/



















































































































































































































































































































Text
michal ZALEWSKI
) - «...^ F.
STILLE
I NETZ
EIN PRAXISHANDBUCH ZU
PASSIVER RECONNAISSANCE
UND INDIREKTEN ANGRIFFEN
„Zalewski's book should be read by
anyone interested in Computer security."
Srijith Krishnan Nair, ACM Reviews.com
HANSER
NO STAUCH
PRESS
Michal Zalewski
Stille im Netz
Ein Praxishandbuch
zu passiver Reconnaissance und
indirekten Angriffen
HANSER
Copyright © 2005 by Michal Zalewski. Title of English-language original: Silence on the Wire,
ISBN 1-59327-046-1, publishedbyNo Starch Press.
Geiman-language edition Copyright © 2007 by Carl Hanser Verlag. All rights reserved.
Übersetzung: Christian Alkeinper, Karlsruhe
Alle in diesem Buch enthaltenen Informationen, Verfahren und Darstellungen wurden nach bestem
Wissen zusammengestellt und mit Sorgfalt getestet. Dennoch sind Fehler nicht ganz auszuschließen.
Aus diesem Grund sind die im vorliegenden Buch enthaltenen Informationen mit keiner
Verpflichtung oder Garantie irgendeiner Art verbunden. Autoren und Verlag übernehmen infolgedessen keine
juristische Verantwortung und werden keine daraus folgende oder sonstige Haftung übernehmen, die
auf irgendeine Art aus der Benutzung dieser Informationen — oder Teilen davon — entsteht.
Ebenso übernehmen Autoren und Verlag keine Gewähl' dafür, dass beschriebene Verfahren usw. frei
von Schutzrechten Dritter sind. Die Wiedergabe von Gebrauchsnamen, Handelsnamen,
Warenbezeichnungen usw. in diesem Buch berechtigt deshalb auch ohne besondere Kennzeichnung nicht
zu der Annahme, dass solche Namen im Sinne der Warenzeichen- und Markenschutz-Gesetzgebung
als frei zu betrachten wären und daher von jedermann benutzt werden dürften.
Bibliografische Information Der Deutschen Nationalbibliothek
Die Deutsche Nationalbibliothek verzeichnet diese Publikation in der
Deutschen Nationalbibliografie; detaillierte bibliografische Daten sind im
Internet über http://dnb.d-nb.de abrufbar.
Dieses Werk ist urheberrechtlich geschützt.
Alle Rechte, auch die der Übersetzung, des Nachdruckes und der Vervielfältigung des Buches, oder
Teilen daraus, vorbehalten. Kein Teil des Werkes darf ohne schriftliche Genehmigung des Verlages
in irgendeiner Form (Fotokopie, Mikrofilm oder ein anderes Verfahren) — auch nicht für Zwecke der
Unterrichtsgestaltung — reproduziert oder unter Verwendung elektronischer Systeme verarbeitet,
vervielfältigt oder verbreitet werden.
© 2007 Call Hanser Verlag München Wien
Lektorat: Fernando Schneider
Herstellung: Monika Kraus
Umschlagdesign: Marc Müller-Bremer, Rebranding, München
Umschlaggestaltung: MCP ■ Susanne Kraus GbR, Holzkirchen
Datenbelichtung, Druck und Bindung: Kösel, Krugzell
Ausstattung patentrechtlich geschützt. Kösel FD 351, Patent-Nr. 0748702
Printed in Geimany
ISBN-10: 3-446-40800-2
ISBN-13: 978-3-446-40800-5
www.hanser.de/cornputer
Für Maja
Über den Autor
Michal Zalewski ist Autodidakt im Bereich der IT-Sicherheitsforschung. Er arbeitet an so
unterschiedhchen Themen wie Entwicklungsprinzipien für Haidwaie und Betiiebssysteme
einerseits und der Netzwerktechnologie andererseits. Zalewski ist ein erfahrener Bugjäger
und seit Mitte der Neunzigerjahre regelmäßiger BugTraq-Poster. Femer ist er Autor
beliebter Sicherheitsutilitys wie pOf einem Tool für passives Betiiebssystem-Fingeiprinting.
Außerdem hat er eine Anzahl von der Kritik gelobter Artikel verfasst.
Michal Zalewski hat als Sicherheitsfachrnann für viele bekannte Unternehmen (darunter
zwei große Telekormnunikationsfirmen) in seinem Herkunftsland Polen und in den
Vereinigten Staaten gearbeitet. Er ist nicht nur ein begeisterter Forscher und Gelegenheitspro-
grarnrnierer, sondern beschäftigt sich nebenbei auch ein wenig mit Bereichen wie der
künstlichen Intelligenz, der angewandten Mathematik und der Elektronik und ist außerdem
Fotograf aus Leidenschaft.
Inhalt
Einleitung 1
Teil I - Die Quelle
1 Die redselige Tastatur 7
1.1 Zufall — wofür eigentlich? 8
1.1.1 Zufallszahlen automatisiert erzeugen 11
1.2 Wie sicher sind Zufallsgeneratoren? 12
1.3 I/O-Entropie: Hier kommt die Maus! 13
1.3.1 Interrupts in der Praxis 13
1.3.2 Abkürzung ohne Rückfahrschein 16
1.3.3 Von der Bedeutung, pedantisch zu sein 18
1.4 Entropie—je mehr desto besser 18
1.5 Angriff: Folgen eines jähen Paradigmenwechsels 20
1.5.1 Tastatureingaben unter der Lupe 21
1.5.2 Taktiken zur Verteidigung 24
1.5.3 Zufallszahlenerzeugung via Hardware — die bessere Lösung? 25
1.6 Denkanstöße 26
1.6.1 Entfernte Tirningangriffe 27
1.6.2 Ausnutzen der Systemdiagnose 27
1.6.3 Reproduzierbare Unberechenbarkeit 28
2 Mehrarbeit fällt auf 29
2.1 BoolesErbe 29
2.2 Auf dem Weg zum Universaloperator 30
2.2.1 DeMorgan im Einsatz 31
2.2.2 Komfort ist notwendig 32
2.2.3 Die Komplexität beim Schöpfe packen 33
2.3 ... und weiter in die Welt der Materie 34
2.4 Der stromlose Computer 34
2.5 Eine Computerkonstruktion, die ein ganz klein wenig weiter verbreitet ist 36
V
2.5.1 Logikgatter 36
2.6 Von Logikoperatoren zu Berechnungen 37
2.7 Von der elektronischen Eieruhr zum Computer 40
2.8 Turingund die Komplexität von Anweisungsmengen 42
2.8.1 Endlich: Funktionalität 43
2.8.2 Der Heilige Gral: Em programmierbarer Computer 44
2.8.3 Fortschritt durch Schlichtheit 45
2.8.4 Aufgabenverteilung 46
2.8.5 Ausfuhrungsstufen 47
2.8.6 Speicher ist nicht gleich Speicher 48
2.8.7 Mehr desselben: Pipelining 49
2.8.8 Das große Problem beim Pipelining 50
2.9 Auswirkungen — die kleinen Unterschiede 51
2.9.1 Mit Ablaufmustern Daten rekonstruieren 52
2.9.2 Bit für Bit 53
2.10 In der Praxis 54
2.10.1 Early-Out-Optimierung 55
2.10.2 Funktionierender Code — selbstgemacht 57
2.11 Vorbeugung 59
2.12 Denkanstöße 59
3 Die zehn Häupter der Hydra 61
3.1 Aufschlussreiche TV-Ausstrahlung 61
3.2 Datenschutz mit beschränkter Häftling 64
3.2.1 Er war's, erwar's, er war's! 64
3.2.2 Moment mal: *_~lq'@@ ... und Ihr Passwort lautet 66
4 Wirken für das Gemeinwohl 67
4.1 Das große Krabbeln 67
Teil II - Der sichere Hafen
5 Blinkenlichten 75
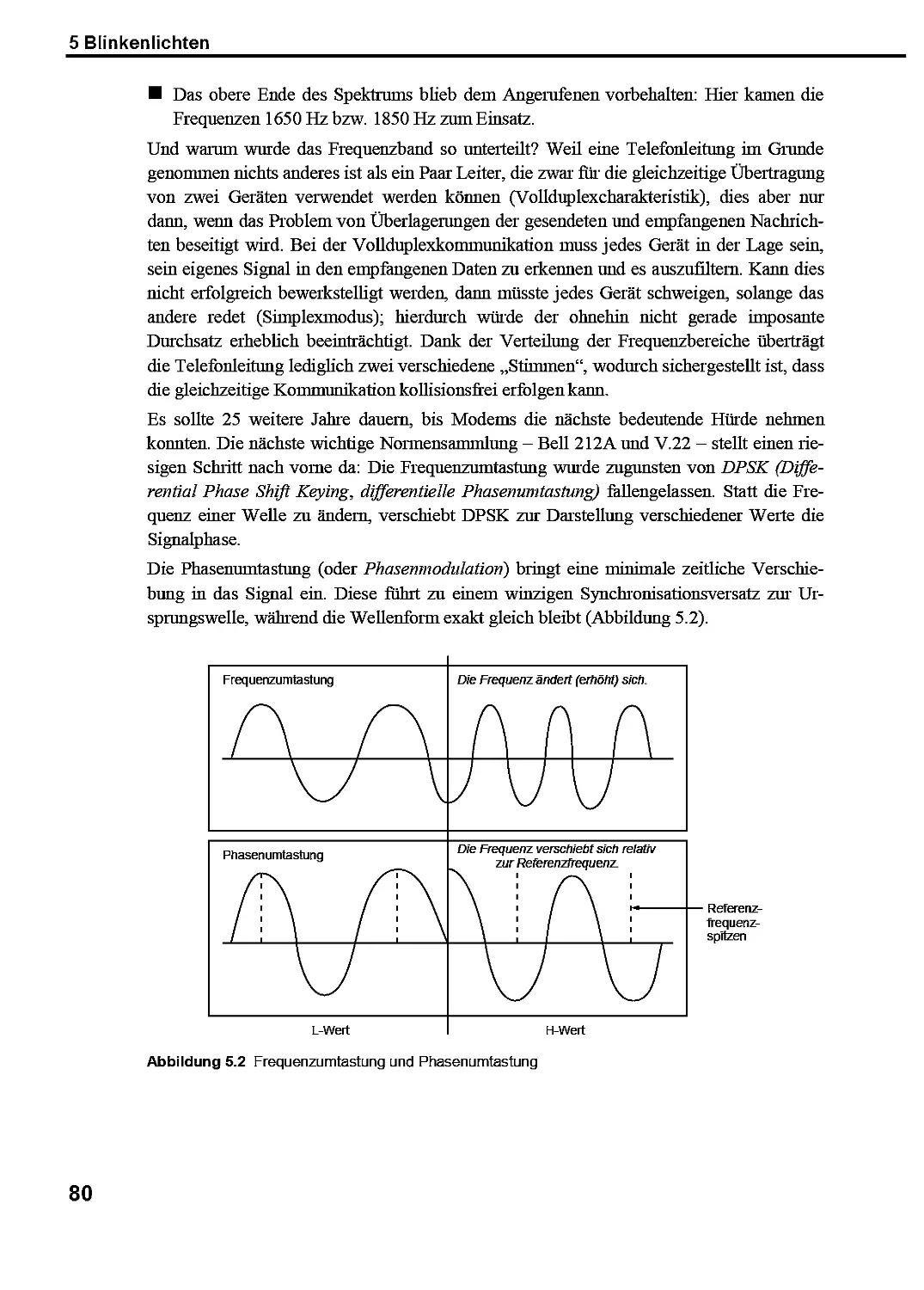
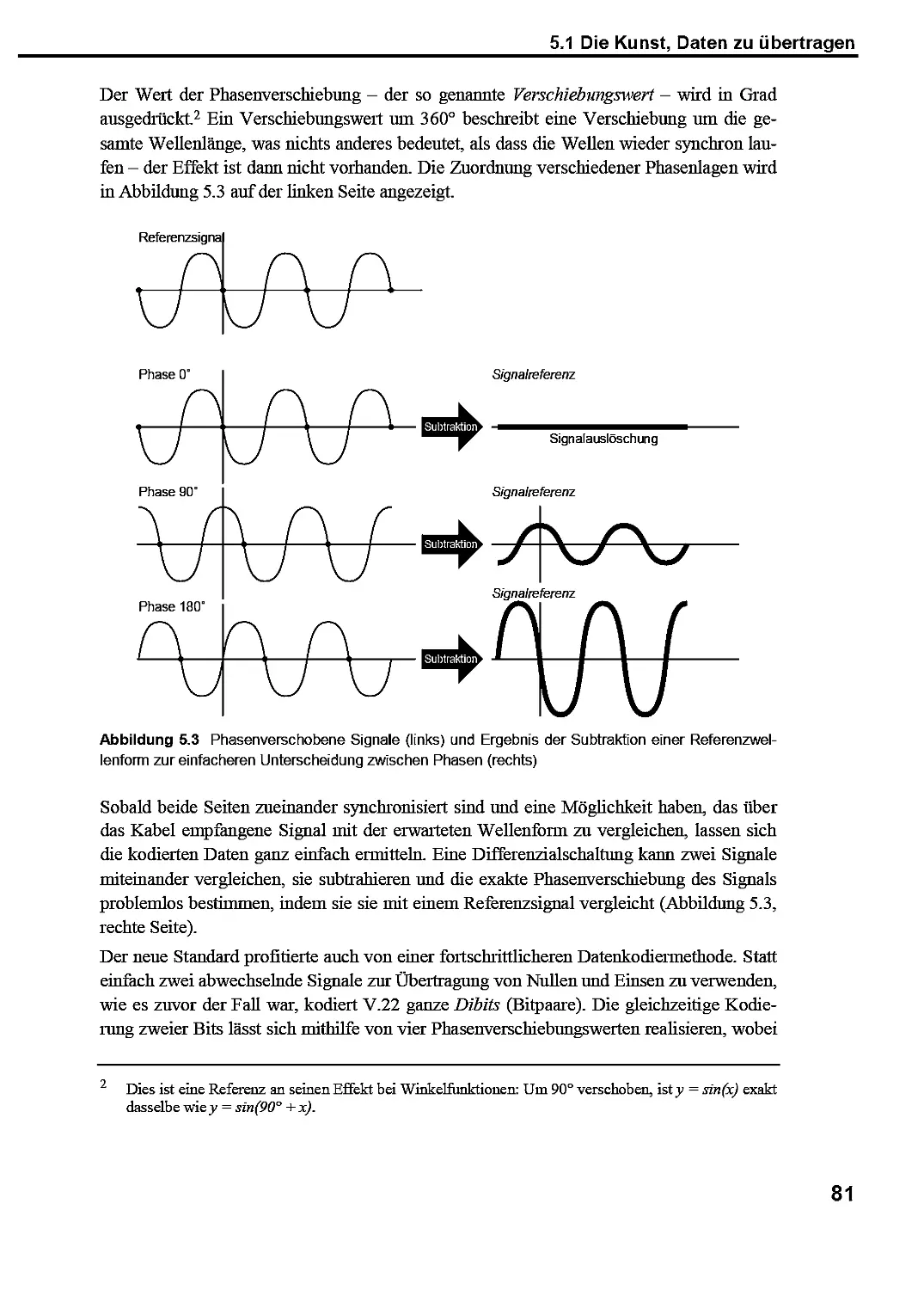
5.1 Die Kunst, Daten zu übertragen 75
5.1.1 Wie aus Ihrer Mail eine Menge Lärm wird — und dann wieder eine Mail 78
5.1.2 Die Situation heute 84
5.1.3 Manchmal ist auch ein Modem nur ein Modem 85
5.1.4 Kollisionen unter Kontrolle 86
5.1.5 Hinter den Kulissen: Die Sache mit den Leitungen — und unsere Lösung dafür 88
5.1.6 Blihkenlichten in der Kommunikation 90
5.2 Die Auswirkungen der Ästhetik 91
5.3 Spionageausrüstung selbstgebaut 93
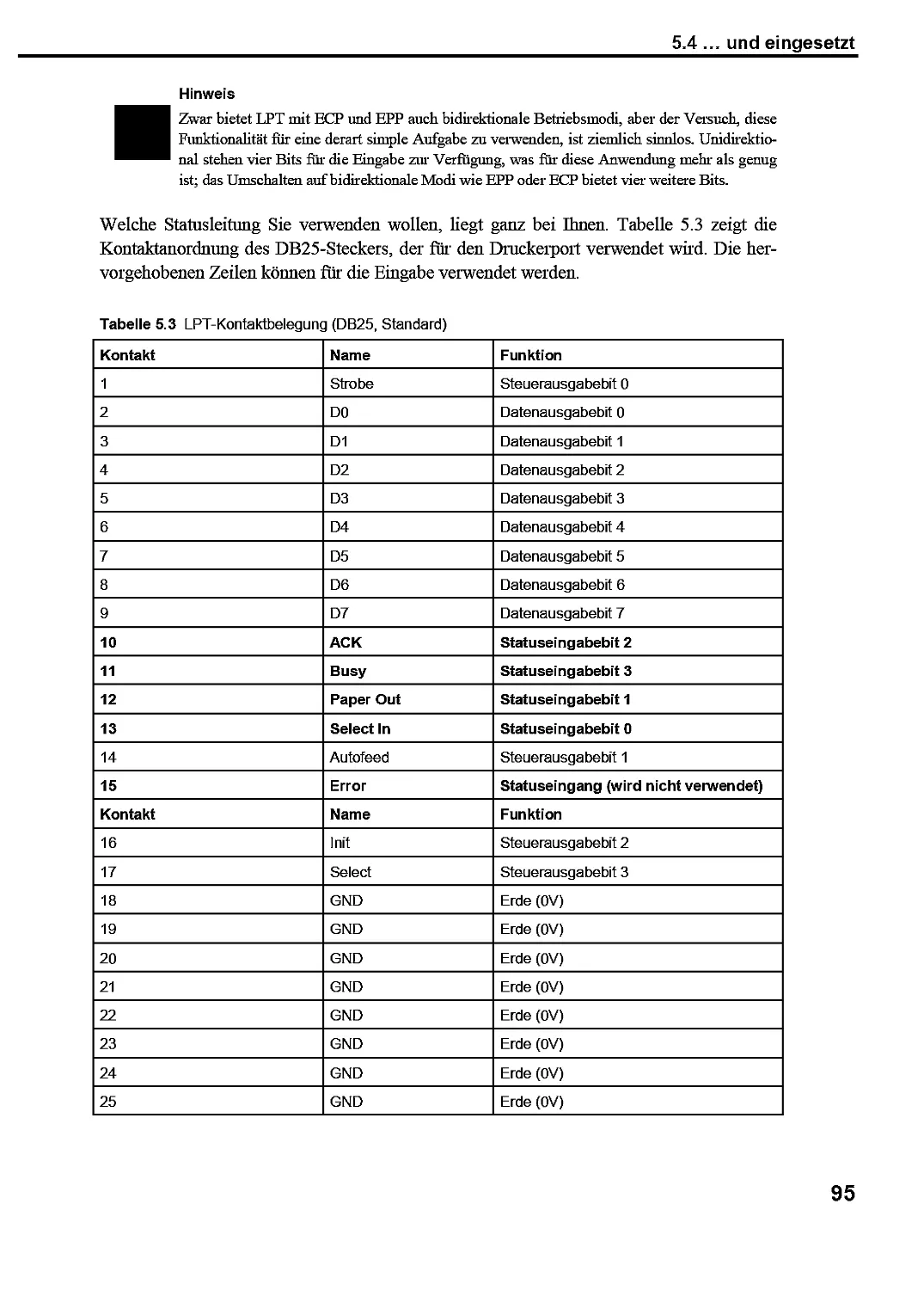
5.4 ... und eingesetzt 94
5.5 Wie man die Zeigefreudigkeit von LEDs bändigt — und warum es dann doch nicht klappt...97
5.6 Denkanstöße 101
6 Echos der Vergangenheit 103
6.1 Der Turmbau zu Babel 103
6.1.1 Das OSI-Modell 104
6.2 Der fehlende Satz 106
6.3 Denkanstöße 108
7 Sicherheit in geswitchten Netzwerken 109
7.1 Ein wenig Theorie 110
7.1.1 Adressauflösung und Switching 110
7.1.2 Virtuelle Netzwerke und Datenverkehrsrnanagement 112
7.2 Angriff auf die Architektur 114
7.2.1 CAM-Überlauf und erlauschte Daten 114
7.2.2 Weitere Angriffsszenarien: DTP, STPund Trunks 115
7.3 Vorbeugung 116
7.4 Denkanstöße 116
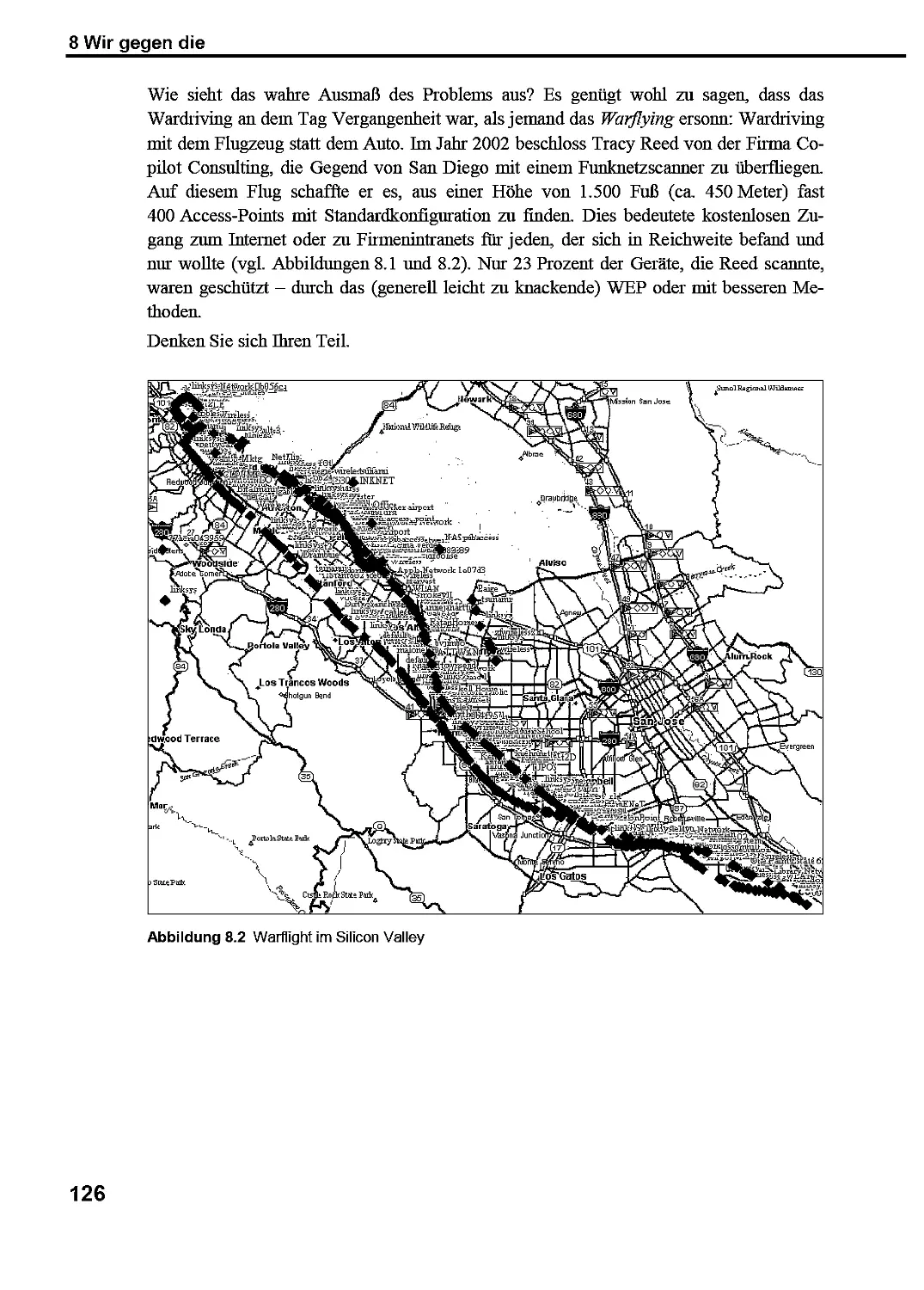
8 Wir gegen die 119
8.1 logische" Blinkenlichten und ihre ungewöhnliche Verwendung 121
8.1.1 Zeig mir, wie du tippst, und ich sage dir, wer du bist 121
8.2 Private Daten, wohin man auch sieht 122
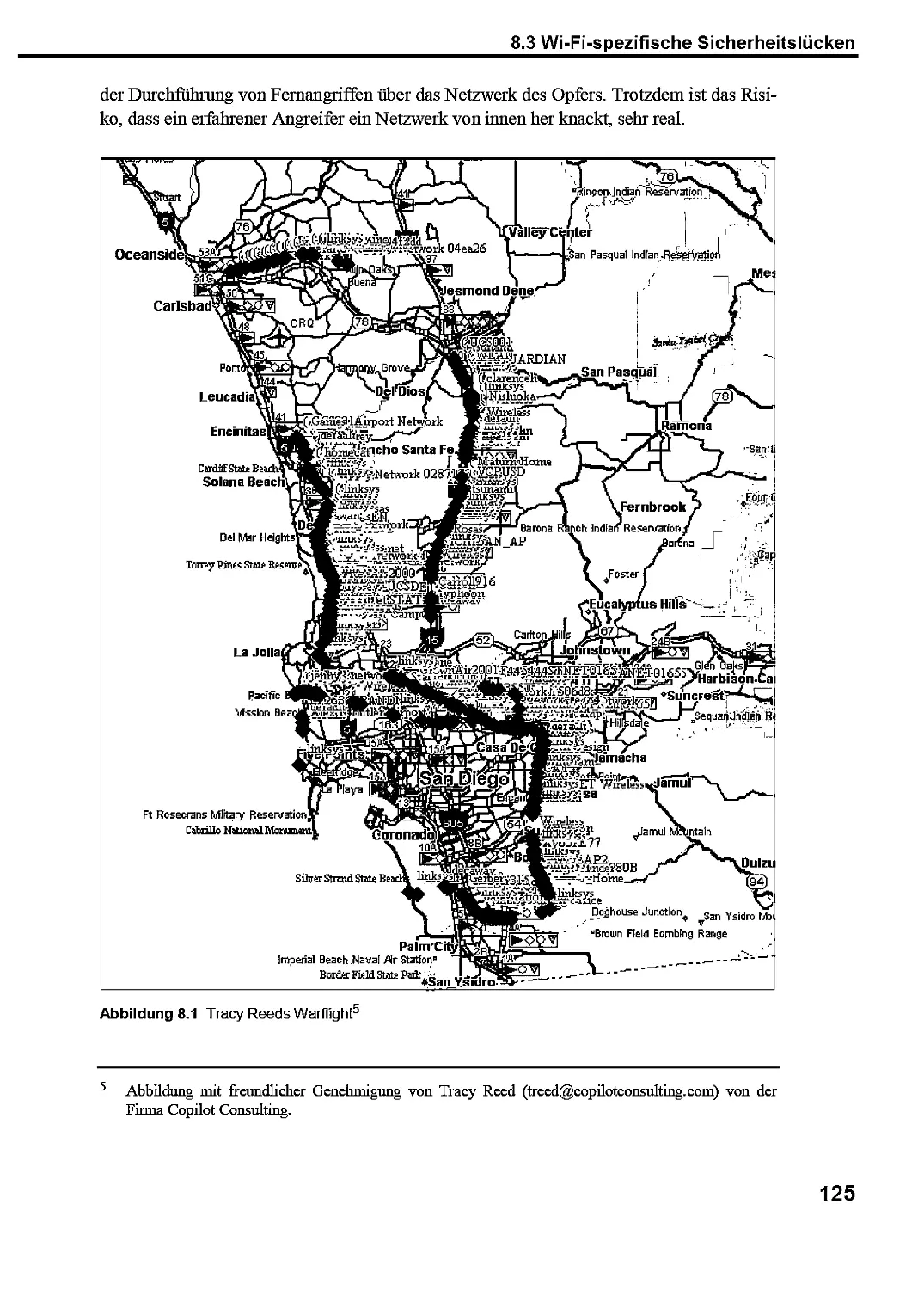
8.3 Wi-Fi-spezifische Sicherheitslücken 123
Teil IM-In der Wildnis
9 Der verräterische Akzent 129
9.1 Die Sprache des Internets 130
9.1.1 Routing auf naive Art 131
9.1.2 Routing im wirklichen Leben 132
9.1.3 Der Adressraum 132
9.1.4 Fingerabdrücke auf dem Umschlag 135
9.2 Das IP-Protokoll 135
9.2.1 Protokollversion 135
9.2.2 Header-Länge 136
9.2.3 Diensttyp (Type of Service, TOS) 137
9.2.4 Paketlänge 137
9.2.5 Absenderadresse 137
9.2.6 Zieladresse 138
9.2.7 Kennung des übergeordneten Protokolls 138
9.2.8 TTL 138
9.2.9 Flags und Offsets 139
9.2.10 IP-Kennung 141
9.2.11 Prüfsumme 141
9.3 Jenseits von IP 141
9.4 Das UDP-Protokoll 142
9.4.1 Einführung in die Portadressierung 143
9.4.2 Übersicht zum UDP-Header 144
9.5 TCP-Pakete 144
9.5.1 TCP-Handshake mit Steuer-Flags 145
9.5.2 Weitere Parameter des TCP-Headers 148
9.5.3 TCP-Optionen 150
9.6 ICMP-Pakete 152
9.7 Bühne frei für passives Fingerprinting 154
9.7.1 Schnüffeln in IP-Paketen: Die gute alte Zeit 154
9.7.2 Der TTL-Startwert (IP-Schicht) 155
9.7.3 Das DF-Flag (IP-Schicht) 155
9.7.4 Die IP-Kennung (IP-Schicht) 156
9.7.5 Diensttyp (IP-Schicht) 156
9.7.6 Felder mit erzwungenen Null- und Nichtnullwerten (TP- und TCP-Schichten) 157
9.7.7 Quellport (TCP-Schicht) 157
9.7.8 Fenstergröße (TCP-Schicht) 158
9.7.9 Dringlichkeitszeiger und Bestätigungsnummer (TCP-Schicht) 159
9.7.10 Reihenfolge und Einstellungen von Optionen (TCP-Schicht) 159
9.7.11 Fensterskalierung (TCP-Schicht) 159
9.7.12 MSS (Option in der TCP-Schicht) 160
9.7.13 Zeitstempeldaten (Option in der TCP-Schicht) 160
9.7.14 Andere Schauplätze passiven Fingeiprintings 161
9.8 Passives Fingeiprinting in der Praxis 161
9.9 Passives Fingeiprinting in der praktischen Anwendung 163
9.9.1 Statistikermittlung und Ereignisprotokollierung 164
9.9.2 Optimierung von Inhalten 164
9.9.3 Durchsetzung von Richtlinien 165
9.9.4 Die Sicherheit des kleinen Mannes 165
9.9.5 Sicherheitstestsund angriffsvorbereitende Beurteilung 165
9.9.6 Erstellung von Kundenprofilen und Eindringen in die Privatsphäre 166
9.9.7 Spionage und verdeckte Aufklärung 166
9.10 Wie man Fingeiprinting verhindert 166
9.11 Denkanstöße: Der verhängnisvolle Fehler bei der IP-Fragmentierung 167
9.11.1 Wie man TCP zertrümmert 170
10 Schäfchen zählen für Fortgeschrittene 173
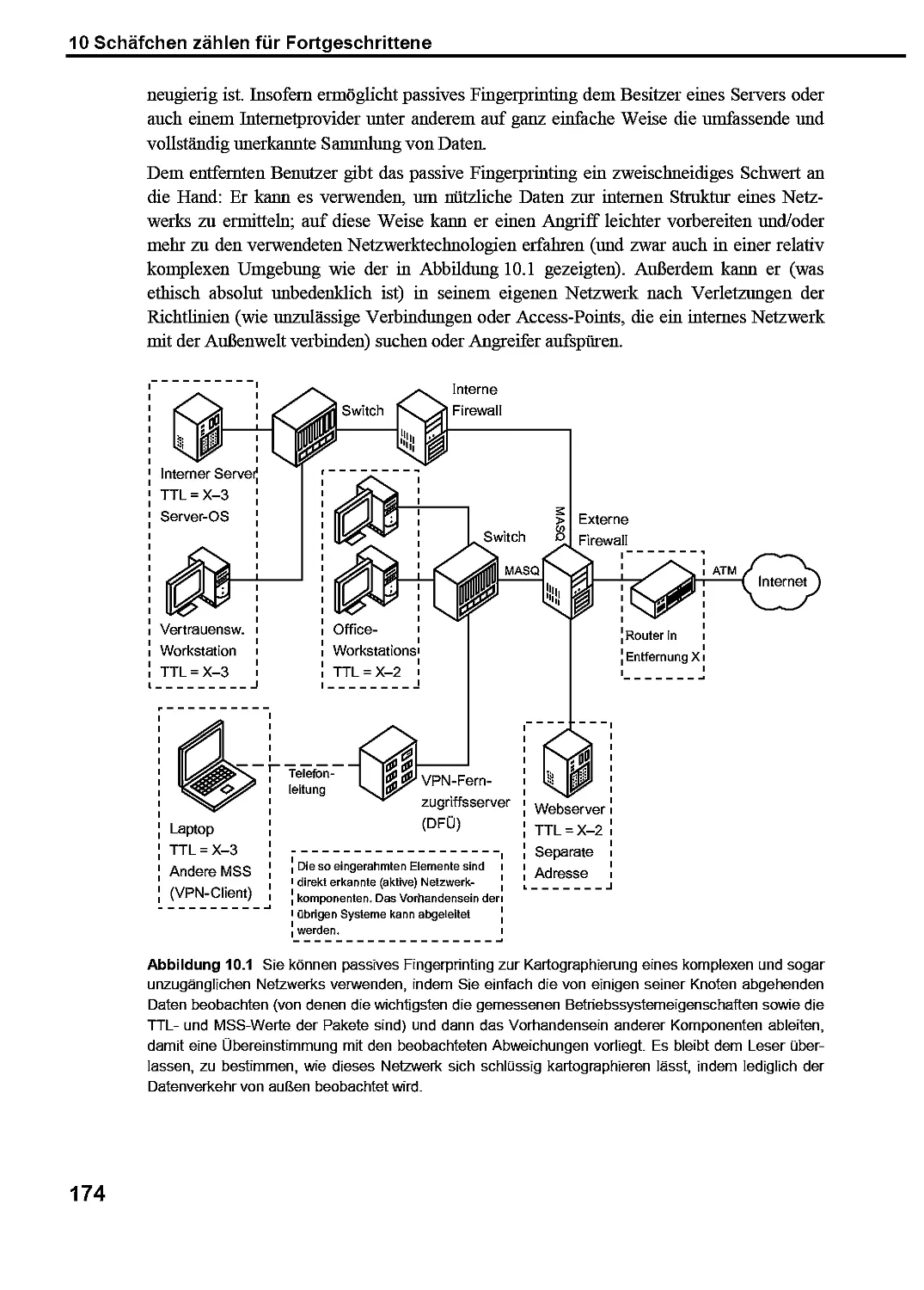
10.1 Vor-und Nachteile des traditionellen passiven Fingerprintings 173
10.2 Eine kurze Geschichte der Sequenznummern 176
10.3 Holen Sie mehr aus Ihren Sequenznummern 177
10.4 Koordinatenverzögerung: Zeitliche Abfolgen in Bildern 179
10.5 Schöne Bilder: Die Galerie des TCP/TP-Stapels 182
10.6 Angreifen mit Attraktoren 189
10.7 Zurück zum Fingeiprinting 192
10.7.1 ISNProber: Theorie in Aktion 193
10.8 Wie man die passive Analyse verhindert 194
10.9 Denkanstöße 194
11 Anomalien erkennen und nutzen 197
11.1 Grundlagen zu Paket-Firewalls 198
11.1.1 Zustandslose Filterung und Fragmentierung 199
11.1.2 Zustandslose Filterung und unsynchrone Daten 200
11.1.3 Zustandsbehaftete Paketfilter 202
11.1.4 Neuschieiben von Paketen und NAT 203
11.1.5 Lost in Translation 204
11.2 Der Mummenschanz und seine Folgen 206
11.3 Roulette spielen mit der Segmentgröße 207
11.4 Zustandsbehaftete Nachverfolgung und unerwartete Antworten 208
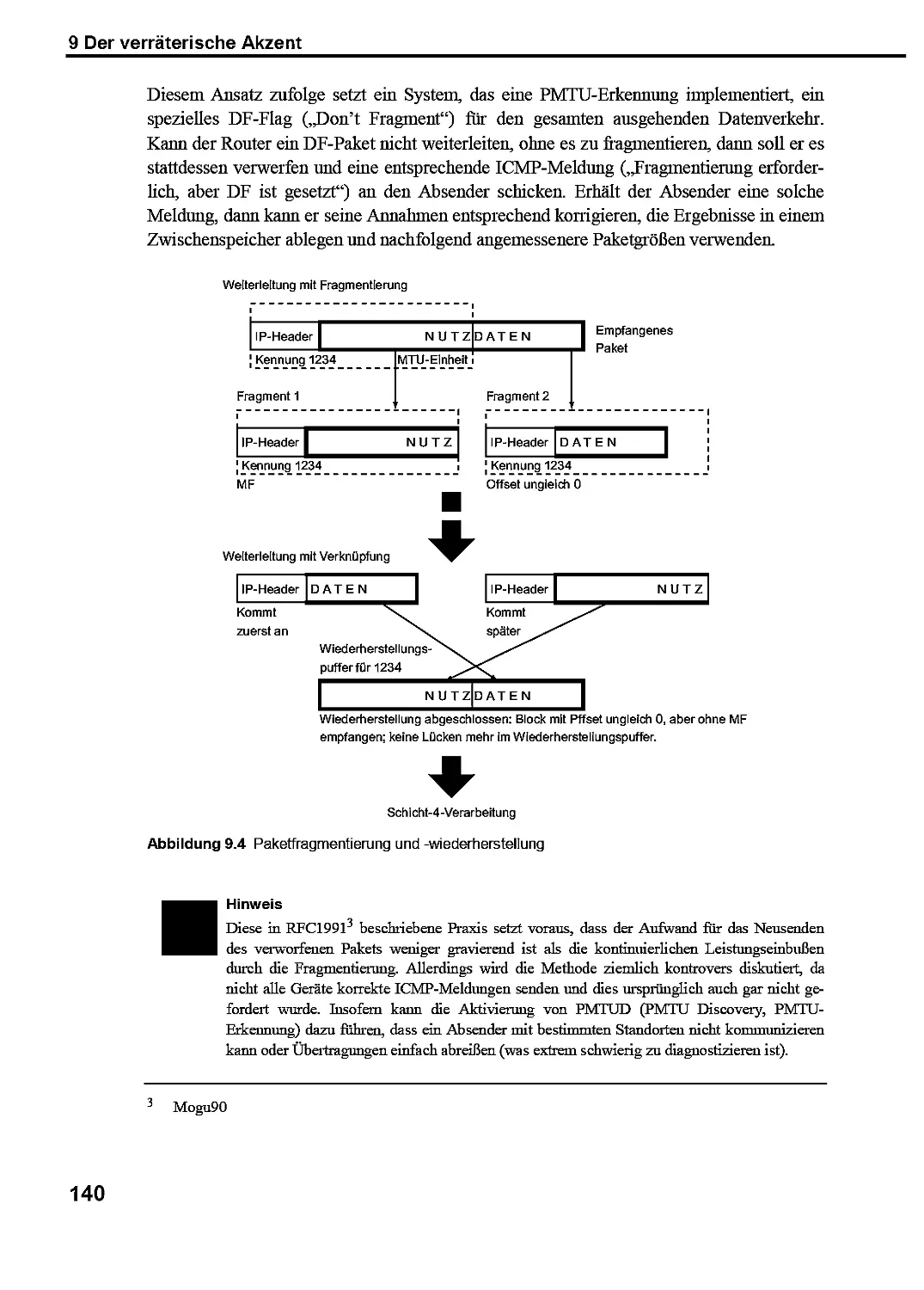
11.5 Zuverlässigkeit oder Leistung: Der Streit ums DF-Bit 210
11.5.1 Ausfallszenarien für die PMTU-Erkennung 210
11.5.2 Der Kampf gegen PMTUD und seine Nebenprodukte 212
11.6 Denkanstöße 212
12 Löcher im Datenstapel 215
12.1 Kristjans Server 215
12.2 Erstaunliche Erkenntnisse 216
12.3 Die Offenbarung: Reproduktion eines Phänomens 218
12.4 Denkanstöße 219
13 Schall und Rauch 221
13.1 Der Missbrauch von IP, oder: Port-Scanning für Fortgeschrittene 222
13.1.1 Eins, zwei, drei, vier, Eckstein 222
13.1.2 Idle-Scanning 223
13.2 Idle-Scanning abwehren 225
13.3 Denkanstöße 226
14 Clientidentifikation: Die Ausweise, bitte! 227
14.1 Die Kunst der Tarnung 228
14.1.1 Wie man das Problem angeht 229
14.1.2 Wie die Lösung aussehen könnte 229
14.2 Eine (ganz) kurze Geschichte des Web 230
14.3 Eine Einführung in HTTP 232
14.4 Wie HTTP besser wird 234
14.4.1 Latenzverringerung per Notnagel 234
14.4.2 Caching von Inhalten 236
14.4.3 Sitzungen mit Cookies verwalten 238
14.4.4 Cache und Cookies: Die Mischung macht's 240
14.4.5 Wie man die Cache-Cookie-Attacke verhindert 240
14.5 Verrat! Verrat! 241
14.5.1 Verhaltensanalyse: Eine einfache Fallstudie 242
14.5.2 Was uns der Künstler mit seinem Bild sagen will 244
14.5.3 Gentlemen, startyour engines! 246
14.5.4 Was sonst noch hinter dem Horizont lauert 246
14.6 Vorbeugung 248
14.7 Denkanstöße 248
15 Das Opfer als Nutznießer 249
15.1 Angriffsmetriken definieren 250
15.2 Den Beobachter beobachten 254
15.3 Denkanstöße 255
Teil IV - Das große Ganze
16 Parasitic Computing, oder: Kleinvieh macht auch Mist 259
16.1 Knabbern an der CPU 260
16.2 Praktische Aspekte 263
16.3 Parasitic Storage — früher 265
16.4 Parasitic Storage — heute 267
16.5 Anwendungen, soziale Gesichtspunkte und Abwehr 273
16.6 Denkanstöße 274
17 DieTopologie des Netzwerks 275
17.1 Momentaufnahmen 275
17.2 Herkunftsnachweis mit Topologiedaten 278
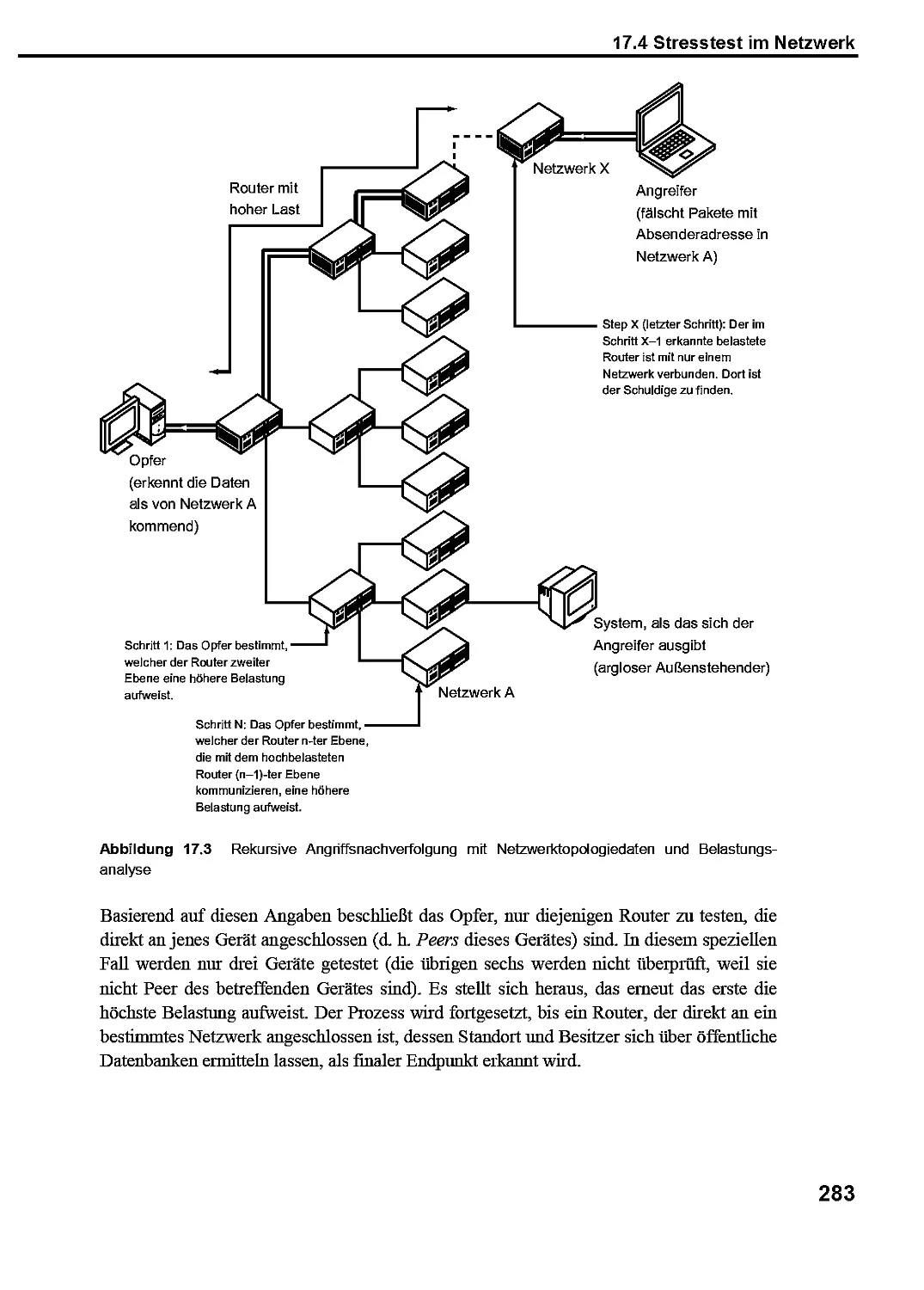
17.3 Netzwerktriangulation mit Topologiedaten 280
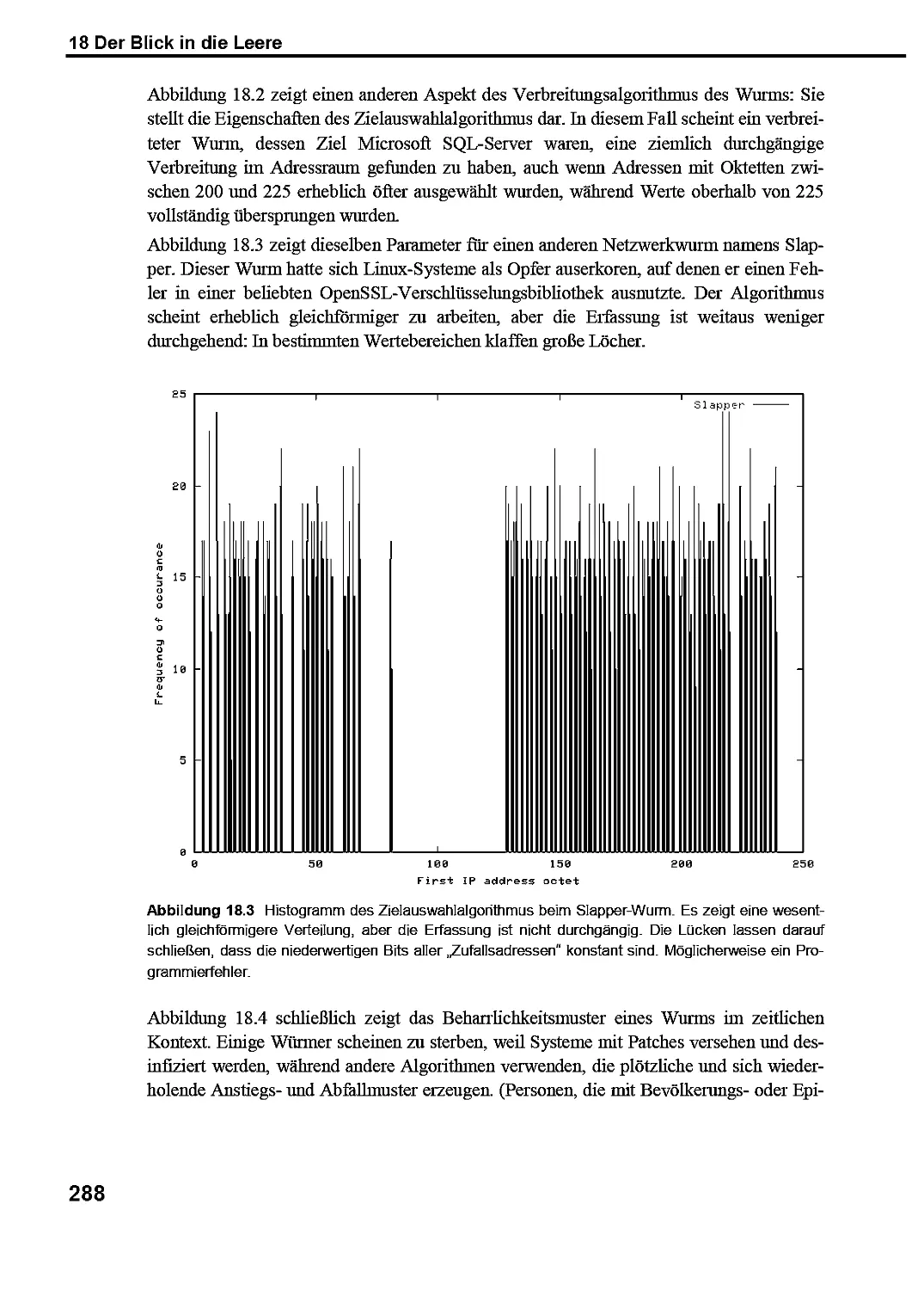
17.4 Stresstest im Netzwerk 282
17.5 Denkanstöße 284
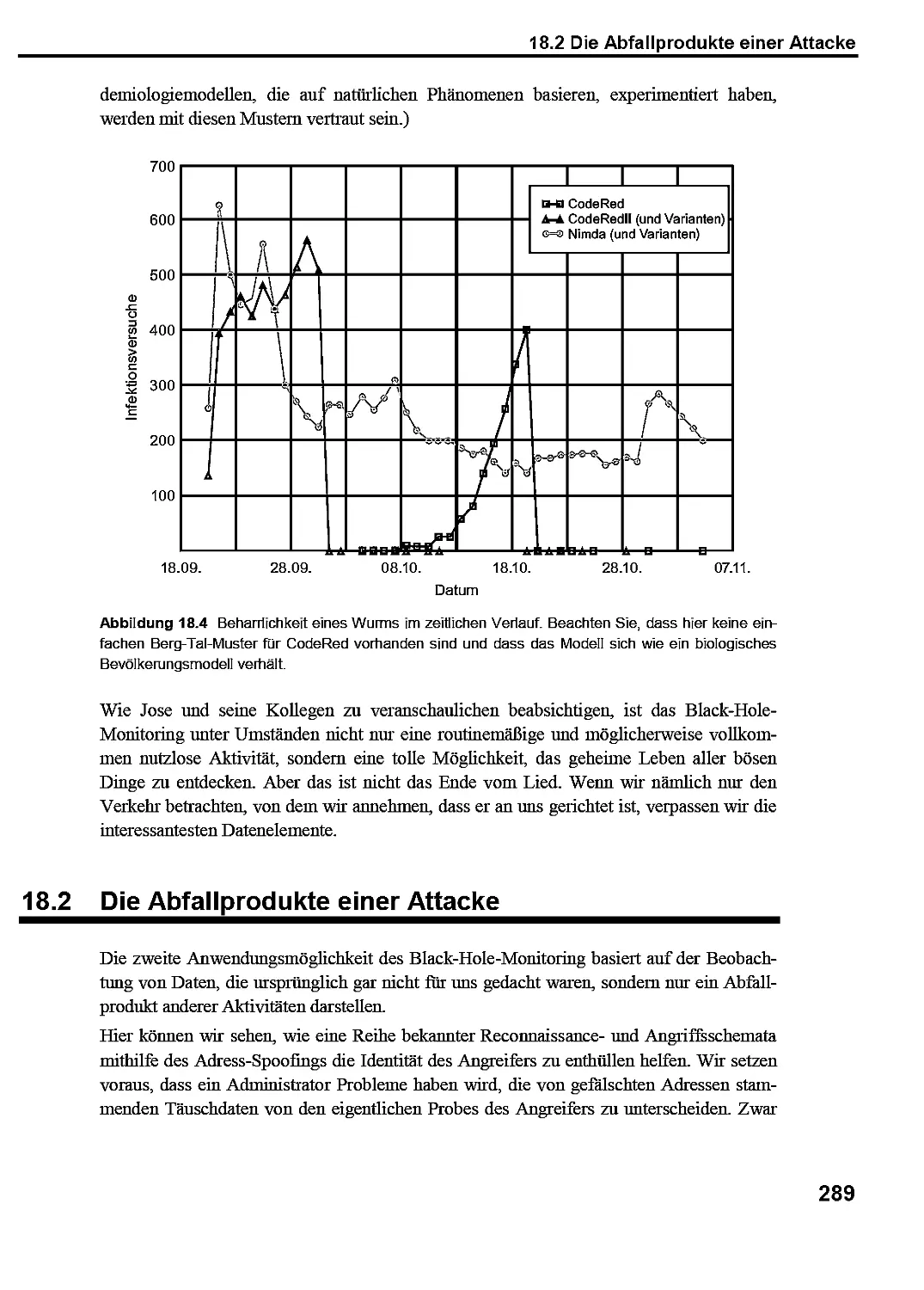
18 Der Blick in die Leere 285
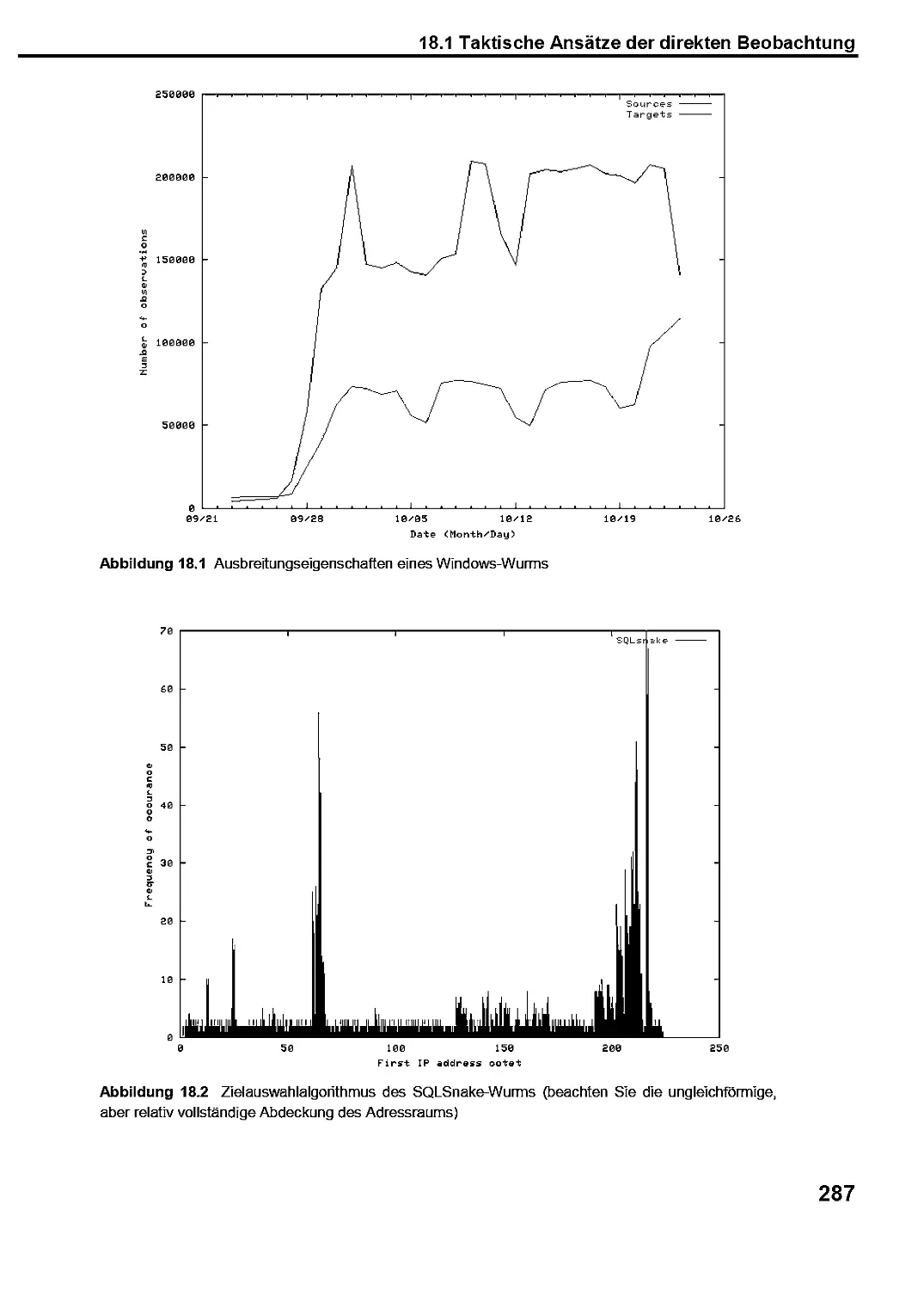
18.1 Taktische Ansätze der direkten Beobachtung 285
18.2 Die Abfallprodukte einer Attacke 289
18.3 Wie man verstümmelte oder fehlgeleitete Daten erkennt 291
18.4 Denkanstöße 293
Nachwort 295
Literatur 297
Register 301
Vorwort
Was braucht es, um einen Roman zur Computersicherheit zu schieiben? Oder besser: Um
überhaupt einen Roman zur modernen Datenverarbeitung zu schieiben?
Einen jungen und doch sehr erfahrenen Autor mit Begabungen in vielen Bereichen wie
Computing, Mathematik und Elektronik, vielleicht der Robotertechnik als Hobby,
zahlreichen anderen, auf den ersten Blick fachfrernden Interessen (wie beispielsweise der
fatalistischen erotischen Fotografie) und dem ausgeprägten Wunsch, zu schieiben - wobei diese
Begabung gleichermaßen ausgeprägt ist.
Es war einmal in einem dunklen und weitgehend unerforschten Wald. Dort gebaren die
(Hirnzellen-)Bäume dank Zauberwerk ein Datenbit. Sie sandten es einen reißenden
Fluss hinab, bis es das riesige Meer (des Internets) erreichte. Dort fand es ein neues
Heim, sein Grab oder vielleicht auch einen Platz in einem Museum.
Und so beginnt unsere Geschichte. Ob unser kleines Bit gut oder böse ist, spielt keine
Rolle: Bereits in jungen Jahren wird es den Strom erreichen, der in eine strahlende
Burg führt, welche aus weißem Metall gebaut ist (und den meisten doch nur als
schwarzer Kasten gilt). Es wird durch das Portal treten und sich zum Schalter begeben,
um sich anzumelden. Wäre es nicht so naiv und blauäugig, es hätte die Gruppe
verkommen aussehender Bits längst bemerkt, die den Schalter von Ferne beäugen und zur
Kenntnis nehmen, wann immer Bits ein- oder auschecken; allerdings hätte es sowieso
keine andere Wahl gehabt, als mit der Anmeldung fortzufahren.
Nach einer kurzen Erholung würde unser Held gebeten, sich seinen Geschwistern oder
einer anderen Gruppe von Bits beizugesellen. Gemeinsam würden sie ihre Leiber dann
sämtlichst in ein gebrauchtes Schlauchboot quetschen. Ein vorsichtiges Bit könnte
Abfallbits im Boot bemerken, die mutmaßlich von einer vorherigen Fracht übrig
geblieben sind. (Aber ist das eigentlich wirklich Abfall?)
Nach einer langen und beengten Fahrt durch Staus und vorbei an vielen
Verkehrsampeln (deren Lichtzeichen selbstverständlich beachtet werden) gelangen unsere Bits in
einen sicheren Hafen und schippern dort zu den Landungsbrücken. Wird man sie von
den Burgen und Leuchttürmen in der Nähe aus wahrnehmen? Wird jemand hingehen
und verzeichnen, wann die Ampeln umschalteten — nur um genau sagen zu können,
XI
wann unser Trupp fuhr? Wird irgendjemand Scheinwerfer auf den Pier richten und
dort Fotos machen? Werden die anderen bösen Bits die Identität unserer Haudegen
übernehmen und zuerst absegeln? Unsere Bits würden es nicht wissen.
Und so wechseln sie am Pier das Gefährt und stechen erneut in See. Die Fahrt unserer
Helden geht weiter, und es stehen ihnen noch viele Gefahren bevor ...
Nein, Michal Zalewskis Buch verbirgt die technischen Abläufe nicht hinter einer Mär, wie
ich es gerade getan habe. Stattdessen beschreibt es alle Fakten klar und deutlich und
vermittelt die Lösungen für die größten Herausforderungen gleich zu Anfang jedes Kapitels.
Und trotzdem macht es Spaß, dieses Buch zu lesen.
Stille im Netz ist in vielerlei Hinsicht einmalig. Zwei Aspekte aber treten besonders
deutlich zutage: Zunächst bietet es eine ausführliche Beschreibung fast aller wesentlichen
Phasen der Datenverarbeitung, die das moderne ,Jnternetworking" ermöglichen — von der
ersten Tastaturbetätigung bis zum gewünschten endgültigen Ergebnis dieser Handlung.
Zweitens skizziert es die weitgehend vernachlässigten, zu wenig erforschten und
inhärenten Sicherheitsfragen, die mit der Netzwerktechnologie im Ganzen und mit jeder ihrer
einzelnen Phasen verbunden sind. Die hier behandelten Sicherheitsprobleme eignen sich
gut, um die verschiedenen Formen der Erforschung von Schwachstellen sowohl aus der
Perspektive des Angreifers als auch aus der des Verteidigers zu demonstrieren, und
bestärken den Leser darin, weitere Untersuchungen in diesem Bereich anzustellen.
Natürlich kann ein Buch über Computersicherheit niemals vollständig sein. In Stille im
Netz provoziert Zalewski durch seinen Ansatz, all die veitiauten, hochgiadig gefährlichen
und weitverbreiteten Sicherheitslücken und Angriffe, die heutzutage von fast allen
Mitgliedern der Datensicherheits-Cormnunity beschrieben werden, außen vor zu lassen. Er
erzählt Ihnen vielmehr etwas über subtile tastaturbasierte Timingangriffe, erwähnt aber
nicht, dass Trojanische Pferde, die Tastatureingaben protokollieren können, derzeit nicht
nur wesentlich häufiger auftreten, sondern generell auch einfacher zu realisieren sind, als
es die von ihm beschriebene Angriffsform je sein wird.
Man ist zu fragen versucht, warum Timingangriffe erwähnt werden, Trojaner jedoch nicht.
Nun, solche auf Ablaufmustem basierenden Angriffe werden auch von den Profis im
Bereich IT-Sicherheit weitgehend unterschätzt, während Trojanische Pferde eine Bedrohung
darstellen, die weithin bekannt und offenkundig ist. Die Anfälligkeit gegenüber Timingan-
griffen ist eine strukturelle Eigenschaft zahlreicher häufig eingesetzter Komponenten,
wählend die Implantation eines Trojaners entweder einen Softwarefehler oder ein Fehlver-
halten des Endbenutzers erfordert.
Von nur sehr wenigen Ausnahmen abgesehen werden Sie in Stille im Netz
konsequenterweise nicht die kleinste Einlassung zu vielfach ausgenutzten Softwarebugs finden - nicht
einmal universelle „Bugklassen" wie Pufferüberläufe werden hier mit einem Wort
erwähnt. Wenn Sie mit den gängigen Computersicherheitsrisiken nicht vertraut sind und
dieses Wissen erwerben wollen, dann müssen Sie sich unter Umständen auch weniger
spannendes Material (insbesondere zu den von Ihnen verwendeten Betriebssystemen) zu
Vorwort
Gemüte führen, welches Sie im Internet und in anderen Büchern finden. Dann aber wird
dieses Buch sie mitnehmen auf eine spannende Reise.
Warum aber sollte man sich der Stille widmen, fragen Sie sich? Die Stille ist doch ein
Nichts! In gewissem Sinne schon. Eine Null ist in diesem gewissen Sinne auch ein Nichts.
Aber sie ist auch eine Zahl — ein Konzept, ohne welches wir die Welt nicht verstehen
können.
Genießen Sie die Stille — so gut wie möglich.
Alexander Peslyak
Gründer und technischer Direktor von Openwall, Inc.
besser bekannt unter dem Namen
Solar Designer
Leiter des Openwall-Projekts
XIII
Einleitung
Ein paar Worte zu meiner Person
Ich bin wohl schon als Cornputerfreak geboren worden, aber meine Abenteuer in der
Netzwerksicherheit begannen eigentlich nur' durch einen Zufall. Ich habe es immer gehebt,
zu experimentieren, neue Ideen zu erforschen und scheinbar fest urnrissene, aber doch
verlockende Herausforderungen anzugehen, die innovative und kreative Vorgehensweisen
erforderten — auch wenn ich am Ende nicht immer erfolgreich war. Als ich jung war,
verbrachte ich meine Zeit vorzugsweise mit manchmal riskanten und oftmals peinlichen
Versuchen, die Welten der Chemie, der Mathematik, der Elektronik und schließlich auch der
Computertechnik zu erforschen, statt den ganzen Tag lang mit meinem Rad um den Block
zu heizen. (Wahrscheinlich übertreibe ich ein bisschen, aber meine Mutter hat sich
scheinbar ständig Sorgen gemacht.)
Kurz nach meiner ersten Begegnung mit dem Internet (Mitte der Neunziger, etwa acht
Jahre, nachdem ich mein erstes , JTallo Weif'-Programm auf meinem gehebten 8-Bit-Rechner
entwickelt hatte) erhielt ich ein sehr ungewöhnliches Gesuch. Es handelte sich um ein
Werbeschreiben, welches - wie abwegig! — mich (und ein paar Tausend andere Leute)
aufforderte, Mitglied eines Untergrundteams vermutlich bösartiger Black-Hats zu werden. Ich
ging dann zwar nicht in den Untergrund - vielleicht aufgrund eines stark ausgeprägten
Selbsterhaltungstriebs (welcher mancherorts auch mit dem Begriff „Feigheit" beschrieben
wird) —, aber irgendwie motivierte mich dieser Vorfall, den Bereich der
Computersicherheit genauer zu erforschen. Da ich hobbymäßig bereits viel programmiert hatte, fand ich es
fesselnd, mir Code aus einer anderen Perspektive anzusehen und Wege zu suchen, wie
man einen Algorithmus rnehr machen lassen kann als das, wofür er ursprünglich gedacht
war. Das Internet schien mir eine unerschöpfliche Ressource für die Art von
Herausforderungen zu sein, die ich mir erträumte — ein riesiges und komplexes System, das nur einem
Prinzip gehorchte: Traue niemandem! So fing alles an.
Ich verfüge nicht über den Background, den Sie vielleicht von einem normalen
Sicherheitsexperten erwarten würden, denn schließlich ist das heute ja ein ganz respektabler'
Beruf. Ich habe niemals eine formale Ausbildung im Bereich der Computertechnik erhalten
Einleitung
und kann auch keine Sammlung von Zertifikaten bedeutend klingender Institutionen
vorweisen. Sicherheit war einfach immer eine meiner großen Leidenschaften (und
mittlerweile lebe ich auch davon). Ich gehöre auch nicht zu den typischen Cornputerfreaks: Hin und
wieder nehme ich etwas Abstand von meiner Arbeit, um sie aus einer gesunden Distanz zu
betrachten. Und manchmal mache ich auch eine Zeit lang überhaupt nichts mit Computern.
All diese Umstände sind — im Guten oder vielleicht auch Schlechten — in Fonn und Inhalt
dieses Buches eingeflossen. Mein Ziel besteht darin, anderen meine Sicht der
Computersicherheit zu präsentieren — und nicht die, die gewöhnlich gelehrt wird. Für mich ist
Sicherheit kein isoliertes Problem, das gelöst werden muss. Sie ist auch kein Prozess, den man
Schritt flu' Schritt abarbeiten kann. Ebenso wenig steht und fällt sie mit dem Fachwissen in
einem bestimmten Bereich. Unter Sicherheit verstehe ich eine Übung in der Betrachtung
des gesamten Ökosystems und im Verstehen aller dazu gehörenden Komponenten.
Ein paar Worte zu diesem Buch
Auch im fahlen Licht unserer Monitore besehen sind wir menschliche Wesen. Man hat uns
gelehrt, anderen zu vertrauen, und man will ja auch nicht überrnäßig argwöhnisch
erscheinen. Also müssen wir einen vernünftigen Kornprorniss zwischen Sicherheit und
Produktivität finden, um ein angenehmes Leben fuhren zu können.
Das Internet aber ist anders als die Gesellschaften im wirklichen Leben. Man kann keinen
allgemeinen Nutzen daraus ziehen, sich an die Regeln zu halten. Zudem muss man
virtuelle Missetaten nur selten bereuen. Wir können dem System also nicht einfach trauen, und
alle Versuche, auch nur eine einzige Regel zu ersinnen, die sich auf alle Probleme
anwenden lässt, sind unweigerlich zum Scheitern verurteilt. Instinktiv ziehen wir eine Grenze,
um „uns" von „denen" abzuschotten, und betrachten dies dann als sicheres Eiland. Dann
fangen wir- an, nach feindlichen Schiffen am Horizont Ausschau zu halten. Nur allzu bald
tauchen die ersten Sicherheitsprobleme auf: lokal eingrenzbare Abnormitäten, die sich
ganz einfach definieren, diagnostizieren und beheben lassen. Aus dieser Perspektive
werden die Angreifer von klar definierten Motiven angetrieben, und wir- können sie rechtzeitig
erkennen und stoppen, wenn wir nur aufmerksam genug sind.
Doch in der virtuellen Welt sieht manches anders aus: Sicherheit ist mehr als das Fehlen
von Bugs, und Schutz besteht nicht nur darin, sich außerhalb der Reichweite von
Angreifern zu befinden. Praktisch jedem Vorgang, bei dem Daten im Spiel sind, wohnen
sicherheitstechnische Aspekte inne, die uns in dem Moment offenbar weiden, in dem wir- über
den Bereich des eigentlichen Ziels hinaussehen, das mit dem Prozess erreicht weiden soll.
Die Kunst, Sicherheit zu verstehen, besteht einfach darin, Grenzen zu überschreiten und
die Perspektiven zu wechseln.
Dies ist ein unkonventionelles Buch - zumindest hoffe ich das. Es handelt sich nicht um
ein Kompendium von Problemen oder einen Leitfaden zur Absicherung Ihrer Systeme.
Vielmehr beginnt es mit dem Versuch, dem Weg eines Datenelements zu folgen - von
dem Moment, in dem Sie Ihre Hände auf die Tastatur legen, über die gesamte Strecke bis
hin zum Empfänger am anderen Ende der Leitung. Behandelt werden Technologien und
2
Einleitung
ihre Sicherheitsaspekte, wobei wir uns auf Probleme konzentrieren werden, die nicht als
Bugs bezeichnet werden können - Probleme, bei denen kein Angreifer, kein zu
analysierender und zu behebender Fehler, ja, noch nicht einmal ein Angriff vorhanden ist
(zumindest kein Angriff, den wir von zulässigen Aktivitäten unterscheiden können). Ziel dieses
Buches ist es, zu demonstrieren, dass die einzige Möglichkeit, das Internet zu verstehen,
darin besteht, genug Mut zu haben, um jenseits der Spezifikationen zu agieren oder
zwischen den Zeilen zu lesen.
Wie der Untertitel bereits nahe legt, behandelt dieses Buch in erster Linie Datenschutz-
und Sicherheitsprobleme, die Bestandteil der täglichen Kornmunikation und
Datenverarbeitung sind. Einige dieser Problerne haben tiefgreifende Auswirkungen, während andere
lediglich interessant und anlegend sind. Keines der beschriebenen Probleme wirkt sich
direkt auf Ihre Umgebung aus oder zerstört Daten auf Ihrer Festplatte. Die vermittelten
Informationen sind nützlich und wertvoll für IT-Profis und beschlagene Amateure, die eine
Herausforderungen für ihre grauen Zellen suchen und mehr zu den diffusen Folgen
struktureller Entscheidungen erfahren wollen. Dieses Buch ist für jene gedacht, die lernen
wollen, wie man diese Feinheiten nutzt, um seine Umgebung zu kontrollieren und der
Außenwelt stets einen Schritt voraus zu sein.
Das Buch ist in vier Teile gegliedert. Die ersten drei behandeln Phasen des Datenflusses
und die dabei zum Einsatz kommenden Technologien. Der letzte Abschnitt hingegen
betrachtet das Netzwerk als Ganzes. Jedes Kapitel beschreibt die relevanten Elemente der zur
Veraibeitung von Daten in den einzelnen Phasen verwendeten Technologien, erläutert die
relevanten sicherheitstechnischen Auswirkungen, veranschaulicht möghche Nebeneffekte
und bietet (sofern möglich) Lösungsvorschläge für die behandelten Probleme und
Empfehlungen zur Vertiefung des jeweiligen Themas. Ich werde mein Bestes geben, um
weitgehend ohne Elemente wie Diagiamme, Tabellen, Spezifikationen usw. auszukommen. (Um
eine größere Zahl von Fußnoten kommen Sie allerdings nicht herum.) Da online eine
Menge gutes Referenzmaterial verfügbar ist, habe ich mein Hauptaugenmerk darauf
gelegt, dieses Buch einfach zu einer vergnüglichen Angelegenheit zu machen.
Können wir anfangen?
3
Die Quelle
Von den Problemen, die bereits auftauchen,
lange bevor man Daten über das Netzwerk versendet
1 Die redselige Tastatur
Erstes Kapitel. In welchem wir ergründen werden, wie sich
Tastaturaktivitäten überwachen lassen - aus ganz, ganz großer Entfernung
Von der Sekunde an, in der Sie die erste Taste auf Ihrer Tastatur drücken, machen sich
Daten, die Sie versenden, auf eine lange Reise durch die virtuelle Welt. Bereits Mikrosekun-
den, bevor Pakete durch Glasfaserleitungen rasen und von Satelritentransceivem
weitergeleitet werden, begibt sich ein Datenelement auf einen langen Trip quer durch ein
beeindruckendes Labyrinth aus Schaltkreisen. Noch ehe Ihre Tastatureingaben vom Betriebssystern
empfangen und Anwendungen gestaltet wurden, sind bereits zahlreiche präzise und subtil
agierende rnaschinennahe Mechanismen mit einem Vorgang befasst, der für Hacker jeder
Alt interessant und auch für Sicherheitsfachleute von großer Bedeutung ist. Der Weg in die
Gefilde des Users birgt viele Überraschungen.
In diesem Kapitel werden wir uns mit den frühen Phasen der Datenbewegung und den
Möglichkeiten befassen, die sich Ihren (potenziell niederträchtigen) Mitbenutzem bieten,
viel zu viel über das herauszufinden, was Sie - an Ihrern Terminal vermeintlich geschützt
- so treiben.
Ein charakteristisches Beispiel potenzieller Datenoffenlegung durch die Art und Weise,
wie ein Computer Eingaben veraibeitet, finden wir in einem Bereich vor, der - zumindest
auf den ersten Blick - so gar nichts damit zu tun zu haben scheint: der schwierigen
Aufgabe, Zufallszahlen mit einem Gerät zu erzeugen, welches vollkommen berechenbar arbeitet.
Eine weniger offensichtliche Verbindung mag schwer vorstellbar sein, doch das Problem,
von dem die Rede ist, ist ausgesprochen real, und ein heimlicher Beobachter kann eine
ganze Menge aus den Aktivitäten eines Benutzers herleiten - von seinen Passwörtem bis
hin zu privaten E-Mails.
1 Die redselige Tastatur
1.1 Zufall - wofür eigentlich?
Computer sind vollständig detenninistisch, d. h. sie verarbeiten Daten auf eine Art und
Weise, die von einer Ordnung wohldefinierter Gesetzmäßigkeiten geregelt wird. Techniker
und Ingenieure geben ihr Bestes, um Schwächen beim Herstellungsprozess und
Unzulänglichkeiten der elektronischen Komponenten selbst (z. B. in Bezug auf Interferenzen und
andere Störungen) auszugleichen — alles nur, um zu gewährleisten, dass die Systeme
immer derselben Logik folgen und korrekt arbeiten. Wenn solche Komponenten aufgrund
von Alterung oder Belastung nicht rnehr wie erwartet funktionieren, betrachten wir den
Computer als fehlerhaft.
In Kombination mit ihren fantastischen Rechenkünsten ist es vor allem die Fähigkeit dieser
Maschinen, ein derartiges Maß an Konsistenz zu erzielen, die Computer zu einem solch
großartigen Werkzeug für' all jene machen, die sie zu beherrschen und zu kontrollieren
verstehen. Eines muss natürlich klar- sein: Es ist nicht alles Gold, was glänzt, und nicht alle,
die über die Unzuverlässigkeit von Computern schimpfen, haben unrecht. Trotz makelloser
Funktion der Hardware neigen Cornputerprogramme bei verschiedenen Gelegenheiten zu
Fehlverhalten. Das liegt daran, dass zwar' Computerhardware konsistent und zuverlässig
arbeiten kann (und dies häufig auch tut), man aber normalerweise nie langfristige
Voraussagen zum Verhalten eines einigermaßen komplexen Cornputerprogramms treffen kann —
von einer komplexen Matrix voneinander abhängiger Programme (wie etwa einem
Betriebssystem) einmal ganz abgesehen. Dies macht eine Bewertung von Cornputerpro-
grarnrnen auch dann recht schwierig, wenn ein detailliertes, einigermaßen stringentes und
doch fehlerfreies hypothetisches Modell dessen vorliegt, was das Programm tun sollte.
Warum? Nun, 1936 wies Alan Turing, einer der Urväter des Computers, durch eine Reduc-
tio ad absurdum (Zuriickfuhrung auf einen Widerspruch) nach, dass es keine
allgemeingültige Methode zur Bestimmung des Ergebnisses einer beliebigen Computerprozedur' (oder
eines Algorithmus) innerhalb einer endlichen Zeit geben kann (wiewohl spezifische
Methoden für einige Algorithmen durchaus existieren können).1
In der Praxis bedeutet dies, dass Sie zwar' nicht davon ausgehen können, dass Ihr'
Betriebssystem oder Ihre Textverarbeitung sich für' alle Ewigkeit so verhalten werden, wie Sie oder
der Programmautor es sich wünschen, aber Sie können mit gutem Grund erwarten, dass
zwei Instanzen einer Textverarbeitung auf Systemen, die auf derselben Hardware basieren,
bei gleicher Eingabe ein konsistentes und identisches Verhalten an den Tag legen
(natürlich immer vorausgesetzt, dass nicht eine der Instanzen durch ein vom Himmel fallendes
Klavier zerstört oder aufgrund anderer externer Einflüsse widriger Art beeinträchtigt wird).
Für' die Softwareuntemehmen ist dies zwar eine sehr willkommene Erkenntnis, aber uns
Sicherheitsleuten wäre sicher in manchen Fällen wohler, wenn Computer ein bisschen
weniger deterministisch wären - weniger in Bezug darauf, wie sie sich verhalten, als darauf,
was aufgrund dessen passieren kann.
Tiiri36
8
1.1 Zufall - wofür eigentlich?
Betrachten wir etwa die Datenverschlüsselung und insbesondere jenes geheimnisvolle
Wesen namens „Kryptografie mit öffentlichen Schlüsseln". Diese neuartige und brillante
Form der Verschlüsselung (und nicht nur dies) wurde in den Siebzigerjahren des
20. Jahrhunderts von Whitfield Diffie und Martin Hellman vorgestellt und bereits kurz
darauf von Ron Rivest, Adi Sharnir und Len Adleman zu einem umfassenden System
ausgebaut. Sie basiert auf einer ganz einfachen Idee: Manche Dinge sind schwieriger als
andere. Das ist natürlich auf den ersten Blick einleuchtend, aber wenn man das eine oder andere
Konzept der höheren Mathematik mit einfließen lässt, steht man über kurz oder lang mit
einer bahnbrechenden Erfindung dar.
Traditionell verlangt symmetrische Verschlüsselung nach einem identischen, gemeinsamen
„Geheimwert" (also einem Schlüssel), der an alle Paiteien eines geheimen KoHimunika-
tionsvorgangs ausgegeben wird. Der Schlüssel ist erforderlich und auch ausreichend, um
die übertragenen Daten zunächst zu ver- und später wieder zu entschlüsseln. Auf diese
Weise kann ein Dritter die Information auch dann nicht ermitteln, wenn er die Verschlüs-
selungsHiethode kennt. Die Tatsache, dass zur Kommunikation ein gemeinsames
Geheimnis erforderlich ist, bedingte, dass dieser Ansatz nicht immer optimal für die Computer-
koHimunikation geeignet war, denn zunächst einmal mussten die Paiteien einen sicheren
Datenkanal einrichten, bevor überhaupt Kommunikation stattfinden konnte: Die
Übertragung des Geheimnisses über einen unsicheren Kanal hätte das System anfallig für eine
unerwünschte Entschlüsselung gemacht. In der Welt der Computer kommunizieren Sie
häufig mit Systemen oder Leuten, die Sie noch nie gesehen haben und zu denen Sie keinen
sicheren oder erschwinglichen KoHimunikationskanal aufbauen können.
Die Verschlüsselung mit öffentlichen Schlüsseln hingegen benötigt kein gemeinsames
Geheimnis. Jede Partei verfügt über zwei Datenelemente: den öffentlichen Schlüssel, der zur
Verschlüsselung von Daten dient, zur Entschlüsselung jedoch ungeeignet ist, und den
privaten Schlüssel, mit dem eine zuvor verschlüsselte Mitteilung entschlüsselt werden kann.
Die Paiteien können ihre öffentlichen Schlüssel nun über einen unsicheren Kanal
austauschen - auch auf die Gefahr hin, dass dieser ausspioniert wird. Sie übermitteln einander die
(für Dritte unbrauchbare) Informationen, die zur Verschlüsselung von Nachrichten
zwischen den Paiteien erforderlich sind, behalten aber den Teil, der für den Zugriff auf die
verschlüsselten Daten benötigt wird, für sich. Und siehe da: Die sichere Kommunikation
zwischen Personen, die einander vollkommen fremd sind - also etwa zwischen einem
Kunden, der in seiner Wohnung auf dem Sofa hockt, und dem Server eines Onlinehändlers
-, schien nun Wirklichkeit geworden zu sein.
Im Wesentlichen fußt das ursprüngliche RSA-Verschlüsselungssystem2 auf der
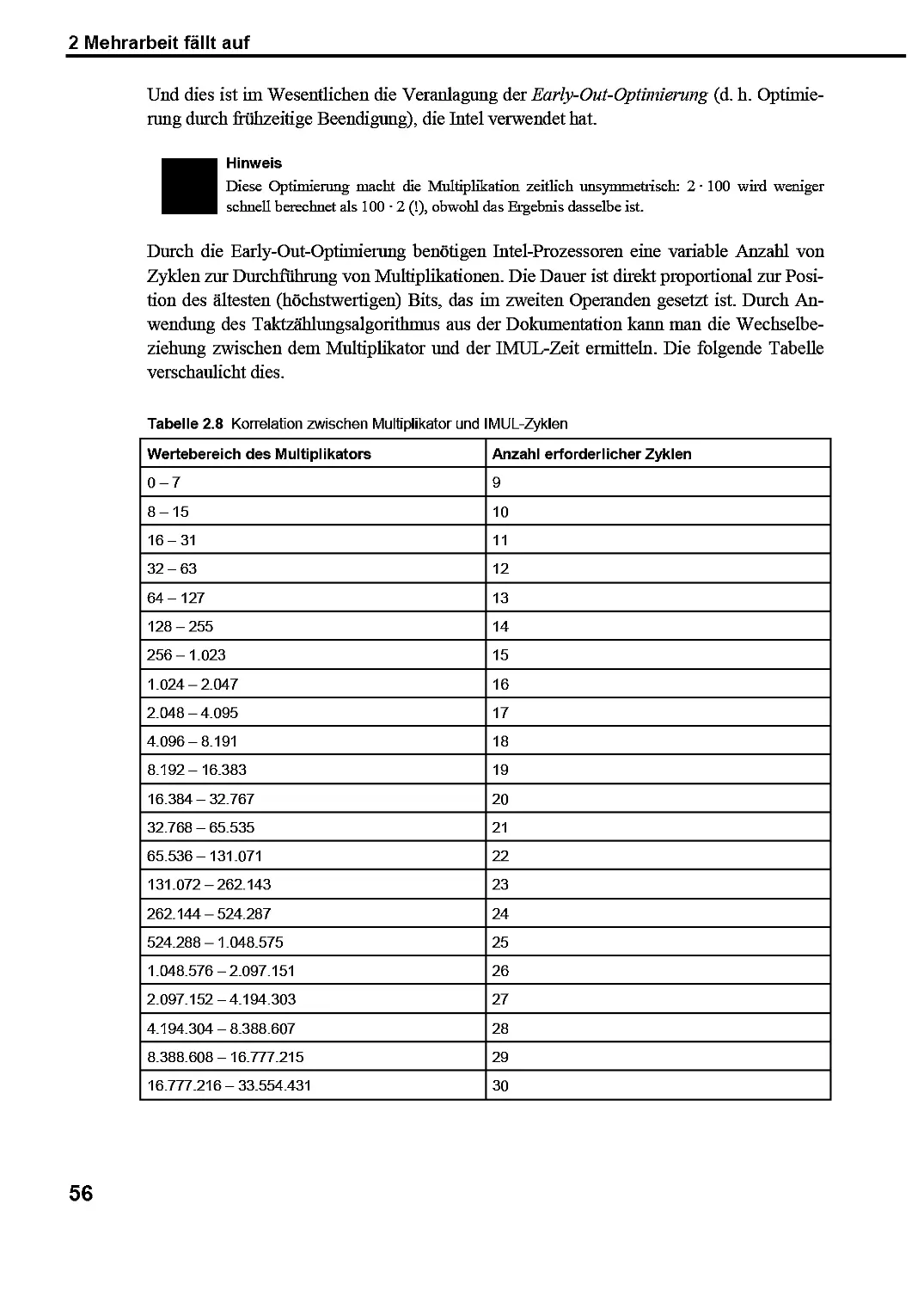
Beobachtung, dass die rechentechnische Komplexität der Multiplikation zweier behebig großer
Zahlen vergleichsweise geling ist: Sie ist direkt proportional zur Anzahl der zu
multiplizierenden Ziffern. Die Komplexität beim Suchen von Faktoren einer großen Zahl (Faktorisie-
rung) ist hingegen wesentlich höher (sofern Sie nicht gerade als sprichwörtliches Rechen-
Die Benennung „RSA" wurde von den ersten Buchstaben der Nachnamen der Entwickler abgeleitet
Rivest, Shainir und Adleman.
9
1 Die redselige Tastatur
genie bei den Schlapphüten tätig sind). Der RSA-Algorithmus wählt zunächst zwei
behebige, sehr große Primzahlen3 p und q aus, die er miteinander multipliziert. Dann erstellt er
auf der Basis dieses Produkts und einer teilelfremden Zahl4 (p—l)(q-l) einen öffentlichen
Schlüssel. Dieser Schlüssel kann zur Verschlüsselung von Daten verwendet werden, ist
allein allerdings nicht ausreichend, um Daten zu entschlüsseln, wenn ein Rückgriff auf die
Faktorisierang nicht möglich ist.
Und der Haken ist: Die Faktorisierang ist bei Produkten zweier großer Primzahlen häufig
nicht praktizierbar und vereitelt demzufolge solche Angriffe. Die schnellste universelle
Faktorisierang für ganze Zahlen auf traditionellen Computern, das allgemeine
Zahlkörpersieb (engl. General Number Field Sieve, GNFS), würde mehr als tausend Jahre benötigen,
um Faktoren einer solchen 1024-Bit-Ganzzahl zu ermitteln, wenn man eine Rate von einer
Million Tests pro Sekunde voraussetzt. Für einen noiinalen PC hingegen ist das Ermitteln
zweier Primzahlen, die ein derart großes Produkt bilden, lediglich eine Frage von
Sekunden.
Wie bereits oben erwähnt, erzeugen Sie bei RSA neben Ihrem öffentlichen auch einen
privaten Schlüssel. Dieser Schlüssel enthält eine zusätzhche Information zu den Primzahlen
und erlaubt damit die Entschlüsselung der mit dem öffentlichen Schlüssel chiffrierten
Daten. Dieser Trick ist möglich dank des chinesischen Resttheorems, des Eulerschen
Theorems und anderer etwas absonderlicher, aber nichtsdestoweniger faszinierender
mathematischer Konzepte, die der besonders neugierige Leser allein erforschen mag.5
Im Laufe der Zeit wurden einige weitere Kryptosysteme mit öffentlichen Schlüsseln
entwickelt, die auf anderen anspruchsvollen Problemen der Mathematik fußen (z. B.
Kryptosysteme über elliptische Kurven usw.). All diese System aber haben das Konzept der
öffentlichen und privaten Schlüssel gemeinsam. Diese Methode hat sich als praktikabel für
den Schutz von E-Mails, Webfransaktionen und ähnlichem erwiesen - und zwar auch in
Situationen, in denen die beiden betreffenden Parteien niemals zuvor miteinander
kommuniziert haben und es auch keinen sicheren Kanal gibt, über den vor dem Herstellen einer
Verbindung zusätzhche Informationen ausgetauscht werden können.0 Fast jede heutzutage
verwendete Verschlüsselungsmethode - von SSH (Secure Shell) und SSL (Secure Sockets
Layer) bis hin zu digital signierten Updates oder Smartcards - existiert dank der
freundlichen Mithilfe der Herren Diffie, Hellman, Rivest, Shamir und Adleman.
Eine Primzahl ist eine positive ganze Zahl, die nur durch 1 und sich selbst teilbar ist.
Eine Zahl, die für x teilerfreind ist (man bezeichnet dies auch als „relativ prirn zu x"), hat außer 1 und
—1 keinen Faktor mit x gemein: Der größte gemeinsame Teiler ist also 1.
Rive78
Der Vollständigkeit halber soll an dieser Stelle angemerkt werden, dass die Ad-hoc-Kryptografie mit
öffentlichen Schlüsseln unter anderem anfällig für Man-in-the-Middle-Angiiffe ist; hierbei gibt sich
der Angreifer als einer der Endpunkte aus und übermittelt einen eigenen, gefälschten öffentlichen
Schlüssel, um die Kommunikationsvorgänge abfangen zu können. Um solche Angriffe zu verhindern,
müssen zusätzliche Ansätze zur Prüfung der Schlüsselauthentizität ins Auge gefasst werden —
entweder durch Verwendung einer sicheren Austauschmethode oder durch Einrichtung einer zentralen
Zertifizierungsstelle für Schlüssel (Infrastruktur öffentlicher Schlüssel, PKI).
10
1.1 Zufall - wofür eigentlich?
1.1.1 Zufallszahlen automatisiert erzeugen
Freilich gibt es ein Problem: Bei der Implementierung von RSA auf einem
deterministischen System besteht der erste Schritt in der Erzeugung zweier sehr großer Primzahlen p
und q. Das Suchen einer großen Primzahl ist für den Computer ganz einfach, es gibt aber
einen winzigen Haken: Dritten muss es unmöglich sein, diese Primzahlen zu erraten, und
sie dürfen auch auf keinem Computer identisch sein. (Andernfalls würde ein Angriff auf
diesen Algorithmus keine Faktorisierang erfordern, und/» und q könnten von jedem
ermittelt werden, der über einen ähnlichen Computer verfügt.)
Im Laufe der letzten Jahre wurde eine Reihe von Algorithmen entwickelt, die mögliche
Primzahlen (Pseudoprimzahlen) schnell finden und dann prompt vorläufige Primalitätstests
durchführen, mit denen die Pseudoprimzahlen überprüft werden.7 Um aber eine wirklich
unvorhersagbare Primzahl erstellen zu können, benötigen wir ein gerüttelt Maß an
Entropie oder Zufälligkeit, um entweder blindlings eine der Primzahlen in einem Bereich
auszuwählen oder aber an einer zufällig gewählten Stelle zu beginnen und dann die erste
Primzahl auszuwählen, über die wir stolpern.
Zwar ist die Notwendigkeit eines gewissen Maßes an Zufall zum Zeitpunkt der
Schlüsselerstellung wesentlich, aber damit endet diese Notwendigkeit noch nicht. Die Kryptografie
mit öffentlichen Schlüsseln basiert auf ziemlich komplexen Berechnungen und ist
demzufolge ziemlich langsam. Dies gilt insbesondere im Vergleich mit der traditionellen
Kryptografie mit symmetrischen Schlüsseln, die kurze gemeinsame Schlüssel und eine Anzahl
Operationen verwendet, die Maschinen sehr schnell ausführen können.
Um Funktionalitäten wie SSH zu implementieren, bei denen eine gewisse Leistung
vorausgesetzt wird, ist es sinnvoller, die ersten Konimunikationsschritte und die
Basisverifizierung mithilfe von Algorithmen durchzufuhren, die auf öffentlichen Schlüsseln basieren,
um auf diese Weise einen sicheren Kanal zu erstellen. Der nächste Schritt besteht im
Austausch eines kompakten, vielleicht 128 Bits umfassenden symmetrischen Schlüssels,
woraufhin auf die altmodische symmetrische Kryptografie umgeschaltet wird. Das
Hauptproblem bei der symmetrischen Kryptografie wird behoben, indem anfänglich ein sicherer
(wenn auch langsamer) Kanal für den Austausch eines gemeinsamen Geheimnisses
eingerichtet und dann auf schnellere Algorithmen umgeschaltet wird. Auf diese Weise profitiert
der Benutzer von der höheren Leistung, ohne Einbußen in punkto Sicherheit hinnehmen zu
müssen. Doch um Kryptografie sinnvoll nutzen zu können, benötigen wir noch ein
gewisses Maß an Entropie, damit wir auch einen wirklich nicht vorhersagbaren Schlüssel für
jede sichere Kommunikationssitzung erzeugen können.
Maur94
1 Die redselige Tastatur
1.2 Wie sicher sind Zufallsgeneratoren?
Programmierer haben viele Möglichkeiten für Computer entwickelt, scheinbar zufällige
Zahlen zu erzeugen. In den Regel heißen diese Algorithmen PRNGs (Pseudo Random
Nurnber Generators, Pseudozufallszahlengeneratoren).
Pseudozufallszahlengeneratoren sind für triviale Aufgaben wie das Erzeugen „zufälliger"
Ereignisse für Computerspiele oder bedeutungslose Betreffzeilen besonders aufdringlicher
Spammails absolut ausreichend. Nehmen wir etwa den linearen Kongmenzgenerator8, ein
klassisches Beispiel für einen solchen Algorithmus. Trotz seines seltsamen Namens macht
dieser Zufallsgenerator nichts anderes, als bei jeder Erzeugung einer „Zufallszahl" eine
Folge einfacher Operationen (Multiplikation, Addition und Modulo9) durchzuführen. Der
Generator verwendet dabei seine vorherige Ausgabe r, um den nächsten Ausgabewert rt+1
zu berechnen (wobei t die Zeit ist):
}'t+i = (a ■ rt + c) mod M
Der Modulooperator steuert den Bereich und verhindert Überläufe (hierunter versteht man
Fälle, in denen das Ergebnis zu einem bestimmten Zeitpunkt den vordefinierten
Wertebereich verlässt). Wenn r0, a, Mund c - die Steuervariablen des Generators - sämtlichst
positive Ganzzahlen sind, dann liegen alle Ergebnisse dieser Gleichung im Bereich zwischen 0
undM-i.
Die Ausgabe dieses Algorithmus mag zwar - in leicht optimierter Form - statistische
Eigenschaften aufweisen, die sie zur Erzeugung von Pseudozufallszahlen geeignet
erscheinen lassen, aber bei diesen Operationen gibt es nichts, was nicht vorhersagbar wäre. Und
hier liegt das Problem: Ein Angreifer kann ganz einfach eine eigene Kopie des Generators
entwickeln und damit eine behebige Anzahl von Ergebnissen bestimmen, die unser
Generator erzeugen wird. Selbst dann, wenn wir mit einem Ausgangszustand des Generators
(r0) beginnen, der dem Angreifer nicht bekannt ist, kann dieser häufig mit Erfolg wichtige
Eigenschaften dieses Wertes ableiten, indem er lediglich die nachfolgenden Ausgabewerte
des Generators betrachtet, der vom Opfer verwendet wird, und mit diesem Wissen seinen
eigenen Generator so trimmen, dass er sich wie unsere Version verhält. Tatsächlich wurde
schon vor mehr als zehn Jahren eine allgemeine Methode zur Rekonstruktion und
Vorhersage aller polynomen Kongruenzgeneratoren entwickelt10; es wäre also ziemlich unklug,
dieses bescheidene, doch etwas unbequeme Detail zu übergehen, macht es doch die
Chance, diesen Algorithmus bei kritischen Aufgaben zu verwenden, vollends zunichte.
* Knut97
Der Modulooperator gibt den Restwert einer ganzzahligen Division zweier Zahlen zurück. So hat z. B.
7 geteilt durch 3 das ganzzahlige Ergebnis 2 zur Folge, der Restwert ist 1: 7 = 2 - 3 + 1. Insofern ist
7 mod 3 = 1.
10 Kraw92
12
1.3 I/O-Entropie: Hier kommt die Maus!
Im Laufe der Zeit hat sich herauskristallisiert, dass es - von massiven Speicherfehlem und
einer Prozessorschmelze abgesehen - nur eine einzige sinnvoll einsetzbare Möglichkeit für
einen Computer gibt, praktisch unvorhersagbare Zahlen zu erzeugen: Man muss möglichst
viele praktisch unvorhersagbare Eigenschaften aus der physischen Umgebung des Systems
ableiten und diese dann als Werte an eine Anwendung weitergeben, die echte
Zufallsangaben benötigt. Problematisch ist dabei, dass ein Durchschnittscomputer keine „Sinne" hat,
mit denen er offensichtlich zufällige externen Faktoren in seiner Umgebung „erspüren"
könnte. Doch zum Glück kennen wir eine recht gute Möglichkeit, diese Schwierigkeit zu
umgehen.
1.3 I/O-Entropie: Hier kommt die Maus!
Bei praktisch jedem Cornputersystern melden externe Geräte relevante asynchrone
Ereignisse (z. B. Daten, die von der Netzwerkkalte verfügbar gemacht oder über die Tastatur
eingegeben werden) unter Verwendung eines hardwareseitig implementierten Interraptrne-
chanisiiius. Jedem Gerät ist eine Hai-dwareinterruptnurmner (TRQ-Nuimner) zugewiesen,
und alle Geräte melden wichtige Entwicklungen, indem sie eine Spannung ändern. Diese
Spannungsänderung wird über eine Leitung in das Innere des Computers übertragen, die
dem jeweiligen IRQ entspricht. Ein Gerät namens PIC (Programmable Interrupt
Controller, programmierbarer Interruptcontroller) interpretiert diese Änderungen und macht sie
dem oder den Hauptprozessoren verfügbar.
Auf Anweisung des Prozessors entscheidet der PIC, ob, wann, wie und mit welcher
Priorität Anforderungen externer Geräte an die Haupteinheit weitergeleitet werden. Dies
erleichtert dem Prozessor die Verwaltung von Ereignissen auf effiziente und zuverlässige Weise.
Hat der Prozessor ein Signal vom PIC empfangen, dann unterbricht er seine derzeitige
Aufgabe (es sei denn, er ignoriert vorübergehend alle Intemiptanforderangen, was bei
extremer Auslastung notwendig sein kann). Als nächstes ruft er einen Code auf, der ihm vom
Betriebssystem zugewiesen wurde und mit dessen Hilfe er die Meldungen des oder der
externen Geräte verarbeitet. Sobald dieses Programm das Ereignis entgegengenommen hat,
stellt der Prozessor den unterbrochenen Prozess und den zugehörigen Kontext (d. h. den
Zustand der Umgebung zum Zeitpunkt der Unterbrechung) wieder her und fährt fort, als
ob nichts gewesen wäre.
1.3.1 Interrupts in der Praxis
In der Praxis umfasst der Vorgang der Erkennung einer externen Bedingung und der
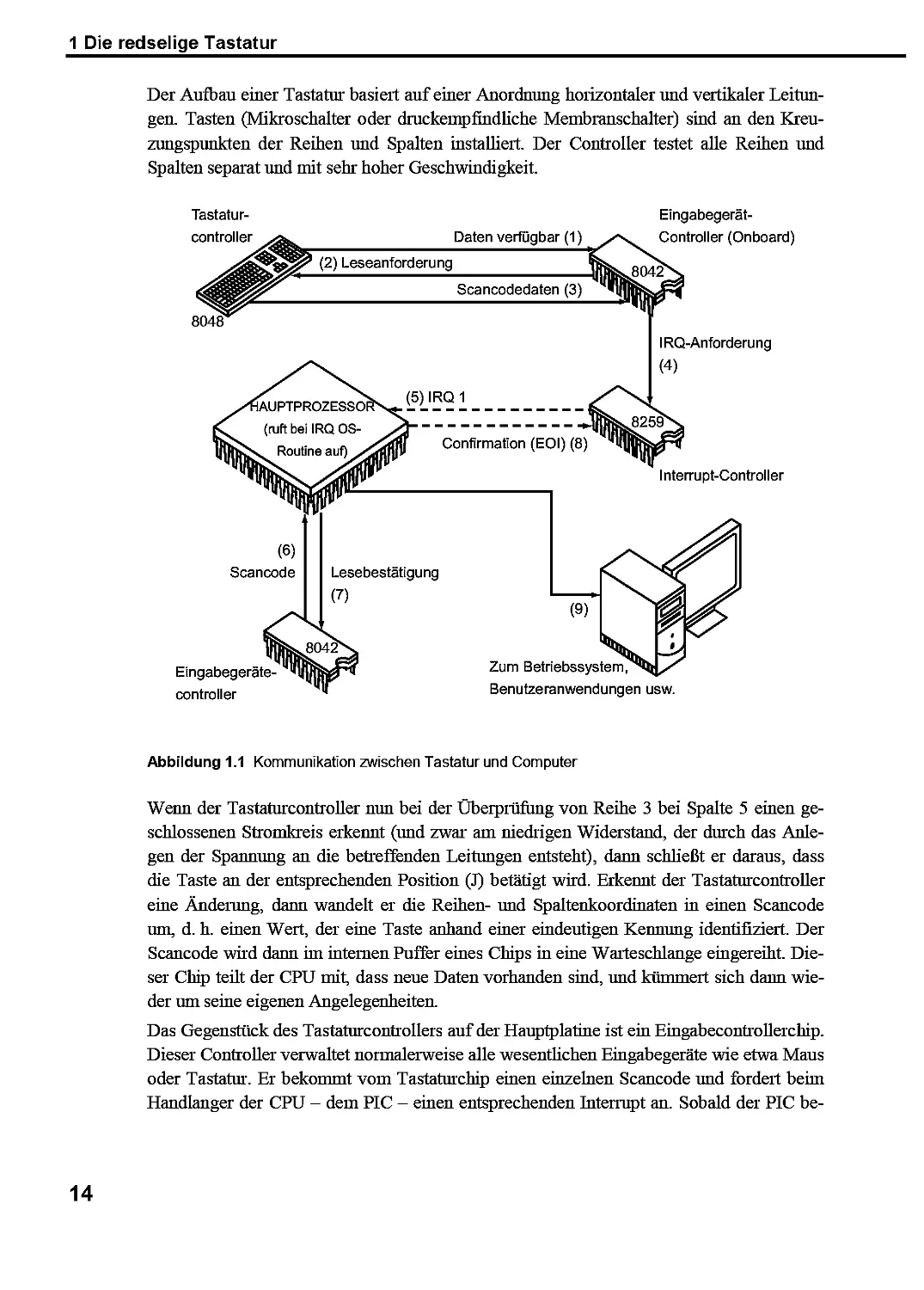
Erzeugung und Inempfangnahme eines IRQ viele weitere Schritte. Abbildung 1.1 zeigt die
Abfolge der Ereignisse, die beim Betätigen oder Loslassen einer Taste auf der
Computertastatur ausgelöst werden. Bevor Sie auch nur eine einzige Taste anrühren, ist ein winziger
Mikrochip in Ihrer Tastatur - der Tastaturcontroller - bereits fortlaufend damit beschäftigt,
die Tastatur auf Zustandsänderungen zu prüfen.
13
1 Die redselige Tastatur
Der Aufbau einer Tastatur basiert auf einer Anordnung horizontaler und vertikaler
Leitungen. Tasten (Mikroschalter oder druckempfindliche Membranschalter) sind an den
Kreuzungspunkten der Reihen und Spalten installiert. Der Controller testet alle Reihen und
Spalten separat und mit sehr hoher Geschwindigkeit.
Tastaturcontroller
Daten verfügbar (1)
(2) Leseanforderung
Scancodedaten (3)
8048
(5) IRQ 1
Eingabegerät-
Controller (Onboard)
IRQ-Anforderung
(4)
Confirmation (EOI) (8)
Interrupt-Controller
(6)
Scancode
Eingabegeräte
Controller
Lesebestätigung
(7)
Zum Betriebssystem,
Benutzeranwendungen usw.
Abbildung 1.1 Kommunikation zwischen Tastatur und Computer
Wenn der Tastaturcontroller nun bei der Übeipriifung von Reihe 3 bei Spalte 5 einen
geschlossenen Stromkreis erkennt (und zwar am niedrigen Widerstand, der durch das
Anlegen der Spannung an die betreffenden Leitungen entsteht), dann schließt er daraus, dass
die Taste an der entsprechenden Position (J) betätigt wird. Erkennt der Tastaturcontroller
eine Änderung, dann wandelt er die Reihen- und Spaltenkoordinaten in einen Scancode
um, d. h. einen Wert, der eine Taste anhand einer eindeutigen Kennung identifiziert. Der
Scancode wird dann im internen Puffer eines Chips in eine Warteschlange eingereiht.
Dieser Chip teilt der CPU mit, dass neue Daten vorhanden sind, und kümmert sich dann
wieder um seine eigenen Angelegenheiten.
Das Gegenstück des Tastaturcontrollers auf der Hauptplatine ist ein Eingabecontrollerchip.
Dieser Controller verwaltet normalerweise alle wesenthchen Eingabegeräte wie etwa Maus
oder Tastatur. Er bekommt vom Tastaturchip einen einzelnen Scancode und fordert beim
Handlanger der CPU - dem PIC - einen entsprechenden Interrupt an. Sobald der PIC be-
14
1.3 I/O-Entropie: Hier kommt die Maus!
reit ist, genau diesen Interrupt bereitzustellen, sendet er das entsprechende Signal an den
Prozessor, welcher dann (normalerweise) seine aktuelle Aufgabe unterbricht und den
Interrupt-Händler aufruft, der vom Betriebssystem installiert wurde. Aufgabe des Handlers ist
es, die Daten zu lesen und dem Chip mitzuteilen, dass er den Scancode erfolgreich gelesen
hat. Der Eingabecontroller fahrt dann mit seinem nonnalen Betiieb fort und erhält früher
oder später von der Tastatur einen anderen Scancode, sofern Daten im Puffer vorhanden
sind.11
Dieser Ansatz ist für die Erzeugung von Zufallszahlen wichtig, auch wenn seine
Bedeutung eher indirekter Natur ist. Der Computer verwendet ein asynchrones
Benachrichtigungssystem (nämlich Interrupts) für Ereignisse: Er erhält Informationen zu
Benutzeraktivitäten praktisch verzögerungsfrei und mit höchster Genauigkeit. Am interessantesten
dabei sind vielleicht die exakt gemessenen Intervalle zwischen den Anschlägen auf der
Tastatur. Zwar sind auch diese Angaben nicht unbedingt unvorhersehbar, aber sie stellen die
wohl beste Quelle für externe, rnessbare und gewissermaßen nichtdetenninistische Signale
dar, die das System bekommen kann. Und deswegen greifen Autoren sicherer PRNG-
Implementiemngen, um das deterministische Wesen von Computern zu umgehen und dem
Zufall Einlas s in ihre Berechnungen zu gewähren, zur Enfropieemiittlung häufig auf das
generell unvorhersehbare Verhalten bestimmter Geräte zurück: Mäuse, Tastaturen,
Netzwerkkarten und manchmal auch Festplattenlaufwerke. Zu diesem Zweck fügen sie im
Interrupt-Händler für das Betriebssystem zusätzlichen Code ein, der bestimmte Parameter für
jedes geeignete Ereignis aufzeichnet.
Nun ließe sich zwar einwenden, dass keine dieser Quellen fortlaufend „echte" Zufallswerte
bereitstellen kann - denn schließlich ist, wenn der Benutzer die Buchstaben Rhinoz eingibt,
die Wahrscheinlichkeit, dass eros folgt, schon relativ hoch -, aber in einem gewissen Maß
ist das Verhalten aus praktischer Sicht ebenso unvorhersagbar wie meine Vorstellung von
einem Nashorn (und ich möchte an dieser Stelle schließlich keine akademische Diskussion
über den freien Willen und deterministische Universen beginnen). Diese Methode der
Entropieeinbringung funktioniert zufriedenstellend, denn sie integriert mehrere Faktoren, die
ein Angreifer realistisch betachtet nicht berücksichtigen, überwachen oder vorhersagen
kann, ohne den Verstand zu verlieren. Die Erfassung von Daten aus all diesen Quellen
über einen längeren Zeitraum hinweg erlaubt uns nach den Gesetzen der
Wahrscheinlichkeit die Generierung eines bestimmten Entropiewertes. Sammeln wir die Daten in einem
Puffer, dann erzeugen wir einen Entropiepool, der je nach Angebot an und Nachfrage nach
nicht voraussagbaren Daten entweder voll oder leer ist. Leider sind die kleinen zufälligen
Elemente im Pool - die etwa dem von kosmischen Energien gesteuerten Bedienen von
Tastatur oder Maus entstammen - immer noch mit vielen leicht vorhersagbaren Daten
gemischt. Insofern lassen sie sich zumindest direkt noch nicht für die Produktion von Zu-
fallszahlen einsetzen.
Auf vielen Architekturen rnuss dem PIC manuell mitgeteilt werden, dass der Interrupt verarbeitet
wurde und keine weiteren Interrupts mehr blockiert werden müssen. Dies wird mit dem EOI-Code (End of
Interrupt) realisiert.
15
1 Die redselige Tastatur
Um zu gewährleisten, dass die tatsächliche Menge an Entiopie, die im Zuge der Pflege und
Auffüllung des Entropiepools ermittelt wird, sich gleichmäßig auf alle PRNG-Ausgabebits
verteilt (und gleichzeitig alle vorhandenen nicht vorhersagbaren Daten berücksichtigt
werden), muss der Pool mit einer Hash-Funktion verarbeitet, d. h. gänzlich geschüttelt und
gerührt werden, sodass kein Bereich des Pools leichter vorauszusagen ist als ein anderer.
Jedes Ausgabebit muss auf gleiche Weise von allen Eingabebits abhängen - und dies auf
eine nichttriviale Alt. Dies zu erreichen, ohne zu wissen, welche Datenelemente
vorhersagbar sind und welche nicht (also Informationeil, die mit einem Computer, der
Tastaturaktionen oder Mausbewegungen überwacht, nicht ermittelt werden können), kann eine
schwierige Aufgabe sein.
1.3.2 Abkürzung ohne Rückfahrschein
Zum Glück gibt es sichere Einweg-Hash-Funktionen (so genannte „Message-Digest-
Funktionen"). Dieses Vorzeigeprodukt modemer Kryptografie hilft uns beim Vermischen
der Daten, um für jedes Ausgabebit das Maximum an Entiopie herauszuholen. Dabei spielt
es keine Rolle, wie uneinheitlich die Eingabedaten sind. Solche Funktionen erzeugen einen
verkürzten Zielwert mit einer festen Länge, also eine eindeutige Kennung für eine
beliebige Eingabedatenmenge. Aber das ist noch nicht alles.
Alle unumkehrbaren Hash-Funktionen weisen zwei wichtige Eigenschaften auf:
■ Die Berechnung des verkürzten Zielwertes ist relativ einfach. Allerdings ist es nicht
möglich, die ursprüngliche Eingabe oder ihre Eigenschaften aus dem Ergebnis
abzuleiten: Eine behebige Änderung der Eingabe wirkt sich auf alle Eigenschaften der
Ausgabe mit ebenso hoher Wahrscheinlichkeit aus wie jede andere Änderung.
■ Die Wahrscheinlichkeit, dass zwei unterschiedliche Eingaben dieselbe Verkürzung
erzeugen, wird nur durch die Größe des Zielwertes bestimmt. Ist der Zielwert
ausreichend groß (d. h. groß genug, um umfangreiche Suchvorgänge praktisch unmöglich zu
machen), dann ist es unmöglich, zwei Eingabewerte zu finden, die denselben
Ausgabewert erzeugen. Derzeit gelten Zielwerte mit einer Länge zwischen 128 und 160 Bit
als ausreichend groß; sie entsprechen einer Menge von 3,4E+38 bis l,46E+48
Kombinationen.
Infolgedessen stellen Verkürzungsfunktionen eine Möglichkeit dar, die in den
Eingabedaten vorhandene Entiopie gleichförmig auf die Ausgabedaten zu verteilen. Hierdurch wird
das Problem der generell zufälligen, aber lokal vorhersagbaren Entiopiequellen beseitigt:
Wir ermitteln eine annähernde Menge Entiopie aus der Umgebung, vermischen diese ggf.
mit vorhersagbaien Daten und können dann eine Verkürzung erzeugen, die garantiert
ebenso unvorhersagbar ist wie die anfangs ermittelte Entropie - unabhängig davon, wie die
Eingangsentiopie auf die Eingabedaten verteilt wurde.
Wie nun funktionieren Verkürzungsfunktionen? Auch hier basieren einige auf
mathematischen Problemen, die, soweit wir wissen, sehr schwierig zu lösen sind. Tatsächlich lässt
sich jede sichere symmetrische oder auf öffentlichen Schlüssel fußende Kryptografie ganz
einfach in eine sichere Hash-Funktion umwandeln. Solange die Menschheit keine wirklich
16
1.3 I/O-Entropie: Hier kommt die Maus!
clevere Lösung flu- eines dieser Probleme findet, sollte man sich auf diesen Ansatz
verlassen können.
Wenn wir aber nun die wirklich schweren Geschütze auffahren, haben wir am Ende nur
langsame und übermäßig komplizierte Tools zur Erzeugung von Verkürzungen, die für
kompakte Implementierungen meist unbrauchbar sind; dies gilt insbesondere für die
Integration einer solchen Lösung mit einem Betriebssystem. Die Alternative besteht darin, die
Daten so zu verarbeiten, dass die gegenseitige Abhängigkeit aller Eingabe- und
Ausgabebits ausreichend komplex ist, um die Eingabe vollständig zu verschleiern, und zu hoffen,
dass dies „gut genug" ist, um bekannte Kryptoanalysemethoden zu überfordern. Weil aber
„hoffentlich gut genug" in der Infonnationswissenschaft ein durchaus gängiges Motto ist,
wollen wir dies gerne als sinnvollen Ansatz akzeptieren.
Der Vorteil der letztgenannten Gruppe von Algorithmen, zu der auch verbreitete
Funktionen wie MD2, MD4, MD5 und SHA-1 gehören, besteht darin, dass sie normalerweise
wesentlich schneller und zudem leichter zu verwenden sind als ihre auf schwierigen
mathematischen Aufgaben fußenden Gegenstücke, und dass sie zudem, sofern sie sauber erstellt
wurden, nicht für die einschlägigen Tricks der Kryptoanalyse anfällig sind. Ihre Schwäche
hingegen ist die Tatsache, dass sie nicht nachweisbar sicher sind, denn keine dieser
Methoden lässt sich auf ein klassisches, schwer zu lösendes Problem zurückführen. Und in der
Tat haben einige dieser Methoden bereits gewisse Schwächen an den Tag gelegt.12
Wie bereits früher angedeutet, besteht ein wesentlicher Vorzug der Verkifrzungsfunktionen
in Bezug auf die Erzeugung pseudozufalliger Zahlen darin, dass sie sich für ein
Datensegment ausführen lassen, das n Zufallsbits und eine behebige Anzahl vorhersagbarer Bits
enthält, und (dank der beiden weiter oben beschriebenen Grundeigenschaften von Einweg-
Hash-Funktionen) auf dieser Grundlage eine Verkürzung erzeugen, bei der n Entropiebits
gleichmäßig auf alle Bits in der Verkürzung verteilt werden. Infolgedessen ist die
Verkürzungsfunktion ein ausgesprochen probates Mittel zur Entiopieextraktion. Indem wir eine
ausreichende Menge Daten, die von einem generell unvorhersagbaren Interrupt-Händler
gesammelt wurden, durch eine Verkiü-zungsfunktion verarbeiten lassen, können wir
Zufallszahlen erzeugen, ohne verwendbare Informationen zur exakten Form der Daten
preiszugeben, mit denen wir diese Zahlen erstellt haben. Zudem besteht kein Risiko, dass eine
schwache Eingabe sich nennenswert auf die Ausgabe auswirkt. Wir müssen lediglich
sicherstellen, dass einem Block von Interruptdaten eine ausreichende Menge Entropie
entnommen und der Veifcürzungsfunktion zugeführt wird - andernfalls steht das gesamte
System auf tönernen Füßen. Wenn der Angreifer beträchtliche Teile der Daten vorhersagen
kann, die wir zur Erzeugung von Zufallszahlen verwenden, und für den Rest nur eine
Handvoll möglicher Kombinationen existiert, dann kann er eine erfolgreiche Brate-Force-
Attacke gegen unsere Implementierung reiten, indem er ganz einfach alle möglichen Werte
ausprobiert und überprüft. Verwenden wir beispielsweise eine Verkürzungsfunktion, die
unabhängig von der Anzahl der tatsächlich gesammelten Daten 128-Bit-Digests erzeugt,
dann müssen wir vor dem Verkürzen sicherstellen, dass mindestens 128 Eingabebits für
12 Bakh95
1 Die redselige Tastatur
den Angreifer unvorhersehbar sind - ganz gleich, ob nun 200 oder 2.000.000
Tastenanschläge als Grundlage verwendet werden.
1.3.3 Von der Bedeutung, pedantisch zu sein
An dieser Stelle folgt ein kleines Beispiel dafür, was passieren kann, wenn die Dinge nicht
so funktionieren wie gewünscht. Angenommen, ein Benutzer möchte ein Shellskript
schreiben. Zum betreffenden Zeitpunkt ist der Entropiepool des Systems leer (etwa weil
kurz zuvor eine zufallszahlenhungrige Operation durchgeführt wurde). Daran, dass vi
delallusers.sh ausgefühlt wird, bemerkt der Angreifer, dass der Benutzer im Begriff ist, ein
Skript zu schreiben; außerdem geht er davon aus, dass das Skript mit etwas in der Art von
#!/bm/sh anfangt. Zwar kann er nicht sicher sein, was als nächstes kommt, hat aber den
begründeten Verdacht, dass das Skript mit dem Aufruf eines Shellbefehls beginnen wird;
die Wahrscheinlichkeit, dass irgendein altmodisches Gedicht über Rhinozerosse folgt, ist
hingegen eher gering.
An dieser Stelle nun fordert irgendein Verschlüsselungs-Utihty unverrnittelt eine 128-Bit-
Zufallszahl beim System an, die es als Sitzungsschlüssel zum Schutz der Kommunikation
verwenden will. Das System jedoch kann den Entopieumfang, der in dem Puffer, in dem
der Vorgang des Schreibens der ersten Skriptzeilen aufgezeichnet wurde, vorhanden ist,
nicht korrekt einschätzen. Der Angreifer hat nun leichtes Spiel. Der Computer weiß gar
nicht, ob die in genau diesem Moment vom Benutzer durchgeführte Aktion von anderen
vorhergesagt werden kann oder nicht; er kann nur (unterstützt von den vom Programmierer
getroffenen Annahmen) darauf spekulieren, dass die Benutzeraktionen sich im Laufe der
nächsten Minuten oder Stunden zu einem Ergebnis summieren werden, das nicht präzise
vorhergesagt werden kann, und dass dieser Teil der Eingabe im Durchschnitt tatsächlich
von den Faktoren abhängt, die für den Angreifer nicht vorhersehbar sind.
An dieser Stelle kennt der Angreifer den größten Teil des Entropiepools und hat bezüglich
des ihm unbekannten Anteils nur ein paar tausend Optionen zur Auswahl (während
gleichzeitig das Betriebssystem davon überzeugt ist, dass in diesem Puffer weitaus rnehr
Entropie vorhanden ist). Und dies stellt für jemandem, der von einem Computer unterstützt
wird, wohl kaum eine große Herausforderung dar. Statt also eine 128-Bit-Zufallszahl zu
erhalten, deren Anzahl möglicher Kombinationen im neununddreißigstelligen Bereich
hegt, bekommt die arglose Kryptografieanwendung eine Zahl zurück, die auf einer
Eingabe basiert, welche nur ein paar tausend Werte annehmen kann. Diese lässt sich vom
Angreifer ganz einfach via Trial-and-Error ermitteln, woraufhin er schon bald in der Lage
sein wird, die Daten, die doch scheinbar so sicher waren, zu entschlüsseln.
1.4 Entropie - je mehr desto besser
Da es praktisch unmöglich ist, die Menge an Entropie, die für einen Benutzer angesammelt
wurde, auf kurze Sicht exakt vorherzusagen, integrieren alle Implementierungen die Ver-
18
1.4 Entropie -je mehr desto besser
kürzung oder den internen PRNG-Status in den Vorgang der Erzeugung neuer Ausgaben,
damit das zuvor beschriebene Problem der vorhersagbaren PRNG-Ausgabe gar nicht erst
entsteht. Die vorherige Ausgabe wird Teil der Gleichung, die zur Berechnung des nächsten
PRNG-Wertes verwendet wird.
Bei diesem Ansatz müssen, sobald eine ausreichende Menge Entropie vom System
ermittelt wurde, die aktuellsten Daten, die zum Auffüllen des Entropiepools verwendet werden,
nicht jederzeit völlig zufällig sein, um ein Mindestmaß an Sicherheit zu gewährleisten.
Doch es gibt noch ein weiteres Problem: Wenn die Implementierungen für längere Zeit mit
alter, geerbter Entropie arbeiten, die wieder und wieder mit MD5 oder SHA-1 gehasht
wird, dann werden sie letztendlich von der Sicherheit des Verküi-zungsalgorithmus
abhängig, der aufgrund des Leistungs- und Sicherheitskompromisses, den wir oben beschrieben
haben, nicht hundertprozentig vertrauenswürdig ist. Außerdem müssen die Hashing-
Funktionen nicht unbedingt von kompetenten Kryptografen einer entsprechenden
Eignungsprüfung für den jeweiligen Zweck unterzogen worden sein. Die Implementierung
basiert dann nicht rnehr einfach nur auf den Bit-Hashing-Eigenschaften einer
Verkürzungsfunktion, sondern steht und fällt nun mit der Unverwundbarkeit gegenüber
Crackerangriffen. Wird bei jedem nachfolgenden Schritt auch nur ein bisschen Information zum internen
Zustand des Erzeugers offenbart und werden gleichzeitig keine neuen Daten zum Pool
hinzugefügt, dann können die Daten langfristig dazu geeignet sein, den internen Zustand mit
einiger Sicherheit rekonstruieren oder erraten zu können. Dies kann eine Vorhersage des
zukünftigen Verhaltens des Gerätes möglich machen. Andererseits wird, wenn neue
Zufallsdaten mit einer Häufigkeit hinzugefugt werden, die - zumindest statistisch - eine
umfassende Wiederverwendung des internen Zustandes vermeidet, ein Angriff auch dann
weitaus schwieriger, wenn die Hashing-Funktion selbst nicht niehr funktionsfähig ist.
Viele Experten sind der Ansicht, dass ein solches Maß an Vertrauen in und Abhängigkeit
von der Hashing-Funktion für sehr anspruchsvolle Anwendungen ungeeignet ist. Aus
diesem Grund ist es für eine Implementierung wichtig, ein Auge darauf zu haben, dass ein
Mindestmaß an im System gesammelter Entropie vorhanden ist, die, sofern auch nicht in
jedem Augenblick korrekt, doch eine allgemeine statistische Tendenz widerspiegelt, die
wir von den verwendeten Quellen erwarten können. Kleinere vorübergehende
Fluktuationen bei der Veifügbarkeit externer Entropie - wie etwa bei dem oben beschriebenen
Skriptbeispiel - können und werden auftreten; sie werden aber durch den Algorithmus zur
Wiederverwendung der Ausgabe ausgeglichen. Trotzdem ist es erforderlich, exakte
langfristige Vorhersagen zu machen, damit ein häufiges Auffüllen des internen Entropiepools
sichergestellt und die Gefährdung minimiert ist, sollte die Hashing-Funktion nach einer
gewissen Zeit den internen Zustand Stück für Stück preisgeben. Insofern niuss die
Implementierung Buch darüber führen, wie viel Entropie in Daten für Benutzelprozesse
umgesetzt wurde, und gegebenenfalls die Ausgabe weiterer Zufallszahlen unterbinden, bis
wieder eine ausreichende Menge Entropie zur Verfügung steht.
Ein gutes Beispiel für eine zweckmäßige PRNG-Implementierung, die alle oben genannten
Faktoren berücksichtigt, ist das exzellente System, welches 1994 von Theodore Ts'o vom
Massachusetts Institute of Technology ersonnen wurde. Seine Methode namens
1 Die redselige Tastatur
/dev/random wurde zunächst in Linux implementiert, später folgten andere Systeme wie
FreeBSD, NetBSD und HP/UX. Ts'os Ansatz überwacht eine Anzahl von I/O-Ereignissen
auf dem System und ermittelt Zeitabstände und andere wichtige Interrupteigenschaften.
Außerdem wird der Entropiepool beim Beenden des Systems auf Festplatte gespeichert
und nach dem Neustart weiterverwendet; auf diese Weise wird verhindert, dass das System
nach dem Start einen vollständig vorhersagbaren Zustand aufweist. So wird ein Angriff
zusätzlich erschwert.
1.5 Angriff: Folgen eines jähen Paradigmenwechsels
Welches Problem nun könnte in Verbindung mit diesem scheinbar narrensicheren System
zur Bereitstellung nicht vorhersagbarer Zufallszahlen für anspruchsvolle Anwendungen
auftreten? Gar keins. Zumindest nicht dort, wo man es erwarten würde. Die Zahlen, die
erzeugt werden, sind tatsächlich schwer vorherzusagen.
Trotzdem hat der Entwickler dieses Ansatzes einen kleinen Denkfehler gemacht - mit
fatalen Folgen. Theodore Ts'os Technik setzt voraus, dass der Angreifer ein Interesse daran
hat, Zufallszahlen basierend auf seinen Kenntnissen des Systems und seiner Umgebung
vorauszusagen. Was aber wäre, wenn der Angreifer genau das Gegenteil will?
Der Angreifer kann, wenn er über ein Konto auf dem betreffenden Computer verfügt, auch
dann, wenn er gar keinen direkten Zugriff auf die Daten hat, die der Benutzer eingibt, den
exakten Moment, an dem die Eingabeaktivitäten im System auftauchen, ermitteln, indem
er zunächst den Entropiepool leert (was ganz einfach durch gezieltes Abrufen und
nachfolgendes Verwerfen von Zufallsdaten auf dem System erfolgen kann) und dann die
Verfügbarkeit der PRNG-Ausgabe überwacht. Erfolgen keine I/O-Aktivitäten, dann stehen dem
PRNG keine neuen Daten zur Verfügung, weil die Entropieschätzung sich nicht ändert.
Wird nun eine Taste betätigt oder losgelassen, dann hat der Angreifer ein paar Daten zur
Verfügung, aus denen er ableiten kann, dass eine Taste betätigt oder losgelassen wurde.
Auch andere Ereignisse wie etwa Festplattenzugriffe erzeugen PRNG-Ausgabedaten, aber
die Menge und die Ablaufmuster der auf diese Weise ermittelten Entropie unterscheiden
sich in ihren Eigenschaften von den tastaturerzeugten rntermptdaten. Insofern ist es
möglich und auch nicht besonders schwer, Ereignisse aufgrund der Menge der zu einem
gegebenen Zeitpunkt vorhandenen Daten zu unterscheiden: Die Daten von Tastaturanschlägen
sehen anders aus als die von Festplattenaktivitäten.
Letztendlich führt eine Methode, mit der ein Höchstmaß an Sicherheit bei der Erzeugung
von Zufallszahlen erzielt werden soll, also zu einer Beeinträchtigung der Privatsphäre des
Benutzers: das Vorhandensein dieser Funktion zur Einschätzung der Entropie, die von
einer externen Stelle zur Verfügung gestellt wird, kann missbraucht und dazu verwendet
werden, bestimmte Aspekte der Eingabeaktivitäten auf dem System zu überwachen. Zwar
kann der Angreifer nicht genau erkennen, was eingetippt wird, aber für das Schreiben
bestimmter Wörter auf der Tastatur gibt es charakteristische Ablaufmuster. Dies gilt insbe-
20
1.5 Angriff: Folgen eines jähen Paradigmenwechsels
sondere, wenn präzise Informationen zu den Zeitpunkten des Anschlagens und Loslassens
der Taste vorhanden sind, was hier ja auch der Fall ist. Durch eine Übeipiiifung dieser
Muster kann der Angreifer dann die eigentlich Eingabe ableiten, zumindest aber leichter
erraten.
1.5.1 Tastatureingaben unter der Lupe
Eine Tiefenanalyse, die von einem Forschungsteam an der University of California
durchgeführt wurde13, lässt darauf schließen, dass es durchaus möglich ist, bestimmte
Eigenschaften der Benutzereingabe abzuleiten - oder die Eingabe womöglich sogar vollständig
zu rekonstruieren -, indem man einfach das Timing der Tastaturaktionen betrachtet. Man
kam zu dem Ergebnis, dass die Intervalle zwischen den Tastenbetätigungen zwar bei
geübten Tastaturschreibem und unterbrechungsfreiern Tippen durchaus gewisse Schwankungen
aufweisen können, dass aber vorherrschende Ablaufhiuster für jede Abfolge zweier Tasten
ganz offensichtlich sind.
Der Grund hierfür ist die Tatsache, dass unsere Hände auf eine ganz bestimmte Weise auf
der Tastatur zu liegen kommen, und dass die Position einer Taste auf der Tastatur sich
darauf auswirkt, wie schnell wir die nächste Taste mit unseren Fingern erreichen können. So
unterscheidet sich beispielsweise der zeitliche Abstand bei der Tastenfolge E —» N von
dem der Folge M—» 1. Das liegt daran, dass beim ersten Fall eine Hand die linke Seite der
Tastatur und die andere die rechte Seite bedient (Abbildung 1.2), d. h. die Eingabe der
beiden Zeichen erfordert praktisch keine Bewegung, und die beiden Tasten werden fast
gleichzeitig angeschlagen- das Intervall hegt bei weniger als 100 Millisekunden. Die
Folge M —» 1 hingegen ist vergleichsweise umständlich und benötigt demzufolge wesentlich
niehr Zeit.
OOOOOOOC
OOOOOOO
OOODOOO
OOOOOOt
Rückschritt
f \
Eng.
Umschalttaste
]
Leertaste
Alt
J Istrg 1
Abbildung 1.2 Die üblichen Bedienbereiche auf einer Tastatur: Die dunkelgrauen Tasten werden
normalerweise von der linken Hand bedient, die hellen von der rechten Hand.
Aufgrund der Analyse einer Anzahl von Proben schätzen die Autoren dieser
Untersuchung, dass ca. 1,2 Datenbits pro betätigter Taste den Timingwerten entnommen werden
SongOl
21
1 Die redselige Tastatur
können. Durch Beobachtung von Tastenfolgemntervallen ist es möglich, eine Menge von
Tastaturaktionen zu ermitteln, die das jeweilige Muster höchstwahrscheinlich erzeugt
haben, was es wiederum einfacher macht, die exakte Abfolge der eingegebenen Tasten zu
erraten. Der Ansatz, Bruchteile von Bits zu zählen, mag auf den ersten Blick grotesk
erscheinen, bedeutet aber eigentlich, dass die Anzahl der Möglichkeiten für jede Taste um
den Faktor 21'2 oder etwa das 2,40-fache reduziert werden kann. Bei einem normalen
Tastaturanschlag, der normalerweise erst einmal nicht rnehr als 6 Bits Zuiälligkeit erzeugt,
verringert dies die Optionsmenge von ca. 64 auf 26 Elemente.
In der Summe verkleinert dieser Umstand also den Suchraum: Wir sehen, dass es, wenn
wir die betätigten Tasten erraten wollen, eine Möglichkeit gibt, die Anzahl der
Eventualitäten zu verringern. Zwar mag diese Verringerung für sich genommen nicht besonders
beeindruckend erscheinen, aber wenn Sie den Urnstand einbeziehen, dass die über die
Tastatur eingegebenen Daten selbst wahrscheinlich nicht von wahllos betätigten Tasten
stammen, sondern sinnvoll sind, dann stellt sich der Sachverhalt schon anders dar. Die Entropie
eines englischsprachigen Texts hegt bei nur ca. 0,6 bis 1,3 Bit pro Zeichen14, d. h. man
benötigt durchschnitthch nur 1,5 bis 2,5 Versuche, um das nächste Zeichen erfolgreich
vorherzusagen. Mithilfe einer Methode, die den Suchraum weiter verkleinert, ist es möghch,
eindeutige Wörterbuchübereinstimmungen für fast alle Eingabedaten zu ermitteln.
Um ihre Schätzungen zu verifizieren und das Problem in der Praxis zu demonstrieren,
haben die Wissenschaftler zum Erraten von Tastenanschlägen das Verborgene Markow-
Modell und den Viterbi-Algorithmus eingesetzt. Ein Markow-Modell stellt eine Methode
zur Beschreibung eines diskreten Systems dar, in dem der nächste Wert nur von seinem
aktuellen Zustand und nicht von den vorherigen Werten abhängt (Markow-Kette). Das
Verborgene Markow-Modell ist eine Variante, die eine Methode zur Beschreibung eines
Systems darstellt, bei dem jeder interne Zustand eine Beobachtung erzeugt, während der
eigentlich Zustand selbst nicht bekannt (also verborgen) ist. Dieses Modell wird häufig in
Anwendungen wie etwa der Spracherkennung eingesetzt, deren Ziel es ist, einer
bestimmten Manifestation (aufgezeichnete Wellenform) die reinen Daten (Textdarstellung des
gesprochenen Wortes) zu entnehmen.
Die Autoren der Studie schlussfolgem, dass das Verborgene Markow-Modell auf die
Analyse von Tastenbetätigungen anwendbar ist, und gehen davon aus, dass den internen
Zustand des Systems die Angaben zu den betätigten Tasten darstellen; die Beobachtung im
Verborgenen Markow-Modell sind die zeitlichen Abstände zwischen den Anschlägen.
Man könnte nun einwenden, dass dies eine übermäßige Vereinfachung ist, denn
insbesondere in der in Abbildung 1.3 gezeigten Situation könnte eine tiefergehende Abhängigkeit
vorhanden sein.
Der Viterbi-Algorithmus stellt eine Möglichkeit dar, Probleme in Verbindung mit dem
Verborgenen Markow-Modell zu lösen. Der Algorithmus kann verwendet werden, um die
wahrscheinlichste Abfolge der internen Zustände basierend auf einer Folge von Beobach-
14 Shan50
22
1.5 Angriff: Folgen eines jähen Paradigmenwechsels
tungen zu erkennen. In diesem speziellen Fall bestimmen wir damit die wahrscheinlichste
Folge von Zeichen auf der Basis einer Folge zeitlicher Abstände.
Das Endergebnis der Anwendung des Viterbi-Algorithmus ist eine Verringerung des Such-
raums um den Faktor 50 bei Passwörtern mit einer Länge von acht Zeichen, die nicht aus
einem Wörterbuch stammen. Bei der Rekonstruktion eines eingegebenen
wörterbuchbasierten Textes in englischer Sprache ist dieser Faktor wahrscheinlich erheblich höher.
OOO
Im.. llfv»
ffHv
[aiigl ^
DO
A
OOOE
LOOOj
DOOC
)OOOC
jsgangszi
)OG
jstan
llsIrllRnEtadif.
" | law
d
OOOOOOOOOOOOOII
" lOOOOOC
)QOOOO
"TQQQG
Anschlag der Taste W
OOOOOOOOOOOOOG
IQQQQDQpanQQ \~\
]OOOOl \1 n TvlElkt
Anschlag der Taste P
OOOOOOOOOJDJDJDO
0OOOOOOO
QQQ
oofl
Anschlag der Taste V
Abbildung 1.3 Die Notwendigkeit, die linke Hand im vorherigen Schritt an eine andere Position setzen
zu müssen, wirkt sich auf die Geschwindigkeit der Folge P —> V aus. Das Markow-Modell ist nicht in
der Lage, die vorherige Position der Hand bei Handwechseln zu berücksichtigen.
Werfen wir nun einen Blick auf die Überwachung von Interrupts. Die oben erwähnte
Studie konzentrierte sich auf Teihnformationen, die durch das Abhören von SSH-
Datenverkehrsrnustem (Secure Shell) gewonnen wurden. Im Falle der
Interruptüberwachung erhält der Angreifer erheblich mehr Informationen. Zum Ersten stehen ihm Angaben
zur Dauer eines Tastenanschlags ebenso zur Verfügung wie zu den zeithchen Abständen
zwischen den Anschlägen. Die Dauer des Anschlags hängt vom verwendeten Finger ab:
Beim Zeigefinger ist der Kontakt am kürzesten, beim Ringfinger wahrscheinlich am
längsten usw. Dies sind wesentliche Informationen, die die Eingrenzung eines geeigneten
Tastaturbereichs beträchtlich erleichtem.
Zweitens erlauben es die Daten dem Angreifer auch, Handwechsel zu überwachen, d. h.
den Moment, in dem ein Zeichen von der linken und das darauffolgende Zeichen von der
rechten Hand (oder umgekehrt) angeschlagen wird. Weil die beiden Hände von jeweils
unterschiedlichen Hemisphären im Gehirn gesteuert werden, schlagen fast alle geübten Tasta-
23
1 Die redselige Tastatur
turschreiber beim Handwechsel mehr oder weniger häufig die zweite Taste bereits an,
bevor sie die erste losgelassen haben. Zwar sind diese Anschlag- und Loslassereignisse als
solche nicht zu unterscheiden, aber ein besonders kurzer Abstand zwischen zwei
Tastaturereignissen ist ein klares Anzeichen für dieses Phänomen. In einigen seltenen Situationen -
und besonders dann, wenn der Schreiber in Eile ist -, erfolgt der zweite Anschlag nicht nur
vor dem Loslassen, sondern bereits vor dem Anschlagen der ersten Taste. Dies führt zu
verbreiteten Rechtschreibfehlern des Typs „udn" (statt „und").
Abbildung 1.4 zeigt einen protokollierten Ablauf von Tastaturaktionen. Der Benutzer gibt
das Wort evil ein. Der mittlere Finger der linken Hand betätigt für eine mittlere Zeitdauer
die Taste E. Danach kommt es zu einer beträchtlichen Pause, bevor als nächstes V
eingegeben wild; dies hegt daran, dass der Schreiber die gesamte Hand bewegen rnuss, um die
Taste VmA dem Zeigefinger zu erreichen (der Daumen kann hierfür nicht benutzt werden,
da die Leertaste im Weg ist). Die Taste Fwird - ebenso wie /— nur ganz kurz
angeschlagen, wobei hierbei jeweils der Zeigefinger zum Einsatz kommt. Es gibt auch eine sichtbare
Überschneidung: Aufgrund des Handwechsels wird / angeschlagen, bevor V losgelassen
wird. Abschließend betätigt der Ringfinger nach einer kleinen Pause (aufgrund des nicht
erforderlichen Handwechsels) die Taste L, wobei der Anschlag relativ lange dauert.
0
0
0
0
111 h 1111| 111 h 1111|111 h 1111| 111| 111 h 1111| 111 h 1111| 111 h 1111| 111| 111 h 1111| 111 h 1111| 111 h 1111| 111|111 h 1111
Zeit «-
Abbildung 1.4 Ablaufmuster für Anschlagen und Loslassen bei Handwechsel
Insofern kann man vernünftigerweise davon ausgehen, dass es möglich ist, bei einem
solchen Angriff eine wesentlich höhere Erfolgsquote zu erziehen. (Die meisten dieser
Faktoren waren in dem Szenario, welches in dem oben erwähnten Weißbuch beschrieben wird,
nicht verfügbar.)
1.5.2 Taktiken zur Verteidigung
Jetzt wissen wir also, welches Potenzial das Belauschen einer Tastatur birgt. Doch wie
können wir uns dagegen verteidigen? Die beste Möglichkeit besteht in der Nutzung eines
separaten Tastaturentropiepuffers angemessener Größe. Der Puffer wird erst dann geleert
und sein Inhalt an die PRNG-KemiinpleHientierung übergeben, wenn ein Überlauf erfolgt
oder eine gewisse Zeitspanne vergangen ist, die erheblich größer ist als die üblichen Inter-
24
1.5 Angriff: Folgen eines jähen Paradigmenwechsels
valle zwischen Tastatuianschlägen (d. h. mehrere Sekunden). Auf diese Weise sind durch
Überwachung ermittelte Timingangaben unbrauchbar.
Bei dieser Lösung erhält der Angreifer nur zwei Alten von Informationen. Wenn der
Puffer beim Überlauf geleert wird, kann der Angreifer erkennen, dass eine (von der
Puffergröße abhängige) Anzahl von Tasten innerhalb eines rnessbaren Zeitraums angeschlagen
wurde; er kann die exakten Intervalle zwischen den einzelnen Tastaturaktivitäten jedoch nicht
erkennen. Die zweite Möglichkeit ergibt sich aus dem zeitgesteuerten Leeren des Puffers
und zeigt dem Angreifer, dass eine oder mehrere Tasten während eines festgelegten
Zeitraums betätigt wurden; es lassen sich jedoch keine Angaben dazu ennitteln, wie viele
Ereignisse dies waren und wann genau sie aufgetreten sind. Die auf diese Weise
ermittelbaren Informationen sind für ablaufbezogene Angriffe nur von geringem Wert, denn sie
lassen sich lediglich zur Ermittlung allgemeiner statistischer Angaben zur Tastaturaktivität
nutzen, was für sich genommen in den meisten Mehrbenutzerumgebungen keinerlei
Bedrohung darstellt.
1.5.3 Zufallszahlenerzeugung via Hardware - die bessere Lösung?
Viele moderne Hardwareplattformen implementieren physische Zufallszahlengeneratoren,
die oft auch als TRNGs (Trae Random Number Generators, Generatoren für echte
Zufallszahlen) bezeichnet werden. Diese Geräte erlauben die zuverlässigere Erzeugung wirklich
unvorhersagbarer Daten (im Gegensatz zur Sammlung von Informationen, von denen man
lediglich annimmt, dass sie nicht vorhersagbar sind) und stellen die zur Entropiebildung
generell empfohlene Vorgehensweise dar, sofern eine solche Funktionalität vorhanden ist.
Zwei zum Zeitpunkt der Abfassung dieses Buchs verbreitete Lösungen sind von Intel und
"VTA entwickelte integrierte Schaltungen.
Der Intel-Generator ist mit Chipsätzen wie dem i810 ausgestattet und verwendet einen
konventionellen Aufbau mit zwei Oszillatoren. Der Hochfrequenzoszillator erzeugt ein
Basissignal, welches im Wesentlichen ein Muster abwechselnder logischer Zustände
(010101010101 ...) darstellt. Der andere Oszillator ist ein Niederfrequenzgerät, das mit
einer Nominalfrequenz von einem Hundertstel der Frequenz des Hochgeschwindigkeitsos-
zillators berieben wird; die tatsächliche Frequenz aber wird von einem Widerstand
moduliert, der als eine erste Entropiequelle dient.
Bestimmte messbare Eigenschaften eines Widerstandes ändern sich infolge von Wärme-
rauschen und anderen zufälligen Materialeffekten. Der Niederfrequenzoszillator steuert die
Entnahme von Proben des Wechselsignals mit nun zufälligen Häufigkeiten (fallende
Flanke des Oszillatorausgangssignals). Das Signal wird dann - nach einer erförderlichen
Anpassung und , Aufbereitung" mithilfe der Korrektur nach von Neumann - der Außenwelt
zur Verfügung gestellt. Eine sorgfältige Analyse von Aufbau und tatsächlicher Ausgabe
des Generators, die von Benjamin Jun und Paul Kocher von Cryptography Research15
Jun99
1 Die redselige Tastatur
durchgeführt wurde, hat gezeigt, dass die Ausgabequalität konstant hoch ist und der
Generator je Ausgabebit eine geschätzte Entropie von 0,999 Bits erzeugt.
Der VIA C3-Generator („Nehemiah") basiert auf einem etwas anderen Aufbau, der einen
Satz Oszillatoren verwendet, die aber nicht als separate Rauschquellen, sondern als
spezieller Widerstandsanschluss dienen. Verwendet wird hier der interne Jitter
(Signalunbeständigkeit) der Oszillatoren - ein Effekt, der einer Reihe interner und externer Faktoren
zugeordnet werden kann und außerdem durch eine konfigurierbare ,3ias-Funktion" (zur
Erzeugung systematischer Fehler) gesteuert wird.
In diesem Fall hat eine separate Analyse durch Cryptography Research10 aufgezeigt, dass
der Generator offensichtlich eine Entropie geringerer Qualität liefert als sein Gegenstück:
Sie hegt im Bereich zwischen 0,855 und 0,95 Bits je Ausgabebit. Dies ist ein bedenkliches
Ergebnis, wenn die Generatorausgabe in unveränderter Form als vollständig zufällige
Zahlen - etwa zur SchlUsselgenerierung oder für andere kritische Aufgaben - verwendet wird,
denn die Menge eigentlicher Entropie verringert sich entsprechend. Um dieses Problern zu
beheben, können wir dem Generator Hiehr Daten als eigentlich notwendig entnehmen und
diese mit einer sicheren Hashing-Funktion (z. B. SHA-1) verarbeiten, um einen Mangel an
systematischem Fehler oder Entropie zu beseitigen. Dieser Ansatz ist empfohlene Praxis
für TRNG-spezifische Probleme, solange sich die unerwünschten Effekte innerhalb
angemessener Grenzen bewegen (d. h. solange jedes Bit noch ein ausreichendes Maß an
Entropie in sich trägt).
Mehrere Experten haben auch vorgeschlagen, nichtspezialisierte Eingabegeräte - z. B.
Webcams oder eingebaute Mikrofone - als Entropiequelle einzusetzen. CCD-Sensoren in
Digrtalkameras neigen zur Erzeugung von Pixelrauschen, und ein erheblich übersteuertes
Mikrofonsignal ist grundsätzhch eine geeignete Quelle für Zufallsrauschen. Allerdings gibt
es keine universelle Methode zur Einrichtung eines solchen Generators, denn es gibt
herstellerspezifische Unterschiede bei den Schaltungen verbreiteter Mediengeräte, weswegen
die Qualität der erzeugten „Zufallszahlen" nicht gewährleistet ist. Und tatsächlich nehmen
einige Geräte scheinbar zufällige, aber doch vollständig vorhersagbare Funkstöningen oder
bestimmte schaltungsinteme Signale auf. Außerdem erzeugen manche Geräte
(insbesondere CCD-Sensoren) statische Rauschmuster: Diese scheinen zwar zufällig, ändern sich aber
nicht unverrnittelt, weswegen es geiährlich sein kann, sich einzig und allein darauf zu
verlassen.
1.6 Denkanstöße
Ich habe mich entschieden, die tiefgründige Beschreibung einiger interessanter Konzepte
auszulassen. Nichtsdestoweniger können diese eine wertvolle Inspiration für weitere
Erkundungen sein.
Qyp03
26
1.6 Denkanstöße
1.6.1 Entfernte Timingangriffe
Theoretisch könnte es möghch sein, den PRNG-Timingangriff auch über ein Netzwerk
auszuführen. Bestimmte kryptografieiahige Dienste implementieren eine symmetrische
Kryptografie. Nach Herstellen eines langsameren asymmetrischen Stioms mithilfe der PKI
und der Verifizierung der beiden beteiligten Parteien wird ein symmetrischer
Sitzungsschlüssel erstellt, und die beiden Endpunkte schalten auf die schnellere symmetrische
Alternative um.
■ Es ist eventuell möghch, die Ablaufmuster von Tastaturanschlägen zu überwachen,
indem man dafür sorgt, dass die Anwendung einen im System vorhandenen
Entropiepool bis zu dem Punkt aufbraucht, an dem gerade eben nicht rnehr genug
Entropie vorhanden ist, um einen neuen Sitzungsschlüssel zu generieren. Die Anwendung
verzögert dann die Erstellung eines symmetrischen Schlüssels, bis wieder genug
Entropie vorhanden ist, um den Rest eines Schlüssels zu erstellen; dies aber wird - neben
anderen Möglichkeiten - beim nächsten Anschlagen oder Loslassen einer Taste der
Fall sein.
■ Meiner Ansicht nach wird eine solche Attacke eher in einem Testfeld als in irgendeiner
realen praktischen Anwendung Erfolg haben. Mein Fachlektor allerdings ist anderer
Meinung, weswegen Sie meine Aussage lediglich als einen möglichen Standpunkt
betrachten sollten. Eine interessante Analyse der University of Virginia17 kritisierte die
im erwähnten Dokument beschriebene Studie zu SSH-Ab laufen dahingehend, dass
bereits die Signalunbeständigkeiten im Netzwerk ein Ermitteln von Ablaufmustem
unmöglich machen würden; allerdings sei darauf hingewiesen, dass die konstante
Wiederholung einer Aktivität (z. B. die Eingabe desselben Passworts bei jeder Anmeldung)
zufällige Netzwerkleistungsschwankungen durchaus kompensieren könnte.
1.6.2 Ausnutzen der Systemdiagnose
Es gibt Systeme, die bessere Möglichkeiten haben, Angaben zu Tastaturaktivitäten und
andere Ablaufdaten wiederherzustellen. Nach der Veröffenthchung meiner Studie zum
PRNG-Timing wurde ich darauf hingewiesen, dass Linux eine Datei /proc/intermpts
enthält, die interruptspezifische Statistikübersichten anzeigt; ihr Sinn ist die Bereitstellung
einiger nützlicher Leistungsdaten. Durch Überprüfen der Änderungen beim rnterruptzähler
von IRQ 1 ist es möghch, dieselben Ablaufinfonnationen zu erhalten, die sich mithilfe
eines PRNG ermitteln lassen; hierbei sind zudem Implikationen von Festplatten- und
Netzwerkaktivitäten bereits ausgefiltert, d. h. die Entblößung der Privatsphäre erfolgt in
ähnlichem Maße wie beim oben beschriebenen Fall.
HogyOl
1 Die redselige Tastatur
1.6.3 Reproduzierbare Unberechenbarkeit
Andere Probleme, die einen Blick wert sein könnten, beziehen sich auf die PRNG-
Irnplernentierung selbst. Wenn Sie dieselbe Hardware in großen Stückzahlen erwerben und
in jedem Ihrer Systeme installieren (was gängige Praxis ist), dann kann dies ein Problem
bei Servern darstellen, die konsolenseitig nicht besonders stark beanspracht werden.
Risiken bestehen auch, wenn eine Installation mithilfe spezieller Klontools gespiegelt und das
Image dann auf eine größere Anzahl von Servern aufgespielt wird. In all diesen
Situationen ist am Ende unter Umständen zu lange zu wenig wirkliche Entropie vorhanden.
28
2 Mehrarbeit fällt auf
Zweites Kapitel. In dem wir erfahren, wie man einen Computer aus Holz baut
und Informationen sammelt, indem man einem echten Computer bei der
Arbeit zusieht
Die Daten, die Sie eingegeben haben, befinden sich nun im sicheren Hafen der
Anwendung, die Sie gestaltet haben. Das Programm nimmt sich die Zeit, zu entscheiden,
was mit den Daten geschehen soll, wie sie zu inteipretieren sind und welche Handlungen
nun als nächste durchzuführen sind.
In diesem Kapitel werden wir die maschinennahe Mechanik der Datenveraibeitung im
Detail untersuchen und einige der Probleme benennen, die tief unter dem Kühlkörper Ihres
Prozessors lauem. Dabei werden wir besonderes Augenmerk auf Rückschlüsse legen, die
sich durch einfaches Beobachten ziehen lassen: Beobachten, wie ein System bestimmte
Programme ausführt und wie lange die Erledigung bestimmter Aufgaben dauert. Als
Zugabe werden wir zudem einen voll funktionsfähigen Computer aus Holz bauen.
2.1 Booles Erbe
Um den Aufbau eines Prozessors zu verstehen, müssen wir zurückkehren zu den Tagen,
als noch niemand ahnen konnte, dass es so etwas wie Prozessoren überhaupt einmal geben
würde. Alles begann seinerzeit ganz unschuldig im 19. Jahrhundert, als George Boole
(1815 -1864), Autodidakt auf dem Gebiet der Mathematik, ein einfaches binäres
Algebrasystem ersann, das als Rahmen zum Verstehen und Gestalten eines formalen
Logikkalküls dienen sollte. Sein Ansatz reduzierte die Menge der logischen
Grundkonzepte auf drei einfache algebraische Operationen, welche auf Elemente
angewendet werden können, die zwei gegenteilige Zustände - wahr und falsch - abbilden.
Diese Operationen sind:
29
2 Mehrarbeit fällt auf
■ Disjunktionsoperator (OR, ODER). Dieser ist wahr, wenn mindestens einer der
Operanden1 wahr ist.2
■ Konjunktionsoperator (AND, UND). Dieser ist nur wahr, wenn alle Operanden wahr
sind.
■ Negationsoperator (NOT, NICHT). Dieser ist wahr, wenn der (einzige) Operand
falsch ist.
Wiewohl simpel in seiner Struktur, erwies sich das Boolesche Algebramodell als
leistungsfähiges Tool zur Lösung logischer Probleme und anderer mathernatischer
Aufgaben. Letztendlich war es dieses Modell, welches es zahlreichen beherzten Visionären
ermöglichte, den Traum von der intelligenten analytischen Maschine Wirklichkeit werden
zu lassen, die eines Tages unser tägliches Leben ändern sollte.
Für die meisten versierten Computerbenutzer ist die Boolesche Logik heute kaum mehr ein
Buch mit sieben Siegeln - ganz anders als der Weg, der von dieser Sammlung trivialer
Operationen zu unseren modernen Computern fühlt. Wir werden mit der Erforschung
dieses Pfades beginnen, indem wir zunächst einmal versuchen werden, die Essenz dieses
Modells in seiner einfachsten Form zu erfassen.
2.2 Auf dem Weg zum Universaloperator
Der Pfad zur Schlichmeit nimmt häufig genug scheinbar unnötig komplexe Wege. Auch
dieser Fall bildet keine Ausnahme. Bereits hier - am Anfang der Ausführungen - müssen
wir das Werk eines anderen Mathematikers des 19. Jahrhunderts einbeziehen: Augustus
DeMorgan (1806 -1871). DeMorgans Gesetz besagt: Die Negation einer Disjunktion ist
die Konjunktion der Negationen. Diese niederträchtige Übung zur Verschleierung trivialer
Konzepte hat für die Boolesche Logik - und damit letztendhch auch für den Aufbau
digitaler Schaltungen - einige tiefgreifende Folgen.
Einfach gesagt, erläutert DeMorgans Gesetz, dass, wenn eine von zwei Bedingungen (oder
beide) nicht erfüllt sind, die Aussage, dass beide Bedingungen erfüllt sind (oder - anders
gesagt - eine Konjunktion der Bedingungen auftritt), ebenso falsch ist. Urngekehrt gilt
dasselbe natürlich auch.
Das Gesetz folgert, dass NOT OR (a, b) logisch äquivalent mit AND (NOT a, NOT b) sein
sollte. Wir wollen dies an einem Beispiel aus dem wirklichen Leben veranschaulichen, in
dem a und b folgendes darstellen:
■ a = „Peter mag Milch"
■ b = „Peter mag Äpfel"
Ein Operand ist ein Element, welches inithilfe eines Operators verglichen wird.
Das logische OR ist nicht exklusiv, d. h. es bedeutet „eines von beiden Elementen" und nicht
„entweder das eine oder das andere Element".
30
2.2 Auf dem Weg zum Universaloperator
Die beiden Seiten von DeMorgans Gleichung können nun wie folgt formuliert werden:
OR (NOT a, NOT b) e> Peter mag NICHT Milch ODER Peter mag NICHT Äpfel
NOT AND (a, b) ö Es ist NICHT wahr, dass Peter Milch UND Äpfel mag
Die beiden Ausdrücke sind funktionell äquivalent. Wenn wahr ist, dass Peter eine
Abneigung entweder gegen Milch oder gegen Äpfel hat, dann ist der erste Ausdruck wahr.
Ebenso ist wahr, dass er beide nicht mag, d. h. der zweite Ausdruck ist ebenfalls wahr.
Die Umkehrung der Situation fühlt ebenfalls zu einer Übereinstimmung: Wenn es nicht
wahr ist, dass Peter wenigstens eine der angebotenen Lebensmittel verabscheut, dann mag
er beide (und der erste Ausdruck ist falsch). In diesem Fall ist ebenso wenig wahr, dass er
beide nicht mag (weswegen der zweite Ausdruck ebenfalls falsch ist).
2.2.1 DeMorgan im Einsatz
Um Logikanweisungen auszuwerten, ohne dabei auf die Mittel der Intuition oder eine
Kristallkugel zurückzugreifen, kann es hilfreich sein, so genannte Wahrheitstabellen zu
erstellen, die alle Ergebnisse aller möglichen Kombinationen wahrer und falscher
Operatoren in übersichtlicher Form enthalten.
Die folgenden beiden Tabellen stellen die Ausdrücke des obigen Beispiels dar. Jede
Tabelle enthält Spalten für beide Operatoren und die entsprechenden Ergebnisse für alle
möglichen Wahr/Falsch-Kombinationen. Und so sehen Sie in der ersten Zeile, dass die
ersten beiden Spalten - die Operanden für NOT AND(a, b) - falsch sind. Dies fühlt dazu,
dass AND(a, b) ebenfalls falsch ist - NOT AND(a, b) ist mithin wahr. Das Ergebnis finden
Sie in der dritten Spalte.
Wie Sie sehen, verhalten sich die beiden Ausdrücke identisch.
Tabelle 2.1 NOT AND(a, b): AND mit negiertem Ergebnis
Operand 1 (a)
FALSCH
FALSCH
WAHR
WAHR
Operand 2 (a)
FALSCH
WAHR
FALSCH
WAHR
Ergebnis
WAHR
WAHR
WAHR
FALSCH
Tabelle 2.2 OR(NOT a, NOT b): OR mit negierten Operanden
Operand 1
FALSCH
FALSCH
WAHR
WAHR
Operand 2
FALSCH
WAHR
FALSCH
WAHR
Ergebnis
WAHR
WAHR
WAHR
FALSCH
31
2 Mehrarbeit fällt auf
Was aber haben nun Peters lukullische Leidenschaften mit der Entwicklung von
Computern zu tun? Nichts weniger, als dass DeMorgans Gesetz im Kontext Boolescher
Operatoren die Bedeutung hat, dass die Menge der Basisoperatoren, die die Boolesche
Algebra kennt, teilweise redundant ist: Eine Kombination aus NOT und einem behebigen
der beiden anderen Operatoren (OR und AND) ist immer ausreichend, um den
verbleibenden
Operator zu bilden. Ein Beispiel:
OR (a, b) e> NOT AND(NOT a, NOT b)
AND (a, b) e> NOT OR(NOT a, NOT b)
Diese Auslegung verringert die Anzahl der Operatoren auf zwei, aber das Boolesche
System lässt sich noch weiter vereinfachen.
2.2.2 Komfort ist notwendig
Einige weitere Operatoren sind zur Implementierung Boolescher Logik zwar nicht
zwingend erforderlich, ergänzen die vorhandenen Möglichkeiten aber sinnvoll. Diese
Zusatzoperatoren NAND (NOT AND) und NOR (NOT OR) sind nur dann wahr, wenn AND
bzw. OR falsch sind:
NAND(a, b) e> NOT AND(a, b) e> OR(NOT a, NOT b)
NOR(a, b) e> NOT OR(a, b) e> AND(NOT a, NOT b)
Diese neuen Funktionen sind nicht komplexer als AND und OR. Für jede gibt es eine
Wahrheitstabelle mit vier Zuständen (also vier Zeilen), d. h. der Wert kann mit ebenso viel
Aufwand errnittelt werden.
■ Hinweis
NOR und NAND gehören nicht zu den Basisoperanden, weil beide keiner häufig verwendeten,
grundlegenden Forrn einer logischen Beziehung zwischen Aussagen entsprechen und sich
auch nicht in einer atornischen Darstellung in der Alltagssprache wiederfinden.
Ich habe nun also ein paar neue Operatoren vorgestellt, die von den vorhandenen
Operatoren abgeleitet sind und scheinbar keinen anderen Zweck zu verfolgen scheinen, als
denjenigen unter uns, die ausgesprochen eigenartige logische Abhängigkeiten oder Probleme
mithilfe einer formalen Notierung darstellen wollen, die Sache etwas einfacher zu machen.
Warum eigentlich?
Nun, die Emfühiiing von NAND und NOR ermöglicht es uns, ganz ohne AND, OR und
NOT auszukommen. Dies bringt uns unserem Ziel der Einfachheit näher und gestattet es,
das gesamte System der Booleschen Algebra mit immer weniger Elementen und
Operatoren zu beschreiben.
Die Bedeutung dieser negierten Hilfsoperatoren besteht darin, dass Sie mit ihnen ein
vollständiges Boolesches Algebrasystem erstellen können. Letztendlich können Sie sogar alle
Basisoperatoren mit NAND nachbauen, wie nachfolgend veranschaulicht wird (dabei steht
32
2.2 Auf dem Weg zum Universaloperator
W für „wähl-" und F für „falsch"3). Wie das? Nun, augenscheinlich sind die folgenden
Aussagepaare äquivalent:
NOT a e> NAND(W, a)
AND(a, b) e> NOT NAND(a, b) e> NAND(W, NAND(a, b))
OR(a, b) e> NAND(NOT a, NOT b) e> NAND(NAND(W, a), NAND(W, b))
Alternativ können wir auch wie folgt formulieren, sofern wir ausschließlich NOR (statt
NAND) verwenden wollen:
NOT a e> NOR(F, a)
OR(a, b) e> NOT NOR(a, b) e> NOR(F, NOR(a, b))
AND(a, b) e> NOR(NOT a, NOT b) e> NOR(NOR(F, a), NOR(F, b))
2.2.3 Die Komplexität beim Schöpfe packen
Es ist schwer zu glauben, dass sich die Essenz der gesamten elektronischen
Datenverarbeitung mithilfe nur eines einzigen der verfügbaren Logikoperatoren einfangen lässt. Sie
können die meisten komplexen Algorithmen, ansprachsvoUen Berechnungen, topaktuellen
Spiele und das Intemetsurfen mit einer Matrix einfacher Schaltungen implementieren, die
auf einer der folgenden Wahlheitstabellen basieren, mit denen Eingabesignale in
Ausgabesignale umgewandelt werden.
Tabelle 2.3 Zustandstabelle für NAND
Operand 1
FALSCH
FALSCH
WAHR
WAHR
Operand 2
FALSCH
WAHR
FALSCH
WAHR
Ergebnis
WAHR
WAHR
WAHR
FALSCH
Tabelle 2.4 Zustandstabelle für NOR
Operand 1
FALSCH
FALSCH
WAHR
WAHR
Operand 2
FALSCH
WAHR
FALSCH
WAHR
Ergebnis
WAHR
FALSCH
FALSCH
FALSCH
Puristen mögen einwenden, dass W beispielsweise äquivalent zu AND(a, a) ist, denn dieser Ausdruck
ist immer wähl-. Gleichermaßen ist F äquivalent zu NOT AND(a, a), denn dieser Ausdruck ist immer
falsch. Mit anderen Worten: Wir haben kein neues Konzept oder Gleichungselement vorgestellt,
sondern an dieser Stelle lediglich die Notierung ein wenig vereinfacht.
33
2 Mehrarbeit fällt auf
Sie wenden ein, das führe doch zu nichts? Wie könnte man denn mit dieser simplen Menge
von Abhängigkeiten ein Gerät bauen, das in der Lage ist, komplexe Probleme zu lösen?
Ein Gerät, dem es gelingt, Ihren Kreditantrag ebenso höflich wie bestimmt abzulehnen?
Und was bitte schön hat eine Theorie, die auf den Zuständen „wahr" und „falsch" basiert,
mit digitalen Schaltkreisen gemeinsam?
2.3 ... und weiter in die Welt der Materie
Der Mechanismus, den Boole entwickelt hat, hat nichts Komplexes an sich. Er verlangt
lediglich zwei gegenteilige logische Zustände: „wahr" und „falsch", 0 und 1, „blaugrün"
und „purpurn", 999 und 999,5. Die eigentliche Bedeutung, die physische Daistellung und
das Medium spielen keine Rolle. Was hingegen wichtig ist, ist die frei gewählte
Konvention, die bestimmte Zustände des Mediums mit einer bestimmten Menge logischer Werte
verknüpft.
Computer, wie wir sie kennen, benutzen zwei verschiedene Spannungspegel in einem
Stromkreis und interpretieren diese als Werte, die ihre Konstrukteure als 0 und 1
bezeichnen. Diese Werte, die im Stromkreis übertragen werden, stellen die beiden Ziffern im
binären Zahlensystem dar. Niemand kann uns allerdings daran hindern, irgendeine andere
Methode zur Übertragung der Daten zu verwenden: eine Wasserströrnung, eine chemische
Reaktion, Rauchzeichen oder auch Drehmomente, die von einem Satz meisterhaft
gefertigter Holzzahnräder übertragen werden. Die Information bleibt stets dieselbe -
unabhängig vom Informationsträger.
Der Schlüssel zur Implementiemng der Booleschen Logik in der physischen Welt ist
einfach, sobald man definiert hat, wie logische Werte physisch dargestellt werden. Nun
müssen wir nur noch eine Möglichkeit finden, einen Satz Komponenten auf eine spezielle
Weise anzuordnen, damit diese Werte so manipuliert werden können, dass unser Computer
genau das tut, was wir wollen. Wir kommen darauf in Bälde zurück; zunächst aber wollen
wir herausfinden, wie man Signale manipuliert und echte Logikgeräte implementiert.
Diese werden gemeinhin als Gatter bezeichnet. In unserem Fall: Holzgatter.
2.4 Der stromlose Computer
Der Schritt von einer Anzahl theoretischer Operationen, die die Welt der trockenen
Mathematik hervorgebracht hat, hin zu einem Gerät, welches Strömungen, Drehmomente oder
elektrische Signale so reduzieren kann, dass ein logischer Operator nachgeahmt wird,
scheint eine recht aufwändige Aufgabe zu sein. Eigentlich aber ist es gar nicht so schwer.
Abbildung 2.1 zeigt einen ganz einfachen Zahnradsatz, der die NOR-Funktionalität mit-
hilfe einer drehmornentbasierten Logik implementiert. Wenn das , Ausgaberad" still steht,
stellt es den Zustand 0 dar. Wird auf dieses Rad nun ein Drehmoment ausgeübt, dann ist
34
2.4 Der stromlose Computer
der Zustand 1. Das Gerät überträgt das Drehmoment von einer externen Quelle nur dann
an die Ausgabe, wenn kein Drehmoment auf die beiden steuernden „Eingaberäder"
ausgeübt wild. Theoretisch ist eine externe Energiequelle nicht erforderlich, und der Aufbau
könnte auch etwas einfacher sein; in der Praxis jedoch würden Reibung und andere
Faktoren die Konstruktion eines komplexeren Satzes vollkorninen selbstständiger Gatter
erheblich erschweren.
Das Ausüben eines Drehmoments auf eines der Eingaberäder (oder auf beide Räder) zieht
das kleine Verbindungszahnrad heraus - das Ausgabezahnrad bleibt stehen. Wenn
hingegen die Eingaberäder stehen bleiben, wird das Verbindungsrad von einer Feder wieder in
die Ursprungsposition gezogen. Die Wahrheitstabelle für dieses Gerät entspricht exakt der
von NOR.
Eingabe 1
Abbildung 2.1 Aufbau eines mechanischen NOR-Gatters
Wie bereits erwähnt, sind NOR oder NAND alles, was wir zur Implementierung eines
Booleschen Logikoperators benötigen. Zwar würde die Möglichkeit, weitere Operatoren
zu ergänzen, ohne NAND- und NOR-Gatter neu kombinieren zu müssen, unser Gerät
kleiner und effizienter machen, aber für die Funktion ist dies nicht erforderlich.
Wenn wir das vertrackte Detail übergehen, alle Gatter so zu verschalten, wie wir es
gewohnt sind, dann können wir daraus schließen, dass Computer sich mit praktisch jeder
Technologie konstruieren lassen.4
Und natürlich sind nichtelektrische Computer keine fromme Mär. Zu den berühmtesten Beispielen
gehören die Analytical Engine von Charles Babbage, und auch Ansätze wie die Nanotechnologie sind
vielversprechend. Vgl. Merk93.
35
2 Mehrarbeit fällt auf
2.5 Eine Computerkonstruktion, die ein ganz klein wenig
weiter verbreitet ist
Zwar begann der Cornputerboorn der letzten Jahrzehnte mit dem pfiffigen Konzept des
Transistors, doch ist dieser weder durch seine einzigartige Qualität noch durch
irgendwelches Zauberwerk dafür prädestiniert. Es handelt sich schlichtweg um die kostengünstigste,
bedienungsfreundlichste und effizienteste Konstruktion, die uns derzeit zur Verfügung
steht.
Anders als unsere möglicherweise weit überlegene Holzzahnradmaschine leiten die von
uns benutzten elektronischen Computer lediglich Elektrosignale mithilfe von Transistoren
weiter - winzig kleinen Geräten, bei denen zwischen zwei Knoten (Anschlusspunkten) ein
Strorn in definierter Richtung fließt, sobald eine Spannung an den dritten Knoten angelegt
wird. Transistoren lassen sich recht effizient miniaturisieren, benötigen nur wenig Leistung
und sind zudem zuverlässig und billig.
2.5.1 Logikgatter
Der Transistor ist einfach aufgebaut. Er ist eigentlich sogar zu einfach aufgebaut, als dass
er für sich genommen Boolesche Logik in sinnvoller Form implementieren könnte.
Werden Transistoren jedoch passend zu Logikgattem verschaltet, dann kann man mit ihnen
alle einfachen und erweiterten Operationen der Booleschen Algebra durchführen.
Das AND-Gatter lässt sich implementieren, indem man zwei Transistoren seriell anordnet,
sodass beide einen niedrigen Widerstand aufweisen (also „an" sein) müssen, bevor die
Spannung zum Ausgang fließen kann. Jeder Transistor wird über eine separate
Eingangsleitung angesteuert. Das Ausgangssignal wird mithilfe eines Widerstands nominell
„herabgesetzt", hat also die Massespannung 0 („falsch"); wenn beide Transistoren eingeschaltet
sind, kann ein kleiner Strorn fließen, und der Ausgangswert übersteigt 0.
Das OR-Gatter wird implementiert, indem parallele Transistoren konfiguriert werden,
sodass einer der vorhandenen Transistoren aktiviert werden kann, damit die Ausgabe einen
Wert ungleich 0 erreichen kann (dies entspricht „wahr").
Das letzte Basisgatter NOT wird mit einem einzigen Transistor und einem Widerstand
implementiert. Die Ausgabe von NOT ist bei inaktivem Transistor 1 (was rnithilfe des
Widerstands realisiert wird) und wird auf 0 herabgesetzt, sobald der Transistor öffnet.
Abbildung 2.2 zeigt den Aufbau der drei einfachen Transistorgatter AND, OR und NOT.
■ Hinweis
Sie werden feststellen, dass sich AND- und OR-Gatter ohne Hinzunahnie weiterer
Komponenten in NAND- bzw. NOR-Gatter uniwandeln lassen. Es reicht aus, einen Aufbau zu
wählen, der beim Schema für NOT-Gatter abgeguckt ist: Widerstand und „Ausgangspunkt"
werden zur Versorgungsspannung verschoben, wodurch die Ausgabelogik umgekehrt wird.
36
2.6 Von Logikoperatoren zu Berechnungen
AND-Gatter
Eing. 1
Eing. 2
Ausg.
OR-Gatter
Eing.1 y
Eing. 2 __
Ausg.
NOT-Gatter
Ausg.
Eing. A
Abbildung 2.2 Transistorbasierte Logikgatter: Konstruktion und Symbole
Wir haben nun einen Punkt erreicht, an dem wir Transistoren kombinieren können, um
eines der Universalgatter zu implementieren; allerdings können wir noch so viele
Gatteibauen - mit echter elektronischer Datenverarbeitung hat das noch nichts zu tun.
Sicher ist alles, was bislang in diesem Kapitel gesagt wurde, faszinierend, aber was kann
man mit Boolescher Logik anderes anfangen, als Denkspiele zu Peters Ernährung
aufzulösen?
2.6 Von Logikoperatoren zu Berechnungen
Die Kombination trivialer Boolescher Logikoperationen eröffnet uns eine Vielzahl
überraschender Fähigkeiten. So können wir etwa Rechenoperationen mit den Binärdarstellungen
von Zahlen dmchführen. Und dies ist die Stelle, an der es interessant wird.
So lässt sich beispielsweise eine Eingabezahl mithilfe einer Gruppe von XOR- und AND-
Gattem um den Wert 1 erhöhen. Dies ist der allererste Schritt auf unserem Weg zur
Addition. Abbildung 2.3 zeigt den Aufbau eines Zählers, der auf diesem Konzept basiert.
Und was ist nun wieder „XOR"? XOR ist noch ein „bequemer" Boolescher Logikoperator:
Er ist wahr, wenn genau einer seiner Operanden wahr ist. XOR (exklusives OR) wird
häufig zur Notationsvereinfachung verwendet, ist aber andererseits durch Kombination von
AND, NOT und OR einfach zu implementieren. Es ist wie folgt definiert:
XOR(a, b) e> AND(OR(a, b), NOT AND(a, b))
Nun aber zurück zu unserer Schaltung. Was kann man damit anfangen? Das in
Abbildung 2.3 gezeigte Gerät lässt sich mit einer in Binärförm notierten Zahl füttern. In diesem
Beispiel ist die Zahl auf drei Bits beschränkt, der Aufbau lässt sich aber ganz einfach so
erweitem, dass auch größere Eingabezahlen verarbeitet werden können.
Dieses einfache Rechengerät funktioniert nach dem gleichen Prinzip wie das schriftliche
Addieren: Der Verarbeitung erfolgt von rechts nach links, und es sind Überträge möglich.
Der einzige echte Unterschied besteht darin, dass das Binärprinzip zur Anwendung
kommt.
37
2 Mehrarbeit fällt auf
Wir wollen einmal sehen, wie das funktioniert. Wir nehmen eine Binärzahl, die in eine
Zeile geschrieben ist. Diese Zahl wollen wir nun um den Wert 1 erhöhen. Wir beginnen -
wie wir es von der Dezirnaladdition her kennen - bei der Stelle ganz rechts.
Eingabezahl
1»
',
'*
J
NOT—f~\
KU^\J
\
1 "\ c *
AND J
r
1—"*>
AND ]
u
j xorV
j xorV
o„
—•
o2
—•
03 (Übertrag)
Ausgabezahl
Abbildung 2.3 Einfache „Plus-1 -Schaltung"
Dort finden wir eine Binärziffer. Wenn wir eine solche Ziffer um 1 erhöhen, sind nur zwei
Ergebnisse möglich: Wenn die vorhandene Ziffer 0 ist, ist die Ausgabe 1 (0+1 = 1).
Andernfalls ist die Ausgabe 0, und wir müssen 1 in die nächste Spalte übertragen (1 + 1 = 10).
Mit anderen Worten tun wir zweierlei: Wir erzeugen eine Ausgabe, die eine Negation der
Eingabe ist (1 für 0 oder 0 für 1), und wir behalten, wenn die Eingabeziffer 1 ist, eine 1 im
Sinn, die später eingefugt werden muss.
Dies ist genau das, was diese Schaltung tut - für die erste Eingabeziffer I0. Das oberste
Gatter verarbeitet die Eingabe, indem es sie negiert und als O0 ausgibt. Außerdem wird der
Eingabewert den Gattern zugeführt, die für die Verarbeitung der nächsten Spalte zuständig
sind (00.
O0 = NOT I0
Q)= lo
So, nun haben wir die Zahl um 1 erhöht. Wenn kein Übertrag von der vorherigen Spalte
vorhanden ist, dann bleibt nichts mehr zu tun. Ohne Übertrag sollte Oi J_i widerspiegeln; ist
allerdings ein Übertrag vorhanden, dann müssen wir den Fall auf gleiche Weise bearbeiten
wie beim Hinzuaddieren von 1 zur vorherigen Spalte: Die Ausgabe muss negiert werden,
und ein Wert wird ggf. in die nächste Spalte übertragen.
Von diesem Punkt an wird jeder nachfolgende Ausgabewert (On für w > 0) entweder direkt
von In kopiert, sofern kein Bit aus der vorherigen Spalte übertragen wurde, oder aufgnind
der Addition eines Übertragsbits um den Wert 1 erhöht (was wiederum einer Negation
entspricht). Und ist wird, wenn In = 1 ist, der Übertrag Cn dieser Spalte ebenfalls 1 sein,
während On = 0 ist (denn binär ist 1 + 1 =10). Unter Umständen haben Sie bereits festgestellt,
38
2.6 Von Logikoperatoren zu Berechnungen
dass die Ausgabe an der Position n eigentlich nur das Ergebnis einer XOR-Operation des
Eingabewerts an der Position n und des Übertragbits der Spalte n — 1 ist. Insofern erzeugt
die Schaltung den Wert On durch eine XOR-Verknüpfung des von Cn_i übertragenen Bits
mit dem Wert von In und eine AND-Verknüpfung des Übertrags von Cvi mit In, um zu
bestimmen, ob ein Übertrag in die nächste Spalte erfolgen rnuss:
On = XOR(In,Cn_l)
Cn = AND(In,Cn_1)
Betrachten Sie das folgende Beispiel: Wir wollen den Eingabewert 3 (binär 011) um 1
erhöhen. Die Eingabewerte sehen wie folgt aus:
Io=l
Ii=l
I2 = 0
Die Schaltung erzeugt O0 durch Negjerang von I0, d. h. O0 = 0. Da L, ungleich 0 ist, erfolgt
zudem ein Übertrag in die nächste Spalte. In der nächsten Spalte setzt das XOR-Gatter Oi
auf 0, denn It war zwar 1, aber es erfolgte ein Übertrag von der vorherigen Spalte
(1 + 1 = 10). Auch hier kommt es wieder zu einem Übertrag in die nächste Spalte.
In einer weiteren Spalte ist zwar I2 = 0, aber das AND-Gatter zeigt einen Ubeitragswert
aus der vorherigen Spalte an, weil die beiden vorherigen Eingabewerte jeweils 1 waren. Es
erfolgt kein Übertrag in die letzte Spalte. Die Ausgabe lautet:
O0 = 0
Oi = 0
o2 = i
O0 = 0
.. .oder 0100, was - dezimal ausgedrückt - ganz zufällig 4 entspricht.
Und siehe da: Das ist +1, geschrieben in Binärform.
■ Hinweis
Wir haben soeben das erste Berechnungsproblein in Begriffen der Booleschen Algebra
ausgedrückt. Sie könnten nun versucht sein, den Aufbau so zu erweitem, dass Sie damit zwei
beliebige Zahlen — statt nur einer Zahl und der Zahl 1 — addieren können. Nichtsdestoweniger
macht die Grundschaltung einen Großteil vom A und O der EDV aus.
Digitale Rechenschaltungen funktionieren, indem man bestimmte Eingabedaten durch ein
Array clever angeordneter Logikgatter führt, die ihrerseits Additions-, Subtraktions-, Mul-
tiplikations- und andere einfache Vorgänge an einer Anzahl Bits durcMuhren. Das hat nur
wenig mit Zauberei zu tun.
Bislang habe ich erläutert, wie man mithilfe von Siliziumchips oder zurechtgesägten
Holzscheiben festgelegte Grundoperationen wie etwa Berechnungen mit ganzen Zahlen
durchführen kann. Allerdings fehlt in diesem Bild noch etwas: Wenn Sie Ihren Computer zum
ersten Mal einschalten, werden Sie nämlich feststellen, dass Textverarbeitungsprograrnrne,
39
2 Mehrarbeit fällt auf
Spiele und Tauschbörsensoftware keineswegs fest in ein fürchterlich komplexes Array von
Logikgattern in der CPU einkodiert sind. Wo zum Teufel ist also die Software?
2.7 Von der elektronischen Eieruhr zum Computer
Der echte Wert eines Computers hegt in seiner Fähigkeit, sich so programmieren zu
lassen, dass er auf eine ganz bestimmte Alt und Weise agiert - also eine Folge von
Softwarebefehlen gemäß einem bestimmten Plan ausführt.
Abbildung 2.4 veranschaulicht den nächsten Schritt auf unserem Weg zur Entwicklung
einer flexiblen Maschine, die rnehr kann, als nur eine einzige, fest verdrahtete Aufgabe
erledigen: nämlich die Speicherung und Ablage von Daten. In der Abbildung sehen wir eine
Speichereinheit, die unter der Bezeichnung Flipflop bekannt ist. Diese Speicherzelle hat
zwei Steuerleitungen namens „Set" („Setzen") und „Reset" („Zurücksetzen"). Wenn an
keinem dieser Eingänge ein Signal anliegt, behält das Gatter seinen aktuellen Zustand
aufrecht. Dies hegt an einer Rückleitung zwischen seinem Eingang und dem Ausgang zum
OR-Gatter. Die vorherige Ausgabe von OR wird über ein AND-Gatter gefühlt, weil die
andere Leitung auf 1 gesetzt ist (negiertes „Reset"); dessen Ausgabe wird wieder durch
OR geführt, weil das andere Eingangssignal 0 ist („Set"). Der Ausgangsstatus wird
aufrechterhalten, solange die Gatter mit Spannung versorgt werden.
Wenn am Eingang „Set" ein Signal anliegt, dann wird das OR-Gatte auf den Ausgabeweit
1 gesetzt und behält diesen Wert auch bei, wenn kein Signal mehr an „Set" anliegt. Liegt
an „Reset" ein Signal an, dann wird das AND-Gatter auf 0 gesetzt und die Rückführungs-
schleife wird unterbrochen: Die Ausgabe der Schaltung iällt auf 0. Dies bleibt auch so,
wenn „Reset" wieder signalfrei ist. Wenn an beiden Steuerleitungen ein Signal anliegt,
wird die Schaltung instabil. Das ist nicht gerade schön - besonders, wenn es sich um einen
mechanischem Computer handelt.
Taktsignal
Daten
Flipflopzelle
Ausgabe
OR) » >
Änderungsschnittstelle
Abbildung 2.4 Flipflopspeicher mit praktischer Schnittstelle
40
2.7 Von der elektronischen Eieruhr zum Computer
Die Wahlheitstabelle für diesen Aufbau sieht wie folgt aus (Vbezeichnet dabei einen
behebigen Logikwert):
Tabelle 2.5 Wahrheitstabelle für Flipflopschaltung
Set
0
1
0
1
Reset
0
0
1
1
Qm
V
-
-
-
Qt
V
1
0
instabil
Eine praktischere Variante einer Fhpflopschaltung, die über eine „Ändemngsschnittstelle"
(siehe Abbildung 2.4) verfügt, verwendet zwei AND-Gatter und ein NOT-Gatter, sodass
der Zustand einer Eingangsleitung immer dann (von einer Abtast- und Halteschaltung) er-
fasst wird, wenn ein externes „Taktsignal" abgesetzt wird. Dieser Aufbau beseitigt das
Vorhandensein instabiler Eingangssignalkornbinationen und erleichtert auf diese Weise die
Verwendung eines solchen Speichers zum Ablegen von Daten.
Tabelle 2.6 Verbesserte Wahrheitstabelle für Flipflopschaltung
Eingangssignal
-
S
Taktsignal
0
1
Qm
V
-
Qt
V
s
Diese triviale Gatterkonfiguration weist eine entscheidende Eigenschaft auf: Sie kann
Daten speichern. Eine einzelne Zelle kann nur ein einziges Bit speichern, die
Speicherkapazität lässt sich jedoch durch Kombination einer Anzahl von Flipflops erweitern. Zwar gibt es
heutzutage viele verschiedene Speicherkonstruktionen, aber die Bedeutung dieser
Funktionalität bleibt doch die gleiche: Sie gestattet das Ausführen von Prograrnrnen. Wie das?
In der Grundausführung speichert der Chip einen besonderen Wert, der häufig als
Befehlszeiger bezeichnet wird, auf einem internen Speicherelement auf dem Chip selbst. Dieses so
genannte Register besteht aus mehreren Flipflops. Da gängige Computer synchronisiert
arbeiten (d. h. alle Prozesse werden von einem Taktgenerator zeitlich festgelegt, der mit
sehr hoher Frequenz arbeitet), wählt der Zeiger bei jedem Taktzyklus eine Speicherzelle
aus dem Hauptspeicher aus. Die auf diese Weise abgerufenen Steuerdaten wählen und
aktivieren die für die Verarbeitung der Daten geeignete Rechenschaltung.
Bei manchen Steuerdaten fühlt unser hypothetischer Chip eine Addition durch, bei anderen
ist er Bestandteil einer Eingabe-Ausgabe-Operation. Nach dem Abrufen eines
Steuerdatenelementes (d. h. aller Maschinenanweisungen) muss der Chip seinen Anweisungszeiger
weiterschalten, damit er auf das Lesen des nächsten Befehls im nächsten Zyklus vorberei-
41
2 Mehrarbeit fällt auf
tet ist. Dank dieser Funktionalität können wir mit dem Chip eine Folge von
Maschinenanweisungen ausführen. Und ein Programm ist nichts anderes als eine solche Folge.
Es ist nun an der Zeit herauszufinden, welche Operationen der Chip ausführen können
rnuss, um einsetzbar zu sein.
2.8 Turing und die Komplexität von Anweisungsmengen
Wie sich herausstellt, muss der Prozessor gar nicht so komplex sein. Vielmehr ist die
Menge der Anweisungen, die ein Chip benötigt, um eine behebige Aufgabe
durchzuführen, erstaunlich klein. Die Chui-ch-Tuiing-These besagt, dass jede Berechnung der
physischen Welt von einer Turingmaschine - einem primitiven Computermodell - ausgeführt
werden kann. Die nach Ihrem Erfinder benannte Turingmaschine ist ein einfach
strukturiertes Gerät, das mit einem potenziell endlos langen, aus einzelnen Zellen bestehenden
Band arbeitet - einem hypothetischen, völlig abstrakten Speichermedium. Jede Zelle kann
ein einzelnes, einem „Maschinenalphabet" entnommenes Zeichen speichern, welches
lediglich der Name einer endlichen, sortierten Menge möglicher Werte ist. (Dieses Alphabet
hat nichts mit Alphabeten zu tun, wie wir sie kennen, sondern wurde lediglich so benannt,
um unter Laien für angemessene Verwirrung zu sorgen.)
Femer ist das Gerät mit einem internen Register ausgestattet, welches eine endliche
Anzahl gleichermaßen interner Zustände enthalten kann. Eine Turingmaschine beginnt in
einem gegebenen Zustand bei einer bestimmten Bandposition und liest dann ein Zeichen aus
einer Zelle auf dem Band aus. Jedem Automaten ist eine Menge von Änderangsmustern
zugeordnet, die beschreiben, wie sein interner Zustand geändert werden kann, was
basierend auf der Situation nach dem Lesevorgang auf dem Band gespeichert wird und wie man
das Band (optional) um eine Zelle bewegt. Eine solche Menge von Übergängen definiert
die Regeln zur Berechnung des nächsten Zustandes des Systems basierend auf den
aktuellen Eigenschaften. Diese Regeln werden häufig mit einer Zustandsänderangstabelle wie
der folgenden dokumentiert.
Tabelle 2.7 Zustandsänderungstabelle
Aktueller Zustand
Ct
0
1
st
so
so
Neuer Zustand/Aktion
Ct+i
1
0
S(H
S1
so
VORWÄRTS
-
ZURÜCK
Die Tabelle besagt, dass, wenn der aktuelle Wert der Zelle, an der sich die Maschine
derzeit befindet, 0 ist, und der interne Zustand der Maschine in diese Moment SO ist, das
Gerät den Zustand von C auf 1 und den internen Zustand auf Sl setzen und den Lesekopf
nicht bewegen wird.
42
2.8 Turing und die Komplexität von Anweisungsmengen
Abbildung 2.5 zeigt ein Beispiel einer Turingmaschine, die an der Zelle C positioniert ist
und den internen Zustand S hat.
Wir wollen dies im Einzelnen durchgehen. Wie Sie Abbildung 2.5 entnehmen können,
verwendet die Maschine ein Alphabet mit den beiden Zeichen 0 und 1 und hat zwei interne
Zustände SO und Sl. Sie beginnt im Zustand SO. (Die Anfangsbedingungen können
behebig definiert werden, und genau das habe ich hier auch gemacht.) Wenn die Maschine am
Ende (also beim niederwertigen Bit) einer auf dem Band gespeicherten Binärzahl
positioniert wild, arbeitet Sie entsprechend folgender Logik:
■ Wenn das Zeichen unter dem Lesekopf 0 ist, wird es zu 1, und der Zustand der
Maschine wird zu Sl. Dies entspricht der ersten Änderung, die in Tabelle 2.7
dokumentiert ist. Da keine Änderungsregel von Sl vorhanden ist, bleibt die Maschine beim
nächsten Zyklus stehen.
■ Wenn das Zeichen unter dem Lesekopf 1 ist, wird es zu 0, und der Zustand bleibt
derselbe. Femer bewegt die Maschine den Lesekopf auf dem Band gemäß der zweiten
Änderungsregel nach links. Danach wiederholt sich der gesamte Vorgang beginnend an
der neuen Position, weil die Maschine in Ihrem aktuellen Zustand verbleibt, für den
weitere Änderungsregeln definiert sind.
2.8.1 Endlich: Funktionalität
Auch wenn es jetzt überraschend klingen mag: Diese spezielle Maschine ist tatsächlich
zweckmäßig und implementiert eine Aufgabe, die rnehr als nur theoretischen Wert haben
kann: Sie führt Grundrechnungen aus. Genauer gesagt tut sie das Gleiche wie unsere
weiter oben beschriebene „Plus-1-Schaltung". Sie implementiert sogar denselben
Algorithmus: Bits auf dem Band werden - beginnend an der letzten Stelle - invertiert, bis 0
gefunden (und ebenfalls invertiert) wird.
so
0 1 0
SO, C = 1
110 0 1 CwirdO
1
1 ■ iänd~C Band bewe9t sich nach LINKS; S ändert sich nicht.
SO
0 1
0 1
S1
1
SO, C = 0
0 1110 0 1 C wird 1
Band C Keine Bandbewegung; S wird auf S1 gesetzt.
Zustand S1 Ist die Abschlussbedingung.
1110 0 1 Die Maschine bleibt stehen.
BandC
Abbildung 2.5 Ausführungsstufen einer Turingmaschine
43
2 Mehrarbeit fällt auf
Dies ist natürlich nur die Spitze des Eisbergs. Eine echte Turingmaschine kann jeden nur
vorstellbaren Algorithmus implementieren. Das einzige Problem besteht darin, dass jeder
Algorithmus die Implementieiimg eines eigenen Satzes mit Änderungsregeln und internen
Zuständen erfordert, d. h. wir müssen für jede neue Aufgabe eine neue Tuiingmaschine
bauen. Dies ist auf lange Sicht wohl kaum realisierbar.
Zum Glück aber gibt es einen Sonderfall dieser Maschine, die Universelle Turingmaschine
(UTM). Diese verfügt über einen Anweisungssatz, der ausreichend entwickelt ist, um alle
möglichen Turingmaschinen zu implementieren und jeden behebigen Algorithmus
auszuführen, ohne die Änderungstabelle modifizieren zu müssen.
Diese „Übennaschine" ist weder besonders abstrakt noch außerordentlich komplex. Ihre
Existenz ist garantiert, weil sich (gemäß der bereits erwähnten Church-Turing-These) für
die Ausführung jedes endlichen Algorithmus eine passende Turingmaschine entwickeln
lässt. Da die Methode zum „Ausführen" der Maschine bereits selbst einen endlichen
Algorithmus darstellt, lässt sich auch hierfür eine Maschine entwickeln.
Ein paar Anmerkungen zur Komplexität dieser Maschine: Eine Maschine mit einem Bit,
also zwei Elementen (die kleinste entwickelte UTM) erfordert 22 interne Zustände und
Anweisungen, die Zustandsänderungen beschreiben, um Algorithmen auf einem sequen-
ziellen unendlichen Speicherband auszuführen.5 Diese Menge ist durchaus Überschaubai-.
2.8.2 Der Heilige Gral: Ein programmierbarer Computer
Die Tuiingmaschine ist auch weit mehr als nur ein hypothetisches abstraktes Gerät, das
Mathematiker zur eigenen Erbauung nutzen: Es handelt sich um ein Konstrukt, das
nachgerade danach schreit, rnithilfe eines speziell entwickelten, Booleschen, logikbasierten
elektronischen (oder mechanischen) Gerätes implementiert und vielleicht auch erweitert zu
werden, um seinen Nutzen zu steigern. Dies bringt uns einen Schritt näher an den
sinnvollen Einsatz von Computern. Das einzige Problem besteht darin, dass die Anforderung eines
unendlich langen Eingabebandes sich in der physischen Welt nicht realisieren lässt.
Nichtsdestoweniger können wir einen Großteil davon zur Verfügung stellen, was eine
Hardwareversion der Tuiingmaschine zur Lösung der meisten Probleme des täglichen
Lebens recht nützlich macht. Bühne frei für den Universalcomputer.
Echte Computer gehen natürlich weit über das hinaus, was sich mit einem Ein-Bit-
Speicher mit sequenziellem Zugriff machen lässt; auf diese Weise wird die Menge der
Anweisungen, die zur Erzielung einer vollständigen Turingimplernentierung erforderlich
sind, erheblich reduziert. Eine UTM, die mit einem Alphabet mit 18 Zeichen arbeitet,
erfordert lediglich zwei interne Zustände, um korrekt zu arbeiten. Echte Computer hingegen
arbeiten normalerweise mit einem „Alphabet", das mindestens 4.294.967.296 Zeichen
(32 Bit) enthält - und oft auch weit mehr. Dies erlaubt einen nichtsequenziellen Speicher-
Rogo98
44
2.8 Turing und die Komplexität von Anweisungsmengen
zugriff und die Verwendung sehr vieler Register mit einer astronomisch großen Zahl
möglicher interner Zustände.
Letztendlich beweist das UTM-Modell - und unsere täglichen Erfahrungen bestätigen dies
auch -, dass es möglich ist, eine flexible, programmierbare Verarbeitungseinheit zu
konstruieren, die nur eine Handvoll Merkmale aufweist und mit zwei oder drei internen
Registern (Befehlszeiger, Schreiblesezeiger für Daten und unter Urnständen ein Akkumulator)
und einer kleinen Menge von Anweisungen auskommt. Es ist absolut rnachbar, ein solches
Gerät mit nur ein paar hundert Logikgattern zu erstellen - auch wenn moderne Systeme
weitaus rnehr verwenden.
Wie Sie sehen, ist die Idee, einen Computer selbst zu bauen, gar nicht einmal so abwegig.
Selbst, wenn man dabei Holz als Werkstoff benutzt.
2.8.3 Fortschritt durch Schlichtheit
Wenn man mit einer so kleinen Menge Anweisungen arbeiten muss, ist es natürlich recht
schwierig, daraus ein schnelles oder einfach zu programmierendes Gerät zu entwickeln.
Universelle Turingmaschinen können (auch, weil sie so einfach gestrickt sind) praktisch
alles machen, aber sie sind enervierend langsam und schwierig zu programmieren - so
schwierig, dass sogar die Irnplernentierung einer rnaschinengestützten Übersetzung aus
Klartextsprachen in Maschinencode rnühselig ist. Aber es soll ja Programmierer geben, die
das Risiko eines längeren Klinikaufenthaltes durchaus einzugehen bereit sind.
Architekturen oder Sprachen, die sich zur Erzielung Turingscher Vollständigkeit auf ein zu
elementares Niveau begeben, heißen auch Turingteei-gruben. Dies bedeutet, dass es zwar
theoretisch möglich ist, mit ihrer Hilfe jede behebige Aufgabe dmchführen zu können, dies
aber in der Praxis nicht rnachbar ist und selbst der Versuch bereits zu zeitaufwändig und
beschwerlich wäre. Die Konfiguration sogar einfachster Aufgaben wie der Multiplikation
ganzer Zahlen oder der Verschiebung von Speicherinhalten kann Ewigkeiten dauern, und
ihre Ausführung dauert dann noch einmal doppelt so lang. Doch es gilt: Je weniger
Aufwand und Zeit zur Erledigung einfacher und periodischer Aufgaben erforderlich sind und
je geringer die Anzahl der Aufgaben ist, die von einer Software mithilfe einer Anzahl
separater Anweisungen zu erledigen sind, umso besser.
Eine häufig verwendete Vorgehensweise zur Verbesserang der Funktionalität und Leistung
einer Verarbeitungseinheit besteht darin, bestimmte wiederholt auftretende Aufgaben,
deren Duichführung in der Software eher lästig wäre, hardwareseitig zu implementieren.
Diese einfachen Aufgaben (etwa Multiplikation oder die Ablehnung von Kreditanträgen)
werden mithilfe eines Arrays spezialisierter Schaltungen implementiert. Sie stellen
insofern praktische Erweiterungen der Architektur dar und erlauben eine zügigere und der
geistigen Gesundheit zuträglichere Entwicklung von Programmen. Gleichzeitig kann das
System diese Funktion aber nach wie vor in einer programmierten, flexiblen Reihenfolge
ausführen.
Erstaunlicherweise ist es, wenn man bei der Konstruktion eines Prozessors über die ersten
paar Schritte hinaus ist, nicht immer passend, die Komplexität der Schaltungen linear zu
45
2 Mehrarbeit fällt auf
erhöhen, damit die Prozessoren etwa höhere Geschwindigkeiten erzielen, effizienter
arbeiten und ein besseres Feature-Set aufweisen. Sie können natürlich eine große Zahl von
Schaltungen zur Durchführung aller vorstellbaren komplexen Aufgaben erstellen, die
häufig durchgeführt werden müssen. Dies allerdings ist erst praktikabel, wenn eine
Architektur vollständig ausgereift ist und Ihr Budget es Ihnen gestattet, weiteren Aufwand und
Ressourcen in die Konstruktion eines Chips zu investieren. Zwar werden Programme auf einer
solchen Plattform tatsächlich schneller ausgeführt und sind einfacher zu schreiben, aber
das eigentliche Gerät ist weitaus schwieriger zu bauen, braucht rnehr Energie und könnte
für den täglichen Einsatz schlichtweg zu sperrig oder zu teuer sein. Um komplexe
Algorithmen wie die Division oder Fließkornrnaoperationen in einem Schritt zu verarbeiten,
wird ein wahnsinnig großes Array mit vielen Gattern benötigt, die zudem vorwiegend
untätig sind.
2.8.4 Aufgabenverteilung
Statt den kostspieligen (und wohl auch etwas naiven) Ansatz der Konstruktion von
Blöcken zur Ausführung ganzer Anweisungen in einem Schritt zu verfolgen, sollte man das
Modell der Ausführung einer Anweisung je Zyklus beiseite lassen, bis man einen
funktionsfähigen Aufbau und viel Zeit hat, um diesen zu optimieren. Eine bessere Möglichkeit,
komplexe Funktionalitäten hardwareseitig zu implementieren, besteht darin, die Aufgabe
in kleinste Bestandteile aufzuteilen und umfassende Aufgaben über mehrere Zyklen
hinweg auszuführen.
Bei einem solchen Mehrzyklussystem durchläuft der Prozessor eine Anzahl interner Stufen
— ähnlich wie die Plus-1-Turingmaschine im obigen Beispiel. Der Prozessor führt die
Daten in der korrekten Reihenfolge durch einfache Schaltungen und implementiert auf diese
Weise Schritt für Schritt eine komplexe Funktionalität, die sich auf die elementaren
Komponenten stützt. Statt also mit einem komplexen Gerät alle Berechnungen sofort
auszuführen, könnte der Prozessor mit einer Schaltung die einzelnen Bits von 32-Bit-Ganzzahlen
multiplizieren und Überträge ermitteln und dann in einem 33. Zyklus das Endergebnis
erzeugen. Oder er könnte bestimmte unabhängige Vorbereitungsaufgaben dui-chführen, die
der eigentlichen Operation voranschreiten. Dies würde uns von der Aufgabe entbinden,
Dutzende von Schaltungen für jede Variante eines Operationscodes abhängig davon zu
entwickeln, wo dieser seine Operanden abholt oder Ergebnisse speichert.
Ein weiterer Vorteil dieses Ansatzes besteht darin, dass er ein effizienteres Management
der Hardwareressourcen ermöglicht: Bei simplen Operanden wird ein Algorithmus
variabler Komplexität schneller fertig gestellt, braucht also nur so viele Zyklen wie absolut
notwendig. Man kann beispielsweise davon ausgehen, dass eine Division durch 1 weniger
Zeit benötigt als eine Division durch 187.371.
Eine einfach gestrickte, billige Schaltung mit maximaler Auslastung und variabler
Ausführungszeit kann sehr schnell kostengünstiger sein als ein komplexes und leistungshungriges
Pendant mit konstanter Ausführungszeit. Zwar versuchen einige moderne Prozessoren,
innerhalb einer festen Anzahl von Zyklen immer mehr Aufgaben auszuführen, aber praktisch
46
2.8 Turing und die Komplexität von Anweisungsmengen
alle davon haben einmal als Multizyklusarchitekturen ihr Dasein begonnen. Auch bei
diesen großen Jungens bleibt — wie Sie gleich sehen werden — das Modell nur selten wirklich
einzyklig.
Zunächst aber wollen wir herausfinden, wie dieser Vorteil der Schlichtheit durch Multi-
zyklusausfiihrung nach hinten losgehen kann.
2.8.5 Ausführungsstufen
Eine Variante der Multizyklusausführung ist eine Methode, die eine Aufgabe nicht in eine
Anzahl sich wiederholender Schritte, sondern eine Folge separater, aber universeller Vor-
bereitungs- und Ausfuhnmgsstufen aufteilt. Mithilfe dieser Methode — des so genannten
Stagings — steigern moderne Prozessoren ihre Leistung, ohne dass sie deswegen in
gleichem Maße komplexer werden müssten. Diese Implementienmg von Ausfiihrungsstufen
ist zu einem der wichtigeren Merkmale eines Prozessors geworden.
Moderne Prozessoren können jede Anweisung in eine Menge weitgehend unabhängiger
kleiner Schritte übersetzen. Bestimmte Schritte lassen sich rnithilfe von
Universalschaltungen umsetzen, die von allen Anweisungen verwendet werden und so zur
Gesamtvereinfachung beitagen. Beispielsweise kann die Schaltung, die für eine bestimmte Aufgabe
vorgesehen ist (ich denke dabei sofort wieder an unseren Favoriten: die Multiplikation),
universeller gestaltet und als Teil verschiedener komplexerer Anweisungen wiederverwendet
werden, indem man sie von Aufgaben des universellen I/O-Handlings entbindet. Die
Menge der Ausführungsstufen und Übergänge hängt von der Architektur ab, ähnelt aber
normalerweise weitgehend dem in Abbildung 2.6 gezeigten Schema.
Abbildung 2.6 zeigt die folgenden Stufen an:
■ Anweisung holen und dekodieren. Der Prozessor ruft eine Anweisung aus dem
Speicher ab, übersetzt sie in eine rnaschinennahe Folge und entscheidet dann, wie
fortzufahren ist und welche Daten an alle nachfolgenden Stufen zu übergehen sind. Die
Schaltung wird für alle Operationen verwendet.
■ Operanden holen und dekodieren. Der Prozessor holt rnithilfe einer
Universalschaltung Operanden für diese spezielle Anweisung aus den betreffenden Quellen (z. B. aus
angegebenen internen Registern), damit die Hauptschaltung nicht alle möglichen
Operandenkombinationen und Abholstrategien unterstützen muss.
■ ALU. Eine ALU (Arithmetic Logic Unit, arithmetisch-logische Einheit), die für die
Dmchfühmng der betreffenden Operation — unter Umständen auch in mehreren
Schritten — maßgeschneidert ist, wird aufgerufen, um eine bestimmte Rechenaufgabe
auszuführen. Bei nichtaiithmetischen Anweisungen (z. B. Speicheltransfer) werden
genetische oder dedizierte ALU-Schaltungen gelegentlich zur Berechnung von Quell- und
Zieladressen verwendet.
■ Speicherung. Das Ergebnis wird an der Zielposition gespeichert. Bei nichtarithmeti-
schen Operationen wird der Speicherinhalt zwischen zwei Positionen kopiert.
47
2 Mehrarbeit fällt auf
Anweisung
holen/dekodieren
Operand
holen/dekodieren
ALU-Stufe
N
"►
Speicherung
"►
"►
►
Anweisung 1
FERTIG
Anweisung 2
FERTIG
Abbildung 2.6 Ausführungsstufen von Basisanweisungen
Für sich genommen mag dies lediglich als Variante der regulären Multizyklusausfuhrung
und als Maßnahme zur Wiederverwendung von Schaltungen erscheinen— eine Maßnahme,
die bei modernen Prozessorkonstruktionen weit verbreitet ist. Aber wie Sie noch sehen
werden, ist dies auch für die Ausführungsgeschwindigkeit von allerhöchster Wichtigkeit.
2.8.6 Speicher ist nicht gleich Speicher
Die Geschichte ist aber mit schlichten Schaltungen noch nicht zu Ende. Ein weiterer
Vorteil des Multizyklusaufbaus besteht darin, dass die Prozessorgeschwindigkeit nicht rnehr
vom Speicher beschränkt wird denn dieser ist die langsamste Komponente des Systems.
Externer Speicher für Verbrauchersysteme ist erheblich langsamer als moderne
Prozessoren und weist zudem eine hohe Zugriffs- und Schreiblatenz auf. Die maximale
Geschwindigkeit eines Einzelzyklusprozessors wird dadurch festgelegt, wie schnell er zuverlässig
auf Speicher zugreifen kann — und zwar auch dann, wenn er nicht fortlaufend auf Speicher
zugreift. Er muss schlichtweg deswegen so langsam sein, weil eine der
Einzelzyklusanweisungen, die ihm zugeführt werden, auf Speicher zugreifen könnte; und deswegen muss
einfach genug Zeit hierfür eingeplant werden. Im Gegensatz dazu gestatten Multizykluskon-
struktionen es dem Prozessor, sich soviel Zeit wie erforderlich zu nehmen und sogar ein
paar Zyklen lang untätig zu bleiben, sofern dies notwendig sein sollte (etwa bei Speicher-
I/O-Operationen); andererseits muss er mit voller Geschwindigkeit laufen, wenn er interne
Berechnungen dui-chfühit. Überdies ist es bei der Verwendung von Multizyklus Systemen
einfacher, speicherintensive Operationen zu beschleunigen, ohne in schnelleren
Hauptspeicher investieren zu müssen.
Der Flipflopaufbau, der gemeinhin als SRAM (Static RAM, statisches RAM) bezeichnet
wird bietet gelinge Zugriffslatenzen und benötigt wenig Leistung. Aktuelle Ausführungen
benötigen etwa 5 Nanosekunden, was dem Zyklusintervall einiger Prozessoren entspricht.
Leider benötigt dieser Aufbau aber auch eine beträchtliche Anzahl von Komponenten pro
Flipflop — etwa sechs Transistoren je Bit.
Anders als SRAM verwendet DRAM (Dynamic RAM, dynamisches RAM), der zweite
heutzutage weit verbreitete Speichertyp, zur Speicherung von Daten ein Array mit Kon-
48
2.8 Turing und die Komplexität von Anweisungsmengen
densatoren. Kondensatoren jedoch neigen zur Entladung und müssen deswegen regelmäßig
aufgefrischt werden. DRAM benötigt rnehr Leistung als SRAM und hat eine wesentlich
höhere Zugriffs- und Andenmgslatenz (bis zu 50 Nanosekunden). Andererseits ist DRAM
wesentlich billiger herzustellen als SRAM.
Die Verwendung von SRAM als Hauptspeicher ist praktisch unbekannt, denn dies
verbietet sich aus Kostengründen quasi von selbst. Außerdem gäbe es Probleme bei der Nutzung
der sich hierdurch ergebenden Leistungssteigerung, denn in diesem Fall könnte es
notwendig sein, den Speicher mit beinahe derselben Geschwindigkeit wie die CPU zu betreiben.
Unerfreulich: Weil Hauptspeicher ziemlich groß ist und zudem erweiterbar sein soll, muss
er außerhalb des Prozessors positioniert werden. Der Prozessorkem kann zwar
normalerweise mit einer Geschwindigkeit laufen, die wesentlich höher ist als die seiner Umgebung,
aber es entstehen erhebliche Probleme mit der Zuverlässigkeit, wenn die Daten über
größere Stecken transportiert werden müssen: Leiterbahnkapazität auf der Hauptplatine,
Störungen, Kosten für sehr schnelle Peripheriechips usw.
Statt nun die aufgrund der Kosten inakzeptablen Ansätze der Verwendung schnelleren
Speichers oder der Integration des gesamten Speichers auf der CPU zu verfolgen, gehen
die Hersteller in der Regel einen vernünftigeren Weg. Fortschrittliche Prozessoren sind mit
schnellem, aber erheblich kleinerem Speicher im Kern ausgestattet. Hierbei wird meist
SRAM oder ein Derivat verwendet, welches zur Zwischenspeichemng der meistbenutzten
Speicherregionen und manchmal auch zur Speicherang bestimmter CPU-spezifischer
Zusatzdaten verwendet wird. Wann immer also ein Speichersegment im Cache gefunden wird
(Cacheteffer), kann auf dieses sehr schnell zugegriffen werden. Nur dann, wenn ein
Speichersegment aus dem Hauptspeicher geholt werden muss (Cachefehlschlag), kann es zu
einer beträchtlichen Verzögerang kommen; in diesem Fall muss der Prozessor einige
seiner Operationen eine Zeit lang verschieben. (Einzelzyklusprozessoren können das interne
Caching nicht vollständig ausnutzen.)
2.8.7 Mehr desselben: Pipelining
Wie bereits erwähnt, bietet das Staging einen beträchtlichen Geschwindigkeitsvorteil, der
weit über einen traditionellen Multizyklusansatz hinausgeht. Es gibt allerdings einen
wesentlichen Unterschied zwischen diesen Methoden: Da viele Stufen von verschiedenen
Anweisungen gemeinsam verwendet werden, gibt es keinen Gnmd, die Ausführung nicht
ein wenig zu optimieren.
Abbildung 2.6 zeigt, dass, wenn separate Stufen auch separat ausgeführt werden, bei jedem
Zyklus nur ein bestimmter Teil des Geräts benutzt wird. Auch wenn die Anweisung, die
gerade ausgeführt wird, die ersten Stufen bereits passiert hat, blockiert sie bis zu ihrem
Abschluss doch die gesamte CPU. Bei Systemen mit einer großen Zahl von
Ausführungsstufen (ihre Anzahl en-eicht oder überschreitet bei modernen Chips häufig einen Wert von
10; beim Pentium 4 sind es sogar rnehr als 20) fühlt dies zu einer irrsinnigen
Verschwendung von Rechenleistung.
49
2 Mehrarbeit fällt auf
Eine Lösung besteht darin, die nächste Anweisung bereits in die Ausführangs-Pipeline
einzuspeisen, sobald die vorherige Anweisung zu nächsten Stufe fortgeschritten ist (siehe
Abbildung 2.7). Sobald eine bestimmte Stufe der ersten Anweisung abgeschlossen ist und
die Ausführung zur nächsten Stufe fortschreitet, wird der vorherigen Stufe bereits ein Teil
der nachfolgenden Anweisung zugeführt. Wenn die erste Anweisung abgeschlossen ist, ist
die nächste nur eine Stufe vom Abschluss entfernt, die übernächste zwei Stufen usw. Die
Ausführungsdauer verringert sich dadurch ausgesprochen drastisch, und die Chipnutzung
wird durch diese Kaskadierungsrnethode optimiert.
Dieses Pipelining funktioniert wunderbar, solange die Anweisungen nicht voneinander
abhängen und keine die Ausgabe eines Vorgängers verarbeitet, der sich noch in der Pipeline
befindet. Sollten die Anweisungen jedoch aufeinander aufbauen, dann sind erhebliche
Probleme vorprogrammiert. Insofern muss eine Spezialschaltung implementiert werden,
die die Pipeline überwacht und derartige Blockiersituationen verhindert.
Das Pipelining stellt aber noch mehr Herausforderungen. So kann sich bei einigen
Prozessoren etwa die Menge der Stufen bei verschiedenen Operationen unterscheiden. Nicht alle
Stufen sind immer anwendbar, und es kann sogar vorteilhaft sein, eine oder mehrere zu
überspringen. Bestimmte einfache Operationen können die Pipeline begreiflicherweise
wesentlich schneller durchlaufen, weil keine Operanden geholt oder gespeichert werden
müssen. Femer können einige Stufen unterschiedlich viele Zyklen benötigen, was zum
Kollisionsrisiko beiträgt, wenn zwei Anweisungen gleichzeitig dieselbe Ausführangsstufe
erreichen. Um dies zu verhindern, müssen bestimmte Zusatzmechanisrnen wie Pipeline-
Bubbles entwickelt werden: operationsfreie Stufen, deren Zweck darin besteht, bei Bedarf
flüchtige Verzögerungen einzubringen.
Anweisung
holen/dekodieren
Operand
holen/dekodieren
tfc
w
F
1
P
ALU-Stufe
h
►
1
w
Speicherung
k
p-
Anweis
FERTK
P*
Anweisung 2
FERTIG
Abbildung 2.7 Pipeline-Ausführungsmodell
2.8.8 Das große Problem beim Pipelining
Traditionelle Pipelines sind hervorragend, um mit einem einfachen, mehrstufigen
Chipaufbau eine hohe Leistung zu erzielen, indem die Latenz nachfolgender Anweisungen
verringert und eine optimale Schaltungsnutzung gewährleistet wird. Allerdings sind sie auch
nicht ohne Prob lerne: Es ist beispielsweise nicht möglich, Anweisungen in einer Pipeline
50
2.9 Auswirkungen - die kleinen Unterschiede
über eine Bedingungsanweisung mit Verzweigungen hinaus zu transportieren, wenn diese
Anweisung die weitere Rograrnrnausführang ändern könnte.
Tatsächlich ist dies häufig möglich, aber der Prozessor weiß natürlich nicht, welchem Aus-
führiingspfad er folgen soll; wird eine falsche Entscheidung gefällt, dann muss die gesamte
Pipeline geleert werden, sobald eine Verzweigungsanweisung auftritt. (Die CPU muss
auch das Festschreiben von Änderungen verzögern, die von diesen Anweisungen
vorgenommen wurden, denn schließlich wurden die Anweisungen nicht ausgefühlt.) Durch das
Entleeren der Pipeline kommt es zu einer weiteren Verzögerung.
Und unglücklicherweise (zumindest für diesen Aufbau) sind viele prozessorintensive
Aufgaben — darunter etwa viele Video- und Audioalgorithmen — auf kleine Bedingungsschlei-
fen angewiesen, die millionenfach wiederholt werden und sich auf diese Weise
katastrophal auf die Pipeline-Architektur auswirken.
Die Antwort auf dieses Problern ist die Verzweigungsprognose. Hierfür verwendete
Verzweigungsprädiktoren sind meistens ziemlich einfach gestrickte Zählerschaltungen, die
die aktuelle Codeausführang überwachen und rnithilfe eines kleinen Verlaufspuffers das
wahrscheinliche Ergebnis einer konditionalen Verzweigungsoperation vorherzusagen
versuchen (auch wenn häufig komplexere Entwürfe zum Einsatz kommen0).
Alle Verzweigungsprädiktoren verwenden eine Strategie, die für einen gegebenen Code
die optimale Pipelining-Leistung ermöglichen soll: Wenn eine bestimmte
Verzweigungsanweisung häufiger ausgeführt wird, ist es besser, die Anweisungen zu holen und in der
Pipeline zu transportieren. Natürlich kann die Prognose fehlschlagen; in diesem Fall muss
die gesamte Warteschlange verworfen werden. Allerdings erzielen moderne Prädiktoren
Erfolgsraten von bis zu 90 Prozent bei konventionellem Code.
2.9 Auswirkungen - die kleinen Unterschiede
Die hochentwickelten Optimierungen, die in modernen Prozessoren implementiert sind,
haben eine Reihe interessanter Auswirkungen zur Folge. Wir stellen fest, dass die Ausfiih-
mngszeiten von den folgenden Merkmalen abhängen, die sich in drei Gruppen aufteilen
lassen:
■ Konstruktionstyp und Operationskomplexität. Es gibt Operationen, die wesentlich
schneller ausgeführt werden als andere.
■ Operandenwerte. Bestimmte Multizyklenalgorithmen arbeiten umso schneller, je
einfacher die Eingabewerte sind. Die Multiplikation eines Wertes mit 0 ist generell
ziemlich trivial und erfolgt daher sehr zügig.
■ Speicherposition, von der die für die Anweisung erforderlichen Daten abgerufen
werden. Daten im Cache sind schneller verfugbar.
6 Mile02
2 Mehrarbeit fällt auf
Die Wichtigkeit, Verbreitung und Auswirkung jeder dieser Eigenschaften hängt vom
exakten Aussehen der fraglichen Prozessorarchitektur ab. Das erste Merkmal — variable
Ausfuhrungszeiten für Anweisungen — ist allen MultizyMusarchitekturen gemein, aber unter
Umständen bei einigen einfach gestrickten Chips nicht vorhanden. Die zweite Eigenschaft
— die Abhängigkeit von Operanden— stirbt bei den Spitzenprozessoren zunehmend aus.
Bei den Geräten der Oberklasse arbeiten ALU- und FPU-Komponenten (Floating Point
Unit, Fheßkominaeinheit) manchmal mit einer Geschwindigkeit, die höher ist als die der
CPU selbst. Insofern können Unterschiede in der Rechengeschwindigkeit — sofern sie denn
überhaupt vorhanden sind — nicht exakt gemessen werden, weil ein Großteil der
Berechnung während eines einzigen Prozessortaktes erfolgt.
Die letzte Gruppe der Ablaufparameter — die Abhängigkeit von der Speicherposition — ist
im Gegensatz zum vorherigen Punkt nur bei modernen Hochleistungscomputern
vorhanden und bei Mittelklassecontrollem und diversen eingebetteten Konstruktionen unbekannt.
Die ersten beiden Gruppen — die Abhängigkeit von der Operationskomplexität und vom
Operandenwert — können sich auch auf einer Ebene äußern, die knapp über der CPU steht:
der Software. Prozessoren enthalten Rechenwerke, die mit relativ kleinen ganzen Zahlen
(zwischen 8 und 128 Bits) und einigen Fließkornmazahlen normalerweise problemlos
klarkommen; moderne Kryptografie und viele andere Anwendungen erfordern aber die
Manipulation sehr großer Zahlen mit häufig Hunderten oder Tausenden von Stellen,
hochpräzisen Fließkominazahlen oder verschiedenen mathematischen Operationen, die hardwaresei-
tig nicht implementiert sind. Aufgrund dessen wird diese Funktionalität in der Regel in
Softwarebibliotheken implementiert. Die Algorithmen in diesen Bibliotheken wiederum
benötigen mit hoher Wahrscheinlichkeit abhängig von den Charakteristika der Operation
und der Operanden unterschiedlich viel Zeit zur Verarbeitung.
2.9.1 Mit Ablauf mustern Daten rekonstruieren
Es gibt Gründe, die dafür sprechen, dass ein Angreifer verschiedene Eigenschaften der
Operanden oder einer durchgeführten Operation erschließen könnte, indem er überwacht,
wie lange ein Programm zur Verarbeitung von Daten benötigt. Hierdurch entsteht ein
potenzielles Sicherheitsrisiko, weil in verschiedenen Szenarien zumindest einer der
Operanden ein geheimer Wert sein kann, der Dritten keinesfalls bekannt werden darf.
Zwar mag die Idee der Rekonstruktion von Daten durch jemanden, der mit der Stoppuhr in
der Hand neben Ihnen steht, bizarr anmuten, aber moderne Prozessoren enthalten präzise
Zähler, die es dem Kundigen gestatten, exakte Zeitabstände zu bestimmen. Natürlich
können einige Operationen auch beträchtlich zeitaufwändiger sein: Die Ausfuhrung
bestimmter komplexer Operationscodes auf der Intel-Plattform kann mehrere Tausend Zyklen
benötigen. Angesichts der kontinuierlichen Zunahme des Netzwerkdurchsatzes und immer
schnelleren Reaktionszeiten ist es aber noch nicht einmal völlig unmöglich, diese
Informationen von einem Remote-System aus zu ermitteln.
Das Wesen der Daten, die als Maß für die Rechenkomplexität verwendet werden können,
ist möglicherweise nicht auf den ersten Blick erkennbar. Für diejenigen unter Ihnen, denen
52
2.9 Auswirkungen - die kleinen Unterschiede
es genau so geht, hat Paul Kocher von Cryptography Research bereits im letzten
Jahrtausend (genauer gesagt, in den Neunzigern7) ein großartiges Beispiel für einen solchen
Angriff gebracht. Hierbei kam der RSA-Algorithmus zur Anwendung, den wir bereits in
Kapitel 1 beschrieben haben.
2.9.2 Bit für Bit...
Kocher beobachtete, dass der Vorgang der Entschlüsselung von Daten im RSA-
Algorithmus relativ simpel ist und auf der Auflösung der folgenden Gleichung basiert:
T=ckmodM
Hierbei ist T die entschlüsselte Nachricht, c die verschlüsselte Nachricht, k der
Geheimschlüssel und Mein Modulo, der Teil eines Schlüsselpaares ist.
Ein einfacher ganzzahliger Modulopotenzierungsalgorithmus, der in einer typischen
Implementierung eingesetzt wird, hat eine ganz wichtige Eigenschaft: Wenn ein bestimmtes
Bit des Exponenten 1 ist, wird ein Teil des Ergebnisses berechnet, indem eine
Modulomultiplikation an einem Teil der Basis (d. h. einigen Bits von c) durchgeführt wird. Ist das Bit
0, dann wird dieser Schritt übergangen. Und auch wenn der Schritt nicht übergangen wird,
variiert — wie bereits erwähnt — die Zeit, die die Software zur Ausführung der
Multiplikation benötigt. Die meisten einfachen Fälle — wie etwa die Multiplikation mit einer
Zweierpotenz — werden schneller gelöst als andere.
Aufgrund dessen ist es bei einem solchen System offensichtlich möglich, eine Menge
Angaben zum Schlüssel (k) zu bestimmen, indem man wiederholt überprüft, wie lange das
Entschlüsseln einer Information dauert. Auch auf Plattformen, auf denen die Hardware-
rnultiplikation eine feste Zeit benötigt, ergibt sich ein Ablaufmuster häufig aus der
Verwendung softwareseitig implementierter Multiplikationsalgorithmen (wie dem Karatsuba-
Algorithmus), die zur Verarbeitung großer Zahlen benötigt werden — Zahlen, wie sie bei
der Kryptografie mit öffentlichen Schlüsseln verwendet werden. Nachfolgende Bits des
Exponenten bilden den privaten Schlüssel, während die Basis eine Darstellung der
Nachricht ist, die gesendet wurde bzw. für den neugierigen Zuschauer sichtbar ist.
Der Angriff ist vergleichsweise simpel: Der Übeltäter sendet dem Opfer zwei ähnliche,
aber doch leicht unterschiedliche Segmente verschlüsselter Daten. Diese unterscheiden
sich in einem Abschnitt X, d. h. die Entschlüsselung dieses Bereichs benötigt jeweils
unterschiedlich viel Zeit. Eine der Varianten von X ist, was die Vorstellung des Bösewichts
von der Implementierung der Modulomultiplikation aufseiten des Opfers betrifft, ein ganz
einfacher Fall, was eine schnelle Entschlüsselung von X gestatten würde. Die zweite
Variante wird rnehr Zeit benötigen.
Wenn das Opfer zum Entschlüsseln und Beantworten der beiden Folgen dieselbe Zeit
benötigt, dann kann der Angreifer sicher davon ausgehen, dass der Teil des Schlüssels, der
zur Dekodierang des Bereichs X verwendet wurde, aus Nullen besteht. Überdies kann er
Koch99
2 Mehrarbeit fällt auf
voraussetzen, dass der Multiplikationsalgorithmus die naheliegendste Optimierung
vorgenommen hat (nämlich die, überhaupt keine Multiplikation durchzuführen).
Benötigt jedoch einer der Fälle mehr Zeit, dann ist offensichtlich, dass in beiden Fällen
eine Multiplikation durchgeführt wurde, wobei einer der Fälle einfacher zu lösen war. Der
entsprechende Teil des Geheirnschlüsselbits muss also ein Wert ungleich 0 sein.
Indem man diese Methode einsetzt — nämlich aufeinanderfolgende Bits der verschlüsselten
Nachlicht als ,3ereich X" zu setzen und dann einfach verschlüsselte Nachlichten, die in
diesem Szenario funktionieren, zu erzeugen oder (sofern genug Zeit vorhanden ist) auf
diese zu waiten—, ist es möglich, jedes Bit des Schlüssels zu rekonstruieren.
■ Hinweis
Forschungen geben Grund zu der Annahme, dass dieser Ansatz sich erfolgreich auf praktisch
jeden Algorithmus anwenden lässt, der in einer variablen Zeit ausgeführt wird, und
beschreiben einige praktische Optimierungen für den Angriff, z. B. die Möglichkeit der Nutzung einer
eingeschränkten Fehlererkennungs- und -koiTekturfunktionalität.
2.10 In der Praxis
Die Möglichkeit, greifbare Eigenschaften von Operanden für Rechenanweisungen allein
auf der Basis von Zeitangaben abzuleiten, ist der offensichtlichste, effizienteste und
interessanteste Vektor für die Dui-chführung rechenkomplexitätsbasierter Angriffe. Andere
Methoden wie die Abläufe bei Cachetreffern und -fehlschlagen erfordern normalerweise
eine wesentlich detailliertere Analyse und offenbaren in jedem Zyklus weniger
Informationen.
Es ist klar, dass dieses Problem bis zu einem gewissen Grad viele Sofrwarealgorithmen
betreffen würde, z. B. Berechnungsbibliotheken für große Zahlen, wie sie in Kryptografie-
anwendungen häufig zum Einsatz kommen. Wenn man aber Sofrwarealgorithmen und die
gesamte Theorie beiseite lässt, dann stellen sich nach wie vor ein paar wichtige Fragen:
Wie real ist die Abhängigkeit von der Ausführungszeit auf der Hardwareebene, und wie
kann sie gemessen werden?
Ein Beispiel haben wir zur Hand: Zumindest ein Teil der IA32-Architektur von Intel legt
dieses Verhalten an den Tag. Das 80386 Pi'ogrammer's Reference Manual8 beschreibt
unter der Kurzbezeichnung IMUL einen Operations code für die Multiplikation
vorzeichenbehafteter Integer-Zahlen. In seiner Giirndform multipliziert der Operations code den im
Akkumulator (einem Mehizweckarbeitsregister, das auf dieser Plattform den Namen
[E]AX hat) vorhandenen Wert mit einem Wert, der in einem anderen Register gespeichert
ist. Das Ergebnis wird dann wieder in den Akkumulator zurückgespeichert.
Die Dokumentation fährt fort:
Inte86
54
2.10 In der Praxis
Der 80386 verwendet einen Early-Out-Multiplikationsalgorithmus. Die tatsächliche
Zahl der Takte hängt von der Position des höchstwertigen Bits im optimierenden
Multiplikator ab. (...) Die Optimierung erfolgt gleichermaßen für positive und negative
Werte. Aufgrund des Early-Out-AIgorithmus sind die angegebenen Taktzahlen
Minimal- bzw. Maximalwerte. Um die eigentlichen Takte zu berechnen, verwenden Sie die
folgende Formel:
Tatsächliche Taktung bei m # 0: Maximum(Grenzwei"t(log2(m)), 3) + 6 Takte
Tatsächliche Taktung bei m = 0:9 Takte
Das mag kryptisch klingen, die Bedeutung ist aber ganz einfach: Der Prozessor optimiert
die Multiplikation basierend auf dem Wert des Multiplikators. Statt den Multiplikanden zu
vervielfachen, bis alle Bits des Multiplikators aufgebraucht sind, Uberspiingt er Nullen am
Anfang des Operanden.
2.10.1 Early-Out-Optimierung
Um die Bedeutung dieser Vorgehensweise bei der Multiplikation ganzer Zahlen nachzu-
vollziehen, stellen Sie sich eine traditionelle iterative Multiplikationsmethode vor, wie
auch Sie sie in der Schule gelernt haben — diesmal allerdings im Binärformat. Eine
hypothetische „stumme" Implementierung dieses Algorithmus fühlt die folgenden Operationen
durch.
00000000 00000000 11001010 11111110 Multiplikand (P)
00000000 00000000 00000000 00000110 Multiplikator (R)
00000000
00000000
00000000
00000000
00000000
00000000
+ 0
00000000
00000000
00000001
00000011
00000000
00000000
00000000
00000100
00000000
10010101
00101011
00000000
00000000
00000000
11000001
00000000
1111110
111110
00000
0000
000
11110100
p
p
p
p
p
p
p
*
*
*
*
*
*
*
R[0] = P *
R[l] = P *
R[2] = P *
R[3] = P *
R[4] = P *
R[5] = P *
R[31] = P '
0
1
1
0
0
0
■r
Es sollte offensichtlich sein, dass eine große Zahl dieser Operationen absolut unnötig und
ungerechtfeitigt ist und dass die Fortsetzung einer Operation schlichtweg sinnlos ist, wenn
alle nachfolgenden Bits des Multiplikators Nullen sind. Ein sinnvollerer Ansatz besteht
mithin darin, sie zu übergehen:
00000000 00000000 11001010 11111110 Multiplikand (P)
00000000 00000000 00000000 00000110 Multiplikator (R) - optimiert
00000000 00000000 00000000 00000000 P * R[0] = P * 0
00000000 00000001 10010101 1111110 P * R[l] = P * 1
00000000 00000011 00101011 111110 P * R[2] = P * 1
... Schluss jetzt - führende Nullen bei R werden ignoriert!
00000000 00000100 11000001 11110100
55
2 Mehrarbeit fällt auf
Und dies ist im Wesentlichen die Veranlagung der Earfy-Out-Optimierung (d. h.
Optimierung durch frühzeitige Beendigung), die Intel verwendet hat.
■ Hinweis
Diese Optimierung macht die Multiplikation zeitlich unsymmetrisch: 2-100 wird weniger
schnell berechnet als 100 - 2 (!), obwohl das Ergebnis dasselbe ist.
Durch die Early-Out-Optimierung benötigen Intel-Prozessoren eine variable Anzahl von
Zyklen zur Dui-chfuhrung von Multiplikationen. Die Dauer ist direkt proportional zur
Position des ältesten (höchstweitigen) Bits, das im zweiten Operanden gesetzt ist. Durch
Anwendung des Taktzählungsalgorithmus aus der Dokumentation kann man die
Wechselbeziehung zwischen dem Multiplikator und der IMUL-Zeit ermitteln. Die folgende Tabelle
verschaulicht dies.
Tabelle 2.8 Korrelation zwischen Multiplikator und IMUL-Zyklen
Wertebereich des Multiplikators
0-7
8-15
16-31
32-63
64-127
128-255
256-1.023
1.024-2.047
2.048-4.095
4.096-8.191
8.192-16.383
16.384-32.767
32.768 - 65.535
65.536-131.071
131.072-262.143
262.144-524.287
524.288-1.048.575
1.048.576-2.097.151
2.097.152-4.194.303
4.194.304-8.388.607
8.388.608-16.777.215
16.777.216-33.554.431
Anzahl erforderlicher Zyklen
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
2.10 In der Praxis
33.554.432-67.108.863
67.108.864 -134.217.727
134.217.728 - 268.435.455
268.435.456 - 536.870.911
536.870.912-1.073.741.823
1.073.741.824 - 2.147.483.647
31
32
33
34
35
36
Eine ähnliche Abhängigkeit besteht bei negativen Multiplikatorwerten.
2.10.2 Funktionierender Code - selbstgemacht
Das folgende Codelisting zeigt eine praktische Irnplernentierung in C für Unix-Systeme
und -Derivate und kann zur Enmttlung und Messung von Unterschieden in Ablaufmustern
verwendet werden. Das Programm wird mit zwei Parametern aufgerufen: dem
Multiplikanden (der eigentlich keine Auswirkungen auf die Leistung haben sollte) und dem
Multiplikatoren (der wahrscheinlich bei Early-Out-Optimierungen verwendet wird und sich
daher auf die Geschwindigkeit der gesamten Operation auswirkt). Das Programm fühlt
256 Tests von 500 aufeinanderfolgenden Multiplikationen mit den gewählten Parametern
durch und gibt die kürzeste gemessene Zeit zurück.
Wir führen 256 Tests durch und wählen das beste Ergebnis aus, um Fälle auszugleichen, in
denen die Ausführung vom System für eine gewisse Zeit unterbrochen wird — dies kommt
in Multitasking-Umgebungen relativ häufig vor. Nun kann ein einzelner Test von einem
solchen Vorfall beeinträchtigt werden, aber zumindest einige in einer Folge
aufeinanderfolgender Tests werden mit hoher Wahrscheinlichkeit ohne Unterbrechung durchgeführt.
Der Code verwendet die Systemuhr, um die Ausführungsdauer in Mikrosekunden zu
messen.
■ Hinweis
Mehrere moderne Intel-Chips verfügen über einen präzisen Zeitgabeinechanisinus, der über
den Operationscode RDTSC verfügbar ist. Diese Methode des Zugriffs auf den internen
Taktzyklenzähler ist auf älteren Plattformen nicht vorhanden, weswegen wir sie hier außer Acht
lassen.
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/time.h>
#include <limits.h>
int main(int argc,char** argv) {
int Shortest = INT_MRX;
int i,p,r;
if (arge != 3) {
printf("Usage: %s multiplicand multiplier\n",argv[0]);
exit (1) ;
57
2 Mehrarbeit fällt auf
*/
p=atoi (argv[l] ) ;
r=atoi (argv[2] ) ;
for (i=0;i<25S;i++) {
int ct;
struct timeval s;
struct timeval e;
gettimeofday(&s,NULL);
asm(
" movl $500,%%ecx \n"
"imul_loop: \n"
" movl %%esi,%%eax \n"
" movl %%edi,%%edx \n"
" imul %%edx,%%eax \n"
loop imul_loop
"ax'
(p), »D"
, "ex",
(r)
'dx"
\n"
gettimeofday(&e,NULL);
et
(
.tv_usec
.tv sec -
- s.tv_usec
s.tv sec )
/* Schleifenwiederholungszähler (R) */
/* Beim 1. Durchlauf auskommentieren
* 1000000;
if (et < shortest) shortest = ct;
printf ("T[%d,%d]
return 0;
%d usec\n",p,r,shortest)
}
Indem wir den Code mit anfangs auskornmentierter IMUL-Anweisung kompilieren und
das Programm mit wülkürlichen Parametern aufrufen, können wir den
Verwaltungsaufwand des Zeitnahmecodes (TIdle) veranschlagen. Liegt dieser Wert außerhalb des Bereichs
zwischen 10 und 100 Mikrosekunden (was groß genug ist, um beim Auslesen eine feine
Abstufung zu ermöglichen, aber niedrig genug, um die Chance zu maximieren, dass keine
Unterbrechung durch das Betriebssystern erfolgt), dann stellen Sie den
Schleifenwiederholungszähler R, der standardmäßig auf 500 gesetzt ist, neu ein.
Nach der Wiederherstellung der IMUL-Anweisung und der Neukornpilierung und
Ausführung des Programms mit einem gewählten Multiplikanden D und dem
Wiederholungszähler R ist es möghch, den zurückgegebenen Zeitnäherungswert TDR zur Veranschlagung der
Prozessorzyklen CDR zu verwenden, die für die IMUL-Operation erforderlich waren,
sofern die Betriebsfrequenz des Prozessors (FMHz) bekannt ist:
Cd, r = (Td, r — THle) ■ r^^^ — R
Erwartungsgemäß tagen bei neueren und anspruchsvolleren Chips Pipelining und
Verzweigungsprognosen ihren Teil bei und verzerren das Ergebnis leicht, aber für eine
brauchbare Schätzung ist es allemal ausreichend.
58
2.11 Vorbeugung
Hinweis
■ Bei neueren Intel-Prozessoren ist die Zeit, die zur Durchführung einer Multiplikation
erforderlich ist, bereits konstant.
2.11 Vorbeugung
Es gibt eine Reihe von Methoden, um sich gegen die Analyse der Rechenleistung zu
schützen. Die offensichtlichste Lösung besteht darin, dafür zu sorgen, dass die Ausführung
aller Operationen die gleiche Zeit benötigt. Allerdings ist dies schwierig und fühlt häufig
zu schweren Leistungseinbußen, weil alle Berechnungen derart verlängert werden rnüssten,
dass sie in ihrer Dauer der langsamsten Operation entsprechen.
Das Ergänzen zufälliger Verzögerungen scheint eine annehmbare Verteidigungstaktik für
Anwendungen zu sein, sofern die Latenz unkritisch ist. Dies würde insbesondere
nichtinteraktive Netzwerkdienste betreffen und fühlt zu einer Verringerung der
Prozessorbelastung. Allerdings lässt sich dieses Zufallsrauschen effizient ausfiltern, wenn der Angriff
wiederholt ausgeführt werfen kann.
Ein weiterer Ansatz — das so genannte Blinding — basiert darauf, dass man eine gewisse
Menge Rauschen im System selbst erzeugt, indem man zufällige oder auf andere Weise
unechte Daten mit der tatsächlichen Eingabe des Algorithmus kombiniert, um es dem
Angreifer auch bei einer Anfälligkeit des VerschlUsselungsalgorithmus gegenüber Tirning-
Angriffen unmöglich zu machen, sinnvolle Eigenschaften der Eingabe abzuleiten. Danach
werden die überflüssigen Daten, die wird gar nicht verschicken wollen, entfemt. Zwar ist
die Leistungseinbuße in diesem Fall wesentlich geringer, aber es ist schwierig, das
Blinding gut zu implementieren.
2.12 Denkanstöße
Das war eine sehr erschöpfende Beschreibung — ich hoffe, Sie fanden es lehrreich. Wie
üblich, beende ich das Kapitel mit einigen Fragen und Problemen, die Sie unter Umständen
recht interessant finden.
■ Zwar habe ich mich vorwiegend auf die Auswirkungen von auf der Rechenkomplexität
basierenden Angriffen auf kryptografiespezifische Anwendungen konzentriert, aber das
Problem ist nicht auf diesen Bereich beschränkt, sondern äußert sich überall dort, wo
persönliche oder vertrauliche Daten verarbeitet werden. Es lassen sich bestimmt
verschiedene grundlegende Angaben zu HTTP-Anfordenmgen oder SMTP-Traffic
erschließen, indem man den entsprechenden Dienst auf einem System sorgfältig
beobachtet. Können Sie sich weitere praktische Anwendungen vorstellen?
■ Auch wenn die Daten, die von einem Dienst verarbeitet werden, nicht geheim sind,
können Angaben zur Rechenkomplexität von gewissem Nutzen sein. Betrachten wir
59
2 Mehrarbeit fällt auf
etwa Anwendungen wie Netzwerk-Daernons, die die Offenlegung von Geheimnissen
verhindern, indem sie Fehler- und Erfolgsmeldungen unter Umständen übermäßig
universeller Natur erzeugen. Dies soll es unter anderem einem Angreifer möglichst schwer
machen, herauszufinden, ob eine Anmeldung aufgrund eines falsch geschriebenen
Passworts oder aber deswegen fehlgeschlagen ist, weil der Benutzer gar nicht existiert.
Allerdings kann der gewiefte Beobachter aus der Zeit, die benötigt wurde, um die
Meldung zu senden, erschließen, welcher Pfad im Code tatsächlich ausgefühlt wurde und
ob der Fehler gleich am Anfang (bei der Prüfung auf einen korrekten Benutzernamen)
oder erst später (bei der Überprüfung des Passworts) erfolgte. Experimentieren Sie mit
den konventionellen Netzwerkdiensten wie SSH, POP3 und Telnet, um festzustellen,
ob es rnessbare und konsistente Unterschiede gibt.
■ Wie üblich neigen auch die besten Verteidigungsmaßnahmen gegen die Enthüllung von
Informationen dazu, im unerwarteten Moment zu versagen. Außerdem ist die
rechentechnische Komplexität nicht die einzige Möglichkeit zu ermitteln, was in einem
Siliziumchip vor sich geht. Befrachten wir etwa folgendes Beispiel: Biham und Shainir9
haben ein brillantes System zum Knacken „sicherer" Chips entwickelt, die in
Smartcards verwendet werden. Zweck von Smartcards ist die sichere Speicherung von Daten
— z. B. persönlichen Geheimzahlen oder kryptografischen Schlüsseln —, die nur
bestimmten Authentifizieningsdiensten und vertrauenswürdigen Clients preisgegeben
werden dürfen. Wie sich herausstellte, kann man die Eigenschaften der geschützten
Daten oder den Schutzmechanismus erschließen, indem man das Gerät rnissbraucht und
Fehler durch mechanische Belastung, energiereiche Strahlung, Überhitzung oder
ähnliche externe Faktoren hervorruft, die zu einem Fehlverhalten beim Gerät führen.
Ich meine, das sollten Sie wissen.
9 Biha96
60
3 Die zehn Häupter der Hydra
Drittes Kapitel. In welchem wir weitere reizende Abläufe kennen lernen
werden, die zu einem sehr frühen Zeitpunkt im Kommunikationsprozess
auftreten
In den Kapiteln 1 und 2 haben ich zwei getrennte Datenenthülhingsszenarien beschrieben,
die auftreten können, weil Versuche, die Funktionalität des Computers zu erweitern bzw.
seine Wartung zu vereinfachen, zwar brillant ersonnen, aber letztendlich doch nur
unzureichend zu Ende gedacht wurden. Die passive Schnüffelei ermöglichenden Vektoren, die
durch diese strukturellen Entscheidungen erschlossen werden, sind tief unterhalb der
eigentlichen Implementierung verborgen und gewähren faszinierende Einblicke in die
frühesten Bedrohungen für verarbeitete Daten.
Andererseits ist das Risiko naturgemäß auf die physische oder logische Nähe zur
überwachten Umgebung beschränkt. Zwar gibt es bereits sehr früh auf dem Weg eines
Datensegments eine praktisch unendliche Anzahl von Möglichkeiten, Daten zu enthüllen, ich
habe aber beschlossen, diese beiden Fälle herauszustreichen - wegen ihrer Einzigartigkeit,
ihrer Schönheit und der relativen Leichtigkeit, mit der ein entschlossener Angreifer eine
Attacke ausführen kann. Doch auch die übrigen Szenarien sind der Erwähnung wert,
weswegen ich in diesem Kapitel einige der interessanteren Möghchkeiten anreißen will, die
zwar keine umfassende Beschreibung rechtfertigen, Sie aber unter Umständen als
Gegenstand einer eigenen, weitergehenden Analyse interessieren könnten.
3.1 Aufschlussreiche TV-Ausstrahlung
In den Fünfzigerjahren des letzten Jahrhunderts erkannte die Wissenschaft, dass
elektromagnetische Strahlen häufig geeignet sind, Informationen zum Verhalten des
abstrahlenden Geräts ganz einfach wiederherzustellen oder zu rekonstruieren. Bei diesen Strahlen
61
3 Die zehn Häupter der Hydra
handelt es sich um unerwünschte Störungen, die von praktisch allen elektronischen, elek-
troHiechanischen und elektrischen Geräten ungeachtet ihrer Konstruktion und des
vorgesehenen Zwecks erzeugt werden und sich über Stiomleitungen oder die Luft - häufig über
beträchtliche Entfernungen hinweg - ausbreiten.
Zuvor war man der Ansicht gewesen, dass das Problem der elektromagnetischen Strahlung
aufgrund des Risikos unvorhergesehener Störungen zwischen gesonderten Geräten oder
Schaltungen zwar durchaus für die Technik als solche relevant sei, dass sie aber von
keinerlei Wert für Personen sei, die die vom betreffenden Gerät ausgesendeten
Funkfrequenzen überwachen. Als allerdings die Welt in die Ära des Datenkriegs eintrat und
elektronische Datenverarbeitungs- und Telekommunikationsgeräte immer weiter entwickelt und
zunehmend (auch für die Übertragung oder Speicherung vertraulicher oder sensibler
Daten) eingesetzt wuiden, bereitete den Herrschenden der freien Welt (und auch der nicht
ganz so freien Welt) die Folgerung, dass ein entfernter Beobachter einen Teil der von
einem System verarbeiteten Daten rekonstruieren könnte, indem er einfach eine bestimmte
Frequenz abhört, erhebliche Kopfschmerzen.
Der Begriff TEMPEST (Transient Electrornagnetic Pulse Emanation Standard) stammt aus
einer Geheimstudie zur elektroHiagnetischen Emission, die das amerikanische Militär in
den Sechzigerjahren erstellt hat, und wurde ursprünglich als Bezeichnung für eine
Sammlung von Maßnahmen verwendet, mit denen die Enthüllung von Emissionen elektrischer
Schaltungen verhindert werden sollte, die sensible Daten bearbeiteten. Später wurde daraus
dann ein Schlagwort zur Beschreibung einer allgemeinen Klasse von Problemen und
Methoden, die mit dem Abfangen und Rekonstruieren von Funkfrequenzernissionen in
Zusammenhang stehen.
Zwar klang diese Gefährdung in den Ohren der Skeptiker anfangs mehr wie der Plot eines
schlechten Science-Fiction-Rornans als nach einer tatsächlichen Bedrohung, aber eine
wichtige Forschungsarbeit1, die 1985 vom Wim van Eck veröffentlicht wurde,
veranschaulichte, dass es relativ einfach wäre (und auch tatsächlich ist), das auf einem Röhrenmonitor
angezeigte Bild durch Abfangen der Funkfrequenzsignale, die von den
Hochspannungsschaltungen im Geräteinnern erzeugt werden, zu rekonstruieren.
Ein normaler Röhrenrnonitor (Abbildung 3.1) baut seine Anzeige auf, indem er Zeile für
Zeile jeden Punkt des Bildes nacheinander mit sehr hoher Geschwindigkeit ansteuert und
die Signalstärke abhängig von der Position des jeweiligen Bildpunkts moduliert. Zu
diesem Zweck wird ein dünner Elektronenstrahl von einer Kathode am hinteren Ende des
Geräts ausgegeben. Dieser Elektronenstrahl trifft auf die Anode (eine Schicht leitfähigen
Materials auf der Anzeigefläche), die dann ihrerseits Lichtphotonen aussendet, die wir sehen
können. Der Elektronenstrahl wird durch eine spezielle Schaltung moduliert und zudem
durch einen Satz von Elektrornagneten positioniert und kann so den gesamten
Anzeigebereich von links nach rechts und von oben nach unten überstreichen - auf dem Bildschirm
entsteht das Bild, welches dann kontinuierlich aktualisiert wird. Wim van Eck stellte fest,
1 Eck85
62
3.1 Aufschlussreiche TV-Ausstrahlung
dass die Oszillatoren, die die Elektromagneten und die Kathodenelektronik steuern,
verschiedene Arten charakteristischer Signale auf Standardfrequenzen aussenden. Es ist recht
einfach, diese Signale im FunkspektmHi zu erkennen2, und jedes dieser Signale ist
normalerweise deutlich und stark genug, um ein ziemlich billiges Gerät bauen und die
Emissionen von Röhrengeräten auch aus relativ großer Entfernung ermitteln zu können.
Abbildung 3.1 Bildabtastung beim Röhrengerät und zugehöriger Erzeugungsprozess
■ Hinweis
Emissionen sind natürlich nicht auf Kathodenstrahlröhren beschränkt und kommen bei LCD-
bzw. TFT-Displays und allen Computerschaltungen gleichermaßen vor. Ebenso häufig treten
sie in Datenbussen auf, über die Daten zwischen separaten Chips übertragen werden. Die
Reise der Daten führt dabei durch ein umfangreiches Netz auf der Hauptplatine angeordneter,
relativ langer und sehr verwinkelter Leiterbahnen, die unter anderem als ausgezeichnete
Antenne fungieren (auch wenn die Einfachheit der Extraktion und Interpretation eines bestimmten
Signals ebenso erheblich variieren kann wie der Emissionsbereich).
Zwar gibt es - abgesehen von militärischen und nachrichtendienstlichen Anwendungen
(insbesondere während des Kalten Krieges3) - keine nachprüfbaren Berichte zu in freier
Wildbahn ausgeführten Emissionsattacken, aber es sind ein paar Anekdoten aus dem
Bereich der Industriespionage in der Fachliteratur beschrieben.4
Offenbai- hat diese Angriffsform ihre Einschränkungen: Der Angreifer muss sich in der
Nähe des Ziels befinden. Femer muss er, sofern er nicht gerade analoge Röhreninonitore
überwacht, mit teuren und aufwändigen Gerätschaften ausgestattet sein. Dies gilt
insbesondere für die Kontrolle modemer störungsarmer Displays und aktueller Prozessoren und
Bussen mit hoher Taktung. Andererseits ist die Vorbeugung gegen solche Attacken
schwierig und kostspielig.
Deswegen und aufgrund von Störungen durch Stromleitungen müssen Anhänger des „Naturradios",
die die von der Erde erzeugten, sehr tiefen Audiofrequenzsignale belauschen wollen, mit ihrer Auf-
zeichnungsausrüstung lange Wege zu völlig entlegenen Orten zurücklegen.
Murp97
Schw96
63
3 Die zehn Häupter der Hydra
3.2 Datenschutz mit beschränkter Haftung
Die bislang beschriebenen Risikoszenarien lassen sich als unerwünschte oder
unvorhergesehene Folgen der Alt und Weise beschreiben, wie eine bestimmte Technologie entwickelt
oder eingesetzt wurde. Diese Folgen sind aufgetreten, obwohl die Ziele oder Erwartungen
von Entwickler und Endbenutzer identisch waren. In manchen Fällen jedoch führt die
Gefährdung zu kleinen Unterschieden bei den Zielen und Erwartungen der beiden Gruppen.
Zwar sind datenschutzspezifische Problerne auf Softwareebene, die der Inkompetenz oder
Hinterlist des Programmierers entstammen, berüchtigt und gewöhnlich auch
allgegenwärtig, aber subtilere strukturelle Probleme, die für sich genommen eigentlich keinen Mangel
darstellen, treten ebenso auf. Einige der interessanteren Problemfälle in diesem Bereich
fallen in die Kategorie der Datenoffenlegung in elektronischen Dokumenten.
Wenn wir ein Dokument abfassen, gehen wir natürlich davon aus, dass alle Informationen,
die sich nicht auf den Inhalt des Dokuments beziehen (und insbesondere Informationen,
die den Urheber eindeutig identifizieren), vor Dritten, die auf das Dokument zugreifen
können, verborgen werden, sofern der Autor eine Offenlegung nicht gezielt ermöglicht.
Aber die Ära der Klartexteditoren ist lange vergangen. Heutzutage unterstützen Dokument-
fonnate umfassende Speicherfunktionen für Metadaten. Der Zweck dieser Vorgehensweise
besteht darin, Dokumente einfacher attributieren zu können, um sie nachfolgend
indizieren, durchsuchen und nachverfolgen zu können. Was daran besorgniserregend ist, ist die
Tatsache, dass die Entwickler solcher Autorensysteme dazu neigen, bestimmte Angaben
automatisch eintragen zu lassen. Dabei hat der eigentliche Urheber des Dokuments häufig
nur wenig bis gar keine Kontrolle über den Prozess - ja, er wird in der Regel noch nicht
einmal darauf hingewiesen. Obwohl diese Praxis tatsächlich als ein weiterer Versuch
gewertet werden kann, die Umgebung benutzerfreundlicher und (für den Benutzer)
transparenter zu gestalten, sind sich nur die wenigsten der Tatsache bewusst, dass dieser Umstand
weitgehend unbekannt ist.
3.2.1 Er war's, er war's, er war's!
Ein bei Autorensystemen häufig auftretendes Problem besteht darin, dass bestimmte
Anwendungen eindeutige Attribute (Tags) speichern, die es ermöglichen, ein Dokument
seiner Quelle zuzuordnen. Dies gilt insbesondere für Microsoft Word. Hier wurde jahrelang
mithilfe der Hardwareadresse der Netzwerkkalte des Computers - sofern vorhanden - eine
GUID (Globally Unique Identifier, global eindeutige Kennung) in das Dokument
eingetragen - unabhängig davon, ob es sich dabei um ein Kochrezept oder ein Handbuch zum
Bombenbau handelte. Zwar wurde dieses Problem in den aktuelleren Versionen der
Officesuite von Microsoft behoben, aber diese Praxis hatte eine Reihe interessanter
Auswirkungen:
■ Jedes Gerät hat eine eindeutige Netzwerkkaitenadresse. Da Hardwareadressen zum
Auffinden eines bestimmten Geräts im lokalen Netzwerk verwendet werden, ist diese
Eindeutigkeit erforderlich, um Probleme zu verhindern, die entstünden, wenn zwei
64
3.2 Datenschutz mit beschränkter Haftung
Computer mit derselben Hardwareadresse an dasselbe Netzwerk angeschlossen
würden. Insofern kann die im GUTD-Feld eines Microsoft Word-Dokuments vorhandene
Nummer zur eindeutigen Identifizierung des Autors verwendet werden - unabhängig
davon, ob diese Person das Dokument anonym verfasst oder signiert hat. Dieser
Umstand kann sowohl als wertvolles Werkzeug der Forensik als auch als effiziente
Möglichkeit gewertet werde, in bestimmten Situationen die Meinungsfreiheit zu
unterdrücken: So könnte etwa ein Boss die Attribute benutzen, um allzu gesprächige
Mitarbeiter loszuwerden.
■ Hardwareadressen werden den Herstellern chargenweise zugeordnet. Ferner werden
Netzwerkkalten bei der Herstellung häufig mit aufeinanderfolgenden Nummern
versehen und dann en gros an Computerhersteller verkauft. Insofern kann ein verschlagener
Schnüffler nicht nur ermitteln, wer eine bestimmte Karte gebaut hat, sondern auch, wer
sie verkauft an - und an wen. In vielen Situationen lässt sich eine bestimmte
Hardwareadresse bis zu einem bestimmten Gerät zurückverfolgen - und damit bis zu einer
Privatperson oder einer Organisation. Der entschlossene Ermittler kann auf diese Weise
unter Umständen die Herkunft eines bestimmten Dokuments ermitteln.
■ Da Hardwareadressen chargenweise zugewiesen werden, lassen sich unter Umständen
auch Rückschlüsse auf die Hardwarekonfiguration des Systems ziehen, auf dem ein
Dokument erstellt wurde. Zwar ist die hiervon ausgehende Bedrohung nur geling, kann
sich aber als interessante Informationsquelle für diejenigen von uns erweisen, die leicht
zum Schmunzeln zu bringen oder besonders neugierig sind.
Ein Teil der Funktionalität ist dem Benutzer zwar eigentlich zugänglich, aber die
Parameter sind derart tief in der Bedienoberfläche vergraben, dass ein „Normalbenutzer" keine
Ahnung davon hat, was gespeichert wird und wie man die Voreinstellung ändert.
Produktivitätssoftware wie Microsoft Word und OpenOfSce ist berüchtigt für das Einfügen von
Angaben zum „Standardverfasser". Für diese Angaben werden normalerweise die Daten
der Softwarelizenz oder aber Parameter verwendet, die bei der ersten Ausführung
eingegeben wurden. Diese Daten werden dann tief in den Metadaten des Dokuments abgelegt, wo
die meisten Benutzer sowieso nicht suchen würden. Obwohl dies ein recht praktisches
Feature sein kann - insbesondere bei der gemeinsamen Nutzung von Dokumenten -,
überwiegen die Datenschutzbedenken mögliche Vorteile für den Endbenutzer doch bei weitem.
Ein anderes Beispiel ist die „benutzerfreundliche" Praxis, in das Feld „Titel" in den
MetaHeadern eines Dokuments den ersten Satz des betreffenden Dokuments einzusetzen. Dies
ist zwar eigentliche eine nette Idee, aber die Auswahl ist oft von Dauer, d. h. auch dann,
wenn der erste Absatz später geändert wird (sodass das neue Angebot nun an eine
Mitbewerber adressiert ist), lässt sich der ursprüngliche Inhalt von einem aufmerksamen
Beobachter ableiten. Auch hier enthüllt das „Merkmal" rnehr, als der Autor dem Empfänger
eines Dokuments zu eröffnen gedachte.
Ältere Versionen von Microsoft Word speicherten Dokumente häufig auch, ohne zuvor
alle Daten zu löschen, die zuvor vom Benutzer entfernt worden waren. Hierdurch stellten
diese Dokumente im Endeffekt Undo-Informationen bereit und zeichneten alle vorherigen
Versionen des Textes auf. Diese Informationen ließen sich im Nachhinein von jedem
3 Die zehn Häupter der Hydra
halbwegs fähigen Angreifer mithilfe einer Software wiederherstellen, die OLE-Container
(Object Linking and Embedding) analysieren kann (in diesem Format speichert die
Textverarbeitung alle Daten). Dieses Problem ist besonders schwerwiegend, wenn eine ältere
Version eines Dokuments als Vorlage wiederverwendet und an einen anderen Empfänger -
unter Umständen einen Mitbewerber des ursprünglichen Adressaten - gesendet wird. Die
Möglichkeit, eine ältere Version eines Angebots, einer Bewerbung oder einer offiziellen
Antwort an einen Kunden wiederherzustellen, ist auf jeden Fall unterhaltsam und
lehrreich, aber für den Absender nicht immer wünschenswert.
Natürlich kann man angesichts der aktuellen Tendenz hin zum Trasted Computing und zur
zunehmenden „Haftung" im Sinne einer Verringerung von Urheberrechtsverletzungen
vernünftigerweise davon ausgehen, dass es gängige Praxis werden wird, alle Dokumente zu
attributieren, sodass sie jeweils zum Verfasser zurückverfolgt werden können.
3.2.2 Moment mal: *_~1q'@@ ... und Ihr Passwort lautet...
Die letzte Gruppe von Problemen, die vielen Textverarbeitungen gemein ist, sind
Speicherlecks. Diese Forrn der Offenlegung ist das Ergebnis schierer Inkompetenz oder
unzureichender Erprobungen, unterscheidet sich jedoch von anderen Codemängeln darin, dass
der Code nicht selbst für einen Angriff anfallig gemacht wird, sondern dem aufmerksamen
Beobachter einige nützliche Hinweise preisgibt. Ob das Problem auf das Programm selbst
beschränkt ist oder von systemweiten Lecks verursacht wird (was insbesondere für
Systeme mit unzureichendern Speicherschutz gilt, also etwa Windows 3.x oder Windows 9x),
spielt keine Rolle: Die ausgetretenen Daten können sensible Informationen wie weitere
Dokumente, Browserverläufe, Inhalte von E-Mails oder sogar Passwörter enthalten.
Das Problem tritt auf, wenn eine Anwendung beispielsweise einem Bearbeitungspuffer
einen Speicherblock zuweist, der zuvor vielleicht für eine andere Aufgabe verwendet
worden war, und dabei vergisst, die Daten in diesem Block zu löschen, bevor er für einen ganz
anderen Zweck verwendet wird. Aus Perforrnancegründen wird der Speicher nicht immer
neutralisiert, bevor er einer Anwendung zur Verfügung gestellt wird. Die Anwendung
verwendet und überschreibt dann unter Umständen nur einen kleinen Teil des
Speicherblocks, schreibt aber den gesamten zugewiesenen Datenblock beim Speichern der Datei:
Es werden also sowohl die gewünschten Daten als auch einige Restinhalte gespeichert, die
wer weiß wie alt sind. Es ist wohl keine Überraschung, zu erfahren, dass ältere Versionen
von Microsoft Word einst benichtigt dafür waren, beträchtliche Mengen von RAM mit
praktisch allen erzeugten Dokumenten zu speichern.
Das Problem ist mehrfach bei Microsoft Word aufgetaucht, zuerst 1998 bei allen
Versionen, 2001 dann nur noch auf Mac OS. Es gibt Gerüchte, dieses Verhalten sei auch auf
anderen Systemen beobachtet worden, aber diese Vorfälle sind spärlich dokumentiert.
66
4 Wirken für das Gemeinwohl
Viertes Kapitel. In dem die Frage, wie der Computer die Absichten seines
Benutzers bestimmt, gestellt wird. Und unbeantwortet bleibt
Den Liebreiz eines angemessen umfangreichen und vielfältigen Cornputemetzwerks - und
gleichzeitig eines seiner größten Probleme - macht die Tatsache aus, dass Sie niemandem,
der an dieses Netzwerk angeschlossen ist, blindlings vertrauen können: Ihr Gegenüber
muss nicht der sein, der zu sein er vorgibt, und es ist unmöglich, die Absichten oder
wirklichen Triebkräfte hinter seinen Aktionen zuverlässig zu bestimmen.
Ich werde das Problern der Identitätsbestimmung einer Quelle im dritten Teil dieses Buchs
behandeln, wenn ich die Architektur des Netzwerks sezieren und die Risiken erforschen
werde, die sich aus der Art und Weise ergeben, wie ein Netzwerk aufgebaut ist. Allerdings
ist das Problern der Absichten eines solchen Urhebers ein separater und faszinierender
Aspekt der Cornputersicherheit, der häufig schwerwiegende und fernliegende soziale und
rechtliche Auswirkungen haben kann, die weit über die Welt der Datenverarbeitung
hinausgehen. In dem Maße, wie wir Computer immer besser darin machen, die Absichten
ihrer Benutzer vorherzusagen (was für sich genommen bereits ein Mittel zur Erlangung
von Intuitivität und Benutzerfreundlichkeit ist), und ihnen zunehmend mehr Autonomie
verleihen, wird es immer einfacher, eine solche Maschine zu einem Werkzeug in den
Händen des Gegners zu machen, statt dem Benutzer zu helfen.
4.1 Das große Krabbeln
Über diesen Bereich wurden bereits Myriaden von Abhandlungen verfasst, nebst einer
Anzahl hitziger Diskussionen zu der Frage, wer denn daran Schuld hat und wen man belangen
könnte, wenn etwas danebengeht. Meiner Ansicht nach ist es zwar wichtig, das Problem
hier anzureißen, aber unangemessen, Ihnen eine bestimmte Sicht der Dinge zu verrnitteln.
67
4 Wirken für das Gemeinwohl
Insofern will ich diesen Teil des Buches mit einem kurzen und sehr technischen Artikel
beschließen, den ich urspilinghch 2001 im Phrack-Magazin (Vol. 57) veröffenthcht habe.
Ich habe ein paar kleinere Änderungen daran vorgenommen und werde mich jeden
weiteren Kommentars enthalten.
Warten Sie mal kurz, der muss hier doch irgendwo ... Ja, hier ist er:
==Phrack Inc.==
Volume 0x0b, Issue 0x39, Phile #0x0a of 0x12
-=[ Wider das System: Der Aufstand der Roboter ]:
-=[ (C)Copyright 2001 Michal Zalewski <lcamtuf@bos.bindview.com> ]=-=
-- [1] Einleitung
" ... besteht der große Unterschied zwischen dem Web und herkömmlichen, gut
gepflegten Sammlungen darin, dass sich praktisch nicht kontrollieren
lässt, was die Leute ins Web stellen. Wenn man diese Flexibilität,
beliebige Inhalte zu veröffentlichen, mit dem enormen Einfluss kombiniert, den
Suchmaschinen auf das Datenrouting haben, dann werden Unternehmen, die
Suchmaschinen gezielt manipulieren, um Umsätze zu machen, sehr schnell zu
einem erheblichen Problem."
-- Sergej Brin, Lawrence Page [A]
Stellen Sie sich einen entfernten Angreifer vor, der ein Remote-System
übernimmt, ohne überhaupt Daten an sein Opfer zu schicken. Stellen Sie
sich einen Angriff vor, der schlicht darauf basiert, eine Datei zu
erstellen, mit der sich Tausende von Computern gefährden lassen, und für
dessen Ausführung keine lokalen Ressourcen erforderlich sind. Willkommen
in der Welt von aufwandsfreien Exploit-Techniken, Automation und anonymen
wie auch praktisch unaufhaltsamen Angriffen, die auf der ständig
zunehmenden Komplexität des Internets basieren.
Aufwandsfreie Exploits schreiben einen Wunschzettel und lassen diesen
dann irgendwo im Cyberspace zurück, wo er von anderen gefunden werden
kann. Die "Hilfsarbeiter des Internets" [B] -- Hunderte von unermüdlichen
Robotern, Datenbrowsern, Suchmaschinen und intelligenten Agenten, die
niemals ruhen -- kommen irgendwann vorbei, finden und registrieren den
Wunschzettel und werden so ungewollt zum Werkzeug in den Händen des
Angreifers. Einen dieser Automaten können Sie vielleicht aufhalten, aber
Sie werden sie sicher nicht alle stoppen können. Vielleicht finden Sie
heraus, wie ihre Befehle aussehen, aber wissen Sie, wie diese Befehle
morgen aussehen werden? Nein, denn diese lauern in den Tiefen des noch
nicht indizierten Cyberspace.
Diese Privatarmee ist stets zu Diensten: Sie nimmt die Befehle entgegen,
die man ihr zukommen lässt. Sie lässt sich einsetzen, ohne dass man dafür
den Oberbefehl ergreifen müsste. Sie tut das, wofür sie gemacht ist --
und das auf optimale Art und Weise. Willkommen in der neuen Wirklichkeit,
in der unsere KI-Maschinen sich gegen uns erheben können.
Betrachten wir einen Wurm. Einen Wurm, der nichts tut. Er wird von
Dritten getragen und weitergegeben, infiziert sie aber nicht. Dieser Wurm
erstellt nun eine Liste von 10.000 Zufallsadressen mit bestimmten Befehlen.
Dann wartet er. Intelligente Agenten nehmen diese Liste auf, und mit
ihren vereinten Kräften versuchen sie dann, die Ziele anzugreifen. Stellen
Sie sich weiter vor, dass sie dabei nicht besonders viel Glück haben und
eine Erfolgsrate von gerade einmal 0,1 Prozent erzielen. Nun sind also
zehn neue Hosts infiziert. Auf jedem dieser Hosts tut der Wurm nun wieder
genau dasselbe: Er stellt eine Liste zusammen. Nun kommen die Agenten
zurück und infizieren hundert neue Hosts. Und so setzt sich die Geschichte
fort.
68
4.1 Das große Krabbeln
Agenten sind praktisch unbemerkbar, denn die Leute haben sich
mittlerweile an ihr Vorhandensein und ihre Beharrlichkeit gewöhnt. In einer
Endlosschleife rücken Agenten ganz langsam vor. Sie arbeiten systematisch. Sie
verschicken nur wenig Daten, d. h. Verbindungen bleiben immer verfügbar;
ein Zusammenbruch des Netzwerks, Spitzenwerte beim Datenverkehr oder
andere verräterische Anzeichen der Infektion sind nicht erkennbar. Woche
für Woche probieren sie behutsam neue Hosts aus, und ihre Forschungen
nehmen kein Ende. Ist es möglich, festzustellen, dass sie einen Wurm in
sich tragen? Unter Umständen ...
-- [2] Ein Beispiel
Als mir diese Vorstellung in den Sinn kam, probierte ich einen ganz
einfachen Ansatz aus, um zu sehen, ob ich recht hatte. Mein Ziel waren
diverse universelle Webcrawler. Ich erstellte also ein sehr kurzes HTML-
Dokument, legte dieses irgendwo auf meiner Website ab und wartete dann
ein paar Wochen. Und sie kamen: AltaVista, Lycos und Dutzende anderer.
Sie fanden neue Links, nahmen sie begierig auf und waren dann tagelang
nicht mehr gesehen.
bigipl-snat.sv.av.com:
GET /indexme.html HTTP/1.0
sjc-fe5-l.sjc.lycos.com:
GET /indexme.html HTTP/1.0
Später kamen sie wieder, um nachzusehen, ob ich ihnen neues Futter
bereitet hatte.
http://somehost/cgi-bin/script.pl?pl=../../../../attack
http://somehost/cgi-bin/script.pl?pl=;attack
http://somehost/cgi-bin/script.pl?pl=|attack
http://somehost/cgi-bin/script.pl?pl="attack"
http://somehost/cgi-bin/script.pl?pl=$(attack)
http://somehost:54321/attack?~id~
http://somehost/AAAAAAAAAAAAAAAAAAAAA...
Die Links stellten jeweils simulierte Sicherheitslücken dar, und die Bots
folgten ihnen. Zwar wirkten sich diese Exploits nicht auf meinen Server
aus, aber sie hätten problemlos bestimmte Skripten oder den vollständigen
Webserver eines Remote-Systems verändern können. Auf diese Weise hätten
sich über das Skript beliebige Befehle ausführen lassen können, um in
beliebige Dateien zu schreiben oder -- besser noch -- einen Pufferüberlauf
zu verursachen:
sjc-feS-l.sjc.lycos.com:
GET /cgi-bin/script.pl?pl=;attack HTTP/1.0
212.135.14.10:
GET /cgi-bin/script.pl?pl=$(attack) HTTP/1.0
bigipl-snat.sv.av.com:
GET /cgi-bin/script.pl?pl=../../../../attack HTTP/1.0
Dankbar stellten die Bots auch Verbindungen mit Nicht-HTTP-Ports her, die
ich für sie vorbereitet hatte, und begannen einen Kommunikationsvorgang,
indem sie Daten sendeten, die ich in URLs übergeben hatte; auf diese
Weise wurde es möglich, sogar andere Dienste als nur Webserver anzugreifen:
GET /attack?~id~ HTTP/1.0
Host: somehost
Pragma: no-cache
Accept: text/*
User-Agent: Scooter/1.0
From: scooter@pa.dec.com
69
4 Wirken für das Gemeinwohl
GET /attack?~id~ HTTP/1.0
User-agent: Lycos_Spider_(T-Rex)
From: spider@lycos.com
Accept: */*
Connection: close
Host: somehost:54321
GET /attack?~id~ HTTP/1.0
Host: somehost:54321
From: crawler@fast.no
Accept: */*
User-Agent: FAST-WebCrawler/2.2.6 (crawler@fast.no; [...])
Connection: close
Neben den bekannten Websuchmaschinen antworteten auch einige andere
private Webcrawler und Agenten, die von bestimmten Organisationen und
Unternehmen betrieben werden. Bots von ecn.purdue.edu, visual.com, poly.edu,
inria.fr, powerinter.net und xyleme.com sowie eine ganze Reihe nicht i-
dentifizierter Engines fanden meine Seite und fraßen, was ich ihnen
vorsetzte. Zwar akzeptierten einige Roboter nicht alle Adressen (einige
Crawler indizieren keine CGI-Skripten, während andere vor
Nichtstandardports zurückschrecken), aber die Mehrheit selbst der leistungsfähigsten
Bots griff praktisch alle Ziele an, die ich angegeben hatte, und selbst
die vorsichtigeren ließen sich immer so täuschen, dass sie zumindest ein
paar Angriffe durchführten.
Dieses Experiment ließe sich so abändern, dass eine Sammlung echter
Sicherheitslücken zum Einsatz kommen könnte: Tausende von
Webserverüberläufen, Unicode-Problemen bei Servern wie Microsoft IIS oder Skriptprobleme.
Und statt auf meinen eigenen Server zu zeigen, könnten die Bots auf eine
Liste zufällig erzeugter IP-Adressen oder eine beliebige Auswahl von
.com-, .org- oder .net-Servern zeigen. Oder Sie setzen die Bots auf einen
Dienst an, der durch Übergeben eines bestimmten Eingabestrings attackiert
werden kann.
Es gibt ein ganzes Heer von Robotern, die eine Vielzahl von Gattungen,
Funktionen und Intelligenzstufen umfassen. Und diese Roboter tun, was
immer man ihnen sagt.
-- [3] Soziale Überlegungen
Wer nun ist schuld, wenn ein "besessener" Webcrawler Ihr System
erfolgreich attackiert? Die naheliegendste Antwort lautet: der Autor der
Webseite, auf der der Crawler sich infiziert hat. Aber Webseitenautoren sind
schwer zu ermitteln, und der Indizierungszyklus eines Crawlers beträgt
mehrere Wochen. Es ist schwierig zu ermitteln, wann eine bestimmte Seite
in Netz gestellt wurde, denn das Einstellen lässt sich auf viele
unterschiedliche Arten ermöglichen, und manche Seiten werden sogar von anderen
Robotern erstellt. Es gibt keine Möglichkeit zur Rückverfolgung im Web,
die eine ähnliche Funktionalität bietet wie die im SMTP-Protokoll
implementierte. Außerdem erinnern sich viele Crawler gar nicht daran, wo sie
neue URLs "erlernt" haben. Weitere Probleme werden von Indizierungs-Flags
verursacht, z. B. von "noindex" in Verbindung mit der Option "nofollow".
In vielen Fällen lassen sich die Identität eines Autors und der Ursprung
eines Angriffs nie zweifelsfrei klären.
Aufgrund einer Gleichstellung mit anderen Fällen kann man davon ausgehen,
dass, sollten solche Angriffe Wirklichkeit werden, die Entwickler
intelligenter Bots zur Implementierung bestimmter Filter gezwungen wären oder
andernfalls Schadenersatz in enormer Höhe an die Opfer zahlen müssten1.
Anmerkung des Übersetzers: Der Autor bezieht sich hier auf die gängige Rechtsprechung in den
Vereinigten Staaten, die den Leidtragenden von Produktfehlern aus europäischer Sicht exorbitant hohe
Schadensersatzsummen zuzusprechen. In einer Anmerkung hält er zudem fest: „Ein weiteres Problem
besteht darin, dass nicht alle Crawler unter die Gesetzgebung der amerikanischen Staaten fallen; die
Rechtsprechung anderer Länder kann sich im Bereich des Coniputermissbrauchs erheblich
unterscheiden".
70
4.1 Das große Krabbeln
Wenn Sie andererseits die Anzahl und Vielfalt bekannter Sicherheitslücken
berücksichtigen, scheint es praktisch unmöglich, die zur Beseitigung
bösartigen Codes erforderlichen Inhaltsfilter implementieren zu können. Und
so besteht das Problem fort.
-- [4] Abwehr
Wie bereits erwähnt, bieten Webcrawler selbst angesichts der schieren
Vielzahl webbasierter Anfälligkeiten nur eingeschränkte
Verteidigungsund Vermeidungsfunktionen. Es ist unmöglich, alle bösartigen
Codesequenzen einfach auszusperren, und ein heuristischer Ansatz ist problematisch:
Eine Eingabe, die für ein Skript gültig und auch erforderlich ist, kann
in einem anderen Fall durchaus für einen Angriff verwendet werden. Ein
sinnvoller Verteidigungsansatz besteht darin, dafür zu sorgen, dass alle
potenziellen Opfer sichere und aktuelle Software verwenden, aber dieses
Konzept ist aus verschiedensten Gründen extrem unbeliebt. (Ich habe auf
die Schnelle einen sehr unwissenschaftlichen Test durchgeführt: Die Suche
nach dem String "CGI vulnerability" auf Google, bei der ein Filter
aktiviert war, der passende Dokumente nur einmal nannte, förderte
52.100 Ergebnisse zutage. [C]) Eine andere Verteidigungsmethode gegen
infizierte Bots ist die Verwendung der Standardausschlussdatei /robots.txt
[D]. Der Preis hierfür ist jedoch hoch: Ihre Site wird von nun an von
Suchmaschinen teilweise oder vollständig geschnitten, was in den meisten
Fällen nicht wünschenswert oder gar unannehmbar ist. Außerdem gibt es
Bots, die derart beschädigt oder gezielt so geschrieben sind, dass sie
/robots.txt ignorieren, wenn sie einer direkten Verknüpfung mit einer
neuen Website folgen.
-- [5] Referenzen
[A] S. Brin und L. Page: The Anatomy of a Large-Scale Hypertextual Web
Search Engine" (Googlebot-Konzept). Stanford University.
URL: http://www7.scu.edu.au/programme/fullpapers/1921/coml921.htm
[B] The Web Robots Database.
URL: http://www.robotstxt.org/wc/active.html
[C] L. D. Stein: Web Security FAQ.
URL: http://www.w3.org/Security/Faq/www-security-faq.html
[D] M. Koster: A Standard for Robot Exclusion.
URL: http://info.webcrawler.com/mak/projects/robots/norobots.html
| = [ EOF ] = |
Es erscheint praktisch unmöghch, einen automatisierten Missbrauch vorherzusagen, wenn
man die Absicht hinter einer bestimmten Benutzerhandlung nicht vorausahnen und
einordnen kann. Dies aber wird in absehbarer Zeit auch nicht der Fall sein. Mittlerweile nimmt
die Anzahl der Systeme, die auf eine automatisierte Interaktion mit anderen Entitäten
angewiesen sind, Jahr für Jahr zu. Aufgrund dessen ist dieses Thema heute vielleicht noch
interessanter als vor ein paar Jahren, als ich den Artikel geschrieben habe. Denn in der
Zwischenzeit haben immer rnehr ausgefuchste Würmer mit hohem Verbreitungspotenzial
im Internet zugeschlagen.
71
4 Wirken für das Gemeinwohl
Hat diese Geschichte eine Moral, oder gibt es ein nahehegende Schlussfolgerung?
Eigentlich nicht. Allerdings sollte man stets im Hinterkopf behalten, dass Maschinen auch dann
nicht immer im Auftrag ihrer Betreiber agieren, wenn sie nicht augenscheinlich
übernommen wurden oder unverblümt für feindselige Aktionen verwendet werden. Die Absicht und
den Ort zu bestimmen, an dem der Wunsch, eine verruchte Handlung auszuführen, seinen
Ursprung nahm, kann eine kolossale Herausforderung sein. Wir werden uns dem in
späteren Kapiteln widmen.
72
Der sichere Hafen
Von den Gefahren, die zwischen Computer
und Internet lauern
5 Blinkenlichten
Fünftes Kapitel. In welchem wir erkennen, dass auch Liebreiz tödlich sein
kann, und lernen, LEDs zu lesen
Im ersten Teil dieses Buches haben wir uns auf verschiedene Probleme konzentriert, die
den Aufbau des Dateneingabepunkts im System betreffen. Diese Probleme beschränkten
sich auf das Erschließen der Eingabe durch die Beobachtung scheinbar bezugsloser
Verhaltensmuster durch einen Benutzer, der lokalen Zugriff auf das System hat. Wenn aber
die Daten ihren Weg zum Adressaten fortsetzen und dieses System verlassen, wird die
Angriffsfläche größer, und die Probleme werden greifbarer.
Der zweite Teil dieses Buches behandelt einige der Probleme, die auftreten, wenn die
Daten das Urspmngssystern verlassen haben, aber noch in Reichweite sind - der Moment,
bevor sie in das Internet eintreten. Die hier beschriebenen Risiken beschränken sich
weitgehend auf den physischen Bereich eines LAN und seiner direkten Umgebung. Ein Angriff
in diesem Bereich erfordert einen Beobachtungspunkt, der zwar zum Ursprungssystem
lokal sein muss, aber keinen Zugriff auf Systemebene benötigt.
Das in diesem Kapitel beschriebene Problern unterscheidet sich in gewisser Hinsicht von
den zuvor behandelten: Die Schwachstelle manifestiert sich auf der Hardwareebene -
ähnlich wie bei TEMPEST, doch ein wenig anders. Die Schönheit dieses Phänomens und die
Leichtigkeit, mit der es sich ohne Spezialgeräte beobachten lässt, rechtfertigen mehr als
nur einen flüchtigen Blick.
5.1 Die Kunst, Daten zu übertragen
Dass es Computern möglich sein muss, mit anderen elektronischen Geräten zu
kommunizieren, war seit Anbeginn der praktischen Datenverarbeitung ebenso offensichtlich wie die
75
5 Blinkenlichten
Schwierigkeit, diese Möglichkeit zuverlässig und kostengünstig zu implementieren Wir
können die interne Kommunikation eines Systems steuern, indem wir reichhaltige und
maßgeschneiderte Schnittstellen für alle wesentlichen Komponenten, für die dies
wünschenswert ist, bereitstellen, präzise Signaleigenschaften definieren und einen allgemeinen
Referenztakt für alle Operationen verwenden, damit Absender und Empfänger jederzeit
wissen, wann Daten zu senden sind bzw. wann man auf Empfang gehen soll. Die
Kommunikation über lange Strecken oder mit Geräten, die mit billigen, mchtspezialisierten
Schnittstellen ausgestattet sind, stellt jedoch eine andere Herausforderung dar: Der
Computer muss nämlich über ein Medium kommunizieren, welches nicht den Grad an Freiheit
bietet, den wir von der systeminternen Kommunikation her gewohnt sind.
Tatsächlich aber ist die Situation eigentlich genau umgekehrt. Der Kunde erwartet
einfache, praktische, bequeme und preiswerte Lösungen Computer über 96-adrige, anndicke
Leitungen zum Meterpreis von 100 Euro aneinander anzubinden, ist offensichtlich keine
solche Lösung. Einfachheit ist also notwendig. Im Kern nutzt jeder externe Kornmunika-
tionskanal praktisch immer die serielle Übertragung aufeinanderfolgender Bits, die erst
dann, wenn sie wieder zusammengesetzt und gruppiert werden, numerische Werte,
Zeichenketten oder andere Daten bilden, die in der Systemumgebung des Absenders oder
Empfängers nativ sind. Wenn im scheinbar trivialsten und offensichtlichsten Szenario zwei
Maschinen oder Geräte, die nur über ein Leitungspaar miteinander verbunden sind, Daten
austauschen müssen, dann tun sie dies, indem sie einen der Leiter auf eine relativ zum
anderen (Referenz-)Leiter höhere oder niedrigere Spannung setzen oder - allgemeiner
formuliert - unterschiedliche Signale oder Zustände verwenden. Dies tun sie, um
aufeinanderfolgende Datenbits mit einer gegebenen Frequenz zu senden: einer Frequenz, die auf
beiden Geräten weitestmöglich synchronisiert sein muss.
Aber bereits bei einem so einfachen Aufbau ergeben sich von Anfang an eine Reihe von
Problemen. Zunächst einmal benutzen die Geräte keinen gemeinsamen Referenztakt. Zwar
haben beide interne quarzgesteuerte Taktgeber, aber keine zwei bezahlbaren Taktgeber
können jemals genau genug sein, um über einen längeren Zeitraum hinweg eine schnelle
und zuverlässige Kommunikation zu gewählleisten - aufgrund von kleinen
Fertigungsdefekten, Interferenzen und anderen physischen Bedingungen. Und die serielle
Kommunikation braucht nun einmal eine präzise arbeitende Synchronisation. Das unkomplizierte
Bitkodierschema, welches wir unter der Bezeichnung NRZ (Non-Return-to-Zero) kennen,
gibt einfach ein Signal (also eine Spannung) für 0 und ein anderes Signal für 1 aus. In
einem solchen System ist es einfach, die beiden Endpunkte synchron zu halten, wenn die
Werte sich regelmäßig ändern: Das System muss lediglich eine fallende oder steigende
Flanke erkennen, diese als Referenz benutzen und seine eigene Taktung entsprechend
einstellen. Tritt aber eine längere Folge von Einsen oder Nullen auf, dann wird es für den
Empfänger zunehmend schwierig, genau zu bestimmen, wie viele Bits eigentlich gesendet
werden Tatsächlich kann bereits eine kleine Taktabweichung Probleme verursachen, und
es gibt keine Möglichkeit, dies während des Austauschs einer konstanten Bitfolge
auszugleichen
76
5.1 Die Kunst, Daten zu übertragen
Die offensichtliche Lösung, einfach ein separates, unterscheidbares Timingsignal zwischen
die Daten zu setzen, stellt nicht immer die bequemste und effektivste Methode dar: Ein
Mehl- an Komplexität und auch ein geringerer Durchsatz werden oft als lästig empfunden.
Um dieses Problern effizient zu lösen, verwenden viele Systeme die so genannte
Manchester-Kodierung. Der Algorithmus der Manchester-Kodierung, die gemeinsam mit NRZ in
Abbildung 5.1 gezeigt ist, kodiert Daten nicht über Signalpegel, sondern über die Signal-
flanken. Die ursprüngliche, bereits erwähnte NRZ-Kodierung verwendet eine interne Uhr,
um die Spannungspegel mit konstanter Rate zu messen, wobei niedrige Spannungsweite
als 0 und hohe Werte als 1 interpretiert werden. Die Manchester-Kodierung hingegen
überfragt die Daten in den Übergängen von der niedrigen zur hohen Spannung oder umgekehrt.
Bei einem solchen System wird das Signal auf einen hohen Pegel geschaltet, um die binäre
1 anzuzeigen; der Wechsel auf einen niedrigen Pegel zeigt die binäre 0 an.1
0 1110
NRZ-
Kodierung:
Zeit (Zyklen)
I
+5V
0V
0 1110
Manchester-
Kodierung:
Zeit (Zyklen)
Abbildung 5.1 Kodierungen für die Datenübertragung über serielle Leitungen: NRZ- und Manchester-
Kodierung
Zwar erfordert diese Kodierung keine Synchronisierung der Taktgeber, aber in ihrer
bislang beschriebenen Form ist sie noch nicht gut genug: Es gibt keine Möglichkeit, zwei
binäre Nullen oder Einsen zu kodieren, denn ein Übergang vom niedrigen zum hohen
Spannungspegel lässt sich nicht zweimal hintereinander realisieren, ohne dazwischen wieder
auf den niedrigen Pegel zurückzukehren (und umgekehrt). Damit derartige Datentypen
kodiert werden können, werden Übergänge, die kurz nach einer steigenden oder fallenden
Signalflanke auftreten, ignoriert; auf diese Weise kann das System mehrere
aufeinanderfolgende Nullen oder Einsen kodieren, indem in der Mitte des Zyklus wieder der vorherige
Spannungspegel eingenommen wird. Um die „Amnesieperiode" nach einem Übergang zu
verwalten, ist ein einfacher, einmal auslösender Intervalltaktgeber erforderlich.
Die Struktur einer seriellen Verbindung, die auf dem beschriebenen Selbstsynchronisie-
mngsschema basiert, wird häufig erweitert, um eine Vollduplexkommunikation zu
erlauben, bei der die beiden beteiligten Partner gleichzeitig kommunizieren können - entweder
Oder auch umgekehrt —je nach Aufbau des Senders.
77
5 Blinkenlichten
über zwei separate Sende- und Empfangsleitungen oder durch Verwendung
fortschrittlicher Echoerkennungs- und -kornpensierungstricks zur Unterscheidung zwischen dem
eigenen Signal und den Daten, die von der anderen Seite gesendet werden. Einige Medien
erfordern oder gestatten zwar anspruchsvollere Signalsysteme - z. B. den Versand mehrerer
Bits je Zyklus -, das Kornmunikationsprinzip bleibt jedoch stets das gleiche, und die
Manchester-Kodierung über die kleinste mögliche Zahl von Leitern (meistens zwei) ist
vorherrschend.
Ausgestattet mit dem Grundwissen zur seriellen Kommunikation über „Leiterpaare"
wollen wir nun einen Bück auf zwei bedeutende Beispiele der seriellen Kommunikation in der
Netzwerktechnik werfen, erfahren, wie Daten intern ausgetauscht werden, und sehen, wie
diese Daten bei Dritten landen können, ohne dass der Benutzer etwas davon mitbekommt.
5.1.1 Wie aus Ihrer Mail eine Menge Lärm wird - und dann wieder
eine Mail
Das wohl verbreitetste Gerät für die Computerkornmunikation über große Entfernungen ist
ganz sicher das Modem. Ursprünglich in den 1950em zur Wartung und Ansteuemng
bestimmter militärspezifischer Geräte an entfernten Standorten entwickelt, war es das
Modem, das den Massen den Zugang zum Internet ermöglicht hat. Zwar wird das Modem
heute häufig als veraltet beteachtet, aber es war Ursprung vieler modemer Technologien,
z. B. ebenso schneller wie auch kostengünstiger DSL-Systeme (Digital Subscriber Line)
oder Kabelmodems. Diese Geräte verwenden sämtlichst intelligente Variationen derselben
Technik zur Kommunikation über Telefonleitungen oder andere nichtdedizierte
Analogmedien unter Verwendung hörbarer oder unhörbarer Signale. Forschungen, deren Zweck
die Verbesserung von Modems war, trugen auch zu unserem Verständnis für zahlreiche
umfassende Probleme elektronischer Strukturen im Allgemeinen und von Computer- und
Netzwerkstndcturen im Besonderen bei. Insofern sind Kenntnisse zur Funktionsweise von
Modems wichtig, um andere - modernere - Memoden der Datenfernübertragung verstehen
zu können
Das universale Wesen einer Telefonleitung macht sie zum prädestinierten Medium für die
Computerkornmunikation Telefonleitungen findet man fast überall, und Telefonsysteme
bieten exzellente Funktionalitäten zur Rufweglenkung; hierdurch ist es möglich, mit wenig
oder gar ganz ohne Aufwand praktisch jeden behebigen Ort zu kontaktieren. Es gibt
allerdings einen kleinen Nachteil: Telefonleitungen wurden entwickelt, um die menschliche
Stimme als Wellenform innerhalb eines schmalen Frequenzbandes zu übertragen (dieses
ist nur wenige Kilohertz breit). Da diese Frequenzen als Spannungsänderungen über ein
Leiterpaar aufgezeichnet und über eine Anzahl analoger Repeater und Verstärker
weitergeleitet wurden, war die Übertragungsqualität nicht besonders hoch. Sie musste eben auch
nur gut genug sein, damit die Gesprächspartner einander hören und verstehen konnten.
Und weil das Gehirn ein ganz ausgezeichnetes Signalfilterungs- und
Signalverarbeitungssystem darstellt, waren gelegentliches Rauschen oder Lautstärkeschwankungen
unproblematisch. (Dies änderte sich erst viel später, als die Kundschaft immer kleinlicher wurde.)
78
5.1 Die Kunst, Daten zu übertragen
Dagegen werden Computer normalerweise so konstruiert, dass sie binäre Informationen
austauschen, die als relativ exakte Spannungspegel kodiert und über kurze, sorgfältig
gefeitigte Leitungen mit hoher Signalqualität und niedrigern Widerstand übertragen werden.
Diese sind so ziemlich das Gegenteil der langen, schlecht geschirmten Telefonleitungen
mit ihren unzureichenden Signaleigenschaften. Computer tauschen auch wesentlich
schneller und wesentlich rnehr Nachlichten aus, als es Menschen normalerweise tun.
Insofern hatten Modementwickler - um es einmal nett zu formulieren - eine unangenehme
Herausforderung zu meistern: Sie mussten einen Weg finden, Datenbits nicht nur so zu
kodieren, dass sie über eine Leitung effizient an ein entferntes System übeitiagen werden
konnten (was durch die Manchester-Kodierung ein bisschen einfacher geworden war),
sondern die Kodierung musste auch in Form von Audiosignalen erfolgen, die sich am
anderen Ende der Leitung präzise voneinander unterscheiden lassen mussten - ungeachtet
meist völlig unvorhersagbarer Spannungsänderungen und anderer Verfälschungen auf dem
Übertragungsweg. Sie hatten robuste Fehlerkorrektuialgorithmen und verschiedene
Übertragungsraten zu implementieren, um den unterschiedlichsten Beeinträchtigungen
Rechnung zu tragen: schlechte Leitungsqualität, gelegentliches Übersprechen, Lastkraftwagen,
die über unterirdische Telefonleitungen fahren, Vogelnester auf Telefonrnasten usw. Die
Entwickler nahmen zur Kenntnis, verfielen ins Grübeln und schenkten uns dann - nach nur
knapp 40 Jahren - eine bezahlbare und akzeptabel schnelle Methode für die
Kornmunikation zwischen Computern. Wir wollen kurz skizzieren, wie diese Entwicklung im Laufe
der Jahrzehnte fortschritt und reifte - und wie die Grundlagen im Wesentlichen doch
dieselbe blieben.
Die Geschichte der Entwicklung und Standaidisierang kommerzieller Modems begann in
den 1960em, als zwei Standaids konzipiert wuiden: Bell 103/113 und V.21. Diese beiden
Standaids definierten Vollduplexverbindungen mit einer (für damalige Verhältnisse)
erstaunlich hohen Übertragungsrate von 300 Baud (Bit/Sekunde). Hierzu kam eine
Technologie namens FSK (Frequency Shifi Keying, Frequenzumtastung) zum Einsatz. FSK ist ein
rätselhaft klingender Begriff, der allerdings ein recht simples Signalkodierschema
bezeichnet: Er verwendet zwei verschiedene Töne zur Darstellung unterschiedlicher Werte, näm-
lich eine Frequenz für- Signale mit gesetztem Pegel (H-Signale, vom Englischen high) und
eine weitere für Signale mit nicht gesetztem Pegel (L-Signale, low). Der Vorteil der
Verwendung von Frequenzen im Audiobereich gegenüber anderen Signaltypen ist
beträchtlich: Es handelt sich um die einzige Signalform, die sich relativ problemlos über das
Telefonsystem weiterleiten lässt - denn schließlich wurde das System für genau diesen Zweck
entwickelt. Alle anderen Signale würden bestenfalls bis zur Unkenntlichkeit verstümmelt
werden, bevor sie das jenseitige Ende der Leitung erreichen könnten - oder aber
schlimmstenfalls sofort von Bandpassfiltem im Signalweg ausgefütert werden.
Neben der Definition der FSK-Kodierung unterteilten die genannten Standaids
Bell 103/113 und V.21 den Frequenzbereich, der von Telefonleitungen übeitiagen werden
kann, in zwei Unterbereiche:
■ Eines der Modems - der Anrufer - verwendet eine Frequenz von 980 Hz für die
Kodierung von L-Signalen und 1180 Hz für H-Signale.
5 Blinkenlichten
■ Das obere Ende des Spektrums blieb dem Angerufenen vorbehalten: Hier kamen die
Frequenzen 1650 Hz bzw. 1850 Hz zum Einsatz.
Und warum wurde das Frequenzband so unterteilt? Weil eine Telefonleitung im Grunde
genommen nichts anderes ist als ein Paar Leiter, die zwar für die gleichzeitige Ubeitiagung
von zwei Geräten verwendet werden können (Vollduplexcharakteristik), dies aber nur
dann, wenn das Problern von Überlagerungen der gesendeten und empfangenen
Nachrichten beseitigt wird. Bei der Vollduplexkornmunikation muss jedes Gerät in der Lage sein,
sein eigenes Signal in den empfangenen Daten zu erkennen und es auszufiltem. Kann dies
nicht erfolgreich bewerkstelligt werden, dann rnüsste jedes Gerät schweigen, solange das
andere redet (Simplexmodus); hierdurch würde der ohnehin nicht gerade imposante
Durchsatz eihebhch beeinträchtigt. Dank der Verteilung der Frequenzbereiche übeitiägt
die Telefonleitung lediglich zwei verschiedene „Stimmen", wodurch sichergestellt ist, dass
die gleichzeitige Kornmunikation kollisionsfrei erfolgen kann.
Es sollte 25 weitere Jahre dauern, bis Modems die nächste bedeutende Hürde nehmen
konnten. Die nächste wichtige Nonnensammlung - Bell 212A und V.22 - stellt einen
riesigen Schritt nach vorne da: Die Frequenzumtastung wurde zugunsten von DPSK
(Differential Phase Shifi Keying, differentielle Phasemimtastung) fallengelassen. Statt die
Frequenz einer Welle zu ändern, verschiebt DPSK zur Darstellung verschiedener Werte die
Signalphase.
Die Phasenumtastung (oder Phasenmodulation) bringt eine minimale zeitliche
Verschiebung in das Signal ein. Diese führt zu einem winzigen Synchronisationsversatz zur
Ursprungswelle, während die Wellenfonn exakt gleich bleibt (Abbildung 5.2).
Frequenzumtastung
Phasenumtastung
Die Frequenz ändert (erhöht) sich.
Die Frequenz verschiebt sich relativ
zur Referenzfrequenz.
■ Referenz-
Ifequenz-
spitzen
L-Wert H-Wert
Abbildung 5.2 Frequenzumtastung und Phasenumtastung
80
5.1 Die Kunst, Daten zu übertragen
Der Wert der Phasenverschiebung - der so genannte Verschiebungswert - wird in Grad
ausgedrückt.2 Ein Verschiebungswert um 360° beschreibt eine Verschiebung um die
gesamte Wellenlänge, was nichts anderes bedeutet, als dass die Wellen wieder synchron
laufen - der Effekt ist dann nicht vorhanden. Die Zuordnung verschiedener Phasenlagen wird
in Abbildung 5.3 auf der linken Seite angezeigt.
Referenzsigna
Phase 0
Signalreferenz
Abbildung 5.3 Phasenverschobene Signale (links) und Ergebnis der Subtraktion einer
Referenzwellenform zur einfacheren Unterscheidung zwischen Phasen (rechts)
Sobald beide Seiten zueinander synchronisiert sind und eine Möglichkeit haben, das über
das Kabel empfangene Signal mit der erwarteten Wellenform zu vergleichen, lassen sich
die kodierten Daten ganz einfach ermitteln. Eine Differenzialschaltung kann zwei Signale
miteinander vergleichen, sie subtrahieren und die exakte Phasenverschiebung des Signals
problemlos bestimmen, indem sie sie mit einem Referenzsignal vergleicht (Abbildung 5.3,
rechte Seite).
Der neue Standard profitierte auch von einer fortschrittlicheren Datenkodiennethode. Statt
einfach zwei abwechselnde Signale zur Übertragung von Nullen und Einsen zu verwenden,
wie es zuvor der Fall war, kodiert V.22 ganze Dibits (Bitpaare). Die gleichzeitige
Kodierung zweier Bits lässt sich mithilfe von vier Phasenverschiebungswerten realisieren, wobei
Dies ist eine Referenz an seinen Effekt bei Winkelfunktionen: Um 90° verschoben, ist y = sinfx) exakt
dasselbe wie y = sin(90° + x).
81
5 Blinkenlichten
der Verschiebungsumfang zur Daistellung der möghchen Werte so gewählt werden muss,
dass die Werte gleichförmig und mit möglichst großem Abstand voneinander auf das 360°-
SpektruHi verteilt werden und auf diese Weise optimal voneinander unterscheidbar sind
(Tabelle 5.1).
Tabelle 5.1 Verwenden von Phasenverschiebungen zum Kodieren zweier Datenbits (Dibit)
Dibit
00
01
10
11
Phasenverschiebung
90°
0°
180°
270°
Die Verwendung von Dibits erlaubte erheb lieh höherer Übertragungsraten (1.200 Baud),
ohne dass die physische Modulationsrate für das Signal hätte erhöht werden müssen. Pro
Ton wurden also doppelt so viele Daten (doppelt so viele Bits) übertragen.
■ Hinweis
Zwar ist es theoretisch möglich, auch bei FSK ein erweitertes Alphabet aus
zusammengesetzten Signalen, die Dibits ähneln, zu verwenden (also Signale, die niehr als zwei Zustände
darstellen und so mehr als ein Bit gleichzeitig kodieren können), aber dies ist etwas
problematischer. FSK-Signale müssen Subharmonische und andere Frequenzen vermeiden, die bei der
Übertragung über Telefonsysteme besonders störanfällig sind, weswegen der Umfang
möglicher Zustände erheblich eingeschränkt ist. Der Vorteil von DPSK gegenüber FSK besteht
darin, dass eine feste Frequenz verwendet wird, die bekanntermaßen am wenigsten anfällig für
Übertragungsprobleme ist und so auch bei höheren Übertragungsraten zuverlässig eingesetzt
werden kann.
In den folgenden Jahren beschleunigte sich das Forschungstempo ein wenig, und eine
Reihe neuer Standaids wurde aufgelegt. Der Standard V.22bis fühlte das Konzept der
Signalisierung mit einem längeren Alphabet fort: DPSK wurde mit der Amplitudenmodulation
(Signallautheit) kombiniert, und es entstand eine zweidimensionale Menge mit 16 Werten.
Der Übergang von einem gemessenen Signal in Binärwerte wurde mithilfe einer
zweidimensionalen Tabelle ausgedrückt. Der Wert, dem ein Signal entspricht, wird ermittelt,
indem zunächst die Spalte basierend auf dem gemessenen Phasenverschiebungswert ennit-
telt und dann die passende Zeile für die gemessene Amplitude gesucht wird. Ein
vereinfachtes, aber analoges 2 • 4-Beispiel zeigt Tabelle 5.2.
Tabelle 5.2 Zweidimensionale Kodierung dreier Bits mithilfe zweier verschiedener Signalparameter
Niedrige
Amplitude
Hohe Amplitude
Phase 0°
000 (0)
100(4)
Phase 90°
001 (1)
101 (5)
Phase 180°
010 (2)
110(6)
Phase 270°
011 (3)
111 (7)
82
5.1 Die Kunst, Daten zu übertragen
Um die Verwirrung noch zu erhöhen, nannte man diesen Ansatz QAM (Quadratlire
Amplitude Modulation, Quadraturamplitudenmodulation). QAM ermöglichte den Sprang von
1.200 auf 2.400 Bit/s - nicht durch Erhöhung der Signalmodulationsrate, sondern durch
Steigerung der Anzahl von Bedeutungen, die ein einzelnes Signalatom haben kann.
Der nächste größere Schritt in der Evolution war V.32. V.32 war der erste Ansatz, der ein
ganz neues Konzept einführte: Statt die Frequenzen aufzuteilen, wurde eine
fortgeschrittene EchokoHipensierungsschaltung3 verwendet, um das vom Gerät selbst übertragene Signal
in den über die Leitung empfangenen Daten zu erkennen und abzuziehen. Diese Methode
gestattete beiden Geräten (Sender und Empfänger) die Verwendung des gesamten (statt nur
des halben) Frequenzspektrurns, wobei trotzdem ein Vollduplexbetrieb implementiert
wurde.
Die Entwicklung schritt fort, und bald erschien das V.34-Protokoll auf der Bildfläche.
Zwar änderte sich die Rate, bei der das Signal gefahrlos und ohne erhebhche Störungen
geändert werden konnte, im Laufe der Jahre nicht merklich, aber trotzdem war dieser
Standard erheblich schneller als die Vorgänger. V.34 erzielt einen Durchsatz von 28.800 Baud,
der von den Hersteilem gelegentlich noch ein wenig nach oben auf einen Wert von
33.600 Baud (33,6 Kbit/s) gedrückt wurde, indem 2.500 statt 3.500 Signalproben
(Alphabetsymbole) pro Sekunde gesendet wurden; allerdings kombiniert er aus vier
verschiedenen Kodierschemata eine vierdimensionale Struktur mit 1.664 möglichen Zuständen. Auf
diese Weise lassen sich 41 Bits auf einmal senden. Wie sich zeigt, geht es also nicht nur
um die Geschwindigkeit als solche, sondern darum, was man aus dem macht, was man hat.
Es wird weithin angenommen, dass der V.34-Standard und seine Derivate sich der
theoretischen Grenze der Datenübertragung über das sprachbasierte Telefonnetz bereits sehr
stark annähern. Dies mag zwar angesichts der Tatsache, dass heutzutage praktisch nur
noch Modems mit einer Rate von 56 Kbit/s eingesetzt werden, etwas abwegig erscheinen.
Die Sache hat aber einen Haken: 56-Kbit/s-Geräte erzielen diese Übertragungsrate auf eine
ganze andere Weise als analoge Lösungen. Wenn man weiß, dass die meisten Telefonnetze
mittlerweile von analoger auf digitale Technik umgestellt wurden und die meisten Inter-
netprovider ihre Systeme inzwischen direkt an das digitale TelekoHimunikationsSystem
anschließen, dann ist offensichtlich, dass die Provider wieder auf eine nahehegende, aber bis
vor kurzeni nicht verfügbare Lösung zurückgreifen können: Die Änderung von
Netzspannungen anstatt einer Verschiebung von Frequenzen beim Senden von Daten an einen
Teilnehmer. Da das Signal von Anfang an in Form digitaler Daten übertragen wird - und über
unterirdische Kupferleitungen nur bis zur nächstgelegenen Vennittlungsstelle des
Netzbetreibers geleitet wird -, gibt es praktisch keine Probleme mit der Signalqualität; die
einzige Einschränkung stellt die Sprachübeitragungsfunktionalität dar, die in der Telefonsys-
Echokornpensierangsschaltungen versuchen, vorn Gerät selbst gesendete Signale von denen zu
trennen, die vom Gegenüber stammen, und erstere dann auszublenden oder aber zumindest erheblich
abzuschwächen. Verschiedene Typen solcher Geräte werden häufig eingesetzt — nicht nur bei der
Übertragung digitaler Daten, sondern auch zur Verbesserung der Übertragungsqualität bei Telefonanrufen, zur
Beseitigung von Mila-ofonrückkopplungen bei Musikkonzerten und ähnlichen Veranstaltungen und zur
Lösung vieler anderer alltäglicher Probleme.
83
5 Blinkenlichten
temhardware implementiert ist. Mit über 8.000 Symbolen pro Sekunde, aber unter
Verwendung eines beträchtlich kleineren Alphabets (normalerweise etwa 128 Symbole oder
Spannungspegel) ist es möglich, Daten mit höherer Geschwindigkeit als gewöhnlich an
einen Teilnehmer zu senden, dessen 56-Kbit/s-Modem über hochwertige Leitungen
angebunden ist. Der Upstieam - also die Ubeitiagung vom Teilnehmer zum Provider - erfolgt
allerdings nach wie vor über die alte Vorgehensweise und ist insofern erheblich langsamer.
Insofern ist das Modem nur teilweise 56-Kbit/s-fähig - und auch nur dann, wenn die
Bedingungen es zulassen.
5.1.2 Die Situation heute
Viel hat sich nicht geändert seit der Konzipierung der Modemtechnologie. In dem Maße,
wie die Übertragungsprotokolle fortschritten, wurden auch die Fehlerkorrektur- und Re-
servernechanisHien verbessert, die für eine zuverlässige Ubeitiagung erforderlich sind -
wenn etwa Ihr Vierbeiner mal wieder Telefonkabel zum Frühstück hatte. Standaids
schössen wie Pilze aus dem Boden: V.42 brachte eine einfache PnifsuinmeniinplementieiTmg
(Cyclic Redundancy Check, CRC) mit sich, MNP-1 bis MNP-4 proprietäre
Fehlerkorrekturalgorithmen, V.42bis und MNP-5 Integiitätspräfung in Verbindung mit Komprimierung
und so fort. Aber die wirkliche Revolution steht uns noch bevor.
Oder ist sie schon da? Sie könnten einwenden, dass DSL und Kabelmodems eine
bahnbrechende Technologie darstellen, die die Welt verändert haben. Ich halte dagegen, dass diese
Technologien ihren älteren Cousins - den Modems - eigentlich doch recht ähnlich sind.
Die einzigen bedeutsamen Unterschiede bestehen darin, dass sich der andere Endpunkt -
der Server, der alle Verbindungen verwaltet - nun nicht rnehr in einer entfernten Stadt
befindet, in der der Provider ansässig ist, sondern in der nächstgelegenen Vermittlungsstelle
des Netzbetreibers, und die Verbindung erfolgt direkt über Kupferkabel von der Wohnung
des Kunden. Da diese Direktverbindungen keine anderen Geräte passieren, können die
entsprechenden Geräte hohe, unhörbare Frequenzen und subtilere Signale verwenden, die im
Telefonnetz verstümmelt oder aber gar nicht weitergeleitet würden. Im Gegensatz dazu
war das gute alte Modem strikt auf einen schmalen Bereich hörbarer Frequenzen und
Signale beschränkt, für deren Ubeitiagung das Telefonsystem vorgesehen war (und die es
infolgedessen auch gut übertragen hat). In vielerlei Hinsicht haben es die DSL-Geräte heute
viel leichter als das gute alte Modern.
Wie wir sehen, ist die Entwicklung eines Modems eigentlich eine recht komplexe und
schwierige Aufgabe. Deswegen hat es auch Jahrzehnte gedauert, um uns von den teuren
und klobigen 300-Baud-Geräten zu der Situation zu bringen, die wir heute vorfinden.4
Erstaunlicherweise aber können all diese Geräte miteinander kommunizieren — sogar mit
Geräten, die schon zehn Jahre alt sind, und mit Übertragungsraten, die wir schon lange
erfolgreich verdrängt haben. Wir alle sind uns der heute bekannten Standards einschließlich ihrer
Bing88
84
5.1 Die Kunst, Daten zu übertragen
Vielzahl von Alternativen und Verzweigungen bewusst. Macht nicht gerade dieser
Umstand Modems zu einem Wunder in der Geschichte der Computerentwicklung?
Aber wer zieht die Strippen?
5.1.3 Manchmal ist auch ein Modem nur ein Modem
Die Kommunikation zwischen Modems ist natürlich weder der Anfang noch das Ende der
Geschichte. Das Modem ist nur ein Teil einer ziemlich trägen Middleware, und noch nicht
einmal einer von Format. Damit ein Modem zu irgend etwas nutze ist, muss es mit einem
Computer kommunizieren können, um Befehle entgegenzunehmen und Daten
auszutauschen, auch wenn es nur zu so etwas Profanern wie dem Surfen im Internet verwendet
wild. Interne Modems haben es leicht: ISA (Integrated Systems Architecture), PCI (Pe-
ripheral Component Interconnect), PCMCIA (PC Memory Card International Association)
und einige andere dedizierte Busse bieten schnelle und ziemlich vielfältige parallele
Schnittstellen, die den Kommunikationsvorgang ganz einfach gestalten.
Externe Modems (z. B. Analog- oder DSL-Modems) hingegen müssen den steinigen Weg
der seriellen Anbindung gehen. Die meisten Analogmodems verwenden das bekannte
serielle RS-232-Protokoll (welches in den Neunzigern etwas prägnanter in EIA/TIA-232-E
umbenannt wurde5); viele neuere Vaiianten setzen hingegen auf USB (Universal Serial
Bus). Wenn wir uns den Datenenthüllungsszenarien mit diesen Geräten annähern, werden
wir auch einen Blick daiauf riskieren, was mit den Daten auf ihrem Weg zwischen Modem
und Computer passiert, denn dies spielt bei einer Attacke eine wesentliche Rolle.
Zwar müssen externe Modems inhumane Kommunikationsrnittel nicht nur für
Verbindungen mit Remote-Systemen, sondern auch mit dem lokalen Rechner selbst verwenden, aber
dank der physischen Nähe zum Computer und der Tatsache, dass Schnittstellen wie RS-
232 digital arbeiten und von Anfang an für den Einsatz mit Computern konzipiert waren,
ist diese Stufe weitaus einfacher als die Modulation und Demodulation von
Telefonsignalen, für die Bitmoderns berühmt sind.
RS-232 verwendet eine relativ unkomplizierte Implementierung der bipolaren Kodierung
für Daten, die über zwei separate Leitungen ausgetauscht werden, und unterstützt diese mit
einer Anzahl von NRZ-Steuerleitungen. Um das Leben interessanter zu gestalten, bietet es
eine Vielzahl von Verbindungs- und Rotokollfunktionen, die eine Implementierung von
Grund auf relativ schwierig gestalten: das asynchrone Wesen der Schnittstelle, eine
Unmenge möglicher Einstellungen und Geschwindigkeiten und unkonventionelle
Spannungspegel. Trotz allem aber stellt RS-232 noch nicht einmal ansatzweise eine Herausforderung
für einen Entwickler dar, der die Signalmodulation über Telefonleitungen bewältigt hat.
USB hingegen ist ein Versuch, die serielle Schnittstelle zu standardisieren und zu
vereinheitlichen. Obwohl USB komplexere Schaltungen erfordert als RS-232, um für einen
Computer eine Schnittstelle zu einem Gerät bereitzustellen — weil etwa u. a. eine höhere
5 EIA91
5 Blinkenlichten
Abstraktionsebene und höhere Übertragungsraten vorhanden sind —, ist USB universell
(daher der Name) und zeichnet sich durch weniger Merkwürdigkeiten und überkommene
Funktionalitäten aus.
Eine weitere gängige Methode zur Kommunikation mit lokalen Geräten ist nicht zuletzt
auch der Einsatz von Ethernet, einer Technik, die USB ähnelt, aber älter ist. Schauen wir
uns also zunächst Ethernet an— früher oder später kommen alle diese Kornmunikationspro-
tokolle wieder zusammen.
5.1.4 Kollisionen unter Kontrolle
Ethernetnetzwerke sind im Grunde genommen die fortgeschrittene Variante einer seriellen
Verbindung mit vielen Teilnehmern.0 Ein Ethemetnetzwerk setzt sich aus einer Anzahl
von Computern zusammen, die durch ein gemeinsames Medium aneinander angebunden
sind. Dies ist in seiner einfachsten Ausprägung nichts fürchterlich Komplexes — einfach
nur ein paar ziemlich gewöhnlicher Leitungen. Wenn ein Gerät im Netzwerk dieses
Medium nutzt, legt es eine Spannung an den Leiter an; alle anderen angeschlossenen Systeme
können die Daten dann inteipretieren, indem Sie die Spannungen messen. Eine Reihe von
Tests gewährleistet dabei, dass mehrere Geräte die Leitung nicht gleichzeitig verwenden
und dass, wenn es doch zu einem Zusammenstoß kommt, die Wiederherstellung
unproblematisch ist. Aber auch, wenn man diese Möglichkeit in Betracht zieht, ist die
Grundstruktur verglichen mit Modems schier unglaublich trivial.
Um das Problem zu umgehen, dass zwei angeschlossene Systeme gleichzeitig zu
kommunizieren beginnen, hat man einen Standard namens CSMA/CD (Carrier Sense Multiple
Access with Collision Detection) ersonnen, der als zentraler Mechanismus die gesamte
Kommunikation über Ethernet regelt. Bevor Daten gesendet werden, arbeitet jedes
angeschlossene Gerät eine CSMA/CD-Prozedur ab, um festzustellen, ob ein anderes Gerät das
Kabel gerade benutzt, indem es die elektrischen Eigenschaften des Modems überprüft.
Findet gerade keine andere Übertragung statt, dann wechselt das Gerät in die
Übertragungsphase und sendet seine Daten hinaus in das Netzwerk.
In dieser Phase werden die Daten über die Leitung als Folge von Bits übertragen. Hierbei
kommt die bipolare Kodierung zum Einsatz: Die Daten enthalten jeweils einen Header mit
allen nötigen Angaben zu Absender und Empfänger sowie eine Prüfsurnme, deren Zweck
der Schutz der Datenintegrität im Falle externer oder interner Störungen vierbeiniger und
anderer Alt ist. Eine Netzwerkschnittstelle, die davon ausgeht, im Auftrag eines
Empfängers zu handeln — etwa weil sie die im Paket erkannte Zieladresse mit der auf der Karte
gespeicherten eindeutigen MAC-Adresse (Hardwareadresse) verglichen und eine
Übereinstimmung erkannt hat —, sollte diesen Datenverkehr akzeptieren und die Prüfsumrne
verifizieren. Gleichzeitig sollten alle anderen Beteiligten diesen Frame ignorieren; wenn sie dies
jedoch nicht tun (und praktisch alle Kalten können dazu angewiesen werden), dann kann
der Benutzer Datenverkehr, der an Dritte gerichtet ist, natürlich anzeigen oder auf diesen
6 Spiu-00
86
5.1 Die Kunst, Daten zu übertragen
reagieren. (Sie sehen schon, dass Ethernet im Geiste abwegiger Gutgläubigkeit und Unei-
gennützigkeit entwickelt wurde — ein nobler, doch vernunftwidriger Ansatz.)
Es ist möglich (und auch recht wahrscheinlich), dass zwei Geräte in einem Ethernetnetz-
werk im exakt gleichen Moment mit der Ubeitragung beginnen, obwohl sich beide nur
Mikro- oder Nanosekunden zuvor vergewissert haben, dass kein anderer Beteiligter Daten
sendet. Und wenn nun tatsächlich beide im exakt gleichen Moment die Übertragung
starten, dann ist die Katastrophe vorprogrammiert. Zwei Übertragungen werden vermischt und
verstümmelt, und beim Empfänger schlägt der Prüfsurnmentest dann fehl. Oder?
Zwar ist der Einsatz der Prüfsurnme, die in der Spezifikation für Ethemet-Frarnes
festgelegt ist, in aller Regel ausreichend, um die Genauigkeit der Datenübertragung zu
verifizieren, aber wenn die Leitung voll ist und Hunderte oder Tausende Kollisionen innerhalb
kürzester Zeit auftreten, dann ist es mit der Effizienz vorbei: Die Riifsumrne ist so knapp,
dass von Zeit zu Zeit zufällig das korrekte Ergebnis herauskommen wird. Das
Wahrscheinlichkeitsgesetz sagt uns, dass einige beschädigte Pakete — rein zufällig — die gleiche
Prüfsumme haben werden wie das jeweilige ursprüngliche Paket. Aber auch, wenn wir das
Problem der Priifsurnmenrnängel ignorieren, sollten wir Kollisionen so bald wie möglich
beenden: Lässt man Kollisionen wuchern, dann wird man postwendend feststellen, dass
eine ausreichend schnelle Neuübertragung beschädigter oder verworfener Frames im
Netzwerk nicht rnehr möglich ist. Schließlich hat der Absender es ohne Anzeichen eines
Problems versandt, und der Empfänger hat nichts erhalten, was auch nur im Entferntesten
an ein Paket mit Nutzdaten erinnerte.
Die Lösung verbirgt sich hinter der zweiten Abkürzung im Standard: CD steht für „Colli-
sion Detection" (Kollisionserkennung). Die Spezifikation weist den Absender an, die
Netzwerkleitung zu überwachen, solange er sich anderen gegenüber äußert. Wird ein
anderer Teilnehmer bei dem Versuch ertappt, zur selben Zeit zu kommunizieren, dann sollte
dies (ebenfalls durch eine einfache Messung der elektrischen Eigenschaften der Leitung)
erkannt werden, woraufhin die Übertragung sofort abbricht. Femer sollte das Gerät auch
einen so genannten Jam-Code (d. h. ein Störsignal) senden, um sicherzustellen, dass beide
Frames — der, der vom Gerät selbst versendet wurde, und der Störenfried — vorbehaltlos
gelöscht werden, ohne dass es überhaupt zu einer Verifizierung der Prüfsurnmen kommt;
der Empfänger sollte das Jam-Signal erkennen und daraufhin den Empfang der Daten, die
er gerade verarbeitet, abbrechen. Das Gerät wartet dann einen (anfangs) möglichst
zufälligen, nach und nach immer länger werdenden Zeitraum — den so genannten Backoff— ab,
bevor die Neuübeitiagung erfolgt; hierdurch soll die Wahrscheinlichkeit einer erneuten
Kollision minimiert werden.
■ Hinweis
Wollen Sie was Lustiges hören? Der Mechanismus für den Jam-Code erlegt dem Protokoll
eine ungewöhnliche Anforderung auf. Alle Frames müssen eine Mindestlänge (!) aufweisen,
wobei der Wert so berechnet wird, dass der Jam-Code erzeugt und an alle Systeme im
Netzwerk gesendet werden kann, bevor die Übertragung des Frames abgeschlossen ist. Bei sehr
kurzen Frames kann es sein, dass hierfür nicht genug Zeit vorhanden ist. Aus diesem Grund
muss der Absender alle ausgehenden Übertragungen künstlich erweitern.
5 Blinkenlichten
0
0
$
^, SENDER A
M Will senden,
j? erkennt Signal
und wartet
x. SENDER B
W[ Sendet Daten
St EMPFÄNGER
n Empfängt
7 Daten
0
$
$
s, SENDER A
H Wartet eine
7 Zeit lang
s, SENDER B
fl Wartet eine
7 Zeit lang
■^ EMPFÄNGER
SENDERA
Keine Aktivität
erkannt
Senden wird
vorbereitet
SENDERB
Will auch
senden
EMPFANGER
SENDERA
Startet
Neuübertragung
SENDERB
Wartet.
EMPFANGER
Empfangt Daten
SENDERA
Sendet Daten
SENDERB
Sendet Daten
Kollision!
EMPFÄNGER
O
Empfängt
beschädigte
Daten
SENDERA
Sendet.
SENDERB
Erwacht sieht
anderes Signal
wartet...
EMPFÄNGER
Still receives..
SENDERA
EMPFANGER
lEmpfängt Jam-
'Code, löscht
erhaltene Daten
$
&
ÖJ
s, SENDER A
fl Fertig!
s. SENDERB
f\ Kein Signal
7* erkannt startet
Neuübertragg.
s. EMPFÄNGER
ifj Empfängt
7 Daten
Abbildung 5.4 Phasen der Ethemetkommunikafion
Abbildung 5.4 zeigt die genaue Abfolge der Ereignisse in einem typischen
Kollisionsszenario. Wie Sie sehen, hofft Sender A, Daten an den Empfänger übermitteln zu können,
stellt aber fest, dass eine andere Ubeitragung stattfindet, und beschließt demzufolge, eine
Zeit lang zu warten, bis die andere Ubeitragung endet. Dann bereitet sich Sender A auf den
Versand seiner Daten vor. Leider tut Sender B genau dasselbe, und beide gelangen fast
gleichzeitig zu dem Schluss, dass das Versenden der Daten sicher ist.
Beide probieren also eine Übertragung, und die Daten werden verstümmelt. Zu diesem
Zeitpunkt nun erkennen beide die jeweils andere Übertragung und senden ganz schnell
einen Jam-Code, um den Empfänger anzuweisen, den betreffenden Frame zu verwerfen.
Abschließend halten beide Sender für einen zufälligen Zeitrauni still und schaffen es danach
hoffentlich, ihre Übertragungen nicht wieder gleichzeitig zu starten.
5.1.5 Hinter den Kulissen: Die Sache mit den Leitungen - und
unsere Lösung dafür
Zwar ist das Ethernetprotokoll kein Beispiel für eine besonders gut skalierbare oder
elegante Konstruktion, aber es ist erstaunlich leistungsfähig und einfach einzusetzen. So er-
88
5.1 Die Kunst, Daten zu übertragen
rnöglichte es die Einrichtung preiswerter Netzwerke mit einer Peer-Struktur unter
Verwendung von Koaxialkabeln an praktisch jedem beliebigen Ort. Aufgrund dessen wurde es
zum De-facto-Standard und hat viele andere (teils überlegene, aber teurere oder
proprietäre) Netzwerkarchitekturen ersetzt.
Natürlich hatte das einfache Ethernet über Koaxialkabel seine Einschränkungen und
Nachteile: Es basierte im Wesentlichen auf einem langen Leiterkabel, an das an
verschiedenen Punkten Geräte angeschlossen waren und das an beiden Enden Widerstände
aufwies. Eine solche Konstruktion ist nun nicht gerade etwas, dem man die Verantwortung für
die Kommunikation in einem Bürokornplex anvertrauen möchte. Eine kleine, schwer zu
findende Panne wie etwa ein kurzgeschlossener Anschluss konnte die gesamte
Infrastruktur außer Gefecht setzen. Insofern war ein fortgeschrittener — zudem nur unwesentlich
teurerer — Ersatz sehr willkommen.
Elektronische Multiport-Repeater (Hubs) erlaubten das mühelose Herstellen der
Verbindungsstrecken rnithilfe von LP-Kabeln (Lwisted Pair, also verdrillte Leiterpaare). Dies
waren in der Regel CAT3- und CAT5-Kabel mit RJ-45-Steckem. Die Inbetriebnahme sah so
aus, dass man seinen Rechner einfach mit einem kurzen Kabel an eine Blackbox anschloss,
und schon konnten alle an diese Blackbox angeschlossenen Geräte mit ihm
kommunizieren. Probleme mit der Elektrik oder die Möglichkeit, dass ein Kabelbrach das gesamte
Netzwerk zum Ausfall bringen konnte, gehörten der Vergangenheit an.
Hubs sind im Grande genommen einfache Repeater, die den gesamten an einem Port
empfangenen Datenverkehr an alle anderen Ports weiterleiten. Sie ermöglichen die Erstellung
einfach umzukonfigurierender und zuverlässigerer Netzwerke mit Stemtopologie, tiagen
ansonsten aber wenig bei. Wenn das Netzwerk wächst, dann machen die Kosten der
Übertragung jedes einzelnen Datenbits an alle Punkte und die Tatsache, dass nur ein Gerät
gleichzeitig über das Netzwerk kommunizieren kann, nur allzu deutlich, dass die
Einfachheit dieser Struktur gleichzeitig auch ihren größten Nachteil darstellt.
Die Lösung waren Switches. Switches sind die nächste Generation der Hubs. Ausgestattet
mit einem richtigen Prozessor und ein wenig Speicher, ermöglichen Sie eine zusätzliche
Analyse auf höherer Ebene und stellen eine teurere Alternative zu Hubs dar.
Diese Analyse verknüpft Hardwareadressen mit bestimmten Ports und optimiert das
Routing von Frames, indem bestimmte Pakete im Unicast-Modus direkt an den passenden
Ausgangsanschluss übergeben werden, statt sie im Broadcasting-Verfahren an alle Punkte
zu senden (siehe Abbildung 5.5). Hierdurch wird die Leistungsfähigkeit mirfangreicher
Netzwerke erheblich verbessert.
■ Hinweis
Wollen Sie noch was Lustiges hören? Echte Hubs sind heutzutage fast ausgestorben. Praktisch
alle 10/100-Mbit/s-Geräte, die angeboten werden, enthalten eigentlich einfache
Switch-Chipsätze. Es ist schlichtweg einfacher, den Chip umzuetikettieren, als mehrere Varianten zu
entwickeln und zu pflegen.
89
5 Blinkenlichten
Ich schätze, spätestens an dieser Stelle fragen Sie sich, worauf zum Teufel ich hinaus will.
Was sollen denn Modems mit der Enthüllung von Daten zu tun haben? Welche Bedeutung
haben serielle Verbindungen in diesem Kontext? Was soll die Abhandlung über Ethernet?
Und was bitteschön sind Blinkenlichten?
Ich bin froh, dass Sie fragen. Wir werden nun darauf eingehen. Auf Ihre letzte Frage,
meine ich.
y*^S Empfänger t*^yr Empfänger
Abbildung 5.5 Hubs und Switches im LAN
5.1.6 Blinkenlichten in der Kommunikation
Früher waren die fest kühlschrankgroßen Computer mit zahlreichen, hervorstechend
angeordneten Diagnoseoberflächen ausgestattet. Hierzu gehörten Matrizen mit winzigen
Lämpchen, die unter anderem gewisse unergründliche Eigenschaften des internen Zustandes
einer Maschine anzeigten: Welche Werte haben die internen Register, welche Flags wurden
vom Zentralprozessor gesetzt, wurde die Katze heute schon gefüttert usw. In dem Maße,
wie Computer zuverlässiger und kompakter wurden und der Dui-chschnittsbenutzer die
inneren Abläufe des Systems nicht rnehr verstehen rnusste, um es effizient einsetzen zu
können, verschwanden diese Lämpchen zunehmend. Immer höhere Taktgeschwmdigkeiten
trugen ebenfalls zu ihrem Niedergang bei, denn irgendwann war der Zeitpunkt gekommen,
an dem es dem menschlichen Auge nicht rnehr möglich war, den Anzeigen eine sinnvolle
Bedeutung zu entnehmen, änderten sich diese doch tausend- oder millionenfach in jeder
Sekunde.
Bei einigen Anwendungen jedoch blieben die Lämpchen vorhanden. So sind etwa fest alle
Netzwerkgeräte mit LEDs auf der Vorder- oder Rückseite ausgestattet. Diese ermöglichen
5.2 Die Auswirkungen der Ästhetik
Verbindungsdiagnosen: Sie zeigen etwa an, ob ein bestimmtes Modul oder ein Anschluss
einwandfrei funktionieren, das System ans Netzwerk angeschlossen ist, Daten übertragen
werden usw. Diese Anzeigen sind aber auch nicht nur ein einfaches Diagnosetool: Ihre
hypnotischen Muster muten merkwliidig an, und ihr Mysterium pflanzt die Saat von
Furcht, Verzagtheit und Demut in die Herzen jener Unwissenden, die das Reich des Ser-
verraurns betoten.
Der Begriff Blinkenlichten (oder Blinkenlights) wird seit dem finsteren Mittelalter der
Computertechnik zur Bezeichnung der vielbewunderten Einrichtung von Diagnoselämp-
chen auf Rechengeräten verwendet —jener Lampen, die den Cornputerfreak in seinen
langen und einsamen Nächten vor dem Terminal in ein sanftes grünes Licht tauchten. Das
Wort stammt von einem Hinweisschild, das in Pseudodeutsch abgefasst war und das
irgendein Witzbold in den Fünfzigern in den EDV-Laboren von IBM aufgehängt hat.
(Dieses Schild war selbst bereits eine Parodie auf einen nicht computerbezogenen Scherz aus
dem 2. Weltkrieg.) Das Schild hing bald darauf in vielen Serverräumen und
Laboreinrichtungen in aller Welt. Es lautete wie folgt7:
ACHTUNG!
ALLES LOOKENSPEEPERS!
Alles touristen und non-technischen looken peepers! Das computermachine
ist nicht fuer gefingerpoken und mittengrabben. Ist easy schnappen
der springenwerk, blowenfusen und poppencorken mit spitzensparken.
Ist nicht fuer gewerken bei das dumpkopfen. Das rubbernecken sichtseeren
keepen das cotton-pickenen hans in das pockets muss,- relaxen und watchen
das blinkenlichten.
Kormnunikationseiniichtungen gehören zu den letzten Bereichen, in denen es noch
Leuchtanzeigen gibt (und das wird sich scheinbar auch so bald nicht ändern). Aber das ist
noch nicht alles. Praktisch alle diese Einrichtungen verwenden für die Kommunikation
serielle Leitungen. Und für aus Gründen der Einfachheit und Ästhetik sind diese Aktivitäts-
LEDs manchmal direkt — über eine einfache Ansteuerschaltung — mit der Empfangs- oder
Sendeleitung des Geräts verbunden. Der Vorhang fällt.
5.2 Die Auswirkungen der Ästhetik
Es dauerte Jahrzehnte, bis das Problem erkannt wurde. Und als es dann so weit war — im
Jahre 2002 —, waren wir alle vor den Kopf gestoßen, so simpel und augenscheinlich war es.
Es war derart peinlich, dass man versucht war, mehrfach mit dem Kopf vor die Wand zu
rennen.
In ihrer Forschungsarbeit „Information Leakage frorn Optical Emanations"8 beschrieben
Joe Lughry und David A. Umphiess ein neuartiges Signalenthüllungsszenario bei be-
Raym96
Lugh02
5 Blinkenlichten
stimmten Alten von Netzwerkeinrichtungen (vorzugsweise Modems). Sie zogen die
Schlussfolgerung, dass jemand, der diese Anzeigedioden genau beobachtete, anderes im
Sinn haben könnte, als sich von Zauberlichtem betören zu lassen.
Anders als Glühlampen haben LEDs sehr schnelle Ansprech- und Abfallzeiten, d. h. sie
schalten sich praktisch verzögerungsfrei ein und aus. Dieser Umstand ist nicht
überraschend, denn schließlich werden hochwertige LEDs auch zur Ansteuerang von
Glasfaserverbindungen und anderen optoelektronischen KoHimunikationskanälen verwendet. Mithin
spiegelt das Blinken einer LED, die an einer seriellen Datenleitung hängt, tatsächlich oft
einzelne Bits wider, die über die Leitung übertragen werden. Wenn es eine Möglichkeit
gäbe, diese Aktivitäten mit ausreichender Geschwindigkeit aufzuzeichnen, dann ist auch
vorstellbar, dass diese Daten ermittelt werden können, sofern man die winzigkleine Lampe
am Gerät mit dem bloßen Auge (oder einem Teleobjektiv) erkennen kann.
Diese Aibeit sorgte in der Industrie für gehörigen Wirbel — die einen spielten sie herunter,
die anderen überbewerteten sie. Die Folge war ein großes Durcheinander, und seitdem hat
sich wenig geändert. Viele widersprüchliche Berichte entstanden als Reaktion auf das
Dokument; sein Grundsatz aber ist einfach und wahrhaft anmutig. Die Anmut dieser Methode
besteht darin, dass es ganz simpel ist, ein Gerät zum Empfang des Signals zu bauen: Die
gleichermaßen billigen und verbreiteten Gegenstücke zu LEDs — Fotodioden und
Fototransistoren — sind leicht zu besorgen und ebenso leicht mit dem Computer zu verkoppeln. Und
anders als bei den in Kapitel 3 beschriebenen TEMPEST-Aktionen ist die Offenbarangs-
zone nicht Gegenstand moderner Märchen oder ausschließlich im Testfeld erzielter
Ergebnisse, sondern lässt sich direkt beobachten und messen.
Im Zuge ihrer Forschungen haben die Autoren eine Anzahl Experimente durchgeführt, um
nachzuweisen, dass das Signal sich aus einer Entfernung von 20 Metern aufzeichnen lässt,
ohne dass hierfür eine zusätzliche digitale Signalaufbereitung erforderlich gewesen wäre.
Der gesunde Menschenverstand legt nahe, dass selbst dies eine Untertreibung ist —
insbesondere wenn gute optische Einrichtungen zum Einsatz kommen. (Die Autoren
verwendeten ein Objektiv mit einer Brennweite von 100 mm und dem Blendenöffhungswert f2.0;
ein wesentlich besseres Teleobjektiv ist allerdings schon für viele Spiegeheflexkameras
auch im nichtprofessionellen Bereich erhältlich. Und wenn jemand so richtig Geld
ausgeben will, kann er auch ein ultrahochwertiges Objektiv mit einer Brennweite von sage und
schreibe 1.200 mm erwerben.)
Die Aibeit nimmt einen defensiven Standpunkt ein, und der sorgfältige Leser könnte den
Eindruck gewinnen, dass einige der aufgefühlten Geräte gegen dieses Problem gefeit seien.
Allerdings weisen, wie Sie im Abschnitt zur Vorbeugung weiter unten in diesem Kapitel
noch erfahren werden, insbesondere einige Ethernetgeräte eine subtilere Variante der
Schwachstelle auf. Zunächst aber sollten Sie das Problem mit eigenen (Cornputer-)Augen
betrachten. Meinen Sie nicht auch?
92
5.3 Spionageausrüstung selbstgebaut...
5.3 Spionageausrüstung selbstgebaut...
Die Tatsache, dass es extiem einfach ist, ein Bespitzelungsgerät zu bauen, macht genau
dies so verlockend. In diesem Abschnitt finden Sie mehrere Vorschläge und grobe
Schaltbilder, die zeigen, wie man ein solches Gerät baut und an einen konventionellen Computer
anschließt. Zwar ist die Schaltung nicht gerade komplex, man braucht kein Fachmann für
Löttechnik zu sein, und eine Software zum Entwerfen des Leiterplattenaufbaus ist auch
nicht erforderlich, aber ein Minimum an elektrotechnischen Fertigkeiten ist ebenso
wünschenswert wie eine Dosis gesunden Menschenverstandes. Obwohl die externen
Schnittstellen modemer Rechner relativ robust und narrensicher sind, besteht immer das Risiko
eines Schadens am Computer, wenn man in Heirnarbeit gebastelte Geräte auf wahrhaft
innovative Weise oder aber in einem kurzen Moment geistiger Umnachtung anschließt. Das
ist selbst den größten Experten schon passiert.
Der Grundaufbau ist extiem einfach. Er basiert auf einem einzelnen Fototransistor (einer
Komponente, die aus einem von einer integrierten Fotodiode angetriebenen Transistor
besteht), einem leistungsarmen npn-Transistor zur geringfügigen Verstärkung des Signals
(nicht unbedingt notwendig) und eine Anzahl Potentiometer (etwa im Bereich von
lOkOhrn, damit ausreichend viel Flexibilität gewährleistet ist), um die Spannung
versuchsweise herunterzuregeln und die Empfindlichkeit sowie die Schwellwerte der
Schaltung zu steuern. Hinsichtlich der Komponenten gibt es keine besonderen Anforderungen,
allerdings hängt die Leistungsfähigkeit der Schaltung von der Qualität ab. Sie sollten einen
Fototransistor verwenden, der im Bereich des sichtbaren Lichts ein ordentliches
Ansprechverhalten aufweist, wobei eigentlich auch alle billigen Exemplare funktionieren sollten.
(Zur Information sei angemerkt, dass eine grüne LED eine Wellenlänge von ca. 520 mn
aufweist.) Abbildung 5.6 zeigt eine Beispielschaltung.
Die optimale Betriebsspannung der Schaltung hegt bei ca. 5 V. Der Maxirnalstiom ist
niedrig: Eine Stromquelle, die 10 bis 50 rnA liefert, ist mehr als ausreichend. Eine
Mahnung: Wenn Sie eine Quelle verwenden, die eine höhere Spannung anlegt, riskieren Sie
eine Beschädigung des Cornputeranschlusses oder der Computers selbst. Gleiches gilt,
wenn Sie eine leistungsfähigere Quelle verwenden und den Fluss stäikerer Ströme durch
die Schaltung nicht unterbinden.
■ Hinweis
Wenn Sie für Rvarl oder Rvar2 einen sehr niedrigen Widerstand wählen, kann es zu einem
Kurzschluss der Schaltung kommen. Sollten Sie also gedankenlos mit den Reglern
herumspielen, empfiehlt sich die Ergänzung eines Festwiderstands zur Begrenzung der Stromaufhahme.
Sie müssen den Fototransistor vor externen Lichtquellen schützen. Dies lässt sich etwa mit
einem hchrundurchlässigen Rohr bewerkstelligen. Da der Transistor keinen Scharfstel-
lungsmechanismus aufweist, lassen sich damit wohl kaum weiter entfernte Signale (mit
Ausnahme des Urngebungslichts) auffangen. Daher sollten sie ihn zum Testen anfangs
vollständig abdecken, um Dunkelheit zu simulieren, und dann mit einer LED die Schaltung
93
5 Blinkenlichten
anregen. Sie können auch eine weitere LED vorübergehend zwischen Masse und
Ausgangsleitung setzen, um die Schaltung zu testen. Die Prüf-LED sollte leuchten, wenn der
Sensor auf eine Lichtquelle gerichtet wird, und andernfalls rnehr oder minder dunkel
bleiben.
Vcc
2N2222
oder ähnlicher npn-Transistor
Rvar2
VW
zum Computer
GND
Abbildung 5.6 Einfache Empfängerschaltung
5.4
und eingesetzt
Wenn die Schaltung mit integrierter Prüf-LED so weit funktioniert, können Sie zufrieden
sein: Sie haben gerade einen fantasievollen TV-Femtester gebaut. Da universelle
Fototransistoren billiger Bauart nur zu bereitwillig Infraiotlicht auffangen, sollte Ihre Schöpfung
nun Infrarotstrahlen in sichtbares Licht umwandeln — rnehr aber auch nicht. Um den
Nutzen zu steigern, müssen Sie eine Verbindung von der Schaltung zum Computer herstellen.
Hierzu bietet sich die paiallele Druckerschnittstelle (LPT-Schnittstelle) an, sofern Ihr
Computer über eine solche verfügt. Leider wird dieses für den Hacker fabelhafte
Werkzeug bei vielen kompakteren und anspruchsvolleren Systemen zunehmend weggelassen.
Zwar war die LPT-Schnittstelle urspiiinghch nur zur Ausgabe vorgesehen (d. h. für den
unidirektionalen Betrieb konzipiert), aber sie bietet eine Reihe von Statusrückleitungen,
z. B. „Paper Out", „Busy" und „Acknowledgment". Diese sollten es dem Rechner
ermöglichen, bei Bedarf Probleme zu melden. Die Daten, die über diese Schnittstelle gelangen,
lassen sich relativ einfach durch Zugriff auf Port 0x379 (LPT1-Statusregister) auf einem
PC-kompatiblen System auslesen. Wenn Sie eine Schaltung an den Parallelport
anschließen, können Sie ganz einfach Informationen an den Computer übermitteln. Wenn Sie in
Betracht ziehen, die Schaltung an eine andere Schnittstelle anzuschließen, dann lassen Sie
sich gesagt sein, dass LPT wesentlich schneller als beispielsweise RS-232 ist und Sie sich
dabei nicht mit profanen Protokollen, Signalisierungssysternen oder unkonventionellen
Spannungspegeln befassen müssen. Außerdem müssen Sie — anders als bei USB und
ähnlichen aktuellen Systemen — keine SpezialController verwenden, um einem recht
komplexen Protokoll lediglich beizubringen, mit Ihrem PC zu kommunizieren.
5.4... und eingesetzt
Hinweis
■ Zwar bietet LPT mit ECP und EPP auch bidirektionale Betriebsinodi, aber der Versuch, diese
Funktionalität für eine derart simple Aufgabe zu verwenden, ist ziemlich sinnlos. Unidirektio-
nal stehen vier Bits für die Hingabe zur Verfügung, was für diese Anwendung mehr als genug
ist; das Umschalten auf bidirektionale Modi wie EPP oder ECP bietet viel' weitere Bits.
Welche Statusleitung Sie verwenden wollen, hegt ganz bei Ihnen. Tabelle 5.3 zeigt die
Kontaktanordnung des DB25-Steckers, der für den Druckerport verwendet wird. Die
hervorgehobenen Zeilen können flu' die Eingabe verwendet werden.
Tabelle 5.3 LPT-Kontaktbelegung (DB25, Standard)
Kontakt
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Kontakt
16
17
18
19
20
21
22
23
24
25
Name
Strebe
DO
D1
D2
D3
D4
D5
D6
D7
ACK
Busy
Paper Out
Select In
Autofeed
Error
Name
Init
Select
GND
GND
GND
GND
GND
GND
GND
GND
Funktion
Steuerausgabebit 0
Datenausgabebit 0
Datenausgabebit 1
Datenausgabebit 2
Datenausgabebit 3
Datenausgabebit 4
Datenausgabebit 5
Datenausgabebit 6
Datenausgabebit 7
Statuseingabebit 2
Statuseingabebit 3
Statuseingabebit 1
Statuseingabebit 0
Steuerausgabebit 1
Statuseingang (wird nicht verwendet)
Funktion
Steuerausgabebit 2
Steuerausgabebit 3
Erde (0V)
Erde (0V)
Erde (0V)
Erde (0V)
Erde (0V)
Erde (0V)
Erde (0V)
Erde (0V)
95
5 Blinkenlichten
Sie schließen die Schaltung an diesen Port an, indem Sie den Bezugserdkontakt des
Steckers mit einem der in Ihrer Schaltung verwendeten Punkte verbinden und die
Ausgangsleitung an einen behebigen der fünf verfügbaren Kontakte anschließen. (Vergessen Sie
nicht, zuerst die für die Diagnose verwendete LED abzutrennen.) Als nächstes überwachen
Sie den Statusport, denn Sie werden ihn zunächst dem Licht aussetzen und den Sensor
dann abdecken. In beiden Fällen hängt der Messwert davon ab, wie Sie die Schaltung
angeschlossen haben. Der exakte Wert ist dabei unwichtig; wesentlich ist, dass sich die
beiden Werte unterscheiden lassen.
Weil die Chiplogik etwas andere Eingangspegel benötigt als Ihre Test-LED, müssen Sie
Rvar2 unter Urnständen ein wenig optimieren, bis Sie, wenn Sie den Sensor abdecken,
andere Werte erhalten, als wenn Sie ihn dem Lichteinfall aussetzen. Zu diesem Zweck ist es
am besten, wenn Sie den Port in Echtzeit am Computer selbst überwachen können.
Aufweiche Weise Sie den Zustand des Ports überwachen können, hängt vom
Betriebssystem und der von Ihnen verwendeten Programmiersprache ab. Wenn Sie etwa C verwenden,
heißt die Funktion zum Auslesen des Wertes eines Ports iiib (port); in diesem Fall
würden Sie also iiib (0x379) absetzen und dann den Rückgabewert überprüfen. Bei anderen
Sprachen lautet der Name der Funktion wahrscheinlich ähnlich: Suchen Sie etwa nach in,
inport, readport usw. Windows-Benutzer finden das eingebaute Utility debug und die
zugehörige Funktion i (,,Port auslesen") unter Umständen recht praktisch.
■ Hinweis
Auf manchen Systemen wie etwa Linux müssen Sie unter Umständen zuerst beim System eine
Erlaubnis anfordern, um auf einen bestimmten Port zugreifen zu dürfen. Weitere
Informationen finden Sie in der Dokumentation zu iopl(3) oder einem ähnlichen Aufruf.
So, nun ist es so weit: Richten Sie Ihre Sonde auf eine behebige an einem Gerät
vorhandene LED, stellen Sie den Sensor entsprechend der Helhgkeit ein und beginnen Sie mit dem
Auslesen abwechselnder Muster heller und dunkler Signale, um zu ermitteln, welche
Daten ausgetauscht werden (sofern überhaupt Daten ausgetauscht werden).
■ Hinweis
Wenn Sie neugierig sind, können Sie einmal die Helligkeit der Anzeigediode selbst statt einer
binären Darstellung ihres Zustandes überprüfen. Möglicherweise stellt sich heraus, dass es,
obwohl eine bestimmte LED nicht dafür vorgesehen ist, ein Signal in der seriellen Leitung
direkt in Blinkmuster umzusetzen, zu einem analogen Übersprechen zwischen den Schaltungen
kommt und das Signal einen gewissen Einfluss auf die Helligkeit hat. Ein billiger Analog-
Digital-Wandler schreit geradezu danach, auf diese Weise eingesetzt zu werden.
Sie können diese Methode verwenden, um die Frequenz von weniger als einer Million Bits
pro Sekunde zu messen. Dies sollte ausreichend sein, um die Übertragung vieler
Netzwerkkarten zu erfassen, nicht unbedingt jedoch flu- Ethemetports (über die mindestens
10 Millionen Bits pro Sekunde übertragen werden). Jenseits dieser Erfassungskapazität
wird Ihr LPT-Port sehr wahrscheinlich die physischen Durchsatzgrenzen erreichen. Doch
keine Angst: Solange der Sensor (Fototransistor) mit einer für die Erfassung der fraglichen
96
5.5 Wie man die Zeigefreudigkeit von LEDs bändigt - und warum es dann doch nicht klappt
Kormnunikation erforderlichen Rate umschalten kann, haben Sie noch eine weitere Option.
Zur Erinnerung: LPT ist eine parallele Schnittstelle. Um höhere
Erfassungsgeschwindigkeiten wie etwa für Ethernet zu erzielen, kombinieren Sie einen ganz einfachen Taktgeber,
eine Zählerschaltung und einen Satz Abtast- und Haltespeicher (wie etwa 74LS377), um
die Daten sequenziell zwischen den cornputerseitigen Portleseversuchen zu speichern. Sie
können diese Information für kurze Zeit abspeichern und dann durch Verwendung
mehrerer Statuskontakte (oder durch Umschalten des Ports in einen bidirektionalen Modus)
problemlos mehrere Bits (Proben) in einem Rutsch - also einem Lesezyklus - an den
Computer senden. Auf diese Weise erhöhen Sie die Leserate auf das Vier- oder Achtfache.
Ich erspare Ihnen einen weiteren, vielleicht überflüssigen Exkurs in die Welt der
Elektronik. Wenn Sie mit der Idee der Hochgeschwindigkeits- oder der analogen Probenentnahme
hebäugeln oder einfach nur Spaß daran haben, irgendwas zusammenzulöten und dann an
einen Computer anzuschließen, dann sollten Sie einen Bück in meine recht umfassende
Einführung werfen, die sich unter dem dünnen Schleier eines Projekts zur Erstellung eines
computergesteuerten Roboters verbirgt.9
Es folgt für alle, die sich mehr für die praktischen Seiten des Themenbereichs Sicherheit
interessieren, eine kurze Abhandlung zu der Frage, wie man diesem Problern begegnen
kann, wenn man nicht alle LEDs im Rechenzentrum mit Klebeband abkleben will.
5.5 Wie man die Zeigefreudigkeit von LEDs bändigt - und
warum es dann doch nicht klappt
Die einfachste Lösung für dieses Problem, die auch in der ursprünglichen Forschungsarbeit
vorschlagen wurde, ist die Impulsdehnung - eine Praxis, deren Zweck darin besteht, das
Blinken einer Anzeige zu verzeichnen, indem man einige der Blinkimpulse verlängert und
auf diese Weise eine Wiederherstellung der Daten praktisch unmöglich zu machen scheint.
Impulsdehnungsschaltungen sind eine Gmppe relativ einfach stndcturierter Geräte, die die
Dauer eines empfangenen H-Signals um eine bestimmte Zeit verlängern. Die meisten
einfachen Irnpulsdehner verwenden hierzu einen Kondensator, der durch das Vorhandensein
eines Eingangssignals aufgeladen wird und sich dann langsam wieder entlädt. Dieser
Kondensator ist über einen binären Diskriminator angebunden; dies ist nicht der Name eines
neuen Actionfilms mit austeokahfomischem Hauptdarsteller, sondern ein Gerät, das
Analogdaten in ein binäres Ausgabeformat wandelt, indem es einen bestimmten Schwellwert
ansetzt: Es wird also für alle Eingangsspannungswerte über n eine bestimmte Spannung,
die eine logische 1 repräsentiert, und für alle darunter hegenden Eingangswerte eine der
logischen 0 entsprechende Spannung ausgegeben. In diesem Fall dient ein bestimmter
Kondensatorladestand als Unterscheidungsschwelle.
Sie finden sie unter http://lcamtiif.coredump.cx/robot.txt.
97
Fortgeschrittenere und zuverlässigere Ausfonnungen einschließlich digitaler Schaltungen
sind ebenfalls gängig, und sie alle können in Hubs und Switches eingesetzt werden, damit
die LEDs auch schön leuchten. Ohne sie würde das mit häufig mehr als 50 Zyklen je
Sekunde sehr hochfrequente Blinken angesichts der Trägheit unserer optischen
Wahrnehmung normalerweise dazu führen, dass wir die Diode als - wenn auch schwach, so doch
konstant - leuchtend wahrnehmen würden. Ein Diskriminator sorgt dafür, dass die LED
durch Einsen öfter angesprochen wird als durch Nullen, indem die Impulsdauer der
logischen 1 gedehnt wird. So wird die LED heller und blinkt weniger oft. Abbildung 5.7 zeigt
das Verhalten eines solchen Irnpulsdehners: Eine einzelne Spitze (logische 1) wird auf die
dreifache Länge gedehnt, wohingegen Nullimpulse nicht angerührt werden.
Eingabe: 01000
I
+5V
0V
Zyklen *-
Ausgabe: 01000
I I I
+5V
0V
Zyklen *-
Abbildung 5.7 Impulsdehnverhalten (3fach)
Da LEDs wie bereits erwähnt in erster Linie der Optik dienen, scheint dies auch ein guter
Ansatz zu sein, das Problern der Datenoffenlegung durch Lichtabgabe zu lösen, indem man
dem Angreifer nur Rückschlüsse zu bestimmten allgemeinen Eigenschaften des
Datenverkehrs gestattet. Auf diese Weise kann der Angreifer maximal ein paar generelle Fakten
ennitteln, z. B. wann etwas gesendet wird und wann nicht.10
Was aber auf den ersten Bhck eine gute Lösung zu sein scheint, muss dies nicht immer
sein. Betrachten Sie die folgenden Beispieldaten und das entsprechende Signal auf der
seriellen Leitung:
10
Dies ist zwar technisch gesehen nach wie vor ein Angriffsszenario in dem Sinne, wie wir es in
Kapitel 1 definiert haben, aber es ist deutlich weniger effektiv und praktikabel, denn wir erhalten nur eine
grobe Ahnung dessen, was passiert, und keine Kopie der Daten.
5.5 Wie man die Zeigefreudigkeit von LEDs bändigt - und warum es dann doch nicht klappt
Daten:
010100100000100001 1000001 1000000
NRZ-Signal:
y\z\-j~\ r\ r~\ r~\
Angenommen, das Signal wird durch einen 5fach-Irnpulsdehner verarbeitet, der jede 1 um
fünf zusätzliche Zyklen verlängert. (Die Autoren der Forschungsarbeit halten eine
Verlängerung um den Faktor 2 für ausreichend, aber wir wollen es an dieser Stelle der
Veranschaulichung wegen ein wenig übertreiben.)
Ursprungssignal:
j\/\-y\ r\ r~\ r~\
Mit Impulsdehnung (5x) bearbeitetes Signal:
J \J \J V_
Daten, die sich über die LED nach der Dehnung ablesen lassen:
01111111111011111111111011111100
Es hat zwar den Anschein, als wären fast alle wichtigen Infonnationen im Vergleich zum
Eingangssignal, das wir abfangen wollen, verloren gegangen, aber es lässt sich doch eine
Menge davon wiederherstellen. Hierzu sind vier wichtige Beobachtungen erforderlich:
■ Es ist ersichtlich, dass alle Bereiche in der impulsgedehnten Ausgabe, die 0 sind, auch
im Originalsignal 0 gewesen sein müssen.
■ Jeder gedehnte Einserbereich muss von einer 1 an der Anfangsposition im
Originalsignal ausgelöst worden sein.
■ Jede Folge von m Einsen muss ursprünglich mindestens eine 1 für alle n Zyklen
enthalten haben, wobei n der Dehnungsfaktor der Schaltung ist; andernfalls gäbe es Lücken
in der Folge. Die Anzahl der Einsen in einem Datenblock, der in der Ausgabe von einer
Folge von Einsen dargestellt wird, muss größer als oder gleich dem aufgerundeten
Ergebnis von m + n sein.
■ Jede Folge endet nach exakt n — 1 Nullen im UrsprungsdatenstroHi. Wir wissen, dass
diesen Nullen eine 1 vorangegangen sein muss, weil die Folge andernfalls früher
geendet hätte.
Wenn wir diese Erkenntnisse auf das vorherige Beispiel anwenden, können wir den
größten Teil der Daten wie folgt rekonstruieren:
99
5 Blinkenlichten
Ausgabe des Impulsdehners:
J \J \J V_
01????1000001??7? 710000011000000
* 1 '
x Hier steht mindestens eine 1
Im vorherigen, recht realistischen Beispiel gingen weniger als 9 von 32 Datenbits aufgrund
der Impulsdehnung verloren und lassen sich nachfolgend nicht mehr rekonstruieren. (Die
verlorenen Bits sind in der Grafik als Fragezeichen dargestellt.) Auf diese Weise haben wir
99,999988 Prozent des potentiellen Suchraums wiederhergestellt. Die restlichen Daten
müssen wir erraten, was (insbesondere, wenn die erschnüffelten Daten einen normalen
Text - z. B. eine E-Mail - darstellen) im Vergleich zu unserem Ausgangspunkt relativ
einfach ist. Die Autoren der Forschungsarbeit waren der Ansicht, dass Werte von 1,5 oder 2
für n ausreichend wären, um die Daten zu verschleiern; das rnuss aber nicht unbedingt der
Fall sein.
Das obige Wiederherstellungssystem funktioniert bei gedehnten Nullen oder Einsen
gleichermaßen. Manche Leitungsverbindungen verwenden RZ-Kodierangen (Retum-to-Zero),
die der weiter oben beschriebenen Manchester-Kodierung ähneln. Weil sich das Signal
hier kontinuierlich ändert, kann die zweifache Dehnung in der Tat ausreichend sein, um
alle Daten zu verschleiern. Dies trifft aber nur zu, wenn die LED von einem Signal
„angestoßen" wird, welches vor der ersten internen Dekodierung nach NRZ hegt; das aber ist in
den meisten Situationen nicht der Fall. Tatsächlich ist die Anwendung der Impulsdehnung
auf RZ-kodierte Signale meist eine recht alberne Idee, weil die LED dann konstant
leuchten würde; aufgrund dessen scheint es relativ zwecklos zu sein, dies als erstes zu tun.
Wie bereits oben erwähnt, ergibt sich ein weiteres Problern aus der Qualität des Impuls-
dehners und seiner Anfälligkeit gegenüber Störeinflüssen, die von anderen internen
Schaltungen stammen: Schwankungen der LED-Spannungen, die zu leichten
Helligkeitsänderungen während einer Dehnungsperiode führen, können ebenfalls gewisse Informationen
preisgeben. Dies gilt insbesondere für kondensatorbasierte Lösungen.
Deswegen können einige Systeme - und hier besonders Ethemetgeräte, die das
Impulsdehnungsprinzip bekanntennaßen einsetzen - teilweise für Angriffe anfällig sein, obwohl
die schon mehrfach erwähnte Arbeit die Ansicht vertritt, dass es keine direkte Verbindung
zwischen den übertragenen Daten und dem Verhalten einer LED gibt (diese Annahme
fußte auf Beobachtungen eines aufgezeichneten Blinkmusters, die mit einem Oszilloskop
gemacht wurden).
Insbesondere bei anderen Kodieningstypen oder dann, wenn die Impulsdehnung aus einem
anderen Grund nicht wünschenswert ist (weil der Entwickler etwa verhindern will, dass die
LED flu- die Dauer der Übertragung kontinuierlich leuchtet), besteht die optimale Lösung
darin, die Leitung mit einer relativ niedrigen Frequenz von vielleicht 20 Hz abzutasten und
den Abtastwert in einem Register zu speichern, wo er verbleibt, bis der nächste Wert
ermittelt und gespeichert wird. Genau dieses Register steuert dann die LED-Anzeige.
So, und ab jetzt wird wieder Klartext geredet.
100
5.6 Denkanstöße
5.6 Denkanstöße
Neben den LEDs von Netzwerkgeräten lassen sich andere - viele andere! - gleichennaßen
interessante Szenarien finden, bei denen Informationen durch Lichternission preisgegeben
werden, auch wenn der Urnfang dieser Informationen erheblich geringer sein kann.
Beteachten wir etwa Festplattenaktivitätsanzeigen. Natürlich verwendet die
Festplattenkommunikation keine serielle Signalisierung; vielmehr werden Datensegmente, die von
einzelnen Bytes bis zu 32-Bit-Wörtern reichen, gleichzeitig über eine Anzahl Signalleitungen
übertragen. Und obwohl die LED normalerweise so angeschlossen ist, dass lediglich der
Zustand einer speziellen Steuerleitung angezeigt wird, ist es nichtsdestoweniger möglich,
viele Aspekte der Systemaktivitäten abzuleiten, indem man Zugriffszeiten oder die Menge
der geschriebenen oder gelesenen Daten ermittelt. (Je nachdem, wie die LED
angeschlossen ist, lassen sich entweder einer dieser Werte oder sogar beide messen.) Obwohl es
unwahrscheinlich ist, dass diese Information einem Angreifer einen direkten Vorteil
verschaffen würde, lassen sich bestimmte externe I/O-Aktivitäten mit Beobachtungen der
Festplattenaktivitätsanzeige kombinieren und so interessante Schlussfolgerungen ziehen.
(Mir sind allerdings keine Forschungen in dieser Richtung bekannt.)
Andere potenzielle Angriffssituationen beziehen sich auf USB-Geräte und andere
proprietäre Schnittstellen. Wie bereits erwähnt, ist USB ein serieller Bus, und es gibt USB-Geräte,
die Aktivitätsanzeigen aufweisen.
Es gibt verschiedene weitere ungewöhnliche und rätselhafte Enthiülungsszenarien, die
angedacht und teilweise erforscht, zumindest aber ausprobiert wurden. Hierzu gehört das
Messen akustischer Effekte beim Neuladen von Kondensatoren, wenn die CPU
verschiedene Leistungsebenen abhängig von der ausgeführten Anweisung benötigt11, oder das
Vermessen einer Blackbox durch Analyse ihrer Leistungsaufnahme rnithilfe der
statistischen Analyse.12 Auch hier wurden noch keine umfassenden Forschungen zu den
Enthüllungskanälen durchgeführt (wenn man mal vom klassischen Beispiel - der Messung der
Abstrahlung elektromagnetischer Felder - absieht). Dies scheint also ein durch lohnens-
werter Ansatz zu sein. Ich wünsche Ihnen dabei recht viel Glück. :-)
11 Sham04
12 KochOO
101
6 Echos der Vergangenheit
Sechstes Kapitel. In welchem wir anhand eines skurrilen Fehlers in Ethernet
lernen, wie wichtig es ist, deutlich zu sprechen
Im vorherigen Kapitel haben wir die Grundlagen der Ethernetkonununikation angerissen.
Diese scheinbar narrensichere und dabei überraschend simple Methode ist offensichtlich
nicht in der Lage, schwerwiegende Sicherheitsprobleme zu vemrsachen - vielleicht mit
Ausnahme eines potenziellen Missbrauchs der Vertrauensbeziehung, der durch das
reguläre Versenden der Daten an alle Punkte im Netzwerk (Broadcasting) möglich wird. Dies ist
eine wohlbekannte und wohlverstandene Eigenschaft von Ethemetnetzwerken;
entsprechende Abhilfernaßnahmen sind unter anderem der Einsatz von Switches und Bridges und
die Netzwerksegmentierung.
Nichtsdestoweniger äußert sich dieser Aspekt auf völlig unvorhergesehene Alt und Weise.
Das hegt in erster Linie an der unglücklichen Wahl der Wörter (bzw. an ihrem Fehlen) in
den offiziellen Implementierungsanforderungen für Ethemettreiber. Folge ist ein
weitverbreitetes Implementiemngsproblem, das inzwischen ein solches Ausmaß erreicht hat, dass
es ein eigenes Kapitel in diesem Buch verdient hat. In diesem Kapitel erläutern wir eine
interessante Fallstudie dieser Klasse von Problernen, an denen niemand schuld sein will.
6.1 Der Turmbau zu Babel
Das Ethernetprotokoll stellt alle erforderlichen Mittel zur Verfügung, um Bytes über eine
Leitung zu verbreiten, nämlich ein rnaschinennahes Datenkodiersystern und ein Datenfor-
rnat, das einen Teil der Daten aufnehmen kann. Der Ethemet-Frarne enthält
Versandanweisungen (d. h. wer die Daten sendet und wer als Empfänger vorgesehen ist) sowie eine
kurze Beschreibung des gekapselten Datentyps. Weitere Methoden zur Fehlererkennung sind
ebenfalls vorhanden. Der gesamte Frame wird dann an alle Systeme (einschließlich des
103
6 Echos der Vergangenheit
potenziellen Empfangers) geschickt. Funktionalitätsseitig ähnelt Ethernet den
Datenkapselungssystemen über verschiedene Medien oder in verschiedenen Anwendungen wie etwa
Frame Relay, ATM (Asynchronous Transfer Mode), PPP (Point-to-Point Protocol) usw.
Die Frage lautet: Welche Daten sollten durch einen solchen Ethemet-Frame übertragen
werden? Computer verwenden Hunderte von Formaten und Anwendungsprotokollen und
können unterschiedlichste Anwendungen von Netzwerkspielen und Chat-Clients bis hin zu
wissenschaftlichen Simulationen ausfuhren. Aufgnind dessen ist es zwar möglich, aber
nicht sinnvoll, die Daten für einen entfernten Empfänger einfach in einem Ethemet-Frame
zu kapseln, denn der Empfänger würde gar nicht wissen, was er mit ihnen anfangen sollte:
Handelt es sich um eine eingehende E-Mail? Ein Bild aus dem Internet? Oder vielleicht
doch Konfigurationsdaten? Man weiß es nicht so genau. Die Unterscheidung wird zudem
durch die Tatsache erschwert, dass ein normaler Computer eine Vielzahl von Programmen
praktisch zeitgleich ablaufen lässt.
Ethernet wirft aber noch ein anderes Problem größeren Ausmaßes auf: Wie erreicht man
den Gegenüber? Das Broadcasting von Daten an alle Punkte im lokalen Netzwerk ist
einfach; was aber, wenn das andere System - der Punkt, den einer der lokalen Benutzer zu
erreichen hofft - gar nicht lokal ist? Was, wenn er über ein WAN (Wide-Area Network)
erreicht werden muss und ein ganz anderes Sicherungsschichtprotokoll verwendet? Sogar
dann, wenn wir einen Weg finden, die Daten jenem entfernten Empfänger zukommen zu
lassen, bleibt doch eine grundlegende Frage: Wie muss das Paket adressiert werden?
Ethernet verwendet ein eigenes, spezielles Adressierungsscherna. Hosts werden anhand
ihrer theoretisch eindeutigen Hardwareidentifikationsnurnmer - der MAC-Adresse (Media
Access Control, Medienzugriffssteuerung) - kontaktiert, die vom Hersteller in jeden
Ethernetadapter fest eingebrannt wird. Diese Adressen sind nur für Ethernet von
Bedeutung; für andere Netzwerktypen spielen sie keine Rolle und sind zudem weitgehend
ungeeignet, eine Hardwarekornponente zu orten, sofern Sie nicht gerade Zugriff auf die lokale
Konfiguration haben. Hierdurch entsteht ein Problem mit der Vertrauenswürdigkeit: Wer
beispielsweise hat eine Karte mit der MAC-Adresse 00:0D:56:E3:FB:E4 gekauft, und wo
befinden sich Karte und Käufer jetzt? Können Sie wirklich darauf bauen, dass Sie es mit
dem ursprünglichen Käufer und nicht mit einem Betrüger zu tun haben?
Maschinennahe Adressierungsschernata wie dieses sind für die Weiterleitung von Daten
zum Empfänger normalerweise unbrauchbar, sofern die Hardware mit der jeweiligen
MAC-Adresse nicht direkt an das physische Netzwerk des Absenders angeschlossen ist. Es
gibt keine Möglichkeit, eine physische Gerätekennung einem Punkt auf diesem Globus
direkt zuzuordnen und daraus einen Pfad zu erschließen, der für den Versand der Daten
verwendet werden sollte.
6.1.1 Das OSl-Modell
Die Protokolle der Sicherungsschicht wurden entwickelt, um die Kommunikation
zwischen lokalen Knoten bzw. - in Extremfällen - zwischen zwei festen Endpunkten einer
gemeinsamen Verbindung zu ermöglichen. Um Netzwerkverbunde zu ermöglichen und
104
6.1 Der Turmbau zu Babel
einige praktischere Anwendungen von Netzwerken praktikabel zu machen, wurde eine
hierarchische Struktur der Netzwerkprotokolle entwickelt: das OSI-Modell.
Das in Abbildung 6.1 gezeigte OSI-Modell (Open Systems Interconnection) definiert die
physische Verbindungsebene (oder Bitübertmgungsschicht) als unterste Schicht und setzt
Funktionen höherer Ebenen darauf auf. Protokolle auf Leitungsebene bilden die zweite
Schicht (Sichemngsschicht) und sind erwartungsgemäß als Möglichkeit definiert, mit
anderen lokalen Knoten zu kommunizieren, die dieselbe physische Verbindung nutzen. Diese
Protokolle übertragen übergeordnete, nicht leitungsspezifische Protokolldaten, die der
dritten Schicht des Modells - der Vennittlungsschicht - entstammen. Das IP-Protokoll
(Internet Protocol) ist das wohl bekannteste Beispiel für ein solches Protokoll.
Ethernet-Frame (Schicht 2)
^ rj) <Ü c5
3 1.1«
IP-Paket (Schicht 3)
I
TCP/UDP-Paket (Schicht 4)
Kontextkennung.
Prüfsumme
Anwendungsprotokolle
(Schicht 7)
NUTZDATEN
Abbildung 6.1 Physisches Datenlayout im OSI-Modell (Beispiel)
Die dritte Schicht vermittelt Informationen über das allgemeine Wesen des Datenverkehrs
sowie universelle Kennungen von Ursprung und Endziel der Daten. Hier kommt eine
netzwerkspezifische Adressierung zum Einsatz, die das Routing des Pakets erleichtert.
Anders als bei Protokollen der zweiten Schicht werden die Daten der dritten Schicht
unterwegs nicht gelöscht oder modifiziert und enthalten auch keine leitungsspezifischen
Merkmale wie MAC-Adressen, CSMA/CD-Zusatzdaten usw.
Die vierte Schicht stellt ein Vehikel zur Herstellung bestimmter KoHimunikationskanäle
zwischen Endpunkten bereit, beginnend und endend auf einem gegebenen System. Auf
diese Weise wird eine Möglichkeit zur gleichzeitigen Kommunikation mehrerer Typen und
Kanäle vermittelt. Keines der Protokolle der vierten Schicht muss von Zwischensystemen
verstanden werden, damit die Daten ordnungsgemäß beim Empfanger ausgehefert werden
können. Die Pakete werden nur vom endgültigen Empfänger interpretiert, der anhand inner
bestimmt, welche Anwendung die Daten erhalten soll und wie sich das Datensegment zu
den benachbarten Paketen verhält.
Die nächsten Schichten des OSI-Modells sind wahrscheinlich weniger interessant und
verschmelzen tendenziell miteinander. Die fünfte Schicht soll Verlässhchkeitsfunktionen
bereitstellen, die häufig entweder in den Protokollen der Schicht 4 wie etwa TCP/IP
(Transmission Control Protocol/Intemet Protocol) oder auf Anwendungsebene vorhanden sind. In
105
6 Echos der Vergangenheit
manchen Fällen sind sie noch nicht einmal implementiert (nämlich dann, wenn eine
zuverlässige Kormnunikation gar nicht erforderlich ist). Die sechste Schicht bietet
„Bibliotheksfunktionen" wie etwa Entkomprimiemng und Dekodierung der Daten und wird wie auch
Schicht 5 vorzugsweise über Funktionen auf der Anwendungsebene realisiert. Die siebte
Schicht schließlich ist die Anwendungsschicht. Hier werden die Daten in ein spezifisches
Format übertragen.
Beachten Sie, dass die oberen Schichten des OSI-Modells unabhängig von den unteren
Schichten sind, denn sie beziehen sich auf die übertragenen Daten. Zum betreffenden
Zeitpunkt lassen sich die unteren Schichten nach und nach entfernen, ohne dass die Daten oder
die Fähigkeit, sie weiterzuverarbeiten, verloren gehen. Die zweite Schicht wird bei jedem
Zwischensystem verworfen und neu erstellt, die dritte lässt sich entfernen, sobald die
Daten beim Zielsystem angekommen sind. Schicht 4 wird vor dem Übergeben der Daten an
die Clientanwendung gelöscht.
Die Vermittlungsschicht (Schicht 3) bleibt normalerweise vollkommen unabhängig vom
darunter vorhandenen Sicherungsschichtprotokoll; sie enthält vollständige Angaben zu
Absender und Empfänger, einen Mechanismus für den Integritätsschutz (Prüfsurnmenbil-
dung) und Informationen zur Größe der übertragenen Nutzdaten. Dies ist genau das, was
IPtut.
Eine wichtige Auswirkung dieser Konstruktion besteht darin, dass alle überflüssigen
Daten, die während des Transports in Schicht 2 an das Paket angehängt werden, die Alt und
Weise, wie der Adressat die IP-Angaben interpretiert, nicht beeinträchtigen.
6.2 Der fehlende Satz
Im vorigen Kapitel erwähnte ich bei der Beschreibung von Ethernet eine interessante
Anforderung, die sich aus der Notwendigkeit ergibt, den Jam-Code im Falle einer Kollision
zuverlässig im Netzwerk verschicken zu können: die Mindestlänge eines Ethemet-Frames.
Diese Anforderung wurde auch Bestandteil der offiziellen Kapselungsspezifikationen für
IP über Ethernet (z. B. RFC1042, „A Standard for the Transit of Internet Protocol Da-
tagrarns Over IEEE 802 Networks"1), die vorsehen, dass Frames, die die erforderliche
Mindestlänge unterschreiten, aufgefüllt werden. Dieses Auffüllen (auch Padding genannt)
kann nach Bedarf aus gefühlt werden und wirkt sich nicht auf die in der IP-Schicht
übertragenen Daten aus, da sich die in den IP-Headem angegebene Paketlänge nicht ändert.
Insofern werden die Fülldaten vom Empfänger nicht als Teil der Daten übergeordneter OSI-
Schichten interpretiert.
Es gibt allerdings ein kleines Problern: Zwar erfordert der RFC das Auffüllen der Daten
mit Nullen, er gibt aber nicht an, wer die Fülldaten richten oder einfügen und auf welcher
Softwareebene das Auffüllen erfolgen soll. Die Notwendigkeit, dass die Fülldaten einen
Post88
106
6.2 Der fehlende Satz
bestimmten Wert haben müssen, ist auch eine Anforderung, die ihrem Wesen nach
ziemlich willkürlich ist. Insofern wird ihr keine Aufmerksamkeit zuteil: Hätten sie andere
Werte, dann würde sich das nicht auf die Funktionsweise des Protokolls auswirken, weil die
überzähligen Daten beim Empfang einfach verworfen werden.
Um die Verwirrung noch zu steigern, bieten viele Netzwerkkalten eine so genannte Auto-
padding-Funktion, die vom Betriebssystem an die Hardware gesendete Pakete ergänzt,
wenn diese zu kurz geraten sind; die Funktion prüft aber nicht den eigentlichen Inhalt der
Fiüldaten, wenn das erforderliche Auffüllen bereits softwareseitig erfolgt ist. Dies hat auf-
seiten einiger Entwickler zu viel Konfusion gefühlt, denn diese entschieden, dass die
Größenanforderung zu beachten sei, und änderten die Größe eines Pakets in der Software,
indem sie einfach die deklarierte Länge erweiterten. Häufig bemerkten sie nicht, dass die
Daten zwischen dem Ende des IP-Pakets und dem des aufgefüllten Frames weder vom
Treiber noch vom Betriebssystem oder der Hardware initialisiert (d. h. auf 0 gesetzt) wurden.
Dieser Umstand blieb jahrelang weitgehend unbemerkt, obwohl er eine knifflige Frage
aufwarf, die Netzwerkhacker regelmäßig in den Wahnsinn trieb: Die Pakete, die sie aus
lokalen Systemen abriefen, enthielten an ihrern Ende häufig eine Menge irrelevanten
Datenmülls wie etwa Fragmente von Webseiteninhalten oder sogar Chatprotokollen. Die
Hacker machten die Ernpfängerseite dafür verantwortlich - Hardware, Anwendungen zur
Datenverkehrsanalyse oder Bibliotheken seien fehlerhaft -, aber schließlich gaben sie es auf,
nach der Ursache zu suchen, denn die Relevanz dieses Sachverhaltes war vemachlässigbar.
Und so erhielt das Problern niemals die Aufmerksamkeit, die es eigentlich verdient hätte.
Zumindest nicht, bis Ofir Arkin und Josh Anderson von @Stake sich die Sache genauer
ansahen. Ihr im Jahr 2003 erschienener Beitag „EtherLeak: Ethernet Frame Padding
Information Leaks"2 untersucht diesen Aspekt im Detail. Die Autoren stellten fest, dass bei
einer großen Zahl mai'ktfuhrender Systeme - z. B. Linux, NetBSD, Microsoft Windows
und anderen Plattformen - am Ende eines neu erstellten Ethemet-Frames keine
Initialisierung des Speichers durchgeführt wird, nachdem seine Länge geändert wurde. Einigen
Implementierungen gelingt es noch nicht einmal, die Größe des Frames korrekt abzuändern
oder eine passende Anzahl von Bytes an die Hardwareschicht zu senden.
Aufgrund dessen wird das IP-Paket mit den Daten aufgefüllt, die gerade im betreffenden
Bereich des Systemspeichers vorhanden sind und zuvor eigentlich für andere Zwecke dort
abgelegt wurden. Der Speicher kann also je nach Treiber oder Betiiebssystem entweder
einen Teil eines zuvor gesendeten Pakets oder ein anderes Fragment des Kernel-Speichers
enthalten. Und an dieser Stelle entsteht ein faszinierendes Datenenthiülungsszenario: Ein
Angreifer sendet unscheinbare und zulässige Daten an das Opfer und erhält mit etwas
Glück potenziell sensible Daten zurück. Der Umfang der preisgegebenen Daten ist in der
Regel ausreichend, um Besorgnis auszulösen.
Die Schwachstelle beschränkt sich auf ein einzelnes Ethemetnetzwerk und ist insofern
örtlich relativ beschränkt und in einer typischen LAN-Umgebung unkritisch. Es bleibt aber
2 Ai-ki03
6 Echos der Vergangenheit
ein Problem von einiger Bedeutung, und auch wenn jedes lokale Netzwerk teilweise
anfällig flu- Schnüffeleien ist, so gestattet dieses Problern doch einige Schlussfolgerungen, die
über den Rahmen des Offensichtlichen hinausgehen:
■ Bei Systemen, die für Ethernet-Frames dynamische Puffer verwenden (z. B. Linux),
können in den Fülldaten nicht nur Teile des vorherigen Frames auftauchen, sondern
auch Fragmente anderer Speichelinhalte, z. B. angezeigte oder bearbeitete Dokumente,
URLs, Passwörter oder andere sensible Daten. In diesem Fall kann ein sorgfältiger
Beobachter unter Umständen auf Informationen zugreifen, die sich auf andere Weise nicht
im Netzwerk erschleichen lassen.
■ Bei Systemen, die statische Puffer nur zur Vorbereitung der Ethernet-Frames
verwenden, lässt sich das Problem nutzen, um in Systeme einzudringen, die gegen Sniffer
geschützt sind (z. B. Switches). Auf diese Weise kann der Angreifer Daten einer anderen
Verbindung abfangen.
■ Bei bestimmten statischen Pufferkonstruktionen werden unter Urnständen Daten eines
anderen Segments auf einem Multihoming-System offengelegt, dessen eine
Schnittstelle an ein allgemeines LAN angeschlossen ist, während die andere mit einem
eingeschränkten Netzwerk verbunden ist. Auf diese Weise gelangen Teile möglicherweise
geheimer Daten in die öffentliche Infrastruktur.
Die Autoren des Dokuments haben verschiedene Open-Source-Implementienmgen
umfassend überprüft und festgestellt, dass eine Vielzahl von Ansätzen und Pufferentwürfen
eingesetzt wird und dass es kein vorherrschendes Reservierungs- und Verwendungskonzept
für Puffer gibt. Und was schließen sie daraus? Dass eine typische Netzwerkumgebung
früher oder später von allen drei Problerntypen betroffen sein wird.
6.3 Denkanstöße
Das hier beschriebene Problem ist für Ethernet und für das Netzdesign nicht
ungewöhnlich: Solche Fälle treten meistens auf wenn eine ansonsten sehr detaillierte
Implementierungsdokumentation einen erforderlichen Schritt auslässt oder nur ungenau beschreibt.
Viele Entwickler übersehen das Problem bei der Implementierung des Standards
schlichtweg. Wären rnehr derartig schwammige Anweisungen vorhanden, dann wäre ein
Entwickler wahrscheinlich gezwungen, über das Problem nachzudenken; stattdessen implementiert
er einfach Schiittanleitungen, weswegen er weitaus anfälliger dafür ist, einen Fehler zu
begehen. „Narrensichere" Anweisungen, die beschreiben, wie bestimmte Aufgaben
durchzuführen sind - und nicht, welche Ziele erreicht werden sollen -, gehen oft nach hinten los.
Wir werden - wenn auch in einem etwas anderem Kontext - in Teil ZU dieses Buches noch
einmal auf das Problem protokollspezifischer Datenlecks zurückkommen.
108
7 Sicherheit in geswitchten
Netzwerken
Siebtes Kapitel. In welchem wir auch erfahren, warum Ethernet-LANs nie
richtig in Ordnung gebracht werden können - egal, wie sehr man es auch
probiert
Ememetnetzwerke bieten keine einfache und universelle Möglichkeit, die Integrität oder
Vertraulichkeit der übertragenen Daten zu gewählleisten, und sind auch nicht so
konstruiert, dass sie bösartigen, gezielt eingespeisten Datenverkehr abwehren. Ethernet ist
lediglich Mittel zu dem Zweck, eine Anzahl lokaler, mutmaßhch vertrauenswürdiger
Systeme aneinander anzubinden.
Ein solches Maß an Vertrauen ist in der Planungsstufe wahrscheinlich angemessen und für
Peer-Systeme im selben Netzwerk (und meist auch am selben physischen Standort)
theoretisch ausreichend. Aber wie sagt das alte Sprichwort: Theoretisch gibt es keinen
Unterschied zwischen Theorie und Praxis. In der Praxis aber sieht das ganz anders aus.
Wie sich zeigt, ist eine vollständige Kontrolle lokaler Netzwerke schwierig, und sie
müssen vor ihren eigenen Benutzern ebenso geschützt werden wie vor externen Bedrohungen.
In jedem expandierenden LAN wird - egal ob intern oder von außen - früher oder später
ein Schurke auftauchen, der einen Fehler an einem der Systeme auszunutzen versuchen
wird. Das Auftreten einer solchen Schwachstelle ist nur eine Frage der Zeit - das muss
jeder Netzwerkadministrator irgendwann einmal erfahren.
Praktische Netzwerksicherheit geht weit über das Hochziehen von
Verteidigungseinrichtungen am Rande des Netzwerks hinaus: Es ist die Kunst, sicherheitsrelevante Vorfälle
erkennen, Angriffspunkte ininiinieren und die Risiken auf allen Ebenen bewerten und
verstehen zu können. Welches Problem stellt sich? Eine ungeschützte Ememetinfrastruktur ist
anfällig für alle Arten von Datenklau, Überfällen und Fällen von Identitätsübemahme:
Wenn ein Angreifer oder ein zulässiger, aber böswilliger Benutzer nach Durchbrechen der
109
7 Sicherheit in geswitchten Netzwerken
einzigen Verteidigungslinie ein einzelnes System im Netzwerk in seine Gewalt bringen
kann, dann kann er die gesamte Infrastruktur minieren und mit minimalem Aufwand auf
bestimmte Ressourcen und Dienste zugreifen oder diese übernehmen.
7.1 Ein wenig Theorie
Ethernet-Switches könnten eine Lösung für dieses Problem darstellen. Es handelt sich
dabei um eine Gattung cleverer Geräte, die dafür sorgen, dass Unicast-Daten in der zweiten
OSI-Schicht an den passenden Port statt - im Broadcasting-Verfahren - an alle Knoten
weitergeleitet werden (wie es bei Hubs oder Direktverbindungen der Fall ist). Viele Leute
glauben, dass Switches die sicherheitsspezifischen Probleme lösen könnten, die mit der
Fähigkeit in Verbindung stehen, von einem System aus Daten Dritter zu beobachten oder
zu rauben; dies stimmt aber nicht. Die Lösung ist nicht so einfach, und die Verwirrung, die
diese Fehlannahme auslöst, verursacht oft so viel Schaden, dass die Vorteile der
Verwendung von Switches rnehr als ausgeglichen werden. Aber wir wollen uns zunächst den
wichtigen Dingen zuwenden. Um die Bedrohung zu verstehen, müssen wir erst einmal
begreifen, wie Ethernet-Switches wirklich funktionieren.
7.1.1 Adressauflösung und Switching
Die gesamte Kommunikation innerhalb eines lokalen Netzwerks basiert auf dem in
Kapitel 5 beschriebenen Adressierungsscherna. Eindeutige Kennungen, die
Endpunktkomponenten von den Ffardwareherstellem zugewiesen werden, dienen zur Kontaktierung von
Systemen und zur Auslieferung von Daten-Frames. Allerdings sind das Internet und die
Mehrzahl modemer privater Netzwerke um eine flexiblere und universellere Protokollsuite
hemm aufgebaut und verwenden ein Adressierungssystern in der dritten OSI-Schicht: die
so genannten IP-Adressen. Die IP-Adresse wird in erster Linie zur Lenkung der Daten über
die ganze Welt hin zu einem passenden lokalen Netzwerk verwendet. Hierbei kommt eine
Hierarchie von Routing-Tabellen auf Mittels Systemen zum Einsatz, die auf dem gesamten
Globus verteilt sind: Erst dann, wenn das Paket den Rand des Zielnetzwerks erreicht, muss
der endgültige Empfänger auf althergebrachte Weise - durch Nachschlagen der
Hardwareadresse - angesprochen werden.
Wenn ein System im lokalen Netzwerk beschließt, einen anderen lokalen Punkt über eine
bestimmte IP-Adresse anzusprechen, dann bestimmt es mithilfe eines speziellen Adress-
auflösungsprotokolls - des ARP-Protokolls (Address Resolution Protocol) - die
Verknüpfung zwischen der physischen Adresse einer Netzwerkkalte (der Basis für
Adressierungssysteme im lokalen Netzwerk) und der universellen Systemkennung für das Internet,
nämlich der IP-Adresse.1 Der Absender sendet dazu eine ARP-Abfrage an eine spezielle
Broadcast-Adresse im lokalen Netzwerk. Diese reservierte Adresse ist für alle Systeme im
Pluin82
110
7.1 Ein wenig Theorie
Netzwerk garantiert erreichbar und funktionsfähig - unabhängig davon, welche
Hardwareadresse den einzelnen Knoten zugewiesen ist. In diesem Szenario wird erwartet, dass das
System, welches annimmt, das Recht zu Verwendung der in der Abfrage angegebenen IP-
Adresse zu haben, eine Antwort an den Absender schickt und darin seine Hardwareadresse
angibt; alle anderen Punkte sollten das empfangene ARP-Paket stillschweigend ignorieren.
Nach diesem Datenaustausch kennen die beiden beteiligten Parteien die IP- und MAC-
Adressen des jeweils anderen. Sie sollten die Ergebnisse nun in einem speziellen Puffer
ablegen, damit nicht jedes Mal, wenn ein neuer Datenaustausch stattfinden soll, der
gesamte Abfragevorgang aufs Neue erfolgen muss, und dann mit der eigentlichen
Kommunikation fortfahren; im Gegensatz dazu tauschen sie jedoch einige Pakete basierend auf der IP-
Adressierung aus. Dieser Aufbau ist ein wunderbares Beispiel althergebrachter
Gutgläubigkeit und Liebenswürdigkeit. Was aber kann man nun tun, um die Gefährdung durch
einen bösartigen Zuschauer im selben Netzwerk, der jemand anderes zu sein vorgibt, zu
verringern? Und wie verhindert man, dass neugierige Benutzer oder üble Gegenspieler zu weit
gehen? Die Hersteller von Ethemethardware haben den Netzwerkadministratoren einen
Bärendienst erwiesen, indem sie eine Änderung der MAC-Adresse bei den meisten
gängigen Geräten zum Kinderspiel gemacht haben - wohl um eine Neuprograrnrnierang für den
Fall zu ermöglichen, dass eines Tages doch einmal eine Chaige Netzwerkkalten das Werk
verlässt, deren Adressen bereits vergeben waren.
Auch in diesem Fall scheinen Switches das Problem zu lösen. Das Grundkonzept eines
intelligenten Switchs basiert darauf, den MAC-Adresscache auf der Ebene eines zwischen-
geschalteten Netzwerkgeräts zu duplizieren. Ein Switch ist mit zahlreichen Ethemetports
ausgestattet, an die jeweils ein System (oder manchmal auch eine Gruppe von Systemen)
angeschlossen ist. Statt aber wie ein tumber Repeater zu arbeiten, der alle an einem Port
empfangenen Daten über alle anderen Ports weiterleitet (wie Ethemet-Hubs es tun),
versuchen Switches, sich die MAC-Adressen der Systeme zu merken, die an die einzelnen Ports
angeschlossen sind, und erstellen auf diese Weise MAC-Port-Zuordnungen (im Gegensatz
zu den MAC-IP-Verknüpfungen, die von Endpunktsystemen erzeugt werden).
Die Daten, die im CAM (Content Addressable Memory, Assoziativspeicher)2 abgelegt sind,
bestimmen, wohin die eingehenden Pakete weitergeleitet werden. Wenn Daten ankommen,
versucht der Switch zu ermitteln, an welchem Port der Adressat hängt. Sobald diese
Angabe verfügbar ist, wird das Paket direkt an den betreffenden Port (und nur dorthin)
weitergeleitet; andere Ports bekommen die Daten nicht zu sehen, was auch die Leistung des
Netzwerks optimiert.
Wie der Name bereits sagt, lässt sich dieser Speichertyp direkt von dem Parameter adressieren, dessen
Wert Sie bestimmen wollen; hierdurch wild Zeit eingespart, die normalerweise fiir die Suche nach dem
Parameter benötigt würde. Ein einfaches Beispiel für einen Assoziativspeicher ist ein
Bibliothekskatalog: Sie müssen nicht alle Bücher in der Bibliothek durchgehen, um ein bestimmtes zu finden, sondern
anhand der Frage, was Sie suchen (ein Inforcnationseleinent zum „Inhalt"), bestimmen, wo Sie suchen
müssen.
111
7 Sicherheit in geswitchten Netzwerken
7.1.2 Virtuelle Netzwerke und Datenverkehrsmanagement
Einige fortgeschrittenere Switch-Lösungen bieten zusätzliche Funktionen, die die
Verwaltung umfangieicher Netzwerke vereinfachen und Kosten und Dauer der Inbetriebnahrne
verringern sollen. Diese Funktionen scheinen auch die Netzwerksicherheit zu erhöhen. Im
Einzelnen geht es um folgendes:
■ VLAN (Virtual LAN, virtuelles LAN). Dies ist ein generischer Name für eine Reihe
von Methoden, mit deren Hilfe ein Pool mit Ports eines physischen Gerätes in eine
Anzahl logischer Netzwerke unterteilt wird; hierdurch werden Daten für eine Portgruppe
von anderen Daten getrennt, und es wird ein Übergreifen von Daten zwischen diesen
beiden Portgruppen auf der Switch-Ebene verhindert. (Dieses System wird meistens
unter Verwendung des Standaids IEEE 802. IQ implementiert; siehe auch den nächsten
Punkt dieser Aufzählung.) Die Implementienmg eines VLAN ist eine Alt Aufteilung
eines einzelnen Switchs in mehrere vollkommen unabhängige Geräte, nur ist die
VLAN-Lösung weitaus flexibler und kostengünstiger, denn Sie können Ihr Netzwerk
nach Beheben uniformen und physische Ressourcen behebig neu verteilen. VLANs
lösten bei Ihrer Einführung allerorten viel Begeisterung unter den Netzwerktechnikem
aus, denn sie verhießen eine einfache und doch leistungsfähige Lösung zur Erstellung
separater Netzwerke an einem einzelnen Gerät oder zur Trennung der Server von den
Workstations - ohne dass man für jede Gruppe einen dedizierten Switch hätte kaufen
müssen.
■ Trunking (Bündelung). Das Trunking stellt eine natürliche Erweiterung des VLAN-
Grundkonzepts dar. Trunks tunneln mithilfe des Frame-Taggings nach IEEE 802.IQ
mehrere logische VLAN-Verbindungen über dieselbe Leitung; auf diese Weise ist der
Benutzer nicht gezwungen, getrennte Leitungen für jedes VLAN zu verlegen, das zwei
Geräte miteinander verbindet (Abbildung 7.1). Pakete einiger oder aller VLANs am
Quell-Switch werden mit einer ausreichenden Anzahl an Attributen oder Tags
versehen, um dem Header des Ethemet-Frames das sendende VLAN entnehmen zu können,
dann über eine konventionelle Verbindung zum anderen Endpunkt getunnelt, dekodiert
und beim Empfönger schließlich wieder auf die einzelnen VLANs verteilt. Durch diese
Vorgehensweise wird zwar die Leistung im Vergleich zur Verwendung separater Kabel
pro Subnetz verringert, sie ist aber schlicht und einfach praktischer. Trunking-Systeme
arbeiten häufig auch mit DTP (Dynamic TrunJäng Protocol). Hierbei handelt es sich
um ein Protokoll zur automatischen Konfiguration von Trunks, welches Geräten das
selbstständige Ermitteln und Austauschen gekapselter Frames anderer Trunking-fähiger
Geräte ermöglicht, ohne dass spezielle Handlungen seitens des Administrators
erforderlich wären.
112
7.1 Ein wenig Theorie
802.1Q-Trunk
Pakete aus beiden
VLANs,
gekennzeichnet mit Tags
Abbildung 7.1 VLAN-Trunking in Aktion. Die VLANs erstrecken sich über zwei Geräte. Geräte aller
Instanzen der VLANs 1 und 2 können jeweils miteinander kommunizieren, ein „Übersprechen" von
VLAN 1 in VLAN 2 und umgekehrt ist jedoch nicht möglich.
STP (Spanning Tree Protocol). Das STP-Rotokoll gestattet Ihnen die Erstellung
redundanter Netzwerkstrukturen, in denen Switches an mehreren Standorten aus Gründen
der Fehlertoleranz miteinander verbunden sind. Normalerweise könnten Broadcast-
Daten und andere Pakete bei einer solchen Konfiguration in einer Endlosschleife
kreisen, weil Daten, die an einer Schnittstelle empfangen und an einer anderen wieder
ausgegeben werden, letztendlich wieder beim ursprünglichen Absender landen
(Abbildung 7.2, links). Dies würde auch die Netzwerkleistung erheblich beeinträchtigen.
Wenn man ein Netzwerk plant, ist es oft schwierig, das versehentliche Erstellen solcher
Broadcast-Schleifen zu vermeiden. Auch ist es manchmal wünschenswert,
Architekturen mit potenziellen Schleifen zu erstellen, bei denen ein Switch an zwei oder rnehr
andere Switches angeschlossen ist, denn ein solches Netzdesign ist wesentlich fehlertole-
ranter, und ein einzelnes Gerät oder eine Leitungsverbindung lassen sich
herausnehmen, ohne das gesamte Netzwerk in zwei getrennte „Inseln" aufzuspalten.
Damit sich Schleifen bilden und andere komplexe Architekturen erstellen lassen, ohne
dass es zu schwer-wiegenden Leistungseinbußen kommt, implementiert STP eine Aus-
wahlmethode, um einen Switch als „Stamrnknoten" zu selektieren. Auf der Basis der
Ergebnisse des Auswahlprozesses wird beginnend bei diesem Stammknoten eine
baumförrnige Datenverteilungshierarchie erstellt; Verbindungen, die eine umgekehrte
Ausbreitung des Broadcast-Datenverkehrs verursachen könnten, werden
vorübergehend deaktiviert (Abbildung 7.2, rechts). Sie können diese einfache, sich selbst
organisierende Hierarchie schnell anpassen, wenn einer der Knoten ausfällt, und eine Leitung
reaktivieren, die zuvor vielleicht unnötig schien.
113
7 Sicherheit in geswitchten Netzwerken
Redundante (fehlertolerante)
Switch-Architektur
Redundante Architektur
mit STP-Wahl
Stamm'
knoten
Abbildung 7.2 Paketsturmproblem und STP-Auswahlsystem: Auf der linken Seite ist ein
fehlertolerantes Netzwerk ohne STP abgebildet, bei dem einige Pakete (praktisch) für immer zwischen den
Switches kreisen werden. Auf der rechten Seite sehen wir dasselbe Netzwerk, in dem jedoch eines der
Geräte durch STP automatisch als Stammknoten ausgewählt wurde und dessen Topologie die
Beseitigung von Schleifen gestattet. Fällt eine Verbindung aus, dann lässt sich das Netzwerk
umkonfigurieren, um einen korrekten Betrieb zu gewährleisten.
7.2 Angriff auf die Architektur
Die bislang beschriebenen Mechanismen wurden für ein Netzwerk, das keinerlei
Sicherheitsfunktionen bietet, entwickelt, um die elementaren Komponenten zu optimieren und
dabei gleichzeitig eine hohe Leistung zu gewährleisten.3 Während gewisse, häufig
auftretende, wohlbekannte und leicht zu verhindernde Angriffe wie beispielsweise das MAC-
Spoofing (bei dem ein Angreifer eine ARP-Meldung manipuliert und die Identität eines
Geräts mit einer bestimmten IP-Adresse annimmt) weithin als Nachteil der LAN-
Technologje anerkannt und mit entsprechend konfigurierten Switches relativ einfach zu
umgehen sind, gibt es andere gravierende Mängel, die weniger trivial und auch nicht ganz
so einfach abzustellen sind. Es ist nicht immer nachvollziehbar, dass Lösungen, die ge-
meinhin als der Sicherheit förderlich angesehen werden, eigentlich gar keine Hilfe
darstellen.
7.2.1 CAM-Überlauf und erlauschte Daten
Einer der Aufsehen enegenderen Gründe dafür, Switches nicht als Sicherheitsfunktion in
Betracht zu ziehen, ist der CAM-Überlauf. Der CAM, der die MAC-Port-Verknüpfungen
speichert, hat eine feste und begrenzte Größe und im Allgemeinen einen nichtselektiven
Aufbau. Wenn Angaben zu einem System im CAM nicht aufgefunden werden können, hat
der Switch nur noch eine Möglichkeit, das Paket auszuliefern: Er rnuss in den Hub-Modus
Sene02
114
7.2 Angriff auf die Architektur
wechseln und das Paket als Broadcast an alle Systeme weiterleiten - in der Hoffnung, dass
der Empfänger die betreffenden Daten als an ihn gerichtet erkennt und dass andere
Systeme so nett sind, sie vollständig zu ignorieren. Insofern kann ein sorgfältig arbeitender
Angreifer eine Taktik zur Erzeugung einer großen Zahl gefälschter ARP-Abfragen und
-Antworten oder einiger anderer Pakete verwenden, die die Identitäten einer Vielzahl
anderer Netzwerkgeräte nachahmen - und so den CAM des Switchs bis zum Rand füllen.
Sofern dies gelingt, hat der Angriff die Netzwerksicherheit verringert, indem er das
intelligente Routing von Frames auf dem Switch außer Gefecht gesetzt und den Switch
gezwungen hat, alle Daten wieder als Broadcasts zu senden. Nun kann der Angieifer alle Kornmu-
nikationsvorgänge überprüfen - ganz so, als ob im Netzwerk überhaupt kein Switch
vorhanden wäre. Er kann dies sogar tun, ohne die Identität des Empfängers anzunehmen oder
den Netzwerkbetiieb spürbar zu stören; die Wahrscheinlichkeit, dass das Opfer überhaupt
nichts von dem Angriff bemerkt, ist also eher hoch. Dies ist ein strukturelles Problern: Es
hegt nicht in einem Mangel bei der vorgesehenen Verwendung dieser Geräte, sondern in
einer ebenso weitverbreiteten wie schwerwiegenden Falschauffassung dessen begründet,
was Switches eigentlich tun. Und verlassen Sie sich drauf: Es ist in einer gewöhnlichen
Umgebung praktisch unmöglich, dieses Problem umfassend zu lösen. Einige Switches
implementieren Grenzwerte für Ports und zeitliche Abläufe, um solche Angriffe zu
verhindern, aber diese sind nicht hundertprozentig effizient.
7.2.2 Weitere Angriffsszenarien: DTP, STP und Trunks
Andere Probleme sind in der Regel einfacher zu vermeiden und für das Opfer leichter
festzustellen, veranschaulichen aber trotzdem die ethemetspezifischen Sicherheitsfragen. So
stellt etwa ein Angriff auf den bereits erwähnten DTP-Mechanismus eine interessante
Möglichkeit dar. Die DTP-Autonegotiation (automatische Aushandlung von Übertra-
gungsparametem) ist häufig für alle Ports eines Geräts aktiviert, um die Einrichtung zu
vereinfachen. Das Problem besteht nun darin, dass der gewiefte Angieifer vorgeben kann,
ein Trunking-fähiger Switch (statt nur eine einfache Workstation oder ein profaner Server)
zu sein. Sobald nun der echte Switch das vermeintlich freundlich gesinnte Gerät erkennt,
erhält der Angieifer 802. IQ-Frames mit Tags, die Datenverkehr für andere von dem
Switch bediente VLANs erhalten; auf diese Weise kann der Ganove Daten abhören oder
bösartigen Code in Netzwerke einspeisen, mit denen er eigentlich gar nicht kommunizieren
dürfte. In vielen Netzwerken, in denen derselbe Switch sowohl geschützte
(„entmilitarisierte") Netzwerke als auch die normale LAN-Infrastruktur des Unternehmens verwaltet,
lassen sich durch einen solchen Angriff sehr aussagekräftige Daten in Besitz bringen,
indem man Systeme in einem der Netzwerke dazu veranlasst, mit dem anderen zu interagje-
ren bzw. darin zu schnüffeln.
Sie können dieses DTP-Problern bei einigen Geräten lösen, indem Sie die
Standardkonfiguration abändern und die dedizierten, Trunking-fähigen Ports des Switchs explizit
definieren. Allerdings ist das Problem damit noch nicht vollständig beseitigt: Unser anderer
kleiner Helfer - STP - lässt sich auf ähnliche Weise missbrauchen, denn damit kann sich
ein Angieifer selbst als Stammknoten auswählen und einen Gutteil der Daten im Netzwerk
115
7 Sicherheit in geswitchten Netzwerken
abfangen. In einer typischen Filmenumgebung ist das Deaktivieren von STP unter
Umständen noch viel problematischer.
Es gibt aber noch ein weiteres Problem, wenn ein Trunk in einem nichtdedizierten VLAN
seinen Anfang oder sein Ende nimmt (d. h. der Port, der für das Trunking verwendet wird,
befindet sich in einem VLAN, das auch von Workstations benutzt wird). Durch Einspeisen
bereits mit Tags versehener Frames lassen sich Daten auch in einen Trunk injizieren. Dies
ist zweifelsohne ein Konfigurationsproblem, welches zudem häufig übersehen wird, da
viele Techniker annehmen, dass die Methode zur Implementiemng von Trunks weitaus
fortgeschrittener und mächtiger ist, als dies tatsächlich der Fall ist.
7.3 Vorbeugung
Diese Probleme sind - insbesondere in einem Netzwerk, das nicht während aller Ent-
wicklungs- und Expansionsphasen umfassend und genauestens überwacht wurde - häufig
schwer zu lösen. Zwar bieten bestimmte High-End-Geräte erweiterte
Sicherheitsfunktionen, um potenziellen Angriffsvektoren zu begegnen und einige der Risiken zu lindem oder
ganz zu beseitigen, aber sicherheitstechnische Gesichtspunkte spielten bei der Entwicklung
von Ethernetnetzwerken eine gelinge Rolle. Dies gilt auch für die intelligenten Geräte, die
diese Netzwerke verwalten sollen. Ein Angreifer kann einige dieser Funktionen (oder alle)
ausschalten und das Netzwerksicherheitsmodell auf den am wenigsten wünschenswerten
Zustand zurückfahren.
Zwar gibt es Memoden und rigide Praktiken, mit denen man ein lokales Ethemetnetzweik
absichern kann, aber mal ganz abgesehen von der schieren Anzahl der Vektoren machen es
die Komplexität dieses Vorgangs und die zusätzlichen finanziellen Aufwendungen und
Leistungseinbußen, die er mit sich bringt, offenbar, dass diese Technologie keinesfalls im
Hinblick auf praktische Netzwerksicherheit entwickelt wurde.
7.4 Denkanstöße
Als Ethernet entwickelt wurde, war es nicht abwegig, Sicherheitsaspekte bei den
strukturellen Entscheidungen außen vor zu lassen und die Last der Netzwerkabsicherung höheren
Aichitektuien, Verschlüsselungslösungen usw. zu übertragen. Im Laufe der Zeit jedoch hat
diese anfängliche Entscheidung immer stärker zu den Waitungsgesamtkosten für Ethemet-
netzwerke und zur Schwierigkeit beigetragen, diese einigermaßen angriffssicher zu
machen, ohne die Funktionalität umfassend einzuschränken.
Das Problem ist auch nicht auf Ethernet beschränkt. Viele Netzwerke, die als
vertrauenswürdig auf der Basis von Kriterien des physischen Zugangs bzw. des Hardwarezugriffs
entwickelt wurden - beispielsweise auch die Telefonsysteme dieser Welt - sind vom
Wesen her und auf nicht beeinflussbare Weise internen Risiken ausgesetzt, und es gibt nur
116
7.4 Denkanstöße
wenige oder aber gar keine Möglichkeiten, diese Angriffsflächen klein zu halten und die
Kollateralschäden, die die Übernahme nur eines einzigen Systems im Netzwerk mit sich
bringt, zu kontrollieren. In dem Maße, wie die Größe von Netzwerken zunimmt und die
Anzahl der Austauschmöglichkeiten wächst, nähert sich die Wahrscheinlichkeit, dass ein
System von einem Angreifer übernommen wird oder auf der Ebene des physischen oder
des Femzugriffs unzureichend geschützt ist, unerbittlich einem Wert von 100 Prozent.
Zwar ist es traditionell erforderlich, auf den Backbone (statt auf eine Endbenutzerstation)
zuzugieifen, um das System zu übernehmen (weswegen sich die Situation im Vergleich zu
Ethernet etwas anders daisteilt), aber heutzutage schwächen VoIP-Systeme (Voice over IP)
diese Schwierigkeit ab, denn sie gestatten häufig kinderleichtes Spoofing und andere
Tricks, weil sie dem Endbenutzer einfach zu viel Vertrauen entgegenbringen.
117
8 Wir gegen die
Achtes Kapitel. In welchem die Frage behandelt wird, was innerhalb der
lokalen Grenzen „unseres" Netzwerks passieren kann - und das ist eine ganze
Menge
LAN-Strukturen wie Token Ring oder das allgegenwärtige Ethernet wurden in der
Annahme entwickelt, dass es nicht notwendig sei, die Sicherheit auf der Ebene (bzw. in der
Schicht) der zur Übertragung der eigentlichen Daten verwendeten Technologie zu
gewählleisten. In der Fnihzeit der Computer wurde von Benutzem, die ein Netzwerk gemeinsam
nutzten, Fairplay erwartet.
Auch wenn man nur aus diesem Grund annehmen könnte, dass die Entwickler von
Ethernet einfach keinen Grund gesehen haben, richtige Sicherheitsfunktionen in der
Spezifikation zu implementieren, so muss man ihnen doch ihren ungerechtfertigten Optimismus
vorwerfen und kritisieren, dass sie das Unvermeidliche nicht vorhergesehen haben.
Ethernet lässt einfach keinen Raum zur einfachen Implementierung von Methoden, mit denen
sich Integrität und Vertraulichkeitsgrade in den übergeordneten OSI-Schichten, Geräten
und Anwendungen überprüfen lassen und die eine Verifizierung des Absenders erlauben.
Folgeprotokolle und Konnnunikationssysteme versuchten, den Datenschutz und ein
Mindestmaß an Unbestechlichkeit zumindest teilweise nachzuieichen, scheiterten aber an dem
Punkt, an dem man erkannte, dass die Implementierung einer angemessenen
Sicherheitsstufe nicht möglich sei, ohne dass man die SicherungsSchicht von Grund auf neu
entwickelt. Die einzige andere Möglichkeit, die blieb, bestand darin, rechentechnisch
aufwändige und komplexe kryptografische Vehikel auf das System aufzusetzen, deren schiere
Komplexität die Anzahl der entdeckten Sicherheitslücken Jahr für Jahr vergrößert.
Diese bedauerliche und später halbwegs beabsichtigte Tendenz hat im Endeffekt zur
Erstellung von Netzwerkmechanismen geführt, die zwar alle ganz gut funktionieren und
halbwegs kostengünstig sind, aber keinesfalls geeignet sind, auch nur einigermaßen
sensible Daten zu verwalten, wenn ein feindlich gesinntes Individuum anwesend ist (und in ei-
119
8 Wir gegen die
nein LAN sind praktisch alle ausgetauschten Benutzerdaten sensibel). Lösungen, die sich
dieser Probleme anzunehmen versuchen - z. B. VPN-Amvendungen (Virtual Private
Network, virtuelles privates Netzwerk), eine verschlüsselte Kapselung für einige wenige der
verbreitetsten Webprotokolle, fortschrittliche Switches usw. -, sind in der Regel weitaus
teurer und vertrackter, als es notwendig gewesen wäre, wäre der Sicherheitsbereich bereits
bei der Entwicklung des Grundkonzepts für ein Ethernetkomrnunikationssystem ein
Schlüsselfaktor gewesen.
Bevor wir an diesem Punkt angekommen waren, lebten wir eine ganze Zeit lang in einer
Alt Dämmerschlaf. Als man dann der Realität ins Auge sehen musste, dass mangelnde
Sicherheit tatsächlich ein Problem war (zu Zeiten der Intemetexpansion und der plötzlichen
drastischen Zunahme von Angriffen auf Systeme), konzentrierten sich die ersten
Verteidigungsmaßnahmen auf die Außenwelt und ignorierten dabei die Bedrohungen, die von
innen kamen - schließlich war das Netzwerk selbst „vertrauenswürdig". Es sollte aber nicht
allzu lange dauern, bis eine Reihe von Unternehmen und Institutionen einige schmerzhafte
Lektionen lernen mussten. Im Laufe der Zeit wurde dann offenbar, dass nach außen
gerichtete Befestigungen wie Firewalls und Intmsion-Detection-Systeme selbst dann, wenn sie
untemehmensweit einwandfrei konfiguriert waren, allein nicht ausreichten. Die Vermitt-
lungsschicht war nach wie vor anfällig, denn sie gestattete es internen Benutzern, den
Datenaustausch zu gefährden, ohne auch nur eine Sicherheitslücke auf einem einzigen System
im Finnennetzwerk auszunutzen.
Man könnte nun einwenden, dass das Netzwerk durch Verwendung geeigneter Verschlüs-
selungsrnethoden zur Identitäts- und Integritätsverifizierung an allen Schnittstellen
gesichert werden könnte; aber das ist oft nicht praktikabel oder gar unmöglich - insbesondere
dann, wenn man die Leistung und Zuverlässigkeit des Netzwerks nicht beeinträchtigen und
die Kosten niedrig halten will (ganz zu schweigen von Kompatibilitätsproblemen in
Zusammenhang mit verschiedenen Betriebssysternen oder Anwendungen). Außerdem ist, wie
ich bereits erwähnte, Kryptografie nicht immer der Schlüssel: Es ist zwar wesentlich
einfacher, einen erfolgreichen Angriff duichzuführen, wenn die Daten sichtbar sind und
abgefangen werden können (beispielsweise bei Wiedergabe- oder Ablaufmusterangriffen), aber
bestimmte Faktoren - z. B. das Problem des Paddings von Ethernet-Frames, von dem
bereits die Rede war - können alle Bemühungen durchkreuzen, den Benutzer zu schützen.
In Teil II dieses Buchs werden wir einige der Bedrohungen behandeln, die spezifisch für
lokale Netzen sind. Diese Schwachstellen machen Daten zugänglich, ohne dass jemals eine
konventionelle Attacke durchgeführt wird. Diese ganzen Probleme werden uns begleiten,
solange Netzwerke den alten und bewährten Entwurf verwenden, der für die moderne
Netzwerktechnik weitgehend ungeeignet ist.
Doch wir wollen uns nicht aufhalten. Bevor wir aber in die wilde und faszinierende Welt
jenseits der Gienzen des lokalen Netzwerks eintauchen, wollen wir noch einen Blick auf
einige weitere (und ziernlich konkrete) Enthüllungsszenarien werfen.
120
8.1 „Logische" Blinkenlichten und ihre ungewöhnliche Verwendung
8.1 „Logische" Blinkenlichten und ihre ungewöhnliche
Verwendung
Ein solches Szenario behandelt den Missbrauch logischer „Anzeigen", also Indikatoren
wie beispielsweise Zähler, Flags und andere Apparaturen, die nicht optisch dargestellt,
sondern auf einem Computer verwaltet und in Softwareanwendungen verfügbar gemacht
werden, die in LANs häufig implementiert werden. Logische Indikatoren sind praktisch,
setzen aber ebenfalls voraus, dass das lokale Netzwerk vertrauenswürdig ist.
Das SNMP-Protokoll (Simple Network Management Protocol)1 ist die verbreitetste
Methode zur Überwachung und gelegentlich auch zur Administration von Netzwerkgeräten.
SNMP wird häufig auf Endpunktsystemen wie Servern und Workstations, aber auch auf
Netzwerkgeräten wie etwa Switches, Routern und Druckern implementiert.
Das Protokoll erlaubt das Lesen (oder Ändern) einer abstrakten Darstellung vieler Systern-
und Anwendungsintema, Betiiebs- und Konfigurationsparameter und Statistiken. Mit
SNMP können Sie bei einem Netzwerkdrucker die Anzahl der Netzwerkkalten, über die er
verfügt, oder seine Laufzeit abfragen. Die gleiche Methode können Sie auch verwenden,
um bei einem Mainframe dieselben Angaben abzurufen, obwohl diese vom Gerät intern
auf eine auf jedem System völlig unterschiedliche Weise ermittelt werden. Aus diesem
Grund macht SNMP das Überwachen und Verwalten heterogener Umgebungen ohne
Implementierung einer Vielzahl von Zugriffsprotokollen und Piiifprozeduren ganz einfach.
Natürlich weist SNMP eine Menge sicherheitsrelevanter Probleme in Bezug auf
Implementierung und Gebrauch auf, aber darum geht es mir hier gar nicht. Auch bei
ordnungsgemäßer Implementierung kann das Protokoll eine Offenlegung von
Sicherheitsinformationen zur Folge haben, indem es etwa schreibgeschützten Zugriff auf scheinbar irrelevante
Statistiken zu einer Netzwerkschnittstelle gewährt. (Diese Sicherheitslücke lässt sich
beseitigen, indem die Funktionalität des Rotokolls sorgfältig auf das Notwendige beschiänkt
wild, aber dies ist bei bestimmten Netzwerkgeräten gar nicht möglich.) Ein gewiefter
Angreifer kann Frame- oder Paketzähler auf einem System beobachten, auf dem SNMP läuft,
und dann mit diesen Informationen Profile für Ablaufmusterangriffe erstellen, die die
Wiederherstellung von Daten interaktiver Sitzungen oder anderer interessanter Angaben
ermöglichen; die Vorgehensweise ähnelt dabei der in Kapitel 1 beschriebenen.
Oha! Aber sollte es denn wirklich möglich sein, dass allein deswegen so viel passieren
könnte?
8.1.1 Zeig mir, wie du tippst, und ich sage dir, wer du bist
Zwar habe ich Probleme dieser Kategorie bereits mehrfach erwähnt, und die davon
ausgehende Gefahr mag auch sehr abstrakt erscheinen, aber die Folgen sind selbst dann real,
wenn der Wiederherstellungsvektor, dem ich mich in Kapitel 1 widmete, nicht berücksich-
Case90
8 Wir gegen die
tigt wird. Beispielsweise hat eine Gruppe deutscher Forscher vom Institut für
Bankinnovation ein kommerzielles Rodukt namens PSYLock entwickelt, welches Biostatistiken auf
der Basis von Tastenanschlagsrnustem erstellt2: Mit PSYLock ließen sich Benutzer
eindeutig identifizieren (und deswegen unter Umständen auch zurückverfolgen), indem man
untersuchte, wie sie ihre Tastatur benutzten.
PSYLock nutzt in erster Linie Messungen der Intervalle zwischen den Tastaturaktionen -
ein Trick, den ich zuvor bereits beschrieben habe. Vorausgesetzt, Paketzähler für einen
bestimmten Computer lassen sich beobachten und darauf basierend berechnen, wann im
Verlauf einer interaktiven Sitzung eine Taste vom Benutzer betätigt wurde, können Sie eine
Person unabhängig vom verwendeten Terminal zweifelsfrei identifizieren. Es ließen sich
einige interessante Anwendungen bösaitiger wie auch kontioUierender Natur basierend auf
der Anwendung dieses Konzepts in der Vennittlungsschicht ersinnen. Wenn der Angreifer
weiß, dass eine interaktive Sitzung auf der Basis irgendeines Fernzugriffsprotokolls
durchgeführt wild, für die sich die SNMP-Statistiken zum Switch-Port überwachen lassen, dann
kann er durch wiederholte Abfrage des Zählers ermitteln, wann Tasten angeschlagen
werden, und daraus Rückschlüsse ziehen - etwa was eingegeben wird oder wer es eingibt.
Auch eine „Lightversion" des Angriffs ist machbar, die keine fortgeschrittene
Modellierung in der Alt benötigt, wie wir sie weiter oben beschrieben haben. In einem BugTraq-
Beitrag namens „Passive Analysis of SSH (Secure Shell) Traffic"3 beschreiben Solar
Designer und Dug Song unter anderem noch ein Angriffsszenario, diesmal unter Verwendung
des SSH-Rotokolls, einer gängigen Methode zur Verbindung mit einem Remote-System.
Obwohl SSH verschlüsselt ist, ist es bei Versionen, die vor Abfassung des genannten
Beitrags erschienen, möglich, die Länge eines Passworts zu errnitteln, indem man die Größe
eines bei der Anmeldung beobachteten Pakets analysiert (das Passwort wird nach der
Eingabe durch den Benutzer als genau ein Datensegment verschickt).
Diese Methode ließe sich ebenso gut auf andere Kryptografieprotokolle anwenden, die die
Passwortlänge nicht aktiv verbergen, indem sie das Passwort vor dem Versand mit
Fülldaten erweitern. Und folgerichtig lässt sich der Angriff ausführen, indem man einfach einen
SNMP-Bytezähler (statt des eigentlichen Datenverkehrs) beobachtet.
8.2 Private Daten, wohin man auch sieht
Es gibt einen weiteren Grund dafür, dass wir nicht allzu erfreut von der Aussicht sein
sollten, einen ungebetenen Gast hinter den Kulissen unseres Netzwerks vorzufinden
(unabhängig davon, ob wir die dort vorhandenen Daten für sensibel halten oder nicht): Viele
Softwareanwendungen verletzen das Rinzip des geringsten Erstaunens. Das Prinzip des
geringsten Erstaunens ist eine Grundregel der Softwareentwicklung, die im Wesentlichen
2 Bank03
3 SolaOl
122
8.3 Wi-Fi-spezifische Sicherheitslücken
besagt, dass ein Programm so auf Benutzelhandlungen reagieren sollte, wie der Benutzer
es annimmt - auf eine konsistente, intuitive, vorhersagbare oder anderweitig zu erwartende
Weise. Wie sich aber herausstellt, übermitteln viele Programme unterschiedlicher
Softwareanbieter eine bemerkenswerte Anzahl wertvoller Daten (weitaus mehr als man
erwarten würde) und stellen Benutzer damit vor Situationen, auf die sie nicht gefasst sind. Wie
üblich spielt Microsoft Windows bei diesen im wahrsten Sinne des Wortes
„verblüffenden" Programmen die führende Rolle und tut sich bei der Übermittlung von Daten in
gezielter, aber häufig leicht zu übersehender und unauffälliger Weise besonders hervor. Aber
der freundliche Softwareriese ist beileibe nicht allein.
Es wissen wohl nur die wenigsten Benutzer, dass Windows, wenn es Mitglied einer
Domäne und für die Verwendung servergespeicherter Profile konfiguriert ist, bei jeder
Anoder Abmeldung des Benutzers große Teile der Registrierung des Benutzers an den Dornä-
nencontroller sendet. (Solche Profile sollen es Benutzem ermöglichen, sich von einer
anderen Workstation aus anzumelden und auf ihre persönlichen Daten zuzugreifen.) Die im
Profil enthaltenen Daten mögen zwar auf den ersten Blick ziemlich wertlos erscheinen,
aber sie bergen verschiedene persönliche Einstellungen und Verlaufsinfonnationen, die
recht interessant sein können: eine Liste der zuletzt ausgeführten Befehle, die zuletzt
besuchten Webseiten, die zuletzt geöffneten Dokumente und ähnliches.
Es gibt ein ähnliches, vielleicht noch verblüffenderes Phänomen: Wenn das Starnmver-
zeichnis eines Benutzers innerhalb der Domäne auf einem Netzlaufwerk liegt, ruft
Windows alle vom Benutzer im Fenster „Ausführen" eingegebenen Befehle zunächst auf dem
Remote-Server und dann lokal ab. Auf diese Weise werden alle Befehle, die der Benutzer
abgesetzt hat, dem aufmerksamen Beobachter über das SMB-Protokoll (Server Message
Block) enthüllt.
Diese und viele weitere Beispiele machen uns auf schmerzhafte Weise deutlich, dass
praktisch alle Netzwerkdaten als vertraulich zu gelten haben. Insofern sind lokale Netze im
Allgemeinen nicht besondere gut für die Übertragung häufig auftretender Daten geeignet.
Ausgenommen sind lediglich spezielle, eingeschränkte oder zusätzlich geschützte
Konfigurationen. Und es gibt keine geeignete Möglichkeit, diese Daten zu schützen, ohne
schwere Geschütze wie verschlüsselte IP-Tunnel oder ähnliche Software einzusetzen oder
jeden einzelnen Aspekt der Netzwerktechnologie von Grund auf neu zu entwickeln.
8.3 Wi-Fi-spezifische Sicherheitslücken
Es wäre nicht fair, dieses Kapitel zu beenden, ohne ein Wort zu den Problemen bei Wi-Fi,
der drahtlosen Variante von Ethernet, zu verlieren.
Drahtlose Netzwerke nach dem IEEE 802.11-Standard haben im Untemehmensbereich wie
auch bei Privatbenutzern mächtig an Fahrt gewonnen. Leider stellte sich bereits lange,
bevor die Technologie flächendeckend akzeptiert wurde (und obwohl sie mit der Absicht
entwickelt wurde, im Vergleich zu leitungsgestützten Entwürfen ein Mehr an Sicherheit zu
123
8 Wir gegen die
bieten), heraus, dass die korrekte Inbetriebnahme von Wi-Fi gar nicht einfach ist. Das liegt
möglicherweise daran, dass man versuchte, Wi-Fi ein wenig zu sehr in die Schuhe seines
älteren Binders einzupassen.
Der 802.11-Standard unterscheidet sich hinsichtlich seiner Betriebsprinzipien nicht
besonders von Ethernet. Er verwendet das traditionelle System nach dem Motto „Einer redet,
und alle hören zu"; der einzige Unterschied besteht darin, dass als Signalmedium kein Lei-
terpaar, sondern eine bestimmte Funkfrequenz zum Einsatz kommt. Was uns gleich zum
ersten Prob lern von 802.11 bringt.
Im Mai 2004 gab das ISRC (Information Security Research Centre) der Queensland Uni-
versity of Technology Ergebnisse seiner Untersuchungen bekannt: Jedes 802.11-Netzwerk
in jedem behebigen Unternehmen kann innerhalb von Sekunden außer Gefecht gesetzt
werden, indem man einfach ein Signal überträgt, dass die Kommunikation anderer Parteien
erfolgreich unterbindet. Natürlich gilt dies auch für Ethernet; dort muss man allerdings
zunächst eine physische Verbindung zum Netzwerk herstellen, was ein Aufspulen des
Angreifers natürlich erheblich vereinfacht und eine Lösung des Problems erleichtert:
Überprüfen Sie einfach den Switch und folgen Sie dem Kabel. Dieser Angriff kommt eigentlich
nicht überraschend, ist aber auch nicht das, was die Nutzer in der Industrie vorausgesehen
haben.
Das ist aber noch nicht alles. Dort, wo der 802.11-Standard versucht hat, Angriffe auf
Medienebene zu unterbinden, hat er gnadenlos versagt. WEP (Wired Equivalent Privacy)
wurde für Wi-Fi-Netzwerke entwickelt, um Schutz gegen das Abhören von
Netzwerksitzungen durch Dritte zu bieten und so ein Maß an Sicherheit zu gewährleisten, das mit dem
traditioneller LANs vergleichbar- ist. Allerdings fanden Forscher der University of
California und von Zero Knowledge Systems im Jahre 2001 eine Menge stndctureller Mängel im
WEP-Entwurf die das System weitgehend ungeeignet machten. Bedauerlicherweise war
Wi-Fi zu jenem Zeitpunkt bereits so weit verbreitet, dass eine Implementierung
notwendiger Änderungen sich schwierig gestaltete.4
Hinzu kommt erschwerend, dass die Nutzung von WEP optional und bei den meisten
Netzwerkgeräten abgeschaltet ist: Diese Einrichtungen nehmen eingehende Daten
bereitwillig entgegen und leiten sie weiter. Dies ist bei leitungsgestützten Netzwerken, bei denen
eine zusätzliche Sicherheitsebene in der Bitübertragungsschicht gegeben ist, zwar durchaus
akzeptabel; Funknetze hingegen stehen jedem offen, der gerade in der Nähe ist.
Die Praxis des Wardrivings, bei dem man sich - mit einem Auto und einem Wi-Fi-fähigen
Laptop bewaffnet - auf Netzwerkerkundungstour macht, wurde extrem populär, nachdem
man feststellte, dass die Funknetze größerer Unternehmen mehrheitlich teilweise oder
vollständig geöffnet waren. Besonders erfolgreich war man dabei in großen
Einkaufszentren und Geschäftsvierteln praktisch aller Städte. Die Angriffe verlaufen meist recht simpel
und reichen vom Erschnorren eines Intemetzugangs bis hin zum Versand von Spam oder
BoriOl
124
8.3 Wi-Fi-spezifische Sicherheitslücken
der Dmchiuhrung von Fernangriffen über das Netzwerk des Opfers. Trotzdem ist das
Risiko, dass ein erfahrener Angreifer ein Netzwerk von innen her knackt, sehr real.
Abbildung 8.1 Tracy Reeds Warflight5
Abbildung mit freundlicher Genehmigung von Tracy Reed (treed@copiloteonsulting.com) von der
Firma Copilot Consulting.
125
8 Wir gegen die
Wie sieht das wahre Ausmaß des Problems aus? Es genügt wohl zu sagen, dass das
Wardiiving an dem Tag Vergangenheit war, als jemand das Warßying ersonn: Wardriving
mit dem Flugzeug statt dem Auto. Im Jahr 2002 beschloss Tracy Reed von der Firma
Copilot Consulting, die Gegend von San Diego mit einem Funknetzscanner zu überfliegen.
Auf diesem Flug schaffte er es, aus einer Höhe von 1.500 Fuß (ca. 450 Meter) fast
400 Access-Points mit Standardkonfiguiation zu finden. Dies bedeutete kostenlosen
Zugang zum Internet oder zu Filmenintranets für jeden, der sich in Reichweite befand und
nur wollte (vgl. Abbildungen 8.1 und 8.2). Nur 23 Prozent der Geräte, die Reed scannte,
waren geschützt - durch das (generell leicht zu knackende) WEP oder mit besseren
Methoden.
Denken Sie sich Ihren Teil.
Abbildung 8.2 Warflight im Silicon Valley
126
In der Wildnis
Wenn Sie erst im Internet sind, wird es richtig schlimm
9 Der verräterische Akzent
Neuntes Kapitel. In dem wir das passive Fingerprinting kennen lernen und
feststellen müssen, dass subtilste Unterschiede in unserem Verhalten
Anderen gegenüber Zeugnis darüber ablegen, wer wir sind
Im Internet — dem „Netz der Netze" — entziehen sich Daten, die an einen entfernten
Gegenüber gesendet werden, der Kontrolle des Absenders. Anders als im lokalen Intranet,
welches für Pakete in aller Regel ein sicherer Hafen ist, sofern kein Unbefugter eindringt,
ist es, sobald die Daten in freier Wildbahn unterwegs sind, nicht mehr möglich, die
Gefahren einzuschätzen und effizient zu handhaben, die ihnen dort draußen drohen: Niemand
kann den Pfad der Daten steuern oder die Absichten aller an der Kommunikation
beteiligten Parteien bestimmen — von ihrem jeweihgen Sicherheitsansatz ganz zu schweigen. In
einem derart komplexen Netzwerk ist die Wahrscheinlichkeit, dass an einem Standort auf
dem Weg zum Empfänger Böses im Schilde gefühlt wird, weder vemachlässigbar noch
einfach einzuschätzen. Tatsächlich kann sogar die Person, mit der Sie eine zulässige
Verbindung herstellen, Hintergedanken haben. Oder sie ist einfach ein bisschen neugierig.
„Unaufgeforderte Datenerfassungsversuche" (um sie einmal so zu nennen) unterscheiden
sich auch aus einigen anderen Gründen, wenn sie über das Internet ausgeführt werden. Das
Wichtigste aber ist: Sie müssen nicht gezielt erfolgen, und sie sind nicht auf ein
bestimmtes Segment in einer physischen Infrastruktur begrenzt. Da der Aufwand vonseiten des
Angreifers so gering ist, stellen solche Angriffe eine realistische Möglichkeit dar,
potenziell interessante Daten in die Hände zu bekommen, bevor überhaupt klar ist, wie man von
ihnen — finanziell oder auf andere Weise — profitieren kann. Außerdem wird die Trennlinie
zwischen Gut und Böse noch undeutlicher: Der Angreifer kann nämlich Ihr bester Freund
sein. Die Rentabilität allgemeiner Spionage und Kontrolle zum Zwecke der
Marktuntersuchung und Profilerstellung ist für viele einfach zu verlockend, als dass man ihr
widerstehen könnte. Die Welt der Dienstleistungen ist nicht in Schwarz und Weiß zu
unterteilen, und für viele stellt eine flexible Handhabung der eigenen Grundsätze ein durchaus
pragmatisches Geschäftsmodell dar.
129
9 Der verräterische Akzent
Dieser Teil des Buches befasst sich mit den Gefahren, die durch die offene Struktur des
Internets begründet sind, und mit der Fähigkeit anderer, viel rnehr über Sie herauszufinden,
als Sie erwarten würden — und viel mehr, als sie jemals brauchen würden, um Ihnen etwa
eine interessante Website, ein lustiges Netzwerkspiel oder ähnliche Dienstleistungen
anbieten zu können. Im Internet ist der Feind nicht rnehr der einsame Ine von Gegenüber, der
die LEDs auf Ihrern Switch durch ein hochwertiges Teleobjektiv beobachtet: Die hier
beschriebenen Risiken ermöglichen in massivem Urnfang Profüerstellungen,
Nachverfolgungen, Datensammlungen, Industriespionage, Netzwerkerkundungen und
angriffsvorbereitende Analysen. Und sie sind viel realer als die Szenarien, die wir bis hierher kennen
gelernt haben.
Sie müssen die Gefahren kennen, um ein ausreichendes Niveau an Datenschutz
gewährleisten oder effiziente Konüolleinrichtungen für Benutzer (und auch für völlig Fremde, die
sich Ihrern Netzwerk nähern) einsetzen zu können. Ein solches Gespür ist ferner
wesentlich, um in einer Welt, in der der Grat zwischen begründeter Sorge um persönliche Daten
und pathologischer Paranoia sehr schmal ist, einen klaren Kopf zu behalten.
Ich werde mit einer Abhandlung zu den wesentlichen Netzwerkprotokollen, die im Internet
zum Einsatz kommen, und ihren datenschutztechnischen Auswirkungen beginnen. Können
wir anfangen?
9.1 Die Sprache des Internets
Die offizielle Sprache des Internets ist das IP-Protokoll (Internet Protocol), dessen ver-
breitetster Dialekt die Version 4 ist. Das in RFC7931 spezifizierte Protokoll stellt eine
Möglichkeit zur Implementierang einer standardisierten Methode bereit, um Daten über
große Entfernungen und eine Vielzahl von Netzwerken mit möglichst wenig Aufwand zu
übertragen. IP-Pakete bilden die dritte Schicht des bereits früher beschriebenen OSI-
Modells und bestehen aus einem Header, der die zur Auslieferung eines Datensegments an
den endgültigen Empfänger — den entfernten Endpunkt — erforderlichen Angaben enthält,
und einem Datenteil, der die Nutzdaten (d. h. die Daten übergeordneter OSI-Schichten)
enthält und direkt auf den Header folgt.
Die Routing-Informationen, die der Absender im IP-Paket vor dem Versand angibt, sind
die Absender- und Zieladresse sowie eine Anzahl von Parametern, die den Vorgang des
Datentransfers vereinfachen oder Zuverlässigkeit und Leistung optimieren. Wenn ein
System im lokalen Netzwerk mit einem entfernten Partner kommunizieren will, der nicht
direkt über die physische Leitung erreichbar ist (zumindest nicht, soweit der Host dies weiß),
sendet es ein IP-Paket mit der Zieladresse des endgültigen Empfängers — in einen Frame
einer untergeordneten Schicht gekapselt — an einen bestimmten lokalen Computer, von
dem es annimmt, dass er als Vermittler (oder Gateway) des Netzwerks agiert, in welchem
Post81a
130
9.1 Die Sprache des Internets
sich der Absender befindet. Das Gateway ist ein Multihome-Gerät, d. h. es ist gleichzeitig
Bestandteil mehrerer Netzwerke, zwischen denen es als Verbindungsglied dient. Das
Gateway sollte wissen, wie das Paket nach „draußen" geroutet werden rnuss, was mit dem
Paket geschehen soll und wer die Daten als nächster bekommt, wenn weitere Stationen
erforderlich sind, bevor die Daten den Empfänger erreichen können.
Systeme, deren Aufgabe das Routing der Daten vom lokalen Gateway bis zum Ernpian-
gemetzwerk ist, lesen die in der IP-Schicht vorhandenen Daten aus und entscheiden dann,
wie die Pakete weiterzuleiten sind. Diese Entscheidungen treffen sie auf der Basis ihrer
Kenntnisse zur Erreichbarkeit bestimmter Netzwerke, (fn diesem Kontext verstehen wir
unter einem Netzwerk einen Pool von Netzwerkadressen, die an einem gemeinsamen
Standort vorhanden sind.)
9.1.1 Routing auf naive Art
In seiner einfachen Ausprägung verwendet ein Router eine feste Routing-Tabelle, mit der
er zwischen einer Anzahl lokaler Netze (an die er Daten direkt ausliefern kann) und der
Außenwelt, die er nicht kennt, unterscheiden kann. Aufgrund dessen muss der gesamte
Datenverkehr, der nicht für das lokale Netzwerk bestimmt ist, an einen übergeordneten
Router weiterleitet werden, der wahrscheinlich besser weiß, wohin die Daten geliefert werden
müssen.
Empfänger in Netzwerk B oder
D? Dann Daten zustellen, sonst
welter zum nächsten Router.
Router 2 ^J^Router 3
Der Absender will ein System
in Netzwerk C kontaktleren.
Router 1 Ist das Default-
Gateway des Absenders.
Abbildung 9.1 Ein einfach konstruiertes WAN-Routing-Schema
Abbildung 9.1 zeigt ein Beispiel für eine solche Routing-Struktur. Der Absender (links im
Bild) versucht, ein Paket an ein System zu schicken, dessen Adresse im Netzwerk C hegt.
Über dieses Netzwerk ist dem Absender nichts bekannt. Um die Zustellung zu
ermöglichen, sendet der Absender die Daten an das lokale Gateway — in der Hoffnung, dass es
weiß, wo es nach dem Empfänger zu suchen hat. Allerdings erreicht dieses System — Rou-
Absender
Empfänger In Netzwerk A?
Dann Daten zustellen, sonst
weiter zum nächsten Router.
Router 1
Netzwerk D
131
9 Der verräterische Akzent
ter 1 — nur das Netzwerk des Absenders sowie das Netzwerk A. A ist ein anderes
Netzwerk, das nichts mit C zu tun hat. Weil das Ziel sich nicht im lokalen Netzwerk befindet,
entscheidet der Router, dass es am besten ist, das Paket an einen übergeordneten WAN-
Router (Router 2) zu schicken, den er lokal erreichen kann.
Auch dieses Gerät hat keine direkte Verbindung mit Netzwerk C, sondern kann nur Hosts
in den Netzwerken B und D direkt erreichen. Allerdings weiß es, dass Router 3 die
Zieladresse kontaktieren kann — und deswegen bestimmt weiß, wie fortgefahren werden soll.
Also wird das Paket dorthin weitergeleitet, und Router 3 kann die Daten lokal an den
endgültigen Empfänger ausliefern. Alles lehnt sich zufrieden zurück und klopft sich angesichts
dieses Erfolgs gegenseitig auf die Schulter.
9.1.2 Routing im wirklichen Leben
In der Praxis sind Netzwerke häufig hochgradig redundant und weisen keine strikt lineare
Architektur auf. Vielmehr haben sie eine komplexe, verzweigte Struktur, die die Auswahl
des optimalen und wirtschaftlichsten Pfades schwierig machen würde, wäre man auf die
Verwendung einer statischen Konfiguration angewiesen. (Angesichts der infrastruktuiellen
Änderungen, die sich infolge des Wachstums Ihres Netzwerks ergeben, können Sie die
Herausforderung, immer auf dem neuesten Stand zu bleiben, getrost vernachlässigen.)
Aufgrund dessen wird eine angemessenere Routing-Strategie implementiert, sobald die
übertragenen Daten einen Backbone-Router erreichen. Ein Backbone-Router wird von
einem Netzbeteiber eingesetzt und ist ein dediziertes WAN-Gerät, das mehrere von einem
bestimmten Anbieter kontrollierte Netzwerke zu einem komplexen Ganzen verbindet,
welches man als autonomes System bezeichnet. Backbone-Router sind normalerweise mit
Schnittstellenverbindungen zu anderen großen Routern ausgestattet und verwenden einen
hochentwickelten Algorithmus zur Pfadsuche und ein riesiges „Telefonbuch" der
Netzwerkblöcke und ihrer Parameter. Dieses durch das BGP-Protokoll (Boundary Gateway
Protocol) dynamisch gesteuerte Adressverzeichnis ermöglicht das Auffinden des
geeignetsten Pfades zum Zielsystem; die Aufgabe muss also nicht mehr blindlings
irgendwelchen Systemen in der Hoffnung zugewiesen werden, dass sie die Daten irgendwie korrekt
weiterleiten.
9.1.3 Der Adressraum
Dieser Vorgang wäre allerdings ziemlich undurchführbar, wenn Zielnetzwerke einfach nur
aus einer Anzahl Adressen bestünden, die den Geräten in aller Welt willkürlich
zugewiesen würden. Die Definition eines autonomen Systems müsste in diesem Fall alle Adressen
auflisten und würde sehr bald gigantische Ausmaße erreichen. Um dieses Problem zu
lösen, werden den Backbone-Anbietem stattdessen zusammenhängende Adressblöcke
zugewiesen; Endbenutzer oder kleinere Anbieter können dann jeweils eine oder mehrere
Adressen leasen. Das Routing zum Providemetzwerk basiert auf dem Nachschlagen (Lookup)
der Ziel-IP-Adresse innerhalb der zugewiesenen Adressbereiche und dann innerhalb des
132
9.1 Die Sprache des Internets
Netzwerks basierend auf einem weiteren Lookup in detaillierteren Routing-Tabellen. Ein
autonomes System kann also als Bereich von IPv4-Adressen (oder auch als Gruppe von
Bereichen dieser Adressen) definiert werden. Dabei kommt eine Netzmaskenmethode zum
Einsatz.
Die einzelne IPv4-Adresse, die bei jeder IP-Kornmunikation zur eindeutigen Identifikation
eines Endpunktsystems verwendet wird, hat eine recht einfache Struktur: Sie besteht aus
32 Bits, die aus Gründen der praktischen Handhabung in vier Bytes zu je acht Bits
aufgeteilt werden. Insgesamt ergeben sich so 4.294.967.296 mögliche Adressen. Die Adresse
wird traditionell in Foim von vier durch Punkte getrennten Bytewerten geschrieben, die
jeweils einen Wert zwischen 0 und 255 haben. So entspricht beispielsweise 195.117.3.59
dem ganzzahligen 32-Bit-Wert 3.241.036.664.
Fortlaufende IP-Adressblöcke sind die Grundlage des Paket-Routings. Sie stehen am
Anfang der IPv4-Adressierung, denn sie definieren sowohl den Teil der IP-Adresse, der für
alle Systeme, die zum autonomen System gehören, feststeht und konstant ist, als auch den
Teil der Adresse, der seitens des Netzwerkbesitzers auf unterschiedliche Werte eingestellt
werden kann, damit er seinen unterschiedlichen Computern eindeutige Kennungen
zuweisen kann.
Wenn ein Netzwerk definiert wird, dann wird eine Anzahl der höherwertigen Bits einer IP-
Adresse — theoretisch zwischen ein und 31, in der Realität acht bis 24 Bits — als
Netzadresse reserviert. Der feste Teil dieser Adresse ist allen Adressen gemein, die zum betreffenden
Netzwerk gehören (und deswegen wahrscheinlich auch dorthin geroutet werden). Die
verbleibenden niederwertigen Bits können behebig eingestellt werden, um Systemen
innerhalb des Netzwerks Adressen zuzuweisen.
Historisch betrachtet2 war die Größe eines Netzwerks oder die Anzahl der festgesetzten
höherwertigen Bytes eine Funktion der Adresse und konnte aus der Netzwerkadresse selbst
ermittelt werden. Basierend auf den wichtigsten Adressbits ließen sich Adressen
gruppieren: Es gab Klasse-A-Netzwerke (bei denen die ersten acht Bits feststanden und die rnehr
als 16 Millionen mögliche Benutzeradressen boten), Klasse-B-Netzwerke (mit 16 festen
Bits und jeweils rnehr als 65.000 Hosts) und schließlich Klasse-C-Netzwerke (mit 24
festen Bits und je 256 Hostadressen). Von dieser Konstellation ausgehend können Sie, wenn
die IP-Adresse Ihres Systems mit der Zahl 1 beginnt, bereits feststellen, dass es sich um
ein Klasse-A-Netzwerk handelt und dass alle anderen Systeme mit diesem Präfix sich
„neben" Ihrern System befinden.
Seinerzeit schien eine solche Verteilung durchaus praktisch, aber der rPv4-Adressraurn
schrumpfte beträchtlich, nachdem den ursprünglichen Initiatoren (d. h. den US-
Streitkräften, Xerox, IBM und ein paar weiteren Global Players) in der Frühzeit des
Internets eine Handvoll Klasse-A-Adressen zugewiesen worden war und diese Organisationen
offenbar nicht allzu begeistert von der Idee waren, davon wieder ein paar abzugeben —
auch wenn sie noch nicht einmal einen Brachteil des Adressraums verwenden, den sie für
2 RFC796 (Post81b)
9 Der verräterische Akzent
die öffentliche Infrastruktur erhalten haben. Auch begannen, als das Internet kommemali-
siert wurde und IP-Adressen zu einer Ressource wurden, für die Benutzer zahlen mussten,
eben diese Benutzer, größere Adiessbereiche zu ordern, die ihren Anforderungen besser
entsprachen. So kamen einige Leute mit vier Adressen aus, während andere einen Bestand
von 8.000 fortlaufenden Adressen benötigten. Und die Benutzer fingen damit an, ihren
Internetadressraum weiterzuverkaufen oder auf andere Weise zu partitionieren.
Das Ergebnis ist, dass der aktuelle Adressraum auf absonderliche Art zerstückelt ist:
Häufig sind winzige Bereiche des Raums ausgeschlossen und werden aus größeren, ansonsten
fortlaufenden Blöcken umgeleitet, und das ursprüngliche Partitionierungsschema wird
weitgehend ignoriert. Jeder Netzwerkadresse ist nun eine Netzmaskenspezifikation
zugeordnet, weil es nur mit der IP-Adresse allein nicht mehr möglich ist, zu sagen, welchem
Netzwerk ein System angehört. In der Netzmaske sind die Bits an den Positionen gesetzt,
die in der Netzwerkadresse feststehen; die Bits der Positionen in der Adresse, die innerhalb
des Netzwerks frei geändert werden können, sind in der Netzmaske jeweils 0.
Wie Abbildung 9.2 zeigt, bleiben, wenn man 24 Bits der Netzwerkadresse 195.117.3.0
fixiert, acht Bits am Ende übrig, die geändert werden können. Wir können also 256
Adressen zwischen 195.117.3.0 und 195.117.3.255 erstellen, die zu diesem Netzwerk gehören.
(In der Praxis bleiben 254 mögliche Hosts, weil die erste und die letzte Adresse des
Bereichs für besondere Zwecke reserviert sind.) Mit dieser relativ schlichten Spezifikation
eines Netzwerks mit Adressen ist es einfach, zu ermitteln, welche Adressen zu diesem
Netzwerk gehören und welche an ein als Gateway agierendes System übermittelt werden
sollen (und welche nicht).
Netzmaske: 255.255.255.0 I 11111111 11111111 11111111 00000000
Netzwerk: 195.117. 3.0 | 11000011 01110101 00000011 00000000
1— Um als zu einem bestimmten Netzwerk gehörend
betrachtet zu werden, müssen bei Adressen alle Bits,
die in der Netzmaske gesetzt sind, mit einer
„Prototypadresse" des Netzwerks (hier 195.117.3.0) identisch
sein.
Gültige Hostadresse in diesem Netzwerk:
195.117. 3.59 I 11000011 01110101 00000011 00111011
Bei einer gültigen Adresse muss dieser feste
Bereich mit der Netzwerkadresse identisch sein.
Ungültige Hostadresse (nicht im selben Netzwerk):
195.117. 4.59 I 11000011 01110101 00000100 00111011
Bei einer ungültigen Hostadresse stimmen einige der
festen Bits nicht mit der Netzwerkadresse überein!
Abbildung 9.2 Regeln für die Adressierung im Netzwerk
134
9.2 Das IP-Protokoll
Dieses Adressierungsschema mag verwirrend und unnötig kompliziert erscheinen, aber es
ist nichtsdestoweniger erfolgreich: Wir können ohne gioßen rechentechnischen Aufwand
Adresspools mit bestimmten Systemen verknüpfen und zwischen Systemen unterscheiden.
Bei all seiner Komplexität gelingt es dem Internet in der Regel ohne gioßen Aufwand, ein
System innerhalb wirklich kurzer Zeit ausfindig zu machen.
9.1.4 Fingerabdrücke auf dem Umschlag
Wir wissen jetzt, wie die Daten von Punkt A zu Punkt B kommen. Was aber unterwegs
passiert, ist wesentlich spannender als die Bestimmung des Pfades. Wir wollen einmal
genauer betrachten, was zwischen den Routem und unseren Endsystemen ausgetauscht wird.
Sie mögen der Ansicht sein, dass die interessantesten Informationen doch wohl die
Nutzdaten im Innern der Pakete sind, die über das Internet übertragen werden (schließlich
werden in jeder Sekunden Unmengen von privaten E-Mails und spannenden Inhalten über den
gesamten Globus übertragen), aber es steckt noch viel mehr dahinter.
Das Format der IP-Pakete, die für das Routing der Daten verwendet werden, und die
Schicht-4-Daten, die zur Kapselung der eigentlichen Anwendungsdaten benutzt werden,
sind relativ akkurat und in erstaunlicher Eindeutigkeit in den RFCs definiert. Allerdings
können auch bei kompetenter Implementierung des TCP-Stapels die zugrundeliegenden
Informationen einen beträchtlich größeren und dauerhafteren Wert für den Empfänger
haben als die eigentlichen Nutzdaten, die er empfängt. Eine Enthüllung auf dieser Ebene
erfolgt unbeabsichtigt und unerwartet. Bevor wir aber mehr hierzu erfahren, müssen wir
zunächst den Aufbau der zugrundehegenden Protokolle kennen lernen.
9.2 Das IP-Protokoll
Zunächst ein paar Grundlagen. Das IP-Protokoll stellt eine universelle Methode zur
Auslieferung von Daten über große Entfernungen in der dritten Schicht des OSI-Modells
bereit. Es enthält eine Anzahl von Parametern, die von den Zwischensystemen inteipretiert
und möglicherweise modifiziert werden sollen. Abbildung 9.3 zeigt den IP-Header.
9.2.1 Protokollversion
Dies ist ein vier Bit langer Wert, der bei allen IPv4-Paketen fest auf 4 (binär 0100) gestellt
ist. IPv4-ist das Standardprotokoll (und in vielen Fällen auch das einzige Protokoll) für
Schicht 3 über das Internet. Versuche, mit IPv6 eine modernere Implementienmg
durchzusetzen, waren bislang nicht besonders erfolgreich — meiner Meinung nach in erster Linie
deswegen, weil das neue und erweiterte IP-Adressfonnat für Otto Normaladministrator
wesentlich schwieriger zu merken ist.
135
9 Der verräterische Akzent
9.2.2 Header-Länge
Dies ist ebenfalls ein vier Bit langer Wert, der die Gesamtlänge des IP-Headers angibt. Die
Angabe erfolgt in Blöcken zu je vier Bytes (dies erlaubt die Darstellung von Längen
zwischen 0 und 60 Byte mithilfe der 16 möglichen Werte des Feldes). Der Parameter gibt der
Implementierung an, an welcher Stelle die Analyse des IP-Headers enden soll (dieser kann
aufgrund zusätzlicher „Optionen", die an das Ende des Headers angehängt werden und
unmittelbar vor den Inhalten übergeordneter Schichten stehen, unterschiedlich lang sein).
Außerdem ermöglicht die Angabe das Überspringen eines Teils des Headers: Optionen
lassen sich vernachlässigen oder gar vollständig ignorieren, und man wechselt direkt zu
den eigentlichen Nutzdaten.
0 4 8 0 3
gs
Version
\8
12
//
16/ / 20 /24
/
/
Länge des
Internet-
Headers
Kennung
Time-to-Live (TTL)
Protokoll
/
28
32
-A-
/
/ Gesamtlänge
Flags
Fragmentoffset
Header-Prüfsumme
Quelladresse
Zieladresse
Optionen
Fülldaten
Daten
Abbildung 9.3 Aufbau des IP-Headers
Da IP-Optionen normalerweise lediglich für Diagnosezwecke eingesetzt werden — sie
ermöglichen etwa den Versand eines Pakets über eine bestimmte Paketroute (und sonst
eigentlich nichts anderes) —, sind praktisch alle IP-Pakete, auf die man in freier Wildbahn
trifft, 20 Bytes lang (d. h. dieses Feld hat den Wert 5); diese 20 Bytes entsprechen genau
dem festgelegten Teil des Headers. Werte von weniger als 20 Bytes sind natürlich
fehlerhaft, und eine vernünftige Implementierung wird ein solches Paket ignorieren. Allerdings
ist Vernunft leider nicht immer die Regel.
136
9.2 Das IP-Protokoll
9.2.3 Diensttyp (Type of Service, TOS)
Die Bedeutung dieses 8-Bit-Feldes ist vemachlässigbar. Es enthält eine Beschreibung der
Routing-Priorität: Sie gibt an, dass ein redliches Handeln des Absenders vorausgesetzt
wird und er festlegen kann, ob dieser Datenverkehr von besonderer Wichtigkeit ist oder
auf andere Alt priorisiert werden darf. Der Wert wird gelegenthch in lokalen Installationen
verwendet, in denen ein bestimmter Vertrauensgrad angewendet werden kann; im Internet
allerdings wird er weitgehend ignoriert.
Das Feld umfasst drei Abschnitte:
■ Die ersten drei Bits geben die Priorität an.
■ Die nächsten vier beschreiben die erwünschte Routing-Methode. Hierzu werden
abstrakte Konzepte wie „hohe Zuverlässigkeit" oder „geringe Latenz" verwendet, die der
Router selbst interpretieren soll.
■ Der letzte Teil — ein einzelnes Bit — ist reserviert und hat stets 0 (!) zu sein.
9.2.4 Paketlänge
Dieses 16 Bit umfassende Feld gibt die Gesamtlänge des IP-Pakets einschließlich der
Nutzdaten an. Zwar hegt der Maximalwert bei 65.535, aber die zulässige Größe eines
Pakets wird oft auf einen wesentlich niedrigen Wert gesetzt, da das untergeordnete Protokoll
dies erfordert. So hat Ethernet beispielsweise einen MTU-Wert (Maximum Transmission
Unit, maximale Paketgröße) von 1.500 Bytes, d. h. ein System, das über Ethernet
angebunden ist, wird keine Pakete versenden, die größer sind als dieser Wert. Meist hegt der
MTU-Wert zwischen 576 und 1.500 Bytes; MTUs mit einem Wert von rnehr als 16 oder
18 Kbyte kommen praktisch nicht vor.
■ Hinweis
Amüsant: Die Größenbeschränkung eines IP-Pakets in Höhe von n Bytes (die sich aus der
MTU ergibt) bestimmt auch die erforderliche Bandbreitenzunahnie für IP-Datenverkehr: Pro
n — 20 Bytes, die an eine übergeordnete Schicht übergeben werden, werden immer mindestens
20 Bytes Header-Daten hinzugefügt.
9.2.5 Absenderadresse
Dieser 32-Bit-Wert ist eine IP-Adresse des oben beschriebenen Formats, die den
ursprünglichen Ausgangspunkt des Kornmunikationsvorgangs angibt. Da das IP-Paket vom
Absender zusammengestellt wird und der Anreiz, diesen Parameter beim Verlassen des
Absendemetzwerks auf Richtigkeit zu prüfen, eher gering ist, ist dieser Wert für sich genommen
eigentlich nicht glaubwürdig. Allerdings erlaubt er Rückschlüsse hinsichtlich der Frage,
wem wir antworten können; und wenn wir annehmen, dass die Angabe glaubwürdig ist,
dann können wir sie auch verwenden, um dem Absender zu antworten. Der Vorgang der
bewussten Fälschung dieses Weites wird normalerweise als IP-Spoofing bezeichnet.
137
9 Der verräterische Akzent
9.2.6 Zieladresse
Dieser 32-Bit-Wert gibt die Adresse des endgültigen Empfängers der Daten an. Wie alle
anderen IP-Parameter kann der Absender die Adresse nach eigenem Gutdünken
auswählen. Zwischensysteme verwenden sie zur korrekten Weiterleitung des Pakets.
9.2.7 Kennung des übergeordneten Protokolls
Dies ist ein 8-Bit-wert, der angibt, was flu- Nutzdaten in diesem IP-Paket transportiert
werden: TCP, UDP, ICMP oder eine der exotischeren Optionen, denen wir uns weiter unten
widmen werden.
9.2.8 TTL
TTL (Tirne-to-Live) ist ein 8-Bit-Zähler, der die Lebensdauer von IP-Daten angibt. Um
das Auftreten von Endlosschleifen in dem Fall zu verhindern, dass irgendetwas mit den
Routing-Tabellen so gar nicht stimmen will, wird der Zähler jedes Mal, wenn er ein
Zwischensystem passiert oder sehr lange in einer Sendewarteschlange ausharren muss, um
dem Wert 1 verringert. Erreicht der Zähler den Wert 0, dann wird das Paket verworfen,
wovon der Absender unter Umständen freundlicherweise durch ein ICMP-Paket in
Kenntnis gesetzt wird. Wie alle anderen Werte wird auch der TTL-Wert nach Maßgabe des
Absenders eingestellt, kann aber angesichts seiner Bitbreite nicht größer werden als 255.
Ein interessanter Nebeneffekt des TTL-Zählers besteht darin, dass er das Nachvollziehen
der Route zu einem entfernten System erlaubt: Eine Nachricht mit einem TTL-Wert von 1
verfällt am ersten Router auf dem Weg zum Ziel (was der Router dem Absender über eine
ICMP-Nachricht meldet); eine Nachricht mit dem TTL-Wert 2 verfallt am darauffolgenden
Abschnitt usw. Durch Versenden von Paketen, deren TTL-Werte nach und nach erhöht
werden, und Überwachen der entsprechenden ICMP-Antworten des Typs „TTL
abgelaufen" lässt sich eine Kartographie der Router und anderer IP-fähiger Geräte auf dem Weg
zum Empfänger erstellen. Diese Methode heißt traceroute und wird häufig zur Diagnose
von Routing-Problemen und für angriffsvorbereitende Analysen eingesetzt.
Der Nutzen für den Angreifer hegt in der Tatsache, dass sich bestimmte Wirkungen
erzielen lassen, ohne das vorgesehene Opfer tatsächlich bereits anzugreifen: Wenn Sie es etwa
auf www.microsofl.com abgesehen haben sollten, können Sie stattdessen den Router des
Netzwerks, in dem sich dieser Server befindet, oder die Router der zugehörigen Intemet-
provider in der Hoffnung ins Visier nehmen, den gesamten Datenverkehr erfassen und
gefälschte Antworten zurückschicken zu können. Hierdurch würden Sie den Server selbst
von der Außenwelt abschneiden und der Außenwelt durch Übernahme der Identität
vorgaukeln, dass die Site www.microsoft.com sich geändert hat. Selbstverständlich ist dies nur
ein Beispiel.
138
9.2 Das IP-Protokoll
9.2.9 Flags und Offsets
Diese 16-Bit-Werte steuern einen interessanten — und zudem den wohl inängelbehaftetsten
— Aspekt des IP-Paket-Routings. Sie werden verwendet, wenn ein großes Paket von einem
Zwischensystem über eine Verbindung weitergeleitet werden muss, deren MTU geringer
ist als die Paketgröße. In diesem Fall „passt" das Paket so nicht in das Medium.
Hier ein willkürlich gewähltes Beispiel: Ein Absender, der via Ethernet angebunden ist,
kann ein Paket mit einer Größe von bis zu 1.500 Bytes versenden (und macht das oft
auch). Wenn allerdings der erste Router, auf den das Paket trifft, die Daten über ein DSL-
Modem weiterleitet, dann tritt ein Problern auf: Die normale MTU einer DSL-Leitung (die
für sich bereits eine eigenwillige Kombination von Kapselungen über andere Protokolle
darstellt) beträgt 1.492. Da passt ein Paket mit 1.500 Bytes einfach nicht durch.
Angesichts der Vielfalt von Leitungsfonnaten, die im Internet verwendet werden, stellt
dies ein schwerwiegendes Problern dar. Der Lösungsansatz besteht darin, das IP-Paket
(genauer gesagt, die enthaltenen Nutzdaten) in mehrere separate IP-Pakete aufzuspalten
oder zu fragmentieren und Informationen hinzuzufügen, die es dem Empfänger gestatten,
die Nutzdaten wieder zusammenzusetzen, bevor er sie an die übergeordneten Schichten
übergibt. Das Ergebnis ist eine geänderte Anzahl von Paketen, die über die betreffende
Leitung übertragen werden können. Ein Offset (Versatz), der in jedem Fragment enthalten
ist, gibt an, wie die einzelnen Datenfragmente wieder zusammengesetzt werden müssen,
nachdem der endgültige Empfänger sie erhalten hat.
Außerdem ist in den Headern aller Fragmente mit Ausnahme des letzten ein spezielles
MF-Flag („More Fragments") gesetzt. Wenn das Zielsystem ein Paket mit gesetztem MF-
Flag oder eines mit gesetztem Datenblockoffset, aber ohne MF-Flag erhält (dies ist dann
die letzte Teilsendung eines fragmentierten Pakets), dann weiß es, dass für die
Wiederherstellung des Originalpakets ein Ternporärspeicherbereich reserviert und dann gewaltet
werden muss, bis alle noch fehlenden Teile eingetroffen sind, bevor das Paket
weiterverarbeitet werden kann.
Abbildung 9.4 veranschauhcht den Prozess der Fragmentieiimg und Wiederherstellung, in
dessen Verlauf ein übergroßes Paket zunächst in zwei Blöcke unterteilt und dann vom
Empfänger wieder zusammengesetzt wird, obwohl die Blöcke in der falschen Reihenfolge
eingetroffen sind.
Dieser Vorgang funktioniert zwar, ist aber recht ineffizient. Es dauert seine Zeit, bis die
Systeme die Daten fragmentiert bzw. wiederhergestellt haben, und die Abschlusspakete
enthalten oft sehr wenig Nutzdaten (nämlich nur die paar Bytes, die nicht über eine
Verbindung eines anderen Typs übermittelt werden können). Es wäre natürlich besser, wenn
der Absender von vorneherein die niedrigste MTU zwischen seinem Standort und dem Ziel
kennen und seine Pakete entsprechend erstellen würde. (Diesen MTU-Wert nennt man
auch Pfad-MTU oder kurz PMTU.) Leider bietet IP keine flexible und anständige
Möglichkeit, dies zu implementieren — was Forscher allerdings nicht daran gehindert hat, eine
clevere Lösung zu finden.
139
9 Der verräterische Akzent
Diesem Ansatz zufolge setzt ein System, das eine PMTU-Erkennung implementiert, ein
spezielles DF-Flag („Don't Fragment") für den gesamten ausgehenden Datenverkehr.
Kann der Router ein DF-Paket nicht weiterleiten, ohne es zu fragmentieren, dann soll er es
stattdessen verwerfen und eine entsprechende ICMP-Meldung („Fragmentierung
erforderlich, aber DF ist gesetzt") an den Absender schicken. Erhält der Absender eine solche
Meldung, dann kann er seine Annahmen entsprechend korrigieren, die Ergebnisse in einem
Zwischenspeicher ablegen und nachfolgend angemessenere Paketgrößen verwenden.
Weiterleitung mit Fragmentierung
IP-Header
; Kennung 1234
Fragment 1
IP-Header
NUTZ
DATEN
MTU-Elnheit
Fragment 2
Empfangenes
Paket
NUTZ
IP-Header
DATEN
]Kennung 1234 ]Kennung 1234
MF Offset ungleich Ö
Weiterleitung mit Verknüpfung
Wiederherstellung abgeschlossen: Block mit Pffset ungleich 0, aber ohne MF
empfangen; keine Lücken mehr Im Wiederherstellungspuffer.
Schlcht-4-Verarbeitung
Abbildung 9.4 Paketfragmentierung und -Wiederherstellung
Hinweis
Diese in RFC1991 beschriebene Praxis setzt voraus, dass der Aufwand für das Neusenden
des verworfenen Pakets weniger gravierend ist als die kontinuierlichen Leistungseinbußen
durch die Fragmentierung. Allerdings wird die Methode ziemlich kontrovers diskutiert, da
nicht alle Geräte korrekte ICMP-Meldungen senden und dies ursprünglich auch gar nicht
gefordert wurde. Insofern kann die Aktivierung von PMTUD (PMTU Discovery, PMTU-
Erkennung) dazu fuhren, dass ein Absender mit bestimmten Standorten nicht kommunizieren
kann oder Übertragungen einfach abreißen (was extrem schwierig zu diagnostizieren ist).
Mogu90
140
9.3 Jenseits von IP
9.2.10 IP-Kennung
Die Kennung (TD) ist ein 16-Bit-Wert, der bei Auftreten einer Fragmentierung die
Unterscheidung zwischen IP-Paketen gestattet. Ohne IP-Kennungen würden, wenn zwei Pakete
gleichzeitig fragmentiert würden, deren Fragmente bei der Wiederherstellung hochgradig
verstümmelt, vertauscht oder auf andere Weise beschädigt werden.
IP-Kennungen bezeichnen mehrere Wiederherstellungspuffer für verschiedene Pakete
eindeutig. Der für diesen Zweck verwendete Wert wird oft ausgewählt, indem ein Zähler mit
jedem gesendeten Paket einfach hochgezählt wird. So hat das erste von einem System
stammende Paket die Kennung 0, das zweite die Kennung 1 usw.
■ Hinweis
Bei Systemen, an denen die PMTUD aktiviert ist, sind eindeutige IP-Kennungen nicht
erforderlich, weil eine Fragmentierung theoretisch gar nicht auftritt, und der Wert wird meist auf 0
gesetzt (auch wenn man einwenden könnte, dass dies nicht besonders klug ist, weil einige —
auch verbreitete — Geräte das DF-Flag ignorieren).
9.2.11 Prüfsumme
Die Prüfsurnme ist eine 16-Bit-Zahl, die eine einfache Fehlererkennung ermöglicht. Sie
muss an jeder Zwischenstation neu berechnet werden, weil bestimmte Parameter (z. B.
TTL) sich konstant ändern. Deswegen ist hierfür ein schneller, aber nicht besonders
zuverlässiger Algorithmus vorgesehen. Zwar ist der Begriff prüfsurnme" heutzutage meist nur
noch dem Namen nach eine echte Prüfsumme (weil meist Algorithmen wie CRC32 oder
verschlüsselungstechnisch sichere Verkiü-zungsfunktionen zum Einsatz kommen), aber die
IP-Prüfsumme ist in der Tat eine Summe oder zumindest etwas Ahnliches, weil hier und
dort Negationen auf Bitebene eingestreut werden4, um Gegner zu täuschen. Oder vielleicht
doch eher, um sicherzustellen, dass die Prüfsurnme auch bei Auftreten üblicher
Übertragungsfehler korrekt bleibt.
9.3 Jenseits von IP
Eine Folge von vielen der strukturellen Entscheidungen, die bei der Entwicklung von IPv4
getroffen wurden, ist das Fehlen einer vernünftigen Zustellungsgarantie, auch wenn das
Netzwerk selbst zuverlässig agiert. Zwar sollen IP-Kennungen das Risiko von Kollisionen
bei der Paketwiederherstellung minimieren, aber die relativ geringe Breite von 16 Bits (die
65.536 Werte gestattet) kann gelegentlich Probleme verursachen, wenn zwei Pakete mit
identischen Kennungen gleichzeitig wiederhergestellt werden sollen. Außerdem sind die
Technisch gesehen (auch wenn es an dieser Stelle weniger wichtig ist) basiert die IP-Prüisumme auf
dem 16-Bit-Einerkomplement einer Summe von Einerkomplementen der Daten, für die die Prüfsurnme
erstellt wird.
141
9 Der verräterische Akzent
Prüfsummen von IP-Headem für einen zuverlässigen Integritätsschutz schlichtweg
unzureichend: Eine willkürliche Änderung im Paket könnte trotz allem zur identischen Prüf-
sumrne fuhren. Femer gibt es, wenn das Netzwerk tatsächlich ausfallen sollte, keine
Möglichkeit, herauszufinden, welche Daten verloren gegangen sind, auch wenn der Fehler
etwas so Profanes ist wie eine kurze Überlastung einer einzelnen Netzwerkkomponente.
Schließlich bietet das IP-Protokoll auch keine Möglichkeit, den Absender einer Nachricht
zu verifizieren: Man ist darauf angewiesen, dass der tatsächliche Absender derjenige ist,
der im IP-Header aufgeführt ist. Die Aufgabe, nach Bedarf Funktionen zur Integritäts- und
Zuverlässigkeitspriifung bereitzustellen, ist übergeordneten Protokollen vorbehalten. Und
dieser Bedarf ist in der Regel auch vorhanden. Insofern sind Protokolle, die IP
übergeordnet sind, auch erforderlich.
TCP und in geringeren! Maße auch UDP bieten nicht nur den dringend notwendigen
Schutz für den Datenverkehr, sondern ermöglichen dem Benutzer auch die Angabe eines
Empfängers (oder Absenders) auf eine Weise, die nicht nur auf ein bestimmtes System
verweist.
Während der IP-Header gerade genug Informationen enthält, um die Daten zwischen zwei
Systemen zu routen, nicht jedoch, um zu entscheiden, an welche Anwendung sie
ausgeliefert werden sollen, erweitern UDP und TCP den Horizont um eine weitere Dimension: Sie
erschließen die Domäne der Endsysteme, denn sie sagen dem Empfänger, an welche
Anwendung er die eingehenden Daten übergeben soll.
9.4 Das UDP-Protokoll
Nach Definition in RFC7685 bietet UDP (User Datagram Protocol) eine minirnale
Obermenge der IP-Funktionalität. UDP ergänzt eine Methode zur lokalen Auslieferung der
Daten, orientiert sich aber hinsichtlich der Zuverlässigkeit (bzw. deren Nichtvorhandenseins)
an der untergeordneten Schicht. Gleiches gilt jedoch auch für den gelingen Mehraufwand.
Die Verwendung von UDP zur Kommunikation kann mit einem Telefondienst verglichen
werden, bei dem Wörter manchmal vertauscht werden oder ganz aus Sätzen herausfallen
und es auch keine zuverlässige Anruferkennung gibt; dafür aber ist der Anruf billig, und
Ihre Anrufe werden zügig beantwortet.
Der UDP-Header (Abbildung 9.5) bietet ein Minimum an Funktionalität und ist recht
einfach gestrickt. Er bringt eine kleine Anzahl Parameter ein, die vom Zielsystem interpretiert
und verwendet werden können, um ein Paket an eine bestimmte Anwendung zu übergeben
oder sicherzustellen, dass es unterwegs nicht verstümmelt wurde.
5 Post80
142
9.4 Das UDP-Protokoll
1 1 1
Quellport
Länge
l l l
Zielport
Prüfsumme
: Daten :
Abbildung 9.5 Struktur des UDP-Headers
UDP wird für einzelne Abfragen, in Situationen, in denen Zustandsangaben keine Rolle
spielen, oder aber dann verwendet, wenn Leistungsfähigkeit und Aufwandsbeschränkung
wichtiger sind als Zuverlässigkeit. So wird UDP etwa häufig für die DNS-
Namensauflösung (Domain Name System), einfache Protokolle zum Stalten und
automatischen Konfigurieren des Systernstarts (BOOTP), Sfreainingtechnologien, die gemeinsame
Nutzung von Netzwerkdateisystemen usw. eingesetzt.
9.4.1 Einführung in die Portadressierung
UDP bringt das Konzept von Quell- und Zielports zusätzlich zu den Absender- und
Zieladressen ein. (Dieses System teilt es mit TCP, einem etwas besser entwickelten Protokoll
der Schicht 4, das ich im nächsten Abschnitt behandeln werde.) Ein Port ist eine 16-Bit-
Zahl, die entweder von einer Anwendung auf einem Endsystem, welche Daten senden oder
empfangen will, gewählt oder aber vom Betriebssystem zugewiesen wird (in diesem Fall
spricht man vom „kurzlebigen" Port).
Ein Port dient als Mittel, um Daten einer bestimmten Anwendung oder einem Dienst auf
einem Multitasking-System zuzuführen, sodass zwischen Programmen eine gleichzeitige
Kommunikation möglich ist. So kann beispielsweise ein Namensserverprozess
beschließen, auf Port 53 auf eingehende Anfragen zu lauschen, während das Logprograrnui Daten
überwacht, die über Port 514 eingehen. Ports ermöglichen es Clients, gleichzeitig mit
diesen Prozessen zu kommunizieren. Femer ist es, wenn die Implementierung eine
ordentliche Trennung von Quellport-/Zielportpaaren unterstützt, möglich, dass zwei Clients
verschiedene kurzlebige Quellports verwenden, um gleichzeitig mit dem gleichen Dienst
(z. B. auf Port 514) zu kommunizieren, ohne dass es Probleme mit der Frage gibt, welche
Clientanwendung welche Antwort vom entfernten Dienst erhalten soll.
Damit das Zielsystem zwischen Daten, die für verschiedene Anwendungen vorgesehen
sind, unterscheiden und sie wie gewünscht ausliefern kann, muss der Absender die
Zielportnummer bei allen Paketen angeben. Der Absender legt für jede Clientanwendung einen
anderen Quellport fest, sodass, sobald der Server antwortet, diese Antwort an die korrekte
Komponente weitergeleitet wird.
143
9 Der verräterische Akzent
Bei diesem Portadressierungssystern ist ein Wertequadrupel — Quellhost, Quellport,
Zielhost und Zielport — erforderlich, um eine ordnungsgemäße Trennung der Datenströrne und
eine einwandfreie Sitzungsverwaltung für gleichzeitige Verbindungen zu gewährleisten,
die von einem bestimmten System stammen oder an ein solches gerichtet sind. Die
Struktur hat zur Folge, dass zu einem gegebenen Zeitpunkt maximal 65.535 Clients0 derselben
IP-Adresse Verbindungen mit der Außenwelt herstellen können und dass maximal
65.535 Dienste über eine IP-Adresse lauschen können - zumindest dann, wenn man keine
cleveren Ideen entwickelt. (Allerdings ist die Wahrscheinlichkeit, dass wir in absehbarer
Zukunft ganz erheblich unter dieser Einschränkung zu leiden haben werden, eher geling.)
9.4.2 Übersicht zum UDP-Header
Der oben in Abbildung 9.5 gezeigte UDP-Header folgt auf den IP-Ffeader und steht vor
den eigentlichen Nutzerdaten in den UDP-Paketen. Er besteht aus nur wenigen Feldern:
Quell- und Zielport (je 16 Bit), Paketlänge und einer 16-Bit-Prüfsumme zum Zweck einer
zusätzlichen Integritätsprüfung.
Und jetzt zu etwas völlig anderem.
9.5 TCP-Pakete
Zweck des in Abbildung 9.6 gezeigten TCP-Protokoll-Headers (Transmission Control Pro-
tocol, definiert in RFC7937) ist die Bereitstellung einer zuverlässigen, datenstrornbasierten
Methode zur Herstellung einer sinnvollen Kommunikation zwischen zwei Systemen. TCP
ist besser als UDP für Anwendungen aller Art geeignet; ausgenommen sind lediglich
solche Anwendungen, die rnehr als nur einfache, kurze Mitteilungen und Einzeldaten
übermitteln wollen.
Obwohl die technische Implementierung auf der Verwendung separater IP-Datagramme
basiert, die das Netzwerk durchqueren, ähnelt der Kornmunikationsmodus einer
hergestellten TCP-Verbindung (die aus Sicht der Anwendung ein virtueller Kanal ist) eher einem
ganz nonnalen Telefongespräch. Anders als bei UDP-Daten können Sie beim Einsatz von
TCP sicher sein, dass der Empfänger die Daten immer so bekommt, wie sie gesendet
wurden (bzw. dass der Kornmunikationsvorgang vollständig abgebrochen wird, wenn eine
Datenwiederherstellung im Fehlerfall nicht möglich ist). Unter normalen Bedingungen
können Sie außerdem darauf bauen, dass die Identität des Teilnehmers korrekt ist, aber diese
Sicherheit wird - auch und gerade in Bezug auf die Leistungsfähigkeit - teuer erkauft.
Technisch gesehen sind es natürlich 65.536 Ports, aber der Port 0 darf nicht verwendet werden, selbst
wenn das Betriebssystem und/oder die Anwendungen dies standardwidrig zulassen würden.
Post81c
144
9.5 TCP-Pakete
■ i m I ^ I ä I
—r-^—
\ \
4 \ \
_l \
8
12
16
/ 20
24
28
32
\ "^
\Qufellport
\ \
\ \
Zielport
Sequenznjjrjimer
Datenoffset
\ \
\ \
Reserviert \
Bestätig unashummer
Prüfsumme
Fenster
Dringlichkeitszeiger
Optionstyp 1
Optionslänge 1
Optionsdaten 1
Optionstyp 1
Optionslänge 1
Optionslänge 1
Fülldaten
Daten
Abbildung 9.6 Struktur des TCP-Headers
Bei TCP bauen zwei Endpunkte zunächst eine Verbindung auf. Hierbei kommt der so
genannte Drei-Schritte-Handshake zum Einsatz. Hierbei gleichen die beteiligten Paiteien
durch Versand (normalerweise) leerer Pakete - also solcher, die nur Header und keine
Nutzdaten enthalten - ihre Ziele ab, verifizieren die Identität des jeweils anderen und
handeln Sequenz- und Bestätigungsnummern für den Beginn der Datenkornmunikation aus.
Diese Nummern, die als 32-Bit-Werte dargestellt werden, gewährleisten eine zuverlässige
und nahtlose Übertragung, denn sie werden im Zuge des Datenversandes hochgezählt.
Dies wiederum gestattet dem Empfänger, die eingehenden Pakete in die richtige
Reihenfolge zu bringen und festzustellen, ob ein Teil der Daten fehlt.
9.5.1 TCP-Handshake mit Steuer-Flags
Eine TCP-Sitzung beginnt, wenn ein entferntes System den Wunsch äußert, eine
Verbindung mit einem bestimmten Port auf dem Zielcomputer herzustellen. Das Remote-System
sendet in diesem Fall ein leeres Paket mit einem gesetzten Synchronisierungs-Flag (dem
145
9 Der verräterische Akzent
SYN-Flag) und einer ersten Sequenznurnmer im Header an den Empfänger. Nach Empfang
dieses Pakets muss, was auch immer als Antwort gesendet wird, diese Sequenznurnmer
enthalten, um akzeptiert zu werden. Wenn das Zielsystem die korrekte Antwort nicht
innerhalb einer angemessenen Zeitspanne sendet, dann wird das Paket erneut gesendet, bis
entweder die Auslieferang erfolgreich ist oder der Absender den Eindruck gewinnt, dass er
es nun oft genug probiert hat, und die Verbindung schließt.
Die Sequenznurnmer gewährleistet, dass die Antwort auf das Paket tatsächlich vom
Empfänger und nicht von einem Dritten stammt, der weiß, dass die Kommunikation stattfindet,
und sie abfangen will. Außerdem ist dank der Sequenznummer sichergestellt, dass die
Antwort kein verlorengegangenes, fehlgeleitetes Paket einer vorherigen Sitzung ist, das
letztendlich doch seinen Weg nach Hause gefunden hat, sondern eine Reaktion auf die
betreffende Anfrage des Absenders. (Bei 32-Bit-Zahlen und 4.294.967.296 möglichen
Werten ist die Wahrscheinlichkeit einer Kollision erheblich geringer als bei den IP-
Kennungen mit ihren nur 16 Bits. Auf diese Weise sind sowohl versehentliche
Missgeschicke als auch Erfolge knobelnder Angreifer ziernlich unwahrscheinlich.)
Vom Empfänger wird erwartet, dass er auf die SYN-Anforderung mit einem ähnlichen
Paket reagiert, das an den Absender und den von ihm verwendeten Quellport adressiert ist.
Bei diesem Paket sollte das RST-Flag (Reset) im Header gesetzt sein; auf diese Weise gibt
es an, dass es nicht bereit ist, eine Sitzung einzurichten. (Auf diesem Endpunkt läuft kein
Programm, das bereit ist, Verbindungsanfragen zu beantworten.) Dieses Paket muss neben
einer Antwort auch die ursprünglich übennittelte Sequenznummer benennen. Alternativ -
also in dem ungewöhnlichen Fall, dass der Empfänger tatsächlich willens ist, eine
Verbindung herzustellen und mit dem Fremden zu kommunizieren - sollte er mit einem ähnlich
aufgebauten Antwortpaket reagieren, bei dem jedoch das SYN- und das ACK-Flag
(Acknowledgment; dies ist ein Bestäü'gungs-Flag) gesetzt sind; auf diese Weise zeigt er
an, dass er die Anforderung akzeptiert. Ebenso angegeben sein sollte die Sequenznummer,
die er von nun an als Bestandteil aller Antworten erwartet, die zu dieser Sitzung gehören
sollen.
Im letzten Schritt des Handshakes sendet der Absender ein einzelnes ACK-Paket, um
sicherzustellen, dass beide Systeme die zuvor ausgetauschten Sequenz- und Bestätigungs-
nurnmem kennen und bezüglich der Transaktion auf derselben Seite stehen. Wenn die
Kommunikation diesen Punkt erreicht, gehen die beiden beteiligten Endpunkte mit einiger
Sicherheit davon aus, dass sowohl Absender als auch Empfänger der sind, der sie zu sein
vorgeben. Warum dieses? Nun, jeder der beiden kann den Datenverkehr beobachten, der
an seine jeweilige Adresse gesendet wird. Andernfalls hätte ein Endpunkt, der lediglich
seine IP-Adresse fälschte, um eine ebenso gefälschte Verbindung im Namen eines Dritten
herzustellen, keine Ahnung, welche Nummer er in seine Antwort an den Gegenüber
eintragen sollte. Überdies wäre dieser Gegenüber wohl recht überrascht, festzustellen, dass
jemand ihm unaufgefordert SYN+ACK- oder ACK-Pakete zu schicken versucht.
Dieses Handshake-Protokoll beseitigt die Chance, dass ein Fremder die Daten einfach
fälscht, behebt aber nicht das Problem, dass sich ein feindseliger, aber berechtigter Benut-
146
9.5 TCP-Pakete
zer in einem zulässigen Pfad zwischen den Systemen befindet (auch wenn dieser Fall -
verglichen mit dem Spoofing ins Blaue hinein - doch recht unwahrscheinlich ist).
■ Hinweis
Obwohl das Problem der Verwendung von ISNs (Initial Sequence Nurnbers, Ausgangsse-
quenznummem), die schwer vorauszusagen sind, nicht als solches betrachtet wurde und viele
Systeme Strukturen wie etwa einfache Inkrementalgeneratoren verwendeten, wurde die
Möglichkeit, das ein Außenstehender entweder aufs Geradewohl eine Sitzung durch Fälschen eines
TCP-Handshakes einleitete oder Daten in bereits laufende Verbindungen einspeiste, natürlich
mit der Zeit doch ein wenig problematisch. Eine sorgfältige Auswahl der anfänglichen TCP-
Sequenznurnmem dergestalt, dass ein Dritter nicht prophezeien kann, wie Ihr System auf ein
eingehendes Paket antworten wird, gilt heute als absolut notwendig, und es gibt bereits
mehrere Ansätze, um diese Aufgabe zu erledigen.
Wenn der Handshake abgeschlossen ist, können die betieffenden Parteien Daten
austauschen, wobei sie sich bei jedem Vorgang gegenseitig die Sequenznummem bestätigen.
Pakete, die eine abweichende Sequenznummer aufweisen (welche außerhalb des zulässigen
„Fensters" liegt) werden einfach ignoriert. Diese Nurnmem werden bei jedem Vorgang
konstant erhöht und spiegeln so die Menge der Daten wieder, die bis zum betieffenden
Zeitpunkt gesendet wurden. Dies ermöglicht die Verarbeitung der Pakete in der korrekten
Reihenfolge beim Empfänger, auch wenn sie dort nicht in dieser Reihenfolge eintreffen.
Um die Zuverlässigkeit zu gewährleisten, muss ein Paket neu übertragen werden, wenn es
nicht innerhalb eines bestimmten Zeitraums bestätigt wurde.
Beendet wird eine Sitzung, indem ein Paket mit gesetztem iTZTV-Flag und passender
Bestätigungsnummer von einem der Beteiligten empfangen wird. Wenn zu irgendeinern
Zeitpunkt eines der Systeme keine Lust rnehr hat und die Sitzung sofort beenden will (etwa
weil es aus seiner Sicht nichts rnehr zu bereden gibt, die Gültigkeit der Sitzung abgelaufen
ist oder der Gegenüber bestimmte Regeln verletzt hat), dann wird ein RST-Paket gesendet.
Auf der linken Seite von Abbildung 9.7 sehen Sie einen erfolgreich dmchgeführten,
korrekt abgelaufenen TCP-Handshake, rechts ein fehlgeschlagenes IP-Spoofing, dessen
Verursacher die Einrichtung einer Sitzung im Namen eines unschuldigen Systems bezweckte,
das überhaupt keine Ambitionen hegt, Daten mit dem Empfänger auszutauschen. Der
Angreifer kann die von dem System, in dessen Namen er agieren will, verwendete Antwort
weder sehen noch vorhersagen und den Handshake aufgrund dessen nicht abschließen -
von einem tatsächlichen Austausch von Daten in der TCP-Sitzung ganz zu schweigen.
Kevin Mitnick, einer der berühmtesten und am wohl kontroversesten diskutierten Black Hats, griff
einmal den Computer von Tsutomu Shimomura an, indem er mithilfe des TCP-Spoofings die Identität
einer vertrauenswürdigen Workstation annahm — ein Vorgang, der Tsutomu ziemlich aufregte und
Belichten zufolge Mitnick langfristig nicht sehr geholfen hat.
9 Bell96
147
9 Der verräterische Akzent
Ordnungsgemäßer Handshake
Einfaches Spoofing-Szenario
Client
Sendet SYN-Paket mit
eindeutiger Sequenz-
JSendet SYN+ACK-Paket mit
eindeutiger Sequenznummer
Client und erhaltener Nummer
zur Bestätigung zurück
Server
Server
Sendet ACK-Nummer zur
Bestätigung der Sequenz-
'Client nummer des Servers zurück
Server
Beide tauschen normale
ACK-Pakete mit Nutzdaten
Client aus; Sequenznummern werden
Jeweils erhöht, um die Menge
der übertragenen Daten
widerzuspiegeln (NeuObertragung
erfolgt nach Bedarf)
Server
Beide Selten senden
ein FIN-Paket, um die
'Client Sitzung zu beenden
Server
Client
Angreifer nimmt
Identität der IP-Adresse des
Clients an, um ihn zu
täuschen oder das Vertrauen
des Servers auszunutzen
Server
Client
Server antwortet an IP-
Adresse des Clients; der
Angreifer erkennt die vom
Server gewählte
Sequenznummer nicht und kann kein
gültiges ACK-Paket Imitieren
Server
Abbildung 9.7 Vollständiger TCP-Handshake und typischer fehlgeschlagener Spoofing-Angrrff
Wie bereits angemerkt, bietet TCP einen ordentlichen Schutz gegen
Zuverlässigkeitsprobleme im Netzwerk und ist für die geordnete sitzungsbasierte Kommunikation gut geeignet.
Der Preis jedoch sind erforderliche Zusatzdaten, die sowohl infolge des Handshakes als
auch auf beiden Endsystemen zur Pflege der Steuerinformationen für die Verbindung
anfallen. Die Aufrechterhaltung dieses Zustandes fordert einen hohen Tribut, denn für jede
Verbindung müssen Sequenznurnrnern und der aktuelle Status des Datenstrorns
(Handshake-, Datenaustausch- und Abschlussphasen) im Auge behalten werden; zudem muss
eine Kopie aller gesendeten, aber noch nicht bestätigten Daten für den Fall einer
erforderlichen Neuversendung gespeichert werden usw.
Aufgrund der hohen Speicher- und Leistungsanforderungen fallen Implementierungen des
TCP-Stapels häufig DoS-Angriffen (Denial of Service, Dienstverweigerung) zum Opfer.
9.5.2 Weitere Parameter des TCP-Headers
Es gibt im TCP-Header noch ein paar andere Parameter, die ebenfalls wichtige Aspekte
der Paketinterpretation und -ausliefening steuern. Diese kommen im weiteren Verlauf der
148
9.5 TCP-Pakete
Konversation zur Geltung, wenn wir versuchen, Informationen zum Absender zu eirnitteln,
indem wir einfach einen Blick auf die Paketdaten werfen. Abbildung 9.6 weiter oben in
diesem Kapitel enthält eine vollständige Aufführung der TCP-Felder.
■ Absender- und Zielports. Diese 16-Bit-Werte geben die logische Herkunft und das
Ziel auf Absender- und Empfängersystemen an. Sie ähneln den Quell- und Zielport-
parametem von UDP, aber die Porträume für UDP und TCP werden auf der
Systemebene getrennt gehalten, d. h. eine Anwendung kann auf UDP-Port 1234 horchen,
während eine andere selbiges auf Port 1234 im TCP-Raum tut. Die Daten werden
entsprechend den Protokollangaben im IP-Header weitergeleitet.
■ Sequenz- und Bestätigungsnummern. Diese 32-Bit-Werte sichern die Sitzungsinte-
grität. Eine Sequenznurnmer ist ein Wert, von dem der Absender erwartet, dass er vom
Empfänger an ihn zurückgerneldet wird. Eine Bestätigungsnummer ist der vom
Empfänger an den Absender zurückgesandte Wert. Er hat nur bei gesetztem ACK-Flag
Aussagekraft.
■ Datenoffset (nicht zu verwechseln mit dem Offsetparameter für IP-Fragmente).
Die in diesem Feld enthaltenen Informationen geben an, wo im Paket der Header endet
und die Nutzdaten beginnen. Wie bei IP-Headem kann die Länge des TCP-Headers
variieren, wenn bestimmte Einstellungen variabler Länge am Ende angehängt wurden.
Diese Angabe ermöglicht das einfache Springen zu den eigentlichen Daten, ohne zuvor
alle Headerdaten auslesen zu müssen.
■ Flags. Diese 8-Bit-Werte definieren spezielle Eigenschaften eines Pakets. Jedes der
angegebenen Bits in diesem Feld repräsentiert ein spezielles Flag, das separat gesetzt
oder gelöscht werden kann. Aufgrund dessen lassen sich TCP-Flags nach Beheben
kombinieren. Wie oben beschrieben, definieren Primär-Flags (SYN, ACK, RST und
FIN), wie ein Paket innerhalb einer TCP-Sitzung zu interpretieren ist, während Sekun-
dcir-Flags bestimmte Aspekte der Auslieferung von Nutzdaten und anderer erweiterter
Funktionen wie Überlastungsmeldungen steuern; letztere werden aber nicht verwendet,
um den Status der Verbindung selbst zu ändern.
■ Hinweis
Zwar lassen sich die Hags willkürlich setzen und löschen, aber eine Reihe möglicher
Kombinationen ist schlicht unzulässig oder falsch (z. B. SYN+RST; diese Kombination ist
bedeutungsfrei und formal nicht statthaft). Nur einige Kombinationen sind für den Handshake und
die normale Datenverarbeitung maßgeblich. Die einzelnen Systeme reagieren unterschiedlich
auf illegale Elag-Kombinationen, weswegen das Senden gefälschter Pakete mit seltsamen
Kombinationen zur Ermittlung des Betriebssystems auf der anderen Seite sehr beliebt ist.
■ Fenstergröße. Dieses 16-Bit-Feld steuert die maximale Menge der Daten, die gesendet
werden können, ohne dass ein zugehöriges Bestätigungspaket empfangen wird. Ein
höherer Wert gestattet das gleichzeitige Senden von mehr Daten, ohne dass eine
Bestätigung abgewartet werden muss, kann sich aber negativ auf die Leistung auswirken,
wenn ein Teil der Daten unterwegs verloren geht und deswegen nicht bestätigt wird; in
diesem Fall müssen die entsprechenden Pakete erneut gesendet werden.
149
9 Der verräterische Akzent
■ Prüfsumme. Diese einfache 16-Bit-Prüsurnme schützt die Integrität der Schicht-4-
Daten und ähnelt den entsprechenden Funktionen in UDP- und IP-Headem.
■ Dringlichkeitszeiger. Dieses Feld wird nur vom Empfänger ausgewertet, wenn das
URG-Flag {Urgent, eines der Sekundär-Flags) in einem Paket gesendet wird. Ist URG
nicht gesetzt, dann wird der in diesem Bereich des Headers angegebene Wert einfach
ignoriert. Das Flag zeigt an, dass der Absender den Empfänger auffordert, eine
bestimmte Meldung an die Anwendung, die die Daten verarbeitet, direkt weiterzuleiten.
Dies lässt sich wahrscheinlich auf eine „dringliche" Situation zurückführen, sodass das
Paket an einer früheren Position in den logischen Datenstrorn eingefügt wird, als es
sonst der Fall wäre. Der tatsächliche Offset wird vom Wert des Dringlichkeitszeigers
gesteuert. In der normalen Kommunikation kommt diese Technik nur selten zum
Einsatz.
9.5.3 TCP-Optionen
Der Block mit Optionen, der sich am Ende des Headers befindet, weist eine variable Länge
auf und dient der Angabe zusätzlicher Einstellungen und Parameter für das Paket. In
manchen Fällen ist er leer (d. h. er hat eine Länge von 0 Bytes), häufiger aber dient er dem
Aufführen von Erweiterungen des Protokolls, die später hinzugefügt wurden, aber
diejenigen Implementierungen nicht behindern sollen, die diese Erweiterungen nicht verstehen.
Der Optionsblock ist so aufgebaut, dass Systeme, die eine bestimmte Option nicht
erkennen, diese problemlos ignorieren können. Nachfolgend aufgeführt sind die wichtigsten
Optionen:
■ MSS (Maximum Segment Size, maximale Segmentgröße). Dieser 16-Bit-Wert
entspricht der MTU im Netzwerk des Absenders abzüglich der Größe der Header
untergeordneter Schichten. So gibt er die maximale Länge der Pakete an, die wieder an den
Absender zurückgeschickt werden können, ohne dass es unterwegs zu
Fragmentierungen kommt. Der Absender gewährleistet rnithilfe der MSS-Einstellungen immer dann
eine optimale Leistung, wenn der Empfanger große Datensegmente zurückgibt, die
andernfalls fragmentiert würden, was wiederum die Bandbreite beeinträchtigen würde.
Leider wird die MSS-Option vom Endsystem gemäß seinem Wissen bezüglich der
Größe der Pakete eingestellt, die in seiner unmittelbaren Netzwerkumgebung
verarbeitet werden können, d. h. das häufig auftretende Problem der Fragmentierung auf
Zwischensystemen wild hierdurch nicht beseitigt. (Dies ist der Grund dafür, dass auf IP-
Ebene die oben beschriebene PMTU-Erkennung implementiert wurde.)
■ Fensterskalierung. Dieser 8-Bit-Wert, der in RFC123210 beschiieben ist, erweitert den
Bereich des in der ursprünglichen Definition des TCP-Headers bereits vorhandenen
Fenstergrößenfeldes. Es hat sich nämlich herausgestellt, dass die Bestätigung von
jeweils 64 Kbyte Daten (der größte mit den 16 Bits des Originalparameters darstellbare
Wert) einen Leistungsengpass verursachen kann, wenn große Datenmengen wie etwa
10 Jaco92
150
9.5 TCP-Pakete
Multimediadaten über Verbindungen mit großer Bandbreite, aber hoher Latenz
übertragen werden. Die Fensterskalierung ist eine Methode zur Erweiterung der
Fenstergröße, damit rnehr Daten gesendet werden können, ohne dass diese zwischenzeitlich
bestätigt werden Hiüssten. Dies beschleunigt den Datentransfer, andererseits müssen
aber, wenn ein einzelnes Paket fehlt, mehr Daten neu übertragen werden.
■ Optionen für selektive Bestätigungen. Diese Option ist in RFC201811 beschrieben.
Wenn breitere Fenster verwendet werden, dann erfordert der Verlust nur- eines einzigen
Paketes die Neuübertragung der gesamten unbestätigten Datengruppe, was eine
erhebliche Verschwendung von Bandbreite darstellt. Um dies zu verhindern, wurde eine
Methode zur selektiven Bestätigung von Datenblöcken entwickelt. Endpunkte geben durch
Übermittlung der Option Selective ACKPermitted zunächst einmal an, dass sie willens
und in der Lage sind, diese Funktionalität zu implementieren. Danach bestätigen sie,
sofern möglich, mithilfe der eigentlichen Option Selective Acknowledgment im Header
nichtfortlaufende Datenblöcke. Die Iinplementiemng dieser Technik kann die Leistung
erheblich steigern, allerdings werden rnehr Speicher- und
Datenverarbeitungskapazitäten benötigt.
■ Zeitstempeloption. Diese leistungssteigemde Option, die aus zwei 32-Bit-Werten
besteht, ist in RFC 1232 definiert. Diese Methode zur Übennittlung und Rückmeldung
von Zeitstempeln, die normalerweise auf irgendeine Weise basierend auf der
Systemoder Laufzeit erstellt werden, erlaubt jedem Endpunkt eine Schätzung der Zeit, die die
Daten flu- den Hin- und Rückweg zum bzw. vom Gegenüber benötigen (Rundreisezeit,
engl. Round-Trip Time). Der wesentliche Vorteil dieser Option besteht darin, dass der
Absender die Zeit, die ein Paket normalerweise benötigt, um sein Ziel zu erreichen,
ermitteln und gegebenenfalls eine TCP-Neuübertragung einleiten kann, wenn keine
Antwort eintrifft. Eine weitere Anwendung der Zeitsternpeloption besteht darin,
Kollisionen von Sequenznurnmern zu verhindern, was beispielsweise passieren kann, wenn
ein Paket, das schon vor Ewigkeiten abgeschickt wurde, doch noch beim Empfänger
eintrifft, nachdem in der Zwischenzeit bereits wieder mehrere Gigabyte Daten
ausgetauscht wurden und der Sequenznurnmernzähler einen vollständigen Umlauf
durchgeführt hat. Diese Funktion heißt auch PAWS (Protection Against Wrapped Sequence).
■ EOL. Diese Option ist als Abschluss der Optionen zu interpretieren. Sie weist den
Empfanger an, nachfolgende Daten nicht mehr als Teil des Headers zu verarbeiten. Da
die Größe des TCP-Headers in Einheiten definiert ist, die länger sind als ein einzelnes
Byte, kann, wenn alle Optionen angegeben wurden, bis zum Beginn der Nutzdaten
noch ein „leerer" Datenbereich folgen, weil vor den Nutzdaten immer vollständige 4-
Byte-Blöcke stehen müssen. Mit der EOL-Option kann verhindert werden, dass der
Empfanger diese Fülldaten zu analysieren versucht.
■ NOP. Diese Option bedeutet „tue nichts" und wird vom Empfänger mehr' oder weniger
einfach ignoriert. Der Absender kann (und sollte) NOPs in einem Paket als Fülldaten
Math96
9 Der verräterische Akzent
verwenden, um mehrere Multibyteoptionen anzuordnen (dies ist aufgrund von
Leistungs- und Architektuibeschiänkungen bei einigen Prozessoren erforderlich12).
T/TCP (Transacrional TCP). Diese etwas esoterische Erweiterung unterstützt
separate virtuelle Sitzungen (Transaktionen) innerhalb einer laufenden TCP-Sitzung.
Hierdurch kann man den Mehraufwand drosseln, der durch die Notwendigkeit verursacht
wird, jedes Mal, wenn Sie eine bestimmte Operation mit nur einmal benötigten
Diensten ausführen wollen, einen vollständigen Handshake durchzuführen. So etwas kommt
häufiger vor, wenn eine Anwendung eine Anzahl separater Transaktionen mit einem
Server verarbeiten will. Die Erweiterung wird nur selten eingesetzt und ist in erster
Linie für bestimmte Datenbanksysteme geeignet.13
9.6 ICMP-Pakete
ICMP-Pakete (Internet Control Message ProtocoL definiert in RFC79214) werden zur
Übermittlung von Diagnoseinformationen und Benachrichtigungen zu anderen
Protokolltypen gesendet. Auf der logischen Ebene als Teil der Schicht 3 zu betrachten, werden
ICMP-Pakete als Nutzdaten in IP-Paketen übeitragen und unterscheiden sich insofern nicht
von Nutzdaten der Schicht 4. ICMP übeitiägt keine neuen Benutzenaumdaten zwischen
den Endpunkten, sondern stellt stattdessen eine einfache Signalisierangsmethode für IP
bereit. Abbildung 9.8 zeigt die Struktur des ICMP-Headers.
Typ
12
_l_
16
Code
20
_l_
24
_l_
28
_l_
32
Prüfsumme
Meldungsinhalt
(für Fehlermeldungen, gekapselter Teil des ursprünglichen IP-Datagramms)
Abbildung 9.8 Aufbau des ICMP-Headers
12
14
„Erforderlich" bedeutet hier- „für eine korrekte Verarbeitung unumgänglich". Es gibt Prozessoren, die
erhebliche Leistungseinbußen aufweisen, wenn sie auf Datenstrukturen mit mehreren Bytes zugreifen
müssen, die nicht auf Längen von 32 oder 64 Bit abgeglichen sind. Andere Prozessoren erzeugen einen
schweren Ausnahmefehler (eine so genannte Execution Trap) und verweigern fortan jeden weiteren
Betriebsschritt. Natürlich kann ein dreister Absender gezielt Daten ungeeigneter Länge in den Puffer
einspeisen — in der Hoffnung, dass das Zielsystem bei Empfang eines solchen Systems einfach in sich
zusammenfällt. Intelligente Betriebssysteme fangen so etwas allerdings durch eine Prüfung ab oder
versuchen zuerst, die Daten in einen Bereich korrekter Länge zu kopieren, bevor sie sie verarbeiten.
Man sollte jedoch nicht allzu sehr auf die Vemunftbegabtheit von Betriebssystemen bauen
Vgl. RFC1644 (Brad94).
Post81c
152
9.6 ICMP-Pakete
Beim Austausch von TCP- oder UDP-Daten werden die unterschiedlichsten ICMP-Daten
gesendet. Sie geben gewöhnlich an, dass ein bestimmtes Paket nicht ausgeliefert werden
konnte, die Gültigkeitsdauer wählend der Übertragung überschritten wurde oder es aus
irgendeinem Grund abgewiesen wurde. Bestimmte ICMP-Pakettypen können auch spontan
gesendet werden: Es gibt Pakete, die Router bekannt machen, Echoanforderungen (,,Ping")
usw.
Wie bei UDP-Paketen ist auch der ICMP-Header recht einfach strukturiert. Er enthält die
folgenden Felder:
■ Nachrichtentyp. Dieses 8-Bit-Feld gibt eine allgemeine Kategorie des Ereignisses an,
aufgrund dessen das Paket gesendet wurde (z. B. „Empfänger nicht erreichbar"). Das
Feld kann auch eine nicht auf ein Ereignis bezogene Meldung enthalten, aber das
kommt eher selten vor.
■ Nachrichtencode. Dieser 8-Bit-Wert nennt - sofern möglich - das eigentliche
Problem. Er hängt vom Nachrichtentyp ab und beschreibt den auslösenden Umstand in
detaillierterer Form (z. B. „Netzwerk nicht erreichbar", „Host nicht erreichbar", „Port
nicht erreichbar" oder Kommunikation durch Administrator unterbunden"). Welcher
Unterschied im Grad der Detailliertheit zwischen dem Nachrichtentyp und dem
Nachrichtencode liegen soll, ist allerdings unklar.
■ Paketprüfsumme. Dieses Feld gewählleistet, dass das Paket nicht beschädigt wurde.
Die Funktionalität entspricht dem entsprechenden Feld bei UDP und TCP.
Der Header eines ICMP-Pakets ist relativ einfach strukturiert und bietet an sich gar nicht
genug Informationen, um das gemeldete Problem analysieren zu können oder zu ermitteln,
welcher Datenverkehr diese Meldung überhaupt erzeugt hat. Stattdessen befinden sich
diese Angaben im Nutzdatenbereich des Pakets, welcher dem Header unmittelbar folgt.
Zwar hängen die Nutzdaten eines ICMP-Pakets von der Nachricht ab, in der Regel
enthalten sie aber den Anfang des Pakets, das die Meldung ausgelöst hat. Auf diese Weise kann
der Empfänger bestimmen, welchem KoHimunikationsvorgang die Nachricht zuzuordnen
ist und welche Anwendung von dem Problem in Kenntnis gesetzt werden sollte. Femer
kann hiermit sichergestellt werden, dass der Absender des ICMP-Pakets tatsächlich ein
System, das sich irgendwo auf der Route zwischen den beiden betreffenden Computern
befindet, und kein Unbefugter ist. Andernfalls würde der Absender nicht erkennen können,
welche Daten eigentlich ausgetauscht werden. (Insbesondere wäre es nicht möglich, die
exakten Sequenznurnmem in den TCP-Paketen zu bestimmen.) Hierdurch wird verhindert,
dass der Lauscher an der Wand gefälschte Mitteilungen sendet, die
Konnektivitätsprobleme vortäuschen und einen Endpunkt dazu bringen, die Verbindung zu trennen. Zumindest
in der Theorie. Natürlich kann es recht schwierig sein, die Guten von den Bösen zu
unterscheiden, denn einige Systeme sind berüchtigt dafür, die Originaldaten zu verstümmeln
oder falsch anzugeben.
153
9 Der verräterische Akzent
9.7 Bühne frei für passives Fingerprinting
Was nun hat die Struktur dieses Protokolls mit der Privatsphäre von Benutzern zu tun? Die
Antwort mag absonderlich anmuten: Obwohl der Aufbau von IP-, TCP-, UDP- und ICMP-
Paketen recht strikt ist und die in diesen Headern übertragenen Daten nicht gerade
besonders auskunftsfieudig sind, ermöglichen Unterschiede in der Alt und Weise, wie die
verschiedenen Betriebssysteme Informationen zu diesen Paketen hinzufügen, nicht nur
Aussagen zum verwendeten Betriebssystem, sondern auch zur Version, die auf einem
bestimmten Computer läuft. Diese Unterschiede sind besonders auffällig beim Umgang mit
Daten, die in der Spezifikation nicht eindeutig und angemessen behandelt oder von den
normalen Qualitätssicherungsroutinen nicht analysiert werden (z. B. eingehende Pakete
mit unzulässige Flag-Kombination wie etwa SYN+RST).
Aufgrund der Ergebnisse umfangreicher Forschungen an unterschiedlichen
Betriebssystemen durch Belastungstests der jeweiligen Implementiemngen kann man guten Gewissens
feststellen, dass keine zwei Implementierungen der IP-Protokollsuite bei Betriebssystemen
identisch sind. Mithilfe komplizierter Analysevorgänge lassen sich Unterschiede zwischen
demselben Betriebssystem auf leicht unterschiedlichen Plattformen ebenso ausmachen wie
zwischen leicht unterschiedlichen Versionen eines Betriebssystems. Aktive Analysetools
wie dem TCP/UDP-Fingerprinter und -Portscanner NMAP von Fyodor oder dem ICMP-
Fingerprinter Xprobe von Ofir Arkin nutzen Fehler oder Unzulänglichkeiten aus, die auf
jedem System vorhanden sind. Sie identifizieren Typ und Version des Betriebssystems,
indem sie verschiedene Alten verstümmelter und unnormaler Pakete senden und dann die
ausgelösten Reaktionen messen und analysieren.
9.7.1 Schnüffeln in IP-Paketen: Die gute alte Zeit
Die Methoden des System-Fingerprintings enden hier nicht. Eigentlich ist das Einprügeln
auf das entfernte System durch die Übermittlung suspekter und leicht erkennbarer Daten
eher alles andere als eine subtile Art, dieses Problem anzugehen.
Im Frühjahr 2000 demonstrierten zwei Mitglieder der Subterrain Security Group mit den
Spitznamen bind und aempirei, dass es häufig möglich ist, sich Informationen zu einer
entfernten Einheit in einem Netzwerk zu verschaffen, ohne einen Kommunikationsvorgang
der indiskreten Art (oder überhaupt irgendeine Art der Kommunikation) mit ihr
durchzuführen. (Der Code und die Ergebnisse wurden zuerst auf der DefCON 8 präsentiert, einer
etwas überbewerteten Hackermesse, die im Jahr 2000 stattfand.) Bei dieser Methode, die
man heute als passives Fingerprinting bezeichnet, geht es um das passive (ach!)
Beobachten unregelmäßigen Datenverkehrs, der von einem entfernten System stammt. Zwar sind
die Metriken, die von dieser Methode verwendet werden, weitaus subtiler und auch
beschränkter als die von Fyodor und seinen Vorgängern benutzten, aber eine gerüttelt Maß
an Forschungsarbeit (zu der ich, wie ich mit Stolz sagen darf, verschiedentlich beitragen
durfte) hat ausreichend viele Beobachtungen ermöglicht, um einen ziemlich
beeindruckenden Präzisionsgrad zu erzielen.
154
9.7 Bühne frei für passives Fingerprinting
Damit Sie besser verstehen können, was sich einem einzelnen Paket, das über das
Netzwerk empfangen wurde, entnehmen lässt, wollen wir einen Bück auf die Metriken werfen,
auf die wir passives Fingerprinting gründen können, und untersuchen, was sie uns über den
Gegenüber sagen können. Für diese Untersuchung wollen wir den im Internet verbreitets-
ten Datenverkehrstyp sezieren: ein völlig normales und zulässiges TCP-Paket in einer IP-
Schale.
9.7.2 Der TTL-Startwert (IP-Schicht)
Wir eiinnem uns: Das TTL-Feld legt die Anzahl der Systeme fest, die ein Paket passieren
darf, bevor es als unzustellbar verworfen wird. Der TTL-Wert eines Pakets wird dabei
jedes Mal dann verringert, wenn es einen Router passiert. Erreicht das Feld den Wert 0, dann
wird das Paket aus dem Netzwerk entfernt.
Da es keine definierten Anforderungen gibt, welchen Startwert das Feld vom Absender
erhält, würfeln viele Entwickler von IP-Stapeln den Standardwert für „ihr" System quasi
einfach aus. Zwar kann ein passiver Zuschauer den Staitwert des Pakets ohne zusätzliche
Tests nicht exakt ermitteln (weil das Paket mit größter Wahrscheinlichkeit mehrere Router
passiert hat, bevor es in Sichtweite des Zuschauers gekommen ist), aber er weiß zumindest
schon einmal, dass dieser Startwert höher gewesen sein muss als der, den er dem Paket im
aktuellen Zustand entnommen hat. Außerdem übersteigt die Dui-chschnittsentfemung
zwischen zwei Computern im Internet einen Wert von 15 Zwischengeräten („Hops") nur
selten, und ein Abstand von mehr als 30 Hops kommt eigentlich nicht vor. Aufgrund dessen
kann man als Schnüffler sicher davon ausgehen, dass der Ursprungswert irgendwo
zwischen der beobachteten TTL und der Summe dieser TTL plus 30 hegen muss (aber
natürlich nicht höher als 256).
Da wir die Startwerte verbreiteter Betiiebssysteme kennen, können wir mit einiger
Sicherheit auf den Betriebssystemtyp schließen, den der Absender verwendet. (Linux-Systeme
und BSD-Derivate verwenden normalerweise den Staitwert 64, Windows 128 und einige
echte UNIX-Abkörnrnlinge 255.) Wenn wir einmal basierend auf diesem und anderen
Faktoren das Betiiebssystem ermittelt haben, das da Paket gesendet hat, können wir unter
Umständen bestimmen, wie weit der Absender von unserem Beobachtungspunkt entfernt ist,
indem wir die beobachtete TTL von dem Wert abziehen, der offenbar als Staitwert
verwendet wurde. Durch Abgleichen dieses Weites mit der zuvor ermittelten (oder
anderweitig bekannten) Entfernung zum Absendemetzwerk können wir nachfolgend ein paar
Schlussfolgerungen über die Organisation des absenderseitigen internen Netzwerks ziehen.
9.7.3 Das DF-Flag (IP-Schicht)
Das DF-Flag besagt, dass, wenn ein Paket nicht über eine bestimmte Netzwerkverbindung
gesendet werden kann, dieses nicht fragmentiert, sondern verworfen werden soll. Indem
wir feststellen, ob dieses Flag gesetzt ist, können wir bestimmen, ob das System den oben
beschriebenen PMTUD-Mechanismus verwendet, wodurch wir weitere Hinweise auf das
155
9 Der verräterische Akzent
verwendete Betriebssystem erhalten. Außerdem wird hierdurch zwischen zwei großen
Gruppen von Betriebssystemen unterschieden: Nur neuere IP-Implementiemngen nutzen
diese Methode, während alle anderen nicht daran interessiert sind, das Flag in ausgehenden
Paketen zu setzen.
9.7.4 Die IP-Kennung (IP-Schicht)
Wie bereits weiter oben (im Abschnitt zu den Unzulänglichkeiten der
Paketfragmentierung) erwähnt, setzen bestimmte PMTUD-fähige Betriebssysterne die IP-Kennung bei
einigen (oder allen) ausgehenden Daten auf 0, weil sie der Ansicht sind, dass die Daten nicht
fragmentiert werden sollen, und es sicherheitstechnische Bedenken bezüglich der
Preisgabe einer IP-Kennung gibt. (Wir werden in Kapitel 13 darauf zurückkommen.) Deswegen
können wir solche Systeme identifizieren, indem wir überprüfen, ob die IP-Kennungen
eingehender Pakete auf 0 stehen.
Die Sache hat allerdings einen Haken: Zwar setzen einige PMTUD-fähige Betriebssysterne
die IP-Kennung immer auf 0, andere hingegen tun dies jedoch zu unvorhergesehenen
Zeitpunkten — aus dem einfachen Grund, dass der Auswahlbereich für IP-Kennungen nicht
allzu groß ist. Anders gesagt: Wenn Sie ein Paket mit einer IP-Kennung ungleich 0 sehen,
dann können Sie sicher davon ausgehen, dass dies kein System ist, das Nullwerte für alle
ausgehenden Daten setzt. Erkennen Sie jedoch in einem Paket einen solchen Nullweit,
dann kann dies von einem besonderen Exemplar eines PMTUD-fähigen Systems, aber
auch von einem „regulären" System verursacht worden sein, dass für dieses Paket zufällig
den Wert 0 gewählt hat.
Die Wahrscheinlichkeit, dass dies passiert, ist zwar geling, aber nicht vemachlässigbar. Sie
sollten insofern IP-Kennungen mit Nullwerten entweder mit Vorbehalt betrachten (und nur
Kennungen ungleich 0 verwenden, um die Menge möglicher Betriebssysteme
einzugrenzen), oder denselben Absender mehrfach beobachten, um sicherzustellen, dass er
konsequent Nullwerte verwendet.
9.7.5 Diensttyp (IP-Schicht)
Dieses Feld sollte strukturseitig eigentlich so eingestellt sein, dass es Priorität und Typ des
Datenverkehrs widerspiegelt, damit Zwischensysteme erkennen können, wie mit dem
Paket zu verfahren ist. Allerdings wird eine solche Einstellung praktisch nie vorgenommen.
Die meisten Betriebssysteme setzen das Feld auf einen willkürlichen Wert, da dies ohne
stärkere Beeinträchtigung des TCP-Betrieb möglich ist. Je nachdem, wie wichtig der
Entwickler sich nimmt, setzt er den Parameter standardmäßig auf 0 oder findet es
angemessener, rnithilfe einer bestimmten Bitkombination alle Pakete, die sein System verlassen, mit
Attributen wie „geringe Latenz", „hohe Zuverlässigkeit" oder ähnlichem zu versehen.15
Es gibt auch Entwickler, die das Bit „Must Be Zero" („Null erzwingen") dieses Parameters setzen (was
in einer vorschriftsmäßigen Anwendung niemals geschehen dürfte), um eine eigene Note einzubringen.
156
9.7 Bühne frei für passives Fingerprinting
Dies gibt uns einen Vorteil: Weil wir die Vorgabewerte bestimmter Betriebssysteme
kennen, können wir deren Anzahl in Bezug auf das vom Absender verwendete System weiter
eingrenzen. Die Verwirrung wird allerdings dadurch gesteigert, dass einige unhöfliche
DSL-Betreiber und andere Provider dieses Feld bei ausgehendem Datenverkehr manchmal
ändern. Ihre Hoffnung besteht darin, dass der eine oder andere Router auf der anderen
Seite des Globus auf diesen Trick hereinfällt und wirklich glaubt, dass Pakete mit dem
Attribut „hohe Priorität" tatsächlich bevorzugt behandelt und schneller als andere Datenströrne
weitergeleitet werden müssen, was den Kunden des jeweiligen Providers beschleunigtes
Surfen im Web ermöglicht. (Dass ist gelingt, ist allerdings zu bezweifeln.)
Nicht nur die Betriebssysteme, sondern auch die Intemetprovider können den Wert des
Diensttypfeldes relativ frei auswählen. (So verwendet beispielsweise ein Anbieter aus
Schweden eine interessante und ziemlich einzigartige Kombination gesetzter Bits, die sich
auf den Wert 3 summieren, und setzt Diensttypbits für die Einstellung „hoher Durchsatz".)
Diese Praxis macht es uns aber auch relativ einfach, erkannten Daten einem bestimmten
Internetprovider zuzuordnen, indem wir lediglich die Auswahl der Diensttypbits betrachten
— dies erspart uns eine aktive Analyse der Quell-IP-Adresse (etwa durch Ermitteln bei
einer Registrierungsstelle).
9.7.6 Felder mit erzwungenen Null- und Nichtnullwerten (IP- und
TCP-Schichten)
Die IP- und TCP-Spezifikationen schreiben eine Anzahl von Feldern vor, die für eine
zukünftige Verwendung reserviert sind. Alle aktuellen Systeme sollten diese Felder auf 0
setzen, sodass Werten ungleich 0 an der jeweiligen Paketposition in Zukunft eine
bestimmte Bedeutung zugeordnet werden kann.
Natürlich gibt es einige Implementieningen, die diese Felder vor dem Versand entgegen
der Spezifikation nicht auf 0 setzen. Diese Angelegenheit wird zudem auf der
Qualitätssicherungsebene nicht beseitigt, weil sie keine spürbaren Probleme verursacht, und andere
Systeme weisen Pakete aufgrund dieses Makels auch nicht ab — nach dem Motto „Vorsicht
ist die Mutter der Porzellankiste". Insofern kann dieses Problem noch Ewigkeiten
fortbestehen — vielleicht sogar so lange, bis diese Bits im Rahmen irgendeiner TCP-Erweiterung
tatsächlich verwendet werden, die dann auf solchen mangelhaften Systemen mehr oder
minder eindrucksvoll scheitert. Auch hier ist die Überprüfung dieser Werte eine weitvolle
Infonnationsquelle, die uns recht genaue Hinweise auf das vom Absender verwendete
Betriebssystem gibt.
9.7.7 Quellport (TCP-Schicht)
Der Quellport gibt den Ursprung einer Verbindung auf der Absenderseite an. Jedes System
verfolgt einen Ansatz zur Zuweisung so genannter kurzlebiger (Absender-)Ports für
ausgehende Verbindungen; indem man also die beobachtete Portnummer überprüft, kann man
häufig das Betriebssystem des Absenders ableiten. Außerdem verwenden Systeme, die das
157
9 Der verräterische Akzent
Masquerading einsetzen, nonnalerweise einen recht speziellen Portbereich für diesen
Zweck. Beim Masquerading, das auch als n:l-Netzadressübersetzung bezeichnet wird,
werden aus einem privaten Netzwerk ausgehende Daten so umformuliert, dass sie alle vom
selben System (dem Masquerading-Systern) zu stammen scheinen; Antworten, die dieses
System empfängt, werden zurückübersetzt und dann innerhalb des privaten Netzwerks an
den erforderlichen Empfänger ausgeliefert.
Das Masquerading wird häufig gleichermaßen in Unternehmens- und Heimnetzwerken
eingesetzt, um Adressen einzusparen. Das interne Netzweit kann einen großen Pool mit
Adressen verwenden, die ihm technisch gesehen gar nicht zugewiesen sind. Diese
Adressen werden aus dem Internet nicht in dieses Netzwerk (und auch in kein anderes) geroutet.
Trotzdem können Systeme, die diese Adressen verwenden, auf das Internet zugreifen,
indem sie ihre ausgehenden Daten über ein Agentensystem leiten. Dieses System verwendet
seine eigene, ordnungsgemäße IP-Adresse, um entfernte Systeme im Namen des
ursprünglichen Absenders zu kontaktieren. Dieser Ansatz schützt auch interne Systeme, denn ein
Außenstehender kann keinesfalls unaufgefordert eine Direktverbindung mit einem internen
System aufnehmen — eine Verbindung nach draußen kann nur von innen her aufgebaut
werden.
Indem man den Bereich der Quellports untersucht, der von den anderen Beteiligten
gewählt wird, kann man auch hier Rückschlüsse auf das verwendete Betriebssystem ziehen
und — wenn man den erkannten Bereich mit anderen Beobachtungen abgleicht — ermitteln,
ob sich der Absender in einem privaten Netzwerk befindet, in dem die Adressübersetzung
zum Einsatz kommt (in diesem Fall würden die für das Betriebssystern erwarteten
Quellports höchstwahrscheinlich nicht mit den tatsächlich beobachteten Ports übereinstimmen).
Wenn das Absendemetzwerk die Adressübersetzung verwendet, lassen sich außerdem
bestimmte Rückschlüsse bezüglich der Art des zur Übersetzung benutzten Gerätes ziehen, da
verschiedene Produkte unterschiedliche Bereiche gebrauchen.
9.7.8 Fenstergröße (TCP-Schicht)
Wie wir wissen, bestimmt die Fenstergröße die Menge der Daten, die ohne Bestätigung
gesendet werden können. Die jeweilige Einstellung wird häufig auf der Basis der
Vorgaben gewählt, die der Entwickler von seinem indischen Guru oder anderen spirituell
maßgeblichen Institutionen erhält. Die beiden meistverwendeten Ansätze besagen, dass der
Wert entweder ein Vielfaches der MTU abzüglich der Protokoll-Header sein sollte — ein
Wert, der auch als MSS (Maximum Segment Size) bezeichnet wird —, oder aber einfach
groß genug und irgendwie „rund". Ältere Linux-Versionen (etwa 2.0) verwendeten
Zweierpotenzen (z. B. 16.384). Bei Linux 2.2 wechselte man dann zum 1 lfachen oder 22fachen
der MMS (warum auch immer), und neuere Linux-Versionen verwenden das Zwei- oder
Vierfache des MMS-Werts. Die Sega Dreamcast — eine netzwerkfähige Spielekonsole —
benutzt den Wert 4.096, und bei Windows wird häufig 64.512 verwendet.
Eine Anwendung kann den vom Betriebssystem verwendeten Fenstergrößenwert zwar oft
ändern, um eine Leistungssteigerang zu erzielen, aber von dieser Möglichkeit wird nur sel-
158
9.7 Bühne frei für passives Fingerprinting
ten Gebrauch gemacht. (Das Vorhandensein eines Wertes, der vom für ein Betriebssystem
erwarteten Standardwert abweicht, erlaubt unter Umständen einen Rückschluss auf die
verwendete Anwendung. Eines der wenigen Beispiele für eine solche Anwendung ist
Opera, ein leidlich bekannter Webbrowser.)
9.7.9 Dringlichkeitszeiger und Bestätigungsnummer (TCP-Schicht)
Die in den Feldern für den Dringlichkeitszeiger (16 Bits) und die Bestäü'gungsnummem
(32 Bits) angegebenen Werte werden nur verwendet, wenn ein passendes TCP-Flag (URG
bzw. ACK) im Paket gesetzt ist. Sind diese Flags nicht gesetzt, dann sollten die Werte auf
0 gesetzt werden, was aber wiederum häufig nicht getan wird. Einige Systeme initialisieren
sie einfach auf einen Wert ungleich 0, wodurch allerdings kein echtes Problem entsteht: Da
die Werte ohne gesetztes Flag gar nicht ausgewertet werden, erlauben sie lediglich die
Identifizierung eines bestimmten Betriebssystems.
In machen Fällen allerdings werden diese Werte überhaupt nicht initialisiert, sondern
einfach aus dem Puffer kopiert, der zur Herstellung des TCP-Pakets verwendet wird — egal,
was dort zum jeweiligen Zeitpunkt gerade gespeichert ist. Ich habe dieses Verhalten, als
ich mich mit dem passiven Fingerprinting für verschiedene Betriebssysteme beschäftigte,
bei den Protokollstapeln von Windows 2000 und Windows XP beobachtet: Immer dann,
wenn zwei TCP-Sitzungen gleichzeitig stattfanden, tauchten Teile der Daten einer früheren
Sitzung in der aktuellen erneut auf. (Wir werden in Kapitel 11 noch darauf eingehen.) Dies
sagt uns, dass die betreffende Person im Hintergrund noch etwas anderes erledigt, und
enthüllt uns zudem einige Informationen, die an einen Gegenüber übermittelt wurde. Aber
hallo!
9.7.10 Reihenfolge und Einstellungen von Optionen (TCP-Schicht)
Die exakte Reihenfolge und Auswahl der Optionen in einem Paket sieht auf jedem Be-
triebssystern anders aus. Da nicht festgelegt ist, wie Optionen in einem Paket sortiert sein
müssen, gibt es einige „verräterische" Kombinationen. So verwendet beispielsweise
Windows bei SYN-Paketen die charakteristische Abfolge MSS, NOP, NOP, Selective ACK
Permitted, während Linux gemeinhin die Reihenfolge MSS, Selective ACK Permitted,
Zeitstempel, NOP, Fensterskalierung benutzt. Natürlich ist auch dies eine hervorragende
Möglichkeit, Betriebssysterne auseinander zu halten.
9.7.11 Fensterskalierung (TCP-Schicht)
Der Skalierungsfaktor für die Fenstergröße ist normalerweise auf 0 gesetzt. Einige
Betriebssysteme allerdings setzen hier standardmäßig einen höheren Wert oder erhöhen den
Wert permanent für bestimmte Datentypen, sofern sie meinen, dass dies sinnvoll sein
könnte — wenn also etwa ein Benutzer gerade einen raubkopierten Film aus einem P2P-
Netzwerk heruntergeladen oder einen umfangreichen Download anderer Alt abgeschlossen
hat (wobei letzteres natürlich ein bisschen weniger wahrscheinlich ist).
159
9 Der verräterische Akzent
9.7.12 MSS (Option in der TCP-Schicht)
Dieses Feld, welches die maximale Segmentgröße angibt, ist bei einigen Betriebssystemen
auf einen bestimmten Wert festgelegt, während es bei anderen den Typ des direkten
Netzwerkanschlusses des Geräts angibt. Verschiedene Netzwerktypen arbeiten mit
unterschiedlichen MTUs, d. h. man kann feststellen, ob ein Benutzer eine sehr schnelle DSL-
Verbindung oder eine schnöde Modemanbindung benutzt.
9.7.13 Zeitstempeldaten (Option in der TCP-Schicht)
Da dieser Wert häufig der Systernlaufzeit entspricht, kann man diese durch Überprüfung
der Zeitsternpeloption oft feststellen. Außerdem kann man mehrere Systeme voneinander
unterscheiden, indem man die Zeitsternpelvariationen in den eingehenden Daten überprüft:
Verschiedene Systeme haben unterschiedliche Betriebszeiten (und die Wahrscheinlichkeit,
dass sie zum exakt gleichen Zeitpunkt gestaltet wurden, ist ziemlich unwahrscheinlich),
wogegen derselbe Computer einen kontinuierlich ansteigenden Zeitsternpelwert
verwendet.
Dies ist in zweierlei Situation recht praktisch. Die erste hegt vor, wenn eine Anzahl
Systeme mit derselben IP-Adresse arbeitet (wie z. B. beim Masquerading). In diesem Fall
kann ein neugieriger Webmaster auch dann, wenn alle Anforderungen von derselben
Adresse stammen und auf den ersten Bück nicht unterscheidbar zu sein scheinen, bestimmen,
wie viele eindeutige Benutzer des Unternehmens X ihre Website aufgerufen haben, und wo
diese Benutzer sich aufhalten.
Die zweite Anwendung ermöglicht das Zurückverfolgen eines einzelnen Benutzers, der —
warum auch immer — von IP-Adresse zu IP-Adresse springt. Warum könnte das jemanden
interessieren, und warum könnte die andere Seite feststellen wollen, ob der Benutzer so
etwas tut? Nun, beispielsweise könnte der Benutzer zwischen verschiedenen Adressen
wechseln, die zu einem Pool dynamischer IP-Adressen gehören, die einer Einwahlleitung
zugewiesen sind (indem er die Verbindung trennt und dann neu herstellt). Auf diese Weise
könnte er etwa vortäuschen wollen, dass es sich um bedeutungs- und zusammenhanglose
Aktivitäten handelt — statt um einen wohldurchdachten, umfassenden Angriffsversuch.
Auch denkbar ist, dass Interaktionsbeschränkungen etwa in einem Intemetforurn, einer On-
lineumfrage oder einer Abstimmung (durch eine profane mehrfache Stimmabgabe)
umgangen werden sollen. All dies gehört zum üblichen Zeitvertreib der Jugend von heute.
Die Zeitmessung der Zeitstempeloption arbeitet gewöhnlich recht präzise, denn sie basiert
auf einer Taktquelle mit einer Frequenz von 100 oder 1.000 Hz (obwohl einige Systeme
auch 64 oder 1.024 Hz oder andere, dazwischenliegende Werte verwenden). Dieser Grad
an Präzision ist ausreichend, um auch zwischen ähnlichen Systemen unterscheiden zu
können, die alle — etwa nach einem Stromausfall — zum rnehr oder weniger gleichen Zeitpunkt
hochgefahren wurden. Deswegen sind extrem genaue Aussagen möglich.
160
9.8 Passives Fingerprinting in der Praxis
9.7.14 Andere Schauplätze passiven Fingerprintings
Wir haben in diesem Kapitel die Metriken beschrieben, die am häufigsten zur Bestimmung
des Betriebssystems eines entfernten Hosts (und zur Nachverfolgung seiner Benutzer)
verwendet werden, ohne dass diese Benutzer überhaupt etwas davon mitbekommen. Es
gibt jedoch viele aufregende, aber weniger gut erforschte Aspekte der Kommunikation, die
über diese Grundlagen hinausgehen und sich für dieselben (und andere) Zwecke einsetzen
lassen.
Beispielsweise werden bei einer interessanten Variante des Fingerprintings nicht die
Pakete selbst untersucht, sondern es werden die Tirning- und Antwortraten bestimmter ICMP-
Meldungen, TCP-Neuübertragungen und ähnlicher Vorgänge gemessen. Die Werte, die für
alle Ablauf- und Neuübertragungszähler verwendet werden, ermöglichen ein präzises und
eindeutiges Profiheren eines Systems. Ein CRONOS-Projekt, das auf den Forschungen
von Franck Veysset, Olivier Courtay und Olivier Ffeen vom Intranode Research Team
basiert, zielt darauf ab, ein Tool zum aktiven Fingerprinting dieser Metriken zu entwickeln;
allerdings sind Anwendungen für passives Fingeipiinting ebenso verlockend.
Ein weiterer vielversprechender Ansatz besteht dagegen darin, andere Anomalien oder
ungewöhnliche Einstellungen zu kombinieren und zu messen. Hierzu könnten etwa die
Verwendung bestimmter Zeitstempelwerte durch einen Absender, mit Bestätigungsnummem
identische Sequenznummem, ungewöhnliche Flag-Konfigurationen, Nutzdaten in
Steuerpaketen, die Verwendung der EOL-Option und vieles andere mehr gehören. Diese
Eigenschaften lassen sich ebenfalls zur Unterscheidung zwischen Betriebssystemen verwenden,
auch wenn sie häufig nur für eine gelinge Anzahl von Implementierungen kennzeichnend
sind. (Der Algorithmus, der zur Auswahl der ersten Sequenznummer verwendet wird, ist,
wie Sie im nächsten Kapitel erfahren werden, häufig ebenfalls eine weitvolle
Informationsquelle.)
9.8 Passives Fingerprinting in der Praxis
Diese Metriken erlauben die präzise Identifizierung von Betriebssystemen und ihren
Konfigurationen sowie von Netzwerkpararnetem und die ebenso effiziente wie unauffällige
Überwachung von Benutzem. Zwar mag es schwierig zu glauben sein, dass dies möglich
ist, aber ein von mir geschriebenes Tool namens pOf implementiert die meisten dieser
Techniken zur Ermittlung und Analyse der Informationen, die in SYN-, SYN+ACK- und
RST-Paketen enthalten sind, auf eine vollständig passive Weise und mit hoher
Erfolgsquote.
Schauen wir uns doch einmal ein Beispiel an, um die Effizienz dieses Ansatzes
nachzuweisen. Tabelle 9.1 zeigt eine Anzahl wichtiger Parameter, die aus einem echten TCP-
Paket stammen, das im Netzwerk erfasst wurde. Was können uns die Werte über das
Betriebssystem des Absender sagen?
161
9 Der verräterische Akzent
Tabelle 9.1 Werte eines im Netzwerk abgefangenen TCP-Pakets
Protokoll
IPv4
TCP
TCP-Optionen
Parameter
Absenderhost
Zielhost
Flags
TTL
Kennnummer
Wert
nimue (10.3.0.1)
nightside (10.3.0.3)
DF
57
4428
keine IP-Optionen (Paketgröße: 20)
Absenderport
Zielport
Flags
Sequenznummer
Bestätigungsnummer
Fenstergröße
1:MSS
2: Selective ACK Permitted
3: Zeitstempel
4: Fensterskalierung
3803
80 (HTTP)
SYN
1418000073
0
32120
1460
170330930
0
Das ist schon eine ganze Menge. Wir wollen doch einmal sehen, was wir diesen
Beobachtungen entnehmen können:
■ Da das DF-Flag in den IP-Headem gesetzt ist, muss das System PMTUD verwenden.
Zu den Systemen, die dieses tun, gehören neuere Versionen von Linux, FreeBSD,
OpenBSD, Solaris und Windows. IRK, AK, viele kommerzielle Firewalls10 und
andere Systeme, die aus Zuverlässigkeitsgilinden PMTUD nicht implementieren, können
wir damit ausschließen.
■ Der TTL-Wert des Pakets befragt 57. Wir wissen, dass der TTL-Ausgangswert nicht
niedriger sein kann, denn er wird während der Übertragung zunehmend verringert.
Außerdem ist es unwahrscheinlich, dass dieser Staitwert größer als 87 ist (dies wäre ein
wirklich weit entferntes System). Wir können dies zahlreichen UNIX-Versionen
zuordnen, die alle einen TTL-Staitwert von 64 aufweisen; Windows (Startwert 128),
Solaris vor Version 8 (255) und verschiedene Netzwerkgeräte (32) können wir hingegen
ausschließen.
Eine Firewall ist eigentlich ein Router mit Filtereigenschaften, der häufig in der Lage ist,
Entscheidungen auf der Basis der Eigenschaften von Daten übergeordneter Schichten zu verstehen und auch zu
treffen.
162
9.9 Passives Fingerprinting in der praktischen Anwendung
■ Die IP-Kennung des Pakets ist ungleich 0. Hierdurch wird Linux 2.4 und höher
ausgeschlossen, ebenso mehrere neuere Releases anderer verbreiteter Betriebssysterne.
■ Der Absenderport liegt im rneistverwendeten Bereich zwischen 1.024 und 4.095. Dies
allein erlaubt uns zwar nicht das Ausschließen weiterer Betriebssysteme, aber wir
können sicher davon ausgehen, dass das System vor der aktuellen mehr als
2.700 Verbindungen hergestellt hat, und dass die Verwendung des Masquerading sehr
unwahrscheinlich ist.
■ Auswahl und Reihenfolge der Optionen (MSS, Selecttve ACK, Zeitstempel,
Fensterskalierung) sprechend für Linux 2.2 und höher.
■ Die Fenstergröße ist ein Vielfaches des MSS-Wertes (MSS ■ 22). Das einzige System,
zu dem dieser Wert passt, ist Linux 2.2.
■ Im Paket konnten keine Anomalien, Verletzungen von RFCs oder andere
Auffälligkeiten festgestellt werden, was unsere Annahme bestätigt, dass wir es mit einem Linux-
System zu tun haben.
■ Der MSS-Wert lässt auf eine Ethernet- oder eine modemgestützte PPP-Verbindung
schließen (MTU: 1.500).
■ Die Laufzeit des Systems beträgt ca. 19 Tage, und es ist sieben Systeme entfernt.
Gewiss lassen sich einzelne Metriken von Anwendungen oder durch Kniffe seitens des
Benutzers ändern. (So neigen etwa viele Nutzer dazu, den TTL-Wert zu ändern oder
bestimmte Einstellungen zu aktivieren oder zu deaktivieren, weil sie Leitfaden zur Netz-
werkoptirnierung gelesen oder Anwendungen ausgeführt haben, die einfallsreiche Namen
wie „Systemdoktor" haben.) Allerdings lassen sich basierend auf unseren Beobachtungen
derart viele Rückschlüsse ziehen, dass wir eine zuverlässige Möglichkeit gefunden haben,
das Betriebssystem eines Computers zu erkennen, indem wir das System ermitteln, bei
dem wir in den meisten Kategorien Übereinstimmungen erzielen.
In diesem Fall haben wir guten Grund anzunehmen, dass das fragliche Betriebssystern
Linux 2.2 und der Absender über eine Ethernet- oder eine Einwahlverbindung mit dem
Internet verbunden ist. Basierend auf dieser Annahme können wir auch schließen, dass das
System sieben Hops entfernt ist (64 — 57; dabei ist 64 der TTL-Ausgangswert bei Linux-
Systemen). Wenn sich mehrere Benutzer hinter dieser IP-Adresse verbergen, dann können
wir sie ganz einfach zählen, indem wir ihre Sitzungen basierend auf den
Systemeigenschaften und den Zeitstempeldaten (sofern verfügbar) unterscheiden.
9.9 Passives Fingerprinting in der praktischen
Anwendung
Datenverkehr im Netzwerk, der vom Ernplänger oder einem Außenstehenden (z. B. einem
Internetprovider zwischen Absender und Empfänger) beobachtet wird, kann zahlreiche
Informationen vermitteln, die über die tatsächlich ausgetauschten Daten hinausgehen. Hierzu
163
9 Der verräterische Akzent
gehören unter anderem auch bestimmte Angaben zum Betriebssystem des Absenders. Wie
oben bereits angemerkt, ist die Angriffsfläche beträchtlich und auch recht interessant, denn
anders als bei von Anwendungen übertragenen Daten ist sie nicht offensichtlich und
entzieht sich zudem oft der Kontrolle des Benutzers. Zwar können Benutzer ihre
Browsereinstellungen und auch die anderer Anwendungen ändern, um Überwachung, Identifizierung
und Nachverfolgung zu verhindern, aber die Sicherheitslücke, die in den unteren Schichten
(TP- und TCP-Schicht) vorhanden ist, kann dieses Bemühen ganz einfach unterminieren,
indem sie dem Beobachter genau so viel Informationen zum Opfer zur Verfügung stellt,
wie das Opfer zu verbergen versucht. In diesen Schichten finden sich zudem Daten, die für
die Sicherheit der Infrastruktur von grundsätzlicher Bedeutung sind, z. B. nützliche
Hinweise zum Aufbau des Zielnetzwerks und implementierter Schutzmaßnahmen.
Aber passives Fingerprinting kann nicht nur zu Datenschutzverletzungen, sondern
durchaus auch für absolute legitime Aufgaben aus dem Bereich der Reconnaissance verwendet
werden. Der Bereich der praktischen (und durchaus auch häufig eingesetzten)
Anwendungen für passives Fingerprinting erstreckt sich über das gesamte ethische Spektrum: von der
Heimtücke bis zur legitimen Verteidigung.
9.9.1 Statistikermittlung und Ereignisprotokollierung
Eine der eher legitimen Anwendungen passiven Fingerprintings besteht in der
Überwachung des Netzwerks zur Dmchführung objektiver, nicht für Angriffe vorgesehener
Analysen zu verwendeten Plattformen und Netzwerkumgebungen. Hiermit soll sichergestellt
werden, dass alle Benutzer Dienste erhalten, die für ihre Software optimiert sind.
Außerdem sollte gewährleistet sein, dass keine größere Benutzergruppe auf irgendeine Weise
benachteiligt wird. Auch die Eimittlung von Daten zu potenziellen Angreifern oder
anderen unautorisierten Aktivitäten lässt sich mithilfe des passiven Fingerprintings erheblich
erleichtem. Und in der Tat wird das passive Fingerprinting zu Forschungszwecken im
Bereich von Honigtopfansätzen umfassend eingesetzt.
■ Hinweis
Honigtöpfe (Honeypots) sind ein Konzept, das von Lance Spitzner von Sun Microsystems
aggressiv beworben und erforscht wird. Ziel dieser Vorgehensweise ist es, dem Besitzer eines
Honigtopfs möglichst viel Informationen zu Gegnern und ihren Zielen zukommen zu lassen
Hierzu kommen bestimmte Geräte zum Einsatz, deren Wert in ihrer unautorisierten und
illegalen Verwendung liegt und die für die Infrastruktur keine tatsächliche Bedeutung haben,
obwohl sie dies vorgeben. Diese Geräte sind die eigentlichen Honigtöpfe.
9.9.2 Optimierung von Inhalten
Eine aktive Anwendung für passives Fingeipiinting dient der Bereitstellung von Diensten,
die für einen bestimmten Ernpiänger optimiert sind. Diese Optimierung basiert auf einer
17 Spit02
164
9.9 Passives Fingerprinting in der praktischen Anwendung
unmittelbaren Analyse der Konfiguration, die für den Zugriff auf den Server benutzt wird.
Ich halte es für meine Pflicht, hier ein etwas ruchloses Plug-in für eines meiner bereits
erwähnten Tools zu erwähnen: pOf. pOf bietet eine Methode, mit der Parameter von unlängst
von anderen Anwendungen eingegangenen Verbindungen abgefragt werden können. Dies
macht die Aufgabe der Inhaltsoptimierung wesentlich einfacher: Ein Webskript muss nicht
rnehr viel über TCP und IP wissen; es fragt einfach bei pOf an: „Hey, wer ist der Typ, mit
dem ich rede?". Und erhält darauf eine sinnvolle Antwort.
9.9.3 Durchsetzung von Richtlinien
Erkennung und mögliche Sperrung veralteter oder nichtkonformer Systeme (z. B. solcher,
die eine Untemehinensrichtlinie verletzen oder ein Sicherheitsrisiko darstellen) oder eine
Verseuchung mit unautorisierten Netzwerkanbindungen ist eine weitere interessante
Anwendung für das passive Fingerprinting. Seit Version 3.4 bietet OpenBSD eine Methode
zum Routen und Urnleiten von Daten basierend auf den Ergebnissen der Betriebssystern-
erkennung, was die Durchsetzung von Richtlinien auf der Basis von Eigenschaften eines
entfernten Betriebssystems durchaus realisierbar macht. Dieselbe Funktionalität ist nun als
Teil des Patch-O-Matic-Codes für Netfilter unter Linux verfügbar. Beide
Implementierungen basieren auf pOf oder wurden davon inspiriert.
9.9.4 Die Sicherheit des kleinen Mannes
Das passive Fingeiprinting kann auch verwendet werden, um bestimmte Angriffsflächen
zu rninirnieren. Zwar ist es mit gewissem Aufwand möglich, die Fingerpiinting-Methode
zu hintergehen, aber das Fingeiprinting kann durchaus verwendet werden, um zu
verhindern, dass bestimmte Alten von Clients (wie etwa Windows-Systeme, die häufig mit Spy-
ware, Backdoors und Würmern verseucht sind und oft als Spam-Versender oder für
indirekte Angriffe missbraucht werden) den einen oder anderen Basisdienst im Netzwerk
benutzen, während weniger bedenkliche Einheiten daraufzugreifen dürfen.
9.9.5 Sicherheitstests und angriffsvorbereitende Beurteilung
Aktives Fingerprinting wird oft bereits im Ansatz von Firewalls und anderen Lösungen
gestoppt, die IP-Daten sorgfältig filtern und analysieren. Passives Fingeiprinting hingegen
erlaubt die Untersuchung auch extrem aggressiv geschützter Systeme und die Kar-
tographierung von Netzwerken, ohne Alarm auszulösen.
Bei Sicherheitstests und -beurteilungen mithilfe des passiven Fingerprintings verwendet
man einen zweifachen Ansatz. Zunächst lässt sich der eingehende Datenverkehr
analysieren. Obwohl der Beobachter warten muss, bis sich das Ziel mit seinen Systemen
verbunden hat, lässt sich die Verbindung nachfolgend recht leicht induzieren, ohne dass dort ein
Verdacht entsteht. Tatsächlich ist es häufig ausreichend, eine bestimmte E-Mail oder einen
Link auf eine Website an das Opfer zu senden, um auch die gewiefteste Paketfilterlösung
zu überwinden. Zweitens kann das passive Fingeiprinting zur Analyse der Antworten auf
165
9 Der verräterische Akzent
zulässige Daten an einen verfugbaren Dienst eingesetzt werden, um die Parameter des
Remote-Systems zu ermitteln. Wenn ein Black-Hat zwar weiß, wie er ein internes
Netzwerk erfolgieich angreift, aber rnehr zu dessen interner Struktur herausbekommen will, um
das Risiko einer vorzeitigen Entdeckung zu minimieren, dann kann sich das passive Fin-
gerprinting als recht nützlich erweisen. Dies gilt auch für legitime Sicherheitstests, für die
man von der Organisation, die überprüft wird, bezahlt wird.
9.9.6 Erstellung von Kundenprofilen und Eindringen in die
Privatsphäre
Viele Unternehmen treiben ausgesprochen viel Aufwand, um wertvolle Informationen zu
den Gewohnheiten, Vorheben und Verhaltensweisen von Menschen zu sammeln (und
diese dann auch zu verkaufen). Zwar werden diese Angaben in der Regel für
Marketingzwecke benutzt, sie können aber zumindest theoretisch auch gegen eine bestimmte Person
eingesetzt werden. Die Möglichkeit, Benutzerhandlungen durch einen Abgleich der
Ergebnisse von Fingerprinting-Aktionen an verschiedenen Positionen, die das Ziel besucht hat, zu
verfolgen — sei es zur Kartographierung interner Netzwerke und verwendeter Software, zur
Überwachung Einzelner oder zur Ermittlung anderer statistischer Daten von Wert —, kann
eine Informationsquelle sein, die entweder für sich bereits einen bedeutenden Wert
darstellt oder zur Steigerung der Attraktivität anderer politisch nicht ganz korrekter Angebote
beitagen kann.
9.9.7 Spionage und verdeckte Aufklärung
Die Möglichkeit, Zusatzinformationen zur Netzwerkarchitektur eines Mitbewerbers und zu
Benutzerverhalten und -vorheben zu gewinnen, ist oftmals sehr verlockend. Obwohl das in
Ihren Ohren wie ein schlechter Science-Fiction klingen mag, ist es im Grunde genommen
einfach nur ein zielorientierterer Typ der oben beschriebenen Profilerstellung.
9.10 Wie man Fingerprinting verhindert
Angesichts der Komplexität eines typischen IP-Stapels ist es extrern schwierig, das
Fingerprinting generell zu unterbinden. Allerdings ist es möglich, bestimmte Aspekte zu
behandeln und einige Typen bekannter Fingerprinting-Softwaie außer Gefecht zu setzen,
indem man ermittelt, welcher Parameter für diese die größte Bedeutung hat — und diesen
dann einfach ändert. So enthalten bestimmte Paketfüterlösungen wie etwa pf in OpenBSD
einen Paketnorrnalisierungsdienst, der sicherstellt, dass alle ausgehenden Daten „gleich"
aussehen. Hierdurch lassen sich zwar einige Aspekte des Fingerprintings bis zu einem
gewissen Grad ausschalten — oder das Fingerprinting wird zumindest erschwert, indem einige
behebte Programme weniger genaue Ergebnisse zurückgeben —, aber vollständig gelöst
wird das Problem dadurch nicht.
166
9.11 Denkanstöße: Der verhängnisvolle Fehler bei der IP-Fragmentierung
Wenn auch die sorgiältige und scheinbar umfassende manuelle oder automatisierte
Modifikation bestimmter Betriebssystemeinstellungen oder TCP-Parameter die Systernidentifi-
zierang erschweren kann, so sind doch bestimmte Verhaltensweisen tief im Kernel
vergraben und können nicht angepasst werden. Es ist beispielsweise ziemlich schwierig, die
Reihenfolge der Optionen in einem Paket zu ändern. Außerdem gehen Benutzer, die manuelle
Änderungen vornehmen, das Risiko ein, dass die von ihrern System stammenden Pakete an
eindeutigen Eigenschaften zu erkennen sind, was Datenschutz und Anonymität auch nicht
unbedingt förderlich ist.
Glücklicherweise gibt es gewisse Lösungen, die bestimmte Testformen behandeln. So
ändert etwa IP Personality von Gael Roualland und Jean-Marc Saffroy den TCP-Stapel so ab,
dass bestimmte Tools den Eindruck gewinnen, er stamme von einem anderen System. Mit
IP Personality können Sie NMAP sogar glauben machen, dass Ihr System ein Laserdnicker
von Hewlett-Packaid ist! Allerdings ergeben sich daraus ein paar Probleme. Zum einen
kann man den TCP-Stapel seines Systems problemlos seiner Robustheit berauben, indem
man versucht, die Identität eines Gerätes anzunehmen, das generell einen schwachen
Stapel einsetzt. Wenn Sie beispielsweise, um den besonderen Kennzeichen eines Druckers zu
entsprechen, für alle Verbindungen einfachste Sequenznurnmem verwenden, dann wird
irgendjemand diesen Umstand früher oder später zu nutzen wissen, um Ihren
Datenaustausch zu stören oder darin herurnzupfuschen. Außerdem funktionieren
Softwareanwendungen wie IP Personality nur bei den verbreitetsten, bekanntesten und
bestdokumentierten Programmen, während für die übrigen keine Erfolgsgarantie gewählt wird, denn die
Eigenschaften variieren von Anwendung zu Anwendung, und dies gilt auch für die Alt und
Weise, wie diese Eigenschaften interpretiert werden. Sie können also lediglich hoffen, die
unentschlossenen und naiven „Mainstream-Angreifer" zum Narren zu halten, weil diese
Tools benutzen, über die Sie Bescheid wissen.
■ Hinweis
Anders als Agentengeräte für das Masquerading leiten Proxy-Firewalls und andere Proxy-
Geräte Pakete nicht weiter, sondern fangen Verbindungen ab und erstellen stattdessen neue
Verbindungen unter Verwendung eines eigenen IP-Stapels. Sie stellen die einzige umfassende
Lösung gegen das Fingerprinting in den Schichten 3 und 4 des OSI-Modells dar, wirken sich
allerdings in hohem Maße nachteilig auf die Leistung aus und sind aufgrund der enorm
gesteigerten Komplexität extrem fehleranfällig. Außerdem ist ein Fingerprinting der Anwendung
selbst auf einer höheren Ebene durchaus noch möglich.
9.11 Denkanstöße: Der verhängnisvolle Fehler bei der IP-
Fragmentierung
Bei der Beschreibung der Merkmale, die das IP-Protokoll definieren, erwähnte ich hin und
wieder, dass der Vorgang der Fragmentierung und Wiederzusarnuiensetzung von Paketen
einen schweren Fehler aufweist. Dieser Gedanke entstammt in erster Linie einer ziemlich
167
9 Der verräterische Akzent
interessanten Beobachtung, die ich machte, während ich dieses Buch schrieb. Zwar ist das
Konzept auf einen aktiven und erkennbaren Angriff bezogen, der von einer offenbar
niederträchtigen Entität durchgeführt wird (auch wenn diese nicht ganz einfach geortet
werden kann), aber es handelt sich um einen einmaligen und interessanten Makel, der im
Aufbau des IP-Protokolls begründet hegt. Er ist nicht Folge eines klar definierten Fehlers,
sondern eher eine Kollision von Paradigmen auf unterschiedlichen Strukturebenen die
beide (interessanterweise) von Jon Postel, einem der Väter der IP-Protokollsuite, spezifiziert
wurden. Ich habe beschlossen, diesen Fehler am Ende dieses Kapitels näher zu erläutern —
als Denkanstoß für jene, die sich für die Pathologie der Cornputerfehler interessieren.
Zunächst wollen wir einen Bück auf die Sachlage von heute werfen. Oder besser: auf die
Sachlage von gestern, da wir eine ziemlich angestaubte Angriffstechnik, die ich bereits im
Abschnitt zu TCP beschrieben habe, aus der Mottenkiste holen werden. Die fragliche
Methode — das blinde Spoofing — wurde zuerst Mitte der Achtzigerjahre von Robert T. Morris
beschrieben.18 Hochkonjunktur hatte sie ein Jahrzehnt später, seitdem aber hat ihre
Bedeutung immer stärker abgenommen. Wir werden uns auf ein bestimmtes Beispiel des blinden
Spoofings konzentrieren: das Einspeisen bestimmter Daten in eine vorhandene Sitzung,
um diese zu stören und den Server davon zu überzeugen, dass sein Benutzer einen
bestimmten Befehl abgesetzt hat — oder den Benutzer davon, dass er gerade eine bestimmte
Antwort vom Server erhält. Diese Technik wird häufig als Connection HijacMng
(Entführung einer Verbindung) bezeichnet.
Unter normalen Umständen muss ein Unbefugter, der Daten in einen vorhandenen TCP-
Datenstrorn einspeisen will, zunächst die Sequenznurnmem bestimmen, die von
mindestens einer der beteiligten Parteien verwendet werden. Obwohl ein solcher Angriff eine
hochsensible Angelegenheit ist und gegen eine bestimmte, laufende Verbindung gerichtet
sein muss, kann er erfolgreich durchgeführt werden (und wird dies häufig auch), wenn die
Sequenznummem vorhersehbar sind. In den späten Neunzigerjahren gab es eine ganze
Menge Tools, mit denen Windows-TCP-Sitzungen mit IRC-Netzwerken (Internet Relay
Chat) beheiligt wurden — sei es zum eigenen Spaß oder aus anderen Gründen. Dabei wurde
der wenig robuste Windows-Algorithmus zur ISN-Bestimmung ausgenutzt: Es war ganz
einfach, ab und an ein einzelnes RST-Paket einzuspeisen und den einen oder anderen
Benutzer aus dem Chat zu werfen. Wh fanden das damals lustig.
Heute sieht die Situation etwas anders aus. Dank der Bemühungen vieler Forscher
(einschließlich der bescheidenen Beiträge des Autors dieser Zeilen) gelang es den Entwicklern
in harter Arbeit, die Vorhersagbarkeit von ISNs in TCP-Verbindungen zu erschweren.
Viele Versuche, die Qualität und Robustheit von Sequenznurnmerngeneratoren bei den
verbreiteten Betriebssystemen zu verbessern, haben am Ende dazu geführt, dass Angriffe auf
der Basis einer ISN-Vorhersage erheblich schwieriger geworden sind. Es gibt zwar ein
paar Ausnahmen, aber die sind nicht der Rede wert. Systeme, die fortlaufende ISNs
verwenden, sind weitgehend ausgestorben: Ein Angreifer, der die Nummern bei einem
Kommunikationsvorgang mit einem Gegenüber nicht bestimmen kann, ist gezwungen, den ge-
Mon-85
168
9.11 Denkanstöße: Der verhängnisvolle Fehler bei der IP-Fragmentierung
samten 32-Bit-Raum mögücher Werte zu durchsuchen, um einen präzisen Dateneinfuge-
angriff auszuführen. Dies sind etwa 4.294.967.296 Kombinationen. (Wenn er die Sitzung
lediglich abbrechen oder wirksam verstümmeln will, dann sind es ein paar Werte weniger.)
Im Zuge eines solchen Angriffs müssten etwa 80 Gbyte Daten gesendet werden, damit der
Erfolg garantiert wäre. Machbai- geht anders.
Allerdings hat sich, was die tatsächlichen Vorteile angeht, die sich durch eine erfolgreich
ausgefühlte Dateneinspeisung erzielen lassen, nur wenig geändert. Zwar werden Kormnu-
nikationsvorgänge zunehmend über Kanäle ausgeführt, die eine Verschlüsselung
unterstützen, aber die Bedeutung dieser Attacken hat nicht wesenthch abgenommen: Es gibt nach
wie vor eine Menge vielversprechender Angriffsszenarien. Hier ein paar Beispiele:
■ Daten lassen sich in unverschlüsselte Verbindungen zwischen Servern oder zwischen
Routem einspeisen. Dies betrifft etwa den Austausch von E-Mails,
DNS-Zonentransfers, die BGP-Kornmunikation usw. Ein Großteil der zwischen Servern ausgetauschten
Daten lässt sich vom Angreifer erzeugen und kann trotzdem sensible oder
vertrauenswürdige Daten enthalten, was gezielte und zeitlich abgestimmte Angriffe vereinfacht.
■ Daten lassen sich in unverschlüsselten Datenverkehr zwischen Client und Server
einfügen. Betroffen hiervon sind FTP-Dateidownloads (File Transfer Protocol) oder HTTP-
Meldungen (Hyper-Text Transfer Protocol). Mithilfe eines solchen Angriffs lassen sich
gefährliche, belastende oder schädliche Inhalte an unbedarfte Besucher übermitteln,
oder es lässt sich der Eindruck erwecken, dass der unschuldige Besucher einen Angriff
auszuführen versucht habe.
■ Daten lassen sich in eine vorhandene Sitzung einspeisen, um eine Sicherheitslücke zu
nutzen, die in einem Dienst auf einer Ebene vorhanden ist, die dem nicht
authentifizierten Benutzer gar nicht zugänglich ist. Dies gilt gleichermaßen für verschlüsselten und
unverschlüsselten Datenverkehr. So kann etwa ein Dienst wie das E-Mail-Zugriffs-
protokoll POP3 (Point of Presence) verschiedene Befehle nur dann entgegennehmen,
wenn der Benutzer sich zuvor erfolgreich angemeldet hat. Vor der Anmeldung sind die
einzigen verfügbaren Befehle diejenigen, die sich direkt auf den Authentifizie-
rungsprozess beziehen (nämlich die Anweisungen USER und PASS). Ohne gültiges
Passwort kann der Angreifer einen Fehler in einem der später verfügbaren Befehle (wie
etwa RETR, einem Befehl, mit dem eine bestimmte Nachricht aus einem Postfach
abgerufen wild) nicht ausschlachten. Gelingt es dem Angreifer jedoch, eine gefälschte
RETR-Anförderung in die laufende Sitzung eines authentifizierten Benutzers
einzuspeisen, dann hat er gewonnen.
■ Auch ein sicherer und verschlüsselter, integritätsgeschützter Datenstrorn ist anfällig für
einen DoS-Angriff wenn eine Sitzung mit nur einem einzigen, meisterhaft gefeitigten
Paket erledigt wird.
Insofern ist es durchaus verlockend, Daten ohne große Probleme einspeisen zu können,
ohne das gesamte Spektrum möglicher Sequenznummern ausprobieren zu müssen. Und
genau dies ist der Punkt, an dem sich eine Fragmentieiimg als ziemlich nützhch erweisen
kann.
169
9 Der verräterische Akzent
9.11.1 Wie man TCP zertrümmert
Wenn ein IP-Paket, das TCP-Nutzdaten enthält, fragmentiert wird (unbestreitbar ein bei
Dateiübertragungen häufig auftretender Fall — und einer, der sich nicht immer einfach
verhindern lässt, indem man das DF-Flag setzt, wie es einige Betriebssysteme tun), dann
durchqueren die Daten das Netzwerk in mehreren Blöcken und werden erst nach dem
Eintreffen beim Empfänger wieder zusammengesetzt. Ein gewitzter Angreifer kann — in der
Vorahnung einer Fragmentierung — ein speziell erstelltes, unzulässiges IP-Fragment
versenden, dass sich als vom erwarteten Absender stammendes Fragment ausgibt. Beim
Empfang dieses Fragments kann es mit etwas Glück — eine Frage des präzisen Tunings —
dazu kommen, dass der Empfänger dieses statt des echten Fragments zur
Wiederherstellung des ursprünglichen Pakets verwendet.
In diesem Angriffsszenario wird das erste Fragment (welches die vollständigen TCP-
Header einschließlich exakter Angaben zu Ports, Sequenznummem usw. enthält) mit einer
gefährlichen Nutzlast verknüpft, die der Angreifer gefälscht hat. Infolgedessen muss der
Angreifer die Sequenznummem oder andere Sitzungsdaten gar nicht kennen, um seine
Daten in den Frame einzuspeisen; auf diese Weise unterläuft er alle Bemühungen zur ISN-
Erzeugung. Ist der Angriff abgeschlossen, dann besteht das letzte vom Empfänger
verarbeitete Paket aus gültigen, aus einem zulässigen Fragment kopierten Header-Daten und der
schädlichen Nutzlast, die vom Angreifer eingebracht wurde.
■ Hinweis
Der Angreifer kann jeden Teil der Nutzdaten im ersten Segment ersetzen, indem er eine
leichte Überschneidung zwischen den Fragmenten festlegt; viele Betriebssysteme reagieren auf
solche Überschneidungen, indem sie die zuvor erhaltenen Daten mit einer neueren Kopie ü-
berschreiben. Irn Extremfall kann er Angreifer alle Daten in einem TCP-Paket mit Ausnahme
der Sequenznuinrner erfolgreich ersetzen
Natürlich fehlen noch einige Teile des Puzzles. Aber neben der Notwendigkeit eines
präzisen Tunings und dem Wissen, wann die Übertragung stattfindet19, gibt es nur noch zwei
Hindernisse, die der Angreifer in diesem Szenario aus dem Weg schaffen muss:
■ Das Fragment muss eine korrekte IP-Kennung aufweisen, damit es einwandfrei einge-
passt wird. Zum Glück ist dies auf vielen Systemen kein Problem, da IP-Kennungen
sequenziell gewählt werden. Aufgrund dessen lässt sich die Nummer, die zum
betreffenden Moment erwartet wird, einfach durch Aufbau einer Testverbindung ermitteln.
Einige Systeme — allen voran OpenBSD, FreeBSD und Solaris — bieten zufällige IP-
Kennungen, welche den Angriff erschweren, aber nicht verhindern können. Der An-
Das Tuning selbst ist kein so großes Problem, wie es auf den ersten Blick scheinen mag. Der Angreifer
kann das gefälschte zweite Fragment bei Bedarf zeitlich ein wenig vorziehen; in diesem Fall erstellt
der Empfanger einen Wiederherstellungspuffer und wartet auf die übrigen Teile, die innerhalb eines
bestimmten Zeitraums eintreffen müssen. Wenn dann das erste zulässige Fragment eintrifft, dann wird
der Puffelinhalt als vollständig wiederhergestellt betrachtet, ohne dass der „echte" zweite Block noch
ankommen muss.
170
9.11 Denkanstöße: Der verhängnisvolle Fehler bei der IP-Fragmentierung
greifer rnuss lediglich ein paar tausend Kombinationen (statt mehrerer Milliarden)
überprüfen, weil das IP-Kennungsfeld mit nur zwei Bytes relativ klein ist.
■ Der TCP-Header enthält eine Prüfsumme, die nach der Wiederherstellung überprüft
wild. Die vom Angreifer geänderten Prüfsurnmendaten müssen mit denen der
ursprünglichen Nutzdaten identisch sein. Da allerdings die Struktur einer TCP-
Prüfsurnme recht trivial ist (es handelt sich lediglich um eine Abwandlung einer
einfachen 16-Bit-Summe), lassen sich Nutzdaten fertigen, die die Prüfsurnme des Pakets
nicht ändern, sofern der Originalbereich, der ersetzt werden soll, dem Angreifer
bekannt ist. (Dies ist in der Regel der Fall — besonders während einer Dateiübertragung,
wenn der Angreifer gefahrlichen Code oder bösartige Inhalte in einen öffentlich
zugänglichen Teil der Daten einspeisen will.)
Die Berechnung der Prüfsumme eines Pakets, dass aus den Header-Wörtern Hl und H2
sowie den Nutzdaten PI, P2 und P3 besteht, ist nachfolgend vereinfacht dargestellt:
C = Hl + H2 ... + PI + P2 + P3 ...
Hl, H2 und C sind dem Angreifer nicht bekannt. (Header enthalten Sequenznummem, und
diese wirken sich auf die Prüfsurnme aus.) Der Angreifer verfügt über keine Möglichkeit,
dieses Paket selbst zu untersuchen, aber er weiß, dass das Opfer eine bestimmte —
vorhersagbare — Transaktion auf Anwendungsebene durchfühlt. (Solche Transaktionen können
etwa das Abrufen neuer E-Mails, das Herunterladen einer Webseite, ein Chat mit Freunden
oder Ahnliches sein.) Der Angreifer kann die Nutzdaten PI, P2 und P3 ableiten und will
sie durch die eigenen gefälschten Wörter Nl und N2 ersetzen, wobei ein drittes Wort als
RlifsurnmenkoHipensierung (CC) hinzugefügt wird, sodass die Prüfsumme weiterhin
gültig ist.
C = H1+H2...+N1+N2 + CC...
Wenn man diese Gleichungen nach CC auflöst, kann man daraus schließen, dass die
Prüfsumme mit CC = (P1+P2 + P3—Nl— N2) kompensiert werden muss. Der Angreifer
kann das Paket dann so abändern, dass die Prüfsurnme dieselbe bleibt, ohne dass er das
gesamte Paket kennen muss; er benötigt lediglich den ersetzten Teil. Auf dieser Basis lässt
sich die Kornpensierung korrekt berechnen und die Prüf summe beibehalten.
171
10 Schäfchen zählen für
Fortgeschrittene
Zehntes Kapitel. In welchem wir die erhabene Kunst der Bestimmung von
Netzwerkarchitektur und Computerstandort erkunden werden
Reconnaissance oder Kartographierung des Netzwerks bezeichnet die Kunst, eine Anzahl
von Vektoren zur Datenpreisgabe, die den wichtigsten Korninunikationsprotokollen im
Internet innewohnen, zu nutzen, um Systeme und Netzwerke zu erkennen oder potenzielle
Angreifer, Benutzer, Kunden oder Mitbewerber zu orten. Es handelt sich hierbei um die
derzeit wohl höchstentwickelte, weitverbreitetste und bedeutendste Anwendung der
passiven Datenanalyse, die zudem direkt eingesetzt werden kann. Allerdings hat sie auch einen
Anteil an den Problemen, die sich sowohl auf ihre Genauigkeit als auch auf die Einsetz-
barkeit in bestimmten Szenarien auswirken. Dies gilt insbesondere für bekannte und
erprobte Methoden des passiven Fingerprintings bei TCP/EP.
10.1 Vor- und Nachteile des traditionellen passiven
Fingerprintings
Die Verwendung von Metriken des passiven Fingerprintings, die im vorigen Kapitel
behandelt wurden, erlaubt Ihnen eine relativ einfache Erkennung verschiedener
Eigenschaften des Betriebssystems und Netzwerks auf der Gegenseite. Zudem ermöglichen diese
Methoden in manchen Fällen die Nachverfolgung einzelner Benutzer, wenn diese ihre
Adresse ändern oder sie mit anderen Benutzem desselben Netzwerks gemeinsam verwenden. Sie
können diese Methoden einsetzen, ohne mit dem entfernen System zu kommunizieren,
solange Sie den beobachteten Mitmenschen nur dazu überreden können, mit einem
bestimmten Netzwerk zu interagieren, oder die von ihm stammenden Netzwerkdaten eine
bestimmte Gruppe von Systemen passieren, die von jemandem kontrolhert werden, der ausreichend
173
10 Schäfchen zählen für Fortgeschrittene
neugierig ist. Insofern ermöglicht passives Fingeiprinting dem Besitzer eines Servers oder
auch einem Intemetprovider unter anderem auf ganz einfache Weise die umfassende und
vollständig unerkannte Sammlung von Daten.
Dem entfernten Benutzer gibt das passive Fingeiprinting ein zweischneidiges Schwert an
die Hand: Er kann es verwenden, um nützliche Daten zur internen Struktur eines
Netzwerks zu ennitteln; auf diese Weise kann er einen Angriff leichter vorbereiten und/oder
rnehr zu den verwendeten Netzwerktechnologien erfahren (und zwar auch in einer relativ
komplexen Umgebung wie der in Abbildung 10.1 gezeigten). Außerdem kann er (was
ethisch absolut unbedenklich ist) in seinem eigenen Netzwerk nach Verletzungen der
Richtlinien (wie unzulässige Verbindungen oder Access-Points, die ein internes Netzwerk
mit der Außenwelt verbinden) suchen oder Angreifer aufspüren.
Interner Server!
TTL = X-3
Server-OS
Vertrauensw.
Workstation
TTL = X-3
i i
Interne
Firewall
Externe
Firewall
Office-
Workstationsi
TTL = X-2
Telefön-
leltung
KW
Laptop
TTL = X-3
Andere MSS
(VPN-Client)
VPN-Fem-
zugriffs Server
(DFÜ)
i Die so eingerahmten Elemente sind
i direkt erkannte (aktive) Netzwerk-
i komponenten. Das Vorhandensein der
i Obrigen Systeme kann abgeleitet
i werden.
ATM
j Router In
! Entfernung X i
Internet
Abbildung 10.1 Sie können passives Fingerpnnting zur Kartographiemng eines komplexen und sogar
unzugänglichen Netzwerks verwenden, indem Sie einfach die von einigen seiner Knoten abgehenden
Daten beobachten (von denen die wichtigsten die gemessenen Betriebssystemeigenschaften sowie die
TTL- und MSS-Werte der Pakete sind) und dann das Vorhandensein anderer Komponenten ableiten,
damit eine Übereinstimmung mit den beobachteten Abweichungen vorliegt. Es bleibt dem Leser
überlassen, zu bestimmen, wie dieses Netzwerk sich schlüssig kartographieren lässt, indem lediglich der
Datenverkehr von außen beobachtet wird.
174
10.1 Vor- und Nachteile des traditionellen passiven Fingerprintings
Die datenschutzspezifischen Einbußen sind für den einzelnen Benutzer in diesem Fall
vernachlässigbar, sofern die Möglichkeit, die von einem Benutzer vorgenommenen
Handlungen mit weiteren Angaben zu verknüpfen, die mithilfe des Fingerprintings gewonnen
wurden, oder die Fähigkeit zumNachveifolgen eines Benutzer über mehrere Domänen hinweg
kein besonderes Problem darstellen. (Dies ist normalerweise nur dann der Fall, wenn das
Verhalten des Benutzers ohnehin von Anfang an fragwürdig ist.) Andererseits geben die
Einschränkungen der Privatsphäre für alle Benutzer in ihrer Summe durchaus Anlass zur
Sorge, und die mithilfe des Fingerprintings oder verwandter Methoden gewonnenen
Erkenntnisse können einen erheblichen Marktwert aufweisen. (Beispielsweise zahlen
Werbeagenturen wesentlich rnehr für Ihre privaten Daten, wenn diese mit Angaben zu Ihren
Vorheben und Interessen kombiniert sind.) Zudem kann eine Offenlegung der internen
technischen Abläufe in einem Netzwerk für Unternehmen und andere Institutionen mit sensibler
Infrastruktur durchaus unerwünscht sein.
Aber es ist noch nicht aller Tage Abend. Wie ich oben bereits angemerkt habe, gibt es,
wenn man mit passivem Fingerprinting akkurate Ergebnisse erzielen will, doch das eine
oder andere Problem. Das Problem der Zuverlässigkeit beim traditionellen passiven
Fingerprinting von Betriebssystemen ergibt sich aus der Frage, wie einfach der ungebetene
Beobachter ins Bockshorn gejagt werden kann, indem einige oder gar alle
Netzwerkeinstellungen, die das beobachtete System verwendet, sorgfältig optimiert werden. Auch
wenn die Änderung aller Einstellungen nicht ganz einfach ist, kann eine teilweise erfolgte
Modifikation bereits ausreichend sein, um bestimmte automatisierte Analyseversuche
zurückzuschlagen (hurra!) oder einen Administrator fehlzuleiten, der gerade einen
sicherheitsrelevanten Vorfall untersucht (oha!). Dies ist zwar kein Problem von erheblicher
Bedeutung und insofern auch für statistische Analysen wenig wichtig, aber in einzelnen
Fällen kann ein Zuwenig an Zuverlässigkeit schon bedenklich sein.
Außerdem basieren die Funktionalitäten des Fingerprintings zur Nachverfolgung und
Ermittlung von Benutzem, die wir in Kapitel 9 so eingehend erläutert haben, fast vollständig
auf der Verfügbarkeit von Parametern wie den Zeitstempelinformationen in TCP/IP-
Paketen. Alle anderen Eigenschaften sind entweder standardisiert oder bieten zu wenig
Optionen, um — von ganz wenigen Ausnahmen abgesehen — eine eindeutige
Positivbestimmung eines einzelnen Computers zu gestatten. Wenn diese Daten nicht verfügbar sind,
weil die betreffende Leistungserweiterung deaktiviert ist (wie beispielsweise bei den
meisten Windows-Valianten), dann ist die exakte Erkennung eines Systems nicht möghch. Dies
verringert den potenziellen Wert der Daten sowohl für die Angehörigen eines emsigen
Zirkels übler Verschwörer, der — wie wir alle wissen — hinter unseren wertvollsten
Geheimnissen her ist, als auch für Sicherheitsprüfer oder Fachleute der Computerforensik. Ohne
eine zeitsternpelbasierte Erkennungsfunktionalität kann es unmöglich sein, verschiedene
identische Systeme voneinander zu unterscheiden, die hinter einem Masquerading-Gerät
platziert sind, oder einen Benutzer zu ermitteln, dessen IP-Adresse sich bei jeder
Neuverbindung über ein Modem ändert.
Eine andere, möglicherweise interessantere, vielversprechendere und herausfordernde
Methode des passiven Fingerprintings nutzt jedoch auf ganz einfache Weise die Mängel des
175
10 Schäfchen zählen für Fortgeschrittene
passiven Fingerprintings selbst. Diese neue Ansatz macht es extrem schwierig, den
entfernten Beobachter in die Irre zu führen, und ist praktisch uneingeschränkt geeignet, um
Systeme zurückzuverfolgen. Was aber vielleicht noch interessanter ist: Diese Methode
erlaubt es, zwischen verschrienen Instanzen eines absolut identischen Systems mit absolut
identischer Konfiguration zu unterscheiden. Auf diese Weise wird die Masquerading-
Erkennung auf ein ganz neues Niveau gehoben. Diese Technik verwendet die
Eigenschaften des Mechanismus zur Sequenznummemgenerierung in TCP/EP — und malt nebenbei
auch einige schöne Bilder.
10.2 Eine kurze Geschichte der Sequenznummern
Aus dem vorherigen Kapitel wissen wir, dass ISNs (erste zu verwendende Sequenznum-
rnem) eine Methode darstellen, mit deren Hilfe in TCP die Sitzungsintegrität geschützt und
— de facto — ein grundlegendes Maß an Sicherheit implementiert werden soll.
Der einzige wirklich universelle Ansatz, eine unverschlüsselte TCP/IP-Sitzung gegen Da-
teninjizierang, Hijacking oder Täuschung durch einen vollkommen Unbekannten zu
schützen, besteht darin, zu gewährleisten, dass die ISNs auf eine Weise ausgewählt werden, die
für den Angreifer keinesfalls vorhersagbar ist. Dies verringert auch die Chancen, beim
Erraten der ISN ins Blaue hinein einen Treffer zu landen (und ein Paket zu fälschen, das dann
als zulässiger Teil der Sitzung des Opfers akzeptiert wird), auf ein Maß, bei dem das
Risiko in der Raxis keine große Rolle mehr spielt — und zwar auch dann, wenn der Angreifer
zum Sturm auf das System bläst und Tausende von Paketen in der Hoffnung sendet, dass
nur ein einziges davon eine in etwa passende Sequenznurnmer enthält.
In den frühen Achtzigerjahren schienen die Sicherheitsaspekte der TCP-basierten
Kommunikation kein Problem darstellen, um das man sich groß Sorgen machen musste: Das
Internet war eine überschaubare, in sich geschlossene und vielleicht sogar ein bisschen
elitäre Umgebung, die von Wissenschaftlern und ähnlichen Zeitgenossen genutzt wurde. Aus
diesem Grund definierte die RFC-Spezifikation des TCP-Protokolls keine Anforderungen
bezüglich der ISN-Festlegung, und fast alle frühen (und auch nicht rnehr ganz so frühen)
Implementierungen des TCP/IP-Stapels verwendeten triviale zeit- oder zählerbasierte
Algorithmen, die fortlaufende Zahlen für aufeinanderfolgende Verbindungen zurückgaben.
Zu jener Zeit schien die Idee, diesen Nummern Zufallswerte zuweisen zu wollen, eine
völlige Verschwendung von Rechenleistung zu sein. Außerdem würde dies die
Wahrscheinlichkeit von SequenznuHimernkollisionen unnötig erhöhen. (Eine Kollision ist eine
Situation, in der zwei ISNs, die für aufeinanderfolgende Verbindungen zu einem Host
ausgewählt wurden, einander zu ähnlich sind und hierdurch die Möglichkeit besteht, dass ältere
Pakete, die verzögert beim Empfänger eintreffen, im Kontext der falschen Verbindung
interpretiert werden könnten. Natürlich ist bei zufälliger Auswahl von Sequenznummem die
Wahrscheinlichkeit höher, dass diese kurzfristig Kollisionen erzeugen, als bei der Auswahl
fortlaufender Werte.)
176
10.3 Holen Sie mehr aus Ihren Sequenznummern
Das Internet hat sich jedoch seit den Achtzigerjahren erheblich weiterentwickelt, die
Verfügbarkeit ist heute wesentlich höher, und die Benutzergerneinde ändert und vergrößert
sich fortlaufend. Und weil auch immer rnehr wichtige Daten über die Leitungen geschickt
wurden, nahm die Bedeutung von Sicherheitsfragen zu. Leider müssen Integritäts- und
Datenschutzmechanismen in punkto Verbreitung und Zuverlässigkeit noch mit dem Internet
gleichziehen: Nicht alle Dienste unterstützen eine Verschlüsselung, nicht alle Benutzer
wissen, wann sie diese einzusetzen haben, und die meisten Benutzer wissen auch nicht,
wie sie Verschlüsselungszeitifikate, die ihre Gegenüber mitschicken, ordnungsgemäß
auswerten. (Letzteres ist der wohl wichtigste Aspekt.)
Im Laufe der Zeit — und insbesondere angesichts des verbreiteten praktischen, wenn auch
in erster Linie auf Chat-Dienste beschränkten Missbrauchs schwacher ISN-
GenerierungsHiethoden Mitte der Neunzigeijahre - wurde offenbar, dass für TCP/TP-
Datenströrne ein zumindest rudimentärer Integritätsschutz erforderlich war. Das galt auch
für den verschwindend gelingen Brachteil der Daten, die tatsächlich in verschlüsselter
Form versendet wurden, denn eine Beschädigung der Trägerschicht durch das Einfügen
von gefälschten Daten oder RST-Paketen war ebenso unerwünscht, auch wenn die
Auswirkungen sich auf die Trennung der Verbindung (d. h. auf eine Dienstverweigerung)
beschränkten und keine Fremddaten eingefügt wurden.
Die einzige Möglichkeit, diese Probleme zu beheben, ohne jedes einzelne TCP-
Kommunikationssystem, das der Menschheit bekannt war, von Grund auf neu zu
konstruieren, bestand darin, dafür zu sorgen, dass das Protokoll selbst möglichst schwierig
angreifbar ist. Deswegen unternahmen zahlreiche Entwickler Anstrengungen, um sich von
der veralteten und gefährlichen Erzeugung einfacher fortlaufender ISNs möglichst weit zu
entfernen. Obwohl diese Bemühungen in der Tat halfen, die Widerstandsfähigkeit einer
Verbindung gegenüber blindem Spoofing zu verbessern, schufen sie doch gleichzeitig
auch einige interessante Vektoren zur Datensarnmlung, die anspruchsvolleres Fingerprin-
ting von Systemen und Netzwerken ermöglichten - sei es zur Sicherheitsprüfung oder zur
Vorbereitung eines Angriffs.
10.3 Holen Sie mehr aus Ihren Sequenznummern
Natürhch ist aus Gründen der Quahtätssicherung wie auch für Sicherheitsübeiprtifungen
wichtig, die guten ISN-Generierungsirnplernentierungen von den schlechten unterscheiden
zu können. Bis vor kurzem basierte die Vorgehensweise zur Bewertung der Qualität
generierter ISNs in der Regel entweder auf einer Analyse des Quellcodes oder auf bestimmten
eindimensionalen Tests des Bitstrorns aufeinanderfolgender ISNs, um einschätzen zu
können, wie viel Entropie von jedem Ausgabebit übertragen wird. Ersteres ist häufig komplex
und kostenaufwändig, fehleranfälhg und zudem nicht immer möglich (sofern der
Quellcode eines bestimmten Systems nicht öffentlich zugänglich ist), dem letzteren hingegen
fehlt die Fähigkeit, subtilere Sequenzabhängigkeiten und andere Eigenschaften eines
Generators auf zuverlässige und lesbare Weise zu erfassen; stattdessen konzentriert sich die-
177
10 Schäfchen zählen für Fortgeschrittene
ser Ansatz eher auf statistische Schwächen als auf den Zusammenhang zwischen Werten,
die für aufeinanderfolgende Verbindungen zurückgegeben werden. Offensichtlich ist es
praktisch unmöglich, die Sicherheit einer Implementierung nachzuweisen, indem man nur
ihre Ausgabe beobachtet. Es ist aber einfach zu prüfen, ob bestimmte gängige Probleme
vorhanden sind, und zu gewährleisten, dass der zugrundehegende Algorithmus
ausreichend robust ist. Und doch waren auch diesbezüglich die eingesetzten Prüfmethoden recht
schwach (um es einmal wohlwollend auszudrücken).
Sowohl die ursprünglichen, unsicheren ISN-Generatorkonstruktionen als auch einige
moderne Lösungen basieren auf additiven, iterativen Rechensystemen, die neue Werte
basierend auf ihrer vorherigen Ausgabe errechnen. Nur die Komplexität des
Neuberechnungsalgorithmus und der in den Prozess einfließende Urnfang der praktischen Unvorhersehbar-
keit scheinen hierbei zu variieren. Die einzigen sicheren Ausprägungen, die nicht auf
traditioneller Arithmetik fußen, sind einige neuere Varianten, die relativ langsame, aber kryp-
tografisch sicherere Verküi-zungsfunktionen zur Implementierung iterativer Systeme
verwenden. In allen Fällen wäre es allerdings interessant, nach einer komplexeren Beziehung
zwischen aufeinanderfolgenden Ergebnissen zu suchen, die der Generator für neue
Beziehungen erzeugt - weil man dann nämlich unter Umständen mögliche Fehler im
Algorithmus erkennen könnte.
Wenn sich eine offensichtliche Abhängigkeit zwischen der Ausgabe des ISN-Generators
zu einem Zeitpunkt t und der zu einem Zeitpunkt t~hc. beobachten lässt, dann kann der
Angreifer natürlich bereits vor der Verbindung, die er zu stören oder zu imitieren hofft, eine
Verbindung herstellen, um die ISN-Ausgabe zum Zeitpunkt t zu ermitteln. Auf der Basis
der beobachteten zurückgegebenen Sequenznurnmer kann er dann die Antwort bestimmen,
die in der Zukunft (t+x) von seinem Gegenüber erzeugt werden wird. Aufgrund dessen
kann der Angreifer ein gültiges Paket für die neue Verbindung fälschen, obwohl er die dort
verwendete ISN nicht direkt ermitteln kann.
Dies hatte ich im Sinn, als ich 2001 einige Forschungen anstellte, an deren Ende eine
vereinheitlichte Methode zur Untersuchung weniger offensichtlicher zeillicher
Abhängigkeiten in ISN-Folgen stehen sollte, die auf entfernten Systemen erkannt wurden. Meine
Ergebnisse flössen in einen Artikel ein, in dem einige der Algorithmen zur ISN-Generierung
im Detail untersucht wurden, um eine Möglichkeit zur Erkennung von Feinheiten zu
finden, die über die Wahrnehmung der augenscheinlichen Muster und Fehler hinausgeht,
welche wir bereits kennen. Diese Abhandlung mit dem Titel „Strange Attractors and
TCP/EP Sequence Number Analysis"1 basierte auf einem Ansatz, der in der angewandten
Mathematik wohlbekannt, in der Welt der Netzwerktechnologie aber ziemlich neu ist.
1 ZaleOl
178
10.4 Koordinatenverzögerung: Zeitliche Abfolgen in Bildern
10.4 Koordinatenverzögerung: Zeitliche Abfolgen in Bildern
Wenn man es heute mit einem ISN-Generator in einer Blackbox - also einem der
modernen Systeme mit nicht frei zugänglichem Quellcode - zu tun bekommt, dann sieht man nur
die Ausgabe als Folge von in TCP/EP-Paketen übertragenen 32-Bit-Werten, nicht aber den
zugrundeliegenden Algorithmus. Bei vielen Betriebssystemen ist der Code proprietär und
wohlgehütet - weit jenseits der Reichweite eines gewöhnlichen Sterblichen. Und sogar bei
Open-Source-Systemen können die Quellcodes raffiniert und irreführend sein, und am
Ende machen Sie die gleichen Fehler wie der ursprüngliche Entwickler.
Eine typische Eingabe, die wir auswerten müssten, könnte etwa so aussehen:
S0 = 244782
Sx = 245581
Sa = 246380
S3 = 247175
S, = 247975
S5 = 248771
Ist die Abhängigkeit dieser Zahlen voneinander auf den ersten Bhck augenfällig? Und
wenn ja: Gibt es eine relativ universelle Methode für den Computer, dieses und auch
komplexere Schemata nachzuvollziehen?
Eine elegante Lösung schien weit entfernt. Ich hoffte, eine Methode entwickeln zu können,
mit der sich ein paar universelle Eigenschaften des zugrundeliegenden ISN-Algorithmus
allein dadurch ermitteln ließen, dass man die Ausgabe analysierte. Aber bevor ich dies tat,
hielt ich es - auch im Sinne einer vereinfachten Analyse - für wünschenswert und
praktischer, von der Annahme auszugehen, dass es, weil viele Implementierungen auf der
Wiederholung bestimmter Rechenoperationen basieren, besser wäre, anstelle der absoluten
Werte die Änderungen zwischen aufeinanderfolgenden Ergebnissen zu beobachten. Die
Beobachtung von Differenzen kann bei solchen Algorithmen von Vorteil sein, und weitere
Rückschlüsse bezüglich der verwendeten Generatoren würden auch nicht negativ beein-
flusst. Zu diesem Zweck müssen wir eine diskrete Ableitung der Eingabefolge berechnen:
die rnkrernente zwischen den Elementen von S. Die sich hieraus ergebende Differenzfolge
D, die natürlich bei t = 1 beginnt, ergibt sich aus der folgenden Gleichung:
Dt = St-Su
In diesem Beispiel ergibt sich als Differenzfolge:
Dx = 799
Da = 795
D3 = 799
D4 = 795
D5 = 799
Wenn man also die eigentlichen Werte ignoriert und nur auf die Dynamik der ISNs
eingeht, wird die zugrundeliegende Abhängigkeit offenbar. Dies gilt generell für alle
Implementierungen, die diesen Berechnungstyp verwenden. (Bei Systemen, die nicht auf
einfachen iterativen Berechnungen basieren, hat dies allerdings praktisch keinerlei Relevanz
179
10 Schäfchen zählen für Fortgeschrittene
und wirkt sich im Sinne dieser Analyse auch nicht nennenswert auf die Qualität der Daten
aus.)
■ Hinweis
Ein besonders pedantischer Forscher würde auch versuchen, zeitliche Unregelmäßigkeiten
während der Probenerfassung auszugleichen Wir hingegen gehen diesbezüglich von einem
festen zeitlichen Abstand (Zeitbasis 1) zwischen den einzelnen Erfassungsvorgängen aus.
Allerdings können sich bei der Hochgeschwindigkeitserfassung Faktoren wie beispielsweise die
Netzwerkleistung erheblich auf das Timing auswirken. Um sicherzustellen, dass diese Timing-
unterschiede Algorithmen, bei denen der Taktgeber als Parameter zur ISN-Erzeugung zum
Einsatz kommt, nicht beeinflussen, ist es unter Umständen sicherer, stattdessen die Gleichung
D, = (S, — S,-i) -T- T, zu verwenden (hierbei drückt T, die Verzögerung zwischen der Erfassung
von Si_j und S, aus).
Der Vorteil dieses Ansatzes bei der Anwendung auf Systeme mit iterativer Berechnung ist
augenfällig. Abgesehen von ganz einfachen Fällen ist die Methode allein kaum
ausreichend: Wir bewegen uns von einer profanen, schwierig zu analysierenden Datenfolge zur
nächsten.
Mein nächster Schritt bestand nun darin, die Differenzfolge in eine Form zu konvertieren,
die sich von einem Menschen oder einer Maschine leicht auf das Vorhandensein weniger
offensichtlicher Zusammenhänge untersuchen ließe als die im obigen Beispiel
beschriebene. Hierfür gibt es zumindest für die erstgenannten Adressaten nichts besseres als ein
dreidimensionales Modell der Systemdynamik. Leider haben wir bei ISNs lediglich genug
Informationen, um Bilder in einer Dimension - auf eine Achse - zu zeichnen. Wie also
können wir unsere Daten in eine ansprechende dreidimensionale Form bringen?
Die Lösung besteht darin, die Datenmenge zu erweitern, indem wir eine Strategie zur Ko-
ordmatenrekonstruktion anwenden: zeitverzögerte Koordinaten. Wir verwenden eine
Methode, die jede Probe erweitert, indem virtuelle Koordinaten basierend auf den vorherigen
Proben in der Folge konstruiert werden. Wenn die vorhandene Probe dem Koordinatenwert
x zugeordnet ist, können wir diese Technik zur Zuordnung der Werte y und z für jede
vorhandene Probe verwenden und so eine Dreiergruppe (Tripel) mit den Koordinaten x, y und
z erstellen, welche ausreicht, um jede Probe genau einem Punkt (in diesem Fall einem
Pixel) im dreidimensionalen Raum zuzuordnen. (Die Technik ist im Übrigen nicht auf drei
Dimensionen beschränkt. Allerdings erschien es für die Zwecke der Veranschaulichung
und Datenanalyse nicht praktikabel, einen höheren Wert zu wählen. Die meisten Menschen
jedenfalls kommen mit mehr als drei Dimensionen ohnehin nicht besonders gut zurecht.
Zumindest nicht, wenn sie nüchtern sind.)
Zeitverzögerte Koordinaten werden so berechnet, dass die zweite Koordinate mithilfe des
zum Zeitpunkt t—1 erfassten Wertes gebildet wird, die dritte entspricht dem zum
Zeitpunkt t — 2 beobachteten Wert usw. In dieser speziellen Anwendung werden die
Koordinaten für den Zeitpunkt t mithilfe der folgenden Gleichungen ermittelt:
180
10.4 Koordinatenverzögerung: Zeitliche Abfolgen in Bildern
xt = Dt = St— St_j
yt= -Df-i= St-i ~ $t-2
Zt = Dt-2 = St-2 — St-3
Wenn man eine Folge neu gebildeter Tripel (x,y,z) für ein System annimmt, das auf
zeitliche Abhängigkeiten getestet wird, dann ist es möglich, das Verhalten eines Systems zur
ISN-Generierung im dreidimensionalen Raum darzustellen. Da die Position eines Pixels,
der eine bestimmte Probe repräsentiert, sowohl vom aktuellen Wert als auch von einer
Anzahl vorheriger Ergebnisse abhängt, führen viele auch sehr komplexe Abhängigkeiten zu
abstrakten, aber erkennbaren Mustern unregelmäßiger Dichte im Phasenraum, wodurch ein
eindeutiges „Portrait" des zugrundeliegenden Algorithmus entsteht. (In Bezug auf solche
Portraits bezeichnet der Begriff Attraktor eine Form, die die Dynamik eines Systems
grafisch darstellt. Die Fonn stellt eine „Spur" von Zuständen dar, die das System zyklisch
durchläuft oder entfaltet, wenn es sich selbst überlassen bleibt.)
Abbildung 10.2 ist die Wiedergabe einer Datemnenge, die ursprünglich wie folgt aussah:
4293832719
3994503850
429438S178
134819
42947S8138
191541
4294445483
4294608504
4288751770
88040492
Abbildung 10.2 Dreidimensionale Wiedergabe der im Text beschriebenen Datenmenge
181
10 Schäfchen zählen für Fortgeschrittene
Die Abbildungen 10.3 bis 10.5 veranschaulichen ein paar andere gängige, doch nicht
unbedingt deutliche Abhängjgkeitsrnuster.
Abbildung 10.3 Dreidimensionale Wiedergabe einer Datenmenge, die mithitfe einer komplexen, aber
unsicheren Funktion zur Zufallszahlengenerierung gewonnen wurde
10.5 Schöne Bilder: Die Galerie des TCP/IP-Stapels
Die Visualisierungsrnethode funktionierte hervorragend: Sie erzeugte für viele ImpleHien-
tierungen, von denen man angenommen hatte, dass sie ausreichend sicher seien, Muster
von einzigartiger und oft instinktiv beklemmender Schönheit. Weitere Bilder finden Sie
auf den nächsten Seiten dieses Kapitels. Aber haben diese Bilder ein größeres Potenzial,
als uns ledighch schwer quantifizierbare Parameter und Eigenschaften eines Generators
optisch zu veranschaulichen? Könnte ein Angreifer diese mysteriösen dreidimensionalen
Formen auf sinnvolle Weise einsetzen? Oder könnte ein Computer sie auf irgendeine
Weise untersuchen, um uns eindeutig zu sagen, was falsch und was richtig ist? Ist ein sonnen-
blumenfönniger Generator einfacher zu knacken als einer, dessen Bild eine Ziegelmauer
zeigt?
182
10.5 Schöne Bilder: Die Galerie des TCP/IP-Stapels
Abbildung 10.4 Wiedergabe eines PRNG ohne offenbare Zusammenhänge, aber mit erkennbaren
systematischen Fehlem
Abbildung 10.5 Verbreitetes Zeitabhängigkeitsmuster, beobachtet unter fehlerhaften Bedingungen
183
10 Schäfchen zählen für Fortgeschrittene
Bevor wir diese Frage beantworten, gestatten Sie mir, mich selbst zu unterbrechen und
eine kleine Galerie rnehr oder minder interessanter Ergebnisse zu präsentieren, die ich
während der Abfassung der ursprünglichen Abhandlung erstellen konnte. Auf diese Weise lässt
sich die Vielzahl und Anmut einiger der beobachteten Muster demonstrieren - getreu dem
Motto „Eine 3-D-Ansicht sagt rnehr als tausend Worte". Die Abbildungen 10.6 bis 10.14
portraitieren die PRNGs verschiedener Betriebssysteme.
Nicht alle Darstellungen haben denselben Maßstab; einige Formen sind wesentlich kleiner
als andere. Der Maßstab und andere Parameter lassen sich der obersten Zeile der einzelnen
Graphen entnehmen (vgl. Abbildung 10.6).
AktualteX-PosWon
AktuelsY-PosItion
Sichtbarer
Bereich
Zoomfaktor
BItgrOße der Darstellung
Drehfaktor der Darstellung
Aktuel sichtbare
Punkte (%)
Anzahl sichtbarer Punkte
und Gesamtanzahl
Abbildung 10.6 Windows 98. Die hier gezeigte Menge hat einen Durchmesser von ca. 128, was
bedeutet, dass aufeinanderfolgende ISNs um eine Zahl erhöht werden, die etwa sieben Bits „Zufälligkeit"
transportiert. Innerhalb der Menge gibt es ein auffälliges Frequenzmuster, welches dem im vorherigen
Abschnitt beschriebenen stark ähnelt und möglicherweise auf eine einfache zeitliche Abhängigkeit in
allen Ergebnissen schließen lässt. Die Größe des Attraktors ist erschreckend gering.
184
10.5 Schöne Bilder: Die Galerie des TCP/IP-Stapels
Abbildung 10.7 FreeBSD4.2. Ein 16 Bit breiter, gleichmäßiger Würfel
kleiner, aber wirklich zufälliger Inkremente pro Schritt.
wahrscheinlich ein Anzeichen
Abbildung 10.8 HP/UX 11. Eine merkwürdige X-Flügelstruktur mit einer Breite von 18 Bits, aber
offensichtlich unregelmäßig - wohl ein Anzeichen für starke Zusammenhangsebenen eines fehlertiaften
PRNG.
185
10 Schäfchen zählen für Fortgeschrittene
Abbildung 10.9 Mac OS 9. Eine ähnliche, aber etwas andere 17-B"it-Struktur.
Abbildung 10.10 Windows NT 4.0 SP3. Auch hier finden wir ein auffälliges Attraktionsmuster und
einen winzigen Attraktor mit einer Breite von 8 Bits vor.
186
10.5 Schöne Bilder: Die Galerie des TCP/IP-Stapels
Abbildung 10.11 IRIX 6.5. Eine 16 bis 18 Bits breite, hochgradig unregelmäßige Wolke.
Wahrscheinlich ein fehlerhafter Algorithmus.
Abbildung 10.12 NetWare 6. Ein scheinbar zufälliges System mit einer 32-Bit-Attraktorwolke. Diese
besteht jedoch aus einer großen Zahl hochdichter Punkte und ist nicht regelmäßig.
187
10 Schäfchen zählen für Fortgeschrittene
Abbildung 10.13 UNICOS 10.0.0.8. Eine seltsame, 17 Bits breite Wolke mit unregelmäßigen
Dehnungen, die auf höhere Trefferwahrscheinlichkeiten schließen lassen.
Abbildung 10.14 OpenVMS 7.2 (TCP/lP-Standardstapel). Eine 32 Bit breite Struktur nur geringer
Zufälligkeit. Sie zeigt auffällige, aber recht ungewöhnliche Zusammenhangsmuster, die auf einen
schadhaften PRNG-Aufbau verweisen.
188
10.6 Angreifen mit Attraktoren
10.6 Angreifen mit Attraktoren
Nun aber zurück zur Frage mit den Sonnenblumen und den Ziegelsteinen. In der Tat haben
diese schönen Bilder für den echten Cornputerfreak eine weitaus größere Bedeutung, als
nur das Auge zu erfreuen. Wie sich zeigt, eizeugen die für die einzelnen Betriebssysteme
erfassten Attraktorstrukturen eine Matrix möglicher ISN-Verhaltensmuster, deren Dichten
den Wahrscheinlichkeiten eines bestimmten Typs einer zeitlichen Abhängigkeit oder eines
statistischen Musters entsprechen, das sich durch den zeitlichen Verlauf ergibt. Regionen
höherer Dichte innerhalb des Attraktors entsprechen Zusammenhängen, die aufgetreten
sind und deren Auftreten auch in Zukunft wahrscheinlicher ist, während weniger stark
gefüllte Bereiche mit geringerer Wahrscheinlichkeit verwendet werden. Aufgrund dessen
kann, wenn der Attraktor eines bestimmten Betriebssystems grafisch dargestellt ist, der
Angreifer zukünftige Ergebnisse einfacher erraten. Wie aber lassen sich diese Fonnen nun
wiederum exakten ISN-Werten zuordnen?
Der Schlüssel zur erfolgreichen Attacke besteht darin, zu erkennen, dass die Koordinate x
jedes Punkts im Attraktor vom Wert Dt abhängt, d. h. von den Sequenznummem, die zu
den Zeitpunkten t und t — 1 beobachtet werden (denn es gilt: Dt = St— St_j). Die Koordinate
y hingegen hängt von Dt_j (ISNs bei t — 1 und t — 2) und die Koordinate z von Dt_3 (ISNs
bei t — 2 und t — 3) ab.
Nehmen wir nun an, unser Angreifer habe drei „Sonden" (engl. Probes) an ein Remote-
System geschickt, für das der Attraktor des Betriebssystems bekannt ist. Diese Probes
entsprechen den Zeitpunkten t — 3, t — 2 und t — 1 und sind — natürlich — ausreichend, um die
Koordinaten y und z für den Zeitpunkt zu rekonstruieren, der das Verhalten des Systems zu
exakt diesem Zeitpunkt in der Ateaktorstruktur bezeichnet.
Mithilfe dieser Informationen kann der Angreifer ausgehend von Unregelmäßigkeiten in
der Attraktorstruktur, die er bislang beobachtet hat, den Wert x für bekannte y und z
ableiten, die wahrscheinlich häufig auftreten werden als andere. Die Koordinaten y und z
entsprechen einer einzelnen Geraden im AttraktorrauHi, die senkrecht zur x-Ebene steht (vgl.
Abbildung 10.15): der Menge der Punkte mit allen möglichen x-Werten, bei denen jedoch
die weiteren Koordinaten bekannt sind. Diejenigen Punkte, bei denen die Gerade Attrak-
torbereiche großer Dichte schneidet oder sich diesen annähert, bilden die Menge der Werte
für die Koordinate x, die eine sehr hohe Wahrscheinlichkeit aufweisen. Die Bereiche mit
der geringsten Dichte hingegen weisen offenbar die geringste Wahrscheinlichkeit auf, den
korrekten Wert für x zu stellen, denn schließlich erschienen dort bei vorherigen Messungen
überhaupt keine Attraktorpunkte.
Die Möglichkeit, eine Menge von Kandidaten für den Wert x für bekannte y und z zu
konstruieren, ist ein wesentlicher Schritt auf dem Weg zur erfolgreichen Attacke: Wenn der
Angreifer St_j kennt (und diesen Wert hat er sich ja, wie Sie sich erinnern werden, schon
zuvor besorgt), dann kann er problemlos St für jeden in Frage kommenden Wert x (Df) wie
folgt berechnen:
189
10 Schäfchen zählen für Fortgeschrittene
Wenn er drei vorhergehende Sequenznummern St_3, St_2 und S^ enmttelt hat, kann er auf
diese Weise eine Menge in Frage kommender Werte für die nächste Sequenznummer St
berechnen, die das angegriffene System mit hoher Wahrscheinlichkeit für die nächste
Verbindung verwenden wird — ein Verbindung, die der Angreifer zwar nicht hergestellt hat, in
die er aber eindringen zu können hofft. Der Angreifer kann dann eine Attacke ausführen,
indem er TCP/EP-Pakete mit den passenden Sequenznummem sendet; er muss dabei nicht
von Anfang an richtig hegen, denn alle falschen Werte werden von der entfernten
Implementierung schlicht ignoriert. Sobald aber der Wert eines der gefälschten Pakete mit der
innerhalb eines Zeitfensters erwarteten Nummer übereinstimmt, werden die Daten
akzeptiert, wodurch der Schutz der Sitzungsintegrität, den TCP/EP bietet, aufgehoben ist.
Abbildung 10.15 ,flngriffsgerade", die den Attraktor schneidet
Diese Angriffsform hat natürlich auch ein paar Nachteile:
■ Die beobachtete Dynamik ist unter Urnständen spezifisch für die
Beobachtungsbedingungen oder die Quelle selbst. Allerdings ist dies angesichts der beim Einsatz dieser
Technik gegen verbreitete Implementierungen erzielten Erfolgsrate eher
unwahrscheinlich.
■ Wenn die Menge der in Frage kommenden Werte besonders groß ist (wie es etwa bei
Algorithmen der Fall ist, die gleichförmige Attraktorwolken ohne eindeutige
Unregelmäßigkeiten erzeugen), dann ist dieser Ansatz nicht rnehr praktikabel, da zu viele
Versuche erforderlich sind, um einen korrekten Wert zu erraten.
190
10.6 Angreifen mit Attraktoren
■ Da es häufig nicht möglich ist, die gesamte von der ISN-Implementierung eines
Betriebssystems erzeugte Wertefolge zu erfassen (weil einige Systeme lange oder sogar
unbeschränkte Zyklen aufweisen), lässt sich kein vollständiger Attraktor bilden.
Aufgrund dessen müssen Sie einen Näherangsansatz verfolgen: Ein Wert kommt in Frage,
wenn ein Punkt innerhalb eines gegebenen Radius um einen bestimmten Punkt auf der
Geraden (y,z) vorhanden ist. Hierdurch wird die Tatsache kompensiert, dass auch
relativ dichte Bereiche des Attraktors Lücken aufweisen können.
Um die Ergebnisse vergleichbar zu halten und eine Methode zur vergleichenden
Bewertung der Qualität eines ISN-Generators aufzustellen, beschloss ich, die Erfolgsrate mit
einer eingeschränkten Anzahl von Versuchen empirisch zu bewerten. Insbesondere wollte
ich errnitteln, wie hoch die Wahrscheinlichkeit ist, dass man bei 5.000 Versuchen die
korrekte Zahl findet. Dabei ging ich von der Voraussetzung aus, dass ein Angreifer, der eine
Netzwerkverbindung geringer bis moderater Geschwindigkeit verwendet, innerhalb einer
kurzen Zeitspanne maximal 5.000 Pakete versenden kann.2
Um die Gültigkeit dieses Ansatzes zu verifizieren, entschied ich femer, die
Erfolgswahrscheinlichkeit zu testen, indem ich die von den Remote-Systemen erhaltenen Eingabedaten
in zwei Teile aufspaltete: einen Teil zur Bildung des Attraktors und einen zweiten zur
I^irchführung der eigentlichen Tests. Beim Test wurden vier aufeinanderfolgende Se-
quenznummem auf einmal eingelesen, von denen dann drei einer Implementierung
zugeführt wurden, deren Aufgabe darin bestand, basierend auf den Attraktordaten eine Menge
von 5.000 Werten zu erzeugen. Die Ausgabe wurde dann mit der vierten aus der
Testdatenmenge ermittelten Zahl verglichen. Dieser Test wurde für jeden Attraktor mehrere
hundert Mal für fortlaufende ISN-Quadnipel wiederholt, um einen annähernden Trefferanteil
zu bestimmen, der in der Praxis angibt, wie groß die Wahrscheinlichkeit ist, dass er
Angreifer mit seinem Ansatz Erfolg hat.
Tabelle 10.1 zeigt einige der Ergebnisse für die Systeme in der Attraktorengalerie.
Tabelle 10.1 Betriebssystemspezifische Erfolgsraten für attraktorbasierte Angriffe
Betriebssystem
IRIX 6.5.15
OpenVMS 7.2
Windows NT 4.0 SP3
Windows 98
FreeBSD 4.2
HP/UX 11
Mac OS 9
Angriffserfolgsrate
25% (25 von 100 Versuchen)
15,00%
97,00%
100,00%
1%
100,00%
89,00%
Das kleinste SYN-Paket hat 40 Bytes, d. h. 5.000 SYN-Pakete benötigen eine Bandbreite von
mindestens 200 Kbyte. Diese Datennienge lässt sich über eine Modeinverbindung mit der V42.bis-Kompri-
mierung innerhalb von 10 bis 20 Sekunden erfolgreich versenden. Die Auswahl dieses Schwellwerts
ist zwar willkürlich, scheint aber angemessen.
191
10 Schäfchen zählen für Fortgeschrittene
Dieser Ansatz erwies sich als relativ effektiv3, woraufhin viele Anbieter ihre Algorithmen
eilends umgestalteten oder Angaben zur deren Sicherheit revidierten. Thema einer
Folgestudie, die ich im Jahr darauf (2002) veröffentlichte, war übrigens die Überprüfung einiger
dieser Änderungen, die nicht durchgehend zufriedenstellend waren.
Die wirkhch wichtige Frage aber ist: Was hat das alles mit passivem Fingerprinting von
Betriebssystemen zu tun?
10.7 Zurück zum Fingerprinting
Tatsächlich ergeben sich einige wahrhaft faszinierende Konsequenzen aus der
Möglichkeit, die Dynamik des Sequenznummerngenerators eines bestimmten Systems
entschlüsseln zu können, und der Tatsache, dass die meisten Implementierungen bestimmte, mehr
oder minder eindeutige Phasenraumrnuster aufweisen. Der ersichtlichste Trick ist die
Anwendung der ISN-Erfassung auf das gute alte Betiiebssystem-Fingerprinting.
Indem man ein paar Sequenznummem beobachtet, die man sich von einem entfernten
System besorgt hat (etwa zu dem Zeitpunkt, an dem ein Beteiligter versucht, mehrere
Verbindungen mit einem Server herzustellen), kann man versuchen, einen Attraktor zu finden,
der mit den Daten eine größtmögliche Übereinstimmung aufweist, indem man die
beobachteten Daten mit einer Bibliothek bekannter Atteaktoren vergleicht. (Die Nummern
müssen nicht unbedingt mithilfe der beschriebenen Angriffsrnethode vorhersagbar sein, es
muss sich lediglich der Attraktor eines Systems unterscheiden lassen.)
Im Vergleich zum traditionellen passiven Fingerpiinting gibt uns diese Methode zwar
einen weniger detaillierten Einblick in die Konfiguration des Systems, aber dafür ist sie
praktisch idiotensicher. Um einen solchen Angriff abzuwehien, müssten Sie die Alt und
Weise der Sequenznummemgenerierung ändern; es ist aber praktisch unmöglich, die
Einstellungen zur ISN-Generierung aus dem Benutzerraum heraus abzuwandeln, und eine
Modifikation des Kernels ohne Beeinträchtigung der Sicherheit erfordert in der Regel eine
Menge Kenntnisse und Erfahrung (vom Zugriff auf den Quellcode ganz zu schweigen).
So, war das jetzt alles? Natürlich nicht!
Diese Ergebnisse gelten für Szenarien, in denen eine präzise Dateneinspeisung oder -fälschung
notwendig ist. Ist weniger Genauigkeit erforderlich oder besteht das einzige Ziel des Angreifers darin,
eine Störung auszulösen, dann wird das entfernte System nicht nur Pakete mit exakter Sequenznummer,
sondern auch solche akzeptieren, die sich in die Fenstergröße einpassen, wie sie in den TCP/IP-
Paiametem angegeben ist (siehe Kapitel 9). Mit anderen Wollen werden DoS-Angriffe noch
erfolgreicher werden.
192
10.7 Zurück zum Fingerprinting
10.7.1 ISNProber: Theorie in Aktion
Doch nun genug jetzt von Bildern und grauer Theorie! Wir wollen doch einmal sehen, wie
die ISN-Erfassung in der Praxis funktioniert und wie sie dabei hilfreich sein kann, die
Konfiguration eines entfernten Systems zu bewerten oder seine Instanzen zu identifizieren.
Zum Glück (für mich) gibt es ein Programm, das an dieser Stelle keinesfalls unerwähnt
bleiben sollte.
Nachdem er meine Abhandlung zur TCP/IP-ISN-Analyse gelesen hatte, entwickelte Toni
Vandepoel ein tolles Tool namens ISNProber. ISNProber unterscheidet durch Verwendung
der Sequenznurnmemanalyse mehrere Instanzen desselben Betriebssystems. Dabei macht
das Tool sich die Tatsache zunutze, dass zwei verschiedene Systeme mit hoher
Wahrscheinlichkeit in unterschiedlichen Bereichen des Attraktors angeordnet sind.
Das Mindeste, was ISNProber uns anhand des Erscheinungsbildes der beobachteten ISNs
mitteilen kann, ist, dass zwei Systeme sich hinter einer gemeinsamen Adresse verbergen.
Aus Giiinden der Verständhchkeit wollen wir einmal annehmen, dass das System Y eine
ISN-Generatorstruktur verwendet, die immer um den Wert 1 hochzählt. Wir fassen also
eine IP-Adresse der Website Mnviv.beispiel.com ins Auge und wollen ermitteln, wie viele
Systeme dort vorhanden sind. Zunächst identifizieren wir www.beispiel.com als System Y,
stellen mehrere aufeinanderfolgende Verbindungen her und beobachten die folgenden
ISNs: 10, 11,534,13,540, 19.
Es sollte klar sein, dass die kleineren Zahlen (10, 11, 13, 19) eine Sequenz bilden, die von
einem Computer stammt, der entweder weniger Daten sendet und empfängt oder eine
kürzere Laufzeit hat, während die höheren Werte einem anderen System zuzuordnen sind.
Aufgrund dessen „bedienen" zwei Computer dieselbe öffentliche IP-Adresse gemeinsam —
vielleicht hinter einem Lastausgleichssystem. Außerdem können wir durch Variation der
Erfassungsintervalle den Typ des Lastausgleichssystems, seinen Ansatz zur Verteilung von
Anfragen und den von ihm empfangenen Datenverkehr überprüfen.
Dieser Ansatz erlaubt nicht nur eine Unterscheidung von Systemen, die sich hinter einer
gemeinsamen Adresse verbergen, sondern auch das Aufspüren von Benutzern des
Systems Y, wenn diese von einer IP-Adresse zur nächsten wechseln, solange sie ihre
Computer nicht neu stalten (und dadurch den ISN-Zähler zurücksetzen). Bei Systemen, die
komplexere Ansätze für ISN-Generatoren bieten als der in unserem Beispiel beschriebene,
kann die Unterscheidung noch schwieriger sein, sie ist aber sicherlich möglich, solange die
ISNs nicht über alle 32 Bits hinweg zufallig sind. (Und wenn sie das sind, dann treten
sicher sehr bald Probleme in Bezug auf Kollisionen auf.)
Die hier verwendete Vorgehensweise erfordert lediglich, dass im Algorithmus zur ISN-
Erzeugung ein Mindestmaß an Vorhersehbarkeit vorhanden sein muss. Insofern scheint die
Analyse von TCP/IP-ISNs eine vielversprechende Alternative oder Ergänzung zum
passiven Fingerprinting zu sein und kann, was recht bedauerlich ist, auch als nützliches
Werkzeug zur Verletzung des Datenschutzes und zum Nachverfolgen von Benutzem dienen.
193
10 Schäfchen zählen für Fortgeschrittene
10.8 Wie man die passive Analyse verhindert
Eine Abwehr der Vorhersage von Sequenznummem ist relativ einfach, und gute Lösungen
wie etwa die Spezifikation von RFC19484 stehen bereits seit langer Zeit zur Veifügung. Im
Gegensatz dazu ist das Verhindern der passiven ISN-Analyse recht schwierig, weil das
Problem nicht nur auf den Schwächen der Algorithmen basiert, sondern auch auf ihrer
Verschiedenartigkeit, weswegen nur wenige Systeme dieselben ISN-Charakteristika
aufweisen. Auch bei Systemen, die RFC 1948 implementieren oder andere kryptografisch
sichere, externe und entropiebasierte Generatoren verwenden, können sich die
Verhaltensmuster erheblich unterscheiden — abhängig von den Feinheiten des Algorithmus und den
Annahmen des Implementierers bezüglich der Frage, welche Werte ausreichend sind, um
einen Angriff abzuwehren.
Ein Mindestmaß an Sicherheit lässt sich erzielen, indem man eine SPI-Firewall (Stateful
Packet Inspection) einsetzt, die alle Sequenznummem in ausgehenden Paketen neu
schreibt.5 Auf diese Weise erscheinen alle innerhalb eines geschützten Netzwerks
vorhandenen Systeme rnehr oder minder identisch. Leider bieten nur einige Systeme diese
Funktionalität, und nur einige können sie auch nutzen.
10.9 Denkanstöße
Die Technik der Phasenraumanaryse ist in Bereichen nützlich, die weit über die Erzeugung
von Sequenznurnmern hinausgehen. Andere Parameter, die pseudozufällig oder gemäß
einem internen Schema gewählt werden — beispielsweise die Kennungsfelder von IP-
Paketen, Kennungen von DNS-Anfragen (siehe Abbildung 10.16), anwendungserzeugte
„Geheim-Cookies", die Benutzersitzungen kennzeichnen usw. —, lassen sich erfolgreich
analysieren, um entweder Mängel in einem Aufbau zu finden oder eine Implementierung
zu identifizieren und weitere Analysen zu vereinfachen oder einen Angriff zu ermöglichen.
4 Bell96
5 Solar Designer weist darauf hin, dass dies sich auch als cleverer Ansatz zum Rindringen in eine Nicht-
SPI-FirewaU verwenden lässt. Die Firewall verknüpft möglicherweise (beispielsweise über ein XOR)
die ursprüngliche Sequenznummer mit dem sicheren Hash eines Geheimschlüssels kombiniert mit
einem Quadrupel aus Adressen und Ports, die eine Verbindung eindeutig identifizieren. Bei der
Rückgabe der Pakete könnte dieser Hash dann (durch eine weitere XOR-Verknüpfung) entfernt worden sein.
In dieser Foim passt das Paket zu der Vorstellung, die der interne Host von der Verbindung bei der
Auslieferung hat; außerhalb der Firewall besteht es aber nur aus einer unvorhersehbaren, völlig
zufälligen 32-Bit-Folge. Dies könnte für alle ISN-Implementierungen mit Ausnahme derer funktionieren,
die schwerstbeschädigt (d. h. sich häufig wiederholend und kollisionsanfällig) sind.
194
10.9 Denkanstöße
Abbildung 10.16 Interessantes Attraktormuster für die Implementierung der Namensauflösung bei
Linux
Einiges an Arbeit ist in dieser Richtung bereits erfolgt, weiteres wird in Kürze
dazukommen. In einer Abhandlung, die sich teilweise auf meine ursprüngliche Untersuchung
bezieht, gewährt Joe Steward Einblicke in einige Probleme des DNS-Systems, die sich aus
Boom der Vorhersagernethoden für Sequenznummem ergeben. Er stellt fest, dass ein
UDP-basiertes DNS-Protokoll Methoden zur Anfi-ageübeipi1ifung umfasst, die auch den
billigsten Spoofing-Angriffen nicht den geringsten Widerstand entgegenzusetzen haben.
Zudem weicht die gelinge Qualität der eindeutigen Anfragekennungen, die von
verschiedenen Implementierungen erzeugt werden, das Schema zusätzlich auf und macht es extrem
anfällig für die Einspeisung bösartiger Daten. Angesichts der Tatsache, dass DNS einer der
Kerndienste des Internets und die Aussicht, eine DNS-Antwort für eine behebte Website
so zu falschen, dass alle Benutzer eines bestimmten Netzwerks auf eine andere Seite
umgeleitet werden, alles andere als unattraktiv ist, steht das Fälschen von DNS-Paketen ganz
oben auf meiner Liste bagatellisierter Gefahren im Internet.
Dan Kaminsky zeigt unter http://w\v\v.doxpara.com/pics/index.php?album=phent}',opy
einige interessante, fortgeschrittene Visualisiemngen scheinbar zufälliger Daten. Wirklich
sehenswert.
11 Anomalien erkennen und nutzen
Elftes Kapitel. In dem wir erfahren, was man kleinen Mängeln im
Netzwerkverkehr so alles entnehmen kann
In den vorherigen Kapiteln habe ich detailliert eine Anzahl von Möglichkeiten beschrieben
und analysiert, potenziell oder Hiutrnaßlich wertvolle Datenblöcke von scheinbar
irrelevanten, „technischen" Parametern zu trennen, die mit jeder Nachricht mitgeschickt werden,
die ein Verdächtiger über das Netzwerk sendet. Wie Sie — wie ich hoffe — gesehen haben,
erhalten wir eine beträchtliche Menge von Daten zum Absender, von deren Übermittlung
dieser nichts ahnt (oder deren Übermittlung er zumindest nicht deaktivieren kann, worüber
er eher unglücklich sein dürfte). In einer perfekten und frohgemuten Welt könnten wir
mithilfe einer Vielzahl von Tricks zur Paket- und Datenstromanalyse viele Eigenschaften
der anderen Seite messen und ihr Verhalten der Signatur eines bestimmten Systems oder
einer Netzwerkkonfiguration zuordnen.
Die Wirklichkeit sieht allerdings ein bisschen anders aus: Einige der beobachteten
Parameter weichen zumindest geringfügig von den Wertemengen ab, die normalerweise von
einem bestimmten, vom Benutzer eingesetzten Gerät oder einer Netzwerkkonfiguration
erwarten werden. Sie können diese scheinbar sinnlosen und zufalligen Diskrepanzen zwar
einfach ignorieren und das Herkunftssystem trotzdem erfolgreich erkennen oder seine
Benutzer ausfindig machen, aber dies zu tun ist nicht unbedingt weise. Wir lernen zwar von
Kindesbeinen an, scheinbar bedeutungslose Plagegeister wie diese zu vernachlässigen,
aber nichts in der Welt der Computer geschieht ohne guten Grund (sofern man den Begriff
„gut" einigermaßen weit fasst), und wenn man die Mechanismen hinter diesen offenbar
zufälligen Anomalien und Minderheitsmustern erforscht, statt sie beiseite zu lassen, dann
kann man viele wichtige, zuvor verborgene Charakteristika der Netzwerkkonfiguiation in
Erfahrung bringen.
Ich möchte in diesem Kapitel einen genaueren Bück auf einige der Prozesse werfen, die
sich auf die beobachteten Eigenschaften eines Systems auswirken können. Ich werde die
197
11 Anomalien erkennen und nutzen
tieferen Ursachen des von diesen Technologien bedingten Verhaltens, den Zweck der
Technologien (oder sein Fehlen) und die sich daraus ergebenden Folgen erläutern.
Selbstredend stammen die meisten der reproduzierbaren Änderungen an IP-Paketen, die
hier beschrieben werden, von modernen Typen IP-fähiger Zwischengeräte. Aus diesem
Grund werde ich mit einer Abhandlung zu zwei Themen beginnen, die wir allzu lang
vernachlässigt haben: Firewalls im Allgemeinen und NAT im Besonderen.
Firewalls werden als heimliche Bollwerke konstruiert, und je weniger darüber bekannt ist,
was die andere Seite verwendet, um so besser für sie. Doch trotz unerbittlicher Firewall-
Richtlinien und -Einstellungen sind diese Geräte, weil sie immer komplexer werden und
immer besser geeignet sind, aktuellen Herausfordeningen entgegenzutreten, auch immer
einfacher mithilfe indirekter oder passiver Sondierungsrnethoden zu untersuchen.
11.1 Grundlagen zu Paket-Firewalls
Verbreitete Firewalls1 sind im Grunde genommen eine Klasse von
Routing-Zwischengeräten, die so aufgebaut sind, dass sie der grundsätzlichen Aufgabe eines
Routing-Zwischengeräts entgegenarbeiten. Im Gegensatz zu,gichtigen" Routem — Systemen, die auf der
Basis von Daten, die in die dritte OSI-Schicht einkodiert sind, unterscheidungslose Routing-
Entscheidungen treffen— sollen Firewalls Daten übergeordneter Schichten (wie z. B. TCP-
oder sogar HTTP-Daten) interpretieren, verarbeiten oder sogar modifizieren. Obwohl die
Firewall-Technologie noch relativ neu ist, ist sie bereits wohlbekannt und etabliert und
findet sich in Heim- und Unternehmensnetzen gleichermaßen. Firewalls sind so aufgebaut,
dass sie bestimmte Datentypen, die an bestimmte Dienste gerichtet sind, abweisen,
zulassen oder umleiten, und werden (was keine Überraschung ist) verwendet, um den Zugriff
auf bestimmte Funktionen und Ressourcen für den gesamten Datenverkehr zu
beschränken, der ein solches Gerät passiert. Aus diesem Grund stellen sie eine zugegebenermaßen
leistungsfähige Sicherheits- und Netzmanagementlösung dar, die aber manchmal
überschätzt und überbewertet wird.
Der Schlüssel zum Erfolg von Firewalls in allen Netzwerkumgebungen besteht darin, dass
sie eine Gruppe komplexer Systeme mithilfe einer einzelnen, vergleichsweise robusten
Komponente schützen und eine ausfallsichere Sicherheitsmaßnahme bereitstellen, wenn
ein Konfigurationsprobleni einen ungeschützten Dienst oder eine anfällige Funktion auf
einem geschützten Server verfugbar macht. (In extremen Fällen werden Firewalls einfach
verwendet, um Konfigurationsfehler und Warrungsrnängel bei einem geschützten System
zu verdecken. Die Folgen sind in der Regel katastrophal.)
ZwicOO
198
11.1 Grundlagen zu Paket-Firewalls
11.1.1 Zustandslose Filterung und Fragmentierung
Einfache Firewalls sind zustandslose Paketfilter. Sie überprüfen lediglich bestimmte
Eigenschaften aller Pakete, z. B. den Zielport, der in TCP-SYN-Paketen zur
Verbindungsherstellung enthalten ist. Allein auf den erkannten Eigenschaften basierend entscheiden sie,
ob das Paket passieren darf oder nicht. Die zustandslose Ausführung ist exteem schlicht,
zuverlässig und Speicher- und ressourcenschonend. So kann eine zustandslose Firewall bei
einem Mailserver eingehende Verbindungen auf solche beschränken, die an Port 25
(SMTP) gerichtet sind, indem sie alle SYN-Pakete mit Ausnahme der an diesen Port
adressierten verwirft. Da ohne ein erstes SYN-Paket aber keine Verbindung aufgebaut werden
kann, kann ein Angreifer über andere Ports nicht sinnvoll mit Anwendungen
kommunizieren. Um ihren Zweck zu erfüllen, muss die Firewall nicht annähernd so schnell oder
komplex wie der Mailserver selbst sein, denn sie muss über laufende Verbindungen und die
jeweiligen Zustände nicht Buch führen.
Das Problem dieses vollständig transparenten Schutzes besteht darin, dass die Firewall und
der endgültige Empfänger einige Parameter unterschiedlich auffassen könnten. Nehmen
wir beispielsweise an, ein Angreifer überzeugt die Firewall davon, dass er eine Verbindung
mit einem zulässigen Port herstellt, maßschneidert seine Daten aber so, dass der
Empfänger sie anders versteht und eine Verbindung über einen Port herstellt, der von der Firewall
eigentlich geschützt werden soll. Auf diese Weise könnte ein Angreifer auf einen
anfälligen Dienst oder eine Administationsoberfläche zugreifen. Und schon gibt es ein Problem.
Zwar klingt es recht unwahrscheinlich, dass ein solches Missverständnis auftreten könnte,
aber erstaunlicherweise lässt es sich ganz einfach einrichten - mithilfe unseres alten
Freundes, der Paketfragmentierung und unter Verwendung einer Vorgehensweise, die man
gemeinhin als Oveiiapping-Fragment Attack2 (Angriff mit überschneidenden Paketen)
bezeichnet und die zuallererst 1995 in RFC1858 beschrieben wurde. In dieser Situation
sendet der Angreifer ein Startpaket, welches den Anfang der SYN-Anforderung gemäß TCP
enthält, an einen Port, der von der Firewall des Opfers freigegeben ist (z. B. den bereits
erwähnten Port 25). Diesem Paket fehlt nur ein winziger Teil am Ende, und das MF-Flag
(„More Fragments") ist im IP-Header gesetzt. Aber warum sollte sich die Firewall schon
um die abschließenden Daten eines Pakets scheren?
Die Firewall untersucht das Paket nun, und weil es sich um ein SYN-Paket handelt, wird
der Zielport geprüft und für annehmbar befunden. Das Paket wird durchgewunken, aber
der Empfänger interpretiert es nicht sofort. (Sie erinnern sich? Wir haben den Wiederher-
stellungsprozess in Kapitel 9 beschrieben.) Stattdessen wird das Paket aufbewahrt und
harrt der erfolgreichen Defragmentierung, die aber erst stattfinden wird, wenn der
abschließende Block des Pakets ankommt.
Nun sendet der Angreifer ein zweites Paketfragment. Dieses zweite Paket wird so erstellt,
dass es sich mit dem Ursprungspaket gerade soweit überschneidet, dass es an der
entsprechenden Stelle im Wiederherstellungspuffer den im TCP-Header gespeicherten Zielport
Ziem95
11 Anomalien erkennen und nutzen
überschreibt. Das Fragment wird so formuliert, dass es bei einem Offset ungleich null
beginnt; in ihm fehlt praktisch der gesamte TCP-Header - bis auf den zu überschreibenden
Teü.
Aus diesem Grund (und weil Angaben fehlen, die erforderlich sind, um die Flags eines
TCP-Pakets oder andere wesentliche Parameter zu überprüfen, anhand derer die Firewall
bestimmen könnte, ob die Daten zugelassen oder blockiert werden sollen) wird das zweite
Fragment von einer zustandslosen Firewall normalerweise unbehelligt weitergeleitet.
Wenn nun dieses zweite Paket vom Empfänger mit dem ersten kombiniert wird,
überschreibt es den ursprünglichen Zielport mit einem heiklen, vom Angreifer gewählten Wert
und öffnet so eine Verbindung mit einem Port, der eigentlich von der Firewall geschützt
werden sollte.
Oha!
■ Hinweis
Um sicheren Schutz gegen diesen Angriff zu bieten, fuhrt eine sorgfältig durchkonstruierte zu-
standslose Firewall zunächst eine Defragmentierung durch, bevor sie die Paket analysiert.
Hierdurch aber wird sie ein bisschen weniger „zustandslos" und auch weniger transparent.
11.1.2 Zustandslose Filterung und unsynchrone Daten
Ein weiteres Problem mit zustandslosen Paketfiltern besteht darin, dass sie eigentlich gar
nicht so gut zupacken, wie wir es uns erhoffen. Eine Filterung kann nur dann durchgeführt
werden, wenn ein Paket auch alle Informationen enthält, die notwendig sind, damit der
Filter eine begründete Entscheidung über die weitere Verfahrensweise treffen kann. Da auf
den einleitenden Handshake folgend eine TCP-Verbindung weitgehend symmetrisch ist -
d. h. die beiden Beteiligten haben gleiche Rechte und verwenden zum Austausch von
Daten denselben Datentyp (ACK-Pakete) -, ist es nicht einfach, Filter sinnvoll auf andere als
die Staitdaten einer Verbindung anzuwenden. Es gibt keine Möglichkeit zu bestimmen,
wer (wenn überhaupt) die Verbindung hergestellt hat, über die Pakete ausgetauscht
werden, wenn Verbindungen nicht nachverfolgt und aufgezeichnet werden. Insofern ist es ein
bisschen schwierig, die Filterrichtlinie, mit deren Hilfe die Firewall ACK- und andere
,,mittlere" Daten wie FEST- und RST-Pakete überprüfen soll, sinnvoll zu definieren.
Normalerweise stellt das Unvermögen, Daten jenseits der SYN-Pakete zu filtern, kein
Problem dar. Schließlich kann ein Angreifer, der die einleitenden SYN-Pakete nicht
anliefern kann, auch keine Verbindung herstellen. Aber die Sache hat einen Haken: Wie
Systeme Nicht-SYN-Daten an einen bestimmten Port handhaben, hängt davon ab, ob ein Port
geschlossen ist oder das System auf diesem Port horcht. So antworten einige Betriebssys-
teme mit einem RST auf umherirrende FIN-Pakete, erzeugen aber keine Antwort bei Ports,
die offen (also horchend) sind.3
Einige Aspekte dieses Verhaltens (die Neigung, auf herrenlose und unerwartete Pakete an
geschlossene Ports mit RST zu antworten und dieselben Daten nicht zu berücksichtigen, wenn sie an Ports
adressiert sind, auf denen ein Dienst auf Verbindungen horcht) werden durch RFC793 diktiert, andere stellen
lediglich gängige Praxis einer bestimmten Gruppe von Implementierern dar.
200
11.1 Grundlagen zu Paket-Firewalls
Ansätze wie FEST- oder ACK-Scans (die erstmals von Uriel Maiinon im Phrack Magazine
beschrieben wurden4) oder NHL- und Xmas-Scans (Scans mit unzulässigen Paketen, in
denen keine bzw. alle Flags gesetzt sind) können auf diese Weise gegen zustandslose Pa-
ketfilter eingesetzt werden, um angriffsvorbereitende Angaben dazu zu sammeln, welche
Ports auf einem Remote-System offen sind, oder festzuhalten, welche Daten von der
Firewall abgewiesen werden. Die Tatsache, dass jemand erfahren kann, dass ein bestimmter
Port offen ist, stellt an sich noch keine Gefahr dar, wenn keine Möglichkeit vorhanden ist,
eine passende Verbindung mit ihm herzustellen. Allerdings enthüllt ein Scan dieser Alt
häufig extrern wertvolle Informationen zu Netzwerkinterna - beispielsweise zum
verwendeten Betriebssystem oder zu laufenden Diensten -, die eingesetzt werden können, um
einen Angriff einfacher oder effizienter oder seine Entdeckung schwieriger zu gestalten,
sobald die erste Verteidigungslinie durchbrochen oder unterlaufen wurde. Aus diesem Grund
gilt dieser Ansatz als potenzielle Schwäche einer zustandslosen Firewall.
Eine wahrscheinlich gefahrlichere Bedrohung hegt in Verbindung mit dem Mechanismus
der SYN-Cookies vor, wenn diese mit zustandslosen Filtern verknüpft werden. SYN-
Cookies dienen dem Schutz von Betriebssysternen vor Resource Starvation-Angn&en, bei
denen der Angreifer eine sehr große Zahl gefälschter Verbindungsanfragen an den Host
sendet (was an sich keine schwere Aufgabe darstellt). Aufgrund dessen niuss der
Empfänger SYN+ACK-Antworten zurückschicken und zusätzlich Speicher und andere Ressourcen
reservieren, wenn er diese scheinbar bald beginnenden Verbindungen zu seinen TCP-
Statustabellen hinzufügt. Die meisten Systeme, die einem solchen Angriff ausgesetzt sind,
verbrauchen entweder übermäßig viel Ressourcen und werden unerträglich langsam, oder
sie verweigern allen Clients ab einem gewissen Zeitpunkt den Dienst, bis diese falschen
Verbindungen ungültig werden.
Um dieses potenzielle Problem zu beheben, verwenden SYN-Cookies im ISN-Feld aller
SYN+ACK-Antworten eine kryptografische Signatur (die eigentlich eine Verkürzung ist
und die Verbindung eindeutig identifiziert) und streichen die Verbindung dann vollständig
aus ihrern Gedächtnis. Erst wenn die ACK-Antwort vom Host eintrifft - und nur dann,
wenn die Bestätigungsnurnmer den Kryptografietest erfolgreich übersteht -, wird die
Verbindung zur Statustabelle hinzugefügt.
Das Problem bei SYN-Cookies besteht allerdings darin, dass bei einer solchen
Konstruktion die Möglichkeit besteht, dass das SYN-Paket (ebenso wie die SYN+ACK-Antwort)
überhaupt nicht gesendet worden ist. Wenn der Angreifer ein ISN-Cookie erstellen kann,
welches den SYN-Cookie-Algorithmus des Hosts übersteht (weil der Angreifer unter
Umständen über ausreichend Bandbreite verfügt oder der Algorithmus schwach ist), dann
kann er ein ACK-Paket senden, das beim Remote-Host das Hinzufügen einer neuen
Verbindung zur Statustabelle bewirken würde - trotz der Tatsache, dass zuvor weder ein SYN-
Paket gesendet noch ein SYN+ACK-Paket empfangen wurde. Eine zustandslose Firewall
4 Maim96
11 Anomalien erkennen und nutzen
könnte in diesem Fall nicht wissen, dass gerade eine Verbindung hergestellt wurde, denn
die einleitende Anfrage hat sie ja niemals erhalten! Da aber kein eröffnendes SYN-Paket
vorhanden war, konnte die Firewall weder die ZP-Adiesse noch den Port überprüfen und
genehmigen oder abweisen. Und doch ist aus heiterem Himmel eine Verbindung
vorhanden.
Das ist ganz schlimm.
11.1.3 Zustandsbehaftete Paketfilter
Um das Problem zustandsloser Filter zu beseitigen, müssen wir einen Teil der
Informationen zum vorherigen Datenverkehr und zum Zustand der laufenden Verbindungen in der
Firewall speichern. Dies ist die einzige Möglichkeit, das Ergebnis der Defragmentierung
transparent vorauszusagen oder den Kontext für Pakete aus (scheinbar) laufenden
Verbindungen zu ermitteln und so festzustellen, ob diese unzulässig sind und verworfen werden
sollen, oder ob sie vom Empfänger erwartet werden und weiterzuleiten sind.
Dank der Tatsache, dass leistungsstarke Cornputersysterne bezahlbar geworden sind,
konnten Firewalls entwickelt werden, die weitaus komplexer und fortschrittlicher sind, als wir
uns dies je vorstellen konnten. Deswegen lag der nächste Schritt nahe: die
„zustandsbehaftete" Verfolgung von Verbindungen - eine Situation, in der die Firewall nicht nur einzelne
Pakete überprüft, sondern sich auch an den Kontext einer Verbindung erinnert und jedes
Paket mit den ihr bekannten Daten abgleicht. Auf diese Weise kann die Firewall das
Netzwerk fest versiegeln und unerwünschte oder unerwartete Daten verwerfen, ohne sich
darauf verlassen zu müssen, dass der Empfänger immer in der Lage ist, guten von
schlechtem Datenverkehr unterscheiden zu können. Statusbehaftete Paketfilter versuchen,
Verbindungen zu überwachen und nur Daten zuzulassen, die einer aktiven Sitzung angehören.
Aufgrund dessen bieten sie bessere Schutz- und Protokollierangsfunktionalitäten.
Die Aufgabe des zustandsbehafteten Filterns stellt natürlich eine größere Herausforderung
dar als das zustandslose Filtern und verbraucht erheblich rnehr Ressourcen. Dies gilt
insbesondere, wenn das von einem solchen Gerät zu bewachende Netzwerk sehr groß ist. Wenn
sie ein umfangreiches Netzwerk schützt, dann erfordert eine Firewall plötzlich sehr viel
Speicher und einen schnellen Prozessor, um Daten zu den laufenden Vorgängen speichern
und aufrufen zu können.
Auch ist bei der zustandsbehafteten Analyse die Wahrscheinlichkeit höher, dass Probleme
oder ein Durcheinander entstehen. Schwierigkeiten treten auf, sobald Firewall und
Endpunkte unterschiedlicher Ansicht bezüghch des Zustands einer gegebenen TCP/IP-Sitzung
sind - eine Situation, die angesichts der Mehrdeutigkeit von Spezifikationen und der
Vielzahl verwendeter Stapel nicht so abwegig ist. Beispielsweise könnte eine Firewall, die eine
Sequenznuininemübeipilifung weniger stringent durchführt als der endgültige Empfänger,
aus dem Empfang eines RST-Pakets, dessen Sequenznurnmem sich nicht innerhalb der
vom Empfänger akzeptierten Grenzen befindet, schließen, dass die Verbindung beendet
wurde, während der Empfänger die Sitzung nach wie vor für geöffnet und in der Lage hält,
202
11.1 Grundlagen zu Paket-Firewalls
weiterhin zugehörige Daten zu übertragen. Oder umgekehrt. Letztendlich hat die zustands-
behaftete Filterung ihren Preis.
11.1.4 Neuschreiben von Paketen und NAT
Die Lösung zur Verbesserung der Paketinterpretation und zur Gewährleistung eines
besseren Schutzes gegen Angriffe, die etwa mithilfe der Paketfragmentierung Firewall-
Richtlinien umgehen, besteht darin, Firewalls die Daten nicht einfach nur weiterleiten zu
lassen, sondern ihnen auch das Neuschreiben von Teilen der Daten zu gestatten. So
versucht etwa ein Ansatz, die Mehrdeutigkeit zu beseitigen, indem er eine Paketdefragmentie-
rung (d. h. eine Rekonstmktion im wörtlichen Sinne) erzwingt, bevor das Paket mit den
vom Netzwerkadrninistrator konfigurierten Zugriffsregeln verglichen wird.
Mit der Entwicklung ansprachsvoUerer Lösungen wurde offenbar, dass das Neuschreiben
der Pakete nicht nur dem Netzwerk zugute kornint, sondern für die Netzwerksicherheit und
-funktionalität geradezu einen Quantensprung darstellt - durch den Einsatz nützlicher
Techniken wie NAT (Network Address Translation, Netzadressübersetzung). Hierunter
versteht man die Verknüpfung bestimmter IP-Adressen mit anderen IP-Adressen vor deren
Weiterleitung und die Entwirrung der Antworten vor der Rücksendung durch ein
geschütztes System. Neben anderen Anwendungen kann ein zustandsbehafteter NAT-Mechanismus
verwendet werden, um fehlertolerante Konfigurationen zu implementieren, in denen genau
eine öffentlich zugängliche IP-Adresse von mehreren internen Servern bedient wird. Wenn
Adressraum eingespart oder die Sicherheit verbessert werden soll, dann kann NAT
außerdem implementiert werden, um dem internen Netzwerk die Verwendung eines Pools
privater, nicht öffentlich zugänglicher Adressen zu ermöglichen und den Hosts im Netzwerk
gleichzeitig eine Kommunikation mit dem Internet zu gestatten, wobei das Netzwerk durch
nur einen Computer mit öffentlich zugänglicher IP-Adresse „maskiert" wird.
Im ersten Szenario schreibt NAT die Zieladressen in den eingehenden Paketen so um, dass
mehrere private Systeme hinter der Firewall bedient werden. Hierdurch entsteht eine
Konfiguration mit fehlertolerantem Lastausgleich, in der aufeinanderfolgende Anforderungen
an eine behebte Website (z. B. http.VAvww.microsofi.com) oder einen anderen kritischen
Dienst auf mehrere Systeme verteilt werden können; fallt eines dieser Systeme aus, dann
können die anderen übernehmen. Diese Aufgabe wird manchmal auch mit dedizierten
Geräten gelöst (die deswegen auch Lastausgleichssysteme heißen), die wiederum häufig auch
von NAT-fahigen Firewalls unterstützt werden.
Das zweite Szenario, das häufig auch als Masquerading bezeichnet wird, basiert auf dem
Neuschreiben der Absenderadressen ausgehender Pakete. Dies erlaubt die Anbindung einer
Anzahl privater und geschützter Systeme (die unter Umständen private Adressen
verwenden, auf die aus dem Internet nicht über dieses Netzwerk geroutet wird, also etwa 10.0.0.0)
an die Außenwelt, wozu die Firewall die ausgehenden Verbindungen überprüft und die
Adressen neu schreibt. Die Systeme sind hinter der Firewall verborgen, und ihre
Handlungen präsentieren sich dem Empfänger außerhalb des NAT-geschützten Netzwerks als von
der Firewall stammend. Die Verbindung wird mit einer bestimmten öffentlichen IP-
203
11 Anomalien erkennen und nutzen
Adresse und einem bestimmten Port verknüpft, und dann werden die Daten weitergeleitet.
Der gesamte Datenverkehr, der vom Empfänger an diese IP-Adresse und diesen Port
zurückgeschickt wild, wild dann wieder so umgeschrieben, dass er an das private System
gerichtet ist, welches die Verbindung aufgebaut hat, und dann in das interne Netzwerk
weitergeleitet. Auf diese Weise bleibt das gesamte private Netzwerk mit Workstations, die
nicht für die Bereitstellung von Diensten im Internet vorgesehen sind, von außen
zumindest auf direktem Wege unerreichbar. Dies erhöht die Sicherheit im Netzwerk erheblich,
verbirgt einen Teil seiner Struktur und spart zudem teuren öffentlichen IP-Adressraum ein,
der andernfalls hätte erworben werden müssen, um alle Systeme im internen Netzwerk zu
versorgen. Mithilfe dieses Systems kann eine Organisation, auf die im Internet nur eine
einzige IP-Adresse verweist, trotzdem ein Netzwerk mit Hunderten oder Tausenden von
Computern aufbauen und diese an das Internet anbinden.
11.1.5 Lost in Translation
Auch die Adressübersetzung ist komplexer, als es den Anschein hat: Einige höhere
Protokolle wählen nicht den schlichten Weg, eine Verbindung mit einem entfernten System
herzustellen und dann einfach ein paar Befehle zu senden. Das ebenso alte wie populäre FTP-
Protokoll (File Transfer Protocol)5 basiert in seinem grundlegendsten und
meistunterstützten Betriebsrnodus auf der Herstellung einer Zweitverbindung vom Server zum Client
(also in Gegenrichtung), um die erforderlichen Daten zu senden; die ursprüngliche, vom
Client aufgebaute Verbindung wird lediglich zum Übermitteln von Befehlen benutzt. Viele
andere Protokolle - insbesondere einige Protokolle für Chat-Programme, P2P- und
Filesharing-Tools, Multimediadienste usw. - setzen ebenfalls merkwürdige oder
ungewöhnliche Strukturen ein, die Rückverbindungen oder Portwechsel erfordern oder bestimmten
sitzungsübergreifenden Datenverkehr wie etwa UDP-Pakete (User Datagram Protocol)
zurück zur Workstation gestatten.
Um diesen Herausforderungen zu begegnen, muss, wenn derartige Protokolle unterstützt
werden sollen, jede Masquerading-Irnplernentierung mit einer Anzahl entsprechender
protokollspezifischer Hilfsprogramme (engl. Helpers) ausgestattet sein. Diese Protokolle
untersuchen die über eine Verbindung ausgetauschten Anwendungsdaten, schreiben sie zum
Teil um und bohren vorübergehend Löcher in die Firewall, um den Datenverkehr in
Gegenrichtung zu gestatten.
Hier stoßen wir auf ein weiteres Problem, das vor einigen Jahren zuallererst von Mikael
Olsson im FTP-Helperö und in der Folge im Zuge entsprechender Nachforschungen auch
in weiteren Helpem erkannt wurde (unter anderem auch vom Autor dieser Zeilen).7 Das
Problem besteht darin, dass diese Helper basierend auf den Angaben, die von einer
Workstation übeitragen wurden, entscheiden, wann und wie für ein bestimmtes Protokoll und
5 Post85
6 OlssOO
7 ZaleOla
204
11.1 Grundlagen zu Paket-Firewalls
eine bestimmte Zieladresse Löcher in der Firewall geöffnet werden. Sie setzen dabei
voraus, dass der vom System erzeugte Datenverkehr im Auftrag des Benutzers und mit seinem
Wissen gesendet wird. Es ist aber klar, dass sich einige Programme wie etwa Webbrowser
so beeinflussen lassen, dass sie bestimmte Netzwerkdaten senden - z. B. Daten, die
„aussehen" wie ein Protokoll, welches das Programm nicht nativ unterstützt. Mehr noch: Diese
Programme können sogar dazu überredet werden, dies automatisch zu tun, indem man
einfach bestimmte gefährliche Inhalte bastelt und diese an die Anwendung sendet. Ein solcher
nachgemachter Datenverkehr kann ein Helper-Programm so in die Irre führen, dass es ein
Loch in der Firewall einrichtet.
Das klassische Beispiel eines solchen Angriffs ist der Missbrauch eines universellen
Webbrowsers: Indem über einen nicht standardkonformen HTTP-Port (der jedoch für FTP-
Daten sehr wohl standardkonfomi ist) ein Verweis auf eine Website oder ein Webelement
ergänzt wird, die bzw. das im Zweifelsfall auf dem System eines Angreifers vorhanden ist,
kann der Client gezwungen werden, eine Verbindung mit dieser Ressource herzustellen
und zu versuchen, eine HTTP-Anforderung abzusetzen. Da der Port, mit dem die
Verbindung hergestellt wird, normalerweise von FTP benutzt wird, horcht der FTP-Helper der
Firewall auf und macht sich zur Mithilfe bereit, sollte diese notwendig sein.
Die folgende Beispieladresse etwa würde dafür sorgen, dass der HTTP-Client eine
Verbindung mit dem FTP-Port herstellt und dann etwas absetzt, was für den Firewall-Helper wie
der FTP-Befehl port aussieht:
HTTP://SERVER:21/FOO<RETURN>PORT MY_IP,122,105<RETURN>
Die vom Client abgesetzte Anforderung würde von einem echten FTP-Dienst am anderen
Ende lediglich als leeres Gewäsch aufgefasst, und seine Antwort wäre für den Webclient,
der die Anforderung abgesetzt hat, wiederum völlig unverständlich. Aber darum geht es
hier gar nicht. Worum es wirklich geht, ist, dass der Angreifer einen Teil der Anfrage
steuern kann: den Dateinamen, den der Client vom Server abruft. Dieser fiktive, vom Schraken
gewählte Dateiname kann alle von ihm gewünschten Daten enthalten. Indem man in den
Dateinamen Teilstrings einfügt, die normalerweise mit FTP-Anforderungen verknüpft
würden, kann der Angreifer einen FTP-Helper austricksen, der die Verbindung nach einem
bestimmten Textbefehl (port) durchsucht; der Helper glaubt dann, dass der Benutzer
versucht, eine bestimmte Datei herunterzuladen. Also darf der Remote-Server vorübergehend
eine Verbindung mit dem Opfer herstellen - in diesem Fall über den Port mit der abwegig
klingenden Nummer 31.337 (122 ■ 256 + 105). Und so lassen wir den Angreifer ein, ohne
dass das Opfer etwas davon mitbekommt. Nun, das ist ja schon wieder mehr, als wir
erwartet haben.
205
11 Anomalien erkennen und nutzen
11.2 Der Mummenschanz und seine Folgen
Alle bislang beschriebenen Szenarien beziehen sich auf den Missbrauch des Masquera-
dings, aber bereits das reine Vorhandensein dieser Funktionalität kann uns eine Menge
über unseren Gegenüber erzählen.
Wie bereits angemerkt, geht das Masquerading keineswegs unaufdringlich zu Werke. Das
Betriebsprinzip besteht im Wesentlichen darin, Teile des ausgehenden Datenverkehrs neu
zu schreiben. Dabei beschränkt es sich nicht auf das Anpassen der Adresse. Insofern kann
der aufmerksame Beobachter nicht nur erschließen, dass das Masquerading eingesetzt
wird, sondern er kann auch das jeweilig verwendete Firewall-Systern ermitteln. Beim
Einsatz des Masqueradings finden wir die folgenden Änderungen vor:
■ Es tritt eine offensichtliche Diskrepanz zwischen der TTL eingehender Pakete und der
erwarteten oder gemessenen Entfernung zum Zielnetzwerk auf. Datenverkehr, der von
jenseits eines Masquerading-Systerns stammt, ist mindestens einen Hop „älter" als ein
Paket, das von einem System kommt, welches seine IP-Adresse für ausgehende
Verbindungen direkt von einem geschützten Netzwerk erhält.
■ In den meisten Fällen lassen sich im Ursprungsnetzwerk verschiedene Systeme oder
leicht unterschiedliche Beüiebssystemkonfigurationen (oder Laufzeiten) ausmachen.
Diese Systeme weisen leicht unterschiedliche TCP/IP-Eigenschaften auf (siehe auch
Kapitel 9 und 10). Wenn wir verschiedene „TCP/IP-Handschriften" in Verbindungen
beobachten, die scheinbar von derselben IP-Adresse stammen, können wir deutliche
Hinweise darauf erhalten, ob NAT auf einem bestimmten Computer mit einem
nachgeschalteten internen Netzwerk vorhanden ist.
■ Schließlich wird der entfernte Beobachter wahrscheinlich auch eine Verschiebung der
Quellports feststellen. Dies ist ein ansonsten sehr ungewöhnlicher Vorfall, der auftritt,
weil Verbindungen, die aus dem Netzwerk stammen, kurzlebige Quellports verwenden,
die sich nicht in dem vom betreffenden Betriebssystem normalerweise verwendeten
Bereich befinden.
Jedes Betriebssystem reserviert einen bestimmten Bereich von Quellports, um lokale End-
punktkennungen für alle ausgehenden Verbindungen zuzuweisen. Allerdings verwendet
eine Firewall häufig einen anderen Portbereich zur Kennzeichnung maskierter
Verbindungen. Dieser Bereich ist spezifisch für das Betriebssystem des NAT-Geräts. In diesem Fall
ist es, wenn der beobachtete Bereich sich von demjenigen unterscheidet, den wir für das
erkannte Betriebssystem erwarten würden, möglich, das Vorhandensein der
Adressübersetzung zu erschließen und manchmal sogar den Typ der verwendeten Firewall zu
bestimmen. Dies kann beispielsweise der Fall sein, wenn Linux, welches normalerweise im
Portbereich zwischen 1.024 und 4.999 operiert, außergewöhnlich hohe Poitnummern
verwendet.
Diese Techniken werden häufig eingesetzt und bilden die Basis für die Masquerading-
Erkennung und die Erkundung maskierter Netzwerke. Aber es gibt noch ein paar weitere
Hilfsmittel zur Erkennung umgeschriebener Pakete.
206
11.3 Roulette spielen mit der Segmentgröße
11.3 Roulette spielen mit der Segmentgröße
Einer der weniger offensichtlichen und insofern auch weniger bekannten Wege, Geräte zu
erkennen, die Pakete umschreiben, und mehr über die Netzwerkkonfiguration zu erfahren,
besteht in der Analyse der MSS-Felder (Maximum Segment Size) eingehender Pakete.
Da die IP-Paketfragmentierung das Datenaufkornmen merklich erhöht, gilt sie aus Sicht
der Systernleistung häufig als Alptraum, weswegen zahlreiche Implementierer sie tunlichst
zu umgehen versuchen. Auf der anderen Seite ist die Fragmentierung, wie wir bereits
gesehen haben, nur schwer zu beseitigen, denn es ist praktisch unmöglich, die MTU eines
Pfades vor Beginn des eigentlichen Kornmunikationsvorgangs exakt, schnell und
zuverlässig zu bestimmen. Auch die beste verfügbare Methode, die PMTU-Erkennung, ist weit
davon entfernt, perfekt zu sein, und wirkt sich, sobald sie ausgelöst wurde, sofort auf die
Übertragungsleistung aus. Damit die korrekte MTU-Einstellung im Trial-and-Error-
Verfahren ermittelt werden kann, müssen einige Pakete, die nicht passen, unter Umständen
verworfen und neu gesendet werden.
Um die Auswirkungen der PMTU-Erkennung auf Leistung und Zuverlässigkeit zu
beseitigen und den Mehraufwand der Fragmentierung zu verringern, ändern viele NAT-Firewalls,
die bestimmte Parameter des ausgehenden Datenverkehrs umschreiben, bei Verbindungen,
die aus dem privaten Netzwerk stammen, auch den im TCP-Header angegebenen MSS-
Parameter auf einen für die aus dem Netzwerk herausführende externe Leitung
geeigneteren Wert. Diese neue Einstellung ist im Zweifelsfall etwas „schmaler" (d. h. sie hat eine
niedrigere MTU) als die des LANs. Diese Änderung stellt sicher, dass der Empfänger nicht
versucht, Daten zu senden, die nicht unfragrnentiert über die Leitung geschickt werden
können (sofern diese den Teil der Infrastruktur mit der niedrigsten MTU darstellt). Auf
diese Weise wird die Wahischeinlichkeit des Auftretens einer Fragmentierung verringert.
Dies setzt voraus, dass, sollte es zu einer MTU-Inkompatibihtät kommen, diese in der
Nähe des Absender- oder Empfangersystems — auf der so genannten„letzten Meile" — auftritt;
dort kommen häufig unterschiedliche Typen von Verbindungen mit geringen MTUs zum
Einsatz, z. B. DSL-Verbindungen oder Funkstecken, und Pakete müssen, um über diese
Verbindungen übertragen werden zu können, „verkleinert" werden.
Allein diese MSS-Verringerung ist nicht ganz einfach zu erkennen. Tatsächlich ist es
unmöglich zu sagen, ob die MSS den erkannten Wert vom Absender erhielt oder dieser
unterwegs geändert wurde. Das heißt, vielleicht mit einer kleinen Ausnahme. Wir wissen aus
Kapitel 9, dass der Algorithmus zur Bestimmung der Fenstergröße auf vielen modernen
Systemen eine Besonderheit aufweist:
Wie wir wissen, bestimmt die Fenstergröße die Menge der Daten, die ohne Bestätigung
gesendet werden können. Die jeweilige Einstellung wird häufig auf der Basis der
Vorgaben gewählt, die der Entwickler von seinem indischen Ouru oder anderen
spirituell maßgeblichen Institutionen erhält. Die beiden meistverwendeten Ansätze
besagen, dass der Wert entweder ein Vielfaches der MTU abzüglich der Protokoll-
Header sein sollte — ein Wert, der auch als MSS (Maximum Segment Size) bezeichnet
207
11 Anomalien erkennen und nutzen
wird —, oder aber einfach groß genug und irgendwie „rund". Ältere Linux-Versionen
(etwa 2.0) verwendeten Zweierpotenzen (z. B. 16.384). Bei Linux 2.2 wechselte man
dann zum 1 Ifachen oder 22fachen der MMS (warum auch immer), und neuere Linux-
Versionen verwenden das Zwei- oder Vierfache des MMS-Werts. Die Sega Dreamcast
— eine netzwerkfähige Spielekonsole — benutzt den Wert 4.096, und bei Windows wird
häufig 64.512 verwendet.
Eine immer größer werdende Anzahl modemer Systeme (einschließlich neuerer Versionen
von Linux und Solaris, bestimmter Windows-Versionen und SCO UnixWare) verwendet
eine Fenstergrößeneinstellung, die ein Vielfaches des MSS-Wertes ist. Aufgrund dessen ist
es einfach festzustellen, ob an der MSS-Einstellung in einem Paket hemmgepfuscht wurde,
denn die Fenstergröße des bearbeiteten Pakets wird dann kein bestimmtes Vielfaches des
MSS mehr sein. Vielmehr ist es sogar wahrscheinlich, dass sie sich überhaupt nicht mehr
durch die MSS teilen lässt.
Indem man die MSS mit der Fenstergröße vergleicht, kann man das Vorhandensein einer
Gruppe von Firewalls, die das MSS-Clamping (d. h. die Anpassung des Wertes an die
nachfolgende Verbindung) auf einer Vielzahl von Systemen unterstützen, zweifelsfrei
nachweisen. Zwar ist das Clamping unter Linux und FreeBSD optional, auf Firewalls und
intelligenten DSL-Routern für Heimnetze wird es jedoch häufig automatisch durchgeführt.
Insofern zeigt eine anomale MSS-Einstellung nicht nur das Vorhandensein eines paketrno-
difizierenden Geräts an, sondern lässt auch auf NAT-Funktionalität schließen, was
wiederum weitere Rückschlüsse auf die Netzwerkverbindung des Absenders zulässt.
11.4 Zustandsbehaftete Nachverfolgung und unerwartete
Antworten
Eine weitere wichtige Konsequenz aus der Nachverfolgung zustandsbezogener
Verbindungen und der Paketmodifikation besteht darin, dass einige von RFCs vorgesehene
Antworten von der Firewall und nicht vom Absender erzeugt werden. Dies erlaubt es dem
Angreifer, ein solches Gerät mit hoher Effizienz zu erkennen und zu sondieren. Wenn eine
Verbindung aus der NAT-Zustandstabelle gelöscht wird — sei es, weil sie ungültig
geworden ist oder von einem der Endpunkte mit einem RST-Paket beendet wurde, das die
Gegenseite nicht erreichte —, dann wird weiterer Datenverkehr der betreffenden Sitzung
anders als bei zustandslosen Paketfiltem nicht an den Empfänger weitergeleitet, sondern
direkt von der Firewall verarbeitet.
Die TCP/IP-Spezifikation schreibt vor, dass ein Empfanger auf alle unerwarteten ACK-
Pakete mit einem RST-Paket antworten soll, damit der Absender weiß, dass die Sitzung,
die er fortsetzen will, nicht oder nicht niehr vom Empfanger unterstützt wird. Einige
Firewalls verweigern im Widerspruch zu den RFCs eine Beantwortung dieser Daten
vollständig: Pakete, die keine vorhandenen Sitzung anzugehören schienen, werden einfach
verworfen. (Dies ist nicht immer klug, denn es kann zu unnötigen Verzögerungen führen, wenn
eine zulässige Verbindung aufgrund von Problemen mit Zwischengeräten abgebaut wird.)
208
11.4Zustandsbehaftete Nachverfolgung und unerwartete Antworten
Viele Geräte jedoch antworten mit dem zulässigen und erwarteten RST-Paket. Hierdurch
wird eine weitere Möglichkeit eröffnet, das Firewall-Gerät zu erkennen und sorgfältig zu
profilieren. Da das Paket von der Firewall von Grund auf neu erstellt wird, beziehen sich
seine Parameter auf die Firewall und nicht auf das, was die Firewall zu schützen versucht.
Dies gibt uns die Möglichkeit, die Firewall mithilfe traditioneller Fingeiprinting-Methoden
zu identifizieren, wie wir sie in Kapitel 9 kennen gelernt haben (Übeipräfung von DF-
Flags, TTL, Fenstergröße, Optionstypen, -werten und -reihenfolge usw.).
Es gibt aber auch noch eine andere Möghchkeit, die uns RFC11228 eröffnet:
4.2.2.12 RST-Segment: RFC-793 Abschnitt 3.4
TCP SOLLTE gestatten, dass ein empfangenes RST-Segrnent Daten enthält.
ERÖRTERUNG: Es wurde darauf hingewiesen, dass ein RST-Segment auch ASCII-
Text enthalten kann, der den Grund für das RST-Paket angibt. Für derartige Daten
wurde noch kein Standard verabschiedet.
Und in der Tat gibt es Systeme, die, obwohl dafür noch kein Standard vorhanden ist, auf
ein verirrtes ACK-Paket mit einer ausführlichen (wenn auch oft kryptischen) RST-
Meldung antworten — in der Hoffnung, dass die Gegenseite Trost darin findet, über die
Ursache Bescheid zu erhalten. Häufig enthalten diese Antworten interne Schlüsselwörter oder
Ansätze schlagen, betriebssysternspezifischen Humors. Hier ein paar Beispiele:
B Mac OS: no tcp, reset; tcp_close, during connect
B HP/UX: tcp_fin_wait_2_timeout, No TCP
B SunOS: new data when detached, tcp_lift_anchor, can't wait
Immer, wenn wir ein auskunftsfreudiges RST-Paket erkennen, das als Reaktion auf
Netzwerkprobleme oder unerwartet erhaltene Daten an den Host gesendet wird, und außerdem
wissen, dass das Remote-System, von dem es stammt, diese ausführlichen Nachrichten
nicht verwendet, wissen wir Bescheid. Wir können den Schluss ziehen, dass zwischen uns
und dem Empfänger ein Gerät — wahrscheinlich eine statusbehaftete Firewall — vorhanden
ist, und wir können sein Betriebssystern ermitteln, indem wir die Antwort aus der Liste der
bekannten Nachlichten gängiger und weniger gängiger Betriebssysteme heraussuchen.
Diese beiden Fingeipiinting-Methoden erweisen sich, wann immer die Daten im Netzwerk
bei kurzzeitigen Netzwerkproblemen beobachtet werden können, als für die Erkennung
vorhandener statusbehafteter Paketfilter extrem effizient. Sie lassen sich auch für aktives
Fingerprinting einsetzen, ohne das Firewall-Gerät selbst ins Visier zu nehmen, indem man
ein herrenloses ACK-Paket an ein Ziel sendet, um zwischen statuslosen und
statusbehafteten Filtern unterscheiden zu können. Ausgehend von der Antwort des Paketempfangers
kann der Angreifer dann eine geeignete Methode entwickeln, um die Firewall anzugehen
(oder Kenntnisse einsetzen, die er auf andere Weise erworben hat).
8 Brad89
11 Anomalien erkennen und nutzen
11.5 Zuverlässigkeit oder Leistung: Der Streit ums DF-Bit
Die PMTU-Erkennung ist ein Fmgeiprinting-Szenario, das eng mit dem der Vermeidung
der IP-Fragmentierung verknüpft ist, wie wir sie in Kapitel 9 kennen gelernt haben.
Aktuelle Versionen des Linux-Kernels (2.2, 2.4, 2.6) und von Windows (2000 und XP)
implementieren und aktivieren die PMTU-Erkennung standardrnäßig. Insofern ist, sofern
diese Einstellung nicht geändert wurde, bei allen Datenpaketen, die von solchen Betriebs-
systemen stammen, das DF-Bit („Don't Fragment") gesetzt. Auch hier neigt der Pfader-
kennungsalgorithmus dazu, Probleme in Situationen zu verursachen, die zwar selten, aber
nicht völlig unbekannt sind.
11.5.1 Ausfallszenarien für die PMTU-Erkennung
Das Problem bei der PMTUD besteht darin, dass sie von der Fähigkeit des Absenders
eines Pakets abhängt, die ICMP-Fehlermeldung „Fragmentierung erforderlich, aber DF ist
gesetzt" empfangen und die optimalen Einstellungen für eine Verbindung bestimmen zu
können. Das Paket, welches die Meldung ausgelöst hat, wird verworfen, bevor es das Ziel
erreicht, d. h. es rnuss in seiner Größe angepasst und dann neu gesendet werden.
Wenn der Absender diese Meldung nicht empfingt, weiß er nicht, dass sein Paket nicht
durchgekommen ist. Dieses fühlt zumindest zu einer Verzögerung, und schlimmstenfalls
wird die Verbindung sogar beendet, denn auch bei einer Neuübertragung werden die Daten
mit hoher Wahrscheinlichkeit nicht über eine Verbindung gesendet werden, deren
maximale Paketgröße geringer ist als das, was der Absender lundurchzuquetschen versucht.
Für die ICMP-Meldung, die erstellt wird, wenn ein Paket zu groß für eine Verbindung ist,
wird jedoch nicht garantiert, dass sie den Absender erreicht. In manchen Netzwerken
werden infolge eines falsch verstandenen Versuchs, die Sicherheit zu erhöhen, alle ICMP-
Meldungen einfach gelöscht. Also wird ein solches Paket selbst dann nicht unbedingt
ausgeliefert, wenn es von einem Gerät gesendet wird.
Aber warum sollten ICMP-Meldungen denn überhaupt gelöscht werden? Nun, in der
Geschichte der Netzwerktechnik gelten viele derartige Meldungen als Urheber von
Sicherheitsproblemen: Bestimmte tibergroße oder fragmentierte ICMP-Pakete beschädigten den
Kernel-Speicher vieler Systeme. (Man kennt diese Angriffsform unter der Bezeichnung
„Ping of Death"). ICMP-Meldungen, die an Broadcast-Adressen gesendet wurden, wurden
auch verwendet, um einen Sturm von Antworten an eine gefälschte Quelladresse zu
entfachen („Srnurf-Angriff') oder DoS-Attacken auszuführen. Außerdem interpretierten
fehlerhaft konfigurierte Systeme eine bestimmte Alt von ICMP-Broadcasts — eine Nachricht zur
Bekanntmachung von Routem9 — oft fälschlicherweise als Befehl zur Änderung ihrer
Router-Bekanntmachungen („Advertisenients") sollen die automatische Konfiguration von Netzwerk-
hosts ermöglichen, ohne dass der Administrator manuell Hilfestellung leisten muss. Der Router sendet
dann regelmäßig — oder auf Anforderung — eine Broadcast-Meldung, die besagt „Hier bin ich. Benutze
mich". Einige Betriebssysteine akzeptieren nicht angeforderte Bekanntmachungen ohne Zögern. Eine
ziemlich schlechte Idee.
210
11.5 Zuverlässigkeit oder Leistung: Der Streit ums DF-Bit
Netzwerkeinstellungen. Da sie diese Nachricht unabhängig vom Grad ihrer
Vertrauenswürdigkeit akzeptierten, eröffnete sich hier eine weitere interessante Möglichkeit zum
Angriff. Aus diesem Grund wird ICMP von vielen gefürchtet. Und blockiert.
■ Hinweis
Den Vorschlag, den gesamten ICMP-Datenverkehr abzuweisen, finden Sie häufig in
kritikfreien Sicherheitsleitfäden, und allzu viele Administratoren beherzigen ihn auch. Ich habe ihn
sogar in einer Empfehlung eines professionellen renommierten Prüfers für einen
Penetrationstest gefunden. Den Namen der betreffenden Person darf ich an dieser Stelle
bedauerlicherweise nicht verlautbaren.
Ein weiteres Problern, das die PMTUD unzuverlässig machen kann, hegt vor, wenn einige
empfangene Fehlermeldungen von Geräten stammen, die den privaten Adressraum
verwenden. Manchmal werden, um Adressen im eingeschränkten (und deswegen
kostspieligen) öffentlichen IP-Adressraum einzusparen, Schnittstellen an dem Kabel, mit dem der
Router und die Firewall eines entfernten Netzwerks angebunden sind, nicht mit den
Adressen konfiguriert, über die das Netzwerk von außen erreichbar ist; stattdessen werden
Adressen aus einem Adresspool zugewiesen, der für den privaten oder lokalen Einsatz
reserviert ist.
Leider setzt der Einsatz des privaten Adressraums die PMTUD außer Gefecht. Warum
dieses? Weil, wenn ein Paket, das von außen kommt, zu groß ist, um von der Firewall des
Empfängers an das Ziel weitergeleitet zu werden, die Firewall eine ICMP-Fehlermeldung
mit ihrer eigenen Absenderadresse zurückschickt. Und diese gehört in diesem Fall zum
Pool privater Adressen. Die Firewall des Absenders des Ursprungspakets kann dann ein
solches Antwortpaket abweisen, denn es kommt zwar von außen, weist aber eine IP-
Adresse aus einem privaten Pool auf (möghcherweise sogar aus einem Bereich, der auch
im privaten LAN des Absenders verwendet wird). Die Firewall lehnt die Annahme dieser
Daten ab, weil solche Faktoren gewöhnlich Anzeichen eines Fälschungsversuchs mit dem
Ziel sind, die Identität eines vertrauenswürdigen internen Hosts vorzugeben. In diesem Fall
allerdings durchbricht diese Entscheidung einen relativ aktuellen PMTUD-Mechanismus,
und am Ende weiß der ursprüngliche Absender nicht, dass sein Paket nicht angekommen
ist.
Und es kommt noch schlimmer: Auch wenn alle Bedingungen erfüllt sind und das Paket
sein Ziel erreicht, kann dies folgenlos bleiben, denn viele moderne Geräte schlanken die
ICMP-Antwortraten ein und senden nur eine begrenzte Anzahl von Meldungen während
eines bestimmten Zeitraums. Auch dies wurde als Sicherheitsmaßnahme implementiert. Da
ICMP-Meldungen lediglich informativen Charakter haben und vor der Einführung von
PMTUD-Algorithmen nicht kritisch für die Kornmunikation waren, schien die
Beschränkung der Antwortete eine vernünftige Möglichkeit zur Abwehr bestimmter Arten von
DoS- oder Bandwidth Stan'aöow-Angriffen zu sein.
211
11 Anomalien erkennen und nutzen
11.5.2 Der Kampf gegen PMTUD und seine Nebenprodukte
Im Lichte dieser Ausführungen besehen scheint die PMTU-Erkennung ein ziemlich
schlechtes Konstmkt zu sein. Sie bietet leistungstechnisch gewisse Verbesserungen, jedoch
um den Reis selten auftretender, aber hartnäckiger und gewöhnlich schwer
diagnostizierbarer Probleme, die Benutzem den Zugriff auf bestimmte Server verweigern oder ihre
Verbindungen unvorhergesehen beenden können. Zwar wurden viele Algorithmen zur
Erkennung so genannter „schwarzer Löcher" entwickelt, die Hosts oder Netzwerke erkennen
sollen, in denen die PMTUD abgeschaltet werden sollte (diese Algorithmen arbeiten mit
unterschiedlichen! Erfolg), aber hierdurch wird das Problem nicht vollständig gelöst, und
es werden zudem weitere Verzögerangen verursacht — und zwar meist dann, wenn diese
am wenigsten gebraucht werden können.
Um diese Probleme zu beseitigen und Beschwerden zu vermeiden, konfigurieren einige
Anbieter kommerzieller Firewalls ihre Lösungen so, dass diese einen ziemlich miesen
Trick verwenden: Sie löschen das DF-Flag im gesamten ausgehenden Datenverkehr. Dies
ist eine subtile und ziemlich behebige Modifikation, aber sie ist auch hervorragend
geeignet, das Vorhandensein eines Paketfilters zu verraten, der Daten umschreibt. Wenn die
Eigenschaften PMTUD-fähiger Systeme unter eine bestimmten Adresse oder in einem
gegebenen Netzwerk beobachtet werden, in den eingehenden Paketen aber die erwarteten DF-
Flags fehlen, dann kann der aufmerksame Beobachter das Vorhandensein und den Typ
einer Firewall erschließen und erhält so ein weiteres winziges Puzzlestück, ohne mit dem
Opfer interagjeren zu müssen.
11.6 Denkanstöße
Hier endet meine kleine Geschichte darüber, wie die Verbesserung und
Leistungssteigerung von Firewalls in punkto Verhinderung von Infiltrierung und direkter Reconnaissance
auch dazu gefühlt hat, dass eben diese Firewalls mittlerweile unter Verwendung einer
indirekten Beurteilung leichter zu untersuchen sind. Doch gestatten Sie mir noch ein kurzes
Abschweifen.
Meine wahrscheinlich bizarrste und interessantes Entdeckung machte ich irgendwann im
Jahr 1999. Sie hat zwar nicht direkt etwas mit dem Aufbau von Firewalls zu tun, bietet
aber dennoch genug Denkanstöße für jene, die am Problem des passiven Fingerprintings
von Zwischensystemen interessiert sind.
Jacek P. Szymanski, mit dem ich damals für kurze Zeit zusammenarbeitete und mit dem
gewisse ungewöhnliche und verdächtige Muster in Netzwerkdaten zu diskutieren ich
später noch das Vergnügen haben sollte10, bemerkte irgendwann einen plötzlichen Anstieg
Eine Kooperation, die in gewissem Sinne zur Bildung einer lose zusammenhängenden Gruppe
polnischer Forscher führte, die in den Jahren 1999 und 2000 damit beschäftigt waren, absonderliche Allen
unerwarteter Datenverkehrsmuster im Netzwerk abzugleichen, nachzuverfolgen und soweit wie
möglich zu erläutern.
212
11.6 Denkanstöße
erheblich beschädigter TCP/IP-Pakete, die über Port 21.536 (und in geringerern Urnfang
auch über andere Ports wie 18.477 und 19.535) eingingen. Die ramponierten Pakete
stammten immer von Ports wie 18.245, 21.331 oder 17.736 und kamen von einer großen
Anzahl von Systemen im Einwahladressraum der nationalen Telefongesellschaft Teleko-
rnunikacja Polska.
Nachdem ein paar dieser Pakete erfasst werden konnten, wurde festgestellt, dass die Daten
ganz erheblich und auf sehr merkwürdige Weise verstümmelt waren. Die Pakete trafen mit
konekt aufgebauten IP-Headern ein (wobei als RotokoUtyp TCP angegeben war), aber auf
diese Header folgten unmittelbar die TCP-Nutzdaten: Die TCP-Header waren schlicht und
einfach verschwunden. Die beobachteten Portkombinationen entstammten der
Interpretation der ersten vier Nutzbytes als Zahlenpaar: Wäre ein TCP-Header vorhanden gewesen,
dann hätten hier die Angaben zu Quell- und Zielport gestanden. Das Paar 18.245 und
21.536 war nichts anderes als eine Darstellung des Textstrings „GET " - vier Zeichen, mit
denen fast alle HTTP-Anfragen beginnen, die über das Netzwerk übertragen werden.
Ähnlich standen 18.477 und 21.331 für „SSH-", die eröffnende Phrase jeder SSH-Sitzung.
19.535 und 17.736 schließlich ließen sich in „EHLO" übersetzen, einen Befehl, mit dem
alle ESMTP-Sitzungen (Extended SMTP) beginnen.
Warum aber diese Art von Datenverkehr so plötzlich auftauchte, blieb uns zunächst
schleierhaft. Und warum kamen die Daten nur aus diesem einen Netzwerk? Warum schließlich
führte diese Form der Paketverstümmelung nicht zu Konnektivitätsproblemen oder
anderen Unannehmlichkeiten für den Benutzer, sofern irgendein Netzwerkgerät sie tatsächlich
erzeugt hatte?
Die Antwort sollte bald folgen. Wie sich herausstellte, stammte der gesamte beobachtete
Datenverkehr von Nortel CVX-Geräten. Dieses Modemzugangssystem hatte der
Netzbetreiber unlängst in Betrieb genommen. Das Problern trat nur sporadisch auf, wenn die
Systembelastung sehr hoch war. Infolgedessen wurde nur ein kleiner Anteil
unvollständiger Pakete gesendet, und nur diese kleine Zahl erreichte auch die Empfönger (zu deren
äußerster Überraschung). Wahrscheinlichste Ursache war eine untaugliche Warteschlangen-
sperrung oder Pufferverwaltung - ein Roblern, welches nur auffiel, wenn zahlreiche
Sitzungen annähernd gleichzeitig verarbeitet wurden. In solchen Fällen schienen bestimmte
Pakete zu früh - während sie noch zusammengesetzt wurden - gesendet worden zu sein,
oder die Implementiemng hatte sie auf andere Weise verstümmelt.
Die Telekornunikacja Polska korrigierte ihre TCP/IP-Implementiemng sehr bald nach der
Inbetriebnahme in Polen, und alle lebten glücklich und zufrieden bis an ihr Ende. Aber wie
Sie sich vorstellen können, waren dies weder die ersten noch die letzten, die versehentlich
einen eindeutigen Fingerabdruck ihrer Systeme in den versandten Paketen hinterließen.
Die Moral der Geschichte besteht darin, dass es immer wieder naiv ist, außer Acht zu
lassen, was wir normalerweise ignorieren. In der Welt der modernen Netzwerktechnik sind
subtile Andeutungen und ungewöhnliche oder unerwartete und unerklärliche
Beobachtungen von größtem Wert. Sie sind leicht zu finden, aber schwierig zu analysieren.
213
11 Anomalien erkennen und nutzen
Vielleicht sind die verschiedenen Methoden, die zur Abwehr des Betriebssystern-
Fingeipiintings eingesetzt werden, Denkanstoß genug und ein Feld für weitere
Forschungen. Verschiedene Anbieter von Firewalls haben versucht, Maßnahmen gegen das Fin-
gerprinting zu implementieren, die ein paar Paketeigenschaften durch Umgestalten
diverser TCP/IP-Parameter (wie etwa IP-Kennungen, TCP-Sequenznummem usw.) verändern.
Selbstverständlich hilft eine solche Lösung in erster Linie dem Angieifer, denn sie erzeugt
ein Ergebnis, das in etwa das Gegenteil von dem ist, wofür sie gedacht war: Sofern nicht
alle Eigenschaften, die für das Fingerprinting anfällig sind (einschließlich Sequenznum-
rnem, Neuübertragungsintervalle, Zeitstempelwert usw.), geändert und homogenisiert
werden, ist es nicht nur möglich, das zugrundehegende Betriebssystem zu erkennen,
sondern auch die Firewall, die für den Schutz des Netzwerks vorgesehen ist.
C'est la vie.
214
12 Löcher im Datenstapel
Zwölftes Kapitel. In welchem wir uns eine weitere kleine Geschichte zu der
Frage zu Gemüte führen, wo man findet, was eigentlich überhaupt nicht
verschickt werden sollte
Manchmal braucht man, um subtile, aber faszinierende und nützliche Anhaltspunkte zu
seinen vernetzten Mitbürgern und ihren Standorten zu finden, lediglich ein bisschen Glück
Zumindest war dies der Fall bei einem ziemlich interessanten und extrem schwierig zu
fassenden Datenenthüllungsvektor, den ich im Jahre 2003 - nach einer mehrere Wochen
dauernden, entmutigenden Jagd - doch noch entdeckte.
12.1 Kristjans Server
Doch der Reihe nach. Vor mehieren Jahren bat ich einen Freund von mir namens Kristjan
darum, rnir ein wenig Festplattenspeicher auf einem seiner Computer zur Verfügung zu
stellen, um eine Anzahl von Projekten auf einem zuverlässigen und schnellen System
ablegen zu können. Er kam meiner Bitte nach, und bald darauf begann ich, nach und nach
fast alle meine Programme und Arbeiten in ihr neues Heim zu verschieben. Unter den
Projekten, die ich übertrug, war auch eine neue Version von pOf, meinem bereits in Kapitel 9
erwähnten Tool für das passive Fingerprinting von Betriebssystemen. Dieses bescheidene
Werkzeug implementierte einige interessante passive Analysetechniken; um aber wirklich
leistungsfähig zu sein, musste es mit einer umfassenden und aktuellen Datenbank mit Be-
triebssystemsignaturen ausgeliefert werden. Die Pflege dieser Datenbank gestaltete sich
schwierig, und schon bald hatte ich keine obskuren Systeme rnehr zur Verfügung, deren
Signaturen ich hätte hinzufügen können.
Während aber das Sammeln von Signaturen für eine Software, die aktives Fingerprinting
ermöglicht, häufig eine zumindest bedenkliche Interaktion mit dem Zielsystem erfordert
(die auch Streitigkeiten schulen, die Netzwerkanbindung belasten und manchmal sogar
215
12 Löcher im Datenstapel
schlecht implementierte TCP/EP-Stapel zum Absturz bringen kann), braucht das passive
Fingerprinting keine derartige Vorgehensweise: Es konnte problemlos bei allen
Betriebssystemen durchgeführt werden, die Verbindungen mit Kristjans Anlage herstellten, um
meine Seite zu lesen. Um Benutzer anzuspornen, mir ihre Angaben zu übermitteln, richtete
ich eine Unterseite ein, auf der jeder Benutzer sofort sein Fingeipiinting-Profil betrachten,
die Angaben zu seinem System korrigieren oder eine neue Signatur hinzufügen konnte.
Diese Seite erwies sich als hervorragende Möglichkeit zur Sammlung von Signaturen und
zur Optimierung der Software. Aber die Geschichte geht noch weiter.
In einer merkwürdigen Wendung der Dinge beschloss Kristjan, sein System als Host für
eine andere, kommerzielle Site zu vermieten, damit es sich selbst finanziell tagen würde.
Edle Aktivitäten wie der Gartenbau oder die Optimierung der Netzwerksicherheit waren,
wie Sie sich sicher vorstellen können, nicht Gegenstand dieser Site. Nein, es ging vielmehr
um die weniger renommierten, vielleicht aber zugkräftigeren Aspekte unseres Lebens: Sex,
Nacktheit und alles, so dazugehört. Ich war hocherfreut, wie es wohl jeder Neid mit ein
bisschen Selbstachtung gewesen wäre - selbstverständlich nicht wegen der angebotenen
Inhalte, sondern weil innerhalb weniger Stunden Millionen von Verbindungssignaturen
wie Manna vom Himmel fielen, die von der von mir entwickelten Software analysiert
werden wollten. Halleluja!
12.2 Erstaunliche Erkenntnisse
Vorsicht ist die Mutter der Porzellankiste: Als ich neuen Code für pOf entwarf, beschloss
ich, eine Anzahl von Plausibüitätspilifungen zu implementieren, um auch die
absonderlichsten, unwahrscheinlichsten oder haarsträubendesten Muster im eingehenden
Datenverkehr zu erkennen. Diese Checks deckten alle möglichen illegalen oder sinnlosen
Kombinationen von TCP/IP-Einstellungen ab. Zwar legte der gesunde Menschenverstand nahe, dass
ich auf keinerlei Pakete stoßen sollte, bei denen die Parameter auf ungewöhnliche Weise
verdreht waren (zumindest nicht bei der Kommunikation mit verbreiteten und insofern gut
erprobten Systemen), aber die Implementierung dieser Funktionalität schien doch
unproblematisch zu sein. Zudem böte, wenn ein System tatsächlich Pakete schickte, die eine
besondere Form der Anornalität an den Tag legten, die Fähigkeit zu ihrer Erkennung eine
ausgezeichnete Möglichkeit, dieses Betriebssystem von ähnlich aussehenden
Implementierungen zu unterscheiden, die den betreffenden Fehler nicht aufwiesen.
Während dieser schönen Monate des gepriesenen Signaturansturrns sah ich die
merkwürdigsten Dinge. Am Ende gelang es mir, das eine oder andere davon zu erklären und für pOf
zu dokumentieren; andere blieben jedoch ein Geheimnis. Die meisten Anornaliepilifungen,
die ich zuvor implementiert hatte, trafen ins Schwarze: Ich stieß geradewegs auf Systeme,
deren TCP/IP-Implementierungen in der Tat eine ganze Reihe ungewöhnlicher Eigenarten
aufwiesen. Eine Sache aber war besonders verstörend und nur schwer zu glauben,
weswegen ich mich entschloss, ihr mehr Beachtung zu schenken.
216
12.2 Erstaunliche Erkenntnisse
Zwei der Tests - einer bezüglich des im TCP/IP-Header angegebenen ACK-Wertes bei
nicht gesetztem ACK-Flag (eine eher vergebliche Aktion) und ein weiterer, der den URG-
Wert bei nicht gesetztem URG-Flag kontrollierte - schienen anfangs relativ bedeutungslos,
denn sie fühlten niemals zu interessanten Ergebnissen. Bis ich etwas sehr Seltsames
feststellte. Ich fand nämlich heraus, dass einige der Windows 2000- und Windows XP-
Systeme, die mit Kristjans Server eine Verbindung herstellten, von Zeit zu Zeit URG- oder
ACK-Werte ungleich null in Paketen aufwiesen, bei denen keines der entsprechenden
Flags gesetzt war (in erster Linie handelte es sich um SYN-Pakete zum Eröffnen einer
neuen Verbindung).
Streng genommen sind vorhandene URG- oder ACK-Werte bei nicht gesetztem Flag kein
Problem Nach RFC793 verlieren die Werte in diesem Fall lediglich ihre Bedeutung:
Dringlichkeitszeiger: 16 Bits
Dieses Feld beschreibt den aktuellen Wert des Dringlichkeitszeigers als positiven
Offset der Sequenznummer in diesem Segment. Der Dringlichkeitszeiger verweist auf die
Sequenznummer des Oktetts, welches den dringenden Daten folgt Dieses Feld wird nur
bei Segmenten interpretiert, bei denen das URG-Steuerbit gesetzt ist.
Auf seine sehr eigene Alt sagt uns RFC793, dass diese Anomalie mit hoher
Wahrscheinlichkeit keine Probleme im Netzwerk verursachen und insofern einfach flu- immer
unbemerkt bleiben wird. Ich allerdings bemerkte sie - schlichtweg deswegen, weil sie ein
bisschen ungewöhnlich war.
Ursprünglich nahm ich an, dass irgendein bestimmtes Netzwerkgerät der Schuldige war -
ähnlich wie bei den meisten in Kapitel 11 beschriebenen Roblemen. Aber dies war nicht
der Fall. Die Treffer stammten von einzelnen Systemen, nicht von ganzen Netzwerken,
und sie waren nicht von Dauer: Sie erschienen lediglich in ein paar Paketen (mit
feststehenden oder sich zufällig ändernden Weiten) und verschwanden dann wieder, um bei
nachfolgenden Verbindungen niemals rnehr aufzutauchen. Außerdem schien sich das
Problem auf Windows zu beschränken: In der Gruppe, die dieses Verhalten an den Tag legte,
waren überhaupt keine Minderheitenbetriebs Systeme vertreten.
Wochenlang versuchte ich, die Ursache dieses Problems aufzuspulen. Im Zuge meiner
Jagd nahm ich einige andere Installationen in kontiolherteren Umgebungen in Betrieb, und
zu meinem großen Erstaunen zeigte sich dieses Problem auch hier - sogar in lokalen
Netzwerken und von absolut aktuellen Systemen stammend, und auch hier wieder nur
kurzzeitig. Auf mein Nachfragen konnten sich die Benutzer nicht erinnern, irgendetwas
besonderes gemacht zu haben, als diese Daten auftraten. Ebenso wenig konnte ich
irgendeinen speziellen Kommunikationstyp oder Handlungsablauf ermitteln, der sie ausgelöst
haben könnte. Es schien einfach kein Muster vorhanden zu sein.
Ich war hochgradig verwirrt.
217
12 Löcher im Datenstapel
12.3 Die Offenbarung: Reproduktion eines Phänomens
Ich war nahe daran, aufzugeben. Ich sandte meine Beobachtungen an verschiedene
öffentliche Mailinglisten (in erster Linie VULN-DEV, eine behebte Security Focus-
Diskussionsliste zum Bereich Sicherheitslücken) und bat dort um weitergehende Analyse
und Feedback anderer Forscher. Es kam keine Antwort. Und dann - nur durch reines
Glück - erwischte ich eine meiner eigenen Teststationen dabei, wie sie bei der Arbeit an
einem ganz anderen Problem genau dieses Verhaltensmuster an den Tag legte. Im
Hintergrund hatte ich einen Sniffer laufen. (Tun wir doch alle, oder?)
Bald hatte ich eine Diagnose: Das Problem trat auf, als die Workstation im Hintergrund
eine Datenübertragung oder eine andere Netzwerkoperation duichführte, während sie
gleichzeitig versuchte, eine weitere Verbindung herzustellen. Bei fast jedem
Betriebssystem wild das Paket, das über die Leitung verschickt werden soll, zunächst im
Hauptspeicher des Systems zusammengesetzt. Hierbei kommt entweder ein statischer Puffer - ein
fester Speicherbereich, der ausschließlich für diesen Zweck verwendet wird - oder ein
dynamischer Puffer zum Einsatz, der nach Bedarf im Speicher reserviert wird und
möglicherweise zuvor für einen ganz anderen Zweck eingesetzt wurde. In diesem speziellen
Szenario, wenn zwei Verbindungen rnehr oder minder gleichzeitig auftraten, schien der
Puffer, der zur Bildung ausgehender Pakete vor ihrer Übergabe an die Netzwerkkalte
benutzt wurde, vor der Verwendung nicht ordnungsgemäß initialisiert worden zu sein, d. h.
mögliche Rückstände von Inhalten, die von einer vorherigen Verwendung für einen
anderen Zweck stammten, wurden nicht bereinigt. Der IrnpleHientierungscode setzt voraus,
dass alle Inhalte im Puffer null sind, und kümmert sich deswegen nicht darum Die Inhalte
werden mithin nicht auf bestimmte Werte eingestellt, wie es dagegen bei ACK- und URG-
Werten der Fall ist, wenn die betreffenden Flags nicht gesetzt sind. Also werden einige
„Inhaltsieste" verschickt.
Natüihch wuiden alle anderen IP- und TCP-Felder ordnungsgemäß initialisiert; nur URG
und ACK wuiden ausgelassen, da sie im betreffenden Kontext keine Bedeutung haben.
Diese Auslassung aber hatte zur Folge, dass ein kleiner Teil der Daten, die zu einer
anderen Verbindung (oder einem anderen Aspekt des Computerbetriebs) gehörten, an die
Gegenseite übermittelt wuiden. Das Problem äußerte sich nur, wenn mehiere Sitzungen liefen
(was beim Intemetsurfen, bei Downloads im Hintergrund und ähnlichen Szenarien
durchaus normal ist), nicht aber, wenn das System untätig ist.
Die Bedeutung der in dieser Situation preisgegebenen Information ist zweifach:
■ Man kann von einem traditionellen Datenoffenlegungsszenario sprechen. Zwar ist der
Umfang der Daten, die in jedem Paket ohne ordnungsgemäß initialisierte URG- und
ACK-Werte offenbar werden, ziemlich geling, und sie müssen auch nicht
aussagekräftig sein (sofern der Puffer nicht zuvor etwas Interessantes enthalten hat), können aber
in bestimmten Szenarien von Wert sein. Dies gilt insbesondere, wenn die gleichzeitig
laufende Verbindung, die unter Umständen sensible Daten enthält, oder der Bug selbst
von einer externen Position induziert werden können.
218
12.4 Denkanstöße
■ Die Sicherheitslücke kann außerdem als praktische Fingeiprinting-Metiik betrachtet
werden, die weitere Informationen zum Betriebssystem und den Zustand preisgibt, in
dem es sich befindet. Dies stellt eine einfach Möglichkeit dar, zwischen Systemen, die
das Netzwerk umfassend nutzen, und solchen zu unterscheiden, die inaktiv sind.
Das war es schon. Und auch wenn die Bedeutung dieser Entdeckung möglicherweise leicht
überschätzt werden kann, wollte ich sie an dieser Stelle erwähnen, um Sie zu erheitern und
Ihnen zu zeigen, wie einfach es sein kann, auch kompliziertere Daten von einer entfernten
Gegenstelle zu erhalten, ohne danach zu fragen.
12.4 Denkanstöße
Wir würden es uns einfach machen, würden wir die gesamte Schuld hierfür den
Entwicklern zuweisen. Zwar sind diese natürlich dafür verantwortlich, dass der Speicher nicht
ordnungsgemäß initialisiert wurde, aber die Idee der Implementierung eines „Einschalten" für
ein Header-Feld ist vielleicht eher ein struktureller Fehler im TCP-Protokoll selbst und
kann zu diesem Problemtyp beitragen. Ahnliche Feinheiten suchen viele
Protokollspezifikationen heim. Wir haben das bereits in Kapitel 7 gesehen, in dem eine ähnliche
Sicherheitslücke dadurch verursacht wurde, dass zu nah an der Spezifikation gearbeitet wurde,
ohne potenzielle Nebeneffekte zu beachten.
219
13 Schall und Rauch
Dreizehntes Kapitel. In dem wir lesen, wie man sich schicklich verbirgt
Viele der Datenenthüllungsszenarien, die wir bislang kennen gelernt haben, erfordern eine
sorgfältige Analyse der Daten, die ein entferntes System übermittelt, denn nur so kann man
gewisse Fakten zum Absender erschließen oder weitere Daten abfangen, über deren
Versand sich der Absender überhaupt nicht im Klaren war. In einigen Fällen jedoch lassen
sich nur Indizien für das Vorhandensein von Aktivitäten finden. Wie wir in den Kapiteln 1
und 2 erfahren haben, kann man durch präzise Interpretation dieser Indizien die
wahlscheinlichen Umstände eines Benutzers oder einer Anwendung, die sensible Daten
verarbeitet, bestimmen und auf diese Weise die Geheimnisse des Opfercornputers enttarnen,
ohne direkten Zugriff auf die Daten selbst zu benötigen.
Einige Merkmale des IP-Protokolls machen viele seiner Implementierungen anfällig für
Sicherheitslücken, die Daten aufgrund von Indizien preisgeben. Dies ähnelt in hohem
Maße dem, was wir bereits von bestimmten PRNG-Typen oder Datenverarbeitungsalgorith-
men variabler Komplexität her kennen. Das sorgfältige Beobachten und nachfolgende
Entschlüsseln dieser Informationen kann von Vorteil sein, denn es gewährt uns zumindest den
erforderlichen Einblick in die allgemeinen Gewohnheiten unseres Gegenübers oder auch in
eine bestimmte Handlung, an der er beteiligt ist.
Bislang haben wir uns in diesem Teil des Buchs auf Angriffe in der IP-Schicht
konzentriert, die eine direkte Beobachtung des vom Absender kommenden Datenverkehrs
erfordern, obwohl andererseits eine direkte Interaktion mit dem Opfer nicht notwendig ist. In
diesem Kapitel jedoch werden wir eine überraschend aktive, aber indirekte IP-basierte
Attacke behandeln, bei der der Angreifer ein Profil seines Opfers erstellt, indem er eine
begründete Annahme zu Faktoren trifft, die ihm verborgen sind. Dies tut er, indem er mit
einem unschuldigen Außenstehenden interagiert, der nicht der eigentliche Gegenstand der
Überprüfung ist und dieser auch nicht zugestimmt hat; er weiß noch nicht einmal etwas
davon. Auf diese Weise erfahrt der Angreifer, was er mit dem eigentlichen Opfer alles
machen kann.
221
13 Schall und Rauch
Daten auf eine solche Weise zu ermitteln, klingt nicht ganz einfach. Aber warum sollen
wir im Geiste der Freaktums nicht den wohl etwas längeren, aber sicher auch
ansprechenderen Weg nehmen und uns diesen etwas genauer ansehen?
13.1 Der Missbrauch von IP, oder: Port-Scanning für
Fortgeschrittene
Schurkische Internetbenutzer verwenden das Port-Scanning häufig für
angriffsvorbereitende Reconnaissance und Betriebssystern-Fingerprinting. Beim Port-Scanning versucht der
Angreifer in spe, eine kurze Verbindung zu jedem Port eines Systems herzustellen und
daraus alle Programme zu ermitteln, die auf Datenverkehr im Netzwerk horchen. Auf diese
Weise kann er bestimmen, an welcher Stelle er angreifen kann, denn er findet so jeden
anfälligen oder auf andere Weise interessanten Netzwerkdienst im System. Außerdem kann
er in vielen Fällen ermitteln, welches Betriebssystem das Opfer verwendet, denn
Standarddienste sind häufig betriebssystemspezifisch.
Das erste Problem beim traditionellen Scanning besteht darin, dass man dabei eine ganze
Menge Lärm veranstaltet: Das Opfer wird einen Anstunn oder sogar einen konstanten
Strorn von Verbindungsversuchen mit ungewöhnlichen Ports feststellen. Sich zu
verbergen, ist aber auch nicht einfach: Der Angreifer niuss schließlich in der Lage sein, die
Antworten auf seine SYN-Pakete zu verarbeiten, denn nur so kann er ermitteln, ob ein Port
offen oder zu ist. Offene Ports antworten mit SYN+ACK-Paketen, geschlossene mit RST-
Paketen, und Ports, die von einer Firewall ausgefiltert wurden, erzeugen entweder gar
keine oder aber eine ICMP-Meldung. Aus diesem Grund kann der Angreifer nicht einfach
eine Absenderadresse in allen ausgehenden Paketen iälschen; er rnuss seine Identität durch
Angabe der Absenderadresse preisgeben, welche dann in das Netzwerk zurückverweist, in
dem er auf eingehende Daten lauscht.
13.1.1 Eins, zwei, drei, vier, Eckstein ...
Unabhängig davon, ob die Gegenseite nur aus Neugier Scans durchführt (um
beispielsweise zu ermitteln, mit welchem Betiiebssystem ein Mitbewerber arbeitet) oder dem Scan
einen Angriffsversuch folgen lässt, wird sie immer versuchen, möglichst wenig Spuren zu
hinterlassen und das Opfer nicht aufzuscheuchen. Netzwerkadministratoren und bestimmte
Behörden haben gegenüber Host- und Netzwerk-Scans eine ziemlich negative Einstellung.
Obwohl die Diskussion darüber, ob diese Scans als kriminell einzustufen sind oder nicht,
noch nicht abgeschlossen ist, kommt es, wenn ein verärgerter Systeinadiiiinistrator
Anzeige erstattet oder Ihr Mitbewerber feststellt, dass einer Ihrer Mitarbeiter versucht, das
Konkurrentennetzwerk zu sondieren, fast immer zu einer Verurteilung - unabhängig von den
wählen Absichten und den weiteren Plänen des wissbegierigen Zeitgenossen.
Eine gängige Alt und Weise, Port-Scans zu tarnen, besteht in der Verwendung von
Täusch-Scans, bei denen der Angreifer SYN-Pakete von einer Anzahl gefälschter Adressen
222
13.1 Der Missbrauch von IP, oder: Port-Scanning für Fortgeschrittene
sowie von seiner eigenen IP-Adresse an die einzelnen Ports schickt. Das Opfer verfahrt mit
diesen gemischten Paketen ebenso wie mit den echten, nur werden die Antworten auf ers-
tere natürlich in die Leere hinausgeschickt. Insofern hat das Opfer es wesentlich schwerer,
zu ermitteln, wer wirkhch hinter dem Scan steckt, denn es müssen - mithilfe sorgfältiger
Analyse oder über ein simples Trial-and-Enor-Verfahren - alle Täuschsysteme aus der
Liste der Paketquellen entfernt werden. Und tiotzdem ist es mit einiger Entschlossenheit
möglich, den Absender ohne Hilfe der Behörden zu ermitteln, auch wenn der Angreifer
hofft, das Opfer dadurch zu entmutigen, dass der Aufwand, einen solchen unbedeutenden
Vorfell vollständig zu klären, einfach zu hoch ist.
13.1.2 Idle-Scanning
Die ultimative Verteidigungsmaßnahme gegen eine Enthüllung kam - wie so oft - von
einem Typen, der zuviel Zeit hatte und diese damit verschwendete, Protokollspezifikationen
zu lesen, statt etwas Produktives zu leisten. Und so entstand eine neue Technik namens
Idle-Scanning. Ursprünglich entwickelt von Salvatore Sanfilippo (alias „antirez") im Jahr
19981, wurde das Idle-Scanning sehr schnell flächendeckend eingesetzt und in
Hackerkreisen (den neugierigen wie auch den üblen) ziemlich schnell sehr populär.
Das Idle-Scanning basiert auf einer bedeutenden Beobachtung. Wh wollen an dieser Stelle
RFC793 zitieren:
Reset-Pakete (RST) müssen generell immer dann gesendet werden, wenn ein Segment
empfangen wird, dass offensichtlich nicht für die aktuelle Verbindung vorgesehen ist.
Nicht gesendet werden darfein Reset, wenn nicht ganz klar ist, ob dies der Fall ist.
TCP-konforme RST-Pakete werden verwendet, um eine Verbindung vorbehaltlos zu
beenden und dem Absender mitzuteilen, dass er von weiteren Kornmunikationsversuchen
Abstand nehmen möge. Das System sendet im Sinne von RFC793 ohne Zögern ein RST-
Paket, wenn unerwartete Daten empfangen werden. (Natürlich werden RST-Pakete selbst
dann, wenn sie unerwartet kommen, nicht beantwortet; andernfalls würde bei der
leichtesten Verstimmung sofort ein endloser Stiom von RST-Paketen in beide Richtungen durch
das Netzwerk rauschen.)
Das Idle-Scanning basiert auf der Tatsache (und missbraucht diese auf clevere Art und
Weise), dass ein Außenstehender, ein Zeugenhost, mit allen unerwarteten Paketen auf
diese Weise verfehlt Die Attacke ermöglicht feindlich gesonnenen Netizens das Scannen
eines Opfers, mit dem sie nicht direkt kormnunizieren wollen. Beim Idle-Scanning
verwendet der Angreifer ein argloses und willkürlich ausgewähltes System im Internet, um ein
drittes System - das eigentliche Opfer - zu scannen, ohne dass seine Identität jemals
enthüllt würde.
Idle-Scanning funktioniert wie folgt: Der Angreifer fälscht ein SYN-Paket an einen Port,
den er auf dem System des Opfers überprüfen will. Dieses Paket ist an den Host des Op-
Sanfi>8
223
13 Schall und Rauch
fers adressiert, die Absenderadresse ist jedoch nicht die des Angreifers, sondern die des
Zeugenhosts. Das mag nicht unbedingt so klingen, als ob man auf diese Weise irgendetwas
bewerkstelligen könnte. Aber warten Sie noch einen Moment ab.
Was als nächstes passiert, hängt davon ab, ob der Port offen ist:
■ Wenn der sondierte Port des Opfers ein RST-Paket an den Zeugenhost zurückschickt,
erhält dieser es und nimmt es still zur Kenntnis, ohne eine Antwort an das Opfer
zurückzuschicken.
■ Ist der Port offen, dann antwortet das Opfer mit SYN+ACK. Der Zeuge stellt zu
seinem größten Erstaunen fest, dass er niemals ein SYN-Paket an das Opfer geschickt hat.
Insofern übermittelt er dem Opfer ein RST-Paket, mit dem er ihm freundlicherweise
mitteilt, dass er auf dem falschen Dampfer sei und sie die Kommunikation nun wohl
besser' beenden sollten. Kleinlaut nimmt das Opfer die Antwort entgegen und löscht
alle Einträge für die Verbindung, die es anzunehmen können hoffte.
Auf den ersten Blick ist der Unterschied schwer zu erfassen. Aber wenn wir noch einmal
in Kapitel 9 nachblättern, dann finden wir dort die folgenden Angaben zu einem der Felder
im IP-Header:
Die Kemnmg (ID) ist ein 16-Bit-Wert, der bei Auftreten einer Fragmentierung die
Unterscheidung zwischen IP-Paketen gestattet Ohne IP-Kennungen würden, wenn zwei
Pakete gleichzeitig fragmentiert würden, deren Fragmente bei der Wiederherstellung
hochgradig verstümmelt, vertauscht oder auf andere Weise beschädigt werden.
IP-Kennungen identifizieren mehrere Wiederherstellungspuffer für verschiedene
Pakete eindeutig. Der für diesen Zweck verwendete Wert wird oft ausgewählt, indem ein
Zähler mit jedem gesendeten Paket einfach hochgezählt wird. So hat das erste von
einem System stammende Paket die Kennung 0, das zweite die Kennung 1 usw.
Weil der Angreifer einen Zeugenhost gewählt hat, der tatsächlich dieses Schema zur
Auswahl der IP-Kennung verwendet (und es gibt viele hierfür' in Frage kommende Schemata),
kann er nun problemlos bestimmen, ob der Zeugenhost ein IP-Paket innerhalb eines
bestimmten Zeitraums gesendet hat oder nicht. Hierzu sendet er einfach vor und nach der
eigentlichen Sondierung ein paar' bedeutungslose Daten an das Zeugensystem und vergleicht
die IP-Kennungswerte in den erhaltenen Antworten. Wenn die beiden Kennungen sich nur'
um den Wert 1 unterscheiden, dann hat das Zeugensystem zwischenzeitlich keine Pakete
versendet. Ist der Unterschied aber größer als 1, dann wurden tatsächlich ein paar' Pakete
ausgetauscht (auch wenn wir nicht genau wissen, mit wem).
Der Angreifer kann auch jeweils unmittelbar vor dem Versand eines gefälschten Paketes
und direkt danach eine Robe an das Opfer senden. Auf diese Weise kann er basierend auf
den Antworten des Zeugenhosts ermitteln, ob ein Port geöffnet oder geschlossen ist.
Wurde die IP-Kennung des Zeugen erhöht, dann hat er höchstwahrscheinüch ein RST-Paket an
das Opfer gesendet, d. h. das Opfer selbst muss zuvor ein SYN+ACK-Paket als Reaktion
auf das gefälschte Paket geschickt haben. Daraus kann der Angreifer schließen, dass der
Port offen ist. Wenn andererseits der Zeuge die nächste erwartete IP-Kennung erzeugt,
224
13.2 Idle-Scanning abwehren
dann hat er keine Daten vorn Opfer erhalten oder aber entschieden, die erhaltenen RST-
Pakete zu ignorieren.
Es gibt natürlich einige praktische Gesichtspunkte. Als wichtigste hiervon sind zu nennen,
dass der Zeuge während des Scans relativ untätig sein sollte, und dass der Test mehrfach
durchgeführt werden rnuss, um falsche Positivwerte zu vermeiden, denn andernfalls
könnten wir die Kornmunikation des Zeugen mit einem Dritten als Hinweis darauf
interpretieren, dass ein bestimmter Port auf dem System des Opfers geöffnet ist.
■ Hinweis
Keines dieser Probleme hat sich jedoch als schwerwiegend erwiesen, und viele
fortgeschrittene Tools — beginnend mit idlescan im Jahr 1999 bis hin zum genialen NMAP —
implementieren das Idle-Scanning und machen ihre Sache gut.
Die Bedeutung des Idle-Scannings besteht darin, dass es den Ursprung eines Scans nicht
einfach dadurch zu verschleiern versucht, das Opfer zu entmutigen, sondern dadurch, die
gesamte identifizierbare Kornmunikation mit dem Angreifer zu unterbinden. Dies
erschwert die Ortung des Angreifers ohne die Hilfe des Besitzers eines Zeugensystems
(dessen IP-Kennungen der Angreifer im Zuge zulässigen Datenaustauschs wie beispielsweise
einer HTTP-Sitzung völlig legitim feststellen kann, weswegen schwierig festzustellen ist,
ob es als Werkzeug missbraucht wurde) oder externer Institutionen (Behörden, Intemet-
provider) erheblich. Da die Behörden normal normalerweise erst eingreifen, wenn das
System bereits geknackt (und nicht nur sondiert) wurde - der neugierige Konkurrent kann also
ruhig schlafen -, und das Opfer erst einmal zugeben muss, dass ein Eindringen
stattgefunden hat (was gerade für große Unternehmen nicht sehr angenehm ist), kann sich der
Angreifer ziemlich sicher fühlen.
■ Hinweis
Zwar scheint sich das Idle-Scanning hinsichtlich der erzielbaren Ergebnisse nicht deutlich von
einem regulären SYN-Scan zu unterscheiden, es bietet aber eine recht einmalige Scanning-
Perspektive. Die Verwendung eines Zeugen erlaubt es dem Angreifer, das Ziel aus der Sicht
des Zeugen zu betrachten. Hat der Zeuge beispielsweise umfassendere Zugriffsberechtigungen
für das System des Opfers (z. B. ein System innerhalb eines geschützten Netzwerks hinter
einer Firewall, ein Computer, für den aus Gründen des praktischeren Zugriffs im Finnennerz-
werk nachlässigere IP-Filterregeln konfiguriert sind usw.), dann können Sie mithilfe des Idle-
Scannings die inneren Abläufe des geschützten Netzwerks ermitteln.
13.2 Idle-Scanning abwehren
Gegenwältig gibt es keine direkte Möglichkeit zur Abwehr eines Idle-Scans und auch
keine einfache Möglichkeit, ihn von einem regulären SYN-Scan zu unterscheiden. Allerdings
kann man sich recht einfach gegen einen Zeugenhost wehren, indem man zufallige oder
konstante IP-Kennungen verwendet (siehe Kapitel 9). Zwar verhindert das keine Angriffe
225
13 Schall und Rauch
gegen Sie - oder Angriffe generell-, denn viele Systeme arbeiten mit fortlaufenden
Kennungen; immerhin aber kann Ihr Netzwerk dann nicht rnehr für diesen Zweck missbraucht
werden.
Um das Umgehen der Firewall durch Übernahme der Perspektive des Zeugenhosts zu
vermeiden, verwenden Sie beim Planen von Zugangskanälen für externe Systeme Ihren
gesunden Menschenverstand und setzen angemessene Filter für eingehende Daten bei
Gateway-Systemen ein: Alle Pakete, die aus dem Internet kommen und eine
Absenderadresse aufweisen, die zu einem geschützten Netzwerk gehört, sollten sofort gelöscht
werden. Zwar werden hierdurch wie bereits erwähnt die Mechanismen der PMTU-Erkennung
ausgehebelt, aber letztendlich werden so mehr Probleme beseitigt als verursacht.
13.3 Denkanstöße
Es ist zwar nicht mehr so einfach, aber nach wie vor möglich, IP-Kennungen für die
Erstellung von iP-Aktivitätsprofilen zu verwenden. Tatsächlich können, wenn das Opfer eine
interaktive Sitzung mit einem Remote-System herstellt, IP-Kennungen sogar verwendet
werden, um Tastaturaktivitäten und ähnliche Handlungen zeitbezogen zu registrieren.
Aufgrund dessen wird diese Methode zu einem der bereits beschriebenen Szenarien für Ab-
laufinusterangriffe. Zudem können Sie Ihr Folterarsenal erweitern, indem Sie die Anzahl
der Pakete messen, die von einem Host zwischen zwei aufeinanderfolgenden Besuchen im
überwachten Netzwerk gesendet wurden.
Sie können auf bestimmten Systemen abhängig von der Struktur des verwendeten ISN-
Generators dieselbe Funktionalität auch mithilfe von TCP-Sequenznummem als IP-
Kennungsanalyse erzielen. Ich möchte Sie ermutigen, diese Idee im Detail zu erforschen.
Weitere Infonnationen zur Jagd auf den Urheber eines Idle-Scans (und anderer gefälschter
Angriffe) finden Sie in Kapitel 17.
226
14 Clientidentifikation: Die Ausweise,
bitte!
Vierzehntes Kapitel. In dem wir erfahren, dass es in vielen Situationen
ungemein praktisch sein kann, durch einen dünnen Schleier zu schauen
Die echte Identität einer Software und ihre Rechtmäßigkeit zu bestimmen, ist im lokalen
Netzwerk keine große Herausfordenmg: Man kontrolliert einfach den Computer, auf dem
die Software ausgefühlt wird. Über das Netzwerk ist diese Aufgabe allerdings nicht mehr
so einfach zu lösen.
Systernadrninisrratoren und Anwendungsentwickler versuchen häufig, zu bestimmen,
welche Software am anderen Ende einer netzwerkbasierten Sitzung eingesetzt wird. Die
Erfolgsquote variiert Wir versuchen aus verschiedenen Giiinden, Softwareanwendungen zu
identifizieren. Im World Wide Web (WWW) besteht das Ziel normalerweise darin, die
Inhalte, die einem Client übermittelt werden, basierend auf der von ihm verwendeten Dar-
stellungs-Engjne zu optimieren. Dabei spielt es keine Rolle, ob die Inhalte zulässig oder
bösartig sind. Das Ziel bei der Clienterkennung besteht in vielen anderen Kornmunika-
tionsSystemen - Instant-Messengers, Mailclients usw. - darin, die Richtlinienkonforrnität
zu gewährleisten und Daten zu erkennen, die von möglicherweise gefährlichen oder
anderweitig unzulässigen Anwendungen stammen. Nicht zuletzt versuchen die
Programmierer selbst, Software zu identifizieren, um zu verhindern, dass unzulässige oder unlizenzier-
te Programme einen bestimmten Netzwerkdienst verwenden (weil dies ihr Einkommen
schmälern würde), oder derartige Fälle zu ermitteln und entsprechende Maßnahmen durch-
zirführen.
Die einfachste und rneistverwendete Möghchkeit, den Gegenüber zu identifizieren, besteht
in der Überprüfung von Angaben, die das entfernte System freiwillig offenbart. Hierzu
kann die Kenntnisnahme einer vom Server übennittelten Willkonimensmeldung ebenso
gehören wie ein Blick auf die von einem Client gesendeten Protokoll-Header (z. B. X-
Maüer in E-Mails, User-Agent bei WWW-Sitzungen usw.) oder die Analyse textbasierter
227
14 Clientidentifikation: Die Ausweise, bitte!
Status- und Fehlermeldungen, die vom Dienst als Reaktion auf bestimmte empfangene
Datenarten gesendet werden.1 Unglücklicherweise ist die erste Methode extrem unzuverlässig
und lässt sich von Benutzern, die etwas zu verbergen haben, leicht unterlaufen; die zweite
Methode hingegen ist aufdringlich und bei Clients recht schwierig einzusetzen, ohne
Probleme zu verursachen. (Die meisten Clientanwendungen brechen beim Auftreten der ersten
Fehlerbedingung ab und beschweren sich; Benutzer, die infolge eines Versuchs, ihre
Software zu ermitteln, eine Fehlenneldung erhalten und trotz Genehmigung nicht auf einen
Dienst zugreifen können, werden alles andere als begeistert sein.)
14.1 Die Kunst der Tarnung
Die Untersuchung textbasierter Bekanntmachungen, die vom Chent erstellt wuiden, ist
nicht nur deswegen unzuverlässig, weil Benutzer ihre Intemetsoftware (Webbrowser,
Mailclients usw.) verschleiern können, sodass die Antworten der meisten verbreiteten
Clients nachgebildet werden, sondern weil sie häufig guten Grund haben, dies zu tun -
entweder, um in der Menge zu verschwinden, oder um Server übers Ohr zu hauen, die dazu
neigen, besser zu wissen, welche Version eines Programms der Besucher verwenden sollte.
Dies ist einfach zu bewerkstelligen, indem man die im Chent implementierte
entsprechende Funktionalität verwendet oder Quellcode bzw. Binärdateien mithilfe einer Vielzahl frei
verfügbarer Tools modifiziert.
Femer haben, weil in vielen Untemehmensumgebungen zwecks Aussperrung
unerwünschter Inhalte damit begonnen wurde, rigorosere Inhaltsfilter zu implementieren, einige
Programmierer, die sich mit eher fragwürdigen Anwendungen beschäftigen, ihrerseits damit
begonnen, diese als harmlose Software zu tarnen. Vor nicht allzu langer Zeit tauchten die
ersten P2P-basierten Musiktauschbörsen, trojanischen Pferde und Spywareanwendungen
auf, deren ausgehende Daten vorgaben, vom marktbeherrschenden Webbrowser - dem
Microsoft Internet Explorer - zu stammen. Gleiches galt für viele Adressen sammelnde
Webcrawler, die von arglistigen Werbeagenturen in aller Welt eingesetzt werden.
Auch andere Protokolle werden von Nachahmern geplagt. So ist es keine Überraschung,
dass die vielgeschmähten, Massen-E-Mails sendenden Anwendungen, die von Sparnrnern
und Bauernfängern eingesetzt werden, sich mehrheitlich als Microsoft Outlook, PINE,
Mutt, Eudora, The Bat! oder Netscape Mail ausweisen. Zweck der Verschleierung ist es,
sich ungesehen an Administratoren vorbeizuschleichen, die, wenn sie auf das
Vorhandensein der Software aufmerksam würden, sehr schnell eine Möglichkeit fänden, sie zu
blockieren. Kein Spammer, der halbwegs bei Verstand wäre, würde seine E-Mails als von
Uncle Bernie's Notorious Mass-Maüer, Extreme Edition stammend ankündigen, denn
dann wäre es zu einfach für einen Benutzer oder einen Spamfilter, sich ihrer zu entledigen.
Ein beliebtes Tool, das mithilfe des Fingerprintings Antworten analysiert, ist AMAP von THC.
Weitere Informationen finden Sie unter http://www.thc.org/releases.php. NMAP von Fyodor identifiziert
Dienste durch die Analyse von Willkommensmeldungen
228
14.1 Die Kunst der Tarnung
14.1.1 Wie man das Problem angeht
Da es ziemlich einfach ist, die von einem Programm zurückgegebenen Textantworten und
WillkoHimensbanner zu modifizieren, müssen wir eine bessere Möglichkeit als den
Vergleich von Antworten finden, um eine Clientsoftware mit ausreichender Genauigkeit zu
identifizieren und Betragsversuche zu enttarnen. Lösungen, die einfach nach weniger
offensichtlichen Parametern oder Antworten suchen, müssen früher oder später scheitern:
Zwar ist es in fast allen Fällen möglich, eine Überprüfung zur Erkennung eines bestimmten
Typs unerwünschter Software zu entwickeln, aber wo man einen Kopf abschlägt, wachsen
drei neue nach.
Sehr schnell wird es deswegen unmöglich, jede einzelne Inkarnation bösartiger Software
zu erledigen. In manchen Fällen lässt sich eine allgemeine Erkennung bösartiger Clients
realisieren, indem man einfach nach Mustern sucht, die den Missbrauchstyp, den wir
abzuwenden versuchen, eindeutig verraten: Der Unterschied zwischen einem ganz normalen
Mailclient und der Software eines Spammers besteht darin, dass ersterer wohl kaum
versuchen wird, zehn Millionen Mails auf einmal abzusetzen. Allerdings ist dieser Ansatz
eingeschränkt: Bei einigen Protokollen und ein paar klar definierten Angriffen kann dies
einwandfrei funktionieren; Datenverkehr im WWW ist eine andere Geschichte, und es ist
schwierig, ins Schwarze zu treffen, ohne am Ende mit einer gigantischen Anzahl von
Fehlalarmen einerseits und zahlreichen entgangenen Programmen andererseits dazustehen.
Da das WWW als Kern aller für Endbenutzer verfügbaren Intemetdienste wahrgenommen
wird, ist es eines der wenigen Protokolle, die einfach allen offen stehen müssen. Insofern
wird Webdatenverkehr von impertinenten Anwendungen am häufigsten zur Maskierung
ihres Verhaltens in einem System und der Daten verwendet, die sie an einen Remote-Host
übeitragen. Es ist nicht ungewöhnlich, wenn Webbrowser Massen von Verbindungen zu
verschiedenen Standorten herzustellen versuchen oder mehrere tausend Anfragen pro
Stunde absetzen. Gleichzeitig ist es aber auch nicht unmöglich, sensible Daten an einen
Remote-Host im Rahmen einer einzigen, kurzen Verbindung zu übennitteln. An dieser
Stelle kommen wir mit der Erstellung von Datenverkehrsprofilen nicht weiter.
14.1.2 Wie die Lösung aussehen könnte
Angesichts all dieser Aspekte könnte man den Eindruck gewinnen, es sei extrem
schwierig, eine Spyware oder ein trojanisches Pferd von einer legitimen Anwendung zu
unterscheiden. Allerdings gibt es, wie sich herausstellt, eine Reihe guter Tools, mit denen sich
genau diese Alten von Software identifizieren lassen. Dem Interessierten eröffnen sich so
Möglichkeiten, Clientanwendungen präzise erkennen zu können. Der vielversprechendste
und universellste Ansatz ist die Verhaltensanalyse (eine etwas übertriebene Bezeichnung
für alte und verstaubte „Ablaufhiuster"). statt den Datenaustausch im Rahmen einer
einzelnen Abfrage zu überprüfen oder die Menge der Verbindungen über die Zeit zu
kontrollieren, analysiert sie subtile interne Abhängigkeiten zwischen aufeinanderfolgenden
Datenabschnitten. Da diese Abhängigkeiten eng mit internen Algorithmen und der Leistung
eines Programms verknüpft sind, sind sie wesentlich schwieriger zu fiüschen als die lrieis-
229
14 Clientidentifikation: Die Ausweise, bitte!
ten anderen Metriken, die wir in Betracht ziehen könnten. Ich werde diesen Ansatz in
diesem Kapitel behandeln und eine Analysegrundausrüstung vorschlagen, mit deren Hilfe
sich ein ausreichendes Maß an Genauigkeit und Detailtreue erzielen lässt. Dabei soll uns
der Datenverkehr im WWW als geeignetes Beispiel dienen.
Bevor wir uns aber den Einzelheiten zuwenden, benötigen wir ein paar Hintergnmdinfor-
rnationen. Wir werden also einen kurzen Blick auf die Geschichte des World Wide Web,
den Aufbau von Webclients und die Protokolle werfen, die diese Clients zur
Kommunikation mit Servern verwenden. Alles begann viel früher, als Sie vielleicht annehmen ...
14.2 Eine (ganz) kurze Geschichte des Web
Das Konzept des World Wide Web ist gar nicht so schwer zu begreifen: Die Idee dahinter
ist die, Benutzem direkten Zugriff auf eine Anzahl von Dokumenten zu gewähren, die
gegenseitig aufeinander und auf andere Dokumente verweisen - „verlinkt" sind - und
verschiedene Alten von Informationen enthalten. Einfacher geht es kaum.
Das Web, wie wir es heute kennen, besteht in erster Linie aus Text mit Metadaten (z. B.
Verknüpfungen mit anderen Dateien, Formatierungen, Kommentaren, dynamischen oder
interaktiven Elementen). Diese werden häufig durch alle möglichen Alten von
Multimediaelementen - Filmen, Musik und verschiedene Anwendungen - ergänzt. Dieser Aufbau
entspricht dem Wesen unserer Zeit und stellt ganz neue Methoden zur Kommunikation und
Inforrnationssuche bereit. Die Idee des Web ist aber nicht neu. Geboren wurde sie viele
Jahre vor der Technologie, die elektronische Dokumente dieser Art erst möglich machte -
vielleicht sogar schon lange, bevor man die Möglichkeit solcher elektronischen
Dokumente überhaupt ernsthaft in Betracht zog.
Laut einer Zeittafel, die das W3C (World Wide Web Consoitium) veröffentlicht hat2,
wurde das Konzept von Hyperlinks 1945 erstmals von Vannevar Bush in der Zeitschrift
Atlantic Monthly beschrieben.3 Bush war während und nach dem zweiten Weltkrieg Leiter des
Office of Scientific Research and Development.
Bush schlug einen Apparat namens Memex vor - ein elektromechanisches Benutzergerät,
das man tatsächlich als nlihen Vorläufer unserer PDAs betrachten kann. Memex (Memoiy
Extender, „Gedächtniserweiterung") bot Speicher für die Dokumente und persönlichen
Dateien eines Benutzers und zielte darauf ab, intuitive Mechanismen für den Datenzugriff zu
verrnitteln. Ein Merkmal von Memex bestand in seiner Fähigkeit, Verknüpfungen
zwischen auf Mikrofilm gespeicherten Dokumenten zu erstellen und diesen auch zu folgen.
Aus irgendeinem Grund aber sorgte die Idee eines irrsinnig komplexen mechanischen
Geräts auf Mikrofilmbasis seinerzeit nicht für Begeisterung.
2 W3CoA
3 Bush45
230
14.2 Eine (ganz) kurze Geschichte des Web
Das Hypertextkonzept tauchte in den nachfolgenden Jahren immer mal wieder auf, und die
ersten cornputerbasierten Implementierungen erblickten in den Sechzigern das Licht der
Welt. Allerdings waren diese Versuche nicht besonders erfolgreich. Das lag in erster Linie
daran, dass die Rechenleistung, die diese Technologie für Benutzer interessant machen
konnte, erst viele Jahre später verfügbar sein sollte.
Der richtige Zeitpunkt kam dann in den Achtzigern. Nach dem Mikrocornputerboorn und
kurz vor dem Frontalangriff der PC-Plattform machte eine Reihe bescheidener Vorschläge
beim CERN (Conseil Europeen pour la Recherche Nucleaire, Europäischer Rat für
Kernforschung) die Runde. Tim Bemers-Lee, Forscher beim CERN, ist allem Anschein nach
offiziell verantwortlich für die Keirnlegung von HTML (HyperText Markup Language).
HTML ist ein Satz von Steuerelementen zur Einbettung von Metadaten, Verknüpfungen
und Medienressourcen in Textdokumente.4 Der erste Webbrowser ließ nicht lange auf sich
waiten. Er lief auf einer damals sehr innovativen und fortgeschrittenen, heute jedoch
praktisch unbekannten Cornputerplattform namens NeXT. Der Browser trug den universellen
Namen „World Wide Web".
Jetzt, wo das Kind einen Namen hatte, war die Revolution nicht mehr aufzuhalten. 1992
reichte Bemers-Lee einen ersten Spezifikationsentwurf für HTTP (HyperText Transfer
Protocol) ein.5 HTTP war als Tool zur Kapselung von HTML-Daten und anderen
Ressourcen für die Kommunikation zwischen Server und Client vorgesehen. 1993 waren die ersten
Webbrowser-Engines verfügbar, und eine Handvoll Webserver boten ihre Inhalte bereits
neugierigen Besuchern feil. Natürlich machte HTTP gerade einmal imposante 0,01 Prozent
des gesamten Backbone-Datenverkehrs aus, aber der Anteil sollte bald zunehmen!
Der erste populäre Webbrowser namens Mosaic wurde am National Center for
Supercomputer Applications der University of Illinois entwickelt. Er machte Anleihen bei Bemers-
Lees Code, ergänzte aber Unterstützung für nichttextbasierte Inhalte und führte Formulare
und viele andere Funktionalitäten ein, die für uns heute völlig normal sind. Der Code von
Mosaic wurde später zu Mozilla, woraus dann noch später der Kerncode für den Netscape
Navigator werden sollte. (Noch ein bisschen später verzweigte die Entwicklung zum
Open-Source-Projekt Mozilla, dessen Codebasis nachfolgend als Grundlage für
Folgegenerationen von Netscape Navigator verwendet wurde. Ist doch ganz einfach, oder?)
Gleichzeitig verwendete, um die Benutzer noch weiter zu verwirren, ein Unternehmen
namens Spyglass Mosaic als Kern eines Browsers, aus dem bald der wichtigste Konkurrent
von Netscape werden sollte: der Microsoft Internet Explorer.
1994 wurde dann das W3C eingerichtet. Zweck dieser Institution war es, die weitere
Entwicklung des Webs zu beaufsichtigen. Die erste offizielle, stark verbesserte und erweiterte
Version des Protokolls wurde 1996 von Bemers-Lee, Roy T. Fielding und Henrik Frystyk
vorgestellt. Kurz darauf folgten die Spezifikationen für HTML 3.2. In den folgenden Jah-
Uin ehrlich zu sein, ist HTML — der Kern des Webs, vre wir es heute kennen — eigentlich überhaupt
keine Neuentwicklung, sondern hat sich eine ganze Menge Anregungen bei SGML (Standard Genera-
lized Markup Language, ISO-Standard 8879, 1986) geborgt
Bern92
231
14 Clientidentifikation: Die Ausweise, bitte!
ren traten immer neuere und umfassendere Versionen von HTTP und HTML auf den Plan,
die nun vom W3C verwaltet wurden. Jetzt kennen Sie das Ende der Geschichte. Oder ist es
nur ihr Anfang?
14.3 Eine Einführung in HTTP
HTTP5 ist ein außerordentlich klar strukturiertes, textbasiertes Protokoll auf der Basis von
TCP/EP. Ein Client für dieses Protokoll stellt eine Verbindung mit einem HTTP-fahigen
Dienst auf einem entfernten Server her und sendet eine Anfrage, über die er eine
bestimmte Ressource beim Server anfordert. Eine HTTP-Anfrage enthält die folgenden Parameter
in der ersten Anfragezeile:
■ Methode für den Ressourcenzugriff. Meistens ruft der Chent einfach eine Datei ab.
Hierzu verwendet er eine GET-Anfrage. (Es gibt allerdings auch andere Methoden für
Aufgaben wie das Versenden von Formulardaten, die Durchführung von
Diagnosearbeiten, das Speichern von Daten auf einem Server oder die Ausführung
bestimmter Erweiterungen.)
■ TJRI (Universal Resource Identifler, universelle Ressourcenkennung). Dies ist ein
Pfad zu einer statischen Datei oder einer dynamischen ausführbaren Datei, die
Gegenstand der Anfrage ist. Handelt es sich um eine dynamische ausführbare Datei, dann
werden in der URI unter Umständen auch weitere, entsprechend kodierte Parameter an
dieses Programm übergeben.
■ Protokollversion. Dies ist die Version des Protokolls, die der Chent unterstützt und
verwenden möchte. Der Server kann, wenn er die vom Chent angegebene Version
nicht unterstützt, in einer niedrigeren Protokollversion antworten. (Fehlt diese Angabe,
dann wird angenommen, dass der Chent HTTP/0.9 verwendet. Dies ist eine frühe und
veraltete Version des Protokolls, die wir hier nicht weiter behandeln werden.)
Eine HTTP-Anfrage kann etwa so aussehen:
GET /show_jplush_toys.cgi?paraml=value¶m2=this+is+a+test HTTP/1.1
Host: www.plush-penguins.com
User-Agent: Joe's Own Web Client (UnixWare)
Accept: text/html, text/piain, audio/wav
Accept-Language: pl, en
Connection: close
Diese Anfrage fordert eine Ressource namens /show_plushJoys.cgi von -www.plush-
penguins.com an. Der Erweiterung cgi der Datei entnehmen wir, dass es sich um ein
dynamisch ausgeführtes Programm handelt, das mit zwei Parametern (paraml und paraml)
aufgerufen wird, die auf das Fragezeichen folgend aufgeführt sind.
6 Fiel99
232
14.3 Eine Einführung in HTTP
Der Clientanforderung kann eine Anzahl textbasierter Header folgen, die -jeweils in einer
Zeile - zusätzliche Parameter angeben. (In obigem Beispiel ist dies der Fall.) Dies können
alle möglichen Angaben sein: vom Feld User-Agent (siehe oben) über die bevorzugte
Sprache für die Inhalte - hier Polnisch und Englisch - bis hin zur Angabe eines virtuellen
Servers, den der Client referenziert. (Wenn mehrere Domänennamen auf dieselbe IP-
Adresse verweisen, kann der Server anhand dieser Angabe bestimmen, ob der Benutzer
nach www.squeaky-ducks.com oder nach www.plush-penguins.com sucht, die beide auf
demselben System hegen könnten.)
Das Protokoll schreibt einige dieser Header verbindlich vor. Welche dies sind, hängt von
der Protokollversion ab, aber die meisten Server sind diesbezüglich ohnehin ziemlich
schlampig und machen kein Aufhebens dämm, wenn der eine oder andere Header fehlt.
Abgesehen davon spezifizieren einige Header Merkmale, die über die eigentliche
Protokollspezifikation hinausgehen.
Jede Anfrage muss mit einer Leerzeile enden, die das Ende der Client-Header angibt. An
dieser Stelle wird bei den meisten Anfragetypen erwartet, dass der Server die Anfrage
verarbeitet und eine Antwort erzeugt. Der Server antwortet meistens mit einer Meldung, deren
Struktur der Anfrage ähnelt. Die Meldung beginnt mit einem HTTP-Antwortcode und
einer Textbeschreibung in der Alt der folgenden:
HTTP/1.0 4 04 Not Found
Content-Type: text/piain
Server: Uncle Mary's Cookie Recipe Server (Linux and proud of it!)
Date: Mon, 09 Feb 2004 19:45:55 GMT
The document you are looking for is nowhere to be found.
Der Rückgabecode oder die Meldung können verschiedene Umstände beschreiben, z. B.
die erfolgreiche Bearbeitung der Anfrage, eine Anweisung an den Browser, doch bitte
woanders zu suchen, oder eine Fehlermeldung wie „File Not Found" (Datei kann nicht
gefunden werden) oder „Perrnission Denied" (Zugriff mangels Berechtigung verweigert). Diesen
Angaben folgen mehrere Header, deren Format dem der Anfrage-Header ähnelt. Sie
beschreiben verschiedene Parameter wie die Version der Serversoftware, die Position, an der
der Browser fortfahren soll, eine Spezifizierung des rnhaltstyps der zurückgegebenen
Datei, eine Angabe zur Unterscheidung von Bildern von Klartext oder von HTML-
Dokumenten von Binärdateien usw. Sofern vorhanden, folgen darauf die eigentlichen
Inhalte.
Wie Sie sehen, ist HTTP eigentlich recht einfach gestrickt. Zwar bietet es einige erweiterte
Funktionalitäten, aber die meisten davon sind recht sonderbar oder werden schlichtweg
selten eingesetzt. (Ich nehme beispielsweise an, dass Sie nicht täglich über die
Fehlermeldung „402 Payment Required" stolpern.) Allerdings wäre es trotzdem naiv, wenn man
annähme, dass dieses einfache Protokoll die Bedürfnisse und Erwartungen heutiger Benutzer
erfüllen könnte.
233
14 Clientidentifikation: Die Ausweise, bitte!
14.4 Wie HTTP besser wird
Die Tage, als eine nonnale Website aus mehreren Kilobyte statischen Texts und einigen
kleinen Grafikelementen (wenn überhaupt) bestanden, sind lange gezählt. Als Computer
leistungsfähiger wurden und man ein 300-Bit/s-Modem nicht mehr in jedem Haushalt,
sondern nur noch im Museum fand, begann im Web die Zeit, in der die äußere Form den
Inhalt dominierte. Hunderte Kbyte Bilder und Unterseiten, Frames und clientseitige
Skripten werden heute eingesetzt, um Sites attraktiver und professioneller wirken zu lassen (was
nicht immer gelingt). Bei vielen Sites sind Multimediainhalte inzwischen der wichtigste
angebotene Datentyp: HTML stellt nur mehr Platzhalter für Bilder, Filme, eingebettete
Java-Programme oder Spiele bereit. Das Web ist heute nicht länger nur eine Möglichkeit,
anderen von den eigenen Projekten und Interessen zu erzählen: Die treibende Kraft
dahinter ist vielmehr die Möglichkeit, Produkte und Dienstleistungen billiger und schneller als
je zuvor zu bewerben und zu verkaufen. Und Werbung verlangt eine auffallende
Präsentation von Produkten und Dienstleistungen.
Webbrowser, Webserver und HTTP selbst mussten an diese sich ändernde Wirklichkeit
angepasst werden, um neue Technologien einsetzen und neuen Trends folgen zu können.
Das Praktische dabei ist, dass viele der neuen Technologien für den Normalsterblichen
interessante sicherheitstechnische Auswirkungen haben und uns auch dabei helfen können,
den Client am anderen Ende der Leitung auf transparente Weise zu identifizieren. Insofern
müssen wir uns die optionalen Funktionen und Erweiterungen näher ansehen, die seit dem
Tag eingeführt wurden, an dem das Web geboren wurde.
14.4.1 Latenzverringerung per Notnagel
Das Problem beim Web und bei einigen anderen aktuellen Protokollen besteht darin, dass
die Inhalte, die einem Benutzer auf einer Multimediasite präsentiert werden, bei
verschiedenen Quellen (möglicherweise sogar unterschiedlichen Domänen) eingesammelt und
dann zusammengesetzt werden müssen. Webseiten trennen die Text- und Forrnatierungs-
angaben von den eigentlichen Bildern und anderen größeren Girnmicks. (Dieser
Gesichtspunkt wird vor allem von jenen geschätzt, die nur über beschränkte Bandbreite verfügen
und schnell auf den Punkt kommen wollen.)
Diese Situation macht es für Clients erforderlich, mehrere Anfragen abzusetzen, um aus
den Antworten eine Webseite zusammenzubauen. Die naivste Möglichkeit, dies zu
erreichen, bestünde darin, jedes einzelne Element separat und nacheinander abzurufen.
Allerdings ist dies in der Praxis nicht tunlich, denn so können Engpässe entstehen: Warurn
sollte man auf das Laden einer Seite warten müssen, weil der Werbeserver so langsam läuft?
Aus diesem Grund setzt der Browser viele Annagen gleichzeitig ab, um das Einsammeln
der Inhalte zu beschleunigen.
Und genau hierin hegt der erste Nachteil von HTTP: Es bietet keine native Möglichkeit,
mehrere gleichzeitige Anfragen zu bearbeiten; diese müssen immer sequenziell abgesetzt
werden.
234
14.4 Wie HTTP besser wird
Dieses Modell des sequentiellen (oder auch seriellen) Datenabrufs fühlt zu einer
beträchtlichen Leistungseinbuße, wann immer eines der Webseitenelemente von einem langsamen
Server oder über eine schlechte Leitung geladen werden muss oder der Server eine Zeit
lang braucht, um ein bestimmtes Element vorzubereiten und dann auszuliefern. Wäre der
sequenzielle Abruf die einzige Option, dann würde eine solche langsame Anfrage das
Absetzen und Bearbeiten nachfolgender Anfragen so lange verzögern, bis die Bearbeitung
dieser langsamen Anfrage abgeschlossen ist.
Da neuere Versionen von HTTP diese Situation nicht verbessert haben, behelfen sich die
meisten Softwaieclients mit einem Notnagel: Der Webbrowser eröfmet einfach mehrere
gleichzeitige, aber separate TCP/EP-Sitzungen mit einem oder mehreren Servern und
versucht, viele Anfragen parallel abzusetzen. Eine solche Lösung ist eigentlich ziemlich
vernünftig, wenn die Seite Ressourcen von mehreren gesonderten Quellen abruft. Allerdings
ist sie ungeeignet, wenn die abgerufenen Ressourcen sich auf demselben System befinden,
denn dann könnten alle Anfragen in derselben Sitzung gestellt und vom Server vernünftig
verarbeitet werden, denn:
■ Der Server hat keine Möglichkeit, die optimale Reihenfolge für die Verarbeitung der
Anfragen zu ermitteln. (Könnte er dies, dann ließen sich die zeitaufwendigsten,
umfangreichsten oder schlicht unbedeutendsten Objekte ans Ende der
Ressourcenübertragung setzen.) Er ist einfach gezwungen, alle Anfragen möglichst zeitnah zu erledigen,
was aber immer noch dazu führen kann, dass die wichtigsten Daten aufgrund erhöhter
CPU-Belastung unnötig verzögert werden.
■ Werden mehrere größere Ressourcen gleichzeitig versandt und schaltet das Steuerpro-
grarnm des Betriebssystems zwischen den Sitzungen hin und her, dann kann es zu
erheblichen Leistungseinbußen kommen, da das Festplattenlaufwerk beim Abrufen
zweier physisch weit voneinander entfernter Dateien ständig und mit hoher Frequenz
zwischen diesen wechseln muss.
■ Neue TCP/EP-Handshakes erhöhen das Datenaufkornmen beträchtlich; das Absetzen
aller Anfragen innerhalb derselben Sitzung ist effizienter. Allerdings bieten neuere
HTTP-Versionen so genannte ÄJeepa/h'e-Funktionen, mit denen diese Auswirkungen
gemildert werden.
■ Das Öffnen einer neuen Sitzung und die Einrichtung eines neuen Prozesses zur
Bearbeitung der Anfragen erhöht das Datenaufkornmen auf Betriebssystemebene und
belastet Geräte wie statusbezogene Firewalls zusätzlich. Zwar versuchen moderne
Webserver, dieses Problem zu minimieren, indem sie Pemianentprozesse ersatzweise
vorhalten, um Anfragen gleich bei ihrer Ankunft zu bearbeiten, aber das Problem lässt sich
nur selten vollständig beseitigen. Bei Nutzung nur einer Sitzung wird ein unnötiges
Mehraufkornmen an Daten vermieden, und der Server kann dann nur diejenigen
Ressourcen reservieren, die erforderlich sind, um die gewählten Anfragen asynchron zu
bearbeiten.
235
14 Clientidentifikation: Die Ausweise, bitte!
■ Nicht zuletzt kann es, wenn nicht der Server, sondern das Netzwerk den Engpass
darstellt, zu Leistungseinbußen kommen, wenn Pakete verworfen werden, weil die Leitung
mit Daten verstopft ist, die gleichzeitig von mehreren Quellen ankommen.
Doch ob gut oder schlecht, wir müssen derzeit mit dieser Architektur leben, und sie ist
immer noch besser als der serielle Abruf. Wir sollten ihr Vorhandensein also akzeptieren
und lernen, sie zu unserem Vorteil zu nutzen.
Wie können uns diese Eigenschaften nun dabei helfen, die Software zu identifizieren, die
der Client verwendet? Ganz einfach. Die Bedeutung des parallelen Dateiabrufs zum Zweck
des Browser-Fingerprintings sollte eigentlich offensichtlich sein: Keine zwei
Abrufalgorithmen sind vollständig identisch, und dies lässt sich auch gut messen.
Bevor wir uns aber dem parallelen Abruf von Daten zuwenden, müssen wir uns noch zwei
andere wichtige Faktoren der Sicherheits- und Datenschutzgleichung für das Web ansehen:
Caches und die Identitätsverwaltung. Sie scheinen zwar nichts miteinander zu tun zu
haben, bilden aber am Ende das logische Ganze. Wir schalten um.
14.4.2 Caching von Inhalten
Die Verwendung lokaler Caches mit Dokumenten, die vom Server empfangen wurden, ist
eines der wichtigeren Merkmale des Web während seiner Expansion in den vergangenen
Jahren.7 Ohne dieses Caching wären die Betriebskosten erheblich höher gewesen.
Das Problem einer an Urnfang und Komplexität zunehmenden Website besteht darin, dass
sie immer mehr Bandbreite benötigt (was sie für ein Unternehmen relativ teuer macht) und
auch bessere Server erforderlich sind, um die Daten mit annehmbarer Geschwindigkeit
bereitzustellen.
Wenn sich nicht Bandbreitenengpässe auf die Leistungsfihigkeit auswirken, dann sind es
Lösungen wie die oben beschriebenen gleichzeitigen Sitzungen, die die Provider stark
beanspruchen. Die Ursache mag für manchen überraschend sein: Wenn eine Person über eine
relativ langsame Verbindung (z. B. ein Modem) vier aufeinanderfolgende Sitzungen
eröffnet, um eine vergleichsweise einfache Seite herunterzuladen, dann müssen auf dem Server
vier Verbindungen und vier Prozesse oder Threads am Laufen gehalten werden, die
schnelleren Verbindungen die Ressourcen wegnehmen.
Schließlich stehen, um die Lage noch zu verschlimmern, voluminöse und komplexe
Websites nicht immer in Einklang mit den Erwartungen der Benutzer. Vergleichsweise lange
Ladezeiten für Seiten galten zwar einst als völlig normal, werden aber mittlerweile als
Ärgernis betrachtet und veitreiben Besucher. Und Forschungen8 belegen tatsächlich, dass der
WWW-Durchschnittsbenutzer maximal zehn Sekunden auf den Download einer Seite zu
Allerdings nimmt seine Bedeutung heute langsam ab: Weil immer mehr Webseiten dynamisch
generiert werden und der Intemet-Backbone zunehmend ausgereifter und funktioneller wird, wird das
Caching früher oder später bedeutungslos sein.
Verschiedene Quellen, zitiert auf http://usability.gov/guidelines/sofihard.html: BoucOO, Mart86,
Mel96, Niel97a, Niel97b, Mel99
236
14.4 Wie HTTP besser wird
waiten bereit ist, bevor er weiterzieht. Folge ist, dass Unternehmen und Dienstleister mehr
Ressourcen und bessere Anbindungen benötigen, um die eingehenden Anfragen bearbeiten
zu können. In der Tat hätte, wären die Dinge so gebheben, wie sie ursprünglich
vorgesehen waren, die Nachfrage nach serverseitigen Ressourcen das Angebot an Kapazitäten
wahrscheinlich bereits vor einiger Zeit erschöpft.
In diesem Zusammenhang hat sich als hilfreich erwiesen, dass Inhalte, die Websurfern
übermittelt werden, statisch sind oder sich selten ändern - zumindest in Relation zu der
Häufigkeit, mit der eine Ressource von Benutzem abgerufen wird. (Dies gilt insbesondere
für große Dateien, z. B. Grafiken, Videos, Dokumente, ausfuhibare Dateien usw.) Indem
die Daten in größerer Nähe zum Endbenutzer zwischengespeichert werden - sei es beim
Internetprovider oder im Browser des Endsystems selbst -, lässt sich der
Bandbreitenbedarf für nachfolgende Besuche von Benutzern, die die gleiche Cache-Engjne verwenden,
erheblich senken. Zudem können die Server den Datenverkehr wesentlich einfacher
verwalten. Auch der Provider profitiert von einem geringeren Bandbreitenverbrauch, denn er
kann nun rnehr Kunden bedienen, ohne in neue Geräte und Verbindungen investieren zu
müssen. Was HTTP jedoch braucht, ist ein Mechanismus, um den Cache fehlerfrei und
aktuell zu halten. Der Autor einer Seite - sei er Mensch oder Maschine - niuss in der Lage
sein, der Cache-Engine sagen zu können, wann eine neuere Version eines Dokuments
abgerufen werden muss.
HTTP bietet standardmäßig zwei Funktionen, um das Caching von Dokumenten zu
implementieren:
■ eine Methode, um mit minimalem Aufwand sagen zu können, ob ein Teil der Daten
geändert wurde, seit die aktuell im Cache vorhandene Version (also die Version, die
beim letzten Besuch gültig war) abgerufen wurde
■ eine Methode zur Bestimmung, welcher Teil der Daten nicht im Cache
zwischengespeichert werden darf - ob aus Sicherheitsgründen, oder weil die Daten bei jedem
Abrufdynamisch neu erstellt werden
Diese Funktionalität wird in der Praxis recht einfach umgesetzt: Der Server gibt alle
zwischenspeicherbaren Dokumente in der regulären HTTP-Sitzung zurück, fügt aber auf
Protokollebene einen Header namens Last-Modified (,»Letzte Änderung") hinzu. Natürlich ist
damit die Ansicht des Servers bezüglich der Frage gemeint, wann das Dokument zuletzt
geändert wurde. Demgegenüber werden Dokumente, die nicht im Cache abgelegt werden
dürfen, vom Server mit dem Vermerk Pragma: no-cache (bzw. Cache-Control: no-cache
in HTTP/1.1) versehen.
Der Clientbrowser (oder eine zwischengeschaltete, vom Intemetprovider betriebene
Cache-Engjne) soll eine Kopie aller nach Maßgabe eines geeigneten Headers
zwischenspeicherbaren Seiten sowie die zugehörigen Angaben zur letzten Änderung im Cache
ablegen. Die zwischengespeicherte Seite soll so lange wie möglich aufbewahrt werden -
entweder, bis der benutzerdefinierte Grenzwert für den Cache überschritten wird oder der
Benutzer den Cache manuell löscht -, sofern kein Expires-He&der vorhanden ist, der
Angaben zum Ablaufdatum der Seite enthält.
237
14 Clientidentifikation: Die Ausweise, bitte!
Wird die Seite später neu besucht, dann erkennt der Client, dass eine ältere Instanz der
Seite im Cache auf der Festplatte vorhanden ist. Der Zugriff erfolgt dann auf eine etwas
andere Weise: Solange das Dokument im Cache vorhanden ist, versucht der Client, die Datei
jedes Mal abzurufen, wenn der Benutzer eine Site erneut besucht, übergibt aber in jeder
Anfrage einen If-Modified-Since-Headei, der den Zeitpunkt angibt, der beim letzten
Besuch der Seite im Last-Modißed-Headei erkannt wurde. Der Server vergleicht nun den
Wert von If-Modified-Since mit seinen Kenntnissen bezüglich der letzten Änderung der
betreffenden Ressource. Wurde die Ressource seitdem nicht verändert, dann wird statt der
angeforderten Daten die HTTP-Fehlermeldung „304 Not Modified" zurückgegeben. Die
eigentliche Dateiübertragung wird also nicht durchgeführt, was Bandbreite einspart (weil
nur ein paar hundert Bytes während dieses Vorgangs ausgetauscht werden). Der Client
(oder die zwischengeschaltete Cache-Engine) soll in diesem Fall eine zuvor
zwischengespeicherte Kopie der Ressource verwenden, statt sie erneut herunterzuladen.
■ Hinweis
Ein aktuellerer Ansatz — die ETag- und If-None-Match-Hcader, die einen Teil der Tagging-
Funktionalität von HTTP/1.1 ausmachen — funktioniert auf ähnliche Weise, sein Ziel ist aber
die Auflösung von Mehrdeutigkeiten in Verbindung mit der Interpretation von Zeitpunkten
der Dateimodifikation, d. h. Problemen in Verbindung mit Dateien, die innerhalb kurzer Zeit
(unterhalb der Auflösung von Last-Modified-ßingabsn) mehrfach geändert oder aus einer
Sicherungskopie wiederhergestellt wurden (weswegen der Andemngszeitpunkt zeitlich vor dem
der letzten zwischengespeicherten Kopie liegt) usw.
14.4.3 Sitzungen mit Cookies verwalten
Eine weitere wichtige und in diesem Zusammenhang scheinbar irrelevante Anforderung
von FfTTP bestand darin, zwischen Sitzungen unterscheiden, diese auch verbindungsüber-
greifend erkennen und Sitzungseinstellungen wie auch Identitätsangaben speichern zu
können. Einige Websites profitieren beispielsweise in erheblichern Maße davon, dass der
Benutzer die persönlichen Einstellungen anpassen kann und die Seiten dann bei jedem
Neuaufruf in dem von ihm gewählten Aussehen wiederhergestellt werden. Natürlich ließe
sich die Identität des Benutzers auch ermitteln, indem man bei jedem Besuch der Seite
einen Anmeldenamen und ein Passwort abfragt und bei korrekter Eingabe die persönlichen
Einstellungen lädt. Allerdings verringert dieser eigentlich zu vernachlässigende
Mehraufwand die Anzahl potenzieller Besucher einer Seite erheblich.
Es wurde also eine transparente und stabile Möglichkeit zum Speichern und Abrufen von
Daten vom Computer des Clients benötigt, um nahtlosen und personalisierten Zugriff auf
Webforen, Mailboxen, Chats und viele andere Funktionalitäten zu ermöglichen, die für
viele Benutzer einen Großteil des Browsens ausmachen. Auf der anderen Seite bedeutete
die Fähigkeit von Websei^eradHiinistratoren, zurückkehrende Besucher erkennen und
identifizieren zu können, indem man sie eindeutig mit einem Tag kennzeichnete, das später
wieder abgerufen werden konnte, auch die Preisgabe der Anonymität im Austausch gegen
ein bisschen Bequemlichkeit. Solche Methoden würden Unternehmen mit geling ausge-
238
14.4 Wie HTTP besser wird
prägter Ethik ein hervorragendes Werkzeug an die Hand geben, um Benutzer zu
kontrollieren und Profile zu erstellen, ihre Einkaufs- und Surfgewohnheiten aufzuzeichnen, ihre
Interessen zu bestimmen usw. Suchmaschinen könnten Anfragen desselben Benutzers einander
zuordnen, und Anbieter, die Ressourcen wie etwa Werbebanner vertreiben, könnten
Benutzer mithilfe dieser Daten auch ohne deren Erlaubnis und ohne Wissen der Sitebetreiber
überwachen.9 Trotz dieser Einwände schien es aber keine bessere, ausreichend universelle
Alternative zu einem solchen Mechanismus zu geben. Dies war die Gebuitsstunde der
Cookies.
Nach Definition in RFC210910 sind Cookies kleine Textdateien, die von einem Server
ausgestellt werden, wenn der Client eine Verbindung zu ihm herstellt. Der Server fügt in
seiner Antwort an den Besucher einen Set-Coo/äe-Header ein. Diese Textdatei ist aufgrund
der zusätzlichen Parameter auf eine bestimmte Domäne, einen Server oder eine Ressource
beschränkt und hat eine endliche Gültigkeitsdauer. Cookies werden von Clientanwendun-
gen, die sie unterstützen, in einer speziellen Containerdatei oder einem Ordner gespeichert
und - mit einem Coofo'e-Header versehen - immer dann automatisch an den Server
zurückgeschickt, wenn erneut eine Verbindung mit der betreffenden Ressouice hergestellt
wird.
Server können Benutzereinstellungen nach Bedarf in Set-Coo/äe-He&dem ablegen, die sie
dann bei späteren Besuchen auslesen. In einer heilen Welt würde die Cookie-Funktionahtät
hier enden. Leider gibt es für Computer keine Möghchkeit, zu ermitteln, was in einem
Cookie gespeichert ist. Ein Server kann beispielsweise eine eindeutige Clientkennung in
den Set-Cookie-He&dei schreiben und diese dann später wieder einlesen, um aktuelle mit
vorherigen Aktivitäten des Benutzers auf dem System zu verknüpfen.
Diese Methode hat nach landläufiger Meinung schwerwiegende datenschutztechnische
Auswirkungen. Einige Aktivisten geben unumwunden zu, Cookies zu hassen, aber die
Opposition gegen diese Technologie macht ihrem Herzen mittlerweile zunehmend seltener
Luft. Mit deaktivierten Cookies durch das Internet zu surfen, wird immer schwieriger, und
es gibt sogar Sites, die Anfragen von Clients, die eine Cookie-Prüfung nicht bestehen, ganz
einfach abweisen. Zum Glück bieten viele Browser umfassende Einstellungen zum
Annehmen, Beschränken oder Abweisen von Cookies und können sogar die Annahme jedes
einzelnen Cookies bestätigen (obwohl letzteres nicht besonders praktikabel ist). Auf diese
Weise lässt sich die Privatsphäre einigermaßen gut schützen, indem man definiert, wer die
„Guten" sind und wem man vertrauen möchte.
Aber hegt unsere Privatsphäre dann in ihren Händen?
Wenn ein Werbebanner oder ein anderes Element einer Website auf einem gemeinsam verwendeten
Server wie http://banners.evilcompany.com abgelegt wird, kann der Betreiber von evilcompany.com
Cookies versenden und immer dann abrufen, wenn eine Person eine Website besucht, auf der Banner
von evilcompany.com angezeigt werden. Selbstredend versenden die meisten Banneranbieter Cookies
und überwachen Benutzer — wenn auch in erster Linie zu Zwecken der Marktforschung.
10 Kris97
239
14 Clientidentifikation: Die Ausweise, bitte!
14.4.4 Cache und Cookies: Die Mischung macht's
Schon lange ist die Privatsphäre beim Webbrowsing ein ganz heißes Eisen, und dies nicht
ohne Grund. Viele Benutzer wollen nicht, dass andere in ihren Einstellungen und
Vorlieben schnüffeln, auch wenn die Umstände keineswegs fragwürdig sind. Warum dieses?
Nun, manchmal möchte man einfach nicht, dass irgendeine nervige Marketingfirma
herauskriegt, dass Sie Informationen zu bestimmten medizinischen Problemen sammeln, und
dieses Wissen dann mit einem bestimmten Konto verknüpft, welches Sie bei einer
bestimmten Mailanbieter haben, denn Sie können keinesfalls wissen, wo diese Informationen
einmal enden werden.
Die Cookie-Steuerung macht das Websurfen für Sie ausreichend komfortabel, während die
bösen Jungs draußen bleiben müssen. Aber auch dann, wenn Sie Cookies abschalten,
können Sie nicht verhindern, dass Daten auf Ihrem System gespeichert werden, die später an
den Server zurückgeschickt werden. Die Funktionalität, die zum Speichern und Abrufen
von Daten auf dem Computer eines Opfers erforderlich ist, ist bei allen Browsern schon
seit langer Zeit vorhanden - ungeachtet der von Ihnen definierten Cookie-Richtlinien. Die
beiden erforderlichen Technologien arbeiten auf ähnliche Weise und unterscheiden sich
nur hinsichtlich ihres vorgesehenen Verwendungszwecks: Cookies und Caching.
Irgendwann im Jahr 2000 schickte Martin Pool einen kurzen, aber recht aufschlussreichen
Beitrag11 an die Bugtraq-Mailingliste und berichtete über eine interessante Beobachtung,
die er mit aktuellen Codebeispielen untermauerte. Er zog den Schluss, dass es - zumindest,
was Systeme angehe, die keine zentralisierten Proxy-Caches verwenden und Kopien
bereits abgerufener Dokumente lokal auf Festplatte speichern (wie die meisten von uns dies
tun) - keinen wesentlichen Unterschied zwischen den Funktionalitäten von Set-Cookie und
Cookie im Vergleich mit Last-Modified und If-Modified-Since gebe. Ein böswilliger Web-
siteadrninistrator kann im Last-Modified-He&dei; der für eine Seite zurückgegeben wird,
die von einem Opfer besucht wird, praktisch jede behebige Meldung speichern. (Selbst
wenn der Header auf Plausibilität geprüft wird, kann er zumindest ein behebiges,
eindeutiges Datum angeben, um den Besucher eindeutig zu identifizieren.) Der Client würde dann
If-Modified-Since mit einer exakten Kopie der eindeutigen Kennung senden, die von einem
arglistigen Betreiber immer dann auf seinem Computer gespeichert wird, wenn er eine
Seite erneut besucht. Und mit der Antwort „304 Not Modified" könnte sichergestellt werden,
dass dieses „Cookie" nicht verworfen wird.
14.4.5 Wie man die Cache-Cookie-Attacke verhindert
Seinen Browser zu verwenden, um die Last-Modified-Daten ein bisschen zu „korrigieren",
scheint auf den ersten Blick eine nette Möglichkeit, diese Sicherheitslücke zu schließen
(wenn auch auf Kosten kleiner Ungenauigkeiten im Cache). Dies ist aber leider nicht der
Fall. Eine andere Variante dieses Angriffstyps basiert auf dem Speichern von Daten in
PoolOO
240
14.5 Verrat! Verrat!
zwischengespeicherten Dokumenten (anstelle der direkten Verwendung von Tags): Ein
hinterlistiger Betreiber kann eine spezielle Seite für ein Opfer präparieren, das eine
Website zum ersten Mal besucht. Diese Seite enthält einen Verweis auf einen eindeutigen
Dateinamen, der als eingebettete Ressource ausgewiesen ist (z. B. ein Bild). Besucht der Client
die Seite dann erneut, so bemerkt der Server den Jf-Modified-Since-Headei und antwortet
mit der Fehlermeldung 304, d. h. er fordert zur Verwendung der vorhandenen Kopie der
Seite auf. Die alte Seite enthält eine eindeutige Dateireferenz, die dann beim Server
abgerufen wird. Auf diese Weise lässt sich die IP-Adresse des Clients mit einer vorherigen
Sitzung verknüpfen, bei der dieser Dateiname bereits übermittelt wurde. Oha.
Natürlich ist die Lebensdauer von „Cookies" im Cache durch die Cachegröße und die
Ablaufeinstellungen zwischengespeicherter Dokumente begrenzt, die vom Benutzer
konfiguriert wird. Allerdings sind diese Werte in der Regel recht großzügig bemessen, und
Informationen, die in den Metadaten einer Ressource gespeichert sind, die nur alle paar Wochen
neu besucht wird, können jahrelang im Cache verbleiben, bis dieser manuell geleert wird.
Für Unternehmen, die Komponenten bereitstellen, die auf Hunderttausenden von Sites
enthalten sind, stellt dies ohnehin kein Problem dar (auch hier sind Banner ein gutes Beispiel).
Der wesentliche Unterschied zwischen diesen Cache-Cookies im Vergleich zu „richtigen"
Cookies ist keine Frage der gebotenen Funktionalität, sondern eher die Leichtigkeit, mit
der sich die oben beschriebene Angriffsfläche nutzen lässt. (Cache-Daten werden auch für
andere Zwecke eingesetzt und können nicht einfach ohne erhebliche Leistungseinbußen
beschränkt werden, die damit verbunden sind, dass die Zwischenspeicherung teilweise
oder vollständig deaktiviert wird.)
Angesichts dieser eigenartigen Wendung können Sie sehen, wie zwei Aspekte des Web
miteinander kollidieren und die Sicherheitsmaßnahmen, die um einen dieser Aspekte
herum aufgebaut sind, einfach außer Kraft gesetzt werden. Die Praxis zeigt, dass guter Wille
nicht immer ausreicht, weil Ganoven nicht immer bereit sind, nach den Regeln zu spielen
und die Technologie so einzusetzen, wie wir es wünschen. Vielleicht macht das
Abschalten von Cookies am Ende doch nicht den Unterschied aus.
Jetzt aber ist es an der Zeit, dass wir uns wieder dem Hauptthema dieses Kapitels
zuwenden.
14.5 Verrat! Verrat!
Nämlich dem Thema der Erkennung von Betrugsversuchen und dem korrekten Fingerprin-
ting von Clientanwendungen. Ich habe bislang erwähnt, dass die Aufgabe, trügerische
Clients zu erkennen, recht komplex, aber nicht unmöglich zu lösen ist, und dass die
Verhaltensanalyse - eine sorgfältige Überwachung der Abfolge von Ereignissen, die von den
fraglichen Browsern erzeugt werden - einen Weg darstellt, den zu gehen sich durchaus
lohnen kann.
241
14 Clientidentifikation: Die Ausweise, bitte!
HTTP ist ein sehr großzügiges Studienobjekt, denn wie wir gesehen haben, finden viele
Aktivitäten mehr oder minder parallel statt, und die Algorithmen zur Warteschlangenbil-
dung und Datenverarbeitung sind recht subtil und für jeden Client spezifisch. Durch
Ermittlung der Anzahl gleichzeitig henintergeladener Dateien, der Abstände zwischen den
Anfragen, der Reihenfolge der Anfragen und anderer kleinster Details einer Sitzung ist es
möglich, die eindeutigen Charakteristika eines Systems auf einer Ebene zu messen, die zu
kontrollieren für den Benutzer wesentlich schwerer ist. So können Sie problemlos
gesetzestreue Bürger von Schwindlern unterscheiden.
Um auf einfachste Weise ein Praxisbeispiel dieses Ansatzes zu vermitteln und dabei so nah
an den echten Anwendungen wie möglich zu bleiben, beschloss ich zu überprüfen, wie viel
sich aus den vorhandenen, relativ beschränkten Datenproben gewinnen lässt, die auch den
meisten von Ihnen zur Verfügung stehen dürften. Deshalb legte ich die Standardlogdateien
einer relativ behebten Website zugrunde, die kaum mehr als eine Million Anfragen
enthielten. Die für die Analyse verwendeten Daten fand ich in einer ganz normalen
Zugriffslogdatei eines Apache-Webservers. Die Datei enthielt Angaben zur Bearbeitungsdauer von
Anfragen, den angeforderten URIs, den über den User-Agent-He&dei bekannt gemachten
Browserdaten und andere ähnlich grundlegende Datentypen. Die Seite, auf die sich diese
Logdatei bezog, besteht aus einigen recht kleinen Bildern vergleichbaier Größe und einem
HTML-Dokument, das diese Bilddateien aufruft.
14.5.1 Verhaltensanalyse: Eine einfache Fallstudie
Die Gewohnheit des Apache-Servers, Anfragen erst dann zu protokollieren, wenn sie
abgeschlossen sind (und nicht bereits, wenn sie bearbeitet werden), könnte man als Problem
auffassen. Tatsächlich aber ist sie recht hilfreich, wenn man voraussetzt, dass die Gruppe
der angeforderten Dateien relativ homogen ist. Die Initiierungsreihenfolge der Anfragen
wild eher durch die Abfolge beeinflusst, in der Ressourcen auf der Hauptseite referenziert
werden, wohingegen die Duichfühnmgsdauer auf einem ganz anderen Blatt steht.
Wahrscheinlichkeiten in Bezug auf die Fertigstellungsreihenfolge hängen von der Anzahl
der Anfragen, den zeitlichen Abständen zwischen ihnen sowie anderen Parametern ab, die
sich in geringem Maße von Browser zu Browser unterscheiden - nur subtil, aber durchaus
spürbar. Insbesondere Browser, die immer eine Verbindung geöffnet halten, arbeiten
Anfragen generell in einer bekannten Reihenfolge ab, z. B. A-B-C-D. Browser, die drei
Verbindungen gleichzeitig öffnen und Anfragen in schneller Reihenfolge verarbeiten, können
genau so gut B-A-C-D, C-B-A-D, C-A-B-D usw. erzeugen. Und in diesen Fällen spielen
die Einreihung der Anfragen in die Warteschlange und die Sitzungsverwaltung die
wichtigste Rolle.
Natürhch dürfen wir nicht vergessen, dass zufällige Faktoren wie etwa die Latenz oder
Zuverlässigkeit des Netzwerks sich ebenfalls erheblich auf die beobachtete Abfolge
auswirken können. Trotzdem ist es vernünftig, davon auszugehen, dass sich bei einer derart
großen Menge von Beispielen Auswirkungen, die nicht browserspezifischer Natur sind,
einpendeln oder die Daten für alle Clients auf ähnliche Weise beeinflussen. Und wenn das
242
14.5 Verrat! Verrat!
passiert, dann werden wir hoffentlich feinste Unterschiede zwischen Browsern erkennen,
die unter eine benutzerfreundlichen Bedienoberfläche im Stillen wirken.
Abbildung 14.1 zeigt die statistische Verteilung beim Versuch von vier verbreiteten
Webclients, die oben beschriebene, zehn Elemente umfassende Webseite zu laden. Jede Kurve
ist in zehn Hauptsegmente unterteilt. Die erste entspricht der HTML-Datei, die direkt
angefordert wird und natürlich das erste Element der Seite bildet. Die übrigen neun Segmente
entsprechen den neun Bildern, die von der HTML-Seite referenziert werden, in der
Reihenfolge, in der sie im HTML-Code aufgeführt sind.
Abbildung 14.1 Unterschiede In Vertialtensmustem beliebter Webclients
Jedes der Segmente wird seinerseits in zehn diskrete Abschnitte auf der X-Achse unterteilt.
(Diese sind in der Abbildung nicht angegeben, damit die Kennlinien erkennbar bleiben.)
Die Kurvenhöhe im w-ten Abschnitt innerhalb eines Segments stellt die Wahischeinlichkeit
dar, mit der diese Datei als w-te Datei in der Abfolge geladen wird.
243
14 Clientidentifikation: Die Ausweise, bitte!
Um die Leserlichkeit zu verbessern, sind die Verteilungswahrscheirüichkeiten als
Prozentwerte zwischen 1 und 100 angegeben (wobei diese den prozentualen Ergebnissen
entsprechen und alle Werte unter 1 aufgerundet wurden). Diskrete Punkte wurden durch
Linien verbunden. Die Kurven wurden dann auf einer logarithmischen Skala (loglO, mit
Hauptteilungen bei 1, 10 und 100) dargestellt, um feine Details zu betonen und den
optischen Vergleich zu vereinfachen.
In einer perfekten Welt mit vollständig sequenziell arbeitenden, vorhersagbaren Browsern
würde das erste Segment nur einen Spitzenwert an der ersten diskreten Position (ganz
links) enthalten, das zweite Segment einen Spitzenwert an der zweiten Position usw. In der
Praxis jedoch setzen viele Browser Abfragen gleichzeitig ab, weswegen die Reihenfolge
sehr schnell durcheinandergebracht ist: Die dritte referenzierte Datei kann am Ende vor der
zweiten oder nach der vierten geladen werden. Je weniger ausgeprägt eine Spitze in einem
Segment ist, desto aggressiver scheint der Abrafalgorithmus des Browsers zu sein - denn
umso höher ist die Wahrscheinlichkeit, dass diese Datei außerhalb der Reihenfolge geladen
wird.
Die Unterschiede sollten offensichtlich sein - auch bei Browsern wie Mozilla und dem
Internet Explorer, die historisch beteachtet auf derselben Engine basieren. Alle Clients
scheinen die Reihenfolge zu beachten, in der die Dateien im Hauptdokument referenziert
werden, d. h. die nachfolgenden Spitzenwerte bewegen sich von Segment zu Segment immer
weiter von links nach rechts. Doch wie Sie sehen, ist Mozilla generell weniger ungeduldig
als der Internet Explorer und beendet den Download der Dateien häufig in der
Reihenfolge, in der sie angefordert wurden. Opera dagegen - als schnellster Browser der Welt
beworben - nimmt es mit der Reihenfolge alles andere als genau: Viele Dateien weisen zwei
oder drei beinahe identische Spitzenwerte aus, was darauf schließen lässt, dass eine Anzahl
von Anforderungen derart schnell abgesetzt wird, dass die Reihenfolge der Fertigstellung
fast beliebig ist und erheblich vom Jitter im Netzwerk beeinflusst wird. Wget schließlich -
ein beliebtes Open-Source-Programm zum Herunterladen von Dateien - habe ich zu Ver-
gleichszwecken hinzugefügt. Es weist ein makellos sequenzielles Muster auf (wie es für
automatisierte Crawler typisch ist), verwendet nur eine Verbindung und lädt alle Dateien
in derselben Reihenfolge.
14.5.2 Was uns der Künstler mit seinem Bild sagen will
Bilder und Kurven sind nett, haben aber wenig bis gar keinen Wert für die automatisierte
Durchsetzung von Richtlinien oder die Missbrauchserkennung. Um die beobachteten
Muster irgendwie quantifizieren zu können und das Fingerprinting ein bisschen realitätsnäher
zu gestalten, ersann ich eine einfache Metrik, die einem Segment eine bessere Wertung
(zwischen 1 und 10) zuordnet, wenn nur ein einzelner Spitzenwert vorhanden ist; je
willkürlicher die Verteilung ist, desto niedriger ist die Weitung. Auf diese Weise ließe sich
eine einfache Signatur mit zehn Weiten für eine bestimmte Software erstellen; mit dieser
könnten dann Beobachtungen verglichen werden, um die entsprechenden Schlüsse zu
ziehen.
244
14.5 Verrat! Verrat!
Um eine Metrik zu konstruieren, die eine relative Qualität (Linearität) Q des beobachteten
Verhaltens im Hauptsegment s ausdrückt, verwendete ich die folgende Formel (bei dieser
bezeichnet/ die Wahrscheinlichkeit, dass die Datei in der Abrufsequenz an der Position n
erscheint, ausgedrückt als prozentualer Wert, damit es bequemer ist und die Puristen sich
ein bisschen auflegen können):
( HE A
1,42
10
v J
Diese Gleichung, wiewohl auf den ersten Blick furchteinflößend, ist eigentlich ziemlich
klar strukturiert. Ich wollte, dass die Formel der Situation, wenn die betreffende Datei am
häufigsten an einer festen Position in einer Abfolge geladen wurde (d. h. ein ./-Wert nahe
bei 100 Prozent und die verbleibenden Wahrscheinlichkeiten nahe bei 0 Prozent liegen),
Vorrang gegenüber solchen Situationen einräumt, in denen alle Position mit gleicher
Wahrscheinlichkeit auftreten werden (d. h. alle/-Werte bei 10 Prozent liegen).
Da die Summe aller Elemente von/feststeht (100 Prozent), besteht die einfachste
Möglichkeit, dies zu erreichen, in der Verwendung einer Summe von Quadraten für jede Folge
von Zahlen ungleich null: Die Summe von Quadraten dieser Zahlen ist immer kleiner als
das Quadrat der Summe. Die größten und kleinsten Ergebnisse sehen wie folgt aus:
102 + 102 + 102 + 102 + 102 + 102 + 102 + 102 + 102 + 102 = 1.000
1002 + 02 + 02 + 02 + 02 + 02 + 02 + 02 + 02 + 02 = 10.000
Die verbleibenden Berechnungen (neben der Surnmierung) dienen lediglich dazu, die
Ergebnisse nach der Rundung sinnvoll auf einer Skala von 0 bis 10 zu verteilen.
Die Ergebnisse der Berechnung dieser Metiik des beobachteten Datenverkehrs der
einzelnen Browser sind als numerischer Wert für jedes Segment in Abbildung 14.1 eingetragen.
Wie erwartet, holt Wget in jedem Segment die volle Punktzahl. Die Weitungen der
anderen Browser bestätigen die vorherigen optischen Beobachtungen und machen sie
greifbarer. Zwar scheinen die Engines von Internet Explorer und Mozilla/Netscape im Grroßen
und Ganzen ähnliche Kennlinien aufzuweisen, aber es lassen sich deutliche Unterschiede
bei den Segmenten 4 bis 6 und in geringerem Maße über die gesamte Abrufsequenz
feststellen. Opera sticht deutlich aus der Gruppe heraus: Die Weitungen sind für jedes
Segment durchgehend niedriger.
Am Ende haben wir, indem wir ein ganz schlichtes Analysewerkzeug eingesetzt haben,
einen Rahmen zur Entwicklung einer praktischen Methode vorgegeben, mit der sich
Browser identifizieren und Betrügereien in einem statistisch signifikanten Muster des HTTP-
Datenverkehrs aufdecken lassen. Sie können dieses Modell erweitern, indem Sie andere
automatisch ladende Elemente wie Skripten, HTML-Stylesheets, Irnage-Maps, Frames und
andere Dateien untersuchen, die noch größere browserspezifische Varianzen aufweisen.
245
14 Clientidentifikation: Die Ausweise, bitte!
Vielleicht hat es der Weihnachtsmann in diesem Jahr leichter, die Liste mit den unartigen
Kindern zu schreiben.
14.5.3 Gentlemen, start your engines!
Ich hoffe lediglich, darlegen zu können, wie einfach es ist, verborgene Eigenschaften einer
unbekannten Anwendung zu erkennen, indem man ihr Verhalten beobachtet, ohne von
bestimmten Annahmen auszugehen oder die Interna eines solchen Programms auseinander zu
nehmen. Die oben angegebenen exakten Zahlen sind wahrscheinlich nicht direkt auf
beliebige andere Websites als die von mir verwendete anwendbar. Insofern stelle ich Ihnen als
Hausaufgabe, eine potenzielle Einsatzmöglichkeit für diese Methode zu finden. Wenn Sie
für eine oder mehrere Sites Profile erstellt haben, können Sie mithilfe der Daten Systeme
basierend auf ihren zeitbezogenen Aktivitätsmustern ermitteln.
Selbstverständlich ist die hier beschriebene Methode ein (vielleicht übermäßig)
vereinfachender Ansatz der Verhaltensanalyse und basiert auf dem womöglich trivialsten aller
möglichen Szenarien. Ich möchte Sie aber anspornen und dazu verleiten, weiterzusuchen.
In weitergehenden Fällen könnten Sie beispielsweise das Umsetzen von Inhalten in
Frames, Tabellen und anderen optischen Containern oder das Umsetzen bestimmter
Dateitypen
überprüfen, um zu bestimmen, welcher Browser verwendet wird - auch ohne
Durchführung statistischer Erhebungen: Bei verschienen hochspezifischen Aspekten der
Browseraktivitäten werden die Unterschiede noch erheblich offensichtlicher. Auch eine clevere
Anwendung der unterschiedlichen zeitlichen Abläufe mag vielversprechend sein.
Berücksichtigen Sie auch folgendes: Sie können elaborierte Formen der Verhaltensanalyse
einen Schritt weiter bringen und sie verwenden, um nicht nur eine Seitenbeschreibungs-
Engjne von einer andere zu unterscheiden, sondern auch Maschinen und Menschen
auseinander zu halten oder sogar einzelne Benutzer zu identifizieren. Wie in Kapitel 8 bereits
dargelegt, sind die Tastaturverwendungsrnuster häufig derart charakteristisch für eine
Person, dass man sie sogar für biometrische Zwecke einsetzen könnte. Ahnlich legen
Forschungen nahe, dass wir anhand der Alt und Weise, wie ein Benutzer Verknüpfungen an-
klickt, eine Auswahl trifft, Informationen liest usw., angeben können, wer oder was hinter
einer Serie von Anfragen steckt.12 Dies liegt zwar näher an wissenschaftlicher Spekulation
als an Tatsachen, aber es ist eine wunderbare Spielwiese, auf der man sich richtig austoben
kann.
14.5.4 Was sonst noch hinter dem Horizont lauert
Anwendungen zu Browseraktivitäten und Verhaltensanalyse gehen über die Erkennung der
Browsersoftware hinaus, und tatsächlich übertreten einige sogar die Grenze von
Datenschutz und Anonymität.
Moba99
246
14.5 Verrat! Verrat!
Eine interessante Forschungsarbeit13, die im Jahr 2000 von Edward Feiten und Michael
Schneider veröffentlicht wurde, leistet einen faszinierenden Beitrag zu den Anwendungs-
rnöglichkeiten dieser Technik: eine Fähigkeit, die eng mit den in modernen Engines
vorhandenen Caching-Mechanisrnen verwandt ist und uns an den Punkt bringt, an dem alle
bislang beschriebenen Elemente zusammenkommen.
Der Grundgedanke ihrer Arbeit ist, dass es durch Einfügen eines Verweises auf eine Datei
auf einer bestimmten Site und nachfolgendes Messen der Verzögerung, auf die der
Browser beim Herunterladen trifft, möglich ist, zu sagen, ob der Benutzer eine bestimmte Site in
den vergangenen Tagen besucht hat. Nichts einfacher als das.
Ich erspare Ihnen einen umfangreichen Exkurs in die Welt von Theorien, Vorhersagen und
Spekulationen (aber nur diesmal) und zeige Ihnen stattdessen ein Beispiel, das beinahe
praxisnah ist. Angenommen, ich betieibe die Domäne Mnvw.rogue-servers.com. Nun habe
ich beschlossen, dass meine Hauptseite aus irgendeinern Grund ein Bild (z. B. eine Ein-
gangsgrafik) referenziert, das von der Site mvw.Mnky-Mttens.com stammt. Das
Bildelement modifiziere ich so, dass es schwer zu finden ist, oder skaliere es so weit herunter,
dass es nicht mehr sichtbar ist, aber es wird vom Browser trotzdern geladen.
Nun besucht ein ahnungsloser Besucher meine Site. War er noch niemals zuvor auf
T>vww.Mnfcy-Mttens.com, dann dauert es eine Weile, bis er das von mir referenzierte Bild
heruntergeladen hat. Ist er jedoch regelmäßiger Gast auf meiner Site, dann ist das Bild
bereits in seinem Cache vorhanden und wird praktisch sofort aufgerufen.
Da dem Verweis auf die Ressource von www.Mnky-Mttens.com Anfragen zu anderen
Bildelementen sowohl vorangehen als auch nachfolgen, ist es durch Einsatz einer
ausgefuchsten Ablaufheuristik möglich, zuverlässig zu messen, ob das Logo übertragen wurde oder
bereits im Cache vorhanden war. All dies reicht aus, um zu bestimmen, ob ein
Neuankömmling auf meiner Site eine bestimmte andere Website (oder einen bestimmten Bereich
dieser Website) häufig besucht - und stellt natürlich auch eine drastische Verletzung seiner
Privatsphäre dar. Zwar wird dieses Szenario wohl kaum für routinemäßiges Ausspionieren
im großen Stil verwendet werden (und zwar deswegen, weil man klare Indizien zurücklässt
und vom Betreiber des Servers bemerkt werden könnte, dessen Benutzer man
ausschnüffeln will), aber gezielte Angriffe können ziemlich erfolgreich sein.
Am Ende passen alle Teile des Puzzles zusammen - vielleicht nur lose, aber sie passen
zusammen. Benutzer, Programme und Gewohnheiten können nur allzu leicht durch den
gewissenhaften Missbrauch moderner Funktionalitäten eines verbreiteten rnternetprotokolls
erkannt werden. Dies zu wissen, wird die geschätzten Benutzer von T>vww.Mnky-Mttens.com
in nächster Zeit wohl kaum ruhig schlafen lassen.
13 FeltOO
247
14 Clientidentifikation: Die Ausweise, bitte!
14.6 Vorbeugung
Das eigene Surfen im Web vollständig anonymisieren zu wollen, scheint eine Schlacht zu
sein, die bereits verloren ist. Zwar sind einige Praktiken zur Optimierung von Datenschutz
und Anonymität von Webbenutzem gängig, aber eine Website kann diese einfach
umgehen, wenn genug kriminelle Energie vorhanden ist.
Das Problern ist leider zu schwerwiegend, um es einfach zu ignorieren. Es ist eine Sache,
wenn eine Institution, der wir vertrauen (z. B. der Internetprovider), Ihre Aktivitäten
kontrollieren kann, aber wenn Leute, mit denen Sie nicht unbedingt regelmäßigen Kontakt
pflegen wollen, routinemäßig Profile mit sensiblen Daten erstellen und diese gemäß ihrem
Geschäftsmodell ebenso routinemäßig an Dritte weiterveräußem, dann ist das eine ganz
andere Angelegenheit. Dies sollte sogar denjenigen unter uns Sorgen bereiten, die
gewohnheitsmäßig weder eine Stanniolmütze aus noch Unterwäsche aus Alufolie tragen.
Andererseits ist die relative Schwierigkeit, vollständig anonym zu bleiben oder vollständig
harmlos zu erscheinen, in Umgebungen, in denen HTTP-Datenverkehr erlaubt sein muss
und die Benutzer trotzdem geschützt und kontrolliert werden sollen, ohne ihre Privatsphäie
über das notwendig Maß hinaus zu verletzen, von großer Bedeutung. In Firmennetzen ist
die Möglichkeit, nicht-richtlinienkonforme Systeme zu ermitteln, ohne Daten manuell
überprüfen zu müssen, wahrhaftig von unschätzbarem Wert und wird von Benutzern und
Systernadrninisti'atoren gleichermaßen geschätzt.
14.7 Denkanstöße
Nicht eine einzige Komponente von HTTP ist schlecht konzipiert, fehlerhaft oder
ungerechtfertigt. Doch wenn wir alles zusammen betachten, dann scheinen viele
Sicherheitsund Datenschutzfunktionen aufgehoben zu werden, und der Benutzer ist der zunehmenden
Anzahl von Lauschern mehr oder minder hilflos ausgeliefert. Traurigerweise können wir
wenig tun, wenn wir nicht bei null anfangen wollen, und es gibt keine Garantie, dass die
Ergebnisse gut funktionieren oder überhaupt so viel Datenschutz gewährleisten würden,
wie es HTTP, HTML und WWW-Clients derzeit tun.
248
15 Das Opfer als Nutznießer
Fünfzehntes Kapitel. In welchem wir feststellen, dass eine optimistische
Lebensauffassung bei der Jagd auf den Angreifer durchaus hilfreich sein kann
Ich habe bislang eine Vielzahl von Problemen beschrieben, die in ihrer Summe erhebliche
Auswirkungen auf die tägliche Kornmunikation haben können - ein Risiko, welches uns
nicht immer gut schlafen lässt. Sie haben gesehen, wie andere das Netzwerk ausnutzen, um
Daten zu stehlen oder rnehr zu bekommen, als Sie es erwarten oder ihnen gestatten
würden, und wie man mithilfe dieser Methoden rnehr Informationen zu Ihrem Untemehmens-
oder Heimnetzwerk, aber auch zu den Angreifern ermittelt, die es darauf abgesehen haben.
Ich hoffe, dass ich Ihnen sowohl einen nützlich Einblick in den Ursprang dieser Probleme
als auch in ihre Vermeidung gewähren konnte, sofern eine solche möglich ist. Ich habe zu
zeigen versucht, dass sich praktisch alle Aktivitäten auf die Sicherheit und die Privatsphäre
auswirken und dass diese Auswirkungen nicht einfach beseitigt werden können, indem
man die richtigen strukturellen Entscheidungen trifft, die richtige Software installiert oder
angemessene Richtlinien implementiert und durchsetzt. Die Preisgabe von Daten kann
schlichtweg nicht vollständig unterdrückt werden, und unsere einzige Hoffnung besteht
darin, dass wir über genug Informationen und Erkenntnisse zu potenziellen
Angriffsszenarien oder Datenlecks verfügen, um die schliminsten davon zu lindem, soweit dies in einer
bestimmten Anwendung möglich ist.
Dieser dritte Teil des Buches behandelte in erster Linie WAN-Technologien und die
Bedrohungen, die dort lauem. Obwohl dies der längste Teil ist und er erst jetzt zum Ende
kommt, ist er weit davon entfernt, einen vollständigen Abriss aller Probleme darzustellen,
die in einem offenen Netzwerk auftreten können. Es wäre eigentlich sogar ziemlich
schwierig (und auch weitgehend sinnlos), alle Varianten eines Problems zu erläutern,
weswegen ich mich entschieden habe, nur die komplexesten, bedrohlichsten oder
faszinierendsten Aspekte der Kornmunikation zwischen Hosts zu behandeln. Ich habe mich, statt
nur Konzepte und Angnffsvektoren aufzuzählen, die lediglich alte Gnmdgedanken neu
veipacken und keine neuen Aspekte beitragen, darauf konzentriert, Angriffsszenarien in
249
15 Das Opfer als Nutznießer
verschiedenen Protokollschichten und auf unterschiedlichen Abstraktionsniveaus zu
beschreiben. Ich hoffe, dass die bislang vermittelten Informationen Ihnen dabei helfen und
Sie dazu ermutigen, weitere Inkarnationen dieser Probleme in anderen Bereichen der
Netzwerk- und Rechentechnik - und vielleicht sogar darüber hinaus - zu suchen.
Im nächsten Teil des Buches erfolgt eine erhebliche Paradigmenverschiebung, denn dort
werden wir erforschen, wie es uns die sorgfältige Beobachtung des Netzwerks als Ganzes
(statt einzelner Systeme) ermöglicht, uns zu verteidigen oder andere anzugreifen. Bevor
wir dieses jedoch tun, wollen wir einen Blick auf ein paar andere Möglichkeiten in einem
der ungewöhnlichsten Bereiche der Netzüberwachung werfen: passive Spionageabwehr,
d. h. die Kunst, rnehr über den Angreifer oder seine Ziele zu erfahren, indem man seine
Handlungen analysiert. Die auf diese Weise gesammelten Daten können uns eine enorme
Anzahl von Anhaltspunkten vermitteln, die das Erkennen der Absichten eines Angreifers,
der verwendeten Tools oder sogar des Angreifers selbst ermöglichen. Ein Profil des
Angreifers zu erstellen, seine Gedanken zu lesen und vielleicht sogar ein Täuschungsmanöver
auszuführen, ist oft bereits an und für sich ein spannendes Erlebnis.
15.1 Angriffsmetriken definieren
Erwartungsgemäß können Sie eine Menge Informationen zu einem rabiaten Angreifer
gewinnen, indem Sie ledighch einige der bereits beschriebenen gängigen TCP/EP-Metriken
auf den beobachteten Datenverkehr anwenden, z. B. passives Betriebssystern-Fingerprin-
ting. Sie können beispielsweise das Tool identifizieren, mit dem ein Port-Scan
durchgeführt wurde.
Auf ähnliche Weise können wir auch das Prinzip der Verhaltensanalyse verwenden, um
Eigenschaften des Angreifers zu erschließen - z. B. durch Beobachtung von Merkmalen
wie den Abständen zwischen Anfragen oder der Reihenfolge dieser Anfragen (konkret also
beispielsweise durch Beantwortung der Frage, wie schnell und in welcher Reihenfolge die
Ports gescannt wurden). Mithilfe der Verhaltensanalyse können wir mit einigem Erfolg
Programme aufspüren oder bei manuell durchgeführten Einbruchs- oder unzulässigen
Beurteilungsversuchen die spezifischen Merkmale eines Angreifers erkennen (beispielsweise,
wie viel Ahnung er von Computern hat).
Eine besonders interessante Methode zur Erschließung des Tools, mit dem der Angreifer
unser Netzwerk scannt, ist die praktische Anwendung einer in Kapitel 9 beschriebenen
Technik- dem Fingerprinting der Port-Abfolge - auf eine völlig neue Aufgabe. Sie basiert
auf der Beobachtung, dass eine große Anzahl heutzutage verwendeter Scanner Netzwerke
und Systeme entweder sequenziell - beginnend beim niedrigsten Port bzw. der niedrigsten
Adresse - scannt oder aber in zufälliger Reihenfolge auf Ressourcen zugreift. Der
letztgenannte Ansatz wird häufiger verwendet und gilt als vorteilhafter, weil hier ein
Lastausgleich stattfinden kann und die Erkennung des Scans zudem etwas erschwert wird. In einer
überraschenden Wendung aber kann der Einsatz der Zufälligkeit sich auch gegen den
Angreifer selbst richten- auf eine durchaus absonderliche Weise.
250
15.1 Angriffsmetriken definieren
Das Problern entsteht, weil die Programmierer von Tools zum Scannen von Netzwerken
untemehmenskritische Anwendungen mit hohen Sicherheitsanfordemngen nicht
berücksichtigen. Die häufigste (und einfachste) Möglichkeit, einen PRNG in Prograrnrne zu
implementieren, die keine kryptografisch sichere Ausgabe erfordern, besteht im Aufruf der
entsprechenden Funktionen des Betriebssystems oder der verwendeten
Programmiersprache. Der ISO-Standard1 für die verbreitetste Programmiersprache der Welt - C - sieht vor,
dass zur Implementierung eines PRNG in einer C-Standardbibliothek ein einfacher linearer
Kongnienzalgorithmus zum Einsatz kommt (vgl. Kapitel 1). Zur Erstellung und
Verwendung des Generators beschreibt der Standard folgenden Ansatz:
1. Der Generator sollte einen 32-Bit-Ausgangswert (S0) erhalten, indem eine Standardbib-
liotheksfunktion srand() aufgerufen wird. Erhält der Generator keinen solchen
Ausgangswert (Keim), dann beginnt er mit einem festen Standardwert, d. h. in allen Fällen
werden identische Ergebnisfolgen erzeugt.
2. Bei jedem Aufruf von rand() - der Hauptfunktion, die wiederholt aufgerufen wird,
um fortlaufend Pseudozufallszahlen zur Verwendung in Benutzeranwendungen zu
erzeugen - wird der Keim S wie folgt neu berechnet: St+1 = St ■ 1.103.515.245 + 12.345.
Das Ergebnis wird auf 32 Bits gekürzt (Modulo 4.294.967.296)
3. Der Rückgabewert für jeden rand () -Aufruf ist das höherwertige Wort von St+1 mod
32.768. In einer 32-Bit-Variante - einem der auf modernen Computern häufiger
eingesetzten Algorithmen - wird die in diesem und im vorherigen Schritt beschriebene
Vorgehensweise mehrfach wiederholt, um aufeinanderfolgende Bitbereiche des
Ergebniswertes zu berechnen.
Alle linearen Kongruenzgeneratoren einschließlich des hier beschriebenen sind für die
allgemeine Kryptoanalysemethodologie anfällig, die in den Neunziger jähren von Ff. Kraw-
czyk vorgestellt wurde (siehe Kapitel 1). Basierend auf der Beobachtung ein paar
fortlaufender (oder anders sortierter) Ausgaben ist es möglich, den internen Zustand des
Generators zu rekonstruieren und auf diese Weise alle vorherigen und zukünftigen Ausgaben
vorherzusagen.
Natürhch ist die unmittelbare Folge dieser Möglichkeit - dass nämlich das Opfer basierend
auf vorherigen Angriffsversuchen bestimmen kann, in welcher Reihenfolge ein Angreifer
versuchen wird, andere Ressourcen auf dem Computer oder im Netzwerk ins Visier zu
nehmen - für sich genommen noch nicht besonders spannend oder wertvoll. Allerdings hat
diese Fähigkeit im Kontext von Netzwerksondierungsversuchen zwei wichtige
Auswirkungen:
■ Wh können unter Umständen S0 bestimmen. Wenn wir wissen oder abschätzen können,
wann der Generator seine Arbeit aufgenommen hat (oder alternativ, welche
allgemeinen Eigenschaften der Ausgangswert aufweisen sollte), dann ist es möglich, den Wert
zu rekonstruieren, mit dem der Generator initialisiert wurde. Da S0 der einzige
Eingabewert des Algorithmus ist, müssen auf identische Keimwerte auch identische Verhal-
1 IS099
15 Das Opfer als Nutznießer
tensweisen folgen, d. h. wir können den Keim ermitteln, indem wir die PRNG-Ausgabe
beobachten.
■ Wir können unter Umständen t rnkrernente bestimmen. Wenn wir den Generatorstatus
erst einmal kennen, ist es möglich, zu ermitteln, wie viele Zufallswerte vom Scanner
durch den Aufruf von rand() zwischen zwei Aufrufen angefordert wurden, mit denen
der Scanner Werte (Poitnummem und Hostadressen) für Pakete verlangt hat, die der
Beobachter abgefangen hat.
Die Bedeutung der ersten Folge dieses Ablaufs - die Fähigkeit, den Initialisierungswert
des Generators zu rekonstruieren - ist vielleicht nicht auf den ersten Blick ersichtlich. Aber
wir müssen noch ein anderes Puzzlestück berücksichtigen: Eine zur Initialisierung eines
Zufallszahlengenerators häufig verwendete Möglichkeit besteht in der Verwendung eines
handlichen 32-Bit-Wertes, der sich oft genug ändert, um zu gewählleisten, dass der PRNG
sich nicht mehrfach identisch verhält. Für diesen Zweck wird häufig der Systernzeitzähler
in Verbindung mit einer anderen kleinen Zahl wie etwa der aktuellen PID (Process ID,
Prozesskennung) eingesetzt, um die Wahrscheinlichkeit zu verringern, dass zwei
Programme, die innerhalb eines sehr kurzen Zeitraums ausgeführt werden, ähnliche
Ergebnisse erzeugen.
Wenn wir dieses Wissen auf den berechneten Wert S0 anwenden, dann kann das
Sondierungsopfer die Systemzeit des Angreifers erkennen. (Ob dies die GMT- oder die lokale
Zeit ist, hängt von den Einstellungen des Betriebssystems und dem Scanneltyp ab.) Und
wenn wir die lokale Zeit des Systems kennen, können wir darauf auf einfachste Weise auf
Herkunft und Identität des Angreifers schließen. Sollte der Angreifer versuchen, uns durch
das Fälschen von Paketen aus verschiedenen Quellen zu verwirren, dann können wir
diejenigen erkannten Quellen ausschließen, bei denen S0 auf eine Zeitzone hinweist, die nicht
zur geografischen Region passt, der die Quelladresse zuzuordnen ist. Vergleichen wir
beispielsweise die geschätzte Systemzeit des Angreifers mit der GMT-Zeit und erkennen,
dass seine Zeitzone um fünf Stunden hinter GMT zurückliegt, dann können wir daraus
schließen, dass der Angreifer mit hoher Wahrscheinlichkeit an der amerikanischen
Ostküste sitzt und nicht in China. Vergleichen wird nun unsere erschlossene Zeitzone mit den
Aufzeichnungen verschiedener IP-Adressblöcke, dann können wir guten Gewissens
mutmaßen, dass die wahre Identität sich eher hinter Paketen eines Internetproviders aus
Boston verbirgt als hinter denen eines Pekinger Providers.
Außerdem können wir den Angreifer, wenn wir seine lokale Zeit kennen, aufspüren, indem
wir den Unterschied zwischen seiner Systeniuhrzeit und der Echtzeit (und die langfristigen
Abweichungen) enmtteln. Da Cornputeruhren in der Regel nicht besonders genau aibeiten
und, sofern sie nicht regehnäßig zu einer externen Quelle synchronisiert werden, relativ
stark - mitunter sogar um mehrere Minuten täglich - abweichen, kann dies ein nützlicher
Ansatz sein, Angriffe abzugleichen, die von derselben Person ausgefühlt wurden.
Unterschiedliche Computer gehen mit hoher Wahrscheinlichkeit systematisch um einen
bestimmten Zeitbetrag vor oder nach, der sich zudem in charakteristischer Weise ändert.
Schließlich kann, wenn die PID neben der Systemzeit als Teil des Mtialisierangskeirns
verwendet wird und bekannt ist, dass die Systemzeit des Angreifers sich in einem be-
252
15.1 Angriffsmetriken definieren
stimmten Bereich bewegt, rnithilfe der PID die Systernlaufzeit oder die Anzahl der Tasks,
die zwischen zwei Scans ausgefühlt werden, näherungsweise bestimmt werden. Da jeder
neue Prozess auf einem Computer einen höheren PID-Wert zugewiesen erhält, ist diese
Abhängigkeit relativ offensichtlich.2
Durch Rekonstruktion des PRNG-Status können wir auch ermitteln, wie viele
Zufallszahlen zwischen der Erzeugung zweier Pakete, die der Empfänger erhalten hat, erzeugt
winden. Wird nur ein System gescannt, dann sollten möglichst keine Lücken, maximal aber
nur marginale Unterschiede aufgnmd von Netzwerkproblemen vorhanden sein. Werden
jedoch mehrere Systeme gescannt, dann lassen sich diese Lücken, die von Paketen, die an
verschiedene Ziele gesendet werden, erzeugt werden, ganz einfach erkennen. Durch diese
Erkennung können wir ermitteln, wie viele Systeme gleichzeitig überprüft werden.
Außerdem ist es, wenn die Scannersoftware zu Täuschungszwecken gefälschte Pakete
erzeugt, die von anderen, zufälligen Hosts zu kommen scheinen, möglich, gefälschte
Adressen - also solche, die mithilfe des PRNG erstellt wurden - auszuschließen (und so die
PRNG-Ausgabe möglicherweise sogar zu verifizieren). Außerdem kann man feststellen,
welche Adresse nicht zur erkannten PRNG-Ausgabe passt; dies muss dann die richtige
Adresse sein, die letztendlich auf den wirklichen Verursacher des Angriffs verweist. Nehmen
wir beispielsweise einmal an, unsere rekonstruierten PRNG-Daten stammten von den
folgenden Adressen:
■ 198.187.190.55 (Dezimaldaistellung: 3334192695)
■ 195.117.3.59 (Dezimaldaistellung: 3279225659)
■ 207.46.245.214 (Dezimaldaistellung: 3475961302)
Daraus können wir nun bestimmen, dass sowohl 3.334.192.695 als auch 3.475.961.302 zu
den ersten Ausgabewerten eines Generators mit dem Keim S0 gehören, während
3.279.225.659 zu keiner der Ausgaben eines rekonstruierten PRNG passt und insofern
wahrscheinlich eine echte Adresse ist.
Mithilfe all dieser Informationen können wir die Absichten eines Angreifers und die von
ihm verwendete Software ermitteln. Mehr noch, wir können sogar das System aufspüren,
auf dem er arbeitet, es mit anderen Daten in einen Zusammenhang bringen, um die wahre
Identität und die geografische Region zu ermitteln, in der er sich befindet, und manchmal
sogar bestimmen, wie er seinen Computer verwendet, während er Scan abläuft.
■ Hinweis
Infolge der beschriebenen Probleme mit der Offenbarung von Laufzeit und Scanverlauf
versucht NMAP mittlerweile, sichere Betriebssystemfunktionen zur Zufallszahlerzeugung (wie
etwa das in Kapitel 1 erwähnte /dev/random) zu verwenden, statt sich auf die Tools der C-
Standardbibliotheken zu verlassen. Allerdings steht diese Methode auf vielen
Betriebssystemen (einschließlich Windows) nicht zur Verfügung. Bei anderen Scannern wurden keine
derartigen Schritte unternommen, um den Angreifer zu schützen
Allerdings bieten einige Betriebssysteme optional die Erzeugung zufälliger PID-Werte, um bestimmte
andere lokale Angriffe schwieliger zu gestalten
253
15 Das Opfer als Nutznießer
15.2 Den Beobachter beobachten
In den letzten zehn Jahren ist das Internet zu einem gigantischen Schlachtfeld geworden.
Computer, die neu angeschlossen werden, werden praktisch sofort von automatisierten
Angriffs-Probes, Würmern und anderen Datentypen überflutet, die sicherheitstechnisch
problematisch sind. Die traditionelle und derzeit ziemlich angesagte Tendenz zur
Erkennung und Verhinderung von Einbrüchen zielt darauf ab, Angriffe zu erkennen und zu
stoppen, indem der Administrator gewarnt wird, sobald von speziell gefeitigten Tools zur
Datenverkehrsanalyse angriffsvorbereitende Sondierungen erkannt werden. In heterogenen
Umgebungen oder solchen, die einfach nur komplex genug sind, erzeugen solche
Programme allerdings rnehr Fehlalarme, als man verarbeiten kann.
In manchen Fällen hingegen stellt die Chance, Angriffe und die von ihnen hervorgerufenen
Reaktionen beobachten zu können, für den Administrator eine fantastische Möglichkeit
dar, Wissenswertes zu Netzwerkproblemen und Angriffen zu erfahren (auch wenn diese
Vorfälle für sich genommen normalerweise nicht der Rede wert sind.) Zum Einen sind in
manchen Netzwerken aktive Erkennung und Daten-Scans zur Durchsetzung von Richtli-
nienkonfonnität und Systemkonfiguration schwierig in Angriff zu nehmen oder in der
Dui-chführung zu aufwändig - sei es aufgrund von Richtlinienbeschiänkungen, langen
Reaktionszeiten, zu kurzen Wartungsfenstem im Netzwerkbetrieb oder Ahnlichem. In einer
solchen Umgebung kann die Möglichkeit, einen Blick auf die Schraken zu erhaschen oder
sie zu ermitteln, einen unschätzbaren Ersatz für die lokal dui-chgeführte aktive Reconnais-
sance darstellen.
Zum Zweiten ist die regelmäßig durchgeführte aktive Erkennung unter Umständen nicht
geeignet, schnell genug auf bestimmte Bedrohungen zu reagieren. Aufgrund dessen kann
die Aussicht, dadurch, dass man einfach die Ergebnisse beobachtet, die andere erhalten, zu
erfahren, wenn irgendetwas daneben geht, ziemlich weitvoll sein. Natürlich ist dies ein
zweischneidiges Schwert: Ein Hacker, der ein Netzwerk angegriffen hat oder dies
beabsichtigt, aber nicht auffallen will und seine Schritte im Voraus plant, kann seinerseits
Daten, die durch andere Erkennungsversuche erzeugt wurden, beobachten und so eigene
Erkenntnisse über ein bestimmtes System sammeln.
Die Aufgabe, Erkenntnisse zu stibitzen, die ein Angreifer gewonnen hat, erscheint nur in
der Theorie einfach: Die Herausforderung, Ergebnisse abzugleichen und zu verarbeiten, ist
alles andere als simpel - insbesondere, wenn man umfangreiche Umgebungen analysiert
oder die Erkenntnisse auf separaten Angriffsversuchen an verschiedenen Standorten
basieren. Am Horizont tauchen aber allmählich Tools auf, die das Kartographieren von
Netzwerken und Systemen mithilfe des „passiven Scannings" ermöglichen sollen. DISCO von
Preston Wood ist ein herausragendes Beispiel.3
DISCO ist erhältlich unter http://www.altmode.com/disco.
254
15.3 Denkanstöße
15.3 Denkanstöße
Ich finde es merkwürdig, dass die in diesem Kapitel beschriebenen Techniken nur- sehr'
selten Gegenstand umfassender Forschungen, veröffenthchter Untersuchungen oder rasch
verfügbarer Tools sind. Angesichts des Angriffserkennungstrends, den die
Honigtopfuntersuchungen von Lance Spitzner losgetreten hat und der von Produkten wie Intrusion-
Detection-Systemen noch angeheizt wurde, sollte man eigentlich erwarten, nicht besonders
viele Versuche zur Erkennung von Angriffen zu sehen (die gewöhnlich ohnehin nicht
besonders spannend sind und normalerweise gut dokumentierte Vektoren und Mängel
ausnutzen), sondern mehr' Anstrengungen, Herkunft und Absicht einer Attacke zu bestimmen
und Ereignisse abzugleichen, die für- sich genommen bedeutungslos sind, aber in
Kombination auf ein Problem hinweisen können.
Ich habe nur ein wenig Licht auf die Spitze des Eisbergs werfen können; selbstverständlich
ist dies einer der Bereiche sein, in denen Forschungen und Beiträge wirklich spannend
werden könnten.
Und jetzt zu etwas völlig anderem ...
255
Das große Ganze
(Von der Verwendung der Aussage „Das Netzwerk ist der
Computer" hat uns unsere Rechtsabteilung an dieser Stelle
abgeraten.)
16 Parasitic Computing, oder:
Kleinvieh macht auch Mist
Sechzehntes Kapitel. In dem sich die alte Wahrheit einmal mehr bestätigt,
dass man, statt einen Job selbst zu machen, besser seine Lakaien
vorschickt
Ich hoffe, Ihnen hat die Fahrt bis jetzt Spaß gemacht. Wir haben ein paar illustre Probleme
in Zusammenhang mit dem Weg von Daten und ihrem Schutz behandelt - ausgehend von
der Eingabe über die Tastatur bis hin zum endgültigen Zielort, der Hunderte oder Tausende
von Kilometern entfernt sein kann. Aber es ist noch viel zu früh für uns, eine Party zu
schmeißen: Es fehlt noch etwas in unserem Bild. Etwas, das viel größer ist als alles, was
wir bislang kennen gelernt haben.
Die dunkle Materie.
Bislang ist das Roblem unserer Geschichte ganz einfach: Kommunikation findet nicht im
luftleeren Raum statt. Zwar beschränkt sich der Vorgang des Datenaustauschs in der Regel
auf zwei Systeme und etwa ein Dutzend Zwischensysteme, aber der große Kontext aller
Ereignisse darf einfach nicht ignoriert werden: Die Eigenschaften der Umgebung können
die Wirklichkeit eines kleinen Plausches zwischen zwei Endpunkten gehörig beeinflussen.
Wir dürfen weder die Bedeutung der Systeme, die nicht direkt in die Kommunikation
eingebunden sind, noch das Gewicht all der kleinen, scheinbar isolierten und trivialen
Ereignisse vernachlässigen, die den Daten auf ihrem Weg zustoßen können. Sich nur auf das zu
konzentrieren, was für eine bestimmte Anwendung oder einen speziellen Fall relevant zu
sein scheint, kann fatal sein; ich hoffe, dies in den bisherigen Kapiteln bereits unterstlichen
zu haben.
Statt also blind in diese Falle zu tappen, habe ich beschlossen, mich dem großen System
der Dinge in all seiner Herrlichkeit bereitwillig zu stellen. Also wird sich in diesem vierten
und letzten Teil des Buches alles um die Sicherheit der Netzwerktechnik als Ganzes
drehen: Wir werden das Internet nicht mehr als Ansammlung von Systemen, die bestimmte
259
16 Parasitic Computing, oder: Kleinvieh macht auch Mist
Aufgaben erledigen, sondern als Ökosystem beteachten. Dabei zollen wir der scheinbar
trägen Masse Tribut, die die Welt zusammenhält.
Dieser Teil des Buches beginnt mit der Analyse eines Konzepts, welches für diesen
Übergang wohl am geeignetsten ist. Für viele Cornputerfreaks hat dieses Konzept - das so
genannte Parasitic Computing (parasitäre Datenverarbeitung) - unsere Sicht des Internets
entscheidend revolutioniert.
16.1 Knabbern an der CPU
Um ein Haar wäre eine kurze Forschungsarbeit, die von Albert-Laszlo Barabasz, Vincent
W. Freeh, Ffawoong Jeong und Jay B. Brochman im Jahr 2001 in Form von Briefen an das
Magazin Nature veröffentlicht wurde1, unbeachtet gebheben. Auf den ersten Bhck schien
der Beitrag auch nicht besonders viel Beachtung verdient zu haben, denn er beinhaltete
eine scheinbar geradezu lachhafte Idee: Die Autoren waren der Ansicht, dass sich im
Rahmen etablierter Netzwerkprotokolle wie TCP/IP Daten erstellen ließen, die (als
Datennachrichten) einem entfernten Computer eine einfache Rechenaufgabe - also ein zu lösendes
Problem - stellten. Das Remote-System würde dieses Problem unbewusst lösen, während
es die Nachricht analysierte und eine Antwort vorbereitete. Aber warum sollte jemand
seine Zeit damit verschwenden, einer empfindungslosen Maschine Rätsel zu stellen? Was
könnte man damit gewinnen? Wäre es nicht ähnlich amüsant, dieses Rätsel selbst zu lösen?
Natürlich ist die Antwort recht interessant.
Zunächst einmal ist das Lösen von Rätseln mit einem Computer eine Angelegenheit für
sich: Ein Großteil der modernen Kryptografie basiert auf der relativen Schwierigkeit, eine
Anzahl so genannter nichtpolynomischer Probleme (NP-Probleme)2 zu lösen. NP-
vollständige Probleme haben die schlechte Angewohnheit, die Party jedes Codeknackers
zum absolut ungünstigsten Zeitpunkt zu sprengen. Die Möglichkeit, sie effizient zu lösen -
wahlweise mithilfe enormer Rechenleistung, cleverer Algorithmen oder beidem - würde
einen glücklichen Erfinder einen Schritt näher an die Weltherrschaft bringen. Der Anreiz
ist also vorhanden, aber wie könnte man das bewerkstelligen?
1 BaraOl
In der Kornplexitätstheorie lassen sich polynomische Probleme mit einer Turing-Maschine in einem
Zeitraum lösen, der polynomisch proportional zur Eingabelänge (Anzahl oder Größe von Variablen,
für die eine Antwort gefunden werden muss) ist Das bedeutet, dass die Zeit, die zur Lösung eines
polynomischen Problems erforderlich ist, direkt der Eingabelänge potenziert zu einem konstanten
Exponenten entspricht, der auch 0 sein kann (in diesem Fall hängt die Zeit keineswegs von der
Eingabelänge ab, wie es etwa bei der Paritätsprüfung der Fall ist). Für nichtpolynomische Probleme gibt es keine
bekannten derartigen Lösungen, weswegen ihre Lösung erheblich mehr Zeit erfordern kann, wenn die
Eingabelänge sich erhöht (was wiederum beispielsweise eine exponentielle Abhängigkeit anzeigt). Für
eine Teilmenge der NP-Probleme — die so genannten NP-vollständigen Probleme — gibt es
nachweislich keine Lösungen mit polynomischer Zeit NP-Probleme gelten allgemein als „schwierig" bei
nichttrivialen Eingaben, wohingegen P-Probleme weniger aufwändig zu lösen sind
260
16.1 Knabbern an der CPU
Die in der genannten Forschungsarbeit vorgestellte Methode ist relativ neuartig. Sie stellt
zunächst fest, dass sich viele NP-Probleme in der Mathematik leicht in Forrn boolescher
Erfüllbarkeitsgleichungen (SAT-Gleichungen, vom Engl. Satisfiability) darstellen lassen.
SAT-Gleichungen stellen diese Probleme als boolesche Logikoperationen dar und
konstruieren im Endeffekt eine Folge von Parametern und Variablen (also eine boolesche
Formel). Ein klassisches Beispiel einer SAT-Gleichung sieht so aus:
P = (x2 XOR x2) AND (~x2 AND x3)
In dieser Formel ist P die Formel (also das Problem) selbst, und Xj bis x3 sind binäre
Eingaben oder Parameter.
Zwar gibt es für die Werte von.rj^ und x3 23 mögliche Kombinationen, aber nur bei einer
dieser Kombinationen wird P wahr: x2= 1, x2 = 0, x3 = 1. Aus diesem Grund sprechen wir
davon, dass nur dieses Tripel eine Lösung von P ist. Das Suchen von Lösungen für SAT-
Gleichungen lässt sich auf die Bestimmung einer Menge von Werten für alle Variablen in
der Gleichung reduzieren, für die die gesamte Formel, die diese Variablen enthält, den
logischen Wert Wahr hat. Zwar sind einfache Erfüllbarkeitsprobleme wie das oben gezeigte
auch ohne Verwendung anderer als des Trial-and-Error-Verfahrens ohne Schwierigkeiten
zu lösen, aber komplexere Fälle mit mehreren Variablen sind tatsächlich NP-vollständig;
insofern lassen sich andere NP-Probleme auf ErfüllbarkeitsprobleHie in polynomischer
(sprich: vernünftiger) Zeit reduzieren.
Und hier hegt das Problem. Wir können ein schwieriges NP-Problerne in Form einer SAT-
Gleichung formulieren, aber davon haben wir nicht viel Wenn es um komplexe
Gleichungen geht, sind selbst die zum Zeitpunkt der Abfassung dieses Textes besten bekannten
Lösungsalgorithmen für SAT-Gleichungen nicht effektiver als eine Brute-Force-Suche, bei
der alle Möglichkeiten ausprobiert werden und der Wert der Formel für jede Möglichkeit
ausgewertet wird. Das bedeutet, dass, wenn wir ein SAT-Problem lösen müssen und
genügend Rechenleistung vorhanden ist, um das Angehen dieses Problems auch nur
ansatzweise in Beteacht zu ziehen, eine Lösung mithilfe von Brate-Force-Methoden nicht einmal so
unvernünftig wäre und wir mit einem komplexeren Ansatz wohl auch nicht viel weiter
kämen. Wir könnten es jedenfalls ausprobieren - was haben wir schon zu verlieren?
Und hier folgt die Lösung, die die Verbindung zwischen SAT-Problemen und der TCP/EP-
basierten Netzwerktechnik birgt. Die gnmdlegende Beobachtung der Forscher ist ziemlich
offensichtlich (zumindest für Leute mit einem Wissensstand wie dem typischen
Abonnenten von Nahire): Der Prüfsummenalgorithmus von TCP (oder IP), wie wir ihn in Kapitel 9
beschrieben haben, ist - obwohl prinzipiell für einen ganz anderen Zweck entwickelt als
zur Lösung von Gleichungen - nichts anderes als eine Anzahl boolescher Operationen, die
aufeinanderfolgend an Teilen der eingehenden Nachricht vorgenommen werden.
Schließlich lässt sich der Algorithmus auf unterster Ebene auf pure boolesche Logik reduzieren,
die an den Wörtern im übertragenen Paket vorgenommen wird. Sie schließen daraus, dass,
indem man spezielle Inhalte im Paket - der „Eingabe" - ablegt, das entfernte System dazu
bringen kann, eine Reihe von Rechenoperationen durchzuführen und ihre Richtigkeit zu
übeipnifen: die Übereinstimmung mit der Priifsuimne, wie sie im TCP- oder IP-Header
angegeben ist.
261
16 Parasitic Computing, oder: Kleinvieh macht auch Mist
Zwar ist die Operation, die vom Remote-System während der Prüfsummenverifizierung
durchgeführt wird, jedes Mal identisch, aber ihre Funktionalität reicht aus, um als
universelles Logikgatter verwendet werden zu können (wir kennen diesen Mechanismus aus
Kapitel 2). Durch Verschachtelung der tatsächlichen geprüften Eingabe mit sorgfältig
gewählten „Steuerwörtem", die die bis dahin berechnete Teilprüfsumme invertieren oder
anderweitig abändern, ist es möglich, jede beliebige boolesche Operation auszuführen.
Dies wiederum hat zur Folge, dass die SAT-Logik ganz einfach mithilfe einer speziellen
Abfolgesteuemng und bestimmter „Eingabebits" in einem Paket rekonstruiert werden
kann, sobald die Daten einem Prüfsummenalgorithmus offenbart werden. Auf die eine
oder andere Weise gewählte Gleichungsvariablen werden mit festen Wörtern
verschachtelt, die benutzt werden, um den aktuellen Prüfsummenwert auf wundersame Weise so zu
verwandeln, dass das Ergebnis der nachfolgenden Operation ein bestimmter boolescher
Operator ist. Das Endergebnis - der Wert, auf den sich ein Paket aufsummiert - bezeichnet
das letztendliche Resultat: den logischen Wert einer Formel, die ausgewertet werden soll.
Aus diesem Grund wird der Erfüllbarkeitstest ganz zufällig genau dann vom entfernten
Empfänger ausgeführt, wenn der beim Empfang gerade versucht, die Prüfsumme zu
verifizieren. Hat die Prüfsurnme den Wert 1 (oder einen anderen Wert, der in unserem SAT-
Berechnungssystem einer SAT-Anweisung entspricht, die wahr ist), dann besteht sie den
Erfüllbarkeitstest für die Variablenwerte, die für dieses spezielle Paket gewählt wurden,
und die Daten werden an die höheren Schichten übergeben und dort weiterverarbeitet.
Schlägt die RiifsuHimenverifizierung fehl, dann war die Fonnel nicht erfüllt, und das
Paket wild stillschweigend verworfen. Mit anderen Worten: Wenn unsere Eingabebits eine
bestimmte Hypothese bezeichnen, dann hat der Empfänger sie entweder verifiziert, oder
sie hat sich als falsch erwiesen; je nach Ergebnis werden dann unterschiedliche
Folgeaktionen durchgeführt.
Femer kann eine Partei, die ein SAT-Problem schnell lösen will, eine Menge aller
möglichen Kombinationen von Variablenwerten (Eingaben) für eine gegebene Fonnel
vorbereiten, diese mit Daten verschachteln, welche eine Kombination der Eingabewerte mit
anderen Werten in wünschenswerter Weise bewirkt, diese Daten in TCP-Pakete verpacken und
dann (fast parallel) an eine große Zahl von Hosts in aller Welt versenden. Die Prüfsurnme
für ein Paket würde dann manuell auf einen Wert gesetzt, von dem wir wissen, dass die
„Hypothese" ihn erzeugen würde, wenn sie wahr wäre, statt ihn tatsächlich zu berechnen.
Nur Hosts, die Pakete mit Variablenwerten erhalten, für die die Fonnel den gewünschten
Wert zum Ergebnis hätte, würden auf die Daten antworten, während die übrigen Systeme
diese Daten aufgrund des Prüfsummenfehlers als beschädigt erachten würden. Auf diese
Weise kann der Absender die korrekte Lösung bestimmen, ohne umfangreiche
Berechnungen durchfuhren zu müssen, und dann einfach die Menge der Werte vermerken, die in
Paketen verwendet worden waren, welche an Hosts gesendet wurden, die auf eine Anfrage
antworteten.
Die Forschungsarbeit fährt dann fort und berichtet von einem erfolgreichen Versuch, ein
NP-Problem mithilfe echter Hosts überall auf der Welt zu lösen; insofern bietet sie nicht
262
16.2 Praktische Aspekte
nur den theoretischen Hintergrund, sondern auch den tatsächlichen Nachweis für die
Durchführbarkeit des Ansatzes.
Die Auswirkungen dieser Technik sind zwar subtil, doch auch wichtig: Es stellt sich
nämlich heraus, dass es möglich ist, Berechnungen effektiv auf ahnungslose und unwillentliche
Remote-Systeme im Netzwerk „auszulagern". Dies betrifft auch Operationen, die
erforderlich sind, um praxisbezogene Cornputerproblerne zu lösen. Dabei werden diese Systeme
nicht im eigentlich Sinne angegriffen, übernommen oder mit bösartiger Software infiziert;
auch eine anderweitige Beeinträchtigung rechtmäßiger Aufgaben findet nicht statt. Eine
Person kann auf diese Weise mit großer Effizienz eine bestimmte Berechnung auf eine
sehr große Anzahl von Systemen verteilen. Zwar werden bei diesem Vorgang nur winzige
und vemachlässigbare Bruchteile der Rechenleistung eines Systems verwendet, aber
nichtsdestoweniger können sich Millionen solcher Systeme, die ein Problem gemeinsam
bearbeiten, schnell zur Leistungsfähigkeit eines echten Supercomputers aufaddieren.
Steht die Weltherrschaft vor der Tür? Nun, so weit ist es noch nicht.
16.2 Praktische Aspekte
Zumindest noch nicht ganz. Der in der bereits erwähnten Arbeit beschriebene Ansatz ist
revolutionär und interessant, stellt aber nicht unbedingt eine besonders praktische
Möglichkeit dar, nach dem Motto „Stehle von den Reichen" einen Supercomputer zu bauen.
Das Ausmaß der Bandbreite, die für die Aufrechterhaltung einer ordentlichen
Rechengeschwindigkeit erforderlich ist, und die Anzahl der Berechnungen, die notwendig sind,
damit die anderen Systeme etwas zu lösen haben, sind ziemlich hoch. Infolgedessen ist dieser
Ansatz nicht effizient genug, um die Lösung komplexer mathematischer Probleme einem
globalen Supercluster willenloser Opfer zu übertragen.
Im bereits erwähnten Ansatz wird die Erfordernis exponentieller Rechenleistung gegen die
Anforderung exponentieller Bandbreite ausgetauscht. Das muss kein besonders
vorteilhafter Handel sein, zumal - wenn man die Beschränkungen bei den Paketgrößen in den
meisten Netzwerken berücksichtigt - nur relativ einfache Tests hinausgeschickt werden
können. (Sie alle ließen sich wahrscheinlich auch in der Zeit lösen, die benötigt wird, um die
entsprechenden Daten über Ethernet zu versenden.) Diese Methode beweist, dass ein
solcher Angriff möglich ist, und schildert ein wahrhaft universelles Szenario, um ihn zu
ermöglichen; wenn man aber speziellere Angriffsszenarien verwendet, könnte man zu
weitaus nützlicheren Ergebnissen gelangen.
Andere Möglichkeiten, Rechenleistung in für einzelne Systeme vemachlässigbarem
Ausmaß zu stehlen, sind wahrscheinlich interessanter und stellen Gelegenheiten dar, billig an
Rechenleistung in beeindruckendern Umfang zu gelangen. So lassen sich beispielsweise
bestimmte Alten von Clientprogrammen (z. B. Webbrowser) ganz einfach verwenden, um
sogar ziemlich komplexe Algorithmen auf recht einfache Weise auszuführen. Ein solches
263
16 Parasitic Computing, oder: Kleinvieh macht auch Mist
Beispiel - das in RFC36073 beschriebene Rechenscherna einer „chinesischen Lotterie" -
wird von einem kleinen Java-Applet verwendet, dessen Einsatz auf Webseiten
Webmastern auf der Website md5crk.com von Jean-Luc Cooke an Herz gelegt wird. Sobald dieses
Applet auf einer Site vorhanden ist, kann jeder Besucher der Site es auf seinem System
ausführen und so eine vernachlässigbare Menge CPU-Zyklen verleihen, die dann als
Beitrag zu einem Projekt dienen, dessen Sinn die Ennittlung von Kollisionen bei MD5-
Verkürzimgsfunktionen ist. (Kollisionen sind zwei verschiedene Meldungen, die dieselbe
Verkürzung erzeugen. Sie sind schwer fassbare und anekdotische, aber definitiv mögliche
Kreaturen4, die es uns gestatten, die Schwächen von Verkürzungsfunktionen besser zu
verstehen, und könnten empirisch nachweisen und veranschaulichen, dass MD5 zu schwach
ist, um gegen moderne Computer bestehen zu können.)
Java-Applets sind kleine, nicht plattformspezifische Programme, die von Webbrowsern
standardmäßig in speziellen, eingeschränkten Umgebungen - so genannten Sandboxen -
ausgeführt werden. Sie haben keinen Zugriff auf die lokalen Festplatten und können
(zumindest in der Theorie) keinen Schaden anrichten, auch wenn sie eingeschränkte
Netzwerkkonnektivität zur Durchfuhrung von Berechnungen und zum Hinzufügen
bestimmter optischer Elemente zu einer Webseite nutzen können. Ihr Zweck ist
normalerweise die Erweiterung der Websitefunktionalität beispielsweise mit interaktiven Spielen,
optischen Effekten usw. Jean-Luc verwendete diese Applets aber zu einem ganz anderen
Zweck: Er wollte potenzielle Kandidaten für Kollisionen suchen und hierzu die vereinte
Leistung Hunderter oder Tausender von Systemen in aller Welt gleichzeitig einzusetzen.
Das Prinzip, auf dem der Betrieb des Applets basierte, war simpel: Es wurde auf
Clientsystemen weltweit ausgeführt, sobald eine entsprechende Website besucht wurde. Einmal
gestartet, versuchte das Applet, MD5-Verkürzungen für verschiedene, willkürlich
ausgewählte Nachrichten zu erstellen. Dies tat es, bis eine Verkürzung gefunden wurde, die
einem bestimmten, behebig ausgewähltem und feststehenden Maskenmuster entsprach. Ein
solches Muster könnte etwa die Form ,jede Verkürzung, bei der die letzten vier Bytes null
sind" oder etwas Ahnliches haben. Das Muster wurde so gewählt, dass es nicht zu lang
dauerte, nach dem Trial-and-Error-Prinzip eine passende Verkürzung zu finden (damit der
Besucher die Website nicht verlassen und so die Ausführung vorzeitig beenden würde),
und dass auch nur ein kleiner Teil aller möglichen Verkürzungen der Regel entspräche.
Leec03
Während die Drucklegung dieses Buches vorbereitet wurde, berichtete ein Teain chinesischer Forscher
der Universität Shandong (bestehend aus den Mitgliedern Xiaoyun Wang, Dengguo Feng, Xuejia Lai
und Hongbo Yu) von einer Methode zur Ermittlung von Kollisionen der Algorithmen MD4, MD5,
HAVAL-128 und RTPEMD-128 und brachte auch entsprechende Beispiele. Dies ist eine der
wichtigsten Neuigkeiten in der modernen Kryptografie. Sie bestätigt, dass diese Funktionen für einige
sicherheitsspezifische Anwendungen ungeeignet sind. Zwar wurde das Projekt md5crk.com mittlerweile
eingestellt, aber sein Beitrag zur Erforschung des Parasitic Computing bleibt bedeutend.
264
16.3 Parasitic Storage - früher
Wurde eine passende Nachricht gefunden, dann meldete das Programm den Kandidaten
„nach Hause" zurück. Der Autor konnte die übermittelten Ergebnisse dann untersuchen.
Das Applet hatte bereits eine Anzahl von Kollisionskandidaten untersucht und aussortiert
und nur diejenigen gemeldet, die einer vordefinierten Bedingung entsprachen (diese waren
zumindest teilweise identisch). Aufgrund der wesentlich geringeren Abweichung bei
derartig ermittelten Angaben ist die Wahrscheinlichkeit einer Kollision in einer Gruppe von n
Einträgen beträchtlich höher als bei vollkommen wahllos ausgesuchten Daten. Analog
könnte man sagen: Die Wahrscheinlichkeit, in einem Obsthaufen, den wir innerhalb eines
Tages durchwühlen können, zwei optisch völlig ununterscheidbare Äpfel zu finden, ist
deutlich höher, wenn wir statt einer Ladung wahllos zusammengewürfelter Früchte
lediglich Äpfel annähernd gleicher Größe und Farbe bestellen.
Zwar funktionierte dieser geniale Ansatz, der bei md5crk.com erstmals eingesetzt wurde,
in der Grauzone der Cyberethik zunächst recht gut und veranschaulichte, wie effektiv und
auch unauffällig Parasitic Computing sein kann. Es hat den Anschein, dass die
Möglichkeit, Prozessorzyklen zu stehlen, die ursprünglich für „rechtmäßige" Zwecke vorgesehen
waren, durchaus, realistisch ist - und möglicherweise häufiger eingesetzt wird, als wir es
wollen. Und diese Möglichkeit wird uns noch eine Zeit lang erhalten bleiben.
Doch kann, so entgegnet uns der Skeptiker ungeduldig, Parasitic Computing denn mehr,
als nur ein paar wenige Prozessorzyklen abknabbern, um Verschlüsselungssysteme zu
knacken? Schließlich ist dies eine Aufgabe, an der die überwiegende Mehrheit von uns
nicht unbedingt interessiert ist.
16.3 Parasitic Storage - früher
Wenn Sie einen Schrei ausstoßen, bewegen sich Schallwellen durch die Luft, die nach und
nach ihre Energie verlieren und in alle Richtungen verstreut werden. Treffen sie jedoch bei
der Ausbreitung auf ein festes Hindernis, dann werden sie zurückgeworfen - und zwar,
wenn der Winkel stimmt, genau in Ihre Richtung. Hörbare Folge ist, dass Sie einen
Sekundenbrachteil nach Ihrem Schrei das Echo Ihrer Stimme hören.
Was aber passiert, wenn ein Prograrnrnierfreak oben auf einem Berg steht, volltönend
seinen Code rezitiert und seine Stimme dabei in Richtung eines Felsentals erhebt? Ich dachte
schon, Sie würden nie fragen. In diesem Fall wird er nicht um eine kluge Beobachtung
umhin kommen: Wenn er schnell rezitiert und das Rezitierte dann sofort vergisst (da er just
in diesem Moment mit anderen Angelegenheiten beschäftigt ist), kann es trotzdem
wiedergewinnen, indem er dem Echo lauscht, welches aus dem Tal zu ihm heraufdringt. Sieh mal
einer an: eine wirklich praktische Datenspeicherrnethode.
Klingt absurd? Vielleicht sind wir auch einfach nur zu jung. Frühe Cornputerspeichermo-
dule verwendeten eine ähnliche akustische Methode, die dem Prozessor die „Offlinespei-
chemng" von Daten und ihre spätere Wiederherstellung gestattete. Statt Luft zu
verwenden, über die sich die Wellen ein bisschen zu schnell ausbreiten, um vernünftige Speicher-
265
16 Parasitic Computing, oder: Kleinvieh macht auch Mist
kapazitäten ohne Konstruktion extrem großer Speichereinheiten erzielen zu können,
verwendete man eine Umgebung, in der sich Schallwellen wesentlich langsamer ausbreiten:
eine mit Quecksilber gefüllte Trommel. Das Rinzip war jedoch dasselbe (und verlieh dem
Begriff Speicherleck eine ganz interessante zusätzliche Dimension). Ein solches Gerät -
das Mercury Delay-Line Memory (quecksilberbasierter Laufzeitkettenspeicher) - wurde
beispielsweise im berühmten UNTVACI eingesetzt.5
Natürlich wurde dieser langsame, klobige, gefährliche und unpraktische Speichertyp
fallengelassen, sobald andere technische Lösungen ausgereift waren. Die Erfindung selbst
wies allerdings einen gewissen Charme auf und sollte nicht so leicht in Vergessenheit
geraten. Eine kurze Präsentation von Saqib A. Khan bei der DefCON-Konferenz in Las
Vegas im Jahr 2002 belebte sie neu und gab uns erste Hinweise auf die Frage, wie man die
Eigenschaften eines umfangreichen Netzwerks zur Bildung ähnlicher Formen von Kurz-
zeitspeichem rnithilfe des Internets als Medium ausnutzen kann. Diesmal allerdings klang
die Beschreibung eines akustischen Speichers in den Ohren all der Hacker und Freaks, die
der Präsentation beiwohnten, nicht lächerlich und primitiv, sondern eher unglaublich cool.
Der akustische Speicher feierte fröhliche Urständ.
Weil die RTT (Round-Trip Time, Rundreisezeit, also die Zeit, die vergeht, bis ein Paket
bei einem Remote-System eintrifft und der Absender die zugehörige Antwort erhält)
ungleich null ist, lässt sich eine bestimmte Datemnenge immer „in der Leitung" halten,
indem man Teile davon fortlaufend sendet, empfangt und auf Echos wartet. Saqib Khan
verwendete zur Erzielung dieses Effekts ICMP-Echoanforderangspakete (Ping-Pakete);
die meisten Systeme im Internet reagieren auf diese Pakete mit Echoantworten, die auch
die ursprünglich gesendeten Nutzdaten enthalten.
Dies war offenbar ein wirklich cooler Trick. Allerdings schien er auch weit davon entfernt,
für irgendeine Anwendung vernünftig einsetzbar zu sein, denn er erforderte die häufige
Neuübeitragung von Datenblöcken. Da die ICMP-Echoantwort praktisch unmittelbar nach
dem Empfang der Echoanfördemng zurückgeschickt wird, lässt sich nur eine gelinge
Menge Daten hinausschicken, bevor sie zurückgesendet wird und aus der Übertragung
wiederhergestellt werden muss. Infolgedessen ist die auf diese Weise „speicherbare"
Datemnenge nicht größer als die Menge, die der Benutzer innerhalb von maximal wenigen
Sekunden versenden kann (wobei ein Wert von weniger als einer Zehntelsekunde wohl
realistischer ist).
Doch: Auch Parasitic Storage lässt sich optimieren.
Man sollte vielleicht erwähnen, dass ein analoger Laufzeitkettenspeicher geringer Kapazität auch in
fiühen Implementierungen von SECAM-TV-Einpfangem verwendet wurde. Anders als bei den TV-
Systemen NTSC oder PAL verwendet das SECAM-Signal eine verringerte Farbauflösung: Die Chro-
minanzkomponenten für Rot und Blau werden nicht gleichzeitig, sondern abwechselnd übertragen. Die
andere Komponente muss dann der vorangehenden Kette entnommen werden, um bestimmen zu
können, wie ein bestimmter Bildpunkt aussehen muss. Aus diesem Grund musste eine
Speichermöglichkeit implementiert werden.
266
16.4 Parasitic Storage - heute
16.4 Parasitic Storage - heute
Im Jahr 2003 verfassten Wojciech Purczynski und ich gemeinsam einen Artikel namens
„Juggling with Packets: Parasitic Data Storage". Wir fühlten das Konzept des Parasitic
Storage ein wenig fort und untersuchten eine Reihe von Methoden, mit denen sich die
Speicherkapazität des Internets erheblich erweitem ließ, während gleichzeitig die zur
Aufrechterhaltung der Daten erforderliche Bandbreite verringert wurde. Bei unseren
Untersuchungen konzentrierten wir uns auf andere Möglichkeiten der Datenspeicherung auf
entfernten Systemen und kategoiisierten diese basierend auf wichtigen Eigenschaften des
Speicherrnediurns: Sichtbarkeit, Flüchtigkeit und Zuverlässigkeit. Außerdem fügten wir
eine detaillierte Beschreibung der hypothetischen Speicherkapazitäten für jede der
Methoden an.
Der Artikel war recht kurz und - wie ich glaube - erfrischend und humorvoll. Deswegen
möchte ich ihn an dieser Stelle aufnehmen.
Mit Paketen jonglieren: Parasitic Storage
"Euer Kerker ist auf einem Abhang gebaut. Und die Monster können nicht
gut mit Murmeln spielen!"
Wojciech Purczynski <cliph@isec.pl>
Michal Zalewski <lcamtuf@coredump.cx>
1) Jonglieren mit Orangen!
Die meisten Leute - darunter auch die Autoren dieses Artikels - haben
bereits einmal versucht, mit drei oder mehr Äpfeln, Orangen oder anderen
zerbrechlichen Objekten ballistischer Art zu jonglieren. Die Folgen sind
in der Regel recht peinlich, aber der beflissene Jonglieradept wird
früher oder später gelernt haben, wie es funktioniert, ohne umfassende
Kollateralschäden in Kauf nehmen zu müssen.
Ein besonders heller Jungjongleur wird vielleicht sogar bemerken, dass,
solange er eine einfache Vorgehensweise befolgt, immer mindestens eines
der Objekte in der Luft ist und er maximal zwei Objekte gleichzeitig
festhalten muss. Doch ab und an rutscht ihm doch immer wieder ein Apfel
durch die Finger, und dieses Verhalten lässt sich sogar bewusst steuern.
Nachdem er ein wenig Spaß beim Jonglieren gehabt hat, gelangt er unter
Umständen irgendwann zu der Einsicht, dass das Ganze doch ziemlich
langweilig ist, und wendet sich wieder seinem Computer zu. Wenn er dann seine
E-Mails abruft, wird der geübte Jongleur feststellen, dass eine normaler
Netzwerkdienst genau eine Aufgabe hat: Daten, die von einem entfernten
System stammen, anzunehmen und zu verarbeiten und alle Schritte
durchzuführen, die seiner Ansicht nach basierend auf der Interpretation der
Daten erforderlich sind. Viele solcher Dienste geben ihr Bestes in Sachen
Robustheit, Fehlertoleranz und der Bereitstellung nützlicher
Rückmeldungen zu den Transaktionen.
In vielen Fällen kann die schlichte Tatsache, dass ein Dienst versucht,
die Daten zu verarbeiten und protokollkonform zu beantworten, auf eine
Weise genutzt werden, von denen die Entwickler seinerzeit niemals zu
träumen gewagt hätten. Eines der spektakulärsten Beispiele, mit dem auch
unser junger Gaukler vertraut sein könnte, ist eine Untersuchung an der
Universität Notre Dame, die als "Parasitic Computing" bezeichnet wird und
in Briefform im Magazin "Nature" veröffentlicht wurde.
267
16 Parasitic Computing, oder: Kleinvieh macht auch Mist
Nichtsdestoweniger nimmt unser Held an, dass solche Versuche im
wirklichen Leben ziemlich impraktikabel sind. Die Kosten für Vorbereitung und
Übermittlung zu lösender Rätsel übersteigen den Nutzen bei weitem, denn
der Absender muss bereits Operationen vergleichbarer Rechenkomplexität
durchführen, um nur die Anfrage absetzen zu können. "Die Rechenleistung
eines solchen Geräts ist erbärmlich!", sagt er sich.
Ein echter Geschicklichkeitskünstler würde sich nun einer anderen Art
ausgelagerter Datenverarbeitung zuwenden - einer, die seinen Kenntnissen
wesentlich mehr entspricht. Warum etwa sollte man nicht einfach einen
verteilten, obstbasierten Datenspeicher implementieren? "Angenommen, ich
schriebe einen einzelnen Buchstaben auf jede Orange und fange dann an, zu
jonglieren. Dann könnte ich mehr Orangenbytes speichern, als es meine
physische Kapazität zuließe (vulgo-. mehr Orangen aufnehmen, als ich mit
meinen Händen halten könnte)!" Brillant. Aber würde das auch ohne Orangen
klappen?
2) Das Gleiche noch mal. Jetzt ohne Orangen
Dieser Artikel fußt auf der Beobachtung, dass es in der gesamten
Netzwerkkommunikation immer eine Latenz zwischen dem Versand von Daten und
dem Erhalt einer Antwort gibt. Diese Latenz ist stets ungleich null (und
häufig sogar beträchtlich) - eine Folge der physischen Beschränkungen des
Mediums und der Zeit, die die beteiligten Computersysteme benötigen, um
die Daten zu verarbeiten.
Wie eine Orange mit einer darauf geschriebenen Nachricht benötigt auch
ein Paket, in dem Daten gespeichert sind, eine gewisse Zeit, bevor es zum
Absender zurückkommt. Und für genau diese Zeit können wir diesen
Paketinhalt getrost vergessen, ohne dass er uns verloren ginge. Insofern hat das
Internet die Kapazität eines Kurzzeitspeichers-. Es ist möglich, ein
Datenelement hinauszuschicken - woraufhin es im Endeffekt gespeichert
ist -, bis wir es in Form einer Antwort zurückerhalten. Indem man eine
Methode zur zyklischen Übertragung von Datenblöcken an und ihrer
Inempfangnahme bei Remote-Hosts entwickelte, könnte man eine beliebige
Menge von Daten konstant "in der Leitung" halten und auf diese Weise ein
flüchtiges Medium hoher Kapazität erstellen.
Dieses Medium kann für speicheraufwändige Operationen wahlweise als
regulärer Speicher dienen oder für bestimmte Arten sensibler Daten verwendet
werden, die keine physischen Spuren auf Festplatten oder anderen
nichtflüchtigen Medien hinterlassen sollten.
Da es nicht als schlechte Programmierpraxis gilt, so viele relevante
Daten an den Absender zurückzuschicken, wie dieser an den Dienst gesendet
hat, und viele Dienste oder Stapel ein hohes Maß an Ausführlichkeit an
den Tag legen, sagt uns unsere Jongliererfahrung, dass es nicht nur
möglich, sondern auch durchaus machbar ist, einen solchen Speicher
einzurichten - und zwar auch über eine langsame Netzwerkanbindung. Anders als
herkömmliche Methoden des Parasitic Storage (wie dem Missbrauch von P2P-
Technologien, offenen FTP-Servern, binären Usenet-Postings usw.) kann
diese spezielle Methode eine Datenspur hinterlassen oder auch nicht; dies
hängt von der Art und Weise der Implementierung ab. Außerdem ist die
Belastung der einzelnen Systeme nicht spürbar. Aus diesem Grund ist die
Gefahr, dass eine solche Methode als Missbrauch bewertet oder überhaupt
entdeckt wird, wesentlich geringer als bei traditionellen Ansätzen.
Insofern ist auch die Möglichkeit, dass die Daten abgehört oder gezielt
gelöscht werden, wesentlich geringer.
3) Klasse-A-Datenspeicherung: Speicherpuffer
Klasse-A-Datenspeicher nutzen die Kapazität, die Laufzeiten innewohnt,
welche aufgrund der Übertragung oder Verarbeitung von Daten bei der
Kommunikation zwischen zwei Endpunkten über Netzwerke auftreten. Die in
ihnen abgelegten Daten bleiben im Speicher eines Remote-Gerätes gespeichert
und werden mit hoher Wahrscheinlichkeit nicht auf eine Festplatte
ausgelagert .
268
16.4 Parasitic Storage - heute
Beispiele für Klasse-A-Speicher sind eine Vielzahl von Konstruktionen,
die auf das Versenden einer Nachricht setzen, von der bekannt ist, dass
sie als Echo teilweise oder vollständig zurückgeschickt wird.
Hierzu gehören die folgenden Paketarten:
- SYN+ACK-Pakete, RST+ACK-Antworten auf SYN-Pakete und ähnliche
Rückmeldungen
- ICMP-Echoantworten
- DNS-Lookup-Antworten und -Cachedaten. Es ist möglich, ein paar Daten
in einer Lookup-Anfrage zu speichern, die dann mit einer NXDomain-
Antwort zurückgesendet wird, oder Daten in einem DNS-Cache abzulegen.
- Serverübergreifendes Message-Relaying in Chatnetzwerken. Das Relaying
von Textmeldungen über IRC-Server o. ä. kann eine beträchtliche
Latenz an den Tag legen.
- Fehler- oder Statusantworten von HTTP, FTP, Web-Proxy oder SMTP
Die wichtigsten Eigenschaften von Klasse-A-Speicher sind:
- niedrige Latenz (zwischen Millisekunden und einigen Minuten), was die
Nützlichkeit für Quasi-RÄM-Anwendungen erhöht
- niedrigere Kapazität je System (gewöhnlich im Kbyte-Bereich), weswegen
er für massive Speicheranforderungen weniger geeignet ist
- nur eine Gelegenheit zum Empfang oder wenige Neuübertragungen, wodurch
im Falle eines Netzwerkfehlers die Zuverlässigkeit beeinträchtigt wird
- geringere Wahrscheinlichkeit einer permanenten Aufzeichnung (die Daten
werden wohl nicht auf einem nichtflüchtigen Medium gespeichert oder
ausgelagert; dies verbessert den Datenschutz und AbStreitbarkeit)
Insbesondere bei der Verwendung von Protokollen höherer Ebenen treten
weitere Merkmale auf, die einige der Probleme in Verbindung mit der
geringen Kapazität und den kurzen Wiederherstellungsfenstern lösen könnten,
die verschiedenen Klasse-A-Speichern gemein sind. So ist es
beispielsweise möglich, eine Verbindung mit SMTP, FTP, HTTP oder irgendeinem anderen
textbasierten Dienst herzustellen und einen Befehl zu senden, von dem
bekannt ist, dass er zu einer Bestätigung oder Fehlermeldung führt, die
neben einem Teil der Ursprungsdaten zurückgemeldet werden. Allerdings
senden wir keine vollständige formatierte Nachricht, sondern lassen einige
erforderliche Zeichen ungesendet. In den meisten Fällen wird ein EOL-
Zeichen (Zeilenende) benötigt, um den Befehl abzuschließen. In diesem
Zustand sind unsere Daten bereits beim entfernten Dienst gespeichert, der
auf den Abschluss des Befehls oder eine Zeitüberschreitung der Verbindung
wartet. Um Zeitüberschreitungen auf der TCP- oder der Anwendungsebene zu
verhindern, müssen regelmäßig operationsfreie Pakete (no-op-Pakete)
gesendet werden. Das Zeichen \0 wird als Leerstring interpretiert, der bei
vielen Diensten keine Wirkung hervorruft, aber ausreicht, die Timer von
TCP und Dienst zurückzusetzen. Ein bekanntes Beispiel für eine Anwendung,
die hierfür anfällig ist, ist Microsoft Exchange.
Der Angreifer kann die Verbindung beliebig lange aufrechterhalten - am
anderen Ende der Leitung wird für den gesamten Zeitraum ein Datenelement
gespeichert. Um die Daten abzurufen, muss der Befehl nur mit dem
fehlenden Abschlusszeichen \r\n beendet werden. Die Antwort wird dann an den
Client gesendet.
Ein gutes Beispiel ist der SMTP-Befehl VRFY:
220 inet-imc-01.redmond.corp.microsoft.com Microsoft.com ESMTP Server
Thu, 2 Oct 2003 15:13:22 -0700
VRFY AAAA. . .
252 2.1.5 Cannot VRFY user, but will take message for
<AAAA...Omicrosoft.com>
269
16 Parasitic Computing, oder: Kleinvieh macht auch Mist
Es lassen sich auf diese Weise etwas mehr als 300 Bytes (einschließlich
nichtdruckbarer Zeichen) speichern - und praktisch sofort wieder abrufen.
Abhängig von der Serversoftware lassen sich mehr Daten speichern, wenn
die HTTP-Methode TRACE in Verbindung mit Daten verwendet wird, die in
beliebigen HTTP-Headern übergeben werden. Aufrechterhaltene Verbindungen
bieten uns beliebig viel Latenz, wodurch eine erhebliche
Speicherkapazität entsteht.
Diese Speicherungsform ist natürlich besser für datenschutzkritische
Anwendungen oder eine latenzarme Speicherung geringer bis mittlerer
Kapazität geeignet (direkte RAM-erweiternde Speicherung für Daten, die keine
sichtbaren Spuren hinterlassen sollen). Sie ist hingegen für kritische
Daten, die keinesfalls verloren gehen dürfen, äußerst ungeeignet, weil
genau dies bei einem Ausfall des Netzwerks passieren könnte.
4) Klasse-B-Datenspeicherung: Festplatten-Warteschlangen
Klasse-B-Datenspeicher verwenden "untätige" Datenwarteschlangen, die
Daten für längere Zeit speichern (wobei die Speicherung durchaus auf der
Festplatte erfolgen kann). MTA-Systeme beispielsweise können E-Mail-
Nachrichten bis zu sieben Tage lang speichern (konfigurationsabhängig
auch noch länger). Diese Funktionalität bietet uns eine lange Verzögerung
zwischen dem Versand der zu speichernden Daten auf dem Remote-Host und
ihrem Abruf. Da ein SMTP-Server die Weiterleitung von E-Mail an den
sendenden Client selbst in der Regel unterbindet, lassen sich
Mailrücksendungen verwenden, um die gespeicherten Daten erst nach längerer Zeit zu
empfangen.
Betrachten Sie etwa folgendes potenzielle Angriffsszenario-.
1. Der Benutzer erstellt eine Liste der SMTP-Server (und zwar möglichst
solcher, die nach menschlichem Ermessen außerhalb der Reichweite des
Feindes liegen).
2. Der Benutzer sperrt (mit "block/drop", nicht mit "reject") alle
eingehenden Verbindungen auf seinem Port 25.
3. Für jeden Server muss der Angreifer die Zeitüberschreitungen für die
Datenübermittlung und die IP-Adresse kontrollieren, mit der er eine
Rückverbindung herstellen will, solange er versucht, die Daten
zurückzuschicken. Dies kann mithilfe einer passenden Probe an eine
lokale Adresse auf dem Server (oder der Anforderung einer DNS-
Benachrichtigung für eine gültige Adresse) geschehen; danach überprüft
man, wie lange der Server eine Rückverbindung herzustellen versucht,
bevor er aufgibt. Der Server selbst muss kein offener
Weiterleitungsserver sein.
4. Nach der Kontrolle der Ziele beginnt der Angreifer mit dem Versand von
Daten. Die Versandgeschwindigkeit ist dabei so gewählt, dass der
Vorgang sich gleichmäßig über den Zeitraum einer Woche verteilt. Die
Daten sollten so unterteilt werden, dass jeder Server einen Datenblock
erhält. Jeder Block wird an einen separaten Server gesendet, um sofort
eine Rückantwort an den Absender zu erzeugen.
5. Der Vorgang der Datenpflege lässt sich auf die Annahme einer
eingehenden Verbindung und den Empfang der Rückantwort maximal eine
Woche nach dem ursprünglichen Versand reduzieren - just zu dem
Zeitpunkt, bevor der Eintrag aus der Warteschlange entfernt wird.
Dies wird gemacht, indem dem betreffenden Server gestattet wird, die
Firewall zu überwinden. Unmittelbar nach dem Empfang des Datenblocks
wird dieser wieder zurückgeleitet.
6. Um auf Datenelemente zugreifen zu können, überprüft der Angreifer,
welcher MTA den betreffenden Block enthält, und gestattet dieser IP
dann, eine Verbindung herzustellen und die Rückantwort auszuliefern.
Dabei sind drei Szenarien möglich:
270
16.4 Parasitic Storage - heute
- Wenn der entfernte MTA den Befehl ETRN unterstützt, dann kann die
Auslieferung sofort durchgeführt werden.
- Befand sich der entfernte MTA-Server innerhalb eines Drei-Minuten-
Zyklus beim Versuch, eine Verbindung zu einem lokalen System
herzustellen (was er immer wieder probiert, da seine SYN-Pakete
verworfen werden, statt mit RST+ACK abgewiesen zu werden), kann die
Verbindung innerhalb von Sekunden hergestellt werden.
- Andernfalls ist es erforderlich, je nach Warteschlangeneinstellungen
zwischen fünf Minuten und einer Stunde zu warten.
Dieses Schema lässt sich durch Verwendung von DNS-Namen anstelle von IP-
Adressen für Benutzer erweitern, die mit dynamischen IP-Adressen
arbeiten, oder kann zusätzlichen Schutz bieten (wenn es etwa notwendig ist,
die Kette sofort zu durchtrennen).
Die wichtigsten Eigenschaften von Klasse-B-Speicher sind:
- hohe Kapazität (mehrere Mbyte) pro System, was ihn zur perfekten Lösung
für die Speicherung großer Dateien usw. macht
- höhere Zugriffslatenz (Minuten bis Stunden), weswegen eher eine
Ähnlichkeit mit einem Bandgerät als mit RAM vorliegt (ausgenommen sind
SMTP-Hosts, die den Befehl ETRN akzeptieren, mit dem eine sofortige
Neuauslieferung versucht wird)
- sehr lange Lebensdauer, zunehmende Kapazität pro Benutzer und mehr
Zuverlässigkeit
- viele Zustellungsversuche, was die Wiederherstellung der Daten auch
nach vorübergehenden Netzwerk- oder Hardwareproblemen einfach gestaltet
- hohe Wahrscheinlichkeit hinterlassener Spuren auf Speichergeräten,
deswegen als Lösung für vollständig abstreitbare Speicherung weniger
geeignet (obwohl hierfür eine große Zahl fremder Systeme überprüft
werden müsste, was nicht unbedingt realisierbar sein muss)
Klasse-B-Speicher ist geeignet zur Ablage regulärer Dateiarchive, großer
Puffer, an die Daten lediglich angehängt werden, verschlüsselter
Ressourcen (bei geeigneter Auswahl der Hosts bleibt die Speicherung praktisch
abstreitbar) usw.
5) Diskrete Klasse-A-Speicherung
In bestimmten Situationen kann es notwendig sein, eine Lösung für die
diskrete Datenspeicherung zu finden, die nicht auf dem lokalen System
selbst erfolgt und es so ermöglicht, die Existenz der Daten an
irgendeinem Ort abzustreiten.
Die Grundanforderung besteht darin, dass die Daten
- erst zurückgesendet werden, wenn eine bestimmte Schlüsselfolge gesendet
wird,
- permanent verworfen wird, ohne Spuren auf nichtflüchtigen
Speichermedien zu lassen, wenn Keepalive-Anfragen ausbleiben.
Diese Funktionalität lässt sich mit Klasse-A-Speicher implementieren.
Hierzu wird die weiter oben beschriebene Methode zur Aufrechterhaltung
verwendet. Um die Daten freizugeben, ist die passende TCP-Sequenznummer
erforderlich, und erst, wenn diese Nummer übermittelt wird, werden die
Daten zurückgegeben oder einem Absender offenbart. Geht der Clientknoten
offline, dann werden die Daten verworfen und mit hoher Wahrscheinlichkeit
überschrieben.
Insofern ist die Sequenznummer der Schlüssel zu den gespeicherten Daten.
Wenn die Lebensdauer der Daten eher kurz ist, nachdem die Keepalives (\0)
ausbleiben, dann ist dies oft bereits ein ausreichender Schutz.
271
16 Parasitic Computing, oder: Kleinvieh macht auch Mist
6) Kapazität im Benutzerzugriff
In diesem Abschnitt werden wir versuchen, die Speicherkapazität
abzuschätzen, die einem einzelnen Benutzer verfügbar ist.
Um fortlaufend eine konstante Menge Daten in das Netzwerk "auszulagern",
müssen wir sie mit schöner Regelmäßigkeit empfangen und wieder
zurücksenden können.
Der Zeitraum, für den die Daten entfernt gespeichert werden können, ist
durch die maximale Lebensdauer Tmax eines einzelnen Pakets begrenzt (dies
beinhaltet auch das Einreihen des Pakets in die Warteschlange und
Verarbeitungsverzögerungen) . Die maximale Menge von Daten, die sich senden
lassen, ist durch die maximal verfügbare Netzwerkbandbreite L beschränkt.
Die maximale Kapazität lässt sich mithin wie folgt definieren-.
Cmax [Byte] = L [Byte/s] • Tmax [s] ^- Pg • Dg
Hierbei gilt: Dg ist die zur Speicherung des ersten Teils eines
Datenblocks auf einem Remote-Host erforderliche Paketgröße. Pg ist die zur
Aufrechterhaltung der auf dem Remote-Host gespeicherten Daten
erforderliche Paketgröße.
Pg und Dg sind gleich und können immer dann weggelassen werden, wenn der
gesamte Datenblock hin- und hergesendet wird; sie unterscheiden sich nur
für Szenarien mit Aufrechterhaltungsbefehlen. Das kleinste TCP/IP-Paket,
mit dem sich dies erzielen lässt, hat 41 Bytes. Die maximale Datenmenge,
die sich mithilfe HTTP-Headern aufrechterhalten lässt, liegt bei etwa
4.096 Bytes.
Hieraus ergibt sich die folgende Auflistung-.
Bandbreite I Klasse A I Klasse B
28,8 Kbit/s
255 Kbit/s
2 Mbit/s
100 Mbit/s
105 Mbyte
935 Mbyte
7,3 Gbyte
355 Gbyte
2 Gbyte
18 Gbyte
14 7 Gbyte
7 Tbyte
Das Internet als Ganzes
In diesem Abschnitt schließlich wollen wir versuchen, die theoretische
Kurzzeitkapazität des gesamten Internets zu berechnen.
Klasse A-.
Um die gesamte theoretischen Kapazität von Klasse-A-Speichern im Internet
bewerten zu können, gehen wir von folgenden Voraussetzungen aus-.
- ICMP-Meldungen bieten die beste Balance zwischen Speicherkapazität
und Erhalt der Ressourcen eines Remote-Systems.
- Ein Betriebssystem hat durchschnittlich eine Paketeingangs-
Warteschlange, die mindestens 54 Pakete aufnehmen kann.
- Die Standard-PMTU liegt bei etwa 1.500 (dies ist die häufigste MTU).
Zur Schätzung der Anzahl von Hosts im Internet verwendeten wir als
Grundlage ein Gutachten des ISC für das Jahr 2003, welches 171.538.297 Systeme
mit Reverse-DNS-Einträgen aufweist (wobei nicht alle IP-Adressen mit
Reverse-DNS funktionsfähig sein müssen). Um dies zu berücksichtigen,
benutzten wir das ICMP-Echoantwortverhältnis, welches auf Grundlage des
letzten Gutachtens berechnet wurde, für das ein solcher Text durchgeführt
wurde (das war 1999) . Damals legten die Angaben nahe, dass ca. 2 0 Prozent
der sichtbaren Systeme auch in Betrieb waren, woraus man schließen kann,
dass die Anzahl der Systeme, die in der Lage sind, auf ICMP-Anfragen zu
reagieren, bei etwa 34.000.000 liegt.
272
16.5 Anwendungen, soziale Gesichtspunkte und Abwehr
Multiplizieren wir nun die Anzahl der Systeme, die auf ICMP-Echoanfragen
antworten, mit der durchschnittlichen Paketcachegröße und der maximalen
Paketgröße (abzüglich der Header), dann kommen wir auf eine theoretische
Gesamtkurzzeitkapazität für ICMP-basierten Klasse-A-Speicher von etwa
3 Tbyte.
Klasse B:
Um die theoretische Klasse-B-Speicherkapazität zu ermitteln, verwenden
wir das Beispiel der MTA-Software. Es gibt keine Obergrenze für die Menge
von Daten, die wir einem einzelnen Host zuführen können. Zwar können wir
sicher davon ausgehen, dass nur Nachrichten mit einer Größe von knapp
unter 1 Mbyte keine nennenswerte Systemlast und andere unerwünschte Effekte
erzielen werden, aber wir nehmen trotzdem eine durchschnittliche maximale
Warteschlangenlänge von 500 Mbyte an.
Unsere eigenen Forschungen legen nahe, dass bei etwa 15 Prozent der
Systeme, die auf Ping-Anfragen antworten, der Port 25 offen ist. Insofern
schätzen wir die Population der SMTP-Server auf 3 Prozent (15 Prozent von
20 Prozent) der Gesamtzahl aller Hosts; dies sind etwas über
5.000.000 Hosts.
Wir erhalten also am Ende eine Speicherkapazität von 2.500 Tbyte.
16.5 Anwendungen, soziale Gesichtspunkte und Abwehr
Und weiter? Welchen praktischen Nutzen bieten Parasitic Computing und Parasitic Sto-
rage, wenn die Vorteile nicht annähernd gut genug sind, um diese Entwürfe zu einer
attraktiven Alternative zum Kauf zusätzlicher Hardware zu machen?
Trotz der Fortschritte in der praktischen Nutzung des Parasitic Computing erscheinen
Anwendungen, die auf die Erweitenmg der reinen Computerleistung oder Speicherkapazität
eines herkömmlichen Systems abzielen, recht sinnlos angesichts des Übermaßes an
billigem Speicher und der Existenz von Gigahertz-Prozessoren.
Das verborgene Potenzial dieser Technologie liegt aber vielleicht in einem völlig anderen
Anwendungsbereich: der flüchtigen Datenverarbeitung. Die Aussicht, einsetzbare verteilte
Computer zu konstruieren, die beliebig verstreut sind und weder physische Spuren
hinterlassen noch an irgendeiner Stelle sinnvolle Daten speichern, kann sich als mächtiges
Datenschutzwerkzeug erweisen und stellt Forensik und Polizeiarbeit vor ganz neue
Herausforderungen. Einen flüchtigen Speicher verwenden zu können, der sich kurz, nachdem man
einen einzelnen Knoten offline genommen hat, quasi selbst zerstört, aber keine häufige
Neuübertragung von Daten verlangt, bietet Kriminellen (oder auch Unterdrückten) eine
Menge Möglichkeiten, Sachverhalte zu leugnen, und erfordert drastische Änderungen bei
konventionellen Methoden der Beweisermittlung.
Stellen Sie sich außerdem flüchtige Systeme vor, die sich, wenn sie einmal gestartet und
initialisiert worden sind, für längere Zeit selbst aufrecht erhalten: Sie existierten nur im
Internet - es gäbe kein lokales physisches Dasein. Es gibt zwei mögliche Entwürfe für
flüchtige verteilte Computersysteme, und keiner der beiden ist völlig abwegig:
■ Systeme können so aufgebaut werden, dass sie eine komplexe Aufgabe erledigen,
indem sie parallel eine Lösung suchen. (Dies wurde bereits durch das oben beschriebene
273
16 Parasitic Computing, oder: Kleinvieh macht auch Mist
SAT-Computing realisiert.) Der Nachteil solcher Systeme besteht darin, dass der Abruf
des Berechnungsergebnisses und das Auslösen der nächsten Verarbeitungsschleife
manuell initiiert werden müssen, indem man das Gesamtsystem dann und wann von ir-
gendeinem Standort aus neu einstartet. In diese Kategorie fallen am ehesten Lösungen,
die auf den maschinennahen Eigenschaften von Protokollen wie TCP basieren.
■ Systeme können so konstruiert sein, dass sie aufeinanderfolgende Iterationen einer
verteilten Datenverarbeitung selbst ausführen. Alle Formen des Missbrauchs komplexerer
Merkmale (z. B. eingebettete Algorithmen zur Dokumenterstellung) und einiger
Netzwerkdienste können eingesetzt werden, um solche Aktivitäten zu ermöglichen.
In jedem Fall können die Folgen recht tiefgreifend sein. Wie beispielsweise nimmt man
eine redundante, sich selbst reparierende Maschine offline, die nicht auf einem einzelnen
System basiert, sondern für Sekundenbrachteile winzige Mengen Speicher und
Prozessorleistung bei anderen borgt - und zu diesem Zweck weder Sicherheitslücken noch eindeutig
erkennbaren Datenverkehr verwendet, der sich ausfiltern ließe? Und ist nicht auch das
Gefühl recht befremdlich, dass wir keine direkte Möglichkeit hätten, die Ziele eines solchen
verteilten Computers zu erkennen? Ich bekunde den Meistern des düsteren Science-Fiction
meinen Respekt: Meiner Meinung nach steht die Herrschaft der Computer kurz bevor, und
ich möchte unsere neuen Gebieter demütigst willkommen heißen.
16.6 Denkanstöße
Ein Schutz gegen Parasitic Computing ist im Allgemeinen extreni schwer zu realisieren.
Die Möglichkeit, Daten zu speichern oder auf anderen Systemen gewisse einfache
Berechnungen auszuführen, ist oft an die Grundfunktionalität von Netzwerkprotokollen
gebunden. Dies ist eine Eigenschaft, die zu entfernen wir nicht in Beteacht ziehen können, ohne
das gesamte Internet, wie wir es kennen, auszulöschen und uns damit eine Menge neuer
Probleme einzuhandeln, die wesentlich schwerwiegender sind als das, welches wir auf
diese Weise behoben haben.
Es ist auch ziemlich schwierig, ein einzelnes System davor zu schützen, ein Knoten für
Parasitic Computing zu werden, denn der Umfang der entwendeten Ressourcen ist meist ein
vemachlässigbarer Anteil an untätiger Prozessorzeit und Speicher und bleibt insofern oft
unbemerkt.
Dass das Parasitic Computing sein volles Potenzial erst noch an den Tag legen und die
Bedrohung - irrelevant oder nicht existent für einzelne Systeme, aber beträchtlich für das
Internet als Ganzes - sich noch eine ganze Zeit lang halten wird, ist sehr wahrscheinlich.
274
17 Die Topologie des Netzwerks
Siebzehntes Kapitel. Welches beschreibt, wie das Wissen der Welt, die uns
umgibt, uns dabei helfen kann, Freund und Feind aufzuspüren
Welche Form hat das Internet? Es gibt kein Komitee, welches darüber wacht oder
entscheidet, wo, wie und warum es sich ausbreiten darf oder wie neue und vorhandene
Systeme zu organisieren oder zu verwalten sind. Das Internet wächst in alle Richtungen - auf
eine Weise, die gleichermaßen von Bedarf, Wirtschaft, Politik, Technologie und blindem
Vertrauen beeinflusst wird.
Doch das Internet ist kein foniüoses Etwas: Es gibt geplante, lokal geregelte Hierarchien
autonomer Systeme mit Core-Routem, die von untergeordneten Knoten umgeben sind und
deren Verknüpfungen entweder von automatischen Mechanismen konfiguriert oder von
Menschen sorgfältig entwickelt werden. Das Internet ist ein beeindruckendes Geflecht: ein
komplexes und zerbrechliches Spinnennetz, das sämtliche Industrie- und
Entwicklungsländer verflicht. Die Aufgabe, diese sich fortwährend ändernde Topologie zu erfassen,
stellt eine echte Herausforderung dar, die große Anziehungskraft ausübt - insbesondere,
wenn man erst einmal festgestellt hat, wie man die gesammelten Inforrnationen nutzen
kann.
In diesem Kapitel werde ich zunächst zwei bemerkenswerte Versuche beschreiben, die
Topologie des Internets zu kartographieren. Danach werde ich einmal mehr über die
potenziellen Einsatzmöglichkeiten der Informationen moralisieren, die sich auf diese Weise
ermitteln lassen, um Dinge zu tun, von denen unsere Vorfahren noch nicht einmal zu
träumen gewagt hätten.
17.1 Momentaufnahmen
Der umfassendste Versuch, das Internet zu kartographieren, wurde von der CAIDA (Co-
operative Association for Internet Data Analysis) durchgefühlt, einer Organisation, die un-
275
17 Die Topologie des Netzwerks
ter anderem von staatlichen amerikanischen Forschungseinrichtungen (NSF, DHS, DAR-
PA) und der Industrie (Cisco, Sun) gesponsert wird. Die Organisation wurde gegründet,
um Datenverkehrs- und Infrastndctuianalysen und Tools zu entwickeln, die der
allgemeinen rntemet-Cornmunity zugute kommen sollten - in der Hoffnung, das Internet besser,
zuverlässiger, flexibler und robuster zu machen.
Seit dem Jahr 2000 ist eines der öffentlichen Hauptprojekte - das Flaggschiff- die
Erstellung und Pflege einer „Landkarte" mit den Kemnetzwerken der autonomen Systemen, die
auf den Namen „Skitter" hört. Zum Zeitpunkt der Veröffentlichung dieses Buches sind
bereits Daten für 12.517 größere autonome Systeme erfasst, was 1.134.643 IP-Adressen und
2.434.073 Verknüpfungen (logischen Pfaden) zwischen diesen entspricht.
Zwar wirkt das Projekt geheimnisvoll, aber die Intemetkarte der CAIDA wurde
ausschließlich unter Verwendung öffentlich zugänglicher BGP-Konfigurationsdaten von
Routern, Ergebnissen empirischer Netzwerktests {traceroute) und WHOIS-Datensätzen für
Netzwerkblöcke erstellt. Die Karte arbeitet mit Polaikoordinaten: Punkte, die die einzelnen
Systeme darstellen, sind in einem Winkel angeordnet, der dem physischen Standort des
offiziellen Zentralstandortes eines Netzwerks und dem Radius entspricht, welcher zur
,,Peering-Relevanz" des betreffenden autonomen Systems passt. Letztgenannter Parameter
wird abgeleitet, indem die Anzahl anderer autonomer Systeme berechnet wird, die laut
Beobachtungen Daten von dem betreffenden Knoten annehmen. Insofern befinden sich
massive Core-Systeme im Zentrum der Karte, während Systeme, die mit nur wenigen anderen
Knoten direkten Kontakt haben, eher am Rande zu finden sind. Linien im Diagramm
geben lediglich die Peering-Beziehungen zwischen Routern wieder.
■ Hinweis
Bedauerlicherweise wurde es uns nicht gestattet, eine grafische Darstellung der Skitter-
Grafiken kostenlos in diesem Buch abzudrucken. Ich möchte Sie aber ermutigen, sich dieses
erstaunliche Bild online unter http://www.caida.org/analysis/topology/as_core_network/pics/
ascoreApr2003.gif anzusehen (es steht dort gebührenfrei zur Ansicht zur Verfügung).
Ein weiterer bemerkenswerter Versuch, das Netzwerk zu kartographieren, nutzte einen
Ansatz, der auf der Analyse der Entfernungen von verschiedenen Netzwerken aus der Sicht
eines bestimmten Standorts (in diesem Fall Bell Laboratories) basierte und eine
baumartige Struktur zum Ergebnis hatte, die ganz anders aussah als das komplexe Gewebe, das von
der CAIDA erstellt worden war. Das Ergebnis dieser Analyse, die von Bill Cheswick im
Jahr 20001 durchgeführt wurde, sehen Sie in Abbildung 17.1. Diese Struktur parametrisiert
das Diagramm nicht abhängig vom physischen oder adininistrativen Standort eines
Systems; die relative Entfernung von der Mitte entspricht vielmehr der Anzahl der Hops
zwischen dem betreffenden Knoten und Bell Laboratories.
ChesOO
276
17.1 Momentaufnahmen
The Interner
SIE1 ^:WkÄ^'
Abbildung 17.1 Bill Cheswicks Intemetkarte
felLOMgES
Obwohl die beiden Ansätze den Eindruck machen, auf massiver Datensainrnlung und
-analyse zu basieren, ist es auch für einen Arnateur nicht übermäßig schwierig, das
Netzwerk zu kartographieren — selbst über eine Verbindung mit relativ geringer Bandbreite.
Die Sondierung aller öffentlich ansprechbaren Subnetze mit einem einzigen Paket erzeugt
maximal ein paar Gbyte Datenverkehr, was sich mit einer gewöhnlichen DSL-Anbindung
innerhalb weniger Stunden, maximal aber eines Tages bewerksteUigen lässt. Die einzigen
Risiken bestehen darin, dass man einige Systenradniinistratoren auf den Plan ruft, aber
angesichts der Verbreitung von CoHiputerwürmem und automatisierten Angriffen dürfte die
Empfindlichkeitsschwelle nur bei den allerwenigsten so niedrig liegen. Die Kartographie-
277
17 Die Topologie des Netzwerks
rang der beobachteten Strukturen des Internets ist möglich (und oft auch lohnend), weil sie
uns viel darüber erzählen kann, wie das internationale Netzwerk organisiert ist.
Wie sich aber herausstellt, können die von CAIDA, Bill Cheswick oder anderen erfahrenen
Benutzern des Internets gewonnen Informationen auch erfolgreich eingesetzt werden, um
das Wesen mysteriöser Daten, über die wir eines Tages stolpern könnten, besser ergründen
und ihre Herkunft schneller ermitteln zu können.
17.2 Herkunftsnachweis mit Topologiedaten
Spoofing ist eines der gegenwältig größten Problerne des Internets - zumindest aber eines
der ärgerlicheren. Blindlings gefälschte Pakete mit nachgemachten oder speziell
ausgewählten, aber vorgetäuschten Absenderadressen können für den Missbrauch von
Vertrauensbeziehungen zwischen Computern oder zur Einspeisung bedenklicher Inhalte (wie etwa
unerwünschter Massen-E-Mails) eingesetzt werden, ohne verräterische Spuren oder
verlässliche Herkunftsangaben zu hinterlassen. Das blinde Spoofing kann auch benutzt
werden, um die Identität eines Angreifers zu verschleiern, der Systemsondierungen durchführt
(vgl. auch das in Kapitel 13 beschriebene Konzept der „Täusch-Scans"). Die schlimmste
Plage allerdings ist das Spoofing mit dem Ziel, DoS-Angriffe auszuführen.
Bei einer normalen DoS-Attacke hat der Administrator die Chance, die Herkunft von
Angriffsdaten zu erkennen, die gegen einen seiner Dienste gerichtet sind (und deren Zweck
im Zweifelsfall darin besteht, diesen Dienst zum Ausfall zu bringen und dem Betreiber
Unannehmlichkeiten oder Verluste zu bescheren). Es ist jedoch möglich, nichtkonforme
Pakete willkürlich zu falschen; in solchen Fällen hat der Administrator keine Handhabe,
denn er kann die vom Angreifer stammenden Daten nicht ausfiltem, ohne andere Benutzer
auszusperren. Seine einzige Hoffnung besteht darin, gemeinsam mit seinem Provider die
tatsächliche Herkunft der Daten in der Sicherungsschicht zu ermitteln und diese Angaben
dem Provider des Angreifers zukommen zu lassen. Aber das dauert lange. Sehr lange.
Außerdem müssen alle Beteiligten auch ohne gerichtlichen Beschluss davon überzeugt
werden, dass dieser Fall aus finanzieller und zeitlicher Hinsicht durchaus eine Untersuchung
wert ist. In Situationen wie diesen ist es für den Systemadrninistrator besonders wichtig,
Tools und Methoden zur Verfugung zu haben, mit denen er zwischen gefälschtem und
legitimen Datenverkehr unterscheiden kann.
Als ich noch in den Vereinigten Staaten wohnte und arbeitete (heute lebe ich in Polen), be-
schloss mein Kollege Mark Loveless, eine Idee zu implementieren, die ursprünglich von
Donald McLachlan vorgeschlagen wurde: Er wollte die TTL des Datenverkehrs zwischen
sich und dem vorgeblichen Absender eines Pakets messen, um automatisch ermitteln zu
können, ob ein eingehendes Paket gefälscht worden war. Die Herausforderung der Her-
kunftsbestimmung eines Netzwerkpakets ist in einer Welt, in der Informationen nicht zu
trauen ist, sehr wichtig, und von der Chance, dies auch zu tun (wenn auch nur in
bestimmten Fällen), könnte man aus erwähnten Gründen in analytischer und administrativer
Hinsicht erheblich profitieren.
278
17.2 Herkunftsnachweis mit Topologiedaten
Um die Idee von Donald und Mark besser verstehen zu können, nehmen wir einmal an,
dass das Remote-System, von dem wir Daten erhalten, sich in einer bestimmten logischen
Entfernung von uns befindet - getrennt durch eine gegebene Anzahl von Netzwerkgeräten.
Insofem weisen alle Pakete, die zulässigerweise von diesem System gesendet wuiden, bei
der Ankunft eine bestimmte TTL auf, die der auf dem betreffenden System standardmäßig
konfigurierten TTL abzüglich der Anzahl der Zwischensysteme entspricht, die das Paket
passiert hat (siehe Kapitel 9). Gefälschter Datenverkehr hingegen stammt mutmaßhch aus
einem ganz anderen Netzwerk, weswegen Entfernung und TTL sich höchstwahrscheinlich
von den erwähnten Beobachtungen unterscheiden. Marks Tool despoof2 vergleicht die
TTLs, die in bestimmten induzierten und zuvor empfangenen Daten erkannt wuiden, um
zwischen zulässigem und gefälschtem Datenverkehr zu unterscheiden.
Allerdings weist diese Methode, obwohl sie in einzelnen Fällen durchaus zufriedenstellend
arbeitet, wenn sie gegen arglose Angreifer eingesetzt wird, mindestens zwei Probleme auf:
■ Ein übervorsichtiger Angreifer könnte die Entfernungen vor der Attacke abmessen und
eine TTL wählen, die dem erwarteten Wert entspricht. Allerdings ist dieser Trick zwar
möglich, aber doch etwas schwierig zu implementieren. Zum Einen ist der Angreifer
unter Umständen physisch nicht in der Lage, eine ausreichend hohe TTL einzustellen,
um einen bestimmten Wert zu erzielen, der dem erwarteten Wert eines echten Pakets
entsprechen würde, wenn das gefälschte Paket beim Empfänger eintrifft. Dieser Plan
des Angreifers könnte vereitelt werden, wenn das System, das er imitieren will, eine
Standard-TTL von 255 (dem Maximalwert) oder knapp darunter verwendet und er
weiter vom Ziel entfernt ist als das imitierte System, In diesem Fall wäre es für ihn
unmöglich, ein Paket zu versehen, das bei der Ankunft am Ziel die gewünschte TTL aufweist.
Natürlich verwenden nur die wenigsten Systeme die höchstmögliche TTL. Außerdem
wird ein Angreifer nur in seltenen Fällen die Identität eines bestimmten Systems
vorgeben wollen.
Die zweite Herausforderung des Angreifers besteht darin, dass er die Distanz zwischen
seinem Opfer und dem imitierten System nicht genau ermitteln kann, sofern er sich
nicht in der Nähe eines dieser Systeme befindet und die Routing-Verhältnisse zwischen
ihnen nicht kennt. Verwendet das Opfer jedoch despoof zur dynamischen
Implementierung von Filterregeln, mit denen gefahrliche Pakete ausgeschlossen werden, dann kann
der Angreifer einfach verschiedene TTLs unterschiedlicher Quellen ausprobieren, bis
er erkennt, dass das Opfer nicht mehr in der Lage ist, eine Entscheidung zu treffen.
(Dies wäre offensichtlich: Das System des Opfers würde anfangen, typische Effekte
einer erfolgreichen Attacke - z. B. Leistungseinbrüche - an den Tag zu legen.)
■ Jedes Mal, wenn ein verdächtiges Paket empfangen wird, muss der Empfanger eine
Überprüfung stalten und warten, bis die Ergebnisse bereitstehen. Insofem ist despoof
als Grundlage einer automatischen Abwehr insbesondere von DoS-Angriffen ungeeig-
Erhältlich unter http://razor.bindview.com/tooIs/desc/despoof_readme.htmL
279
17 Die Topologie des Netzwerks
net. Allerdings kann diese Methode immer noch recht nützlich sein, wenn man die
tatsächliche Herkunft eines Täusch-Scans ermitteln will.
Ohne Kenntnisse zur Topologie eines bestimmten Netzwerks ist es schwierig, etwas
Besseres als despoof zu finden: Die von diesem Tool implementierte Analysemethode ist gut
genug, um viele häufig auftretende Probes und Einzelangriffe zu stoppen. Aber was
kommt danach?
Nun: Kombinieren Sie Marks Programm mit Echtzeitdaten zur Netzwerkstruktur und
ermitteln Sie unter Verwendung des passiven Fingerprintings die Start-TTL eines Systems,
das bestimmte Anfragen sendet. Voilä: Schon ist diese Methode um ein ganzes Stück
leistungsfähiger. Diese Zusatzdaten gestatten es uns, eine erste passive Bewertung des
eingehenden Datenverkehrs durchzuführen, indem wir die beobachteten TTLs und die
bekannten Start-TTLs mit der Entfernung vergleichen, die in der Netzwerkkalte angegeben sind.3
Weil die Entfernung, die wir sehen sollten, sich bestimmen lässt, ohne eine aktive
Sondierung der Netzwerktopologiedaten durchzuführen, können wir sofort und ohne gioßen
Aufwand zwischen zulässigem und ungutem Datenverkehr unterscheiden. Dies wiederum
ermöglicht es, auf massive Vorfalle relativ zuverlässig reagieren und einzelne unauffällige
Probes erkennen zu können, ohne den Angreifer davon in Kenntnis zu setzen, dass ein
Spoofing-Erkennungssystern implementiert ist.
Offenbar kann man dadurch, dass man bei der Betrachtung von Punkt-zu-Punkt-
Beziehungen die Struktur eines Netzwerks berücksichtigt, eine ganze Menge gewinnen.
Aber die Spoofing-Erkennung ist nur der Anfang.
17.3 Netzwerktriangulation mit Topologiedaten
Eine wesentlich interessantere Anwendung von Vennaschungsdaten zur Netzwerktopolo-
gje mit dem Ziel der Datenverkehrsanalyse ist die Netzwerktriangulation. Wir können mit-
hilfe der Netzwerktriangulation die Position eines Angreifers, der gefälschte Pakete sendet,
ohne Unterstützung der Instanzen ermitteln, die den dazwischenliegenden Routing-
Backbone betreiben - er muss nur mehrere Ziele gleichzeitig oder aufeinanderfolgend
angreifen. Dies ist dann tatsächlich Glück im Unglück.
Wenn man es ganz genau nimmt, funktioniert die Triangulation zwar am besten, wenn der
Angreifer mehrere Ziele auswählt, aber in bestimmten Szenarien gelingt sie auch beim
Angriff auf nur einen Dienst. So können wir insbesondere in der Lage sein, dieselbe
Attacke von verschiedenen Standpunkten aus wahrzunehmen, wenn das angegriffene Objekt
mehrere IP-Adressen aufweist und der Dienst über mehrere physische Standorte
bereitgestellt wird — etwa zum Zweck des Lastausgleichs, oder um die gesamte Struktur fehlertole-
Bei eitlem solchen Ansatz inuss der Vergleich der TTLs mit einem gewissen Fehlerspielraurn
durchgeführt werden, weil innerhalb interner Netzwerke mehrere zusätzliche Hops auftreten können.
Außerdem sind manche Routen asymmetrisch, und ihre Länge kann je nach Richtung, in der die Daten
ausgetauscht werden, leicht variieren.
280
17.3 Netzwerktriangulation mit Topologiedaten
rant zu machen (was bei Webdiensten durchaus üblich ist). In allen anderen Szenarien
kommen wir an eine größere Menge Daten, wenn Systernadministiatoren feststellen, dass
mehrere Systeme Ziel eines Angreifers sind und ihre Angaben darüber austauschen.
Unabhängig vom vorhegenden Fall können wir aber triangulieren, sobald Daten, von
denen man annehmen könnte, dass sie von derselben Quelle stammen, an mehieren Zielen
auftauchen. Für jedes Ziel, an dem die Daten auftauchen, befindet sich nur eine bestimmte
Anzahl von Netzwerken in einer Entfernung, die sich durch Beobachtung des Abstandes
ermitteln lässt, den das fragliche Paket zurückgelegt hat (auch dies finden wir durch
Untersuchung der TTL heraus4). Eine Schnittmenge, die für alle an allen Beobachtungspunkten
beobachteten Mengen gebildet wird, würde wesentlich kleiner sein und unter Umständen
vielleicht nur ein einziges Netzwerk enthalten — das Netzwerk, aus dem der Angriff
stammen könnte (Abbildung 17.2).
Beobachtungssystem 3
Abstand zum Angreifer: 3
Abbildung 17.2 Einfache Netzwerktriangulation: Nur ein Absender ist in allen Beobachtungen
vorhanden. Der Angreifer kann Quelladressen fälschen, aber die Opfer nicht täuschen.
Die Möglichkeit, selbst auf die Suche gehen zu können, befreit uns von der
bedingungslosen Abhängigkeit von Internetprovidern und hilft uns, präzise zu ermitteln, wer unser
Netzwerk angreift oder sondiert — und vielleicht auch, herauszufinden, warum er dies tut.
Auch dann, wenn das Tool ZufaUs-TTLs verwendet, ist es möglich, die Entfernung anhand der
beobachteten Maxknal-TTL zu bestimmen, wenn an jedem Ziel eine bestimmte Anzahl von Paketen
erkannt wird (und dies ist fast immer der Fall). Wenn das Scan-Tool beispielsweise die Stail-TTLs
willkürlich im Bereich zwischen 32 und 255 zuweist, aber mehrere tausend Pakete vom Ziel empfangen
werden, bei denen keine TTL erkannt wird, die größer als 247 ist, dann ist der Host mit hoher
Wahrscheinlichkeit 255 — 247 = 8 Systeme entfernt.
281
17 Die Topologie des Netzwerks
Zwar ist dieser Ansatz weitaus schwieriger abzuwehien als der traditionelle Einsatz von
despoof, aber ein kluger Angreifer kann einen Beobachter immer noch hinters Licht
führen, indem er für jedes Ziel eine andere, zufällig zugewiesene TTL (oder einen TTL-
Bereich) verwendet. Zwar sind derzeit keine Tools bekannt, die dies ermöglichen, aber was
nicht ist, kann ja noch werden.
Ist die Schlacht verloren? Nein. Es gibt eine Möglichkeit, zu verhindern, dass Übeltäter
uns auf diese Weise hereinlegen.
17.4 Stresstest im Netzwerk
Die Lösung, die auf den Namen „Netzbelastungsanalyse" hört, wird in Form einer
Forschungsarbeit5 dargereicht, die Hai Brunch und Bill Cheswick im Jahr 2000 auf der LISA-
Konferenz vorstellten. Brunch und Cheswick schlugen eine interessante
Einsatzmöglichkeit für Netzwerktopologiedaten in Baumform (ähnlich Abbildung 17.1) vor, die für einen
bestimmten Standort ermittelt worden waren. Sie legten eine Möglichkeit dar, rnithilfe der
Daten die Herkunft eines bestimmten Typs gefälschten Datenverkehrs — nämlich DoS — zu
erkennen. Der Ansatz selbst ist vergleichsweise simpel und basiert auf der Annahme, dass
ein solcher Angriff nicht nur das System belasten würde, gegen das er gerichtet ist,
sondern auch zwischengeschaltete Router, und dass diese Belastung sich vom Opfer extern
messen und dazu verwenden ließe, den Angreifer ausfindig zu machen.
Die Aufgabe, Netzwerkverbindungen einer Belastungsanalyse zu unterziehen, besteht
darin, zunächst ein Baumdiagramm mit den Leitungen von Ihrern Standort zu allen
Netzwerken im Internet zu erstellen (oder sich dieses zu besorgen) und die einzelnen
Verzweigungen dieser BauHistruktur nach und nach durchzugehen, sobald ein Angriff erfolgt. Für
jeden Zweig (der in Wirklichkeit eine Verbindung mit einem übergeordneten Router
darstellt) können wir die Netzwerklast des Knotens iterativ messen, indem wir Testdaten an
oder über den Router senden, der mit ihm verknüpft ist. (Im erwähnten Forschungsprojekt
wurde eine Ladung UDP-Daten verwendet, aber ICMP-Anfragen oder beliebige andere
Nachrichtentypen könnten ebenfalls eingesetzt werden.) Wir wählen dann einen stärker
belasteten Knoten als potenziellen Kandidaten für die eingehenden Daten aus.
Nachfolgend vermerken und überprüfen wir alle Verzweigungen, die von diesem Knoten
ausgehen, bis wir den Datenverkehr zum Urheber zurückverfolgt haben.
Abbildung 17.3 veranschaulicht ein einfaches Nachverfolgungsszenario. In der ersten
Phase versucht das angegriffene System, die Leistung der drei nächstgelegenen Intemetrouter
zu messen, wenn der Angriff beginnt, und stellt fest, dass er erste (oberste) Router der
derzeit rneistbeanspruchteste ist.
Bi-unOO
282
17.4 Stresstest im Netzwerk
Netzwerk X
Router mit
hoher Last
Opfer
(erkennt die Daten
als von Netzwerk A
kommend)
Schritt 1: Das Opfer bestimmt
welcher der Router zweiter
Ebene eine höhere Belastung
aufweist.
Schritt N: Das Opfer bestimmt, ■
welcher der Router n-ter Ebene,
die mit dem hochbelasteten
Router (n-1)-ter Ebene
kommunizieren, eine höhere
Belastung aufweist.
Angreifer
(fälscht Pakete mit
Absenderadresse in
Netzwerk A)
Step X (letzter Schritt): Der im
Schritt X-1 erkannte belastete
Router ist mit nur einem
Netzwerk verbunden. Dort ist
der Schuldige zu finden.
System, als das sich der
Angreifer ausgibt
(argloser Außenstehender)
Abbildung 17.3
analyse
Rekursive Angriffsnachverfolgung mit Netzwerktopologiedaten und Belastungs-
Basierend auf diesen Angaben beschließt das Opfer, nur diejenigen Router zu testen, die
direkt an jenes Gerät angeschlossen (d. h. Peers dieses Gerätes) sind. In diesem speziellen
Fall werden nur drei Geräte getestet (die übrigen sechs werden nicht überprüft, weil sie
nicht Peer des betreffenden Gerätes sind). Es stellt sich heraus, das erneut das erste die
höchste Belastung aufweist. Der Prozess wird fortgesetzt, bis ein Router, der direkt an ein
bestimmtes Netzwerk angeschlossen ist, dessen Standort und Besitzer sich über öffentliche
Datenbanken ermitteln lassen, als finaler Endpunkt erkannt wird.
283
17 Die Topologie des Netzwerks
Hierbei tritt allerdings ein potenzielles Problem auf: Einige Geräte weisen unter
Umständen aus anderen Gründen als der Verarbeitung von DoS-Daten eine hohe Belastung aus,
andere hingegen mögen viele fieie Rozessorzyklen zur Verfügung haben und lassen sich
von der Weiterleitung gefährlicher Daten nicht besonders aus der Ruhe bringen.
Um dieses Problem zu beheben, schlägt die Arbeit vor, eine künstliche Kurzzeitbelastung
des Routers (durch Erzeugung zusätzlichen Datenverkehrs) zu verursachen und dann zu
beobachten, wie dieser Test sich auf Bandbreite und Latenz der DoS-Anfragen auswirkt:
Ist das betreffende Geräte tatsächlich in die Weiterleitung bösartiger Pakete einbezogen,
dann müsste, solange wir eine Mehrbelastung des Geräts verursachen, die Angriffsrate
sinken (und zwar auch in diesem Fall mit hoher Wahrscheinlichkeit durch die Erzeugung
weiterer gefälschter TCP-, UDP- und ICMP-Annagen, die eher die Prozessorleistung eines
Geräts verbrauchen, als die Schnittstellen zu verstopfen). Aus diesem Grund sollte ein
Abgleich nur bei denjenigen Zweigen erfolgen, die an der Bereitstellung bösartigen
Datenverkehrs beteiligt sind.
Dieses brillante und einfache System wurde in Testumgebungen erfolgreich eingesetzt.
Allerdings kommen verschiedene ethische Aspekte ins Spiel, wenn wir einen Einsatz in
Produktionsumgebungen in Betracht ziehen, denn es bezieht auch die Interaktion mit Routem
mit ein und erlegt ihnen eine zusätzliche Belastung auf.
17.5 Denkanstöße
Die Hauptschwierigkeit bei der Verwendung der in diesem Kapitel beschriebenen
Methoden zum Aufspulen von Angreifern besteht darin, dass wir Netzwerkübersichten für jeden
Standort erstellen und pflegen müssen. Es ist nicht auf den ersten Blick offensichtlich, wie
oft diese Übersichten aktualisiert werden müssen und welche Methoden hierzu am
zuverlässigsten wie auch am wenigsten zudringlich sind.
Ein weiteres potenzielles Problem besteht darin, dass ein Großteil der Kernstruktur des
Internets redundant ist. Einige alternative Routen können möglicherweise nur gewählt
werden, wenn die primäre Route ausfällt oder ausgelastet ist, auch wenn der Wechsel in
manchen Fällen im Zuge eines Lastausgleichs erfolgt. Auf diese Weise können einige auf
empirischer Basis erstellte Übersichten innerhalb von Stunden oder gar Minuten veraltet sein
(auch wenn dieser Fall wohl nicht allzu häufig vorkommt).
Letztendlich gibt es - auch wenn sich private, individuelle Anwendungen verschiedener
Abwehrmethoden gegen das Spoofing als sehr erfolgreich erweisen - eine ganze Reihe
offener Fragen, die beantwortet werden müssen, bevor wir solche Techniken im großen Stil
einsetzen können. Und einige dieser Fragen sind noch nicht einmal technischer Natur.
284
18 Der Blick in die Leere
Achtzehntes Kapitel. In dem wir in den Abgrund sehen und feststellen: Was
uns nicht tötet, macht uns nur hart
Wir haben nunmehr eine Reihe von Möglichkeiten kennen gelernt, Daten zu entdecken
und abzufangen, indem wir die Kommunikation zwischen zwei Systemen beobachten oder
einen Blick auf die Nebeneffekte dieser Kommunikationsvorgänge werfen. Allerdings ist
die Geschichte hier noch nicht zu Ende. Manchmal können wir noch niehr erkennen, wenn
wir die Augen von dem Ziel abwenden, welches wir sondieren wollen.
Eine große Anzahl von Methoden, die gemeinhin als Black-Hole-Monitoring (Beobachten
schwarzer Löcher) bezeichnet werden, widmet sich der Inspektion und Analyse
unerwünschten oder unangeforderten Datenverkehrs, der zufällig, aufgrund einer Fehlers oder
in verstümmelter Form bei einem Ziel eintrifft. Zu diesen Methoden gehört in aller Regel
das Ausführen eines einfachen Paketspeicher-Utilitys und die nachfolgende gewissenhafte
Analyse und Theoriebildung zu jeder einzelnen Beobachtung.
In einer perfekten Welt dürften wir eigenthch keinen Nutzen daiaus ziehen können, dort
nach Daten zu suchen, wo wir keine finden sollten. In der Wirklichkeit jedoch können wir
mithilfe dieser Methoden verirrte Datenbits und unschätzbar wertvolle Hinweise zum
Zustand des Netzwerks als Ganzes sammeln. Zwar sind diese Daten vorzugsweise behebig,
und wir können uns auch nicht aussuchen, wem wir zuhören, aber trotzdem können wir
davon profitieren.
18.1 Taktische Ansätze der direkten Beobachtung
Eine Anwendung des Black-Ffole-Monitorings hegt in der Erkennung und Analyse
globaler Angriffstendenzen. Viele Black-Hats, die im Besitz neuer Angriffsmethoden sind,
scannen häufig einfach große Netzadressblöcke, um anfallige Ziele zu finden, diese
anzugreifen und sie schließlich für gesetzeswidrige Aktivitäten zu nutzen. (Dies kann etwa
285
18 Der Blick in die Leere
die Sammlung von Skip-Hosts1 oder der Aufbau von Dronennetzen für automatisierte
Angriffe sein.) Wh' können das Black-Hole-Monitoring verwenden, um uns auf neue Sicher-
heitslücken aufmerksam machen zu lassen, die bereits ausgenutzt werden, indem wir
einfach warten, bis wir eine Zunahme standaidmäßiger Scanaktivitäten von verschiedenen
Quellen bemerken.
Viele Netzwerkadnunistratoren setzen das Black-Hole-Monitoring ein. Manchmal erfolgt
die Verwendung in Verbindung mit Honigtöpfen, d. h. ein gefölschtes „Ködersystern" wird
im Netzwerk ausgesetzt, um Angreifer anzuziehen, ihre Tools abzufangen und ihre
Techniken zu erkennen2. Auf diese Weise entsteht ein Warnsystem, welches es dem
Administrator gestattet, zu den ersten zu gehören, die von bevorstehenden Ausbrüchen von
Würmern und anderer Malware Kenntnis erlangen. (Sie können mit Black-Hole-Datenverkehr
auch „Rauschpegel" kalibrieren und gezielte Angriffe gegen Ihre Server effizienter
erkennen, ohne auf automatisierte, unterscheidungslose und zweifelhafte Handlungen
zurückgreifen zu müssen.)
Forscher wie Dug Song und Jose Nazario - letzterer unlängst in seinem Buch „Defense
and Detection Strategjes against Internet Worms"3 - versuchen, Black-Hole-Aktivitäten
während massiver Wurmepidemien zu analysieren. Ihr Ziel besteht darin, die Dynamik der
Verteilung (d. h. der Erstausbreitung und Neuinfektion) im Netzwerk besser verstehen und
nachbilden zu können und die Effizienz und Beharrlichkeit der Infektions algorithmen von
Würmern zu prüfen. Ihre Forschungsarbeiten werden uns zukünftig dabei helfen,
Verteidigungsmaßnahmen gegen massive verteilte Bedrohungen zu entwickeln, bieten aber auch
beachtliche Einsichten in den aktuellen Zustand der Netzwerktechnologie. Einige Beispiele
für ihre Erkenntnisse können Sie den Abbildungen 18.1 bis 18.4 entnehmen.
Abbildung 18.1 zeigt, wie ein Wurm sich beim Ausbrach der Epidemie verbreitet. Die
Daten basieren auf der Anzahl der beobachteten Angriffsversuche auf TCP-Port 137, eine
Komponente der NetBIOS-Irnplementierung von Windows, die standardmäßig auf allen
Windows-Computern installiert wird und Ziel zahlreichender sich selbst verbreitender
Malware ist. Beachten Sie in der Abbildung, wie nach einer ersten Woche der Verbreitung
- als die Anzahl sowohl der infizierten Standorte (Quellen) als auch der angegriffenen
Systeme im beobachteten Black-Hole-Netzwerk konstant und rapide anstieg - plötzlich eine
Stabilisierungsperiode eintrat, die sich über mehr als einen Monat erstreckte und drastische
Spitzenwerte und Täler aufwies. Eine solche Verbreitungscharakteristik ist für einen
Wurm und den Zustand des Netzwerks, in dem er operiert, eindeutig und reflektiert auch
die Feinheiten der Zielauswahl- und rnfektionsalgorithmen, die der Autor eingesetzt hat.
Ein Skip-Host ist ein System, das als Zwischengerät zur Ausführung weiterer Angriffe oder anderer
illegaler Aktivitäten (wie dem Versand von Spam-Mails) verwendet wird. Diese Methode erschwert
die Ennittlung des ursprünglichen Versenders, denn dessen Herkunft kann nicht direkt ersehen
werden, und es müssen zu seiner Ermittlung mehrere Administratoren oder Gerichtsbarkeiten
zusammenarbeiten
2 Spit02
3 Naza03
286
18.1 Taktische Ansätze der direkten Beobachtung
Date <Month/Day5
Abbildung 18.1 Ausbreitungseigenschaften eines Windows-Wurms
First IP address outet
Abbildung 18.2 Zielauswahlalgonthmus des SQLSnake-Wurms (beachten Sie die ungleichförmige,
aber relativ vollständige Abdeckung des Adressraums)
287
18 Der Blick in die Leere
Abbildung 18.2 zeigt einen anderen Aspekt des Verbreitungsalgorithmus des Wurms: Sie
stellt die Eigenschaften des Zielauswahlalgorithmus dar. In diesem Fall scheint ein
verbreiteter Wurm, dessen Ziel Microsoft SQL-Server waren, eine ziemlich durchgängige
Verbreitung im Adressraum gefunden zu haben, auch wenn Adressen mit Oktetten
zwischen 200 und 225 erheblich öfter ausgewählt wurden, während Werte oberhalb von 225
vollständig übersprangen wurden.
Abbildung 18.3 zeigt dieselben Parameter für einen anderen Netzwerkwurm namens
Slapper. Dieser Wurm hatte sich Linux-Systeme als Opfer auserkoren, auf denen er einen
Fehler in einer behebten OpenSSL-Verschlüsselungsbibhothek ausnutzte. Der Algorithmus
scheint erheblich gleichförmiger zu arbeiten, aber die Erfassung ist weitaus weniger
durchgehend: In bestimmten Wertebereichen klaffen große Löcher.
ine ise
First IP address octet
Abbildung 18.3 Histogramm des Zielauswahlalgorithmus beim Slapper-Wurm. Es zeigt eine
wesentlich gleichförmigere Verteilung, aber die Erfassung ist nicht durchgängig. Die Lücken lassen darauf
schließen, dass die niederwertigen Bits aller .Zufallsadressen" konstant sind. Möglicherweise ein
Programmierfehler.
Abbildung 18.4 schließhch zeigt das Beharrlichkeitsrnuster eines Wurms im zeitlichen
Kontext. Einige Würmer scheinen zu sterben, weil Systeme mit Patches versehen und
desinfiziert werden, während andere Algorithmen verwenden, die plötzliche und sich
wiederholende Anstiegs- und Abfallmuster erzeugen. (Personen, die mit Bevölkerungs- oder Epi-
288
18.2 Die Abfallprodukte einer Attacke
demiologjemodellen, die auf natürlichen Phänomenen basieren, experimentiert haben,
werden mit diesen Mustern vertraut sein.)
700
600
500
o
| 400
g 300
200
100
t
\
l
J
h
^
\
-(
A
A
\
p«
■Hl
m
//'
-aaaa
V
Sfr^A
1 1 1
b-h Code Red
e=a
/
^7
Nimda (und Varianten)
A
s*H%r®4
AftABaA-B
k—H
\
B
18.09.
28.09.
08.10.
18.10.
28.10.
07.11.
Datum
Abbildung 18.4 Beharrlichkeit eines Wurms im zeitlichen Verlauf. Beachten Sie, dass hier keine
einfachen Berg-Tal-Muster für CodeRed vorhanden sind und dass das Modell sich wie ein biologisches
Bevölkerungsmodell verhält.
Wie Jose und seine Kollegen zu veranschaulichen beabsichtigen, ist das Black-Hole-
Monitoring unter Umständen nicht nur eine routinemäßige und möglicherweise
vollkommen nutzlose Aktivität, sondern eine tolle Möghchkeit, das geheime Leben aller bösen
Dinge zu entdecken. Aber das ist nicht das Ende vom Lied. Wenn wir närnlich nur den
Verkehl- betrachten, von dem wir annehmen, dass er an uns gerichtet ist, veipassen wir die
interessantesten Datenelemente.
18.2 Die Abfallprodukte einer Attacke
Die zweite Anwendungsrnöglichkeit des Black-Hole-Monitoring basiert auf der
Beobachtung von Daten, die ursprünglich gar nicht für uns gedacht waren, sondern nur ein
Abfallprodukt anderer Aktivitäten darstellen.
Hier können wir sehen, wie eine Reihe bekannter Reconnaissance- und Angriffsschernata
mithilfe des Adress-Spoofings die Identität des Angreifers zu enthüllen helfen. Wir setzen
voraus, dass ein Administrator Probleme haben wird, die von gefälschten Adressen
stammenden Täuschdaten von den eigentlichen Probes des Angreifers zu unterscheiden. Zwar
289
18 Der Blick in die Leere
habe ich schon in vorherigen Kapiteln gezeigt, dass dieser Ansatz dem Angreifer keine
vollständige Anonymität gewährt; um den gefälschten Datenverkehr erfolgreich zu
enttarnen, muss der Administrator zum Zeitpunkt des Angriffs umfassende
Protokollierangsund Zusatzmaßnahmen implementieren. Da dies aber nicht immer geschieht, können
Angreifer ihre Attacken häufig effizient kaschieren und selbst aus dem Rampenlicht bleiben.
Unabhängig davon, ob Pakete gefälscht sind oder nicht, wird das angegriffene System in
gutem Glauben auf alle Anfragen antworten - und damit auch auf diejenigen, die scheinbar
von fiktiven Adressen stammen. Allerdings landen nur die Antworten auf Pakete mit
korrekter Quelladresse wieder beim Absender; alle anderen Probes erzeugen Antworten, die
im gesamtem Internet verstreut werden. Und diese können wir oft abfangen.
Zwar mag es unwahrscheinlich erscheinen, dass wir ein solches fehlgeleitetes Paket
empfangen, aber erinnern Sie sich: Eine beträchtliche Anzahl von SYN+ACK-, RST+ACK-
und RST-Paketen wird als Reaktion auf Täusch-Scans oder Angriffe mit SYN-Flutung
erzeugt. Der Adressraum im Internet erscheint riesig: Normalerweise sind bei solchen
Angriffen Millionen von Paketen im Spiel, aber mit der Zeit steigt die Wahrscheinlichkeit,
dass jeder einzelne Netzwerkblock erreicht werden wird. Zwar beträgt die
Wahrscheinlichkeit, dass ein einzelnes, zufällig erzeugtes gefälschtes Paket an eine bestimmte Adresse
zuräckgeleitet wird, nur 1:4.294.967.296 (= 1:232); wenn man aber davon ausgeht, dass ein
normales kleines Subnetz, das einer kleinen Firma oder Organisation gehört, üblicherweise
256 Adressen umfasst (Klasse-C-Netzwerk oder gleichwertiges), dann erhöht sich die
Wahrscheinlichkeit auf 1:16.777.216 (1:224). Eine weitere Erhöhung ist möglich, indem
man Adressbereiche ignoriert, die bekanntermaßen für Sonderzwecke reserviert oder aber
auf andere Weise uninteressant sind und deswegen bei bestimmten Angriffstypen
ausgeschlossen werden.
Weil ein einzelnes SYN-Paket ca. 40 Bytes aufweist (und sich in Massen gut
komprimieren lässt) und eine nonnale Netzwerkanbindung, wie sie einem Gelegenheitshacker zur
Verfugung steht, einen Durchsatz von ca. 10 bis 150 Kbyte pro IP-Schicht pro Sekunde hat
(dies entspricht langsamen DSL-Verbindungen einerseits und Tl andererseits), kann er
250 bis knapp 3.000 Pakete in diesem Zeitrahnien hinausschicken. Dies entspricht einer
Rate von 900.000 bis etwa 10.000.000 Paketen pro Stunde.4
Damit eine typische DoS-Attacke spürbare Ergebnisse erzeugen und dem Opfer größere
Unannehmlichkeiten bereiten kann, muss sie normalerweise mehrere Stunden oder Tage
lang ausgeführt werden. (Der Angreifer will ja, dass die Störung für das Opfer möglichst
lang dauert.) Aufgrund dessen werden Dutzende bis Hunderte Millionen Pakete gesendet,
die eine ähnliche Anzahl von SYN+ACK- oder RST+ACK-Antworten erzeugen.
Angesichts dieser gigantischen Menge Daten ist es ziemlich logisch, davon auszugehen,
dass auch eine relativ kleine Entität die Nebenprodukte einer kleinen SYN-Flut bemerken
kann, auch wenn der Empfängerhost viele Angriffspakete einfach verwirft. Außerdem
Beachten Sie, dass der entschlossene und gewiefte Angreifer, der über viel Erfahrung in Sachen DoS-
Angriffe verfügt, oft über Dutzende oder Hunderte „Zombieknoten" verfügt, die auf seinen Befehl
hören und mit denen er die angegebenen Werte deutlich erhöhen kann.
290
18.3 Wie man verstümmelte oder fehlgeleitete Daten erkennt
würden auch Administratoren, die Klasse-B-Netzwerke (mit 65.536 Adressen, meist im
Besitz größerer Unternehmen, Internetprovider, Forschungseinrichtungen usw.)
überwachen können, relativ schnell viele kleinere Ereignisse erkennen.
Weil all diese „Restantworten" einer DoS-Attacke auf Spoofmg-Basis bestimmte Details
der Nachrichten enthalten, die der Angreifer ursprünglich erstellt hat, um diese Antworten
auszulösen (z. B. Port- und Sequenznummem, Zeitangaben usw.), können wir ihnen
wichtige Informationen zu Typ und Ausmaß des Angriffs entnehmen. Anhand der Antworten
können wir bestimmen, ob ein bestimmter Dienst das Ziel war, wie viele Systeme ins
Visier genommen worden waren, wie viel Bandbreite dem Angreifer zur Verfügung steht und
mit welchem Tool er die Attacke durchgeführt hat. (Hierzu überprüfen wir die Auswahl
der Quellports, die ausgesuchten Sequenznummem und die „zufälligen" IP-Muster.5)
Schließlich bemerken wir bei der Analyse der Absender dieser „Querschläger" unter
Umständen, dass ein bestimmtes Netzwerksegment aufs Kom genommen wird, oder können
eventuell globale „Feindseligkeitstendenzen" erkennen, welche uns eine bessere
Vorbereitung ermöglichen könnten, wenn ein bestimmter Markt oder ein bestimmtes Unternehmen
das Ziel sind. Außerdem können wir mithilfe dieser Informationen mehr zu Angriffen
erfahren, die vom Opfer aufgedeckt wurden, oder falsche Angriffsbehauptungen erkennen.
(Dies sind Behauptungen von Cybertenoristen, die angeben, dass bestimmte Ziele gerade
angegriffen werden; es handelt sich dabei meist um einen PR-Trick, um finanzielle
Verluste zu rechtfertigen oder eine bestimmte politische Forderung auf die Tagesordnung zu
setzen.0)
18.3 Wie man verstümmelte oder fehlgeleitete Daten
erkennt
Diese Anwendung des Black-Hole-Momtorings basiert auf der Überwachung von Daten,
die vermeintlich sinnlos sind, aber trotzdem einen bestimmten Empfänger zu erreichen
scheinen. Um das Problem besser veranschaulichen zu können, lassen Sie mich kurz
abschweifen.
Im Jahr 1999 stalteten ein paar Freunde von mir, Kollegen in Polen und ich ein kleines
Feierabendprojekt. Ziel war es, eine schwer zu definierende Menge von RST+ACK-
Paketen zurückzuverfolgen, die wir in Netzwerken, die von uns administriert wurden,
bemerkt hatten, und ganz allgemein ungewöhnliche und unangeforderte Datenmuster zu
beobachten, die in ungenutzten Netzwerksegmenten eintrafen. Es machte einen Riesenspaß
Beispielsweise falschen einige Tools aufgrund von Programmierfehlem nur Pakete mit gerad- oder
ungeradzahligen IP-Adressen. Analysen wie die von Jose Nazario und anderen durchgeführten sind irn
Erkennen von Angriffstools meist ebenso gut wie im Identifizieren von Würmern.
Kürzlich erst beschuldigten einige Fachleute SCO, ihre Server offline zu nehmen und so zu tun, als
wären sie einer koordinierten DoS-Attacke zum Opfer gefallen; Grund für dieses Verhalten sei eine
Diskreditierung der Linux-Community.
291
18 Der Blick in die Leere
und fühlte, wie Sie sich vielleicht vorstellen können, zu einem gerüttelt Maß an
Spekulationen, als wir versuchten, einige der befremdlichsten Fälle zu klären. Unsere Forschungen
erlaubten es uns auch, niehr über die Welt um uns herum zu erfahren, weil wir auf einige
überaus absonderliche und scheinbar unerklärliche Daten trafen, die uns - nachdem wir sie
anständig analysiert hatten - mehr Einsicht in die gigantischen Verschwörungen unserer
verdrahteten Welt gewährten.
Zwar wurde das Rojekt formal eingestellt, es endete aber trotzdern in meinem privaten
„Museum der zerbrochenen Pakete"7, eine halb scherzhaft gemeinten Webseite, die sich
dem Aufspüren, Dokumentieren und Erläutern von Paketen widmet, die niemals ihren
Empfänger hätten erreichen oder aber niemals so aussehen dürfen, wie sie es taten. Ich
habe das Museum wie folgt beschrieben:
Zweck dieses Museums ist es, eigenartigen, unwillkommenen und missgestalteten
Paketen - verirrte und verwunschene Launen der Natur —, die wir armen Sterblichen auf
den verzweigten Pfaden unserer großen Reise (Leben genannt) antreffen, Schutz zu
gewähren. Unsere Exponate - Sie dürfen sie auch Bewohner nennen - sind häufig nur
mehr ein Schatten dessen, was sie waren, bevor sie auf einen feindlich gesonnenen,
kaputten Router trafen. Einige von ihnen wurden bereits als Freaks in den Tiefen einer
defekten Implementierung des IP-Stapels geboren. Andere waren einst normale Pakete
- so normal wie ihre Freunde (also Sie oder ich) —, gingen aber auf der Suche nach der
elementaren Bedeutung ihrer Existenz verloren und gelangten dorthin, wo niemals ein
Auge sie hätte schauen dürfen. In jedem Fall versuchen wir, die einzigartige
Lebensgeschichte all dieser Pakete zu enträtseln, und wollen Ihnen helfen, zu verstehen, wie
schwer es sein kann, ein einsamer Bote im feindlichen Universum der Bits und Bytes zu
sein.
Und genau das ist es, worauf sich der letzte Typ des Black-Hole-Monitorings reduzieren
lässt. Zwar mag die Aufgabe anfangs sinnlos erscheinen, aber genau dies zu glauben ist
absolut töricht. Das Museum ermöglichte es, auf passive Weise dunkle Geheimnisse
proprietärer Geräte und gut geschützter Netzwerke zu lösen. Und wenn man ein solches
Experiment an anderer Stelle ausfühlte, würde es zweifelsohne zur selben oder noch größerer
Vollendung gelingen.
Einige der Exponate in meinem Museum sind wahre Wunder. So etwa die folgenden:
■ Pakete, die aus Netzwerken stammen, in denen bestimmte Formen von Webbeschleu-
nigern, Routern oder Firewalls eingesetzt werden. Solche Geräte hängen einige Daten
einfach an, löschen andere oder verstümmeln sie auf irgendeine andere Weise. Ein
gutes Beispiel ist ein Fehler in bestimmten Nortel CVX-Geräten, der dafür verantwortlich
ist, dass TCP-Header gelegentlich aus Paketen entfernt werden (davon war in Kapitel
11 bereits die Rede). Die Einmaligkeit eines solchen Fehlere gestattet es uns, eine
Menge über eine Anzahl entfernter Netzwerke zu erfahren, ohne dass wir sie erst
sondieren rnüssten.
Museuin of Brokea Packets, http://lcamtuf.corediimp.cx/mobp.
292
18.4 Denkanstöße
■ Einige aus Leitungsrauschen bestehende Exponate, die Pakete offenbaren, welche
entweder völligen Datenmüll oder aber Daten enthalten, die gewiss nicht zu einer
bestimmten Verbindung gehörten. Eines der außergewöhnlichsten Ausstellungsstücke ist
unangeforderter Datenverkehr, der einen Dump des Inhalts der DNS-Zone .de darstellt
(eine Auflistung aller Domänen in Deutschland). Die Daten konnten nicht von
irgendwoher stammen, weil gewöhnliche Sterbliche nicht das Recht haben, eine solche Liste
zu besitzen. Sie muss also von irgendeiner befugten Stelle kommen, die in der Position
sein muss, solche Daten zu besitzen und zu übertragen. Die Verstümmelung muss
entweder beim Absender oder bei einem Gerät irgendwo im Pfad erfolgt sein. Obwohl alle
Fälle nur wenig Licht auf das Wesen von Pannen im Netzwerk werfen, beglücken
derartige Fälle den Beobachter häufig mit unerwarteten - und oft weitvollen -
Erkenntnissen.
Weitere bemerkenswerte Exponate sind Fälle offensichtlicher Spionage, die als regulärer
Datenverkehr getarnt waren, und viele andere kleinere Prograrnrnier- oder
Netzwerkprobleme. Doch genug der Angeberei - wenn Sie sich veranlasst sehen, rnehr herauszufinden,
besuchen Sie http://lcamtuf.coredump.cx/mobp/.
18.4 Denkanstöße
Viele betrachten Black-Hole-Monitoring nur als weitere (und im Übrigen - angesichts der
Ressourcenknappheit im öffentlichen IP-Adressraum - recht teure) Möglichkeit, Angriffe
gegen ihre Systeme aufzudecken. Der wahre Wert dieser Methode besteht jedoch darin,
dass sie nicht nur die Erkennung bekannter Angriffe ermöglicht - etwas, das man auch
genauso gut an vielen anderen Standorten machen kann, ohne IP-Raum zu verschwenden -,
sondern auch die Identifikation und Analyse subtiler Muster gestattet, die andernfalls in
einem umfassend genutzten Netzwerk unterhalb der „Rauschschwelle" verschwinden
würden.
Natürlich ist diese Art des Black-Hole-Monitorings nicht ganz einfach dmchzuführen und
zudem recht kostspielig. Es dauert seine Zeit, zu erlernen, wie man diese Nadel im
Heuhaufen der normalen Wurm- und Black-Hat-Aktivitäten findet, die in einem ausreichend
großen Netzwerk normalerweise keine andere als nur statistische Bedeutung haben.
Doch der Spaß, diese Nadel schließlich zu finden, ist oft genug einen Versuch wert.
293
Literatur
[Arki03] O. Arkin, J. Anderson: EtherLeak: Ethernet Frame Padding Information Leaks.
@Stake, 2003. http://www. atstake. com/research/advisones/2003/atstake_etherleak_
repoti.pdf
[Bakh95] S. Bakhtiari, R. Safavi-Naini, J. Pieprzyk: Cryptographic Hash Functions: A Survey.
Centre for Computer Security Research, Department of Computer Science, Univer-
sityof Wollongong (Australien), 1995.
[Bank03] N. N.: PSYLock: A typing behaviour based psychometrical authentication method.
Institut für Barikinnovation GmbH, 2003. http://pc50461.uni-regensburg.deäbi/de/
leistungen/research/projekte/einzelprojekte/psylockenglish.htm
[BaraOl] A.-L. Barabasz, V. W. Freeh, H Jeong, J. B. Brochman: Parasitic Computing.
Leserbeitrag in Nature Nr. 412, 2001.
[Bell96] S. Bellovin: RFC 1948: Defending Against Sequence Number Attacks. NetworkWor-
king Group, 1996. http://www.ietf.org/ifc/rfcl948.txt
[Bem92] T. Bemers-Lee: Basic HTTP. 1992. http://www.w3c.org/Protocols/HTTP/
HTTP2.html
[Biha96] E. Biham, A. Shamir: Differential Fault Analysis: Identifying the Structure of
Unknown Ciphers Sealed in Tamper-Proof Devices. 1996.
[Bing88] J. A.C. Bingham: The Theory and Practice of Modem Design. Wiley-Interscience,
1988.
[BoiiOl] N. Borisov, I. Goldberg, D. Wagner: Intercepting Mobile Communications: The
Insecurityof 802.11. 2001.
[BoucOO] A. Bouch, A. Kuchinsky, N. Bhatti: Quality Is in the Eye of the Beholder: Meeting
Users' Requirements for Internet Quality of Service. CHI, 2000.
[Brad89] R. Braden (Hrsg.): RFC 1122: Requirements for Internet Hosts: Communication Lay-
ers. Network Working Group, 1989.
[Brad94] B. Braden: RFC 1644: T/TCP - TCP Extensions for Transactions - Functional
Specification. Network Working Group, 1994.
[brunOO] H Bninch, B. Cheswick: Tracing Anonymous Packets to Their Approximate Source.
2000. http://www. usenix. org/publications/library/proceedingsäisa2000/burch/
burch.html
[Bush45] V. Bush: As We May Think. Atlantic Monthly 176, Nr. 1, 1945. S. lOlff.
[Case90] J. Case, M. Fedor, M. Schoffstall, J. Davin: RFC 1157: A Simple Network
Management Protocol. Network Working Group, 1990.
[ChesOO] B. Cheswick H. Burch, S. Branigan: Mapping and Visualizing the Internet. 2000.
http://mvw.cheswick.com/ches/papers/mapping.ps.gz
[Cryp03] N. N.: Evaluation of VIA C3 Nehemiah RandomNumber Generator. Cryptography
Research Inc., 2003.
[Eck85] W. van Eck: Electromagnetic Radiation from Video Display Units:
An Eavesdropping Risk? PTT Laboratories, Niederlande, 1985.
[EIA91 ] N.N.: Interface Between Data Terminal Equipment and Data Circiüt-Terrninating
Equipment Employing Serial Binary Data Interchange. Electronic Industries
Association, Engineering Department, 1991.
[FeltOO] E. Feiten, M. Schneider: Timing Attacks on Web Privacy. ACM Conference on
Computing and Communications Security, 2000.
[Fiel99] R. Fielding, J. Gettys, J. Mogul, H. Frystyk L. Masinter, P. Leach, T. Berners- Lee:
RFC 2616: HyperText Transfer Protocol - HTTP/1.1. Network Working Group,
1999.
[HogyOl] M. A. Hogye, C. T. Hughes, J. M. Sarfaty, J. D. Wolf: Analysis of Feasibility of
Keystroke Timing Attacks Over SSH Connections. CS588 Research Project, School
of Engineering and Applied Science, University of Virginia, 2001.
[Inte86] Intel 80386 Programmer's Reference Manual, Abschnitt 7.2, IMUL. Intel
Corporation, 1986.
[IS099] ISO/IEC-Standard 9899: Programming Language - C. 1999. http://plg.uwaterloo.ca/
~cforalUN843.ps
[Jaco92] V. Jacobson, B. Braden: RFC 1232: TCP Extensions for High Perfonnance. Network
Working Group, 1992.
[Jun99] B. Jun, P. Kocher: The Intel Random Number Generator. Cryptography Research
Inc., 1999.
[Knut97] Donald E. Knuth: The Art of Computer Programming, Volume 2: Seminumerical
Algorithrns. 3. Auflage, Addison-Wesley, 1997.
[KochOO] P. Kocher, J. Joffe, B. Jun: Differential Power Analysis. Cryptography Research,
Inc., 2000.
[Koch99] P. Kocher: Timing Attacks on Implementations of Diffie-Hellman, RSA, DSS, and
Other Systems. Cryptography Research Inc., 1999.
[Kraw92] H. Krawczyk: How to Predict Congruential Generators. Journal of Algorithrns 13,
Nr. 4, 1992.
[Kris97] D. Kristol, L. Montulli: RFC 2109: HTTP State Management Mechanism. Network
Working Group, 1997.
[Leec03] M. Leech: RFC 3607: Chinese Lottery Cryptoanalysis Revisited. Network Working
Group, 2003.
[Lugh02] J. Lughry, D. A. Umphress: Information Leakage from Optical Emanations. In: ACM
Trans. Info. Sys. Security 5, Nr. 3, 2002.
[Mairn96] U. Maimon: TCP Port Stealth Scanning. Phrack Magazine Nr. 49,1996.
[Mart86] G. Martin, K Corl: System Response Tirne Effects on User Productivity. Behaviour
and Infoimation Technology, Vol. 5, Nr. 1,1986. S. 3ff
[Math96] M. Mathis, J. Mahdavi, S. Floyd, A. Romanow: RFC 2018: TCP Selective Acknow-
ledgment Options. Network Working Group, 1996.
[Maur94] Ueli M. Maurer: Fast Generation of Prime Numbers and Secure Public-Key Cryp-
tographic Parameters. Institute for Theoretical Computer Science, ETH Züiich, 1994.
[Merk93] R. C. Merkle: Two Types of Mechanical Reversible Logic. In: Nanotechnology 4,
1993.
[Mile02] M. Milenkovic, A. Milenkovic, J. Kulick: Demystifying Intel Branch Predictors.
Electrical and Computer Engineering Department, University of Alabama in Hunts-
ville, 2002.
[Moba99] B .Mobasher, R. Cooley, J. Srivastava: Automatic Personalization Based on Web
Usage Mining. ACM Communications Vol. 43, Nr. 8,1999. S. 142ff
[Mogu90] J. Mogul, S. Dearing: RFC 1191: Path MTU Discovery. Network Working Group,
1990.
[Morr85] R. Monis: A Weakness in the 4.2BSD UNIX TCP/IP Software. AT&T Bell
Laboratories, 1985.
[Murp97] I. A. Murphy: Who's Listening? IAM/Secure Data Systems, 1988/97.
[Naza03] J. Nazario: Defense and Detection Strategies against Intemet Worms. Artech House,
2003.
[Niel96] J. Nielsen: Top Ten Mistakes in Web Design. 1996. http://www.useit.com/aleribox/
9605.html
[Niel97a] J. Nielsen: TheNeed for Speed. 1997. http://www.useit.com/alertbox/9703a.html
[Niel97b] J. Nielsen: Changes in Web Usability Since 1994. 1997. http://vAvw.useit.com/
alertbox/9712a. html
[Niel99] J. Nielsen: The Top Ten New Mistakes of Web Design. 1999. http://www.useit.com/
alertbox/990530. html
[OlssOO] M. Olsson: Extending the FTP ALG Vulnerability to any FTP client. VULN-DEV-
Mailingliste, 2000. http:/Avww.securityfocus.com/archive/82/50226
[Plum82] D. C. Plummer: RFC 826: An Ethernet Address Resolution Protocol. Network
Working Group, 1982.
[PoolOO] M. Pool: Privacy Problems with HTTP Cache-Control. Bugtraq, 2000. http://
ceri.uni-stuttgart.de/archive/bugtraq/2000/03/msg00365.html
[Post80] J. Postel: RFC 768: User Datagram Protocol. Network Working Group, 1981.
[Post81a] J. Postel: RFC 791: Internet Protocol. Network Working Group, 1981.
[Post81b] J. Postel: RFC 796: Address Mappings. Network Working Group, 1981.
[Post81 c] J. Postel: RFC 793: Transmission Control Protocol. Network Working Group, 1981.
[Post81d] J. Postel: RFC 792: Internet Control Message Protocol. Network Working Group,
1981.
[Post85] J. Postel, J. Reynolds: RFC 959: File Transfer Protocol. Network Working Group,
1985.
[Post88] J. Postel, J. Reynolds: RFC 1042: A Standard for the Transit of Internet Protocol
Datagrams Over IEEE 802 Networks. Network Working Group, 1988. http://
■www. ietf.oig/ifc/ifcl 042. txt
[Raym96] E. S. Raymond: The New Hacker's Dictionary. 3. Auflage. MIT Press, 1996.
[Rive78] R. L. Rivest, A. Shamir, L. Adleman: A Method for Obtaining Digital Signatures and
Public-Key Cryptosystems. Massachusetts Institute of Technology, 1978.
[Rogo98] J. Rogozhin: A Universal Turing Machine with 22 States and 2 Symbols. In:
Rornanian Journal of Information Science and Technology 1 Nr. 3,1998.
[Sanf98] S. Sanfilippo: New TCP Scan Method. Bugtraq, 1998. http://seclists.org/bugtraq/
1998/Dec/0082.html
[Schw96] W. Schwartau: Information Warfare. 2. Auflage, Thunder's Mouth Press, New York,
1996.
[Sene02] L. Senecal: Layer 2 Attacks and Their Mitigation. Cisco, 2002.
[Sham04] A. Shamir, E. Tromer: Acoustic Cryptanalysis: On Nosy People and Noisy Machines.
2004. (Vorabpräsentation zum Zeitpunkt der Abfassung dieses Buches verfügbar
unter http:/Avww. msdom. weizmann. ac. il/~t)-omer/acoustic/).
[Shan50] C. E. Shannon: Prediction and Entropy of Printed English. Bell Systems Technical
Journal 3,1950.
[SolaOl] Solar Designer, D. Song: Passive Analysis of SSH (Secure Shell) Traffic. Openwall
Project, 2001. http:/Avww.openwa!.Lcom/advisories/OW-003-ssh-trqffic-analysis
[SongOl] D. X Song, D. Wagner, X Tian: Timing Analysis of Keystrokes and Timing Attacks
on SSH University of California, Berkeley, 2001.
[Spit02] L. Spitzner: Honeypots: Tracking Hackers. Addison-Wesley Publishing Company,
2002.
[SpurOO] C E. Spurgeon: Ethernet: The Definitive Guide. O'Reilly & Associates, 2000.
[Stew02] J. Steward: DNS Cache Poisoning: the Next Generation. 2002. http://
ivww. lurhq.com/dnscache.pdf
[Turi36] A. Turing: On Computable Numbers, with an Application to the
Entscheidungsproblem. Proceedings of the London Mathematical Society, 1936.
[W3CoA] World Wide Web Consortmin, o. A. http://www.Mi3c.org/History.html
[ZaleOl] M. Zalewsiä: Strange Attractors and TCP/IP Sequence Number Analysis. Bindview
Corporation, 2001. http://www.bindview.com/Support/RAZOR/Papers/2001/
[ZaleOla] M. Zalewsiä: Linux Kernel IP Masquerading Vulnerability. Bindview Corporation,
2001. http://razor.bindview.conifyublish/advisories/adv_LkIPniasq.htnil
[Ziem95] G. Ziemba, D. Reed, P. Traina: RFC 1858: Security Considerations for IP Fragment
Filtering. Network Working Group, 1995.
[ZwicOO] E. D. Zmcky, S. Cooper, D. Brent Chapman: Building Internet Firewalls. O'Reilly &
Associates, 2000.
Nachwort
Mit dem dieses Buch schließt
Hier endet dieses Buch, aber ich hoffe, dass Ihre Reise hier erst anfangt. Stolz habe ich
Ihnen die Welt komplexer und ungewöhnlicher Sicherheitsprobleme präsentiert, an denen
ich selbst am meisten Spaß habe, und ich wünsche mir, Sie mit meiner Leidenschaft
angesteckt zu haben. Es spielt keine Rolle, ob Sie ein pfiffiger Sicherheitsexperte sind -
vielleicht einer mit rnehr Erfahrung und Beschlagenheit als ich - oder einfach ein Enthusiast,
der ein neues Betätigungsfeld für sich entdeckt: Ich hoffe, dass ich Ihnen eine neue
Perspektive zum Sicherheitsbereich vermitteln konnte - als Herausforderung, aber auch als
Kunst an und für sich und nicht nur als eine Anzahl von Hindernissen, die beseitigt oder
umgangen werden müssen.
Wenn man die subtilen Beziehungen zwischen scheinbar beziehungslosen Komponenten
und Prozessen versteht, kann man die meisten gefährlichen und tückischen
Sicherheitsprobleme effizient beheben und die täglichen Risiken effektiver bewerten und mindern.
Sicherheitsprobleme sollten - egal, wie trivial oder beschränkt sie auch sein mögen - als
Funktion einer Lösung für praktisch alle Herausfordeningen in der Welt der IT und nicht
als widrige Umstände betrachtet werden, die gute Geschäfte beeinträchtigen. Nur dann,
wenn man den Zauber und Channe erkennt, der diesen einander ergänzenden Universen
und ihrer subtilen Interaktion innewohnt, kann man Routine vermeiden und wirklich Spaß
bei der Arbeit gewinnen oder sein Hobby genießen.
Aber jetzt ist es weder der richtig Ort noch die passende Zeit für großes Pathos.
Danke fürs Mitmachen.
295
Register
A
Address Resolution Protocol
siehe ARP 110
Angreifer
identifizieren 249
Angriffe
analysieren 249
Anzeigegeräte 61
Berechnungskomplexität
29
Emission 61
Ethernet 114
Funkfrequenzen 61
Metriken 250
Netzwerkgeräte 75
webbasierte 67
Webcrawler 67
Anzeigegeräte 61
TEMPEST 62
ARP (Address Resolution
Protocol) 110
Assoziativspeicher
siehe CAM 111
Attraktor 181
verwenden 189
Athibutierung 64
Autonegotiation 115
Autonome Systeme 132
Autorensysteme 64
B
Backbone-Router 132
Berechnungskomplexität 29
BGP (Boundary Gateway
Protocol) 132
Black-Hole-Monitoring 285
Anwendungen 285
Blinding 59
Blinkehlichten 75
Boolesche Logik 29
Umsetzung 34
Bots 67
Boundary Gateway Protocol
siehe BGP 132
Browser
identifizieren 227
Bündelung siehe Trunking
112
c
Cache 236
CAIDA (Cooperative
Association for Internet
Data Analysis) 275
CAM (Content Addressable
Memory) 111
Überlauf 114
Carrier Sense Multiple
Access with Collision
Detection siehe CSMA/CD
86
Clamping siehe MSS 208
Clients
identifizieren 227
Computer
mechanischer 34
Prograrnmierbarkeit 44
Speicher 48
Connection Hij acking 168
Content Addressable
Memory siehe CAM 111
Cookies 238
Cooperative Association for
Internet Data Analysis
siehe CAIDA 275
CSMA/CD (Carrier Sense
Multiple Access with
Collision Detection) 86
D
Daten
Herkunft ermitteln 278
Datenübertragung
analoge 78
Dibits 81
DSL 84
Ethernet 86,103
FSK 79
Geschichte 79
Grundlagen 75
Hubs 89
Kollisionen 86
Manchester-Kodierung
77
Modems 78
NRZ 76
QAM 83
Routing 131
RS-232 85
Switches 89
USB 85
DeMorgans Gesetz 30
Anwendung 31
Denial of Service siehe DoS
278
despoof 279
DF-Flag (Don't Fragment)
155,210
Dibits 81
Diensttyp 137,156
Differential Phase Shift
Keying siehe DPSK 80
Differentielle Phasen-
umtastung siehe DPSK 80
Digital Subsciiber Line
siehe DSL 78
Dokumente
Metadaten 64
DoS (Denial of Service)
278
DPSK (Differential Phase
Shift Keying) 80
DRAM (Dynamic RAM)
48
Drei-Schiitte-Handshake
145
DSL (Digital Subscriber
Line) 78,84
DTP (Dynamic Trunking
Protocol) 112
Autonegotiation 115
E
Early-Out-Optirnierung 55
Emission 61
Entropie 11,13
erzeugen 15
Pool 15
Puffer 24
Erfüllbarkeitsgleichungen
siehe SAT-Gleichungen
261
Ethernet 103
Adressierung 104
CSMA/CD 86
Fülldaten 106
Grundlagen 110
Hubs 89
Kollisionen 86
Mängel 119
Sicherheit 109
Switches 89
Tags 112
Trunking 112
F
File Transfer Protocol
siehe FTP 204
Fingerprinting
passives 154,173,250,
Firewalls 197
Grundlagen 198
zustandsbehaftete 202
zustandslose 199
Flipflop 40
Fragmentierung 139,199
Frequency Shift Keying
siehe FSK 79
Frequenzumtastung
siehe FSK 79
FSK (Frequency Shift
Keying) 79
FTP (File Transfer Protocol)
204
Fülldaten 106
Funkfrequenzen 61
Funknetze
WEP 124
Wi-Fi 123
G
GUTD (Globally Unique
Identifier) 64
H
Handshake
Drei- Schritte-Handshake
145
Hashing-Funktionen 16
Hidden Markov Model siehe
Verborgenes Markow-
Modell 22
HMM (Hidden Markov
Model) 22
HTML (HyperText Markup
Language) 231
HTTP (HyperText Transfer
Protocol) 231
Cookies 238
Erweiterungen 234
Grundlagen 232
Header 233,237
sequenzieller Datenabruf
235
Hubs 89
HyperText Markup
Language siehe HTML
231
HyperText Transfer Protocol
siehe HTTP 231
I
ICMP (Internet Control
Message Protocol)
Grundlagen 152
Header 153
Idle-Scanning 221,223
Abwehr 225
Impulsdehnung 97
Inhaltsadressierbarer
Speicher siehe CAM 111
Initial Sequence Number
siehe ISN 176
Register
Internet
Adressierung 132,143
kartographieren 275
Protokolle 130
Routing 130
Topologie 275
WWW 227
Internet Control Message
Protocol siehe ICMP 152
Internet Protocol
siehe IP 105
Interrupt 13
IP (Internet Protocol) 105
Adressen 110
Adressraum 132
Aufbau 135
Flags 139,155,210
Fragmentierung 139,
199
Grundlagen 135
Header 135
Kennung 141,221,224
Netzmasken 134
Offsets 139
Schwächen 141
TTL 138,155,278
IRQ (Interrupt Request)
siehe Interrupt 13
ISN (Initial Sequence
Number)
ermitteln 177
Überblick 176
ISNProber 193
L
LAN (Local Area Network)
Funknetze 123
Risiken 119
Sicherheit 109,119
virtuelles 112
Lastausgleichssysteme 203
LED-Anzeigen 75,90
Leitungsbündelung
siehe Trunking 112
Logik
Boolesche 29,34
Gatter 36
Tmingmaschine 42
Wahrheitstabellen 31
Logikgatter 36
M
MAC-Adresse (Media
Access Control) 104
Manchester-Kodierung 77
Masquerading 158,203
Risiken 206
Maximum Segment Size
siehe MSS 150
Maximum Transmission
Unit siehe MTU 137
Media Access Control
siehe MAC-Adresse 104
Message-Digest-Rinktionen
16
Metadaten 64
Microsoft Word 64, 65
Modems 78
interne vs. externe 85
MSS (Maximum Segment
Size) 150,160,207
Clamping 208
MTU (Maximum
Transmission Unit) 137
N
NAT (Network Address
Translation) 197,203
Netzadressübersetzung
siehe NAT 197
Netzbelastungsaiialyse 282
Netzmasken 134
Netzwerke
Adressauflösung 110
Anomalien 197
Architektur 114
Belastungsanalyse 282
Black- Hole-Monitoring
285
Ethernet 109
LANs 109
Masquerading 158,203
Switching 110
Topologie 275
Triangulation 280
VLAN 112
Netzwerkgeräte 75
Non-Return-to-Zero
siehe NRZ 76
NP-Problem (nicht-
polynomisches Problem)
260
NRZ (Non-Return to Zero)
76
K
Kollisionen 86
Kryptografie 9
mit öffentlichen
Schlüsseln 9
Pseudoprimzahlen 11
RSA 9
unidirektionale 16
o
Oföceprograrnme 64
Open Systems
Interconnection siehe OSI
Modell 104
Operatoren
AND 30
NAND 32
NOR 32
NOT 30
OR 30
XOR 37
OSI-Modell (Open Systems
Ihterconnection) 104
Overlapping Fragment
Attack 199
P
pOf 161,215
Padding siehe Fülldaten
106
Paketfilter
zustandsbehaftete 202
zustandslose 199
Parasitic Computing 259
Abwehr 273
Anwendung 273
Praxis 263
Parasitic Storage 259,265
Passives Fingeiprinting 250
Abwehr 166,194
Attraktoren 192
Geschichte 154
Grundlagen 154
Metriken 155
Praxis 161
Vor-/Nachteile 173
Vorbeugung 166, 194
Path Maximum
Transmission Unit
siehe PMTU 139,207,
210
Pipelining 49
Probleme 50
Verzweigungsprognose
51
PMTU (Path Maximum
Transmission Unit) 139,
207,210
Portadressierung 143
Port-Scanning 250
Idle-Scanning 222
PRNG (Pseudo Random
Number Generator) 12
Prozessor
Register 41
Prüfsurnme 141
Pseudo Random Number
Generator siehe PRNG 12
Pseudoprhnzahlen 11
Pseudozufallszahlen-
generatoren siehe PRNG
12
Q
QAM (Quadrature
Amphtude Modulation)
83
R
Reconnaissance 173
Register 41
Return-to-Zero
siehe RZ 100
Röhrenmonitore 61
TEMPEST 62
Routing
Advertisements 210
Backbone-Router 132
Grundlagen 131
IP-Adressen 132
Praxis 132
RS-232 85
RSA-Algorithiuus 9
RZ (Return-to-Zero) 100
s
SAT-Gleichungen
(Satisfiability) 261
Schlüssel
öffentliche und geheime 9
Schnittstellen
RS-232 85
Sequenznummern 176
Server Message Block
siehe SMB 123
Sicherheit
Tastaturaktivitäten 7
Simple Network
Management Protocol
siehe SNMP 121
Skitter 276
SMB (Server Message
Block) 123
SNMP (Simple Network
Management Protocol)
121
Spanning Tree Protocol
siehe STP 113
Speicher 48
DRAM 48
SRAM 48
Speicherlecks 66
Spoofmg 275
erkennen 278
SRAM (Statte RAM) 48
Staging 47
STP (Spanning Tree
Protocol) 113,115
Switches 89,110
SYN-Cookies 201
T
Tags 64
Tastatur
abhören 23
Bediencharakteristika 21
Funktionsweise 14
überwachen 7
Tastaturaktivitäten 7
TCP (Transmission Control
Protocol)
Dringlichkeitszeiger 150
Flags 145, 149
Grundlagen 144
Handshake 145
Header 144,215
ISNs 176
MSS 150,160,207
Optionen 150,159
Register
TEMPEST (Transient
Electromagnetic Pulse
Emanation Standard) 62
Textverarbeitungs-
progranime 64
Speicherlecks 66
Time-to-Live siehe TTL
138
Tirning-Angriffe
Rechenkomplexität 53
tastaturbasierte 7
Topologie 275
Triangulation 280
TOS (Type of Service)
siehe Diensttyp 137
traceroute 138
Transient Electromagnetic
Pulse Emanation Standard
siehe TEMPEST 62
Transmission Control
Protocol siehe TCP 144
Triangulation 280
TRNG (True Random
Number Generator) 25
Trunking 112
TTL (Time-to-Live) 138,
155,278
Turingmaschine 42
universelle 44
Type of Service
siehe Diensttyp 137
u
UDP (User Datagram
Protocol)
Grundlagen 142
Header 144
Ports 143
Universal Serial Bus
siehe USB 85
Universelle Turmgmaschine
44
USB (Universal Serial Bus)
85
User Datagram Protocol
siehe UDP 142
UTM siehe Universelle
Tiirmgmaschine 44
V
Verborgenes Markow
-Modell 22
Verhaltensanalyse 227,250
Anwendungsvorschläge
246
Definition 229
Praxis 242
Verkürzung siehe Hash-
Funktionen 17
Verschlüsselung
siehe Kryptografie 9
Verzweigungsprognosen 51
Virtual LAN siehe VLAN
112
Virtual Private Network
siehe VPN 120
Viterbi-Algorithmus 22
VLAN (Virtual LAN) 112
Trunking 112
VPN (Virtual Private
Network) 120
w
Wahrheitstabellen 31
Webcrawler 67
WEP (Wired Equivalent
Privacy) 124
Wi-Fi (Wireless Fidelity)
123
World Wide Web siehe
WWW 227
Cache 236
Geschichte 230
z
Zeitverzögerte Koordinaten
179
Zufälligkeit siehe Entropie
11
Zufallszahlen 8
erzeugen 11,25
Generatoren 12,25
Hardwaregeneratoren 25
PRNGs 12
Sicherheit 7
Zwischenspeicher siehe
Cache 236
305
WISSEN, WIE HACKER TICKEN //
■ Zeigt als bislang einziges Buch wenig beachtete Schwachstellen der
Datenkommunikation auf
■ Deckt alle Phasen und Verfahren heutiger Datenkommunikation in
Netzwenken ab
■ Dokumentiert das „Hacker'-Denken sowie nicht alltägliche und deshalb
besonders gefährliche Bedrohungen
\
STILLE IM NETZ // Wer sich mit Fragen der Sicherheit von Netzwerken und der
Datenkommunikation beschäftigt, findet Unmengen an Büchern, die sich entweder
mit den bekannten Hackingszenarien beschäftigen oder sich auf Viren, Trojaner
und Würmer beschränken.
„Stille im Netz" ist anders. Hacker suchen oft nach dem Weg des geringsten
Widerstandes oder nicht alltäglichen Angriffsszenarien. Diese finden sie genau
dort, wo das Wissen um mögliche Gefahren fehlt Deshalb liefert das Buch keine
fertigen Lösungen für konkrete Gefahren und wiegt den Leser nicht in absoluter
Sicherheit denn die ist illusorisch.
Es erklärt vielmehr, wie Hacker denken, wo und wie sie nach Lücken in Systemen
suchen, welche Gefahrentypen es gibt und weshalb sie gefährlich werden können.
Ziel ist es, den Leser dafür zu sensibilisieren, Bedrohungen zu erkennen und
adäquat darauf zu reagieren. Denn nur wer sich in die Logik des Hackers
hineinversetzt so Zalewskis Überzeugung, kann Angriffe wirklich effektiv abwehren.
Ein hochinformatives Buch, das für manchen Aha-Effekt sorgt und zeigt wie man
sich winksam schützt
// Excellentl This is one that I would dub a must-read for anyone working directly with
network security // Tom Bradley, netsecurity.aboutcom
michal ZALEWSKI, der sich seit seiner Jugend mit nahezu allen Aspekten der
Computersicherheit beschäftigt hat als Sicherheitsfachmann für verschiedene
Unternehmen in den USA und seiner Heimat Polen gearbeitet. Er ist anerkannter
Fachmann auf dem Gebiet der Rechner- und Netzwerksicherheit und Autor
zahlreicher Fachartikel.
f-\/\ [\S\}A\ www.hanser.de/computer
ISBN-10: 3-446-40800-2
ISBN-13: 978-3-446-40800-5
IT-Sicherheitsbeauftragte,
Teammitglieder in Securityprojekten sowie
System- und Netzwerkadministratoren
?63Mm="mjß005"