек
изменилось с точностью до наоборот (Рис. Б.4, б).
348 Приложение Б. Эффекты задержки в технологии глубокого субмикрона
1976 г. Америка.
Компания Zilog
разработала мик-
ропроцессор Z80.
1976 г. Стив Воз-
няк (Steve Wozniak)
и Стив Джобс
(Steve Jobs) разра-
ботали микроком-
пьютер Apple 1 на
базе процессора
6502.
Со временем тенденция роста доли внешних задержек сохраняет-
ся, так как размеры внутренних соединений уменьшаются медленнее,
чем размеры вентилей и транзисторов. В современных глубоко-суб-
микронных технологиях доля внешних задержек может составлять 80
процентов и более от величины общей задержки.
Задержки вывод-вывод и точка-точка
По большому счёту задержки типа вывод-вывод (Рп-Рп — pin-to-pin)
и точка-точка (Pt-Pt — point-to-point) являются современными назва-
ниями внутренних и внешних задержек соответственно. Задержка вы-
вод-вывод характеризует собой время от прихода воздействия на вход
вентиля до появления соответствующей реакции на его выходе, а точ-
ка-точка описывает время распространения сигнала между выходом
источника сигнала и входом нагрузки1) (Рис. Б.5).
Вывод-вывод Точка-Точка
Вывод-вывод Точка-Точка
gi-a СП-У * ► 1 ►
Г
J
д2.а
Рис, Б.5, Задержки вывод-вывод и точка-точка
Если быть более точным, то задержка вывод-вывод равна времени
от момента достижения входным сигналом порога срабатывания до
начала соответствующей реакции на выходе вентиля, а задержка точ-
ка-точка. определяется от начала соответствующей посылки источни-
ка сигнала до достижения ею порога срабатывания нагрузки.
Существует ряд причин, почему мы придаём особое значение тому
факту, что в качестве завершающего отсчета для задержки вывод-вы-
вод мы берём начало отклика, так же как задержку точка-точка отсчи-
тываем от начала посылки источника сигнала. В прошлом эти задерж-
ки отсчитывались от времени, когда сигнал достигал уровня 50% от
разницы между 0 и 1. Такой подход был допустим, так как считалось,
что порог срабатывания у вентилей также составляет 50%. Но в связи
со значительным увеличением крутизны импульсов предположим, что
входной порог срабатывания снизился до 30%. Если в этом случае мы
будем полагать, что задержка измеряется от уровня 50 процентов, то
вполне вероятно, что вентиль нагрузки увидит фронт (или спад) им-
пульса до того, как мы будем ожидать его появления. Также при моде-
лировании смешанных (аналоговых и цифровых) сигналов достовер-
ное время прохождения фронта (или спада) импульса от выхода венти-
ля в цифровой части к аналоговым компонентам определяется по
точке, в которой и начинается формироваться фронт импульса на вы-
ходе вентиля.
’) Следует заметить, что разработчики печатных плат обычно не анализируют
внутреннюю структуру электронных компонентов, и обычно рассматривают их
как «чёрные ящики». А упомянули мы об этом потому, что под термином «точка-
точка» эти разработчики могут подразумевать время распространения сигнала
между двумя точками на плате.
Альтернативные модели внутренних соединений 349
Зависимость от состояния и зависимость от крутизны
Все параметры, связанные с входом вентиля (включая задержку
вывод-вывод), которые зависят от логических значений на других вхо-
дах этого элемента, называются зависимыми от состояния. Аналогич-
но, все параметры, связанные с входом вентиля (включая задержку
вывод-вывод), которые зависят от крутизны поступающих на их входы
импульсов, называются зависимыми от крутизны. Эти определения
пока не оказывают существенного влияния на работу устройств, хотя в
недалёком будущем они могут проявить себя по-другому.
Альтернативные модели внутренних соединений
С уменьшением размеров структур на кремниевом кристалле и
увеличением количества вентилей в устройстве, задержки на внутрен-
них соединениях стали более существенными, чем на вентилях, что
привело к увеличению сложности алгоритмов, необходимых для их
точного описания. Кратко эти алгоритмы рассмотрены ниже.
1977 г. Америка.
Компания Apple раз-
работала микро-
компьютер Apple II.
Модель с сосредоточенной нагрузкой
Как отмечалось выше, задержка на вентилях вида вывод-вывод в
первых мультимикронных технологиях доминировали над задержками
вида точка-точка. К тому же, длительность фронтов и спадов сигнала
обычно была больше, чем время, необходимое для их прохождения че-
рез внутренние соединения. В этом случае для описания внутренних
соединений обычно было достаточно так называемой модели внутрен-
них соединений с сосредоточенной нагрузкой (Рис. Б.6).
Рис. Б.6. Модель внутренних соединений с сосредоточенной нагрузкой
Идея этой модели состоит в том, что все ёмкости, связанные с про-
водниками и входами вентиля, объединяют вместе и образуют один
эквивалентный конденсатор. Ёмкость этого конденсатора затем умно-
жалась на параметр вентиля (источника сигнала), который обычно вы-
ражался в нс/пФ для получения значения задержки точка-точка. Мо-
дель с сосредоточенной нагрузкой отличается тем, что все узлы на про-
воднике начинают передачу в одно и тоже время и с одинаковой
крутизной импульса. Эта модель также может называться чистой RC-
моделъю.
350 и Приложение Б. Эффекты задержки в технологии глубокого субмикрона
1977 г. Америка.
Компания
Commodore Business
Machines разрабо-
тала микроком-
пьютер Commodore
РЕТ на базе микро-
процессора 6502.
Распределённая ЯС-модель
Уменьшение размеров электронных устройств в середине 1980-х
годов вызвало потребность в более точном описании внутренних со-
единений, чем это позволяла сделать модель с сосредоточенной на-
грузкой. Вследствие этого появилась распределённая RC-модель
(Рис. Б.7).
Рис. Б. 7. Распределённая RC-модель внутренних соединений
В распределённой RC-модели каждый сегмент проводника рас-
сматривается в виде RC-цепочки. Эта модель характеризуется тем, что
все узлы проводника начинают передачу одновременно, но с разной
крутизной импульсов. Если быть более точным, то крутизна импульса
уменьшается по мере его прохождения через проводник.
Чистая LC-модель
Высокоскоростные внутренние соединения на уровне печатной
платы по своим параметрам приближаются к линиям передачи. В этом
случае чистая LC-модель (где буквы L и С представляют соответствен-
но индуктивность и ёмкость) может быть представлена в виде прямо-
угольного (почти мгновенного) перехода с уровня на уровень, распро-
страняющегося через проводник (Рис. Б.8).
Рис. Б.8. Чистая LC-модель внутренних соединений
Эффекты задержки глубокого субмикрона 351
Эффекты, свойственные линии передачи, не проявляют себя на
уровне кремниевого кристалла, но в больших субмикронных устройс-
твах, как будет показано ниже, задержки этого типа уже начинают иг-
рать значимую роль.
RLC-модель
В больших устройствах, изготовленных по технологии глубокого
субмикрона, скорость передачи сигналов и относительно длинные до-
рожки приводят к возникновению некоторых эффектов, характерных
для линий передач. Однако резистивная природа внутрикристальных
соединений не подвержена чистым LC-эффектам. Поэтому внутрен-
ние проводники таких микросхем могут быть описаны с помощью
RLC-модели (Рис. Б.9).
1977 г. Америка.
Компания
Tendy/Radio Shack
разработала мик-
рокомпьютер TRS-
80 на базе процес-
сора Z80.
Рис, Б.9, RLC-модель внутренних соединений
RLC-модель характеризуется комбинацией сдвига фронта импуль-
са при его распространении через проводник, вызванного LC-компо-
нентами линии передачи, а также значительным уменьшением крутиз-
ны фронта передаваемого импульса из-за RC-составляющей внутрен-
них соединений.
Эффекты задержки глубокого субмикрона
Зависимость задержки вывод-вывод от пути прохождения
сигнала
В современных цифровых микросхемах каждый путь прохождения
сигнала от входа до выхода характеризуется своим значением задержки
вывод-вывод. Например, в 2-входовом логическом вентиле ИЛИ из-
менение сигнала на входе а вызовет изменение сигнала на выходе у
(Рис. Б. 10, а), причем значение задержки в этом случае может отли-
чаться от того, которое будет при изменении сигнала на входе b
(Рис. Б.10, б).
352 Приложение Б. Эффекты задержки в технологии глубокого субмикрона
1977 г. Одна из те-
лефонных компа-
ний впервые приме-
нила в своей рабо-
те оптический вол-
новод.
1978 г. Компания
Apple впервые при-
менила жесткие
диски в персональ-
ных компьютерах.
111111111Н||||||||||||||НН111111111Н11ПНН1
а) Изменение на входе а
и реакция на выходе у
11.....'Illllllllllllllllllllll.....
б) Изменение на входе b
и реакция на выходе у
Рис. Б. 10. Зависимость задержки вывод-вывод от пути прохождения сигнала
Величина задержки вывод-вывод также будет зависеть от вида пос-
тупившего на логический элемент сигнала. Например, в нашем логи-
ческом элементе ИЛИ поступающий на вход а фронт (нарастающий
фронт) импульса будет вызывать на выходе у задержку отличную от
той, которая возникает при поступлении на этот же вход спада (ниспа-
дающий фронт) импульса.
Заметим, что в этом простом примере порог срабатывания на входе
равен 50 процентам, и, как уже говорилось выше, время задержки из-
меряется от момента, когда входное воздействие пересекает порог сра-
батывания, и до того, как сигнал на выходе начнёт изменять своё зна-
чение.
Следует заметить, что технология глубокого субмикрона не огра-
ничивается только зависимостью задержки вывод-вывод от пути про-
хождения сигнала и типа входного воздействия (фронта или спада им-
пульса), и представлены они здесь для того, чтобы подготовить вас к
предстоящим ужасам.
Зависимость задержки вывод-вывод от порога
срабатывания
В цифровых устройствах задержка вывод-вывод зависит от величи-
ны порога срабатывания каждого входа. Объяснить эту зависимость
можно хотя бы тем, что значение задержки начинает отсчитываться
только после того, как входной сигнал достигнет уровня порога сраба-
тывания. Например, если входной порог срабатывания входа а для
фронта импульса установлен на уровне 30% от разницы между логи-
ческим 0 и логической 1 (Рис. Б. 11, а), то реакция на выходе этого ло-
гического элемента появится раньше, чем при пороге на уровне 70%
(Рис. Б.11,б).
Кроме того, крутизна поступающих на вход импульсов также влия-
ет на время, за которое сигнал достигает уровня порога срабатывания.
Чтобы понять этот процесс, давайте представим себе, что у входа а по-
рог срабатывания установлен на уровне 50 процентов. В этом случае
сигнал с высокой крутизной импульсов, поступающих на этот вход
(Рис. Б. 12, а), спровоцирует реакцию на выходе логического элемента
раньше, чем сигнал с более пологим фронтом (Рис. Б.12, б).
Хотя эта зависимость определяет время начала отсчёта задерж-
ки вывод-вывод, это всё же НЕ зависимость задержки вывод-вывод
от крутизны фронта сигнала, рассматриваемой в следующем под-
разделе.
Эффекты задержки глубокого субмикрона 353
а) Порог срабатывания 30% б) Порог срабатывания 70%
на входе а
на входе а
Рис. Б. 11. Зависимость задержки вывод-вывод от порога срабатывания
а) Быстро меняющийся сигнал б) Медленно меняющийся
(крутой фронт) на входе а сигнал (пологий фронт)
на входе а
Рис. Б. 12. Крутизна фронта входного сигнала влияет на время реакции
логического элемента
Зависимость задержки вывод-вывод от крутизны фронта
входного сигнала
Рассмотренный выше пример был отчасти упрощенным, так как
длительность двух рассмотренных задержек вывод-вывод была одина-
ковой и не изменялась при разной крутизне поступающих сигналов.
Некоторые производители САПР всё же называют такой случай «зави-
симостью от крутизны», однако это определение не совсем корректно.
На самом деле, в технологиях глубокого субмикрона величина задерж-
ки может быть действительно зависимой от крутизны, то есть её дли-
тельность может напрямую меняться с изменением крутизны входного
сигнала.
Давайте посмотрим, что произойдёт с сигналом при его прохожде-
нии через входной порог срабатывания вентиля. Значение задержки
вывод-вывод, отсчитываемое от этого порога может быть функцией от
скорости изменения входного сигнала. Например, быстро меняющий-
ся входной сигнал может привести к меньшей задержке вывод-вывод
(Рис. Б. 13, а), чем сигнал с низким значением крутизны (Рис. Б. 13, б).
В действительности зависимость, показанная на Рис. Б. 13, при ко-
торой уменьшение крутизны фронта сигнала приводит к увеличению
задержки, на самом деле является только одним из всех возможных
сценариев. Данный конкретный случай применим к вентилям, реали-
354 Приложение Б. Эффекты задержки в технологии глубокого субмикрона
1979 г. Разработан
язык программиро-
вания Ада, назван-
ный по имени Ады
Августы Лавлейс
(Lady Ada Augusta
Lovelace). Леди Ада
считается первым
программистом.
(Леди Ада Лавлейс
— дочь известного
поэта Байрона, ра-
ботала ассистент-
кой математика
Чарльза Байбиджа
(Charles Babbage). —
Прим, пер.)
»»ННН»11111|||||||||||||||||||||1Н»П111111
а) Сигнал с высокой крутизной б) Сигнал с низкой крутизной
фронта на входе а фронта на входе а
Рис. Б. 13. Зависимость величины задержки вывод-вывод
от крутизны фронта входного сигнала
зованным таким образом, что, скорость переключения транзисторов,
формирующих вентили, напрямую зависит от скорости изменения за-
ряда, приложенного к их входам. При использовании других техноло-
гических решений при реализации вентилей уменьшение крутизны
сигнала на входах приведёт к сокращению задержки вывод-вывод
(длительность которой измеряется от достижения порога срабатыва-
ния до начала изменения сигнала на выходе). Последнее объяснить
можно тем, что медленно меняющийся сигнал на входе позволяет
внутренним транзисторам предварительно накапливать заряды до до-
стижения сигналом порога срабатывания. Когда входной сигнал пере-
сечёт этот порог, вентиль будет уже предварительно подготовлен к на-
чалу работы и произведёт переключение своего выходного сигнала че-
рез меньшее время, чем при изменении сигнала с большей крутизной.
Исключительно для поднятия вашего настроения и ради вашего
удовольствия хочу добавить, что оба рассмотренных эффекта могут
протекать одновременно. В этом случае импульсу с чрезвычайно высо-
кой крутизной фронта (или спада) на входе может соответствовать не-
которое значение задержки вывод-вывод. С уменьшением крутизны
входных импульсов эта задержка будет постепенно увеличиваться, и с
какого то определённого значения крутизны снова начнёт уменьшать-
ся, возможно, даже до меньшего значения, которое соответствовало
импульсу с максимально возможно высокой крутизной!
Зависимость задержки вывод-вывод от состояния вентиля
Кроме крутизны входного сигнала, величина задержки вывод-вы-
вод часто зависит от состояния логического элемента, то есть от логи-
ческих значений, находящихся на других входах рассматриваемого
элемента (Рис. Б.14).
В этом примере показаны два случая, когда сигналу на входе а со-
ответствует один и тот же отклик (в логическом представлении) на вы-
ходе со. Однако если допустить, что входные сигналы имеют одинако-
вое значение крутизны, а входы — одинаковый порог срабатывания,
значение задержек вывод-вывод в этих случаях может отличаться из-за
разных логических значений, представленных на входах b и ci.
А кое-кто говорит, что электроника — скучное и неинтересное занятие!
Эффекты задержки глубокого субмикрона 355
Полный сумматор
iiiiihiihIIIIIIIIHiiiiiiiiiiiiiiiiiiiiiiiiiiii
a) b = 1, ci = О
1979 г. Америка.
Появилась первая
коммерческая про-
грамма Visicalc
spreadsheet (элект-
ронные таблицы),
написанная для
микрокомпьюте-
ров Apple II.
1980 г. Начало раз-
вития беспровод-
ной и сотовой те-
лефонии.
Рис. Б. 14. Зависимость величины задержки вывод-вывод от состояния вентиля
Зависимость выходной характеристики от пути прохождения
сигнала
Могу вас заверить, что с этого места ваша жизнь станет намного
интересней (поверьте мне, разве я вас когда-нибудь обманывал?)До
этого времени мы с вами рассматривали эффекты, которые влияют на
величину задержки распространения сигнала через вентиль, (задержки
вывод-вывод), но многие из этих эффектов также воздействуют на вы-
ходные характеристики сигнала, которые вентиль выдает на свой вы-
ход (или выходы). Например, выходная характеристика вентиля может
зависеть от пути прохождения сигнала от входа до выхода (Рис. Б.15).
а) Входа вызывает быстрое
переключение сигнала на выходе у
б) Вход b вызывает
медленное переключение
сигнала на выходе у
Рис. Б.15. Зависимость выходной характеристики вентиля
от пути прохождения сигнала
В рассмотренном примере в дополнение к тому, что сигналам на
входах а и b соответствуют разные значения задержек вывод-вывод,
выходная характеристика вентиля (и, следовательно, крутизна выход-
ного сигнала) также зависит от того, какой из входов вызвал измене-
ние этого выходного сигнала. Изначально это явление было присуще
МОП-технологиям и не проявлялось в логике на биполярных транзис-
торах, такой как ТТЛ. Однако с дальнейшим развитием технологий
глубокого субмикрона многие из ранее скрытых эффектов задержки
всё больше начали проявлять себя по-иному, пересекая принятые для
них границы.
Можете не отвечать на этот вопрос.
356 Приложение Б. Эффекты задержки в технологии глубокого субмикрона
1980 г. Начало раз-
вития сети
Интернет,
Зависимость выходной характеристики от крутизны
входного сигнала
В дополнение к зависимости выходной характеристики вентиля от
входа, который вызывает изменение выходного сигнала (как было по-
казано в предыдущем разделе), эта характеристика (и крутизна выход-
ного сигнала) также может зависеть от крутизны входных импульсов.
Например, быстроменяющийся сигнал на входе а может вызвать быст-
роменяющийся отклик на выходе (Рис. Б.16, а), а фронт сигнала с ма-
лой крутизной может привести к появлению медленноменяющегося
выходного сигнала (Рис. Б.16, б). Ну, как, вам ещё весело?
а) Быстрое изменение сигнала б) Медленое изменение
на входе а вызывает сигнала а вызывает
быстроменяющийся отклик медленнонарастающий отклик
Рис. Б.16. Зависимость выходной характеристики вентиля
от крутизны входного сигнала
Зависимость выходной характеристики вентиля
от его состояния
Ещё одним фактором, оказывающим влияние на выходную харак-
теристику вентиля, служат логические значения, присутствующие на
его входах, но, в данный момент не вызывающие изменение выходно-
го сигнала. Этот эффект называют зависимостью выходной характе-
ристики вентиля от его состояния (Рис. Б. 17).
IIIIIIIIIIIIRIIIIIIII
4ШН
iiiiiimiiiiiiiiiiH
a) b= 1,ci = 0
11111111И1НЖ11И111111111Н||||||||
б) b = 0,ci=1
Рис. Б. 17. Зависимость выходной характеристики вентиля от его состояния
На Рис. Б. 17 приведены два случая, в которых сигнал на входе a
вызывает идентичные логические отклики на выходе со. Однако если
допустить, что входные сигналы имеют одинаковое значение крутиз-
ны, а сами входы — одинаковый порог переключения, то передаточная
характеристика логического элемента и крутизна выходного сигнала
может зависеть от логических уровней, поданных на входы b и ci.
Эффекты задержки глубокого субмикрона 357
Зависимость порога срабатывания вентиля от его состояния
Как вы уже заметили, при обсуждении зависимости выходной ха-
рактеристики от состояния вентиля предполагалось, что порог сраба-
тывания в рассматриваемых случаях находился на одном и том же
уровне. Если это вас как-то насторожило, то этот подраздел поможет
вам перенести все ужасы технологии глубокого субмикрона.
Смысл заключается в том, что по некоторым причинам входной
порог срабатывания может зависеть от состояния вентиля. Другими
словами, порог может изменяться в зависимости от логических значе-
ний, установленных на других входах (Рис. Б. 18).
Рис. Б. 18. Зависимость входного порога срабатывания вентиля от его состояния
1980 г. Осущест-
влена передача
факса через обыч-
ную телефонную
линию.
1981 г. Америка.
Начато производс-
тво первых ком-
пьютеров IBM PC.
1981 г. Америка.
Разработана пер-
вая компьютерная
мышка.
В этом примере порог срабатывания входа а (точка, при пересече-
нии которой входной сигнал вызывает изменение выхода элемента)
зависит от логических состояний на входах b и ci.
Зависимость величины паразитных элементов вентиля
от его состояния
Кроме зависимости входного порога срабатывания вентиля от его
состояния, ряд характеристик, связанных с входами этого вентиля (та-
ких как величина паразитных ёмкостей) также могут зависеть от логи-
ческих уровней, находящихся на других входах. Например, рассмот-
рим 2-входовый вентиль ИЛИ (Рис. Б. 19).
Ёмкость паразитного конденсатора на входе g2.a (который под-
ключен к выходу другого логического элемента gl.y) может зависеть от
логического значения на входе g2.b. Если на входе g2.b присутствует
логический 0, то изменение сигнала на входе g2.a вызовет изменение
значения на выходе вентиля ИЛИ. В этом случае выходgl.y (входил)
столкнется с относительно большой паразитной ёмкости. Однако если
на вход g2.b подать логическую 1, то изменение сигнала на входе g2.a
не вызовет переключения сигнала на выходе вентиля ИЛИ. При этом
gl.y столкнется с относительно небольшой ёмкостью.
358 Приложение Б. Эффекты задержки в технологии глубокого субмикрона
1981 г. Разработан
первый ноутбук.
Рис. Б. 19. Зависимость величины паразитных ёмкостей вентиля от его состояния
В этом случае можно спросить: «Если логический элемент ИЛИ не
изменяет своё выходное значение, зачем нам беспокоиться о том, что
паразитный конденсатор на входе а изменяет значение своей ёмкости?
Разве мы не можем рассматривать только значение, проявляющееся
при переключении выхода?» На самом деле всё было бы хорошо, если
бы gl.y был подключен только к входу g2.a, но проблема в том, что мы
можем модифицировать схему, и в итоге gl.y окажется подключен к
входам других вентилей.
Этот эффект сначала проявлялся в устройствах эмитгерно-связан-
ной логики (ЭСЛ). Ещё в конце 1980-х существовала одна ЭСЛ-техно-
логия, в которой паразитные конденсаторы на входах вентилей-при-
емников (с точки зрения выходов вентилей-передатчиков) изменяли
свою ёмкость почти на 100 процентов в зависимости от состояния ло-
гических сигналов на других входах. Но это явление больше не ограни-
чивается в своём проявлении только технологией ЭСЛ. Снова повто-
рюсь, эффекты, вызывающие изменение значения задержки, начина-
ют проявлять себя в новом качестве и выходят за пределы
традиционных значений, когда мы продолжаем погружаться в область
глубокого субмикрона.
Влияние изменения нескольких сигналов на задержку
вывод-вывод
До этого времени мы с вами рассматривали случаи, в которых вы-
ходной сигнал изменял своё значение при изменении на входе только
одного сигнала. Очевидно, что картина усложнится при анализе ситуа-
ций, когда выходной сигнал формируется при изменении нескольких
входных сигналов. Например, рассмотрим 2-входовый логический
элемент ИЛИ (Рис. Б.20).
Для простоты примера, предположим, что оба входных сигнала на
выводах а и b полностью одинаковы, так же как одинаковы для этих
входов пороги срабатывания и задержки вывод-вывод.
Сначала рассмотрим случай, когда на одном из входов (к примеру,
на а) меняется сигнал и тем самым вызывает изменение выходного
сигнала (Рис. Б.20, а). В результате такого воздействия значение за-
держки будет соответствовать тому, которое обычно приводится в
справочниках для рассматриваемой микросхемы. Однако если подать
сигналы одновременно на оба входа, то значение задержки вывод-вы-
вод может уменьшиться примерно до 50 процентов от значения, при-
ведённого в справочнике.
Ситуации, когда входной сигнал подаётся на один вход или на оба
входа подаются одновременно два сигнала, представляют собой два
крайних случая. Однако также необходимо учитывать ситуации, когда
Эффекты задержки глубокого субмикрона 359
а) Изменение сигнала
происходит на одном входе
одновременно
Рис. Б.20. Влияние изменения нескольких сигналов на задержку вывод-вывод
б) Изменения сигналов
происходят на двух входах
1983 г. Персональ-
ный компьютер
Lisa компании
Apple впервые поз-
воляет использо-
вать компьютер-
ную мышку и выпа-
дающие меню.
входные сигналы подаются не одновременно, а следуют друг за другом
в непосредственной близости. Например, возьмем логический эле-
мент ИЛИ, показанный на Рис. Б.20 и допустим, что изначально оба
входа находятся в состоянии логического 0. Теперь представьте себе,
что на входе а происходит изменение сигнала, которому соответствует
стандартное, приведённое в справочнике значение задержки. Но до
окончания этого времени на входе b также происходит изменение сиг-
нала. В этом случае значение задержки будет находиться между двумя
упомянутыми выше крайними случаями.
Влияние изменения нескольких сигналов на выходную
характеристику
В дополнение к изменению значения задержки, одновременные
изменения нескольких сигналов также влияют на выходную характе-
ристику вентиля и, следовательно, на крутизну фронта выходного сиг-
нала (Рис. Б.21).
а) Изменение сигнала
происходит на одном входе
11111111111111Н1111||||||||111111111Н1Н1ННН
б) Изменения сигналов
происходят на двух входах
одновременно
Рис. Б.21. Влияние изменения нескольких сигналов на выходную характеристику
Все эти эффекты, вызванные изменениями нескольких входных
сигналов можно оценить простой линейной аппроксимацией. Но, к
сожалению, современные средства верификации, такие как системы
логического моделирования, не всегда обладают необходимыми моду-
лями для расчёта «на лету» параметров этого типа.
360 Приложение Б. Эффекты задержки в технологии глубокого субмикрона
1983 г. Журнал
«Time» назвал ком-
пьютер Человеком
года.
1984 г. Впервые из-
готовлена микро-
схема с памятью
объёмом 1 Мбайт.
Паразитное отражение
В технологиях прошлых лет паразитные эффекты ещё можно было
рассматривать как явления, с ограниченной областью распростране-
ния, которые проявляются в непосредственной близости от анализи-
руемой точки. Рассмотрим, для примера, три вентиля, как показано на
Рис. Б.22.
Раньше в таком примере можно было допустить, что логический
элемент g2 будет служить буфером между элементами gl и g3. Таким
образом, сигнал с выхода gl.y будет подвергаться влиянию паразитных
элементов, например, ёмкостей, связанных только с проводником w7
и входом вентиля g2.a.
Эти предположения теряют свою истинность в сфере глубокого
субмикрона. Возвращаясь к трём логическим элементам, показанным
на Рис. Б.22, следует заметить, что теперь некоторая часть паразитного
сигнала, связанная с проводником и входом вентиля g3.a может от-
разиться и пройти через вентиль g2 и тем самым повлиять на выход gl.y.
Кроме того, если бы вентильg2 представлял собой 2-входовую логичес-
кую функцию, например, исключающее ИЛИ, то величина этих пара-
зитных явлений могла бы зависеть от состояния вентиля, то есть могла
определяться логическим сигналом, установленном на другом входе.
Во время написания этой книги, отражённые паразитные сигналы
слабо влияли на прохождение полезной информации. Однако этих эф-
фектов следует бояться (очень бояться), так как существует вероят-
ность того, что они будут проявлять себя с большей силой по мере то-
го, как мы будем осваивать новые технологические процессы.
Выводы
Большинство из эффектов, влияющих на задержку распростране-
ния сигнала, представленных в этой главе, существовали всегда, даже
в мультимикронных технологиях, но многие из них по степени своей
значимости на три-четыре порядка были меньше других, и при анали-
зе не рассматривались. Когда геометрические размеры устройств пере-
шагнули через барьер в 0.5 микрона и достигли 0.35 мкм, то некоторые
из этих эффектов начали проявлять себя сильнее, и их значимость ста-
ла возрастать с каждой новой ступенькой в технологии изготовления
микросхем и понижении напряжения питания.
К сожалению, развитие многих средств верификации отстаёт от
кремниевых технологий. Если эти средства не будут расширены, что-
бы учитывать все эффекты, возникающие в области глубокого субмик-
рона, то разработчики будут вынуждены использовать жесткие огра-
ничения для того, чтобы быть уверенными, что их устройство функци-
онирует должным образом. Следовательно, разработчики не смогут
воспользоваться всеми потенциальными возможностями новых тех-
нологий, которые появятся в недалёком будущем.
Приложение В.
ЛИНЕЙНЫЙ СДВИГОВЫЙ
РЕГИСТР С ОБРАТНОЙ СВЯЗЬЮ
Ауроборос
Ауроборос — это мифологический змей или дракон, пожирающий
свой хвост, поэтому его тело образует замкнутый круг. Этот символ ис-
пользовался в различных древних мировых культурах для обозначения
бесконечности или возрождения0. В мире электроники прототипом
ауробороса можно назвать линейный сдвиговый регистр с обратной свя-
зью, в котором выходные значения из стандартного сдвигового регист-
ра определённым образом обрабатываются и подаются обратно на его
вход таким образом, чтобы устройство бесконечно вырабатывало пос-
ледовательность определённых данных.
Содержимое этого
приложения взято
из моей книги «Bebop
to the Boolean Boogie
(An Unconventional
Guild to Electronics,
Edition 2)»
(ISBN 0-7506-7543-8)
с любезного разреше-
ния издателя.
Реализация вида «многие к одному»
Линейный сдвиговый регистр с обратной связью (или LFSR — Linear
Feedback Shift Registers) достаточно просто реализуется и полезен во
многих приложениях. В общем случае LFSR формируется из простого
сдвигового регистра с добавлением обратной связи, подключенной к
двум или более точкам в регистровой цепочке, которые называют от-
водами (Рис. ВЛ).
ИСКЛЮЧАЮЩЕЕ ИЛИ
а) Схематичное изображение
б) Реализация
Рис. В.1. LFSR с элементом ИСКЛЮЧАЮЩЕЕ ИЛИ в цепи обратной связи
В этом примере в качестве отводов используются биты 0 и 2, и
простым способом их представления может служить запись вида [0,2].
Все элементы регистра используют общий сигнал синхронизации, ко-
торый опущен на схеме регистра для простоты. Данные, поступающие
на вход LFSR, формируются логической функцией ИСКЛЮЧАЮ-
ЩЕЕ ИЛИ (либо ИСКЛЮЧАЮЩЕЕ ИЛИ-HE), подключенной к от-
0 Не следует пугать с двуглавым змеем Амбисфеном из классической мифоло-
гии, у которого на хвосте росла вторая голова, благодаря чему он мог передвигать-
ся в обоих направлениях.
362 Приложение В. Линейный сдвиговый регистр с обратной связью
1985 г. Впервые для
хранения компью-
терных данных ис-
пользован CD-ROM.
водам в цепочке регистров, а остальные биты регистра формируются
как в обычном сдвиговом регистре.
Последовательность формируемых регистром (LFSR) значений
определяется функцией обратной связи (ИСКЛЮЧАЮЩЕЕ ИЛИ ли-
бо ИСКЛЮЧАЮЩЕЕ ИЛИ-HE), а также расположением отводов в
цепочке регистров. Например, рассмотрим два 3-битных регистра, ис-
пользующих в цепи обратной связи функцию ИСКЛЮЧАЮЩЕЕ
ИЛИ, у первого регистра отводы сформированы по схеме [0,2], а у вто-
рого-11,2] (Рис. В.2).
ИСКЛЮЧАЮЩЕЕ ИЛИ ИСКЛЮЧАЮЩЕЕ ИЛИ
а) ИСКЛЮЧАЮЩЕЕ ИЛИ
на отводах [0,2]
б) ИСКЛЮЧАЮЩЕЕ ИЛИ
на отводах [1,2]
Рис. В.2. Сравнение различных схем реализации отводов
Оба регистра начинают работу с одного и того же начального зна-
чения, но с разными отводами для цепи обратной связи. Из-за этого
формируемые ими значения довольно быстро, с каждым новым так-
том синхронизации, начинают расходиться. В некоторых случаях
LFSR перестает формировать циклическую последовательность значе-
ний через определённое количество шагов. Однако оба регистра, пред-
ставленные на Рис. В.2, будут формировать максимально длинную пос-
ледовательность, которая будет включать в себя все возможные значе-
ния (исключая значения со всеми нулевыми битами) перед тем, как
вернуться к начальному положению.
Двоичное поле, состоящее из п бит, может содержать 2п уникаль-
ных значений, но максимальная длина формируемой LFSR-регистром
последовательности будет составлять всего лишь (2л — 1) чисел. На-
пример, 3-битное поле может содержать одно из 23 = 8 значений, но 3-
битный LFSR-регистр из Рис. В.2 под держивает только (23 — 1) = 7 чи-
сел. Объяснить это можно тем, что LFSR с функцией ИСКЛЮЧАЮ-
ЩЕЕ ИЛИ в цепи обратной связи не поддерживает «запрещённую»
Множество отводов 363
комбинацию, состоящую из последовательности всех нулевых битов,
также как и регистр с функцией ИСКЛЮЧАЮЩЕЕ ИЛИ-НЕ не ра-
ботает с комбинацией со всеми единицами (Рис. В.3)°.
ИСКЛЮЧАЮЩЕЕ ИЛИ
ИСКЛЮЧАЮЩЕЕ ИЛИ-НЕ
а) ИСКЛЮЧАЮЩЕЕ ИЛИ
на отводах [0,2]
б) ИСКЛЮЧАЮЩЕЕ ИЛИ-НЕ
на отводах [0,2]
1989 г. Начал рабо-
ту волоконно-оп-
тический кабель,
проложенный через
Тихий океан (под-
держивающий до
40000телефонных
разговоров одновре-
менно).
Рис. В.З. Сравнение функций ИСКЛЮЧАЮЩЕЕ ИЛИ
и ИСКЛЮЧАЮЩЕЕ ИЛИ-НЕ в цепи обратной связи
Множество отводов
Каждый LFSR-регистр поддерживает ряд комбинаций отводов,
которые обеспечивают формирование последовательности макси-
мальной длины. Проблема заключается в том, чтобы из всех возмож-
ных комбинаций отводов исключить те из них, которые позволяют ге-
нерировать только ограниченное количество состояний.
Только ради собственного развлечения я написал простую про-
грамму на языке С для определения отводов, позволяющих генериро-
вать последовательность максимальной длины для регистров от 2 до
32 бит. Для того чтобы порадовать вас, результаты работы программы
представлены на Рис. В.4 (символом «*» обозначены последователь-
ности, длина которых является простым числом).
Наборы отводов одинаково подходят как для регистров с функци-
ей ИСКЛЮЧАЮЩЕЕ ИЛИ, так и для функции ИСКЛЮЧАЮЩЕЕ
ИЛИ-НЕ, хотя последовательности, формируемые этими регистрами,
разумеется, будут различны. Как уже говорилось, другие комбинации
отводов также могут позволять генерировать последовательность мак-
симальной длины, хотя и в этом случае их вид будет отличаться. На-
0 Если LFSR обнаружит у себя «запрещённую величину», то он остановится
на этом значении, и будет находиться в таком состоянии до тех пор, пока какое-
либо внешнее воздействие не выведет его из этого затруднительного состояния.
364 Приложение В. Линейный сдвиговый регистр с обратной связью
1990 г. Швейцария.
Британский физик
Тим Бернерс-Ли
(Tim Berners-Lee)
установил первый в
мире WWW-сервер.
1993 г. Разработан
Web-браузер
MOSAIC.
Кол-во бит Длина последовательности Отводы
2 3 * Ю.1]
3 7 * [0,2]
4 15 [0.3]
5 31 * [1.4]
6 63 [0,5]
7 127 * [0,6]
8 255 [1,2,3,7]
9 511 [3.8]
10 1023 [2.9]
11 2047 [1,10]
12 4095 [0,3.5,11]
13 8191 * [0,2.3.12]
14 16383 [0,2,4,13]
15 32767 [0,14]
16 65535 [1.2,4,15]
17 131071 * [2,16]
18 262143 [6,17]
19 524287 * [0,1.4.18]
20 1048575 [2.19]
21 2097151 [1,20]
22 4194303 [0,21]
23 8388607 [4,22]
24 16777215 [0,2.3.23]
25 33 554431 [2,24]
26 67108863 [0,1.5,25]
27 134217727 [0,1,4,26]
28 268435455 [2,27]
29 536870911 [1.28]
30 1073741 823 [0,3,5,29]
31 2147483647 * [2,30]
32 4294967295 [1.5,6,31]
Рис. В.4. Отводы для формирования последовательностей максимальной
длины для LFSR от 2 до 32 бит
пример, для 10-битного LFSR-регистра существуют две 2-отводные
комбинации ([2,9] и [6,9]), которые позволяют генерировать последо-
вательность максимальной длины. Также существуют двадцать 4-от-
водных комбинаций, двадцать восемь 6-отводных и десять 8-отвод-
ных комбинаций, которые удовлетворяют критерию максимальной
длины1*.
Очень важно! Необходимо заметить, что комбинации отводов,
представленных на Рис. В.4, могут не самым лучшим образом подхо-
дить для решаемых вами задач по некоторым параметрам, например,
они могут не быть простыми полиномами или могут не иметь равно-
мерного распределения в случайном пространстве. На рисунке приве-
дены только те данные, которые я выбрал из сгенерированных мной ре-
зультатов. Если вы будете использовать LFSR для реальных задачах, то
книга «Error-Correcting Codes» (авторы W. Wesley Peterson и J. Weldor Jr.,
издательство «MIT Press») может помочь вам в определении наилучшей
комбинации отводов. Также могут быть интересны утилиты проверки с
помощью циклического избыточного кода (CRC), рассматриваемых в
разделе «Другие необходимые средства и утилиты» в конце 25 главы.
° Более длинная таблица (охватывающая LFSR-регистры длиной до 168 бит)
представлена в описании устройства ХАРР052 фирмы Xilinx.
Реализация вида «один ко многим» 365
Реализация вида «один ко многим»
Давайте рассмотрим 8-битный LFSR-регистр, для которого необ-
ходимо минимум четыре отвода, чтобы генерировать последователь-
ность максимальной длины. На практике вентиль ИСКЛЮЧАЮЩЕЕ
ИЛИ имеет только два входа, поэтому для создания 4-входовой функ-
ции необходимо использовать три таких вентиля образующих два
уровня логики. Даже в тех случаях, когда LFSR позволяет использо-
вать всего два отвода для формирования максимальной последова-
тельности, по разным причинам может возникнуть необходимость ис-
пользовать их большее количество, например восемь отводов (для это-
го потребуется три уровня логики).
Однако увеличение количества логических уровней в цепи обрат-
ной связи может отрицательно сказаться на максимальной рабочей
частоте LFSR. Решение проблемы заключается в переходе от рассмот-
ренной выше реализации вида «многие к одному» к её аналогам типа
«один ко многим» (Рис. В.5).
1999 г. Компания
Intel разработала
микропроцессор с
тактовой часто-
той 1 ГГц.
б) «Один ко многим»
Рис. В.5. Реализации вида «многие к одному» и «один ко многим»
Традиционная реализация вида «многие к одному» для 8-битного
LFSR-регистра использует отводы [1,2,3,7]. Для того чтобы преобразо-
вать это устройство к виду «один ко многим», необходимо наиболее
значимый отвод, который всегда будет являться старшим битом (в
данном случае 7-й бит), соединить напрямую с самым младшим битом
регистра. Также старший бит в индивидуальном порядке через вентили
ИСКЛЮЧАЮЩЕЕ ИЛИ подсоединяется к другим отводам (в этом
примере это биты [1,2,3]).
Хотя обе реализации будут формировать последовательность мак-
симальной длины, всё же значения этих последовательностей будут
различаться. Главным достоинством метода «один ко многим» являет-
ся то, что в этом случае используется не более одного уровня комбина-
ционной логики в цепи обратной связи независимо от количества за-
действованных отводов.
Конечно, в ПЛИС на этот счёт есть своя особенность, согласно ко-
торой 4-входовая таблица соответствия имеет одинаковое значение за-
366
Приложение В. Линейный сдвиговый регистр с обратной связью
держки для 2-, 3- и 4-входовой реализации функции ИСКЛЮЧАЮ-
ЩЕЕ ИЛИ. В этом случае метод «многие к одному» даёт определённое
преимущество только при использовании LFSR-регистров с числом
отводов более четырёх.
Инициализация LFSR
Интересной особенностью LFSR-регистра с логической функцией
ИСКЛЮЧАЮЩЕЕ ИЛИ в цепи обратной связи является то, что если
он обнаружит у себя внутри значение, состоящее из всех нулей, то он
начнёт с удовольствием выдавать эти нули до тех пор, пока кто-нибудь
или что-нибудь его не остановит. Так же, регистр с функцией ИС-
КЛЮЧАЮЩЕЕ ИЛИ-НЕ, обнаружив у себя все единицы, начнёт
постоянно выдавать их на выход. Эта особенность может проявить се-
бя при включении питания, когда каждый бит регистра устанавливает-
ся случайным образом либо в состояние логического 0, либо в состоя-
ние 1, и не исключена вероятность того, что в результате в регистре ус-
тановиться запрещённая комбинация. Поэтому при использовании
LFSR-регистров возникает необходимость в предварительной уста-
новке начальных значений.
Интересно заметить, что для регистров с функцией ИСКЛЮЧАЮ-
ЩЕЕ ИЛИ-НЕ в цепи обратной связи разрешено использование ком-
бинации, состоящей из всех нулей. Это значит, что для инициализа-
ции таких регистров можно использовать сигнал общего сброса, уста-
навливающий значения всех бит в 0.
Загрузить специфичные данные в регистр можно с помощью его
входов установки и сброса (set и reset). Например, один бит регистра
может быть подключен к сигналу сброса, а остальные к сигналу уста-
новки. При подаче этих управляющих сигналов в LFSR-регистр загру-
зится аппаратно-определяемое начальное значение. Однако в некото-
рых приложениях желательно предусмотреть возможность изменения
значения инициализации. Решить эту задачу можно, например, с по-
мощью подключения мультиплексора на вход LFSR-регистра
(Рис. В.6).
Рис. В.6. Схема загрузки альтернативных начальных значений
Когда на мультиплексор выбран вход для начальной загрузки дан-
ных, то устройство работает как обыкновенный сдвиговый регистр и
принимает поступающие начальные данные. После загрузки началь-
ных значений мультиплексор переходит в режим передачи данных из
цепи обратной связи, и устройство начинает работать уже как LFSR-
регистр.
Очереди FIFO 367
Очереди FIFO
Следует заметить, что формируемые LFSR-регистром необычные
последовательности значений находят применения во многих прило-
жениях. Например, давайте рассмотрим 16-словную функцию памяти
типа FIFO (first-in, first-out — первым прибыл, первым вышел) шириной
4 бита (Рис. В.7).
Рис. В. 7. FIFO на 16 слов
В дополнение к управляющей логике и выходному регистру, FIFO
также содержит указатель чтения и указатель записи, которые пред-
ставляют собой 4-битные регистры, информация с которых преобра-
зуется дешифратором 4:16 для того, чтобы выбрать 1 из 16 слов, нахо-
дящихся в массиве памяти.
Указатели чтения и записи следуют, друг за другом в бесконечном
цикле перебирая адреса массива памяти. При активировании сигнала
записи данные, находящиеся на входной шине, записываются в слово,
адрес которого хранится в указателе записи. После этого указатель за-
писи увеличивает своё значение, и указывает на следующее пустое
слово. Соответственно, по сигналу чтения данные из слова, адрес кото-
рого храниться в регистре чтения, передаются в выходной регистр,
после чего значение указателя чтения увеличивается, после чего он бу-
дет указывать уже на следующее слово с данными0. Также в состав уст-
ройства входит логика, обнаруживающая состояния, когда очередь
полностью опустошается или заполняется, но её рассмотрение не вхо-
дит в задачи этого раздела.
Указатели чтения и записи для 16-словной очереди FIFO часто реа-
лизуются с помощью 4-битных двоичных счётчиков. Однако для этих
целей также можно применить и двоичные последовательности, в час-
тности те, которые генерируются с помощью LFSR-регистра. Как вид-
но из Рис. В.8, эти функции работают фактически одинаково.
Из этого рисунка видно, что различие между двоичным счётчиком
и LFSR-регистром заключается только в их названии. Идея заключа-
ется в том, что для реализации цепи обратной связи для 4-битного дво-
ичного счетчика потребуется несколько логических элементов И и
В этом разделе рассматриваются последовательности запись-увеличение и
чтение-увеличение, однако некоторые очереди FIFO используют методы увеличе-
ние-запись и увеличение-чтение.
368 Приложение В. Линейный сдвиговый регистр с обратной связью
а) 4-битный двоичный счётчик
б) 4-битный LFSR-регистр
Рис. В.8. Двоичный счётчик и LFSR-регистр
ИЛИ, а цепь обратной связи LFSR-регистра состоит только из одного
элемента ИСКЛЮЧАЮЩЕЕ ИЛИ. Это значит, что реализация LFSR-
регистра потребуется меньше дорожек и он будет более эффективен с
точки зрения занимаемого на кристалле места.
Кроме того, сигнал обратной связи LFSR-регистра проходит толь-
ко через один уровень логики, а у двоичного счётчика их несколько.
Другими словами, новое значение данных в LFSR будет формировать-
ся намного раньше, чем у счетчика, то есть регистр может работать на
более высокой частоте. Различие между счётчиком и регистром стано-
вится ещё более отчётливым в очередях FIFO с большим количеством
слов, для которых требуются многобитные указатели. Следовательно,
для некоторых проницательных инженеров LFSR представляет собой
довольно интересное решение0.
Модификация LFSR для формирования
последовательностей длиной 2П
Отрицательным моментом в рассмотренном выше примере ис-
пользования 4-битного LFSR-регистра в составе очереди FIFO было
то, что генерируемая им последовательность состояла всего из 15 зна-
чений (24 — 1), а счетчик в этом случае выдаёт 16 чисел (24). В зависи-
мости от типа приложения, в некоторых случаях разработчики могут
не беспокоиться об этой проблеме, особенно когда речь идёт об очере-
дях большой длины. Однако иногда требуется, чтобы формируемая
LFSR-регистром последовательность содержала все возможные значе-
ния. В этом случае на помощь может придти очень простое решение
(Рис. В.9).
Принцип действия такого регистра заключается в том, что числу,
состоящему из всех нулей, должно предшествовать значение, в кото-
0 Также для этих целей используют так называемые счётчики Грея, но в этом
приложении мы их рассматривать не будем.
Доступ к предыдущему значению 369
Все нули
х
X
Рис. В.9. Модифицированный LFSR-регистр с длиной последовательности 2П
ром старший бит0 установлен в 1, а в остальных ячейках должны быть
записаны нули. В обычной версии LFSR-регистра следующий синхро-
импульс приведёт к установке в единицу младшего бита и сбросу в О
всех остальных. Но в модифицированном LFSR-регистре, изображён-
ном на Рис. В.9, всё будет по другому. В этом устройстве на выходе ло-
гического элемента ИЛИ-НЕ всегда будет находиться значение логи-
ческого 0, за исключением двух случаев — когда все биты будут уста-
новлены в 0, а также в предшествующем случае, то есть когда старший
бит установлен в 1, а остальные находятся в 0. Эти две ситуации приво-
дят к появлению на выходе элемента ИЛИ-НЕ логической 1, которая
инвертирует выходное значение элемента ИСКЛЮЧАЮЩЕЕ ИЛИ.
Это, в свою очередь, вызывает появление в формируемой последова-
тельности значения, состоящего из всех 0, после чего регистр возвра-
щается к обычной работе. (При использовании в цепи обратной связи
логического элемента ИСКЛЮЧАЮЩЕЕ ИЛИ-НЕ элемент ИЛИ-
НЕ может быть заменён на функцию И, которая вызывает появление в
последовательности значения, состоящего из всех единиц.)
Доступ к предыдущему значению
В некоторых приложениях иногда необходимо использовать преды-
дущие значения регистров. Например, в некоторых очередях FIFO со-
стояние полного заполнения обнаруживается, когда указатель записи
указывает на слово, предшествующее указателю чтения* 2). В этом случае
в схеме предполагается наличие компаратора, который должен сравни-
вать текущее значение указателя записи с предыдущим значением ука-
зателя чтения. Аналогично, состояние опустошения очереди может
быть обнаружено, когда указатель чтения указывает на ячейку памяти,
предшествующую указателю записи. В этом случае подразумевается на-
0 Очень часто в сдвиговых регистрах старший бит обозначают с правой сторо-
ны, а младший — с левой. В других устройствах обозначение старших и младших
бит обычно указывается в противоположном порядке.
2) А теперь произнесите это быстро!
370 Приложение В. Линейный сдвиговый регистр с обратной связью
личие второго компаратора, который должен сравнивать текущее значе-
ние указателя чтения с предыдущим значением указателя записи.
При использовании двоичных счётчиков (допустим, что по неко-
торым причинам мы решили применить их для реализации очереди
FIFO) получить предыдущее значение можно двумя способами. Во-
первых, можно установить дополнительные теневые регистры. Каж-
дый раз при увеличении значения счётчика его текущее значение
предварительно копируется в теневой регистр. Также для получения
предыдущего значения из текущих данных можно воспользоваться
блоком комбинационной логики. К сожалению, оба этих метода при-
водят к значительным издержкам в виде дополнительных логических
схем. В отличие от них, LFSR-регистры в действительности могут за-
поминать своё предыдущее состояние. Для этого всего лишь необхо-
димо к старшему биту регистра добавить ещё один бит (Рис. В. 10).
Рис. В. 10. Доступ к предыдущему значению в LFSR-регистре
Шифрование и дешифровка
Необычные последовательности значений, генерируемые LFSR-
регистрами, могут использоваться для шифрования (кодирования) и
дешифровки (декодирования) данных. Битовый поток данных может
быть зашифрован с помощью выполнения над ним операции ИС-
КЛЮЧАЮЩЕЕ ИЛИ с выходным сигналом LFSR-регистра
(Рис. В.11).
ИСКЛЮЧАЮЩЕЕ ИЛИ
ИСКЛЮЧАЮЩЕЕ ИЛИ
Рис. В.11. Шифрование данных с помощью LFSR-регистра
Поступающий на приёмник поток данных может быть дешифро-
ван при помощи выполнения операции ИСКЛЮЧАЮЩЕЕ ИЛИ с
последовательностью данных, генерируемых таким же LFSR-регист-
ром. Безусловно, это довольно простая форма шифрования, которая
не отличается большой защищенностью, но не требует больших затрат
на реализацию и подходит для некоторых приложений.
Контроль с помощью циклических избыточных кодов 371
Контроль с помощью циклических избыточных
кодов
Традиционной сферой применения LFSR-регистров является вы-
числение циклических избыточных кодов ( CRC — cyclic redundancy code),
которые используются для обнаружения ошибок в канале связи. В
этом случае поток передаваемых данных используется для модифика-
ции значений формируемой LFSR-регистром последовательности при
помощи подключения его к цепи обратной связи (Рис. В. 12).
Итоговое CRC-значение, сохранённое в LFSR-регистре, называет-
ся контрольной суммой, и зависит от каждого передаваемого бита. Пос-
ле того, как все данные будут переданы, передатчик посылает приём-
нику значение контрольной суммы. Приёмник также содержит анало-
гичный CRC-блок, и с приёмом данных осуществляет формирование
своего собственного значения контрольной суммы. После приёма всех
данных приёмник сравнивает внутреннее значение контрольной сум-
мы с тем, которое было сформировано передатчиком, и на основании
этого сравнения делает выводы о том, были ли искажения данных в
процессе их передачи.
Этот вид обнаружения ошибок очень эффективен с точки зрения
малого количества информации, который необходимо передавать
вместе с основным блоком данных. Однако недостатком этого метода
служит то, что при этом вы не узнаете о наличии ошибки до тех пор,
пока не закончится передача данных, и в случае ошибки вам придётся
передавать всю информацию заново.
В реальном мире 4-битные блоки подсчёта контрольных сумм не
обеспечивают требуемый уровень достоверности о целостности пере-
даваемых данных, так как могут формировать только (24 — 1) = 15 уни-
кальных значений. Это может привести к проблеме, называемой сов-
мещением (или aliasing), при которой итоговое значение контрольной
суммы совпадает с ожидаемым, но на самом деле вызвано действием
многочисленных ошибок, которые накладываются друг на друга и в
итоге приводят к требуемому CRC-значению. При увеличении коли-
чества бит в блоке CRC увеличивается и количество генерируемых им
уникальных значений, вследствие чего уменьшается вероятность того,
что многочисленные ошибки спровоцируют появление такого значе-
ния контрольной суммы, которое совпадёт с ожидаемым. Поэтому на
практике обычно используют как минимум 16-битные CRC-блоки,
которые могут генерировать 65535 уникальных значений.
Различные протоколы связи используют разное количество бит
для вычисления значения контрольной суммы и разные отводы. Отво-
УЛ Приложение В. Линейный сдвиговый регистр с обратной связью
ды выбираются таким образом, чтобы ошибка в одном отдельном бите
приводила к максимально возможному изменению итогового значе-
ния контрольной суммы. Таким образом, кроме максимальной длины
LFSR-регистры могут также классифицироваться по максимальному
смещению,
В дополнение к проверке целостности данных в системах связи,
CRC-блоки находят широкое применение и в других приложениях,
например, их можно использовать для обнаружения компьютерных
вирусов. В этом приложении под компьютерными вирусами мы будем
подразумевать самовоспроизводящиеся программы, реализованные в
компьютерной системе для различных целей. Эти цели могут прости-
раться от мелких пакостей, таких как отображение смешных или надо-
едливых сообщений, до более гнусных дел, в виде разрушения данных
или операционной системы.
Один из механизмов, с помощью которых компьютерные вирусы
могут скрываться и распространяться, заключается в том, что они при-
соединяют себя к существующим программам. Когда программа начи-
нает выполняться, первым делом инициируется тело вируса, то есть
поверхностная проверка системы покажет наличие в системе только
ожидаемых файлов. Для того чтобы бороться с такой формой вирусной
атаки, можно для каждой программы в системе сгенерировать свою
контрольную сумму, значение которой будет основано на двоичном
коде, формирующем соответствующую программу. Спустя некоторое
время, антивирусная программа может пересчитать контрольные сум-
мы для каждой программы и сравнить их с начальными данными. Раз-
личие данных может служить сигналом к тому, что к коду программы
прикрепился вирус0.
Сжатие данных
Описанные выше блоки вычисления контрольных сумм также мо-
гут применяться и для сжатия данных. Одно такое приложение входит
в механизм тестирования печатной платы и называется функциональ-
ным тестом. Печатная плата, на которой могут находиться тысячи
компонентов и проводников, подключается к функциональному тес-
теру с помощью торцевого разъема, который может содержать сотни
контактов.
Тестер подаёт образцовые сигналы на входы печатной платы, в те-
чение некоторого времени, необходимого для прохождения сигналов
по плате, ожидает ответной реакции и затем сравнивает сигналы на
выходе с сохранёнными ожидаемыми значениями. Этот процесс затем
повторяется для последовательности образцовых входных сигналов,
число которых может достигать десятков и сотен тысяч.
Если в ходе предварительного тестирования в работе печатной пла-
ты была обнаружена ошибка, то для выявления причины сбоев может
использоваться более сложная форма анализа, которая называется уп-
равляемым пробником. В этом случае тестер указывает оператору на не-
обходимость расположить пробник на определённом участке печатной
° К сожалению, разработчики компьютерных вирусов прибегают к всё более
сложным формам построения своих детищ, и некоторые их виды могут формиро-
вать собственное значение контрольной суммы. Когда вирус этого типа прикреп-
ляется к файлу, он может подставлять в своё тело определённые двоичные значе-
ния, которые действуют таким образом, что во время проверки контрольной сум-
мы антивирусная программа получает значение, совпадающее с начальными
данными.
Встроенное самотестирование 373
платы, и после этого начинает прогон всей тестовой последователь-
ности сначала. В ходе проверки тестер сравнивает действительные
данные, поступающие с пробника, с ожидаемыми значениями, сохра-
нёнными в системе. Этот процесс (размещение пробника и перезапуск
тестовой последовательности) повторяется до тех пор, пока тестер не
выявит неисправный компонент или дорожку.
Особое внимание при поддержке стратегии управляемого пробни-
ка уделяется количеству ожидаемых данных, подлежащих хранению.
Давайте рассмотрим тестовую последовательность, содержащую 10000
тестовых воздействий для печатной платы, состоящей из 10000 про-
водников. При отсутствии механизма сжатия данных в системе необ-
ходимо хранить 10000 бит ожидаемых данных для каждого проводни-
ка, то есть 100 миллионов бит для всей системы. Кроме того, для каж-
дого положения управляемого пробника тестер должен сравнивать
10000 бит наблюдаемых данных с таким же количеством данных, со-
хранённых в системе. Таким образом, использование данных без при-
менения механизма сжатия будет неэффективно с точки зрения требо-
ваний к хранению и обработки информации.
Одним из решений этой проблемы может послужить использова-
ние CRC-блока для вычисления контрольных сумм на основе LFSR-
регистра. Последовательность ожидаемых значений для каждого про-
водника может быть пропущена через программно-реализованный 16-
битный CRC-блок. Аналогично, последовательность действительных
значений, наблюдаемых управляемым пробником, может быть пропу-
щена через идентичный CRC-блок, но уже реализованный аппаратно.
В этом случае полученное значение контрольной суммы будет назы-
ваться сигнатурой, а метод управляемого пробника — сигнатурным
анализом. При этом независимо от количества используемых тестовых
воздействий в системе будет храниться только два байта данных для
каждого проводника. К тому же для каждого положения управляемого
пробника тестер будет сравнивать только два байта данных, снятых
пробником, с двумя байтами, хранимыми в системе. Таким образом,
сжатие данных позволяет сократить объем хранимых данных и время,
необходимое для сравнения результатов, что позволяет увеличить ско-
рость проверки печатной платы.
Встроенное самотестирование
Одна из стратегий тестирования, применяемых в сложных интег-
ральных микросхемах, заключается в использовании встроенных
средств самотестирования. Устройства, использующие такие средства,
содержат специальные схемы генерирования тестов и сбора результа-
тов, которые могут быть реализованы на основе LFSR-регистров
(Рис. В.13).
LFSR-регистр, формирующий генератор тестов, используется для
создания последовательности тестовых воздействий, LFSR-регистр в
блоке сбора результатов применяется для наблюдения за результатами
тестирования. Следует заметить, что регистр в блоке сбора результатов
модифицирован для приёма данных в параллельном виде.
Также может понадобиться дополнительная логика для загрузки
новых начальных данных в генератор тестов и для доступа к итоговым
значениям в блоке сбора результатов. Эти схемы для упрощения ри-
сунка не показаны.
Заметим, что LFSR-регистры могут быть различной длины, так как
у тестируемого блока количество входов, на которые подаются воздейс-
твия, и выходов, с которых снимаются результаты, могут различаться.
374 Приложение В. Линейный сдвиговый регистр с обратной связью
Примечание. XOR - ИСКЛЮЧАЮЩЕЕ ИЛИ
Рис, В, 13, Встроенные средства самотестирования
Ещё следует заметить, что все триггеры в генераторе тестов должны
работать с одним синхросигналом. Также по одному синхроимпульсу
должны срабатывать и триггеры блока сбора результатов. Эти два синх-
росигнала могут быть общими для двух блоков, но могут и различаться
(в этом случае должна быть предусмотрена схема их синхронизации).
Синхросигналы на Рис. В.13 не показаны с целью его упрощения.
Генераторы псевдослучайных
последовательностей
Многие компьютерные программы используют в своей работе эле-
менты случайности. Компьютерные игры, такие как Space Invaders,
используют случайные события для ещё большего вовлечения игро-
ков. Графические программы могут использовать случайные числа для
создания сложных и замысловатых моделей. Все формы компьютер-
ного моделирования могут использовать случайности для формирова-
ния более реального представления действительности. Например,
цифровые системы моделирования (смотрите также гл. 19) могут полу-
чить преимущество от применения случайных воздействий в виде вне-
шних прерываний. Случайные воздействия могут дать более реалис-
тичные результаты проверки устройства и позволят обнаружить про-
блемы, не доступные для более структурированных тестов.
Генераторы случайных чисел могут быть выполнены как аппарат-
но, так и программно. Большинство этих генераторов на самом деле не
являются случайными, но создают видимость случайности и поэтому
называются псевдослучайными. На практике псевдослучайные числа
И последнее, но не менее важное 375
имеют определённые преимущества над действительно случайными
последовательностями, так как большинство компьютерных приложе-
ний обычно требуют повторяемости. Например, разработчик системы,
повторяя цифровое моделирование, ожидает идентичного ответа, ко-
торое было получено из системы при предыдущем проходе. Однако
ему также необходима возможность модифицировать начальное зна-
чение генератора псевдослучайных чисел с тем, чтобы при необходи-
мости порождать другие последовательности.
Существуют различные методы генерирования псевдослучайных
чисел, один из которых заключается в использовании LFSR-регистра с
изменяемым отводом значений для обеспечения достаточно хорошего
источника псевдослучайного сигнала.
И последнее, но не менее важное
LFSR-регистры довольно просты в проектировании и находят ши-
рокое применение в различных сферах, но необходимо заметить, что
выбор оптимального полинома (который в конечном счёте сводится к
выбору точки отвода) для конкретного приложения представляет собой
задачу, которая подвластна только мастерам мистических искусств, не
говоря уже о том, что математика этого процесса может быть настолько
сложной, что может заставить даже взрослого человека потерять само-
обладание и расплакаться (я даже не буду говорить о круговых полино-
мах^, которые являются основой выбора необходимого отвода).
Главным образом потому, что я понятия не имею о том, что собой представ-
ляют круговые полиномы!
Об авторе
Клайв Максфилд (или просто «Макс») — сногсшибательный красавец ростом 185 см,
англичанин, чем он и гордится. Кроме того, что он герой и законодатель мод, в широких
кругах общества он является признанным экспертом во всех сферах электроники (по край-
ней мере, по мнению его матери).
После получения степени бакалавра наук в области систем автоматического управления
в 1980 году в политехническом университете г. Шеффилд, Англия (который сейчас называ-
ется Sheffield Hallam University), начал свою карьеру в должности разработчика центральных
процессорных модулей для больших универсальных ЭВМ (мэйнфреймов). Не вдаваясь в
подробности этой длинной истории, просто скажем, что сейчас Макс занимает пост прези-
дента компании TechBites Interactive (www.techbites.com). TechBites предоставляет услуги
консультаций по маркетингу и специализируется на информировании «нетехнической» ау-
дитории о достоинствах технической продукции и услугах посредством сайтов, рекламы,
технической документации, брошюр, вспомогательных материалов, книг и мультимедиа.
В свободное время (Ха!) Макс работает соредактором и соиздателем электронного жур-
нала «ЕРЕ Online» (www.epemag.com) для людей, увлеченных компьютерами и электрони-
кой, а также редактором Интернет-сайта www.eedesign.com. Кроме того, что Макс является
автором множества технических статей и докладов, которые появились в журналах по всему
миру, он написал книги «Bebop to the Boolean Boogie» (An unconventional guide to electronics)
и «Designus Maximus Unleashed» (Banned in Alabama), а также стал соавтором книги «Bebop
of BYTES Back» (An unconventional guide to computers) и «EDA: Where Electronics Begins».
Если фигура нашего автора все еще не оказала на вас впечатления, то скажу большее:
однажды один известный человек назвал Макса «выдающимся деятелем промышленности»
и «экспертом в сфере проектирования полупроводниковых устройств», причем никто ни в
коей мере не побуждал, не принуждал и не вознаграждал этого человека.
Словарь
• ASIC (application specific integration circuit) — специализированная интегральная микро-
схема (другое название — заказная микросхема), изготавливаемая по заказу интег-
ральная микросхема, предназначенная для использования в специфичных приложе-
ниях. Такие устройства могут содержать сотни миллионов логических элементов и
могут использоваться для реализации чрезвычайно больших и сложных функций.
Подобны устройствам ASSP, за исключением того, что ASIC разрабатываются и изго-
тавливаются для специализированных компаний.
• ASSP (application specific standard parts) — специализированная стандартная микросхе-
ма, изготавливаемая по заказу интегральная микросхема, предназначенная для ис-
пользования в специфичных приложениях. Такие устройства могут содержать сотни
миллионов логических элементов и могут использоваться для реализации чрезвы-
чайно больших и сложных функций. Подобна специализированным заказным интег-
ральным микросхемам (ASIC), за исключением того, что ASSP изготавливаются для
массового потребителя.
• BGA (ball grid array) — конструкция корпуса микросхемы, похожая на PGA (pad grid
array), в котором внешние выводы устройства представляют собой токопроводящие
площадки, расположенные и основании корпуса. Однако в BGA выводы представля-
ют собой крошечные металлические шарики припоя, расположенные в виде сетки на
его нижней поверхности.
• BiCMOS (bipolar-CMOS или биполярная + КМОП-структура) — название технологии
или устройств, реализованных на основе одноименной технологии, в которых логи-
ческая функция каждого логического элемента (логического вентиля) реализуется с
помощью маломощных КМОП-транзисторс в, а выходной каскад построен на мощ-
ном биполярном транзисторе.
• BIST (built-in self-test) — стратегия тестирования, которая подразумевает наличие до-
полнительной, встроенной в компонент логики, которая позволяет производить са-
мотестирование устройства.
• CGA (column grid array) — технология изготовления корпусов, подобная PGA (pad grid
array), в котором внешние контакты устройства сформированы в виде массива токо-
проводящих площадок, расположенных на корпусе. В CGA выводы оформлены в ви-
де небольших столбцов припоя, находящегося на этих токопроводящих площадках.
• CPLD (complex programmable logic device) — см. Сложное программируемое логическое
устройство
• CRC (cyclic redundancy check — контроль циклическим избыточным кодом) — вычисле-
ния, используемые для обнаружения ошибок в процессе передачи данных, обычно
выполняются с помощью линейного сдвигового регистра с обратной связью (LFSR).
Такие же вычисления могут быть использованы для других целей, например, для сжа-
тия данных.
• CSP (chip scale package — корпус сравнимый с размерами кристалла) — технология изго-
товления корпусов микросхем, при которой корпус лишь немного больше кристалла.
378 Словарь
• DCM (digital clock manager — цифровой диспетчер синхронизациии) — некоторые блоки
управления синхронизацией основаны на использовании системы фазовой автопод-
стройки частоты, другие используют системы автоматической подстройки по за-
держке. Термин «DCM» используется компанией Xilinx для обозначения специали-
зированных систем, основанных на автоматической подстройке по задержке.
• DSP (digital signal processing — цифровая обработка сигналов) — область электроники,
которая связана с представлением и обработкой сигналов в цифровой форме. Обра-
ботка включает в себя сжатие, распаковку, модуляцию, коррекцию ошибок, фильтра-
цию и другие манипуляции с аудио- (голос, музыка и т. д.) и видеоинформацией,
изображениями и другими подобными данными для телекоммуникации/связи, лока-
ции и обработки изображений (в том числе и в медицине).
• DSP (digital signal processor — цифровой сигнальный процессор или процессор обработ-
ки сигналов) — специальный микропроцессор, который разработан для выполнения
специфичных задач по обработке цифровых данных специального типа с более высо-
кой скоростью и эффективностью, чем микропроцессоры общего назначения.
• FET — см. Полевой транзистор.
• FIFO (first-in first-out — первым пришёл, первым вышел) — специальное устройство
(буфер) или функция памяти, данные с которого считываются в том порядке, в кото-
ром были в него записаны.
• Flash-память — технология энергонезависимой памяти, которая комбинирует в себе луч-
шие свойства технологий ЭСППЗУ и СППЗУ. Название Flash (молния) обозначает то, что
время перепрограммирования у таких микросхем намного меньше, чем у СППЗУ.
• FPGA (field programmable gate array — программируемая пользователем вентильная
матрица), то же что ПЛИС (программируемая логическая интегральная схема) — тип
цифровых интегральных микросхем, состоящих из конфигурируемых (программиру-
емых) логических блоков и конфигурируемых внутренних соединений между этими
блоками. Такая микросхема может быть сконфигурирована (запрограммирована) ин-
женером-разработчиком для выполнения самых разнообразных задач.
• FPIC (field programmable interconnect chip — программируемый пользователем кристалл
внутренних соединений)1) — альтернативное, патентованное название Программируе-
мых пользователем устройств внутренних соединений (FPID).
• FPID (field programmable interconnect device — программируемое пользователем устройс-
тво внутренних соединений) — устройство, используемое для соединения логических
устройств на печатной плате. Может быть динамически перепрограммировано спо-
собом, аналогичным перепрограммированию микросхем FPGA (ПЛИС) на основе
ячеек статического ОЗУ. Так как у каждого FPID-устройства может быть порядка
1000 выводов, то на печатной плате, как правило, требуется небольшое количество
таких устройств.
• FR4 — наиболее часто используемый изоляционный материал для печатных плат.
FR4 изготавливается из волокон стекловолокна, которые склеиваются вместе эпок-
сидной смолой. Печатная плата затем подвергается температурной обработке при
высоком давлении, вследствие чего её волокна плавятся и соединяются вместе, при-
давая плате прочность и жесткость. Первые две буквы в названии этого материала об-
разованы от слов «flame retardant», что значит «огнезащитный состав», а вот людей,
знающих, что обозначает цифра 4, можно пересчитать по пальцам одной руки. FR4 с
технической точки зрения является подвидом оптоволокна, и некоторые люди иног-
да называют его волоконно-оптической платой или волоконно-оптической подложкой.
• GAL (generic array logic — изменяемый массив логики)2) — патентованное название уст-
ройств PAL (programmable array logic — программируемый массив логики) компании
Lattice Semiconductor Corporation.
!) FPIC является торговой маркой компании Aptix Corporation.
2) GAL является торговой маркой компании Lattice Semiconductor Corporation.
Словарь 379
• HDL (hardware description language — язык описания аппаратных средств) — современ-
ные цифровые микросхемы могут содержать сотни миллионов логических элементов
(вентилей), которые просто невозможно описать на схемотехническом уровне (с по-
мощью принципиальной схемы). Поэтому функциональность высокотехнологичных
ИС теперь описывается в текстовой форме с помощью языков семейства HDL. На-
иболее популярными языками являются Verilog, SystemVerilog, VHDL и SystemC.
• HDL-синтез — современное название логического синтеза. См. также Логический
синтез и Физический синтез,
• IP (intellectual property — интеллектуальная собственность) — когда команда инжене-
ров конструирует сложную микросхему, да бы не изобретать велосипед, они могут ре-
шить купить проект одного или нескольких функциональных блоков, которые уже
были кем-то реализованы. Проект таких функциональных блоков и называется ин-
теллектуальной собственностью или IP. Средства интеллектуальной собственности
могут охватывать любые функциональные блоки, в том числе функции связи и мик-
ропроцессоры. Наиболее сложные функции, такие как микропроцессоры, могут на-
зываться ядрами. См. также Аппаратные IP, Программные IP и Микропрограммные IP.
• JEDEC (Joint Electronic Device Engineering Council — Объединенный инженерный совет
по электронным устройствам) — организация, которая разрабатывает, утверждает, и
отслеживает промышленные стандарты, касающиеся электронных устройств решает
спорные вопросы связанные с этими стандартами. В применении к программируе-
мой логике термин JEDEC обозначает текстовый файл, содержащий информацию,
используемую для программирования устройства. Формат файла утверждён комите-
том JEDEC в качестве стандарта и в общем случае называется JEDEC-файлом.
• LFSR (linear feedback shift register — линейный сдвиговый регистр с обратной связью) —
сдвиговый регистр, на вход которого подаётся результат работы функции ИСКЛЮ-
ЧАЮЩЕЕ ИЛИ либо ИСКЛЮЧАЮЩЕЕ ИЛИ-HE, аргументами которой служат
два или более элементов в регистровой цепочке.
• MOSFET — см. канальный полевой униполярный МОП-транзистор.
• NMOS (N-channel MOS) — МОП-структура с каналом л-типа.
• NPN — тип биполярного транзистора, который представляет собой л-р-л-структуру.
• л-тип — фрагмент полупроводника с соответствующими примесями, которые вы-
нуждают его работать в качестве донора электронов.
• OVA (OpenXfera Assertion) — язык формальной проверки, который специально разра-
ботан для максимально эффективного описания свойств и утверждений. OVA обла-
дает большими возможностями для создания сложных регулярных и временных вы-
ражений, позволяющих описывать сложные поведенческие аспекты несколькими
строками исходного кода. Этот язык подарен комитету SystemVerilog компании
Accellera (www.accellera.org) и основан на языке Sugar компании IBM.
• OVL (Open Verification Library — открытая библиотека средств проверки) — библиотека
моделей свойств и утверждений для языков VHDL и Verilog 2К1, управление которой
производится под покровительством компании Accellera (www.accellera.org).
• PAL (programmable array logic — программируемая матричная логика)1)— программируе-
мое логическое устройство, в котором массив элементов И является программируе-
мым, а массив элементов ИЛИ — нет.
• PGA — 1) pad grid array — технология изготовления корпусов микросхем, в которых
внешние контакты представляют собой матрицу токопроводящих площадок, распо-
ложенных на основании корпуса. 2) Pin grid array — технология изготовления корпу-
сов микросхем, в которых внешние контакты представляют собой матрицу контактов
или выводов, расположенных на основании корпуса.
PAL является зарегистрированной торговой маркой компании Monolithic Memories.
380 Словарь
• PLA (programmable logic array — программируемая логическая матрица, ПЛМ) — про-
граммируемые логические устройства, в которых оба массива функций И и ИЛИ яв-
ляются программируемыми. См. также PAL, ПЛУ, ППЗУ.
• PLD (programmable logic device) — см. ПЛУ.
• PMOS (P-channel MOS) — МОП-структура с каналом р-типа.
• PNP — тип биполярного транзистора, который представляет собой р-л-р-структуру.
• PSL (property-specification language — язык описания свойств) —- язык формальной
проверки, который разрабатывался специально для максимально эффективного опи-
сания утверждений и свойств. PSL отличается широкими возможностями для созда-
ния сложных регулярных и временных выражений, и позволяет описывать сложные
поведенческие аспекты с помощью нескольких строк кода. Этот язык представляет
собой промышленный стандарт, контролируемый компанией Accellera
(www.accellera.org), основан на языке Sugar компании IBM.
• р-тип — фрагмент полупроводника с соответствующими примесями, которые вы-
нуждают его работать в качестве акцептора электронов.
• QFP (quad flat pack) — наиболее часто используемый тип корпуса в виде тонкого квад-
рата, выводы в котором расположены со всех четырёх сторон.
• RTL — см. Уровень Регистровых Передач.
• RWM (read-write memory — память типа чтение-запись) — альтернативное (и, возмож-
но, более подходящее) название оперативного запоминающего устройства (ОЗУ).
• SVA (SystemVerilog Assertions) — оригинальная версия языка Verilog не поддерживает
утверждения, но после доработок SystemVerilog начал понимать эти структуры. В
2002 году Synopsys подарила свою утилиту OpenVera Assertions (OVA) компании
Accellera, ответственной за SystemVerilog. В результате работы по объединению этих
продуктов получился SystemVerilogAssertions или SV4.
• SystemVerilog — язык описания аппаратных средств (HDL), который во время написа-
ния этой книги являлся открытым стандартом, поддерживаемый компанией’
Accellera (wwwaccellera.com).
• UDL/I — среди популярных языков описания аппаратных средств Verilog изначально
создавался для решения задач моделирования, в то время как VHDL создавался как
язык описания, где также принималась в расчет необходимость моделирования. В ре-
зультате оба этих языка можно было использовать для описания и последующего мо-
делирования систем, но они не были предназначены для синтеза. Для того чтобы ре-
шить эту проблему, Японская ассоциация развития электронной промышленности (или
JEIDA — Japan Electronic Industry Development Association) в 1990-м году представила
свою собственную версию языка HDL под названием UDL/I (Unified Design Language
for Integrated Circuit — унифицированный язык разработки интегральных микросхем).
Главным преимуществом этого языка являлось то, что он изначально создавался как
для обеспечения моделирования, так и для обеспечения синтеза. Окружение UDL/I
включало в себя системы моделирования и синтеза, к тому же он распространялся
бесплатно (в том числе и с исходными кодами). Однако, когда UDL/I вышел в свет,
языки Verilog и VHDL уже стали настолько популярными, что UDL/I не вызвал осо-
бого интереса у инженеров за пределами Японии.
• Verilog — язык описания аппаратных средств (HDL), который изначально находился
в частной собственности, но затем перерос в открытый стандарт под покровительс-
твом IEEE (The Institute of Electrical and Electronics Engineers, Inc. — Институт инжене-
ров no электротехнике и радиоэлектронике).
• VHDL — язык описания аппаратных средств (HDL), который вышел из стен Минис-
терства обороны США и был преобразован в открытый стандарт.
• VITAL — язык VHDL обладает большими возможностями моделирования цифровых
схем, описанных на высоком уровне абстракции, но не отличается достаточной вре-
менной точностью для использования его в качестве конечного средства моделиро-
Словарь 381
вания. По этой причине в 1992 году на конференции по САПР электронных систем
была представлена VHDL-библиотека начального уровня для заказных микросхем (ASIC)
или VITAL (VHDL Initiative toward ASIC Libraries). Библиотека VITAL являлась попыт-
кой повышения возможностей языка VHDL для применения его в системах времен-
ного моделирования при разработке ПЛИС и заказных микросхем. В итоге в неё
вошла библиотека простых функций, используемых в ПЛИС и заказных микросхе-
мах, и метод обратной корректировки информации о задержке в этих библиотеках
моделей.
• АВМ (адаптивная вычислительная машина — adaptive computing machine, ACM) — но-
вая революционная форма цифровых интегральных микросхем (ИС), характеризую-
щаяся крупномодульной архитектурой и состоящая из узлов, которые могут быть ре-
конфигурируемы (адаптированы) сотни тысяч раз в секунду.
• Адаптивная вычислительная машина — см. АВМ.
• Анализ покрытия на уровне реализации (Implementation-based verification coverage) — это
мероприятия по проверке микроархитектурных особенностей готовой реализации.
Подразумевают под собой ряд решений, которые встраиваются в RTL-описание уст-
ройства для наблюдения за его тупиковыми состояниями, например, это может ка-
саться глубины буфера FIFO и тупиковые ситуации, связанных с его опустошением и
полным заполнением. Такие детали реализации редко удаётся проследить на уровне
спецификации. См. также Макроархитектурные определения, Микроархитектурные
определения, Анализ покрытия на уровне спецификации.
• Анализ покрытия на уровне спецификации (Specification-based verification coverage) —
это мероприятия по проверке высокоуровневых функционалов и макроархитектур-
ных определений. Включают в себя анализ средств ввода/вывода, типов используе-
мых транзакций (в том числе взаимодействие между собой транзакций различных ти-
пов), а также преобразования данных. См. также Макроархитектруные определения,
Микроархитектурные определения и Анализ покрытия на уровне реализации.
• Аналоговая схема — набор компонентов, используемых для обработки, или создания
аналоговых сигналов.
• Аналоговый — непрерывно изменяющаяся величина, которая наиболее точно описы-
вает протекающий в реальном мире процесс с точностью, определяемой средствами
измерений.
• Аналого-цифровое преобразование — см. АЦП.
• Аппаратное ядро — в цифровой электронике термин «аппаратное ядро» обычно ис-
пользуется для обозначения относительно больших логических функций общего на-
значения, которые могут использоваться в качестве составных частей больших уст-
ройств. Например, если заказная микросхема содержит встроенный
микропроцессор, то можно сказать, что микросхема содержит «микропроцессорное
ядро». В эту категорию также можно отнести ядра микроконтроллеров, цифровых сиг-
нальных процессоров — ЦСП (DSP — digital signal processor), коммуникационных функ-
ций и так далее. Такие ядра могут разрабатываться своими силами, но обычно они
покупаются у сторонних разработчиков блоков интеллектуальной собственности
(IP). Существует небольшая разница между аппаратными ядрами для заказных схем
(ASIC) и для ПЛИС (FPGA). В заказных микросхемах аппаратное ядро представляет
собой совокупность логических вентилей с заранее определённым их физическим
положением (относительно друг друга) и внутренними соединениями (жестко-опре-
делёнными проводниками). Это ядро может рассматриваться программой размеще-
ния и разводки как «чёрный ящик», то есть расположение самого ядра определяется
программой размещения и разводки, а его внутренние соединения изменению не
подлежат. Результаты работы программы размещения и разводки затем используются
для создания фотошаблона, по которому изготавливается микросхема. В отличие от
заказных микросхем, в ПЛИС все аппаратные ядра уже физически реализованы в ка-
честве встроенных в структуру аппаратных блоков. В общем случае одна микросхема
382 Словарь
может содержать несколько аппаратных ядер, совместно с программными ядрами и
другими пользовательскими блоками. См. также Программное ядро.
• Аппаратные блоки интеллектуальной собственности (аппаратные IP) — в ПЛИС термин
аппаратные IP обозначает предварительно реализованные блоки, такие как микро-
процессорные ядра, гигабитные интерфейсы, умножители, сумматоры, функции ум-
ножения с накоплением и им подобные. Эти блоки разрабатываются так, чтобы они
были максимально эффективны и с точки зрения потребляемой мощности, и с точки
зрения производительности, и с точки зрения площади, занимаемой на кристалле.
Каждое семейство ПЛИС характеризуется различной комбинацией таких блоков
вместе с различным количеством программируемых логических блоков. См. также
Программные IP и Микропрограммные IP
• Аппаратный — в общем случае этот термин обозначает любую физическую часть
электронной системы, в том числе компоненты, печатные платы, источники пита-
ния, корпуса и мониторы.
• Асинхронный — сигнал, данные которого квитируются или действуют незамедлитель-
но, независимо от сигналов синхронизации.
• АЦП (аналого-цифровое преобразование) — процесс преобразования аналоговых зна-
чений в их цифровые эквиваленты.
• Базисная ячейка — предварительно определённая группа несоединённых транзисто-
ров и резисторов. Эта группа клонируется по всей поверхности массива вентилей в
заказных микросхемах (AISC).
• Байт — группа из восьми двоичных цифр или бит.
• Библиотека схемных элементов — общее название набора логических функций, опре-
делённых производителем заказных микросхем (AISC). В процессе проектирования
разработчики выбирают из библиотеки необходимые функции и соединяют их вмес-
те, тем самым, реализуется необходимая функциональность устройства.
• Бибоп — музыкальный джазовый стиль, возник в 1940-х годах, характеризуется не-
привычным для многих любителей традиционного джаза усложнением гармонии и
ритма.
• Биполярный плоскостной транзистор — семейство транзисторов.
• Бит — двоичное число, которое может принимать одно из двух значений: 0 или 1.
• Блок логических массивов (logical array block — LAB) — термин компании Altera для
программируемых логических блоков, содержащих несколько логических элементов.
• Булева алгебра — математический способ представления логических выражений.
• Вентильная матрица — заказная специализированная микросхема (ASIC), которая пред-
ставляет собой массив изготовленных заводским способом несоединённых между со-
бой компонентов (транзисторов и резисторов), организованных в группы, называе-
мые базисными ячейками (элементами). Разработчик описывает функции устройства
терминами базисных элементов из соответствующей библиотеки, реализуя их соеди-
нение между собой, после чего производитель микросхем по этим соединениям гене-
рирует маску, используемую для создания слоёв металлизациии.
• Вентильная матрица канальная — заказная микросхема (ASIC), организованная в виде
массивов (матриц) базисных ячеек. Свободное пространство между массивами ба-
зисных ячеек называется каналами.
• Вентильная матрица бесканальная — заказная микросхема (ASIC), организованная в
виде единого массива базисных ячеек.
• Верификация модели — см. Формальная верификация.
• Внутрисхемно программируемый (In-system programmable, ISP) — устройство на осно-
ве ячеек статического ОЗУ, flash или другое, аналогичное, которое может быть пере-
программировано, оставаясь на печатной плате.
Словарь 383
Внутрисистемно перепрограммируемый (In-circuit reconfigurable, ICR) — устройство на
ячейках статического ОЗУ или ему подобное, которое может быть динамически пере-
программировано на лету, оставаясь в составе системы.
Восприимчивый к уровню (level sensitive) — так говорится о входе логической функции.
При этом значение функции зависит от текущего состояния (уровня сигнала) на её
входах и не зависит от процесса перехода входных значений с одного логического
уровня на другой.
Восприимчивый к фронту (спаду) (edge sensitive) — так говорится о входе логической
функции. При этом функция воспринимает входную информацию только в момент
перехода входных параметров из одного логического состояния в другое.
Время пролета (time of flight) — время распространения сигнала от одного логического
вентиля (интегральной схемы, оптоэлектронного компонента) до другого.
Встроенное ПО — термин относится к программам или последовательности инструк-
ций, которые загружены в энергонезависимую память устройства.
Высокоимпедансное состояние — состояние, связанное с сигналом, который в теку-
щий момент времени ни к чему не подключен. Высокоимпедансное состояние обыч-
но обозначается символом «Z».
Проектные нормы — термин относится к размеру структур, из которых состоит интег-
ральная микросхема. В качестве таких структур обычно рассматриваются ширина
проводников и длина транзисторных каналов. Размеры других элементов обычно вы-
ражаются в отношении к этим структурам.
Герц — см. Гц.
Гига — приставка (обозначается символом «Г»), которая предназначена для обозна-
чения одного миллиарда или 109. Например, 3 ГГц представляет собой 3x109 Гц.
Глубокий субмикрон — обычно этот термин относится к интегральным микросхемам,
содержащим структуры, размер которых меньше, чем 0.5 микрон (половина одной
миллионной доли метра).
Пд (Герц) — единица измерения частоты. Один Герц обозначает одно колебание в се-
кунду.
Двоичная (бинарная) логика — цифровые логические вентили, выделяющие два опре-
делённых уровня напряжений. Два напряжения используются для представления
двоичных значений 0 и 1 и их логических эквивалентов Истина и Ложь.
Двоичное кодирование — форма задания состояний конечного автомата, требующая
минимального числа переменных состояния.
Двоичное число — число в двоичной системе счисления; двоичное число (которое
обычно называют бит) может принимать одно из двух значений: 0 или 1.
Дерево синхронизации — это понятие относится к способу распространения синхро-
сигналов по кристаллу. Название «дерево синхронизации» произошло оттого, что
синхросигнал разветвляется по мере его прохождения по кристаллу (при этом тригге-
ры и другие элементы можно рассматривать как листья, находящиеся на краях вет-
вей). Эта структура используется для одновременной, насколько это возможно, до-
ставки синхросигналов ко всем триггерам и прочим потребителям.
Диаграмма состояний — графическое представление конечного автомата.
Динамическая формальная верификация — некоторые части устройства оказывается
довольно тяжело проверить посредством моделирования, так как они находятся глу-
боко в структуре устройства и ими довольно сложно управлять с помощью внешних
входов. Для решения этой проблемы в среде проверки используют моделирование
для достижения тупиковой ситуации, затем моделирование автоматически приоста-
навливается и вызывается механизм статической формальной верификации для ос-
новательного тестирования этой тупиковой ситуации. Комбинация средств модели-
рования и традиционной статической формальной верификации называется
384 Словарь
динамической формальной верификацией. См. также Тупиковая ситуация, Формаль-
ная верификация, Статическая формальная верификация.
• Диод — двухконтактное устройство, которое пропускает электричество только в одном
направлении; для тока, протекающего в другом направлении, его действия аналогичны
разомкнутому ключу. В наши дни термин диод почти всегда относится к полупровод-
никовым приборам, хотя он также может изготавливаться в виде вакуумной лампы.
• Дискретизация — часть процесса, в ходе которого аналоговый сигнал преобразуется в
последовательность цифровых значений. Дискретизация относится к выборке значе-
ний аналогового сигнала в определённые моменты времени.
• Дискретное устройство — этот термин обычно относится к электронным компонен-
там, таким как резисторы, конденсаторы, диоды или транзисторы, которые пред-
ставлены в индивидуальном корпусе. Реже этот термин используется для обозначе-
ния простых интегральных микросхем, содержащих небольшое количество
простейших логических вентилей.
• Дорожка — см. Проводник.
• Единовременные затраты на проектирование (nonrecurring engineering, NRE) — в кон-
тексте рассматриваемого материала этот термин обозначает неповторяющиеся (разо-
вые) расходы на проектирование и внедрение в производство заказных микросхем
(ASIC и ASSP) и ПЛИС.
• Ёмкость — количественная характеристика способности двух расположенных рядом
проводников, разделённых изолятором, накапливать заряды, когда к этим проводни-
кам приложена разность напряжений. Ёмкость измеряется в Фарадах.
• Закон Мура — в 1965 году Гордон Мур (Gordon Moore), который в 1968 году стал со-
учредителем Intel Corporation, заметил, что новое поколение устройств памяти появ-
ляется примерно каждые 18 месяцев, и это новое поколение содержит примерно в
два раза больше памяти, чем у его предшественника. Это наблюдение впоследствии
было названо Законом Мура и стало широко применяться в микроэлектронике и ин-
форматике.
• Импеданс — сопротивление протекающему току, вызванное резистивностью, ёмкос-
тью и/или индуктивностью устройств (или паразитных элементов) схемы.
• Индуктивность — свойство проводника, которое позволяет ему аккумулировать энер-
гию в магнитном поле, вызываемом протекающим через него током. Единица изме-
рения — Генри.
• Интегральная схема — см. ИС.
• Интеллектуальная собственность — см. IP.
• Интерфейс языка программирования (PLI) — язык Verilog и система моделирования
Verilog-XL снабжались весьма полезным компонентом, который назывался интер-
фейсом языка программирования или PLI (programming-language interface). В общем
случае такие компоненты называются API (application programming interface — интер-
фейс прикладного программирования). API представляет собой библиотеку програм-
мных функций, которые позволяют внешним программам передавать данные в при-
ложение и получать от него результаты работы. Таким образом Verilog PLI позволял
пользователям расширять возможности языка программирования и системы модели-
рования.
• ИС (интегральная схема (микросхема)) — устройство, состоящее из компонентов, та-
ких как резисторы, диоды, транзисторы, расположенных на одном кристалле полу-
проводникового материала.
• Канал — 1) область между двумя базисными ячейками в канальной вентильной мат-
рице. 2) Зазор между истоком и стоком полевого транзистора с КМОП-структурой.
• Канальный полевой униполярный МОП-транзистор (или MOSFET — metal-oxide-
semiconductor field-effect transistor) — семейство транзисторов.
Словарь 385
• Квантование — 1) часть процесса, в ходе которого аналоговый сигнал преобразуется в
последовательность цифровых значений. Сначала аналоговый сигнал через опреде-
лённый промежуток времени подвергается дискретизации. Затем каждый отсчёт за-
меняется отдельным фиксированным цифровым значением или квантом. 2) Процесс
преобразования числа с плавающей точкой в его эквивалент с фиксированной точ-
кой.
• Керамика — неорганический, неметаллический материал, такой как глинозём, оксид
бериллия, стеатит или форстерит, который обжигается при высоких температурах и
часто используют в электронике при изготовлении подложек или корпусов электрон-
ных компонентов.
• Кило — приставка (обозначается символом «к»), которая предназначена для обозна-
чения одной тысячи или 103. Например, 3 кГц представляет собой ЗхЮ3 Гц.
• КЛБ (конфигурируемый логический блок) — термин компании Xilinx, который нахо-
дится на уровень выше, чем секция. В некоторых устройствах этой компании каждый
конфигурируемый логический блок включает в себя по 2 секции, а некоторые — по 4.
• КМОП (комплементарный металло-оксидный полупроводник) ~ логический вентиль, со-
стоящий из пары комплементарных МОП-транзисторов соответственно п- и р-типов.
• Код Грэя — последовательность двоичных значений, в которых каждая пара располо-
женных рядом чисел отличается от соседней только одним битом, например: 00, 01,
11, 10.
• Комбинаторная логика — см. Комбинационная логика.
• Комбинационная логика — цифровая логическая функция, состоящая из набора про-
стых логических элементов (вентилей) (И, ИЛИ, И-НЕ, ИЛИ-НЕ и др.), в которой
каждое выходное значение напрямую зависит от комбинации входных значений.
Другими словами, любое изменение сигналов на входе тут же спровоцирует распро-
странение сигнала через элементы функции и формирование нового выходного зна-
чения. Эту логику также иногда называют комбинаторной логикой.
• Комплементарный выход — этот термин относится к функции с двумя комплементар-
ными (противоположными) логическими значениями. Эти выходы называются пря-
мым и комплементарным (инверсным) выходами.
• Конечный автомат — функция (программная или аппаратная), которая может состо-
ять из конечного множества состояний и переходить из одного состояния в другое.
• Контрольная сумма — итоговое значение процедуры проверки с помощью циклическо-
го избыточного кода (CRC), записанное в линейном сдвиговом регистре с обратной свя-
зью (LFSR) (или его программном эквиваленте). Также называется сигнатурой в
средствах функциональной проверки с помощью управляемого пробника.
• Конфигурационные данные — биты в конфигурационном файле, которые используют-
ся для непосредственного определения состояния программируемых логических эле-
ментов. См. также Конфигурационные команды и Конфигурационный файл.
• Конфигурационные команды — набор инструкций в конфигурационном файле, кото-
рые указывают устройству на то, какие действия ему необходимо выполнить над кон-
фигурационными данными. См. также Конфигурационные данные и Конфигурационный
файл.
• Конфигурационный логический блок — см. КЛБ.
• Конфигурационный файл — файл, содержащий информацию, которая должна быть
загружена в ПЛИС с тем, чтобы запрограммировать его на выполнение специфичных
функций. Для устройств на основе ячеек статического ОЗУ конфигурационный файл
содержит совокупность конфигурационных данных и конфигурационных команд. В
процессе загрузки конфигурационного файла в устройство передаваемая информа-
ция формируется в конфигурационный двоичный поток. См. также Конфигурацион-
ные данные и Конфигурационные команды.
386 Словарь
• Кремниевый кристалл — хотя в настоящее время известно множество полупроводни-
ковых материалов, наибольшее распространение получил кремний, и поэтому зачас-
тую под кремниевым кристаллом понимают интегральную микросхему.
• Кристалл — бескорпусная интегральная схема (ИС). В этом случае несколько крис-
таллов также представляют собой кристалл.
• Кэш-память — быстродействующая память небольшого объема (обычно реализуется
на ячейках статического ОЗУ), используемая для буферизации данных, циркулирую-
щих между центральным процессором и медленным, дешёвым запоминающим уст-
ройством, таким как динамическое ОЗУ. Высокоскоростная кэш-память использует-
ся для хранения активных команд и данных0, связанных с программой, в то время
как основная масса команд и данных находится в медленной памяти.
• Линейный сдвиговый регистр с обратной связью — см. LFSR.
• Литерал — переменная в булевых выражениях.
• Логическая функция — математическая функция, которая выполняет цифровые опе-
рации над цифровыми данными и возвращает цифровой результат.
• Логическая ячейка — основная конструктивная единица в современных ПЛИС ком-
пании Xilinx. В её состав входят 4-входовая таблица соответствия, мультиплексор, ре-
гистр и вспомогательная логика. См. также логический элемент, КЛБ, блок логических
массивов (LAB) и секция.
• Логический синтез — процесс, в котором с помощью программного обеспечения осу-
ществляется преобразование высокоуровневого текстового представления устройс-
тва (описанного с помощью языка описания аппаратных средств HDL), выполнен-
ного в терминах уровня регистровых передач (RTL — register transfer level), в
эквивалентные им регистровые или булевы выражения. Средства синтеза автомати-
чески выполняют минимизацию и оптимизацию, и затем выдают таблицу соедине-
ний логических вентилей. См. также HDL-синтез и Физический синтез (Physically
aware synthesis).
• Логический элемент — основная конструктивная единица в современных ПЛИС ком-’
пании Altera. В её состав входят 4-входовая таблица соответствия, мультиплексор, ре-
гистр и вспомогательная логика. См. также логическая ячейка, КЛБ, блок логических
массивов (LAB) и секция.
• Логический вентиль — физическая реализация простейшей логической функции.
• Магнитное ОЗУ — тип устройств памяти, широкое распространение которых ожида-
ется примерно с 2005 года, которые потенциально сочетают в себе высокую скорость
статического ОЗУ, большую ёмкость динамического ОЗУ и энергонезависимость
flash-технологии, потребляя при этом минимум энергии.
• Магнитный туннельный переход — структура из двух ферромагнитных слоёв, разде-
лённых тонким изоляционным слоем. Ячейки памяти магнитного ОЗУ представляют
собой пересечение двух проводников (строк и столбцов) с расположенными между
ними магнитными туннельными переходами.
• Макроархитектурные определения — любая разработка начинается с начальной кон-
цепции, которая описывается системными разработчиками и инженерами в виде вы-
сокоуровневых определений. Эти определения и называются макроархитектурными,
и подразумевают под собой разбиение устройства на программные и аппаратные час-
ти, выбор необходимых микропроцессорных ядер, структуры шин и так далее. Затем
эта спецификация передаётся инженерам-разработчикам аппаратной части, которые
начинают свою часть работы с формирования микроархитектурных определений.
См. также Микроархитектурные определения.
В этом контексте «активный» относиться к тем данным и командам, которые в настоящее время ис-
пользуются программой или будут (по мнению операционной системы) использоваться в ближайшем бу-
дущем.
Словарь 387
• Максимальная длина — характеристика «-битного линейного сдвигового регистра с
обратной связью (LFSR), который генерирует последовательность, состоящую из
(2П — 1) значений, прежде чем вернётся к начальному значению.
• Максимальное смещение (maximal displacement) — характеристика линейного сдвигово-
го регистра с обратной связью (LFSR), в котором отводы выбраны таким образом, что
изменение хотя бы одного бита во входном потоке данных приводит к максимально
возможному изменению содержимого регистра.
• Макстерм — элементарная дизъюнктивная форма, логическое ИЛИ над всеми вход-
ными переменными в прямом или инверсном виде.
• Маска — см. Фотошаблон.
• Масочно-программируемые — устройства, такие как постоянное запоминающее уст-
ройство (ПЗУ), программируются в процессе их изготовления с помощью индивиду-
ально-разработанного набора фотошаблонов.
• Мега — приставка (обозначается символом «М»), которая предназначена для обозна-
чения одного миллиона или 106. Например, 3 МГц представляет собой ЗхЮ6 Гц.
• Металлизационный слой (слой металлизации) — слой из токопроводящего материала в
микросхеме, который накладывается или вытравляется для формирования соедине-
ний между логическими вентилями. В одном устройстве может быть несколько слоёв
металлизации, разделённых слоями диэлектрика.
• Метод наращиваемых перемычек — технология, используемая для создания програм-
мируемых интегральных микросхем, программируемые элементы которых основаны
на токопроводящих связях, называемых наращиваемыми перемычками. При покуп-
ке изготовленных по этой технологии микросхем все перемычки находятся в разо-
мкнутом состоянии. Отдельные перемычки можно «нарастить» при помощи импуль-
са высокого тока и напряжения, подаваемого на входы микросхемы.
• Метод плавких перемычек — технология, используемая при изготовлении интеграль-
ных микросхем, в которой программируемые элементы представляют собой микро-
скопические пережигаемые перемычки. При покупке микросхемы, изготовленной
по такой технологии, все перемычки находятся в нетронутом состояний. Индивиду-
ально каждая перемычка может быть удалена при помощи импульса высокого тока и
напряжения, подаваемого на вход устройства.
• Микро — приставка (обозначается символами «мк» или «ц»), которая предназначена
для обозначения одной миллионной части, то есть 10-6. Например, 3 мкс представля-
ет собой ЗхЮ-6 с.
• Микроархитектурные определения — любая разработка начинается с формирования
концепции, которая описывается системными разработчиками и инженерами в виде
высокоуровневых определений. Эти определения называются макроархитектурны-
ми, и подразумевают под собой разбиение устройства на программные и аппаратные
части, выбор необходимых микропроцессорных ядер, структуры шин и так далее. За-
тем эта спецификация передаётся инженерам-разработчикам аппаратной части, ко-
торые начинают свою часть работы с формирования микроархитектурных определе-
ний, в число которых входят детализация управляющих структур, разработка
структуры шин и первичная оценка элементов тракта передачи данных. В качестве
простого примера можно рассмотреть очередь FIFO, для которой на этом этапе опре-
деляются атрибуты — глубина и ширина, характеристики вида блокирующая запись,
неблокирующее чтение, а также алгоритм действия при опустошении или полном за-
полнении очереди. Микроархитектурные определения, которые часто формируются
в результате мозгового штурма на белой доске, могут определять, какие операции бу-
дут выполняться параллельно, а какие последовательно, какие части конструкции
будут конвейеризированы, а какие нет, а также распределение общих ресурсов, если
таковые будут использоваться.
• Микроконтроллер — микропроцессор, дополненный памятью программ и данных,
интерфейсными схемами, генератором тактовых импульсов. Может также иметь тай-
меры, гибкую систему прерываний, АЦП и т. д.
388 Словарь
• Микропрограммные блоки интеллектуальной собственности (Микропрограммные IP) —
в контексте ПЛИС этот термин относится к библиотеке высокоуровневых функций.
В отличие от программных блоков интеллектуальной собственности (программных
IP), эти функции уже оптимально распределены, размещены и разведены по про-
граммируемым логическим блокам (также возможна комбинация с некоторыми ап-
паратными IP-блоками, например, умножителями). По требованию в устройство мо-
жет быть встроено один или несколько таких предопределённых аппаратных IP-
блоков. См. также Аппаратные IP и Программные IP.
• Микропроцессор — компьютер общего назначения, реализованный в одной микро-
схеме (или вместе с группой микросхем, называемой микропроцессорным набором
или чипсетом).
• Милли — приставка (обозначается символом «м»), которая предназначена для обоз-
начения одной тысячной части или 10-3. Например, 3 мс представляет собой Зх 10-3 с.
• Минимизация — процесс уменьшения сложности булевых выражений.
• Минтерм — элементарная конъюнктивная форма, логическая функция И над вход-
ными значениями, в котором каждая переменная встречается только один раз — ли-
бо с отрицанием, либо без него.
• Младший байт — байт в многобайтном слове, который представляет наименьшее
число, обычно находится справа.
• Младший бит — двоичная цифра или бит в двоичном числе, которая представлена на-
именьшей значащим значением, обычно находится в крайне правой позиции.
• Многокристальный модуль — общее название группы внутренних соединений и тех-
нологии изготовления корпусов, относится к бескорпусным микросхемам, располо-
женным на общей подложке.
• Монтажная плата — общее название широкого класса средств внутренних соедине-
ний, который включает в себя жесткие, гибкие и комбинированные платы, которые
по способу расположения проводников также делятся на однослойные, двухслойные,
многослойные и дискретные.
• Мультиплексор (цифровой) — логическая функция, которая использует двоичное чис-
ло, или адрес, для выбора одного из своих входов, и передачи на выход поступающей
на этот вход информации.
• Нано — приставка (обозначается символом «н»), которая предназначена для обозначе-
ния одной миллиардной части или 10“9. Например, 3 нс представляет собой ЗхЮ-9 с.
• Начальное значение (число) — начальное значение, загружаемое в линейный сдвиговый
регистр с обратной связью (LFSR) или генератор псевдослучайных чисел.
• Нибл — см. Полубайт.
• Общий слой — токопроводящий слой, находящийся в или на подложке, обеспечива-
ющий заземление или общий провод для компонентов микросхемы. В микросхеме
может быть несколько таких слоёв, разделённых изоляционными слоями.
• Объединенный инженерный совет по электронным устройствам — см. JEDEC.
• Ограничения — понятие относится к формальной верификации. В процессе верифи-
кации устройства (системы) рассматриваются все возможные комбинации входных
воздействий, следовательно, часто возникает необходимость ограничить входные
воздействия для корректного поведения устройства (системы).
• Однократно программируемый — программируемый электронный компонент, такой
как ПЛУ или ПЛИС, который может быть сконфигурирован (запрограммирован)
только один раз.
• Однокристальная система — согласно распространённому практическому правилу,
под однокристальной понимается система, представляющая собой интегральную
микросхему, состоящую из аппаратных и программных компонентов. В недалёком
прошлом электронные системы состояли из ряда микросхем, каждая из которых вы-
Словарь 389
подняла определённые функции (микропроцессор, связь, память и так далее). Одна-
ко во многих современных высокотехнологичных решениях все эти функции могут
объединяться в одно устройство, такое как заказная микросхема или ПЛИС, которые
также могут попадать под определение однокристальной системы.
ОЗУ (оперативное запоминающее устройство) — запоминающее устройство, в которое
данные могут записываться и считываться. Как правило, такие устройства реализу-
ются в виде интегральных микросхем.
Ом — единица сопротивления. Для обозначения также часто используется греческая
буква О, например, запись 1 MQ представляет собой 1 миллион Ом.
Операционная система — общее название набора основных программ, которые управ-
ляют компонентами компьютера и пользовательским интерфейсом.
Описание — в контексте формальной верификации этот термин объединяет в себе ут-
верждения, свойства, события и ограничения, которые существуют вместе с другими
структурными элементами устройства.
Отвод — выход регистра, используемый для генерирования следующего значения на
входе линейного сдвигового регистра с обратной связью (LFSR).
Паразитные эффекты — эффекты, вызванные действием паразитных сопротивлений,
ёмкостей и индуктивностей материала или топологии проводников или компонентов.
Переменная состояния — один регистр из набора регистров, значения которых пред-
ставляют текущее состояние конечного автомата.
Переходное отверстие — полое или заполненное токопроводящее отверстие в токо-
проводящем материале, которое используется для связи между двумя или более токо-
проводящими слоями.
Пета — приставка (обозначается символом «П»), которая обозначает один миллион
миллиардов или 1015. Например, 3 ПГц представляет собой Зх1015 Гц.
Печатная плата — тип монтажной платы, проводники которой наложены или «напе-
чатаны» на одну или обе стороны. Также могут содержать внутренние сигнальные
слои проводников и слои питания и общего провода.
ПЗУ (постоянное запоминающее устройство) — запоминающее устройство, из которо-
го данные могут только считываться, но не могут в него записываться. Как правило, в
настоящее время ПЗУ реализуются в виде микросхемы.
Пико — приставка (обозначается символом «п»), которая предназначена для обозна-
чения одной тысячной от миллиардной части или 10 . Например, 3 пс представляет
собой ЗхЮ-12 с.
ПЛУ (программируемое логическое устройство) — интегральная микросхема, внутрен-
няя архитектура которой предопределена производителем, но позволяет инженерам
производить ее конфигурирование (программирование) на месте для выполнения
различных функций. В данной книге под терминов ПЛУ подразумеваются простые и
сложные ПЛУ. В отличие от ПЛИС эти устройства содержат относительно неболь-
шое количество логических вентилей и могут реализовать относительно небольшие и
простые функции.
Поверхностный эффект — явление, возникающее при прохождении высокочастотных
сигналов через проводник, при котором электроны распространяются только по по-
верхности этого проводника.
Подкласс средств синтеза — языки описания аппаратных средств (HDL), такие как
Verilog, который изначально разрабатывался совместно со средствами моделирова-
ния, а средства синтеза при этом находились в стороне. Причина этого заключалясь в
том, что системы логического моделирования работали с высокоуровневыми описа-
ниями устройств, а ранние средства синтеза воспринимали только представления,
которые находились не выше уровня регистровых передач (RTL). Поэтому инженеры
были вынуждены работать с подклассом средств синтеза используемого ими языка.
См. также HDL и RTL.
390 Словарь
• Полевой транзистор (FET) — транзистор, управляющий сигнал которого создаёт элек-
тромагнитное поле, которое включает или выключает этот транзистор.
• Полезная площадь кристалла — обозначает величину доступной для использования
площади кристалла.
• Полностью заказная ИС — специализированная заказная интегральная микросхема
(ASIC). При создании полностью заказных микросхем инженеры полностью отвеча-
ли за разработку маски для каждого слоя микросхемы. Поставщики заказных специа-
лизированных микросхем предварительно не создавали никаких компонентов на
кремниевом кристалле заводским способом и не поставляли библиотек предопреде-
ленных логических вентилей или функций.
• Полубайт — группа из четырёх двоичных цифр или бит.
• Полупроводник — особый тип веществ, которые в разных ситуациях обладают свойс-
твами проводника или изолятора.
• Последовательная логика — цифровая функция, выходное значение которой зависит
не только от текущего состояния на её входах, но и от входных значений в предыду-
щие моменты времени. Другими словами, результат зависит от «последовательности»
входных значений. См. также Комбинационная логика.
• ППЗУ (программируемое постоянное запоминающее устройство) — программируемое
логическое устройство, в котором массив логических элементов ИЛИ программируе-
мый, а массив элементов И — нет. Обычно этот термин относится к устройствам па-
мяти, содержимое которых может быть однократно электрически запрограммирова-
но пользователем.
• Преобразование сигнала — усиление, фильтрация и другая обработка (обычно анало-
гового) сигнала.
• Преобразования Де Моргана — преобразование булевых выражений в альтернатив-
ную, зачастую более удобную форму.
• Призрачное программное (аппаратное) обеспечение — ироническое определение про-
граммного (аппаратного) продукта, находящегося в умах разработчиков, но так и не
поставленного на рынок.
• Примитивы — простые логические функции, такие как буфер, НЕ, И, И-НЕ, ИЛИ,
ИЛИ-HE, ИСКЛЮЧАЮЩЕЕ ИЛИ и ИСКЛЮЧАЮЩЕЕ ИЛИ-HE. Также они мо-
гут называться примитивными логическими вентилями.
• Припой — сплав олова и свинца с относительно низкой температурой плавления, ис-
пользуется для соединения легкоплавких металлов. Обычно припой состоит из 60
процентов олова и 40 процентов свинца. Увеличение доли свинца приводит к умягче-
нию припоя и понижению его температуры плавления, и наоборот, при уменьшении
доли свинца плотность припоя и температура плавления увеличивается.
• Проверка на эквивалентность — см. Формальная верификация.
• Проводник — токопроводящее соединение между электронными компонентами. В
интегральных микросхемах такие проводники часто называют слоем металлизации.
• Программируемая пользователем вентильная матрица — см. FPGA.
• Программируемое пользователем устройство внутренних соединений — см. FPID.
• Программируемый пользователем кристалл внутренних соединений — см. FPICX\
• Программное обеспечение — программы или последовательность инструкций, кото-
рые предназначены для исполнения аппаратной частью устройства.
• Программное ядро — в цифровой электронике термин «программное ядро» обычно
используется для обозначения относительно больших логических функций общего
назначения, которые могут применяться при построении больших устройств. Напри-
мер, если заказная микросхема (ASIC) содержит встроенный микропроцессор, то
FPIC является торговой маркой компании Aptix Corporation.
Словарь 391
можно сказать, что в ASIC встроено «микропроцессорное ядро». В эту категорию
также можно включить ядра микроконтроллеров, цифровых сигнальных процессо-
ров, функции связи (такие как универсальные асинхронные порты UART) и так да-
лее. Такие ядра могут разрабатываться внутренними силами, но, как правило, они
приобретаются у сторонних разработчиков блоков интеллектуальной собственности
(или IP — intellectual property). Программные ядра часто представляют собой RTL-
описания, выполненные на языках VHDL/Verilog. В этом случае ядро синтезируется,
затем проходит этап размещения и трассировки совместно с другими блоками, фор-
мирующими устройство. (В некоторых случаях ядро может быть представлено в фор-
ме таблицы соединений вентилей или в виде принципиальной схемы, но такие слу-
чаи встречаются чрезвычайно редко.) Одним из преимуществ программного ядра
является то, что оно при необходимости может быть настроено конечным пользова-
телем, например, из него можно удалить или модифицировать определённые функ-
ции. Между программными ядрами, реализованными для заказных микросхем и для
ПЛИС, существуют некоторые отличия. В заказных микросхемах предполагается,
что ядро представлено в виде RTL-описания, и его синтез, будет выполняться сов-
местно с RTL-описаниями остальных частей устройства. Затем, результат размеще-
ния и трассировки используется для формирования фотошаблонов, с помощью кото-
рых создается микросхема. Другими словами физическая реализация ядра будет
представлять собой аппаратные вентили и соединения между ними. В отличие от за-
казных микросхем, при создании программного ядра для ПЛИС будет сформирована
таблица соединений вентилей, по которой затем создадут конфигурационный файл,
предназначенный для программирования таблиц соответствия и логических блоков
внутри устройства. Каждая микросхема может содержать несколько программных
ядер, а также аппаратные ядра и другую пользовательскую логику. См. также Аппа-
ратное ядро.
Программные средства интеллектуальной собственности (программные IP) — в ПЛИС
это термин обозначает библиотеку исходных кодов высокоуровневых функций, ко-
торые могут входить в состав пользовательского устройства. Эти функции обычно
описываются с помощью языков описания аппаратных средств (HDL), таких как
Verilog или VHDL, терминами уровня регистровых передач (RTL — register transfer level).
Все функции, которые инженеры решат использовать в своих конструкциях, будут
встроены в основной код устройства (который также описывается с помощью RTL) и
впоследствии будут синтезированы в группу программируемых логических блоков
(возможно вместе с некоторыми аппаратными средствами интеллектуальной собс-
твенности). См. также Аппаратные IP и Микропрограммные IP.
Произведение сумм — конъюнкция дизъюнкций.
Простое ПЛУ — изначально все ПЛУ содержали небольшое количество эквивалент-
ных логических элементов и были чрезвычайно простыми. Вскоре на сцене появи-
лись более сложные устройства, поэтому их более простых родственников принято
выделять в отдельную категорию и называть простыми ПЛУ.
Прямое кодирование — представление каждого состояния конечного автомата с по-
мощью индивидуальной переменной состояния; в каждый конкретный момент вре-
мени активной может быть только одна такая переменная состояния.
Псевдокомментарий (прагма) — специальный комментарий, употребляемый в исход-
ном коде языка C/C++ или HDL, который может быть интерпретирован транслято-
рами, компиляторами и другими средствами. Также псевдокомментарии использу-
ются различными средствами формальной верификации.
Псевдослучайный — искусственная последовательность значений, которые внешне
напоминают случайные числа, но всё же периодически повторяются.
Рассыпная логика — малые интегральные схемы (ИС), содержащие несколько простых
фиксированных логических функций, например, четыре 2-входовых элемента И.
Свойство/утверждение — см. Утверждение/свойство.
392 Словарь
• Связующая логика — относительно небольшое количество простой логики, которая
используется для «связи» между собой больших логических блоков, функций или ус-
тройств.
• Секция (slice)— термин компании Xilinx, подразумевает под собой структуру, находя-
щуюся между логической ячейкой и конфигурируемым логическим блоком (КЛБ).
Почему «секция»? Да потому, что это самое подходящее название для такой структу-
ры. В настоящее время секция включает в себя две логических ячейки. См. также
КЛБ, Логическая ячейка, Логический элемент.
• Сигнатура — термин относится к значению контрольной суммы при проведении тес-
тирования с помощью избыточного циклического кода и управляемого пробника.
• Сигнатурный анализ — метод проведения функционального тестирования с примене-
нием управляемого пробника, основанный на сигнатурах.
• Синтез — см. Логический синтез или Физический синтез.
• Синхронный(ая) — 1) сигнал, данные которого не известны или не активируются до
тех пор, пока не придёт следующий синхроимпульс. 2) Система, работа которой син-
хронизируется поступающими на неё синхроимпульсами.
• Системный логический вентиль — у поставщиков ПЛИС часто возникают проблемы,
когда они пытаются установить соответствие между своими устройствами и заказны-
ми микросхемами (ASIC). Например, если у вас есть устройство, построенное на за-
казной микросхеме, которая содержит 500 000 эквивалентных логических вентилей,
и вы желаете реализовать это устройство на ПЛИС, то как узнать, какую ПЛИС для
этого можно использовать? Чтобы решить эту проблему, поставщики ПЛИС в начале
1990-х начали говорить о «системном логическом вентиле». Кое-кто говорит, что это
была благородная попытка использовать терминологию, понятную для инженеров,
использующих заказные микросхемы, другие же утверждают, что это был всего лишь
неудачный маркетинговый шаг.
• Система автоматической подстройки по задержке — некоторые блоки управления син-
хронизацией основаны на использовании устройств фазовой автоподстройки, другие
используют системы автоматической подстройки по задержке. Последние системы
по определению являются цифровыми. Их сторонники утверждают, что они отлича-
ются более высокой точностью, стабильностью, меньшей мощностью потребления,
более низким уровнем шумов.
• Слово — группа сигналов или логических функций, выполняющих одну общую зада-
чу по передаче или хранению одних и тех же данных. Например, значение на ком-
пьютерной шине данных можно назвать словом данных.
• Слово — количество ячеек памяти, логически и физически объединённых в одно це-
лое. Все ячейки в слове обычно считываются и записываются одновременно.
• Сложное программируемое логическое устройство (CPLD — complex programmable logic
device) — устройство, состоящее из нескольких простых программируемых логичес-
ких устройств (SPLD — simple programmable logic device), объединённых общей мат-
рицей внутренних соединений.
• Слой питания — токопроводящий слой в печатной плате или на подложке, обеспечи-
вающий питание компонентов. В микросхеме может быть несколько таких слоёв, ко-
торые разделяются изолирующими слоями.
• Смешанный сигнал — термин обычно относится к микросхемам, которые состоят из
аналоговых и цифровых элементов, следовательно, работают как с аналоговыми, так
и с цифровыми сигналами.
• Событие — в контексте формальной проверки события подобны утверждениям и
свойствам, и в общем случае могут рассматриваться как подмножество утверждений
и свойств. Однако, если утверждения и свойства обычно используются для выявле-
ния нежелательного поведения системы, то события могут использоваться для опи-
сания желательного поведения устройства.
Словарь 393
• Состояние — см. Состояние сигнала,
• Спад импульса — процесс перехода сигнала с уровня логической 1 на уровень логи-
ческого 0.
• Специализированная интегральная микросхема — см. ASIC.
• СППЗУ (стираемое перепрограммируемое постоянное запоминающее устройство) — ин-
тегральная микросхема памяти, содержимое которой может быть электрически за-
программировано инженером-разработчиком. Кроме того, это содержимое может
быть стёрто с помощью внешнего ультрафиолетового излучения, попадающего на
кристалл через кварцевое окно в корпусе микросхемы.
• Старший байт — байт в многобайтном слове, который представляет наибольшее по
значимости число, обычно находится слева.
• Старший бит — двоичная цифра или бит в двоичном числе, которое представлено на-
ибольшим значащим значением, обычно находится в крайне левой позиции числа.
• Статическая формальная верификация — формальная проверка, в ходе которой прове-
ряется всё пространство состояний устройства без использования каких-либо
средств моделирования. Недостатком такого метода является то, что он может ис-
пользоваться только для небольших частей устройства, так как с ростом сложности
конструкции объем пространства состояний увеличивается по экспоненциальному
закону и очень быстро можно достичь точки его «разрыва». См. также Формальная ве-
рификация и Динамическая формальная верификация.
• Статическое ОЗУ — устройство памяти, в которых ядро каждой ячейки реализовано с
помощью четырёх или шести транзисторов, сконфигурированных для работы в ка-
честве триггера или защёлки. Термин «статическое» используется потому, что после
записи в такую ячейку значения оно будет находиться там до тех пор, пока на его мес-
то не будут записаны другие данные или не будет отключено питание.
• Стираемое перепрограммируемое постоянное запоминающее устройство — см. СППЗУ.
• Структурированная специализированная схема — вид заказных микросхем (ASIC),
структура которых представляет собой массив предварительно изготовленных и рас-
положенных по всей поверхности идентичных модулей. Эти модули могут состоять
из смеси логики общего назначения (логических вентилей, мультиплексоров или
таблиц соответствия), регистров и, возможно, небольшого ОЗУ. С увеличением уров-
ня сложности модулей могут быть также предварительно реализованы основные слои
металлизации. Для таких структурированных специализированных схем требуется
только реализация двух-трёх заказных слоёв металлизации (в некоторых случаях до-
статочно только одного слоя металлизации). Такой подход существенно уменьшает
время и стоимость изготовления микросхемы.
• Сумма произведений — дизъюнкция конъюнкций.
• Схемы на стандартных элементах — вид заказных микросхем (ASIC), которые, в отли-
чие от вентильных матриц, не используют концепцию базисной ячейки и не содержат
каких либо предварительно изготовленных компонентов. Производитель микросхем
изготавливает заказной фотошаблон для каждого этапа производства, позволяя каж-
дой логической функции реализовываться с минимально возможным количеством
транзисторов.
• Таблица истинности — табличное представление принципа действия цифровой схе-
мы, устанавливает соответствие между входными и выходными значениями.
• Таблица соответствия (LUT — look-up table) — существует две основные формы реализа-
ции программируемых логических блоков, используемых для построения среднемодуль-
ных архитектур ПЛИС: на основе мультиплексоров и на основе таблиц соответствия.
При использовании таблиц соответствия группа входных сигналов служит индексом
(указателем) ячейки в таблице, в которой содержится результирующее значение.
• Тера — приставка (обозначается символом «Т»), которая обозначает один миллион
миллионов или 1012. Например, 3 ТГц представляет собой ЗхЮ12 Гц.
394 Словарь
• Терм произведения — набор литералов, подобных оператору И.
• Транзистор — трёхконтактное полупроводниковое устройство, которое в мире циф-
ровой техники работает в качестве переключателя.
• Трит — число, используемое в троичной системе счисления. Может принимать три
фиксированных значения: 0, 1 и 2.
• Троичная логика — экспериментальная технология, в которой логические элементы
работают с тремя фиксированными уровнями напряжения для представления троич-
ных чисел.
• Троичная система счисления — система счисления, в которой используются три числа.
• Троичное число — число в троичной системе счисления, часто называемое «трит»,
принимающее одно из значений — 0, 1 или 2.
• ТТЛ (транзисторно-транзисторная логика) — логические вентили, реализованные на
биполярных транзисторах.
• Тупиковое состояние — см. Тупиковая ситуация.
• Тупиковая ситуация — труднодоступное или труднодостижимое функциональное со-
стояние устройства.
• Управляемый пробник — форма функционального теста, в котором тестируется печат-
ная плата для того, чтобы выявить неисправный компонент или проводник.
• Уровень регистровых передач (register transfer level, RTL) — для того, чтобы охаракте-
ризовать функциональность электронной схемы, используется язык описания аппа-
ратных средств (HDL). Если с помощью этого языка описывается работа цифрового
устройства, то для этого могут использоваться различные уровни абстракции. Самым
простым уровнем является таблица соединений логических элементов, в которой
функциональность цифровой схемы описывается в виде набора простейших логи-
ческих элементов (И, ИЛИ, И-НЕ, ИЛИ-НЕ и так далее) и соединений между ними.
Более сложный (более высокий) уровень абстракции называется уровнем регистровых
nepedanfregister transfer level — RTL). В этом случае схема описывается набором эле-
ментов хранения информации (регистров), булевых выражений, управляющей логи-
ки (например, выражений вида если-то-иначе) и сложных последовательностей со-
бытий (например: если синхроимпульс меняет своё состояние и переходит из 0 в 1,
тогда в регистр Л загружается число, представляющее собой сумму чисел, находящих-
ся в регистрах Б и В). Наиболее популярными языками, использующими описание
устройств терминами RTL, являются VHDL и Verilog.
• Утверждение/свойство — термин свойство пришел из области верификации модели
(Model checking), и обозначает характерное функциональное поведение устройства,
которое вы хотите (формально) проверить (например: «после запроса мы ожидаем
ответа в течение 10 тактов»). Термин утверждение пришел из области моделирова-
ния, и обозначает специфическое функциональное поведение устройства, которое
вы хотите наблюдать в процессе моделирования (и сигнализирует об ошибке, если
такое утверждение «срабатывает»). В наши дни, при использовании формальных ме-
тодов и средств моделирования в унифицированных средах, термины свойство и ут-
верждение могут взаимозаменять друг друга, то есть свойство может выступать в ка-
честве утверждения и наоборот.
• ФАПЧ (фазовая автоматическая подстройка частоты) — некоторые системы управле-
ния синхронизацией основываются на фазовой автоматической подстройке частоты
(ФАПЧ). ФАПЧ используются с начала 1940-х годов в аналоговой технике, но в наше
время также широко используются и их цифровые варианты построения.
• Физический синтез — для большинства людей этот вид синтеза подразумевает учёт
информации о реальном расположении различных логических элементов в устройс-
тве, использование этой информации для оценки точных значений задержки распро-
странения сигнала, реализация полученных значений задержек при выполнении
операции итогового расположения элементов и других оптимизаций. Интересно за-
Словарь 395
метить, что физически-специализированный синтез начинается с первого прохода,
используя относительно традиционный логический/HDL алгоритм синтеза. См. так-
же Логический синтез.
Формальная верификация — в недалёком прошлом термин формальная верификация
(проверка) для большинства инженеров являлся синонимом проверки на эквивален-
тность. В контексте рассматриваемого материала проверка на эквивалентность под-
разумевает под собой средства, которые используют формальные (строго математи-
ческие) методы сравнения двух различных представлений одного устройства —
скажем RTL-описания и таблицы соединений вентилей — для определения идентич-
ности их функциональности от входов до выходов. На практике проверка на эквива-
лентность может рассматриваться как подкласс формальной верификации и назы-
ваться верификацией модели (model checking), которая используется при анализе
конечных автоматов системы для тестирования некоторых свойств устройства, кото-
рые обычно называют утверждениями. См. также Статическая формальная верифика-
ция и Динамическая формальная верификация.
Фотошаблон — лист материала, на который нанесено изображение прозрачное либо
не прозрачное для ультрафиолетового излучения, используемый для формирования
элементов интегральной микросхемы на поверхности кристалла.
Фронт импульса — процесс перехода сигнала с уровня логического 0 на уровень логи-
ческой 1.
Функциональное время ожидания (функциональная латентность) — понятие, характе-
ризующее то, что в любой текущий момент времени в устройстве или системе обычно
задействовано (то есть делает что-либо полезное) только часть логических функций,
остальные в данный момент времени не активны.
Функция с 3-мя состояниями — функция, выход которой может принимать три состо-
яния: 0, 1 и Z (высокий импеданс). Такая функция не выдаёт выходной сигнал, когда
она находится в Z-состоянии, следовательно, такой режим можно рассматривать как
её отключение от остальной части схемы.
Химическая механическая полировка — процесс, используемый для сглаживания и
выравнивания поверхности подложки при помощи полирования «наростов», кото-
рые образуются при создании слоёв металлизации (дорожек).
ЦАП (цифро-аналоговое преобразование) — процесс преобразования цифрового зна-
чения в его аналоговый эквивалент.
Центральный процессор — см. ЦП.
Цифровая обработка сигналов — см. ЦОС (DSP).
Цифровая схема — набор логических элементов, используемых для обработки и гене-
рирования цифровых сигналов.
Цифровой — величина, представленная в виде числа из ограниченного диапазона
дискретных значений, называемого квантом. Точность цифрового значения зависит
от количества квантов, используемых для его представления.
Цифровой сигнальный процессор — см. ЦСП (DSP).
ЦОС (цифровая обработка сигналов — digital signal processing, DSP) — область элект-
роники, которая связана с представлением и обработкой сигналов в цифровой фор-
ме. Обработка включает в себя сжатие, распаковку, модуляцию, коррекцию ошибок,
фильтрацию и другие манипуляции с аудио- (голос, музыка и т. д.) и видеоинформа-
цией, изображениями и другими подобными данными для телекоммуникации/связи,
локации и обработки изображений (в том числе и в медицине).
ЦП (центральный процессор) — главный узел компьютера, выполняющий все основ-
ные функции.
ЦСП (цифровой сигнальный процессор) — специальный микропроцессор, который
сконструирован для выполнения специфичных задач по обработке цифровых данных
396 Словарь
специального типа с более высокой скоростью и эффективностью, чем микропро-
цессоры общего назначения.
• Чип — популярное название интегральной микросхемы (ИС).
• Шина — набор сигналов, выполняющих общие функции и передающих сходные дан-
ные. Обычно представляется с помощью векторной формы записи, например 8-бит-
ная шина может обозначаться как [7:0].
• Шина адреса — набор однонаправленных сигналов, используемых процессором (или
подобным устройством) для указания области, к которой необходимо получить доступ.
• Шина данных — набор двунаправленных сигналов, используемый компьютером для
передачи информации из памяти в центральный процессор и наоборот. В общем слу-
чае представляет собой набор сигналов, используемый для передачи данных между
цифровыми функциями.
• Шум — всяческий мусор, который добавляется к электронному сигналу при его про-
хождении через схему. Шумы могут возникать вследствие действия ёмкостных или ин-
дуктивных связей, или из-за влияния внешних источников электромагнитного поля.
• Эквивалентный вентиль — в заказных микросхемах (ASIC) каждая логическая функ-
ция связана со значением эквивалентного вентиля, который необходим для сравне-
ния функций и устройств. Однако определение эквивалентного вентиля зависит от
того, кто об этом говорит.
• Электрически стираемое перепрограммируемое постоянное запоминающее устройство —
см. ЭСППЗУ.
• Эмиттерно-связанная логика — см. ЭСЛ.
• Энергонезависимый — термин относится к устройствам памяти, и обозначает, что ин-
формация в них не теряется при отключении питания системы.
• Энергонезависимый — термин относится к устройствам хранения информации, ин-
формация в которых теряется при отключении напряжения питания, например, к
динамическому или статическому ОЗУ.
• ЭСЛ (эмиттерно-связанная логика) — логические элементы, реализованные с помо-
щью сконфигурированных особым образом биполярных транзисторов.
• ЭСППЗУ (электрически стираемое перепрограммируемое постоянное запоминающее ус-
тройство) — интегральная микросхема памяти, содержимое которой может быть
электрически запрограммировано разработчиком. Кроме того, это содержимое мо-
жет быть электрически стёрто, тем самым, позволяя произвести повторное програм-
мирование.
• Язык описания аппаратных средств — см. HDL.
• Ячейка памяти — единица памяти, используемая для хранения одного двоичного чис-
ла или бита данных.
• Ячейка заказной микросхемы (ASIC Cell) — логическая функция из библиотеки схем-
ных элементов, определяемой производителем заказных микросхем (ASIC).
предметный указатель
О-In Design Automation 108, 173, 267 1076 (IEEE VHDL стандарт) 147 10-гигабайтный Ethernet 282 1364 (IEEE Verilog стандарт) 146 4000 серия ИС 37 4004 микропроцессор 37 5400 серия ИС 36 64b/66b схема кодирования 284 7400 серия ИС 36 8Ь/10Ь схема кодирования 284 c C54xx 301 Calma 125 Carbon Design Systems Inc. 271 CDR 290 CeloxicaLtd. 108 CheckerWare 267 Chipscope 228 Chrysalis Symbolic Design Inc. 263 CLAM 228
А Co-Design Automation 148, 149 Complex programmable logic devices 37
ABEL 47, 138 AccellChip Inc. 193 Actionprobe 227 Aldec Inc. 108, 181 Altera Corp. 106, 110 Altium Ltd. 108, 211, 277 AMAZE 47 AMBA 199 Amplify 239 Anadigm Inc. 106 API 144 Applicon 125 ARM 199 ARM9 301 ASIC 16, 18, 47 ASIC структурированные 52 ASMBL 331 AssistedTechnology 47 ASSP 16, 18 Atmel Corp. 106 Axis Systems 211 Computervision 125 Confluence 109, 312 CoreConnect 199 Covered 321 CoWare 183, 202 CPLD 37 CRC 371 CUPL 47 CVS 318 D Daisy 126 Data I/O 47 DCI 223 DCM 82 Debussy 252, 262 DEF 159 Design Compiler FPGA 238 Design VERIFYer 263 DesignPlayer 271 faff 319
в Digital signal processors 21 Dillon Engineering Inc. 109
Bell Laboratories 35 BGA 219 BIM 211 BIRD75 223 BoardLink 221 Dinotrace 321 DSP 21 DTA 258
398 Предметный указатель
Е HDL/логический синтез 253 HDL-методы проектирования 138, 140
е (язык верификации аппаратного обеспечения) 261 EDA 21, 126 EDGE 300 EDIF 233 EETimes 15 Hier Design Inc. 109 HOL 324 UNL261 I
Elanix 75, 108, 183, 193
electronic design automation 21 Elixent Ltd 107, 299 EMACS 142, 318 IBIS 222 Icarus 110 Icarus Verilog 320, 322 IDE 202
F IEEE 1076 147 IEEE 1364 146
Fairchild Semiconductor 36, 49 Fibre Channel 282 FIFO 77, 168, 169, 268, 285 Fintronic USA Inc. 108 First Silicon Solutions Inc. 108, 228 FLASH 32, 66 FLI 180, 209 FPAA 106, 330 FPGA 18 FPGAXchange 221 FPIC 294 FPID 294 FPNA 107, 295, 298, 330 FPNA ACM 323 FPNA picoArray 299 FR4 342 FSDB 244 Future Design Automation 173 Incisive 277 InifiniBand 282 Intel 30, 37 International Research Corporation 37 InTime Software 159 IP 232, 234 IPflex Inc. 107, 299 J JEDEC 46 JEIDA 148 Jiffy 329 JTAG 103 JTAG-порт 63, 103, 207 L Lattice Semiconductor Corp. 106
G Launchbird Design Systems 75, 312 LEF 759
GAL 43 Gartner DataQuest 75 Gateway Design Automation 144 gcc 318 Gentoo 110 Gentoo Linux 320 GHDL 244 GigaTest Labs 75 GNU 318 Green Hills Software Inc. 109 grep 319 GTKWave 321 gvim 318 Leopard Logic Inc. 106 Linux 317 LISP 318 LRM 145 LUT 54 M MAC 78, 276 Magma Design Automation 156 magnetic RAM 34 make 318 MandrakeSoft 320 MATLAB 183, 189
H MCM 79 Mega-PAL 44
Handel-C 180, 197 Harris Semiconductor 29 HDL 46, 89, 136 Mentor Graphics Corp. 75, 108, 126, 194 MetaPRL 324 MicroBlaze 202
Предметный указатель 399
Micromatrix 49 Micromosaic 49 MIPS 200 Model checking 149, 263 ModelSim 147, 181, 246 Monolithic Memories, Inc. 43 Motorola 107, 299 MPEG 300 MRAM 34 Python 309, 319, 322 р-МОП 36 Q Q90Clxx 202 QuickLogic Corp. 106 Quicksilver Technology Inc. 107, 299 R
N RapidlO 282
Nexar 211 Nios 202 Novas Software Inc. 109, 244, 252, 262 NuSMV 316, 323 п-МОП 36 PC 20 PC A 36 reconfigurable computing 20 Red Hat 320 RLC-модель 351 RTL 89, 137, 244
0 RXD 224
OCI 227 Open Verilog International 146 OpenCores 325 OpenSSH 320 OpenSSL 319 OpenVera Assertions, cm. OVA OSCI 167 OVA 266, 269 OVI 146 OVL 269, 325 s SDF 144, 159, 244 Seamless 211 SignalTap 228 Signetics 47 Silicon Explorer 227 SilverC 307 Silverware 308 Simple programmable logic devices 37 Simpod Inc. 209
P Simucad Inc. 109 Simulink 183, 190, 308
PACT XPP Technologies AG 107, 299 PAL 43 PAL Ассемблер 46 PALASM 46, 138 ParaCore Architect 309 PCI 89 PCI Express 282 PERL 319 PGA 218 picoArray 299 PicoBlaze 202 picoChip 15 picoChip Design Ltd. 107, 299 Pilkington Microelectronics, cm. PMEL PLI 144, 180, 209 PLI Verilog 144 PMEL 329 PowerPC 200 Precision C 176 PROMELA 316, 323 PSL 269 Sirius 300 SkyRail 282 SONET Scrambling 284 SPARK C-to-VHDL 176 Specman Elite 262 SPEEDCompiler 271 SPICE 222 SPIN 316, 323 SPLD 37 SSTA 258 Sugar 266, 269 Superlog 148 SVP 154 SWIFT 209 Synopsys Inc. 15, 108, 238, 269 Synplicity Inc. 15, 109, 237 System Generator 195 System HILO 244 SystemC 149, 166, 167 SystemVerilog 149 SystemVerilog, оператор assert 269
400 Предметный указатель
т A
TDMA 300 Tenison Technology Ltd. 271 Texas Instruments 36 The MathWorks Inc. 109, 183, 189, 308 TPS 324 TransEDA PLC 109, 260 TXD 224 ABM 303 Автокоррекция сдвига фаз 84 Автомобиль 772 Адаптивная вычислительная машина, см. АВМ Узел алгоритмических элементов 304 Алгоритмы высказываемой выполнимости 323 Алгоритмы систолические 68 Анализ искажений сигналов 222
u Анализ на уровне реализации 272
UART 224 UDL/I 148 Анализ на уровне спецификации 272 Анализ производительности 272 Аппаратное обеспечение по запросу 307
V Аппаратные IP 88 Аппаратные блоки интеллектуальной
Valid 126 VCD 244, 262, 321 Vera 268 Verdi 252, 262 Verilator 321 Verilog 144 Verilog 2001 146 Verilog 2005 146 Verilog 95 146 Verilog-XL 144 Verisity Design Inc. 15, 109, 261 VHDL 146 VHDL International 149 VHSIC 146 VI 142, 318 Virtual Machine Works 228 VirtualWire 228 VITAL 147 VTOC 271, 321 собственности 88 Аппаратные микропроцессорные ядра 79 Арифметическая машина 49 Архитектура XBlue 332 Асинхронные элементы 775 Ауроборос 361 АЦП 182, 330 Б База данных быстрых сигналов 244 Базовое кодовое покрытие 271 Базовые элементы моделирования 243 Байт 100 Бардин, Джон 35 Беркнер, Джон 46 Бесканальные ячейки 50 Библиотека элементов 50, 126 Биполярный транзистор 35 Бит 28, 245
w Блок IP 57, 56, 88, 234, 277 Блок встроенного ОЗУ 77
W-CDMA500 Wind River Systems Inc. 109 Блок интеллектуальной собственности, см. Блок IP Блок конфигурируемый логический 75 Блок логических массивов 75
X Богатин, Эрик 75 БПФ 68, 144, 189, 310
X (неизвестное логическое значение) 245 XBlue, архитектура 332 Xilinx Inc. 75, 35, 54, 73, 106, 110, 199, 328, 331 XM Radio 300 XoC 211 Брэттин, Вальтер 35 Булева алгебра 138 Буль, Джордж 104, 138 Буферы с тремя состояниями 153 Быстродействующие схемы 227 Быстрый и грубый синтез 755
Z
Z (высокоимпедансное состояние) 245 В Варьете-холл 772 Ввод/вывод 85, 86
Предметный указатель 401
Ввод/вывод общего назначения 86
Вентильная матрица 49
Вентильная матрица бесканальная 50
Вентильная матрица канальная 50
Верификация 183
Верификация блоков IP 259
Верификация временных параметров 120
Верификация модели 263
Верификация повторная 264
Верификация формальная динамическая 264, 268
Верификация формальная статическая 264, 268
Виртуальная память 296
Виртуальное аппаратное обеспечение 295, 296
Виртуальный логический анализатор 227
Виртуальный макет 154, 217
Виртуальный прототип 154, 155, 217
Виртуальный прототип в ASIC 154
Виртуальный прототип на основе RTL 158
Виртуальный прототип на уровне вентилей 755, 156
Виртуальный прототип на уровне кластеров 157
Виртуальный прототип ПЛИС 160
Внесение предыскажений 288
Внутрикристальные инструментальные средства 227
Внутрисистемно программируемые 18
Воздушный цирк 319
Возраст ПЛИС 92
Восстановление синхронизации 289
Временное соответствие 158
Временной анализ, динамический 258
Время переключения 86
Встроенные блоки ОЗУ 77
Встроенные микропроцессорные ядра 79
Встроенные микропроцессорные ядра
аппаратные 79
Встроенные микропроцессорные ядра
программные 81
Встроенные средства самотестирования 373
Встроенные сумматоры 79
Встроенные умножители 78
Встроенные умножители с накоплением 79
Встроенный самоконтроль 119
Выбор ПЛИС 273
Выбросы перекрёстные 338
Вывод-вывод 348
Выравнивание тактовых сигналов 116
Высокоимпедансное состояние 245
г
Гвидо ван Россум 319
Гемоглобин 336
Генератор кода общей диагностики 304
Генератор ядер 234
Генератор ядер IP 234
Генераторы псевдослучайных
последовательностей 374
Германий 35
Герц, Генрих 83
Гибрид ПЛИС-заказная интегральная схема 58
Гигабитные приёмопередатчики 87
Гигабитные приёмопередатчики, глазковая
диаграмма 291
Гигабитные приёмопередатчики,
дифференциальные пары 279
Гигабитные приёмопередатчики, компенсация 289
Гигабитные приёмопередатчики, конфщурируемые
параметры 286
Гигабитные приёмопередатчики, определение
разделителей 287
Гигабитные приёмопередатчики, скорость
передачи 286
Гигабитные приёмопередатчики, соединение
нескольких блоков 286
Гигабитные приёмопередатчики, стандарт
10-гигабайтный Ethernet 282
Гигабитные приёмопередатчики, стандарт Fibre
Channel 282
Гигабитные приёмопередатчики, стандарт
InifiniBand 282
Гигабитные приёмопередатчики, стандарт PCI
Express 282
Гигабитные приёмопередатчики, стандарт
RapidlO 282
Гигабитные приёмопередатчики, стандарт
SkyRail 282
Глазковая диаграмма 291
Глазковая маска 291
Глубокий субмикрон 61, 339
Гоэринга, Ричард 75
Графический ввод 142
Графическое описания схем 726
д
Даммер, Дж. 36, 290
Данные конфигурационные 93
Двоичная логика 245
Двухпортовый блок ОЗУ 76
Дейкстра, Эдсгер 322
Декларативный 266
Дерево синхронизации 81
Дешифровка 370
Диаграммы двоичного выбора 323
Диллон, Том 278
Динамически реконфигурируемая логика 293
402 Предметный указатель
Динамически реконфигурируемые внутренние
соединения 294
Динамическое ОЗУ 33, 37
Дискретизатор 191
Диспетчер синхронизации 82
Диэлектрик 334
Домен синхронизации 115
Доступ к предыдущему значению 369
Дочерние тактовые сигналы 82
Ё
Ёмкость 335
3
Зависимость от крутизны 349
Зависимость от состояния 349
Заказная интегральная схема 16, 18, 47
Законы Мэрфи 148
Запоминающее устройство 28
Защелки 117
Защита интеллектуальной собственности 62
Зоны синхронизации 115
и
Иерархические принципиальные схемы 733
Индукция 335
Инжекция горячих электронов 37
Инициализация LFSR 366
Интегральные микросхемы 36
Интегрированная среда разработки 202
Интегрированные среды разработки 235
Интерфейс незнакомых слов 180, 209
Интерфейс соединённых устройств 286
Интерфейс языка программирования 144, 180, 209
Испытательный стенд 261
Истерика 38
Итальянский Ренессанс 46
к
Квантование 191
Кварцевое окно 32
Килби, Джек 36
Кластер 157
КМОП 36
Кодек 329
Кодирование конечных автоматов 119
Кодовое покрытие 271
Кодовый генератор Уолша 304
Колода карт 727
Командная разработка 275
Команды конфигурационные 93
Комбинаторная логика 39
Комбинационные петли 775
Коммутационные шумы 343
Компоновка 725, 128
Конвейер 772
Константы 752
Контрольная сумма 377
Конфигурационный порт 96
Конфигурируемые модули логического
анализатора 228
Конфигурируемые стандарты ввода/вывода 86
Конфигурируемый логический блок 75
Концепция логического уровня 114
Концепция пространственной и временной
сегментации 306
Коррекция временных параметров 254
Кремний 35
Крупномодульные ПЛИС 58
Купроглобин 336
Кэш-логика 295, 296
Кэш-память 296
л
Ласковые слова 93
Латентность 114
Линейный сдвиговый регистр с обратной
связью 304, 361
Литерал 41
Логика комбинационная 39
Логическая ячейка 73
Логические уровни 114
Логический анализатор (виртуальный) 227
Логический синтез 141, 253
Логический элемент 74
Логическое моделирование 727
Локальная оптимизация 159
Льюис, Кэрол 75
м
Магнитное ОЗУ 34, 65, 332
Магнитный туннельный переход 34
Мазор, Стэн 37
Макроархитектурные определения 164
Максимально длинная последовательность 362
Масочно-программируемые устройства 28
Масштаб времени 246
Матрица внутренних соеинений 304
Матрица штырьковых выводов 218
Машина Тюринга 185
Мега-PAL 44
Межсимвольная интерференция 284
Предметный указатель 403
Мелкомодульные микросхемы 58
Мелкомодульные ПЛИС 67, 298
Металлизационные слои 28
Металлизация 120
слои металлизации 120
Метод периферийного сканирования 103
Метод плавких перемычек 25
Метод ступенек 194
Методы проектирования архитектурные 141
Методы проектирования средств ЦОС 182
Методы проектирования, SystemC 167
Методы проектирования, расширенный C/C++ 173
Методы проектирования, чистый C/C++ 176
Микроархитектурные определения 164
Микроконтроллер 21
Микроматрица 49
Микромозаика 49
Микропрограммные блоки интеллектуальной
собственности 89
Микропроцессор 37
Микропроцессорные устройства 198
Микросхемах транзисторно-транзисторной
логики 248
МИШ 211
М-код 189
Многокристальный модуль 79, 200
Множественный доступ с разделением по
времени 300
Модель задержки транспортная 249
Модель задержки трёхдиапазонная 249
Модель инерционной задержки 248
Модель интерфейсной шины, см. МИШ
Модель с сосредоточенной нагрузкой 349
Модель транспортной задержки 249
Модуль 52
Монти Пайтон 319
МОП-транзистор 36
Морби, Фил 144
МП 37
Мультиплексирование 226
Мультиплексирование по времени 117
Мультиязычное проектирование 180
Мультиязычные средства проектирования 245
Мультиязычные среды пректирования 196
М-файл 189
Мэрфи, Эдвард 148
н
Наглядность устройства 296, 225
Надамуни, Дай 75
Нано 67
Напряжение ядра 87
^модифицированный (чистый) C/C++ 766
Нескоммутированная логическая матрица 49
Нобелевская премия мира 92
Нойс, Роберт 36
о
Оболочка (узла) 304
Общий сброс 117
Огнезащитный состав 342
Ограничения 265
Однократно программируемые устройства 18
Однокристальные системы 20
Однопортовый блок ОЗУ 76
Одноуровневые принципиальные схемы 132
OEM 107
ОЗУ 28
ОЗУ динамическое 33
ОЗУ статическое 33
Оперативное запоминающее устройство 28
операционная система 168
Орел (и реактивный двигатель) 93
ОС РВ 204, 212
Отводы 361
Отрицательная обратная связь 239
Отрицательный резерв времени 255
п
Параллельная загрузка, ПЛИС в режиме
ведомый 102
Параллельная загрузка, ПЛИС в режиме
ведущий 100
Патент ЕР0437491 (В1) 238
Первая микросхема динамического ОЗУ 37
Первая микросхема ПЛИС 35
Первая микросхема статического ОЗУ 37
Первые ПЛУ 37
Первый микропроцессор 37
Первый транзистор 35
Передача данных 224
Перекрёстные выбросы 338
Перемычка наращиваемая 26
Переход от ПЛИС к заказной микросхеме 237
Переход от ПЛИС к ПЛИС 236
Петли комбинационные 775
Печатная плата 198, 218
ПЗУ 28
Пилкингтон, Аластэр 329
Плавающий затвор 30
ПЛИС 18, 53
ПЛИС и заказные микросхемы, сравнение стилей
проектирования 777
ПЛИС на основе Flash-памяти 65
404 Предметный указатель
ПЛИС на основе мультиплексоров 69
ПЛИС на основе наращиваемых перемычек 63
ПЛИС на основе СППЗУ 65
ПЛИС на основе таблиц соответствия 69
ПЛИС на основе ЭСППЗУ 65
ПЛИС, архитектура 60
ПЛИС, возраст 92
ПЛИС, защита интеллектуальной собственности 62
ПЛИС, перспективы развития 328
ПЛИС, секция 74
ПЛИС, скоростные показатели 278
ПЛИС, схемотехническое проектирование 134
ПЛИС-платформа 56
ПЛМ 41
ПЛУ 18, 37
ПЛУ простые 37
ПЛУ сложные 37
ПЛУ стираемые 32
ПМЛ 43
Поверхностный эффект 257
Повторная верификация 264
Повторный синтез 254
Подкласс средств синтеза 145
Покрытие ветвей исходного кода 271
Покрытие выражений 271
Покрытие состояний 271
Покрытие условий 271
Покрытие утверждений и свойств 271
Покрытие функциональное 271
Полевой транзистор 36
Полевой транзистор л-типа 36
Полевой транзистор р-типа 36
Полирование химико-механическое 257
Положительный резерв времени 255
Полоса 79
Полубайт 100
Порт JTAG 103
Порт конфигурационный 98
Последовательная загрузка, ПЛИС в режиме
ведомый 102
Последовательная загрузка, ПЛИС в режиме
ведущий 99
Последовательные идентичные цифры 284
Постоянное запоминающее устройство 28
Поток конфигурационный двоичный 93
Пошаговое проектирование 216
Поэтапные размещение и разводка 162
ППЗУ 29
Прагма 173, 266
Прием данных 224
Принципиальная схема 120
Проверка временных параметров 120
Проверка на эквивалентность 263
Проверка функциональная 120
Проверяемое устройство 259
Программатор 46, 63
Программируемая коммутационная матрица 44
Программируемые логические матрицы, см. ПЛМ
Программное обеспечение 44
Программные IP 89
Программные блоки интеллектуальной
собственности 89
Программные микропроцессорные ядра 81
Программные СИС 89
Проектирование блочное 215
Проектирование на нескольких языках 148
Проектирование на языке C/C++ 164
Произведение 41
Простейшие системы моделирования 122
Простые ПЛУ 18, 37
Процедурный 266
Процесс программирования устройства 26
Процессоры встроенные ARM 200, 277
Процессоры встроенные MIPS 200, 277
Процессоры встроенные PowerPC 200, 202
Псевдокомментарии 173
р
Рабочие функции 160
Радиация 64
Разделение ресурсов 117
Размещение и разводка 130
Размещение и разводка, поэтапные 162
Разработка системного уровня 203
Разрешение тактовых сигналов 116
Разрыв пространства состояний 268
Рай в шалаше 19
Распределение произведений 42
Распределение ресурсов 152, 185
Распределенное ОЗУ 72, 76
Распределённая RC-модель 350
Рассыпная логика 18
Реализация многие к одному 361
Реализация один ко многим 365
Регенерация 33
Редактор многоугольников 125
Режим конфигурационный 98
Режим повышенной секретности 303
Резерв задержки сигнала 156, 255
Ренессанс 46
Репликация 254
с
C/C++ методы конструирования 166
C/C++ модели микропроцессоров 208
Предметный указатель 405
C/C++ расширенный 166
C/C++ чистый (немодифицированный) 166
САПР 49
САПР электронных устройств 21
Сверхглубокий субмикрон 61, 339
Сверхжесткая структура 63
Свойства 265
Свопинг 296
Связующая логика 20
Секция 74
Семантика 145
Сигнал записи 367
Сигнал чтения 367
Сигнатура 373
Сигнатурный анализ 373
Символ (передачи данных) 283
Символ-разделитель 287
Синтаксис 145
Синтез быстрый и грубый 155
Синтез логический 141, 253
Синтез повторный 254
Синтез расширения 156
Синтез физический 142, 253
СИС жесткие 89
СИС с открытым исходным кодом 325
Система автоматизированного проектирования
электронных устройств 21
Система моделирования System HILO 244
Система моделирования Verilog-XL 144
Система тройного резервирования 64
Системный вентиль 90
Системы моделирования цикловые 251
Системы с перестраиваемой архитектурой 20
Системы событийного моделирования 241
Систолические алгоритмы 68
Скоростные показатели 278
Сложные ПЛУ 18, 37, 44
Слои металлизации 28
Смит, Гэри 75
Событийное колесо 242
Событийное моделирование 241
События (формальная верификация) 265
Совмещение 371
Согласование ввода/вывода 86, 223
Сопоставление 128
Сопротивление 334
Состояние временного соответствия 141
Специализированные языки 189
Специальные цепи отладки 227
Специальные языки формальной верификации 266
Специальные языки, OVA 266, 269
Специальные языки, PSL 266, 269
Специальные языки, Sugar 266, 269
СППЗУ 30
Справочное руководство по языку 145
Спрул, Боб 156
Среда верификации е 261
Среда верификации OpenVera 269
Среда верификации Vera 268
Средневековье 46
Среднемодульные ПЛИС 58, 298
Средства аппаратной интеллектуальной
собственности 88
Средства проектирования с открытым исходным
кодом 317
Средства тестирования 196
Статистический статический временной анализ 257
Статистический статический временной
анализатор 258
Статический временной анализ 131, 246, 256
Статическое ОЗУ 33
Столбцы 28
Стробирование тактовых сигналов 116
Строки 28
Структура 60
Структурированные ASIC 52
Структурное представление 137
Сумма произведений 41
Сумматоры встроенные 77
Схема кодирования 64b/66b 284
Схема кодирования 8Ь/10Ь 284
Схема кодирования SONET Scrambling 284
Схема прямого кодирования 119, 267
Схема ускоренного переноса 76
схемы на стандартных элементах 57
Сюзерланд, Иван 756
т
Таблица соединений вентилей 727
Таблица соответствия 54, 69, 94
Таблица соответствия на 3,4, 5 и 6 входов 72
Таки, Джон 28
Теневые регистры 370
Тестовый стенд 722
Технологический процесс 67
Технология HDL-синтеза 253
Технология проверки условий 173
Торвальдс, Линус 317
Точечный транзистор 35
Точка-точка 348
Транзакция 260
Транзистор 35
Транзистор биполярный 35
Транзисторно-транзисторная логика, см. ТТЛ
Трит 245
406 Предметный указатель
Троичная логика 245
ТТЛ 36
Тюринг, Алан 185
У
Узел обработки битов 304
Уильямс, Стивен 320
Ультрафиолетовое излучение 31
Умножение с накоплением 78
Умножители встроенные 77
Управляемый пробник 372
Уровень абстракции логических вентилей 137
Уровень регистровых передач, см. УРП
Уровень транзисторных ключей 137
УРП 137
Устранение флуктуаций 83
Устройство на логических вентилях 121
Утверждения 148, 265
Утилиты системной разработки 235
ф
Фазовая автоподстройка частоты, см. ФАПЧ
Фазовый сдвиг 81, 84
Файл битовый 93
Файл конфигурационный 93
Файл логических определений 159
Файл физических определений 159
ФАПЧ 85, 116
Фарада 335
Физический синтез 141, 142, 254
Физический уровень 282
Флуктуация 83, 289, 291
ФМШ 260
Формальная верификация 262, 322
Формальной верификации
автоматизированная формулировка логических
выводов 322
Формат задержки 246
Формат стандартных задержек 132, 144
Фортран 47
Фотошаблон 28
Фрейм 97
Функциональная модель шины 260
Функциональная проверка 120
Функциональное покрытие 271
Функциональное представление 137
Функциональный тест 372
Фэггин, Федерико 37
X
Хайатт, Гилберт 37
Харрис, Дэвид 156
Хейман, Фридрих 36
Холзман, Джерард 323
Хорни, Джин 36
Хофстайн, Стивен 36
Хофф, Марсиан 37
ц
ЦАП 182, 330
Целостность сигнала 334
Центральный процессор 198
Цепочка сканирующая 104
Циклическая избыточная проверка 371
Цикловое моделирование 251
Цифровая автоподстройка по задержке 85
Цифровое управления импедансом 223
Цифровой сигнальный процессор, см. ЦСП
Цифровые интегральные микросхемы 18
Цифровые сигнальные процессоры 21
ЦОС 20, 182
ЦСП 21, 183
ч
Частотный синтез 83
Человек года 360
Чечётка 112
Числа с плавающей запятой 190
Числа с фиксированной запятой 191
Чистая LC-модель 350
Чистая RC-модель 349
ш
Шекспир 73
Шеннон, Клод 138
Шина 87
Шинные макроячейки 216
Широкополосный множественный доступ с
кодовым разделением каналов 300
Шифрование 370
Шифрование поточное 63
Шокли, Вильям 35
Шумы общего провода 343
э
Эквивалентный вентиль 90
Эквивалентный конденсатор 349
Электростатическая индукционная машина 53
Элемент задержки 115
Элемент мозаики 52
Эмиттерно-связанная логика 36
Эмулятор машинных команд 209
Энергозависимые устройства 28
Предметный указатель 407
Энергонезависимые устройства 28
ЭСЛ 36
ЭСПЛУ 32
ЭСППЗУ 32
Эффект горячих электронов 339
Эффект линии передачи 344
Эффект Миллера 341
Эффект Миллера наоборот 343
Эффект Эдисона 151
Эффекты задержки глубокого субмикрона 345
ю
Юрский период 345
я
Ядро 51, 195
Ядро аппаратное ПО, 200
Ядро программное 81, 201
Ядро программное MicroBlaze 202
Ядро программное Nios 202
Ядро программное PicoBlaze 202
Ядро программное Q90Clxx 202
Язык верификации аппаратного обеспечения 261
Язык описания аппаратных средств 136
Японская ассоциация развития электронной
промышленности, см. JEIDA
Ячейка базисная 49
Ячейка конфигурационная 94
Ячейка логическая 73