/



























































































































































































































































































































































































































































































































































































































































































Author: Вульф Б.К. Хоп Г.
Tags: компьютерные технологии программное обеспечение
ISBN: 978-5-8459-1146-9
Year: 2007




Text
Шаблоны интеграции
корпоративных
приложений
Проектирование, создание
и развертывание решений, основанных
на обмене сообщениями
Enterprise
Integration
Patterns
Designing, Building,
and Deploying Messaging
Solutions
Gregor Hohpe
Bobby Wolf
With Contributions by
Kyle Brown
Conrad F. D’Cruz
Martin Fowler
Sean Neville
Michael J. Rettig
Jonathan Simon
▼ ▼ ADDISON-WESLEY
Boston San Francisco New York Toronto • Montreal
London Munich Paris Madrid Capetown • Sydney
Tokyo Singapore • Mexico City
Шаблоны интеграции
корпоративных
приложений
Проектирование, создание
и развертывание решений, основанных
на обмене сообщениями
Грегор Хоп
Бобби Вульф
при участии
Кайла Брауна
Конрада Ф. Д’Круза
Мартина Фаулера
Шона Невилла
Майкла Дж. Реттига
Джонатана Саймона
Москва • Санкт-Петербург • Киев
2007
ББК 32.973.26-018.2.75
Х78
УДК 681.3.07
Издательский дом “Вильямс”
Главный редактор С.Н. Тригуб
Зав. редакцией В. Р. Гинзбург
Перевод с английского и редакция А.В. Журавлева, Н.Н. Селиной
По общим вопросам обращайтесь в Издательский дом “Вильямс” по адресу:
info@williamspublishing.com, http://www.williamspublishing.com
115419, Москва, а/я 783; 03150, Киев, а/я 152
Хоп, Грегор, Вульф, Бобби.
Х78 Шаблоны интеграции корпоративных приложений. : Пер. с англ. — М. :
ООО “И.Д. Вильямс”, 2007. — 672 с.: ил. — Парал. тит. англ.
ISBN 978-5-8459-1146-9 (рус.)
В данной книге исследуются стратегии интеграции корпоративных приложений с
помощью механизмов обмена сообщениями. Авторы рассматривают шаблоны проек-
тирования и приводят практические примеры интеграции приложений, демонстри-
рующие преимущества обмена сообщениями и эффективность решений, создаваемых
на основе этой технологии. Каждый шаблон сопровождается описанием некоторой
задачи проектирования, обсуждением исходных условий и представлением элегант-
ного, сбалансированного решения. Авторы подчеркивают как преимущества, так и
недостатки обмена сообщениями, а также дают практические советы по написанию
кода подключения приложения к системе обмена сообщениями, маршрутизации
сообщений и мониторинга состояния системы.
Книга ориентирована на разработчиков программного обеспечения и системных
интеграторов, использующих различные технологии и продукты для обмена сообще-
ниями, такие как Java Message Service (JMS), Microsoft Message Queuing (MSMQ), IBM
WebSphere MQ, Microsoft BizTalk, TIBCO, WebMethods, SeeBeyond, Vitrian др.
ББК 32.973.26-018.2.75
Все названия программных продуктов являются зарегистрированными торговыми марками соответ-
ствующих фирм.
Никакая часть настоящего издания ни в каких целях не может быть воспроизведена в какой бы то ни
было форме и какими бы то ни было средствами, будь то электронные или механические, включая фо-
токопирование и запись на магнитный носитель, если на это нет письменного разрешения издательства
Addison-Wesley.
Authorized translation from the English language edition published by Addison-Wesley, Copyright © 2004.
All rights reserved. No part of this book may be reproduced or transmitted in any form or by any means,
electronic or mechanical, including photocopying, recording or by any information storage retrieval system,
without permission from the publisher.
Russian language edition is published by Williams Publishing House according to the Agreement with R&I
Enterprises XmernauoiuA, Copyiigin^i .
ISBN 978-5-8459-1146-9 (pyc.)
ISBN 0-321-20068-3 (англ.)
© Издательский дом “Вильямс”, 2007
© Pearson Education, Inc., 2004
Оглавление
Введение 24
Глава 1. Решение задач интеграции с помощью шаблонов проектирования 43
Глава 2. Стили интеграции 77
Глава 3. Системы обмена сообщениями 91
Глава 4. Каналы обмена сообщениями 127
Глава 5. Построение сообщений 167
Глава 6. Практикум: простой пример обмена сообщениями 205
Глава 7. Маршрутизация сообщений 243
Глава 8. Преобразование сообщений 339
Глава 9. Практикум: сложный обмен сообщениями 373
Глава 10. Конечные точки обмена сообщениями 477
Глава 11. Управление системой 549
Глава 12. Практикум: управление системой 583
Глава 13. Шаблоны интеграции на практике 609
Глава 14. Кое-что в заключение 629
Приложение А. Список шаблонов проектирования 653
Приложение Б. Шаблоны интеграции корпоративных приложений 660
Основные источники информации 662
Предметный указатель
668
Содержание
Введение 24
Что такое обмен сообщениями 25
Что такое система обмена сообщениями 26
Преимущества обмена сообщениями 27
Недостатки асинхронного обмена сообщениями 30
Мыслим асинхронно 31
Распределенное приложение или интеграция приложений 32
Коммерческие системы обмена сообщениями 32
Форма шаблонов 34
Диаграммы, использованные в книге 36
Примеры и практикумы 38
Как организована эта книга 39
С чего начать 40
Поддержка 41
Резюме 41
Глава 1. Решение задач интеграции с помощью шаблонов проектирования 43
Необходимость интеграции 43
Трудности интеграции 44
Роль интеграционных шаблонов проектирования 46
Типы интеграционных задач 46
Слабое связывание 50
Пример простой интеграции 51
Компоненты слабосвязанного интеграционного решения 55
Пример: “Приборы и устройства” 56
Внутренние системы 57
Размещение заказов 58
Обработка заказов 59
Проверка состояния заказа 65
Изменение адреса клиента 69
Обновление каталога товаров 71
Рассылка новостей 72
Тестирование и мониторинг 73
Резюме 75
Глава 2. Стили интеграции 77
Введение 77
Критерии интеграции приложений 77
Способы интеграции приложений 79
Передача файла (File Transfer) 80
Общая база данных (Shared Database) 83
Удаленный вызов процедуры (Remote Procedure Invocation) 85
Обмен сообщениями (Messaging) 87
Содержание
7
Глава 3. Системы обмена сообщениями 91
Введение 91
Основные концепции обмена сообщениями 91
Об организации книги 92
Канал сообщений (Message Channel) 93
Сообщение (Message) 98
Каналы и фильтры (Pipes and Filters) 102
Конвейерная обработка 104
Параллельная обработка 104
История архитектуры каналов и фильтров 105
Маршрутизатор сообщений (Message Router) 109
Типы маршрутизаторов сообщений 111
Транслятор сообщений (Message Translator) 115
Уровни преобразования 116
Уровни связывания 118
Цепочечные преобразования 118
Конечная точка сообщения (Message Endpoint) 124
Глава 4. Каналы обмена сообщениями 127
Введение 127
Основные вопросы, связанные с применением каналов
обмена сообщениями 127
Решения 128
Канал “точка-точка” (Point-to-Point Channel) 131
Канал “публикация-подписка” (Publish-Subscribe Channel) 134
Канал типа данных (Datatype Channel) 139
Канал недопустимых сообщений (Invalid Message Channel) 143
Канал недоставленных сообщений (Dead Letter Channel) 147
Гарантированная доставка (Guaranteed Delivery) 149
Адаптер канала (Channel Adapter) 154
Мост обмена сообщениями (Messaging Bridge) 159
Шина сообщений (Message Bus) 162
Глава 5. Построение сообщений 167
Введение 167
Сообщение с командой (Command Message) 169
Сообщение с данными документа (Document Message) 171
Сообщение о событии (Event Message) 174
Запрос-ответ (Request- Reply) 177
Обратный адрес (Return Address) 182
Идентификатор корреляции (Correlation Identifier) 186
Цепочка сообщений (Message Sequence) 192
Срокдейстъия сообщения (Message Expiration) 198
Индикатор формата (Format Indicator) 201
Глава 6. Практикум: простой пример обмена сообщениями 205
Введение 205
Запрос-ответ 205
8
Содержание
Публикация-подписка 206
Запрос-отает (JMS) 208
Описание 208
Код 210
Обработка сообщения недопустимого формата 216
Итог 217
Запрос-отает (.NET) 219
Описание 219
Код 221
Обработка сообщения недопустимого формата 225
Итог 226
Публикация-подписка (JMS) 227
Наблюдатель (Observer) 227
Наблюдатель (Observer) в распределенной среде 228
Публикация-подписка 229
Сравнение двух подходов 232
Модель с активным и пассивным источниками данных 233
Проектирование каналов 238
Итог 241
Глава 7. Маршрутизация сообщений 243
Введение 243
Простые маршрутизаторы 243
Составные маршрутизаторы 245
Архитектурные шаблоны 245
Выбор маршрутизатора сообщений 246
Маршрутизатор на основе содержимого (Content-Based Router) 247
Уменьшение зависимостей 249
Фильтр сообщений (Message Filter) 253
Фильтры с сохранением или без сохранения состояния 254
Функции фильтрации, встроенные в системы обмена сообщениями 255
Использование фильтров сообщений вместо маршрутизатора
на основе содержимого 256
Динамический маршрутизатор (Dynamic Router) 259
Список получателей (Recipient List) 264
Надежность 267
Динамический список получателей 268
Эффективность с точки зрения сети 269
Список получателей или канал “публикация-подписка”
с фильтрами сообщений 269
Разветвитель (Splitter) 274
Итеративные разветвители 275
Статические разветвители 276
Упорядоченные или неупорядоченные дочерние сообщения 277
Агрегатор (Aggregator) 283
Детали реализации 285
Стратегии агрегации 286
Преобразователь порядка (Resequencer) 297
Порядковый номер 298
Содержание
9
Внутреннее устройство 299
Борьба с переполнением буфера 300
Обработчик составного сообщения (Composed Message Processor) 307
Рассылка-сборка (Scatter-Gather) 310
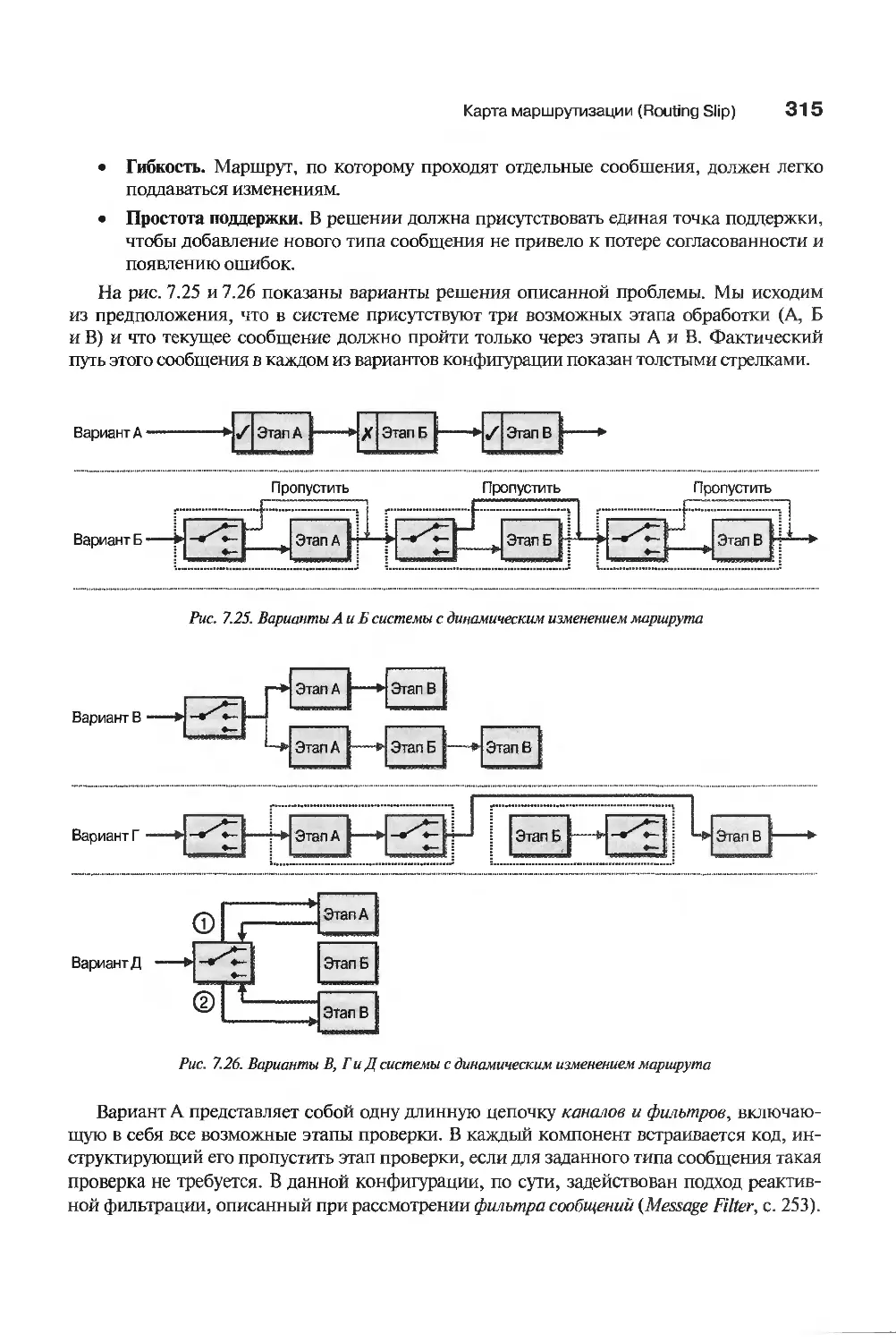
Карта маршрутизации (Routing Slip) 314
Применение карты маршрутизации к унаследованным приложениям 319
Область применения 320
Реализация простого маршрутизатора с картой маршрутизации 320
Диспетчер процессов (Process Manager) 325
Управление состоянием 327
Экземпляры процесса 327
Корреляция 328
Сохранение состояния в сообщениях 329
Создание определения процесса 330
Сравнение диспетчера процессов с другими шаблонами 332
Брокер сообщений (Message Broker) 334
Глава 8. Преобразование сообщений 339
Введение 339
Устранение зависимостей 340
Управление метаданными 340
Преобразование данных в других схемах интеграции 341
Оболочка конверта (Envelope Wrapper) 342
Расширитель содержимого (Content Enricher) 348
Фильтр содержимого (Content Filter) 354
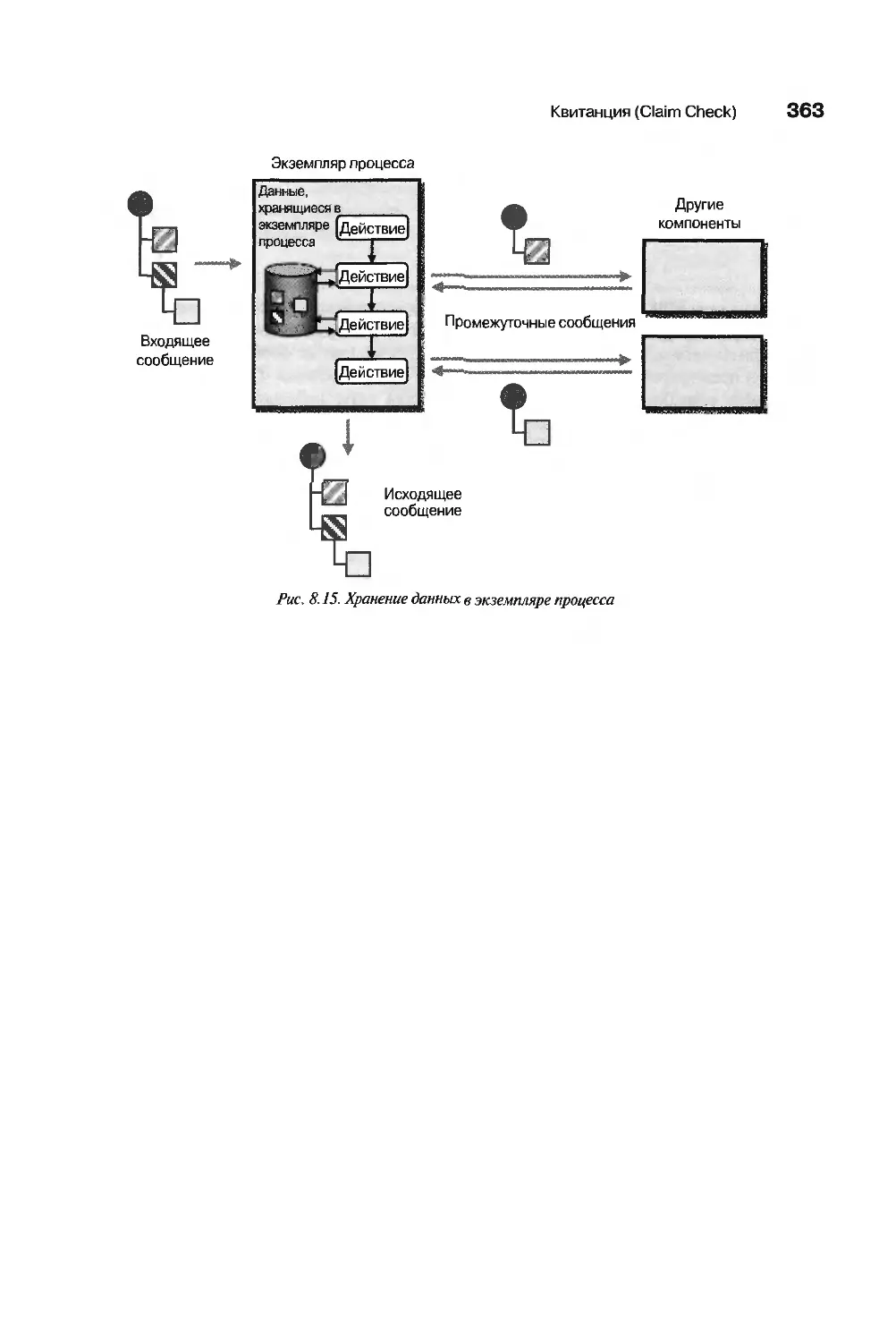
Квитанция (Claim Check) 358
Выбор ключа 360
Использование квитанции для сокрытия информации 361
Использование квитанции с диспетчером процессов 362
Нормализатор (Normalizer) 364
Определение формата сообщения 365
Каноническая модель данных (Canonical Data Model) 367
Способы преобразования 369
Двойное преобразование 370
Разработка канонической модели данных 370
Зависимости между форматами данных 371
Глава 9. Практикум: сложный обмен сообщениями 373
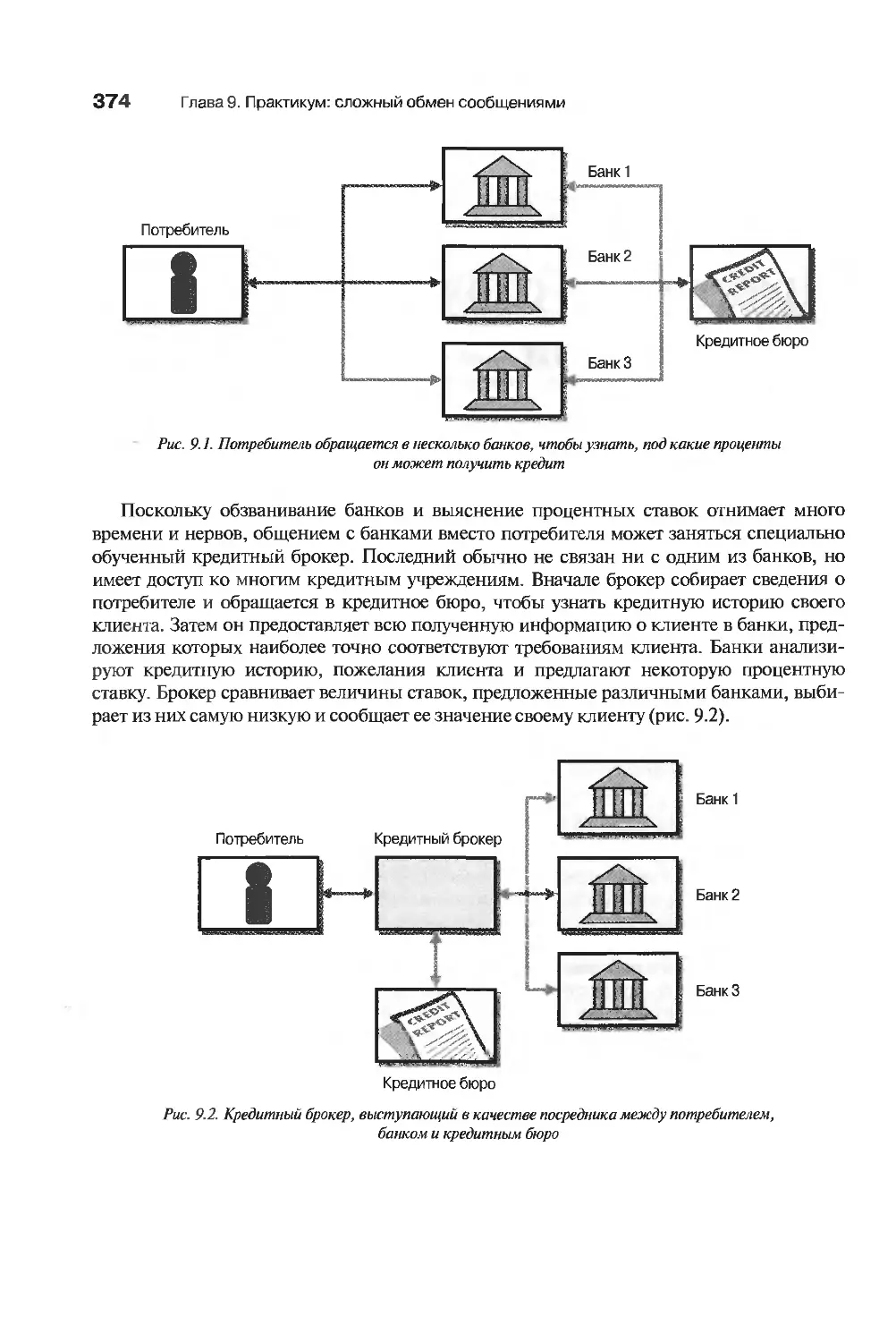
Пример: кредитный брокер 373
Выбор процентной ставки по кредиту 373
Проектирование потока сообщений 375
Режим выполнения операций: синхронный или асинхронный 377
Адресация: распределение или аукцион 378
Стратегии агрегации: несколько каналов или один 380
Управление одновременным доступом 380
Три реализации 381
Синхронная реализация с использованием Web-служб 383
Архитектура решения 383
Соображения по поводу проектирования Web-служб 384
10
Содержание
Набор средств Apache Axis 387
Поиск расположения службы 390
Приложение кредитного брокера 391
Компоненты приложения кредитного брокера 393
Клиентское приложение 409
Запуск решения 410
Ограничения производительности 412
Ограничения данного примера 412
Резюме 413
Асинхронная реализация с использованием MSMQ 414
Экосистема локального брокера 414
Закладываем основы: шлюз обмена сообщениями 415
Базовые классы для общей функциональности 418
Компонент банка 423
Компонент кредитного бюро 425
Компонент кредитного брокера 426
Оптимизация кода кредитного брокера 445
Запуск системы 448
Повышение производительности 449
Несколько слов о тестировании 453
Ограничения данного примера 456
Резюме 457
Асинхронная реализация с использованием Т1ВСО ActiveEnterprise 458
Архитектура решения 458
Набор средств, используемых для реализации 460
Интерфейсы 464
Реализация синхронных служб 465
Процесс кредитного брокера 468
Управление параллельными аукционами 472
Выполнение 473
Резюме 475
Глава 10. Конечные точки обмена сообщениями 477
Введение 477
Шаблоны отправки и получения сообщений 477
Шаблоны потребителей сообщений 478
Некоторые аспекты реализации конечных точек 480
Шлюз обмена сообщениями (Messaging Gateway) 482
Соединение шлюзов в цепочки 486
Обработка исключений системы обмена сообщениями 486
Генерация кода шлюзов 487
Использование шлюзов в процессе тестирования 487
Преобразователь обмена сообшениями (Messaging Mapper) 491
Упрощение кодирования 495
Преобразователь или транслятор 495
Транзакционный клиент (Transactional Client) 498
Опрашивающий потребитель (Polling Consumer) 507
Событийно управляемый потребитель (Event-Driven Consumer) 511
Конкурирующие потребители (Competing Consumers) 515
Содержание
11
Диспетчер сообщений (Message Dispatcher) 521
Избирательный потребитель (Selective Consumer) 528
Постоянный подписчик (Durable Subscriber) 535
Идемпотентный получатель (Idempotent Receiver) 541
Активатор службы (Service Activator) 545
Глава 11. Управление системой 549
Введение 549
Мониторинг и управление 550
Наблюдение и анализ трафика сообщений 550
Тестирование и отладка 551
Шина управления (Control Bus) 552
Обходной путь (Detour) 556
Отвод (Wire Тар) 558
Журнал доставки сообщения (Message History) 561
Хранилище сообщений (Message Store) 565
Интеллектуальный заместитель (Smart Proxy) 567
Тестовое сообщение (Test Message) 577
Вентиль канала (Channel Purger) 579
Глава 12. Практикум: управление системой 583
Управление системой кредитного брокера 583
Оснащение кредитного брокера средствами контроля 583
Управляющая консоль 584
Качество обслуживания кредитного брокера 585
Проверка функциональности кредитного бюро 592
Перемещение при сбое кредитного бюро 598
Усовершенствование управляющей консоли 600
Ограничения примера, приведенного в этой главе 607
Глава 13. Шаблоны интеграции на практике 609
Практикум: система формирования цен на облигации 609
Построение системы 610
Архитектура с учетом шаблонов 610
Структура каналов 616
Выбор канала сообщений 620
Решение проблемы с помощью шаблонов 623
Мигающие ячейки 623
Сбой системы в процессе работы 625
Резюме 628
Глава 14. Кое-что в заключение 629
Новые стандарты и перспективы интеграции корпоративных приложений 629
Связь между стандартами и шаблонами проектирования 630
Основные организации, занимающиеся утверждением стандартов 631
Компоненты бизнес-процессов и внутренний
обмен сообщениями между Web-службами 633
ebXML и ebMS 635
BPEL4WS 638
12 Содержание
WSCI 640
Стандарты компонентов бизнес-процессов для Java 641
Спецификации WS-* 643
Заключение 651
Приложение А. Список шаблонов проектирования 653
Приложение Б. Шаблоны интеграции корпоративных приложений 660
Основные источники информации 662
Предметный указатель 668
Моей семье и всем моим друзьям, которые поддерживали
меня во время написания этой книги.
—Грегор
Шэрон, моей любящей жене.
—Бобби
Предисловие
Джона Крупи
Как вы реагируете на появление новой технологии? Вы изучаете ее. Столкнувшись с плат-
формой J2EE, я не нашел ничего лучшего, кроме как обратиться к ее спецификациям (книг
по J2EE на то время еще не существовало). В частности, я сконцентрировал свое внимание
на подмножестве J2EE— технологии EJB. Тем не менее изучение технологии является
лишь первым шагом к ее эффективному применению. Преимущество платформенных тех-
нологий состоит в том, что они ограничивают разработчика определенным кругом задач.
К сожалению, это не исключает неверного применения самой технологии.
По моим наблюдениям, за последние 15 лет в умах разработчиков программного
обеспечения прочно укоренились идеи эффективного программирования и проектирова-
ния. В настоящее время на рынке существует огромное количество книг по программи-
рованию на Java и С#, однако гораздо меньше по проектированию приложений. Написав
книгу Core J2EE Patterns, мы с Дипаком Алуром (Deepak Alur) и Дэном Малксом (Dan
Malks) хотели помочь 12ЕЕ-разработчикам в создании более эффективного кода. Основ-
ная идея нашей книги заключалась в использовании шаблонов проектирования. Как от-
метил Джеймс Бейти (James Baty), главный инженер компании Sun Microsystems,
“шаблоны являются краеугольным камнем проектирования”. Я полностью согласен
с этим высказыванием. К счастью, так же считают и авторы настоящей книги.
Книга, которую вы держите в руках, посвящена чрезвычайно популярной в последнее
время теме: интеграции приложений с помощью обмена сообщениями. На мой взгляд,
идея обмена сообщениями найдет свое применение не только при интеграции приложе-
ний, но и при создании Web-служб. Как это было на заре появления технологий J2EE
и .NET, вопросам проектирования Web-служб уделяется пока еще очень мало внимания.
Многие считают, что Web-службы являются всего лишь новым способом решения суще-
ствующих задач интеграции, и я полностью с этим согласен. Тем не менее это не отменя-
ет необходимость проектирования самих Web-служб. Изюминка данной книги состоит
в наличии большого количества шаблонов, которые можно применять при проектирова-
нии Web-служб и других интеграционных систем. Бобби и Грегор не балуют читателя
конкретными примерами спецификаций Web-служб, поскольку они все еще нуждаются
в доработке и утверждении. Впрочем, это вполне простительно. Подлинная ценность
книги проявится после объявления соответствующих спецификаций стандартами, что
позволит использовать предложенные шаблоны проектирования для разработки соответ-
ствующих этим стандартам приложений. Вполне вероятно, что создание архитектур,
ориентированных на использование служб, станет основным способом интеграции при-
ложений в ближайшем будущем.
Прочтите эту книгу от начала до конца. Она способна кардинально изменить вашу
карьеру.
Джон Крупи
Бетесда, Мэриленд
Август 2003 г.
Предисловие
Мартина Фаулера
В процессе написания книги Patterns of Enterprise Application Architecture (Фаулер M. Архи-
тектура корпоративных программных приложений.— М.: Издательский дом “Вильямс”,
2004) мне посчастливилось получить подробную рецензию на включенный в нее матери-
ал от Кайла Брауна (Kyle Brown) и Рейчел Рейниц (Rachel Reinitz). В результате нескольких
неофициальных встреч в офисе Кайла в Роли-Дарем мы пришли к выводу, что самым
существенным пробелом моей книги стали системы асинхронного обмена сообщениями.
Безусловно, моя книга содержит множество пробелов и не претендует на звание
исчерпывающего источника информации по шаблонам проектирования корпоративных
приложений. Тем не менее отсутствие в ней описания систем асинхронного обмена
сообщениями особенно болезненно ввиду того, что эти системы будут играть ключевую
роль при решении задач интеграции. Приложения не могут существовать обособленно
одно от другого, и нам нужны методики, позволяющие наладить связь между приложе-
ниями, изначально не предусматривавшими возможность взаимодействия.
На сегодняшний день существует множество различных технологий интеграции при-
ложений. На мой взгляд, наиболее многообещающей из них является обмен сообщения-
ми. Организация эффективного обмена сообщениями— нетривиальная задача, слож-
ность которой обусловливается асинхронной природой сообщений, а также различиями
в подходах к асинхронному программированию.
К сожалению, мне не хватило времени, сил и, что самое главное, знаний, чтобы дос-
тойно раскрыть тему обмена сообщениями в Patterns of Enterprise Application Architecture.
Тем не менее я все-таки нашел решение этой проблемы в виде Грегора и Бобби, взяв-
шихся за написание книги, которую вы сейчас держите в руках.
Следует отметить, что авторы блестяще справились с поставленной перед ними зада-
чей. Если вы уже работали с системами обмена сообщениями, настоящая книга поможет
вам систематизировать накопленный опыт и знания. Если же вы только приступаете
к изучению данной темы, книга поспособствует закладке прочного фундамента, который
пригодится вам при использовании любой технологии обмена сообщениями.
Мартин Фаулер
Мелроуз, Массачусетс
Август 2003 г.
Вступление
Эта книга посвящена интеграции корпоративных приложений с помощью обмена сооб-
щениями. В ней не рассматриваются конкретные технологии или продукты. Вместо
этого она ориентирована на разработчиков и интеграторов, использующих различные
технологии и продукты для обмена сообщениями, такие как:
• МОМ- и EAI-решения IBM WebSphere MQ, Microsoft BizTalk, TIBCO,
WebMethods, SeeBeyond, Vitrian др.;
• реализации спецификации Java Message Service (JMS), внедренные в серверы при-
ложений J2EE, а также в отдельные продукты;
• служба Microsoft Message Queuing (MSMQ), доступная через различные API,
например через классы пространства имен Microsoft .NET System. Messaging;
• новые стандарты Web-служб, поддерживающие асинхронный обмен сообщениями
(например, WS-ReliableMessaging), а также соответствующие API, такие как Java
API for XML Messaging (JAXM) от Sun Microsystems или Web Services Extensions
(WSE) от Microsoft.
Интеграция корпоративных приложений означает нечто большее, чем создание рас-
пределенного приложения с я-уровневой архитектурой. Тогда как отдельный уровень
распределенного приложения не может выполняться самостоятельно, интегрированные
приложения представляют собой независимые сущности, способные к взаимной коор-
динации по принципу слабой связи. Обмен сообщениями позволяет нескольким прило-
жениям передавать данные и команды по сети в соответствии с подходом “отправил
и забыл”. Последнее позволяет вызывающему приложению отправить информацию и
вернуться к выполнению текущей задачи, переложив всю ответственность за доставку
информации на систему обмена сообщениями. При необходимости вызывающее прило-
жение может быть уведомлено о результате доставки информации с помощью функции
обратного вызова. Несмотря на то что по сравнению с синхронным обменом сообще-
ниями асинхронный подход способен усложнить проектирование приложения, возмож-
ность неограниченного числа повторов асинхронного вызова способна существенно
повысить надежность коммуникаций. Асинхронный обмен сообщениями обладает
и другими преимуществами, такими как регулирование числа запросов и балансировка
нагрузки.
Вступление
17
Для кого предназначена эта книга
Эта книга призвана помочь разработчикам приложений и системным интеграторам нала-
дить взаимодействие между приложениями с помощью средств, ориентированных на обмен
сообщениями. В первую очередь, она предназначена для следующих специалистов.
• Архитекторы и разработчики, проектирующие и создающие сложные корпоративные
приложения, которые нуждаются в интеграции с другими приложениями. Мы ори-
ентируемся на разработчиков приложений, использующих современные платфор-
мы, такие как Java 2 Enterprise Edition (J2EE) и Microsoft .NET. С помощью этой
книги вы научитесь соединять приложение с уровнем обмена сообщениями для
взаимодействия с другими приложениями. Следует отметить, что предметом рас-
смотрения этой книги является исключительно интеграция приложений, а не их
создание. Шаблоны проектирования, применяющиеся при создании корпоратив-
ных приложений, рассматриваются в книге Мартина Фаулера Patterns of Enterprise
Application Architecture (Фаулер M. Архитектура корпоративных программных при-
ложений. — М.: Издательский дом “Вильямс”, 2004).
• Архитекторы и разработчики, проектирующие и создающие интеграционные решения,
предназначенные для налаживания взаимодействия между пользовательскими
приложениями. Вероятно, большинство читателей этой книги уже сталкивались с
коммерческими средствами интеграции приложений, такими как IBM WebSphere
MQ, TIBCO, WebMethods, See Beyond, Vitria и др. Каждое из этих средств содержит
реализацию многих шаблонов проектирования, представленных в книге. Помимо
фундаментальных концепций, стоящих за интеграцией приложений, принимать
правильные решения при проектировании вам поможет универсальный язык
шаблонов, не зависящих от конкретного вендора.
• Корпоративные архитекторы, в обязанности которых входит мониторинг про-
граммных и аппаратных активов предприятия. Язык и графическое представление
шаблонов проектирования помогут описать крупномасштабные решения инте-
грации, охватывающие множество различных технологий. Кроме того, язык шаб-
лонов поможет наладить эффективное взаимодействие между корпоративным ар-
хитектором и архитекторами/разработчиками корпоративных приложений и ре-
шений интеграции.
Чему учит эта книга
Основное назначение этой книги — познакомить читателя с принципами проектиро-
вания успешных решений интеграции корпоративных приложений. В процессе ее чтения
вы узнаете:
• преимущества и ограничения асинхронного обмена сообщениями в сравнении
с другими технологиями интеграции;
• как определить каналы обмена сообщениями, в которых нуждается приложение;
регламентировать процедуру получения одного и того же сообщения несколькими
потребителями; обрабатывать сообщения неправильного формата;
18
Вступление
• когда следует отправлять сообщение, какую информацию оно должно содержать
и как использовать специальные свойства сообщений;
• как доставить сообщение в конечную точку его назначения (в том числе и при
отсутствии информации о получателе сообщения);
• как преобразовать сообщение при несовпадении формата отправителя и получателя;
• как спроектировать код соединения приложения с системой обмена сообщениями;
• как проводить управление и мониторинг системы обмена сообщениями.
Что не рассматривается в этой книге
На наш взгляд, все книги, в названиях которых встречается слово “корпоративный”,
делятся на три категории. К первой категории относятся книги, авторы которых стара-
ются всецело охватить предмет обсуждения, однако в конечном итоге останавливаются
на подробном рассмотрении конкретных решений. Книги второй категории содержат
практические советы по разработке конкретных решений, ограничивая при этом диапа-
зон рассматриваемого материала. Наконец, можно попытаться написать книгу, объеди-
няющую в себе лучшие характеристики первых двух категорий, однако в этом случае она
либо не будет закончена, либо будет опубликована настолько поздно, что потеряет свою
актуальность. Настоящая книга относится ко второй категории. Мы попытались напи-
сать книгу о создании интеграционных решений, пожертвовав при этом некоторыми
смежными темами. В частности, мы не рассматривали вопросы безопасности, сложного
отображения данных, рабочих потоков, механизма поддержки правил, масштабируемо-
сти, устойчивости, а также распределенной обработки транзакций (продукты ХА, Tuxedo
и др.). Асинхронный обмен сообщениями был выбран основной темой книги по нес-
кольким причинам. Во-первых, это одна из наиболее перспективных технологий интег-
рации приложений, которой свойственно множество интереснейших вопросов проекти-
рования. Во-вторых, рассмотрение асинхронного обмена сообщениями позволяет абст-
рагироваться от реализации конкретных решений интеграции, предлагаемых различны-
ми вендорами.
Эта книга не является руководством по конкретной технологии обмена сообщениями
или межплатформенному решению. Чтобы подчеркнуть многообразие концепций, пред-
ставленных в книге, мы включили в нее примеры использования целого ряда различных
технологий, таких как JMS, MSMQ, TIBCO, BizTalk и XSL. Каждая из перечисленных
технологий рассматривалась исключительно в аспекте принятия решений проектирова-
ния и возникающих при этом компромиссов. Для подробного изучения какой-либо из
технологий интеграции приложений обратитесь к источникам, перечисленным в конце
книге, или к ресурсам Интернета.
Структура книги
Как следует из названия книги, большая ее часть посвящена шаблонам. Шаблоны —
это проверенный способ представления накопленного опыта и знаний в таких областях,
как архитектура программных приложений, объектно-ориентированное проектирование
и создание интеграционных решений с помощью технологий обмена сообщениями.
Вступление
19
Каждый шаблон состоит из описания некоторой проблемы проектирования, обсуж-
дения исходных условий и представления элегантного, сбалансированного решения.
В большинстве случаев предлагаемое решение является результатом длительного процес-
са поиска. Каждый шаблон “вбирает” в себя опыт, накопленный старшими разработчи-
ками и архитекторами в попытке дать оптимальный ответ на конкретную задачу интегра-
ции. Хотим подчеркнуть, что в этой книге нет “придуманных” нами шаблонов. Шаблон
нельзя “придумать”; к нему можно прийти в результате длительных “полевых” испыта-
ний, извлекая уроки из собственных ошибок.
Если вы уже имеете опыт работы со средствами интеграции корпоративных приложе-
ний и с архитектурой асинхронного обмена сообщениями, то большинство из представ-
ленных в этой книге шаблонов наверняка покажутся вам до боли знакомыми. Однако
даже в этом случае она может принести немалую пользу. Чтение книги поможет закре-
пить знания, накопленные в результате использования технологий обмена сообщениями,
а также поспособствует развитию привычки документирования создаваемых решений
и взаимоотношений между ними. Благодаря универсальному языку шаблонов вы сможе-
те наладить эффективное взаимодействие со своими коллегами.
Представленные в книге шаблоны можно реализовать с помощью различных плат-
форм и языков программирования. Чтобы облегчить процесс встраивания шаблона в
конкретную среду, в книгу были включены примеры реализации шаблонов с привлече-
нием нескольких популярных технологий, таких как JMS, MSMQ, TIBCO, BizTalk, XSL
и др. Кроме того, мы продемонстрировали примеры создания целостных решений, осно-
ванных на сочетании шаблонов проектирования.
Интеграция корпоративных приложений с помощью архитектуры асинхронного об-
мена сообщениями— сложная и увлекательная задача. Искренне надеемся, что наша
книга поможет вам блестяще решить ее.
О фотографии на обложке книги
На обложках всех книг серии A Martin Fowler Signature Book размещается фотография
какого-либо моста. В некотором смысле нам повезло, так как мост великолепно иллюст-
рирует идею интеграции. На протяжении тысячелетий мосты помогали человеку преодо-
левать препятствия в виде рек, горных ущелий и оживленных автострад.
Мост Тайко-баси (“Барабанный мост”) перекинут через пруд перед храмом Сумиёси-
тайся, расположенным в Осаке, Япония. Мы выбрали этот мост за его красоту и элегант-
ность. Синтоистский храм Сумиёси-тайся был построен на берегу бухты Нанива
в III веке н.э. и посвящен божествам, которые оберегали моряков, отправлявшихся в
плавание. За много лет вода отступила, и сейчас храм удален от воды более чем на 5 км.
В начале каждого года Сумиёси-тайся посещают более трех миллионов человек.
Грегор Хоп
Сан-Франциско, Калифорния
Бобби Вульф
Роли, Северная Каролина
Сентябрь 2003 г.
ww. enterpriseintegrationpattems. сот
20
Вступление
Ждем ваших отзывов!
Вы, читатель этой книги, и есть главный ее критик. Мы ценим ваше мнение и хотим
знать, что было сделано нами правильно, что можно было сделать лучше и что еще вы хо-
тели бы увидеть изданным нами. Нам интересны любые ваши замечания в наш адрес.
Мы ждем ваших комментариев и надеемся на них. Вы можете прислать нам бумажное
или электронное письмо либо просто посетить наш Web-сервер и оставить свои замеча-
ния там. Одним словом, любым удобным для вас способом дайте нам знать, нравится
ли вам эта книга, а также выскажите свое мнение о том, как сделать наши книги более
интересными для вас.
Отправляя письмо или сообщение, не забудьте указать название книги и ее авторов,
а также свой обратный адрес. Мы внимательно ознакомимся с вашим мнением и обяза-
тельно учтем его при отборе и подготовке к изданию новых книг.
Наши электронные адреса:
E-mail: info@williamspublishing. com
WWW: http://www .will iamspubl i shing. com
Наши почтовые адреса:
в России: в Украине: 115419, Москва, а/я 783 03150, Киев, а/я 152
Д-р Карл Саган, “Послание внеземным формам жизни” (табличка,
отправленная в космос на американском аппарате серии “Пионер”)
Благодарности
Работа над этой книгой отняла у ее авторов немало времени и сил. Идея создания книги
о шаблонах интеграции, основанных на обмене сообщениями, впервые возникла
в 2001 году в процессе написания Мартином Фаулером своего бестселлера Patterns of
Enterprise Application Architecture (Фаулер M. Архитектура корпоративных программных
приложений. — М.: Издательский дом “Вильямс”, 2004). Кайл Браун (Kyle Brown), один
из рецензентов Patterns of Enterprise Application Architecture, заметил, что в книге Мартина
практически не освещается тема интеграции приложений. Этот пробел стал основным
предметом обсуждения на нескольких встречах между Мартином и Кайлом, на которых
присутствовали также Рейчел Рейниц (Rachel Reinitz), Джон Крупи (John Crupi) и Марк
Вайцель (Mark Weitzel). Осенью 2001 года к дискуссии присоединился Бобби, а зимой
2002 года— Грегор. Летом 2002 года группа единомышленников представила на конфе-
ренции по языкам шаблонов программ (Pattern Languages of Programs— PLoP) две рабо-
ты, одна из которых была написана Бобби и Кайлом, а другая—Грегором. После конфе-
ренции Кайл и Мартин сосредоточились на собственных проектах, а Грегор и Бобби ре-
шили объединить свои статьи для создания фундамента будущей книги. Примерно в это
же время был открыт сайт www.enterpriseintegrationpattems.com, посредством которого ар-
хитекторы и разработчики интеграционных решений всего мира могли принять участие в
совместной работе над содержимым книги. Впоследствии к написанию книги были при-
влечены несколько соавторов. Спустя два года, прошедших с момента критического за-
мечания Кайла относительно содержимого Patterns of Enterprise Application Architecture, ру-
копись настоящей книги была передана издателю.
Эта книга является плодом совместной работы огромного числа людей. Коллеги
и друзья (многих из которых мы приобрели в процессе написания книги) подавали идеи
для размещаемых в книге примеров, проверяли корректность материала с технической
точки зрения, а также снабжали нас бесценными советами и критикой.
Отдельной благодарности заслуживают Кайл Браун и Мартин Фаулер— инициаторы
создания этой книги. Если бы Мартин не принялся писать Patterns of Enterprise Application
Architecture, а Кайл не сформировал группу для обсуждения шаблонов интеграции с помо-
щью обмена сообщениями, наша книга могла бы никогда не увидеть свет.
Огромный вклад в создание книги внесли ее соавторы: Конрад Ф. Д’Круз (Conrad F.
D’Cruz), Шон Невилл (Sean Neville), Майкл Дж. Реттиг (Michael J. Rettig) и Джонатан
Саймон (Jonathan Simon). Написанные ими главы помогли пролить свет на практиче-
скую сторону применения шаблонов проектирования.
Одними из первых критиков книги стали участники конференции по языкам шаблонов
программ PLoP2002: Али Арсанджани (Ali Arsanjani), Кайл Браун, Джон Крупи, Эрик
Эванс (Eric Evans), Мартин Фаулер, Брайан Мэрик (Brian Marick), Тоби Сарвер (Toby
Sarver), Джонатан Саймон, Билл Транделл (Bill Trundell) и Марек Вокач (Marek Vokac).
Благодарности
23
Мы хотели бы поблагодарить рецензентов, множество раз перечитавших черновик
книги и снабдивших нас сотней полезных советов:
• Ричарда Хелма (Richard Helm),
• Люка Хохманна (Luke Hohmann),
• Драгоша Манолеску (Dragos Manolescu),
• Дэвида Райса (David Rice),
• Русс Руфер (Russ Rufer) и всех членов Silicon Valley Patterns Group,
• Мэтью Шорта (Matthew Short).
Отдельное спасибо Русс за привлечение к работе над книгой сообщества Silicon Valley
Patterns Group. Вклад этих людей был поистине неоценим: Роберт Бенсон (Robert
Benson), Трейси Бялик (Tracy Bialik), Джеффри Блейк (Jeffrey Blake), Азад Болур (Azad
Bolour), Джон Брюэр (John Brewer), Боб Эванс (Bob Evans), Энди Фарли (Andy Farlie),
Джефф Глаза (Jeff Glaza), Фил Гудвин (Phil Goodwin), Алан Харриман (Alan Hamman),
Кен Хеджмановски (Ken Hejmanowski), Дебора Кадда (Deborah Kaddah), Ритурадж Кир-
ти (Rituraj Kirti), Ян Луни (Jan Looney), Крис Лопес (Chris Lopez), Джерри Луис (Jerry
Louis), Тао-хунг Ma (Tao-hung Ма), Джефф Миллер (Jeff Miller), Стилян Пандев (Stilian
Pandev), Джон Парелло (John Parello), Хема Пиллей (Hema Pillay), Русс Руфер, Рич Смит
(Rich Smith), Кэрол Тислтуэйт (Carol Thistlethwaite), Дебби Утли (Debbie Utley), Уолтер
Ваннини (Walter Vannini), Дэвид Выдра (David Vydra) и Тед Янг (Ted Young).
Список рассылки Web-сайта www.enterpriseintegrationpattems.com позволил принять
участие в обсуждении материала книги всем желающим. Наибольший вклад в дискуссию
внес Билл Транделл. Среди самых активных участников списка рассылки оказались так-
же Венкатешвар Бомминени (Venkateshwar Bommineni), Данкан Крэгг (Duncan Cragg),
Джон Крупи, Фокко Дегенаар (Fokko Degenaar), Шаилеш Госави (Shailesh Gosavi), Кри-
стиан Холл (Christian Hall), Ральф Джонсон (Ralph Johnson), Пол Джулиус (Paul Julius),
Орьян Люндберг (Oijan Lundberg), Драгош Манолеску, Роб Ми (Rob Мее), Шрикант
Нарасимхан (Srikanth Narasimhan), Майкл Реттиг, Фрэнк Зауэр (Frank Sauer), Джонатан
Саймон, Федерико Спинацци (Federico Spinazzi), Рэнди Стаффорд (Randy Stafford),
Марек Вокач, Джо Уолнз (Joe Walnes) и Марк Вайцель.
Спасибо Мартину Фаулеру за то, что он позволил нам опубликовать книгу в серии
A Martin Fowler Signature Book. Поддержка Мартина придала нам дополнительные силы,
необходимые для завершения работы над книгой.
Мы благодарны Джону Крупи за написанное им предисловие. На протяжении всего
времени работы над книгой Джон был нашим советчиком и вдохновителем, проявляя
при этом незаурядное терпение и прекрасное чувство юмора.
Наконец мы хотели бы выразить огромную признательность замечательным сотруд-
никам издательства Addison-Wesley: главному редактору Майку Хендриксону (Mike
Hendrickson), руководителю производства Эми Флейшер (Amy Fleischer), руководителю
проекта Ким Арни Малкахи (Kim Arney Mulcahy), литературному редактору Кэрол Дж. Ло-
лье (Carol J. Lallier), корректору Ребекке Райдер (Rebecca Rider), составителю предмет-
ного указателя Шэрон Хильгенберг (Sharon Hilgenberg), а также Жаклин Дюсетт
(Jacquelyn Doucette), Джону Фуллеру (John Fuller) и Бернарду Гаффни (Bernard Gaffney).
Мы наверняка забыли упомянуть несколько имен, имевших непосредственное отно-
шение к появлению Enterprise Integration Patterns на свет. Простите нас за это, и еще раз
огромное спасибо за помощь. Надеемся, что все вы так же гордитесь этой книгой, как и мы.
Введение
Корпоративные приложения не могут существовать обособленно одно от другого. Про-
грамма, установленная в магазине розничной продажи, не будет эффективной без взаи-
модействия с программой, установленной на складе, а календарь на КПК— без синхро-
низации с сервером расписаний.
Как правило, разработчики интеграционных решений сталкиваются со следующими
вызовами.
• Ненадежность сети передачи данных. Все интеграционные решения предполагают
передачу информации между устройствами. В отличие от процессов, выполняю-
щихся в пределах одного компьютера, распределенной вычислительной среде
присущ целый ряд недостатков. Зачастую общающиеся системы разделены кон-
тинентами, что вынуждает передавать данные по телефонным линиям, сегментам
локальных сетей, через маршрутизаторы, коммутаторы, общедоступные сети
и спутниковые каналы связи. Доставка информации на каждом из этих этапов
связана с задержкой и риском потери.
• Низкая скорость передачи данных. Время доставки данных через компьютерную
сеть на порядок больше времени вызова локального метода. Таким образом, соз-
дание распределенного приложения требует применения иных принципов проек-
тирования, чем создание приложения, выполняющегося в пределах одного ком-
пьютера.
• Различия между приложениями. Интеграционное решение должно учитывать все
различия (язык программирования, платформа, формат данных), существующие
между объединяемыми системами.
• Неизбежность изменений. Интеграционное решение должно иметь возможность
адаптации к изменению объединяемых им приложений. Зачастую преобразования
в одной системе влекут за собой непредсказуемые последствия для других систем.
Поэтому при интеграции приложений важно уменьшить их взаимозависимость за
счет так называемого слабого связывания.
Для преодоления описанных выше трудностей можно воспользоваться четырьмя
основными подходами.
1. Передача файла (file Transfer, с. 80). Одно приложение создает файл, а другое при-
ложение считывает его. Приложения должны согласовать имя файла, его распо-
ложение, формат, время записи/считывания, а также процедуру удаления.
2. Общая база данных (Shared Database, с. 83). Несколько приложений используют
общую логическую структуру данных, которой соответствует одна физическая ба-
за данных. Наличие единого хранилища данных устраняет проблему передачи
информации между приложениями.
Введение
25
3. Удаленный вызов процедуры (Remote Procedure Invocation, с. 85). Приложение пре-
доставляет доступ к части своей функциональности посредством удаленного вы-
зова процедуры. Взаимодействие между приложениями осуществляется синхрон-
но в режиме реального времени.
4. Обмен сообщениями (Messaging, с. 87). Приложение размещает сообщение в общем
канале, которое затем считывается другим приложением. Приложения должны
согласовать канал, а также формат сообщения. Взаимодействие между приложе-
ниями осуществляется в асинхронном режиме.
Каждый из предложенных подходов имеет собственные преимущества и недостатки.
На практике приложения могут быть интегрированы несколькими способами таким об-
разом, чтобы использовать только сильные стороны того или иного подхода.
Что такое обмен сообщениями
Эта книга посвящена интеграции приложений с помощью обмена сообщениями.
Чтобы лучше понять смысл обмена сообщениями, рассмотрим систему телефонной свя-
зи. Телефонный разговор является ярким примером синхронного взаимодействия. Або-
нент может начать общение с вызываемой стороной только в том случае, если последняя
окажется свободной в момент звонка. Привнесение в эту систему автоответчика делает ее
асинхронной. Если абонент не отвечает, ему можно оставить голосовое сообщение,
которое он сможет прослушать в удобное для него время. Это намного проще, чем пы-
таться дозвониться до абонента вновь и вновь. “Сохранение” части телефонного разго-
вора в виде сообщения и помещение его в очередь для последующего прослушивания
наглядно иллюстрирует сущность обмена сообщениями.
Обмен сообщениями—это технология высокоскоростного асинхронного взаимодей-
ствия между программами с гарантией доставки информации. Программы взаимодейст-
вуют между собой, обмениваясь пакетами данных, называемыми сообщениями. Канал,
или очередь, — это логический маршрут, объединяющий программы и использующийся
для транспортировки сообщений. Канал напоминает массив сообщений, доступный для
одновременного использования многими приложениями. Отправитель, или постав-
щик, — это программа, отправляющая сообщение путем его размещения в канале. Полу-
чатель, или потребитель, — это программа, получающая (а затем удаляющая) сообщение
путем его считывания из канала.
Сообщение представляет собой некоторую структуру данных— строку, байтовый
массив, запись или объект. Оно может быть интерпретировано непосредственно как со-
держащиеся в нем данные, как команда, которую необходимо выполнить получателю,
или как описание события, произошедшего на стороне отправителя. Сообщение состоит
из двух частей— заголовка и тела. Заголовок сообщения содержит метаданные (кто от-
правил сообщение, куда его следует передать и т.п.), которые используются системой об-
мена сообщениями и игнорируются получателем сообщения. Тело сообщения содержит
полезную информацию, которая, как правило, игнорируется системой обмена сообще-
ниями. Упоминая сообщение в разговоре, разработчик приложения обычно имеет в виду
информацию, содержащуюся в теле сообщения.
26
Введение
По сравнению с тремя оставшимися способами интеграции приложений, опыт рабо-
ты с системами обмена сообщениями имеет весьма ограниченное число разработчиков.
Как следствие применение архитектуры асинхронного обмена сообщениями зачастую
требует переосмыслить подход к созданию приложений.
Что такое система обмена сообщениями
Функциональная часть обмена сообщениями обеспечивается отдельной программной
системой, называемой системой обмена сообщениями или связующим ПО, ориентированным
на обмен сообщениями (message-oriented middleware — МОМ). Система обмена сообщениями
имеет много общего с системой баз данных. В частности, схеме базы данных, использую-
щейся для определения формата хранимой информации, соответствуют каналы обмена со-
общениями. Основная задача системы баз данных—- обеспечить надежное хранение ин-
формации, а основная задача системы обмена сообщениями— гарантировать доставку со-
общений с компьютера отправителя на компьютер получателя.
Необходимость наличия системы обмена сообщениями обусловливается ненадежно-
стью сетей передачи данных. Сбой в компьютерной сети— одна из самых распростра-
ненных причин неудавшейся доставки сообщения от отправителя к получателю. Система
обмена сообщениями позволяет гарантировать доставку информации за счет повторной
отправки сообщения (до тех пор, пока оно не будет принято получателем). В идеальных
условиях сообщение доставляется с первого раза, однако, к сожалению, так бывает дале-
ко не всегда.
Процедура передачи сообщения от отправителя к получателю состоит из пяти основных
этапов.
1. Создание. Отправитель создает сообщение, содержащее полезную информацию.
2. Отправка. Отправитель помещает сообщение в канал.
3. Доставка. Система обмена сообщениями доставляет сообщение с компьютера от-
правителя на компьютер получателя.
4. Получение. Получатель извлекает сообщение из канала.
5. Обработка. Получатель считывает полезную информацию.
На рис. 1 проиллюстрированы все основные этапы процедуры передачи сообщения.
Введение
27
Рис. 1. Основные этапы передачи сообщения от отправителя к получателю
с использованием системы обмена сообщениями
На рис. 1 также отражены две важные концепции обмена сообщениями.
1. “Отправить и забыть”. Поместив сообщение в канал на этапе 2, отправитель
может не заботиться о его дальнейшей судьбе—гарантированную доставку сооб-
щения получателю обеспечивает система обмена сообщениями.
2. Передача с промежуточным хранением. На этапе 2 система обмена сообщениями со-
храняет сообщение, помещенное отправителем в канал, на компьютере отправителя
(в оперативной памяти или на жестком диске). На этапе 3 система обмена сообще-
ниями доставляет сообщение с компьютера отправителя на компьютер получателя и
сохраняет его на компьютере получателя. Процесс передачи сообщения с промежу-
точным хранением повторяется, если для достижения компьютера получателя со-
общение должно пройти через несколько других компьютеров.
В описанной выше схеме этапы создания, отправки, получения и обработки сообще-
ния могут показаться излишними. Действительно, почему бы просто не передать нужную
информацию от отправителя к получателю? Создание сообщения и его передача системе
обмена сообщениями позволяет делегировать последней всю ответственность за доставку
данных, тем самым обеспечив надежную передачу единственной копии полезной ин-
формации получателю.
Преимущества обмена сообщениями
Обмен сообщениями обладает множеством преимуществ по сравнению с другими
технологиями интеграции приложений. Коротко говоря, обмен сообщениями более
быстр, чем передача файла (File Transfer, с. 80), обладает лучшей инкапсуляцией по срав-
нению с общей базой данных (Shared Database, с. 83) и более надежен, чем удаленный вызов
процедуры (Remote Procedure Invocation, с. 85).
28
Введение
Ниже перечислены дополнительные преимущества, которые позволяет получить тех-
нология обмена сообщениями.
• Удаленное взаимодействие. Обмен сообщениями позволяет наладить взаимодействие
между отдельными приложениями. Два объекта, относящихся к одному и тому же
процессу, могут совместно использовать данные, размещенные в оперативной памя-
ти. Передача информации с одного компьютера на другой требует выполнения
“сериализации” данных— преобразования соответствующих объектов в байтовый
поток с целью последующей отправки по сети. Как было сказано выше, приложение
может делегировать всю ответственность за передачу данных системе обмена сооб-
щениями, тем самым избавляясь от части сложной функциональности.
• Платформенная/языковая интеграция. Зачастую удаленные системы создаются
с использованием различных платформ, технологий и языков программирования.
Интеграция разнородных систем требует использования связующего ПО, в каче-
стве которого может выступить система обмена сообщениями. Идея использова-
ния системы обмена сообщениями в качестве универсального связующего звена
между приложениями была положена в основу шаблона шина сообщений {Message
Bus, с. 162).
• Асинхронное взаимодействие. Обмен сообщениями позволяет наладить взаимодей-
ствие между приложениями по принципу отправил и забыл (send-and-fotgef). В со-
ответствии с этим принципом отправитель не обязан ожидать подтверждение
о получении и обработке сообщения от принимающей стороны; более того, он
также не обязан ожидать подтверждение о доставке сообщения от системы обмена
сообщениями. Единственное, о чем следует позаботиться отправителю, — это до-
ждаться подтверждения об отправке сообщения, т.е. о его помещении в канал.
Как только сообщение будет передано системе обмена сообщениями, отправитель
может приступить к выполнению имеющихся у него задач.
• Рассогласование во времени. При синхронном взаимодействии отправитель должен
дождаться завершения обработки вызова получателем прежде, чем сделать новый
вызов. Таким образом, скорость размещения вызовов отправителем ограничена
скоростью их обработки получателем. Асинхронное взаимодействие позволяет
размещать и обрабатывать вызовы с разной скоростью, что существенно повышает
эффективность взаимодействия между приложениями.
• Регулирование нагрузки. Слишком большое число удаленных вызовов процедур за
короткий промежуток времени может привести к перегрузке получателя, сниже-
нию его производительности и даже выходу из строя. Система обмена сообщения-
ми формирует очередь запросов, позволяя получателю контролировать скорость
их обработки. Поскольку взаимодействие осуществляется в асинхронном режиме,
ретулирование нагрузки на стороне получателя не оказывает негативного влияния
на отправителя.
• Надежное взаимодействие. В отличие от удаленного вызова процедуры, обмен со-
общениями позволяет наладить надежное взаимодействие между приложениями
за счет подхода, получившего название передача с промежуточным хранением {store-
and-forward). Как упоминалось выше, сообщение представляет собой единицу пе-
редачи информации, инкапсулирующую полезные данные. Когда отправитель по-
Введение
29
мещает сообщение в канал, система обмена сообщениями сохраняет его на ком-
пьютере отправителя. Затем сообщение доставляется получателю и сохраняется на
его компьютере. Предположим, что сохранение сообщения на компьютерах от-
правителя и получателя является надежной операцией. (Чтобы сделать ее еще на-
дежнее, сообщение можно сохранять не в памяти, а на диске компьютера, как
описывается шаблоном гарантированная доставка (Guaranteed Delivery, с. 149).)
Единственным слабым звеном передачи с промежуточным хранением является
доставка сообщения на компьютер получателя. Чтобы нивелировать негативное
влияние возможных сбоев при передаче сообщения, система обмена сообщениями
пересылает его до тех пор, пока оно не будет доставлено по назначению. Автома-
тическая пересылка сообщения позволяет исключить риск потери информации
при возникновении сбоя в сети или на компьютере получателя, что, в свою оче-
редь, делает возможным применение принципа взаимодействия между приложе-
ниями “отправил и забыл”.
• Работа без подключения к сети. Некоторые приложения ориентированы на работу
без подключения к сети. Как правило, подобные приложения предназначены для
выполнения на ноутбуках или КПК и периодически (при наличии сетевого под-
ключения) синхронизируют данные с сервером. Обмен сообщениями— идеаль-
ное решение для синхронизации, позволяющее накапливать данные в очереди
до тех пор, пока приложение не получит доступ к сети.
• Посредничество. Система обмена сообщениями выступает в роли посредника
(Mediator) [12] между взаимодействующими приложениями. Приложение может
использовать систему обмена сообщениями в качестве каталога доступных для ин-
теграции приложений и служб. Если приложение потеряет связь с другими прило-
жениями. ему понадобится восстановить соединение только с системой обмена
сообщениями, а не с каждым отдельным приложением. Функция посредника мо-
жет потребовать от системы обмена сообщениями высокой доступности, баланси-
ровки нагрузки, устойчивости к отказам сетевых соединений, а также поддержки
качества обслуживания.
• Управление потоками. Асинхронное взаимодействие позволяет приложению
не ожидать результата выполнения задачи другим приложением. Вместо этого
приложение может воспользоваться обратным вызовом, уведомляющим его о по-
ступлении ответа (шаблон запрос-ответ — Request-Reply, с. 177). Большое число
заблокированных потоков, а также потоки, заблокированные в течение длитель-
ного времени, могут оказать негативное воздействие на работу приложения. Кро-
ме того, такие потоки трудно восстановить в случае сбоя приложения и его после-
дующего перезапуска. Использование обратного вызова позволяет минимизиро-
вать количество заблокированных потоков, обеспечить стабильную работу
приложения и определить потоки, которые должны быть восстановлены при его
перезапуске.
Итак, существует несколько причин, свидетельствующих в пользу обмена сообще-
ниями. Некоторые из них носят сугубо технический характер, в то время как остальные
представляют собой стратегические решения, принимающиеся на этапе проектирования
приложения. Безусловно, каждое из вышеперечисленных преимуществ обмена сообше-
30
Введение
ниями будет иметь различный вес в контексте конкретных требований, предъявляемых
к приложению. Однако мы уверены, что каждое из них является достаточным аргумен-
том для использования технологии обмена сообщениями при интеграции приложений.
Недостатки асинхронного обмена сообщениями
Несмотря на то что технология асинхронного обмена сообщениями позволяет пре-
одолеть множество трудностей, связанных с интеграцией разнородных приложений, она
не лишена недостатков. Некоторые из них являются неотъемлемой частью асинхронной
модели взаимодействия, в то время как остальные зависят от конкретной реализации
системы обмена сообщениями.
• Сложная модель программирования. Асинхронный обмен сообщениями требует от
разработчиков использования модели событийно управляемого программирования.
В этом случае логика приложения разбивается на множество обработчиков событий,
реагирующих на входящие сообщения. Подобную систему гораздо труднее програм-
мировать и отлаживать, чем систему, основанную на вызове методов. Так, эквива-
лентом простого вызова метода в модели событийно управляемого программирова-
ния является совокупность, состоящая из сообщения с запросом, канала запроса,
сообщения с ответом, канала ответа, идентификатора корреляции и очереди сооб-
щений недопустимого формата (см. шаблон запрос-ответ —Request-Reply, с. 177).
• Порядок доставки сообщений. Система обмена сообщениями гарантирует доставку
сообщения от отправителя к получателю, не оговаривая требующееся для этого
время. В результате может быть нарушен порядок, в котором были отправлены со-
общения. Если последовательность доставки сообщений имеет значение, ее нужно
восстановить, как описано в шаблоне преобразователь порядка (Resequencer, с. 297).
• Необходимость реализации синхронной модели. Не все приложения могут взаимо-
действовать по принципу “отправил и забыл”. К примеру, пользовательский за-
прос о наличии авиабилетов должен быть обработан немедленно, а не в течение
неопределенного промежутка времени. Следовательно, в некоторых системах об-
мена сообщениями должен быть предусмотрен баланс между синхронной и асин-
хронной моделями взаимодействия.
• Производительность. Системы обмена сообщениями вносят дополнительные из-
держки в процесс взаимодействия между приложениями. На создание, отправку,
получение и обработку сообщения уходят время и ресурсы. К тому же передача
большого объема данных может повлечь за собой создание несметного числа со-
общений. Так, зачастую интеграция двух существующих систем начинается с реп-
ликации всех необходимых данных. Репликация большого объема информации с
помощью средств ETL (Extract, Transform and Load— “извлечение, преобразова-
ние, загрузка”) гораздо эффективнее репликации с помощью обмена сообщения-
ми. Таким образом, обмен сообщениями рекомендуется применять для синхрони-
зации данных между приложениями, а не для их первичной репликации.
• Ограниченная поддержка программными платформами. Многие коммерческие сис-
темы обмена сообщениями недоступны для всех платформ. Зачастую единствен-
ный способ интеграции приложений заключается в использовании протокола
Введение
31
FTP, поскольку целевая программная платформа не поддерживается конкретной
системой обмена сообщениями.
• Зависимость от компании-разработчика. Коммерческие системы обмена сообще-
ниями могут основываться на использовании закрытых протоколов. Даже такая
общепринятая спецификация обмена сообщениями, как JMS, не определяет под-
робностей реализации конкретного решения. В результате различные системы об-
мена сообщениями оказываются неспособными к взаимодействию друг с другом.
Это может привести к возникновению новой задачи интеграции: интеграции
нескольких различных интеграционных решений! (См. шаблон мост обмена сооб-
щениями Messaging Bridge, с. 159).
Подведем итог. Технология асинхронного обмена сообщениями не решает всех задач
интеграции. Более того, ее использование может привести к необходимости преодоления
новых трудностей. Взвесьте все “за” и “против”, прежде чем приступить к реализации
конкретного интеграционного решения с помощью обмена сообщениями.
Мыслим асинхронно
Обмен сообщениями— это технология асинхронного взаимодействия приложений с
гарантией доставки данных. В то же время большинство приложений использует син-
хронные вызовы функций; например, процедура вызывает подпроцедуру, один метод вы-
зывает другой или же процедура вызывает другую процедуру через технологию удален-
ного вызова (такую, как CORBA или DCOM). Синхронный вызов требует от вызываю-
щего процесса ожидания завершения выполнения функции подпроцессом. Даже при
использовании удаленного вызова, подразумевающего выполнение подпроцедуры в от-
дельном процессе, вызывающий процесс приостанавливает свое выполнение до возврата
управления (а также результата выполнения подпроцедуры). При использовании асин-
хронного обмена сообщениями приложения могут взаимодействовать по принципу
“отправил и забыл”, позволяющему вызывающему приложению разместить сообщение в
канале и тотчас же вернуться к выполнению текущей задачи. Другими словами, вызы-
вающая процедура продолжает свое выполнение во время вызова подпроцедуры, как по-
казано на рис. 2.
Рис. 2. Семантика синхронного и асинхронного вызовов
32
Введение
Асинхронное взаимодействие имеет ряд отличительных особенностей. Во-первых,
речь идет о более чем одном потоке выполнения. Наличие нескольких потоков позволяет
подпроцедурам выполняться одновременно, что существенно увеличивает производи-
тельность приложения, однако затрудняет его отладку. Во-вторых, результат выполнения
подпроцедуры (если таковой имеется) возвращается посредством механизма обратного
вызова. С одной стороны, это позволяет увеличить производительность, так как вызы-
вающий процесс может заняться выполнением других задач, не дожидаясь возвращения
результата. С другой стороны, вызывающий процесс должен быть готов к обработке ре-
зультата в любой момент (даже во время выполнения другой задачи), а также помнить
контекст, в котором был осуществлен вызов. В-третьих, асинхронные подпроцессы могут
выполняться в любом порядке. Это накладывает на вызывающий процесс еще одно тре-
бование: уметь обрабатывать полученные результаты с учетом их источника и времени
получения. Таким образом, асинхронная модель взаимодействия имеет несколько неос-
поримых преимуществ, однако требует от разработчика переосмыслить способ использо-
вания процедурой своих подпроцедур.
Распределенное приложение или интеграция приложений
Зачастую корпоративные приложения распределяются между несколькими компью-
терами за счет использования n-уровневой архитектуры (усовершенствованный вариант
архитектуры клиент/сервер). Несмотря на то что процессы и-уровневого приложения
выполняются на нескольких компьютерах и взаимодействуют между собой, интеграция
приложений существенно отличается от распределенного приложения.
Почему же использование n-уровневой архитектуры не позволяет говорить об инте-
грации? Во-первых, взаимодействие между общающимися сторонами построено по
принципу сильной связи — ни один из уровней приложения не может функционировать
без оставшихся уровней. Во-вторых, взаимодействие между уровнями синхронно.
В-третьих, пользователи приложения (одно- или многоуровневого) — это люди, которые
привыкли к быстрому отклику системы.
В то же время интеграция подразумевает налаживание взаимодействия между незави-
сящими друг от друга приложениями по принципу слабой связи. Каждое из интегриро-
ванных приложений выполняет определенный круг задач, обращаясь к другим приложе-
ниям для получения некоторой дополнительной функциональности. Интегрированные
приложения взаимодействуют асинхронно, что позволяет им продолжать работу, не до-
жидаясь ответа от вызываемой стороны. Это же делает возможным отказ от жестких вре-
менных ограничений, присущих пользовательским приложениям.
Коммерческие системы обмена сообщениями
Очевидные преимущества интеграционных решений, использующих асинхронный
обмен сообщениями, дали толчок к созданию рынка соответствующего связующего ПО и
средств разработки. Ниже перечислены четыре основные категории коммерческих про-
дуктов, ориентированных на обмен сообщениями.
Введение
33
1. Операционные системы. Популярность технологии обмена сообщениями побуди-
ла разработчиков программного обеспечения интегрировать необходимую ин-
фраструктуру в операционные системы и СУБД. К примеру, корпорация
Microsoft включила в состав операционных систем Windows 2000 и Windows ХР
службу Microsoft Message Queuing (MSMQ). Служба MSMQ доступна посредством
нескольких API, включая компоненты СОМ и классы пространства имен
Microsoft .NET System.Messaging. Аналогичная функциональность (Oracle AQ)
была реализована в СУБД Oracle.
2. Серверы приложений. Впервые компания Sun Microsystems включила специфи-
кацию Java Messaging Service (JMS) в версию 1.2 платформы J2EE. С тех пор прак-
тически все серверы приложений J2EE (такие, как IBM WebSphere и BEA
WebLogic) включают в себя реализацию JMS. Кроме того, эталонная реализация
JMS поставляется в составе J2EE JDK.
3. Решения для интеграции корпоративных приложений. Как правило, решения для
интеграции корпоративных приложений обладают богатой функциональностью
и включают в себя систему обмена сообщениями, средства автоматизации доку-
ментооборота и деловых операций, средства создания порталов и др. Наиболее
известными EAI-решениями являются IBM WebSphere MQ, Microsoft BizTalk,
TIBCO, WebMethods, SeeBeyond, Vitria, CrossWorlds и др. Некоторые из этих про-
дуктов содержат несколько различных API, обеспечивающих обмен сооб-
щениями, в то время как остальные (например, SonicSoftware и Fiorano) ориенти-
руются исключительно на JMS.
4. Средства создания Web-служб. Web-службы привлекли к себе огромный интерес со
стороны разработчиков интеграционных решений. В настоящее время усилия
комитетов и консорциумов по стандартизации сосредоточены на принятии специ-
фикации технологии надежного обмена сообщениями на основе Web-служб
(стандарты WS-Reliability. WS-ReliableMessaging и ebMS). В то же время на рынке
появляется все больше и больше продуктов, реализующих маршрутизацию, преоб-
разование и управление решениями, основанными на использовании Web-служб.
Шаблоны, представленные в этой книге, не ориентированы на конкретного постав-
щика ПО и применимы к большинству интеграционных решений, основанных на обме-
не сообщениями. К сожалению, практически все существующие на рынке системы об-
мена сообщениями используют собственную терминологию. Мы же постарались подоб-
рать простые, описательные имена шаблонов, не зависящие от конкретной технологии
или решения.
Многие поставщики интеграционных решений, основанных на обмене сообщения-
ми, реализовали некоторые из представленных в этой книге шаблонов в своих продуктах.
Читатели, знакомые с терминологией конкретного поставщика, не должны испытывать
трудностей при освоении языка шаблонов. В этом им помогут следующие таблицы.
34
Введение
Терминология коммерческих систем обмена сообщениями
Шаблоны интеграции корпоративных приложений Java Message Service (JMS) Microsoft MSMQ WebSphere MQ
Канал сообщений (Message Channel, с. 93) Destination MessageQueue Queue
Канал “точка-точка” (Point-to- Point Channel, с. 131) Queue MessageQueue Queue
Канал “публикация-подписка” (Publish-Subscribe Channel, с. 134) Topic — —
Сообщение (Message, с. 98) Message Message Message
Конечная точка сообщения (Message Endpoint, с. 124) MessageProducer, MessageConsumer — —
Терминология коммерческих систем обмена сообщениями
Шаблоны интеграции корпоративных приложений TIBCO WebMethods SeeBeyond Vitria
Канал сообщений (Message Channel, с. 93) Subject Queue Intelligent Queue Channel
Канал “точка-точка” (Point-to- Point Channel, с. 131) Distributed Queue Deliver Action Intelligent Queue Channel
Канал “публикация-подписка” (Publish-Subscribe Channel, с. 134) Subject Publish- Subscribe Action Intelligent Queue Publish-Subscribe Channel
Сообщение (Message, с. 98) Message Document Event Event
Конечная точка сообщения Publisher, Publisher, Publisher, Publisher,
(Message Endpoint, с. 124) Subscriber Subscriber Subscriber Subscriber
Форма шаблонов
Идея использования шаблонов для документирования приемов программирования
была популяризирована благодаря таким книгам, как Design Patterns, Pattern Oriented
Software Architecture, Core J2EE Patterns и Patterns of Enterprise Application Architecture
(Фаулер M. Архитектура корпоративных программных приложений.— М.: Издательский
дом “Вильямс”, 2004). Впервые концепция шаблонов и языка шаблонов была представ-
лена в книгах Кристофера Александера (Christopher Alexander) A Pattern Language
и A Timeless Way of Building. Каждый шаблон представляет собой некоторое решение,
которое должно быть принято на этапе проектирования, а также его обоснование. Язык
шаблонов— это набор тесно связанных между собой шаблонов. Применение шаблонов
проектирования является одним из наиболее эффективных способов документирования
экспертных знаний.
Введение
35
Язык шаблонов позволяет решать неограниченное число задач в рамках конкретной
проблемной области. Как правило, каждая решаемая задача предполагает уникальный
выбор и способ использования шаблонов. Эта книга поможет вам найти верный ответ на
любой вопрос, связанный с применением технологии обмена сообщениями.
Использование формы шаблонов не гарантирует успех книги. Недостаточно сказать:
“Для решения этой задачи примените такой-то шаблон’’. Шаблон представляет ценность
только в том случае, если он содержит обоснование сложности задачи, описание возмож-
ных способов ее решения и объяснение преимуществ предлагаемого подхода. Кроме
того, шаблоны должны быть связаны друг с другом для наглядной иллюстрации взаимо-
проникновения проблем проектирования. В этом случае форма шаблонов не только под-
скажет способ решения конкретной задачи, но и поможет выработать подход к успеш-
ному преодолению новых, не предусмотренных авторами этой книги, проблем.
В некотором смысле шаблоны подобны директивам. Они не описывают проблему или
ее решение — вместо этого шаблоны учат решать проблему. Каждый шаблон представ-
ляет собой вопрос, ответ на который необходимо дать разработчику, например “Стоит ли
использовать обмен сообщениями?” или “Будет ли оправдана в данной ситуации отправка
сообщения с командой?". Суть шаблонов и языка шаблонов заключается в способствова-
нии принятию правильных решений в любой (даже не предусмотренной автором шабло-
на) ситуации.
Универсальной формы шаблона не существует. Избранный нами стиль очень близок
к форме Александера, ставшей популярной благодаря книге Кента Бека (Kent Beck)
Smalltalk Best Practice Patterns. Для улучшения восприятия материала мы использовали
такие элементы стилевого оформления, как подчеркивание, курсив, а также наглядные
иллюстрации.
Форма каждого шаблона, представленного в этой книге, состоит из следующих
элементов.
• Имя. Имя шаблона отражает его назначение. Основным критерием, использован-
ным при выборе имени шаблона, была простота употребления этого имени в пред-
ложениях. а значит, и в разговорах между проектировщиками.
• Пиктограмма. В добавок к имени большинство шаблонов имеет пиктограмму.
Необходимость использования пиктограмм была обусловлена тем, что многие
архитекторы привыкли работать с диаграммами, т.е. с визуальным представлением
шаблонов. К тому же применение пиктограмм позволяет наглядно представить
композицию нескольких шаблонов.
• Контекст. В этом разделе описывается ситуация, которая привела к возникнове-
нию задачи. Зачастую в контексте упоминаются другие шаблоны проектирования.
• Задача. Постановка задачи представлена в виде вопросительного предложения, ог-
раниченного двумя горизонтальными линиями.
• Оценка сложности. В этом разделе описываются ограничения, затрудняющие ре-
шение задачи. Также здесь могут упоминаться альтернативные решения, приме-
нение которых по тем или иным причинам нецелесообразно.
• Решение. Описание действий, которые необходимо предпринять для решения
задачи. Постановка задачи и ее решение являются ключевыми компонентами
шаблона. Чтобы облегчить повторное использование книги, для выделения текста
постановки и решения задачи используется одинаковое стилевое оформление.
36
Введение
• Эскиз. Одной из наиболее привлекательных особенностей формы Александера
является наличие эскиза, иллюстрирующего решение задачи. В большинстве слу-
чаев для понимания сути шаблона достаточно взглянуть на его имя и эскиз реше-
ния. Последовав примеру, мы разместили эскиз решения непосредственно после
его описания для каждого шаблона.
• Результат. В этой части рассматриваются особенности применения решения,
а также трудности, которые могут при этом возникнуть
• Что дальше. В этом разделе перечисляются шаблоны, на которые стоит обратить
внимание после применения решения. Как правило, использование одного из
шаблонов ведет к возникновению новых трудностей, для устранения которых сле-
дует обратиться к другим шаблонам. Высокая степень взаимопроникновения шаб-
лонов — одна из основных особенностей, отличающих язык шаблонов от простого
каталога шаблонов.
• Врезки. Врезки содержат информацию о технических подробностях или разновид-
ностях шаблона. Специфическое стилевое форматирование позволяет пропустить
врезку, если она не касается интересующей вас реализации шаблона.
• Примеры. Обычно шаблон содержит один или несколько примеров его примене-
ния на практике. Пример реализации шаблона может содержать как одно лишь
упоминание об известном способе его использования, так и большой сегмент
программного кода. Учитывая разнообразие существующих технологий обмена
сообщениями, мы не рассчитываем на то, что читатель будет знаком с каждой из
них. Именно поэтому мы используем форму шаблона, позволяющую безболез-
ненно пропустить примеры, не потеряв при этом важной информации.
Самое большое преимущество использования шаблонов состоит в том, что, помимо
решения конкретной задачи, шаблон позволяет разрабатывать решения для новых,
не предусмотренных его авторами задач. Таким образом, представленные в книге шабло-
ны могут быть использованы при работе не только с существующими системами обмена
сообщениями, но и с системами обмена сообщениями, которые будут созданы после ее
выхода в свет.
Диаграммы, использованные в книге
Интеграционные решения состоят из множества различных компонентов— прило-
жений, баз данных, конечных точек, каналов, сообщений, маршрутизаторов и т.д. Чтобы
описать интеграционное решение, следует определить нотацию, содержащую средства
для представления вышеперечисленных компонентов. К сожалению, на сегодняшний
день не существует всеобъемлющей, широко известной нотации, с помощью которой
можно было бы описать все аспекты интеграционных решений. Унифицированный язык
моделирования (Unified Modeling Language— UML) отлично подходит для описания
объектно-ориентированных систем с помощью диаграмм классов и взаимодействия, од-
нако он не содержит семантику для описания решений, основанных на обмене сообще-
ниями. Профиль UML для интеграции корпоративных приложений (UML Profile for
EAI — UMLEAI) [42] расширяет семантику диаграмм взаимодействия за счет поддержки
Введение
37
описания обмена сообщениями между компонентами системы. Эта нотация может слу-
жить отличной наглядной спецификацией для генерации кода как часть архитектуры,
управляемой моделью (model-driven architecture— MDA). Тем не менее мы приняли
решение отказаться от профиля UMLEA1 по двум причинам. Во-первых, с помощью
UMLEAI нельзя описать все шаблоны, представленные в этой книге. Во-вторых, нашей
целью является не точная визуальная спецификация, а “эскиз” или “набросок”, способ-
ный максимально просто и лаконично передать суть шаблона. Именно поэтому мы и ре-
шили разработать собственную “нотацию”, не требующую от читателя изучать длинную
документацию по ее использованию. Пример употребления созданной нами нотации
представлен на рис. 3.
На рис. 3 изображено сообщение, передаваемое по каналу компоненту в самом широ-
ком смысле этого слова. Так, это может быть интегрируемое приложение; посредник,
преобразующий сообщения или маршрутизирующий их между приложениями; опреде-
ленная часть приложения. Если на рисунке необходимо подчеркнуть использование
канала, он изображается в виде трехмерной трубки. Однако гораздо чаще акцент перено-
сится на компоненты, а канал изображается в виде линии с указывающей стрелкой.
Два различных способа представления канала на рисунке полностью эквивалентны.
Как показано на рис. 3, сообщению соответствует небольшое дерево с круглым корнем и
квадратными вложенными элементами. Подобный способ представления сообщения
обусловливается использованием многими системами обмена сообщениями древовид-
ных структур данных, таких как документы XML. Элементы дерева могут быть заштрихо-
ваны или залиты определенным цветом для подчеркивания способа их использования в
конкретном шаблоне. В частности, это позволяет создать наглядное визуальное пред-
ставление для шаблонов преобразования, предназначенных для добавления, изменения
порядка следования или удаления полей сообщения.
Сообщение
Канал
Компонент
Рис. 3. Пример визуального представления компонентов интеграционного решения
Описывая структуру приложения, мы не используем стандартные диаграммы классов
и циклограммы UML для представления иерархии классов и взаимодействия между
объектами. Одним из наиболее авторитетных источников информации по нотации UML
является [41].
38
Введение
Примеры и практикумы
Стараясь подчеркнуть широкую применимость шаблонов проектирования, представ-
ленных в этой книге, мы включили в нее множество примеров использования различных
технологий интеграции. Недостаток подобного подхода состоит в том, что читатель мо-
жет не быть знаком с каждой из упомянутых нами технологий. Именно поэтому мы по-
старались сделать все примеры исключительно факультативными—в них не содержится
важной информации, касающейся шаблона. Там, где это было возможно, мы приводили
несколько примеров реализации с использованием различных технологий интеграции.
Включая в текст программный код, мы прежде всего заботились о его удобочитаемо-
сти, а не о возможности выполнения. Фрагмент кода способен снять все вопросы, касаю-
щиеся шаблона. Именно поэтому многие разработчики и архитекторы предпочитают
просмотреть несколько десятков строк кода, а не длинные параграфы текста. Чтобы об-
легчить восприятие кода, мы приводили только наиболее важные методы и классы реше-
ния, а также избегали большинства форм проверки ошибок. Практически все фрагменты
кода не содержат комментариев, поскольку код обсуждается в прилегаюших к нему абза-
цах текста.
Приведение полноценного примера использования шаблона интеграционного реше-
ния весьма затруднительно. Как правило, подобные решения состоят из множества гете-
рогенных компонентов, распределенных между различными системами. К тому же
большинство интеграционных шаблонов тесно связаны с другими шаблонами. Чтобы
продемонстрировать взаимозависимость нескольких шаблонов, мы включили в книгу
несколько сложных примеров в виде так называемых “практикумов” (главы 6, 9 и 12).
Рассмотренные нами примеры иллюстрируют многие проблемы проектирования слож-
ных решений, основанных на обмене сообщениями.
Хотим подчеркнуть, что все примеры, приведенные в книге, носят иллюстративный
характер и не могут применяться в качестве отправной точки при создании интеграцион-
ного решения, пригодного для применения в реальных условиях. В частности, практиче-
ски во всех примерах отсутствует проверка ошибок, а также средства обеспечения надеж-
ности, безопасности и масштабируемости.
При наличии такой возможности мы старались использовать в примерах бесплатные
программные платформы или же платформы, для которых имеется общедоступная проб-
ная версия. Иногда мы применяли коммерческие платформы (такие, как TIBCO
ActiveEnterprise и Microsoft BizTalk) с целью продемонстрировать различие между ис-
пользованием платных программ и разработкой решения “с нуля”. В подобных случаях
мы старались сделать так, чтобы читатель извлек пользу из примера, даже не имея под
рукой необходимых программных средств. Большинство примеров основано на исполь-
зовании таких инфраструктур для обмена сообщениями, как JMS и MSMQ. Это позволя-
ет в полной мере сфокусироваться на существующих проблемах реализации интеграци-
онных решений вместо того, чтобы пытаться избежать их с помощью более функцио-
нального связующего ПО.
Все Java-примеры, приведенные в этой книге, основаны на спецификации JMS 1.1,
включенной в версию 1.4 платформы J2EE. Ко времени опубликования книги большин-
ство серверов обмена сообщениями и серверов приложений будут поддерживать JMS 1.1.
Введение
39
Эталонную реализацию JMS можно загрузить с Web-сайта компании Sun Microsystems
по адресу http://java.sun.com/j 2ee.
Также в книге приводятся примеры, основанные на версии 1.1 платформы Microsoft
.NET и написанные на языке программирования С#. Набор инструментальных средств
разработки для платформы .NET Framework можно загрузить с Web-сайта корпорации
Microsoft по адресу http: //msdn. microsof t. com/net.
Как организована эта книга
Язык шаблонов, представленный в этой книге, представляет собой множество взаи-
мосвязанных шаблонов проектирования. В то же время в языке шаблонов можно выде-
лить несколько ключевых элементов (так называемых корневых шаблонов), формирующих
его логическую структуру.
При группировании шаблонов по главам этой книги учитывался их уровень абстрак-
ции, а также область применения (рис. 4).
Основным шаблоном проектирования книги является шаблон обмен сообщениями
(Messaging, с. 87). К корневым шаблонам относятся шаблоны канал сообщений (Message
Channel, с. 93), сообщение (Message, с. 98), каналы и фильтры (Pipes and Filters, с. 102), мар-
шрутизатор сообщений (Message Router, с. 109), транслятор сообщений (Message Translator,
с. 115) и конечная точка сообщения (Message Endpoint, с. 124). Каждый из корневых шаб-
лонов рассматривается в отдельной главе. Исключение составляет шаблон каналы и
фильтры, рассматриваемая в нем концепция не имеет прямого отношения к обмену со-
общениями, а формирует основу для шаблонов маршрутизации и преобразования.
Рис. 4. Корневые шаблоны проектирования
Описанная выше иерархия шаблонов проектирования рассматривается в следующих
главах.
• Глава 2. В этой главе рассматриваются различные подходы к интеграции прило-
жений, включая обмен сообщениями.
• Глава 3. В этой главе рассматриваются шесть фундаментальных шаблонов проек-
тирования, представленных в книге.
40
Введение
• Глава 4. Приложения взаимодействуют между собой посредством каналов. Каналы
определяют логические маршруты, по которым могут передаваться сообщения.
Эта глава посвящена выбору каналов обмена сообщениями для конкретного при-
ложения.
• Глава 5. В этой главе рассматриваются различные форматы сообщений и их свой-
ства.
• Глава 7. Решения, основанные на обмене сообщениями, предполагают разделение
отправителя и получателя информации. Отправитель пересылает сообщение мар-
шрутизатору, который обеспечивает его доставку получателю. В этой главе рас-
сматриваются различные способы создания маршрутизаторов сообщений.
• Глава 8. Зачастую независимо созданные приложения используют различные
форматы сообщений, кодировку символов и т.п. В этой главе рассматривается
создание промежуточных компонентов, преобразующих формат отправителя
в формат получателя сообщения.
• Глава 10. Многие приложения изначально не приспособлены для участия в систе-
мах обмена сообщениями. В этой главе рассматривается уровень, обеспечиваю-
щий отправку и получение сообщений, который тем самым превращает приложе-
ние в конечную точку системы обмена сообщениями.
• Глава 11. Эта глава посвящена тестированию и мониторингу системы обмена со-
общениями.
Представленные выше главы содержат всю необходимую информацию, касающуюся
интеграции приложений с использованием обмена сообщениями.
С чего начать
Приступая к работе с книгой, охватывающей обширную область знаний, важно опре-
делить наиболее эффективный способ ее прочтения. Несмотря на то что метод чтения
“от корки до корки” гарантирует изучение всего материала, представленного в настоя-
щей книге, это далеко не самый быстрый способ добраться до нужной темы. Начинать
чтение книги с произвольного шаблона — также не самая удачная идея: в этом случае вы
рискуете упустить важную информацию, необходимую для понимания шаблона.
К счастью, представленный в книге язык шаблонов построен вокруг упоминавшихся
выше корневых шаблонов. Все вместе корневые шаблоны позволяют получить наглядное
представление о языке шаблонов, а по отдельности представляют собой прекрасные от-
правные точки для более глубокого изучения технологий обмена сообщениями. Описа-
ние всех корневых шаблонов содержится в главе 3.
В главе 2 рассматриваются основные подходы к интеграции приложений, включая обмен
сообщениями (Messaging, с. 87). Прочитайте эту главу, если вы впервые столкнулись с про-
блемой интеграции приложений и хотите узнать о преимуществах и недостатках сущест-
вующих интеграционных технологий. В противном случае вы можете пропустить главу 2.
Глава 3 содержит описание всех корневых шаблонов, за исключением шаблона обмен
сообщениями, который рассматривается в главе 2. Прочитайте (или хотя бы просмотрите)
главу 3, чтобы получить общее представление об используемом в книге языке шаблонов.
Для более глубокого изучения той или иной темы ознакомьтесь с соответствующим кор-
Введение
41
левым шаблоном, после чего переходите к рассмотрению шаблонов, перечисленных
в описании этого корневого шаблона.
Начиная с главы 4, различным участникам процесса интеграции приложений пред-
лагается обратить внимание на следующий материал.
• Системным администраторам рекомендуется обратить внимание на тему выбора
каналов обмена сообщениями (глава 4) и обслуживания системы обмена сообще-
ниями (глава 11).
• Разработчики приложений должны ознакомиться с вопросом интеграции прило-
жения с системой обмена сообщениями (глава 10) и выбора формата отправляе-
мых сообщений (глава 5).
• Системные интеграторы извлекут максимум пользы из чтения главы 7, посвящен-
ной доставке сообщений в конечные точки, и главы 8, описывающей преобразо-
вание формата отправителя в формат получателя сообщения.
Если вам нужно найти шаблон, подходящий для применения в конкретной ситуации,
обращайте внимание только на постановку задачи и ее решение. Этой информации будет
вполне достаточно, чтобы понять, интересует вас данный шаблон или нет.
Обратите внимание, что порядок следования шаблонов в книге не определяет реко-
мендуемый порядок их изучения. Столкнувшись с той или иной задачей интеграции, вы-
берите соответствующий ей корневой шаблон. Из его контекста вы узнаете, какие шаб-
лоны следует применить перед использованием данного корневого шаблона (их описа-
ния могут располагаться как до, так и после описания корневого шаблона), а из раздела,
предшествующего примерам, — какие шаблоны следует применить после использования
данного корневого шаблона (опять-таки, описания этих шаблонов необязательно будут
следовать после описания корневого шаблона). Другими словами, эта книга представляет
собой “паутину” взаимосвязанных шаблонов, а не их последовательное описание.
Поддержка
Дополнительные материалы к книге, а также информация, касающаяся интеграции
корпоративных приложений, доступна в Интернете на Web-сайте www. enterprisein-
tegrationpatterns. com. Комментарии, пожелания и отзывы присылайте по адресу
authors@enterpriseintegrationpatterns.com.
Резюме
Назначение этого введения — ознакомить читателей со следующими фактами и фун-
даментальными концепциями:
• что такое обмен сообщениями;
• что такое система обмена сообщениями;
• преимущества технологии обмена сообщениями;
• отличия асинхронного и синхронного программирования;
42
Введение
• отличия интеграции приложений от создания распределенного приложения;
• существующие категории коммерческих программных продуктов, поддерживаю-
щих обмен сообщениями.
Кроме того, во введении рассматривалась организация книги и способ подачи мате-
риала. В частности, особое внимание было уделено:
• роли шаблонов в структурировании материала книги;
• нотации, использующейся для описания интеграционных решений;
• назначению и области применения приведенных в книге примеров;
• организации материала;
• определению наиболее эффективного способа изучения материала.
Ознакомившись с базовыми понятиями и способом организации материала, присту-
пим к изучению интеграции корпоративных приложений с использованием обмена
сообщениями.
Глава 1
Решение задач интеграции
с помощью шаблонов
проектирования
В этой главе рассматривается применение шаблонов проектирования для решения
типичной интеграционной задачи. В общей сложности мы познакомимся более чем с
двумя десятками наиболее распространенных шаблонов интеграции.
Необходимость интеграции
Типичная информационная система предприятия насчитывает сотни, если не тыся-
чи, приложений (коммерческих, собственной разработки, унаследованных и т.д.), вы-
полняющихся под управлением различных операционных систем. Тридцать Web-сайтов,
три экземпляра SAP и множество решений уровня подразделения— вполне обыденная
ситуация для крупной компании.
Возникает вопрос: “Как владельцы предприятий допускают такой хаос?”. На первый
взгляд, любой IT-директор, ответственный за подобное “спагетти” из приложений, должен
быть немедленно уволен. На практике, однако же, дело обстоит несколько по-иному.
Во-первых, разработка бизнес-приложений— невероятно сложная задача. Создание
единственного приложения, охватывающего все бизнес-функпии предприятия, практи-
чески невозможно. Наибольшего успеха в создании тяжеловесных бизнес-приложений
достигли разработчики ERP-систем. Однако даже такие гиганты индустрии, как SAP,
Oracle, PeopleSoft и др., вынуждены сконцентрировать свои усилия лишь на части бизнес-
задач типичной компании. Об этом, в частности, красноречиво свидетельствует тот факт,
что на сегодняшний день ERP-системы являются одними из наиболее популярных точек
интеграции.
Во-вторых, распределение бизнес-функций между несколькими приложениями пре-
доставляет компаниям возможность выбора “лучшего” пакета программ для бухгалтер-
ского учета, “лучшего” приложения для управления взаимоотношениями с клиентами,
“лучшей” системы обработки заказов и др. Учитывая многообразие индивидуальных
бизнес-требований предприятий, создание универсального бизнес-приложения не вхо-
дит в интересы разработчиков ПО.
44
Глава 1. Решение задач интеграции с помощью шаблонов проектирования
Современные бизнес-приложения создаются для решения определенной задачи.
Темне менее нескончаемый поток требований к расширению функциональности со
временем приводит к появлению в программном пакете дополнительных функций.
К примеру, многие биллинговые системы обзавелись базовыми возможностями обслу-
живания клиентов и ведения учета. С другой стороны, некоторые разработчики ПО для
обслуживания заказчиков начали встраивать в свои приложения определенные функции
биллинга, такие как прием и удовлетворение заявлений. Определить четкие границы ме-
жду системой обслуживания заказчиков и биллинговой системой в этом случае достаточ-
но трудно. Например, к какой из двух систем следует отнести функцию удовлетворения
заявления клиента относительно выставленного ему счета?
Взаимодействуя с компанией, пользователи (клиенты, бизнес-паргнеры и сотрудники
компании), как правило, не задумываются о том, каким образом осуществляется это
взаимодействие. В то же время выполнение каждой бизнес-функции может затрагивать
сразу несколько внутренних систем компании. К примеру, клиент хочет изменить ин-
формацию о своем адресе, а также проверить, был ли получен его последний платеж.
В большинстве компаний обработка подобного запроса возлагается на две системы:
обслуживания клиентов и биллинга. Подобным образом размещение клиентом нового
заказа требует координации целого ряда различных систем. Компания должна проверить
идентификатор клиента, убедиться в его положительной кредитной репутации, прове-
рить доступность необходимого товара на складе, выполнить заказ, посчитать стоимость
доставки, сформировать и отправить счет и т.д. Таким образом, размещение нового зака-
за затрагивает как минимум 5-6 различных систем компании. С точки зрения клиента,
размещение заказа—это всего лишь одна бизнес-транзакция.
Для поддержания общих бизнес-процессов, а также совместного использования дан-
ных несколькими приложениями последние необходимо интегрировать. Основной
целью интеграции является обеспечение эффективного, надежного и безопасного обме-
на данными между интегрируемыми приложениями.
Трудности интеграции
Интеграция корпоративных приложений — весьма непростое занятие. По определе-
нию интеграция корпоративных приложений подразумевает обеспечение взаимодейст-
вия между множеством программ, выполняющихся под управлением различных плат-
форм и расположенных в различных местах предприятия. Таким образом, фраза простая
интеграция является ни чем иным, как оксюмороном. Некоторые разработчики
ПО предлагают пакеты для интеграции корпоративных приложений (Enterprise
Application Integration — EAI), поддерживающие различные платформы, языки про-
граммирования, а также наиболее популярные бизнес-приложения. К сожалению, тех-
ническая инфраструктура большинства EAI-пакетов учитывает только часть трудностей,
свойственных интеграции корпоративных приложений. Перечислим наиболее распро-
страненные из них.
• В большинстве случаев интеграция корпоративных приложений требует сущест-
венного пересмотра корпоративной политики компании. Как правило, бизнес-
приложения охватывают определенную проблемную область, такую как управле-
ние взаимоотношениями с клиентами (Customer Relationship Management —
Трудности интеграции
45
CRM), биллинг или финансы. Как гласит известный закон Конвэя, “организации,
проектирующие системы, неизбежно производят системы, являющиеся копиями
их организационных структур”. Большинство организационных единиц в компа-
нии создаются для решения конкретных задач. Налаживание взаимодействия ме-
жду различными компьютерными системами приводит к необходимости установ-
ки контактов и между использующими их подразделениями.
В результате объединения большинства бизнес-функций компании деятельность
последней становится зависимой от надлежащего функционирования интеграци-
онного решения. Сбой в работе интеграционного решения может принести ком-
пании миллионные убытки, связанные с потерей заказов, ошибочным направле-
нием платежей и т.п.
Одна из наиболее существенных проблем, связанных с созданием интеграционного
решения, заключается в ограниченном контроле, который имеют разработчики ре-
шения над интегрируемыми приложениями. В большинстве случаев объединяемые
приложения представляют собой унаследованные системы или пакеты программ,
внести изменения в которые не представляется возможным. Часто это приводит к
тому, что на плечи создателей интеграционного решения ложится дополнительная
задача по устранению недостатков в объединяемых приложениях и существующих
между ними различий. Иногда часть интеграционного решения проще реализовать в
конечных точках приложений, однако эта возможность может оказаться недоступ-
ной по причинам политического или технического характера.
Несмотря на растущий спрос на интеграционные решения, эта область разработки
ПО пока еще не может похвастаться наличием большого числа общепринятых стан-
дартов. Существенный толчок по направлению к стандартизации интеграционных
решений дало появление таких технологий, как XML, XSL и Web-службы. К сожале-
нию, слишком активное продвижение на рынок последних привело к появлению
множества “расширений” и “интерпретаций”, также претендующих на звание стан-
дартов. Будет уместным напомнить, что именно недостаток совместимости между
различными “соответствующими стандарту” продуктами стал камнем преткновения
для распространения такой интеграционной технологии, как CORBA.
Существующие стандарты Web-служб XML позволяют преодолеть лишь часть
трудностей интеграции корпоративных приложений. Утверждение, что XML —
это “лингва-франка” системной интеграции, является, мягко говоря, неверным.
Осуществление обмена данными в формате XML уместно сравнить с написанием
текста с использованием только одного романского алфавита. Как известно,
романский алфавит можно применять для представления многих языков и диалек-
тов, неизвестных широкому кругу читателей. То же самое справедливо и для ин-
теграции корпоративных приложений. Из существования единого представления
данных (XML) не следует наличие общей семантики. К примеру, такое простое
понятие, как “счет”, может иметь несколько различных семантик, подтекстов, ог-
раничений и допущений в каждой конкретной системе. Устранение семантиче-
ских различий между объединяемыми системами является одной из наиболее
сложных и трудоемких задач интеграции.
46
Глава 1. Решение задач интеграции с помощью шаблонов проектирования
• Поддержка существующего EAI-решения ничуть не проще, а то и сложнее его разра-
ботки. Развертывание, мониторинг и устранение неполадок в интеграционном ре-
шении требуют наличия у обслуживающего персонала целого ряда навыков. В боль-
шинстве случаев полный набор требуемых навыков удается получить за счет привле-
чения к обслуживанию EAI-решения множества различных служащих компании.
Интеграционные решения являются важнейшим компонентом стратегии развития
современных компаний. К сожалению, они способны значительно усложнить жизнь
IT-персонала вследствие наличия существенных различий между высокоуровневым
представлением EAI-решения (определяемым такими терминами, как “сквозная обра-
ботка”, “Т+1”, “гибкая организация” и т.п.) и его низкоуровневой реализацией (какие
параметры может принимать конструктор класса System.Messaging.XmlMessage-
Formatter?).
Роль интеграционных шаблонов проектирования
Интеграции корпоративных приложений не свойственны простые решения. Тот, кто
утверждает обратное, должен быть невероятно умным (по крайней мере, умнее авторов
этой книги), полностью несведущим (скажем так, слишком “оптимистичным”) или фи-
нансово заинтересованным в том, чтобы убедить вас поверить в простоту интеграции.
Несмотря на то что интеграция приложений представляет собой обширную и слож-
ную для изучения тему, всегда найдутся люди, разбирающиеся в ней на порядок лучше
остальных. Каким секретным знанием они обладают? Что позволяет им с легкостью на-
ходить ответы на всевозможные вопросы интеграции? Дело в том, что эти люди научи-
лись обобщать накопленный ранее опыт в виде так называемых “шаблонов” и применять
их при решении новых интеграционных задач.
В отличие от готовых программных компонентов или фрагментов кода, шаблоны
представляют собой ценные советы, описывающие решение той или иной проблемы.
На практике интеграционные шаблоны проектирования способны заполнить простран-
ство между высокоуровневым представлением задачи интеграции и ее фактической
реализацией.
Типы интеграционных задач
Мы намеренно дали термину интеграция очень широкое определение. Для нас инте-
грация означает объединение компьютерных систем, компаний или людей. Несмотря на
то что данное определение позволяет нам включить в эту книгу огромный объем мате-
риала, мы остановимся на шести наиболее распространенных типах интеграции:
• информационные порталы;
• репликация данных;
• бизнес-функции совместного использования;
• архитектуры, ориентированные на службы;
• распределенные бизнес-процессы;
• В2В-интеграция.
Типы интеграционных задач
47
Конечно же, приведенный выше список ни в коем случае не претендует на звание ис-
черпывающей классификации задач интеграции. Тем не менее он дает наглядное пред-
ставление о проектах, над которыми работают архитекторы интеграционных решений.
Некоторые интеграционные задачи объединяют в себе сразу несколько типов интегра-
ции. К примеру, создание распределенного бизнес-процесса зачастую требует проведе-
ния начальной репликации данных между объединяемыми приложениями.
Зачастую выполнение единственной бизнес-функции охватывает сразу несколько
различных систем компании. К примеру, с целью проверки состояния заказа сотруднику
может потребоваться доступ к системе управления заказами, расположенной на мэйн-
фрейме, а также к системе обработки заказов, принятых посредством Web. Основная
функция информационных порталов (рис. 1.1) заключается в обеспечении представле-
ния информации из нескольких источников. В самых простых информационных порта-
лах экран разделяется на несколько зон, каждая из которых соответствует той или иной
системе. Более сложные порталы поддерживают ограниченное взаимодействие между
зонами, например выбор пользователем элемента списка в зоне А приводит к отображе-
нию подробной информации об этом элементе в зоне Б. Самые сложные информацион-
ные порталы за счет высокого уровня функциональности практически стирают грань
между порталом и интегрированным приложением.
Рис. 1.1. Информационный портал
Многие бизнес-системы нуждаются в доступе к одним и тем же данным. Например,
такая информация, как адрес проживания клиента, может использоваться системой об-
служивания заказчиков (при изменении адреса клиента), системой бухгалтерского учета
(при подсчете налога с продаж), системой доставки товаров (при создании этикетки с ад-
ресом доставки), а также биллинговой системой (при формировании счета). Некоторые
из этих систем могут иметь собственное хранилище данных. При изменении адреса кли-
ента каждая система должна получить копию обновленной информации. Этого можно
добиться с помощью такого типа интеграции, как репликация данных (рис. 1.2).
Существует множество различных способов реализации репликации данных. Функ-
ция репликации может быть встроена в СУБД; нужные сведения можно экспортировать
в файл для последующего импорта в другой системе, а также переслать внутри сообще-
ний с помощью соответствующего связующего ПО.
48
Глава 1. Решение задач интеграции с помощью шаблонов проектирования
Рис. 1.2. Репликация данных
Во многих бизнес-приложениях реализована избыточная функциональность. Так,
сразу нескольким системам может понадобиться проверить номер социального страхова-
ния, правильность указания почтового индекса в адресе проживания или же наличие
определенного товара на складе. Каждую из этих функций можно вынести за пределы
приложений и реализовать в виде функций совместного использования, доступных всем
системам в виде служб (рис. 1.3).
Рис. 1.3. Бизнес-функция совместного использования
Совместно используемая бизнес-функция и репликация данных могут преследовать
схожие цели. К примеру, копирование адреса проживания клиента во все требуемые
системы можно заменить созданием совместно используемой бизнес-функции GetCus-
tomerAddress. Выбор между двумя различными типами интеграции основывается на
многочисленных критериях, таких как степень контроля над интегрируемыми системами
(в отличие от помещения информации в базу данных, вызов совместно используемой
функции предполагает более глубокое вмешательство в систему) и частота изменения
данных (доступ к адресу проживания клиента осуществляется часто, а вот вероятность
изменения последнего невысока).
Совместно используемые бизнес-функции часто называют службами. Служба— это
строго определенная и универсально доступная функция, реагирующая на запросы своих
“потребителей”. Управление службами является одной из наиболее важных задач компа-
нии. Во-первых, интегрируемым приложениям необходимо предоставить доступ к центра-
лизованному списку всех доступных служб (так называемому каталогу служб). Во-вторых,
описание интерфейса каждой службы должно способствовать согласованию контракта
Типы интеграционных задач
49
взаимодействия приложения с этой службой. Обнаружение службы и согласование кон-
тракта взаимодействия с ней—две важнейшие составляющие SOA-архитектуры (рис. 1.4).
SOA-архитектура стирает грань между интеграцией приложений и созданием распре-
деленного приложения. К примеру, при создании нового приложения разработчики мо-
гут полагаться на службы, предоставляемые другими приложениями. В этом случае об-
ращение к службе может быть расценено как интеграция приложений. Однако во многих
SOA-архитектурах вызов внешней службы практически ничем не отличается от вызова
локального метода (за исключением производительности). Таким образом, разработку
нового приложения в рамках существующей SOA-архитектуры можно сравнить с созда-
нием распределенного приложения.
Рис. 1.4. Архитектура, ориентированная на службы
Одним из ключевых признаков того, что приложения необходимо интегрировать,
является участие нескольких различных систем компании в выполнении единственной
бизнес-транзакции (например, размещения заказа клиентом). В большинстве случаев вся
функциональность, необходимая для выполнения бизнес-транзакйии, сконцентрирова-
на в существующих приложениях. Для координации выполнения бизнес-функций, при-
надлежащих различным системам компании, необходимо создать компонент управления
распределенным бизнес-процессом (рис. 1.5).
Рис. 1.5. Распределенный бизнес-процесс
Распределенный бизнес-процесс и SOA-архитектура имеют много общего. Так, все
требуемые бизнес-функции могут быть представлены в виде служб, а бизнес-процесс
реализован внутри обращающегося к этим службам приложения.
До сих пор мы рассматривали взаимодействие между приложениями и бизнес-
функциями внутри компании. Однако во многих случаях требуемая функциональность
50
Глава 1. Решение задач интеграции с помощью шаблонов проектирования
обеспечивается внешними организациями. К примеру, компания-перевозчик может
предоставлять заказчикам службу, позволяющую проследить за доставкой товара. Часто
интеграция приложений затрагивает бизнес-партнеров. Например, заказчик может обра-
титься к розничному продавцу с тем, чтобы узнать стоимость и наличие в продаже опре-
деленного товара. Если нужного товара нет на складе, розничный продавец обращается
к поставщику для того, чтобы узнать, когда будет доставлен этот товар.
Большинство принципов В2В-интеграции (рис. 1.6) аналогичны принципам интеграции
приложений внутри компании. Взаимодействие через Интернет или какую-либо другую сеть,
как правило, приводит к возникновению новых задач, относящихся к транспортным прото-
колам и безопасности. Поскольку многие бизнес-партнеры предпочитают электронный фор-
мат общения, на первый план выходит также вопрос стандартизации форматов данных.
Рис. 1.6. В2В-интеграция
Слабое связывание X
Одним из наиболее популярных терминов в области интеграции корпоративных при-
ложений является термин слабое связывание. Дуг Кэй (Doug Kaye) посвятил этой везде-
сущей концепции целую книгу [20]. Преимущества слабого связывания были известны
давно, однако ключевое место эта концепция заняла благодаря растущей популярности
архитектур на основе Web-служб.
Основной принцип слабого связывания состоит в уменьшении числа допущений,
которые делают друг о друге взаимодействующие стороны (компоненты, приложения,
службы, программы, пользователи). Несмотря на то что наличие дополнительной ин-
формации об участниках и используемом протоколе позволяет повысить эффективность
общения, получаемое при этом решение крайне неустойчиво к изменениям.
Наглядным примером сильного связывания является вызов локального метода, осно-
вывающийся на огромном числе допущений между вызываемой и вызывающей подпро-
граммами. Оба метода должны выполняться в одном и том же процессе (например, вир-
туальной машине) и быть написаны на одном и том же языке программирования
(по крайней мере, использовать общий промежуточный язык или байт-код). Вызываю-
щий метод передает вызываемому методу заранее известное число параметров опреде-
ленного типа. Вызов локального метода происходит мгновенно, т.е. вызываемый метод
получает управление сразу же после осуществления его вызова. Вызывающий метод мо-
жет продолжить свое выполнение только после завершения работы вызываемого метода
(таким образом, вызов локального метода является примером синхронного взаимодейст-
вия). Выполнение вызывающего метода будет продолжено с оператора, следующего
непосредственно после вызова метода. Мгновенный характер взаимодействия между вы-
зываемым и вызывающим методами позволяет исключить возможность нарушения безо-
пасности. Все эти предположения способствуют разработке хорошо структурированных
приложений, функциональность которых разделяется между множеством вызывающих
Пример простой интеграции
51
друг друга методов. Наличие большого числа простых методов обеспечивает возможность
их повторного использования и как следствие — гибкость приложения.
Большое число подходов к интеграции приложений основывается на реализации уда-
ленного взаимодействия с использованием семантики вызова локального метода. Данная
стратегия получила название вызов удаленной процедуры (Remote Procedure Call — RPC)
или вызов удаленного метода (Remote Method Invocation — RMI) и была поддержана раз-
работчиками различных популярных платформ и инфраструктур: CORBA [51], Microsoft
DCOM, .NET Remoting, Java RMI и, наконец, Web-служб в стиле RPC. Реализация уда-
ленного взаимодействия с использованием семантики вызова локального метода имеет
два очевидных преимущества. Во-первых, семантика синхронного вызова метода очень
хорошо известна разработчикам приложений. Во-вторых, использование одинакового
синтаксиса вызова локальных и удаленных методов позволяет отложить принятие реше-
ния о том, какие компоненты должны выполняться локально, а какие— удаленно,
вплоть до развертывания приложения.
К сожалению, удаленное взаимодействие несовместимо со многими предположения-
ми, касающимися вызова локального метода. Более того, использование одинаковой
семантики для вызова локального и удаленного методов ошибочно и может привести
к нежелательным результатам. Еще в 1994 году Вальдо (Waldo) и его коллеги из Sun
Microsystems предупреждали о том, что “методы работы с объектами, взаимодействую-
щими в распределенной системе, существенно отличаются от методов работы с объекта-
ми, взаимодействующими в общем адресном пространстве” [50]. Следует ли приложе-
нию использовать только те удаленные службы, которые написаны на одинаковом с ним
языке программирования? Вызов удаленного метода может потребовать на несколько
порядков больше времени, чем вызов локального метода. Должен ли вызывающий метод
ожидать завершения выполнения вызываемого метода? Что если в результате сбоя в сети
вызываемый метод окажется временно недоступным? Как долго следует ждать? Можно
ли быть уверенным в том, что мы вызываем нужный нам, а не “подставной” метод?
Как исключить возможность подслушивания? Что произойдет в результате изменения
сигнатуры (списка принимаемых параметров) вызываемого метода? Следует отметить,
что в случае поддержки удаленного метода третьей стороной (например, бизнес-
партнером) подобные изменения выходят за пределы нашего контроля. Можно ли допус-
тить сбой вызова метода или необходимо попытаться подобрать параметры, позволяю-
щие осуществить вызов? Становится очевидно, что удаленное взаимодействие нельзя
организовывать в соответствии с теми же допущениями, что и локальный вызов метода.
Результатом применения архитектур, основанных на сильном связывании, при инте-
грации удаленных приложений являются неустойчивые, трудно поддерживаемые и плохо
масштабируемые решения. Многие из “пионеров” Web-служб убедились в этом на соб-
ственном горьком опыте.
Пример простой интеграции
Продемонстрируем негативный эффект сильного связывания и способ его преодоле-
ния на конкретном примере интеграции. Предположим, что нам необходимо создать ин-
терактивную банковскую систему, позволяющую клиентам перечислять средства на свой
счет путем денежного перевода из другого банка. Для достижения такой функционально-
52
Глава 1. Решение задач интеграции с помощью шаблонов проектирования
сти интерфейсное Web-приложение должно быть интегрировано с серверной финансо-
вой системой, управляющей переводом средств.
Наиболее простой способ объединения указанных систем заключается в использовании
протокола TCP/IP. За последние 15 лет стек протоколов TCP/IP был включен практически
во все операционные системы и библиотеки программирования. TCP/IP— это самый рас-
пространенный коммуникационный протокол, обеспечивающий передачу данных между
миллионами компьютеров, подключенных к Интернету и локальным сетям.
Предположим также, что удаленная функция, зачисляющая средства на счет клиента,
принимает в качестве параметров только имя клиента и сумму денежного перевода.
Следующие строки кода вызывают указанную функцию с помощью протокола TCP/IP
(мы выбрали в качестве языка программирования С#, однако данный пример выглядит
практически идентично, будучи написанным на С или Java):
String hostName = "f inance.bank.com";
int port = 80;
IPHostEntry hostinfo = Dns.GetHostByName(hostName);
IPAddress address = hostinfo.AddressList[0];
IPEndPoint endpoint = new IPEndPoint(address, port);
Socket socket = new Socket(address.AddressFamily,
SocketType.Stream, ProtocolType.Tcp);
socket.Connect(endpoint);
byte[] amount = BitConverter.GetBytes(1000);
byte[] name = Encoding.ASCII.GetBytes("Joe");
int bytesSent = socket.Send(amount);
bytesSent += socket.Send(name);
socket.Close();
Приведенный выше код создает сокет с адресом f inance. bank. com и пересылает по
сети два элемента данных (сумму перевода и имя клиента). Таким образом, десять строк
кода заменяют собой сложное связующее ПО наподобие средств ЕА1 или инструмента-
рия RPC.
К сожалению, указанный метод интеграции не лишен ряда существенных недостат-
ков. Одной из наиболее сильных сторон протокола TCP/IP является его широкая под-
держка различными операционными системами и языками программирования. Однако
же независимость TCP/IP от платформы справедлива лишь по отношению к передаче
самых простых структур данных: потоков байтов. Чтобы преобразовать данные в поток
байтов, в приведенном выше коде был использован класс Bitconverter. Этот класс
преобразовывает данные любого типа в массив байтов на основе их внутреннего пред-
ставления в памяти. Подвох состоит в том, что внутреннее представление в памяти це-
лого числа зависит от конкретной компьютерной системы. К примеру, платформа .NET
использует для представления целого числа 32 бит, в то время как некоторые другие
платформы— 64 бит. В рассмотренном выше примере по сети передаются 4 байт, кото-
рые представляют одно 32-битовое целое число. Система, использующая для представ-
Пример простой интеграции
53
ления целого числа 64 бит, считает из сети 8 байт и, таким образом, “захватит” часть бай-
тов, приходящихся на имя клиента.
Кроме того, различные компьютерные системы используют для хранения целочис-
ленных данных формат с разным порядком следования байтов— прямым (начиная
с младшего байта) и обратным (начиная со старшего байта). Предположим, что система,
использующая прямой порядок следования байтов, передает по сети 4 байт:
232 300
232 + 3 х 28 = 1000. Система, использующая обратный порядок следования байтов,
интерпретирует полученную информацию как 232 х 234 + 3 х 216 = 3 892 510 720. Наш кли-
ент стал настоящим богачом! Другими словами, предложенный подход может быть спра-
ведлив только при допущении, что все компьютерные системы используют для хранения
целочисленных данных формат с одинаковым порядком следования байтов.
Второй недостаток указанного метода интеграции заключается в указании адреса уда-
ленного компьютера с помощью DNS-имени (finance. bank. com). Для преобразования
имени компьютера в IP-адрес существует служба DNS, однако что произойдет в случае
перемещения функции зачисления средств на другой компьютер, принадлежащий дру-
гому домену? К тому же, если компьютер даст сбой, нам может понадобиться обратиться
к другому компьютеру с другим DNS-именем. Каждый из указанных сценариев предпо-
лагает внесение изменений в существующий программный код. Зависимость кода вызова
функции зачисления средств на счет клиента от адреса конкретного компьютера в сети
нужно устранить.
Использование для удаленного взаимодействия протокола TCP/IP устанавливает
временную зависимость между общающимися системами. Как известно, протокол
TCP/IP является протоколом с установкой соединения. Это означает, что фактической
передачи информации между двумя системами предшествует стадия установки соедине-
ния (рис. 1.7). При создании TCP-соединения отправитель и получатель данных обмени-
ваются IP-пакетами. Если хотя бы один из трех компонентов взаимодействия — компью-
тер отправителя, сеть или компьютер получателя—даст сбой, установка ТСР-соедине-
ния окажется невозможной.
Рис. 1.7. Пример взаимодействия сильносвязанных приложений
Наконец, даже такое простое взаимодействие основано на использовании строгого
формата данных. Первые 4 байт передаваемой информации соответствуют сумме денег,
последующие—имени клиента. Введение третьего параметра, такого как название валю-
ты, привело бы к необходимости внесения изменений в программный код как на стороне
отправителя, так и на стороне получателя данных.
54
Глава 1. Решение задач интеграции с помощью шаблонов проектирования
В рассмотренном выше примере “простой” интеграции взаимодействие систем осно-
вывается на следующих предположениях.
• Платформа—одинаковое внутреннее представление целых чисел и объектов.
• Расположение — неизменяемый адрес компьютера.
• Время— все компоненты интегрированной системы должны быть доступны
в одно и то же время.
• Формат данных—неизменяемый набор и параметров.
Как отмечалось ранее, степень связывания характеризуется количеством допущений,
которые делают друг о друге взаимодействующие стороны. Очевидно, что предложенный
нами подход к интеграции Web-приложения с банковской системой является типичным
примером сильного связывания.
К счастью, число зависимостей, “связывающих” интегрируемые системы, можно
уменьшить. Прежде всего, перейдем к использованию стандартного, не зависящего
от платформы формата данных, такого как XML. Вместо пересылки данных непосредст-
венно на компьютер получателя направим их в адресуемый канал. Канал— это логиче-
ский адрес, известный как отправителю, так и получателю данных. Использование кана-
лов позволяет устранить зависимость от размещения интегрируемых систем, однако все
еще сохраняет требование об их одновременной доступности (если канал будет реализо-
ван с помощью протокола, ориентированного на установку соединения). Чтобы изба-
виться от этого недостатка, следует организовать очередь запросов, которые будут накап-
ливаться в ней при недоступности сетевого соединения или системы-получателя. Помес-
тив запрос в канал, отправитель может больше не заботиться о его доставке. Создание
очереди запросов предполагает разбиение последних на сообщения—единицу буфериза-
ции и отправки информации. Интегрируемые системы все еще связаны одинаковым
форматом данных, однако эта зависимость может быть легко устранена за счет поддерж-
ки преобразования данных в канале. Если формат одной системы меняется, все, что
нужно сделать,—это изменить преобразователь, а не другую систему. В наибольшей сте-
пени выгода от наличия преобразователя данных ощущается при интеграции множества
приложений, размещающих данные в одном и том же канале.
Общий формат данных, асинхронное взаимодействие по каналам с очередями и пре-
образователи позволяют перейти от сильно- к слабосвязанному решению (рис. 1.8).
Отправитель больше не зависит от внутреннего формата данных или размещения получа-
теля. Более того, после помещения данных в канал отправитель может и вовсе не забо-
титься об их доставке. Устранение зависимостей между интегрируемыми системами
позволяет воспользоваться главным преимуществом слабого связывания— получить
решение, устойчивое к изменениям. Наиболее существенный недостаток подобного под-
хода состоит в увеличении сложности решения, которое теперь уже нельзя будет описать
десятью строками программного кода. В этом случае следует прибегнуть к услугам свя-
зующего ПО, ориентированного на обмен сообщениями. Компоненты подобной инфра-
структуры описываются в следующем разделе этой главы.
Компоненты слабосвязанного интеграционного решения
55
Web-
приложение
Канал
Финансовая
система
<deposit>
<amt>1000</amt>
<acct>Joe</acct‘
</deposit>
Документ
с самоописанием
Рис. 1.8. Пример взаимодействия слабосвязанных приложений
Является ли слабое связывание панацеей? Однозначного ответа здесь нет. Наряду
с очевидными преимуществами, такими как гибкость и масштабируемость, слабое свя-
зывание подразумевает использование сложной программной модели, что существенно
затрудняет проектирование, создание и поддержку интеграционного решения.
Компоненты слабосвязанного интеграционного решения
Объединение двух систем с помощью интеграционного решения предполагает
использование связующего ПО. Рассмотрим типичные компоненты связующего ПО,
ориентированного на обмен сообщениями.
Основной причиной интеграции приложений является необходимость налаживания
обмена данными между ними. Примером данных, передаваемых между приложениями,
является адрес заказчика, вызов удаленной службы или фрагмент HTML-кода информа-
ционного портала. Передачу данных между приложениями обеспечивают два компонен-
та интеграционного решения: сообщение и канал (рис. 1.9). Коммуникационный канал
предназначен для обмена информацией между приложениями. В качестве канала может
использоваться TCP/IP-соединение, общий файл, общая база данных и даже дискета.
В канал помещается сообщение—фрагмент данных, который имеет одинаковое значение
для обоих интегрируемых приложений. Объем информации, передаваемый с помощью
одного сообщения, может быть как очень маленьким (например, телефонный номер
заказчика), так и довольно большим (например, список всех заказчиков и адресов их
проживания).
Рис. 1.9. Основные элементы интеграционного решения, основанного на обмене сообщениями
Администрирование системы
56
Глава 1. Решение задач интеграции с помощью шаблонов проектирования
Несмотря на то что передача сообщений по каналам уже может считаться “простой”
формой интеграционного решения, не стоит останавливаться на достигнутом. Как пра-
вило, разработчики интеграционного решения не могут изменять объединяемые прило-
жения, в частности их внутренний формат данных. К примеру, одна из интегрируемых
систем может хранить имя клиента с помощью полей first_name и last_name, а дру-
гая— с помощью единственного поля Customer_Name. Поскольку возможность изме-
нить внутренний формат данных приложений выпадает крайне редко, связующее ПО
обязано обеспечить механизм преобразования форматов данных между приложениями.
Предположим, что нам необходимо интегрировать более двух систем. Как изменится
механизм обмена данными в этом случае? Наиболее простое решение состоит в указании
системой-отправителем адресов систем-получателей сообщения. К примеру, при изме-
нении адреса клиента система обслуживания заказчиков пересылает обновленную ин-
формацию всем системам, хранящим адрес клиента. Данный подход имеет один сущест-
венный недостаток— каждая система-отправитель должна поддерживать информацию
обо всех системах-получателях сообщения. Как следствие добавление новой системы
может потребовать внесения изменений в существующие системы интеграционного
решения. Было бы гораздо лучше, если бы функция доставки сообщений получателям
была возложена на связующее ПО, а именно на его маршрутизирующий компонент, такой
как брокер сообщений.
Как правило, со временем все интеграционные решения становятся слишком слож-
ными. Приложения, форматы данных, каналы, маршрутизаторы, преобразователи — все
эти элементы зачастую распределены между множеством операционных платформ
и географических размещений. С целью управления интеграционным решением свя-
зующее ПО должно включать в себя подсистему администрирования. Основные задачи
подсистемы администрирования состоят в отслеживании потоков данных, работоспо-
собности компонентов и приложений, а также уведомлении о возникших ошибках.
Казалось бы, мы учли все, что необходимо для создания полноценного интеграцион-
ного решения, — компоненты передачи данных, преобразования формата, маршрутиза-
ции сообщений и администрирования. Однако мы исходили из допущения, что интегри-
руемые приложения могут самостоятельно помещать сообщения в канал. К сожалению,
большинство унаследованных приложений, коммерческих приложений, а также прило-
жений, созданных на заказ, изначально не предназначались для интеграции. Для “под-
ключения” подобных приложений к интеграционному решению используется конечная
точка сообщения — специализированный компонент или адаптер канала {Channel
Adapter, с. 154), предоставленный разработчиком интеграционной платформы.
Пример: “Приборы и устройства”
Рассмотрим пример создания интеграционного решения, основанного на обмене
сообщениями. Предположим, что вымышленная компания “Приборы и устройства”
(ЙРУСТ) закупает у производителей два наименования продукции (приборы и устройст-
ва) и реализует ее розничным потребителям через Интернет (рис. 1.10).
Пример: “Приборы и устройства"
57
Заказчики
Поставщики
Рис. 1.10. Экосистема ПРУСТ
Сформулируем требования, предъявляемые к интеграционному решению (несмотря
на очевидное упрощение, требования, подобные приведенным ниже, часто встречаются
в реальной практике).
• Размещение заказов. Клиент может разместить заказ через Интернет, по телефону
или с помощью факса.
• Обработка заказов. Обработка заказа выполняется в несколько этапов, включая
проверку наличия товара на складе, отправку товара и выставление счета.
• Проверка состояния заказа. Клиент может проверить состояние своих заказов.
• Изменение адреса клиента. Клиент может изменить адрес доставки товара, а также
адрес, по которому будет выслан счет, с помощью Web-приложения.
• Обновление каталога товаров. Компания должна периодически обновлять каталог
товаров, основываясь на данных из каталогов производителей.
• Рассылка новостей. Клиенты могут подписаться на рассылку новостей от ПРУСТ.
• Тестирование и мониторинг. Сотрудники, ответственные за поддержку интеграци-
онного решения, должны иметь возможность мониторинга всех его компонентов и
потоков сообщений.
Рассмотрим реализацию каждого из описанных выше требований по отдельности.
Начав с “простой” формы интеграционного решения, мы постепенно перейдем к более
сложным концепциям, таким как диспетчер процессов (Process Manager, с. 325).
Внутренние системы
IT-инфраструктура ПРУСТ состоит из множества различных приложений, как ком-
мерческих, так и созданных на заказ. На рис. 1.11 показаны внутренние системы ПРУСТ.
ПРУСТ располагает четырьмя каналами взаимодействия с клиентами: Web-сайт,
центр обработки звонков, факс и электронная почта.
58
Глава 1. Решение задач интеграции с помощью шаблонов проектирования
Биллинг/ учет
Web-интерфейс ПРУСТ
Доставка
Центр обработки звонков Склад приборов
Каталог приборов
Входящие факсы
Склад устройств
Исходящая почта
Каталог устройств
Рис. 1.11. IT-инфраструктура ПРУСТ
В число внутренних систем ПРУСТ входят система бухгалтерского учета, выполняю-
щая часть биллинговых функций, и система доставки товаров. Кроме того, ПРУСТ имеет
две системы управления складскими запасами и две системы торговли по каталогу.
Наличие одинаковых систем объясняется тем, что изначально ПРУСТ торговала только
приборами, однако затем поглотила розничного продавца устройств.
Размещение заказов
Размещение заказов—это одна из основных функций создаваемого решения. Заказы
приносят прибыль, однако в настоящий момент они обрабатываются вручную, что вле-
чет за собой большие накладные расходы.
Клиент ПРУСТ может разместить заказ с помощью одного из трех каналов:
Web-сайта, центра обработки звонков и факса. К сожалению, каждая система основана
на применении различных технологий и форматов данных. Система обработки звонков
представляет собой коммерческое приложение, Web-сайт— 12ЕЕ-приложение, создан-
ное на заказ, а система обработки входящих факсов использует ручной ввод данных
в приложение Microsoft Access. Очевидно, что способ обработки заказа не должен зави-
сеть от способа его размещения. Например, заказав товар с помощью центра обработки
звонков, клиент должен иметь возможность проверить состояние заказа с помощью
Web-приложения.
Поскольку размещение заказа— это асинхронный процесс, охватывающий несколь-
ко различных систем, унифицируем его с помощью связующего ПО, ориентированного
на обмен сообщениями. Приложение в центре обработки звонков не обладает средства-
ми для интеграции и должно быть подключено к системе обмена сообщениями с помо-
щью адаптера канала (Channel Adapter, с. 154). Адаптер канала— это компонент, кото-
рый публикует сообщения в канале сообщений (Message Channel, с. 93) при возникновении
события в приложении. В некоторых случаях приложение может и вовсе не знать
о наличии подключенного к нему адаптера канала. Например, приложение, сохраняю-
щее информацию в базе данных, можно подключить к системе обмена сообщениями
с помощью триггеров, срабатывающих при добавлении новых строк в определенные таб-
лицы базы данных и помещающих соответствующие сообщения в канал сообщений.
Пример: “Приборы и устройства”
59
Адаптер канала может выполнять и обратную функцию, извлекая сообщения из канала
сообщений и инициируя определенные действия внутри приложения.
Для подключения к системе обмена сообщениями приложения, применяющегося для
обработки входящих факсов, воспользуемся адаптером канала, соединенным с базой
данных этого приложения. Поскольку Web-приложение разрабатывалось на заказ, созда-
дим внутри него конечную точку сообщения (Message Endpoint, с. 124). Чтобы отделить код
Web-приложения от кода конечной точки сообщения, применим шлюз обмена сообщениями
(Messaging Gateway, с. 482).
Каждая система размещения заказов использует для их представления разные форма-
ты данных. С целью приведения этих форматов к общему формату сообщения, соответ-
ствующего канонической модели данных (Canonical Data Model, с. 367), используются три
транслятора сообщений (Message Translator, с. 115). Каноническая модель данных определя-
ет формат сообщений, не зависящий от конкретного приложения. Таким образом, изме-
нение внутреннего формата данных приложения затрагивает только транслятор сообще-
ний, расположенный между этим приложением и общим каналом сообщений. Все остав-
шиеся приложения, а также соответствующие им трансляторы сообщений, не требуют
внесения изменений. Использование канонической модели данных приводит к разделению
всех сообщений на две категории: канонические сообщения (общие) и сообщения при-
ложений (частные). Сообщение приложения должно обрабатываться только создавшим
его приложением и соответствующим транслятором сообщений. Условимся использовать
в именах каналов сообщений, по которым передаются сообщения приложений, соответст-
вующий префикс, например web_new_order. Имена каналов, по которым передаются
канонические сообщения, будут лишены подобного префикса, например NEW_ORDER.
Так как сообщение о размещении нового заказа должен был принять единственный по-
лучатель, каждый адаптер канала подключается к транслятору сообщений с помощью кана-
ла “точка-точка” (Point-to-Point Channel, с. 131). Следует отметить, что мы могли бы обой-
тись без транслятора сообщений Web-приложения, запрограммировав логику преобразова-
ния в соответствующем шлюзе обмена сообщениями. Однако подобная реализация функций
преобразования может привести к возникновению ошибок программирования, а также на-
рушить целостность предложенного ранее подхода к унификации формата сообщений. Все
трансляторы сообщений размещают сообщения в канале “точка-точка” new_order, что
устраняет различие между заказами, поступившими из разных источников (рис. 1.12).
Канал сообщений NEW_ORDER является так называемым каналом типа данных (Datatype
Channel, с. 139), поскольку по нему передаются сообщения одного и того же типа: сооб-
щения о размещении нового заказа. Это облегчает задачу обработки сообщений, посту-
пающих по каналу new_order. Само же сообщение о размещении нового заказа пред-
ставляет собой сообщение с данными документа (Document Message, с. 171), основное на-
значение которого состоит в передаче данных между приложениями.
Обработка заказов
Обработка заказа предполагает выполнение следующих действий.
• Проверка кредитной репутации клиента. Если у клиента остались неоплаченные
счета, следует отменить новый заказ.
• Проверка наличия товара. Компания не сможет выполнить заказ, если в него
будут включены отсутствующие в данный момент на складе товары.
60
Глава 1. Решение задач интеграции с помощью шаблонов проектирования
Конечная точка
Канал
Транслятор сообщений
Адаптер
канала
Сообщение
о размещении
нового заказа
Рис. 1.12. Обработка заказов, принятых из трех различных источников
• Отправка товара и выставление счета (при условии положительной кредитной
репутации клиента и наличия товара на складе).
Указанную последовательность событий можно воспроизвести с помощью диаграм-
мы операций UML (Unified Modeling Language—унифицированный язык моделирова-
ния). Подобные диаграммы удобно применять для представления процессов, включаю-
щих параллельные действия. Семантика диаграмм операций UML очень проста: после-
довательные действия соединяются стрелками, а параллельные— толстыми линиями,
представляющими операции ветвления и объединения. Операция ветвления подразуме-
вает одновременное начало выполнения всех исходящих действий, а операция объедине-
ния предписывает дождаться завершения выполнения всех входящих действий.
Как показано на рис. 1.13, задачи проверки кредитной репутации клиента и наличия
товара на складе выполняются параллельно. Толстая линия, соответствующая операции
объединения, предписывает дождаться завершения выполнения обеих задач перед вы-
полнением следующего действия. Если оба условия соблюдены, заказ передается на
выполнение. В противном случае выполняется действие по обработке ошибки— компа-
ния может напомнить клиенту оплатить последний счет или уведомить об отсрочке вы-
полнения заказа. Поскольку настоящая книга посвящена проектированию интеграцион-
ных решений, а не моделированию последовательно выполняемых операций, мы не бу-
дем останавливаться на аспектах обработки ошибок. Более подробно эта тема рас-
сматривается в [23] и [35].
Пример: “Приборы и устройства”
61
Рис. 1.13. Диаграмма операций, выполняемых при обработке заказа
Действия, представленные на диаграмме операций, соответствуют различным систе-
мам ПРУСТ. Система бухгалтерского учета проверяет кредитную репутацию клиента,
система управления складскими запасами — наличие товара на складе, а система достав-
ки товара отправляет товар клиенту. Выставляя клиенту счет, система бухгалтерского
учета берет на себя также некоторые функции биллинга. Таким образом, обработка зака-
за представляет собой типичный пример распределенного бизнес-процесса.
Преобразуя логику диаграммы операций в проект интеграционного решения, реали-
зуем операцию ветвления с помощью канала “публикация-подписка” (Publish-Subscribe
Channel, с. 134), а операцию объединения— с помощью агрегатора (Aggregator, с. 283).
Канал “публикация-подписка” отправляет сообщение всем активным потребителям, в то
время как агрегатор объединяет несколько входящих сообщений в одно исходящее со-
общение (рис. 1.14).
Как показано на рис. 1.14, канал “публикация-подписка” передает сообщение о разме-
щении нового заказа системе бухгалтерского учета и системе управления складскими за-
пасами. Агрегатор объединяет сообщение о проверке кредитной репутации клиента и со-
общение о проверке наличия товара на складе, после чего передает полученный результат
маршрутизатору на основе содержимого (Content-Based Router, с. 247). Маршрутизатор на
основе содержимого— это компонент, который принимает сообщение, а затем помешает
его в один из нескольких каналов на основе некоторого правила. На диаграмме операций
UML маршрутизатору на основе содержимого соответствует ромб. Если результат провер-
ки заказа системой бухгалтерского учета и системой управления складскими запасами
62
Глава 1. Решение задач интеграции с помощью шаблонов проектирования
оказался положительным, сообщение направляется в канал validated_order. Послед-
ний является каналом “публикация-подписка", что позволяет передать сообщение как
системе доставки товара, так и биллинговой системе. Если клиент не оплатил предыду-
щий счет или нужного товара не оказалось на складе, маршрутизатор на основе содержи-
мого направляет сообщение в канал invalid_order. Канал invalid_order связан с
системой обработки ошибок (не показана на рисунке), которая уведомляет клиента
о причине отклонения или задержки выполнения заказа.
Агрегатор
размещении
нового заказа
Рис. 1.14. Реализация процесса обработки заказа с помощью технологии асинхронного обмена сообщениями
Доставка
Канал “публикация-
подписка”
Биллинг/
учет
INVALID_ORDER
содержимого
Описав основные этапы передачи сообщения, сосредоточимся на функции управле-
ния складскими запасами. Как известно, компания ПРУСТ имеет две подобные систе-
мы, соответствующие приборам и устройствам. Для корректной маршрутизации запро-
сов о наличии товара на складе применим маршрутизатор на основе содержимого, как по-
казано на рис. 1.15. В зависимости от первой буквы в коде товара (“П” или “У”)
маршрутизатор на основе содержимого будет передавать все входящие запросы о наличии
товара в соответствующую систему управления складскими запасами.
Рис. 1.15. Маршрутизация запросов о наличии товара на складе
Обратите внимание, что значение сообщения, передаваемого по каналу “точка-
точка" (Point-to-Point Channel, с. 131) между маршрутизатором на основе содержимого
и системой управления складскими запасами, отличается от значения сообщения, пере-
даваемого по каналу “публикация-подписка”. Система управления складскими запасами
получает сообщение с командой (Command Message, с. 169), предписывающей выполнить
определенное действие (в данном случае—проверить наличие товара на складе).
Поскольку системы управления складскими запасами приборов и устройств исполь-
зуют различные внутренние форматы данных, преобразуем сообщение канонического
Пример: “Приборы и устройства”
63
формата в формат конкретной системы с помошью трансляторов сообщений (Message
Translator, с. 115).
Предположим, что первая буква в коде товара отлична от букв “П” и “У”. В этом случае
маршрутизатор на основе содержимого направит сообщение в канал недопустимых сообще-
ний (Invalid Message Channel, с. 143) INVALID_ORDER_ITEM. Следует подчеркнуть, что значе-
ние сообщения зависит от канала, который используется для его транспортировки.
Так, одно и то же сообщение, передаваемое по каналам new_order и invalid_order_
item, имеет два разных значения: заказ, предназначенный для выполнения, и заказ, содер-
жащий ошибку.
До сих пор мы предполагали, что все заказы содержат один элемент. Это может соз-
дать неудобства для клиентов, так как им придется размешать отдельный заказ для каж-
дого товара. К тому же обработка нескольких заказов, сделанных одним и тем же клиен-
том, неизбежно приведет к возрастанию накладных расходов. К сожалению, включение
в заказ нескольких элементов усложнит выбор системы управления складскими запаса-
ми, применяющейся для проверки наличия товара на складе. На первый взгляд, эту про-
блему можно решить за счет канала “публикация-подписка”, транспортирующего сооб-
щение о размешении нового заказа обеим системам. Однако как в данном случае отли-
чить заказ, содержащий ошибку? Очевидно, что идеальное решение заключается в
добавлении к логике маршрутизатора на основе содержимого возможности обработки от-
дельных элементов заказа.
Выход из сложившейся ситуации заключается в использовании разветвителя (Splitter,
с. 274)— компонента, разделяющего сообщение на несколько меньших частей. Как по-
казано на рис. 1.16, разветвитель разделяет сообщение о размещении нового заказа на
несколько сообщений о заказе товара, которые передаются соответствующей системе
управления складскими запасами с помощью маршрутизатора на основе содержимого.
Рис. 1.16. Обработка отдельных элементов заказа
64
Глава 1. Решение задач интеграции с помощью шаблонов проектирования
Проверив наличие товаров на складе, сообщения о заказе товара необходимо объеди-
нить в одно сообщение. Для этого применим агрегатор— компонент, объединяющий
несколько входящих сообщений в одно исходящее сообщение. Использование развет-
вителя и агрегатора позволяет отделить обработку отдельных элементов заказа от обра-
ботки заказа как одного целого.
При создании агрегатора необходимо ответить на три ключевых вопроса.
• Какие сообщения о заказе товара принадлежат к одному заказу? (Условие корре-
ляции?)
• Как определить, были ли получены все сообщения, принадлежащие к одному
заказу? (Условие полноты?)
• Как объединить несколько сообщений о заказе товара в одно сообщение о разме-
щении нового заказа? (Алгоритм агрегации?)
Поскольку клиент может разместить несколько последовательных заказов, судить
о принадлежности сообщений к одному заказу по идентификатору клиента нельзя. А это
значит, что нам необходимо ввести идентификатор самого заказа. Для этого добавим
к процессу создания сообщения о размещении нового заказа расширитель содержимого
(Content Enricher, с. 348), как показано на рис. 1.17.
Расширитель содержимого— это компонент, добавляющий недостающие элементы
данных к входящему сообщению. В данном случае расширитель содержимого используется
д ля добавления уникального идентификатора к сообщению о размещении нового заказа.
Адаптер Транслятор
канала сообщении
Рис. 1.17. Использование расширителя содержимого для добавления идентификатора к сообщению
о размещении нового заказа
Определим условие полноты сообщения и алгоритм агрегации. Поскольку агрегатор
принимает все сообщения о заказе товара, включая заказы с ошибкой, условием полноты
сообщения о размещении нового заказа может стать получение агрегатором определен-
ного (заранее известного) числа сообщений о заказе товара с одинаковым идентифика-
Пример: “Приборы и устройства”
65
ционным номером. Алгоритм агрегации заключается в простой конкатенации сообще-
ний о заказе товара в одно сообщение о размещении нового заказа. Полученное сооб-
щение размещается агрегатором в канале validated_order.
Поскольку комбинация разветвителя, маршрутизатора на основе содержимого и агрега-
тора является неотъемлемой частью множества интеграционных решений, она заслужила
статус отдельного компонента— так называемого обработчика составного сообщения
(Composed Message Processor, с. 307). На рис. 1.18 показана обновленная диаграмма процесса
обработки заказа, которая включает в себя символ обработчика составного сообщения.
Канал
“точка-точка
Обработчик
составного
сообщения
Биллинг/
учет
Канал
4публикация-
Сообщение
о размещении
нового заказа
Проверка наличия
товара
Рис. 1.18. Обновленная диаграмма процесса обработки заказа с помощью технологии асинхронного
обмена сообщениями
Канал
“публикация-
Доставка
Биллинг/
учет
Агрегатор Маршрутизатор
на основе invalid_order
содержимого
Проверка состояния заказа
Несмотря на объединение систем с помощью каналов сообщений (Message Channel,
с. 93), на выполнение заказа может уйти достаточно много времени. К примеру, нужного
товара может не оказаться в наличии, в результате чего система управления складскими
запасами будет удерживать сообщение о проверке возможности выполнения заказа до
поступления товара на склад. В этом заключается одно из основных преимуществ асин-
хронного обмена сообщениями— взаимодействие между системами осуществляется по
мере готовности каждой из них. Пока система управления складскими запасами удержи-
вает сообщение о проверке возможности выполнения заказа, система бухгалтерского
учета может проверить кредитную репутацию клиента. При условии успешного выпол-
нения обоих шагов агрегатор (Aggregator, с. 283) публикует сообщение, инициирующее
отгрузку товара и формирование счета.
Растянутость бизнес-процесса во времени также означает, что клиент и менеджеры
компании могут захотеть узнать состояние заказа. Если определенного товара нет на
складе, клиент может захотеть приобрести только те товары, которые есть в наличии.
Кроме того, клиент должен иметь возможность узнать о состоянии доставки товара (дата
отгрузки товара со склада, номер груза и т.п.).
Текущий проект интеграционного решения не предусматривает возможность отслежи-
вания состояния заказа. Сообщения, которые могут об этом свидетельствовать, проходят
одновременно через несколько различных систем. Чтобы судить о состоянии заказа, необ-
ходимо знать содержание последнего относящегося к нему сообщения. Одним из преиму-
ществ канала “публикация-подписка” (Publish-Subscribe Channel, с. 134) является возмож-
ность добавления к каналу новых подписчиков без нарушения хода сообщений. Использу-
ем это свойство для отслеживания сообщений о размещении нового заказа, а также
66
Глава 1. Решение задач интеграции с помощью шаблонов проектирования
сообщений о результатах проверки возможности выполнения заказа, и помещении их в
хранилище сообщений (Message Store, с. 565). По сути, хранилище сообщений является базой
данных, которую можно использовать для выяснения состояния заказа (рис. 1.19).
Рис. 1.19. Для отслеживания состояния заказа используется хранилище сообщений
Поскольку канал “точка-точка” (Point-to-Point Channel, с. 131) предусматривает дос-
тавку сообщения единственному получателю, мы не можем добавить к нему нового под-
писчика. Тем не менее мы можем воспользоваться отводом (Wire Тар, с. 558)— компо-
нентом, извлекающим сообщение из одного канала и помещающего его в два других ка-
нала. Схема, позволяющая извлечь сообщение из канала “точка-точка” и поместить его
в хранилище сообщений, показана на рис. 1.20.
Хранение сообщений в центральной базе данных имеет еще одно существенное пре-
имущество. Первоначальный вариант проекта интеграционного решения предполагал
передачу всех данных сообщения на каждом этапе его обработки. Так, сообщение о про-
верке кредитной репутации должно было содержать не только идентификатор клиента,
но и все данные исходного сообщения о размещении нового заказа. Если сообщение
о размещении нового заказа будет содержаться в хранилище сообщений, компоненты ин-
теграционного решения смогут получать нужные им данные из хранилища при предъяв-
лении квитанции (Claim Check, с. 358). Недостаток подобного подхода состоит в том,
что доступ к центральной базе данных обладает меньшей надежностью, чем передача со-
общений по асинхронным каналам.
Канал
Канал
‘точка-точка’
точка-точка
Хранилище сообщений
Рис. 1.20. Отслеживание сообщений с помощью отвода
Отвод
Пример: “Приборы и устройства”
67
Итак, новый вариант интеграционного проекта предусматривает размещение сообще-
ний в хранилище сообщений, а также использование последнего при обработке сообщений.
Информация, содержащаяся в хранилище сообщений, позволяет определить следующий этап
обработки сообщения, устраняя тем самым необходимость соединения компонентов ин-
теграционного решения с помощью фиксированных каналов сообщений. К примеру, если в
базе данных содержится положительный ответ на сообщение о проверке кредитной репута-
ции клиента, а также положительный ответ на сообщение о проверке наличия товара на
складе, это означает, что заказ может быть выполнен и его можно передать для дальнейшей
обработки системе доставки товара и биллинговой системе. Ранее для принятия подобного
решения использовался агрегатор, однако сейчас логику принятия решений можно реали-
зовать непосредственно в хранилище сообщений. Фактически тем самым мы превращаем
хранилище сообщений в диспетчер процессов {Process Manager, с. 325).
Диспетчер процессов— это центральный компонент, управляющий потоками сооб-
щений в системе (рис. 1.21). Диспетчер процессов обеспечивает две основные функции:
• хранение данных сообщений (внутри “экземпляра процесса”);
• определение следующего этапа обработки сообщения (посредством использова-
ния “эталона процесса”).
Шина служб
Диспетчер процессов
NEW ORDER
□
□
Web-интерфейс
База данных заказов
Биллинг/
учет
Биллинг/
учет
Доставка
Проверить
кредитную
репутацию
клиента
Проверить
наличие товара
Доставить товар
Отправить счет
Рис. 1.21. Обработка заказов с помощью диспетчера процессов
Новая архитектура превращает системы интеграционного решения (например, сис-
тему управления складскими запасами) в общие бизнес-функции, доступные оставшим-
ся компонентам в виде служб. Это упрощает поддержку решения и повышает возмож-
ность повторного использования его элементов. Объединяющим фактором для отдель-
ных служб может стать как поток сообщений (например, проверка наличия отдельных
элементов заказа с помощью обработчика составного сообщения {Composed Message
Processor, с. 307)), так и диспетчер процессов. Тем не менее диспетчер процессов позволяет
68
Глава 1. Решение задач интеграции с помощью шаблонов проектирования
вносить изменения в поток сообщений гораздо проще, чем это можно было бы сделать
с помощью предложенного ранее подхода.
В соответствии с новой архитектурой все службы соединены с общей шиной служб,
позволяющей вызывать службу любому компоненту интеграционного решения.
IT-инфраструктуру ПРУСТ можно привести в соответствие с SOA-архитектурой, доба-
вив функцию поиска службы в централизованном списке (каталоге) служб. Кроме того,
все службы обязаны предоставить контракт интерфейса, описывающий функциональ-
ность службы, а каждая служба типа “запрос-ответ” должна поддерживать концепцию
обратного адреса (Return Address, с. 182). Обратный адрес позволяет вызывающему компо-
ненту (потребителю службы) указать канал, по которому следует передавать сообщение
с ответом. Это делает возможным использование одной и той же службы в нескольких
различных контекстах, каждому из которых может соответствовать собственный канал
для передачи ответных сообщений.
Для хранения данных, относящихся к каждому экземпляру процесса, диспетчер про-
цессов использует постоянное хранилище, такое как файл или реляционная база данных.
Чтобы проверить состояние заказа с помощью Web-интерфейса, следует отправить
сообщение диспетчеру процессов или выполнить запрос к базе данных заказов. Однако
проверка состояния заказа является синхронным процессом, т.е. клиент ожидает полу-
чить ответ немедленно. Поскольку Web-интерфейс представляет собой приложение,
которое разрабатывалось на заказ, мы приняли решение обратиться к базе данных на-
прямую. Общая база данных (Shared Database, с. 83) — наиболее простой и эффективный
подход, позволяющий узнать состояние заказа за максимально короткое время. Единст-
венный его недостаток заключается в сильном связывании Web-интерфейса и базы дан-
ных. Впрочем, в этой ситуации подобный компромисс выглядит вполне допустимым.
Большинство унаследованных систем разрабатывалось без встроенной поддержки та-
ких концепций SOA-архитектуры, как обратный адрес. Чтобы представить эти системы
в виде служб, следует воспользоваться интеллектуальным заместителем (Smart Proxy,
с. 567). Интеллектуальный заместитель расширяет функциональность системы, перехва-
тывая сообщения с запросом и сообщения с ответом, как показано на рис. 1.22.
Интеллектуальный заместитель сохраняет информацию из сообщения с запросом
(например, обратный адрес, указанный запрашивающей стороной), а затем применяет ее
для обработки сообщения с ответом (например, помещает сообщение в нужный канал).
Интеллектуальный заместитель также удобно использовать для отслеживания качества
обслуживания (например, времени отклика) внешней службы.
Интеллектуальный
Рис. 1.22. Интеллектуальный заместитель позволяет представить унаследованную систему
в виде общей службы
Пример: “Приборы и устройства”
69
Изменение адреса клиента
Каждому клиенту ПРУСТ соответствует несколько различных адресов, например
адрес доставки и адрес, на который высылается счет. Чтобы избежать дополнительных
издержек, необходимо позволить клиенту самостоятельно изменять эти адреса с помо-
щью Web-интерфейса.
Для передачи обновленной информации в биллинговую систему, а также в систему
доставки товара можно применить один из двух способов:
• включать данные об адресах клиента в каждое сообщение о размещении нового
заказа;
• реплицировать обновленную информацию в каждую из систем.
Преимущество первого подхода заключается в том, что для его реализации можно ис-
пользовать существующие каналы интеграционного решения. В то же время это означает
необходимость передачи дополнительной информации с каждым сообщением, хотя из-
менение адреса клиента происходит не так уж и часто.
При реализации первого подхода следует помнить, что биллинговая система и систе-
ма доставки товара представлены коммерческими приложениями, не обладающими
встроенными средствами интеграции. Следовательно, существует большая вероятность,
что эти приложения будут использовать адреса, хранящиеся в собственной базе данных,
а не адреса, полученные вместе с сообщением. Чтобы каждая из упомянутых систем
обновляла адреса клиента на основе информации, содержащейся в сообщении о разме-
щении нового заказа, воспользуемся диспетчером процессов (Process Manager, с. 325).
Диспетчер процессов принимает сообщение о размещении нового заказа (содержащее
адреса клиента), а затем передает биллинговой системе (системе доставки товара) два со-
общения, как показано на рис. 1.23.
Рис. 1.23. Включение данных об адресах клиента в сообщение о размещении нового заказа
70
Глава 1. Решение задач интеграции с помощью шаблонов проектирования
Следует помнить, что адаптеры канала {Channel Adapter, с. 154) принимают на вход
частные сообщения, т.е. сообщения, отформатированные в соответствии с требованиями
конкретного приложения. Поскольку сообщение о размещении нового заказа имеет
канонический формат, его необходимо преобразовать с помощью транслятора сообщений
(Message Translator, с. 115). Несмотря на то что логика преобразования может быть
встроена в диспетчер процессов, использование внешних трансляторов сообщений являет-
ся более предпочтительным (дополнительная функциональность может привести к воз-
растанию сложности реализации диспетчера процессов).
Второй подход к распространению обновленной информации об адресах клиента
заключается в ее репликации. Как только клиент изменит один из своих адресов, эта ин-
формация будет передана всем использующим ее системам с помощью канала
“публикация-подписка” (Publish-Subscribe Channel, с. 134). Каждая система хранит адрес
клиента с помощью внутренних механизмов и использует его при поступлении сообще-
ния о размещении нового заказа. Данный подход позволяет уменьшить объем трафика
сообщений (при условии, что клиенты будут размещать заказы чаще, чем изменять адре-
са), а также снизить степень связывания систем. Всякая система, использующая адрес-
ную информацию клиента, может подключиться к соответствующему каналу “публика-
ция-подписка”, не затрагивая при этом другие системы.
Поскольку клиент имеет несколько различных адресов (адрес доставки и адрес, на ко-
торый высылается счет), следует позаботиться о том, чтобы системам передавались адре-
са нужных типов. Другими словами, биллинговая система не должна получить сообще-
ние об изменении адреса доставки товара. Эту функциональность можно обеспечить
с помощью фильтров сообщений (Message Filter, с. 253), пропускающих только те сообще-
ния, которые удовлетворяют определенному критерию (рис. 1.24).
Как отмечалось выше, для преобразования канонического формата сообщений в
формат, используемый приложениями, применяются трансляторы сообщений. Отсутст-
вие транслятора сообщений Web-интерфейса объясняется тем, что формат последнего
был взят за основу канонической модели данных (Canonical Data Model, с. 367). Это может
ограничить гибкость решения, если мы захотим предоставить клиентам другой способ
изменения своих личных данных, однако на данный момент такой подход выглядит
вполне оправданным.
Рис. 1.24. Репликация данныхоб адресах клиента с помощью канала “публикация-подписка”
Пример: “Приборы и устройства'
71
Поскольку обе системы хранят адреса клиентов в реляционных базах данных, обнов-
ление последних осуществляется с помощью адаптеров канала.
Так какой же из двух подходов к обновлению данных об адресах клиентов является
более предпочтительным? В рассматриваемой ситуации объем трафика сообщений
не превышает сотни заказов в день, поэтому оба способа вполне эффективны. Основным
фактором, который может повлиять на выбор того или иного решения, является внут-
ренняя структура используемых приложений. Некоторые приложения позволяют внести
обновленные сведения в базу данных только через свой уровень бизнес-логики. К при-
меру, приложение может провести дополнительную проверку адреса, создать запись в
журнале событий и даже отправить клиенту электронное письмо с уведомлением о смене
адреса. Выполнять все эти действия при обработке каждого заказа, конечно же, излишне.
В данном случае имеет смысл прибегнуть ко второму подходу, т.е. проводить обновление
личных данных клиента только при их фактическом изменении.
В целом же мы отдаем предпочтение таким строго определенным, самодостаточным
операциям, как “Изменить адрес” и “Разместить заказ”, потому что они допускают более
гибкое управление бизнес-процессами. В конечном итоге все сводится к вопросу детализа-
ции интерфейса и связанным с ней преимуществам и недостаткам. Интерфейсы с высокой
степенью детализации могут замедлить работу системы по причине большого числа вызо-
вов удаленных процедур или пересылаемых сообщений. К примеру, рассмотрим интер-
фейс, предоставляющий отдельные методы для изменения полей в адресе клиента. Этот
подход мог бы стать эффективным при условии, что взаимодействие происходит в пределах
одного приложения. Если же речь идет об интеграционном решении, отправка шести или
семи сообщений для обновления адреса клиента является непозволительной роскошью.
Кроме того, интерфейсы с высокой степенью детализации предполагают сильное связыва-
ние компонентов. Если к адресу клиента будет добавлено дополнительное поле, нам пона-
добится внести изменения во все приложения, которые могут обновить адрес.
Интерфейсы с низкой степенью детализации лишены описанных выше недостатков,
однако слишком низкая степень детализации может существенно ограничить гибкость
решения. Если операции “Отправить счет” и “Изменить адрес” будут объединены в одну
внешнюю функцию, мы не сможем изменить адрес без отправки счета. Таким образом,
нужно искать “золотую середину”, определяя степень детализации интерфейса, исходя
из особенностей каждого конкретного сценария.
Обновление каталога товаров
Прежде чем разместить заказ, клиент должен ознакомиться с каталогом имеющихся в
продаже товаров. Каталог товаров ПРУСТ составляется на основе соответствующих ка-
талогов поставщиков. ПРУСТ позволяет своим клиентам одновременно просматривать
оба типа товаров (приборы и устройства), а также включать их в один заказ. Подобная
функциональность является типичным примером информационного портала—данные
из нескольких источников объединяются в одном представлении.
Оба поставщика обновляют каталоги своей продукции раз в три месяца. Следова-
тельно, создавать инфраструктуру обмена сообщениями для передачи обновлений ката-
логов от поставщиков в ПРУСТ не имеет смысла. Вместо этого воспользуемся таким
способом интеграции, как передача файла (File Transfer, с. 80). Одним из преимуществ пе-
редачи файла является возможность обеспечения надежной и эффективной доставки
файлов по общедоступным сетям с помощью FTP или аналогичного ему протокола.
72
Глава 1. Решение задач интеграции с помощью шаблонов проектирования
Для сравнения: большинство инфраструктур асинхронного обмена сообщениями не мо-
гут обеспечить надежного обмена данными через Интернет.
Для преобразования формата каталогов поставщиков во внутренний формат ПРУСТ
применяются трансляторы и адаптеры (рис. 1.25). Следует отметить, что трансляторы
обрабатывают сразу весь каталог, а не его отдельные элементы. Этот подход хорошо за-
рекомендовал себя при работе с большими объемами данных одинакового формата.
Рис. 1.25. Обновление каталога товаров путем передачи файла
Рассылка новостей
Для повышения уровня продаж клиенты ПРУСТ должны периодически уведомляться
о всевозможных специальных предложениях. Клиентам следует предоставить возможность
выбора интересующих их новостей, а также сделать так, чтобы определенные новости были
доступны только некоторым группам клиентов. К примеру, о некоторых акциях можно ин-
формировать только привилегированных клиентов. Несмотря на то что рассылку данных
нескольким получателям может обеспечить канал “публикация-подписка” (Publish-Subscribe
Channel, с. 134), это решение имеет ряд существенных недостатков. Во-первых, канал
“публикация-подписка” позволяет считывать опубликованные сообщения без уведомления
издателя, а, как упоминалось выше, некоторая информация должна быть доступна только
крупным заказчикам. Во-вторых, эффективное использование канала “публикация-
подписка” возможно только в локальных сетях, поскольку передача копии сообщения всем
получателям приводит к созданию избыточного объема сетевого трафика.
Описанная выше функциональность может быть достигнута с помощью динамиче-
ского списка получателей (Recipient List, с. 264) (рис. 1.26). Динамический список получа-
телей представляет собой комбинацию двух маршрутизаторов сообщений (Message Router,
с. 109): списка получателей и динамического маршрутизатора (Dynamic Router, с. 259).
Список получателей— это маршрутизатор, рассылающий сообщения заданному набору
получателей. Основное отличие списка получателей от канала “публикация-подписка”
заключается в том, что список получателей предполагает жесткий контроль за получате-
лями сообщения. Динамический маршрутизатор— это маршрутизатор, алгоритм кото-
рого можно изменять с помощью управляющих сообщений. В рассматриваемом случае
управляющие сообщения могут использоваться для уведомления маршрутизатора о
предпочтениях клиентов (в получении каких новостей они заинтересованы).
Пример: “Приборы и устройства”
73
Рис. 1.26. Рассылка новостей с помощью динамического списка получателей
Если клиенты получают новости по электронной почте, динамический список полу-
чателей можно реализовать с помощью списка рассылки— функциональности, предо-
ставляемой большинством систем для работы с электронной почтой. В этом случае каж-
дый канал получателя будет соответствовать адресу электронной почты клиента. Если же
клиенты получают новости через интерфейс Web-служб, каждый канал получателя будет
представлен SOAP-запросом, а его адрес—унифицированным идентификатором ресур-
са (URI) Web-службы. Этот пример наглядно демонстрирует независимость решения,
основанного на использовании шаблонов проектирования, от конкретной технологии
передачи данных.
Тестирование и мониторинг
Мониторинг потока сообщений является неотъемлемой частью процессов функцио-
нирования и обслуживания интеграционного решения. Некоторые важные бизнес-
метрики, такие как среднее время выполнения заказа, можно узнать с помощью храни-
лища сообщений (Message Store, с. 565). Однако в процессе функционирования интеграци-
онного решения может возникнуть потребность и в более детальной информации. Пред-
положим, что для проверки кредитной репутации клиента привлекается внешнее кре-
дитное агентство. Если кредитный рейтинг клиента слишком низкий, ему следует
отказать в принятии заказа. Поскольку кредитное агентство является внешней организа-
цией, ее услуги оплачиваются в соответствии с некоторым тарифом. Чтобы убедиться
в корректности выставленного счета, следует сопоставить содержащиеся в нем сведения
с фактической статистикой использования услуг кредитного агентства. Очевидно, что та-
кой статистикой не может являться количество заказов, так как бизнес-логика интегра-
ционного решения не предусматривает обращения к внешнему поставщику услуг для
проверки кредитной репутации постоянных клиентов. К тому же между компанией
и кредитным агентством может быть заключено соглашение о качестве обслуживания.
Например, если время ответа на запрос о кредитной репутации клиента превысило опре-
деленный порог, такой запрос не подлежит оплате.
74
Глава 1. Решение задач интеграции с помощью шаблонов проектирования
Таким образом, чтобы собрать статистику использования услуг кредитного агентства,
необходимо отслеживать количество запросов к внешней службе и время получения со-
ответствующих ответов. В связи с этим рассмотрим две ситуации. Во-первых, поскольку
внешняя служба может обрабатывать несколько запросов одновременно, необходимо
предусмотреть механизм сопоставления запросов и ответов. Во-вторых, потребитель
службы должен иметь возможность указать обратный адрес (Return Address, с. 182) —
канал, по которому будет передаваться сообщение с ответом. Последнее требование
является необходимым условием, позволяющим сопоставить сообщение с запросом
к кредитному агентству и соответствующие сообщение с ответом.
Описанная выше функциональность может быть реализована с помощью интеллек-
туального заместителя (Smart Proxy, с. 567), расположенного между внешней службой
и ее потребителями. Интеллектуальный заместитель перехватывает все запросы к службе
и заменяет обратный адрес, указанный потребителем, фиксированным адресом канала,
предназначенного для передачи сообщений с ответом. Другими словами, внешняя служ-
ба помещает все сообщения с ответом в канал, указанный интеллектуальным заместите-
лем. В свою очередь, интеллектуальный заместитель использует обратный адрес, содер-
жащийся в сообщении с запросом, для выбора канала передачи ответа потребителю.
Кроме того, интеллектуальный заместитель замеряет время, прошедшее между отправ-
кой запроса внешней службе и получением от нее ответа на этот запрос. Полученные
данные передаются по шине управления (Control Bus, с. 552) на консоль, как показано
на рис. 1.27.
Рис. 1.27. Использование интеллектуального заместителя для измерения скорости
реагирования внешней службы
Помимо ведения статистики обращений ко внешней службе, интеллектуальный
заместитель может проводить мониторинг ее функционирования. Если кредитное агент-
ство не ответило на запрос в течение определенного промежутка времени, консоли
управления должно быть передано соответствующее сообщение. Гораздо сложнее зафик-
Резюме
75
сировать сбой в работе внешней службы, который может привести к выдаче ею неверных
результатов. К примеру, если кредитное агентство будет определять отрицательный кре-
дитный рейтинг для каждого клиента, компания может потерять множество заказов.
Рассмотрим два механизма проверки результата, возвращаемого внешней службой.
Во-первых, время от времени в поток запросов можно помещать тестовое сообщение
(Test Message, с. 577), содержащее запрос о проверке клиента с заранее известной кредит-
ной репутацией. Полученный результат следует передать верификатору тестовых данных,
который сможет проверить степень точности возвращенного службой результата.
Поскольку интеллектуальный заместитель поддерживает концепцию обратного адреса,
генератор текстовых данных может указать канал, по которому будут передаваться тесто-
вые сообщения с ответом (рис. 1.28).
Во-вторых, для обнаружения сбоя в работе внешней службы можно применить стати-
стическую выборку. Если по причине плохой кредитной репутации клиента отвергается
в среднем один заказ из десяти, отклонение пяти заказов подряд может служить призна-
ком сбоя в работе внешней службы или внутренней бизнес-логики. В этом случае кон-
соль управления должна переслать все пять заказов администратору, который проверит
правильность принятых решений.
Запрос к
кредитному
агентству
Запрос
Клиент
Проверка
тестовых
данных
Генерация
тестовых
данных
Ответ
кредитного
агентства
Тестовый ответ
Консоль управления
Кредитное
агентство
Рис. 1.28. Использование тестового сообщения для проверки результата, возвращаемого внешней службой
Ответ 1
Интеллектуальный
заместитель
Шина управления
Резюме
В этой главе был рассмотрен пример использования различных подходов к интегра-
ции приложений, таких как передача файла (File Transfer, с. 80), общая база данных (Shared
Database, с. 83) и асинхронный обмен сообщениями (Messaging, с. 87). Вы познакомились с
ключевыми шаблонами для работы с потоком сообщений, такими как разветвитель
(Splitter, с. 274), маршрутизатор сообщений (Message Router, с. 109), агрегатор (Aggregator,
с. 283) и диспетчер процессов (Process Manager, с. 325). Несмотря на то что требования,
предъявляемые к интеграционному решению, были намеренно упрощены, задачи, воз-
76 Глава 1. Решение задач интеграции с помощью шаблонов проектирования
никающие при его реализации, часто встречаются на практике. Приведенные в главе
диаграммы созданы с использованием универсальной нотации, не зависящей от конкрет-
ной технологии или разработчика.
Большинство приложений, объединенных в соответствии с рассмотренным сценари-
ем интеграции, являются коммерческими приложениями. Более подробно интеграция
приложений, созданных на заказ, рассматривается в главах 6 и 9.
Оставшаяся часть книги посвящена подробному рассмотрению шаблонов интеграции
корпоративных приложений. Для удобства чтения все шаблоны разделены на семь кате-
горий: базовые шаблоны, шаблоны каналов, шаблоны сообщений, шаблоны маршрути-
зации, шаблоны преобразования, шаблоны конечных точек и шаблоны системного
администрирования.
Глава 2
Стили интеграции
Введение
Основная задача интеграции заключается в налаживании функциональных связей
между приложениями— коммерческими и созданными на заказ, выполняющимися на
различных программных платформах, распределенными между несколькими географи-
ческими точками и т.п. Зачастую интегрируемые приложения не обладают встроенными
средствами интеграции, а также находятся вне сферы административного влияния ком-
пании. В этой главе рассматриваются различные способы интеграции приложений,
каждый из которых предусматривает собственный уникальный подход к решению задач
интеграции.
Критерии интеграции приложений
Основным критерием интеграции является необходимость налаживания взаимодей-
ствия между приложениями. Если бы нам удалось создать приложение, не нуждающееся
в обмене данными с другими приложениями, тема интеграции была бы исчерпана сама
собой. На практике даже небольшая компания использует несколько различных прило-
жений для предоставления необходимой функциональности своим сотрудникам, партне-
рам и клиентам.
Ниже перечислены основные критерии, влияющие на выбор способа интеграции
приложений.
• Связывание приложений. Зависимости между интегрированными приложениями
должны быть сведены к минимуму. Сильное связывание предполагает наличие
большого числа допущений между интегрированными приложениями. Изменение
функциональности единственного приложения может привести к нарушению не-
которых допущений и как следствие — к дестабилизации интеграционного реше-
ния. Таким образом, интерфейсы объединяемых приложений должны обеспечи-
вать необходимую функциональность, одновременно допуская возможность из-
менения внутренней реализации.
• Изменение приложений. Разработчикам интеграционного решения следует мини-
мизировать изменения, вносимые в объединяемые приложения, а также объем
кода, необходимого для интеграции. При этом нужно помнить, что стремление
78
Глава 2. Стили интеграции
к минимизации изменений не должно идти вразрез со стремлением к достижению
необходимой функциональности интеграционного решения.
• Выбор технологии. Некоторые приемы интеграции требуют применения специали-
зированного аппаратного и программного обеспечения. Привлечение дополнитель-
ных средств может привести к существенному повышению стоимости проекта, воз-
никновению зависимости от поставщика решений, а также к увеличению времени,
требующегося на подготовку разработчиков интеграционного решения. С другой
стороны, интеграции “с нуля” свойственны всевозможные непредвиденные обстоя-
тельства, которые могут свести усилия разработчиков к “изобретению колеса”.
• Формат данных. Интегрированные приложения должны использовать одинаковые
форматы данных. Если этого требования не удается достичь ни с помощью встро-
енных средств приложений, ни путем внесения в них изменений, для унификации
формата данных применяются внешние трансляторы.
• Своевременность доставки данных. Один из способов обеспечения своевременной
доставки информации между приложениями предусматривает частый обмен ма-
лыми порциями данных. К сожалению, этот подход оказывается неэффективным,
если речь идет о передаче большого объема информации. В идеальном случае по-
лучатель должен уведомляться о наличии данных, как только они будут доступны
для считывания. Задержка в обмене данными может привести к рассинхронизации
приложений, что, в свою очередь, увеличит сложность интеграционного решения.
• Общая функциональность. Помимо обмена данными, многие интеграционные
решения предусматривают использование приложениями общей функционально-
сти. Несмотря на внешнюю схожесть, вызов функции удаленного приложения
и вызов локальной функции имеют принципиальные отличия, способные оказать
существенное влияние на интеграционное решение.
• Удаленное взаимодействие. Большинство вычислительных процессов, выполняю-
щихся внутри компьютера, синхронны. Другими словами, процедура ожидает за-
вершения выполнения вызванной ею подпроцедуры. Поскольку вызов удаленной
подпроцедуры гораздо медленнее локального вызова, удаленную подпроцедуру
следует вызывать асинхронно, т.е. не дожидаться завершения ее выполнения.
Асинхронное взаимодействие существенно повышает эффективность интеграци-
онного решения, в то же время делая его более сложным в проектировании, разра-
ботке и обслуживании.
• Надежность. Удаленное взаимодействие гораздо менее надежно, чем вызов
локальной функции. Процедура всегда может вызвать подпроцедуру внутри
одного и того же приложения. К сожалению, вызов удаленной подпроцедуры свя-
зан с определенными рисками, а именно с необходимостью корректного функ-
ционирования сети и удаленного приложения. Надежное взаимодействие между
интегрируемыми приложениями обеспечивает асинхронный подход, в соответст-
вии с которым вызывающее приложение продолжает свою работу, не дожидаясь
ответа от удаленной подпроцедуры.
Таким образом, существует несколько различных критериев, влияющих на выбор
способа интеграции приложений. Рассмотрим существующие подходы к интеграции
и связанные с ними преимущества и недостатки.
Введение
79
Способы интеграции приложений
Универсального способа интеграции приложений, в одинаковой степени удовлетво-
ряющего всем рассмотренным выше критериям, не существует. Ниже перечислены
основные стили интеграции приложений, известные на момент написания этой книги.
• Передача файла (Hie Transfer, с. 80). Взаимодействие между приложениями осуще-
ствляется с помощью файлов, в которые помещаются общие данные.
• Общая база данных (Shared Database, с. 83). Взаимодействие между приложениями осу-
ществляется с помощью базы данных, в которой сохраняется общая информация.
• Удаленный вызов процедуры (Remote Procedure Invocation, с. 85). Взаимодействие
между приложениями осуществляется с помощью удаленного вызова процедур,
использующихся для выполнения действий или обмена данными.
• Обмен сообщениями (Messaging, с. 87). Взаимодействие между приложениями осу-
ществляется с помощью системы обмена сообщениями, которые используются
для обмена данными и выполнения действий.
Каждый стиль интеграции рассматривается далее в этой главе в виде шаблона проекти-
рования. Все шаблоны имеют одинаковую постановку задачи—необходимость интегриро-
вать приложения—и очень схожие контексты. Отличия между шаблонами заключаются в
средствах, используемых для достижения результата. Шаблоны перечислены в порядке
совершенствования предлагаемого решения, а также возрастания его сложности.
Как отмечалось ранее, не существует универсального подхода к интеграции приложе-
ний, однако существует способ, оптимальный в рамках конкретного интеграционного
сценария. Каждый стиль интеграции имеет свои преимущества и недостатки. Интегра-
ционное решение может основываться на использовании нескольких различных стилей.
Подобные “гибридные” решения поддерживаются многими пакетами для интеграции
и связующим ПО.
Шаблоны проектирования, рассматривающиеся в остальных главах этой книги, отно-
сятся к такому стилю интеграции, как обмен сообщениями. На наш взгляд, обмен сообще-
ниями позволяет достичь оптимального баланса между критериями интеграции. Одно-
временно это и самый сложный способ интеграции. Поскольку обмен сообщениями был
положен в основу многих коммерческих EAI-продуктов, настоящая книга поможет вам
подготовиться к их использованию.
80
Глава 2. Стили интеграции
Передача файла (File Transfer) к к
Мартин Фаулер (Martin Fowler) I ™ "
Информационная система компании насчитывает множество приложений, создан-
ных с использованием различных языков программирования и программных платформ.
Как наладить взаимодействие и обмен данными между несколькими приложе-
ниями?
В идеальном мире информационная система организации состоит из единственного
приложения, выполняющего все необходимые операции. В действительности даже
самые маленькие компании используют несколько приложений для получения необхо-
димой функциональности. Это обусловлено следующими причинами.
• Организации приобретают программные пакеты, созданные сторонними разра-
ботчиками.
• Между приложениями, созданными в разное время, существуют технологические
отличия.
• Приложения, созданные разными разработчиками, имеют архитектурные отличия.
• Своевременный выпуск приложения на рынок важнее наличия в приложении
встроенных средств интеграции.
В результате каждая организация вынуждена решать задачу обмена данными между
приложениями, созданными с помощью различных языков программирования, предна-
значенных для выполнения на разных программных платформах и реализующих разные
подходы к управлению бизнес-процессами.
Налаживание взаимодействия между подобными приложениями требует умения
объединять приложения как на техническом уровне, так и на уровне бизнес-логики. Что-
бы упростить интеграцию приложений, постарайтесь свести к минимуму объем значимой
информации о функционировании каждого конкретного приложения.
Одной из наиболее важных задач интеграции является создание общего механизма
передачи данных, не зависящего от конкретной платформы или языка программирова-
ния. Постарайтесь не использовать специализированные аппаратные или программные
средства, а обойтись теми возможностями, которые уже есть в наличии.
Файлы— это универсальный механизм хранения данных, встроенный в любую опе-
рационную систему и поддерживающийся любым языком программирования. Таким об-
разом, один из самых простых способов интеграции приложений может быть основан на
использовании файлов.
Одним из наиболее важных решений является выбор общего формата файлов. До не-
давнего времени наиболее распространенным стандартным форматом файлов считался
простой текстовый файл. Современные интеграционные решения основываются на ис-
пользовании формата XML.
Передача файла (File Transfer)
81
Приложение, которому требуется передать данные другому приложению, сохра-
няет их в файле. Ответственность за преобразование форматов файлов ложится
на плечи разработчиков интеграционного решения. Частота создания файлов
зависит от характера бизнес-логики компании.
Также следует определить периодичность создания и считывания файлов приложе-
ниями. Слишком частая работа с файлами может привести к нерациональному исполь-
зованию ресурсов. Как правило, периодичность создания файлов (ежедневно, ежене-
дельно, ежеквартально и т.д.) определяет бизнес-логика компании.
Наиболее существенное преимущество файлов заключается в том, что разработчики
интеграционного решения не нуждаются в дополнительных сведениях о внутренней реа-
лизации интегрируемых приложений. Основная задача интеграторов заключается в пре-
образовании форматов файлов (если это необходимо). Результатом подобного подхода
является слабое связывание интегрируемых приложений. Единственными общедоступ-
ными интерфейсами приложений являются создаваемые этими приложениями файлы.
Простота реализации передачи файла обусловливается также отсутствием необходи-
мости в привлечении дополнительных средств или пакетов для интеграции. Вместе с тем
это приводит к возрастанию нагрузки, ложащейся на плечи разработчиков интеграцион-
ного решения. Объединяемые приложения должны использовать общее соглашение об
именовании и расположении файлов. Приложение, создающее файл, должно обеспечить
уникальность его имени. Кроме того, необходимо разработать механизм удаления старых
файлов, а также механизм блокировки доступа к файлу на время его записи. Если интег-
рируемые приложения не имеют доступа к общему диску, следует также обеспечить ме-
ханизм перенесения файлов между дисками.
Один из наиболее существенных недостатков передачи файла заключается в возможно-
сти рассинхронизации интегрируемых систем вследствие низкой частоты обмена инфор-
мацией. Если заказчик изменит адрес доставки товара утром, а система обслуживания кли-
ентов распространит эту информацию ночью, то на протяжении всего дня система доставки
товаров будет иметь неверные сведения о месте назначения груза. Иногда рассинхрониза-
ция допустима. В конечном итоге люди уже привыкли к тому, что на распространение ин-
формации уходит какое-то время. Однако в некоторых случаях использование устаревшей
информации может привести к крайне нежелательным последствиям. Таким образом, при
определении частоты создания файлов следует всегда исходить из потребностей в наличии
актуальной информации считывающих эти файлы приложений.
82 Глава 2. Стили интеграции
При необходимости частоту создания файлов можно увеличить. В некотором смысле
обмен сообщениями (Messaging, с. 87) сравним с передачей файла при каждом изменении в
данных приложения. К сожалению, создание и обработка большого количества файлов
может привести к нерациональному использованию вычислительных ресурсов.
Более частый обмен данными согласованного формата обеспечивает общая база дан-
ных (Shared Database, с. 83). Для интеграции функциональности приложений используйте
удаленный вызов процедуры (Remote Procedure Invocation, с. 85). Наконец, для частого обме-
на малыми порциями данных (возможно, инициирующими вызовы удаленных функций)
применяйте обмен сообщениями.
Общая база данных (Shared Database)
83
Общая база данных (Shared Database)
Мартин Фаулер (Martin Fowler)
Информационная система компании насчитывает множество приложений, создан-
ных с использованием различных языков программирования и программных платформ.
Бизнес-логика компании предполагает быстрый и надежный обмен информацией между
отдельными системами.
Как наладить взаимодействие и обмен данными между несколькими приложениями?
Основной недостаток передачи файла (File Transfer, с. 80) заключается в несвоевре-
менном обмене данными между приложениями. Вместе с тем требование к работе с наи-
более достоверными данными является стандартным для современного делового мира.
Это не только уменьшает количество ошибок при принятии решений, но и повышает до-
верие сотрудников к информации.
Кроме того, передача файла не предъявляет требований к формату данных. Различия в
восприятии одной и той же информации могут привести к возникновению проблем ин-
теграции. К примеру, в контексте геологической базы данных термин “скважина” может
быть определен как пробуренная скважина, заполненная водой или нефтью. В то же вре-
мя в контексте базы данных, расположенной на производстве, термин “скважина” может
означать несколько пробуренных скважин, объединенных одним нефтедобывающим
оборудованием. Очевидно, что проблема семантического диссонанса гораздо серьезнее,
нежели проблема несовместимости форматов данных. (Более подробно тема семантиче-
ского диссонанса рассматривается в [21].) Чтобы избежать ее, следует хранить информа-
цию в центральной базе данных, доступной для всех интегрируемых приложений.
Интегрируемые приложения сохраняют информацию в общей базе данных
(Shared Database), схема которой удовлетворяет требованиям всех приложений.
84
Глава 2. Стили интеграции
Общая база данных обеспечивает согласованность хранящейся в ней информации.
Все попытки изменения одного и того же фрагмента данных из нескольких различных
источников будут пресекаться администратором транзакций базы данных.
Наиболее простой подход к реализации общей базы данных заключается в использова-
нии реляционной базы данных с поддержкой SQL. Язык запросов SQL поддерживается
практически всеми платформами для разработки приложений, что позволяет не беспо-
коиться о различии в форматах файлов и избавляет от необходимости изучения новой
технологии.
Наличие общей базы данных устраняет проблему семантического диссонанса. Все во-
просы, связанные с интерпретацией данных, могут быть сняты на этапах проектирования
и реализации интеграционного решения.
Одной из наибольших трудностей, присущих рассматриваемому стилю интеграции,
является разработка схемы общей базы данных. Создание унифицированной схемы дан-
ных, удовлетворяющей требованиям нескольких различных приложений, связано со
сложностями как технического, так и политического характера. Если применение уни-
фицированной схемы данных приведет к снижению производительности критически
важного приложения, руководство компании может настоять на необходимости пере-
смотра интеграционного проекта.
Еще одним камнем преткновения для реализации общей базы данных является ком-
мерческое ПО. Большинство коммерческих приложений работает только со встроенной
схемой данных, возможность адаптации которой зачастую оставляет желать лучшего. Ус-
ложняет задачу также тот факт, что создатели коммерческого ПО склонны изменять схе-
му данных с каждой новой версией своих продуктов.
С возрастанием числа обращений к общей базе данных последняя может превратиться
в узкое место интеграционного решения, что приведет к снижению производительности
приложений и увеличению вероятности блокировки данных. Если интегрируемые при-
ложения расположены в нескольких географических точках, доступ к центральной базе
данных будет осуществляться по традиционно медленным линиям связи глобальных се-
тей. Несмотря на то что распределение базы данных между приложениями позволит об-
ращаться к ней по локальной сети, это лишь усложнит ситуацию.
Интеграцию функциональности приложений (в отличие от интеграции их данных)
обеспечивает удаленный вызов процедуры (Remote Procedure Invocation, с. 85). Для частого
обмена малыми порциями данных различных типов (в отличие от использования унифи-
цированной схемы данных) применяйте обмен сообщениями (Messaging, с. 87).
Удаленный вызов процедуры (Remote Procedure Invocation)
85
Удаленный вызов процедуры (Remote Procedure Invocation)
Мартин Фаулер (Martin Fowler)
Информационная система компании насчитывает множество приложений, создан-
ных с использованием различных языков программирования и программных платформ.
Бизнес-логика компании предполагает быстрый обмен информацией и функционально-
стью между отдельными системами.
Как наладить взаимодействие и обмен данными между несколькими приложениями?
Несмотря на то что передача файла {File Transfer, с. 80) и общая база данных (Shared
Database, с. 83) позволяют наладить обмен информацией между приложениями, зачастую
этого оказывается недостаточно. К примеру, изменение адреса проживания клиента может
потребовать выполнения некоторых действий, таких как проверка допустимости адреса.
Одним из наиболее мощных механизмов структурирования приложений является ин-
капсуляция, предусматривающая доступ к данным посредством манипулирующего эти-
ми данными программного кода. Общая база данных представляет собой неинкапсулиро-
ванную структуру, в то время как передача файла отличается замедленной реакцией на
обновление данных.
Неинкапсулированный характер общей базы данных затрудняет поддержку интегриро-
ванных с ее помощью приложений. Изменения в приложении могут повлечь за собой из-
менения в базе данных, что, в свою очередь, скажется на всех оставшихся приложениях.
Как следствие организации, использующие общую базу данных, крайне неохотно относят-
ся к необходимости ее изменения, что может затруднить реализацию новых бизнес-
требований.
Выходом из сложившейся ситуации могло бы стать создание механизма, позволяю-
щего приложению вызывать функцию другого приложения и передавать ей для обработ-
ки необходимые данные.
Представьте каждое приложение в виде объекта или компонента, содержащего
инкапсулированные данные и предоставляющего интерфейс для взаимодейст-
вия с другими приложениями.
Программа А
Программа Б
86
Глава 2. Стили интеграции
По сути, удаленный вызов процедуры представляет собой применение принципов ин-
капсуляции данных к интеграции приложений. Если приложение нуждается в получении
или изменении информации, поддерживаемой другим приложением, оно обращается к
нему посредством вызова функции. Таким образом, каждое приложение самостоятельно
обеспечивает целостность своих данных и может изменять их формат, не затрагивая при
этом оставшиеся приложения.
Удаленный вызов процедуры поддерживается множеством технологий, таких как
CORBA, COM, .NET Remoting и Java RML Зачастую реализация удаленного вызова проце-
дуры предусматривает наличие дополнительных возможностей, например, поддержки
транзакций. Время написания этой книги пришлось на пик популярности Web-служб,
использующих такой стандарт удаленного взаимодействия, как SOAP.
Наличие методов, манипулирующих данными, способствует решению проблемы
семантического диссонанса. Приложение может предоставить несколько интерфейсов
к одним и тем же данным, тем самым позволяя “видеть” их под разными углами.
Несмотря на внешнюю схожесть, удаленный вызов процедуры и вызов локальной функ-
ции имеют принципиальные отличия, способные оказать существенное влияние на ин-
теграционное решение [9, 50].
Следует отметить, что удаленный вызов процедуры характеризуется достаточно сильной
степенью связывания приложений. Зачастую это обусловлено применением при разра-
ботке интеграционного решения принципов, которые применяются при разработке от-
дельного приложения, например принципа последовательного выполнения операций.
Асинхронное взаимодействие слабосвязанных приложений, подразумевающее частый
обмен малыми порциями данных (возможно, инициирующими вызовы удаленных функ-
ций), обеспечивает обмен сообщениями {Messaging, с. 87).
Обмен сообщениями (Messaging)
87
Обмен сообщениями (Messaging)
???
I I
Информационная система компании насчитывает множество приложений, создан-
ных с использованием различных языков программирования и программных платформ.
Бизнес-логика компании предполагает быстрый обмен информацией и функционально-
стью между отдельными системами.
Как наладить взаимодействие и обмен данными между несколькими приложениями?
Передача файла (File Transfer, с. 80) и общая база данных (Shared Database, с. 83) позво-
ляют приложениям получить доступ к общим данным, но не к общей функциональности.
Удаленный вызов процедуры (Remote Procedure Invocation, с. 85) устраняет этот недостаток
за счет сильного связывания интегрируемых приложений. Зачастую же задача интегра-
ции заключается в обеспечении своевременного обмена данными между слабосвязанны-
ми приложениями.
Несмотря на то что передача файла не связывает объединяемые приложения, этот
стиль интеграции не может обеспечить своевременной доставки данных. Напротив, об-
щая база данных обеспечивает быструю доставку информации за счет сильного связыва-
ния приложений.
Удаленный вызов процедуры предполагает использование модели приложения в качест-
ве основы интеграционного решения. Несмотря на внешнюю схожесть, вызов удаленной
функции и вызов локальной функции имеют существенные отличия. Вызов удален-
ной функции гораздо медленнее локального вызова и менее надежен, чем он. Сбой в ра-
боте одного приложения может привести к сбою всех приложений, полагающихся на его
функциональность.
Оптимальное решение должно обладать характеристиками передачи файла, обеспечи-
вая частый, асинхронный обмен малыми порциями данных с уведомлением получателя и
механизмом повторной передачи. В отличие от общей базы данных сведения о представле-
нии и хранении информации должны быть скрыты от интегрируемых приложений. Кро-
ме того, приложение должно иметь возможность удаленного вызова процедуры другого
приложения с гарантированным отсутствием сбоя.
Используйте обмен сообщениями (Messaging) для быстрой, мгновенной, надеж-
ной и асинхронной передачи данных изменяемого формата.
88
Глава 2. Стили интеграции
Асинхронный обмен сообщениями устраняет большинство недостатков распределен-
ных систем. Для передачи сообщения не требуется одновременной доступности отправи-
теля и получателя. Более того, сам факт асинхронного обмена данными побуждает разра-
ботчиков к созданию компонентов, не требующих частого удаленного взаимодействия.
Подобно передаче файла система обмена сообщениями обеспечивает слабое связывание
объединяемых приложений. Сообщения могут быть преобразованы во время передачи без
уведомления отправителя или получателя. Слабое связывание позволяет разработчикам
использовать различные способы доставки сообщений: широковещательную рассылку
всем получателям, маршрутизацию сообщений одному получателю или их группе и т.п.
Необходимость преобразования данных обусловлена наличием у приложений раз-
личных концептуальных моделей, т.е. семантическим диссонансом. В отличие от общей
базы данных, обмен сообщениями не предполагает использования специальных средств для
его устранения. Это связано с тем, что семантический диссонанс неизбежно возникает
при добавлении к интеграционному решению новых приложений (например, в результа-
те слияния информационных систем компаний).
Частый обмен небольшими порциями данных создает предпосылки для использова-
ния приложениями общей функциональности. Если получение сообщения о размеще-
нии нового заказа требует выполнения некоторых действий, они могут быть иницииро-
ваны путем отправки специальных сообщений. Несмотря на то что скорость подобного
взаимодействия ниже, чем при использовании удаленного вызова процедуры, вызывающей
стороне не приходится ждать ответа на отправленное сообщение. На самом деле обмен
сообщениями не такой уж и медленный— достаточно большое число систем обмена
сообщениями используются финансовыми организациями для обработки тысяч котиро-
вок акций в секунду.
Поскольку настоящая книга посвящена обмену сообщениями, можно предположить, что
ее авторы считают этот стиль интеграции приложений наиболее оптимальным. Вместе
с тем не стоит забывать, что обмен сообщениями далеко не идеален. Отметим некоторые из
присущих ему недостатков. Несмотря на то что высокая частота отправки сообщений суще-
ственно снижает вероятность рассогласования данных, присущего передаче файла, она не
позволяет полностью исключить задержку при доставке информации. Большинство разра-
ботчиков не привыкли к “асинхронному” способу мышления, результатом чего стало появ-
ление множества различных правил и приемов программирования. Кроме того, решения,
основанные на обмене сообщениями, сложнее тестировать и отлаживать.
Возможность преобразования сообщений позволяет обеспечить гораздо более слабую
связность приложений, чем этого можно было бы достичь с помощью удаленного вызова
процедуры. Вместе с тем подобная независимость означает дополнительную нагрузку на
разработчиков интеграционного решения, которым приходится создавать множество
строк связующего кода.
Следующие вопросы и ответы помогут пролить свет на подробности реализации обме-
на сообщениями.
4 Как обеспечивается передача пакетов данных?
Отправитель помещает данные, оформленные в виде сообщения (Message, с. 98),
в канал сообщений (Message Channel, с. 93), соединяющий его с получателем.
♦ Как отправитель определяет адрес получателя данных?
Обмен сообщениями (Messaging) 89
Если отправитель не знает адрес получателя данных, он пересылает сообщение мар-
шрутизатору сообщений (Message Router, с. 109), который, в свою очередь, доставляет со-
общение получателю.
♦ Как определить требуемый формат данных сообщения ?
Если отправитель и получатель используют разные форматы данных, отправитель
может передать сообщение транслятору сообщений (Message Translator, с. 115), который
преобразует формат сообщения и передаст его получателю.
♦ Как подключить приложение к системе обмена сообщениями ?
Для подключения к системе обмена сообщениями приложение должно реализовать
конечную точку сообщения (Message Endpoint, с. 124).
г-4*4 ;«*»>'►•••
nW<r" ;
э '?
r.a‘~ s :- .»*<.<
Глава 3
Системы обмена сообщениями
Введение
В главе 2 были рассмотрены различные стили интеграции приложений, включая
обмен сообщениями (Messaging, с. 87). Обмен сообщениями позволяет наладить асинхрон-
ное взаимодействие между слабо связанными приложениями. Передачу данных между
интегрированными приложениями обеспечивает система обмена сообщениями.
Основные концепции обмена сообщениями
Как и большинство технологий, обмен сообщениями (Messaging, с. 87) характеризуется
несколькими базовыми концепциями.
• Каналы. Приложения, объединенные с помощью технологии обмена сообщения-
ми, передают данные по каналам сообщений (Message Channel, с. 93). Изначально
система обмена сообщениями не содержит каналов; они создаются по мере опре-
деления способов взаимодействия приложений.
• Сообщения. Сообщение (Message, с. 98) — это наименьшая единица данных, кото-
рая может быть передана по каналу сообщений. Следовательно, для передачи дан-
ных отправитель должен разбить их на пакеты, которые затем будут упакованы в
сообщения и помещены в канал. Подобным образом получатель извлекает сооб-
щения из канала и выделяет из них полезные данные. Система обмена сообще-
ниями гарантирует доставку сообщений путем их повторной отправки.
• Каналы и фильтры. В самом простом случае система обмена сообщениями достав-
ляет сообщение непосредственно с компьютера отправителя на компьютер полу-
чателя. Однако во многих ситуациях необходима промежуточная обработка от-
правленного сообщения (например, преобразование формата или проверка соот-
ветствия некоторым правилам) прежде, чем оно будет принято получателем.
Архитектура каналов и фильтров (Pipes and Filters, с. 102) описывает процесс орга-
низации многоэтапной обработки сообщения с использованием каналов.
• Маршрутизация. Для того чтобы достичь конечной точки назначения, сообщению
может потребоваться пройти через несколько различных каналов. Иногда слож-
ность маршрута сообщения приводит к тому, что отправитель не может опреде-
92
Глава 3. Системы обмена сообщениями
лить канал, в который необходимо поместить сообщение для его доставки получа-
телю. В этом случае отправитель передает сообщение маршрутизатору сообщений
(Message Router, с. 109)— программному компоненту, играющему роль фильтра в
рамках архитектуры каналы и фильтры. Маршрутизатор определяет канал, в кото-
рый необходимо поместить сообщение для его доставки конечному получателю
или следующему маршрутизатору.
• Преобразование. Зачастую отправитель и получатель используют различные фор-
маты для представления одних и тех же данных. Для преобразования формата от-
правителя в формат получателя сообщение должно пройти через промежуточный
фильтр, получивший название транслятор сообщений (Message Translator, с. 115).
• Конечные точки. Большинство приложений не обладает встроенными средствами
интеграции. Для подключения таких приложений к системе обмена сообщениями
необходим промежуточный код, учитывающий особенности приложения и систе-
мы обмена сообщениями. Этот код является совокупностью конечных точек сооб-
щения (Message Endpoint, с. 124), позволяющих приложению отправлять и прини-
мать сообщения.
Об организации книги
Шаблоны, представленные в этой главе, позволяют получить базовое представление
об интеграции приложений с помощью обмена сообщениями (Messaging, с. 87). Более под-
робно каждый из представленных здесь корневых шаблонов рассматривается в одной из
следующих глав книги (рис. 3.1).
Рис. 3.1. Корневые шаблоны проектирования
Канал сообщений (Message Channel)
93
Канал сообщений (Message Channel)
Компании необходимо наладить взаимодействие между двумя отдельными приложе-
ниями с помощью обмена сообщениями (Messaging, с. 87).
Как наладить взаимодействие между двумя приложениями с использованием
технологии обмена сообщениями?
Наличие системы обмена сообщениями не является достаточным условием для взаи-
модействия подключенных к ней приложений. Другими словами, отправитель не может
использовать систему обмена сообщениями для передачи информации получателю. Если
бы это было так, система обмена сообщениями должна была бы обладать некими
“магическими” свойствами (рис. 3.2).
Приложение
Система обмена
сообщениями
Отправитель
Рис. 3.2. "Магическая” система обмена сообщениями
Детерминированный обмен данными между приложениями обеспечивает набор
соединений.
Соедините приложения с помощью канала сообщений (Message Channel), дос-
тавляющего помещенную в него информацию от отправителя к получателю.
Приложение, которому необходимо отправить информацию, помещает ее не просто
в систему обмена сообщениями, а в конкретный канал сообщений. Подобным образом
приложение, которому необходимо получить информацию, обращается не просто к сис-
теме обмена сообщениями, а к конкретному каналу сообщений.
Система обмена сообщениями подразумевает наличие отдельных каналов сообщений
для каждого типа передаваемой информации. Таким образом, отправитель помещает
информацию не в произвольный канал сообщений, а в канал сообщений, предназначенный
для передачи данных конкретного типа. Аналогично получатель извлекает информацию
из канала сообщений, предназначенного для передачи именно этого типа информации.
В действительности каналы представляют собой логические адреса в системе обмена
сообщениями. Реализация каналов сообщений зависит от конкретной системы обмена
сообщениями. К примеру, все конечные точки сообщения (Message Endpoint, с. 124) могут
быть соединены друг с другом или подключены к центральному коммутатору, а несколь-
ко логических каналов сообщений могут быть представлены одним физическим каналом.
94
Глава 3. Системы обмена сообщениями
Как бы там ни было, логические каналы скрывают детали конкретной реализации от
приложений.
Система обмена сообщениями не содержит заранее сконфигурированных каналов со-
общений. Требуемые каналы сообщений определяются на этапе проектирования инте-
грационного решения и реализуются администратором системы обмена сообщениями.
Несмотря на то что некоторые системы обмена сообщениями поддерживают создание
новых каналов сообщений после начала эксплуатации интеграционного решения, это не
позволяет распространить информацию о новых каналах между всеми приложениями.
Следовательно, количество и назначение каналов сообщений необходимо определить до
этапа развертывания интеграционного решения. (Об исключениях из этого правила рас-
сказывается во введении к главе 4.)
О словаре обмена сообщениями
Существует несколько различных терминов, применяющихся для обозначения при-
ложений, взаимодействующих посредством канала сообщений. Наиболее известными
из них являются термины отправитель и получатель— приложение отправляет ин-
формацию с помощью канала сообщений для ее получения другим приложением. Так-
же популярны термины поставщик и потребитель. Приложения, взаимодействующие
посредством канала “публикация-подписка” (Publish-Subscribe Channel, с. 134), известны
как публикатор и подписчик (следует отметить, что эти термины часто употребляются и
в более широком смысле). Иногда говорят, что приложение слушает канал, по кото-
рому вещает другое приложение. Наконец, существуют такие термины, как клиент и
сервер, однако они настолько устарели, что их употребление в данном контексте может
считаться дурным тоном.
Иногда употребление того или иного термина может показаться некорректным. Так,
в рамках архитектуры Web-служб приложение, отправляющее сообщение с запросом
поставщику службы, называется потребителем. К счастью, применение термина по-
требитель в данном контексте ограничивается сценариями удаленного вызова процеду-
ры (Remote Procedure Invocation, с. 85). В целом же приложение, которое отправляет или
принимает сообщения, можно назвать клиентом системы обмена сообщениями или
конечной точкой сообщения.
Зачастую разработчики интеграционного решения неверно интерпретируют задачу
создания канала сообщений. Как правило, разработчик создает код Java, вызывающий
метод JMS API createQueue, или код .NET, включающий в себя выражение new
MessageQueue, однако ни тот, ни другой не выделяет ресурсы для новой очереди в сис-
теме обмена сообщениями. В действительности подобный код создает экземпляр объек-
та, предоставляющего доступ к ресурсу, который был заранее предусмотрен администра-
тором системы обмена сообщениями.
Планируя каналы сообщений интеграционного решения, следует помнить, что каж-
дый канал отнимает определенный объем оперативной или дисковой памяти. Любая реа-
лизация системы обмена сообщениями предполагает наличие жесткого лимита поддер-
живаемых каналов сообщений. Если разрабатываемое вами интеграционное решение
требует тысяч каналов сообщений, обратите внимание на систему обмена сообщениями,
обладающую незаурядной способностью к масштабированию.
Канал сообщений (Message Channel)
95
Имена каналов сообщений
Поскольку каналы являются логическими адресами, они должны иметь некоторую
форму записи. В большинстве случаев для обращения к каналу сообщений использу-
ется буквенно-цифровое имя, такое как MyChannel. Некоторые системы обмена со-
общениями поддерживают иерархические имена каналов, например MyCorp/Prod/
OrderProcessing/NewOrders.
Все каналы сообщений делятся на два типа: каналы “точка-точка” (Point-to-Point
Channel, с. 131) и каналы “публикация-подписка” (Publish-Subscribe Channel, с. 134).
Поскольку передача разнородной информации по одному и тому же каналу может при-
вести к возникновению непредвиденных ситуаций, рекомендуется использовать не-
сколько каналов типа данных (Datatype Channel, с. 139) или реализовать функциональ-
ность избирательного потребителя (Selective Consumer, с. 528). Кроме того, для каждого
приложения рекомендуется предусмотреть канал недопустимых сообщений (Invalid Message
Channel, с. 143), в который будут помещаться сообщения, не соответствующие опреде-
ленным правилам. Приложение, не имеющее доступа к клиенту обмена сообщениями
(Messaging, с. 87), можно подключить к системе обмена сообщениями с помощью адап-
теров канала (Channel Adapter, с. 154). Набор каналов сообщений формирует шину сообще-
ний (Message Bus, с. 162) для интегрируемых приложений.
Пример: торговля на бирже
Инициатор сделки помещает сообщение с запросом в соответствующий канал сообщений.
Приложение, обрабатывающее запросы о сделках, считывает это сообщение из того же
канала. Если запрашиваемому приложению нужно узнать текущие котировки, оно
помещает сообщение с запросом в другой канал сообщений, специально предназначенный
для получения информации данного типа.
Пример: эталонная реализация службы J2EE JMS
Набор инструментальных средств разработки (SDK) J2EE поставляется с эталонными
реализациями служб J2EE, включая службу JMS. Для запуска эталонного сервера пред-
назначена команда j 2ее, а для настройки каналов сообщений—средство j 2eeadmin:
j2eeadmin -addJmsDestination jms/mytopic topic
j2eeadmin -addJmsDestination jms/myqueue queue
Как только администратор создаст каналы сообщений, к ним можно будет осуществ-
лять доступ из клиентского кода JMS:
Context jndiContext = new Initialcontext О;
Queue myQueue = (Queue) jndiContext.lookup("jms/myqueue");
Topic myTopic = (Topic) jndiContext.lookup("jms/mytopic");
Запрос к службе JNDI не создает очередь или тему, поскольку они были созданы
ранее с помощью команды j2eeadmin. Вместо этого JNDI-запрос создает экземпляр
объекта Queue, который предоставляет доступ к очереди в системе обмена сообщениями.
96
Глава 3. Системы обмена сообщениями
Пример: IBM WebSphere MQ
Следующее выражение создает точку назначения (очередь myQueue) в системе обмена
сообщениями, основанной на использовании связующего ПО IBM WebSphere MQ:
DEFINE Q(myQueue)
Поскольку WebSphere MQ (без полнофункционального сервера WebSphere Application
Server) не содержит реализации службы JND1, мы не можем использовать ее для доступа
к очереди сообщений. В этой ситуации доступ к очереди сообщений реализуется через
JMS-сеанс, как показано ниже:
Session session = // Создание сеанса.
Queue queue = session.createQueue("myQueue");
Пример: Microsoft MSMQ
Связующее ПО Microsoft MSMQ предоставляет несколько различных способов создания
канала сообщений (очереди). В частности, для создания очереди можно воспользоваться
средством Microsoft Message Queue Explorer или консолью Computer Management, как
показано на рис. 3.3.
Рис. 3.3. Консоль Computer Management позволяет создавать, настраивать и удалять очереди сообщений
Канал сообщений (Message Channel) 97
Ниже приведен пример создания очереди сообщений с помощью программного кода:
using System.Messaging;
MessageQueue.Create("MyQueue");
Для доступа к очереди сообщений приложение должно создать экземпляр объекта
MessageQueue:
MessageQueue mq = new MessageQueue("MyQueue");
98
Глава 3. Системы обмена сообщениями
Сообщение (Message)
Приложения, соединенные посредством канала сообщений (Message Channel, с. 93),
взаимодействуют с помощью технологии обмена сообщениями (Messaging, с. 87).
Как наладить обмен данными между двумя приложениями, соединенными с по-
мощью канала сообщений (Message Channel)?
Зачастую наличие канала сообщений воспринимается как достаточное условие для об-
мена данными между двумя приложениями. Однако, в отличие от непрерывного потока
информации, данные большинства приложений состоят из различных элементов, таких
как записи, объекты, строки таблицы базы данных и т.п. Следовательно, канал сообще-
ний должен обладать возможностью передачи разнородных элементов данных.
Что же представляет собой процесс “передачи” информации? К примеру, передача
параметра функции осуществляется посредством передачи указателя на адрес этого па-
раметра в памяти. Подобным образом два потока, разделяющих одну область памяти,
могут обмениваться указателями на записи или объекты.
Поскольку двум различным процессам соответствуют отдельные области памяти,
обмен информацией между процессами возможен только за счет копирования данных из
одной области памяти в другую. Обычно для передачи данных используется поток бай-
тов. Это означает, что первый процесс должен упорядочить данные в поток байтов и с
копировать его во второй процесс. В свою очередь, второй процесс разупорядочить дан-
ные в их исходное состояние. Механизм упорядочивания используется технологией уда-
ленного вызова процедуры (Remote Procedure Call— RPC) для передачи параметров
удаленному процессу и возврата результата.
Таким образом, технология обмена сообщениями подразумевает передачу дискрет-
ных элементов данных путем их упорядочения отправителем и разупорядочения получате-
лем. Чтобы обеспечить возможность передачи разнородной информации, необходимо
предусмотреть общий формат данных, передаваемых по каналу сообщений.
Для передачи информации между двумя приложениями используйте формат
сообщения (Message)— наименьшей единицы данных, которая может быть пе-
редана системой обмена сообщениями по каналу сообщений (Message Channel,
с. 93).
Отправитель
Сообщение
Получатель
Сообщение (Message)
99
Следовательно, для передачи по каналам системы обмена сообщениями данные
должны быть преобразованы в одно или несколько сообщений.
Сообщение состоит из двух основных частей.
1. Заголовок сообщения. Информация, которая используется системой обмена
сообщениями для описания передаваемых данных, включая адрес отправителя,
адрес получателя и т.п.
2. Тело сообщения. Данные, передаваемые внутри сообщения и, как правило, игно-
рируемые системой обмена сообщениями.
Представленная выше концепция отнюдь не нова. Передача информации в виде дис-
кретных сообщений применяется как традиционной почтовой службой, так и системой
электронной почты. В сетях Ethernet данные передаются в виде кадров, а в Интернете—
в виде пакетов TCP/IP.
С точки зрения системы обмена сообщениями все сообщения одинаковы: тело каж-
дого из них содержит данные, которые нужно передать в соответствии с информацией,
размещающейся в заголовке. Однако, с точки зрения разработчика интеграционного
решения, существуют разные типы сообщений, которые отличаются способом их ис-
пользования. Так, для удаленного вызова процедуры применяется сообщение с командой
(Command Message, с. 169), для передачи информации— сообщение с данными документа
(Document Message, с. 171), а для уведомления получателя сообщения об изменении
состояния отправителя— сообщение о событии (Event Message, с. 174). Если удаленное
приложение должно ответить на полученное сообщение, используйте модель запрос-
ответ (Request-Reply, с. 177).
Если приложению необходимо передать информацию, размер которой превышает
максимально допустимый размер сообщения, разбейте ее на меньшие части и отправьте в
виде цепочки сообщений (Message Sequence, с. 192). Если передаваемая информация акту-
альна только в течение ограниченного промежутка времени, отметьте эту особенность,
указав срок действия сообщения (Message Expiration, с. 198). Поскольку все отправители и
получатели сообщений должны использовать один и тот же формат данных, задайте его
с помощью канонической модели данных (Canonical Data Model, с. 367).
Пример: сообщение JMS
Сообщение JMS представлено типом Message, имеющим несколько различных под-
типов.
1. TextMessage. Наиболее распространенный тип сообщения. Тело сообщения
представлено строкой (тип string), такой как простой текст или XML-документ.
Для работы с телом сообщения используйте метод textMessage. getText ().
2. BytesMessage. Универсальный тип сообщения. Тело сообщения представлено
байтовым массивом. Для копирования тела сообщения в указанный массив
используйте метод bytesMessage. readBytes (byteArray).
3. Obj ectMessage. Тело сообщения представлено объектом Java, реализующим
интерфейс java.io.Serializable. Для работы с телом сообщения (тип
Serializable) используйте метод objectMes sage, getobj ect О .
100
Глава 3. Системы обмена сообщениями
4. streamMessage. Тело сообщения представлено потоком данных одного из при-
митивных типов Java. Для работы с телом сообщения используйте методы
readBoolean(), readchar(), readDouble() и т.п.
5. MapMessage. Тело сообщения представлено картой типа java.util .Map со
строковыми (string) ключами. Для работы с телом сообщения используйте
методы getBoolean("isEnabled"), getlnt("numberOfItems") и т.п.
Пример: сообщение .NET
Сообщение .NET представлено типом Message. Доступ к телу сообщения осуществляет-
ся посредством свойства Body (тип Ob j ect), а также свойства ByteStream (тип Stream).
Тип данных, хранящихся в теле сообщения (строка, дата, валюта, число и др.), определя-
ется свойством BodyType.
Пример: сообщение SOAP
Сообщение протокола SOAP версии 1.1 представлено XML-конвертом (корневой эле-
мент SOAP-ENV:Envelope), содержащим необязательный заголовок (элемент SOAP-
ENV:Header) и обязательное тело (элемент soap-ENV: Body). Поскольку этот
XML-документ является наименьшей единицей передачи данных (как правило, для пе-
редачи SOAP-сообщений используется протокол HTTP), он является ни чем иным, как
сообщением (Message).
Ниже приведен типичный пример SOAP-сообщения, содержащего заголовок и тело.
<SOAP-ENV:Envelope
xmlns:SOAP-ENV="http://schemas.xmlsoap.org/soap/envelope/"
SOAP-ENV:encodingStyle="http://schemas.xmlsoap.org/soap/encoding/"/>
<SOAP-ENV:Header >
<t:Transaction
xmlns:t="some-URI"
SOAP-ENV:mustUnderstand="1">
5
</t: Transaction
</SOAP-ENV:Header >
<SOAP-ENV:Body>
<m:GetLastTradePrice xmlns:m="Some-URI">
< symbol>DEF</symbol>
</m:GetLastTradePrice>
</SOAP-ENV:Body>
</SOAP-ENV:Envelope>
SOAP позволяет продемонстрировать рекурсивную природу сообщений. Действитель-
но, поскольку SOAP-сообщение может быть передано с помощью системы обмена сообще-
ниями, это означает, что сообщение системы обмена сообщениями (например, объект JMS
типа javax. jms .Message или объект .NET System.Messaging.Message) будет содер-
жать в себе SOAP-сообщение (данные XML-документа soap-ENV:Envelope). В этом слу-
чае транспортным протоколом SOAP-сообщения будет являться не HTTP, а внутренний
Сообщение (Message) 101
протокол передачи данных системы обмена сообщениями (в свою очередь, внутренний
протокол системы обмена сообщениями может быть основан на использовании протокола
HTTP с дополнительными средствами обеспечения надежной доставки данных). Передаче
сообщения между различными системами обмена сообщениями посвящен шаблон проек-
тирования оболочка конверта (Envelope Wrapper, с. 342).
102
Глава 3. Системы обмена сообщениями
Каналы и фильтры (Pipes and Filters)
Во многих интеграционных сценариях единственное событие может инициировать
целую серию этапов обработки. Предположим, что сообщение о размещении нового за-
каза должно передаваться в зашифрованном виде и нести в себе аутентификационную
информацию в форме цифрового сертификата. Кроме того, необходимо предусмотреть
защиту от дублирования сообщений. Учитывая вышеперечисленные требования, задача
первичной обработки сообщений о размещении нового заказа сводится к преобразова-
нию последовательности зашифрованных сообщений, включающих аутентификацион-
ную информацию, с повторами в последовательность простых текстовых сообщений,
не содержащих избыточных полей данных, без повторов.
Как организовать сложную обработку сообщения, руководствуясь принципами
независимости и гибкости конечного решения?
Одно из возможных решений заключается в создании модуля обработки входящих
сообщений, выполняющего все необходимые преобразования. Однако подобный подход
не удовлетворяет требованию гибкости и усложняет тестирование. К примеру, нам может
понадобиться добавить или удалить определенный этап обработки для сообщений о за-
казах, размещенных крупными клиентами.
Реализация всех функций в одном компоненте снижает возможность его повторного
использования. Напротив, создание небольших, узкоспециализированных компонентов
существенно повышает гибкость решения. Например, обработка сообшений о проверке
состояния заказа требует их расшифровки, однако не требует реализации зашиты от дуб-
лирования. Следовательно, вынесение функции расшифровки в отдельный модуль по-
зволит применять его для обработки сообшений различных типов.
Как правило, интеграционные решения используются для объединения нескольких
гетерогенных систем. Это может привести к тому, что различные этапы обработки сооб-
щения будут выполняться на разных физических устройствах. К примеру, закрытый
ключ, который необходим для расшифровки входящих сообщений, по соображениям
безопасности может быть доступен только для определенного компьютера. Подобным
образом различные этапы обработки сообщения могут быть реализованы с помощью
разных языков программирования или технологий, что будет являться препятствием для
их совместного выполнения в рамках одного процесса.
Реализация каждой функции в виде отдельного компонента еще не гарантирует их неза-
висимость (к примеру, компонент расшифровки может использовать функциональность
компонента аутентификации). Чтобы устранить связи между компонентами, этапы слож-
ной обработки сообщения следует расположить в такой последовательности, которая бы
исключала зависимость одного компонента от другого. Кроме того, все компоненты долж-
ны иметь универсальный внешний интерфейс, допускающий их взаимозаменяемость.
Взаимодействие между компонентами рекомендуется реализовать с помощью асин-
хронного обмена сообщениями. В этом случае компонент сможет отправить сообщение
другому компоненту, не дожидаясь от него ответа. Использование асинхронного обмена
сообщениями позволит организовать одновременную обработку нескольких сообщений,
по одному на каждый компонент.
Каналы и фильтры (Pipes and Filters)
103
Используйте архитектуру каналов и фильтров (Pipes and Filters) для разделения
сложной вычислительной задачи на последовательность простых, независимых
этапов (фильтров), объединенных с помощью каналов.
Канал
Расшифровка
Входящий
заказ
Канал
Канал
Фильтр
Аутентификация
Защита от
дублирования
Канал
Заказ
в формате
простого
текста
Фильтр
Фильтр
Каждый фильтр имеет очень простой интерфейс: он получает сообщение по входя-
щему каналу, обрабатывает его и публикует полученный результат в исходящем канале.
Канал соединяет два фильтра и используется для передачи сообщений. Поскольку все
компоненты обладают одинаковыми внешними интерфейсами, их можно комбиниро-
вать путем подключения к различным каналам. Можно добавлять новые фильтры, уда-
лять или переупорядочивать существующие— и все это без необходимости внесения из-
менений в сами фильтры. Соединение между фильтром и каналом часто называют пор-
том. Простой фильтр имеет один входящий и один исходящий порт.
Решение рассматриваемой нами задачи первичной обработки сообщений о размеще-
нии нового заказа с помощью архитектуры каналов и фильтров предполагает применение
трех фильтров и двух соединяющих эти фильтры каналов. Кроме того, нам понадобится
один дополнительный канал для передачи исходного сообщения компоненту расшиф-
ровки и один канал для передачи обработанного (текстового) сообщения системе управ-
ления заказами.
Архитектура каналов и фильтров является фундаментальной для систем обмена сооб-
щениями: отдельные этапы обработки (фильтры) соединяются посредством каналов со-
общений. На этой архитектуре основано множество шаблонов проектирования, рассмат-
ривающихся в книге (например, шаблоны маршрутизации и преобразования). К тому же
архитектура каналов и фильтров описывает универсальный способ объединения отдель-
ных шаблонов проектирования в более сложные решения.
Канал в архитектуре каналы и фильтры— это абстрактная сущность, соединяющая
компоненты и одновременно отделяющая их друг от друга. Канал позволяет компоненту
отправить сообщение для его последующего получения другим (неизвестным для отпра-
вителя) компонентом. Очевидно, что канал в архитектуре каналы и фильтры может быть
представлен каналом сообщений (Message Channel, с. 93). Благодаря независимости канала
сообщений от языка программирования, а также аппаратной или программной платфор-
мы этапы обработки (фильтры) могут быть распределены между различными компьюте-
рами по соображениям безопасности, производительности, поддержки и др. Если же все
компоненты удается разместить на одном компьютере, следует подумать о более эффек-
тивной реализации каналов, такой как очередь в памяти. Таким образом, при проектиро-
вании компонентов рекомендуется воздерживаться от конкретной реализации интерфей-
са канала. Более подробно этот подход описывается шаблоном проектирования шлюз об-
мена сообщениями (Messaging Gateway, с. 482).
104
Глава 3. Системы обмена сообщениями
Один из недостатков архитектуры каналов и фильтров заключается в использовании
большого числа каналов. Следует помнить, что реализация канала предполагает расходо-
вание ресурсов памяти и процессора. К тому же публикация сообщения в канале требует
преобразования данных из внутреннего формата отправителя в формат инфраструктуры
обмена сообщениями (при получении сообщения выполняется обратная процедура). Та-
ким образом, наличие длинной цепочки фильтров может привести к существенному
снижению производительности вследствие многократного преобразования формата дан-
ных сообщения.
В чистом виде архитектура каналов и фильтров предполагает наличие у каждого
фильтра одного входящего и одного исходящего порта. Специфика обмена сообщениями
(Messaging, с. 87) требует пересмотра этого условия. В частности, компонент может из-
влекать сообщения из более чем одного канала и помещать сообщения в более чем один
канал (примером подобного компонента является маршрутизатор сообщений (Message
Router, с. 109)). Кроме того, несколько фильтров могут считывать сообщения из одного
и того же канала сообщений. Если же сообщение предназначено единственному получате-
лю, для его передачи применяется канал “точка-точка” (Point-to-Point Channel, с. 131).
Применение архитектуры каналов и фильтров позволяет тестировать отдельные компо-
ненты с помощью тестового сообщения (Test Message, с. 577). Тестирование и отладка базо-
вых функций решения гораздо эффективнее, нежели тестирование всего решения целиком.
К примеру, для тестирования функций шифрования и расшифровки данных следует сгене-
рировать большое количество сообщений с произвольным содержимым, передать их для
последовательной обработки компонентам шифрования и расшифровки, а затем сравнить
полученный результат с исходными сообщениями. Подобным образом для тестирования
функции аутентификации следует сгенерировать сообщения с заранее известными кодами
аутентификации и передать их на обработку соответствующему компоненту.
Конвейерная обработка
Объединение компонентов с помощью асинхронных каналов сообщений (Message
Channel, с. 93) позволяет каждому из них выполняться в собственном потоке или процес-
се. Это означает, что, завершив обработку сообщения и поместив его в исходящий канал,
компонент может приступить к обработке нового сообщения, не дожидаясь подтвержде-
ния о получении сообщения следующим компонентом в цепочке. Подобный подход по-
зволяет обрабатывать несколько сообщений одновременно, как показано на рис. 3.4. По
сравнению с последовательной обработкой сообщений конвейерная обработка существенно
повышает пропускную способность системы.
Параллельная обработка
Пропускная способность системы ограничена пропускной способностью ее самого мед-
ленного процесса. Увеличение пропускной способности процесса возможно за счет созда-
ния его нескольких параллельно выполняющихся экземпляров. Гарантия получения сооб-
щения ровно одним из N доступных обработчиков обеспечивается сочетанием канала
“точка-точка” (Point-to-Point Channel, с. 131) и конкурирующих потребителей (Competing
Consumers, с. 515). Следует отметить, что подобный способ увеличения производительности
системы может привести к нарушению порядка обработки сообщений. Если порядок со-
общений имеет значение, нужно ограничиться только одним экземпляром каждого компо-
нента или воспользоваться преобразователем порядка (Resequencer, с. 297).
Каналы и фильтры (Pipes and Filters)
105
Сообщение 1
Сообщение 2
Сообщение 3
Последова-
тельная
обработка
Расшиф-
ровка
Аутенти-
фикация
Защита от
дублиро-
вания
Расшиф- Аутенти- Защита от
ровка фикация дублиро-
DSi-lua
Расшиф-
ровка
Аутенти- Защита от
фикация дублиро-
вания
Врамя
Конвейерная
обработка
Расшиф-
ровка
Аутенти-
фикация
Расшиф-
ровка
Защита от
дублиро-
вания
Сообщение 1
Аутенти-
фикация
Защита от
дублиро-
вания^
Сообщение 2
Расшиф- Аутенти- Защита от
ровка фикация дублиро-
Сообщение 3
Врамя
Рис. 3.4. Конвейерная обработка сообщений с помощью архитектуры каналов и фильтров (Pipes and Filters)
Предположим, что на расшифровку сообщения уходит гораздо больше времени, чем
на его аутентификацию. Чтобы ускорить обработку сообщения, создадим два дополни-
тельных экземпляра компонента расшифровки, как показано на рис. 3.5.
заказ
Рис. 3.5. Повышение пропускной способности системы за счет параллельной обработки сообщений
Заказ
в формате
простого
текста
Использование параллельно выполняющихся экземпляров фильтра наиболее эффек-
тивно, если фильтр не сохраняет свое состояние, т.е. возвращается к исходному состоя-
нию после обработки сообщения. Примером фильтра, сохраняющего состояние, являет-
ся компонент, реализующий защиту от дублирования сообшений.
История архитектуры каналов и фильтров
Простота и эффективность каналов и фильтров (Pipes and Filters) завоевала этой архи-
тектуре огромную популярность, а несложная семантика позволила описать ее формаль-
ными методами.
106
Глава 3. Системы обмена сообщениями
В 1974 году Кан определил вычислительную сеть Кана как набор параллельных про-
цессов, объединенных неограниченными каналами FIFO (First-In, First-Out— первым
прибыл, первым обслужен) [19]. В [11] есть глава, в которой описываются различные ар-
хитектурные стили, включая каналы и фильтры. Монро дает подробное толкование взаи-
моотношения между архитектурными стилями и шаблонами проектирования в [26].
Статья Режин Менье “The Pipes and Filters Architecture” (“Архитектура каналов и фильт-
ров”), опубликованная в [31], послужила основой для шаблона проектирования каналы и
фильтры (Pipes and Filters), включенного в [33]. Практически все реализации каналов
и фильтров соответствуют представленной в [33] схеме “Scenario IV” (“Сценарий IV”),
которая подразумевает наличие активных фильтров, независимо друг от друга считы-
вающих, обрабатывающих и помещающих элементы в каналы. Шаблон, описанный в
[33], предполагает, что каждый элемент проходит одинаковые этапы обработки при пе-
редаче от фильтра к фильтру. Это условие неизбежно нарушается, когда речь заходит о
сценариях интеграции. В большинстве случаев маршрут сообщения определяется дина-
мически на основе содержимого сообщения или административным путем. В действи-
тельности маршрутизация сообщений является настолько обыденной практикой в ин-
теграции корпоративных приложений, что для ее описания предусмотрен отдельный
шаблон проектирования маршрутизатор сообщений (Message Router, с. 109).
Словарь
Обсуждая архитектуру каналов и фильтров (Pipes and Filters), следует обратить внима-
ние на корректность употребления термина фильтр. Позднее нами будут рассмотрены
такие шаблоны проектирования, как фильтр сообщений (Message Filter, с. 253) и фильтр
содержимого (Content Filter, с. 354). Следует отметить, что это далеко не единственные
фильтры среди представленных в данной книге шаблонов. Дело в том, что фильтр в
терминах архитектуры фильтров и каналов совсем не обязательно должен реализовы-
вать функцию отбора (полей или сообщений). Чтобы избежать недоразумения, мы
могли бы переименовать архитектуру каналов и фильтров, что, однако же, способно
привести к еще большей путанице. Употребляя термин фильтр, мы постараемся делать
это так, чтобы читателю было понятно, о чем идет речь— о фильтре архитектуры ка-
налов и фильтров или о шаблонах проектирования фильтр сообщений/фильтр содержи-
мого. Если контекст, в котором будет упоминаться термин фильтр, не позволит сделать
однозначного вывода, для обозначения фильтра архитектуры каналов и фильтров будет
применяться термин компонент.
Архитектура каналов и фильтров имеет сходство с концепцией CSP (Communicating
Sequential Processes—взаимодействие последовательных процессов), впервые представ-
ленной Хоаром в 1978 году [6]. Хоар предлагает использовать простую модель для описа-
ния проблем синхронизации в системах параллельной обработки. Механизм, лежащий
в основе CSP, применяется для синхронизации двух процессов посредством системы
ввода-вывода. Взаимодействие между процессами осуществляется при условии готовно-
сти процесса А к передаче информации процессу Б, а процесса Б— к принятию инфор-
мации от процесса А. Если это условие выполняется только наполовину, один из процес-
сов ставится в очередь ожидания готовности другого процесса. В отличие от интеграци-
онных решений концепция CSP предполагает более сильное связывание процессов и
Каналы и фильтры (Pipes and Fitters)
107
отсутствие поддержки очередей “каналов”. Тем не менее знакомство с ней очень полезно
при изучении архитектуры каналов и фильтров.
Пример: простой фильтр MSMQ (С#)
Ниже приведен код базового класса фильтра с одним входящим и одним исходящим пор-
том. Функциональность класса Processor предельно проста: вывести тело полученного
сообщения на консоль и отправить его через исходящий порт. Для реализации более
полезной функциональности (например, преобразования формата содержимого сообще-
ния или его перенаправления в другой порт) следует создать подкласс класса Processor,
переопределяющий метод ProcessMessage.
Обратите внимание, что экземпляр класса Processor получает ссылки на входящий
и исходящий каналы на этапе своего создания. Таким образом, класс Processor не при-
вязан к каким-либо конкретным каналам или фильтрам, что позволяет создавать
несколько экземпляров фильтров и объединять их в произвольном порядке.
using System;
using System.Messaging;
namespace PipesAndFiIters
{
public class Processor
{
protected MessageQueue inputQueue;
protected MessageQueue outputQueue;
public Processor (MessageQueue inputQueue,
MessageQueue outputQueue)
{
this.inputQueue = inputQueue;
this.outputQueue = outputQueue;
}
public void Process ()
{
inputQueue.ReceiveCompleted += new
ReceiveCompletedEventHandler(OnReceiveCompleted);
inputQueue.BeginReceive();
}
private void OnReceiveCompleted(Object source,
ReceiveCompletedEventArgs asyncResult)
{
MessageQueue mq = (MessageQueue)source;
Message inputMessage =
mq.EndReceive(asyncResult.AsyncResult);
inputMessage.Formatter = new XmlMessageFormatter
(new String[] {"System.String,mscorlib"});
Message outputMessage = ProcessMessage(inputMessage);
outputQueue.Send(outputMessage);
108
Глава 3. Системы обмена сообщениями
mq.BeginReceive();
}
protected virtual Message ProcessMessage(Message m)
Console.WriteLine("Received Message: " + m.Body);
return (m);
Фильтр Processor является примером реализации событийно управляемого потребите-
ля {Event-Driven Consumer, с. 511). Метод Process регистрируется для получения входящих
сообщений и уведомляет систему обмена сообщениями о необходимости вызова метода
OnReceiveCompleted при получении каждого сообщения. Метод OnReceiveCompleted
извлекает данные из объекта события и вызывает виртуальный метод ProcessMessage.
Представленный выше фильтр не является транзакционным. Если во время обработ-
ки сообщения (до его помещения в исходящий канал) произойдет ошибка, сообщение
будет потеряно. Решение данной проблемы описывается шаблоном проектирования
транзакционный клиент {Transactional Client, с. 498).
Маршрутизатор сообщений (Message Router)
109
Маршрутизатор сообщений (Message Router)
Несколько этапов обработки в цепочке каналов и фильтров (Pipes and Filters, с. 102)
соединены с помощью каналов сообщений (Message Channel, с. 93).
Как реализовать возможность передачи сообщения различным фильтрам в зави-
симости от набора условий?
Архитектура каналов и фильтров предусматривает непосредственное соединение
фильтров друг с другом с помощью фиксированных каналов. Подобный подход вполне
оправдан, поскольку в большинстве случаев шаблон каналы и фильтры применяется для
обработки больших наборов однотипных данных [33]. К примеру, при компиляции про-
граммного кода каждая его строка проходит три последовательных этапа обработки: лек-
сический анализ, синтаксический анализ и семантический анализ. Сообщения, приме-
няющиеся в интеграционных решениях, как правило, не связаны с каким-либо набором
данных. В результате каждое сообщение может потребовать свою цепочку вычислений.
Канал сообщений позволяет провести четкую границу между отправителем и получате-
лем сообщения (Message, с. 98). В частности, из этого следует, что несколько приложений
могут публиковать сообщения в одном и том же канале сообщений. В результате канал со-
общений может содержать сообщения, способ обработки которых будет зависеть от их ти-
па, источника или какого-либо другого критерия. Несмотря на то что для передачи со-
общения каждого типа можно задействовать отдельный канал сообщений (более подробно
эта концепция описывается шаблоном проектирования канал типа данных (Datatype
Channel, с. 139)), это приведет к необходимости классификации сообщений отправите-
лями, а также к существенному росту числа каналов сообщений. К тому же способ обра-
ботки сообщения не всегда зависит от его источника. Представим ситуацию, в которой
получатель сообщения определяется динамически на основе общего числа сообщений,
переданных по конкретному каналу. Поскольку это число не может знать ни один из от-
правителей, он не сможет выбрать корректный канал для размещения сообщения.
Канал сообщений обеспечивает простую форму маршрутизации сообщений. Публикуя
сообщение в канале сообщений, приложение теряет контроль за его доставкой. Отныне
маршрут сообщения зависит от компонента, находящегося на другом конце канала сооб-
щений. К сожалению, этот тип “маршрутизации” не учитывает свойства самого сообще-
ния и напоминает использование символа “ | ” для обработки текстовых файлов в систе-
мах UNIX. Подобно каналу сообщений символ “ | ” позволяет создать цепочку каналов и
фильтров, однако на время ее существования все строки текстового файла будут прохо-
дить одни и те же этапы обработки.
Решение о необходимости обработки сообщения, поступившего по общему каналу со-
общений, можно возложить на получателя. Однако как только сообщение будет извлечено
из канала, оно перестанет быть доступным для проверки другим компонентам. Некото-
рые системы обмена сообщениями позволяют просмотреть свойства сообщения без его
извлечения из канала. Тем не менее это решение не является универсальным и к тому же
“привязывает” компонент к определенному типу сообщения. Встраивание логики выбо-
110
Глава 3. Системы обмена сообщениями
ра сообщения в компонент затрудняет его повторное использование и сводит на нет ос-
новное преимущество модели каналов и фильтров— возможность переупорядочивания
компонентов.
Большинство альтернативных подходов предполагает внесение изменений в компо-
ненты. Однако компоненты интеграционных решений— это, как правило, крупные
приложения, модифицировать которые зачастую не представляется возможным. Следо-
вательно, изменение отправителей или получателей сообщений для удовлетворения тре-
бований системы обмена сообщениями не только экономически невыгодно, но и в
большинстве случаев попросту невозможно.
Как уже упоминалось, одним из преимуществ архитектуры каналов и фильтров явля-
ется возможность переупорядочивания компонентов. В частности, это позволяет добав-
лять дополнительные этапы (например, этап, реализующий логику маршрутизации)
в цепочку фильтров, не затрагивая существующие компоненты.
Добавьте специальный фильтр—маршрутизатор сообщений (Message Router),—
который будет извлекать сообщение (Message, с. 98) из одного канала сообщений
(Message Channel, с. 93) и размещать его в другом канале сообщений на основе
заданного условия.
Маршрутизатор сообщений не соответствует базовому определению архитектуры
каналов и фильтров в том смысле, что он имеет несколько исходящих каналов (т.е. более
одного исходящего порта). Вместе с тем особенность этой архитектуры позволяет скрыть
существование маршрутизатора сообщений от соседних с ним компонентов— как и пре-
жде, они извлекают сообщения из входящего канала, обрабатывают их и помещают
в исходящий канал. Ключевое свойство маршрутизатора сообщений состоит в том, что он
не изменяет содержимого сообщения, заботясь только о его корректной доставке.
Использование маршрутизатора сообщений позволяет сосредоточить всю логику при-
нятия решения о доставке сообщения в одном компоненте. Отныне определение новых
типов сообщений, добавление новых этапов обработки или изменение правил маршрути-
зации затронет только один компонент, а именно маршрутизатор сообщений. Кроме того,
прохождение всех входящих сообщений через маршрутизатор сообщений делает возмож-
ной их обработку в корректном порядке.
К сожалению, маршрутизатору сообщений свойственны определенные недостатки.
В частности, он должен обладать информацией обо всех доступных каналах сообщений.
Если эти сведения часто меняются, маршрутизатор сообщений может превратиться в
“узкое место” интеграционного решения. В этом случае рекомендуется переложить от-
Маршрутизатор сообщений (Message Router)
111
ветственность за выбор сообщения на получателя, воспользовавшись каналом
“публикация-подписка” (Publish-Subscribe Channel, с. 134) и набором фильтров сообщений
(Message Filter, с. 253). Метод, подразумевающий использование маршрутизатора сообще-
ний, получил название предиктивная маршрутизация, а метод, возлагающий ответствен-
ность за выбор сообщения на получателя, — реактивная фильтрация (более подробно
сравнение двух подходов приводится в описании шаблона фильтр сообщений в главе 7).
Поскольку использование маршрутизатора сообщений подразумевает добавление но-
вого этапа обработки, это приводит к снижению производительности интеграционного
решения. Чтобы минимизировать негативный эффект предиктивной маршрутизации,
можно запустить несколько параллельных процессов маршрутизатора сообщений или ус-
тановить дополнительное оборудование. Это позволит сохранить пропускную способ-
ность системы (количество сообщений, обработанных за единицу времени) на прежнем
уровне, однако практически неизбежно увеличит ее задержку (время, требующееся для
передачи одного сообщения).
Применение маршрутизаторов сообщений способно превратить преимущество слабо-
связанной системы в ее недостаток. Зачастую слабая связь между компонентами реше-
ния мешает отслеживанию потоков сообщений. Использование маршрутизаторов сооб-
щений только усугубляет положение. Невозможность определения потока сообщений за-
трудняет тестирование, отладку и поддержку интеграционного решения. Для устранения
этой проблемы можно воспользоваться журналом доставки сообщения (Message History,
с. 561), в который заносится информация о компонентах, через которые прошло сооб-
щение. Альтернативный подход заключается в составлении списка всех каналов, к кото-
рым подключены компоненты системы, что позволит создать граф допустимых потоков
сообщений интеграционного решения. Многие средства интеграции корпоративных
приложений (EAI) хранят подобную информацию в центральном репозитории, делая ее
легко доступной для анализа.
Типы маршрутизаторов сообщений
Маршрутизатор сообщений (Message Router) может использовать несколько различных
критериев при определении исходящего канала для отправки сообщения. Наиболее три-
виальный пример маршрутизатора сообщений— это так называемый фиксированный
маршрутизатор. Фиксированный маршрутизатор имеет один входящий и один исходя-
щий канал. Функциональность фиксированного маршрутизатора предельно проста—
извлечь сообщение из входящего канала и поместить его в исходящий канал. Зачем же
нужен такой примитивный маршрутизатор? Во-первых, фиксированный маршрутизатор
может использоваться как временное решение до реализации более интеллектуальной
логики маршрутизации. Во-вторых, фиксированный маршрутизатор может применяться
для перенаправления сообщений между несколькими интеграционными решениями. За-
частую вместе с фиксированным маршрутизатором используются транслятор сообщений
(Message Translator, с. 115) и адаптер канала (Channel Adapter, с. 154).
Многие маршрутизаторы сообщений принимают решение о точке назначения сооб-
щения на основании его свойств, например типа сообщения или значения определенных
полей. Подобные маршрутизаторы получили название маршрутизаторы на основе содер-
жимого (Content-Based Router, с. 247). Более подробно маршрутизатор на основе содержи-
мого описывается соответствующим шаблоном проектирования.
112
Глава 3. Системы обмена сообщениями
Оставшиеся маршрутизаторы сообщений принимают решение о точке назначения со-
общения на основании условий среды. Подобные маршрутизаторы получили название
маршрутизаторы на основе контекста. Как правило, маршрутизаторы на основе контекста
применяются для балансировки нагрузки, тестирования или обеспечения восстановления
при отказе. К примеру, если компонент выйдет из строя, маршрутизатор на основе контек-
ста сможет перенаправить сообщения на обработку другим компонентом с аналогичной
функциональностью. Некоторые маршрутизаторы на основе контекста разделяют поток
сообщений между несколькими каналами для достижения эффекта балансировки нагрузки.
Следует отметить, что возможность балансировки нагрузки можно реализовать и без ис-
пользования маршрутизатора сообщений. В частности, примером балансировки нагрузки
является извлечение сообщений несколькими конкурирующими потребителями (Competing
Consumers, с. 515) из одного и того же канала сообщений (Message Channel, с. 93) для парал-
лельной обработки. Несмотря на это применение маршрутизатора сообщений позволит реа-
лизовать более интеллектуальную логику маршрутизации по сравнению с простой логикой
алгоритма кругового обслуживания, реализуемой каналом сообщений.
Многие маршрутизаторы сообщений являются маршрутизаторами без поддержки со-
стояния. Другими словами, принятие решения о передаче сообщения принимается без
учета ранее переданных сообщений. Маршрутизаторы, которые учитывают обработан-
ные ранее сообщения при принятии решения о точке назначения текущего сообщения,
называются маршрутизаторами с поддержкой состояния. Примером маршрутизатора с
поддержкой состояния является компонент, реализующий защиту от дублирования со-
общений из рассмотренного ранее примера использования архитектуры каналов и фильт-
ров (Pipes and Filters, с. 102).
В большинстве случаев логика маршрутизации жестко закодирована в маршрутиза-
торе сообщений. Тем не менее некоторые маршрутизаторы могут принимать решение о
перенаправлении сообщения на основе информации, полученной по шине управления
(Control Bus, с. 552). Этот подход позволяет изменять критерий маршрутизации, не внося
изменений в маршрутизатор и не затрагивая текущий поток сообщений. К примеру, шина
управления может передать значение некоторой глобальной переменной всем маршрути-
заторам сообщений в системе для перевода последней из тестового режима функциониро-
вания в рабочий. Динамический маршрутизатор (Dynamic Router, с. 259) обладает способ-
ностью к изменению логики маршрутизации на основании управляющих сообщений,
полученных от конечных точек системы.
Более подробно различные типы маршрутизаторов сообщений рассматриваются
в главе 7.
Пример: коммерческие средства EAI
Концепция маршрутизатора сообщений (Message Router) является основой для брокера сооб-
щений (Message Broker, с. 334)—средства, реализованного практически во всех EAI-пакетах.
Брокер сообщений принимает входящие сообщения, тестирует их на предмет наличия оши-
бок, преобразовывает и помещает в требуемый исходящий канал. Подобная архитектура
позволяет максимально изолировать приложения друг от друга, что чрезвычайно важно для
их интеграции. Брокер сообщений реализует всю логику, требующуюся для маршрутизации
сообщений между приложениями, и, по сути, является “интеграционным” аналогом
посредника (Mediator) [12].
Маршрутизатор сообщений (Message Router)
113
Пример: простой маршрутизатор MSMQ (С#)
Следующий код демонстрирует пример реализации простого маршрутизатора, перенаправ-
ляющего все входящие сообщения в один из двух каналов на основе заданного условия,
class SimpleRouter
{
protected MessageQueue inQueue;
protected MessageQueue outQueuel;
protected MessageQueue outQueue2;
public SimpleRouter(MessageQueue inQueue,
MessageQueue outQueuel, MessageQueue outQueue2)
{
this.inQueue = inQueue;
this.outQueuel = outQueuel;
this.outQueue2 = outQueue2;
inQueue.ReceiveCompleted += new
ReceiveCompletedEventHandler(OnMessage);
inQueue.BeginReceive ();
}
private void OnMessage(Object source,
ReceiveCompletedEventArgs asyncResult)
{
MessageQueue mq = (MessageQueue)source;
Message message = mq.EndReceive(asyncResult.AsyncResult);
if (IsConditionFulfilledO)
outQueuel.Send(message);
else
outQueue2.Send(message);
mq.BeginReceive();
}
protected bool toggle = false;
protected bool IsConditionFulfilled ()
{
toggle = !toggle;
return toggle;
Подобно простому фильтру, представленному при описании архитектуры каналов и
фильтров (Pipes and Filters, с. 102), класс SimpleRouter реализует событийно управляемый
потребитель (Event-Driven Consumer, с. 511) сообщений с использованием делегатов. Кон-
структор регистрирует метод OnMessage в качестве обработчика сообщений, поступаю-
щих по каналу inQueue. Среда .NET будет вызывать метод OnMessage для обработки
каждого сообщения, извлеченного из канала inQueue. Метод OnMessage определяет
маршрут сообщения с помощью метода IsConditionFulf illed. В рассмотренном вы-
ше примере метод IsConditionFulf illed реализует простую логику маршрутизации,
114 Глава 3. Системы обмена сообщениями
поочередно помещая сообщения в каналы outQueuel и outQueue2. Маршрутизатор
simp 1 eRouter не является транзакционным. Если во время обработки сообщения (до
его помещения в исходящий канал) произойдет ошибка, сообщение будет потеряно.
Решение данной проблемы описывается шаблоном проектирования транзакционный
клиент (TransactionalClient, с. 498).
Транслятор сообщений (Message Translator)
115
Транслятор сообщений (Message Translator)
Ранее мы рассмотрели шаблоны, касающиеся создания сообщений и их доставки
получателю. Большинство интеграционных решений объединяет разнородные приложе-
ния— унаследованные, коммерческие и созданные на заказ. Как правило, каждое из
этих приложений использует собственную модель данных. К примеру, система бухгал-
терского учета может оперировать такими данными о заказчике, как номер налогопла-
тельщика, а система управления взаимоотношениями с клиентами (CRM) — телефон-
ным номером и адресом проживания. Зачастую модель данных приложения является ос-
новой для схемы базы данных, формата файлов и интерфейса API—точек “соприкосно-
вения” приложения с интеграционным решением.
Вдобавок к внутренним моделям данных приложений интеграционное решение
должно поддерживать стандартные форматы данных, применяющиеся для взаимодейст-
вия с внешними приложениями. Стандартные протоколы и форматы данных создаются
различными консорциумами и комитетами по стандартизации, такими как RosettaNet,
ebXML, OAGIS и др. В большинстве случаев “официальные” форматы данных исполь-
зуются для взаимодействия интеграционного решения с приложениями бизнес -
партнеров и внешних организаций.
Как организовать обмен сообщениями между приложениями, использующими
различные форматы данных?
Если бы все интегрируемые приложения использовали одинаковые форматы данных,
задача преобразования сообшений решилась бы сама собой. К сожалению, это очень
сложно реализовать по целому ряду причин (см. шаблон проектирования общая база дан-
ных (Shared Database, с. 83)). Во-первых, изменение внутреннего формата данных требует
внесения большого объема изменений в бизнес-логику приложения, что экономически
нецелесообразно для большинства унаследованных приложений (вспомним попытку из-
менения единственного поля в рамках “проблемы 2000”).
Во-вторых, использование одинаковых имен полей и, возможно, типов данных может
сочетаться с различным представлением информации, к примеру XML-документ и файл
данных COBOL.
В-третьих, приведение формата данных одного приложения к формату данных дру-
гого приложения приводит к их сильному связыванию. Как известно, одним из ключе-
вых принципов проектирования интеграционных решений является слабая связь между
объединяемыми приложениями (см. шаблон проектирования каноническая модель данных
(Canonical Data Model, с. 367)). Идентичность форматов данных приложений нарушает
этот принцип. Отныне замена приложения или внесение в него изменений (сценарий,
присущий интеграционным решениям) будет иметь существенные последствия для ос-
тальных приложений.
Функция преобразования формата данных может быть встроена в конечную точку со-
общения (Message Endpoint, с. 124). В результате все приложения будут отправлять и при-
нимать сообщения общего формата данных. Однако этот подход предполагает наличие
116
Глава 3. Системы обмена сообщениями
доступа к исходному коду конечной точки, что возможно далеко не всегда. К тому же
встраивание кода преобразования в конечную точку снижает возможность его повтор-
ного использования.
Используйте для преобразования формата данных специальный фильтр—
транслятор сообщений (Message Translator},— расположив его между другими
фильтрами или приложениями.
Входящее
сообщение
Сообщение после
преобразования
Транслятор сообщений (Message Translator}— эквивалент шаблона проектирования
адаптер (Adapter), описанного в [12]. Адаптер преобразует интерфейс компонента в дру-
гой интерфейс, который может быть использован в отличном контексте.
Уровни преобразования
Преобразование сообщений может осуществляться на нескольких различных уров-
нях. К примеру, элементы данных приложений могут иметь одни и те же имя и тип, од-
нако отличаться представлением (ХМ L-документ, файл с разделителями-запятыми и
т.д.). С другой стороны, элементы данных могут иметь одинаковые форматы (например,
XML), однако отличаться именами. Обобщим различные типы преобразования сообще-
ний, разделив их на несколько уровней (табл. 3.1).
Таблица 3.1. Уровни преобразования сообщений
Уровень Объект преобразования Пример Средства/методы
Структуры данных (приложения) Типа данных Сущность, ассоциация, кардинальность Имя поля, тип данных, область определения значения, ограничение, значение кода Приведение отношения “множество-множество” к агрегации Преобразование почтового индекса из числа в строку; объединение полей First Name и Last Name в поле Name; замена названия штата США двузначным кодом Шаблоны структурного преобразования, заказной код Визуальные редакторы преобразования EAI, XSL, обращение к базе данных, заказной код
Транслятор сообщений (Message Translator)
117
Окончание табл. 3.1
Уровень Объект преобразования Пример Средства/методы
Представления данных Формат данных (XML, пары “имя-значение”, поля данных фиксированной длины, форматы EAI-вендоров и др.), набор символов (ASCII, Unicode, EBCDIC), шифрование/сжатие Анализ представления данных с последующим преобразованием в другой формат; шифрование/расшифровка данных Анализаторы XML, анализаторы/генераторы EAI, заказные API
Транспортный Коммуникационные протоколы: сокеты TCP/IP, HTTP, SOAP, JMS, TIBCO Rendezvous Передача данных с использованием одного из коммуникационных протоколов без изменения содержимого сообщения Адаптер канала (Channel Adapter, с. 154), адаптеры ЕА1
Транспортный уровень обеспечивает передачу данных между различными системами.
На этом уровне осуществляется надежный обмен данными между сетевыми сегментами,
включающий исправление ошибок. Некоторые EAl-вендоры разрабатывают собствен-
ные транспортные протоколы (например, TIBCO Rendezvous), в то время как остальные
технологии интеграции основываются на использовании протоколов TCP/IP (например,
SOAP). Преобразование сообщений между различными транспортными уровням можно
реализовать с помощью адаптера канала (Channel Adapter, с. 154).
Уровень представления данных часто называют уровнем синтаксиса. Как следует из его
названия, этот уровень определяет представление передаваемых данных. Поскольку на
транспортном уровне осуществляется передача потока символов или байтов, сложные
структуры данных должны быть преобразованы в строку с помощью одного из распро-
страненных форматов—XML, полей фиксированной длины (например, записей EDI) и
др. Во многих случаях данные сжимаются и (или) шифруются, в результате чего к ним
добавляется дополнительная информация, такая как контрольная сумма или цифровой
сертификат. Объединение систем, использующих различные представления данных, за-
частую предполагает расшифровку, распаковку и анализ данных с последующим созда-
нием нового представления, сжатием и шифрованием (при необходимости).
Уровень типа данных определяет типы данных, на которых основана модель прило-
жения. На этом уровне принимаются такие решения, как способ представления полей
даты (строка или специальная структура), формат почтового индекса и т.п. Большинство
подобных решений фиксируется в так называемом словаре данных. Иногда вопросы, ка-
сающиеся типов данных, выходят за пределы выбора между строковым и числовым пред-
ставлениями значения. Предположим, что информация о продажах товаров сгруппиро-
вана по регионам. Приложение, установленное в отделе продаж, разделяет страну на че-
тыре региона—Запад, Центр, Юг и Восток,—для представления которых используются
буквы “3”, “Ц”, “Ю” и “В” соответственно. В то же время приложение, установленное в
отделе маркетинга, выделяет три дополнительных региона— Тихоокеанский, Северо-
Восточный и Юго-Восточный,— используя для представления регионов двузначные
числа. Какое число следует поставить в соответствие букве “В”?
118
Глава 3. Системы обмена сообщениями
Уровень структуры данных описывает данные с точки зрения модели домена прило-
жения (именно поэтому его вторым названием является уровень приложения). Этот уро-
вень определяет логические сущности, которыми оперирует приложение (например,
“заказчик”, “адрес” или “счет”), а также взаимоотношения между ними (может ли один
заказчик иметь несколько счетов (адресов), могут ли несколько заказчиков иметь одина-
ковые адреса (счета), частью какой сущности (счета или заказчика) является адрес и т.д.).
Зачастую на уровне структуры данных используются диаграммы сущностей и связей,
а также классовые диаграммы.
Уровни связывания
Многие компромиссные решения, принимаемые при интеграции приложений, свя-
заны с необходимостью уменьшения зависимости между объединяемыми системами.
Слабое связывание интегрированных приложений создает основу для эффективного
управления изменениями. Благодаря каналам сообщений (Message Channel, с. 93) прило-
жения могут не знать расположение друг друга. Маршрутизатор сообщений (Message
Router, с. 109) избавляет приложения от необходимости иметь общий канал сообщений.
Несмотря на это приложения могут все еще сильно зависеть друг от друга по причине
связанности внутренних форматов данных. Именно этот уровень связывания и призван
устранить транслятор сообщений (Message Translator, с. 115).
Цепочечные преобразования
Многие сценарии бизнес-интеграции предполагают преобразование данных на не-
скольких различных уровнях. Предположим, что запись заказа покупок EDI 850, пред-
ставленную файлом с фиксированным форматом, следует преобразовать в XML-
документ и отправить по протоколу HTTP в систему управления заказами, использую-
щую отличное определение объекта Order. Необходимые при этом преобразования охва-
тывают все четыре уровня: преобразование способа транспортировки данных с передачи
файла на передачу по протоколу HTTP; преобразование представления данных с файла
фиксированного формата в документ XML; а также преобразование типа и структуры
данных в соответствии с определением объекта Order системы управления заказами.
Преимущество рассмотренной ранее модели многоуровневого преобразования состоит
в независимости каждого уровня от остальных уровней, как показано на рис. 3.6.
Программа А
Уровень структуры данных I
”УровёньттаданныТ”-~
Уровень представления данных
Программа Б
Транспортный уровень
Рис. 3.6. Взаимоотношения между уровнями преобразования
Транслятор сообщений (Message Translator)
119
На рис. 3.7 показан результат объединения нескольких трансляторов сообщений
(Message Translator) с помощью архитектуры каналов и фильтров (Pipes and Filters, с. 102).
Создание одного транслятора сообщений для каждого уровня преобразования позво-
ляет использовать этот компонент в других сценариях интеграции. К примеру, адаптер
канала (Channel Adapter, с. 154) и транслятор сообщений EDI-B-XML представляют собой
универсальное сочетание компонентов, которое можно применять при обработке любых
входящих документов EDL
Адаптер канала
EDI-B-XML
850-в-Сообщение о
размещении заказа
Система управления
заказами
Сообщение о
размещении
заказа
Рис. 3.7. Соединение в цепочку нескольких трансляторов сообщений (Message Translator)
Объединение нескольких трансляторов сообщений в цепочку позволяет при необхо-
димости вносить изменения в ее звенья без затрагивания оставшихся компонентов.
К примеру, замена функции преобразования в файл фиксированного формата функцией
преобразования в файл с разделителями-запятыми сводится к замене компонента на со-
ответствующем уровне преобразования.
Существует несколько различных разновидностей трансляторов сообщений. Оболочка
конверта (Envelope Wrapper, с. 342) предусматривает помещение данных сообщения в
“конверт” для последующей передачи через систему обмена сообщениями. Расширитель
содержимого (Content Enricher, с. 348) добавляет информацию в сообщение, а фильтр со-
держимого (Content Filter, с. 354) удаляет ее. Шаблон проектирования квитанция (Claim
Check, с. 358) предполагает удаление информации для ее последующего извлечения. Нор-
мализатор (Normalizer, с. 364) преобразует несколько различных форматов сообщений в
общий формат. Наконец, каноническая модель данных (Canonical Data Model, с. 367) де-
монстрирует пример совместного использования нескольких трансляторов сообщений
для устранения различий между внутренними форматами данных объединяемых прило-
жений. Каждый из перечисленных шаблонов проектирования реализует сложные струк-
турные преобразования, такие как отображение взаимоотношения “множество-
множество” на взаимоотношение “один-к-одному”.
Пример: структурные преобразования XSL
Консорциум W3C определил стандартный язык преобразования XML-документов—
Extensible Stylesheet Language (расширяемый язык стилей, XSL). Частью XSL является
основанный на правилах язык XSL Transformation (преобразование XSL, XSLT), исполь-
зующийся для преобразования формата документа XML. Рассмотрим конкретный при-
мер, демонстрирующий использование языков XSL и XSLT (более подробно язык XSLT
описывается в [40, 49]).
120
Глава 3. Системы обмена сообщениями
Рассмотрим задачу передачи входящего XML-документа в систему бухгалтерского
учета. При отсутствии отличий на уровне представления данных (XML) остается устра-
нить рассогласование имен полей, типов данных и их структуры. Исходный XML-
документ показан ниже.
<data>
<customer>
<firstname>Joe</firstname>
<lastname >Doe</lastname>
<address type="primary">
<ref id="55355"/>
</address>
<address type="secondary">
<ref id="77889"/>
</address>
</customer>
<address id="55355">
<street>123 Main</street>
<city>San Francisco</city>
<state>CA</state>
<postalcode>94123</postalcode>
<country>USA</country>
<phone type="cell">
<area>415</area>
<prefix>555</prefix>
<number>1234</number>
</phone>
<phone type="home">
<area>415</area>
<prefix>555</prefix>
cnumber>5678</number>
</phone>
</address>
<address id="77889">
<company>ThoughtWorks</company>
<street>410 Townsend</street>
<city>San Francisco</city>
<state>CA</state>
<postalcode>94107</postalcode>
<country>USA</country>
</address>
</data>
XML-документ содержит сведения о заказчике. Каждый заказчик может иметь не-
сколько адресов, каждый из которых, в свою очередь, может содержать несколько теле-
фонных номеров. Поскольку адреса представлены как независимые сущности, несколь-
ко заказчиков могут иметь один адрес.
Транслятор сообщений (Message Translator)
121
Предположим, что система бухгалтерского учета ожидает получить XML-документ
следующего вида (использование немецкого языка в именах тэгов не является чем-то
сверхъестественным в области интеграции корпоративных приложений).
<Kunde>
<Name>Joe Doe</Name>
<Adresse>
<Strasse>123 Main</Strasse>
<Ort>San Francisco</Ort>
<Telefon>415-555-1234</Telefon>
</Adresse>
</Kunde>
Приведенный выше XML-документ имеет более простую структуру, чем исходный.
Кроме отличий в именах тэгов, некоторые поля исходного документа объединяются в
единственное поле в целевом документе. Поскольку результирующая структура не позво-
ляет заказчику иметь несколько адресов или телефонных номеров, необходимо выбрать
соответствующие данные из исходного документа на основании существующих бизнес-
правил. Следующая XSLT-программа выполняет преобразование формата исходного
ХМ L-документа в требуемый формат.
<xsl:stylesheet version="l.О"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="xml" indent="yes"/>
<xsl:key name="addrlookup" match="/data/address" use="@id"/>
<xsl:template match="data">
<xsl:apply-templates select="customer"/>
</xsl:template>
<xsl:template match="customer">
<Kunde>
<Name>
<xsl:value-of select="concat(firstname, 1
lastname)"/>
</Name>
<Adresse>
<xsl:variable name="id"
select="./address[@type='primary']/ref/@id"/>
<xsl:call-template name="getaddr">
<xsl:with-param name="addr"
select="key('addrlookup', $id)"/>
</xsl: call-template;-
</Adresse>
</Kunde>
</xsl:template>
<xsl:template name="getaddr">
<xsl:param name="addr"/>
<Strasse>
<xsl:value-of select="$addr/street"/>
</Strasse>
<Ort>
<xsl:value-of select="$addr/city"/>
</Ort>
<Telefon>
122
Глава 3. Системы обмена сообщениями
<xsl:choose>
<xsl:when test="$addr/phone[@type='cell' ] ">
<xsl:apply-templates
select="$addr/phone[@type=1 cell1]"
mode="getphone"/>
</xsl:when>
<xsl:otherwise>
<xsl:apply-templates
select="$addr/phone[@type='home']"
mode="getphone" / >
</xsl:otherwise>
</xsl:choose>
</Telefon>
</xsl:template>
<xsl:template match="phone" mode="getphone">
<xsl:value-of select="concat(area,
prefix, number)"/>
</xsl:template>
<xsl:template match="*"/>
</xsl:stylesheet>
Приведенный выше код XSL основан на сопоставлении фрагментов текста. Коротко
говоря, инструкции внутри элемента <xsl: template> выполняются всякий раз, когда в
XML-документе встречается фрагмент, определенный атрибутом match. К примеру,
строка
<xsl:template match="customer">
указывает на необходимость выполнения последующих инструкций при обнаружении в
исходном XML-документе тэга <customer>. В данном случае это приводит к формиро-
ванию элемента <Name>, состоящего из имени и фамилии заказчика, а также элемента
<Adresse>. Для извлечения из исходного XML-документа корректного адреса и теле-
фонного номера код XSL вызывает процедуру getaddr. По умолчанию процедура
getaddr извлекает номер мобильного телефона, а если он не определен— номер до-
машнего телефона.
Пример: визуальные средства преобразования
Большинство разработчиков средств интеграции включают в состав своих продуктов ви-
зуальный редактор преобразований, отображающий на экране структуру исходного и це-
левого форматов документа. Пользователю предоставляется возможность ассоциировать
требуемые элементы путем их соединения линиями. Подобный подход к выполнению
преобразований гораздо проще, нежели код XSL. Некоторые вендоры, такие как Contivo,
специализируются исключительно на создании средств преобразования.
На рис. 3.8 показано окно редактора преобразования Microsoft BizTalk Mapper, интег-
рированного в Visual Studio.
Транслятор сообщений (Message Translator)
123
Рис. 3.8. Создание преобразования с помощью перетаскивания
Безусловно, преобразование элементов гораздо удобнее наблюдать на диаграмме, чем
в коде XSL. С другой стороны, детали реализации (например, логика выбора телефон-
ного номера) скрыты за так называемыми функциональными пиктограммами.
Возможность создания преобразования путем перетаскивания существенно упрощает
разработку транслятора сообщений (Message Translator). Тем не менее как только речь за-
ходит об отладке кода или создании сложного интеграционного решения, визуальное
представление преобразования становится скорее недостатком, чем достоинством.
Именно поэтому многие визуальные средства преобразования позволяют переключаться
между визуальным представлением и кодом XSL.
124
Глава 3. Системы обмена сообщениями
Конечная точка сообщения (Message Endpoint)
Приложения обмениваются сообщениями (Message, с. 98) по каналам сообщении
(Message Channel, с. 93).
Как подключить приложение к каналу системы обмена сообщениями?
Приложение и система обмена сообщениями представляют собой две отдельные
программные сущности. Приложение обеспечивает функциональность для пользовате-
лей, в то время как система обмена сообщениями управляет каналами, применяющими-
ся для передачи сообщений. Даже будучи встроенной в приложение, система обмена со-
общениями предоставляет обособленные, специализированные функции подобно СУБД
или Web-серверу. В связи с этим возникает задача подключения приложения к системе
обмена сообщениями (рис. 3.9).
Отправитель
Сообщение Канал
Получатель
Рис. 3.9. Приложения не подключены к системе обмена сообщениями
Система обмена сообщениями представляет собой определенный тип сервера, при-
нимающего запросы и отвечающего на них. Подобно базе данных система обмена сооб-
щениями принимает и доставляет сообщения. Таким образом, система обмена сообще-
ниями является сервером сообщений.
Клиентом сервера сообщений является приложение, взаимодействующее с другими
приложениями с помощью обмена сообщениями. Подобно серверу баз данных сервер
сообщений предоставляет клиентский API, с помощью которого приложение может
взаимодействовать с сервером. Поскольку клиентский API сервера сообщений отражает
специфику конкретной системы обмена сообщениями, приложение должно включать в
себя код подключения к системе обмена сообщениями.
Подключите приложение к каналу обмена сообщениями с помощью конечной точки
сообщения (Message Endpoint)— клиента системы обмена сообщениями, позво-
ляющего приложению отправлять и принимать сообщения (Message, с. 98).
Отправитель
Получатель
Конечная точка сообщения (Message Endpoint)
125
Код конечной точки сообщения (Message Endpoint) создается с учетом особенностей
конкретного приложения и клиентского API системы обмена сообщениями. Оставшаяся
часть приложения не обладает сведениями о формате сообщений, каналах и других под-
робностях взаимодействия посредством обмена сообщениями. Конечная точка сообще-
ния принимает от приложения команду или данные, формирует из них сообщение и от-
правляет его в требуемый канал сообщений. Кроме того, конечная точка получает сооб-
щение от системы обмена сообщениями и передает его содержимое приложению
в понятном для него формате.
Конечная точка сообщения инкапсулирует систему обмена сообщениями от приложе-
ния. Таким образом, внесение изменений в приложение или в клиентский API системы
обмена сообщениями приведет к необходимости правки кода только конечной точки
сообщения.
Конечная точка сообщения может использоваться для отправки или получения сооб-
щений, однако она не может совмещать в себе обе функции. Кроме того, конечная точка
сообщения создается для обслуживания конкретного канала сообщений. Таким образом,
для взаимодействия по нескольким каналам сообщений приложение должно располагать
соответствующим числом конечных точек сообщения. Приложение может использовать
несколько конечных точек сообщения и при обслуживании одного канала, как правило,
для под держки нескольких параллельных потоков сообщений.
Конечная точка сообщения является частным случаем адаптера канала (Channel
Adapter, с. 154), интегрированного в приложение и созданного для его подключения
к конкретной системе обмена сообщениями.
Конечная точка сообщения должна проектироваться как шлюз обмена сообщениями
(Messaging Gateway, с. 482), что позволит скрыть систему обмена сообщениями от прило-
жения. Она может включать в себя преобразователь обмена сообщениями (Messaging
Mapper, с. 491) для передачи данных между объектами домена и сообщениями. Конечная
точка сообщения может быть структурирована как активатор службы (Service Activator,
с. 545), обеспечивая асинхронный доступ к синхронной службе или вызову функции.
Наконец, она может выступать в роли транзакционного клиента (Transactional Client,
с. 498) по отношению к системе обмена сообщениями.
Различные типы конечных точек реализуют разные подходы к получению сообщений.
Получатель сообшений может быть как опрашивающим потребителем (Polling Consumer,
с. 507), так и событийно управляемым потребителем (Event-Driven Consumer, с. 511).
Несколько потребителей могут извлекать сообщения из одного и того же канала с помо-
щью диспетчера сообщений (Message Dispatcher, с. 521) или в соответствии с моделью кон-
курирующих потребителей (Competing Consumers, с. 515). Для реализации логики фильтра
сообщений получатель может применить шаблон избирательного потребителя (Selective
Consumer, с. 528). С помощью шаблона постоянный подписчик (Durable Subscriber, с. 535)
получатель гарантированно не пропустит ни одного сообщения, а с помощью шаблона
идемпотентный получатель (Idempotent Receiver, с. 541) обеспечит защиту от дублирова-
ния сообщений.
126
Глава 3. Системы обмена сообщениями
Пример: классы Messageproducer и Messageconsumer (JMS)
Два основных типа конечных точек сообщений в JMS представлены классами
MessageProducer (используется для отправки сообщений) и Messageconsumer
(используется для получения сообщений). Конечная точка сообщения (Message Endpoint)
использует экземпляр одного из этих классов для отправки или получения сообщений по
соответствующему каналу.
Пример: класс MessageQueue (.NET)
В .NET конечная точка сообщения (Message Endpoint) и канал сообщений (Message Channel,
с. 93) представлены одним и тем же классом—MessageQueue. Конечная точка сообще-
ния использует экземпляр класса MessageQueue для отправки или получения сообще-
ний по соответствующему каналу.
Глава 4
Каналы обмена сообщениями
Введение
В предыдущей главе рассматривался канал сообщений (Message Channel, с. 93). Когда
двум приложениям необходимо обменяться данными, они размещают их в канале, свя-
зывающем эти приложения. Приложение, отправляющее данные, может и не знать, ка-
кое приложение их получит. Но это и не требуется — выбор конкретного канала для от-
правки данных гарантирует, что приложение, потребляющее данные указанного типа на
другом конце канала, и есть требуемый получатель. Благодаря этому приложения, кото-
рые поставляют общие данные, получают возможность взаимодействовать с приложе-
ниями, которые хотят эти данные потреблять.
Основные вопросы, связанные с применением каналов обмена сообщениями
Вопрос использования канала сообщений (Message Channel, с. 93) решается сам собой;
если приложение желает передать или получить данные, ему так или иначе придется ис-
пользовать канал. Проблема состоит в другом: какие каналы нужны приложению и для
чего оно их будет использовать?
• Фиксированный набор каналов. Прежде всего отметим, что набор каналов сообще-
ний, доступных приложению, носит постоянный характер. Разработчик приложе-
ния должен знать, где следует размещать данные того или иного типа, чтобы поде-
литься ими с другими приложениями, и наоборот, где искать данные конкретного
типа, поступившие от других приложений. Указанные маршруты взаимодействия
не могут создаваться динамически и обнаруживаться приложением во время вы-
полнения; они должны быть согласованы еще во время разработки, чтобы прило-
жение знало, откуда поступают данные и куда они уходят. Как всегда, из любого
правила есть исключения: в некоторых ситуациях более практичными оказывают-
ся именно динамические каналы. В качестве одного из таких исключений можно
привести канал ответа в шаблоне запрос-ответ (Request-Reply, с. 177). Отправитель
запроса может создать или получить в свое распоряжение новый канал, неизвест-
ный ответчику, и задать его координаты в виде обратного адреса (Return Address,
с. 182) сообщения с запросом. После этого получатель запроса сможет воспользо-
ваться указанным каналом д ля отправки ответа на запрос. Еще одним исключени-
128
Глава 4. Каналы обмена сообщениями
ем являются реализации систем обмена сообщениями, поддерживающих работу с
иерархическими каналами. Если получатель подпишется на родительский канал, а
отправитель опубликует свое сообщение в новом дочернем канале, неизвестном
получателю, сообщение все равно дойдет до получателя. Впрочем, такие ситуации
действительно встречаются редко. В большинстве случаев каналы задаются еще до
развертывания приложений, а те, в свою очередь, разрабатываются с учетом зара-
нее известного набора каналов.
• Определение набора каналов. Предыдущий вопрос неразрывно связан с вопросом
“Кто решает, какие каналы сообщений будут доступны приложению: система обме-
на сообщениями или само приложение?”. Другими словами, должна ли система
обмена сообщениями определить несколько каналов и в дальнейшем требовать,
чтобы приложения использовали именно их? Или же приложения определяют, ка-
кие каналы им нужны, после чего требуют, чтобы система обмена сообщениями
предоставила им указанные каналы? Простого ответа на этот вопрос не существу-
ет; определение необходимого набора каналов — итеративный процесс. Вначале
приложения решают, какие каналы должны быть предоставлены системой обмена
сообщениями. Остальные приложения пытаются организовать обмен данными с
помощью набора существующих каналов, но, если взаимодействие оказывается
неэффективным, они требуют добавления еще нескольких каналов. Если группа
приложений уже использует устоявшийся набор каналов, то те приложения, кото-
рые присоединяются к обмену данными, тоже будут работать с указанным набо-
ром каналов. В свою очередь, при добавлении к существующим приложениям
новой функциональности могут потребоваться новые каналы.
• Однонаправленные каналы. Довольно много путаницы вызывает вопрос о типе кана-
ла сообщений: он однонаправленный или двунаправленный? С технической точки
зрения — ни тот, ни другой; канал сообщений больше похож на емкость, в которую
одни приложения помещают данные, а другие их извлекают. (Емкость эта, правда,
неким согласованным способом распределена между многими компьютерами.) Но
поскольку данные находятся в сообщениях, которые “путешествуют” от одного при-
ложения к другому, канал становится направленным, причем однонаправленным. Ес-
ли бы канал был двунаправленным, это бы значило, что приложение отправляет и
получает сообщения из одного и того же канала. С технической точки зрения такое
решение возможно, но с практической вряд ли имеет смысл, ведь приложение будет
потреблять собственные сообщения, которые предполагалось отправлять другим
приложениям. По этой причине каналы сообщений делаются однонаправленными.
Как следствие этого для пары приложений, обменивающихся данными в обоих на-
правлениях, понадобится два канала сообщений: по одному на каждое направление.
(См. также шаблон запрос-ответ в следующей главе.)
Решения
Итак, вы поняли, что такое каналы сообщений (Message Channel, с. 93). Теперь давайте
рассмотрим, какой шаблон канала следует выбирать в той или иной ситуации
• “Один-к-одному” или “один-ко-многим”. Если приложение размещает в канале
свои данные, должны ли они быть доступны только одному получателю или же
ими могут воспользоваться любые приложения, для которых эти данные представ-
Введение
129
ляют интерес? Чтобы отправить данные только одному приложению, воспользуй-
тесь каналом “точка-точка” (Point-to-Point Channel, с. 131). Последний не гаранти-
рует, что все данные, размещенные в канале, обязательно попадут к одному и тому
же получателю, потому что у канала может быть много получателей. Тем не менее
каждое отдельное сообщение будет получено одним и только одним приложением.
Если же вы хотите, чтобы данными, размещенными в канале, смогли воспользо-
ваться любые получатели, выберите канал “публикация-подписка” (Publish-Sub-
scribe Channel, с. 134). В этом случае отправленное сообщение будет скопировано
для каждого из получателей.
Тип данных. Любые данные, хранящиеся в памяти компьютера, должны соответст-
вовать какому-то типу: стандартному формату либо структуре с заранее согласо-
ванным значением. В противном случае данные будут представлять собой не более
чем набор нулей и единиц; превратить их в что-либо осмысленное не удастся.
Подобным образом функционируют и системы обмена сообщениями. Содержи-
мое сообщения должно соответствовать определенному типу, чтобы получатель
смог понять структуру его данных. В основе канала типа данных (Datatype Channel,
с. 139) лежит идея о том, что все сообщения в канале должны быть одного и того
же типа. Вот основная причина того, почему системе обмена сообщениями требу-
ется много каналов. Если бы данные могли иметь любой тип, для взаимодействия
двух любых приложений системе обмена сообщениями понадобилось бы только
по одному каналу (в каждом направлении).
Неверные и недоставленные сообщения. Система обмена сообщениями обеспечи-
вает корректную доставку последних, но не гарантирует, что получатель сможет
обработать сообщение. Получатель ожидает, что принятые им данные будут иметь
определенный тип и значение. Но что если полученное сообщение не соответству-
ет его ожиданиям? Все, что можно сделать со странными сообщениями, — это
поместить их в специальный канал недопустимых сообщений (Invalid Message
Channel, с. 143) в надежде, что какая-нибудь служебная программа, которая осуще-
ствляет мониторинг канала, “выловит” сообщение и поймет, что с ним делать.
Во многих системах обмена сообщениями присутствует похожее встроенное сред-
ство, а именно — канал недоставленных сообщений (Dead Letter Channel, с. 147).
Туда помещаются сообщения, которые были успешно отправлены, но по какой-
либо причине не могут быть успешно доставлены. Опять-таки, за каналом должна
наблюдать некоторая служебная программа, которая будет решать, что делать
с недоставленными сообщениями.
Защита от сбоев. Если система обмена сообщениями даст сбой или будет закрыта на
обслуживание, что произойдет с сообщениями? Останутся ли сообщения в канале,
когда система вновь вернется к работе? По умолчанию нет; содержимое каналов
хранится в оперативной памяти. Тем не менее шаблон гарантированная доставка
(Guaranteed Delivery, с. 149) делает каналы постоянными, обеспечивая сохранность
сообщений на диске. Это снижает производительность, зато повышает надежность
обмена сообщениями, даже если сама инфраструктура то и дело отказывает.
Клиенты, не предназначенные для обмена сообщениями. Что если приложение не
может подключиться к системе обмена сообщениями, но все равно стремится уча-
ствовать в этом процессе? В обычных условиях это бы не удалось, но если система
130
Глава 4. Каналы обмена сообщениями
обмена сообщениями может хоть как-то подключиться к приложению — через его
пользовательский интерфейс, интерфейсы API его бизнес-служб, его базу данных
либо сетевое соединение наподобие TCP/IP или HTTP, — тогда для связи прило-
жения с системой обмена сообщениями можно воспользоваться адаптером канала
(Channel Adapter, с. 154). Благодаря этому приложение можно будет подсоединить к
каналу или набору каналов без необходимости вносить изменения в приложение
(а также, вероятно, без необходимости размещать клиент обмена сообщениями на
том же компьютере, что и само приложение). Иногда клиент, якобы “не предна-
значенный для обмена сообщениями”, в действительности оказывается клиентом
обмена сообщениями, только другой системы. В этом случае приложение, являю-
щееся клиентом обеих систем обмена сообщениями, может объединить их в одну,
связав их при помощи моста обмена сообщениями (Messaging Bridge, с. 159).
» Vfc MSpt 'ТОГО Ш
нии подключаются к системе обмена сообщениями и делают свою функциональ-
ность доступной для других приложений через отправку и получение сообщений,
система обмена сообщениями становится центральной точкой выбора и использо-
вания общей функциональности корпоративной системы. Новому приложению
требуется лишь знать, какие каналы нужно использовать для запроса функцио-
нальности, а какие прослушивать в ожидании ответа. Система обмена сообще-
ниями, по сути, превращается в шину сообщений (Message Bus, с. 162), магистраль,
предоставляющую доступ к абсолютно всем (пусть даже неоднородным и посто-
янно меняющимся) приложениям и функциональности корпоративной системы.
Ориентируясь на такое предназначение системы обмена сообщениями с самого
начала ее разработки, можно быстрее и легче достичь интеграционной “нирваны”.
Как видите, настройка корпоративных приложений для обмена сообщениями
(Messaging, с. 87) требует большего, чем просто их подключения к системе обмена сооб-
щениями. Сообщения должны передаваться по каналам сообщений, но “нашлепать”
несколько каналов на скорую руку тоже недостаточно. Каналы должны разрабатываться
специально для передачи данных определенного типа, с учетом типов приложений,
отправляющих и получающих данные. В настоящей главе мы рассмотрим шаблоны про-
ектирования, применяющиеся для решения этой проблемы.
Чтобы лучше проиллюстрировать действие шаблонов, описание каждого из них
снабжено примером создания вымышленной системы биржевой торговли через Интер-
нет. Хотя ни один из этих примеров не должен применяться как основа для разработки
реальной системы торговли на бирже, они хорошо служат в качестве наглядного пособия
по использованию шаблонов.
Канал “точка-точка” (Point-to-Point Channel)
131
Канал “точка-точка” (Point-to-Point Channel)
Приложение использует обмен сообщениями (Messaging, с. 87) для удаленного вызова
процедур или передачи документов.
Может ли приложение, отправившее документ или вызвавшее процедуру, гаранти-
ровать, что документ или вызов будет получен только одним приложением?
Одно из преимуществ удаленного вызова процедуры (Remote Procedure Call — RPC)
заключается в том, что он выполняется в рамках одного удаленного процесса, т.е. получа-
тель вызова либо выполнит процедуру, либо не выполнит ее (и будет сгенерировано исклю-
чение). А поскольку получатель вызывается только один раз, процедура тоже будет выпол-
нена единожды. Но если вызов процедуры будет упакован в сообщение (Message, с. 98)
и размещен в канале сообщений (Message Channel, с. 93), несколько получателей могут уви-
деть сообщение и решить, что вызов процедуры предназначается именно для них.
Система обмена сообщениями могла бы следить за тем, чтобы канал прослушивался
только одним получателем, но это несправедливо ограничит возможности приложений,
которые хотели бы отправить данные нескольким получателям. Получатели, наблюдаю-
щие за каналом, могли бы согласовывать свои действия, чтобы вызываемая процедура
выполнялась только одним из них. Это, однако, привело бы к перегрузке коммуникаци-
онных линий и усилило связь между получателями, которые обычно не зависят друг от
друга. Итак, канал должны прослушивать много получателей (чтобы параллельно обра-
батывать поступающие сообщения), но каждое отдельное сообщение должен потреблять
один и только один получатель.
Чтобы сообщение было принято только одним получателем, отправьте его по
каналу “точка-точка" (Point-to-Point Channel).
Отправитель Заказ Заказ Заказ
№3 №2 №1
Канал
“точка-точка"
Заказ Заказ Заказ
№3 №2 №1
Получатель
Канал “точка-точка” гарантирует, что каждое отдельное сообщение будет потреблено
только одним получателем. У канала может быть много получателей, одновременно об-
рабатывающих сообщения, но только один из них сможет успешно принять конкретное
сообщение. Если несколько получателей попытаются одновременно потребить некото-
рое сообщение, канал сам позаботится о том, чтобы эта операция удалась только одному
из них. Координировать свои действия получателям не придется.
Если у канала “точка-точка” только один получатель, факт, что сообщение будет по-
треблено только один раз, едва ли можно назвать удивительным. Если же канал прослу-
132
Глава 4. Каналы обмена сообщениями
шивается несколькими получателями, они становятся конкурирующими потребителями
(Competing Consumers, с. 515), и канал гарантирует, что сообщение будет получено только од-
ним из них. Такая схема потребления и обработки сообщений прекрасно масштабируется,
поскольку рабочая нагрузка на канал может быть распределена между несколькими потре-
бителями, запущенными в рамках нескольких приложений на нескольких компьютерах.
Если сообщение должно быть получено не одним, а всеми получателями, которые
прослушивают канал, используйте канал “публикация-подписка” (Publish-Subscribe
Channel, с. 134). И наконец, чтобы реализовать удаленный вызов процедуры через обмен
сообщениями, воспользуйтесь шаблоном запрос-ответ (Request-Reply, с. 177) в сочетании
с парой каналов “точка-точка”. Вызов процедуры будет представлять собой сообщение с
командой (Command Message, с. 169), а ответ на вызов — сообщение с данными документа
(Document Message, с. 171).
Пример: торговля на бирже
В системе биржевой торговли запрос на осуществление торговой операции (покупки или
продажи) передается в виде сообщения, которое должно быть принято и выполнено в
точности одним получателем, поэтому сообщение следует отправить по каналу “точка-
точка” (Point-to-Point Channel).
Пример: объект Queue (JMS)
В JMS канал “точка-точка” (Point-to-Point Channel) реализован через интерфейс Queue.
Отправитель использует объект Queuesender, а каждый из получателей — собственный
объект QueueReceiver [14, 17].
Вот как в приложении может использоваться объект Queuesender для отправки со-
общения.
Queue queue = // Получить очередь сообщений через JNDI.
QueueConnectionFactory factory = // Получить фабрику соединений
// через JNDI.
Queueconnection connection = factory.createQueueConnectionО;
QueueSession session = connection.createQueueSession(true.
Session.AUTO_ACKNOWLEDGE);
Queuesender sender = session.createSender(queue);
Message message = session.createTextMessage("The contents
of the message.");
sender.send(message);
А вот как приложение использует объект QueueReceiver, чтобы получить сообщение.
Queue queue = // Получить очередь сообщений через JNDI.
QueueConnectionFactory factory = // Получить очередь сообщений
// через JNDI.
QueueConnection connection = factory.createQueueConnection();
QueueSession session = connection.createQueueSession(true.
Session.AUTO_ACKNOWLEDGE) ,-
Канал “точка-точка" (Point-to-Point Channel)
133
QueueReceiver receiver = session.createReceiver(queue) ;
TextMessage message = (TextMessage) receiver.receive();
String contents = message.getText();
Примечание. В спецификации JMS l.l клиентские интерфейсы API для каналов
“точка-точка” и “публикация-подписка” унифицированы, поэтому код, показанный
здесь, можно упростить, используя объекты Destination, ConnectionFactory,
Connection, Session, Messageproducer и Messageconsumer вместо соответствующих
Queue-аналогов.
Пример: объект MessageQueue (.NET)
В .NET канал “точка-точка” (Point-to-Point Channel) реализован при помощи класса
MessageQueue [39]. Кстати, служба MSMQ, которая реализует обмен сообщениями на
платформе .NET, до выхода версии 3.0 поддерживала только обмен сообщениями по
принципу “точка-точка”.
В отличие от JMS, разделяющей функции фабрики соединений, соединения, сеанса,
отправителя и очереди сообщений, в .NET за выполнение обязанностей всех указанных
объектов отвечает MessageQueue. Отправка сообщения происходит следующим образом.
MessageQueue queue = new MessageQueue("MyQueue") ;
queue.Send("The contents o£ the message.");
Получение сообщения при помощи объекта MessageQueue выглядит так.
MessageQueue queue = new MessageQueue("MyQueue");
Message message = queue.Receive();
String contents = (String) message.Body();
134
Глава 4. Каналы обмена сообщениями
Канал “публикация-подписка” (Publish-Subscribe Channel) ------►
-------->
Приложение использует обмен сообщениями (Messaging, с. 87) для оповещения о собы-
тиях.
Как оповестить о событии всех заинтересованных получателей?
Для реализации широковещательной рассылки существуют хорошо известные, прове-
ренные решения. Шаблон проектирования наблюдатель (Observer) из [12] описывает необ-
ходимость разобщения наблюдателей и субъекта (т.е. инициатора события), чтобы субъект
мог легко организовать оповещение о событии всех заинтересованных наблюдателей вне
зависимости от их количества (даже если оно равно нулю). Расширением наблюдателя яв-
ляется шаблон издатель-подписчик (Publisher-Subscriber) из [33]. В него добавлено описание
канала событии, специально предназначенного для оповещения о событиях.
Это все теория, но как она применяется к системе обмена сообщениями? Сведения
о событии могут быть упакованы в сообщение (Message, с. 98), чтобы обеспечить надежное
оповещение наблюдателей (подписчиков). Тогда в качестве канала событий должен при-
меняться канал сообщений (Message Channel, с. 93). Но как сделать так, чтобы канал обме-
на сообщениями корректно оповестил о событии всех подписчиков?
Каждый подписчик должен быть оповещен о конкретном событии, но только один
раз. Сообщение о событии не может считаться потребленным, пока уведомление не по-
лучат все подписчики; когда же это произойдет, сообщение считается потребленным
и должно быть удалено из канала. Однако необходимость подписчиков координировать
свои действия при потреблении сообщений нарушает принцип разобщения, провозгла-
шенный в шаблоне наблюдатель. Потребители не должны конкурировать друг с другом,
но при этом должны иметь возможность совместно использовать сообщение о событии.
Чтобы копию сообщения о событии получил каждый подписчик канала, отправьте
сообщение по каналу “публикация-подписка”(Publish-Subscribe Channel).
Канал “публикация-подписка” функционирует следующим образом: у него есть один
входной канал, который разбивается на несколько выходных каналов, по одному на каж-
дого подписчика. Когда оповещение о событии публикуется в канале, канал “публикация-
подписка” доставляет копию сообщения в каждый из выходных каналов. На каждом
“выходе” канала есть только один подписчик, которому разрешается потреблять сооб-
щение только один раз. Благодаря этому каждый подписчик получит сообщение только
единожды, после чего потребленные копии сообщения исчезнут из соответствующих вы-
ходных каналов.
Канал “публикация-подписка” (Publish-Subscribe Channel)
135
Канал
“публикация-подписка”
Адрес
изменился
Подписчик
Адрес
изменился Подписчик
Адрес
изменился Подписчик
Помимо всего прочего, канал “публикация-подписка” удобно применять для отладки.
Даже если сообщение предназначено для одного получателя, использование канала
“публикация-подписка” позволяет прослушивать канал сообщений, не вмешиваясь в су-
ществующий поток сообщений. Мониторинг трафика, передающегося по каналу, может
оказаться необычайно полезным при отладке приложений, использующих обмен сооб-
щениями. Он также избавит разработчика от необходимости вставлять в код приложе-
ний, участвующих в обмене сообщениями, сотни выражений с оператором Print. Соз-
дание программы, которая бы прослушивала все активные каналы на предмет сообще-
ний и записывала сведения о них в журнал, может принести не меньше пользы, нежели
хранилище сообщений (Message Store, с. 565).
Возможность свободного прослушивания канала “публикация-подписка” имеет и нега-
тивные стороны. Если система обмена сообщениями передает данные о зарплате между
системой начисления заработной платы и системой бухгалтерского учета, вряд ли вам за-
хочется, чтобы кто-то мог написать простую программу, посредством которой он будет
прослушивать трафик сообщений. При использовании канала “точка-точка” указанная
проблема несколько смягчается: поскольку программа, прослушивающая сообщения,
будет считаться их потребителем (а сообщение, потребленное один раз, удаляется из ка-
нала), сообщения внезапно начнут исчезать, не доходя до истинных получателей, что не-
замедлительно будет обнаружено. Тем не менее во многих реализациях очереди сообще-
ний присутствуют функции, которые позволяют потребителям взглянуть на сообщения,
стоящие в очереди, не потребляя их. Как следствие этого подписка на канал сообщений
должна ограничиваться политиками безопасности. Последние внедрены во многие (но
не во все) коммерческие реализации систем обмена сообщениями. Вдобавок ко всему
средство мониторинга, которое будет фиксировать в журнале активных подписчиков ка-
налов сообщений, может пригодиться для управления системой.
136
Глава 4. Каналы обмена сообщениями
Подписка на каналы при помощи символов подстановки
Многие системы обмена сообщениями позволяют подписчикам каналов “публикация-
подписка” (Publish-Subscribe Channel) использовать специальные символы подстановки.
Это очень мощный прием, благодаря которому потребители сообщений могут подпи-
саться сразу на несколько каналов. К примеру, если некоторое приложение публикует
свои сообщения в каналах MyCorp/Prod/OrderProcessing/NewOrders и МуСогр/
Prod/OrderProcessing/CancelledOrders, другое приложение может подписаться на
канал MyCorp/Prod/OrderProcessing/* и получать все сообщения, касающиеся об-
работки заказов. Еще одно приложение может подписаться на МуСогр/Dev/*, чтобы по-
лучать все сообщения, отправленные приложениями в среде разработки. Использовать
символы подстановки разрешается только подписчикам; издатели всегда должны публи-
ковать сообщения в точно заданном канале. Точный синтаксис и возможности символов
подстановки зависят от производителя системы обмена сообщениями.
Сообщение о событии (Event Message, с. 174) часто отправляется по каналу “публикация-
подписка”, поскольку в оповещении о событии обычно заинтересовано множество сис-
тем. Подписчики могут быть постоянными или временными (см. шаблон постоянный
подписчик (Durable Subscriber, с. 535)). Если оповещения должны быть подтверждены
подписчиками, используйте шаблон запрос-ответ (Request-Reply, с. 177), в котором опо-
вещение будет запросом, а подтверждение — ответом. Хранение каждого сообщения в
канале “публикация-подписка” до тех пор, пока оно не будет получено всеми подписчика-
ми, может потребовать большого количества ресурсов. Для устранения этой проблемы
сообщениям, отправляемым по каналу “публикация-подписка”, можно назначить срок
действия сообщения (Message Expiration, с. 198).
Пример: торговля на бирже
В системе биржевой торговли о совершении торговой операции (например, покупки или
продажи акций) должны быть оповещены сразу несколько систем. Сделайте их подпис-
чиками канала “публикация-подписка” (Publish-Subscribe Channel), в котором будут разме-
щаться сообщения о выполненных операциях.
Аналогичным образом многие потребители будут заинтересованы в отображении или
обработке текущих биржевых котировок. Таким образом, котировки должны распро-
страняться через канал “публикация-подписка”.
Пример: объект Topic (JMS)
В JMS канал “публикация-подписка” (Publish-Subscribe Channel) реализован через интер-
фейс Topic. Отправитель использует объект Topicpublisher, а каждый из получате-
лей — собственный объект Topicsubscriber [14, 17].
Вот как в приложении используется объект TopicPublisher для отправки широко-
вещательного сообщения.
Topic topic = // Получить тему через JNDI.
TopicConnectionFactory factory = // Получить фабрику соединений
// через JNDI.
Канал “публикация-подписка” (Publish-Subscribe Channel)
137
TopicConnection connection = factory.createTopicConnection();
TopicSession session = connection.createTopicSession(true.
Session.AUTO_ACKNOWLEDGE);
TopicPublisher publisher = session.createPublisher(topic);
Message message = session.createTextMessage("The contents of
the message.");
publisher.publish(message);
А вот как приложение использует объект Topicsubscriber, чтобы получить широ-
ковещательное сообщение.
Topic topic = // Получить тему через JNDI.
TopicConnectionFactory factory = // Получить фабрику соединений
// через JNDI.
TopicConnection connection = factory.createTopicConnectionО;
TopicSession session = connection.createTopicSession(true.
Session.AUTO_ACKNOWLEDGE);
Topicsubscriber subscriber = session.createSubscriber(topic);
TextMessage message = (TextMessage) subscriber.receive();
String contents = message.getText();
Примечание. В спецификации JMS 1.1 клиентские интерфейсы API для каналов
“точка-точка” и “публикация-подписка” унифицированы, поэтому код, показанный
здесь, можно упростить, используя объекты Destination, ConnectionFactory,
Connection, Session, Messageproducer и Messageconsumer вместо соответствующих
Topic-аналогов.
Пример: обмен сообщениями по принципу “один-ко-многим” (MSMQ)
В версии MSMQ 3.0 [29] появилась модель обмена сообщениями “один-ко-многим”.
Существует два разных подхода к ее реализации.
1. Многоадресная рассылка сообщений в режиме реального времени. Этот подход
ближе к концепции канала “публикация-подписка” (Publish-Subscribe Channel), но
его реализация полностью зависит от многоадресной рассылки IP через протокол
PGM (Pragmatic General Multicast). По этой причине указанный подход не может
быть использован с протоколами, не основанными на IP.
2. Списки рассылки и многоэлементные имена форматов. Список рассылки
(Distribution List) позволяет отправителю явно разослать сообщение списку полу-
чателей. Это, однако, нарушает концепцию шаблона наблюдатель (Observer),
потому что отправитель теперь должен знать о получателях. Таким образом, дан-
ное средство скорее напоминает список получателей (Recipient List, с. 264), нежели
канал “публикация-подписка”. Многоэлементное имя формата (Multiple-Element
Format Name) задает символический канал, который динамически отображается
на несколько реальных каналов. Это уже ближе к концепции канала “публикация-
подписка”, но все равно требует, чтобы отправитель выбирал между реальным
и символическим каналами.
138 Глава 4. Каналы обмена сообщениями
Общая языковая среда выполнения (Common Language Runtime — CLR), в которой
выполняются приложения .NET, не обеспечивает прямую поддержку модели обмена со-
общениями “один-ко-многим”. Тем не менее доступ к этой функциональности можно
осуществить через интерфейс СОМ [24], который может быть внедрен в код .NET.
Пример: простой обмен сообщениями
В главе 6 приведен пример реализации механизма публикации-подписки с помощью
JMS. Он показывает, как реализовать шаблон наблюдатель {Observer) в распределенной
среде, используя обмен сообщениями.
Канал типа данных (Datatype Channel)
139
Канал типа данных (Datatype Channel)
Приложение использует обмен сообщениями (Messaging, с. 87) для передачи данных
различных типов, например разнообразных документов.
Как приложение должно отправить данные, чтобы получатель знал, как их обраба-
тывать?
Что такое сообщения? Это всего лишь экземпляры одного и того же класса сообще-
ний, определенного системой обмена сообщениями. Содержимое сообщения представ-
ляет собой обычный массив байтов. Хотя такой простой структуры достаточно для пере-
дачи сообщения, ее недостаточно, чтобы получатель смог обработать сообщение долж-
ным образом.
Получатель должен знать структуру данных, отправленных в теле сообщения, и фор-
мат этих данных. Структура данных может представлять собой массив символов, массив
байтов, сериализованный объект, документ XML и т.п. Формат — это, в свою очередь,
записи с полями данных для байтов или символов, класс для сериализованного объекта,
определение схемы для документа XML и т.п. Совокупность этих деталей (т.е. структуры
и формата) иногда называют типом сообщения.
Получателя нужно уведомить о том, к какому типу принадлежит принятое им сооб-
щение. В противном случае он не будет знать, как его обрабатывать. Пусть, к примеру,
отправитель хочет отослать несколько объектов, таких как заказы на поставку, прайс-
листы и запросы. Разумеется, для обработки каждого из них получателю придется вы-
полнить различные действия, поэтому он должен знать, к какому типу принадлежит то
или иное сообщение. Если все сообщения будут просто отправлены по единому каналу
обмена сообщениями, получатель не поймет, как обрабатывать каждое из них (рис. 4.1).
Отправитель
Запрос Прайс-лист Заказ
на поставку
Рис. 4.1. Данные разных типов
Канал
Получатель
Отправитель прекрасно знает, сообщение какого типа он отсылает, но как уведомить
об этом получателя? Отправитель мог бы поместить в заголовок сообщения некий флаг,
как описывается в шаблоне индикатор формата (Format Indicator, с. 201), но тогда полу-
чателю потребуется оператор выбора наподобие Case Of. Данные можно было бы упа-
ковать в сообщение с командой (Command Message, с. 169) с отдельной командой для каж-
дого типа данных. Но отправляя сообщение с командой, мы будто бы уведомляем получа-
теля о том, что с данными нужно что-то сделать (а ведь сообщение отправляется лишь
затем, чтобы просто донести данные до получателя!).
140
Глава 4. Каналы обмена сообщениями
Аналогичная проблема (на сей раз не связанная с сообщениями) возникает при обра-
ботке коллекции элементов. Коллекция должна быть гомогенной, т.е. все ее элементы
должны иметь один и тот же тип, чтобы обработчик заранее знал, как ими манипулиро-
вать. Между тем во многих реализациях коллекции ее элементам вовсе не обязательно
иметь определенный тип. По этой причине программисты вынуждены вставлять в код
проверку, принадлежат ли все элементы коллекции к одному и тому же типу. В против-
ном случае в коллекции могут оказаться элементы разных типов, и обработчик не пой-
мет, как именно следует обрабатывать тот или иной элемент.
Описанный принцип справедлив и для обмена сообщениями, поскольку все сообще-
ния в канале должны принадлежать к одному и тому же типу. Самое простое решение в
этой ситуации — сделать так, чтобы все сообщения имели один и тот же формат; если же
форматы должны отличаться, снабдить каждое сообщение надежным индикатором
формата. Хотя специфика канала не обязывает сообщения иметь один и тот же тип,
этого требует получатель, которому нужно знать, как обрабатывать сообщения.
Используйте для каждого типа данных отдельный канал типа данных (Datatype
Channel), чтобы все данные в конкретном канале принадлежали к одному и тому
Благодаря использованию отдельного канала типа данных для каждого типа данных
все сообщения в конкретном канале будут содержать данные одного и того же типа.
Отправитель, знающий, к какому типу принадлежат данные, выберет канал, в котором
следует разместить сообщение. Получатель посмотрит, по какому каналу были доставле-
ны данные, и поймет, какого они типа.
Как показано на иллюстрации к шаблону, поскольку отправитель хочет отослать дан-
ные трех разных типов (заказы на доставку, прайс-листы и запросы), он должен восполь-
Канал типа данных (Datatype Channel)
141
зоваться тремя каналами. Отсылая элемент данных, отправитель должен выбрать для
него нужный канал типа данных. Принимая элемент данных, получатель автоматически
определит его тип, потому что будет знать, по какому каналу типа данных он пришел.
Канал качества обслуживания
К концепции канала типа данных (Datatype Channel) близка такая стратегия, как канал
качества обслуживания (quality-of-service channel). Пусть компании требуется передать
некоторую группу сообщений с уровнем обслуживания, отличного от того, который
применяется при передаче других сообщений. К примеру, входящие сообщения о но-
вых заказах могут представлять собой основной источник дохода для бизнеса компа-
нии, а посему должны передаваться по чрезвычайно надежному каналу — например,
с использованием гарантированной доставки (Guaranteed Delivery, с. 149), — даже
невзирая на потенциальное снижение производительности. С другой стороны, потеря
сообщения, запрашивающего состояние заказа, — не такое уж неприятное событие,
поэтому его можно отправить по быстрому, но менее надежному каналу. Требуемое
качество обслуживания иногда можно обеспечить и при использовании единственного
канала (например, с помощью приоритета сообщений). Тем не менее параметры каче-
ства обслуживания обычно рекомендуется задавать при создании канала, а не пере-
кладывать это решение на код приложения, которое будет отправлять сообщения.
Таким образом, каждую группу сообщений лучше пересылать по собственному каналу
со специально настроенным под их потребности качеством обслуживания.
Как уже говорилось в разделе, посвященном каналу сообщений (Message Channel, с. 93),
создание и поддержка каналов обходится недорого, но и не бесплатно. Поскольку при-
ложению часто требуется передавать данные множества разных типов, создавать отдель-
ный канал типа данных для каждого из них слишком накладно. В этом случае данные
разных типов могут передаваться по одному каналу с использованием для каждого типа
данных своего избирательного потребителя (Selective Consumer, с. 528). Благодаря этому
один физический канал будет выступать в роли нескольких логических каналов типа дан-
ных. Такая стратегия передачи данных называется мультиплексированием (multiplexing),
или уплотнением. В то время как концепция канала типа данных разъясняет, почему все
сообщения в канале должны иметь один и тот же формат, в шаблоне каноническая модель
данных (Canonical Data Model, с. 367) показано, как сделать, чтобы все сообщения во всех
каналах компании соответствовали некоторому общему формату данных.
Если вы хотите использовать каналы типа данных, но существующий издатель сообще-
ний упорно размещает сообщения в одном канале, можете воспользоваться маршрутизато-
ром на основе содержимого (Content-Based Router, с. 247), чтобы демультиплексировать
(разуплотнить) сообщения. Маршрутизатор распределяет поток сообщений по каналам
типа данных, в каждом из которых содержатся сообщения только одного типа.
Диспетчер сообщений (Message Dispatcher, с. 521), обеспечивающий параллельное по-
требление сообщений, может также применяться для обработки смешанного набора со-
общений согласно типу каждого из них. В каждом сообщении должен быть указан его
тип (обычно это делается с помощью индикатора формата, вставленного в заголовок со-
общения). Диспетчер определяет тип сообщения и передает его исполнителю, предна-
значенному для обработки данных этого типа. Сообщения в канале все равно должны
142 Глава 4. Каналы обмена сообщениями
принадлежать к одному и тому же типу, но это может быть более общий тип, поддержи-
ваемый диспетчером, а не конкретный тип, подлежащий специфической обработке.
Для того чтобы можно было различать версии одного и того же формата данных, при-
меняется индикатор формата, который, в свою очередь, позволяет отсылать такие дан-
ные по одному и тому же каналу типа данных.
Пример: торговля на бирже
Если в системе биржевой торговли формат запроса о котировках отличается от формата
запроса на выполнение торговой операции, для отправки каждого из них следует приме-
нять отдельный канал типа данных (Datatype Channel). Точно так оповещение об измене-
нии адреса может по своему формату отличаться от оповещения о смене брокера, поэто-
му каждый тип оповещения следует рассылать по собственному каналу типа данных.
Канал недопустимых сообщений (Invalid Message Channel)
143
Канал недопустимых сообщений (Invalid Message Channel)
Приложение использует обмен сообщениями (Messaging, с. 87) для получения сообщений
(Message, с. 98).
Как поступить с сообщением, не несущим в себе никакого смысла для получателя?
В теории все, что передается по каналу сообщений (Message Channel, с. 93), является
обычным сообщением, а получатели просто обрабатывают принятые ими сообщения.
Между тем, чтобы обработать сообщение, получатель должен уметь интерпретировать его
данные и понимать их значение. Это не всегда возможно: в теле сообщения могут содер-
жаться синтаксические, лексические или другие ошибки. В заголовке сообщения могут
отсутствовать необходимые поля, или же эти поля могут иметь бессмысленные значения.
Отправитель может создать вполне корректное сообщение, но разместить его в непра-
вильном канале, что приведет к передаче сообщения не тому получателю. И наконец,
злоумышленник может специально отправить некорректное сообщение, чтобы запутать
получателя. Во всех перечисленных случаях получателю нужно придумать способ обра-
ботки сообщений, которые кажутся ему ошибочными.
Канал сообщений должен быть каналом типа данных (Datatype Channel, с. 139). Предпо-
лагается, что каждое из находящихся в нем сообщений принадлежит к заданному для
этого канала типу данных. Если отправитель разместит в канале сообщение не того типа,
доставка сообщения пройдет успешно, но получатель не сможет определить тип сообще-
ния и не будет знать, как его обработать.
В качестве примера сообщения с неправильным типом данных можно привести число-
вое сообщение, передающееся по каналу для текстовых сообщений. Еще один пример не-
корректного формата сообщения — это неправильно оформленный документ XML либо
документ, который не соответствует заранее согласованной схеме или шаблону DTD.
С точки зрения системы обмена сообщениями в них нет ничего из ряда вон выходящего, но
получатель не сможет их обработать, поэтому сообщения будут признаны недопустимыми.
Сообщения, в заголовках которых нет полей, требующихся получателю, также счита-
ются недопустимыми. Если в заголовке сообщения должны присутствовать такие поля,
как идентификатор корреляции (Correlation Identifier, с. 186), идентификатор цепочки сооб-
щений (Message Sequence, с. 192), обратный адрес (Return Address, с. 182) или другие подоб-
ные свойства, но их нет, сообщение будет корректно доставлено, но обработать его полу-
чателю не удастся (рис. 4.2).
Отправитель Недопустимое Канал Получатель
сообщение
Рис. 4.2. Недопустимое сообщение
144
Глава 4. Каналы обмена сообщениями
Что должен сделать получатель, если обнаружит, что сообщение, которое он пытается
обработать, не является допустимым? Сообщение можно вернуть в канал, но тогда оно
снова будет потреблено тем же получателем или кем-то подобным. Более того, сообще-
ния неверного формата, которые игнорируются получателями, будут “захламлять” канал
и негативно сказываться на производительности. Получатель может выбросить недопус-
тимое сообщение, но это усложнит выявление проблем в схеме обмена сообщениями.
Таким образом, системе нужен способ убрать неверные сообщения из канала и помес-
тить их в такое место, где они не будут мешать потоку других сообщений, но могут быть
найдены для диагностики проблем в системе обмена сообщениями.
Получатель должен переместить сообщение неверного формата в канал недопус-
тимых сообщений (Invalid Message Channel). Это специальный канал, предназна-
ченный для сообщений, которые не могут быть обработаны своими получателями.
Отправитель
Сообщения
Канал Получатель Недопустимое Канал
сообщение недопустимых
сообщений
Разрабатывая систему для обмена сообщениями между приложениями, администратор
должен определить один или несколько каналов недопустимых сообщений, которыми будут
пользоваться эти приложения. Канал недопустимых сообщений не будет применяться для
обычного взаимодействия приложений, а следовательно, его можно смело заполнять
неверными сообщениями. Получателем, прослушивающим канал недопустимых сообщений,
может стать обработчик ошибок, который будет диагностировать неверные сообщения.
Канал недопустимых сообщений — это своеобразный журнал записи ошибок для систе-
мы обмена сообщениями. Если в приложении что-то идет не так, ошибку рекомендуется
зафиксировать в журнале. Если же проблемы возникают при обработке сообщения, его
удобно поместить в канал для недопустимых сообщений. Кроме того, если причина некор-
ректности сообщения не слишком очевидна (и программа, прослушивающая канал недо-
пустимых сообщений, может не понять, почему туда попало указанное сообщение), прило-
жение также должно зафиксировать в журнале ошибку с подробным описанием последней.
Помните, что сообщение само по себе не является допустимым или недопустимым.
Допустимость сообщения определяется лишь в контексте конкретного получателя и за-
висит от того, какой формат данных тот ожидает. Сообщение, допустимое для одного по-
лучателя, может оказаться недопустимым для другого. Такие получатели не должны
делить между собой общий канал. Сообщение, допустимое для одного из получателей
канала, должно быть допустимым и для всех остальных получателей этого же канала.
Точно так же, если один из получателей канала сочтет некоторое сообщение недопусти-
мым, оно должно считаться таковым и всеми остальными получателями этого канала.
Отправитель сообщения должен позаботиться о том, чтобы оно оказалось допустимым
для получателей, прослушивающих канал. В противном случае получатели будут игнориро-
вать сообщения указанного отправителя, пересылая их в канал недопустимых сообщений.
Канал недопустимых сообщений (Invalid Message Channel)
145
Похожая (но другая) проблема возникает, если сообшение корректно структурировано,
но имеет семантически неправильное содержимое. К примеру, в сообщении с командой
(Command Message, с. 98) могут содержаться инструкции о необходимости удалить из базы
данных определенную запись, но такой записи там не окажется. Это ошибка не системы
обмена сообщениями, а приложения. С самим сообщением все в порядке, поэтому отправ-
лять его в канал недопустимых сообщений не следует. Ошибка такого рода должна быть об-
работана как недопустимый запрос приложения, а не как недопустимое сообщение.
Разница между ошибками обработки сообщений и ошибками приложения становится
проще и понятнее, если реализовать получателя как активатора службы (Service Activator,
с. 545) или как шлюз обмена сообщениями (Messaging Gateway, с. 482). В указанных шабло-
нах код обработки сообщений отделяется от остальных компонентов приложения. Если
ошибка произойдет во время обработки сообщения, сообщение будет сочтено недопус-
тимым и отправится в канал недопустимых сообщений. Если же она произойдет в процессе
обработки приложением данных, извлеченных из сообщения, это ошибка приложения,
не имеющая никакого отношения к обмену сообщениями.
Канал недопустимых сообщений, содержимое которого игнорируется, несет в себе
не больше пользы, нежели журнал записи ошибок, в который никто никогда не загляды-
вает. Сообщения, помещенные в такой канал, свидетельствуют о проблемах, возникших
в процессе интеграции приложений, а посему должны быть немедленно проанализиро-
ваны. В идеале процесс потребления недопустимых сообщений, выяснения причины их
появления и устранения соответствующих проблем должен быть автоматизирован. Но на
практике причиной появления недопустимых сообщений часто является ошибка коди-
рования или настройки, исправление которой невозможно без участия разработчика или
системного аналитика. Но даже если автоматизация указанного процесса невозможна, у
приложения, использующего систему обмена сообщениями и каналы недопустимых со-
общений, по крайней мере, должен быть процесс, который следит за каналом недопусти-
мых сообщений и оповещает системных администраторов о появлении в канале сообще-
ний неверного формата.
Во многих системах обмена сообщениями реализована похожая концепция под на-
званием канал недоставленных сообщений (Dead Letter Channel, с. 147). В отличие от канала
недопустимых сообщений, содержащего сообщения, которые были успешно доставлены и
получены, но не обработаны, канал недоставленных сообщений предназначен для сообще-
ний, которые не смогли быть доставлены системой обмена сообщениями.
Пример: торговля на бирже
Рассмотрим приложение, выполняющее запросы других приложений на осуществление
торговых операций. Пусть оно по ошибке получает запрос о биржевых котировках либо
запрос на осуществление покупки, в котором не будет указано, какой вид ценных бумаг
следует приобрести, в каком количестве или же кому отправить подтверждение о совер-
шении покупки. В каждом из этих случаев сообщение с запросом, полученное приложе-
нием, будет рассматриваться как недопустимое, т.е. такое, которое не соответствует ми-
нимальному набору требований, необходимых для обработки запроса на выполнение
операции. Как только сообщение будет сочтено недопустимым, приложение-получатель
должно направить его в канал недопустимых сообщений (Invalid Message Channel). Прило-
жения, отсылающие запросы, по желанию могут наблюдать за каналом недопустимых
сообщений, чтобы следить за тем, не был ли отброшен тот или иной запрос.
146 Глава 4. Каналы обмена сообщениями
Пример: спецификация JMS
В спецификации JMS говорится: если объект MessageListener получит сообщение,
но не сможет его обработать, он должен перенаправить сообщение в “некоторый пункт
назначения, специфичный для данного приложения и предназначенный для размещения
сообщений, не поддающихся обработке” [17]. Этим “пунктом назначения” (destination)
и является канал недопустимых сообщений (Invalid Message Channel).
Пример: простой обмен сообщениями
В главе 6 показано, как реализовать получателей, перенаправляющих сообщения, кото-
рые не удалось обработать, в канал недопустимых сообщений (см. примеры реализации
механизма “запрос-ответ” в JMS и .NET).
Канал недоставленных сообщений (Dead Letter Channel)
147
Канал недоставленных сообщений (Dead Letter Channel) ШММШ
Компания использует обмен сообщениями (Messaging, с. 87) для интеграции приложений.
Что делать с сообщениями, которые не удается доставить?
Если получатель принимает сообщение, но не может его обработать, он должен пере-
местить его в канал недопустимых сообщений (Invalid Message Channel, с. 143). Но что делать,
если система обмена сообщениями даже не может доставить сообщение получателю?
Существует целый ряд причин, по которым сообщение не всегда удается доставить
получателю. Канал обмена сообщениями может быть неправильно настроен. После от-
правки сообщения (но еще до его доставки) канал могут внезапно удалить. Срок действия
сообщения (Message Expiration, с. 198) может истечь еще до того, как сообщение будет достав-
лено. Впрочем, даже если срок действия не указан явно, сообщение все равно может уста-
реть, если не будет доставлено в течение слишком долгого времени. Если в заголовок сооб-
щения вставлено значение выбора, которое проигнорируют все избирательные потребители
(Selective Consumer, с. 528), сообщение никогда не прочтут, и оно в конце концов устареет.
Наконец, успешной доставке сообщения могут помешать ошибки в полях заголовка.
Как только система обмена сообщениями определит, что не может доставить сообще-
ние, она должна решить, что с ним делать. Сообщение можно оставить там, где оно есть,
но это приведет к “захламлению” системы. Можно попытаться вернуть сообщение от-
правителю, но отправитель — не получатель и не сможет обнаружить, что ему доставили
сообщение. Можно тихонько удалить сообщение в надежде, что никто не заметит его от-
сутствия, но это, вероятно, станет проблемой для отправителя, который успешно отпра-
вил сообщение и ожидает, что оно будет доставлено, получено и обработано.
Способ функционирования канала недоставленных сообщений зависит от реализации
конкретной системы обмена сообщениями. Иногда указанный канал называют
“очередью недоставленных (или мертвых) сообщений” (dead message queue [27]) или
“очередью недоставленных писем” (dead letter queue [7, 28]). Обычно у каждого компью-
тера, на котором установлена система обмена сообщениями, есть собственный канал не-
доставленных сообщений. По этой причине вне зависимости от того, на каком компьютере
обнаружится недоставленное сообщение, оно будет перемещено из одной локальной
очереди в другую, не рискуя потеряться при передаче по ненадежной сети. Система об-
мена сообщениями зафиксирует, на каком компьютере было обнаружено недоставлен-
ное сообщение, а также по какому каналу оно изначально должно было быть доставлено.
Если система обмена сообщениями определяет, что не может или не должна
доставить сообщение, его необходимо переместить в канал недоставленных
сообщений (Dead Letter Channel).
148
Глава 4. Каналы обмена сообщениями
сообщений
Разница между недоставленным (dead) и недопустимым (invalid) сообщениями заклю-
чается в следующем: недоставленное сообщение, как и следует из его названия, невоз-
можно доставить получателю, а недопустимое сообщение успешно доставлено получате-
лю, принято им, но не может быть обработано. Решение о том, следует ли отправить
сообщение в канал недоставленных сообщений, принимается системой обмена сообще-
ниями путем оценки заголовка. В отличие от этого отправку сообщения в канал недопус-
тимых сообщений осуществляет получатель (из-за ошибок в теле сообщения, отсутствия
интересующих его полей в заголовке и т.п.). Для получателя обнаружение и обработка
недоставленных сообщений выглядит автоматизированным процессом, в то время как
заниматься судьбой недопустимых сообщений должен он сам. Разработчик, использую-
щий существующую систему обмена сообщениями, не может повлиять на то, как по-
следняя обрабатывает недоставленные сообщения, но может внедрить собственный ме-
ханизм обработки недопустимых сообщений (включая недоставленные сообщения,
которые почему-то не были обработаны системой обмена сообщениями как таковые).
Пример: торговля на бирже
В системе биржевой торговли приложение, которое желает осуществить покупку или
продажу, может отправить запрос на выполнение торговой операции. Чтобы гарантиро-
вать, что запрос будет получен в рамках разумного лимита времени (скажем, не дольше
чем через пять минут после отправки), срок действия сообщения (Message Expiration, с. 198)
устанавливается равным пяти минутам. Если за это время сообщение не удалось доста-
вить или же если приложение, выполняющее запросы на покупку/продажу, не смогло
вовремя считать сообщение из канала, то сообщение изымается из канала запросов на
выполнение торговых операций и помещается в канал недоставленных сообщений (Dead
Letter Channel). Система биржевой торговли может осуществлять мониторинг канала
недоставленных сообщений, чтобы вовремя узнавать о сорвавшихся торговых операциях.
Гарантированная доставка (Guaranteed Delivery)
149
Гарантированная доставка (Guaranteed Delivery) -------►
6
Компания использует обмен сообщениями (Messaging, с. 87) для интеграции при-
ложений.
Как гарантировать, что сообщение будет доставлено даже в случае сбоя системы
обмена сообщениями?
Одно из главных преимуществ асинхронного обмена сообщениями перед удаленным
вызовом процедуры состоит в том, что отправитель, получатель и сеть, соединяющая их,
не обязательно должны работать в одно и то же время. Если сеть недоступна, сообщение
будет сохранено до тех пор, пока сеть вновь не начнет работать. Точно так же, если полу-
чатель недоступен, система обмена сообщениями сохранит сообщение и будет пытаться
доставить его до тех пор, пока получатель снова не станет доступным. Описанный про-
цесс, лежащий в основе обмена сообщениями, носит название передача с промежуточ-
ным хранением (store-and-forward). Так где же хранится сообщение прежде, чем продол-
жить свой путь?
По умолчанию система обмена сообщениями хранит сообщение в памяти до тех пор,
пока оно не будет успешно передано в следующий пункт хранения. Такая схема успешно
функционирует при условии, что система обмена сообщениями исправна. Но если по-
следняя выходит из строя (например, из-за того, что один из ее компьютеров внезапно
отключился от электросети, или по причине аварийного завершения процесса обмена
сообщениями), сообщения, хранившиеся в памяти, будут потеряны.
Большинство приложений сталкиваются с аналогичными проблемами. При неожи-
данном отказе приложения данные, хранившиеся в памяти, исчезают. Для предотвраще-
ния этой проблемы приложения используют файлы и базы данных, которые записыва-
ются на диск, благодаря чему безболезненно переживают сбой приложения. Подобный
способ хранения данных на случай отказа нужен и системам обмена сообщениями.
Используйте гарантированную доставку (Guaranteed Delivery), чтобы разместить
приложения в постоянном хранилище данных и избежать их потери в случае
отказа системы обмена сообщениями.
Компьютер 1
Компьютер 2
150
Глава 4. Каналы обмена сообщениями
Согласно концепции гарантированной доставки система обмена сообщениями поме-
щает сообщения во встроенное хранилище данных. У каждого компьютера, на котором
установлена система обмена сообщениями, имеется собственное хранилище данных,
чтобы сообщения хранились локально. Когда отправитель отсылает сообщение, опера-
ция отправки не считается успешно завершенной до тех пор, пока сообщение не будет
надежно сохранено в хранилище данных отправителя. Аналогичным образом сообщение
не будет удаляться из указанного хранилища, пока не будет успешно передано и сохране-
но в следующем хранилище, и т.п. Итак, с момента отправки сообщение всегда будет
храниться на диске как минимум одного компьютера до тех пор, пока не будет успешно
доставлено получателю и принято им.
Наличие постоянного хранилища увеличивает надежность, но приводит к снижению
производительности. Если потеря сообщений из-за отказа системы обмена сообщениями
не так уж и важна, от гарантированной доставки лучше отказаться — так сообщения
будут доходить намного быстрее.
Не следует забывать и о том, что реализация гарантированной доставки в системах
с высоким уровнем трафика может потребовать огромного количества дискового про-
странства. Если поставщик генерирует по нескольку сотен или тысяч сообщений в се-
кунду, тогда даже несколько часов простоя сети приведут к неуемному потреблению мес-
та на жестких дисках. Поскольку сеть недоступна, сообщения должны сохраняться на
локальном жестком диске компьютера, на котором установлен поставщик. Но этот диск
вряд ли рассчитан на хранение такого гигантского объема данных. По этой причине в не-
которых системах обмена сообщениями разрешается настраивать таймаут повторных
попыток (retry timeout). Данный параметр задает, сколько времени сообщение будет хра-
ниться в системе обмена сообщениями. В некоторых приложениях с интенсивным тра-
фиком (например, передающих биржевые котировки в режиме реального времени) зна-
чение тайм-аута может равняться всего нескольким минутам. К счастью, большинство
таких приложений генерируют сообщения о событиях (Event Message, с. 174), которые
можно безбоязненно отбросить через короткий промежуток времени. Более подробно об
этом будет идти речь в разделе, посвященном сроку действия сообщения (Message
Expiration, с. 198).
Гарантированную доставку также рекомендуется отключать на время тестирования и
отладки. Тогда для полной очистки каналов будет достаточно остановить и перезапустить
сервер обмена сообщениями. Сообщения, стоящие в очереди и после перезапуска серве-
ра, могут сильно затруднить отладку даже простых программ для обмена сообщениями.
Пусть, к примеру, отправитель и получатель соединены каналом “точка-точка” (Point-to-
Point Channel, с. 131). Если после перезагрузки сервера в канале все еще будет храниться
старое сообщение, получатель обработает его раньше, чем какие-либо новые сообщения,
отосланные отправителем. Это один из распространенных “подводных камней”, с кото-
рыми сталкиваются отладчики систем асинхронного обмена сообщениями с гарантиро-
ванной доставкой. Во многих коммерческих реализациях систем обмена сообщениями
разрешается очищать отдельные очереди, чтобы во время тестирования обмен сообще-
ниями было легче начать “с нуля”. (См. также раздел, посвященный вентилю канала
(ChannelPurger, с. 579).)
Гарантированная доставка (Guaranteed Delivery)
151
Насколько надежна гарантированная доставка сообщений
Важно помнить, что надежность компьютерных систем измеряется количеством
“девяток”, например 99,9%. Иными словами, достичь 100-процентной надежности
вряд ли вообще возможно, а повышение уровня надежности хотя бы на одну “девятку”
(с 99,9% до 99,99%) приведет к непомерно резкому возрастанию стоимости системы.
Указанное утверждение справедливо и для гарантированной доставки (Guaranteed
Delivery). Всегда возможен сценарий, при котором сообщение все равно будет потеря-
но. К примеру, если жесткий диск, на котором хранятся сообщения, выйдет из строя,
сообщения будут уничтожены. Для повышения надежности дискового хранилища
можно воспользоваться избыточным массивом дисков (RAID или др.). Тогда к уровню
надежности, вероятно, добавится еще одна “девятка”, но достичь ста процентов все
равно не удастся. Кроме того, если сеть будет недоступна на протяжении долгого вре-
мени, сообщения могут заполнить собой жесткий диск компьютера, что приведет
к невозможности записи новых сообщений. Таким образом, гарантированная достав-
ка направлена на защиту системы обмена сообщениями от потенциальных простоев
(таких, как сбой компьютера или сети), но, несмотря на свое название, полной гаран-
тии все же не дает.
В реализации MSMQ для .NET, чтобы содержимое канала сохранялось на диске, канал
нужно объявить транзакционным. Это означает, что отправители сообщений, как правило,
должны быть транзакционными клиентами (Transactional Client, с. 498). В JMS применение
гарантированной доставки к каналу “публикация-подписка” (Publish-Subscribe Channel, с. 134)
гарантирует лишь то, что сообщения будут доставлены активным подписчикам. Чтобы со-
общения гарантированно доставлялись даже тогда, когда подписчик неактивен, последнему
необходимо быть постоянным подписчиком (Durable Subscriber, с. 535).
Пример: торговля на бирже
В системе биржевой торговли запросы на осуществление торговых операций и подтвер-
ждения операций разумно отправлять с использованием гарантированной доставки
(Guaranteed Delivery), чтобы они не потерялись. Оповещения об изменении адреса также
следует отправлять с использованием гарантированной доставки, а вот для обновлений
биржевых котировок это не обязательно. Если обновление котировок потеряется, осо-
бого вреда это не нанесет, а поскольку котировки обновляются весьма часто, размещение
их в постоянном хранилище сделает гарантированную доставку неприемлемой в плане
производительности и расходования ресурсов.
В примере системы биржевой торговли из раздела, посвященного постоянному под-
писчику (Durable Subscriber, с. 535), говорится, что некоторые подписчики данных об из-
менении котировок могут захотеть стать постоянными. В этом случае канал данных об
изменении котировок, вероятно, также должен обеспечивать гарантированную доставку.
Но как при этом удовлетворить нужды подписчиков, которые не желают быть постоян-
ными или не хотят страдать от снижения производительности, вызванного гарантирован-
ной доставкой? Для решения этой проблемы рекомендуем создать два канала, по кото-
рым будут рассылаться обновления котировок: один с гарантированной доставкой,
а другой— без нее. На первый канал должны подписываться только те приложения,
которым нужны абсолютно все обновления котировок, и их подписка должна быть по-
152
Глава 4. Каналы обмена сообщениями
стоянной. Из-за повышенной нагрузки на канал с гарантированной доставкой издатель
может отправлять обновления не так часто, как по второму каналу. (См. также стратегию
канала качества обслуживания в разделе, посвященном каналу типа данных (Datatype
Channel, с. 139).)
Пример: постоянные сообщения (JMS)
Спецификация JMS разрешает задавать необходимость гарантированной доставки
(Guaranteed Delivery) для отдельных сообщений. Иными словами, одни сообщения в ка-
нале могут быть постоянными, а другие — нет [14,17].
Если отправитель хочет сделать сообщение постоянным, он должен воспользоваться
своим объектом Messageproducer, чтобы изменить значение свойства JMSDeliveryMode
указанного объекта сообщения на persistent. Это делается следующим образом.
Session session = // Получить сеанс.
Destination destination = // Получить пункт назначения.
Message message = // Создать сообщение.
MessageProducer producer = session.createProducer(destination);
producer.send(
message,
j avax.j ms.De1iveryMode.PERSISTENT,
javax.jms.Message.DEFAULT_PRIORITY,
j avax.jms.Message.DEFAULT_TIME_TO_LIVE);
Если постоянными должны быть все сообщения, которые отправляются приложени-
ем, можно сделать так, чтобы при отправке сообщения поставщик MessageProducer по
умолчанию применял режим persistent.
producer.setDeliveryMode(j avax.jms.Delivery-Mode.PERSISTENT);
(Вообще-то, стандартным режимом доставки для MessageProducer и так является
persistent.) Теперь все сообщения, отправляемые указанным поставщиком сообще-
ний, автоматически будут постоянными. Поэтому для отправки последующих сооб-
щений достаточно просто воспользоваться методом send.
producer.send(message);
Вместе с тем сообщения, отправляемые по этому же каналу другими поставщиками,
могут быть или не быть постоянными. Все зависит от того, как у них настроен режим
доставки сообщений.
Пример: IBM WebSphere MQ
В системе обмена сообщениями IBM WebSphere MQ гарантированную доставку
(Guaranteed Deliveiy) можно определять как для всего канала, так и для отдельных сооб-
щений. Если канал не является постоянным (в том смысле, что его содержимое не сохра-
няется на постоянном носителе), сообщения не могут быть постоянными. Если же канал
Гарантированная доставка (Guaranteed Delivery)
153
постоянный, его можно настроить так, чтобы все отправляемые по нему сообщения
автоматически делались постоянными (или же чтобы каждое отдельное сообщение
по желанию отправителя могло быть постоянным либо не постоянным).
Канал определяется как постоянный (или не постоянный) во время его создания
в системе обмена сообщениями. Если настроить канал так, как показано ниже, все от-
правляемые по нему сообщения будут постоянными.
DEFINE Q(myQueue) PER(PERS)
А вот как настроить канал, чтобы необходимость гарантированной доставки сообще-
ния задавалась самим отправителем.
DEFINE Q(myQueue) PER(АРР)
В последнем случае режим доставки сообщения может задаваться с помощью
JMS-объекта Messageproducer, как показано в предыдущем примере. Если же канал на-
строен таким образом, что все отправляемые по нему сообщения автоматически становятся
постоянными, тогда параметры режима доставки, заданные объектом Messageproducer,
будут игнорироваться [47].
Пример: постоянные сообщения (.NET)
В .NET для получения постоянных сообщений необходимо создать транзакционную
очередь сообщений.
MessageQueue.Create("MyQueue", true);
Сообщения, отправляемые через такую очередь, автоматически становятся постоян-
ными [7].
154
Глава 4. Каналы обмена сообщениями
Адаптер канала (Channel Adapter)
Многие компании применяют обмен сообщениями (Messaging, с. 87) для интеграции
неоднородных, часто изолированных приложений.
Как подключить изолированное приложение к системе обмена сообщениями,
чтобы оно могло отправлять и получать сообщения?
Большинство приложений, используемых в крупных компаниях, не предназначались
для работы с инфраструктурой обмена сообщениями. На это есть масса причин. Многие
приложения изначально разрабатывались как самодостаточные, изолированные реше-
ния, даже несмотря на то, что содержащиеся в них данные или функциональность могли
бы быть задействованы другими системами. В качестве примера можно привести прило-
жения для мэйнфреймов, которые, как предполагалось, никогда не будут “общаться”
с другими приложениями. К сожалению, наличие унаследованных систем остается одной
из наиболее распространенных проблем интеграции корпоративных приложений.
Еще одна причина вытекает из того факта, что большинство связующего ПО, ориентиро-
ванного на обмен сообщениями, взаимодействует с другими системами посредством соб-
ственных, закрытых API. Как следствие этого разработчику приложения приходится пи-
сать множество интерфейсов для работы с системами обмена сообщениями — по одному
на каждого потенциального производителя связующего ПО.
Приложения, которым нужно обмениваться данными с другими системами, часто
ориентированы на использование более универсальных механизмов взаимодействия,
таких как обмен файлами или работа с таблицами баз данных. Чтение и запись файлов
являются базовыми функциями операционной системы и не зависят от специфических
интерфейсов API того или иного производителя. Точно так большинство бизнес-
приложений уже хранят свои данные в базе данных, поэтому им практически ничего
не стоит поместить туда и данные, предназначенные для других систем. И наконец, при-
ложение может предоставить доступ к своей функциональности посредством некоторого
универсального интерфейса, который может использоваться в любой другой интеграци-
онной стратегии, включая обмен сообщениями.
Другие приложения могут иметь возможность взаимодействия по простому протоколу
наподобие HTTP или TCP/IP. Указанные протоколы, однако, не столь надежны, как
канал сообщений (Message Channel, с. 93), а формат данных, используемый для такого
взаимодействия, специфичен для приложений и часто не совместим с форматом данных,
который применяется системой обмена сообщениями.
Если приложение написано разработчиками компании, к нему теоретически можно
добавить код, который позволит приложению отправлять и получать сообщения. Но это
может повысить сложность приложения, а также вызвать целый ряд “побочных” эффек-
тов. Кроме того, разработчики должны быть знакомы как с логикой приложения, так
и с интерфейсами обмена сообщениями. И разумеется, данный подход предполагает,
Адаптер канала (Channel Adapter)
155
что у компании имеется доступ к коду приложения. Если же оно было куплено у сторон-
него производителя в готовом виде, внести изменения в его код, скорее всего, не удастся.
Используйте адаптер канала (Channel Adaptef), который сможет осуществить дос-
туп к интерфейсу API или данным изолированного приложения, создать на основе
этих данных сообщение и разместить его в канале. Аналогичным образом адаптер
канала может получать сообщения, а затем в зависимости от их содержимого вы-
зывать в приложении ту или иную функциональность.
Адаптер Сообщение
канала
Канал
сообщений
Адаптер канала выполняет роль клиента для системы обмена сообщениями и по ее
требованию вызывает функции приложения через интерфейс последнего. Точно так он
может наблюдать за событиями, происходящими внутри приложения, и в ответ на них
вызывать систему обмена сообщениями. Благодаря такой схеме каждое приложение мо-
жет взаимодействовать с системой обмена сообщениями, а следовательно, и интегриро-
ваться с другими приложениями.
Адаптер канала может подключаться к различным уровням архитектуры приложения
(рис. 4.3). В зависимости от особенностей архитектуры и того, какие данные нужны сис-
теме обмена сообщениями, выделяют несколько типов адаптеров.
Рис. 4.3. Адаптер канала, подключенный к различным уровням архитектуры приложения
156
Глава 4. Каналы обмена сообщениями
1. Адаптер интерфейса пользователя. Адаптеры такого типа, метод работы которых
иногда пренебрежительно называют “прочесыванием экрана” (screen scraping),
эффективны во многих ситуациях. Пусть, к примеру, приложение реализовано на
платформе, которая не поддерживается системой обмена сообщениями, или вла-
делец приложения не слишком заинтересован в его интеграции. Это исключает
возможность функционирования адаптера канала на платформе приложения.
С другой стороны, пользовательский интерфейс таких приложений обычно дос-
тупен с других машин и платформ (например, терминалов 3270). Кроме того, по-
пулярность архитектуры “тонких клиентов” на основе Web привела к некоторому
возрождению интеграции через интерфейс пользователя. Применение пользова-
тельских интерфейсов, основанных на HTML, значительно облегчает создание
HTTP-запроса и обработку результатов. Еще одним преимуществом интеграции
на основе пользовательского интерфейса является отсутствие необходимости
прямого доступа к внутренним механизмам приложения. Иногда предоставление
доступа к внутренним функциям системы невозможно или нежелательно.
Используя адаптер интерфейса пользователя, другие системы получат такой же
доступ к приложению, как и обычный пользователь. Недостатком таких адапте-
ров является потенциальная уязвимость и низкая скорость обмена данными.
Приложение должно обработать данные, введенные “пользователем”, и визуали-
зировать на экране соответствующее окно. Адаптер канала, в свою очередь,
должен преобразовать содержимое этого окна обратно в необработанные данные.
Этот процесс включает в себя много лишних шагов и выполняется довольно мед-
ленно. Кроме того, пользовательские интерфейсы меняются гораздо чаще, чем
логика приложения, а каждое изменение интерфейса пользователя влечет за со-
бой необходимость соответствующего изменения адаптера канала.
2. Адаптер бизнес-логики. Большинство бизнес-приложений предоставляют доступ
к своей функциональности через интерфейсы API (application programming
interface — программный интерфейс приложения). Это может быть как набор
компонентов (например, компоненты EJB, объекты СОМ, компоненты CORBA и
т.п.), так и прямой программный интерфейс (библиотеки C++, C# или Java).
Поскольку указанные интерфейсы специально предназначены для доступа других
приложений, они обычно более стабильны, чем пользовательский интерфейс.
В большинстве случаев доступ через API является и более эффективным. В общем
случае, если приложение обладает нормальным интерфейсом API, наиболее
предпочтительным решением будет именно данный тип адаптера канала.
3. Адаптер базы данных. Многие бизнес-приложения хранят свои данные в реляци-
онной БД. Поскольку вся необходимая информация уже находится в базе данных,
адаптер канала может извлекать ее оттуда, не вторгаясь в работу приложения.
Это, пожалуй, наименее агрессивный способ интеграции приложений. Более то-
го, адаптер канала может добавлять триггеры к интересующим его таблицам и от-
правлять сообщения при каждом изменении данных в таблицах. Адаптеры такого
типа достаточно эффективны и универсальны, учитывая и тот факт, что на рынке
реляционных СУБД доминируют лишь два-три производителя. Это позволяет
подключаться к самым разнообразным приложениям, используя относительно
универсальный адаптер. Недостатком использования адаптера базы данных явля-
ется глубокое вторжение в данные, используемые приложением. Это не так опас-
Адаптер канала (Channel Adapter)
157
но, если мы просто читаем данные, а вот запись обновлений прямо в базу данных,
минуя приложение, — довольно рискованное занятие. Кроме того, многие про-
изводители приложений оставляют за собой право изменять схему базы данных
внезапно и по своему усмотрению. Из-за этого решения с адаптерами базы дан-
ных крайне неустойчивы к изменениям.
Говоря об адаптере канала, следует указать на важное ограничение: адаптеры канала
могут преобразовывать сообщения в вызовы функций приложения, но для этого формат
сообщений должен точно соответствовать реализации компонентов приложения, к кото-
рым обращается адаптер. К примеру, адаптер базы данных обычно требует, чтобы имена
полей во входящих сообщениях были такими же, как имена таблиц и полей в базе данных
приложения. Такой формат сообщений полностью определяется внутренней структурой
конкретного приложения и плохо подходит для обмена данными при интеграции с дру-
гими приложениями. По этой причине большинство адаптеров канала приходится ком-
бинировать с трансляторами сообщений (Message Translator, с. 115). Последние будут пре-
образовывать сообщение из формата, специфичного для указанного приложения, в фор-
мат, совместимый с канонической моделью данных (Canonical Data Model, с. 367).
Адаптеры канала не обязательно должны работать на том компьютере, на котором на-
ходится приложение или база данных. Адаптер канала может подключаться к логике
приложения или базе данных через протоколы наподобие HTTP или ODBC. Это избав-
ляет от необходимости устанавливать дополнительное ПО на сервере приложений или
баз данных. С другой стороны, указанные протоколы не обеспечивают такое качество
обслуживания, какое может предоставить канал обмена сообщениями (например, гаран-
тированную доставку). По этой причине необходимо помнить о том, что удаленное со-
единение с базой данных представляет собой потенциальную точку сбоя.
Некоторые адаптеры канала являются однонаправленными. К примеру, если адаптер
канала подключается к приложению через протокол HTTP, он, вероятно, сможет только
потреблять сообщения и в ответ на них вызывать функции приложения. Распознавать
непосредственные изменения в данных приложения и генерировать сообщения он вряд
ли сможет (разве что только путем повторяющегося опроса, что весьма неэффективно).
Существует интересная разновидность адаптера канала, называемая адаптером
метаданных (Metadata Adapter) или адаптером времени разработки (Design-Time Adapter).
Адаптер такого типа не вызывает функции приложения, а извлекает метаданные, описы-
вающие внутренние форматы данных приложения. Извлеченные метаданные могут за-
тем быть использованы для настройки трансляторов сообщений или для обнаружения из-
менений в форматах данных, используемых приложением (см. раздел “Введение” гла-
вы 8). Многие интерфейсы приложений поддерживают такую процедуру извлечения
метаданных. К примеру, большинство коммерческих баз данных включают в себя набор
системных таблиц, содержащих метаданные в виде описания таблиц приложения. Точно
так большинство платформ компонентов (например, J2EE и .NET) обладают специаль-
ными функциями “отражения” (reflection functions), которые позволяют компоненту
получить сведения о методах, предоставляемых другим компонентом.
Особой разновидностью адаптера канала является мост обмена сообщениями
(Messaging Bridge, с. 159). Он соединяет систему обмена сообщениями не с конкретным
приложением, как обыкновенный адаптер, а с другой системой обмена сообщениями.
158
Глава 4. Каналы обмена сообщениями
Обычно адаптер канала реализуют в виде транзакционного клиента (Transactional
Client, с. 498). Это гарантирует, что каждое действие адаптера будет успешно завершено
как в системе обмена сообщениями, так и в системе, с которой та связывается при по-
мощи адаптера.
Пример: торговля на бирже
Пусть система биржевой торговли ведет журнал котировок, оформив его в виде таблицы ба-
зы данных. Тогда система обмена сообщениями может включать в себя адаптер реляцион-
ной базы данных, который будет извлекать сообщения из канала и помешать данные о ко-
тировках в указанную таблицу. Такой адаптер между каналом и реляционной СУБД будет
представлять собой адаптер канала (Channel Adapter). Система также сможет получать
внешние запросы о котировках из Интернета (по протоколам TCP/IP и HTTP) и пересы-
лать их в виде внутренних запросов по своему внутреннему каналу запросов о котировках.
Адаптер между Интернетом и внутренним каналом также будет адаптером канала.
Пример: коммерческие ЕА1-средства
Производители коммерческих EAI-средств часто включают в состав своих продуктов
коллекцию готовых адаптеров канала (Channel Adapter) для популярных пакетов прило-
жений. Наличие адаптеров значительно упрощает разработку интеграционных решений.
Многие производители также оснащают свои продукты более универсальными адапте-
рами базы данных и наборами средств для разработки ПО (software development
kit — SDK), которые могут применяться для создания собственных адаптеров.
Пример: адаптеры для унаследованных платформ
Некоторые производители ПО выпускают адаптеры для связи популярных систем обме-
на сообщениями с устаревшими системами, функционирующими на платформах UNIX,
MVS, OS/2, AS/400, Unisys, VMS и т.п. Большинство таких адаптеров приспособлены
под конкретную систему обмена сообщениями. К примеру, EnvoyMQ от компании Envoy
Technologies — это адаптер канала (Channel Adapter), позволяющий соединять целый ряд
унаследованных платформ со службой MSMQ. Он состоит из клиентского компонента,
работающего на компьютере с унаследованной системой, и серверного компонента, ко-
торый функционирует на компьютере Windows с установленной на нем службой MSMQ.
Пример: адаптеры для Web-служб
Многие системы обмена сообщениями содержат адаптеры канала (Channel Adapter) для
обмена сообщениями SOAP с транспортом HTTP. Благодаря этому сообщения SOAP
могут передаваться по интрасети с использованием надежной, асинхронной системы об-
мена сообщениями, а также по глобальному Интернету (в том числе через брандмауэры)
с использованием протокола HTTP. Примером такого адаптера является Web Services
Gateway для IBM WebSphere Application Server.
Мост обмена сообщениями (Messaging Bridge)
159
Мост обмена сообщениями (Messaging Bridge)
Компания использует обмен сообщениями (Messaging, с. 87) для взаимодействия между
приложениями. К сожалению, в компании функционирует сразу несколько систем об-
мена сообщениями. Это весьма затрудняет выбор системы, к которой необходимо под-
ключить то или иное приложение.
Как связать несколько систем обмена сообщениями, чтобы сообщения, переда-
ваемые по одной из них, были доступны и в других системах?
Распространенной проблемой интеграции корпоративных приложений является
наличие в компании сразу нескольких систем обмена сообщениями. Они могут появить-
ся в результате слияния или поглощения компаний, в каждой из которых применялась
собственная система обмена сообщениями. Иногда компания, использующая некоторую
систему обмена сообщениями для интеграции унаследованных систем (или приложений
для мэйнфреймов), выбирает другую систему обмена сообщениями для своего сервера
Web-приложений J2EE и .NET. В результате указанные системы приходится интегриро-
вать. Еще один распространенный пример— это приложение, взаимодействующее
с системами нескольких компаний, например В2В-клиент, желающий выступать в каче-
стве покупателя в нескольких аукционных системах. Если в последних используются
разные системы обмена сообщениями, приложение-покупатель может захотеть перено-
сить сообщения, получаемые им в разных системах, в одну внутреннюю систему обмена
сообщениями. И наконец, в качестве еще одного примера можно рассмотреть очень
большую корпорацию с огромным числом каналов сообщений (Message Channel, с. 93) и
конечных точек сообщения (Message Endpoint, с. 124). Такой корпорации может потребо-
ваться несколько экземпляров системы обмена сообщениями, а значит, эти экземпляры
надо как-то связать между собой.
Пусть приложения некоторой компании используют две системы обмена сообщениями.
Если сообщения одной системы не представляют никакого интереса для приложений,
использующих другую систему, тогда обе системы могут оставаться полностью изолиро-
ванными друг от друга. На практике, однако, чаще бывает наоборот: приложения, исполь-
зующие одну систему обмена сообщениями, заинтересованы в том, чтобы передавать свои
сообщения в другую систему обмена сообщениями (или получать их оттуда).
Среди разработчиков весьма распространено заблуждение, что решить такую пробле-
му можно с помощью стандартизированного интерфейса API для обмена сообщениями,
например JMS. Это в корне неверно. С помощью JMS можно сделать так, чтобы две со-
вместимые системы обмена сообщениями выглядели для клиентского приложения, как
одна система, но никак нельзя обеспечить взаимодействие этих систем между собой. Что-
бы системы обмена сообщениями работали друг с другом, они должны быть интеропера-
бельными, т.е. использовать один и тот же формат сообщений, а также одним способом
передавать сообщение из одного хранилища сообщений в другое. Но системы обмена со-
общениями, созданные различными производителями, вряд ли будут интероперабель-
160
Глава 4. Каналы обмена сообщениями
ними; прежде всего, потому, что хранилище сообщений одного производителя будет ра-
ботать исключительно с хранилищами сообщений этого же производителя.
Каждое приложение компании можно оснастить несколькими клиентами: по одному
на каждую систему обмена сообщениями. Это, однако, повысит сложность приложений
и степень дублирования на уровне обмена сообщениями. Избыточность такого решения
становится особенно очевидной, если в компании появится еще одна система обмена
сообщениями, и все существующие приложения понадобится снова модифицировать.
С другой стороны, каждое приложение могло бы взаимодействовать только со своей сис-
темой обмена сообщениями и игнорировать данные в других системах. Это упростит
структуру приложения, но “отрежет” его от целого пласта корпоративных данных.
Нам же требуется следующее: сделать так, чтобы данные из одной системы обмена сооб-
щениями стали доступными для приложений, которые тоже интересуются указанными
данными, но сами используют другую систему обмена сообщениями.
Используйте мост обмена сообщениями (Messaging Bridge) как “связующее зве-
но” между системами обмена сообщениями, которое реплицирует сообщения
из одной системы в другую и наоборот.
Система обмена Мост обмена Система обмена
сообщениями 1 сообщениями сообщениями 2
Если рассматривать систему обмена сообщениями как единый, цельный объект,
то связать между собой две такие системы не представляется возможным. Вместо этого
мы по отдельности связываем канал одной системы и соответствующий ему канал другой
системы. Мост обмена сообщениями— это набор адаптеров канала (Channel Adapter,
с. 154), только в роли приложения, не имеющего возможности отправлять и получать со-
общения, здесь выступает другая система обмена сообщениями, а каждая пара адаптеров
связывает пару соответствующих каналов каждой из систем. Мост выступает в качестве
преобразователя одного набора каналов в другой набор, а также преобразует сообщения
из одного формата в другой. Каналы, связанные мостом, могут применяться как для
передачи сообщений между обычными клиентами систем обмена сообщениями, так и
строго для передачи сообщений в другие системы обмена сообщениями.
Возможно, вам придется вручную реализовывать мост обмена сообщениями для своей
компании. Мост — это специализированный вариант конечной точки сообщения (Message
Endpoint, с. 124), являющийся клиентом обеих систем обмена сообщениями. Когда сообще-
ние размещается в канале одной из систем, мост потребляет это сообщение, а затем отправ-
ляет другое сообщение с таким же содержимым в соответствующий канал второй системы.
Многие готовые системы обмена сообщениями обладают расширениями для связи
с аналогичными системами других производителей. Благодаря этому мост часто можно
купить, а не разрабатывать вручную.
Мост обмена сообщениями (Messaging Bridge)
161
Если другая “система обмена сообщениями” на деле является простым протоколом
наподобие HTTP, воспользуйтесь шаблоном адаптер канала.
Необходимость в наличии моста обмена сообщениями вызвана тем, что каждый произ-
водитель систем обмена сообщениями имеет собственное видение того, как следует
представлять сообщения и каким способом передавать их из одного хранилища в другое.
Между тем для стандартизации указанных подходов можно было бы применять
Web-службы. Передавая сообщения в соответствии со стандартами Web-служб, можно
добиться того, чтобы две копии систем обмена сообщениями (даже от разных производи-
телей) функционировали, как единое целое. Более подробно о стандартах WS-Reliability
и WS-ReliableMessaging будет идти речь в главе 14.
Пример: торговля на бирже
У брокерской фирмы может быть система обмена сообщениями, которая применяется
для передачи данных между ее различными офисами. У банка может быть другая система
обмена сообщениями, используемая для взаимодействия между его отделениями. Пред-
положим, что брокерская фирма и банк решили объединиться в компанию, которая
будет предоставлять банковские и инвестиционные услуги. Какую из систем обмена со-
общениями должна использовать новоиспеченная компания? Вместо того чтобы переде-
лывать половину имеющихся приложений под использование другой системы обмена
сообщениями, компания может воспользоваться мостом обмена сообщениями (Messaging
Bridge), чтобы связать системы. С его помощью приложение банка и приложение брокер-
ской фирмы могут согласовывать свои действия, чтобы, к примеру, перевести деньги
с депозита на счет, предназначенный для оплаты торговых операций.
Пример: мосты MSMQ
Технология MSMQ определяет архитектуру на основе коннекторов, которая позволяет
приложениям, использующим MSMQ, отправлять и получать сообщения из других сис-
тем обмена сообщениями (не MSMQ). Приложение MSMQ, использующее коннектор,
может выполнять такие же операции над каналами других систем обмена сообщениями,
как и над каналами MSMQ [7].
В состав Microsoft Host Integration Server входит служба MSMQ-MQSeries Bridge, ко-
торая обеспечивает совместную работу систем обмена сообщениями MSMQ и MQSeries.
Она позволяет приложениям MSMQ отправлять сообщения по каналам MQSeries и об-
ратно, в результате чего обе системы функционируют, как единое целое.
У компании Envoy Technologies, владеющей лицензией на MSMQ-MQSeries Bridge,
есть схожий продукт под названием Envoy Connect. Он связывает серверы MSMQ и
BizTalk с серверами обмена сообщениями, работающими на платформах, отличных от
Windows (в частности, J2EE), координируя обмен сообщениями на основе J2EE и .NET.
Пример: мосты SonicMQ
Для службы SonicMQ из пакета Sonic Software разработаны специальные продукты серии
SonicMQ Bridge, которые поддерживают IBM MQSeries, TIBCO TIB/Rendezvous и JMS.
С их помощью сообщения из каналов Sonic можно передавать в каналы других систем
обмена сообщениями.
162
Глава 4. Каналы обмена сообщениями
Шина сообщений (Message Bus)
В компании уже долгое время функционирует несколько систем. Теперь они должны
получить возможность обмениваться данными и унифицированным образом отвечать на
набор распространенных бизнес-запросов.
Как организовать согласованную работу отдельных приложений, не поставив их в
зависимость друг от друга, чтобы добавление или удаление одного из приложений
никоим образом не влияло на остальные?
В большой компании часто имеется ряд приложений, которые функционируют неза-
висимо друг от друга, но при этом должны согласованно работать некоторым унифици-
рованным образом. Методология интеграции корпоративных приложений (Enterprise
Application Integration — EAI) определяет решение этой проблемы, но не описывает, как
его реализовать.
Представим себе страховую компанию, предоставляющую несколько видов страховых
услуг (страхование жизни, здоровья, автомобиля, жилья и т.п.). В результате многочис-
ленных корпоративных слияний и изменений в IT-сфере оказалось, что программная
инфраструктура компании состоит из нескольких разнородных приложений, каждое из
которых предназначено для управления теми или иными услугами. Страховой агент, пы-
тающийся продать клиенту несколько разных полисов, должен при оформлении каждого
полиса входить в другую систему и заново выполнять одни и те же действия (рис. 4.4).
Это приводит к бессмысленной трате времени и повышает риск возникновения ошибок.
Страховой
агент
Рис. 4.4. Необходимость интеграции приложений в страховой компании
Страховому агенту требуется одно унифицированное приложение, которое позволило
бы сразу продать клиенту пакет полисов. Другим сотрудникам страховой компании, на-
пример оценщикам или представителям отдела по работе с клиентами, требуются свои
программы для работы со страховыми услугами, но и они хотят, чтобы эти программы
Шина сообщений (Message Bus)
163
функционировали унифицированным образом. Приложения, посвященные отдельным
услугам, должны иметь возможность работать согласованно, чтобы автоматически пред-
лагать скидку клиенту, пожелавшему приобрести несколько полисов, или обрабатывать
страховое требование, которое покрывается сразу несколькими полисами.
Сотрудники IT-департамента страховой компании могли бы переписать все прило-
жения, чтобы те основывались на одной технологии и могли работать совместно друг
с другом, но расходы на замену существующих, исправно функционирующих систем
(даже несмотря на отсутствие возможности совместной работы) были бы слишком вели-
ки. Можно было бы создать специальное унифицированное приложение для страховых
агентов, но тогда его пришлось бы каким-то образом связывать с существующими систе-
мами, которые применяются для управления страховыми услугами. Вместо унификации
систем у компании появится еще одна система, не интегрированная с другими.
Приложение, применяемое страховыми агентами, можно было бы интегрировать
с остальными системами, но это значительно повысило бы его сложность. Изменения
пришлось бы вносить и в приложения для оценщиков и представителей отдела по работе
с клиентами. Что еще печальнее, наличие унифицированных приложений для пользова-
телей-агентов, пользователей-оценщиков и т.п. никак не способствует интеграции при-
ложений, посвященных отдельным услугам, между собой.
Даже если удастся организовать совместную работу указанных приложений, любое
изменение структуры компании нарушит ее. И потом, не все приложения будут доступны
все время, и те из них, которые в настоящий момент работают, должны как можно мень-
ше зависеть от неработающих. Наконец, со временем в компании будут появляться но-
вые приложения и исчезать старые. Добавление и удаление приложений также должно
происходить с минимальным влиянием на остальные приложения. Итак, страховой ком-
пании требуется, чтобы приложения, посвященные отдельным страховым услугам, коор-
динировали свои действия слабо связанным образом и обладали возможностью интегра-
ции с приложениями пользователей (агентов, оценщиков и т.п.).
Организуйте связующее ПО между приложениями в виде шины сообщений
(Message Bus), которая обеспечит согласованную работу приложений через обмен
сообщениями.
Шина сообщений
Приложение
164
Глава 4. Каналы обмена сообщениями
Шина сообщений представляет собой комбинацию канонической модели данных (Canonical
Data Model, с. 367), стандартного набора команд и инфраструктуры обмена сообщениями,
позволяющей разным системам взаимодействовать друг с другом через общий набор ин-
терфейсов. Это напоминает шину компьютера, которая выполняет роль “центрального
узла” общения между процессором, оперативной памятью и периферийными устройства-
ми. Шину сообщений, как и ее аппаратный аналог, образуют несколько компонентов.
1. Стандартная коммуникационная инфраструктура. Штырьки и провода аппаратной
шины PCI выполняют роль стандартной, хорошо известной физической инфра-
структуры компьютера, к которой подключаются любые другие устройства. У шины
сообщений должна быть аналогичная коммуникационная структура, которая будет
выполнять роль межплатформенного, универсального адаптера между любыми
приложениями, подключенными к шине. В качестве таковой обычно используют
систему обмена сообщениями. Указанная инфраструктура может включать в себя
функциональность маршрутизатора сообщений (Message Router, с. 109), чтобы обес-
печить корректную маршрутизацию сообщений между системами. Еще одно рас-
пространенное решение— использовать каналы “публикация-подписка” (Publish-
Subscribe Channel, с. 134) для рассылки сообщений всем получателям.
2. Адаптеры. Подключение систем с шиной сообщений может осуществляться по-
разному. Некоторые приложения могут изначально обладать встроенными воз-
можностями для подключения к шине, но большинству приложений для этого
понадобятся адаптеры. Это коммерческие или разработанные своими силами
адаптеры канала (Channel Adapter, с. 154) и активаторы службы (Service Activator,
с. 545). Они могут специализироваться на обработке заданий (например, вызове
транзакций C1CS с нужными параметрами) или на преобразовании данных из
общего формата, используемого шиной, в конкретные структуры, используемые
теми или иными приложениями. Для этого также понадобится каноническая мо-
дель данных, согласованная всеми участниками общения.
3. Стандартная инфраструктура команд. Архитектура ПК включает в себя стандарт-
ный набор команд, представляющих те или иные операции при взаимодействии
устройств через шину (прочитать байты по указанному адресу, записать байты по
указанному адресу). При обмене сообщениями через шину тоже необходимо
иметь стандартный набор команд, который будет понятен всем участникам обще-
ния. Действие этого механизма описано в разделе, посвященном сообщению с ко-
мандой (Command Message, с. 169). Еще одна распространенная реализация ука-
занного механизма — это канал типа данных (Datatype Channel, с. 139), где реше-
ние о перенаправлении сообщений того или иного типа (например, заказов на
поставку) в конечный пункт назначения в явном виде принимается маршрутиза-
тором сообщений. На этом месте аналогия с аппаратной шиной заканчивается, по-
тому что сообщения, которыми приложения обмениваются через шину сообщений,
имеют куда более высокий уровень сложности, чем простые сообщения типа
“чтение/запись”, передаваемые по физической шине.
В примере со страховой компанией шина сообщений может выполнять роль универ-
сального коннектора между различными системами страхования, а также универсального
интерфейса для клиентских приложений, которым необходимо подключаться к системам
страхования (рис. 4.5).
Шина сообщений (Message Bus)
165
Рис. 4.5. Шина сообщений страховой компании
В схеме, показанной на рис. 4.5, имеется два пользовательских интерфейса. Они зна-
ют только о шине сообщений, но ничего не знают о системах страхования, с которыми свя-
зываются посредством шины. Шина самостоятельно перенаправляет сообщения с коман-
дой в те или иные системы. В некоторых случаях лучшим способом обработки сообщения с
командой является создание адаптера между шиной и системой страхования, который бу-
дет интерпретировать команду, а затем “общаться” с системой страхования на понятном
ей языке (к примеру, вызывая транзакцию CICS или обращаясь к интерфейсу API C++).
В других ситуациях логику обработки команд можно встроить прямо в систему страхова-
ния как дополнительный способ вызова ее функциональности.
Создав шину сообщений для пользовательского интерфейса страхового агента, ее легко
повторно использовать и для интерфейсов других пользователей, например оценщиков,
представителей отдела по работе с клиентами и самих клиентов, применяющих
Web-интерфейс для наблюдения за состоянием собственных счетов. Функциональность
и управление безопасностью в указанных интерфейсах может отличаться, но необходи-
мость работать с системами прикладного уровня одна и та же.
С точки зрения компании шина сообщений образует простую и удобную архитектуру,
ориентированную на службы (service-oriented architecture — SOA). Каждой службе соответ-
ствует как минимум один канал запросов, который принимает запросы в согласованном
формате, а также, вероятно, как минимум один соответствующий канал ответов, кото-
рый поддерживает заранее заданный формат ответов. Каждое приложение, входящее в
инфраструктуру компании, может использовать эти службы, делая запросы и ожидая от-
веты. Каналы запросов, по сути, выполняют роль каталога доступных служб.
Внедрение шины сообщений требует, чтобы во всех использующих ее приложениях при-
менялась одна и та же каноническая модель данных. Приложения, передающие свои сообще-
ния шине, могут зависеть от маршрутизаторов сообщений, которые будут перенаправлять
сообщения в конечные пункты назначения. Приложениям, которые не поддерживают
обмен сообщениями, могут понадобиться адаптеры канала и активаторы службы.
166
Глава 4. Каналы обмена сообщениями
Пример: торговля на бирже
Владельцы системы биржевой торговли хотят, чтобы система предлагала унифицирован-
ный пакет услуг, включая совершение торговых операций на бирже, покупку облигаций,
выставленных на аукцион, обновление котировок, управление портфелем ценных бумаг
и т.п. Все это может потребовать нескольких систем прикладного уровня, которые долж-
ны согласовывать свои действия друг с другом. Чтобы унифицировать упомянутые услуги
для конечного пользователя, в систему можно было бы внедрить промежуточное прило-
жение, которое предлагало бы пользователю выполнение услуг и делегировало полномо-
чия по их выполнению той или иной системе прикладного уровня. Более того, оно могло
бы применяться системами прикладного уровня для координации своих действий. К со-
жалению, такое приложение быстро станет “узким местом” и одной точкой сбоя.
Более удачным подходом является реализация шины сообщений (Message Bus) с каналами
для запроса служб, выполняющих ту или иную услугу, и получения ответов. Эта же шина
может применяться системами прикладного уровня для согласования своих действий друг с
другом. Система интерфейсного уровня просто подключается к шине и использует ее для
вызова служб. Шину сообщений достаточно легко распределить между несколькими компь-
ютерами, чтобы обеспечить отказоустойчивость и балансировку нагрузки.
Подключить приложения интерфейсного уровня к шине сообщений несложно; они
должны лишь отправлять и получать сообщения из нужных каналов. Один графический
интерфейс пользователя может применяться розничным брокером для управления порт-
фелями ценных бумаг (ЦБ) своих клиентов. Другой пользовательский интерфейс, а точ-
нее — Web-интерфейс, может применяться любым клиентом, имеющим доступ к Ин-
тернету и Web-обозреватель, для управления собственным портфелем ЦБ. Еще несколь-
ко приложений интерфейсного уровня (без графического интерфейса пользователя)
могут поддерживать программы управления личными финансами наподобие Intuit
Quicken и Microsoft Money, предоставляя пользователям этих программ возможность за-
гружать сведения о своих активах и текущих котировках. При наличии шины сообщений
разработать новые приложения для пользователей будет намного проще.
Сама система биржевой торговли также может использовать преимущества новой
архитектуры, меняя одно приложение для осуществления торговых операций на другое
или распространяя запросы о котировках на несколько приложений. Чтобы реализовать
изменения подобного рода, достаточно лишь подключить или отключить нужное прило-
жение от шины сообщений. Вносить изменения в другие приложения не потребуется;
они продолжат отправлять сообщения шине сообщений в обычном режиме.
Глава 5
Построение сообщений
Введение
В главе 3 обсуждался шаблон сообщение (Message, с. 98). Когда два приложения хотят
обменяться порцией данных, они упаковывают эти данные в сообщение. Канал сообще-
ний (Message Channel, с. 93) не может передать необработанные данные как таковые, но
может передать их упакованными в сообщение. В связи с необходимостью создания
и отправки сообщения возникает несколько вопросов.
• Цель отправки сообщения. Само по себе сообщение — не более чем набор данных.
Отправитель сообщения, однако, может отсылать его с различными намерениями,
зависящими от того, что (как он ожидает) получатель сделает с сообщением.
Отправитель может отослать сообщение с командой (Command Message, с. 169), ука-
зав, какую функцию или метод он хочет вызвать на стороне получателя. Иными
словами, отправитель сообщает получателю, какой код требуется запустить.
Отправитель может отослать сообщение с данными документа (Document Message,
с. 171), передавая получателю некоторую структуру данных. В этом случае отправи-
тель передает получателю данные, но не требует, чтобы получатель что-то с ними
сделал. И наконец, он может отослать сообщение о событии (Event Message, с. 174),
уведомляя получателя о каких-либо изменениях. При этом отправитель не просит
получателя отреагировать на сообщение — он просто его о чем-то уведомляет.
• Возвращение ответа. Когда приложение отправляет сообщение, оно часто ожидает
ответа с подтверждением того, что сообщение было обработано, и результатом об-
работки. Этот сценарий описан в шаблоне запрос-ответ (Request-Reply, с. 177).
В качестве запроса обычно выступает сообщение с командой, а в качестве ответа —
сообщение с данными документа, содержащее некоторый результат или исключе-
ние. Инициатор запроса должен указать в своем сообщении обратный адрес (Return
Address, с. 182), чтобы получатель, выполнивший запрос, знал, какой канал ис-
пользовать для передачи ответа. Отправитель может ожидать выполнения не-
скольких своих запросов, поэтому ответ на запрос должен содержать идентифика-
тор корреляции (Correlation Identifier, с. 186). Последний указывает, какому запросу
соответствует данный ответ.
168
Глава 5. Построение сообщений
Существует два распространенных сценария с использованием шаблона запрос-
ответ, каждый из которых заслуживает внимания. Оба они предполагают исполь-
зование запроса в виде сообщения с командой и соответствующего ответа в виде со-
общения с данными документа. В первом сценарии (назовем его “удаленный вызов
процедуры с помощью обмена сообщениями”) отправитель хочет не только вы-
звать функцию на стороне получателя, но и получить в ответ значение, сгенериро-
ванное этой функцией. Именно так приложения выполняют удаленный вызов
процедуры (remote procedure call — RPC), используя обмен сообщениями (Messaging,
с. 87). Во втором сценарии, “запрос с помощью обмена сообщениями”, отправи-
тель создает запрос; получатель выполняет запрос и возвращает ответ с результи-
рующим набором данных. Так приложения используют обмен сообщениями для
удаленного выполнения запросов.
• Большие объемы данных. Иногда приложение хочет передать действительно
огромную структуру данных, которая может не уместиться в одном сообщении.
В этом случае разбейте данные на более мелкие порции и отправьте их в виде
цепочки сообщений (Message Sequence, с. 192). Порции данных должны отправляться
именно как цепочка, а не как простая группа сообщений, чтобы получатель смог
воссоздать исходную структуру данных.
• Медленный обмен сообщениями. Одна из основных проблем обмена сообщениями
связана с тем, что отправитель часто не знает, когда сообщение попадет к получа-
телю. Между тем содержимое сообщения может иметь определенную временную
актуальность, поэтому если сообщение не было получено в течение некоторого
промежутка времени, его следует проигнорировать и отбросить. В этом случае от-
правитель может задать срок действия сообщения (Message Expiration, с. 198). Если
по истечении срока действия система так и не смогла доставить сообщение, она
должна уничтожить его или отправить в канал недоставленных сообщений (Dead
Letter Channel, с. 147). Если же получателю все-таки будет доставлено сообщение с
истекшим сроком годности, его следует уничтожить.
Итак, просто использовать сообщение недостаточно. Его следует применять при каж-
дой передаче данных. В этой главе рассматривается еще несколько решений, которые
помогают наладить обмен сообщениями.
Сообщение с командой (Command Message)
169
Сообщение с командой (Command Message)
Приложению необходимо вызывать функциональность других приложений. Обычно
для этого применяют удаленный вызов процедуры (Remote Procedure Invocation, с. 85),
но сейчас приложение хочет воспользоваться всеми преимуществами обмена сообщениями
(Messaging, с. 87).
Как использовать обмен сообщениями для вызова процедуры другого приложения?
Преимуществом удаленного вызова процедуры является его синхронность, благодаря
которой вызов выполняется немедленно. Иногда, впрочем, это преимущество оборачи-
вается недостатком. Если вызов не может быть выполнен немедленно (например, потому
что сеть недоступна или потому что удаленный процесс не выполняется и не перехваты-
вает запросы), он не сработает. Если бы вызов был асинхронным, он бы повторялся сно-
ва и снова до тех пор, пока процедура удаленного приложения не была успешно вызвана.
Локальный вызов более надежен, чем удаленный. Если бы вызывающий метод мог
передать получателю вызов процедуры в виде сообщения (Message, с. 98), получатель мог
бы вызвать необходимую процедуру локально. Итак, вопрос состоит в том, как превра-
тить вызов процедуры в сообщение.
Существует проверенный шаблон для инкапсуляции запроса в объект. Шаблон
команда (Command) из [12] показывает, как превратить запрос в объект, который можно
хранить или передавать дальше. Если бы этот объект был сообщением, его можно было
бы передать по каналу сообщений (Message Channel, с. 93). Аналогичным образом состоя-
ние команды (например, параметры метода) можно было бы сохранить внутри состояния
сообщения.
Используйте сообщение с командой (Command Message) для надежного вызова
процедуры другого приложения.
Отправитель Сообщение Получатель
с командой
[с] — команда
Какого-либо определенного типа сообщений для команд не существует. Сообщение
с командой— это обычное сообщение, в котором содержится команда. В JMS сообще-
ние с командой может быть сообщением любого типа. В качестве примера можно привес-
ти сообщение ObjectMessage, содержащее объект команды Serializable, или сооб-
щение TextMessage, содержащее текст команды в формате XML. В .NET сообщение с
170
Глава 5. Построение сообщений
командой — это сообщение (Message, с. 98), в котором хранится команда. Сообщением
с командой будет и запрос SOAP.
Сообщения с командой обычно отправляются по каналу “точка-точка” (Point-to-Point
Channel, с. 131), чтобы каждая команда была потреблена и выполнена только один раз.
Пример: SOAP и WSDL
Рассмотрим обмен сообщениями SOAP в стиле RPC согласно спецификациям SOAP [36]
и WSDL [45]. В этом случае сообщение-запрос будет разновидностью сообщения с коман-
дой (Command Message). Тело такого сообщения SOAP (документ XML) содержит имя ме-
тода, вызываемого на стороне получателя, а также значения параметров, которые необ-
ходимо передать методу. Имя метода должно быть таким же, как и одно из имен сообще-
ний (атрибут name элемента message), определенных в WSDL-описании службы
получателя.
В этом примере, взятом из спецификации SOAP, вызывается метод получателя
GetLastTradePrice с единственным параметром symbol.
< SOAP-ENV:Envelope
xmlns:SOAP-ENV="http://schemas.xmlsoap.org/soap/envelope/"
SOAP-ENV:encodingStyle="http://schemas.xmlsoap.org/soap/encoding/">
<SOAP-ENV:Body>
<m:GetLastTradePrice xmlns:m="Some-URI">
<symbol>DIS</symbol>
</m:GetLastTradePrice>
</SOAP-ENV:Body>
</SOAP-ENV:Envelope >
Можно было бы ожидать, что имя метода в теле сообщения SOAP будет значением
некоторого стандартного элемента <method>. В действительности же это имя некоторого
специального элемента, к которому добавлен префикс в виде пространства имен т.
Наличие отдельного типа элемента XML для каждого метода позволяет задать имена, ти-
пы и порядок его параметров, а значит, делает проверку правильности данных XML куда
более точной.
Сообщение с данными документа (Document Message)
171
Сообщение с данными документа (Document Message)
Приложение хочет передать данные другому приложению. Это можно было бы сде-
лать с помощью передачи файла (File Transfer, с. 80) или общей базы данных (Shared
Database, с. 83), но указанные подходы имеют ряд недостатков. Предпочтительнее орга-
низовать передачу данных через обмен сообщениями (Messaging, с. 87).
Как использовать обмен сообщениями для передачи данных между приложениями?
Классическая проблема распределенной обработки данных выглядит следующим
образом: у одного процесса есть данные, необходимые другому процессу. Для пересылки
данных можно воспользоваться передачей файла, но указанное решение не слишком
хорошо координирует работу приложений. Файл, созданный одним приложением, может
довольно долго находиться в бездействии, прежде чем его прочитает другое приложение.
Если же файл будет прочитан несколькими приложениями, непонятно, какое из них
должно отвечать за его удаление.
Использование общей базы данных требует добавления к базе данных новой схемы или
принудительного приведения данных в соответствие существующей схеме. Когда же тре-
буемые данные окажутся в базе данных, возникает риск того, что к ним смогут получить
доступ другие приложения, которые не должны видеть эти данные. Наконец, инициировать
прочтение данных получателем будет сложно, а попытка координации действий несколь-
ких получателей приведет к спору относительно того, кто должен удалять эти данные.
Для отправки данных можно воспользоваться удаленным вызовом процедуры (Remote
Procedure Invocation, с. 85), но тогда выходит, что отправитель не только отсылает данные,
но и диктует получателю (через вызываемую процедуру), что с ними нужно сделать. По-
добная ситуация возникает и при отправке данных в сообщении с командой (Command
Message, с. 169). Кроме того, удаленный вызов процедуры предполагает двустороннее взаи-
модействие, что не всегда нужно, если мы хотим просто передать данные из одного при-
ложения в другое.
Несмотря на все вышесказанное, мы хотим передавать данные, используя обмен сооб-
щениями. Последний более надежен, чем удаленный вызов процедуры. Можно восполь-
зоваться каналом “точка-точка” (Point-to-Point Channel, с. 131), чтобы гарантировать по-
требление данных только одним получателем (без дублирования), или же каналом
“публикация-подписка” (Publish-Subscribe Channel, с. 134), если мы хотим, чтобы копию
данных получила каждая заинтересованная сторона. Так как же воспользоваться пре-
имуществами обмена сообщениями, не превращая сообщение (Message, с. 98) в некое подо-
бие удаленного вызова процедуры?
172
Глава 5. Построение сообщений
Используйте сообщение с данными документа (Document Message) для надежной
передачи структуры данных между приложениями.
Отправитель
Сообщение
сданными
документа
Получатель
В отличие от сообщения с командой, которое уведомляет получателя о необходимости
вызвать определенное поведение, сообщение с данными документа просто передает дан-
ные, а получатель должен сам решить, что с ними делать (если нужно делать вообще).
В качестве данных может выступать элементарная единица данных, объект или структура
данных, которую можно разложить на несколько более мелких частей.
Сообщение с данными документа во многом напоминает сообщение о событии (Event
Message, с. 174). Основная разница между ними определяется своевременностью достав-
ки и содержимым. Главной частью сообщения с данными документа является его содер-
жимое, т.е. сам документ. Важно успешно передать документ, а своевременность его от-
правки и получения играет второстепенную роль. При передаче сообщения с данными
документа стоит подумать о гарантированной доставке (Guaranteed Delivery, с. 149), а срок
действия сообщения (Message Expiration, с. 198), пожалуй, не играет роли. В противопо-
ложность этому сам факт существования сообщения о событии и его своевременная дос-
тавка часто играют куда более важную роль, чем его содержимое.
Сообщение с данными документа может быть сообщением любого типа из числа тех,
которые поддерживаются системой обмена сообщениями. В JMS в качестве сообщения с
данными документа может выступать сообщение Obj ectMessage, содержащее объект
данных Serializable, или сообщение TextMessage, содержащее данные в формате
XML. В .NET это сообщение (Message, с. 98), в котором хранятся данные, а в SOAP —
сообщение с ответом на запрос.
Сообщения с данными документа обычно отправляются по каналу “точка-точка”, что-
бы исключить возможность дублирования. Обмен сообщениями может применяться для
реализации единственного рабочего потока путем передачи документа приложению, ко-
торое будет модифицировать документ и передавать его другому приложению. В некото-
рых случаях сообщение с данными документа может подлежать широковещательной рас-
сылке посредством канала “публикация-подписка”, но это приведет к появлению много-
численных копий одного и того же документа. Копии должны быть доступны только для
чтения. В противном случае, если получатель внесет изменения в свою копию документа,
система окажется заполненной версиями документа, содержащими различные данные.
В шаблоне запрос-ответ (Request-Reply, с. 177) ответ обычно является сообщением с дан-
ными документа, где документ — это результат выполнения запроса.
Сообщение с данными документа (Document Message)
173
Пример: Java и XML
Следующий пример, взятый из примера схемы XML в [13], показывает, как представить
простой заказ на поставку в виде документа XML и отправить его, как сообщение,
используя JMS.
Session session = // Получить сеанс.
Destination dest = // Получить пункт назначения.
MessageProducer sender = session.createProducer(dest);
String purchaseorder =
" <po id=\"48881\" submitted=\"2002-04-23\">
<shipTo>
<company>Chocoholics</company>
<street>2112 North Street</street>
<city>Cary</city>
<state>NC</state>
<postalCode>27522</postalCode>
</shipTo>
<order>
citem sku=\"22211\" quantity=\"40\">
<description>Bunny, Dark Chocolate,
Large</description>
</item>
</order>
</po>";
TextMessage message = session.createTextMessage();
message.setText(purchaseorder);
sender.send(message);
Пример: SOAP и WSDL
Рассмотрим сообщение SOAP в стиле документа, построенное согласно спецификациям
SOAP [36] и WSDL [45]. Оно будет разновидностью сообщения с данными документа
(Document Message). Тело такого сообщения SOAP — это документ XML (или другая
структура данных, которая была преобразована в документ XML), а само сообщение пе-
редает указанный документ от отправителя (например, клиента) к получателю
(например, серверу).
Еще одним примером рассматриваемого шаблона будет сообщение-ответ при обмене
сообщениями SOAP в стиле RPC. Тело такого сообщения (документ XML) содержит ре-
зультат выполнения вызванного метода. В этом примере, взятом из спецификации SOAP,
отправителю запроса возвращается результат выполнения метода GetLastTradePrice.
<SOAP-ENV:Envelope
xmlns:SOAP-ENV="http://schemas.xmlsoap.org/soap/envelope/"
SOAP-ENV:encodingStyle="http://schemas.xmlsoap.org/soap/encoding/"/>
<SOAP-ENV:Body>
<m:GetLastTradePriceResponse xmlns:m="Some-URI">
<Price>34.5</Price>
</m:GetLastTradePriceResponse>
</SOAP-ENV:Body>
</SOAP-ENV:Envelope >
174
Глава 5. Построение сообщений
Сообщение о событии (Event Message)
Несколько приложений хотели бы использовать оповещения о событиях, чтобы со-
гласовывать свои действия. При этом желательно, чтобы для оповещения применялся
обмен сообщениями (Messaging, с. 87).
Как использовать обмен сообщениями для передачи событий из одного приложе-
ния в другое?
Иногда о событии, произошедшем в одном объекте, требуется уведомить другой
объект. Классическим примером указанного сценария является архитектура “модель-
представление-контроллер” из [33]. В ней модель, меняющая состояние, должна уведо-
мить об этом свои представления, чтобы те соответствующим образом обновили свой
внешний вид. Оповещение об изменениях может пригодиться и в распределенных систе-
мах. К примеру, в В2В-системе компании может понадобиться уведомить своих партне-
ров об изменении цен или полном обновлении каталога продукции.
Для уведомления других приложений о событии можно воспользоваться удаленным
вызовом процедуры (Remote Procedure Invocation, с. 85), но тогда получатель должен немед-
ленно принять событие, даже если он в настоящий момент в нем не нуждается. Кроме
того, использование удаленного вызова процедуры (RPC) предполагает, что оповещаю-
щий процесс знает каждого слушателя и вызывает RPC у каждого слушателя.
Шаблон наблюдатель (Observer) из [12] описывает, как разработать субъект, который
будет объявлять о событиях, и наблюдателей, потребляющих эти события. Субъект уве-
домляет наблюдателя о событии, вызывая метод наблюдателя Update (). Указанный ме-
тод может быть реализован как RPC, но тогда он будет обладать всеми недостатками уда-
ленного вызова процедуры.
Гораздо разумнее было бы рассылать оповещения в асинхронном режиме, т.е. в виде
сообщений (Message, с. 98). Благодаря этому отправитель станет отсылать оповещения
тогда, когда будет готов это сделать, а каждый наблюдатель примет оповещение в удоб-
ный для себя момент.
Когда у субъекта появляется событие, о котором следует оповестить остальных, он
создает объект события, упаковывает его в сообщение и размещает в канале как сообще-
ние о событии. Наблюдатель получает сообщение о событии, извлекает событие и обраба-
тывает его. Оповещение о событии через обмен сообщениями не меняет само событие,
а лишь обеспечивает доставку оповещения наблюдателю.
Сообщение о событии может быть сообщением любого типа из числа тех, которые под-
держиваются системой обмена сообщениями. В Java событие может быть объектом или
данными, такими как документ XML, а значит, может быть передано посредством JMS
как Obj ectMessage, TextMessage и т.п. В .NET это сообщение (Message, с. 98), в кото-
ром хранится событие.
Сообщение о событии (Event Message)
175
Используйте сообщение о событии (Event Message) для надежного, асинхронного
оповещения других приложений о разнообразных изменениях.
Наблюдатель
Разница между сообщением о событии и сообщением с данными документа (Document
Message, с. 171) определяется своевременностью доставки и содержимым. Содержимое
сообщения о событии обычно не играет особой роли. Довольно часто тело таких сообще-
ний и вовсе пустое; наблюдатель реагирует на сам факт получения сообщения. Гораздо
более важна своевременность доставки. Субъект должен разослать оповещения, как
только произойдет событие, а наблюдатель должен успеть обработать его, пока оно еще
не потеряло своей актуальности. События случаются довольно часто и требуют немед-
ленной доставки оповещений о себе другим приложениям, а значит, использование
гарантированной доставки (Guaranteed Delivery, с. 149) вряд ли оправдано. Куда лучше
указать срок действия сообщения (Message Expiration, с. 198). Он гарантирует, что событие
будет обработано вовремя или же не обработано вообще.
В сценарии В2В-интеграции для уведомления партнеров об изменении цены или про-
дуктовой линейки можно использовать сообщение о событии, сообщение с данными доку-
мента либо комбинацию их обоих. Если в сообщении говорится о том, что изменилась
цена на определенную модель жесткого диска, это событие. Если же в сообщении содер-
жится описание жесткого диска, включая и его новую цену, это документ, отправленный
как событие. Аналогичным образом сообщение, уведомляющее о появлении нового ка-
талога и его адресе в Интернете, является событием, тогда как такое же сообщение,
содержащее новый каталог, будет событием, в котором содержится документ.
Какой подход лучше? В шаблоне наблюдатель эта ситуация описывается как выбор
между так называемыми моделью проталкивания (модель с активным источником дан-
ных) и моделью вытягивания (модель с пассивным источником данных). В модели про-
талкивания (push model) информация об изменении отсылается в составе обновления.
176
Глава 5. Построение сообщений
В свою очередь, модель вытягивания (pull model) предусматривает рассылку минимального
объема информации, а наблюдатели, которые хотят получить больше информации, за-
прашивают ее, отослав субъекту вызов метода GetState (). А вот как указанные модели
применяются к обмену сообщениями.
• Модель проталкивания. Сообщение представляет собой комбинацию сообщения
о событии и сообщения с данными документа. Доставка сообщения означает, что со-
стояние изменилось, а содержимое сообщения будет новым состоянием. Данная
модель более эффективна в ситуации, когда такие подробности интересуют всех
наблюдателей. В противном случае она будет нести в себе худшие признаки сооб-
щений обоих типов: громадное сообщение, которое рассылается слишком часто
и при этом игнорируется большинством наблюдателей.
• Модель вытягивания. Для оповещения применяется набор из трех сообщений:
• обновление, т.е. сообщение о событии, которое уведомляет наблюдателя о неко-
тором событии;
• запрос о состоянии, т.е. сообщение с командой, которое применяется заинтересо-
ванным наблюдателем для запроса деталей события у субъекта;
• ответ о состоянии, т.е. сообщение с данными документа, в котором субъект отсы-
лает наблюдателю детали события.
Преимуществом модели вытягивания является небольшой размер сообщений
с обновлениями. Детали события запрашивают лишь те наблюдатели, которым
они интересны, причем каждый наблюдатель может запросить только те дан-
ные, которые нужны именно ему. Недостаток указанной модели связан с необ-
ходимостью создания дополнительных каналов, а также интенсивностью
результирующего трафика, вызванной большим количеством сообщений.
Более подробно о том, как реализовать концепцию наблюдателя, используя обмен со-
общениями, будет рассказано в главе 6 (пример, посвященный реализации механизма
публикации-подписки с помощью JMS).
Ограничивать число получателей сообщения о событии путем применения канала
“точка-точка” (Point-to-Point Channel, с. 131) обычно не требуется. Как правило, сообще-
ние о событии является широковещательным и распространяется по каналу “публикация-
подписка” (Publish-Subscribe Channel, с. 134), чтобы уведомление смогли получить все за-
интересованные стороны. В отличие от сообщения с данными документа, которое обяза-
тельно должно быть потреблено получателем (чтобы исключить потерю документа), по-
лучатель сообщения о событии может его просто проигнорировать, если слишком занят,
чтобы заниматься его обработкой. По этой причине подписчики таких сообщений часто
не являются постоянными подписчиками (Durable Subscriber, с. 535). Еще раз подчеркнем,
что сообщение о событии — ключевой объект в реализации шаблона наблюдатель с ис-
пользованием обмена сообщениями.
Запрос-ответ (Request-Reply)
177
Запрос-ответ (Request-Reply)
Если два приложения взаимодействуют посредством обмена сообщениями (Messaging,
с. 87), их обшение получается односторонним. Можно ли организовать двустороннее
общение?
Как организовать обмен сообщениями, чтобы отправитель сообщения получал
на него ответ?
Обмен сообщениями предусматривает одностороннее взаимодействие участвующих
в нем приложений. Сообщения (Message, с. 98) “путешествуют” по каналу сообщений
(Message Channel, с. 93) в одном направлении: от отправителя к получателю. Такая асин-
хронная передача сообщений повышает надежность доставки и отделяет отправителя от
получателя.
Проблема состоит в том, что зачастую взаимодействие компонентов должно быть дву-
сторонним. Когда программа вызывает функцию, она получает в ответ значение этой
функции. Когда программа создает запрос, она получает результат выполнения запроса.
Когда один компонент уведомляет другой об изменении, он часто хочет получить под-
тверждение о том, что уведомление было получено. Но как организовать двусторонний
обмен сообщениями?
Отправитель и получатель могли бы одновременно использовать одно и то же сооб-
щение. Тогда каждое приложение могло бы добавить к сообщению свою информацию,
чтобы ее потребило другое приложение. Но это нарушает главный принцип обмена со-
общениями: сообщение вначале отправляется, а затем принимается, поэтому отправи-
тель и получатель не могут осуществлять доступ к сообщению в одно и то же время.
Отправитель мог бы хранить ссылку на сообщение. Затем, как только получатель по-
мещает в сообщение свой ответ, отправитель мог бы “вытянуть” сообщение обратно.
В качестве примера можно представить себе бельевую веревку, натянутую между окнами
соседних зданий на два колеса. Вы прикрепляете прищепкой записку и крутите колесо,
пока записка не дойдет до окна соседа. Сосед читает записку и пишет на ней ответ, после
чего вы снова тянете веревку к себе. Но канал сообщений — это не бельевая веревка,
которую можно смотать обратно. Канал передает сообщения только в одном направле-
нии. Нам же требуется двусторонний обмен сообщениями по двунаправленному каналу.
В схеме запрос-ответ присутствуют два участника.
1. Инициатор запроса отправляет сообщение с запросом и ждет, когда придет сооб-
щение с ответом.
2. Ответчик получает сообщение с запросом и реагирует на него, отсылая сообщение
с ответом.
178
Глава 5. Построение сообщений
Отправьте пару сообщений запрос-ответ (Request-Reply), каждое по собственно-
му каналу.
Канал запросов может быть каналом “точка-точка” (Point-to-Point Channel, с. 131)
либо каналом “публикация-подписка” (Publish-Subscribe Channel, с. 134). Выбор того или
иного типа канала зависит от того, кем должен быть обработан запрос: всеми заинтересо-
ванными участниками или же только одним получателем. Канал ответов, в свою очередь,
почти всегда является каналом “точка-точка”, поскольку устраивать широковещатель-
ную рассылку ответа обычно не имеет смысла — ответ должен вернуться только к тому,
кто отсылал запрос.
Если вызывающий процесс выполняет удаленный вызов процедуры (Remote Procedure
Invocation, с. 85), поток вызывающего приложения должен быть заблокирован на все
время, пока он ожидает ответа. В шаблоне запрос-ответ у инициатора запроса есть два
подхода к получению ответа.
1. Синхронная блокировка. Поток вызывающего приложения отправляет сообщение
с запросом, блокирует свое выполнение в ожидании ответа как опрашивающий
потребитель (Polling Consumer, с. 507), а затем обрабатывает ответ. Такая схема
проста в реализации, но если вызывающее приложение выйдет из строя, после
перезапуска ему будет сложно восстановить заблокированный поток. Наличие за-
прашивающего потока, ожидающего ответа, означает, что в указанный момент
времени может существовать только один необработанный запрос или что канал
ответов для этого запроса будет доступным только для указанного потока.
2. Асинхронный обратный вызов. Один поток вызывающего приложения отправляет
сообщение с запросом и предоставляет интерфейс обратного вызова для ответа.
Другой поток прослушивает канал ответов. Когда приходит ответ на запрос, ука-
занный поток запускает соответствующий обратный вызов, который восстанав-
ливает контекст вызывающего процесса и обрабатывает ответ. В этом случае не-
сколько необработанных запросов могут совместно использовать один и тот же
канал ответов, а один поток ответов способен обрабатывать ответы на разные за-
просы. Если инициатор запроса выйдет из строя, он может восстановиться, про-
сто перезапустив поток ответов. Но необходимо учитывать дополнительную
сложность, вызванную появлением механизма обратного вызова, который должен
восстановить контекст вызывающего процесса.
Запрос-ответ (Request-Reply)
179
Рассуждать, какими должны быть приложения, обменивающиеся запросами и отве-
тами, довольно скучно. Гораздо интереснее поговорить о том, что представляют собой
запрос и ответ.
1. Удаленный вызов процедуры с помощью обмена сообщениями. В этом сценарии
обмен сообщениями применяется для реализации удаленного вызова процедуры.
Запрос — это сообщение с командой (Command Message, с. 169), описывающее
функцию, которую должен вызвать ответчик. Ответ — это сообщение с данными
документа (Document Message, с. 171), содержащее результат выполнения функции
или исключение.
2. Запрос с помощью обмена сообщениями. Этот сценарий применяется для выполне-
ния запросов (к базе данных и т.п.) посредством обмена сообщениями. Запрос —
сообщение с командой, содержащее текст запроса к базе данных, а ответ — резуль-
тирующий набор данных, который может быть отправлен в виде цепочки сообще-
ний (Message Sequence, с. 192).
3. Уведомление/подтверждение. Этот сценарий описывает уведомление о событии
с последующим подтверждением того, что уведомление было получено. Запрос —
сообщение о событии (Event Message, с. 174), посредством которого выполняется
уведомление, а ответ — сообщение с данными документа, подтверждающее полу-
чение уведомления. Последнее, в свою очередь, тоже может быть запросом (если
заинтересованный наблюдатель хочет получить больше сведений о событии).
Запрос аналогичен вызову метода. Из этого следует, что ответ на запрос может при-
нимать одну из трех форм.
• Пустой ответ. Сообщение с ответом просто уведомляет вызывающее приложение
о том, что выполнение метода завершено, и вызывающее приложение может рабо-
тать дальше.
• Результат. Объект, являющийся результатом выполнения метода.
• Исключение. Объект исключения, указывающий на то, что вызываемый метод
аварийно завершил свою работу до успешного окончания его выполнения, а также
на причины такого поведения.
В сообщении с запросом должен содержаться обратный адрес (Return Address, с. 182),
чтобы ответчик знал, куда отсылать ответ. В сообщении с ответом должен присутствовать
идентификатор корреляции (Correlation Identifier, с. 186), указывающий, к какому запросу
относится указанный ответ.
Пример: сообщения SOAP 1.1
Сообщения SOAP в стиле RPC представляют собой пары запрос-ответ (Request-Reply).
Сообщение-запрос указывает, какую службу на стороне получателя хочет вызвать отпра-
витель, а сообщение-ответ содержит результат выполнения этой службы либо ошибку
(fault), аналог исключения в SOAP [36].
180
Глава 5. Построение сообщений
Пример: обмен сообщениями “запрос-ответ” (SOAP 1.2)
В SOAP 1.1 сообщения-ответы были описаны лишь в общих чертах. В SOAP 1.2, нако-
нец-то, появилось явное определение шаблона под названием обмен сообщениями
“запрос-ответ” (Request-Response Message Exchange, см. [37]). Данный шаблон описывает
концепцию отдельного, потенциально асинхронного ответа на запрос SOAP.
Пример: объекты Requestor (JMS)
JMS включает в себя несколько компонентов, которые могут быть использованы для
реализации решения запрос-ответ (Request-Reply).
Объект TemporaryQueue — это очередь сообщений, которая может быть создана
программным путем и существует столько времени, сколько существует создавший ее
объект соединения. Читать сообщения из очереди могут только те потребители сообще-
ний (объекты Messageconsumer), которые были созданы тем же самым объектом соеди-
нения, поэтому по отношению к указанному объекту соединения они являются закры-
тыми (private) [17].
Как поставщики сообщений (объекты Messageproducer) узнают о появлении новой,
закрытой очереди сообшений? Инициатор запроса создает временную очередь
TemporaryQueue и задает ее имя в свойстве JMSReplyTo сообщения с запросом.
(См. шаблон обратный адрес (Return Address, с. 182).) Аккуратный ответчик отправит от-
вет на запрос в указанную очередь сообщений, о которой он совершенно ничего не знал
бы, если бы ее имя не было значением свойства сообщения с запросом. Благодаря такому
простому механизму инициатор запроса гарантирует, что ответы всегда будут поступать в
заданную очередь.
Недостатком временных очередей является то, что при закрытии соединения соответ-
ствующая ему очередь сообщений и все ее содержимое уничтожаются. По этой же при-
чине временные очереди сообщений не способны обеспечить гарантированную доставку
(Guaranteed Delivery, с. 149). Если система обмена сообщениями даст сбой, соединение
будет потеряно, а значит, очередь и содержащиеся в ней сообщения пропадут.
В JMS также присутствует класс QueueRequestor, предназначенный для отправки
запросов и получения ответов. Экземпляр этого класса содержит объекты Queuesender
для отправки запросов и QueueReceiver для получения ответов. Каждый объект
QueueRequestor создает собственную временную очередь для получения ответов и ука-
зывает ее имя в свойстве JMSReplyTo сообщения с запросом [17]. Отправка запросов
и получение ответов объектом QueueRequestor выглядят очень просто.
Queueconnection connection = // Получить соединение.
Queue requestQueue = // Получить очередь.
Message request = // Создать сообщение с запросом.
QueueSession session = connection.createQueueSession(false.
Session.AUTO_ACKNOWLEDGE);
QueueRequestor requestor = new QueueRequestor(session, requestQueue);
Message reply = requestor.request(request);
Запрос-ответ (Request-Reply) 181
Метод request отправляет сообщение с запросом и блокирует свое выполнение
до тех пор, пока не получит сообщение с ответом.
Временная очередь сообщений TemporaryQueue, используемая объектом Queue-
Requestor, является каналом “точка-точка” (Point-to-Point Channel, с. 131). Эквивален-
тами очереди сообщений и инициатора запроса для канала “публикация-подписка”
(Publish-Subscribe Channel, с. 134) будут объекты TemporaryTopic и TopicRequestor
соответственно.
182
Глава 5. Построение сообщений
Обратный адрес (Return Address)
Приложение использует обмен сообщениями {Messaging, с. 87) для реализации меха-
низма запрос-ответ {Request-Reply, с. 177).
Как ответчик узнает, куда необходимо отправить сообщение с ответом?
Сообщения часто рассматриваются как полностью независимые объекты. Многие,
например, считают, что отправитель может разместить сообщение в том канале, в кото-
ром захочет. Между тем сообщения часто связаны друг с другом. Так, в паре запрос-
ответ оба сообщения кажутся независимыми, но на самом деле сообщение с ответом
в точности соответствует одному и только одному сообщению с запросом. Вот почему
ответчик, обрабатывающий сообщение с запросом, не может отослать ответ по любому
каналу, по которому пожелает. Ответ необходимо отправить по тому каналу, который
прослушивается инициатором запросов в ожидании ответа.
Канал, по которому необходимо отправлять ответы, можно задать прямо в коде ответ-
чика, но это сделает программное обеспечение менее гибким и усложнит его обслужива-
ние. Более того, один и тот же ответчик может обрабатывать сообщения от разных ини-
циаторов запроса, а значит, выбор канала ответов для каждого сообщения будет зависеть
от того, какой инициатор отправил соответствующий запрос (рис. 5.1).
Возможна и такая ситуация, когда инициатор запроса не хочет, чтобы ответ был от-
правлен ему самому. Вместо этого у него может быть специальный процессор обратных
вызовов, предназначенный для обработки ответов, который наблюдает не за тем кана-
лом, за которым наблюдает инициатор запроса (или же инициатор запроса вообще не на-
блюдает за какими-либо каналами). И наконец, у инициатора запроса может быть не-
Обратный адрес (Return Address)
183
сколько процессоров обратных вызовов, а ответы на разные запросы одного и того же
инициатора нужно отправлять разным процессорам.
Канал ответов не обязательно должен возвращать ответы самому инициатору запроса;
он может передать их любому объекту, на который будут возложены полномочия по об-
работке ответа. Достаточно лишь, чтобы этот объект прослушивал канал, заданный ини-
циатором запроса. Итак, даже зная, кем и (или) по какому каналу был отправлен запрос,
ответчик не всегда может с уверенностью сказать, куда именно следует отослать ответ
(а если и может, ему придется потратить некоторое время на определение нужного кана-
ла ответов). Ситуация значительно упростится, если в запросе будет явно указано, по ка-
кому каналу необходимо отправить ответ. Осталось лишь придумать, как это сделать.
В сообщении с запросом должен содержаться обратный адрес {Return Address),
указывающий, куда необходимо отправить сообщение с ответом.
Канал Канал
Благодаря наличию обратного адреса ответчик не должен заранее знать, куда необхо-
димо отправить ответ; он просто получит адрес канала ответов из сообщения с запросом.
Если ответы на разные сообщения необходимо отсылать в разные каналы, ответчик из
каждого отдельно взятого сообщения с запросом сможет определить, куда нужно отсы-
лать соответствующий ответ. Таким образом, знание того, какие каналы необходимо ис-
пользовать для отправки запросов и ответов, будет инкапсулировано в инициаторе за-
просов. Фиксировать их в коде ответчика не придется. Обратный адрес не является
частью данных, передаваемых приложением, а следовательно, должен быть вынесен
в заголовок сообщения.
Обратный адрес сообщения аналогичен полю “Reply-То” (“Ответить”) письма элек-
тронной почты. Значение этого поля обычно совпадает со значением поля “From”
184
Глава 5. Построение сообщений
(“От”), но при желании владелец почтового ящика может задать, чтобы ответы на его со-
общения приходили на другой адрес электронной почты, отличный от текущего.
Когда сообщение с ответом отправляется по каналу, заданному обратным адресом,
к нему может понадобиться добавить идентификатор корреляции (Correlation Identifier,
с. 186). Обратный адрес говорит получателю запроса о том, по какому каналу следует
отправить сообщение с ответом, а идентификатор корреляции сообщает отправителю
запроса, к какому запросу относится полученный им ответ.
Пример: свойство JMSReplyTo (JMS)
У сообщений JMS есть свойство JMSReplyTo, предназначенное специально для хране-
ния обратного адреса (Return Address). Его значением является не строка с именем объекта
Destination, а сам объект Destination (Topic или Queue). Это гарантирует, что
объект назначения, т.е. канал сообщений (Message Channel, с. 93) действительно существует
или, по крайней мере, существовал на момент отправки запроса [17, 27].
Если отправитель хочет задать канал ответов, являющийся объектом Queue, это мож-
но сделать следующим образом.
Queue requestQueue = // Задать очередь запросов.
Queue replyQueue = // Задать очередь ответов.
Message requestMessage = // Создать сообщение с запросом.
requestMessage.setJMSReplyTo(replyQueue);
Messageproducer requestsender = session.createProducer(requestQueue);
requestsender.send(requestMessage);
Получатель запроса отправляет сообщение с ответом. Вот как это делается.
Queue requestQueue = // Задать очередь запросов.
Messageconsumer requestReceiver =
session.createConsumer(requestQueue);
Message requestMessage = requestReceiver.receive();
Message replyMessage = // Создать сообщение с ответом.
Destination replyQueue = requestMessage.getJMSReplyTo();
Messageproducer replysender = session.createProducer(replyQueue);
replySender.send(replyMessage);
Пример: свойство ResponseQueue (.NET)
У сообщений .NET тоже есть специальное свойство для задания обратного адреса (Return
Address), называющееся ResponseQueue. Значение этого свойства является объектом
MessageQueue (например, каналом сообщений) и задает очередь, в которую нужно отпра-
вить сообщение с ответом [7, 39].
Обратный адрес (Return Address) 185
Пример: запрос-ответ (Web-службы)
В SOAP 1.2 описан шаблон обмен сообщениями “запрос-ответ” (Request-Response Message
Exchange, см. [37]), но в нем отсутствует определение адреса, по которому необходимо
отослать ответ на запрос. Чтобы обмен сообщениями SOAP действительно стал асин-
хронным и позволил отделить ответчика от инициатора запросов, указанный шаблон
SOAP должен поддерживать необязательный обратный адрес (Return Address).
Описанная проблема решается с помощью недавно появившегося стандарта
WS-Addressing. В нем говорится, как задать конечную точку Web-службы и какие элемен-
ты XML для этого использовать. Такая конечная точка может использоваться в сообще-
нии SOAP в качестве обратного адреса. Более подробно о стандарте WS-Addressing идет
речь в главе 14.
186
Глава 5. Построение сообщений
Идентификатор корреляции (Correlation Identifier)
Приложение использует обмен сообщениями (Messaging, с. 87) для реализации меха-
низма запрос-ответ (Request-Reply, с. 177) и получило сообщение с ответом.
Как инициатор запроса, получивший сообщение с ответом, узнает, к какому запро-
су оно относится?
Когда один процесс вызывает другой через удаленный вызов процедуры (Remote
Procedure Invocation, с. 85), вызов выполняется в синхронном режиме, поэтому путаницы
относительно того, к какому вызову относится полученный результат, быть не может.
Но обмен сообщениями имеет асинхронную природу. С точки зрения вызывающего при-
ложения он выглядит так: приложение делает вызов, а результат возвращается несколько
позднее. Вызывающее приложение может даже не помнить о том, что оно делало запрос,
или же оно могло сделать так много запросов, что не знает, к какому из них относится
полученный результат. Иными словами, вызывающее приложение просто не знает, что
делать с результатом (рис. 5.2), а это ставит под сомнение целесообразность выполнения
вызовов вообще!
Ответчик
Инициатор
запроса
Запросы
Ответы
Рис. 5.2. Результат не удается сопоставить с запросом!
Существует несколько подходов, помогающих избежать недоразумений при сопос-
тавлении результата и запроса. Во-первых, вызывающее приложение может делать по
одному вызову за раз и не отправлять новый вызов, пока не придет ответ на предыдущий.
Тогда в каждый момент времени у приложения будет только один необработанный
запрос, но это весьма негативно скажется на его производительности. Во-вторых, вызы-
вающее приложение может предположить, что ответы приходят в том же порядке, в ко-
тором отправлялись запросы. Но система обмена сообщениями не знает, в каком именно
порядке сообщения будут доставляться ответчику (см. шаблон преобразователь порядка
— Resequencer, с. 297). Кроме того, на обработку запросов может потребоваться разное
время, поэтому предположение о порядке поступления результатов вряд ли окажется
верным. И наконец, вызывающее приложение может построить запросы таким образом,
Идентификатор корреляции (Correlation Identifier)
187
чтобы на них не нужно было отсылать ответы, но это ограничение делает обмен сообще-
ниями почти что бессмысленным.
В действительности вызывающему приложению нужно, чтобы в сообщении с ответом
содержался какой-то указатель или ссылка на сообщение с запросом. К сожалению, со-
общения не находятся в постоянной памяти, где на них можно было бы сослаться при
помощи переменных. Но сообщению можно было бы присвоить некий уникальный
идентификатор или ключ наподобие того, который есть у каждой записи в таблице реля-
ционной СУБД. Такой идентификатор мог бы применяться для того, чтобы отличать со-
общение от других сообщений, клиентов, использующих сообщение, и т.п.
В сообщении с ответом должен содержаться уникальный идентификатор корре-
ляции (Correlation Identifier* 1), который показывает, к какому запросу относится дан-
ный ответ.
Корреляция Идентификатор сообщения
Инициатор Ответы ' Ответчик
запроса «
Идентификатор корреляции
В схеме “запрос-ответ”, изображенной на диаграмме шаблона идентификатор корре-
ляции, задействованы шесть участников.
1. Инициатор запроса. Приложение, выполняющее некоторую бизнес-задачу путем
отправки запроса и обработки полученного ответа.
2. Ответчик. Другое приложение, которое получает запрос, обрабатывает его и вы-
сылает ответ. При этом оно извлекает из запроса его идентификатор и помещает
его в ответ в качестве идентификатора корреляции.
3. Запрос. Сообщение (Message, с. 98), отправленное инициатором запроса ответчику
и содержащее идентификатор запроса.
4. Ответ. Сообщение, отправленное ответчиком инициатору запроса и содержащее
идентификатор корреляции.
5. Идентификатор запроса. Маркер в сообщении с запросом, который уникальным
образом идентифицирует запрос.
6. Идентификатор корреляции. Маркер в сообщении с ответом, значение которого
совпадает со значением идентификатора запроса.
188
Глава 5. Построение сообщений
Схема действия идентификатора корреляции такова: когда инициатор запроса создает
сообщение с запросом, он присваивает запросу уникальный идентификатор. Последний
должен отличаться от идентификаторов всех запросов, которые в настоящий момент на-
ходятся в режиме ожидания, т.е. на которые еще не получены ответы. Когда ответчик об-
работает запрос, он сохраняет идентификатор этого запроса и вставляет его в сообщение
с ответом в качестве идентификатора корреляции. После этого ответ передается инициа-
тору запроса. Инициатор извлекает из ответа идентификатор корреляции и определяет,
к какому запросу он относится. Описанное решение получило название идентификатор
корреляции, потому что вызывающее приложение коррелирует (т.е. сопоставляет, находит
связь) каждый ответ с запросом, к которому тот относится.
Как часто бывает при обмене сообщениями, инициатор запроса и ответчик должны
согласовать между собой несколько моментов: имя и тип свойства, в котором будет хра-
ниться идентификатор запроса, а также имя и тип свойства, в котором будет храниться
идентификатор корреляции. Следует договориться и о том, будут ли эти свойства заранее
определены в форматах сообщений с запросом и ответом, или же их можно добавлять как
пользовательские свойства. К примеру, если инициатор запроса хранит идентификатор
запроса в XML-элементе первого уровня по имени requestid, а значением этого эле-
мента является целое число, ответчик должен знать об этом, чтобы найти значение иден-
тификатора запроса и правильно его обработать. Значения идентификатора запроса
и идентификатора корреляции обычно принадлежат к одному и тому же типу; если же
это не так, то инициатор запроса должен знать, как ответчик преобразует идентификатор
запроса в идентификатор корреляции.
Идентификатор корреляции является упрощенной, ориентированной на сообщения
версией шаблона маркер асинхронного завершения (Asynchronous Completion Token) из [34].
Инициатор запроса — это инициатор (Initiator), ответчик — это служба (Service), компо-
нент инициатора запроса, который обрабатывает ответ, — это обработчик завершения
(Completion Handler), а идентификатор корреляции, используемый для сопоставления от-
вета с запросом — это маркер асинхронного завершения.
Идентификатор корреляции (как, впрочем, и идентификатор запроса) обычно поме-
щается не в тело, а в заголовок сообщения. Идентификатор запроса не является частью
команды или данных, которые инициатор запроса пытается передать ответчику. В дейст-
вительности ответчик вообще не использует идентификатор запроса; он просто сохраня-
ет идентификатор, который был в запросе, и добавляет его в ответ для облегчения работы
инициатора запроса. Поскольку тело сообщения представляет собой осмысленное
содержимое, передаваемое из одной системы в другую, а идентификатор не является
частью этого содержимого, он должен выноситься в заголовок.
Суть настоящего шаблона состоит в том, что сообщение с ответом содержит некий
маркер (идентификатор корреляции), который уникальным образом идентифицирует
соответствующий запрос (через идентификатор запроса). Существует несколько подхо-
дов к реализации этого шаблона.
Самый простой подход — присвоить каждому запросу уникальный идентификатор
(например, идентификатор сообщения), а затем использовать его же в качестве иденти-
фикатора корреляции. Это однозначно привяжет ответ к запросу. Но инициатора запроса
в действительности редко интересует, какому именно сообщению с запросом соответст-
вует ответ. Гораздо важнее вспомнить, в ходе какой бизнес-задачи был создан этот запрос,
чтобы завершить выполнение этой задачи при помощи данных, содержащихся в ответе.
Идентификатор корреляции (Correlation Identifier)
189
У бизнес-задачи (например, выполнить торговую операцию на бирже или отгрузить
товар в соответствии с заказом на поставку), вероятно, есть собственный уникальный
идентификатор бизнес-объекта (например, идентификатор заказа). Последний также
можно было бы использовать в качестве идентификатора корреляции. Тогда при получе-
нии ответа инициатор запроса может извлечь из него идентификатор корреляции и,
минуя само сообщение с запросом, сразу же перейти к бизнес-объекту, который стал
причиной выполнения запроса. В этом случае указанные идентификаторы должны хра-
ниться не в свойствах, встроенных в формат сообщений с запросом и ответом, а в неко-
торых пользовательских свойствах, значения которых идентифицируют бизнес-объект,
ставший причиной выполнения запроса и отправки ответа.
Возможен и компромиссный подход, при котором инициатор запроса будет хранить
сопоставление идентификаторов запросов и идентификаторов бизнес-объектов. Это мо-
жет пригодиться тогда, когда идентификаторы бизнес-объектов должны быть конфиден-
циальными, или же когда инициатор запроса не может контролировать реализацию от-
ветчика, который просто копирует идентификатор сообщения с запросом в идентифика-
тор корреляции. В этом случае, когда инициатор запроса получает ответ, он извлекает
идентификатор корреляции и ищет для него сопоставление с идентификатором бизнес-
объекта. Найденный идентификатор позволяет возобновить выполнение бизнес-задачи,
в ходе которой был сделан соответствующий запрос, с использованием данных, содер-
жащихся в ответе.
Идентификаторы сообщения и корреляции хранятся в разных свойствах объекта со-
общения, поэтому пары “запрос-ответ” могут образовывать последовательности. Это
происходит тогда, когда запрос приводит к появлению ответа, а ответ, в свою очередь,
содержит новый запрос. Последний также приводит к появлению ответа и т.п. Тогда
идентификатор сообщения уникальным образом идентифицирует текущий запрос, со-
держащийся в сообщении. Если же в сообщении есть еще и идентификатор корреляции,
значит, данное сообщение является не только запросом, но и ответом на предыдущий за-
прос, заданный идентификатором корреляции (рис. 5.3).
' Запрос Г Ответ 1 . . .. . Ответ 2 Г Ответ 3
Идентификатор сообщения Идентификатор сообщения “4 Идентификатор сообщения 1340 Идентификатор сообщения 430
Идентификатор пиИ корреляции Идентификатор loq корреляции Идентификатор 234 корреляции Идентификатор оде корреляции
Тело сообщения Тело сообщения у Тело сообщения Тело сообщения >
Рис. 5.3. Последовательность запросов и ответов
Подобное “нанизывание” запросов и ответов уместно только тогда, когда приложе-
ние хочет воссоздать всю последовательность сообщений от окончательного ответа до
исходного запроса. Обычно же приложение интересует лишь исходный запрос, а количе-
ство промежуточных ответов, которые понадобились для его выполнения, никого не
волнует. В этой ситуации первое же сообщение, идентификатор корреляции которого не
равен NULL, должно считаться ответом, а все последующие ответы должны иметь такой
же идентификатор корреляции, как и первый ответ.
В то время как идентификатор корреляции вставляется в ответ и используется для со-
поставления ответа с запросом, в самом запросе часто должен присутствовать обратный
адрес {Return Address, с. 182), который указывает, по какому каналу необходимо отправить
190
Глава 5. Построение сообщений
ответ. И наконец, не следует путать идентификатор корреляции с идентификаторами
цепочки сообщений (Message Sequence, с. 192). Первый используется для сопоставления па-
ры сообщений, отправленных ответчиком и инициатором запроса, а вторые — для опреде-
ления места сообщения в последовательности сообщений от одного и того же отправителя.
Пример: свойство JMSCorrelationlD (JMS)
У сообщений JMS есть встроенное свойство для хранения идентификатора корреляции.
Оно называется JMSCorrelationlD и часто используется в сочетании с другим встроен-
ным свойством, JMSMessagelD [17, 27]. Задание идентификатора корреляции в сообще-
нии с ответом выполняется следующим образом.
Message requestMessage = // Получить сообщение с запросом.
Message replyMessage = // Создать сообщение с ответом.
String requestID = requestMessage.getJMSMessagelD();
replyMessage.setJMSCorrelationlD(requestID);
Пример: свойство Correlationld (.NET)
В .NET у каждого сообщения есть свойство Correlationld строкового типа. Оно зада-
ется для ответного сообщения, а его значением обычно является идентификатор исход-
ного сообщения. Кроме того, у объекта MessageQueue есть два интересных метода:
ReceiveByCorrelationld(string) и PeekByCorrelationld(string). Первый из
них позволяет потребить сообщение с заданным идентификатором корреляции (если та-
ковое имеется в очереди сообщений), а второй — взглянуть на сообщение с заданным
идентификатором корреляции, не потребляя его [7, 39].
Пример: запрос-ответ (Web-службы)
Стандарты Web-служб, например SOAP 1.1 [36], не обеспечивают должной поддержки
асинхронного обмена сообщениями, но в SOAP 1.2 такая поддержка уже намечается.
Указанный стандарт содержит описание шаблона обмен сообщениями “запрос-ответ”
(Request-Response Message Exchange, см. [37]), являющийся базовым компонентом асин-
хронного обмена сообщениями SOAP. К сожалению, в нем не задекларирована поддерж-
ка “нескольких запросов, одновременно находящихся в стадии ожидания”, а следова-
тельно, в сообщении не предусмотрено наличие стандартного (пусть даже необязатель-
ного) поля для хранения идентификатора корреляции.
На практике наличие у инициатора запроса нескольких еще не обработанных запро-
сов — далеко не редкость. В статье [44] обсуждается несколько различных сценариев с
асинхронной работой Web-служб. В четырех из них— “Запрос-ответ” (Request-
Response), “Удаленный вызов процедуры” (Remote Procedure Call) (когда транспортный
протокол не обладает прямой поддержкой синхронного обмена запросами и ответами),
“Множество асинхронных ответов” (Multiple Asynchronous Responses) и “Асинхронный
обмен сообщениями” (Asynchronous Messaging) — в заголовок сообщений SOAP вклю-
чаются поля Messageld и ResponseTo, которые позволяют сопоставить ответ с запро-
сом. Ниже приведен пример пары таких сообщений.
Идентификатор корреляции (Correlation Identifier)
191
Сообщение-запрос SOAP с идентификатором сообщения
<?xml version="l. О" ?s
< env:Envelope xmlns:env="http://www. w3 . org/ 2 0 0 2 / 0 6 / soap -enve1ope"s
<env:Headers
<n:MsgHeader xmlns:n="http://example.org/requestresponse"s
<n:Message!dsuuid:09233523-345b-4351-b623-
5dsf35sgs5d6c/n:MessageIds
</n:MsgHeader>
</env:Headers
<env:Bodys
</env:Bodys
</env:Envelopes
Сообщение-ответ SOAP с идентификатором корреляции, указывающим на исходный запрос
<?xml version="l.О" ?s
<env:Envelope xmlns:env="http://www.w3.org/2002/06/soap-envelope"s
<env:Headers
<n:MsgHeader xmlns:n="http://example.org/requestresponse"s
<n:Message!dsuuid:09233523-567b-2891-b623-
9dke28yod7m9</n:MessageIds
<n:ResponseTosuuid:09233523-345b-4351-b623-
5dsf35sgs5d6c/n:ResponseTos
</n:MsgHeaders
</env:Headers
<env:Bodys
</env:Bodys
</env:Envelopes
Как и в предыдущих примерах для JMS и .NET, запрос SOAP содержит уникальный
идентификатор сообщения, а ответ SOAP — идентификатор корреляции, значение кото-
рого равно идентификатору сообщения запроса.
192
Глава 5. Построение сообщений
Цепочка сообщений (Message Sequence)
Приложение должно отправить большой объем данных другому процессу, больше,
чем может уместиться в одном сообщении. Или приложение сделало запрос, но резуль-
тирующий набор данных слишком велик и не умещается в одном сообщении.
Как использовать обмен сообщениями для передачи сколь угодно большого объе-
ма данных?
На первый взгляд может показаться, что сообщение способно принимать любые, да-
же очень большие размеры. На практике же объем данных, который можно поместить в
одно сообщение, обычно ограничен. В одних системах обмена сообщениями такое огра-
ничение абсолютно. В других сообщениям позволяется достигать сравнительно больших
размеров, но большие сообщения все равно снижают производительность. Наконец, да-
же если система обмена сообщениями допускает передачу сообщений очень большого
размера, поставщик или потребитель сообщений может ввести собственные ограничения
относительно того, какой объем данных они способны обработать за один раз. К приме-
ру, многие системы на основе COBOL или мэйнфреймов поставляют или потребляют
данные только порциями по 32 Кбайт.
Так как же приспособиться к подобным ограничениям? Один способ — настроить
приложение таким образом, чтобы ему никогда не пришлось передавать больше данных,
чем может уместиться в одном сообщении. К сожалению, такое ограничение может по-
мешать приложению предоставлять желаемую функциональность. Если большой объем
данных появляется в результате выполнения запроса, вызывающее приложение может
создать несколько запросов, по одному на каждую порцию результируюших данных, но
это приведет к возрастанию сетевого трафика. Кроме того, указанный подход предпола-
гает, что вызывающее приложение заранее знает количество порций результирующих
данных. Получатель может прослушивать канал ответов в ожидании порций данных, по-
ка те не перестанут поступать (но как он узнает, что они перестали поступать?), а затем
попытается воссоздать на их основе исходную, большую структуру данных, но это чрева-
то многочисленными ошибками.
Идею передачи данных большого размера можно почерпнуть у компаний, занимаю-
щихся доставкой товаров по почте. Если заказ слишком большой, его упаковывают в не-
сколько коробок и помечают их соответствующими надписями, например “1 из 3”, “2 из
3” и “3 из 3”. Благодаря этому получатель будет знать, какие именно части заказа он по-
лучил и сколько их всего должно быть. Описанный метод можно с успехом применить и к
обмену сообщениями.
Цепочка сообщений (Message Sequence)
193
Если из-за ограничения на максимально допустимый размер сообщений большой
объем данных приходится разбивать на несколько порций, отправьте данные в ви-
де цепочки сообщений (Message Sequence), снабдив каждое сообщение из цепоч-
ки несколькими идентификаторами.
Цепочка №1
^Цепочка Л г Цепочка Р ' Цепочка Л
Позиция 1 Позиция 2 Позиция п
Длина п Длина п • • • Длина п
^Тело сообщения^ Тело сообщения ^Гело сообщения^
Каждое сообщение, входящее в цепочку сообщений, помечается тремя идентификато-
рами.
1. Идентификатор цепочки. Идентифицирует пакет сообщений, в составе которого
отправляется данное сообщение.
2. Идентификатор позиции. Задает порядок расположения каждого сообщения в це-
почке сообщений.
3. Ицдикатор длины или конца. Показывает, сколько всего сообщений входят в па-
кет, или отмечает последнее сообщение в пакете. В последнем случае длина це-
почки равняется значению идентификатора позиции такого сообщения (или зна-
чению идентификатора плюс один, если нумерация начиналась с нуля).
Обычно цепочки сообщений конструируют таким образом, чтобы в каждом сообщении
содержалась информация относительно того, сколько всего сообщений входит в цепочку.
Вместо этого можно указывать, является ли текущее сообщение последним в цепочке,
присваивая индикатору конца значение TRUE или FALSE (рис. 5.4).
Последова- тельность №7 ^Цепочка 7^ г Цепочка 7Л ^Цепочка 75 • • • г Цепочка 7Л
Позиция 0 Позиция 1 Позиция 2 Позиция п-1
Конец F Конец F Конец F Конец Т
^Тело сообщение ^ело сообщения. ^Тело сообщения, ^Тело сообщения,
Рис. 5.4. Цепочка сообщений с индикатором конца
Представим себе, что набор данных необходимо отправить в виде пакета из трех со-
общений. Идентификатор цепочки такого пакета сообщений будет выражаться некото-
рым уникальным значением. Идентификаторы позиций для каждого сообщения будут
разными: 1, 2 или 3 (если нумерация начинается с единицы). Если отправитель с самого
начала знает общее число сообщений цепочки, тогда индикатор длины для каждого
сообщения будет равен 3. Если же отправитель не знает, сколько всего сообщений будет в
цепочке, и отсылает сообщения, пока не закончатся данные (например, если данные
194
Глава 5. Построение сообщений
отправляются в виде потока), то индикатор конца для каждого сообщения, за исключе-
нием последнего, будет равняться FALSE. Когда отправитель поймет, что следующее со-
общение станет последним в цепочке, он присвоит индикатору конца этого сообщения
значение TRUE. И в том, и в другом случае у получателя будет достаточно информации,
чтобы правильно собрать фрагменты данных в единое целое, даже если эти фрагменты
поступают в произвольном порядке.
Если получатель ожидает прибытие цепочки сообщений, то любые отправляемые ему
данные должны быть отосланы в виде цепочки, даже если цепочка будет состоять из одного
сообщения. В противном случае, если такой получатель примет “одинокое” сообщение,
не имеющее идентификаторов цепочки сообщений, он может ошибочно принять его за недо-
пустимое и отправить в канал недопустимых сообщений {Invalid Message Channel, с. 143).
Если до получателя дойдут не все сообщения из цепочки, полученные им сообщения
тоже придется перенаправить в канал недопустимых сообщений.
Для отправки и получения цепочек сообщений приложение может воспользоваться
транзакционным клиентом {Transactional Client, с. 498). Все сообщения, входящие в це-
почку, можно отослать в рамках одной транзакции. Тогда ни одно сообщение не будет
доставлено получателю до тех пор, пока они все не будут успешно отправлены. Анало-
гичным образом получатель может захотеть, чтобы все сообщения из цепочки потребля-
лись им в рамках одной транзакции. В этом случае он фактически не потребит ни одно из
сообщений до тех пор, пока не получит их все. Если в цепочке не хватает хотя бы одного
сообщения, получатель может выполнить откат транзакции, чтобы позднее попытаться
снова потребить указанные сообщения. Во многих реализациях систем обмена сообще-
ниями, если цепочка сообщений отправляется в рамках одной транзакции, сообщения бу-
дут потребляться в том порядке, в котором они были отправлены, что существенно об-
легчит работу получателя по воссозданию исходной структуры данных.
Если цепочка сообщений является ответом в схеме запрос-ответ {Request-Reply, с. 177),
идентификатор цепочки и идентификатор корреляции {Correlation Identifier, с. 186) обычно
совпадают. Они будут представлены разными свойствами только в том случае, если при-
ложение, отправившее запрос, ожидает на него несколько ответов, и хотя бы один из от-
ветов может состоять из нескольких частей. Если же для запроса ожидается только один
ответ, создание отдельных уникальных идентификаторов для цепочки и для сопоставле-
ния ответа с запросом будет избыточным.
Цепочка сообщений обычно несовместима с конкурирующими потребителями {Competing
Consumers, с. 515) или диспетчером сообщений {Message Dispatcher, с. 521). Если разные
потребители/исполнители получат разные сообщения из цепочки, никто из них не сможет
поодиночке собрать данные в единое целое. По этой причине цепочку сообщений нужно
передавать по каналу сообщений {Message Channel, с. 93) с единственным потребителем.
Вместо цепочки сообщений для отправки большого объема данных можно воспользовать-
ся квитанцией {Claim Check, с. 358). Если оба приложения, которые должны обменяться
большим объемом данных, имеют доступ к общей базе данных или файловой системе, со-
храните в ней данные и передайте в сообщении только ссылку на них. Тогда для передачи
данных хватит одного-единственного сообщения; разбивать их на порции не придется.
Использование цепочки сообщений аналогично использованию разветвителя {Splitter,
с. 274) в сочетании с агрегатором {Aggregator, с. 283). Первый из них разбивает большое
сообщение на последовательность более мелких, а второй собирает из них исходное со-
общение. При использовании разветвителя и агрегатора исходное и конечное сообще-
Цепочка сообщений (Message Sequence)
195
ния могут иметь очень большой размер, в то время как цепочка сообщений позволяет
конечным точкам сообщения (Message Endpoint, с. 124) разбивать данные перед отправкой
каких-либо сообщений и собирать их обратно уже после получения сообщений.
Пример: передача большого документа
Представим себе, что отправителю нужно отослать документ гигантского размера, который
не поместится в одно сообщение (или же его просто непрактично отсылать весь сразу).
К примеру, максимальный размер сообщения в MSMQ составляет 4 Мбайт. В этом случае
документ можно разбить на части, после чего отправить их посредством цепочки сообщений
(Message Sequence). Для каждого сообщения необходимо указать его порядковый номер в
цепочке сообщений и общее количество сообщений в цепочке. О том, как отправить много-
компонентную цепочку сообщений с помощью MSMQ, рассказывается в [7].
Пример: многоэлементный запрос
Представьте себе запрос, который извлекает из базы данных список книг заданного авто-
ра. Поскольку такой список может быть очень большим, система обмена сообщениями
может быть построена таким образом, чтобы каждая найденная запись возвращалась в
отдельном сообщении. Тогда в каждом сообщении необходимо указать, к какому запросу
оно относится, каков его порядок в цепочке сообщений (Message Sequence) и сколько всего
должно быть сообщений.
Пример: распределенный запрос
Представьте себе запрос, который по частям выполняется несколькими получателями.
Если у частей запроса есть порядок, его следует указать в ответных сообщениях, чтобы
правильно собрать части ответа в единое целое. Каждый получатель должен знать собст-
венную позицию в общем порядке получателей и указывать ее в своей ответной цепочке
сообщений (Message Sequence).
Пример: JMS и .NET
Ни в JMS, ни в .NET нет встроенных средств для поддержки цепочек сообщений (Message
Sequence). По этой причине приложения, предназначенные для работы с сообщениями,
должны реализовать собственные поля для хранения идентификаторов цепочки сообще-
ний. В JMS приложение может определить собственные свойства в заголовке сообщения.
В .NET такая возможность отсутствует. Поля для хранения указанных идентификаторов
можно определить и в теле сообщения. Помните, что если получатель цепочки сообще-
ний должен фильтровать сообщения на основе их порядка в цепочке, фильтрация значи-
тельно облегчится, если поле будет храниться в заголовке, а не в теле сообщения.
196
Глава 5. Построение сообщений
Пример: множество асинхронных ответов (Web-службы)
Текущие стандарты Web-служб не обеспечивают должной поддержки асинхронного обмена
сообщениями, но консорциум W3C начал задумываться о ее реализации. В статье [44] рас-
сматривается несколько различных сценариев с асинхронной работой Web-служб. В одном
из них— в сценарии под названием “Множество асинхронных ответов” (Multiple
Asynchronous Responses) — в заголовок сообщения SOAP включаются поля Messageld и
ResponseTo, которые позволяют сопоставить ответ с запросом, а в тело сообщения вклю-
чаются поля SequenceNumber и Total InSequence, задающие порядковый номер сообще-
ния и общее число сообщений в цепочке соответственно. Ниже приведен пример запроса,
ответ на который отправляется в виде цепочки сообщений (Message Sequence).
Сообщение-запрос SOAP с идентификатором сообщения
<?xml version="l.О" ?>
cenv:Envelope xmlns:env="http://ww.w3.org/2002/06/soap-envelope">
cenv:Headers
cn:MsgHeader xmlns:n="http://example.org/requestresponse">
cn:MessageIdsuuid:09233523-345b-4351-b623-
5dsf35sgs5d6c/n:MessageIds
</n:MsgHeader>
c/env:Headers
cenv:Bodys
c/env:Bodys
c/env:Envelopes
Первое сообщение-ответ SOAP с идентификаторами цепочки сообщений, идентификато-
ром сообщения и идентификатором корреляции, указывающим на исходный запрос
c?xml version="l.0" ?s
cenv:Envelope xmlns:env="http:I/vm.w3.org/2002/06/soap-envelope"s
cenv:Headers
cn:MsgHeader xmlns:n="http://example.org/requestresponse"s
<!-- Messageld уникален для каждого сообщения-ответа --s
с!-- ResponseTo одинаков для всех сообщений-ответов в ueno4Ke--s
cn:Messageldsuuid:09233523-567b-2891-b623-
9dke28yod7m9</п:Messagelds
<n:ResponseTosuuid:09233523-345b-4351-b623-
5dsf35sgs5d6c/n:ResponseTos
</n:MsgHeaders
<s:Sequence xmlns:s="http://example.org/sequence"s
cs:SequenceNumberslc/s:SequenceNumbers
cs:TotalInSequences5</s:TotalInSequences
c/s:Sequences
</env:Headers
<env:Bodys
</env:Bodys
</env:Envelopes
Цепочка сообщений (Message Sequence)
197
Последнее сообщение-ответ SOAP с идентификаторами цепочки сообщений, идентифика-
тором сообщения и идентификатором корреляции, указывающим на исходный запрос
<?xml version="l.О" ?s
<env:Envelope xmlns:env="http://www.w3.org/2002/06/soap-enve1ope">
cenv:Headers
<n:MsgHeader xmlns:n="http://example.org/requestresponse"s
<!-- Messageld уникален для каждого сообщения-ответа -->
<!-- ResponseTo одинаков для всех сообщений-ответов в цепочке -->
<n:Message!dsuuid:40195729-sj20-pso3-1092-
p20dj28rkl04c/n:Message!ds
<n:ResponseTosuuid:09233523-345b-4351-Ь623-
5ds f 3 5sgs 5d6 </n:ResponseTo
</n:MsgHeaders
<s:Sequence xmlns:s="http:11 example.org/sequence">
<s:SequenceNumbers5</s:SequenceNumber>
<s:TotalInSequences5c/s:TotalInSequences
</s:Sequences
</env:Headers
<env:Bodys
</env:Bodys
</env:Envelopes
Поле ResponseTo в заголовке сообщения-ответа используется не только как иденти-
фикатор корреляции, но и как идентификатор цепочки ответов. Поля SequenceNumber
и TotallnSequence в теле каждого сообщения-ответа являются идентификатором
позиции текущего сообщения и индикатором длины цепочки соответственно.
198
Глава 5. Построение сообщений
Срок действия сообщения (Message Expiration)
Приложение использует обмен сообщениями (Messaging, с. 87). Если данные или
запрос, содержащийся в сообщении (Message, с. 98), не были получены в течение опреде-
ленного времени, они становятся бесполезными и должны быть проигнорированы.
Как уведомить получателя о том, что по истечении некоторого времени сообщение
устаревает и его не следует принимать во внимание?
Обмен сообщениями де-факто гарантирует, что сообщение в конце концов будет достав-
лено своему получателю. К сожалению, система обмена сообщениями не знает, сколько
времени займет эта доставка. К примеру, если сеть, соединяющая отправителя и получа-
теля, будет отключена на неделю, то на доставку сообщения тоже может потребоваться
неделя, а то и больше. Обмен сообщениями обеспечивает высоконадежную передачу дан-
ных независимо от уровня надежности участников этого процесса (отправителя, получа-
теля и сети), но в ненадежной среде доставка данных может длиться слишком много вре-
мени. (См. также шаблон гарантированная доставка (Guaranteed Delivery, с. 149).)
Зачастую содержимое сообщения имеет ограниченный “срок годности”, по истечении
которого оно теряет свою актуальность. Приложение, запрашивающее текущие значения
биржевых котировок, вряд ли заинтересуется ответом, если не получит его в течение мину-
ты. Это означает, что и запрос, и ответ должны передаваться очень быстро. Значения бир-
жевых котировок меняются так быстро, что через минуту-две безнадежно устаревают.
Если отправитель отослал сообщение и долго не получает ответ, он никак не может
отменить вызов или повторить его еще раз, не рискуя при этом получить ответы на оба
вызова. Точно так получатель мог бы проверять время отправки каждого сообщения и
отклонять сообщения, которые были отосланы слишком давно, но у каждого отправите-
ля может быть свое понимание того, что значит “слишком давно”. Как же определить,
какие сообщения должны быть отброшены по причине устаревания? Для этого отправи-
телю нужен способ задания “времени жизни” сообщения.
Если время, на протяжении которого сообщение сохраняет свою актуальность, уже
истекло, а сообщение так и не было потреблено, значит, оно устарело. Потребители сис-
темы обмена сообщениями будут игнорировать устаревшее сообщение; они отнесутся к
нему так, как если бы сообщения никогда не существовало. Большинство систем обмена
сообщениями перенаправляет устаревшие сообщения в канал недоставленных сообщений
(Dead Letter Channel, с. 147), а другие системы их просто уничтожают. Указанное поведе-
ние часто поддается настройке.
Срок действия сообщения можно сравнить со сроком годности на пачке молока. По ис-
течении даты, указанной после слов “Годен до”, молоко лучше не пить. Точно так, если
срок действия сообщения истекает, система обмена сообщениями больше не должна пы-
таться доставить указанное сообщение получателю. Если же получатель вовремя принял
сообщение, но не смог обработать его до истечения срока действия, отбрасыванием со-
общения должен заняться именно он.
Срок действия сообщения (Message Expiration)
199
Используйте срок действия сообщения (Message Expiration), чтобы задать проме-
жуток времени, по истечении которого сообщение должно считаться устаревшим.
сообщений
Срок действия сообщения представляет собой метку времени (дату и время), которая
указывает, как долго после отправки сообщение будет годным или же в какой момент
времени оно устареет. Данный параметр может быть абсолютным или относительным.
Абсолютный срок действия задает дату и время, по истечении которых сообщение поте-
ряет смысл. Относительный срок действия указывает, в течение какого времени после
отправки сообщение будет считаться годным. Для преобразования относительного срока
действия в абсолютный системе обмена сообщениями достаточно воспользоваться датой
и временем отправки сообщения. Кроме того, система обмена сообщениями должна ав-
томатически настраивать метку времени для получателей, находящихся в других часовых
поясах, учитывать переход на летнее время и выполнять любые другие действия по согла-
сованию системных часов отправителя и получателя.
У срока действия сообщения есть родственное свойство, задающее время отправки сооб-
щения. При использовании абсолютного срока действия его метка времени должна идти
позже, чем метка времени отправки сообщения. В противном случае срок действия сооб-
щения истечет немедленно. Во избежание этой проблемы срок действия обычно задают в
относительном формате. Тогда система обмена сообщениями вычисляет окончание срока
действия по формуле “момент устаревания = момент отправки + время жизни”.
Когда сообщение устаревает, система обмена сообщениями может просто его унич-
тожить или же перенаправить в канал недоставленных сообщений. Получатель, который не
смог вовремя обработать принятое им сообщение, должен направить его в канал недопус-
тимых сообщений (Invalid Message Channel, с. 143). Если сообщение размещается в канале
“публикация-подписка” (Publish-Subscribe Channel, с. 134), каждый подписчик получает
собственную копию сообщения. Некоторые копии могут успешно дойти до получателей,
200
Глава 5. Построение сообщений
а некоторые — устареть еще до их потребления. В схеме запрос-ответ (Request-Reply,
с. 177) задавать срок действия ответа надо с большой осторожностью. Если сообщение с от-
ветом устареет, отправитель запроса никогда не узнает, был ли получен сам запрос. По этой
причине, если для ответа указывается срок действия, в отправитель запроса необходимо
встроить специальный обработчик ситуации, когда ожидаемый ответ так и не придет.
Пример: параметр TitneToLive (JMS)
В спецификации JMS срок действия сообщения (Message Expiration) фигурирует под назва-
нием “время жизни сообщения” (message time-to-live) [14, 17]. У сообщений JMS есть
встроенное свойство JMSExpiration, позволяющее задать срок годности сообщения,
но отправитель не должен задавать его посредством метода Message.setJMS-
Expiration (long) , потому что при отправке сообщения значение этого свойства будет
переопределено поставщиком JMS. Вместо этого отправитель должен воспользоваться
своим объектом Messageproducer (Queuesender или TopicPublisher), чтобы устано-
вить время жизни для всех отправляемых им сообщений. Это делается с помощью метода
Messageproducer. setTimeToLive (long). Отправитель также может указать время
жизни отдельно взятого сообщения, используя метод Messageproducer. send (Message
сообщение, int режимДоставки, int приоритет, long времяЖизни), где четвер-
тый параметр — это время жизни сообщения в миллисекундах. Время жизни — это от-
носительный параметр, задающий, через какое время после отправки сообщения оно бу-
дет признано устаревшим.
Пример: свойства TimeToBeReceived и TimeToReachQueue (.NET)
В .NET у объекта сообщения есть два свойства, позволяющих задать срок действия со-
общения: TimeToBeReceived и TimeToReachQueue. Свойство TimeToReachQueue оп-
ределяет, как долго сообщение может добираться до очереди назначения, прежде чем оно
“застрянет” в исходной очереди на неопределенное время. Свойство TimeToBeReceived
задает, в течение какого времени сообщение должно быть потреблено получателем, что
включает в себя общее время доставки сообщения в очередь назначения плюс время, ко-
торое сообщение может находиться в этой очереди, прежде чем попадет к получателю.
Указанное свойство эквивалентно свойству JMSExpiration в JMS. Значения свойств
TimeToBeReceived и TimeToReachQueue принадлежат к типу System.TimeSpan, за-
дающему длительность промежутка времени [7, 39].
Индикатор формата (Format Indicator)
201
Индикатор формата (Format Indicator)
Несколько приложений, взаимодействующих посредством обмена сообщениями
(Messaging, с. 87), используют некоторый согласованный друг с другом формат данных
сообщения, например корпоративную каноническую модель данных (Canonical Data Model,
с. 367). Со временем, однако, в этом формате могут появиться изменения.
Как спроектировать формат данных сообщения, чтобы предусмотреть в нем воз-
можность изменений в будущем?
Даже если вы разработаете формат данных, который будет устраивать всех участников
обмена сообщениями, в дальнейшем требования к формату могут измениться. В инте-
грационном решении может появиться еше несколько приложений, у которых будут свои
требования к формату данных; в сообщения может понадобиться включать новые дан-
ные; или же разработчики могут отыскать более удачный способ структурирования тех
же данных. Разработка единой корпоративной модели данных — и так весьма сложное
занятие, но создать модель, которая многие годы сможет удовлетворять нужды компании
без каких бы то ни было изменений, практически невозможно.
Изменение корпоративного формата данных — не проблема, если все приложения
меняются вместе с ним. Если все приложения одновременно прекратят использовать
старый формат и перейдут на новый, они продолжат взаимодействовать друг с другом в
нормальном режиме. В реальной жизни, однако, одни приложения переводятся на новый
формат раньше, другие — позже, а третьи, которые используются не так часто, могут и
вовсе остаться в первоначальном виде. Наконец, даже если бы все приложения были од-
новременно переведены на новый формат данных, в каналах наверняка останутся какие-
то сообщения в старом формате.
На практике приложениям приходится одновременно поддерживать и старый, и но-
вый форматы данных. Для этого приложение должно уметь различать, какие сообщения
находятся в старом формате, а какие в новом.
Одно из возможных решений этой проблемы — использовать отдельный канал для
сообщений в новом формате. Но это чревато появлением огромного количества каналов,
дублированием многих компонентов, а также сложностью настройки, потому что каждое
приложение придется все время подстраивать под постоянно растущий набор каналов.
Более удачным решением является использование одного и того же канала для сооб-
щений старого и нового форматов. Тогда получателям сообщений понадобится простой
и быстрый способ различения их форматов. В каждом сообщении должно быть указано,
какой формат данных оно использует.
Включите в структуру сообщения индикатор формата (Format Indicator), который
будет указывать, какой именно формат используется данным сообщением.
202
Глава 5. Построение сообщений
Используя индикатор формата, отправитель может уведомить получателя о формате
отсылаемого им сообщения. Благодаря этому получатель узнает, в каком из нескольких
возможных форматов создано текущее сообщение, и поймет, как его следует интерпре-
тировать.
Существует три основных подхода к реализации индикатора формата.
1. Номер версии. Число или строка, которая уникальным образом идентифицирует
формат. Отправитель и получатель должны предварительно договориться о том,
какому формату будет соответствовать тот или иной индикатор. Использование
указанного подхода избавляет отправителя и получателя от необходимости созда-
вать общий репозиторий дескрипторов формата. Недостаток же состоит в том, что
все участники общения должны знать, какому формату соответствует каждый
конкретный индикатор и где в сообщении его искать.
2. Внешний ключ. Уникальный идентификатор (например, имя файла, ключ записи
базы данных или ссылка URI), который задает документ с описанием формата
данных, т.е. схему. Отправитель и получатель должны согласовать сопоставление
ключей и документов, а также формат документа схемы. Сильной стороной этого
подхода является то, что внешний ключ очень компактен и может указывать на
подробное описание формата данных, хранящееся в общем репозитории. Глав-
ный недостаток вызван тем, что каждому участнику обмена сообщениями придет-
ся извлекать документ с описанием формата из потенциально удаленного ресурса.
3. Документ с описанием формата. Схема, описывающая формат данных. При ис-
пользовании этого подхода документ схемы не нужно извлекать с помощью
внешнего ключа или определять по номеру версии; он будет внедрен в само со-
общение. Отправитель и получатель должны договориться о формате схемы. Пре-
имущество этого подхода заключается в том, что сообщения становятся самодос-
таточными. К сожалению, это же приведет к увеличению объема трафика сооб-
щений, потому что в каждом сообщении будут содержаться сведения о формате,
которые на самом деле редко меняются.
Номер версии или внешний ключ может храниться в заранее оговоренном поле заго-
ловка сообщения. Получатели, которых не интересует версия формата, могут проигно-
рировать это поле. Документ с описанием формата может оказаться слишком длинным
или сложным, чтобы размещаться в поле заголовка. В этом случае тело сообщения долж-
но состоять из двух частей: схемы и данных.
Пример: XML
В мире документов XML встречаются примеры всех трех подходов. Первый из них —
это объявление XML, например, такого вида:
<?xml version="l.0"?>
Здесь 1.0 — это номер версии, который задает соответствие документа указанной вер-
сии спецификации XML.
Индикатор формата (Format Indicator)
203
В качестве примера второго подхода можно привести объявление типа документа, ко-
торое может принимать одну из двух форм. Это может быть внешний идентификатор, со-
держащий системный идентификатор, например:
<!D0CTYPE greeting SYSTEM "hello.dtd">
Системный идентификатор hello.dtd — это внешний ключ, который задает файл
шаблона DTD, описывающего формат текущего документа XML. Объявление также мо-
жет быть задано локально, например:
<!DOCTYPE greeting [
<!ELEMENT greeting (#PCDATA)>
]>
Объявление разметки < 'element greeting (#pcdata) > — это документ с описа-
нием формата, т.е. внедренный документ схемы, описывающей формат текущего доку-
мента XML [48].
Глава 6
Практикум: простой пример
обмена сообщениями
Введение
Ранее в этой книге были рассмотрены базовые компоненты обмена сообщениями,
такие как канал сообщений (Message Channel, с. 93), сообщение (Message, с. 98) и конечная
точка сообщения (Message Endpoint, с. 124). Кроме того, вы ознакомились с различными
типами каналов сообщений, а также с шаблонами проектирования, применяющимися
при построении сообщений. Настоящая глава посвящена двум практическим примерам
создания простых интеграционных решений.
• Запрос-ответ демонстрирует (с применением Java и .NET/C#) использование об-
мена сообщениями для отправки сообщения с запросом и получения сообщения с
ответом.
• Публикация-подписка демонстрирует использование интерфейса JMS Topic для
реализации шаблона проектирования наблюдатель (Observer) [12].
Запрос-ответ
Данный пример демонстрирует использование технологии обмена сообщениями для
отправки сообщения с запросом и получения сообщения с ответом. Реализация столь
нехитрой функциональности возлагается на два основных класса.
• Requestor (инициатор запроса). Объект, отправляющий сообщение с запросом
и ожидающий сообщения с ответом.
• Replier (ответчик). Объект, получающий сообщение с запросом и отправляющий
сообщение с ответом.
206
Глава 6. Практикум: простой пример обмена сообщениями
Классы Requestor и Replier иллюстрируют применение целого ряда шаблонов
проектирования.
• Канал сообщений (Message Channel, с. 93) и канал “точка-точка” (Point-to-Point
Channel, с. 131). Один канал сообщений используется для передачи сообщения
с запросом, а другой—для передачи сообщения с ответом.
• Сообщение с данными документа (Document Message, с. 171). Тип сообщения
с запросом и сообщения с ответом по умолчанию.
• Запрос-ответ (Request-Reply, с. 177). Два сообщения, пересылаемые по двум
каналам и обеспечивающие двустороннее взаимодействие между двумя приложе-
ниями.
• Обратный адрес (Return Address, с. 182). Канал, по которому следует передавать
сообщение с ответом.
• Идентификатор корреляции (Correlation Identifier, с. 186). Идентификатор сообще-
ния с запросом, соответствующего сообщению с ответом.
• Канал типа данных (Datatype Channel, с. 139). Все сообщения, передающиеся по
каждому каналу, должны иметь один и тот же тип.
• Канал недопустимых сообщений (Invalid Message Channel, с. 143). Канал, в который
помещаются сообщения недопустимого типа.
Кроме того, кол примера демонстрирует использование нескольких шаблонов проек-
тирования, рассматривающихся в главе 10.
• Опрашивающий потребитель (Polling Consumer, с. 507). Способ получения сообще-
ний с ответом—инициатором запроса.
• Событийно управляемый потребитель (Event-Driven Consumer, с. 511). Способ полу-
чения сообщений с запросом—ответчиком.
Для реализации примера “запрос-ответ” были выбраны две программные платфор-
мы, использующие технологию обмена сообщениями.
• JMSAPIBJ2EE
• MSMQ API в Microsoft .NET с использованием языка программирования C#
Публикация-подписка
Данный пример демонстрирует реализацию шаблона проектирования наблюдатель
(Observer) [12] с помощью канала “публикация-подписка” (Publish-Subscribe Channel,
с. 134). Будет рассмотрена реализация моделей уведомления с активным (push) и пассив-
ным (pull) источниками данных. Кроме того, мы представим оптимальную стратегию
выбора каналов сообщений при создании сложного интеграционного решения с множе-
ством субъектов и наблюдателей.
Введение
207
Пример “публикация-подписка” иллюстрирует реализацию нескольких шаблонов
проектирования, рассмотренных в предыдущих главах книги.
• Канал “публикация-подписка” {Publish-Subscribe Channel, с. 134). Канал, обеспечи-
вающий уведомление по типу “публикация-подписка”.
• Сообщение о событии {Event Message, с. 174). Тип сообщения, использующегося для
отправки уведомлений.
• Запрос-ответ {Request-Reply, с. 177). Способ, которым наблюдатель запрашивает
состояние субъекта в рамках модели с пассивным (pull) источником данных.
• Сообщение с командой {Command Messag/e, с. 169). Тип сообщения, используемого
наблюдателем для запроса состояния субъекта.
• Сообщение с данными документа {Document Message, с. 171). Тип сообщения,
используемого субъектом для отправки сведений о своем состоянии наблюдателю.
• Обратный адрес {Return Address, с. 182). Способ, которым субъект уведомляет
наблюдателя о своем состоянии.
• Канал типа данных {Datatype Channel, с. 139). Основной признак того, что два раз-
личных субъекта могут использовать один и тот же канал для уведомления одина-
ковых групп наблюдателей.
Кроме того, код примера демонстрирует использование нескольких шаблонов проек-
тирования, рассматривающихся в главе 10.
• Шлюз обмена сообщениями {Messaging Gateway, с. 482). Способ инкапсуляции кода
обмена сообщениями субъектом и наблюдателем.
• Событийно управляемый потребитель {Event-Driven Consumer, с. 511). Способ полу-
чения уведомлений наблюдателем.
• Постоянный подписчик {Durable Subscriber, с. 535). Способ, обеспечивающий
гарантированное получение уведомления наблюдателем.
Пример “публикация-подписка” реализован средствами JMS, поскольку этот API
обеспечивает явную поддержку канала “публикация-подписка” через интерфейс Topic.
В отличие от JMS, в MSMQ подобный уровень поддержки не предусмотрен.
208
Глава 6. Практикум: простой пример обмена сообщениями
Запрос-ответ (JMS)
Рассмотрим простой пример обмена сообщениями, реализованный с помощью
JMS [16]. Данный пример иллюстрирует использование шаблона проектирования
запрос-ответ (Request-Reply, с. 177). Инициатор запроса отправляет запрос, который
принимается ответчиком. В свою очередь, ответчик отправляет ответ, который принима-
ется инициатором запроса. Сообщения недопустимого формата помещаются в специ-
альный канал, как показано на рис. 6.1.
Рис. 6.1. Компоненты примера “запрос-ответ”
Пример “запрос-ответ” был создан на основе спецификации JMS версии 1.1 и пред-
назначен для выполнения на платформе J2EE версии 1.4.
Описание
Пример “запрос-ответ” предполагает использование двух основных классов.
1. Requestor (инициатор запроса). Конечная точка сообщения (Message Endpoint,
с. 124), отправляющая сообщение с запросом и ожидающая получения ответного
сообщения.
2. Replier (ответчик). Конечная точка сообщения, ожидающая получения сообще-
ния с запросом и реагирующая на него путем отправки сообщения с ответом.
Распределенное взаимодействие между инициатором запроса и ответчиком достига-
ется за счет наличия у каждого из них выполняющейся копии виртуальной машины Java
(Java Virtual Machine — JVM).
Система обмена сообщениями примера “запрос-ответ” содержит три очереди.
1. jms/RequestQueue. Очередь, используемая инициатором запроса для отправки
сообщения с запросом ответчику.
2. jms/ReplyQueue. Очередь, используемая ответчиком для отправки сообщения
с ответом инициатору запроса.
3. jms/invalidMessages. Очередь, используемая инициатором запроса и ответчи-
ком для отправки сообщений недопустимого формата.
Запрос-ответ (JMS)
209
Следующий текст выводится в окне командной строки после запуска инициатора
запроса.
Sent request
Time: 1048261736520 ms
Message ID: ID:_XYZ123_1048261766139_6.2.1.1
Correl. ID: null
Reply to: com.sun.jms.Queue: jms/ReplyQueue
Contents: Hello world.
Обратите внимание, что отправка сообщения с запросом возможна вне зависимости
от того, способен ли ответчик получить и обработать это сообщение.
Следующий текст выводится в окне командной строки после запуска ответчика и по-
лучения сообщения с запросом.
Received request
Time: 1048261766790 ms
Message ID: ID:_XYZ123_1048261766139_6.2.1.1
Correl. ID: null
Reply to: com.sun.jms.Queue: jms/ReplyQueue
Contents: Hello world.
Sent reply
Time: 1048261766850 ms
Message ID: ID:_XYZ123_1048261758148_5.2.1.1
Correl. ID: ID:_XYZ123_1048261766139_6.2.1.1
Reply to: null
Contents: Hello world.
Проанализируем приведенный выше текст. Во-первых, обратите внимание на то, что
запрос был получен спустя 30270 мс после его отправки инициатором запроса.
Во-вторых, идентификатор полученного сообщения с запросом совпадает с идентифика-
тором отправленного сообщения с запросом. В-третьих, содержимое сообщения
(“Hello world.”) не изменилось при передаче. (В рассматриваемом примере сообщение
с запросом представляет собой сообщение с данными документа (Document Message, с. 171),
однако в большинстве реальных ситуаций сообщение с запросом реализуется в виде
сообщения с командой (Command Message, с. 169).) В-четвертых, очередь jms/ReplyQueue
указана в сообщении с запросом как точка назначения ответного сообщения (типичный
пример реализации шаблона проектирования обратный адрес (Return Address, с. 182)).
Сравним текст, сгенерированный ответчиком при получении запроса и отправке
ответа. Во-первых, ответ был отправлен спустя 60 мс после получения запроса. Во-
вторых, идентификатор сообщения с запросом отличается от идентификатора сообще-
ния с ответом, поскольку это два разных сообщения. В-третьих, содержимое сообщения
с запросом дублируется в ответном сообщении. В-четвертых, точка назначения ответного
сообщения не указана, так как это сообщение не предполагает ответа. В-пятых, иденти-
фикатор корреляции сообщения с ответом совпадает с идентификатором сообщения с
запросом (сообщение с ответом использует шаблон проектирования идентификатор кор-
реляции (Correlation Identifier, с. 186)).
210
Глава 6. Практикум: простой пример обмена сообщениями
Получив сообщение с ответом, инициатор запроса сгенерирует следующий текст.
Received reply
Time:
1048261797060 mS
Message ID: ID:_XYZ123_1048261758148_5.2.1.1
Correl. ID: ID:_XYZ123_1048261766139_6.2.1.1
Reply to: null
Contents: Hello world.
Как следует из приведенной выше информации, сообщение с ответом было получено
спустя 30 210 мс после его отправки. Идентификатор полученного сообщения с ответом
совпадает с идентификатором отправленного сообщения с ответом. Содержимое сооб-
щения с ответом идентично содержимому сообщения с запросом, а идентификатор кор-
реляции указывает инициатору запроса, к какому запросу относится данный ответ.
Следует также отметить, что инициатор запроса завершает свою работу, как только
получает ответ на отправленный им запрос. С другой стороны, ответчик никогда не пре-
кращает свою работу, поскольку он не знает, когда может получить запрос. Чтобы завер-
шить выполнение ответчика, следует перейти в соответствующее ему окно командной
строки и нажать клавишу <Enter>.
Код
Ниже приведен код класса Requestor.
import javax.jms.Connection;
import javax.jms.Destination;
import javax.jms.JMSException;
import javax.jms.Message;
import javax.jms.Messageconsumer;
import j avax.jms.MessageProducer;
import javax.jms.Session;
import javax.jms.TextMessage;
import j avax.naming.NamingException;
public class Requestor {
private Session session;
private Destination replyQueue;
private MessageProducer requestproducer;
private Messageconsumer replyconsumer;
private MessageProducer invalidproducer;
protected Requestor() {
super();
public static Requestor newRequestor(Connection connection.
String requestQueueName, String replyQueueName,
String invalidQueueName)
throws JMSException, NamingException {
Requestor requestor = new Requestor();
Запрос-ответ (JMS)
211
requestor.initialize(connection, requestQueueName,
replyQueueName, invalidQueueName);
return requestor;
}
protected void initialize(Connection connection.
String requestQueueName, String replyQueueName,
String invalidQueueName)
throws NamingException, JMSException {
session = connection.createSession(false.
Session.AUTO_ACKNOWLEDGE);
Destination requestQueue = Jndiutil.getDestination(
requestQueueName);
replyQueue = Jndiutil.getDestination(replyQueueName);
Destination invalidQueue = Jndiutil.getDestination(
invalidQueueName) ,-
requestproducer = session.createProducer(requestQueue);
replyConsumer = session.createConsumer(replyQueue);
invalidproducer = session.createProducer(invalidQueue);
}
public void send() throws JMSException {
TextMessage requestMessage = session.createTextMessage();
requestMessage.setText("Hello world.");
requestMessage.setJMSReplyTo(replyQueue);
requestproducer.send(requestMessage);
System.out.println("Sent request");
System.out.printin("\tTime: " + System.currentTimeMillis() +
" ms");
System.out.printin("\tMessage ID: " +
requestMessage.getJMSMessagelD());
System.out.printin("\tCorrel. ID: "+
requestMessage.getJMSCorrelationlD());
System.out.printin("\tReply to: " +
requestMessage.getJMSReplyTo());
System.out.printin("\tContents: " +
requestMessage.getText() ) ;
}
public void receiveSync() throws JMSException {
Message msg = replyConsumer.receive();
if (msg instanceof TextMessage) {
TextMessage replyMessage = (TextMessage) msg;
System.out.println("Received reply ");
System.out.printin("\tTime: " +
System.currentTimeMillis() + " ms");
System.out.printin("\tMessage ID: " +
replyMessage.getJMSMessagelD());
System.out.printin("\tCorrel. ID: " +
replyMessage.getJMSCorrelationlD());
System.out.printin("\tReply to: " +
replyMessage.getJMSReplyTo());
212
Глава 6. Практикум: простой пример обмена сообщениями
System.out.printin("\tContents: " +
replyMessage.getText());
} else {
System.out.printin("Invalid message detected");
System.out.println("\tType: " +
msg.getClass().getName() ) ;
System.out.printin("\tTime: " +
System.currentTimeMillis() + " ms");
System.out.printin("\tMessage ID: " +
msg.getJMSMessagelD())
System.out.printin("\tCorrel. ID: "+
msg.getJMSCorrelationlD());
System.out.printin("\tReply to: " +
msg.getJMSReplyTo());
msg.setJMSCorrelationlD(msg.getJMSMessagelD() ) ;
invalidProducer.send(msg)
System.out.printin("Sent to invalid message queue");
System.out.printin("\tType: " +
msg.getClass().getName());
System.out.println("\tTime: " +
System.currentTimeMillis() + " ms");
System.out.printin("\tMessage ID: " +
msg.getJMSMessagelDO ) ;
System.out.printin("\tCorrel. ID: " +
msg.getJMSCorrelationlD());
System.out.printin("\tReply to: " +
msg.getJMSReplyToO ) ;
}
}
}
Класс Requestor может использоваться любым приложением, нуждающимся в от-
правке запросов и получении ответов. Чтобы инициализировать инициатор запроса, ему
следует передать объект соединения с системой обмена сообщениями, а также JNDI-
имена очереди запросов, очереди ответов и очереди сообщений недопустимого формата.
Метод initialize класса Requestor выполняет следующие действия.
• Использует объект соединения для создания сеанса. Несмотря на то что приложе-
нию требуется единственное подключение к системе обмена сообщениями, каж-
дый компонент приложения, нуждающийся в отправке запросов и получении
ответов, должен иметь собственный сеанс.
• Использует имена очередей для их поиска. Имена очередей представлены JNDI-
идентификаторами. Поиск очереди осуществляется с помощью класса Jndiutil.
• Создает объект типа Messageproducer для отправки сообщений с помощью оче-
реди запросов, объект типа MessageQonsumer для получения сообщений с помо-
щью очереди ответов и объект типа M&ssageProducer для помещения сообщений
в очередь сообщений недопустимого формата.
Запрос-ответ (JMS)
213
Метод send () класса Requestor используется для отправки сообщений с запросом
и выполняет следующие действия.
• Создает объект типа TextMessage и присваивает его содержимому значение
“Hello world.”.
• Задает обратный адрес (Return Address, с. 182) сообщения.
• Отправляет сообщение с помощью метода send() объекта requestproducer,
подключенного к очереди запросов.
• Выводит информацию, касающуюся только что отправленного сообщения. Обра-
тите внимание, что идентификатор сообщения присваивается системой обмена
сообщениями по факту отправки сообщения.
Метод receiveSync () класса Requestor используется для получения ответных со-
общений и выполняет следующие действия.
• Получает сообщение с ответом с помощью метода receive () объекта
replyconsumer, подключенного к очереди ответов. Поскольку метод receive ()
реализует синхронный подход к взаимодействию, блокируя очередь на время по-
лучения сообщения, инициатор запроса является опрашивающим потребителем
(Polling Consumer, с. 507). Синхронная природа метода receive () отражена в на-
звании метода receiveSync ().
• Если полученное сообщение является объектом типа TextMessage, инициатор
запроса извлекает содержимое сообщения и выводит его на экран.
• Если полученное сообщение не является объектом типа TextMessage, инициатор
запроса отправляет его в очередь сообщений недопустимого формата. Поскольку
отправка сообщения приведет к изменению его идентификатора, инициатор
запроса использует исходный идентификатор сообщения в качестве идентифика-
тора корреляции (см. шаблон проектирования идентификатор корреляции
(Correlation Identifier, с. 186)).
Итак, созданный нами инициатор запроса обладает всей необходимой функциональ-
ностью для отправки запроса, получения ответа и перенаправления сообщения недопус-
тимого формата в специально предусмотренную для этого очередь. (Следует отметить,
что аналогичную функциональность обеспечивает класс JMS QueueRequestor. Тем не
менее мы прибегли к собственной реализации инициатора запроса для более наглядной
демонстрации его работы.)
Ниже приведен код класса Replier.
inport javax.jms.Connection;
import javax.jms.Destination;
import javax.jms.JMSException;
inport javax.jms.Message;
import javax.jms.Messageconsumer;
import javax.jms.MessageListener;
import javax.jms.MessageProducer;
import javax.jms.Session;
import javax.jms.TextMessage;
214
Глава 6. Практикум: простой пример обмена сообщениями
import j avax.naming.NamingException;
public class Replier implements MessageListener {
private Session session;
private Messageproducer invalidproducer;
protected Replier() {
super();
}
public static Replier newReplier(Connection connection,
String requestQueueName, String invalidQueueName)
throws JMSException, NamingException {
Replier replier = new Replier();
replier.initialize(connection, requestQueueName,
invalidQueueName);
return replier;
}
protected void initialize(Connection connection.
String requestQueueName, String invalidQueueName)
throws NamingException, JMSException {
session = connection.createSession(false,
Session.AUTO_ACKNOWLEDGE);
Destination requestQueue =
Jndiutil.getDestination(requestQueueName);
Destination invalidQueue =
Jndiutil.getDestination(invalidQueueName);
Messageconsumer requestconsumer =
session.createConsumer(requestQueue);
MessageListener listener = this;
requestconsumer.setMessageListener(listener);
invalidProducer = session.createProducer(invalidQueue);
}
public void onMessage(Message message) {
try {
if ((message instanceof TextMessage) &&
(message.getJMSReplyTo() != null)) {
TextMessage requestMessage = (TextMessage) message;
System.out.println("Received request");
System.out.printin("\tTime: " +
System.currentTimeMillis() + " ms");
System.out.println("\tMessage ID: " +
requestMessage.getJMSMessagelD());
System.out.println("\tCorrel. ID: " +
requestMessage.getJMSCorrelationlD());
System.out.printin("\tReply to: " +
requestMessage.getJMSReplyTo());
System.out.printin("\tContents: " +
Запрос-ответ (JMS)
215
requestMessage.getText() ) ;
String contents = requestMessage.getText();
Destination replyDestination =
message.getJMSReplyTo();
MessageProducer replyproducer =
session.createProducer(replyDestination);
TextMessage replyMessage =
session.createTextMessage();
replyMessage.setText(contents);
replyMessage.setJMSCorrelationlD(
requestMessage.getJMSMessageID());
replyProducer.send(replyMessage);
System.out.println("Sent reply");
System.out.printin("\tTime: " +
System.currentTimeMillis() + " ms");
System.out.printin("\tMessage ID: " +
replyMessage.getJMSMessagelD());
System.out.printin("\tCorrel. ID: " +
replyMessage.getJMSCorrelationlDO);
System.out.printin("\tReply to: "+
replyMessage.getJMSReplyTo());
System.out.printin("\tContents: " +
replyMessage.getText());
} else {
System.out.println("Invalid message detected");
System.out.printIn("\tType: " +
message. getClass () . getName ());
System.out.println("\tTime: " +
System.currentTimeMillis() + " ms");
System.out.printin("\tMessage ID: " +
message.getJMSMessagelD());
System.out.printin("\tCorrel. ID: " +
message.getJMSCorrelationlD());
System.out.println("\tReply to: " +
message.getJMSReplyToO);
message.setJMSCorrelationlD(
message.getJMSMessagelD());
invalidProducer.send(message);
System.out.println("Sent to invalid message queue");
System.out.printin("\tType: " +
message.getClass().getName());
System.out.printin("\tTime: " +
System.currentTimeMillis() + " ms");
System.out.println("\tMessage ID: " +
message.getJMSMessagelD());
System.out.printin("\tCorrel. ID: " +
message.getJMSCorrelationID());
System.out.printin("\tReply to: " +
message.getJMSReplyToO);
}
216
Глава 6. Практикум: простой пример обмена сообщениями
} catch (JMSException е) {
е.printStackTrace() ;
}
}
}
Класс Replier может использоваться любым приложением, которому необходимо
получать запросы и отправлять ответы. Чтобы инициализировать ответчик, ему следует
передать объект соединения с системой обмена сообщениями, а также JNDI-имена оче-
реди запросов и очереди сообщений недопустимого формата (объект очереди ответов
указывается с помощью обратного адреса сообщения с запросом).
Метод initialize класса Replier похож на одноименный метод класса Requestor,
за исключением нескольких отличий.
• Ответчик не создает объект типа Messageproducer для очереди ответов.
• Поскольку ответчик является событийно управляемым потребителем (Event-Driven
Consumer, с. 511), он реализует интерфейс MessageListener. Система обмена со-
общениями автоматически вызывает метод ответчика onMessage при поступле-
нии в очередь запросов нового сообщения.
После инициализации ответчик переходит в режим ожидания сообщений. В отличие
от инициатора запроса, периодически проверяющего очередь ответов на поступление но-
вого сообщения, ответчик является событийно управляемым потребителем, ожидающим
вызова метода onMessage. Метод onMessage вызывается автоматически системой обме-
на сообщениями и выполняет следующие действия.
• Как и инициатор запроса, ответчик предполагает, что полученное сообщение
является объектом типа TextMessage. Кроме того, сообщение должно содержать
обратный адрес. Если сообщение не удовлетворяет перечисленным условиям, оно
помещается в очередь сообщений недопустимого формата (в ту же очередь, кото-
рая используется инициатором запроса).
• Если сообщение удовлетворяет всем условиям, ответчик реализует свою часть
шаблона обратный адрес, а именно — создает объект типа Messageproducer для
отправки сообщений с ответом. Обратите внимание, что очередь ответа задается
динамически при получении сообщения с запросом.
• Ответчик создает сообщение с ответом, используя в качестве идентификатора
корреляции идентификатор сообщения с запросом.
• Ответчик отправляет сообщение с ответом и выводит на экран его подробности.
Таким образом, ответчик обладает всей необходимой функциональностью для полу-
чения запроса и отправки ответа.
Обработка сообщения недопустимого формата
Рассмотрим пример реализации канала недопустимых сообщений (Invalid Message
Channel, с. 143). Этому каналу соответствует очередь jms/invalidMessages, которая
используется JMS-клиентом (конечной точкой сообщения (Message Endpoint, с. 124)) для
отправки сообщения, которое он не может обработать.
Запрос-ответ (JMS)
217
Чтобы продемонстрировать обработку сообщений недопустимого формата, мы созда-
ли класс invalidMessenger, специально предназначенный для помещения в канал
запроса некорректных сообщений. Напомним, что канал запроса является каналом типа
данных (Datatype Channel, с. 139), регламентирующим определенный формат передавае-
мых сообщений. Поскольку сообщение, сгенерированное объектом типа Invalid-
Messenger, не соответствует требуемому формату данных, получатель переместит его
в очередь сообщений недопустимого формата.
Следующий текст выводится в окне командной строки при отправке сообщения
недопустимого формата.
Sent invalid message
Type: com.sun.jms.ObjectMessagelmpl
Time: 1048288516959 ms
Message ID: ID:_XYZ123_1048288516639_7.2.1.1
Correl. ID: null
Reply to: com.sun.jms.Queue: jms/ReplyQueue
Обратите внимание, что сообщение является объектом типа ObjectMessage, в то
время как ответчик ожидает получения объекта типа TextMessage. Следующий текст
выводится в окне командной строки при получении ответчиком некорректного сообще-
ния и его помещении в очередь сообщений недопустимого формата.
Invalid message detected
Type: com.sun.jms.Obj ectMessagelmpl
Time: 1048288517049 ms
Message ID: ID:_XYZ123_1048288516639_7.2.1.1
Correl. ID: null
Reply to: com.sun.jms.Queue: jms/ReplyQueue
Sent to invalid message queue
Type: com.sun.jms.Obj ectMessagelmpl
Time: 1048288517140 ms
Message ID: ID:_XYZ123_1048287020267_6.2.1.2
Correl. ID: ID:_XYZ123_1048288516639_7.2.1.1
Reply to: com.sun.jms.Queue: j ms/ReplyQueue
Следует отметить, что сообщение, помещаемое в очередь сообщений недопустимого
формата, получает новый идентификатор. Чтобы сохранить исходный идентификатор
сообщения, ответчик копирует его в идентификатор корреляции (Correlation Identifier,
с. 186). Код ответчика, реализующий обработку сообщения недопустимого формата,
находится в методе onMessage класса Replier. Аналогичный код инициатора запроса
находится в методе receiveSync () класса Requestor.
Итог
В рассмотренном примере описываются два класса, Requestor и Replier (точки
обмена сообщениями (Message Endpoint, с. 124)), предназначенных для реализации взаимо-
действия посредством обмена парой сообщений (Message, с. 98) запрос-ответ (Request-
Reply, с. 177). Сообщение с запросом содержит обратный адрес (Return Address, с. 182)
в виде объекта очереди, предназначенной для передачи сообщения с ответом. Сообщение
с ответом содержит идентификатор корреляции (Correlation Identifier, с. 186), позволяю-
218 Глава 6. Практикум: простой пример обмена сообщениями
щий сопоставить сообщение с ответом и сообщение с запросом. Для получения сообще-
ний с ответом инициатор запроса реализует шаблон проектирования опрашивающий
потребитель (Polling Consumer, с. 507). В отличие от инициатора запроса ответчик получа-
ет сообщения с запросом в соответствии с шаблоном проектирования событийно управ-
ляемый потребитель (Event-Driven Consumer, с. 511). Очереди запроса и ответа реализова-
ны в виде каналов типа данных (Datatype Channel, с. 139). Если инициатор запроса или от-
ветчик не может обработать сообщение, он перемещает его в канал недопустимых
сообщений (InvalidMessage Channel, с. 143).
Запрос-ответ (.NET)
219
Запрос-ответ (.NET)
Рассмотрим простой пример обмена сообщениями, реализованный с помощью .NET
[39] и С#. Данный пример иллюстрирует использование шаблона проектирования за-
прос-ответ (Request-Reply, с. 177). Инициатор запроса отправляет запрос, который при-
нимается ответчиком. В свою очередь, ответчик отправляет ответ, который принимается
инициатором запроса. Сообщения недопустимого формата помещаются в специальный
канал, как показано на рис. 6.2.
Инициатор
запроса
Ответчик
Рис. 6.2. Компоненты примера “запрос-ответ”
Пример “запрос-ответ” был создан с помощью платформы Microsoft .NET и предна-
значен для выполнения на компьютере под управлением операционной системы
Windows ХР с поддержкой MSMQ [29].
Описание
Пример “запрос-ответ” предполагает использование двух основных классов.
1. Requestor (инициатор запроса). Конечная точка сообщения (Message Endpoint,
с. 124), отправляющая сообщение с запросом и ожидающая ответное сообщение.
2. Replier (ответчик). Конечная точка сообщения, ожидающая сообщение с запро-
сом и реагирующая на него путем отправки сообщения с ответом.
Распределенное взаимодействие между инициатором запроса и ответчиком достига-
ется за счет наличия у каждого из них отдельной копии программы .NET.
Система обмена сообщениями примера “запрос-ответ” содержит три очереди.
1. . \private$\RequestQueue. Очередь, используемая инициатором запроса для
отправки сообщения с запросом ответчику.
2. ,\private$\ReplyQueue. Очередь, используемая ответчиком для отправки со-
общения с ответом инициатору запроса.
3. . \private$\InvalidMessages. Очередь, используемая инициатором запроса и
ответчиком для отправки сообщений недопустимого формата.
220
Глава 6. Практикум: простой пример обмена сообщениями
Следующий текст выводится в окне командной строки после запуска инициатора
запроса.
Sent request
Time:
Message ID:
Correl. ID:
Reply to:
Contents:
09:11:09.165342
8b0fc389-f21f-423b-9eaa-c3a881a34808\149
.\private$\ReplyQueue
Hello world.
Обратите внимание, что отправка сообщения с запросом возможна вне зависимости
от того, способен ли ответчик получить и обработать это сообщение.
Следующий текст выводится в окне командной строки после запуска ответчика и по-
лучения сообщения с запросом.
Received request
Time:
Message ID:
Correl. ID:
Reply to:
Contents:
Sent reply
Time:
Message ID:
Correl. ID:
Reply to:
Contents:
09:11:09.375644
8b0fc389-f21f-423b-9eaa-c3a881a34808\149
<n/a>
FORMATNAME:DIRECT=OS:XYZ123\private $\ReplyQueue
Hello world.
09:11:09.956480
8b0fc389-f21f-423b-9eaa-c3a881a34808\150
8b0fc389-f21f-423b-9eaa-c3a881a34808\149
<n/a>
Hello world.
Проанализируем приведенный выше текст. Во-первых, обратите внимание на то, что
запрос был получен спустя 210 302 мс после его отправки инициатором запроса.
Во-вторых, идентификатор полученного сообщения с запросом совпадает с идентифика-
тором отправленного сообщения с запросом. В-третьих, содержимое сообщения (“Hello
world.”) не изменилось при передаче. В-четвертых, очередь . \private$\ReplyQueue
указана в сообщении с запросом как точка назначения ответного сообщения (типичный
пример реализации шаблона проектирования обратный адрес (Return Address, с. 182)).
Сравним тексты, сгенерированные ответчиком при получении запроса и отправке
ответа. Во-первых, ответ был отправлен спустя 580 836 мс после получения запроса.
Во-вторых, идентификатор сообщения с запросом отличается от идентификатора сооб-
щения с ответом, поскольку это два разных сообщения. В-третьих, содержимое сообще-
ния с запросом дублируется в ответном сообщении. В-четвертых, точка назначения от-
ветного сообщения не указана, так как это сообщение не предполагает ответа. В-пятых,
идентификатор корреляции сообщения с ответом совпадает с идентификатором сообще-
ния с запросом (сообщение с ответом использует шаблон проектирования идентифика-
тор корреляции (Correlation Identifier, с. 186)).
Получив сообщение с ответом, инициатор запроса сгенерирует следующий текст.
Received reply
Time: 09:11:10.156467
Message ID: 8b0fc389-f21f-423b-9eaa-c3a881a34808\150
Correl. ID: 8b0fc389-f21f-423b-9eaa-c3a881a34808\149
Reply to: <n/a>
Contents: Hello world.
Запрос-ответ (.NET)
221
Как следует из приведенной выше информации, сообщение с ответом было получено
спустя примерно 0,2 с после его отправки. Идентификатор полученного сообщения с от-
ветом совпадает с идентификатором отправленного сообщения с ответом. Содержимое
сообщения с ответом идентично содержимому сообщения с запросом, а идентификатор
корреляции указывает инициатору запроса, к какому запросу относится данный ответ.
Следует также отметить, что инициатор запроса завершает свою работу, как только
получает ответ на отправленный им запрос. С другой стороны, ответчик никогда не пре-
кращает свою работу, поскольку он не знает, когда может получить запрос. Чтобы завер-
шить выполнение ответчика, следует перейти в соответствующее ему окно командной
строки и нажать клавишу <Enter>.
Код
Ниже приведен код класса Requestor.
using System;
using System.Messaging;
public class Requestor
{
private MessageQueue requestQueue;
private MessageQueue replyQueue;
public Requestor(String requestQueueName, String replyQueueName)
{
requestQueue = new MessageQueue(requestQueueName);
replyQueue = new MessageQueue(replyQueueName);
replyQueue.MessageReadPropertyFilter.SetAll();
((XmlMessageFormatter)replyQueue.Formatter).TargetTypeNames =
new string[]{"System.String,mscorlib"};
}
public void SendO
{
Message requestMessage = new Message();
requestMessage.Body = "Hello world.";
requestMessage.ResponseQueue = replyQueue;
requestQueue.Send(requestMessage);
Console.WriteLine("Sent request");
Console.WriteLine("\tTime: {0}",
DateTime.Now.ToString("HH:mm:ss.ffffff"));
Console.WriteLine("\tMessage ID: {0}", requestMessage.Id);
Console.WriteLine("\tCorrel. ID: {O}",
requestMessage.Correlationld);
Console.WriteLine("\tReply to: {0}",
requestMessage.ResponseQueue.Path);
Console.WriteLine("\tContents: {0}",
requestMessage.Body.ToString());
}
public void ReceiveSync()
222
Глава 6. Практикум: простой пример обмена сообщениями
Message replyMessage = replyQueue.Receivet);
Console.WriteLine("Received reply");
Console.WriteLine("\tTime: {0}" ,
DateTime.Now.ToString("HH:mm:ss.ffffff"));
Console.WriteLine("\tMessage ID: {0}", replyMessage.Id);
Console.WriteLine("\tCorrel. ID: {0}",
replyMessage.Correlationld);
Console.WriteLine("\tReply to: {0}", "<n/a>");
Console.WriteLine("\tContents: {0}" ,
replyMessage.Body.ToString());
}
}
Класс Requestor может использоваться любым приложением, нуждающимся в от-
правке запросов и получении ответов. Чтобы инициализировать инициатор запроса,
ему следует передать имена очереди запросов и очереди ответов.
Конструктор класса Requestor выполняет следующие действия.
• Использует имена очередей для их поиска. Имя очереди представляет собой путь к
ресурсу MSMQ.
• Задает фильтр свойств очереди ответа таким образом, чтобы сообщение считыва-
лось из очереди вместе со всеми своими свойствами. Кроме того, конструктор ука-
зывает на необходимость интерпретации содержимого сообщения с использова-
нием строкового формата.
Метод Send () класса Requestor используется для отправки сообщений с запросом
и выполняет следующие действия.
• Создает объект типа Message и присваивает его содержимому значение “Hello
world.”.
• Задает обратный адрес {Return Address, с. 182) сообщения.
• Отправляет сообщение с помощью метода Send () объекта requestQueue.
• Выводит информацию, касающуюся только что отправленного сообщения. Обра-
тите внимание, что идентификатор сообщения присваивается системой обмена
сообщениями по факту отправки сообщения.
Метод ReceiveSync () класса Requestor используется для получения ответных
сообщений и выполняет следующие действия.
• Вызывает метод Receive () объекта replyQueue для получения сообщения.
Поскольку метод Receive () реализует синхронный подход к взаимодействию,
блокируя очередь на время получения сообщения, инициатор запроса является
• опрашивающим потребителем (Polling Consumer, с. 507). Синхронная природа мето-
да Receive () отражена в названии метода ReceiveSync ().
• Извлекает содержимое сообщения и выводит его на экран.
Запрос-ответ (.NET)
223
Итак, созданный нами инициатор запроса обладает всей необходимой функциональ-
ностью для отправки запроса и получения ответа.
Ниже приведен код класса Replier.
using System;
using System.Messaging;
class Replier {
private MessageQueue invalidQueue;
public Replier(String requestQueueName, String invalidQueueName)
{
MessageQueue requestQueue =
new MessageQueue(requestQueueName);
invalidQueue = new MessageQueue(invalidQueueName);
requestQueue.MessageReadPropertyFilter.SetAll();
((XmlMessageFormatter)requestQueue.Formatter).TargetTypeNames =
new string[]{"System.String,mscorlib"};
requestQueue.ReceiveCompleted += new
ReceiveCompletedEventHandler(OnReceiveCompleted);
requestQueue.BeginReceive();
}
public void OnReceiveCompleted(Object source,
ReceiveCompletedEventArgs asyncResult)
{
MessageQueue requestQueue = (MessageQueue)source;
Message requestMessage =
requestQueue.EndReceive(asyncResult.AsyncResult);
try
{
Console.WriteLine("Received request");
Console. Writ eLine ( "\tTime.- {0} ",
DateTime.Now.ToString("HH:mm:ss.ffffff"));
Console.WriteLine("\tMessage ID: {o}",
requestMessage.Id);
Console.WriteLine("\tCorrel. ID: {0}", "<n/a>");
Console.WriteLine("\tReply to: {O}",
requestMessage.ResponseQueue.Path);
Console.WriteLine("\tContents: {0}",
requestMessage.Body.ToStringO);
string contents = requestMessage.Body.ToStringO;
MessageQueue replyQueue = requestMessage.ResponseQueue;
Message replyMessage = new Message();
replyMessage.Body = contents;
replyMessage.Correlationld = requestMessage.Id;
replyQueue.Send(replyMessage);
Console.WriteLine("Sent reply");
224
Глава 6. Практикум: простой пример обмена сообщениями
Console.WriteLine("\tTime: {0}",
DateTime.Now.ToString("НН:mm:ss.ffffff"));
Console.WriteLine("\tMessage ID: {0}",
replyMessage.Id);
Console.WriteLine("\tCorrel. ID: {0}",
replyMessage.Correlationld);
Console .WriteLine ("\tReply to: {0}", "<n/a>");
Console.WriteLine("\tContents: {0}",
replyMessage.Body.ToStringO);
}
catch ( Exception ) {
Console.WriteLine("Invalid message detected");
Console.WriteLine("\tType: {0}",
requestMessage.BodyType);
Console.WriteLine("\tTime: {0}",
DateTime.Now.ToString("HH:mm:ss.ffffff"));
Console.WriteLine("\tMessage ID: {0}",
requestMessage.Id);
Console.WriteLine("\tCorrel. ID: {0}", "<n/a>");
Console.WriteLine("\tReply to: {0}", "<n/a>");
requestMessage.Correlationld = requestMessage.Id;
invalidQueue.Send(requestMessage);
Console.WriteLine("Sent to invalid message queue");
Console.WriteLine("\tType: {0}",
requestMessage.BodyType);
Console.WriteLine("\tTime: {0}",
DateTime.Now.ToString("HH:mm:ss.ffffff"));
Console.WriteLine ("\tMessage ID: {o}’’,
requestMessage.Id);
Console.WriteLine("\tCorrel. ID: {o}",
requestMessage.Correlationld);
Console.WriteLine("\tReply to: {o}",
requestMessage.ResponseQueue.Path);
}
requestQueue.BeginReceive();
}
}
Класс Replier может использоваться любым приложением, которому необходимо
получать запросы и отправлять ответы. Чтобы инициализировать ответчик, ему следует
передать имена очереди запросов и очереди сообщений недопустимого формата (объект
очереди ответов указывается с помощью обратного адреса сообщения с запросом).
Конструктор класса Replier похож на конструктор класса Requestor, за исключе-
нием нескольких отличий.
• Ответчик не создает объект типа MessageQueue для очереди ответов.
• Поскольку ответчик является событийно управляемым потребителем (Event-Driven
Consumer, с. 511), он создает экземпляр делегата ReceiveCompletedEvent-
Handler. Система обмена сообщениями автоматически вызывает метод ответчика
OnReceiveCompleted при поступлении в очередь запросов нового сообщения.
Запрос-ответ (.NET)
225
После инициализации ответчик переходит в режим ожидания сообщений. В отличие
от инициатора запроса, периодически проверяющего очередь ответов на поступление но-
вого сообщения, ответчик является событийно управляемым потребителем, ожидающим
вызова метода OnReceiveCompleted. Метод OnReceiveCompleted вызывается автома-
тически системой обмена сообщениями и выполняет следующие действия.
• Создает объект очереди запроса типа MessageQueue.
• Извлекает сообщение из очереди запроса с помощью метода EndReceive и выво-
дит на экран содержимое сообщения.
• Ответчик реализует свою часть шаблона обратный адрес, а именно создает объект
типа MessageQueue для отправки сообщений с ответом. Обратите внимание,
что очередь ответа задается динамически при получении сообщения с запросом.
• Создает сообщение с ответом, используя в качестве идентификатора корреляции
идентификатор сообщения с запросом.
• Отправляет сообщение с ответом и выводит на экран его подробности.
• Как и инициатор запроса, ответчик предполагает, что полученное сообщение
является объектом типа Message. Кроме того, сообщение должно содержать об-
ратный адрес. Если сообщение не удовлетворяет перечисленным условиям, оно
помещается в очередь сообщений недопустимого формата (при этом идентифика-
тор корреляции нового сообщения устанавливается равным идентификатору
исходного сообщения).
• Завершив обработку сообщения, ответчик вызывает метод BeginReceive для воз-
врата в режим ожидания сообщений.
Таким образом, ответчик обладает всей необходимой функциональностью для полу-
чения запроса и отправки ответа.
Обработка сообщения недопустимого формата
Рассмотрим пример реализации канала недопустимых сообщений {Invalid Message
Channel, с. 143). Этому каналу соответствует очередь . \private$\InvalidMessages,
которая используется MSMQ-клиентом {конечной точкой сообщения {Message Endpoint,
с. 124)) для отправки сообщения, которое он не может обработать.
Чтобы продемонстрировать обработку сообщений недопустимого формата, мы созда-
ли класс invalidMessenger, специально предназначенный для помещения в канал за-
проса некорректных сообщений. Напомним, что канал запроса является каналом типа
данных {Datatype Channel, с. 139), регламентирующим определенный формат передавае-
мых сообщений. Поскольку сообщение, сгенерированное объектом типа Invalid-
Messenger, не соответствует требуемому формату данных, получатель переместит
его в очередь сообщений недопустимого формата.
Следующий текст выводится в окне командной строки при отправке сообщения
недопустимого формата.
Sent request
Type: 768
Time: 09:39:44.223729
226
Глава 6. Практикум: простой пример обмена сообщениями
Message ID: 8b0fc389-f21f-423b-9eaa-c3a881a34808\168
Correl. ID: 00000000-0000-0000-0000-000000000000\0
Reply to: .\private$\ReplyQueue
Обратите внимание, что сообщение имеет двоичный формат (Туре: 768), в то время
как ответчик ожидает получения сообщения в формате XML. Следующий текст выводит-
ся в окне командной строки при получении ответчиком некорректного сообщения и его
помещении в очередь сообщений недопустимого формата.
Invalid message detected
Type: 768
Time: 09:39:44.233744
Message ID: 8b0fc389-f21f-423b-9eaa-c3a881a34808\168
Correl. ID: <n/a>
Reply to: <n/a>
Sent to invalid message queue
Type: 768
Time: 09:39:44.233744
Message ID: 8b0fc389-f21f-423b-9eaa-c3a881a34808\169
Correl. ID: 8b0fc389-f21f-423b-9eaa-c3a881a34808\168
Reply to: FORMATNAME:DIRECT=OS:XYZ123\private$\ReplyQueue
Следует отметить, что сообщение, помещаемое в очередь сообщений недопустимого
формата, получает новый идентификатор. Чтобы сохранить исходный идентификатор
сообщения, ответчик копирует его в идентификатор корреляции {Correlation Identifier,
с. 186). Код ответчика, реализующий обработку сообщения недопустимого формата, на-
ходится в методе OnReceiveCompleted класса Replier.
Итог
В рассмотренном примере описываются два класса, Requestor и Replier {точки
обмена сообщениями {Message Endpoint, с. 124)), предназначенные для реализации взаимо-
действия посредством обмена парой сообщений {Message, с. 98) запрос-ответ {Request-
Reply, с. 177). Сообщение с запросом содержит обратный адрес {Return Address, с. 182)
в виде объекта очереди, предназначенной для передачи сообщения с ответом. Сообщение
с ответом содержит идентификатор корреляции {Correlation Identifier, с. 186), позволяю-
щий сопоставить сообщение с ответом и сообщение с запросом. Для получения сообще-
ний с ответом инициатор запроса реализует шаблон проектирования опрашивающий
потребитель {Polling Consumer, с. 507). В отличие от инициатора запроса, ответчик полу-
чает сообщения с запросом в соответствии с шаблоном проектирования событийно
управляемый потребитель {Event-Driven Consumer, с. 511). Очереди запроса и ответа реали-
зованы в виде каналов типа данных {Datatype Channel, с. 139). Если инициатор запроса или
ответчик не может обработать сообщение, он перемещает его в канал недопустимых сооб-
щений {Invalid Message Channel, с. 143).
Публикация-подписка (JMS)
227
Публикация-подписка (JMS)
Этот пример демонстрирует преимущества модели обмена сообщениями “публика-
ция-подписка” (рис. 6.3), а также описывает ее альтернативы.
Рис. 6.3. Публикация-подписка
Чтобы оценить сильные стороны канала “публикация-подписка” (Publish-Subscribe
Channel, с. 134), необходимо рассмотреть задачу реализации шаблона проектирования
наблюдатель (Observer) в распределенной среде.
Наблюдатель (Observer)
В соответствии с шаблоном проектирования наблюдатель (Observer) [12] объект уведом-
ляет зависящие от него объекты об изменении в своем состоянии. В терминологии шаблона
наблюдатель объект, анонсирующий изменение своего состояния, называется субъектом,
а объект, желающий получить уведомление об изменении состояния субъекта, — наблюда-
телем. При изменении своего состояния субъект вызывает метод Notify!), который,
в свою очередь, вызывает метод Update () для каждого наблюдателя. Чтобы узнать новое
состояние субъекта, наблюдатель вызывает метод Getstate (). Кроме того, субъект должен
реализовать методы Attach (Наблюдатель} и Detach (На блюда тель), предназначенные
для регистрации/отмены регистрации наблюдателей.
Шаблон проектирования наблюдатель предусматривает два способа передачи инфор-
мации о состоянии субъекта наблюдателю: модель с активным источником данных и мо-
дель с пассивным источником данных. В соответствии с моделью с активным источником
данных (push model) методу Update () наблюдателя передается в качестве параметра новое
состояние субъекта. Таким образом, заинтересованные наблюдатели могут не вызывать
метод Getstate (). В то же время данная модель предполагает передачу информации
о состоянии субъекта также незаинтересованным наблюдателям. Модель с пассивным
источником данных (pull model) предписывает субъекту уведомлять наблюдателей только
о самом факте изменения своего состояния. Наблюдатели, заинтересованные в получе-
нии более подробной информации, должны запрашивать ее у субъекта самостоятельно.
Модель с активным источником данных основана на единственном одностороннем
взаимодействии— субъект передает данные наблюдателю при вызове метода Update ().
В отличие от нее модель с пассивным источником данных основана на трех последова-
тельных односторонних взаимодействиях— субъект уведомляет наблюдателя, наблюда-
228
Глава 6. Практикум: простой пример обмена сообщениями
тель запрашивает текущее состояние субъекта и наконец субъект передает данные о сво-
ем текущем состоянии наблюдателю. Как вскоре будет показано, количество односто-
ронних взаимодействий оказывает влияние на сложность проектирования и производи-
тельность модели уведомления.
Наиболее простая реализация метода субъекта Notify (), предполагающая использо-
вание одного потока, характеризуется низкой производительностью. Наличие единст-
венного потока приведет к тому, что наблюдатели будут уведомляться об изменениях по-
следовательно, один за другим. Уведомляя своих наблюдателей (список которых может
достигать внушительных размеров), субъект не может выполнять какие-либо другие дей-
ствия. Кроме того, этот процесс может затянуться, если наблюдатель использует поток
уведомления для запрашивания у субъекта его текущего состояния.
Гораздо более эффективный способ реализации метода субъекта Notify () заключа-
ется в выполнении каждого вызова метода Update () в собственном потоке. В этом слу-
чае все наблюдатели могут уведомляться одновременно, и каждый из них может исполь-
зовать поток уведомления, не затрагивая при этом остальных наблюдателей. Недостаток
подобного подхода обусловливается сложностью проектирования модели уведомления в
многопоточной среде.
Наблюдатель (Observer) в распределенной среде
Шаблон проектирования наблюдатель (Observer) основывается на том, что субъект и все
его наблюдатели выполняются в пределах одного и того же приложения. Несмотря на то
что данный шаблон поддерживает переход к распределенной модели (подразумевающей
выполнение субъекта и наблюдателей в различных областях памяти), это сложно осущест-
вить по нескольким причинам. Во-первых, необходимо обеспечить удаленный вызов мето-
дов Update (), GetState (), Attach (Наблюдатель) И Detach (Наблюдатель) (см. шаб-
лон проектирования удаленный вызов процедуры (Remote Procedure Invocation, с. 85)).
Во-вторых, поскольку субъект должен иметь возможность вызывать методы всех наблюда-
телей и наоборот, каждый объект должен выполняться в среде с брокером запросов
к объектам (object request broker — ORB). В-третьих, приложения, участвующие в обмене
данными, должны поддерживать маршалинг передаваемых объектов.
Таким образом, реализация шаблона проектирования наблюдатель в распределенной
среде сопряжена с некоторыми трудностями, в числе которых стоит отметить обеспече-
ние многопоточности и удаленный вызов методов.
Кроме того, удаленный вызов процедуры предполагает одновременную доступность ис-
точника вызова, адресата и сетевого соединения. Если субъект анонсирует изменение сво-
его состояния, а наблюдатель не может обработать соответствующее уведомление (к приме-
ру, он отключен от сети), он теряет возможность узнать новое состояние субъекта. По-
скольку это может привести к рассинхронизации наблюдателя и субъекта, применение
шаблона проектирования наблюдатель в распределенной среде теряет всяческий смысл.
Условиям распределенной среды больше удовлетворяет модель с активным, нежели
с пассивным источником данных. Как упоминалось ранее, модель с активным источни-
ком данных основана на единственном одностороннем взаимодействии, в то время как
модель с пассивным источником данных— на трех последовательных односторонних
взаимодействиях. Таким образом, модель с активным источником данных требует вы-
полнения одного удаленного вызова (метод Update ()), а модель с пассивным источни-
Публикация-подписка (JMS)
229
ком данных— по крайней мере, двух (Update () и Getstate ()). Поскольку удаленный
вызов процедуры более ресурсоемок, нежели локальный вызов, дополнительные вызовы
удаленных методов способны привести к существенному снижению производительности.
Публикация-подписка
Шаблон проектирования канал “публикация-подписка” (Publish-Subscribe Channel,
с. 85) реализует шаблон наблюдатель (Observer), приспосабливая его к использованию
в распределенной среде. Реализация шаблона наблюдатель производится в три этапа.
1. Администратор системы обмена сообщениями создает канал “публикация-
подписка”. (Объект Topic в JMS.)
2. Приложение, выступающее в роли субъекта, создает объект Topicpublisher
(типа Messageproducer) для отправки сообщений по каналу.
3. Каждое приложение, выступающее в роли наблюдателя, создает объект
Topicsubscriber (типа Messageconsumer) для получения сообшений посред-
ством канала. (Аналог вызова метода Attach (Наблюдатель) в шаблоне проекти-
рования наблюдатель.)
Выполнение перечисленных выше действий приводит к установке соединения между
субъектом и наблюдателями. Отныне для уведомления наблюдателей об изменении
состояния субъекта последний отправляет сообщение. Благодаря свойствам канала
“публикация-подписка” копию сообщения получает каждый наблюдатель.
Следующий код реализует функцию уведомления об изменении состояния субъекта.
import javax.jms.Connection;
import j avax.jms.ConnectionFactory;
import javax.jms.Destination;
import javax.jms.JMSException;
import j avax.jms.Messageproducer;
import javax.jms.Session;
import javax.jms.TextMessage;
import j avax.naming.NamingException;
public class SubjectGateway {
public static final String UPDATE_TOPIC_NAME = "jms/Update";
private Connection connection;
private Session session;
private Messageproducer updateProducer;
protected SubjectGateway() {
super();
}
public static SubjectGateway newGatewayO throws JMSException,
NamingException {
Subj ectGateway gateway = new SubjectGateway();
gateway.initialize();
return gateway;
230
Глава 6. Практикум: простой пример обмена сообщениями
protected void initialize() throws JMSException, NamingException {
ConnectionFactory connectionFactory =
JndiUtil.getQueueConnectionFactory();
connection = connectionFactory.createConnection();
session = connection.createSession(false.
Session.AUTO_ACKNOWLEDGE);
Destination updateTopic =
JndiUtil.getDestination(UPDATE_TOPIC_NAME);
updateProducer = session.createProducer(updateTopic);
connection.start();
}
public void notify(String state) throws JMSException {
TextMessage message = session.createTextMessage(state);
updateProducer.send(message);
}
public void release() throws JMSException {
if (connection != null) {
connection.stop();
connection.close();
}
}
}
Класс Subj ectGateway выполняет роль шлюза обмена сообщениями (Messaging
Gateway, с. 482) между субъектом (его код не показан) и системой обмена сообщениями.
Субъект создает шлюз (экземпляр класса Subj ectGateway) и использует его для широ-
ковещательной рассылки уведомлений. По сути, метод субъекта Notify () вызывает
метод Subj ectGateway, notify (Строка). Шлюз анонсирует изменение состояния
субъекта путем отправки сообщения по каналу уведомлений.
Следующий код реализует функцию получения уведомления об изменении состояния
субъекта.
import javax.jms.Connection;
import javax.jms.ConnectionFactory;
import javax.jms.Destination;
import javax.jms.JMSException;
import javax.jms.Message;
import j avax.jms.Messageconsumer;
import javax.jms.MessageListener;
import javax.jms.Session;
import javax.jms.TextMessage;
import j avax.naming.NamingException;
public class ObserverGateway implements MessageListener {
public static final String UPDATE_TOPIC_NAME = "jms/Update";
private Observer observer;
private Connection connection;
private Messageconsumer updateConsumer;
Публикация-подписка (JMS)
231
protected ObserverGateway() {
super();
}
public static ObserverGateway newGateway(Observer observer)
throws JMSException, NamingException {
ObserverGateway gateway = new ObserverGateway();
gateway.initialize(observer);
return gateway;
}
protected void initialize(Observer observer) throws
JMSException, NamingException {
this.observer = observer;
ConnectionFactory connectionFactory =
JndiUtil.getQueueConnectionFactory();
connection = ConnectionFactory.createConnection();
Session session = connection.createSession(false.
Session. RUTO__ACKNOWLEDGE} ,-
Destination updateTopic =
JndiUtil.getDestination(UPDATE_TOPIC_NAME);
updateConsumer = session.createConsumer(updateTopic);
updateConsumer.setMessageListener(this);
}
public void onMessage(Message message) {
try {
TextMessage textMsg = (TextMessage) message;
String newState = textMsg.getText();
update(newState);
} catch (JMSException e) {
e.printStackTrace();
}
}
public void attach() throws JMSException {
connection.start();
}
public void detach() throws JMSException {
if (connection != null) {
connection.stop();
connection.close();
}
}
private void update(String newState) throws JMSException {
observer.update(newState);
Подобно классу Subj ectGateway класс ObserverGateway выполняет роль шлюза
обмена сообщениями между наблюдателем (его код не показан) и системой обмена сооб-
щениями. Наблюдатель создает шлюз (экземпляр класса ObserverGateway), после чего
232
Глава 6. Практикум: простой пример обмена сообщениями
вызывает метод attach () для подключения к субъекту (аналог метода Attach (.Наблю-
датель) в шаблоне проектирования наблюдатель). Поскольку шлюз ObserverGateway
является событийно управляемым потребителем (Event-Driven Consumer, с. 511), он реализует
интерфейс MessageListener, требующий наличия метода onMessage. Получив сообще-
ние, шлюз извлекает из него сведения о текущем состоянии субъекта и вызывает метод
update (Строка), который, в свою очередь, вызывает одноименный метод наблюдателя.
Классы Subj ectGateway и ObserverGateway реализуют модель С активным ИСТОЧ-
НИКОМ данных в рамках шаблона проектирования наблюдатель. Сообщение, отправлен-
ное с помощью метода Sub j ectGateway, notify (Строка), не только уведомляет на-
блюдателя о произошедшем изменении, но и содержит в себе сведения о новом состоя-
нии субъекта. Далее в этой главе будет рассмотрен альтернативный способ передачи
информации о текущем состоянии субъекта наблюдателю, предполагающий использова-
ние модели с пассивным источником данных.
Сравнение двух подходов
В распределенной среде модель уведомления “публикация-подписка” (основанная на
обмене сообщениями) обладает несколькими преимуществами перед моделью наблюда-
теля (Observer) (основанной на технологии удаленного вызова процедуры).
• Упрощенное уведомление. Реализация метода субъекта Notify () сводится к от-
правке сообщения по каналу. Аналогично для получения уведомления методу на-
блюдателя Update () необходимо всего лишь извлечь сообщение из канала.
• Упрошенная регистрация/отмена регистрации. Вместо регистрации/отмены регистра-
ции у субъекта наблюдателю достаточно подписаться/отказаться от подписки на ка-
нал. В этом случае су&ьект не обязан реализовывать методы Attach (Наблюдатель)
и Detach (Наблюдатель) (эти методы могут быть реализованы наблюдателем
для инкапсуляции функциональности, связанной с подпиской/отказа от подписки
на канал).
• Упрощенная работа с потоками. Поскольку канал доставляет сообщение с уведом-
лением всем наблюдателям, субъекту достаточно иметь один поток обновления.
В то же время каждый наблюдатель использует для получения информации о со-
стоянии субъекта отдельный поток. Это упрощает реализацию субъекта, а также
обеспечивает независимость наблюдателей друг от друга.
• Упрощение удаленного доступа. Ни субъекту, ни наблюдателю не нужно реализо-
вывать удаленные методы или являться частью среды с брокером запросов к
объектам (ORB). Единственное требование, предъявляемое к субъекту и наблюда-
телям, заключается в наличии доступа к системе обмена сообщениями.
• Повышенная надежность. Система обмена сообщениями позволяет накапливать
уведомления в очереди, делая возможной регулировку скорости обработки уве-
домлений наблюдателем. Если наблюдатель хочет получать уведомления, отправ-
ленные во время его автономной работы, он должен огласить себя постоянным
подписчиком (Durable Subscriber, с. 535).
Общей особенностью обоих подходов является сериализация данных. Как бы ни был
реализован наблюдатель— посредством технологии удаленного вызова процедуры или
Публикация-подписка (JMS)
233
обмена сообщениями, — данные о состоянии субъекта передаются из области памяти
субъекта в область памяти наблюдателя посредством маршалинга.
Единственным недостатком подхода “публикация-подписка” является необходи-
мость использования обмена сообщениями, так как это предполагает реализацию субъекта
и наблюдателей в виде клиентов общей системы обмена сообщениями. И все же, как по-
казывает практика, применение подхода “публикация-подписка”, основанного на обме-
не сообщениями, гораздо проще традиционного подхода, основанного на технологии
удаленного вызова процедуры.
Модель с активным и пассивным источниками данных
Еще одним потенциальным недостатком подхода “публикация-подписка” является
сложность модели уведомлений с пассивным источником данных. Модель с пассивным
источником данных требует большего числа односторонних взаимодействий, нежели мо-
дель с активным источником данных. Как известно, увеличение числа взаимодействий в
распределенной среде может привести к существенному снижению производительности.
Взаимодействие между субъектом и наблюдателями проще реализовать с помощью
технологии удаленного вызова процедуры, чем с помощью обмена сообщениями. Методу
Update (), предполагающему одностороннее взаимодействие, соответствует удаленная
процедура, не возвращающая значение, или единственное сообщение о событии (Event
Message, с. 174), отправленное субъектом наблюдателю. Поскольку метод Getstate ()
предполагает двустороннее взаимодействие, для его реализации потребуется либо уда-
ленная процедура, возвращающая состояние субъекта, либо пара сообщений запрос-
ответ (Request-Reply, с. 177): сообщение с командой (Command Message, с. 169), запраши-
вающее состояние субъекта, и сообщение с данными документа (Document Message, с. 171),
возвращающее информацию о состоянии субъекта наблюдателю.
Сложность применения шаблона запрос-ответ заключается отнюдь не в отправке
двух сообщений, а в необходимости наличия двух каналов, применяющихся для транс-
портировки этих сообщений. Один из каналов используется для отправки запроса со-
стояния субъекту, а другой—для передачи описания состояния наблюдателю (рис. 6.4).
Несмотря на то что все наблюдатели могут использовать один и тот же канал запроса,
каждому из них понадобится отдельный канал ответа. (Идентификаторы корреляции
(Correlation Identifier, с. 186) позволяют использовать общий канал ответа, однако это ус-
ложняет реализацию.)
Рис. 6.4. Использование модели с пассивным источником данных
234
Глава 6. Практикум: простой пример обмена сообщениями
Необходимость иметь отдельный канал ответа для каждого наблюдателя может при-
вести к резкому росту общего количества каналов. К тому же количество наблюдателей
способно динамически изменяться во время выполнения, что не позволит предугадать
требуемое количество статических каналов. Трудноразрешимой является также задача
сопоставления каналов с наблюдателями.
Справиться с вышеперечисленными проблемами вам поможет интерфейс JMS
TemporaryQueue [14]. (См. также шаблон проектирования запрос-ответ.) Наблюдатель
создает временную очередь, указывает ее в запросе как обратный адрес (Return Address,
с. 182) и ожидает ответа от субъекта. К сожалению, частое создание новых очередей
в большинстве случаев малоэффективно (это зависит от конкретной реализации системы
обмена сообщениями), и к тому же временные очереди не могут использоваться для
гарантированной доставки (Guaranteed Delivery, с. 149). Тем не менее это наиболее прием-
лемый способ реализации модели с пассивным источником данных.
Класс Pul ISub j ectGateway демонстрирует реализацию шлюза субъекта с использо-
ванием модели с пассивным источником данных.
import javax.jms.Connection;
import javax.jms.ConnectionFactory;
import javax.jms.Destination;
import javax.jms.JMSException;
import javax.jms.Message;
import javax.jms.Messageconsumer;
import javax.jms.MessageListener;
import javax.jms.Messageproducer;
import javax.jms.Session;
import javax.jms.TextMessage;
import javax.naming.NamingException;
public class PullSubjectGateway {
public static final String UPDATe_TOPIC_NAME = "jms/Update";
private PullSubject subject;
private Connection connection;
private Session session;
private Messageproducer updateProducer;
protected PullSubjectGateway() {
super();
}
public static PullSubjectGateway newGateway(PullSubject subject)
throws JMSException, NamingException {
PullSubjectGateway gateway = new PullSubjectGateway () ,-
gateway.initialize(subject);
return gateway;
}
protected void initialize(PullSubject subject) throws
JMSException, NamingException {
this.subject = subject;
ConnectionFactory ConnectionFactory =
Публикация-подписка (JMS)
235
JndiUtil.getQueueConnectionFactory();
connection = connectionFactory.createConnection();
session = connection.createSession(false.
Session.AUTO_ACKNOWLEDGE);
Destination updateTopic =
JndiUtil.getDestination(UPDATE_TOPIC_NAME);
updateProducer = session.createProducer(updateTopic);
new Thread(new GetStateReplier()).start();
connection.start();
}
public void notifyNoState() throws JMSException {
TextMessage message = session.createTextMessage();
updateProducer.send(message);
}
public void release() throws JMSException {
if (connection != null) {
connection.stop();
connection.close() ;
}
}
private class GetStateReplier implements Runnable,
MessageListener {
public static final String GET_STATE_QUEUE_NAME =
"jms/GetState";
private Session session;
private Messageconsumer requestconsumer;
public void run() {
try {
session = connection.createSession(false.
Session.AUTO_ACKNOWLEDGE);
Destination getStateQueue =
Jndiutil.getDestination(GET_STATE_QUEUE_NAME);
requestconsumer =
session.createConsumer(getStateQueue);
requestconsumer.setMessageListener(this);
} Catch (Exception e) {
e.printStackTrace();
}
}
public void onMessage(Message message) {
try {
Destination replyQueue = message.getJMSReplyTo();
Messageproducer replyproducer =
session.createProducer(replyQueue);
Message replyMessage =
session. createTextMessage (subject. getStats ()) ,
236
Глава 6. Практикум: простой пример обмена сообщениями
replyProducer.send(replyMessage);
} catch (JMSException e) {
e.printStackTrace();
}
}
}
}
Классы PullSubjectGateway И Subj ectGateway ВО МНОГОМ ПОХОЖИ. Класс
PulISubj ectGateway содержит ссылку на субъект, позволяющую шлюзу запрашивать
состояние субъекта по требованию наблюдателя. Методу notify (Строка) соответствует
метод notifyNoState (), в названии которого отражен тот факт, что модель с пассив-
ным источником данных не предполагает передачу состояния субъекта в уведомлении.
Основной отличительной особенностью класса Pullsub j ectGateway является внут-
ренний класс GetstateReplier, реализующий интерфейсы Runnable (поддержка вы-
полнения в собственном потоке) и MessageListener (поддержка модели событийно
управляемого потребителя (Event-Driven Consumer, с. 511)). Метод onMessage извлекает
обратный адрес из сообщения с запросом и отправляет по этому адресу ответ, содержа-
щий сведения о текущем состоянии субъекта.
import javax.jms.Destination;
import javax.jms-JMSException;
import javax.jms.Message;
import javax.jms.Messageconsumer;
import javax.jms.MessageListener;
import javax.jms.Queue;
import javax.jms.Queueconnection;
import javax.jms.QueueConnectionFactory;
import javax.jms.QueueRequestor;
import javax.jms.Queuesession;
import javax.jms.Session;
import javax.jms.TextMessage;
import javax.naming.NamingException;
public class PullObserverGateway implements MessageListener {
public static final String UPDATE_TOPIC_NAME = "jms/Update";
public static final String GET_STATE_QUEUE_NAME = "jms/GetState";
private Pullobserver observer;
private Queueconnection connection;
private QueueSession session;
private Messageconsumer updateConsumer;
private QueueRequestor getStateRequestor;
protected PullObserverGateway() {
super();
}
public static PullObserverGateway newGateway(Pullobserver
observer)
throws JMSException, NamingException {
PullObserverGateway gateway = new PullObserverGateway();
Публикация-подписка (JMS)
237
gateway.initialize(observer);
return gateway;
}
protected void initialize(Pullobserver observer) throws
JMSException, NamingException {
this.observer = observer;
QueueConnectionFactory ConnectionFactory =
JndiUtil.getQueueConnectionFactory();
connection = ConnectionFactory.createQueueConnection();
session = connection.createQueueSession(false.
Session.AUTO_ACKNOWLEDGE);
Destination updateTopic =
JndiUtil.getDestination(UPDATE_TOPIC_NAME);
updateConsumer = session.createConsumer(updateTopic) ;
updateConsumer.setMessageListener(this);
Queue getStateQueue = (Queue)
JndiUtil.getDestination(GET_STATE_QUEUE_NAME);
getStateRequestor = new QueueRequestor(session,
getStateQueue);
}
public void onMessage(Message message) {
try {
updateNoState();
} catch (JMSException e) {
e.printStackTrace() ;
}
}
public void attach() throws JMSException {
connection.start();
}
public void detachO throws JMSException {
if (connection != null) {
connection.stop();
connection.close();
}
}
private void updateNoState() throws JMSException {
TextMessage getStateRequestMessage =
session.createTextMessage();
Message getStateReplyMessage =
getStateRequestor.request(getStateRequestMessage);
TextMessage textMsg = (TextMessage) getStateReplyMessage;
String newState = textMsg.getText();
observer.update(newState);
238
Глава 6. Практикум: простой пример обмена сообщениями
За исключением кода, реализующего модель с пассивным источником данных, класс
PullObserverGateway имеет много общего с классом ObserverGateway. Кроме объек-
та updateconsumer, предназначенного для получения уведомлений, процедура инициа-
лизации класса PullObserverGateway Создает объект getStateRequestor типа
QueueRequestor (см. шаблон проектирования запрос-ответ), предназначенный для за-
проса состояния субъекта. Метод onMessage игнорирует содержимое сообщения,
поскольку модель с пассивным источником данных не предполагает передачу состояния
субъекта в уведомлении. Таким образом, функциональность метода onMessage сводится
К вызову метода updateNoState ().
Разница для наблюдателя между моделью с активным и моделью с пассивным источ-
ником данных заключается в отличиях между методами updateNoState () и
update (Строка). В то время как метод update (Строка) принимает состояние субъекта
в виде параметра, метод updateNoState () вынужден запрашивать его с помощью
объекта getStateRequestor. (Ожидая ответ на запрос состояния субъекта, однопоточ-
ный шлюз не может обрабатывать другие уведомления. Если передача сообщения с за-
просом или сообщения с ответом потребует длительного времени, поступающие уведом-
ления будут накапливаться в очереди.)
Таким образом, модель с пассивным источником данных гораздо сложнее модели
с активным источником данных. Она требует большего числа каналов (включая времен-
ный канал для каждого наблюдателя), сообщений (три сообщения для обновления каж-
дого наблюдателя вместо единственного сообщения для обновления всех наблюдателей)
и как следствие программного кода и потоков.
Проектирование каналов
До сих пор рассматривалась задача уведомления наблюдателей субъекта с единствен-
ным состоянием. С помощью модели с активным источником данных передача инфор-
мации между субъектом и наблюдателями осуществлялась посредством канала
“публикация-подписка” (Publish-Subscribe Channel, с. 134).
Реальные приложения гораздо сложнее. Они могут содержать несколько субъектов,
анонсирующих свои изменения. Кроме того, каждый субъект может иметь несколько
независимо изменяющихся состояний— аспектов. Единственный наблюдатель может
быть заинтересован в нескольких различных аспектах нескольких субъектов, порой пред-
ставляющих собой экземпляры не одного, а нескольких классов.
Таким образом, семантика уведомления наблюдателей в реальных приложениях спо-
собна оказаться весьма сложной. Шаблон проектирования наблюдатель (Observer) вклю-
чает в себя описание нескольких типичных ситуаций наподобие “наблюдение за не-
сколькими субъектами” и “явное указание интересующих аспектов”. Кроме того, шаб-
лон проектирования конверт с собственным адресом и маркой (Self-Addressed Stamped
Envelope), или SASE, описывает комбинацию наблюдателя и команды (Command), в соот-
ветствии с которой наблюдатель определяет команду, которую должен отправить субъект
при возникновении того или иного изменения [2].
Основной вопрос, возникающий в контексте использования обмена сообщениями
для решения задачи уведомления наблюдателей, касается общего количества требуемых
каналов.
Публикация-подписка (JMS)
239
Рассмотрим наиболее простую ситуацию. Предположим, что информационная сис-
тема компании насчитывает несколько различных приложений, хранящих контактные
данные заказчика (например, почтовый адрес). Если одно из приложений обновляло
адрес, оно должно было уведомить об этом все заинтересованные приложения.
Для решения этой задачи следует воспользоваться каналом “публикация-подписка”.
Приложение, изменяющее адрес, анонсирует изменение путем публикации сообщения
в канале. Приложения, заинтересованные в получении уведомлений об изменении адреса,
подписываются на тот же канал. Ниже приведен пример сообщения об изменении адреса.
<Addrеs s Chang е cu s tomer_id="12345">
<OldAddress>
<Street>123 Wall Street</Street>
<City>New York</City>
<State>NY</State>
<Zip>10005</Zip>
</OldAddress>
<NewAddress>
<Street>321 Sunset Blvd</Street>
<City>Los Angeles</City>
<State>CA</State>
<Zip>90012</Zip>
</NewAddress>
</Addre s sChange >
Предположим также, что информационная система компании включает в себя группу
приложений, которым необходимо уведомлять другую группу приложений об отсутствии
товара на складе. Эта ситуация аналогична рассмотренной ранее, и для ее решения также
можно воспользоваться каналом “публикация-подписка". Ниже приведен пример сообще-
ния об отсутствии товара на складе.
<OutofProduct>
<ProductID>12345</ProductID>
<StoreID>67890</StoreID>
<QuantityRequested>100</QuantityRequested>
</OutOf Product >
Можно ли использовать один и тот же канал для передачи сообщений об изменении ад-
реса и сообщений об отсутствии товара на складе? Скорее всего, нет. Во-первых, канал ти-
па данных (Datatype Channel, с. 139) накладывает определенные ограничения на тип переда-
ваемых по каналу сообщений. Поскольку элемент <Addresschange> отличается от эле-
мента <OutOfProduct>, сообщение об изменении адреса имеет другую XML-схему,
нежели сообщение об отсутствии товара на складе. Изменив формат данных, можно сде-
лать так, чтобы указанные сообщения соответствовали одинаковой XML-схеме, однако в
этом случае логику определения типа сообщения придется переложить на получателя
сообщения. Недостаток подобного подхода состоит в том, что приложения будут часто по-
лучать не интересующие их уведомления. Следовательно, сообщения об изменении адреса
и сообщения об отсутствии товара на складе должны передаваться по отдельным каналам.
240
Глава 6. Практикум: простой пример обмена сообщениями
Рассмотрим еще один тип сообщения, а именно сообщение об изменении кредитной
репутации клиента.
<CreditRatingChange customer_id="12 34 5">
<OldRating>AAA</OldRating>
<NewRat ing >BBB< /NewRat ing >
</CreditRat ingChange >
По аналогии с сообщением об изменении адреса и сообщением об отсутствии товара
на складе для передачи сообщения об изменении кредитной репутации клиента будет
использоваться отдельный канал.
К сожалению, подобный подход может привести к резкому росту общего числа кана-
лов сообщений. Множество разнообразных характеристик клиента (имя, контактная
информация, кредитная репутация, уровень обслуживания, скидка и т.п.) потребует соз-
дания адекватного числа каналов для передачи уведомлений.
Увеличение числа каналов незамедлительно скажется на производительности систе-
мы обмена сообщениями. Каналы с низким объемом трафика приведут к пустой трате
ресурсов, а каналы, по которым передается множество мелких сообщений, — к сущест-
венным издержкам обмена сообщениями. Проблема роста числа каналов коснется также
приложений, использующих отдельные потоки для отправки (получения) сообщений по
каждому каналу.
Более рациональный подход заключается в передаче сообщений об изменении адреса
и сообщений об изменении кредитной репутации по одному каналу, поскольку каждое из
этих изменений касается характеристик клиента. В то же время сообщения об отсутствии
товара на складе следует передавать по другому каналу, так как эти данные вряд ли при-
годятся приложениям, оперирующим сведениями о клиенте.
Как упоминалось ранее, канал типа данных требует, чтобы все передаваемые по нему
сообщения имели один и тот же формат. В то же время сообщения об изменении адреса и
сообщения об изменении кредитной репутации клиента имеют разные XML-схемы.
Ниже приведен пример унифицированных сообщений об изменении данных клиента
с одинаковым корневым и различными вложенными элементами.
<CustomerChange customer_id=" 12 345">
<AddressChange>
<01dAddress>
<Street>123 Wall Street</Street>
<City>New York</City>
<State>NY</State>
<Zip>10005</Zip>
</01dAddress>
<NewAddress>
<Street>321 Sunset Blvd</Street>
<City>Los Angeles</City>
<State>CA</State>
<Zip>90012</Zip>
</NewAddress>
<IAddre s sChange >
</Cus tome rChange >
<CustomerChange customer_id="1234 5">
Публикация-подписка (JMS)
241
<CreditRatingChange>
<01dRating>AAA</01dRating>
<NewRating>BBBc/NewRating>
</CreditRatingChange>
</CustomerChange>
Некоторые приложения могут быть заинтересованы в получении уведомлений об из-
менении кредитной репутации клиента, но не его адреса, и наоборот. Подобные прило-
жения подходят для роли избирательного потребителя (Selective Consumer, с. 528). Если
реализация шаблона избирательный потребитель доставляет трудности, а система обмена
сообщениями поддерживает большое число каналов, используйте отдельный канал
для передачи сообщений каждого типа.
В целом же большинство задач проектирования корпоративных приложений не име-
ют универсальных решений. Основная цель, которую должны ставить перед собой разра-
ботчики, используя канал “публикация-подписка”,— обеспечить доставку наблюдателям
интересующих их уведомлений и не допустить чрезмерного увеличения числа каналов.
Итог
Шаблон проектирования канал “публикация-подписка” (Publish-Subscribe Channel,
с. 85) реализует шаблон наблюдатель (Observer), приспосабливая его к использованию в
распределенной среде. Использование канала существенно упрощает реализацию метода
субъекта Notify () и метода наблюдателя update (). Система обмена сообщениями по-
зволяет реализовать шаблон наблюдатель в распределенной среде, обеспечивая надеж-
ную доставку уведомлений. Модель с активным источником данных более простая и за-
частую более эффективная, нежели модель с пассивным источником данных. Несмотря
на это модель с пассивным источником данных также может применяться совместно
с обменом сообщениями. Количество каналов, требующихся для передачи уведомлений,
может либо равняться количеству отслеживаемых характеристик, либо выбираться в за-
висимости от количества групп однородных характеристик, отслеживаемых одними
и теми же наблюдателями. Преимущества, предоставляемые каналом “публикация-
подписка”, заслуживают того, чтобы обратить внимание на технологию обмена сообще-
ниями (Messaging, с. 87) и использовать ее для интеграции приложений.
Глава 7
Маршрутизация сообщений
Введение
Ранее в этой книге был рассмотрен шаблон проектирования маршрутизатор сообще-
ний (Message Router, с. 109), позволяющий обеспечить слабую связь между источником
сообщения и точкой его назначения. Настоящая глава посвящена специальным типам
маршрутизаторов сообщений, использующихся в интеграционных решениях. Большинст-
во описанных здесь шаблонов проектирования представляют собой доработку шаблона
маршрутизатор сообщений. Оставшиеся шаблоны проектирования получены путем ком-
бинации нескольких маршрутизаторов сообщений и предназначены для решения более
сложных задач интеграции. В целом, шаблоны маршрутизации сообщений можно разде-
лить на три группы.
• Простые маршрутизаторы. Разновидности маршрутизатора сообщений, перена-
правляющие сообщения из одного входящего канала в один или несколько исхо-
дящих каналов.
• Составные маршрутизаторы. Комбинации нескольких простых маршрутизаторов,
предназначенных для создания сложных потоков сообщений.
• Архитектурные шаблоны. Описание архитектурных стилей, основанных на приме-
нении маршрутизаторов сообщений.
Простые маршрутизаторы
Маршрутизатор на основе содержимого (Content-Based Router, с. 247) перенаправляет
сообщение в тот или иной исходящий канал в результате анализа его содержимого.
Таким образом, приложение, сгенерировавшее сообщение, помещает его в канал, а дос-
тавку сообщения выполняет маршрутизатор на основе содержимого.
Фильтр сообщений (Message Filter, с. 253) является особой формой маршрутизатора
на основе содержимого. Проанализировав сообщение, фильтр сообщений перенаправляет
его в исходящий канал только в том случае, если содержимое сообщения удовлетворяет
заданному условию. В противном случае сообщение игнорируется. Фильтр сообщений
подобен избирательному потребителю (Selective Consumer, с. 528), но является частью
системы обмена сообщениями, а избирательный потребитель встраивается в конечную
точку сообщения (Message Endpoint, с. 124).
244
Глава?. Маршрутизация сообщений
Маршрутизатор на основе содержимого и фильтр сообщений могут использоваться для
решения одной и той же задачи проектирования. Маршрутизатор на основе содержимого
перенаправляет сообщение в исходящий канал в зависимости от встроенного критерия.
Аналогичной функциональности можно добиться с помощью канала “публикация-
подписка” (Publish-Subscribe Channel, с. 134) и массива фильтров сообщений, по одному на
каждого возможного получателя. Каждый фильтр игнорирует сообщение, не удовлетво-
ряющее критерию соответствующей точки назначения. Несмотря на то что маршрутиза-
тор на основе содержимого позволяет сосредоточить всю логику маршрутизации в одном
компоненте, он остается зависимым от возможного изменения списка получателей.
Массиву фильтров сообщений подобная зависимость не свойственна. Более подробно срав-
нение двух подходов приводится в описании шаблона проектирования фильтр сообщений.
Маршрутизатор сообщений (Message Router, с. 109) использует фиксированный набор
правил для определения точки назначения входящего сообщения. Динамический мар-
шрутизатор (Dynamic Router, с. 259) позволяет изменять логику маршрутизации с помо-
щью управляющих сообщений, отправляемых с использованием специального порта.
В главе 4 были представлены концепции канала “точка-точка” (Point-to-Point
Channel, с. 131) и канала “публикация-подписка”. Иногда возникает необходимость отпра-
вить сообщение нескольким получателям, сохраняя над ними контроль. Подобную
функциональность предоставляет список получателей (Recipient List, с. 264). По существу
список получателей является маршрутизатором на основе содержимого, доставляющим со-
общение более чем одному получателю.
Некоторые сообщения содержат набор элементов. Чтобы обработать каждый элемент
отдельно, следует разбить сообщение на несколько более простых сообщений с помощью
разветвителя (Splitter, с. 274), а затем обработать каждое из полученных сообщений.
Для воссоздания сообщения, разделенного на несколько отдельных частей с помо-
щью разветвителя, используется агрегатор (Aggregator, с. 283). Агрегатор принимает по-
ток сообщений, идентифицирует части составного сообщения и объединяет их в одно
сообщение. В отличие от других шаблонов маршрутизации агрегатор представляет собой
маршрутизатор сообщений с сохранением состояния, поскольку ему приходится хранить
сообщения до выполнения определенного условия. Таким образом, прежде чем опубли-
ковать исходящее сообщение, агрегатор накапливает несколько входящих сообщений.
Поскольку технология обмена сообщениями предназначена для объединения прило-
жений или компонентов, выполняющихся на нескольких различных компьютерах,
сообщения могут обрабатываться параллельно. К примеру, несколько процессов могут
извлекать сообщения из одного и того же канала. Скорость выполнения процессов, как
правило, неодинакова, что приводит к нарушению порядка обработки сообщений.
Для восстановления исходного порядка применяется преобразователь порядка (Resequen-
cer, с. 297) — маршрутизатор сообщений с сохранением состояния, накапливающий со-
общения до момента образования ими корректной последовательности. В отличие от аг-
регатора, количество сообщений, опубликованных преобразователем порядка, совпадает
с количеством полученных им сообщений.
В табл. 7.1 перечислены свойства различных маршрутизаторов сообщений (за исклю-
чением динамического маршрутизатора, поскольку каждый маршрутизатор может быть
реализован как динамический).
Введение
245
Таблица 7.1. Типы маршрутизаторов сообщений
Шаблон проектирования Количество полученных сообщений Количество отправленные сообщений Сохраняется к ли состояние? Комментарий
Маршрутизатор на основе содержимого (Content-Based Router, с. 247) 1 1 Нет (в большинстве случаев) —
Фильтр сообщений (Message Filter, с. 253) 1 0 или 1 Нет (в большинстве случаев) —
Список получателей (Recipient List, с. 264) 1 Несколько (включая 0) Нет —
Разветвитель (Splitter, с. 274) 1 Несколько Нет —
Агрегатор (Aggregator, с. 283) Несколько 1 Да —
Преобразователь порядка (Resequencer, с. 297) Несколько Несколько Да Количество отправленных
сообщений рав-
няется количеству
полученных
сообщений
Составные маршрутизаторы
Ключевое преимущество архитектуры каналов и фильтров (Pipes and Filters, с. 102)
состоит в возможности объединения фильтров. Шаблоны проектирования обработчик
составного сообщения (Composed Message Processor, с. 307) и рассылка-сборка (Scatter-Gather,
с. 310) представляют собой сложные решения, состоящие из нескольких маршрутизато-
ров сообщений (Message Router, с. 109). Обработчик составного сообщения разделяет входя-
щее сообщение на несколько частей, а шаблон рассылка-сборка рассылает копию сооб-
щения нескольким получателям.
Шаблоны обработчик составного сообщения и рассылка-сборка предусматривают мар-
шрутизацию сообщения одновременно нескольким получателям и сборку ответных
сообщений. Можно сказать, что эти шаблоны реализуют параллельную маршрутизацию
сообщения. Последовательная маршрутизация сообщения (прохождение сообщения
через несколько последовательных этапов обработки) обеспечивается шаблонами проек-
тирования карта маршрутизации (Routing Slip, с. 314) и диспетчер процессов (Process
Manager, с. 325). Карта маршрутизации позволяет явно задать этапы обработки сообще-
ния. Диспетчер процессов обеспечивает большую гибкость, однако он требует пересылки
сообщения центральному компоненту после каждого этапа обработки.
Архитектурные шаблоны
Маршрутизаторы сообщений (Message Router, с. 109) позволяют создавать интеграци-
онные решения, основанные на использовании центрального брокера сообщений (Message
Broker, с. 334). Шаблон брокер сообщений описывает так называемый архитектурный
стиль звезда (hub-and-spoke).
246
Глава 7. Маршрутизация сообщений
Выбор маршрутизатора сообщений
В этой главе описываются 12 шаблонов проектирования. Диаграмма, представленная
на рис. 7.1, облегчает выбор маршрутизатора для применения в конкретных условиях.
В точности одно
Обработка одного
сообщения за раз (без
сохранения состояния)
Простые
маршрути-
заторы
Одно сообщение
на выходе
Несколько вариантов
Сложные
маршрути-
заторы
Последовательная
обработка
Несколько
сообщении на
выходе
сохранением
Рис. 7.J. Диаграмма выбора маршрутизатора
Одновременная
обработка нескольких
сообщений (с
состояния)
Параллельная
обработка
Разделение сообщени
То же количество
сообщений на выходе
Ноль или одно
Параллельная
обработка
Широковещание сообщений
Предопределенная, линейная
Последовательная
обработка
Меньшее количество
сообщений на выходе
К примеру, если вам нужен простой маршрутизатор с единственным сообщением
на входе и несколькими последовательными сообщениями на выходе, ваш выбор должен
остановиться на разветвителе (Splitter, с. 274). Кроме того, диаграмма иллюстрирует
тесную взаимосвязь между некоторыми шаблонами проектирования. К примеру, карта
маршрутизации (Routing Slip, с. 314) и диспетчер процессов (Process Manager, с. 325) могут
использоваться для решения однотипных задач, весьма далеких от области применения
фильтра сообщений (Message Filter, с. 253).
Маршрутизатор на основе содержимого (Content-Based Router)
247
Маршрутизатор на основе содержимого (Content-Based Router)
Рассмотрим задачу проектирования системы обработки заказов. Каждый новый заказ
проверяется на достоверность и возможность его выполнения. Последнюю функцию
осуществляет система управления складскими запасами. Наличие нескольких последова-
тельных этапов обработки создает предпосылку для применения архитектурного стиля
каналы и фильтры (Pipes and Filters, с. 102). Однако в большинстве сценариев корпоратив-
ной интеграции существует несколько систем управления складскими запасами, каждая
из которых может подтвердить наличие только определенного типа товаров.
Как поступить в ситуации, когда реализация единственной логической функции
распределяется между несколькими физическими системами?
Интеграционные решения призваны наладить взаимодействие между существующи-
ми приложениями. Поскольку большинство приложений создавались без учета возмож-
ности их объединения, бизнес-функции интеграционных решений зачастую оказывают-
ся распределенными между несколькими различными системами. К примеру, в результа-
те слияния компаний одна и та же бизнес-функция может дублироваться несколькими
программными комплексами. Кроме того, множество компаний, выполняющих роль
агрегаторов или посредников, как правило, контактируют с несколькими системами
с одинаковой функциональностью, такой как проверка возможности выполнения заказа,
размещение заказа и т.д. В свою очередь, каждая из подобных систем может находиться
под управлением одной или нескольких компаний. К примеру, такой Интернет-магазин,
как Amazon, позволяет приобрести множество наименований товаров, от книг до одежды
и рабочих инструментов. Таким образом, в зависимости от типа товара каждый заказ
может обрабатываться программными комплексами различных продавцов.
Предположим, что компания продает товары двух категорий: приборы и устройства.
Каждой категории товара соответствует собственная система управления складскими за-
пасами. Предположим также, что каждый товар имеет уникальный номер. Получив за-
каз, необходимо решить, какую систему управления складскими запасами следует ис-
пользовать для его обработки. Для этого можно предусмотреть два отдельных канала, по
одному на каждую категорию товара. Однако это потребует от заказчиков знания внут-
ренней архитектуры системы обработки заказов. Реализацию бизнес-функции, распре-
деленной между несколькими системами, необходимо скрыть от оставшейся части ин-
теграционного решения. Таким образом, все сообщения о размещении нового заказа
должны поступать по одному и тому же каналу.
Мы могли бы перенаправить заказ всем системам управления складскими запасами
(с помощью канала “публикация-подписка” — Publish-Subscribe Channel, с. 134), тем са-
мым переложив принятие решения о возможности обработки заказа на каждую отдель-
ную систему. Подобный подход облегчает добавление новых систем управления склад-
скими запасами, однако требует координации существующих систем. Что случится, если
248
Глава 7. Маршрутизация сообщений
заказ не будет обработан ни одной системой или же будет обработан сразу несколькими
системами? К тому же невозможность обработать заказ воспринимается большинством
систем управления складскими запасами, как ошибка. Вполне возможно, что обработка
каждого заказа приведет к возникновению ошибок во всех системах, за исключением од-
ной системы управления складскими запасами. Отличить подобные ошибки от
“настоящих” ошибок, таких как ошибка формата сообщения, будет очень непросто.
Один из альтернативных подходов заключается в использовании номера товара в
качестве адреса канала. В результате каждому товару будет соответствовать отдельный
канал, предназначенный для размещения сообщений о заказе, а системе управления
складскими запасами придется отслеживать все каналы, соответствующие находящимся
на складе товарам. К сожалению, наличие широкого ассортимента товаров нивелирует
преимущества данного подхода, поскольку слишком большое число каналов приведет
к снижению производительности и управляемости системы обмена сообщениями.
Кроме того, не стоит забывать о необходимости минимизации трафика сообщений.
Предположим, что сообщение о размещении нового заказа передается последовательно
каждой системе управления складскими запасами. Первая система, которая может
выполнить заказ, принимает сообщение и обрабатывает его. Если система не может вы-
полнить заказ, она передает сообщение следующей системе. Подобный подход исключа-
ет возможность обработки сообщения одновременно несколькими системами. Если по-
следняя система не смогла обработать сообщение, это значит, что оно не может быть об-
работано ни одной из систем. Следует отметить, что данное решение предполагает
наличие у каждой системы достаточной информации для передачи сообщения следую-
щей системе. Это напоминает шаблон проектирования цепочка обязанностей {Chain
of Responsibility) [12]. К сожалению, в мире интеграции с помощью обмена сообщениями
последовательная передача сообщения по цепочке систем может привести к существен-
ным издержкам. К тому же подобный подход предполагает взаимодействие отдельных
систем, что невозможно, если некоторые системы находятся под управлением внешних
бизнес-партнеров.
Таким образом, нам необходимо решение, распределяющее одну бизнес-функцию
между несколькими системами, эффективно использующее каналы сообщений, мини-
мизирующее трафик сообщений, а также гарантирующее, что каждый заказ будет обра-
ботан в точности одной системой управления складскими запасами.
Используйте маршрутизатор на основе содержимого {Content-Based Router)
для передачи сообщений получателю в зависимости от содержимого сообщения.
Новый заказ
Маршрутизатор
Склад
приборов
Склад
устройств
Маршрутизатор на основе содержимого (Content-Based Router)
249
Маршрутизатор на основе содержимого анализирует сообщение и помещает его в тот
или иной канал в зависимости от содержащихся в сообщении данных. Маршрутизация
может осуществляться на основе всевозможных критериев, таких как существование по-
лей, наличие определенных значений полей и т.д. Поскольку маршрутизатор может быть
подвержен частой отладке, функцию маршрутизации следует максимально упростить.
В более сложных интеграционных сценариях маршрутизатор на основе содержимого
может определять исходящий канал на основе набора изменяемых правил.
Уменьшение зависимостей
Маршрутизатор на основе содержимого (Content-Based Router) — одна из наиболее рас-
пространенных форм маршрутизатора сообщений (Message Router, с. 109). Маршрутиза-
тор на основе содержимого реализует так называемую предиктивную маршрутизацию.
Другими словами, он обладает сведениями о возможностях всех остальных систем. Бла-
годаря этому каждое входящее сообщение направляется на обработку непосредственно
в требуемую систему, чго позволяет говорить об эффективности маршрутизации. Недос-
таток маршрутизатора на основе содержимого заключается в том, что он вынужден под-
держивать информацию обо всех известных получателях. Добавление, удаление или из-
менение получателя приводит к необходимости внесения изменений в маршрутизатор
на основе содержимого. Это затрудняет поддержку интеграционного решения.
Зависимости маршрутизатора на основе содержимого от получателей можно избежать,
предоставив последним возможность контроля за процессом маршрутизации. Подобный
подход называется реактивной фильтрацией, поскольку он позволяет каждому участнику
отфильтровывать нужные ему сообщения. Распределенное управление процессом мар-
шрутизации устраняет необходимость в наличии маршрутизатора на основе содержимого.
Более подробно реактивная фильтрация и связанные с ней издержки рассматриваются
в шаблонах проектирования фильтр сообщений (Message Filter, с. 253) и карта маршрути-
зации (Routing Slip, с. 314).
Компромиссным решением между маршрутизатором на основе содержимого и реак-
тивной фильтрацией является динамический маршрутизатор (Dynamic Router, с. 259),
позволяющий получателям уведомлять маршрутизатор на основе содержимого о своих
возможностях. Маршрутизатор на основе содержимого поддерживает список возможно-
стей всех получателей и перенаправляет входящие сообщения в соответствии с этими
сведениями. Недостаток данного решения заключается в его сложности по сравнению
с простым маршрутизатором на основе содержимого.
Пример: маршрутизатор на основе содержимого (C# и MSMQ)
Код, приведенный ниже, описывает очень простой маршрутизатор на основе содержимого
(Content-Based Router), который распределяет сообщения по очередям, исходя из первой
буквы тела сообщения. Если текст в теле сообщения начинается с “W”, маршрутизатор
перенаправляет сообщение в очередь widgetQueue, а если с “G” — в очередь
gadgetQueue. Если же тело сообщения начинается с любой другой буквы, сообщение
отправляется в очередь dunnoQueue, которая в данном случае представляет собой типич-
ный пример канала недопустимых сообщений (Invalid Message Channel, с. 143). Маршрути-
затор не поддерживает сохранение состояния; иными словами, принимая решение
о маршрутизации сообщения, он “не помнит” о предыдущих сообщениях.
250
Глава 7. Маршрутизация сообщений
class ContentBasedRouter
{
protected MessageQueue inQueue;
protected MessageQueue widgetQueue;
protected MessageQueue gadgetQueue;
protected MessageQueue dunnoQueue;
public ContentBasedRouter(MessageQueue inQueue,
MessageQueue widgetQueue,
MessageQueue gadgetQueue,
MessageQueue dunnoQueue)
this.inQueue = inQueue;
this.widgetQueue = widgetQueue;
this.gadgetQueue = gadgetQueue;
this.dunnoQueue = dunnoQueue;
inQueue.ReceiveCompleted +=
new ReceiveCompletedEventHandler(OnMessage);
inQueue.BeginReceive();
private void OnMessage(Object source,
ReceiveCompletedEventArgs asyncResult)
{
MessageQueue mq = (MessageQueue)source;
mq.Formatter = new System.Messaging.XmlMessageFormatter
(new String[] {"System.String,mscorlib"});
Message message = mq.EndReceive(asyncResult.AsyncResult);
if (IsWidgetMessage(message))
widgetQueue.Send(message);
else if (IsGadgetMessage(message))
gadgetQueue.Send(message);
else
dunnoQueue.Send(message);
mq.BeginReceive();
protected bool IsWidgetMessage (Message message)
{
String text = (String)message.Body;
return (text.StartsWith("W"));
}
protected bool IsGadgetMessage (Message message)
{
String text = (String)message.Body;
return (text.StartsWith("G"));
}
}
В настоящем примере мы реализуем событийно управляемый потребитель сообще-
ний, регистрируя метод OnMessage в качестве обработчика сообщений, прибывающих
по входящему каналу inQueue. Вследствие этого .NET вызывает метод OnMessage для
Маршрутизатор на основе содержимого (Content-Based Router)
251
каждого сообщения, поступившего в очередь inQueue. Свойство Formatter очереди
сообщений говорит платформе .NET о том, какой тип сообщений следует ожидать.
В нашем примере используются только простые строковые сообщения. Метод
OnMessage определяет, куда необходимо перенаправить сообщение, и уведомляет плат-
форму .NET о своей готовности получить следующее сообщение (для этого вызывается
метод BeginReceive очереди сообщений). Чтобы свести объем кода к минимуму,
в маршрутизатор не была включена поддержка транзакций. Если такой маршрутизатор
выйдет из строя после того, как потребит сообщение из входящего канала, но до того, как
отправит сообщение в исходящий канал, сообщение будет потеряно. В следующих главах
книги будет рассказываться о том, как сделать конечную точку сообщения транзакцион-
ной (см. шаблон транзакционный клиент (Transactional Client, с. 498)).
Пример: брокер сообщений (TIBCO)
Маршрутизация сообщений является столь востребованной функцией, что большинство
пакетов интеграции включают в себя встроенные инструменты для упрощения построе-
ния логики маршрутизации. В предыдущем примере для MSMQ и C# нам пришлось
вручную прописывать, как извлечь сообщение из входящего канала, десериализовать его,
проанализировать и опубликовать в нужном исходящем канале. В большинстве пакетов
средств интеграции логика такого типа может быть реализована с помощью простого пере-
таскивания мышью. Кодировать приходится лишь непосредственно логику выбора канала.
Одним из популярных пакетов средств интеграции, позволяющих реализовать логику
маршрутизации сообщений, является TIBCO ActiveEnterprise. В его состав входит сред-
ство TIB/MessageBroker, предназначенное для создания простых потоков сообщений
с преобразованием и маршрутизацией. Если с помощью TIB/MessageBroker реализовать
маршрутизатор, распределяющий сообщения по первой букве текста, он будет выглядеть
так, как показано на рис. 7.2.
Рис. 7.2. Маршрутизатор на основе содержимого в TIB/MessageBroker
Рассмотрим схему движения сообщений слева направо. Крайний слева компонент
(белый треугольник, указывающий вправо) — это подписчик, потребляющий сообще-
ния из канала router.in. Имя канала задается в окне свойств, не показанном на
рис. 7.2. Содержимое сообщения направляется издателю (белый треугольник в правом
252
Глава?. Маршрутизация сообщений
углу рисунка). Линия, соединяющая выход подписчика Data с входом издателя Message,
обозначает, что маршрутизатор на основе содержимого (Content-Based Router) не вносит
изменений в тело сообщения. Чтобы определить, в какой исходящий канал необходимо
поместить сообщение, функция ComputeSubject (в центре рисунка) анализирует
содержимое сообщения. В качестве таблицы соответствий между содержимым сообще-
ния и именем канала назначения используется так называемый словарь, который на ри-
сунке обозначен как Мар. Словарь настроен следующим образом.
Код элемента заказа Имя канала
G gadget
W widget
Функция ComputeSubject использует первую букву текста сообщения (в нашем
примере это код продукта), чтобы с помощью словаря определить исходящий канал,
в который следует перенаправить данное сообщение. Чтобы получить полное имя кана-
ла, к результату, извлеченному из словаря, впереди добавляется строка router.out.
(например, router. out. widget). Тогда каждый элемент заказа, код которого начинает-
ся с буквы “G”, будет перенаправлен в канал router.out.gadget, а элементы заказа,
код которых начинается с “W”, — в канал router. out. widget.
Реализация функции ComputeSub j ect в TIBCO выглядит следующим образом.
concat("router.out.",DGet(map,Upper(Left(OrderItem.ItemNumber,1))))
Функция ComputeSubject извлекает первую букву из кода продукта (с помощью
функции Left) и преобразует ее в букву в верхнем регистре (с помощью функции
Upper). Полученный результат используется в качестве ключа для извлечения из словаря
имени нужного исходящего канала (функция DGet).
Данный пример наглядно демонстрирует преимущества коммерческих средств инте-
грации. Мы смогли добиться той же функциональности, что и в предыдущем примере,
однако вместо нескольких десятков строк кода ограничились написанием лишь одной
небольшой функции. Кроме того, платформа TIBCO автоматически заботится о под-
держке транзакционности, управления потоками и управления системой. С другой сто-
роны, документировать создание решений с помощью графических средств разработки
сложнее, чем просто привести фрагмент кода. Чтобы рассказать об этом в книге, нам
пришлось воспользоваться копиями экрана, а многие важные параметры вообще скрыты
в полях свойств, не показанных на экране.
Фильтр сообщений (Message Filter)
253
Фильтр сообщений (Message Filter)
Продолжая пример с обработкой заказов, предположим, что руководство компании
“Приборы и устройства” решило уведомлять крупных клиентов об изменениях цен и
специальных предложениях (например, что в ноябре цена на все устройства будет сни-
жена на 10%). Некоторые клиенты, однако, могут быть заинтересованы в получении све-
дений лишь об определенных товарах. К примеру, если заказчик приобретает только
приборы, его вряд ли заинтересует распродажа устройств.
Как избежать получения ненужных сообщений?
Самый простой способ избавить себя от ненужных сообщений — подписаться только
на те каналы, по которым доставляется интересующая информация. Этот подход задей-
ствует встроенную способность к маршрутизации, которой обладают каналы “публика-
ция-подписка” (Publish-Subscribe Channel, с. 134). Компонент получает только сообщения,
передающиеся по каналам, на которые он подписан. К примеру, можно создать один
канал для рассылки обновлений цен на приборы и еще один канал, в котором будут пуб-
ликоваться обновления цен на устройства. В этом случае клиенты компании смогут сами
выбирать, на какой канал или каналы подписываться. У данного подхода есть еще одно
преимущество: добавление новых подписчиков не потребует внесения изменений в сис-
тему. С другой стороны, получение сообщений по каналу “публикация-подписка” обычно
ограничено простым бинарным условием: если компонент подписан на канал, он полу-
чает все сообщения из этого канала. Единственный способ предоставить компоненту
больше выбора в том, какие сообщения получать, а какие нет, — создать как можно
больше каналов. При работе с комбинацией нескольких параметров число каналов мо-
жет быстро вырасти до ужасающих значений. К примеру, если мы хотим рассылать све-
дения о скидках на приборы или устройства 5, 10 или 15%, нам потребуется целых
шесть каналов “публикация-подписка” (два вида продукции умножить на три вида ски-
док). Такой подход значительно затрудняет управление каналами и чреват огромным по-
треблением системных ресурсов. Итак, нам нужно решение, обладающее большей гибко-
стью, чем простая подписка на каналы.
Помимо всего прочего, будущее решение должно легко изменяться. К примеру, мы
могли бы легко модифицировать маршрутизатор на основе содержимого (Content-Based
Router, с. 247), чтобы перенаправить сообщение сразу в несколько пунктов назначения
(концепция, описанная при рассмотрении шаблона список получателей (Recipient List,
с. 264)). Такой предиктивный маршрутизатор отправляет каждому получателю только
интересующие того сообщения, поэтому получателю не приходится выполнять какие-
либо дополнительные действия. С другой стороны, на отправителя сообщений наклады-
вается обязанность настраивать систему для каждого отдельного получателя. Если набор
получателей или их предпочтения часто меняются, поддержка такого решения превраща-
ется в кошмар.
254
Глава?. Маршрутизация сообщений
Можно было бы просто рассылать сообщения всем компонентам с тем, чтобы каж-
дый компонент самостоятельно отбрасывал ненужные сообщения. К сожалению, этот
подход предполагает, что у нас есть контроль над самим компонентом. Между тем во
многих сценариях интеграции приходится иметь дело с готовыми, унаследованными или
другими приложениями, не находящимися под контролем текущей организации.
Используйте особую разновидность маршрутизатора сообщений (Message Router,
с. 109) под названием фильтр сообщений (Message Filter). С его помощью из кана-
ла можно удалять нежелательные сообщения на основе набора критериев.
Обновление Обновление Обновление Ешщщшици—ивЛ Обновление Обновление
цены цены цены Фильтр сообщений цены цены
приборов устройств приборов приборов приборов
Фильтр сообщений — это маршрутизатор сообщений с одним исходящим каналом. Если
содержимое входящего сообщения соответствует критерию, заданному фильтром сообще-
ний, сообщение направляется в исходящий канал. В противном случае оно отбрасывается.
В нашем примере для реализации такого подхода следует создать один общий канал
“публикация-подписка”, который будет прослушиваться всеми клиентами. После этого кли-
ент сможет воспользоваться фильтром сообщений, чтобы отбирать сообщения на основании
собственных предпочтений, как, например, тип продукции или величина скидки.
Фильтр сообщений можно рассматривать как частный случай маршрутизатора на осно-
ве содержимого, направляющего полученное сообщение в исходящий канал либо в так
называемый нулевой канал (null channel), который уничтожает все опубликованные в нем
сообщения. Назначение такого канала аналогично назначению папки /dev/null, при-
сутствующей во многих операционных системах, или же шаблону null-объект (Null Object,
см. [32]).
Фильтры с сохранением или без сохранения состояния
В примере с продажей приборов и устройств описывается фильтр сообщений (Message
Filter) без сохранения состояния: фильтр анализирует отдельное сообщение и принимает
решение о его отбрасывании исключительно на основе информации, содержащейся
в этом сообщении. По этой причине фильтру сообщений не обязательно сохранять
состояние при переходе от сообщения к сообщению. Компоненты, не сохраняющие со-
стояние, обладают одним преимуществом: они позволяют одновременно запускать по
нескольку экземпляров компонента для ускорения обработки. Иногда, впрочем, филыпру
сообщений приходится сохранять состояние, например когда он должен вести журнал со-
общений. Один из популярных сценариев такого типа предполагает использование
фильтра сообщений для устранения повторяющихся сообщений. Если каждое сообщение
обладает уникальным идентификатором, фильтр может сохранять идентификаторы по-
лученных сообщений, чтобы выявлять повторяющиеся сообщения, сравнивая иденти-
фикатор каждого нового сообщения со списком имеющихся идентификаторов.
Фильтр сообщений (Message Filter)
255
Функции фильтрации, встроенные в системы обмена сообщениями
Некоторые инфраструктуры обмена сообщениями обладают встроенной функцио-
нальностью фильтра сообщений (Message Filter). Так, некоторые системы публикации-
подписки, включая большинство реализаций JMS, позволяют определять иерархическую
структуру для каналов “публикация-подписка” (Publish-Subscribe Channel, с. 134). Предпо-
ложим, что компания “Приборы и устройства” публикует сведения о специальных пред-
ложениях для устройств в канале wgco. update. promotion. widget. Подписчик, в свою
очередь, может применять символы подстановки для подписки на некоторое подмноже-
ство каналов. К примеру, если он прослушивает тему wgco .update. * .widget, то будет
получать все обновления (изменения цен и специальные предложения), касающиеся
устройств. Другой подписчик, прослушивающий тему wgco.update.promotion.*,
будет получать сведения обо всех специальных предложениях, касающихся приборов и
устройств, но не будет получать обновления цен. Наличие иерархии каналов позволяет
детализировать семантику канала путем присоединения к его имени уточняющих пара-
метров, благодаря чему потребители смогут фильтровать сообщения, задавая допол-
нительные критерии как часть имени канала. Тем не менее гибкость, которую обеспечи-
вает иерархическое именование каналов, все равно проигрывает возможностям фильтра
сообщений. Фильтр, к примеру, может передавать клиенту сообщение об изменении цены
только в том случае, если она изменилась более чем на 11,5%. Согласитесь, выразить это
с помощью имени канала было бы сложно.
Другие системы обмена сообщениями поддерживают работу с избирательными потре-
бителями (Selective Consumer, с. 528), реализованными внутри приложений-получателей.
Такие потребители отбирают сообщения с помощью селекторов (selectors) — условных
выражений, оценивающих определенные поля заголовка или свойства входящего сооб-
щения прежде, чем оно будет передано приложению-получателю. Если значение выра-
жения окажется ложным, сообщение будет проигнорировано и не будет передано логике
приложения. В данном случае селектор выполняет роль фильтра сообщений, встроенного
в приложение. Хотя использование селектора все равно подразумевает модификацию
приложения (что не всегда возможно при интеграции), выполнение правил выбора
встроено в инфраструктуру обмена сообщениями. Одно важное отличие фильтра сообще-
ний от избирательного потребителя состоит в том, что получатель, использующий послед-
него, не потребляет сообщения, которые не соответствуют заданным критериям. Фильтр
сообщений, в свою очередь, извлекает из входящего канала все сообщения, а затем публику-
ет в исходящем канале только те из них, которые соответствуют заданным критериям.
Поскольку избирательный потребитель регистрирует критерий выбора в инфраструк-
туре обмена сообщениями, последняя может применять этот критерий для принятия
внутренних решений, касающихся маршрутизации. Предположим, что получатель сооб-
щений находится в другом сегменте сети (или даже в Интернете). Было бы слишком рас-
точительно перенаправлять сообщение от одного маршрутизатора к другому только для
того, чтобы оно добралось до фильтра сообщений и было безжалостно отброшено. С дру-
гой стороны, мы хотим использовать фильтр сообщений, чтобы контроль над их маршру-
тизацией осуществлялся самими получателями, а не центральным маршрутизатором
сообщений (Message Router, с. 109). Если фильтр сообщений является частью интерфейса
API, предоставленного подписчику инфраструктурой обмена сообщениями, последняя
может легко поместить критерий выбора поближе к источнику. Это сохранит контроль
256
Глава?. Маршрутизация сообщений
подписчика над маршрутизацией сообщений, но позволит избежать нежелательного
сетевого трафика. Такое поведение напоминает работу динамического списка получате-
лей (Recipient List, с. 264).
Использование фильтров сообщений вместо маршрутизатора
на основе содержимого
Используя канал “публикация-подписка” (Publish-Subscribe Channel, с. 134) в сочетании
с массивом фильтров сообщений (Message Filter), можно реализовать функциональность,
эквивалентную той, которую обеспечивает маршрутизатор на основе содержимого
(Content-Based Router, с. 247). Два варианта реализации такой функциональности показа-
ны на рис. 7.3 и 7.4.
Маршрутизатор
на основе содержимого
Обновление чиямшшшвжшшЛ
цены
приборов
Приборы
Рис. 7.3. Вариант 1: использование маршрутизатора на основе содержимого
Рис. 7.4. Вариант 2: использование широковещательного канала и массива фильтров сообщений
В примере, показанном на рис. 7.3 и 7.4, присутствуют два получателя сообщений:
получатель “Приборы” и получатель “Устройства”. Каждый из них заинтересован в по-
лучении только тех сообщений, которые касаются определенного вида продукции
(приборов или устройств соответственно). В первом случае (см. рис. 7.3) маршрутизатор
Фильтр сообщений (Message Filter)
257
на основе содержимого заранее оценивает содержимое каждого сообщения и сразу на-
правляет его нужному получателю.
Во втором случае, показанном на рис. 7.4, отправитель помещает сообщение в канал
“публикация-подписка”, доступный обоим получателям. Каждый получатель, в свою оче-
редь, оснащен собственным фильтром сообщений, с помощью которого отбрасывает
ненужные сообщения. К примеру, получатель “Устройства” использует фильтр уст-
ройств, пропускающий только те сообщения, которые касаются цены устройств.
Основные различия между описанными решениями перечислены в табл. 7.2.
Таблица 7.2. Различия между вариантами реализации
Маршрутизатор на основе содержимого Канал “публикация-подписка” с фильтрами сообщений
Каждое сообщение получает только один потребитель Каждое сообщение может быть получено несколькими потребителями
Централизованное управление и поддержка (предиктивная маршрутизация) Распределенное управление и поддержка (реактивная фильтрация)
Маршрутизатор должен знать о потребителях. При добавлении или обновлении потребителей может потребоваться обновление маршрутизатора Знать о получателях не требуется. Добавление или удаление получателей выполняется очень просто
Часто используется для бизнес-транзакций, например для обработки заказов Часто используется для уведомления о событиях или д ля рассылки информационных сообщений
Как правило, более эффективен при работе с очередями сообщений Как правило, более эффективен при работе с каналами “публикация-подписка”
Как выбрать более подходящий вариант? Иногда выбор того или иного решения
определяется требуемой функциональностью. Например, чтобы одно и то же сообщение
могло обрабатываться разными получателями, вы должны воспользоваться каналом
“публикация-подписка” в сочетании с фильтрами сообщений. В большинстве случаев,
однако, выбор решения зависит от того, какие компоненты системы должны управлять
маршрутизацией сообщений. Контроль над маршрутизацией должен быть централизо-
ванным, или же его лучше переложить на плечи получателей? Если сообщения содержат
секретные данные, которые должны быть доступны только конкретным получателям,
необходимо использовать маршрутизатор на основе содержимого — опасно доверять
фильтрацию сообщений другим получателям. В качестве примера предположим, что
VIP-клиентам компании предлагаются специальные скидки. Не стоит ожидать, что ос-
тальные клиенты проигнорируют такие сообщения.
На выбор варианта реализации могут повлиять и соображения, связанные с работой
сети. Если у вас есть удобный способ широковещательной рассылки информации
(например, многоадресная IP-рассылка по внутренней сети), использование фильтров
может оказаться весьма эффективным, а заодно избавит систему от потенциального
“узкого места” в виде единственного маршрутизатора. Но если информацию приходится
передавать по Интернету, вы будете ограничены соединениями типа “точка-точка”.
В подобных случаях предпочтительнее использовать централизованный маршрутизатор,
поскольку он позволит избежать отправки сообщений всем получателям вне зависимости
258 Глава?. Маршрутизация сообщений
от интересов последних. Если же вы хотите передать контроль над маршрутизацией
получателям сообщений, но из соображений сетевой эффективности вынуждены ис-
пользовать маршрутизатор, имеет смысл воспользоваться динамическим списком получа-
телей (Recipient List, с. 264). Список получателей такого типа выполняет роль динамиче-
ского маршрутизатора (Dynamic Router, с. 259), позволяя получателям подстраивать мар-
шрутизатор под свои предпочтения с помощью управляющих сообщений. Предпочтения
получателей сохраняются в базе данных или в виде базы правил. При поступлении
нового сообщения список получателей направляет его всем получателям, чьим критериям
оно соответствует.
Динамический маршрутизатор (Dynamic Router)
259
Динамический маршрутизатор (Dynamic Router)
Система использует маршрутизатор сообщений (Message Router, с. 109) для распреде-
ления сообщений между несколькими пунктами назначения.
Как избежать зависимости маршрутизатора от всех возможных пунктов назначе-
ния, не теряя эффективности его работы?
Маршрутизатор сообщений отличается высокой эффективностью, потому что может
направить сообщение сразу в требуемый пункт назначения. Другие решения, касающие-
ся маршрутизации сообщений (особенно с использованием реактивной фильтрации),
менее эффективны, поскольку в своей работе руководствуются методом проб и ошибок.
К примеру, карта маршрутизации (Routing Slip, с. 314) направляет каждое сообщение
в первый попавшийся пункт назначения. Если он оказывается тем, что нужно, он при-
нимает сообщение; в противном случае оно направляется в следующий пункт назначе-
ния, и т.п. Фильтр сообщений (Message Filter, с. 253) также рассылает сообщения всем воз-
можным получателям вне зависимости от того, заинтересованы они в получении этих со-
общений или нет.
Использование решений, основанных на распределенной маршрутизации, чревато
еще одной проблемой: получателей может оказаться слишком много или не оказаться
вообще. И та, и другая ситуации могут остаться незамеченными, если не воспользоваться
центральным компонентом маршрутизации.
Вышеизложенные причины побуждают к тому, чтобы воспользоваться маршрутиза-
тором сообщений, который знает о каждом пункте назначения, а также включает в себя
правила распределения сообщений по пунктам назначения. Но если перечень возмож-
ных пунктов назначения часто меняется, поддержка такого маршрутизатора может чрез-
мерно усложниться.
Помимо обычных входящих и исходящих каналов, динамический маршрутизатор ис-
пользует дополнительный управляющий канал. Во время запуска системы каждый потен-
циальный получатель отправляет динамическому маршрутизатору по этому каналу специ-
альное сообщение, в котором объявляет о своем присутствии и перечисляет условия, при
которых может обрабатывать сообщения. Динамический маршрутизатор сохраняет на-
стройки каждого получателя в базе правил. При поступлении нового сообщения динами-
ческий маршрутизатор просматривает базу правил и отправляет сообщение тому получа-
телю, правила которого оно удовлетворяет. Это позволяет эффективно реализовать пре-
диктивную маршрутизацию без необходимости ставить динамический маршрутизатор
в зависимость от каждого потенциального получателя.
260
Глава?. Маршрутизация сообщений
Используйте динамический маршрутизатор (Dynamic Router) — маршрутизатор,
который можно настраивать с помощью специальных конфигурационных сооб-
щений, присылаемых получателями.
В самом базовом сценарии каждый получатель уведомляет динамический маршрути-
затор о своем существовании и настройках маршрутизации во время запуска системы.
Для этого все получатели должны знать об управляющем канале, используемом динами-
ческим маршрутизатором. Кроме того, последний должен сохранять правила маршрути-
зации в некотором постоянном хранилище. В противном случае, если динамический мар-
шрутизатор выйдет из строя и будет перезапущен, он не сможет восстановить правила
маршрутизации. Вместо этого маршрутизатор после перезапуска может разослать широ-
ковещательное сообщение всем потенциальным получателям, чтобы заставить их вы-
слать в ответ управляющие сообщения. Такая конфигурация более надежна, но требует
дополнительного канала “публикация-подписка” (Publish-Subscribe Channel, с. 134).
Иногда имеет смысл усовершенствовать управляющий канал, чтобы получатели мог-
ли как подписываться, так и отписываться от получения сообщений. Это позволит полу-
чателям добавлять себя в схему маршрутизации или удалять себя из нее во время работы
системы.
Поскольку получатели не зависят друг от друга, динамическому маршрутизатору при-
ходится сталкиваться с конфликтами правил, как, например, заинтересованность разных
получателей в сообщениях одного и того же типа. Для решения таких конфликтов может
применяться несколько разных стратегий.
1. Игнорировать управляющие сообщения, которые конфликтуют с существующи-
ми сообщениями. Такой подход гарантирует, что база правил маршрутизации
будет защищена от конфликтов. Следует, однако, учесть, что состояние таблицы
маршрутизации будет зависеть от того, в каком порядке запускаются потенциаль-
ные получатели. Если все они будут запущены одновременно (и одновременно же
отправят по управляющему каналу свои настройки), поведение маршрутизатора
может стать непредсказуемым.
Динамический маршрутизатор (Dynamic Router)
261
2. Отправить сообщение первому получателю с подходящими критериями. Этот
подход допускает наличие в таблице маршрутизации конфликтующих правил;
конфликты решаются по мере поступления сообщений.
3. Отправить сообщение всем получателям с подходящими критериями. Этот под-
ход превращает динамический маршрутизатор в список получателей (Recipient List,
с. 264). Из поведения маршрутизатора на основе содержимого (Content-Based
Router, с. 247) следует, что для каждого входящего сообщения публикуется по од-
ному исходящему сообщению. Данная стратегия нарушает это правило.
Главными недостатками динамического маршрутизатора являются сложная архитек-
тура решения, а также трудности, связанные с отладкой динамически настраиваемых
систем.
Использование динамического маршрутизатора — еще один пример ситуации, в ко-
торой связующее ПО, ориентированное на обмен сообщениями, выполняет те же функ-
ции, что и нижние уровни сетей IP. Динамический маршрутизатор играет ту же роль, что
и динамические таблицы маршрутизации, используемые для передачи IP-пакетов из
одной сети в другую. Протокол, применяющийся компонентами-получателями для
настройки динамического маршрутизатора, в свою очередь, аналогичен IP-протоколу RIP
(Routing Information Protocol — протокол информации о маршрутах), о котором можно
прочитать в [38].
Динамические маршрутизаторы часто используют в архитектурах, ориентированных
на службы (SOA). Если клиентскому приложению нужен доступ к некоторой службе, оно
отправляет динамическому маршрутизатору сообщение с именем этой службы. Маршру-
тизатор, в свою очередь, ведет так называемый служебный каталог— перечень всех
служб с именами каналов, которые они прослушивают. Содержимое каталога формиру-
ется на основе управляющих сообщений, полученных от поставщиков служб. Когда от
клиента приходит запрос на доступ к некоторой службе, динамический маршрутизатор
ищет ее имя в служебном каталоге, а затем направляет сообщение в нужный канал. Такая
конфигурация позволяет клиентским приложениям отправлять сообщения с командами
в один и тот же канал, не заботясь о характере каждой конкретной службы или располо-
жении ее поставщика, даже если поставщик меняется.
Похожий шаблон под названием клиент-диспетчер-сервер (Client-Dispatcher-Server, см.
[33]) позволяет клиенту отсылать запросы к службе, не зная физического местонахожде-
ния ее поставщика. Диспетчер пользуется списком зарегистрированных служб, чтобы ус-
тановить соединение между клиентом и физическим сервером, реализующим запраши-
ваемую службу. Динамический маршрутизатор выполняет аналогичную функцию, но от-
личается от диспетчера тем, что может проводить более интеллектуальную маршрути-
зацию, нежели простой просмотр таблицы.
Пример: динамический маршрутизатор (C# и MSMQ)
Расширим приведенный ранее пример маршрутизатора на основе содержимого (Content-
Based Router, с. 247), чтобы последний выполнял роль динамического маршрутизатора
(Dynamic Router). Новый компонент прослушивает два канала: inQueue и controlQueue.
Управляющая очередь принимает сообщения в формате Х:имя_очереди. Каждое такое
сообщение означает, что динамический маршрутизатор должен направлять все сообще-
ния, текст которых начинается с символа X, в очередь по имени имя_очереди.
262
Глава?. Маршрутизация сообщений
class DynamicRouter
protected MessageQueue inQueue;
protected MessageQueue controlQueue;
protected MessageQueue dunnoQueue;
protected IDictionary routingTable =
(IDictionary)(new Hashtable());
public DynamicRouter(MessageQueue inQueue,
MessageQueue controlQueue,
MessageQueue dunnoQueue)
this.inQueue = inQueue;
this.controlQueue = controlQueue;
this.dunnoQueue = dunnoQueue;
inQueue.ReceiveCompleted +=
new ReceiveCompletedEventHandler(OnMessage);
inQueue.BeginReceive();
controlQueue.ReceiveCompleted +=
new ReceiveCompletedEventHandler(OnControlMessage);
controlQueue.BeginReceive();
}
protected void OnMessage(Object source,
ReceiveCompletedEventArgs asyncResult)
{
MessageQueue mq = (MessageQueue)source;
mq.Formatter = new System.Messaging.XmlMessageFormatter
(new String)] {"System.String,mscorlib"});
Message message = mq.EndReceive(asyncResult.AsyncResult);
String key = ((String)message.Body).Substring(0, 1);
if (routingTable.Contains(key))
{
MessageQueue destination =
(MessageQueue)routingTable[key];
destination.Send(message) ;
}
else
dunnoQueue.Send(message) ;
mq.BeginReceive();
11 Формат управляющего сообщения:
// X:имя_очереди в одной строке.
protected void OnControlMessage(Object source,
ReceiveCompletedEventArgs asyncResult)
MessageQueue mq = (MessageQueue)source;
mq.Formatter = new System.Messaging.XmlMessageFormatter
(new String[] {"System.String,mscorlib"});
Динамический маршрутизатор (Dynamic Router)
263
Message message = mq.EndReceive(asyncResult.AsyncResult);
String text = ((String)message.Body);
String [] split = (text.Split(new char[] 2));
if (split.Length == 2)
String key = split [0];
String queueName = split [1];
MessageQueue queue = FindQueue(queueName);
routingTable.Add(key, queue);
}
else
dunnoQueue.Send(message);
}
mq.BeginReceive();
}
protected MessageQueue FindQueue(string queueName)
{
if ('MessageQueue.Exists(queueName))
return MessageQueue.Create(queueName);
}
else
return new MessageQueue(queueName);
В данном примере используется очень простой механизм разрешения конфликтов —
“побеждает последний”. Если два компонента заинтересованы в получении сообщений,
текст которых начинается с символа X, сообщение получит только второй компонент,
поскольку в таблице Hashtable каждому значению ключа соответствует только одна
очередь сообщений. Обратите также внимание, что очередь dunnoQueue теперь может
получать сообщения двух типов: входящие сообщения, которые не соответствуют ни од-
ному из правил маршрутизации, а также управляющие сообщения, присланные в недо-
пустимом формате.
264
Глава?. Маршрутизация сообщений
Список получателей (Recipient List)
Маршрутизатор на основе содержимого (Content-Based Router, с. 247) позволяет напра-
вить сообщение в требуемый пункт назначения, основываясь на содержимом этого со-
общения. Такая маршрутизация происходит “прозрачно” для исходного отправителя
в том смысле, что он просто отсылает сообщение в канал, а обо всем остальном заботится
маршрутизатор.
В некоторых случаях, однако, сообщению требуется заранее назначить одного или
нескольких получателей. Здесь можно провести прямую аналогию со списками рассыл-
ки, реализованными во многих системах электронной почты. Создавая электронное
письмо, отправитель указывает список его получателей. После этого почтовая система
доставляет содержимое письма каждому из его получателей. В качестве еше одного при-
мера, на сей раз из области интеграции корпоративных приложений, можно привести си-
туацию, когда одна и та же функция может быть выполнена несколькими поставщиками.
К примеру, компания может заключить контракт сразу с несколькими кредитными бю-
ро, каждое из которых способно оценить кредитную репутацию клиента. Если клиент
хочет получить небольшой кредит, сообщение с запросом можно просто перенаправить в
первое доступное кредитное бюро. Если же желаемый размер кредита довольно велик,
запрос можно направить сразу в несколько кредитных бюро, сравнить полученные
результаты и только затем принять решение о выдаче кредита. В этом случае содержимое
списка получателей будет зависеть от желаемой суммы кредита.
В другой ситуации компания может разослать запрос клиента списку поставщиков,
чтобы узнать цену на запрашиваемые элементы заказа. Вместо того чтобы отсылать запрос
всем возможным поставщикам, их можно выбирать, исходя из предпочтений клиентов.
Как разослать сообщение меняющемуся списку получателей?
Настоящая проблема представляет собой обобщение вопроса, на решение которого
направлен маршрутизатор на основе содержимого, поэтому некоторые соображения
и альтернативы, приведенные при описании этого шаблона, могут пригодиться и здесь.
Большинство систем обмена сообщениями работают с каналами “публикация-
подписка” (Publish-Subscribe Channel, с. 134). Канал такого типа доставляет копию каждого
опубликованного в нем сообщения всем получателям, подписавшимся на этот канал.
Таким образом, набор получателей формируется на основании подписки на конкретный
канал или тему. Но перечень активных подписчиков канала является в какой-то степени
фиксированным и не может меняться для каждого конкретного сообщения. Нам же ну-
жен такой канал, который бы доставлял каждое сообщение своему списку получателей.
Реализовать такое поведение сложно, поскольку подписка на канал “публикация-
подписка” имеет только два состояния — подписчик либо получает все сообщения из
канала, либо не получает их вообще.
Список получателей (Recipient List)
265
Каждый потенциальный подписчик канала может фильтровать входящие сообщения
по их содержимому. Обычно для этого применяется фильтр сообщений (Message Filter,
с. 253) или избирательный потребитель (Selective Consumer, с. 528). К сожалению, в реше-
ниях такого типа логика выбора получателей распределяется между отдельными подпис-
чиками, что значительно затрудняет поддержку системы. Чтобы сохранить единую точку
контроля, к сообщению можно прикрепить список предполагаемых получателей. Когда
такое приложение будет разослано всем возможным получателям, каждый из них, кто
не нашел себя в списке получателей, должен отбросить сообщение.
И тот, и другой подходы страдают от чрезвычайно низкой эффективности: каждый
получатель должен обработать абсолютно все сообщения только для того, чтобы отбро-
сить большую их часть. Кроме того, работа такой системы во многом зависит от
“честности” получателей, потому что получатель может решить обработать сообщение,
которое ему не предназначалось. Это совершенно нежелательно в ситуациях, когда со-
держимое сообщения должно сохраняться в секрете от некоторых получателей
(например, когда запрос цены на товар отправляется только определенным поставщи-
кам, а остальные поставщики должны его проигнорировать).
Можно также требовать, чтобы отправитель публиковал сообщение отдельно для ка-
ждого получателя. В этом случае, однако, вся нагрузка по доставке сообщений получате-
лям ляжет на отправителя сообщений. Это практически невозможно, если отправитель
представляет собой готовое приложение. Кроме того, внедрение логики выбора получа-
телей в само приложение теснее привяжет его к интеграционной инфраструктуре. Между
тем приложения, подвергающиеся интеграции, обычно не знают даже о том, что они во-
обще участвуют в интеграционном решении. Вряд ли стоит ожидать, что такое приложе-
ние будет содержать логику маршрутизации сообщений.
Определите по одному каналу для каждого потенциального получателя. Затем
воспользуйтесь списком получателей (Recipient List), чтобы проанализировать
входящее сообщение, определить перечень желаемых получателей и разослать
сообщение по всем каналам, соответствующим получателям из этого перечня.
266
Глава 7. Маршрутизация сообщений
Логику, внедренную в список получателей, можно разбить на две отдельные части,
хотя их часто реализуют вместе. Первая часть составляет список желаемых получателей,
а вторая просто проходит по готовому списку и рассылает копию сообщения каждому
из получателей (рис. 7.5). Список получателей, как и маршрутизатор на основе содержи-
мого, обычно не вносит изменений в содержимое сообщения.
Рис. 7.5. Список получателей может самостоятельно составлять перечень получателей (вверху)
или брать его у другого компонента (внизу)
Список желаемых получателей сообщения может браться из самых разных источни-
ков. Иногда созданием списка занимается внешний (по отношению к списку получате-
лей) компонент. К примеру, отправитель сообщения может сгенерировать перечень по-
лучателей и прикрепить его к сообщению. Списку получателей останется только пройтись
по готовому перечню. При пересылке входящего сообщения список получателей обычно
удаляет из него вложенный перечень получателей, чтобы уменьшить размер сообщения,
а также чтобы скрыть от получателей имена друг друга. Предоставление перечня получа-
телей вместе с входящим сообщением имеет смысл и тогда, когда пункт назначения каж-
дого сообщения определяется внешними факторами, например выбором пользователей.
В большинстве случаев, однако, список получателей самостоятельно составляет пере-
чень требуемых получателей, исходя из содержимого сообщения и набора правил, вне-
Список получателей (Recipient List)
267
дренного в список получателей. Эти правила могут быть прописаны прямо в коде или же
настроены, как будет показано ниже.
К списку получателей применимы все те соображения насчет связывания, которые
приводились при обсуждении маршрутизатора сообщений (Message Router, с. 109). Пре-
диктивная рассылка сообщений отдельным получателям может привести к более тесному
связыванию компонентов, поскольку центральному компоненту необходимо будет знать
о группах остальных компонентов.
Чтобы список получателей мог контролировать продвижение информации, необходи-
мо гарантировать, что получатели не смогут подписываться прямо на входящий канал,
обходя при этом сам список получателей.
Надежность
Компонент список получателей (Recipient List) отвечает за рассылку входящего сооб-
щения всем получателям, чьи имена присутствуют в списке. Надежная реализация списка
получателей должна иметь возможность обработать входящее сообщение, но “потребить”
его только после успешной рассылки всех исходящих сообщений. По этой причине спи-
сок получателей должен гарантировать, что получение одного сообщения и отправка не-
скольких сообщений будут выполняться в рамках одной атомарной операции. Если спи-
сок получателей выйдет из строя, он должен перезапуститься и завершить операцию, ко-
торая на момент сбоя находилась в процессе выполнения. Этого можно достичь
несколькими способами.
1. Одна транзакция. Список получателей может использовать транзакционные кана-
лы и размещать копии сообщения в исходящих каналах в рамках одной транзак-
ции. Он не подтвердит отправку сообщений до тех пор, пока все они не будут по-
мещены в исходящие каналы. Это гарантирует, что будут отправлены либо все со-
общения, либо ни одно из них.
2. Постоянный список получателей. Список получателей может “помнить”, каким
адресатам уже были отправлены копии сообщения, а каким еще нет, чтобы в слу-
чае сбоя и перезапуска он смог разослать сообщение оставшимся получателям.
Перечень получателей может храниться на диске или в базе данных, чтобы при
сбое компонента список получателей он не потерялся.
3. Идемпотентные получатели. Если список получателей вышел из строя, после пере-
запуска он может просто еще раз разослать сообщение всем получателям. В этом
случае все получатели сообщений должны быть идемпотентными получателями
(Idempotent Receiver, с. 541). Идемпотентными называются такие функции, кото-
рые не изменяют состояние системы, если применяются сами к себе. В терминах
обмена сообщениями это означает, что состояние компонента не меняется, если
одно и то же сообщение обработано дважды, трижды и т.д. Сообщения могут быть
идемпотентными в силу своего содержания (например, такие сообщения, как
“Распродажа устройств продлится до 30 мая” или “Пришлите мне цену на уст-
ройство XYZ”, не принесут никакого вреда, если их получат по нескольку раз
подряд). Если это не так, получающий компонент можно сделать идемпотент-
ным, вставив перед ним специальный фильтр сообщений (Message Filter, с. 253),
который будет отбрасывать повторяющиеся сообщения. Подход с применением
идемпотентности очень удобен: если вы не уверены в том, что получателю было
268
Глава 7. Маршрутизация сообщений
доставлено сообщение, отправьте его еще раз. Похожий механизм используется
протоколом TCP/IP для обеспечения надежной доставки сообщений без лишней
нагрузки на сеть [38].
Динамический список получателей
Первоначальная идея списка получателей (Recipient List) состоит в централизованном
контроле за рассылкой сообщений. Несмотря на это его удобно применять, чтобы полу-
чатели могли сами настраивать правила, хранящиеся в списке получателей, к примеру,
если получатели хотят подписаться на определенные сообщения, но не могут сформули-
ровать критерии выбора с помощью тем канала “публикация-подписка” (Publish-Subscribe
Channel, с. 134). Критерии такого типа уже упоминались при рассмотрении шаблона
фильтр сообщений (Message Filter, с. 253), например “принять сообщение, если пена уст-
ройства меньше 48 долларов 31 цента”. Чтобы минимизировать объем сетевого трафика,
сообщения все равно следует рассылать только заинтересованным участникам (нас не
устраивает ситуация, при которой сообщение доставляется всем получателям, а они уже
сами решают, обрабатывать его или нет). Чтобы добиться такой функциональности, по-
лучатели могут отправлять списку получателей свои предпочтения по специальному
управляющему каналу. Список получателей сохраняет эти предпочтения в базе правил
и использует для настройки перечня получателей при поступлении каждого нового со-
общения. Этот подход предоставляет подписчикам контроль над выбором сообщений,
но вместе с тем задействует функциональность списка получателей для эффективного
распределения сообщений. Данное решение сочетает в себе черты списка получателей с
динамическим маршрутизатором (Dynamic Router, с. 259), а посему называется динамиче-
ский список получателей (рис. 7.6).
Рис. 7.6. Динамический список получателей настраивается самими получателями через управляющий канал
Данный подход хорошо подходит для примера с обновлениями цен, который рас-
сматривался при обсуждении шаблона фильтр сообщений. Однако его нельзя применять в
ситуации, когда у нескольких поставщиков запрашивается цена на один и тот же товар
(см. начало раздела), поскольку мы хотим сами выбирать поставщиков, участвующих в
обработке заказа.
Список получателей (Recipient List)
269
Эффективность с точки зрения сети
Какой подход более эффективен: отправка сообщения всем возможным получателям,
чтобы они сами отбирали нужные сообщения, или же отправка сообщения избранным
получателям? Ответ на этот вопрос во многом зависит от реализации инфраструктуры
обмена сообщениями. В общем случае можно предположить, что чем больше получате-
лей у сообщения, тем больший объем сетевого трафика оно создает. Но существуют и ис-
ключения. Некоторые системы публикации-подписки основаны на многоадресной
IP-рассылке и могут направлять сообщения нескольким получателям в рамках одной се-
тевой передачи (повторная передача требуется только в случае потери сообщений).
Действие многоадресной IP-рассылки основано на свойствах топологии “шина”, приме-
няемой в сетях Ethernet. Когда пакет IP отправляется по сети, его получают все сетевые
адаптеры, находящиеся в том же сегменте Ethernet, что и отправитель. Сетевой адаптер
проверяет, кому предназначается пакет, и игнорирует его в случае, если адрес назначения
пакета не совпадает с IP-адресом этого адаптера. При многоадресной маршрутизации все
получатели, входящие в заданную группу многоадресной рассылки, могут считывать
пакет из шины. В результате один и тот же пакет может быть получен несколькими адап-
терами, которые затем передают данные соответствующим приложениям. Такой подход
может быть весьма эффективен для локальных сетей с топологией “шина”, но не подхо-
дит для Интернета, где требуются соединения TCP/IP типа “точка-точка”. Из всего вы-
шесказанного можно сделать вывод: чем дальше находятся получатели, тем выгоднее ис-
пользовать список рассылки (Recipient List) вместо канала “публикация-подписка” (Publish-
Subscribe Channel, с. 134).
Эффективность широковещательной рассылки зависит не только от инфраструктуры
сети, но и от соотношения между обшим количеством получателей и числом тех из них,
которым предназначается сообщение. Если списки получателей в большинстве случаев
включают в себя всех или практически всех получателей системы, возможно, имеет
смысл организовать простую широковещательную рассылку, чтобы те немногие получа-
тели, которые не должны обрабатывать сообщение, сами занимались его отбрасыванием.
Если же в обработке каждого конкретного сообщения заинтересовано сравнительно мало
получателей, гораздо удобнее и выгоднее воспользоваться списком получателей.
Список получателей или канал “публикация-подписка” с фильтрами сообщений
По ходу главы мы уже несколько раз противопоставляли реализацию одной и той же
функциональности с использованием предиктивной маршрутизации и реактивной
фильтрации. На рис. 7.7 первый вариант реализации представлен списком получателей
(Recipient List), а второй — каналом “публикация-подписка” (Publish-Subscribe Channel,
с. 134) в сочетании с массивом фильтров сообщений (Message Filter, с. 253). Некоторые
соображения, приведенные при сравнении маршрутизатора на основе содержимого
(Content-Based Router, с. 247) с комбинацией канала “публикация-подписка” и филыпров
сообщений применимы и здесь. Но в случае со списком получателей сообщение может рас-
сылаться нескольким получателям, что делает вариант с фильтрами более эффективным.
270
Глава?. Маршрутизация сообщений
Рис. 7.7. Сравнение списка получателей с массивом фильтров сообщений
Сравнительные характеристики обоих решений приведены в табл. 7.3.
Таблица 7.3. Различия между вариантами реализации
Список получателей Канал “публикация-подписка” с фильтрами сообщений
Централизованное управление и поддержка (предиктивная маршрутизация) Распределенное управление и поддержка (реактивная фильтрация)
Список получателей (Recipient List) должен знать о потребителях. При добавлении или обновлении потребителей может потребоваться модификация списка (она не нужна лишь при использовании динамического списка получателей, но тогда теряется централизованный контроль над маршрутизацией) Знать о получателях не требуется. Добавление или удаление получателей выполняется очень просто
Часто используется лля бизнес-транзакний, например для запроса цены на товар Часто используется для уведомления о событиях или для рассыпки информационных сообщений
Как правило, более эффективен при работе с очередями сообщений Как правило, более эффективен при работе с каналами “публикация-под- писка” (зависит от инфраструктуры)
Если разослать сообщение нескольким получателям, позднее может понадобиться
сверить результаты. К примеру, если запросить кредитный балл клиента в нескольких
кредитных бюро, придется подождать, пока все они не пришлют ответы, чтобы сравнить
полученные результаты и вычислить среднее значение. В других, менее критичных си-
туациях для оптимизации пропускной способности компонентов можно взять любой от-
вет, который придет первым. Стратегии такого типа обычно реализуют в рамках шаблона
проектирования агрегатор (Aggregator, с. 283). Шаблон рассылка-сборка (Scatter-Gather,
с. 310), в свою очередь, описывает ситуации, в которых компонент получает одно сооб-
щение, рассылает его нескольким получателям, а затем снова комбинирует полученные
ответы в одно сообщение.
Список получателей (Recipient List)
271
Динамический список получателей может применяться для реализации канала
“публикация-подписка”, если система обмена сообщениями обладает только каналами
“точка-точка” (Point-to-Point Channel, с. 131). В этом случае в списке получателей будет
храниться перечень всех каналов “точка-точка”, получатели которых подписаны на оп-
ределенную тему. Каждая тема может быть представлена одним конкретным экземпля-
ром списка получателей. Это решение может пригодиться и тогда, когда необходимо
применить специальные критерии, чтобы дать получателям возможность подписаться на
некоторый источник данных. В отличие от каналов “публикация-подписка”, на которые
может подписаться любой компонент, в список получателей легко внедрить логику, огра-
ничивающую доступ к источнику данных путем внесения в список лишь избранных под-
писчиков. При этом, конечно же, предполагается, что подписчики не могут получать
сообщения непосредственно из канала, ведущего к списку получателей.
Пример: кредитный брокер
В примере сложного обмена сообщениями (глава 9) список получателей (Recipient List)
применяется для того, чтобы разослать запрос на получение кредита только в избранные
банки. В главе 9 описаны реализации списка получателей на Java, C# и TIBCO.
Пример: динамический список получателей (C# и MSMQ)
Код, приведенный ниже, расширяет пример динамического маршрутизатора (Dynamic
Router, с. 259), превращая его в динамический список получателей (Recipient List). Струк-
туры кодов в обоих примерах очень похожи. Объект DynamicRecipientList прослуши-
вает две входящие очереди сообщений. По одной из них (inQueue) поступают обычные
сообщения, которые требуется переслать получателям, а по другой (controlQueue) —
управляющие сообщения, с помощью которых получатели настраивают список получате-
лей под свои предпочтения. Каждое сообщение в управляющей очереди должно пред-
ставлять собой строку, разделенную на две части двоеточием (). Первая часть строки —
это набор символов, задающих предпочтения получателя. Получатель хочет принимать
все сообщения, текст которых начинается с одного из заданных символов. Вторая часть
управляющего сообщения задает имя очереди, которую прослушивает данный получа-
тель. К примеру, управляющее сообщение W: WidgetQueue указывает объекту Dynamic-
RecipientList на необходимость перенаправлять все входящие сообщения, текст кото-
рых начинается с буквы “W”, в очередь widgetQueue. Точно так сообщение WG: widget-
GadgetQueue инструктирует DynamicRecipientList направлять все сообщения, начи-
нающиеся с буквы “W” или “G”, в очередь WidgetGadgetQueue.
class DynamicRecipientList
{
protected MessageQueue inQueue;
protected MessageQueue controlQueue;
protected IDictionary routingTable =
(IDictionary)(new Hashtable());
public DynamicRecipientList(MessageQueue inQueue,
272
Глава?. Маршрутизация сообщений
MessageQueue controlQueue)
{
this.inQueue = inQueue;
this.controlQueue = controlQueue;
inQueue.ReceiveCompleted +=
new ReceiveCompletedEventHandler(OnMessage);
inQueue.BeginReceive();
controlQueue .ReceiveCompleted +=
new ReceiveCompletedEventHandler(OnControlMessage);
controlQueue.BeginReceive();
}
protected void OnMessage(Object source,
ReceiveCompletedEventArgs asyncResult)
{
MessageQueue mg = (MessageQueue)source;
mq.Formatter = new System.Messaging.XmlMessageFormatter
(new String[] {"System.String,mscorlib"});
Message message = mq.EndReceive(asyncResult.AsyncResult);
if (((String)message.Body).Length > 0)
{
char key = ((String)message.Body)[0];
ArrayList destinations = (ArrayList)routingTable[key];
foreach (MessageQueue destination in destinations)
{
destination.Send(message);
Console.WriteLine("sending message " + message.Body +
" to " + destination.Path);
// "Отправка сообщения в очередь".
} }
mq.BeginReceive();
// Формат управляющего сообщения:
// XYZ:имя_очереди в одной строке.
protected void OnControlMessage(Object source,
ReceiveCompletedEventArgs asyncResult)
{
MessageQueue mq = (MessageQueue)source;
mq.Formatter = new System.Messaging.XmlMessageFormatter
(new String[] {"System.String,mscorlib"});
Message message = mq.EndReceive(asyncResult.AsyncResult);
String text = ((String)message.Body);
String [] split = (text.Split(new char[] 2) ) ;
if (split.Length == 2)
{
char[] keys = split[0].ToCharArray();
String queueName = split [1];
MessageQueue queue = FindQueue(queueName);
foreach (char c in keys)
Список получателей (Recipient List)
273
{
if (!routingTable.Contains(c))
{
routingTable.Add(c, new ArrayList());
}
( (ArrayList) (routingTable [c] ) ) .Add(queue)
Console.WriteLine("Subscribed queue " + queueName +
" for message " + c);
// "Подписан на очередь для сообщения".
}
}
mq.BeginReceive();
}
protected MessageQueue FindQueue(string queueName)
{
if (!MessageQueue.Exists(queueName))
{
return MessageQueue.Create(queueName);
}
else
return new MessageQueue(queueName);
} 1
В классе DynamicRecipientList применяется более интеллектуальный (читай:
“более сложный”) способ хранения настроек получателей. Чтобы оптимизировать обра-
ботку входящих сообщений, DynamicRecipientList ведет таблицу HashTable, в кото-
рой в качестве ключа применяется первая буква входящего сообщения. В отличие от
примера для динамического маршрутизатора (Dynamic Router, с. 259), в таблице
HashTable каждому ключу соответствует не единственная очередь назначения, а массив
всех очередей, подписанных на сообщения заданного типа. Когда Dynamic-
RecipientList получает сообщение, он извлекает из таблицы HashTable список оче-
редей назначения, а затем прокручивает список, чтобы разослать в каждую очередь по
одной копии сообщения.
В настоящем примере не использовалась очередь dunnoQueue, предназначенная для
обработки входящих сообщений, которые не соответствуют ни одному критерию (как это
было в примере для маршрутизатора на основе содержимого (Content-Based Router, с. 247)
или динамического маршрутизатора). Это связано с тем, что список получателей обычно
не рассматривает нулевое число получателей сообщения как ошибку.
В примере, показанном выше, получатели не мотут отписываться от приема сообще-
ний. В нем также не отслеживается повторяющаяся подписка. К примеру, если получа-
тель дважды подпишется на один и тот же тип сообщения, он будет получать по две ко-
пии сообщения. Такое поведение отличается от обычной семантики публикации-
подписки, в которой получатель может подписаться на каждый конкретный канал только
один раз. При желании класс DynamicRecipientList легко изменить, чтобы запретить
повторяющуюся подписку.
274
Глава?. Маршрутизация сообщений
Разветвитель (Splitter)
□
□
Сообщения, проходящие сквозь интеграционное решение, часто состоят из несколь-
ких элементов. К примеру, заказ, размещенный клиентом, обычно включает в себя не-
сколько видов продукции. Как подчеркивалось в описании шаблона маршрутизатор на
основе содержимого (Content-Based Router, с. 247), каждый вид товара может фигурировать
в отдельной системе управления складскими запасами. Необходимо придумать такой
способ обработки заказа, чтобы каждый входящий в него элемент обрабатывался на ин-
дивидуальной основе.
Как организовать обработку сообщения, если оно содержит несколько элемен-
тов, каждый из которых должен обрабатываться по-своему?
Решение описанной проблемы должно быть достаточно универсальным, чтобы оно
подходило для работы с различными типами и количеством элементов. Например, заказ
может состоять из любого числа пунктов, поэтому будущее решение не должно ориенти-
роваться на фиксированный размер заказа. Не следует делать слишком много предполо-
жений и о том, какие типы элементов могут встречаться в сообщении. Так, если компа-
ния “Приборы и устройства” завтра начнет продавать книги, нам понадобится миними-
зировать влияние переориентации производства на общее решение.
Помимо всего прочего, необходимо сохранить контроль над элементами заказа и из-
бежать повторной обработки или потери данных. К примеру, с помощью канала
“публикация-подписка” (Publish-Subscribe Channel, с. 134) заказ можно разослать во все
системы управления складскими запасами, чтобы каждая из них сама выбирала элемен-
ты, которые может обработать. Этот подход обладает тем же недостатком, который упо-
минался при рассмотрении маршрутизатора на основе содержимого', элемент заказа
может быть по ошибке обработан несколько раз или не обработан вообще.
Наконец, будущее решение должно эффективно использовать сетевые ресурсы.
Отправка заказа целиком в каждую складскую систему с тем, чтобы та обработала лишь
его небольшую часть, может привести к ненужному возрастанию объема трафика сооб-
щений, особенно если число пунктов назначения увеличится.
Чтобы не отправлять целое сообщение много раз, его можно разбить на несколько не-
больших сообщений по числу систем управления складскими запасами. Каждое из таких
сообщений будет содержать только те пункты заказа, которые могут быть обработаны
конкретной системой. Это во многом напоминает концепцию маршрутизатора на основе
содержимого за исключением того, что сообщение разбивается на части, после чего каж-
дая из них подвергается маршрутизации, как самостоятельное сообщение. Описанный
подход достаточно эффективен, но привязывает решение к знанию о конкретных типах
элементов и соответствующих пунктах назначения. Что если системе понадобится сме-
нить правила маршрутизации? Это приведет к необходимости модифицировать услож-
нившийся “маршрутизатор элементов”. В предыдущих главах книги мы применяли ар-
Разветвитель (Splitter)
275
хитектуру каналов и фильтров (Pipes and Filters, с. 102), чтобы разбить процедуру обработ-
ки на четко определенные, хорошо компонуемые этапы. Почему бы не задействовать
преимущества этой архитектуры и здесь?
Используйте разветвитель (Splitter), чтобы разбить сложное сообщение на не-
сколько небольших сообщений. Каждое из них будет содержать данные, касаю-
щиеся отдельного элемента исходного сообщения.
Для каждого элемента (или подмножества элементов) входящего сообщения развет-
витель публикует по одному отдельному сообщению. Во многих случаях желательно,
чтобы в каждом из полученных сообщений повторялись некоторые общие элементы
данных. Это необходимо для того, чтобы каждое дочернее сообщение стало самодоста-
точным и могло обрабатываться без сохранения состояния. Кроме того, наличие таких
избыточных элементов впоследствии позволит скомпоновать дочерние сообщения в од-
но. К примеру, в каждом сообщении с информацией об элементе заказа должен содер-
жаться номер заказа, чтобы элемент заказа впоследствии можно было снова сопоставить
с заказом и другими связанными с ним сущностями, например с клиентом, разместив-
шим заказ (рис. 7.8).
Рис. 7.8. Копирование общего элемента данных в каждое из дочерних сообщений
Итеративные разветвители
Как уже упоминалось, во многих системах интеграции корпоративных приложений
данные организованы в виде дерева. Огромное преимущество древовидной структуры за-
ключается в ее рекурсивности. Каждый дочерний узел дерева является корнем некото-
276
Глава?. Маршрутизация сообщений
рого вложенного дерева и т.д. Благодаря этому, в частности, из дерева сообщений можно
извлечь фрагмент и обрабатывать его, как самостоятельное дерево сообщений. Исполь-
зуя деревья сообщений, разветвитель (Splitter) легко настроить так, чтобы он обошел все
дочерние узлы заданного узла и для каждого из них отправил по одному сообщению.
Такая реализация разветвителя будет полностью универсальной, поскольку в ней не де-
лается каких-либо предположений о количестве и типе дочерних элементов. Большинст-
во коммерческих средств интеграции предлагает подобную функциональность под на-
званием итератор (iterator) или синтезатор (sequencer). Поскольку мы во избежание
путаницы стараемся воздерживаться от употребления жаргона производителей, в даль-
нейшем такой вид разветвителя будет называться итеративным.
Статические разветвители
Использование разветвителя (Splitter) отнюдь не ограничивается выделением элемен-
тов заказа. Большое сообщение может быть разбито на более мелкие просто для упроще-
ния обработки. К примеру, ряд В2В-стандартов, описывающих обмен информацией, оп-
ределяют весьма обширные форматы сообщений. Такие раздутые сообщения часто по-
являются в результате коллективного обсуждения стандарта. Что еще печальнее,
огромные фрагменты таких сообщений почти не используются. В большинстве случаев
такое гигантское сообщение удобно разбить на несколько более мелких, каждое из кото-
рых будет нести в себе порцию данных из исходного сообщения. Это значительно облег-
чает разработку дальнейших преобразований, а также благотворно отражается на работе
сети, потому что полученные небольшие сообщения можно распределять по компонен-
там, которые работают только с частью громадного сообщения. Дочерние сообщения
часто публикуются не в одном общем канале, а в разных, поскольку соответствуют раз-
ным подтипам сообщений. В сценариях такого рода количество дочерних сообщений
обычно является фиксированным, в то время как более универсальный разветвитель
предполагает переменное число элементов сообщения. Чтобы отличить описанный здесь
разветвитель от универсального, назовем его статическим разветвителем. Статический
разветвитель (рис. 7.9) функционально эквивалентен широковещательному каналу,
за которым следует набор фильтров содержимого (Content Filter, с. 354).
Рис. 7.9. Статический разветвитель разбивает большое сообщение на фиксированное
число более мелких сообщений
Разветвитель (Splitter)
277
Упорядоченные или неупорядоченные дочерние сообщения
В некоторых случаях дочерним сообщениям удобно присвоить порядковые номера.
Это облегчает отслеживание сообщений и упрощает работу агрегатора (Aggregator, с. 283).
Кроме того, в каждое дочернее сообщение имеет смысл включить ссылку на исходное
(комбинированное) сообщение, чтобы результат обработки отдельных сообщений можно
было сопоставить с исходным сообщением. Такая ссылка будет выступать в роли иден-
тификатора корреляции (Correlation Identifier, с. 186).
Если сообщения перед отправкой упаковываются в конверты (см. шаблон оболочка
конверта (Envelope Wrapper, с. 342)), каждому дочернему сообщению следует предоста-
вить собственный конверт, чтобы оно стало совместимым с инфраструктурой обмена со-
общениями. К примеру, если в соответствии с требованиями инфраструктуры в заголов-
ке каждого сообщения должна стоять метка времени, необходимо скопировать метку
времени исходного сообщения в заголовок каждого из дочерних сообщений.
Пример: разбивка заказа, представленного XML-документом (С#)
Многие системы обмена сообщениями работают с форматом XML. Предположим, что
входящее сообщение с заказом выглядит следующим образом.
corders
<dates7/18/2002</dates
<ordernunibers3825968</ordernumbers
<customer>
<ids!2345</ids
cnamesJoe Doe</name>
</customers
corderitemss
<items
<quantitys3.0</quantitys
<itemnosW1234</itemnos
<descriptionsA Widgetc/descriptions
</items
<items
<quantitys2.0</quantitys
<itemnosG2345</itemnos
<descriptionsA Gadgetc/descriptions
</items
</orderiternss
</orders
С помощью разветвителя (Splitter) заказ необходимо разбить на отдельные элементы.
В нашем примере разветвитель должен сгенерировать два таких сообщения.
corderitems
<dates7/18/2002</dates
< orde rnumbe rs3825968</ordernumbers
<customeridsl2345</customerids
<quantitys3.0</quantitys
<itemnosW1234</itemnos
<descriptionsA Widgetc/descriptions
278
Глава 7. Маршрутизация сообщений
</orderitem>
<orderitem>
<date>7/18/2002</date>
< or de rnumbe r > 3 8 2 5 9 6 8 </orde rnumbe r >
<customerid>12345</customerid>
<quantity>2.0</quantity>
<itemno>G2345</itemno>
<description>A Gadget</description>
</orderitem>
К каждому сообщению orderitem добавляется дата заказа, номер заказа, а также
идентификатор клиента. Все эти сведения берутся из исходного сообщения с заказом.
Добавление к новым сообщениям идентификатора клиента и даты заказа делает каждое
из этих сообщений самодостаточным и избавляет потребителя сообщений от необходи-
мости сохранять контекст при переходе от одного сообщения к другому. Это важно, если
сообщения должны обрабатываться серверами, не поддерживающими сохранение
состояния. Поле ordernumber добавляется для того, чтобы впоследствии элементы зака-
за можно было снова скомпоновать в единое целое (см. шаблон агрегатор — Aggregator,
с. 283). В этом примере мы исходим из предположения, что для выполнения заказа поря-
док его элементов не играет роли, поэтому включать в дочерние сообщения номера эле-
ментов не требуется.
Вот как выглядит код разветвителя на языке С#.
class XMLSplitter
{
protected MessageQueue inQueue;
protected MessageQueue outQueue;
public XMLSplitter(MessageQueue inQueue,
MessageQueue outQueue)
{
this.inQueue = inQueue;
this.outQueue = outQueue;
inQueue.ReceiveCompleted +=
new ReceiveCompletedEventHandler(OnMessage);
inQueue. BeginReceive () ,-
outQueue.Formatter = new ActiveXMessageFormatter();
protected void OnMessage(Object source,
ReceiveCompletedEventArgs asyncResult)
{
MessageQueue mq = (MessageQueue)source;
mq.Formatter = new ActiveXMessageFormatter();
Message message = mq.EndReceive(asyncResult.AsyncResult);
XmlDocument doc = new XmlDocument();
doc.LoadXml((String)message.Body);
Разветвитель (Splitter)
279
XmlNodeList nodeList;
XmlElement root = doc.DocumentElement;
XmlNode date = root.SelectSingleNode("date");
XmlNode ordernumber = root.SelectSingleNode("ordernumber");
XmlNode id = root.SelectSingleNode("customer/id");
XmlElement customerid = doc.CreateElement("customerid") ;
customerid.InnerText = id.InnerXml;
nodeList = root.SelectNodes("/order/orderitems/item");
foreach (XmlNode item in nodeList)
{
XmlDocument orderltemDoc = new XmlDocument();
orderltemDoc.LoadXml("corderitem/>");
XmlElement orderitem = orderltemDoc.DocumentElement;
orderitem.AppendChild(orderltemDoc.ImportNode(date,
true));
orderitem.AppendChild(orderltemDoc.
ImportNode(ordernumber, true));
orderitem.AppendChild(orderltemDoc.
ImportNode(customerid, true));
for (int i=0; i < item.ChildNodes.Count; i++)
{
orderitem.AppendChild(orderltemDoc.
ImportNode(item.ChildNodes[i], true));
outQueue.Send(orderitem.OuterXml);
}
mq.BeginReceive();
Большая часть кода, приведенного выше, касается обработки XML. Класс
XMLSplitter использует ту же структуру событийно управляемого потребителя (Event-
Driven Consumer, с. 511), которая применялась в предыдущих примерах. Каждое входящее
сообщение инициирует вызов метода OnMessage, преобразующего тело сообщения в до-
кумент XML. Дальнейшие манипуляции выглядят следующим образом: метод
OnMessage извлекает из документа с заказом необходимые значения, после чего прохо-
дит по всем вложенным элементам <item>. Для прокрутки элементов <item> применя-
ется выражение XPath вида /order/orderitems/item. Простое выражение XPath очень
похоже на путь к файлу — оно спускается по дереву документа, последовательно находя
элементы, заданные в выражении. Для каждого элемента <item> создается новый доку-
мент XML, в который копируются поля, извлеченные из заказа и вложенных элементов
данного элемента <item>.
280
Глава?. Маршрутизация сообщений
Пример: разбивка заказа, представленного XML-документом (C# и XSL)
Вовсе не обязательно манипулировать узлами и элементами XML вручную. Вместо этого
можно создать документ XSL, который будет преобразовывать XML-документ в желае-
мый формат и затем создавать на его основе исходящие сообщения. Такое решение на-
много легче поддерживать, если предполагается, что формат документа может изменить-
ся. Все, что придется сделать, — модифицировать преобразование XSL; код C# трогать
не придется.
Реализация, показанная ниже, использует метод Transform класса XslTransform,
чтобы преобразовать входящий документ в промежуточный формат. В промежуточном
документе каждому из будущих сообщений с элементами заказа будет соответствовать по
одному дочернему элементу orderitem. Код C# просто проходит по всем дочерним эле-
ментам и для каждого из них публикует по одному сообщению.
class XSLSplitter
{
protected MessageQueue inQueue;
protected MessageQueue outQueue;
protected String stylesheet = "...\\0rder20rderItem.xsl";
protected XslTransform xslt;
public XSLSplitter(MessageQueue inQueue,
MessageQueue outQueue)
{
this.inQueue = inQueue;
this.outQueue = outQueue;
xslt = new XslTransform();
xslt.Load(stylesheet, null);
outQueue.Formatter = new ActiveXMessageFormatter();
inQueue. ReceiveCompleted += new
ReceiveCompletedEventHandler(OnMessage);
inQueue.BeginReceive();
}
protected void OnMessage(Object source,
ReceiveCompletedEventArgs asyncResult)
{
MessageQueue mq = (MessageQueue)source;
mq.Formatter = new ActiveXMessageFormatter();
Message message = mg.EndReceive(asyncResult.AsyncResult);
try
{
XPathDocument doc = new XPathDocument
(new StringReader((String)message.Body));
XmlReader reader = xslt.Transform(doc, null,
new XmlUrlResolver());
XmlDocument allltems = new XmlDocument();
Разветвитель (Splitter)
281
allltems.Load(reader);
XmlNodeList nodeList = allltems.DocumentElement.
GetElementsByTagName("orderitem");
foreach (XmlNode orderitem in nodeList)
{
outQueue.Send(orderItern.OuterXml);
}
}
catch (Exception e) { Console.WriteLine(e.ToString()); }
mq.BeginReceive();
}
}
Чтобы облегчить редактирование и тестирование документа XSL, он будет считывать-
ся из отдельного файла. Наличие последнего также позволяет менять поведение развет-
вителя без необходимости заново компилировать код.
<xsl:stylesheet version="l.О"
xmlns:xs1="http://www.w3.org/1999/XSL/Trans form">
<xsl:output method="xml" version="l.0" encoding="UTF-8"
indent="yes"/>
<xsl:template match="/order">
corderitems»
<xsl:apply-templates select="orderitems/item"/>
</orderiterns>
</xsl:template>
<xsl:template match="item">
<orderitem>
<date>
<xsl:value-of
select="parent::node()/parent::node()/date"/>
</date>
<ordernumber>
<xsl:value-of
select="parent::node()/parent::node()/ordernumber"/»
<I ordernumber>
<customerid>
<xsl:value-of
select="parent::node()/parent::node()/customer/id"/>
</customerid>
<xsl:apply-templates select="*"/>
</orderitem>
</xsl:template»
<xs1:template match="*">
<xsl:copy»
<xsl:apply-templates select="@* | node()"/>
</xsl:copy>
</xsl:template»
</xsl -.stylesheet
282
Глава 7. Маршрутизация сообщений
XSL — это декларативный язык. Чтобы понимать его, необходимо самому написать
хотя бы пару документов XSL или прочитать хорошую книгу, например [40]. Преобразо-
вание XSL, код которого показан выше, находит в документе XML все вхождения эле-
мента order (в нашем примере такой элемент один). Найдя указанный элемент, XSL
создает корневой элемент для нового исходящего документа (документы XML должны
иметь только один корневой элемент) и начинает обрабатывать все элементы item, най-
денные им внутри элемента orderitems. Для каждого из обнаруженных элементов item
создается новый “шаблон”. Он копирует элементы date, ordernumber и customerid из
элемента order (находящегося на два уровня выше элемента item) и присоединяет к
ним все остальные элементы, вложенные в item. В результате преобразования каждому
элементу item исходного документа будет соответствовать по одному элементу
order item нового документа. Благодаря этому коду C# будет легче просматривать эле-
менты заказа и публиковать их в виде отдельных сообщений.
Чтобы сравнить производительность обеих реализаций, мы решили провести не-
большой тест. Для этого мы опубликовали во входящей очереди 5000 сообщений с зака-
зами, запустили разветвитель и измерили, сколько времени ему потребовалось, чтобы
отправить 10 000 сообщений с элементами заказов в исходящую очередь. Все указанные
действия выполнялись в рамках одной программы на единственном компьютере с ис-
пользованием локальных очередей сообщений. У класса XMLSplitter на выполнение
теста ушло 7 секунд, а у разветвителя на основе XSL — 5,3 секунды. Для сравнения: про-
цессор, который просто потребляет сообщение из входящей очереди и публикует два
точно таких же сообщения в исходящей очереди, обработал 5000 сообщений примерно за
2 секунды. Это время (назовем его базисным) включает в себя потребление процессором
5000 сообщений из входящей очереди, а также потребление средствами тестирования
10 000 сообщений, опубликованных процессором. Выходит, что манипуляции заказом с
применением XSL выполняются немного быстрее, чем перенос элементов из входящего
сообщения в исходящие “вручную” (если вычесть базисное время, вторая реализация
окажется примерно на 35% быстрее первой). Разумеется, и ту, и другую программы мож-
но усовершенствовать для достижения максимальной производительности, но было ин-
тересно сравнить их выполнение, что называется, “плечом к плечу”.
Агрегатор (Aggregator)
283
Агрегатор (Aggregator)
О
о
Разветвитель {Splitter, с. 274) удобно применять, чтобы разбить одно сообшение
на несколько более мелких, каждое из которых должно обрабатываться отдельно. Список
получателей (Recipient List, с. 264) или канал ‘‘публикация-подписка” (Publish-Subscribe
Channel, с. 134) незаменим, когда сообщение с запросом необходимо одновременно на-
править ряду получателей, чтобы затем иметь возможность выбрать один из нескольких
ответов. В большинстве сценариев такого рода дальнейшие действия зависят от успеш-
ной обработки вспомогательных сообщений, к примеру, если из предложений несколь-
ких поставщиков требуется выбрать предложение с самой низкой ценой или же если кли-
енту необходимо выставить счет за заказ только после того, как все элементы заказа будут
взяты со склада.
Как скомбинировать содержимое разных, но связанных между собой сообщений,
чтобы полученный результат можно было обрабатывать, как единое целое?
Асинхронный характер обмена сообщениями затрудняет сбор информации из не-
скольких сообщений. Сколько сообщений необходимо обработать? Если сообщение рас-
сылается по широковещательному каналу, системе не всегда известно, сколько получате-
лей прослушивают канал, а следовательно, сколько ответов следует ожидать.
Даже если воспользоваться разветвителем, сообщения с ответами могут прибывать
не в том порядке, в котором они были созданы. Поскольку вспомогательные сообщения
могут перемещаться по разным маршрутам, инфраструктура обмена сообщениями обыч-
но гарантирует доставку каждого сообщения, но не гарантирует доставку в требуемом
порядке. Кроме того, вспомогательные сообщения могут обрабатываться разными ком-
понентами с разной скоростью, а следовательно, порядок их доставки будет нарушен.
Более подробное описание этой проблемы приведено в разделе, посвященном шаблону
проектирования преобразователь порядка (Resequencer, с. 297).
Наконец, многие инфраструктуры обмена сообщениями функционируют в таком ре-
жиме, который обеспечивает доставку сообщения требуемому получателю, но не знает,
когда именно это произойдет. Сколько времени следует ожидать сообщение? Если ждать
слишком долго, это приведет к задержке дальнейшей обработки. Если сразу двигаться
дальше, не ожидая недостающее сообщение, необходимо придумать способ работы с не-
полной информацией. Да и как быть, если недостающее сообщение (или сообщения)
все-таки придет? Иногда такое сообщение удается обработать отдельно, но в других слу-
чаях это может привести к повторяющейся обработке. Если же запоздавшее сообщение
будет проигнорировано, это приведет к окончательной потере его содержимого.
Все эти проблемы весьма затрудняют обработку отдельных, но связанных между
собой сообщений.
284
Глава?. Маршрутизация сообщений
Используйте агрегатор {Aggregator) — фильтр с сохранением состояния, кото-
рый собирает и сохраняет отдельные сообщения, пока не получит полный набор
связанных между собой сообщений. После этого агрегатор составляет на их ос-
нове единое сообщение и публикует его для дальнейшей обработки.
Элемент Элемент Элемент
заказа 1 заказа 2 заказа 3
Агрегатор
Сообщение об
обработке заказа
Агрегатор представляет собой особый фильтр из архитектуры каналов и фильтров
(Pipes and Filters, с. 102), который получает поток сообщений и выявляет сообщения, кор-
релирующие друг с другом. Собрав полный набор связанных между собой сообщений
(о том, как определять полноту набора, будет рассказано немного позже), агрегатор из-
влекает из них информацию и публикует в исходящем канале единое, агрегированное
сообщение.
В отличие от большинства предыдущих шаблонов маршрутизации, агрегатор является
компонентом с сохранением состояния (stateful). Простые шаблоны маршрутизации наподо-
бие маршрутизатора на основе содержимого (Content-Based Router, с. 247) часто функциони-
руют без сохранения состояния (stateless). Такие компоненты обрабатывают входящие сооб-
щения одно за другим, не сохраняя какую-либо информацию в промежутках между их по-
ступлением. После обработки сообщения компонент находится в том же состоянии,
в котором пребывал до обработки. Агрегатор не может функционировать без сохранения
состояния, потому что должен сохранять каждое входящее сообщение, пока не получит все
связанные между собой сообщения. После этого он должен скомпоновать информацию из
всех указанных сообщений в агрегированное сообщение. Отметим, что агрегатору не обяза-
тельно хранить каждое входящее сообщение целиком. К примеру, если речь идет о предло-
жениях на аукционе, достаточно хранить лишь предложение с самой лучшей на текущий
момент ценой и соответствующий идентификатор участника торгов. Несмотря на это агре-
гатор все равно должен хранить некоторую информацию в промежутке между поступлени-
ем сообщений, значит, он работает с сохранением состояния.
Разрабатывая агрегатор, необходимо позаботиться о следующих аспектах.
1. Корреляция. Какие входящие сообщения связаны друг с другом?
2. Условие полноты. Когда агрегатор готов опубликовать итоговое сообщение?
3. Алгоритм агрегации. Как скомпоновать полученные сообщения в одно итоговое
сообщение?
Агрегатор (Aggregator)
285
Корреляция обычно достигается проверкой типа входящих сообщений или использо-
ванием явного идентификатора корреляции (Correlation Identifier, с. 186). Основные вари-
анты условий полноты и алгоритмов агрегации будут перечислены в разделе, посвящен-
ном стратегиям агрегации.
Детали реализации
В силу событийно управляемого характера системы обмена сообщениями агрегатор
(Aggregator) может получать связанные между собой сообщения в любое время и в произ-
вольном порядке. Чтобы правильно распределять входящие сообщения по группам свя-
занных между собой сообщений, агрегатор ведет список активных агрегатов, т.е. агрега-
тов, для которых уже были получены какие-либо сообщения. Когда агрегатор получает
новое сообщение, он проверяет, не является ли оно частью существующего агрегата.
Если для указанного сообщения не нашлось подходящего агрегата, агрегатор предпола-
гает, что данное сообщение является первым из некоторого набора сообщений и создает
для него новый агрегат. После этого сообщение добавляется к новому агрегату. Если же
агрегат существует, сообщение просто добавляется к найденному агрегату.
Добавив к агрегату новое сообщение, агрегатор проверяет условие его полноты. Если
оно оказывается истинным, то из сообщений, накопленных в агрегате, извлекается ин-
формация, на ее основе формируется итоговое Сообщение, после чего оно публикуется в
исходящем канале. Если же условие полноты ложно, итоговое сообщение не формирует-
ся и агрегат остается активным, ожидая поступления дополнительных сообщений.
Описанная стратегия проиллюстрирована нд рис. 7.10. В этом простом примере вхо-
дящие сообщения связываются друг с другом с помощью идентификатора корреляции
(Correlation Identifier, с. 186). Когда на вход агрегатора поступает первое сообщение
с идентификатором корреляции 100, тот инициализирует новый агрегат и помещает в него
полученное сообщение. В нашем примере для Достижения полноты агрегату необходимо
собрать как минимум три сообщения, поэтому текущий агрегат еще не является полным.
Получив второе сообщение с идентификатором корреляции 100, агрегатор добавляет его к
уже существующему агрегату. Опять-таки, агрегат еще не полон. В третьем сообщении
содержится другой идентификатор корреляции, а именно 101. Для него создается новый,
собственный агрегат. Четвертое сообщение имеет идентификатор корреляции 100, следо-
вательно, относится к первому агрегату. Когда оно будет помещено в агрегат, число со-
общений в агрегате станет равно трем, а значит, условие полноты будет достигнуто.
Агрегатор формирует итоговое сообщение, помечает указанный агрегат как полный
и публикует итоговое сообщение в исходящем кд нале.
Стратегия, описанная выше, предусматривает- создание нового агрегата каждый раз при
поступлении сообщения, которое не может быть сопоставлено с существующим агрегатом.
Таким образом, агрегатору не нужно иметь предварительных знаний об агрегатах, которые
могут быть им сгенерированы. Назовем такой агрегатор самозапускающимся.
В зависимости от выбранной стратегии агрегации возможны ситуации, когда входя-
щее сообщение относится к уже закрытому агрегату — иными словами, когда оно при-
бывает после публикации итогового сообщения. Чтобы для такого сообщения по ошибке
не был создан новый агрегат, агрегатор должен хранить список агрегатов, которые были
закрыты. Чтобы такой список не разросся до бесконечности, его периодически следует
очищать. Необходимо, однако, быть очень внимательным и не удалять из списка закры-
тые агрегаты слишком рано, потому что это моя<ет привести к созданию новых агрегатов
286
Глава 7. Маршрутизация сообщений
для запоздавших и уже ненужных сообщений. Поскольку в списке должен содержаться
не весь агрегат, а лишь сведения о том, что он был закрыт, можно легко организовать
эффективное хранение списка закрытых агрегатов и встроить в алгоритм его очистки
безопасное граничное значение. Наконец, можно воспользоваться шаблоном срок дейст-
вия сообщения (Message Expiration, с. 198), чтобы игнорировать сообщения, прибытие ко-
торых задержалось на чрезмерно долгое время.
Входящие
сообщения
Идентификатор
корреляции
Идентификатор
сообщения
Агрегаты
Исходящие
сообщения
Рис. 7.10. Схема работы агрегата
Для повышения надежности решения в целом агрегатор можно настроить на прослу-
шивание специального управляющего канала, позволяющего вручную очищать все ак-
тивные агрегаты или же только выбранный агрегат. Такое свойство может пригодиться,
чтобы вывести систему из состояния ошибки без необходимости перезапускать агрега-
тор. Аналогичное свойство, позволяющее агрегатору по требованию публиковать в спе-
циальном канале список всех активных агрегатов, может принести немалую пользу
в процессе отладки. Оба упомянутых свойства являются типичными примерами функ-
ций, встраиваемых в шину управления (Control Bus, с. 552).
Стратегии агрегации
Существует множество стратегий, предназначенных для определения полноты агрегата.
Набор доступных стратегий, прежде всего, определяется тем, известно ли, сколько сообще-
ний должно поступить на вход агрегатора (Aggregator). В некоторых случаях агрегатор знает,
сколько вспомогательных сообщений должно прийти, потому что обладает копией исход-
ного составного сообщения или же потому что в каждом из отдельных сообщений указано
их общее число (как было описано в примере разветвителя (Splitter, с. 274)). Наиболее рас-
пространенные стратегии определения полноты выглядят следующим образом.
1. Ожидать всех. Подождать, пока придут все ответы. Этот сценарий лучше всего
подходит для обсуждавшегося ранее примера с заказами. Неполный заказ может
не иметь смысла. По этой причине, если в течение указанного времени ожидания
агрегатор не получит ответы по всем элементам заказа, он должен выдать ошибку.
Агрегатор (Aggregator)
287
Указанный подход наиболее удобен в качестве основы для принятия решений, но
вместе с тем может оказаться самым медленным и уязвимым (не считая того, что
необходимо знать общее количество ожидаемых сообщений). Достаточно пропа-
жи или задержки хотя бы одного сообщения, и дальнейшая обработка всего агре-
гата будет невозможна. Устранение такой ошибки в слабо связанной системе мо-
жет представлять серьезную проблему, потому что асинхронное движение сооб-
щений затрудняет четкое распознавание условия ошибки (сколько времени
должно пройти прежде, чем сообщение будет объявлено “пропавшим”?). Один из
способов решить проблему с недостающим сообщением — запросить его еще раз.
Однако для этого агрегатору нужно знать источник сообщения, что может при-
вести к появлению дополнительных зависимостей между агрегатором и другими
компонентами.
2. Время ожидания. Подождать ответы некоторое заранее заданное время, по исте-
чении которого принять решение на основе тех сообщений, которые успели при-
быть за это время. Если в течение заданного времени не пришло ни одного ответа,
система может выдать исключение или повторить попытку. Это удобно, если все
входящие ответы оцениваются по некоторой шкале и в качестве итогового ис-
пользуется только сообщение (или небольшая группа сообщений) с самым высо-
ким баллом. Такой подход часто применяется в сценариях-“аукционах”.
3. Первый — лучший. Дождаться самого первого (быстрого) ответа, а все последую-
щие ответы проигнорировать. Это самый быстрый подход, предполагающий, од-
нако, отбрасывание большого объема информации. Он может пригодиться в сце-
нариях с торгами на аукционе или бирже, где время ответа критично.
4. Время ожидания с досрочным завершением. Подождать заданный интервал време-
ни или дождаться первого сообщения с баллом не ниже заданного минимума.
В подобном сценарии агрегатор завершит работу раньше положенного срока, ес-
ли обнаружит очень хороший ответ; в противном случае он будет ждать до оконча-
ния срока. Если по истечении времени ожидания не было выявлено явного победи-
теля, он определяется путем ранжировки всех полученных за это время сообщений.
5. Внешнее событие. Иногда агрегация завершается при возникновении некоторого
внешнего бизнес-события. К примеру, в финансовой индустрии конец операци-
онного дня может сигнализировать об окончании агрегации входящих сообщений
с ценами. Использование фиксированного таймера для такого события снижает
гибкость решения. Кроме того, бизнес-событие, спроектированное в виде сообще-
ния о событии (Event Message, с. 174), позволяет осуществлять центральное управ-
ление системой. Агрегатор может принимать сообщения о событии по специально-
му управляющему каналу или получать особым образом отформатированное
сообщение, указывающее на конец агрегации.
Выбор условия полноты агрегата неразрывно связан с выбором алгоритма агрегации.
Ниже приведено несколько стратегий, применяющихся для компоновки сообщений,
полученных агрегатором, в единое итоговое сообщение.
1. Выбор “лучшего” ответа. Данный подход предполагает наличие единственного
лучшего ответа, например самой низкой цены на один и тот же элемент заказа.
Это позволяет агрегатору принять решение и опубликовать для дальнейшей обра-
288
Глава 7. Маршрутизация сообщений
ботки только "лучшее” сообщение. К сожалению, в реальной жизни критерии
выбора редко имеют такую простую форму. К примеру, выбор лучшего предложе-
ния для заказа товара может зависеть не только от цены, но и от времени достав-
ки, числа единиц товара, имеющихся на складе, списка предпочитаемых постав-
щиков и т.д.
2. Сжатие данных. Агрегатор может применяться для сокращения объема трафика
сообщений, если те слишком интенсивно генерируются источником. В подобных
случаях имеет смысл подсчитать среднее значений, присутствующих в отдельных
сообщениях, или вставить числовые поля из каждого сообщения в общее сообще-
ние. Это удобно, если каждое сообщение соответствует некоторому числовому
значению, например числу полученных заказов.
3. Сбор данных для дальнейшей оценки. Агрегатор не всегда способен самостоятельно
принять решение относительно того, как выбрать лучший ответ. Несмотря на это
его все равно можно использовать для сбора отдельных сообщений и их компо-
новки в единое сообщение. Последнее может представлять собой простое объе-
динение данных из отдельных сообщений. Решение об агрегации в таком случае
будет принято позднее другим компонентом или человеком.
Довольно часто стратегией агрегации можно управлять с помощью параметров.
К примеру, стратегию, предусматривающую ожидание на протяжении заданного проме-
жутка времени, можно настроить на максимальное время ожидания. Аналогичным обра-
зом, если агрегатор должен ждать, пока на вход поступит сообщение со значением выше
некоторого порога, желаемое пороговое значение, скорее всего, будет задано заранее. Ес-
ли указанные параметры допускается настраивать во время выполнения, агрегатор мо-
жет обладать отдельным входящим каналом, по которому будут доставляться управляю-
щие сообщения (например, со значениями параметров). Управляющие сообщения могут
содержать и другую информацию, например ожидаемое число связанных между собой
сообщений, что позволит агрегатору реализовать более эффективные условия полноты.
В подобных сценариях агрегатор не просто автоматически запускает новый агрегат при
получении первого сообщения. Он получает предварительную информацию, относя-
щуюся к ожидаемому набору сообщений. В качестве такой информации может выступать
копия исходного сообщения с запросом (например, сообщение рассылки-сборки {Scatter-
Gather, с. 310)), дополненная необходимыми сведениями о параметрах. После этого аг-
регатор создает новый агрегат и помещает в него сведения о параметрах (рис. 7.11). Когда
на вход агрегатора поступают отдельные сообщения, они сопоставляются с соответст-
вующим агрегатом. Чтобы отличить такой вариант агрегатора от самозапускающегося,
назовем его инициализированным. Такая конфигурация, очевидно, возможна только при
наличии доступа к исходному сообщению, а он есть далеко не всегда.
Агрегатор применяется во многих приложениях. Его часто комбинируют с разветви-
телем или списком получателей {Recipient List, с. 264) для получения составных шаблонов.
Более подробно о них будет рассказано в разделах, посвященных шаблонам обработчик
составного сообщения {Composed Message Processor, с. 307) и рассылка-сборка.
Агрегатор (Aggregator)
289
Агрегированное сообщение
Рис. 7.11. Принцип работы инициализированного агрегатора
Пример: кредитный брокер
В главе 9 кредитный брокер использует агрегатор (Aggregator), чтобы выбрать из ответов,
присланных банками, предложение с самой низкой процентной ставкой. В данном при-
мере применяется инициализированный агрегатор, так как список получателей (Recipient
List, с. 264) заранее информирует его, какое количество сообщений следует ожидать.
В главе 9 приведены примеры реализации агрегатора с помощью Java, C# и TIBCO.
Пример: использование агрегатора для обнаружения пропавших сообщений
Джо Уолнес (Joe Walnes) продемонстрировал нам интересный способ использования аг-
регатора (Aggregator). Его система отправляет сообщения с помощью последовательности
компонентов, которые, к сожалению, не отличаются высокой надежностью. Проблему
не решает даже использование гарантированной доставки (Guaranteed Delivery, с. 149), по-
тому что обычно компоненты отказывают уже после потребления сообщения. Поскольку
они не являются транзакционными клиентами (Transactional Client, с. 498), сообщение,
находящееся в процессе обработки, теряется. Чтобы исправить ситуацию, Джо решил
направлять входящее сообщение по двум параллельным маршрутам: одна копия сообще-
ния проходит через необходимые, но ненадежные компоненты, а другая — в обход ком-
понентов через канал гарантированной доставки. После этого сообщения с двух маршру-
тов попадают на вход агрегатора, как показано на рис. 7.12.
290
Глава 7. Маршрутизация сообщений
Ненадежные компоненты
Агрегатор
Рис. 7.12. Агрегатор с временем ожидания выявляет пропавшие сообщения
Агрегатор использует условие полноты “время ожидания с досрочным завершением”.
Это означает, что агрегатор завершает свою работу либо по истечении времени ожида-
ния, либо если получит оба связанных между собой сообщения. Алгоритм агрегации за-
висит от того, какое из условий будет выполнено первым. Если агрегатор получает оба
сообщения, обработанное сообщение передается дальше без каких-либо изменений.
Если же заканчивается время ожидания, значит, один из компонентов дал сбой и “съел”
сообщение. В этом случае агрегатор публикует сообщение об ошибке, уведомляя опера-
торов о том, что какой-то компонент вышел из строя. К сожалению, указанные компо-
ненты приходится перезапускать вручную, но в более интеллектуальной конфигурации
система могла бы автоматически перезапускать компоненты и повторно отправлять по-
терявшиеся сообщения.
Пример: агрегатор (JMS)
Ниже приведен пример реализации агрегатора (Aggregator) с использованием интер-
фейса API JMS. Агрегатор получает от поставщиков сообщения с предложениями цены
на элементы заказа по одному каналу, агрегирует все сообщения, касающиеся конкрет-
ного элемента заказа, и публикует сообщение с самой низкой ценой в другом канале.
Для корреляции предложений используется свойство AuctioniD (номер аукциона), вы-
ступающее в роли идентификатора корреляции (Correlation Identifier, с. 186) для сообще-
ний. Стратегия агрегации состоит в том, чтобы получить минимум три предложения.
Агрегатор является самозапускающимся и не требует внешней инициализации (рис. 7.13).
Результат аукциона
□◄-О
О
Сообщения с предложением цены
Номер аукциона: 123
Вендор: ЗАО “Лидер"
Цена: 1,56
Агрегатор
Номер аукциона: 123
Вендор: НПО “Приборы"
Цена: 1,65
Номер аукциона: 123
Вендор: ЗАО “Лидер"
Цена: 1.56
номер аукциона: 123
Вендор: НПО “Устройства”
Цена: 1.83
Рис. 7.13. Агрегатор выбирает предложение с самой низкой ценой
Агрегатор (Aggregator)
291
Решение включает в себя следующие классы (рис. 7.14).
1. Класс Aggregator содержит логику, описывающую получение сообщений, их аг-
регацию и отправку итоговых сообщений. Взаимодействует с агрегатами через ин-
герфейс Agg-rega te.
2. Класс AuctionAggregate реализует интерфейс Aggregate. Указанный класс
выступает в качестве адаптера (Adapter, см. [12]) между интерфейсом Aggregate
и классом Auction. Такая конструкция позволяет избавить класс Auction от
ссылок на интерфейс API JMS.
3. Класс Auction содержит коллекцию полученных предложений, касающихся од-
ного и того же элемента заказа. Класс Auction реализует стратегию агрегации,
например Поиск самого выгодного предложения и определение полноты агрегата.
4. Класс Bid — это вспомогательный класс, в котором хранятся данные, относя-
щиеся к предложению поставщика. Данные входящего сообщения преобразуются
в объект Bid, чтобы к ним можно было осуществлять доступ через сильно типи-
зированный интерфейс. Это позволяет сделать логику класса Auction полностью
независимой от интерфейса API JMS.
Рис. 7.14. Диаграмма классов дм агрегатора-аукциона
В основе решения лежит класс Aggregator. Он должен включать в себя два JMS-
объекта Destination: один для входящего канала, а другой— для исходящего. Класс
Destination является JMS-абстракцией класса Queue, соответствующего каналу
“точка-точка” (Point-to-Point Channel, с. 131), либо класса Topic, аналогом которого яв-
ляется канал “публикация-подписка” (Publish-Subscribe Channel, с. 134). Наличие такой аб-
стракции позволяет создать код JMS, не зависящий от типа канала. Это очень удобно при
292
Глава?. Маршрутизация сообщений
тестировании или отладке. К примеру, во время тестирования можно использовать темы
публикации-подписки, чтобы легко “прослушивать” трафик сообщений, а при внедре-
нии системы в реальную среду переключиться на очереди.
public class Aggregator implements MessageListener
static final String PROP_CORRID = "AuctionlD";
Map activeAggregates = new HashMap();
Destination inputDest = null;
Destination outputDest = null;
Session session = null;
Messageconsumer in = null;
MessageProducer out = null;
public Aggregator (Destination inputDest,
Destination outputDest, Session session)
this.inputDest = inputDest;
this.outputDest = outputDest;
this, session = session,-
}
public void run()
{
try {
in = session.createConsumer(inputDest);
out = session.createProducer(outputDest);
in.setMessageListener(this);
} catch (Exception e) {
System.out.printin("Exception occurred: " +
e.toString () ) ;
// "Возникло исключение".
public void OnMessage(Message msg)
{
try {
String correlationlD =
msg.getStringProperty(PROP_CORRID);
Aggregate aggregate =
(Aggregate)activeAggregates.get(correlationlD);
if (aggregate == null) {
aggregate = new AuctionAggregate(session);
activeAggregates.put(correlationlD, aggregate);
}
//--- игнорировать сообщение, если агрегат уже закрыт.
if (!aggregate.isCompleteО) {
aggregate.addMessage(msg);
if (aggregate.isComplete()) {
MapMessage result =
Агрегатор (Aggregator)
293
(MapMessage)aggregate.getResultMessage();
out.send(result);
}
}
} catch (JMSException e) {
System.out.printin("Exception occurred: " +
e.toString());
// "Возникло исключение".
}
}
}
Класс Aggregator является событийно управляемым потребителем (Event-Driven
Consumer, с. 511) и реализует интерфейс MessageListener, а значит, должен реализовать
метод onMessage. Поскольку Aggregator слушает канал сообщений для потребителя
Messageconsumer, каждый раз, когда в пункт назначения потребителя прибывает новое
сообщение, JMS вызывает метод onMessage. Получив входящее сообщение, Aggre-
gator извлекает из него идентификатор корреляции (хранится как свойство сообщения)
и проверяет, существует ли для этого идентификатора агрегат. Если такового не обнару-
жилось, Aggregator создает новый экземпляр класса AuctionAggregate. После этого
Aggregator проверяет, является ли текущий агрегат по-прежнему активным (т.е. не по-
лон ли он). Если агрегат больше не активен, входящее сообщение отбрасывается. Если
же агрегат активен, Aggregator добавляет к нему сообщение и проверяет, не выполнено
ли условие полноты. Если это так, Aggregator извлекает из агрегата сообщение о самом
выгодном предложении цены и публикует его.
Код класса Aggregator носит весьма общий, универсальный характер. Зависимость
от данного конкретного примера присутствует только в двух строках кода. В первой из
них агрегатор предполагает, что идентификатор корреляции хранится в свойстве объекта
сообщения AuctionlD. Вторая строка — это создание экземпляра класса Auction-
Aggregate. Чтобы избежать этой ссылки, можно было бы воспользоваться фабрикой,
которая возвращает объект типа Aggregate и создает внутри себя экземпляр класса
AuctionAggregate. Поскольку наша книга посвящена интеграции корпоративных при-
ложений, а вовсе не объектно-ориентированному проектированию, мы решили не ус-
ложнять пример и оставить зависимость в покое.
Класс AuctionAggregate содержит реализацию интерфейса Aggregate. Сам ин-
терфейс довольно прост и включает в себя объявления лишь трех методов: добавление
сообщения (addMessage), определение полноты агрегата (isComplete) и получение
лучшего результата (getBestMessage).
public interface Aggregate {
public void addMessage(Message message);
public boolean isComplete();
public Message getResultMessage();
}
Вместо того чтобы внедрять стратегию агрегации в класс AuctionAggregate, мы ре-
шили создать отдельный класс Auction, реализующий стратегию агрегации, но не зави-
сящий от API JMS.
294
Глава?. Маршрутизация сообщений
public class Auction
ArrayList bids = new ArrayList();
public void addBid(Bid bid)
{
bids.add(bid);
System.out.printin(bids.size() + " Bids in auction.");
}
public boolean isCompleteO
{
return (bids.size() >= 3);
}
public Bid getBestBidO
{
Bid bestBid = null;
Iterator iter = bids.iterator();
if (iter.hasNext())
bestBid = (Bid) iter.next();
while (iter.hasNext()) {
Bid b = (Bid) iter.nextO;
if (b.getPrice() < bestBid.getPrice()) {
bestBid = b;
return bestBid;
Структура класса Auction довольно проста. Класс включает в себя три метода, ана-
логичные тем, которые объявлены в рамках интерфейса Aggregate, но сигнатуры мето-
дов отличаются — вместо класса Message, специфичного для JMS, в них используется
сильно типизированный класс Bid. В нашем примере условие полноты очень простое —
агрегатор просто ожидает три сообщения. Между тем, отделив стратегию агрегации от
класса AuctionAggregate и интерфейса API JMS, можно легко усовершенствовать
класс Auction, внедрив в него более интеллектуальную логику.
Как уже говорилось, класс AuctionAggregate выступает в качестве адаптера между
интерфейсом Aggregate и классом Auction. Адаптер — это класс, преобразующий ин-
терфейс некоторого класса в другой интерфейс.
public class AuctionAggregate implements Aggregate {
static String PROP_AUCTIONID = "AuctionlD";
static String ITEMID = "ItemID";
static String VENDOR = "Vendor";
static String PRICE = "Price";
private Session session;
private Auction auction;
Агрегатор (Aggregator)
295
public AuctionAggregate(Session session)
this, session = session-
auction = new Auctionf);
}
public void addMessage(Message message) {
Bid bid = null;
if (message instanceof MapMessage) {
try {
MapMessage mapmsg = (MapMessage)message;
String auctionlD =
mapmsg.getStringProperty(PROP_AUCTIONID);
String itemID = mapmsg.getString(ITEMID);
String vendor = mapmsg.getString(VENDOR);
double price = mapmsg.getDouble(PRICE);
bid = new Bid(auctionlD, itemID, vendor, price);
auction.addBid(bid);
} catch (JMSException e) {
System.out.println(e.getMessage());
public boolean isComplete()
{
return auction.isComplete();
}
public Message getResultMessage() {
Bid bid = auction.getBestBidO;
try {
MapMessage msg = session.createMapMessage();
msg.setStringProperty(PROP—AUCTIONID,
bid.getCorrelationlDO);
msg.setstring(ITEMID, bid.getltemlD());
msg.setstring(VENDOR, bid.getVendorName());
msg.setDouble(PRICE, bid.getPrice());
return msg;
} catch (JMSException e) {
System.out.println("Could not create message: " +
e.getMessage());
// "Невозможно создать сообщение".
return null;
}
}
Взаимодействие между классами приложения проиллюстрировано на рис. 7.15.
296
Глава?. Маршрутизация сообщений
Рис. 7.15. Циклограмма агрегатора-аукциона
В нашем примере для простоты предполагается, что номера аукционов глобально
уникальны. Это позволяет нам не заботиться об очистке списка открытых аукционов —
он постоянно растет. В реальном приложении во избежание утечки памяти список аук-
ционов следовало бы периодически очищать.
Поскольку код, приведенный выше, ссылается только на объект Destination, его
можно запускать как с темами (Topic), так и с очередями сообщений (Queue). В реаль-
ной среде такое приложение, скорее всего, применялось бы в сочетании с каналом
“точка-точка” (аналог объекта Queue в JMS), поскольку у предложений поставщиков
был бы только один получатель, а именно — агрегатор. Как описывается в разделе, по-
священном каналу “публикация-подписка”, использование темы может упростить тести-
рование и отладку. К теме легко добавить дополнительного слушателя, не влияя на поток
сообщений. Отлаживая приложение, основанное на обмене сообщениями, часто удобно
запустить отдельное окно слушателя. В нем будут отслеживаться все сообщения, кото-
рыми обмениваются участники. Во многих реализациях JMS в именах тем разрешается
использовать символы подстановки. В этом случае, чтобы подписаться на все темы, слу-
шателю достаточно задать в качестве имени темы символ *. Отладчику очень удобно
пользоваться простым слушателем, который отображает все сообщения, отосланные в
рамках темы, а также заносит сведения о них в файл для дальнейшего анализа.
Преобразователь порядка (Resequencer)
297
Преобразователь порядка (Resequencer)
Маршрутизатор сообщений (Message Router, с. 109) считывает сообщения из входящего
канала и распределяет их по разным исходящим каналам, основываясь на содержимом
сообщений или других критериях. Поскольку сообщения перемещаются по различным
маршрутам, одни из них могут пройти через свои этапы обработки быстрее других, в ре-
зультате чего порядок следования сообщений будет нарушен. Между тем для дальнейшей
обработки часто требуется, чтобы сообщения поступали в исходном порядке (к примеру,
для поддержания целостности данных).
Как упорядочить поток связанных между собой сообщений, если они были дос-
тавлены не в той последовательности, в которой отправлены?
Очевидно, что для решения проблемы с нарушением порядка сообщений последний
необходимо сохранять с самого начала. Поддерживать порядок гораздо проще, нежели
пытаться упорядочить смешанные сообщения. Именно по этой причине в университет-
ских библиотеках читателям часто запрещают самим ставить книги обратно на полки.
Если централизованно контролировать процесс возврата книг на полки, правильный по-
рядок будет гарантирован всегда или почти всегда. К сожалению, в асинхронной системе
обмена сообщениями поддерживать порядок не легче, чем в комнате подростка, пусть
это и более эффективный подход.
Нарушение порядка следования сообщений в большинстве случаев возникает тогда,
когда разным сообщениям приходится проходить через разные этапы обработки.
Для большей наглядности рассмотрим простенький пример. Предположим, что мы име-
ем дело с пронумерованной последовательностью сообщений. Пусть все сообщения с
четными номерами должны подвергнуться специальному преобразованию, а все сооб-
щения с нечетными номерами — остаться без изменений. Тогда сообщения с нечетными
номерами появятся в результирующем канале сразу же после передачи, в то время как
сообщения с четными номерами скопятся в очереди к компоненту, выполняющему пре-
образование. Если преобразование происходит медленно, все сообщения с нечетными
номерами могут оказаться в результирующем канале еще до того, как в него попадет хотя
бы одно сообщение с четным номером, что полностью нарушит очередность следования
сообщений (рис. 7.16).
Vl Л 1
Медленное
Маршрутизатор
на основе
содержимого
преобразование
Рис. 7.16. Нарушение порядка следования сообщений
1
298
Глава?. Маршрутизация сообщений
Чтобы избежать нарушения порядка, можно было бы воспользоваться механизмом об-
ратной связи (уведомления), гарантирующим, что в каждый момент времени через систему
будет проходить только одно сообщение. Это означает, что следующее сообщение не будет
отправлено до тех пор, пока не завершится обработка предыдущего сообщения. Такой кон-
сервативный подход позволяет решить проблему с очередностью сообщений, но обладает
двумя существенными недостатками. Во-первых, он может значительно замедлить работу
системы. Если до этого в ней параллельно функционировало несколько обработчиков,
большая часть системных ресурсов будет простаивать без дела. Во многих случаях парал-
лельную обработку применяют именно с целью повышения производительности, поэтому
сужение трафика до одного сообщения нивелирует смысл всего решения. Во-вторых, чтобы
использовать данный подход, мы должны контролировать отправку сообщений обрабаты-
вающим компонентам. В реальной жизни, однако, мы часто находимся на стороне получа-
теля и не имеем контроля над исходными копиями сообщений.
Агрегатор (Aggregator, с. 283) получает поток сообшений, выбирает из него связанные
между собой сообщения и компонует их в одно сообщение в соответствии с некоторой
стратегией агрегации. Выполняя эти действия, агрегатору проходится учитывать тот факт,
что отдельные сообщения могут поступать в любое время и в любом порядке. Для решения
этой проблемы агрегатор сохраняет сообщения до тех пор, пока не получит все связанные
между собой сообщения. Только после этого публикуется итоговое сообщение.
Используйте преобразователь порядка (Resequencer) — фильтр с сохранением
состояния, который собирает и упорядочивает сообщения с тем, чтобы их можно
было опубликовать в исходящем канале в заданном порядке.
Преобразователь порядка
Преобразователь порядка получает поток сообщений с нарушенной очередностью, со-
храняет их во внутреннем буфере до тех пор, пока не получит всю последовательность
целиком, а затем публикует сообщения в исходящем канале в правильном порядке. Важ-
но, чтобы исходящий канал сохранял порядок и сообщения были доставлены следующе-
му компоненту в нужной последовательности. Как и большинство других маршрутизато-
ров, преобразователь порядка обычно не вносит изменений в содержимое сообщения.
Порядковый номер
Для корректного функционирования преобразователя порядка (Resequencer) у каждого
сообщения должен быть порядковый номер, или идентификатор позиции (см. также
шаблон цепочка сообщений (Message Sequence, с. 192)). Порядковый номер отличается от
идентификатора сообшения или идентификатора корреляции (Correlation Identifier, с. 186).
Идентификатор сообшения — это специальный атрибут, который уникальным образом
идентифицирует каждое сообщение. Однако в большинстве случаев идентификаторы не-
Преобразователь порядка (Resequencer)
299
возможно сравнивать: это случайные значения, часто даже не числовые. Впрочем, даже
если идентификаторы сообщений выражаются числовыми значениями, настоятельно
рекомендуем не нагружать существующий идентификатор дополнительной семантикой
порядкового номера. Идентификаторы корреляции предназначены для сопоставления
полученных ответов с исходными запросами (см. шаблон запрос-ответ (Request-Reply,
с. 177)). Единственным требованием к идентификаторам корреляции является уникаль-
ность; они не должны быть числовыми или образовывать последовательность. Итак, что-
бы сохранить порядок последовательности сообщений, необходимо определить отдель-
ное поле, позволяющее отслеживать позицию каждого сообщения в последовательности.
Обычно такое поле можно вставить в заголовок сообщения.
Генерация порядковых номеров может отнять больше времени, нежели создание уни-
кальных идентификаторов. Последние часто можно генерировать распределенным спо-
собом, комбинируя уникальную информацию о местонахождении (например, МАС-адрес
сетевого адаптера) с текущим временем. Именно таким образом функционирует боль-
шинство алгоритмов генерации глобальных уникальных идентификаторов (globally
unique identifier — GUID). В свою очередь, для генерации порядковых номеров сообще-
ний обычно нужен единый счетчик, который будет присваивать номера в рамках всей
системы. Порядковые номера должны не просто располагаться в порядке возрастания,
но и образовывать непрерывную последовательность. В противном случае преобразовате-
лю порядка будет трудно выявлять недостающие сообщения. Если отнестись к генератору
порядковых номеров без должного внимания, он легко может превратиться в “узкое
место” системы. Если сообщения, которые необходимо упорядочить, появляются на свет
в результате применения разветвителя (Splitter, с. 274), механизм нумерации сообщений
лучше всего встроить непосредственно в разветвитель. В разделе, посвященном шаблону
проектирования поле идентификации (Identity Field) в [9], содержится несколько полезных
советов по поводу того, как генерировать ключи и порядковые номера.
Внутреннее устройство
Наличие порядковых номеров гарантирует, что преобразователь порядка (Resequencer)
сможет идентифицировать связанные между собой сообщения, поступающие в непра-
вильной очередности. Но что именно он должен делать при поступлении таких сообще-
ний? Нарушение порядка означает, что сообщение с большим порядковым номером
прибывает раньше сообщения, имеющего меньший порядковый номер. Преобразователь
порядка должен хранить сообщение с большим номером, пока не получит все
“недостающие” сообщения с меньшими номерами. Когда в буфере оказывается непре-
рывная последовательность сообщений, начинающаяся с минимально возможного но-
мера, преобразователь порядка отправляет ее в исходящий канал, после чего удаляет
отправленные сообщения из буфера (рис. 7.17).
В простом примере, показанном на рис. 7.17, преобразователь порядка по очереди по-
лучает сообщения с порядковыми номерами 1, 3, 5 и 2. Предполагается, что номера со-
общений в последовательности начинаются с № 1, поэтому первое сообщение может
быть с полным правом отправлено в исходящий канал и удалено из буфера. Следующее
сообщение помечено номером 3, значит, не хватает сообщения № 2. Преобразователь по-
рядка помещает сообщение № 3 в буфер и ждет, пока в нем не появится непрерывная по-
следовательность сообщений, начинающаяся с № 2. Та же операция выполняется с со-
общением № 5. Когда на вход преобразователя порядка поступает сообщение № 2, в бу-
300
Глава?. Маршрутизация сообщений
фере оказывается последовательность сообщений с номерами 2 и 3. Преобразователь по-
рядка публикует их и удаляет из буфера. Сообщение № 5 останется в буфере до тех пор,
пока в последовательности не заполнится оставшаяся дыра в виде сообшения № 4.
П+З
Рис. 7.17. Принцип работы преобразователя порядка
Входящие
сообщения
Буфер
Исходящие
сообщения
Борьба с переполнением буфера
Какого размера должен достигать буфер преобразователя порядка {Resequencer)! Если
мы имеем дело с длинным потоком сообщений, буфер может стать довольно большим.
Еще хуже, если конфигурация системы включает в себя несколько обрабатывающих
компонентов, каждый из который работает с определенным типом сообщений. Если
один из таких компонентов даст сбой, мы получим длинный поток неупорядоченных со-
общений, и переполнения буфера практически не миновать. В некоторых случаях при-
нять “зависшие” сообщения могут очереди сообщений. Это срабатывает только тогда,
когда инфраструктура обмена сообщениями позволяет выбирать сообшения для считы-
вания из очереди, а не автоматически считывать первым самое старое сообщение. В этом
случае мы можем опросить очередь и узнать, попало ли в нее первое из недостающих со-
общений, не потребляя все остальные сообщения. Но даже такие хранилища в конце
концов переполнятся.
Один надежный способ избежать переполнения буфера — контролировать работу по-
ставщика сообщений, используя активные уведомления, как показано на рис. 7.18.
Уведомление
Рис. 7.18. Отправка активного уведомления позволяет избежать переполнения буфера
Преобразователь порядка (Resequencer)
301
Как уже говорилось, отправлять по одному сообщению за раз крайне неэффективно.
Необходимо придумать более интеллектуальный алгоритм поддержания порядка.
Так, преобразователь порядка может уведомлять поставщика сообщений о том, сколько
свободных “ячеек” осталось в буфере. Тогда поставщик сможет отправить указанное ко-
личество сообщений — даже если их очередность будет полностью нарушена, они все
уместятся в буфере, а значит, преобразователь порядка легко расставит их в нужной по-
следовательности. Данный подход представляет собой весьма удачный компромисс меж-
ду эффективностью и требованиями к размеру буфера. Однако, чтобы вставить в путь
следования сообщений буфер отправки и ограничитель, необходимо иметь доступ к ис-
ходному, упорядоченному потоку сообщений.
Описанный подход весьма напоминает принцип работы сетевого протокола TCP/IP.
Одним из ключевых свойств TCP является гарантия последовательной доставки пакетов
по сети. Каждый пакет может проходить по собственному сетевому пути, поэтому в ре-
альных ситуациях нарушение очередности пакетов встречается довольно часто. Получа-
тель пакетов владеет кольцевым буфером, используя его в качестве “скользящего окна”.
Получатель и отправитель договариваются о том, какое количество пакетов может быть
отправлено до получения следующего подтверждения. Поскольку отправитель не может
отправить следующую порцию пакетов, не получив информации о том, сколько этих па-
кетов должно быть, он не сможет забросать получателя пакетами или вызвать переполне-
ние буфера. Существуют также определенные правила, позволяющие предотвратить воз-
никновение так называемого “синдрома узкого окна” (Silly Window Syndrome — SWS),
при котором отправитель и получатель могут оказаться в крайне неэффективном режиме
работы, отправляя и принимая по одному пакету за раз.
Еще одно возможное решение проблемы с переполнением буфера — сгенерировать
заменитель отсутствующего сообщения. Этот подход можно применять, если получатель
лояльно относится к “достаточно хорошим” данным сообщений и не требует точных
данных абсолютно по каждому сообщению или же если скорость важнее точности.
К примеру, при передаче голоса по IP-сетям повторный запрос потерявшегося пакета
приведет к значительной задержке голосового потока и вызовет недовольство абонента,
поэтому вместо недостающего пакета лучше просто вставить пустой пакет.
Большинство разработчиков приложений считают надежность сетевых соединений
аксиомой, не требующей доказательства. Между тем иногда совсем нелишне взглянуть на
внутреннее устройство TCP, потому что IP-трафик сам по себе является асинхронным
и ненадежным, и протоколу TCP приходится сталкиваться с теми же проблемами, что и
решениям интеграции корпоративных приложений. Более подробно о TCP и IP расска-
зывается в [38 и 43].
Пример: преобразователь порядка (.NET и MSMQ)
Чтобы продемонстрировать действие преобразователя порядка {Resequencer) на практике,
воспользуемся конфигурацией, показанной на рис. 7.19.
Тестовая конфигурация состоит из четырех основных компонентов, каждый из кото-
рых реализован в виде класса С#. Компоненты взаимодействуют друг с другом посредст-
вом очередей сообщений MSMQ, предоставленных службой Message Queuing, встроен-
ной в операционные системы Windows 2000 и Windows ХР.
302
Глава?. Маршрутизация сообщений
1. Компонент MQSend функционирует в качестве генератора тестового сообщения
(Test Message, с. 577). Тело каждого тестового сообщения представляет собой про-
стую текстовую строку. Кроме того, MQSend оснащает каждое сообщение поряд-
ковым номером, который хранится в свойстве AppSpecif ic объекта сообщения.
Нумерация сообщений начинается с единицы, а общее число сообщений может
быть задано с помощью командной строки. MQSend публикует сообщения в за-
крытой очереди inQueue.
Delayprocessor
0,3 с
inQueue
outQueue
MQSend
0,7 c
sequenceQueue
MQSequenceReceive
Resequencer
1,3c
Puc. 7.19. Тестовая конфигурация преобразователя порядка
2. Компонент DelayProcessor считывает сообщения из очереди inQueue. Единст-
венная “обработка” заключается в том, что сообщение публикуется в исходящей
очереди outQueue с некоторой задержкой. Для имитации балансировки нагрузки
в нашей тестовой конфигурации используются три компонента DelayProcessor.
3. Компонент Resequencer собирает в буфер сообщения с нарушенной очередно-
стью и публикует их в правильном порядке в очереди sequenceQueue.
4. Компонент MQSequenceReceive считывает сообщения из очереди sequenceQueue
и проверяет, действительно ли порядковые номера сообщений, заданные свойством
AppSpecif ic, следуют строго по возрастанию.
Пример текста, появляющегося на экране в результате работы тестовой конфигура-
ции, показан на рис. 7.20. Легко заметить, что обработчики DelayProcessor работают
с неодинаковыми скоростями. Как и ожидалось, на вход преобразователя порядка сооб-
щения прибывают в абсолютно хаотичной последовательности (в нашем примере это 3,
4,1, 5, 7, 2 и т.д.). Преобразователь порядка буферизует входящие сообщения, если не хва-
тает некоторых промежуточных сообщений. Когда недостающее сообщение появляется,
преобразователь порядка публикует полную последовательность в требуемом порядке.
Проанализировав тестовую конфигурацию, легко понять, что у компонентов
DelayProcessor и Resequencer есть много общего: они оба считывают сообщения из
входящей очереди и публикуют их в исходящей очереди. Единственное отличие между
компонентами состоит в том, что происходит между считыванием и публикацией, т.е.
в особенностях обработки сообщения. По этой причине мы создали общий класс, инкап-
сулирующий в себе базовую функциональность такого универсального фильтра
(см. шаблон каналы и фильтры — Pipes and Filters, с. 102). Указанный базовый класс
включает в себя методы для создания очереди сообщений, а также для асинхронного по-
лучения, обработки и отправки сообщений. Мы назвали его Processor (рис. 7.21).
Преобразователь порядка (Resequencer)
303
DelayProcessor
Processing messages from
inQueue to outQueue
Delay: 0.3 seconds
Received Message: Message 3
Received Message: Message 4
Received Message: Message 5
Received Message: Message 7
Received Message: Message 8
Resequencer
Processing messages from
inQueue to outQueue
Delay: 0.7 seconds
Received Message: Message 1
Received Message: Message €
Received Message: Message 10
Processing messages from
inQueue to outQueue
Delay: 1.3 seconds
Received Message: Message 2
Received Message: Message 9
Processing messages from
outQueue to sequenceQueue
Received message index 3
Buffer range: 1 - 3
Received message index 4
Buffer range: 1 - 4
Received message index 1
Buffer range: 1 - 4
Sending message with index 1
Received message index 5
Buffer range: 2 - 5
Received message index 7
Buffer range: 2 - 7
Received message index 2
Buffer range: 2 - 7
Sending message with index 2
Sending message with index 3
Sending message with index 4
Sending message with index 5
Received message index 6
Buffer range: 6 -7
Sending message with index 6
Sending message with index 7
Received message index 8
Buffer range: 8 - 8
Sending message with index 8
MQSequenceReceive
Receiving messages from
.\private$ \sequenceQueue
Received Message:
initialized
Received Message:
Received Message:
Received Message:
Received Message:
Received Message:
Received Message:
Received Message:
1 - sequence
Message 2 - OK
Message 3 - OK
Message 4 - OK
Message 5 - OK
Message € OK
Message 7 - OK
Message 8 - OK I
Puc. 7.20. Текст, выданный на экран тестовыми компонентами
Processor
Рис. 7.21. Классы Delayprocessor и Resequencer
наследуют один и тот же базовый класс Processor
Стандартная реализация класса Processor просто копирует сообщения из входящей
очереди в исходящую. Чтобы создать преобразователь порядка, необходимо переопреде-
лить базовую реализацию метода ProcessMessage. Новый метод ProcessMessage до-
бавляет полученное сообщение в буфер, реализованный в виде таблицы хэширования
Hashtable. В качестве ключа в буфере используется порядковый номер сообщения, хра-
нящийся в свойстве AppSpecific. Когда в буфер добавляется новое сообщение, метод
SendConsecutiveMessages проверяет, не появилась ли в буфере непрерывная последо-
вательность сообщений, начинающаяся с минимально возможного порядкового номера.
Если это так, метод отправляет все следующие друг за другом сообщения, после чего уда-
ляет их из буфера.
304
Глава?. Маршрутизация сообщений
Resequencer.cs
using System;
using System.Messaging;
using System. Collections;
using MsgProcessor;
namespace Resequencer
{
class Resequencer : Processor
private int startindex = 1;
private IDictionary buffer =
(IDictionary)(new Hashtable());
private int endindex - -1;
public Resequencer(MessageQueue inputQueue,
MessageQueue outputQueue)
: base (inputQueue, outputQueue) {}
protected override void ProcessMessage(Message m)
AddToBuffer(m);
SendConsecutiveMessages();
}
private void AddToBuffer(Message m)
{
Int32 msgindex = m.AppSpecific;
Console.WriteLine("Received message index {o}",
msgIndex);
// "Получено сообщение номер ".
if (msgindex < startindex)
{
Console.WriteLine("Out of range message index!
Current start is: {o}", startindex);
// "He попадает в диапазон номеров сообщений!"
// "Текущий диапазон начинается с номера ".
}
else
{
buffer.Add(msgindex, m);
if (msgindex > endindex)
endindex = msgindex;
}
Console.WriteLine(" Buffer range: {0} - {1}",
startindex, endindex);
// "Диапазон сообщений в буфере: ".
}
private void SendConsecutiveMessagesО
{
while (buffer.Contains(startindex))
Преобразователь порядка (Resequencer)
305
Message m = (Message)(buffer[startindex]);
Console.WriteLine("Sending message with index {O}",
startindex);
/I "Отправка сообщения номер ".
outputQueue.Send(m);
buffer.Remove(startIndex);
startlndex++;
}
}
}
}
Как видим, преобразователь порядка предполагает, что последовательность сообще-
ний начинается с номера 1. Это справедливо в том случае, если поставщик сообщений
тоже начинает нумерацию сообщений с единицы, и оба компонента следуют этому
соглашению на протяжении всего времени своего функционирования. Чтобы сделать
преобразователь порядка более гибким, поставщик сообщений должен согласовать с ним
принцип нумерации перед отправкой первого сообщения последовательности. Это на-
поминает сообщения SYN, которыми обмениваются отправитель и получатель во время
сеанса связи по протоколу TCP [38].
В текущей реализации преобразователя порядка также не предусмотрено никаких мер
предосторожности против переполнения буфера. Предположим, что компонент Delay-
Processor вследствие сбоя или другой неисправности “съест” сообщение. Преобразова-
тель порядка будет ожидать пропавшее сообщение, пока его буфер в конце концов
не переполнится. В сценариях с большим объемом трафика поставщик сообщений и преоб-
разователь порядка должны договориться о размере окна, описывающем максимальное
количество сообщений, которые могут уместиться в буфере преобразователя порядка. Когда
буфер заполнится до отказа, обработчик ошибок должен будет принять решение относи-
тельно того, как поступить с пропавшим сообщением. К примеру, можно инициировать его
повторную отправку или “вбросить” вместо него суррогатное, пустое сообщение.
Структура базового класса Processor довольно проста. Он описывает асинхронную
обработку сообщений, используя методы BeginReceive и EndReceive. Поскольку по
окончании обработки сообщений легко забыть вызвать метод BeginReceive, мы вос-
пользовались шаблонным методом (template method), в который внедрен этот обязатель-
ный шаг. Теперь производные классы смогут переопределять метод ProcessMessage,
не беспокоясь об асинхронной обработке.
Processor.cs
using System;
using System.Messaging;
using System.Threading;
namespace MsgProcessor
{
public class Processor
{
protected MessageQueue inputQueue;
protected MessageQueue outputQueue;
306
Глава?. Маршрутизация сообщений
public Processor (MessageQueue inputQueue,
MessageQueue outputQueue)
this.inputQueue = inputQueue;
this.outputQueue = outputQueue;
inputQueue.Formatter = new
System.Messaging.XmlMessageFormatter
(new String!] {"System.String,mscorlib"});
inputQueue.MessageReadPropertyFilter.ClearAll();
inputQueue.MessageReadPropertyFilter.AppSpecific = true;
inputQueue.MessageReadPropertyFilter.Body = true;
inputQueue.MessageReadPropertyFilter.Correlationld =
true;
inputQueue.MessageReadPropertyFilter.Id = true;
Console.WriteLine("Processing messages from " +
inputQueue.Path + " to " +
outputQueue.Path);
// "Передача сообщений из ... в ...".
}
public void Process()
{
inputQueue.ReceiveCompleted += new
ReceiveCompletedEventHandler(OnReceiveCompleted);
inputQueue.BeginReceive();
}
private void OnReceiveCompleted(Object source,
ReceiveCompletedEventArgs asyncResult)
{
MessageQueue mq = (MessageQueue)source;
Message m = mq.EndReceive(asyncResult.AsyncResult);
m.Formatter = new System.Messaging.XmlMessageFormatter
(new Stringf] {"System.String,mscorlib"});
ProcessMessage(m);
mq.BeginReceive();
}
protected virtual void ProcessMessage(Message m)
{
string body = (string)m.Body;
Console.WriteLine("Received Message: " + body);
// "Получено сообщение: ".
outputQueue.Send(m);
}
}
}
Обработчик составного сообщения (Composed Message Processor)
307
Обработчик составного сообщения (Composed Message Processor)
□
□
Вернемся к примеру обработки заказов, который рассматривался в разделах, посвя-
щенных шаблонам маршрутизатор на основе содержимого (Content-Based Router, с. 247)
и разветвитель (Splitter, с. 274). Напомним, что в нем описывается обработка входящего
заказа, состоящего из нескольких элементов. Для каждого элемента заказа требуется
проверить его наличие на складе в соответствующей системе управления складскими за-
пасами (для каждого вида или нескольких видов товара существует своя система). После
выполнения всех проверок заказ необходимо передать на следующий этап обработки.
Как аккуратно провести сообщение по маршруту его следования, если сообще-
ние состоит из нескольких элементов, каждый из которых проходит собственную
обработку?
В задаче, описанной выше, хорошо просматриваются элементы нескольких уже зна-
комых вам шаблонов проектирования. Разветвитель может разбить сообщение на не-
сколько отдельных частей. Маршрутизатор на основе содержимого может распределить
полученные сообщения по требуемым этапам обработки в зависимости от типа или со-
держимого сообщения. Архитектурный стиль каналы и фильтры (Pipes and Filters, с. 102)
позволяет связать воедино оба указанных шаблона, чтобы каждый из элементов состав-
ного сообщения направлялся на соответствующие этапы обработки (рис. 7.22).
Рис. 7.22. Комбинация разветвителя и маршрутизатора
Склад приборов
Склад устройств
308
Глава?. Маршрутизация сообщений
В нашем примере это означает, что каждый элемент заказа направляется на проверку
в соответствующую систему управления складскими запасами. Указанные системы пол-
ностью отделены друг от друга, и каждая из них получает только те элементы заказа,
которые соответствуют хранящимся на ее складах видам товара.
Конфигурация, показанная на рис. 7.22, обладает одним существенным недостатком:
нельзя определить, все ли элементы заказа действительно найдены на складах и готовят-
ся к отправке. Кроме того, необходимо извлечь цены на все товары (учитывая оптовые
скидки) и составить из них единый счет. Для этого дальнейшая обработка заказа должна
происходить так, как если бы он все еше был одним сообщением, даже несмотря на то.
что его уже разбили на несколько более мелких сообщений.
Один из возможных подходов состоит в том, чтобы просто собрать все элементы зака-
за, прошедшие через конкретную систему управления складскими запасами, и сформи-
ровать на их основе отдельный заказ. После этого такой подзаказ может обрабатываться,
как единое целое: он будет собран и доставлен, после чего клиенту будет выслан счет.
Каждый подзаказ будет рассматриваться как независимый процесс. В некоторых ситуа-
циях из-за отсутствия централизованного контроля над дальнейшим процессом обработ-
ки такой подход может стать единственным допустимым решением. Компания Amazon,
к примеру, применяет его в отношении целого ряда продаваемых ею товаров. Заказы по-
падают в различные компании по выполнению заказов и управляются уже оттуда.
К сожалению, такой подход не всегда удобен для самого покупателя. Последний
может получить несколько поставок товара и несколько счетов. Оформить возврат или
разрешить спорную ситуацию будет не всегда легко. Это не слишком большая проблема
для покупателей, заказывающих книги по Интернету. Гораздо хуже, если отдельные эле-
менты заказа зависят друг от друга. Предположим, что заказ включает в себя элементы
кухонной “стенки”. Покупатель будет не слишком доволен, если ему привезут громадные
коробки с полками и дверцами и сообщат, что остальная необходимая фурнитура пока
что отсутствует и будет доставлена в неопределенный срок.
Асинхронный характер систем обмена сообщениями делает распределение заданий
куда более сложным, чем вызовы синхронных методов. Можно было бы проанализиро-
вать элемент заказа, подождать ответа соответствующей складской системы и только за-
тем перейти к анализу следующего элемента. Это упростит зависимости между элемента-
ми, но существенно снизит эффективность работы системы. Хотелось бы в полной мере
воспользоваться преимуществами того, что каждая система может параллельно обраба-
тывать несколько заказов.
Обработчик составного сообщения использует агрегатор (Aggregator, с. 283), чтобы со-
брать ответы на запросы, которые были отправлены на обработку в разные системы
управления складскими запасами. Каждый обрабатывающий компонент отправляет
агрегатору ответ, в котором сообщает о наличии на складе соответствующего элемента
заказа. Агрегатор собирает отдельные ответы и обрабатывает их с помощью заранее за-
данного алгоритма.
Используйте обработчик составного сообщения (Composed Message Processor}.
Он разбивает составное сообщение на несколько частей, направляет каждое из
полученных сообщений на необходимую обработку, а затем снова собирает
в единое сообщение.
Обработчик составного сообщения (Composed Message Processor)
309
Поскольку все сообщения, касающиеся отдельных элементов заказа, появляются на
свет в результате разбивки одного и того же сообщения, агрегатору можно передать до-
полнительную информацию, а именно — число производных сообщений, чтобы приме-
нить более эффективную стратегию агрегации. Несмотря на это обработчику составного
сообщения приходится сталкиваться с рядом других проблем, связанных с пропавшими
или задерживающимися сообщениями. Как следует поступить, если система управления
складскими запасами временно недоступна? Отложить обработку всех заказов, вклю-
чающих в себя товары из этой системы? Или, может быть, отправить их в очередь исклю-
чений для последующей оценки оператором? Нужно ли повторно отправлять сообщение
с запросом при отсутствии одного из ответов? Более подробное обсуждение этих вопро-
сов приведено в разделе, посвященном агрегатору.
Обработчик составного сообщения является хорошим примером слияния нескольких
независимых шаблонов проектирования в более сложный шаблон. Для остальных ком-
понентов системы обработчик составного сообщения будет выглядеть обычным фильтром
с одним входящим и одним исходящим каналами (рис. 7.23), обеспечивая тем самым
эффективную абстракцию сложного внутреннего устройства.
Новый заказ
составного Проверенный
сообщения заказ
Рис. 7.23. Обработчик составного сообщения в роли простого фильтра
310
Глава?. Маршрутизация сообщений
Рассылка-сборка (Scatter-Gather)
В примере обработки заказов, описанном в предыдущих разделах, каждый элемент зака-
за, отсутствующий на складе компании, мог предоставляться одним или несколькими
внешними поставщиками. При этом нужный товар может оказаться или не оказаться в на-
личии, на него могут быть назначены разные цены, товар может доставляться в разное вре-
мя и т.д. Чтобы выполнить заказ наилучшим способом, можно узнать цены у всех постав-
щиков и решить, какой из них обеспечивает лучшие условия поставки требуемого товара.
Как организовать обработку и дальнейшее продвижение сообщения, если на оп-
ределенном этапе оно должно быть разослано нескольким получателям, каждый
из которых может прислать свой ответ?
Очевидно, готовое решение должно обладать гибкостью в выборе получателей запро-
са. Список поставщиков можно определить самому, а можно объявить аукцион, в кото-
ром разрешается участвовать всем заинтересованным поставщикам. Поскольку контроль
над получателями отсутствует (или практически отсутствует), нужно быть готовым к по-
лучению ответов от некоторых, но не от всех получателей. Такие изменения правил аук-
циона не должны влиять на структурную целостность решения.
Количество получателей и сведения о них должны быть скрыты от любых дальнейших
этапов обработки. Подобная инкапсуляция позволяет сохранить независимость осталь-
ных компонентов от маршрутов следования отдельных сообщений.
Необходимо также координировать дальнейшее продвижение сообщений. Пожалуй,
самое простое решение этой проблемы состоит в том, чтобы каждый получатель запроса
публиковал свой ответ в канале, а последующие компоненты сами решали, что делать с
полученными сообщениями. Для этого, однако, указанные компоненты должны знать о
сообщении, разосланном нескольким получателям. Кроме того, последующим компо-
нентам будет сложно обрабатывать отдельные сообщения, ничего не зная о примененной
к ним логике маршрутизации.
Из вышесказанного видно, что логику маршрутизации, получателей, а также даль-
нейшую обработку отдельных сообщений имеет смысл скомбинировать в один логиче-
ский компонент.
Шаблон рассылка-сборка направляет сообщение с запросом нескольким получателям.
После этого он использует агрегатор (Aggregator, с. 283), чтобы собрать ответы получате-
лей и объединить их в одно итоговое сообшение с ответом.
Используйте шаблон рассылка-сборка (Scatter-Gather) для широковещательной
рассылки сообщения нескольким получателям и последующей агрегации отве-
тов в единое сообщение.
Рассылка-сборка (Scatter-Gather)
311
Агрегатор
Существует два варианта рассылки-сборки, в которых применяются различные меха-
низмы отправки сообщения с запросом предполагаемым получателям.
1. Распределение с помощью списка получателей (Recipient List, с. 264). При исполь-
зовании этого подхода рассыпка-сборка может контролировать набор получателей,
но она должна знать о канале сообщений каждого получателя.
2. Аукцион. Рассылка-сборка использует канал “публикация-подписка” (Publish-
Subscribe Channel, с. 134) для широковещательной рассылки сообщения с запро-
сом всем заинтересованным получателям. В этом случае рассылка-сборка может
ограничиться единственным каналом рассылки, но теряет контроль над выбором
получателей.
Данное решение во многом напоминает обработчик составного сообщения (Composed
Message Processor, с. 307). Главное отличие между ними состоит в том, что обработчик со-
ставного сообщения с помощью разветвителя разбивает исходное сообщение на несколь-
ко более мелких частей, а рассылка-сборка отправляет копии исходного сообщения цели-
ком, рассылая их в широковещательном режиме по каналу “публикация-подписка”. К со-
общению с запросом, скорее всего, будет добавлен обратный адрес (Return Address, с. 182),
чтобы все ответы можно было собирать в один канал. Рассылка-сборка, как и обработчик
составного сообщения, агрегирует ответы в соответствии с заранее заданными бизнес -
правилами. В нашем примере агрегатор может отбирать лучшие предложения поставщи-
ков. Агрегировать ответы для рассылки-сборки часто сложнее, нежели для обработчика
составного сообщения, потому что количество получателей, участвующих в обработке
запроса, может быть неизвестно.
Как рассылка-сборка, так и обработчик составного сообщения отправляют сообщение
нескольким получателям, а затем комбинируют ответы в одно итоговое сообщение с по-
мощью агрегатора. Следует отметить, что обработчик составного сообщения выполняет
синхронизацию параллельных действий. Если время выполнения отдельных действий
сильно варьируется, дальнейшая обработка сообщения будет задержана даже в том слу-
312
Глава 7. Маршрутизация сообщений
чае, если выполнение многих подзадач (или даже всех, кроме одной) уже завершено.
Сравните это с простотой и инкапсуляцией, свойственными рассылке-сборке. Неплохим
компромиссом между двумя альтернативами может стать каскадный агрегатор, конст-
рукция которого позволяет инициировать дальнейшую обработку данных при наличии
некоторого подмножества результатов.
Пример: кредитный брокер
Кредитный брокер, описанный в главе 9, использует шаблон рассылка-сборка (Scatter-
Gather), чтобы разослать запрос на получение кредита нескольким банкам и отобрать
лучший из полученных ответов. В указанной главе продемонстрирована реализация рас-
сылки-сборки как на основе списка получателей (Recipient List, с. 264), так и при помощи
канала “публикация-подписка” (Publish-Subscribe Channel, с. 134). Первый механизм опи-
сан в примере асинхронной реализации с использованием MSMQ, а второй — в анало-
гичном примере с использованием TIBCO ActiveEnterprise.
Пример: комбинация шаблонов
Воспользуемся шаблоном рассылка-сборка (Scatter-Gather), чтобы реализовать уже знако-
мый пример заказа приборов и устройств. Рассылку-сборку можно скомбинировать с об-
работчиком составного сообщения (Composed Message Processor, с. 307), чтобы обработать
входящий заказ, разбить его на отдельные элементы, разослать каждый элемент заказа
нескольким поставщикам, агрегировать предложения цен по каждому элементу заказа в
лучшее предложение цены по этому элементу, а затем еще раз агрегировать лучшие пред-
ложения цен по элементам заказа в готовый заказ (рис. 7.24). Это весьма распространен-
ный пример комбинации нескольких шаблонов для получения общего решения. Компо-
новка отдельных шаблонов проектирования в более крупный шаблон позволяет рассмат-
ривать решение на более высоком уровне абстракции, а также менять детали реализации,
не затрагивая остальные компоненты системы.
Агрегатор
D<-D
Обработчик составного сообщения
Запрос цены для
каждого элемента
заказа
“Лучшая” цена для
каждого элемента
заказа
Рис. 7.24. Комбинация рассылки-сборки и обработчика составного сообщения
Рассылка-сборка (Scatter-Gather)
313
Пример, показанный на рис, 7.24, также хорошо демонстрирует всю многоликость
шаблона агрегатор (Aggregator, с. 283). В рассматриваемом решении применяются два аг-
регатора, каждый из которых имеет собственное назначение. Первый агрегатор, являю-
щийся частью рассылки-сборки, выбирает самое выгодное предложение из тех, которые
были присланы поставщиками. Такому агрегатору не обязательно требовать наличия от-
ветов от абсолютно всех поставщиков (иногда скорость ответа важнее низкой цены), зато
алгоритм комбинирования ответов в общее сообщение может быть довольно сложным.
К примеру, клиент может заказать 100 приборов, а у поставщика с самой низкой ценой
на складе имеется только 60 приборов. Агрегатор должен решить, нужно ли принять это
предложение и докупить оставшиеся 40 приборов у другого поставщика. Второй агрега-
тор, функционирующий в рамках обработчика составного сообщения, может иметь куда
более простую логику, потому что всего лишь объединяет ответы, полученные от первого
агрегатора, в одно сообщение. С другой стороны, генерация такого сообщения возможна
лишь при получении ответов по всем элементам заказа, поэтому второму агрегатору при-
ходится предусматривать обработку разнообразных ошибок, таких как отсутствие ответа
по некоторому элементу.
314
Глава 7. Маршрутизация сообщений
Карта маршрутизации (Routing Slip)
Большинство шаблонов маршрутизации, о которых рассказывалось в настоящей гла-
ве, направляет входящие сообщения в один или несколько пунктов назначения в соот-
ветствии с некоторым набором правил. Иногда, однако, сообщение должно быть направ-
лено не одному компоненту, а целой последовательности компонентов. Предположим,
к примеру, что архитектура каналов и фильтров (Pipes and Filters, с. 102) используется для
обработки входящих сообщений, которые должны пройти через последовательность эта-
пов обработки и проверки бизнес-правил. Поскольку характер проверок может сильно
варьироваться и зачастую зависит от внешних систем (например, проверка кредитных
карт), каждый тип этапа проверки будет реализован в виде отдельного фильтра. Каждый
фильтр анализирует входящее сообщение и применяет к нему бизнес-правило или набор
правил. Если сообщение не удовлетворяет условиям, заданным набором правил, оно от-
правляется в канал исключений. Каналы, соединяющие фильтры, определяют последо-
вательность проверок, которым должно подвергнуться сообщение.
Предположим, однако, что набор проверок, применяемых к сообщению, зависит от
типа последнего. К примеру, заказы на поставку не нуждаются в проверке кредитных
карт, а сообщения с заказами, отосланные клиентами по виртуальной частной сети, не
всегда необходимо подвергать дешифровке и аутентификации. Чтобы приспособиться к
таким требованиям, необходимо придумать конфигурацию, в которой сообщение в зави-
симости от своего типа может проходить через разные последовательности фильтров.
Как последовательно провести сообщение через несколько этапов обработки,
если на момент проектирования системы последовательность этапов неизвест-
на и может различаться для каждого сообщения?
Архитектурный стиль каналы и фильтры предлагает довольно изящный подход, при
котором последовательность этапов обработки представляется в виде независимых
фильтров, соединенных каналами. В стандартной конфигурации фильтры связаны между
собой фиксированными каналами. Если же мы хотим, чтобы сообщения могли динами-
чески направляться на разные фильтры, можно воспользоваться специальными фильт-
рами, выполняющими роль маршрутизаторов сообщений (Message Router, с. 109).
Маршрутизаторы динамически определяют следующий фильтр, на который необходимо
направить сообщение.
Ключевые требования к решению нашей проблемы можно сформулировать в виде
четырех пунктов.
• Эффективное продвижение сообщений. Сообщения должны проходить только через
требуемые этапы обработки, избегая ненужных компонентов.
• Эффективное использование ресурсов. В решении не должно применяться слиш-
ком много каналов, маршрутизаторов и других ресурсов.
Карта маршрутизации (Routing Slip)
315
• Гибкость. Маршрут, по которому проходят отдельные сообщения, должен легко
поддаваться изменениям.
• Простота поддержки. В решении должна присутствовать единая точка поддержки,
чтобы добавление нового типа сообщения не привело к потере согласованности и
появлению ошибок.
На рис. 7.25 и 7.26 показаны варианты решения описанной проблемы. Мы исходим
из предположения, что в системе присутствуют три возможных этапа обработки (А, Б
и В) и что текущее сообщение должно пройти только через этапы А и В. Фактический
путь этого сообщения в каждом из вариантов конфигурации показан толстыми стрелками.
ВариантА
Рис. 7.25. Варианты А и Б системы с динамическим изменением маршрута
Рис. 7.26. Варианты В, ГиДсистемы с динамическим изменением маршрута
Вариант А представляет собой одну длинную цепочку каналов и фильтров, включаю-
щую в себя все возможные этапы проверки. В каждый компонент встраивается код, ин-
структирующий его пропустить этап проверки, если для заданного типа сообщения такая
проверка не требуется. В данной конфигурации, по сути, задействован подход реактив-
ной фильтрации, описанный при рассмотрении фильтра сообщений (Message Filter, с. 253).
316
Глава 7. Маршрутизация сообщений
Простота такого решения не вызывает сомнений, однако смешение бизнес-логики
(проверка) с логикой маршрутизации (принятие решения о необходимости проверки) за-
трудняет повторное использование компонентов. Кроме того, вполне вероятна ситуация,
когда сообщения двух разных типов должны проходить через одни и те же этапы провер-
ки, только в разном порядке. Реализовать подобное поведение в жестко связанной
цепочке этапов будет крайне сложно.
Чтобы отделить бизнес-логику от логики маршрутизации и повысить гибкость кон-
фигурации, логику “шлюза” внутри каждого компонента следует заменить маршрутиза-
торами на основе содержимого (Content-Based Router, с. 247). Это приведет к появлению
цепочки всех возможных этапов проверки, каждому из которых предшествует отдельный
маршрутизатор на основе содержимого (вариант Б на рис. 7.25). Когда на вход маршрути-
затора попадает новое сообщение, маршрутизатор проверяет его тип и решает, нужно ли
пропускать сообщение такого типа через текущий этап проверки. Если такой этап дейст-
вительно необходим, сообщение подвергается проверке. В противном случае сообщение
направляется в обход текущего этапа проверки прямо на следующий маршрутизатор, на-
поминая поведение шаблона обходной путь (Detour, с. 556). Такая конфигурация хорошо
подходит для случаев, когда все этапы проверки не зависят друг от друга, и решение о
маршрутизации может приниматься локально перед каждым этапом проверки. С другой
стороны, каждому сообщению приходится проходить через целый ряд маршрутизаторов,
даже если в действительности к нему необходимо применить лишь пару проверок. Коли-
чество всех возможных компонентов увеличивается вдвое, поэтому, если библиотека
этапов проверки достаточно велика, поток сообщений окажется слишком интенсивным
для такой простой функции. Кроме того, логика маршрутизации будет распределена ме-
жду большим количеством фильтров, вследствие чего сложнее понять, через какие этапы
проверки фактически проходит сообщение определенного типа. Появление нового типа
сообщения может вызвать необходимость модификации абсолютно каждого маршрути-
затора. Наконец, данная конфигурация страдает от тех же недостатков, что и вариант А:
жесткий порядок прохождения этапов проверки.
Чтобы ввести в систему центральную точку управления, можно воспользоваться все
тем же маршрутизатором на основе содержимого, расположив его в самом начале пути.
За маршрутизатором может находиться несколько отдельных цепочек каналов и фильт-
ров — по одной для каждого типа сообщения. Каждая цепочка содержит последователь-
ность этапов проверки, через которые должно проходить сообщение заданного типа.
Маршрутизатор на основе содержимого анализирует входящее сообщение и направляет
его в нужную цепочку (вариант В на рис. 7.26). В этом случае сообщение будет проходить
только через нужные этапы обработки (плюс маршрутизатор в самом начале пути).
Таким образом, данный вариант конфигурации является самым эффективным из тех,
которые уже были рассмотрены, потому что для достижения желаемой функционально-
сти к пути сообщения добавляется только один этап маршрутизации. Структура подоб-
ного решения также позволяет легко проследить путь, по которому перемещается сооб-
щение конкретного типа. К сожалению, для реализации такого решения необходимо же-
стко зафиксировать все допустимые комбинации правил проверки. Нельзя не учитывать
и тот факт, что один и тот же этап проверки может фигурировать сразу в нескольких це-
почках этапов. Запуск нескольких экземпляров такого компонента приведет к ненужно-
му дублированию. Наконец, если система поддерживает слишком много типов сообще-
ний, такое решение будет чрезвычайно трудно обслуживать из-за огромного числа
Карта маршрутизации (Routing Slip)
317
экземпляров компонентов и связывающих их каналов. Итак, вариант В является крайне
эффективным, но весьма неудобен в плане поддержки.
Чтобы обойтись без жесткого фиксирования всех возможных комбинаций этапов
проверки, между каждой парой этапов необходимо вставить маршрутизатор на основе
содержимого, как это сделано в варианте Г (см. рис. 7.26). Обратите внимание: во избе-
жание проблем, свойственных реактивной фильтрации (с которыми мы сталкивались
при рассмотрении варианта Б), маршрутизатор вставляется не перед очередным этапом
проверки, а после него. (Еще один дополнительный маршрутизатор располагается в са-
мом начале цепочки.) Маршрутизаторы должны обладать достаточно сложной логикой,
чтобы после прохождения очередного этапа проверки сообщение направлялось на сле-
дующий требуемый этап, а не просто на следующий доступный этап цепочки. На первый
взгляд, такой подход напоминает реактивную фильтрацию, потому что сообщение про-
ходит через меняющийся набор маршрутизаторов и фильтров. Однако в данной ситуации
маршрутизаторы демонстрируют более высокий уровень интеллекта, чем принятие про-
стых решений тиля “да-нет”, что позволяет сообщению избежать ненужных этапов
маршрутизации. К примеру, в нашем простом сценарии сообщение проходит только
через два маршрутизатора, в то время как в варианте Б — через три. Вариант Г обладает
достаточной гибкостью и эффективностью, но не решает проблемы централизованного
контроля — логика маршрутизации по-прежнему разбросана между большим количест-
вом независимых маршрутизаторов, что затрудняет поддержку решения.
Для устранения последнего недостатка все маршрутизаторы на основе содержимого
можно скомбинировать в один “супермаршрутизатор” (вариант Д на рис. 7.26). После
прохождения очередного этапа проверки сообщение возвращается супермаршрутизато-
ру, который определяет следующий необходимый этап. В такой конфигурации сообще-
ние заданного типа будет направляться только на требуемые фильтры. Поскольку все
решения по поводу маршрутизации теперь принимаются одним и тем же маршрутизато-
ром, необходимо разработать механизм запоминания этапов, которые уже были пройде-
ны сообщением. По этой причине супермарщрутизатор должен сохранять состояние
процесса (или же каждый фильтр должен прикреплять к сообщению ярлык со своим
именем, чтобы супермаршрутизатор видел, какой фильтр был пройден последним). Кро-
ме того, при прохождении каждого этапа проверки сообщение будет передаваться
по двум каналам: к компоненту и обратно к супермаршрутизатору. Объем трафика в та-
кой системе будет в два раза превышать тот, который наблюдался в варианте В.
В начало системы вставляется специальный компонент, составляющий список этапов
обработки, через которые должно пройти каждое сообщение. После этого он прикрепля-
ет к сообщению полученный список и начинает процесс, направляя сообщение на пер-
вый этап обработки. Соответствующий компонент обрабатывает сообщение, а затем за-
глядывает в карту маршрутизации и передает сообщение на следующий указанный в ней
этап обработки.
Карта маршрутизации выполняет те же функции, что и листок с фамилиями сотруд-
ников, прикрепленный к корпоративному журналу. Прочитав журнал, сотрудник должен
передать его кому-нибудь из лиц, указанных в списке, которые еще не читали журнал.
Единственное отличие состоит в том, что в карте маршрутизации строго определен поря-
док прохождения компонентов, а журнал можно передавать из рук в руки в любой после-
довательности (хотя первым, конечно же, должен быть шеф).
318
Глава 7. Маршрутизация сообщений
Прикрепите к каждому сообщению карту маршрутизации (Routing Slip), задаю-
щую необходимую последовательность этапов обработки. Упакуйте каждый этап
проверки в специальный маршрутизатор сообщений, который будет читать карту
маршрутизации и направлять сообщение на следующий компонент в списке.
Доставить сообщение
согласно карте
маршрутизации
Шаблон проектирования карта маршрутизации сочетает в себе централизованное
управление (вариант Д) и эффективность жестко зафиксированной последовательности
этапов (вариант В). Мы заранее определяем полную схему маршрутизации и прикрепля-
ем ее к сообшению, поэтому последнему не приходится постоянно возвращаться к цен-
тральному маршрутизатору для дальнейшего принятия решений. Каждый компонент до-
полнен простой логикой маршрутизации. В описываемом решении предполагается, что
логика маршрутизации встроена в сам компонент-обработчик. Напомним, что эта осо-
бенность во многом стала причиной того, почему нам не понравился вариант А. Чем же
лучше карта маршрутизации! Ключевая разница состоит в том, что в карте маршрутиза-
ции используются универсальные маршрутизаторы, поведение которых не зависит от из-
менения пути следования сообщений того или иного типа. Логика маршрутизации,
встроенная в каждый компонент, аналогична обратному адресу (Return Address, с. 182), где
адрес получателя выбирается из некоторого списка адресов. Как и при использовании
шаблона обратный адрес, компоненты сохраняют возможность повторного использова-
ния и произвольной компоновки, даже несмотря на внедрение некоторого объема логики
маршрутизации. Вдобавок ко всему составление таблицы маршрутизации может выпол-
няться в одной центральной точке, никоим образом не затрагивая код какого-либо из об-
рабатывающих компонентов.
Разумеется, в каждой бочке меда обязательно найдется ложка дегтя. Карта маршру-
тизации, как и остальные решения, обладает некоторыми ограничениями. Во-первых,
после прикрепления к сообщению карты маршрутизации его размер несколько увеличи-
вается. В большинстве случаев речь идет о незначительном увеличении, однако необхо-
димо учитывать тот факт, что сообщение теперь несет в себе состояние процесса (список
пройденных этапов). Это может привести к появлению других побочных эффектов.
Карта маршрутизации (Routing Slip)
319
К примеру, если сообщение пропадет, мы потеряем не только его содержимое, но и дан-
ные процесса (т.е. куда направлялось сообщение в текущий момент). По этой причине
состояние всех сообщений удобно хранить в некоторой центральной точке, что облегчит
генерацию отчетов или восстановление после сбоя.
Еще одним ограничением карты маршрутизации является невозможность изменить
путь следования сообщения после того, как оно было отправлено на обработку. Из этого
следует, что маршрут сообщения должен быть известен заранее и не может зависеть от
промежуточных результатов, полученных на предыдущих этапах обработки. Между тем
во многих реальных бизнес-процессах дальнейший путь следования сообщений часто
определяется именно промежуточными результатами. К примеру, в зависимости от на-
личия на складе требуемого количества заказанного товара (в соответствии с отчетом
системы управления складскими запасами) сообщение может понадобиться направить
по другому пути. Вышесказанное также означает, что центральный компонент должен
уметь заранее определять маршрут следования сообщения. Это может несколько снизить
устойчивость решения и чревато теми же проблемами, что и использование маршрути-
затора на основе содержимого.
Применение карты маршрутизации к унаследованным приложениям
Принцип работы карты маршрутизации (Routing Slip) предполагает, что в компонен-
ты-обработчики можно внедрить логику маршрутизации. Но при наличии готовых или
унаследованных приложений возможность вносить изменения в функциональность са-
мого компонента есть далеко не всегда. В подобном случае приходится прибегать к по-
мощи внешнего маршрутизатора, который будет взаимодействовать с компонентом по-
средством обмена сообщениями (рис. 7.27). Это неизбежно ведет к увеличению числа
используемых каналов и компонентов. Тем не менее карта маршрутизации все равно бу-
дет представлять собой наилучший компромисс с точки зрения эффективности, гибко-
сти и простоты поддержки.
Входная Адаптер Унаследованное
Рис. 7.27. Реализация карты маршрутизации в системе с унаследованными приложениями
320
Глава 7. Маршрутизация сообщений
Область применения
Карту маршрутизации (Routing Slip) рекомендуется использовать в следующих
сценариях.
1. Цепочка бинарных этапов проверки. Поскольку к сообщению не добавляется
дополнительная информация, пропадает ограничение, вызванное невозможно-
стью менять маршрут сообщения в процессе обработки. С другой стороны,
не может не радовать тот факт, что для изменения последовательности этапов
проверки достаточно настроить центральную карту маршрутизации. Каждый
компонент может выбрать одно из двух действий: прервать обработку сообщения
из-за возникновения ошибки или передать сообщение на следующий этап.
2. Каждый этап обработки представляет собой преобразование без сохранения со-
стояния. В качестве примера предположим, что мы получаем заказы от ряда биз-
нес-партнеров. Все заказы поступают по общему каналу, но каждый партнер при-
сылает их в своем формате. Как результат сообщениям с заказами могут понадо-
биться разные преобразования: к сообщениям от одних партнеров нужно
применять дешифровку, к сообщениям от других — не нужно и т.п. Хранение от-
дельной карты маршрутизации ддя каждого партнера позволяет легко настраивать
и модифицировать этапы преобразования его сообщений с помощью одного цен-
трального компонента.
3. На каждом этапе происходит сбор данных, но не принимаются решения (см. так-
же шаблон расширитель содержимого — Content Enricher, с. 348). Иногда входящее
сообщение содержит лишь ссылки, по которым при необходимости можно из-
влечь другие данные. К примеру, сообщение с заказом на подключение к линии
DSL может содержать только номер домашнего телефона будущего абонента.
Необходимо обратиться к внешним источникам, чтобы узнать имя и фамилию
клиента, определить, какой офис обслуживает территорию проживания клиента,
вычислить расстояние от дома клиента до офиса компании и т.п. Только получив
сообщение со всеми необходимыми данными, можно решить, какой пакет услуг
лучше предложить клиенту. В сценарии такого типа принятие решений отклады-
вается на конец процесса, поэтому для сбора всей необходимой информации
можно воспользоваться картой маршрутизации. Следует, однако, хорошо поду-
мать, так ли нужна в данной ситуации гибкость, которую обеспечивает карта
маршрутизации. Не будет ли достаточно простой, жестко зафиксированной це-
почки каналов и фильтров!
Реализация простого маршрутизатора с картой маршрутизации
Одним из недостатков маршрутизатора на основе содержимого (Content-Based Router,
с. 247) является необходимость внедрения в него знаний о каждом потенциальном полу-
чателе и правил маршрутизации для этого получателя. В слабо связанной системе, как
правило, нежелательно иметь центральный компонент, несущий в себе знания о ряде
других компонентов. Альтернативой маршрутизатору на основе содержимого может слу-
жить канал “публикация-подписка” (Publish-Subscribe Channel, с. 134) в сочетании с набо-
ром фильтров сообщений (Message Filter, с. 253). Более подробно об этом рассказывается в
разделе, посвященном фильтру сообщений. Такая конфигурация позволяет каждому по-
Карта маршрутизации (Routing Slip)
321
лучателю самостоятельно решать, какие сообщения он желает обрабатывать. В то же
время ее использование чревато многократной обработкой одних и тех же сообщений.
Существует еще одна возможность предоставить получателям право самим решать, стоит
ли обрабатывать текущее сообщение. Она состоит в том, чтобы воспользоваться моди-
фицированной версией карты маршрутизации (Routing Slip), выступающей в роли цепоч-
ки обязанностей (Chain of Responsibility) [12]. В цепочке обязанностей каждый компонент
может принимать сообщение на обработку или передавать его следующему компоненту в
списке (рис. 7.28). Карта маршрутизации в таком решении представляет собой статиче-
ский список всех получателей. Из этого следует, что центральный компонент все равно
должен знать обо всех потенциальных получателях. Но теперь ему не придется знать
о том, какие сообщения потребляются каждым компонентом.
Системы
управления
Заказ не
обработан
Заказ
обработан
маршрутизации
Рис. 7.28. Использование карты маршрутизации вместо маршрутизатора на основе содержимого
Использование карты маршрутизации устраняет риск многократной обработки сооб-
щений. Кроме того, с ее помощью легко выявлять сообщения, которые не были обработа-
ны ни одним компонентом. Главным недостатком такого подхода является более низкая
скорость обработки и увеличение объема сетевого трафика. В отличие от маршрутизатора
на основе содержимого, который всегда публикует одно сообщение вне зависимости от числа
систем, среднее число сообщений, публикуемых картой маршрутизации, равно половине
количества систем. Чтобы сократить это число, системы можно организовать таким обра-
зом, чтобы сообщение вначале получала та система, которая с наибольшей вероятностью
сможет его обработать, и т.д. Тем не менее число сообщений все равно будет больше, чем
при использовании предиктивного маршрутизатора на основе содержимого.
В некоторых случаях необходимо иметь больше контроля над маршрутом сообщения,
нежели способен обеспечить простой последовательный список компонентов, или же
нужна возможность менять путь сообщения на основе промежуточных результатов.
Для удовлетворения требований такого рода лучше воспользоваться диспетчером процес-
сов (Process Manager, с. 325), поддерживающим выбор, ветвление и объединение. Карта
маршрутизации по своей сути является частным случаем динамически настраиваемого
бизнес-процесса. Необходимо тщательно оценить все преимущества и недостатки карты
маршрутизации в сравнении с центральным диспетчером процессов. Динамическая карта
маршрутизации сочетает в себе преимущества центральной точки поддержки с эффек-
тивностью фиксированной цепочки этапов обработки. К сожалению, повышение слож-
322
Глава 7. Маршрутизация сообщений
ности системы существенно затрудняет ее анализ и отладку, поскольку информация о со-
стоянии маршрутизации распределена между сообщениями. Кроме того, с появлением в
семантике определения процесса таких конструкций, как ветвление и объединение,
конфигурационный файл становится слишком сложным для понимания и поддержки.
Можно было бы включить условные выражения в таблицу маршрутизации и дополнить
модули маршрутизации, внедренные в каждый компонент, чтобы они могли интерпрети-
ровать условные команды для определения следующего пункта в маршруте сообщения.
Необходимо, однако, следить за тем, чтобы простота решения не исчезла под грузом до-
полнительной функциональности. Если системе действительно нужна такая сложная
логика маршрутизации, вероятно, имеет смысл пожертвовать эффективностью работы
карты маршрутизации и воспользоваться более мощным диспетчером процессов.
Пример: использование карты маршрутизации в качестве составной службы
Создавая архитектуру, ориентированную на службы, простую логическую функцию час-
то раскладывают на последовательность нескольких независимых этапов. Это обычно
происходит по двум причинам. Во-первых, готовые приложения часто обладают интер-
фейсами с высокой степенью детализации, основанными на собственных внутренних
API. Интегрируя такие приложения в обшее решение, мы хотим работать на более высо-
ком уровне абстракции. К примеру, операция “Новая учетная запись клиента” может
выполняться биллинговой системой в несколько этапов: создать нового клиента, вы-
брать для него план обслуживания, задать параметры адреса, проверить кредитные дан-
ные и т.п. Во-вторых, выполнение одной логической функции может быть распределено
между несколькими системами. Мы хотим скрыть этот факт от других систем, чтобы по-
лучить возможность перераспределять обязанности между системами, не влияя на ос-
тавшуюся часть интеграционного решения. Чтобы в ответ на одно сообщение с запросом
выполнить несколько внутренних шагов, можно воспользоваться картой маршрутизации
(Routing Slip). Последняя дает возможность выполнять разные запросы, поступившие по
одному и тому же каналу. Карта маршрутизации проводит сообщение через несколько
этапов обработки, но для оставшихся компонентов это выглядит, как один этап (рис. 7.29).
Операция АБВ
Данные
Поиск
Обработчик 1
Обработчик 2
Обработчик 3
Операция АБВ
Канал 1
Канал 2
Канал 3
Канал 1
[Данные |
|Данные|
Маршрутизатор
Маршрутизатор
Канал 3
Канал 1
Канал 2
Канал 3
Возврат
Данные*
| Данные |
Маршрутизатор
Канал 1
Канал 2
Канал 3
Возврат
Данные*
Карта
маршрути-
зации
Канал 1
Канал 2
Канал 3
Возврат
Данные
Канал 1
Канал 2
Канал 3
Возврат
Данные*
Рис. 7.29. Использование карты маршрутизации в качестве составной службы
Карта маршрутизации (Routing Slip)
323
Последовательность этапов обработки, через которые проводится сообщение, выгля-
дит следующим образом.
1. Входящее сообщение с запросом, в котором указаны имя желаемой операции
и все необходимые данные, отправляется компоненту поиска.
2. Компонент поиска извлекает из служебного каталога список этапов обработки,
относящихся к заданной операции. К заголовку сообщения добавляется список
каналов, через которые оно должно пройти (каждый канал соответствует одному
“элементарному” этапу обработки). В конец списка каналов вставляется имя ка-
нала возврата, чтобы по завершении обработки сообщение вернулось к компо-
ненту поиска.
3. Компонент поиска публикует сообщение в канале для прохождения первого этапа
обработки.
4. Каждый маршрутизатор считывает сообщение из канала и передает его постав-
щику службы. Когда поставщик возвращает сообщение после обработки, мар-
шрутизатор помечает соответствующее действие как выполненное и отправляет
сообщение в следующий канал, указанный в таблице маршрутизации.
5. Компонент поиска потребляет сообщение, пришедшее по каналу возврата, и от-
правляет его инициатору запроса. С точки зрения внешних компонентов описан-
ный процесс будет выглядеть, как простой обмен сообщениями “запрос-ответ”.
Пример: спецификация WS-Routing
Довольно часто запрос к Web-службе должен проходить через целый ряд промежуточ-
ных компонентов. Для решения этой проблемы корпорация Microsoft разработала спе-
цификацию WS-Routing (Web Services Routing Protocol— протокол маршрутизации
Web-служб). WS-Routing представляет собой протокол на основе SOAP, предназначен-
ный для маршрутизации сообщений от отправителя через ряд посредников к получате-
лю. WS-Routing обладает более богатой семантикой, чем карта маршрутизации (Routing
Slip), однако последнюю можно легко реализовать с помощью WS-Routing. В примере,
приведенном ниже, показан заголовок сообщения SOAP, которое следует из узла А в узел
D через промежуточные компоненты В и С (задаются элементами <wsrp: via>).
< SOAP-ENV:Envelope
xmlns:SOAP-ENV="http://www.w3.org/2001/06/soap-envelope">
< SOAP-ENV:He ade r>
<wsrp:path xmlns:wsrp="http://schemas.xmlsoap.org/rp/">
<wsrp:action>http://www.im.org/chat</wsrp:action>
<wsrp: tosoap: //E. com/some/endpointc/wsrp: to>
<wsrp:fwd>
<wsrp:via>soap://B.com</wsrp:via>
<wsrp:via>soap://C.com</wsrp:via>
</wsrp:fwd>
<wsrp:from>soap://А.com/some/endpoint</wsrp:from>
<wsrp:id>uuid:84b9f5d0-33fb-4a81-b02b-
5b760641cld6</wsrp:id>
/wsrp:path>
324 Глава 7. Маршрутизация сообщений
</SOAP-ENV:Header>
<SOAP-ENV:Body>
</SOAP-ENV:Body>
</SOAP-ENV:Envelope >
Как и большинство спецификаций, посвященных Web-службам, WS-Routing со вре-
менем, скорее всего, будет развиваться и (или) сольется с другими спецификациями.
Мы привели этот пример в качестве иллюстрации того, что предпринимает сообщество
Web-служб в отношении проблем маршрутизации.
Диспетчер процессов (Process Manager)
325
Диспетчер процессов (Process Manager)
Шаблон проектирования карта маршрутизации {Routing Slip, с. 314) демонстрирует,
как провести сообщение через динамически определяемую последовательность этапов
обработки. В основе упомянутого решения лежат два ключевых предположения: после-
довательность этапов обработки должна быть определена перед отправкой сообщения на
первый этап, а также должна быть линейной. Во многих случаях эти предположения ока-
зываются неверными. К примеру, решение о дальнейшей маршрутизации сообщения
может приниматься непосредственно в ходе обработки на основе промежуточных резуль-
татов. Этапы обработки тоже не обязательно будут следовать друг за другом — довольно
часто некоторые из них должны выполняться параллельно.
Как провести сообщение через несколько этапов обработки, если на момент
проектирования системы требуемые этапы обработки неизвестны и не обяза-
тельно будут выполняться последовательно друг за другом?
Одно из основных преимуществ архитектурного стиля каналы и фильтры {Pipes and
Filters, с. 102) — это возможность связать отдельные обрабатывающие компоненты
(“фильтры”) в произвольную цепочку, соединив их между собой каналами. Тогда каждое
сообщение будет проходить через последовательность обрабатывающих компонентов
(или этапов обработки). Чтобы получить возможность менять последовательность этапов
обработки для каждого сообщения, можно воспользоваться несколькими маршрутиза-
торами на основе содержимого {Content-Based Router, с. 247). Такое решение обеспечивает
максимальную гибкость, но сильно страдает от того, что логика маршрутизации разбро-
сана между целым рядом компонентов. Карта маршрутизации заранее составляет путь
следования сообщения, чем обеспечивает наличие центральной точки контроля за мар-
шрутизацией сообщений. С другой стороны, она не позволяет менять маршрут следова-
ния сообщения на основе промежуточных результатов или одновременно выполнять не-
сколько этапов обработки.
Можно сохранить центральную точку контроля и вместе с тем повысить гибкость ре-
шения, если после прохождения каждого этапа обработки контроль над маршрутизацией
будет возвращаться центральному компоненту. Последний, в свою очередь, будет опре-
делять следующий этап обработки сообщения. Следуя этому подходу, мы получим не-
сколько иную структуру процесса: центральный компонент, этап обработки, централь-
ный компонент, этап обработки и т.п. Таким образом, центральный компонент будет по-
лучать сообщение после прохождения каждого очередного этапа обработки. Получив
сообщение, центральный компонент должен посмотреть, какой этап обработки был
пройден последним, проанализировать промежуточные результаты и на основании этих
данных определить следующий требуемый этап или этапы обработки. Чтобы принимать
такие решения, центральный компонент должен получать от обрабатывающих компо-
нентов достаточное количество информации. Однако этот подход сделает обрабатываю-
326
Глава?. Маршрутизация сообщений
щие компоненты зависимыми от существования центрального компонента, поскольку
они могут быть вынуждены передавать постороннюю информацию, относящуюся не к
ним самим, а только к центральному компоненту. Чтобы отделить обрабатывающие
компоненты и связанные с ними форматы сообщений от центрального компонента, по-
следний необходимо снабдить некоторым подобием “памяти”. В ней будут храниться
сведения о том, какой этап был пройден последним по состоянию на данный момент.
Управляйте маршрутизацией сообщений с помощью диспетчера сообщений
(Process Manager). Это центральный компонент, который сохраняет состояние
процесса обработки сообщения и определяет следующий требуемый этап обра-
ботки на основе промежуточных результатов.
Для начала проясним: проектирование диспетчера процессов само по себе представля-
ет весьма обширную тему, вполне заслуживающую отдельной книги. (А не выпустить ли
нам том 2 с шаблонами, касающимися проектирования рабочих потоков или управления
бизнес-процессами?) В данную же книгу описание диспетчера процессов было включено,
прежде всего, с целью логического завершения темы шаблонов маршрутизации, а заодно
и ознакомления с рабочими потоками и моделированием процессов. Ни в коем случае не
следует рассматривать его как полный курс проектирования бизнес-процессов.
Диспетчер процессов организует движение сообщений по принципу звезды (hub-and-
spoke), как показано выше на диаграмме шаблона. Вначале входящее сообщение выпол-
няет инициализацию диспетчера процессов. Назовем это сообщение инициализирующим.
Основываясь на встроенных правилах, диспетчер процессов отправляет сообщение (1) на
первый этап обработки (этап А). Когда компонент А заканчивает обработку сообщения,
он возвращает сообщение с ответом диспетчеру процессов. Диспетчер определяет, какой
этап обработки должен быть выполнен следующим, и отправляет сообщение (2) соответ-
ствующему компоненту (в нашем примере компоненту Б). Как видим, весь трафик со-
общений проходит через “центр”, в результате чего движение сообщений действительно
напоминает лучи звезды (в сетях такую топологию еще называют центрально-лучевой).
Слабой стороной такого центрального элемента является опасность превращения дис-
петчера процессов в “узкое место”.
Универсальность диспетчера процессов можно с полным правом назвать как преиму-
ществом, так и недостатком. Диспетчер процессов способен выполнять любой набор эта-
пов в последовательном или параллельном режиме, а значит, с его помощью можно ре-
Диспетчер процессов (Process Manager)
327
шить практически любую проблему интеграции. Большинство шаблонов, описанных в
этой главе, можно было бы реализовать с помощью диспетчера процессов. В действитель-
ности многие производители пакетов интеграции пытаются (и небезуспешно) убедить
пользователей своей продукции в том, что каждая задача интеграции решается исключи-
тельно с помощью процессов. Мы, со своей стороны, считаем, что использовать диспет-
чер процессов абсолютно в каждой ситуации — явно перегибать палку. Это может отвлечь
от сути проблемы проектирования, а также вызвать чрезмерную нагрузку на производи-
тельность системы.
Управление состоянием
Одна из ключевых функций диспетчера процессов (Process Manager) — сохранять со-
стояние процесса между поступлением сообщений. К примеру, когда сообщение после
второго этапа обработки возвращается к диспетчеру процессов, последний должен запом-
нить, что это был этап номер 2 в заданной (и, вероятно, довольно длинной) последова-
тельности этапов. Не следует поручать запоминание этого факта самому этапу обработ-
ки, потому что на протяжении одного и того же процесса он может встретиться несколь-
ко раз. К примеру, компонент Б может одновременно быть вторым и четвертым по счету
этапом обработки в рамках одного и того же процесса. Вследствие этого ответ, отправ-
ленный компонентом Б, в зависимости от контекста процесса может содержать инструк-
цию для диспетчера процессов о необходимости перехода к этапу обработки 3 или 5.
Чтобы правильно определить требуемый этап обработки, не усложняя логику обрабаты-
вающего компонента, диспетчер процессов должен запомнить номер этапа, на котором
выполнение процесса находится в данный момент.
Диспетчер процессов удобно реализовать таким образом, чтобы, помимо номера теку-
щего этапа, он мог сохранять дополнительную информацию, например результаты, полу-
ченные на предыдущем этапе обработки, если они имеют значение для последующих эта-
пов. К примеру, если результаты этапа 1 понадобятся на одном из следующих этапов,
диспетчер процессов может сохранить эту информацию, избавляя обрабатывающие компо-
ненты от необходимости передавать ее взад-вперед. Это позволяет отдельным этапам не за-
висеть друг от друга, поскольку они не должны заботиться о данных, созданных или по-
требленных на других этапах. По сути, диспетчер процессов выполняет функцию квитанции
(Claim Check, с. 358) — шаблона, о котором будет рассказываться в следующей главе.
Экземпляры процесса
Поскольку выполнение процесса может охватывать большое количество этапов обра-
ботки, а значит, отнимать много времени, диспетчер процессов (Process Manager) может
получать новые инициализирующие сообщения прямо во время выполнения предыду-
щих процессов. Чтобы диспетчер процессов смог параллельно управлять обработкой
нескольких сообщений, для каждого входящего сообщения необходимо создавать новый
экземпляр процесса (process instance). Последний сохраняет состояние, связанное с выпол-
нением процесса, запущенного при помощи инициализирующего сообщения. Состояние
включает в себя текущий этап выполнения процесса и любые сопутствующие данные.
Каждый экземпляр процесса обладает уникальным идентификатором процесса.
Важно различать концепции экземпляра процесса и определения процесса (также на-
зываемого шаблоном процесса). Определение процесса (process definition) — это конструк-
328
Глава 7. Маршрутизация сообщений
ция, задающая последовательность шагов, которые должны быть выполнены в ходе про-
цесса. В объектно-ориентированном программировании определению процесса соответ-
ствует понятие класса. Экземпляр процесса, в свою очередь, представляет собой актив-
ное выполнение конкретного определения процесса. В объектно-ориентированном
программировании ему соответствует понятие экземпляра класса, т.е. объекта. На рис. 7.30
изображен простой пример определения процесса с двумя экземплярами процесса.
Первый экземпляр (идентификатор процесса 1234) в настоящий момент выполняет
шаг 1. Второй экземпляр процесса (идентификатор процесса 5678) параллельно выпол-
няет шаги 2 и 5.
Экземпляры процесса
Идентификатор процесса -1234
Текущий шаг -1
Идентификатор процесса - 5678
Текущий шаг - 2,5
Диспетчер процессов
Рис. 7.30. Два экземпляра процесса, созданных на основе одного и того же определения процесса
Корреляция
Поскольку в системе могут параллельно выполняться несколько экземпляров процес-
са, диспетчеру процессов (Process Manager) нужен способ сопоставления входящего сооб-
щения с правильным экземпляром процесса. Если в примере из предыдущего раздела
диспетчер процессов получит сообщение от одного из обрабатывающих компонентов, как
он узнает, для какого именно экземпляра процесса оно предназначается? Разные экзем-
пляры процесса могут проходить через один и тот же этап обработки, поэтому диспетчер
процессов не сможет определить нужный экземпляр по имени канала или типу сообще-
ния. Прочитав эти слова многие из вас уже наверняка вспомнили об идентификаторе
корреляции (Correlation Identifier, с. 186). Идентификатор корреляции позволяет компонен-
ту сопоставлять полученный ответ с некогда отправленным запросом. Для этого в сооб-
щение с ответом помещается уникальный идентификатор, который каким-то образом
связывает его с исходным запросом. Используя идентификатор корреляции, компонент
может правильно сопоставить ответ с запросом даже в том случае, если ранее он отправил
несколько запросов, однако ответы на них прибывают совсем в другом порядке. Анало-
гичный механизм сопоставления требуется и диспетчеру процессов. Когда диспетчер про-
цессов получает сообщение от обрабатывающего компонента, он должен уметь сопоста-
вить это сообщение с экземпляром процесса, который и отправил данное сообщение
указанному компоненту. С этой целью диспетчер процессов должен вставлять в сообще-
ния, отправляемые обрабатывающим компонентам, некоторый идентификатор корреля-
ции. Закончив обработку сообщения, компонент тоже должен вставить в свой ответ,
отправляемый диспетчеру, идентификатор корреляции. В качестве идентификатора кор-
реляции таких сообщений можно использовать уникальный идентификатор процесса.
Диспетчер процессов (Process Manager)
329
Сохранение состояния в сообщениях
Очевидно, что одним из наиболее важных свойств диспетчера процессов (Process
Manager) является управление состоянием. Как же без этого обходились предыдущие
шаблоны, спросите вы? В классической архитектуре каналов и фильтров (Pipes and Filters,
с. 102) состоянием управляют каналы, по которым передаются сообщения. Для большей
наглядности снова вернемся к предыдущему примеру. Если бы нам требовалось реализо-
вать процесс с помощью фиксированной последовательности компонентов, связанных
между собой каналами сообщений (Message Channel, с. 93), он выглядел бы примерно так,
как показано на рис. 7.31. Пусть данная система находится в том же состоянии, что и
система на рис. 7.30. Тогда первый экземпляр процесса соответствует сообщению с иден-
тификатором 1234, которое находится в канале, ожидая, пока его обработает компо-
нент 1. Второй экземпляр процесса, в свою очередь, соответствует двум сообщениям
с идентификатором 5678, которые ожидают своей обработки компонентами 2 и 5. Когда
компонент 1 потребит сообщение и завершит его обработку, он отправит новое широко-
вещательное сообщение компонентам 2 и 4, что в точности соответствует поведению
диспетчера процессов на рис. 7.30.
Рис. 7.31. Сохранение состояния с помощью каналов
Схема движения сообщений, показанная на рис. 7.31, поразительно напоминает
диаграммы деятельности UML, которые часто используют для моделирования поведения
диспетчера процессов. Вообще говоря, с помощью такой абстрактной нотации можно мо-
делировать поведение системы на этапе проектирования, а затем решать, какой архитек-
турный стиль выбрать для ее реализации: распределенную архитектуру каналов и фильт-
ров или же архитектуру “звезда” с использованием центрального диспетчера процессов.
Хотя объем этой книги не позволяет нам углубляться в недра проектирования моделей
процессов, отметим, что многие из описанных в ней шаблонов широко применяются при
проектировании таких моделей.
На практике центральная архитектура на основе диспетчера процессов и распределен-
ная архитектура каналов и фильтров в чистом виде встречаются крайне редко (как, впро-
чем, и большинство других архитектурных решений). Во многих случаях имеет смысл ис-
пользовать несколько диспетчеров процессов, каждый из которых будет отвечать за кон-
кретный аспект более крупного процесса. Диспетчеры процессов, в свою очередь, могут
взаимодействовать между собой в рамках архитектуры каналов и фильтров.
330
Глава 7. Маршрутизация сообщений
Явное управление состоянием внутри диспетчера процессов может потребовать созда-
ния более сложных компонентов, зато облегчит генерацию отчетов о выполнении про-
цессов. К примеру, в большинстве реализаций диспетчера процессов предусматривается
возможность запрашивать состояние экземпляра процесса. Это позволяет легко увидеть,
сколько заказов в текущий момент ожидают своего подтверждения или были отложены
из-за нехватки товара на складах. Кроме того, каждому клиенту можно сообщить о со-
стоянии его заказа. При использовании фиксированной последовательности каналов и
компонентов для получения той же самой информации пришлось бы исследовать все кана-
лы сообщений. Описанное свойство диспетчера процессов играет важную роль не только для
получения отчетов, но и для отладки системы. Использование центрального диспетчера
процессов облегчает извлечение текущего состояния процесса и связанных с ним данных.
Отладка полностью распределенной архитектуры обычно оказывается куда более сложной
задачей и практически невозможна без привлечения таких механизмов, как журнал достав-
ки сообщения (Message History, с. 561) м хранилище сообщений (Message Store, с. 565).
Создание определения процесса
Большинство коммерческих пакетов интеграции включает в себя компонент диспет-
чер процессов (Process Manager) в сочетании с визуальными средствами, предназначенны-
ми для моделирования определений процессов. Почти все упомянутые визуальные сред-
ства используют нотацию, аналогичную диаграммам деятельности UML. Это не удиви-
тельно, поскольку семантика диспетчера процессов очень похожа на семантику диаграмм
деятельности. Кроме того, диаграммы деятельности являются хорошим наглядным пред-
ставлением параллельно выполняющихся ^адач. До недавнего времени большинство
производителей средств интеграции преобразовывали визуальную нотацию во внутрен-
нее, специфичное для конкретного производителя определение процесса, которое долж-
но было выполняться механизмом выполнения процессов. Однако тенденция к стандар-
тизации разнообразных аспектов распределенных архитектур с четким сдвигом в сторону
Web-служб высветила важную роль определений процессов. Последние получили свое
отображение сразу в трех “языках” Web-служб. Корпорация Microsoft определила язык
XLANG, который поддерживается семейством ее средств моделирования BizTalk. IBM, в
свою очередь, предложила черновой вариант спецификации WSFL (Web Services Flow
Language) [46]. Некоторое время назад обе компании решили объединить свои усилия,
результатом чего стало появление на свет стандарта BPEL4WS (Business Process Execution
Language for Web Services) [4]. BPEL4WS —- это мощный язык, описывающий модель
процессов в виде документа XML. Цель состоит в том, чтобы определить стандартизиро-
ванный язык, выполняющий роль посредника между средствами моделирования процес-
сов и механизмами выполнения диспетчеров процессов. Используя такой язык, можно
было бы смоделировать процессы с помощью продуктов производителя А, а затем вы-
полнять их с помощью механизмов выполнения процессов производителя Б. Более под-
робно о влиянии стандартов Web-служб на интеграцию будет рассказываться в главе 14.
Семантику определения процесса можно описать довольно простыми терминами. Ба-
зовой элементарной единицей в определении процесса является операция (activity), кото-
рую также часто называют задачей (task) или действием (action). Операция может состоять
в том, чтобы отправить сообщение другому компоненту, подождать входящее сообщение
или выполнить конкретную внутреннюю функцию (например, преобразовать сообщение
с помощью транслятора сообщений — Message Translator, с. 115). Операции могут быть
Диспетчер процессов (Process Manager)
331
соединены друг с другом последовательно или параллельно (с помощью ветвлений и объ-
единений). Наличие ветвления (fork) позволяет выполнять несколько операций одновре-
менно. Ветвление семантически эквивалентно каналу “публикация-подписка” (Publish-
Subscribe Channel, с. 134) в жестко связанной архитектуре каналов и фильтров (Pipes and
Filters, с. 102). Объединение (join) синхронизирует параллельные потоки выполнения, соз-
давая единый поток. Выполнение процесса после объединения может продолжаться
только в том случае, если каждый из параллельных потоков завершил выполнение всех
возложенных на него действий. В архитектуре каналов и фильтров функции объединения
часто выполняет агрегатор (Aggregator, с. 283). В шаблоне процесса также иногда требует-
ся употребить операцию выбора (branch), т.е. задать точку принятия решения, чтобы путь
выполнения мог меняться в зависимости от содержимого некоторого поля сообщения.
Эта операция эквивалентна маршрутизатору на основе содержимого (Content-Based Router,
с. 247). Многие средства моделирования также предусматривают возможность проекти-
рования циклов, однако последние, по сути, представляют собой частный случай выбора.
На рис. 7.32 продемонстрировано семантическое сходство между определением процесса
(представленным в виде диаграммы деятельности UML) и архитектурой каналов и фильт-
ров, реализованной с помощью языка шаблонов, описанных в этой книге. Сходство меж-
ду приведенными схемами действительно налицо, даже несмотря на то, что физические
реализации весьма и весьма отличаются друг от друга.
Рис. 7.32. Пример диаграммы деятельности UML и соответствующей реализации
архитектуры каналов и фильтров
332
Глава?. Маршрутизация сообщений
Сравнение диспетчера процессов с другими шаблонами
Мы уже неоднократно сравнивали базовую архитектуру каналов и фильтров (Pipes and
Filters, с. 102) с картой маршрутизации (Routing Slip, с. 314) и диспетчером процессов
(Process Manager). Пришло время подытожить ключевые сходства и отличия между ука-
занными шаблонами и подчеркнуть основные моменты, касающиеся выбора той или
иной архитектуры. Все они приведены в табл. 7.4.
Таблица 7.4. Сравнение каналов и фильтров, карты маршрутизации и диспетчера
процессов
Распределенные каналы и фильтры Карта маршрутизации Центральный диспетчер процессов
Поддерживает сложные потоки сообщений Поддерживает только простые, линейные потоки Поддерживает сложные потоки сообщений
Сложно изменить путь следования сообщений Легко изменить путь следования сообщений Легко изменить путь следования сообщений
Нет центральной точки сбоя Потенциальная точка сбоя (составление таблицы маршрутизации) Потенциальная точка сбоя
Распределенная архитектура (крайне эффективна во время выполнения) Почти полностью распределенная архитектура Архитектура “звезда” (может привести к появлению “узкого места”)
Нет центральной точки администрирования и отчетности Центральная точка администрирования, но нет центральной точки отчетности Центральная точка администрирования и отчетности
Наличие центральной точки контроля и управления состоянием также может озна-
чать появление центральной точки сбоя или “узкого места” производительности.
По этой причине большинство реализаций диспетчера процессов позволяет сохранять со-
стояние экземпляров процессов в некотором постоянном хранилище, например в файле
или в базе данных. В этом случае реализация может задействовать механизмы хранения
избыточных данных, подобные тем, которые обычно применяются в СУБД корпоратив-
ного уровня. Широкое распространение также получила идея одновременного запуска
нескольких диспетчеров процессов. В общем случае реализовать параллельное функцио-
нирование диспетчеров процессов несложно, поскольку экземпляры процесса не зависят
друг от друга. Это позволяет распределить экземпляры процесса между несколькими ме-
ханизмами выполнения процессов. Если механизм выполнения процессов сохраняет всю
информацию о состоянии в совместно используемой базе данных, система может стать
достаточно надежной для того, чтобы пережить сбой механизма выполнения процес-
сов — выполнение процесса будет тут же подхвачено другим аналогичным механизмом.
Недостатком описанного подхода является необходимость внесения в центральную базу
данных состояния каждого экземпляра процесса после каждого этапа обработки.
Это может легко превратить базу данных в новое “узкое место” производительности.
Как это часто бывает, проектировщику приходится искать баланс между производитель-
ностью, надежностью, стоимостью и простотой поддержки.
Диспетчер процессов (Process Manager)
333
Пример: кредитный брокер
В асинхронной реализации кредитного брокера с помощью MSMQ (см. главу 9) присут-
ствует простой диспетчер процессов (Process Manager). В этом примере функциональность
диспетчера процессов создается “с нуля” путем написания классов C# как для самого
диспетчера, так и для определений процессов. Реализация того же примера с помощью
TIBCO ActiveEnterprise (глава 9) получена с помощью коммерческого средства управле-
ния процессами.
Пример: Microsoft BizTalk Orchestration Designer
Большинство коммерческих средств интеграции обладает встроенными функциями про-
ектирования и выполнения процессов. К примеру, пользователи продуктов Microsoft
BizTalk могут создавать определения процессов с помощью средства Orchestration
Designer, встроенного в среду разработки Visual Studio .NET.
В простом примере, показанном на рис. 7.33, процесс получает сообщение с заказом и
выполняет две параллельные операции. В ходе первой из них создается сообщение с за-
просом к системам управления складскими запасами, а в ходе второй — сообщение
с запросом к системе кредитования. Получив ответы на оба сообщения, процесс продол-
жает свое выполнение. Наличие визуальной нотации сильно повышает читабельность
определения процесса.
Рис. 7.33. Окно средства Orchestration Designer из пакета Microsoft BizTalk 2004
334
Глава 7. Маршрутизация сообщений
Брокер сообщений (Message Broker)
Многие шаблоны проектирования, о которых рассказывалось в этой главе, описыва-
ют способы маршрутизации сообщения в требуемую точку назначения без какого-либо
участия со стороны приложения-отправителя. Большинство этих шаблонов посвящено
конкретным типам логики маршрутизации. В совокупности, однако, они могут решить
более глобальную проблему.
Как отделить пункт назначения сообщения от его отправителя, сохраняя центра-
лизованный контроль над сообщениями?
Использование простого канала сообщений (Message Channel, с. 93) само по себе уже
обеспечивает наличие уровня косвенности между отправителем и получателем — отпра-
витель знает только о канале, но не о получателе. Однако, если у каждого получателя бу-
дет собственный канал, такой уровень косвенности во многом потеряет свою значи-
мость. Вместо адреса получателя отправитель должен будет знать имя канала, соответст-
вующего этому получателю.
Практически все решения, основанные на обмене сообщениями (кроме разве что са-
мых тривиальных соединяют между собой несколько различных приложений. Если бы
для соединения каждой пары приложений создавались отдельные каналы сообщений,
число каналов стремительно разрослось бы до ужасающей величины и превратило инте-
грационное решение в нечто, напоминающее тарелку со спагетти (рис. 7.34).
Рис. 7.34. Интеграционное “спагетти”, образованное множеством соединений “точка-точка
Брокер сообщений (Message Broker)
335
На рис. 7.34 показано, что создание прямых каналов между каждой парой отдельных
приложений может вызвать неконтролируемый рост их количества и свести на “нет”
главные преимущества маршрутизации сообщений по каналам. Интеграционные архи-
тектуры такого типа часто появляются на свет в результате постепенного расширения не-
когда небольшой системы. Вначале системе обслуживания клиентов нужно было об-
щаться только с системой бухгалтерского учета. Затем от системы обслуживания клиен-
тов стали также требовать, чтобы она извлекала информацию из системы управления
складскими запасами, а системе отгрузки товара поручили обновлять систему бухгалтер-
ского учета, внося в нее расходы по погрузке, и т.д. Как видим, очередное добавление в
систему “еще одного элемента” может легко нарушить общую целостность решения.
Явное взаимодействие приложения с остальными системами значительно затрудняет
поддержку решения. К примеру, если в системе обслуживания клиентов меняется адрес
покупателя, она должна разослать соответствующее уведомление всем системам, в кото-
рых хранятся копии этого адреса. Кроме того, каждый раз при добавлении новой систе-
мы, использующей адреса покупателей, в систему обслуживания клиентов придется вно-
сить изменения.
Некоторое подобие базовой маршрутизации сообщений обеспечивают каналы
“публикация-подписка" (Publish-Subscribe Channel, с. 134). Сообщение, размещенное в та-
ком канале, доставляется каждому приложению, подписавшемуся на этот канал. Это хо-
рошо подходит для простых сценариев широковещательной рассылки, но в реальной
жизни правила маршрутизации обычно имеют куда более сложную структуру. К приме-
ру, выбор системы, в которую необходимо направить входящее сообщение с заказом,
может зависеть от размера или характера этого заказа. Чтобы не налагать на приложение
лишние обязанности по определению пункта назначения сообшения, связуюшее
ПО должно включать в себя маршрутизатор сообщений (Message Router, с. 109), который
может распределять сообшения по требуемым пунктам назначения.
Шаблоны маршрутизации сообшений, рассмотренные ранее в этой главе, помогают
отделить отправителя от получателей. Так, список получателей (Recipient List, с. 264)
позволяет “забрать” у отправителя знания о получателях и перенести эти знания в слой
связующего ПО. Перемещение логики маршрутизации в слой связующего ПО имеет сра-
зу два благоприятных последствия. Во-первых, многие коммерческие пакеты связуюшего
ПО и средств интеграции включают в себя инструменты и библиотеки, предназначенные
специально для выполнения маршрутизации. Это облегчает кодирование, поскольку
разработчику больше не нужно вручную описывать событийно управляемые потребители
(Event-Driven Consumer, с. 511), управление потоками или другие аспекты, касаюшиеся
конечной точки сообщения (Message Endpoint, с. 124). Во-вторых, реализация логики мар-
шрутизации внутри слоя связующего ПО позволяет сделать ее “умнее”, чем это было бы
возможно в рамках самого приложения. Например, использование динамического списка
получателей избавляет от необходимости модифицировать код интеграционного реше-
ния при добавлении в него новых систем.
Следует, однако, отметить, что управлять большим количеством отдельных маршру-
тизаторов сообщений не намного проще, чем интеграционным “спагетти”, от которого
мы пытались уйти в самом начале раздела.
336
Глава?. Маршрутизация сообщений
Воспользуйтесь централизованным брокером сообщений (Message Broker) —
компонентом, который получает сообщения от разных отправителей, определяет
требуемые пункты назначения и распределяет сообщения по нужным каналам.
Реализуйте внутренний механизм брокера сообщений с помощью других мар-
шрутизаторов сообщений (Message Router, с. 109).
Использование централизованного брокера сообщений часто определяют как цен-
трально-лучевую топологию, или архитектурный стиль “звезда” (надо сказать, весьма
наглядное название).
Шаблон брокер сообщений имеет несколько иную направленность, чем большинство
шаблонов маршрутизации, описанных в этой главе. В отличие от них он является
не шаблоном проектирования, а архитектурным шаблоном, следовательно, его можно
сравнить с архитектурным стилем каналы и фильтры (Pipes and Filters, с. 102). Напомним,
что последний описывает фундаментальный способ связывания отдельных компонентов
для формирования более сложных потоков сообщений. В отличие от него брокер сообще-
ний изначально касается крупных решений и направлен на борьбу с неизбежной сложно-
стью управления такими системами.
Брокер сообщений не является цельным, неделимым компонентом. Напротив, он име-
ет сложную внутреннюю структуру, в которой используется целый ряд шаблонов мар-
шрутизации, представленных в этой главе. Решив использовать брокер сообщений в каче-
стве архитектурного шаблона, для его реализации можно выбрать любую подходящую
разновидность или разновидности маршрутизатора сообщений.
Преимущество единой точки поддержки, которую обеспечивает брокер сообщений,
может превратиться в его недостаток. Если все сообщения системы проходят через один
брокер сообщений, последний почти наверняка будет представлять собой “узкое место”.
Существует несколько приемов, позволяющих обойти эту проблему. Прежде всего отме-
тим, что брокер сообщений как архитектурный шаблон подразумевает лишь разработку
одного компонента, выполняющего маршрутизацию. В нем не содержится никаких ука-
заний насчет того, сколько экземпляров этого компонента может быть развернуто в сис-
теме с целью эксплуатации. Если структура брокера сообщений не предусматривает сохра-
Брокер сообщений (Message Broker)
337
нение состояния (т.е. если он состоит исключительно из компонентов, работающих без
сохранения состояния), то можно безо всяких опасений развернуть несколько экземпля-
ров брокера для улучшения пропускной способности системы. Свойства канала “точка-
точка” (Point-to-Point Channel, с. 131) гарантируют, что каждое входящее сообщение будет
потреблено только одним экземпляром брокера сообщений. Кроме того, в реальной жизни
итоговое решение почти всегда оказывается комбинацией шаблонов. Аналогичным обра-
зом во многих сценариях интеграции имеет смысл разработать несколько разных броке-
ров сообщений, каждый из которых будет специализироваться на небольшой порции ре-
шения. Это позволит избежать создания некоего “сверхброкера сообщений”, структура
которого окажется непомерно сложной для управления и поддержки. Обратной стороной
описанного подхода, очевидно, является потеря единой точки поддержки и потенциаль-
ное появление новой разновидности интеграционного “спагетти”, на сей раз образован-
ного многочисленными брокерами сообщений. В качестве превосходного архитектурного
стиля, в котором используется комбинация брокеров сообщений, можно предложить ие-
рархию брокеров сообщений, показанную на рис. 7.35. Такое решение напоминает конфи-
гурацию сети, состоящей из отдельных подсетей. Если сообщение должно быть передано
только между двумя приложениями, принадлежащими одной и той же подсети, управ-
лять его маршрутизацией может локальный брокер сообщений. Если же сообщение на-
правляется в другую подсеть, локальный брокер сообщений передает его центральному
брокеру сообщений, который и определяет окончательную точку назначения сообщения.
Центральный брокер сообщений выполняет те же функции, что и локальный, но отвечает
за разобщение не отдельных приложений, а целых подсистем, каждая из которых состоит
из нескольких приложений.
Рис. 7.35. Иерархия брокеров сообщений обеспечивает разобщение приложений и подсистем
без создания единственного “сверхброкера”
Поскольку назначение брокера сообщений состоит в том, чтобы максимально ослабить
связь между отдельными приложениями, ему обычно приходится иметь дело с преобра-
зованием сообщений из одного формата данных в другой. Абстрагирование брокером
маршрутизации сообщений никак не поможет приложению-отправителю, если тому
338
Глава?. Маршрутизация сообщений
необходимо отослать сообщение в (предположительно неизвестном) формате приложе-
ния-получателя. Для решения этих проблем применяется ряд шаблонов преобразования
сообщений, о которых будет рассказываться в следующей главе. Довольно часто внутри
брокера сообщений используется каноническая модель данных (Canonical Data Model, с. 367),
позволяющая избежать знаменитой проблемы “N2” (с увеличением числа получателей
системы число трансляторов, необходимое для преобразования сообщений между каж-
дой парой получателей, растет в квадрате).
Пример: коммерческие средства интеграции
Большинство коммерческих пакетов интеграции снабжено средствами, помогающими
значительно упростить создание брокеров сообщений (Message Broker) для интеграционных
решений. Как правило, такие пакеты обладают рядом возможностей, предназначенных
для поддержки разработки и развертывания брокеров сообщений. Ниже перечислены
основные из них.
1. Встроенный код конечной точки. Большинство коммерческих пакетов средств
интеграции включает в себя готовый код, описывающий отправку и получение
сообщений через шину сообщений. Разработчику не нужно заботиться о написа-
нии кода, касающегося транспортных аспектов системы.
2. Визуальные средства проектирования. Коммерческие средства интеграции позво-
ляют разработчику проектировать структуру брокера сообщений, используя много-
численные визуальные компоненты, в том числе маршрутизаторы, точки приня-
тия решений и преобразователи. Подобные средства значительно повышают на-
глядность перемещения сообщений и сводят объем “ручного” кодирования таких
компонентов к написанию одной-двух строк кода (обычно это функция оценки
или некоторое правило).
3. Поддержка во время выполнения. Многие коммерческие пакеты средств интегра-
ции обладают развитым механизмом поддержки, помогающим как развертывать
решение в рабочей среде, так и осуществлять мониторинг потока сообщений,
проходящих через брокер сообщений.
Глава 8
Преобразование сообщений
Введение
В приложениях, которые необходимо интегрировать посредством системы обмена со-
общениями, редко используются одинаковые форматы данных. Об этом уже говорилось
в разделе, посвященном транслятору сообщений (Message Translator, с. 115). К примеру,
понятие объекта “клиент” в системе бухгалтерского учета существенно отличается от та-
кового в системе управления взаимоотношениями с клиентами. Вдобавок ко всему в од-
ной системе данные могут храниться в виде реляционной структуры, тогда как в другой
для организации данных будут применяться “плоские” файлы или документы XML.
Использование готовых приложений часто означает невозможность модифицировать их
для облегчения взаимодействия с другими системами. Вместо этого интеграционное
решение должно уметь приспосабливаться к различиям между неоднородными система-
ми и устранять связанные с этим проблемы. Общим решением, направленным на избав-
ление от проблем, касающихся различий между системами, является транслятор сообще-
ний. В данной главе рассматривается несколько разновидностей этого шаблона, приме-
няющихся для решения более конкретных задач.
Большинство систем обмена сообщениями предъявляют специфические требования
к формату и содержимому заголовка сообщения. Мы предлагаем поместить полезную
информацию сообщения в оболочку конверта (Envelope Wrapper, с. 342), удовлетворяю-
щую требованиям инфраструктуры обмена сообщениями. Если на пути своего следова-
ния сообщение вынуждено проходить через несколько подобных инфраструктур, совмес-
тимости с требованиями последних можно добиться путем комбинирования нескольких
оболочек конверта.
Если система назначения работает с полями данных, которые не были включены в
заголовок сообщения исходной системой, для обработки сообщения понадобится расши-
ритель содержимого (Content Enricher, с. 348). Последний находит недостающую инфор-
мацию или вычисляет ее на основе имеющихся данных. Фильтр содержимого (Content
Filter, с. 354) выполняет прямо противоположное действие, т.е. удаляет из сообщения
нежелательные данные. Квитанция (Claim Check, с. 358) также удаляет данные из сообще-
ния, однако сохраняет их для последующего извлечения. И наконец, нормализатор
(Normalizer, с. 364) преобразует поступающие сообщения в единый формат.
340
Глава 8. Преобразование сообщений
Устранение зависимостей
Преобразование сообщений — один из основных моментов интеграции корпоратив-
ных приложений. Канал сообщений (Message Channel, с. 93) и маршрутизатор сообщений
(Message Router, с. 109) устраняют базовые зависимости между приложениями, избавляя
одно приложение от необходимости знать местонахождение другого. Приложение-
отправитель размещает сообщение в канале сообщений, не беспокоясь о том, какое при-
ложение его получит. К сожалению, данный метод не избавляет от целого ряда зависимо-
стей, связанных с расхождениями в форматах сообщений. Если приложение-отправитель
должно преобразовывать сообщения в формат, понятный приложению-получателю,
говорить о разобщении приложений путем внедрения канала сообщений — по меньшей
мере, наивно. Любая модификация приложения-получателя или замена его другим при-
ложением приведет к необходимости внесения изменений в приложение-отправитель.
Устранить такую зависимость помогает транслятор сообщений (Message Translator, с. 115).
Управление метаданными
Преобразование сообщений из одного формата в другой выполняется путем обработ-
ки метаданных (служебной информации, описывающей фактический формат данных со-
общения). Пусть в сообщении, отправленном одним приложением другому, говорится
о том, что клиент с идентификатором 123 переехал из Сан-Франциско, штат Калифор-
ния, в Роли, штат Северная Каролина. Тогда соответствующие метаданные могут описы-
вать, что в сообщении об изменении адреса содержится числовое поле, значением кото-
рого является идентификатор клиента, а также два текстовых поля длиной до
40 символов каждое, в которых хранятся названия города и штата соответственно.
Метаданные играют настолько важную роль в интеграции корпоративных приложе-
ний, что большинство интеграционных решений можно рассматривать как взаимодейст-
вие двух параллельных систем. Одна из систем будет работать с фактическими данными
сообщениями, а другая — с метаданными. Многие шаблоны, используемые для форми-
рования потока данных сообщений, могут применяться и для управления потоком мета-
данных. Например, адаптер канала (Channel Adapter, с. 154) способен не только переме-
щать сообщения между приложением и системой обмена данными, но и извлекать мета-
данные из внешних приложений, загружая их в центральный репозиторий метаданных.
Используя указанный репозиторий, разработчики интеграционных решений могут опре-
делять преобразование метаданных приложения в каноническую модель данных (Canonical
Data Model, с. 367).
На рис. 8.1 изображен пример интеграции двух приложений, которые должны обме-
ниваться сведениями о клиентах. В каждой из систем информация о клиенте организо-
вана по-разному. К примеру, в программе А имя и фамилия клиента хранятся в двух от-
дельных полях, тогда как в программе Б эти же данные занимают одно поле. Кроме того,
программа А работает с индексом местности, в которой проживает клиент, а програм-
ма Б — с аббревиатурой штата. Сообщения, передаваемые программой А программе Б,
должны подвергнуться преобразованию, чтобы программа Б получила данные в понят-
ном для себя виде. Реализация такого преобразования значительно упрощается, если
адаптеры канала смогут извлекать и метаданные, например данные, описывающие фор-
мат сообщения. Извлеченные метаданные могут быть загружены в репозиторий, что су-
щественно упростит настройку и проверку правильности транслятора сообщений
Введение
341
(Message Translator, с. 115). Метаданные можно хранить в различных форматах. Так, для
хранения метаданных XML-сообщений применяется XSD. Другие EAI-средства работа-
ют с закрытыми форматами метаданных, но позволяют администраторам импортировать
и экспортировать метаданные в ряд других форматов.
Поток метаданных на стадии проектирования
Программа А
Метаданные
программы Б
Репозиторий
метаданных
String(40)
String(40)
Integer
Метаданные
программы A
String(80) Name
String(2) State
FirstName
LastName
ZIP
Транслятор сообщений
Адаптер
канала
Адаптер
канала
Name=Joe Doe
State=CA
FirstName=Joe
LastName=Doe
ZIP=94123
Поток сообщений на стадии выполнения
Рис. 8.1. Интеграция метаданных
Настроить ।
Программа Ь
Преобразование данных в других схемах интеграции
Многие принципы, реализованные в рассматриваемых здесь шаблонах преобразова-
ния, вполне применимы и к другим интеграционным решениям, не основанным на об-
мене сообщениями. К примеру, шаблон передача файла (File Transfer, с. 80) выполняет
функции обмена файлами между системами. Удаленный вызов процедуры (Remote Procedure
Invocation, с. 85) должен отсылать запросы в формате, применяемом вызываемой служ-
бой, даже если внутри вызывающего приложения данные организованы по-другому.
Для выполнения указанных действий вызывающему приложению обычно приходится
выполнять преобразование данных. Некоторые из наиболее совершенных на сегодняш-
ний день механизмов преобразования данных (такие, как Informatica и Data Mirror)
включены в набор средств ETL. Обычно подобные средства занимаются преобразовани-
ем не отдельных сообщений, а сразу больших порций данных.
В этой главе рассматриваются разновидности базового шаблона транслятор сообще-
ний (Message Translator, с. 115). Мы не станем углубляться в детали структурных преобра-
зований между сущностями (например, как преобразовать данные из одной модели в
другую, если в первой модели клиент и адрес связаны отношениями “многие-ко-
многим”, а во второй модели поле адреса входит в запись о клиенте.) Об этом лучше про-
читать в [21]. Несмотря на солидный возраст, эта классическая книга о представлении
данных и отношений между ними до сих пор не утратила своей актуальности.
342
Глава 8. Преобразование сообщений
Оболочка конверта (Envelope Wrapper)
В большинстве систем обмена сообщениями данные сообщения делятся на заголовок
и тело. Это отражено в шаблоне сообщение (Message, с. 98). Заголовок включает в себя
служебные поля, используемые инфраструктурой обмена сообщениями для управления
потоком последних. Между тем большинство корпоративных приложений, объединяе-
мых интеграционным решением, не умеет работать с подобными дополнительными эле-
ментами данных. Более того, такие поля часто рассматриваются ими как неправильные,
поскольку не соответствуют формату сообщений, используемому самим приложением.
С другой стороны, компоненты системы обмена сообщениями, отвечающие за маршру-
тизацию сообщений между приложениями, требуют обязательного наличия в заголовке
определенных полей и при отсутствии таковых сочтут сообщение ошибочным.
Как реализовать обмен сообщениями между существующими приложениями, если
система обмена сообщениями предъявляет особые требования к формату
последних, например обязательное шифрование тела сообщения или наличие
в заголовке определенных полей?
Предположим, что система обмена сообщениями функционирует на основе закрытой
схемы безопасности. Чтобы сообщение было принято на обработку другими компонен-
тами системы, оно должно содержать некоторые учетные данные. Такая схема безопас-
ности помогает бороться с неавторизованными пользователями, “вбрасывающими”
в систему свои сообщения. Вдобавок ко всему содержимое сообщения может быть за-
шифровано, чтобы предотвратить несанкционированное прослушивание канала, что яв-
ляется особенно важным при реализации механизмов публикации-подписки. К сожале-
нию, существующие приложения, интегрируемые посредством системы обмена сообще-
ниями, редко “осведомлены” о таких понятиях, как идентификация пользователя или
шифрование сообщений. В результате необработанные сообщения, отправленные ис-
ходным приложением, должны быть преобразованы в сообщения, удовлетворяющие
требованиям системы обмена сообщениями.
В некоторых больших компаниях функционирует сразу несколько инфраструктур об-
мена сообщениями. Для перенаправления сообщения из одной инфраструктуры в другую
может применяться мост обмена сообщениями (Messaging Bridge, с. 159). В каждой системе
обмена сообщениями обычно выдвигаются собственные требования к формату тела и
заголовка сообщения. Для сравнения снова обратимся к сценарию передачи данных по-
средством существующих протоколов на основе TCP/IP. В большинстве случаев связь с
другой системой ограничивается конкретным протоколом, например Telnet или SSH
(Secure Shell). Чтобы системы смогли взаимодействовать, скажем, и по протоколу FTP,
данные FTP нужно инкапсулировать в пакеты, понятные поддерживаемому протоколу.
В точке назначения содержимое пакета будет извлечено. Такой процесс называется
туннелированием (tunneling).
Оболочка конверта (Envelope Wrapper)
343
Инкапсулируя один формат сообщения внутри другого, система может потерять дос-
туп к части полезной информации. Большинство систем обмена сообщениями разрешает
своим компонентам — например, маршрутизатору сообщений (Message Router, с. 109) —
осуществлять доступ только к тем полям данных, которые являются частью определен-
ного системой заголовка сообщения. Если одно сообщение будет упаковано в поле дан-
ных внутри другого сообщения, указанный компонент не сможет добраться до полей ис-
ходного сообщения, необходимых для маршрутизации или преобразования последнего.
По этой причине некоторые поля данных должны быть вынесены из исходного сообще-
ния в заголовок упакованного сообщения.
Используйте оболочку конверта (Envelope Wrappet}, чтобы упаковать данные при-
ложения в формат (“конверт"), совместимый с требованиями инфраструктуры обме-
на сообщениями. Распакуйте сообщение, когда оно прибудет в точку назначения.
Система обмена сообщениями
Процесс упаковки сообщения в конверт с последующей распаковкой состоит из пяти
шагов.
1. Исходное приложение публикует сообщение в необработанном виде. Формат
такого сообщения обычно определяется характером приложения и не соответст-
вует требованиям инфраструктуры обмена сообщениями.
2. Упаковщик принимает необработанное сообщение и преобразует его в формат,
удовлетворяющий требованиям системы обмена сообщениями. Процесс упаков-
ки может включать в себя добавление полей в заголовок, шифрование сообще-
ния, внедрение учетных данных для проверки системой безопасности и т.п.
3. Система обмена сообщениями передает упакованное сообщение в пункт назначения.
4. Доставленное сообщение попадает к распаковщику. Последний убирает измене-
ния, внесенные упаковщиком: удаляет ненужные поля заголовка, расшифровыва-
ет сообщение или проверяет учетные данные.
5. Сообщение “в чистом виде” доставляется получателю.
344
Глава 8. Преобразование сообщений
В конверт обычно упаковывается как заголовок сообщения, так и его тело, т.е. полез-
ная информация. Для большей наглядности заголовок можно сравнить с надписью на
почтовом конверте, которая применяется работниками почтового отделения для достав-
ки письма в нужное место. Содержимое конверта — это и есть тело сообшения, или по-
лезная информация. Она не интересует (а точнее, почти не интересует) почтовую службу
до тех пор, пока не дойдет до пункта назначения.
Упаковщик часто добавляет к необработанному сообщению новую информацию.
К примеру, чтобы внутреннее сообщение компании можно было отослать по почте,
необходимо знать индекс места назначения. В этом смысле оболочка конверта напомина-
ет расширитель содержимого (Content Enricher, с. 348). В отличие от последнего, однако,
оболочка конверта не расширяет фактическое содержимое сообщения, а лишь добавляет
сведения, необходимые для маршрутизации, контроля за перемещением и обработки
сообщений. Эти сведения могут быть созданы “на ходу” (например, генерация уникаль-
ного идентификатора сообщения или добавление метки времени), взяты из самой ин-
фраструктуры (например, извлечение контекста безопасности) либо извлечены упаков-
щиком из тела сообщения и вынесены в заголовок (например, ключевое поле, содержа-
щееся в тексте необработанного сообщения). Последнюю операцию часто называют
продвижением (promotion), потому что поле, которое до этого было скрыто в тексте сооб-
щения, “продвигается” в заголовок, в результате чего становится видимым.
Иногда несколько упаковщиков применяются друг за другом (как будет показано
позднее в примере с почтовой системой). В результате оказывается, что полезная инфор-
мация внутри конверта содержит еще один конверт, который, в свою очередь, включает
в себя заголовок и полезную информацию (рис. 8.2).
Рис. 8.2. Последовательное применение упаковщиков приводит к созданию иерархической
структуры конвертов
Оболочка конверта (Envelope Wrapper)
345
Пример: формат сообщений SOAP
Базовый формат сообщений SOAP [36] относительно прост. Он описывает конверт,
содержащий заголовок и тело сообщения. В примере, приведенном ниже, показано, как
описать конверт с заголовком и телом сообщения, внутри которого содержится еще один
конверт с заголовком и телом. “Комбинированное” сообщение отправляется посредни-
ку, который распаковывает внешнее сообщение и пересылает внутреннее сообщение.
Подобное наслоение посредников часто встречается при выходе за так называемую гра-
ницу доверия. Чтобы посредники не увидели тело и заголовок реального сообщения
(например, для сохранения конфиденциальности лица, которому оно отправлено), его
можно закодировать и упаковать в другое сообщение. Получатель распакует сообщение,
декодирует полезную информацию и перешлет незакодированное сообщение в рамках
доверенной среды.
<env:Envelope xmlns:env="http:I/www.w3.org/2001/06/soap-envelope">
<env:Header env:actor="http://example.org/xmlsec/Bob">
<n:forward xmlns:n="http://example.org/xmlsec/forwarding">
<n:window>120</n:window>
</n:forward>
</env:Header>
<env:Body>
<env:Envelope xmlns:env="http://www.w3.org/2001/06/soap-
envelope">
<env:Header env:actor="http://example.org/xmlsec/Alice"/>
<env:Body>
<secret xmlns="http://example.org/xmlsec/message">
The black squirrel rises at dawn</secret>
</env:Body>
</env:Envelope>
</env:Body>
</env:Envelope>
Пример: TCP/IP
Все привыкли считать TCP/IP единым понятием, хотя в действительности этот термин
описывает два протокола. Протокол IP отвечает за базовую адресацию и маршрутизацию,
a TCP обеспечивает надежную установку соединения поверх IP. Согласно многоуровне-
вой модели OSI TCP — это протокол транспортного уровня (transport layer), a IP —
сетевого (network layer). Данные TCP/IP обычно передаются по сети Ethernet, реализую-
щей канальный уровень (data link layer) модели OSI.
Исходя из вышеизложенных соображений, данные приложений сначала упаковыва-
ются в конверт TCP, который затем помещается в конверт IP. Последний, в свою
очередь, упаковывается в конверт Ethernet. Поскольку сети ориентированы на работу
с потоками данных, конверт может состоять из заголовка (header) и окончания (trailer),
отмечающих начало и конец потока данных соответственно. Структура данных приложе-
ния, упакованных для передачи по сети Ethernet, изображена на рис. 8.3.
346
Глава 8. Преобразование сообщений
Рис. 8.3. Данные приложения последовательно упакованы в несколько конвертов для передачи по сети
Итак, данные приложения были последовательно упакованы в три конверта: TCP
(транспортный конверт), IP (сетевой конверт) и Ethernet (канальный конверт). Конверты
TCP и IP состоят только из заголовков, а конверт Ethernet — из заголовка и окончания.
Более подробно о TCP/IP можно прочитать в [38].
Пример: почтовая система
Функцию шаблона оболочка конверта (Envelope Wrapper) можно сравнить с действиями,
выполняемыми при отправке и получении писем (рис. 8.4). Предположим, что сотрудник
компании написал записку, предназначенную для коллеги из другого отдела. Чтобы эта
записка была доставлена, она должна быть “упакована” в стандартный конверт, приме-
няющийся для рассылки корреспонденции внутри компании, на котором должны быть
указаны имя получателя и номер отдела. Если же необходимый отдел находится в другом
здании или даже в другом городе, записка в “корпоративном” конверте будет вложена в
конверт большего размера и отправлена по обычной почте. Согласно требованиям поч-
товой службы США на новом конверте должен быть указан индекс и почтовый адрес.
Итак, дважды упакованное письмо попадает в почтовое отделение, где его решают доста-
вить авиатранспортом. Для этого все письма, предназначенные для доставки в указанный
регион страны, запечатывают в большой пакет со штрих-кодом. В последнем закодировано
трехбуквенное обозначение аэропорта, куда необходимо доставить указанный почтовый
пакет. Когда пакет прибывает в аэропорт назначения, его распаковывают в обратной
последовательности до тех пор, пока не доберутся до исходной записки, которая и переда-
ется получателю. Этот пример хорошо демонстрирует смысл такого понятия, как
туннелирование: внутренняя корреспонденция компании передается в другую часть страны
посредством воздушных грузоперевозок точно так, как пакеты многоадресной рассылки
UDP для передачи в другой сегмент глобальной сети передаются по соединению TCP/IP.
Оболочка конверта (Envelope Wrapper)
347
Рис. 8.4. Передача записки в другой отдел компании по обычной почте
Данный пример также удобен для иллюстрации такой распространенной практики,
как последовательное применение упаковщиков и распаковщиков с использованием
архитектуры каналов и фильтров (Pipes and Filters, с. 102). Сообщения могут упаковывать-
ся в несколько этапов и должны быть распакованы посредством симметричной последо-
вательности действий. В соответствии с концепцией каналов и фильтров независимость
отдельных этапов упаковки и распаковки друг от друга позволяет гибко изменять меха-
низм обмена сообщениями, удаляя из него ненужные шаги. К примеру, шифрование со-
общений может оказаться излишним, если трафик направляется не в Интернет, а в вир-
туальную частную сеть (VPN).
348
Глава 8. Преобразование сообщений
Расширитель содержимого (Content Enricher)
Нередко случается, что получатель сообщения требует больше информации, чем
может предоставить исходная система. В качестве примера рассмотрим три системы,
обменивающиеся сообщениями с адресом клиента. В одной из них используется только
индекс местности, где проживает клиент, потому что разработчики системы сочли, что
информация о городе и штате будет избыточной. Вторая система требует, чтобы адрес
клиента включал в себя не только индекс, но также город и стандартное сокращение
штата. И наконец, третья система работает с адресами произвольной формы (с целью
поддержки адресов, находящихся за пределами США), а потому название штата в ней
пишется полностью. Можно привести и такой пример: система-отправитель работает
с идентификаторами клиентов, а системе-получателю требуются полное имя и адрес кли-
ента. И наконец, еще одна ситуация: пусть сообщение, отправленное системой управле-
ния заказами, содержит только номер заказа. Нам же требуется узнать идентификатор
клиента, сделавшего заказ, чтобы передать его CRM-системе. В реальной жизни подоб-
ных сценариев много, и все они требуют решения проблемы с нехваткой полей в отправ-
ленном сообщении.
Как обеспечить взаимодействие с другой системой, если отправитель сообщения
предоставил не все данные, требующиеся получателю?
Указанная задача является частным случаем транслятора сообщений (Message Translator,
с. 115), поэтому некоторые аспекты последнего с успехом применяются и к ней. С другой
стороны, она слегка отличается от базовых примеров, приведенных в разделе, посвящен-
ном транслятору сообщений. В описании транслятора сообщений предполагалось, что дан-
ные, необходимые получателю, уже содержатся во входящем сообщении, только в невер-
ном формате. В теперешнем примере, однако, простой реорганизации полей сообщения
недостаточно; мы должны самостоятельно дополнить его требуемой информацией.
Рассмотрим пример, изображенный на рис. 8.5. Система календарного планирования в
поликлинике публикует сообщение о том, что пациент совершил плановое посещение вра-
ча. В сообщении содержатся имя пациента, его или ее идентификатор в указанной поли-
клинике (например, номер карточки), а также дата посещения. Система бухгалтерского
учета должна зафиксировать в журнале сведения о посещении врача и уведомить об этом
страховую компанию. Для этого ей требуются имя и фамилия пациента, его номер карточ-
ки социального страхования (SSN) и название страховой компании (insurance carrier).
Между тем в системе календарного планирования такой информации нет; она хранится
в системе обслуживания клиентов. Каковы варианты решения указанной проблемы?
Расширитель содержимого (Content Enricher)
349
Посещение врача
Рис. 8.5. Системе бухгалтерского учета требуется больше информации, чем может
предоставить система календарного планирования
Вариант А. Модифицировать систему календарного планирования с тем, чтобы в ней
сохранялась дополнительная информация. Когда в системе обслуживания клиентов меня-
ются сведения о пациенте (например, из-за того, что пациент перешел под опеку другой
страховой компании), соответствующие изменения должны быть продублированы и в сис-
теме календарного планирования. После этого система календарного планирования сможет
отправить системе бухгалтерского учета сообщение, содержащее всю необходимую инфор-
мацию (рис. 8.6). К сожалению, такой подход обладает двумя существенными недостатка-
ми. Во-первых, он требует внесения изменений во внутреннюю структуру системы кален-
дарного планирования. В большинстве случаев, однако, подобные системы представляют
собой готовые приложения сторонних производителей, следовательно, модифицировать их
под свои нужды нельзя. Во-вторых, даже если система календарного планирования подда-
ется настройке, необходимость внесения в некоторую систему изменений, основанных на
потребностях другой системы, имеет нежелательные последствия. Что если мы решим от-
править пациенту письмо, подтверждающее факт посещения им врача? Придерживаясь
указанного подхода, нам следовало бы снова изменить систему календарного планирова-
ния, чтобы разместить в ней почтовый адрес пациента. Между тем интеграционное реше-
ние гораздо легче обслуживать, если отделить систему календарного планирования от осо-
бенностей приложений, потребляющих сообщения о визите к врачу.
Вариант Б. Вместо того чтобы хранить сведения о пациенте в системе календарного пла-
нирования, последняя может запросить номер карты социального страхования и сведения о
страховой компании у системы обслуживания клиентов. Полученные данные добавляются
в сообщение о посещении врача (см. рис. 8.6). Такой подход решает первую проблему —
нам больше не нужно модифицировать систему календарного планирования. Но остается
еще одна проблема: система бухгалтерского учета должна уведомить систему календарного
планирования о том, что ей требуются номер карты социального страхования и координаты
страховой компании. Понадобится специальное сообщение типа “Уведомление о парамет-
рах страхования”, но в слабо связанных системах одна подсистема не должна диктовать
другой, что делать. По этой причине мы отправляем сообщение о событии (Event Message,
с. 174), а подсистемы сами решают, что следует предпринять. Тем не менее указанный под-
ход теснее привязывает систему обслуживания клиентов к системе календарного планиро-
вания, так как последняя должна знать, где искать недостающую информацию. Усиливает-
ся ее связь и с системой бухгалтерского учета. Как мы уже знаем, наличие сильных связей
ведет к неустойчивости интеграционных решений.
350
Глава 8. Преобразование сообщений
Посещение врача _
».....
Система
учета
Посещение врача
г........
Система
учета
Система
календарного
плдн
Система
обслуживания
данные о клиенте
Система
календарного
Извлечь данные
Система
обслуживания
клиентов
А: дублирование данных
Б: запрос данных у
системы обслуживания клиентов
Система
учета
Система
календарного
ллани^ания
'1 Посещение
врача
Посещение
врача <
В: преобразование сообщений
системой обслуживания клиентов
Рис. 8.6. Возможные решения проблемы расширения содержимого
Вариант В. Некоторых из упомянутых зависимостей можно избежать, если сообщение
о посещении врача отправить вначале не системе бухгалтерского учета, а системе обслу-
живания клиентов. Последняя извлечет требуемую информацию и самостоятельно от-
правит ее системе бухгалтерского учета (см. рис. 8.6). Благодаря такой схеме система
календарного планирования дистанцируется от последующего потока сообщений.
При этом, однако, нам понадобится ввести следующее бизнес-правило: страховая ком-
пания получает счет после того, как посещение пациентом врача будет зафиксировано в
системе обслуживания клиентов. Как следствие этого потребуется внесение изменений
в логику системы обслуживания клиентов. Если последняя представляет собой готовое
приложение стороннего производителя, внести указанное изменение будет сложно,
но даже если это и удастся сделать, система обслуживания клиентов станет косвенно от-
вечать за отправку счетов. Это не проблема, если все данные, необходимые системе бух-
галтерского учета, есть в системе обслуживания клиентов. Однако, если некоторые поля
придется запрашивать у других систем, мы придем к тому же, с чего начинали.
Вариант Г (не показан на рисунке). Изменить систему бухгалтерского учета, чтобы она
запрашивала только идентификатор пациента, а затем самостоятельно извлекала номер
карты социального страхования и сведения о страховой компании из системы обслужи-
Расширитель содержимого (Content Enricher)
351
вания клиентов. Данный подход, как и все предыдущие, не лишен недостатков
Во-первых, система бухгалтерского учета привязывается к системе обслуживания клиен-
тов. Во-вторых, модификация системы бухгалтерского учета, которая в большинстве
случаев представляет собой готовое решение, также не всегда возможна.
Используйте расширитель содержимого (Content Enrichef), если хотите получить
доступ к внешнему источнику данных, чтобы дополнить сообщение необходимой
информацией.
Расширитель содержимого
Расширенное сообщение
Источник данных
Расширитель содержимого использует информацию из входящего сообщения
(например, ключевые поля), чтобы извлечь недостающие данные из внешнего источни-
ка. Извлеченные данные присоединяются к сообщению. В зависимости от потребностей
приложения-получателя информация, которая содержалась в исходном сообщении, мо-
жет быть перенесена в конечное сообщение, а может быть отброшена за ненадобностью.
Откуда же расширитель содержимого возьмет недостающую информацию? Наиболее
распространенные источники таких данных выглядят следующим образом.
1. Вычисления. При необходимости расширитель содержимого может вычислять недос-
тающие данные. В этом случае требуемая информация внедряется в сообщение со-
ответствующим алгоритмом. К примеру, если системе-получателю требуются на-
звание города и аббревиатура штата, а система-отправитель предоставляет только
индекс местности, алгоритм определяет по нему название города и штата и вставля-
ет их в сообщение. Возможен и такой вариант: формат данных, понятный системе-
получателю, подразумевает наличие поля, в котором будет указан размер сообще-
ния. Тогда расширитель содержимого просуммирует длину всех полей сообщения, на
основании чего вычислит размер последнего. Такая разновидность расширителя со-
держимого весьма сходна с базовым транслятором сообщений (Message Translator,
с. 115), поскольку для извлечения данных не требуется внешний источник.
2. Среда. Расширитель содержимого может извлекать дополнительную информацию
прямо из рабочей среды. Ярким примером такой информации является метка
времени. Если получатель требует, чтобы каждое сообщение содержало метку
времени, а отправитель такой информации не предоставляет, расширитель содер-
352
Глава 8. Преобразование сообщений
жимого может извлечь значение текущего времени из операционной системы и
вставить его в сообщение.
3. Другая система. Самый распространенный вариант, при котором расширителю со-
держимого приходится извлекать недостающие данные из другой системы.
Это может быть база данных, файл, каталог LDAP, приложение или пользователь,
который вручную вводит требуемую информацию.
Иногда внешний источник данных, к которому обращается расширитель содержимо-
го, располагается в рамках другой системы или даже за пределами компании. Взаимодей-
ствие между расширителем содержимого и таким источником данных может осуществ-
ляться посредством шаблона обмен сообщениями (Messaging, с. 87) или любого другого
коммуникационного механизма (см. главу 2). Поскольку взаимодействие между расши-
рителем содержимого и источником данных по определению является синхронным
(расширитель содержимого не сможет отправить дополненное сообщение, пока источник
данных не возвратит требуемую информацию), использование протокола синхронного
обмена данными (например, HTTP или подключения ODBC) может принести более вы-
сокие результаты, чем работа в асинхронном режиме. Расширитель содержимого по своей
природе тесно связан с источником данных, поэтому обеспечивать слабое связывание
с помощью канала сообщений (Message Channel, с. 93) не так уж и важно.
Но вернемся к нашему примеру. Для извлечения дополнительных данных из системы
обслуживания клиентов можно воспользоваться расширителем содержимого, как показа-
но на рис. 8.7. Благодаря этому система календарного планирования сможет самоустра-
ниться от работы со страховой информацией или с системой обслуживания клиентов.
Все, что от нее потребуется в дальнейшем, — опубликовать сообщение о посещении вра-
ча. Поиском недостающей информации займется расширитель содержимого. Отметим
также, что наличие последнего предотвратит зависимость системы бухгалтерского учета
от системы обслуживания клиентов.
Расширитель содержимого часто применяют для обработки ссылок, содержащихся в
сообщении. Чтобы облегчить управление сообщениями и уменьшить их размер, вместо
объекта со всеми элементами данных в сообщение вставляют простую ссылку на объект.
Расширитель
Посещение врача содержимого Посещение врача
Рис. 8.7. Использование расширителя содержимого в примере с посещением врача
Расширитель содержимого (Content Enricher)
353
Обычно такая ссылка имеет форму ключа или уникального идентификатора. По прибы-
тии сообщения в конечную точку необходимо обратиться к источнику данных, чтобы из-
влечь объект по соответствующей ссылке. Для выполнения этой задачи рекомендуем
воспользоваться расширителем содержимого. При этом, конечно же, следует учитывать
соотношение выгод и потерь. Использование ссылок, безусловно, сокращает объем дан-
ных в исходных сообщениях, но требует дополнительных обращений к источнику дан-
ных. Производительность такой системы, главным образом, зависит от того, сколько
компонентов способны оперировать ссылками, а сколько должны использовать расши-
ритель содержимого для восстановления некоторых фрагментов исходного сообщения.
Так, если на пути к получателю сообщение проходит сквозь целый ряд посредников, ис-
пользование ссылок на объекты позволяет существенно уменьшить объем трафика со-
общений. Расширитель содержимого для загрузки недостающей информации можно
вставить на последнем этапе, непосредственно перед доставкой сообщения конечному
получателю. Если же сообщение уже содержит данные, которые нежелательно переда-
вать от посредника к посреднику, можно воспользоваться квитанцией (Claim Check,
с. 358), чтобы заменить данные ссылкой, сохранив их для последующего извлечения.
Пример: обмен сообщениями с внешними партнерами
Расширитель содержимого (Content Enricher) можно применять для взаимодействия
с внешними партнерами, требующими, чтобы формат сообщения соответствовал кон-
кретному стандарту (например, ebXML). Подобные сообщения, однако, часто имеют
большой размер и содержат огромное количество данных. Использовать их во внутрен-
них операциях компании неудобно. Для решения этой проблемы предлагаем максималь-
но упрощать формат внутренних сообщений, а при отправке за пределы компании до-
полнять их недостающей информацией с помощью расширителя содержимого. Аналогич-
ным образом для удаления ненужной информации из поступающих сообщений можно
использовать фильтр содержимого (Content Filter, с. 354), как показано на рис. 8.8.
Внешние партнеры
Г раницы организации
Рис. 8.8. Использование комбинации “расширитель содержимого — фильтр содержимого"
при взаимодействии с внешними партнерами
354
Глава 8. Преобразование сообщений
Фильтр содержимого (Content Filter)
Расширитель содержимого (Content Enricher, с. 348) применяется в тех ситуациях, когда
получатель сообщения требует больше информации, чем может предоставить отправи-
тель. Иногда, впрочем, получатель заинтересован в противоположном: очистить сообще-
ние от ненужных данных.
Как упростить работу с большими сообщениями, если получателя интересует
лишь малая часть содержащихся в них данных?
Зачем удалять из сообщения ценные элементы данных, спросите вы? Одна из наибо-
лее распространенных причин — безопасность. Приложение, запрашивающее данные у
службы, не всегда имеет право на просмотр всех элементов данных, содержащихся в от-
ветном сообщении. Если поставщик службы не осведомлен о применяемой схеме безо-
пасности (обычно так оно и бывает), он будет возвращать все элементы данных вне зави-
симости от личности пользователя. Необходимо добавить еще один шаг, на котором из
сообщения будут изыматься важные данные, запрещенные для просмотра автором за-
проса. Пусть, к примеру, система начисления заработной платы предоставляет простой
интерфейс, выводящий все данные о сотруднике компании. В число этих данных входит
размер заработной платы, номер карты социального страхования и другие сведения. Если
вы создаете службу, которая возвращает дату начала работы сотрудника в компании, то,
конечно же, захотите удалить из ответного сообщения всю конфиденциальную инфор-
мацию прежде, чем сообщение попадет к пользователю, отправившему запрос.
Еще одна причина, по которой из сообщения предпочитают удалять ненужные эле-
менты данных, связана с упрощением обработки сообщений и сокращением объема
сетевого трафика. Во многих корпоративных системах запуск процессов инициируют
сообщения, получаемые от бизнес-партнеров. В силу очевидных соображений взаимо-
действие со сторонними участниками желательно основывать на стандартизированном
формате сообщений. В качестве примера можно привести многочисленные форматы
данных на основе XML, предназначенные для использования в конкретных отраслях ин-
дустрии, такие как RosettaNet, ebXML, ACORD и др. К сожалению, несмотря на удобство
согласованных стандартов для общения с внешними партнерами, итоговые сообщения
получаются слишком громоздкими. Зачастую они состоят из сотен полей и имеют весьма
запутанную многоуровневую структуру. Такие документы совершенно не подходят для
обмена сообщениями внутри компании. К примеру, большинство визуальных средств
преобразования данных (функционирующих по типу “перетащить и отпустить”) стано-
вятся совершенно непригодными, если преобразуемые документы состоят из сотен эле-
ментов. Отладка систем, работающих с документами такого вида, и вовсе превращается в
кошмар. По этой причине рекомендуется упрощать входящие сообщения, оставляя в них
лишь те элементы, которые действительно нужны системам внутри компании. Удаление
фильтр содержимого (Content Filter)
355
элементов данных до известной степени повышает полезность такого сообщения, по-
скольку отсутствие избыточных и ненужных данных делает сообщение более содержа-
тельным и в то же время снижает риск разработчика сделать ошибку.
Используйте фильтр содержимого (Content Filter), чтобы удалить из сообщения
все лишнее, оставляя только нужные элементы данных.
Сообщение
Сообщение
Фильтр содержимого может применяться не только для удаления элементов данных,
но и д ля упрощения структуры сообщения. Зачастую сообщение организовано в виде де-
рева. Многие сообщения, пришедшие из внешних систем или готовых приложений,
включают в себя десятки уровней вложенных, повторяющихся групп элементов,
поскольку они сгенерированы в соответствии с общими, нормализованными структура-
ми баз данных. В силу известных ограничений и допущений о структуре сообщения да-
леко не все системы способны работать с таким количеством вложенных уровней.
На помощь приходит фильтр содержимого, который “сводит” разветвленную иерархию
элементов к простому списку, понятному всем системам компании (рис. 8.9).
Рис. 8.9. Упрощение структуры сообщения с помощью фильтра содержимого
Набор из нескольких фильтров содержимого может использоваться как статический
разветвитель (Splitter, с. 274) для разбиения сложного сообщения на более мелкие, каж-
дое из которых описывает определенный аспект сложного сообщения (рис. 8.10).
356
Глава 8. Преобразование сообщений
Рис. 8.10. Использование группы фильтров содержимого в качестве статического разветвителя
Пример: адаптер базы данных
Во многих интеграционных решениях для подключения к существующим системам
применяются адаптеры канала (Channel Adapter, с. 154). Формат сообщений, публикуе-
мых такими адаптерами, обычно соответствует внутренней структуре существующего
приложения. В качестве примера рассмотрим подключение адаптера к базе данных,
схема которой показана на рис. 8.11.
Рис. 8.11. Пример схемы базы данных
В реляционных базах данных объекты принято хранить в отдельных таблицах, свя-
занных между собой внешними ключами и таблицами отношений (в нашем примере таб-
лица account_contact связывает таблицы account и contact). Многие коммерческие
адаптеры баз данных преобразуют связанные таблицы в сообщения с иерархической
структурой. Последние содержат дополнительные поля наподобие первичных и внешних
ключей, которые могут не интересовать получателя сообщения. Чтобы облегчить обра-
ботку сообщений такого типа, можно воспользоваться фильтром содержимого (Content
Фильтр содержимого (Content Filter)
357
Filter), который превращает иерархическую структуру в “плоский” список и оставляет
в нем только поля, нужные получателю.
На рис. 8.12 показана реализация фильтра содержимого с помощью визуального сред-
ства преобразования данных. Легко увидеть, как сообщение, состоящее из десятков по-
лей, разбросанных по различным уровням, превращается в простое сообщение из пяти
полей. Обработка такого сообщения другими компонентами системы производится куда
проще и, что немаловажно, эффективнее, чем многоуровневого сообщения в его перво-
начальном виде.
Inputs
@ Non Schema Inputs
E g| P_ACCOUNT
j B8Iacct_no
) ffi[ DESCRIPTION *-~---------
& Э ADB_SEQUENCE_ACCOUNT_CONTAr
‘ • Ж ACCT_NO
i Ж CONTACTJD
ЯВЕ CONTACT-TYPE
& SADB_SEQUENCE_CONTACT
г Ж CONTACTJD
4 Ж NAME»-----------------
Ж SALUTATION
В Э ADB_SEQUENCE_ADDRESS
Г Ж ADDRESSJD
‘ Ж CONTACTJD
123 ADDRESS_TYPE
t Ж STREET*-----------
яисггу *•------------
; ;-ЖДР , .
Ж Description!
@ Contact
•®[ Name
Ж Street
Ж City
Ж ZIP_____
Puc. 8.12. Упрощение структуры сообщения при помощи адаптера базы данных
Разумеется, фильтр содержимого — далеко не единственное решение данной пробле-
мы. К примеру, в базе данных можно создать представление (view), которое будет анали-
зировать связи между таблицами и возвращать “плоский” результирующий набор дан-
ных. Это, очевидно, самое простое решение, но только в том случае, если к базе данных
можно добавлять представления. Во многих ситуациях, однако, целью интеграции явля-
ется как можно меньшая степень вмешательства в существующие системы, что может
подразумевать запрет на создание новых представлений.
358
Глава 8. Преобразование сообщений
Квитанция (Claim Check)
Расширитель содержимого {Content Enricher, с. 348) применяется в ситуациях, когда со-
общение необходимо дополнить недостающей информацией. Для достижения противо-
положного эффекта используют фильтр содержимого {Content Filter, с. 354), удаляющий из
сообщения ненужные элементы данных. Но что если данные требуется удалить не на-
всегда, а на время? Предположим, что в сообщении содержится набор данных, которые
представляют интерес для получателя, но не играют никакой роли на промежуточных
этапах его передачи и обработки. Наличие дополнительных данных замедляет обработку
сообщения и затрудняет отладку, поэтому от них следовало бы временно избавиться.
Как сократить объем данных в пересылаемом сообщении, но не потерять их?
Одни системы обмена сообщениями жестко ограничивают размер последних. Другие
используют представление данных с помощью XML, что увеличивает размер сообщения
на порядок, а то и больше. Иными словами, передача больших объемов данных посред-
ством сообщений хотя и надежна, но далеко не всегда эффективна.
Отметим также, что передача в сообщении небольшого объема данных предотвращает
зависимость промежуточных систем от информации, не предназначенной для них.
К примеру, если сообщение с информацией об адресе при пересылке из одной системы в
другую проходит через целый ряд промежуточных систем, последние могут начать делать
определенные допущения о структуре адреса и, таким образом, попасть в зависимость от
формата сообщения. Минимизация объема данных в сообщении сокращает риск воз-
никновения подобных скрытых допущений.
Рассмотренный ранее фильтр содержимого помогает сократить объем данных, но не
гарантирует возможность их восстановления. По этой причине содержимое сообщения
следует сохранить таким образом, чтобы при необходимости его можно было извлечь.
Для извлечения данных, касающихся конкретного сообщения, нужен ключ, уникаль-
ным образом связывающий сообщение с его данными. В качестве ключа можно было бы
воспользоваться идентификатором сообщения, но это не позволило бы промежуточным
компонентам передавать ключ посредством новых сообщений, потому что у нового со-
общения будет совершенно другой идентификатор.
Сохраните содержимое сообщения в постоянном хранилище, а промежуточным
компонентам передайте квитанцию {Claim Check}. Она будет использоваться
промежуточными компонентами для извлечения необходимой информации из хра-
нилища.
Квитанция (Claim Check)
359
Сообщение
с данными
Регистрация багажа
Сообщение
с квитанцией
Расширитель содержимого
Сообщение
с данными
Хранилище данных
Действие квитанции можно разбить на пять этапов.
1. Прибывает сообщение с данными.
2. Компонент “регистрация багажа” (Check Luggage) генерирует уникальный ключ
для информации, содержащейся в сообщении. Впоследствии этот ключ будет ис-
пользоваться в качестве квитанции.
3. Компонент “регистрация багажа” извлекает данные из сообщения, помещает их в
постоянное хранилище (например, в файл или базу данных) и сопоставляет с
ключом.
4. Данные, помещенные в хранилище, удаляются из сообщения. Вместо них добав-
ляется квитанция.
5. Другой компонент использует расширитель содержимого, чтобы на основании
квитанции извлечь из хранилища требуемые данные.
Описанный процесс во многом напоминает регистрацию и получение багажа в аэро-
порту. Если пассажир не хочет нести багаж с собой в салон самолета, он регистрирует и
сдает его у стойки авиакомпании. На каждую сумку или чемодан наклеивается уникаль-
ный номер. Такие же номера наклеиваются и на билет, после чего багаж благополучно
“уезжает” на движущейся ленте. По прибытии в аэропорт назначения пассажир забирает
свои вещи.
Как видно из иллюстрации к шаблону, данные, содержавшиеся в исходном сообще-
нии, все равно должны быть “перемещены” в пункт назначения. Можно ли тогда гово-
рить, что при внедрении указанной схемы мы выигрываем в производительности? Безус-
ловно, потому что передача данных через систему обмена сообщениями зачастую менее
эффективна, чем размещение этих же данных в некотором центральном хранилище.
К примеру, сообщение может проходить многочисленные этапы маршрутизации, не тре-
бующие наличия в сообщении всех элементов данных. На каждом из таких этапов сооб-
щение может подвергаться маршалингу и демаршалингу, шифрованию и расшифровке
и т.п. Выполнение подобных операций ведет к интенсивному расходованию системных
ресурсов, так зачем же применять их к данным, которые понадобятся лишь на заключи-
360
Глава 8. Преобразование сообщений
тельном этапе? Квитанцию удобно также применять в ситуации, когда сообщение прохо-
дит через ряд промежуточных компонентов и возвращается к отправителю. В этом случае
компоненты “регистрация багажа” и расширитель содержимого будут локализованы в
рамках одной и той же системы, а основной массе данных вообще не придется проходить
через сеть (рис. 8.13).
Сообщение
сданными
Преобразованное
сообщение
с данными
Рис. 8.13. Локальное хранение и извлечение данных при передаче сообщения по сети
Выбор ключа
Как правильно выбрать ключ для связывания сообщения с данными? На этот счет
существует несколько соображений.
1. В теле сообщения уже может содержаться некоторый бизнес-ключ, например
идентификатор клиента.
2. Для связи сообщения с данными можно воспользоваться идентификатором
сообщения.
3. Можно сгенерировать уникальный идентификатор.
Квитанция (Claim Check)
361
На первый взгляд, самым простым решением является использование существую-
щего бизнес-ключа. Если из сообщения выбрасываются некоторые сведения о клиенте,
их впоследствии можно будет извлечь по идентификатору клиента. Передавая указанный
ключ другим компонентам, нужно ответить на такой вопрос: “Следует ли предупреждать
эти компоненты о том, что указанный ключ не является неким абстрактным понятием,
а представляет собой идентификатор клиента?”. Использование идентификатора в каче-
стве абстрактного ключа имеет важное преимущество: мы можем обрабатывать все клю-
чи одним и тем же способом, а также создать универсальный механизм извлечения дан-
ных из БД на основе абстрактного ключа.
Использовать идентификатор сообщения в качестве ключа для извлечения данных —
не самая удачная идея, потому что появление у элемента данных (в нашем случае — у
идентификатора сообщения) двойной семантики может вызвать конфликт. Предполо-
жим, что квитанцию (Claim Check), связывающую некоторое сообщение с данными, не-
обходимо вставить в другое сообщение. Новому сообщению будет присвоен совершенно
другой идентификатор, поэтому мы не сможем использовать его для извлечения исход-
ных данных. Использование идентификатора сообщений в качестве ключа имеет смысл
только в том случае, когда доступ к данным осуществляется в рамках одного сообщения.
Как видим, в общем случае для ключа лучше создать новый элемент, чем воспользовать-
ся одним из существующих.
Не все данные, помещенные в хранилище, нужно держать там до скончания века.
Но как удалить информацию, ставшую ненужной? Можно изменить семантику компонен-
та, извлекающего данные из хранилища, чтобы после считывания он удалял данные. К со-
жалению, в таком случае данные можно будет считать только один раз. Вместо этого дан-
ным можно назначить срок годности и периодически запускать процесс сборки мусора, ко-
торый будет уничтожать данные старше определенного возраста. И наконец, от удаления
данных можно отказаться. Это может потребоваться тогда, когда в качестве хранилища
данных используется некоторая бизнес-система (например, система бухгалтерского учета),
в которой должны храниться все данные, накопившиеся за время ее функционирования.
Реализация хранилища данных может принимать самые разнообразные формы. Наи-
более очевидным вариантом является база данных, но при необходимости в роли храни-
лища может выступать группа XML-файлов или буфер оперативной памяти. Иногда для
хранения данных используется приложение. Важно лишь, чтобы хранилище было дос-
тупным для остальных компонентов интеграционного решения, которым может понадо-
биться восстановить исходное содержимое полученных сообщений.
Использование квитанции для сокрытия информации
Хотя первоначальным назначением квитанции (Claim Check) является избавление от
необходимости пересылать большие объемы данных, она может выполнять и другие
функции. Довольно часто при отправке сообщения за пределы корпоративной системы
из него необходимо удалить важную, конфиденциальную информацию (рис. 8.14). Ины-
ми словами, внешние партнеры должны получить только то, что они должны знать.
К примеру, отправляя данные о сотрудниках компании внешней системе, лучше сослать-
ся на сотрудников с помощью “абстрактных” идентификаторов, чем использовать для
этой цели личную информацию наподобие номеров карт социального страхования.
Когда внешняя система закончит обработку данных, мы восстановим полный вариант
сообщения, объединив данные из хранилища с содержимым сообщения, возвращенного
362
Глава 8. Преобразование сообщений
внешней системой. Еще лучше сгенерировать для таких сообщений специальный (и, ко-
нечно же, уникальный) ключ, чтобы ограничить набор действий, который сможет осуще-
ствлять внешняя система при помощи ключа, содержащегося в сообщении. Это предот-
вратит “вбрасывание” в нашу систему сообщений вредоносного характера. Сообщения,
содержащие неправильный, уже использованный либо устаревший ключ, будут заблоки-
рованы расширителем содержимого (Content Enricher, с. 348) при попытке извлечь данные
с помощью некорректного ключа.
Граница доверия
Регистрация багажа
L-
Расширитель содержимого
Полное
ответное
сообщение
Усеченное
сообщение
Внешняя
обработка
данных
Рис. 8.14. Предотвращение отправки важных данных за границы доверия
Исходное
сообщение
Хранилище
данных
Ответное
сообщение
Использование квитанции с диспетчером процессов
Если система взаимодействует с несколькими внешними участниками, функции кви-
танции (Claim Check) может выполнять диспетчер процессов (Process Manager, с. 325). При
поступлении нового сообщения диспетчер процессов создает экземпляры процесса
(называемые также заданиями или задачами). С каждым экземпляром процесса можно
связать дополнительные данные. Экземпляр процесса, по сути, станет выполнять роль
хранилища для данных, извлеченных из сообщения. Благодаря этому диспетчер процессов
сможет отправить внешним участникам сообщения, содержащие только те данные, ко-
торые интересуют того или иного участника. Вставлять в сообщение полный объем дан-
ных не нужно, потому что эта информация уже зафиксирована в “хранилище” процесса.
Когда от внешнего участника приходит ответ диспетчер процессов объединяет новые
данные с теми, которые хранятся в экземпляре процесса (рис. 8.15).
Квитанция (Claim Check)
363
Входящее
сообщение
Экземпляр процесса
Другие
компоненты
Рис. 8.15. Хранение данных в экземпляре процесса
364
Глава 8. Преобразование сообщений
Нормализатор (Normalizer)
В сценариях В2В-интеграции нередки случаи, когда компания получает сообщения от
разных бизнес-партнеров. Эти сообщения могут иметь один и тот же смысл, но совер-
шенно различаться по формату, который обычно зависит от особенностей внутренних
систем и предпочтений партнеров. К примеру, наша компания ThoughtWorks однажды
занималась разработкой решения для поставщика услуг кабельного телевидения, взи-
мающего с клиентов плату за каждый просмотренный фильм. Указанному поставщику
приходилось принимать и обрабатывать данные о просмотре фильмов более чем от
1700 филиалов, причем формат большинства сообщений не соответствовал стандарту.
Как организовать обработку входящих сообщений, эквивалентных по смыслу,
но различных по формату?
Самым простым решением с технической точки зрения кажется введение единого
формата для всех участников обмена сообщениями. Оно может сработать, если речь идет
о большой корпорации, полностью контролирующей обмен продукцией с бизнес-
партнерами или каналы поставки. К примеру, если корпорация General Motors пожелает,
чтобы ее поставщики присылали сообщения об обновлении состояния заказа в едином
формате, можно не сомневаться, что какой-нибудь мелкий поставщик покорно согла-
сится с ее требованиями. К сожалению, такая роскошь позволительна лишь гигантам ин-
дустрии. Напротив, во многих бизнес-моделях получателя сообщений позиционируют
как пассивного “накопителя” информации. Соглашениями между партнерами преду-
сматривается, что объем изменений, которые необходимо внести в инфраструктуру сис-
тем каждого из них, должен быть минимальным. В результате “накопителю” информа-
ции приходится иметь дело с разнообразнейшими форматами данных, от записей EDI
и файлов с разделителями-запятыми до документов XML или Excel, присылаемых по
электронной почте.
Работая с несколькими партнерами, нельзя забывать о таком факторе, как частота
изменений. Каждый из участников обмена сообщениями предпочитает не только рабо-
тать в собственном формате, но и периодически его менять. Вдобавок ко всему партнеры
могут приходить и уходить. Даже если отдельно взятый партнер вносит изменения в ис-
пользуемый им формат данных не чаше раза в два-три года, наличие нескольких десятков
партнеров может быстро привести к тому, что изменения станут появляться чуть ли
не каждый месяц, а то и каждую неделю. Важно, чтобы указанные изменения были как
можно надежнее изолированы от остального механизма обработки данных. В противном
случае даже небольшое изменение формата сообщений распространится на всю систему.
Чтобы отделить основную часть системы от многообразия форматов входящих сооб-
щений, необходимо преобразовать полученные сообщения в общий формат. При этом
для каждого из форматов входящих сообщений потребуется отдельный транслятор сооб-
щений (Message Translator, с. 115). Самый простой способ реализовать данное решение —
Нормализатор (Normalizer)
365
воспользоваться коллекцией каналов типа данных (Datatype Channel, с. 139), по одному на
каждый тип сообщения. После этого каждый канал типа данных будет подключен к соот-
ветствующему транслятору сообщений. Недостаток этого подхода состоит в том, что
огромное количество форматов сообщений приведет к появлению такого же количества
каналов типа данных.
Используйте нормализатор (Normalizer), чтобы перенаправить сообщения разных
типов на соответствующие трансляторы сообщений (Message Translator, с. 115),
где они будут преобразованы в единый формат.
Нормализатор
Сообщения в разных
форматах
Сообщения в
одном формате
В состав нормализатора входит по одному транслятору сообщений на каждый формат
данных, а также маршрутизатор сообщений (Message Router, с. 109), распределяющий вхо-
дящие сообщения по нужным трансляторам.
Определение формата сообщения
Распределение сообщений по трансляторам сообщений (Message Translator, с. 115)
предполагает, что маршрутизатор сообщений (Message Router, с. 109) способен самостоя-
тельно определить тип входящего сообщения. Во многих системах обмена сообщениями
к заголовку сообщения добавляется поле, указывающее на его тип. Наличие такого поля,
разумеется, значительно упростило бы определение типа сообщения. К сожалению,
в большинстве сценариев В2В-интеграции сообщения приходят в формате, непонятном
внутренней системе обмена сообщениями организации-получателя. Это могут быть
самые разнообразные форматы, например файлы с разделителями-запятыми или доку-
менты XML, для которых не определена схема. (Что поделаешь, мир так далек от совер-
шенства!) Вот почему нам нужно придумать более общий способ идентификации форма-
та входящего сообщения. Работая с документами XML, предположение о типе данных
часто делается на основании имени корневого элемента. Если в нескольких форматах
данных фигурирует один и тот же корневой элемент, можно воспользоваться запросами
XPath, чтобы просмотреть документ на наличие определенных вложенных элементов.
Анализ файлов с разделителями-запятыми требует более нестандартного подхода.
366
Глава 8. Преобразование сообщений
Иногда формат сообщения удается определить на основе количества полей и их типов
(например, числовые или текстовые). Если же данные поступают в виде файлов, самый
простой способ идентифицировать формат данных — использовать имя файла или струк-
туру папок с файлами в качестве своеобразного канала типа данных (Datatype Channel,
с. 139). Каждый бизнес-партнер компании может уникальным образом называть свои фай-
лы в соответствии с некоторым соглашением именования. После этого маршрутизатор со-
общений будет использовать имя файла, чтобы перенаправить сообщение на нужный транс-
лятор сообщений.
Использование маршрутизатора сообщений, помимо всего прочего, дает возможность
применять одни и те же преобразования данных сразу несколькими бизнес-партнерами.
Это может пригодиться, если партнеры работают с одинаковыми форматами данных или
же если механизм преобразования достаточно универсален и легко адаптируется к раз-
личным форматам сообщений. К примеру, запросы XPath замечательно подходят для по-
иска элементов в документах XML, даже если форматы документов существенно отлича-
ются один от другого.
Поскольку нормализатор часто встречается в интеграционных решениях, мы выдели-
ли его в отдельный шаблон и снабдили собственной пиктограммой (рис. 8.16).
Сообщения
в разных форматах
Нормализатор
Рис. 8.16. Нормализатор в действии
Сообщения
в одном формате
Каноническая модель данных (Canonical Data Model)
367
Каноническая модель данных (Canonical Data Model)
Мы разрабатываем несколько приложений, которые будут взаимодействовать друг
с другом при помощи обмена сообщениями {Messaging, с. 87). В каждом из приложений
применяется собственный внутренний формат данных.
Как минимизировать число зависимостей при интеграции приложений, использую-
щих различные форматы данных?
Выбирая формат данных, разработчик ориентируется лишь на особенности создавае-
мого им приложения. Если предполагается, что приложение будет обмениваться сооб-
вданяжм/т с некоторой неизвестной заранее системой, очевидно, что в приложении будет
использоваться тот формат сообщений, который лучше всего подходит для удовлетворе-
ния его потребностей. Вот почему в приложениях, разрабатываемых независимо друг от
друга, часто используются неодинаковые форматы сообщений. Аналогичным образом
коммерческие адаптеры, предназначенные для интеграции готовых приложений, публи-
куют и потребляют сообщения в том формате, который соответствует внутренней струк-
туре обслуживаемого ими приложения.
Транслятор сообщений {Message Translator, с. 115) позволяет устранить проблемы, свя-
занные с различием форматов сообщений, без необходимости вносить изменения в ло-
гику приложений или уведомлять их о формате данных друг друга. К сожалению, если в
обмене данными принимает участие сразу несколько приложений, на каждую пару уча-
стников понадобится по отдельному транслятору сообщений (рис. 8.17).
Рис. 8.17. При увеличении количества систем, взаимодействующих одна с другой,
количество необходимых трансляторов сообщений резко возрастает
Учитывая, что каждое из интегрируемых приложений может публиковать или потреб-
лять сообщения целого ряда типов, количество трансляторов сообщений, необходимых
для преобразования сообщений из одного формата в другой, может увеличиться до не-
мыслимых значений. При добавлении хотя бы нескольких участников обмена данными
число трансляторов сообщений быстро выходит- из-под контроля.
368
Глава 8. Преобразование сообщений
Хотя использование транслятора сообщений избавляет приложения от необходимости
учитывать форматы данных других приложений, указанное решение само по себе зависит
от форматов данных приложений, и зависит слишком сильно. Изменение формата дан-
ных, используемого одним из приложений, приводит к необходимости вносить измене-
ния во все трансляторы сообщений, связывающие указанное приложение с другими. Точ-
но так же, если к интеграционному решению добавляется новое приложение, потребует-
ся создать новые трансляторы сообщений для взаимодействия указанного приложения
с каждым из существующих приложений. Со временем количество трансляторов сообще-
ний разрастется настолько, что их поддержка превратится в сущий кошмар.
И наконец, нельзя забывать о том, что появление на пути следования сообщений оче-
редного этапа преобразования негативно отражается на скорости доставки и снижает
пропускную способность системы обмена сообщениями.
Создайте каноническую модель данных (Canonical Data Model), не зависящую от
каких-либо конкретных приложений. Добейтесь того, чтобы приложения создавали
и потребляли сообщения в общем формате.
Транслятор
Транслятор
Каноническая модель данных
Каноническая модель данных обеспечивает появление дополнительного уровня кос-
венности между отдельными форматами данных, используемыми в приложениях. Если в
интеграционном решении появится новое приложение, разработчику придется добавить
всего лишь одно-два преобразования между приложением и канонической моделью данных
вне зависимости от того, сколько приложений уже участвует в обмене данными.
Использование канонической модели данных может показаться лишним, если интегра-
ционное решение охватывает небольшое число приложений. Данный метод, однако,
очень быстро оправдывает себя с возрастанием их количества. Предположим, что в ин-
теграционном решении каждое приложение отправляет и получает сообщения от каж-
дого из остальных приложений. Тогда для решения, состоящего из двух приложений, по-
надобится только два транслятора сообщений, если данные преобразуются непосредст-
венно из одного формата в другой, и четыре транслятора сообщений при использовании
канонической модели данных. Решению, состоящему из трех приложений, и в том и в дру-
гом случае потребуется по шесть трансляторов сообщений. Теперь внимание! Решение,
состоящее из шести приложений, потребует целых 30 (!) трансляторов сообщений без ис-
пользования канонической модели данных и только 12 трансляторов сообщений, если кано-
ническая модель данных используется.
Каноническая модель данных (Canonical Data Model)
369
Каноническая модель данных принесет пользу и в том случае, если существующее при-
ложение планируется в будущем заменить новым. К примеру, если ряд приложений
взаимодействует с унаследованной системой, которая впоследствии будет заменена но-
вой, переход к новой системе пройдет намного проще, если заблаговременно внедрить
в исходное решение каноническую модель данных.
Способы преобразования
Как добиться, чтобы приложения отправляли и принимали данные в одном и том же
формате? Существует несколько основных возможностей.
1. Изменить формат данных, используемый внутри приложения. Теоретически такой
вариант возможен, но в реальной жизни почти не встречается. Если бы настроить
готовые приложения на использование одного и того же формата данных было
так легко, нам вообще не понадобился бы обмен сообщениями (Messaging, с. 87);
вместо него было бы гораздо практичнее использовать обгцую базу данных (Shared
Database, с. 83).
2. Внедрить в приложение преобразователь обмена сообщениями (Messaging Mapper,
с. 491). Если приложение не приобретено у стороннего производителя, а создано
силами компании, для получения желаемого формата данных можно воспользо-
ваться преобразователем обмена сообщениями.
3. Использовать внешний транслятор сообщений (Message Translator, с. 115). Внеш-
ний транслятор сообщений поможет преобразовать сообщение из формата, спе-
цифичного для конкретного приложения, в формат, заданный канонической моде-
лью данных (Canonical Data Model). Зачастую это единственный возможный вари-
ант преобразования сообщений, отправленных готовым приложением.
Выбор между преобразователем обмена сообщениями и внешним транслятором сообщений
определяется сложностью предполагаемых преобразований и возможностью модификации
приложения. Использование готовых приложений сторонних производителей обычно ис-
ключает применение преобразователя обмена сообщениями, потому что исходный код таких
приложений недоступен. Для приложений, созданных внутри компании, выбор того или
иного решения зависит, главным образом, от сложности преобразований. Многие пакеты
средств интеграции включают в себя визуальные редакторы преобразований, значительно
ускоряющие формулирование правил преобразования. К сожалению, они становятся весь-
ма неудобными в использовании, если преобразования слишком сложны.
Используя внешний транслятор сообщений, следует различать открытые (канони-
ческие) и закрытые (специфические для конкретного приложения) сообщения. Сообще-
ния, которыми приложение обменивается со своим транслятором сообщений, считаются
закрытыми (private), потому что никакое другое приложение не должно их использовать.
Как только транслятор преобразует сообщение в формат, совместимый с канонической
моделью данных, сообщение становится открытым (public) и может использоваться
другими системами.
370
Глава 8. Преобразование сообщений
Двойное преобразование
При использовании канонической модели данных {Canonical Data Model) время обработ-
ки потока сообщений увеличивается. Каждому сообщению вместо одного преобразова-
ния теперь приходится претерпевать целых два: одно преобразование из формата исход-
ного приложения в общий формат и еще одно — из общего формата в формат приложе-
ния-получателя. По этой причине использование канонической модели данных часто
называют двойной трансляцией {double translation), а преобразование из формата одного
приложения непосредственно в формат другого — прямой трансляцией {direct translation).
Каждое преобразование увеличивает задержку потока сообщений. Таким образом, для
систем, требующих очень быстрого отклика, единственным допустимым решением оста-
ется прямая трансляция. В реальной жизни при выборе способа преобразования сооб-
щений часто приходится жертвовать либо производительностью, либо гибкостью. Луч-
шее, что можно посоветовать в подобной ситуации (если вопрос производительности не
слишком критичен), — используйте более гибкое решение (т.е. каноническую модель дан-
ных). В последнем случае проблему производительности можно несколько смягчить, если
организовать балансировку нагрузки преобразований при параллельном функциониро-
вании нескольких трансляторов сообщений {Message Translator, с. 115).
Разработка канонической модели данных
Разработка канонической модели данных {Canonical Data Model) может оказаться непро-
стым заданием. В истории большинства крупных компаний имеется хотя бы одна не-
удачная попытка создания “корпоративной модели данных”. Для получения сбаланси-
рованной модели разработчики должны стремиться к тому, чтобы унифицированный
формат данных одинаково хорошо подходил для всех приложений, которые планируется
интегрировать. Вероятность успешного создания канонической модели данных значитель-
но возрастает, если учесть, что последняя не обязана отображать весь набор данных,
содержащийся во всех приложениях. Достаточно “промоделировать” только те элементы
данных, которые действительно участвуют в обмене сообщениями (рис. 8.18). Это суще-
ственно снизит сложность будущего решения.
Рис. 8.18. Моделирование только тех данных, которые имеют отношение к обмену сообщениями
Каноническая модель данных (Canonical Data Model)
371
Использование канонической модели данных имеет и тактическое преимущество: оно
позволяет разработчикам и бизнес-пользователям обсуждать интеграционное решение в
терминах сферы деятельности компании, а не конкретной реализации некоторого паке-
та. К примеру, в приложениях сторонних производителей стандартное понятие клиента
может быть представлено совершенно разными объектами, такими как “счет”, “контакт”
и “плательщик”. Введение канонической модели данных часто является первым шагом
к разрешению семантических конфликтов между приложениями [21].
Зависимости между форматами данных
Вернемся к рис. 8.17, на котором показано, сколько трансляторов сообщений {Message
Translator, с. 115) необходимо для преобразования данных между форматами приложе-
ний, участвующих в обмене сообщениями. Он очень похож на рис. 7.34 из раздела,
посвященного брокеру сообщений {Message Broker, с. 334). Это напоминает о том, что зави-
симости между приложениями могут существовать на нескольких уровнях. Использова-
ние каналов сообщений {Message Channel, с. 93) обеспечивает наличие общего маршрута
транспортировки сообщений и устраняет зависимости между транспортными протоко-
лами отдельных приложений. Маршрутизаторы сообщений {Message Router, с. 109), в свою
очередь, избавляют приложение-отправитель от необходимости знать о расположении
приложения-получателя. При использовании стандартного представления данных
(такого, как XML) зависимость от специфических типов данных, используемых в кон-
кретных приложениях, аннулируется. И наконец, каноническая модель данных {Canonical
Data Model) решает проблемы, связанные с форматами данных и семантикой сообщений.
Ничто не вечно под луной, и формат сообщений тоже. Вот почему сообщения,
построенные в соответствии с канонической моделью данных, должны включать в себя
индикатор формата {Format Indicator, с. 201).
Пример: WSDL
Если приложение осуществляет доступ к внешней службе, последняя может заранее ука-
зать, какую каноническую модель данных {Canonical Data Model) необходимо использовать.
В мире Web-служб XML для описания формата данных используется язык WSDL
(Web Services Definition Language— язык определения Web-служб). Более подробно
о WSDL можно прочитать в [45]. WSDL задает структуру запросов и ответов, которые
может потреблять и выдавать указанная Web-служба. Формат таких сообщений часто от-
личается от внутреннего формата данных, используемого приложением, которое предос-
тавляет службу. Как видим, WSDL описывает каноническую модель данных, которая долж-
на использоваться обоими участниками “общения”. Схема двойной трансляции в этом
случае состоит из преобразователя обмена сообщениями {Messaging Mapper, с. 491) или
шлюза обмена сообщениями {Messaging Gateway, с. 482), внедренного в потребитель службы,
и интерфейса удаленного доступа {Remote Facade, см. [9]), внедренного в поставщик службы.
372
Глава 8. Преобразование сообщений
Пример: TIBCO ActiveEnterprise
Многие пакеты EAI-средств включают в себя полный набор инструментов для определе-
ния и описания канонической модели данных (Canonical Data Model). К примеру, в состав
платформы TIBCO ActiveEnterprise входит средство Designer, позволяющее разработчику
изучить все распространенные определения сообщений. Они могут быть импортированы
из определений схем XML или экспортированы в них. Если реализация транслятора
сообщений (Message Translator, с. 115) выполняется с помощью встроенного набора визу-
альных инструментов, в окне Designer отображаются как формат данных, специфичный
для приложения, так и каноническая модель данных, хранящаяся в центральном репозито-
рии форматов данных. Это значительно упрощает настройку транслятора для работы
с указанными форматами данных (рис. 8.19).
Рис. 8.19. TIBCO Designer: графическое средство для задания канонической модели данных
Глава 9
Практикум: сложный обмен
сообщениями
Пример: кредитный брокер
В этой главе рассказывается, как скомпоновать шаблоны маршрутизации и преобразо-
вания сообщений в одно большое решение. В качестве примера мы решили смоделировать
получение потребительского кредита при наличии предложений нескольких банков. Разу-
меется, в нашей книге указанный бизнес-процесс значительно упрощен — мы не собира-
емся посвящать вас в тонкости финансового дела, а хотим сосредоточиться на обсуждении
шаблонов интеграции. Основываясь на шаблонах, описанных в предыдущих главах, мы
рассмотрим и создадим три различные реализации процесса получения кредита, используя
разные языки программирования, технологии и модели обмена сообщениями.
Выбор процентной ставки по кредиту
Собираясь взять кредит, потребитель обычно обзванивает несколько банков, чтобы
найти предложение с самой низкой процентной ставкой. В каждом банке у потребителя
узнают номер его карты социального страхования, желаемую сумму кредита, а также же-
лаемый срок кредитования (т.е. количество месяцев, за которые клиент должен выпла-
тить сумму кредита). После этого банк изучает кредитную историю предполагаемого
клиента. Обычно для этого обращаются в кредитное бюро (рис. 9.1). Проанализировав
желания клиента и его кредитную историю, банк предлагает клиенту взять кредит под
некоторую процентную ставку (или вежливо отказывает в выдаче кредита). Получив
предложения по величине процентной ставки от всех банков, клиент выбирает предло-
жение с самой низкой процентной ставкой.
374
Глава 9. Практикум: сложный обмен сообщениями
Рис. 9.1. Потребитель обращается в несколько банков, чтобы узнать, под какие проценты
он может получить кредит
Поскольку обзванивание банков и выяснение процентных ставок отнимает много
времени и нервов, общением с банками вместо потребителя может заняться специально
обученный кредитный брокер. Последний обычно не связан ни с одним из банков, но
имеет доступ ко многим кредитным учреждениям. Вначале брокер собирает сведения о
потребителе и обращается в кредитное бюро, чтобы узнать кредитную историю своего
клиента. Затем он предоставляет всю полученную информацию о клиенте в банки, пред-
ложения которых наиболее точно соответствуют требованиям клиента. Банки анализи-
руют кредитную историю, пожелания клиента и предлагают некоторую процентную
ставку. Брокер сравнивает величины ставок, предложенные различными банками, выби-
рает из них самую низкую и сообщает ее значение своему клиенту (рис. 9.2).
Банк 2
Потребитель
Кредитный брокер
БанкЗ
Кредитное бюро
Рис. 9.2. Кредитный брокер, выступающий в качестве посредника между потребителем,
банком и кредитным бюро
Пример: кредитный брокер
375
Проектирование потока сообшений
Мы хотим разработать систему, выполняющую роль кредитного брокера, используя
шаблоны интеграции корпоративных приложений, которые рассматривались в предыду-
щих главах. Вначале перечислим задачи, которые должен выполнять кредитный брокер.
1. Получить от потребителя запрос на выдачу кредита при заданных требованиях.
2. Узнать кредитный балл и кредитную историю потребителя в кредитном бюро.
3. Решить, в какие банки следует обращаться для получения кредита.
4. Отправить запрос о возможности получения кредита в каждый из выбранных
банков.
5. Собрать ответы из всех выбранных банков.
6. Определить, какое из предложений является лучшим.
7. Возвратить результаты потребителю.
Посмотрим, какие шаблоны могут пригодиться для проектирования и реализации
кредитного брокера. На первом этапе брокер получает входящий запрос. Эта тема будет
подробно рассматриваться в следующей главе, поэтому пока что пропустим этот шаг
и предположим, что сообщение клиента каким-то образом было получено брокером.
После этого брокер должен извлечь некоторую дополнительную информацию, а именно
кредитный балл клиента. Для выполнения этой задачи идеально подходит расширитель
содержимого (Content Enricher, с. 348). Собрав всю необходимую информацию, брокер
должен определить, в какие банки следует перенаправить сообщение с запросом.
Для этого будет применяться еше один расширитель содержимого, составляющий список
получателей запроса. Отправкой сообщения с запросом нескольким получателям и ком-
бинированием полученных ответов в одно сообщение займется рассылка-сборка (Scatter-
Gather, с. 310). Последняя, в свою очередь, будет рассылать сообщение в банки посредст-
вом канала “публикация-подписка" (Publish-Subscribe Channel, с. 134) или списка получате-
лей (Recipient List, с. 264). Когда каждый из банков вышлет ответ с предложенным значе-
нием процентной ставки, рассылка-сборка построит на их основе одно сообщение с луч-
шей процентной ставкой для клиента, для чего будет использоваться агрегатор
(Aggregator, с. 283). Схема обмена сообщениями с использованием указанных шаблонов
будет выглядеть так, как показано на рис. 9.3.
Мы еще не учли тот факт, что в каждом из банков может применяться собственный
формат сообщений с запросами и ответами. Поскольку мы стремимся отделить логику
маршрутизации и агрегации от специфических форматов сообщений, используемых бан-
ками, между брокером и банками необходимо вставить трансляторы сообщений (Message
Translator, с. 115). Чтобы преобразовать ответы банков в общий формат, можно восполь-
зоваться нормализатором (Normalizer, с. 364), как показано на рис. 9.4.
376
Глава 9. Практикум: сложный обмен сообщениями
Запрос на
получение
кредита
Лучшая
процентная
ставка
Получить список
банков
Набор правил
Кредитное бюро Получить Список
кредитный балл получателей
Агрегатор
Кредитный брокер
Рис. 9.3. Структура простого кредитного брокера
Банки
Рис. 9.4. Окончательная структура кредитного брокера
Пример: кредитный брокер
377
Режим выполнения операций: синхронный или асинхронный
Мы описали процесс обмена сообщениями, а также перечислили шаблоны, которые
будут применяться для описания структуры кредитного брокера. Пришло время погово-
рить о режиме, в котором брокер будет осуществлять свои операции. Существует два ос-
новных варианта.
• Синхронный (последовательный). Брокер запрашивает значение процентной ставки
у одного банка и ждет ответа. Когда приходит ответ, брокер обращается в следую-
щий банк, и т.д.
• Асинхронный (параллельный). Брокер обращается сразу во все банки и ждет, пока
они не пришлют ответы.
Для иллюстрации каждого из вариантов можно использовать циклограммы UML.
Синхронный режим подразумевает последовательную обработку всех запросов на полу-
чение кредита (рис. 9.5). Таким решением проще управлять, потому что оно не связано с
параллельными потоками и другими проблемами одновременной обработки данных.
С другой стороны, такое решение весьма неэффективно, потому что банки обладают
независимыми вычислительными ресурсами и могут безо всякого ущерба для себя одно-
временно выполнять запросы брокера. При последовательной обработке данных процесс
ожидания ответа конечным потребителем может сильно затянуться.
Рис. 9.5. Синхронная, последовательная обработка запросов на получение кредита
378
Глава 9. Практикум: сложный обмен сообщениями
При выборе асинхронного режима обработки данных все запросы отправляются сра-
зу, поэтому каждый банк может тут же приступать к обработке своего запроса. Закончив
обработку запросов, банки возвращают результаты кредитному брокеру. Указанное
решение обеспечивает намного более высокую скорость обработки данных. К примеру,
если запросы отправляются в п банков и каждый банк тратит одинаковое время на вы-
полнение запроса, то данное решение будет выполняться в п раз быстрее предыдущего.
Кредитный брокер должен уметь принимать ответы от банков в любом порядке — никто
не гарантирует, что они придут в той же последовательности, в которой были отправлены
запросы. Циклограмма асинхронной обработки запросов показана на рис. 9.6. Стрелки
с незакрашенными концами (запрос величины процентной ставки) означают асинхрон-
ный вызов метода GetLoanQuote.
Рис. 9.6. Асинхронная, параллельная обработка запросов на получение кредита
Еще одним важным преимуществом асинхронного вызова с использованием очереди
сообщений является возможность создавать несколько экземпляров поставщика службы.
К примеру, если кредитное бюро окажется “узким местом” в плане доступности, можно
создать два экземпляра этого компонента. Поскольку кредитный брокер не отсылает со-
общение с запросом непосредственно компоненту кредитного бюро, а ставит его в оче-
редь сообшений, нас не интересует, какой именно экземпляр кредитного бюро обработа-
ет сообщение, — ответ все равно окажется в требуемом канале ответов.
Адресация: распределение или аукцион
Определяя наилучшую процентную ставку с помощью шаблона рассылка-сборка
{Scatter-Gather, с. 310), можно воспользоваться одним из двух механизмов адресации:
канал “публикация-подписка” {Publish-Subscribe Channel, с. 134) или список получателей
{RecipientList, с. 264). Выбор механизма адресации, главным образом, зависит от того,
в какой степени мы хотим влиять на список банков, участвующих в обработке конкрет-
ного запроса. Опять-таки, у нас есть несколько вариантов (рис. 9.7).
• Фиксированная адресация. Перечень банков зафиксирован непосредственно в коде
приложения. Каждый запрос вне зависимости от его содержания направляется
в один и тот же набор банков.
Пример: кредитный брокер
379
• Распределение. Брокер вырабатывает определенный набор критериев касательно
того, какие банки подходят для выполнения конкретного запроса. К примеру, за-
прос клиента с плохой кредитной историей вряд ли следует отсылать в банк, спе-
циализирующийся на обслуживании VIP-клиентов.
• Аукцион. Брокер организует широковещательную рассылку сообщения, размещая
его в канале “публикация-подписка”. Любой банк, заинтересованный в выдаче кре-
дитов, может подписаться на этот канал и предложить свою “цену” (т.е. ставку по
кредиту). Иными словами, определение лучшей ставки происходит по принципу
аукциона. Банки могут по желанию подписываться на канал и отписываться от
него. И разумеется, каждый банк может применять собственный критерий отно-
сительно того, участвовать ли ему в “аукционе” ставок.
Рис. 9.7. Возможные механизмы адресации запросов
Какой из вышеперечисленных вариантов лучше всего подходит в нашей ситуации?
Как всегда, однозначного ответа на этот вопрос не существует. Выбор того или иного ва-
рианта определяется как бизнес-правилами, так и техническими предпочтениями и ог-
раничениями. Первый вариант адресации — самый простой и дает брокеру полный кон-
троль над списком банков, но, если банки будут стремительно появляться и исчезать,
данное решение обернется настоящим хаосом. Кроме того, банк может быть не в вос-
торге от получения множества заведомо неподходящих запросов, потому что получение
каждого запроса связано с некоторыми внутренними расходами банка. И наконец, при
использовании этого подхода стратегия агрегации, скорее всего, потребует, чтобы все
банки отвечали на запрос. Но банки наверняка захотят сохранить за собой право отказа
от рассмотрения конкретных запросов.
Вариант распределения (с использованием списка получателей) позволяет брокеру са-
мому решать, какие банки следует привлечь для обработки конкретного запроса. Благодаря
этому брокер может сократить число запросов, а также отдать предпочтение конкретным
банкам на основе бизнес-отношений. С другой стороны, использование данного решения
требует внедрения в компонент кредитного брокера дополнительной бизнес-логики. Отме-
тим также, что и в первом, и во втором случаях для контроля за потоком сообщений каждо-
му банку понадобится собственный канал сообщений {Message Channel, с. 93).
При широковещательной рассылке запроса по каналу “публикация-подписка” каждый
банк самостоятельно определяет, будет ли он обслуживать тот или иной запрос. Для от-
сеивания нежелательных запросов банк может воспользоваться фильтром сообщений
(Message Filter, с. 253) или реализовать избирательный потребитель (Selective Customer.
с. 528). При данном подходе кредитный брокер избавляется от необходимости реагиро-
380
Глава 9. Практикум: сложный обмен сообщениями
вать на появление и исчезновение банков, но объем работы на стороне банков увеличи-
вается. Указанному решению требуется только один канал сообщений, но он должен быть
реализован как канал “публикация-подписка”. Во многих эффективных схемах публикации-
подписки используется многоадресная IP-рассылка, которая обычно не осуществляет
маршрутизацию сообщений по глобальным сетям или Интернету. В других реализациях
указанной схемы канал “публикация-подписка” эмулируется с помощью массива каналов
“точка-точка” (Point-to-Point Channel, с. 131) и списка получателей. Этот подход сохраняет
простую семантику канала “публикация-подписка”, но менее эффективен в плане использо-
вания каналов и пропускной способности сети. Еще несколько рассуждений по поводу вы-
бора между маршрутизацией и схемой публикации-подписки с использованием фильтров
приведены в описании шаблона фильтр сообщений (Message Filter, с. 253).
Стратегии агрегации: несколько каналов или один
Как следует организовать получение ответов с предложенными значениями процентных
ставок? У нас есть два варианта: создать единый канал, в котором все банки будут разме-
щать свои ответы, или же предоставить каждому банку собственный канал ответов.
Использование общего канала снижает затраты на создание и обслуживание множества от-
дельных каналов, но требует, чтобы в каждом сообщении с ответом содержалось указание
на то, какой банк прислал это сообщение. Кроме того, при наличии общего канала ответов
агрегатор (Aggregator, с. 283) не знает, скольких сообщений с ответами следует ожидать, если
только эта информация не будет передана ему списком получателей (Recipient List, с. 264).
Мы называем такой агрегатор инициализированным. Если рассылка запросов в банки бу-
дет осуществляться по принципу аукциона с использованием канала “публикация-подписка”
(Publish-Subscribe Channel, с. 134), количество возможных ответов будет неизвестно даже
кредитному брокеру. По этой причине в агрегатор придется внедрить некоторое условие
завершения операции, не зависящее от общего числа участников. К примеру, агрегатор
может просто ждать до тех пор, пока не получит как минимум три ответа. Но даже это будет
рискованно, если в обслуживании запроса временно участвуют только два банка. В этом
случае у агрегатора может истечь время ожидания, после чего он сообщит, что количества
ответов недостаточно для выбора лучшей процентной ставки.
Управление одновременным доступом
Такая служба, как кредитный брокер, должна уметь работать с несколькими клиента-
ми одновременно. К примеру, если мы предполагаем, что кредитный брокер будет функ-
ционировать как Web-служба, или собираемся подключить его к общедоступному сайту в
Интернете, мы не сможем контролировать число потребителей и рискуем получать по
нескольку сотен или тысяч запросов одновременно. Чтобы кредитный брокер мог парал-
лельно обрабатывать клиентские запросы, можно воспользоваться двумя стратегиями:
• запуск нескольких экземпляров кредитного брокера;
• запуск одного событийно управляемого экземпляра.
Первая стратегия предполагает параллельное функционирование нескольких экземп-
ляров компонента кредитного брокера. Можно запускать отдельный экземпляр брокера
для каждого клиентского запроса или же организовать “пул” активных процессов броке-
ра и назначать очередной входящий запрос следующему доступному процессу. В послед-
Пример: кредитный брокер
381
нем случае применяется диспетчер сообщений {Message Dispatcher, с. 521). Если доступных
процессов пока что нет, запросы ставятся в очередь в ожидании, пока освободится
какой-нибудь процесс. Пул процессов удобен тем, что расходует ограниченный, заранее
заданный объем системных ресурсов. К примеру, число одновременно выполняющихся
экземпляров кредитного брокера можно ограничить двадцатью. В противоположность
этому, если запускать новый экземпляр брокера для каждого клиентского запроса, при
резком возрастании числа запросов ресурсы системы будут быстро исчерпаны. Кроме
того, наличие пула активных процессов дает возможность повторно использовать суще-
ствующие процессы для выполнения разных запросов. Это существенно экономит время
на создание экземпляра процесса и его инициализацию.
Поскольку большая часть ресурсов, необходимых брокеру, уходит на ожидание отве-
тов внешних участников (кредитного бюро и банков), запуск слишком большого числа
процессов может оказаться неудачной идеей. Вместо этого можно запустить единствен-
ный экземпляр процесса, который будет реагировать на события, т.е. на поступление
входящих сообщений. Обработка отдельного сообщения (например, ответа из банка
с величиной процентной ставки) — сравнительно простое задание, поэтому один про-
цесс способен обслуживать много параллельных запросов. При таком подходе системные
ресурсы будут использоваться более эффективно, а управление решением упростится,
потому что нам придется наблюдать только за одним экземпляром процесса. Потенци-
альным недостатком такого подхода является невысокая масштабируемость, вызванная
привязкой к одному процессу. В реальной жизни многие приложения используют ком-
бинацию обеих стратегий, выполняя по нескольку параллельных процессов, каждый
из которых может одновременно обрабатывать большое число запросов.
Для одновременной обработки запросов каждое сообщение в системе должно быть
сопоставлено с правильным экземпляром процесса. К примеру, банку может быть удоб-
но отсылать все ответы в фиксированный канал. Это означает, что канал ответов может
в одно и то же время содержать сообщения с процентными ставками для разных клиен-
тов. Чтобы понять, запросу какого клиента соответствует то или иное значение процент-
ной ставки, в каждое сообщение необходимо добавить идентификатор корреляции
(Correlation Identifier, с. 186).
Три реализации
Чтобы реализовать образец кредитного брокера, нужно принять три важных решения:
выбрать режим обработки запросов кредитного брокера к банкам, механизм адресации
при рассылке запросов в банки и стратегию агрегации. Необходимо также выбрать язык
программирования и инфраструктуру обмена сообщениями. Комбинируя режимы, стра-
тегии, языки и программные продукты, получаем множество вариантов реализации кре-
дитного брокера. В этой главе мы представим три решения, которые, на наш взгляд, наи-
более удачно иллюстрируют преимущества и недостатки разных вариантов реализации.
Как и во всех примерах этой книги, выбор конкретных технологий определяется нашими
предпочтениями и не может говорить о превосходстве продуктов того или иного произ-
водителя. Основные характеристики каждого решения приведены в табл. 9.1.
382
Глава 9. Практикум: сложный обмен сообщениями
Таблица 9.1. Основные характеристики реализаций кредитного брокера,
рассматриваемых в этой главе
Реали- зация Режим обработки данных Адресация Агрегация Тип канала Продукты и технологии
А Синхронный Распределение Канал \УеЬ-служба/8ОАР Java и Apache Axis
Б Асинхронный Распределение Идентификатор корреляции Очередь сообщений C# и Microsoft MSMQ
В Асинхронный Аукцион Идентификатор корреляции “Публикация- подписка” TIBCO ActiveEnterprise
В первом решении будет использован синхронный режим обработки данных на осно-
ве Web-служб, реализованный с помощью Java и Apache Axis. Взаимодействие брокера с
каждым из банков будет осуществляться по отдельному каналу HTTP, играющему роль и
канала запросов, и канала ответов. По этой причине стратегия агрегации будет заклю-
чаться в использовании отдельного канала ответов для каждого банка, и корреляции не
потребуется. В основу второго решения положен асинхронный режим обработки данных
с использованием очереди сообщений. Мы реализуем ее с помощью MSMQ, но реализа-
ция посредством JMS или IBM WebSphere MQ выглядела бы практически так же. И на-
конец, в последнем решении лучшая процентная ставка определяется по принципу аук-
циона. Для реализации указанного решения используется инфраструктура публикации-
подписки TIBCO ActiveEnterprise, а также средство TIB/Integration Manager, реализую-
щее шаблон диспетчер процессов (Process Manager, с. 325). В решениях Б и В все сообще-
ния с ответами поступают в единый канал, а для сопоставления ответов с запросами кон-
кретных клиентов применяются идентификаторы корреляции (Correlation Identifier, с. 186).
Синхронная реализация с использованием Web-служб
383
Синхронная реализация с использованием Web-служб
Конрад Ф. Д’Круз (Conrad F. D’Cruz)
В настоящем разделе описывается реализация кредитного брокера с использованием
Java и Web-служб XML. Для создания и развертывания Web-служб будет использован на-
бор средств с открытым исходным кодом Apache Axis. Мы не хотели превращать свой
пример в банальное упражнение на тему написания Java-приложений, поэтому решили
воспользоваться указанным набором средств, чтобы абстрагироваться от сложностей
реализации интерфейса синхронной Web-службы. Вместо этого основное внимание
будет уделено решениям, принимаемым в процессе проектирования системы синхрон-
ного обмена сообщениями.
Архитектура решения
На рис. 9.8 показана общая архитектура синхронной реализации кредитного брокера
на основе Web-служб. В ней можно выделить семь интерфейсов, посредством которых
осуществляется взаимодействие между кредитным брокером и остальными компонента-
ми решения. Как уже отмечалось, для взаимодействия между каждой парой участников
общения будет применяться протокол SOAP поверх HTTP.
Рис. 9.8. Архитектура синхронного решения на основе Web-служб
Первый интерфейс — это точка входа в Компонент кредитного брокера, которая
применяется клиентским приложением для передачи сообщения, содержащего запрос на
получение кредита. Этот же интерфейс применяется для возвращения клиенту оконча-
тельного значения процентной ставки. Хотя на рис. 9.8 не показан сервер Axis, именно
он получает от клиента сообщение (Message, с. 98) и реализует активатор службы (Service
Activator, с. 545).
384
Глава 9. Практикум: сложный обмен сообщениями
Второй интерфейс располагается между брокером и кредитным бюро. Кредитное бю-
ро — это внешнее учреждение, которое предоставляет брокеру интерфейс Web-службы
для получения данных о потребителе, необходимых для обращения в банк. Кредитный
брокер расширяет запрос клиента данными, полученными от кредитного бюро, реализуя
расширитель содержимого (Content Enricher, с. 348).
Оставшиеся пять интерфейсов размещаются между кредитным брокером и каждым из
банков (в нашем примере их пять). Каждый интерфейс применяется для получения вели-
чины процентной ставки, под которую предлагает выдать кредит соответствующий банк.
Все интерфейсы предоставляют доступ к одной и той же функциональности, однако
форматы соответствующих сообщений SOAP могут различаться. Таким образом, перед
отправкой запроса в банк кредитный брокер должен преобразовать сообщение с запро-
сом, полученное от клиента, в формат, поддерживаемый этим банком.
Кредитный брокер напрямую контактирует с каждым банком, используя предиктив-
ную маршрутизацию. Иными словами, набор банков, которые будут участвовать в обра-
ботке запроса, становится известен непосредственно перед тем, как им отправляют
запрос. На данном этапе кредитный брокер отправляет запрос выбранным банкам,
используя список получателей (Recipient List, с. 264). Поскольку в каждом банке может
применяться собственный формат запросов, кредитный брокер должен воспользоваться
массивом трансляторов сообщений (Message Translator, с. 115), чтобы преобразовать
запрос в формат, требуемый каждым из банков.
Аналогичным образом каждое сообщение с ответом должно быть преобразовано в
общий формат посредством нормализатора (Normalizer, с. 364), чтобы все ответы можно
было скомпоновать в одно сообщение с лучшей процентной ставкой. Сообщения с за-
просом и ответом передаются в синхронном режиме; выполнение клиента и кредитного
брокера блокируется, пока каждый банк не пришлет ответ (или не истечет время ожида-
ния). Кредитный брокер синтезирует все ответы в одно сообщение с лучшим значением
процентной ставки и отсылает его клиенту.
Синхронный обмен сообщениями удобно применять в проблемных средах, в которых
предпочтительнее использовать простые решения. Используя синхронный обмен сооб-
щениями, не нужно беспокоиться об обработке асинхронных событий, безопасности
потоков или инфраструктуре, необходимой для их поддержки. Клиент вызывает
Web-службу кредитного брокера и ждет ответа от сервера. Описываемое решение состоит
из нескольких компонентов, каждый из которых выполняет синхронный вызов следую-
щего компонента и ждет ответа.
Соображения по поводу проектирования Web-служб
Web-службы XML функционируют на основе простого протокола доступа к объектам
(Simple Object Access Protocol — SOAP). Спецификация SOAP, утвержденная консорциу-
мом W3C, описывает протокол на основе XML, предназначенный для обмена сообщения-
ми между децентрализованными и распределенными системами. Более подробно о SOAP
можно прочитать на сайте консорциума W3C по адресу http: / /www. w3. org/TR/SOAP.
К сожалению, буква S в аббревиатуре SOAP, означающая “simple” (“простой”), уже
давно утратила всякий смысл. Мы часто шутим, что SOAP1 следовало бы переименовать
в сложный протокол удаленного доступа (Complex Remote Access Protocol — CRAP).
1 “Soap” в переводе с английского означает “мыло”. — Примеч. пер.
Синхронная реализация с использованием Web-служб
385
Можете посмотреть в словаре, как переводится получившаяся аббревиатура. Если же
говорить серьезно, то разработка даже простого интерфейса Web-службы требует глубо-
кого изучения терминологии, а также преимуществ и недостатков, связанных с приняти-
ем тех или иных решений. Наша книга ни в коей мере не является учебником по
Web-службам. Тем не менее для понимания дальнейшего материала главы мы решили
кратко обсудить следующие особенности проектирования Web-служб:
• транспортный протокол;
• выбор между синхронным и асинхронным обменом сообщениями;
• стиль кодирования (кодированный или литеральный);
• стиль привязки (RPC или документ);
• надежность и безопасность.
Транспортный протокол
Спецификация SOAP создавалась для того, чтобы приложения могли выполнять син-
хронные RPC-вызовы служб через сеть способом, не зависящим от применения кон-
кретных технологий. Фактически она описывает создание отдельных сообщений с запро-
сом и ответом для каждого вызова Web-службы (как определено в документе WSDL, опи-
сывающем эту службу). Хотя протокол SOAP изначально разрабатывался с упором на
обмен сообщениями, большая часть приложений с Web-службами в качестве транспорт-
ного протокола использует HTTP. Выбор HTTP выглядит вполне логичным, потому что
это самый распространенный протокол в Web, который “умеет” проникать сквозь
брандмауэры. С другой стороны, как следует из полного названия протокола HTTP —
HyperText Transfer Protocol (протокол передачи гипертекста), — он разрабатывался для
того, чтобы пользователи с Web-обозревателями могли извлекать документы из Интерне-
та, а вовсе не для взаимодействия приложений друг с другом. По своей сути протокол
HTTP ненадежен и ориентирован на синхронное извлечение документов — клиенское
приложение использует одно и то же соединение для отправки запроса серверу и для по-
лучения ответа. Таким образом, Web-службы, использующие HTTP, так или иначе будут
осуществлять синхронный обмен запросами и ответами, потому что асинхронный обмен
сообщениями по ненадежному каналу полезен не более, чем попытка отправить письмо,
запечатав его в бутылку и бросив посреди океана.
Выбор между синхронным и асинхронным обменом сообщениями
В синхронной реализации Web-службы клиентское соединение остается открытым
даже после того, как сервер получит запрос клиента. Клиент будет ждать, пока сервер
не возвратит ответ. Преимущество использования синхронного RPC-взаимодействия со-
стоит в том, что клиентское приложение быстро узнает состояние операции, которая вы-
полняется Web-службой (придет ответ или истечет время ожидания). К сожалению,
использование синхронного обмена сообщениями имеет серьезное ограничение: по-
скольку соединение каждого клиента остается открытым вплоть до получения результата,
серверу, скорее всего, придется иметь дело с огромным количеством параллельных
соединений. Это значительно повышает сложность серверного приложения. Если один
из вызовов поставщика службы даст сбой, серверное приложение должно запустить
механизм, который перехватит ошибку и возобновит обработку данных (либо сообщит
об ошибке) прежде, чем перейдет к обработке других синхронных вызовов.
386
Глава 9. Практикум: сложный обмен сообщениями
В настоящее время большинство наборов средств для разработки Web-служб по умол-
чанию поддерживает только синхронный обмен сообщениями. Тем не менее, используя
существующие стандарты и платформы для создания асинхронных очередей сообщений,
некоторым производителям удалось эмулировать асинхронный обмен сообщениями для
Web-служб. Несколько организаций, компаний и рабочих групп, занимающихся созда-
нием стандартов для Web-служб, уже поняли необходимость поддержки асинхронного
обмена сообщениями и приступили к разработке соответствующих стандартов (на-
пример, WS-ReliableMessaging). Более подробно о последних стандартах Web-служб мож-
но прочитать на сайте консорциума W3C (http: //www. w3. org), а также в главе 14.
Стиль кодирования
Понятие кодирования SOAP привело к появлению небольшой путаницы. В специфи-
кации SOAP определяется так называемый стиль кодирования (encoding style), который
задается атрибутом encodingstyle. Он может быть двух видов: кодированный (encoded) и
литеральный (literal). Первый из них задается путем присвоения атрибуту encodingstyle
значения http: / /schemas.xmlsoap.org/soap/encoding, а второй — путем присвое-
ния некоторого другого значения (или никакого вообще). Стиль кодирования определя-
ет, как объекты и параметры приложения представляются с помощью XML “на лету”.
Кодированный стиль, также называемый кодированием SOAP (SOAP encoding), определя-
ется в разделе 5 спецификации SOAP. В этом разделе рассматривается примитивный ме-
ханизм преобразования описаний типов данных из языков программирования в формат
XML. При литеральном стиле, называемом также документолитералъным (doc/literal),
предполагается, что такого преобразования делать не нужно. Вместо этого информация о
типах данных предоставляется некоторым внешним механизмом. Последним обычно яв-
ляется документ WSDL, использующий схемы XML для описания того, какие в точности
типы данных применяются в сообщении SOAP.
Необходимость кодирования SOAP была вызвана тем, что спецификация SOAP была
написана еще до принятия консорциумом W3C спецификации XSD (XML Schema
Definition — определение схемы XML). По этой причине в спецификации SOAP требова-
лось предусмотреть какой-то способ кодирования информации о типах данных, а также па-
раметров, отсылаемых вместе с вызовом процедуры. Это особенно важно для сложных ти-
пов данных, таких как массивы. В разделе 5.4.2 спецификации SOAP подробно описывает-
ся, как представлять массивы в языке XML с помощью типа схем SOAP - ENC: Array.
С появлением спецификации схем XML (http://www.w3.org/TR/xmlschema-0)
большинство языков программирования перестали нуждаться в кодировании SOAP, обза-
ведясь собственными преобразованиями (или правилами сериализации) типов данных в
схемы XML. К примеру, спецификация JAX-RPC описывает, как типы данных Java преоб-
разуются в элементы схемы XML, и наоборот. Необходимость дополнительного кодирова-
ния отпала, в результате чего кодирование SOAP было вытеснено литеральным кодирова-
нием, заданным внешним документом XML (обычно в форме документа WSDL).
Стиль привязки
Спецификация WSDL описывает два различных стиля привязки (binding styles) опера-
ции к SOAP. Атрибут style элемента soap:binding может иметь два значения: грс
и document. Если документ WSDL описывает операцию, значение атрибута
soap: binding style которой равно грс, значит, получатель запроса должен интерпре-
Синхронная реализация с использованием Web-служб
387
тировать его, используя правила, содержащиеся в разделе? спецификации SOAP.
Это, к примеру, означает, что:
• имя элемента XML внутри тела сообщения SOAP (он называется элементом-
оберткой (wrapper element)) должно совпадать с именем вызываемой операции,
написанной на языке программирования;
• каждая часть сообщения внутри этого элемента должна в точности (т.е. по имени
и порядку) соответствовать параметру упомянутой операции, написанной на язы-
ке программирования;
• возвращаться должен только один элемент (он должен называться xxxResponse,
где ххх — имя соответствующей операции на языке программирования), внутри
которого будет содержаться один и только один элемент, являющийся результатом
выполнения операции.
Стиль документа намного свободнее, чем RPC. Сообщение с таким стилем привязки
просто должно быть построено на основе правильно оформленного документа XML,
а механизм выполнения SOAP сам решит, как его обрабатывать. Многие современные
средства (например, выпускаемые корпорацией Microsoft) применяют стиль документа
и литеральный стиль для представления семантики RPC. Само сообщение при этом от-
правляется в качестве сообщения с командой (Command Message, с. 169), а имя вызываемой
операции и ее параметры кодируются в документе.
Надежность и безопасность
В главе 14 Шон Невилл рассказывает о развитии стандартов, затрагивающих вопросы
надежности и безопасности Web-служб. В нашем решении используется самая основная
и, пожалуй, все еще самая распространенная комбинация технологий, упоминавшихся в
предыдущих разделах: это SOAP поверх HTTP с синхронным взаимодействием, а также
кодирование сообщений с использованием стандартного стиля кодирования SOAP и
стиля привязки RPC. Все это приближает поведение Web-службы к принципам работы
удаленного вызова процедуры (Remote Procedure Invocation, с. 85). Мы решили пойти этим
путем, чтобы избежать долгих дискуссий на тему внутреннего устройства Web-служб (все,
больше об этом говорить не будем!) и сосредоточиться на сравнении синхронной реали-
зации Web-служб с другими реализациями.
Набор средств Apache Axis
Чтобы разъяснить некоторые важные моменты нашего решения, мы решили вклю-
чить в главу краткое описание архитектуры Axis. Более подробно об этом наборе средств
можно прочитать на Web-сайте Apache Axis по адресу http: / /ws. apache. org/axis.
В главе 3 описывается шаблон конечная точка сообщения (Message Endpoint, с. 124).
Он представляет собой механизм, используемый приложением для подключения к кана-
лу обмена сообщениями с целью отправки и получения сообщений. В нашем приложе-
нии кредитного брокера платформа Axis сама по себе представляет канал обмена сооб-
щениями, и ее основной функцией является обработка сообщений “по поручению”
пользовательского приложения.
388
Глава 9. Практикум: сложный обмен сообщениями
Сервер Axis реализует шаблон активатор службы (Service Activator, с. 545). В главе 10
рассказывается, как с помощью активатора службы связать канал сообщений (Message
Channel, с. 93) с синхронной службой в приложении, чтобы при получении сообщения
происходил вызов этой службы.
Активатор службы реализован в рамках сервера Axis, поэтому разработчику не нужно
заботиться об указанной функциональности. Код нашего приложения будет содержать
только бизнес-логику, а все операции по обработке сообщений возьмет на себя сервер Axis.
Модель клиентского программирования (client-programming) Axis предусматривает
оснащение клиентского приложения компонентами для вызова адреса URL конечной
точки с последующим получением ответа от сервера. В нашем примере клиент кредит-
ного брокера представляет собой синхронное клиентское приложение, использующее
модель клиентского программирования Axis. На сервере Axis, в свою очередь, есть по од-
ному слушателю для каждого транспортного протокола, поддерживаемого указанным
сервером. Когда клиент отправляет сообщение в конечную точку, транспортный слуша-
тель, функционирующий в рамках платформы Axis, создает объект контекста сообщения
(message context) и передает его по цепи запросов. Контекст сообщения включает в себя
собственно сообщение, полученное от клиента, а также свойства, добавленные к нему
транспортным клиентом.
Платформа Axis состоит из серии обработчиков (Handlers), которые вызываются в оп-
ределенном порядке в зависимости от конфигурации развертывания, а также от того, кто
обращается к платформе — клиент или сервер. Обработчики являются частью подсисте-
мы потока сообщений (Message How) и сгруппированы в цепи (Chains). Сообщения с за-
просами обрабатываются последовательностью обработчиков из цепи запросов. Все со-
общения с ответами проходят по соответствующей цепи ответов через последователь-
ность обработчиков ответов.
На рис. 9.9 приведена схема, иллюстрирующая внутреннее устройство платформы
Axis. Более подробное описание архитектуры Axis приведено на сайте http: / /ws.
apache.org/axis.
Axis Engine
Puc. 9.9. Механизм выполнения Axis
Синхронная реализация с использованием Web-служб
389
Платформа Axis включает в себя несколько подсистем, которые в сочетании друг
с другом реализуют функциональность канала сообщений. Платформу могут использовать
как клиентские, так и серверные приложения. В нашем примере фигурируют следующие
подсистемы Axis:
• подсистема модели сообщений (Message Model) определяет XML-синтаксис
сообщений SOAP;
• подсистема потока сообщений (Message Flow) определяет пепи разработчиков,
которым будут передаваться сообщения;
• подсистема обработчиков службы (Service) определяет обработчик для службы
(SOAP, XML-RPC);
• транспортная подсистема (Transport) определяет варианты транспорта для переда-
чи сообщений (например, HTTP, JMS, SMTP);
• подсистема поставщиков (Provider) определяет, какие поставщики необходимы
для разных типов классов (например, Java RPC, EJB, MDB).
Как уже говорилось, разработчику нужно сосредоточить свои усилия только на созда-
нии приложения, реализующего бизнес-логику. Затем это приложение может быть раз-
вернуто на сервере Axis. Существует три способа того, как развернуть класс Java в виде
Web-службы и сделать его доступным в качестве службы конечной точки:
• автоматическое развертывание;
• использование дескриптора развертывания Web-служб (Web Services Deployment
Descriptor — WSDD);
• создание прокси-классов на основе существующего документа WSDL.
Первый и самый простой способ развертывания — написать класс, содержащий биз-
нес-логику приложения, и сохранить его в виде файла JWS (исходный файл Java с расши-
рением . jws). Файл JWS не нуждается в компиляции и может быть сразу же развернут
путем копирования исходного файла на сервер в каталог webapps. После этого каждый
публичный метод класса станет доступным в качестве Web-службы. Имя файла JWS ста-
новится частью адреса конечной точки, например:
http://имя_узла:номер_порта/axis/LoanBroker.jws
Axis 1.1 автоматически генерирует документ WSDL на основе Web-служб, развернутых
на сервере. WSDL — это XML-подобный язык, описывающий общедоступный интер-
фейс Web-службы (т.е. методы, доступные через этот интерфейс) и расположение этой
службы (т.е. адрес URL). Автоматическое создание документа WSDL позволяет другим
приложениям исследовать удаленный интерфейс, предоставленный классом Web-служ-
бы. Документ WSDL может также применяться для автоматического создания клиент-
ских классов-“заглушек”, инкапсулирующих вызов Web-службы внутри обычного класса
Java. Недостаток же этого метода заключается в том, что разработчик не может контро-
лировать параметры развертывания.
Второй способ предполагает развертывание скомпилированного класса с использова-
нием WSDD, что позволяет разработчику контролировать параметры развертывания,
такие как область действия класса. По умолчанию класс развертывается в контексте за-
390
Глава 9. Практикум: сложный обмен сообщениями
проса; иными словами, для каждого запроса, полученного Web-службой, создается
новый экземпляр класса. Когда обработка запроса заканчивается, экземпляр класса
уничтожается. Если же экземпляр класса должен существовать на протяжении всего
сеанса, чтобы обслуживать разные запросы одного и того же клиента, нужно определить
этот класс в контексте сеанса. Наконец, в некоторых приложениях требуется, чтобы все
клиенты осуществляли доступ к единственному экземпляру класса; экземпляр класса
должен быть доступен на протяжении всего времени работы приложения, а значит,
Web-служба определяется в контексте приложения.
Последний способ более сложен, чем два первых, но он позволяет создавать классы-
скелетоны и прокси-классы на основе существующего документа WSDL (с помощью
средства wsd!2java). В прокси-классах и скелетонах инкапсулирован весь код, касаю-
щийся SOAP. Благодаря этому разработчику не приходится вручную писать какой-либо
код, касающийся работы с SOAP (или Axis). Достаточно лишь вставить бизнес-логику
в тело методов сгенерированного скелетона.
Чтобы не усложнять структуру приложения кредитного брокера и его развертывание,
все Web-службы в данном примере будут реализованы посредством автоматического раз-
вертывания (с помощью файлов JWS). С точки зрения клиента, написать код вызова
Web-службы можно и вручную. Мы могли бы воспользоваться средством wsd!2 j ava для
генерации фиктивных служб, которые затем вызывались бы клиентским кодом, но ре-
шили свести автоматическую генерацию кода к минимуму, поскольку это затрудняет
последовательный анализ решения.
Поиск расположения службы
Прежде чем перейти к описанию приложения кредитного брокера, необходимо рас-
смотреть несколько общих процедур, которые помогают облегчить развертывание реше-
ния. Чтобы вызвать Web-службу, развернутую на некотором сервере, клиентское прило-
жение должно знать адрес URL конечной точки этой Web-службы. В модели Web-служб
приложение выполняет поиск расположения Web-службы, доступ к которой ему требует-
ся осуществить, в общем реестре служб.
Создание репозиториев для хранения адресов конечных точек Web-служб регламен-
тируется стандартом UDDI (Universal Description, Discovery and Integration — универ-
сальное описание, поиск и интеграция). К сожалению, обсуждение этого стандарта вы-
ходит за рамки данной книги. Более подробную информацию о нем можно получить по
адресу http://www.uddi.org. В нашем примере адреса конечных точек Web-служб
будут вписаны в код самого приложения. С другой стороны, чтобы облегчить разверты-
вание кода примера, мы создали файлы свойств как для клиентского, так и для сервер-
ного приложений. В файле свойств содержатся пары типа “имя-значение” для парамет-
ров имя_узла и номер_порта, описывающих соответствующие значения вашей копии
сервера Axis. Это несколько упростит процедуру развертывания приложения кредитного
брокера в вашей среде. В некоторых классах Java также будет присутствовать служебный
метод, называющийся readProps(). Он предназначен для чтения файлов, содержащих
параметры развертывания сервера Axis. Метод readProps () не фигурирует ни в одном
из функциональных аспектов приложения кредитного брокера.
Любая распределенная вычислительная платформа, будь то Java, RMI, CORBA или
Web-службы SOAP, требует, чтобы параметры, передаваемые методам при удаленном
вызове, были определены как переменные элементарных типов или же как объекты,
Синхронная реализация с использованием Web-служб
391
которые могут быть сериализованы при передаче в сеть или из сети. Эти параметры
являются свойствами объектов сообщений, которые клиент отправляет серверу. Чтобы
лишний раз не усложнять приложение кредитного брокера, ответ кредитного брокера
клиенту будет возвращаться в виде Java-объекта string. Если параметры, передаваемые
при вызове метода, принадлежат к элементарным типам данных (например, int или
double), их следует упаковать в заранее определенные объекты-оболочки, называемые
оболочками типов (Integer, Double и т.д.).
Приложение кредитного брокера
На рис. 9.10 изображена диаграмма классов для компонента кредитного брокера.
Основная бизнес-логика кредитного брокера инкапсулирована в классе LoanBrokerws.
Этот класс является производным от класса, предоставленного платформой Axis и реали-
зующего активатор службы (Service Activator, с. 545), чтобы при получении запроса SOAP
осуществлять вызов метода из класса LoanBrokerws. Класс LoanBrokerws также ссыла-
ется на ряд классов шлюзов, которые реализуют детали взаимодействия с внешними
компонентами, такими как кредитное бюро и банки. Соответствующая логика инкапсу-
лирована в классах CreditAgencyGateway, LenderGateway и BankQuoteGateway.
Единственный интерфейс службы, предназначенный для взаимодействия кредитного
брокера с внешним миром, выполняет роль конечной точки сообщений для клиента, пы-
тающегося получить доступ к службе кредитного брокера. Определять отдельный шлюз
обмена сообщениями (Messaging Gateway, с. 482) не нужно, поскольку его роль будет играть
сама платформа Axis.
Взаимодействие между компонентами синхронной реализации кредитного брокера
показано на рис. 9.11. Вначале кредитный брокер вызывает компонент шлюза кредит-
ного бюро (CreditAgencyGateway). Последний дополняет минимальный набор данных,
предоставленных клиентом, кредитным баллом и длиной кредитной истории указанного
клиента. Кредитный брокер использует расширенные данные для обращения к шлюзу
392
Глава 9. Практикум: сложный обмен сообщениями
LenderGateway. Этот компонент реализует список получателей (Recipient List, с. 264),
который анализирует данные, полученные от кредитного брокера, и на их основе опреде-
ляет набор банков, способных обслужить запрос на получение кредита.
Рис. 9.11. Циклограмма кредитного брокера
Когда список потенциальных заимодателей определен, кредитный брокер обращается
к шлюзу BankQuoteGateway. Этот компонент выполняет функции предиктивной мар-
шрутизации, по очереди вызывая каждый из банков. Компонент банка, в свою очередь,
служит интерфейсом для доступа к реальной банковской операции. К примеру, класс
Bankl является интерфейсом для доступа к Web-службе Bankiws. jws, имитирующей
определение возможной ставки по кредиту. Когда на вход реальной службы поступает
запрос от кредитного брокера, она выполняет некоторую канцелярскую работу, связан-
ную с анализом предоставленных ей данных, а затем выдает предлагаемое значение про-
центной ставки. В нашем примере значение процентной ставки будет генерироваться
“фиктивной” банковской Web-службой.
Шлюз BankQuoteGateway собирает все ответы, полученные от банков, и выбирает
лучшее значение процентной ставки из предложенных. Окончательный ответ отправля-
ется кредитному брокеру, который приводит данные к нужному формату и возвращает
готовый отчет клиенту.
Чтобы не загромождать рис. 9.11 лишними деталями, мы показали на нем только два
из пяти имеющихся банков. В зависимости от того, какой список получателей был сгене-
рирован для конкретного запроса, кредитный брокер может обращаться с запросом как в
один банк, так и в несколько (и даже во все пять) банков сразу.
Синхронная реализация с использованием Web-служб
393
Циклограмма, показанная на рис. 9.11, прекрасно иллюстрирует последовательную
обработку запросов на получение кредита, направленных в каждый из банков. Последо-
вательная обработка имеет свои преимущества, потому что приложение можно запустить
в рамках единственного потока, по очереди обращаясь в каждый из банков. Приложению
не нужно запускать множество потоков для одновременного запроса процентной ставки
у каждого из банков, а значит, не нужно заботиться о многочисленных проблемах, кото-
рыми чревата параллельная обработка данных. С другой стороны, получение ответов из
всех банков отнимает достаточно много времени, поскольку кредитный брокер не может
отправить запрос в следующий по списку банк, не дождавшись ответа из предыдущего.
Как следствие этого клиенту, отправившему запрос на получение кредита, придется до-
вольно долго ждать ответа.
Компоненты приложения кредитного брокера
Перейдем к проектированию функциональных аспектов приложения кредитного
брокера. Как говорилось ранее, платформа Axis может поддерживать как клиентские, так
и серверные приложения. Это позволяет удаленному клиенту осуществлять доступ к
опубликованной конечной точке через сеть. Серверному приложению также может по-
надобиться выступить в роли клиента, чтобы осуществить доступ к конечной точке ка-
кой-то другой Web-службы, вне зависимости от того, где она находится, — на том же или
на удаленном сервере. Мы продемонстрируем эти возможности, представив ключевые
компоненты нашего решения в виде Web-служб. Правда, последние будут функциониро-
вать на одном и том же экземпляре нашего сервера.
Приложение кредитного брокера должно реализовывать следующие функции:
• принятие запроса клиента;
• запрос и получение данных от кредитного бюро;
• реализация службы кредитного бюро;
• получение значений процентной ставки;
• реализация банковских операций.
Принятие запроса клиента
Реализация кредитного брокера содержится в файле JWS с именем Loan-
Brokerws. jws. Класс кредитного брокера включает в себя единственный публичный
метод, доступный в качестве Web-службы: getLoanQuote. Чтобы начать обработку кли-
ентского запроса на получение кредита, брокеру нужно знать три параметра: номер кар-
ты социального страхования (SSN), выступающий в качестве идентификатора клиента,
желаемую сумму кредита и срок кредитования в месяцах.
LoanBrokerWS.jws
public String getLoanQuote(int ssn, double loanamount, int
loanduration) {
String results =
results = results + "Client with ssn= " + ssn +
" requests a loan of amount= " + loanamount +
394
Глава 9. Практикум: сложный обмен сообщениями
" for " + loanduration + " months" + "\n\n";
// "Клиент с номером карты социального страхования XX просит
// выдать кредит на сумму XX сроком на XX месяцев."
results = results +
this.getLoanQuotesWithScoreS(ssn,loanamount,loanduration);
return results;
}
Единственное, что выполняет метод, код которого показан выше, — вызывает метод
getLoanQuotewithscores. Последний возвращает строку, которая затем отправляется
обратно клиенту по цепочке ответов платформы Axis. По окончании цепочки транспорт-
ный слушатель, получивший запрос, принимает сообщение с ответом и передает его кли-
енту по сети.
Поскольку мы используем автоматическое развертывание файла JWS для компонента
кредитного брокера, Axis генерирует файл WSDL для службы LoanBrokerws. Ниже при-
ведено содержимое этого файла.
<wsdl:definitions xmlns:wsdl="http://schemas.xmlsoap.org/wsdl/"
xmlns:wsdlsoap="http://schemas.xmlsoap.org/wsdl/soap/"
xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<wsdl:message name="getLoanQuoteRequest">
<wsdl:part name="ssn" type="xsd:int"/>
<wsdl:part name="loanamount" type="xsd:double"/>
<wsdl:part name="loanduration" type="xsd:int"/>
</wsdl:message>
<wsdl:message name="getLoanQuoteResponse">
<wsdl:part name="getLoanQuoteRetum" type="xsd:string"/>
</wsdl:message>
<wsdl:portType name="LoanBrokerWS">
<wsdl:operation name="getLoanQuote" parameterOrder=”ssn
1oanamount 1oandurat i on">
cwsdl:input message="intf:getLoanQuoteRequest"
name ="ge t LoanQuot eReque s t"/>
<wsdl:output message="intf:getLoanQuoteResponse"
name="getLoanQuoteResponse"/>
</wsdl: operation:»
</wsdl:portType>
<wsdl:binding name="LoanBrokerWSSoapBinding"
type="int f:LoanBrokerws">
<wsdlsoap:binding style="rpc"
transport="http://schemas.xmlsoap.org/soap/http"/>
<wsdl:operation name="getLoanQuote">
<wsdlsoap zoperation soapAction=""/>
<wsdl:input name="getLoanQuoteRequest">
<wsdlsoap:body
encodingStyle="http://schemas.xmlsoap.org/soap/encoding/"
namespace="..." use="encoded"/>
</wsdl:input>
<wsdl:output name="getLoanQuoteResponse">
<wsdlsoap:body
Синхронная реализация с использованием Web-служб
395
encodingStyle="http://schemas.xmlsoap.org/soap/encoding/"
namespace="..." use="encoded"/>
</wsdl:output>
</wsdl:operation>
</wsdl:binding>
<wsdl .-service name= "LoanBrokerWSService":»
<wsdl:port binding="intf:LoanBrokerWSSoapBinding"
name="LoanBrokerWS">
<wsdlsoap:address
location="http://192.168.1.25:8080/axis/LoanBrokerWS.jws"/>
</wsdl:port>
</wsdl:service>
</wsdl:definitions>
В целях экономии места мы сократили документ WSDL, оставив в нем лишь наиболее
важные элементы. Элемент <wsdl: service:», расположенный ближе к концу документа,
определяет имя службы (LoanBrokerWSService) и расположение конечной точки.
Элемент <wsdl.- operat ion> задает имя метода (операции), а также параметры, которые
должен указать клиент для доступа к Web-службе LoanBrokerWSService. Две пары
дескрипторов <wsdl: message> определяют сообщения с запросом и ответом для опера-
ции getLoanQuote — getLoanQuoteRequest и getQuoteLoanResponse с соответст-
вующими параметрами, которые они передают или получают от Web-службы. Элемент
<wsdl: binding:» указывает, что мы используем стиль привязки RPC (более подробно о
нем говорилось в начале примера). Наконец, элемент <wsdlsoap.-body> означает, что
мы используем стиль кодирования SOAP (а не документолитеральный).
Чтобы просмотреть файл WSDL, сгенерированный вашим сервером Axis, введите
в окно обозревателя адрес URL, показанный ниже. Слова имя_узла и номер_порта сле-
дует заменить соответствующими значениями для вашего сервера.
http://имя_узла:HOMep_nopra/axis/LoanBrokerWS.jws?wsdl
Запрос и получение данных от кредитного бюро
Еще одной обязанностью кредитного брокера является сбор дополнительных данных
о клиенте, необходимых для обращения в банки. Ниже показано, как кредитный брокер
реализует функции расширителя содержимого (Content Enricher, с. 348).
LoanBrokerWS.jws
private String getLoanQuotesWithScores
(int de_ssn, double de_loanamount, int de_duration) {
String qws_results =
"Additional data for customer: credit score
and length of credit history\n";
// "Дополнительные данные о клиенте:
// кредитный балл и длина кредитной истории."
int ssn = de_ssn;
double loanamount = de__loanamount ;
int loanduration = de_duration;
int credit_score = 0;
int credit_history_length = 0;
396
ГлаваЭ. Практикум: сложный обмен сообщениями
CreditProfile creditprofile =
CreditAgencyGateway.getCustomerCreditProfile(ssn);
credit_score = creditprofile.getCreditScore() ;
credit_history_length =
creditprofile.getCreditHistoryLength();
qws_results = qws_results + "Credit Score= " + credit_score +
" Credit History Length= " + credit_history_length;
// "Кредитный балл — XX, кредитная история — XX."
qws_results = qws_results + "\n\n";
qws_results = qws_results + "The details of the best quote
from all banks that responded are shown below: \n\n”;
// "Ниже показаны детали о лучшем предложении
// ставки по кредиту."
qws_results = qws_results + getResultsFromLoanClearingHouse
(ssn,loanamount,loanduration,credit_history_length,credit_score);
qws_results = qws_results + "\n\n";
return qws_results;
Теперь перейдем к описанию операций кредитного бюро, которые являются следую-
щей логической частью приложения кредитного брокера. Чтобы оставить код SOAP за
рамками приложения кредитного брокера и минимизировать число зависимостей между
брокером и кредитным бюро, воспользуемся шаблоном шлюз (Gateway) из [9]. Последний
обладает двумя ключевыми преимуществами: во-первых, он абстрагирует технические
детали общения от приложения, а во-вторых, если мы решим отделить интерфейс шлюза
от его реализации, то в целях тестирования сможем заменить реальную внешнюю службу
фиктивной службой (Service Stub', см. [9]).
Шлюз CreditAgencyGateway, код которого показан ниже, абстрагирует технические
детали взаимодействия между шлюзом кредитного бюро и Web-службой кредитного
бюро (CreditAgencyWS). При необходимости такую службу можно заменить фиктивной.
Шлюз принимает идентификатор клиента (SSN) и запрашивает у кредитного бюро
дополнительные данные. Кредитное бюро в ответ на запрос возвращает кредитный балл
и длину кредитной истории указанного клиента. Оба указанных значения требуются,
чтобы кредитный брокер смог разослать запрос клиента в банки. Шлюз CreditAgency-
Gateway содержит весь код, который выполняется на стороне клиента для доступа к
Web-службе CreditAgencyWS, реализованной в файле CreditAgencyWS. jws.
CreditAgencyGateway .java
public static CreditProfile getCustomerCreditProfile(int ssn){
int credit_score = 0;
int credit_history_length = 0;
CreditProfile creditprofile = null;
try {
Синхронная реализация с использованием Web-служб
397
CreditAgencyGateway.readProps() ;
creditprofile = new CreditProfile();
String creditagency_ep = "http://" + hostname + +
portnum + "/axis/CreditAgencyWS.jws";
Integer il = new Integer(ssn);
Service service = new Service();
Call call = (Call) service.createCall();
call.setTargetEndpointAddress(new
java.net.URL(creditagency_ep));
call.setOperationName("getCreditHistoryLength");
call.addParameter("opl", XMLType.XSD_INT,
ParameterMode.IN);
call.setReturnType(XMLType-XSD_INT);
Integer retl = (Integer)
call.invoke(new Object [] {il});
credit_history_length = retl.intValue();
call.setOperationName("getCreditScore");
Integer ret2 = (Integer)
call.invoke(new Object [] {il});
credit_score = ret2.intValue();
creditprofile.setCreditScore(credit_score);
creditprofile.setCreditHistoryLength(credit_history_length);
Thread.sleep(credit_score);
}catch(Exception ex){
System.out.println("Error accessing the
CreditAgency Webservice");
// "Ошибка доступа к Web-службе кредитного бюро."
}
return creditprofile;
} }
Мы воспользовались шаблоном шлюз, чтобы показать, как серверное приложение
использует клиентскую платформу Axis для доступа к другой Web-службе, расположен-
ной на том же или на удаленном сервере.
Реализация службы кредитного бюро
Код Web-службы кредитного бюро содержится в файле CreditAgencyWS. jws, текст
которого приведен ниже. Чтобы отослать запрос клиента в банк, брокеру необходимо
знать значение кредитного балла клиента и длину его кредитной истории. В кредитном
бюро хранятся данные обо всех клиентах, которые когда-либо в прошлом брали кредиты.
Для получения необходимых сведений достаточно лишь указать идентификатор клиента.
398
Глава 9. Практикум: сложный обмен сообщениями
CreditAgencyWS.jws
public int getCreditScore(int de_ssn) throws Exception
{
int credit_score;
credit_score = (int) (Math.random 0 *600+300);
return credit_score;
public int getCreditHistoryLength(int de_ssn) throws Exception
{
int credit_history_length;
credit_history_length = (int) (Math.randomO *19+1) ;
return credit-history_length-,
}
Ниже приведен код файла WSDL, автоматически сгенерированного для файла
Credit AgencyWS. jws сервером Axis.
<wsdl:definitions xmlns:wsdl="http://schemas.xmlsoap.org/wsdl/"
xmlns:wsdlsoap="http://schemas.xmlsoap.org/wsdl/soap/">
<wsdl:message name="getCreditScoreResponse">
<wsdl:part name="getCreditScoreReturn" type="xsd:int"/>
</wsdl:message»
<wsdl:message name="getCreditHistoryLengthRequest">
<wsdl:part name="de_ssn" type="xsd:int"/>
</wsdl:message>
<wsdl:message name="getCreditScoreRequest">
<wsdl:part name="de_ssn" type="xsd:int"/>
</wsdl:message>
<wsdl:message name="getCreditHistoryLengthResponse">
<wsdl:part name="getCreditHistoryLengthReturn"
type="xsd:int"/>
</wsdl:message>
<wsdl:portType name="CreditAgencyWS">
<wsdl:operation name="getCreditHistoryLength"
parameter0rder="dessn">
<wsdl:input
message="intf:getCreditHistoryLengthRequest"
name="getCreditHistoryLengthRequest"/>
<wsdl:output
message="intf:getCreditHistoryLengthResponse"
name ="getCreditHist oryLengthRe spons e"/>
</wsdl: operation:»
<wsdl:operation name="getCreditScore"
parameter0rder="de_ssn">
<wsdl:input message="intf:getCreditScoreRequest"
name="getCreditScoreRequest"/>
<wsdl:output message="intf:getCreditScoreResponse"
Синхронная реализация с использованием Web-служб
399
name="getCreditScoreResponse"/>
</wsdl:operation>
</wsdl:рогtType >
<wsdl:binding name="CreditAgencyWSSoapBinding"
type="intf:CreditAgencyWS">
</wsdl:binding>
<wsdl:service name="CreditAgencyWSService">
<wsdl:port binding="intf:CreditAgencyWSSoapBinding"
name="CreditAgencyWS">
<wsdlsoap:address
location="http://192.168.1.25:8080/axis/CreditAgencyWS.jws"/>
</wsdl:port>
</wsdl:service>
</wsdl:definitions>
Элемент <wsdl:service> определяет Web-службу кредитного бюро credit-
AgencyWSService и задает конечную точку, к которой будет осуществлять доступ клиент
(в данном случае — кредитный брокер). Элемент <wsdl: operat ion> определяет два пуб-
личных метода, описанных в файле CreditAgencyWS. jws, а именно — getCreditScore
и getCreditHistoryLength. Для каждого из этих методов определяется пара сообщений
“запрос-ответ”, которые задаются с помощью дескрипторов <wsdl :message>. Это сооб-
щения getCreditScoreRequest, getCreditScoreResponse, getCreditHistory-
LengthRequest и getCreditHistoryLengthResponse.
Опять-таки, в целях экономии места мы сжали или выбросили многие элементы
файла WSDL, оставив только наиболее важные из них. Чтобы увидеть полный текст фай-
ла, сгенерированного вашим сервером, воспользуйтесь следующим адресом URL (слова
имя_узла и номер_порта следует заменить соответствующими значениями для вашего
сервера).
http://имя_узла:номер_порта/axis/CreditAgencyWS.jws?wsdl
В нашем примере Web-служба кредитного бюро не предоставляет какой-либо реаль-
ной функциональности. Вместо этого она возвращает случайные данные, которые могут
быть использованы другими частями приложения.
Получение значений процентной ставки
Дополнив данные, полученные от клиента, необходимой информацией, кредитный
брокер обращается к собственной функции по имени getResultsFromLoan-
clearingHouse (“извлечь данные из расчетного центра”). Как будет видно немного
позднее, данная функция добывает для кредитного брокера всю необходимую информа-
цию о предложениях по кредитованию.
getResultsFromLoanClearingHouse(ssn, loanamount, loanduration,
credit_history_length, credit_score);
Если структура приложения усложнится или же если кредитному брокеру потребуется
использовать внешний расчетный центр, функцию getResultsFromLoanClearingHouse
400
Глава 9. Практикум: сложный обмен сообщениями
можно выделить в отдельный логический компонент. В нашем примере функциональность
расчетного центра можно разбить на три части:
• составление списка заимодателей, которые могут обслужить запрос текущего
клиента;
• вычисление лучшей ставки по кредиту из тех, которые были предложены банками,
входящими в список заимодателей;
• форматирование итоговых данных о лучшей процентной ставке и возвращение
полученной информации кредитному брокеру.
Ниже приведена реализация каждой из трех описанных функций.
LoanBrokerWS.jws
private String getResultsFromLoanClearingHouse(int ssn,
double loanamount, int loanduration,
int credit_history_length, int credit_score) {
String lch_results="Results from Loan Clearing House
// "Результаты, полученные из расчетного центра:"
ArrayList lenderlist = LenderGateway.getLenderList
(loanamount, credit_history_length, credit_score);
BankQuote bestquote = BankQuoteGateway.getBestQuote
(lenderlist, ssn, loanamount,
loanduration, credit_history_length,
credit_score);
lch_results = "Out of a total of " + lenderlist.size() +
" quote(s), the best quote is from" +
this.getLoanQuotesReport(bestquote);
// "Из X процентных ставок лучшую предоставил XX."
return lch_results;
Вначале расчетный центр кредитного брокера должен составить список заимодате-
лей, которые могут обслужить текущий запрос клиента. Чтобы абстрагировать функцию
выбора заимодателей от кредитного брокера, мы создали класс LenderGateway. Чтобы
сделать решение более интересным, эту функцию можно было бы тоже инкапсулировать
внутри Web-службы, однако проектирование последней требует куда более тщательного
подхода. Особое внимание следует уделять типам параметров и возвращаемых значений,
потому что они должны обладать способностью к сериализации при передаче в сеть и из
сети. Чтобы не усложнять пример, мы решили внедрить логику выбора заимодателей
в простой класс Java, вызываемый кредитным брокером.
Кредитному брокеру было бы очень удобно, если бы шлюз LenderGateway возвра-
щал набор конечных точек служб для подходящих банков. У этого подхода, однако, есть
существенный недостаток — идентификацию Web-служб банков пришлось бы прописы-
вать прямо в коде шлюза LenderGateway. В реальной жизни такой подход значительно
осложняет поддержку решения, поскольку банки продаются, покупаются или объединя-
Синхронная реализация с использованием Web-служб
401
ются чаще, чем IT-проектировщики меняют работу. Мы воспользуемся другим, более
надежным решением, о котором поговорим при обсуждении класса BankQuoteGateway.
Метод getLenderList, код которого показан ниже, возвращает набор заимодателей
(т.е. банков), которые способны обслужить текущий запрос клиента.
LenderGateway.java
public static ArrayList getLenderList(double loanamount,
int credit—history_length,
int credit_score){
ArrayList lenders = new ArrayList();
LenderGateway.readProps();
if ((loanamount >= (double)75000) && (credit_score >= 600) &&
(credit_history_length >= 8))
lenders.add(new Bankl(hostname, portnum));
lenders.add(new Bank2(hostname, portnum));
if (((loanamount >= (double)10000) &&
(loanamount < = (double)74999)) &&
(credit_score >= 400) && (credit—history_length >= 3))
lenders.add(new Bank3(hostname, portnum));
lenders, add (new Bank4 (hostname, portnum) ) ,-
lenders.add(new Banks(hostname, portnum));
return lenders;
Данный метод реализует шаблон проектирования список получателей (Recipient List,
с. 264). В нашем примере база правил состоит из очень простых условных выражений if,
которые выбирают один или несколько банков на основе некоторых заранее заданных
критериев. Кроме того, чтобы запрос клиента всегда обслуживался хотя бы одним бан-
ком, в список заимодателей по умолчанию добавляется банк 5.
Получив список потенциальных заимодателей, кредитный брокер передает его шлюзу
BankQuoteGateway, чтобы тот начал собирать предлагаемые значения процентных ста-
вок и выбирать из них лучшее. Наличие данного шлюза позволяет абстрагировать внут-
ренний механизм интерфейса банка. Кредитному брокеру достаточно запросить у шлюза
BankQuoteGateway лучшее значение процентной ставки, как показано в следующем вы-
зове метода.
BankQuote bestquote = BankQuoteGateway.getBestQuote(lenderlist,
ssn, loanamount, loanduration,
credit—history_length,credit—score) ;
402
Глава 9. Практикум: сложный обмен сообщениями
Шлюз BankQuoteGateway отвечает на запрос кредитного брокера, получая от каж-
дого из банков, внесенных в список заимодателей, значение процентной ставки, а затем
выбирая из полученных значений лучшее (т.е. самое низкое). Ниже приведен код метода
getBestQuote.
BankQuoteGateway.java
public static BankQuote getBestQuote(ArrayList lenders, int ssn,
doub1e 1oanamount,
int loanduration,
int credit_history_length,
int credit_score){
BankQuote lowestquote = null;
BankQuote currentquote = null;
ArrayList bankquotes = BankQuoteGateway.getBankQuotes(lenders,
ssn, loanamount, loanduration,
credit_history_length, credit_score);
Iterator allquotes = bankquotes.iterator();
while (allquotes.hasNext()){
if (lowestquote == null){
lowestquote = (BankQuote)allquotes.next();
}
else{
currentquote = (BankQuote)allquotes.next 0;
if (currentquote.getlnterestRate() <
lowestquote.getlnterestRate()){
lowestquote = currentquote;
} } 1
return lowestquote;
Самой важной строкой в коде, показанном выше, является вызов метода get-
BankQuotes. Последний не только выполняет сбор банковских предложений по типу
управляемого аукциона, но и реализует шаблон агрегатор (Aggregator, с. 283). Ниже при-
веден код метода getBankQuotes.
public static ArrayList getBankQuotes(ArrayList lenders, int ssn,
double loanamount,
int loanduration,
int credit_history_length,
int credit_score) {
ArrayList bankquotes = new ArrayList();
BankQuote bankquote = null;
Bank bank = null;
Синхронная реализация с использованием Web-служб
403
Iterator banklist = lenders.iterator О;
while (banklist.hasNext()){
bank = (Bank)banklist.next();
bankquote = bank.getBankQuote(ssn, loanamount,
loanduration,
c redi t_hi s tory_length,
credit_score);
bankquotes.add(bankquote);
}
return bankquotes;
Функциональность управляемого аукциона реализуется с помощью цикла while.
Оператор while извлекает из списка заимодателей название очередного банка, а затем
вызывает метод getBankQuote, генерирующий для этого банка значение ставки по кре-
диту, как будет показано в коде ниже. Обратите внимание на порядок, в котором пере-
числены параметры при вызове метода getBankQuote. О важности этого порядка мы
поговорим чуть позже, когда займемся проектированием банков и соответствующих
Web-служб.
bank.getBankQuote(ssn, loanamount, loanduration,
credit_history_length, credit_score);
Ответ шлюза BankQuoteGateway кредитному брокеру формируется на основе списка
bankquotes типа ArrayList, в котором хранятся значения процентных ставок, предло-
женных банками. Метод getBestQuote прокручивает этот список, выбирает из него
наименьшее значение процентной ставки и возвращает кредитному брокеру.
Как уже упоминалось, банки и Web-службы банков будут спроектированы таким об-
разом, чтобы они имитировали реальные банковские операции. Функции банков при
этом будут отделены от функций кредитного брокера. Благодаря этому классы банков
смогут воспользоваться преимуществами шаблона шлюз (Gateway) из [9], о котором гово-
рилось при обсуждении класса CreditAgencyGateway.
Для начала определим абстрактный класс Bank.
Bank.java
public abstract class Bank {
String bankname;
String endpoint = "";
double prime_rate;
public Bank(String hostname. String portnum){
this.bankname = "";
thi s.prime_rate = 3.5;
public void setEndPoint(String endpt){this.endpoint = endpt;}
public String getBankName(){return this.bankname;}
public String getEndPoint(){return this.endpoint;}
public double getPrimeRate(){return this.prime_rate;}
404
Глава 9. Практикум: сложный обмен сообщениями
public abstract BankQuote getBankQuote(int ssn,
double loanamount, int loanduration,
int credit_history_length, int credit_score) ,-
public void arbitraryWait(){
try{
Thread.sleep((int)(Math.random()*10)*100);
Jcatch(java.lang.InterruptedException intex){
intex.printStackTrace();
В нашем примере процесс получения процентной ставки от банка грубо имитирует
выполнение реальной банковской операции. Вначале выполняется некоторый объем
канцелярской работы. После этого происходит доступ к компьютеризированной системе
вычисления ставок по кредиту, а затем снова выполняется некоторый объем рутинной
работы, прежде чем предлагаемое значение ставки по кредиту будет возвращено шлюзу
BankQuoteGateway.
Абстрактный класс Bank и производные от него классы (от Bankl до ВапкБ) пред-
ставляют собой модель функционирования обычного банка. В нашем примере банк при-
нимает запрос на получение кредита, и его сотрудники начинают прилежно анализиро-
вать предоставленную клиентом информацию, одновременно проверяя ее достоверность.
Мы решили смоделировать рутинную работу клерков с помощью метода случайного
ожидания arbitraryWait, реализованного в абстрактном классе Bank и вызываемого
методом getBankQuote. Чтобы сделать пример еще интереснее, мы воспользовались
Web-службами для моделирования компьютеризированной системы вычисления про-
центных ставок. Для банка п система вычисления процентных ставок моделируется с по-
мощью Web-службы Banknws, а ее код хранится в файле Banknws. jws. У нас есть пять
классов банков (от Bankl до Banks), а следовательно, и пять систем вычисления про-
центных ставок (от Bankiws до Bank5WS соответственно). В каждой из систем вычисле-
ния процентных ставок используется собственный формат списка параметров, переда-
ваемых методу getQuote (как и в реальной жизни, в которой в банках чаще всего ис-
пользуются собственные, отличные друг от друга форматы данных). Это означает, что
классу банка придется использовать транслятор сообщений (Message Translator, с. 115),
чтобы перед вызовом Web-службы преобразовывать сообщение в необходимый формат.
Мы покажем, как это делается, когда закончим рассматривать классы банков.
Обратите внимание, что метод getBankQuote в абстрактном классе Bank является
абстрактным методом, а передаваемые ему параметры расположены в строго определен-
ном порядке. Теперь рассмотрим реализацию одного из производных классов банков
(в качестве примера мы выбрали Bankl). Структура класса идентична для всех банков.
Отличаются лишь значения свойств (название банка и адрес конечной точки), которые
задаются конструктором при создании объекта банка.
Синхронная реализация с использованием Web-служб
405
Bank 1.java
public class Bankl extends Bank {
public Bankl(String hostname. String portnum){
super(hostname,portnum);
bankname = "Exclusive Country Club Bankers\n";
String epl = "http://" + hostname + + portnum +
"/axis/BanklWS.jws";
this.setEndPoint(epl) ;
public void setEndPoint(String endpt){this.endpoint = endpt;}
public String getBankName(){return this.bankname;}
public String getEndPoint(){return this.endpoint;}
public BankQuote getBankQuote(int ssn, double loanamount,
int loanduration,
int credit_history_length,
int credit_score) {
BankQuote bankquote = new BankQuote();
Integer il = new Integer(ssn);
Double i2 = new Double(prime_rate);
Double i3 = new Double(loanamount);
Integer i4 = new Integer(loanduration);
Integer 15 = new Integer(credit_history_length);
Integer i6 = new Integer(credit_score);
try{
Service service = new Service();
Call call = (Call) service.createCall();
call.setTargetEndpointAddress( new
j ava.net.URL(endpoint) );
call.setOperationName("getQuote");
call.addParameter( "opl", XMLType.XSD_INT,
ParameterMode.IN );
call.addParameter( "op2", XMLType.XSD_DOUBLE,
ParameterMode.IN );
call.addParameter( "op3", XMLType.XSD_DOUBLE,
ParameterMode.IN );
call.addParameter( "op4", XMLType.XSD_INT,
ParameterMode.IN );
cal1.addParameter( "op5", XMLType.XSD_INT,
ParameterMode.IN );
call.addParameter( "op6", XMLType.XSD_INT,
ParameterMode.IN );
call.setReturnType( XMLType.XSD_DOUBLE);
Double interestrate = (Double)
406
Глава 9. Практикум: сложный обмен сообщениями
call.invoke( new Object [] {il,i2,13,14,i5,i6});
bankquote.setBankName(bankname);
bankquote.setlnterestRate(interestrate.doubleValue());
}catch(Exception ex){
System.err.printin("Error accessing the axis
webservice from " + bankname);
// "Ошибка доступа к Web-службе Axis банка XX."
BankQuote badbq = new BankQuoteO;
badbq.setBankName("ERROR in WS");
// "Ошибка Web-службы."
return badbq;
}
arbitraryWait();
return bankquote;
Как видно из кода, показанного выше, в реализации метода getBankQuote для пер-
вого банка параметры располагаются в следующем порядке.
public BankQuote getBankQuote(int ssn, double loanamount,
int loanduration,
int credit_history_length,
int credit_score)
Реализация банковских операций
Как уже говорилось, в каждом банке применяется собственный формат списка пара-
метров, которые передаются системе вычисления процентных ставок. Это означает, что
метод getBankQuote класса Bank реализует шаблон проектирования транслятор сооб-
щений (Message Translator, с. 115) и перед вызовом Web-службы конкретного банка дол-
жен преобразовывать порядок параметров. Сигнатуры метода getQuote для Web-служб
каждого из банков выглядят следующим образом.
BanklWS
getQuote(int ssn, double prime_rate,
double loanamount, int loanduration,
int credit_history_length, int credit_score)
BanklWS
getQuote(double prime_rate, double loanamount,
int loanduration, int credit_history_length,
int credit_score, int ssn)
Bank3WS
getQuote(double loanamount, int loanduration,
int credit_history_length, int credit_score,
int ssn, double prime_rate)
Синхронная реализация с использованием Web-служб
407
Bank4WS
getQuote(int loanduration, int credit_history_length,
int credit_score, int ssn,
double primerate, double loanamount)
Bank5WS
getQuote(int credit_history_length, int credit_score,
int ssn, double prime_rate,
double loanamount, int loanduration)
Фактическая реализация метода getQuote в нашем примере представляет собой три-
виальный алгоритм, возвращающий случайное значение процентной ставки. Ниже при-
веден код метода getQuote для Web-службы первого банка.
BanklWS.jws
public class BanklWS {
public double getQuote(int ssn, double prime_rate,
double loanamount, int loanduration,
int credit_history_length, int credit_score)
{
double ratepremium = 1.5;
double int_rate = primerate + ratepremium +
(double)(loanduration/12)/10 +
(double)(Math.random()*10)/10;
return int_rate;
}
В реальной жизни формулы вычисления процентной ставки куда более сложны
и включают в себя огромное количество параметров. Метод getQuote возвращает число
типа double, равное значению процентной ставки, под которую банк согласен выдать
кредит текущему клиенту.
Как и раньше, сервер Axis автоматически генерирует файл WSDL для каждой
Web-службы банка. Полный текст этого файла для банка 1 находится на сервере по сле-
дующему адресу.
http://имя_узла:номер—порта/axis/BanklWS.jws?wsdl
Ниже приведено содержимое файла WSDL для Web-службы BanklWS .jws (в сокра-
щенном виде). Файлы WSDL для Web-служб других банков имеют аналогичные форма-
ты, но отличаются в определении параметров.
<wsdl:definitions xmlns:wsdl="http://schemas.xmlsoap.org/wsdl/"
xmlns:wsdlsoap="http://schemas.xmlsoap.org/wsdl/soap/">
<wsdl:message name="getQuoteRequest">
<wsdl:part name="ssn" type="xsd:int"/>
<wsdl:part name="prime_rate" type="xsd:double"/>
408
Глава 9. Практикум: сложный обмен сообщениями
<wsdl:part name="loanamount" type="xsd:double"/>
<wsdl:part name="loanduration" type="xsd:int"/>
<wsdl:part name="credit_history_length" type="xsd:int"/>
<wsdl:part name="credit_score" type="xsd:int"/>
</wsdl:message>
<wsdl:message name="getQuoteResponse">
<wsdl:part name="getQuoteReturn" type="xsd:double"/>
</wsdl:message>
< wsdl:portType name="BanklWS">
<wsdl:operation name="getQuote" parameterOrder="ssn
prime_rate loanamount loanduration
credit_history_length credit_score">
<wsdl:input message="intf:getQuoteRequest"
name="getQuoteRequest" / >
<wsdl:output message="intf:getQuoteResponse"
name="getQuoteResponse"/>
</wsdl:operation>
</wsdl:portType>
<wsdl:binding name="BanklWSSoapBinding" type="intf:BanklWS">
</wsdl:binding>
<wsdl:service name="BanklWSService">
<wsdl:port binding="intf:BanklWSSoapBinding"
name="BanklWS">
<wsdlsoap:address
location="http://192.168.1.25:8080/axis/BanklWS.jws"/>
</wsdl:port>
</wsdl:service>
</wsdl:definitions>
Легко увидеть, что в файле WSDL содержится одна операция, getQuote, определенная
с помощью элемента <wsdl:operations которую сервер Axis сопоставляет с методом
getQuote класса BanklWS.jws. Элемент <wsdl:service> определяет Web-службу
BanklWS. Наконец, пара сообщений “запрос-ответ” (getQuoteRequest и getQuote-
Response соответственно) определяется с помощью элементов <wsdl: messages
Значение процентной ставки, предложенное банком, сохраняется в объекте
BankQuote, который затем добавляется в коллекцию, возвращаемую шлюзу BankQuote-
Gateway. Специального форматирования объект BankQuote не требует; кроме того, все
подобные объекты, возвращаемые банками, имеют одну и ту же структуру. Это избавляет
нас от необходимости использовать нормализатор (Normalizer, с. 364) для преобразования
сообщений с ответами в единый формат.
Получив коллекцию процентных ставок, шлюз BankQuoteGateway выбирает из них
ставку с наименьшим значением и возвращает соответствующий объект BankQuote кре-
дитному брокеру. Кредитный брокер извлекает из полученного объекта все необходимые
данные, составляет на их основе итоговый отчет и отправляет его клиенту. Ниже приве-
ден код метода, применяющегося для составления отчета.
Синхронная реализация с использованием Web-служб
409
BankQuoteGateway.java
private static String getLoanQuotesReport(BankQuote bestguote){
String bankname = bestguote.getBankName();
double bestrate =
((double)((long)(bestguote.getlnterestRate()*1000))I(double)1000);
String results = "\nBank Name: " + bankname +
"Interest Rate: " + bestrate;
return results;
Клиентское приложение
Клиентское приложение представляет собой интерфейс, используемый потенциаль-
ным заемщиком для доступа к приложению кредитного брокера. Основной обязанно-
стью клиентского приложения является сбор информации о заемщике в функциональ-
ной среде пользовательского интерфейса с проверкой ошибок. От глаз заемщика, одна-
ко, надежно скрыт тот факт, что клиентское приложение выделяет три фрагмента данных
и готовит их для доставки в конечную точку серверного приложения. Для простоты
мы решили превратить клиентское приложение в класс Java, главный метод которого
будет принимать информацию о заемщике в виде аргументов командной строки. В ре-
альной жизни пользовательский интерфейс следовало бы реализовать в виде окна
“толстого клиента” или же создать “тонкий клиент”, предусматривающий ввод данных
в Web-обозреватель. Клиент также может быть частью другой бизнес-системы, в которой
развернута модель клиентского программирования. Ниже приведена самая главная часть
клиентского приложения, касающаяся вызова Web-службы кредитного брокера.
Service service = new Service();
Call call = (Call) service.createCall();
call.setTargetEndpointAddress( new java.net.URL(endpoint) );
call.setOperationName( "getLoanQuote" );
call.addParameter( "opl", XMLType,XSD_INT, ParameterMode.IN );
call.addParameter( "op2", XMLType.XSD_DOUBLE, ParameterMode.IN );
call.addParameter( "op3", XMLType.XSD_INT, ParameterMode.IN );
call.setReturnType( XMLType.XSD_STRING );
String ret = (String) call.invoke( new Object []
{ssn, loanamount, loanduration});
Самыми важными здесь являются строки, которые определяют имя метода
(getLoanQuote), а также задают параметры и тип возвращаемого значения. Метод get-
LoanQuote принимает в качестве параметров идентификатор клиента, сумму кредита, а
также срок, на который предполагается взять кредит. Результатом выполнения
метода является значение типа string.
В данном примере не используется UDDI (механизм поиска Web-служб), поэтому
адрес URL конечной точки Web-службы приходится указывать в самом коде. Поскольку
мы решили развернуть приложение кредитного брокера в виде файла JWS, адрес конеч-
410
Глава 9. Практикум: сложный обмен сообщениями
ной точки будет иметь стандартный формат, определенный интерфейсом API Axis для
JWS. Адрес URL конечной точки в нашей конфигурации будет выглядеть так, как пока-
зано ниже (слова имя_узла и номер_порта следует заменить соответствующими значе-
ниями для вашего сервера).
http://имя_узла:HOMep_nopTa/axis/LoanBroker.jws
Клиентское приложение, выполнение которого блокируется на все время ожидания
ответа, примет от кредитного брокера отформатированный отчет и отобразит его в спе-
циальном окне пользовательского интерфейса. Вместо этого содержимое отчета можно
сохранить в файле или распечатать на принтере.
Запуск решения
В этом разделе предполагается, что у вас уже установлены сервер Axis и приложение
кредитного брокера. Вначале необходимо перезапустить сервер (или запустить его, если
до этого он не работал). Чтобы узнать, как правильно запустить или перезапустить сервер
Axis, обратитесь к справочной документации Tomcat.
Проверьте правильность функционирования Tomcat и Apache Axis. Для этого открой-
те на клиентском компьютере окно командной строки или запустите сеанс оболочки.
После этого выполните одну из команд, показанных ниже (для компьютеров, работаю-
щих под управлением UNIX/Linux или Microsoft Windows).
java -classpath %CLASSPATH% LoanQueryClient [ИД_клиента]
[ сумма_кредита ] [ срок_в_ме сяцах]
или
java -classpath $CLASSPATH LoanQueryClient [ИД_клиента]
[сумма_кредита] [срок_в_месяцах]
К примеру,
java -classpath %CLASSPATH% LoanQueryClient 199 100000.00 29
Это приведет к вызову Web-службы кредитного брокера, в результате работы которой
на экране появятся строки примерно следующего содержания.
Calling the LoanBroker webservice at 1053292919270 ticks
LoanBroker service replied at 1053292925860 ticks
Total time to run the query = 6590 milliseconds
The following reply was received from the Loan Clearing House
Client with ssn= 199 requests a loan of amount= 100000.0 for 29
months
Additional data for customer: credit score and length of credit
history
Credit Score= 756 Credit History Length= 12
Синхронная реализация с использованием Web-служб
411
The details of the best quote from all banks that responded are shown
below:
Out of a total of 3 quote(s), the best quote is from
Bank Name: Exclusive Country Club Bankers
Interest Rate: 6.197
Можете протестировать работу кредитного брокера, вводя различные суммы кредитов
во время работы клиентского приложения. Мы же перейдем к анализу результатов, полу-
ченных при работе одного экземпляра клиента. Позднее мы попробуем запустить не-
сколько клиентов сразу.
Анализ выходных данных
Клиентское приложение запоминает, в какой момент времени произошел вызов ко-
нечной точки Web-службы кредитного брокера на сервере Axis. Клиент также фиксирует
время, когда сервер возвратил ответ. Оба значения времени, а также разница между ними
вставляются в отчет клиентского приложения и отображаются на экране.
Calling the LoanBroker webservice at 1053292919270 ticks
LoanBroker service replied at 1053292925860 ticks
Total time to run the query = 6590 milliseconds
Web-служба расчетного центра кредитного брокера отображает все детали запроса за-
емщика, отправленного по сети клиентским приложением.
Client with ssn= 199 requests a loan of amount= 100000.0 for
2 9 months
Расчетный центр кредитного брокера также сообщает дополнительные данные о за-
емщике, которые были собраны для передачи банкам вместе с запросом на получение
кредита.
Additional data for customer: credit score and
length of credit history
Credit Score= 756 Credit History Length= 12
Кредитный брокер анализирует данные и составляет перечень банков, которые могут
обслужить запрос с указанными параметрами. После этого он преобразует данные заем-
щика в форматы, которые поддерживаются отобранными банками, и ждет, пока из каж-
дого банка придет ответ. Поскольку данное приложение функционирует в синхронном
режиме, выполнение кредитного брокера блокируется до тех пор, пока банк не пришлет
ответ или пока не истечет время ожидания.
Кредитный брокер собирает все ответы, анализирует предлагаемые значения ставки
по кредиту и выбирает из них наименьшее. Окончательное значение процентной ставки
форматируется и отсылается клиенту вместе со всеми необходимыми данными. Вот как
на экране выглядит пример выбора лучшей процентной ставки из трех значений, при-
сланных банками.
412
Глава 9. Практикум: сложный обмен сообщениями
Out of a total of 3 quote(s), the best quote is from
Bank Name: Exclusive Country Club Bankers
Interest Rate: 6.197
Из текста, показанного выше, видно, что кредитный брокер получил от банков три
ответа, выбрал из них лучшее значение процентной ставки и возвратил его клиенту.
Ограничения производительности
Как уже говорилось при обсуждении циклограммы работы кредитного брокера (см.
рис. 9.11), на получение клиентом итогового значения процентной ставки уходит доста-
точно много времени, потому что кредитный брокер не может отправить запрос следую-
щему банку, пока не получит ответ от предыдущего. Вследствие этого заемщику, отпра-
вившему запрос, приходится довольно долго ждать ответа. Мы провели ряд эталонных
тестов с использованием одного клиента и подсчитали среднее время выполнения запро-
са (получилось около 8 секунд). После этого мы запустили четыре экземпляра клиента
(каждый в отдельном окне на одном и том же клиентском компьютере) и получили такие
средние значения.
Client 1: 12520
Client 2: 12580
Client 3: 15710
Client 4: 13760
milliseconds
milliseconds
milliseconds
milliseconds
Конечно же, эти тесты даже с огромной натяжкой нельзя считать научными или дока-
зательными. Тем не менее очевидно, что производительность системы резко снижается,
когда к приложению кредитного брокера одновременно пытаются получить доступ
несколько клиентов.
Ограничения данного примера
Чтобы облегчить рассмотрение примера кредитного брокера, мы решили реализовать
все Web-службы в виде файлов JWS. Для развертывания таких служб достаточно просто
скопировать соответствующие файлы JWS на сервер Axis. Недостатком такого подхода,
однако, является то, что для каждого запроса создается новый экземпляр класса службы,
который уничтожается сразу после выполнения запроса. Это означает, что некоторая
часть времени, потраченного сервером на выполнение запроса, уходит только на созда-
ние экземпляра класса службы.
Можно было бы выбрать куда более сложный путь и представить Web-службу в виде
файла класса Java, который разворачивался бы с помощью файла WSDD. Это позволило
бы нам самим выбирать, сколько времени должен существовать экземпляр класса Web-
службы: на протяжении клиентского сеанса или же в течение работы всего приложения.
В действительности вопрос, как разворачивать Web-службу, играет важную роль при
проектировании реальных приложений. Если бы мы решили пожертвовать простотой ра-
ди более оптимального способа развертывания, описание этого примера заняло бы в не-
сколько раз больше страниц книги, а детали проектирования стали бы чересчур сложны.
Синхронная реализация с использованием Web-служб 413
Резюме
В этом разделе мы последовательно прошли этапы реализации приложения кредит-
ного брокера с использованием синхронных Web-служб SOAP/HTTP. Мы воспользова-
лись предиктивной маршрутизацией, чтобы передать запрос на получение кредита в не-
сколько подходящих банков. Преимущества и недостатки указанного метода неодно-
кратно обсуждались по ходу раздела. Нам также пришлось пойти на несколько
компромиссов в плане проектирования, чтобы не затягивать рассмотрение примера и
описание технических деталей развертывания. Общая идея состояла в том, чтобы обсу-
дить сильные и слабые стороны избранного подхода. Мы также продемонстрировали
практическое использование целого ряда шаблонов проектирования, описанных в на-
стоящей книге. Это поможет вам приспособить синхронный предиктивный подход к
другим предметным областям.
414
Глава 9. Практикум: сложный обмен сообщениями
Асинхронная реализация с использованием MSMQ
В настоящем разделе рассказывается, как реализовать пример кредитного брокера
(см. введение к главе) с помощью Microsoft .NET, C# и MSMQ. Платформа Microsoft
.NET включает в себя пространство имен System.Messaging, предоставляющее про-
граммам .NET доступ к службе MSMQ (Microsoft Message Queuing), внедренной в по-
следние версии операционной системы Windows (Windows 2000, Windows ХР и Windows
Server 2003). Рассматривая пример, мы обсудим принятие тех или иных решений проекти-
рования и покажем реализацию примера на практике. Основное внимание при этом будет
уделяться именно аспектам проектирования , чтобы данное решение имело ценность даже
для тех, кто не является ярым приверженцем С#. В действительности большая часть приве-
денного здесь кода (за исключением обращений к System.Messaging) будет выглядеть
практически одинаково, если реализовать данный пример с помощью Java и JMS.
Некоторые из функций решения, описанного в этом разделе, вероятно, можно было
бы реализовать при помощи меньшего объема кода, используя средство интеграции на-
подобие Microsoft BizTalkServer. Мы специально не стали прибегать к подобным средст-
вам по двум причинам. Во-первых, они не бесплатны, и для запуска даже такого простого
примера пришлось бы приобретать лицензию. Во-вторых, мы хотели продемонстриро-
вать явную реализацию всех требуемых функций.
Решение состоит из набора выполняемых файлов, поэтому его компоненты можно
было бы распределить между разными компьютерами. Чтобы максимально упростить
пример и избежать необходимости устанавливать Active Directory, мы используем ло-
кальные, частные сообщения. По этой причине решение в том виде, в котором оно при-
ведено в этой книге, должно запускаться на одном компьютере.
В данной реализации кредитного брокера используется асинхронный обмен сообще-
ниями с помощью очередей сообщений. Как уже говорилось в начале главы, это позво-
ляет одновременно обрабатывать несколько запросов на получение кредита, однако тре-
бует сопоставления сообщений с запросами и ответами. По ходу примера многие реше-
ния проектирования будут продиктованы именно соображениями, касающимися
асинхронной обработки данных.
Экосистема локального брокера
Чтобы лучше понять структуру локального брокера, взглянем на нее снаружи. Внача-
ле изучим все внешние интерфейсы, которые должны поддерживаться брокером
(рис. 9.12). Поскольку очереди сообщений являются однонаправленными, необходимо
создать пару очередей, чтобы организовать взаимодействие с другим компонентом по ти-
пу “запрос-ответ” (простой пример реализации подобного взаимодействия с помощью
.NET приведен в главе 6). Кредитный брокер будет получать запросы по каналу (т.е. по
очереди сообщений) loanRequestQueue и отвечать тестовому клиенту по каналу loan-
ReplyQueue. Взаимодействие с кредитным бюро происходит с помощью аналогичной
пары очередей. Вместо того чтобы создавать по паре очередей для каждого банка, мы ре-
шили, что все банки будут направлять свои ответы в общую очередь bankReplyQueue.
Список получателей (Recipient List, с. 264) рассылает сообщение с запросом по очередям
сообщений отдельных банков. Агрегатор (Aggregator, с. 283), в свою очередь, выбирает
Асинхронная реализация с использованием MSMQ
415
лучшую процентную ставку из сообщений с ответами, которые были отправлены банка-
ми в общую очередь bankReplyQueue. Комбинация списка получателей и агрегатора эк-
вивалентна шаблону рассылка-сборка (Scatter-Gather, с. 310), работающему по принципу
распределения. Для простоты все банки в нашем примере будут использовать один и тот
же формат сообщений, поэтому нормализатор (Normalizer, с. 364) не потребуется. Но по-
скольку общий формат банковских сообщений отличается от формата, используемого
клиентом, нам все равно понадобится один транслятор сообщений (Message Translator,
с. 115) для преобразования ответов банков в ответы кредитного брокера. Мы решили
спроектировать кредитный брокер в виде диспетчера процессов (Process Manager, с. 325).
Вместо того чтобы реализовывать кредитный брокер в виде отдельных компонентов, от-
деленных друг от друга очередями сообщений, брокер будет представлять собой единый
компонент, все функции которого выполняются внутри него. Этот подход позволяет уст-
ранить лишнюю нагрузку, которая могла бы возникнуть при обмене сообщениями между
этими компонентами по очередям сообщений, но требует, чтобы кредитный брокер под-
держивал работу нескольких параллельных экземпляров процессов.
Тестовый клиент
Проверить
banklQueue
creditReplyQueue
creditRequestQueue
bank2Queue
loanReques tQueue
bank3Queue
bank4Queue
Кредитный брокер
loanReplyQueue
Кредитное
бюро
Список
получателей
Создать тестовое
сообщение
bankReplyQueue
□
Рис. 9.12. Кредитный брокер с интерфейсами для доступа к очередям сообщений
Транслятор
Агрегатор
БанкЗ
Банк 4
bank5Queue
Закладываем основы: шлюз обмена сообщениями
Эта книга вовсе не является учебником по System.Messaging или MSMQ. По этой
причине имеет смысл выделить функции, специфичные для MSMQ, в отдельные классы,
чтобы не загромождать код приложения командами MSMQ (рис. 9.13). Для этой цели за-
мечательно подходит шаблон шлюз (Gateway, см. [9]), обладающий двумя значительными
преимуществами. Во-первых, он абстрагирует технические детали взаимодействия от
приложения. Во-вторых, если мы решим отделить интерфейс шлюза от его реализации,
то на время тестирования сможем заменить реальную внешнюю службу фиктивной служ-
бой (Service Stub', см. [9]).
416
Глава 9. Практикум: сложный обмен сообщениями
Рис. 9.13. Шлюз отделяет детали MSMQ от приложения и облегчает тестирование
В нашем примере для шлюза обмена сообщениями (Messaging Gateway, с. 482) определя-
ются два интерфейса: IMessageSender и IMessageReceiver. Их структура очень про-
ста, практически тривиальна. Интерфейс IMessageSender пригоден лишь для отправки
сообщения, a IMessageReceiver (угадайте с трех раз!) — для получения сообщения.
Кроме того, у IMessageReceiver есть метод Begin, который сигнализирует о том, что
можно начинать отправку сообщений. Такая простая структура интерфейсов облегчает
определение реализующих их классов.
IMessageSender.cs
namespace MessageGateway
{
using System.Messaging;
public interface IMessageSender
{
void Send(Message mess);
}
}
IMessageReceiver.cs
namespace MessageGateway
{
using System.Messaging;
public interface IMessageReceiver
Асинхронная реализация с использованием MSMQ
417
{
OnMsgEvent OnMessage
{
get;
set ;
}
void Begin();
MessageQueue GetQueueO;
}
}
Фактическая реализация указанных интерфейсов будет содержаться в классах Mes-
sageSenderGateway и MessageReceiverGateway. Методы этих классов настраивают
параметры очередей сообщений, такие KaKMesaageReadPropertyFilter и Formatter.
Класс MessageReceiverGateway использует шаблонный метод (Template Method', см.
[12]) для обработки мелких, но очень важных деталей, как, например, вызова метода
mq.BeginReceive (который, в свою очередь, инициирует запуск события ReceiveCom-
pleted)по окончании обработки сообщения.
Поскольку мы определили очень ограниченные интерфейсы, для них можно создать
такую реализацию, которая вообще не будет использовать очередь сообщений. Так,
на рис. 9.13 класс MockQueue (“суррогатная очередь”) реализует оба интерфейса, даже
не ссылаясь на очередь сообщений! Когда приложение отправляет сообщение,
MockQueue сразу же запускает событие OnMessage с этим сообщением в качестве аргу-
мента. Это значительно облегчает тестирование приложения в рамках одного адресного
пространства без необходимости заботиться об аспектах асинхронного обмена сообще-
ниями. (Впоследствии мы еще немного поговорим о тестрировании.)
Строка OnMsgEvent OnMessage в коде интерфейса IMessageReceiver может
потребовать некоторых пояснений для тех, кто только начинает знакомиться с С#.
Платформа .NET снабжает шаблон наблюдатель (Observer, см. [12]) языковыми средства-
ми под названием события (events) и делегаты (delegates). OnMsgEvent — это делегат,
определенный в классе MessageReceiverGateway.
public delegate void OnMsgEvent(Message msg);
Делегат позволяет объектам регистрироваться на события определенного типа. Когда
происходит событие, .NET вызывает все зарегистрировавшиеся на него объекты. Экзем-
пляр делегата можно вызвать несколькими способами. Самый простой из них —
это прямой вызов с помощью имени данного экземпляра.
OnMsgEvent receiver;
Message message;
receiver(message);
Тем, кто хочет больше узнать о делегатах, могу посоветовать обратиться к какой-
нибудь хорошей книге по .NET или С#. Реализация делегатов в общей языковой среде
выполнения (Common Language Runtime — CLR) хорошо описана в [3].
418
Глава 9. Практикум: сложный обмен сообщениями
Базовые классы для общей функциональности
Взглянув на сценарий работы кредитного брокера, легко понять, что некоторые
из участвующих в нем компонентов обладают общими функциями. К примеру, и банк,
и кредитное бюро выступают в качестве службы, которая получает запрос из одного ка-
нала, обрабатывает его и публикует результат в другом канале. Звучит довольно просто,
да? Но поскольку мы обитаем в мире асинхронного обмена сообщениями, даже реализа-
ция простой схемы “запрос-ответ” требует определенной изобретательности. Во-первых,
компонент, вызывающий службу, должен указать обратный адрес (Return Address, с. 182),
по которому следует отправить ответ. Это позволяет разным компонентам обращаться к
одной и той же службе, но получать ответы из разных очередей сообщений. Служба также
должна поддерживать идентификаторы корреляции (Correlation Identifier, с. 186), чтобы
вызывающий компонент мог сопоставить полученный ответ с запросом. Наконец, если
служба получит сообщение в непонятном для нее формате, она в идеальном виде должна
будет перенаправить его в канал недопустимых сообщений (Invalid Message Channel, с. 143),
а не просто выбросить.
Чтобы избежать дублирования кода (одного из смертных грехов объектно-ориен-
тированного программирования), создадим класс MQService, который будет включать в
себя поддержку обратного адреса и идентификатора корреляции. В действительности под-
держка идентификатора корреляции на стороне сервера представляет собой ни что иное,
как копирование идентификатора входящего сообщения в идентификатор корреляции
исходящего сообщения. В нашем примере мы также копируем значение свойства Арр-
Specific, потому что, как будет видно позднее, иногда сообщения приходится
сопоставлять не по идентификатору, а по Значению данного свойства. MQService также
заботится о том, чтобы ответ доставлялся по указанному обратному адресу. Поскольку
последний предоставляется инициатором Запроса, единственным параметром инициали-
зации для объекта MQService является имя очереди запросов, т.е. очереди, в которую
поступают новые сообщения с запросами. Если инициатор запроса забудет указать
обратный адрес, служба RequestReplyService отправит ответ в канал недопустимых
сообщений. Туда же можно помещать и запросы, ставшие причиной сбоя. Впрочем, для
простоты в данном примере мы не будем заниматься обработкой ошибок.
MQService.cs
public abstract class MQService
{
static protected readonly String InvalidMessageQueueName =
".Wprivate$\\invalidMessageQueue";
IMessageSender invalidQueue = new
MessageSenderGateway(InvalidMessageQueueName);
protected IMessageReceiver requestQueue;
protected Type requestBodyType,-
public MQService(IMessageReceiver receiver)
{
requestQueue = receiver;
Register(requestQueue);
Асинхронная реализация с использованием MSMQ
419
public MQService(String requestQueueName)
{
MessageReceiverGateway q = new
MessageReceiverGateway(requestQueueName, GetFormatter());
Register(q);
this.requestQueue = q;
Console.WriteLine("Processing messages from " +
requestQueueName);
// "Обработка сообщений из" + имя очереди.
protected virtual IMessageFormatter GetFormatter()
{
return new XmlMessageFormatter(new Type[]
{ GetRequestBodyType() });
protected abstract Type GetRequestBodyType();
protected Object GetTypedMessageBody(Message msg)
try
{
if (msg.Body.GetType().Equals(GetRequestBodyType()))
{
return msg.Body;
}
else
{
Console.WriteLine("Illegal message format.");
// "Неверный формат сообщения."
return null;
}
}
catch (Exception e)
{
Console.WriteLine("Illegal message format" +
e.Message);
// "Неверный формат сообщения."
return null;
public void Register(IMessageRecelver rec)
{
OnMsgEvent ev = new OnMsgEvenf(OnMessage);
rec.OnMessage += ev;
}
public void Run()
{
requestQueue.Begin();
}
420
Глава 9. Практикум: сложный обмен сообщениями
public void SendReply(Object outObj, Message inMsg)
{
Message outMsg = new Message(outObj);
outMsg.Correlationld = inMsg.Id;
outMsg.AppSpecific = inMsg.AppSpecific;
if (inMsg.ResponseQueue != null)
{
IMessageSender replyQueue = new
MessageSenderGateway(inMsg.ResponseQueue);
replyQueue.Send(outMsg);
}
else
{
invalidQueue.Send(outMsg);
}
}
protected abstract void OnMessage(Message inMsg);
}
Класс MQService объявлен как абстрактный, потому что в нем не содержится реализа-
ции методов GetRequestBodyType и OnMessage. Поскольку мы хотим, чтобы наши ком-
поненты как можно чаще имели дело с сильно типизированными бизнес-обьектами, а не с
типами данных сообщений, класс MQService проверяет тип данных в теле сообщения и
приводит его к нужному типу бизнес-данных. Проблема заключается в том, что наш абст-
рактный базовый класс не знает, к какому типу следует привести тип данных в теле сооб-
щения, потому что базовый класс может применяться разными службами, каждая из кото-
рых наверняка использует собственные типы сообщений. Чтобы вынести в базовый класс
как можно больший объем работы, связанный с сообщениями, мы создали метод Get-
TypedMessageBody и абстрактный метод GetRequestBodyType. Каждый класс, произ-
водный от MQService, должен реализовать метод GetRequestBodyType, чтобы задать
ожидаемый им тип входящих сообщений. MQService использует этот тип для инициализа-
ции объекта XMLMessageFormatter и проверки соответствия тела сообщения заданному
типу сообщения. По окончании проверки производный класс может спокойно привести
тело входящего сообщения к нужному типу бизнес-данных, не опасаясь инициировать ис-
ключение. Обработка исключений в теле метода GetTypedMessageBody довольно прими-
тивна — в консоли просто печатается соответствующее сообщение. Разумеется, в реальном
приложении мы реализовали бы куда более “умный” подход, предполагающий работу
с журналом или, что еще лучше, с шиной управления (Control Bus, с. 552).
Реализация метода OnMessage отдана на откуп классам, производным от MQService.
В следующем фрагменте кода приведены две реализации данного метода: синхронная и
асинхронная. Синхронная реализация (класс RequestReplyService) вызывает вирту-
альный метод ProcessMessage, ожидает, пока он возвратит сообщение с ответом, а за-
тем вызывает метод SendReply. В противоположность этому асинхронная реализация
(класс AsyncRequestReplyService) определяет виртуальный метод ProcessMessage
без выходных параметров, а вызов метода SendReply должен осуществляться производ-
ными классами.
Асинхронная реализация с использованием MSMQ
421
MQService.cs
public class RequestReplyService : MQService
{
public RequestReplyService(IMessageReceiver receiver) :
base(receiver) {}
public RequestReplyService(String requestQueueName) :
base (requestQueueName) {}
protected override Type GetRequestBodyType()
return typeof(System.String);
}
protected virtual Object ProcessMessage(Object o)
{
String body = (String)o;
Console.WriteLine("Received Message: " + body);
return body;
protected override void OnMessage(Message inMsg)
{
inMsg.Formatter = GetFormatter();
Object inBody = GetTypedMessageBody(inMsg);
if (inBody != null)
{
Object outBody = ProcessMessage(inBody);
if (outBody != null)
{
SendReply(outBody, inMsg);
public class AsyncRequestReplyService : MQService
{
public AsyncRequestReplyService(IMessageReceiver receiver) :
base(receiver) {}
public AsyncRequestReplyService(String requestQueueName) :
base (requestQueueName) {}
protected override Type GetRequestBodyType()
{
return typeof(System.String);
protected virtual void ProcessMessage(Object o. Message msg)
{
String body = (String)O;
Console.WriteLine("Received Message: " + body);
422
Глава 9. Практикум: сложный обмен сообщениями
protected override void OnMessage(Message inMsg)
{
inMsg.Formatter = GetFormatter();
Object inBody = GetTypedMessageBody(inMsg);
if (inBody != null)
{
ProcessMessage(inBody, inMsg);
} }
}
И тот, и другой классы содержат реализацию виртуальных методов GetRequestBodyType
и ProcessMessage, используемую по умолчанию при отсутствии реализации указанных
методов в производном классе. Метод GetRequestBodyType указывает, что тело сооб-
щения должно быть простой строкой, а метод ProcessMessage печатает эту строку в
консоли. Вообще-то, можно было бы обойтись без реализации виртуальных методов
в классах RequestReplyService и AsyncRequestReplyService, чтобы методы оста-
лись абстрактными. Это позволило бы компилятору выявить любой производный класс,
разработчик которого забыл реализовать хотя бы один из абстрактных методов. В нашей
ситуации, однако, весьма удобно иметь подобную реализацию “по умолчанию”, чтобы
применять ее при отладке или тестировании.
Итоговая диаграмма базовых классов для служб кредитного брокера показана
на рис. 9.14 (классы Bank, CreditBureau и LoanBroker будут рассматриваться в сле-
дующих разделах главы).
Рис. 9.14. Диграмма базовых классов для служб обмена сообщениями кредитного брокера
Асинхронная реализация с использованием MSMQ
423
Компонент банка
Создав необходимые базовые классы и наделив их функциями, можно переходить
к реализации логики приложения. Самый простой способ получить решение — созда-
вать компоненты в порядке обратной зависимости. Вначале мы создадим компоненты,
которые не зависят ни от каких других. Это позволит нам запустить и протестировать
указанные компоненты в отрыве от остального приложения. Одним из таких компонен-
тов, безусловно, является банк. Кредитный брокер зависит от банков, но каждый из бан-
ков сам по себе не зависит от других компонентов. Кроме того, банк является ярким
примером службы “запрос-ответ”, поэтому реализация банка состоит лишь в том, чтобы
наследовать класс RequestReplyService и расписать необходимую бизнес-логику.
Прежде чем начать работу над внутренней структурой банка, мы должны определить
его внешний интерфейс. Необходимо описать типы сообщений для запросов на получе-
ние кредита и ответов банка. Для простоты предположим, что все банки используют один
и тот же формат сообщений, поэтому можно определить общий класс для всех пяти
экземпляров банков. Язык C# поддерживает структуры. Ими мы и воспользуемся для
определения типов сообщений.
Типы сообщений, поддерживаемые банком
public struct BankQuoteRequest
{
public int SSN;
public int Creditscore;
public int HistoryLength;
public int LoanAmount;
public int LoanTerm;
public struct BankQuoteReply
{
public double InterestRate;
public String QuotelD;
public int ErrorCode;
Поскольку мы хотим использовать один класс для всех экземпляров банка, нужно
“параметризовать” класс банка, чтобы получить возможность наделять его разным пове-
дением. В нашем примере банки представляют собой весьма примитивные инстанции, по-
этому единственные параметры, которыми они обладают, — это BankName, RatePremium
и MaxLoanTerm. Параметр RatePremium задает процент, который берет банк сверх учет-
ной ставки, т.е. по сути, маржу прибыли банка. Параметр MaxLoanTerm определяет
самый большой срок (в месяцах), на который банк согласен выдать кредит. Если клиент
хочет получить кредит на более длительный срок, ему будет отказано в выдаче кредита.
Описав всевозможные конструкторы и аксессоры, можем приступить к реализации унас-
ледованного метода ProcessMessage.
424
Глава 9. Практикум: сложный обмен сообщениями
Bank.cs
internal class Bank : RequestReplyService
protected override Type GetRequestBodyType()
{
return typeof(BankQuoteRequest);
protected BankQuoteReply ComputeBankReply(BankQuoteRequest
requestStruct)
BankQuoteReply replyStruct = new BankQuoteReply();
if (requestStruct.LoanTerm <= MaxLoanTerm)
replyStruct.InterestRate = PrimeRate + RatePremium
+ (double)(requestStruct.LoanTerm / 12)/10
+ (double)random.Next(10) / 10;
replyStruct.ErrorCode = 0;
else
{
replyStruct.InterestRate = 0.0;
replyStruct.ErrorCode = 1;
replyStruct.QuotelD = String.Format("{0}-{1:00000}",
BankName, quoteCounter);
quoteCounter++ ;
return replyStruct;
protected override Object ProcessMessage(Object o)
{
BankQuoteRequest requestStruct;
BankQuoteReply replyStruct;
requestStruct = (BankQuoteRequest)o;
replyStruct = ComputeBankReply(requestStruct);
Console.WriteLine("Received request for SSN {0} for
{l:c} / {2} months", requestStruct.SSN,
requestStruct.LoanAmount,
requestStruct.LoanTerm);
//"Получен запрос для номера SSN XXX на сумму XX
// на X месяцев."
Thread.Sleep(random.Next(10) * 100);
Console.WriteLine (" Quote: {0} {1} {2}",
replyStruct.ErrorCode, replyStruct.InterestRate,
replyStruct.QuotelD);
return replyStruct;
Асинхронная реализация с использованием MSMQ
425
Легко заметить, что конкретной службе приходится реализовывать только методы
GetRequestBodyType и ProcessMessage. Служба может благополучно привести
объект, переданный в качестве аргумента методу ProcessMessage, к нужному типу биз-
нес-данных, потому что данный объект уже был проверен базовым классом на соответст-
вие заданному типу сообщения. Как видим, код данного компонента практически
не имеет дела с сообщениями — все детали, связанные с обменом сообщениями, были
вынесены в базовые классы. Таким образом, классы MQService и RequestReply-
Service выполняют роль активатора службы (Service Activator, с. 545), отделяя приложе-
ние от деталей обмена сообщениями.
Метод ComputeBankReply включает в себя всю необходимую для банка бизнес-
логику. Ах, если бы и в жизни все было так просто! Впрочем, наша книга посвящена не
макроэкономике, а обмену сообщениями, поэтому мы взяли на себя смелость немного
упростить экономические схемы. Итоговая процентная ставка вычисляется как сумма
учетной ставки, маржи прибыли (выбирается банком), некоторой величины, зависящей
от желаемого срока кредитования, а также некоторой случайной составляющей. Если
срок, на который клиент надеется получить кредит, превышает значение MaxLoanTerm,
метод возвращает код ошибки. Каждой процентной ставке, предложенной клиенту, при-
сваивается уникальный идентификатор, поэтому при необходимости к ней можно вер-
нуться позднее. В нашей реализации идентификатор генерируется простым счетчиком,
каждый раз увеличивающим значение идентификатора на 1.
Чтобы придать банковским транзакциям более реалистичный вид, в методе Process-
Message предусмотрена небольшая случайная задержка (от 0,1 до 1 секунды). Данный
метод также фиксирует в консоли сведения о некоторых действиях. Это может приго-
диться для отслеживания работы банка, если мы запустим метод ProcessMessage внут-
ри простого приложения консоли.
Чтобы запустить компонент банка, необходимо создать его экземпляр с требуемыми
параметрами, а затем вызвать метод Run, унаследованный от класса MQService.
Поскольку обработка сообщений выполняется посредством событий, указанный метод
сразу же завершает свое выполнение. Таким образом, мы должны следить за тем, чтобы
не завершить работу программы сразу же после ее начала. Для наших целей вполне дос-
таточно вставить после вызова метода Run какое-нибудь простое выражение наподобие
Console.ReadLine().
Компонент кредитного бюро
Реализация компонента кредитного бюро аналогична таковой для банка. Единствен-
ное, что отличается, — это типы сообщений и бизнес-логика. Кредитное бюро умеет ра-
ботать с такими типами сообщений.
Типы сообщений, поддерживаемые кредитным бюро
public class CreditBureauRequest
{
public int SSN;
}
public class CreditBureauReply
{
public int SSN;
426
Глава 9. Практикум: сложный обмен сообщениями
public int Creditscore;
public int HistoryLength;
Код метода ProcessMessage практически совпадает с кодом одноименного метода в
классе банка за исключением того, что в классе кредитного бюро он работает с другими
структурами данных и вызывает другую логику приложения. Как и для банка, в методе
ProcessMessage кредитного бюро предусмотрена небольшая задержка.
CreditBureau.cs
private int getCreditScore(int ssn)
{
return (int)(random.Next(600) + 300);
}
private int getCreditHistoryLength(int ssn)
{
return (int)(random.Next(19) + 1);
Компонент кредитного брокера
У нас появились функционирующий компонент кредитного бюро, а также класс
Bank, позволяющий создать несколько экземпляров банка. Пришло время переходить к
проектированию внутренней структуры кредитного брокера. Выделить функции, кото-
рые должен предоставлять кредитный брокер, нам помогут шаблоны маршрутизации и
преобразования, описанные в этой книге. Внутренние функции брокера можно разбить
на три группы: интерфейс запроса-ответа, принимающий запросы от клиентов, интер-
фейс кредитного бюро и интерфейс банка (рис. 9.15).
Рис. 9.15. Внутренняя структура кредитного брокера
Асинхронная реализация с использованием MSMQ
427
Как и прежде, начнем с создания частей кредитного брокера, которые зависят только
от уже разработанных нами компонентов. Поскольку в предыдущих разделах главы мы
занимались разработкой служб банка и кредитного бюро, вполне логично создать интер-
фейсы для доступа кредитного брокера к указанным внешним компонентам. Интерфейс
кредитного бюро, определенно, должен быть проще, поэтому давайте начнем с него.
Шлюз кредитного бюро
Чтобы узнать кредитную историю клиента, необходимую банку для принятия реше-
ния о выдаче кредита, брокер должен обратиться к кредитному бюро. Это предполагает
отправку сообщений внешнему компоненту и получение от него ответов. Упаковав дета-
ли отправки универсального сообщения в шлюз MessageGateway, мы смогли отделить
оставшуюся часть приложения от многих тонкостей работы с MSMQ. Из этих же сооб-
ражений нам следует инкапсулировать обмен сообщениями с внешним кредитным бюро
в шлюзе кредитного бюро. Последний будет выполнять очень важную функцию семан-
тического расширения, позволяя кредитному брокеру пользоваться бизнес-методами на-
подобие GetCreditScore, а не методами, предназначенными для работы с сообщения-
ми (SendMessage и т.п.). Это повысит читабельность кода кредитного брокера и обеспе-
чит надежную инкупсуляцию взаимодействия между брокером и кредитным бюро.
Уровни абстракции, которых можно достичь благодаря “нанизыванию” шлюзов, пока-
заны на рис. 9.16.
Рис. 9.16. Шлюзы обеспечивают дополнительный уровень абстракции кредитного брокера от
инфраструктуры обмена сообщениями
Чтобы запросить кредитный балл клиента, шлюз должен создать экземпляр структу-
ры CreditBureauRequest, как этого требует кредитное бюро. Ответ от кредитного бю-
ро, в свою очередь, приходит в виде структуры CreditBureauReply. Ранее уже говори-
лось о том, что данное решение состоит из нескольких выполняемых файлов, благодаря
чему кредитный брокер и кредитное бюро могут функционировать на разных компьюте-
рах. Это, однако, означает, что кредитный брокер может не иметь доступа к типам дан-
ных, определенным в сборке кредитного бюро. Мы действительно не хотим, чтобы кре-
дитный брокер каким-либо образом ссылался на внутреннюю реализацию кредитного
бюро, поскольку это лишит нас преимуществ слабого связывания. Предполагается, что
кредитный брокер абсолютно ничего не знает о том, какой компонент обслуживает за-
просы на получение кредитной истории клиентов. С другой стороны, кредитному броке-
ру нужен доступ к структурам, определяющим формат сообщений. К счастью, набор
средств разработки Microsoft .NET Framework SDK включает в себя средство под назва-
428
Глава 9. Практикум: сложный обмен сообщениями
нием XML Schema Definition Tool (xsd. exe), которое умеет генерировать схемы XML на
основе сборки, а затем использовать их для создания исходного кода С#. Указанный
процесс продемонстрирован на рис. 9.17.
public struct CreditBureauRequest
public struct CredltBureauReply
internal class CreditBureau
ямгаягаттамтштеввпгашитмгатияяяеявявятявгаяявтяз
CreditBureau.exe
xsd.exe
[System.Xml.Serialization.
XmlRootAttribute(Namespace="",
IsNullable=false)]
public class CreditBureauRequest ( {
public int SSN;
CreditBureauStub.cs
CreditBureauInterface.cs
LoanBroker
Puc. 9.17. Создание исходного кода C# на основе другой сборки
Программа xsd. exe извлекает из сборки общедоступные определения типов, а затем
создает файл схемы XML на основе определения типа и дополнительных параметров,
управляющих сериализацией. В нашем примере xsd. exe сгенерировала следующую схему.
<?xml version="l.О" encoding="utf-8"?>
<xs:schema elementFormDefault="qualified"
xmlns:xs="http://www.w3.org/2001/XMLSchema">
<xs:element name="CreditBureauRequest"
type="CreditBureauRequest" />
<xs:complexType name="CreditBureauRequest">
<xs:sequence>
<xs:element minOccurs="l" maxOccurs="1"
name="SSN" type="xs:int" />
</xs:sequence>
</xs:complexType>
<xs:element name="CredltBureauReply"
type="CredltBureauReply" />
Асинхронная реализация с использованием MSMQ
429
<xs:complexType name="CreditBureauReply">
<xs:sequence>
<xs:element minOccurs="l" maxOccurs="l"
name="SSN" type="xs:int" />
<xs:element minOccurs="l" maxOccurs="1"
name="CreditScore" type="xs:int" />
<xs:element minOccurs="l" maxOccurs="l"
name="HistoryLength" type="xs:int" />
</xs:sequence>
</xs:complexType>
<xs:element name="Run" nillable="true" type="Run" />
<xs:complexType name="Run" />
</xs:schema>
Обычно служба выставляет такое определение схемы на обозрение потенциальных
вызывающих компонентов. Это дает последним возможность получать требуемый фор-
мат сообщений разными способами. Прежде всего, вызывающий компонент может в яв-
ном виде построить сообщение с запросом, совместимое с определением схемы XML.
Вместо этого он может воспользоваться встроенной сериализацией .NET, но и тогда
у него будет выбор между несколькими языками программирования, поскольку CLR
не зависит от конкретного языка.
Мы решили использовать встроенную сериализацию .NET. По этой причине мы еще
раз запускаем xsd.exe, чтобы создать исходные файлы, которые будут использоваться
потребителем службы. Полученный файл выглядит следующим образом.
//
// This source code was auto-generated by xsd,
// Version=l.1.4322.573.
//
namespace CreditBureau {
using System.Xml.Serialization;
III <remarks/>
[System.Xml.Serialization.XmlRootAttribute(Namespace="",
IsNullable=false)]
public class CreditBureauRequest {
III <remarks/>
public int SSN;
Следует отметить, что сериализация и десериализация XML в .NET допускают слабое
связывание компонентов. Таким образом, сообщение с запросом, отправляемое кредит-
ному бюро, не обязательно должно принадлежать в точности к тому же типу CLR, что и
сообщения, используемые в самой реализации кредитного бюро. Достаточно лишь, что-
бы его XML-представление содержало все необходимые элементы. Благодаря этому,
в частности, инициатор запроса сможет отправить сообщение, XML-представление ко-
торого содержит дополнительные элементы, никоим образом не влияя на обмен сообще-
430
Глава 9. Практикум: сложный обмен сообщениями
ниями. В нашем же примере мы исходим из предположения, что кредитный брокер
стремится в точности следовать формату сообщений, используемому кредитным бюро,
и применяем одни и те же типы данных на обоих концах общения.
Итак, теперь мы готовы отправлять кредитному бюро сообщения в нужном формате.
Следует, однако, помнить, что такое взаимодействие является асинхронным с отдельны-
ми, асинхронными запросами и ответами. Разумеется, шлюз кредитного бюро можно
было бы спроектировать таким образом, чтобы после отправки запроса он ожидал полу-
чения ответа. К сожалению, у такого подхода есть существенный недостаток: пока кре-
дитное бюро обрабатывает сообщение, брокер будет бездействовать. Такой тип псевдо-
синхронной обработки может привести к появлению “узкого места” производительно-
сти. Если каждый этап обработки данных станет псевдосинхронным, это означает, что
кредитный брокер сможет обрабатывать только по одному клиентскому запросу за раз.
К примеру, брокер не сможет запросить кредитную историю нового клиента, пока не по-
лучит ответы всех банков на запрос предыдущего клиента. Для большей наглядности
представьте себе, что кредитный брокер выполняет два основных действия: узнает кре-
дитный балл клиента и получает значение лучшей процентной ставки. Если предполо-
жить, что кредитный брокер допускает только последовательное выполнение, процесс
обработки запросов будет выглядеть так, как показано в верхней части рис. 9.18.
Рис. 9.18. Конвейерная обработка значительно повышает пропускную способность приложения
Поскольку основной объем работы на самом деле выполняется внешними компонен-
тами, кредитный брокер большую часть времени бездействует в ожидании результатов
(не самое эффективное использование системных ресурсов, правда?). Если же реализо-
вать кредитный брокер в виде событийно управляемого потребителя (Event-Driven
Consumer, с. 511), приложение сможет обрабатывать по нескольку запросов одновремен-
но и принимать результаты по мере их поступления. Такой режим обработки мы называ-
ем конвейерным (pipeline). При его использовании масштабируемость системы будет зави-
сеть от вычислительной мощности внешних компонентов, а не от кредитного брокера.
Если запустить только один экземпляр кредитного бюро, выигрыш в скорости обработки
может быть не столь очевиден, потому что запросы все равно задержатся в очереди сооб-
Асинхронная реализация с использованием MSMQ
431
щений кредитного бюро. Но если мы решим одновременно запустить несколько экземп-
ляров кредитного бюро, увеличение производительности приложения будет налицо.
(К вопросу производительности мы вернемся немного позднее.)
Существует два основных способа сделать кредитный брокер событийно управляе-
мым. Можно реализовать последовательный режим обработки, но для каждого входя-
щего запроса создавать новый поток. Вместо этого можно сделать так, чтобы система
обмена сообщениями уведомляла брокера об ожидающем событии. В последнем случае
она будет сама управлять потоками выполнения. У каждого из указанных подходов есть
свои преимущества и недостатки. Код последовательной реализации более читабелен.
С другой стороны, если кредитный брокер, в основном, занимается распределением со-
общений между внешними компонентами, у нас может появиться огромное число пото-
ков, которые не занимаются ничем другим, кроме как ожидают поступления сообщений.
Такие потоки потребляют большой объем системных ресурсов, а пользы от них немного.
Как видим, управление потоками лучше поручить системе обмена сообщениями. Когда в
системе появится сообщение, готовое к потреблению, она инициирует выполнение бро-
кера. Это позволит нам работать с одним потоком выполнения и не заботиться об управ-
лении потоками. При этом, однако, нам придется учитывать тот факт, что выполнение
происходит не в рамках одного последовательного метода, а разбросано по нескольким
фрагментам кода, которые выполняются по мере поступления сообщений.
Многие уже наверняка догадались, что для реализации событийно управляемого по-
ведения в .NET будут использоваться делегаты. В нашем примере определение делегата
для класса CreditBureauGateway выглядит следующим образом.
public delegate void OnCreditReplyEvent(CredltBureauReply
creditReply, Object ACT);
Используя экземпляры делегата, мы будем уведомлять шлюз кредитного бюро о том,
какой метод следует вызвать при получении результата. Шлюз кредитного бюро возвра-
щает вызывающему компоненту ответ в виде правильно типизированной структуры
CredltBureauReply. Вместе с ответом передается так называемый маркер асинхронного
завершения (Asynchronous Completion Token; см. [34]), или ACT. Этот маркер позволяет вы-
зывающему компоненту передавать шлюзу некоторые данные и получать их обратно при
поступлении соответствующего сообщения с ответом (см. также шаблон шлюз обмена со-
общениями (Messaging Gateway, с. 482)).
Итак, у нас есть определение делегата. Осталось реализовать метод GetCreditScore,
запрашивающий кредитный балл клиента, а также метод, который обрабатывает входя-
щее сообщение с ответом, сопоставляя маркеры ACT и вызывая соответствующий
экземпляр делегата.
CreditBureauGateway.cs
internal struct CreditRequestProcess
{
public int CorrelationlD;
public Object ACT;
public OnCreditReplyEvent callback;
}
432
Глава 9. Практикум: сложный обмен сообщениями
internal class CreditBureauGateway
{
protected IMessageSender creditRequestQueue;
protected IMessageReceiver creditReplyQueue;
protected IDictionary activeProcesses =
(IDictionary) (new Hashtable());
protected Random random = new Random();
public void Listen()
{
creditReplyQueue.Begin();
}
public void GetCreditScore(CreditBureauRequest quoteRequest,
OnCreditReplyEvent OnCreditResponse, Object ACT)
{
Message requestMessage = new Message(quoteRequest);
requestMessage.ResponseQueue =
creditReplyQueue.GetQueue();
requestMessage.AppSpecific = random.Next();
CreditRequestProcess processinstance =
new CreditRequestProcess();
processinstance.ACT = ACT;
processinstance.callback = OnCreditResponse;
processinstance.CorrelationlD =
requestMessage.AppSpecific;
creditRequestQueue.Send(requestMessage);
activeProcesses.Add(processinstance.CorrelationlD,
processinstance);
}
private void OnCreditResponse(Message msg)
{
msg.Formatter = GetFormatter();
CreditBureauReply replyStruct;
try
{
if (msg.Body is CreditBureauReply)
{
replyStruct = (CreditBureauReply)msg.Body;
int CorrelationlD = msg.AppSpecific;
if (activeProcesses.Contains(CorrelationlD))
{
CreditRequestProcess processinstance =
(CreditRequestProcess)(activeProcesses[CorrelationlD]);
processinstance.callback(replyStruct,
processinstance.ACT);
activeProcesses.Remove(CorrelationlD);
Асинхронная реализация с использованием MSMQ
433
}
else { Console.WriteLine
("Incoming credit response does
not match any request"); }
// "Входящий запрос не соответствует требованиям."
}
else
{ Console. WriteLine ("Illegal reply."),- }
// "Недопустимый ответ."
}
catch (Exception e)
{
Console.WriteLine ("Exception: {o}1', e.ToString () ) ;
}
}
}
Когда вызывающий компонент запрашивает кредитный балл клиента с помощью ме-
тода GetCreditScore, шлюз кредитного бюро создает новый экземпляр структуры
CreditRequestProcess. Коллекция activeProcesses содержит содержит по одному
экземпляру данной структуры на каждый исходящий запрос. Ссылка на элемент коллек-
ции выполняется по идентификатору корреляции {Correlation Identifier, с. 186) соответст-
вующего сообщения. Структура CreditRequestProcess также включает в себя экземп-
ляр делегата OnCreditReplyEvent. Наличие собственного экземпляра делегата у каж-
дого сообщения позволяет вызывающему компоненту указывать для конкретных
запросов разное расположение обратного вызова. Как будет показано ниже, это позволя-
ет вызывающему компоненту применять делегаты для управления состоянием разговора.
Важно отметить, что в нашем примере для сопоставления сообщений не используется
встроенный идентификатор сообщения. Вместо этого мы присваиваем случайное целое
число свойству AppSpecific и сопоставляем входящие сообщения по значению этого
свойства. (Помните, мы построили класс RequestReplyService таким образом, чтобы
в сообщение с ответом копировался не только идентификатор сообщения, но и значение
свойства AppSpecific?) Зачем сопоставлять сообщения по каким-то другим свойствам,
если есть идентификатор сообщения, спросите вы? Преимущество идентификатора со-
общения состоит в том, что он уникален для каждого сообщения в системе. Это же, од-
нако, ограничивает гибкость нашего решения. Сопоставление запроса и ответа по иден-
тификатору сообщения с запросом не позволяет вставить в путь следования сообщения
какие-либо промежуточные компоненты (например, маршрутизатор). Посредник, встав-
ленный между клиентом и службой, будет потреблять исходное сообщение, полученное
от клиента, и публиковать новое. Легко догадаться, что идентификатор корреляции со-
общения с ответом будет совпадать с идентификатором сообщения, полученного служ-
бой от посредника, но никак не исходного сообщения, отправленного кредитным броке-
ром (рис. 9.19).
Решить эту проблему можно двумя способами. Во-первых, можно поручить посред-
нику, чтобы он перехватывал не только запросы, но и ответы и оснащал сообщения с от-
ветами правильным значением идентификатора корреляции. Пример такого подхода
приведен в описании шаблона интеллектуальный заместитель {Smart Proxy, с. 567).
Во-вторых, для сопоставления сообщений можно использовать какое-нибудь специаль-
434
Глава 9. Практикум: сложный обмен сообщениями
Рис. 9.19. Посредник препятствует сопоставлению сообщений по идентификаторам,
сгенерированным системой
ное поле, чтобы все связанные между собой сообщения, проходящие сквозь посредник и
службу, имели один и тот же идентификатор корреляции. В нашем примере мы отдали
предпочтение второму подходу, чтобы посреднику было проще перехватывать сообще-
ния с запросами между брокером и кредитным бюро (это пригодится нам в главе 12).
Как выбрать значение для свойства AppSpecif ic? Можно было бы использовать после-
довательные числовые значения, но тогда пришлось бы следить за тем, чтобы нумерация
двух одновременно отправленных сообщений не начиналась с одного и того же числа.
Можно было бы создать централизованный модуль генерации идентификаторов
(например, базу данных), гарантирующий уникальность идентификаторов в пределах
системы, но зачем так усложнять наш простенький пример? Вот почему мы решили вос-
пользоваться случайными числами. .NET генерирует случайные числа как 32-битные це-
лые числа со знаком, поэтому вероятность повторения составляет один к двум миллиар-
дам (вполне приемлемый риск).
Создав шлюз кредитного бюро, мы добились желаемого уровня абстракции от инфра-
структуры очередей сообщений Windows. Единственными общедоступными элементами
шлюза кредитного бюро (помимо конструкторов) являются делегат и два метода.
delegate void OnCreditReplyEvent(CredltBureauReply creditReply,
Object ACT);
class CreditBureauGateway {
void Listen() {...}
void GetCreditScore(CreditBureauRequest quoteRequest,
OnCreditReplyEvent OnCreditResponse, Object ACT) {...}
}
Е1и одна из вышеперечисленных конструкций не ссылается на сообщение или оче-
редь сообщений. Такое поведение имеет ряд преимуществ. Во-первых, мы можем легко
реализовать “фиктивную” версию шлюза кредитного бюро, которая вообще не будет ра-
ботать с очередями сообщений (подобно классу MockQueue). Во-вторых, мы сможем за-
менить реализацию шлюза кредитного бюро, если решим воспользоваться другой инфра-
Асинхронная реализация с использованием MSMQ
435
структурой обмена сообщениями. К примеру, если бы вместо MSMQ мы использовали
интерфейс Web-служб в сочетании с SOAP и HTTP, общедоступные методы шлюза,
скорее всего, не пришлось бы менять вообще.
Шлюз банка
Шлюз банка построен по тем же принципам, что и шлюз кредитного бюро. Мы ис-
пользуем тот же процесс, что и раньше, для получения исходного кода структур сообще-
ний с запросом и ответом, которые описываются в сборке банка. Общедоступная часть
шлюза банка очень похожа на таковую шлюза кредитного бюро.
delegate void OnBestQuoteEvent(BankQuoteReply bestQuote,
Object ACT);
class BankGateway {
void Listen() {...}
void GetBestQuote(BankQuoteRequest quoteRequest,
OnBestQuoteEvent OnBestQuoteEvent,
Object ACT) {...}
}
Внутренний механизм работы шлюза банка более сложен, нежели механизм работы
шлюза кредитного бюро, потому что при взаимодействии по типу рассылки-сборки
(Scatter-Gather, с. 310) одно сообщение BankQuoteRequest направляется сразу в не-
сколько банков. Аналогичным образом одно сообщение BankQuoteReply обычно явля-
ется результатом компоновки ответов из нескольких банков. Первое действие реализует-
ся при помощи списка получателей (Recipient List, с. 264), а второе — при помощи агрега-
тора (Aggregator, с. 283). Начнем со списка получателей. Он должен выполнять три
основные функции:
• вычисление нужных получателей;
• отправка сообщения получателям;
• инициализация агрегатора, предназначенного для обработки входящих ответов.
Как было описано во введении к этой главе, в данной реализации шаблона рассылка-
сборка используется адресация по типу распределения (distribution), т.е. кредитный брокер
сам определяет, в какие банки необходимо отослать каждый конкретный запрос. Этот
подход имеет смысл, если банки взимают с брокера плату за обработку каждого запроса
или же если между брокером и банком существует соглашение, согласно которому бро-
кер должен проводить предварительную оценку запроса. Кредитный брокер принимает
решение о рассылке запроса в те или иные банки, исходя из кредитного балла клиента,
желаемой суммы кредита и длины кредитной истории. Каждое соединение с банком бу-
дет инкапсулировано в классе, производном от абстрактного класса Bankconnection.
Производный класс содержит ссылку на адрес очереди сообщений, а также метод Сап-
HandleLoanRequest, определяющий, следует ли направлять запрос в этот банк. Класс
BankConnect ionManager просто прокручивает список всех соединений с банками и со-
ставляет перечень банков, готовых принять запрос. Если бы число банков было доста-
точно большим, следовало бы подумать о реализации настраиваемой системы правил.
Мы же предпочли более простой и наглядный подход.
436
Глава 9. Практикум: сложный обмен сообщениями
internal class BankConnectionManager
{
static protected Bankconnection[] banks =
{new Bankl(), new Bank2(), new Bank3(),
new Bank4(), new Banks() } ;
public IMessageSender[] GetEligibleBankQueues
(int Creditscore, int HistoryLength, int LoanAmount)
{
ArrayList lenders = new ArrayList();
for (int index = 0; index < banks.Length; index++)
{
if (banks[index].CanHandleLoanReguest(Creditscore,
HistoryLength, LoanAmount))
lenders.Add(banks[index].Queue);
}
IMessageSender[] lenderArray =
(IMessageSender [])Array.Createlnstance
(typeof(IMessageSender), lenders.Count);
lenders.CopyTo(lenderArray);
return lenderArray;
}
}
internal abstract class Bankconnection
{
protected MessageSenderGateway queue;
protected String bankName = "";
public MessageSenderGateway Queue
{
get { return queue; }
}
public String BankName
{
get { return bankName; }
}
public Bankconnection (MessageQueue queue)
{ this.queue = new MessageSenderGateway(queue); }
public Bankconnection (String queueName)
{ this.queue = new MessageSenderGateway(queueName); }
public abstract bool CanHandleLoanReguest(int Creditscore,
int HistoryLength, int LoanAmount);
}
internal class Bankl : Bankconnection
{
protected String bankname = "Exclusive Country Club Bankers";
public Bankl () : base (".\\private$\\banklQueue") {}
public override bool CanHandleLoanReguest(int Creditscore,
int HistoryLength, int LoanAmount)
{
return LoanAmount >= 75000 && Creditscore >= 600 &&
Асинхронная реализация с использованием MSMQ
437
HistoryLength >= 8;
}
}
Когда BankConnectionManager составит перечень подходящих банков, разослать со-
общение будет несложно — достаточно прокрутить полученный список. В реальном при-
ложении прокрутка списка должна проходить в рамках одной транзакции, чтобы избежать
ситуаций, когда сообщение из-за каких-то ошибок будет разослано лишь в некоторые бан-
ки. В данном примере мы снова не стали этого делать из соображений простоты.
internal class MessageRouter
{
public static void SendToRecipientList (Message msg,
IMessageSender[] recipientList)
{
lEnumerator e = recipientList.GetEnumerator();
while (e.MoveNext())
{
((IMessageSender)e.Current).Send(msg);
}
}
Итак, сообщение с запросом на получение кредита разослано в требуемые банки.
Теперь необходимо инициализировать агрегатор, который будет заниматься компоновкой
ответов, пришедших из банков, в одно сообщение. В силу событийно управляемого пове-
дения кредитного брокера агрегатор должен быть готов паралелльно обрабатывать ответы
для нескольких запросов, т.е. держать по одному активному агрегату на каждый запрос,
пребывающий в состоянии ожидания. Это означает, что прибывающие ответы на запрос
должны уникальным образом сопоставляться с конкретным агрегатом. К сожалению, в ка-
честве идентификатора корреляции нельзя использовать идентификатор сообщения, пото-
му что список получателей должен разослать по отдельному сообщению в каждый из подхо-
дящих банков. К примеру, если запрос на кредит соответствует условиям трех банков, спи-
ску получателей понадобится отправить три уникальных сообщения, по одному на каждый
банк. У каждого из отправленных сообщений будет свой идентификатор, поэтому, если
проводить корреляцию по идентификатору сообщения, у трех ответов будут три разных
идентификатора корреляции, даже несмотря на то, что все они относятся к одному и тому
же агрегату. Это помешает агрегатору идентифицировать связанные между собой сообще-
ния. Можно было бы сделать так, чтобы агрегат сохранял идентификаторы всех разослан-
ных сообщений и затем сопоставлял каждый из них с идентификаторами корреляции отве-
тов, но это привносит в систему ненужное усложнение. Вместо этого мы будем просто гене-
рировать собственные идентификаторы корреляции — по одному на каждый агрегат, а не
на каждое отправленное шлюзом сообщение. Такой идентификатор (числовой) будет при-
сваиваться свойству AppSpecif ic исходящих сообщений с запросом. Класс банка наследу-
ет класс RequestReplyService, в котором уже заложена передача значения свойства App-
Specif ic в сообщение с ответом. Когда из банка приходит ответ с предлагаемым значени-
ем процентной ставки, шлюз BankGateway может легко сопоставить полученное
сообщение с нужным агрегатом (рис. 9.20).
438
Глава 9. Практикум: сложный обмен сообщениями
AppSpecific=2
MsglD=7AFFE
Банк 1
AppSpecific =2
MsglD=4ACDC
AppSpecific=1
MsglD=12E5D
AppSpecific=2
MsglD=14433
Банк 2
БанкЗ
AppSpecific=1
MsglD=45AC4
AppSpecific=2
Quote=5.2%
AppSpecific=1 |
Quote=6.8% |
AppSpecific=2
Quote=7.9%
AppSpecific=1
Quote=5.5%
AppSpecmc=2
Quote=6.4%
Puc. 9.20. Шлюз банка использует свойство AppSpeci fi с объекта сообщения, чтобы сопоставлять
ответы с агрегатами
Шлюз банка инициализирует агрегат, используя идентификатор агрегата (генери-
руется с помощью простого счетчика) и количество ожидаемых сообщений. Кроме того,
кредитный брокер как вызывающий компонент должен предоставить экземпляр делегата
и при необходимости может задать объектную ссылку на маркер асинхронного заверше-
ния (ACT), как это было при описании шлюза кредитного бюро. Сама стратегия агрега-
ции очень проста. Агрегат считается полным, когда все банки, получившие запрос, при-
сылают сообщение с ответом. Число ожидаемых сообщений задается списком получате-
лей при инициализации агрегата. Напомним также, что у банков есть возможность
отказаться от предложения процентной ставки. В нашем примере мы требуем, чтобы
банки, отказавшиеся предоставить кредит, прислали ответ с кодом ошибки (в противном
случае агрегат бы не стал полным). При желании стратегию агрегации легко изменить,
чтобы, к примеру, по истечении одной секунды агрегат перестал принимать ответы и вы-
брал лучшую процентную ставку из имеющихся на настоящий момент.
internal class BankQuoteAggregate
{
protected int ID;
protected int expectedMessages;
protected Object ACT;
protected OnBestQuoteEvent callback;
Асинхронная реализация с использованием MSMQ
439
protected double bestRate = 0.0;
protected ArrayList receivedMessages = new ArrayList();
protected BankQuoteReply bestReply = null;
public BankQuoteAggregate(int ID, int expectedMessages,
OnBestQuoteEvent callback. Object ACT)
{
this.ID = ID;
this.expectedMessages = expectedMessages;
this.callback = callback;
this.ACT = ACT;
}
public void AddMessage(BankQuoteReply reply)
{
if (reply.ErrorCode == 0)
{
if (bestReply == null)
{
bestReply = reply;
}
else
{
if (reply.InterestRate < bestReply.InterestRate)
{
bestReply = reply,-
}
}
}
receivedMessages.Add(reply);
}
public bool IsCompleteO
{
return receivedMessages.Count == expectedMessages;
}
public BankQuoteReply getBestResult()
{
return bestReply;
}
public void NotifyBestResult()
{
if (callback != null)
{
callback(bestReply, ACT);
}
}
}
440
Глава 9. Практикум: сложный обмен сообщениями
Имея в своем распоряжении диспетчер соединений с банками (Bankconnection-
Manager), список получателей и агрегат, реализовать функции шлюза банка становится
несложно.
BankGateway.cs
internal class BankGateway
{
protected IMessageReceiver bankReplyQueue;
protected BankConnectionManager connectionManager;
protected IDictionary aggregateBuffer =
(IDictionary)(new Hashtable());
protected int aggregationCorrelationlD;
public void Listen()
{
bankReplyQueue.Begin();
}
public void GetBestQuote(BankQuoteRequest quoteRequest,
OnBestQuoteEvent OnBestQuoteEvent,
Object ACT)
{
Message requestMessage = new Message(quoteRequest);
requestMessage.AppSpecific = aggregationCorrelationlD;
requestMessage.ResponseQueue = bankReplyQueue.GetQueue();
IMessageSender[] eligibleBanks =
connectionManager.GetEligibleBankQueues(quoteRequest.Creditscore,
quoteRequest.HistoryLength,
quoteRequest.LoanAmount);
aggregateBuf f er.Add(aggregat ionCorrelat ionlD,
new BankQuoteAggregate(aggregationCorrelationlD,
eligibleBanks.Length, OnBestQuoteEvent, ACT));
aggregationCorrelationID++;
MessageRouter.SendToRecipientList(requestMessage,
eligibleBanks);
}
private void OnBankMessage(Message msg)
{
msg.Formatter = GetFormatter();
BankQuoteReply replyStruct;
try
{
if (msg.Body is BankQuoteReply)
{
replyStruct = (BankQuoteReply)msg.Body;
int aggregationCorrelationlD = msg.AppSpecific;
Console.WriteLine("Quote {0:0.00}% {1} {2}",
replyStruct.InterestRate,
Асинхронная реализация с использованием MSMQ
441
replystruct.QuotelD,
replystruct.ErrorCode);
if
(aggregateBuffer.Contains(aggregationCorrelationlD))
{
BankQuoteAggregate aggregate =
(BankQuoteAggregate)(aggregateBuffer[aggregationCorrelationlD]);
aggregate.AddMessage(replyStruct);
if (aggregate.IsComplete())
{
aggregate.NotifyBestResult();
aggregateBuf fer.Remove
(aggregationCorrelationlD);
else
{ Console.WriteLine("Incoming bank response
does not match any aggregate"); }
// "Ответ банка не соответствует
// ни одному из агрегатов."
else
{ Console.WriteLine("Illegal request."); }
// "Недопустимый запрос."
catch (Exception e)
{
Console.WriteLine("Exception: {0}", e.ToString()) ;
} 1
Когда шлюз BankGateway получает ответ банка, выполняется метод OnBankMessage.
Данный метод преобразует входящее сообщение в нужный тип и определяет, к какому
агрегату относится сообщение, с помощью значения свойства AppSpecif ic. Как только
агрегат станет полным (как определено в классе BankQuoteAggregate), шлюз банка вы-
зовет экземпляр делегата, предоставленный кредитным брокером.
Прием запросов кредитным брокером
Обзаведясь хорошо инкапсулированными шлюзами банка и кредитного бюро, можно
приступать к реализации принятия запросов от клиентов. Ранее мы обсуждали базовые
классы MQService и AsyncRequestReplyService. Класс LoanBroker наследует Asyn-
cRequestReplyService, потому что он может отправлять результат в очередь ответов не
сразу, а только по завершении еще нескольких асинхронных операций (получение кре-
дитного балла и взаимодействие с банками).
Первое, что нужно сделать при реализации кредитного брокера, — определить типы
сообщений, с которыми он работает. Вот как они выглядят.
public struct LoanQuoteRequest
{
public int SSN;
publie doub1e LoanAmount;
442
Глава 9. Практикум: сложный обмен сообщениями
public int LoanTerm;
public struct LoanQuoteReply
{
public int SSN;
public double LoanAmount;
public double InterestRate;
public string QuotelD;
}
Теперь создадим класс, который наследует AsyncRequestReplyService и переопре-
деляет метод ProcessMessage.
Обработка сообщений
Класс кредитного брокера отличается от классов, созданных нами ранее, поскольку
процесс обработки запроса, запускаемый любым входящим сообщением, не укладывает-
ся в рамки одного метода. Вместо этого завершение процесса зависит от последователь-
ности внешних событий. Кредитный брокер может получать события трех типов:
• поступление нового запроса на получение кредита;
• поступление ответа от кредитного бюро с кредитным баллом клиента (через шлюз
CreditBureauGateway);
• поступление ответа от банка (через шлюз BankGateway).
Поскольку логика кредитного брокера разбросана между несколькими обработчика-
ми событий, нам необходимо отслеживать состояние брокера. Вот где в дело вступают
маркеры асинхронного завершения! Вспомните, что шлюзы кредитного бюро и банка
позволяют вызывающему компоненту (т.е. кредитному брокеру) передавать вместе с за-
просом ссылку на некоторый объект. При получении ответа шлюз возвращает кредитно-
му брокеру эту ссылку. Чтобы воспользоваться данной возможностью, определим класс
маркера асинхронного завершения (ACT).
internal class ACT
{
public LoanQuoteRequest loanRequest;
public Message message;
public ACT(LoanQuoteRequest loanRequest, Message message)
{
this.loanRequest = loanRequest;
this, message = message,-
}
}
Класс act включает в себя копию исходного сообщения с запросом (в котором,
в свою очередь, содержатся идентификатор сообщения и обратный адрес, необходимые
для создания сообщения с ответом), а также структуру LoanQuoteRequest (чтобы из-
влечь из нее номер карты социального страхования и сумму кредита и скопировать их в
сообщение с ответом). С технической точки зрения в классе act содержится некоторое
Асинхронная реализация с использованием MSMQ
443
количество избыточной информации, потому что содержимое структуры LoanQuote-
Request можно было бы извлечь и из сообщения с запросом. Тем не менее для удобства
доступа к сильно типизированной структуре вполне можно пожертвовать несколькими
лишними байтами памяти.
Оставшаяся часть кода кредитного брокера выглядит следующим образом.
LoanBroker.cs
internal class LoanBroker : AsyncRequestReplyService
{
protected ICreditBureauGateway creditBureauInterface;
protected BankGateway bankinterface;
public LoanBroker(String requestQueueName,
String creditRequestQueueName,
String creditReplyQueueName,
String bankReplyQueueName,
BankConnectionManager connectionManager):
base(requestQueueName)
{
creditBureauInterface = (ICreditBureauGateway)
(new CreditBureauGatewaylmp(creditRequestQueueName,
creditReplyQueueName));
creditBureauInterface.Listen();
bankinterface = new BankGateway(bankReplyQueueName,
connectionManager);
bankinterface.Listen();
protected override Type GetRequestBodyType()
{
return typeof(LoanQuoteRequest);
protected override void ProcessMessage(Object o, Message msg)
{
LoanQuoteRequest quoteRequest;
quoteRequest = (LoanQuoteRequest)o;
CreditBureauRequest creditRequest =
LoanBrokerTranslator.GetCreditBureaurequest(quoteRequest);
ACT act = new ACT(quoteRequest, msg);
creditBureauInterface.GetCreditScore(creditRequest,
new OnCreditReplyEvent(OnCreditReply), act);
private void OnCreditReply(CreditBureauReply creditReply,
Object act)
{
ACT myAct = (ACT)act;
444
Глава 9. Практикум: сложный обмен сообщениями
Console.WriteLine("Received Credit Score -- SSN {o}
Score {1} Length {2}", creditReply.SSN,
creditReply.CreditScore,
creditReply.HistoryLength);
// "Получен кредитный балл."
BankQuoteRequest bankRequest =
LoanBrokerTranslator.GetBankQuoteRequest(myAct.loanRequest,
creditReply);
bankinterface.GetBestQuote(bankRequest,
new OnBestQuoteEvent(OnBestQuote), act);
private void OnBestQuote(BankQuoteReply bestQuote, Object act)
{
ACT myAct = (ACT)act;
LoanQuoteReply quoteReply =
LoanBrokerTranslator.GetLoanQuoteReply
(myAct.loanRequest, bestQuote);
Console.WriteLine("Best quote {0} {1}",
quoteReply.InterestRate, quoteReply.QuotelD);
SendReply(quoteReply, myAct.message);
} 1
Класс LoanBroker наследует AsyncRequestReplyService, который поддерживает
получение запросов и отправку ответов с соответствующими идентификаторами корре-
ляции. В классе LoanBroker переопределяется метод ProcessMessage, предназначен-
ный для обработки входящих сообщений с запросами. Метод ProcessMessage создает
новый экземпляр маркера асинхронного завершения (ACT) и обращается к шлюзу
кредитного бюро, чтобы запросить кредитный балл клиента. Самое интересное, что на
этом выполнение метода... заканчивается! Обработка запроса продолжается, когда шлюз
кредитного бюро вызывает метод OnCreditReply, переданный экземпляру делегата On-
CreditReplyEvent методом ProcessMessage. Метод OnCreditReply использует мар-
кер асинхронного завершения и структуру CredltBureauReply (ответ кредитного бю-
ро), чтобы сформировать запрос к банку на получение процентной ставки, и обращается
к шлюзу банка для передачи сообщений с запросом. На сей раз в качестве метода обрат-
ного вызова экземпляру делегата OnBestQuoteEvent передается метод OnBestQuote.
Как только шлюз банка получает ответы от всех банков, он вызывает указанный метод
через экземпляр делегата и возвращает ему маркер асинхронного завершения.
Метод OnBestQuote использует значение процентной ставки и маркер асинхронного за-
вершения для создания ответа клиенту и отправляет его, используя базовую реализацию
метода SendReply.
В исходном коде, приведенном выше, упоминается еще один класс — LoanBroker-
Translator. Данный класс включает в себя ряд статических методов, облегчающих пре-
образование между различными форматами сообщений.
Код класса LoanBroker наглядно демонстрирует один из компромиссов, на который
пришлось пойти при проектировании решения. С одной стороны, в коде класса нет ссы-
Асинхронная реализация с использованием MSMQ
445
.ток на обмен сообщениями или каких-либо концепций, связанных с потоками
(исключение составляет лишь наследование класса AsyncRequestReplyService), что
благоприятно влияет на читабельность кода. С другой стороны, выполнение основной
функции класса разбросано между тремя методами, которые ссылаются друг на друга не
напрямую, а лишь через делегатов. Из-за этого понять процесс выполнения может лишь
тот, кто хорошо проанализирует все решение, включая внешние компоненты.
Оптимизация кода кредитного брокера
Если посмотреть на принцип работы кредитного брокера, легко заметить, что данные
в нем отделены от функциональности. В приложении есть один экземпляр класса Loan-
Broker, который имитирует работу нескольких экземпляров с помощью коллекции мар-
керов асинхронного завершения. Несмотря на всю пользу маркеров асинхронного за-
вершения, их использование противоречит духу объектно-ориентированного програм-
мирования из-за разделения данных (маркеры) и функциональности (логика кредитного
брокера) — двух сущностей, которые образуют объект. Впрочем, мы можем оптимизиро-
вать код класса LoanBroker, чтобы избежать постоянного обращения к маркерам асин-
хронного завершения, если используем делегаты несколько иным способом. Делегаты по
своей сути являются сильно типизированными указателями на функции, т.е. указывают
на конкретный экземпляр объекта. Вместо того чтобы передавать шлюзам банка и кре-
дитного бюро ссылку на метод единственного экземпляра класса LoanBroker, делегат
можно использовать в качестве указателя на конкретный экземпляр “объекта процесса”,
содержащего не только текущее состояние запроса (как маркер асинхронного заверше-
ния), но и логику кредитного брокера. Для этого мы превратим маркер асинхронного за-
вершения в новый класс по имени LoanBrokerProcess и перенесем в него функции,
связанные с обработкой сообщений.
internal class LoanBrokerProcess
{
protected LoanBrokerPM broker;
protected String processID;
protected LoanQuoteRequest loanRequest;
protected Message message;
protected CreditBureauGateway CreditBureauGateway;
protected BankGateway bankinterface,-
public LoanBrokerProcess(LoanBrokerPM broker.
String processID,
CreditBureauGateway CreditBureauGateway,
BankGateway bankGateway,
LoanQuoteRequest loanRequest, Message msg)
{
this.broker = broker;
this.CreditBureauGateway = broker.CreditBureauGateway;
this.bankinterface = broker.Bankinterface;
this.processID = processID;
this.loanRequest = loanRequest;
this.message = msg;
446
Глава 9. Практикум: сложный обмен сообщениями
CreditBureauRequest creditRequest =
LoanBrokerTranslator.GetCreditBureaurequest(loanRequest);
creditBureauGateway.GetCreditScore(creditRequest,
new OnCreditReplyEvent(OnCreditReply), null);
private void OnCreditReply(CreditBureauReply creditReply,
Object act)
{
Console.WriteLine("Received Credit Score -- SSN {0}
Score {1} Length {2}", creditReply.SSN,
creditReply.Creditscore,
creditReply.HistoryLength);
BankQuoteRequest bankRequest =
LoanBrokerTranslator.GetBankQuoteRequest(loanRequest,
creditReply);
bankinterface.GetBestQuote(bankRequest,
new OnBestQuoteEvent(OnBestQuote), null);
private void OnBestQuote(BankQuoteReply bestQuote, Object act)
{
LoanQuoteReply quoteReply =
LoanBrokerTranslator.GetLoanQuoteReply (loanRequest,
bestQuote);
Console.WriteLine("Best quote {0} {1}",
quoteReply.InterestRate,
quoteReply.QuotelD);
broker.SendReply(quoteReply, message);
broker.OnProcessComplete(processID);
Методы, приведенные выше, больше не ссылаются на маркер асинхронного заверше-
ния, переданный шлюзами банка и кредитного бюро, потому что вся необходимая
информация хранится в объекте LoanBrokerProcess. Когда процесс (т.е. обработка
запроса) будет завершен, LoanBrokerProcess отправит сообщение с ответом, используя
метод SendReply, унаследованный им от класса AsyncRequestReplyService. После
этого он уведомит объект LoanBrokerPM о завершении процесса. Для реализации уве-
домления можно было бы применить делегат, но мы предпочли воспользоваться ссылкой
на экземпляр брокера.
Наличие класса LoanBrokerProcess несколько упрощает основной класс кредит-
ного брокера.
internal class LoanBrokerPM : AsyncRequestReplyService
{
protected CreditBureauGateway creditBureauGateway;
protected BankGateway bankinterface;
protected IDictionary activeProcesses =
(IDictionary)(new Hashtable());
public LoanBrokerPM(String requestQueueName,
String creditRequestQueueName,
Асинхронная реализация с использованием MSMQ
447
String creditReplyQueueName,
String bankReplyQueueName,
BankConnectionManager connectionManager):
base(requestQueueName)
{
creditBureauGateway = new
CreditBureauGateway(creditRequestQueueName,
creditReplyQueueName);
creditBureauGateway. Listen () ,-
bankinterface = new BankGateway(bankReplyQueueName,
connectionManager);
bankinterface.Listen();
protected override Type GetRequestBodyType()
{
return typeof(LoanQuoteRequest);
}
protected override void ProcessMessage(Object o.
Message message)
{
LoanQuoteRequest quoteRequest;
quoteRequest = (LoanQuoteRequest)o;
String processID = message.Id;
LoanBrokerProcess newProcess =
new LoanBrokerProcess(this, processID,
creditBureauGateway, bankinterface,
quoteRequest, message);
activeProcesses.Add(processID, newProcess);
public void OnProcessComplete(String processID)
{
activeProcesses.Remove(processID);
Класс LoanBrokerPM, по сути, представляет собой общую реализацию диспетчера
процессов {Process Manager, с. 325). При поступлении нового сообщения он создает новый
экземпляр процесса. Когда выполнение процесса завершается, диспетчер удаляет экзем-
пляр процесса из списка активных процессов. Идентификатор сообщения используется
диспетчером в качестве уникального идентификатора соответствующего экземпляра
процесса. Теперь, чтобы изменить поведение кредитного брокера, достаточно просто
внести необходимые изменения в класс LoanBrokerProcess, который никак не ссыла-
ется на обмен сообщениями (за исключением того, что передает сообщение в качестве
аргумента). Кажется, наши усилия, потраченные на правильную инкапсуляцию и опти-
мизацию кода, окупились с лихвой. Окончательная структура компонента кредитного
брокера показана на рис. 9.21.
448
Глава 9. Практикум: сложный обмен сообщениями
Рис. 9.21. Диаграмма классов кредитного брокера
Запуск системы
Главные компоненты приложения кредитного брокера готовы; осталось лишь поза-
ботиться о тестовом клиенте. Структура тестового клиента напоминает таковую для
шлюза кредитного бюро. Тестовый клиент может выполнить заданное число повторяю-
щихся запросов и сопоставить полученные ответы с отправленными ранее запросами
Запустив все процессы (банков, кредитного бюро и кредитного брокера), можно начать
выполнение примера. Мы также используем ряд простых классов, чтобы запустить ука-
занные компоненты в качестве приложений консоли. По ходу выполнения на экране
“пробегает” большой объем информации, позволяюшей следить за прохождением сооб-
щений по системе (рис. 9.22).
Асинхронная реализация с использованием MSMQ
449
Рис. 9.22. Пример работы кредитного брокера, построенного с помощью MSMQ
Повышение производительности
Получив работающее решение, можно начать сбор статистики о его производитель-
ности, чтобы сравнить пропускную способность асинхронного и синхронного решений.
Используя генератор тестовых данных, мы отправляем кредитному брокеру 50 случайных
запросов. Генератор тестовых данных сообщает, что получение 50 сообщений с ответами
заняло чуть более 33 секунд (рис. 9.23).
-ceived re ponses 47 65 ->В3.00 7.3 Neighhorhoad-0WO15"
hatched to request 26.80 seconds
fheceived r< pen e: .48 $118,998.00 5.6 CountryClub~0O»l2
hatched to request - 27.06 seconds
Receiued response: 49 $25,000.08 7.5 Retail-BiOlS
hatcjsed to request ~ 27.55 seconds
Received response: 50 $11П,5ВЙ.“0 0 ЕййОЙ: Ho Qualifying Quotes
hatched to request - 27.78 seconds
₽>» Iota! elapsed time: 88:00:33.5627119 secs
= - average response tio>e 15.31 secs
Л/с. 9.23. Отправка SO сообщений с запросами и получение ответов
Можно предположить, что на обработку каждого запроса ушло 33/50 = 0,6 секунд.
Увы, это не так! Пропускная способность кредитного брокера составила 50 запросов за
33 секунды, однако на обработку некоторых запросов было потречено по 27 секунд.
450
Глава 9. Практикум: сложный обмен сообщениями
Почему система функционирует так медленно? Давайте взглянем на состояние очередей
сообщений в некоторый момент времени (рис. 9.24).
В очереди запросов creditRequestQueue накопилось— ни много, ни мало —
31 сообщение! Очевидно, “узким местом” нашей системы является кредитное бюро, по-
тому что все запросы на получение кредита вначале должны пройти именно через этот
компонент. Для повышения производительности системы воспользуемся преимущест-
вами слабого связывания и запустим еще два экземпляра кредитного бюро. Теперь по-
смотрим, помогла ли данная мера устранить “узкое место” (рис. 9.25).
Рис. 9.24. В очереди запросов к кредитному бюро скопилось 31 сообщение
kv'ceivcd r° ponse: 47 $73.000-00 0 ERROR: Но (
Hatched to request - 15-El scrods
ht-cekied response: 49 $115,080.00 Й FrfflOR: Ho Qualifying Quotes
[ Hatched to request 15.61 seconds
Received response; 48 $90,000.00 9 Paun5hop-04i^98
Hatched to request - 15,02 seconds
Received response: 50 $45,000,00 0 ERROR: Ha Qualifying Quotes
Hatched to request - 16.43 seconds
r-® Total elapsed tir«e: 00:00:21.5596550 s».cs
average response tine 8.63 secs
Puc. 9.25. Обработка 50 сообщений с запросами при наличии трех экземпляров кредитного бюро
Асинхронная реализация с использованием MSMQ
451
Общее время обработки 50 запросов сократилось до 21 секунды, а самое продолжи-
тельное время ожидания ответа составило 16 секунд. В среднем клиенту приходилось
дожидаться ответа от кредитного брокера 8,63 секунды, т.е. половину от первоначального
значения. Кажется, нам удалось избавиться от “узкого места”, но пропускная способ-
ность системы возросла далеко не так сильно, как мы надеялись. Вспомните, однако, что
в нашем примере все процессы запускаются на одном и том же компьютере, поэтому им
приходится бороться за системные ресурсы. Давайте снова взглянем на состояние очере-
дей сообщений, чтобы убедиться, что “узкое место” в лице кредитного бюро действи-
тельно устранено (рис. 9.26).
Рис. 9.26. В системе появилось новое “узкое место” — банк 5
Неужели мы избавились от одного “узкого места” только для того, чтобы заполучить
другое? И почему им стал именно банк 5? В нашем примере банк 5 — это ломбард,
выдающий кредиты всем, кто может предоставить залог, поэтому данное учреждение
участвует в обработке практически каждого запроса. Можно было бы поступить, как в
предыдущем случае, запустив несколько экземпляров банка 5. Но на практике нельзя
ожидать, что ломбард запустит сразу несколько служб исключительно для того, чтобы
повысить пропускную способность нашей системы. Другой вариант — изменить логику
маршрутизации для запросов к банкам. Поскольку процентная ставка, под которую лом-
бард выдает кредит, значительно превышает процентные ставки других банков, она ока-
жется самой выгодной для клиента только тогда, когда остальные банки вообще откажут-
ся выдать кредит. Учитывая это соображение, мы можем повысить эффективность сис-
темы, не направляя ломбарду запросы, которые могут обслужить остальные банки. Такое
изменение никак не повлияет на общее поведение системы.
452
Глава 9. Практикум: сложный обмен сообщениями
Итак, изменим поведение класса BankConnect ionManager, чтобы в банк 5 отправ-
лялись только те запросы, которые не могут быть приняты ни одним из оставшихся бан-
ков. Код класса станет выглядеть следующим образом.
internal class BankConnectionManager
static protected BankConnection[] banks =
{new Banklf), new Bank2(), new Bank3(), new Bank4()
};
static protected BankConnection catchAll = new Bank5();
public IMessageSender [] GetEligibleBankQueues(int Creditscore,
int HistoryLength, int LoanAmount)
ArrayList lenders = new ArrayList();
for (int index = 0; index < banks.Length; index++)
if (banks[index].CanHandleLoanRequest(Creditscore,
HistoryLength, LoanAmount))
lenders.Add(banks[index].Queue);
}
if (lenders.Count == 0)
lenders.Add(catchAll.Queue);
IMessageSender!] lenderArray =
(IMessageSender [])Array.Createlnstance
(typeof(IMessageSender), lenders.Count);
lenders.CopyTo(lenderArray);
return lenderArray;
}
}
Результат работы модифицированного диспетчера соединений показан на рис. 9.27.
1 ей ге ро е : 43 $45,030,00 б.? R°tail-00^*23
Matched to reque t ~ 6-01 seconds
Received resрог e: 48 $50,0vf*.,00 0 EEflfcX: No Qualifying Quotes
Hatched to request - 5.70 seconds
Rvt-vii.d re ponse: 49 $3в,000.00 7.4 Р-» tai 1-00024
Hatched to request - 5.91 setun'.s
H*cua»iued re^por^se: 50 $110,000.00 8.8 PawnSh-’p-@0034
Matched to reqwest - 6.29 seconds
Total elapsed tine: 00'00:12.3232948 sues
av rage response tij e 3.68 Secs
-I
Puc. 9.27. Обработка 50 сообщений с запросами при наличии трех экземпляров кредитного бюро и
модифицированного диспетчера соединений с банками
Результаты тестирования показывают, что 50 запросов были обработаны за 12 секунд,
что составляет примерно половину от предыдущего значения. Еще важнее то, что среднее
время обработки запроса теперь не превышает 4 секунд, а это в 4 раза меньше, чем ис-
ходное значение! Данный пример хорошо демонстрирует преимущества предиктивной
маршрутизации с помощью списка получателей {Recipient List, с. 264). Поскольку маршру-
тизацией запросов управляет кредитный брокер, мы можем сами решать, насколько
“умной” должна быть логика маршрутизации, без необходимости подвергать изменени-
Асинхронная реализация с использованием MSMQ
453
ям внешние компоненты. Обратная сторона такого преимущества состоит в том, что кре-
дитный брокер становится зависимым от информации о внутренних компонентах.
К примеру, исходный класс BankConnect ionManager абсолютно одинаково относится
ко всем банкам, а вот работа модифицированной версия диспетчера полностью основы-
вается на том факте, что банк 5 удовлетворяет все запросы, предлагая заведомо высокую
процентную ставку, и к нему следует обращаться лишь при отсутствии других вариантов.
Если же у банка 5 появятся более выгодные предложения, кто гарантирует, что клиенты
по-прежнему будут получать самую низкую процентную ставку?
В окне, показанном на рис. 9.27, также видно, что сообщения с ответами не всегда
приходят в том же порядке, в котором были сделаны запросы. Легко заметить, что после
ответа на запрос 43 пришел ответ на запрос 48. Поскольку ни один ответ не пропал, это
означает, что тестовый клиент получил ответы на запросы 44-47 еще до ответа на за-
прос 43. Почему так произошло? Судя по тексту на рис. 9.27, запрос 43 был направлен в
банк под названием General Retail Bank (банк 3). У этого банка самые мягкие требования
после банка Pawn Shop (он же ломбард, он же банк 5), и он чаще других соглашается вы-
дать кредит, следовательно, его очередь сообщений обычно “забита” запросами. Если за-
просы 44-47 заведомо не удовлетворяли критериям банка General Retail Bank, шлюз бан-
ка сразу же получил для них ответы из Pawn Shop, в то время как запрос 43 все еще ожи-
дал своей участи в очереди bank3Queue. Поскольку поведение кредитного брокера
полностью управляется событиями, он ответит на запрос, как только получит значения
процентных ставок из всех банков. Если значения ставок по кредиту для запроса 44 при-
будут раньше, чем для запроса 43, кредитный брокер вначале отправит тестовому клиенту
ответ на запрос 44. Этот сценарий также подчеркивает важность использования идентифи-
каторов корреляции (Correlation Identifier, с. 186). С их помощью тестовый клиент сможет со-
поставить запросы с ответами, даже если последние будут прибывать не в том порядке.
Настройка асинхронных систем, основанных на обмене сообщениями, может ока-
заться весьма сложным занятием. В данном примере мы задействовали некоторые из ба-
зовых технологий обнаружения и устранения “узких мест”. Впрочем, даже такого про-
стого примера было достаточно, чтобы понять: устранение одного “узкого места”
(кредитное бюро) может легко привести к возникновению другого (банк 5). Вы также
увидели преимущества асинхронного обмена сообщениями и событийно управляемых
потребителей. В самом деле, 50 запросов удалось обработать за 12 секунд, т.е. в 8-10 раз
быстрее, чем при использовании синхронного решения!
Несколько слов о тестировании
Пример кредитного брокера хорошо демонстрирует, как усложняется простое прило-
жение, когда оно становится распределенным, асинхронным и событийно управляемым.
Понадобилось около десятка классов и делегатов, чтобы справиться с событийно управ-
ляемой природой асинхронного обмена сообщениями. Повышение сложности приложе-
ния также означает появление дополнительного риска, связанного с возникновением
ошибок. Из-за асинхронной природы приложения такие ошибки труднее обнаружить,
воспроизвести или устранить, поскольку они зависят от конкретных, временных усло-
вий. Вследствие всего вышесказанного разработчик систем, основанных на обмене со-
общениями, должен самым тщательным образом подходить к вопросу тестирования.
Данная тема настолько обширна, что ей можно было бы посвятить отдельную книгу.
454
Глава 9. Практикум: сложный обмен сообщениями
Пока же мы приведем лишь несколько простых действенных советов, которые можно
свести к трем правилам:
• изолируйте приложение от реализации обмена сообщениями с помощью интер-
фейсов и классов реализации;
• протестируйте бизнес-логику с помощью тестов модулей, прежде чем подключать
ее к среде обмена сообщениями;
• подготовьте “суррогатную” реализацию слоя обмена сообщениями, чтобы протес-
тировать работу приложения в синхронном режиме.
Изоляция приложения от реализации обмена сообщениями
Тестировать одно приложение куда проще, чем несколько распределенных приложе-
ний, связанных между собой многочисленными каналами обмена сообщениями. Работая
с единственным приложением, легко отследить весь путь выполнения. Кроме того, нам
не нужна сложная процедура для запуска удаленных компонентов системы, а также не
требуется очищать каналы в промежутках между выполнением тестов (см. шаблон проек-
тирования вентиль канала (Channel Purger, с. 579)). Иногда на время тестирования неко-
торых функций другие внешние функции удобно заменить “заглушками”. К примеру,
тестируя шлюз банка, мы можем заменить шлюз кредитного бюро фиктивной службой,
чтобы не посылать сообщения настоящему, внешнему процессу кредитного бюро.
Как организовать тестирование в рамках одного приложения с минимальным влия-
нием на код системы? Для этого реализацию шлюза обмена сообщениями (Messaging
Gateway, с. 482) можно отделить от определения его интерфейса. Это позволит применять
разные реализации одного и того же интерфейса (рис. 9.28).
ICreditBureauGateway
I-------------------------------1
___________|_____________ |
Cr edi tBureauGatewayImp MockCredi tBureauGatewayImp
Puc. 9.28. Отделение интерфейса шлюза кредитного бюро от его реализаций
Поскольку вся логика, касающаяся обмена сообщениями с кредитным бюро, инкапсу-
лирована внутри шлюза кредитного бюро, можно определить очень простой интерфейс:
public interface ICreditBureauGateway
{
void GetCreditScore(CreditBureauRequest quoteRequest,
OnCreditReplyEvent OnCreditResponse,
Object ACT);
void Listen();
Асинхронная реализация с использованием MSMQ
455
Теперь можно создать фиктивную реализацию шлюза кредитного бюро, которая дей-
ствительно не будет подключаться к очереди сообщений, а вместо этого будет вызывать
заданный экземпляр делегата непосредственно в рамках метода GetCreditScore. Фик-
тивная реализация содержит ту же логику, что и настоящий шлюз кредитного бюро, по-
этому оставшаяся часть кредитного брокера даже не узнает о произошедшей замене.
public class MockCreditBureauGatewaylmp : ICreditBureauGateway
private Random random = new Random();
public MockCreditBureauGatewaylmp()
{ }
public void GetCreditScore(CreditBureauRequest quoteRequest,
OnCreditReplyEvent OnCreditResponse,
Object ACT)
CreditBureauReply reply = new CreditBureauReply();
reply.Creditscore = (int)(random.Next(600) + 300);
reply.HistoryLength = (int)(random.Next(19) + 1) ;
reply.SSN = quoteRequest.SSN;
OnCreditResponse(reply, ACT);
}
public void Listen 0
{ }
}
Тестирование бизнес-логики с помошью тестов модулей
Реализация класса CreditBureau стала примером четкого разделения функций, ка-
сающихся обмена сообщениями (инкапсулированных в базовом классе), и бизнес-
логики (которая в нашем простом примере была сведена к генератору случайных чисел).
В реальной ситуации бизнес-логика наверняка была бы куда более сложной. В таком
случае методы getCreditScore и getCreditHistoryLength стоит вынести в отдель-
ный класс, который никак не зависит от слоя обмена сообщениями (пусть это и не так
очевидно, наследование все равно влечет за собой зависимость между производным, ба-
зовым и родственными им классами). После этого можно воспользоваться средством
тестирования модулей наподобие nUnit (www.nunit.org), чтобы создавать тестовые
сценарии, не заботясь об обмене сообщениями.
Создание “суррогатной” реализации слоя обмена сообщениями
Фиктивная реализация интерфейса ICreditBureauGateway проста и удабна для тес-
тирования. С другой стороны, она полностью заменяет собой настоящий код, связанный
с работой шлюза кредитного бюро, поэтому класс CreditBureauGatewaylmp придется
подвергать отдельному тестированию. Чтобы устранить зависимость от очередей сооб-
щений (и связанную с этим нагрузку на систему), но при этом протестировать код класса
CreditBureauGatewaylmp, можно воспользоваться фиктивной реализацией интерфей-
456
Глава 9. Практикум: сложный обмен сообщениями
сов IMessageReceiver и IMessageSender. Простая реализация фиктивной отправки
сообщений может выглядеть следующим образом.
public class MockQueue: IMessageSender, IMessageReceiver
{
private OnMsgEvent onMsg = new OnMsgEvent(DoNothing);
public void Send(Message msg){
onMsg(msg);
}
private static void DoNothing(Message msg){
}
public OnMsgEvent OnMessage
get { return onMsg; }
set { onMsg = value; }
}
public void Begin()
{
}
public MessageQueue GetQueueO
{
return null;
}
}
Легко заметить, что метод Send сразу же запускает экземпляр делегата OnMsgEvent,
не обращаясь к какой-либо очереди сообщений. Чтобы использовать фиктивную очередь
MockQueue для тестирования шлюза кредитного бюро, нужно обязательно ответить на
запрос сообщением правильного типа; просто передать запрос в качестве ответа нельзя.
Реализация фиктивного ответа здесь не показана, но ее можно сделать очень простой,
если, к примеру, использовать некоторое фиксированное сообщение с ответом.
Ограничения данного примера
Прочитав данный раздел, вы еще раз убедились в том, что даже простая система об-
мена сообщениями (а кредитному брокеру, по сути, приходится выполнять только два
действия: получать кредитные баллы и получать лучшие значения процентной ставки)
может иметь достаточно сложную структуру по причине асинхронной природы обмена
сообщениями и слабого связывания компонентов. Между тем, чтобы сохранить относи-
тельную читабельность примера, нам пришлось сделать еще несколько упрощений. В ча-
стности, мы не рассматривали такие вопросы:
обработка ошибок;
транзакции;
безопасность потоков.
Асинхронная реализация с использованием MSMQ
457
В данном примере не предусматривалось наличие какого-либо управляемого меха-
низма обработки ошибок. Компоненты просто выдают сообщения об ошибках в разно-
образных окнах консоли, что, разумеется, не годится для настоящих систем. В реальной
ситуации сообщения об ошибках следовало бы направлять в центральную консоль, что-
бы оператор системы получал уведомления унифицированным способом. Для этого хо-
рошо подходят шаблоны управления системой, описанные в главе 11, в частности шина
управления (Control Bus, с. 552).
В нашем примере не использовались и транзакционные очереди сообщений. К при-
меру, если маршрутизатор сообщений MessageRouter отправит запрос только в два
банка из четырех, а затем выйдет из строя, некоторые банки обработают запрос, а неко-
торые — нет. Точно так же, если кредитный брокер выйдет из строя после того, как
получит ответы от всех банков, но перед тем, как отправит ответ клиенту, клиент так и
останется без ответа. В реальных системах подобные действия должны выполняться в
рамках транзакции, чтобы входящие ответы не потреблялись до тех пор, пока не будет
отправлен исходящий ответ клиенту.
Наша реализация кредитного брокера выполняется в единственном потоке, а посему
мы не заботились о безопасности потоков. К примеру, метод BeginReceive не применя-
ется к очереди входящих сообщений (спрятанной в классе MessageReceiverGateway)
до тех пор, пока не завершится обработка предыдущего сообщения. Это замечательно
подходит для демонстрационных целей (и работает куда быстрее, чем синхронная реали-
зация), но в реальной системе для обеспечения высокой пропускной способности следо-
вало бы использовать диспетчер сообщений (Message Dispatcher, с. 521), управляющий
несколькими потоками выполнения.
Резюме
В настоящем разделе рассматривалась реализация кредитного брокера с использова-
нием асинхронных очередей сообщений и MSMQ. Мы намеренно не стали скрывать от
читателей детали реализации, чтобы высветить реальные проблемы, возникающие при
создании асинхронных приложений, основанных на обмене сообщениями. По ходу раз-
дела основное внимание уделялось не интерфейсам обмена сообщениями для продуктов
конкретных производителей, а решениям и компромиссам, принимающимся на этапе
проектирования, поэтому данный пример пригодится и тем разработчикам, которые пи-
шут программы не на С#.
Пример, приведенный в этом разделе, наглядно демонстрирует сложность реализации
даже простой системы, основанной на обмене сообщениями. Многие действия, которые
в обычных приложениях выполняются чуть ли не автоматически (например, вызов мето-
да), могут потребовать от разработчика значительных усилий, если их реализовать с уче-
том асинхронного обмена сообщениями. К счастью, используя шаблоны, мы получаем
удобный язык для описания основных решений проектирования без необходимости
слишком углубляться в тонкости продуктов конкретного производителя.
458
Глава 9. Практикум: сложный обмен сообщениями
Асинхронная реализация с использованием TIBCO ActiveEnterprise
Майкл Дж. Реттиг (Michael J. Rettig)
В основе обеих предыдущих реализаций кредитного брокера лежат платформы инте-
грации, обладающие лишь базовой функциональностью канала сообщений {Message
Channel, с. 93). К примеру, и Axis, и MSMQ имеют интерфейсы API, предназначенные
для отправки или получения сообщений из канала сообщений. Обо всех остальных аспек-
тах обмена сообщениями приходится заботиться самому приложению. Авторы книги
специально выбрали такой тип реализации, чтобы показать, как построить интеграцион-
ное решение “с нуля”, используя широкодоступные библиотеки Java или С#.
Многие коммерческие пакеты средств интеграции обладают куда большим объемом
функциональности, помогающей упростить разработку интеграционных решений. В со-
став таких пакетов обычно входит визуальная среда разработки, позволяющая создавать
трансляторы сообщений {Message Translator, с. 115) и диспетчеры процессов {Process
Manager, с. 325), просто перетаскивая их компоненты мышью. Многие пакеты также
включают в себя сложные функции управления системами и метаданными. Для третьей
(и последней) реализации примера, описанного в этой главе, был выбран пакет интегра-
ции TIBCO ActiveEnterprise. Как и в предыдущих реализациях кредитного брокера, ос-
новное внимание здесь будет уделяться решениям и компромиссам, к которым прихо-
дится прибегать в процессе проектирования. Специфика конкретного продукта будет за-
тронута только в той мере, в которой это необходимо для понимания решения, поэтому
данный пример может пригодиться даже тем, кто еще никогда не работал с TIBCO
ActiveEnterprise. Более подробно об указанном пакете интеграции и его производителе
можно прочитать по адресу http: / /www. tibco. com.
Настоящая реализация кредитного брокера отличается от реализаций, рассмотренных
ранее, еще и тем, что рассылка-сборка {Scatter-Gather, с. 310) в ней осуществляется по типу
аукциона. При таком подходе вместо списка получателей {Recipient List, с. 264) применя-
ется канал “публикация-подписка” {Publish-Subscribe Channel, с. 134), поэтому запрос на
получение кредита может рассылаться любому числу банков. Рассылка-сборка такого
типа реализует динамический шаблон запрос-ответ {Request-Reply, с. 177) с неизвестным
количеством слушателей. Кроме того, в реализации кредитного брокера используется
функциональность бизнес-процессов, предоставляемая диспетчером процессов Т1В/
IntegrationManager.
Архитектура решения
Наше приложение представляет собой простую систему, отсылающую в банки запро-
сы на получение кредита. Клиент делает запрос с помощью интерфейса кредитного бро-
кера. Брокер добавляет к запросу кредитный балл клиента, а затем рассылает запрос в не-
сколько банков. Получив ответы от банков, брокер выбирает самую выгодную процент-
ную ставку и возвращает ее клиенту (рис. 9.29).
Асинхронная реализация с использованием TIBCO ActiveEnterprise
459
Банк 1
credit.loan.request
INBOX
customer.loan.request
Создать тестовое
сообщение
Кредитное
бюро
INBOX
Банк 5
bank.loan.reply
Кредитный брокер
Диспетчер
процессов
Проверить
результат
bank. loan, request р—— ,,
----» санк и
Тестовый клиент
Рис. 9.29. Архитектура кредитного брокера TIBCO
БанкЗ
Клиенты системы ожидают, что интерфейс кредитного брокера будет функциониро-
вать в синхронном режиме по принципу запрос-ответ (Request-Reply, с. 177). Клиент от-
правляет брокеру запрос на получение кредита и ожидает от него ответа. Кредитный бро-
кер, в свою очередь, использует шаблон запрос-ответ для общения с кредитным бюро,
чтобы узнать кредитный балл клиента. Получив исходный запрос клиента, кредитный
брокер может выполнять асинхронные операции, скрывая их за распределенным, син-
хронным интерфейсом. Это позволяет кредитному брокеру осуществлять рассылку-сборку
(Scatter-Gather, с. 310) по типу аукциона, размещая запросы на получение кредита в кана-
ле “публикация-подписка” (Publish-Subscribe Channel, с. 134).
Аукцион начинается с публикации клиентского запроса в канале “публикация-
подписка” по имени bank.loan.request. Каждый банк, заинтересованный в выдаче
кредитов, может прослушивать данный канал и предлагать свои значения процентных
ставок. Количество банков, отвечающих на запрос, неизвестно и может отличаться для
каждого запроса. Аукцион проводится в следующем режиме: кредитный брокер разме-
щает запрос в канале bank.loan.request, а затем ждет заранее заданное время, про-
слушивая канал bank.loan.reply на предмет предложений банков. Каждый раз при
получении нового “предложения цены” (т.е. ответа со значением процентной ставки)
счетчик времени сбрасывается, чтобы другие банки при желании смогли предложить бо-
лее выгодный вариант. Все предложения делаются публично, поэтому каждый банк мо-
жет следить за предложениями других банков и оперативно на них реагировать, размещая
в канале ответов встречные предложения.
Запрос, размещенный в канале кредитным брокером, может получить любое неиз-
вестное заранее количество банков. Это существенно отличается от поведения списка по-
лучателей (Recipient List, с. 264), который предусматривает рассылку запросов строго оп-
ределенному набору банков. Указанная особенность аукциона повлияла и на условие
полноты агрегатора (Aggregator, с. 283). Последний теперь не ждет, пока поступят ответы
от всех банков (как было в предыдущих реализациях примера), а завершает аукцион, ос-
новываясь исключительно на времени ожидания. Все ответы, пришедшие по окончании
аукциона (т.е. по истечении времени ожидания), просто игнорируются. Если в течение
460
Глава 9. Практикум: сложный обмен сообщениями
заданного интервала времени агрегатор не получил ни одного ответа, он сообщает кли-
енту о том, что им не было получено ни одного значения процентной ставки. Схема рабо-
ты агрегатора показана на рис. 9.30.
Рис. 9.30. Диаграмма деятельности, описывающая поведение диспетчера процессов
В нашем примере функции расширителя содержимого (Content Enricher, с. 348) и агре-
гатора будут реализованы внутри диспетчера процессов (Process Manager, с. 325). Именно
поэтому на рис. 9.29 не показаны детали взаимодействия расширителя содержимого и аг-
регатора — они ведь внедрены в единый компонент! Вместо этого воспользуемся диа-
граммой деятельности, которая представляет собой определение шаблона процесса, ис-
пользуемое диспетчером процессов. Исходная диаграмма деятельности (см. рис. 9.30) чет-
ко определяет роль кредитного брокера и может использоваться в качестве основы для
шаблона процесса. Из диаграммы видно, что у кредитного брокера есть несколько обя-
занностей. Они легко трансформируются в диаграмму процессов, которая наглядно по-
казывает точный порядок событий и путей решения.
Набор средств, используемых для реализации
Чтобы понять структуру нашего решения, необходимо хоть немного разбираться в ба-
зовых концепциях платформы TIBCO. Реализуя решения на основе TIBCO, часто прихо-
дится оценивать разные средства на предмет того, насколько хорошо каждое из них под-
Асинхронная реализация с использованием TIBCO ActiveEnterprise
461
ходит для решения конкретной проблемы, потому что иногда проблему можно решить с
помощью сразу нескольких средств. Хитрость состоит в том, чтобы выбрать самое луч-
шее. В данной книге мы ограничимся обсуждением только тех продуктов TIBCO. кото-
рые требуются для реализации нашего примера, а именно:
• TIB/RendezVous;
• TIB/IntegrationManager;
• TIBCO Repository.
TIB/RendezVous
В основе платформы TIBCO лежит транспортный уровень TIB/RendezVous, отве-
чающий за отправку и получение сообщений TIBCO по информационной шине (information
bus). TIBCO поддерживает целый ряд транспортных средств, включая JMS, HTTP, FTP,
электронную почту и многие другие. В нашем примере TIB/RendezVous выступает в ка-
честве транспорта для передачи сообщений. Данный продукт поддерживает как син-
хронный, так и асинхронный обмен сообщениями, а также каналы “точка-точка” (Point-
to-Point Channel, с. 131) ^каналы “публикация-подписка” (Publish-Subscribe Channel, с. 134).
Каждый канал может быть настроен на различные уровни обслуживания:
• надежный обмен сообщениями (RV) — высокая производительность при разум-
ной вероятности потери сообщений;
• сертифицированные сообщения (RVCM) — доставка как минимум один раз;
• транзакционный обмен сообщениями (RVTX) — гарантированная доставка один
и только один раз.
Как и MSMQ, TIBCO предоставляет открытый интерфейс API для создания решений,
основанных на обмене сообщениями, с использованием Java или C++, а также включает
в себя ряд средств, позволяющих упростить процесс разработки.
TIB/IntegrationManager
TIB/IntegrationManager — это средство разработки TIBCO, включающее в себя поль-
зовательский интерфейс для создания решений на основе рабочих потоков, а также ме-
ханизм диспетчера процессов (Process Manager, с. 325) для выполнения этих решений.
Графический интерфейс TIB/IntegrationManager обладает целым рядом средств настрой-
ки и реализации, хранящихся в репозитории TIBCO. Последний выступает в качестве
“центра” конфигурации системы — в нем хранятся все метаданные, рабочие потоки
и пользовательский код.
Главным отличием настоящей реализации кредитного брокера от решений, разраба-
тываемых на уровне исходного кода, является присутствие компонента рабочего потока.
В нашем примере TIB/IntegrationManager отвечает за синхронный и асинхронный обмен
сообщениями, а также за базовое управление рабочим потоком, включая сохранение
состояния сеанса на стороне сервера (Server Session State', см. [9]). Для простоты понима-
ния примера TIB/IntegrationManager можно разбить на три части: канал, генератор зада-
ний и диаграмму процессов (рис. 9.31).
462
Глава 9. Практикум: сложный обмен сообщениями
Диспетчер процессов
(IntegrationManager)
Определение процесса
(Диаграмма процессов)
Экземпляр(ы) процессов
(Задание)
Рис. 9.31. Компоненты средства разработки TIB/IntegrationManager
Каждый процесс в TIB/IntegrationManager создает “задание”, или экземпляр процесса
(process instance). Последний выступает в качестве главного объекта сеанса, состояние
которого должно сохраняться на стороне сервера. Данный объект включает в себя put- и
get-операции для сохранения объектов, а также вспомогательные методы для взаимодей-
ствия с сеансом. Простой графический интерфейс позволяет разработчикам создавать
определения процессов (которые в TIBCO называются диаграммами процессов), задаю-
щие последовательность операций, выполняющихся в ходе задания. Определения про-
цессов во многом схожи с диаграммами деятельности UML, поскольку тоже состоят из
операций, или задач, соединенных между собой линиями перехода (рис. 9.32). Но диа-
граммы процессов описывают только “каркас” решения: за каждой задачей (прямоуголь-
ником на диаграмме) скрывается приличный объем настроек и кода. К примеру, для на-
шего решения требуется написать код, обрабатывающий запросы на получение кредита.
В качестве языка сценариев в TIB/IntegrationManager используется ECMAScript (из-
вестный также под названием JavaScript).
Типичная диаграмма процессов состоит из ряда задач интеграции. Это могут быть
управляющие задачи (ветвление, синхронизация или точки принятия решений), сиг-
нальные задачи (отправка и получение сообщений), а также выполняющие задачи
(преобразование данных, маршрутизация и системная интеграция). Простая диаграмма,
показанная на рис. 9.32, состоит из двух задач: задачи ECMAScript, которая выполняет
небольшой объем пользовательской логики, а также сигнальной задачи, публикующей
сообщение в канале. Переходы между задачами, в свою очередь, могут включать в себя
логику выбора того или иного маршрута в зависимости от содержимого сообщения или
других критериев.
Асинхронная реализация с использованием TIBCO ActiveEnterprise
463
Рис. 9.32. Пример диаграммы процесса в TIB/IntegrationManager
TIBCO Repository
Для интеграции сообщений и обмена ими почти всегда требуются какие-либо дан-
ные, позволяющие описывать фактический формат сообщения (см. введение к главе 8).
В TIBCO классы метаданных определяются как объекты ActiveEnterprise (АЕ), храня-
щиеся в репозитории TIBCO. Каждый объект АЕ, отправленный по каналу сообщений,
включает в себя индикатор формата (Format Indicator, с. 201), показывающий, какому
определению класса соответствует данное сообщение.
Управление метаданными сообщения является важной частью процесса разработки.
В TIBCO метаданные можно определить прямо в среде разработки, извлечь их из внеш-
них систем, таких как реляционные СУБД (с помощью адаптера метаданных, как расска-
зывается в описании шаблона адаптер канала (Channel Adapter, с. 154)), или импортиро-
вать из схем XML. Метаданные позволяют в явном виде описать контракт для объектов и
сообщений в системе. Определив классы метаданных в репозитории TIBCO, можно соз-
давать объекты и манипулировать ими с помощью сценариев ECMAScript.
// Создание экземпляра класса TIBCO АЕ.
var bank = new aeclass.BankQuoteRequest();
bank.CorrelationlD = job.generateGUIDO ;
bank.SSN = job.request.SSN;
464
Глава 9. Практикум: сложный обмен сообщениями
Помните, однако, что мы работаем в динамической среде со сценариями и ограни-
ченной проверкой типов на этапе компиляции. Изменение определения метаданных мо-
жет легко нарушить работу других частей системы. Без надлежащей практики разработки
и тестирования решения, основанные на обмене сообщениями, могут легко превратиться
в системы, работающие “только на добавление” (метаданные будут добавляться и добав-
ляться, но никогда не будут меняться из-за боязни что-нибудь испортить).
Интерфейсы
Из рис. 9.29 видно, что в состав нашего решения входят следующие службы.
• Кредитный брокер:
• получает исходный запрос от клиента;
• узнает значение кредитного балла клиента;
• проводит аукцион для банков;
• возвращает клиенту лучшее значение процентной ставки.
• Кредитное бюро:
• возвращает значение кредитного балла на основе номера социального страхо-
вания клиента (SSN).
• Банк (-и):
• предлагает (-ют) значение процентной ставки на основе кредитного балла кли-
ента и желаемой суммы клиента.
Доступ к каждой из служб осуществляется через внешний интерфейс. Для каждого
интерфейса необходимо выбрать:
• тип взаимодействия (синхронный или асинхронный);
• уровень обслуживания.
Тип взаимодействия для интерфейсов определяется самой архитектурой решения.
Службам кредитного брокера и кредитного бюро нужны синхронные интерфейсы,
а взаимодействие с банками будет полностью происходить в асинхронном режиме.
Уровни обслуживания для систем, основанных на обмене сообщениями, могут быть
достаточно сложными, в особенности при наличии сценариев перемещения при сбое.
К счастью, в примере с кредитным брокером реализовать требуемое качество обслужива-
ния довольно просто. В случае сбоя, такого как превышение времени ожидания, потеря
сообщений или отказ системы, исходное сообщение с запросом может быть отослано
еще раз (кредитный брокер по своему характеру является идемпотентным получателем
{Idempotent Receiver, с. 541)). Помните, что на этом этапе клиент только запрашивает и
получает значение процентной ставки, но не заключает никакого официального согла-
шения по выдаче кредита. Разумеется, предположение о том, что запрос может быть вы-
слан несколько раз, должно быть задокументировано в системе и хорошо известно всем
участникам процесса. К примеру, банки должны осознавать, что один и тот же запрос на
получение кредита по техническим причинам может быть доставлен им дважды. Если
банк отслеживает запросы конкретного клиента с целью выявления мошенников, ренте-
Асинхронная реализация с использованием TIBCO ActiveEnterprise
465
ние, вероятно, придется изменить, чтобы избежать отправки повторяющихся запросов.
Для этого можно воспользоваться гарантированной доставкой (Guaranteed Delivery, с. 149)
или другим аналогичным решением.
Реализация синхронных служб
Система кредитного брокера обладает двумя синхронными интерфейсами. Один из
них предназначен для связи клиента с кредитным брокером, а другой располагается меж-
ду кредитным брокером и кредитным бюро. В TIBCO обмен сообщениями в стиле RPC
(удаленного вызова процедур) реализован с помощью операций, использующих шабло-
ны запрос-ответ (Request-Reply, с. 177) и сообщение с командой (Command Message, с. 169).
Указанные операции, по сути, представляют собой синхронную оболочку для базового
механизма обмена сообщениями, лежащего в основе TIBCO. Во время вызова операций
TIBCO можно прослушивать шину, по которой передаются сообщения с запросами и от-
ветами. Сообщение с запросом публикуется в заранее заданном канале, например cus-
tomer, loan, request. Заголовок такого сообщения включает в себя обратный адрес
(Return Address, с. 182), задающий адрес так называемого канала inbox, в который сле-
дует отправить ответ. Платформа TIBCO скрывает асинхронные детали обмена сообще-
ниями за моделью программирования RPC. В TIB/IntegrationManager операции над
предметной областью (например, получение кредитного балла клиента) определяются
как часть классов АЕ и могут вызываться из среды моделирования процессов. К примеру,
чтобы предоставить доступ к кредитному брокеру через синхронный интерфейс, необхо-
димо выполнить несколько шагов, о которых рассказывается ниже. Аналогичные шаги
выполняются и при реализации службы кредитного бюро.
Определение класса АЕ
Классы АЕ определяют формат данных для сообщений, отправляемых по каналам
TIB/RendezVous. Определение класса в TIB/IntegrationManager происходит совсем
не так, как в обыкновенной среде разработки. Для определения классов АЕ в
TIB/IntegrationManager применяется диалоговое окно, показанное на рис. 9.33. В этом
окне можно выбрать имя класса, а затем задать его атрибуты. Атрибуты класса могут быть
числами типа Integer, Float или Double, а также экземплярами других классов АЕ.
Определение операций класса АЕ
К интерфейсу можно добавлять методы. Точно так же к классу АЕ можно добавлять
операции, задавая их параметры и типы возвращаемых значений. На данном этапе реали-
зацию операции (как и метода интерфейса) указывать не требуется. Реализация описывает-
ся ниже, когда канал при помощи генератора заданий будет связан с экземпляром процесса.
Создание диаграммы процесса
Диаграмма процесса описывает реализацию операции. Операции, используемые в
нашем примере, должны возвращать некоторое значение. Между тем, в отличие от мето-
дов, реализованных путем кодирования, у диаграммы процесса нет “возвращаемого”
значения. Вместо этого необходимо указать ячейку в задании, в которую будет помещено
возвращаемое значение. Все это делается в генераторе заданий. Следует также помнить о
необходимости правильно присвоить значение ячейке задания в диаграмме процесса.
Фактическая реализация диаграммы процесса будет рассматриваться ниже.
466
Глава 9. Практикум: сложный обмен сообщениями
Рис. 9.33. Определение атрибутов и операций класса АЕ
Создание клиент/серверного канала для получения запросов
Для каждого канала можно задать транспорт, формат сообщений, службу и тему. Для
выполнения наших синхронных операций нужен клиент/серверный канал. В качестве
классов сообщений можно задать классы АЕ, созданные нами на шаге 1. В роли транс-
порта было решено выбрать TIB/RendezVous с надежным обменом сообщениями (RV).
Эти и другие свойства канала настраиваются с помощью диалогового окна, показанного
на рис. 9.34.
Настройка генератора заданий для создания экземпляра диаграммы процесса
Генератор заданий извлекает из канала значение и передает его диаграмме процесса,
создавая задание и инициализируя его ячейки (slots). После этого создается экземпляр
диаграммы процесса. Выполнение процесса продолжается согласно пути, определенному
диаграммой деятельности. Когда выполнение процесса завершится, генератор заданий
возвращает ответ в канал. На рис. 9.35 изображено окно генератора заданий с именем оп-
ределенной нами операции.
Асинхронная реализация с использованием TIBCO ActiveEnterprise
467
Рис. 9.34. Определение свойств канала
Рис. 9.35. Настройка генератора заданий
468
ГлаваЭ. Практикум: сложный обмен сообщениями
Процесс кредитного брокера
Определив синхронные службы, можно приступать к реализации кредитного брокера,
который свяжет все части нашего приложения в единое целое. На рис. 9.36 показана
диаграмма процесса кредитного брокера в TIB/IntegrationManager. Она определяет пове-
дение компонента кредитного брокера. Напомним, что ранее мы уже определили опера-
цию АЕ, канал и генератор заданий. С их помощью будет выполняться создание экземп-
ляра диаграммы процесса, когда клиент отправит сообщение в канал CustomerRequest.
Некоторые соображения по поводу проектирования
Необходимо тщательно следить за тем, какие компоненты включаются в диаграмму
процесса. Большие диаграммы со сложной структурой быстро становятся неуправляе-
мыми. Очень важно, чтобы понятия, фигурирующие в рамках диаграммы, были четко
отделены друг от друга. Следует, прежде всего, всячески избегать смешения бизнес-
логики и логики процесса в пределах одного и того же определения процесса. Разумеется,
не всегда просто понять, что относится к логике процесса, а что — к бизнес-логике. Для
большей наглядности попробуйте описать логику процесса в терминах взаимодействия с
внешней системой: к какой системе необходимо подключиться на следующем этапе, что
делать, если система недоступна, и т.д. Понятия, описывающие бизнес-логику, обычно
имеют более тесное отношение к предметной области: как активизировать заказ, как вы-
числить кредитный балл или, скажем, как подсчитать процентную ставку по кредиту.
Учитывая сложный характер бизнес-кода, для его реализации лучше воспользоваться
полноценным языком разработки. Большинство средств управления процессами, вклю-
чая TIB/IntegrationManager, предусматривают непосредственную интеграцию решений
с Java или другим языком программирования.
Те, кто знакомы с концепцией “модель^представление-контроллер” [33], могут ана-
логичным образом представить себе реализацию кредитного брокера в TIBCO
ActiveEnterprise — достаточно лишь заменить слово “представление” словом “рабочий
поток”. Полученная структура будет выглядеть следующим образом.
1. Рабочий поток. Визуализированная модель рабочего потока.
2. Контроллер. Механизм выполнения процесса, который получает по шине сооб-
щений уведомления о событиях, а затем выполняет требуемые компоненты рабо-
чего потока.
3. Модель. Код бизнес-логики, лежащий в основе решения (ECMAScript, JavaScript,
Java, 12ЕЕит.д.).
Реализация модели процесса
На рис. 9.36 показана диаграмма процесса, одни элементы которой соответствуют
выполнению сценариев, а другие описывают пользовательские задачи, касающиеся ин-
теграции. Одно из главных преимуществ моделирования процесса с помощью визуаль-
ных средств состоит в сходстве “кода” (т.е. диаграммы процесса) с диаграммой деятель-
ности UML, которая применялась еще на этапе проектирования решения (см. рис. 9.30).
Поскольку за каждым элементом диаграммы может скрываться фрагмент кода или
важные конфигурационные параметры, давайте рассмотрим каждую задачу и опишем ее
более подробно.
Асинхронная реализация с использованием TIBCO ActiveEnterprise
469
Рис. 9.36. Определение процесса кредитного брокера
Первый элемент диаграммы соответствует сценарию ECMAScript, который создает
экземпляр класса АЕ и присваивает значения его свойствам.
var credit = new aeclass.CreditBureauRequest();
credit.SSN = job.request.SSN;
job.creditRequest = credit;
Созданный выше объект кредитного запроса применяется в качестве параметра при
выполнении следующей операции, в ходе которой происходит синхронное обращение к
кредитному бюро. Последнее, в свою очередь, реализовано в виде отдельной диаграммы
процесса, состоящей из единственной задачи ECMAScript, которая получает сообщение
и возвращает кредитный балл клиента. Использование синхронной операции означает,
470
Глава 9. Практикум: сложный обмен сообщениями
что процесс кредитного брокера будет бездействовать до тех пор, пока не прибудет ответ
кредитного бюро.
Получив сообщение с ответом от кредитного бюро, необходимо создать новый объект
АЕ, чтобы разослать запрос на получение кредита всем заинтересованным банкам. Для
реализации этой функции воспользуемся задачей Mapper, позволяющей проводить гра-
фическое отображение элементов данных из одних источников на элементы данных из
других источников. Mapper, по сути, представляет собой визуальную реализацию шабло-
на транслятор сообщений (Message Translator, с. 115). Задача Mapper хорошо демонстриру-
ет преимущества управления метаданными. Поскольку средство TIB/IntegrationManager
обладает доступом к метаданным, определяющим структуру каждого объекта, Mapper
отображает структуру объектов источника и назначения и позволяет сопоставлять их по-
ля, просто щелкая мышью. Из рис. 9.37 видно, что новый объект bankRequest создается
на основе значений соответствующих полей объектов creditReply и request. Мы так-
же используем метод generateGUlD объекта задания, чтобы сгенерировать уникальный
идентификатор корреляции (Correlation Identifier, с. 186), а затем присваиваем его полю
CorrelationlD объекта bankRequest. Как вы вскоре узнаете, поле CorrelationlD не-
обходимо для того, чтобы кредитный брокер мог одновременно обрабатывать несколько
запросов на получение кредита.
Рис. 9.37. Создание запроса к банкам с помощью задачи Mapper
Асинхронная реализация с использованием TIBCO ActiveEnterprise
471
Вместо визуальной задачи Mapper для выполнения этой же операции можно было бы
воспользоваться сценарием ECMAScript. Ниже приведен фрагмент кода, в котором соз-
дается новый экземпляр класса BankQuoteRequest, а затем каждому из его полей при-
сваивается значение соответствующего поля из объекта-источника.
var bank = new aeclass.BankQuoteRequest();
// Создать ИД, чтобы уникальным образом идентифицировать
// транзакцию.
// Это понадобится позднее для фильтрации ответов.
bank.CorrelationlD = job.generateGUID();
bank.SSN = job.request.SSN;
bank.Creditscore = job.creditReply.Creditscore;
bank.HistoryLength = job.creditReply.HistoryLength;
bank.LoanAmount = j ob.re que s t.LoanAmount;
bank.LoanTerm = job.request.LoanTerm;
j ob.bankReque st = bank;
Выбор реализации транслятора сообщений — с помощью визуальной задачи Mapper или
же сценария ECMAScript — зависит от типа и сложности преобразования. Задача Mapper
обеспечивает удобное визуальное представление связей между объектами источника и на-
значения, но, если у объектов много полей, прослеживать эти связи будет затруднительно.
С другой стороны, у задачи Mapper есть специальные функции, позволяющие отображать
повторяющиеся поля (например, массивы) с помощью одной строки кода, в то время как
при использовании языка сценариев разработчику пришлось бы писать цикл.
Перейдем к следующей задаче на диаграмме процесса кредитного брокера
(см. рис. 9.36). Это очень простой сценарий ECMAScript, создающий экземпляр массива
bids, в котором будут размещаться входящие ответы банков. Указанный сценарий
состоит всего лишь из одной строки.
job.bids = new Array();
Следующая задача на диаграмме — операция Signal Out, которая публикует объект
bankRequest в канале bank. loan, request. Это асинхронная операция, поэтому про-
цесс сразу же переходит к выполнению следующего шага, не ожидая, пока придет ответ.
Следующая задача прослушивает канал bank.loan.reply на предмет входящих
сообщений с ответами банков. Если сообщение будет получено в пределах заданного
интервала времени, оно добавится в массив bids.
job.bids[job.bids.length] = job.loanReply;
Когда промежуток времени, выделенный на проведение аукциона, завершится, задача
signal in инициирует переход процесса к выполнению последнего шага. Соответст-
вующая задача ECMAScript реализует алгоритм агрегации, выбирая лучшую процентную
ставку из предложенных банками. Сценарий, код которого приведен ниже, создает
новый экземпляр класса LoanQuoteReply, помещает в полученный объект ответа значе-
ния полей SSN и LoanAmount, взятые из объекта запроса, а затем прокручивает массив
bids в поисках лучшей (т.е. самой низкой) процентной ставки.
472
Глава 9. Практикум: сложный обмен сообщениями
var loanReply = new aeclass.LoanQuoteReply();
loanReply.SSN = job.request.SSN;
loanReply.LoanAmount = job.request.LoanAmount;
var bids = job.bids;
for(var i = 0; i < bids.length; i++) {
var item = bids[i];
if(i == 0 || (item.InterestRate < loanReply.InterestRate)){
loanReply.InterestRate = item.InterestRate;
loanReply.QuotelD = item.QuotelD;
}
}
job.loanReply = loanReply;
Последняя строка сценария ECMAScript размещает объект ответа в ячейке задания,
чтобы затем вернуть этот ответ клиенту. Мы настроили генератор заданий кредитного
брокера таким образом, чтобы в качестве сообщения с ответом он возвращал клиенту
содержимое ячейки loanReply (рис. 9.38). Когда выполнение процесса завершится,
генератор заданий извлечет сообщение, хранящееся в ячейке задания loanReply, и воз-
вратит полученное значение клиенту.
Рис. 9.38. Настройка набора правил генератора задании с целью
возвращения лучшей процентной ставки
Управление параллельными аукционами
Реализация аукциона не обошлась без “подводных камней”. Наибольшую трудность,
пожалуй, представляет возможность параллельного проведения нескольких аукционов.
Чтобы устроить аукцион, кредитный брокер публикует в канале асинхронное сообщение,
а затем на протяжении заданного промежутка времени собирает все поступающие отве-
ты. Но если одновременно проходит несколько аукционов, необходимо гарантировать,
что каждый кредитный брокер будет получать не все ответы подряд, а только те из них,
которые относятся к обрабатываемому им запросу.
Чтобы отбрасывать нежелательные сообщения, мы воспользовались идентификато-
ром корреляции (Correlation Identifier, с. 186) и избирательным потребителем (Selective
Consumer, с. 528). В идеальном случае такая фильтрация должна была бы происходить
Асинхронная реализация с использованием TIBCO ActiveEnterprise
473
на уровне канала, а не экземпляра процесса. Для этого, однако, потребовалось бы дина-
мически создавать темы каналов во время выполнения, по одной теме на каждый прово-
димый аукцион. Ограничения реализации, которыми пока что обладает TIB/Integration-
Manager, не позволяют применить описанный подход. Когда во время выполнения соз-
дается экземпляр диаграммы процесса, он должен зарегистрировать все прослушиваемые
им темы. Это позволяет механизму выполнения процессов прослушивать любые сооб-
щения по заданным темам и при необходимости ставить их в очереди. Наличие очередей
предотвращает появление ошибок, возникающих, когда экземпляр диаграммы процесса
публикует сообщение в одной теме, а затем переходит в другое состояние, чтобы прослу-
шивать вторую тему в ожидании ответа. В асинхронной среде, если переход в другое со-
стояние отнимает слишком много времени, ответ может прийти раньше, чем экземпляр
диаграммы процесса подпишется на соответствующую тему. Вот почему экземпляру
диаграммы процесса удобно собирать входящие сообщения в очередь. К сожалению, при
этом приходится отказываться от динамического создания тем. Учитывая требования
нашего примера, фильтрация на уровне экземпляра процесса происходит без каких-либо
затруднений. Каждому экземпляру процесса назначается уникальный идентификатор
(а именно, идентификатор корреляции), который затем передается в банк процессов и
включается в каждый ответ. Чтобы реализовать фильтрацию с помощью сигнальной
задачи signal in, достаточно одной строки кода ECMAScript.
(event.msg.CorrelationlD == job.bankRequest.CorrelationlD)
Выполнение
Закончив все подготовительные работы, можно приступать к запуску решения.
Для этого нам, прежде всего, потребуется механизм выполнения процессов Т1В/
IntegrationManager. Чтобы протестировать решение, в репозиторий будет помещен не-
большой тестовый клиент, который каждые 5 секунд отправляет запрос на получение
кредита. Аналогичные “фиктивные” службы будут использоваться в качестве кредитного
бюро и банков. Одно из преимуществ канала “публикация-подписка” (Publish-Subscribe
Channel, с. 134) состоит в возможности прослушивать поток передающихся по нему со-
общений. Мы воспользовались простым средством, которое печатает содержимое всех
сообщений в консоли (см. фрагмент кода, приведенный ниже). Для простоты мы урезали
содержимое сообщений и оставили только актуальные поля, убрав индикаторы формата
и другие служебные данные. Оставшиеся поля включают в себя время отправки, темы и
имена каналов с ответами (_inbox). Такие каналы выполняют роль обратного адреса
(Return Address, с. 182) для синхронных служб.
tibrvlisten: Listening to subject >
2003-07-12 16:42:30 (2003-07-12 21:42:30.032000000Z):
subject=customer.loan.request,
reply=_INBOX.C0A80164.1743F10809898B4B60.3,
SSN=1234567890 LoanAmount=100000.000000 LoanTerm=360
2003-07-12 16:42:30 (2003-07-12 21: 42 : 30.052000000Z) :
subj ect=credit.loan.request,
reply=_INBOX.C0A80164.1743F10809898B4B60.4,
SSN=1234567890
474
Глава 9. Практикум: сложный обмен сообщениями
2003-07-12 16:42:30 (2003-07-12 21:42:30.092000000Z):
subj ect=bank.loan.request,
SSN=1234567890 CreditScore=345 HistoryLength=456
LoanAmount=100000.000000
CorrelationID="pUQI3GEWK5Q3d-QiuLzzwGM-zzw" LoanTerm=360
2003-07-12 16:42:30 (2003-07-12 21:42:30.1120000002):
subject=bank.loan.reply,
InterestRate=5.017751 QuoteID="5E0xlK_dK5Q3i-QiuMzzwGM-zzw"
ErrorCode=0 CorrelationID="
pUQI3GEWK5Q3d-QiuLzzwGM-zzw"
2003-07-12 16:42:30 (2003-07-12 21:42:30.1120000002):
subject=bank.loan.reply,
InterestRate=5.897514 QuoteID="S9iIAXqgK5Q3n-QiuNzzwGM-zzw"
ErrorCode=0 CorrelationID="
pUQI3GEWK5Q3d-QiuLzzwGM-zzw"
Из текста, приведеного выше, видно, что тестовый клиент отправил сообщение с за-
просом в канал customer. loan, request. В сообщении содержатся номер карты соци-
ального страхования клиента (SSN), а также желаемая сумма кредита и срок, на который
требуется получить кредит (100 тыс. долл, сроком на 360 месяцев). В качестве обратного
адреса в сообщении указан закрытый канал ответов, принадлежащий данному клиент}’
( inbox. С0А80164.1743F10809898B4B60. з), поэтому кредитный брокер поймет, куда
следует отправлять сообщение с ответом.
Следующая запись в консоли соответствует сообщению с запросом, отправленному
брокером кредитному бюро. Роль обратного адреса в этом сообщении выполняет закры-
тый канал inbox кредитного брокера. Для определения кредитного балла клиента
службе кредитного бюро требуется только номер карты социального страхования. Ответ
кредитного бюро не был перехвачен нашим средством записи сообщений в консоль, по-
тому что каналы _inbox являются закрытыми.
Получив кредитный балл клиента, кредитный брокер публикует сообщение с запро-
сом на получение кредита в канале bank. loan, request. В нашем примере на него сразу
же отвечают две фиктивные службы банков, каждая из которых предлагает свое значение
процентной ставки. Каждому из ответов также присваивается уникальный идентифика-
тор QuoteiD, чтобы клиент впоследствии смог сослаться на полученное предложение.
Через несколько секунд время, выделенное на проведение аукциона, истекает. Посколь-
ку мы не можем перехватить ответ, отправленный кредитным брокером тестовому клиен-
ту, давайте заглянем в журнал отладки механизма диспетчера процессов, чтобы прове-
рить, действительно ли тестовый клиент получил самое низкое значение процентной
ставки. В сообщении, приведенном ниже, содержатся не только величина процентной
ставки и значение идентификатора корреляции, но также индикатор формата {Format
Indicator, с. 201), показывающий, к какому классу принадлежит ответ.
reply= class/LoanQuoteReply {
SSN=1234567890
InterestRate=5.017751017038945
LoanAmount=100000.0
QuoteID=5E0xlK_dK5Q3i-QiuMzzwGM-zzw
Асинхронная реализация с использованием TIBCO ActiveEnterprise
475
Резюме
Решение, описанное в предыдущих разделах, обладает весьма интересными особен-
ностями, по которым его можно сравнить с другими реализациями того же самого при-
мера. Визуальные рабочие потоки удобны для наблюдения и понимания. Но, как и в слу-
чае с кодом, при усложнении реализации относительная простота решения может обер-
нуться страшной путаницей. Динамический характер рассылки-сборки {Scatter-Gather,
с. 310) способствует четкому разобщению участников механизма публикации-подписки.
Кредитный брокер может публиковать запросы к банкам, ничего не зная о самих банках,
подписавшихся на канал запросов. Точно так же агрегатор (Aggregator, с. 283), приме-
няющийся для компоновки ответов банков в итоговое сообшение, не обязательно дол-
жен знать число ожидаемых ответов. Потенциальным недостатком такой гибкости может
стать трудность обнаружения ошибок, возникших из-за неправильного указания имени
темы, опечатки разработчика или пропажи сообщений.
Визуальный подход, основанный на использовании платформы TIBCO, является
комплементарным по отношению к реализации на уровне кода. Гибкость, прозрачность
и мощность кодирования не поддаются сомнению, однако использование графического
интерфейса позволяет существенно упростить выполнение задач высокого уровня слож-
ности. Создание конфигурации является важной частью интеграции, и графическая сре-
да разработки приходится здесь как нельзя кстати. Иногда может казаться, что разработ-
чики обязаны делать выбор между написанием кода вручную и использованием коммер-
ческого средства разработки. Между тем указанные приемы могут вполне успешно
сосуществовать. К примеру, средство TIB/IntegrationManager можно применять для мо-
делирования рабочих потоков в интеграционном решении, а компоненты сеанса J2EE —
для реализации логики предметной области.
Чтобы не загромождать пример отвлекающими деталями, мы сделали его довольно
простым для понимания. В реальной жизни такие простые сценарии практически не
встречаются. Визуальные средства разработки могут ускорить создание решения “с ну-
ля”, но в то же время способны серьезно ограничить возможности разработчиков. Сред-
ства управления процессами помогают скрыть сложные детали обмена сообщениями.
Благодаря им разработчики могут сконцентрировать свои усилия на интеграции, не забо-
тясь о том, что происходит “за кулисами” взаимодействия приложений. Не забывайте,
однако, что полное пренебрежение инфраструктурой обмена сообщениями уже привело
к преждевременной кончине не одного проекта.
Глава 10
Конечные точки
обмена сообщениями
Введение
В главе 3 рассматривался шаблон конечная точка сообщения (Message Endpoint, с. 124).
Он описывает, как подключить приложение к системе обмена сообщениями, чтобы оно
могло получать и отправлять сообщения. Разрабатывая интеграционное решение с исполь-
зованием объектов JMS MessageProducer И Messageconsumer или, скажем, пространства
имен .NET System.Messaging, вы создаете конечную точку обмена сообщениями. Если
же вы используете коммерческий пакет связующего ПО, большая часть этого кода предос-
тавляется поставщиком в виде готовых библиотек и других средств разработки.
Шаблоны отправки и получения сообщений
Некоторые шаблоны конечных точек применимы и к отправителям, и к получателям.
Они описывают общие аспекты подключения приложений к системе обмена сообще-
ниями.
• Инкапсуляция кода, касающегося обмена сообщениями. В общем случае приложение
не должно знать о том, что оно использует обмен сообщениями (Messaging, с. 87) для
интеграции с другими приложениями. Большая часть кода приложения должна быть
написана без учета обмена сообщениями. В тех точках, где приложение интегрирует-
ся с другими программами, должна располагаться небольшая “прослойка” кода, ко-
торая отвечает за интеграцию со стороны данного приложения. Если интеграция
корпоративных приложений реализована через обмен сообщениями, тогда этой
“прослойкой” кода, связывающей приложение с системой обмена сообщениями,
является шлюз обмена сообщениями (Messaging Gateway, с. 482).
• Преобразование данных. Прекрасно, если приложение-отправитель и приложение-
получатель используют одно и то же внутреннее представление данных и если оно
совпадает с форматом сообщения. К сожалению, чаще случается наоборот: отпра-
витель и получатель не могут договориться о формате данных, или в сообщении
478
Глава 10. Конечные точки обмена сообщениями
используется другой формат данных, нежели внутри приложения (например, с це-
лью поддержки других отправителей и получателей). В подобных ситуациях следу-
ет применять преобразователь обмена сообщениями (Messaging Mapper, с. 491), по-
могающий конвертировать данные из формата приложения в формат сообщения.
• Внешнее управление транзакциями. Использование транзакций и управление ими
осуществляется внутри системы обмена сообщениями. Каждый внешний вызов
метода получения или отправки по умолчанию выполняется в рамках отдельной
транзакции. Тем не менее поставщики и потребители сообщений могут восполь-
зоваться транзакционным клиентом (Transactional Client, с. 498), чтобы осуществ-
лять внешнее управление транзакциями. Это может пригодиться для пакетной от-
правки сообщений или для координации обмена сообщениями с другими тран-
закционными службами.
Шаблоны потребителей сообщений
Другие шаблоны конечных точек могут применяться только к потребителям сообще-
ний. Отправлять сообщения легко. Основное вопросы, возникающие во время отправки,
связаны с тем, когда должно быть отправлено сообщение, что в нем должно содержаться
и как уведомить получателя о его назначении. Все эти проблемы решаются с помощью
шаблонов построения сообщений, описанных в главе 5. Как только сообщение будет
сформировано, его отправка не составит никакого труда. Получение сообщений, в свою
очередь, — задача не из простых. Вот почему так много шаблонов конечных точек каса-
ются получения сообщений.
Одним из главных аспектов потребления сообщений является регулирование
(throttling), т.е. способность приложения управлять скоростью потребления пришедших
ему сообщений. Как говорилось во введении к этой книге, высокая интенсивность кли-
ентских запросов может привести к перегрузке сервера. При использовании удаленного
вызова процедуры (Remote Procedure Invocation, с. 85) стабильная работа сервера едва ли не
полностью зависит от скорости поступления клиентских запросов. При обмене сообще-
ниями (Messaging, с. 87) сервер тоже не в состоянии контролировать интенсивность, с ко-
торой клиенты присылают свои запросы, но он может управлять скоростью, с которой
обрабатывает эти запросы. Приложение ворсе не обязано получать и обрабатывать сооб-
щения так же быстро, как они доставляются системой обмена сообщениями. Оно может
обрабатывать их с любой приемлемой для себя скоростью. Сообщения тем временем бу-
дут накапливаться в канале сообщений (Message Channel, с. 93), образуя очередь, которая
обрабатывается по принципу “первым прибыл, первым обслужен” (first come, first
served). Но если сообщений накапливается слишком много, а у сервера есть ресурсы, по-
зволяющие ускорить их обработку, для повышения пропускной способности сервера
можно воспользоваться конкурирующими потребителями сообщений. Таким образом,
шаблоны, перечисленные ниже, помогают приложению регулировать скорость, с кото-
рой оно потребляет сообщения.
Большинство шаблонов потребителей сообщений можно разбить на пары. Каждый из
элементов пары представляет собой тот илг' иной вариант функционирования конечной
точки. В одном и том же приложении могут существовать конечные точки, спроектиро-
ванные разными способами, но одна конечная точка может реализовать только один ва-
риант. Наконец, элементы разных пар можно сочетать друг с другом, что приводит к по-
явлению огромного числа способов реализации конечных точек.
Введение
479
Синхронный или асинхронный потребитель. Один из вариантов реализации конечной
точки состоит в том, какой тип потребителя использовать: опрашивающего потреби-
теля (Polling Consumer, с. 507) или событийно управляемого потребителя (Event-Driven
Consumer, с. 511) [7,14,17]. Опрос обеспечивает самое лучшее регулирование, потому
что если сервер занят, он не будет просить у канала новых сообщений, и накопив-
шиеся сообщения будут поставлены в очередь. Потребители, поведение которых
управляется событиями, обрабатывают сообщения по мере их поступления, что мо-
жет привести к перегрузке сервера; с другой стороны, каждый потребитель может
обрабатывать только по одному сообщению одновременно, поэтому ограничение
числа потребителей хорошо регулирует интенсивность потребления.
Передача сообщения строго определенному потребителю или произвольный выбор
потребителя. Еще одна пара шаблонов описывает, как группа потребителей может
обрабатывать группу сообщений. Если каждый потребитель получит по сообще-
нию, сообщения будут обрабатываться параллельно. Самый простой подход к па-
раллельной обработке сообщений — реализация конкурирующих потребителей
(Competing Consumers, с. 515): один канал “точка-точка” (Point-to-Point Channel,
с. 131) прослушивается несколькими потребителями. Каждый из них потенциаль-
но может взять на обработку любое сообщение; система обмена сообщениями са-
ма решает, кому отдать то или иное сообщение. Если же вы хотите самостоятельно
контролировать распределение сообщений между потребителями, воспользуйтесь
диспетчером сообщений (Message Dispatcher, с. 521). В этом случае канал прослуши-
вается только одним потребителем (диспетчером). Получив сообщение, диспетчер
передает его на обработку одному из нескольких исполнителей. Приложение мо-
жет регулировать интенсивность получения сообщений, ограничивая число по-
требителей или исполнителей. Кроме того, диспетчер сообщений способен реали-
зовать явное регулирование нагрузки.
Принятие всех сообщений или фильтрация. По умолчанию любое сообщение, дос-
тавленное по каналу сообщений, становится доступным любой конечной точке со-
общения, которая прослушивает этот канал. Между тем потребителя может интере-
совать получение сообщений только определенного типа или с другими заданны-
ми свойствами. Тогда он может воспользоваться шаблоном избирательный пот-
ребитель (Selective Consumer, с. 528), чтобы описать, какой тип сообщений он хочет
получать. После этого потребителю будут доставляться только те сообщения, ко-
торые соответствуют предоставленному им описанию.
Подписка временно отключенных потребителей. В связи с использованием канала
“публикация-подписка” (Publish-Subscribe Channel, с. 134) часто возникает вопрос
“Что делать, если подписчик канала, заинтересованный в получении определен-
ных данных, временно отсоединен от сети или выключен на время выполнения
административных работ? Пропустит ли он сообщения, появившиеся в канале за
время его простоя?”. По умолчанию подписка действует на протяжении только
того времени, когда подписчик подключен к сети и активен. Чтобы приложение не
потеряло сообщения, опубликованные в канале, когда оно было недоступно, вос-
пользуйтесь шаблоном постоянный подписчик (Durable Subscriber, с. 535).
480
Глава 10. Конечные точки обмена сообщениями
• Идемпотентность. Иногда одно и то же сообщение доставляется по нескольку раз.
Так происходит тогда, когда система обмена сообщениями не уверена в успешной
доставке сообщения или когда качество обслуживания канала сообщений было
снижено с целью повышения производительности. Получатели сообщений же
обычно предполагают, что каждое сообщение доставляется в точности один раз, и
повторная обработка сообщений часто приводит к проблемам. Идемпотентный
получатель (Idempotent Receiver, с. 541) учитывает возможность появления одина-
ковых сообщений и обрабатывает их таким образом, чтобы они не привели к сбою
приложения-получателя.
• Синхронная или асинхронная служба. Еще одно нелегкое решение связано с тем,
как должен осуществляться вызов служб приложения: в синхронном режиме
(с помощью удаленного вызова процедуры) или в асинхронном (через обмен сообще-
ниями). Разные клиенты могут предпочитать разные подходы; разные обстоятель-
ства тоже могут требовать различных подходов. Если окончательно остановиться
на одном конкретном подходе сложно, не мучайте себя— выберите сразу оба
Активатор службы (Service Activator, с. 545) подключает канал сообщений к службе
приложения, функционирующей в синхронном режиме, так что получение сооб-
щения приводит к вызову службы. Синхронные клиенты могут обращаться
к службе напрямую; асинхронные могут вызывать службу, отправив ей сообщение.
Некоторые аспекты реализации конечных точек
Еще одна важная тема, поднимающаяся в этой главе, — сложность использования
транзакционного клиента (Transactional Client, с. 498) в сочетании с другими шаблонами.
Событийно управляемый потребитель (Event-Driven Consumer, с. 511), как правило, не спо-
собен осуществлять корректное управление внешними транзакциями. Диспетчер сообще-
ний (Message Dispatcher, с. 521), в принципе, может управлять транзакциями, но реализа-
ция такого решения потребует значительных усилий со стороны разработчика. Наконец,
управление внешними транзакциями с помощью конкурирующих потребителей (Com-
peting Consumers, с. 515) чревато тяжелыми последствиями. Самое безопасное решение —
использовать транзакционный клиент вместе с одним опрашивающим потребителем
(Polling Consumer, с. 507), но этот вариант удовлетворит далеко не всех.
Отдельно следует упомянуть о компонентах Message-Driven Beans (MDB), входящих
в состав Enterprise Java Beans (EJB) [10, 14]. Объект MDB — это потребитель сообщений,
который одновременно является событийно управляемым потребителем и транзакцион-
ным клиентом, поддерживающим распределенные транзакции J2EE (например, XARe-
source). Кроме того, группа объектов MDB может динамически направляться на обра-
ботку сообщений в качестве конкурирующих потребителей, даже если речь идет о канале
“публикация-подписка” (Publish-Subscribe Channel, с. 134), Реализовать такую странную
комбинацию в коде приложения собственными силами было бы весьма тяжело, но опи-
санная функциональность предоставляется в готовом виде как встроенное свойство EJB-
совместимых контейнеров (таких, как BEA WebLogic и IBM WebSphere). (Как реализова-
на платформа MDB? Контейнер, по своей сути, реализует диспетчер сообщений с пулом
повторно используемых исполнителей. При этом каждый исполнитель потребляет сооб-
щение в рамках собственного сеанса и транзакции, а размер пула может динамически
меняться.)
Введение 481
Наконец, помните, что одна конечная точка сообщения (Message Endpoint, с. 124) может
прекрасно сочетать в себе несколько шаблонов, описанных в этой главе. Так, группа кон-
курирующих потребителей может быть реализована в виде опрашивающих потребителей,
которые также являются избирательными потребителями (Selective Consumer, с. 528) и вы-
полняют роль активаторов службы (Service Activator, с. 545) для доступа к службе прило-
жения. Диспетчер сообщений, в свою очередь, может быть событийно управляемым потре-
бителем и постоянным подписчиком (Durable Subscriber, с. 535), использующим преобразо-
ватель обмена сообщениями (Messaging Mapper, с. 491). Не забывайте также, что любая
конечная точка должна представлять собой шлюз обмена сообщениями (Messaging Gateway,
с. 482). Разработчик интеграционного решения изначально должен думать не о выборе
того или иного шаблона, а о выборе комбинации шаблонов. В этом-то и состоит вся пре-
лесть решения проблем с помощью шаблонов.
Существует масса способов превратить приложение в конечную точку сообщения.
В следующих разделах главы вы ознакомитесь с этими способами и узнаете о том, как из-
влечь из них максимальную пользу.
482
Глава 10. Конечные точки обмена сообщениями
Шлюз обмена сообщениями (Messaging Gateway)
Приложение осуществляет доступ к другой системе посредством обмена сообщениями
{Messaging, с. 87).
Как инкапсулировать доступ к системе обмена сообщениями, скрыв его от осталь-
ных частей приложения?
Большинство пользовательских приложений осуществляет доступ к инфраструктуре
обмена сообщениями через интерфейс API, предоставленный ее поставщиком. Несмотря
на разнообразие таких интерфейсов, они часто предоставляют доступ к аналогичным
функциям, например “открыть канал”, “создать сообщение” и “отправить сообщение”.
Хотя такой интерфейс позволяет приложению отправлять любые сообщения по каналам
любых типов, понять цель отправки подобных сообщений, как правило, весьма сложно.
Решения, основанные на обмене сообщениями, неизбежно наследуют его асинхрон-
ный характер. Это усложняет кодирование доступа к внешней функции через обмен со-
общениями. Вместо того чтобы просто вызвать метод GetCreditScore, возвращающий
значение кредитного балла клиента, приложение вынуждено отослать сообщение с за-
просом и ждать, что ответ на него придет позднее. Более подробно указанная схема опи-
сана в шаблоне запрос-ответ {Request-Reply, с. 177). Разработчик приложения может
не захотеть возиться с событиями, описывающими приход сообщений, и предпочесть
простую семантику синхронного вызова функции.
Слабое связывание приложений имеет много архитектурных преимуществ, таких как
устойчивость по отношению к небольшим изменениям в формате сообщений (т.е. к добав-
лению новых полей). Обычно слабое связывание достигается путем использования доку-
ментов XML или других структур данных, не являющихся сильно типизированными, как
классы Java или С#. В процессе компиляции такие данные не проверяются на соответствие
типу, а значит, можно легко пропустить опечатку в имени поля или несоответствие типов
данных. Все это чревато большими сложностями и ошибками. Таким образом, гибкость
форматов данных часто достигается за счет усилий разработчиков приложения.
Иногда, чтобы реализовать даже самую простую логическую функцию посредством
обмена сообщениями, приходится отправлять сразу несколько сообщений. К примеру,
для выполнения простенькой функции, извлекающей сведения о клиенте, могут понадо-
биться три сообщения: одно — для извлечения адреса, другое — для извлечения кредит-
ного балла, а третье — для получения личных данных. Каждое из этих сообщений может
обрабатываться разными системами. Зачем же захламлять код приложения логикой,
необходимой для получения и отправки трех отдельных сообщений? Чтобы уменьшить
нагрузку на приложение, можно было бы воспользоваться шаблоном рассылка-сборка
{Scatter-Gather, с. 310), который получает от клиента одно сообщение, отправляет службе
три разных сообщения, а затем объединяет три полученных ответа в одно сообщение.
К сожалению, у нас не всегда есть возможность добавить к приложению такую функцию.
Шлюз обмена сообщениями (Messaging Gateway)
483
Используйте шлюз обмена сообщениями (Messaging Gateway). Это класс, который
инкапсулирует в себе вызовы методов, специфичных для обмена сообщениями,
а приложению вместо них предоставляет доступ к методам, специфичным для
предметной области.
Шлюз обмена сообщениями инкапсулирует код, относящийся к отправке и получению
сообщений, и отделяет его от остального кода приложения. Оставшаяся часть приложе-
ния даже не подозревает о существовании системы обмена сообщениями и о свойствах с
труднопроизносимыми именами наподобие Message.MessagePropertyFilter. Арр-
Specific. Вместо этого она видит только простые и понятные бизнес-функции,
такие как GetCreditScore (“получить кредитный балл”), которые принимают сильно
типизированные параметры, как и любые другие методы. Шлюз обмена сообщениями яв-
ляется специальной версией более общего шаблона шлюз (Gateway, см. [9]), ориентиро-
ванной на обмен сообщениями.
Шлюз обмена сообщениями располагается между приложением и системой обмена со-
общениями, как показано на рис. 10.1. Он предоставляет приложению интерфейс API,
специфичный для предметной области. Поскольку приложение не знает, что использует
систему обмена сообщениями, шлюз легко заменить другой реализацией, использующей
иную технологию интеграции, например удаленный вызов процедур или Web-службы.
। Система
обмена
I—.—I сообщениями
Рис. 10.1. Шлюз устраняет прямые зависимости между приложением и системой обмена сообщениями
Многие шлюзы обмена сообщениями отправляют сообщение другому компоненту
и ждут ответа (см. шаблон запрос-ответ). Такой шлюз можно реализовать при помощи
двух подходов.
1. Блокирующий (синхронный) шлюз обмена сообщениями.
2. Событийно управляемый (асинхронный) шлюз обмена сообщениями.
Блокирующий шлюз обмена сообщениями отправляет сообщение и ждет, пока придет
ответ. Получив ответ, он обрабатывает сообщение и возвращает результат приложению
(рис. 10.2). Только после этого приложение вновь продолжает свое выполнение.
484
Глава 10. Конечные точки обмена сообщениями
Система обмена
сообщениями
Приложение
Шлюз обмена
сообщениями
Рис. 10.2. Блокирующий (синхронный) шлюз обмена сообщениями
Блокирующий шлюз обмена сообщениями инкапсулирует в себе асинхронный характер
обмена сообщениями, предоставляя логике приложения обычный синхронный метод.
По этой причине приложение ничего не знает об асинхронности своего взаимодействия с
другими системами. К примеру, блокирующий шлюз может предоставить приложению
следующий метод:
int GetCreditScore(string SSN)
Этот подход существенно облегчает создание кода, описывающего взаимодействие
приложения со шлюзом обмена сообщениями. В то же время он негативно сказывается на
производительности приложения. Вместо того чтобы заняться выполнением других
задач, оно вынуждено терпеливо ждать ответа от шлюза.
Событийно управляемый шлюз обмена сообщениями не скрывает от приложения асин-
хронный характер своего взаимодействия с системой обмена сообщениями. Когда при-
ложение выполняет бизнес-запрос к шлюзу обмена сообщениями, оно вместе с другими па-
раметрами передает шлюзу имя метода обратного вызова, специфичного для предметной
области. Сразу же после этого приложение продолжает свое выполнение и может занять-
ся другими делами. Когда шлюз получает сообщение с ответом, он обрабатывает его,
а затем инициирует обратный вызов (рис. 10.3).
Шлюз обмена сообщениями (Messaging Gateway)
485
Рис. 10.3. Событийно управляемый (асинхронный) шлюз обмена сообщениями
К примеру, если реализовать шлюз обмена сообщениями на C# с использованием деле-
гатов, его интерфейс, доступный приложению, может выглядеть следующим образом:
delegate void OnCreditReplyEvent(int Creditscore);
void RequestCreditScore(string SSN,
OnCreditReplyEvent OnCreditResponse);
Метод RequestCreditScore принимает дополнительный параметр, задающий метод
обратного вызова, который должен быть запущен при получении сообщения с ответом.
У метода обратного вызова есть параметр Creditscore, с помощью которого шлюз обмена
сообщениями может передать приложению результат обработки запроса. В зависимости от
платформы или языка программирования обратный вызов можно реализовать с помощью
указателей на функции, ссылок на объекты или делегатов (см. вышеприведенный фрагмент
кода). Обратите внимание: несмотря на событийно управляемый характер такого интер-
фейса, он ни в коей мере не зависит от конкретной технологии обмена сообщениями.
Вместо обратного вызова приложение может периодически опрашивать шлюз, чтобы
узнать, не прибыли ли результаты. Данный подход позволяет сохранить простоту интер-
фейса без блокирования работы приложения, фактически реализуя шаблон полусинхрон-
ная/полуасинхронная обработка {Half-Sync/Half-Async, см. [34]). Этот шаблон описывает
использование буферов входящих сообщений, благодаря которым приложение может
опрашивать шлюз на предмет прибытия результатов в любое удобное для себя время.
Одна из проблем использования событийно управляемого шлюза обмена сообщениями
состоит в том, что приложение должно сохранять некоторую метку запроса в промежутке
486
Глава 10. Конечные точки обмена сообщениями
времени между отправкой запроса и событием обратного вызова (при использовании
блокирующего шлюза эту обязанность берет на себя стек вызовов). Когда шлюз обмена
сообщениями инициирует запуск обратного вызова, приложение должно иметь возмож-
ность сопоставить ответ со сделанным ранее запросом, чтобы продолжить обработку
правильного потока выполнения. Чтобы упростить выполнение этой операции, шлюз
может разрешить приложению передавать вызываемому методу ссылку на некоторый
произвольный набор данных. При запуске асинхронного обратного вызова эти данные
будут возвращены приложению, и приложение сможет сопоставить ответ с запросом.
Взаимодействие такого типа часто называют маркером асинхронного завершения
(Asynchronous Completion Token, см. [34]).
Общедоступный интерфейс событийно управляемого шлюза обмена сообщениями,
поддерживающего маркер асинхронного завершения (ACT), может выглядеть следую-
щим образом:
delegate void OnCreditReplyEvent(int Creditscore, Object ACT);
void RequestCreditScore(string SSN,
OnCreditReplyEvent OnCreditResponse, Object ACT);
Метод RequestCreditScore принимает дополнительный параметр, а именно ссылку
на объект универсального типа. Шлюз обмена сообщениями сохраняет эту ссылку, ожи-
дая, когда прибудет сообщение с ответом. При получении ответа шлюз вызывает экземп-
ляр делегата OnCreditReplyEvent, передавая приложению результат выполнения опе-
рации, а также ссылку на объект. Хотя поддержка маркера асинхронного завершения
очень удобна для приложения, она грозит “утечкой памяти”, если шлюз обмена сообще-
ниями сохранит ссылку на объект, но ответ так никогда и не прибудет.
Соединение шлюзов в цепочки
Иногда имеет смысл создать несколько слоев шлюзов обмена сообщениями (Messaging
Gateway), как показано на рис. 10.4. Шлюз нижнего уровня абстрагирует синтаксис сис-
темы обмена сообщениями, но еще сохраняет общую семантику обмена сообщениями,
например метод SendMessage. Благодаря наличию такого шлюза оставшаяся часть при-
ложения будет защищена от возможного перехода компании на другую технологию
обмена сообщениями (например, с MSMQ на Web-службы). Базовый шлюз обмена сооб-
щениями “упаковывается” в дополнительный шлюз, который трансформирует общий
API обмена сообщениями в API, специфичный для предметной области (например, вме-
сто метода SendMessage здесь фигурирует метод GetCreditScore). Такая конфигура-
ция шлюзов использовалась нами в примере асинхронной реализации кредитного броке-
ра с помощью MSMQ (см. главу 9).
Обработка исключений системы обмена сообщениями
Шлюз обмена сообщениями (Messaging Gateway) нужен не только для того, чтобы упро-
стить написание кода приложения, но и для устранения зависимости кода приложения
от конкретных технологий обмена сообщениями. Этого легко достичь, упаковав вызовы
методов, относящихся к обмену сообщениями, в интерфейс шлюза обмена сообщениями.
Следует, однако, помнить и о том, что большинство слоев системы, описывающих обмен
сообщениями, выдает соответствующие исключения, например invalidDestination-
Шлюз обмена сообщениями (Messaging Gateway)
487
----1
Обмен
сообщениями
------9--------
\
\
Реализация,
специфичная
для платформы
Рис. 10.4. Цепочка шлюзов, обеспечивающих разные уровни абстракции
Exception в JMS. Если мы действительно хотим сделать код приложения не зависящим
от библиотек обмена сообщениями, шлюз обмена сообщениями должен перехватывать лю-
бые исключения, специфичные для обмена сообщениями, и генерировать вместо них ис-
ключения, специфичные для предметной области (или общие исключения). Код, описы-
вающий такую обработку исключений, может оказаться немного запутанным, но он
принесет огромную пользу, если мы решим сменить базовую технологию обмена сооб-
щениями (например, JMS на Web-службы).
Генерация кода шлюзов
Довольно часто код шлюза обмена сообщениями {Messaging Gateway) можно сгенериро-
вать на основе метаданных, предоставленных внешним источником. Такая практика
весьма распространена в мире Web-служб. Практически каждый производитель или
платформа с открытым исходным кодом предлагает средство наподобие wsdl 2 j ava, ко-
торое подключается к документу WSDL, описывающему внешнюю Web-службу. На ос-
новании этого документа генерируются классы Java (или С#, или другого необходимого
разработчику языка программирования), которые инкапсулируют в себе весь громоздкий
код, связанный с обработкой взаимодействия по протоколу SOAP, и выставляют “на
публику” только простой вызов функции. Мы создали аналогичное средство, которое
считывает из репозитория TIBCO определение схемы сообщений и создает класс Java,
повторяющий указанную схему. Это позволяет разработчикам приложения отправлять
правильно типизированные сообщения TIBCO ActiveEnterprise без необходимости вни-
кать в детали интерфейса API от TIBCO.
Использование шлюзов в процессе тестирования
Шлюз обмена сообщениями {Messaging Gateway) — прекрасное средство тестирования.
Поскольку весь код, касающийся обмена сообщениями, упакован в интерфейс, специ-
фичный для предметной области, можно легко создать фиктивную реализацию этого ин-
терфейса. Мы отделим интерфейс от реализации и создадим две реализации:
“настоящую”, которая действительно будет осуществлять доступ к системе обмена
сообщениями, и “фальшивую”, пригодную только для тестирования (рис. 10.5).
“Фальшивая” реализация шлюза (MockCreditBureauGatewaylmp на рис. 10.5) будет
выполнять роль фиктивной службы {Service Stub, см. [9]) и позволит нам протестировать
приложение в отрыве от системы обмена сообщениями. Фиктивная служба также может
488
Глава 10. Конечные точки обмена сообщениями
пригодиться для отладки приложения, использующего событийно управляемый шлюз
обмена сообщениями. Тестовая служба для такого шлюза может просто запускать метод
обратного вызова (или вызывать экземпляр делегата) прямо из метода запроса, фактиче-
ски обрабатывая запрос и ответ в одном потоке выполнения. Это существенно упрощает
пошаговую отладку.
ICreditBureauGateway
Г
J.
CreditBureauGateway1ир
MockCreditBureauGatewayImp
Рис. 10.5. Использование шлюза в качестве средства тестирования
Пример: шлюз для асинхронной реализации кредитного брокера (MSMQ)
Код, приведенный ниже, описывает работу шлюза кредитного бюро из примера асин-
хронной реализации кредитного брокера с помощью MSMQ (глава 9).
public delegate void OnCreditReplyEvent(CreditBureauReply
creditReply, Object ACT);
internal struct CreditRequestProcess
{
public int CorrelationlD;
public Object ACT;
public OnCreditReplyEvent callback;
}
internal class CreditBureauGateway
{
protected IMessageSender creditRequestQueue;
protected IMessageReceiver creditReplyQueue;
protected IDictionary activeProcesses =
(IDictionary)(new Hashtable());
protected Random random = new Random();
public void Listen()
{
creditReplyQueue.Begin();
}
public void GetCreditScore(CreditBureauRequest quoteRequest,
OnCreditReplyEvent OnCreditResponse,
Object ACT)
{
Message requestMessage = new Message(quoteRequest);
Шлюз обмена сообщениями (Messaging Gateway)
489
requestMessage.ResponseQueue = creditReplyQueue.GetQueueO;
requestMessage.AppSpecific = random.Next();
CreditRequestProcess processinstance = new
CreditRequestProcess();
processinstance.ACT = ACT;
processinstance.callback = OnCreditResponse;
processinstance.CorrelationlD = requestMessage.AppSpecific;
creditRequestQueue.Send(requestMessage);
activeProcesses.Add(processinstance.CorrelationlD,
processinstance);
}
private void OnCreditResponse(Message msg)
{
msg.Formatter = GetFormatter();
CreditBureauReply replyStruct;
try
{
if (msg.Body is CreditBureauReply)
{
replyStruct = (CreditBureauReply)msg.Body;
int CorrelationlD = msg.AppSpecific;
if (activeProcesses.Contains(CorrelationlD))
{
CreditRequestProcess processinstance =
(CreditRequestProcess)(activeProcesses[CorrelationlD]);
processinstance.callback(replyStruct,
processinstance.ACT);
activeProcesses.Remove(CorrelationlD);
}
else
{
Console.WriteLine("Incoming credit response does
not match any request");
// "Полученный ответ не соответствует ни одному
// запросу".
}
}
else
{ Console.WriteLine("Illegal reply."); }
// "Недопустимый ответ".
}
catch (Exception e)
{
Console.WriteLine("Exception: {0}", e.ToString());
}
}
}
490 Глава 10. Конечные точки обмена сообщениями
Легко заметить, что общедоступный метод GetCreditScore и делегат OnCredit-
ReplyEvent никак не ссылаются на систему обмена сообщениями. Такая реализация по-
зволяет вызывающему приложению передать ссылку на произвольный объект в качестве
маркера асинхронного завершения (ACT). Шлюз CreditBureauGateway сохраняет
ссылку на объект в словаре, индексированном по идентификатору корреляции {Correlation
Identifier, с. 186) сообщения с ответом. При получении ответа шлюз Credit-
BureauGateway может извлечь из словаря данные, связанные с соответствующим запро-
сом. Вызывающему приложению не придется заботиться о том, как происходит сопос-
тавление сообщений с запросом и ответом.
Преобразователь обмена сообщениями (Messaging Mapper)
491
Преобразователь обмена сообщениями (Messaging Mapper)
Когда приложение использует обмен сообщениями (Messaging, с. 87), данные сообщений
(Message, с. 98) часто формируются на основе объектов предметной области приложения.
Так, если мы используем сообщение с данными документа (Document Message, с. 171), тело
сообщения может непосредственно представлять собой один из объектов предметной об-
ласти. При использовании сообщения с командой (Command Message, с. 169) некоторые по-
ля данных, относящиеся к команде, тоже, как правило, извлекаются из объектов пред-
метной области. Разумеется, между объектами и сообщениями существуют очевидные
различия. К примеру, связь между объектами чаше всего определяется с помощью ссы-
лок на объекты и отношений наследования. Многие инфраструктуры обмена сообще-
ниями не поддерживают эти понятия, потому что им приходится взаимодействовать с
самыми разными приложениями, и далеко не все из них имеют объектно-ориенти-
рованную архитектуру.
Как организовать перемещение данных между объектами предметной области и
инфраструктурой обмена сообщениями, не нарушая их независимость?
Почему бы не сделать так, чтобы сообщения в точности напоминали объекты пред-
метной области? Тогда описанная проблема решилась бы сама собой, но... Во многих
случаях мы не можем управлять форматом сообщения из-за того, что он задан канониче-
ской моделью данных (Canonical Data Model, с. 367) или популярным стандартом обмена
сообщениями (например, ebXML). Единственное, что можно сделать, — опубликовать
сообщение в формате, соответствующем структуре объектов предметной области, а на
уровне обмена сообщениями воспользоваться транслятором сообщений (Message
Translator, с. 115), чтобы преобразовать сообщение в общий формат. Этот подход часто
используется адаптерами сторонних систем (например, адаптерами баз данных), не по-
зволяющих преобразовывать данные внутри приложения.
Вместо этого сообщение можно создать и опубликовать в правильном формате уже
на уровне предметной области. Тогда отдельный транслятор сообщений не потребуется.
Этот вариант способствует повышению производительности, поскольку мы не публику-
ем промежуточное сообщение. Кроме того, если модель предметной области включает в
себя много небольших объектов, их удобно с самого начала скомбинировать в одно со-
общение, чтобы упростить маршрутизацию и повысить эффективность работы слоя об-
мена сообщениями. Даже если мы сможем позволить себе дополнительный этап преоб-
разования, то столкнемся с ограничениями, если захотим создавать сообщения, повто-
ряющие структуру объектов предметной области. Недостатком описанного подхода
является зависимость предметной области от формата сообщений, что значительно
усложняет поддержку предметной области, если формат сообщений вдруг изменится.
Большинство систем обмена сообщениями поддерживает понятие объекта
“сообщение” в качестве части интерфейса API. Такой объект сообщения инкапсулирует
в себе данные, которые должны быть отправлены по каналу. Во многих случаях подоб-
ный объект может содержать только данные скалярных типов (например, текстовые
строки, числа или даты), но не поддерживает наследование или ссылки на объекты.
Это одно из ключевых различий между взаимодействием в стиле RPC (т.е. удаленным
492
Глава 10. Конечные точки обмена сообщениями
вызовом процедур) и асинхронным обменом сообщениями. Пусть мы отсылаем некото-
рому компоненту асинхронное сообщение, содержащее ссылку на объект. Чтобы обрабо-
тать такое сообщение, компонент-получатель должен извлечь объект по его ссылке.
Для этого ему следовало бы запросить объект у источника сообшения. Но взаимодейст-
вие типа “запрос-ответ” противоречит основным мотивам использования асинхронного
обмена сообщениями (таким, как слабое связывание компонентов). Что еще хуже, к тому
времени, когда асинхронное сообщение будет получено подписчиком канала, сам
объект, заданный ссылкой, может больше не существовать.
Одна из попыток решить проблему ссылок на объекты состоит в том, чтобы просле-
дить дерево зависимостей объекта и включить в сообщение все объекты, зависящие от
исходного. К примеру, если объект Order (“заказ”) ссылается на пять объектов Or-
deritem (“пункты заказа”), в сообщение можно включить пять объектов. Это гарантиру-
ет, что получатель будет иметь доступ ко всем данным, на которые ссылается “корневой”
объект. К сожалению, если мы используем сложную модель предметной области с мно-
жеством переплетающихся связей, сообщение быстро разрастется до недопустимых раз-
меров. Хотелось бы иметь больше контроля над тем, что будет включено в сообщение, а
что — нет.
Давайте на секунду предположим, что наш объект предметной области включает в се-
бя все необходимые данные и не содержит ссылок на другие объекты. Несмотря на это
мы все равно не сможем вставить в сообщение весь объект — большинство инфраструк-
тур обмена сообщениями не поддерживают работу с объектами, чтобы не попадать в за-
висимость от конкретных языков программирования. Исключение составляют интер-
фейс JMS Obj ectMessage и класс Message из пространства имен .NET System. Messaging,
поскольку указанные системы обмена сообщениями ориентированы на использование
вместе с конкретным языком (JMS) либо конкретной программной платформой (общая
языковая среда выполнения .NET). Можно было бы сериализовать объект, превратив его
в строку, и сохранить в строковом поле data (“данные”), которое поддерживается прак-
тически каждой системой обмена сообщениями. У этого подхода тоже есть свои недос-
татки. Во-первых, маршрутизатор сообщений (Message Router, с. 109) не сможет использо-
вать свойства объекта в целях маршрутизации, потому что строковое поле будет
“непроницаемо” для слоя обмена сообщениями. Во-вторых, наличие такого поля услож-
нит отладку и тестирование, потому что нам придется дешифровать его содержимое.
В-третьих, если тело каждого сообшения будет состоять из единственного строкового по-
ля, мы не сможем выполнять маршрутизацию сообшений на основе их типов, поскольку
для инфраструктуры обмена сообщениями все сообщения будут выглядеть абсолютно
одинаково. В-четвертых, инфраструктура обмена сообщениями не проверяет правиль-
ность содержимого поля данных, что значительно затруднит проверку корректности
формата сообщения. Наконец, мы не сможем использовать средства сериализации, вхо-
дящие в состав библиотек времени выполнения конкретного языка программирования,
потому что такие средства обычно не совместимы с другими языками. Придется писать
собственные методы сериализации.
Некоторые системы обмена сообщениями поддерживают работу с полями XML в теле
сообщения, поэтому объекты можно было бы сериализовать в формат XML. Это немного
смягчит негативные факторы, описанные выше, потому что дешифровать содержимое
сообшений будет легче, а из некоторых слоев обмена сообщениями можно будет напря-
мую осуществлять доступ к элементам полей XML. При этом, однако, нам придется
Преобразователь обмена сообщениями (Messaging Mapper)
493
иметь дело с довольно громоздкими сообщениями и ограниченной проверкой правиль-
ности типов данных. Кроме того, мы все равно должны создать код, который будет пре-
образовывать объект в документ XML и наоборот. В зависимости от используемого языка
программирования это может оказаться довольно сложной задачей, в особенности если
применяется относительно старый язык, не поддерживающий отражение (reflection).
Существует достаточно причин для того, чтобы отделить код преобразования от кода
объектов предметной области. Во-первых, не стоит внедрять в логику приложения код
более низкого уровня, ведь в большинстве случаев слой обмена сообщениями и логику
приложения будут разрабатывать две разные группы программистов. Если “слепить”
и тот, и другой код в один объект, командам разработчиков будет трудно действовать па-
раллельно.
Во-вторых, внедрение кода, выполняющего преобразование, в объект предметной
области сделает этот объект зависимым от инфраструктуры обмена сообщениями, пото-
му что код преобразования должен вызывать методы из интерфейса системы обмена со-
общениями (например, чтобы создать экземпляр класса Message). В большинстве случа-
ев такая зависимость нежелательна, поскольку мешает повторно использовать объекты
предметной области в другом контексте, в котором применяется система обмена сооб-
щениями от другого производителя или не применяется вообще.
Мы часто наблюдаем, как программисты упаковывают интерфейс APT инфраструкту-
ры обмена сообщениями в своеобразные “слои абстракции”, тем самым отделяя про-
граммный интерфейс указанной инфраструктуры от кода, который с ним взаимодейству-
ет. Наличие такого слоя способствует появлению дополнительного уровня косвенности,
поскольку интерфейс обмена сообщениями отделяется от его реализации. Благодаря
этому мы сможем повторно использовать код, описывающий обмен сообщениями, даже
если перейдем к использованию инфраструктуры обмена сообщениями другого произво-
дителя. Все, что понадобится сделать, — это реализовать новый слой абстракции, преоб-
разующий интерфейс обмена сообщениями в API новой системы. К сожалению, данный
подход не устраняет зависимости объектов предметной области от слоя обмена сообще-
ниями. Вместо интерфейса конкретного производителя объекты предметной области
станут ссылаться на абстрактный интерфейс обмена сообщениями, но использовать их в
контексте, в котором вообще не применяется обмен сообщениями, все равно не удастся.
Многие сообщения создаются на основе нескольких объектов предметной области.
Поскольку мы не можем передавать ссылки на объекты через инфраструктуру обмена
сообщениями, нам, скорее всего, понадобится включить в сообщение поля из других
объектов. В некоторых случаях в одном сообщении может содержаться целое “дерево”
зависимых объектов.
В каком же классе должен находиться код преобразования? Один и тот же объект
предметной области в сочетании с другими объектами может быть частью разных типов
сообщений, поэтому простого ответа на этот вопрос не существует.
Преобразователь обмена сообщениями осуществляет доступ к одному или нескольким
объектам предметной области и преобразует их в сообщение, совместимое с каналом обме-
на сообщениями. Преобразователь выполняет и обратную функцию, создавая или обнов-
ляя объекты предметной области на основе содержимого входящих сообщений. Поскольку
преобразователь обмена сообщениями реализован в виде отдельного класса, ссылающегося и
на объект(ы) предметной области, и на слой обмена сообщениями, указанные слои не зна-
ют о существовании друг друга (как, впрочем, и самого преобразователя).
494
Глава 10. Конечные точки обмена сообщениями
Создайте отдельный преобразователь обмена сообщениями (Messaging Mapper1),
содержащий логику преобразования данных между инфраструктурой обмена
сообщениями и объектами предметной области. Ни объекты, ни сама инфраструк-
тура не будут догадываться о его существовании.
Преобразователь обмена сообщениями является конкретизированной версией шаблона
преобразователь (Mapper, см. [9]). В некоторых аспектах он аналогичен преобразователю
данных (Data Mapper, см. [9]). Каждый, кто работал со стратегиями объектно-
реляционного преобразования, наверняка понимает сложность преобразования данных
между программными слоями, использующими разные парадигмы. Аналогичные про-
блемы свойственны и преобразователю обмена сообщениями, однако подробное обсужде-
ние всех возможных аспектов выходит за рамки данной книги. В качестве хорошего под-
спорья рекомендуется прочитать об архитектурных шаблонах источников данных в [9].
Преобразователь обмена сообщениями отличается от распространенной концепции
слоя абстракции, в который упаковывают интерфейс API обмена сообщениями. При ис-
пользовании слоя абстракции объекты предметной области не знают об интерфейсе об-
мена сообщениями, но знают о самом слое абстракции. Слой абстракции, по сути, вы-
полняет роль шлюза обмена сообщениями (Messaging Gateway, с. 482). В отличие от этого
при использовании преобразователя обмена сообщениями объекты даже не подозревают,
что система имеет дело с обменом сообщениями.
Преобразователь обмена сообщениями напоминает шаблон посредник (Mediator,
см. [12]) в том плане, что тоже применяется для разобщения некоторых элементов.
В случае с посредником, однако, элементы знают о его существовании, в то время как о
присутствии преобразователя обмена сообщениями не догадывается ни один элемент.
Если ни объекты предметной области, ни инфраструктура обмена сообщениями не
знают о существовании преобразователя обмена сообщениями, как же происходит вызов
его методов? В большинстве случаев вызов преобразователя выполняется с помощью
событий, инициированных инфраструктурой обмена сообщениями либо приложением.
Поскольку ни одно из них не зависит от преобразователя обмена сообщениями, уведомле-
ние о событиях может выполняться с помощью отдельного кода или же путем превраще-
ния преобразователя в шаблон наблюдатель (Observer, см. [12]). К примеру, если в качест-
ве инфраструктуры обмена сообщениями используется JMS, можно реализовать интер-
фейс MessageListener, который будет уведомлять нас о поступлении входящих
сообщений. Аналогичным образом для уведомления о важных событиях, произошедших
с объектами предметной области, и вызова преобразователя можно воспользоваться
наблюдателем. Если же вызов преобразователя обмена сообщениями должен осуществлять-
ся непосредственно из приложения, необходимо определить интерфейс преобразователя,
чтобы приложение, по крайней мере, не зависело от его реализации.
Преобразователь обмена сообщениями (Messaging Mapper)
495
Упрощение кодирования
Некоторые реализации преобразователя обмена сообщениями (Message Mapper) содер-
жат множество повторяющегося кода: извлечь содержимое поля из объекта предметной
области и сохранить его в объекте сообщения; перейти к следующему полю; повторять до
тех пор, пока не будут получены значения всех полей. Такая схема заполнения объекта
сообщения достаточно сложна и подозрительно попахивает многократным дублировани-
ем кода. К счастью, существует целый ряд средств, позволяющих избежать подобных
проблем. Во-первых, можно написать обобщенный преобразователь обмена сообщениями,
использующий отражение для извлечения значений полей из объекта предметной облас-
ти некоторым универсальным способом. К примеру, он может пройтись по всем полям
объекта предметной области и скопировать содержимое каждого поля в одноименное по-
ле объекта сообщения. Такая схема, очевидно, будет работать только тогда, когда имена
полей в обоих объектах совпадают. Кроме того, в соответствии с нашими предыдущими
рассуждениями необходимо придумать способ обработки ссылок на объекты, поскольку
сохранить их в объекте сообщения нельзя. В качестве альтернативы можно предложить
создание кода преобразователя обмена сообщениями с помощью настраиваемого генерато-
ра кода. Это повысит гибкость именования полей (имя поля объекта сообщения необяза-
тельно должно совпадать с таковым объекта предметной области), а также позволит нам
разработать более “умный” способ обработки ссылок. Недостатком такого генератора
является сложность тестирования и отладки, но если сделать его достаточно универсаль-
ным, эти процедуры придется повторять только один раз.
Некоторые платформы наподобие Microsoft .NET обладают встроенными средствами
сериализации объектов в документы XML и наоборот. Впрочем, даже если платформа
делает вместо программиста часть работы по преобразованию объекта в сообщение, ее
действия все равно ограничиваются синтаксическим преобразованием. Если полностью
переложить выполнение указанной задачи на платформу, она просто-напросто создаст
сообщение, в точности копирующее объект предметной области. Как уже говорилось,
это не всегда желательно, потому что ограничения и критерии структуры сообщений
серьезно отличаются от таковых для объектов предметной области. Имеет смысл опреде-
лить набор “интерфейсных объектов”, структура которых будет соответствовать желае-
мой структуре сообщений, и использовать встроенные средства платформы для преобра-
зования указанных объектов в сообщения и наоборот. В этом случае преобразователь об-
мена сообщениями будет управлять преобразованием данных между настоящими
объектами предметной области и интерфейсными объектами. Описанные интерфейсные
объекты во многом напоминают объекты переноса данных (Data Transfer Object, см. [9]),
хотя мотивы их создания несколько различаются.
Преобразователь или транслятор
Даже при наличии преобразователя обмена сообщениями (Message Mapper) нелишне ис-
пользовать транслятор сообщений (Message Translator, с. 115), чтобы конвертировать со-
общения, сгенерированные преобразователем, в сообщения, совместимые с канонической
моделью данных (Canonical Data Model, с. 367), как показано на рис. 10.6. Это способствует
появлению дополнительного уровня косвенности. Преобразователь обмена сообщениями
может применяться для решения проблем, связанных со ссылками на объекты и преоб-
разованием типов данных, а структурные преобразования сообщений можно отдать
496
Глава 10. Конечные точки обмена сообщениями
транслятору сообщений, находящемуся в рамках слоя обмена сообщениями. За дополни-
тельное разобщение придется заплатить созданием еще одного компонента и небольшим
снижением производительности, но это не так страшно. Кроме того, сложные преобра-
зования иногда легче вручную описать на языке программирования, чем использовать
всевозможные графические “примочки” из готовых пакетов интеграционных средств.
Сообщение
в каноническом
формате
Транслятор
сообщений
Сообщение
в формате
приложения
Рис. 10.6. Комбинация преобразователя и транслятора сообщений
Используя преобразователь обмена сообщениями в сочетании с транслятором сообще-
ний, мы создаем дополнительный уровень косвенности между каноническим форматом
данных и объектами предметной области. Говорят, что информатика — это такая об-
ласть науки, в которой любая проблема решается путем добавления еще одного уровня
косвенности. Верно ли это в нашем случае? Наличие дополнительного уровня косвенно-
сти дает возможность адаптироваться к изменениям канонического формата данных
внутри слоя обмена сообщениями без необходимости модифицировать код приложения.
Оно также позволяет нам упростить логику преобразования в коде приложения, перекла-
дывая выполнение сложных преобразований полей и типов данных (например, число-
вого поля ziP_Code в буквенно-числовое Postal_Code) на средства преобразования из
слоя обмена сообщениями, специально оптимизированные для выполнения действий
такого рода. В этом случае преобразователь обмена сообщениями будет, в основном, зани-
маться разрешением ссылок на объекты и удалением из будущего сообщения ненужных
деталей, касающихся объектов предметной области. Очевидным недостатком дополни-
тельного уровня косвенности является тот факт, что изменение объекта предметной об-
ласти может потребовать внесения соответствующих изменений как в преобразователь
обмена сообщениями, так и в транслятор сообщений. Если нам удастся организовать авто-
матическую генерацию кода преобразователя обмена сообщениями, указанная проблема
будет практически решена.
Преобразователь обмена сообщениями (Messaging Mapper) 497
Пример: преобразователь обмена сообщениями в JMS
Вернемся к примеру реализации шаблона агрегатор (Aggregator, с. 283) для JMS. В этом
примере класс AuctionAggregate представляет собой преобразователь обмена сообще-
ниями (Message Mapper) между системой обмена сообщениями JMS и классом Bid. Мето-
ды addMessage и getResultMessage выполняют преобразование сообщений JMS
в объекты Bid и наоборот. Ни система обмена сообщениями, ни класс Bid не знают
о наличии преобразователя и выполняемых им действиях.
498
Глава 10. Конечные точки обмена сообщениями
Транзакционный клиент (Transactional Client)
Обычно управление транзакциями осуществляется внутри системы обмена сообще-
ниями. Хотелось бы, однако, чтобы внешний клиент тоже мог управлять транзакциями,
влияющими на его поведение.
Может ли клиент управлять транзакциями, в рамках которых он взаимодействует с
системой обмена сообщениями?
Работа системы обмена сообщениями должна основываться на использовании тран-
закций. У одного канала сообщений (Message Channel, с. 93) может быть несколько отпра-
вителей и получателей. По этой причине система должна координировать обмен сооб-
щениями, чтобы отправители случайно не Перезаписали сообщения (Message, с. 98) друг
друга, чтобы разные получатели канала “точка-точка” (Point-to-Point Channel, с. 131)
не потребили одно и то же сообщение или, скажем, чтобы все подписчики канала
“публикация-подписка” (Publish-Subscribe Channel, с. 134) получили только по одной ко-
пии сообщения. Для управления этими действиями в системе обмена сообщениями
используются транзакции. Они гарантируют, что сообщение будет добавлено в канал или
не будет добавлено в канал, что оно будет считано из канала или не будет считано из ка-
нала и т.п. Транзакции (в частности, двухэтапные распределенные транзакции) должны
применяться и для того, чтобы скопировать сообщение с компьютера отправителя на
компьютер получателя таким образом, чтобы в любой отдельно взятый момент времени
сообщение находилось только на одном из компьютеров.
Конечные точки сообщения (Message Endpoint, с. 124), занимающиеся отправкой и полу-
чением сообщений, по своей природе являются транзакционными. Метод отправки, раз-
мещающий сообщение в канале, делает это в рамках транзакции, чтобы изолировать свое
сообщение от других, которые в это же самое время могли быть добавлены в канал или уда-
лены из него. Метод получения тоже использует транзакцию, чтобы сообщение не было по-
треблено сразу несколькими слушателями канала “точка-точка” или чтобы оно не было
дважды прочитано одним и тем же подписчиком канала “публикация-подписка”.
Транзакции часто описывают с помощью четырех свойств, обозначаемых аббревиату-
рой ACID: атомарные (atomic), согласованные (consistent), изолированные (isolated) и ус-
тойчивые (durable). Сообщение по определению является атомарным, а транзакции, в рам-
ках которых осуществляется гарантированная доставка (Guaranteed Delivery, с. 149), —
устойчивыми. Но все транзакции, касающиеся обмена сообщениями, обязаны быть согла-
сованными и изолированными. Нельзя сказать, что “сообщение вроде бы находится в ка-
нале”, — оно там или есть, или нет. Кроме того, процессы отправки и получения сообще-
ний конкретным приложением должны быть изолированы от любых других потоков и при-
ложений, выполняющих отправку и получение сообщений по тому же каналу.
Если клиент хочет просто отправить или получить сообщение, его вполне устроит сис-
тема внутренних транзакций инфраструктуры обмена сообщениями. Но иногда приложе-
ние нуждается в более обширных транзакциях, чтобы координировать отправку нескольких
Транзакционный клиент (Transactional Client)
499
сообщений или согласовывать обмен сообщениями с операциями над другими ресурсами.
Среди наиболее популярных сценариев такого рода можно назвать следующие.
• Отправка-получение пары сообщений. Получить одно сообщение и отправить дру-
гое, как, например, в шаблоне запрос-ответ (Request-Reply, с. 177) или при реали-
зации фильтра сообщений, такого как маршрутизатор сообщений (Message Router,
с. 109) или транслятор сообщений (Message Translator, с. 115).
• Группа сообщений. Отправка или получение группы связанных между собой сооб-
щений, таких как цепочка сообщений (Message Sequence, с. 192).
• Координация “сообщение — база данных”. Комбинация отправки или получения
сообщения с обновлением базы данных, как, скажем, в шаблоне адаптер канала
(Channel Adapter, с. 154). К примеру, когда приложение получает и обрабатывает
сообщение о заказе продукта, оно должно также обновить базу данных, в которой
хранятся сведения о наличии продуктов на складе. В другом примере отправитель
сообщения с данными документа (Document Message, с. 171) может захотеть удалить
сохраненный документ, но только после того, как тот будет успешно доставлен.
Аналогичным образом получатель может захотеть сохранить документ до тех пор,
пока тот не будет успешно потреблен.
• Координация “сообщение — рабочий поток”. Использование пары сообщений
запрос-ответ для выполнения единицы работы и применения транзакций для по-
лучения гарантии, что единица работы не будет открыта, пока не будет отослан за-
прос, и не будет закрыта, пока не будет получен ответ.
Каждый из сценариев, подобных описанным выше, должен осуществляться в рамках
большой атомарной транзакции, в которой могут быть задействованы несколько сооб-
щений и дополнительные транзакционные хранилища. Транзакция необходима для того,
чтобы, если часть сценария (например, получение сообщения) будет выполнена, а другая
часть сценария (например, обновление базы данных или отправка второго сообще-
ния) — нет, все части сценария можно было отменить (так, как будто бы они никогда
не выполнялись) и начать операцию с самого начала.
К сожалению, модель внутренних транзакций, используемая системой обмена сооб-
щениями, не позволяет приложению согласовывать обработку сообщения с другими со-
общениями или ресурсами. Приложению нужен способ внешнего управления транзак-
циями системы обмена сообщениями и их комбинирования с другими транзакциями
этой же или любой другой системы.
И отправитель, и получатель могут быть транзакционными. В первом случае сообще-
ние не будет добавлено в канал до тех пор, пока отправитель не подтвердит выполнение
транзакции. Во втором случае сообщение не будет удалено из канала, пока получатель не
подтвердит выполнение транзакции. Отправитель, применяющий транзакции в явном
виде, может отсылать сообщения получателю, использующему транзакции в неявном ви-
де, и наоборот. У одного и того же канала могут быть отправители и получатели обоих
типов. Схема работы транзакционного получателя показана на рис. 10.7.
500
Глава 10. Конечные точки обмена сообщениями
Воспользуйтесь транзакционным клиентом (Transactional Client), чтобы сделать
сеанс работы клиента с системой обмена сообщениями транзакционным. Благо-
даря этому клиент сам сможет задавать границы транзакций.
Рис. 10.7. Последовательность действий транзакционного получателя
На рис. 10.7 приложение получает сообщение, но система обмена сообщениями пока
что не удаляет его из канала. Если на этом этапе приложение даст сбой, после возобнов-
ления его работы сообщение все еше будет находиться в канале, а значит, не потеряется.
Получив сообщение, приложение начинает его обработку. Когда приложение завершит
обработку сообщения и окончательно убедится в том, что хочет потребить это сообще-
ние, оно подтверждает выполнение транзакции. Получив подтверждение, система обме-
на сообщениями удаляет указанное сообщение из канала. Если теперь приложение вый-
дет из строя, после восстановления его работы сообщения больше не будет в канале.
Транзакционный клиент (Transactional Client)
501
Итак, прежде чем подтвердить выполнение транзакции, приложение должно действи-
тельно закончить обработку сообщения.
Как внешнее управление транзакциями системы обмена сообщениями помогает при-
ложению координировать выполнение нескольких задач? Вот как действует приложение
в каждом из упоминавшихся сценариев.
Отправка-получение пары сообщений
1. Что сделать. Начать транзакцию, получить и обработать первое сообщение, соз-
дать и отправить второе сообщение, после этого подтвердить выполнение тран-
закции. (Такое поведение часто реализуют в рамках шаблонов запрос-ответ,
маршрутизатор сообщений и транслятор сообщений.)
2. Чего мы этим добьемся. Первое сообщение не будет удалено из своего канала до
тех пор, пока второе сообщение не будет успешно добавлено в свой (разумеется,
другой) канал.
3. Тип транзакции. Если оба сообщения отправляются по каналам одной и той же
системы обмена сообщениями, мы имеем дело с простой транзакцией. Если
же каналы управляются разными системами обмена сообщениями, как, напри-
мер, в случае с мостом обмена сообщениями (Messaging Bridge, с. 159), это будет рас-
пределенная транзакция, координирующая работу двух систем.
4. Предупреждение. Описанная транзакция может применяться только получателем
запроса, который отправляет ответ. Инициатор запроса не может использовать
одну и ту же транзакцию, чтобы отослать запрос и ждать ответа. Если он попыта-
ется это сделать, запрос никогда не будет отправлен (потому что транзакция от-
правки не будет подтверждена), а значит, ответ не прилет.
Группа сообщений
1. Что сделать. Начать транзакцию, по очереди отправить или получить все сообще-
ния из группы (например, из цепочки сообщений), после этого подтвердить выпол-
нение транзакции.
2. Чего мы этим добьемся. При отправке группы сообщений ни одно из них не будет
добавлено в канал до тех пор, пока они все не будут успешно отправлены. При
получении группы сообщений ни одно из них не будет удалено из канала до тех
пор, пока они все не будут успешно получены.
3. Тип транзакции. Поскольку все сообщения отправляются или приходят по одному
и тому же каналу, он будет управляться одной системой обмена сообщениями,
а значит, транзакция будет простой. Кроме того, во многих реализациях систем
обмена сообщениями отправка группы сообщений в рамках одной транзакции
гарантирует, что на другом конце канала они будут получены в том же порядке,
в котором были отправлены.
Координация “сообщение — база данных”
1. Что сделать. Начать транзакцию, получить сообщение, обновить базу данных, по-
сле этого подтвердить выполнение транзакции. Или же обновить базу данных, от-
править сообщение, чтобы уведомить об обновлении другие компоненты, и под-
502
Глава 10. Конечные точки обмена сообщениями
твердить выполнение транзакции. (Такое поведение часто реализуют в шаблоне
адаптер канала.)
2. Чего мы этим добьемся. Сообщение не будет удалено из канала до тех пор, пока не
произойдет обновление базы данных (или же база данных не будет обновлена, по-
ка не удастся разослать соответствующие уведомления).
3. Тип транзакции. Поскольку в системе обмена сообщениями и базе данных исполь-
зуются собственные диспетчеры транзакций, их действия будут охватываться рас-
пределенной транзакцией.
Координация “сообщение — рабочий поток”
1. Что сделать. Использовать пару сообщений запрос-ответ для выполнения едини-
цы работы. Начать транзакцию, открыть единицу работы, отправить сообщение
с запросом, подтвердить выполнение транзакции. Или же начать другую транзак-
цию. получить сообщение с ответом, закрыть или аварийно завершить единицу
работы, подтвердить выполнение транзакции.
2. Чего мы этим добьемся. Единица работы не будет успешно закрыта, пока запрос не
будет отправлен; ответ не будет удален из канала, пока единица работы не будет
обновлена.
3. Тип транзакции. Поскольку в системе обмена сообщениями и в механизме управ-
ления рабочим потоком используются собственные диспетчеры транзакций, их
действия будут охватываться распределенной транзакцией.
Действия, описанные выше, гарантируют, что приложение не потеряет полученное
сообщение или не забудет его отправить. Ес л и в процессе получения или отправки про-
изойдет сбой, приложение выполнит откат транзакции и попытается начать сначала.
Транзакционные клиенты, использующие событийно управляемые потребители
(Event-Driven Consumer, с. 511), могут работать не так, как ожидается. Обычно такой по-
требитель должен подтверждать выполнение транзакции, в рамках которой он получил
сообщение, и только затем передавать сообщение приложению. Если после этого прило-
жение проанализирует сообщение и решит, что не хочет его потреблять, или же если
приложение обнаружит ошибку и захочет выполнить откат потребления, оно не сможет
этого сделать, потому что не будет иметь доступа к транзакции. Таким образом, событий-
но управляемый потребитель будет функционировать одинаково вне зависимости от того,
является ли его клиент транзакционным.
Системы обмена сообщениями могут принимать участие в распределенных транзакци-
ях, хотя таковые поддерживаются не всеми реализациями. В JMS поставщик может выпол-
нять роль ресурса ХА и принимать участие в транзакциях JTA (Java Transaction API, см.
[18]). Такое поведение определяется классами ХА из пакета javax. jms (в частности,
javax. jms.XASession), а также классами Из пакета javax. transaction.ха. В специ-
фикации JMS рекомендуется, чтобы клиенты JMS не пытались обрабатывать распределен-
ные транзакции напрямую. По этой причине Приложение должно использовать поддержку
распределенных транзакций, предоставляемую сервером приложений J2EE. Очереди сооб-
щений MSMQ также могут участвовать в транзакциях ХА; в .NET такое поведение задается
свойством MessageQueue. Transactional и классом MessageQueueTransaction.
Транзакционный клиент (Transactional Client)
503
Как уже говорилось, транзакционный клиент удобно использовать в сочетании с други-
ми шаблонами. В качестве примера можно привести шаблоны запрос-ответ, цепочка сооб-
щений, адаптер канала, а также фильтры сообщений в каналах и фильтрах {Pipes and Filters,
с. 102). Аналогичным образом получатель сообщения с событием {Event Message, с. 174) мо-
жет захотеть, чтобы сообщение удалялось из канала лишь тогда, когда получатель полно-
стью обработает событие. Транзакционный клиент плохо сочетается с событийно управляе-
мым потребителем или диспетчером сообщений {Message Dispatcher, с. 521). Лучше не исполь-
зовать его и с конкурирующими потребителями {Competing Consumers, с. 515), а вот с одним
опрашивающим потребителем {Polling Consumer, с. 507) проблем быть не должно.
Пример: транзакционный сеанс (JMS)
В JMS клиент может стать транзакционным при создании сеанса [14,17].
Connection connection = // Получить соединение.
Session session =
connection.createSession(true. Session.AUTO_ACKNOWLEDGE);
Этот сеанс будет транзакционным, потому что значение первого параметра метода
createSession равно true.
Когда клиент использует транзакционный сеанс, он должен явно подтверждать
отправку и получение, чтобы те действительно произошли.
Queue queue = // Получить очередь.
Messageconsumer consumer = session.createConsumer(queue);
Message message = consumer.receive();
На этом этапе сообщение считается потребленным только с точки зрения своего тран-
закционного получателя. Другие получатели все еще рассматривают его как доступное.
session.commit();
После подтверждения транзакции (если, конечно, оно не привело к возникновению
исключений) сообщение будет считаться потребленным с точки зрения всех получателей
системы обмена сообщениями.
Пример: транзакционная очередь сообщений (.NET)
В .NET очереди сообщений по умолчанию не являются транзакционными. Чтобы
использовать транзакционный клиент, очередь сообщений следует явно создать как
транзакционную.
MessageQueue.Create("MyQueue", true);
У нас появилась транзакционная очередь сообщений. Каждое действие клиента по от-
ношению к этой очереди (отправка или получение) может быть транзакционным либо не-
транзакционным. Транзакционная операция получения выглядит следующим образом.
504
Глава 10. Конечные точки обмена сообщениями
MessageQueue queue = new MessageQueue("MyQueue");
MessageQueueTransaction transaction =
new MessageQueueTransaction();
transaction.Begin();
Message message = queue.Receive(transaction);
transaction.Commit();
Хотя клиент получил сообщение, оно все равно оставалось в очереди до тех пор, пока
клиент не подтвердил успешное выполнение транзакции [39].
Пример: транзакционный фильтр (MSMQ)
В примере, приведенном ниже, базовый фильтр, рассмотренный нами при описании
шаблона каналы и фильтры (Pipes and Filters, с. 102), расширяется с учетом использования
транзакций. Мы реализуем сценарий “Отправка-получение пары сообщений”, получая и
отправляя сообщения в рамках одной транзакции. Обратите внимание: чтобы превратить
фильтр в транзакционный, понадобилось лишь несколько строк кода. Для управления
транзакцией будет применяться переменная типа MessageQueueTransaction. Мы от-
кроем транзакцию перед тем, как потребим входящее сообщение inputMessage, и под-
твердим ее выполнение после того, как опубликуем исходящее сообщение outputMes-
sage. Если в процессе получения или отправки возникнет исключение, мы выполним
аварийное завершение транзакции. Это приведет к откату всех действий, связанных с по-
треблением и публикацией сообщения. Входящее сообщение вернется в очередь и снова
станет доступным для всех потребителей системы.
public class TransactionalFilter
{
protected MessageQueue inputQueue;
protected MessageQueue outputQueue;
protected Thread receiveThread;
protected bool stopFlag = false;
public TransactionalFilter (MessageQueue inputQueue,
MessageQueue outputQueue)
this.inputQueue = inputQueue;
this.inputQueue.Formatter = new
System.Messaging.XmlMessageFormatter
(new String[] {"System.String,mscorlib"});
this.outputQueue = outputQueue;
}
public void Process()
{
Threadstart receiveDelegate = new
Threadstart (this.ReceiveMessages) ,-
receiveThread = new Thread(receiveDelegate);
receiveThread.Start();
}
private void ReceiveMessages()
Транзакционный клиент (Transactional Client)
505
MessageQueueTransaction myTransaction = new
MessageQueueTransaction();
while (IstopFlag)
try
myTransaction.Begin() ,-
Message inputMessage =
inputQueue.Receive(myTransaction);
Message outputMessage = ProcessMessage(inputMessage);
outputQueue.Send(outputMessage, myTransaction);
myTransaction. Commit () ,-
}
catch (Exception e)
Console.WriteLine(e.Message +
" - Transaction aborted ");
// "Транзакция прервана".
myTransaction.Abort();
}
}
}
protected virtual Message ProcessMessage(Message m)
Console.WriteLine("Received Message: " + m.Body);
return m,-
}
}
Как проверить работу транзакционного клиента (Transactional Client)'! Мы создадим
класс, производный от базового класса TransactionalFilter, и назовем его Random-
lyFailingFilter. Для каждого потребленного сообшения указанный фильтр генериру-
ет случайное число от 0 до 10. Если это число окажется меньше, чем 3, фильтр выдаст не-
которое исключение (на наш взгляд, для этого примера лучше всего подойдет Argument -
NullException). Если реализовать этот фильтр поверх базового, нетранзакционного
фильтра, описанного в рамках шаблона каналы и фильтры, мы будем терять примерно
каждое третье сообщение.
public class RandomlyFailingFilter : TransactionalFilter
Random rand = new Random();
public RandomlyFailingFilter(MessageQueue inputQueue,
MessageQueue outputQueue)
: base (inputQueue, outputQueue) { }
protected override Message ProcessMessage(Message m)
string text = (string)m.Body;
Console.WriteLine("Received Message: " + text);
506
Глава 10. Конечные точки обмена сообщениями
if (rand.Next(10) < 3)
Console.WriteLine("EXCEPTION");
throw (new ArgumentNullExc^ption());
if (text == "end")
stopFlag = true;
return (tn) ;
}
}
Чтобы удостовериться в том, что при использовании транзакционной версии фильтра
отброшенные сообщения не будут потеряны, проведем небольшой тест. Мы опубликуем
последовательность сообщений во входящей очереди, а затем проверим, в правильном ли
порядке происходит получение сообщений из исходящей очереди. Важно помнить, что
-исходящие сообщения останутся в том же порядке только тогда, когда запускается одпп
экземпляр транзакционного фильтра. Если параллельно запустить несколько экземпля-
ров фильтра, порядок сообщений может (и должен) измениться. Более подробно об этом
рассказывается при описании шаблона преобразователь порядка (Resequencer, с. 297).
public void RunTestsO
{
MessageQueueTransaction myTransaction = new
MessageQueueTransaction();
for (int i=0; i < messages.Length; i++)
myTransaction.Begin();
inQueue.Send(messages[i], myTransaction);
myTransaction.Commit();
}
for (int i=0; i < messages.Length; i++)
{
myTransaction.Begin();
Message message = outQueue.Receive(new TimeSpan(0,0,3),
myTransaction);
myTransaction.Commit();
String text = (String)message.Body;
Console.Write(text);
if (text == messages[i])
Console.WriteLine(" OK");
else
Console.WriteLine(" ERROR").
}
Console.WriteLine("Hit enter to exit");
// "Для выхода нажмите ENTER".
Console.ReadLine();
Опрашивающий потребитель (Polling Consumer)
507
Опрашивающий потребитель (Polling Consumer)
Приложение должно потреблять сообщения (Message, с. 98), но оно хочет самостоя-
тельно выбирать, когда именно потреблять то или иное сообщение.
Может ли приложение потреблять сообщения только тогда, когда оно готово это
делать?
Потребители сообщений нужны системе обмена сообщениями только по одной при-
чине — чтобы потреблять сообщения. Каждое сообщение соответствует некоторому
объему работы, поэтому потребители обрабатывают сообщения и делают всю необходи-
мую работу.
Но как потребитель узнает о том, что в канале появилось новое сообщение? Самый
простой способ — постоянно проверять канал на наличие новых сообщений. Когда по-
требитель встречает новое сообщение, он потребляет его и переходит к следующему но-
вому сообщению. Такой процесс называется опросом (polling).
Главное преимущество опроса состоит в том, что потребитель может запросить из ка-
нала следующее сообщение только тогда, когда готов это сделать. Таким образом, потре-
битель получает сообщения с удобной для себя интенсивностью (а не по мере того, как
они прибывают в канал).
Приложение должно воспользоваться опрашивающим потребителем (Polling
Consume/1). Когда такой потребитель хочет получить сообщение, он выполняет яв-
ное обращение к каналу.
Отправитель Сообщение
Получателя такого типа часто называют синхронным, потому что поток получателя бло-
кирует свое выполнение до тех пор, пока не будет получено сообщение. Мы решили назвать
его опрашивающим потребителем, поскольку получатель опрашивает канал на предмет по-
явления в нем новых сообщений, обрабатывает полученное сообщение и обращается к ка-
налу за следующим. Во многие интерфейсы API систем обмена сообщениями для удобства
включен метод Receive (или подобный), который блокирует работу получателя, пока со-
общение не будет доставлено, а также методы наподобие ReceiveNoWait () и Receive (0),
508
Глава 10. Конечные точки обмена сообщениями
которые сразу же возвращают результат, если в канале не окажется сообщения. Разница
между упомянутыми методами становится заметной только в том случае, если потребитель
опрашивает канал чаще, чем прибывают новые сообщения.
Опрашивающий потребитель — это объект, который используется приложением для
получения сообщений путем явного запроса сообщений из канала. Когда приложение
готово к получению нового сообщения, оно выполняет опрос потребителя. Тот, в свою
очередь, извлекает сообщение из канала и передает его получателю (рис. 10.8). Способ
извлечения потребителем сообщения из канала зависит от реализации и может включать
в себя опрос или не включать его. Все, что должно знать приложение, — что оно не полу-
чит сообщение, пока само об этом не попросит.
Рис. 10.8. Последовательность действий опрашивающего потребителя
Когда приложение выполняет опрос потребителя на предмет новых сообщений, по-
требитель блокирует свое выполнение, пока не получит сообщение, которое необходимо
возвратить приложению (или до выполнения другого условия, например истечения вре-
мени ожидания). Получив сообщение, приложение может заняться его обработкой.
Когда приложение закончит обработку сообщения и захочет получить еще одно сообще-
ние, оно снова начнет опрос потребителя.
Используя опрашивающие потребители, приложение может контролировать, сколько
сообщений потребляется одновременно. Для этого приложение ограничивает число оп-
рашивающих потоков. Это позволяет избежать перегрузки приложения слишком боль-
шим количеством запросов; лишние сообщения будут стоять в очереди, пока получатель
их не обработает.
Опрашивающий потребитель (Polling Consumer)
509
Обычно приложение-получатель использует минимум по одному потоку на каждый
канал, который хочет опрашивать. На самом деле, однако, оно может применять один
общий поток для опроса всех каналов. Это поможет сэкономить число опрашивающих
потоков, если в каналах редко появляются сообщения. Чтобы с помощью одного потока
опросить один канал (исходя из предположения, что поток бездействует, пока не прибу-
дет сообщение), используйте версию метода Receive, которая блокирует работу получа-
теля, пока не придет сообщение. Если же с помощью одного потока необходимо опро-
сить несколько каналов либо если до прибытия сообщения поток должен выполнять ка-
кую-то другую работу, воспользуйтесь версией метода получения с ограниченным
временем ожидания или методом наподобие ReceiveNoWait (). Тогда если поток обна-
ружит, что канал пуст, он перейдет к опросу следующего канала или переключится на
выполнение другой работы.
Потребитель, который слишком часто опрашивает канал или слишком долго блоки-
рует потоки, может оказаться неэффективным. В подобной ситуации большую пользу
принесет событийно управляемый потребитель (Event-Driven Consumer, с. 511). Несколько
опрашивающих потребителей могут быть конкурирующими потребителями (Competing
Consumers, с. 515). Диспетчер сообщений (Message Dispatcher, с. 521) тоже может быть реа-
лизован в виде опрашивающего потребителя. Последний, в свою очередь, может быть из-
бирательным потребителем (Selective Consumer, с. 528) и постоянным подписчиком (Durable
Subscriber, с. 535). Наконец, опрашивающий потребитель может функционировать в каче-
стве транзакционного клиента (Transactional Client, с. 498), чтобы контролировать факти-
ческое удаление сообщений из канала.
Пример: методы получения сообщений (JMS)
В JMS для синхронного потребления сообщений применяется метод Messageconsumer.
receive [14,17]. Существует три его разновидности.
1. receive (). Блокирует работу получателя, пока в канале не появится новое сооб-
щение, и возвращает это сообшение.
2. receiveNoWait (). Проверяет, есть ли в канале сообщение, и возвращает это со-
общение или NULL.
3. receive (long). Блокирует работу получателя, пока в канале не появится новое
сообщение или пока не истечет заданное время ожидания. Возвращает это сооб-
щение (если оно есть) или NULL (если по истечении времени ожидания сообще-
ние так и не пришло).
Ниже приведен простой фрагмент кода, в котором описываются создание объекта по-
требителя и получение сообщения.
Destination dest = // Получить объект назначения.
Session session = // Создать сеанс.
Messageconsumer consumer = session.createConsumer(dest);
Message message = consumer.receive();
510
Глава 10. Конечные точки обмена сообщениями
Пример: методы получения сообщений (.NET)
В .NET для синхронного потребления сообщений применяется метод MessageQueue.
receive [39]. Существует несколько его разновидностей, самые простые из которых пе-
речислены ниже.
1. Receive (). Блокирует работу получателя, пока в канале не появится новое сооб-
щение, и возвращает это сообщение.
2. Receive (Timespan). Блокирует работу получателя, пока в канале не появится
новое сообщение, и возвращает это сообщение. Если по истечении времени ожи-
дания сообщение так и не появится, выдает исключение MessageQueue-
Exception.
Ниже приведен простой фрагмент кода, в котором описывается получение сообще-
ния из существующей очереди.
MessageQueue queue = // Получить очередь.
Message message = queue.Receive();
Событийно управляемый потребитель (Event-Driven Consumer)
511
Событийно управляемый потребитель (Event-Driven Consumer)
Приложение должно потреблять сообщения (Message, с. 98) сразу же, как только они
прибывают.
Как настроить приложение на автоматическое потребление сообщений по мере
их прибытия?
Главный недостаток опрашивающего потребителя (Polling Consumer, с. 507) состоит
в том, что когда в канале нет сообшений, потребитель впустую блокирует потоки и (или)
расходует процессорное время. Опрос позволяет клиенту контролировать скорость
потребления, но приводит к чрезмерной трате ресурсов, когда потреблять нечего.
Вместо того чтобы постоянно спрашивать у канала, не появились ли в нем новые
сообщения, канал мог бы сам сообщать клиенту об их поступлении. Иными словами,
не заставляйте клиент запрашивать сообщение — просто передайте ему сообщение, как
только оно появится в канале.
Приложение должно использовать событийно управляемый потребитель (Event-
Driven Consumer), которому автоматически передаются сообщения, появившиеся
в канале.
Отправитель Сообщение
Получатель такого типа еще называется асинхронным, потому что у него нет рабо-
тающего потока до тех пор, пока поток обратного вызова не доставит сообщение.
Мы решили назвать его событийно управляемым потребителем, поскольку в данном случае
доставку сообщения можно сравнить с событием, приводящим получатель в действие.
Событийно управляемый потребитель — это объект, который вызывается системой
обмена сообщениями при поступлении в канал потребителя нового сообщения. Потре-
битель передает сообщение приложению с помощью метода обратного вызова, предос-
тавленного интерфейсом API приложения. Способ получения сообщения системой об-
мена сообщениями зависит от реализации последней и может быть или не быть собы-
тийно управляемым. Потребитель должен знать лишь то, что он может бездействовать до
тех пор, пока его не вызовет система обмена сообщениями и не передаст ему сообщение.
512
Глава 10. Конечные точки обмена сообщениями
Событийно управляемый потребитель приводится в действие системой обмена сообще-
ниями. Сам же он запускает метод обратного вызова, специфичный для приложения.
Чтобы устранить “разрыв” между приложением и системой обмена сообщениями, у потре-
бителя должна быть реализация, специфичная для приложения и в то же время совмести-
мая со стандартным интерфейсом API, определенным системой обмена сообщениями.
Код событийно управляемого потребителя состоит из двух частей.
1. Инициализация. Приложение создает объект потребителя, специфичный для при-
ложения, и сопоставляет его с конкретным каналом сообщений (Message Channel,
с. 93). Код инициализации достаточно запустить один раз, после чего потребитель
будет готов получать сообщения.
2. Потребление. Потребитель получает сообщение и передает его на обработку при-
ложению. Этот код запускается по одному разу для каждого потребленного сооб-
щения.
Приложение создает собственный потребитель и сопоставляет его с каналом. После
инициализации объекта потребителя он (как, впрочем, и приложение) может бездейст-
вовать, не запуская активные потоки до тех пор, пока его не уведомят о поступлении
нового сообщения.
Когда сообщение будет доставлено, система обмена сообщениями вызовет метод
потребителя, уведомляющий о поступлении нового сообщения, и передаст ему в качестве
параметра это сообщение. Потребитель воспользуется методом обратного вызова, чтобы
передать полученное им сообщение приложению (рис. 10.9). Получив сообщение, при-
ложение сможет заняться его обработкой. Когда приложение закончит обработку сооб-
щения, оно вместе с потребителем сможет снова бездействовать до тех пор, пока в канале
не появится следующее сообщение. Обычно система обмена сообщениями не запускает
по нескольку потоков на один потребитель, поэтому потребитель сможет обрабатывать
только по одному сообщению за раз.
Событийно управляемый потребитель автоматически потребляет новые сообщения по
мере их появления. Если же вы хотите самостоятельно контролировать интенсивность
получения сообщений, воспользуйтесь опрашивающим потребителем (Polling Consumer,
с. 507). Несколько событийно управляемых потребителей могут быть конкурирующими
потребителями (Competing Consumers, с. 515). Диспетчер сообщений (Message Dispatcher,
с. 521) тоже может быть реализован в виде событийно управляемого потребителя. Послед-
ний, в свою очередь, может быть избирательным потребителем (Selective Consumer, с. 528)
и постоянным подписчиком (Durable Subscriber, с. 535). Сочетать событийно управляемый
потребитель с транзакционным клиентом (Transactional Client, с. 498) крайне нежелатель-
но (см. пример реализации событийно управляемого потребителя в JMS).
Пример: MessageListener (JMS)
В JMS событийно управляемым потребителем (Event-Driven Consumer) является класс, реа-
лизующий интерфейс MessageListener [14]. Указанный интерфейс содержит объявле-
ние одного-единственного метода по имени onMessage (Message). Потребитель реали-
зует метод onMessage для обработки сообщения. Ниже приведен простой пример реали-
зации событийно управляемого потребителя, а точнее — той его части, которая касается
потребления сообщений (т.е. исполнителя).
Событийно управляемый потребитель (Event-Driven Consumer)
513
Рис. 10.9. Последовательность действий событийно управляемого потребителя
public class MyEventDrivenConsumer implements MessageListener {
public void onMessage(Message message) {
// Обработать сообщение.
}
}
Другая часть кода событийно управляемого потребителя, касающаяся инициализации,
создает объект исполнителя (являющийся экземпляром класса MessageListener) и со-
поставляет его с потребителем сообщений из желаемого канала.
Destination destination = // Получить пункт назначения.
Session session = // Создать сеанс.
Messageconsumer consumer = session.createConsumer(destination);
MessageListener listener = new MyEventDrivenConsumer();
consumer.setMessageListener(listener);
Теперь, когда сообщение будет доставлено в пункт назначения, поставщик JMS вызо-
вет метод MyEventDrivenConsumer. onMessage, передав ему в качестве параметра дос-
тавленное сообщение.
Обратите внимание: в JMS событийно управляемый потребитель, одновременно являю-
щийся транзакционным клиентом (Transactional Client, с. 498), будет работать не так, как
ожидается. Обычно откат транзакции выполняется тогда, когда код, описывающий тран-
закцию, выдает исключение. Но сигнатура метода MessageListener.onMessage
514
Глава 10. Конечные тачки обмена сообщениями
не предусматривает выдачу исключений (таких, как JMSException), и исключение вре-
мени выполнения приравнивается к ошибке программиста. Если такое исключение воз-
никнет, поставщик JMS отреагирует на него доставкой следующего сообщения, а сооб-
щение, которое привело к возникновению исключения, будет потеряно [14, 17]. Для ус-
пешной реализации транзакционного, событийно управляемого поведения лучше
использовать компоненты MDB [10, 14].
Пример: ReceiveCompletedEventHandler (.NET)
В .NET часть кода событийно управляемого потребителя {Event-Driven Consumer), касаю-
щаяся потребления сообщений, реализует метод, имя которого передается экземпляру
делегата ReceiveCompletedEventHandler. Такой метод должен принимать два пара-
метра: очередь сообщений MessageQueue и объект ReceiveCompletedEventArgs, в ко-
тором хранятся аргументы для события ReceiveCompleted [39]. Данные аргументы ис-
пользуются методом для извлечения сообщения из очереди и его последующей обработ-
ки. Ниже приведен пример реализации такого метода.
public static void MyEventDrivenConsumer(Object source,
ReceiveCompletedEventArgs asyncResult)
MessageQueue mq = (MessageQueue) source;
Message m = mq.EndReceive(asyncResult.AsyncResult);
11 Обработать сообщение.
mq.BeginReceive();
return;
}
В другой части кода событийно управляемого потребителя, касающейся инициализа-
ции, прописано, что для обработки события ReceiveCompleted очередь должна создать
экземпляр делегата ReceiveCompletedEventHandler и передать ему в качестве пара-
метра имя вышеупомянутого метода.
MessageQueue queue = // Получить очередь.
queue.ReceiveCompleted +=
new ReceiveCompletedEventHandler(MyEventDrivenConsumer);
queue.BeginReceive();
Теперь, когда в очереди появится новое сообщение, очередь инициирует событие Re-
ceiveCompleted, а оно приведет к запуску метода MyEventDrivenConsumer.
Конкурирующие потребители (Competing Consumers)
515
Конкурирующие потребители (Competing Consumers)
Приложение использует обмен сообщениями (Messaging, с. 87), но не успевает обраба-
тывать сообщения с той же скоростью, с которой они появляются в канале.
Как организовать параллельную обработку нескольких сообщений одним и тем же
клиентом?
Сообщения (Message, с. 98) прибывают по каналу сообщений (Message Channel, с. 93)
в некоторой последовательности. Вполне естественно, что потребитель тоже пытается
обрабатывать их последовательно, по мере поступления. К сожалению, последовательное
потребление может происходить слишком медленно, вследствие чего сообщения начнут
накапливаться в канале. Это превратит систему обмена сообщениями в “узкое место”
и негативно скажется на производительности всего решения в целом. Причины того, что
скорость поступления сообщений опережает скорость их потребления, могут быть раз-
ными — сообщения в канале публикуются несколькими отправителями; простой сети
вызывает большое скопление сообщений, которые после возобновления работы сети
будут отправлены одновременно; получатель вышел из строя, а затем возобновил свою
работу; потребление и обработка сообщения требуют куда больше усилий, чем его созда-
ние и отправка, и т.п.
Чтобы ускорить обработку сообщений, приложение могло бы использовать несколько
каналов, но это не решит проблему до конца. Один из каналов может превратиться в
“узкое место”, в то время как другой будет подолгу простаивать. Отправителям тяжело
угадать, какой из двух, на первый взгляд, эквивалентных каналов необходимо использо-
вать. Тем не менее наличие нескольких каналов позволит организовать параллельную
обработку сообщений, распределив их между несколькими потребителями (по одному на
каждом канале). К сожалению, производительность такого решения все равно будет
ограничена числом каналов, определенных приложением.
Итак, увеличение числа каналов не устранит проблему. Необходимо, чтобы несколь-
ко потребителей могли обрабатывать сообщения из одного канала.
Конкурирующие потребители — это группа потребителей, каждый из которых предна-
значен для получения сообщений по одному и тому же каналу “точка-точка” (Point-to-Point
Channel, с. 131). Когда в канале появляется новое сообщение, его теоретически может полу-
чить любой из потребителей. Система обмена сообщениями (а точнее, ее конкретная реа-
лизация) сама решает, какому потребителю отдать сообщение. Со стороны же это выглядит
так, как будто потребители соревнуются друг с другом за право получить сообщение. Полу-
чив сообщение, потребитель может передать его на обработку оставшейся части своего
приложения. Данное решение работает только на каналах “точка-точка”. Если реализовать
его на канале “публикация-подписка” (Publish-Subscribe Channel, с. 134), потребители станут
обрабатывать многочисленные копии одних и тех же сообщений.
516
Глава 10. Конечные точки обмена сообщениями
Создайте несколько конкурирующих потребителей (Competing Consumers),
которые смогут параллельно обрабатывать сообщения, пришедшие по одному
и тому же каналу.
Получатель
Схема работы конкурирующих потребителей показана на рис. 10.10.
Каждый из конкурирующих потребителей выполняется в собственном потоке, поэтому
обработка сообщений может происходить параллельно. Средства управления транзак-
циями в системе обмена сообщениями следят за тем, чтобы каждое вновь прибывшее со-
общение доставалось только одному потребителю. Пока этот потребитель занят обработ-
кой сообщения, канал может доставлять другие сообщения, которые будут параллельно
приниматься и обрабатываться другими потребителями. Канал координирует действия
потребителей, гарантируя, что они получат разные сообщения. Потребителям не нужно
самим согласовывать свои действия друг с другом.
Потребители обрабатывают сообщения в параллельном режиме, поэтому скорость
потребления будет определяться не тем, сколько времени отнимает обработка одного
сообщения, а тем, как быстро канал будет подавать сообщения потребителям. Если чис-
ло потребителей невелико, скорость обработки сообщений может оставаться “узким ме-
стом” производительности системы, однако увеличение числа потребителей способно
смягчить или даже устранить эту проблему (в зависимости от того, насколько велик
объем системных ресурсов).
Конкурирующие потребители (Competing Consumers)
517
Рис. 10.10. Последовательность действий конкурирующих потребителей
Чтобы потребители могли одновременно обрабатывать сообщения, каждый из них
должен выполняться в отдельном потоке. Для опрашивающих потребителей (Polling
Consumer, с. 507) это означает, что каждый потребитель должен проводить параллельный
опрос в рамках собственного потока. Если же конкурирующие потребители являются
событийно управляемыми потребителями (Event-Driven Consumer, с. 511), система обмена
сообщениями должна выделить на каждого из них по одному потоку. Этот поток будет
применяться для передачи сообщения потребителю, а затем использоваться потребите-
лем для обработки сообщения.
Хорошая система обмена сообщениями определит, что канал прослушивается
несколькими конкурирующими потребителями, и организует внутреннее распределение
сообщений по принципу диспетчера сообщений (Message Dispatcher, с. 521). Это гаранти-
рует, что каждое сообщение будет доставлено только одному потребителю, и позволит
избежать конфликтов, которые могут возникнуть, если несколько потребителей сочтут
себя получателями одного и того же сообщения. Менее “интеллектуальная” система до-
пустит, чтобы несколько потребителей попытались получить одно и то же сообщение.
Если это действительно произойдет, сообщение достанется тому потребителю, который
первым подтвердит выполнение своей транзакции. Оставшиеся потребители не смогут
успешно подтвердить выполнение транзакций и будут вынуждены совершить откат.
Система обмена сообщениями, в которой несколько потребителей могут попытаться
принять одно и то же сообщение, существенно снижает эффективность функционирова-
ния транзакционного клиента (Transactional Client, с. 498). Клиент думает, что получил
сообщение, потребляет его, тратит свои силы на его обработку, а затем терпит неудачу,
когда пытается подтвердить выполнение транзакции (потому что сообщение уже было
потреблено его конкурентом). Частое выполнение подобных действий снижает произво-
дительность приложения-получателя, хотя назначение конкурирующих потребителей
518
Глава 10. Конечные точки обмена сообщениями
состояло как раз в обратном. По этой причине производительность транзакционных
конкурирующих потребителей необходимо тщательно измерить; она может существенно
различаться для разных реализаций и конфигураций систем обмена сообщениями.
Конкурирующие потребители могут применяться не только для распределения нагруз-
ки между несколькими потоками потребителей одного и того же приложения. Потребле-
ние можно распределить и между несколькими приложениями (например, процессами).
В этом случае, если одно приложение не в состоянии достаточно быстро потреблять
сообщения, ему на помощь можно снарядить еще несколько приложений-получателей
(в каждом из которых, в свою очередь, будет по нескольку потоков потребителей). Такая
возможность теоретически позволяет повысить скорость обработки сообщений до лю-
бого желаемого уровня; единственным ограничением здесь будет способность системы
обмена сообщениями доставлять большое количество сообщений по одному каналу.
Координация действий конкурирующих потребителей друг с другом зависит от кон-
кретной реализации системы обмена сообщениями. Если клиент хочет реализовать
такую координацию собственными силами, он должен воспользоваться диспетчером
сообщений. Конкурирующие потребители могут быть опрашивающими потребителями,
событийно управляемыми потребителями или комбинацией тех и других. Как уже отмеча-
лось, использование транзакционных конкурирующих потребителей может привести к
напрасному расходованию ресурсов, если потребителям сообщений, не успевшим отпра-
вить подтверждение обработки, придется постоянно проводить откат транзакций.
Пример: простые конкурирующие потребители (JMS)
Рассмотрим простой пример реализации конкурирующих потребителей {Competing
Consumers) в Java. В нашем примере несколько потребителей запускаются внешним
объектом (драйвером/диспетчером), код которого здесь не показан. Каждый потребитель
выполняется в собственном потоке, а для его остановки вызывается метод stopRun-
ning().
Сеанс JMS должен быть однопоточным [14, 17]. Сеанс сериализует порядок потреб-
ления сообщений [14, 17]. По этой причине, чтобы конкурирующие потребители кор-
ректно функционировали в собственных потоках и могли параллельно потреблять сооб-
щения, у каждого из них должен быть собственный сеанс (а значит, и собственный
объект Messageconsumer). В спецификации JMS не оговаривается семантика доставки
сообщений конкурирующим получателям QueueReceiver. Более того, в ней не требует-
ся, чтобы данный подход работал вообще. Таким образом, приложения, использующие
эту технологию, не обладают свойством переносимости и могут функционировать не-
одинаково для разных поставшиков JMS [14, 17].
Класс CompetingConsumer реализует интерфейс Runnable, чтобы каждый из потре-
бителей мог выполняться в отдельном потоке; это позволит потребителям одновременно
обрабатывать сообщения. Все потребители используют один и тот же объект соединения
(Connection), но каждый из них создает собственный сеанс (Session). Это очень важ-
но, потому что сеанс поддерживает работу только с одним потоком. Каждый потребитель
получает из очереди сообщение и обрабатывает его; затем процесс повторяется.
import javax.jms.Connection;
import javax.jms.Destination;
import javax.jms.JMSException;
Конкурирующие потребители (Competing Consumers)
519
import javax.jms.Message;
import j avax.jms.MessageConsumer;
import javax.jms.Session;
import j avax.naming.NamingException;
public class CompetingConsumer implements Runnable {
private int performerlD;
private Messageconsumer consumer;
private boolean isRunning;
protected CompetingConsumer() {
super();
public static CompetingConsumer newConsumer(int id.
Connection connection. String queueName)
throws JMSException, NamingException {
CompetingConsumer consumer = new CompetingConsumer0;
consumer.initialize(id, connection, queueName);
return consumer;
protected void initialize(int id. Connection connection,
String queueName)
throws JMSException, NamingException {
performerlD = id;
Session session = connection.createSession(false.
Session.AUTO_ACKNOWLEDGE);
Destination dispatcherQueue =
JndiUtil.getDestination(queueName);
consumer = session.createConsumer(dispatcherQueue);
isRunning = true;
public void runt) {
try {
while (isRunning())
receiveSync();
} catch (Exception e) {
e.printStackTrace() ;
private synchronized boolean isRunning() {
return isRunning;
public synchronized void stopRunning() {
isRunning = false;
private void receiveSync() throws JMSException,
InterruptedException {
Message message = consumer.receive();
520
Глава 10. Конечные точки обмена сообщениями
if (message != null)
processMessage(message);
}
private void processMessage(Message message)
throws JMSException, InterruptedException {
int id = message.getlntProperty("cust_id");
System.out.println(System.currentTimeMillis() +
": Performer #" + performerID +
" starting; message ID " + id) ;
Thread.sleep(500);
System.out.println(System.currentTimeMillis() +
Performer #" + performerlD +
" processing.");
Thread.sleep(500);
System.out.printin(System.currentTimeMillis() +
": Performer #" + performerlD +
" finished.");
}
}
Как видим, создать простой конкурирующий потребитель несложно. Главное —
реализовать интерфейс Runnable и выполнить запуск потребителя в отдельном потоке.
Диспетчер сообщений (Message Dispatcher)
521
Диспетчер сообщений (Message Dispatcher)
Приложение использует обмен сообщениями (Messaging, с. 87). Необходимо, чтобы
один канал сообщений (Message Channel, с. 93) прослушивался несколькими потребителя-
ми, работающими в согласованном режиме.
Как наладить согласованное распределение и обработку сообщений между потре-
бителями одного и того же канала?
Если канал “точка-точка” (Point-to-Point Channel, с. 131) прослушивается нескольки-
ми потребителями, они будут выступать в качестве конкурирующих потребителей
(Competing Consumers, с. 515). Это удобно, когда все они являются взаимозаменяемыми,
но не подходит при использовании специализированных потребителей (когда желатель-
но, чтобы конкретные потребители принимали конкретные сообщения).
Если потребители прослушивают канал “публикация-подписка” (Publish-Subscribe Chan-
nel, с. 134), это не принесет желаемого эффекта. Вместо того чтобы распределять между со-
бой нагрузку, все потребители будут обрабатывать копии одних и тех же сообщений.
Функцию специализированных потребителей могли бы выполнять избирательные по-
требители (Selective Consumer, с. 528), но эта возможность под держивается не во всех сис-
темах обмена сообщениями. Впрочем, даже если она и поддерживается, системы обмена
сообщениями не всегда допускают выбор сообщения на основе значений из его тела.
Типы условных выражений, которые поддерживаются системами, могут быть слишком
просты для адекватного выбора нужного сообщения. Скорость оценки таких выражений
может быть крайне мала (а ведь их придется оценивать снова и снова!). Структуру выра-
жений придется согласовывать таким образом, чтобы одно значение выбора не могло
подпадать сразу под несколько выражений (т.е. чтобы сообщение всегда подходило толь-
ко для одного потребителя), а также чтобы не осталось значений выбора, не охваченных
ни одним из выражений. Для решения последней проблемы можно предусмотреть спе-
циальный способ обработки значений выбора, которые не были обработаны другими по-
требителями, а также любых непредвиденных значений.
Могут быть созданы потребители, которые будут специализироваться на обработке
сообщений определенных типов, а для распределения таких сообщений по потребителям
можно воспользоваться каналами типа данных (Datatype Channel, с. 139). Однако количе-
ство разных типов может быть таким большим, что создание отдельного канала на каж-
дый тип окажется неоправданным. Может случиться и так, что типизация сообщений
будет основываться на динамически меняющихся критериях. Реализовать доставку таких
сообщений с помощью фиксированного набора каналов трудно. Наконец, в компании
уже может быть большое количество каналов, создающих нагрузку на систему обмена
сообщениями, и увеличение этого числа еще в несколько раз (по количеству типов сооб-
щений) просто недопустимо.
Каждую из этих проблем легко решить, если потребители смогут работать вместе. Чтобы
избежать многократной обработки одного и того же сообщения, достаточно уведомить ос-
522
Глава 10. Конечные точки обмена сообщениями
тальных потребителей, что оно уже было обработано одним из них. Потребители могут
быть специализированными; если один из них получит “не свое” сообщение, он может пе-
редать его потребителю с нужной специализацией. Наконец, с целью экономии каналов
обмена сообщениями такие потребители могут быть размещены на одном канале. Они
будут согласовывать свои действия, чтобы сообщения попадали к нужным потребителям.
К сожалению, потребители — это крайне независимые объекты, действия которых
трудно поддаются координации. Специализированные потребители можно сделать дос-
таточно универсальными, чтобы они могли обрабатывать любое сообщение или переда-
вать работу другим, но это потребует серьезных усилий со стороны разработчиков, а так-
же существенно увеличит нагрузку на потребителей. Все потребители должны будут знать
друг о друге, а также о том, какие из них сейчас заняты, а какие — нет (чтобы по ошибке
не передать работу потребителю, занятому обработкой другого сообщения). Таким обра-
зом, организация совместной работы потребителей требует радикальной смены стан-
дартного подхода к архитектуре последних.
Некоторую помощь в этом деле может оказать шаблон посредник (Mediator, [12]).
Посредник координирует работу группы объектов, благодаря чему им не нужно согласо-
вывать свои действия друг с другом. Поскольку мы имеем дело с обменом сообщениями,
нам нужен посредник, который будет координировать действия потребителей канала.
Тогда каждый потребитель сможет сосредоточиться на обработке сообщений определен-
ного вида, а координатор будет следить за тем, чтобы поступающие сообщения попадали
к нужным потребителям.
Создайте диспетчер сообщений (Message Dispatched, который будет потреблять
сообщения из канала и распределять их между исполнителями.
Получатель
Диспетчер сообщений (Message Dispatcher)
523
Шаблон диспетчер сообщений состоит из компонентов двух видов.
1. Диспетчер. Объект, который потребляет сообщения из канала, а затем раздает их
исполнителям.
2. Исполнитель. Объект, который получает от диспетчера сообщение и обрабатывает его.
Когда диспетчер сообщений получает сообщение, он определяет, какому исполнителю
необходимо передать это сообщение. Получив сообщение, исполнитель может передать
его на обработку оставшейся части своего приложения. Объект исполнителя может зано-
во создаваться диспетчером или выбираться из пула доступных исполнителей. Каждый
исполнитель запускается в собственном потоке, что делает возможной одновременную
обработку сообщений. Все потребители могут подходить для обработки любых сообще-
ний, или же диспетчер может выбирать конкретный потребитель в зависимости
от свойств сообщения. Схема работы диспетчера сообщений показана на рис. 10.11.
Рис. 10.11. Последовательность действий диспетчера сообщений
Когда диспетчер получает сообщение, он передает его на обработку доступному ис-
полнителю. Если исполнитель обрабатывает сообщение, используя поток диспетчера,
то выполнение диспетчера блокируется до тех пор, пока исполнитель не завершит обра-
ботку сообщения. Если же исполнитель обрабатывает сообщение в собственном потоке,
то после запуска этого потока диспетчер может сразу же принимать другие сообщения
и передавать их другим исполнителям, чтобы обработка сообщений велась параллельно.
В последнем случае скорость потребления сообщений будет зависеть только от того, как
быстро диспетчер принимает и передает сообщения, и не зависеть от скорости их обра-
ботки отдельными исполнителями.
524
Глава 10. Конечные точки обмена сообщениями
Диспетчер выполняет роль соединения “один-ко-многим” между одним каналом
и группой исполнителей. Основная работа ложится на плечи исполнителей; диспетчер
лишь раздает задания, получая сообщение и подбирая для него нужный исполнитель.
Более того, если исполнители запускаются в собственных потоках, диспетчер не блоки-
рует свое выполнение на время обработки сообщения. Из этого следует, что диспетчер
способен потреблять сообщения с той же скоростью, с которой они подаются системой
обмена сообщениями, а значит, не рискует превратиться в “узкое место”.
Диспетчер сообщений является упрощенной версией шаблона реактор (Reactor,
см. [34]), ориентированной на обмен сообщениями. Сам диспетчер является реактором,
а исполнители, обрабатывающие сообщения, — конкретными обработчиками событий
(Concrete Event Handler). Канал сообщений выступает в качестве синхронного “разуплот-
нителя” событий (Synchronous Event Demultiplexer), подавая диспетчеру по одному со-
общению за раз. Сами сообщения напоминают дескрипторы (Handle), но имеют куца
более простую структуру. Настоящий дескриптор, как правило, является ссылкой на
данные ресурса, а сообщение непосредственно содержит в себе эти данные. (Так бывает
не всегда. Если данные сообщения находятся во внешнем хранилище, а само сообщение
является квитанцией (Claim Check, с. 358), значит, сообщение содержит ссылку на данные
и больше напоминает классический дескриптор реактора.) Разным типам дескрипторов
требуются обработчики событий разных типов, в то время как канал сообщений является
каналом типа данных, а значит, все сообщения (дескрипторы) принадлежат к одному
типу. К одному типу обычно относятся и исполнители.
Использование канала типа данных подразумевает, что все сообщения канала отно-
сятся к одному типу и все потребители канала могут обрабатывать сообщения такого ти-
па. Реактор же указывает на возможность использования диспетчера сообщений для полу-
чения по одному каналу данных разных типов и последующей обработки этих данных с
помощью специфических исполнителей. В каждом сообщении должен быть указан его
тип. Диспетчер определяет, к какому типу принадлежит сообщение, и передает его ис-
полнителю, предназначенному для обработки сообщений такого типа. В этом случае
диспетчер вместе со специализированными исполнителями может рассматриваться как
альтернатива каналам типа данных и как частный случай избирательных потребителей.
Одно из отличий диспетчера сообщений от конкурирующих потребителей касается воз-
можности распределения между несколькими приложениями. Конкурирующие потреби-
тели могут быть представлены несколькими процессами (например, приложениями),
а группа исполнителей обычно выполняется в рамках того же процесса, что и диспетчер
(хотя и в разных потоках). Если бы исполнитель и диспетчер выполнялись в разных про-
цессах, диспетчеру пришлось бы взаимодействовать с исполнителем по схеме удаленного
вызова процедуры (Remote Procedure Invocation, с. 85), что полностью противоречит прин-
ципам обмена сообщениями.
Поскольку в диспетчере сообщений присутствует только один потребитель, данный
шаблон хорошо сочетается с каналом “точка-точка” и каналом “публикация-подписка".
При обмене сообщениями по схеме “точка-точка” диспетчер сообщений является непло-
хой альтернативой конкурирующим потребителям. Вариант с диспетчером может быть
более предпочтителен в том случае, если система обмена сообщениями плохо справляет-
ся с большим числом потребителей или же если схема управления несколькими потреби-
телями меняется в зависимости от реализации системы обмена сообщениями.
Диспетчер сообщений (Message Dispatcher)
525
Принцип работы исполнителей во многом напоминает поведение событийно управ-
ляемого потребителя (Event-Driven Consumer, с. 511), хотя сам диспетчер может быть как
событийно управляемым, так и опрашивающим потребителем (Polling Consumer, с. 507).
Реализовать диспетчер в рамках транзакционного клиента (Transactional Client, с. 498) до-
вольно трудно. Предположим, что клиент является транзакционным. Тогда диспетчер
должен разрешить исполнителю обработать сообщение прежде, чем завершить транзак-
цию. Диспетчер сможет подтвердить выполнение транзакции только в том случае, если
обработка сообщения была успешно завершена. Если же исполнителю не удалось обра-
ботать сообщение, диспетчер обязан выполнить откат транзакции. Поскольку каждому
исполнителю может понадобиться выполнить откат своего сообщения, диспетчер должен
создать по одному сеансу на каждого исполнителя, а затем использовать этот сеанс, что-
бы получить сообщение для соответствующего исполнителя и завершить его транзакцию.
Поскольку транзакционный клиент плохо сочетается с событийно управляемым потреби-
телем, такой диспетчер должен быть опрашивающим потребителем.
Исполнителей, обрабатывающих сообщения, удобно реализовывать в виде событийно
управляемых потребителей. В JMS это означает реализацию исполнителя с использова-
нием интерфейса MessageListener. Последний включает в себя объявление одного
метода, onMessage (Message), который принимает сообщение и выполняет всю необхо-
димую обработку. Это позволяет четко отделить исполнителя от диспетчера. В .NET
исполнитель должен быть экземпляром делегата ReceiveCompletedEventHandler даже
несмотря на то, что диспетчер на самом деле не генерирует события ReceiveCompleted.
Следует, однако, помнить, что такие событийно управляемые подходы могут быть не со-
вместимы с интерфейсом, необходимым для запуска исполнителя в собственном потоке.
Чтобы не тратить силы на разработку собственного диспетчера сообщений, попробуйте
заменить его конкурирующими потребителями в сочетании с каналом типа данных или
группой избирательных потребителей. Диспетчер сообщений может быть опрашивающим
потребителем или событийно управляемым потребителем. Использовать его в качестве
транзакционного клиента не слишком эффективно, да и нежелательно.
Пример: диспетчер (.NET)
Обычно диспетчер сообщений (Message Dispatcher) передает сообщения исполнителям, как
будет показано в примере для Java. В .NET для распределения сообщений предусмотрен
другой вариант: диспетчер использует метод просмотра Реек, чтобы обнаружить в канале
новое сообщение и узнать его идентификатор. После этого исполнителю передается лишь
идентификатор сообщения, а не все сообщение целиком. Получив идентификатор, испол-
нитель применяет метод ReceiveByid, чтобы потребить назначенное ему сообщение.
Благодаря такой схеме каждый исполнитель берет на себя не только обработку сообщений,
но и их потребление. Это помогает решить проблемы параллельной обработки, в особенно-
сти если потребители являются транзакционными клиентами (Transactional Client, с. 498).
Пример: простой диспетчер (Java)
Рассмотрим простой пример реализации диспетчера сообщений и исполнителя с помо-
щью Java. В более совершенной реализации диспетчер мог бы поддерживать пул из не-
скольких исполнителей, следить за тем, какие из них в настоящий момент готовы к обра-
ботке сообщений, и использовать соответствующий пул потоков. В нашем примере все
526
Глава 10. Конечные точки обмена сообщениями
это опущено, но каждый исполнитель все равно запускается в собственном потоке,
поэтому обработка сообщений может вестись параллельно.
Объект-драйвер, управляющий работой диспетчера (не показан в этой книге), много-
кратно запускает метод receiveSync (). Каждый раз при запуске этого метода диспетчер
получает очередное сообщение, создает новый экземпляр исполнителя (Performer) и
запускает его в отдельном потоке.
import javax.jms.Connection,-
import javax.jms.Destination;
import javax.jms.JMSException;
import javax.jms.Message;
import javax.jms.Messageconsumer;
import javax.jms.Session;
import javax.naming.NamingException;
public class MessageDispatcher {
Messageconsumer consumer;
int nextID = 1;
protected MessageDispatcher () {
super();
}
public static MessageDispatcher newDispatcher(Connection
connection. String queueName)
throws JMSException, NamingException {
MessageDispatcher dispatcher = new MessageDispatcher0;
di spatcher.initialize(connection, queueName);
return dispatcher;
}
protected void initialize(Connection connection.
String queueName)
throws JMSException, NamingException {
Session session = connection.createSession(false,
Session.AUTO-ACKNOWLEDGE);
Destination dispatcherQueue =
JndiUtil.getDestination(queueName);
consumer = session.createConsumer(dispatcherQueue);
}
public void receiveSync() throws JMSException {
Message message = consumer.receive();
Performer performer = new Performer(nextID++, message);
new Thread(performer).start();
Класс Performer должен реализовать интерфейс Runnable, чтобы каждый исполни-
тель мог запускаться в собственном потоке. Метод run (), объявленный в интерфейсе
Runnable, просто вызывает метод processMessage О. Когда обработка сообщения
будет закончена, объект Performer станет доступным для механизма “сборки мусора”.
Диспетчер сообщений (Message Dispatcher)
527
import javax.jms.JMSException;
import javax.jms.Message;
public class Performer implements Runnable {
private int performerlD;
private Message message;
public Performer(int id. Message message) {
performerlD = id;
this.message = message;
}
public void run() {
try {
processMessage();
} catch (Exception e) {
e.printStackTrace() ;
} }
private void processMessage() throws JMSException,
InterruptedException {
int id = message.getlntProperty("cust_id");
System.out.printin(System.currentTimeMillis() +
Performer #" + performerlD +
" starting; message ID " + id) ;
Thread.sleep(500);
System.out.printIn(System.currentTimeMillis() +
": Performer #" + performerlD + " processing.");
Thread.sleep(500);
System.out.printin(System.currentTimeMillis() +
": Performer #" + performerlD + " finished.");
}
}
Как видим, создать простой диспетчер и потребитель несложно. Главное — реализо-
вать интерфейс Runnable и выполнить запуск потребителя в отдельном потоке.
528
Глава 10. Конечные точки обмена сообщениями
Избирательный потребитель (Selective Consumer)
Приложение использует обмен сообщениями (Messaging, с. 87). Оно потребляет сообще-
ния (Message, с. 98) из канала сообщений (Message Channel, с. 93), но хочет получать не все
сообщения, а лишь некоторые из них.
Может ли потребитель сообщений выбирать, какие сообщения он хочет получать?
По умолчанию, если канал сообщений прослушивается только одним потребителем,
все сообщения, поступающие в канал, будут доставляться именно этому потребителю.
Аналогичным образом, если канал прослушивается несколькими конкурирующими
потребителями (Competing Consumers, с. 515), каждое сообщение может попасть к любому
из потребителей и обязательно попадет к какому-нибудь из них. Потребитель не может
выбирать сообщения, которые он принимает; он получает любое прибывшее сообщение,
каким бы оно ни оказалось.
Такое поведение вполне допустимо, если потребитель хочет получать все сообщения
из канала (обычно так и бывает). Но как быть, если потребитель желает получать только
определенные сообщения? В качестве примера представьте себе приложение, обрабаты-
вающее сообщения с запросами на получение кредита. Вполне естественно, что запросы
на сумму кредита до 100 тыс. долл, будут обрабатываться по-другому, нежели запросы,
в которых эта сумма превышает 100 тыс. долл. Для реализации такого подхода можно
было бы создать два потребителя: один — для обработки запросов с небольшими сумма-
ми кредита, а другой — с большими. Но мы знаем, что каждый из потребителей может по-
лучить любое сообщение. Как убедиться, что сообщения попали к нужным потребителям?
Самый простой способ — сделать так, чтобы потребитель получал любое попавшее
к нему сообщение. Если он увидит, что потребленное им сообщение не того типа, он
должен как-то передать его нужному потребителю. К сожалению, реализовать такую схе-
му достаточно трудно. Экземпляры потребителей обычно не знают друг о друге, и найти
незанятый потребитель будет весьма сложно. Можно сделать так, чтобы потребитель воз-
вращал неподходящее сообщение в канал, но кто гарантирует, что он не потребит его
снова? Еще один вариант— пусть каждый из потребителей получает все сообщения,
а затем отбрасывает те из них, которые ему не нужны. Это позволит достичь желаемого
результата, но приведет к появлению многочисленных копий сообщений и лишней трате
ресурсов на потребление сообщений, которые все равно будут отброшены.
Для каждого типа сообщений можно определить отдельный канал. Тогда отправитель
будет отсылать сообщения по заранее заданным каналам, а получатели будут точно знать,
что сообщения, полученные из конкретного канала, принадлежат к нужному им типу.
Такое решение будет не слишком динамичным. В процессе работы системы получатели
могут изменить критерии выбора сообщений, что потребует определения новых каналов
и перераспределения сообшений, уже опубликованных в каналах. Это также означает,
Избирательный потребитель (Selective Consumer)
529
что отправители должны знать критерии выбора получателей и то, как эти критерии меня-
ются. Набор критериев должен храниться в свойстве объекта получателя, а не канала, а со-
общения в канале должны содержать указание на то, каким критериям они соответствуют.
Мы хотим, чтобы сообщения, соответствующие разным критериям, отправлялись по
одному и тому же каналу, а получатели этого канала могли указывать, какие сообщения
их интересуют, чтобы потреблять только те из них, которые соответствуют заданным
критериям.
Воспользуйтесь избирательным потребителем (Selective Consume/1). Он фильт-
рует сообщения, доставленные по каналу, и потребляет только те из них, которые
соответствуют его критериям.
Поставщик, задающий Сообщения со
значение выбора значениями выбора
В процессе отбора сообщений принимают участие три компонента.
1. Поставщик, задающий значение выбора. Задает значение выбора для сообщения
перед его отправкой.
2. Значение выбора. Одно или несколько значений, заданных в сообщении, на основа-
нии которых потребитель принимает решение, интересует ли его это сообщение.
3. Избирательный потребитель. Получает только те сообщения, которые соответст-
вуют его критериям выбора.
Прежде чем отослать сообщение, отправитель задает некоторое значение выбора.
Когда сообщение прибывает на другой конец канала, избирательный потребитель прове-
ряет его значение выбора и смотрит, удовлетворяет ли это значение заданным критери-
ям. Если это так, потребитель принимает сообщение и передает его своему приложению
для последующей обработки. Схема действия избирательного потребителя показана
на рис. 10.12.
Когда отправитель создает сообщение, он также задает его значение выбора; затем от-
правитель отсылает сообщение. Когда система обмена сообщениями доставляет сообще-
ние, избирательный потребитель проверяет его значение выбора и решает, нужно ли по-
треблять это сообщение. Если значение выбора соответствует заданным критериям, потре-
битель получает сообщение и с помощью обратного вызова передает своему приложению
на обработку.
Избирательные потребители часто применяются в группах: один потребитель фильт-
рует сообщения по одному набору критериев, другой — по другому и т.п. В примере
с приложением, обрабатывающим запросы на получение кредита, один потребитель
будет отбирать сообщения, в которых значение выбора удовлетворяет условию “меньше
530
Глава 10. Конечные точки обмена сообщениями
или равно 100000”, а другой — “больше 100000”. Тогда каждому потребителю достанутся
только те запросы, которые его интересуют.
Если несколько избирательных потребителей прослушивают канал “точка-точка”
{Point-to-Point Channel, с. 131), они становятся конкурирующими потребителями. Если
критерии двух потребителей пересекаются и значение выбора одного из сообщений
удовлетворяет оба критерия, принять сообщение может любой из потребителей. Потре-
бители должны- быть спроектированы таким образом, чтобы любое сообщение с допус-
тимым значением выбора было принято по крайней мере одним из них. В противном
случае сообщение, значение выбора которого не соответствует ни одному из критериев,
так и не будет потреблено и останется в канале навсегда или, по крайней мере, до истече-
ния срока действия сообщения {Message Expiration, с. 198).
Избирательный
потребитель
Получатель
Поставщик,
задающий
значение выбора
Система обмена
сообщениями
“Доставить”
Обратный вызов
Обработать
Рис. 10.12. Последовательность действий избирательного потребителя
Избирательный потребитель (Selective Consumer)
531
Если избирательные потребители получают сообщения по каналу “публикация-
подписка” (Publish-Subscribe Channel, с. 134), каждому потребителю будут доставлены
копии всех сообщений. Те из них, которые не соответствуют критериям конкретного
потребителя, будут им проигнорированы. В этом случае система обмена сообщениями
может отбросить ненужные сообщения (а точнее, ненужные копии), потому что они бы-
ли успешно доставлены, но никогда не будут потреблены. Описанный процесс можно
оптимизировать, если система обмена сообщениями заранее увидит, что сообщение
не заинтересует потребителя, и даже не будет пытаться его доставить. Это позволит
уменьшить количество передаваемых по каналу копий каждого сообщения. Такая схема
отбрасывания ненужных сообщений не зависит от параметров гарантированной доставки
(Guaranteed Delivery, с. 149), постоянного подписчика (Durable Subscriber, с. 535) и (или)
срока действия сообщения.
Если на одном каналу разместить несколько избирательных потребителей, он сможет
заменить собой набор каналов типа данных (Datatype Channel, с. 139). Разным типам со-
общений можно присвоить различные значения выбора, чтобы каждый из потребителей
получал только сообщения определенного типа (рис. 10.13). Это позволяет организовать
эффективную обработку сообщений разных типов с помощью одного-двух каналов, что
особенно важно в компаниях, требующих слишком большого количества каналов
(больше, чем в состоянии обслужить система обмена сообщениями).
Использование избирательных потребителей для эмуляции каналов типа данных
нежелательно, если сообщения определенного типа необходимо скрыть от определенных
приложений-получателей. Хотя система обмена сообщениями гарантирует, что сообще-
ния из канала будут успешно получены только авторизованными приложениями, автори-
зация конкретных значений выбора обычно не проводится. По этой причине злоумыш-
ленник, имеющий право извлекать сообщения из данного канала, может изменить свой
критерий выбора и получить доступ к сообщениям, которые он не должен видеть. Чтобы
Получатель
Рис. 10.13. Конкурирующие, избирательные потребители
532
Главв 10. Конечные точки обмена сообщениями
гарантировать безопасность секретных сообщений, лучше воспользоваться отдельными
каналами типа данных.
Для распределения сообщений вместо избирательных потребителей можно восполь-
зоваться диспетчером сообщений (Message Dispatcher, с. 521). Диспетчер использует встро-
енные критерии выбора, чтобы определить, какому исполнителю необходимо передать
то или иное сообщение. Если сообщение но подойдет ни одному из исполнителей, дис-
петчер не станет отбрасывать его или оставлять в канале, а перенаправит в канал недопус-
тимых сообщений (Invalid Message Channel, с. 143). Как и в случае с конкурирующими
потребителями, выбор между избирательными потребителями и диспетчером сообщений
определяется тем, кто должен проводить распределение сообщений: система обмена со-
общениями или клиент. Если система обмена сообщениями не поддерживает избира-
тельные потребители как таковые, распределение сообщений придется реализовать
своими силами с помощью диспетчера сообщений.
Как уже говорилось, если значение выбора некоторого сообщения не подойдет ни од-
мому >а сообщение будет проигнорировано (гак, как если бы
у канала вообще не было получателей). Аналогичная проблема встречается и в процедурном
программировании при использовании операторов ветвления типа switch... case. В та-
ких выражениях можно предусмотреть специальный вариант default (или подобный),
охватывающий любые значения, которые не Подошли для остальных вариантов. Применяя
описанный подход к обмену сообщениями, кажется вполне логичным создание потребите-
ля, который будет обрабатывать сообщения, не подошедшие остальным потребителям.
К сожалению, такой вариант не принесет желаемых результатов. Критерий выбора такого
потребителя должен охватывать все возможные значения, следовательно, указанный потре-
битель будет конкурировать со всеми остальными избирательными потребителями. Для соз-
дания подобного потребителя лучше воспользоваться диспетчером сообщений, который
будет реализовывать выражение switch... case, предусматривающее передачу непред-
виденных сообщений некоторому специальному потребителю.
Неплохой альтернативой избирательным потребителям являются фильтры сообщений
(Message Filter, с. 253). Они предназначены для достижения той же цели, но другими спо-
собами. При использовании избирательных потребителей получателям доставляются
абсолютно все сообщения, а каждый получатель игнорирует те из них, которые ему
не нужны. Фильтр сообщений размещается между каналом, по которому было отправлено
сообщение, и каналом, по которому оно будет доставлено получателю. Фильтр анализи-
рует сообщения, отосланные отправителем, и передает в канал получателя только те из
них, которые заинтересуют последнего. Таким образом, нежелательные сообщения изна-
чально не попадают в канал получателя, а значит, игнорировать нечего. Фильтр сообще-
ний удобно использовать, чтобы избавляться от сообщений, которые не нужны ни одно-
му из потребителей. Избирательные потребители предпочтительнее тогда, когда отдельно
взятое сообщение кого-то интересует, а кого-то — нет.
В качестве еще одной альтернативы можно предложить маршрутизатор на основе со-
держимого (Content-Based Router, с. 247). Маршрутизатор такого типа, как и фильтр, га-
рантирует доставку по каналу только тех сообщений, которые интересуют получателя.
Это помогает повысить производительность и безопасность потребителей. Но избира-
тельные потребители являются более гибким решением. Каждый новый критерий выбо-
ра потребует создания еще одного объекта потребителя (что не так уж сложно проделать в
работающей системе), в то время как каждый новый вариант маршрутизации в маршру-
Избирательный потребитель (Selective Consumer)
533
тизаторе на основе содержимого потребует создания нового исходящего канала (а это да-
леко не просто, если система работает) и нового потребителя для этого канала. В качестве
примера представьте себе, что компания решила выделить в отдельную группу кредиты
среднего размера (от 50 до 150 тыс. долл.) и обрабатывать запросы на их получение
отдельно от запросов на получение маленьких и больших кредитов. Если сообщения рас-
пределяются с помощью маршрутизатора на основе содержимого, нам придется создать
отдельный канал для запросов на получение кредитов среднего размера, создать потреби-
тель, который будет прослушивать этот канал, а также изменить правила, в соответствии
с которыми маршрутизатор распределяет запросы по каналам. Нужно позаботиться и о
том, что случится, когда изменения вступят в силу, потому что на этот момент в каналах
могут оставаться сообщения, которые теперь попадут к неправильным потребителям.
А вот при использовании избирательных потребителей нам всего лишь потребуется заме-
нить два типа потребителей (для сумм меньше 100 тыс. и больше 100 тыс. долл.) тремя
типами потребителей (для сумм до 50 тыс., от 50 тыс. до 150 тыс. и свыше 150 тыс. долл.).
Как видим, подход с использованием маршрутизатора куда более статичен, нежели под-
ход с избирательными потребителями.
В идеальном случае значение выбора должно располагаться в заголовке сообщения,
чтобы избирательному потребителю не пришлось анализировать содержимое его тела
(а также знать, как это делается).
Подведем итоги. Избирательные потребители, прослушивающие один канал, заменя-
ют собой набор каналов типа данных. При использовании избирательных потребителей
сообщения, не подходящие одному получателю, могут быть потреблены другими получа-
телями. Это отличается от поведения фильтра сообщений, который вообще не допускает
нежелательные сообщения до получателей. Избирательные потребители более динамич-
ны, чем маршрутизатор на основе содержимого. Избирательный потребитель может быть
опрашивающим потребителем (Polling Consumer, с. 507) или событийно управляемым
потребителем (Event-Driven Consumer, с. 511), а также являться частью транзакционного
клиента (Transactional Client, с. 498). Если же вы хотите сами реализовать отбор сообще-
ний, воспользуйтесь диспетчером сообщений.
Пример: разделение сообщений по типам
Если система биржевой торговли обладает ограниченным количеством каналов, для от-
правки цен на облигации и выполнения торговых операций может применяться один
канал. Получатели сообшений первого и второго типов будут сильно различаться, поэто-
му важно, чтобы каждое сообщение попало к нужному получателю. Чтобы решить эту
проблему, отправитель присваивает сообщению, в котором содержатся цены на облига-
ции, значение выбора QUOTE. Такое сообщение будет принято только тем избиратель-
ным потребителем (Selective Consumer), который занимается обработкой цен на облига-
ции. Сообщения, содержащие инструкции по выполнению торговых операций, будут
иметь значение выбора TRADE. Благодаря этому сообщения двух типов могут успешно
передаваться по общему каналу.
534
Глава 10. Конечные точки обмена сообщениями
Пример: строка отбора сообщений (JMS)
В JMS экземпляр класса Messageconsumer (QueueReceiver или Topicsubscriber)
может быть создан с использованием строки отбора сообщений (message selector string).
Эта строка будет применяться для фильтрации доставленных сообщений по значению
некоторого свойства [14, 17]. Вначале отправитель задает имя и значение свойства сооб-
щения, по которому впоследствии будет производиться фильтрация.
Session session = // Получить сеанс.
TextMessage message = session.createTextMessage();
message.setText("<quote>SUNW</quote>");
message.setStringProperty("req_type", "quote");
Destination destination = //Получить пункт назначения.
MessageProducer producer = session.createProducer(destination);
producer.send(message);
Получатель, в свою очередь, задает строку отбора, которая будет выступать в качестве
критерия фильтрации.
Session session = // Получить сеанс.
Destination destination = //Получить пункт назначения.
String selector = "req_type = 'quote'";
Messageconsumer consumer =
session.createConsumer(destination, selector);
Такой получатель будет игнорировать все сообщения, значение свойства req_type
(“тип запроса”) которых не равно quote, — так, как если бы эти сообщения вообще
никогда не доставлялись в пункт назначения.
Пример: методы Peek, ReceiveByld и ReceiveByCorrelationld (.NET)
В .NET метод MessageQueue.Receive не поддерживает строки отбора сообщений, по-
добные тем, которые есть в JMS. Вместо этого получатель может воспользоваться мето-
дом MessageQueue. Peek, чтобы взглянуть на сообщение, не потребляя его. Если сооб-
щение соответствует желаемому критерию, тогда получатель может извлечь его из очере-
ди сообщений с помощью метода MessageQueue.Receive. Такая схема не всегда
надежна, потому что сообщение, возвращенное методом Receive, может быть не тем со-
общением, которое просматривалось с помощью метода Реек. По этой причине реко-
мендуем воспользоваться методом ReceiveByld, в котором получатель указывает иден-
тификатор желаемого сообщения. В этом случае он получит именно то сообщение, кото-
рое просматривал посредством метода Реек.
Существует еще один похожий метод, ReceiveByCorrelationld. При его вызове
получатель указывает значение идентификатора корреляции сообщения, которое требу-
ется получить. Это может пригодиться, чтобы получить ответ на конкретный запрос, ото-
сланный отправителем. (См. также описание шаблонов запрос-ответ {Request-Reply,
с. 177) и идентификатор корреляции (Correlation Identifier, с. 186).)
Постоянный подписчик (Durable Subscriber)
535
Постоянный подписчик (Durable Subscriber)
Приложение получает сообшения по каналу “публикация-подписка” {Publish-Subscribe
Channel, с. 134).
Как избежать потери сообщений, если подписчик временно отключен от системы
обмена сообщениями?
Почему вообще возникла такая проблема? После того как сообщение попадает в ка-
нал, оно остается там до тех пор, пока не будет потреблено, не устареет (см. шаблон срок
действия сообщения {Message Expiration, с. 198)) либо не пропадет в результате сбоя систе-
мы (конечно же, если на канале не применяется гарантированная доставка — Guaranteed
Delivery, с. 149). Это справедливо для канала “точка-точка” {Point-to-Point Channel,
с. 131), но канал “публикация-подписка” функционирует несколько по-другому.
Когда сообщение размещается в канале “публикация-подписка”, оно должно быть дос-
тавлено каждому подписчику этого канала. Точный способ определения того, что сооб-
щение было доставлено всем подписчикам, зависит от конкретной реализации системы
обмена сообщениями. Можно хранить сообщение в канале до тех пор, пока перечень
подписчиков, не получивших сообщение, не станет пустым; можно создать копии сооб-
щения и доставить их каждому подписчику и т.п. В любом случае сообщение будет полу-
чено только теми подписчиками, которые прослушивают канал в момент публикации
этого сообщения. Если подписчик временно отключен от канала, он не получит сообще-
ние, даже если секунду спустя снова подпишется на канал. (Существует и такой нюанс:
что произойдет, если подписчик подключится к каналу “примерно” в тот же момент,
когда было опубликовано сообщение? Получит ли он это сообщение? Ответ на данный
вопрос зависит от реализации системы обмена сообщениями. Чтобы гарантированно
уберечь себя от потери сообщений, подписчики должны подключаться к каналу хотя бы
немного раньше, чем будет опубликовано сообщение.)
На практике подписчик отказывается от подписки на канал, закрывая свое соедине-
ние с каналом. Таким образом, явно проводить отказ от подписки необязательно; доста-
точно просто закрыть соединение.
Часто приложение отключается от канала именно потому, что перестает интересо-
ваться сообщениями, которые в нем публикуются. Разумеется, такое приложение пред-
почтет игнорировать сообщения, появившиеся в канале после его отключения. К приме-
ру, В2В-приложение компании, продающей кирпичи, может подписаться на канал, в ко-
тором публикуются запросы на приобретение кирпичей. Если компания перестала
продавать кирпичи или они временно закончились, она наверняка решит отключиться от
этого канала, чтобы не получать запросы, которые все равно не сможет выполнить.
Иногда, однако, такое поведение получателя может привести к потере важных сооб-
щений. Если приложение вышло из строя или было отсоединено от канала для выполне-
ния административных работ, оно может заинтересоваться, какие сообщения публико-
вались в канале за время его отсутствия. Да и вообще, главная идея обмена сообщениями
536
Глава 10. Конечные точки обмена сообщениями
состоит в том, чтобы обеспечить максимальную надежность взаимодействия отправите-
ля, получателя и сети, даже если они не работают в одно и то же время.
Итак, многие приложения отключаются от канала, потому что больше не хотят полу-
чать сообщения, которые в нем публикуются. Но иногда приложение вынуждено отклю-
читься на короткий срок и после возобновления своей работы хочет иметь доступ ко всем
сообщениям, которые публиковались в канале за время его простоя. Обычно подписчик
канала пребывает в одном из двух состояний: подключен (подписан) или отключен
(не подписан), но существует и третье состояние — неактивен (inactive). Это подписчик,
который по каким-то причинам был отключен от канала, но остался подписан на этот
канал и хочет получать сообщения, появившиеся в нем за время своего отсутствия.
Если подписчик был подключен к каналу “публикация-подписка”, но отключен в мо-
мент прибытия сообщения, как узнать, нужно ли сохранять это сообщение до того вре-
мени, когда подписчик снова вернется в строй? Другими словами, как система обмена
сообщениями определит, в каком состоянии находится подписчик: в неактивном или не
подписанном? Для этого необходимо иметь два вида подписки: подписку, которая закан-
чивается, когда получатель отключается, и подписку, которая действует даже при отклю-
чении получателя и может быть аннулирована только тогда, когда получатель откажется
от подписки на канал явным способом.
По умолчанию подписка на канал действительна только до закрытия соединения.
Итак, нам нужен еще один вид подписки, которая будет сохраняться при переходе полу-
чателя в неактивное состояние.
Воспользуйтесь постоянным подписчиком (Durable Subscriber), чтобы получать
сообщения, которые публиковались в канале за время отсутствия подписчика.
Получатель
Постоянный подписчик (Durable Subscriber)
537
При наличии постоянной подписки система обмена сообщениями сохраняет сооб-
щения для неактивного подписчика и доставляет их, когда подписчик вновь подключит-
ся к системе. Благодаря этому подписчик не пропустит ни одного сообщения, даже когда
он отключен. Постоянная подписка никак не влияет на поведение получателя или систе-
мы обмена сообщениями, когда подписчик активен (т.е. подключен). Подписчик, под-
ключенный к каналу, ведет себя одинаково вне зависимости от того, является ли его под-
писка постоянной. Разница в поведении системы обмена сообщениями проявляется
лишь тогда, когда подписчик от нее отключен.
Постоянный подписчик— это просто подписчик канала “публикация-подписка”.
Но когда такой подписчик отключается от системы обмена сообщениями, он становится
неактивным, и система обмена сообщениями будет сохранять для него все сообщения,
публикующиеся в канале за время простоя подписчика. Другие подписчики того же
канала могут не быть постоянными; тогда они являются временными подписчиками.
Схема работы постоянного подписчика приведена на рис. 10.14. Вначале постоянный
подписчик должен подписаться на канал обмена сообщениями. Затем, когда подписчик
закрывает соединение, он становится неактивным. Пока подписчик неактивен, издатель
публикует в канале новое сообщение. Если бы подписчик не был постоянным, он бы
пропустил сообщение, но поскольку он является постоянным подписчиком, сообщение
для него будет сохранено. Когда постоянный подписчик вновь подпишется на канал и ста-
нет активным, система обмена сообщениями доставит ему упомянутое сообщение
(а также все другие сообщения, сохраненные для данного подписчика). Подписчик полу-
чит сообщение и обработает его либо передаст на обработку своему приложению.
Если по окончании обработки подписчик больше не хочет получать сообщения, он снова
закрывает соединение и становится неактивным. На сей раз, однако, подписчик больше
не заинтересован в том, чтобы система обмена сообщениями сохраняла для него сооб-
щения, поэтому он отказывается от подписки на канал.
Существует одно интересное соображение: что случится, если постоянный подписчик
никогда не откажется от подписки на канал? Пока подписчик неактивен, система обмена
сообщениями продолжит послушно сохранять для него сообщения. Если в течение дол-
гого времени подписчик так и не вернется к прослушиванию канала, сообщений нако-
пится слишком много. Решить эту проблему поможет срок действия сообщения. Кроме
того, система обмена сообщениями может ограничивать число сообщений, которые
сохраняются для неактивного подписчика.
Пример: торговля на бирже
Система биржевой торговли может использовать канал “публикация-подписка” {Publish-
Subscribe Channel, с. 134), чтобы рассылать обновления биржевых котировок. Каждый раз
при изменении котировок в канале публикуется новое сообщение. Пусть один из под-
писчиков канала— это приложение с графическим интерфейсом, которое отображает
текущие значения котировок на определенных биржах, а второй подписчик — база дан-
ных, в которой хранится разброс некоторых котировок за день.
Оба приложения должны быть подписчиками канала, в котором публикуются обнов-
ления котировок. Приложение с графическим интерфейсом не обязательно должно вла-
деть постоянной подпиской, потому что оно отображает текущие значения котировок.
Если такое приложение вдруг выйдет из строя и потеряет связь с каналом, оно все равно
не сможет отображать изменения котировок. Так зачем же их сохранять? В противопо-
538
Глава 10. Конечные точки обмена сообщениями
ложность ему база данных должна быть постоянным подписчиком (Durable Subscriber).
Пока она работает, она может отображать разброс котировок за день. Если же она вне-
запно отключится от канала, то после повторного подключения сможет обработать нако-
пившуюся информацию и обновить значение разброса.
Пример: постоянная подписка (JMS)
JMS поддерживает постоянную подписку для объектов Topicsubscriber [14, 17].
Одна из проблем постоянной подписки касается того, как отличить старого подпис-
чика, который снова подключился к системе, от совершенно нового подписчика. В JMS
наличие постоянной подписки определяется тремя критериями:
• тема, на которую осуществляется подписка;
• идентификатор клиента д ля заданного соединения;
• имя подписки для заданного подписчика.
Рис. 10.14. Действие постоянной подписки
Постоянный подписчик (Durable Subscriber)
539
Идентификатор клиента — это свойство фабрики соединений, к которой принадле-
жит соответствующее соединение. Оно задается при создании фабрики соединений с по-
мощью административных средств системы обмена сообщениями. Имя подписки долж-
но быть уникальным для каждого подписчика (для конкретной темы и идентификатора
клиента).
Для создания постоянного подписчика (Durable Subscriber) применяется метод Ses-
sion. createDurableSubscriber.
ConnectionFactory factory = // Получить фабрику соединений.
//У фабрики есть идентификатор клиента.
Connection connection = factory.createConnectionO;
II У соединения будет тот же идентификатор клиента,
// что и у фабрики соединений.
Topic topic = // Получить тему.
String clientID = connection.getClientIDО;
// На случай, если вы захотите узнать идентификатор клиента.
String subscriptionName = "subscriber!";
// Некоторый уникальный идентификатор подписки.
Session session =
connection.createSession(false, Session.AUTO_ACKNOWLEDGE);
Topicsubscriber subscriber =
session.createDurableSubscriber(topic, subscriptionName);
Теперь постоянный подписчик активен и может получать сообщения, относящиеся
к заданной теме (как, впрочем, и любой другой подписчик, не являющийся постоян-
ным). Чтобы сделать подписчика неактивным, закройте его, как показано ниже:
subscriber.close();
Подписчик отключен, а значит, неактивен. Все сообщения, публикуемые в теме,
на которую он подписался, будут сохранены и доставлены указанному подписчику, когда
он вновь станет активным.
Чтобы опять сделать подписчик активным, необходимо создать новый постоянный
подписчик с теми же темой, идентификатором клиента и именем подписки. Код для вы-
полнения этих действий будет совпадать с кодом, показанным выше (только следите
за тем, чтобы использовать ту же самую тему, фабрику соединений и имя подписки).
Поскольку для создания постоянного подписчика и для его повторного подключения
к теме используется один и тот же код, только система обмена сообщениями сможет по-
нять, кто перед ней: старый или новый подписчик. Из этого следует интересный вывод:
приложение, вновь подключившееся к теме, может оказаться совершенно не тем прило-
жением, которое ранее от нее отключалось. Если новое приложение будет использовать
ту же тему, ту же фабрику соединений (а значит, тот же идентификатор клиента) и то же
имя подписки, что и предыдущее приложение, система обмена сообщениями не сможет
отличить новое приложение от старого и доставит ему все сообщения, которые не успела
доставить старому приложению до его отключения.
540 Глава 10. Конечные точки обмена сообщениями
Обзаведясь постоянной подпиской на тему, приложение станет получать все сообще-
ния, публикуемые в этой теме, даже если подписчик закрывает свое соединение (или
неожиданно выходит из строя, и соединение закрывается системой обмена сообщения-
ми). Чтобы система обмена сообщениями перестала сохранять в очереди сообщения для
неактивного подписчика, он должен в явной форме отказаться от подписки на тему.
subscriber.close();
// Подписчик неактивен, сообщения сохраняются.
session.unsubscribe(subscriptionName);
// Подписчик удален.
После выполнения метода unsubscribe соответствующая подписка удаляется, и сис-
тема обмена сообщениями перестает сохранять сообщения для указанного подписчика.
Идемпотентный получатель (Idempotent Receiver)
541
Идемпотентный получатель (Idempotent Receiver)
Даже если отправитель отсылает сообщение только единожды, получатель может
принять его несколько раз.
Что делать получателю, если сообщение было доставлено несколько раз?
В главе 3 обсуждалось, как повысить надежность каналов обмена сообщениями с по-
мощью гарантированной доставки (Guaranteed Delivery, с. 149). К сожалению, высокий
уровень надежности иногда приводит к появлению сообщений-“двойников”. В других
ситуациях обеспечить гарантированную доставку не представляется возможным, потому
что взаимодействие между компонентами изначально основано на использовании нена-
дежных протоколов. Это часто встречается в сценариях В2В-интеграции, в которых со-
общения приходится отсылать по Интернету с использованием протокола HTTP. В по-
добных случаях надежная доставка сообщений может достигаться лишь повторной от-
правкой сообщения до тех пор, пока получатель не пришлет подтверждение получения.
Если из-за ненадежной связи подтверждение будет потеряно, отправитель снова вышлет
сообщение, которое в действительности уже было принято получателем (рис. 10.15).
Сбой сети
Отправитель
Получатель
Сообщение
--------------->
Подтвердить
Сообщение
Подтвердить
Дубликат сообщения
Рис. 10.15. Дублирование сообщений, вызванное проблемами с отправкой подтверждения
Многие системы обмена сообщениями содержат встроенные механизмы борьбы
с дубликатами сообщений, что избавляет приложение от необходимости следить за их
появлением. К сожалению, уничтожение дубликатов внутри самой инфраструктуры об-
мена сообщениями приводит к появлению дополнительной нагрузки. Если получатель в
силу своей природы устойчив по отношению к дубликатам — к примеру, получатель без
состояния, который обрабатывает сообщения с командой (Command Message, с. 169) по типу
запросов, — отказ от их обработки в системе обмена сообщениями позволит повысить
пропускную способность последней. По этой причине некоторые системы обмена сооб-
щениями заботятся только о том, чтобы сообщение было доставлено хотя бы один раз,
542
Глава 10. Конечные точки обмена сообщениями
и перекладывают обработку повторяющихся сообщений на сами приложения. Другие
системы позволяют приложению указать, хочет ли оно само заниматься дубликатами.
К примеру, в спецификации JMS для этого предусмотрен режим dups_ok_acknowledge.
Сообщения-“двойники” могут появиться и при сбое распределенной транзакции.
Многие готовые приложения, подключенные к инфраструктуре обмена сообщениями
с помощью коммерческих адаптеров, не способны корректно участвовать в распределен-
ной двухэтапной транзакции. Если сообщение рассылается нескольким приложениям и
его отправка приводит к сбою одного или более приложений, системе будет сложно вос-
становиться из такого несогласованного состояния. Если получатели умеют игнориро-
вать повторяющиеся сообщения, отправитель может еще раз отослать сообщение всем
получателям. Те из них, которые уже получили и обработали исходное сообщение, про-
сто проигнорируют новую копию. Те же приложения, которые не смогли корректно
потребить исходное сообщение, попытаются принять его дубликат.
Воспользуйтесь идемпотентным получателем (Idempotent Receive/), который
умеет корректно обрабатывать сообщения, полученные по нескольку раз.
Термин идемпотентный используется в математике для обозначения функции,
результат которой не меняется, если применить эту функцию к самой себе: f(x) = f(f(x)).
Если перенести эту концепцию на обмен сообщениями (Messaging, с. 87), идемпотентным
будет называться сообщение, действие которого не зависит от того, сколько раз оно было
получено. Это означает, что сообщение можно спокойно отправлять любое количество
раз и не волноваться, что при потреблении дубликатов сообщения у получателя возник-
нут проблемы.
Для достижения идемпотентности можно воспользоваться двумя основными
способами.
1. Явное удаление дубликатов сообщения (de-duping).
2. Определение семантики сообщения с учетом идемпотентности.
Получатель может следить за тем, какие сообщения он уже получил, и самостоятельно
удалять дубликаты. Для облегчения этой задачи можно воспользоваться уникальным
идентификатором сообщения. Используя идентификатор, мы не привязываем семантику
сообщения-дубликата к содержимому сообщения. Каждому сообщению будет просто на-
значаться уникальный идентификатор. Во многих системах обмена сообщениями
(например, JMS) такие идентификаторы присваиваются автоматически.
Чтобы приложение могло выявлять и уничтожать повторяющиеся сообщения, оно
должно вести список идентификаторов полученных ранее сообщений. Одна из ключевых
архитектурных проблем состоит в том, насколько длинным должен быть такой список и
нужно ли размещать его в постоянном хранилище данных (например, на жестком диске).
Выбор того или иного решения, как правило, определяется схемой взаимодействия меж-
ду отправителем и получателем. В самом простом случае отправитель отсылает по одному
сообщению за раз и ждет, пока получатель пришлет подтверждение. В такой ситуации
получателю достаточно сравнить идентификатор нового сообщения с идентификатором
предыдущего. Если идентификаторы совпадают, получатель проигнорирует новое сооб-
щение. Тогда получателю придется хранить список, состоящий лишь из одного иденти-
Идемпотентный получатель (Idempotent Receiver)
543
фикатора. На практике такая схема взаимодействия может оказаться крайне неэффектив-
ной, особенно если значение задержки (время доставки сообщения от отправителя к полу-
чателю) слишком велико для достижения желаемой скорости работы канала. В подобной
ситуации отправитель может захотеть отправить целую группу сообщений, не дожидаясь
подтверждения доставки каждого из них. Из этого, однако, следует, что получателю придет-
ся хранить более длинный список идентификаторов полученных им сообщений. Размер
“памяти” получателя будет зависеть от того, сколько сообщений может отослать отправи-
тель, не дожидаясь подтверждения доставки от получателя. Похожие соображения приво-
дились при описании шаблона преобразователь порядка {Resequencer, с. 297).
Избавление от повторяющихся сообщений — еще один пример, в котором можно
провести аналогию с низкоуровневым протоколом TCP/IP. Когда пакеты IP передаются
по сети, в ней могут появиться пакеты-“двойники”. Протокол TCP/IP помогает изба-
виться от дубликатов, прикрепляя к каждому пакету уникальный идентификатор. Отпра-
витель и получатель договариваются о “размере окна”, которое выделяется получателем
для обнаружения дубликатов. Более подробное описание реализации этого механизма в
TCP/IP приведено в [38].
Иногда в качестве идентификатора сообщения используют некоторый бизнес-ключ, а
устранение дубликатов поручают слою хранения. В качестве примера предположим, что
сообщение сохраняет входящие заказы в базе данных. Если в каждом заказе содержится
его уникальный номер, тогда попытка поместить в таблицу базы данных повторяющийся
заказ окончится неудачей. Такое решение выглядит весьма изящным, поскольку выявле-
нием дубликатов (а точнее, повторяющихся ключей) теперь занимается СУБД, а она хо-
рошо приспособлена к решению задач такого рода. Следует, однако, быть крайне осто-
рожным, потому что у ключевого поля появилась двойная семантика. Иными словами,
мы привязали к бизнес-полю (номер заказа) семантику инфраструктуры (повторяющееся
сообщение). Теперь представим, что в соответствии с новыми бизнес-требованиями кли-
ентам было разрешено вносить изменения в существующие заказы, отправляя еще одно
сообщение с тем же номером заказа (это весьма распространенная практика). В этом
случае нам придется менять структуру сообщения, поскольку его уникальный идентифи-
катор был привязан к бизнес-полю.
Необходимость использования базы данных для избавления от дубликатов часто воз-
никает тогда, когда для связи с базой данных применяется адаптер, предоставленный
производителем системы обмена сообщениями. Во многих случаях такие адаптеры не
умеют бороться с дубликатами сообщений, поэтому устранением дубликатов приходится
заниматься самой базе данных.
Второй подход к достижению идемпотентности состоит в определении такой семантики
сообщения, чтобы повторная отправка последнего не оказала никакого влияния на систе-
му. К примеру, вместо того чтобы определить сообщение как “Положить на счет 12345 еще
10 долларов”, его можно сформулировать следующим образом: “Установить баланс счета
12345 равным 110 долларам”. Если текущий баланс счета равен 100 долларам, отправка лю-
бого из сообщений приведет к одному и тому же результату. Но второе сообщение будет
идемпотентным, потому что его повторная отправка не изменит конечный результат (в от-
личие от первого сообщения, которое будет все время добавлять на счет по 10 долларов).
Разумеется, в данном примере не учитывалось наличие других сообщений; например, если
в промежутке между исходным сообщением и дубликатом прибудет новое сообщение,
“Установить баланс счета 12345 равным 150 долларам”.
544
Глава 10. Конечные точки обмена сообщениями
Пример: MIDL (Microsoft Interface Definition Language)
Язык описания интерфейсов Microsoft (Microsoft Interface Definition Language — MIDL)
поддерживает понятие идемпотентности как часть семантики удаленного вызова. Уда-
ленную процедуру можно объявить идемпотентной с помощью атрибута [idempotent].
Согласно спецификации MIDL, “атрибут [idempotent] показывает, что операция не
изменяет состояние объекта и возвращает один и тот же результат при каждом после-
дующем применении. Выполнение операции несколько раз эквивалентно ее выполне-
нию один раз.”
interface IFoo;
[
uuid(5767B67C-3F02-40ba-8B85-D8516F20A83B),
pointer_default(unique)
]
interface IFoo
{
[idempotent]
bool GetCustomerName
(
[in] int CustomerlD,
[out] char *Name
) ;
}
Активатор службы (Service Activator)
545
Активатор службы (Service Activator)
У приложения есть служба, которую нужно сделать доступной для других приложений.
Как спроектировать службу, чтобы ее можно было вызывать как с помощью разно-
образных технологий обмена сообщениями, так и посредством технологий, не свя-
занных с обменом сообщениями?
Приложение не всегда стремится самостоятельно решать, в каком режиме должна вы-
зываться служба (операция в шаблоне слой служб {Service Layer) из [9]): синхронном или
асинхронном. Иногда оно хочет, чтобы для службы поддерживались оба режима вызова.
В реальной жизни выбор того или иного режима часто определяется используемой тех-
нологией. К примеру, если приложение реализовано с помощью EJB, для поддержки
синхронных клиентов ему могут понадобиться компоненты сеанса (session beans), а для
поддержки клиентов обмена сообщениями — компоненты MDB*.
Разработчики В2В-приложения, которое в силу своей деятельности должно обмени-
ваться данными с другими системами, могут не знать, с какими программами будет об-
щаться их приложение и как это общение будет происходить. Существует так много тех-
нологий обмена сообщениями и форматов данных, что внедрить в приложение поддерж-
ку их всех (так, на всякий случай) просто не представляется возможным1 2.
Получение и обработка сообщения часто выполняются в несколько этапов; разделять
эти этапы слишком сложно, да и не всегда нужно. С другой стороны, код конечной точки
сообщения {Message Endpoint, с. 124), сочетающий в себе выполнение разных задач — по-
лучение сообщения, извлечение его содержимого и обработка содержимого для выпол-
нения некоторой операции, — практически непригоден для повторного использования.
Разработчики, занимающиеся созданием клиентов для разных стилей взаимодейст-
вия, часто заново реализуют одну и ту же службу для каждого клиента. Это существенно
усложняет поддержку каждого нового стиля взаимодействия и повышает риск того, что
поведение службы будет существенно отличаться от стиля к стилю. Необходимо, чтобы
одна служба могла поддерживать разные стили взаимодействия.
Активатор службы может работать в одном направлении (только запрос) или в обоих
направлениях (запрос-ответ). Сама служба может представлять собой простой вызов ме-
тода, синхронный и локальный. Возможно, она является частью слоя служб. Активатор
может всегда вызывать одну и ту же службу (если это прописано в его коде), а может ис-
пользовать отражение, чтобы определять, какую службу следует вызвать при получении
того или иного сообщения. Активатор обрабатывает все детали, связанные с обменом со-
общениями, а затем вызывает службу, как обычный синхронный клиент. Благодаря это-
му служба даже не подозревает, что она была вызвана посредством обмена сообщениями.
Схема работы активатора показана на рис. 10.16.
1 Пример Марка Вайцеля.
2 Пример Люка Хохмана.
546
Глава 10. Конечные точки обмена сообщениями
Создайте активатор службы (Service Activate^. Он будет связывать сообщения,
Рис. 10.16. Последовательность действий активатора службы в схеме “запрос-ответ ”
Активатор службы (Service Activator)
547
На рис. 10.16 активатор службы потребляет сообщение с запросом, выступая в каче-
стве опрашивающего потребителя (Polling Consumer, с. 507) или событийно управляемого
потребителя (Event-Driven Consumer, с. 511). Активатор знает формат сообщения и извле-
кает из его тела необходимые данные, чтобы узнать, какую службу требуется вызвать и
какие параметры ей передать. После этого активатор вызывает службу, как обычный
синхронный клиент, и блокирует свое выполнение, пока служба не возвратит результат.
Получив результат, активатор (по желанию разработчика) может создать сообщение с от-
ветом, поместить в него результат выполнения службы и отправить обратно инициатору
запроса. Отправка активатором ответа превращает вызов службы в пример реализации
шаблона запрос-ответ (Request-Reply, с. 177).
Наличие активатора службы позволяет реализовать службу таким образом, как будто
она всегда вызывается в синхронном режиме. Активатор получает асинхронное сообще-
ние, определяет, какую службу следует вызвать и какие данные ей передать, а затем осу-
ществляет вызов службы в синхронном режиме. Служба как таковая не ориентирована на
работу с сообщениями, однако благодаря активатору ее удается вызывать и через обмен
сообщениями.
Если активатору службы не удается успешно обработать сообщение, оно считается
недопустимым и должно быть отправлено в канал недопустимых сообщений (Invalid
Message Channel, с. 143). Если активатор обработал сообщение и успешно вызвал службу,
то любая ошибка, произошедшая в процессе ее выполнения, должна считаться семанти-
ческой ошибкой приложения и обрабатываться самим приложением.
Разработчики не всегда в состоянии предугадать все возможные способы доступа
к службам, которые могут понадобиться их партнерам в будущем, но они по крайней
мере знают, какие службы будет предоставлять их приложение, и могут реализовать эти
службы. Впоследствии, чтобы добавить новый способ доступа к службе, им будет доста-
точно создать еще один активатор, работающий с другой технологией или другим форма-
том данных.
Шаблон активатор службы также описывается в [5] — именно там он впервые поя-
вился под таким названием. Версия шаблона, предлагаемая в [5], несколько отличается
от нашей. Там предполагается, что активатор является событийно управляемым потреби-
телем и что служба существует заранее. Тем не менее и в той, и в другой версиях шаблона
предлагаются одинаковые решения описанной проблемы. Активатор службы довольно
близок к шаблону полусинхронная/полуасинхронная обработка (Half-Sync/Half-Async) из
[34], который разделяет обработку службы на синхронный и асинхронный слои.
Активатор службы обычно получает сообщения с командой (Command Message, с. 169),
описывающие, какую службу требуется запустить. Активатор службы выступает в роли
шлюза обмена сообщениями (Messaging Gateway, с. 482), отделяя службу от деталей обмена
сообщениями. Активатор может быть опрашивающим потребителем или событийно
управляемым потребителем. Если служба поддерживает транзакции, активатор должен
быть транзакционным клиентом (Transactional Client, с. 498), чтобы потребление сообще-
ния выполнялось в рамках той же транзакции, что и вызов службы. Несколько активато-
ров могут функционировать в качестве конкурирующих потребителей (Competing Con-
sumers, с. 515) или координировать свою работу при помощи диспетчера сообщений
(Message Dispatcher, с. 521). Если активатору службы не удается успешно обработать со-
общение, оно должно быть отправлено в канал недопустимых сообщений.
548 Глава 10. Конечные точки обмена сообщениями
Пример: компоненты Enterprise JavaBeans (J2EE)
Используя компоненты EJB [10], службу можно инкапсулировать в компонент сеан-
са, а затем реализовать компоненты MDB для обработки разных сценариев обмена со-
общениями. Один компонент будет применяться для получения сообщений JMS одного
формата из одного источника, другой — для сообщений JMS другого формата из другого
источника, третий — для сообщений SOAP/Web-служб и т.п. Каждый компонент MDB,
обрабатывающий сообщение путем вызова службы, представляет собой активатор
службы (Service Activator). Клиенты, которые хотят вызывать службу в синхронном режи-
ме, могут напрямую осуществлять доступ к компоненту сеанса.
Глава 11
Управление системой
Введение
Разработка решения, основанного на обмене сообщениями, — дело, конечно, непро-
стое. Но эксплуатация такого решения не менее сложна: интеграционное решение, осно-
ванное на обмене сообщениями, может генерировать, маршрутизировать и преобразовы-
вать по нескольку тысяч или даже миллионов сообщений в день. При этом мы постоянно
сталкиваемся с исключениями, “узкими местами” производительности и изменениями в
системах, участвующих в обмене сообщениями. Ситуация усугубляется еще и тем, что
компоненты распределены между разными платформами и компьютерами, физически
удаленными друг от друга.
Помимо сложности и масштаба интеграции распределенных приложений (как приоб-
ретенных в готовом виде, так и написанных разработчиками компании), тестирование и
отладку системы значительно затрудняют архитектурные преимущества слабого связы-
вания. Мартин Фаулер называет это симптомом “мечта архитектора, кошмар разработ-
чика”: архитектурные принципы слабого связывания и косвенности сокращают число
допущений, которые системы делают друг о друге, благодаря чему обеспечивается гиб-
кость системы. С другой стороны, тестирование системы, в которой поставщик сообще-
ний не знает, кто будет их потреблять, может оказаться чрезвычайно сложным заданием.
Прибавьте к этому асинхронные и временные аспекты обмена сообщениями, и положе-
ние станет поистине плачевным. К примеру, решение, основанное на обмене сообще-
ниями, может даже не предусматривать возможность получения поставщиком сообще-
ний ответа от потребителя. Или взять хотя бы такой момент: инфраструктура обмена со-
общениями обычно гарантирует доставку сообщения, но не знает, когда именно это
произойдет. Все это существенно усложняет разработку контрольных тестов, которые
будут основываться на результатах процедуры доставки сообщений.
Отслеживать перемещение потока сообщений можно на двух уровнях абстракции.
Типичное решение, предназначенное для управления системой (system management), на-
блюдает за тем, сколько сообщений было отправлено или как долго длилась обработка
сообщения. Указанные решения не исследуют данные самого сообщения за исключени-
ем, пожалуй, нескольких полей в его заголовке, таких как идентификатор сообщения или
журнал доставки сообщения (Message History, с. 561). В противоположность этому реше-
550
Глава 11. Управление системой
ния, предназначенные для мониторинга бизнес-активности (business activity monitoring —
ВАМ), концентрируются на анализе полезной информации, содержащейся в теле сооб-
щения (к примеру, на общей сумме заказов, сделанных за последний час). Многие из
шаблонов, описанных в этой главе, достаточно универсальны и могут использоваться и в
том, и в другом качестве. Тем не менее, поскольку мониторинг деловой активности —
абсолютно другая сфера, имеющая много общих проблем с организацией хранилищ дан-
ных (технология, которой мы не касались вообще), шаблоны, приведенные в этой главе,
будут рассматриваться исключительно в контексте управления системой.
Основным назначением шаблонов управления системой является поддержание рабо-
ты сложных систем, основанных на обмене сообщениями. Шаблоны, описанные в этой
главе, можно разбить на три категории: мониторинг и управление, наблюдение и анализ
трафика сообщений, а также тестирование и отладка.
Мониторинг и управление
Шина управления (Control Bus, с. 552) обеспечивает наличие единой точки управления
и мониторинга распределенного решения. Шина соединяет различные компоненты сис-
темы с центральной консолью управления, которая отображает состояние каждого ком-
понента и выполняет мониторинг трафика сообщений, проходящих сквозь компоненты.
Консоль может применяться и для отправки компонентам управляющих команд,
например для того, чтобы изменить путь следования потока сообщений. Возможно, вам
захочется, чтобы сообщения подверглись дополнительным процедурам, например про-
верке правильности или фиксации в журнале. Поскольку появление дополнительных
этапов следования сообщений может привести к перегрузке системы, нужно иметь воз-
можность включать и отключать их через шину управления. Это делается с помощью
обходного пути (Detour, с. 556).
Наблюдение и анализ трафика сообщений
Иногда требуется проанализировать содержимое некоторого сообщения, не влияя
на прохождение остального потока сообщений. Перехватить сообщение поможет отвод
(Wire Тар, с. 558).
Выполняя отладку системы, основанной на обмене сообщениями, крайне важно
знать маршрут, по которому проходило то или иное сообщение. Журнал доставки сообще-
ния (Message History, с. 561) фиксирует, через какие компоненты проходило сообщение на
всем пути своего следования. При этом он реализован таким образом, что компоненты
системы сохраняют свою независимость друг от друга.
В отличие от журнала доставки сообщения, который привязан к конкретному сообще-
нию, централизованное хранилище сообщений (Message Store, с. 565) ведет полный учет со-
общений, проходящих сквозь систему. В сочетании с журналом доставки сообщения оно
способно анализировать все возможные пути следования сообщений в системе.
Отвод, журнал доставки сообщения и хранилище сообщений помогают анализировать
асинхронный поток сообщений. Чтобы следить за сообщениями, отправленными служ-
бам запроса-ответа, в маршрут следования сообщений нужно вставить интеллектуальный
заместитель (Smart Proxy, с. 567).
Введение 551
Тестирование и отладка
Тестирование системы обмена сообщениями перед ее развертыванием в рабочей сре-
де — весьма нужная процедура. Но проверка системы не должна заканчиваться на этапе
тестирования. Необходимо активно следить за правильным функционированием рабо-
тающей системы. Для этого в систему периодически вбрасывается тестовое сообщение
(Test Message, с. 577).
Если компонент ведет себя неправильно или выходит из строя, в канале могут поя-
виться нежелательные сообщения. В процессе тестирования удобно иметь возможность
очищать канал от оставшихся в нем сообщений, чтобы тестируемые компоненты не по-
лучали “мусора”. Это делается при помощи вентиля канала (Channel Purger, с. 579).
552
Глава 11. Управление системой
Шина управления (Control Bus)
Корпоративные интеграционные решения носят распределенный характер. По сути,
одно из определяющих качеств корпоративной системы обмена сообщениями состоит в
том, чтобы обеспечивать взаимодействие между разобщенными системами путем мар-
шрутизации и преобразования данных. В большинстве случаев системы, обменивающие-
ся сообщениями, разбросаны по разным сетям, зданиям, городам или даже континентам.
Как организовать эффективное управление системой обмена сообщениями, если
ее компоненты распределены между несколькими программными платформами и
разбросаны на большой территории?
Распределенная, слабо связанная архитектура обеспечивает гибкость и масштабируе-
мость решения. В то же время она чрезвычайно сложна в плане администрирования и
контроля. Как, к примеру, узнать, что все компоненты системы включены и исправно
функционируют? Простой анализ состояния процессов не подойдет, потому что процес-
сы распределены между большим количеством компьютеров. Кроме того, если от уда-
ленного компьютера не удалось получить сведения о состоянии процесса, что это может
означать: сбой удаленного компьютера или поломку сети?
Работая с распределенной системой, необходимо не только знать о состоянии ее ком-
понентов, но и наблюдать за ее динамическим поведением. Каков объем потока сообще-
ний? Возникают ли непредусмотренные задержки на пути следования сообщений?
Не переполнены ли каналы? Для получения такой информации необходимо отслеживать
время перемещения сообщений между компонентами или сквозь них. Все это предпола-
гает сбор и комбинирование информации с нескольких компьютеров сети.
Наконец, простого чтения информации, предоставленной компонентами, может ока-
заться недостаточно. Зачастую в процессе работы системы в нее необходимо внести не-
которые исправления или изменить конфигурационные параметры, например включить
или отключить механизм ведения журнала. Многие приложения используют файлы
свойств и журналы записи ошибок для чтения конфигурационной информации или фик-
сации сведений о сбоях. Этот подход хорошо работает до тех пор, пока приложение охва-
тывает только один компьютер или, по крайней мере, небольшое число компьютеров.
В большом, распределенном решении файлы свойств нужно было бы копировать на уда-
ленные машины с помощью некоторого механизма передачи файлов. Это предполагает,
что файловая система на каждом из компьютеров открыта для удаленного доступа, что
весьма рискованно с точки зрения безопасности и не всегда осуществимо, если компью-
теры соединены через Интернет или глобальную сеть, не поддерживающую протоколы
сопоставления файлов. Кроме того, управление многочисленными версиями локальных
файлов свойств может обернуться так называемым “кошмаром управления”.
Шина управления (Control Bus)
553
Кажется вполне естественным переложить выполнение некоторых из перечисленных
выше задач на систему обмена сообщениями. К примеру, для изменения конфигурации
компонента ему можно отправить управляющее сообщение, которое будет передано и
доставлено, как обычное сообщение. Это решает большинство проблем взаимодействия
компонентов, но приводит к появлению новых затруднений. К конфигурационным со-
общениям должны применяться более строгие политики безопасности, чем к обычным
сообщениям приложений. Неправильно сформированное управляющее сообщение мо-
жет легко привести к отказу компонента. А что если компонент неисправен, вследствие
чего в канале продолжает накапливаться очередь из сообщений? Если мы отправим
управляющее сообщение, которое должно перезапустить компонент, оно попросту за-
стрянет в этой очереди и не достигнет цели. Некоторые системы обмена сообщениями
поддерживают назначение сообщениям приоритета, что позволяет продвинуть управляю-
щие сообщения в начало очереди. К сожалению, эта возможность есть далеко не у всех сис-
тем, и приоритет не спасет, если очередь переполнена до предела и не принимает еще одно
сообщение. Кроме того, некоторые управляющие сообщения должны иметь более низкий
приоритет, чем обычные сообщения приложений. Если компонент периодически публику-
ет сообщения о своем состоянии, задержка или потеря сообщения “Я исправен”, вероятно,
окажется куда менее болезненной, чем потеря сообщения “Заказ на 1 млн долларов”.
Используйте шину управления (Control Bus) для управления корпоративным инте-
грационным решением. Шина управления использует тот же механизм обмена со-
общениями, что и данные приложений, однако применяет отдельные каналы для
передачи данных, касающихся управления компонентами, которые участвуют
в продвижении потока сообщений.
Поток сообщений
Каждый компонент системы будет подключен к двум подсистемам обмена сообще-
ниями.
1. Поток сообщений приложения
2. Шина управления
Поток сообщений приложения переносит все сообщения, касающиеся приложений.
Компоненты системы подписываются на эти каналы и публикуют в них сообщения, как
и в обычном сценарии без управления системой. Вдобавок ко всему каждый компонент
отправляет и получает сообщения по каналам, которые образуют шину управления.
Эти каналы подключаются к центральному управляющему компоненту.
554
Глава 11. Управление системой
Шина управления хорошо подходит для передачи сообщений следующих типов.
1. Конфигурационные сообщения. Каждый компонент, участвующий в передаче по-
тока сообщении, должен иметь настраиваемые параметры, значения которых
могут изменяться по требованию других компонентов. В число этих параметров
входят адреса каналов, форматы данных сообщений, тайм-ауты и т.п. Чтобы
узнать подобную информацию, компоненты не обращаются к файлам свойств,
а пользуются шиной управления для извлечения сведений из центрального репози-
тория. Последний образует единую точку конфигурации параметров интеграци-
онного решения во время выполнения. К примеру, таблица маршрутизации
в маршрутизаторе на основе содержимого (Content-Based Router, с. 247) может нуж-
даться в автоматическом обновлении в зависимости от условий системы, таких
как перегрузка и отказ компонента.
2. Пульсы. Каждый компонент системы может периодически отсылать по шине
управления сообщение, называемое пульсом (heartbeat), чтобы центральная кон-
соль знала, что компонент функционирует. Пульс также может включать в себя
некоторые сведения о компоненте, например число обработанных им сообщений
или объем доступной оперативной памяти на компьютере, на котором установлен
компонент.
3. Тестовые сообщения. Сообщение-пульс уведомляет шину управления о том, что
компонент работает, но оно содержит лишь ограниченный объем информации
о том, правильно ли компонент обрабатывает сообщения. Чтобы проверить рабо-
ту компонента, мы можем “вбросить” в поток сообщений тестовое сообщение,
а затем извлечь его и посмотреть, правильно ли оно было обработано компонен-
том. Поскольку указанный подход несколько сглаживает разницу между шиной
управления и потоком сообщений приложения, мы выделили его в отдельный
шаблон тестовое сообщение (TestMessage, с. 577).
4. Исключения. Каждый компонент может отправить по шине управления исключения,
сгенерированные каналом, чтобы их оценила управляющая консоль. О серьезных
исключениях может понадобиться уведомить оператора. Правила, определяющие
обработку исключений, должны быть заданы в центральном обработчике.
5. Статистические сообщения. Каждый компонент может собирать статистику о ко-
личестве обработанных им сообщений, среднем уровне пропускной способности,
среднем времени обработки сообщения и т.п. Некоторые из этих данных могут
зависеть от типа сообщения, поэтому мы сможем определить, не переполняют ли
систему сообщения определенного типа. Поскольку приоритет статистических
сообщений обычно ниже приоритета других сообщений, для доставки данных та-
кого типа шиной управления часто применяются каналы с негарантированной дос-
тавкой или с низким приоритетом.
6. Активная консоль. Большинство действий, перечисленных в этом списке, можно
объединить для отображения в центральной консоли. С ее помощью операторы
могут оценивать состояние системы обмена сообщениями и при необходимости
предпринимать корректирующие действия.
Шина управления (Control Bus)
555
Большинство функций шины управления в точности соответствуют классическим
функциям управления сетью, использующимся для мониторинга и обслуживания любого
сетевого решения. Шина управления позволяет реализовать аналогичные функции управ-
ления на уровне системы обмена сообщениями, по сути, поднимая их с более низкого
уровня сетей IP на более высокий уровень обмена сообщениями. Наличие функциональ-
ности управления играет такую же важную роль для успешной эксплуатации инфра-
структуры обмена сообщениями, как и для сетевой инфраструктуры. К сожалению,
отсутствие стандартов управления системами, основанными на обмене сообщениями,
значительно затрудняет построение для них корпоративных решений управления с воз-
можностью повторного использования.
Проектируя компоненты, участвующие в обработке сообщений, мы снабжаем обра-
ботчик тремя интерфейсами (рис. 11.1). Интерфейс входящих данных получает из канала
входящие сообщения. Интерфейс исходящих данных отправляет обработанные сообще-
ния в исходящий канал. И наконец, интерфейс управляющих данных отсылает и получа-
ет управляющие сообщения из шины управления.
Входящие
Исходящие
Рис. 11.1. Ключевые интерфейсы компонента, участвующего в обмене сообщениями
Пример: оснащение кредитного брокера средствами контроля
В главе 12 показано, как использовать шину управления, чтобы оснастить кредитный бро-
кер, разработанный нами в главе 9, средствами управления и контроля. В их состав вхо-
дит простая управляющая консоль, которая отображает состояние компонентов в режи-
ме реального времени. (См. главу 12.)
556
Глава 11. Управление системой
Обходной путь (Detour)
Иногда маршрут следования сообщений требуется изменить под влиянием некоторых
внешних факторов.
Как направить сообщение на прохождение дополнительных этапов обработки
с целью проверки правильности, отладки или тестирования?
Проверка правильности сообшений, которые перемешаются между компонента-
ми, — очень полезное средство отладки. Тем не менее подобный дополнительный этап
требуется далеко не всегда, а при постоянном выполнении способен серьезно замедлить
работу системы.
Возможность включать в путь следования сообщений дополнительные этапы обра-
ботки или же пропускать их в зависимости от некоторой директивы “из центра” может
оказаться весьма эффективной при отладке или настройке производительности системы.
К примеру, в процессе тестирования системы можно сделать так, чтобы сообщения про-
ходили дополнительную проверку правильности. С другой стороны, если пропускать
этот этап при эксплуатации системы, производительность последней может существенно
повыситься. Такую проверку можно сравнить с выражениями assert, которые вставля-
ются в исходный код и выполняются на этапе отладки, но не переносятся в выполняе-
мый файл готового приложения.
Аналогичным образом в процессе поиска и устранения неполадок сообщение может
проходить через дополнительные компоненты с целью мониторинга или ведения журна-
ла. Возможность включать и отключать подобные шаги позволяет максимизировать про-
пускную способность каналов обмена сообщениями в нормальном режиме работы.
Создайте обходной путь (Detoui) с помощью маршрутизатора на основе содер-
жимого (Content-Based Router, с. 247), действия которого контролируются через
шину управления (Control Bus, с. 552). В одном состоянии маршрутизатор направ-
ляет входящие сообщения на дополнительные этапы проверки, а в другом —
прямо в канал назначения.
Источник
Обходной путь (Detour)
557
В шаблоне обходной путь используется простой маршрутизатор на основе содержимого
с двумя выходными каналами. По одному выходному каналу нетронутое сообщение пе-
редается в конечный пункт назначения. Если же от шины управления получена соответст-
вующая инструкция, маршрутизатор направляет сообщения в другой канал. Отсюда со-
общение передается дополнительным компонентам, которые анализируют и (или) изме-
няют сообщение. После этого сообщение направляется в конечный пункт назначения.
Если обходной маршрут содержит только один компонент, то можно получить более
эффективное решение, скомбинировав обходной путь и указанный компонент в единый
фильтр. Это решение, однако, предполагает, что в компонент, расположенный на обход-
ном маршруте, можно добавить логику включения/отключения дополнительных этапов,
контролируемую через шину управления.
Преимущество управления обходным путем через шину управления состоит в том, что
несколько обходных путей можно одновременно активизировать или отключать с помо-
щью одной команды, отправленной по шине управления. Для этого управляющую консоль
связывают с обходными путями посредством канала “публикация-подписка” (Publish-
Subscribe Channel, с. 134).
558
Глава 11. Управление системой
Отвод (Wire Тар)
ЗДрчвяижвЯ"
Каналы “точка-точка” (Point-to-Point Channel, с. 131) часто применяются для переда-
чи сообщений с данными документа (Document Message, с. 171), поскольку они гарантиру-
ют, что сообщение будет потреблено в точности одним получателем. Между тем при тес-
тировании, мониторинге или устранении неполадок необходимо иметь возможность
исследовать содержимое всех сообщений, которые перемещаются по каналу.
Как просмотреть содержимое сообщений, которое передается по каналу “точка-
точка” ^Point-to-Point Channei, с. 131)?
Иногда очень полезно знать, какие сообщения путешествуют по каналу, например,
в целях простой отладки или для помещения сообщений в хранилище сообщений (Message
Store, с. 565). Но для этого к каналу “точка-точка” не может быть добавлен еще один
слушатель, потому что тот будет первым потреблять сообщения, передающиеся по кана-
лу, и они не дойдут до конечного получателя.
Можно было бы сделать так, чтобы отправитель или получатель публиковал сообще-
ние в отдельном канале для анализа с целью отладки. К сожалению, для этого нам при-
шлось бы модифицировать огромное количество компонентов. Кроме того, если мы
имеем дело с готовыми приложениями сторонних производителей, внести в них подоб-
ные изменения вряд ли удастся.
Существующий канал можно заменить каналом “публикация-подписка” (Publish-
Subscribe Channel, с. 134). Тогда канал можно будет прослушивать с целью проверки со-
общений, не влияя на их доставку конечным получателям. Но механизм публикации-
подписки изменяет семантику канала. К примеру, несколько конкурирующих потребите-
лей (Competing Consumers, с. 515) могут получать сообщения по каналу “точка-точка”,
основываясь на том факте, что каждое конкретное сообщение получит только один по-
требитель. Изменение типа канала на канал “публикация-подписка” приведет к тому, что
каждый потребитель будет получать все сообщения. Это весьма нежелательно, если,
к примеру, входящие сообщения содержат заказы, которые теперь будут обрабатываться
по нескольку раз. Впрочем, даже если канал прослушивается только одним потребите-
лем, использование канала “публикация-подписка” может оказаться менее эффективным
или надежным, нежели использование канола “точка-точка”.
Многие системы обмена сообщениями предоставляют метод, позволяющий компо-
ненту просматривать сообщения внутри канала “точка-точка", не потребляя их. У дан-
ного подхода, однако, есть одно важное ограничение: как только конечный получатель
потребит сообщение, метод просмотра больше не сможет видеть это сообщение. Таким
образом, указанный подход не позволяет анализировать сообщения после того, как они
были потреблены.
Отвод (Wire Тар)
559
Можно было бы вставить в канал специальный компонент, выполняющий роль про-
межуточного получателя или “перехватчика”. Перехватчик потребляет сообщение из
входного канала, анализирует его, а затем передает нетронутое сообщение в выходной
канал. К сожалению, в процедуре анализа часто задействованы сообщения из нескольких
каналов (например, когда требуется измерить, сколько времени сообщение шло от од-
ного компонента к другому), а посему указанную функцию нельзя реализовать с помо-
щью одного фильтра в одном канале.
Вставьте в канал отвод (Wire Тар). Это простой список получателей (Recipient
List, с. 264), который публикует каждое входящее сообщение в главном, а также
во вторичном каналах.
Отвод
Отвод, также известный под названием тройник (tee), — это фиксированный список
получателей с двумя выходными каналами. Он потребляет сообщения из входного канала
и публикует нетронутое сообщение в обоих выходных каналах. Чтобы вставить отвод
в канал обмена сообщениями, необходимо создать дополнительный канал и настроить
конечный получатель на потребление сообщений из второго канала. Поскольку анализ
сообщений выполняется отдельным компонентом, мы можем вставить универсальный
отвод в любой канал, не боясь случайно изменить поведение первичного канала. Это по-
вышает возможность повторного использования и сокращает риск нежелательных
побочных эффектов при добавлении отвода к существующему решению.
Удобно сделать отвод программируемым через шину управления (Control Bus, с. 552),
чтобы вторичный канал (“отвод”) можно было включать и выключать. Тогда мы сможем
инструктировать отвод, чтобы он публиковал сообщения во вторичном канале только во
время тестирования или отладки.
Главным недостатком отвода является дополнительная задержка, связанная с по-
треблением и повторной публикацией сообщений. Многие наборы средств интеграции
автоматически декодируют сообщение, даже если оно публикуется в другом канале без
изменений. Кроме того, новое сообщение получит идентификатор сообщения и метку
времени, которые будут отличаться от таковых исходного сообщения. Указанные опера-
ции вкупе с дополнительной нагрузкой могут привести к отказу существующих механиз-
мов. К примеру, если идентификатор исходного сообщения используется в качестве
идентификатора корреляции (Correlation Identifier, с. 186), внедрение отвода приведет
560
Глава 11. Управление системой
к отказу решения, потому что идентификатор повторно опубликованного сообщения будет
отличаться от идентификатора исходного. Это одна из причин того, почему идентифика-
тор сообщения не рекомендуется применять в качестве идентификатора корреляции.
Поскольку отвод публикует два отдельных сообщения, важно не сопоставлять их по
идентификаторам сообщений. Даже несмотря на то, что первичный и вторичный каналы
получают два абсолютно одинаковых сообщения, большинство систем обмена сообще-
ниями автоматически присваивают новый идентификатор каждому сообщению в систе-
ме. Это означает, что исходное сообщение и его “двойник” будут иметь разные иденти-
фикаторы сообщений.
Существующий брокер сообщений (Message Broker, с. 334) может быть легко расширен
для выполнения функций отвода, потому через этот центральный компонент уже прохо-
дят все сообщения системы.
Важным ограничением отвода является невозможность изменения сообщений, про-
ходящих по каналу. Если над сообщениями необходимо выполнять какие-то действия,
воспользуйтесь обходным путем (Detour, с. 556).
Пример: кредитный брокер
В главе 12 мы расширим пример кредитного брокера, вставив отвод (Wire Тар) в канал
запросов, соединяющий брокер и кредитное бюро. Это делается для того, чтобы вести
журнал запросов к указанной внешней службе (см. главу 12).
Пример: использование нескольких отводов для измерения времени прохож-
дения сообщения по каналу
Одним из преимуществ отвода (Wire Тар) является возможность скомбинировать несколь-
ко отводов для отправки копий сообщений на анализ некоторому центральному компонен-
ту. В качестве последнего может выступать хранилище сообщений (Message Store, с. 565) или
другой компонент, анализирующий связи между сообщениями, такие как временной ин-
тервал между прохождением по каналу двух связанных сообщений. Анализируя время про-
хождения конкретного сообщения между двумя заданными точками, мы должны основы-
вать свои вычисления на времени отправки вторичных сообщений (рис. 11.2), чтобы не ис-
казить вычисления временем путешествия этих сообщений по каналам.
Рис. 11.2. Использование пары отводов для подсчета времени прохождения сообщения по каналу
Журнал доставки сообщения (Message History)
561
Журнал доставки сообщения (Message History)
Одним из ключевых преимуществ системы, основанной на обмене сообщениями,
является слабая связь между ее участниками. Отправитель и получатель сообщения
не делают (или практически не делают) допущений друг о друге. Если получатель извле-
кает сообщение из канала обмена сообщениями, он, как правило, не знает и не желает
знать о том, каким приложением оно было размещено в канале. Сообщение по определе-
нию является самодостаточным объектом и не привязывается к конкретному отправите-
лю. Это одна из главных архитектурных особенностей систем, в которых для взаимодей-
ствия между компонентами используется обмен сообщениями.
К сожалению, эта же особенность системы может серьезно усложнить отладку и ана-
лиз зависимостей. Если мы точно не знаем, куда следует сообщение и через какие ком-
поненты оно проходит, как можно оценить влияние на систему изменения формата
сообщения? Точно так же, если мы не знаем, какое приложение опубликовало то или иное
сообщение, нам будет крайне сложно решить проблему, связанную с этим сообщением.
Как организовать эффективный анализ и отладку пути следования сообщений
в слабо связанной системе?
Шина управления (Control Bus, с. 552) отслеживает состояние каждого компонента,
обрабатывающего сообщения, но ее совершенно не интересует маршрут, по которому
проходит то или иное сообщение. Можно было бы модифицировать каждый компонент
системы, чтобы тот публиковал в шине управления уникальные идентификаторы всех про-
ходящих через него сообщений. Полученную информацию можно было бы затем соби-
рать в некоторую общую базу данных, т.е. в хранилище сообщений (Message Store, с. 565).
Для реализации описанного подхода требуется наличие развитой инфраструктуры,
включая отдельное хранилище данных. Кроме того, если компонент решит изучить мар-
шрут следования сообщения, ему понадобится отправить запрос в центральную базу
данных. Это чревато превращением базы данных в “узкое место”.
Проследить путь прохождения сообщения по системе не так просто, как кажется.
На первый взгляд, для этого логично использовать уникальный идентификатор сообще-
ния. Однако, когда некоторый компонент, например маршрутизатор сообщений (Message
Router, с. 109), обработает сообщение и опубликует его в выходном канале, готовое сооб-
щение получит новый идентификатор, никак не указывающий на его связь с исходным
сообщением. По этой причине нам понадобится ввести новый ключ, который будет ко-
пироваться из исходного в выходное сообщение, чтобы впоследствии их можно было
связать друг с другом. Этот подход неплох, если для каждого исходного сообщения ком-
понент публикует в точности одно выходное сообщение. К сожалению, большинство
компонентов поступает как раз наоборот. К примеру, список получателей (Recipient List,
с. 264), агрегатор (Aggregator, с. 283) и диспетчер процессов (Process Manager, с. 325) в ответ
на одно входящее сообщение часто публикуют несколько исходящих и наоборот.
562
Глава 11. Управление системой
Вместо того чтобы определять путь следования сообщения, наблюдая за его меткой,
сообщение может само собирать список компонентов, которые встретились на его пути.
Если каждому компоненту системы будет присвоен уникальный идентификатор, компо-
нент может добавлять свой идентификатор в каждое публикуемое им сообщение.
Присоедините к сообщению журнал доставки сообщения (Message History.
Это список всех приложений или компонентов, через которые сообщение прошло
на своем пути следования.
Журнал доставки сообщения включает в себя список всех компонентов, через которые
прошло сообщение. Каждый компонент, обрабатывающий сообщение (в том числе и его
создатель), добавляет в этот список новую запись. Журнал доставки сообщения должен
быть частью заголовка, потому что он содержит контрольную информацию, специфич-
ную для системы. Вынесение этой информации в заголовок позволит отделить ее от тела
сообщения, содержащего данные, специфичные для приложения.
Не каждое сообщение, публикуемое компонентом, является результатом обработки
одного сообщения. Так, агрегатор публикует одно сообщение, несущее в себе информа-
цию, взятую из нескольких сообщений. Каждое из них могло иметь собственный журнал
доставки. В этой ситуации для создания журнала доставки сообщения можно поступить
двумя способами. Если мы хотим отследить полный путь следования всех сообщений,
журнал доставки сообщения можно организовать в виде дерева. Благодаря рекурсивному
характеру древовидных структур журналы доставки разных сообщений можно объеди-
нить в один узел. Вместо дерева в качестве журнала доставки можно использовать про-
стой список, в котором будет фиксироваться путь следования только одного исходного
сообщения. Этот подход хорош в ситуации, если путь следования одного сообщения иг-
рает более важную роль для конечного результата, чем маршруты других, вспомогатель-
ных сообщений. К примеру, в сценарии с аукционом (см. главу 9) нас, скорее всего, будет
интересовать журнал доставки только “победившего” сообщения.
Журнал доставки сообщения наиболее полезен в ситуациях, когда сообщения проходят
сквозь ряд разнообразных фильтров, в совокупности выполняющих некоторую бизнес-
функцию или процесс. Если же вы хотите управлять путем следования сообщения, вос-
пользуйтесь диспетчером процессов. Последний создает по одному экземпляру процесса
на каждое входящее сообщение-триггер. Это позволит централизованно управлять про-
хождением сообщений через компоненты, избавляя от необходимости прилагать к каж-
дому сообщению журнал его доставки.
Журнал доставки сообщения (Message History)
563
Пример: предотвращение бесконечных циклов
Наличие журнала доставки сообщения (Message History) играет важную роль при оповеще-
нии о событиях с помощью канала “публикация-подписка” (Publish-Subscribe Channel,
с. 134). Пусть мы реализуем систему, которая оповещает другие системы об изменении
адреса клиента по каналу “публикация-подписка”. Каждое изменение адреса рассылается
всем заинтересованным системам, чтобы они могли обновить свои данные. Описанный
подход очень гибок в плане добавления новых систем — новая система будет автомати-
чески получать широковещательное сообщение без необходимости вносить какие-либо
изменения в существующую систему обмена сообщениями. Теперь рассмотрим систему
обслуживания клиентов, хранящую адреса последних в базе данных приложения. Каждое
изменение поля базы данных инициирует рассылку сообщения, уведомляющего осталь-
ные системы об изменении адреса. В соответствии с концепцией механизма публикации-
подписки оповещение о событии получат все системы, подписавшиеся на канал
“публикация-подписка”. Но на этот канал должна быть подписана и сама система обслу-
живания клиентов, например, для того, чтобы получать от другой системы обновление
адреса, сделанное клиентом через Web-сайт! Это означает, что система обслуживания
клиентов получит опубликованное ею же сообщение. Оно инициирует обновление поля
базы данных, что, в свою очередь, приведет к отправке нового сообщения об изменении
адреса и т.п. У нас появится бесконечный цикл оповещений об изменении адреса. Во из-
бежание возникновения такого цикла приложения, подписавшиеся на канал, мотут про-
сматривать журнал доставки сообщения, чтобы игнорировать сообщения, отправленные
ими же самими.
Пример: TIBCO ActiveEnterprise
Многие пакеты EAI-средств поддерживают ведение журналов доставки сообщения
(Message History). К примеру, в TIBCO ActiveEnterprise заголовок каждого сообщения
включает в себя поле отслеживания. В нем хранится список всех компонентов, через ко-
торые прошло сообщение. В связи с этим важно отметить, что компоненты TIBCO
ActiveEnterprise назначают исходящему сообщению тот же идентификатор, который был
у потребленного сообщения. Это облегчает наблюдение за путем следования сообщений
через компоненты, но вместе с тем означает, что идентификатор сообщения не является
уникальным в пределах системы, потому что несколько сообщений будут иметь один и
тот же идентификатор. К примеру, при реализации списка получателей (Recipient List,
с. 264) идентификатор потребленного сообщения будет перенесен в каждое исходящее
сообщение.
В примере, приведенном ниже, показано содержимое сообщения, которое прошло
через несколько компонентов, включая два процесса TIBCO IntegrationManager с имена-
ми OrderProcess и VrfyCustStub.
tw.training.customer.verify.response
{
RVMSG_ INT 2 ApfntA 10
RVMSG_ "int 2 AverA 30
RVMSG_ Tnt 2 Afcype2 1
RVMSG ’rvmsg 108 *dataA
564 Глава 11. Управление системой
{
RVMSG_STRING 23 'class* "VerifyCustomerResponse
RVMSG_INT 4 Aidx* 1
RVMSG_STRING 6 CUSTOMER_ID "12345"
RVMSG_STRING 6 ORDER_ID "22222"
RVMSG_INT 4 RESULT 0
RVMSG_RVMSG 150 ^tracking*
RVMSG_STRING 28 ^icT "40EaDEoiBIpcYk6qihzzwB5Uzzw"
RVMSG_STRING 41 Л1Л "imed_debug_enginel-OrderProcess-Job-4300"
RVMSG_STRING 47 "2" "imed_debug_enginel-VrfyCustStub-Job-4301"
Хранилище сообщений (Message Store)
565
Хранилище сообщений (Message Store)
Как уже говорилось в разделе, посвященном журналу доставки сообщения (Message
History, с. 561), архитектурный принцип слабого связывания обеспечивает гибкость ин-
теграционного решения, но усложняет анализ его динамического поведения.
Как использовать содержимое сообщений в отчетах, не нарушая слабо связанный
и краткосрочный характер системы обмена сообщениями?
Асинхронный обмен сообщениями гарантирует доставку, но не знает время этой дос-
тавки. На практике, однако, время отклика системы часто играет критическую роль.
Кроме того, в асинхронной системе обмена сообщениями отдельные сообщения сущест-
вуют и обрабатываются “сами по себе”. Между тем, нам могут понадобиться сведения,
охватывающие несколько сообщений, например число сообщений, прошедших через
систему за определенный промежуток времени.
Журнал доставки сообщения прекрасно иллюстрирует, как удобно иметь возможность
узнавать “источник” сообщения. На основании этих данных можно вывести интересную
статистику о пропускной способности канала и времени прохождения сообщения. Един-
ственный недостаток журналов доставки сообщения состоит в том, что они разбросаны по
отдельным сообщениям. Собрать указанную информацию в один отчет нелегко; к тому
же время жизни сообщения может быть довольно коротким. Как только сообщение будет
потреблено, журнал доставки сообщения окажется недоступным.
Для создания более или менее содержательных отчетов данные сообщения нужно со-
хранять в некотором постоянном центральном хранилище.
Используйте хранилище сообщений (Message Store) для централизованного хра-
нения информации о каждом сообщении.
566
Глава 11. Управление системой
Работая с хранилищем сообщений, можно воспользоваться преимуществами асинхрон-
ного характера инфраструктуры обмена сообщениями. Отправляя сообщение в основной
канал, мы отправляем дубликат этого сообщения в специальный канал, откуда оно попа-
дает в хранилище сообщений. Отправку дубликата может выполнять сам компонент, через
который прошло сообщение, или же вставленный в канал отвод (Wire Тар, с. 558). Вто-
ричный канал, передающий копию сообщения, можно считать частью шины управления
(Control Bus, с. 552). Отправка второго сообщения в режиме “передать и забыть” не при-
ведет к замедлению основного потока сообщений приложения, но увеличит нагрузку
на сеть. Вот почему в хранилище рекомендуется помещать не все сообщение, а лишь не-
сколько ключевых полей, необходимых для дальнейшего анализа, таких как идентифика-
тор сообщения, имя канала, по которому оно было отправлено, а также метка времени.
Выбор данных для помещения в хранилище сообщений — отдельный и очень важный
вопрос. Очевидно, что чем больше данных у нас есть о сообщении, тем шире возможно-
сти создания отчетов. С другой стороны, следует учитывать нагрузку на сеть и ограни-
ченный объем хранилища. Даже если мы сохраним все данные сообщения, возможности
по созданию отчетов все равно будут ограничены. Заголовки сообщений обычно имеют
похожее строение, а вот структура тела сообщения сильно зависит от типа последнего и
может оказаться труднодоступной для внешних приложений (например, если в теле со-
общения содержится сериализованный объект Java). Это затрудняет создание отчета на
основе элементов данных, находящихся в теле сообщения.
Поскольку данные в теле сообщения могут иметь разные форматы для каждого типа
сообщения, нужно придумать другие варианты хранения. Если для каждого типа сооб-
щения создать схему хранения (например, таблицы), соответствующую его внутренней
структуре данных, мы сможем применить индексы и выполнять сложный поиск по со-
держимому сообщений. Это, однако, предполагает, что для каждого типа сообщений бу-
дет создана отдельная структура хранения. Поддерживать работу такого хранилища будет
очень и очень сложно. Вместо этого содержимое сообщения можно хранить в виде не-
структурированных данных в формате XML, поместив их в одно длинное символьное по-
ле. Это позволит нам применить универсальную схему хранения. Мы все еще сможем де-
лать запросы к полям заголовка, но не сможем извлекать поля из тела сообщения. Тем не
менее, идентифицировав конкретное сообщение, мы сможем воссоздать его содержимое
на основе документа XML, находящегося в хранилище сообщений. И наконец, для хране-
ния сообщений можно применять репозиторий XML. В хранилищах такого типа доку-
менты XML индексируются для последующего извлечения и анализа.
Хранилище сообщений может разрастись до огромных размеров, поэтому в большинст-
ве случаев необходимо предусмотреть механизм его очистки. Данные более старых сооб-
щений могут переноситься в архивную базу данных или же просто уничтожаться.
Пример: коммерческие ЕА1-средства
Некоторые средства интеграции корпоративных приложений обладают поддержкой хра-
нилища сообщений (Message Store). К примеру, в MSMQ отправленные или полученные
сообщения могут автоматически помещаться в очередь журнала (journal queue). Microsoft
BizTalk по желанию сохраняет все документы (сообщения) в базе данных SQL Server для
дальнейшего анализа.
Интеллектуальный заместитель (Smart Proxy)
567
Интеллектуальный заместитель (Smart Proxy)
Для отслеживания и анализа сообщений, проходящих через компонент, можно вос-
пользоваться парой отводов (Wire Тар, с. 558), но этот подход предполагает, что компо-
нент публикует сообщения в фиксированном выходном канале. Между тем многие ком-
поненты, функционирующие по типу служб, публикуют ответные сообщения в канале,
заданном обратным адресом (Return Address, с. 182), который был указан в сообщении
с запросом.
Как отслеживать сообщения, проходящие через службу, если ответ на каждый за-
прос публикуется в канале, заданном обратным адресом (Return Address, с. 182)?
Чтобы следить за сообщениями, проходящими через службу, нужно перехватывать
и запрос, и ответ. Перехватить сообщение с запросом легко — достаточно воспользо-
ваться отводом. Перехватывать ответы гораздо сложнее, потому что служба публикует их
в разных каналах в зависимости от того, какой обратный адрес был указан в сообщении
с запросом.
От большинства служб, работающих по принципу запрос-ответ (Request-Reply,
с. 177), требуется поддержка обратного адреса, чтобы инициатор запроса мог задать
канал, по которому следует отправить ответ. Если изменить поведение службы, чтобы все
ответы отправлялись по фиксированному каналу, инициаторам запросов станет весьма
сложно извлекать из канала нужные ответы. Некоторые системы обмена сообщениями
позволяют потребителям просматривать отдельные сообщения в очереди, но этот подход
слишком привязан к реализации и не срабатывает в ситуациях, когда ответ передается не
автору запроса, а другому компоненту.
Как уже обсуждалось в разделе, посвященном отводу, изменение компонента с целью
анализа сообщений не всегда желательно или вообще возможно. Если мы работаем с го-
товым приложением стороннего производителя, то наверняка не сможем модифициро-
вать его код и будем вынуждены разработать некоторое внешнее решение. Точно так не
всегда удобно, чтобы логика анализа сообшений была реализована прямо в приложении,
в особенности потому, что характер логики может меняться в зависимости от того, в ка-
ком режиме функционирует приложение: в рабочем или в тестовом. Вынесение функций
анализа в отдельный, самодостаточный компонент повышает гибкость, возможность по-
вторного использования и тестируемость компонентов системы.
Извлеките и сохраните обратный адрес (Return Address, с. 182), заданный ини-
циатором запроса, а затем замените его адресом интеллектуального замести-
теля (Smart Proxy). Когда служба отправит сообщение с ответом, перенаправьте
его на первоначально заданный обратный адрес.
568
Глава 11. Управление системой
Инициатор
запроса 1
Инициатор
запроса 2
Очередь ответов 2
Очередь запросов
Служба
Очередь ответов 1
Очередь ответов
службы
Очередь запросов
к службе
Интеллектуальный
заместитель
Интеллектуальный заместитель перехватывает сообщения, отосланные по каналу за-
просов в службу запрос-ответ. Из каждого входящего сообщения интеллектуальный за-
меститель извлекает обратный адрес, заданный инициатором запроса, и сохраняет его.
После этого обратный адрес в заголовке сообщения заменяется адресом канала ответов,
который прослушивается интеллектуальным заместителем. Когда в этот канал попадает
сообщение с ответом, интеллектуальный заместитель выполняет все необходимые ана-
литические операции, извлекает исходный обратный адрес и с помощью маршрутизатора
сообщений (Message Router, с. 109) отправляет ответ требуемому получателю.
Интеллектуальный заместитель удобно использовать и тогда, когда внешняя служба
не поддерживает работу с обратными адресами и отправляет ответы в фиксированный
канал. Чтобы обеспечить поддержку обратных адресов, на другом конце такого канала
можно поставить интеллектуальный заместитель. В данном случае он не будет выпол-
нять никаких аналитических операций, а просто займется перенаправлением сообщений
с ответами в нужные каналы.
Обратный адрес, указанный инициатором запроса, должен сохраняться таким обра-
зом, чтобы интеллектуальный заместитель мог сопоставлять входящие ответы с обрат-
ными адресами и направлять сообщения с ответами в нужные каналы. Сведения об об-
ратном адресе можно сохранить в двух местах:
• внутри сообщения;
• внутри интеллектуального заместителя.
Чтобы сохранить обратный адрес внутри сообщения, интеллектуальный заместитель
может добавить к сообщению новое поле, содержащее этот адрес. Служба запрос-ответ
должна скопировать это поле в сообщение с ответом. Все, что остается сделать интел-
лектуальному заместителю, — извлечь содержимое этого поля из сообщения с ответом и
направить ответ в соответствующий канал. Это решение позволяет упростить структуру
интеллектуального заместителя, но требует вмешательства в службу запрос-ответ. Если
указанную службу нельзя модифицировать, реализовать такой вариант хранения обрат-
ного адреса, скорее всего, не удастся.
В качестве альтернативы интеллектуальный заместитель может хранить обратные
адреса в специальном хранилище, к примеру в структуре памяти или в реляционной
СУБД. Поскольку назначение интеллектуального заместителя состоит в том, чтобы от-
слеживать сообщения с запросами и ответами, он зачастую все равно должен сохранить
данные запроса, чтобы затем сопоставить их с ответом и проанализировать оба сообще-
Интеллектуальный заместитель (Smart Proxy)
569
ния в совокупности. Этот подход позволяет интеллектуальному заместителю сопостав-
лять запросы и ответы. Большинство служб запрос-ответ поддерживает работу с иденти-
фикаторами корреляции (Correlation Identifier, с. 186), копируя их из сообщения с запросом
в сообщение с ответом. Если интеллектуальному заместителю не разрешается вносить
изменения в исходный формат сообщения, он может воспользоваться этим полем для
сопоставления запроса и ответа.
Рекомендуется все же, чтобы интеллектуальный заместитель создавал собственный
идентификатор корреляции, и вот почему. Во-первых, не все инициаторы запросов указы-
вают идентификатор корреляции. Во-вторых, идентификатор корреляции, предоставленный
инициатором запроса, должен быть уникальным только в пределах запросов этого инициа-
тора и может повторяться в сообщениях других отправителей запросов. Поскольку по кана-
лу ответов, ведущему от службы к интеллектуальному заместителю, теперь передаются
ответы на запросы разных инициаторов, использование исходных идентификаторов корре-
ляции может оказаться ненадежным. Гораздо лучше, если при поступлении запроса интел-
лектуальный заместитель будет извлекать из него исходный идентификатор корреляции и
сохранять его вместе с обратным адресом, а на его место ставить собственный идентифика-
тор корреляции. Последний будет применяться для того, чтобы при получении ответа из-
влечь из хранилища исходные значения идентификатора корреляции и обратного адреса.
Некоторые службы используют идентификатор сообщения с запросом в качестве
идентификатора корреляции сообщения с ответом. Это приводит к появлению еще одной
проблемы. Служба скопирует идентификатор сообщения с запросом, полученного ею от
интеллектуального заместителя, в сообщение с ответом и отправит его все тому же ин-
теллектуальному заместителю. Последний должен заменить идентификатор корреляции
сообщения с ответом идентификатором исходного сообщения с запросом, чтобы ини-
циатор запроса смог правильно сопоставить запрос и ответ. Описанный процесс проде-
монстрирован на рис. 11.3.
Рис. 11.3. Хранение и замена идентификатора корреляции и обратного адреса
570
Глава 11. Управление системой
Важно отметить, что все четыре сообщения (исходный запрос, запрос от интеллекту-
ального заместителя службе, ответ службы интеллектуальному заместителю, ответ
интеллектуального заместителя конечному получателю) будут иметь уникальные иден-
тификаторы сообщений даже несмотря на то, что все они относятся к прохождению по
системе одного и того же “логического’' сообщения.
Пример: простой интеллектуальный заместитель (MSMQ и С#)
Реализовать интеллектуальный заместитель {Smart Proxy) не так сложно, как кажется.
Код, показанный ниже, описывает решение, состоящее из двух инициаторов запросов,
интеллектуального заместителя и простой службы. Интеллектуальный заместитель под-
считывает время обработки сообщения и передает это значение шине управления {Control
Bus, с. 552), чтобы отобразить его в центральной консоли (рис. 11.4). Мы хотим, чтобы
инициаторы запросов могли сопоставлять запросы и ответы по идентификаторам сооб-
щений или же по числовому свойству AppSpecif ic объекта Message.
Интеллектуальный
заместитель
Рис. 11.4. Пример простого интеллектуального заместителя
Для удобства написания кода мы определим базовый класс Messageconsumer,
инкапсулирующий в себе код, который требуется для создания событийно управляемого
потребителя сообщений. Классы, наследующие Messageconsumer, смогут просто пере-
определить виртуальный метод ProcessMessage для выполнения любой необходимой
обработки сообщений, и им не придется беспокоиться о конфигурации очереди сообще-
ний или о событийно управляемой обработке. Выделение указанного кода в общий базо-
вый класс облегчит создание тестовых клиентов и фиктивной службы запрос-ответ
{Request-Reply, с. 177), состоящей всего из нескольких строк кода.
Интеллектуальный заместитель (Smart Proxy)
571
Класс MessageConsumer
public class Messageconsumer
{
protected MessageQueue inputQueue;
public Messageconsumer (MessageQueue inputQueue)
{
this.inputQueue = inputQueue;
SetupQueue(this.inputQueue);
Console.WriteLine(this.GetType().Name + ": Processing
messages from " + inputQueue.Path);
}
protected void SetupQueue(MessageQueue queue)
{
queue.Formatter = new System.Messaging.XmlMessageFormatter
(new String[] {"System.String,mscorlib"});
queue.MessageReadPropertyFilter.ClearAll();
queue.MessageReadPropertyFilter.AppSpecific = true;
queue.MessageReadPropertyFilter.Body = true;
queue.MessageReadPropertyFilter.Correlationld = true;
queue.MessageReadPropertyFilter.Id = true;
queue.MessageReadPropertyFilter.ResponseQueue = true;
public virtual void Process()
{
inputQueue.ReceiveCompleted +=
new ReceiveCompletedEventHandler(OnReceiveCompleted);
inputQueue.BeginReceive();
}
private void OnReceiveCompleted(Object source,
ReceiveCompletedEventArgs asyncResult)
{
MessageQueue mq = (MessageQueue)source;
Message m = mq.EndReceive(asyncResult.AsyncResult);
m.Formatter = new System.Messaging.XmlMessageFormatter
(new String!] {"System.String,mscorlib"});
ProcessMessage(m);
mq.BeginReceive();
}
protected virtual void ProcessMessage(Message m)
{
String text =
try
{
text = (String)m.Body;
}
catch (InvalidOperationException) {};
Console.WriteLine(this.GetType().Name +
Received Message " + text);
}
}
572
Глава 11. Управление системой
Имея в своем распоряжении класс Messageconsumer, можно приступать к созданию
интеллектуального заместителя. Он будет включать в себя два объекта Messageconsumer:
один — для потребления запросов, пришедших от инициаторов запросов (объект Smart -
ProxyRequestConsumer), а другой — для потребления ответов, возвращенных службой
запрос-ответ (объект SmartProxyReplyConHumer). Кроме того, в интеллектуальном за-
местителе будет определена таблица хэширования (объект Hashtable), хранящая данные
сообщения в промежутке между отправкой запроса и получением ответа.
Класс SmartProxyBase
public class SmartProxyBase
{
protected SmartProxyRequestConsumer requestconsumer;
protected SmartProxyReplyConsumer replyconsumer;
protected Hashtable messageData;
public SmartProxyBase(MessageQueue inputQueue,
MessageQueue serviceRequestQueue,
MessageQueue serviceReplyQueue)
{
messageData = Hashtable.Synchronized(new Hashtable());
requestconsumer = new SmartProxyRequestConsumer(inputQueue,
serviceRequestQueue, serviceReplyQueue, messageData);
replyconsumer = new
SmartProxyReplyConsumer(serviceReplyQueue, messageData);
}
public virtual void Process()
{
requestconsumer.Process();
replyconsumer.Process ();
}
}
Класс SmartProxyRequestConsumer сравнительно прост. В нем хранится важная
информация из исходного сообщения с запросом (идентификатор сообщения, обратный
адрес (Return Address, с. 182), свойство AppSpecif ic и текущее время). Она помешается в
таблицу хэширования, содержимое которой индексируется по идентификатору нового
сообщения с запросом, отправленного службе интеллектуальным заместителем. Служба
запрос-ответ поддерживает работу с идентификатором корреляции (Correlation Identifier,
с. 186), копируя идентификатор указанного сообщения с запросом в поле CorrelationlD
сообщения с ответом. Это позволит интеллектуальному заместителю при получении от-
вета извлечь из таблицы хэширования нужные данные. SmartProxyRequestConsumer
также заменяет обратный адрес, заданный свойством ResponseQueue, адресом очереди
сообщений, которую интеллектуальный заместитель прослушивает в ожидании ответов.
И наконец, мы включили в класс SmartProxyRequestConsumer виртуальный метод
AnalyzeMessage, чтобы производные классы могли выполнять всю необходимую обра-
ботку сообщений.
Интеллектуальный заместитель (Smart Proxy)
573
Класс SmartProxyRequestConsumer
public class SmartProxyRequestConsumer : Messageconsumer
protected Hashtable messageData;
protected MessageQueue serviceRequestQueue;
protected MessageQueue serviceReplyQueue;
public SmartProxyRequestConsumer(MessageQueue requestQueue,
MessageQueue serviceRequestQueue,
MessageQueue serviceReplyQueue,
Hashtable messageData) : base(requestQueue)
{
this.messageData = messageData;
this.serviceRequestQueue = serviceRequestQueue;
this.serviceReplyQueue = serviceReplyQueue;
}
protected override void ProcessMessage(Message requestMsg)
{
base.ProcessMessage(requestMsg);
MessageData data = new MessageData(requestMsg.Id,
requestMsg.ResponseQueue, requestMsg.AppSpecific);
requestMsg.ResponseQueue = serviceReplyQueue;
serviceRequestQueue.Send(requestMsg);
messageData.Add(requestMsg.Id, data);
AnalyzeMessage(requestMsg);
}
protected virtual void AnalyzeMessage(Message requestMsg)
{
}
}
Объект SmartProxyReplyConsumer прослушивает канал ответов службы. Получив от-
вет, метод ProcessMessage этого класса извлекает данные соответствующего сообщения с
запросом, сохраненные объектом SmartProxyRequestConsumer, и вызывает шаблонный
метод AnalyzeMessage. После этого он копирует значения свойств Correlationld и
AppSpecif ic в конечное сообщение с ответом и направляет его в канал, заданный обрат-
ным адресом из исходного сообщения с запросом.
Класс SmartProxyReplyConsumer
public class SmartProxyReplyConsumer : Messageconsumer
protected Hashtable messageData;
public SmartProxyReplyConsumer(MessageQueue replyQueue,
Hashtable messageData) : base(replyQueue)
this.messageData = messageData;
}
protected override void ProcessMessage(Message replyMsg)
{
base.ProcessMessage(replyMsg);
574
Глава 11. Управление системой
String corr = replyMsg.Correlationld;
if (messageData.Contains(corr))
{
MessageData data = (MessageData)(messageData[corr]);
AnalyzeMessage(data, replyMsg);
replyMsg.Correlationld = data.CorrelationlD;
replyMsg.AppSpecific = data.AppSpecific;
MessageQueue outputQueue = data.ReturnAddress;
outputQueue.Send(replyMsg);
messageData.Remove(corr) ;
}
else
{
Console.WriteLine(this.GetType().Name +
"Unrecognized Reply Message");
// Отправить сообщение в очередь недопустимых сообщений.
}
}
protected virtual void AnalyzeMessage(MessageData data.
Message replyMessage)
{
}
}
Чтобы собрать метрику (время обработки сообщения) и отправить ее шине управления,
мы создадим классы, производные от Smart ProxyBase и Smart ProxyReplyConsumer.
Новый класс MetricsSmartProxy создает экземпляр класса SmartProxyReplyConsumer-
Metrics в качестве объекта, потребляющего сообщения. Класс SmartProxyReply-
ConsumerMetrics, в свою очередь, содержит простую реализацию метода AnalyzeMes-
sage, который подсчитывает время между получением запроса и ответа и отправляет эти
данные вместе с числом необработанных сообщений, данные которых до сих пор нахо-
дятся в таблице хэширования, в очередь сообщений шины управления. При необходимо-
сти описанный метод легко расширить для выполнения более сложных вычислений.
Очередь сообщений шины управления подсоединена к простому генератору, который за-
писывает каждое входящее сообщение в файл.
Класс MetricsSmartProxy
public class MetricsSmartProxy : SmartProxyBase
{
public MetricsSmartProxy(MessageQueue inputQueue,
MessageQueue serviceRequestQueue,
MessageQueue serviceReplyQueue,
MessageQueue controlBus) :
base (inputQueue, serviceRequestQueue, serviceReplyQueue)
{
replyconsumer = new SmartProxyReplyConsumerMetrics
(serviceReplyQueue, messageData, controlBus);
}
}
Интеллектуальный заместитель (Smart Proxy)
575
Класс SmartProxyReplyConsumerMetrics
public class SmartProxyReplyConsumerMetrics :
SmartProxyReplyConsumer
{
MessageQueue controlBus;
public SmartProxyReplyConsumerMetrics(MessageQueue replyQueue,
Hashtable messageData,
MessageQueue controlBus) :
base(replyQueue, messageData)
{
this.controlBus = controlBus;
}
protected override void AnalyzeMessage(MessageData data.
Message replyMessage)
{
TimeSpan duration = DateTime.Now - data.SentTime;
Console.WriteLine(" processing time: {0:f}",
duration.TotalSeconds);
if (controlBus != null)
{
controlBus.Send(duration.TotalSeconds.ToString() +
+ messageData.Count);
}
}
}
На рис. 11.5 изображена диаграмма классов, показывающая отношения между клас-
сами, которые используются в нашем решении.
Рис. 11.5. Диаграмма классов для примера простого интеллектуального заместителя
576
Глава 11. Управление системой
Чтобы протестировать интеллектуальный заместитель, мы создали фиктивную служ-
бу запрос-ответ. Она не выполняет никаких действий и просто выжидает случайный
промежуток времени от 0 до 200 мс. Интеллектуальный заместитель получает запросы от
двух инициаторов запросов, каждый из которых публикует по 30 сообщений с интерва-
лом 100 мс. Сообщения из очереди шины управления перехватываются и записываются в
файл журнала. Полученный файл был загружен в Microsoft Excel. На его основе мы соз-
дали замечательную диаграмму, показанную на рис. 11.6.
Рис. 11.6. Статистика времени отклика, собранная интеллектуальным заместителем и
визуализированная консолью шины управления
Легко заметить, что размер очереди сообщений (Queue Size) и соответствующее время
отклика (Response Time) постепенно увеличиваются до тех пор, пока размер очереди
не достигает 13 сообщений. К этому времени инициаторы запросов прекращают отсы-
лать сообщения, поэтому размер очереди начинает уменьшаться. Время отклика тоже
уменьшается, но остается в пределах секунды, поскольку сообщения, которые сейчас
обрабатываются, провели именно столько времени в очереди запросов.
Тестовое сообщение (Test Message)
577
Тестовое сообщение (Test Message)
В разделе, посвященном шине управления (Control Bus, с. 552), описывается несколько
подходов к мониторингу состояния системы обмена сообщениями. Каждый компонент
системы может периодически публиковать в шине управления сообщения-пульсы. Они
информируют механизм мониторинга о том, что компонент все еще активен. Помимо
этого, в теле пульса может содержаться важная статистика работы компонента, например
число обработанных сообщений, среднее время, необходимое для обработки одного
сообщения, или процент загрузки центрального процессора на локальном компьютере.
Что произойдет, если компонент активно обрабатывает сообщения, но искажает их
по причине внутреннего сбоя?
Простой механизм пульсов не в состоянии выявить ошибку, описанную выше,
поскольку он действует только на уровне компонентов и не знаком с форматами сообще-
ний, используемых приложением.
Вставьте в поток сообщений тестовое сообщение (Test Message), чтобы убедить-
ся в исправном функционировании компонентов, обрабатывающих сообщения.
Вбрасыватель
тестовых
Реальное Реальное
сообщение 1 сообщение 2
“Отделитель’
тестовых
Шаблон тестовое сообщение включает в себя следующие компоненты.
1. Генератор тестовых данных создает сообщения, которые должны быть отправлены
компоненту для тестирования его работы. Тестовые данные могут быть фиксиро-
ванными, могут браться из файла или же генерироваться на случайной основе.
2. “Вбрасыватель” тестовых сообщений вставляет тестовые данные в поток обычных
сообщений, отправляемых компоненту. “Вбрасыватель” должен помечать тесто-
578
Глава 11. Управление системой
вые сообщения, чтобы их было невозможно спутать с реальными сообщениями
приложений. Для этого в заголовок тестового сообщения вставляется специаль-
ное поле. Если же мы не можем вносить изменения в структуру сообщения, для
индикации тестовых сообщений можно использовать специальные значения по-
лей, которые не встречаются в реальной жизни (например, OrderlD = 99999).
Указанный подход изменяет семантику данных приложения, потому что одно и то
же поле начинает представлять как обычные данные приложения (номер реаль-
ного заказа), так и управляющую информацию (“Это тестовое сообщение”).
По этой причине к нему следует прибегать лишь в крайних случаях.
3. “Отделитель” тестовых сообщений извлекает из выходного потока сообщений
результаты обработки тестовых данных. Для этого обычно используется маршру-
тизатор на основе содержимого (Content-Based Router, с. 247).
4. Верификатор тестовых данных сравнивает полученные результаты с ожидаемыми и
при обнаружении несоответствия выдает исключение. В зависимости от характера
тестовых данных верификатору может понадобиться доступ к исходным данным.
Без отделителя тестовых сообщений можно обойтись, если тестируемый компонент
поддерживает обратный адрес (Return Address, с. 182). В этом случае генератор тестовых
данных может включить в сообщение адрес специального тестового канала в качестве
обратного адреса, чтобы тестовым сообщениям не пришлось проходить через оставшую-
ся часть системы. Обратный адрес, в свою очередь, будет выполнять роль той самой мет-
ки, которая отличает тестовые сообшения от обычных.
Использование тестовых сообщений относят к механизмам активного мониторинга
(active monitoring). В отличие от пассивного мониторинга механизмы активного монито-
ринга не полагаются на информацию, предоставленную компонентами (файлы журна-
лов, пульсы и т.п.), а сами проверяют его работу. Активный мониторинг обычно позво-
ляет провести тестирование на более глубоком уровне, потому что тестовые данные про-
ходят те же этапы обработки, что и обычные сообщения. Он также хорошо подходит для
компонентов, не предусматривающих возможность пассивного мониторинга.
Одним из потенциальных недостатков активного мониторинга является дополни-
тельная нагрузка на компонент, обрабатывающий сообщения. Необходимо найти баланс
между частотой тестирования и минимизацией негативного влияния на производитель-
ность. Активный мониторинг также может привести к дополнительным расходам, если за
обработку компонентом каждого сообщения взимается плата. Это часто встречается при
работе с внешними компонентами, к примеру, если мы запрашиваем кредитную историю
клиентов у внешнего кредитного бюро.
Активный мониторинг подходит не для всех компонентов. Компоненты, занимаю-
щиеся ведением базы данных, могут не отличить тестовые данные от обычных и занести
содержимое тестовых сообщений в базу данных. Неужели вы хотите, чтобы тестовые
заказы были включены в годовой отчет о прибыли компании?
Пример: кредитный брокер: тестирование работы кредитного бюро
В главе 12 мы будем использовать тестовое сообщение (Test Message) для активного мони-
торинга работы внешнего кредитного бюро.
Вентиль канала (Channel Purger)
579
Вентиль канала (Channel Purger)
Рассматривая пример реализации механизма “запрос-ответ” с помощью JMS (глава 6),
мы столкнулись с простой, но очень интересной проблемой. Наше решение состояло из
инициатора запроса, который отправляет сообщение получателю и ждет ответа. Для пере-
дачи сообщений в примере использовались два канала “точка-точка” (Point-to-Point
Channel, с. 131): канал запросов requestQueue и канал ответов replyQueue (рис. 11.7).
Инициатор запроса
L
Рис. 11.7. Действие механизма “запрос-ответ”
Мы запустили ответчик, а затем инициатор запросов. Вдруг произошла очень стран-
ная вещь: в окне консоли инициатора запросов появилось уведомление о получении от-
вета еще до того, как ответчик уведомил нас о поступлении ему запроса. Что это? Кон-
соль задержала сведения, присланные ответчиком? Не придумав ничего лучшего, мы ре-
шили выключить ответчик и перезапустили инициатор запросов. Ответ на запрос
появился снова! Волшебство? Нет, просто побочный эффект сохранения сообщений.
Еще до того, как мы включили инициатор запросов и ответчик, в канале ответов присут-
ствовало старое, лишнее сообщение. Скорее всего, его появление было вызвано каким-
то предыдущим сбоем. Каждый раз, когда мы запускали инициатор запросов, он разме-
щал новое сообщение в канале запросов и тут же получал “лишний” ответ из канала от-
ветов. Откуда нам было знать, что это ответ на совершенно другой запрос?! Когда ответ-
чик получил новый запрос, он разместил в канале replyQueue новый ответ, поэтому во
время следующего тестирования “волшебство” повторилось. Просто удивительно, какие
фокусы может выкинуть асинхронный обмен сообщениями, сохраняющимися на посто-
янной основе, даже в самых простых ситуациях!
Как избавиться от ненужных сообщений, оставшихся в канале, чтобы они не ме-
шали тестированию или эксплуатации системы?
Каналы сообщений (Message Channel, с. 93) обязаны обеспечивать надежную доставку
сообщений даже тогда, когда получатель недоступен. Для этого канал сохраняет сообще-
ния, которые еще не были потреблены получателем. Это, вне всяких сомнений, полезное
свойство каналов может привести к путанице во время тестирования или тогда, когда
один из компонентов неправильно себя ведет (и не использует транзакционное потреб-
ление или создание сообщений). И в том, и в другом случаях в канале может быстро ско-
питься груда лишних сообщений, как, например, в ситуации, описанной выше. Мы не
сможем запустить в систему тестовые данные, пока не будут потреблены те самые лиш-
580
Глава 11. Управление системой
ние сообщения. Одно дело, если “забытые” сообщения представляют собой многомил-
лионные заказы, и совсем другое, если каналы, переполненные старыми запросами и от-
ветами, мешают тестированию или отладке системы.
В таком простом примере, как наш, отладку системы можно существенно облегчить,
если воспользоваться идентификатором корреляции (Correlation Identifier, с. 186). Взглянув
на идентификатор, инициатор запроса сразу поймет, что полученное им сообщение не
является ответом на только что отосланный запрос. После этого “лишнее” сообщение
можно уничтожить или отправить в канал недопустимых сообщений (Invalid Message
Channel, с. 143). В других ситуациях распознать нежелательное или повторяющееся со-
общение не так просто. К примеру, если сообщение неправильно сформировано и при-
вело к сбою получателя, последний не сможет перезапуститься, пока не будет удалено
плохое сообщение. В противном случае он снова выйдет из строя сразу же после запуска.
Разумеется, этот пример выявляет наличие у получателя дефекта, который должен быть
исправлен (ни одно неправильно сформированное сообщение не должно приводить
к сбою компонента), но удаление плохого сообщения позволит восстановить работу сис-
темы еще до устранения дефекта.
Еще один способ избежать появления в каналах “забытых” сообщений — воспользо-
ваться временными каналами (в JMS для этого есть специальный метод create-
TemporaryQueue). Такие каналы предназначаются для обмена данными с приложением
по схеме “запрос-ответ” и теряют все сообщения, как только приложение закрывает свое
соединение с системой обмена сообщениями. Опять-таки, этот подход ограничен про-
стым механизмом “запрос-ответ” и не защищает от сообщений, оставшихся в других,
постоянных каналах.
Может показаться, что избежать появления лишних сообщений поможет управление
транзакциями, поскольку публикация, обработка и потребление сообщений будут прохо-
дить в рамках одной транзакции. Тогда, если в процессе обработки сообщения компонент
даст сбой, сообщение не будет считаться потребленным. Аналогичным образом сообщение
с ответом не будет опубликовано до тех пор, пока компонент не даст финального подтвер-
ждения на отправку сообщения. Нужно, однако, помнить, что транзакции не защищают от
ошибок программирования. В нашем простом примере механизма “запрос-ответ” ошибка
программиста могла привести к тому, что инициатор запроса не прочитал ответ из канала
replyQueue. Тогда сообщение, несмотря на свою потенциальную транзакционность,
“застрянет” в канале ответов, что приведет к описанной ранее ситуации.
Используйте вентиль канала (Channel Purged), чтобы очистить канал от нежела-
тельных сообщений.
Сообщение
Вентиль канала
Вентиль канала (Channel Purger)
581
Базовый вариант вентиля канала просто удаляет из канала все сообщения, которые в
нем находятся. Этого вполне достаточно для большинства сценариев тестирования, ко-
гда мы хотим вернуть систему в исходное состояние. Если же речь идет об отладке рабо-
тающей системы, нам может понадобиться удалить лишь отдельное сообщение либо
группу сообщений, соответствующих определенным критериям, таким как идентифика-
тор сообщения или значения заданных полей.
Во многих случаях достаточно, чтобы вентиль канала просто извлекал из канала все
сообщения и уничтожал их. В других ситуациях необходимо, чтобы вентиль канала со-
хранял удаленные сообщения для последующего анализа или повторной отправки.
Это может пригодиться, если сообщения в канале приводят к неисправности системы,
и для продолжения эксплуатации их требуется удалить. Тем не менее, когда проблема бу-
дет устранена, мы захотим вновь запустить сообщения в канал, чтобы система не потеря-
ла их содержимое. Разумеется, перед повторным “вбрасыванием” сообщения, скорее
всего, придется отредактировать. Такое решение сочетает в себе черты вентиля канала и
хранилища сообщений (Message Store, с. 565).
Пример: вентиль канала (JMS)
Ниже показано, как реализовать простой вентиль канала (Channel Purger) с помощью
Java. В данном примере вентиль просто удаляет из канала все находящиеся в нем сооб-
щения. Класс ChannelPurger ссылается на два внешних класса, исходный код которых
здесь не показан.
1. JmsEndpoint. Базовый класс, который должен использоваться любым компонентом,
участвующим в обмене сообщениями через JMS. Содержит заранее инициализиро-
ванные экземпляры классов Connection И Session.
2. Jndiutil. Реализует вспомогательные функции для инкапсуляции поиска объектов
JMS через JNDI.
import javax.jms.JMSException;
import j avax.jms.Messageconsumer;
import j avax.jms.Queue;
public class ChannelPurger extends JmsEndpoint
{
public static void main(String[] args)
{
if (args.length != 1) {
System.out.printin("Usage: j ava ChannelPurger
<queue_name>");
System.exit(1);
}
String queueName = new String(args[0]);
System.out.printin("Purging queue " + queueName);
// "Очистка очереди " + имя очереди.
ChannelPurger purger = new ChannelPurger();
purger.purgeQueue(queueName);
582
Глава 11. Управление системой
private void purgeQueue(String queueName)
{
try {
initialize();
connection.start();
Queue queue = (Queue) JndiUtil.getDestination(queueName);
Messageconsumer consumer = session.createConsumer(queue);
while (consumer.receiveNoWait() != null)
System.out.print(".");
connection.stop();
} catch (Exception e) {
System.out.printin("Exception occurred: " + e.toString());
} finally {
if (connection != null) {
try {
connection.close();
} catch (JMSException e) {
// Игнорировать.
Глава 12
Практикум:
управление системой
Управление системой кредитного брокера
Из этой главы вы узнаете, как использовать шаблоны управления системой, описан-
ные в предыдущей главе, для мониторинга и контроля конкретного решения, основан-
ного на обмене сообщениями. В качестве примера будет использована реализация кре-
дитного брокера для C# и MSMQ из главы 9 (см. раздел, посвященный асинхронной реа-
лизации с использованием MSMQ). Мы не собираемся изменять исходное решение,
а лишь дополним его, поэтому знание кода, приведенного в главе 9, не так уж критично.
Как и в первоначальной реализации, цель нашего примера состоит не столько в том, что-
бы разъяснить использование интерфейсов API для MSMQ, сколько в том, чтобы на-
глядно продемонстрировать реализацию шаблонов, описанных в этой книге, для систе-
мы обмена сообщениями, основанной на использовании очередей. Структура решения
будет очень похожей, если попытаться реализовать его с помощью Java/JMS или IBM
WebSphere MQ. Основное внимание по ходу главы уделяется принятию архитектурных
решений и поиску компромиссов, поэтому ее материал будет полезен даже тем, кто
не работает с C# и MSMQ.
Оснащение кредитного брокера средствами контроля
Реализация кредитного брокера включает в себя четыре главных компонента,
изображенных на рис. 12.1.
• Потребитель (или тестовый клиент) делает запрос на получение кредита.
• Кредитный брокер выполняет роль центрального диспетчера процессов и коорди-
нирует взаимодействие между кредитным бюро и банками.
• Кредитное бюро оказывает кредитному брокеру услугу, которая заключается в под-
счете кредитных баллов клиентов.
• Каждый банк получает от кредитного брокера запрос на получение кредита. Про-
анализировав параметры запроса и кредитную историю клиента, банк возвращает
брокеру значение процентной ставки, под которую он согласен выдать кредит
указанному клиенту.
584
Глава 12. Практикум: управление системой
Банк 1
Банк 2
БанкЗ
Рис. 12.1. Структура кредитного брокера
В большинстве сценариев интеграции у нас нет доступа к внутренним механизмам
приложений. Мы можем лишь наблюдать за компонентами и управлять ими извне. Что-
бы максимально приблизить пример к реальной жизни, каждый компонент кредитного
брокера будет рассматриваться как “черный ящик”. С учетом этого ограничения наше
решение по оснащению кредитного брокера средствами контроля должно соответство-
вать следующим требованиям.
• Управляющая консоль. Нам нужен единый интерфейс, который будет отображать
состояние всех компонентов системы и в случае необходимости позволит пред-
принять корректирующие действия.
• Качество обслуживания кредитного брокера. В первоначальном варианте решения
мы разработали тестовый клиент, который отслеживает время отклика кредитного
брокера (время, прошедшее между отправкой запроса и получением ответа от бро-
кера). В реальной жизни клиенты не будут выполнять эту функцию вместо нас, за-
то могут вовсю жаловаться, что система слишком медленно работает. Поэтому мы
хотим, чтобы управляющая подсистема перехватывала эту информацию и отправ-
ляла ее в центральную консоль.
• Проверка функционирования кредитного бюро. Кредитное бюро— это внешняя
служба стороннего поставщика. Мы хотим убедиться в том, что оно правильно
выполняет свою работу, периодически отправляя ему тестовые сообщения.
• Перемещение при сбое кредитного бюро. Если обнаружится, что кредитное бюро
работает неправильно, запросы на получение кредитной истории клиентов долж-
ны временно перенаправляться другому поставщику аналогичной службы.
Управляющая консоль
Чтобы оценить степень исправности решения в целом, нужно собрать показатели
работы всех компонентов в единую точку, каковой является управляющая консоль.
Последняя также должна контролировать прохождение сообщений и параметры компо-
нентов, чтобы при возникновении сбоя мы могли пустить сообщения по другому мар-
шруту или изменить поведение требуемого компонента.
Управляющая консоль взаимодействует с другими компонентами с помощью обмена
сообщениями. Для этого она использует отдельную шину управления (Control Bus, с. 552),
Управление системой кредитного брокера
585
по которой передаются только сообщения, касающиеся управления системой, и не пере-
даются обычные данные приложений.
Поскольку наша книга посвящена интеграции корпоративных приложений, а не про-
ектированию пользовательского интерфейса, структура управляющей консоли будет
очень простой. Многие производители ПО предлагают средства отображения статисти-
ческих данных в режиме реального времени. Впрочем, для визуализации результатов
вполне можно воспользоваться компонентами Visual Basic и Microsoft Office, например
Excel. Наконец, для многих операционных систем и программных платформ существуют
собственные инструментарии управления, такие как Java/JMX (Java Management Exten-
sions) и Microsoft WMI (Windows Management Instrumentation). В нашем решении визуа-
лизация данных будет производиться вручную, чтобы меньше зависеть от интерфейсов
API конкретных производителей и лучше продемонстрировать внутреннюю структуру
подсистемы мониторинга. Консоль будет создаваться по мере реализации конкретных
функций управления.
Качество обслуживания кредитного брокера
Первое требование к управляющей подсистеме таково: она должна измерять качест-
во, с которым кредитный брокер обслуживает своих клиентов. При выполнении монито-
ринга такого типа нас интересует не бизнес-содержимое отдельных сообщений (т.е. про-
центная ставка, предложенная клиенту), а лишь время, прошедшее между отправкой за-
проса и получением ответа. Сложность измерения времени отклика заключается в том,
что клиент может задать канал, по которому следует направить ответ, в виде обратного
адреса {Return Address, с. 182), поэтому мы не сможем слушать фиксированный канал в
ожидании ответа. К счастью, решить эту дилемму помогает интеллектуальный замести-
тель (Smart Proxy, с. 567). Он перехватывает сообщение с запросом, извлекает и сохраня-
ет обратный адрес, указанный клиентом, а затем заменяет его адресом фиксированного
канала ответов. В результате служба (в нашем примере это кредитный брокер) отправляет
все ответы в один канал. Интеллектуальный заместитель прослушивает этот канал и со-
поставляет полученные ответы с сохраненными ранее запросами. После этого сообщение
с ответом направляется по обратному адресу, изначально заданному клиентом (рис. 12.2).
Клиент
loanReplyQueife
Кредитное бюро
Банки
loanRequestQueue
brokerRequestQueue
Грту' ' 1
Интеллектуальный
заместитель
brokerReplyQueue
controlBusQueue
Кредитный
брокер
т
Обратный адрес, заданный клиентом
S, Управляющая
• консоль
Рис. 12.2. Оснащение кредитного брокера интеллектуальным заместителем
586
Глава 12. Практикум: управление системой
Чтобы воспользоваться преимуществами интеллектуального заместителя, мы
“вставляем” его между клиентом и кредитным брокером (см. рис. 12.2). Это останется
незамеченным для клиента, поскольку интеллектуальный заместитель будет прослуши-
вать тот же канал запросов, который первоначально прослушивался кредитным броке-
ром (loanRequestQueue). Теперь мы можем запустить кредитный брокер с новыми па-
раметрами, чтобы вместо канала loanRequestQueue он слушал brokerRequestQueue.
Интеллектуальный заместитель инструктирует кредитный брокер, чтобы тот отправлял
все сообщения с ответами в канал brokerReplyQueue. Отсюда они будут разосланы по
обратным адресам, заданным клиентами в исходных сообщениях с запросами.
Мы хотим использовать интеллектуальный заместитель для измерения времени откли-
ка кредитного брокера, а также числа запросов, которые обрабатываются брокером в кон-
кретный момент времени. Чтобы измерить время отклика, интеллектуальный заместитель
фиксирует момент времени, когда он получил от клиента сообщение с запросом (оно же
считается временем отправки запроса брокеру. — Примеч. ред.). Получив ответ на этот за-
прос, интеллектуальный заместитель вычитает время отправки запроса из текущего време-
ни, вычисляя время, прошедшее между отправкой запроса и получением ответа. Чтобы
оценить число активных запросов, которыми одновременно управляет кредитный брокер,
интеллектуальный заместитель подсчитывает количество сохраненных им запросов, на ко-
торые еще не получены ответы. Интеллектуальный заместитель не способен отличить
сообщения, стоящие в очереди brokerRequestQueue, от сообщений, которые уже начали
обрабатываться брокером, поэтому полученный показатель будет равен сумме количества
тех и других. Обновить число запросов, которые обрабатываются брокером, можно в любой
момент при получении сообщения с запросом или ответом.
Статистика, собранная интеллектуальным заместителем, передается по шине управле-
ния (Control Bus, с. 552) центральной консоли с целью мониторинга и анализа. Можно от-
сылать статистику для каждого клиентского запроса, но при большом количестве запро-
сов это приведет к загромождению сети. Вставка интеллектуального заместителя в мар-
шрут следования сообщений и так удваивает число отправляемых сообщений (две пары
сообщений “запрос-ответ” вместо одной), поэтому отправка еще одного, контрольного
сообщения для каждого запроса крайне нежелательна. Вместо этого мы воспользуемся
таймером, чтобы интеллектуальный заместитель отправлял статистические данные через
заданные промежутки времени, например через каждые 5 секунд. Сообщение со стати-
стикой может содержать несколько итоговых показателей (например, максимум, мини-
мум и среднее время отклика) или же детализированную информацию по всем сообще-
ниям, прошедшим через интеллектуальный заместитель за это время. Чтобы минимизи-
ровать размер таких сообшений и не усложнять структуру консоли, мы решили
ограничиться отправкой итоговых данных.
Для реализации интеллектуального заместителя кредитного брокера мы воспользу-
емся базовыми классами, рассмотренными в предыдущей главе при описании шаблона
интеллектуальный заместитель (Smart Proxy, с. 567). От классов SmartProxyBase,
SmartProxyRequestConsumer и SmartProxyReplyConsumer будут созданы производ-
ные классы, как показано на рис. 12.3. Исходный код указанных классов можно найти
в разделе, посвященном шаблону интеллектуальный заместитель.
Управление системой кредитного брокера
587
Рис. 12.3. Диаграмма классов для интеллектуального заместителя кредитного брокера
Как и исходный класс SmartProxyBase, класс LoanBrokerProxy включает в себя
два отдельных потребителя сообщений. Первый из них предназначен для потребления
входящих запросов клиентов (объект LoanBrokerProxyRequestConsumer), а второй —
для потребления ответов, присланных брокером (LoanBrokerProxyReplyConsumer).
Оба класса потребителей наследуют соответствующие базовые классы (SmartProxy-
RequestConsumer и SmartProxyReplyConsumer) и добавляют к ним новую реализа-
цию метода AnalyzeMessage.
Давайте взглянем на реализацию класса LoanBrokerProxy. Его конструктор прини-
мает те же параметры, что и конструктор базового класса SmartProxyBase, плюс ссылку
на очередь сообщений шины управления и интервал отчетности в секундах.
Для хранения статистических данных в классе LoanBrokerProxy выделены два свойст-
ва типа ArrayList: свойство performancestats, в котором хранятся интервалы времени
между отправкой запроса и получением ответа в секундах, и свойство queuestats, каждый
элемент которого представляет количество обрабатывающихся сообщений с запросами
(те, которые находятся в очереди brokerRequestQueue или в процессе обработки кредит-
ным брокером). При запуске заранее запрограммированного таймера метод OnTimerEvent
делает “снимок” данных из каждой коллекции. В дальнейшем будет анализироваться
именно эта копия данных, а сами данные тем временем продолжат обновляться.
588
Глава 12. Практикум: управление системой
Класс LoanBrokerProxy
public class LoanBrokerProxy : SmartProxyBase
{
protected MessageQueue controlBus;
protected ArrayList performanceStats;
protected ArrayList queueStats;
protected int interval;
protected Timer timer;
public LoanBrokerProxy(MessageQueue inputQueue,
MessageQueue serviceRequestQueue,
MessageQueue serviceReplyQueue,
MessageQueue controlBus,
int interval) :
base (inputQueue, serviceRequestQueue, serviceReplyQueue)
{
messageData = Hashtable.Synchronized(new Hashtable());
queueStats = ArrayList.Synchronized(new ArrayList());
performanceStats = ArrayList.Synchronized(new ArrayList());
this.controlBus = controlBus;
this.interval = interval;
requestconsumer = new
LoanBrokerProxyRequestConsumer(inputQueue,
serviceRequestQueue, serviceReplyQueue, messageData,
queueStats);
replyconsumer = new
LoanBrokerProxyReplyConsumer(serviceReplyQueue,
messageData, queueStats, performanceStats);
}
public override void Process()
{
base.Process();
TimerCallback timerDelegate = new
TimerCallback(OnTimerEvent);
timer = new Timer(timerDelegate, null, interval*1000,
interval*1000);
}
protected void OnTimerEvent(Object state)
{
ArrayList currentQueueStats;
ArrayList currentPerformanceStats;
lock (queueStats)
{
currentQueueStats = (ArrayList)(queueStats.Clone());
queueStats.Clear();
}
Управление системой кредитного брокера
589
lock (performanceStats)
{
currentPerformanceStats =
(ArrayList)(performanceStats.Clone());
performanceStats.Clear();
}
SummaryStats summary = new SummaryStats(currentQueueStats,
currentPerformanceStats);
if (controlBus != null)
controlBus.Send(summary);
}
}
Объект LoanBrokerProxy использует структуру SummaryStats для вычисления мак-
симума, минимума и среднего значения собранных данных и отправляет полученную ста-
тистику по шине управления. Мы бы могли повысить эффективность вычислений, обновляя
итоговые данные при поступлении каждого входящего сообщения, чтобы хранить не все
данные, а только итоговые показатели. Но задержка в вычислениях дает возможность ме-
нять степень детализации данных, которые мы хотим публиковать в шине управления.
Объект LoanBrokerProxyRequestConsumer обрабатывает сообщения с запросами,
поступающие на вход интеллектуального заместителя. Экземпляр базового класса
SmartProxyRequestConsumer отвечает за хранение важных данных сообщения в таб-
лице хэширования messageData. Экземпляр базового класса SmartProxyReply-
Consumer, в свою очередь, извлекает данные из таблицы хэширования при получении
ответа. Таким образом, мы можем подсчитать текущее число запросов, находящихся в
стадии обработки, определив размер таблицы хэширования messageData. Объект Loan-
BrokerProxyRequestConsumer хранит ссылку на коллекцию queuestats из класса
LoanBrokerProxy, чтобы при поступлении очередного сообщения внести в коллекцию
новые данные.
Класс LoanBrokerProxyRequestConsumer
public class LoanBrokerProxyRequestConsumer :
SmartProxyRequestConsumer
{
ArrayList queueStats;
public LoanBrokerProxyRequestConsumer(MessageQueue
requestQueue,
MessageQueue serviceRequestQueue,
MessageQueue serviceReplyQueue,
Hashtable messageData,
ArrayList queueStats) :
base(requestQueue, serviceRequestQueue,
serviceReplyQueue, messageData)
{
this.queueStats = queueStats;
590
Глава 12. Практикум: управление системой
protected override void ProcessMessage(Message requestMsg)
{
base.ProcessMessage(requestMsg);
queueStats.Add(messageData.Count);
Когда интеллектуальному заместителю приходит сообщение с ответом, объект Loan-
BrokerProxyReplyConsumer производит необходимые вычисления. Вначале он под-
считывает, сколько времени прошло между отправкой запроса и получением ответа, и
добавляет полученное значение в коллекцию performancestats. Затем он вычисляет
количество запросов, оставшихся в таблице хэширования messageData, и добавляет это
ЧИСЛО В коллекцию queueStats.
Класс LoanBrokerProxyReplyConsumer
public class LoanBrokerProxyReplyConsumer :
Smart ProxyReplyConsumer
{
ArrayList queueStats;
ArrayList performanceStats;
public LoanBrokerProxyReplyConsumer(MessageQueue replyQueue,
Hashtable messageData,
ArrayList queueStats,
ArrayList performanceStats) :
base(replyQueue, messageData)
{
this.queueStats = queueStats;
this.performanceStats = performanceStats;
}
protected override void AnalyzeMessage(MessageData data,
Message replyMessage)
{
TimeSpan duration = DateTime.Now - data.SentTime;
performanceStats.Add(duration.TotalSeconds);
queueStats.Add(messageData.Count);
}
}
Структура Summarystats вычисляет максимальное, минимальное и среднее значения
собранных данных. Число обработанных запросов подсчитывается путем вычитания
размера коллекции performanceStats (данные собираются только для сообшений с от-
ветами) из размера коллекции queueStats (данные собираются дважды — и для запро-
сов, и для ответов). Реализация этой структуры вполне тривиальна, поэтому мы решили
не включать ее в книгу, чтобы не заполнять целую страницу лишним кодом.
Вставив в путь следования сообщений интеллектуальный заместитель, мы начали со-
бирать статистику. Для этого мы настроили два тестовых клиента, каждый из которых
сделал по 50 запросов на получение кредита. Результаты, собранные интеллектуальным
Управление системой кредитного брокера
591
заместителем, приведены в табл. 12.1. (Мы воспользовались простым преобразованием
XSL, чтобы сформировать таблицу HTML на основе данных, опубликованных в очереди
ControlBusQueue в формате XML.)
Таблица 12.1. Статистика работы кредитного брокера
Метка времени Количество Время обработки, с Размер очереди
Запросов Ответов Мини- мальное Среднее Макси- мальное Мини- мальный Средний Макси- мальный
14:11:02,96 44424 0 0 0,00 0,00 0,00 0 0 0
14:11:07,97 18424 89 7 0,78 2,54 3,93 1 42 82
14:11:12.97 92424 11 9 4,31 6,43 8,69 83 87 91
14:11:17,98 66424 0 8 9,39 10,83 12,82 77 80 84
14:11:22,99 40424 0 8 13,80 15,75 17,48 69 72 76
14:11:28,00 14424 0 7 18,37 20,19 22,18 62 65 68
14:11:33,00 88424 0 6 22,90 24,83 26,94 56 58 61
14:11:38,01 62424 0 10 27,74 29,53 31,62 46 50 55
14:11:43,02 36424 0 9 31,87 34,47 36,30 37 41 45
14:11:48,03 10424 0 7 36,87 39,06 40,98 30 33 36
14:11:53,03 84424 0 9 41,75 43,82 45,14 21 25 29
14:11:58,04 58424 0 8 45,92 47,67 49,67 13 16 20
14:12:03,05 32424 0 8 50,86 52,58 54,59 5 8 12
14:12:08,06 06424 0 4 55,41 55,96 56,69 1 2 4
14:12:13,06 80424 0 0 0,00 0,00 0,00 0 0 0
592
Глава 12. Практикум: управление системой
Загрузив данные о размере очереди в Excel, мы получили диаграмму, изображенную
на рис. 12.4.
Как видим, двух тестовых клиентов оказалось более чем достаточно, чтобы с головой
загрузить кредитный брокер. В какой-то момент времени размер очереди сообщений, нахо-
дящихся в стадии обработки, превысил 90. Кредитный брокер обрабатывает запросы
со стабильной скоростью (примерно два запроса в секунду). Из-за большого числа запро-
сов, скопившихся в очереди, время отклика довольно мало и в худшем случае составляет
почти минуту. На основании этих фактов можно сделать два важных вывода: кредитный
брокер с честью выдержал большую нагрузку, но время отклика слишком велико. Чтобы
улучшить этот показатель, можно запустить несколько экземпляров кредитного брокера
или же кредитного бюро. (Как показала первоначальная реализация кредитного брокера
в главе 9, “узким местом” производительности оказалась именно служба кредитного бюро.)
Рис. 12.4. Статистика, собранная интеллектуальным заместителем кредитного брокера
Проверка функциональности кредитного бюро
Вторая функция управляющей подсистемы нашего кредитного брокера— следить
за правильностью работы кредитного бюро, представленного внешней службой. Кредит-
ный брокер обращается к этой службе для получения кредитного балла клиента, прислав-
шего запрос на получение кредита. На основе данной информации банки принимают
решение о том, под какую процентную ставку они MOiyr выдать кредит указанному клиенту.
Чтобы проверить, правильно ли функционирует внешняя служба кредитного бюро,
в систему периодически будут “вбрасываться” тестовые сообщения (Test Message, с. 577).
Поскольку служба кредитного бюро поддерживает обратный адрес (Return Address, с. 182),
мы сможем легко “вбросить” в систему тестовое сообщение, не нарушая движение
остального потока сообщений. Для возврата тестовых сообщений будет предусмотрен
специальный канал ответов, а значит, необходимость в создании “отделителя”
и “вбрасывателя” тестовых сообщений отпадает (рис. 12.5).
Управление системой кредитного брокера
593
Клиент
у} WS1.4. :
monitorReplyQueue
creditRequestQueue
Кредитное
бюро
creditReplyQueue
Банки
Кредитный брокер
Монитор кредитного
бюро
Генератор
тестовых
данных
Верификатор
тестовых
данных
controlBusQueue
Управляющая
консоль
Рис. 12.5. Мониторинг работы службы кредитного бюро
Для тестирования правильности работы кредитного бюро нам нужны генератор и ве-
рификатор тестовых данных. Генератор тестовых данных создает данные, которые будут
отправлены тестируемой службе. Сообщение, отправляемое кредитному бюро, имеет
очень простую структуру: его единственное обязательное поле — это номер карты соци-
ального страхования (social security number — SSN). Для тестирования мы будем исполь-
зовать специальный, фиксированный номер карты социального страхования, принадле-
жащий фиктивному лицу. Это позволит сравнить результат обработки сообщения с зара-
нее известным правильным результатом. Таким образом, мы не только проверим,
поступают ли сообщения с ответами, но и сможем убедиться в том, что они правильные.
В примере кредитного брокера, приведенном в главе 9, кредитное бюро представляло со-
бой простую службу, которая в ответ на любой номер карты социального страхования
возвращает случайное число из определенного диапазона. По этой причине верификатор
тестовых данных не ожидает получить конкретное значение — он просто проверяет, по-
падает ли кредитный балл в заданный диапазон (например, от 300 до 900). Если результат
обработки тестовых данных из-за вычислительной ошибки выпадает из указанного диа-
пазона (например, равен нулю), верификатор отсылает соответствующее уведомление
управляющей консоли.
Верификатор тестовых данных проверяет и время отклика внешней службы. Если со-
общение с ответом не будет получено в пределах заданного промежутка времени, об этом
также уведомят управляющую консоль. Чтобы минимизировать нагрузку на сеть, вери-
фикатор уведомляет консоль только в том случае, если ответ задержался или пришел в
неправильном формате. Если же служба работает корректно, никаких уведомлений
не отсылается. Единственным исключением из этого правила является ситуация, когда
после обнаружения ошибки монитор получает от службы правильное сообщение с отве-
том. В этом случае консоли отправляется сообщение, уведомляющее о том, что служба
594
Глава 12. Практикум: управление системой
вновь успешно работает. Наконец, во время запуска монитор уведомляет консоль о своем
существовании. Такое сообщение позволяет консоли “вычислить” все активные монито-
ры, чтобы она могла отображать состояние каждого из них.
В реализации монитора применяются два отдельных таймера. Один нужен для от-
правки тестовых сообщений через заданные промежутки времени, а второй выдает ис-
ключение, если ответ не пришел в течение заданного времени ожидания (рис. 12.6). Тай-
мер sendTimer задает интервал отправки, т.е. время, которое должно пройти между по-
следним получением ответа (или истечением времени ожидания) и отправкой нового
тестового сообщения. Таймер timeoutTimer запускается в момент отправки монитором
сообщения с запросом. Если ответ прибудет в пределах заданного времени ожидания,
таймер timeoutTimer сбрасывается и перезапускается при отправке следующего тесто-
вого запроса. Если же по истечении времени ожидания ответ не пришел, timeoutTimer
инициирует отправку монитором сообщения об ошибке в шину управления (Control Bus,
с. 552). После этого монитор запускает таймер sendTimer, чтобы по истечении интерва-
ла отправки отослать новое сообщение с запросом. В реальных сценариях время ожида-
ния, как правило, относительно невелико (несколько секунд), а интервал отправки тес-
товых сообщений более длинный и составляет около минуты.
Интервал
отправки
Интервал
отправки
Интервал
отправки
Время
ожидания
Запрос Ответ
Время
ожидания
Время
ожидания
''г
Запрос
г~
Запрос
тг
Плохой
ответ ▼
Время
Уведомление
об ошибке
Уведомление
об ошибке
Рис. 12.6. Мониторинг функционирования службы кредитного бюро
На рис. 12.6 показаны зависимости между двумя таймерами. В нашем примере монитор
отправляет тестовое сообщение и запускает таймер timeoutTimer. Сообщение с ответом
приходит, когда срок ожидания еще не закончился, поэтому монитор останавливает и сбра-
сывает timeoutTimer, после чего запускает sendTimer. По истечении интервала отправки
монитор отсылает новое тестовое сообщение и перезапускает timeoutTimer. На этот раз по
окончании времени ожидания ответ так и не пришел, поэтому монитор отсылает шине
управления уведомление об ошибке. Одновременно с этим он заново запускает sendTimer.
Для реализации монитора вполне достаточно одного класса. Класс Monitor наследу-
ет класс Messageconsumer, код которого приводился в описании шаблона интеллекту-
альный заместитель (Smart Proxy, с. 567). Messageconsumer настраивает входящий канал
и запускает событийно управляемый потребитель (Event-Driven Consumer, с. 511), который
будет получать сообщения. Для каждого поступающего сообщения вызывается виртуаль-
ный метод ProcessMessage. Любой класс, наследующий Messageconsumer, может пе-
реопределить этот метод для выполнения собственных действий над сообщением.
Метод Process инструктирует объект Messageconsumer начать потребление сооб-
щений. Класс Monitor расширяет базовую реализацию этого метода, запуская таймер
sendTimer. Последний, в свою очередь, инициирует запуск метода OnSendTimerEvent.
Метод Process также отсылает шине управления сообщение типа Monitorstatus, чтобы
оповестить центральную консоль о своем существовании.
Управление системой кредитного брокера
595
Класс Monitor: отправка сообщений
public override void Process О
{
base.Process();
sendTimer = new Timer(new TimerCallback
(OnSendTimerEvent), null, interval*1000, Timeout.Infinite);
Monitorstatus status = new Monitorstatus(
Monitorstatus.STATUS_ANNOUNCE, "Monitor On-Line", null,
MonitorlD);
Console.WriteLine(status.Description);
controlQueue.Send(status);
laststatus = status.Status;
protected void OnSendTimerEvent(Object state)
{
CreditBureauRequest request = new CreditBureauRequest();
request.SSN = SSN;
Message requestMessage = new Message(request);
requestMessage.Priority = Messagepriority.AboveNormal;
requestMessage.ResponseQueue = inputQueue;
Console.WriteLine(DateTime.Now.ToString() + " Sending request
message");
// Время + "отправка сообщения с запросом".
requestQueue.Send(requestMessage);
correlationlD = requestMessage.Id;
timeoutTimer = new Timer(new TimerCallback(OnTimeoutEvent),
null, timeout*1000, Timeout.Infinite);
Метод OnSendTimerEvent создает новое сообщение с запросом. Единственным по-
лем этого сообщения является номер карты социального страхования клиента (SSN).
Для тестирования, напомним, используется фиксированный SSN. Данный метод также
сохраняет идентификатор сообщения, чтобы впоследствии сравнивать его с идентифи-
каторами корреляции (Correlation Identifier, с. 186) сообщений с ответами. И наконец, он
запускает таймер timeoutTimer, чтобы проверить, прибудет ли сообщение с ответом
в течение заданного времени ожидания.
Свойству Priority тестового сообщения присваивается значение AboveNormal
(“выше обычного”). Сообщение с таким приоритетом будет обработано ранее, чем
обычные сообщения, скопившиеся в очереди к службе кредитного бюро. Если бы тесто-
вое сообщение “застряло” в очереди, служба кредитного бюро могла быть ошибочно вос-
принята монитором как недоступная. В данном случае установка более высокого при-
оритета совершенно безопасна, потому что генератор тестовых данных “вбрасывает”
очень маленький объем тестовых сообщений. Если же “вбросить” в канал запросов много
сообщений с высоким приоритетом, это может нарушить следование обычных сообще-
ний, что никак не стыкуется с концепцией управляющей подсистемы (минимальное
вмешательство в работу приложения).
596
Глава 12. Практикум: управление системой
Главным методом класса Monitor является метод ProcessMessage. Он выполняет
функции верификатора тестовых сообщений, оценивая входящие сообщения с ответами.
Вначале метод ProcessMessage останавливает таймер timeoutTimer, а затем проверяет
поступившее сообщение на правильность идентификатора корреляции, правильность ти-
па данных в теле сообщения и попадание присланного кредитного балла в заданный ин-
тервал. Если хотя бы одна из этих проверок выявляет ошибку, метод формирует сообще-
ние Monitorstatus и отправляет его по каналу шины управления. Кроме того, монитор
проверяет предыдущее состояние службы, хранящееся в переменной laststatus. Если
состояние изменяется с “ошибка” на “ОК”, метод ProcessMessage отсылает соответст-
вующее уведомление по шине управления.
Класс Monitor: получение сообщений
protected override void ProcessMessage(Message msg)
{
Console.WriteLine(DateTime.Now.ToString() +
" Received reply message");
// Время + "получено сообщение с ответом".
if (timeoutTimer != null)
timeoutTimer.Dispose();
msg.Formatter = new XmlMessageFormatter(new Type[]
{typeof(CredltBureauReply)});
CredltBureauReply replystruct;
Monitorstatus status = new Monitorstatus();
status.Status = Monitorstatus.STATUS_OK;
status.Description = "No Error";
status.ID = MonitorlD;
try
{
if (msg.Body is CredltBureauReply)
{
replystruct = (CredltBureauReply)msg.Body;
if (msg.Correlationld != correlationlD)
{
status.Status =
Monitorstatus.STATUS_FAILED_CORRELATION;
status.Description = "Incoming message correlation" +
" ID does not match outgoing message ID";
// "ИД корреляции ответа не соответствует ИД запроса".
}
else
{
if (replystruct.Creditscore < 300
replystruct.Creditscore > 900
replystruct.HistoryLength < 1
replystruct.HistoryLength > 24)
{
status.Status = Monitorstatus.STATUS_INVALID_DATA;
status.Description =
"Credit score values out of range";
Управление системой кредитного брокера
597
// "Значение кредитного балла не попадает в
// заданный диапазон".
} }
}
else
{
status.Status = Monitorstatus.STATUS_INVALID_FORMAT;
status.Description = "Invalid message format"; }
// "Недопустимый формат сообщения".
}
catch (Exception e)
{
Console.WriteLine("Exception: {0}", e.ToStringO ) ;
status.Status = Monitorstatus.STATUS_INVALID_FORMAT;
status.Description = "Could not deserialize message body";
// "He удалось восстановить тело сообщения".
}
StreamReader reader = new StreamReader (msg.Bodystream);
status . MessageBody = reader. ReadToEnd () ,-
Console.WriteLine(status.Description);
if (status.Status != Monitorstatus.STATUS_OK ||
(status.Status == Monitorstatus.STATUS_OK &&
laststatus != Monitorstatus.STATUS_OK))
{
controlQueue.Send(status);
}
laststatus = status.Status;
sendTimer.Dispose();
sendTimer = new Timer(new TimerCallback(OnSendTimerEvent),
null, interval*1000, Timeout.Infinite);
Если в течение заданного интервала не прибыло ни одно сообщение с ответом, тай-
мер timeoutTimer вызывает метод OnTimeoutEvent. Последний отсылает шине управ-
ления сообщение Monitorstatus и заново запускает таймер sendTimer, начиная отсчи-
тывать интервал, по истечении которого будет отправлено новое сообщение с запросом.
Класс Monitor: время ожидания истекло
protected void OnTimeoutEvent(Object state)
{
Monitorstatus status = new Monitorstatus(
Monitorstatus.STATUS_TIMEOUT, "Timeout", null, MonitorlD);
Console.WriteLine(status.Description);
controlQueue.Send(status);
laststatus = status.Status;
timeoutTimer.Dispose();
sendTimer = new Timer(new TimerCallback(OnSendTimerEvent),
null, interval*1000, Timeout.Infinite);
}
598
Глава 12. Практикум: управление системой
Перемещение при сбое кредитного бюро
Данные, полученные в результате мониторинга работы внешнего кредитного бюро,
можно использовать для реализации схемы перемещения при сбое (failover). Благодаря ей
кредитный брокер продолжит работать даже в том случае, если служба кредитного бюро
выйдет из строя. Стоит отметить, что базовая форма перемещения при сбое уже обеспечи-
вается каналами “точка-точка” (Point-to-Point Channel, с. 131). Когда канал “точка-точка”
прослушивается несколькими конкурирующими потребителями (Competing Consumers, с. 515),
выход из строя одного потребителя не приведет к прерыванию обработки данных, потому
что сообщением займутся другие потребители. Кроме того, активные конкурирующие
потребители распределяют между собой обработку сообщений, а значит, реализуют про-
стой механизм балансировки нагрузки. Зачем же тогда реализовывать специальную схему
перемещения при сбое? При использовании внешних служб мы можем быть ограничены
простыми каналами (например, SOAP поверх HTTP), которыми не поддерживаются конку-
рирующие потребители. Балансировка нагрузки между несколькими службами тоже жела-
тельна далеко не всегда. К примеру, главный поставщик службы может предоставлять нам
скидку, если количество запросов будет не ниже определенного уровня. Если распределить
трафик между двумя поставщиками, скидки не будет, а значит, использование службы
обойдется дороже. Возможен и другой вариант, когда в качестве главного поставщика
службы применяется более дешевый поставщик, а к дорогому поставщику обращаются
только в случае сбоя дешевого. (Тема принятия тех или иных архитектурных решений из
соображений лицензирования прекрасно раскрыта в [ 15 ].)
Чтобы в явном виде реализовать механизм перемещения при сбое, мы помещаем
маршрутизатор сообщений (Message Router, с. 109) в канал запросов к кредитному бюро,
как показано на рис. 12.7. В зависимости от обстоятельств маршрутизатор направляет за-
прос главному поставщику службы кредитного бюро (толстые черные стрелки) или за-
пасному поставщику (тонкие черные стрелки). Поскольку запасной поставщик службы
может использовать формат сообщений, отличный от того, который применяется глав-
ным поставщиком, мы упаковываем и распаковываем запрос, направленный запасному
поставщику, с помощью пары трансляторов сообщений (Message Translator, с. 115). Сам
маршрутизатор представляет собой маршрутизатор сообщений на основе контекста и
управляется центральной консолью через шину управления (Control Bus, с. 552). Централь-
ная консоль получает данные от монитора кредитного бюро, реализация которого рас-
сматривалась в предыдущем разделе. Если монитор сообщит об ошибке, консоль уведо-
мит маршрутизатор сообщений о необходимости перенаправить трафик запросов запас-
ной службе кредитного бюро (рис. 12.7).
Пока маршрутизатор перенаправляет трафик сообщений второй службе кредитного
бюро, монитор продолжает отсылать тестовые сообщения главной службе. Когда мони-
тор убеждается в том, что главная служба вновь работает корректно, и уведомляет об этом
центральную консоль, последняя инструктирует маршрутизатор сообщений о необходи-
мости вновь направлять сообщения главной службе. На рис. 12.7 не показан монитор,
тестирующий работу запасной службы кредитного бюро, но на самом деле для выполне-
ния этой операции достаточно воспользоваться вторым экземпляром монитора.
Управление системой кредитного брокера
599
Рис. 12.7. Схема перемещения при сбое с помощью маршрутизатора сообщений на основе контекста
Рассмотрим реализацию маршрутизатора сообщений на основе контекста. Класс Con-
textBasedRouter наследует все тот же базовый класс Messageconsumer, предназна-
ченный для обработки входящих сообщений. Метод ProcessMessage проверяет значе-
ние переменной control и в зависимости от него направляет сообщения в главный или
запасной выходной канал.
Класс ContextBasedRouter
delegate void ControlEvent(int control);
class ContextBasedRouter : Messageconsumer
{
protected override void ProcessMessage(Message msg)
{
if (control == 0)
{
primaryOutputQueue.Send(msg);
}
else
{
secondaryOutputQueue.Send(msg);
} }
protected void OnControlEvent(int control)
{
this.control = control;
Console.WriteLine("Control = " + control);
600
Глава 12. Практикум: управление системой
Значение переменной control задается методом OnControlEvent, который вызыва-
ется объектом ControlReceiver. Класс ControlReceiver также наследует Message-
Consumer, поскольку он прослушивает канал шины управления на предмет сообщений.
Класс ControlReceiver создает экземпляр делегата ControlEvent, чтобы при получе-
нии управляющего события с числовым значением вызывать метод OnControlEvent.
Для тех, кто не знаком с делегатами: делегаты — это красивый и безопасный (в плане
ошибок, связанных с преобразованием типов) способ осуществить обратный вызов без
необходимости реализовывать еше один интерфейс или использовать указатели на функ-
ции. Более подробно о делегатах можно прочитать в [3].
Класс ControlReceiver
class ControlReceiver : Messageconsumer
{
protected ControlEvent controlEvent;
public ControlReceiver(MessageQueue inputQueue,
ControlEvent controlEvent) : base (inputQueue)
{
this.controlEvent = controlEvent;
}
protected override void ProcessMessage(Message msg)
{
String text = (string)msg.Body;
Double resNum;
if (Double.TryParse(text. Numberstyles.Integer,
NumberFormatInfo.Invariantinfo, out resNum))
{
int control = int.Parse(text);
controlEvent(control);
} }
}
Усовершенствование управляющей консоли
Первый вариант нашей управляющей консоли был настолько прост, что мы даже не
стали включать в книгу его исходный код. Все действия консоли заключались в том, что-
бы получить сообщение и записать его содержимое в файл для дальнейшего анализа
(например, создания диаграммы в Excel). Теперь мы решили сделать консоль немного
“умнее”. Во-первых, когда монитор главного кредитного бюро уведомляет о появлении
ошибки, консоль должна сообщить маршрутизатору сообщений (Message Router, с. 109)
о необходимости перенаправить запросы запасному кредитному бюро. Мы предпочли
реализовать эту функциональность внутри консоли, чтобы отделить монитор от маршру-
тизатора сообщений на основе контекста. По сути, управляющая консоль будет высту-
пать в качестве посредника (Mediator, см. [12]). Кроме того, централизованная реализация
логики перемещения при сбое дает нам одну точку обслуживания для правил управления
системой. Управляющие консоли от коммерческих производителей часто включают в се-
Управление системой кредитного брокера
601
бя настраиваемые системы правил, позволяющие выбирать корректирующие действия
на основе событий, о которых объявляется по шине управления (Control Bus, с. 552).
Во-вторых, мы хотим снабдить центральную консоль простым пользовательским ин-
терфейсом, отображающим текущее состояние системы. Получить глобальную картину
состояния системы обмена сообщениями достаточно сложно, в особенности если пути
следования сообщений могут внезапно меняться. Наш пользовательский интерфейс бу-
дет простым, но довольно полезным. Чтобы представить взаимодействие между компо-
нентами, мы воспользуемся языком пиктограмм, принятым в этой книге. На данный
момент пользовательский интерфейс отображает только ту часть решения, которая каса-
ется перемещения при сбое кредитного бюро (рис. 12.8). Напомним, указанный меха-
низм реализован при помощи маршрутизатора сообщений и двух служб.
ж Management Contote
Рис. 12.8. Управляющая консоль показывает, что обе службы кредитного бюро активны
Когда монитор обнаруживает ошибку и консоль сообщает маршрутизатору о необхо-
димости перенаправить трафик сообщений, мы должны обновить пользовательский ин-
терфейс, чтобы отобразить новое состояние системы (рис. 12.9). Пиктограмма маршру-
тизатора показывает новый путь следования сообщений с запросами, а цвет главного
кредитного бюро меняется на более темный, что означает сбой компонента.
Рис. 12.9. Управляющая консоль показывает, что служба главного кредитного бюро
вышла из строя и трафик запросов перенаправлен запасной службе
602
Глава 12. Практикум: управление системой
Рассмотрим наиболее важные моменты реализации управляющей консоли. Мы со-
средоточимся на той части кода, которая касается управления системой, и не будем тро-
гать методы, предназначенные для отображения самих окон. Итак, управляющая кон-
соль должна получать от монитора сообщения о состоянии компонентов. Чтобы макси-
мально повысить надежность консоли, доступ к содержимому сообщений будет
осуществляться в слабо связанной манере путем считывания отдельных полей из тела со-
общения, содержащего данные в формате XML. Этот подход позволяет сохранить рабо-
тоспособность консоли даже в том случае, если компоненты решат добавить к формату
сообщений новые поля.
Наверное, никого из вас не удивит тот факт, что класс консоли наследует все тот же
класс Messageconsumer, поэтому мы покажем реализацию только конструктора и мето-
да ProcessMessage. Указанный метод просто считывает поток данных тела сообщения
(Bodystream) в текстовую строку и передает ее на анализ другим компонентам.
Класс MariagenrentCorfsofe: метод ProcessMessage
public delegate void ControlMessageReceived(String body);
public class Managementconsole : Messageconsumer
protected Logger logger;
public MonitorStatusHandler monitorStatusHandler;
public ControlMessageReceived updateEvent;
public Managementconsole(MessageQueue inputQueue,
string pathName) : base(inputQueue)
{
logger = new Logger (pathName)
monitorStatusHandler = new MonitorStatusHandler();
updateEvent += new ControlMessageReceived(logger.Log);
updateEvent += new
ControlMessageReceived(monitorStatusHandler.OnControlMessage);
}
protected override void ProcessMessage(Message m)
Stream stm = m.Bodystream;
StreamReader reader = new StreamReader (stm);
String body = reader.ReadToEndO;
updateEvent(body);
}
}
Для уведомления объекта Logger, отвечающего за ведение журнала, и обработчика
MonitorStatusHandler о получении сообщений об изменении состояния компонентов
используется делегат ControlMessageReceived. Это позволяет легко добавлять к сис-
теме другие объекты, которые тоже хотят получать управляющие сообщения, без необхо-
димости вносить изменения в код метода ProcessMessage.
Управление системой кредитного брокера
603
Одним из объектов, анализирующих сообщения об изменении состояния компонен-
тов, является MonitorStatusHandler. Вначале он загружает тело сообщения в XML-
документ и проверяет, есть ли в нем корневой элемент <MonitorStatus>. Если это так,
MonitorStatusHandler извлекает из документа значения полей, представленные эле-
ментами <id> и <Status>. После этого вызывается событие updateEvent, представ-
ляющее собой экземпляр делегата Monitorstatusupdate. Любой объект из приложения
управляющей консоли может воспользоваться указанным делегатом, чтобы получать
уведомления об изменении состояния компонентов. Все, что для этого нужно сделать
объекту, — предусмотреть в своем классе реализацию метода с той же сигнатурой (т.е.
типом возвращаемого значения и списком аргументов), что и объявление делегата Moni-
torStatusUpdate.
Класс MonitorStatusHandler
public delegate void MonitorStatusUpdate(String Id, int Status);
public class MonitorStatusHandler
{
public MonitorStatusUpdate updateEvent;
public void OnControlMessage(String body)
XmlDocument doc = new XmlDocument();
doc.LoadXml(body);
XmlElement root = doc.DocumentElement;
if (root.Name == "Monitorstatus")
{
XmlNode statusNode = root.SelectSingleNode("Status");
XmlNode idNode = root.SelectSingleNode("ID");
if (idNode!= null && statusNode != null)
{
String msgID = idNode.InnerText;
String msgStatus = statusNode.InnerText;
Double resNum;
int status = 99;
if (Double.Tryparse(msgStatus, Numberstyles.Integer,
NumberFormatlnfo.Invariantinfo, out resNum))
{
status = (int)resNum;
}
updateEvent(msgiD, status);
604
Глава 12. Практикум: управление системой
В графическом интерфейсе нашей консоли есть несколько компонентов, следящих за
событием MonitorStatusUpdate, которое инициируется объектом Monitorstatus-
Handler. Первые два из них — это графические элементы управления, представляющие
службы главного и запасного кредитного бюро в окне консоли. Каждый элемент управ-
ления фильтрует события на предмет уникального идентификатора “своего” компонен-
та. Когда состояние компонента изменяется, элемент управления меняет свой цвет в ок-
не консоли. Код, показанный ниже, выполняется в процессе инициализации окна кон-
соли и привязывает элементы управления, соответствующие главному и запасному
кредитным бюро, к обработчику MonitorStatusHandler управляющей консоли. Полу-
чение консолью сообщения об обновлении состояния компонентов приводит к вызову
методов OnMonitorStatusUpdate каждого из упомянутых элементов управления.
Инициализация окна консоли
console = new Managementconsole(controlBusQueue, logFi 1 eName) ,-
primaryCreditBureauControl =
new ComponentStatusControl("Primary Credit Bureau",
"PrimaryCreditService");
primaryCreditBureauControl.Bounds =
new Rectangle(300, 30, COMPONENT_WIDTH, COMPONENT_HEIGHT);
secondaryCreditBureauControl =
new ComponentStatusControl("Secondary Credit Bureau",
"SecondaryCreditService");
secondaryCreditBureauControl.Bounds =
new Rectangle(300, 130, COMPONENT_WIDTH, COMPONENT_HEIGHT);
console.monitorStatusHandler.updateEvent += new
MonitorStatusUpdate(primaryCreditBureauControl.
OnMonitorStatusUpdate);
console.monitorStatusHandler.updateEvent += new
MonitorStatusUpdate(secondaryCreditBureauControl.
OnMonitorStatusUpdate);
Еще одним компонентом, следящим за событием MonitorStatusUpdate, является
FailOverHandler. Это невизуальный компонент, анализирующий сообщения о состоя-
нии, чтобы определить, нужно ли включать перемещение при сбое. Если состояние мо-
нитора изменилось (для проверки этого факта мы используем логическую операцию XOR
(“исключающее ИЛИ”), которая обозначается оператором *), объект FailOverHandler
отправляет сообщение с командой в специально предназначенный для этого канал
команд. В нашем примере этот канал подсоединен к описанному ранее маршрутизатору
сообщений на основе контекста. Получив команду, маршрутизатор перенаправляет запро-
сы на получение кредитного балла другому поставщику службы кредитного бюро.
Управление системой кредитного брокера
605
Класс FailOverHandler
public delegate void FailOverStatusUpdate(String ID,
string Command);
public class FailOverHandler
{
public void OnMonitorStatusUpdate(String ID, int status)
{
if (componentID == ID)
{
if (IsOK(status) * IsOK(currentStatus))
{
String command = IsOK(status) ? "0" : "1";
commandQueue.Send(command);
currentstatus = status;
updateEvent(ID, command);
}
}
}
protected bool IsOK(int status)
{
return (status == 0 || status >= 99);
}
}
Обработчик FailOverHandler также вызывает событие updateEvent, являющееся
экземпляром делегата FailOverStatusUpdate. Как и в случае с объектом MonitorSta-
tusHandler, мы можем зарегистрировать любой компонент, создающий экземпляр
этого делегата для получения уведомлений об изменении состояния объекта FailOver-
Handler. В нашем примере мы регистрируем еще один, визуальный компонент
FailOverControl, внешний вид которого обновляется при переключении к другому по-
ставщику службы кредитного бюро. Связь между компонентами FailOverControl и
FailOverHandler осуществляется в коде, инициализирующем окно консоли.
Инициализация окна консоли
failOverControl = new FailOverControl("Credit Bureau Failover",
"PrimaryCreditService");
failOverControl.Bounds = new Rectangle(100, 80, ROUTER_WIDTH,
COMPONENT_HEIGHT);
FailOverHandler failOverHandler =
new FailOverHandler(commandQueue, "PrimaryCreditService");
console.monitorStatusHandler.updateEvent +=
new MonitorStatusUpdate(failOverHandler.OnMonitorStatusUpdate);
failOverHandler.updateEvent += new
FailOverStatusUpdate(failOverControl.OnMonitorStatusUpdate);
606
Глава 12. Практикум: управление системой
Связывая отдельные компоненты в коде управляющей консоли с помощью делегатов
и событий, мы получаем слабо связанную архитектуру. Это дает возможность повторно
использовать отдельные компоненты и составлять из них другие архитектурные решения,
такие как шаблон каналы и фильтры (Pipes and Filters, с. 102), описанный в начале книги.
Передача сообщений, прибывающих по шине управления, другим компонентам с помо-
щью делегатов фактически эквивалентна созданию в приложении внутреннего канала
“публикация-подписка” (Publish-Subscribe Channel, с. 134). Поскольку управляющие сооб-
щения прибывают по каналу “точка-точка” (Point-to-Point Channel, с. 131), мы вынужде-
ны использовать один потребитель, который затем оповещает о событии всех заинтере-
сованных подписчиков внутри консоли.
Схема оповещения о событиях отдельных компонентов управляющей консоли изо-
бражена на рис. 12.10.
Рис. 12.10. Оповещение о событиях внутри управляющей консоли
Визуализация обмена сообщениями между компонентами системы с помощью гра-
фического интерфейса центральной консоли — мощное средство управления системой.
Некоторые производители предлагают пакеты средств разработки, позволяющие визу-
ально группировать компоненты и соединять их входные и выходные порты, чтобы соз-
давать распределенные приложения, основанные на обмене сообщениями. К примеру,
пакет средств разработки Fiorano Tifosi (www. f iorano. com) включает в себя инструмент
под названием Distributed Applications Composer. Он помогает построить распределенное
решение с одним графическим интерфейсом, даже если все компоненты этого решения
выполняются на разных компьютерах или платформах. Для соединения распределенных
компонентов с центральной управляющей консолью в Distributed Applications Composer
применяется шина управления.
Управление системой кредитного брокера
607
В нашем простом примере визуализацию соединений между компонентами решения
(например, рисование линии между пиктограммой маршрутизатора и прямоугольника-
ми, представляющими службы кредитного бюро) приходилось прописывать прямо в коде
консоли. Многие средства интеграции дают пользователю возможность применять гра-
фический интерфейс для разработки решений “с нуля”. Этот подход облегчает использо-
вание тех же графических средств для отображения сведений о состоянии решения.
Чтобы применять указанные средства для графического представления существую-
щей системы, можно проанализировать, как ее компоненты обмениваются сообщения-
ми. Существует два фундаментальных подхода к выполнению анализа такого типа: ста-
тический и динамический. Статический анализ (static analysis) предполагает изучение ка-
налов, в которых каждый компонент публикует и получает сообщения. Если один
компонент публикует сообщения в том же канале, на который подписан другой компо-
нент, компоненты можно соединить линией. Многие пакеты EAI-средств, например
TIBCO ActiveEnterprise, сохраняют информацию такого типа в центральном репозито-
рии, что значительно облегчает проведение статического анализа. Суть динамического
анализа (dynamic analysis) заключается в исследовании отдельных сообщений, которые
циркулируют в системе, и “прокладки” соединений между компонентами в зависимости
от происхождения сообшений, получаемых конкретным компонентом. Данная задача
значительно упрощается, если сообщения системы включают в себя журнал доставки со-
общения (Message History, с. 561). Впрочем, отсутствие журнала не помешает нам воссоз-
дать путь следования сообщений, если в каждом из них содержится поле с информацией
об отправителе (многие системы обмена сообщениями вставляют в сообщение такое по-
ле с целью аутентификации).
Ограничения примера, приведенного в этой главе
Чтобы уместить пример в тесные рамки одной главы, нам пришлось сделать несколь-
ко упрощений. К примеру, наш механизм перемещения при сбое не охватывает сообще-
ния, которые уже находились в очереди к главному кредитному бюро, когда оно вышло
из строя. Эти сообщения так и останутся в очереди, пока работа главной службы не будет
восстановлена. Кредитный брокер продолжит функционировать в обычном режиме, по-
тому что он сопоставляет ответы кредитного бюро с запросами клиентов, но запросы на
получение кредита, которым соответствуют “застрявшие” сообщения, не будут обрабо-
таны, пока главное кредитное бюро не возобновит работу. Чтобы улучшить время откли-
ка кредитного бюро в сценарии перемещения при сбое, мы должны реализовать функ-
цию повторной отправки, которая позволит кредитному брокеру еще раз отослать запро-
сы, безнадежно застрявшие в очереди к неисправному кредитному бюро. Вместо этого
маршрутизатор, отвечающий за перемещение при сбое, может сохранять все сообщения,
полученные им со времени последнего подтверждения того, что служба кредитного бюро
исправна. Если обнаружится, что служба вышла из строя, маршрутизатор может еще раз
отправить сохраненные им сообщения, потому что часть из них, скорее всего, была обра-
ботана некорректно или не обработана вообще. Этот подход может привести к дублиро-
ванию сообщений с запросами (и соответствующих сообщений с ответами), но посколь-
ку служба кредитного бюро и кредитный брокер являются идемпотентными получателя-
ми (Idempotent Receiver, с. 541), появление сообщений-“двойников” не опасно — копии
ответов будут просто проигнорированы.
608 Глава 12. Практикум: управление системой
В данном примере нам удалось продемонстрировать реализацию лишь нескольких
функций управления из огромного числа тех, которые могут быть представлены с помо-
щью шаблонов из главы 11. К примеру, мы могли бы производить мониторинг трафика
сообщений между всеми компонентами системы, устанавливать пороги производитель-
ности, организовать отправку сообщений-пульсов каждым компонентом системы и т.п.
В действительности добавление к распределенному решению, основанному на обмене
сообщениями, надежных средств управления и мониторинга может потребовать от раз-
работчиков и кодировщиков столько же (если не больше) усилий, сколько создание са-
мого решения.
Глава 13
Шаблоны интеграции
на практике
Практикум: система формирования цен на облигации
Джонатан Саймон (Jonathan Simon)
Давайте немного отвлечемся от общих разговоров о языке шаблонов. Шаблон —
это абстракция идеи в форме, пригодной для повторного использования. Зачастую
слишком общий характер шаблонов, делающий их такими полезными, затрудняет их по-
нимание. Иногда самый лучший способ объяснить суть шаблонов — продемонстриро-
вать их использование на примере из реальной жизни. Именно из реальной жизни —
я говорю не о гипотетическом сценарии, который мог бы произойти, а о ситуации, кото-
рая происходит и будет происходить на практике.
В этой главе рассказывается, как применять шаблоны для решения задач проектиро-
вания. В качестве примера будет рассматриваться реальная система формирования цен
на облигации, на создание которой (от чернового проекта до внедрения в эксплуатацию)
у меня ушло два года. Мы изучим возможные сценарии и возникающие в ходе их выпол-
нения проблемы, а затем посмотрим, как решить их с помощью шаблонов. Этот процесс,
помимо всего прочего, включает в себя принятие решений относительно выбора шабло-
нов, а также комбинирование и приспособление шаблонов для удовлетворения собст-
венных нужд. Все это делается с учетом особенностей системы и обстоятельств ее функ-
ционирования, таких как бизнес-требования, решения клиентов, архитектурные и тех-
нические требования, а также интеграция унаследованных систем. Цель такого подхода
состоит в том, чтобы прояснить понимание шаблонов через практическое применение
последних.
610
Глава 13. Шаблоны интеграции на практике
Построение системы
Один из крупных инвестиционных банков США решил создать систему формирова-
ния цен на облигации, чтобы ускорить работу своего отдела купли-продажи облигаций.
В настоящее время трейлеры должны отсылать цены на огромное количество облигаций
сразу на несколько бирж, каждая из которых имеет собственный пользовательский ин-
терфейс. Цель внедрения системы состоит в том, чтобы как можно тщательнее скрыть
детали ценообразования для всех видов облигаций, инкапсулировав их вместе с аналити-
ческими функциями, специфичными для рынка облигаций, в едином пользовательском
интерфейсе. Это означает необходимость интеграции и взаимодействия нескольких ком-
понентов по различным коммуникационным протоколам. Схема взаимодействия
компонентов на верхнем уровне системы показана на рис. 13.1.
Рис. 13.1. Обмен данными на верхнем уровне системы
Вначале в систему попадают рыночные данные. Это данные, касающиеся цены
и других характеристик облигации, которые показывают, по какой цене люди хотят по-
купать и продавать облигации на свободном рынке. Рыночные данные немедленно от-
правляются в аналитическую подсистему, которая вносит в них изменения. Аналитиче-
ская подсистема основана на математических функциях финансовых приложений, ме-
няющих цену и другие атрибуты облигаций. Это универсальные функции, которые
используют параметры, вводимые пользователем, чтобы адаптировать результат выпол-
нения функции к конкретному виду облигаций. Клиентское приложение, функциони-
рующее на компьютере каждого трейдера, настраивает аналитическую подсистему под
нужды последнего. Оно контролирует специфику обработки каждого вида облигаций,
для которого указанный трейдер формирует цену. После прохождения через аналитиче-
скую подсистему измененные данные отправляются на разнообразные биржи, где трей-
деры других компаний продают или покупают облигации.
Архитектура с учетом шаблонов
Мы рассмотрели процесс обмена данными в системе формирования цен на облига-
ции. Теперь попробуем решить несколько архитектурных проблем, появившихся у нас
в процессе проектирования. Что мы знаем на данный момент? Трейдерам нужно прило-
жение с высоким уровнем надежности, функционирующее на платформах Windows NT
Solaris. По этой причине мы решили реализовать клиентское приложение в вше
“толстого клиента” Java — он не зависит от платформы и способен быстро реагировать
Практикум: система формирования цен на облигации
611
на параметры, введенные пользователем, и предоставление рыночных данных. На сторо-
не сервера мы наследуем старые компоненты C++. Компонент, занимающийся предос-
тавлением и обработкой рыночных данных, взаимодействует с инфраструктурой обмена
сообщениями TIBCO Information Bus (TIB).
Мы наследуем такие компоненты.
• Сервер предоставления рыночных данных. Публикует входящие рыночные данные
(т.е. рыночные цены на облигации) в канале TIB.
• Аналитическая подсистема. Выполняет аналитическую обработку входящих ры-
ночных данных и публикует измененные данные в виде широковещательного со-
общения в канале TIB (рис. 13.2).
• Сервер доставки. “Общается” с биржами. Они представлены сторонними компо-
нентами и не контролируются банком (рис. 13.3).
Рис. 13.2. Унаследованная система обработки рыночных данных
Сервер
доставки
Рис. 13.3. Унаследованная система доставки
Нужно решить, как организовать взаимодействие отдельных подсистем (“толстого
клиента” Java, компонента обработки рыночных данных и сервера доставки). “Толстый
клиент” мог бы напрямую взаимодействовать с унаследованными серверами, но это по-
требовало бы реализации на стороне клиента слишком большого объема бизнес-логики.
Вместо этого мы создадим пару шлюзов Java, которые будут общаться с унаследованны-
ми серверами: шлюз ценообразования для компонента обработки рыночных данных и
612
Глава 13. Шаблоны интеграции на практике
шлюз доставки для отправки цен на биржи. Это позволит достичь хорошего уровня ин-
капсуляции соответствующей бизнес-логики. Текущая схема взаимодействия компонен-
тов системы показана на рис. 13.4. Символы “???” над стрелками обозначают, что мы
еще не знаем, как будет организовано взаимодействие некоторых компонентов.
Шлюз
ценообразо-
вания
“Толстый
клиент”
Шлюз
доставки
Рис. 13.4. Система и ее компоненты
Первый неясный момент касается способа интеграции “толстого клиента” Java с дву-
мя Java-шлюзами, чтобы осуществлять обмен данными. В данной книге предлагаются
четыре подхода к интеграции: передача файла (File Transfer, с. 80), общая база данных
(Shared Database, с. 83), удаленный вызов процедуры (Remote Procedure Invocation, с. 85) и
обмен сообщениями (Messaging, с. 87). Общую базу данных можно откинуть сразу, потому
что мы хотим создать уровень абстракции между клиентом и базой данных и не хотим,
чтобы в коде клиента осуществлялся доступ к базе данных. Аналогичным образом можно
отбросить и передачу файла, поскольку отправка текущих цен на биржи должна происхо-
дить с минимальной задержкой. Остаются два варианта: удаленный вызов процедуры и об-
мен сообщениями.
Платформа Java обладает встроенной поддержкой как удаленного вызова процедуры,
так и обмена сообщениями. Интеграцию в стиле RPC можно осуществить, используя ком-
поненты Remote Method Invocation (RMI), CORBA или Enterprise Java Beans (EJB). Стан-
дартным интерфейсом API для интеграции через обмен сообщениями является Java
Messaging Service (JMS). И тот, и другой типы интеграции достаточно легко реализовать
на платформе Java.
Итак, какой же тип интеграции лучше подойдет для нашего проекта: удаленный вызов
процедуры или обмен сообщениями? В системе функционирует только по одному экземп-
ляру шлюза ценообразования и шлюза доставки, но к указанным службам обычно под-
ключается сразу несколько “толстых клиентов” (по одному на каждого трейдера, кото-
рый в настоящий момент находится в системе). Более того, банк хотел бы, чтобы система
Практикум: система формирования цен на облигации
613
формирования цен на облигации носила универсальный характер и могла бы применять-
ся другими приложениями. Таким образом, помимо неопределенного числа “толстых
клиентов”, у нас может быть неопределенное число других приложений, использующих
данные о ценах, которые выходят из шлюзов.
“Толстый клиент” или другие приложения, использующие данные о ценах, могут до-
вольно легко применять RPC, чтобы обращаться к шлюзам для получения данных о це-
нах и запуска механизма обработки. С другой стороны, данные о ценах будут постоянно
публиковаться, а определенные клиенты заинтересованы только в определенных данных,
поэтому организовать своевременную доставку каждому клиенту нужных ему данных бу-
дет сложно. Клиенты могли бы опрашивать шлюзы, но это приведет к чрезмерной за-
грузке каналов. Гораздо лучше, чтобы шлюзы сами предоставляли клиентам данные по
мере появления последних. В этом случае, однако, потребуется, чтобы каждый шлюз от-
слеживал, какие клиенты активны на данный момент времени и какие данные требуются
каждому из них. Затем, при появлении новой порции данных (что происходит десятки
раз в секунду) шлюз должен выполнять удаленный вызов каждого заинтересованного
клиента, чтобы передать тому данные. В идеальном случае все клиенты должны одновре-
менно оповещаться о появлении данных, поэтому каждый удаленный вызов процедуры
должен выполняться в собственном параллельном потоке. Такая схема может оказаться
вполне жизнеспособной, но по ходу уточнения разнообразных деталей ее сложность не-
померно возрастет.
Обмен сообщениями значительно упрощает описанную проблему. Используя обмен со-
общениями, можно определить разные каналы для передачи разных типов данных о це-
нах. Когда шлюз получит новую порцию данных, он упакует их в сообщение и опублику-
ет его в канале “публикация-подписка” (Publish-Subscribe Channel, с. 134), предназначен-
ном для работы с этим типом данных. Тем временем клиенты, заинтересованные в
получении данных определенного типа, будут прослушивать соответствующий канал.
Благодаря этому шлюзы смогут легко рассылать новые данные всем, кто ими интересует-
ся, без необходимости знать о том, сколько приложений прослушивают канал и что они
собой представляют.
Клиентам все равно нужен способ вызова функциональности шлюзов. Поскольку в
нашей системе всего два шлюза и при синхронном вызове метода выполнение клиента
может блокироваться, взаимодействие “клиент-шлюз” довольно легко реализовать в ви-
де RPC. Тем не менее, поскольку для взаимодействия “шлюз-клиент” уже используется
обмен сообщениями, этот же подход, вероятно, стоит применить и для общения в обрат-
ном направлении.
Итак, взаимодействие между шлюзами и клиентами будет целиком и полностью ос-
новано на обмене сообщениями. Поскольку все указанные компоненты будут написаны
на Java, в качестве инфраструктуры обмена сообщениями логично выбрать JMS
(рис. 13.5). Как следствие этого у нас появляется шина сообщений (Message Bus, с. 162),
или архитектура, которая позволит интегрировать будущие системы с текущей, не внося
или практически не внося изменений в инфраструктуру обмена сообщениями. Благодаря
этому бизнес-функциональность приложения впоследствии сможет легко применяться
любыми другими приложениями, разработанными банком.
614
Глава 13. Шаблоны интеграции на практике
“Толстый
клиент"
Java
3 с++
Ф
Сервер
предоставления
данных и
аналитическая
подсистема
Подсистема
доставки
TIBCO
Рис. 13.5. Взаимодействие компонентов Java с помощью JMS
JMS — это всего лишь спецификация, поэтому нам нужно выбрать одну из коммерче-
ских JMS-совместимых систем обмена сообщениями. Мы остановили свой выбор на IBM
MQSeries, потому что банк, для которого разрабатывалась система, использует серверы
приложений WebSphere и много других продуктов IBM (значит, у нас уже есть вспомога-
тельная инфраструктура и корпоративная лицензия на использование MQSeries).
Следующий неясный момент можно сформулировать так: как связать систему обмена
сообщениями MQSeries с изолированным сервером доставки, написанным на C++, а также
с компонентами предоставления и обработки рыночных данных, которые общаются друг
с другом через TIB? Необходимо, чтобы потребители сообщений MQSeries имели доступ к
сообщениям TIB, но как это сделать? Пожалуй, мы могли бы воспользоваться шаблоном
транслятор сообщений (Message Translator, с. 115), чтобы преобразовывать сообщения TIB в
сообщения MQSeries. Хотя в качестве транслятора сообщений может выступать клиент C++
для MQSeries, его использование приведет к потере независимости сервера JMS. Платфор-
ма TIBCO включает в себя интерфейс API для взаимодействия с Java, но менеджер и разра-
ботчик банка отвергли возможность его применения.
Практикум: система формирования цен на облигации
615
Чтобы создать мост от сервера TIB к серверу MQSeries, необходимо организовать
взаимодействие между кодом C++ и Java. Для этого можно было бы воспользоваться
компонентами CORBA, но как тогда насчет обмена сообщениями? Более детальное изу-
чение транслятора сообщений показывает, что в плане использования коммуникацион-
ных протоколов данный шаблон весьма схож с адаптером канала (Channel Adapter, с. 154).
Суть адаптера канала состоит в том, чтобы связывать приложения, не предназначенные
для обмена сообщениями, с системой обмена сообщениями. Пара адаптеров канала, со-
единяющих между собой две системы обмена сообщениями, образует мост обмена сооб-
щениями (Messaging Bridge, с. 159).
Назначение моста обмена сообщениями — передавать сообщения из одной системы
обмена сообщениями в другую. Именно это мы и собираемся делать, только с добавлени-
ем взаимодействия между Java и C++. Мы можем реализовать межплатформенный мост
обмена сообщениями, используя комбинацию двух адаптеров канала и компонентов
CORBA. Для этого мы разработаем два облегченных сервера адаптеров канала-, один —
на C++ для управления взаимодействием с TIB, а второй— на Java для управления
взаимодействием с JMS. Эти адаптеры канала, которые одновременно являются конеч-
ными точками сообщения (Message Endpoint, с. 124), будут общаться друг с другом при по-
мощи CORBA. Почему мы не выбрали JNI? Потому что CORBA уже применяется в ком-
пании в качестве корпоративного стандарта. Мост обмена сообщениями, по сути, эмули-
рует преобразование сообщений между, казалось бы, несовместимыми системами об-
мена сообщениями и языками программирования (рис. 13.6).
Мост обмена сообщениями
Адаптер
C++/TIB
<---->
CORBA
Адаптер
Java/JMS
Рис. 13.6. Организация моста обмена сообщениями при помощи адаптеров канала
Текущая структура системы формирования цен на облигации, включая шлюзы и
другие компоненты, показана на рис. 13.7. Это хороший пример практического приме-
нения шаблонов. Мы скомбинировали два адаптера канала с протоколом, не предназна-
ченным для обмена сообщениями, чтобы организовать мост обмена сообщениями, т.е. ис-
пользовали один шаблон для реализации другого. Мы также изменили контекст адапте-
ров канала, чтобы с их помощью связать две системы обмена сообщениями с протоколом
преобразования из одного языка программирования в другой, не имеющим никакого от-
ношения к обмену сообщениями. (Напомним, что в классическом варианте адаптер ка-
нала применяется для связи приложения, не предназначенного для обмена сообщения-
ми, с системой обмена сообщениями.)
616
Глава 13. Шаблоны интеграции на практике
Шлюз
ценообразо-
вания
“Толстый
клиент”
Шлюз
доставки
Шлюз
доставки
на C++
Шлюз
ценообразо-
вания на C++
Рис. 13.7. Текущая структура системы с адаптерами канала
Сервер
доставки
^JMS^
Структура каналов
Работая с шаблонами, необходимо не только знать, в каких ситуациях нужно исполь-
зовать тот или иной шаблон, но и уметь использовать их наиболее эффективно. В каждой
реализации шаблона следует учитывать специфику программной платформы, а также
другие критерии проектирования. В этом разделе мы попытаемся выяснить наиболее
эффективный способ применения канала “публикация-подписка” (Publish-Subscribe
Channel, с. 134) в контексте взаимодействия между сервером, подающим рыночные дан-
ные, и аналитической подсистемой.
Рыночные данные рассылаются сервером, написанным на C++. Последний в режиме
реального времени публикует их в канале TIB. При этом для каждого вида облигаций
применяется собственный канал “публикация-подписка”. Может показаться, что создание
собственного канала для каждого нового вида облигаций — это уже слишком. На деле,
однако, все не так страшно, поскольку в TIBCO реального создания каналов не происхо-
дит. Вместо этого на каналы ссылаются при помощи иерархического набора имен, назы-
ваемых темами (subjects). Сервер TIBCO фильтрует поток сообщений по теме, отправляя
сообщение с каждой новой темой в отдельный виртуальный канал. В результате у нас
оказывается весьма облегченный вариант канала сообщений.
Практикум: система формирования цен на облигации
617
Мы могли бы создать систему, которая публикует сообщения в небольшом количест-
ве каналов, а подписчики прослушивают каналы на предмет только тех цен, которые их
интересуют. Для этого подписчикам пришлось бы воспользоваться фильтром сообщений
(Message Filter, с. 253) или избирательным потребителем (Selective Consumer, с. 528), чтобы
фильтровать поток данных на предмет интересующих их цен, решая, нужно ли обрабаты-
вать каждое полученное ими сообщение. Учитывая, что рыночные данные публикуются в
каналах, соответствующих отдельным видам облигаций, подписчики могут зарегистри-
роваться на получение обновлений для конкретного набора облигаций. Это позволит
подписчикам эффективно “фильтровать” сообщения путем выборочной подписки на
каналы вместо того, чтобы принимать решение о необходимости обработки того или
иного сообщения уже после того, как оно получено. Важно отметить, что использование
большого числа каналов сообщений с целью избежать фильтрации — нестандартный
способ их применения. В контексте TIBCO, однако, выбор между большим числом кана-
лов и фильтрацией сводится к другому: нужно ли реализовывать собственные фильтры
или лучше использовать средства фильтрации каналов, встроенные в TIBCO?
Перейдем к проектированию аналитической подсистемы. Это еще один сервер
C++/TIB, который изменяет рыночные данные и заново публикует их в TIB. Хотя созда-
ние такого сервера выходит за рамки Java/JMS, мы тесно сотрудничаем с командой раз-
работчиков C++, которая занимается его проектированием, потому что именно мы явля-
емся главным потребителем указанной подсистемы. Проблема состоит в том, чтобы най-
ти структуру канала, которая позволит организовать широковещательную рассылку
измененных рыночных данных наиболее эффективным образом.
От сервера предоставления рыночных данных нам досталась идея использовать для
каждого вида облигаций отдельный канал сообщений (Message Channel, с. 93). На первый
взгляд, логично, чтобы измененные рыночные данные также рассылались по отдельным
каналам сообщений, соответствующим тому или иному виду облигаций. К сожалению, в
нашем случае это неприемлемо, поскольку аналитическая логика, меняющая цены на
облигации, специфична для каждого трейдера. Если мы отправим измененные данные
трейдеров в каналы, соответствующие виду облигаций, то нарушим целостность данных,
заменив общие рыночные данные данными, специфичными для трейдера. Во избежание
этого сведения, специфичные для трейдеров, можно упаковывать в сообшения другого
типа, чтобы подписчики самостоятельно решали, какие сообшения их интересуют.
Но тогда клиентам придется реализовать собственные фильтры, чтобы отбрасывать со-
общения, предназначенные для других трейдеров. Кроме того, интенсивность потока со-
общений, получаемых подписчиками, существенно возрастет, что создаст совершенно
ненужную нагрузку на подписчиков.
Можно предложить два варианта создания и распределения каналов.
1. По одному каналу на каждого трейдера. У каждого трейдера есть собственный канал,
предназначенный для получения измененных рыночных данных. Тогда исходные
рыночные данные останутся нетронутыми, а приложение каждого трейдера будет
прослушивать свой канал сообщений на предмет обновления цен (рис. 13.8).
2. По одному каналу на каждый вид облигаций для каждого трейдера. Для каждого
трейдера создается по нескольку собственных каналов сообщений. Каждый из них
предназначается сугубо для получения измененных данных по одному виду об-
лигации. Пусть, к примеру, исходные рыночные данные для облигации АБВ пуб-
ликуются в канале “Облигация АБВ”. Тогда измененные данные по этому виду
618
Глава 13. Шаблоны интеграции на практике
облигаций будут публиковаться следующим образом: для трейдера А — в канале
“Трейдер А, облигация АБВ”, для трейдера Б — в канале “Трейдер Б, облигация
АБВ” и т.п. (рис. 13.9).
Сервер предоставления
рыночных данных
Аналитическая
Г-----
Облигация АБВ
Облигация БВГ
-----——.---->
Рис. 13.8. По одному каналу на каждого трейдера
Сервер предоставления Аналитическая
Рис. 13.9. По одному каналу на каждый вид облигаций для каждого трейдера
У каждого из описанных подходов есть свои преимущества и недостатки. К примеру,
во втором из них используется гораздо больше каналов, нежели в первом. В худшем слу-
чае число каналов сообщений будет равняться общему количеству видов облигаций, умно-
женному на количество трейдеров. В принципе, число создаваемых каналов можно огра-
ничить сверху. Мы знаем, что у банка около 20 трейдеров, и каждый из них работает
лишь с несколькими сотнями видов облигаций, не больше. Это позволяет установить
верхнюю границу равной 10 000 каналам, что не так уж и много по сравнению с почти
100 000 каналов сообщений, которые использует сервер предоставления рыночных дан-
ных. Кроме того, поскольку мы используем TIB и каналы сообщений сравнительно недо-
роги, их количество не играет особой роли. Полное число каналов сообщений могло бы
Практикум: система формирования цен на облигации
619
представлять проблему с точки зрения управляемости. Каждый раз при добавлении но-
вого вида облигаций в системе пришлось бы создавать по одному каналу для каждого
трейдера. Это весьма нежелательно в очень динамической системе, но наша система по
своей сути статична. Кроме того, у нее есть инфраструктура для автоматического управ-
ления каналами сообщений. В комбинации с аналогичной архитектурой унаследованных
компонентов это минимизирует негативный эффект. Разумеется, это вовсе не означает,
что количество каналов сообщений можно безосновательно раздувать до гигантских раз-
меров. Вместо этого мы реализуем архитектурный подход, предполагающий использова-
ние большого числа каналов тогда, когда на это есть причины.
В нашем случае такие причины есть, и связаны они с расположением логики мар-
шрутизации. Если мы реализуем подход “По одному каналу на каждого трейдера”, ана-
литической подсистеме понадобится логика, которая будет группировать входящие и ис-
ходящие каналы. Для чего это нужно, спросите вы? Дело в том, что входящие каналы
аналитической системы будут соответствовать видам облигаций, а исходящие — трейде-
рам, вследствие чего аналитической подсистеме придется перенаправлять данные для
одного трейдера из разных входящих каналов сообщений в один канал, соответствующий
указанному трейдеру. Все это превращает аналитическую подсистему в маршрутизатор
на основе содержимого (Content-Based Router, с. 247), реализующий пользовательскую ло-
гику маршрутизации для нашего приложения.
В соответствии со структурой шины сообщений (Message Bus, с. 162) аналитическая
подсистема является универсальным сервером, который может использоваться другими
системами, поэтому не следует захламлять ее функциональностью, специфичной для
конкретной системы. Во избежание всего этого мы могли бы применить второй подход,
“По одному каналу на каждый вид облигаций для каждого трейдера”. Это позволит со-
хранить изолированность входящих рыночных данных при некотором увеличении числа
каналов сообщений. Прежде чем данные из каналов достигнут клиента, необходимо про-
пустить их сквозь маршрутизатор на основе содержимого, чтобы свести число каналов к
управляемому. Мы не хотим, чтобы клиентскому приложению, функционирующему на
компьютере трейдера, пришлось прослушивать тысячи или десятки тысяч каналов сооб-
щений. В связи с этим возникает новый вопрос: куда поместить маршрутизатор на основе
содержимого? Самое простое решение— сделать так, чтобы адаптер канала (Channel
Adapter, с. 154) C++/TIB перенаправлял все сообщения на шлюз ценообразования по
единственному каналу сообщений. Это плохо по двум причинам: во-первых, мы разброса-
ем бизнес-логику между C++ и Java, а во-вторых, потеряем на стороне TIB преимущест-
во отдельных каналов сообщений, которое позволяло избежать последующей фильтрации
потока данных. Учитывая расположение компонентов Java, маршрутизатор на основе со-
держимого можно внедрить в шлюз ценообразования или же создать промежуточный
компонент между шлюзом ценообразования и клиентом.
Теоретически, если бы мы сохранили разделение каналов сообщений по видам облига-
ций на всем пути к клиенту, шлюз ценообразования выполнял бы широковещательную
рассылку информации о ценах по той же структуре каналов, что и аналитическая подсис-
тема вкупе с предыдущим шлюзом. Это означает дублирование всех каналов TIB, соот-
ветствующих видам облигаций, в JMS. Даже если мы вставим промежуточный компо-
нент между шлюзом ценообразования и клиентом, шлюзу все равно придется дублиро-
вать все каналы в JMS. Но реализация логики маршрутизации непосредственно в рамках
шлюза ценообразования позволит избежать дублирования большого количества каналов
620
Глава 13. Шаблоны интеграции на практике
в JMS и ограничиться созданием лишь нескольких каналов — по одному на каждого
трейдера. Шлюз ценообразования регистрируется через адаптер канала C++/TIB в каче-
стве потребителя на каждый вид облигаций для каждого трейдера системы. Затем шлюз
перенаправляет каждому клиенту только те сообщения, которые касаются соответст-
вующего трейдера (рис. 13.10). Благодаря этому на стороне JMS будет находиться не-
большое количество каналов сообщений, и в то же время мы получим максимальную вы-
году от разделения каналов на стороне TIB.
Трейдер Б, облигация БВГ
Трейдер А, облигация АБВ
Трейдер А, облигация БВГ
Трейдер Б, облигация АБВ
Рис. 13.10. Полная схема передачи обработанных рыночных данных клиентам
Адаптер Java/JMS
Обсуждение структуры каналов сообщений — хороший пример того, насколько важна
интеграция шаблонов проектирования. Нашей целью было выявить самый эффектив-
ный способ использования каналов сообщений. Сказать, что мы используем тот или иной
шаблон, недостаточно. Необходимо понять, как лучше всего реализовать указанный
шаблон и внедрить его в систему для решения насущных проблем. Помимо этого, дан-
ный пример наглядно иллюстрирует влияние бизнес-факторов. Если бы мы могли реали-
зовать бизнес-логику в любом из компонентов системы, мы бы остановились на куда бо-
лее простом подходе “По одному каналу на каждого трейдера”, предполагающем исполь-
зование намного меньшего числа каналов.
Выбор канала сообщений
В предыдущих разделах главы мы обсудили механизм взаимодействия компонентов
Java/JMS и C++/TIBCO, а также наметили структуру каналов сообщений (Message Channel,
с. 93). Теперь необходимо решить, какой тип каналов сообщений JMS будет применяться
для взаимодействия между компонентами Java. Перед этим, однако, давайте рассмотрим
схему обмена сообщениями на верхнем уровне системы (рис. 13.11). У нас есть два шлюза
(ценообразования и доставки), которые взаимодействуют с клиентом. Измененные ры-
ночные данные поступают к клиенту из шлюза ценообразования, а клиент отправляет их
шлюзу доставки. Кроме того, клиентское приложение отправляет сообщения шлюзу це-
нообразования, чтобы настроить “под себя” аналитическую логику, применяемую к ка-
ждому виду облигаций. Наконец, шлюз доставки также отсылает клиентскому приложе-
нию сообщения, в которых подтверждает обновление цен на различных биржах.
Практикум: система формирования цен на облигации
621
В спецификации JMS описываются два типа каналов сообщений: объект Queue, соот-
ветствующий каналу “точка-точка” (Point-to-Point Channel, с. 131), и объект Topic, пред-
ставляющий канал “публикация-подписка” (Publish-Subscribe Channel, с. 134). Напомним,
что канал “публикация-подписка” применяется тогда, когда сообщение должны получить
все заинтересованные потребители, а канал “точка-точка” гарантирует, что каждое кон-
кретное сообщение будет получено только одним потребителем, имеющим на это право.
Шлюз
ценообразо-
вания
Обновление цен
Параметры
<----------
Обновление цен
Подтверждение
обновлений
Рис. 13.11. Обмен сообщениями в системе
Шлюз
доставки
Многие разработчики подобных систем ограничились бы простой широковещатель-
ной рассылкой сообщений всем клиентским приложениям, предоставляя клиентам пра-
во самим решать, нужно ли обрабатывать то или иное сообщение. Нам, к сожалению, та-
кая схема не подойдет, поскольку каждому клиентскому приложению приходит огромное
количество сообщений с данными о ценах. Если рассылать обновления цен даже незаин-
тересованным трейдерам, клиентам придется тратить массу ресурсов только на то, чтобы
решать, нужно или не нужно обрабатывать каждое конкретное обновление.
Удачным выбором стал бы канал “точка-точка”, поскольку клиент отправляет каж-
дое конкретное сообщение только одному серверу и наоборот. Но у заказчика было биз-
нес-требование, чтобы трейдер мог входить в систему с нескольких компьютеров одно-
временно. Если трейдер зайдет в систему с двух машин, а обновление цен будет отправ-
лено по каналу “точка-точка”, сообщение будет получено только одним клиентским
приложением. Это связано с тем, что каждое сообщение, отправленное по каналу
“точка-точка”, может получить лишь один потребитель (рис. 13.12). Обратите внима-
ние, что сообщение получает только первое из клиентских приложений, запущенных од-
ним и тем же трейдером.
Шлюз ценообразования
1------------------1-----------------7
Трейдере
Трейдер Б
Трейдер А
Облигация КЛМ
Рис. 13.12. Рассылка обновлений цен на облигации по каналам “точка-точка1
622
Глава 13. Шаблоны интеграции на практике
Указанную проблему можно было бы решить, используя список получателей (Recipient
List, с. 264). В этом случае сообщения отправляются только тем получателям, которые
внесены в список. Используя этот шаблон, можно было бы создать списки получателей,
в каждый из которых внести все экземпляры клиентского приложения, используемые
конкретным трейдером. Отправка сообщения, предназначенного некоторому трейдеру,
привела бы к доставке этого сообщения всем приложениям, перечисленным в списке,
т.е. всем экземплярам клиентского приложения, относящимся к этому трейдеру
(рис. 13.13). Недостатком описанного подхода является необходимость реализации
большого объема логики, предназначенной для управления получателями и рассылки
сообщений.
Шлюз ценообразования
I t i
Трейдер А
Облигация КЛМ
t I
ТрейдерБ
Облигация КЛМ
Рис. 13.13. Рассылка обновлений цен на облигации с помощью списка получателей
ТрейдерВ
Облигация КЛМ
Схема использования каналов “точка-точка” в сочетании со списком получателей
имеет право на жизнь, но нельзя ли придумать что-нибудь получше? Используя каналы
“публикация-подписка”, система могла бы рассылать сообщения по каналам, специфич-
ным для трейдеров, а не для клиентских приложений. Тогда все приложения, обрабаты-
вающие сообщения для одного трейдера, получат и обработают предназначенное ему со-
общение (рис. 13.14).
Шлюз ценообразования
Г I i
Трейдер А Трейдер Б Трейдер В
Облигация КЛМ
Облигация КЛМ
Облигация КЛМ
Рис. 13.14. Рассылка обновлений цен на облигации по каналам “публикация-подписка”
Каналы “публикация-подписка” тоже обладают существенным недостатком: они не га-
рантируют, что сообщение, отправленное клиентом серверу, будет обработано только
один раз. Возможна ситуация, при которой будет создано несколько экземпляров сер-
верного компонента, и каждый из них обработает одно и то же сообщение. Это может
привести к рассылке неправильных цен.
Практикум: система формирования цен на облигации
623
Вспоминая схему обмена данными в нашей системе, можно прийти к выводу, что ка-
ждый канал сообщений должен передавать данные только в одном направлении. Почему?
Как уже говорилось, взаимодействие “сервер-клиент” может осуществляться по каналу
“публикация-подписка’’ и не может осуществляться по каналу “точка-точка”. И наобо-
рот, взаимодействие “клиент-сервер” может происходить по каналу “точка-точка”, но
никак не по каналу “публикация-подписка”. Поскольку у нас нет необходимости исполь-
зовать один и тот же канал сообщений для обмена данными в обоих направлениях, переда-
ча данных от клиента к серверу и обратно будет осуществляться по отдельным каналам,
причем по каналам разных типов. Взаимодействие “сервер-клиент” будет происходить
по каналу “публикация-подписка”, а взаимодействие “клиент-сервер” — по каналу
“точка-точка” (рис. 13.15). Такая комбинация каналов сообщений позволит системе взять
лучшее из обоих механизмов рассылки, нейтрализовав все недостатки последних.
Шлюз
ценообразо-
вания
Обновление цен
(“публикация-
подписка")
Параметры
(“точка-точка”)
Обновление цен
(“публикация-
подписка"^
Подтверждение
обновлений
(“точка-точка”)
Шлюз
доставки
Рис. 13.15. Обмен сообщениями с учетом типа каналов
Решение проблемы с помощью шаблонов
Шаблоны — это инструменты, а коллекцию шаблонов можно сравнить с набором
инструментов. Шаблоны помогают решать проблемы, не только глобальные, но и поточ-
ные. Некоторые думают, что шаблоны применяются исключительно на стадии проекти-
рования. Это равносильно высказыванию, что молоток и дрель нужны только во время
строительства дома и совершенно бесполезны во время ремонта. Правда состоит в том,
что шаблоны при правильном применении способны приносить немалую пользу на всех
стадиях проекта. В оставшихся разделах главы мы продолжим анализировать шаблоны,
чтобы найти решение проблем, появившихся в процессе эксплуатации системы форми-
рования цен на облигации.
Мигающие ячейки
Трейдеры хотят, чтобы при получении новых рыночных цен на какой-то вид облигации
соответствующая ячейка таблицы начинала мигать; это позволит трейдеру сразу заметить
изменения. Клиент Java получает сообщение с новыми данными, которое инициирует об-
новление кэша данных клиента и в конце концов приводит к миганию ячейки в таблице.
Проблема состоит в том, что обновления приходят слишком часто. Стек потоков графиче-
ского интерфейса пользователя быстро переполняется, и клиентское приложение в конце
концов “зависает”. Мы будем исходить из предположения, что мигание ячеек удалось ка-
ким-то образом реализовать, и сконцентрируем свое внимание на потоке сообшений, ини-
циирующих процесс обновления. Детальный анализ данных о производительности систе-
мы показывает, что клиентское приложение получает по нескольку обновлений в секунду;
разница между приходом двух обновлений может составлять менее миллисекунды. Хоте-
624
Глава 13. Шаблоны интеграции на практике
лось бы несколько замедлить поток сообщений, и в этом нам помогут два шаблона: агрега-
тор (Aggregator, с. 283) и фильтр сообщений (Message Filter, с. 253).
Первое, что приходит на ум, — реализовать фильтр сообщений, который будет кон-
тролировать скорость потока сообщений путем отбрасывания обновлений, полученных в
течение слишком короткого времени. В качестве примера предположим, что мы хотим
игнорировать сообщения, пришедшие в течение 5 миллисекунд после предыдущего.
Фильтр сообщений может кэшировать время получения последнего принятого сообщения
и отбрасывать все, что придет на протяжении следующих 5 миллисекунд (рис. 13.16). Та-
кое небрежное отбрасывание данных приемлемо далеко не во всех приложениях, но для
нашей системы из-за высокой частоты обновлений оно подходит идеально.
В:10:10:000 В:10:10:002 В:10:10:437
В:10:10:000 В:10:10:437
В:минугы:секунды:миллисекунды
Рис. 13.16. Фильтрация сообщений на основе времени получения
Проблема описанного подхода заключается в том, что не все поля данных обновляют-
ся в одно и то же время. Каждый вид облигации обладает примерно 50 характеристиками,
которые отображаются на экране пользователя (включая цену). Понятно, что не все ха-
рактеристики облигации будут обновляться абсолютно в каждом сообщении. Если сис-
тема проигнорирует несколько следующих друг за другом сообщений, она может пропус-
тить обновление какой-то характеристики, что приведет к потере важных данных.
Еще один шаблон, представляющий интерес в плане замедления потока сообще-
ний, — это агрегатор. Он применяется для объединения нескольких связанных между
собой сообщений в одно сообщение, что позволяет сократить интенсивность их потока.
Агрегатор может сохранить копию полей данных из первого сообщения, а затем при по-
ступлении следующих сообщений обновлять лишь новые или измененные поля. Через
некоторое время накопленные сведения об облигации будут пересланы клиенту в виде
одного сообщения (рис. 13.17). Пока что предположим, что агрегатор, как и фильтр со-
общений, высылает клиенту сообщение каждые 5 миллисекунд. Позднее мы рассмотрим
еще одну альтернативу.
Обновление Обновление
(поле 1) (поля 1,2)
Рис. 13.17. Объединение частичных обновлений в одно сообщение с помощью агрегатора
Практикум: система формирования цен на облигации
625
Агрегатор, как и любой другой шаблон, вовсе не является панацеей; у него есть свои
плюсы и минусы, требующие самого тщательного изучения. Один потенциальный минус
связан вот с чем: внедрение агрегатора существенно сократит объем потока сообщений
только в том случае, если сообщения, поступающие в течение короткого промежутка
времени, будут касаться одного и того же вида облигаций (или хотя бы небольшого числа
видов). Мы ничего не добьемся, если клиент Java будет получать обновления одного поля
по всем видам облигаций, которыми торгует трейдер. К примеру, если в течение задан-
ного промежутка времени мы получим 1000 сообщений, касающихся четырех видов об-
лигаций, объем потока сообщений за этот промежуток времени сократится с 1000 до
4 сообщений. Но если на протяжении такого же промежутка времени мы получим
1000 сообщений, описывающих 750 видов облигаций, объем потока сообщений сокра-
тится с 1000 до 750 сообщений — не такой уж большой выигрыш в сравнении с затра-
ченными усилиями. Беглый анализ реальных обновлений показывает, что клиент Java
получает много сообщений с обновлениями полей для одного и того же вида облигации,
а значит, в нашем случае агрегатор является хорошим решением.
Осталось выяснить, как агрегатор будет узнавать о необходимости отправки скомпо-
нованного сообщения. В описании указанного шаблона предусмотрено несколько алго-
ритмов для выполнения подобных действий. Агрегатор может отправлять накопленное
содержимое по истечении заданного промежутка времени, после заполнения всех тре-
буемых полей в наборе данных и т.п. Проблема всех этих подходов состоит в том, что по-
ток сообщений контролируется агрегатором, а не клиентом, и главное “узкое место” в
данном случае представляет собой не поток сообщений, а клиент. Агрегатор предполага-
ет, что получатели скомпонованных им сообщений (в данном случае это клиентское
приложение) являются событийно управляемыми потребителями (Event-Driven Consumer,
с. 511), т.е. потребителями, поведение которых определяется событиями из внешнего ис-
точника. Чтобы клиентское приложение могло контролировать поток сообщений, кли-
ент должен быть превращен в опрашивающий потребитель (Polling Consumer, с. 507), т.е. в
потребитель, который постоянно проверяет наличие новых сообщений. Это можно сде-
лать, создав фоновый поток, который постоянно прокручивает набор данных по видам
облигаций и отмечает любые изменения, появившиеся со времени предыдущей итера-
ции. Благодаря этому клиент будет самостоятельно контролировать время получения им
сообщений и как следствие этого гарантировать, что он никогда не переполнится сооб-
щениями, даже в моменты особо интенсивного поступления обновлений. Чтобы реали-
зовать эту схему, достаточно отправить агрегатору (Aggregator, с. 283) сообщение с коман-
дой (Command Message, с. 169), которое будет инициировать обновление. Агрегатор в ответ
вышлет сообщение с данными документа (Document Message, с. 171), содержащее набор об-
новленных полей, которые будут обрабатываться клиентом.
Решение отдать предпочтение агрегатору, а не фильтру сообщений основывалось ис-
ключительно на бизнес-требованиях нашей системы. И тот, и другой шаблоны прекрас-
но справляются с замедлением потока сообщений, но использование фильтра сообщений
повлекло бы за собой нарушение целостности данных системы.
Сбой системы в процессе работы
Отладив мигание ячеек с измененными данными, мы стали наблюдать за функциони-
рованием системы в рабочей среде. В один прекрасный день служба MQSeries дала сбой,
что привело к отказу нескольких компонентов. Мы долго боролись с проблемой и нако-
626
Глава 13. Шаблоны интеграции на практике
нец обнаружили, что причина отказа связана с очередью недоставленных сообщений, ко-
торая представляет собой реализацию канала недоставленных сообщений (Dead Letter
Channel, с. 147) для MQSeries. Очередь разрослась настолько, что произошел отказ всего
сервера. Проанализировав содержимое очереди недоставленных сообщений, мы увидели,
что она состоит исключительно из сообщений с измененными рыночными данными, для
которых истек срок действия. Появление таких сообщений связано с наличием
“медленных потребителей”, т.е. потребителей, которые недостаточно быстро обрабаты-
вают сообщения. Пока сообщения ждут своей обработки, они устаревают и отправляют-
ся в канал недоставленных сообщений. Более подробно об этом рассказывается в описании
шаблона срок действия сообщения (Message Expiration, с. 198). Огромное число сообщений
с истекшим сроком годности в очереди недоставленных сообщений четко свидетельству-
ет о том, что поток сообщений слишком интенсивен, и приложения-получатели попро-
сту не успевают их обрабатывать (рис. 13.18). Чтобы еще немного замедлить поток сооб-
щений, обратимся к шаблонам.
^0 1
Слушатель
Время ожидания
: □□□
Канал недоставленных
сообщений
Рис. 13.18. "Узкое место”
Вначале посмотрим, нельзя ли решить описанную проблему при помощи агрегатора
(Aggregator, с. 283) подобно тому, как это делалось в предыдущем разделе для отладки
мигания ячеек. Структура системы предполагает, что клиентское приложение момен-
тально перенаправляет обновленные данные на биржи. Системе не разрешается выжи-
дать, чтобы собрать несколько сообщений и скомпоновать их в одно, поэтому от идеи
использования агрегатора придется отказаться.
Существует еще два шаблона, ориентированных на решение проблемы с одновремен-
ным потреблением сообщений: конкурирующие потребители (Competing Consumers, с. 515)
и диспетчер сообщений (Message Dispatcher, с. 521). Сильной стороной первого шаблона
является параллельная обработка входящих сообщений. Это достигается благодаря не-
скольким получателям, прослушивающим один и тот же канал. Каждое входящее сооб-
щение обрабатывает только один получатель, а остальные направляются на обработку
следующих сообщений. К сожалению, нашей системе конкурирующие потребители не
подойдут, потому что взаимодействие “сервер-клиент” происходит по каналам “публи-
кация-подписка” (Publish-Subscribe Channel, с. 134). Реализация конкурирующих потреби-
телей на канале “публикация-подписка” означает, что все потребители будут обрабатывать
Практикум: система формирования цен на облигации
627
одно и то же входящее сообщение. Это совершенно не имеет смысла и полностью проти-
воречит назначению шаблона. Что ж, отказываемся и от этого подхода.
Диспетчер сообщений предполагает создание пула из нескольких исполнителей. Каж-
дый из них может запускать собственный поток выполнения. Один главный потребитель
(диспетчер) прослушивает канал сообщений (Message Channel, с. 93) и делегирует полномо-
чия по обработке сообщения одному из незанятых исполнителей, а затем немедленно
возвращается к прослушиванию (рис. 13.19). Данная схема обладает теми же преимуще-
ствами параллельной обработки сообщений, что и конкурирующие потребители, но мо-
жет применяться и в сочетании с каналом “публикация-подписка”.
Тд 42 42
Рис. 13.19. Диспетчер сообщений в действии
Внедрить диспетчер сообщений в нашу систему несложно. Мы создаем объект Mes-
sageListener по имени Dispatcher. Он содержит коллекцию других объектов Message-
Listener, каждый из которых называется Performer. Когда вызывается метод onMessage
объекта Dispatcher, он, в свою очередь, извлекает из коллекции объект Performer, кото-
рый и будет производить фактическую обработку сообщения. Результатом выполнения
метода является объект Dispatcher, который возвращается моментально. Это гарантирует
высокую скорость обработки сообщений независимо от интенсивности их потока. Указан-
ная схема одинаково хорошо работает и на канале “публикация-подписка”, и на канале
“точка-точка”. При наличии такой инфраструктуры клиент может получать сообщения
практически с любой частотой. Если же клиентское сообщение все равно медленно обраба-
тывает полученные им сообщения, оно будет иметь дело с отложенной обработкой данных
и потенциально устаревшими данными, а не с сообщениями, срок годности которых истек
еще во время нахождения в канале сообщений JMS.
Сбой, описанный в этом разделе, и его устранение с помощью диспетчера сообщений
являются отличными примерами того, что возможности шаблонов не бесконечны.
Мы обнаружили проблему производительности, вызванную недочетом проектирования,
из-за которого клиент не мог проводить параллельную обработку входящих сообщений.
628
Глава 13. Шаблоны интеграции на практике
Применение шаблонов существенно смягчило негативные последствия проблемы, но не
устранило ее полностью, потому что реальная проблема заключалась в клиенте, ставшем
“узким местом”. Это нельзя исправить даже при помощи тысячи шаблонов. Позднее мы
изменили схему обмена данными, чтобы сообщения, вышедшие из шлюза ценообразо-
вания, направлялись сразу на шлюз доставки. Таким образом, шаблоны могут помочь в
проектировании и обслуживании системы, но они не в состоянии спасти систему с изна-
чально плохой архитектурой.
Резюме
В этой главе мы рассмотрели применение шаблонов для реализации нескольких раз-
личных аспектов системы формирования цен на облигации, включая решение проблем,
возникших на начальном этапе проектирования, и исправление крупного недочета, вы-
явленного в процессе эксплуатации системы. По ходу дела мы обращали внимание на
реализацию шаблонов в продуктах сторонних производителей, унаследованных компо-
нентах, а также системах обмена сообщениями JMS и TIBCO. Еще и еще раз отметим,
что данный пример полностью взят из реальной жизни. Проектируя и обслуживая систе-
мы, мы постоянно сталкиваемся с аналогичными типами проблем проектирования, тех-
нических и бизнес-проблем. Надеемся, что материал этой главы поможет вам лучше по-
нять шаблоны и научиться применять их при разработке собственных систем.
Глава 14
Кое-что в заключение
Новые стандарты и перспективы интеграции корпоративных приложений
Шон Невилл (Sean Neville)
В наши дни данные все чаще и чаще перемещаются между системами и предметными
областями по каналам сообщений. По мере того как разработчики и проектировщики
учатся применять шаблоны, описывающие работу систем обмена сообщениями, мир
информационных технологий пополняется новыми стандартами и продуктами, которые
расширяют область действия указанных шаблонов. Сами шаблоны проектирования с те-
чением времени практически не меняются, а лишь доказывают свою жизнеспособность.
Однако стратегии их реализации быстро совершенствуются, что позволяет разработчи-
кам применять их в более широких сферах деятельности. Так, область применения фун-
даментального шаблона сообщение (Message, с. 98) постепенно расширялась по мере того,
как стандарт электронного обмена данными (Electronic Data Interchange — EDI) сменял-
ся закрытым связующим ПО, ориентированным на обмен сообщениями, открытым
стандартом XML и Web-службами на основе SOAP, глобальным языком выполнения
бизнес-процессов (Business Process Execution Language — BPEL) и т.д.
В этой главе мы попробуем заглянуть в будущее интеграции корпоративных приложе-
ний на основе обмена сообщениями. Иными словами, мы поговорим о новых, развиваю-
щихся стандартах, с которыми наверняка придется считаться разработчикам приложений
середины и конца 2000-х годов. Многие из этих стандартов еще не вошли в широкое упот-
ребление, но уже обладают солидной поддержкой со стороны лидеров индустрии и, скорее
всего, станут основой для реализации интеграционных шаблонов (в частности, в SOA-
архитектурах). Большинство из них расширяют зарождающиеся технологии Web-служб на
типы шаблонов, описанные в данной книге. Прочитав настоящую главу, вы узнаете, поче-
му эти стандарты имеют такое большое значение для шаблонов проектирования, какие ор-
ганизации занимаются их разработкой и как они приходят к подобным идеям. Мы также
проведем краткий обзор технических решений для интеграции бизнес-процессов, постро-
енных на основе наиболее перспективных стандартов Web-служб и Java.
630
Глава 14. Кое-что в заключение
Связь между стандартами и шаблонами проектирования
Самый высокий уровень абстракции в архитектуре ПО достигается с помощью двух
факторов: стиля программирования (объектно-ориентированное, ориентированное на
службы, порождающее и т.п.) и языка шаблонов (как тот язык, который описывается в
данной книге). Если конкретный стиль программирования или шаблон многократно
подтверждает свою пригодность и если контекст, в котором он используется, достаточно
распространен, стратегии реализации шаблона в различных условиях обычно оказыва-
ются схожими. В конце концов мы приходим к тому, что решения на основе шаблонов,
предназначенные для разных платформ, программных продуктов и областей примене-
ния, обладают лишь несколькими различиями. Последние, однако, в большинстве своем
носят семантический характер и всячески препятствуют расширению области действия
приложений и шаблонов, на которых те основаны. Избавиться от таких досадных отли-
чий помогают формально согласованные, общепринятые стандарты.
Если тактика или стратегия реализации шаблона стандартизирована, польза от него
вовсе не снижается. Шаблон не вытесняется стандартом — скорее, наоборот. Как ствол
дерева обрастает годовыми кольцами, хороший шаблон утверждается, постепенно охва-
тывая все больше и больше областей применения. Это становится возможным благодаря
тому, что разные реализации шаблона могут взаимодействовать друг с другом. В качестве
примера возьмем типичное приложение J2EE, ориентированное на обмен сообщениями.
Шаблон наподобие каналов и фильтров (Pipes and Filters, с. 102) может существовать
на разных уровнях такого приложения — внутри самого приложения, внутри сервера, на
котором установлено приложение, внутри контейнеров и служб этого сервера, внутри
фильтров и других компонентов, образующих подсистему обмена сообщениями, и так
далее по нисходящей.
Новые, стремительно набирающие обороты стандарты обмена сообщениями и
Web-служб будут способствовать утверждению шаблонов, описанных в этой книге, рас-
ширяя возможности разработчиков, которые пользуются указанными стандартами для
реализации шаблонов. Стандарты наподобие BPEL и WS-Reliability расширяют область
действия шаблонов, выходя за рамки языков программирования и программных продук-
тов на более глобальный уровень взаимодействия между человеком и компьютером.
К примеру, такой шаблон, как идентификатор корреляции (Correlation Identifier, с. 186),
может использоваться не только для простого сопоставления сообщений с запросами и
ответами, но и для корреляции компонентов процессов, в состав каждого из которых
входит целый ряд асинхронных отправителей и получателей сообщений. При отсутствии
стандарта обмена сообщениями Java-программист может реализовать маршрутизатор со-
общений (Message Router, с. 109) на уровне кода, чтобы анализировать содержимое отдель-
ных XML-сообщений и программным путем перенаправлять их на вход конкретных
служб или фильтров. Наличие стандартов рабочих потоков и так называемых “стандар-
тов хореографии” (choreography standards) позволит тому же самому программисту при-
менить свои знания в области маршрутизатора сообщений на более высоком уровне абст-
ракции, чтобы управлять продвижением рабочих потоков между составными компонен-
тами бизнес-процессов. Другими словами, разработчики приложений могут перестать
тратить драгоценное время на связывание протоколов и заняться связыванием бизнес-
процессов и служб из разных предметных областей.
Новые стандарты и перспективы интеграции корпоративных приложений
631
Польза шаблонов проектирования и выбранного стиля программирования при разра-
ботке сложных систем прямо пропорциональна умению разработчика приложения при-
менять общие, межплатформенные стратегии реализации. В наши дни стратегии работы
с шаблонами обмена сообщениями в J2EE часто подразумевают использование JMS, JCA
или JAX-RPC, а завтра это могут быть MDA-технологии (Model Driven Architecture) или
сценарии на основе схем. Любые подобные изменения в стратегии реализации только
повышают значимость шаблонов, если разработчику удается корректно определить шаб-
лон в текущем контексте и задействовать необходимые стандарты. Применение стандар-
тов — лучший на сегодняшний день способ использования общих стратегий реализации
для повышения уровня овладения языком шаблонов.
Основные организации, занимающиеся утверждением стандартов
Вопреки расхожему мнению стандарты изобретаются не для удовлетворения нужд
алчных производителей, которые, как всегда, страшно далеки от народа. Назначение
стандартов состоит в унификации и совершенствовании подходов к реализации, изобре-
тенных и применяемых разработчиками приложений. Реализуя шаблоны проектирова-
ния, приведенные в этой книге, вы, сами того не осознавая, вносите свой вклад в разра-
ботку стандарта, даже если не связываетесь напрямую с рабочей группой, занимающейся
созданием его спецификации. Организациям и консорциумам, контролирующим дея-
тельность рабочих групп, не всегда удается корректно вычленить и ассимилировать под-
ходы к реализации, но цель их состоит именно в этом.
Стандарт официально появляется на свет, когда изобретатель или группа изобретате-
лей направляют формальное предложение в организацию по стандартизации. Обычно
для этого они должны быть членами указанной организации. В каждой организации по
стандартизации предусмотрены собственные правила трансформации предложений в
стандарт, и все члены организации привязаны к этим правилам. Процесс принятия стан-
дарта обычно подразумевает формирование рабочей группы или комитета, занимающе-
гося дальнейшей разработкой спецификации под наблюдением руководства организа-
ции. Руководство также принимает окончательное решение по поводу утверждения стан-
дарта. В процессе принятия стандарта самыми “горячими” темами часто являются права
интеллектуальной собственности и политика лицензирования. Точки зрения на эти во-
просы могут различаться не только между разными организациями по стандартизации,
но и между разными рабочими группами в рамках одной и той же организации.
Ниже перечислены основные организации, которые занимаются разработкой стан-
дартов, касающихся обмена сообщениями и Web-служб.
• W3C. Консорциум World Wide Web (World Wide Web Consortium; www.w3c.org)
является автором многих базовых Web-технологий, которые, в свою очередь, ис-
пользуются в качестве основы другими организациями по стандартизации. Кон-
сорциумом W3C управляет международная группа исследователей и инженеров, а
в его состав входит ряд крупных производителей, поставщиков содержимого, пра-
вительственных организаций, исследовательских лабораторий и т.п. В процессе
своего принятия стандарт выносится на открытое, совместное обсуждение рабо-
чей группы, а затем — на суд широкой общественности. Все это может растянуть-
ся на месяцы и годы, зато самым положительным образом отражается на качестве
стандартов. Технологии, разработанные W3C, обычно не являются объектом пра-
632
Глава 14. Кое-что в заключение
ва интеллектуальной собственности. В число стандартов, принятых W3C, входят
SOAP и WSDL, а также все базовые спецификации XML. Рабочая группа W3C под
названием Web Services Choreography Working Group, созданная в 2003 году, зани-
мается разрешением конфликтов между спецификациями бизнес-процессов и
обеспечивает дефинитивную базу для интеграции приложений с использованием
Web-служб.
• OASIS. Одной из нескольких организаций, создающих стандарты на основе техно-
логий, разработанных W3C, является OASIS (www. oasis-open. огд). Данная аббре-
виатура расшифровывается как Organization for the Advancement of Structured
Information Standards (Организация распространения структурированных информа-
ционных стандартов). В настоящее время усилия этого некоммерческого консор-
циума производителей (кстати говоря, обладающего привилегиями на утверждение
принципов разработки языка SGML) сосредоточены на принятии глобальных стан-
дартов электронной коммерции. Технические комитеты OASIS занимаются разра-
боткой многих перспективных стандартов Web-служб, таких как ebXML и
WS-Reliability. OASIS также осуществляет хостинг портала www. xml. огд.
• WS-L Организация по развитию возможности взаимодействия Web-служб
(Web Services Interoperability Organization; www. ws - i. огд) стремится доказать, что
стандарты и технологии Web-служб могут применяться для организации сотруд-
ничества между бизнес-партнерами в универсальном, интероперабельном стиле.
Продвигаемые ею протоколы и методологии использования Web-служб подходят
для самых разнообразных систем, языков и платформ. Ключевым средством дос-
тижения этой цели является спецификация WS-I Basic Profile, охватывающая на-
бор стандартов Web-служб (в Basic Profile 1.0 это были XML Schema 1.0, SOAP 1.1,
WSDL 1.1 и UDDI 2.0), а также соглашений о том, как они должны применяться в
сочетании друг с другом. Иными словами, WS-I играет некую объединяющую роль
в обеспечении такого сотрудничества производителей Web-служб, которое облег-
чало бы деятельность разработчиков приложений. Организация WS-I была осно-
вана и управляется ведущими производителями Web-служб, включая Microsoft,
IBM, BEA Systems, Oracle и др.
• JCP. Организация Java Community Process (JCP; www. j cp. org), работающая под
эгидой Sun Microsystems, создает привязки языка Java и интерфейсы J2EE для
Web-служб и стандартов обмена сообщениями, разрабатывающихся другими ор-
ганизациями. Исторически сложилось так, что процесс стандартизации в JCP не
является открытым. Хотя он происходит при участии экспертных групп и предпо-
лагает совместное рассмотрение предложений, как это делается в других организа-
циях по стандартизации, права интеллектуальной собственности на новые разра-
ботки обычно остаются за Sun Microsystems, а производители ПО на основе Java и
J2EE вынуждены приобретать лицензии. Большинство экспертных групп JSR
также работают под руководством инженеров из Sun. Несмотря на нехватку от-
крытости, которая невыгодно отличает JCP от других подобных организаций, она
серьезно выигрывает от того внимания, которое ей уделяет Sun, и избавлена от
давления со стороны внешних факторов.
Новые стандарты и перспективы интеграции корпоративных приложений
633
• Консорциумы производителей. Чтобы не потерять контроль хотя бы над некоторы-
ми из появляющихся технологий Web-служб, давнишние соперники наподобие
IBM и Microsoft периодически объединяются для публикации собственных стан-
дартов, не подтверждая их в какой-либо организации по стандартизации. Приме-
ром таковых, в частности, является большинство спецификаций WS-*. Стандарты,
разработанные консорциумами производителей, впоследствии часто направляют-
ся на утверждение в организацию по стандартизации. Например, весьма перспек-
тивный стандарт BPEL, развитием которого занимается OASIS, начинал свое су-
ществование как совместное детище Microsoft и IBM. Активность производителей
в области разработки стандартов подогревается желанием сохранить за собой пра-
во интеллектуальной собственности. Создание спецификаций подобного рода по-
зволяет достичь интероперабельности без возни с лицензиями, что вполне удовле-
творяет разработчиков приложений, интегрирующих популярные платформы (как
те, которые разрабатываются Microsoft и IBM). Впрочем, “открытость” подобных
стандартов, разумеется, весьма спорна.
Компоненты бизнес-процессов и внутренний обмен сообщениями
между Web-службами
Аристотель вряд ли подозревал о существовании объектно-ориентированного про-
граммирования, структурной декомпозиции и моделирования предметной области.
Несмотря на это он умудрился поставить риторический вопрос, над которым до сих пор
ломают голову лучшие умы программной инженерии. Древнегреческого философа вол-
новало, из чего состоит мир: из объектов или процессов?
Современные стандарты обмена сообщениями отвечают на этот вопрос в лучших тра-
дициях философии дзен-буддизма: да. Мир — это группа объектов, главной характеристи-
кой которых являются процессы, посредством которых они взаимодействуют с другими
объектами. Поведение объекта по отношению к другим объектам часто играет куда более
важную роль, чем его внутреннее строение. В мире Web-служб и интеграции корпоратив-
ных приложений гибридное представление “объект-процесс” часто называют компонентом
бизнес-процесса (business process component). Компонент бизнес-процесса объединяет группу
служб в логическую единицу, взаимодействующую с другими подобными единицами по-
средством обмена сообщениями для достижения высокомасштабируемого, гибкого про-
движения логики и данных. С точки зрения многих производителей Web-служб и организа-
ций по стандартизации, будущее обмена сообщениями — именно в слиянии процессов,
объектов и шаблонов взаимодействия в компонент бизнес-процесса.
Компонент процесса — это глобальное представление набора служб, играющих важ-
ную роль в интеграции корпоративных приложений. Для большей наглядности восполь-
зуемся примером из привычного нам “некомпьютерного” мира. Человек водит машину.
И человек, и машина являются отдельными, крайне сложными системами. Но, если рас-
сматривать человека и машину с точки зрения процессов, они будут выглядеть, как еди-
ный компонент процесса, определенный через взаимодействие человека с машиной и не
зависящий от того, каково строение человека и машины в отрыве друг от друга. Компо-
нент процесса также описывает взаимодействие указанного компонента “человек-
машина” с другими аналогичными компонентами на дороге. Опять-таки, нас не волнует
внутреннее строение других автомобилей или сидящих в них водителей. Не путайте ком-
понент процесса с простым предоставлением внешнего интерфейса, потому что компо-
634
Глава 14. Кое-что в заключение
нент процесса также включает в себя правила взаимного поведения объектов, исполь-
зующих этот интерфейс.
Согласно стандартам обмена сообщениями компонент бизнес-процесса — это еди-
ный компонент, состоящий из набора Web-служб и определения того, как они отправля-
ют и получают сообщения. Web-службы и другие пункты назначения сообщений являют-
ся теми самыми “кирпичиками”, из которых складываются более сложные конструкции,
взаимодействие которых регулируется шаблонами обмена сообщениями. Последние
описывают как построение компонента процесса, так и связывание нескольких компо-
нентов процессов в единое приложение. Стандарты бизнес-процессов регламентируют
корреляцию сообщений между Web-службами для создания потоков выполнения, а так-
же описывают, как должны себя вести Web-службы при обработке ошибок, транзакциях
и обмене данными.
Еще один пример, на сей раз имеющий более близкое отношение к бизнес -
процессам, показан на рис. 14.1. В данном примере заказ на поставку товара обрабатыва-
ется компонентом процесса, включающим в себя несколько обслуживающих операций.
Рис. 14.1. Компонент бизнес-процесса предоставляет единую конечную точку для доступа к ряду
взаимодействующих внутри него Web-служб
Рассмотрим действия, выполняющиеся внутри компонента процесса.
• Каждая операция в компоненте процесса “Заказ на поставку” выполняется соот-
ветствующей Web-службой. Разные Web-службы, предоставляющие доступ к опе-
рациям, могут находиться на удаленных узлах в рабочих средах бизнес-партнеров.
Новые стандарты и перспективы интеграции корпоративных приложений
635
• При получении заказа на поставку происходит одновременный вызов четырех
операций. Некоторые из них имеют зависимости, которые должны разрешаться в
синхронном режиме. На рис. 14.1 такие зависимости обозначены пунктирными
стрелками.
• Две “пунктирные” зависимости показывают, что для подсчета полной стоимости
заказа необходимо знать затраты на страхование и транспортировку. Еще одна за-
висимость означает, что страховой договор должен быть подписан до того, как
производитель подтвердит включение в график производства ресурсов, необходи-
мых для выполнения заказа.
• Когда все обслуживающие операции будут выполнены в асинхронном режиме,
обработка заказа на поставку закончится. Клиенту обмена сообщениями больше
не нужно по отдельности взаимодействовать с каждой из служб и управлять зави-
симостями между ними, т.е. реализовывать поведение диспетчера процессов
(Process Manager, с. 325). Компонент процесса предоставляет общую сетевую
конечную точку для доступа ко всем службам, а управление обменом сообщения-
ми и зависимостями между службами осуществляется внутри компонента, что
значительно упрощает задачу клиента.
• Компонент процесса “Заказ на поставку”, в свою очередь, связан с другим компо-
нентом процесса, “Обработка счета”.
Более глубокое знакомство с интеграцией и компонентами бизнес-процессов обеспе-
чивают четыре стандарта: инициатива ebXML, два конкурирующих предложения под на-
званиями BPEL и WSCI, а также набор отдельных спецификаций, объединенных общим
префиксом WS-*, каждая из которых описывает фрагменты одной и той же функцио-
нальности в более конкретном ключе.
ebXMLHebMS
Еще до появления SOAP и WSDL многие светлые головы, занимавшиеся проектами
совместной работы бизнес-приложений и В2В-интеграции, понимали необходимость
создания открытой, безопасной и межплатформенной инфраструктуры для обмена биз-
нес-информацией с помощью XML-сообщений. На решение этой проблемы было на-
правлено несколько спецификаций и инициатив, объединенных под общим названием
электронный бизнес, использующий язык XML (Electronic Business using XML — ebXML).
Позднее инициатива ebXML расширилась с учетом SOAP и других стремительно наби-
рающих популярность технологий обмена сообщениями. Управление ebXML совместно
осуществляют уже упоминавшийся консорциум OASIS и подкомитет ООН по упроще-
нию торговых процедур и электронному бизнесу (UN/CEFACT). Указанный подкоми-
тет, в частности, известен тем, что дал жизнь стандарту EDI; ebXML в какой-то степени
представляет собой следующий логический этап эволюции EDI.
Спецификации, входящие в состав ebXML, посвящены разнообразным темам: как
корпорации оповещают о своих бизнес-процессах и ищут бизнес-процессы потенциаль-
ных партнеров; как партнеры договариваются о взаимодействии и инициируют его; как
использовать реестры, чтобы упростить обнаружение и инициализацию бизнес-
общения; какими свойствами должна обладать инфраструктура обмена сообщениями,
чтобы облегчить такое общение. Последняя тема привлекла к себе особое внимание и
636
Глава 14. Кое-что в заключение
может рассматриваться не только в сочетании с другими спецификациями, входящими в
состав ebXML, но и как отдельная инициатива, имеющая большое значение для шабло-
нов обмена сообщениями.
В отличие от других стандартов, упоминающихся в этой главе, стандарт ebMS нельзя
в полной мере отнести к “новым” или “развивающимся”. Он уже добился широкого
признания в области интеграции бизнес-процессов, дополнения EDI-систем и расшире-
ния спецификации SOAP для обеспечения безопасности и надежности Web-служб.
Разработка стандарта ebMS была начата консорциумом OASIS в 1999 году и продолжа-
лась около трех лет. В настоящее время ebMS задействован в разработке других стандар-
тов бизнес-процессов.
Назначение инфраструктуры ebMS (Electronic Business Messaging Service) состоит в том,
чтобы упростить обмен бизнес-сообщениями в рамках платформы XML. Последняя,
однако, не требует, чтобы полезная информация сообщения обязательно находилась в
формате XML — она может принимать любой вид, включая традиционный формат EDI
и двоичные форматы. По этой причине ebMS может инкапсулировать существующие
системы обмена сообщениями и выполнять роль гибкого “моста”, содержащего набор
реализаций транслятора сообщений (Message Translator, с. 115). Это особенно удобно при
распространении интеграционного решения на экстрасети и В2В-взаимодействие между
бизнес-партнерами. Важной областью применения ebMS является связывание закрытых
МОМ-систем (Message Oriented Middleware — связующее ПО, ориентированное на об-
мен сообщениями), принадлежащих разным корпорациям. Для проверки подобной ин-
тероперабельности различные производители и разработчики провели целый ряд проце-
дур тестирования. Еще одной критически важной особенностью ebMS является под-
держка унаследованных EDI-систем. Это позволяет корпорациям в полной мере
использовать свои предыдущие долгосрочные инвестиции в EDI, компенсируя недостат-
ки этих систем преимуществами Web-служб и XML.
Спецификацию ebMS следует рассматривать не только как очередной виток эволюции
EDI, но и как значительное усовершенствование стандартных служб на основе SOAP.
Передача данных XML в системе ebMS предполагает использование конвертов SOAP, ко-
торые включают в себя специфичные для ebMS заголовки SOAP (применяются для записи
уникальных идентификаторов сообщений, меток времени, цифровых подписей и т.п.),
а также манифест, содержащий метаданные со сведениями о полезной информации сооб-
щения. Таким образом, ebMS использует механизм заголовков SOAP для реализации шаб-
лонов маршрутизации сообщений, а также ряда шаблонов конечных точек обмена сообще-
ниями, таких как идемпотентный получатель (Idempotent Receiver, с. 541) и другие шаблоны,
связанные с гарантированной доставкой последовательности сообщений.
Инфраструктура обмена сообщениями ebMS передает полезную информацию сооб-
щений, используя стандарт SOAP with Attachments (SOAP с вложениями). С его помо-
щью полезная информация сообщения прикрепляется к конверту SOAP примерно так
же, как вложения к письмам электронной почты. Опять-таки, на формат полезной ин-
формации не накладывается никаких ограничений: это могут быть данные XML, двоич-
ные данные, ссылки на внешние данные и т.п. Более того, полезная информация каж-
дого сообщения может иметь собственную цифровую подпись, а разработчикам, реали-
зующим ebMS, разрешается добавлять собственные процедуры аутентификации
и авторизации. Структура сообщения ebMS показана на рис. 14.2.
Новые стандарты и перспективы интеграции корпоративных приложений
637
Конверт коммуникационно! oki a(HTTI SMTI FTP и т.п:)
Конверт SOAP с вложениями MIME
ЧастьМ1МЕ
Полезная информация
Рис. 14.2. Сообщение ebMS представляет собой сообщение SOAP с вложениями МШЕ
По умолчанию доставка сообщений осуществляется в асинхронном режиме, но в
ebMS возможна и синхронная доставка сообщений. Механизм обработки ошибок ebMS
также достаточно интеллектуален и в зависимости от реализации может выдавать не
только сообщения об ошибках, специфичные для типа полезной информации, но и со-
общения SOAP Fault.
Для обеспечения надежности применяется важный элемент реализации ebMS —
обработчики службы сообщений ebXML (ebXML Message Service Handlers), сохраняющие
сообщения на стороне отправителя. Разработчики могут предусматривать семантические
объявления наподобие “один и только один раз” и “сохранить и передать” для отдельных
638
Глава 14. Кое-что в заключение
сообщений или для групп сообщений. Стандарт ebMS задает службы, управляющие по-
следовательной доставкой и контролем за доставкой. Последний реализуется с помощью
службы состояния сообщений (Message Status Service), представляющей собой ни что иное,
как шину управления (Control Bus, с. 552). Служба Message Status Service позволяет запраши-
вать состояние сообщения, отправленного ранее с помощью ebMS. Если заглянуть в ее
“недра”, то окажется, что проверка состояния сообшения реализована с помощью журнала
доставки сообщения (Message History, с. 561) и других связанных с ним шаблонов.
Более подробно об инициативе ebXML можно прочитать на сайте http://www.
ebxml.огд. Спецификация ebMS хранится по адресу http: //www. ebxml.огд/specs/
ebMS2. pdf.
BPEL4WS
Business Process Execution Language for Web Services, или BPEL4WS, — это новый
популярный стандарт, предназначенный для описания компонентов бизнес-процессов и
их взаимодействия. Его сокращенное название часто произносится как “би-пел” (или,
что еще хуже, “би-пел фо вусс”). BPEL4WS образовался в результате слияния двух кон-
курирующих предложений от IBM и Microsoft. В спецификации Web Services Flow
Language, или WSFL, предложенной компанией IBM, описывалось создание и связыва-
ние конечных точек Web-служб для управления рабочими потоками. XLANG от
Microsoft, в свою очередь, определяла синтаксис и модель разработки для создания ком-
понентов рабочего потока, как это реализовано в Microsoft BizTalk Server. BPEL4WS во-
брал в себя черты обеих спецификаций: он определяет синтаксис как для объединения
существующих служб в компоненты процесса, так и для описания интерфейсов этих
компонентов с целью связывания их в более крупные рабочие потоки. Стандарт
BPEL4WS появился на свет в результате сотрудничества BEA, IBM и Microsoft и был пе-
редан на утверждение в OASIS.
Согласно стандарту BPEL4WS связки Web-служб (партнеров) должны помещать и из-
влекать сообщения XML из хранилищ сообщений (контейнеров) в соответствии с прави-
лами (действиями). Логический набор связок служб, контейнеров сообщений и действий
образует единый компонент бизнес-процесса. Спецификация BPEL, по сути, определяет
диспетчер процессов (Process Manager, с. 325), который создает карту маршрутизаций
(Routing Slip, с. 314), постоянный подписчик (Durable Subscriber, с. 535), канал типа данных
(Datatype Channel, с. 139) и другие компоненты на основе декларативного синтаксиса
XML. Чтобы создать компонент бизнес-процесса, подобный показанному на рис. 14.1,
разработчики объявляют поведение на языке XML (возможно, с помощью визуальных
средств) и не нуждаются в том, чтобы описывать обмен сообщениями между службами
программным путем.
Огромную роль для BPEL играет WSDL, поскольку компонент BPEL состоит из Web-
служб и управляет Web-службами, в основе которых лежат документы WSDL. Компонент
бизнес-процесса перенаправляет сообщения в конечные точки служб, объявленные в до-
кументах WSDL этих служб; сами же сообщения отформатированы в соответствии с объ-
явлениями сообщений WSDL. Синтаксис BPEL связывает элементы portType с опера-
циями набора Web-служб, импортируя WSDL-файлы последних и объявляя, какие по-
следовательности действий будут применяться для получения сообщений от служб, куда
их следует отправлять, когда и как отвечать, когда вызывать другие Web-службы и т.п.
Новые стандарты и перспективы интеграции корпоративных приложений
639
Чтобы установить связи между службами, разработчик приложения импортирует
WSDL-документы Web-служб, образующих компонент бизнес-процесса, и определяет
партнерские отношения между этими службами с помощью элемента BPEL service-
LinkType. Последний ссылается на элементы portType Web-служб, участвующих в
функционировании рабочего потока, и на партнерские роли, которые они играют по от-
ношению к процессу. Благодаря этому разработчик может ссылаться на указанные связи
и роли, когда описывает поступление сообщений на вход и выход Web-служб.
Задав отношения между службами, разработчик использует BPEL, чтобы создать кон-
тейнеры для сообщений, применяющихся службами в качестве входных и выходных дан-
ных. Контейнеры во многом напоминают каналы типа данных для типов сообщений, опре-
деленных в WSDL. В зависимости от реализации контейнера его также можно рассматри-
вать как разновидность общей базы данных {Shared Database, с. 83) с добавлением
инкапсуляции и встроенной семантики совместной работы. С этой точки зрения контейнер
является общим репозиторием данных, который используется отдельными службами.
Помимо соединения контейнеров со службами посредством элементов BPEL, доступ к со-
держимому контейнера может осуществляться напрямую через расширения XPath.
Компонент BPEL предоставляет доступ к своим точкам входа и выхода в рамках еди-
ного интерфейса и делает это по тому же принципу, что и входящие в него Web-службы:
с помощью WSDL. Очевидно, однако, что WSDL-документ компонента бизнес-процесса
несколько отличается от WSDL-документа Web-службы. Элементы portType компонен-
та бизнес-процесса определяют точки входа и выхода для единого процесса, а не отдель-
ные фрагменты логики, реализованные в виде методов и собранные в одном интерфейсе.
Поведение компонента BPEL объявляется как набор действий. В рамках одного кон-
кретного действия бизнес-процессы могут отсылать сообщения службе (в этом случае
Web-служба является вызываемым партнером)', получать сообщения от службы (в этом
случае Web-служба является клиентским партнером)', отвечать на сообщение, отосланное
клиентским партнером; определять на основе некоторого логического правила, нужно ли
отправить или получить сообщение; ожидать в течение заранее запланированного про-
межутка времени; сообщать о возникновении ошибки; копировать сообщения из одного
места в другое; наконец, просто ничего не делать.
Каждому из перечисленных выше базовых действий соответствует свой элемент
в XML-грамматике BPEL. Разработчик использует элемент invoke, чтобы отправлять
сообщения вызываемому партнеру, а также элементы receive и reply для получения
сообщения от клиентского партнера и ответа на его сообщение. Элементы наподобие
flowHpick распределяют логику между каналами выполнения (параллельными или на
основе событий). Элемент throw облегчает процедуру уведомления об ошибках, а эле-
менты wait, empty и terminate приостанавливают или прерывают выполнение. Струк-
турирование действий выполняется с помощью элементов while, sequence и pick,
а для объявления условий в BPEL применяются выражения XPath.
Создав исходный файл XML с определением служб, образующих бизнес-процесс,
объявлением контейнеров сообщений, которые будут использоваться этими службами,
а также объявлением последовательности действий, выполняющихся в ходе обмена со-
общениями, разработчик может приступать к развертыванию компонента бизнес-
процесса. На этом этапе в дело вступают аспекты реализаций BPEL4WS, касающиеся
выполнения.
640
Глава 14. Кое-что в заключение
Документы BPEL могут не только описывать отношения между Web-службами, но и
выступать в качестве выполняемых файлов, подающихся на вход обработчика BPEL4WS.
Последний интерпретирует файлы BPEL и создает ряд конструкций, позволяющих осуще-
ствлять обмен приложениями между службами, которые являются частью бизнес-процесса.
Будучи реализацией диспетчера процессов, среда выполнения BPEL4WS управляет потоком
сообщений и коррелирует его прохождение между Web-службами. Обработчик BPEL4WS
принимает на вход все необходимые документы, динамически генерирует на их основе ин-
фраструктуру обмена сообщениями и управляет этой инфраструктурой.
Текст спецификации BPEL можно найти по адресу http: / /www-128. ibm. сот/ de -
ve1ope rworks/webs ervi ces/library/ws-bpel/.
WSCI
Спецификация Web Service Choreography Interface, или WSCI (часто произносится как
“виски”), направлена на решение тех же проблем, что и BPEL. Вначале указанные спе-
цификации противостояли друг другу и поддерживались конкурирующими группами
производителей (за исключением дальновидной BEA Systems, которая принимала уча-
стие в разработке и той, и другой). Спецификация WSCI поддерживалась компаниями
Sun, Intalio, SAP и BEA и была передана на рассмотрение консорциуму W3C. В настоя-
щее время, однако, несколько первоначальных приверженцев WSCI оказывают всяче-
скую поддержку спецификации BPEL.
WSCI была создана под влиянием языка моделирования бизнес-процессов (Business
Process Modeling Language — BPML). Хотя последний и не имеет прямого отношения к
шаблонам интеграции, упомянуть о нем в данной книге, определенно, стоит. BPML
представляет бизнес-процессы с помощью метаязыка на основе XML, используемого при
моделировании процессов. Многие аспекты рабочих потоков BPML перешли в WSCI, но
BPML также включает в себя сопутствующую графическую нотацию и язык запросов.
Положения спецификации WSCI, как и BPEL, основаны на том факте, что интегра-
ция корпоративных приложений предусматривает интенсивное длительное общение
между службами (а не единичные вызовы операций, как это предполагается в базовых
протоколах Web-служб). WSC1 описывает способ связывания сообщений, касающихся
разных операций, в составные процессы. Это, помимо всего прочего, гарантирует, что
сообщения будут отправляться или приниматься в правильном порядке, что отправка
и получение будут осуществляться в соответствии с задекларированными бизнес-пра-
вилами, что при необходимости сообщения будут отправляться в транзакционном режи-
ме, а также что обмен сообщениями будет описываться и управляться как единый
глобальный процесс. Максимально задействуя преимущества Web-служб перед класси-
ческими закрытыми МОМ-решениями, WSCI также обеспечивает возможность динами-
ческого обнаружения Web-служб, использования гетерогенных протоколов и децентра-
лизованной координации рабочего потока.
Подобно BPEL, WSCI во многом опирается на язык WSDL, в частности на объявле-
ния конечных точек Web-служб, типы portType, операции и типы сообщений. Действия
WSCI в точности соответствуют операциям, описанным в WSDL-документах Web-служб.
Более того, синтаксис WSCI внедрен непосредственно в файл WSDL. Объявления WSCI
находятся либо в файле, импортирующем WSDL-документы взаимодействующих служб,
либо в WSDL-документе единственной службы, управление операциями которой осуще-
Новые стандарты и перспективы интеграции корпоративных приложений
641
ствляется с помощью WSCI. Элементы WSCI содержатся внутри элемента WSDL defi-
nitions.
Основным понятием WSCI является действие (action), в рамках которого происходит
обмен сообщениями между Web-службами. Действия сгруппированы в элементы процес-
сов таким образом, чтобы они происходили последовательно, параллельно, в цикле или
при выполнении условий. Набор процессов группируется с помощью объявления интер-
фейса; соответствующий элемент interface является интерфейсом для доступа к ком-
поненту процесса и напрямую внедрен в WSDL-определения Web-службы. Многие эле-
менты действий в WSCI аналогичны таковым в BPEL и тоже включают в себя поддержку
выражений XPath.
Текст спецификации WSCI можно найти в Интернете по адресу http://www.w3.
org/TR/wsci/.
Стандарты компонентов бизнес-процессов для Java
Как уже говорилось, организация JCP создает привязки языка Java и интерфейсы
J2EE для сторонних стандартов. В частности, речь идет о стандартах, разработанных
группой Object Management Group (OMG) и консорциумом W3C. Некоторое время назад
JCP начала применять указанный подход и к стандартам Web-служб, созданием которых
занимаются организации наподобие WS-L Результатом напряженного труда экспертных
групп JCP стало появление на свет (и определенная шумиха, вызванная этим появлени-
ем) двух документов, описывающих привязки Java для компонентов бизнес-процессов:
Process Definition for Java (JSR-207) от BEA Systems и Java Business Integration (JSR-208) от
Sun Microsystems. Хотя на первый взгляд указанные предложения пересекаются, в дейст-
вительности они, скорее, дополняют друг друга. В JSR-207 описывается способ быстрого
создания компонентов обмена сообщениями или компонентов процессов посредством
метаданных, прикрепленных к коду Java. JSR-208, в свою очередь, описывает, как эти
компоненты взаимодействуют друг с другом, с контейнерами и с остальным миром J2EE
и Web-служб. Таким образом, JSR-207 представляет собой микро-, a JSR-208 — макро-
взгляд на стандартизацию обмена сообщениями между компонентами процессов в Java.
Process Definition for Java (JSR-207)
Спецификация Process Definition for Java (JSR-207), предложенная компанией BEA
Systems, описывает метаданные, интерфейсы и модель выполнения для создания компо-
нентов бизнес-процессов в среде Java/J2EE. Разработчики этого, несомненно, очень
важного документа JSR стремились определить стандартные средства создания компо-
нентов бизнес-процессов с использованием языка программирования Java и Javadoc-
подобных конструкций метаданных. Указанный механизм, предложенный в качестве до-
полнения к J2EE, также может применяться для построения Java-реализаций инициатив
бизнес-процессов, таких как BPEL4WS, WSC1 и проекты рабочей группы Web Services
Choreography Working Group.
В качестве простого синтаксиса для описания бизнес-процессов была выбрана техно-
логия Java Language Metadata (JSR-175). Метаданные можно применить непосредственно
к исходному коду Java для динамической генерации и привязки поведения процессов,
включая поддержку асинхронного обмена сообщениями, параллельное выполнение,
корреляцию сообщений, маршрутизацию сообщений, обработку ошибок и другие рас-
пространенные операции над потоком сообшений. Семантика метаданных должна быть
642
Глава 14. Кое-что в заключение
достаточно богатой, чтобы поддерживать параметры, которые используются контейне-
ром компонента при развертывании последнего для динамического создания инфра-
структуры обмена сообщениями и решения вопросов, описанных во введении к главе 5.
Отметим, что разработчикам не обязательно использовать спецификацию JSR-207
для построения компонентов бизнес-процессов в J2EE. Создать такие компоненты мож-
но и без нее, но это слишком трудоемкий процесс, который требует применения шабло-
нов обмена сообщениями на очень низком уровне и приводит к появлению рабочих по-
токов, поддержка которых обойдется чрезвычайно дорого. Указанная спецификация уп-
рощает создание компонентов бизнес-процессов, чтобы разработчики могли применять
свои навыки на более высоком уровне, быстро и легко создавая мощные приложения
с невысокими затратами на расширение и обслуживание.
Более подробно о Process Definition for Java можно прочитать по адресу http: //www.
jcp.org/еп/jsr/detail?id=207.
Java Business Integration (JSR-208)
Компания Sun предложила спецификацию Java Business Integration (JBI), чтобы опре-
делить интерфейсы поставщиков служб (service provider interface — SPI) с целью созда-
ния среды бизнес-интеграции для спецификаций BPEL4WS, WSCI и проектов
Web Services Choreography Working Group. В JBI не предлагаются новые Java-интерфейсы
или нотации, зато содержится описание новых механизмов развертывания и компонов-
ки. Вместо добавления новых интерфейсов API для разработчиков приложений, основ-
ное внимание в JBI сосредоточено на инфраструктуре интеграции, а ее SPI будут приме-
няться прежде всего производителями ПО, создающими модели компонентов обмена со-
общениями и процессов для построения интеграционного решения в среде Java.
Экспертная группа по разработке JBI стремится следовать идеям рабочей группы Web
Services Choreography Working Group и гарантировать, что стандарты, созданные послед-
ней, будут полностью совместимы с J2EE.
JBI имеет достаточно амбициозное назначение: сопоставить разные системы и стандар-
ты протоколов, т.е. разные синтаксисы, используемые для описания отношений между
процессами, включая специфичные синтаксисы, используемые производителями, а также
синтаксисы, которые стали стандартными, — друг с другом и с J2EE. Спецификация JBI
определяет Java-привязку для управления сообщениями вне зависимости от специфики
процессов и обмена сообщениями. Она также включает в себя описание нового компонов-
щика, который расширяет стандартный механизм компоновки J2EE (в файлы WAR, JAR,
RAR и EAR) для поддержки развертывания компонента JBI в среде J2EE.
Согласно JBI поддержка компонентов процессов осуществляется благодаря наличию
трех основных факторов: привязок, машин и среды. Привязки (bindings) — это коммуника-
ционные форматы, которые включают в себя форматы сообщений и сетевой транспорт
вместе с их сопоставлениями, а также формируют некую “оболочку” вокруг форматов ра-
бочих потоков, таких как BPEL. Машины (machines) — это контейнеры служб и процессов,
которые содержат бизнес-процессы и управляют ими. Наконец, среда (environment) — это
глобальная система управления процессами, которая связывает друг с другом гетерогенные
машины и привязки. В JBI среда рассматривается как основа интеграционной системы,
с которой взаимодействуют машины и привязки. Механизм развертывания и компоновки
JBI, по задумке авторов последней, обеспечивает стандартный способ подключения ком-
Новые стандарты и перспективы интеграции корпоративных приложений
643
понентов процессов к среде, однако фактическое создание таких компонентов выходит за
рамки данной спецификации.
Спецификация Process Definition for Java (JSR-207), описанная в предыдущем разде-
ле, рассматривается создателями JBI как способ построения компонентов процессов,
а среда выполнения, в которой должны функционировать указанные компоненты, хоро-
шо укладывается в концепцию машины JBL Чтобы корректно взаимодействовать со сре-
дой интеграции, такая машина должна реализовывать транслятор сообщений (Message
Translator, с. 115), активатор службы (Service Activator, с. 545), оболочку конверта (Envelope
Wrapper, с. 342), а также другие шаблоны, необходимые для предоставления доступа к фор-
матам и поведению протоколов, фшурируюшим в перечисленных шаблонах, через JBL
Более подробно о Java Business Integration (JBI) можно узнать по адресу http: //www.
jcp.org/en/jsr/detail?id=208.
Спецификации WS-*
Помимо спецификаций и стандартов, о которых было рассказано ранее, существует
ряд куда менее амбициозных проектов, предназначенных для расширения концепции
Web-служб на основе SOAP и WSDL с целью обеспечения надежности, безопасности,
поддержки состояния и качества обслуживания. Указанные спецификации, название
большинства из которых начинается с префикса WS-, основываются на технологиях
W3C, и каждая из них посвящена довольно узкой проблеме.
К сожалению, чистые намерения разработчиков стандартов для Web-служб постоян-
но омрачаются появлением многочисленных конкурирующих версий, которые поддер-
живаются разными группами производителей. Вероятно, именно из-за этого их практи-
чески не реализуют в реальных продуктах. Неразбериха в мире стандартов уже приняла
угрожающие размеры. Тем не менее спецификации WS-*, определенно, заслуживают
внимания, поскольку изложенные в них идеи и приемы могут оказаться полезными для
разработчиков приложений, применяющих технологии Web-служб наподобие SOAP и
WSDL для интеграции корпоративных приложений путем обмена сообщениями. Кроме
того, эти стандарты наверняка найдут должное применение в продуктах производителей,
которыми они, собственно говоря, и были предложены (IBM, BEA, Microsoft, Oracle и т.п.).
В следующих разделах мы рассмотрим несколько наиболее примечательных специ-
фикаций WS-*, направленных на решение проблем транзакционности, надежности,
маршрутизации, безопасности и поддержки состояния.
WS-Coordination и WS-Transaction
Большинство популярных транспортов и протоколов Web-служб не поддерживают
работу с состоянием и не являются надежными, следовательно, не обеспечивают качест-
во обслуживания, необходимое для осуществления транзакционных процессов. Эти не-
достатки представляют собой действительно серьезную проблему. На практике они озна-
чают, что если разработчик хочет использовать интеграционный механизм на основе
Web-служб, он должен разработать собственную схему транзакций в рамках этого инте-
грационного механизма. Вызовы служб, которые осуществляются через асинхронный
обмен сообщениями, должны обладать возможностью пакетного выполнения в качестве
единой атомарной единицы, чтобы при сбое хотя бы одного вызова выполнять откат всех
вызовов как единого целого (или чтобы сбой такой единицы приводил к запуску некото-
рого механизма компенсации). Подобное поведение весьма распространено в закрытых
644
Глава 14. Кое-что в заключение
МОМ-системах. Спецификации WS-Coordination и WS-Transaction решают описанную
проблему для Web-служб.
Спецификация WS-Coordination разрабатывалась при участии BEA, Microsoft и IBM.
Она определяет способ создания и распространения информации о контексте всеми
службами, участвующими в продвижении потока сообщений, даже в асинхронном режи-
ме или при наличии сбоев синхронизации. В спецификации описывается расширяемая
платформа, предназначенная для создания протоколов, координирующих работу служб и
приложений. Функционирование таких протоколов координации происходит путем соз-
дания и регистрации контекстов на основе XML, которые распространяются с помощью
сообщений SOAP и используются компонентами-координаторами, расположенными во
всех конечных точках взаимодействующих сторон. Такие контексты могут применяться
для поддержки поведения приложений, например, с целью согласования результата рас-
пределенной транзакции. Спецификация WS-Transaction, в свою очередь, использует
WS-Coordination для распространения распределенных транзакций на вызовы служб.
WS-Transaction определяет способ мониторинга и измерения успешности или неудачи
каждого действия в потоке действий. На практике это означает следующее: когда сооб-
щение SOAP прибывает в конечную точку, из него отфильтровывается заголовок, содер-
жащий контекст координации (для выполнения этой задачи могут применяться шаблоны
фильтр содержимого (Content Filter, с. 354) и разветвитель (Splitter, с. 274)), а затем заголо-
вок отправляется на анализ координатору транзакций.
Фрагмент конверта SOAP, приведенный ниже, включает в себя простой пример кон-
текста координации, позволяющий превратить операции над сообщениями SOAP в тран-
закционные. Информация о контексте, содержащаяся в заголовке SOAP, применяется
координаторами для регистрации приложений с целью получения транзакционных со-
бытий, таких как подготовительный этап двухэтапного процесса подтверждения, откат и
подтверждение.
<SOAP-ENV:Envelope xmlns:SOAP-ENV="http://www.w3.org/2001/12/soap-
envelope" >
< SOAP-ENV:Header >
<wscoor:Coordinationcontext
xmlns:wscoor="http://schemas.xmlsoap.org/ws/2002/08/wscoor"
xmlns:wsu="ht tp://schemas.xmlsoap.org/ws/2 002/07/utility"
xmlns:myTransactableApp="http://foo.com/baz”>
<wsu:Identifier>http://foo.com/baz/bar</wsu:Identifier
<wsu:ExpireS>2004-12-31T18:00:00-08:00</wsu:Expires>
<wscoor:CoordinationType>
http://schemas.xmlsoap.org/ws/2002/08/wstx
</wscoor:Coordinat ionType >
<wscoor:RegistrationService>
<wsu:Address>
http://foo.com/coordinationservice/registration
</wsu:Address>
</wscoor:Regi strat ionService >
Новые стандарты и перспективы интеграции корпоративных приложений
645
<myTransactableApp:IsolationLevel>
RepeatableRead
</myTransactableApp:IsolationLevel>
</wscoor:CoordinationContext>
</SOAP-ENV:Header >
<!-- SOAP BODY (snipped)
</SOAP-ENV:Envelope >
В спецификации WS-Transaction определяются два типа координации, которые раз-
работчики могут использовать в своих приложениях: атомарная транзакция (atomic
transaction — АТ) и бизнес-активность (business activity — BA).
Атомарные транзакции неплохо укладываются в рамки классических технологий рас-
пределенных транзакций, таких как ХА. Они применяются для осуществления операций
с относительно коротким временем жизни, в которых допускаются блокирование ресур-
сов (потоков, фрагментов источников данных и т.п.) и абсолютный откат операций.
WS-Transaction предусматривает способ связывания закрытых реализаций ХА (включая
под держку двухэтапного подтверждения транзакции) с Web-службами.
Бизнес-активность— это, как правило, “долгоживущий” процесс, который может
состоять из нескольких атомарных транзакций. Глобальный откат такой большой тран-
закции в случае возникновения единственного сбоя обычно нежелателен. Гораздо лучше,
если сбой одной атомарной транзакции в рамках бизнес-активности будет инициировать
запуск другого набора вызовов служб и отправку других сообщений. Отправка сообще-
ний может представлять собой некоторый механизм компенсации, позволяющий устра-
нить последствия ошибки таким образом, чтобы сохранить часть истории выполнения
бизнес-активности. В качестве примера можно привести бизнес-активность, которая
включает в себя бронирование билетов на авиарейс, машины, номера в гостинице и ложи
в театре. Все эти действия выполняются пользователем на протяжении двух-трех дней.
Каждое действие в этом потоке действий может быть представлено атомарной транзак-
цией. Даже если одна из атомарных транзакций даст сбой, выполнять согласованный от-
кат всех остальных транзакций нет необходимости. Вместо этого необходимо запустить
механизм компенсации, который позволит успешно осуществить один из этапов путеше-
ствия другим способом.
Создатели спецификаций WS-Coordination и WS-Transaction демонстрируют весьма
многообещающие попытки обеспечить надежное, интеллектуальное поведение систем
при возникновении сбоя в процессе обмена сообщениями между Web-службами. Продук-
ты, построенные на основе этих спецификаций, должны намного облегчить труд разработ-
чиков, вынужденных проектировать собственные схемы транзакций и координации дейст-
вий для приложений-поставщиков Web-служб, обменивающихся сообщениями.
Более подробно о спецификации WS-Transaction можно прочитать по адресу
http://dev2dev.bea.com/technologies/webservices/ws-transaction.jsp.
WS-Reliability и WS-ReliableMessaging
Механизм обмена сообщениями между Web-службами, как правило, должен обеспе-
чивать надежную, гарантированную доставку сообщений даже в случае сбоя сети, ком-
646
Глава 14. Кое-что в заключение
понентов или приложений, а также включать в себя схему сохранения сообщений и се-
мантику повторной отправки. К сожалению, современные популярные технологии
Web-служб не обладают подобной надежностью. К примеру, протокол SOAP в своем ис-
ходном виде (без усовершенствований) не слишком пригоден для использования в сце-
нариях корпоративного обмена сообщениями, потому что его популярные привязки не
гарантируют надежную доставку сообщений.
Для решения описанной проблемы разработчикам приложений приходится самостоя-
тельно обеспечивать надежность обмена сообщениями, используя возможность расшире-
ния механизмов Web-служб, таких как заголовки SOAP. Избавить разработчиков от этой
необходимости призваны новые стандарты, как, например, спецификации WS-Reliability и
WS-ReliableMessaging. Как уже заведено в зарождающемся мире стандартов Web-служб, эти
спецификации, относящиеся к одной и той же проблемной области, поддерживаются раз-
ными группами разработчиков, а следовательно, конкурируют друг с другом.
Спецификация WS-Reliability наделяет Web-службы на основе SOAP способностью
обмениваться сообщениями в асинхронном режиме, с гарантированной доставкой, без
дубликатов и с упорядочиванием сообщений. Это стандарт на основе SOAP, предназна-
ченный для управления агрегацией сообщений и созданием цепочек сообщений. Кроме
того, в WS-Reliability описан стандартный прием реализации гарантированной доставки
(Guaranteed Delivery, с. 149), преобразователя порядка (Resequencer, с. 297) и некоторых
других шаблонов. Данная спецификация использует механизм заголовков SOAP для до-
бавления к заголовкам сообщений элементов MessageHeader, ReliableMessage, Mes-
sageOrder и RMResponse. Эти элементы задают идентификаторы сообщений (такие,
как порядковый номер сообщения в последовательности сообшений и идентификатор
группы), метку времени, время жизни, тип сообщения, сведения об отправителе и полу-
чателе, а также информацию о подтверждении получения. Спецификация WS-Reliability
разработана группой производителей ПО, в число которых входят Sun, Oracle и Sonic, и
утверждена консорциумом OASIS. Она испытала огромное влияние со стороны ebMS.
Согласно спецификации WS-Reliability получатель сообщения SOAP должен подтвер-
дить его получение либо отправить ответное сообщение об ошибке, используя элемент
RMResponse заголовка SOAP. Если отправитель исходного сообщения не получит под-
тверждение, он еще раз отправит то же самое сообщение, присвоив ему тот же идентифи-
катор, который был у исходного сообщения. Отправитель обязан хранить исходное со-
общение, пока у того не истечет время жизни, пока не будет получено подтверждение по-
лучения или же пока получатель не сообщит об ошибке. Получатель также обязан
хранить сообщение, пока оно не будет надежно передано логике приложения.
Чтобы гарантировать доставку сообщений по принципу “один и только один раз”, в
спецификации WS-Reliability предусмотрен механизм хранения порядкового номера
сообщения в последовательности сообщений, который может быть реализован на основе
требований приложения. Сообщения SOAP, сгруппированные в последовательность,
могут иметь общий идентификатор группы, однако в заголовке каждого из них будет ука-
зан собственный порядковый номер. Это поможет получателю расположить сообщения в
правильном порядке, прежде чем передавать их приложению.
Текст спецификации WS-Reliability находится по адресу www.oasis-open.org/
commi 11 ее s/document s.php ?wg_abbrev=ws rm.
В спецификации WS-ReliableMessaging описывается аналогичный протокол, предна-
значенный для надежной доставки сообщений между распределенными приложениями
Новые стандарты и перспективы интеграции корпоративных приложений
647
при наличии сбоев. Его описание не основывается на какой-либо конкретной техноло-
гии, а значит, данный протокол может быть реализован с использованием целого ряда сете-
вых транспортных технологий и привязок. (Следует, однако, отметить, что WS-Reliable-
Messaging включает в себя одну привязку для SOAP.) Спецификация WS-ReliableMessaging
поддерживается компаниями BEA, IBM и Microsoft, но на момент написания этой книги
еще не была передана в какую-либо организацию по стандартизации.
Спецификация WS-ReliableMessaging опирается на те же принципы, что и WS-Reliability.
В ней тоже используются подтверждения, обратные вызовы, идентификаторы и посто-
янные хранилища сообщений, а также предполагается выдача подробных сообщений об
ошибках. Кроме того, она обеспечивает доставку сообщений в соответствии с одной из
четырех базовых схем доставки: не более чем один раз; как минимум один раз; один
и только один раз; в том же порядке, в котором были отправлены сообщения. Пример
доставки последовательности сообщений в соответствии со спецификацией WS-Reliable-
Messaging показан на рис. 14.3.
Ключевым различием между конкурирующими спецификациями надежности являет-
ся тот факт, что WS-ReliableMessaging опирается на другие важные спецификации
Web-служб, такие как WS-Security и WS-Addressing. На практике это означает, что
WS-ReliableMessaging для поддержки сведений о безопасности и состоянии использует
конкретные идиомы из других стандартов. WS-Reliability тоже поддерживает указанные
возможности, но пока что не требует использования идиоматических выражений из
других новых стандартов.
Более подробно о спецификации WS-ReliableMessaging можно прочитать по адресу
http://www.oasis-open.org/committees/tc_home,php?wg_abbrev=wsrm.
WS-Conversation
Спецификация WS-Conversation описывает протокол, предназначенный для управле-
ния асинхронным обменом сообщениями с поддержкой состояния между отправителем
и получателем (в качестве последних обычно выступают две конечные точки SOAP).
Данная спецификация не использует инкапсулирующий компонент бизнес-процесса для
управления обменом сообщениями с поддержкой состояния между несколькими партне-
рами. Вместо этого она позволяет организовать аналогичный обмен сообщениями между
одним клиентом и одной службой (где клиент также может быть службой) куда более
простым способом.
Протокол, описанный в WS-Conversation, задействует механизм заголовков SOAP для
отправки вместе с сообщениями SOAP некоторых идентификаторов или маркеров. Когда
отправитель и получатель начинают общаться, протокол использует элемент заголовка
startHeader для задания идентификатора разговора (conversation header), а также URI об-
ратного вызова. Во всех последующих сообщениях, являющихся частью этого разговора,
используются элементы заголовка ContinueHeader (запрос) и CallbackHeader (ответ),
и они будут содержать тот же идентификатор, который был задан в начале разговора.
Вообще-то, заголовки SOAP могут применяться для обмена сообщениями с поддерж-
кой состояния и без привлечения стандартных механизмов наподобие того, который
описан выше. Впрочем, польза от наличия общего механизма для клиентов и служб раз-
ных платформ очевидна. Данный механизм является формализацией шаблонов агрега-
тор (Aggregator, с. 283) и обработчик составного сообщения (Composed Message Processor,
с. 307), использующих идентификатор корреляции (Correlation Identifier, с. 186) для сопос-
тавления нескольких сообщений с одним сеансом.
648
Глава 14. Кое-что в заключение
Отправитель
I
Отправка
последовательности
из трех сообщений
_______________
Согласование
Получатель
t
Доставка
последовательности
из трех сообщений
работы протокола
Отправка 1-го сообщения
“уникальным ИД в заголовке
>
Отправка 2-го сообщения,
которое теряется в процессе передачи*’ //
Надежный
отправитель
сообщений
____________Отправка 3-го сообщения _______
с уникальным ИД и маркером последнего сообщения
Подтверждение получения
сообщений 1 и 3
Надежный
пункт
назначения
сообщений
__________Повторная отправка______________
2-го сообщения с запросом подтверждения
Подтверждение получения
>ний
ЛдЛ Расстановка сообщений
в правильном порядке
I------------►
Рис. 14.3. WS-ReliableMessaging обеспечивает гарантированную последовательную доставку сообщений
путем отправки подтверждений, в которых указываются уникальные идентификаторы, заданные
элементом заголовка SOAP
В крупных интеграционных проектах, в которых службы и компоненты для простоты
удобнее представлять в виде “черных ящиков”, более перспективным выглядит приме-
нение подхода, который предполагает внешнее управление состоянием через компонент
процесса или стандарты хореографии. Тем не менее спецификация WS-Conversation
является хорошим примером того, что можно сделать при наличии более обширного
контроля над клиентами и службами.
Новые стандарты и перспективы интеграции корпоративных приложений
649
WS-Security
Хотя спецификации наподобие WS-ReliableMessaging, WS-Coordination и WS-Addressing
описывают различные механизмы, идентифицирующие отправитель сообщения, ни одна
из них не гарантирует, что отправитель действительно является тем, за кого себя выдает.
В стандартах, входящих в состав WS-I Basic Profile (XML Schema, SOAP, WSDL и UDDI),
ничего не говорится о том, как проверять и гарантировать подлинность отправителя или
как сохранить целостность сообщения. Первые производители Web-служб оставляли
свои службы открытыми и доступными для всех или же защищали их с помощью собст-
венных, закрытых протоколов безопасности. Использование последних приводило к по-
явлению нежелательной связи между отправителями и получателями, противоречащей
концепции асинхронных и слабо связанных узлов сообщений.
Для решения описанных проблем была предложена спецификация WS-Security, кото-
рую также часто называют языком безопасности Web-служб (Web Services Security
Language — WSSL). Из всех спецификаций WS-* эта получила, пожалуй, наибольшую
поддержку среди главных производителей платформ для Web-служб. WS-Security была
создана совместными усилиями Microsoft, IBM и Verisign, а затем передана в OASIS.
Кроме того, она была признана такими “китами” индустрии, как Sun, BEA, Intel, SAP,
IONA, RSA Security и т.п.
WS-Security не предлагает новых технологий безопасности, а является своеобразным
“связующим звеном” между SOAP и существующими технологиями безопасности.
Она включает в себя описание универсальных, расширяемых средств сопоставления
маркеров безопасности с сообщениями SOAP и передачи этих маркеров конечным точ-
кам SOAP. В ней также приведен стандартный подход к кодированию в сообщениях
SOAP двоичных маркеров безопасности, таких как цифровые сертификаты и билеты
Kerberos. Данная спецификация не описывает конкретные, фиксированные протоколы,
а определяет универсальный набор механизмов, позволяющих реализовать различные
протоколы безопасности и внедрить в схему защиты любое число доменов доверия, фор-
матов подписей и технологий шифрования. Максимально задействуя цифровые серти-
фикаты, краткую проверку подлинности и реализации таких технологий, как инфра-
структура открытого ключа (Public Key Infrastructure — PKI), Kerberos, SSL и другие,
WS-Security показывает, как применять привычные средства Internet-безопасности к ко-
нечным точкам SOAP.
Помимо проверки подлинности отправителя, WS-Security может обеспечивать цело-
стность сообщения, т.е. защищать его содержимое от несанкционированного просмотра
посредником в процессе передачи по сети. Это достигается благодаря использованию
стандартов XML Signature и XML Encryption, разработанных консорциумом W3C. Но ес-
ли в процессе передачи данных не задействованы промежуточные компоненты и сторон-
ние службы, для защиты сообщений SOAP куда удобнее использовать обычный HTTPS.
В модели безопасности, описанной в WS-Security, предполагается, что отправитель
сообщения SOAP передает вместе с сообщением ряд сведений о себе: идентификатор от-
правителя, группу, привилегии и т.п. Все эти сведения группируются в так называемый
подписанный маркер безопасности. Получатель сообщения должен подтвердить эти све-
дения. Маркеры и подписи передаются внутри заголовка SOAP, а точнее — с помощью
элемента security пространства имен ws-Security. Если при проверке получателем
сведений об отправителе возникнет ошибка, она может принадлежать к одному из двух
типов: ошибка поддержки (указывает на то, что конечная точка не поддерживает кон-
650
Глава 14. Кое-что в заключение
кретный маркер или алгоритм шифрования) или ошибка отказа (сюда относится боль-
шинство других ошибок, включая и те, которые касаются недопустимых маркеров и под-
писей). В спецификации не требуется, чтобы система всегда сообщала об ошибках отка-
за, потому что они могут возникнуть вследствие атаки злоумышленника. Если же система
выдает уведомление об ошибке, оно принимает форму сообщения SOAP Fault с кодами
ошибок, определенными в спецификации.
Полный текст спецификации WS-Security можно найти на сайте любого из произво-
дителей, участвовавших в ее разработке. На сайте IBM она хранится по адресу
http://www-128.ibm.com/developerworks/library/ws-secure.
WS-Addressing, WS-Policy и другие спецификации WS-*
Существует еще целый ряд спецификаций WS-*, обладающих разными уровнями
поддержки и признания среди ведущих производителей ПО. Некоторые из них охваты-
вают довольно узкие аспекты Web-служб, как, например, WS-Addressing, определяющая
XML-элементы, с помощью которых в сообщении идентифицируются конечные точки
Web-служб. Создатели этой спецификации стремятся поддержать обмен сообщениями с
помощью разнообразных посредников, таких как диспетчеры конечных точек, прокси,
брандмауэры и шлюзы, вне зависимости от используемой транспортной технологии.
По своей сути WS-Addressing является стандартным способом задания, кем было отправ-
лено сообщение (“От:”) и кому оно предназначается (“Кому:”). Данная спецификация
позволяет привлекать Web-службы на основе SOAP к созданию решений, основанных на
использовании списка получателей (Recipient List, с. 264). Кроме того, поскольку
WS-Addressing позволяет задать адрес, на который получатель исходного сообщения
должен отправить ответ, она может рассматриваться как стандартный подход к решению
проблем, поднятых при рассмотрении шаблона обратный адрес (Return Adress, с. 182).
Спецификация Web Services Policy Framework, она же WS-Policy, определяет синтак-
сис описания политик Web-службы. Такие политики включают в себя метаданные, опи-
сывающие требования к службе, предпочтения, возможности и желаемое качество об-
служивания. Сопутствующая спецификация Web Services Policy Assertions Language (WS-
PolicyAssertions) позволяет проверить, поддерживает ли конечная точка службы или со-
общения конкретную политику. Процесс проверки включает в себя анализ объявлений
WS-Policy на предмет конкретной требуемой политики. Наконец, спецификация Web
Services Policy Attachment (WS-PolicyAttachment) описывает, как указанные стандарты
политик укладываются в существующие технологии Web-служб. В частности, она опре-
деляет, как сопоставлять выражения политик с определениями типов WSDL, а политики,
специфичные для реализации, — с типами WSDL portType.
По мере того как производители стремятся формализовать популярные приемы реали-
зации Web-служб, используемые разработчиками приложений (а заодно побыстрее нало-
жить на них права интеллектуальной собственности), рынок стандартов пополняется все
новыми и новыми спецификациями WS-*. Многие разработчики приложений, основанных
на обмене сообщениями, следят за развивающимися стандартами, выхватывая из них наи-
более полезные или интересные моменты. Помните, однако, что главным залогом успеш-
ного создания приложения является шаблон, а не текст стандарта. Соответствие специфи-
кациям WS-* еще не является обязательным условием реализации межплатформенных
корпоративных систем обмена сообщениями, и если зарождающийся стандарт является
помехой в принятии какого-либо решения, его следует просто проигнорировать.
Новые стандарты и перспективы интеграции корпоративных приложений
651
Заключение
Хорошие стандарты расширяют область действия шаблонов проектирования, обеспе-
чивая возможность межплатформенного взаимодействия разных реализаций одного и
того же шаблона. В настоящее время масса усилий направлена на то, чтобы расширить
шаблоны обмена сообщениями с помощью стандартов Web-служб. Основное внимание в
большинстве из них уделяется построению и поведению компонентов рабочего потока,
называемых компонентами бизнес-процессов. Стандарты наподобие BPEL, WSCI и спе-
цификаций WS-* позволяют решить многие проблемы, описанные в этой книге, и реали-
зуют несколько из приведенных в ней шаблонов.
К сожалению, процесс утверждения стандартов не лишен недостатков. Новые, разви-
вающиеся стандарты иногда конфликтуют один с другим и могут вконец запутать разра-
ботчиков интеграционных решений. Современные стандарты ни в коем случае нельзя
считать полностью готовым, зрелым и отлаженным решением. Разработчик приложения,
использующий шаблоны, не должен слишком уповать на стандарты; вместо этого ему
следует сосредоточиться на конкретных случаях применения тех или иных шаблонов.
Проанализируйте, какой подход к решению проблемы предлагают стандарты, и восполь-
зуйтесь описанными в них идиоматическими реализациями шаблона, если они кажутся
вам не лишенными смысла или же если они могут принести пользу в конкретной ситуа-
ции (вне зависимости от того, стандартизирован ли данный подход в продуктах конкрет-
ного производителя). Нелишне позаботиться и об “обратной связи” с организациями по
стандартизации, исследуя и критикуя создаваемые ими стандарты, а также внося свои
предложения. Это гарантирует, что стандарты действительно найдут применение на
практике и не будут рассматриваться разработчиками как чисто теоретические, искусст-
венные измышления или эксперименты производителей. По мере “взросления” стандар-
тов обмена сообщениями архитекторы ПО начнут задумываться о том, как применение
стандартов может способствовать расширению корпоративных интеграционных реше-
ний, повышению их мощности и надежности, уменьшению риска и затрат на их реализа-
цию, а также переходу решений на принципиально новые уровни сложности.
Приложение А
Список шаблонов
проектирования
ц Агрегатор (Aggregator, с. 283). Как скомбинировать содержимое раз-
□ —ных, но связанных между собой сообшений, чтобы полученный ре-
□ зультат можно было обрабатывать как единое целое?
Каноническая модель данных (Canonical Data Model, с. 367). Как мини-
мизировать число зависимостей при интеграции приложений,
использующих различные форматы данных?
Адаптер канала (Channel Adapter, с. 154). Как подключить изолиро-
ванное приложение к системе обмена сообщениями, чтобы оно мог-
ло отправлять и получать сообщения?
Вентиль канала (Channel Purger, с. 579). Как избавиться от ненужных
сообщений, оставшихся в канале, чтобы они не мешали тестирова-
нию или эксплуатации системы?
Квитанция (Claim Check, с. 358). Как сократить объем данных в пере-
сылаемом сообщении, но не потерять их?
Сообщение с командой (Command Message, с. 169). Как использовать
обмен сообщениями для вызова процедуры другого приложения?
Конкурирующие потребители (Competing Consumers, с. 515). Как орга-
низовать параллельную обработку нескольких сообщений одним и
тем же клиентом?
Обработчик составного сообщения (Composed Message Processor, с. 307).
Как аккуратно провести сообщение по маршруту его следования, ес-
ли сообщение состоит из нескольких элементов, каждый из которых
проходит собственную обработку?
654
Приложение А. Список шаблонов проектирования
D
Расширитель содержимого (Content Enricher, с. 348). Как обеспечить
взаимодействие с другой системой, если отправитель сообщения
предоставил не все данные, требующиеся получателю?
Фильтр содержимого (Content Filter, с. 354). Как упростить работу с
большими сообщениями, если получателя интересует лишь малая
часть содержащихся в них данных?
Маршрутизатор на основе содержимого (Content-Based Router, с. 247).
Как поступить в ситуации, когда реализация единственной логиче-
ской функции распределяется между несколькими физическими сис-
темами?
Шина управления (Control Bus, с. 552). Как организовать эффективное
управление системой обмена сообщениями, если ее компоненты
распределены между несколькими программными платформами и
разбросаны на большой территории?
Идентификатор корреляции (Correlation Identifier, с. 186). Как инициа-
тор запроса, получивший сообшение с ответом, узнает, к какому за-
просу оно относится?
Канал типа данных (Datatype Channel, с. 139). Как приложение должно
отправить данные, чтобы получатель знал, как их обрабатывать?
Канал недоставленных сообщений (Dead Letter Channel, с. 147). Что де-
лать с сообщениями, которые не удается доставить?
Обходной путь (Detour, с. 556). Как направить сообщение на прохож-
дение дополнительных этапов обработки с целью проверки правиль-
ности, отладки или тестирования?
Сообщение с данными документа (Document Message, с. 171). Как ис-
пользовать обмен сообщениями для передачи данных между прило-
жениями?
Постоянный подписчик (Durable Subscriber, с. 535). Как избежать поте-
ри сообщений, если подписчик временно отключен от системы об-
мена сообщениями?
Динамический маршрутизатор (Dynamic Router, с. 259). Как избежать
зависимости маршрутизатора от всех возможных пунктов назначе-
ния, не теряя эффективности его работы?
Приложение А. Список шаблонов проектирования
655
Оболочка конверта (Envelope Wrapper, с. 342). Как реализовать обмен
сообщениями между существующими приложениями, если система
обмена сообщениями предъявляет особые требования к формату по-
следних, например обязательное шифрование тела сообщения или
наличие в заголовке определенных полей?
Сообщение о событии (Event Message, с. 174). Как использовать обмен
сообщениями для передачи событий из одного приложения в другое?
Событийно управляемый потребитель (Event-Driven Consumer, с. 511).
Как настроить приложение на автоматическое потребление сообще-
ний по мере их прибытия?
Передача файла (File Transfer, с. 80). Как наладить взаимодействие и
обмен данными между несколькими приложениями?
Индикатор формата (Format Indicator, с. 201). Как спроектировать
формат данных сообщения, чтобы предусмотреть в нем возможность
изменений в будущем?
► Гарантированная доставка (Guaranteed Delivery, с. 149). Как гаранти-
ровать, что сообщение будет доставлено даже в случае сбоя системы
обмена сообщениями?
Идемпотентный получатель (Idempotent Receiver, с. 541). Что делать
получателю, если сообщение было доставлено несколько раз?
Канал недопустимых сообщений (Invalid Message Channel, с. 143). Как
поступить с сообщением, не несущим в себе никакого смысла для
получателя?
Брокер сообщений (Message Broker, с. 334). Как отделить пункт назна-
чения сообщения от его отправителя, сохраняя централизованный
контроль над сообщениями?
Шина сообщений (Message Bus, с. 162). Как организовать согласован-
ную работу отдельных приложений, не поставив их в зависимость
друг от друга, чтобы добавление или удаление одного из приложений
никоим образом не влияло на остальные?
Канал сообщений (Message Channel, с. 93). Как наладить взаимодейст-
вие между двумя приложениями с использованием технологии обме-
на сообщениями?
Диспетчер сообщений (Message Dispatcher, с. 521). Как наладить согла-
сованное распределение и обработку сообщений между потребите-
лями одного и того же канала?
656
Приложение А. Список шаблонов проектирования
Конечная точка сообщения (Message Endpoint, с. 124). Как подключить
приложение к каналу системы обмена сообщениями?
Срок действия сообщения (Message Expiration, с. 198). Как уведомить
получателя о том, что по истечении некоторого времени сообщение
устаревает и его не следует принимать во внимание?
Фильтр сообщений (Message Filter, с. 253). Как избежать получения не-
нужных сообщений?
Журнал доставки сообщения (Message History, с. 561). Как организовать
эффективный анализ и отладку пути следования сообщений в слабо
связанной системе?
Маршрутизатор сообщений (Message Router, с. 109). Как реализовать
возможность передачи сообщения различным фильтрам в зависимо-
сти от набора условий?
Цепочка сообщений (Message Sequence, с. 192). Как использовать обмен
сообщениями для передачи сколь угодно большого объема данных?
Хранилище сообщений (Message Store, с. 565). Как использовать содер-
жимое сообщений в отчетах, не нарушая слабо связанный и кратко-
срочный характер системы обмена сообщениями?
Транслятор сообщений (Message Translator, с. 115). Как организовать
обмен сообщениями между приложениями, использующими различ-
ные форматы данных?
Сообщение (Message, с. 98). Как наладить обмен данными между двумя
приложениями, соединенными с помошью канала сообщений
(Message Channel)1}
Мост обмена сообщениями (Messaging Bridge, с. 159). Как связать не-
сколько систем обмена сообщениями, чтобы сообщения, передавае-
мые по одной из них, были доступны и в других системах?
Шлюз обмена сообщениями (Messaging Gateway, с. 482). Как инкапсули-
ровать доступ к системе обмена сообщениями, скрыв его от осталь-
ных частей приложения?
Преобразователь обмена сообщениями (Messaging Mapper, с. 491).
Как организовать перемещение данных между объектами предмет-
ной области и инфраструктурой обмена сообщениями, не нарушая
их независимость?
Приложение А. Список шаблонов проектирования
657
Обмен сообщениями {Messaging, с. 87). Как наладить взаимодействие и
обмен данными между несколькими приложениями?
Нормализатор {Normalizer, с. 364). Как организовать обработку
входящих сообшений, эквивалентных по смыслу, но различных по
формату?
Каналы и фильтры {Pipes and Filters, с. 102). Как организовать слож-
ную обработку сообщения, руководствуясь принципами независимо-
сти и гибкости конечного решения?
> Канал “точка-точка” {Point-to-Point Channel, с. 131). Может ли при-
ложение, отправившее документ или вызвавшее процедуру, гаранти-
ровать, что документ или вызов будет получен только одним прило-
жением?
Опрашивающий потребитель {Polling Consumer, с. 507). Может ли при-
ложение потреблять сообщения только тогда, когда оно готово это
делать?
Диспетчер процессов {Process Manager, с. 325). Как провести сообще-
ние через несколько этапов обработки, если на момент проектирова-
ния системы требуемые этапы обработки неизвестны и не обязатель-
но будут выполняться последовательно друг за другом?
Канал “публикация-подписка” {Publish-Subscribe Channel, с. 134). Как
оповестить о событии всех заинтересованных получателей?
Список получателей {Recipient List, с. 264). Как разослать сообщение
меняющемуся списку получателей?
Удаленный вызов процедуры {Remote Procedure Invocation, с. 85).
Как наладить взаимодействие и обмен данными между несколькими
приложениями?
Запрос-ответ {Request-Reply, с. 177). Как организовать обмен сооб-
щениями, чтобы отправитель сообшения получал на него ответ?
Преобразователь порядка {Resequencer, с. 297). Как упорядочить поток
связанных между собой сообщений, если они были доставлены не в
той последовательности, в которой отправлены?
658
Приложение А. Список шаблонов проектирования
Обратный адрес (Return Address, с. 182). Как ответчик узнает, куда не-
обходимо отправить сообщение с ответом?
Карта маршрутизации (Routing Slip, с. 314). Как последовательно
провести сообщение через несколько этапов обработки, если на мо-
мент проектирования системы последовательность этапов неизвест-
на и может различаться для каждого сообщения?
Рассылка-сборка (Scatter-Gather, с. 310). Как организовать обработку и
дальнейшее продвижение сообщения, если на определенном этапе
оно должно быть разослано нескольким получателям, каждый из ко-
торых может прислать свой ответ?
Избирательный потребитель (Selective Consumer, с. 528). Может ли по-
требитель сообщений выбирать, какие сообщения он хочет получать?
Активатор службы (Service Activator, с. 545). Как спроектировать
службу, чтобы ее можно было вызывать как с помощью разнообраз-
ных технологий обмена сообщениями, так и посредством техноло-
гий, не связанных с обменом сообщениями?
Общая база данных (Shared Database, с. 83). Как наладить взаимодей-
ствие и обмен данными между несколькими приложениями?
Интеллектуальный заместитель (Smart Proxy, с. 567). Как отслеживать
сообщения, проходящие через службу, если ответ на каждый запрос
публикуется в канале, заданном обратным адресом (Return Address)?
Разветвитель (Splitter, с. 274). Как организовать обработку сообще-
ния, если оно содержит несколько элементов, каждый из которых
должен обрабатываться по-своему?
Тестовое сообщение (Test Message, с. 577). Что произойдет, если ком-
понент активно обрабатывает сообщения, но искажает их по причине
внутреннего сбоя?
Транзакционный клиент (Transactional Client, с. 498). Может ли клиент
управлять транзакциями, в рамках которых он взаимодействует с
системой обмена сообщениями?
Отвод (Wire Тар, с. 558). Как просмотреть содержимое сообщения,
которое передается по каналу “точка-точка” (Point-to-Point Channel)?
® J. 4?
• rs
Приложение Б
Шаблоны интеграции
корпоративных приложений
Точки обмена сообщениями
ро| Конечная точка сообщения (124)
НП Шлюз обмена сообщениями (482)
Преобразователь обмена
сообщениями (491)
~|@)| Транзакционный клиент (498)
|<>| Опрашивающий потребитель (507)
|~Н Событийно управляемый потребитель (511)
•|~^$| Конкурирующие потребители (515)
Диспетчер сообщений (521)
И Избирательный потребитель (528)
-ГХ® Постоянный подписчик (535)
Идемпотентный получатель (541)
Активатор службы (545)
Построение сообщений
Xs
Ъ
Те
□—>
□
Сообщение (98)
Сообщение с командой (169)
Сообщение с данными документа (171)
Сообщение о событии (174)
Запрос-ответ (177)
Обратный адрес (182)
Идентификатор корреляции (186)
tfffia Цепочка сообщений (192)
О Срок действия сообщения (198)
Индикатор формата (201)
I
I
I
Конечная I
точка Сообщение
Канал
Программа
А
Каналы обмена сообщениями
Канал сообщений (93)
----- Канал "точка-точка” (131)
—ЕЕ* Канал "публикация-подписка” (134)
rabtni Канал типа данных (139)
* , в Канал недопустимых
сообщений (143)
<—-В Канал недоставленных сообщений (147)
g Г аранти рован ная доставка (149)
Dth3 Адаптер канала (154)
Мост обмена сообщениями (159)
Шина сообщений (162)
Приложение Б. Шаблоны интеграции корпоративных приложений
661
Маршрутизация сообщений
Каналы и фильтры (102) UEEJ Агрегатор (283)
РИг! Маршрутизатор сообщений (109) Преобразователь порядка (297)
Маршрутизатор на основе L>g-o| Обработчик составного
содержимого (247) сообщения (307)
LV.J Фильтр сообщений (253) Рассылка-сборка (310)
Динамический маршрутизатор (259) 1Д°ДР1 Карта маршрутизации (314)
Список получателей (264) Диспетчер процессов (325)
[ | Разветвитель (274) Брокер сообщений (334)
Преобразование
сообщений
|&О| Транслятор сообщений (115)
I 1 Оболочка конверта (342)
|°~Р| Расширитель содержимого (348)
Фильтр содержимого (354)
I Квитанция (358)
|» ^° | Нормализатор (364)
Каноническая модель данных (367)
——
/
/
/
/
Управление
системой
Мониторинг
Шина управления (552)
| z7| Обходной путь (556)
т—I Отвод (558)
Журнал доставки сообщения (561)
Q Хранилище сообщений (565)
ЩС Интеллектуальный заместитель (567)
Тестовое сообщение (577)
| X? | Вентиль канала (579)
Основные источники
информации
1. Christopher Alexander, Sara Ishikawa, & Murray Silverstein. A Pattern Language: Towns,
Buildings, Construction. — Oxford University Press, 1977, ISBN 0195019199.
Цитаты из этого поистине исторического произведения встречаются едва ли не в
каждой книге, посвященной шаблонам. Один из нас в свое время использовал шаб-
лоны, предложенные Александером, для проектирования пляжного домика на уро-
ках дизайна интерьера. Интересно отметить, что идея Александера разложить архи-
тектуру любого объекта на отдельные легко компонуемые конструкции берет свое
начало из занятий математикой. В своей работе “Notes on the Synthesis of Form”
(“Заметки о синтезе формы”) он упоминает несколько программ, написанных им
на коде ассемблера IBM 7090. Как видим, невероятный успех архитектурных шаб-
лонов Кристофера Александера среди разработчиков ПО не совсем случаен.
2. Sherman Alpert, Kyle Brown, & Bobby Woolf. The Design Patterns Smalltalk
Companion. —Addison-Wesley, 1998, ISBN 0201184621.
Своеобразная переработка материала, изложенного в [12], для среды программи-
рования, которая обладает общей библиотекой классов и запускается в рамках
виртуальной машины с поддержкой механизма сборки мусора. На время написа-
ния книги это был Smalltalk, но многие из предложенных в ней идей вполне при-
менимы к Java и .NET/C#.
3. Don Box. Essential .NET, Volume 1: The Common Language Runtime. — Addison-
Wesley, 2002, ISBN 0201734117. (Дон Бокс, Крис Селлз. Основы платформы .NET,
том 1. Общеязыковая исполняющая среда. — М.: Издательский дом “Вильямс”,
2003, ISBN 5-8459-0455-2.)
Все, что вы хотели знать об особенностях общей языковой среды выполнения
(CLR), но боялись спросить.
4. IBM, BEA Systems, Microsoft, SAP AG, Siebel Systems. Business Process Execution
Language for Web Services, Version 1.1. —July 30,2002.
http://www-128.ibm.com/developerworks/library/specification/ws-bpel/
Спецификация BPEL4WS 1.1.
5. Deepak Alur, John Crupi, & Dan Malks. Core J2EE Patterns: Best Practices and Design
Strategies (2nd edition). — Prentice Hall PTR, 2003, ISBN 0131422464.
Очень хорошая книга о шаблонах интеграции корпоративных приложений для Java.
Основные источники информации
663
6. C.A.R. Ноаге. “Communicating Sequential Processes”. — Communications of the ACM, 1978.
Чтобы ознакомиться с полным текстом этой статьи, необходимо иметь доступ к
интерактивной библиотеке АСМ.
7. Alan Dickman. Designing Applications with MSMQ. — Addison-Wesley, 1998,
ISBN 0201325810.
Одна из глав этой книги, “Solutions to Message Problems” (“Решение проблем, свя-
занных с обменом сообщениями”), содержит множество информации о корреля-
ции, событийно управляемых потребителях, сериализации и десериализации объ-
ектов. К сожалению, возраст книги указывает на то, что все примеры в ней напи-
саны на Visual Basic с использованием компонентов СОМ либо на C++.
8. Bruce Powell Douglass. Real-Time Design Patterns.— Addison-Wesley, 2003,
ISBN 0201699567.
Эта книга подтверждает переносимость шаблонов проектирования между пред-
метными областями. Некоторые из шаблонов обеспечения надежности, предло-
женных Дугласом, прекрасно зарекомендовали себя в контексте корпоративного
обмена сообщениями.
9. Martin Fowler. Patterns of Enterprise Application Architecture. — Addison-Wesley, 2003,
ISBN 0321127420. (Мартин Фаулер. Архитектура корпоративных программных
приложений.—М.: Издательский дом “Вильямс”, 2004, ISBN 5-8459-0579-6.)
Самая авторитетная книга об архитектурных шаблонах приложений. Несмотря на
весьма солидный объем (в книге описывается 51 шаблон), автор умудрился со-
хранить простоту и увлекательность изложения, не жертвуя при этом точностью
технических деталей.
10. Sun Microsystems. Enterprise JavaBeans Specification, Version 2.0. — August 14, 2001.
http://java.sun.com/products/ejb/docs.html
Спецификация EJB 2.0.
11. Mary Shaw & David Garlan. Software Architecture: Perspectives on an Emerging
Discipline. — Prentice Hall, 1996, ISBN 0131829572.
В этой книге содержится хорошая глава об архитектурных стилях, включая кана-
лы и фильтры (Pipes and Filters).
12. Erich Gamma, Richard Helm, Ralph Johnson, & John Vlissides. Design Patterns:
Elements of Reusable Object-Oriented Software. — Addison-Wesley, 1995,
ISBN 0201633612. (Гамма Э., Хелм P., Джонсон P., Влиссидес Д. Приемы объект-
но-ориентированного программирования. Паттерны проектирования. — СПб.: Пи-
тер, 2003, ISBN 5-272-00355-1.)
Вторая по популярности и частоте цитирования (после [1]) книга о шаблонах
проектирования.
13. Steve Graham, Simon Simeonov, Toufic Boubez, Glen Daniels, Doug Davis, Yuichi
Nakamura, & Ryo Nyeama. Building Web Services with Java: Making Sense of XML,
SOAP and UDDI. — SAMS Publishing, 2002, ISBN 0672321815.
Очень хорошая книга об использовании Java для разработки Web-служб.
664
Основные источники информации
14. Mark Hapner, Rich Burridge, Rahul Sharma, Joseph Fialli, & Kim Haase. Java
Messaging Service API Tutorial and Reference. — Addison-Wesley, 2002,
ISBN 0201784726.
Описание работы инфраструктуры обмена сообщениями JMS от авторов ее спе-
цификации.
15. Luke Hohmann. Beyond Software Architecture: Creating and Sustaining Winning
Solutions. — Addison-Wesley, 2003, ISBN 0201775948.
Люк напоминает нам о том, что в основе архитектурных решений лежат не только
технологии, но и бизнес-правила, схемы лицензирования, а также множество
других внешних факторов.
16. Sun Microsystems. Java Message Service (JMS). — 2001-2003.
http://java.sun.com/products/jms/
Интерфейс Java Message Service API, часть платформы Java 2, Enterprise Edition
(J2EE).
17. Sun Microsystems. Java Message Service (the Sun Java Message Service 1.1
Specification). — April 12,2002.
http://java.sun.com/products/jms/docs.html
Спецификация JMS 1.1.
18. Sun Microsystems. Java Transaction API (JTA). — 2001-2003.
http://java.sun.com/products/jta/
Интерфейс Java Transaction API, часть платформы Java 2, Enterprise Edition
(J2EE).
19. G. Kahn. “The Semantics of a Simple Language for Parallel Programming”. —
Information Processing 74: Proc. IFIP Congress 74. — North-Holland Publishing
Co., 1974.
20. Doug Kaye. Loosely Coupled: The Missing Pieces of Web Services. — RDS Press, 2003,
ISBN 1881378241.
Свежий взгляд на Web-службы. Вместо формального описания многочисленных
API читателей знакомят с фундаментальными аспектами программных архитек-
тур, ориентированных на службы. Книга написана нейтральным языком, свобод-
ным от технических деталей и профессионального жаргона. Разработчику, кото-
рому никак не удается реализовать тот самый злосчастный вызов по протоколу
SOAP, материал книги может показаться слишком абстрактным, зато она пре-
красно подойдет техническим менеджерам и проектировщикам, которым прихо-
дится объяснять подобные концепции людям, далеким от информационных тех-
нологий.
21. William Kent. Data and Reality. — IstBooks, 2000, ISBN 1585009709.
Классическая книга (впервые она была издана еще в 1978 году), в которой расска-
зывается, почему так сложно моделировать реальный мир с помощью компью-
терных систем.
Основные источники информации
665
22. Rhys Lewis. Advanced Messaging Applications with MSMQ and MQSeries. — Que, 2000,
ISBN 078972023X.
23. Frank Leyman & Dieter Roller. Production Workflow: Concepts and Techniques. —
Prentice Hall PTR, 1999, ISBN 0130217530.
24. Microsoft. Multiple-Destination Messaging. — February, 2003.
http://windowssdk. msdn. microsoft. com/en-us/library/ms 7O6929.aspx
Обзор новой возможности MSMQ 3.0, позволяющей отправлять сообщения в не-
сколько пунктов назначения.
25. Dragos Manolescu. “Micro-Workflow: A Workflow Architecture Supporting
Compositional Object-Oriented Software Development.” — University of Illinois, 2000.
http://micro-workflow.com/PhDThesis
26. Robert T. Monroe, Drew Kompanek, Ralph Melton, & David Garlan. “Stylized
Architecture, Design Patterns, and Objects.” — 1996.
http://www-2.cs.cmu.edu/afs/cs/project/compose/ftp/pdf/ObjPattemsArch-ieee97.pdf
27. Richard Monson-Haefel & David A. Chappell. Java Message Service. —O’Reilly, 2001,
ISBN 0596000685.
Пожалуй, самая знаменитая книга о JMS.
28. IBM. WebSphere MQ (ранее MQSeries).
http://www-306.ibm.com/software/integration/wmq/
Один из самых старых и самых известных продуктов для интеграции и обмена со-
общениями.
29. Microsoft. Microsoft Message Queuing (MSMQ).
www.microsoft.com/windows2000/technologies/communications/msmq/
Технология обмена сообщениями, встроенная в Windows 2000, Windows ХР и
Windows Server 2003.
30. Pattern Forms. — Cunningham & Cunningham. Wiki-Wiki-Web. — Last edited on
April 13,2005.
http://c2. com/cgi/wiki ?PattemForms
Список часто используемых форм шаблонов и их отличий.
31. James Coplien & Douglas Schmidt (Editors). Pattern Languages of Program Design. —
Addison-Wesley, 1995, ISBN 0201607344.
Протоколы первой конференции PLoP, положенные в основу некоторых более
поздних книг, таких как [33]. В данном томе содержатся статьи Фрэнка Бушманна
и Режин Менье “Система шаблонов” (Frank Buschmann and Regine Meunier,
“A System of Patterns”), Режин Менье “Каналы и фильтры” (Regine Meunier, “The
Pipes and Filters Architecture”), а также Дианы Мюларц “Архитектуры интеграции
на основе шаблонов” (Diane Mularz, “Pattern-Based Integration Architectures”).
32. Robert Martin, Dirk Riehle, & Frank Buschmann (Editors). Pattern Languages of
Program Design 3. — Addison-Wesley, 1998, ISBN 0201310112.
666
Основные источники информации
Третий сборник материалов с конференций PLoP (PLoP, EuroPLoP и т.п.; см.
http://hillside.net/conferences/). Содержит описания шаблонов, которые впоследст-
вии легли в основу [34]: акцептор-коннектор (Acceptor-Connector), маркер асинхрон-
ного завершения (Asynchronous Completion Token) и двойная блокировка (Double-
Checked Locking). В нем также рассматриваются два шаблона, разработанных ав-
торами настояшей книги: null-объект (NullObject) и объект типа (Type Object).
33. Frank Buschmann, Regine Meunier, Hans Rohnert, Peter Sommerlad, & Michael Stal.
Pattern-Oriented Software Architecture —Wiley, 1996, ISBN 0471958697.
Замечательная книга о шаблонах проектирования.
34. Douglas Schmidt, Michael Stal, Hans Rohnert, & Frank Buschmann. Pattern-Oriented
Software Architecture, Vol. 2. — Wiley, 2000, ISBN 0471606952.
Еще несколько шаблонов проектирования. В томе 2 книги основное внимание
уделяется функционированию распределенных систем и параллельной обработке
данных.
35. Alec Sharp & Patrick McDermott. Workflow Modeling: Tools for Process Improvement and
Application Development. — Artech House, 2001, ISBN 1580530214.
Книга посвящена моделированию рабочего потока. Интересное пособие для ана-
литиков и архитекторов бизнес-решений.
36. World Wide Web Consortium. W3C Simple Object Access Protocol (SOAP) 1.1
Specification. — W3C Note, May 8, 2000.
http://www. w3. org/TR/SOAP/
Спецификация SOAP 1.1.
37. World Wide Web Consortium. SOAP Version 1.2, Part 2: Adjuncts.— W3C
Recommendation, June 24, 2003.
http://www. w3. org/TR/soap 12-part2/
“Дополнительные части” спецификации SOAP 1.2.
38. W. Richard Stevens. TCP/IP Illustrated, Volume 1: The Protocols. — Addison-Wesley,
1994, ISBN 0201633469.
39. Microsoft. “System.Messaging namespace”, .NET Framework, version 1.1.
http://msdn.microsoft.com/library/default.asp?url=/library/en-
us/cpref/html/frhfsystemmessaging.asp
40. Jeni Tennison. XSLT and XPath on the Edge. — John Wiley & Sons, 2001,
ISBN 0764547763.
41. Martin Fowler. UML Distilled: A Brief Guide to the Standard Object Modeling Language
(3rd edition). — Addison-Wesley, 2003, ISBN 0321193687.
Чудесный справочник по диаграммам UML — как они должны выглядеть и что
означают.
42. Object Management Group. “ UML Profile for Enterprise Application Integration. ” — 2002.
http://www.omg.org/technology/documents/modeling_spec_catalog.htm
Основные источники информации
667
43. Gary R. Wright & W. Richard Stevens. TCP/IP Illustrated, Volume?: The
Implementation. — Addison-Wesley, 1995, ISBN 020163354X.
44. World Wide Web Consortium. “Web Services Architecture Usage Scenarios.” — W3C
Working Draft, May 14, 2003.
http://www. w3. org/TR/ws-arch -scenarios/
Очередные соображения консорциума W3C по поводу того, как следует применять
Web-службы и каким требованиям должны соответствовать их спецификации.
45. World Wide Web Consortium. Web Services Description Language (WSDL) 1.1.—
W3C Note, March 15, 2001.
http://www. w3. org/TR/wsdl
Спецификация WSDL 1.1.
46. IBM. Web Services Flow Language (WSFL) 1.0. — May, 2001.
http://www-3.ibm.com/software/solutions/webservices/pdf/WSFL.pdf
Спецификация WSFL 1.0.
47. IBM. WebSphere MQ Using Java (2nd edition). — October, 2002.
http://publibfp.boulder.ibm.com/epubs/pdf/csqzawll.pdf
Справочник разработчика для Java-программистов, использующих инфраструк-
туру обмена сообщениями WebSphere MQ от IBM [28].
48. World Wide Web Consortium. Extensible Markup Language (XML) 1.0 (2nd
edition). — W3C Recommendation, October 6, 2000.
http://www. w3. org/TR/REC-xml
Спецификация XML 1.0.
49. World Wide Web Consortium. XSL Transformations (XSLT) Version 1.0. — W3C
Recommendation, November 16,1999.
http://www. w3. org/TR/xslt
Спецификация XSLT 1.0.
50. Jim Waldo, Geoff Wyant, Ann Wollrath, & Sam Kendall. “A Note on Distributed
Computing.” — Technical Report SMLITR-94-29. — Sun Microsystems Laboratories,
November 1994.
http://research.sun.com/techrep/1994/smli_tr-94-29.pdf
51. Ron Zahavi. Enterprise Application Integration with CORBA. John Wiley & Sons, 1999,
ISBN 0471327204.
Предметный указатель
А
Application Programming Interface (API), 156
В
Business Process Execution Language for Web
Services (BPEL4WS), 330; 638
Business Process Modeling Language
(BPML), 640
c
Common Language Runtime (CLR), 138
E
Electronic Business Messaging
Service (ebMS), 636
Electronic Business using XML (ebXML), 635
Extensible Stylesheet Language (XSL), 119
J
Java Business Integration (JSR-208), 642
Java Community Process (JCP), 632
Java Language Metadata (JSR-175), 641
M
Microsoft Interface Definition Language
(MIDL), 544
О
OASIS, 632
P
Pragmatic General Multicast (PGM), 137
Process Definition for Java (JSR-207), 641
R
Remote Procedure Call (RPC), 57
Routing Information Protocol (RIP), 261
s
Service-Oriented Architecture (SOA), 49
Silly Window Syndrome (SWS), 301
Simple Object Access Protocol (SOAP), 384
u
Unified Modeling Language (UML), 60
Universal Description, Discovery and
Integration (UDDI), 390
w
W3C, 631
Web Service Choreography Interface (WSCI), 640
Web Services Deployment Descriptor
(WSDD), 389
Web Services Flow Language (WSFL), 330
Web Services Security Language (WSSL), 649
WS-Addressing, 650
WS-Conversation, 647
WS-Coordination, 643
WS-I, 632
WS-Policy, 650
WS-Reliabifity, 645
WS-ReliableMessaging, 645
WS-Security, 649
WS-Transaction, 643
X
XML Schema Definition (XSD), 386
XSL Transformation (XSLT), 119
A
Активный мониторинг, 578
Анализ
динамический, 607
статический, 607
Атомарная транзакция, 645
Предметный указатель
669
Б
Бизнес-активность, 645
В
Ветвление, 331
д
Двойная трансляция, 370
Действие, 330
Делегат, 417
Демультиплексирование, 141
3
Заголовок, 345
Задача, 330
И
Интеграция, 46
Итератор, 276
К
Канал, 54; 55
нулевой, 254
Канальный уровень (OSI), 345
Кодирование SOAP, 386
Компонент бизнес-процесса, 633
м
Маршрутизатор
без поддержки состояния, 112
на основе контекста, 112
с поддержкой состояния, 112
Машина, 642
Модель
с активным источником данных, 175\ 227
с пассивным источником данных, 776; 227
Мультиплексирование, 141
О
Объединение, 331
Окончание, 345
Операция, 330
Опрос, 507
Передача с промежуточным хранением, 149
Перемещение при сбое, 598
Предиктивная маршрутизация, 249
Привязка, 642
Продвижение, 344
Процесс
определение, 327
экземпляр, 327
Прямая трансляция, 370
Пульс, 554
Р
Реактивная фильтрация, 249
Регулирование, 478
С
Селектор, 255
Семантический диссонанс, 83
Сетевой уровень (OSI), 345
Синтезатор, 276
Слабое связывание, 50
Служба, 48
Сообщение, 54; 55
закрытое, 369
недопустимое, 148
недоставленное, 148
открытое, 369
Среда, 642
Стиль кодирования, 386
документолитеральный, 386
кодированный, 386
литеральный, 386
т
Таймаут повторных попыток, 150
Тема, 676
Транспортный уровень (OSI), 345
Тройник, 559
Туннелирование, 342; 346
Ф
Файл, 80
Фильтр, 106
Научно-популярное издание
Грегор Хоп, Бобби Вульф
Шаблоны интеграции корпоративных
приложений
Литературный редактор
Верстка
Художественный редактор
Корректоры
Л. И. Красножан
А. В. Плаксюк
С.А. Чернокозинский
Л.А. Гордиенко,
Л. В. Чернокозинская
Издательский дом “Вильямс”
127055, г. Москва, ул. Лесная, д. 43, стр. 1
Подписано в печать 16.11.2006. Формат 70x100/16
Гарнитура Newton. Печать офсетная
Усл. печ. л. 54,18. Уч.-изд. л. 41,00
Тираж 2000 экз. Заказ № 3275.
Отпечатано по технологии CtP
в ОАО “Печатный двор” им. А. М. Горького
197110, Санкт-Петербург, Чкаловский пр., 15