/











































Text
САРАТОВСКИЙ ГОСУДАРСТВЕННЫЙ МЕДИЦИНСКИЙ УНИВЕРСИТЕТ
КАФЕДРА ОБЩЕС i ВЕННОГО ЗДОРОВЬЯ И ЗДРАВООХРАНЕНИЯ
МЕДИЦИНСКАЯ
СТАТИСТИКА
Mei одические рекомендации
для студентов медицинских ВУЗов
САРА ТОВ 2002
Учебно-методическое пособие содержит методику организации
статистического исследования, вычисления относительных и средних
величин, специальных и непараметрических методов анализа для оценки
здоровья населения и деятельности учреждений здравоохранения.
Предназначено для студентов медицинских ВУЗов.
Составители: Н.Г. Астафьева, Н.В. Абызова, Н.Е. Белянко,
Л.В. Боброва, В.М. Марон
Рецензенты: И.А. Захаров, заведующий кафедрой экономики,
управления здравоохранения и медицинского
страхования СГМУ, д.м.н., профессор
Б.С. Юшина, заместитель главного врача по
организационно-методической работе областной
клинической больницы, к.м.н.
Утверждено и рекомендовано к печати
координационно-методическим Советом
государственного медицинского университета
Центральным
Саратовского
© Саратовский государственный
медицинский университет, 2002
МЕТОДИКА СТАТИСТИЧЕСКОГО ИССЛЕДОВАНИЯ
Статистика - самостоятельная общественная наука, изучающая количест-
венную сторону массовых общественных явлений в неразрывной связи с их каче-
ственной стороной.
Статистика, изучающая вопросы, связанные с медициной, гигиеной и здра-
воохранением, носит название медицинской статистики. Роль медицинской ста-
тистики в практической и научной работе врача велика. Умелое ее использование
позволяет своевременно оценить уровень общественного здоровья и эффектив-
ность проводимых лечебно-профилактических мероприятий. Для руководителя
любого звена здравоохранения своевременная и качественная статистическая ин
формация является основой совершенствования организационных форм управле-
ния. От подготовленности врача в вопросах медицинской статистики во многом
зависит правильный статистический анализ работы любого подразделения здра-
воохранения. Знание методов медицинской статистики позволяет рассматривать
и определять тенденции демографических процессов, заболеваемости, физиче-
ского развития населения и т.д.
Медицинская статистика является основным методом социальной медицины
и организации здравоохранения.
Медицинская статистика делится на два основных раздела:
• шагистику здоровья населения
• шагистику здравоохранения
Статистика здоровья населения дает количественную характеристику со-
стояния здоровья различных групп населения в зависимости от комплекса соци-
ально-экономических, природных, биологических факторов, которые находятся в
тесной взаимосвязи.
Состояние здоровья населения характеризуются тремя группами показате-
лей:
• показатели заболеваемости и инвалидности
• показатели физического развития
• санитарно-демографические показатели
Статистика здравоохранения изучает сеть медицинских учреждений и
кадры, их деятельность по оказанию лечебно-профилактической помощи населе-
нию, использование материальных средств в здравоохранении и пр.
Любое статистическое исследование начинается с определения и четкой
формулировки цели и задач исследования.
Задачей социально-гигиенического исследования может быть изучение раз-
личных аспектов здоровья населения, деятельности системы здравоохранения для
обоснования конкретных управленческих решений.
Цель исследования предусматривает использование полученных данных для
практического здравоохранения.
Например, задачи исследования - изучение общей заболеваемости населения
в зависимости от пола, возраста, профессии, места жительства и других особен-
ностей, цель - разработка мероприятий по снижению общей заболеваемости в
данных группах.
Этапы статистического исследования
Статистическое исследование включает в себя четыре последовательных
этапа:
• составление плана и программы
• сбор статистического материала (статистическое наблюдение)
• обработка собранного материала
• анализ полученных данных
I этап. Составление плана и программы исследования
Этот этап является подготовительным к проведению статистического иссле-
дования.
ПЛАН статистического исследования включает в себя:
1. Определение объекта наблюдения - статистической совокупности, о кото-
рой будут собирать сведения
2. Определение места исследования - территории, учреждений
3. Определение времени (сроков) проведения исследования
4. Определение вида (единовременное, текущее) и метода (сплошной, не-
сплошной) статистического наблюдения. Их подробное описание будет дано при
освещении второго этапа статистического исследования
5. Исполнители и руководитель исследования
6. Материально-техническое обеспечение исследования
7 Оценка стоимости исследования
ПРОГРАММА статистического исследования включает в себя:
А. Определение статистической совокупности, единицы совокупности, еди-
ницы наблюдения
Б. Определение программы наблюдения, то есть определение первичного
статистического документа, содержащего перечень подлежащих регистрации
признаков
В. Определение программы разработки материала , то есть выбор группи-
ровки материала и составление макетов разработочных таблиц с различной
группировкой признаков.
А. Определение статистической совокупности, единицы совокупности и
единицы наблюдения.
Статистическая совокупность - масса однородных явлений, объединен-
ных рядом однородных признаков, взятых вместе и входящих в совокупность
Например: ipymia родившихся, ipyima умерших, ipyuna больных данным заболе-
ванием, население района, города, группа осмотренных.
Объект статистического наблюдения - это та совокупность, о которой
должны быть собраны сведения.
Единица совокупности - это первичный элемент объекта статистического
наблюдения, являющийся носителем признаков, подлежащих регистрации и ос-
3
новой ведущегося при исследовании счета . Например: каждый родившийся, ка-
ждый умерший, каждый случай заболевания, каждый осмотренный и т.д.
Единица наблюдения - это та первичная ячейка из которой могут быть по-
лучены единицы совокупности. Единицей наблюдения определяется в зависимо-
сти от цели исследования, это может быть: семья, рабочие данного цеха, жители
того или иного района.
Единицы совокупности имеют признаки сходства (место жительства, время
проведения исследования и др.) и признаки различия - учетные признаки (пол,
возраст, диагноз заболевания, сроки госпитализации, исходы лечения и др.)
Учетные признаки по характеру делят на :
• атрибутивные (описательные) - выраженные словесно (под,
диагноз, наличие вредных привычек и др.)
• количественные признаки - выраженные числом (возраст, стаж-
работы, уровень артериального давления, сроки пребывания в стацио-
наре и др.)
По роли в совокупности различают:
• факторные признаки - влияющие на изучаемое явление (пол,
возраст, профессия, вредные привычки и т.д.)
• результативные признаки - изменяющиеся под влиянием фак-
торных признаков ( диагноз, исход лечения и др.).
Различают генеральную и выборочную статистическую совокупность.
Генеральная совокупность состоит из всех единиц, которые могут быть к
ней отнесены с учетом цели исследования. Генеральная совокупность как прави-
ло состоит из бесконечно большого числа единиц. Например: все больные с дан-
ной патологией, все жители данной территории и т.д. В связи с невозможностью,
а часто с нецелесообразностью анализа всех единиц, составляющих генеральную
совокупность, исследуется часть генеральной совокупности - выборочная сово
купность.
Выборочная совокупность - часть генеральной совокупности, отобранная
для исследования и предназначенная для характеристики всей генеральной сово-
купности.
Выборочная совокупность должна отвечать двум требованиям:
1. Качественная репрезентативность (представительность) всех состав-
ляющих ее признаков по отношению к признакам генеральной совокупности.
Она должна обладать основными характерными чертами генеральной совокуп-
ности, то есть быть типичной по отношению к ней.
2. Количественная репрезентативность (представительность). Выбороч-
ная совокупность должна быть достаточной по объему (числу наблюдений), что-
бы более точно выразить особенности генеральной совокупности.
Количественная представительность достигается расчетом необходимого
числа наблюдений, качественная представительность - способом отбора единиц
из генеральной совокупности.
Б. Определение программы наблюдения - это выбор первичного стати-
стического документа, содержащего перечень подлежащих регистрации при-
4
знаков, а также четко сформулированные вопросы , на которые необходимо по-
лучить ответы при проведении статистического наблюдения.
Существуют официальные программы сбора статистического материала (по
учетным формам). Это государственные учетные и отчетные документы органов
и учреждений здравоохранения, социального страхования и социального обеспе-
чения (например, “Статистический талон для регистрации заключительных
(уточненных) диагнозов”, форма 025-2/у , “Статистическая карта выбывшего из
стационара”, форма 066/у, “Медицинское свидетельство о смерти”, форма 106/у
и др.).
Программа может быть также составлена специально составлена исследова-
телем для углубленного изучения наиболее важных проблем по разработанным
для этого различным бланкам (картам выкопировки из истории болезни, анкетам,
опросным листам и т.д.). Исследователь должен помнить, что статистическая кар-
та является документом, подтверждающим наблюдение, дает возможность про-
верить правильность записи, поэтому она должна содержать паспортные данные:
фамилию, имя, отчество, номер истории болезни, из которой взяты сведения , на-
звание учреждения и т.д. Составленная и заполненная карта должна быть подпи-
сана лицом, проводящим исследование.
Статистические исследования при которых используют специально органи-
зованные про, рам мы, дают дополнительную, более углубленную информацию,
широко применяемую в оценке состояния здоровья населения и анализе деятель-
ности учреждений здравоохранения (например: перепись населения,, выборочное
изучение общей заболеваемости, демографических процессов, различных виды
специализированной амбулаторно-поликлинической, стационарной помощи и
Т.д.)
В. Определение программы разработки материала включает в себя выбор
группировки материала и составление макетов таблиц.
Смысл группировки материала заключается в разделении статистической
совокупности на однородные группы по определенным признакам для изучения
тех или иных закономерностей, Из множества признаков нужно выбрать самые
существенные, поэтому выбор группировочных признаков требует всесторонне-
го анализа сущности изучаемого явления. Группировки основных признаков
могут быть представлены в различных комбинациях в зависимости от целей и
задач исследования. Например, при необходимости раздельного изучения забо-
леваемости детей, подростков, взрослых, пожилых группировка по возрасту ос-
новывается на анатомо-физиологических данных, указывающих в каком возрасте
ребенок становится подростком, подросток - взрослым и т.д., а возрастные ин-
тервалы представляют собой следствие установленных физиологических разли-
чий.
Группировка может производить по количественным и качественным при-
знакам.
Типологическая группировка - группировка по качественному (атрибу-
тивному) признаку - это разделение совокупности на группы по описательным
признакам, не имеющим количественного выражения (распределение больных по
5
профессиям, диагнозам, полу, тяжести заболевания; медицинских учреждений по
характеру их деятельности - больницы, поликлиники, диспансеры).
Вариационная группировка - группировка по количественному признаку,
это разделение совокупности на группы на основе числовых значений признака
(группировка по возрасту, стажу работы, росту, массе тела, длительности заболе-
вания).
Различают первичную и вторичную группировку.
Первичная группировка проводится по детальным признакам (группировка
по стажу с интервалом в один год), вторичная - для получения более крупных
групп (группировка по стажу с интервалов в пять лет - группы: до5 лег, от 5 до
10 лет, от 10 до 15 и т.д.).
Составление макетов статистических таблиц
Статистическая таблица - количественная характеристика изучаемой со-
вокупности. В статистических таблицах наглядно отражаются результаты стати-
стического наблюдения.
В каждой статистической таблице различают табличное подлежащее и
табличное сказуемое.
Табличное подлежащее - главный (основной) учетный признак по которому
проведена группировка материала, располагается в левой части статистической
таблицы.
Табличное сказуемое - учетные признаки, которых характеризуют подле-
жащее, располагаются в правой части таблицы в заголовке вертикальных столб-
цов.
При составлении статистических таблиц соблюдают ряд требований, к
основным из которых относятся:
• заголовок таблицы должен раскрывать ее содержание
• в заголовке таблицы указывают единицы измерения приведенных
данных
• табличное подлежащее располагается в левой части таблицы (в гори-
зонтальных строках), табличное сказуемое в правой части (в верти-
кальных строках)
• нулевые значения признака обозначают знаком "тире"
• наличие общих и погрупповых итоговых строк
В зависимости от числа использованных признаков и их группировки разли-
чают простые, групповые и комбинационные таблицы.
В простой статистической таблице материал сгруппирован по одному при-
знаку, такая таблица представляет общую сводку данных.
В групповой таблице - подлежащее характеризуется несколькими самостоя-
тельными, не связанными между собой признаками.
В комбинационной таблице- подлежащее характеризуется несколькими
взаимосвязанными признаками. Такая таблица в аналитическом отношении явля-
ется наиболее ценной.
6
Макет простой таблицы
Распределение травм по локализации
Локализация травмы Количество больных
Перелом лучевой кости
Перелом шейки бедра
Перелом костей таза
Итого
Макет групповой таблицы
Состав выбывших из стационара по диагнозам, полу и возрасту
Диагноз Пол Возраст Всего
м ж до 20 21-30 31-40 41-50
Итого
Макет комбинационной таблицы
Распределение пороков сердца среди детей различного возраста и пола
Диагноз Возраст Всего
0-3 года 4-6 лет 7-14 лет
м ж оба пола м ж оба пола м Ж оба пола м ж Оба пола
Порок сердца врож- денный
Порок сердца приоб- ретен- ный
Итого
II этап. Сбор материала (статистическое наблюдение)
Статистическое наблюдение это регистрация изучаемых единиц на спе-
циальных учетных медицинских документах.
Статистическое наблюдение классифицируется с учетом полноты ох-
вата единиц совокупности, учета фактов по времени и способу наблюдения.
7
Признаки Классификации Виды наблюдения Разновидности
1.По учету факторов во времени Текущее -
Единовременное -
2.По полноте охвата единиц совокупности Сплошное -
Несплошное а) выборочное
б)основного массива
в) монографическое
З.По способу наблюде- ния Непосредственное на- блюдение
Выкопировка данных анамнестический метод
Текущее наблюдение (постоянное) применяется при изучении быстро ме-
няющихся явлений, зависящих от условий жизни, состояния медицинской помо-
щи и др. Это систематический учет явления в течение определенного периода
времени, статистические данные собираются путем регистрации случаев по мере
из возникновения (учет рождаемости, смертности, заболеваемости, травматизма,
госпитализации).
Единовременное наблюдение (одномоментное) применяется при изучении
медленно меняющихся явлений, когда изучаемое явление не имеет тенденции к
быстрому изменению, регистрация данных проводится на определенный момент
времени. Единовременное наблюдение отражает статику явления, то есть дает как
бы одномоментную фотографию изучаемого явления (перепись населения, про-
филактические осмотры, перепись медицинских учреждений, и др.)
По полноте охвата различают сплошное и несплошное наблюдение.
Сплошное наблюдение предусматривает регистрацию всех случаев, состав-
ляющих генеральную совокупность. Сплошным методом собирают сведения о
числе родившихся, умерших,, обратившихся в поликлинику, о численности боль-
ных, врачей и др Для сплошного метода является характерным собирание массо-
вого материала при относительно ограниченном числе учетных признаков , что,
однако, не позволяет провести углубленный анализ.
При несплошном методе наблюдения учитываются не все единицы сово-
купности, а только часть их, по которой судят о свойствах всего объекта наблю-
дения. Несплошное наблюдение имеет ряд преимуществ: оно меньше по объему,
для его осуществления требуется меньше сил и средств, оно позволяет применить
более совершенные способы учета фактов, то есть расширить программу иссле-
дования. В зависимости от характера объекта исследования и поставленных за-
дач несплошное исследование организуется по разному.
Разновидностями несплошного наблюдения являются:
монографическое наблюдение - это детальное описание отдельных, харак-
терных в каком - либо отношении единиц совокупности (описание типичных
8
случаев течения заболеваний, описание типичных объектов территории при ме-
дико-географическом исследовании, и др.)
метод основного массива - это изучение явления в месте его наибольшего
проявления, изучаются объекты на которых сосредоточено большинство изучае-
мых явлений, то есть изучение преобладающей доли единиц совокупности ( на-
пример, изучение исходов лечения, диспансеризации, организационных форм об-
служивания, больных гастроэнтерологического, нефрологического, пульмоноло-
гического профиля по данным специализированных центров)
Наиболее совершенным видом несплошного наблюдения является выбо-
рочное исследование, при котором характеристика всей совокупности дается на
основании некоторой части ее, отобранной специальными методами.
По способу организации различают следующие виды выборочного наблю-
дения:
• случайный отбор -отбор единиц совокупности на основании таблиц
случайных чисел или методом жеребьевки, при этом способе каждая единица
имеет равную возможность попасть в выборку. При случайном отборе единиц
создаются условия для действия закона больших чисел - в массе случайной вы-
борки проявляется общая закономерность, свойственная изучаемому явлению в
целом.
• механический отбор имеет в своей основе арифметический подход к
отбору единиц. Единицы генеральной совокупности распределяют в какой-
либо последовательности по любому случайному признаку (например, истории
болезни распределяют по дням поступления больных, или по первой букве фа-
милии, по номерам), материал разбивают на равные части и из них в заранее
обусловленном плане отбирают каждую пятую, или десятую, или иную едини-
цу, таким образом, чтобы обеспечить требуемый объем выборки (10%,20% и
т.д.)
• типологический отбор проводится путем деления всей генеральной со-
вокупности на качественно однородные группы по ведущим признакам , из
которых отбирают в случайном или механическом порядке единицы. В ре-
зультате такого отбора в выборочной совокупности отдельные типические
группы будут представлены в том же соотношении, что и в генеральной сово-
купности, что увеличивает точность такого способа выборки.
• гнездовой отбор (серийный) применяется в тех случаях, когда нет воз-
можности проводить выборку из всей совокупности в виду большой террито-
рии обследования. В этом случае вся совокупность делится на однородные
“серии” (гнезда), отбор серий проводится в случайном или механическом по-
рядке, отбирают “объекты” (гнезда), которые в дальнейшем изучаются сплошь
или выборочно.
Для углубленного изучения взаимосвязи менее изученных признаков при ис-
ключении признаков, влияние которых известно, используют метод направлен-
ного отбора. Например влияние возраста и пола на распространенность гипер-
тонической болезни известно, поэтому для углубленного исследования можно
использовать совокупность лиц одного пола и возраста. Одним из видов направ-
ленного отбора является когортный метод - это изучение совокупности, которая
9
состоит из единиц, объединенных сроком наступления определенного события, и
прослеженного в один и тот же интервал времени (наблюдение за группой детей
одновременно родившихся, за группой лиц, одновременно вступивших в брак,
имеющих одинаковый стаж работы на предприятии). Когортный метод позволяет
сделать своего рода срез в том месте изучаемого явления, в котором наиболее яр-
ко проявляются те или иные закономерности.
Различают несколько способов наблюдения.
Непосредственное наблюдение, когда сведения регистрируют при непо-
средственном осмотре больного или здорового человека, при проведении сапи-
тарно- гигиенического обследования объекта. Выкопировка данных - получение
сведений из учетно-отчетных форм и другой медицинской документации. Ис-
пользуется при изучении рождаемости, смертности, заболеваемости, инвалидно-
сти, деятельности медицинских учреждений. Анамнестический способ получе-
ния информации основан на получении сведений от больных или близких род-
ственников и их воспоминаниях о событиях, которые ранее были в их жизни.
Способ может быть осуществлен путем опроса “лицом к лицу” (устное интервью)
или заочного опроса (письменное анкетирование). Содержание вопросов в анкете
должно отвечать целям и задачам исследования, а ответы не должны вызывать
затруднений у опрашиваемых.
III этап. Обработка собранного материала
На этом этапе производятся:
1. Проверка материала на полноту и правильность заполнения учетных докумен-
тов, устранение дубликатов.
2. Шифровка (кодирование) путем проставления условного знака около каждого
признака.
3. Раскладка карт по группам в соответствии с шифром, подсчет карт в каждой
группе.
4. Составление общей сводки, занесение результатов подсчета в макеты таблиц
заранее установленной формы для получения сравнительных и обобщающих
величин.
IV этап. Анализ полученных данных
Этот этап складывается из :
• вычисления показателей ( средних и относительных величин)
• построения графических изображений, иллюстрирующих полученные
данные
• сравнения результатов исследования
• формулировки выводов, заключения и предложений по данному иссле-
дованию.
На этом этапе применяются специальные статистические методики: метод
стандартизации, метод корреляции, дисперсионный анализ и пр.
10
АБСОЛЮТНЫЕ И ОТНОСИТЕЛЬНЫЕ ВЕЛИЧИНЫ
На третьем этапе статистического исследования в результате сводки мате-
риала при подсчёте данных наблюдения по группам в разработочных таблицах
получают абсолютные числа, которые характеризуют количественное выраже-
ние изучаемого явления.
Абсолютные числа или величины имеют в статистике определённое значе-
ние. Абсолютными величинами выражаются, например, население городов,
стран, редкие заболевания и редко встречающиеся явления.
В медицинской практике абсолютными величинами могут также выражаться
все индивидуальные данные, которые получают от больного (частота сердечных
сокращений, артериальное давление, количество молочных и постоянных зубов у
ребенка в различные возрастные периоды). Но абсолютные величины (числа) ма-
лопригодны для сравнения их друг' с другом и анализа, т.к. они дают характери-
стику изучаемому явлению, но глубоко его не раскрывают. Для того, чтобы мож-
но было провести анализ и сделать правильные выводы, необходимо абсолютные
числа преобразовать в производные величины (относительные или средние).
Относительные величины (показатели, статистические коэффициенты)
рассчитываются путем деления одной абсолютной величины на другую и умно-
жения полученной дроби на какой-либо коэффициент (основание) - 100, 1000,
10000 и т.д.. Соответственно этому, относительные величины могут выражаться в
процентах (%), промилле (%<>), продецемилле (%о0) и т.д.
Различают следующие группы относительных величин :
1. Показатели экстенсивности (или распределения)
2. Показатели интенсивности (или частоты)
3. Показатели соотношения (обеспеченности)
4. Показатели наглядности
Показатели экстенсивности (структуры, распределения, состава явле-
ния) характеризуют распределение целого на составляющие его части по их
удельному весу. Эти показатели характеризуют распределение явления внутри
одной совокупности. При этом вся совокупность (целое явление) принимается за
100 %, а часть определяется как искомое.
Методика вычисления показателя экстенсивности:
часть явления х 100
целое явление
Экстенсивные показатели вычисляют, когда необходимо определить струк-
туру явления: распределение родившихся по полу и весу при анализе рождаемо-
сти; распределение умерших по полу, возрасту, причинам смерти при анализе
смертности; распределение больных по полу, возрасту, диагнозу и срокам госпи-
тализации при анализе заболеваемости; состав населения по полу, возрасту, обра-
зованию, профессии и занятости в сфере производства; распределение больнич-
ных коек по профилю при анализе структуры коечного фонда.
и
ПРИМЕР: В больнице 450 коек, из них 60 коек педиатрических. Необходимо определить
удельный вес педиатрических коек. Доля педиатрических коек вычисляется следующим обра-
зом:
количество педиатрических коек х 100 60 х 100= 13,3%
общее количество коек в больнице 450
Показатели экстенсивности характеризуют состав явлений в конкретное
время, в конкретном месте. Для динамических сравнений эти показатели не при-
годны. Сравнение удельных весов позволяет судить лишь о их порядковом номе-
ре в структуре (заболеваемости, смертности и т.д.), но нс дает возможности гово-
рить о частоте, распространенности данного явления. Для этой цели всегда необ-
ходимо знать численность среды, в которой происходит явление, и вычислить ин-
тенсивные показатели.
Показатели интенсивности (частоты, распространенности) характеризу-
ют частоту (уровень) явления в той среде, из которой это явление происходит.
Показатели интенсивности определяют соотношение между изучаемым явлением
и средой, его продуцирующей (т.е. соотношение между двумя однородными со-
вокупностями). Для вычисления показателя интенсивности нужно знать величи-
ну интересующего нас явления и величину той среды, в которой данное явление
наблюдается.
Методика вычисления показателя интенсивности:
явление х 100 ( 1000,10000 и т.д.)
среда
Средой обычно является население в целом или отдельные его группы (воз-
растные, половые, профессиональные и т.д.).
Явление- случаи заболеваний, смертей, рождений, осложнений и т.д.
Показатели, рассчитанные на все население (совокупность), называются об-
щими.
Показатели, рассчитанные на отдельные ipynribi, называются специальными.
Выбор коэффициента при вычислении показателей частоты зависит от чис-
ла наблюдений и размера среды. Чем меньше явление, частоту которого необхо-
димо определить, тем больше должен быть коэффициент для получения пока-
зателя, выраженного целым числом (10 000, 100 000) и, наоборот, чем больше яв-
ление, тем коэффициент должен быть меньше (100, 1 000).
Интенсивные показатели применяются при анализе заболеваемости (частота
того или иного заболевания на той или другой территории, т.е. определение
уровня заболеваемости и распросз'раненности, частота инвалидности, заболевае-
мости с временной утратой трудоспособности, летальность в стационаре); в сани-
тарно-демографической статистике (общие и специальные показатели рождаемо-
сти, смертности, младенческой и материнской смертности).
ПРИМЕР: Необходимо определить частоту пораженности флюорозом школьников стар-
ших классов (10, 11-е классы), проживающих в районе с высоким содержанием фтора в воде,
если известно, что из общего количества старшеклассников (520 человек) у 92 школьников об-
наружен флюороз.
• число случаен флюороза х 1000 92 х 1000 = 177
число школьников 10, 11-х классов 520
12
Следовательно, распространённость флюороза среди старшеклассников в районе с низким
содержанием фтора в воде - 177 на 1000 школьников.
Показатели соотношения (обеспеченности) характеризуют со-
отношение двух разнородных, не связанных между собой совокупностей, сопос-
тавляемых только логически, по их содержанию. Они вычисляются так же, как и
показатели интенсивности, но их отличие от последних заключается в том, что
интересующие нас явления не представляют собой продукт той среды, на кото-
рую производится расчет, т.е. эти показатели определяют отношение между раз-
нородными совокупностями. Применяются эти показатели для характеристики
обеспеченности населения койками, врачами, местами в детских садах, лекарст-
венными препаратами и т.д.
Показатели соотношения выражаются обычно на 10 000 населения.
Методика вычисления показателя соотношения :
одна совокупность х 10 000
другая совокупность
ПРИМЕР: В районе с населением 65 000 человек имеется 27 терапевтов и 4 с томатолога.
Показатель обеспеченности терапевтами составит:
27 х 10 000-4.2
65 000
Показатель обеспеченности стоматологами составит:
4 х 10 000 = 0,6
65 000
Таким образом, обеспеченность населения района терапевтами составляет - 4,2; стомато-
логами - 0,6 на 10 000 населения.
Показатели наглядности применяются для определения изменений,
происшедших с тем или иным явлением в течение какого-либо периода времени,
или для сравнения друг с другом аналогичных явлений на разных территориях.
Они показывают, во сколько раз (или на сколько процентов) произошло увеличе-
ние или уменьшение сравниваемых величин. Расчеты могут проводится на абсо-
лютных, относительных или средних величинах. При этом, в зависимости от по-
ставленной задачи, одна из величин принимается за 100%, или за единицу (в
кратностях).
Для выражения этих показателей составляется пропорция.
Методика вычисления показателя наглядности:
сравниваемый уровень х 100
исходный уровень
ПРИМЕР: В четырех районах: А, Б, В, Г - частота черепно-мозговых травм составила со-
ответственно 3,8; 5.6; 4,5; 5,8 на 10 000 населения.
Травматизм в районе А - 3,8 условно принимается за 100%, тогда травматизм
в районе Б: в районе В : в районе Г:
5,6 х 100=147.4% 4,5 х 100= 118.2% 5,8x 100- 152,6%
3,8 3,8 3,8
13
Полученные результаты означают, что травматизм в районах Б, В, и Г превышаег травма-
тизм в районе А соответственно на 47,4 %, 18,2 %, 52,6 %
ГРАФИЧЕСКОЕ ИЗОБРАЖЕНИЕ СТАТИСТИЧЕСКИХ ДАННЫХ
Графическое изображение широко используется как способ для наглядного
представления статистических данных и зримого выявления закономерно-
стей.
Графические изображения могут быть построены как по абсолютным, так и
по относительным и средним величинам.
Виды графических изображений:
Диаграммы
• линейные
• внутристолбиковые
• радиальные
• столбиковые
• секторные
• объемные
• фитурные
Картограммы
Картодиа)рамм ы
Диаграмма - это 1рафик, в котором статистические данные изображаются
различными геометрическими фигурами (столбиком, линиями, окружностями и
Т.Д.).
Картограмма - это схематическая географическая карта, на которой различ-
ной окраской или штриховкой показано распределение какого-либо явления в
пространстве.
Картодиаграмма - это сочетание схематической географической карты с
одним из видов диаграмм (столбиковые, секторные и другие).
Линейные диаграммы - применяются для изображения динамики того или
другого явления или процесса, выраженных в показателях интенсивности, соот-
ношения, наглядности, средних или абсолютных величинах. С помощью линей-
ной диаграммы можно изображать рост численности населения, динамику мла-
денческой смертности и т.д. При построении этого тина графических изображе-
ний на горизонтальной линии (абсцисс) откладывают равные отрезки по числу
тех единиц времени (часов, дней, месяцев, лет), при помощи которых измеряется
изображаемое явление. Если отрезки времени неравны, то размеры их должны
пропорционально соответствовать единице измерения. На вертикальной линии
(ординате) наносят деления в единицах измерения изучаемого явления. На верти-
кальных линиях, параллельных ординате, отмечают точками величину изобра-
жаемых явлений. Соединив точки линиями, получают линейную диаграмму. На
одном графике может быть изображено несколько линий разного цвета или раз-
личной штриховки.
Столбиковая диаграмма - применяется для изображения динамики или ста-
тики явления в соответствии с избранным масштабом. Столбиковые диаграммы
14
строят в виде вертикальных или горизонтальных столбцов (“лент”). Ширина
столбиков, так же как и расстояние между ними, должно быть одинаковым. В ви-
де столбиков целесообразно изображать интенсивные показатели или показатели
соотношения для одного периода времени, но для разных коллективов, террито-
рий.
Внутристолбиковая диаграмма применяется для изображения структуры
явления, выраженной экстенсивными показателями. Она представляет собой
прямоугольник, в котором цветом или штриховкой выделены составляющие его
части в соответствии с их удельным весом. Высота прямоугольника в этом слу-
чае принимается равной сумме всех частей, составляющих целое. Составные час-
ти целого располагаются внутри прямоугольника в порядке убывания их удельно-
го веса.
Секторная (круговая) диаграмма - также применяется для изображения
структуры явления и представляет собой круг, разделенный радиусами на секто-
ра, которые выделяются различной штриховкой или цветом. При построении сек-
торной диаграммы необходимо с помощью транспортира на окружности отло-
жить в градусах части, пропорциональные расширению явления, состав которого
требуется изобразить. К точкам, намеченным на окружности, проводятся радиу-
сы. Сектора выделяются различной штриховкой или расцветкой.
Объемная диаграмма - применяется для изображения статистических вели-
чин в виде шара, куба и других объемных геометрических фигур. Они могут ил-
люстрировать показатели интенсивности, соотношения, наглядности.
Радиальная диаграмма - строится на системе полярных координат при изо-
бражении динамики явления за замкнутый цикл времени (сутки, неделя, год).
Они применяются для изображения явлений, имеющих сезонный характер (на-
пример, сезонные колебания заболеваемости респираторными вирусными ин-
фекциями, дизентерией и пр.). Радиус окружности принимается за среднедневное
(среднемесячное, среднегодовое) число заболеваний. Каждый радиус соответст-
вует определенному месяцу года, отсчет которых ведется по часовой стрелке. На
радиусах и их продолжениях откладывают величины соответствующие средне-
дневным (среднемесячным, среднегодовым) числам заболеваний. Точки, отме-
ченные на радиусах и их продолжениях, соединяют линиями и получают много-
угольник, изображающий сезонные колебания изучаемого явления.
Правила построения диаграмм
1. Каждая диаграмма должна иметь надпись, в которой четко, кратко и вме-
сте с тем исчерпывающе следует указать содержание диаграммы, время и место, к
которым относятся изображаемые данные
2. Диаграмма должна строится по определенному масштабу с указанием
единиц измерения, в которых представлены статистические величины.
3. Черчение диаграмм, основанных на системе полярных координат следует
начинать с проведения двух линий - безосной (абсциссы) и масштабной (ордина-
ты)
4. Для каждой диа1раммы должны быть даны пояснения, обозначающие ка-
ждую расцветку или штриховку (экспликация).
15
ДИНАМИЧЕСКИЕ РЯДЫ
Динамический ряд - это ряд, состоящий из однородных величин, показы-
вающих изменение явления во времени.
Для того, чтобы анализировать динамику того или иного процесса, необходи-
мо уметь сопоставить динамические ряды разных типов, уметь их выравнивать и
анализировать.
Числа динамического ряда принято называть уровнем ряда.
Уровни ряда могут быть представлены абсолютными величинами (изменение
количества лейкоцитов у больных под влиянием лучевой терапии), относитель-
ными показателями (изменение инфекционной заболеваемости под влиянием им-
мунизации) и средними величинами (среднечасовая нагрузка врачей по дням не-
дели).
Динамические ряды существуют простые и сложные.
Простой динамический ряд представлен абсолютными величинами.
Сложный динамический ряд представлен средними величинами и интенсив-
ными показателями.
Простой динамический ряд может быть двух видов: моментный и интер-
вальный.
Моментный ряд - это ряд, характеризующий явление на определенную дату
(момент).
Уровень моментного ряда не подлежит дроблению (в разные промежутки
времени).
В качестве примера моментного динамического ряда может служить динами-
ка численности населения России, динамика численности врачей.
ПРИМЕР. Количество больных, находящихся на лечении в областной больнице в на-
чале апреля месяца 2001 г. 1.04.01 307 чел. 2.04.01 - 299 чел 3.04.01 -301 чел. 4.04.01 - 304 чел. 5.04.01 302 чел. 6.04.01 303 чел. 7.04.01 - 302 чел.
Интервальный ряд - это ряд, характеризующий изменение явлений за опреде-
ленный период, интервал (сутки, неделя, месяц, год).
Интервальный ряд в отличие от моментного можно разделить на более дроб-
ные периоды, а также можно укрупнить интервалы.
Интервальные ряды составляют числа не только родившихся, но и числа
умерших, заболевших и других, т.е. числа, которые зависят от промежутка вре-
мени.
Выбор величины в интервальном ряду (год, месяц, неделя, день, час) опреде-
ляется степенью изменчивости явления (смертность, заболеваемость, рождае-
мость). Чем медленнее изменяется явление во времени, тем крупнее должны быть
периоды наблюдения.
16
ПРИМЕР. Данные о числе поступивших больных в стационар за I квартал 2001 г.
Январь - 434 чел.
Февраль - 386 чел.
Март - 424 чел.
К сложному ряду относится ряд, состоящий из средних величин (средняя дли-
тельность лечения, среднегодовое число коек за несколько лет), а также из отно-
сительных величин (заболеваемость, смертность, рождаемость за несколько лет).
1992 104,0
1993 - 118,0
1994-119,0
1995-123,0
ПРИМЕР. Среднекоечная мощность районных больниц Саратовской области на 10000
населения:
1988- 97,0
1989- 96,5
1990- 106,0
1991 - 103,0
Динамические ряды могут быть подвергнуты различного рода преобразовани-
ям, целью которых является выяснение особенностей изменения изучаемого
процесса, а также достижение большей наглядности. Для более наглядного выра-
жения нарастания или убывания ряда можно преобразовать его по максимуму
или по минимуму (т.е. вычисляется показатель наглядности).
Существует несколько способов преобразования динамического ряда:
• укрупнение интервалов
• расчет групповой средней
• расчет скользящей средней
1. Укрупнение интервалов производится путем суммирования данных за ряд
смежных периодов.
ПРИМЕР. Сезонные колебания случаев ангины в г.А в 2001 г.
Месяцы Число Заболе- ваний но ме- сяцам По кварта- лам 1 2 3 4 5 6 7 8 9 ю Тн 12 И ГОТО
12 9 19 3 13 3 38 7 230 288 53 0 370 380 231 137 260 3268 3268
455 950 628 1280
Данные таблицы свидетельствуют, что помесячные колебания ангины то
увеличиваются, то уменьшаются. После укрупнения интервалов по кварталам
года можно увидеть определенную закономерность: наибольшее число заболе-
ваний в летне-осенний период.
2. Расчет групповой средней заключается в определении средней величины
каждого укрупненного периода. Для этого надо суммировать смежные уровни со-
седних периодов, а затем сумму разделить на число слагаемых.
ПРИМЕР. Динамика расхождения клинических и патологоанатомических диагнозов в
областной больнице г. Н. за 1994 - 2001 гг.
17
Год 1994 1995 1996 1997 1998 1999 2000 2001
Процент расхож- дения диагно- зов 11.0 9,8 8,0 9,2 8,2 8.6 8,5 7,9
Группо- вая средняя 10,4 8,6 8,4 8,2 : !
Уровни динамического ряда представляют собой волнообразные колебания. Выравнивания
динамического ряда путем расчета групповой средней позволили получить данные, довольно
четко характеризующие тенденцию к постепенному снижению случаев расхождения диагнозов
в областной больнице.
3 Расчет скользящей средней позволяет каждый уровень ряда заменить средней
величиной из данного уровня и двух средних с ними. Этот метод дает возможность
сгладить, устранить резкие колебания динамического ряда.
Год 1994 1995 1996 1997 Г 1998 1999 2000 2001
Процент расхож- дения диш но- зов 11.0 9,8 8,0 9,2 8,2 8,6 8.5 7,9
Средняя сколь- зящая 9-6 9,0 И т. д.
Способ
вычис- 1988 (11,0 + 9,8 + 8.0): 3 - 9.6 и т. д.
ления ।
I
средней___________________ ]
Выравненный ряд при помощи скользящей средней представляет последовательную
тенденцию снижения процента расхождения диагнозов.
При анализе динамического ряда, характера происходящих изменений во времени, их
темпа вычисляют следующие показатели:
• абсолютный прирост (или снижение)
• темп прироста (или снижения)
• темп роста
• абсолютное значение одного процента прироста (или снижения)
Абсолютный прирост (или снижение) представляет собой разность предыдущего и по-
следующего уровней
Темп прироста (или снижения) процентное отношение абсолютного прироста к пре-
дыдущему уровню
Темп роста - процентное соотношение каждого последующего уровня к предыдущему
Темп прироста представляет собой геми роста минус 100%
Абсолютное значение 1% прироста - отношение абсолютного прироста к темпу при-
роста.
ПРИМЕР. Заболеваемость с временной утратой трудоспособности в 1994 году была 40,0 дня па
100 рабочих, в 1995 году 70,0 дня на 100 рабочих.
Абсолютный прирост 70,0 40,0 30,0
1«
Темп прироста- (30х100)/40 =75%
1% прироста - 30/70 =0,4
Темп роста = (70 х 100) /40 = 175% (абсолютное число дней).
При графическом изображении динамического ряда удобнее пользоваться ли-
нейными или кривыми диаграммами (данные о динамике сети учреждений здра-
воохранения, оснащенности лечебных учреждений, данные о заболеваемости,
смертности).
СРЕДНИЕ ВЕЛИЧИНЫ. МЕТОДИКА ВЫЧИСЛЕНИЯ СРЕДНЕЙ
АРИФМЕТИЧЕСКОЙ, ОЦЕНКА ЕЕ ТИПИЧНОСТИ И ДОСТОВЕРНОСТИ
Важным групповым свойством статистической совокупности является средний
уровень признака, который характеризуется средними величинами.
Средняя величина - это величина, одним числом характеризующая всю сово-
купность в целом.
Различают несколько видов средних величин: средняя арифметическая, сред-
няя геометрическая, средняя гармоническая, средняя квадратическая, средняя
прогрессивная, средняя хронологическая. В практической деятельности врача
наиболее часто используются средняя арифметическая (М) и особые средние -
мода (Мо) и медиана (Me).
Средние величины находят широкое применение в научных эксперименталь-
ных и клинических исследованиях для характеристики физиологических показа-
телей организма в норме и патологии, при обработке лабораторных данных. Они
используются также для оценки здоровья населения, при характеристике физиче-
ского развития (средний рост, средняя масса тела), при анализе деятельности ле-
чебно-профилактических учреждений (показатели нагрузки врачей, посещаемо-
сти поликлиники, среднее число жителей на участке, среднегодовая занятость
больничной койки, средняя длительность пребывания в стационаре и пр.). Нельзя
обойтись без вычисления средних величин и в специальных социально-
гигиенических исследованиях: средняя жилая площадь на человека, средний воз-
раст, средний стаж работы в группах работающих, среднее содержание химиче-
ского вещества во внешней среде и т.д.
При использовании средних величин необходимо соблюдать два важнейших
условия.
1. Средние величины должны быть вычислены из качественно однород-
ных совокупностей. Если статистическая совокупность неоднородна, то рассчи-
танная на основе ее данных средняя не будет правильно отражать типичные ха-
рактерные особенности изучаемого явления.
2. Средние величины должны быть исчислены на массовых материалах, т.е. в
совокупности должно быть достаточно большое число наблюдений. Это тре-
бование основано на законе больших чисел.
ВАРИАЦИОННЫЙ РЯД И ЕГО ЭЛЕМЕНТЫ
В каждой совокупности ее отдельные единицы отличаются друг от друга по ве-
личине изучаемого признака. Это различие называется вариацией.
19
Группировка единиц совокупности по величине варьирующего признака дает
вариационные ряды.
Вариационный ряд - это ряд числовых значений изучаемого признака.
Каждый вариационный ряд включает в себя следующие элементы:
• варианта (V) - каждое отдельное числовое значение признака в совокуп -
ности (рост каждого ребенка, частота пульса каждого больного, число лей-
коцитов в крови каждого обследованного и т.д.), в том числе Vmin - наи-
меньшая варианта и Vmax - наибольшая варианта, ограничивающие вариа-
ционный ряд
• частота или математический вес (Р) - число, которое показывает, сколько
раз данный признак (варианта) встречается в совокупности
• число наблюдений (п) - сумма всех частот (п = 1Р)
• интервал - разность между двумя соседними вариантами (V3-V2, V2-VL т.д.)
• амплитуда - разность между наибольшей и наименьшей вариантами (Vmax -
Vmin)
• мода (Мо) - варианта, которая встречается в вариационном ряду наиболее
часто (т.е. имеющая наибольшую частоту или наибольший математический
вес)
• медиана (Me) - величина, которая делит вариационный ряд на две равные
части по числу наблюдений. Если число наблюдений четное, то место распо-
ложения середины вариационного ряда определяется по формуле п_,
если нечетное - п + 1 2
2
ПРИМЕР: Распределение обследованных рабочих по частоте пульса
Частота пульса в 1 мин. (V) Число обследованных (Р)
66 1
68 2
69 3
70 5
72 3
76 1
п=15 Мо = 70
Me - 70 (8-я варианта, т.к. по обе
стороны от нее находится
равное число вариант)
ВИДЫ ВАРИАЦИОННЫХ РЯДОВ
• ранжированный (упорядоченный) ряд - такой, в котором числовые значе-
ния вариант располагаются последовательно, по убыванию или по зарастанию (5,
7, 8, 12, 26, 31, 38 и т.д.)
• неранжированный ряд - такой, в котором варианты располагаются беспоря-
дочно (34,6, 12,45,24, 7, 98 и т.д.)
20
• прерывный (дискретный) ряд - такой, в котором варианты выражены толь-
ко целым числом и не могут иметь промежуточных значений (число детей в се-
мье, число лейкоцитов в крови, частота пульса, число посещений, пр.)
• непрерывный ряд - такой, в котором варианты могут принимать любые зна-
чения, в том числе и дробные (рост, масса тела, время, затраченное на прием од-
ного больного, содержание в крови или воздухе различных веществ, пр.)
• простой (развернутый) ряд - такой, в котором каждая варианта и соответст-
вующая ей частота обозначены отдельно. Ряд, в котором каждая варианта встре-
чается с частотой, равной единице, называется простым невзвешенным, а если с
разной частотой - простым взвешенным.
• сгруппированный (интервальный) ряд - такой, в котором варианты соеди-
нены в группы, объединяющие их но величине в пределах определенного интер-
вала.
Составление сгруппированного вариационного ряда
Простой, несгруппированный ряд, особенно при большом объеме совокупно-
сти, является громоздким и неудобным для вычисления средних величин, поэто-
му он обычно составляется при небольшом числе наблюдений (п < 30).
При большом числе наблюдений (п > 30) строят сгруппированный ряд на осно-
ве интервала (i), показывающего число вариант, объединенных в одну группу.
Группировку рядов проводят следующим образом:
I. Определяют размах ряда (амплитуду) вычитанием минимальной варианты
из максимальной (Vmax - Vmin)
2. Полученное число делят на желаемое количество групп - так определяется
интервал.
3. Начиная с минимальной варианты, строят вариационный ряд. Границы ин-
тервалов должны быть четкими, исключающими попадание одной и той же ва-
рианты в разные группы.
Правильно составленный сгруппированный (интервальный) ряд должен отве-
чать следующим требованиям:
1. Все варианты распределения должны войти в труппы.
2. Общее число выделенных групп должно быть не менее 7 (иначе вычисленная
средняя арифметическая будет неточной) и не более 15 (иначе ряд будет большим
и громоздким).
3. Каждая новая последующая группа должна начинаться с новой последующей
варианты, т.е. одна и та же варианта не должна встречаться в двух смежггьгх
группах.
4. Интервал должен быць одинаковым в каждой группе, т.е. в каждую группу
должно входить одинаковое число вариант. Размер интервала определяют, исходя
из характера изучаемого признака, из числа выбранных трупп, количества вари-
ант и числа наблюдений. Величина интервала выбирается также с учетом целей и
задач исследования.
5. Каждая группа в сгруппированном ряду должна иметь начальную и конеч-
ную варианты, т.е. не должно быть так называемых открытых групп (например,
до 5 лет, старше 60 лет и т.п.).
21
6. Каждой группе присваивается частота, равная сумме частот всех вариант,
вошедших в группу.
ПРИМЕР: Результаты измерения массы тела девочек 12 лет
Масса тела в кг (V) Число лиц (Р)
27 1
28 1
29 2
30 5
31 8
32 10
3.3 13
34 15
35 14
36 10
37 7
38 4
39 2
40 1
41 1
С целью упрощения вариационного ряда производим группировку вариант по три (интервал
3) и получаем сгруппированный ряд:
Масса тела в кг (V) Число случаев (Р)
27-29 4
.30 - 32 23
33-35 42
36-38 21
39-41 4
Дальнейшее упрощение сгруппированного ряда заключается в предваритель-
ном определении середины интервала (центральной варианты).
В прерывных сгруппированных вариационных рядах центральная варианта оп-
ределяется как полусумма начальной и конечной вариант в группе и ей при-
сваивается суммарная частота всех вариант, вошедших в данную группу:
Масса тела в кг (V) Число лиц (Р)
(27 + 29): 2 - 28 4
31 23
34 42
37 21
40 4
В непрерывных сгруппированных вариационных рядах центральная варианта
определяется как полусумма начальных вариант соседних групп.
22
Масса тела в кг (V) Число лиц (Р)
27,0 - 29,9 4
30,0 - 32,9 23
33,0 - 35,9 42
36,0 - 38,9 21
39,0-41,9 4
Центральная варианта для первой группы данного ряда равняется (27,0 + 30,0): 2 = 28,5 см и
т.д.
МЕТОДИКА ВЫЧИСЛЕНИЯ СРЕДНЕЙ АРИФМЕТИЧЕСКОЙ
Средняя арифметическая (М) - производная вариационного ряда, которая
одним числом характеризует весь ряд и выражает его основную закономерность.
Вычисление простой и взвешенной средней арифметической
Средняя арифметическая простая вычисляется для простого невзвешенного
вариационного ряда, в котором варианты встречаются с частотой, равной едини-
це (Р=1), и определяется как сумма всех вариант (XV), деленная на число на-
блюдений (п):
У г
М - =*-- , где М - средняя арифметическая
V - варианты
S - знак суммирования
п - число наблюдений
ПРИМЕР: Содержание сахара в крови (в мг%)
Уровень сахара (V) Число случаев (Р)
105 1
103 1
102 1
101 1
100 1
100 1
99 1
98 1
97 1
95 1
XV = 1000 п= 10
EV 1000
М= п = 10 - 100 мг %
Средняя арифметическая взвешенная вычисляется в тех случаях, когда в ва-
риационном ряду отдельные значения вариант повторяются (Р>1).
М = ——
и
где М - средняя арифметическая
V - варианты
Р - частоты
S - знак суммирования
п - число наблюдений
23
ПРИМЕР:
Результаты измерения массы тела юношей 18 лет
Масса тела в кг (V) Число лиц (Р) VP
64 2 128
63 3 189
62 9 558
61 6 366
60 4 240
59 1 59
п = 25 ZVP 1540
XVP 1540
М = п = 25 = 61,6 кг
Вычисление средней арифметической по способу моментов
(условных отклонений)
При больших числовых значениях признака в значительных по объему сово-
купностях средняя арифметическая вычисляется упрощенным способом, который
называется “способ моментов” или “способ условных отклонений”.
Вычисление средней арифметической по способу моментов основано на с ле-
дующих ее свойствах:
1. Каждая варианта отклоняется от средней в большую или в меньшую сто-
рону. Это отклонение (d) может быть выражено положительным или отрицатель-
ным числом.
2. Сумма отклонений с положительным знаком всегда равна сумме отклоне-
ний с отрицательным знаком, следовательно, алгебраическая сумма отклонений
всех вариант от средней равна нулю ( это свойство средней лежит в основе
данного способа вычисления).
3. Средняя арифметическая равна любой произвольно взятой величине плюс
среднее отклонение от нее всех членов ряда, которое имеет выражение ZPd и
называется моментом первой степени (обозначается буквой А) п
Средняя арифметическая вычисляется по формуле:
XdP л.
М — Mt -i —, где М - средняя арифметическая
п
Mi - “условная” средняя арифметическая
d - отклонение условной средней от вариант
Р - частота
п - число наблюдений
£ - знак суммирования
Вычисление ведется от “условной” средней (М)). За среднюю условно при-
нимается любая варианта, чаще мода (как наиболее часто встречающаяся вариан-
та). Если эта величина действительно средняя арифметическая, то сумма откло-
нений всех вариант от нее будет равна нулю. Если сумма отклонений будет рав-
24
няться какой-то величине, то это означает, что “условная” средняя не соответст-
вует действительной и к ней требуется поправка (момент первой степени - А):
XPd
Если А = п тогда М = М| + А
ПРИМЕР: Средняя дневная нагрузка врача-терапевта в поликлинике
Число больных (V) Число приемов (Р) d(d = V-M,) Pd
14 2 -4 -8
15 ' 1 -3 -3
16 3 _ 2 -6
17 3 -1 -3
18 4 0 0
19 4 +1 + 4
20 3 4 2 + 6
21 2 + 3 + 6
п = 22 XPd = - 4
iPd -4
М, - 18; п - 22 - -0,18
Таким образом, М = 18 + (-0,18) = 17,82,
Последовательность вычислений:
1. Выбираем “условною” среднюю М|~ 18 больных
2. Определяем отклонение ( d) каждой варианты от “условной” средней
d - V - М,
3. Найденные отклонения умножают на частоты Р х (V - М|) = Pd
4. Вычисляем алгебраическую сумму всех отклонений ZPd - - 4
5. По формуле определяем среднюю арифметическую
XPd -4
М = Mi г п М = 18 + 22 = 18 + (-0,18) - 17,82
ПАРАМЕТРЫ СРЕДНЕЙ АРИФМЕТИЧЕСКОЙ
Средние величины являются важными характеристиками совокупности, од-
нако они полностью не раскрывают индивидуальные значения признака, которые
отличаются от средних и различаются между собой. Средние величины скрывают
изменчивость, колеблемость признака, его рассеянность.
При обработке вариационного ряда недостаточно только лишь вычислить
среднюю арифметическую, нужно еще оценить, насколько она типична и досто-
верна для данной совокупности. Для этого в статистике существуют специальные
параметры средней - мера типичности и мера достоверности.
ОЦЕНКА ТИПИЧНОСТИ СРЕДНЕЙ АРИФМЕТИЧЕСКОЙ
Чем вариационный ряд более компактен, менее рассеян, тем лучше средняя
арифметическая характеризует данную совокупность.
Если вариационный ряд растянут, отдельные значения вариант сильно от-
клоняются от средней (т.е. имеется большая вариабельность, колеблемость при-
знака), то средняя хуже характеризует ряд в целом и является менее типичной для
данной совокупности.
25
Таким образом, кроме средней необходима еще одна характеристика ряда:
его колеблемость.
Простейшей мерой колеблемости ряда является амплитуда (вариационный
размах), т.е. разность крайних вариант. Например, при подсчете частоты пульса у
одной группы обследованных средняя составляла 68, минимальное число было
60, а максимальное - 70. У второй группы средняя частота пульса составляла так-
же 68, но наименьшее число было 55, а наибольшее - 80. Амплитуда в первой
группе значительно меньше и, следовательно, все значения группируются вокруг
средней. Вторая совокупность более разнообразна, ее рассеяность велика и коле-
бания отдельных значений от средней больше; следовательно, средняя в этой
группе менее типична, чем в первой группе.
Мерой колеблемости, изменчивости признака и мерой типичности
средней арифметической является среднее квадратическое отклонение (сиг-
ма - ст), которое определяется по формуле (по способу моментов):
а= [Еф'Г
V п п J
ПРИМЕР: Результаты измерения массы тела мальчиков 12 лет
Масса тела (V) Число лиц (Р) d = (V-M|) Pd d2 d2P
20 1 -5 -5 25 25
22 5 -3 - 15 9 45
23 6 -2 - 12 4 24
25 = М| 10 0 0 0 0
28 5 3 15 9 45
29 4 4 16 16 64
31 2 6 12 36 72
п-ЗЗ XPd = 11 EPd2 = 275
EPd? (XPdY 1275 /11\2
a = ±Vn -Гп ) - ± V 33 ЦЗЗ/-+ 8,3-(О,33)2 = + л/8,3 - 0,1= ± 2,86 кг
Чем больше среднее квадратическое отклонение, тем выше колеблемость
данного вариационного ряда.
Для оценки типичности средней арифметической с помощью среднего квад-
ратического отклонения в статистике применяется так называемое “правило трех
сигм”. Это правило основано на законе нормального распределения и отражает
теоретическую закономерность распределения вероятностей случайных со-
бытий в условиях бесконечно большого количества наблюдений.
Согласно теории вероятности, в явлениях, подчиняющихся закону нормально-
го распределения, между значениями средней арифметической ( М ), средним
квадратическим отклонением ( о ) и отдельными значениями вариант существует
cipoiax зависимость: в интервале МЛ а находится 68,3% всех вариант ряда, в
интервале М±2а- 95,5%, в интервале М±3а находится 99,7% всех вариант,
т.е. практически весь вариационный ряд укладывается в этот предел.
26
Таким образом, среднее квадратическое отклонение является стандартным
отклонением, позволяющим предвидеть вероятность появления такого значения
изучаемого признака, которое находится в пределах заданных границ.
М ± 1 ст -> 68,3%
М ± 2 ст -> 95,5%
М ± 3 ст —> 99,7%
Для того, чтобы проверить, насколько средняя арифметическая типична
для той совокупности, из которой она вычислена, нужно к ней прибавить и
отнять утроенную сигму ( М±3ст ). Если в полученный интервал данный ва-
риационный ряд укладывается, то средняя типична; если не укладывается -
средняя нетипична, совокупность неоднородна и число наблюдений недос-
таточно.
Графическим изображением “правила трех сигм” является кривая нормально-
го распределения (биноминальная кривая Ньютона, кривая Гаусса).
Форма этой кривой отражает степень вариабельности результатов наблюде-
ний: при большой разбросанности данных она будет пологой, при малой разбро-
санности - крутой. В силу симметричности кривой перпендикуляр, опущенный из
ее максимума на ось абсцисс, пересекает ее в точке, соответствующей среднему
значению данных, отложенных по этой оси ( М, Mo, Me).
Практическое значение среднего квадратического отклонения
• Сигма характеризует однородность вариационного ряда
• Зная среднюю величину и сигму, можно определить крайние значения вари-
ант и, при необходимости, построить вариационный ряд. Например: среднее ар-
териальное давление у мужчин 30-39 лет было 120 мм рт. ст. при ст = 10 мм.
Тогда Vmin = М - 3 ст = 120 - 30 = 90 мм
Vmax = М + 3 ст = 120 + 30^ 150 мм
СТАТИСТИЧЕСКАЯ ОЦЕНКА ДОСТОВЕРНОСТИ ПОЛУЧЕННЫХ ДАННЫХ
Полученные в результате статистического исследования средние и относи-
тельные величины должны отражать закономерности, характерные для всей со-
вокупности. Результаты исследования обычно тем достовернее, чем больше сде-
лано наблюдений, и наиболее точными они являются при сплошном исследова-
нии (т.е. при изучении генеральной совокупности). Однако должны быть доста-
точно надежны и данные, полученные путем выборочных исследований, т.е. на
относительно небольшом числе наблюдений.
Различие результатов выборочного исследования и результатов, которые мо-
гут быть получены на генеральной совокупности, представляет собой ошибку
выборочного исследования, которую можно точно определить математическим
путем. Метод ее оценки основан на закономерностях случайных вариаций, уста-
новленных теорией вероятности.
ОЦЕНКА ДОСТОВЕРНОСТИ СРЕДНЕЙ АРИФМЕТИЧЕСКОЙ
Средняя арифметическая, полученная при обработке результатов научно-
практических исследований, под влиянием случайных явлений может отличаться
27
от средних, полученных при проведении повторных исследований. Поэтому, что-
бы иметь представление о возможных пределах колебаний средней, о том, с ка-
кой вероятностью возможно перенести результаты исследования с выборочной
совокупности на всю генеральную совокупность, определяют степень достовер-
ности средней величины.
Мерой достоверности средней я&игется средняя ошибка средней ариф-
метической ( ошибка репрезентативности - ш ). Ошибки репрезентативности
возникают в связи с тем, что при выборочном наблюдении изучается только часть
генеральной совокупности, которая недостаточно точно ее представляет. Факти-
чески ошибка репрезентативности является разностью между средними, полу-
ченными при выборочном статистическом наблюдении, и средними, которые бы-
ли бы получены при сплошном наблюдении (т.е. при изучении всей генеральной
совокупности).
Средняя ошибка средней арифметической вычисляется по формуле:
ш = -?= при числе наблюдений больше 30 (п > 30) и
л/л
__о
m = ± VTbl при небольшом числе наблюдений (п < 30).
Ошибка репрезентативности прямо пропорциональна колеблемости ря-
да (сигме) и обратно пропорциональна числу наблюдений.
Следовательно, чем больше число наблюдений, (т.е. чем ближе по числу на-
блюдений выборочная совокупность к генеральной), тем меньше ошибка репре-
зентативности.
Интервал, в котором с заданным уровнем вероятности колеблется истинное
значение средней величины или показателя, называется доверительным интер-
валом, а его границы - доверительными границами. Они используются для оп-
ределения размеров средней или показателя в генеральной совокупности.
Доверительные границы средней арифметической и показателя в генеральной
совокупности равны:
M±tm
Р ± tm , где t - доверительный коэффициент
Доверительный коэффициент ( t ) - это число, показывающее, во сколько
раз надо увеличить ошибку средней величины или показателя, чтобы при данном
числе наблюдений с желаемой степенью вероятности утверждать, что они не
выйдут за полученные таким образом пределы.
С увеличением t степень вероятности возрастает.
Т. к. известно, что полученная средняя или показатель при повторных наблю-
дениях, даже при одинаковых условиях, в силу случайных колебаний будут отли-
чаться от предыдущего результата, теорией статистики установлена степень ве-
роятности, с которой можно ожидать, что колебания эти не выйдут за определен-
ные пределы. Так, колебания средней в интервале М ± 1т гарантируют ее
точность с вероятностью 68,3% (такая степень вероятности не удовлетворяет
28
исследователей), в интервале М ± 2т - 95,5% (достаточная степень вероятности)
и в интервале М ±3т - 99,7% (большая степень вероятности).
М ± 1 ш -> 68,3 %
М ± 2 m —> 95,5 %
М ± 3 ш > 99,7 %
Для медико-биологических исследований принята степень вероятности
95% (t = 2), что соответствует доверительному интервалу М ±2 т.
Это означает, что практически с полной достоверностью (в 95%) можно
утверждать, что полученный средний результат (М) отклоняется от ис-
тинного значения не больше, чем на удвоенную (М ±2 т) ошибку.
Конечный результат любого медико-статистического исследования выражает-
ся средней арифметической и ее параметрами:
М ± Зет ± 2m
ОЦЕНКА ДОСТОВЕРНОСТИ ОТНОСИТЕЛЬНЫХ ВЕЛИЧИН (ПОКАЗАТЕЛЕЙ)
Средняя ошибка показателя также служит для определения пределов его слу-
чайных колебаний, т.е. дает представление, в каких пределах может находиться
показатель в различных выборках в зависимости от случайных причин. С увели-
чением численности выборки ошибка уменьшается.
Мерой достоверности показателя является его средняя ошибка ( m ), ко-
торая показывает, на сколько результат, полученный при выборочном исследова-
нии, отличается от результата, который был бы получен при изучении всей гене-
ральной совокупности.
Средняя ошибка показателя определяется по формуле:
р? «
mp = , где тр - ошибка показателя
р - показатель
q - величина, обратная показателю (100-р, 1000-ри
т.д. в зависимости от того, на какое основание
рассчитан показатель)
п - число наблюдений
ПРИМЕР: Из стационара выбыло 289 больных, умерло 12.
Показатель летальности: 12 х100
р = 289 = 4,1%
/' 4,1 х (100-4ТГ" /' 4,1 х 95,9
шр=±У 289 -+/ 289 =±1.16%
Возможные пределы колебаний показателя равняются 4,1% + 1,16% (Р+шр).
ОЦЕНКА ДОСТОВЕРНОСТИ РАЗНОСТИ СРЕДНИХ И ОТНОСИТЕЛЬНЫХ
ВЕЛИЧИН
В научных исследованиях и клинической практике с целью сравнения двух
средних величин или показателей (например, для выявления преимуществ одного
метода лечения перед другим, сопоставления результатов исследования в кон-
трольной и экспериментальной группах, сравнения показателей здоровья двух
групп населения и т.п.) возникает необходимость не только определить их раз-
ность, но и оценить ее достоверность.
Разность между двумя средними или относительными величинами (показате-
лями), каждая из которых имеет свою ошибку, также имеет свою ошибку.
Средняя ошибка разности ( mpaJH) вычисляется по формуле:
mpa,H = ± т Ш] + m2 , где Ш| и т2 - средние ошибки сравниваемых
величин
Т.о., ошибка разности равняется корню квадратному из суммы квадратов
ошибок сравниваемых величин.
Мерой достоверности разности двух величин является критерий досто-
верности ( критерий Стьюдента -1):
м. - м,
для средних величин -7^-=^
д/от,2 Щ
Р-Р
для относительных величин
+т^
где t - критерий достоверности
М| и М2 - сравниваемые средние
pi и р2 - сравниваемые показатели
ГП|2 и пз22 - их ошибки
Для медико-биологических исследований принято считать, что если
критерий достоверности t >2, то различие двух величин (средних или отно-
сительных) следует считать существенным, достоверным, доказанным с ве-
роятностью в 95%. Если t < 2, то различие величин не доказано.
ПРИМЕР. Требуется определить достоверность разности показателей (средний бал успе-
ваемости) студентов медицинского института. На лечебном факультете средний балл составил
3,86 + 0,04 , на педиатрическом - 4,03 ± 0,04.
Mi - М2 _4.03 -3.86 0,17
t = ± Гт? + т/^Го,О42 ) 0,04z - - 3,0
Таким образом, в данном случае различие между средними величинами следует считать
статистически достоверным.
зо
СПЕЦИАЛЬНЫЕ СТАТИСТИЧЕСКИЕ МЕТОДИКИ
МЕТОД СТАНДАРТИЗАЦИИ
Общие показатели интенсивности, полученные на 4 этапе статистического
исследования при статистическом анализе, не всегда правильно выявляют зако-
номерности изучаемых явлений, так как на их уровень может влиять различие
состава сравниваемых совокупностей , в отношении которых эти показатели рас-
считаны . При сравнении показателей, характеризующих то или иное явление (за-
болеваемость, рождаемость, летальность и т ,д) их различия могут определяться
не только разным уровнем распространенности этих явлений, но и неоднородно-
стью состава сравниваемых совокупностей . Эта неоднородность может быть
обусловлена различным возрастным, половым, профессиональным или другим
составом совокупностей.
Так, например , при изучении заболеваемости в двух изучаемых коллектива,
необходимо учитывать их возрастно-половую структуру.
Статистический метод, при котором можно устранить влияние на результаты
исследования различий сравниваемых совокупностей , неоднородных по своему
составу, называется методом стандартизации.
Сущность этого метода заключается в том, что сравниваемые явления ис-
кусственно ставятся в одинаковые условия относительно группового рас-
пределения среды, т.е. совокупности, которые характеризуют анализируе-
мые показатели, условно считают одинаковыми.
Результатом проведения этого метода является вычисление стандартизован-
ных показателей. Эти показатели, при сопоставлении их с обычными интенсив-
ными показателями, позволяют сделать вывод, связаны ли различия в интенсив-
ных показателях с неоднородностью составов сравниваемых совокупностей .
Стандартизованные показатели являются условными и не отражают
истинных размеров изучаемого явления. Они применяются только для сравне-
ния и анализа данной ситуации вследствие того, что рассчитаны они при искусст-
венно созданных условиях и не отражают действительного размера явлений.
Существует три метода расчета стандартизованных показателей: прямой,
косвенный и обратный косвенному.
При проведении медицинских исследований обычно пользуются прямым
методом стандартизации, который состоит из трех этапов.
1. Вычисление погрупповых показателей, т.е. ’’истинных” или обычных
относительных величин, характеризующих изучаемое явление в двух сравнивае-
мых совокупностях. В зависимости от характера исследования это Moi-ут быть
показатели заболеваемости, инфицированности, травматизма, смертности, и т.д.,
рассчитанные по группам (по диагнозам, тяжести заболевания, полу, возрасту,
месту жительства и т.д.)
2. Вычисление стандарта, т.е. нового искусственного распределения среды
в определенном масштабе. За масштаб стандарта берется основание (коэффи-
циент), на который рассчитывались показатели на первом этапе:
100,1000,10000 и т.д.
31
3. Вычисление стандартизованных показателей.
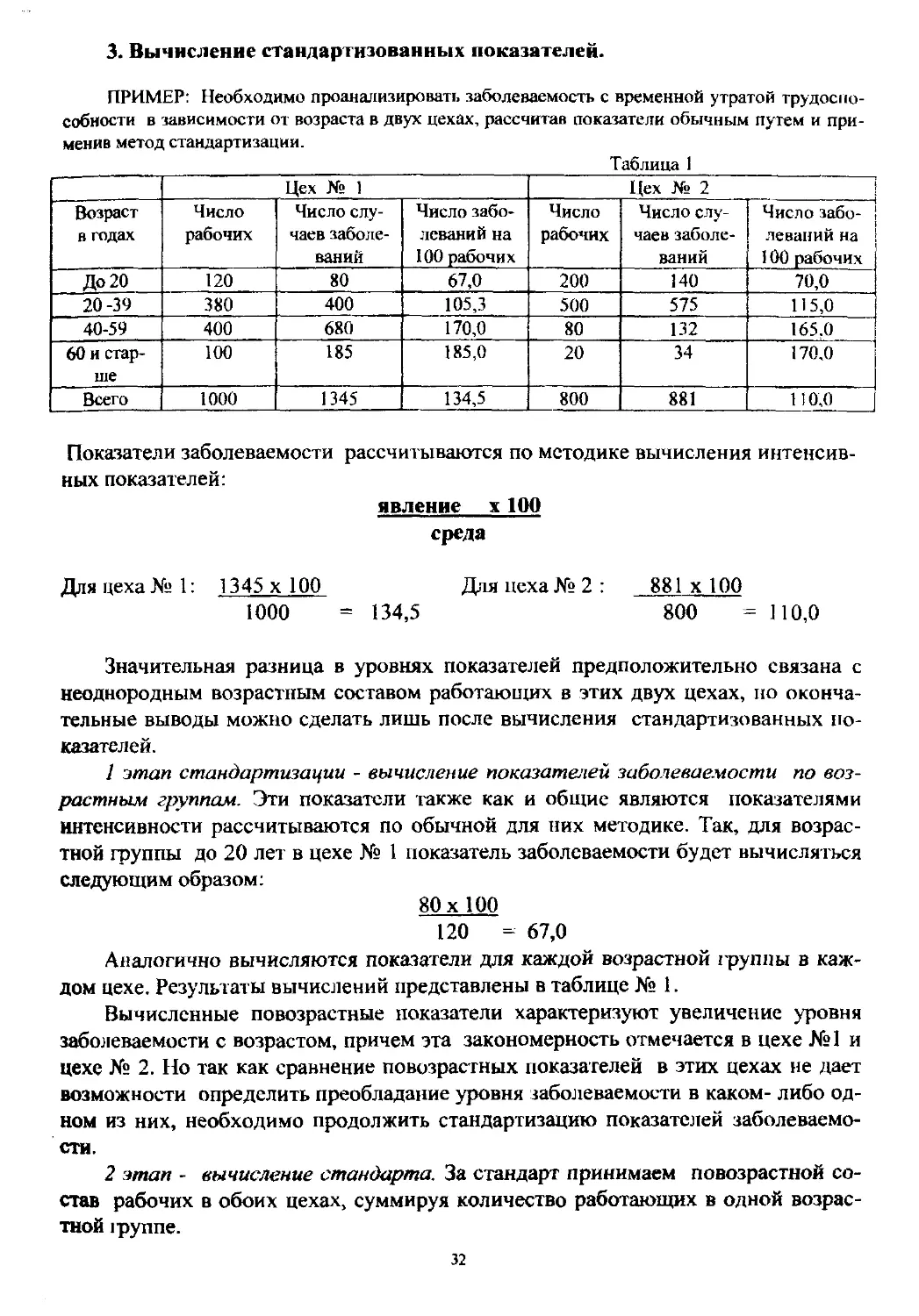
ПРИМЕР: Необходимо проанализировать заболеваемость с временной утратой трудоспо-
собности в зависимости от возраста в двух цехах, рассчитав показатели обычным путем и при-
менив метод стандартизации.
Таблица 1
Цех № 1 Цех № 2
Возраст в годах Число рабочих Число слу- чаев заболе- ваний Число забо- леваний на 100 рабочих Число рабочих Число слу- чаев заболе- ваний Число забо- леваний на 100 рабочих
До 20 120 80 67,0 200 140 70,0
20-39 380 400 105,3 500 575 115,0
40-59 400 680 170,0 80 132 165,0
60 и стар- ше 100 185 185,0 20 34 170,0
Всего 1000 1345 134,5 800 881 110,0
Показатели заболеваемости рассчитываются по методике вычисления интенсив-
ных показателей:
явление х 100
среда
Для цеха № 1: 1345 х 100 Для цеха № 2 : 881 х 100
1000 = 134,5 800 = 110,0
Значительная разница в уровнях показателей предположительно связана с
неоднородным возрастным составом работающих в этих двух цехах, но оконча-
тельные выводы можно сделать лишь после вычисления стандартизованных по-
казателей.
1 этап стандартизации - вычисление показателей заболеваемости по воз-
растным группам. Эти показатели также как и общие являются показателями
интенсивности рассчитываются по обычной для них методике. Так, для возрас-
тной группы до 20 лет в цехе № 1 показатель заболеваемости будет вычисляться
следующим образом:
80 х 100
120 = 67,0
Аналогично вычисляются показатели для каждой возрастной группы в каж-
дом цехе. Результаты вычислений представлены в таблице № 1.
Вычисленные повозрастные показатели характеризуют увеличение уровня
заболеваемости с возрастом, причем эта закономерность отмечается в цехе №1 и
цехе № 2. Но так как сравнение повозрастных показателей в этих цехах не дает
возможности определить преобладание уровня заболеваемости в каком- либо од-
ном из них, необходимо продолжить стандартизацию показателей заболеваемо-
сти.
2 этап - вычисление стандарта. За стандарт принимаем повозрастной со-
став рабочих в обоих цехах, суммируя количество работающих в одной возрас-
тной ipynne.
32
Общая численность коллектива, взятого за стандарт, берется равной основа-
нию, в отношении которого выражены показатели на 1 этапе, т.е. 100. Следова-
тельно за стандарт принимается распределение по возрасту 100 человек Расчеты
по второму этапу представлены в таблице №2.
Таблица 2
Возраст Число работающих Число рабо- тающих в обоих цехах Стандарт(повозрастной со- став работающих в обоих цехах в процентах)
цех №1 цех№2
до 20 120 200 320 18
20-39 380 500 880 49
40-59 400 80 480 26
60 и старше 200 20 120 7
Всего 1000 800 1800 100
Стандарт для каждой возрастной группы рассчитывается по методике
вычисления показателей экстенсивности:
часть явления х100
целое явление
Зная, что целое явление - это число работающих в обоих цехах, а часть явле-
ния - количество работающих в каждой возрастной групп , вычисляем, например,
стандарт для возрастной группы до 20 лет:
320x100%
1800 = 18%
Аналогичным образом вычисляют стандарт для каждой возрастной группы
работающих в двух цехах.
3 этап - вычисление стандартизованных показателей
Примем условно, что распределение работающих в обоих цехах по возрас-
там одинаково и соответствует стандарту, и рассчитаем ожидаемое количество
заболеваний при новом, условном распределении работающих по возрастам.
Таблица 3
Возраст Заболеваемость на 100 рабо- тающих Стандарт Число заболеваний в стан- дарте
до 20 67,0 70,0 18 12,0 12,6
20-39 105,3 115,3 49 51,6 56,3
40-59 170,0 165,0 26 44,2 42,9
60 и старше 185,0 170,0 7 12,9 Н,9
Всего 134,5 110,0 100 120,7 123,7
В графах 2 и 3 представлены показатели заболеваемости по двум цехам, вы-
численные на 1 этапе. В графе 4 - стандарт- повозрастного состава работающих,
вычисленный на втором этапе, данные граф 5 и 6 получают следующим обра-
зом: в возрасте до 20 лет в цехе № 1 показатель заболеваемости на 100 работаю-
щих -67,0, а в цехе №2 - 70,0. Следовательно, среди 18 работающих (по стандар-
ту) заболеваний будет:
зз
в цехе № 1 67.0 х 18
100 = 12,0
в цехе К»2 70 х 18
100 -12,6
По такой же методике вычисляют числа других строк в двух последних ipa-
фах (учитывая повозрастные показатели заболеваемости и стандарт). Сложив
числа промежуточных стандартизованных показателей по возрастам в графах 5 и
6, получим стандартизованные показатели на 100 работающих для каждого цеха.
По результатам стандартизации можно сделать вывод: если бы возрастной
состав работающих в двух цехах был бы одинаков, то в цехе Ле 2 показате-
ли заболеваемости были бы выше, чем в цехе Л° 1 (123,7 и 120,7 соответст-
венно). Следовательно, более высокий уровень заболеваемости в цехе Ле 1
объясняется неблагоприятным составом рабочих по возрасту.
МЕТОД КОРРЕЛЯЦИИ
Различают два типа связи между явлениями: функциональную и корреляци-
онную связь.
Функциональная связь предполагает строгую зависимость между явления-
ми. Это такой вид соотношения между двумя признаками, когда каждому
значению одного из них соответствует строго определенное значение друго-
го. Такой вид связи характерен для точных наук. Примером ее могут служить
скорость движения и время пребывания в пути, радиус круга и длина окружности
и т.п.
Между явлениями в медицине и биологии наблюдается корреляционная
связь, то есть такая связь при которой значению каждой величины одного
признака соответствует несколько значений другого взаимосвязанного с ним
Признака. На характер и величину этой связи влияют различные условия и об-
стоятельства.
Примерами корреляционной связи могут быть: связь между ростом и массой
тела, связь между температурой тела и частотой пульса, между частотой после-
операционных осложнений и сроками проведения операций при острых заболе-
ваниях органов брюшной полости, связь между заболеваемостью дифтерией и
степенью охвата профилактическими прививками.
Наличие, величину и характер связи между явлениями можно установить с
помощью статистического метода - метода корреляции, который проводится на
4 этапе статистического исследования при анализе полученных результатов.
Практическое значение установления корреляционной связи:
• выявление причинно-следственной связи между факторными и резуль-
тативными признаками (при оценке физического развития, для определения
связи между условиями труда, быта и состоянием здоровья, при определении за-
висимости частоты случаев болезни от возраста, стажа, наличия производствен-
ных вредностей и пр.)
• выявление зависимости параллельных изменений нескольких признаков
от какой-то третьей величины (например, под воздействием высокой темпе-
34
ратуры в цехе происходит изменение кровяного давления, вязкости крови, часто-
ты пульса и пр.).
По направлению связь между явлениями может быть прямой (положитель-
ной), когда с увеличением или уменьшением одного явления соответственно
увеличивается или уменьшается другое явление (например, с увеличением воз-
раста увеличивается количество пораженных кариесом зубов в расчете на одного
обследованного, с увеличением экспозиции между началом острого процесса в
брюшной полости и проведением операции увеличивается число осложнений и
летальность) и обратной (отрицательной), когда с увеличением одного явления
другое явление уменьшается или наоборот с уменьшением одного явления
другое соответственно увеличивается (например, с увеличением возраста ре-
бенка уменьшается количество молочных зубов, с уменьшением содержания йода
в воде и пище увеличивается число заболеваний щитовидной железы и т.д.).
По силе корреляционная связь может быть:
• сильной
• средней
• слабой
Величина, которая одним числом характеризует направление и силу связи
между признаками, называется коэффициентом корреляции ( р ). Пределы ко-
лебаний коэффициента корреляции от 0 до ± 1.
Оценка размеров коэффициента корреляции
Оценка размеров корре- ляции (сила связи) Величина коэффициента корреляции
прямая связь (+ ) обратная связь ( - )
Связь отсутствует 0 0
Слабая (малая, низкая) от 0 до 0,3 от 0 до - 0,3
Средняя (умеренная) от 0,3 до 0,7 от - 0,3 до -0,7
Сильная (большая, высо- кая) от 0,7 до 1 от - 0,7 до 1
Методические требования к вычислению коэффициента корреляции;
• измерение связи возможно только в качественно однородных совокуп-
ностях (например, измерение связи между ростом и массой тела в совокупно-
стях, однородных по возрасту и полу)
• расчет может производиться как на абсолютных, так и на производ-
ных величинах (относительных и средних)
• для вычисления коэффициента корреляции используются только не-
сгруппированные данные
• число наблюдений должно быть менее 30.
Существует два метода определения коэффициента корреляции:
1. Метод квадратов (Пирсона) используется в тех случаях, когда требуется
точное установление силы связи между признаками и когда признаки имеют
только количественное выражение.
35
2. Ранговый метод (Спирмена) является наиболее простым способом опре-
деления коэффициента корреляции. Его применяют тогда, когда нет необходимо-
сти в точном установлении силы связи, а достаточно ориентировочных данных.
Основным принципом метода ранговой корреляции является сопостав-
ление порядковых номеров (рангов) величин, характеризующих сравниваемые
явления.
ПРИМЕР: Необходимо измерить величину и характер связи между заболеваемо-
стью острыми респираторными инфекциями и заболеваемостью пневмонией , по данным семи
районов.
Корреляция мет одом рангов между заболеваемостью острыми респираторными
инфекциями и пневмонией
Заболеваемость ОРЗ на 1000 на- селения Заболеваемость пневмонией на 1000 населения Ранговые номера по уров- ню заболеваемости Разность между ран- гами (d) Квадрат разности рангов (d2)
ОРЗ Пневмония
352 64 1 1 0 0
228 60 6 2 4 16
340 52 2 3 1 1
300 48 3 4 1 1
196 46 7 5 2 4
258 41 4 6 2 4
237 32 5 7 2 4 Ed2 = 30
В графах 1 и 2 представлены исходные данные о заболеваемости острыми
респираторными инфекциями и пневмонией по семи районам. В графах 3 и 4 ука-
заны порядковые номера (ранги) уровней заболеваемости ОРЗ (графа 3) и пнев-
монией ( графа 4), причем порядковые номера в этих графах расположены по
убыванию величин изучаемых явлений. Так, наибольший уровень заболеваемости
ОРЗ - 352, ему соответствует порядковый номер 1, затем в порядке убывания сто-
ит уровень заболеваемости - 340, ему соответствует порядковый номер 2, долее
300 - 3, 258 - 4, 237 - 5, 228 -6, 196 -7.По аналогичной системе располагаются ран-
говые номера , соответствующие различному уровню заболеваемости пневмони-
ей: 64-1, 60-2, 52- 3, 48 - 4 ,46-5 ,41-6, 32-7.
В графе 5 представлена разность между порядковыми номерами соответст-
вующих величин в обоих рядах ( d ). Для первой строки: 1-1=0, для второй стро-
ки 6-2=4 и т.д. Затем эта разность возводится в квадрат и полученные числа за-
писываются в графу 6, после чего они суммируются ( Ed2 = 30).
Коэффициен т корреляции рангов вычисляется по формуле:
где р - коэффициент корреляции
л - число парных членов коррелируемых рядов (в нашем примере их 7)
d - разность между рангами
d2 - квадрат разности рангов
6 - константа, предусмотренная методикой вычисления по данной форм
Z - знак суммирования
36
В нашем примере коэффициент корреляции ( 0,47) означает, что между заболеваемостью
острыми респираторными заболеваниями и заболеваемостью пневмонией существует прямая,
средней тесноты связь.
Достоверность коэффициента корреляции рангов определяется его сред-
ней ошибкой (nip) , которая определяется по формуле:
Коэффициент корреляции считается достоверным, если он в 3 раза и более
превышает свою ошибку:
_е
t = m > 3
1 - 0.472
Для нашего примера: тр = >17-1 = 0,28
В данном случае достоверность коэффициента корреляции недостаточно высокая, так как
он (0,47) примерно в два раза превышает свою ошибку.
НЕПАРАМЕТРИЧЕСКИЕ КРИТЕРИИ СТАТИСТИЧЕСКОЙ
ОЦЕНКИ ЗНАЧИМОСТИ РАЗЛИЧИЙ
Одной из основных задач статистической обработки материала (лабораторных
и клинических исследований ) является доказательство значимости различий ме-
жду двумя или несколькими группами наблюдений, выявление силы и достовер-
ности связи в изучаемых явлениях, определение степени влияния одних призна-
ков на другие.
В большинстве медицинских исследований для определения существенности
различий двух сравниваемых групп наблюдений используют, главным образом,
параметрический критерий t Стьюдента, который позволяет решить существенны
или нет различия между двумя сравниваемыми выборками, получить четкий от-
вет на вопрос, принадлежат ли сравниваемые выборки к разным генеральным со-
вокупностям или к одной. Однако, применение критерия t Стьюдента обосновано
лишь в том случае, когда сравниваемые выборки имеют нормальное распределе-
ние. При нормальном распределения признака наибольшее количество частот
изучаемого признака близко по размерам к средней величине ряда, а в обе сторо-
ны от этой варианты частоты постепенно уменьшаются.
В тех случаях, когда имеется малое число наблюдений и характер распределе-
ния неизвестен, когда кроме количественных характеристик результаты выраже-
ны полуколичественными, а иногда и описательными характеристиками, методы
классической статистической обработки материалов, или так называемые пара-
метрические методы, не всегда могут быть использованы.
Статистические методы, позволяющие обрабатывать и оценивать результаты
наблюдений, выраженные как в строго количественной форме, гак и в полуколи-
37
явственном или качественном виде, без учета характера их распределения, объе-
диняют в группу так называемых непараметрических статистических методов.
Название данных тестов связано с тем, что эти показатели не требуют вычис-
ления параметров для характеристики частоты явления, для характеристики
среднего уровня признака, среднего квадратического отклонения, средней ошиб-
ки средней арифметической и показателя, необходимых при использовании па-
раметрических критериев.
Основными преимуществами непараметрических критериев статистической
оценки значимости различий являются: возможность обнаружить существенные
различия при распределениях, отличающихся от нормального, в случаях, когда
форма распределения неизвестна и перед оценкой значимости различий не про-
верялась; способность дать хорошие результаты при любом распределении, а
также при малом числе наблюдений; высокая чувствительность, не уступающая
критерию Стьюдента; возможность выявить различия в качественных изменени-
ях, а также в форме распределений, при отсутствии различий в средних тенден-
циях; небольшая трудоемкость расчетов и сравнительная простота их.
Для характеристики одной совокупности или сравнения двух групп наблюде-
ний применяются следующие основные непараметрические критерии:
Для характеристики одной совокупности может быть использован критерий
проверки гипотезы о случайном характере флюктуаций, который дает воз-
можность решить, являются ли случайными или систематическими колебания ре-
зультатов, полученных при проведении какого-либо исследования.
ПРИМЕР. При обследовании тщательно подобранной контрольной группы получены коле-
бания показателей щелочной фосфатазы нейтрофилов (в процентах). Необходимо установить,
случайны или нет эти флюктуации.
32,44,28, 32,38, 31, 41, 31, 28, 24, 31, 30, 26, 27, 31,25, 27, 36, 29, 33, 38, 41, 35, 26, 29, 33, 37,
41,40,36.
Для решения поставленного вопроса с помощью критерия проверки гипотезы о случайном
характере флюктуаций располагают варианты ряда в возрастающем порядке: 24, 25, 25, 26, 27,
27,28,28, 29, 29, 30, 31, 31, 32, 32, 33, 33, 35, 36, 36, 37, 38, 38, 40,41, 41,41, 44.
Находят медиану полученного ряда, которая равна полусумме 15- ой и 16-ой вариант, т.к.
число наблюдений составляет 30, т.е. (31»32)/2=31.5
Затем сравнивают медиану с исходными данными, расположенными в первоначальном
порядке, при этом варианты большие, чем медиана, заменяют знаком +, меньшие заменяют
знаком -. Если в ряду имеются варианты, равные медиане, их заменяют знаком + или случай-
ным способом. В результате получают:
+ + - + + . + —...-. + - + + + + -- + + + + +
12345 6 78 9 10
Определяют и подсчитывают число серий одинаковых знаков (Р), в данном примере оно
равно 11. Полученное число серий сравнивают с табличными. Если полученное число серий (Р)
меньше, чем Poms или больше, чем Р0975, то нулевая гипотеза о случайном характере колебаний
Отвергается.
В приведенном примере, где число наблюдений равно 30, число серий, необходимых для
признания колебаний случайными, согласно таблице составляет от 10 до 21. Следовательно,
в приведенном примере колебания результатов исследования являются случайными и пра-
вильность подбора контрольной группы подтверждается еще одним тестом.
38
Верхние и нижние пределы общего числа серий (Р) для различного числа наблюдений
п 0.025 0,975 п 0,025 0,975 N 0,025 0,075
10 2 9 24 7 18 40 14 27
12 3 10 26 8 19 50 18 33
14 3 12 28 9 20 60 22 39
16 4 13 30 10 21 80 31 51
18 5 14 32 И 22 100 40 61
20 6 16 34 И 24 120 49 72
22 7 16 36 12 25 140 58 83
Для оценки различия двух связанных (сопряженных) совокупностей может
быть использован критерий знаков.
Критерий знаков применяется при анализе экспериментальных и клиниче-
ских данных, когда варианты двух или более сравниваемых совокупностей со-
пряжены между собой попарно. Сущность критерия знаков заключается в том,
что оцениваются не сами количественные значения результатов, а только на-
правленность их изменения (увеличение, уменьшение, без изменения). Оценка ре-
зультатов проводится по специальным таблицам с заданной вероятностью Р. В
таблицах приводятся значения того минимального числа наблюдений (опытов), в
котором должно проявиться однозначное влияние исследуемого фактора из об-
щего количества проведенных наблюдений. Нулевая гипотеза, т.е. предположе-
ние о том, что полученная в опыте разница случайна, принимается тогда, когда
количество менее часто встречающихся знаков больше табличных критических
чисел. Если же это число равно или меньше критического числа менее часто
встречающихся знаков, го обнаруженные изменения признаются существенными.
ПРИМЕР. Оценка при помощи критерия знаков изменения количества лейкоцитов в 1 мкл.
крови у 12 обследованных здоровых лиц до исследования, а также через !6 часа и через 1 час
после перорального приема 70-80 мл. 0.5% раствора новокаина.
Обследован- ный В контроле Через '/г часа Разница (с контролем) Через 1 час Разница (с контролем)
1 7600 6800 10200 4-
2 8600 7400 - 1020 +
3 7600 9200 4- 9200 +
4 8800 8200 - 1060 1-
5 6000 6400 + 7800 4
6 6000 5800 - 7200 4-
7 5200 5800 4 6600 4
8 10600 10200 - 14400 4
9 5800 ‘ 5600 - 8000 4
10 6800 8400 1020 4
11 1080 8000 - 1300 4
12 8600 7400 - 1210 4-
Для оценки полученных результатов подсчитывают число наблюдений, в ко-
торых наблюдался положительный (+) или отрицательный (-) эффект, определяют
по таблице (Z) - минимальное число наблюдений с однозначным результатом,
39