/





































































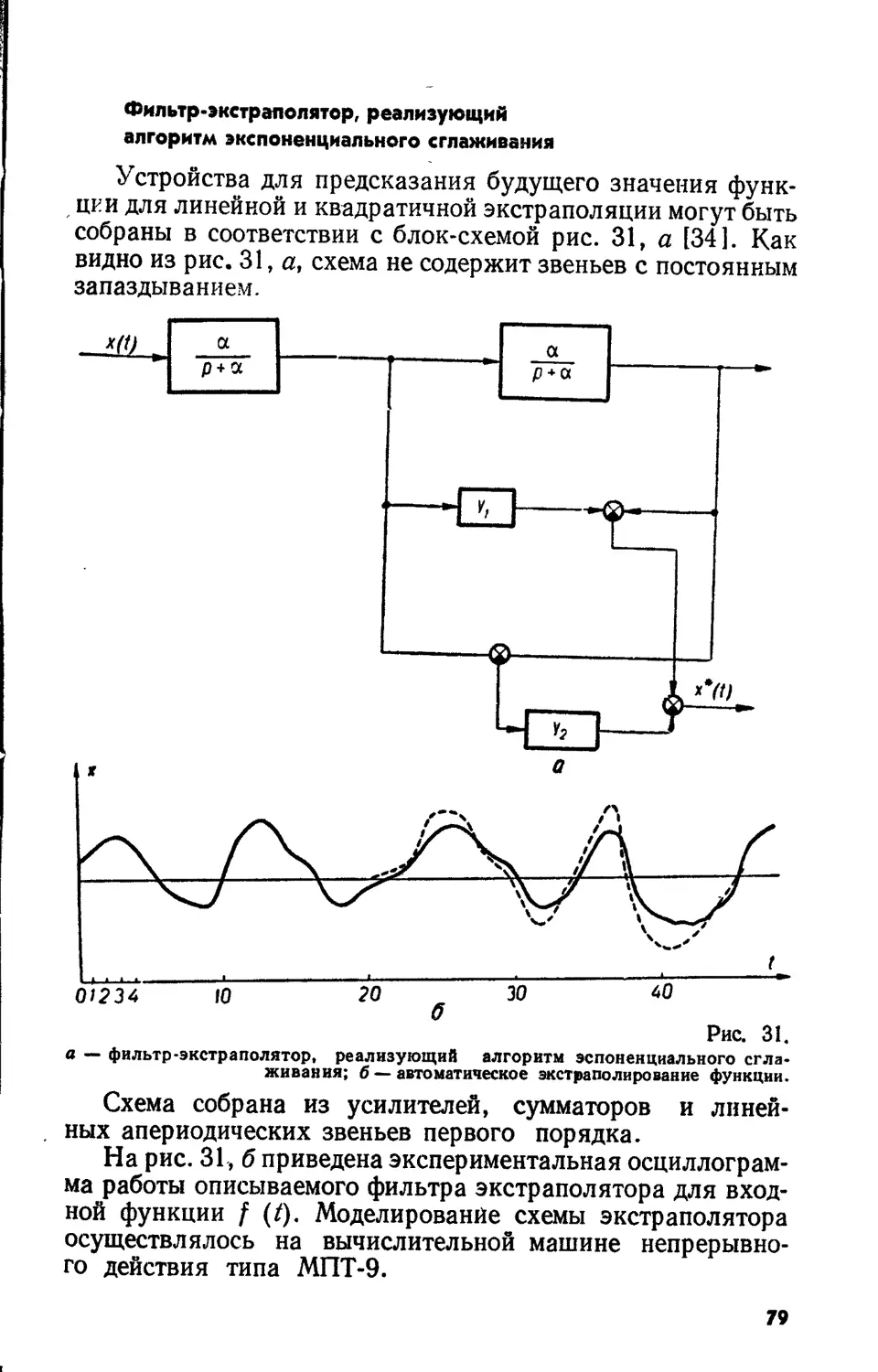















































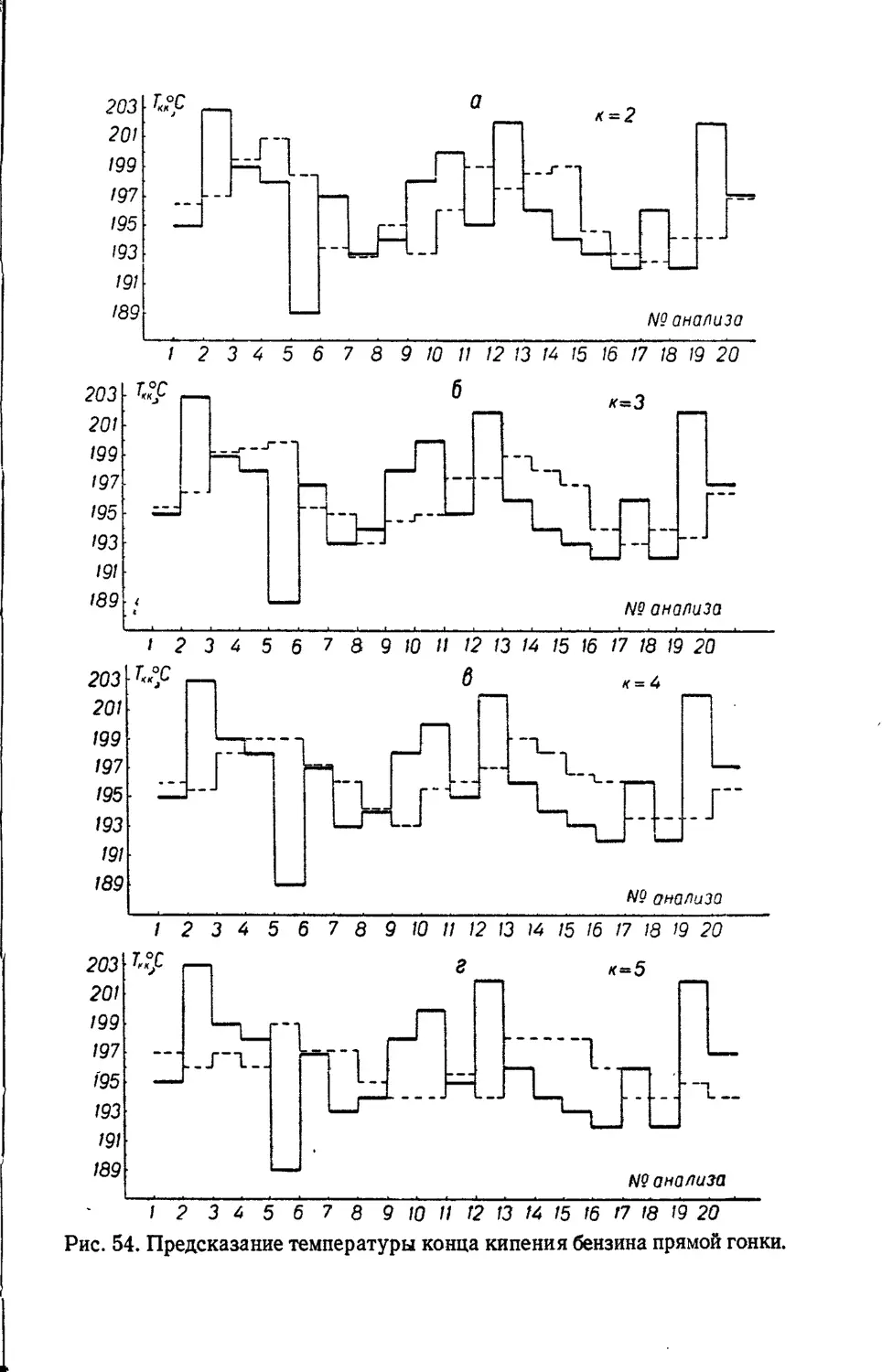

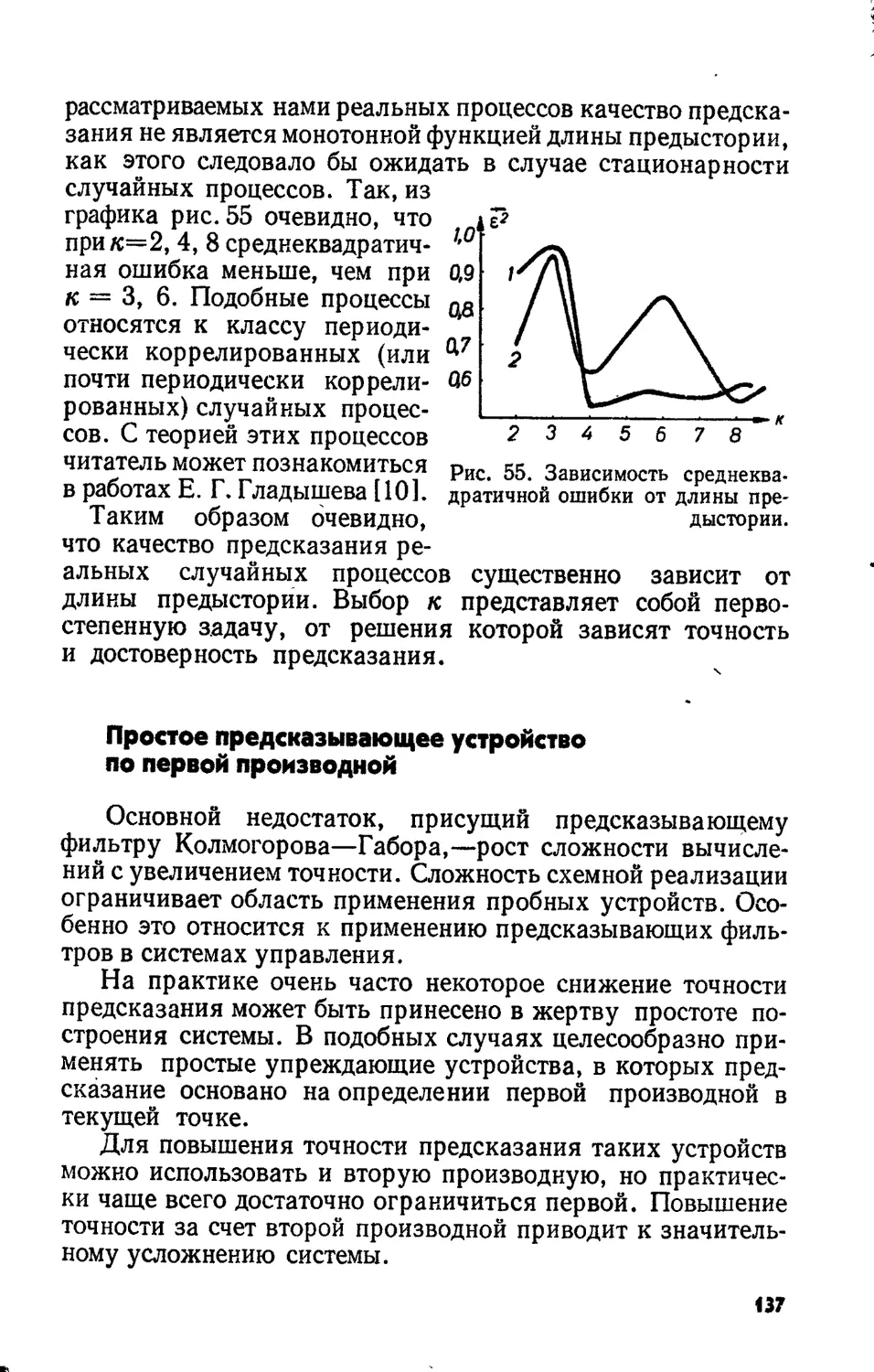




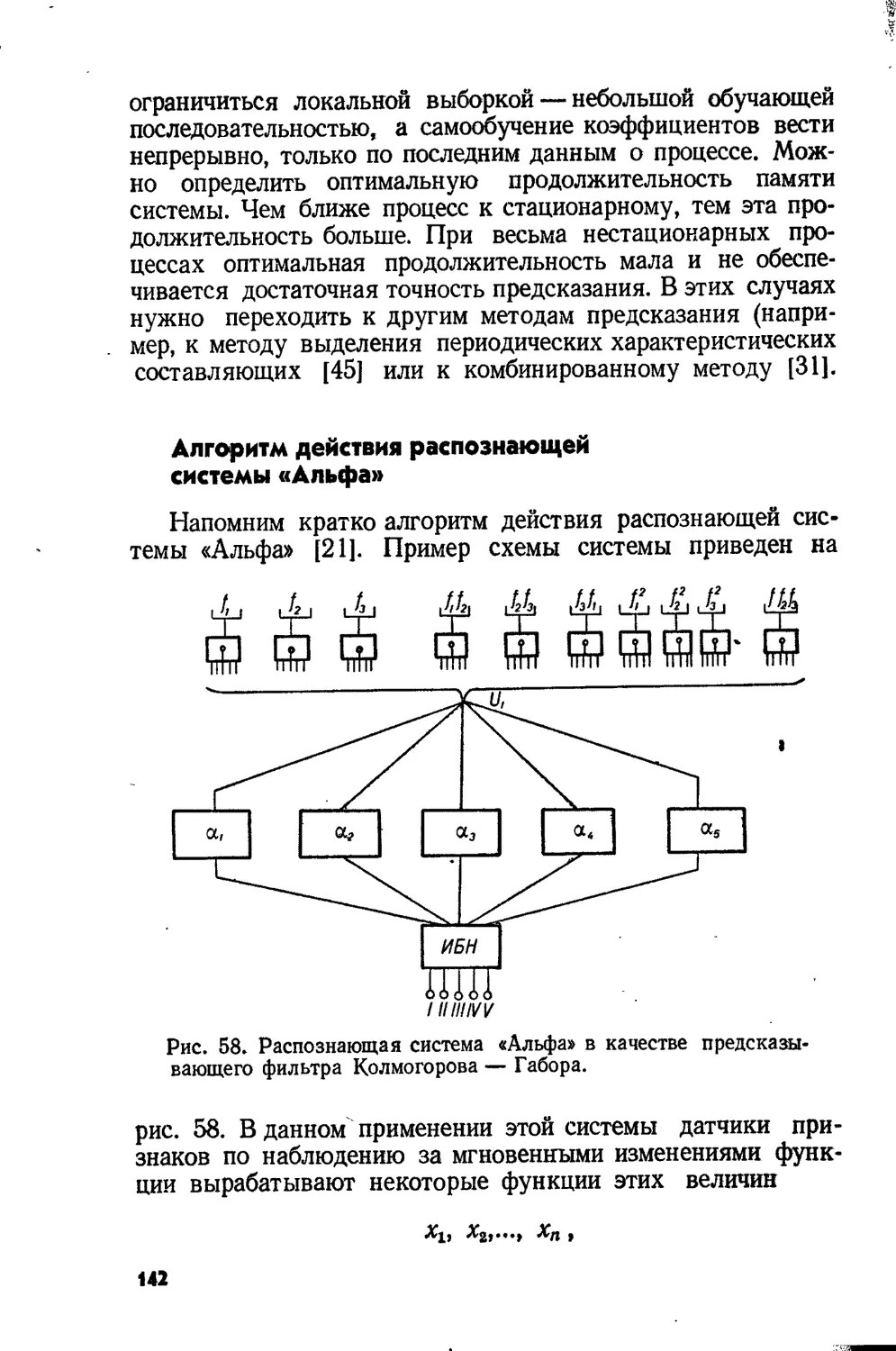







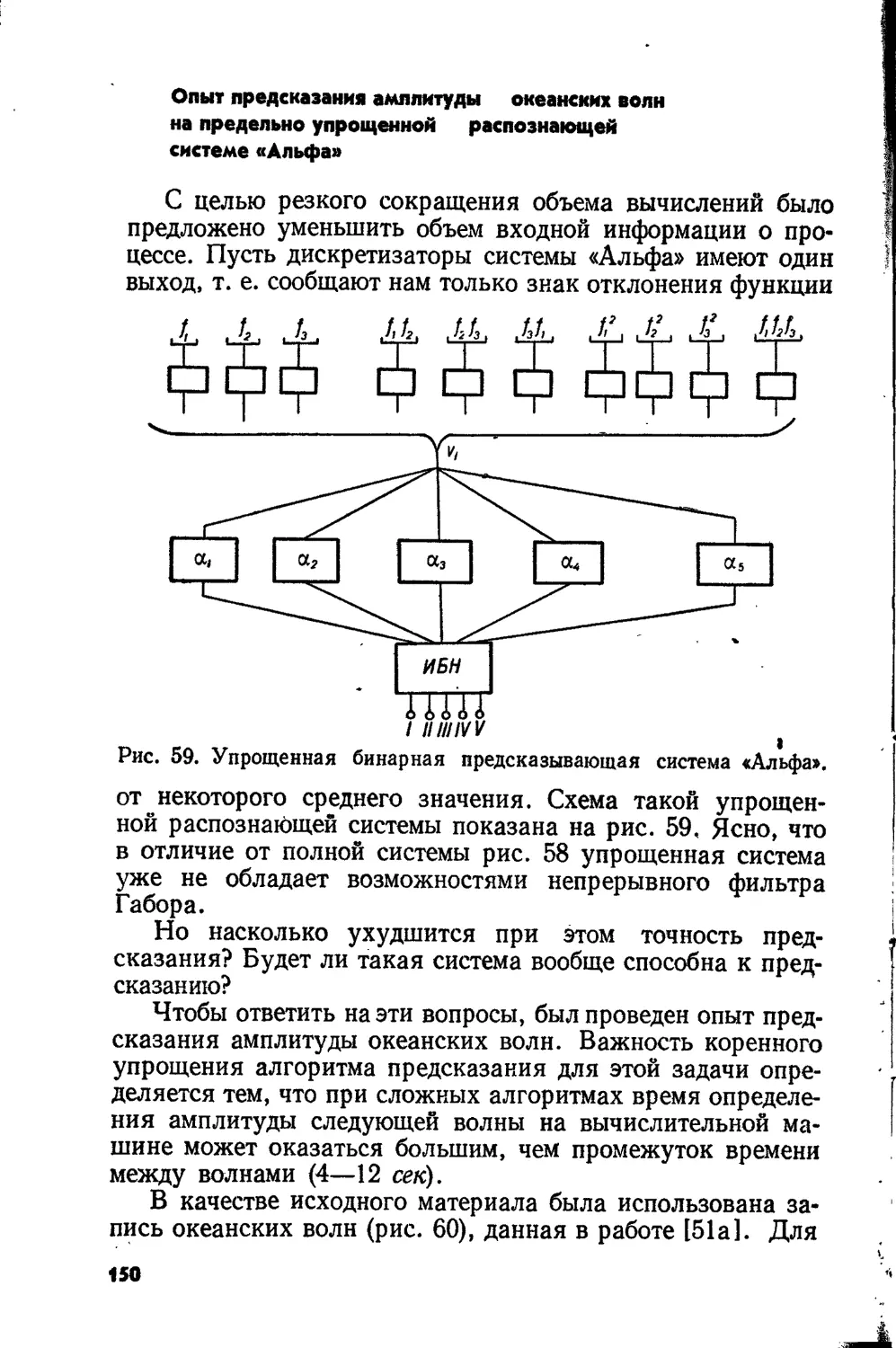
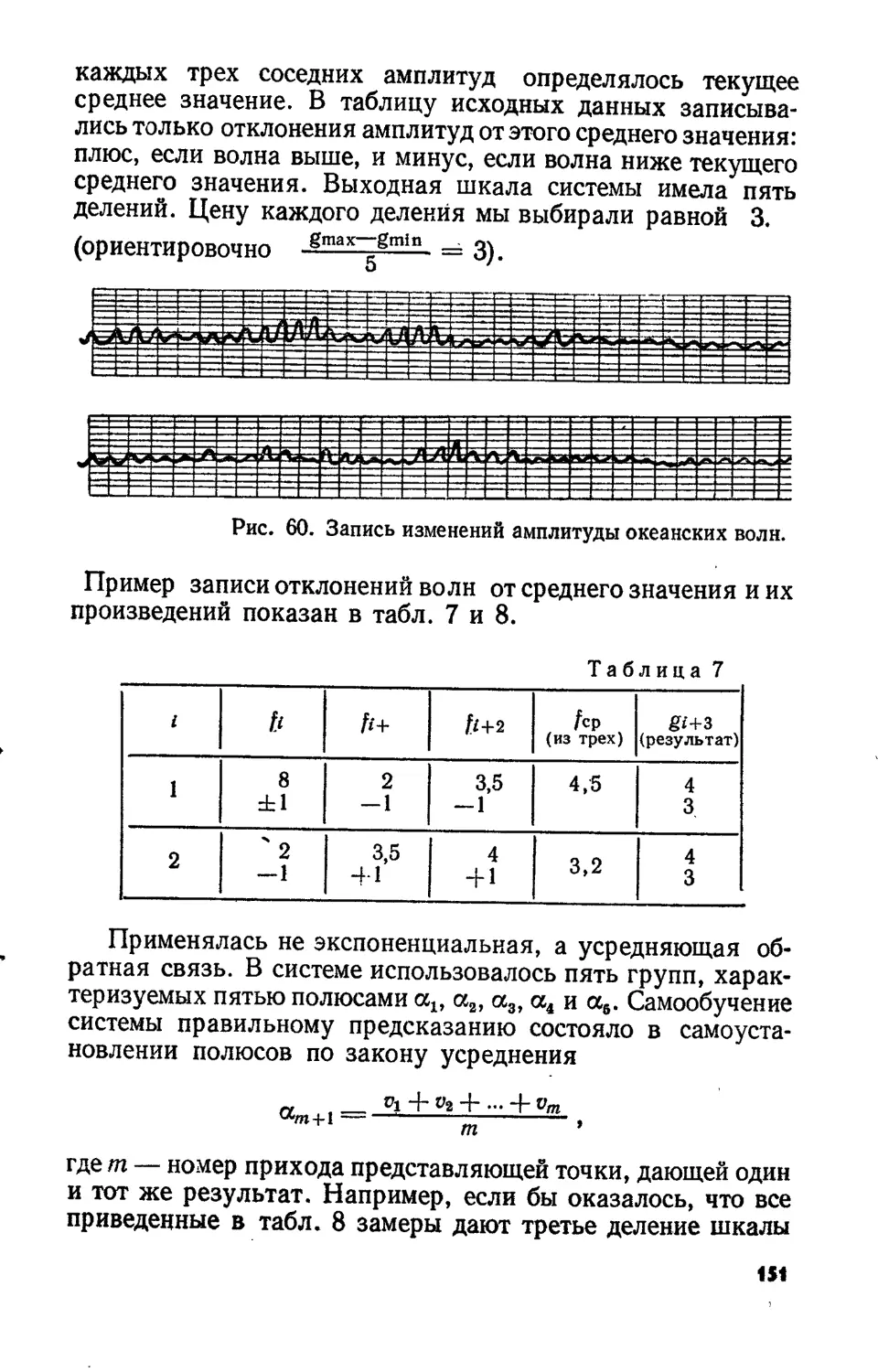


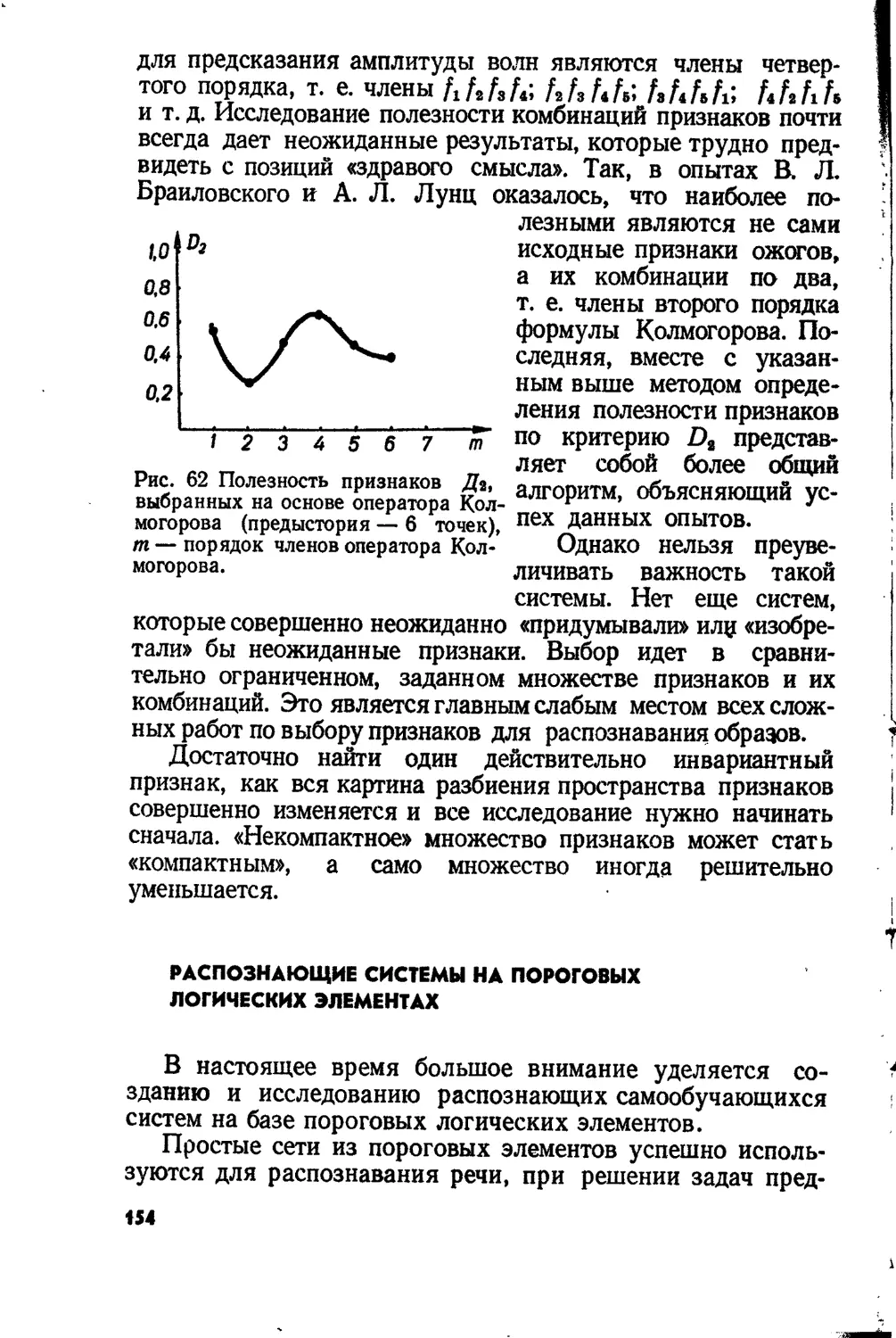



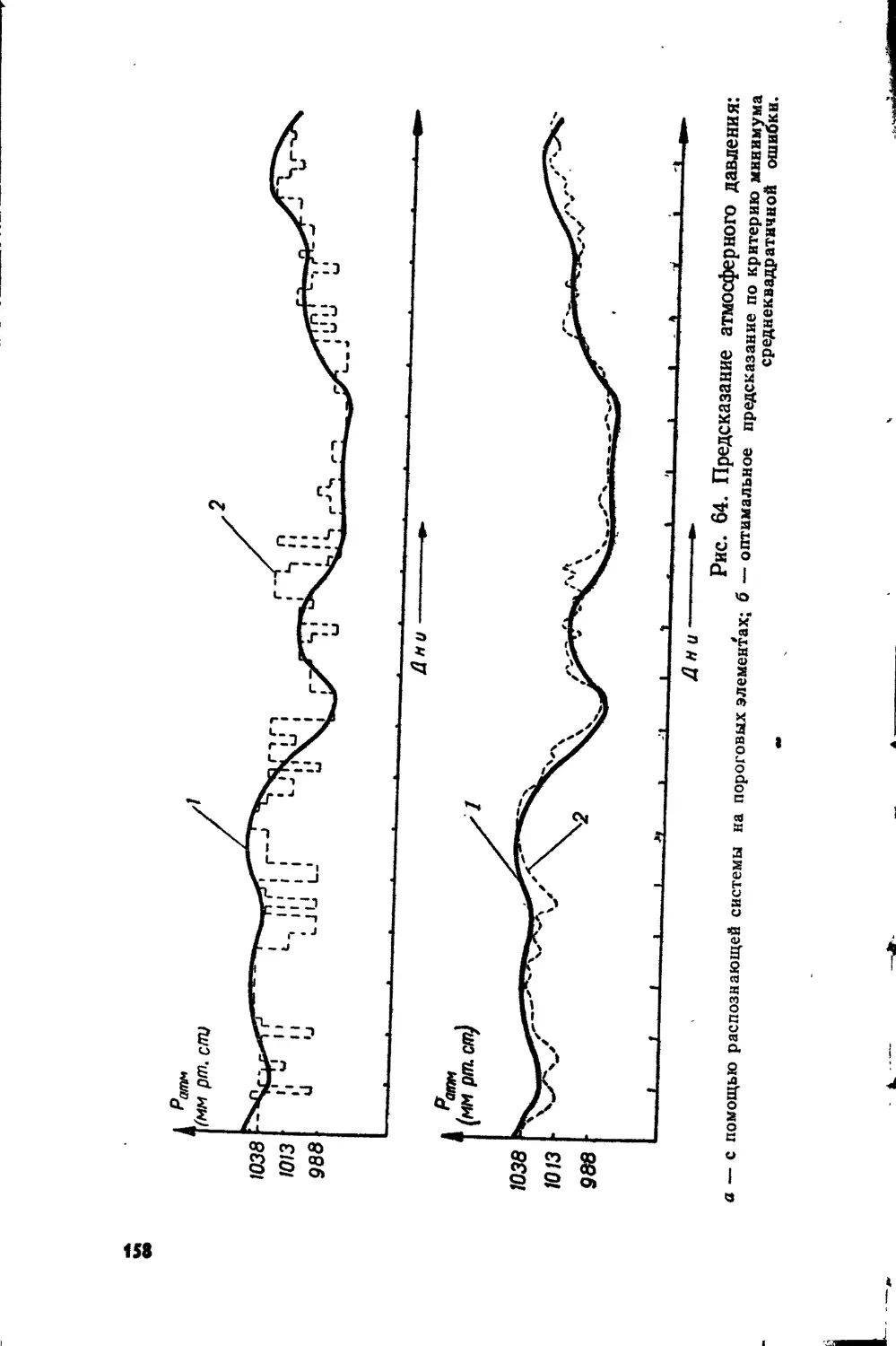

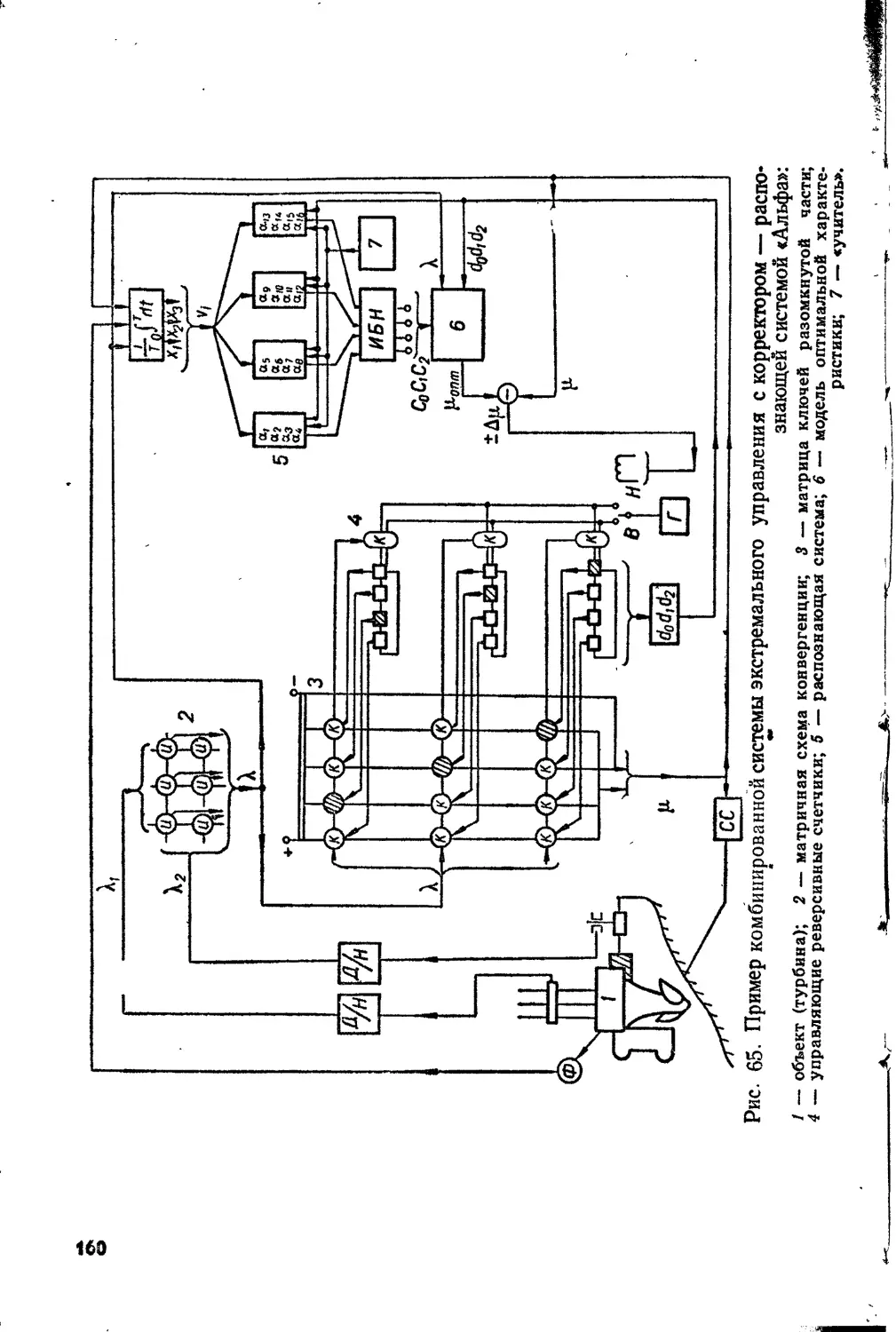





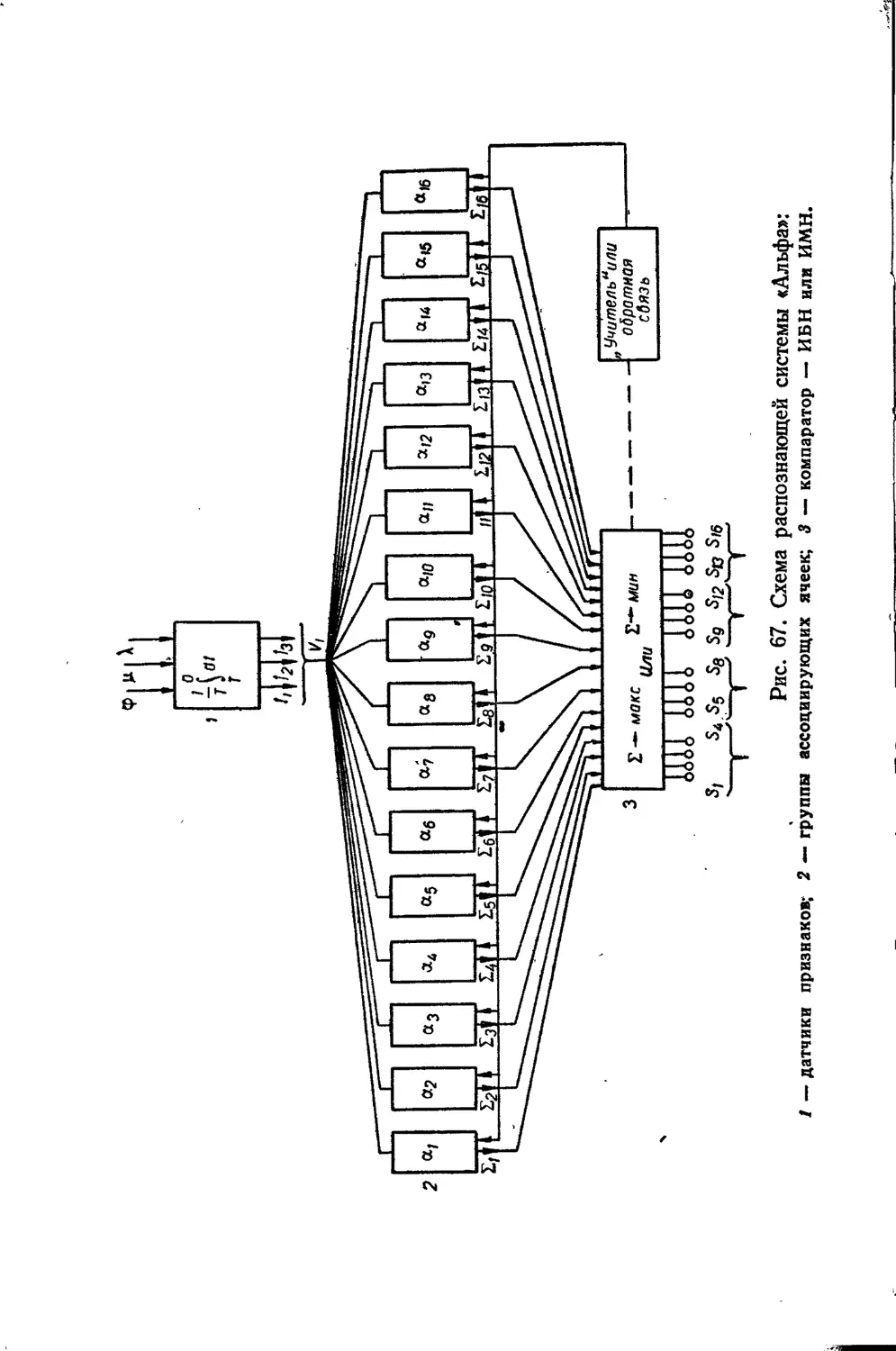









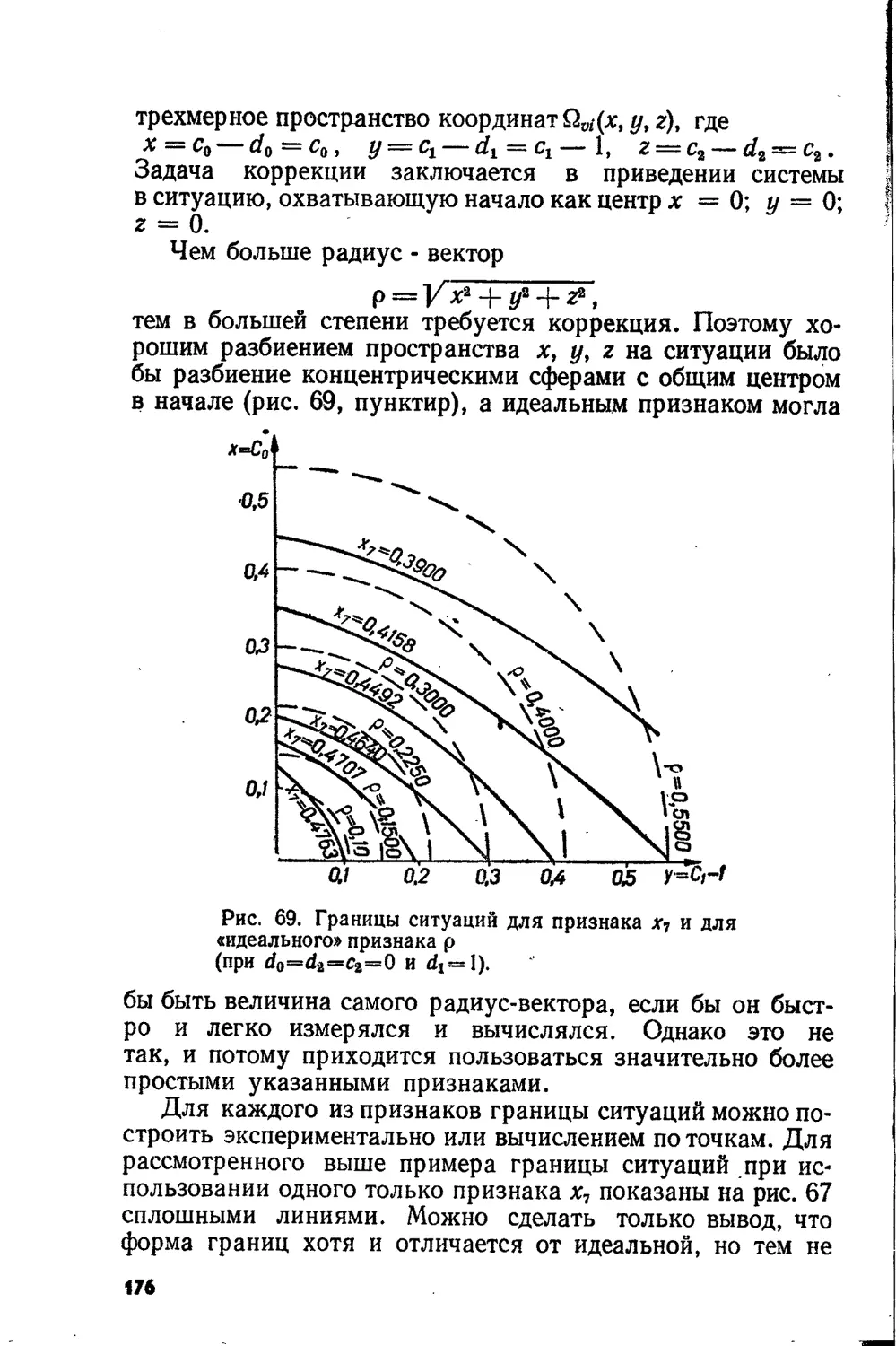





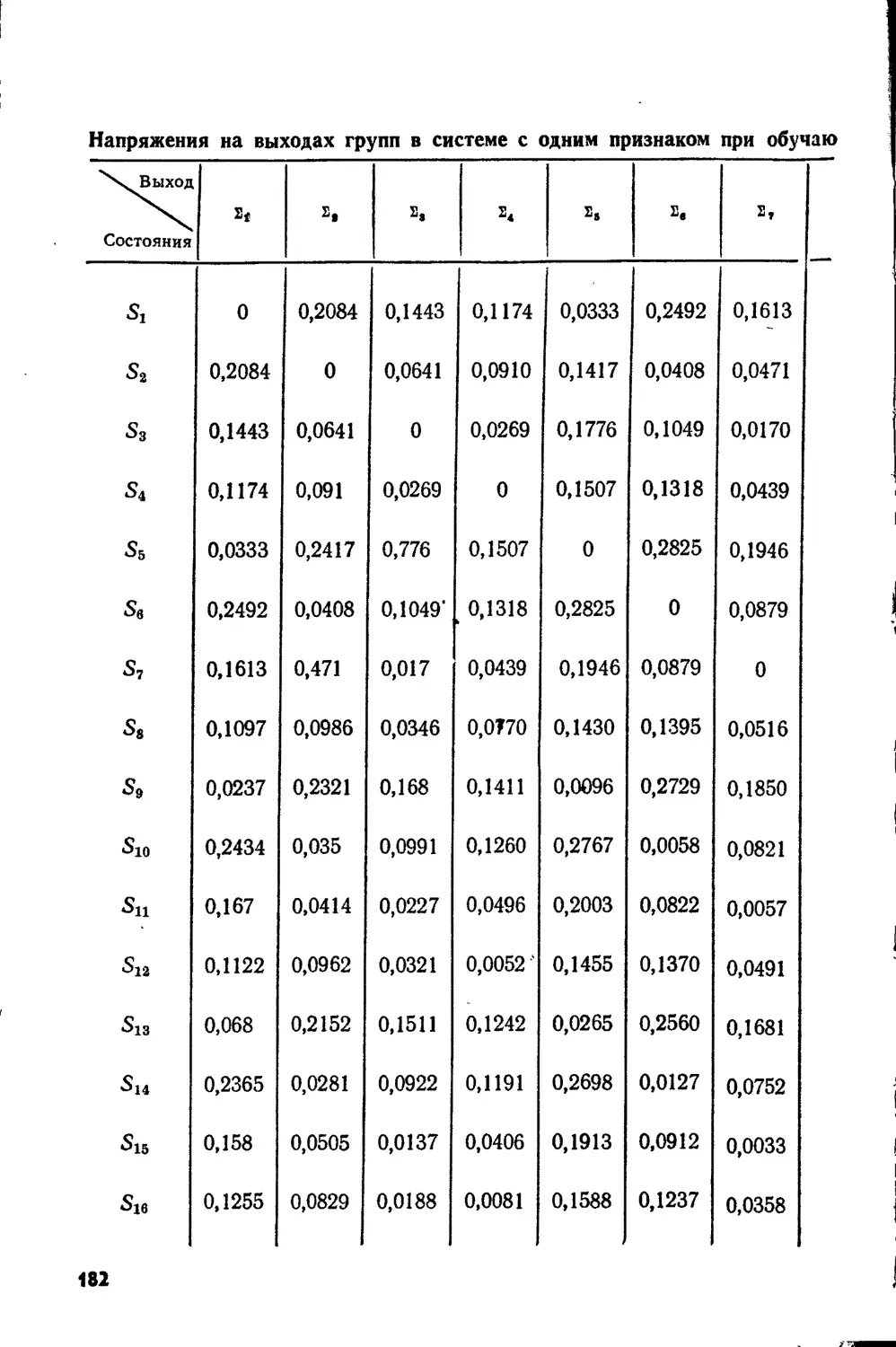
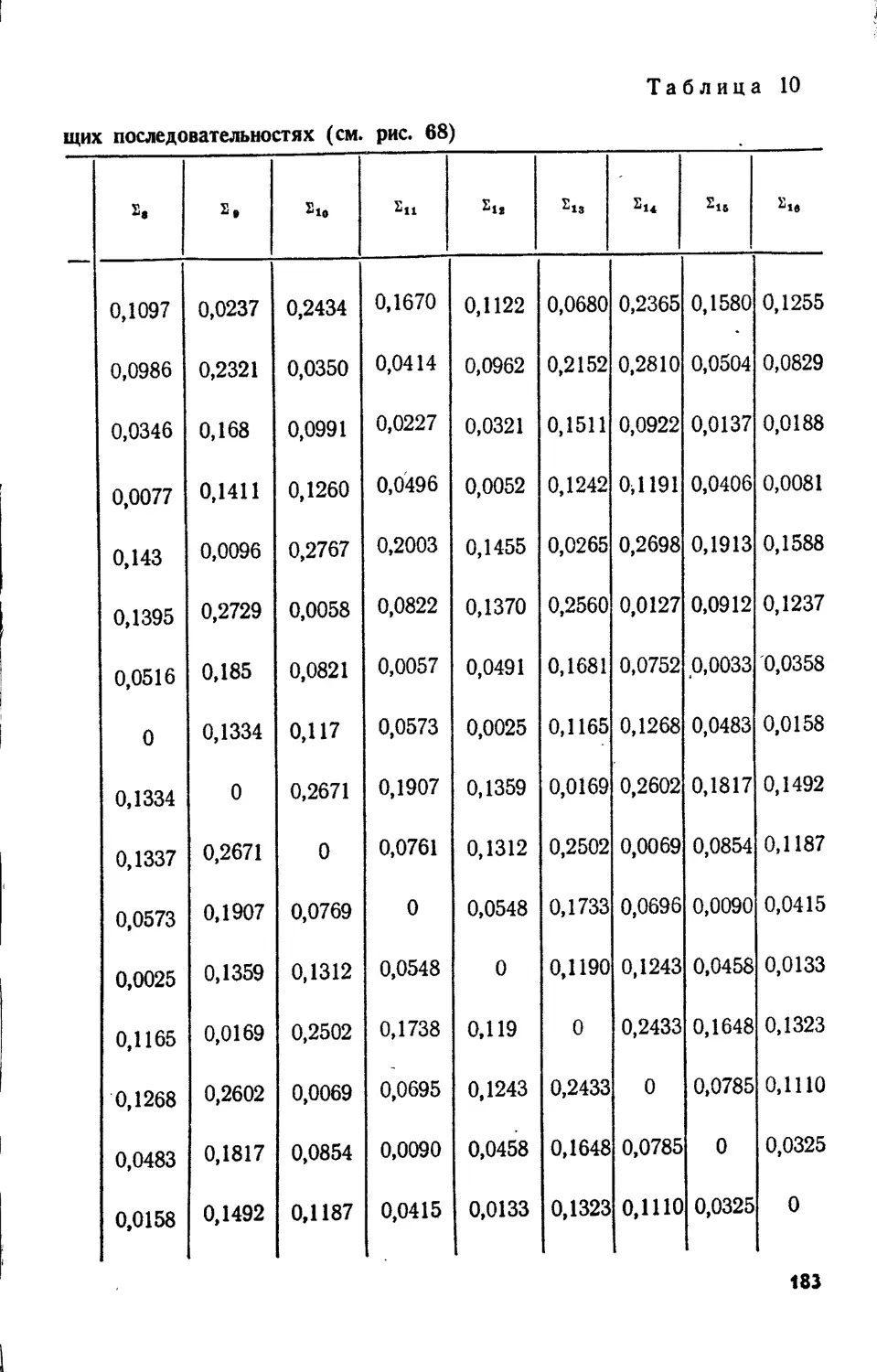


































Text
А. Г. ИВАХНЕНКО
В. Г. ЛАПА
академия наук УКРАИНСКОЙ ССР
А. Г. ИВАХНЕНКО
В. Г. ЛАПА
КИБЕРНЕТИЧЕСКИЕ
ПРЕДСКАЗЫВАЮЩИЕ
УСТРОЙСТВА
Киев —1965
6 П 2. 15
И 23
Книга посвящена изложению некоторых
вопросов теории предсказания детермини-
рованных и случайных процессов. Особое
внимание уделяется реализации различных
алгоритмов-операторов предсказания на элек-
тронных цифровых вычислительных машинах.
Отдельное место занимают вопросы при-
менения распознающих систем, и в частности
системы „Альфа4 * в качестве предсказываю-
щих фильтров.
Описанные методы иллюстрируются на
примерах из энергетики, гидрологии, нефте-
химии, медицины, управления производ-
ственными процессами.
Книга может быть полезна специалистам,
работающим в различных областях науки
и техники, интересующимся методами ста-
тистических предсказаний и конкретными
приложениями этих методов.
3—3—14
Б. 3. № 19-64 КИЕВСКАЯ ФАБРИКА НАБОРА
ВВЕДЕНИЕ
Благодаря применению автоматических систем ре-
шение многих сложных задач управления стало возможным
без непосредственного вмешательства человека. По мере
усложнения структуры управляемых объектов, увеличения
объема информации о протекающих в них процессах че-
ловек часто не в состоянии наилучшим образом осуществ-
лять функции управления. Это объясняется недостатком
времени, в течение которого должно быть принято опти-
мальное решение, невозможностью мобилизовать в короткий
срок значительный объем памяти, свойством забывания
информации и рядом других факторов.
Сложные системы автоматического управления обла-
дают большим быстродействием и достаточным объемом за-
поминающих устройств.
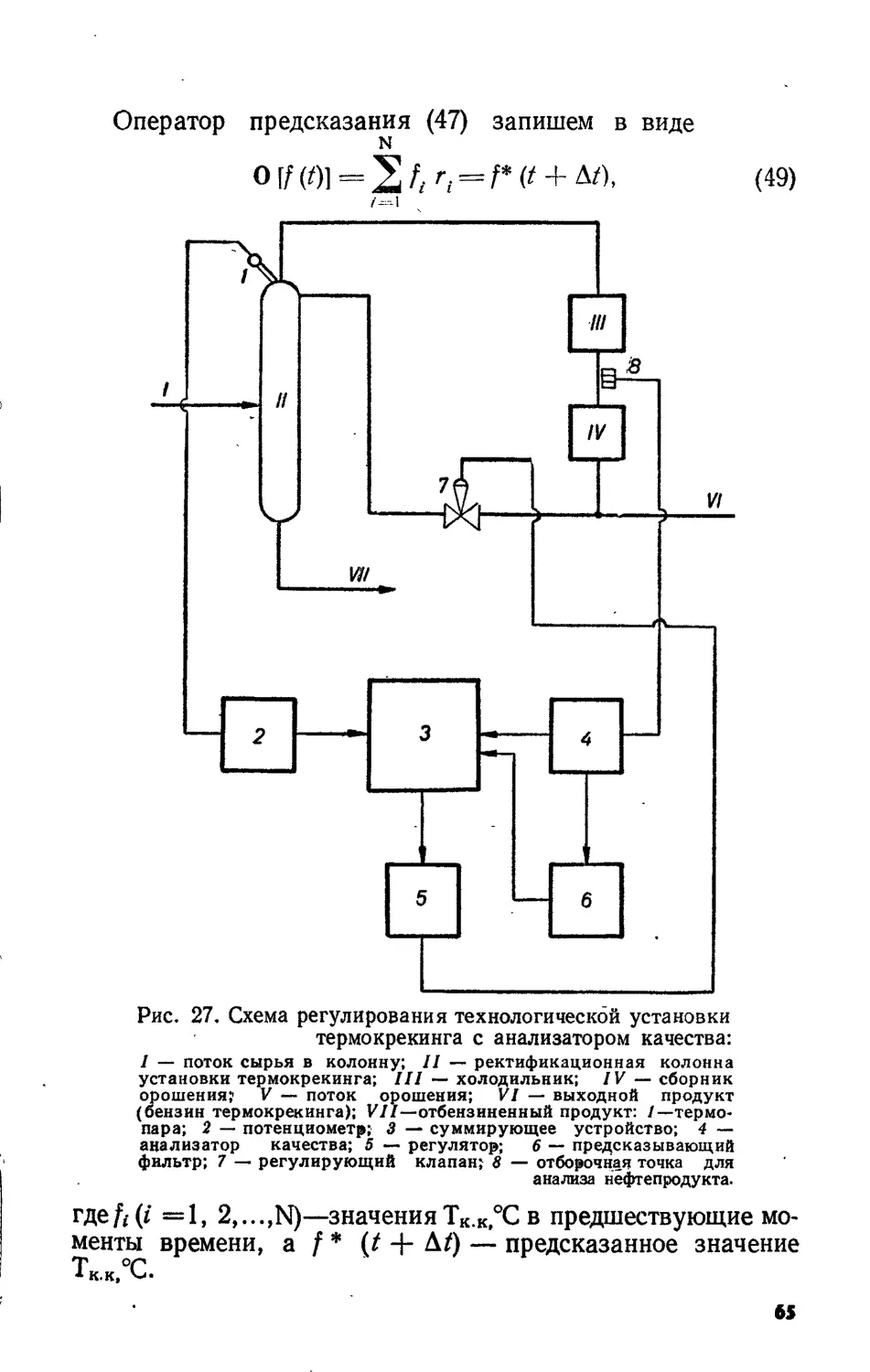
Кроме того, они должны осуществлять многие функции
«интеллектуального» характера, такие, как сопоставление
различных вариантов решения задачи, выбор наилучшего
варианта в соответствии с определенными критериями, учет
изменения внешних воздействий и изменение в связи с этим
характера решения и критериев.
Поскольку характер моделируемых в автоматических
системах мыслительных способностей постоянно усложняет-
ся, следует при создании подобных систем учитывать одно
из важных качеств, присущих человеческому мышлению,—
способность обучаться предсказанию.
з
Ни одно действие не совершается человеком без того,
чтобы он в достаточно определенной форме не предвидел
результатов этого действия.
При постановке задачи предсказания в технике, очевид-
но, невозможно обойтись без исследования того, как выпол-
няются соответствующие функции в живых организмах.
Советскими физиологами «.. .показаны не только формы пред-
сказания, но и некоторые конкретные физиологические
процессы, которые способствуют этому,— указывает ака-
демик П.К. Анохин.—«Однако вся эта грандиозная проблема,
связанная с механизмами предвидения в работе мозга, да-
ющими власть над будущим, еще далеко не разработана».
Эта проблема важна как для нейрофизиологии, так и для
техники.
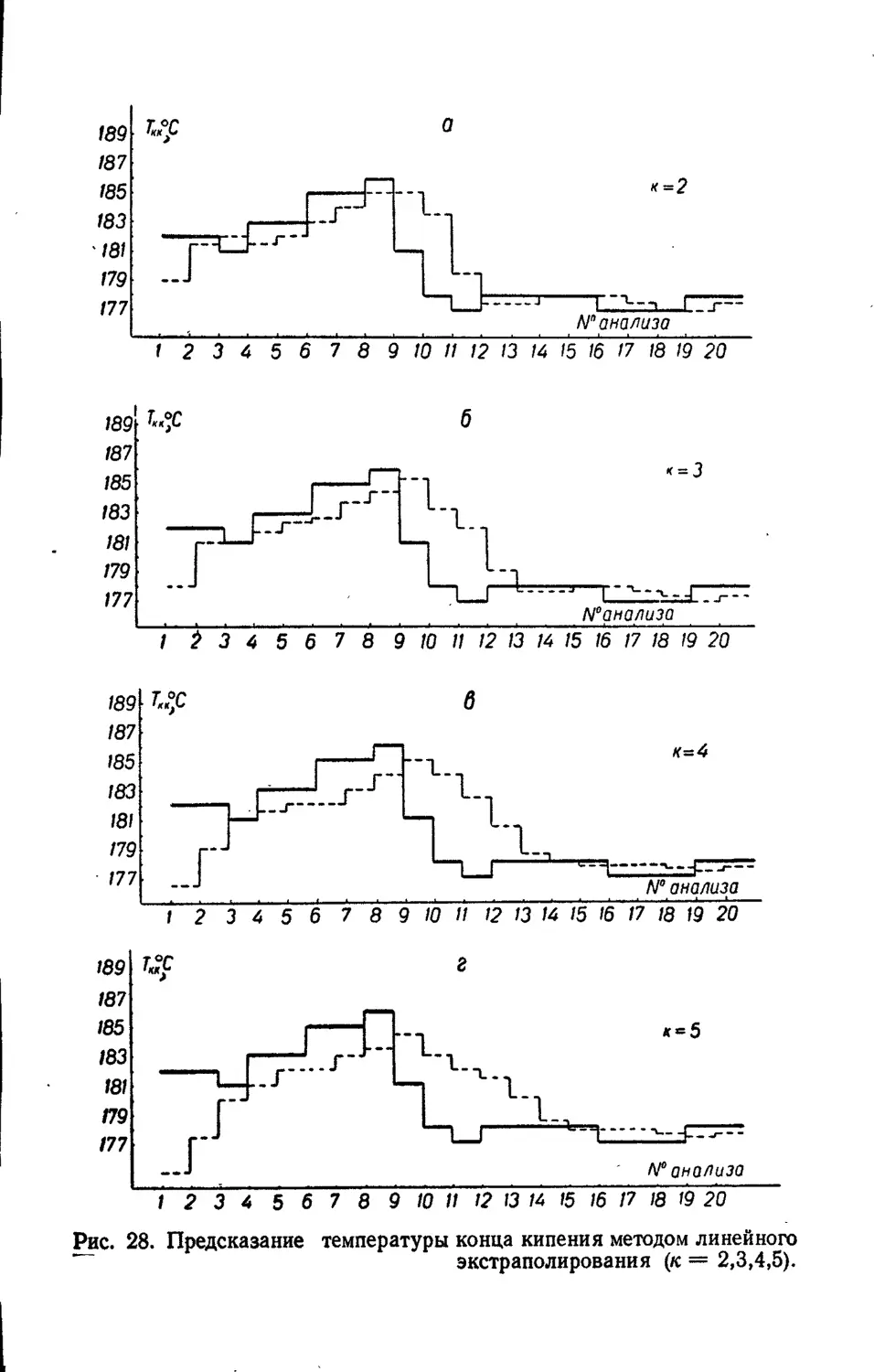
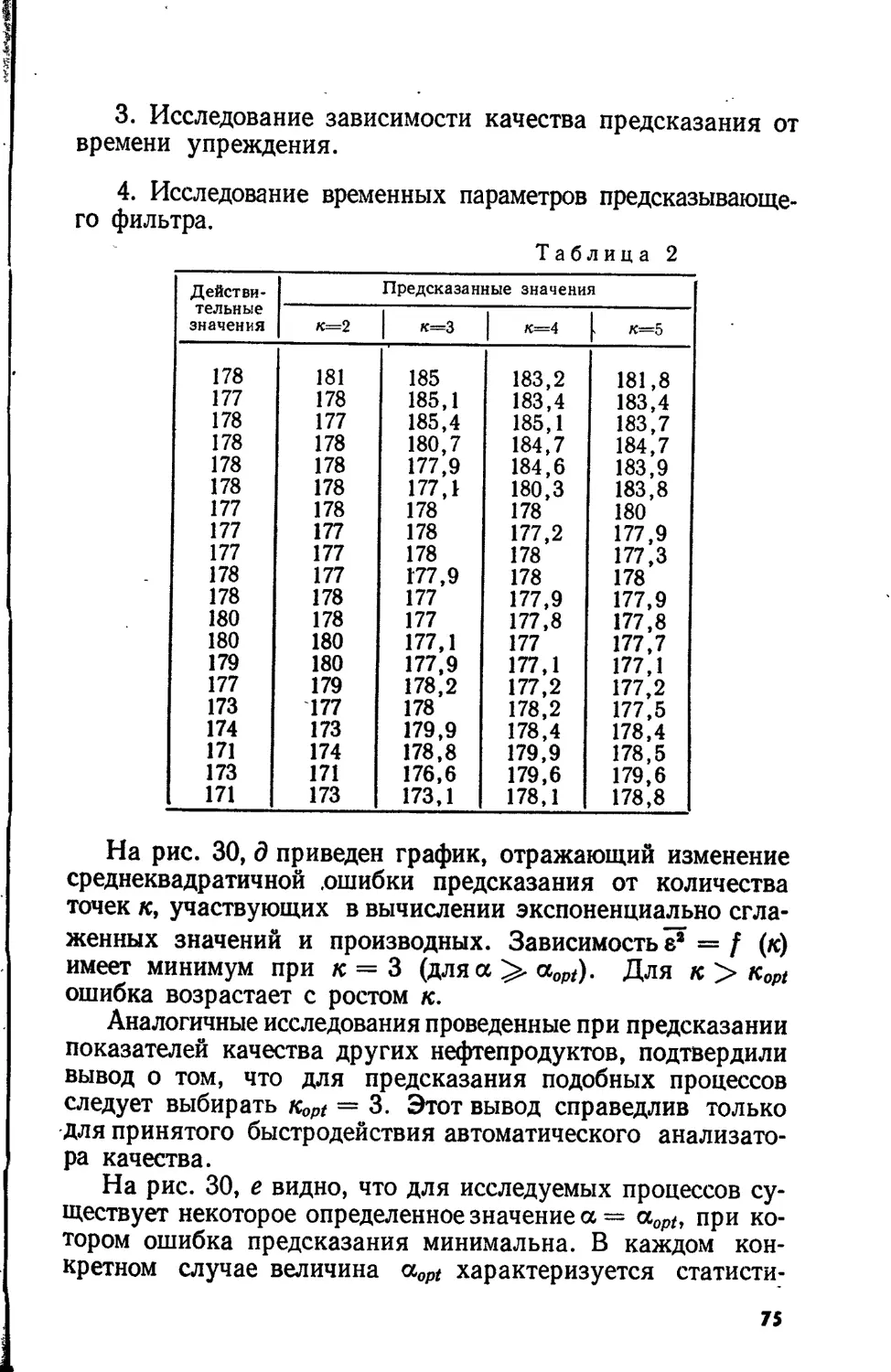
Кибернетика уже сейчас позволяет объяснить многие
механизмы предсказания.
Кибернетические самообучающиеся предсказывающие
фильтры, воплощенные в реальные электронные схемы, мо-
гут служить моделями предсказывающих механизмов мозга.
ОСНОВА ПРЕДСКАЗАНИЯ — ОПЫТ ПРОШЛОГО
Одна из основных гипотез о природе предсказания бу-
дущего заключается в том, что выводы о возможности или
вероятности будущего события либо ряда событий дела-
ются на основании изучения, анализа и обобщения преды-
дущего опыта — истории предсказываемого явления. Эта
идея, в частности, положена в основу развивающейся в нас-
тоящее время статистической теории предсказаний.
Однако можно встретиться с фактами предсказания бу-
дущего, которые на первый взгляд кажутся совершенно не
связанными с прошлым. Известно, что опыт представляет
собой гораздо больший объем сведений, чем тот, который че-
ловек может сознательно выделить. Поэтому утверждения
о том, что некоторые случаи предсказания не могут объяс-
няться предшествующим опытом, поскольку точно такое
событие или ситуация в прошлом не наблюдались, нельзя
считать основательными.
Доказано, что многое запоминается человеком незави-
симо от его сознания и содержится в его латентной, скрытой
памяти.
Ряд работ по нейрофизиологии свидетельствует о том,
что запечатленная (сознательно или бессознательно) в па-
4
мяти информация не исчезает. Канадский ученый В. Пен-
филд показал, в частности, что при создании определенных
условий, например при пропускании слабого тока через
электроды, приложенные к вискам, у пациента возникают
ощущения, относящиеся к прошлому. Вспоминаются давно
пережитые и нередко забытые события. Известно явление
гипертрофического обострения памяти, или гипермнёзии,
возникающей в результате некоторых заболеваний мозга.
Человек вспоминает совершенно забытые факты, имевшие
место в прошлом, может цитировать по памяти целые стра-
ницы ранее прочитанных книг.
Объем сведений о прошлом, размеры опыта прошлого
в различных условиях не могут быть одинаковыми. Исходя
из этого можно предположить, что самые неожиданные на
первый взгляд предсказания, и особенно точность их сов-
падений с действительностью, имеют твердую «историчес-
кую» почву. Эти предсказания базируются на опыте прош-
лого, на анализе прошлых событий, подсознательно запе-
чатленных в нашей памяти и под воздействием определенной
совокупности причин, вызываемых в сферу сознания.
Возможно, что значительную часть опыта прошлого со-
ставляет информация, заложенная в живом организме ге-
нетическим путем, и представляющая собой «концентриро-
ванный опыт» предков.
Прежде чем попытаться выяснить возможную струк-
туру механизма накопления опыта и предсказания, озна-
комимся с несколькими основными понятиями. Определим
задачи предсказания детерминированных и вероятностных,
или стохастических, процессов, а также выясним понятие
непредсказуемой «чистой» случайности.
ПРЕДСКАЗАНИЕ
ДЕТЕРМИНИРОВАННЫХ ПРОЦЕССОВ
Детерминированными называются процессы, вызванные
действием ряда известных причин. Зная результат действия
каждой из них, мы можем точно рассчитать суммарный ре-
зультат. Обычно (в линейных системах) действует принцип
супперпозиции (наложения), который можно сформулиро-
вать так: общий эффект от действия нескольких причин
равен сумме эффектов от действия каждой причины, взятой
в отдельности.
Изучение детерминированных процессов основано на ин-
дуктивном методе — методе изучения причин и следствий.
Большинство законов классической физики относится к де-
терминированным, в первую очередь к механике твердых
тел. Орбиты планет и звезд могут быть высчитаны с любой
требуемой степенью точности. Следовательно, можно дос-
таточно точно предсказать затмение Луны или Солнца либо
рассчитать местоположение спутника.
Интервал времени, отделяющий момент предсказания то-
го или иного явления от момента его наступления, обычно
называют временем упреждения.
Научное предвидение детерминированных процессов ха-
рактеризуется тем, что время упреждения может быть сколь-
ко угодно большим. Увеличение времени упреждения не сни-
жает точности предсказания детерминированных процессов.
В вероятностных, или стохастических, процессах это пра-
вило не действует. Нестационарность процессов позволяет
осуществлять предсказание только на сравнительно корот-
кий срок. Удлинение времени упреждения при требуемом
качестве предсказания является основной задачей при раз-
работке методов статистического предсказания.
ПРЕДСКАЗАНИЕ СЛУЧАЙНЫХ ПРОЦЕССОВ '
Если много раз повторять какое-либо наблюдение, ис-
пытание, каждый раз стараясь точно воспроизвести одни
и те же условия, то вместо того, чтобы получать одинаковые
результаты, при каждом отдельном измерении мы будем
получать результат, отличный от других. Каждый раз
сказывается влияние не только тех условий, которые мы
воспроизвели, но и тех, которые мы воспроизвести не в со-
стоянии. Подверженное подобному разбросу событие на-
зывается случайным. Последовательности таких случайных
событий, рассматриваемые в функции времени, известны под
названием случайных процессов. В случайном процессе мож-
но проследить результат действия ряда причин, но рассчи-
тать его мы не можем.
Изучение случайных процессов основано на дедуктивном
методе — причинную связь явлений проследить нельзя, хотя
такая связь объективно существует.
В реальных процессах, наблюдаемых в жизни, следует
различать три составляющие:
6
1) детерминированную часть, поддающуюся точному рас-
чету индуктивным методом;
2) вероятностную часть, выявляемую дедуктивным ме-
тодом по длительному наблюдению за процессом с целью
определения вероятностных закономерностей процесса;
3) «чисто» случайную часть, принципиально не поддаю-
щуюся никакому предсказанию.
Рассмотрим сначала примеры из области предсказания
«случайных» величин. Так, при подбрасывании вверх ку-
бика, одна грань которого окрашена в красный цвет, а пять
остальных граней — в синий, требуется предсказать, ка-
кого цвета будет верхняя грань при следующем бросании.
Нетрудно установить, что в данном примере.детерминиро-
ванная часть отсутствует, вероятностное предсказание дает
цифру */« — с такой вероятностью можно предсказать, что
выпадет синий цвет.
В игре с подбрасыванием монеты требуется предсказать,
упадет ли монета гербом или обратной стороной — решкой.
При большом количестве подбрасываний (примерно в поло-
вине случаев) монета падает гербом, а в половине — решкой.
Это пример «чистой» случайности, или равновероятного ис-
хода, принципиально не поддающегося никакому пред-
сказанию.
Убедительным примером может быть также любая дос-
таточносложная. игра, например футбол. В предсказании
результатов игры детерминированная составляющая отсут-
ствует (рассчитать ничего нельзя), но имеется явно выражен-
ная вероятностная составляющая, которую можно опреде-
лить, наблюдая ряд игр данных команд. Кроме того, в игре
обязательно присутствует принципиально непредсказуемый
элемент «чистой» случайности. Без этого элемента игра пе-
рестала бы быть игрой.
Рассмотрим пример реального случайного процесса.
Долгое время оставался неясным вопрос о причинах и
закономерностях приливов и отливов. Кеплер и Ньютон свя-
зали это явление с Луной. В дальнейшем Лаплас подтвердил
теорию Кеплера и Ньютона строго математически, что дало
возможность предсказывать на каждый день время прилива
и отлива с большой точностью.
Рассмотрим вопрос о приливах с точки зрения деления
процесса на детерминированную, вероятностную и «чисто»
случайную часть. В данном процессе присутствуют все три
части. Детерминированная часть процесса обусловлена Лу-
1
ной и в малой степени Солнцем и точно рассчитывается по
теории Лапласа. Кроме того, имеется случайная часть,
вызываемая ветром, изменением состава и плотности воды,
температуры и многих других причин, часть из которых нам
неизвестна. Наблюдая длительное время результат дейст-
вия этих факторов, можно определить вероятности откло-
нений от точного расчета, нечто вроде «розы ветров» для дан-
ного места берега океана.
Совокупность детерминированной и вероятностной час-
тей является наилучшим (оптимальным) предсказанием. Сра-
внение этого оптимального предсказания с действительным
приливом дает возможность определить элемент непред-
сказуемой, или «чистой», случайности. Ошибки измеритель-
ных приборов обычно составляют значительную часть этой
«чистой» случайности. С развитием измерительной техники
эта часть «чистой» случайности уменьшается. Все сказанное
относится к предсказанию времени прилива и еще в большей
степени к предсказанию величины поднятия уровня воды.
В последней задаче существенное значение имеют волны,
пример предсказания амплитуды которых мы рассмотрим
подробно в четвертой главе.
При подбрасывании кубика детерминированная часть
процесса равна нулю, так как обычно рассчитать ничего
нельзя. При подбрасывании монеты детерминированная и
вероятностная части равны нулю — процесс чисто случай-
ный. В процессе, отражающем океанские приливы и отливы,
присутствуют все три части: детерминированная, вероятност-
ная и «чисто» случайная. С развитием точных наук детермини-
рованная часть, поддающаяся точному расчету, непрерывно
увеличивается. Развитие теории и техники статистических
предсказаний увеличивает надежность вероятностного пред-
сказания. Однако в реальных процессах «чисто» слу-
чайная часть не может быть сведена к нулю. Эта часть
определяет тот наивысший уровень, к которому мы асимп-
тотически приближаемся по мере повышения качества пред-
сказания детерминированной и вероятностной частей
процесса.
Разработка методов расчета детерминированных процес-
сов и выделение вероятностной части являются основными
проблемами теории предсказаний.
Если процесс плохо изучен, то некоторую долю детер-
минированной его части приходится отнести к вероятност-
йой. И далее, некоторую долю вероятностной части прихо-
8
дится отнести к «чистой» случайности. Точность предска-
зания от этого резко ухудшается.
По мере накопления материала вырисовываются опреде-
ленные закономерности, позволяющие переходить к более
уверенным предсказаниям на основе причинно-следствен-
ных связей и в дальнейшем к теоретическим построениям.
Хотя во многих процессах элемент «чистой» случайности,
не поддающейся никакому предсказанию, принципиально
нельзя свести к нулю, все же основной задачей теории пред-
сказаний является максимальное увеличение причинной, де-
терминированной части, как и постоянное уточнение веро-
ятностного предсказания. Часть процесса, относимая нами
к «чистой» случайности при наилучшем, оптимальном пред-
сказании, минимальна и не может быть больше умень-
шена.
В некоторых процессах, называемых стационарными, ве-
роятностные характеристики постоянны. Здесь с течением
времени наблюдения вероятностная часть предсказывается
все более и более точно.
В идеальном случае, при очень большом времени наблюде-
ний, время упреждения может стать любым. Так, весьма точно
можно предсказать среднюю температуру июля на несколь-
ко лет вперед. Приливы и отливы с учетом господствующих
ветров также могут быть примером стационарного процесса.
Значительно труднее свести к возможному минимуму
непредсказуемую «чистую» случайность в квази-стацио-
нарных и еще труднее — в нестационарных процессах, ве-
роятностные характеристики которых с течением времени
изменяются. Примером может быть предсказание средней
температуры июля на много десятков или даже на сотни лет
с учетом изменения климата земли. Фактически каждый
реальный процесс является нестационарным, но мы можем
считать его стационарным, если его вероятностные характе-
ристики мало изменяются за время упреждения. Поэтому в
реальных случайных процессах, в силу их нестационарности,
точность предсказания с увеличением времени упреждения
падает.
В связи с этим основной задачей теории статистичес-
ких предсказаний является разработка методов (формул
или алгоритмов) предсказания, при которых время упре-
ждения больше, чем при других методах.
Рассмотрим некоторые примеры.
9
Предсказание процессов по их параметрам
в данный момент времени
Самый простой метод предсказания будущего состоит
в предположении, что «завтра будет то же, что и сегодня».
Отметим, что такой примитивный метод предсказания по-
годы оказывается правильным в 70% случаев. Вероятность
правильного предсказания по правилу «без изменений» чрез-
вычайно быстро убывает с увеличением времени упреждения.
Предсказание на более длительный срок требует учета
не только нынешнего состояния процесса, но и скорости
его изменения. Не-
сколько более совер-
шенный метод пред-
сказания основан на
предположении о по-
стоянстве процентно-
го роста или убыва-
ния. Например, та-
ким методом пользу-
ются в демографии.
Данные о народона-
селении отдельных
стран и континентов
обрабатываются на
вычислительных ма-
шинах, причем опре-
деляется среднее число рождений и смертей на 1000 че-
ловек, а также процент ежегодного прироста населе-
ния. При этом абсолютный прирост увеличивается из
года в год. Нарве. 1 приведена кривая роста народона-
селения мира. По этой кривой мешено предсказать, что в
1975 г. народонаселение мира достигнет 4 миллиардов. Пред-
положение о постоянстве процентного роста или убывания
действительно только на сравнительно короткий промежу-
ток времени, когда условия протекания предсказываемого
процесса почти одинаковы. Поэтому не имеет смысла поль-
зоваться данной кривой, экстраполируя ее на XXI век.
Каждая реальная кривая имеет свои ограничения. Все
физические величины, кроме угла поворота колеса, не могут
превзойти некоторого «насыщения».
Для прогноза на длительный срок требуется дальней- -
шее усложнение формулы, по которой определяются буду-
10
щие значения. Можно, например, учитывать не только со-
стояние процесса и скорость изменения, но и ускорение*
а возможно, третью и более высокие производные по времени.
В ряде случаев такое усложнение дает хорошие результаты,
так как увеличивает вероятность правильного предсказания
на более длительные сроки. Все же и здесь срок правильного
предсказания определяется свойствами процесса, постоян-
ством коэффициентов формулы предсказания (состояние, ско-
рость изменения, ускорение и т. д.). В ряде процессов, на-
зываемых стационарными, эти коэффициенты постоянны.
Для таких процессов указанные методы предсказания весь-
ма эффективны.
Предсказание процессов по параметрам
в данный момент времени
и по их предыстории
Для увеличения времени упреждения при предсказании
многих процессов, кроме параметров, в данный момент вре-
мени нужно учитывать и их изменение в предыдущее время —
предысторию. Примером может быть предсказание погоды.
Система метеорологических станций впервые была орга-
низована во Франции в 1856 г., а в 1858 к этой системе прим-
кнули и другие страны, в том числе и Россия.
Первые метеорологические наблюдения в России отно-
сятся ко. времени основания Петербурга. Сохранились наб-
людения вскрытия и замерзания Невы с 1706 г., количества
осадков — с 1741 и температуры — с 1753 г. Регулярная
сеть метеорологических станций была организована в 1830 г.
Однако только широкое использование телеграфа позволило
перейти от предсказания погоды по наблюдениям, делаемым
в одном пункте, к более точному предсказанию погода при
помощи составления синоптических карт.
Синоптические карты позволяют проследить путь дви-
жения циклонов и антициклонов. Так, для европейского
материка наблюдается общее правило, заключающееся в
том, что если циклон движется к востоку, то область вы-
сокого давления и высокой температуры находится к югу
от центра циклона. Наоборот, если циклон движется к за-
паду, то указанные области лежат к северу от центра и т. д.
Значительно уточняется прогнозирование в связи с ис-
пользованием специальных метеорологических спутников
Земли.
к
Долгосрочные предсказания погоды возможны только
с привлечением вероятностных методов. Детерминирован-
ные методы здесь, по-видимому, недостаточны.
Применение вычислительных машин
для предсказания погоды
При предсказании погоды следует также учитывать де-
терминированную часть (влияние Солнца, внутреннего тепла
Земли ит. п.), вероятностную часть и элемент «чистой» слу-
чайности. Например, можно точно подсчитать, что если бы
погасло Солнце, то на поверхности Земли установилась бы
равномерная температура 14 Г С (т. е. температура намного
выше абсолютного нуля, соответствующего — 273° С).
Уточнение предсказания погоды означает сведение к ми-
нимуму части, относимой нами к «чистой» случайности,
хотя последняя никогда не будет равна нулю.
В настоящее время приблизительно 20% всех предска-
заний погоды не оправдывается. Есть основания предпола-
гать, что эта цифра может быть уменьшена до 2-*-3%, при
одновременной большей конкретизации предсказаний (ука-
зание точного количества осадков, точных границ области
их выпадения, точной температуры и т. д.). К такой неболь-
шой предельной величине может быть сведена непредска-
зуемая «чистая» случайность.
Для качественного предсказания погоды необходимо ре-
шать большое количество уравнений, описывающих проис-
ходящие в атмосфере процессы, с большим количеством ис-
ходных данных, изменяющихся в широком диапазоне. Так,
для предсказания погоды на сутки приходится учитывать
около 3000 исходных данных метеорологической инфор-
мации.
При прогнозе йа трое суток потребуется уже около
20000 исходных данных. Задача долгосрочного прогно-
за — до сезона — может быть решена при учете около
100000 данных.
Обработка такого огромного объема информации немыс-
лима без вычислительных машин с большим быстродейст-
вием и значительным объемом памяти. Поэтому Московский
мировой метеорологический центр уже полностью перешел
на прогноз погоды с помощью вычислительных машин.
Применение статистических методов требует учета раз-
личных зависимостей и связей между действующими фак-
12
торами, выявленных многолетними исследованиями. В нас-
тоящее время накоплено огромное количество сведений, и
мобилизовать «память архивов» возможно только при исполь-
зовании вычислительных машин.
ЭВМ позволяют непрерывно запоминать информацию о
погоде, поступающую от многочисленных (исчисляемых де-
сятками тысяч) метеостанций, обработать ее и предсказать
погоду как на основании прямого решения уравнений аэро-
динамики, так и при помощи подсчета вероятностей (детер-
минированный и вероятностный методы). Предсказание
погоды, следовательно, является типичной многомерной за-
дачей, ибо требует указания изменений температуры, дав-
ления и других величин не только во времени, но и по по-
верхности планеты.
В Московском государственном университете проводит-
ся оперативный прогноз погоды. Применение быстродейст-
вующих вычислительных машин дало возможность метеоро-
логам прогнозировать давление, скорость ветра, температу-
ру и т. п. не синоптическими методами, как это делалось до
сих пор, а методом динамической метеорологии. Основными
уравнениями, связывающими давление, скорость ветра, тем-
пературу, являются уравнения движения, неразрывности,
состояния и притока тепла, в которых отбрасывают все ме-
теорологические несущественные члены (так называемые
метеошумы). Задача краткосрочного прогноза метеороло-
гических элементов состоит из трех этапов: 1) анализа и
обработки исходного материала; 2) прогноза на время Т
этих исходных данных (Т — 12; 24; 36 или 48 ч) и 3) пред-
сказания погоды по полученным данным.
Решение задачи предсказания погоды на сутки занимает
7 мин машинного времени.
В лаборатории NANWER (США) установлена вычисли-
тельная машина, которая составляет карты погоды для воен-
но-морского флота. Машина обрабатывает данные о погоде,
поступающие от 5000 метеостанций, и на основе этих данных
составляет прогнозы на сутки вперед по всему северному
полушарию. Сведения о погоде в интересующей точке на-
ходятся посредством интерполирования данных, получен-
ных от метеостанций, расположенных вблизи этой точки.
Вычислительная машина обрабатывает отдельно данные о
давлении и температуре. В результате вычислений вычер-
чиваются карты погоды. Программа прогнозирования по-
годы была составлена на основе статистической теории и
и
законов метеорологии. На прогнозирование одной состав-
ляющей погоды (например, давления) затрачивается 5 мин.
Важные данные для предсказания погоды можно
получить из исследования верхних слоев атмосферы, что
осуществляется при помощи метеорологических спутников.
Так, спутники помогут определить места зарождения тай-
фунов, дадут ясную картину общепланетных атмосферных
процессов. Цветные снимки Земли, сделанные нашими
космонавтами, тоже служат задачам прогнозирования пого-
ды. Огромное количество быстро поступающей разнообраз-
ной информации требует автоматизации наблюдений и пере-
дачи данных. Поэтому надежное предсказание погоды можно
обеспечить только при детальном учете метеорологичес-
ких данных, получаемых на Земле и в Космосе и при
создании и использовании соответствующих систем передачи
данных в вычислительные машины.
Другие геофизические прогнозы
Трудно переоценить значение предсказания при опре-
делении перспектив и наиболее целесообразных фор$< исполь-
зования естественных источников энергии в народном хо-
зяйстве [22]. Энергия речного стока превращается в электро-
энергию на многочисленных гидроэлектростанциях. Солнеч-
ные батареи питают приборы и аппаратуру спутников и
космических кораблей. Энергия приливов будет преобразовы-
ваться в электроэнергию на первенце нашей морской гидро-
энергетики — Кислогубской приливной электростанции.
14
Для других видов геофизических прогнозов, связанных,
например, со среднегодовым расходом воды на реках, годо-
выми суммами осадков на больших территориях, годовыми
суммами энергий землетрясений и т. д., значительные ус-
пехи достигнуты именно благодаря применению вероятно-
стных методов предсказания. Так, Ю. М. Алехин [1 ] успешно
применил метод линейного экстраполирования случайных
временных последовательностей для предсказания годовых
стоков рек.
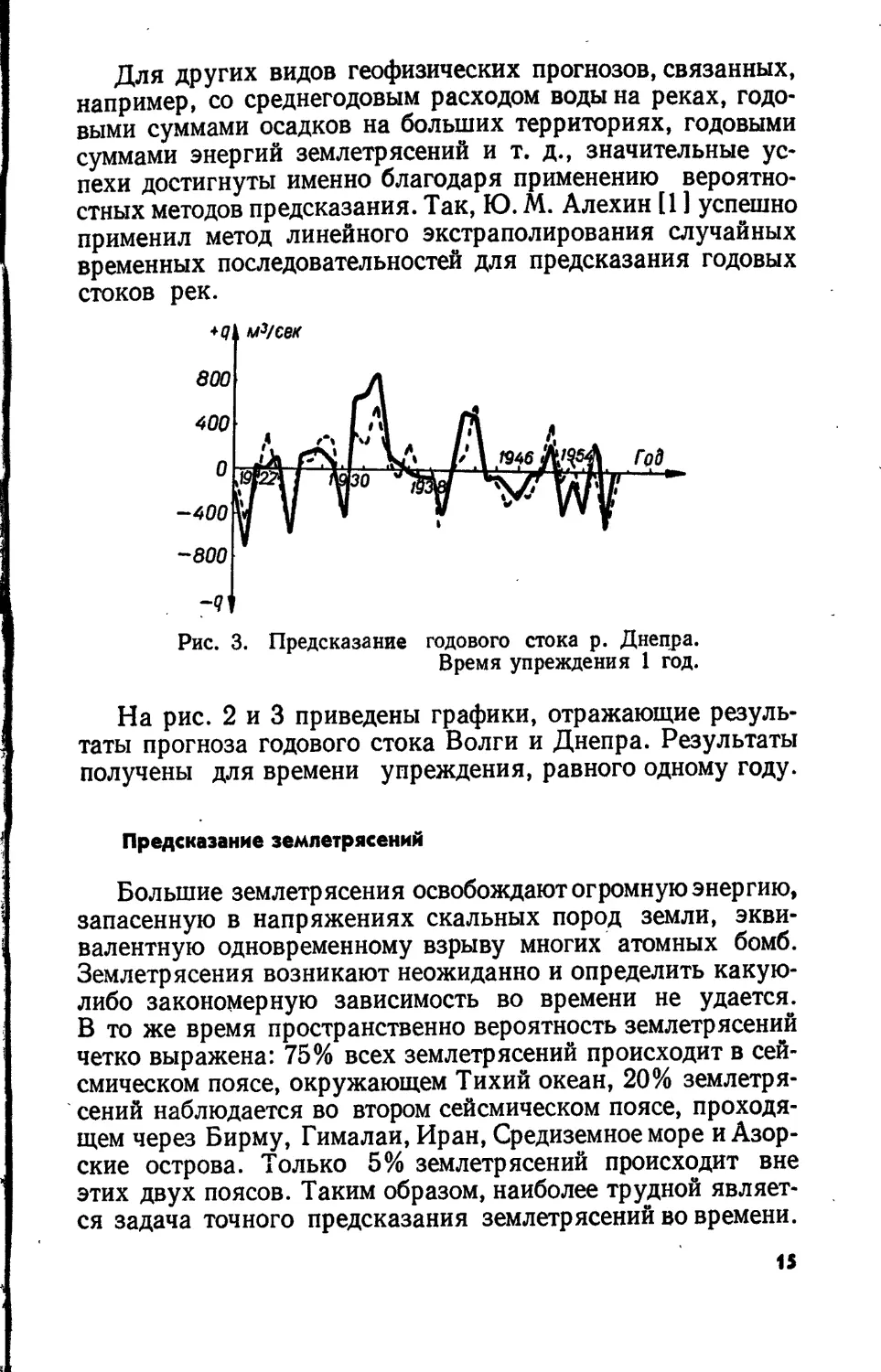
Рис. 3. Предсказание годового стока р. Днепра.
Время упреждения 1 год.
На рис. 2 и 3 приведены графики, отражающие резуль-
таты прогноза годового стока Волги и Днепра. Результаты
получены для времени упреждения, равного одному году.
Предсказание землетрясений
Большие землетрясения освобождают огромную энергию,
запасенную в напряжениях скальных пород земли, экви-
валентную одновременному взрыву многих атомных бомб.
Землетрясения возникают неожиданно и определить какую-
либо закономерную зависимость во времени не удается.
В то же время пространственно вероятность землетрясений
четко выражена: 75% всех землетрясений происходит в сей-
смическом поясе, окружающем Тихий океан, 20% землетря-
сений наблюдается во втором сейсмическом поясе, проходя-
щем через Бирму, Гималаи, Иран, Средиземное море и Азор-
ские острова. Только 5% землетрясений происходит вне
этих двух поясов. Таким образом, наиболее трудной являет-
ся задача точного предсказания землетрясений во времени.
15
Для достаточно точного предсказания землетрясений
в сейсмических районах организуется сеть наблюдательных
пунктов. Сложные измерительные приборы применяются для
измерения сжатия и наклона земной поверхности. Измеря-
ются косвенные величины: скорость прохождения сейсмиче-
ских волн, изменение электрической проводимости земли
и магнитное склонение.
. Японские ученые, в частности, показали, что изменение
магнитного склонения, вызываемое сжатием верхних слоев
20
Угол
склонении
(мин) л
18
16
X г/ XII / // /// IV V VI VII
Рис. 4. Изменение магнитного склонения.
земной поверхности,
является наиболее су-
щественным факто-
ром, который позво-
лит повысить точ-
ность предсказания
времени землетрясе-
ния. На рис. 4 пока-
зана типичная кривая
изменения магнитно-
го склонения [55].
Характерный пик
увеличения магнитно-
го склонения пред-
, По кривой видно, что
шествует сильному землетрясению.
время может быть предсказано за несколько месяце^ с точ-
ностью до двух-трех недель. Возможно и дальнейшее по-
вышение точности предсказания.
Предсказание уровня грунтовых вод
В связи с проектированием и строительством гидротех-
нических сооружений, например водохранилищ, часто воз-
никает задача прогноза уровня грунтовых вод в окружаю-
щих массивах.
Изменение уровня грунтовых вод является длительным
и непериодическим процессом. Предсказание заключается
в расчете перемещения границы свободной поверхности
(поверхности депрессии), для чего требуется решать нели-
нейные уравнения параболического типа. При этом накла-
дываются конкретные начальные и краевые условия, опре-
деляющие историю процесса и геологическое строение мас-
сива и учитывающие изменения коэффициентов фильтрации
в исследуемом объеме.
16
Трудность задачи состоит в решении таких уравнений.
Исследуемая зависимость в результате линеаризации может
быть сведена к уравнению типа уравнения теплопровод-
ности.
Для решения таких задач применяются сложные вычис-
лительные устройства — сеточные интеграторы, модели
ЭГДА, ЭВМ.
Детерминированность предсказания в данном случае оп-
ределяется явно выраженным и точно определенным воз-
действием.
Бывают случаи, когда изменение уровней грунтовых вод
определяется совокупностью разнообразных причин. Изме-
нение уровня грунтовых вод в таких случаях может интер-
претироваться как стохастический процесс, зависящий от
поливов, дренирования, количества выпадающих осадков
и колебания уровня воды в реках (два последних воздей-
ствия сами по себе являются стохастическими). В таких слу-
чаях вся теория предсказания случайных процессов при-
менима в полной мере.
Предсказание коррелированных
процессов
В примере задачи предсказания землетрясений важно
обратить внимание на то, что в отличие от других задач
здесь предсказание ведется по наблюдению за процессами,
связанными (коррелированными) с интересующим нас про-
цессом (по магнитному склонению). Такой прием является
общим, имеющим широкую область применения.
Часто предысторию процесса, который необходимо пред-
сказать, мы не можем проследить. Однако имеются данные
о другом процессе, связанном с первым функциональной
или корреляционной связью. Например, при управлении
производственным процессом можно прогнозировать изме-
нения какого-либо параметра', не прибегая к его непосред-
ственному измерению, а используя данные о другом пара-
метре, связанном с первым. Это особенно важно в тех слу-
чаях, когда часть параметров трудно измерима или нежелате-
лен прямой отбор информации с объекта.
В наиболее общей формуле предсказания, кроме членов,
отражающих параметры основного процесса в данный мо-
мент и его предысторию, имеются члены, определяющие
2 474
17
параметры и предысторию других величин, коррелирован-
ных с основным процессом.
Попытки составления формул (правил или алгоритмов)
наиболее точных предсказаний, учитывающих все указанные
выше факторы, показывают, что пользование такими форму-
лами связано с огромным объемом вычислительной работы.
Между тем, запрограммировать на больших вычислительных
машинах можно лишь сравнительно простые алгоритмы.
Поэтому следует применить систему обратной связи. В прог-
рамме вычислительной машины или в специализированном
поэлементном устройстве реализуется поиск наилучшего
алгоритма предсказания (при заданном объеме устройства).
Машина автоматически оставляет в программе (формуле
предсказания) только те члены, влияние которых на точность
предсказания оказалось существенным. В главе 4 мы
рассмотрим примеры предсказания амплитуды океанских
волн, показателей работы предприятия, уровней речного
дна и предсказание атмосферного давления, на которых бо-
лее конкретно показан этот прием самонастройки формулы
предсказания.
Одномерные и многомерные задачи
предсказания
В простейшем случае требуется предсказать изменение
величины или ряда величин во времени. Такую задачу пред-
сказания можно назвать одномерной. Предсказание погоды
на поверхности земли является примером более сложной
многомерной задачи, так как требуется рассмотреть процесс
не только во времени, но и в пространстве. При этом встре-
чаются случаи, когда процессы можно отнести к чисто слу-
чайным во времени и в то же время они вероятностны в
пространстве. Примерами могут быть задачи прогнозиро-
вания нагрузки энергосистем, распространения вредителей
сельскохозяйственных растений, предсказания землетря-
сений и многие другие.
Применение математического прогнозирования
в планировании и управлении энергосистемами
В последние годы в каждой крупной энергосистеме соз-
даны вычислительные центры, располагающие цифровыми
вычислительными машинами. Здесь решаются задачи оп-
18
тимального развития системы, расширения существующих
и постройки новых мощных электростанций. Выполняется
долгосрочное предсказание для того, чтобы выяснить возмож-
ный спрос электроэнергии и тепла. Это предсказание должно
определять уровень развития как генераторов и передающей
сети, так и добычи топлива и развития других источников
энергии.
Эта задача предсказания, очевидно, многомерна, ибо
необходимо определить изменение величин не только
во времени, но и в пространстве: требуется указать места
сосредоточения потребителей и генерирующих станций.
Прогноз для защиты растений
от вредителей и болезней
Прогноз для защиты растений является также многомер-
ной задачей. Требуется предсказать: где, когда и в каком
количестве появятся вредители растений, чтобы принять
необходимые меры для защиты. До сих пор математи-
ческие методы для решения этой задачи не применялись.
Прогноз выполняется по чисто эмпирическим правилам.
Например, подсчитав количество куколок весной, можно
предсказать выход гусениц летом и т. п. В книге [38] приво-
дятся примеры удачных предсказаний появления коло-
радского жука, рака картофеля и т. д. Имеется полная
возможность увеличить долгосрочность и точность пред-
сказаний при помощи применения цифровых вычислитель-
ных машин.
Предсказание в биологии и медицине
Последнее десятилетие характеризуется интенсивным
внедрением математических методов, средств вычислитель-
ной техники и технической кибернетики в медико-биоло-
гические исследования и практическую медицину. В тече-
ние ряда лет «медицинская» математика ограничивалась
в основном применением методов математической статистики
для обработки результатов наблюдений и исследований,
для количественной оценки и подтверждения правильности
выводов.
В настоящее время значительно повысился интерес,
проявляемый врачами и учеными — представителями био-
логических наук — к различным математическим методам
2'
19
вплоть до новейших достижений в области теоретичес-
кой кибернетики (теории информации, теории игр, теории
массового обслуживания, теории распознавания обра-
зов и т. д.).
Использование новейших средств технической киберне-
тики и вычислительной техники дает возможность качест-
венно по-новому подойти к решению многих задач, связан-
ных с исследованием живых организмов.
Возникшие в результате плодотворного сотрудничества
математиков, биологов, инженеров новые науки — биоло-
гическая кибернетика, бионика, нейрокибернетика — бурно
развиваются, обогащая биологов новыми данными о живом
организме и помогая представителям точных наук учитывать
при создании высокоэффективных технических устройств
опыт,накопленный природой.
Дальнейшим крупным шагом в этом направлении явится
применение в биологии и медицине теории статистических
предсказаний и соответствующих технических средств.
Развитие нейрохирургии, хирургии сердца и легких
со все более усложняющимися методами оперативного вме-
шательства на жизненно важных органах ставит на по-
вестку дня вопрос о создании автоматических регулято-
ров ряда физиологических параметров человеческого
организма. •
В процессе создания этих регуляторов необходимо учи-
тывать особенности реакции живого организма, обуслов-
ленные его компенсаторными возможностями. Резкие и
острые расстройства функции возникают не тотчас же после
начала действия вредоносного фактора, а лишь спустя
определенное время, в течение которого наступают наруше-
ния, а затем срыв компенсаторных механизмов. Поэтому
для своевременного включения автоматических регуляторов
и в процессе их работы необходимо определенное упреж-
дение.
Предсказывающие устройства, работающие последова-
тельно с приборами, которые регистрируют изменения
различных показателей, позволят предупредить возмож-
ные нарушения в ходе операции.
Применение предсказывающих устройств для обработки
данных исследования больных с прогрессирующими
заболеваниями даст возможность более точно судить о
своевременности и показанности того или иного метода
лечения.
20
Предсказание при управлении
производственными процессами
Современные промышленные предприятия характеризу-
ются высоким уровнем автоматизации.
Непрерывное увеличение количества измерительных и
регистрирующих приборов, моделирование с помощью
средств вычислительной техники, изучение статических
и динамических характеристик объектов — все эти меры
направлены на достижение основной цели: оптимального
управления производственными процессами.
Технологические установки химических предприятий,
объекты металлургической промышленности, большие си-
стемы организации и планирования и многие другие объекты
характеризуются значительной иннерционностью. Например
в нефтяной промышленности при использовании автоматичес-
ких анализаторов качества результаты анализа становятся
известными через 20—25 мин после отбора пробы продукта.
Таким образом, регулирование по показателю качества
осуществляется со значительным запаздыванием. Оче-
видно, что если бы приборы обладали способностью на ос-
новании анализа предыдущих изменений технологических
параметров предсказывать их будущие изменения, ка-
чество регулирования можно было бы значительно повы-
сить.
Большим объемом и трудоемкостью работ характеризу-
ются предприятия горнорудной промышленности. Комп-
лексная автоматизация крупных угольных и рудных карье-
ров является чрезвычайно актуальной задачей. Оптималь-
ное управление горными машинами и транспортными сред-
ствами, диспетчерская служба и многие другие вопросы
решаются с привлечением новейших математических мето-
дов, средств вычислительной техники и технической кибер-
нетики. При создании систем автоматического регулиро-
вания горнотранспортными комплексами и отдельными
машинами может быть достигнут значительный эффект бла-
годаря применению методов теории статистических предска-
заний и устройств, реализующих эти методы.
Дальнейших успехов можно ожидать в связи с примене-
нием теории и техники статистических предсказаний в сфере
организации и планирования народного хозяйства с учетом
перспективных планов.
На различных этапах автоматизации производства и для
различных задач управления методы и технические средства
21
для решения этих задач должны быть различны. Если,
например, задача управления достаточно эффективно
решается одноконтурной системой автоматического регули-
рования, то для повышения качества регулирования с пред-
сказанием можно применить специализированное предска-
зывающее устройство, реализующее определенный алго-
ритм предсказания. При многоконтурном регулировании
также можно создать специализированное устройство для
предсказания производственных показателей, зависящих
от влияния многих факторов..
Однако, учитывая постоянное усложнение задач управ-
ления и использование в связи с этим управляющих вычи-
слительных машин, в ряде случаев создание специализи-
рованных предсказывающих устройств не является обяза-
тельным. Их функции будут с успехом выполнять управля-
ющие машины.
Что касается специализированных устройств для пред-
сказания будущих значений различных производствен-
ных показателей, то здесь значительных успехов можно
ожидать в связи с использованием для предсказания систем
распознавания образов и ситуаций. В этом направлении
сейчас ведутся интенсивные работы как в нашей стране,
так и за рубежом.
В заключение следует сказать, что использование до-
стижений в области теории и техники предсказ’аний —
необходимое условие дальнейшего совершенствования на
пути к оптимальному управлению.
Рассмотренные примеры далеко не полностью характери-
зуют область приложения теории статистических предска-
заний. Несомненно, что по мере дальнейшего развития
и совершенствования ее методы будут все более широко
внедряться в практику научных исследований и в различ-
ные отрасли народного хозяйства.
В последующих главах будут рассмотрены методы
предсказания детерминированных и случайных процессов.
Значительное внимание уделено моделированию пред-
сказывающих фильтров на универсальных цифровых вы-
числительных машинах и применению различных методов
для предсказания реальных процессов.
Особое место занимает изложение вопросов, связанных
с применением распознающих систем в качестве предсказы-
вающих фильтров.
22
Г Л А В A I.
ПРЕДВИДЕНИЕ
ДЕТЕРМИНИРОВАННЫХ ПРОЦЕССОВ.
ИНТЕРПОЛИРОВАНИЕ И ЭКСТРАПОЛИРОВАНИЕ
ЗАДАЧИ ИНТЕРПОЛИРОВАНИЯ И ЭКСТРАПОЛИРОВАНИЯ
В детерминированных процессах случайные откло-
нения настолько малы, что эти процессы можно заранее
достаточно точно рассчитать. Примерами таких процессов мо-
гут служить движение небесных тел, а также движение про-
стых механизмов, например маятника, всякое изменение
или перемещение, происходящее точно по расписанию или
графику и т. п. Законы, управляющие такими процессами,
иногда известны и могут быть выражены в виде аналити-
ческих функций, графиков или таблиц (например, расписа-
ние движения поездов).
Часто эти функции остаются неизвестными. Но они
существуют, и в соответствии с ними протекает тот или иной
процесс, совершается то или иное движение. Функции эти
представляют собой решения, или, иначе, интегралы урав-
нений динамики интересующих нас механизмов либо си-
стем.
При изучении детерминированных процессов возникает
два типа задач, связанных с определением значений неко-
торой функции в интересующих нас точках по известным
значениям этих функций в других точках. Рассмотрим
такие задачи.
Задача интерполирования заключается в
нахождении значения функции внутри отрезка наблюдения.
Сама функция, как указывалось, может при этом оставать-
ся неизвестной. Однако в большинстве случаев необходимо
знать, к какому классу функций она относится: выражается
23
ли она прямой линией, параболой второй степени, куби-
ческой параболой, гармонической функцией и т. п.
Пусть известны значения функции f ); i= 1, 2,..., п
в точках t0 < 4 < ... < tn. Требуется определить значения
этой функции в точках 4 , лежащих между заданными точ-
ками tt < tj < 4+i.
Например, при линейном интерполировании значения
функции в некоторой средней точке t0 < t < tt равно
f (О = гЕт ft) - / &)] + f (4)- (1)
Ч ‘'О
Задача экстраполирования заключается в
нахождении значений функции в точке, лежащей вне от-
резка наблюдения, по ее значениям внутри этого отрезка.
Наиболее распространенным является линейное и параболи-
ческое экстраполирование, при котором функция выражает-
ся параболой второй, третьей или более высокой степени.
Обычно чем меньше время, на которое экстраполируется
процесс, тем точнее определение будущего значения функции.
Это связано с тем, что указанные функции только прибли-
женно представляют (аппроксимируют) действительные за-
коны, управляющие процессом.
।
Подбор аппроксимирующего многочлена
Как уже говорилось, вид аппроксимирующей функции
определяется физикой процесса и, следовательно, соответст-
вует виду решений (интегралов) уравнения динамики сис-
темы. Например, если известно, что некоторое множество
цифр выражает собой величину угла отклонения маятни-
ка, то ясно, что они должны удовлетворять закону гармо-
нических колебаний. Задача значительно усложняется,
если физика процесса неизвестна и мы не знаем вида функ-
ции решения. Тогда приходится подбирать вид аппрокси-
мирующей функции так, чтобы она некоторым наилучшим об-
разом прошла через заданные точки.
Во многих случаях исходная информация задается в ви-
де конечного множества точек (выборки), и задачи интер-
полирования и экстраполирования будут решены до кон-
ца, если будет найдено аналитическое выражение, которому
все эти точки удовлетворяют.
24
Допустим, задана следующая выборка данных:
t=l 2345
/= 1,111 1,248 1,417 1,624 1,875.
Предполагается, что выборка является достаточно пред-
ставительной, т. е. достаточно хорошо отображает все основ-
ные свойства функции. Подбор аппроксимирующего много-
члена начнем с наиболее простого выражения. Предположим,
что процесс описывается уравнением прямой линии
= (2)
Выбрав произвольно две точки выборки (например, пер-
вую и последнюю), пишем уравнение прямой два раза
1,111=а + 6-1,
1,875 = а+ 6-5.
Получена система из двух уравнений с двумя неизвест-
ными — коэффициентами аппроксимирующего многочле-
на а и Ь. Решая эти уравнения совместно, находим
о = 0,920; 6 = 0,191.
Теперь можно проверить, правильно ли мы угадали вид
аппроксимирующего многочлена. Для этого находим зна-
чения аппроксимирующей функции при тех же значениях
аргумента
/=1 2 3 4 5
+♦=1,111 1,302 1,493 1,684 1,875.
Точность приближения можно оценить по величине ва-
риации
/7 >'1
Чем меньше вариация, тем точнее подобран аппроксимиру-
ющий многочлен, тем ближе будут предсказанные .значения
к действительным.
Повторим то же исследование для параболы второй сте-
пени:
f* = a + bt +сЛ (4)
1 Здесь и в дальнейшем предсказанное значение отмечается
звездочкой.
25
Выбрав произвольно три точки (например, начало, середину
и конец выборки), получим систему из трех уравнений с тре-
мя неизвестными:
1,111 = а + b-1 + с-1,
1,417 = а+6-3+с-9,
1,875 = а + Ь-5 -J- с-25.
Решая эти уравнения, находим:
а = 1,015; 6 = 0,077; с = 0,019.
Квадратический аппроксимирующий многочлен дает та-
кую последовательность значений функции:
t=\ 2345
/*= 1,111 1,245 1,417 1,627 1,875.
Находим величину вариации:
6 = 4й—100 = 0,79%.
fl-fl
Убеждаемся, что вариация уменьшилась. Следовательно,
полином второй степени значительно лучше аппроксими-
рует данную функцию.
Чтобы еще больше повысить точность аппроксимации,
перейдем к полиному третьей степени:
f* = а + bt + ct2dt3. (5)
Действуя аналогично предыдущему, напишем систему и
четырех уравнений с четырьмя неизвестными:
1,111 = а + b-1 + с-1 + d-1,
1,417 = аН- 6-3 + с-9 + d-27,
l,624 = a + &-4 + c-16 + d-64,
1,875 = а + 6-5 +с-25+ d-125.
Решая уравнения совместно, находим
а =1,0; 6 = 0,1; с = 0,01; d = 0,001.
Определяя вариацию, убеждаемся, что она равна нулю:
о = 0.
Следовательно, найденный многочлен третьей степени
точно описывает исходную функцию. Если такой результат
26
в других задачах нельзя получить, то следует остановиться
на аппроксимирующем многочлене, дающем достаточно
малую вариацию — порядка нескольких процентов. Если
добиться этого не удастся и вариация остается большой,
то это может быть признаком того, что исходный процесс не
является детерминированным, что кроме регулярной в нем
присутствует значительная случайная составляющая. В этом
случае рассмотренные здесь способы подбора аппроксими-
рующего полинома уже недействительны. Нужно пере-
йти к методам предсказания случайных процессов, которые
будут рассмотрены в главе 2, посвященной предсказанию
случайных процессов.
Если же получено выражение, дающее малую или (что
лучше) нулевую вариацию, то задачи интерполирования и
экстраполирования становятся тривиальными. Пользуясь
полученным выражением, легко находим значения инте-
ресующей нас функции в любой момент времени как в прош-
лом, так и в будущем.
В рассмотренном числовом примере можно «предсказать»,
что при t = 6 величина f = 2,187. Мы разгадали процесс,
нашли уравнение, которым он описывается.
Рассмотрим еще один пример. Приведем данные о чис-
ленности народонаселения Европы за период с 1850 по
1930 г. (в млн. человек): 1850 г.— 267; 1860 — 284; 1870 —
306; 1880 — 332; 1890 — 364; 1900 — 399; 1910 — 441;
1920 — 449; 1930 — 491.
Предположим, что известны только значения численно-
сти населения за 1860, 1870 и 1880 гг. На основании этих
сведений определим численность населения в 1864 г., т. е.
решим задачу интерполирования. Воспользовавшись фор-
мулой квадратического интерполирования (4), получим:
а — b + с = 284,
а — 306,
а —|- b -|- с = 332.
Аргумент при равноотстоящих значениях удобно обо-
значать следующим образом: первое значение — 1860 г.—
принимаем за — 1, второе — за 0, а третье — за 1. Тогда
значение аргумента в предсказываемой точке — 1864 г.—
равно — 0,6.
Решая эти уравнения, находим значения коэффициентов
а = 306; b = 24; с = 2.
27
Учитывая вычисленные значения коэффициентов,
запишем интерполяционную формулу в виде
/ = 306 + 24/ + 2/а.
Подставив в нее t — — 0,6, получим
/_0,6 = 306 + 24 (— 0,6) + 2 (— 0,6)« = 292,32.
Округляя до целых значений, численность населения
получим равной 292 млн. человек.
Теперь, исходя из предположения, что закономерность,
действующая внутри интервала, сохраняется вне его, опре-
делим численность населения в 1900, 1910 и 1920 гг. Это —
задача экстраполирования.
Для решения задачи воспользуемся основными свойства-
ми интерполяционных формул. Эти свойства для интерполя-
ционной формулы n-го порядка заключаются в следующем:
а) разности n-го порядка
А? = А"-1 — А"-1 = А" = Д«-1 — Д«-> =... = const.
1 Z * о I
б) разности п + 1-го порядка
Д«+1 = А* — Д« = Д« — А» = 0.
При квадратичном экстраполировании получим
/1800 3/1890 + 3/1880 — /1870 = 0,
откуда *
Аэоо = 3 • 264 — 3 • 332 + 306 = 402 (млн. человек).
Если использовать кубическое экстраполирование,
т. е. положить четвертую разность равной нулю,
Двое 4/1890 + 6/1880 — 4/187о + /18в0 = 0,
получим сходный результат:
Лэоо = 4 • 364 — 6 • 332 + 4 • 306 — 284 — 404 (млн. человек).
На самом деле численность населения на 1900 г. состав-
ляла 399 млн. человек.
Отклонения, как видим, не очень значительны. Путем
вычисления вариации можно убедиться, по какой
из формул получается наилучшее предсказанное значение.
Применим эти формулы для предсказания численности
населения в 1920 г.
/1920 = 3-441 — 3 • 399 + 364 = 490 (млн. человек),
fi92O = 4-441 — 6-399 + 4-364 — 332 = 494 (млн. человек).
28
В действительности же по переписи 1920 г. в Европе
насчитывалось 449 млн. человек. Полученные по формулам
значения 490 и 494 примерно совпадают с результатами пе-
реписи 1930 г.—491. Таким образом, предсказание не
оправдалось. Но оно не оказалось бесполезным, так как
позволило оценить громадный ущерб, нанесенный первой
империалистической войной населению Европы.
Автоматическое интерполирование
Решением задач, подобных рассмотренным в предыдущем
примере, занимаются статистики. Объем обрабатываемой
информации непрерывно увеличивается, и сами задачи
становятся все более сложными. На помощь статистикам
приходят универсальные вычислительные машины.
Проблема автоматизации производственных процессов
и оптимального управления различными объектами потре-
бовала создания специализированных устройств, позволя-
ющих решать задачи интерполирования и экстраполирова-
ния. Например, для программного управления металлоре-
жущими станками потребовалось создать устройства, кото-
рые по известным координатам нескольких точек положе-
ния режущего инструмента могли бы воспроизвести всю
траекторию движения.
Такие устройства получили название автоматических
интерполяторов. Они широко применяются при раскрое
металлических плит и листов, в следящих системах для
управления объектами, требующими высокой точности зада-
ния траектории и др. Рассмотрим примеры наиболее про-
стых интерполяторов.
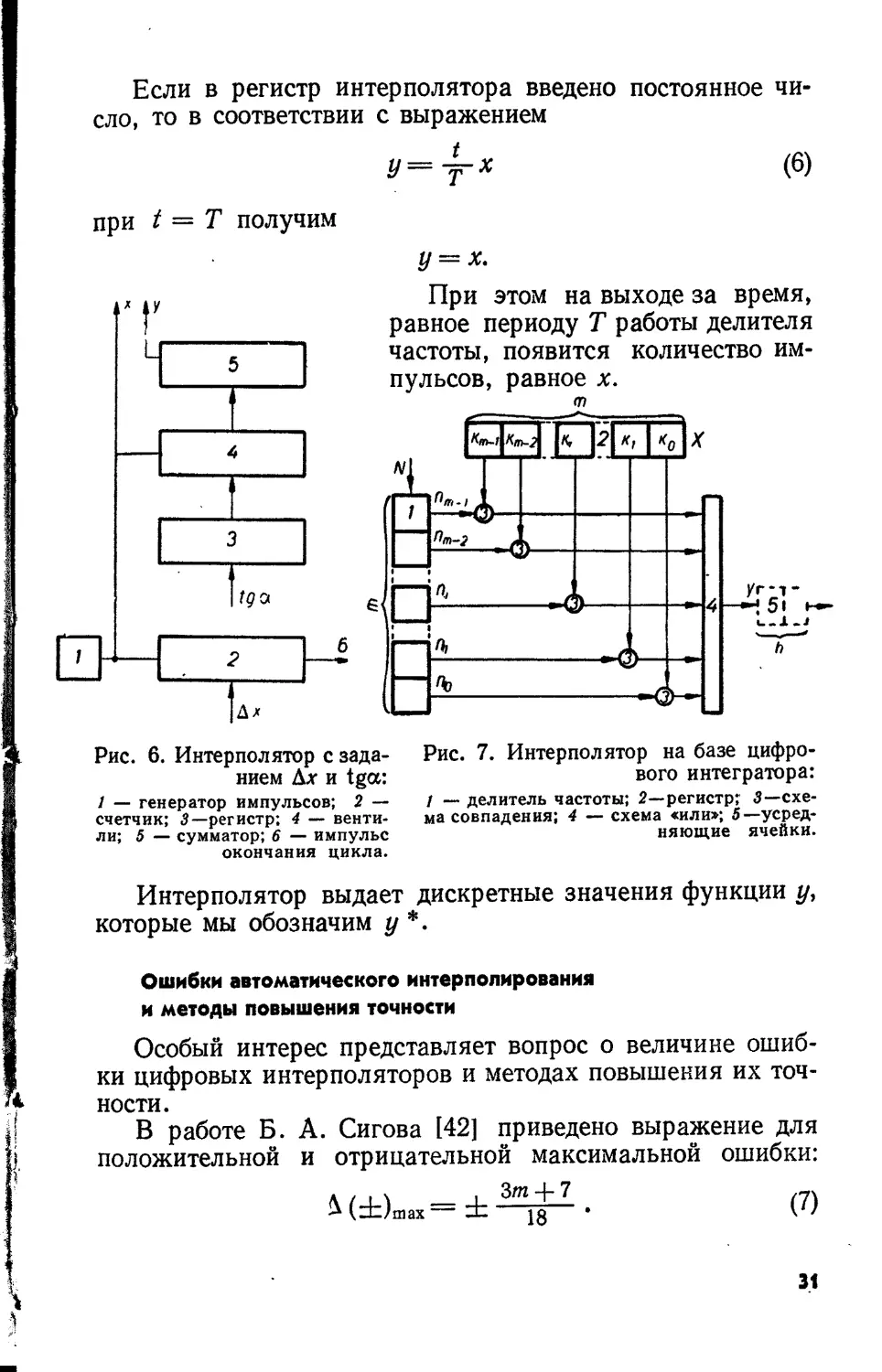
Линейные интерполяторы
На рис. 5 приведена блок-схема линейного цифрового
интерполятора, исходными данными для которого являют-
ся значения sin а и cos а , где а — угол наклона интерпо-
лируемой траектории к оси х.
Подобный интерполятор применяется для управления по-
дачей режущего инструмента при автоматической обработ-
ке деталей. При обработке отрезка длины I в регистры 4 и 6
вводятся величины синуса и косинуса угла наклона обра-
батываемого отрезка к оси х. Величина отрезка с данным
углом наклона при фиксированной частоте генератора
29
определяется временем поступления импульсов на схему
деления 2. Это время в свою очередь задается суммой импуль-
сов х-\-у (количество импульсов, соответствующее полному
перемещению по координате). Как только сумма импуль-
сов х-\-у установится равной числу, занесенному на счетчик 8,
с последнего выдается импульс окончания цикла и на
Рис. 5. Линейный интерполятор:
1 — генератор импульсов; 2 — делитель частоты; 3, 5 — вен-
тили; 4, 6 — регистры; 7 — схема «или»; 8 — счетчик; 9 —
импульс окончания цикла.
вход 2 перестают поступать импульсы генератора. Управ-
ление подачей инструмента осуществляется сигналами на
шинах «Ось х» и «Ось у».
Приведем еще примеры линейных интерполяторов.
В интерполяторе, блок-схема которого приведена на рис. 6,
начальными заданиями служат величины tga и Дх.
Линейный интерполятор (рис. 7) построен на базе циф-
рового интегратора [42]. Принцип действия его заклю-
чается в следующем.
30
Если в регистр интерполятора введено постоянное чи-
сло, то в соответствии с выражением
У ~ % (6)
при t = Т получим
У = х.
При этом на выходе за время,
равное периоду Т работы делителя
частоты, появится количество им-
пульсов, равное х.
m
1,
I
\2 К,
П,
-Ф--
—ф
ф
4
уг-т
h
Ф
%
Рис. 6. Интерполятор с зада-
нием Дх и tga:
1 — генератор импульсов; 2 —
счетчик; 3— регистр; 4 — венти-
ли; 5 — сумматор; 6 — импульс
окончания цикла.
Рис. 7. Интерполятор на базе цифро-
вого интегратора:
/ — делитель частоты; 2—регистр; 3—схе-
ма совпадения; 4 — схема «или»; 5—усред-
няющие ячейки.
Интерполятор выдает дискретные значения функции у,
которые мы обозначим у *.
Ошибки автоматического интерполирования
и методы повышения точности
Особый интерес представляет вопрос о величине ошиб-
ки цифровых интерполяторов и методах повышения их точ-
ности.
В работе Б. А. Сигова [42] приведено выражение для
положительной и отрицательной максимальной ошибки:
*(±)ши=±^-- (7)
31
Здесь т — количество разрядов исходного числа х.
Очевидно, что с увеличением т ошибка увеличивается и
при /п>3 можно считать, что увеличение ошибки происхо-
дит по линейному закону. Эта зависимость показана на рис. 8
в виде графика.
Для уменьшения ошибки Атахбыло предложено ввести
в выходные цепи интегратора некоторое количество тригер-
ных ячеек — Л. В дальнейшем бу-
дем называть их усредняющими.
На рис. 7 эти ячейки очерчены
пунктиром. При отсутствии усред-
няющих ячеек количество импуль-
сов на выходе интерполятора рав-
нялось сумме количеств импульсов
по открытым каналам:
АН,
т-\
У* = ^iki ni •
i=0
(8)
Теперь значение выходной ве-
личины можно записать в .виде
Рис. 8. Зависимость ошиб-
ки интерполирования от
количества разрядов ис-
ходного числа.
г т—1
У* =
i=Q
2h
(9)
т
где h — количество усредняющих ячеек.
Для максимальных положительной и отрицательной
ошибок будем иметь выражения
Л (лл — 3/n + 7±2-ffl+1
h (+)fflax 18-2*
(Ю)
И
Д/_ \ 3/п—11 ± 2—т+1 , Л ,1П
h( }тах (------------1Г2Л------+ V • о о
Из этих формул следует, что с увеличением числа усред-
няющих ячеек максимальные положительные и отрицатель-
ные ошибки уменьшаются (рис. 9).
Дополнительное уменьшение ошибки может быть до-
стигнуто при введении в усредняющие ячейки некоторого
начального числа s (смещения).
32
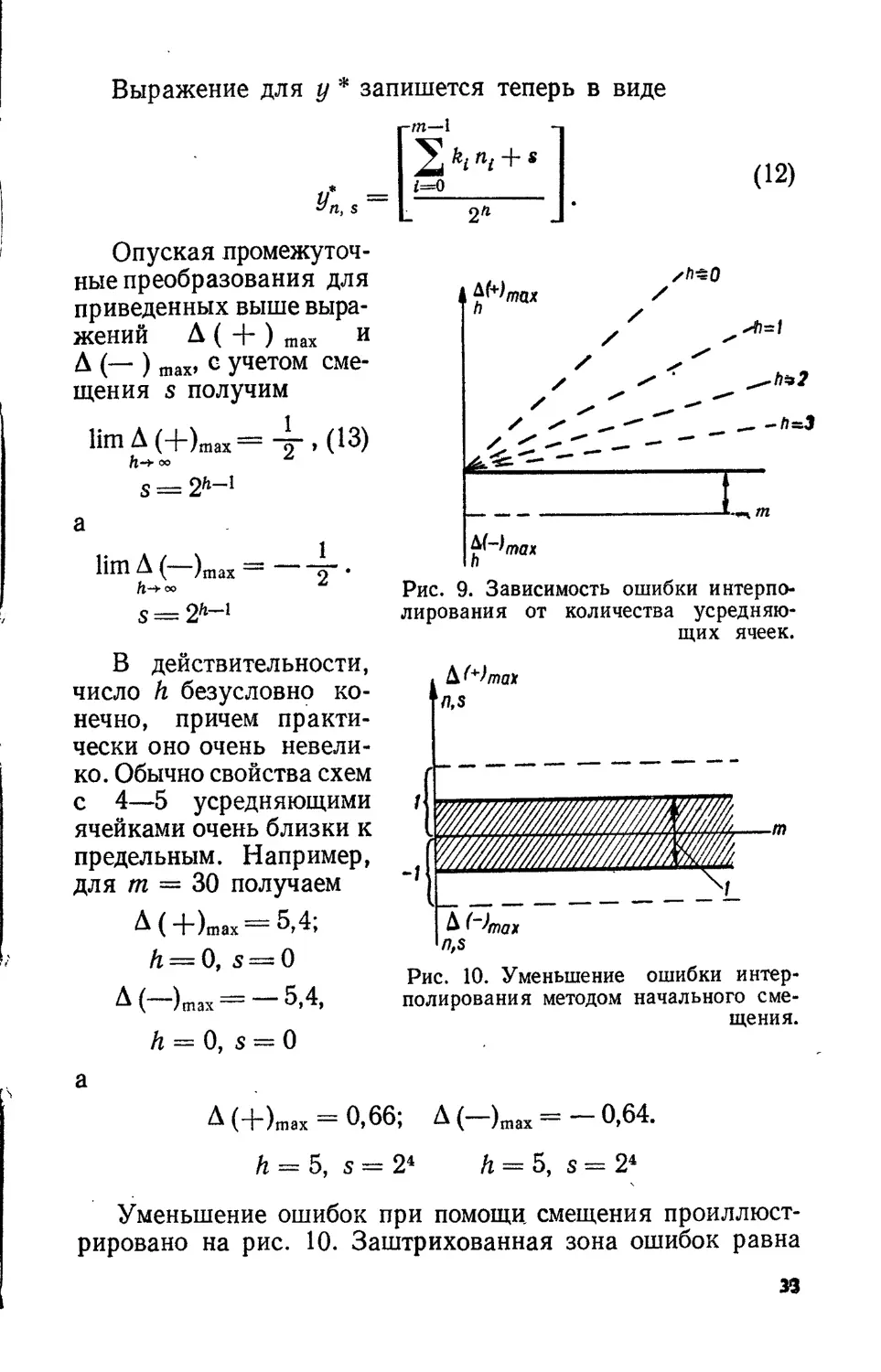
Выражение для у * запишется теперь в виде
Уп,г
-т-Л
^ikini + s
i=0________
2Л
(12)
Опуская промежуточ-
ные преобразования для
приведенных выше выра-
жений Д ( + ) шах И
А (— ) шах, с учетом сме-
щения $ получим
lim Д (+)fflax = 4 ’ (13)
сю
s = 2h-!
а
lim А ( )тах = х-.
о©
s = 2^
В действительности,
число h безусловно ко-
нечно, причем практи-
чески оно очень невели-
ко. Обычно свойства схем
с 4—5 усредняющими
ячейками очень близки к
предельным. Например,
для т = 30 получаем
А ( +)тах = 5,4;
h = 0, s = 0
А ( )тах 5,4,
h = 0, s — 0
Рис. 9. Зависимость ошибки интерпо-
лирования от количества усредняю-
щих ячеек.
A Wmax
А
n,s
Рис. 10. Уменьшение ошибки интер-
полирования методом начального сме-
щения.
а
Д (+)тах = 0,66; Д (-)тах = - 0,64.
h = 5, s -- 24 h = 5, s = 24
Уменьшение ошибок при помощи, смещения проиллюст-
рировано на рис. 10. Заштрихованная зона ошибок равна
33
шагу дискретности. Меняя смещение, можно получить только
положительные или только отрицательные ошибки или рас-
положить зону ошибок симметрично оси абсцисс.
Применение усредняющих ячеек и начальное смещение
привели к положительным результатам и в схемах квадра-
тичных интерполяторов. В них тоже был получен значитель-
ный выигрыш в точности.
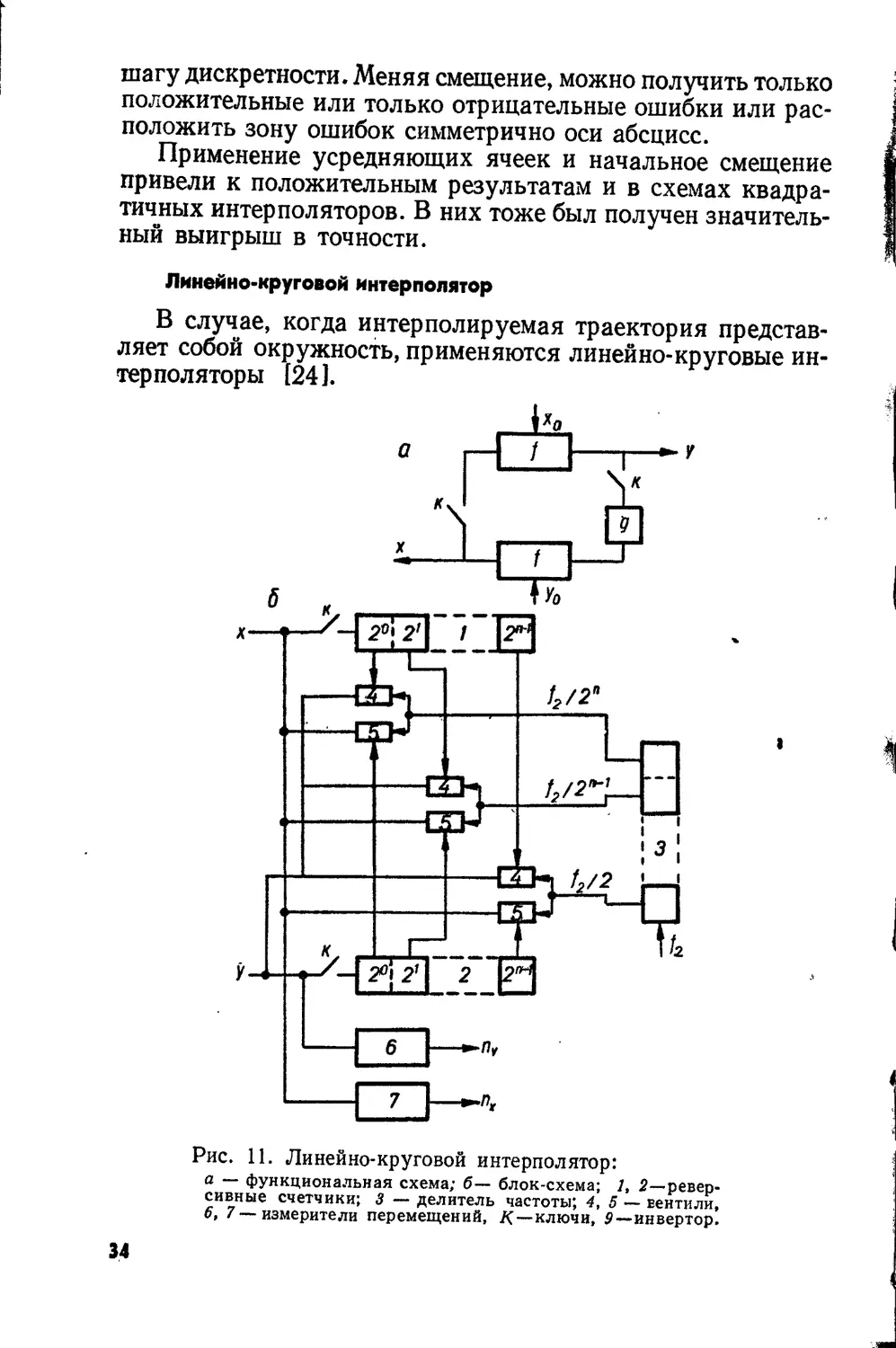
Линейно-круговой интерполятор
В случае, когда интерполируемая траектория представ-
ляет собой окружность, применяются линейно-круговые ин-
терполяторы [24].
Рис. 11. Линейно-круговой интерполятор:
а — функциональная схема; б— блок-схема; Z, 2—ревер-
сивные счетчики; 3 — делитель частоты; 4, 5 — вентили,
6, 7 — измерители перемещений, К—ключи, 9—инвертор.
34
Схема такого интерполятора представлена на рис. 11.
Устройство состоит из двух интеграторов и инвертора и
предназначено для решения дифференциального уравнения
вида
dy х
dx у
Решением этого уравнения является уравнение окруж-
ности
у* + хг = 7?2.
Если ключи к разомкнуты, то интерполируется прямая
с углом наклона к оси х
а = arc tg — .
5 Уо
При размыкании одного из ключей к воспроизводится
парабола, а при исключении из схемы инвертора 1 — ги-
пербола.
В начале работы интерполятора в измерители перемеще-
ния 6 и 7 задаются полные перемещения по осям х и у в до-
полнительном коде. Работа схемы продолжается, пока ре-
гистры 6 и 7 не переполняются поступающими на них выход-
ными импульсами управления.
Квадратичные интерполяторы
Для интерполирования кривых второго порядка вида
у = а + Ьх + сх2
применяются квадратичные, или параболические, интер-
поляторы. На рис. 12 приведена блок-схема параметриче-
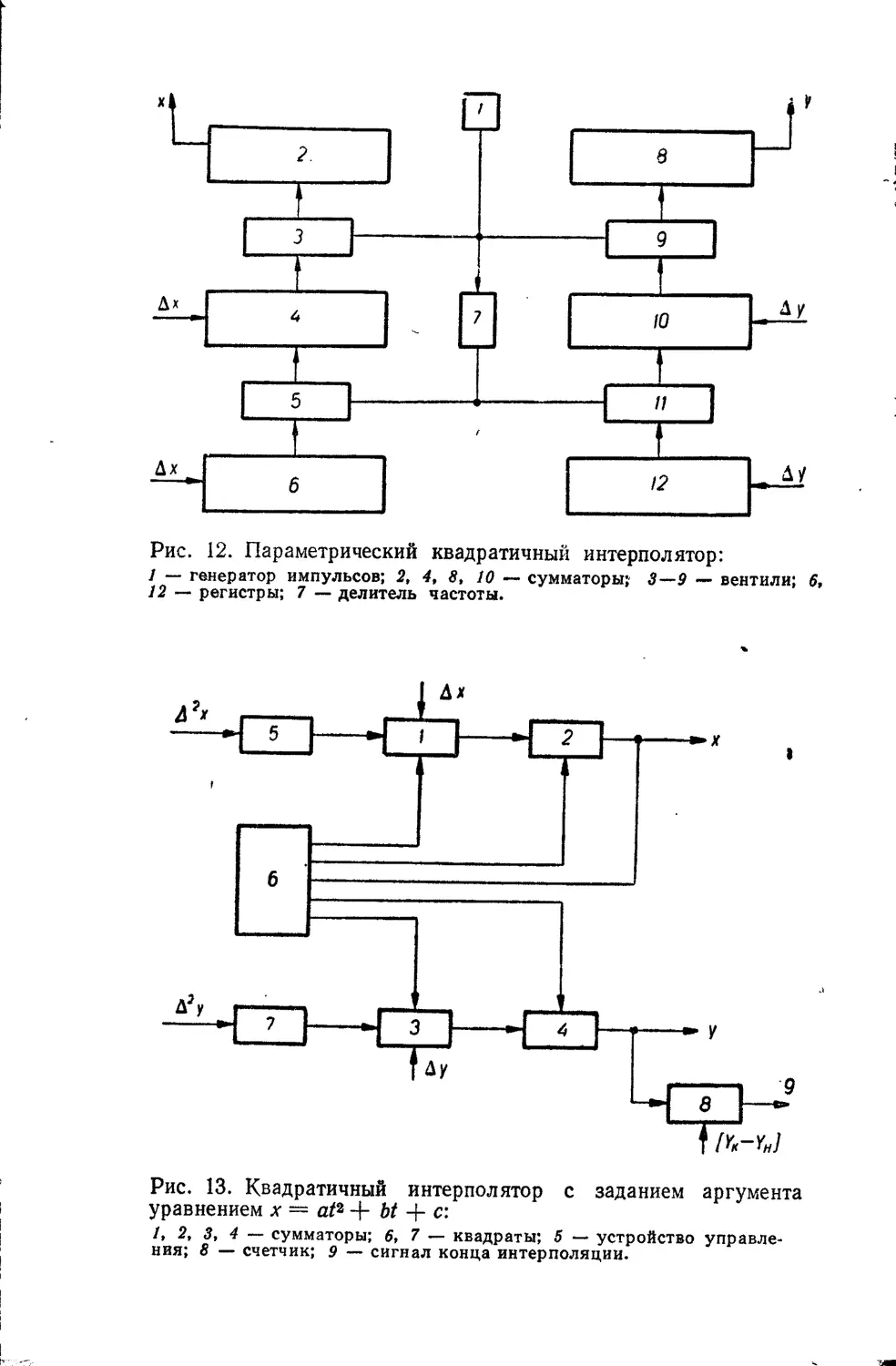
ского квадратичного интерполятора. Работа его, как и
большинства описанных в литературе параболических ин-
терполяторов, основана на разностном методе. В суммато-
рах 2 и 8 накапливаются величины хг и у,, причем целые
части этих величин выдаются в виде импульсов по осям
х и у. В сумматорах 4 и 10 записаны текущие значения первых
разностей Дх,(/), &yi(t). В регистрах 6 и /2 хранятся значе-
ния вторых разностей Д2х<(/), Д2у,(7).
Работа схемы описывается разностными уравнениями:
Дх(-(/) = Axz_i (/) + А2х (/),
Д^(0 = Д^-1(0 + Д^(0-
35
Рис. 12. Параметрический квадратичный интерполятор:
1 — генератор импульсов; 2, 4, 8, 10 — сумматоры; 5—9 — вентили; 5,
12 — регистры; 7 — делитель частоты.
Рис. 13. Квадратичный интерполятор с заданием аргумента
уравнением х = at2 + bt + с:
1, 2, 3, 4 — сумматоры; 6, 7 — квадраты; 5 — устройство управле-
ния; 8 — счетчик; 9 — сигнал конца интерполяции.
На рис. 13 представлена блок-схема интерполятора,
в котором. координата задается уравнением
х = at* + bt + с,
а координата у изменяется в соответствии с уравнением
у = аухг + bjX + q.
Для решения этих уравнений используется разностный
метод. В сумматорах 1 и 2 производится суммирование раз-
ностей по координате х, а в сумматорах 3 и 4 суммируются
разности по координате у. Перед началом работы разность
конечного ук и начального значений координаты уп заносится
на счетчик 8 в дополнительном коде. После переполнения
счетчика выдается сигнал перехода к следующему участку
траектории.
Интерполяторы высших порядков
На рис. 14 приведена схема электронного устройства
для кубического интерполирования. В качестве входных
сигналов используется дискретная последовательность, полу-
Ч 4 F
Рис. 14. Кубический интерполятор:
1 — интегрирующие усилители; 2 — масштабные усилители; 3 — им-
пульсные элементы; 4 — генератор импульсов.
ченная с помощью амплитудно-импульсной модуляции.
Интерполирование осуществляется по формуле
f (а +Т + т)=/(а) + А/(а) {д/(а) +
- + -2§j- [AV (а)] + -з^г [ДV (а)1,
37
где f (а + Т + т ) — значение интерполируемой функции
в момент времени а + Т + т;
а — начальный момент времени;
Т — период поступления дискретных зна-
чений функции /;Д У;ДУ;Д3/— соот-
ветственно первая, вторая и третья
разности функции /; 0 < т Т.
Рис. 15. Интерполятор четвертой степени:
1 — считывающее устройство; 2 — блок памяти; 3 — сум-
матор; 5 — преобразователи; 6 — устройство записи на ма-
гнитную ленту; 7 — преобразователь опорной частоты; 8 —
генератор прямоугольных импульсов; 9 — генератор; 10 —
блок контурной скорости; 11 — блок конца интерполяции;
12 — блок управления.
ДУ(а), Д2/(а), вычисляются по формулам:
ДУ(а) = /(а+Л-/(«),
Д V (а) = f (а + 2Т) - 2f (а + Т) + f (а),
Ду (а) = -/(а) + з/(а + 7) - 3/(а + 2Т) + /(а + ЗТ).
Схема интерполятора содержит три интегрирующих
усилителя — 1, два инвертирующих усилителя — 2, три
38
импульсных элемента — ИЭ, управляемых от генератора
импульсов — ГИ. ГИ управляется входными импульсами.
Импульсные элементы синхронно и синфазно с поступлением
входных импульсов снимают и запоминают на один период
напряжение с выходов интегрирующих усилителей. Посто-
янные времени интегрирующих усилителей и коэффициент
передачи инверторов, а также весовые коэффициенты для
слагаемых в двух суммирующих цепочках на входах инте-
грирующих усилителей 9 и 12 выбираются таким образом,
чтобы напряжение на выходе в момент времени а + ЗТ + т
было равно значению интерполируемой функции в момент
времени а + Т + т. Это осуществляется путем соответ-
ствующего подбора сопротивлений.
Интерполятор работает с запаздыванием 2 Т. Схема ИЭ
состоит из запоминающего коммутатора, ключевой лампы
и двух разделительных усилителей. Ключевой лампой слу-
жит двойной триод, половины которого соединены парал-
лельно встречно. Он управляется импульсами от ГИ.
Входной и выходной усилители представляют собой ка-
тодные повторители с лампой вместо катодного сопротив-
ления, выполненные на двойном триоде.
Блок-схема цифрового интерполятора четвертой степени
приведена на рис. 15. Внешними устройствами интерполя-
тора являются: считывающее устройство 1 и устройство
записи на магнитную ленту 6. Хронирующим элементом
служит генератор импульсов 9, который управляет блоком
контурной скорости 10. Генератор прямоугольных импуль-
сов 8 выдает разрешающие сигналы на преобразователи
записи 5. Управление блоком записи осуществляется от
преобразователя опорной частоты 7. Исходные данные и
промежуточные результаты записываются в запоминающем
устройстве 2. При соответствующих начальных установках
в сумматоре 3 схема воспроизводит функцию
x = f(y),
где х является решением уравнения
ах* + Ьх3 4- + dx — у = 0.
Результаты решения через дешифратор 4 и преобразо-
ватели 5 передаются в блок записи на магнитную ленту.
Управляют работой схемы центральное управляющее
устройство 12 и блок конца интерполирования 11.
39
Автоматическое жстраполирование
Автоматизация решения задач экстраполирования осу-
ществляется специализированными вычислительными уст-
ройствами — экстраполяторами.
Если на вход этих устройств подать некоторую функцию,
то на выходе получим ее упрежденные значения. При этом
оба сигнала — и входной и выходной — могут быть как
непрерывными функциями, так и дискретными последова-
тельностями.
Экстраполяторы дискретные и непрерывные
Рассмотрим несколько схем экстраполяторов [18].
Допустим нужно найти значение функции х (t) вточке по
известным значениям х (t) в точках tlt h, tz (см. рис. 12).
Рис. 16. Экстраполяция по трем точкам:
Д — задержка; /, 2, 3 — блок умножения; 4 — сумматор.
Через известные точки проводится кривая второго по-
рядка
х(0=а/2 + ^4-с.
При t = 0, t — —A, t — —2А получим xt = с,
xt, — xt, — И + аА2,
xti = Xt, — 26 A + 4aA2,
где A— шаг квантования по времени.
Из этих уравнений находим аппроксимирующий мно-
гочлен в виде
х = Xt, (xtl — 4xt, + 3 Xt,) t +
+ -2xHxg — Xt, +Xi,)t\
40
или xti = 3xtl — 3xit + xt,.
Упрежденное значение сигнала равно сумме предшест-
вующих значений, отстоящих друг от друга на интервал Д,
умноженных на соответствующие коэффициенты веса. Блок-
схема экстраполятора приведена на рис. 16.
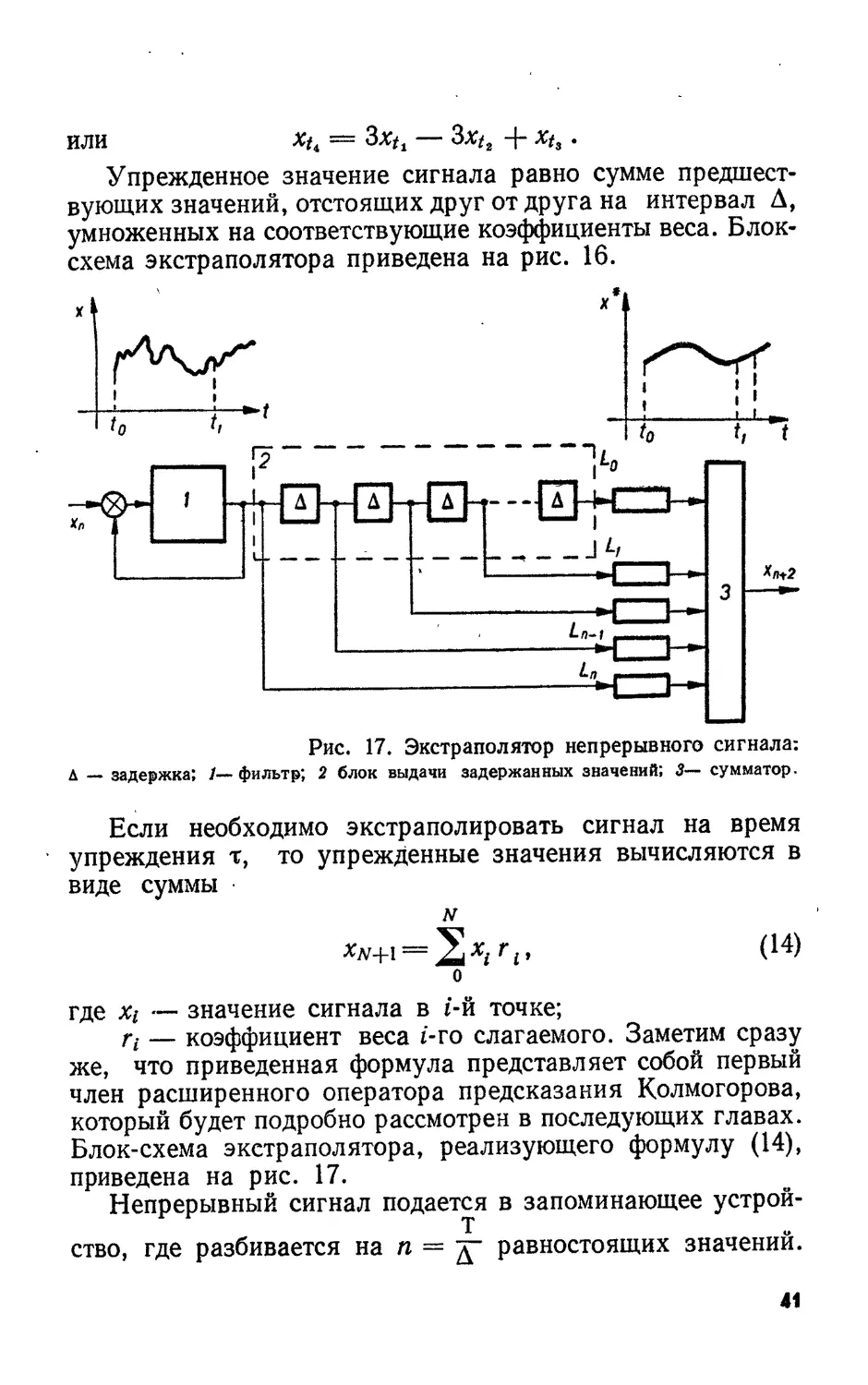
Рис. 17. Экстраполятор непрерывного сигнала:
Д — задержка; /—фильтр; 2 блок выдачи задержанных значений; 5— сумматор.
Если необходимо экстраполировать сигнал на время
упреждения т, то упрежденные значения вычисляются в
виде суммы
= Г1> (14)
о
где Xi — значение сигнала в г-й точке;
г,- — коэффициент веса i-ro слагаемого. Заметим сразу
же, что приведенная формула представляет собой первый
член расширенного оператора предсказания Колмогорова,
который будет подробно рассмотрен в последующих главах.
Блок-схема экстраполятора, реализующего формулу (14),
приведена на рис. 17.
Непрерывный сигнал подается в запоминающее устрой-
Т
ство, где разбивается на п = д' равностоящих значений.
41
Сигнал с каждой ячейки памяти, умноженный на свой
коэффициент веса г, поступает на сумматор. Так как вход-
ной сигнал изменяется непрерывно, на выходе сумматора
получаем его непрерывное упрежденное значение. Подоб-
ный экстраполятор может быть реализован как в виде счет-
но-решающего устройства непрерывного действия, так и на
цифровых элементах (рис. 18).
В преобразователе 2 дискретного экстраполятора осу-
ществляется преобразование значений непрерывного вход-
Рис. 18. Экстраполятор дискретного действия:
/ — блок управления; 2 — преобразователь; 3 — сдвигающий регистр; } —
блок весовых коэффициентов; 5 — схема формирования адреса; 6 — запоми-
нающее устройство; 7 — сумматор.
ного сигнала в цифровую форму. С помощью сдвигающего
регистра 3 и блока весовых коэффициентов 4 мы можем, в
соответствии с (14), последовательно перемножить дискрет-
ные значения экстраполируемой функции на коэффици-
енты rt.
Схема формирования адреса 5 обеспечивает запись про-
изведений xi ъ в определенные ячейки запоминающего уст-
ройства 6. Произведения rt затем суммируются в сумма-
торе 7.
Экстраполятор для непрерывного упреждения
Часто значения измеряемой величины могут быть полу-
чены только в дискретные моменты времени, а нужно знать
вероятное значение сигнала не только в некоторый буду-
щий момент t + А/, но и иметь непрерывное значение этого
42
сигнала в интервале [/, t + ДЛ. Пользуясь известными ма-
тематическими приемами, можно отыскать закономерность
изменения коэффициентов веса в течение одного интер-
вала дискретности.
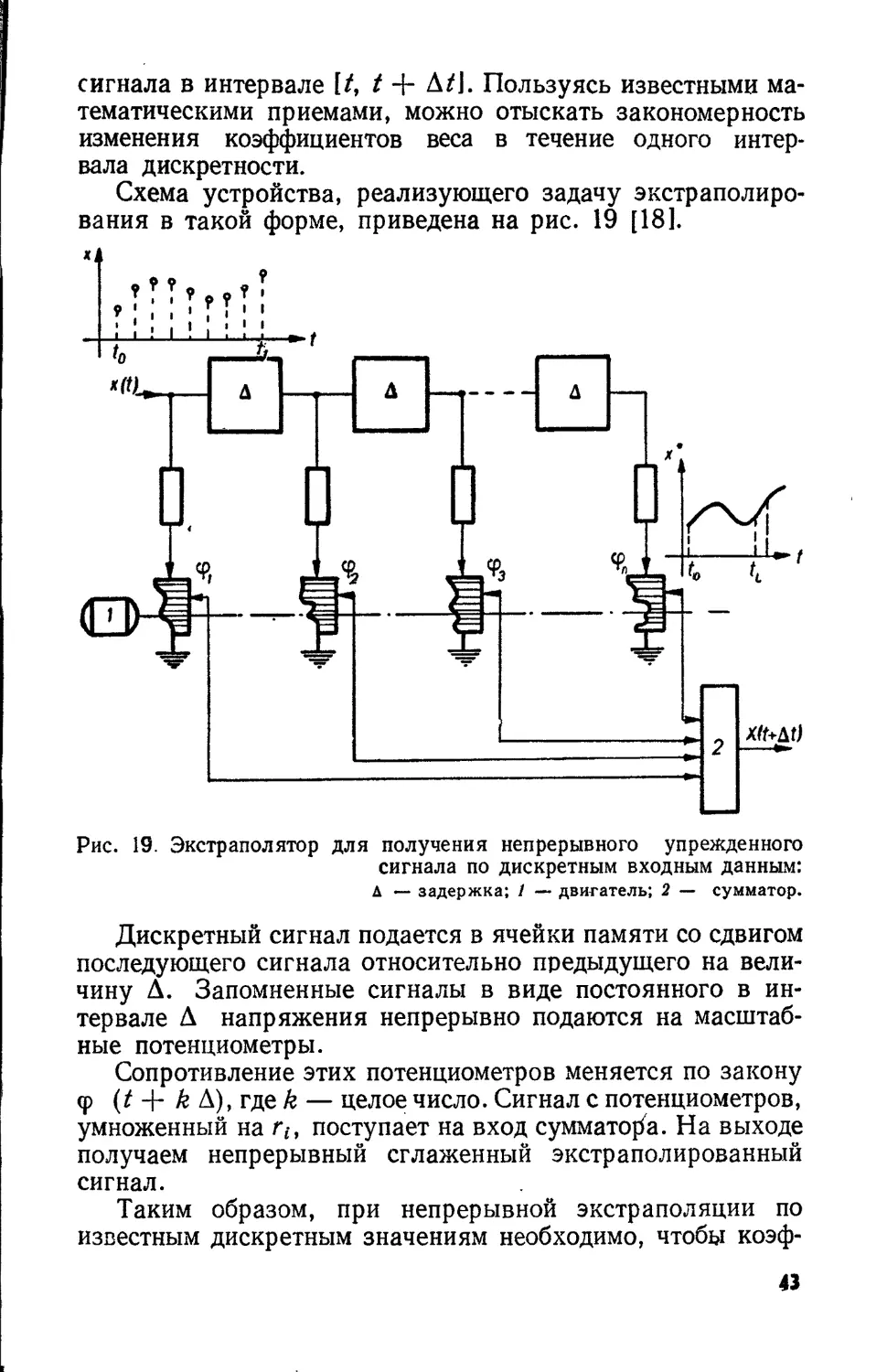
Схема устройства, реализующего задачу экстраполиро-
вания в такой форме, приведена на рис. 19 [18].
Рис. 19. Экстраполятор для получения непрерывного упрежденного
сигнала по дискретным входным данным:
А — задержка; 1 — двигатель; 2 — сумматор.
Дискретный сигнал подается в ячейки памяти со сдвигом
последующего сигнала относительно предыдущего на вели-
чину Д. Запомненные сигналы в виде постоянного в ин-
тервале Д напряжения непрерывно подаются на масштаб-
ные потенциометры.
Сопротивление этих потенциометров меняется по закону
<р (t + k Д), где k — целое число. Сигнал с потенциометров,
умноженный на rt, поступает на вход сумматора. На выходе
получаем непрерывный сглаженный экстраполированный
сигнал.
Таким образом, при непрерывной экстраполяции по
известным дискретным значениям необходимо, чтобы коэф-
43
фициенты веса представляли собой некоторые функции вре-
мени — rt (f).
Условия инвариантности и синтез
интерполяторов и экстраполяторов
Применение экстраполяторов и интерполяторов в схе-
мах управления требует от их конструкторов выполнения
целого ряда специальных требований.
В зависимости от конкретных задач эти устройства долж-
ны обеспечивать заданную точность, обладать определен-
ным быстродействием, быть надежными и по возможности
простыми. На помощь инженерам приходят теоретические
методы. Значительные успехи при решении указанных
задач достигнуты благодаря применению теории инвариант-
ности.
Условия инвариантности
На рис. 20 представлена схема разомкнутой импульсной
следящей системы. Условие абсолютной инвариантности
для нее является условием
равенства входного и выход-
ного сигналов в любой мо-
Рис. 20. Разомкнутая импульсная Мент времени. i
следящая система: Запишем математическое
/ — импульсный момент; 2 — непре- выражение ПереДЭТОЧИОЙ фун-
рывная часть. КЦИИ раЗОМКНуТОЙ СИСТеМЫ
Z*(q, s) =#*(?, 8)Х*(0. (15)
Обозначим через х (/) входной сигнал, через К (р) — пе-
редаточную функцию приведенной непрерывной части сис-
темы и через Z (Г) — выходной сигнал.
Применяя обычно принятую замену переменных
7=у-, , 7 = п4е(т = 0, 1, 2, ...; 0<8< 1),
запишем составляющие выражения (15):
Z*(<7. e) = D{z(0} = D(zrn, 8]}=D |Z (<?)},
К* (q, е) = D = D [k [n, 8]} = D |K (</)}, (16)
X* (q) = D [x (7)}r=J = D (x pi]} = D [X (?)}.
44
. К условию равенства входного сигнала выходному в
любой момент времени
z[n, е]=х[п, е] (17)
применим D-преобразование.
Получим
Z*(<7, 8) = Х*(<7, е). (18)
Учитывая (16), найдем условие абсолютной инвариант-
ности для разомкнутой импульсной системы:
К* (^8)=^^-. (19)
В ряде задач при точном воспроизведении формы вход-
ного сигнала допускается запаздывание выходного сигнала.
В этих случаях условие инвариантности записывается
в виде
г(/) = х(/— а), (20)
где а — время запаздывания, или сдвиг между входным
x(f) и выходным z(t) сигналами.
Схемы, реализующие условия инвариантности
Пусть входной сигнал заранее йзвестен. Однако инфор-
мация, поступающая на вход системы, представляет собой
значения входного сигнала в дискретные моменты времени.
Задачу построения интерполяторов и экстраполяторов для
подобных случаев можно свести к построению импульсных
систем, инвариантных в смысле (17) — (20).
Более подробно методы синтеза таких систем изложены
в работах Ю. В. Крементуло [27, 28].
Рассмотрим здесь только одну дискретно-непрерывную
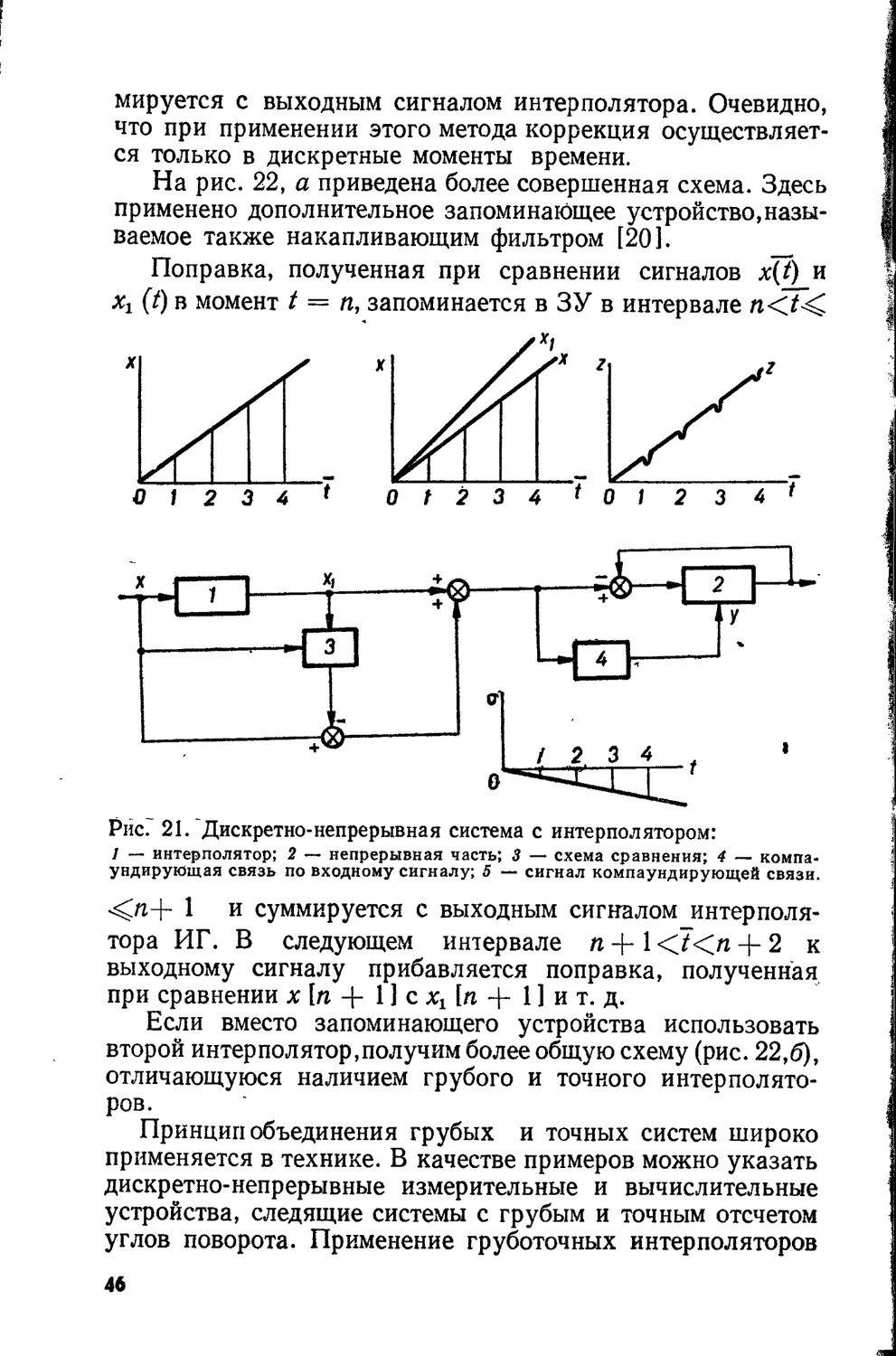
систему с интерполятором (рис, 21). На вход интерполятора
поступают значения сигнала в моменты t = пТ . На выхо-
де получаем непрерывную функцию
Xi (7) = х (0 + Ах (/),
где х(7) — непрерывный входной сигнал, Ах(/) — ошибка
из-за неточной работы интерполятора. Сравнивая сигнал xt (/)
с х (7) в моменты t —п, можно уменьшить ошибку интер-
полирования. Поправка, полученная при сравнении, сум-
45
мируется с выходным сигналом интерполятора. Очевидно,
что при применении этого метода коррекция осуществляет-
ся только в дискретные моменты времени.
На рис. 22, а приведена более совершенная схема. Здесь
применено дополнительное запоминающее устройство, назы-
ваемое также накапливающим фильтром [20].
Поправка, полученная при сравнении сигналов x(t) и
хх (t) в момент t = п, запоминается в ЗУ в интервале
Рис. 21. Дискретно-непрерывная система с интерполятором:
1 — интерполятор; 2 — непрерывная часть; 3 — схема сравнения; 4 — компа-
ундирующая связь по входному сигналу; 5 — сигнал компаундирующей связи.
1 и суммируется с выходным сигналом интерполя-
тора ИГ. В следующем интервале п + 1 <7<п + 2 к
выходному сигналу прибавляется поправка, полученная
при сравнении х [и + 11 с Xj [и + 1 ] и т. д.
Если вместо запоминающего устройства использовать
второй интерполятор,получим более общую схему (рис. 22,6),
отличающуюся наличием грубого и точного интерполято-
ров.
Принцип объединения грубых и точных систем широко
применяется в технике. В качестве примеров можно указать
дискретно-непрерывные измерительные и вычислительные
устройства, следящие системы с грубым и точным отсчетом
углов поворота. Применение груботочных интерполяторов
46
и экстраполяторов позволит во многих случаях повысить
точность работы системы и упростить схему.
«Грубый интерполятор» (ИГ) синтезируется по условиям
инвариантности. Небольшие отклонения выходного сиг-
нала ИГ —Ах(/) уменьшаются «точным интерполятором»
(ИТ). ИТ преобразует разность между х[п] и xjn] в по-
правку а[п, е], закон изменения которой в интервале
n<t < n + 1 определяется законом интерполирования ИТ.
Рис. 22. Системы с интерполятором:
а — с накапливающим фильтром; б — груботочная система; 1 — грубый
интерполятор; 2 — накапливающий фильтр; 3 — схема сравнения; 4 —точный
интерполятор.
В каждом конкретном случае этот закон выбирается из
условий: 1) точности работы ИГ; 2) точности всей системы;
3) простоты конструкции и др.
В этой главе мы рассмотрели задачи интерполирования
и экстраполирования, познакомились с устройствами, поз-
воляющими автоматизировать решение этих задач. При этом
мы исходили из предположения, что процессы являются
детерминированными и могут быть описаны некоторыми
аналитическими функциями. Получаемые с учетом этого
допущения положительные результаты подтверждают, что
используемые методы и устройства можно считать прием-
лемыми.
47
Если же наблюдаются значительные отклонения пред-
сказанных значений от действительных, то это указывает
на наличие в процессах случайных составляющих. В тех
случаях, когда случайные факторы оказывают существенное
влияние на протекание процессов, детерминированное пред-
сказание не оправдывается.
Тогда на помощь приходит теория вероятностей, тео-
рия случайных процессов, математическая статистика. На
их основе в последние два десятилетия сформировались но-
вые методы, объединенные под общим названием статис-
тической теории предсказаний.
ГЛАВА 2
ПРЕДСКАЗАНИЕ СТАЦИОНАРНЫХ
СЛУЧАЙНЫХ ПРОЦЕССОВ
КРАТКИЕ СВЕДЕНИЯ ИЗ ТЕОРИИ ВЕРОЯТНОСТЕЙ
И ТЕОРИИ СЛУЧАЙНЫХ ФУНКЦИЙ
Случайные события. Случайные величины.
Случайные процессы
Результаты экспериментов, многократных измере-
ний, выпадение числа очков игральной кости, падение
снаряда на некотором расстоянии от цели характеризуются
непостоянным исходом.
В теории вероятностей различные возможные исходы
испытаний называются случайными событиями. Каждое
испытание определяется одной или несколькими перемен-
ными величинами. Если в результате испытания эти пере-
менные величины могут принимать те или иные значения,
то такие переменные называют случайными величинами.
Предположим, мы выбираем наугад какую-нибудь деталь
из большой партии однотипных деталей. Размеры выбран-
ной детали являются случайными величинами. Поскольку
результаты исследований и измерений обычно оцениваются
числами, случайные величины могут принимать различные
числовые значения. Если случайные величины принимают
отдельные, изолированные друг от друга значения, которые
можно перечислить, то эти случайные величины называются
дискретными. Случайные величины, которые непрерывно
изменяются в функции некоторого параметра и значения
которых не могут быть заранее перечислены, называются
непрерывными.
Классическая теория вероятностей рассматривает «мас-
совые» случайные явления. Массовое явление представляет
собой совокупность многократных повторений явления или
3 474
49
действий «наудачу», рассматриваемых в целом и без учета
хронологической последовательности.
В отличие от классической теории вероятностей, теория
вероятностных, или стохастических процессов, развитая в
основном А. Н. Колмогоровым и А. Я. Хинчиным, опери-
рует процессами и последовательностями (дискретными про-
цессами) случайных явлений. Случайные процессы и после-
довательности представляют собой совокупности случайных
величин в динамике их развития. Это — те же массовые
явления. Но они рассматриваются не в виде, например,
однородного массива случайных чисел, а в виде последо-
вательности чисел в хронологии появления величин, ко-
торым они соответствуют.
Примерами случайных процессов могут служить измене-
ния координаты броуновской частицы, флюктуации в элек-
трцческих цепях, вибрации узлов станка во время его рабо-
ты, изменение температуры больного в ходе болезни, изме-
нение биоэлектрической активности мозга и т. п.
Частость и вероятность
%
Предположим, что в группе из 1000 человек есть люди,
рост которых менее 165 см. Мы производим серию испытаний.
Испытание заключается в измерении роста каждого челове-
ка. В результате оказалось, что в группе 250 человек’ рост
которых ниже 165 см. Говорят, что частость появления че-
ловека ростом ниже 165 см в группе из 1000 человек
к,= тобог =0’25-
В подавляющем большинстве случаев при многократных
повторениях испытания частость появления события А в
серии из М испытаний обнаруживает устойчивость. Она очень
редко существенно отклоняется от некоторого положитель-
ного постоянного числа.
Это положительное число, меньшее единицы, представля-
ющее собой количественную оценку возможности случайно-
го события А, называется его вероятностью.
Вероятность, обычно обозначаемая символом Р(А),
представляет собой как бы физическую константу, связан-
ную со случайным событием А. Частости этого события в
различных конкретных сериях испытаний являются случай-
ными проявлениями этой постоянной характеристики, выра-
S0
жающей вполне определенную объективную связь между
комплексом условий и случайным событием. Значение веро-
ятности изменяется, как только изменяется основной ком-
плекс условий.
Интегральная функция распределения
случайной величины
Обозначим через Ф(/) вероятность того, что случайная
величина х принимает значение меньше t. Ф (/) называется
интегральной функцией распределения величины х. Посколь-
ку любая вероятность дол-
жна лежать в интервале
между 0 и 1, то для всех
значений t имеем
о<Ф(о< 1.
Пусть /2 > Ь- Тогда ве-
роятность того, что х<4, бу-
дет больше или равна веро-
ятности того, что х < /1( т. е.
функция Ф (0 не может
уменьшаться с возрастани-
ем t. Типичная форма ин-
Рис. 23. Интегральная функция рас-
пределения.
тегральной функции распределения приведена на рис. 23.
Если случайная величина х является результатом изме-
рения какой-либо характеристики объекта, случайным обра-
зом выбранного из N объектов, то Ф (t) практически оп-
ределяет относительную долю тех объектов, для которых
х </. Группа из N объектов обычно называется генераль-
ной совокупностью.
Функция плотности вероятности.
Нормальный закон распределения
Пусть Ф(/)—интегральная функция распределения слу-
чайной величины х. Тогда вероятность того, что
, Д / .. . д
/ 2 + 2
(при А > 0) определяется разностью
ф('+4)-®(‘—?)•
3’
51
При А -* 0 предел отношения
lim
д
= /(/)
называется плотностью вероятности случайной величины
х в точке х — t. Плотность вероятности f (/) является функ-
цией/и называется функцией плотности случайной величины.
Если случайная величина х дискретная, то интегральная
функция распределения является ступенчатой и функция
плотности вероятности не существует.
Рис. 24. Нормальная функция плотности вероятности.
Если проинтегрировать функцию плотности вероятности
f (t) в пределах t1 — h (4 < 4), то интеграл . •
I f (0 dt
ti
даст вероятность того, что х принимает значение, лежащее
между и h.
Одной из наиболее важных функций плотности вероят-
ности является так называемая нормальная функция плот-
ности вероятности (рис. 24). Она определяется выражением
’ (21)
где р и а — некоторые постоянные. Говорят, что случай-
ная величина х подчиняется нормальному распределению
вероятностей, если ее функция плотности вероятности
определяется выражением (21).
52
Математическое ожидание и высшие моменты
случайной величины
Математическое ожидание, или среднее значение слу-
чайной величины, представляет собой результат вероятност-
ного осреднения возможных значений этой случайной вели-
чины. При этом осреднении весом каждого возможного зна-
чения служит вероятность этого значения.
В частности, математическое ожидание (среднее значе-
ние) дискретной случайной величины х при конечном числе
N ее возможных значений равно сумме произведений каж-
дого из этих значений на его вероятность
N
МХ = 2^(*Л (22)
i=i
где М — знак математического ожидания.
Функция <р (х) случайной величины сама является случай-
ной величиной. Математическое ожидание функции (х —»с)*,
где k — любое целое положительное число, а
с — постоянная, называется моментом порядка k величины
х относительно с. Особый интерес представляет случай, ког-
да с = MX. Математическое ожидание функции (х — MX)ft
называется моментом порядка k величины х относительно
среднего. Момент второго порядка относительно среднего,
т. е.
М (х —- МХ)а — DX, (23)
называется дисперсией.
Корень квадратный из дисперсии называется стандарт-
ным отклонением, или средним квадратическим отклоне-
нием.
Например, в рассмотренной выше нормальной функции
плотности вероятности
/(/) = 2- е
у у 2л а
математическое ожидание случайной величины х равно р,
а дисперсия равна а2.
S3
Условная частость. Условная вероятность.
Зависимые и независимые события
Часто из всей серии испытаний необходимо выделить
те, в результате которых появилось некоторое событие В,
а уже затем определять частость интересующего нас со-
бытия.
Если частость события А вычисляется не для всех испы-
таний, а только для той последовательности испытаний, в
результате которых появилось событие В, то такая частость
называется условной частостью события А относительно В.
Условные частости обладают всеми свойствами частостей,
в том числе и свойством стабилизации при неограниченном
увеличении количества испытаний. В качестве объектив-
ной количественной характеристики события А в его взаи-
моотношениях с событием В можно ввести понятие услов-
ной вероятности, аналогично тому, как это было сделано
для понятия вероятности события А.
Условной вероятностью события А относительно В на-
зывается отношение вероятности совместного появления со-
бытий А и В к вероятности события В
Р(А\В) = Р-^. (24)
Если условная вероятность события А относительно В
не равна вероятности события А, то событие Л называется
зависимым от В. Если же условная вероятность события А
относительно В равна вероятности события А, то событие
А называется независимым от В.
Пример [14]. В механическом цехе изготовлена пар-
тия валиков численностью 100 штук. Из них 15 являются
эллиптичными, 50 — конусными, 25 — одновременно эл-
липтичными и конусными и 10 валиков дефектов не имеют.
Событие Э заключается в том, что взятый наудачу валик
окажется эллиптичным, а событие К. — в том, что валик
окажется конусным. Подсчитаем вероятности различных
событий:
^)=-тг-=<и
В (К) = -^^-=0,75,
В (ЭК) =-1г = 0,25.
54
Предположим, что взятый наудачу валик оказался ко-
нусным. Но он может оказаться и эллиптичным. Подсчитаем
вероятность того, что взятый нами наудачу валик с одним
дефектом обладает еще и другим.
По формуле (24) получаем:
Р Р (Ж) 0,25 .—, q оо
Р(5|д)— — 0>75 ~0,дЗ.
Аналогично
р " °’625-
Очевидно, что в данном случае Р (Э\К)^= Р (Э)
и Р (К|Э) =# Р (К). Следовательно, события 3 и К зави-
симы.
Основные понятия и определения теории
случайных функций
Случайные функции. Законы распределения.
Марковские процессы
Случайной функцией называется функция, значение ко-
торой при каждом значении аргумента (или нескольких
аргументов) является случайной величиной. Полученная
в результате одного опыта функция называется реализацией
случайной функции.
Случайные функции времени обычно называют случай-
ными, или стохастическими, процессами.
При каждом данном значении аргумента t значение слу-
чайной функции Х(/) представляет собой обычную скаляр-
ную случайную величину. Полной вероятностной характери-
стикой значения случайной функции является ее закон рас-
пределения.
Одномерный закон распределения случайной функции
X (/) зависит от t как от параметра и может быть задан од-
номерной плотностью вероятности Д (%, /).
Двумерным законом распределения случайной функции
X (/) называется совместный закон распределения ее значе-
ний Х(Д), Х(/г) при двух произвольно взятых значениях
Ъ и tz аргумента /. В общем случае n-мерным законом
распределения случайной функции Х(/) называется закон
5S
распределения совокупности ее значений X (/,),.,Х (th)
при п произвольно взятых значениях tt ........ th аргу-
мента t.
Примером случайных функций, исчерпывающей харак-
теристикой которых являются двумерные законы распре-
деления, могут служить марковские случайные процессы.
Марковским случайным процессом, или случайным процес-
сом без последствия, называется случайная функция пара-
метра t, значения которой при tt < tt < ... < th при лю-
бом п образуют простую цепь Маркова [15]. В соответствии
с определением простой цепи Маркова условный закон
распределения значения X(4+i) случайной функции в бу-
дущий момент зависит только от значения случайной вели-
чины X(th) в настоящий момент и не зависит от значений
случайных величин Х(/х),..., Х(4—0 в прошлые моменты.
Математическое ожидание
и корреляционная функция случайной функции.
Взаимная корреляционная функция
Математическим ожиданием случайной функции X (/)
называется такая функция тх (f), значение которой при каж-
дом данном значении аргумента t равно математическому
ожиданию значения случайной функции при том же /:
тх (0 = М[Х(0].
Это некоторая средняя функция, около которой группи-
руются и относительно которой колеблются все возможные
реализации случайной функции (рис. 25).
В качестве меры рассеивания случайной функции прини-
мается дисперсия. Это такая функция, значение которой при
и
каждом данном значении аргумента равно дисперсии значе-
ния случайной величины при этом значении аргумента.
Для того чтобы учесть влияние значений случайной функ-
ции друг на друга при различных значениях аргумента,
кроме дисперсии, задают корреляционные моменты значений
случайной функции, соответствующие всем возможным па-
рам аргументов.
Корреляционный момент значений х (/), х (f) случайной
функции X (/) является функцией двух независимых пере-
менных t и t':
Kx(t, П = М[Х0(Г)Х<>(Г)]. (26)
Эта функция обычно называется корреляционной (или
автокорреляционной) функцией случайной функции X (/).
Через Х° (/) обозначено отклонение случайной функции
X (/)отее математического ожидания (центрированная слу-
чайная функция).
Взаимной корреляционной функцией, или корреляционной
функцией связи двух случайных функций X (t) и Y (s), назы-
вается корреляционный момент значений этих функций при
произвольно взятых значениях их аргументов t и s:
KxHAs) = M[X»(/)y«(S)J. (27)
Случайные функции называются коррелированными, ес-
ли их взаимная корреляционная функция неравна тождест-
венно нулю. Если же взаимная корреляционная функция
двух случайных функций тождественно равна нулю, то
такие случайные функции называются некоррелированными.
Стационарные случайные функции. Эргодическое свойство
стационарной случайной функции
Случайная функция X (/) называется стационарной в
широком смысле, если ее математическое ожидание посто-
янно, а корреляционная функция зависит только от разно-
сти аргументов t и Г:
тх (/) = м [X (/)] = const,
Кх (t, kx (х), (28)
где т = t — t'.
п
Из определения вытекает, что корреляционная функция
стационарной случайной функции одной переменной яв-
ляется функцией одной переменной т .
Дисперсия стационарной случайной функции X(f) равна
D[X(0]= Kx(t, t) = kx(O). (29)
Дисперсия стационарной случайной функции постоян-
на и равна значению корреляционной функции в начале
координат.
Важным классом стационарных случайных функций
являются эргодические стационарные случайные функции.
Стационарная случайная функция X (/) эргодична, если
ее корреляционная функция kx (т) неограниченно убывает по
модулю при [т] -> оо, т. е., если для любого е> 0 можно
найти такую величину То, что
| kx (t) I < 8 при |т|>Т0. (30)
Случайные процессы, описываемые стационарными эр-
годическими случайными функциями, сохраняют посто-
янство статистических параметров на реализациях любой
как угодно большой длины.
Мы познакомились с основными понятиями и опреде-
лениями теории вероятностей и теории случайных функций.
Этими понятиями и определениями мы будем оперировать
в дальнейшем при рассмотрении различных задач предска-
зания.
КРИТЕРИЙ КАЧЕСТВА ПРЕДСКАЗАНИЯ.
КРИТЕРИИ ОПТИМАЛЬНОСТИ
Критерий минимума среднеквадратичной ошибки
Задача интерполирования и экстраполирования может
быть сформулирована и для случайных процессов и после-
довательностей.
Однако вместо нахождения значений функции внутри или
вне отрезка наблюдения следует говорить о нахождении
некоторой функции, определяемой по исходным значениям
случайного процесса с точки зрения удовлетворения неко-
торому общему критерию оптимальности.
В большинстве случаев таким критерием является дости-
жение минимума среднеквадратичной ошибки отклонения
58
искомой аппроксимирующей функции от исходной случай-
ной функции или от некоторого множества точек (выборки),
представляющих последнюю.
В общем случае минимум среднеквадратичной ошибки
достигается при
оо
f*= J h.............Mdf. (31)
— оо
В выражении (31) f * — предсказываемая функция, ft ,
/г,..., — выборка предыдущих значений функции,
........— условная вероятность получения f при Д, /г,..., /п.
Замечательным свойством критерия минимума средне-
квадратичной ошибки является то, что этот критерий дает
единственное решение задачи. В самом деле, уравнение
М(/—/*)* = Г2 (32)
описывает многомерный параболоид и, следовательно, при
любом пути изменения параметров предсказывающей мо-
дели (математического оператора или предсказывающего
устройства) достижение минимума неизбежно. В начале
четвертой главы мы более подробно остановимся на реали-
зации этого критерия в предсказывающих устройствах.
Рассмотрим еще несколько критериев оптимальности
предсказания.
Критерий минимума суммы
интегральной квадратичной ошибки
и дисперсии случайной ошибки
Если предсказываемая функция представляет собой сум-
му регулярной составляющей (полезного сигнала) и слу-
чайной стационарной составляющей (помехи)
/(/)=$(/) + #(/), (33)
то можно сформулировать критерий оптимальности сле-
дующим образом.
Запишем интегральную квадратичную ошибку в виде
ео
f &dt, (34)
о
где 8 = 3 (t + Д/) — 3* (I + ДО- (35)
59
В выражении (35) S* (/ + ДО — регулярная составляющая
предсказанной функции.
Предсказанная функция записывается в виде
f* =.S*(f + Д/) + N* (t 4- Д/). (36)
Обозначим дисперсию случайной ошибки — DAT*.
Предсказание назовем оптимальным, если обеспечива-
ется минимум суммы с весом а интегральной квадратичной
ошибки (34) и с весом с дисперсии случайной ошибки при
удовлетворении условия
lira е (0 = 0. (37)
t -> 00
Исходя из этого можно сформулировать задачу аналити-
ческого конструирования упредителя [16]. Требуется найти
функции в (О, S * (/) и некоторую весовую функцию <р(/),
удовлетворяющие (35), (37) и минимизирующие функционал
оо
l=a\&dt + cDN*. (38)
о
Рассмотренный критерий целесообразно применять для
конструирования оптимальной системы фильтрации и пред-
сказания процессов, описываемых выражением (33).
Произвольные критерии оптимальности *
Рассмотрим стационарный случайный процесс, который
является гауссовым в широком смысле слова. Это означа-
ет, что сигнал описывается выражением
N
S(0 = m(0 + 2^A(0, (39)
z=i
где т (f) — нормальный случайный сигнал;
N
2 nfi (0 — линейная комбинация N известных функций
/з=1
с коэффициентами гг ;
коэффициенты rt являются случайными величинами,
также имеющими нормальное распределение.
На сигнал аддитивно наложена помеха N (t), имеющая
нормальное распределение.
Таким образом, мы снова имеем дело с предсказанием
процесса вида
/(/) = $ (0 + ^(0-
м
Оптимальное предсказание осуществляется при минимиза-
ции некоторого критерия ошибки (функции стоимости) С (в).
В случае среднеквадратического критерия ошибки С (е) =
= е2 оптимальное нелинейное предсказание эквивалентно
оптимальному линейному в смысле Винера [62] при та-
ком же критерии ошибки. Аналогичный результат получен
для случая четных С (—е) — С (е) неубывающих критериев.
Вывод также справедлив для асимметричных неубывающих
критериев ошибки. .С(£)
Пусть задан произвольный
критерий ошибки, например в /
виде графика (рис. 26). /
Общая теорема Пугачева [39 ] «кУ'Ч /
утверждает, что в этом случае £
оптимальная нелинейная система —— ~ ”
(в частности, система, осуществ-
ляющая оптимальное предсказа- п ос _ .
. г » Рис. 26. График изменения
ние) является оптимальной ли- критерия ошибки,
нейной системой в смысле Винера
с весовой функцией w (t, т) при среднеквадратичном кри-
терии ошибки, к которому иногда прибавляется некото-
рая постоянная «смещения» ц:
t
О[/(/)] = J w(t, T)/(T)dT + |*. (40)
— 00
Если критерий ошибки —функция четная, постоянная сме-
щения всегда равна нулю.
Приведем алгоритм синтеза нелинейной оптимальной
системы, минимизирующей математическое ожидание произ-
вольного критерия ошибки.
1. Отыскиваем линейную оптимальную (в смысле Вине-
ра) систему с весовой функцией w (t, т). В качестве критерия
при этом принимается минимум среднеквадратичной ошибки.
2. Определим среднеквадратичную ошибку обычными
методами. *
3. Определим математическое ожидани е и дисперсию этой
ошибки.
4. Найдем постоянную смещения, минимизируя инте-
грал
00
£[С(е)]= J C(8)/(e)d8, (41)
61
где f(e) — плотность вероятности ошибки оптимальной
линейной системы с неизвестным математическим ожиданием
т'.
Положим
°о _ (s—т')*
-^Г$С(8) Л = 0 (42)
-00
и разрешим это уравнение относительно т'. Тогда
р = т — т'. (43)
Оптимальная нелинейная система описывается урав-
нением
ОО
о[/(/)]= J w(t, T)f(T)dT + p.
«—00
(44)
Единственным ограничением в теореме Пугачева являет-
ся условие нормального распределения случайной составля-
ющей сигнала и случайной помехи. Однако при решении
реальных задач методом моделирования на вычислительных
машинах непрерывного действия удалось получить хоро-
шие результаты и в тех случаях, когда это условие не вы-
полняется [60].
Оптимальное, наиболее точное предсказание достигается
в том случае, когда исходные данные (признаки) имеют
нормальное или гауссовское распределение.
Ясно, что даже при наилучшем, оптимальном предсказа-
нии мы не можем рассчитывать на точное совпадение этих
функций: случайный процесс всегда имеет некоторый не-
предсказуемый элемент «чистой» случайности. Точность
предсказания может быть оценена по величине вариации
6= 100%.
fl_fl
Но даже при оптимальном предсказании случайных процес-
сов вариация не равна нулю. Только при предсказании не-
случайных детерминированных процессов, таких, например,
как движение небесных тел, вариация может быть равна
нулю: предсказываемая функция точно соответствует дей-
ствительному процессу (с погрешностью вычисления)
N
s=°-
1
62
Кроме рассмотренных критериев в последнее время
делаются попытки применения для синтеза оптимальных
систем различных игровых критериев, например мини-
максных. Особенно эффективно применение таких критериев
при оптимизации «больших систем» [3].
Ниже рассмотрим ряд задач предсказания стационар-
ных случайных процессов и последовательностей. Крите-
рием оптимальности во всех случаях принимался критерий
минимума среднеквадратичной ошибки.
ПРЕДСКАЗАНИЕ СТАЦИОНАРНЫХ СЛУЧАЙНЫХ
ПОСЛЕДОВАТЕЛЬНОСТЕЙ
Метод и формула А. Н. Колмогорова
Для стационарных случайных процессов, значения ко-
торых известны в дискретные моменты времени, задача
экстраполирования была сформулирована следующим об-
разом [26а].
Пусть f (/) представляет собой действительную случай-
ную величину, соответствующую каждому целому t в ин-
тервале — оо</ < оо.
Если математическое ожидание
т = М [/(/)] = const
и корреляционная функция
- М [(/ (t + А/) - т) (f (/) - т)]
не зависят от t, то f (/)—стационарна. Без ограничения
общности можно положить
т = М[/(/)] = 0. (45)
Тогда
К« = М[/(/ + Д/)7(0]. (46)
Задача линейного экстраполирования стационарной по-
следовательности, удовлетворяющей условию (45), заклю-
чается в подборе при заданных п > 0 и А/ О таких дей-
ствительных коэффициентов гр при которых линейная ком-
бинация
О[/(0] = Г1/(^— 1)+/•»/(/ — 2)4-... + г„ Kt—n) (47)
63
случайных величин f(t — 1), f (t — 2),..., представляет воз-
можно более точное приближение к случайной величине
f (t + Д/). В качестве меры точности такого приближения
принят критерий
s* = М (/(* +ДО-O[f (/)])’.
Если известны некоторые моменты К. д< , то легко решает-
ся задача отыскания таких г., при которых в^= 8gmjn
Задача интерполирования заключается в оценке f (О по
значениям f (t + 1), f (t + 2),..., f (t + n), f (t — 1),...,
/G-n).
Здесь также в качестве меры точности принят критерий
^=M(f(/)-Q [/(/)])*,
где
Q If (0] = rj (f + 1) + г J (t + 2) + ... + г-г f (t - 1)+... (48)
с постоянными действительными коэффициентами. Задача
“o’ “o’
интерполирования сводится к определению е7 = 8/min.
Доказательство существования пределов для 8/ и
решедре задач отыскания их значений приведены в [26а].
Рассмотрим пример решения задачи линейного экстрапо-
лирования стационарного случайного процесса.
।
Предсказание изменения показателя качества
продукта нефтехимического предприятия
Задача предсказания
На рис. 27 представлена схема автоматического регули-
рования технологической установкой термокрекинга неф-
теперерабатывающего завода [311.
Выходной продукт — бензин термокрекинга, одним из
показателей качества которого является температура кон-
ца кипения. Автоматический анализатор каждые полчаса
определяет этот показатель и регистрирует величину Тк.к,° С
с помощью самопишущего прибора на картограмме.
Используя данные о значениях за некоторый про-
межуток времени, предшествующий моменту t, требуется
предсказать значения Тк.к,° С в некоторый будущий момент
времени t + ДЛ Практически интервал Д/ равен промежут-
ку времени между анализами.
64
Оператор предсказания (47) запишем в виде
N
О [f (01 = 2 ft rt = + (49)
Рис. 27. Схема регулирования технологической установки
термо крекинга с анализатором качества:
I — поток сырья в колонну; II —• ректификационная колонна
установки термокрекинга; III — холодильник; IV — сборник
орошения? V — поток орошения; VI — выходной продукт
(бензин термокрекинга); VII—отбензиненный продукт: /—термо-
пара; 2 — потенциометр; 3 — суммирующее устройство; 4 —
анализатор качества; 5 — регулятор; 6 — предсказывающий
фильтр; 7 — регулирующий клапан; 8 — отборочная точка для
анализа нефтепродукта.
гд,е ft(i =1, 2 N)—значения Тк.к,°C в предшествующие мо-
менты времени, a f * (t + Д/) — предсказанное значение
Тк.к,°C.
65
Задача заключается в отыскании таких коэффициентов
rit чтобы
F = M[f(/ + A/)-f*(/ + A/)]==i2min. (50)
Коэффициенты rit при которых условие (50) выполняется,
считаются оптимальными, а об операторе (49) говорят, что он
обучен предсказанию будущих значений данной случайной
последовательности.
Алгоритм обучения оператора предсказания
Запишем логическую схему алгоритма обучения опера-
тора предсказания
2 112
| ЕСс f S | Rco f . (51)
В выражении (51):
Е — оператор вычисления среднеквадратичной ошибки
по множеству известных значений функции (при
тех или иных значениях коэффициентов);. ___________
С — оператор сравнения вычисленной ошибки в8
с наперед заданной величиной е^п, удовлетворя-
ющей требуемой точности; ,
с — логическое условие, считающееся выполненным
при
;
R — оператор вычисления новых коэффициентов;
со — тождественно ложное условие;
S — оператор окончания процесса обучения.
Алгоритм работает следующим образом. Элементы схемы
срабатывают один за другим слева направо, начиная с край-
него левого. Если следующий элемент схемы является ло-
гическим условием, то могут возникнуть два случая. Если
логическое условие выполняется, то срабатывает очередной
элемент схемы; если же не выполняется, то происходит
переход по стрелке. Символ | обозначает начало стрелки, а
| —конец [33].
Первый шаг обучения. Определяем сред-
неквадратичную ошибку представления функции f (/)
оператором (’49) на известном интервале времени при произ-
вольных значениях коэффициентов.
м
Из всей последовательности выбираем значения fi, ft,...,
fK, fK+l и вычисляем
f*K+l ~
<=1
Последовательность fi, ft,... длины к назовем преды-
сторией. Затем берем последовательность ft, ft,..., fK+2 и вы-
числяем (f*K+2 —fK+2)\ где
я+1
rifi
i=2
И T. Д.
Среднеквадратичная ошибка по множеству известных зна-
чений функции f (/) на первом шаге обучения определяется
выражением
N
е2 i=K+\---------
1 = N— к+1
Сравнивая полученную ошибку ef с , оцениваем
качество представления функции f (/) оператором (49)
при выбранных значениях коэффициентов. Если е® >
осуществляем второй шаг обучения.
Изменяем значения rt в соответствии с алгоритмом мини-
мизации фуНКЦИИ (/?).
Отыскиваем значение ошибки при втором шаге —
и сравниваем вновь полученное значение с е^.п.
Процесс обучения заканчивается, если в результате
сравнения полученной при очередном I = ом шаге e,f с е^[п
получим
8/ 8min •
При этом оператор считается обученным предсказанию
будущих значений данной функции, а коэффициенты, ис-
пользуемые для вычисления оператора (49), являются опти-
мальными.
67
Предсказание следующего значения функции осуществ-
ляется. путем реализации алгоритма вычисления оператора
(49) при
ft = гOpt.
Решение и результаты
Задача предсказания была запрограммирована и решена
на универсальной электронной цифровой вычислительной
машине.
Таблица 1
Действитель- ные значения Предсказанные значения ,
№=2 к=3 к=4 I №=5
182 179 178 176,5 175
182 181 181 179 177,4
181 182 ' 181 181 180
183 181,5 . 181,6 181,5 181
183 182 182,3 182 182
185 183 182,6 182 182
185 184 183,6 183 183
186 185 184,6 184 183,4
181 185 185,3 185 .184,4
178 183,5 183,3 184 183
177 179,5 182 182,5 182
178 177,5 179 180,5 181,4 .
178 177,5 177,6 178,5 180
178 178 177,6 178 178,4
178 178 178 177,75 177,8
177 178 178 177,75 177,8
177 177,5 177,6 177,75 177,8
177 177 177,3 177,5 177,6
178 177 177 177,25 177,4
178 177,5 177,3 177,5 177,6
Минимизация функции (rz) производилась методом
наискорейшего спуска [4]. Действительные и предсказан-
ные значения ТК К°С приведены в табл. 1. На рис. 28 представ-
лены графики изменения действительных и предсказанных
значений Тк.к, °C для различного числа точек предыстории
(к = 2, 3, 4, 5). Очевидно, что результаты предсказания
зависят от длины предыстории. Этот вопрос рассмотрим в
главе 4, когда будем решать задачи предсказания с исполь-
зованием расширенного оператора предсказания.
J89| ЦС
/87
/ 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
Рис. 28. Предсказание температуры конца кипения методом линейного
экстраполирования (к = 2,3,4,5).
Предсказание по формулам
экспоненциального сглаживания
(метод Брауна)
В последнее время значительное развитие получила тео-
рия экспоненциального сглаживания [50, 50а 1.
Экспоненциальное сглаживание (по Брауну) основано
на предположении, что предсказываемое значение некоторой
функции f (t) может быть выражено рядом Тейлора:
ft+м — ft + Ы + (Л/)а + — +
+4—<52>
Члены ряда Тейлора выражаются формулами экспонен-
циального сглаживания. Приводим формулу для экспонен-
циально сглаженной величины первого порядка:
S< (/) = aft 4- (1 — а) . (53)
Таким образом, новое усредненное значение St(f) равно
последнему известному значению функции /(/), умноженному
на коэффициент а (где а^ 1), плюс предыдущее усреднен-
ное значениеS^j, умноженное на (1 —а). При а— 1 полу-
чаем доверчивую перезапись прошлых значений, предсказа-
ние по правилу «без изменения».
Менее чувствительные системы, применяемые при боль-
ших помехах, используют значения 1 > а > 0,5, а наиболее
консервативные 0,5 > а > 0,1.
= + (П,
(0 = aS? (О + (1 - a) S3,., (/), (54)
S? (f) = aS?-1 (0 + (1 - «) (Л-
Теперь остается выразить члены ряда Тейлора через
усредненные величины. В зависимости от того, сколько чле-
нов ряда мы используем, применяются следующие формулы.
Один член ряда:
= ft = St(f). (55)
70
Два члена ряда:
fHu = (56)
Три члена ряда:
U/ = A+4-^ + 4-
ft = 3St(f)-3S*(f) + 330; (57)
^ = ТТ^^0-2330 + 33(/)];
4-= 2(Г^Р Кб - 5а) S3 0 - 2 (5 - 4а) 32 (/) +
+ (4-За) 3’0].
Цифровое моделирование
Предсказывающий фильтр, реализующий оператор (52),
должен выполнять следующие операции:
1. Вычисление экспоненциально сглаженных величин,
требуемых порядков в соответствии с (54).
2. Определение членов оператора
/0, ,... в соответствии с (55)—(57).
Ul Cl С
3. Суммирование членов ряда (52).
Алгоритм работы предсказывающего фильтра запишем
в виде
3 1 1 2 2 4 4 3
где Т — оператор выдачи значений точек предыстории (сдви-
ги по предсказываемой последовательности);
S — оператор вычисления экспоненциально сглаженных
величин;
а — логическое условие, выполненное при получении
St,
X — оператор вычисления f (/) (первого члена ряда);
71
Рис. 29. Блок-схема моделирования предсказывающего фильтра, реали
зующего алгоритм экспоненциального сглаживания.
D — оператор вычисления членов второго, третьего
и т. д. порядков;
Р —логическое условие, выполненное при получении
члена оператора высшего порядка;
2 — оператор суммирования членов ряда (52);
у — логическое условие, выполненное при окончании
цикла упреждения;
О — останов;
<о — тождественно ложное условие.
На рис. 29 приведена блок-схема реализации алгоритма
на ЭЦВМ. Кроме собственно реализации алгоритма предска-
зания, программа предусматривает работу в режиме с пере-
менным коэффициентом а. Качество предсказания оцени-
вается по величине среднеквадратичной ошибки при различ-
ных значениях а. Как будет показано далее, коэффициент
а зависит от статистических характеристик предсказываемой
последовательности и для различных реальных процессов
может принимать различные значения.
Программа позволяет в процессе работы с исходными
данными исследуемого процесса выбирать оптимальное
значение а, при котором получается наилучшее качество
предсказания (в смысле 8min). Таким образом, цифровая мо-
дель предсказывающего фильтра работает в режиме обу-
чения, а после определения включается в общую програм-
му решения задачи управления.
Предсказание изменения показателей
качества нефтепродуктов
и исследование предсказывающего фильтра
В качестве примера рассмотрим предсказание темпера-
туры конца кипения бензина прямой гонки. При решении
этой задачи воспользуемся данными, которыми мы опери-
ровали при решении задачи предсказания методом линей-
ного экстраполирования.
Зададимся значением а =0,1. Интервал предсказания,
равный 30 мин, примем за единицу. Как и в задаче линейно-
го экстраполирования, предсказание будем осуществлять по
2, 3, 4 и 5 точкам предыстории.
Для к = 2:
при t = — 2 50=182; Si20=182;
79
при t = — 1 S_! 0 = 0,1 • 182 + 0,9-182 = 182;
Si, 0 = 0,1 • 182 + 0,9-182 = 182.
Используем два члена ряда Тейлора
/_! = 2S_j (f) — Si, 0 = 2 • 182 — 182 = 182;
f. = f-, + <W=I82.
Для к = 3:
при t= — 3 S-з 0=182; Si3 0= 182;
при / = — 2 S_a 0 = 0,1-182+ 0,9-182= 182;
Si2 0 = 0,1-182 + 0,9-182= 182;
при / = — 1 S_X0 = O,1-181 +0,9-182= 181,9;
Si, 0 = 0,1 • 181,9 + 0,9-182 = 184,99.
Используя два члена ряда Тейлора, получим:
/L1 = 2S_10 — Si, 0=182,
-f- = dhr is-i -s-i (01=o,oi,
+-g-^='181,99,
и т. д.
Результаты решения задачи на универсальной цифровой
вычислительной машине приведены в табл. 2. На рис. 30
представлены графики изменения действительных и пред-
сказанных значений ТК.К,°С для различного числа точек пре-
дыстории (к = 2, 3, 4, 5).
Сформулируем основные задачи исследования предска-
зывающего фильтра.
1. Исследование влияния длины предыстории к на ка-
чество предсказания.
2. Исследование зависимости качества предсказания от
параметра а.
74
3. Исследование зависимости качества предсказания от
времени упреждения.
4. Исследование временных параметров предсказывающе-
го фильтра.
Таблица 2
Действи- тельные значения Предсказанные значения
к=2 | к=3 | к=4 [ к—5
178 181 185 183,2 181,8
177 178 185,1 183,4 183,4
178 177 185,4 185,1 183,7
178 178 180,7 184,7 184,7
178 178 177,9 184,6 183,9
178 178 177,1 180,3 183,8
177 178 178 178 180
177 177 178 177,2 177,9
177 177 178 178 177,3
178 177 177,9 178 178
178 178 177 177,9 177,9
180 178 177 177,8 177,8
180 180 177,1 177 177,7
179 180 177,9 177,1 177,1
177 179 178,2 177,2 177,2
173 177 178 178,2 177,5
174 173 179,9 178,4 178,4
171 174 178,8 179,9 178,5
173 171 176,6 179,6 179,6
171 173 173,1 178,1 178,8
На рис. 30, д приведен график, отражающий изменение
среднеквадратичной .ошибки предсказания от количества
точек к, участвующих в вычислении экспоненциально сгла-
женных значений и производных. Зависимость в2 = f (к)
тлеет минимум при к = 3 (для а > aopZ). Для к > «0₽<
ошибка возрастает с ростом к.
Аналогичные исследования проведенные при предсказании
показателей качества других нефтепродуктов, подтвердили
вывод о том, что для предсказания подобных процессов
следует выбирать Kopt = 3. Этот вывод справедлив только
для принятого быстродействия автоматического анализато-
ра качества.
На рис. 30, е видно, что для исследуемых процессов су-
ществует некоторое определенное значение a — aopt, при ко-
тором ошибка предсказания минимальна. В каждом кон-
кретном случае величина aopt характеризуется статисти-
75
Рис. 30. Предсказание температуры конца кипения методом
экспоненциального сглаживания (к = 2,3,4,5).
кой процесса. Для процессов, отражающих изменения
Тк к, °C нефтепродуктов, величина аор< лежит в пределах
0,2—0,4.
Если сопоставить рис. 30, д и 30,' е, то становится оче-
видным, что при а — a,opt качество предсказания практи-
чески мало зависит от длины предыстории.
На рис. 30, ж приведены графики зависимости качества
предсказания от величины времени упреждения е2 — f (&f).
Предыдущие исследования проводились при А? = 1, т. е.
при предсказании к + 1-го значения по к предыдущим.
Ошибка определялась как средняя по множеству предска-
занных таким образоМ-Значений.
При исследовании 82 = по к известным значениям
определялось к + 1-е, а к + 2-е значение вычислялось с
учетом к + 1-го предсказанного значения, а не действи-
тельного.
Из рис. 30, ж видно, что среднеквадратичная ошибка пред-
сказания резко возрастает с увеличением АЛ Однако при
а = aopt эта ошибка минимальна и мало зависит от времени
упреждения.
Объем вычислений, а следовательно, и время реализации
описываемого алгоритма зависят только от количества то-
чек предыстории, участвующих в вычислении экспоненциаль-
но сглаженных значений и производных. Поскольку ^ремя
цикла вычисления экспоненциально сглаженных величин
постоянно, зависимость /предска3. = f (к) — линейна.
Таким образом, результаты этих исследований позволяют
выбрать наилучшим образом параметры предсказывающе-
го фильтра.
В связи с изменением внешних условий и параметров регу-
лируемых процессов необходимо периодически переклю-
чать предсказывающий фильтр из режима предсказания в ре-
жим обучения. Наибольший эффект при этом можно полу-
чить, если использовать в качестве управляющей вычисли-
тельную машину, работающую по мультипрограммному
принципу. Подобная машина позволяет реализовать
одновременно несколько независимых программ и в нашем
случае дает возможность осуществлять управление с пред-
сказывающим фильтром в качестве параллельного коррек-
тора.
78
Фильтр-экстраполятор, реализующий
алгоритм экспоненциального сглаживания
Устройства для предсказания будущего значения функ-
ции для линейной и квадратичной экстраполяции могут быть
собраны в соответствии с блок-схемой рис. 31, а [34]. Как
видно из рис. 31, а, схема не содержит звеньев с постоянным
запаздыванием.
Схема собрана из усилителей, сумматоров и линей-
ных апериодических звеньев первого порядка.
На рис. 31, б приведена экспериментальная осциллограм-
ма работы описываемого фильтра экстраполятора для вход-
ной функции f (/). Моделирование схемы экстраполятора
осуществлялось на вычислительной машине непрерывно-
го действия типа МПТ-9.
79
ПРЕДСКАЗАНИЕ СТАЦИОНАРНЫХ СЛУЧАЙНЫХ
ПРОЦЕССОВ
Метод Винера
Пусть полный входной сигнал некоторой системы пред-
ставляется выражением
f(O = S(O + AZ(O,
гдеЗ (0 — сигнал, несущий полезную информацию, a N (0—
шум.
Требуется в идеальном случае определить такую систему,
чтобы сигнал на ее выходе был равен 3 (/ + Д0.
В случае Д t = 0 система называется фильтром.
В случае Д/>0 и Af(/)=O система называется упредителем.
В общем случае система должна выполнять одновремен-
но обе операции — фильтрацию и упреждение. Такую
систему мы будем в дальнейшем называть предсказывающим
фильтром.
Н. Винером [62] развита теория подобных систем, ко-
торая основывается на следующих допущениях:
1. Функции S(t) и N(t) являются стационарными и ста-
ционарно связанными случайными процессами.
2. Критерием для выбора «наилучшей» возможной сис-
темы является среднеквадратичное значение разности между
действительным сигналом и желаемым сигналом на выходе
системы
= М [S (/+ АО — S* (? + А/)]2.
3. Операция, осуществляемая для фильтрации и пред-
сказания, предполагается линейной операцией над имею-
щейся информацией.
Другими словами, система должна представлять собой ли-
нейный физически осуществимый фильтр. Физическую осу-
ществимость не следует отождествлять с возможностью
воплотить систему в реальной конструкции. Требование фи-
зической осуществимости заключается в том, чтобы реак-
ция системы на единичную импульсную функцию обраща-
лась в нуль для /<0.
Поскольку свойства линейной системы полностью харак-
теризуются импульсной переходной функцией IT (0> выходной
80
сигнал системы можно представить в виде интеграла типа
свертки:
ОО
$*(/ + Д/) = JlS(Z — r) + N(t — т)Г(т)(/т. (58)
о
Тогда для среднеквадратичной ошибки справедливо
. выражение
оо
г* (0 = S2 (/ + ДО — 2 J [S(/-|-Д0$ (/ — т) +
О
оо
. 4-3(/ + Д/)ЛГ(/—т)]№ (т)dr + J W(тх)dr,
О
00
J W (r^[S(t-r^+N(t-rMS(t-r^+N(t^5\ dr,. (59)
о '
Принимая во внимание, что корреляция между x(t)
и y(t)
Кху СО = х (t)y(t + r), (60)
и обозначая
Kss (О + К ns (0= Ф (О. (61)
Kss (0 + Kns (О + (О + Knn (О = ф (О.
перепишем формулу (59):
00
ё» = Kss (0) — 2 J ф (М + т) W (0 dt +
О
оо оо
+ J w (Ti) dr, J W (т2) ф (та — Тх) dr,. (62)
о о
Теперь задача может быть сформулирована следующим об-
разом. Известны корреляционные функции Kss, Kns, Ksn,
Knn- Необходимо отыскать импульсную переходную функ-
цию W(t), такую, чтобы
е2 — min.
Положив при этом IF(0/<o=0, мы автоматически выполня-
ем условие физической осуществимости.
4 474
81
Из рассмотренной общей задачи следуют важные частные
случаи, такие, как задача фильтрации (А/ = 0) и задача
«чистого» предсказания (N(t)=O).
Метод Заде и Рагаззини
Обобщение теории Винера для случая конечного времен-
ного интервала рассмотрено Заде и Рагаззини [61 ]. Их
метод основан на следующих допущениях:
1. Рассматриваемые сигналы состоят из: а) неслучайной
функции времени, представимой полиномами степени, не
превышающей некоторого определенного числа п, и о ко-
торых ничего, кроме и, не известно; б) стационарной слу-
чайной функции времени, корреляционная функция кото-
рой известна.
2. Импульсная переходная функция при
Рассмотрим временную функцию f(t), состоящую из S(t)
и N(t).
Выход предсказывающего фильтра S* (/) связав с S(t)
линейным оператором У(р):
S*(t) = Y(p)S(t). (63)
Запишем S* в виде интеграла типа свертки: ,
со
£*(/) = j w(v)S(f— T)dr, (64)
— oo
где о>(т) — импульсная переходная функция идеального
упредителя.
В самом общем случае оцениваемая при предсказании
или фильтрации величина S* (/) может быть функциона-
лом от S(t).
В табл. 3 даны некоторые возможные значения У(р) и
w (f) для различных S *(/).
Предполагается, что
= + (65)
где р(/) — неслучайная временная функция, которая мо-
жет быть представлена полиномом по t порядка не выше п;
т(0 — стационарная случайная составляющая;
m(t) и и(0 описываются корреляционными функциями
Kmm(T) И Кпп (Т).
82
Таблица 3
№ п.п Отношение S*(f) и S(t) Оцениваемая величина Г(р) МО
1 S*(i)=S(f) Настоящее значение S(t) 1 й(0
2 S*(f)=S'(t) » » S'(/) Р д(О(0
3 s*(t)=s"(o » » S"(0 рг д(2)(<)
4 S*(/)=S(t+&t) Будущее или прошлое значение S(t) (Д£ «+» или «—») е^Р «(/4Д0
Кроме того, предполагается, что m(f) и n(t) центрирова-
ны и некоррелированы.
На рис. 32 представлена блок-схема предсказывающего
фильтра для рассматриваемой задачи.
Рис. 32. Предсказывающий фильтр Заде — Рагаззини.
При отсутствии шумов и выполненном условии физичес-
кой реализуемости ошибка
8 = /* (О —S* (/) (66)
отсутствует.
При этом оператор реального упредителя Я(р) иденти-
чен Y(p). Это случай тривиальный.
Если Н(р) и Y(p) не совпадают, то необходимо опреде-
лить W(f) такую, чтобы
е* = [Г (О —S* (OF = min. (67)
4‘
83
Оптимальный предсказывающий фильтр должен удов-
летворять следующим условиям:
а) средняя по множеству ошибка равна нулю для всех
значений
б) вариация е по множеству — минимальна.
Запишем выходной сигнал в виде
/*(0 = jF(T)/(/_T)dT. (68)
о
На практике оказывается необходимым ограничить
интервал входной функции некоторым конечным Т. Тогда
т
= (69)
о
Учитывая, что
f (О = Р + +«(/), (70)
и выразив
Р (t _ т) = Р (0 - %Р' (0 + 4 Р" (Z) + ... + (-1)’ -£ рп (0,
получим
f*(/)=(O-im/(/) + ^.p"(f)+ ... +
т 1
+(- -£г ® + Jw & m V -т)dx +
о
т
+ — x)dx, (72)
о
где р0, pt,... — моменты F(/), равные
т
pv = J tv W (т) dx, v = 0, 1, 2, n. (73)
о
Поскольку m(t) и п(/) центрированные стационарные
функции, f *(/) hS *(0 зависят лишь от неслучайных соста-
вляющих сигнала:
г -
Jr(T)p(/-T)dT, (74)
о
84
или
/* (О = |ЛОР (О - И1р‘ (О + ... + (- 1)" р™ (О (75)
и S*~(t) = Y(p)S(t), (76)
или
S^=Y(p)p(t). (77)
Сравнивая (75) и (77), можно записать условие а) следу-
ющим образом:
Y(р) р(t) - ЦоР(О -Р1Р' (О + ... 4- (-1)" -^-Р" (О- (78)
Тождество (78) определяет величины р,
Иными словами, идеальный оператор предсказания У(р)
определяется из (78) первыми (n+1) моментами импульсной
переходной функции оптимального упредителя. В качес-
тве примера рассмотрим случай
У(р) S (0 = 5(/+ АО (при ±А/).
Формула (78) перепишется в виде
р (/ + А/) = рор (О — рхр' (О + р" (О +... +
+ (-1)в-^-р<я>(0. (79)
Сравнив
рц+до=р (о - д/р' (о + р" (о +... +
+ (-1)"-£гР(п)(0 (80)
с (79), получим систему
Ро = J(F(OdT= 1,
о
т
[хх = J (т) d% — А/,
' о
т
= J %п W (т) dr = Мп. (81)
о
85
При удовлетворении условию а) из исследования (66),
(72), (78) следует
т
g = j U7 (т) [m (/ — т) д (/ — т)] dx — Y (р) m (/), (82)
о
или
т
8= J1F(t) \m(t — т) + n(t — т)] dx —
о
оо
— У w(x)tn(t— T)dx. (83)
—— 00
Тогда
L
е2 = lim -j- 1 е2dt. (84)
£->«> L ft
После ряда промежуточных преобразований окончательное
выражение для среднеквадратичной ошибки имеет вид:
т т
ё2 = J j W fa) W fa) [Kmm fa —12) + Knn fa — T2)] cfadT2 —
oo T
— 2 У J W fa) W fa) Kmm fa — T2) tfatfa +
— 00 0
I
OO 00
+ J J ®fa)^fa)K/n/nfa —T2) 4facfa. (85)
— OO -00
Последний член уравнения (85) не зависит от w(f). Посколь-
ку w(f) является ядром (п + 1) уравнений (83), задача
минимизации е2 в отношении класса w(f), удовлетворяющих
(73), сводится к минимизации выражения
Т ( т
I = J W fa) dTx KlF fa) \Kmm fa — ^2) “1“ Knn fa — ^2)] dt% —
0 (o
00
2 J (^2) (^1 ^2) dx2 2X0 2%!^ — ... —-
— 00
(86)
где %0, ...... —множители Лагранжа.
86
Устремляя вариацию / к нулю, получаем минимальную
ошибку е2 при значении W (/), удовлетворяющем интеграль-
ному уравнению
т
f W (т) [Knun (t — Т) + Кпп {t - Т)] d% = К + + ... +
оо
+ М"+ j W(li}Kmm(t — x)dX, 0</<Т.
—-ОО
(87)
Оптимальный предсказывающий фильтр находится из
уравнений (73) и (87). Следует отметить, что решение инте-
гральных уравнений при синтезе оптимальных предсказыва-
ющих фильтров представляет значительные трудности. Для
отдельных частных случаев методы решения приведены в [61].
Метод Боде и Шеннона
Этот метод фильтрации и предсказания случайных про-
цессов основан на выражении среднеквадратичной ошибки
через спектральные плотности
мощности сигнала и шума.
Основная задача заключает-
ся в определении Y (со) (рис. 33).
Какова при этом Y (со) будет
ошибка предсказания?
Среднюю мощность ошибки
S'tt+btj
Рис. 33. Предсказывающий
фильтр Боде и Шеннона.
e = S(/ +А/) — £*(/-)- Д/)
для некогеррентных частот можно вычислить суммировани-
ем составляющих различных частот
е2 = J [ | Y (со) |2 N (со) + | Y (и) — |2 Р (©)] dm, (88)
—-оо
где Р(со) — мощность сигнала;
a N(<s>) — мощность шума.
Требуется минимизировать еа путем соответствующего вы-
бора У (со) с учетом условия физической реализуемости.
87
Если f(f) = S(t) 4- У(/) пропустить через фильтр с уси-
___________________i_
лением [Р(<в) 4- jV(<o) ] 2 , то получим плоский спектр. Пусть
минимально фазовый фильтр с характеристикой У^со) об-
ладает усилением [Р(<о) 4-N(a>) ] 2. Тогда и У1(<о) и УГ1 (®)—
физически реализуемые фильтры.
Если бы ДО была известна в интервале— оо</<со, то
наилучшей операцией, примененной к входу, была бы опе-
рация, удовлетворяющая равенству
<89>
Если фазовая характеристика —В(<о), то (89) эквивален-
тно операции
У2 (®) ---М(90)
[/>(«)+ п(и)]~
над У1(со), имеющим характер белого шума.
Соответствующая весовая функция
со
2Г 5 (91)
—“ >
Это функция физически неосуществимого фильтра.
Положим
IF3(0 =
W2(t 4-ДО
0
при t 0,
при t < 0.
(92)
F3(0 представляет собой весовую функцию физически осуще-
ствимого фильтра с передаточной функцией У3(ш). Тогда
передаточная функция оптимального предсказывающего
фильтра для ДО = 5(0 4- М(0 выразится в виде
У4(<о) = УГ1(®)У3(ф). (93)
Как и в случае винеровской постановки, из рассмотрен-
ной выше общей задачи могут быть выделены частные слу-
чаи чистого предсказания и чистой фильтрации.
88
Нелинейная фильтрация сигналов
Задача оптимальной нелинейной фильтрации
Все рассмотренные выше задачи основывались на общем
допущении о том, что операция, выполняемая над исход-
ной информацией, линейна. Нелинейные системы в сравне-
нии с линейными при определенных обстоятельствах могут
дать меньшую среднеквадратичную ошибку, чем самые
лучшие (в смысле среднеквадратичной ошибки) линейные
системы.
Ниже рассмотрим класс систем, описываемый общим
соотношением
N ОО
<S* (t) = 2 f w (т) — Т)] dr, (94)
n=0 0
где S*(f) — выходной сигнал системы;
ДО — входной сигнал системы;
(т) — весовая функция линейной части системы;
8„Ы — набор линейно независимых функций. [29].
Задача заключается в определении набора оптимальных
весовых функций wn (т), если имеется достаточная статисти-
ческая информация о входном и желаемом выходном сиг-
налах.
Такую систему можно рассматривать, как систему нес-
кольких параллельных каналов, каждый из которых со-
стоит из нелинейного элемента без памяти и последователь-
но подключенной линейной цепочки с памятью (рис. 34).
Весовая функция каждой цепочки равна о>л(т). Если wn (т)=
= ап б(т), то рассматриваемая система превращается в мно-
гоканальную систему без памяти.
Оптимальную систему определим как систему, обеспе-
чивающую минимум выражения
82 = [5 (Z) — S*(Z)]2. .
Введем в рассмотрение равенство
S(t) = g[f(t)},
где g — оператор определенного класса Этот оператор
действует на все значения /(/) в интервале [ —оо,/] либо
на часть этих значений и имеет конечный средний квадрат.
89
Вариация среднеквадратичной ошибки в2, вызван-
ная вариацией ah(f) оператора g(f), определяется равенством
Аё2 = — 2ай [Д {g (Д — S*} + a2 h И2. (95)
Здесь 8 — малая постоянная, a h[f\ — оператор того
же класса, что и g[/].
Чтобы g[/] был оптимальным оператором, должно вы-
полняться равенство
= - 2й И (g [х] — S*} = 0, (96)
Рис. 34. Нелинейный фильтр с памятью.
так как а — 0; h [/]{g [Д —S*} = 0.
Выражение (96) представляет собой необходимое и доста-
точное условие оптимальности g[/].
Определим класс нелинейных систем (известны под на-
званием многоканальные системы без памяти степени N):
N
•S(0 = g[fl = 2WUfl. (97)
m=0
где kgm — постоянные;
функции 6т[Д — ортонормальные полиномы f степени т.
Каждый полином t0m (Д характеризуется некоторым ве-
сом р(Д, причем р(Д представляет собой плотность вероят-
ности входного сигнала.
90
Наиболее общая формула для h[f] имеет вид
N
= Ш (98)
i=0
Подставляя (98) в (96), имеем
N Г N i
2 м2 W =о-
Z=0 (wi=0 J
Так как
(* ) 0 при tn = i,
1еЛ/10т1/1Р1/М/= 0Jf]0mtfl= 1 /•
J 11' 1 m 4 1 г '<1 1 I» > тт J | прИ т
получаем
N N
2^=2мдл5*- (")
1=0 т=0
Поскольку khi принимают произвольные значения, то
для того, чтобы удовлетворялось (99), должно существовать
единственное решение для постоянных кы-
^ = 0Л/Г$*. (100)
В силу е0 [/] — 1
= = 5^(0. (101)
Таким образом, многоканальная система без памяти
порядка N определяется равенством
N
р [ Л01=2 D“ 0<=у (о+s* ДО» (102>
1=1
где
D _ емл^-^) .
н vs*
Из (102) получаем
__________________________ N
={/[/(/)! -S^))a = 2 0°3)
t=i
Так как 0(- [/] = 0 при п 0,
) 1 при I — т;
то е.ие„и-|0 пр„,^т.
91
В (102) и (103) vs и vs»~— соответственно среднеквадратич- I
ные отклонения заданного выходного сигнала и выходно- 1
го сигнала оптимальной системы. I
Определим класс многоканальных систем с памятью по- I
рядка N. I
No» |
5(0 = £[/] = 2 J^m(T)0m[/(/-T)]rfT. (104) I
m=0 0 ?
Наиболее общее выражение для h[f] ;
N ~
h [/] = 2 J kM (*) 0/ [f (t — т)] dr.
i=o о г
Подстановка в (97) дает
N «» Г N о© -V
J khn (4) 2 J kgm (T2) Cim (Tj — T2) dT2 i
1=0 0 _m=0 0 £
— WZ — tj) $*(/)№ = 0, (105) ;
где Clm (t) = 0,- [f (0] 0m [/ (t — t)].
Используя основную теорему вариационного исчисле-
ния и принимая во внимание, что все £«(т) произвольные
весовые функции физически реализуемой линейной части
системы (т. е. &ы(т) = 0 для т<0), получаем , «
No»
2 J ^ет (тг) Cim (Ti ~ rfT2= 0rt [f (t— Tj) £*(/)], (106) |l
m~0 0 «
при т>0 4 = 0, 1,2, 3,... f
Так как |
cn м^!Оприт¥:О’ li
m I 1 при m — 0, |i
и о» if (01=1, |!
TO I'
oo -**1 '
Ugo(T)dT = ^o=S*(^ (107) Г
и b I,
N ~ I'
J kgfn (^2) Cim (^1 ^2) d^2 4s*Dri (Tj), при Tx > 0 (108) j
0 ®
где
п = ем/1 (< — T)J [S* (0 — S* (01 .
11 vs*
Из (107) и (108) следует, что
N N оо оо
VS = 2 2 И ki (Т1) km (Т«) С&» (Т1 — dTidT» =
0 0
N со
=2JD/.(T)vs*^(T)rfT- <109)
<=1 о
Система (109) может быть решена методом неопределен-
ных коэффициентов [62].
Коэффициенты С;т(т) и Vs»D/i(t) можно определить мо-
делированием. При этом должны быть известны достаточно
длинные реализации входного сигнала системы и желае-
мого выходного сигнала.
Описанный метод оптимизации может быть применен для
проектирования нелинейных фильтров. В качестве приме-
ра рассмотрим синтез нелинейного фильтра для выделения
радиосигналов из их смеси с помехами [291.
Расчет оптимального нелинейного
фильтра
Используя нелинейный фильтр рассматриваемого клас-
са, можно получить существенное уменьшение среднеква-
дратичной ошибки. Предположим, что на вход приемника
приходит полезный сигнал, представляющий собой слу-
чайную последовательность импульсов S(t).
На этот сигнал аддитивно наложена помеха N(t), т. е.
x(t) = aS(t) + bN(t).
В случае стационарности сигнала /£* представляет
собой функцию только интервала времени т.
Если 5(0 и N{f) статистически независимы, то
~fn = 2 (")аГ bn~r Sr Nn~r
r=0
93
и
ft > ft* = 2 2 (") («) a'+" ^m-q-rN^-ч .
r=0 <7=0
Кроме того,
ft S» = 2 (?)ar &"~r S^N"-'.
r=0
В нашем примере выражение для SnSm имеет вид
1 2
w= 4 id+(- i)w) (1+(- D")+
+ р(1_(_1)«)(1_(_ 1)»)].
Шум характеризуется гауссовым распределением, он
имеет такую же автокорреляционную функцию, как и по-
лезный сигнал.
JV1jVa = S1S2 = p = e?W.
Таким образом, остальные функции N" N™ могут быть
легко найдены.
Положим а2 = 0,8; Ь2 = 0,2; 2; а2 + Ь2 = 1.
о
В этом случае ортонормальные полиномы имеют вид: ’
0, И = 1;
01И = х;
02 [х] = 1,1785№ — 1,1785;
63 [х] = 0.9836Х3 — 1,6918х;
0jx] = 8510x« —2,6852х2+ 1,2216;
06 [xj = 6194х6 — 2,7823х3 + 2,3127 х.
Коэффициенты a Dfti оказываются равными:
aDu = 0,8;
aDai = 0;
aDsl = — 0,2518;
aD41 — 0;
aD51 = 0,1414.
94
Уравнение пятой степени для многоканального фильтра
без памяти имеет вид
S = 1,5530х — 0,64 Их8 4- 0,0876х» (НО),
при требуемом входном сигнале aS*(f).
Рис. 35. Нелинейный оптимальный фильтр.
Точное выражение для оптимального нелинейного фильтра
записывается в виде
S = ath-f-.
На рис. 36 показаны
графики уравнений для
фильтров с различными
а и b для двух видов
уравнений — (110) и
(1П).
Многоканальный
фильтр для случая а2=0,8
и Ь2 = 0,2 приведен на
рис. 35.
Отношение средне- Рис зб. График уравнений для филь-
квадратичных ошибок тров с различными с и б,
этого нелинейного фи-
льтра и оптимального линейного фильтра вычислено и
построено в виде графика (рис. 37).
Следует заметить, что получение точного уравнения
фильтра требует привлечения численных методов решения
задачи и выполнения большого объема вычислений.
В теории предсказанияS(t) == x(t + Д/).
Следовательно,
Dn (т) = Сп(/-т). (112)
95
Таким образом, если Сл(т) при то оптимальный
упредитель является линейным, так как система (111) при-
нимает вид
J (^2) Ci (Tj т2) йт2 — vx Cu (Г -f- Tj). (ИЗ)
о
В общей задаче фильтрации и предсказания, как и для
линейных систем, рассматривается
п(/)],
S*(/)=S(/ +до.
Рис. 37. Среднеквадратичная ошибка нелинейного
фильтра и оптимального линейного фильтра.
Описанные в настоящей главе методы находят широкое
применение при решении разнообразных практических
задач. Это задачи: фильтрации и предсказания радио-, те-
лефонных, телеграфных сигналов; задачи передачи и приема
телевизионных сигналов по методу отклонений; задачи опре-
деления траектории и сопровождения летательных аппаратов
и многие другие. Статистическая теория предсказаний может
быть широко применена в биологии и медицине. Так, пер-
спективной представляется гипотеза о механизме воспри-
ятий зрительных образов по отклонениям. Согласно этой
гипотезе, в каждый момент времени в зрительные центры
96
мозга поступает не вся информация о воспринимаемом изо-
бражении, а лишь информация об отклонениях от предшес-
твующего изображения. Этот принцип используется в ши-
роко развернувшихся в настоящее время работах по созда-
нию новых систем передачи телевизионных изображений.
Сотрудничество инженеров и биологов может оказаться
весьма плодотворным с точки зрения выяснения многих
неясных пока вопросов, касающихся механизма распозна-
вания образов. В свою очередь, правильный ответ на эти
вопросы позволит создать наиболее эффективные системы
распознавания, причем не только зрительных, но и звуко-
вых и осязательных образов, например при управлении раз-
личными манипуляторами с помощью мышечных токов
(миоуправление).
ПРЕДСКАЗАНИЕ НЕСТАЦИОНАРНЫХ
СЛУЧАЙНЫХ ПРОЦЕССОВ
Постановка задачи
В предыдущей главе мы познакомились с основами
теории Колмогорова—Винера и ее применением для предска-
зания и фильтрации стационарных случайных процессов
и последовательностей. Рассмотрим более общую *3адачу
предсказания нестационарных случайных процессов.
Пусть известны значения x(t) в некотором интервале
0</<Т0. По этим данным мы хотим определить значения
x(t) в интервале T0<t^T. ’
Значения x(f) можно представить в виде следующего
сходящегося в среднем ряда [13]:
ПИ)
В выражении (114) а* — случайные величины, такие,
что математические ожидания
Mak = 0, a Makak' = б**',1 (115)
Ф* (0 — собственные функции интегрального уравнения
т
Аф (0 — У г (I, т) ф (т) dr, (116)
о
а Aft — соответствующие собственные значения.
1 ( 1 при k = kf,
kk' t 0 при k k't
98
Обозначим через 1л(Х) гильбертово пространство, по-
рожденное величинами x(t) при и через Pl4x) опе-
ратор проектирования на это пространство. В данном слу-
чае Lz(X) совпадает с пространством А, натянутым на орто-
нормированную систему векторов a* (k = 1,2,.. .), так что
для нахождения предсказанного значения в момент t +Д/
надо составить ряд
х*(/4-Д/) = Р£,(Х) = 2^Ма^(/ + Д/)- (117>
fe=l
Но _ ,
Mak х (f + Д/) = V Ьк Мх (t + Д/) J х (/) <pft (/) dt =
т
= J г (/ + А/, (118)
т
и так как при
0<т.<Т Jr(t, т)фА(0<// = ЛАф*(т), (119)
т
то естественно положить
X (t + ДО = • (120)
V
Здесь ф* (/+Д/) продолженные до точки t -f-Д/ собствен-
ные функции интегрального уравнения с ядром г(/,т). Та-
ким образом, наилучшее предсказанное значение может быть
вычислено по формуле
х*{t+до = 2^ • (121)
й=1 V
Это представление было предложено Каруненом [561.
Оно основано на определении наилучшего предсказанного
значения, как самой близкой к x(t -j-Д/) точки простран-
ства 1л(Х).
Метод характеристических составляющих
Исследуемые процессы часто могут содержать естествен-
ные составляющие, значение которых позволяет значитель-
но облегчить решение задачи предсказания.
Для широкого класса процессов реализации (или вы-
борочные функции) могут быть представлены небольшими
количествами «характеристических составляющих». Эти сос-
99
тавляющие обусловлены физической природой объекта, по-
рождающего процесс.
При таких условиях использование большого числа вы-
борочных функций не является ни необходимым, ни жела-
тельным. Более того, именно составляющие, а не корреля-
ционная функция, характеризуют процесс.
В этих случаях винеровское предсказание уже не явля-
ется приемлемым.
Рассмотрим один из методов предсказания нестационар-
ных случайных процессов, предложенный Э.Д. Фармером [45].
Определение характеристических составляющих
Предположим, что xm(t) (т—1,2,3,... ,М) М выборочных
функций нестационарного случайного процесса. Требуется
определить характеристические (в каком-то смысле) состав-
ляющие процесса.
Один из простых способов определения 1-й составляющей
заключается в отыскании функции фх(/), скалярного множи-
теля jA, и последовательности коэффициентов ат1, таких,
что функции yr%1ami<Pi(/),(rn= 1,2,...,Л1) приближенно, И смыс-
ле минимума средних квадратов, равны выборочным функ-
циям Хщф. Ошибка для m-й реализации имеет вид
]/" (Ь22)
Среднеквадратичная ошибка, усредненная по времени и
множеству, равна
М Т
в2 = jjy J [Хщ Omi фх (Ol8 (123)
m=l 0
Константы pA, ami и функции <px(/) могут быть выбраны
так, чтобы эта ошибка была минимальной. Минимум дости-
гается в том случае, когда вариация еа относительно вариации
первого порядка величин ]/гХ1апц и функции срх(/) равна
нулю, т. е. когда
т т
J Фх (0 Хт (/) dt = V Mmi J ф? (О dt, т = 1, 2...М,
О о
м м
citni хт (t) == &т\ Ф1 (0> 0 < / <C T. (124)
m—1 tn=l
100
Функцию ф1(/) и вектор tfmi без потери общности можно нор-
мировать так, чтобы выполнялись соотношения:
т
о
м
2 <&=*>•
tn—1
Условия минимума при этом принимают вид
т
&tnl = V J Ф1 (0 %m (О dt
О
М
’|ЛХ(р1(/)=-^- ami Хщ (/)
т=1
Исключение ami из этих двух соотношений дает
м т
"ЛГ 2 J 'Pi (т)Хт (т> drXm $ = $
(125)
ИЛИ
т
f R (t, *) <Р1 (т) dr = (/), (126)
о
где /?(/,т) — корреляционная функция, образованная
усреднением М выборочных функций
м
R ”0 ~ (0 хт (т). (127)
Из выражения (126) видно, что ф1(/) есть собственная функ-
ция видоизмененного интегрального уравнения Винера —
Хопфа.
Объединяя уравнения (123) и (126), получим выражение
для минимума среднеквадратичной ошибки
82 — —
fcmin —
- т
J R(t, T)dT —
.0
(128)
Ошибка минимальна в случае, если fa — наибольшее или
доминантное собственное значение и, следовательно, <pi(0—
доминантная собственная функция.
1С1
Вторую составляющую можно определить, потребовав,
чтобы уХ flm2 <рг(0 являлось наилучшей среднеквадратичной
аппроксимацией. Из этого следует, что должно быть вто-
рым по величине собственным значением, а <ра(/) — со-
ответствующей собственной функцией. Продолжая эти рас-
суждения, мы получим разложение функции в виде (114).
Автокорреляционную функцию 7?(т,т') также можно раз-
ложйть по характеристическим составляющим процесса
оо
R (Ъ Т') = 2 к Фл СО ф* (*')• (129)
Л=1
Можно также показать, что все собственные числа либо
положительны, либо равны нулю.
Важное свойство разложения xm(t) состоит в том, что если
ряд ограничить К членами, то проинтегрированная по вре-
мени среднеквадратичная ошибка
т к
&T=$R(x, x')dx' — 2^- (130) .
О л-1
Выражение
т
J/?(t, x')dxr
0
равно средней энергии процесса на интервале (0, Т).
С учетом (129) эту энергию можно выразить в виде
Т ОО
j>(T, т')</т' = 2\- (131)
0 А=Г
Объединяя (130) и (131), получаем
ОО
2 Ч (132)
Л==Л+1
Таким образом, интеграл от среднеквадратичной ошиб-
ки равен сумме опущенных собственных значений; число чле-
нов, необходимое для достижения данной точности, легко
определяется из (130) и (132). Собственное число , явля-
ющееся существенно неотрицательным, можно интер-
претировать как энергию, связанную с &-й составляющей
процесса.
102
Весовая функция винеровского упредителя может быть
описана составляющими <pft (/). Предположим, требуется,
чтобы учредитель оценил входную выборочную функцию в
момент времени Т = 14-А/ по входной выборочной функ-
ции, известной на интервале (О, То), где Тй<Т. Весовая
функция удовлетворяет соотношению
Та
J R *') g (Т., т') dr' = R(T, т), 0 < т < То. (129)
о
Если /?(т,т') разложена в ряд (129), то интегральное
уравнение примет вид То
То
2 М(т) J g(T0, т) ф* (т) dr = 2 К 4k (Т) <р*(т). (133)
k о k
Умножение на ф* '(т) и интегрирование по т на интервале
(О, То) дает
2 А/*' he gte — Аые Фа (T) hk', (134)
А' А'
где
Го
Аа' == f Фа (т) Фа'(т) (135)
о
Поскольку функция, определяемая рядом
2^аФа СО,
А
должна быть равна нулю в интервале 7,0<т<Т, то
2^'^' = 0, (136)
А'
где
т
Bkk' = f 4 k {г} фй- (т) dr. (137)
6
Матрицы А и В с элементами и В^' соответственно
являются идемпотентными, т. е. удовлетворяют уравнениям
А3 = А и В3 = В. (138)
103
Поскольку функции составляющих ортонормальны на всем
интервале (О, Т), то
^ + В=’1 !> (139)
АВ = ВА = 0/ '
где I—единичная матрица. Выраженная характеристичес-
кими составляющими среднеквадратичная ошибка пред-
сказания в уравнении (123):
е2 (То) = 2 h {gk - Фа (140)
Л=1
Эта ошибка минимальна, если gk удовлетворяет (134) и
(136), т. е. при
— 'S ^kk’ ^k' Фа' (Г)
Г, * . (141)
2а Bkk' gk’ = о
к'
Из (138) и (139) следует, что сумма рангов А и В равна
рангу единичной матрицы. Следовательно, в (141) столько
независимых уравнений, сколько неизвестных gk, и реше-
ние единственно. В совокупности эти уравнения полностью
эквивалентны уравнению Винера—Хопфа.
Предсказание процесса
по его характеристическим составляющим (
Задача предсказания является задачей оценки значений
выборочной функции х(0 нестационарного процесса в ин-
тервале Т0</<Т по известным значениям x(t) в интервале
0<^<Т0.
Установлено (131), что если процесс представляется
в виде комбинации его характеристических составляющих,
то интеграл от среднеквадратичной ошибки
Т к
~&Т = J/?(t, x')dx’ — 2ч-
О А=1
Соответственно такой точности выборочная функция x(f)
может быть представлена в виде
К
х (0 = 2 ФА (0, 0 < t < Т, (142)
1
где Ck — постоянные коэффициенты.
104
Это разложение справедливо на всем интервале (0,Т),
включая ту его часть, в которой нужно предсказать x(t). Сле-
довательно, задача предсказания сводится к задаче опре-
деления последовательности коэффициентов ск. Этот
метод предсказания автоматически описывает выборочную
функцию как комбинацию ее характеристических состав-
ляющих.
Один из методов отыскания коэффициентов Сь заклю-
чается в удовлетворении следующему условию: разложение
(142) должно быть наилучшей среднеквадратической ап-
проксимацией функции х(/) в интервале 0<7<Т0, на ко-
тором эта функция известна. При этом коэффициенты опре-
деляются из системы линейных уравнений
к т„ т„
2 с*' J (т) Ч*' (т)dx = f х (т) Ф* (т)dx- (143)
Й-1 О о
Рассмотрим пример.
Применение метода характеристических составляющих
для предсказания изменений нагрузки электростанций
Предсказание потребления электроэнергии требуется
для того, чтобы заранее упорядочить работу электростан-
ций и заблаговременно обеспечить безаварийную работу
сетей электроснабжения.
Для предсказания кривые ежедневного изменения нагруз-
ки нужно разделить на части, соответствующие периодам
в несколько часов. Эти периоды включают интервал Тй<^^Т
и непосредственно предшествующий отрезок 0<7<То.
Нагрузка зависит от метеорологических условий, по-
требления энергии предприятиями, радио, телевидением
и т. д. Причем наибольшее влияние оказывают метеорологи-
ческие условия. Нагрузку Хтп в /n-й части дня n-й момент
можно представить в виде
Хтп = «л 4“ А (Т'т) Рл 4” ft (Lm) Уп 4“ fs (^m) $п 4“ ••• • (144)
В выражении (144) fiTm, ft(Lm), fs(Wm)—соответственно
обозначены функции температуры Тт, интенсивности света
LOT, скорости ветра Wm. Величина On — основная нагрузка.
Коэффициенты Pn.Yn.Sn,..учитывают изменяющееся со временем
влияние параметров погоды. В соответствии с (144) каждый
105
Рис. 39. Кривые действительной и предсказанной нагрузки на 28 ноября.
Рис. 41. Кривые действительной и предсказанной нагрузки на 5 декабря
вектор нагрузки линейно зависит от векторов а, (5, у, 8,...
Если нагрузка представлена К членами в виде комбинации
ее характеристических составляющих, то хтп записывается
в виде
к
Хщп = фЛя • 0^5)
А=1
Ошибка разложения не изменится, если вектор состав-
ляющих заменить линейно независимыми комбинациями.
Поскольку вектор минимизирует ошибку разложения,
6-мерное многообразие, образованное векторами составля-
ющих и их линейными комбинациями, дает по сравнению
с другими 6-мерными многообразиями минимальную
ошибку, а, 0, у, 6... в уравнении (144) можно рассматри-
вать как векторы, принадлежащие многообразию векторов
составляющих. Таким образом, составляющие описывают
основные тенденции нагрузки при средних для периода
регистрации условиях погоды. Весовые коэффициенты сот*
зависят от метеорологических параметров, относящихся к
/n-й доле дня.
На рис. 38—41 приведены кривые действительной и'пред-
сказанной нагрузок для двух дней ноября и двух дней
декабря 1961 г. Нагрузка предсказывалась на интервал в
8 ч в большом районе с максимальным потреблением «5000
мгвт. Характеристические составляющие вычислялись по
данным за 20 предшествующих дней. Каждая из предска-
занных кривых была вычислена за полчаса до ее начала.
Результаты, полученные для утреннего пика, хорошо
согласуются с предсказанием, выполненным центром управ-
ления с использованием метеорологических данных.
Предсказание вечернего пика в среднем менее точно (45).
Комбинированный метод предсказания
нестационарных случайных процессов
Существует широкий класс реальных нестационарных
случайных процессов, которые могут быть представлены
в виде некоторой неслучайной функции времени и ад-
дитивно наложенной на нее стационарной случайной фун-
кции z(0 [39]:
*Р) = Ф(О + г(О-
(146)
108
Выпадение осадков в определенном районе за год, по-
требление материалов и запасных частей на предприятии
в течение периода отчетности при неизменном плане, су-
точное потребление электроэнергии, колебания темпера-
туры больных при идентичном протекании одной и той же
болезни — все это примеры нестационарных процессов, ко-
торые могут быть с большей или меньшей достоверностью
описаны выражением (146).
Рис. 42. Нестационарный случайный процесс.
Ниже предлагается метод, позволяющий решать задачи
предсказания подобных процессов.
Пусть известны М реализаций нестационарного слу-
чайного процесса. Для удобства решения задачи предска-
зания на цифровой вычислительной машине каждую реа-
лизацию представим в виде дискретной последовательности
значений {х/ ), / = 1,2,..., N (рис. 42). Значения X/ от реа-
лизации к реализации претерпевают изменения, которые
описываются стационарной случайной функцией.
Если обозначить / - е значение i • й реализации —
Хц, то все элементы хц можно представить в виде прямоу-
гольной случайной матрицы
i = 1, 2...Л4,
X = (xz/) у _ 1, 2, Л/.
Каждый вектор-столбец этой матрицы представляет собой
стационарную последовательность значений (х;- ), а вектор-
строка — одну реализацию нестационарного случайного
процесса.
109
Пусть, далее, из множества (V значений реализации с
номером М + 1 известно некоторое количество значений п.
Эти значения обозначим хм+i,/.
Задача предсказания заключается в оценке значений
по известным значениям Ху(i = 1, 2,,.., Af;
/ = 1,2,...,М) и Xj (] € и).
Запишем предсказываемую реализацию (вектор-стро-
ку) в виде
к
^,=1^ (147)
В выражении (147) У7* назовем составляющими векторами.
Требуется отыскать такие значения Fk и коэффициентов
Ck, чтобы вектор х*м +1 с компонентами х* м + 1, / наилуч-
шим образом в смысле некоторого критерия приближался
к Хм+1 для j $ п.
Учитывая стационарный характер изменений х/ от реа-
лизации к реализации, можно определить x*M+ij, пользуясь
расширенным оператором предсказания (158):
м мм
xm+i, I= 2 хц ri “Ь 2 xidxij rtj, "Ь • 048)
у=11^=1
Члены расширенного оператора предсказания представ-
ляют собой соответствующие компоненты F*/ составляющих
векторов Fk'. •
м
2 хц ri ~ Л/ »
(=1
м м
Xi,j XiJ Гlilt ~ ^21 ’
6=1 i,=l
м' ’ ‘м ’ ' ' ' К
2 — 2 г{гА}дП х‘к=?ц'
k=l Zft=l 1 Й/Л 1
(149)
В качестве критерия наилучшего приближения пред-
сказанных значений к действительным примем критерий
минимума среднеквадратичной ошибки:
п / k \»
(iso)
/=i \ *=i /
110
Тогда коэффициенты ск определяются из уравнений
К / п \ П
^2 I М Fk’i I 5=5 Fk'j %jt
A>=1 \/=l / /=!
(151)
аналогичных тем, которые даются Фармером для вычисления
коэффициентов при характеристических составляющих [45].
Значение К. определяет количество составляющих Fk, необ-
ходимое для достижения заданной точности в соответствии
с выбранным критерием.
Подставив найденные коэффициенты с* в (147), получим
предсказанные значения хм+ь/-
Таким образом, полученные ранее с помощью расши-
ренного оператора предсказания значения Fkj являются
по сути предсказанными значениями М + 1-ой реализа-
ции процесса, вычисленными по М известным реализа-
циям (предыстории). Значения Xm+i,j представляют собой уточ-
ненные значения предсказываемой М + 1-ой реализации,
причем это уточнение производится за счет некоторого ко-
личества известных ее значений.
Вторая модификация
комбинированного метода
Значения Хм+i, / можно определить, пользуясь мето-
дом экспоненциального сглаживания:
* + 4-
где хм(0 — экспоненциально;сглаженные значения функции.
Тогда компоненты Fkj составляющих векторов Fk за-
пишутся в виде:
XMj — Fij,
^L.M = F
dt 1
1 dkxW К*-?
ТГ ~Fki-
111
Если в качестве критерия принят критерий минимума сред-
неквадратичной ошибки, то коэффициенты в выражении
(147) определяются из системы уравнений (151).
С помощью предложенного метода может быть решена
задача предсказания М + Лой реализации нестационар-
ного процесса (для Z>1). Однако точность предсказания
при реализации как расширенного оператора предсказания,
так и метода экспоненциального сглаживания падает с уве-
личением Д/. Следовательно, точность определения сос-
тавляющих векторов Fk для М+ l-ой реализации с увеличе-
нием номера I уменьшается.
Увеличение точности при предсказании комбинирован-
ным методом можно получить, реализуя алгоритм непрерыв-
ного вычисления коэффициентов с*. Алгоритм заключается
в том, что вычисленные по известным п значениям М + Ай
реализации коэффициенты ск используются для определения
будущих значений только до того момента, когда становится
известным п + 1-е действительное значение М + Ай реа-
лизации. После этого коэффициенты с* пересчитываются
с учетом п + 1-го действительного значения.
В качестве примера применения комбинированного метода
предсказания нестационарных случайных процессов рассмот-
рим задачу предсказания изменений нагрузки энергосистемы.
Эти изменения находят свое отражение в суточных графи-
ках. Для удобства применения метода функция изменения
нагрузки во времени представляется в виде дискретной по-
следовательности значений. Шаг дискретности во времени
примем такой же, каким обычно пользуются в энергосис-
темах — 1 ч.
Пусть требуется предсказать изменения нагрузки в
какой-либо определенный день недели, например в суб-
боту. В качестве предыстории используем суточные графи-
ки изменения нагрузки за соответствующие дни недели в
прошлом, т. е. за несколько прошедших суббот. По данным
графиков, составляющих предысторию, пользуясь (149),
отыщем значения ckFk . Далее, используя (150) и (151), по- '
лучим предсказанные значения интересующего нас суточ- ,
ного графика.
Следует заметить, что при предсказании суточных изме-
нений нагрузки в полные рабочие дни (со вторника по пят-
ницу) в качестве предыстории не обязательно брать гра-
фики одноименных дней. Что же касается предвыходных,
выходных и праздничных дней, то соответствующие им
суточные кривые в значительной степени конфигуративно
отличаются от графиков полных рабочих дней.
Для полных рабочих дней комбинированный метод поз-
воляет получить предсказание со среднеквадратичным от-
клонением в пиках а = J/W = б—8.
На рис, 43 приведен график изменения нагрузки в один
из «нестандартных» дней — субботу. Предсказанные зна-
чения, полученные с помощью описанного метода, нанесе-
ны на график вместе с действительными значениями. На
этом же графике отмечены значения, полученные при прог-
нозировании в соответствии с действующей в настоящее
время методикой. Комбинированный метод обеспечивает
значительно лучшее качество предсказания — а — 12 про-
тив о= 23, получаемой при прогнозе по существующей ме-
тодике.
Рассмотрим еще один пример применения метода.
5 474
11Э
Предсказание изменений внутричерепного давления
при кровоизлиянии в головной мозг
Экспериментальное воспроизведение внутримозгового
кровоизлияния (биологическая модель)
В лаборатории экспериментальной нейрохирургии Укра-
инского научно-исследовательского института нейрохирур-
гии были проведены исследования изменения внутричереп-
ного (ликворного) давления в ответ на вдыхание углекис-
лоты при экспериментально воспроизведенном внутри-
мозговом кровоизлиянии.
. Эта реакция отражает функциональное состояние сосу-
дов головного мозга и дает возможность судить о фазе раз-
вития патологического процесса.
Во внутричерепное пространство подопытного живот-
ного вводилась игла, через которую поступала кровь
из бедренной артерии. Подбором игл с различным диамет-
ром каналов моделировались разрывы сосудов разных
калибров.
В ходе опытов, через определенные интервалы времени
осуществлялись пробы на вдыхание углекислого газа, Этот
тест избран в связи с тем, что углекислота, оказывая сосу-
дорасширяющее действие на мелкие артерии и капилляры
мозга, по-разному влияет на мозговое кровообращение, а
следовательно, и на характер изменения ликворного давле-
ния в норме, при наличии внутричерепного очага, когда
исходный уровень давления еще не изменяется (стадия ком-
пенсации) и на фоне начинающегося изменения давления
(стадия субкомпенсации). Результаты опыта регистрирова-
лись в виде непрерывных кривых на полиграфе и в
цифровой форме при помощи электронного цифрового реги-
стрирующего устройства в комплексе с соответст-
вующими датчиками.
Изменение ликворного давления в течение одной пробы
на СО2 представляет собой дискретную последовательность
интересующих нас параметров этой пробы (см. рис. 45).
Были приняты обозначения параметров, приведенные в
табл. 4.
114
Таблица 4
№ п. п. Обозначение Единица изме- рения Параметр
1 *0 мм вод. cm. Начальное значение ликворно- го давления
2 Х1тах Та же Максимальное значение Рликв первого подъема
3 Xmin " » » Значение Рликв в точке пере- гиба
4 Хтах Наивысшее значение Рликв дан- ной пробы
5 dP(+) dt » » Скорость нарастания Рликв
6 dP(-) dt » » Скорость падения Рликв
7 h сек. Время от начала пробы до момента, соответствующего Англах
8 t» Время между Х1тах И Xmin
9 ts » Время между Алах и Xmin
10 tf > Время окончания действия СОа
11 XN мм вод. ст. Значение Рликв в момент /4
Критерий качества предсказания
Обычно в задачах фильтрации и предсказания применя-
ется критерий минимума среднеквадратичной ошибки
М[х(0 — =7U-
Однако при удовлетворении этого критерия существует
вероятность отдельных значительных отклонений предска-
занных значений от действительных. В настоящее время
разработан ряд более жестких критериев. К ним относятся
критерий наименьшего риска, критерий минимума суммы
среднеквадратичной ошибки и дисперсии, взятых с соответ-
ствующими весами, и некоторые другие. При решении рас-
s’ 11S
сматриваемой задачи мы потребуем выполнения дополни-
тельного условия:
Абсолютная величина отклонения предсказанного зна-
чения от действительного не должна превышать некоторую
заранее заданную величину Д.
Таким образом, коэффициенты в выражении (148)
отыскиваются из условия
Л4 (Х/ X/)* = 8mjn
при
I Xi — х*|<Д.
Решение и результаты
Задача предсказания проб на вдыхание углекислоты
была запрограммирована и решена на электронной цифро-
вой вычислительной машине. На определение параметров
четырех предсказанных проб затрачено около 6 мин ма-
шинного времени (включая печать результатов) при быс-
тродействии ЭЦВМ порядка 3 тыс. операций в секунду.
Таблица 5
Параметр обозначе- ния +1 x*M+i %M + 2 X*M + 2 X* M-j-o
Хо Хтах Xmin Хтах Щ+) di dP(~) dt h t* h /n 115 120 120 130 0,277 —0,044 10,0 15,0 39,0 120 130 113 123 118 138 0,444 —0,083 9,0 16,0 40,0 119 123 75 80 78 102 0,778 —0,222 6,0 11,0 24,0 114 75 72 82 77 102 0,889 —0,242 5,0 10,0 23,0 120 73 95 102 100 115 0,556 -0,111 8,0 13,0 33,0 118 110 88 105 102 123 1,007 —0,139 9,0 13,0 29,0 120 102 90 95 92 117 0,556 -0,139 7,0 12,0 28,0 116 100 85 98 92 125 0,666 -0,333 6,0 12,0 29,0 115 90
Полученные результаты приведены в табл. 5. Графики
действительных и предсказанных кривых изменений лик-
ворного давления при вдыхании углекислого газа представ-
лены на рис. 44—47.
116
35
//5
j Р/1ЦК.6
(мм бод. cm)
।
Рис. 44. Кривая изменения ликворного давления. Проба 1.
Рис. 45. Кривая изменения ликворного давления. Проба 2.
120
ЮО
1 ? MjKG
(мм M cm)
(t)
to*3O to+60 to+9O №
Рис. 46. Кривая изменения ликворного давления. Проба 3.
Предсказанные кривые хорошо отражают качествен-
ную картину процесса. Достигнутая точность вполне со-
ответствует требованиям, предъявляемым к подобным био-
логическим исследованиям.
Предсказания развития процессов при различных ос-
трых и хронических заболеваниях могут быть исполь-
зованы в диагностических и прогностических целях при
решении вопроса о своевременности и показанности опера-
тивного вмешательства.
ГЛАВА 4
Распознающие системы
в качестве предсказывающих
фильтров и регуляторов
В последние годы рядом ученых предложены ав-
томатические устройства, которые после некоторого пери-
ода начальной наладки (обучения) могут достаточно точ-
но предсказывать протекание разнообразных процессов.
В качестве материала, на котором осуществляется обу-
чение этих устройств, используются записи процесса в
прошлом — предыстория. Качество предсказания, получае-
мого с помощью таких устройств, легко оценить, если срав-
нить их выходные сигналы с действительными значениями
предсказываемого процесса. Схему и параметры предска-
зывающего устройства можно при этом выбрать так, что-
бы точность предсказания с течением времени повы-
шалась.
Если этот выбор будет осуществляться автоматически
при помощи обратных связей, то мы получим самонастра-
ивающийся предсказывающий фильтр.
Реализуя тот или иной алгоритм предсказания, самона-
страивающийся предсказывающий фильтр автоматически
улучшает свою структуру и уточняет значения своих пара-
метров. Это происходит в результате наблюдения за ходом
процесса.
Система все время учитывает поступающие новые дан-
ные о ходе процесса и автоматически уточняет предска-
зание.
Универсальный предсказывающий фильтр с самонастрой-
кой в процессе обучения был предложен английским уче-
122
ным проф. Д. Габором [54]. Этот фильтр реализует алгоритм
предсказания, заключающийся в отыскании оптимальных
весовых коэффициентов расширенного оператора предска-
зания.
Конструктивно фильтр был выполнен в виде аналого-
вого устройства с использованием магнитных и пьезоэлек-
трических умножителей. В качестве примера использования
этого устройства можно привести решение задачи предска-
зания амплитуды океанских волн. Точность предсказания
была получена порядка нескольких процентов.
;Предполагалось использовать фильтр для предсказа-
ния показателей экономической конъюнктуры .Однако объем
входных устройств фильтра для этой задачи оказался недо-
статочным. В настоящее время опыты на специализирован-
ном аналоговом устройстве прекращены. Реализация того
же самого алгоритма производится на быстродействующей
универсальной цифровой машине «Атлас», установлен-
ной в Лондонском университете.
В наших опытах мы не отказались от специализирован-
ных самообучающихся фильтров, что целесообразно толь-
ко при существенном упрощении алгоритма самонастройки
параметров (коэффициентов). Основное предложение сос-
тоите переходе к использованию бинарных самоорганизу-
ющихся распознающих систем в качестве самообучающих-
ся предсказывающих фильтров.
Идея самоорганизации наиболее точно была выражена
в работах Ф. Розенблата [59, а, б]. Он предложил статис-
тическую модель мозга, которая обладает свойствами обу-
чения и самообучения. Эта модель получила название —
перцептрон. Впоследствии это название стали применять
не только к модели, предложеннрй автором, но и для дру-
гих аналогичных систем.
Перцептроны могут самостоятельно, без помощи человека,
распознавать й классифицировать входные сигналы по призна-
кам, которые не заданы заранее. В июне 1960 г. был успешно
продемонстрирован процесс обучения перцептрона чтению
букв.
На рис. 48 представлена упрощенная блок-схема маши-
ны «Перцептрон». Буквы или другие изображения, которые
машина должна научиться распознавать и классифицировать,
проектируются на экран, состоящий из фотоэлементов. Фо-
тоэлементы преобразуют изображения в большое число элек-
трических сигналов. Каждый фотоэлемент случайным об-
123
разом соединен с полем ассоциирующих элементов (ячеек).
В результате суммирования сигналов, поступающих от
ассоциирующих элементов, возбуждаются те или иные ис-
полнительные элементы, указывающие, к какому образу от-
носится данное изображение.
В первом перцептроне Ф. Розенблата поле фотоэлемен-
тов (около 400) соединено случайными связями с усилителя-
ми, а затем таким же образом с сервомоторами.
Рис. 48. Упрощенная блок-схема машины «Перцептрон».
__ 1
На усилители подаются смещения, которые могут изме-
няться либо учителем — человеком, либо датчиком обрат-
ной связи.
Рассмотрим процесс обучения перцептрона. Допустим, мы
хотим научить его различать буквы А и Б, т. е. добиться то-
го, чтобы при проектировании на поле фотоэлементов буквы
А срабатывали одни исполнительные элементы, а при проек-
тировании буквы Б—другие. Для этого мы должны «поощрять»
в виде подачи соответствующих смещений те усилители, ко-
торые включают нужные выходы, и затруднить («наказать»)
другие, приводящие в действие ненужные выходы. Законы
поощрений и наказаний могут быть различными [59].
Процесс «самообучения» перцептрона происходит дру-
гим способом, при котором смещения изменяются не чело-
веком, а поступают по цепям обратной связи от выходов
к усилителям.
Перцептрон называют статистической системой, так как
в нем могут быть использованы вероятностные входы и
124
все его основные элементы (датчики, ассоциирующие эле-
менты и выходные элементы) соединены случайно выбран-
ными связями. Если применить детерминированные датчики,
настроенные на прием определенных признаков, а элемен-
ты системы соединить всеми возможными связями, то полу-
чим систему типа перцептрон. Такая система была разра-
ботана одним из авторов. Схема системы представлена
на рис. 49.
Существенным отличием рассматриваемой системы яв-
ляется наличие в ней отдельного контура положительной об-
ратной связи и индикатора наибольшего напряжения, ука-
зывающего, какая из групп ассоциирующих элементов дает
наибольшее напряжение.
Каждому образу отвечает одна группа ассоциирующих
элементов. Правильный ответ дает та группа, на выходе ко-
торой (в результате «голосования» большого числа распре-
делительных элементов) получается наибольшее напряжение.
На рис. 49 показаны для простоты только три таких груп-
пы. Здесь представлен вариант «с полной входной информа-
цией» при равном участии ассоциирующих элементов.
Ф. Розенблат сформулировал две теоремы, выражающие
концепцию самоорганизации. В соответствии с этими тео-
ремами, только «бесконечный перцептрон», имеющий бес-
конечное число датчиков, может начать действовать без на-
чальной организации. Чем больше степень начальной орга-
низации, тем меньшим числом элементов можно обойтись,
тем дешевле перцептрон.
Поэтому при конструировании практических схем же-
лательно исходить из некоторой начальной организации,
хотя она принципиально и не является необходимой.
Практически наименьшая начальная информация за-
ключается в простом перечне признаков входных сигналов,
которые могут быть когда-либо полезны для различения
этих сигналов, без указания, к какому сигналу они отно-
сятся.
Указанная выше система (см. рис. 49) была в дальнейшем
улучшена и получила название системы «Альфа» [21 ].
Основные преимущества бинарных систем по сравнению
с непрерывными, например по сравнению с фильтром проф.
А. Габора, состоят в следующем:
1. Для действия системы требуется весьма небольшая
информация о процессе. Нужно знать только, превысит ли
показатель процесса определенный уровень или нет. До-
125
Рйс. 49. Структур-
ная схема распозна-
ющей системы с по-
ложительной обрат-
ной связью.
1 — различаемый об-
раз; 2 — входное ус-
тройство; 3—5 — дат-
чики; 6 — группы ас-
социирующих эле-
ментов; 7 — прямые
усилители; 8 — ре-
версирующие усили-
тели; 9 —сумматоры;
10 —индикатор боль-
шого напряжения;
11 — управление по-
рядком самообучения;
12 — положительная
связь самообучения;
13 — разомкнутая
связь обучения.
пущение о нормальном распределении признаков не суще-
ственно.
2. При наличии второй положительной обратной свя-
зи система может автоматически отбирать наиболее полез-
ные исходные данные или признаки [211. Наиболее эффектив-
ное использование возможностей системы приводит к зна-
чительному уменьшению ее объема. Кроме того, распозна-
ющая система принципиально может быть построена так,
что будут выдаваться сигналы о том, что используемые приз-
наки недостаточны и требуются новые данные о процессе.
Ниже мы подробно рассмотрим схему и алгоритм действия
аналогового самонастраивающегося фильтра Д. Габора, а
затем остановимся на применении бинарной распознающей
системы «Альфа» для целей предсказания.
УНИВЕРСАЛЬНЫЙ ПРЕДСКАЗЫВАЮЩИЙ ФИЛЬТР
С САМОНАСТРОЙКОЙ В ПРОЦЕССЕ ОБУЧЕНИЯ
Проблема синтеза оптимального линейного предсказы-
вающего фильтра была впервые сформулирована Колмо-
горовым в 1942 г. Что касается нелинейного фильтра, то
было высказано мнение, что формальное решение задачи не
будет иметь практического значения. Это объясняется боль-
шим количеством вычислений и огромным объемом работы
по сбору данных. Но ученые время от времени возвраща-
лись к идее создания такого фильтра, поскольку предсказа-
ние сложных стохастических процессов имело бы существен-
ное значение при решении важных проблем управления
производством, планирования, экономики, социологии и в
других областях.
В 1954 г. английский ученый проф. Д. Габор предложил
определить круг математических задач, подлежащих решению
и исследованию при создании оптимального фильтра. Фильтр
должен представлять собой реализацию чрезвычайно гиб-
кого математического оператора, учитывающего настоя-
щие и прошлые значения любой функции времени, с которой
он оперирует. Параметры фильтра должны постоянно улуч-
шаться в процессе обучения. В устройство заводятся зна-
чения случайных последовательностей, которые должны
фильтроваться или предсказываться. Последовательности,
называемые также выборками, должны быть достаточно длин-
П7
ними, чтобы было обеспечено полное представление функции.
Это означает, что выборки должны быть такой длины, что-
бы вычисленные по ним статистические параметры можно
было считать статистическими параметрами всего процесса.
Основная трудность при практическом применении те-
ории линейной фильтрации и предсказания Колмогорова-
Винера заключается в том, что в этой теории рассматривают-
ся сигналы в неограниченном диапазоне частот.
В случае решения задачи предсказания реальными ус-
тройствами с ограниченной полосой пропускания F не-
прерывно изменяющийся сигнал может быть представлен
в виде дискретной последовательности значений этого сиг-
нала, следующих через интервалы, равные сек.
Расширенный оператор предсказания
Наиболее общим функциональным выражением предысто-
рии временной функции в ограниченном частотном диапа-
зоне является следующая последовательность дискретных
значений:
N N N
<W)] = 2U + 2 2 А.А.ПЛ + -... (|58)
1=0 i,=0 Z,=0
Коэффициентами этой последовательности являются
переходные функции, определенные лишь для целых зна-
чений аргумента.
Нетрудно увидеть, что первая сумма — не что иное,
как обобщенный линейный предсказывающий фильтр.
Коэффициент rt определяет влияние дискретного значения
ft функции, соответствующего моменту на i интервалов
раньше, чем настоящий момент.
Вторая сумма составлена из произведений этих дискрет-
ных значений по два, включая квадраты. Коэффициенты
rilit определяют веса пар значений в моменты на tl и ti
интервалов ранее настоящего момента и т. д. Эти суммы дол-
жны охватывать всю предысторию.
Если предыстория разделена на N интервалов, то опе-
ратор содержит N + 1 член первого порядка (первой сум-
мы), -я-(Л^4- 1)(W + 2) членов второго порядка, 4- (N + 1)
о
128
(N + 2)(N + 3) членов третьего порядка и т. д. Совершенно
очевидно, что количество членов оператора сильно возрас-
тает с увеличением порядка.
Схема предсказывающего фильтра
Блок-схема предсказывающего фильтра показана на рис. 50.
Блок задержки 1 представляет собой устройство записи на
магнитной ленте с головками, расположенными ступен-
чато.
На одной из дорожек магнитной ленты записана иско-
мая функция О*(/). В случае предсказания эта функция
считывается сдвинутой вперед головкой со входной ленты.
Рис. 50. Блок-схема предсказывающего фильтра с самонастройкой в
процессе обучения:
/ — устройство записи на магнитной ленте; 2 — блок настраиваемых пара-
метров; 3 — блок сравнения; 4 — квадраторы; 5 — интеграторы; 6 — мини-
мизатор; 7 — блок настройки переменных параметров.
Собственно фильтр 2 состоит из арифметического ус-
тройства и набора настраиваемых параметров. В качестве
последних используются потенциометры.
Выходной сигнал фильтра и искомая функция заводятся
в блок сравнения, определяющий ошибку предсказания. В
качестве критерия, как и в теории линейных фильтров, при-
нят критерий наименьшей среднеквадратичной ошибки:
{О1/(/)]-О*(0} = eLn. (159)
Левая часть этого выражения является положительно
определенной квадратичной формой коэффициентов г. Сле-
довательно, решение всегда существует. Кроме того, по-
129
скольку оператор предсказания линейный относительно г,
это решение единственно.
В функции аргументов г среднеквадратичную ошибку
можно представить многомерным эллиптическим парабо-
лоидом. Поэтому достижение минимума неизбежно при ис-
пользовании любого алгоритма уменьшения г2. Для слу-
чая одной и двух переменных это показано на рис. 51. Оба
параметра должны настраиваться попеременно.
При этом оптимальные коэффициенты определяются из
выражения
______i_ У-1-У+1
ор‘ 2 у_г 4- у+1 - 2у0 •
Если же воспользоваться разностями, то
— _1_ А~1 ~ А'±L
r°Pt ~ 2 ' Д_х+Д+1
и
Ут in— Уй 2 2 1 ^+1)'
Рис. 51. Оптимизация настройки пере-
менных параметров:
а — один переменный параметр; б — два
переменных параметра.
Для увеличения бы-
стродействия в описыва-
емом предсказывающем
фильтре блоки сравне-
ния 3, квадраторы 4 и
интеграторы 5 повторе-
ны трижды, поэтому за
каждый цикл обучения
ошибка определяется
для трех значений вы-
бранного параметра г{ :
для Г[ — 0 и для самых
больших положительно-
го и отрицательного зна-
чений. На основании
этих значений миними-
затор 6 автоматически
определяет оптималь-
ное значение, на которое должен быть настроен пара-
метр г/ , и величину e8min- Блок настройки 7 устанавливает
необходимое значение п. Затем цикл обучения повторяется.
Как правило, при наличии М настраиваемых параметров
130
число циклов обучения, необходимых для достижения eamin,
др
составляет величину порядка После этого говорят, что
фильтр обучился предсказанию значений данной случай-
ной последовательности.
Другими словами, предсказывающий фильтр, обучив-
шийся наилучшим (в смысле е2 = min) образом предска-
зывать значения тренировочных последовательностей, будет
аналогично работать с другими выборками той же стохасти-
ческой последовательности. Это утверждение основано на
следующих допущениях:
1. Рассматриваемые случайные процессы являются
эргодическими, т. е. сохраняющими постоянство статисти-
ческих параметров на каких угодно длинных последова-
тельностях.
2. В процессе обучения машина определяет все нужные
статистические параметры и воспроизводит их.
С помощью описанного фильтра были проведены сле-
дующие опыты:
1. Преобразование синусоидального сигнала в другой
синусоидальный сигнал, сдвинутый по фазе и отличный по
амплитуде.
2. Фильтрация синусоидального сигнала с наложенным
шумом.
Предсказание изменений показателя
качества продукта нефтехимического предприятия
Рассмотрим пример применения предсказывающего филь-
тра Колмогорова—Габора.
На рис. 52 представлена схема автоматического регули-
рования ректификационной колонны одной из технологичес-
ких установок нефтеперерабатывающего завода (установ-
ки АВТ).
Выходным продуктом этой установки является бензин
прямой гонки. В схему регулирования включен анализа-
тор качества, автоматически определяющий температуру
конца кипения бензина. При осуществлении регулирования
технологической установки по показателю качества выход-
ного продукта важно знать не только текущие значения по-
казателя и его отклонения от нормы, но и значения пока-
зателя в некоторые будущие моменты. Это дает возможность
131
регулировать процесс с упреждением, учитывая возможные
будущие отклонения. Подобный метод известен под названи-
ем «опережающей компенсации». Предсказывающий фильтр
Рис. 52. Схема автоматического регулирования ректифи-
кационной колонны установки АВТ:
I — поток сырья; II — ректификационная колонна установки
АВТ; III — холодильник; IV — сборник орошения; V — поток
орошения; VI — выходной продукт (бензин прямой гонки);
VII — отбензиненный продукт; / — термопара; 2 — потенцио-
метр; 3 — суммирующее устройство; 4 — анализатор каче-
ства; 5 — регулятор; $ — предсказывающий фильтр; 7 — ре-
гулирующий клапан; 8 — отборная точка для анализа продукта.
(см. рис. 52) определяет будущие значения показателя ка-
чества, которые используются как исходная информация в
системе автоматического регулирования технологической ус-
тановки. Если в системе управления производственным про-
132
цессом имеется универсальная цифровая вычислительная
машина, то во многих случаях функции предсказываю-
щего фильтра целесообразно возложить на нее.
Моделирование предсказывающего фильтра
на ЭЦВМ
Запишем алгоритм работы предсказывающего фильтра.
Процесс обучения оператора:
1 112 235 3 44 5
|Taf | f | |Мгу| 2EptS|Ra>t. (160)
В выражении (160):
T — оператор выдачи задержанных значений fa, (i =
= 0, 1,обучающей последовательности;
a — логическое условие, считающееся выполненным
при i = к;
М! — оператор вычисления произведений задержан-
ных значений;
Р — логическое условие, считающееся выполненным, *
когда все произведения задержанных значений
получены;
Мг — оператор умножения значений fa и произведений
A, fit> fit fit ft,. и т- Д- на соответствующие коэф-
фициенты веса;
у — логическое условие, считающееся выполненным,
когда получены все составляющие оператора пред-
сказания O[f(t)l;
2 — оператор вычисления O[f(t)l;
Е — оператор вычисления среднеквадратичной ошибки;
р — логическое условие, считающееся выполненным,
если
[0[/(/)]-НФ1’“4;
S — конец обучения;
R — оператор вычисления новых коэффициентов веса
%
<о — тождественно ложное условие.
Процесс предсказания:
| Та | | Мф f | Mropt Y 12S. (161)
133
В выражении (161)—Мг°р/—оператор умножения произ-
ведений fit fit, fix fijit и т. д. на оптимальные коэффициенты
ropt, полученные в результате обучения оператора (160).
Рис. 53. Блок-схема программы моделирования пред-
сказывающего фильтра на ЭЦВМ.
В рассматриваемой задаче алгоритм был реализован на
универсальной цифровой вычислительной машине.
Блок-схема программы моделирования приведена на
рис. 53. Действительные и предсказанные значения показателя
134
I 2 3 4 5 б 7 8 9 10 II 12 13 14 15 16 17 18 19 20
Рис. 54. Предсказание температуры конца кипения бензина прямой гонки.
Таблица 6
Действитель- ные значения Предсказанные значения
к=2 | к=3 | к=4 | к=5
196 196,5 195,5 196 197
203 197 196,5 195,5 196
199 199,5 199 198 197
198 201 199,5 199 196
189 198,6 200 199 199
197 193,5 195,5 197 197
193 193 195 196 197
194 195 193 194 195
198 193 194,5 193 194
200 196 195 195,5 194
195 199 197,5 196 195,5
202 .197,5 197,5 197 194
196 198,5 199 199 198
194 199 198 198 198
193 194,5 197 196,5 198
192 193 194 196 196
196 192,5 193 193,5 194
192 194 194 193,5 194
202 194 193,5 193,5 195
197 197 196,5 195,5 Ь94
Тк.к, °C приведены в табл. 6. На рис. 54 представлены графики
действительных и предсказанных значений Тк,к. Обучение
оператора производилось при различном количестве* зна-
чений предыстории (к = 2, 3, 4, 5).
О влиянии длины предыстории
на качество предсказания
Если проанализировать рассмотренный пример, а так-
же примеры, разобранные ранее в главе второй, то станет
очевидным, что существенное влияние на качество предска-
зания оказывает количество к известных значений ft (I —
= 1, 2,...,«), которые участвуют в вычислении оператора
01/(01-
Для наглядности рассмотрим несколько примеров. На
рис. 55 представлены зависимости критерия качества пред-
сказания от количества известных значений предсказываемо-
го процесса, принимающих участие в вычислении оператора
01/(01- В качестве критерия принят, как и ранее, минимум
среднеквадратичной ошибки. Из графиков видно, что для
136
рассматриваемых нами реальных процессов качество предска-
зания не является монотонной функцией длины предыстории,
как этого следовало бы ожидать в случае стационарности
случайных процессов. Так, из
графика рис.55 очевидно, что кГг
прик=2,4, 8 среднеквадратич- 1,0
ная ошибка меньше, чем при 0,9 //уц
к = 3, 6. Подобные процессы / \l
относятся к классу периоди- / \\ / \
чески коррелированных (или 2 VZ \
почти периодически кор рели- Q6 ___
рованных) случайных процес- . ''' . х
сов. С теорией этих процессов 2 3 4 5 6 7 8
читатель может познакомиться Рис. 55. зависимость среднеква-
в работах Е. Г. Гладышева [10]. дратичной ошибки от длины пре-
Таким образом очевидно, дыстории.
что качество предсказания ре-
альных случайных процессов существенно зависит от
длины предыстории. Выбор к представляет собой перво-
степенную задачу, от решения которой зависят точность
и достоверность предсказания.
Простое предсказывающее устройство
по первой производной
Основной недостаток, присущий предсказывающему
фильтру Колмогорова—Габора,—рост сложности вычисле-
ний с увеличением точности. Сложность схемной реализации
ограничивает область применения пробных устройств. Осо-
бенно это относится к применению предсказывающих филь-
тров в системах управления.
На практике очень часто некоторое снижение точности
предсказания может быть принесено в жертву простоте по-
строения системы. В подобных случаях целесообразно при-
менять простые упреждающие устройства, в которых пред-
сказание основано на определении первой производной в
текущей точке.
Для повышения точности предсказания таких устройств
можно использовать и вторую производную, но практичес-
ки чаще всего достаточно ограничиться первой. Повышение
точности за счет второй производной приводит к значитель-
ному усложнению системы.
137
Точность предсказания устройствами подобного рода
снижается в области изменения знака первой производной
предсказываемой функции по времени. Очевидно, что для
повышения точности предсказания следует по мере рас-
ширения спектра частот предсказываемой функции умень-
шать интервал предсказания. Известно, что ширину спек-
тра частот какого-либо процесса достаточно полно характе-
ризует его автокорреляционная функция. Вычислим нор-
мированную автокорреляционную функцию рх (т) в одной
точке при некотором определенном значении т. Если теперь
выбрать время упреждения А/ по формуле
Д/ = £рх(т), (162)
то можно подобрать такую зависимость между величиной
интервала предсказания и крутизной автокорреляцион-
ной функции, при которой погрешность предсказания не
превышала бы заданной.
Предсказанное значение
x(t М) = x(t) + Ах(0, (163)
где х(0 — текущее значение функции.
Коэффициент пропорциональности k в выражении (162)
равен максимальному времени упреждения.
Чем медленнее изменяется процесс во времени, тем боль-
ше время упреждения. Нормированная автокорреляционная
функция таких процессов приближается к единице. •
Быстро изменяющиеся процессы, характеризующиеся
широким спектром частот, будут иметь очень малое время
упреждения, так как их нормированная автокорреляцион-
ная функция при тех же т приближается к нулю.
Уменьшая время упреждения, можно добиться сколь
угодно высокой точности. Однако для практических задач
необходимо стремиться не только к всемерному повыше-
нию точности, но и к возможному увеличению времени уп-
реждения.
Для оценки качества предсказания было предложено
принять критерий максимума суммы, составленной из вели-
чины, обратно пропорциональной ошибке предсказания и
отношения действительного времени упреждения к макси-
мальному [6]:
1>=-р-+4- <164>
Очевидно, функция <р= F(A^) имеет экстремум, посколь-
ку с возрастанием времени упреждения среднеквадратичная 138
138
ошибка непрерывно возрастает. Используя это свойство
зависимости (164), можно построить самонастраивающуюся
систему, которая при помощи изменения времени упрежде-
ния непрерывно находила бы максимум показателя качест-
ва предсказания. Для этой цели можно использовать либо
поисковую экстремальную систему, либо беспоисковую
дифференциальную экстремальную систему. Принцип ра-
боты дифференциальных систем описан в книге В. И. Ва-
сильева «Дифференциальные системы регулирования» (71.
Предсказание рельефа речного дна
Описанный выше метод можно проиллюстрировать на
примере предсказания рельефа речного дна. Решение этой
задачи очень важно, например, для оптимального управ-
ления при судовождении.
Рис. 56. Предсказание рельефа речного дна:
1—контур рельефа; 2—предсказание с постоянным шагом; 3—пред-
сказание с переменным шагом.
Контуры рельефа участка речного дна и его предсказан-
ные значения приведены на рис. 56. Расчеты показали, что
введение переменного интервала предсказания резко повы-
шает точность предсказания (рис. 56).
РАСПОЗНАЮЩАЯ СИСТЕМА «АЛЬФА» —
ПРЕДСКАЗЫВАЮЩИЙ ФИЛЬТР
Предсказание дискретных резуль-
татов. Если ряд сходных циклических процессов отли-
чается только по начальным условиям, а в дальнейшем про-
текает приблизительно в постоянных условиях, то резуль-
139
тэты этих процессов могут быть распределены по видам
начальных условий с целью предсказания результатов по-
добных процессов в будущем. Для выполнения такого обоб-
щения опыта можно использовать любую самообучающую-
ся распознающую систему с классификацией образов по вы-
ходным величинам [21, стр. 302]. Свойство распознающей
системы разделять множество изображений на классы об-
разов можно использовать для классификации начальных
условий (признаков) по результатам. Так, В. Л. Браилов-
ский и А. Л. Лунц в опытах по предсказанию результата
лечения ожогов использовали 12 входных признаков (пло-
щадь раны, локализация ожога, степень ожога, возраст боль-
ного, сопутствующие заболевания, осложнения, данные
медицинских анализов и т. д.). Предсказывался исход лече-
ния — выздоровление или смерть.
Предсказание непрерывны хпроцес-
с о в. Как известно, непрерывные величины могут быть при-
ближенно заменены рядом дискретных величин. Поэтому
распознающие системы могут быть применены и для пред-
сказания непрерывных процессов. Примером может слу-
жить работа по предсказанию длительности срока'службы
транзисторов по виду кривых изменения токов, наблюдаемых
в течение 10 мин. Время — непрерывная величина — раз-
бивается на ряд отрезков и таким образом требуется обу-
чить систему предсказывать номер отрезка. •
В соответствии с теоремой Ляпунова, при увеличении чис-
ла слагаемых случайных величин закон распределения их
суммы стремится к нормальному распределению вероят-
ности. Этим объясняется то, что очень многие стационар-
ные процессы в природе имеют нормальное распределение.
Наиболее общей формулой для предсказания будущего зна-
чения стационарной функции времени является формула
Колмогорова
п п п
ет = г0 + fnt fnt ГП±П2 +
О 0 0
п п п
+ fnt fn2fn3rП1Л2Л8 + •••>
ООО
где g[f(t)] — будущее, предсказываемое значение функции;
fnt — значения этой функции в прошлом.
140
Первая сумма представляет собой линейный фильтр с
постоянной передаточной функцией, вторая — квадратич-
ный фильтр, третья — кубический и т. д. Коэффициенты
определяют влияние (вес) каждого члена формулы на
предсказываемое значение функции. Поясним формулу на
Рис. 57. Задача предсказания амплитуды следующей волны по
значениям амплитуд трех предыдущих волн.
/? — число уровней дискретизации выходной величины.
примере (рис. 57). Для предсказания будущего значения
функции по трем данным о ходе изменения этой функции
в прошлом (предыстории) получим формулу в виде много-
члена:
g I/ (0] = flrl + firi + 1зГа + ft rt + rf + Гв + /Jjf, +
4* fiA/e 4* + fi Гю + /2^11 + /згм + + ZjfsTi* +
4~ /2 fir 1» + /2 f»ri« "b fl fir«"I" fl f*r1» + fifsfsri»»
где g — значение функции f(t) в будущий момент времени
4- Т;
f, — значение функции f(t) в момент времени —2Т;
ft — значение функции f(t) в момент времени —Т;
fs — значение функции f(t) в данный момент времени 0;
гх, г2,..,г19 — коэффициенты влияния (веса ) каждого члена.
Самообучение распознающей системы, используемой в
качестве предсказывающего фильтра, состоит в определении
величины коэффициентов влияния на основании данных не-
которой обучающей последовательности. Этот процесс само-
установления коэффициентов для стационарных случай-
ных процессов нужно выполнить один раз, причем чем
длиннее обучающая последовательность данных, тем точ-
нее предсказание. Для почти стационарных процессов лучше
141
9
ограничиться локальной выборкой — небольшой обучающей
последовательностью, а самообучение коэффициентов вести
непрерывно, только по последним данным о процессе. Мож-
но определить оптимальную продолжительность памяти
системы. Чем ближе процесс к стационарному, тем эта про-
должительность больше. При весьма нестационарных про-
цессах оптимальная продолжительность мала и не обеспе-
чивается достаточная точность предсказания. В этих случаях
нужно переходить к другим методам предсказания (напри-
мер, к методу выделения периодических характеристических
составляющих [45] или к комбинированному методу [31].
Алгоритм действия распознающей
системы «Альфа»
Напомним кратко алгоритм действия распознающей сис-
темы «Альфа» [21]. Пример схемы системы приведен на
Рис. 58. Распознающая система «Альфа» в качестве предсказы-
вающего фильтра Колмогорова — Габора.
рис. 58. В данном применении этой системы датчики при-
знаков по наблюдению за мгновенными изменениями функ-
ции вырабатывают некоторые функции этих величин
Xg, Xg,..., Хп ,
142
которые обычно в теории распознавания образов называют-
ся признаками. Совокупность признаков образует входной
вектор «изображения», или «представляющую точку»,
Vi(xlt х2, ..., хп).
Вектор Vi поступает на входы групп ассоциирующих ячеек
(триггеров или реле), в которых вырабатываются скаляр-
ные произведения вектора у,- входа на некоторые, записан-
ные в каждой из этих групп, внутренние векторы а* (гх,
гг, гз,..,гп), называемые прототипами, или полюсами,
Si = = («2 v(), .... S„ = (% v).
Число групп равно числу различаемых образов, т. е. деле-
ний предсказываемой величины.
Скалярные произведения подаются на компаратор (ин-
дикатор большого напряжения — ИБН), в результате чего
система выбирает большее из них и тем самым указывает об-
раз (деление предсказываемой величины). При самообуче-
нии положение полюсов изменяют обратные связи [21].
Обучение системы состоит в целесообразном выборе по-
люсов групп.
Закон поощрения системы «Альфа» выражается урав-
нением
„ ___ От ~Ь 1 + ^гРт—2 + — 4~ 1°1
m+l 1 + + ^2 + ••• + km—1 ’
где т — число срабатываний данной группы; Л(т) — «функ-
ция забывания» предыдущих показов.
При й(т) = 0 получим «доверчивую» обратную связь
®т+1 === Ут>
при которой соответствующий вектор прототипа сразу при-
нимает значение вектора последнего по времени показа изо-
бражения.
При k(m) — 1 получим «усредняющую» обратную связь,
при которой конец вектора прототипа удерживается в «цен-
тре тяжести» области данного образа:
„ _ °т + Vm—i + ... +
--------------------.
Возможно применение экспоненциального закона убы-
вания коэффициентов по мере срабатывания данного выхода:
®т+1 — Н” (Ущ — ат) 6, Где 0 6 1.
143
При 8 = 1 получим закон поощрения «доверчивой» об-
ратной связи.
Экспоненциальный закон поощрения наиболее просто
осуществляется в системах с непрерывными ассоциирую-
щими ячейками.
Возможен еще один вид закона «поощрения», удобного
для реализации в релейных системах, при котором полюс обу-
чаемой группы после каждого срабатывания соответствую-
щего ей выхода перемещается на один шаг в сторону
выходного изображения. Этот шаг может быть постоянным
или уменьшающимся по экспоненциальному закону.
Система «Альфа» обобщает отдельные изображения в об-
ласти — образы. Поясним свойство обобщения на примере
системы «Альфа», имеющей всего три группы реле, состояние
которых на п -ом такте работы системы характеризуется тре-
мя полюсами —
®1п > ®2п > •
Датчики подают на вход системы вектор vn. Тогда на
выходах группы получим три напряжения:
= (ОС|Я Ця), Sgn = (C<2n Vn), S&i = (®3n Vn).
ИБН работает по следующему алгоритму:
а) если Ein>S&»H 21„>2з„, то срабатывает выход 1 и fiepe-
обучается первая группа;
б) если 22n>S]„ и 22л>23я,то срабатывает выход 2 и пере-
обучается вторая группа;
в) если S3n>Sin и ^зп>^2п, то срабатывает выход 3 и пере-
обучается третья группа.
Все состояния, удовлетворяющие первому условию, бу-
дут отнесены системой к первой ситуации, второму — ко
второй, третьему—к третьей.В этом и состоит обобщение.
Во всех случаях действие положительной обратной связи
только усиливает указанные неравенства и приводит к еще
большему «закреплению» выходов:
2цп+1) = (ацл+о vn) Sin; S2(n+и — (»2(n+i) On) Sjn;
s3(n+l) = (®3(п+1)Оя) S3„.
Напомним, что в других распознающих системах исполь-
зуются другие датчики, прототипы, алгоритмы сравнения и
законы поощрения. В системе с выбором минимального квад-
144
рата расстояния между представляющей точкой и полюса-
ми используется алгоритм сравнения
к
2g = (Vim OLsm)*
m=l
с последующей процедурой минимизации величины S3 (в от-
личие от процедуры отыскания максимального значения ска-
лярного произведения в системе «Альфа»).
Система «Альфа» сравнивает расстояние между полюса-
ми и изображением в пространстве Хемминга, а система с
выбором минимума квадрата расстояния— в обычном эвкли-
довом.
В качестве прототипов не обязательно используются век-
торы, вместо них применяются уравнения границ областей
отдельных образов в многомерном пространстве признаков,
коррелированные прототипы и др.
Самообучение предсказывающего фильтра по
методу множественно-корреляционного анализа
Среднеквадратичная ошибка предсказания определяется
выражением
п
где ga — действительное значение функции (в будущем);
g — предсказываемое значение функции.
Она является положительной, определенной квадратич-
ной формулой коэффициентов влияния. Минимум ошибки
всегда существует, а так как уравнение относительно г ли-
нейно, то он является единственным минимумом. Множест-
венно-корреляционный (регрессионный) анализ позволяет вы-
брать коэффициенты влияния так, чтобы получить минимум
среднеквадратичной ошибки предсказания.
Например, введя для трех значений обозначения
fl = Х1, А == Х2 , fз = Хз , /2 = Х4 » fl = Хь , fl = Х6 ,
flh^Xlt = /3 = х10, = /33 = х12,
f^fz — *13 > fI /з = *14 > flf\— *15 , flf^ — Xie f fl fl — *17 ,
/3 /2 = *18 t fifzfz — Xi9 ,
6 474
14$
получим уравнение предсказания в линейном виде
g = г0 + гл + ггх3 + г3х3 + гл + гл + г6хе + гл +
4* Г8Х8 4“ Г9Х3 4" Г10*10 4- Г11*11 4” Г12*12 4“ f13Х13 4~ f 14*14 4*
4" Г 16*15 4“ Г1Л« 4" Г 17*17 4* Г18*18 4* Г 19*19 •
Выражение для среднеквадратичной ошибки принимает
вид
п
Д = 4- У (^0 — Г0 — ГгХ± — Г3Х3 — Г3Х3 — ... — Г19*19)а.
п —
Желая определить минимум среднеквадратичной ошибки,
находим значения двадцати частных производных и прирав-
ниваем их нулю
= 0, = 0, = 0, .... = 0.
дг3 ’ Sri огй дг13
Эти уравнения и являются основными расчетными урав-
нениями («нормальными уравнениями регрессии»). В развер-
нутом виде получим (черточки над корреляционными коэф-
фициентами обозначают операцию усреднения по всем дан-
ным обучающей последовательности):
г9 4- гл 4- гл 4- гл 4-... 4- г19х19 = go.
гл 4- 4- г2*л 4- гл*з 4- - 4- г18ад. =
г0*2 4-Л*л 4- г3Ц+ г3хл 4- - 4- Г19*Л9 = gob,
гл.4- 4- гл*1» 4- - 4- г19Х19 = £<л9.
Число уравнений для однозначного решения не может
быть меньше числа неизвестных. Поэтому минимальная
продолжительность обучающей последовательности равна
числу членов формулы Колмогорова. Если предыстория
охватывает N интервалов, то формула Колмогорова содер-
жит + 1 членов первого порядка, -у (N 4- 1) {N 4- 2)
членов второго порядка, y-(N 4- 1)(М + 2)(JV 4- 3) чле-
нов третьего порядка и т. д. Например, при N = 3 должно
быть не меньше 20 замеров. Каждый замер должен включать
в себя три значения функции из предыстории и соответству-
ющее действительное ее значение, последовавшее за ними
(см. рис. 57). На практике длина обучающей последователь-
ности должна быть увеличена в пять-десять раз по сравнению
146
с минимальной. Это позволяет устранить влияние неточности
измерения функции. Число уравнений при этом не увели-
чивается, но увеличивается объем вычислений корреля-
ционных коэффициентов, входящих в эти уравнения.
Мы показали алгоритм применения регрессивного ана-
лиза для определения коэффициентов формулы Колмого-
рова главным образом для того, чтобы оценить объем необ-
ходимой вычислительной работы и указать длину обуча-
ющей последовательности исходных данных.
Самообучение предсказывающего фильтра
по итерационному алгоритму Габора
Профессор Д. Габор [541 предложил итерационный ал-
горитм, основанный, как и метод множественно-корреля-
ционного анализа, на поиске минимума среднеквадратичной
ошибки, т. е. дающий тот же результат несколько другим
способом. Среднеквадратичная ошибка предсказания как
функция коэффициентов влияния является многомерным эл-
липтическим параболоидом, вершина которого и является
целью поиска. Поиск минимума ошибки можно выполнить
различными методами: методом Гаусса—Зейделя (т. е. по-
очередным изменением коэффициентов), методом градиента,
или наискорейшего спуска, и т. п. Профессор Габор при-
менил в своем самонастраивающемся фильтре экстраполя-
ционный метод поиска минимума. Положение минимума
вычисляется по трем точкам параболы. Вывод экстраполя-
ционной формулы прост (см. рис. 51). Из условия миниму-
ма среднеквадратичной ошибки находим оптимальное зна-
чение некоторого коэффициента
Д = а0 + 0^+ а^г'2,
d\ n 1 ai
~dr^ ~ ° ИЛИ rt °pt ~ 2" di
Уравнение параболы для любых трех избранных точек
дает три расчетных уравнения:
Д' = а0 + ахг' + а3г’2,
Д" ^Oo + Otr’ + О2<2,
Д'" = а, 4- + а%г’2.
6* 147
Определив отсюда значения коэффициентов at и а^, получим
искомую экстраполяционную формулу
_________1_ A' (r'i2 — r’i2) + Л" (г? — '?) + Д'" ('? — r'j2)
riopt 2 д'(г" —»•,) + ^'(ri-rl)+ Лт(г{'—г')
Далее определение коэффициентов формулы Колмогоро-
ва сводится к последовательности итераций: а) задавшись
произвольными значениями коэффициентов, вычисляем три
значения ошибки Д', Д" и Д'" для трех значений одного из
коэффициентов г/, г/', г/". По этим величинам, пользуясь экс-
траполяционной формулой, находим оптимальное значение
коэффициента п; б) приняв это оптимальное значение, повто-
ряем вычисления для следующего коэффициента ri+i и т. д.
до тех пор, пока величина среднеквадратичной ошибки не
стабилизируется на каком-то значении. В процессе итераций
ошибка должна монотонно уменьшаться. Величина ошибки
в конце итерационного процесса является мерой точности
предсказания.
По объему вычислительной работы итерационный метод
ненамного лучше метода множественно-корреляционного ана-
лиза, однако проще программируется на вычислительных
машинах. Требования к длине обучающей последователь-
ности те же. Число усредняемых при определении средне-
квадратичной ошибки режимов практически должно
превосходить число определяемых коэффициентов формулы
Колмогорова в пять—десять раз. Преимуществом являе-
тся простота осуществления самообучающегося фильтра
на аналоговых элементах.
Распознающая система «Альфа» в качестве
предсказывающего самообучающегося фильтра
Схема распознающей системы «Альфа» (см. рис. 58) пол-
ностью воспроизводит все возможности, заложенные в
непрерывном самообучающемся фильтре Габора, с тем
ограничением, что в ней используется дискретное представ-
ление величин в виде бинарных кодов. Пусть, например, в
коде «со сменой знака» задано
Д = 0,3= + 1+ 1 — 1 —1 — 1;
/2 = 0,1 = + 1—1—1 —1 —1;
/з = 0,9 = + 1 + 1 + 1 + 1 -Н 1.
143
Тогда на вход системы поступит общий код «изображения»
или «представляющей точки»: vt — (0,3; 0,1; 0,9...) =
+ 1 + 1 — 1 - 1 - 1 + 1-1-1- 1— 1+ 1 + 1 + 1+1 + 1....
Этот код поступает на некоторое количество групп ас-
социирующих ячеек, число которых равно числу делений R
предсказываемой величины. На рис. 57 показано пять
делений, соответственно чему на рис. 58 показано пять
групп.
Каждая группа характеризуется своим полюсом (или
прототипом, эталоном). На выходе каждой из групп полу-
чается напряжение, пропорциональное скалярному произ-
ведению входного кода на код полюса. Например, если
полюс первой группы тоже будет
Oj=(0,3; 0,1; 0,9) = + 1 + 1 — 1 — 1 — 1 + 1 — 1 — 1—
— 1 —1 + 1 + 1 + 1+1+1 ....
то на ее выходе получим максимально возможное напряжение
2i = (at vt) = t/max.
Ясно, что большим будет напряжение той группы, у кото-
рой полюс в n-мерном пространстве признаков ближе к
представляющей точке. При равенстве полюса ak и пред-
ставляющей точки Vi получим максимум возможного на-
пряжения, что и показано в данном примере. Индикатор
наибольшего напряжения ИБН находит полюс, ближай-
ший к данной представляющей точке, и таким образом
предсказывает будущее значение функции.
В результате процесса обучения полюса самоустанавли-
ваются в положении, при котором ошибка предсказания не
превышает ошибку, получаемую в непрерывном фильтре
Габора, больше чем на половину дискретного деления.
Система может быть реализована на реле или триггерных
ячейках, или же запрограммирована на универсальной
машине. Рост объема вычислений с увеличением требований
к точности предсказания — основная трудность, прису-
щая фильтру Габора, — остается и здесь. Точность пред-
сказаний увеличивается как с увеличением числа наблюдае-
мых промежутков /V, так и с увеличением числа разрядов
дискретизаторов п, и уменьшается с увеличением количества
уровней дискретизации выхода R. К этому вопросу мы
вернемся ниже.
149
Опыт предсказания амплитуды океанских волн
на предельно упрощенной распознающей
системе «Альфа»
С целью резкого сокращения объема вычислений было
предложено уменьшить объем входной информации о про-
цессе. Пусть дискретизаторы системы «Альфа» имеют один
выход, т. е. сообщают нам только знак отклонения функции
от некоторого среднего значения. Схема такой упрощен-
ной распознающей системы показана на рис. 59. Ясно, что
в отличие от полной системы рис. 58 упрощенная система
уже не обладает возможностями непрерывного фильтра
Габора.
Но насколько ухудшится при этом точность пред-
сказания? Будет ли такая система вообще способна к пред-
сказанию?
Чтобы ответить на эти вопросы, был проведен опыт пред-
сказания амплитуды океанских волн. Важность коренного
упрощения алгоритма предсказания для этой задачи опре-
деляется тем, что при сложных алгоритмах время определе-
ния амплитуды следующей волны на вычислительной ма-
шине может оказаться большим, чем промежуток времени
между волнами (4—12 сек).
В качестве исходного материала была использована за-
пись океанских волн (рис. 60), данная в работе [51а]. Для
150
каждых трех соседних амплитуд определялось текущее
среднее значение. В таблицу исходных данных записыва-
лись только отклонения амплитуд от этого среднего значения:
плюс, если волна выше, и минус, если волна ниже текущего
среднего значения. Выходная шкала системы имела пять
делений. Цену каждого деления мы выбирали равной 3.
(ориентировочно gma*~gmln = 3)
Рис. 60. Запись изменений амплитуды океанских воли.
Пример записи отклонений волн от среднего значения и их
произведений показан в табл. 7 и 8.
Таблица 7
i ь fi+ f.i+2 /ср (из трех) gi+3 (результат)
1 8 ±1 2 -1 3,5 — 1 4,5 4 3
2 1 ' to 3,5 +1 4 +1 3,2 4 3
Применялась не экспоненциальная, а усредняющая об-
ратная связь. В системе использовалось пять групп, харак-
теризуемых пятью полюсами а1} а2, а3, а4 и а6. Самообучение
системы правильному предсказанию состояло в самоуста-
новлении полюсов по закону усреднения
„ Р, 4~ Р, + — + vm
т
где т — номер прихода представляющей точки, дающей один
и тот же результат. Например, если бы оказалось, что все
приведенные в табл. 8 замеры дают третье деление шкалы
151
выхода амплитуды волны, то полюс третьей группы мож-
но было бы определить так:
а3 = + 1+1 — 1—1 — 1 + 1 + 1 + 1 — 1 ит. д.
Таблица 8
fi А+1 f'i+2 f-1, fi+2 ?l+i и fi+li fi+2
+1 -1 —1 — 1 -1 +i +i +i ±1
-1 Н +1 -1 —1 +i +i +i -1
Рис. 61. Зависимость качества предска-
зания от количества точек предыстории
и уровней дискретизации:
3 — количество правильных предсказаний
(в %); N — количество точек предыстории;
п —количество уровней дискретизации вход-
ных величин; R — количество уровней дис-
кретизации предсказываемой величины.
В соответствии с
оценкой, данной выше,
для самообучения полю-
сов использовалась обу-
чающая последователь-
ность из 140 замеров не
менее трех соседних зна-
чений амплитуд волн и
последующей. После обу-
чения полюса уже не
двигались, и система бы-
ла включена на пред-
сказание. Оказалось, что
она предсказывает ам-
плитуду следующейввол-
ны с точностью ±10%
правильно в 80 случаях
из 100, 10—20 случаев
представляют собой эле-
мент н епр едсказуемой
«чистой» случайности в
данном процессе; с то-
чностью ± 20 % пред-
сказываются правильно
96 волн из 100. Таким
образом, весьма упро-
щенная система при сра-
внительно небольшом
объеме вычислений все
же способна к предска-
занию процессов с ука-
занной точностью.
152
Исследование точности предсказания
и полезности признаков
(членов формулы предсказания)
Было проведено исследование влияния числа уровней на
точность предсказания. Полученные зависимости приведены
на рис. 61. Первый график на этом рисунке показывает, что
увеличение числа учитываемых интервалов предыстории W
повышает точность предсказания. Второй график служит
основным оправданием применения упрощенной системы
рис. 59 вместо полной системы рис. 58. Оказалось, что с уве-
личением числа делений п дискретизаторов точность пред-
сказания увеличивается незначительно. Наконец, зависи-
мость 6 от R (рис. 61) иллюстрирует очевидный факт, что
увеличение числа делений шкалы выхода снижает число
правильных ответов системы.
Самопроизвольный выбор
наиболее полезных признаков
В работе Г. Л. Отхмезури [361 указано, что отбор наиболее
информативных или полезных признаков, используемых для
распознавания, также можно выполнить детерминирован-
но при помощи расчета величины того или иного критерия
полезности признака. Можно организовать самопроизволь-
ный процесс выбора наиболее полезных признаков при
помощи так называемой второй положительной обратной
связи. Здесь можно использовать любой из предлагаемых
разными авторами критериев, например критерий числа раз-
решаемых споров Di [21], критерий разрешающей способ-
ности системы R, критерий дивергенции или критерий из-
менения энтропии.
Система пробует различные комбинации множества приз-
наков и выбирает наилучшую комбинацию при заданных
ограничениях, например, по общему количеству использу-
емых признаков, ч
На примере предсказания амплитуды волны проверя-
лась также возможность отбрасывания некоторых членов
формулы Колмогорова (рис. 62). Пользуясь критерием
«числа разрешаемых споров» определяем информатив-
ную полезность отдельных групп членов формулы. Неожи-
данно оказалось, что самыми информативными признаками
153
для предсказания амплитуды волн являются члены четвер-
того порядка, т. е. члены АААА; АААА; АААА; ДАДД
и т. д. Исследование полезности комбинаций признаков почти
всегда дает неожиданные результаты, которые трудно пред-
видеть с позиций «здравого смысла». Так, в опытах В. Л.
Браиловского и А. Л. Лунц оказалось, что наиболее по-
Рис. 62 Полезность признаков Да,
выбранных на основе оператора Кол-
могорова (предыстория — 6 точек),
т — порядок членов оператора Кол-
могорова.
лезными являются не сами
исходные признаки ожогов,
а их комбинации по два,
т. е. члены второго порядка
формулы Колмогорова. По-
следняя, вместе с указан-
ным выше методом опреде-
ления полезности признаков
по критерию Dt представ-
ляет собой более общий
алгоритм, объясняющий ус-
пех данных опытов.
Однако нельзя преуве-
личивать важность такой
системы. Нет еще систем,
которые совершенно неожиданно «придумывали» илц «изобре-
тали» бы неожиданные признаки. Выбор идет в сравни-
тельно ограниченном, заданном множестве признаков и их
комбинаций. Это является главным слабым местом всех слож-
ных работ по выбору признаков для распознавания образов.
Достаточно найти один действительно инвариантный
признак, как вся картина разбиения пространства признаков
совершенно изменяется и все исследование нужно начинать
сначала. «Некомпактное» множество признаков может стать
«компактным», а само множество иногда решительно
уменьшается.
РАСПОЗНАЮЩИЕ СИСТЕМЫ НА ПОРОГОВЫХ
ЛОГИЧЕСКИХ ЭЛЕМЕНТАХ
В настоящее время большое внимание уделяется со-
зданию и исследованию распознающих самообучающихся
систем на базе пороговых логических элементов.
Простые сети из пороговых элементов успешно исполь-
зуются для распознавания речи, при решении задач пред-
154
сказания погоды, в системах автоматического управления
и при решении задач диагностики (например, анализе
электрокардиограмм).
Основное звено самообучающейся машины — порого-
вый элемент, который иногда называют «адаптивным ней-
роном». Блок-схема такого элемента приведена на рис. 63, а.
Двоичные входные сигналы х1гхгхп принимают значения
+1 или —1. Внутри нейрона формируется линейная комби-
нация входных сигналов. Весовые коэффициенты представля-
ют собой коэффициенты усиления Wi , которые могут прини-
мать как положительные, так и отрицательные значения. Вы-
ходной сигнал элемента равен +Г, если взвешенная сумма
входных сигналов больше определенного порога, и — 1 во
всех остальных случаях. Величина порога определяется
выбором коэффициента W'w+i. Соответствующий входхлг+ь
называемый пороговым, постоянно подключен к источнику
+ 1. Если, например, установлен порог, равный 0, то
х+1
линейная комбинация входных сигналов у — 'ZWiXi
1=4
(4-1 «>о
вызывает на выходе порогового элемента сигнал г =[_j* у<о.
155
При изменении коэффициента kw+i изменяется постоян-
ная, добавляемая к линейной комбинации входных
сигналов.
При данных значениях весовых коэффициентов (коэф-
фициентов усиления) каждая из 2" возможных входных ком-
бинаций соответствует одному из двух значений выхода + 1
или — 1. В адаптивном нейроне эти коэффициенты устанав-
ливаются в процессе обучения.
Один из вариантов построения обучающейся машины
показан на рис. 63, б.
Выходы пороговых элементов z1( га,..., гм могут рассмат-
риваться как компоненты некоторого Л4-мерного бинар-
ного вектора z. Допустим, нам нужно распознать L образов.
Из всего множества 2я выходных векторов могут быть вы-
браны L векторов, которые наилучшим образом представля-
ют распознаваемые. Эти выбранные векторы обозначим
vL .Тогда вектор z будет отнесен к тому образу i,
представляющий вектор которого vi ближе всех остальных
к z. Это означает, что скалярное произведение
z-Vi — maxz-Vj, (i, j—l, 2.. L).
Индикатор большого напряжения показывает, к како-
му из векторов vi ближе всего располагается z.
Рассмотрим процесс обучения. «
Весовые коэффициенты первоначально устанавливают-
ся равными нулю. На входы поступает комбинация при-
знаков хи x2,...,Xn, соответствующая первому образу. Ес-
ли ответ, данный машиной, верен, никаких изменений не
производится. Если же ответ не верен, тогда некоторые из
компонентов вектора z отличаются от соответствующих ком-
понентов вектора о,- . В этом случае выходные сигналы не-
которых пороговых элементов (из тех, которые дали несов-
падение) меняются на обратные с тем, чтобы приблизить
z к Vi.
Количество корректируемых элементов принимается
равным некоторому числу d' = p-d, где d — число всех
нейронов, которые дали несовпадение, а р — некоторая
величина, меняющаяся в пределах 0<;р<^1. Значение р оп-
ределяется экспериментально. Если, например, р = -р то
это означает, что корректируется четвертая часть всех
нейронов, давших несовпадение.
156
Предсказание изменений атмосферного давления
Если описанная машина применяется для целей пред-
сказания, то в этом случае входными сигналами служит
предыстория, а выход представляет собой предсказанные
значения интересующего нас процесса. В качестве примера
применения обучающейся машины для предсказания рас-
смотрим задачу определения будущих значений атмо-
сферного давления (рис. 64, а). Предысторией служит по-
следовательность четырех значений давления — давление
в данный момент и величины давлений за три последних
часа, измененные на двух различных уровнях.
Качество предсказания оценивалось по величине по-
нижениявариации q = [1-------ii—. 100%. В описан-
ном примере было получено понижение вариации, </= 63,3 %.
Оптимальное предсказание (по минимуму среднеквадратич-
ной ошибки) для тех же исходных данных дает величину
понижения вариации q — 76,2%, а при применении ли-
нейного регрессионного анализа q = 60,4%. Результат
оптимального предсказания представлен на рис. 64, б.
Отметим, что ошибки как в случае предсказания с по-
мощью обучающейся машины, так и в случае оптимального
предсказания характеризуются некоторой общей тенден-
цией. Это свидетельствует о том, что ошибки предсказа-
ния в большей степени объясняются вероятностным харак-
тером процесса и наличием непредсказуемой «чистой» слу-
чайности, чем применением того или другого метода (на-
пример, применением обучающейся машины).
О ПРИМЕНЕНИИ РАСПОЗНАЮЩИХ СИСТЕМ
В КАЧЕСТВЕ ОБУЧАЮЩИХСЯ КОРРЕКТОРОВ
ЭКСТРЕМАЛЬНОГО УПРАВЛЕНИЯ
В данном разделе рассматриваются беспоисковые сис-
темы экстремального управления, не применяющие проб-
ных шагов изменения регулирующих воздействий на объек-
те. Основные предложения в данной задаче основаны на
использовании методов «пассивного эксперимента» с даль-
нейшим применением регрессионного анализа [21 а, 44, 571.
Среди ряда затруднений, которые встречаются при этом,
можно указать очень большой объем вычислений при решении
157
Рис. 64. Предсказание атмосферного давления:
а — с помощью распознающей системы на пороговых элементах; б — оптимальное предсказание по критерию минимума
среднеквадратичной ошибки.
уравнений на цифровых вычислительных машинах. Так,
задача алгоритмизации процесса в ректификационной
колонне приводится к системе из 20 уравнений с 20 перемен-
ными. Продолжительность решения уравнений и необ-
ходимость применения больших периодов усреднения
входных данных [57] приводит к малому быстродействию
регулятора.
Требования к корреляционному (регрессионному) регу-
лятору могут быть значительно снижены, если последний
используется только как корректор для быстродейству-
ющей разомкнутой части системы управления, которая
осуществляется в виде переключающей матрицы ключей
(рис. 65, слева).
Возникает мысль о том, чтобы методы «активного» или
«пассивного» эксперимента использовать только для обу-
чения распознающей системы, в которой нет необходимос-
ти решать уравнения. Пользуясь некоторыми признаками,
система после обучения должна распознать «ситуации» и
тем самым дать правильные указания для коррекции харак-
теристики разомкнутой части. Ниже дано определение
понятий «состояние» (или «изображение») и «ситуация»
(или «образ»), выполнен синтез схемы и выбор наиболее
полезных (информативных) признаков для распознающей
системы — корректора.
Основным ограничением, принимаемым нами, является
допущение о том, что распределение возмущений остает-
ся почти постоянным, хотя само оно может быть для
нас неизвестным. При больших изменениях распределе-
ния распознающую систему нужно наново переобучить.
В дальнейшем изложении это ограничение снимается
при помощи специального приема построения датчиков
признаков.
Кроме того, предполагается, что инерция объекта не-
велика или на выходе системы можно включить звено с об-
ратным оператором (упредитель), восстанавливающее точ-
ную осциллограмму изменения показателя качества. Опыт
показывает, что аналоговые модели выполняют обратное
преобразование в измерительных цепях достаточно точно.
Для объектов с постоянным отставанием применяется «упре-
дитель Смита» [43]. Другой возможностью является введе-
ние запаздывания в цепи измерения регулирующих и воз-
мущающих воздействий, равного запаздыванию в цепи пока-
зателя качества. Однако этот способ компенсации инерции
159
—[cc]*L------------— --------------------------------------
Рис. 65. Пример комбинированной системы экстремального управления с корректором — распо-
* знающей системой «Альфа»:
1 — объект (турбина); 2 — матричная схема конвергенции; 3 — матрица ключей разомкнутой части;
4 — управляющие реверсивные счетчики; 5 — распознающая система; 6 — модель оптимальной характе-
ристики; 7 — «учитель».
объекта хотя и проще осуществляется, но нежелателен, так
как замедляет действие корректора.
Схема разомкнутой части в виде переключающей мат-
рицы ключей не является единственно возможной. В дру-
гом варианте разомкнутая часть выполняется, в свою оче-
редь, как распознающая система, полюса которой («полюс-
ный газ») обучаются, например, по алгоритму, изложен-
ному в работе [25]. В этом варианте регрессионный формуль-
ный корректор выполняет роль учителя разомкнутой части
системы экстремального управления.
Желательно дополнить алгоритм, используемый в
этой работе, законами взаимодействия полюсов между СО'
бой так, как это показано ниже.
Постановка задачи коррекции
Обычно экстремальная характеристика объекта может
быть аппроксимирована обобщенным степенным рядом вто-
рой или третьей степени. Например, для объекта — гидро-
турбины (см. рис. 65) можно написать:
ф == а» 4- Oil* + а2Х1 + аЛ 4- 4- 4- 4-
4* £g|uA2 4" OjAjAj 4* a10p,3 4- 4- <ZigA| 4- 4- виР^^г 4*
4“ aisAfA2 4- 4- 4- + o^pAjAj,
где ф — показатель экстремума (к.п.д. турбины);
[л — регулирующее воздействие (угол поворота лопастей);
Alt Аа—основные возмущающие воздействия (напор воды и
нагрузка турбины).
Если применить конвергенцию (разворачивание) матриц
дискретных значений возмущений в строку обобщенного воз-
мущения A (At А2), то ту же характеристику можно предста-
вить более простым полиномом, с двумя аргументами:
Ф = а9 4- oyi 4- а2А 4- а^р? 4- а4А2 4- а5рА 4- а6А8 4- а7р?,
где (в случае разворачивания в обычном порядке строки за
строкой)
А = [Ах 4-Zx (А^ — 1)] Д/;
I — число уровней дискретизации;
Д/— шаг дискретизации.
161
В большинстве случаев удается выбрать такой порядок
разворачивания матриц, при котором оптимальная харак-
теристика объекта получается гладкой, такой, что ее мож-
но аппроксимировать прямой или параболой второй степени.
При этом оптимальная характеристика объекта, на кото-
рой желательно все время работать, определяется уравне-
нием
= 0 при % = const или 1 =с0 + qp + с2р8,
г— “1 • л— 2аз • г — За?
0 а5 at as
Наилучшие результаты дает разворачивание в порядке
от меньшего среднего значения р к следующему, большему.
Если и при этом характеристика получается слишком слож-
ной формы, то приходится отказаться от конвергенции и
повышать степень аппроксимирующего полинома. Это
только увеличивает объем распознающей системы и’ про-
должительность ее обучения.
В случае полинома второй'степени задача коррекции со-
стоит в том, чтобы удерживать среднюю линию характеристи-
ки разомкнутой части
1 = d0 +
возможно ближе к оптимальной характеристике объекта, т. е.
при медленных смещениях, поворотах и изгибах этой харак-
теристики возможно быстрее установить
х—с0 — de —— 0, у — q dj 0; с2 d20.
Речь идет только о совмещении средней линии, так как в
беспоисковой экстремальной системе характеристика
разомкнутой части принципиально не должна совпадать
по форме с оптимальной характеристикой объекта. Она яв-
ляется прямой или параболой второй степени с наложен-
ными на нее небольшими «зубцами», заменяющими поиско-
вые колебания на объекте [21а 1. Принципиальный характер
данного запрета связан с известным правилом теории ин-
терполяции, по которому точки (узлы) интерполяции не
могут быть выбраны произвольно, в частности на одной
прямой.
162
Другое определение понятий «состояние»
(«изображение») и «ситуация» («образа»)
Ранее [21а] мы характеризовали состояние экстремаль-
ной системы координатами точки в пространстве
й»/ (<Pi, Фа,..., фя, Pj,..., |лРД1,"., )• Соответственно мы опре-
делили ситуацию как определенную область этого простран-
ства.
Теперь изменим подход и будем характеризовать со-
стояние системы координатами точки в пространстве
Qvi(c0, съ с2, d0, dlt d2). Соответственно ситуацию теперь следует
определить как некоторую область этого нового простран-
ства координат. Задача коррекции состоит в том, чтобы
привести систему в область, где с0 = dt; = di,
С2 = di.
Теперь под состоянием (или изображением) мы будем
понимать всевозможные взаимные расположения средней
линии характеристики разомкнутой части и оптималь-
ной характеристики объекта. Предполагается, что ко-
ординаты са, сх, a, d>, dt, di могут принимать только ряд
фиксированных дискретных значений. Поэтому общее чис-
ло возможных состояний, которые нужно различать,
является конечным. На рис. 66 представлены 16 состояний
комбинированной экстремальной системы, используемые
ниже в примере.
Общее количество возможных состояний равно
5 = 4+4 (4 -1) + 44 (4 -1) + 444 (4 — 1) +
+ Zt444 (4 — 1),
где 4,4, 4, 1з, lit 4 — число дискретных уровней измерения
координат с0, clt с2, da, dlt di. Легко подсчитать, что при
реально используемом числе делений общее число возможных
состояний выражается астрономически большими циф-
рами. Ни одна реально осуществимая система не может
иметь столько выходов.
Подобная проблема возникает и при распознавании зри-
тельных образов. Если, например, при распознавании букв
используется 100 признаков, то число возможных кодов
равно 2100. Чтобы только перебрать такое количество ва-
риантов на быстродействующей машине со скоростью сче-
та 10е сравнений в секунду, потребовалось бы более тысячи
лет. Выход найден в том, что близкие в некотором смысле
163
изображения классифицируются как один образ (свойство
обобщения).
Так же следует поступить и в рассматриваемом случае
классификации состояний экстремальной системы на
(?,=» t)o=0,25 d,=/ ао=0 й,-133 0о=0,25 tf,=0,75
Рис. 66. Центральные состояния 16 «ситуаций», которые требуется
различать.
ситуации. Например, используя только две группы (два
полюса), мы тем самым разбиваем пространство координат
с0, q, q, d0, dlt d2 на две области — ситуации.
Все состояния, попавшие в первую ситуацию, система
укажет на первом выходе, а состояния, попавшие во вторую
область,— вызовут срабатывание второго выхода. Таким
образом, число ситуаций определяется числом полюсов,
и их границы совпадают с границами «областей притяжения»
164
этих полюсов. Обучение или самообучение системы имеет
целью рациональный выбор положения полюсов и границ.
Обычно при проектировании системы можно указать
некоторое сравнительно небольшое число характерных
(центральных) состояний, которые должны явиться центра-
ми ситуаций после обучения системы. При обучении полюса
размещают в точках, лежащих по возможности ближе к этим
центральным состояниям. Тогда ситуацией можно назвать
область пространства й^(с0, ci> с2> *4» d2), где находится
все множество состояний, которые система обобщает с за-
данным центральным состоянием (прототипом).
Применение распознающей системы «Альфа»
для различения ситуаций
Пример схемы системы дан на рис. 67. При данном при-
менении распознающей системы датчики признаков по на-
блюдению за мгновенными изменениями величин <р, р, X вы-
рабатывают некоторые интегральные функции этих вели-
чин Xi, хг,.., хп, которые обычное теории распознавания
образов называются признаками. Основное преимущество
распознающей системы состоит в том, что она является
очень способным «учеником» и после обучения действует
на порядок быстрее, чем ее «учитель». Надобность в «учи-
теле» отпадает после того, как распознающая систе-
ма обучится правильно различать достаточное число
ситуаций.
Допустим, что в результате анализа полезности призна-
ков мы отобрали три полезных признака xlt х2, х8 (п = 3).
Вектор на входе системы будет: vt (xlt xt, xs). Полюса tn
групп ассоциирующих ячеек также будут иметь по три
составляющих — а^Гц, ri2, rlg); а^, Г24» ^4з)>”->
гт2 , Гтз). Напряжения на выходах групп соответ-
ственно будут равны:
S, = = ruXi 4- r12x2 4- rlsx3,
S2 = (оед) = r21Xt 4- r22x2 4- ri3x3,
M = гзЛ 4- rsix8 4- ГзэХз.
Если мы, например, хотим обучить первую группу от-
носить данную представляющую точку к первой ситуации,
165
1 — датчики признаков; 2 - 3 £ —- макс Г"*“ мин L —. — обратная или 1 сбязь ни !Ш Ш1 Дй $1 $4. $5 $8 $9 $12 $G $16 Рис. 67. Схема распознающей системы «Альфа»: - группа ассоциирующих ячеек; 3 — компаратор — ИБН или ИМН. _ „ ---’«ч
то мы должны выбрать ru, г12, гы так, чтобы скалярное произ-
ведение было больше других: S1>S2; S1>S3;...; 2x>Sm.
Известно, что скалярное произведение двух векторов
равно сумме произведений проекций этих векторов. Мак-
симум первого скалярного произведения достигается при
равенствах:
гхх = хх; гха = хг; rxs = ха.
Если мы хотим, чтобы первое центральное состояние вызвало
срабатывание выхода первой группы, то полюс этой груп-
пы нужно установить в точке, отвечающей этому состоянию.
Выше мы говорили о разбиении пространства коорди-
нат с0, ci, с2, d9, dlt dt на области — ситуации. Каждой
точке координатного пространства П»/(сь, сх, са, dQ, dt, d2)
отвечает определенное геометрическое место точек коорди-
натного пространства признаков хх, х2, х3,..., хп . Последнее
также можно разбить на области — ситуации. При обучении по-
люс следует установить в центре ситуации, отвечающей задан-
ному центральному состоянию в обеих координатных системах.
Однако практически мы не можем длительно и точно под-
держивать пребывание системы в заданном центральном
состоянии, так как распределение возмущений и форма экс-
тремального холма постоянны только в первом приближении.
В действительности они изменяются во времени вокруг не-
которого среднего значения. Поэтому приходится устанавли-
вать полюс в «центре тяжести» точек — состояний, относящих-
ся к заданной ситуации. При большом числе измерений «центр
тяжести» совпадает с центральным состоянием одновременно
как в пространстве (с0, сх, с2, dn, dlt d£, так и в простран-
стве признаков х2, ха,... ,хп ).
Эго соображение указывает нам правило обучения полю-
сов: полюс обучаемой группы нужно расположить в центре
ситуации, определяемом как среднее арифметическое всех
точек обучающей последовательности, относящихся к дан-
ной ситуации. Наблюдая работу объекта во всевозможных
состояниях и зная (от «учителя») номер ситуации, к кото-
рой они относятся, можем составить таблицы или графики
обучающих последовательностей (рис. 68). Выбрав данные,
относящиеся к одной и той же ситуации, находим положение
полюса соответствующей ей группы в обученном состоянии
при помощи усреднения (npHC0=const; ct=const; c2=const):
т т. г
_ If _ f "“If
Hi = J Xid/; r12 = x2= J x2d/; r13 = x3 = у I x3d/.
о b о
167
A
€0Т'
°3-2-1 о
Рис. 68. Примеры последовательностей при равномерном
распределении вероятностей возмущения.
Это второе по счету усреднение требуется только в период
обучения полюсов. Первое усреднение требуется постоян-
но при выработке признаков хь ха, ха,...,хп-
Уменьшение продолжительности обучения полюсов
при помощи интерполяции
С увеличением числа ситуаций и групп соответственно
удлиняется время обучения. Средние значения признаков
xlt хг, ...,хп должны быть «показаны» для каждой ситуации
с тем, чтобы установить в этих точках полюса групп. Для
сокращения обучения можно использовать самопроизволь-
ное установление полюсов по формулам интерполяции или
регрессионного анализа. Поясним это.
Легко отличить «закрепленные» полюса, указанные уже
«учителем», от «незакрепленных», еще не указанных им.
Незакрепленные полюса не остаются постоянными, а пере-
мещаются в некоторой функции уже указанных полюсов.
Например,, при линейной интерполяции координаты неза-
крепленных полюсов можно определить по формулам
_ г1а+1) + гЩ-1) . r2(i+V) + r2(i~l). .
rli 2 ’ r2i 2 ’
, rm(i—1)
rmi-----------2 •
При таком алгоритме незакрепленные полюса «отталкива-
ются» друг от друга как частички некоторого «полюсного
газа» [21а] и располагаются на равных друг от друга рас-
стояниях по прямым, соединяющим уже указанные, «за-
крепленные» полюса. В результате такого движения полю-
сов процесс обучения сокращается.
Выяснение состава множества «признаков»
Для выяснения состава множества признаков, часть ко-
торых мы подадим на вход распознающей системы, обра-
тимся к регрессионному анализу.
По регрессионному методу коэффициенты определяют-
ся из условия получения минимума среднего квадрата
ошибки
и
А = 4" 2 62 = (‘Ро — ф)2 = (Ф — «11-1 — «зЦ2 — — а,ц3)2.
169
Минимум обязательно существует и является единствен-
ным, так как ошибка — линейная функция коэф-
фициентов Взяв производные при ф0=ф, находим че-
тыре нормальных уравнения регрессии:
дк ___ л. дА ___л дА ______л д&
да± ’ да3 ’ да5 9 да7
откуда
Ojp 4- а3й8 + 4- OjH3 = №;
OipT4- a3f? 4- 4- а7ц5 =й*Фо >
OjpA? 4- 4- 4- а7ц41 = цАф0,
4- ОзН5 + asP4^ + <*4** = Р8<₽в •
Четные члены опущены, так как они не влияют на коэф-
фициенты с0, ci и с?- Число уравнений регрессии при этом
сокращается в два раза.
Решая уравнения, можно найти коэффициенты
_______________£i_- г____с -
С° ~ as ’ С* “___________а„ ’ с' - ~аГ
и, следовательно, определить оптимальную характеристику
объекта. Обозначим: 1
0 Xi = ф = у- J фС?/, —т 0 х2=Й = 4" J —Г 0 х3=Х = J Mt, —т 0 Х4 = Ф» = -1.у —т 0 xt — р2 = -у- У i^dt, —т 0 x6 = F=-l- J tedt, —т 0 х, = ФР= -1-Уф|Х4/Л —т 0 Х8 = ф! = -1- У qMt, —Т 0 х9 = рЛ = J ^kdt —г 0 ^и=ф8==4'1 ^-Т
170
0 xu=p3= -i- J рМ/, —Г 0 хм==1?=-1-у K*dt, —т
0 x12=P=^rJ X’dA —Г 0 хм=ф«рг= у- J ф2рМ/, —г
0 х13=<р^=-1- J Ф2рЛ, —Г 0 х24=ф^?=^гУф2ХМ/, —Г
0 x14=^x т 0 xS5=j?F= у- У p?^dt, —Т
0 х16=р2Ф=у- J р»ф^, —т 0 ^e=₽jr=y у.Ф’р^. —т 0
0 Х1в=Мф — у- J Х2фЛ, —Г х87=ф81= у- У <psXdi,
0 х17=р2Х » ~ J р2АЛ/, —т 0 *w=P<P = у- У иМА —т
0 х18=Ц1 = у- J №pdt, —т 0 хм=р8Х = уг У ц’Хс?/, —Г
0 х18=ф|Д,=у J ф|лХс//, —Г 0 Хзо=Х8ф = у-У Л8фс/д —Г
0 X20=V4=-^j Ф4^, т 0 xS1=X8p = y- У ks}idt.
0 Х21 = рТ = у- J рМ/, —Г
При таких обозначениях решения нормальных уравне-
ний можно записать в следующем виде (положим ос, = с2 =
= 0):
С»---Ле
Х17Хц>х21—ХаХгэХа»—ХцХцХаа.
Х5Х1»Хи4-ХцХ15Х17фХ7Х11Ха)—Х7Х17Х21—хъХиХ^—ХцХщХш ’
171
c1==J-2
^5
—*15*17*17—X5X19X29—*7*11*25
XbXtfXzi^XiiXibXyj-^-XiXiiXw—X7X17X21—X5X15X20—*11*11*19
Эти решения показывают, что для распознающих си-
стем множество признаков нужно искать среди величин
xt, хг, x3,...,Xj,... Ясно, что множество признаков x6,xh xu, xis,
xlt, хи, хг1, хгз, х2в, х29 полностью решает задачу распознава-
ния ситуаций, но оно слишком сложно и избыточно для
решения задачи различения заданного числа центральных
состояний.
Выбор полезных (информативных) признаков
Все найденные признаки обладают важным свойством:
величина их зависит только от ситуации и не зависит от
порядка изменения мгновенных значений величин <р, р. и X,
если распределение вероятности прихода дискретных зна-
чений возмущения постоянно. На рис. 68 показаны при-
меры последовательностей изменения возмущения Л, име-
ющие равномерное распределение вероятности р(Х) = const.
Ясно, что как обучающие, так и испытательные или рабо-
чие последовательности значений <р, р, X, поступающие на
распознающую систему, должны быть достаточно длитель-
ными, чтобы передать объективно существующее распреде-
ление вероятности возмущений. Именно этим определяется
быстродействие распознающей системы как корректора.
Запаздывание действия равно приблизительно половине
времени усреднения, т. е. половине длительности представ-
ленной последовательности (ть = 1,5 мин для последователь-
ностей, изображенных слева на рис. 3, и т: = 3,0 мин для
последовательностей справа). Это запаздывание меньше, чем
запаздывание определения характеристики объекта по ре-
грессионному методу [57J.
В теории распознавания известны многие методы оцен-
ки полезности признаков (по числу разрешаемых споров
Ds, энтропийный критерий, критерий дивергенции и др.
1211). Однако все они разработаны для бинарных признаков
«да — нет». Особенностью рассматриваемой задачи яв-
ляется то, что признаки представляют собой не бинарные,
а непрерывные величины. Непрерывные признаки прихо-
дится оценивать непосредственно по величине, которую
они принимают во всех распознаваемых ситуациях.
Рассмотрим пример выбора наиболее полезных признаков.
172
Допустим, что объект описывается нелинейным уравнением
ф = 1 — (р. — сД — с0)2.
Тогда для значений с0, с1; d0, dt, указанных на рис. 66, при
любой из последовательностей X,показанных на рис. 67, по-
лучим значения первых по номеру 19 признаков, приведен-
ные в табл. 9.
Признаки можно разделить на четыре группы:
группа а: х,, х13, *16. *к>;
группа б: xlt х4, хв, хи, хи, х17;
группа в: х2, х5, х9, xu, х1в, х1в;
группа г: х3, хе, xlt.
Признаки группы «а» несут в себе информацию об изме-
нениях как ф, так и р, и потому могут быть использованы
для построения распознающих систем, действующих всего
по одному признаку. Признаки группы «б» содержат инфор-
мацию об изменениях ф, а признаки группы «в» — об изме-
нениях р. Эти признаки можно использовать только попарно
(т. е. один признак из группы «б» и один из группы «в»),
так как в противном случае можно найти неразличимые
состояния, дающие равные значения Xt или х2 (см. табл. 9:
состояния: Sj и Se для xt и др.). Наконец признаки группы «г»
бесполезны для нашей задачи, так как связаны только с %.
Более полезными признаками следует признать при-
знаки группы «а» еще и потому, что даже при увеличении
крутизны экстремального холма среди них всегда мож-
но найти признак, монотонно возрастающий по обе стороны
«хребта» и, следовательно, однозначно определяющий его
положение. В данной задаче достаточно применить всего
один признак х,, чтобы различить все 16 заданных состояний.
Границы ситуаций при идеальном
и реальном признаках
Если в системе предусмотреть прибор или программу,
которые после каждого изменения местоположения и формы
характеристики разомкнутой части выполняют такое из-
менение места отсчета и преобразование координат ц и
при котором эта характеристика прямолинейна, всегда рас-
положена под углом 45° и проходит через начало координат
(d0 = 0; <4 = 1; d2 = 0), то исследование приобретает
более изящную форму. Вместо шестимерного пространства
Qw(c0, clt Ci, d^ dlt di) можно рассматривать более простое
173
Значение признаков в шестнадцати состояниях (при р (X)-const)
Признаки Х1 х» х9 Хл х> х9 X? х*
Состояния
$1 0,9975 0,4833 0,5 0,995 0,2775 0,29167 0,4823 0,4987 0,2833
5г 0,9433 0,7333 0,5 0,8904 0,5816 0,2917 0,6907 0,4717 0,4083
5з 0,9702 0,6510 0,5 0,9416 0,5003 0,2917 0,6266 0,4818 0,1811
$4 0,9832 0,6093 0,5 0,9668 0,3966 0,2917 0,5997 0,4932 0,0857
$5 0,9267 0,4833 0,5 0,8592 0,2775 0,2917 0,4498 0,4633 0,2833
$в 0,9975 0,7333 0,5 0,995 0,5817 0,2917 0,7315 0,4987 0,4083
$7 0,9832 0,6510 0,5 0,9617 0,5003 0,2917 0,6436 0,4939 0,3811
$8 0,9754 0,6093 0,5 0,9520 0,3966 0,2917 0,5921 0,4841 0,3357
$9 0,9595 0,4833 0,5 0,9218 0,2775 1 0,2917 0,4586 0,4737 0,2833
510 0,9887 0,7333 0,5 0,9775 0,5817 0,2917 0,7257 0,4952 0,4083
5ц 0,9974 0,6510 0,5 0,9947 0,5003 0,2917 0,6493 0,4986 0,3811
512 0,9802 0,6093 0,5 0,9615 0,3966 0,2917 0,5945 0,4857 0,3357
51з 0,9752 0,4833 0,5 0,9515 0,2775 0,2917 0,4755 0,4912 0,2833
514 0,9834 0,7333 0,5 0,9673 0,5817 0,2917 0,7188 0,4902 0,4083
515 0,9877 0,6510 0,5 0,9658 0,5003 0,2917 0,6403 0,4918 0,3811
51в 0,9970 0,6093 0,5 0,9952 0,3966 0,2917 0,6078 0,4987 0,3357
Пример расчета первой цифры таблицы: по рис. 68 находим: = 0,25,
—0,05, = 0,5 0,05, р3 = 0,75 — 0,05. Далее определяем ф по формуле:
174
Таблица 9
X1Q Хц хи *13 *14 *15 хи *17 *18 %19
0,9925 0,1725 0,1875 0,4807 0,4975 0,2769 0,1763 0,2910 0,1813 0,2877
0,841 0,4868 0,1875 0,651 0,4452 0,5477 0,3491 0,2758 0,2542 0,3855
0,9144 0,4178 0,1875 0,6033 0,4645 0,4798 0,3187 0,2801 0,2440 0,3657
0,9509 0,2703 0,1875 0,593 0,4866 0,3925 0,2341 0,2887 0,2074 0,3216
0,7973 0,1725 0,1875 0,4175 0,4296 0,2576 0,1763 0,3075 0,1813 0,2624
0,9925 0,4868 0,1875 0,7295 0,4975 0,5802 0,3491 0,3325 0,2542 0,4073
0,9437 0,4178 0,1875 0,6363 0,4881 0,4967 0,3187 0,2894 0,2440 0,3783
0,9295 0,2703 0,1875 0,5761 0,4689 0,3843 0,2341 0,2804 0,2074 0,3240
0,8869 0,1725 0,1875 0,4360 0,4495 0,2612 0,1763 0,2733 0,1813 0,266
0,9665 0,4868 0,1875 0,7195 0,4906 0,5761 0,3491 0,2894 0,2542 0,4048
0,992 0,4178 0,1875 0,6474 0,4973 0,4989 0,3187 0,2909 0,2440 0,3801
0,94380 0,2703 0,1875 0,5803 0,4722 0,3856 0,2341 0,2811 0,2074 0,3249
0,9289 0,1725 0,1875 0,4682 0,4827 0,2725 0,1763 0,2876 0,1813 0,2796
0,9516 0,4868 0,1875 0,7055 0,4806 0,5693 0,3491 0,2856 0,2542 0,3995
0,9491 0,4178 0,1875 0,6306 0,4837 0,4925 0,3187 0,8696 0,2440 0,3747
0,9927 0,2703 0,1875 0,6047 0,498 0,3957 0,2341 0,2909 0,2074 0,3349
Х2 = 0,05, Х3 = 0,75. Соответственно по рис. 66 будет: pi = 0,25 —
<₽!=0,9975, <р2=0,9975, <рз=0,9975; отсюда: х, = J£1±J&±3*. = 0,9975.
175
трехмерное пространство координат Й0/(х, у, г), где
х = == 9 у — с, d± = Cj —• 1, г — с% d2 ~— с% •
Задача коррекции заключается в приведении системы
в ситуацию, охватывающую начало как центр х = 0; у = 0;
2 = 0.
Чем больше радиус - вектор
Р = )/х2 + ^ + г2,
тем в большей степени требуется коррекция. Поэтому хо-
рошим разбиением пространства х, у, z на ситуации было
бы разбиение концентрическими сферами с общим центром
в начале (рис. 69, пунктир), а идеальным признаком могла
Рис. 69. Границы ситуаций для признака х7 и для
«идеального» признака р
(при do=da=(^=0 и dj=l).
бы быть величина самого радиус-вектора, если бы он быст-
ро и легко измерялся и вычислялся. Однако это не
так, и потому приходится пользоваться значительно более
простыми указанными признаками.
Для каждого из признаков границы ситуаций можно по-
строить экспериментально или вычислением по точкам. Для
рассмотренного выше примера границы ситуаций при ис-
пользовании одного только признака х7 показаны на рис. 67
сплошными линиями. Можно сделать только вывод, что
форма границ хотя и отличается от идеальной, но тем не
176
менее в квадрате х>0, у>0 по своему характеру близка
к идеальной.
Способ выработки признаков при отклонениях
распределения возмущений от наиболее вероятной кривой
(преобразование распределения)
Способ состоит в отборе только таких точек, которые от-
вечают среднему распределению возмущений. Замеры, на-
рушающие заданное среднее распределение, просто про-
пускаются.
ПокажехМ способ на примере. Допустим, что средним или
наиболее вероятным распределением является равномерное
Рис. 70. Структура датчика признаков с выделением эф-
фекта равномерного распределения возмущений из лю-
бого другого (отличного от нуля):
ЗУ — запоминающие устройства последнего по времени значе-
ния показателя качества Ф; С — селектор тройки ЗУ с минималь-
ным запаздыванием х
распределение, такое, как на рис. 68. Тогда при помощи
специальных отборочных фильтров нужно пропустить точ-
ки, нарушающие равномерность. Например, пусть будет
Xj — 0,25, Ла = 0,5, Лз = 0,25, Л4 = 0,5, Л5 = 0,75. Тогда
фильтр должен пропустить каждое значение по одному, т. е.
точки Л1( Л2, Л5. Ясно, что процесс выработки признаков
при этом затягивается, так как приходится ждать, пока пос-
тупят все значения Л. В данном примере процесс затянется
на две трети периода.
Практически датчик признаков может быть построен по
принципу, напоминающему принцип построения глаза не-
которых насекомых (например, пчелы).
177
7 474
Во всех вершинах зубцов характеристики разомкнутой
части устанавливаются запоминающие устройства, записы-
вающие последнее по времени значение показателя экстрему^
ма (рис. 70). Устройства соединяются по три, но так, чтобы
в эти тройки не попали точки, лежащие на одной прямой.
Два крайних устройства располагаются на равных рас-
стояниях от среднего (в случае выделения равномерного
распределения). Все тройки запоминающих устройств по-
дают свои сигналы на селектор. Последний выбирает ту
тройку, в которой время запаздывания (равное половине
периода, в течение которого сработали все три устройства)
меньше, чем у других троек. При параболической характе-
ристике запоминающие устройства соединяются по четыре,
во всевозможных комбинациях, исключая те, которые дают
нулевые значения определителей или нарушают выделяе-
мое распределение возмущений.
Оценка признаков по критерию
разрешающей способности
Если признаки измеряются точно, а возмущением яв-
ляется смещение экстремального холма по плоскости р.—X без
изменения его формы и, кроме того, распределение вероят-
ности возмущения остается неизменным, то распознающая
система может различить любое число состояний, равное чис-
лу ее групп.Однако реально всегда существуют отклонения от
этих идеальных условий. Это приводит к тому, что система
не будет различать очень близкие друг к другу состояния.
Отсюда возникает задача всемерного повышения разре-
шающей способности системы, определение которой дано
в [21]. Напомним, что разрешающая способность определя-
ется разностью скалярных произведений наибольшего и
следующего за ним по величине.
Алгоритм распознающей системы таков, что признаки
могут быть только бесполезны или полезны в той или иной
мере (Винер: «Нет зла, а есть отсутствие добра»). Поэтому
чем больше признаков подано на систему, тем выше ее раз-
решающая способность, хотя объем системы от этого воз-
растает. Стремясь уменьшить объем, следует выбирать
комбинации признаков, которые при почти одинаковом
объеме системы дают наиболее высокую разрешающую
способность.
Покажем на примере метод расчета разрешающей
178
способности. Обозначим через xlt х^,...,хп разряды вектора
входного изображения (признаки), а через гъ,........гп
соответствующие разряды полюсов. Тогда при vt (хх, х2,._,х„)
и а*(Г1, гг,...,гп)
\ = (“ft vi>= riX1 + ГаХз + ГзХз + ••• + гп хп не-
очевидно, что максимум скалярного произведения совпа-
дает с минимумом разности отдельных разрядов. Поэтому
в алгоритме системы «Альфа» можно использовать вместо
выбора наибольшего скалярного произведения (при помощи
индикатора большего напряжения ИБН) выбор наимень-
шей разности (при помощи индикатора меньшего напряже-
ния ИМН)
= (vt — afe) = (rx — xx) + (r2 — x2) + ... + (r„ — xj -> min.
Скалярный вариант удобен при бинарных признаках и для
унитарного кода. Разностный вариант алгоритма удобен
для непрерывных (небинарных) признаков, так как позво-
ляет просто применить двоичный код. Остановимся на при-
менении разностного варианта алгоритма системы «Альфа».
Сравним между собой разрешающую способность трех си-
стем: 1) с одним признаком х,; 2) с двумя признаками хг и
х^ 3) с тремя признаками хь х2 и х,. В процессе обучения,
после того как будут показаны все 16 состояний (см. рис. 64),
полюса групп примут следующие значения:
В системе по признаку х,:
^ = 0,4823, г5 = 0,4490, г9 « 0,4586, г13 « 0,4755,
га « 0,6907, гв = 0,7315, г10 ~ 0,7257, г14 = 0,7188,
г3 = 0,6266, Гч =и 0,6436, Гц 0,6493, г15 = 0,6403,
г4 = 0,5997, г8~ 0,5921, г12 « 0,5945, г1в = 0,6078,
В системе по признакам хх и х2:
Гц 0,9975, г81 « 0,4833, г15 = 0,9267, Г25 ==* 0,4833,
Г12 “=? 0,9433, г22 “ 0,7333, fie — 0,9975, Г2в = 0,7333,
г18« 0,9702, г23 в 0,6510, Г17 « 0,9832, Г27 в 0,6510,
г14 - 0,9832, г24 « 0,6093, г18 « 0,9754, г28 = 0,6092,
Г19 — 0,9595, Г29 в 0,4833, q_13 - 0,9752, г2_13 “ 0,4833,
гх_хв-0,9887, Г2_1О = 0,7333, г « 0,9834, 1—14 г2_м = 0,7333,
гх_ц = 0,9974, Г2-Н " °-6510- г1-15 “ 0,9827, г2_18 = 0,65Ю,
г1-и “ °’9802> Г2_13 = 0,6093, г, ,. = 0,9976 1—10 г2_1в = 0,6093.
7* 17»
В системе по признакам хь х2 и х7 полюса те же, что и в
первых двух системах. Другими будут только индексы при
rk . Подсчитав по приведенной выше формуле напряжения на
выходах всех 16 групп, появляющиеся при показе каждого
из 16 центральных состояний, мы можем выбрать наимень-
шую разность и тем самым определить разрешающую спо-
собность каждой из сравниваемых систем.
Для краткости, в качестве примера приведена толь-
ко одна таблица (табл. 10), для первой системы с одним
признаком х7.
Рассмотрение табл. 10 показывает, что в первой системе,
с одним признаком х7 R — 0,0025, во второй системе, с
двумя признаками х2 и х2 R = 0,003, в третьей системе, с
тремя признаками хп х2 и х, R = 0,0073.
С увеличением числа используемых признаков разрешаю-
щая способность действительно возрастает. Таким об-
разом, в этом смысле лучшей из сравниваемых является
третья система. Она допускает наибольшие колебания кри-
вой распределения вероятности возмущений и формы холма,
не делая при этом ошибки. При наличии ошибок число при-
знаков приходится увеличивать.
Пример схемы использования
распознающей системы в качеств^ корректора
Как показано на рис. 65, распознающая система исполь-
зуется для установления на модели параметров с0, clt с2 оп-
тимальной характеристики объекта управления. Коэффи-
циенты d0, di, di всегда известны.
Поэтому для резкого уменьшения числа групп распо-
знающей системы можно применить переключение полюсов
в зависимости от положения характеристики разомкнутой
части г* (d0, <4, d2).
В рассмотренном выше примере это дает сокращение
числа групп с 16 до 4 (рис. 65), соответственно числу
различаемых комбинаций значений коэффициентов с0, си
с2 (рис. 66).
Для осуществления корректора «скоростного» типа, где
требуется указать только направление регулирования,
достаточно сравнить реальный объект с моделью
Др = — р, чтобы выработать соответствующий
сигнал:
180
при Др, < — 6 — «регулировать, поднять харак-
теристику разомкнутой части в
области данного Ъ;
при — 6 < Др < 6 — «так держать»;
при Др > 6 — «регулировать, опустить характеристику».
Для построения корректора позиционного типа опти-
мальное значение регулирующего воздействия рор/ при по-
мощи следящей системы непосредственно устанавливается
на разомкнутой части системы.
О возможности самообучения корректора
На рассмотренном выше примере корректора мы снова
можем продемонстрировать различие двух противополож-
ных подходов к решению проблемы управления.
Детерминированный подход состоит в получении алго-
- ритма объекта управления и действующих на него возмуще-
ний с последующим решением уравнений на вычислитель-
ных машинах.
В рассмотренной задаче он сводится к вычислению коэф-
фициентов сй, Ср сг по формулам регрессионного анализа,
что, во-первых, требует наличия точной информации об
объекте и возмущениях, а во-вторых,— большого объема
памяти машины и недопустимо больших затрат времени на
усреднение данных и решение уравнений.
Кибернетический подход состоит в замене точных расче-
тов обучением распознающей системы по результатам опы-
тов на реальном объекте при минимальной исходной ин-
формации. Алгоритм объекта может быть слишком сложным
для управления или вообще неизвестным. Распределение
возмущений также неизвестно. Сложный алгоритм «учитель»
используется только во время обучения. «Учителем» может
быть человек или интерполятор, основанный на методах
активного или пассивного эксперимента. Обучение прово-
дится по записям работы объекта в прошлом, как это дела-
ется для распознающих систем, работающих в качестве
предсказывающих фильтров. В рассмотренной задаче пос-
ле окончания обучения для определения ситуаций требуется
только вычисление одного простого признака или несколь-
ких. Таким образом, задача определения точных значений
коэффициентов с0, съ сг заменяется задачей разбиения про-
странства с0, сх, с2, d0, dx, d2 (или пространства признаков
хх, хг, xs,...,xn) на области — ситуации.
181
Напряжения на выходах групп в системе с одним признаком при обучаю
^Х^Выход Состояния 21 s4 2» Ee
0 0,2084 0,1443 0,1174 0,0333 0,2492 0,1613
s2 0,2084 0 0,0641 0,0910 0,1417 0,0408 0,0471
«$3 0,1443 0,0641 0 0,0269 0,1776 0,1049 0,0170
«4 0,1174 0,091 0,0269 0 0,1507 0,1318 0,0439
s5 0,0333 0,2417 0,776 0,1507 0 0,2825 0,1946
0,2492 0,0408 0,1049’ 0,1318 0,2825 0 0,0879
s7 0,1613 0,471 0,017 0,0439 0,1946 0,0879 0
$8 0,1097 0,0986 0,0346 0,0770 0,1430 0,1395 0,0516
0,0237 0,2321 0,168 0,1411 0,0096 0,2729 0,1850
510 0,2434 0,035 0,0991 0,1260 0,2767 0,0058 0,0821
5ц 0,167 0,0414 0,0227 0,0496 0,2003 0,0822 0,0057
512 0,1122 0,0962 0,0321 0,0052' 0,1455 0,1370 0,0491
51з 0,068 0,2152 0,1511 0,1242 0,0265 0,2560 0,1681
514 0,2365 0,0281 0,0922 0,1191 0,2698 0,0127 0,0752
515 0,158 0,0505 0,0137 0,0406 0,1913 0,0912 0,0033
516 0,1255 0,0829 0,0188 0,0081 0,1588 0,1237 0,0358
182
Таблица 10
щих последовательностях (см. рис. 68)
Se 2ц 212 2хз 2U 2ц 2ц
0,1097 0,0237 0,2434 0,1670 0,1122 0,0680 0,2365 0,1580 0,1255
0,0986 0,2321 0,0350 0,0414 0,0962 0,2152 0,2810 0,0504 0,0829
0,0346 0,168 0,0991 0,0227 0,0321 0,1511 0,0922 0,0137 0,0188
0,0077 0,1411 0,1260 0,0496 0,0052 0,1242 0,1191 0,0406 0,0081
0,143 0,0096 0,2767 0,2003 0,1455 0,0265 0,2698 0,1913 0,1588
0,1395 0,2729 0,0058 0,0822 0,1370 0,2560 0,0127 0,0912 0,1237
0,0516 0,185 0,0821 0,0057 0,0491 0,1681 0,0752 0,0033 0,0358
0 0,1334 0,117 0,0573 0,0025 0,1165 0,1268 0,0483 0,0158
0,1334 0 0,2671 0,1907 0,1359 0,0169 0,2602 0,1817 0,1492
0,1337 0,2671 0 0,0761 0,1312 0,2502 0,0069 0,0854 0,1187
0,0573 0,1907 0,0769 0 0,0548 0,1733 0,0696 0,0090 0,0415
0,0025 0,1359 0,1312 0,0548 0 0,1190 0,1243 0,0458 0,0133
0,1165 0,0169 0,2502 0,1738 0,119 0 0,2433 0,1648 0,1323
0,1268 0,2602 0,0069 0,0695 0,1243 0,2433 0 0,0785 0,1110
0,0483 0,1817 0,0854 0,0090 0,0458 0,1648 0,0785 0 0,0325
0,0158 0,1492 0,1187 0,0415 0,0133 0,1323 0,1110 0,0325 0
183
Если вместо «учителя» применить положительные об-
ратные связи, то, как и в случае самопроизвольного разли-
чения букв, система «Альфа» сама научится различать си-
туации.
Однако, так же как распознающая система не может
без указаний извне правильно назвать буквы, и в данном при-
менении система «без учителя» принципиально не может
приписать значения величин с0, с1г с2 для каждой раз-
личаемой ею ситуации.
Названия или величины может указать только «учи-
тель», либо в другом случае они могут быть выработаны
в процессе конкурентного «выживания» из большего
числа систем, у которых эти названия приписываются
ситуациями случайным образом.
Распознающая система — позиционный корректор
для систем управления циклическими процессами j
Прежде всего убедимся в том, что распознающая система
может различать входные сигналы по любым и, в частности,
по их начальным частям. В'качестве примера снова исполь- ;
зуем алгоритм системы «Альфа». Пусть имеются два входных
сигнала:
01 = +1—1 — 1 + 1 —— 1 + 1 + 1 +
v2 = — 1+1 — 1 — 1 — 1 — 1 — 1 — 1 — 1 + 1.
В обученном состоянии полюса системы имеют те же
коды:
а1=+1 — 1 — 1+1 — 1 — 1 — 1 + 1 + 1 +1,
а, = — 1 + 1 — 1 — 1 — 1 — 1 — 1 — 1 — 1 + 1.
Такой унитарный код с несколькими плюсами мы полу-
чим, если не станем применять схему конвергенции на входе.
При использовании последних плюс будет только в одном
месте кода, но это принципиально не изменяет дальней-
ших выходов и отражается только на объеме (число элемен-
тов) системы.
Определим скалярные произведения на каждом этапе
(предполагается, что разряды кода выясняются постепенно:
сначала известно только несколько начальных разрядов,
потом добавляется еще следующий и т. д.).
184
Таблица 11
Скалярные произведения
Этап 1 2 3 4 5 6 7 8 9 10
Si=(a1ol) •41 4-2 +3 +4 4-5 +6 +7 4-8 +9 410
S2=(axt>a) —1 —2 —1 —2 —1 0 —1 —2 —3 —2
Ss=(<%2^1) —1 —2 —1 —2 —1 0 —1 —2 —3 —2
S4=(a2»8) 41 +2 +3 +4 — +6 +7 48 +9 4-ю
Мы убедились на примере, что распознающая система
различает входные сигналы и v2 даже по начальным час-
тям их кодов, так как всегда:
при vi = Vi (ал) > (a2fi),
при Vi = О, (OjVa) < (оцо*).
Именно на этом основана надежность распознающих сис-
тем при выходе из строя большой части датчиков. Подобно
тому как живой организм продолжает функционировать при
выходе из строя его части, распознающая система в анало-
гичных условиях также продолжает действовать правиль-
но. Можно только показать, что при этом снижается ее раз-
решающая способность 1211. С увеличением длины кода
разрешающая способность возрастает.
Если две представляющие кривые, приводящие к раз-
ным результатам, в начале совпадают, то распознающая сис-
тема дает равные напряжения на двух выходах, т. е. скажет
«не знаю», вплоть до момента, когда представляющие кри-
вые разойдутся.
Используем обнаруженное таким образом свойство рас-
познающих систем предсказывать конечные оценки (снача-
ла неуверенно, а потом все более точно) для построения ком-
бинированной детерминированно-самообучающейся систе-
мы (рис. 71). Разомкнутая часть системы представлена на
рис. 72. Корректор представляет собой распознающую сис-
тему «Альфа» с пятью группами ассоциирующих ячеек (ней-
ронов) соответственно оценкам 1, 2, 3, 4 и 5. На вход сис-
темы подаются последовательности изменения координат
L, Т и К (в коде со «значущим плюсом»).
Например:
иг = _1 — 1 + 1 — + 1+1 — 1 — 1.
8 474
185
Рис. 71. Корректор — распознающая система для управления циклическим процессом.
Координата К представляет собой номер замкнутого клю-
ча разомкнутой части и отображает собой регулирующее
воздействие р.
Пользуясь оценками, полученными в конце циклов, си-
стема прежде всего обучается различать коды по результи-
рующим оценкам.
Рис. 72. Разомкнутая часть системы управления циклическим
процессом.
Алгоритм обучения полюсов распознающей системы,
используемой в качестве позиционного корректора, мы рас-
смотрели выше и поэтому здесь не повторяем его.
Распознающие предсказывающие системы применяют во
временной области. Если одна и та же представляющая кри-
вая получает непрерывно изменяющиеся оценки <рп <р2, <р3,...
... <рл , причем процесс изменения оценок случайный и стацио-
нарный, то, пользуясь формулой Колмогорова, можно
предсказать будущий код изменения оценки за время одно-
го цикла. Это можно использовать для уточнения управле-
8* 187
Рис. 73. Нереверсивный корректор с дополнительным предсказанием результата данной последователь-
ности режимов.
Г1 Ъ+2
ния, если выполняются определенные условия (стацио-
нарность случайного процесса, при котором действительна
формула Колмогорова).
Если в изменении оценок обнаруживаются периодиче-
ские и некоторые другие повторяющиеся изменения, то
для предсказания используется метод характеристических
составляющих либо комбинированный метод (см. выше). Так
или иначе, можно приближенно определить будущую оценку
данного цикла воздействий.
Выше мы показали, что распознающая система может
различать представляющие кривые по их начальным участ-
кам. Это также является одной из форм использования рас-
познающих систем для предсказания.
Совсем другой пример возможного использования пред-
сказывающей системы «Альфа» показан на рис. 73. Здесь
система используется для ускорения получения оценки цик-
ла. Кривую обобщенного возмущения Lm в функции номера
этапа программы Т рассматриваем как случайный процесс.
Значит, можно применить систему «Альфа» (или всякую
другую распознающую систему) для предсказания как бу-
дущих значений возмущения L'm, так и непосредственно кор-
релированного с ним показателя качества цикла Ф, подоб-
но тому, как это мы выше сделали для предсказания ампли-
туды морских волн. Как только система обучена и предска-
зывает в основном правильно, нажимается кнопка К. При
этом на запоминающих устройствах записывается предска-
зываемое значение показателя качества. Система может ли-
бо продолжать движение (если установка ЗУ осталась наи-
большей), либо изменить код и перейти на следующую
по величине оценки представляющую кривую (если уста-
новка ЗУ стала ниже установок других ЗУ). Так система
автоматически учитывает предсказание результата ее
действия.
В начале каждого данного этапа мы располагаем пол-
ной информацией о величине всех координат, кроме коорди-
наты к, которую следует выбрать.
Для этого можно применить поиск на обученной распо-
знающей системе (а не на объекте). Подавая на вход распо-
знающей системы все возможные значения к, выбираем те из
них, при которых предсказанная оценка выше.
189
Перцептрон для предсказания результата
циклических процессов
Алгоритм предсказания. Основное отли-
чие «полного» перцептрона от более простых распознающих
систем (например, от распознающей системы «Альфа» [21])
состоит в том, что в нем распознавание изображений про-
исходит не по одному усредненному прототипу или эталону,
а по многим случайным прототипам. В процессе обучения
устанавливается «коэффициент веса» или степень участия
каждого из случайных прототипов в образовании данного
образа, что в дальнейшем и используется для классифика-
ции изображений на образы или классы. Типичной рабо-
той такого направления являются опыты Браена [51].
Мы используем этот принцип многих случайных прото-
типов для предсказания результата циклического процесса.
Схема перцептрона — предсказывающего фильтра дана на
рис. 74.
Процесс, результат которого ' требуется предсказать,
известен нам в некоторой его начальной части на протяже-
нии n-тактов (интервалов времени). Продолжительность
всего цикла принимается за 100 единиц, следовательно,
0 < п 100. На протяжении известного нам участка про-
цесса последний может быть представлен вектором
Vi(n) = Xt, Х2, Х3..Хп,
который и является «изображением», подлежащим распоз-
наванию. С каждым новым тактом число измерений вектора
увеличивается на единицу (рис. 75). Координаты хъ х2,...,хп
называются «признаками» данного изображения. Задача
состоит в том, чтобы по наблюдению за изменениями вектора
Vi предсказать его координату в конце процесса h1M или
указать максимальное значение йтах.
В качестве случайных прототипов можно использовать,
конечно, чисто случайные точечные или криволинейные
маски, как это делалось в опытах Браена. Но при этом мы
бы потеряли информацию, имеющуюся в известных реализа-
циях процесса, что привело бы к увеличению объема системы
и продолжительности ее действия. Для упрощения системы
в качестве случайных прототипов можно использовать пре-
дыдущие реализации данного процесса, результаты которых
известны.
190
Рис. 74. Схема перцептрона:
Л&7?тхал2нные процессы; 3 - пороговые элемен-
ячейки); 4 — регулировка веса; 5 — сумматор:
о обратные связи; 7 — пороговые элементы 8*.
! — наблюдаемый процесс;
ты 8t (ассоциирующие
Прототипы Результаты
r'2...... r'n), hlt
a2(rj, r"2, r"), th,
r™, .... rf>). hm
Размерность прототипов равна размерности изображения
и, следовательно, возрастает
Рис 75. Наблюдаемый процесс,
результат которого требуется
предсказать.
на единицу с каждым новым
тактом. Далее, в соответст-
вии с алгоритмами действия
перцептрона с многими слу-
чайными прототипами, следу-
ет определить скалярные про-
изведения
21 = (а1У<),
2a = (asv;), ....
2 = (а о).
tn ' т г
Эти скалярные произведения являются мерой близости
изображения к прототипу в пространстве признаков. Так
как важно учесть только наличие расхождения кривых а
не его знак, то величины ординат^елятся на квадрат большей
из них.
Пример. Допустим, нам заданы такие исходные данные:
п 1 2 3 4 5
Vi Xi = 30 хг = 40 х3 = 40 xt — 50 А = 70
а* гх = 20 г2 = 40 г3 = 50 г4 = 50 г5 = 60
Тогда скалярное произведение равно
2 = (vi = V + ХзГз + х*г* + ХзГ^ =
1 /30-20 , 40-40 , 40-50 50-50 . 70-60
5 302 402 *" 502 "Г 602 + 702 /
= -&~ 0,862.
Конец вектора называют «представляющей точкой»,
а концы векторов прототипов ak —«полюсами». Если пред-
ставляющая точка и полюс совпадают — = а*, то
192
скалярное произведение векторов равно наибольшему
значению — единице (2тах =1).
Конечно, можно использовать и другие меры близости
представляющей точки к тому или иному полюсу. Например,
иногда используется квадрат расстояния между ними (ква-
дратичная ошибка). Ограничимся использованием скаляр-
ных произведений, являющихся также корреляционными
коэффициентами.
Подсчитав скалярные произведения (для каждого п-го
такта наблюдаемого процесса), мы в соответствии с алго-
ритмом перцептрона должны отобрать только наибольшие
из них, а именно те значения, которые превышают некото-
рый порог, при О ©ij < 1. Этим самым производится от-
бор прототипов, достаточно близких к наблюдаемому про-
цессу. Если бы мы выбрали порог очень высоким, так, чтобы
остался только один прототип, то тем самым перешли бы от
полного перцептрона к упрощенному — к распознающей си-
стеме «Альфа».
Скалярные произведения, или, другими словами, на-
пряжения пороговых элементов (ассоциирующих ячеек),
превысившие порог ©i j, определяют собой весовые коэффици-
енты (степень участия) wt , с которыми суммируются резуль-
таты соответствующих эталонных процессов:
Ш1 = + + Ws = Sl+S.+ --|-Sm ’ •••’
т Si -r|- Sa Ч- — -4-
(где скалярные произведения 2/ < ©ц следует положить
равными нулю).
Предсказываемый результат наблюдаемого процесса оп-
ределяется сумматором
^предск = + W2h2 + ...+Wmhn.
Обучение перцептрона. Для правильного
предсказания необходимо выбрать величины порогов ©ц
ассоциирующих ячеек. Это достигается при помощи обу-
чения по известным реализациям процесса, образующим
обучающую последовательность. Процессы, входящие в
обучающую последовательность, не входят в число
эталонных случайных процессов. Обучение ведется сначала
при достаточно большом и постоянном п = const, а затем
при п = var.
193
Для обучения результат предсказания Лп₽едск сравнивается
с результатом каждого из эталонных процессов, давшим на-
пряжение выше порогового значения ©и. Определяется ква-
дратичная ошибка
= (Лпредск /гг)2, 0 f < /и*
Если квадратичная ошибка больше некоторого второго
порогового значения 0s, то порог 01 соответствующей ас-
социирующей ячейки, увеличивается на небольшой шаг Д01
или по экспоненциальному закону 0n+i = 0„ + (1—0„ )6,
где О 6 1 • Тем самым «доверие» к данному эталонному
процессу и его роль в предсказании уменьшаются. На следу-
ющем такте и при предсказании других процессов роль дан-
ного эталона будет уже ослаблена. Наоборот, если оказы-
вается, что квадратичная ошибка достаточно мала, порог
соответствующей ассоциирующей ячейки снижается на
постоянный небольшой шаг или по экспоненциальному
закону.
Роль «правильно работающих» эталонов соответственно
увеличивается, что и требуется для повышения точности
предсказания.
ЭЛЕМЕНТЫ ТЕОРИИ УСТОЙЧИВОСТИ
И ТЕОРИИ ИНВАРИАНТНОСТИ КОМБИНИРОВАННЫХ СИСТЕМ,
СОДЕРЖАЩИХ ПРЕДСКАЗЫВАЮЩИЕ ФИЛЬТРЫ
В системе автоматического регулирования связи, содер-
жащие предсказывающие фильтры, называются вероятност-
ными связями.
При разработке вопросов теории устойчивости и теории
инвариантности систем, содержащих вероятностные связи,
прежде всего желательно определить передаточные опера-
торные функции предсказывающих фильтров. Рассмотрим
два наиболее простых примера линейных фильтров.
Дискретный предсказывающий фильтр
Предсказание функции <р (/) происходит по первым
одинарным членам формулы предсказания и по данным
наблюдения от момента t = —7\ до момента t = —Тг
(рис. 76).
194
В данном примере используется постановка задачи, ти-
пичная для самообучающихся датчиков-, известны предыду-
- щие значения величины, требуется определить ее значение
в данный момент времени.
Требуется предсказать значение функции в момент
- “ разбиваем на п равных участков
О ) 2 3 4 5 6*1
Рис. 76. Предсказание будущего зна-
чения функции <p(Z) как среднего за
время усреднения T=Ti = Тг.
t = б. Интервал Т\ — Т2
с продолжительностью
Д/ и находим
Фвер (0) =
__ г1ф1 4~ г2ф2 4~ — Ч~ Гпфи.
Г1 Ч1, Г* + Г3 + ••• + гп
где г1( г2,..., —коэф-
фициенты «закона забы-
вания» (веса), определя-
емые в процессе обучения
предсказывающего филь-
тра, <f>! — значение <р при t = Т2; <р„ — значение <р при
Для простоты положим сначала t = Тг, r± = r2, ra = 1.
Тогда
Фвер = V (Ф^1 + Ф*~2 + ... + фг~л],
где z = 1ыр .
Искомая передаточная функция равна
Р(р) = -^
Твх
г~14- г~2 4- г~3 -Ь... г~~я ,
. п
Если коэффициенты веса не равны единице, то получим
р (п\______ Фвых Г12 1 -fr- г2г 2 4~ ••• 4~ z п
V Фвх п +/•» + -. ^ГЯ
Непрерывный предсказывающий фильтр
Рассмотрим наиболее простую непрерывную вероят-
ностную связь, предсказывающую будущее наиболее ве-
роятное значение как среднее за некоторое время наблю-
дения (см. рис. 76):
t-т,
Фвер = т __р J Ф (0 dt.
41 18 t-T,
19$
Так мы предсказываем многие события: если в течение
ряда последних дней удерживалась хорошая погода, то
весьма вероятно, что и завтра сохранится хорошая погода
и т. п.
Для более точного предсказания время Та должно быть
по возможности меньше (в некоторых случаях Тг = 0), а
интервал усреднения ДТ = Тг — Т2 выбирается в зави-
симости от характера кривой ф (t). Он должен быть в не-
сколько раз больше периода основной гармоники разложе-
ния этой кривой в гармонический ряд.
Действие такого предсказывающего устройства можно
описать уравнением
t—т, р-г,
Твер = _Тг f Ф (0 dt — Ti_Tt Ф (0 dt +
t-т, I го о
+ J Ф (0 dt = f Ф (0 dt — J Ф (f)dt
—“ J * 2 L<—т, t—Ti
В операторной форме получим следующую передаточ-
ную функцию:
Рф (р) = Лиг- = ^р. = - 1 • -L (е-^ _
Ч>ВХ ф Т1 — Т2 р
’ (О
Если задана «функция забывания», например е \в
приведенных выше выражениях нужно заменить ф (t) на
Ф(/) е
И
Условия инвариантности для систем
с вероятностными обучающимися связями
Ниже выведены и частично исследованы условия абсо-
лютной инвариантности и условия устойчивости систем с
вероятностными связями, схемы которых представлены на
рис. 77. Здесь приведены все практически наиболее важ-
ные системы:
а) одноконтурная следящая система со связью по основ-
ному возмущению (входному сигналу),
б) одноконтурная система стабилизации со связью по
основному возмущению (нагрузке объекта регулирования),
в) двухконтурная (дифференциальная) следящая систе-
ма без связи по возмущению,
г) двухконтурная (дифференциальная) система стабили-
зации без связи по возмущению.
Заштрихованные квадраты — устройства, вычисляющие
вероятностные значения. Необязательно, чтобы в каждой
Фбер
г
и
Рис. 77. Основные схемы
систем с вероятностными связями:
а, б — со связями по основному возмущению; в, г — без связей по возмуще-
нию (дифференциальные).
из рассматриваемых систем были две вероятностные связи.
Некоторые из связей могут быть детерминированными, т. е.
обычными. В таком случае передаточную функцию соответст-
вующего квадрата следует принять равной единице. Квадрат
РФ (р) изображает обучающуюся обратную связь, Рч-(р) —
обучающуюся разомкнутую связь, Pv(p) — вероятностную
связь в «системе с обучающимся прототипом».
Переходим к математическому описанию и исследованию
систем рис. 75. В табл. 12 представлены уравнения динами-
ки элементов, в табл. 13 — уравнения динамики систем в
целом.
Устойчивость. Характеристические уравнения, знаки
корней которых определяют собой устойчивость систем,
197
Таблица 12
Уравнения динамики элементов систем (к рис. 77)
Для рис. 77, а Для рис. 77, б
ees:» .8 « п । ° 3» *53 XJ ‘1 д е s *? S т(р)Ф№р 4- /(Р)Ьвер, М = Ф = У^р)М-р(р)Ц фвер =Рф(Р)Ф> Liep = PL(p)£
Для рис. 77, в Для рис. 77, г
2 т(р)Фкр-^п(р)М М-У&^ + Ч, Ф=Уг(р)Я ^вер ~Р^Р)М, Фвер-^фООФ 2= — т(р)Фк ф п(р)М M=Y1(p)S, Ф=Г2(р)Л4-₽(р)£, ^вер =-рм(Р)М фвер=Рф(Р)ф
I
Таблица 13
Уравнения динамики систем в целом (к рис. 77)
Для рис. 77, а Для рис. 77, б
[1^т(р)Г1(р)У8(р)Рф(р)]Ф= =*(р)Г1(р)Га(р)Рчг(р)Т [1-^т(р)У1(р)УМРф(р')]Ф= =[11(Р)У1(Р)У^Р)РЬ (P)-M]L
Для рис. 77, в Для рис. 77, г
[1 — n(p)Yi(p)Pм(р) 4-Нр)П(р)У2(р)Рф(р)]Ф = = Уь(р)Ч и-пЮУМУРмЮ&тЮУг (р)Га(р)Рф(р)]Ф = -₽(р)11-п (p)ri(p)PM(p)]b
198
даны в табл. 12. Уже на данном этапе рассмотрения можно
сделать следующие выводы:
1. Устойчивость систем стабилизации и следящих систем
определяется одинаковыми по структуре характеристиче-
скими уравнениями.
2. Вероятностные (предсказывающие) устройства ра-
зомкнутых связей на устойчивость систем не влияют, так
как операторы Рчг(р) или PL (р) в условия устойчивости не
входят.
3. В случае наличия в системе вероятностных обратных
связей, когда Р®(р) =/= 1 или Рм(р) 4= 1, устойчивость сис-
темы зависит от передаточных функций этих связей и в об-
щем случае значительно ухудшается по сравнению с детер-
минированной системой (для которой РФ (р) = 1 и Рм(р) —
= 1), так как вероятностные связи имеют транспортное
запаздывание, которое трудно компенсировать.
4. Располагая возможностью произвольного выбора
коэффициентов оператора внешней обратной связи
т (р) = т0 4- т±р + т^р* 4- т3р® 4-...,
можно получить устойчивую систему при любом знаке и ве-
личине знака коэффициентов внутренней обратной связи:
п (р) = «о 4- «1Р 4- пгрг 4- п8р8 4- - •
Известно, что при выполнении условий абсолютной ин-
вариантности в системах без связей по возмущению прихо-
дится применять положительную внутреннюю обратную
связь п0 > 0. Многие авторы еще недавно утверждали, что
будто бы при этом система обязательно приходит на грань
устойчивости (теряет свою «грубость»). Очевидно, это не так.
Системы без связей по возмущению можно настроить как на
положительную, так и на нулевую или даже на отрицатель-
ную установившуюся и динамическую ошибку при сохра-
нении их устойчивости [201. Системы (рис. 77, в и 77,г) могут
оставаться устойчивыми и «грубыми» (т. е. такими, что
малые изменения параметров не изменяют существен-
но их свойств) при настройке на абсолютную инвариант-
ность.
Абсолютная инвариантность. Условия абсолютной ин-
вариантности, при которой для следящих систем Ф ==
а для систем стабилизации Ф = 0, представлены в табл. 15.
Эти условия могут быть использованы для определения к (р),
I (р) и п (р), обеспечивающих идеальную работу систем без
199
установившейся и динамической ошибки. Операторы т(р)
и Yi(p) используем для выбора необходимой жесткости и
устойчивости по правилам компромиссной настройки или
по статическим методам.
При выполнении условий инвариантности, указанных
в табл. 15, устраняется действие всех помех, входящих в
систему, в «вилке» дифференциальных связей, т. е. между
точками I и II (рис. 77, в и 77, г), в том числе и действие ста-
тистически заданных возмущений, например, помех типа
«белого шума» (стрелки N (t) на рис. 77, в и 77, г).
Пример. Рассмотрим синтез измерительных связей
системы (рис. 77, б) из условий компромиссной настройки
и инвариантности, в случае наличия только одной вероят-
ностной связи — по основному возмущению (нагрузке).
Допустим, задано:
У(р) =
at
Tip + 1
уИр) —(T2p + i)(aTV, + i) >
Р= (Тар 4- П₽(ТзР + 1) ’
pl (Р) = -у 0~riP —е-г‘₽),
/ (пХ_ Ф •"
(Р) ^/Jp^... ’
т (р) = /По + ”ЧР + /П2р2 + Шзр3 + ... .
Оператор замкнутой связи т(р) выбираем из условий
компромиссной настройки, обеспечивающей оптимальное
соотношение жесткости и устойчивости. Если, например,
требуется жесткость s = 100 при ед = 20, то, очевидно,
S—1 99 е
т0 —-----=
0 агаа 20
Остальные коэффициенты оператора — т*, т3 — вы-
бираются так, чтобы обеспечить оптимальное затухание
свободных колебаний системы (например, так, чтобы в сис-
теме второго порядка относительный коэффициент затуха-
ния С1Л = 0,25; в системе третьего порядка безразмерные
параметры Вышнеградского х = 1,2, у = 3 и т. д.). Эта
процедура хорошо известна, и мы на ней не останавливаемся.
200
Более сложным и интересным является синтез оператора
разомкнутой связи I (р) на основе условий инвариантности.
Таблица 14
Характеристика уравнения систем и выражения
для жесткости S: (к рис. 77)
Для рис. 77, а Для рис. 77, б
1Ч-т(р)Г1(р)Г2(р)Рф(р) = 0, s = (l+moaia^) 1+т(р)У1(р)Гг(р)Рф(р)=0, s= (1 4- moaiaaP®.)
Для рис. 77, в Для рис. 77, г
1—п(р)Г1(р)Рм(р) + + m{p)Yl(p)Y£p)Pes>(p)~Q, s= (1—noaiPMi> 4-аго^ааРф^ 1-и(р)Г1(р)Рм(р)4- ^m(p)Yx(p)Yi(p)P<s>{p)^G, s - (1 — no«iPA<. + ®в®1««Рф.)
Условия абсолютной инвариантности (см. табл. 15) позво-
ляют определить (синтезировать)
Кп\ = Ро (W + О
W Ъ (pHa(p)PL(p) — PL (p)
при
pL (p) = Л1Гг • -j- (е~ГгР — e~T'p).
Таблица 15
Условия абсолютной инвариантности систем (к рис. 77)
Для рис. 77, а Для рис. 77, б
1 4-Нр)1'1(р)Г2(р)Рф (р) = =Л(р)Г1(р)Га(р)Рч,(р) Цр^рЖа^ (р) - Р(р>=0
Для рис. 77, в Для рис. 77, г
1-п(р)Ух(р)Рм(р)4- 4- т(р)У1(р)Г2(р)Рф (р) = У8(р) l-nipjY^pjP^pj^O
201
Находим
цп} _ Г P»(Ti-T2) _ , Ро(Т1-Г2)Т1 ' J 1
[ сца2 р~^ а1Я2 р] e-Ttp_e-TlP •
Делаем вывод, что в данной системе компаундирующая
связь по возмущению должна иметь вид
/(₽)-(/>+
т. е. содержать два параллельно включенных дифференци-
атора с коэффициентами
/’ — (Т'1 — jj — Р°Т1 — ^г)
1 aja2 2 ща2
и последовательно включенное звено опережения с переда-
точной функцией
е-тгр _.е-т,р > где > Т’а •
Такое опережение легко получить в системах програм-
много управления, где будущее изменение возмущения из-
вестно и где можно подавать сигнал на вход разомкнутой
вероятностной связи с определенным опережением.
Так же просто получить любое требуемое опережение в
вероятностных связях при циклическом повторении про-
цессов. Например, можно сравнительно точно предсказать
среднюю температуру на любой предстоящий месяц года.
Введение опережения резко улучшает динамику переход-
ных процессов в системах с вероятностными связями.
В системе стабилизации, где будущее значение нагрузки
неизвестно, осуществить такое опережающее звено практи-
чески невозможно. Поэтому приходится согласиться на
приближенное выполнение условий инвариантности. Зада-
ча сводится к максимально возможному сближению идеаль-
ного оператора, обеспечивающего абсолютную инвариант-
ность при наличии вероятностной связи
(> —- и
и оператора реально осуществимого четырехполюсника
Нп\— •••
202
Нужно выбирать коэффициенты реально осуществимого
дифференциатора так, чтобы обе функции возможно меньше
отличались друг от друга. Задача может быть решена мно-
гими методами (по Чебышеву и др.). Применим один из
наиболее простых методов: используем разложение экспо-
ненциальных функций в ряд. Ограничимся тремя членами
ряда
1 __________________________1____________________
е~ТаР _e-riP л _ Тгр+ 1 T2pi _. W!_Tip + 1 Т2рг „
\ Z / \ Z
1_________________
(Л-Тг)р+ -
1
Р(Т\-Тг) +
Приравнивая оба выражения, находим
; tn\_ h ~Ь кР _ „/'г__'г х Г Р» ~4~ Рот1Р 1_J_______
l(P>— fo+l'lP ~P{Jl /2)[ «Л. J е~Т^-е~Т^ —
_ _______Ро ~Ь PqTjP___
«1О2 — -g-aia2 (7*1—Т4) р
откуда получаем
/о = Ро» 4 — РоЧ, 4==Ctia2’ 4 ~ 2-а1аг(7'1 — Л).
Синтез системы закончен: операторы т(р) и 1(р),
обеспечивающие оптимальную устойчивость и инвариант-
ность к нагрузке L(t), найдены.
Таким образом, мы рассмотрели условия инвариант-
ности и условия устойчивости систем с вероятностными
связями. Вполне очевидна применимость общей теории
комбинированных систем к вероятностным обучающимся
системам.
Экспериментальный способ нахож-
дения наиболее эффективной форму-
лы предсказания. Если процесс, подлежащий
предсказанию, настолько неизучен, что нет уверенности
в том, что формула Колмогорова является наиболее общей
и наилучшей, то можно почти механически пробовать наугад
различные формулы предсказания.
203
Получив оценки полезности тех или иных членов формулы,
мы можем отбросить малополезные члены и таким способом
постепенно выработать наиболее подходящую формулу,
дающую наиболее высокий процент правильного пред-
сказания при заданном объеме вычислительной работы.
Л. И. Воронова, в частности, показала, что для предска-
зания амплитуды волн можно использовать ряд Тейлора,
причем точность предсказания снижается незначительно,
но зато значительно уменьшается объем вычислений.
В начале данного раздела мы говорили о том, что си-
стем, реализующих «чистую» случайность, не существует.
Даже при подбрасывании монеты из-за каких-то постоян-
но действующих факторов (изгибы монеты, манера бросать
и т. п.) монета чаще падает на одну сторону, чем на другую,
и, следовательно, кроме «чистой» случайности действует
вероятностный закон. Однако чистая случайность вполне
реальна. Как бы мы ни уточняли формулы регрессии, как
бы ни повышали число их членов и выбирали самые полез-
ные из них,— успех предсказания вероятностного процес-
са принципиально не может быть равным 100%. Только
для вполне детерминированных, поддающихся расчету про-
цессов может быть получен такой результат. При совершен-
ствовании методов предсказания» случайных процессов точ-
ность повышается, но всегда остается непредсказуемая
часть, выражающая собой элемент чистой случайности.
Если бы мы увеличили число членов формулы Колмогоро-
ва или перешли к непрерывным величинам, то вполне воз-
можно, что в примере с океанскими волнами получили бы
точность предсказания больше 80%. Но несколько процен-
тов возможной ошибки осталось бы, ибо в данном процессе
имеется элемент чистой случайности.
* *
*
В заключение отметим, что формула Колмогорова (в
применении ее к дискретному фильтру «Альфа») может объ-
яснить, а следовательно, и направить успех многих опытов
по предсказанию.
А. Л. Лунц и В. Л. Браиловский в опытах по предска-
занию лечения ожогов использовали 12 входных призна-
ков (площадь раны, локализация ожога, степень ожога,
возраст больного, сопутствующие заболевания, осложнения,
данные анализа крови и т. д.), которые применяли
204
каждый в отдельности, а также в комбинации по два, по
три и т. д. Было установлено, что наиболее полезная инфор-
мация содержится в логических произведениях некоторых
из входных признаков.
Формула Колмогорова и использованный выше метод
определения полезности ее отдельных членов и представ-
ляет собой математический алгоритм, объясняющий успех
указанных опытов.
В дальнейшем методика организации опытов по предска-
занию, основанная как на непрерывных, так и на бинарных
входных признаках, должна учитывать математическое ос-
нование и структуру расширенного оператора предсказания.
CYBERNETIC FORECASTING FILTERS
Forecasting programs designed for large general-purpose com-
puters constitute an important new tool in the control of production and
economics. An example of such «big» forecasting programming is the
work of Professor Richard Stone of Cambridge, who computerized the
economics of the United Kingdom for 1970.
Nevertheless, small forecasting filters have their own domain of
application. They can be realized not only as programs for general-
purpose computers, but also as simple analog devices with high quick
response. The first of such devices was constructed on the basis of the
operator of Academician Kolmogoroff’s formula by Professor DenrJs
Gabor at Imperial College (London) in 1955. Since then many other
forecasting filters have been designed for different purposes and in ac-
cordance with different formulae (algorithms) — for instance, at Kiev
Polytechnic Institute, where the authors work.
These different forecasting algorithms are considered, and many
new recommendations are given in thisabook.
The authors discuss three principal methods of forecasting in addition
to some others.
1. Forecasting of determined processes, i. e. extrapolation and in-
terpolation.
2. Forecasting of stochastic processes, based on statistical forecas-
ting theory.
3. Forecasting based on adaptation or learning of the forecasting
filters.
Professor Gabor’s filter was a self-learning one. It is shown in the
book that the perceptron — the best known cognitive system — can
also be used as a simple forecasting filter. Thus, there is no dividing
line between cognitive systems and forecasting filters, for forecasting
in the cognition of the future. The theory of cognitive systems can be
applied to the designing of forecasting filters and, vice versa, the well
developed theory of statistical forecasting can be used in cognitive sys-
tem design.
The main problem is realization of optimum forecasting precision,
the comparison of the precision and simplicity of various algorithms
of forecasting. Sometimes, as in the case of control, quick response of
the forecasting filters is also important. Some recommendation are gi-
ven on the basis of a study of the precision of forecasting in the general
form; some, on the basis of calculation of examples. All calculations
were performed on digital computers.
206
The examples are taken from chemical industry, biology, ocean tur-
bulence processes, forecasting of the relief of the Dnieper river bottom,
and so forth.
The most important is the original proposal to combine the forecas-
ting method developed for non-stationary processes (presented by Pro-
fessor Farmer at the second IFAC Congress) with Kolmogoroff’s basic
method, developed for stationary processes only. The combined met-
hod of forecasting yielded good results in forecasting intracranial pres-
sure in neurosurgery.
A special part of the book is devoted to the use of forecasting filters
or cognitive systems in production control. Extremum control of the
plant should be effected by a combination of open loop control and a
corrector, smoothly correcting the characteristics of the open loop part.
Cognitive systems and forecasting filters can be used as correctors.
Forecasting filters furnish the only possibility of constructing a
control system for periodical processes, since prediction of the result
of the process is essential for its control. This problem is also discussed.
ЛИТЕРАТУРА
1. Алехин Ю. М. Статистические прогнозы в геофизике.
Изд-во Ленингр. ун-та, 1963.
2. Б а р р е т У. Ф. Загадочные явления человеческой психики.
М., 1914.
3. Б и р С. Кибернетика и управление производством. Физмат-
гиз, М., 1963.
4. Б у т К. Численные методы. Физматгиз, М., 1960.
5. Вальд А. Последовательный анализ. Физматгиз, М., 1960.
6. Васильев В. И. Светальский Б. К. О точности пред-
сказывающих устройств.—Автоматика, 1965, 4.
7. Васильев В. И. Дифференциальные системы регули-
рования. Изд-во АН УССР, 1963.
8. В а с и л ь е в Л. Л. 'Таинственные явления человеческой
психики. Господитиздат, М., 1964.
9. В а с и л ь е в Л. Л. Вкушение на расстоянии. Госполит-
издат, М., 1962.
10. Г л а д ы ш е в Е. Г. О периодически коррелированных слу-
чайных последовательностях. — ДАН1 СССР, 1961, 137, 1026.
11. Гладышев Е. Г. К теории периодически коррелирован-
ных случайных последовательностей и процессов. Автореферат дис.,
М., 1963.
12. Г н е д е н к о Б. В. Курс теории вероятностей. Гостех-
издат, М., 1954.
13. Г р е н а н д е р У. Случайные процессы и статистические
выводы. ИЛ, М., 1961.
14. Дунин-Барковский И. В., Смирнов Н. В.
Теория вероятностей и математическая статистика. Гостехиздат,
М., 1955.
15. Д ы н к и н Е. Б. Марковские процессы. Физматгиз, М., 1963.
16. Жук Д. К- О применении метода обратных операторов к
синтезу много контурных систем.— Автоматика, 1963, 4; 1964, 6.
17. 3 а й ц е в А. Г. Аналитическое конструирование систем,
воспроизводящих полезный сигнал в присутствии помех. А и Т. 1963, 2.
18. 3 е л ь к и н Э. Г. Построение экстраполяторов. А и Т. 1962,
23, 9.
18а. Зелькин Э. Г. Построение экстраполяторов. Науч,
докл. высш, школы. МЭИ, 1958, 2.
19. И в а х н е н к о А. Г., Воронова Л. И. Распозна-
ющая система «Альфа» как обучающийся фильтр и экстремальный ре-
гулятор без поисковых колебаний.— Автоматика, 1964, 3.
20. И в а х н е н к о А. Г. Электроавтоматика. ГостехиздатУССР,
К., 1957.
208
21. Ивахненко А. Г. Самообучающиеся системы с положи-
тельными обратными связями. Изд-во АН УССР, 1963.
21а. И в а х и е н к о А. Г. Сравнение свойств основных схем
комбинированного экстремального управления.— Автоматика, 1964,
4 и 5.
22. Исследования характеристик режима возобновляющихся ис-
точников энергии воды, ветра и солнца. Изд-во УзССР, 1963.
23. К а ж и н с к и й Б. Б. Биологическая радиосвязь. Изд-во
АН УССР, 1962.
24. Карибский В. Вм Чернышев А. В. Цифровые
интерполяторы для систем программного управления. ЦИНТИ, М.,
1962.
25. Керекеснер И. П. иЧеховой Ю. Н. Алгоритмы
обучения разомкнутой системы экстремального управления.— Автома-
тика, 1965, 2.
26. К о л м о г о р о в А. Н. Стационарные последовательности
в гильбертовом пространстве.— Бюлл. МГУ, 1941, 2, 6.
26а. Колмогоров А. Н. Интерполирование и экстраполи-
рование стационарных случайных последовательностей. — Изв.
АН СССР. Сер. матем. и естеств. наук, 1941, 5.
27. Крементуло Ю. В. К условию абсолютной инвариант-
ности для разомкнутых импульсных систем.— Автоматика, 1960, 2.
28. К р е м е н т у л о Ю. В. Синтез интерполяторов из условий
инвариантности.— Автоматика, 1961, 5.
29. Л а б б о к Д. К. Оптимизация одного класса нелинейных
фильтров.— Тр. I конгр. ИФАК, М., 1961, 3.
30. Л а п а В. Г. Комбинированный метод предсказания неста-
ционарных процессов.— Автоматика, 1965, 3.
31. Л а п а В. Г. Предсказание биологических нестационарных
случайных процессов методом характеристических составляющих.—
Автоматика, 1964, 4.
32. Л е н и н г Дж., Б е т т и н Р. Г. Случайные процессы
в задачах автоматического управления. ИЛ, М., 1958.
33. Л я п у н о в А. А. О некоторых общих вопросах киберне-
тики.— В кн.: Проблемы кибернетики, Физматгиз, М., 1958, 1.
34. Мандровський-Соколов Б. Ю. Про |реал1защю
екстраполюючих ф!льтр!в з експонешцальним згладжуванням.— Авто-
матика, 1964, 3.
35. Мелентьев П. В. Приближенные вычисления. Физмат-
гиз, М., 1962.
36. О т х м е з у р и Г. Л. О свойствах признаков и шестой обрат-
ной положительной связи.— Автоматика 1963, 2.
37. П о м о р ц е в М. Очерк учения о предсказании погоды (си-
ноптическая метеорология). СПб., 1889.
38. Прогноз в защите растений от вредителей и болезней. Изд-во
АН Латв. ССР, Рига, 1964.
39. П у г а ч е в В. С. Теория случайных функций и ее приме-
нение к задачам автоматического управления. Физматгиз, М., 1960.
40. С а п а р и н а Е. В. Кибернетика внутри нас. «Молодая
гвардия», 1962.
41. Сергиенко Т. М., Волошин М. Я., Л а п а В. Г.
Использование методов математического прогнозирования в нейрохи-
рургической практике. Докл. на Всесоюз. конфер. нейрохирургов.
Л., 1964.
209
42. С и г о в Б. А. Повышение точности работы цифрового ин-
тегратора, построенного на основе делителя частоты.— Автоматика,
1962, 1.
1962^* С “ И Т О R Ж Автоматическое регулирование. М.,
44. Солодовников В. В. Введение в статистическую дина-
мику линейных систем регулирования. М., 1960.
45. Ф а р м е р Э. Д. Метод предсказания нестационарных про-
цессов и его применение к задаче оценки нагрузки. Докл. на II контр.
ИФАК, М., 1963.
46. Ц ы п к и н Я. 3. Теория линейных импульсных систем.
Физматгиз, М., 1963.
47. Ястремский Б. С. Некоторые вопросы математиче-
ской статистики. Госстатиздат, М., 1961.
48. В е г п а г d В. Measuring the worls population explosion. New
Sientist, 1962, 313, Nov.
49. В о d e H. W., ShennonC. E. A Simplifide Derivation
of Linear Least — Square Smoothing and Prediction Theory. Proc. IRE,
1959, 38, 4,
50. В г о w n R. G. Statistical Forcasting for Inventory Control.
McGrow Hill, N. Y., 1959.
50a. Brown R. G., Meyer R. F. The fundamental Theory
of Exponential Smoothing. Opus. Res., 1961, 9.
51. Bryan J. S. Experiments in Adaptive Pattern Recognition,
IEEE Trans, on military electronics, 1963, Apr.— July.
52. D u d a R. О., M a c h a n i k J. M. An Adaptive Prediction
Technique and its Application to Weather Forecasting. Wescon Techn.
Papers, 1963, 7.
53. Electronics, 1960, 6.
54. Gabor D., W i 1 b у W.,’Woodcock R. A Universal
Nonlinear Filter, Predictor and Simulator wich Optimizes Itself by a
Learning Process. Proc. Inst. Electr. Eng., 1961, 40.
55. G a b о r D. Predicting Machines. Scientia, Rev. Int. Syntese
Sci., Milano, 1962, 5, Mai.
56. К a r h u n e n K. Uber ein Extrapolationproblem in dem Hil-
bertshem Raum. 11. Skand. mat. Kongress, 1952.
57. P e s h e 1 M. Uber die Anwendigkeit von Korrelations Meto-
den in der Regelungstechnick. Messen stevern regeln, 1965, 1.
58. L a b b о c k G. K. The Optimisation of a Class of Non Linear
Filters. Proc. Inst. Electrical Engineers, Pt C, Monogr. 1959, N 344E.
59. R о s e n b 1 a 11 F. Perceptual Generalization over Transfor-
mation Groups. In: Self — Organizing Systems, Pergamon Press, 1960.
59a . Rosenblatt F. Perceptron Simulation Experiments.
Proc. IRE, 1960, March.
596. Rosenblatt F. Principles of Neurodynamics. Spartans
Books, Woshington, 1962.
60. Streets R. B. Arbitrary Non-Mean-Square Error Criteria.
IEEE Trans. Autom. Control, 1963, 8, 4.
61. Z a d e h L. A., Ragazzini J. R. An Extention of Wiener’s
Theory of Prediction J. Appl. Phys., 1950, 21, 7.
62. Wiener N. The Exstrapolation, Interpolation and Smoothing
of Stationary Time-Series. J. Willey, N. Y., 1949.
СОДЕРЖАНИЕ
Введение .................................................... 3
Основа предсказания — опыт прошлого....................... 4
Предсказание детерминированных процессов ........ 5
Предсказание случайных процессов ......................... 6
Предсказание процессов по их параметрам в данный момент
времени ............................................. 10
Предсказание процессов по параметрам в данный момент
времени и по их предыстории ........................... 11
Применение вычислительных машин для предсказания
погоды ............................................. 12
Другие геофизические прогнозы * . .............'. . 14
Предсказание землетрясений ........... 15
Предсказание уровня грунтовых вод ....... 16
Предсказание коррелированных процессов ................ 17
Одномерные и многомерные задачи предсказания .... 18
Применение математического прогнозирования в плани-
ровании и управлении энергосистемами................ 18
Прогноз для защиты растений от вредителей и болезней 19
Предсказание в биологии и медицине.................. 19
Предсказание при управлении производственными процес-
сами ............................................... 21
Глава /. Предвидение детерминированных процессов. Интерпо-
лирование и экстраполирование
Задачи интерполирования и экстраполирования......... 23
Подбор аппроксимирующего многочлена.................. 24
Автоматическое интерполирование...................ч. 29
Линейные интерполяторы ........................... 29
Ошибки автоматического интерполирования и методы
повышения точности ............................... 31
Линейно-круговой интерполятор ...................... 34
Квадратичные интерполяторы .......... 35
Интерполяторы высших порядков................. 37
Автоматическое экстраполирование ...................... 40
Экстраполяторы дискретные и непрерывные ..... 40
Экстраполятор для непрерывного упреждения....... 42
Условия инвариантности и синтез интерполяторов и экстрапо-
ляторов ............................................ 44
Условия инвариантности ............................. 44
Схемы, реализующие условия инвариантности .... 45
.211
г
Глава 2 Предсказание стационарных случайных процессов
Краткие сведения из теории вероятностей и теории случайных
функций .................................................... 49
Случайные события. Случайные величины. Случайные про-
цессы ................................................. 49
Частость и вероятность ............................. 50
Интегральная функция распределения случайной вели-
чины ............................................... 51
Функция плотности вероятности. Нормальный закон
распределения ...................................... 51
Математическое ожидание и высшие моменты случайной
величины ........................................... 53
Условная частость. Условная вероятность. Зависимые
и независимые события .............................. 54
Основные понятия и определения теории случайных функций 55
Случайные функции. Законы распределения. Марковские
процессы ........................................... 55
Математическое ожидание и корреляционная функция слу-
чайной функции. Взаимная корреляционная функция . 56
Стационарные случайные функции. Эргодическое свой-
ство стационарной случайной функции ................ 57
Критерий качества предсказания. Критерий оптимальности . . 58
Критерий минимума среднеквадратичной ошибки........... 58
Критерий минимума суммы интегральной квадратичной ошиб-
ки и дисперсии случайной ошибки ....................... 59
Произвольные критерии оптимальности ................... 60
Предсказание стационарных случайных последовательностей . 63
Метод и формула А. Н. Колмогорова ..................... 63
Предсказание изменения показателя качества продукта неф-
техимического предприятия *......................... 64
Задача предсказания................................. 64
Алгоритм обучения оператора предсказания........... 66
Решение и результаты................................ 68
Предсказание по формулам экспоненциального сглажива-
ния (метод Брауна) .................................... 70
Цифровое моделирование ........................ 71
Предсказание изменения показателей качества нефте-
продуктов и исследование предсказывающего фильтра . 73
Фильтр-экстраполятор, реализующий алгоритм экспо-
ненциального сглаживания............................ 79
Предсказание стационарных случайных процессов............ 80
Метод Винера........................................ 80
Метод Заде и Рагаззини ............................... 82
Метод Боде и Шеннона .................................. 87
Нелинейная фильтрация сигналов ........................ 89
Задача оптимальной нелинейной фильтрации ..... 89
Расчет оптимального нелинейного фильтра ..... 93
Глава 3 ’ Предсказание нестационарных случайных процессов
Постановка задачи ..................................... 98
Метод характеристических составляющих ................. 99
Определение характеристических составляющих . . . 100
Предсказание процесса по его характеристическим состав-
ляющим ..............................................104
212
Применение метода характеристических составляющих
для предсказания изменений нагрузки электростанций 105
Комбинированный метод предсказания нестационарных слу-
чайных процессов ....................................108
Вторая модификация комбинированного метода ..... 111
Предсказание изменений внутричерепного давления при
кровоизлиянии в головной мозг ........................114
Экспериментальное воспроизведение внутримозгового
кровоизлияния (биологическая модель) ...... 114
Критерий качества предсказания ................. 115
Решение и результаты ...............'..............116
Глава 4, Распознающие системы в качестве предсказы-
вающих фильтров и регуляторов..................... 122
Универсальный предсказывающий фильтр с самонастройкой
в процессе обучения...................................127
Расширенный оператор предсказания....................128
Схема предсказывающего фильтра ..................... 129
Предсказание изменений показателя качества продукта неф-
техимического предприятия ............................131
Моделирование предсказывающего фильтра на ЭЦВМ . 133
О влиянии длины предыстории на качество предсказа-
ния ..........................................136
Простое предсказывающее устройство по первой производной 137
Предсказание рельефа речного дна....................139
Распознающая система «Альфа» — предсказывающий фильтр 139
Алгоритм действия распознающей системы «Альфа» ... 142
Самообучение предсказывающего фильтра по методу мно-
жественно-корреляционного (регрессионного) анализа ... 145
Самообучение предсказывающего фильтра по итерационно-
му алгоритму Габора ................................ 147
Распознающая система «Альфа» в качестве предсказываю-
щего самообучающегося фильтра.........................148
Опыт предсказания амплитуды океанских волн на пре-
дельно упрощенной распознающей системе «Альфа» . . 150
Исследование точности предсказания и полезности призна-
ков (членов формулы предсказания)...................153
Самопроизвольный выбор наиболее полезных признаков —
Распознающие системы на пороговых логических элементах . 154
Предсказание изменений атмосферного давления . . . 157
О применении распознающих систем в качестве обучающихся
корректоров экстремального управления .................... —
Постановка задачи коррекции .........................161
Другое определение понятий «состояние» («изображение»)
и «ситуация» («образ»)................................163
Применение распознающей системы «Альфа» для различения
ситуаций ............................................ 165
Уменьшение продолжительности обучения полюсов при
помощи интерполяции ............................... 169
Выяснение состава множества «признаков».............. —
Выбор полезных (информативных) признаков ............172
Границы ситуаций при идеальном и реальном при-
знаках .............................................173
Способ выработки признаков при отклонениях распреде-
213
ления возмущений от наиболее вероятной кривой (пре-
образование распределения) ........................177
Оценка признаков по критерию разрешающей способ-
ности .............................................178
Пример схемы использования распознающей системы в
качестве корректора ...............................180
О возможности самообучения корректора ...... 181
Распознающая система — позиционный корректор для
систем управления циклическими процессами .... 184
Перцептрон для предсказания результата циклических про-
цессов .......................................... 190
Элементы теории устойчивости и теории инвариантности комби-
нированных систем, содержащих предсказывающие фильтры . 194
Дискретный предсказывающий фильтр ..................... —
Непрерывный предсказывающий фильтр ...................195
Условия инвариантности для систем с вероятностными обу-
чающимися связями ....................................196
Cybernetic Forecasting Filters ..........................206
Литература...............................................208
I
ИВАХНЕНКО АЛЕКСЕЙ ГРИГОРЬЕВИЧ,
ЛАПА ВАЛЕНТИН ГРИГОРЬЕВИЧ
КИБЕРНЕТИЧЕСКИЕ ПРЕДСКАЗЫВАЮЩИЕ
УСТРОЙСТВА
Редактор Р. Л. И м а с
Художественный редактор'И. П. Антонюк
Оформление художника Б. И. Бродского
Технический редактор Н. А. Турбанова
Корректор 3. И. Б е х
БФ 36 600. Зак. Xs 474. Изд. Xs 249. Тираж 18 000.
Формат бумаги 84Х1081/8#. Печ. физ. листов 6,75.
Условн. печ. листов 11,34. Учетно-издат. листов 10,08.
Подписано к печати 24/XI 1965 г. Цена 50 коп.
Издательство .Наукова думка*, Киев, Репина, 3.
Киевская фабрика набора Государственного комитета Совета Министров УССР
по печати ул. Довженко, 5