/






















































































































































































































































































Author: Акулов О.А. Медведев Н.В.
Tags: информационные технологии вычислительная техника обработка данных учебники и учебные пособия по кибернетике учебник для технических вузов
ISBN: 5-98119-630-X
Year: 2005




Text
УЧЕБНИК ДЛЯ ТЕХНИЧЕСКИХ ВУЗОВ
О.А. АКУЛОВ,
Н.В. МЕДВЕДЕВ
Информатика
БАЗОВЫЙ КУРС
Структура и свойства
информации
Принципы построения
вычислительных устройств
Системы обработки, хранения
и передачи информации
Контроль и защита информации
«Ж ОМЕГА-А
О.А. Акулов
Н.В. Медведев
базовый курс
2 издание,
исправленное и дополненное
Допущено УМО по университетскому
политехническому образованию
в качестве учебника
для студентов высших учебных заведений,
бакалавров, магистров,
обучающихся по направлениям
Информатика и вычислительная техника»
Жомега-л
Москва 2005
УДК 004(075.8)
ББК32.81я73-1
А44
Рецензенты:
доктор технических наук, заведующий кафедрой АСУ МГТУ
им. Н.Э. Баумана, профессор В.М. Черненький;
доктор физико-математических наук, заведующий сектором ВЦ РАН,
профессор В. К. Леонтьев
Акулов, Олег Анатольевич, Медведев, Николай Викторович.
А44 Информатика: базовый курс: учеб, пособие для студентов
вузов, обучающихся по направлениям 552800,654600 «Инфор-
матика и вычислительная техника»/О.А. Акулов, Н.В. Мед-
ведев. 2-е изд., испр. и доп. — М.: Омега-Л, 2005. — 552 с. —
ISBN 5-98119-630-Х.
I. Медведев, Николай Викторович.
Агентство CIP РГБ
В книге изложены основы современной информатики как комп-
лексной научно-технической дисциплины, включающей изучение
структуры и общих свойств информации и информационных про-
цессов, общих принципов построения вычислительных устройств,
а также систем обработки, хранения и передачи информации. Рас-
смотрены актуальные вопросы контроля и защиты информации
в автоматизированных системах. Представлены определения клю-
чевых понятий и конкретные вопросы по темам курса.
Для студентов высших учебных заведений, бакалавров, магист-
ров, обучающихся по специальности «Информатика и вычислитель-
ная техника», а также студентов, изучающих естественные науки.
УДК 004(075.8)
ББК32.81я73-1
ISBN 5-98119-630-Х
© О.А. Акулов, 2005
© Н.В. Медведев, 2005
© Омега-Л, 2005
Предисловие
Учебник охватывает основные разделы современной информа-
тики как комплексной научно-технической дисциплины, занима-
ющейся изучением структуры и общих свойств информации, ин-
формационных процессов, разработкой на этой основе информа-
ционной техники и технологии, а также решением научных и ин-
женерных проблем создания, внедрения и эффективного исполь-
зования компьютерной техники и технологии во всех сферах об-
щественной практики.
Учебник создан на основе чтения авторами курса лекций по
информатике в Московском государственном техническом уни-
верситете им. Н.Э.Баумана.
Главы с первой по пятую закладывают теоретическую базу ин-
форматики.
В главах с шестой по восьмую излагаются общие характерис-
тики процессов обработки, хранения и передачи информации,
способы их технической реализации.
Девятая глава посвящена актуальным вопросам контроля и за-
щиты информации в автоматизированных системах.
В заключение представлен список использованной литературы.
Учебник рассчитан на студентов младших курсов высших учеб-
ных заведений, бакалавров, магистров, обучающихся по направ-
лению «Информатика и вычислительная техника». По существу
это базовый курс, который знакомит их с широким спектром зна-
ний в данной области. Кроме того, может быть использован в ка-
честве ознакомительного курса по информатике для студентов,
изучающих естественные науки.
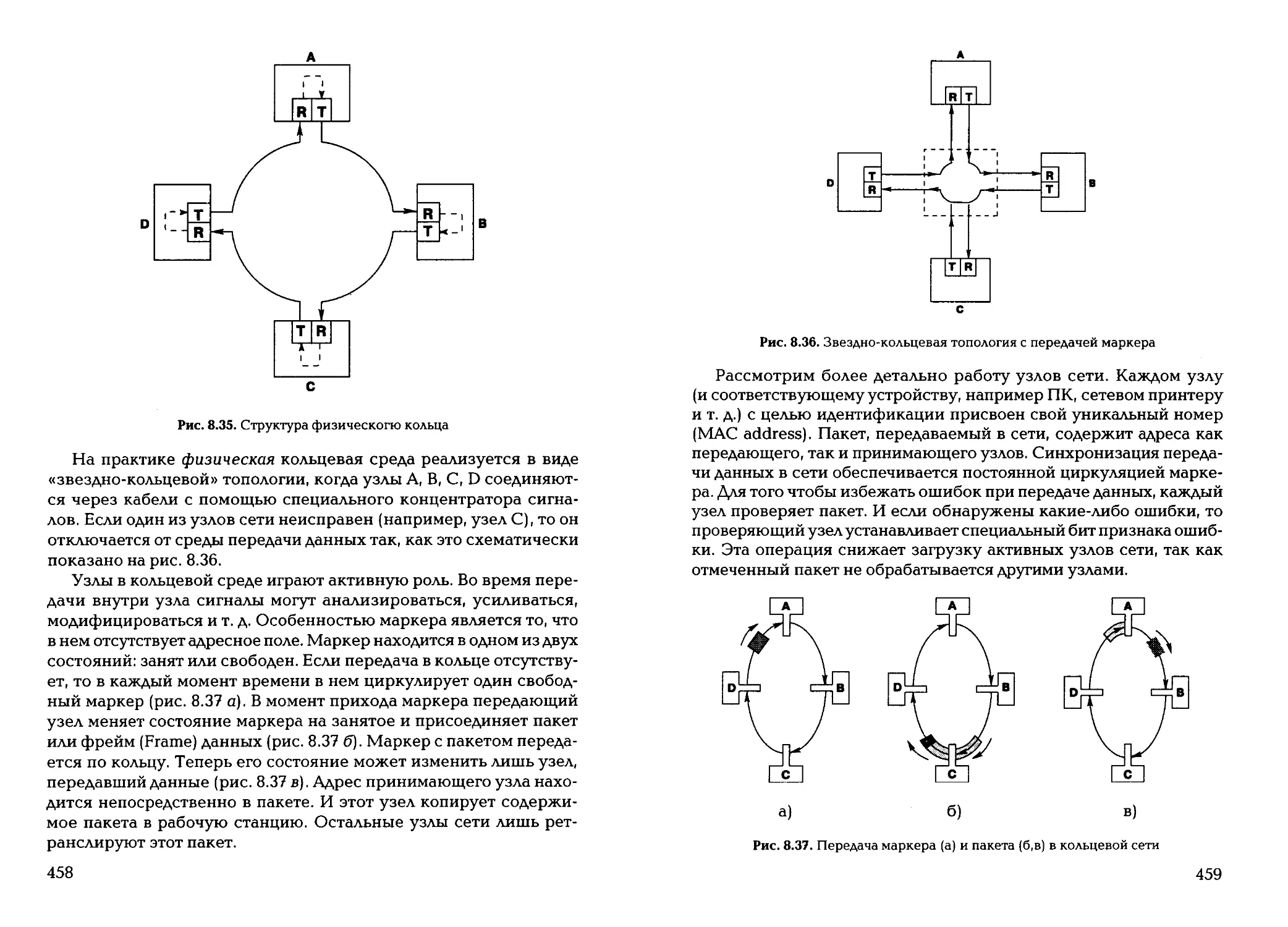
Тлава /
Информация и информатика
1.1. ПОНЯТИЕ ИНФОРМАЦИИ
Вся жизнь человека так или иначе связана с накоплением и об-
работкой информации, которую он получает из окружающего мира,
используя пять органов чувств — зрение, слух, вкус, обоняние и ося-
зание. Как научная категория «информация» составляет предмет
изучения для самых различных дисциплин: информатики, кибер-
нетики, философии, физики, биологии, теории связи и т. д. Несмот-
ря на это, строгого научного определения, что же такое информа-
ция, до настоящего времени не существует, а вместо него обычно
используют понятие об информации. Понятия отличаются от опре-
делений тем, что разные дисциплины в разных областях науки и тех-
ники вкладывают в него разный смысл с тем, чтобы оно в наиболь-
шей степени соответствовало предмету и задачам конкретной дис-
циплины. Имеется множество определений понятия информации,
от наиболее общего философского (информация есть отражение ре-
ального мира) до наиболее частного прикладного (информация есть
сведения, являющиеся объектом переработки). Вот некоторые из них:
сообщение, осведомление о положении дел, сведения о чем-
либо, передаваемые модели;
уменьшаемая, снимаемая неопределенность в результате по-
лучения сообщений;
передача, отражение разнообразия в любых процессах и
объектах, отраженное разнообразие;
товар, являющийся объектом купли-продажи знаний для до-
стижения определенных целей;
данные как результат организации символов в соответствии
с установленными правилами;
продукт взаимодействия данных и адекватных им методов;
сведения о лицах, предметах, фактах, событиях, явлениях и
процессах независимо от формы их представления.
Наряду с названными существуют сотни других, зачастую про-
тиворечащих друг другу или взаимоисключающих определений
4
информации. Многообразие этих определений свидетельствует о
широте подхода к понятию информации и отражает становление
концепции информации в современной науке.
Первоначально смысл слова «информация» (от лат. Informatio —
разъяснение, изложение) трактовался как нечто присущее только
человеческому сознанию и общению: «знания, сведения, сообще-
ния, известия, передаваемые людьми устным, письменным или дру-
гим способом». Затем смысл этого слова начал расширяться и обоб-
щаться. Так, с позиций материалистической теории познания од-
ним из всеобщих свойств материи (наряду с движением, развити-
ем, пространством, временем и др.) было признано отражение, зак-
лючающееся в способности адекватно отображать одним реальным
объектом другие реальные объекты, а сам факт отражения состоя-
ний одного объекта в состояниях другого (или просто одного объек-
та в другом) и означает присутствие в нем информации об отражае-
мом объекте. Таким образом, как только состояния одного объекта
находятся в соответствии с состояниями другого объекта (напри-
мер, соответствие между положением стрелки вольтметра и напря-
жением на его клеммах или соответствие между нашим ощущени-
ем и реальностью), это значит, что один объект отражает другой,
т. е. содержит информацию о другом.
Высшей, специфической формой отражения является сознание
человека. Кроме этого, существуют и другие формы — психичес-
кая (присущая не только человеку, но и животным, несущая в себе
информацию, способную влиять на их эмоциональные состояния
и поведение), раздражимость (охватывающая, помимо прочего, ра-
стения и простейшие организмы, реагирующие на слабые меха-
нические, химические, тепловые контакты с окружающей средой)
и самая элементарная форма — запечатление взаимодействия
(присущая и неорганической природе, и элементарным частицам,
т. е. всей материи вообще) (рис. 1.1).
Формы отражения Сознание
Психика
Раздражимость
Запечатление взаимодействия
Неорганическая природа Растительный мир Животный мир Человек
Рис. 1.1. Формы отражения в живой и неживой природе
5
Так, кусок каменного угля несет в себе «отражение» событий, про-
изошедших в далекие времена, т. е. обладает свойством информатив-
ности. Деловое письмо с предложениями сотрудничества информа-
тивно, постольку-поскольку отражает серьезные намерения опреде-
ленного учреждения или ведомства. Команда приступить к конкрет-
ным действиям (запуску ракеты, отправке груза, производству вы-
числений и т. п.) содержит информацию о подготовленности соот-
ветствующих служб и своевременности предпринимаемых шагов.
Информация не является ни материей, ни энергией. В отличие
от них она может возникать и исчезать. В указанных примерах ин-
формация в куске каменного угля или делового письма может ис-
чезнуть, если исчезнет ее носитель, например сгорит.
Особенность информации заключается в том, что проявляется
она только при взаимодействии объектов, причем обмен инфор-
мацией может совершаться не вообще между любыми объектами,
а только между теми из них, которые представляют собой органи-
зованную структуру (систему). Элементами этой системы могут
быть не только люди: обмен информацией может происходить в
животном и растительном мире, между живой и неживой приро-
дой, людьми и устройствами. Так, информация, заключенная в кус-
ке каменного угля проявится лишь при взаимодействии с челове-
ком, а растение, получая информацию о свете, днем раскрывает
свои лепестки, а ночью закрывает их.
Понятие «информация» обычно предполагает наличие двух
объектов — «источника» информации и «приемника» (потреби-
теля, адресата) информации (рис. 1.2).
Среда
распространения
Рис. 1.2. Структурные компоненты обмена информацией
6
Информация передается от источника к приемнику в матери-
ально-энергетической форме в виде сигналов (например, электри-
ческих, световых, звуковых и т. д.), распространяющихся в опре-
деленной среде.
Сигнал (от лат. signum — знак) — физический процесс (явление),
несущий сообщение (информацию) о событии или состоянии объек-
та наблюдения.
Информация может поступать непрерывно или дискретно, т. е.
в виде последовательности отдельных сигналов. Соответственно
различают непрерывную и дискретную информацию.
Информация — специфический атрибут реального мира, представ-
ляющий собой его объективное отражение в виде совокупности сиг-
налов и проявляющийся при взаимодействии с «приемником» инфор-
мации, позволяющим выделять, регистрировать эти сигналы из окру-
жающего мира и по тому или иному критерию их идентифицировать.
Из этого определения следует, что:
• информация объективна, так как это свойство материи —
отражение;
информация проявляется в виде сигналов и лишь при взаи-
модействии объектов;
одна и та же информация различными получателями может
быть интерпретирована по-разному, в зависимости от «на-
стройки» «приемника».
Человек воспринимает сигналы посредством органов чувств, ко-
торые «идентифицируются» мозгом. Поэтому, например, при на-
блюдении одного и того же объекта человек с лучшим зрением мо-
жет получить больше информации об объекте, чем тот, у которого
зрение хуже. В то же время, при одинаковой остроте зрения, в слу-
чае, например, прочтения текста на иностранном языке, человек,
не владеющий этим языком, вообще не получит никакой инфор-
мации, так как его мозг не сможет ее «идентифицировать». При-
емники информации в технике воспринимают сигналы с помощью
различной измерительной и регистрирующей аппаратуры. При
этом приемник, обладающий большей чувствительностью при ре-
гистрации сигналов и более совершенными алгоритмами их обра-
ботки, позволяет получить большие объемы информации.
7
Информация имеет определенные функции и этапы обращения
в обществе. Основными из них являются:
познавательная, цель которой — получение новой инфор-
мации. Функция реализуется в основном через такие этапы
обращения информации, как:
— ее синтез (производство),
— представление,
— хранение (передача во времени),
— восприятие (потребление);
* коммуникативная — функция общения людей, реализуемая
через такие этапы обращения информации, как:
— передача (в пространстве),
— распределение;
* управленческая, цель которой — формирование целесооб-
разного поведения управляемой системы, получающей ин-
формацию. Эта функция информации неразрывно связана
с познавательной и коммуникативной и реализуется через
все основные этапы обращения, включая обработку.
Без информации не может существовать жизнь в любой фор-
ме и не могут функционировать созданные человеком любые ин-
формационные системы. Без нее биологические и технические
системы представляют груду химических элементов. Общение,
коммуникации, обмен информацией присущи всем живым суще-
ствам, но в особой степени — человеку. Будучи аккумулирован-
ной и обработанной с определенных позиций, информация дает
новые сведения, приводит к новому знанию. Получение инфор-
мации из окружающего мира, ее анализ и генерирование состав-
ляют одну из основных функций человека, отличающую его от
остального живого мира.
1.2. ИНФОРМАЦИОННЫЕ ПРОЦЕССЫ И СИСТЕМЫ
В общем случае роль информации может ограничиваться эмо-
циональным воздействием на человека, однако наиболее часто она
используется для выработки управляющих воздействий в автома-
тических (чисто технических) и автоматизированных (человеко-
машинных) системах [8]. В подобных системах можно выделить
отдельные этапы (фазы) обращения информации, каждый из ко-
торых характеризуется определенными действиями.
8
Последовательность действий, выполняемых с информацией, на-
зывают информационным процессом.
Системы, реализующие информационные процессы, называют ин-
формационными системами.
Основными этапами (фазами) обращения информации в сис-
темах являются:
сбор (восприятие) информации;
подготовка (преобразование) информации;
передача информации;
обработка (преобразование) информации;
хранение информации;
отображение (воспроизведение) информации.
Так как материальным носителем информации является сигнал,
то реально это будут этапы обращения и преобразования сигна-
лов (рис. 1.3).
Рис. 1.3. Этапы обращения информации в автоматизированных системах
На этапе восприятия информации осуществляется целенаправ-
ленное извлечение и анализ информации о каком-либо объекте
(процессе), в результате чего формируется образ объекта, прово-
дятся его опознание и оценка. Главная задача на этом этапе — отде-
лить полезную информацию от мешающей (шумов), что в ряде слу-
чаев связано со значительными трудностями. Простейшим видом
восприятия является различение двух противоположных состояний:
наличия («да») и отсутствия («нет»), более сложным — измерение.
9
На этапе подготовки информации осуществляется ее первич-
ное преобразование. На этом этапе проводятся такие операции, как
нормализация, аналого-цифровое преобразование, шифрование.
Иногда этап подготовки рассматривается как вспомогательный на
этапе восприятия. В результате восприятия и подготовки получает-
ся сигнал в форме, удобной для передачи, хранения или обработки.
На этапе передачи информация пересылается из одного места в
другое (от отправителя получателю — адресату). Передача осуществ-
ляется по каналам различной физической природы, самыми распро-
страненными из которых являются электрические, электромагнит-
ные и оптические. Извлечение сигнала на выходе канала, подвержен-
ного действию шумов, носит характер вторичного восприятия.
На этапах обработки информации выявляются ее общие и су-
щественные взаимозависимости, представляющие интерес для си-
стемы. Преобразование информации на этапе обработки (как и на
других этапах) осуществляется либо средствами информационной
техники, либо человеком.
В общем случае под обработкой информации понимается любое
ее преобразование, проводимое по законам логики, математики, а
также неформальным правилам, основанным на «здравом смысле»,
интуиции, обобщенном опыте, сложившихся взглядах и нормах по-
ведения. Результатом обработки является тоже информация, но либо
представленная в иных формах (например, упорядоченная по каким-
то признакам), либо содержащая ответы на поставленные вопросы
(например, решение некоторой задачи). Если процесс обработки
формализуем, он может выполняться техническими средствами. Кар-
динальные сдвиги в этой области произошли благодаря созданию
ЭВМ как универсального преобразователя информации, в связи с чем
появились понятия данных и обработки данных.
Данными называют факты, сведения, представленные в формали-
зованном виде (закодированные), занесенные на те или иные носите-
ли и допускающие обработку с помощью специальных технических
средств (в первую очередь ЭВМ).
Обработка данных предполагает производство различных опе-
раций над ними, в первую очередь арифметических и логических,
для получения новых данных, которые объективно необходимы
(например, при подготовке ответственных решений).
10
На этапе хранения информацию записывают в запоминающее
устройство для последующего использования. Для хранения инфор-
мации используются в основном полупроводниковые, магнитные и
оптические носители. Решение задач извлечения хранимой инфор-
мации (поиска информации) связано с разработкой классификаци-
онных признаков и схем размещения хранимой информации, сис-
тематизацией, правилами доступа к ней, порядком ее пополнения и
обновления, т. е. всем тем, что определяет возможность целенаправ-
ленного поиска и оперативного извлечения хранимой информации.
Этап отображения информации должен предшествовать эта-
пам, связанным с участием человека. Цель этого этапа — предос-
тавить человеку нужную ему информацию с помощью устройств,
способных воздействовать на его органы чувств.
Информационные системы можно классифицировать по различ-
ным признакам. Так, по сфере применения информационные систе-
мы подразделяются на: административные, производственные, учеб-
ные, медицинские, военные и др. По территориальному признаку: ин-
формационные системы района, города, области и т. п. С точки зрения
возможности организации конкретных информационных процессов
различают информационно-справочные, информационно-поиско-
вые системы, системы обработки и передачи данных, системы связи.
Большинство автоматизированных информационных систем
являются локальными системами и функционируют на уровне
предприятий и учреждений. В настоящее время происходит ин-
тенсивный процесс интеграции таких систем в корпоративные
системы и далее — в региональные и глобальные системы.
Системы более высокого уровня становятся территориально рас-
средоточенными, иерархичными как по функциональному принципу,
так и по их технической реализации. Обеспечение взаимодействия
территориально рассредоточенных систем требует протяженных вы-
сокоскоростных и надежных каналов связи, а увеличение объема об-
рабатываемой информации—ЭВМ высокой производительности. Это
приводит к необходимости коллективного использования дорогосто-
ящих средств автоматизации (ЭВМ и линий связи) и обрабатываемой
информации (баз данных). Техническое развитие как самих электрон-
ных вычислительных машин, так и средств связи, позволило решить
эту проблему путем перехода к созданию распределенных информа-
ционно-вычислительных сетей коллективного пользования.
Централизация различных видов информации в одной сети дает
возможность использовать ее для решения широкого спектра за-
11
дач, связанных с административным управлением, планировани-
ем, научными исследованиями, конструкторскими разработками,
технологией производства, снабжением, учетом и отчетностью.
Если поставляемая информация извлекается из какого-либо
объекта (процесса), а выходная применяется для целенаправлен-
ного изменения состояния того же объекта (процесса), причем або-
нентом, использующим информацию для выбора основных управ-
ляющих воздействий (принятия решения), является человек, то
такую автоматизированную информационную систему называют
автоматизированной системой управления (АСУ).
Управление и информация служат основными понятиями ки-
бернетики — науки об общих принципах управления в различных
системах: технических, биологических, социальных и др.
Управление — функция организованных систем различной при-
роды (технических, биологических или социальных), направленная на
реализацию их целевых установок и поддержание внутренне присущей
им структуры.
Понятие «кибернетика» как научный термин введено в первой
половине XIX века французским физиком Андре Мари Ампером,
который назвал кибернетикой (от греч. слова кибернетикос —
искусный в управлении) науку, занимающуюся изучением искус-
ства управления людьми, обществом. В Древней Греции этого ти-
тула удостаивались лучшие мастера управления боевыми колес-
ницами. Впоследствии слово «кибернетикос» было заимствовано
римлянами — так в латинском языке появилось слово «губерна-
тор» (управляющий провинцией).
Кибернетика — наука, изучающая с единых позиций связь и уп-
равление (самоуправление) в организованных системах любой физи-
ческой природы.
Основоположником кибернетики считается выдающийся аме-
риканский математик Норберт Винер (1894—1964), а датой ее рож-
дения —1948 г., когда он опубликовал книгу «Кибернетика или уп-
равление и связь в животном и машине». Сущность кибернетики
в самом общем виде может быть выражена основными ее закона-
ми, структура и содержание которых приведены на рис. 1.4 [7].
12
Формулировка общих законов управления
1. Всякое управление есть 2. Всякое управление есть 3. Всякое управление обычно
целенаправленный процесс информационный процесс осуществляется
в замкнутом контуре
1. Процессы сбора
информации
2. Процессы обработки
и представления
информации
для принятия решений
3. Процессы хранения
и передачи информации
Управляющий
объект
Рис. 1.4. Состав и содержание общих законов управления
Таким образом, кибернетическая система (система управления)
может рассматриваться как совокупность двух систем — управля-
ющего объекта и объекта управления. При этом управляющая си-
стема воздействует на объект управления, подавая на него управ-
ляющие сигналы (управляющие воздействия). Для выработки уп-
равляющих решений, обеспечивающих достижение цели управ-
ления, управляющая система получает информацию о состоянии
объекта управления по линии обратной связи.
Автоматизированные системы управления нашли широкое при-
менение во всех сферах современного общества, в первую очередь
как системы управления технологическими процессами и коллек-
тивами людей. АСУ технологическими процессами служат для ав-
томатизации различных функций на производстве. Они широко
используются при организации поточных линий, изготовлении
микросхем, для поддержания технологического цикла в машино-
строении и т. п. Информационные системы организационного уп-
равления предназначены для автоматизации функций управлен-
13
ческого персонала, например информационные системы управле-
ния банками, гостиницами, торговыми фирмами и т. п.
1.3. ИНФОРМАЦИОННЫЕ РЕСУРСЫ И ТЕХНОЛОГИИ
Особенностью современного этапа развития общества является
переход от индустриального общества к информационному. Про-
цесс, обеспечивающий этот переход, называют информатизацией.
Информатизация общества — организованный социально-эконо-
мический и научно-технический процесс создания оптимальных усло-
вий для удовлетворения информационных потребностей и реализации
прав граждан, органов государственной власти, органов местного са-
моуправления, организаций, общественных объединений на основе
формирования и использования информационных ресурсов [25].
Неизбежность информатизации обусловлена резким возраста-
нием роли и значения информации. Для нормального функциони-
рования организации любого масштаба уже не достаточно только
традиционных для индустриального общества ресурсов (материаль-
ных, природных, трудовых, финансовых, энергетических), необхо-
димо знать, как наиболее эффективно эти ресурсы использовать,
иметь информацию о технологиях. Поэтому существенным ресур-
сом стала информация. Информационные ресурсы в настоящее
время рассматриваются как отдельная экономическая категория,
важнейший стратегический ресурс общества.
Информационные ресурсы — отдельные документы и отдельные
массивы документов, документы и массивы документов в информа-
ционных системах (библиотеках, архивах, фондах, банках данных, дру-
гих информационных системах).
Информационная система — организационно упорядоченная со-
вокупность документов, информационных технологий, в том числе с
использованием средств вычислительной техники и связи, реализую-
щих информационные процессы [25].
В общем случае под информационными ресурсами понимают
весь имеющийся в информационной системе объем информации,
14
отчужденной от ее создателей и предназначенной для обществен-
ного использования.
Основной особенностью информационных ресурсов является то,
что в отличие от других видов ресурсов (материальных, природных и
др.) они практически неисчерпаемы; по мере развития общества и
роста потребления информации их запасы не убывают, а растут. Эта
специфика информационных ресурсов хорошо иллюстрируется сле-
дующим высказыванием: «Если у вас есть по яблоку и вы обменяе-
тесь ими, у вас опять будет по яблоку, но если у вас есть по идее и вы
обменяетесь ими, то у каждого их будет по две». Более того, в процес-
се применения информационные ресурсы постоянно развиваются и
совершенствуются, избавляясь от ошибок и уточняя свои параметры.
Выделяют пассивную и активную формы информационных ре-
сурсов. К пассивной форме относятся книги, журнальные статьи,
патенты, банки данных и т. п. Примерами активных форм служат:
модель, алгоритм, проект, программа и т. п.
Государственная политика в сфере формирования информацион-
ных ресурсов и информатизации направлена на создание условий
для эффективного и качественного информационного обеспечения
решения задач социально-экономического развития. Основными на-
правлениями государственной политики в этой области являются:
• обеспечение условий для развития и защиты всех форм соб-
ственности на информационные ресурсы;
• формирование и защита информационных ресурсов;
создание и развитие федеральных и региональных информа-
ционных систем и сетей, обеспечение их совместимости и вза-
имодействия в едином информационном пространстве РФ;
создание условий для качественного и эффективного инфор-
мационного обеспечения граждан, органов государственной
власти, органов местного самоуправления, организаций и об-
щественных объединений на основе государственных инфор-
мационных ресурсов;
содействие формированию рынка информационных ресур-
сов, услуг, информационных систем, технологий и средств
их обеспечения;
формирование и осуществление единой научно-технической
и промышленной политики в сфере информатизации с уче-
том современного мирового уровня развития информацион-
ных технологий;
" создание и совершенствование системы привлечения инве-
стиций и механизма стимулирования разработки и реализа-
ции проектов информатизации;
15
• развитие законодательства в сфере информационных про-
цессов, информатизации и защиты информации.
Базовой технической составляющей процесса информатизации
общества является компьютеризация.
Под компьютеризацией понимается развитие и внедрение тех-
нической базы — компьютеров, обеспечивающих оперативное по-
лучение результатов переработки информации и ее накопление.
Научным фундаментом процесса информатизации общества яв-
ляется информатика, призванная создавать новые информацион-
ные технологии и системы для решения задач информатизации.
Технология (от греч. techne — искусство, мастерство, умение и греч.
logos — слово, учение) — совокупность методов обработки, изготов-
ления, изменения состояния, свойств, формы сырья, материала или
полуфабриката, осуществляемых в процессе производства продукции.
Основными компонентами материальных технологий являют-
ся: подготовка сырья и материалов, производство материального
продукта, сбыт произведенных продуктов потребителям.
В информационной технологии в качестве исходного материа-
ла выступает информация. В качестве конечного продукта — так-
же информация, но это качественно новая информация о состоя-
нии объекта, процесса или явления. При этом основными компо-
нентами информационных технологий служат: сбор данных (пер-
вичной информации), обработка данных, получение результатной
информации и передача ее потребителю.
Выделяют несколько поколений информационных технологий:
• самую древнюю — «наскально-берестяную»;
«бумажную», связанную с изобретением печатного станка
(середина XVвека);
«безбумажную», или «электронную», относящуюся к появ-
лениюм ЭВМ (середина XX века);
«новую информационную технологию», связанную с внедре-
нием персональных ЭВМ и телекоммуникационных средств
(с середины 80-х годов прошлого века).
Новая информационная технология (компьютерная информаци-
онная технология) — технология, основанная на использовании пер-
сональных компьютеров и телекоммуникационных средств.
16
В процессе информатизации общества происходит проникно-
вение информационных технологий во все сферы жизнедеятель-
ности общества, в том числе и связанные с принятием ответствен-
ных решений. При этом уже сейчас информационные технологии
оказывают решающее воздействие на многие сферы деятельнос-
ти людей, человеческих коллективов и общество в целом. Однако
указанное воздействие в некоторых случаях может иметь и нега-
тивный характер [7].
Во-первых, вычислительная техника все более широко внедряет-
ся в системы управления такими технологическими процессами, вы-
ход которых за регламентированные пределы грозит не только круп-
ными авариями, но и крупномасштабными катастрофами (системы
управления вооружением, атомными реакторами и т. п.). Отличитель-
ной особенностью таких систем управления является необходимость
осуществления сложных видов обработки больших объемов инфор-
мации в крайне ограниченные сроки. В силу этого сложность систем
неуклонно растет, а гарантировать отсутствие ошибок в программ-
ном обеспечении, исчисляемом многими десятками миллионов ма-
шинных команд, практически невозможно. Помимо этого, возмож-
ны сбои или отказы аппаратуры, провокационные и диверсионные
действия персонала, заражение компьютеров электронными виру-
сами и т. п. Нетрудно представить себе возможные последствия та-
ких событий в системе военного назначения. Иными словами, в со-
временных условиях надо защищать как системы обработки инфор-
мации от воздействия внешней среды, так и среду от воздействия ин-
формации, находящейся в системах обработки. Должна быть обес-
печена не только безопасность информации, накапливаемой, храни-
мой и обрабатываемой в системах, но также и информационная бе-
зопасность окружающей среды, т. е. предупреждение негативного
воздействия на окружающую среду, которое может иметь место в
результате непредусмотренных (ошибочных или злоумышленных)
видов обработки.
Во-вторых, массовое использование вычислительной техники
в различных сферах деятельности резко увеличивает потенциаль-
ные возможности нарушения гражданских прав и свобод челове-
ка, поскольку в условиях повсеместного внедрения новых инфор-
мационных технологий расширяются возможности ведения досье
на людей, подслушивания телефонных разговоров, несанкциони-
рованного чтения электронной почты, контролирования вкладов,
осуществления компьютерной слежки и т. п.
2 А-210
17
В-третьих, увеличивается опасность нарушения авторского пра-
ва и права собственности, в первую очередь на программные про-
дукты. Во многих случаях программное обеспечение как отдель-
ными пользователями, так и целыми организациями приобретает-
ся в результате незаконного копирования, т. е. хищения.
В-четвертых, информатизация может являться и источником со-
циальной напряженности. Так, автоматизация производства ведет
к полному изменению технологии, что влечет за собой смену но-
менклатуры профессий и сокращение численности персонала. При
этом не все люди могут легко освоить новую специальность или
найти новое место работы.
Заслуживает быть отмеченным и такой несколько необычный
аспект, как опасность профанации искусства, поскольку широкие
возможности современных ЭВМ позволяют существенно интен-
сифицировать процесс творчества, а интенсификация его сверх
некоторой меры неизбежно скажется на качестве произведения.
Кроме того, по мнению некоторых ученых, у руководителей и спе-
циалистов, длительное время и регулярно использующих вычис-
лительную технику в процессе своей деятельности, атрофируют-
ся опыт и интуиция относительно важных своих функций.
Негативные аспекты информационных технологий необходимо
учитывать при решении задач информатизации. Эти проблемы дол-
жны также стать предметом изучения современной информатики.
1.4. ИНФОРМАТИКА И ЕЕ ПРЕДЫСТОРИЯ
Задачи накопления (хранения), обработки и передачи информа-
ции стояли перед человечеством на всех этапах его развития. Каж-
дому этапу соответствовал определенный уровень развития средств
информационного труда, прогресс развития которых всякий раз
придавал человеческому обществу новое качество. Долгое время
средства хранения, обработки и передачи информации развивались
отдельно по этим трем направлениям табл. 1.1. Этот период в исто-
рии развития информатики можно назвать ее предысторией.
В течение долгого времени основными инструментами для ре-
шения задач обработки и передачи информации были мозг, язык
и слух человека. Первое кардинальное изменение пришло с при-
ходом письменности (по мнению ученых, речь возникла более ты-
сячи веков назад, изобретение письменности относится к третьему
18
Q
ST
3
*5
rQ
X
f
X
s
8
tQ
<
о
©
я
x
о
x
tr
«
s
a.
о
•e
X
X
и
a>
R
X
H
X
n
м
я
ua
E
fl
h
Г)
X
§
я
£
I
я
e
X
I
f
£
X
8
о
5
S
I
s
J X
H
s
3 &
X
8
5
5
111
ill?
3 3
al
= s
K
hil
§
a
m
g
X
i I*
§.x *
S л x
о S g
e; Я g
s
X
s
X
S
Ух
г
g “ I
Г
sS
<3 S
s'
s
=:
s
5
8 =
ij
“ X
о
e
3
ffi
si
11
3
s
s 3
x
я
g
s
X
5
s!
4 !S
a ®
s
X
s
3
5
a
г :s
i S
5
o -
5
X
- Й
1 I
z
s
f?
о
3
g
s
-e-
X
2
2
8
X
2
Л
g
2
о
X
X
I
B®x
C s s 2
-I *
>f2fS
X o. x
S
В J §
s s< Z,
X
2
x
x
2
X
3
и
X
X
s
8
s
X
I
I
X
g
8
X
S'
E(
X
X
g
£
X
X
I
X
cq a
X
a
i
3
&
X
X
г>
3
я
s
3
s
з
x
s
53“
X
Й
1 I
5 |
X
5
X
2
s
ЭХ
thii
8 S
4 A
Q>
г
о
Ч
X
I
3
о
z
I
X
X
X
о
z
£
s
I
X
Q.
x
s
s
X
X
H
8
X
I
X
S
«j
S
3
X
li
i
z
5!
X
X
3
fiB
5
?s
§8
2
о
x
s
X
3
X
3
X
a
s
s
_ о
gs
x
s
X
3
x.
i
5
1
§
X
ЗГ
s
§
V -
= g
8.C
8 *
зХ
X
X
X
i
s
U!
x •©• 2
§ 5 x
E < E
3^2
ffi s
§
8
A
§
9 9 5
I 8 .
h! h
3
S'S
X
8
X
s
I
2
3 £ §
g
X
3
X
X
X
s
8
Z
z
i!
b
& 5
3
X
3
i
<4
s
*
§
*
3
H
X
Cu
E
a
X
KJ
s
В
s
4
I
V
5
9X
-sz-л!
gifts iliafF
7 X X U U ©
X X
11
§ §
5
3
о
8.U |
ШН
8
p
5
3
8
s
з
i
!
z
a
§ _
“'g
z
5
u
= :X
a ©
O. x
2 e-
Б =
* X
I
p
a
g.
S
о
X
3
г
s
z
S !<>
X X E
S X
я x 3
Ц-
s 3
i*
X
i I
« 3
5^
z m
о
5
s
ц
I
rt X
= s
il
x
S
a
4
з
s
8
ч
s
X
x
X
B-F §=i
i = i Й
Я
s
X
X
E
Zl&bg'l
S £ g >x
§ p § i
2 " «
f Hit
1
«g
О Л
S
X
8
3
3
5 e s
x S o.
§ u
м x x
§3 я
I §
г a
ьс
8 5
E
£m В
i
-s
0^7?
x
X
©
5
X
X
s° Ovi
ht
НИН:
£
t X
X
3 ?
Hi
Id J
5
co
X
*
S
g
g
CM
g
2
3
5
3
8
X
M
X
*
s
и a. M
f S I
S
*
з
X
:X
3
ffi
8
%
X
г
8
g
fll p
* g
S
8
C £! §
X д£_
« aS"
ex
X и
X s
* X
i.
з «ecg
Ц*
Ш
Hi"
P
k
3
03
s
s a
Й
I®
X
x
5,8
8 3
II
о a
» i,
s
a
s -
g g
§ 8.
§
§
X
8
z'
s,
s
§ 3
« ¥
3 g
8 8
° 2
о
z
8
'g
if 8 Oi
x 3
§ о s
3
о
о =:
lii
W
Hi
— e E
w
x
x
I
!a
rO \©
. з
M
2.
19
Окончание табл. 1.1
20
тысячелетию до н. э.). Это привело к гигантскому качественному
и количественному скачку в развитии общества, появилась воз-
можность передачи знаний от поколения к поколению. Изобрете-
ние книгопечатания (середина XV века) радикально изменило ин-
дустриальное общество, культуру, организацию деятельности.
Эти два этапа (письменность и книгопечатание) создали прин-
ципиально новую технологию накопления и распространения (пе-
редачи) информации, избавившую человечество от необходимос-
ти всецело полагаться на такой зыбкий и ненадежный инструмент,
каким является человеческая память.
Конец XIX века ознаменован изобретением электричества,
благодаря которому появились телеграф, телефон, радио, позво-
ляющие оперативно передавать и накапливать информацию в лю-
бом объеме.
Бурное развитие науки и промышленности в XX веке, неудер-
жимый рост объемов поступающей информации привели к тому,
что человек оказался не в состоянии воспринимать и перерабаты-
вать все ему предназначенное. Возникла необходимость класси-
фицировать поступления по темам, организовать их хранение, до-
ступ к ним, понять закономерности движения информации в раз-
личных изданиях и т. д. Исследования, позволяющие разрешить воз-
никшие проблемы, стали называть информатикой. В этом смысле
информатика — научная дисциплина, изучающая структуру и об-
щие свойства научной информации, а также закономерности всех
процессов научной коммуникации.
Информатика, являясь базой библиотечного дела, многие годы
так и занималась узкоконкретной областью изучения структуры
и общих свойств научной информации, передаваемой посредством
научной литературы. Постановка вопроса о завладении информа-
тикой всем кругом вопросов, который связан с разработкой эф-
фективных методов сбора, хранения, обработки и преобразования
имеющейся информации в знания, прежде была неправомерной,
так как не существовало почти ничего общего в методах сбора и
обработки информации у медиков, географов, психологов, физи-
ков, филологов и т. д. С этой точки зрения много общего между
собой имели математика и физика, химия и медицина. Примеров
отдельных связей было много, но общего стержня, вокруг которо-
го объединились бы все науки, не было.
Положение существенно изменилось с появлением электрон-
но-вычислительных машин (ЭВМ).
21
Первые ЭВМ создавались для проведения расчетов в атомной
физике, в летательной и ракетной технике. Последовавшее да-
лее внедрение ЭВМ в области административного управления и
экономики дало не только большой экономический эффект, но и
привело к созданию и бурному росту новой промышленной от-
расли — средств и методов электронной обработки информации.
Электронно-вычислительные машины стали обрабатывать чис-
ловую, текстовую, графическую и другую информацию. Появи-
лись новые ЭВМ, новые методы и средства общения с ними. Ин-
формация стала товаром.
Вычислительная техника сразу же показала свою эффектив-
ность в тех областях человеческой деятельности, где широко ис-
пользовались методы математического моделирования — точные
количественные методы. Сюда относятся физика, механика, хи-
мия, геофизика и т. д.
Развитие электронно-вычислительной техники, средств и мето-
дов общения с ней, создание автоматизированных информацион-
но-поисковых систем, методов распознавания образов привели к
тому, что ЭВМ стали эффективным инструментом и для «описатель-
ных» наук, которые раньше считались недоступными для методов
математического моделирования (биология, юридические науки, ис-
тория и т. п.). В них шло накопление отдельных фактов, давалось
качественное описание объектов и событий. Использование ново-
го рабочего инструмента значительно повысило эффективность
проведения описательного анализа изучаемых объектов в таких
науках. Появилось новое направление исследований, связанное с
машинным моделированием человеческих интеллектуальных фун-
кций, — разработка «искусственного интеллекта».
Миниатюризация средств вычислительной техники, снижение ее
стоимости позволили создавать станки с программным управлени-
ем, гибкие автоматизированные производства, станки-роботы, в ко-
торых ЭВМ решает задачи сбора, хранения, обработки, преобразо-
вания информации и на основании ее анализа вырабатывает соот-
ветствующие решения. В более сложных задачах человек, используя
электронную технику, берет ответственность за принятие решения
на себя. В этом случае ЭВМ анализирует огромные объемы инфор-
мации и предлагает возможные варианты. Человек, познакомившись
с этими вариантами, либо выбирает лучший, с его точки зрения, либо
ставит перед машиной новые условия и ждет следующего совета. Так,
в режиме диалога происходит процесс принятия решения.
22
Проведение любого эксперимента связано с получением инфор-
мации, регистрируемой различными датчиками или непосред-
ственно органами чувств человека. В ходе эксперимента инфор-
мацию надо принять и записать, обработать по специальным алго-
ритмам, преобразовать к удобному для анализа виду. Далее, иссле-
дуя полученные результаты, необходимо сделать выводы.
При этом не имеет значения, какой это эксперимент — физи-
ческий, биологический, химический и т. д., передают ли датчики
данные прямо в ЭВМ или показания приборов сначала записыва-
ют в тетрадь, а потом вводят их в машину. Главное в том, что нуж-
ны алгоритмы сбора данных и записи их в запоминающие устрой-
ства в таком виде, который позволяет находить эти данные повтор-
но, считывать и анализировать.
Другой важнейшей составной частью эксперимента является
обработка данных по разработанным алгоритмам и составленным
на их основе программам для вычислительной машины.
На следующем этапе активно используются программы преоб-
разования данных к удобному для исследования виду (построение
графиков, таблиц, рабочих чертежей и т. д.) и их выдача (отобра-
жение информации) или передача другим участникам эксперимен-
та, находящимся на значительном расстоянии. Как правило, такие
программы не ориентированы на конкретную предметную область,
они достаточно универсальны.
Таким образом, мы выделили задачи, которые являются общи-
ми для всех наук при обработке информации с помощью ЭВМ. На-
учным фундаментом для их решения и стала новая наука — ин-
форматика.
В этом смысле слово «информатика» второй раз появляется в
научной среде. Теперь — как перевод с французского informatique.
Французский термин informatique (информатика) образован пу-
тем слияния слов information (информация) и automatique (автома-
тика) и означает «информационная автоматика или автоматизи-
рованная переработка информации». В англоязычных странах это-
му термину соответствует синоним computer science (наука о вы-
числительной технике).
Появление ЭВМ сыграло решающую роль в оформлении ин-
форматики как науки, но и сама ЭВМ, ее создание, функциониро-
вание и применение — тоже предмет изучения информатики.
Практика показала, что использование ЭВМ резко повысило про-
изводительность труда на производстве и в науке, оказало силь-
23
ное влияние на научно-технический прогресс. В то же время су-
ществует и обратное влияние — задачи науки и практики предъяв-
ляют конструкторам и разработчикам программ требования для
создания новых, более высокопроизводительных ЭВМ, ориенти-
рованных на решение конкретных проблем.
Раннее употребляемый в русском языке термин «информатика»,
связанный с узкоконкретной областью изучения структуры и об-
щих свойств научной информации, передаваемой с помощью науч-
ной литературы, в современных условиях приобретает более ши-
рокое значение — название комплексной научно-технической дис-
циплины, призванной создавать новые информационные техноло-
гии и средства для решения проблем информатизации в различных
областях человеческой деятельности: производстве, управлении,
науке, образовании, торговле, финансовой сфере, медицине и др.
Информатика — комплексная научно-техническая дисциплина,
занимающаяся изучением структуры и общих свойств информации,
информационных процессов, разработкой на этой основе информа-
ционной техники и технологии, а также решением научных и инже-
нерных проблем создания, внедрения и эффективного использования
компьютерной техники и технологии во всех сферах общественной
практики.
1.5. СТРУКТУРА ИНФОРМАТИКИ
И ЕЕ СВЯЗЬ С ДРУГИМИ НАУКАМИ
Ядро современной информатики образуют три составные час-
ти, каждая из которых может рассматриваться как относительно
самостоятельная научная дисциплина (рис. 1.5).
Теоретическая информатика — часть информатики, занимаю-
щаяся изучением структуры и общих свойств информации и ин-
формационных процессов, разработкой общих принципов пост-
роения информационной техники и технологии. Она основана на
использовании математических методов и включает в себя такие
основные математические разделы, как теория алгоритмов и ав-
томатов, теория информации и теория кодирования, теория фор-
мальных языков и грамматик, исследование операций и др.
24
Теоретическая
информатика
Основные
разделы:
теория алгорит-
мов и автоматов;
теория
информации;
теория
кодирования;
математическая
логика;
теория
формальных
языков
и грамматик;
исследование
операций и др.
Средства информатизации
технические программные
средства обработки информации; средства передачи информации; средства хранения информации; средства представления информации системное программное обеспечение; инструментарий технологии программирования; пакеты прикладных программ
Информационные системы и технологии
• ввода/вывода, сбора, хранения, передачи и обработки данных;
• подготовки текстовых и графических документов;
• защиты информации;
• программирования, проектирования, моделирования, обучения,
диагностики, управления объектами, процессами, системами
(информационно-справочные, информационно-поисковые системы,
современные глобальные системы хранения и поиска информации,
включая Интернет и др.)
Рис. 1.5. Структура информатики
Средства информатизации (технические и программные)—раздел,
занимающийся изучением общих принципов построения вычисли-
тельных устройств и систем обработки и передачи данных, а также
вопросов, связанных с разработкой систем программного обеспечения.
Информационные системы и технологии — раздел информа-
тики, связанный с решением вопросов по анализу потоков инфор-
мации, их оптимизации, структурировании в различных сложных
системах, разработкой принципов реализации в данных системах
информационных процессов.
25
Иногда информационные технологии называют компьютерны-
ми технологиями или прикладной информатикой. Само слово
«компьютер» произошло от английского computer, переводимого
на русский язык как «вычислитель», или электронная вычислитель-
ная машина — ЭВМ.
Технические (аппаратные) средства, или аппаратура компьюте-
ров, в английском языке обозначаются словом hardware, которое пе-
реводится как «твердые изделия». Для обозначения программных
средств, под которыми понимается совокупность всех программ, ис-
пользуемых компьютерами, и область деятельности по их созданию
и применению, используется слово software (в переводе — «мягкие
изделия»), которое подчеркивает способность программного обес-
печения модифицироваться, приспосабливаться и развиваться.
Изучением закономерностей и форм движения информации
в обществе, возникающих в современном обществе информаци-
онных, психологических, социально-экономических проблем и
методов их решения занимается новое направление исследований
в области информатики — социальная информатика.
Информатика — очень широкая сфера научных знаний, возник-
шая на стыке нескольких фундаментальных и прикладных дисциплин.
Фундаментальная наука — наука, изучающая объективные зако-
ны природы и общества, осуществляющая теоретическую системати-
зацию знаний о действительности.
К фундаментальным принято относить те науки, основные по-
нятия которых носят общенаучный характер, используются во мно-
гих других науках и видах деятельности.
Как комплексная научная дисциплина информатика связана
с (рис. 1.6):
философией и психологией — через учение об информации
и теорию познания;
математикой — через теорию математического моделирова-
ния, дискретную математику, математическую логику и те-
орию алгоритмов;
лингвистикой — через учение о формальных языках и о зна-
ковых системах;
кибернетикой — через теорию информации и теорию уп-
равления;
физикой и химией, электроникой и радиотехникой — через
«материальную» часть компьютера и информационных систем.
26
Рис. 1.6. Связь информатики с другими науками
Роль информатики в развитии общества чрезвычайно велика.
Она является научным фундаментом процесса информатизации
общества. С ней связано прогрессивное увеличение возможнос-
тей компьютерной техники, развитие информационных сетей,
создание новых информационных технологий, которые приводят
к значительным изменениям во всех сферах общества: в произ-
водстве, науке, образовании, медицине и т. д.
Контрольные вопросы =
1. Какие определения понятия «информация» Вы знаете?
2. Назовите формы отражения в живой и неживой природе.
27
3. Назовите основные структурные компоненты процесса обмена ин-
формацией.
4. Какие функции и формы движения в обществе имеет информация?
5. Что такое информационный процесс?
6. Назовите основные этапы обращения информации в автоматизи-
рованных системах.
7. Что такое данные?
8. Назовите состав и содержание общих законов управления.
9. Что такое информационный ресурс и в чем его особенности?
10. В чем состоит процесс информатизации?
11. В чем отличие процессов компьютеризации и информатизации?
12. Определите суть информационных технологий.
13. Какие негативные последствия несет с собой появление новых
информационных технологий?
14. Расскажите об истории развития средств информационного труда.
15. Как и для чего появилась информатика?
16. Дайте определение информатики.
17. Какова общая структура современной информатики?
18. Как информатика связана с другими науками?
Тлава 2
Количество и качество информации
2.1. УРОВНИ ПРОБЛЕМ ПЕРЕДАЧИ ИНФОРМАЦИИ
При реализации информационных процессов всегда происхо-
дит перенос информации в пространстве и времени от источника
информации к приемнику (получателю) (см. рис. 1.2). При этом для
передачи информации используют различные знаки или симво-
лы, например естественного или искусственного (формального)
языка, позволяющие выразить ее в некоторой форме, называемой
сообщением.
Сообщение — форма представления информации в виде совокуп-
ности знаков (символов), используемая для передачи.
Сообщение как совокупность знаков с точки зрения семиоти-
ки (от греч. semeion — знак, признак) — науки, занимающейся ис-
следованием свойств знаков и знаковых систем, может изучаться
на трех уровнях [8]:
синтаксическом, где рассматриваются внутренние свойства
сообщений, т. е. отношения между знаками, отражающие
структуру данной знаковой системы. Внешние свойства изу-
чают на семантическом и прагматическом уровнях;
семантическом, где анализируются отношения между зна-
ками и обозначаемыми ими предметами, действиями, каче-
ствами, т. е. смысловое содержание сообщения, его отноше-
ние к источнику информации;
прагматическом, где рассматриваются отношения между со-
общением и получателем, т. е. потребительское содержание
сообщения, его отношение к получателю.
Таким образом, учитывая определенную взаимосвязь проблем
передачи информации с уровнями изучения знаковых систем, их
разделяют на три уровня: синтаксический, семантический и праг-
матический.
29
Проблемы синтаксического уровня касаются создания теоре-
тических основ построения информационных систем, основные
показатели функционирования которых были бы близки к предель-
но возможным, а также совершенствования существующих сис-
тем с целью повышения эффективности их использования. Это
чисто технические проблемы совершенствования методов пере-
дачи сообщений и их материальных носителей — сигналов. На этом
уровне рассматривают проблемы доставки получателю сообщений
как совокупности знаков, учитывая при этом тип носителя и спо-
соб представления информации, скорость передачи и обработки,
размеры кодов представления информации, надежность и точность
преобразования этих кодов и т. п., полностью абстрагируясь от
смыслового содержания сообщений и их целевого предназначе-
ния. На этом уровне информацию, рассматриваемую только с син-
таксических позиций, обычно называют данными, так как смыс-
ловая сторона при этом не имеет значения.
Современная теория информации исследует в основном про-
блемы именно этого уровня. Она опирается на понятие «количе-
ство информации», являющееся мерой частоты употребления зна-
ков, которая никак не отражает ни смысла, ни важности переда-
ваемых сообщений. В связи с этим иногда говорят, что теория ин-
формации находится на синтаксическом уровне.
Проблемы семантического уровня связаны с формализацией
и учетом смысла передаваемой информации, определения степе-
ни соответствия образа объекта и самого объекта. На данном уров-
не анализируются те сведения, которые отражает информация,
рассматриваются смысловые связи, формируются понятия и пред-
ставления, выявляется смысл, содержание информации, осуществ-
ляется ее обобщение.
Проблемы этого уровня чрезвычайно сложны, так как смысло-
вое содержание информации больше зависит от получателя, чем
от семантики сообщения, представленного на каком-либо языке.
На прагматическом уровне интересуют последствия от полу-
чения и использования данной информации потребителем. Про-
блемы этого уровня связаны с определением ценности и полезно-
сти использования информации при выработке потребителем ре-
шения для достижения своей цели. Основная сложность здесь со-
стоит в том, что ценность, полезность информации может быть
совершенно различной для различных получателей и, кроме того,
она зависит от ряда факторов, таких, например, как своевремен-
30
ность ее доставки и использования. Высокие требования в от-
ношении скорости доставки информации часто диктуются тем,
что управляющие воздействия должны осуществляться в реаль-
ном масштабе времени, т. е. со скоростью изменения состояния
управляемых объектов или процессов. Задержки в доставке или
использовании информации могут иметь катастрофические по-
следствия.
2.2. МЕРЫ ИНФОРМАЦИИ
Для каждого из рассмотренных выше уровней проблем переда-
чи информации существуют свои подходы к измерению количе-
ства информации и свои меры информации. Различают соответ-
ственно меры информации синтаксического уровня, семантичес-
кого уровня и прагматического уровня.
2.2.1. Меры информации синтаксического уровня
Количественная оценка информации этого уровня не связана
с содержательной стороной информации, а оперирует с обезли-
ченной информацией, не выражающей смыслового отношения
к объекту. В связи с этим данная мера дает возможность оценки
информационных потоков в таких разных по своей природе объек-
тах, как системы связи, вычислительные машины, системы управ-
ления, нервная система живого организма и т. п.
Для измерения информации на синтаксическом уровне вводят-
ся два параметра: объем информации (данных) — Vg (объемный
подход) и количество информации — I (энтропийный подход).
Объем информации Vg (объемный подход). При реализации ин-
формационных процессов информация передается в виде сообще-
ния, представляющего собой совокупность символов какого-либо
алфавита. При этом каждый новый символ в сообщении увеличи-
вает количество информации, представленной последовательнос-
тью символов данного алфавита. Если теперь количество инфор-
мации, содержащейся в сообщении из одного символа, принять за
единицу, то объем информации (данных) V в любом другом сооб-
щении будет равен количеству символов (разрядов) в этом сооб-
щении. Так как одна и та же информация может быть представле-
на многими разными способами (с использованием разных алфа-
31
битов), то и единица измерения информации (данных) соответ-
ственно будет меняться.
Так, в десятичной системе счисления один разряд имеет вес,
равный 10, и соответственно единицей измерения информации
будет дит (десятичный разряд). В этом случае сообщение в виде п-
разрядного числа имеет объем данных Vg — п дит. Например, четы-
рехразрядное число 2003 имеет объем данных V = 4 дит.
В двоичной системе счисления один разряд имеет вес, равный
2, и соответственно единицей измерения информации будет — бит
(bit — binary digit — двоичный разряд). В этом случае сообщение в
виде n-разрядного числа имеет объем данных V = п бит. Напри-
мер, восьмиразрядный двоичный код 11001011 имеет объем дан-
ных V = 8 бит.
д
В современной вычислительной технике наряду с минимальной
единицей измерения данных «бит» широко используется укруп-
ненная единица измерения «байт», равная 8 бит. При работе с боль-
шими объемами информации для подсчета ее количества приме-
няют более крупные единицы измерения, такие как килобайт
(Кбайт), мегабайт (Мбайт), гигабайт (Гбайт), терабайт (Тбайт):
1 Кбайт = 1024 байт = 210 байт;
1 Мбайт = 1024 Кбайт = 220 байт = 1 048 576 байт;
1 Гбайт = 1024 Мбайт = 230 байт = 1 073 741 824 байт;
1 Тбайт = 1024 Гбайт = 240 байт = 1 099 511 627 776 байт.
Следует обратить внимание, что в системе измерения двоичной
(компьютерной) информации, в отличие от метрической системы,
единицы с приставками «кило», «мега» и т. д. получаются путем
умножения основной единицы не на 103= 1000, 106= 1000 000 ит. д.,
а на 2,0= 1024, 220= 1048576 и т. д.
Количество информации I (энтропийный подход). В теории ин-
формации и кодирования принят энтропийный подход к измере-
нию информации. Этот подход основан на том, что факт получе-
ния информации всегда связан с уменьшением разнообразия или
неопределенности (энтропии) системы. Исходя из этого количе-
ство информации в сообщении определяется как мера уменьше-
ния неопределенности состояния данной системы после получе-
ния сообщения. Неопределенность может быть интерпретирова-
на в смысле того, насколько мало известно наблюдателю о данной
системе. Как только наблюдатель выявил что-нибудь в физичес-
кой системе, энтропия системы снизилась, так как для наблюдате-
ля система стала более упорядоченной.
32
Таким образом, при энтропийном подходе под информацией
понимается количественная величина исчезнувшей в ходе како-
го-либо процесса (испытания, измерения и т. д.) неопределеннос-
ти. При этом в качестве меры неопределенности вводится энтро-
пия Н, а количество информации равно:
I = H —Н , (1)
где Нарг — априорная энтропия о состоянии исследуемой системы
или процесса.
HQps— апостериорная энтропия.
Апостериори (от лат. a posteriori — из последующего) — проис-
ходящее из опыта (испытания, измерения).
Априори — (от лат. a priori — из предшествующего) — понятие,
характеризующее знание, предшествующее опыту (испытанию),
и независимое от него.
В случае когда в ходе испытания имевшаяся неопределенность
снята (получен конкретный результат, т. е. Haps = 0), количество
полученной информации совпадает с первоначальной энтропией
I = Нарг’
Рассмотрим в качестве исследуемой системы дискретный ис-
точник информации (источник дискретных сообщений), под ко-
торым будем понимать физическую систему, имеющую конечное
множество возможных состояний {а;}, / = 1, т .
Все множество А = { at, а2, ..., аш} состояний системы в теории
информации называют абстрактным алфавитом, или алфавитом
источника сообщений.
Отдельные состояния at, а? ат называют буквами или симво-
лами алфавита.
Такая система может в каждый момент времени случайным обра-
зом принять одно из конечных множеств возможных состояний —
а. При этом говорят, что различные состояния реализуются вслед-
ствие выбора их источником.
Поскольку одни состояния выбираются источником чаще, а
другие реже, то в общем случае он характеризуется ансамблем А,
т. е. полной совокупностью состояний с вероятностями их появле-
ния, составляющими в сумме единицу:
3 А-210
33
. ( a, a2 ... aN ] "
P2-^]'причем2л" • (21)
Введем меру неопределенности выбора состояния источника.
Ее можно рассматривать и как меру количества информации, по-
лучаемой при полном устранении неопределенности относитель-
но состояния источника. Мера должна удовлетворять ряду есте-
ственных условий. Одним из них является необходимость моно-
тонного возрастания с увеличением возможностей выбора, т. е. чис-
ла возможных состояний источника N, причем недопустимые со-
стояния (состояния с вероятностями, равными нолю) не долж-
ны учитываться, так как они не меняют неопределенности.
Ограничиваясь только этим условием, за меру неопределенно-
сти можно было бы взять число состояний, предположив, что они
равновероятны. Однако в этом случае при N= 1, когда неопреде-
ленность отсутствует, такая мера давала бы значение, равное еди-
нице. Кроме того, она не отвечает требованию аддитивности,
состоящему в следующем.
Если два независимых источника с числом равновероятных со-
стояний N и М рассматривать как один источник, одновременно
реализующий пары состояний nf,m., то естественно предположить,
что неопределенность объединенного источника должна равнять-
ся сумме неопределенностей исходных источников. Поскольку
общее число состояний объединенного источника равно NM, то
искомая функция должна удовлетворять условию:
f(MN) = f(M) + f(N). (2.2)
Соотношение (2.2) выполняется, если в качестве меры неопре-
деленности источника с равновероятными состояниями и харак-
теризующего его ансамбля А принять логарифм числа состояний:
Н(А) = logN. (2.3)
Тогда при N= 1 Н(А) = 0 и требование аддитивности выполняется.
Указанная мера была предложена американским ученым
Р. Хартли в 1928 г. Основание логарифма в формуле (2.3) не имеет
принципиального значения и определяет только масштаб или еди-
ницу измерения. В зависимости от основания логарифма приме-
няют следующие единицы измерения:
1. Биты — при этом основание логарифма равно 2:
Н(А) = log2N.
(2.4)
34
2. Наты — при этом основание логарифма равно е:
H = InN;
3. Диты — при этом основание логарифма равно 10:
H = IgN.
Так как современная информационная техника базируется на
элементах, имеющих два устойчивых состояния, то в информати-
ке в качестве меры неопределенности обычно используют форму-
лу (2.4). При этом единица неопределенности называется двоич-
ной единицей, или битом, и представляет собой неопределенность
выбора из двух равновероятных событий.
Формулу (2.4) можно получить эмпирически: для снятия не-
определенности в ситуации из двух равновероятных событий не-
обходим один опыт и соответственно один бит информации, при
неопределенности, состоящей из четырех равновероятных собы-
тий, достаточно двух бит информации, чтобы угадать искомый
факт. Эти рассуждения можно продолжить: 3 бита информации
соответствуют неопределенности из 8 равновероятных событий,
4 бита — 16 равновероятных событий и т. д. Например, для опре-
деления карты из колоды, состоящей из 32 карт, достаточно 5 бит
информации, т. е. достаточно задать 5 вопросов с ответами «да»
или «нет», чтобы определить искомую карту.
Таким образом, если сообщение указывает на один из п равно-
вероятных вариантов, то оно несет количество информации, рав-
ное log2n. Действительно, из наших примеров 1од232 = 5,1од216 = 4,
1од28 = 3 и т. д. Ту же формулу можно словесно выразить иначе:
количество информации равно степени, в которую необходимо
возвести число 2, чтобы получить число равновероятных вариан-
тов выбора, т. е. 2‘= 16, где /=4 (бита).
Предложенная мера позволяет решать определенные практи-
ческие задачи, когда все возможные состояния источника инфор-
мации имеют одинаковую вероятность.
В общем случае степень неопределенности реализации состоя-
ния источника информации зависит не только от числа состояний,
но и от вероятностей этих состояний. Если источник информации
имеет, например, два возможных состояния с вероятностями 0,99
и 0,01, то неопределенность выбора у него значительно меньше,
чем у источника, имеющего два равновероятных состояния, так
как в этом случае результат практически предрешен (реализация
состояния, вероятность которого равна 0,99).
35
Американский ученый К. Шеннон обобщил понятие меры нео-
пределенности выбора Н на случай, когда Н зависит не только от
числа состояний, но и от вероятностей этих состояний (вероятно-
стей р выбора символов а. алфавита А). Эту меру, представляю-
щую собой неопределенность, приходящуюся в среднем на одно
состояние, называют энтропией дискретного источника инфор-
мации.
Н = -Zp,log р,..
/=1
(2-5)
Если снова ориентироваться на измерение неопределенности
в двоичных единицах, то основание логарифма следует принять
равным двум.
N
н = -Xp,log2p,..
/=1
(2.6)
При равновероятных выборах всеp=l/Nn формула (2.6) пре-
образуется в формулу Р. Хартли (2.3):
w 111
Н = -Zp. log p,=-N—log — = -N—(log 1 - log N) = log2 N.
/=1 2 N 2 N N 2 2
Предложенная мера была названа энтропией не случайно. Дело
в том, что формальная структура выражения (2.5) совпадает с энт-
ропией физической системы, определенной ранее Больцманом.
Согласно второму закону термодинамики энтропия Н замкнутого
пространства определяется выражением:
1 лг т.
Н =--------Дли, In------ глр
Мп — число молекул в данном пространстве; т. — число молекул,
обладающих скоростью v. + Av. Так как т./Мп есть вероятность
того, что молекула имеет скорость v.+Av, то Н можно записать
N
как И = -£ Pjlnp^ Данная формула полностью совпадает с (2.5) —
/=1
в обоих случаях величина Н характеризует степень разнообразия
системы.
Используя формулы (2.4) и (2.6), можно определить избыточ-
ность D алфавита источника сообщений — А, которая показыва-
36
ет, насколько рационально применяются символы данного алфа-
вита:
D= [HmJA)~H(A)]/[HmJA)], (2.7)
где Нтах(А} — максимально возможная энтропия, определяемая по
формуле (2.4);
Н(А) — энтропия источника, определяемая по формуле (2.6).
Суть данной меры заключается в том, что при равновероятном
выборе ту же информационную нагрузку на знак можно обеспе-
чить, используя алфавит меньшего объема, чем в случае с нерав-
новероятным выбором.
Пример. Согласно экспериментальным данным безусловные
вероятности букв русского и английского алфавитов характери-
зуются табл. 2.1 и 2.2 соответственно.
Требуется найти энтропии источников А1 и А2, выдающих текст
из букв русского и английского алфавитов соответственно, при от-
сутствии статистических связей между буквами, а также вычис-
лить избыточность источников, выдающих тексты, обусловленную
неравновероятностью выбора букв.
Талица 2.1 Таблица 2.2
Бук- ва Вероят- ность Бук- ва Вероят- ность Бук- ва Вероят- ность
Про- бел 0,175 к 0,028 ч 0,012
0 0,090 м 0,026 и 0,010
Е 0,072 д 0,025 X 0,009
А 0,062 п 0,023 ж 0,007
И 0,062 У 0,021 ю 0,006
т 0,053 я 0,018 ш 0,006
Н 0,053 ы 0,016 ц 0,004
С 0,045 3 0,016 щ 0,003
Р 0,040 ь, ъ 0,014 э 0,002
В 0,038 Б 0,014 ф 0,002
Л 0,035 Г 0,013
Бук- ва Вероят- ность Бук- ва Вероят- ность Бук- ва Вероят- ность
Про- бел 0,2 н 0,047 W 0,012
Е 0,105 D 0,035 G 0,011
Т 0,072 L 0,028 В 0,010
О 0,065 С 0,023 V 0,008
F 0,063 F 0,023 К 0,003
N 0,058 и 0,023 X 0,001
I 0,055 м 0,021 J 0,001
R 0,052 р 0,018 Q 0,001
S 0,052 Y 0,012 Z 0,001
Решение. Найдем энтропии источников А1 и А2, используя фор-
мулу (2.6).
37
Н(А1) = — 0,1751og20,175-0,091og20,09-...-0,0021og20,002 = 4,35
(бит/символ).
Н(А2) = — 0,21од20,2 — 0,1051од20,105-...-0,0011од20,001 » 4,03
(бит/символ).
По формуле (2.4) находим:
Нтах(А1) = 1од232 = 5 (бит/символ).
Нтах(А2) = 1од227 = 4,75 (бит/символ).
Избыточность источников находим по формуле (2.7):
£>(А1) = (5 —4,35)/5 = 0,13.
О(А2) = (4,75 —• 4,03)/4,75 = 0,15.
Полученные результаты позволяют сделать вывод о том, что
избыточность, а следовательно, и неравномерность распределения
вероятностей букв источника А2 — латинского алфавита больше,
чем у источника А1 — русского алфавита.
2.2.2. Меры информации семантического уровня
Для измерения смыслового содержания информации, т. е. ее
количества на семантическом уровне, наибольшее распростране-
ние получила тезаурусная мера, которая связывает семантические
свойства информации со способностью пользователя принимать
поступившее сообщение [14]. Действительно, для понимания и ис-
пользования полученной информации получатель должен обладать
определенным запасом знаний. Полное незнание предмета не по-
зволяет извлечь полезную информацию из принятого сообще-
ния об этом предмете. По мере роста знаний о предмете растет и
количество полезной информации, извлекаемой из сообщения.
Если назвать имеющиеся у получателя знания о данном пред-
мете «тезаурусом» (т. е. неким сводом слов, понятий, названий
объектов, связанных смысловыми связями), то количество инфор-
мации, содержащееся в некотором сообщении, можно оценить
степенью изменения индивидуального тезауруса под воздействи-
ем данного сообщения.
Тезаурус — совокупность сведений, которыми располагает пользо-
ватель или система.
Иными словами, количество семантической информации, из-
влекаемой получателем из поступающих сообщений, зависит от
38
степени подготовленности его тезауруса для восприятия такой
информации.
В зависимости от соотношений между смысловым содержани-
ем информации S и тезаурусом пользователя Sp изменяется коли-
чество семантической информации 1с, воспринимаемой пользова-
телем и включаемой им в дальнейшем в свой тезаурус. Характер
такой зависимости показан на рис. 2.1. Рассмотрим два предель-
ных случая, когда количество семантической информации 1с рав-
но 0:
при Sp = 0 пользователь не воспринимает (не понимает) по-
ступающую информацию;
при Sp —> оо пользователь «все знает», и поступающая ин-
формация ему не нужна.
Рис. 2.1. Зависимость количества семантической информации,
воспринимаемой потребителем, от его тезауруса Ic = f(Sp)
Максимальное количество семантической информации потре-
битель приобретает при согласовании ее смыслового содержания
S со своим тезаурусом Sp (Sp = Sp opt), когда поступающая ин-
формация понятна пользователю и несет ему ранее неизвестные
(отсутствующие в его тезаурусе) сведения.
Следовательно, количество семантической информации в со-
общении, количество новых знаний, получаемых пользователем,
является величиной относительной. Одно и то же сообщение мо-
жет иметь смысловое содержание для компетентного пользовате-
ля и быть бессмысленным для пользователя некомпетентного.
При оценке семантического (содержательного) аспекта инфор-
мации необходимо стремиться к согласованию величин S и Sp.
39
Относительной мерой количества семантической информации
может служить коэффициент содержательности С, который оп-
ределяется как отношение количества семантической информа-
ции к ее объему:
С=//Уд
С Д.
Еще один подход к семантическим оценкам информации, раз-
виваемый в рамках науковедения, заключается в том, что в каче-
стве основного показателя семантической ценности информации,
содержащейся в анализируемом документе (сообщении, публика-
ции), принимается количество ссылок на него в других докумен-
тах. Конкретные показатели формируются на основе статистичес-
кой обработки количества ссылок в различных выборках.
2.2.3. Меры информации прагматического уровня
Эта мера определяет полезность информации (ценность) для
достижения пользователем поставленной цели. Она также вели-
чина относительная, обусловленная особенностями использования
этой информации в той или иной системе.
Одним из первых отечественных ученых к этой проблеме об-
ратился А.А. Харкевич, который предложил принять за меру цен-
ности информации количество информации, необходимое для до-
стижения поставленной цели, т. е. рассчитывать приращение ве-
роятности достижения цели. Так, если до получения информации
вероятность достижения цели равнялась а после ее получения —
pt, то ценность информации определяется как логарифм отноше-
ния р/р0-.
р,
I = log2рх - log2p0 = log2 — (2.8)
Pq
Таким образом, ценность информации при этом измеряется
в единицах информации, в данном случае в битах.
Выражение (2.8) можно рассматривать как результат норми-
ровки числа исходов. В пояснение на рис. 2.2 приведены три схе-
мы, на которых приняты одинаковые значения числа исходов 2
и 6 для точек 0 и 1 соответственно. Исходное положение — точка 0.
На основании полученной информации совершается переход
в точку 1. Цель обозначена крестиком. Благоприятные исходы
40
изображены линиями, ведущими к цели. Определим ценность по-
лученной информации во всех трех случаях:
а) число благоприятных исходов равно трем: р=1/2, р, = 3/6 = 1/2
и, следовательно,
/=log2(p/p0) = log2l = 0;
б) имеется один благоприятный исход: р=1/2, pt = 1/6,
I = log2 — = —log2 3 = -1,58;
в) число благоприятных исходов равно четырем: рд = 1/2, р( =
= 4/6 = 2/3,
Рис. 2.2. К вопросу о ценности информации:
а) I = 0; б) I = — 1,58 (дезинформация); в) / = 0,42
В примере б) получена отрицательная ценность информации
(отрицательная информация). Такую информацию, увеличива-
ющую исходную неопределенность и уменьшающую вероят-
ность достижения цели, называют дезинформацией. Таким об-
разом, в примере б) мы получили дезинформацию в 1,58 двоич-
ной единицы.
Дальнейшее развитие данного подхода базируется на статис-
тической теории информации и теории решений. Сущность мето-
да состоит в том, что, кроме вероятностных характеристик не-
определенности объекта, после получения информации вводятся
функции штрафов или потерь и оценка информации производит-
ся в результате минимизации потерь. Максимальной ценностью
41
обладает то количество информации, которое уменьшает потери
до ноля при достижении поставленной цели.
2.3. КАЧЕСТВО ИНФОРМАЦИИ
Эффективность применения и качество функционирования
любых систем во многом определяется качеством информации, на
основе которой принимаются управляющие решения. Составля-
ющие качества информация отражены на рис. 2.3.
Качество информации — совокупность свойств информации, ха-
рактеризующих степень ее соответствия потребностям (целям, цен-
ностям) пользователей (средств автоматизации, персонала и др.).
Выделяют внутреннее качество — содержательность (присущее
собственно информации и сохраняющееся при ее переносе в дру-
гую систему) и внешнее — защищенность (присущее информации,
находящейся или используемой только в определенной системе) [16].
Рис. 2.3. Составляющие качества информации
42
Содержательность информации — совокупность сведений о
конкретном объекте (системе) или процессе, содержащаяся в сооб-
щениях и воспринимаемая получателем. Содержательность отра-
жает семантическую емкость информации, содержащейся в инфор-
мационных массивах (массивах данных, массивах программ, сооб-
щениях, фактах). Содержательная информация используется, как
правило, для выработки и принятия управляющего воздействия.
Содержательность информации определяется такими свойства-
ми, как значимость и кумулятивность.
Значимость информации — свойство информации сохранять
ценность для потребителя с течением времени, т. е. не подвергать-
ся «моральному» старению.
Составляющими значимости являются полнота и идентичность.
Полнота информации — свойство содержательной информа-
ции, характеризуемое мерой ее достаточности для решения опре-
деленных задач. Полнота (достаточность) информации означает,
что она обеспечивает принятие правильного (оптимального) реше-
ния. Из этого следует, что данное свойство является относитель-
ным: полнота информации оценивается относительно вполне оп-
ределенной задачи или группы задач. Поэтому, чтобы иметь воз-
можность определить показатель полноты информации, необхо-
димо для каждой существенно значимой задачи или группы задач
иметь перечень тех сведений, которые требуются для их решения.
Как неполная, т. е. недостаточная для принятия правильного ре-
шения, так и избыточная информации снижают эффективность
принимаемых пользователем решений.
Идентичность — свойство, заключающееся в соответствии
содержательной информации состоянию объекта. Нарушение
идентичности связано с техническим (по рассогласованию призна-
ков) старением информации, при котором происходит расхожде-
ние реальных признаков объектов и тех же признаков, отображен-
ных в информации. Обычно закон старения информации представ-
ляют в виде рис. 2.4.
На данном рисунке tg обозначает момент времени генерирова-
ния (получения) оцениваемой информации, при этом коэффици-
ент К, характеризующий идентичность информации, равен 1. За-
кон старения информации определяется четырьмя характерными
интервалами:
Atj— продолжительностью времени, в течение которого оце-
ниваемая информация полностью сохраняет свою идентичность;
43
At, — продолжительностью времени, в течение которого иден-
тичность информации падает, но не более чем на одну четверть;
At3 — продолжительностью времени, в течение которого иден-
тичность информации падает наполовину;
At4 — продолжительностью времени, в течение которого иден-
тичность информации падает на три четверти.
Рис. 2.4. Общий вид закона старения информации
Кумулятивность информации — свойство содержательной
информации, заключенной в массиве небольшого объема, доста-
точно полно отображать действительность.
Задачу обеспечения кумулятивности информации можно ре-
шать без учета и с учетом опыта и квалификации конкретного по-
требителя информации, применяя соответственно формально-тех-
нические и социально-психологические приемы. К числу формаль-
но-технических приемов относится, например, агрегирование —
получение сводных показателей различного уровня обобщения или
выбор отдельных показателей из массивов исходных данных. Эти
и другие формальные приемы направлены на построение моделей
типа «многое в одном», когда действительность отображается
с помощью малого числа символов. Такие модели называются
44
гомоморфными, а соответствующее свойство — гомоморфизмом
информации. Это формально-техническая составляющая кумуля-
тивности информации.
Гомоморфизм информации — свойство содержательной инфор-
мации, связанное с достаточно полным отображением действи-
тельности, представленной информационными массивами большо-
го объема, с помощью малого числа информационных единиц (сим-
волов) на основе соответствующих моделей агрегирования.
Информационное обеспечение конкретного потребителя мо-
жет осуществляться с учетом его опыта, квалификации и других
свойств, а также с учетом решаемых им задач. Информация, спе-
циально отобранная для конкретного потребителя, обладает опре-
деленным свойством — избирательностью. Это социально-психо-
логическая составляющая свойства кумулятивности.
Избирательность информации — свойство содержательной
информации, заключающееся в достаточно полном отображении
действительности, представленной информационными массивами
большого объема, с помощью малого числа информационных еди-
ниц (символов) на основе учета квалификации, опыта и других
качеств конкретного потребителя.
Защищенность отражает внешнее качество информации, оп-
ределяемое совокупностью свойств информации, обеспечиваемых
системой контроля и защиты информации (КЗИ) в конкретной
информационной системе. Основными из них являются свойства,
заключающиеся в способности не допускать случайного или целе-
направленного искажения или разрушения, раскрытия или моди-
фикации информационных массивов, соответственно достовер-
ность, конфиденциальность и сохранность информации. При пе-
реносе информации в другую систему (среду) эти свойства исче-
зают.
Достоверность информации — свойство информации, харак-
теризуемое степенью соответствия (в пределах заданной точнос-
ти) реальных информационных единиц (символов, знаков, запи-
сей, сообщений, информационных массивов и т. д.) их истинному
значению и определяемое способностью КЗИ обеспечить отсут-
ствие ошибок переработки информации, т. е. не допустить сниже-
ния ценности информации при принятии управленческих реше-
ний, искажений информационных массивов (ИМ), их смыслового
значения, замены единичных символов ИМ и других из-за несо-
вершенства организации (структуры) процесса переработки,
45
несовершенства алгоритмов, ненадежной работы аппаратно-про-
граммных средств, ошибок пользователей и т. д.
Требуемый уровень достоверности информации достигается
путем внедрения методов контроля и защиты информации на всех
стадиях ее переработки, повышением надежности комплекса тех-
нических и программных средств информационной системы, а
также административно-организационными мерами (моральным
и материальным стимулированием, направленным на снижение
числа ошибок, улучшением условий труда персонала и др.).
Критериями оптимальности при этом, как правило, являются:
минимизация вероятности искажения единичного массива
информации;
" максимизация достоверности переработки информации как
некоторой функции вероятности ошибки;
• минимизация времени переработки ИМ и материальных зат-
рат при ограничении на достоверность;
* минимизация суммарного среднего времени на обработку,
контроль и исправление ИМ;
* минимизация суммарных потерь с учетом затрат на разра-
ботку и функционирование структур контроля, исправление
ошибок и на потери в информационной системе (ИС) при
использовании недостоверной информации и т. п.
Конфиденциальность информации — свойство информации,
позволяющее сохранять предоставленный ей статус. Конфиден-
циальность информации характеризуется такими показателями,
как доступность, скрытность и имитостойкость информации.
Доступность информации характеризуется степенью разгра-
ничения действий объектов информационной системы (операто-
ров, задач, устройств, программ, подсистем и др.) и заключается в
возможности использования ИМ по требованию объектов систе-
мы, имеющих соответствующие полномочия (мандаты).
Скрытность информации характеризуется степенью маски-
ровки информации и отражает ее способность противостоять рас-
крытию смысла ИМ (семантическая скрытность на основе обра-
тимых преобразований информации), определению структуры
хранимого ИМ или носителя (сигнала-переносчика) передавае-
мого ИМ (структурная скрытность на основе необратимых пре-
образований, использования спецаппаратуры, различных форм
сигналов-переносчиков, видов модуляции и др.) и установлению
факта передачи ИМ по каналам связи (энергетическая скрыт-
46
ность на основе применения широкополосных сигналов-перенос-
чиков ИМ, организации периодического маскирующего обмена
ИМ и др.).
Имитостойкость информации определяется степенью ее защи-
щенности от внедрения ИМ, имитирующих авторизованные (за-
регистрированные) массивы, и заключается в способности не до-
пустить навязывания дезинформации и нарушения нормально-
го функционирования информационной системы.
Требуемый уровень конфиденциальности ИМ достигается пу-
тем дополнительных преобразований (семантических, криптогра-
фических и др.) информации, контроля полномочий программно-
технических средств, ресурсов ИС и лиц (операторов, персонала,
пользователей и др.), взаимодействующих со средствами автома-
тизации и разграничения доступа к ИМ. Критериями оптимально-
сти при этом, как правило, являются:
минимизация вероятности преодоления («взлома») защиты;
максимизация ожидаемого безопасного времени до «взло-
ма» подсистемы защиты;
минимизация суммарных затрат (интеллектуальных, финан-
совых, материальных, временных и др.) на разработку и эк-
сплуатацию подсистемы КЗИ при ограничениях на вероят-
ность несанкционированного доступа к ресурсам ИС;
минимизация суммарных потерь от «взлома» защиты и зат-
рат на разработку и эксплуатацию соответствующих элемен-
тов подсистемы КЗИ и т. п.
Сохранность информации — свойство информации, харак-
теризуемое степенью готовности определенных ИМ к целево-
му применению и определяемое способностью КЗИ обеспечить
постоянное наличие и своевременное предоставление ИМ, не-
обходимых для автоматизированного решения целевых и функ-
циональных задач системы, т. е. не допускать разрушения ИМ
из-за несовершенства носителей, механических повреждений,
неправильной эксплуатации, износа и старения аппаратных
средств, ошибок персонала и несанкционированных корректи-
ровок, недостатков в программных средствах и т. д. Основными
показателями сохранности являются целостность и готовность
информации.
Целостность информации характеризуется степенью аутентич-
ности (подлинности) ИМ в информационной базе и исходных до-
кументах (сообщениях) и определяется способностью КЗИ обес-
47
печить, насколько это возможно, физическое наличие информа-
ционных единиц в информационной базе в любой момент време-
ни, т. е. не допустить случайных искажений и разрушения ИМ из-
за дефектов и сбоев аппаратных средств, действия «компьютер-
ных вирусов», ошибок оператора (при вводе информации в инфор-
мационную базу или обращении к ней), ошибок в программных
средствах (операционных системах, СУБД, комплексах приклад-
ных программ и др.).
Готовность информации характеризуется степенью работо-
способности ИМ при выполнении целевых и функциональных за-
дач системы и определяется возможностью КЗИ обеспечить сво-
евременное предоставление необходимых неразрушенных ИМ.
Необходимый уровень сохранности ИМ достигается путем вве-
дения специальной организации хранения и подготовки, регене-
рации и восстановления ИМ, использования дополнительных ре-
сурсов для их резервирования, что позволяет значительно умень-
шить влияние разрушающих факторов на эффективность функ-
ционирования ИС в целом. Основными критериями оптимальнос-
ти при этом являются:
* максимизация вероятности успешного решения определен-
ной частной задачи системы при наличии соответствующих
ИМ, их дубликатов, копий;
* максимизация вероятности восстановления ИМ;
минимизация среднего времени решения задачи системы;
* минимизация среднего времени восстановления ИМ;
максимизация вероятности сохранности ИМ за фиксирован-
ный интервал времени их эксплуатации;
минимизация стоимостных затрат на дополнительные носи-
тели информации для размещения резервных ИМ, потерь от
разрушения ИМ и т. п.
2.4. ВИДЫ И ФОРМЫ ПРЕДСТАВЛЕНИЯ ИНФОРМАЦИИ
В ИНФОРМАЦИОННЫХ СИСТЕМАХ
Все многообразие окружающей нас информации можно клас-
сифицировать по различным признакам. Так, по признаку «об-
ласть возникновения» информацию, отражающую процессы, яв-
ления неодушевленной природы, называют элементарной, или
механической, процессы животного и растительного мира —
48
биологической, человеческого общества — социальной. Инфор-
мацию, создаваемую и используемую человеком, по обществен-
ному назначению можно разбить на три вида: личная, массовая
и специальная. Личная информация предназначается для конк-
ретного человека, массовая для любого желающего ею пользо-
ваться (общественно-политическая, научно-популярная и т. д.),
а специальная — для применения узким кругом лиц, занимаю-
щихся решением сложных специальных задач в области науки,
техники, экономики и т. п. Информация может быть объектив-
ной и субъективной. Объективная информация отражает явле-
ния природы и человеческого общества. Субъективная инфор-
мация создается людьми и отражает их взгляд на объективные
явления.
В автоматизированных информационных системах выделяют:
структурную (преобразующую) информацию объектов си-
стемы, заключенную в структурах системы, ее элементов
управления, алгоритмов и программ переработки инфор-
мации;
содержательную (специальную, главным образом осведом-
ляющую, измерительную и управляющую, а также научно-
техническую, технологическую и др.) информацию, извле-
каемую из информационных массивов (сообщений, команд
и т. п.) относительно индивидуальной модели предметной об-
ласти получателя (человека, подсистемы).
Первая связана с качеством информационных процессов в си-
стеме, с внутренними технологическими эффектами, затратами на
переработку информации. Вторая — как правило, с внешним це-
левым (материальным) эффектом.
Один из возможных вариантов классификации информации в
автоматизированных системах представлен на рис. 2.5.
При реализации информационных процессов передача инфор-
мации (сообщения) от источника к приемнику может осуществ-
ляться с помощью какого-либо материального носителя (бумаги,
магнитной ленты и т. п.) или физического процесса (звуковых или
электромагнитных волн).
В зависимости от типа носителя различают следующие виды
информации (рис. 2.6):
документальную;
акустическую (речевую);
• телекоммуникационную.
4 А-210
49
:. 2.5. Классификация информации в автоматизированных системах
50
Информация
Рис. 2.6. Классификация информации в зависимости от типа носителя
Документальная информация представляется в графическом
или буквенно-цифровом виде на бумаге, а также в электронном
виде на магнитных и других носителях.
Речевая информация возникает в ходе ведения разговоров, а так-
же при работе систем звукоусиления и звуковоспроизведения. Но-
сителем речевой информации являются акустические колебания
(механические колебания частиц упругой среды, распространяю-
щиеся от источника колебаний в окружающее пространство в виде
волн различной длины) в диапазоне частот от 200...300 Гц до 4...6 кГц.
Телекоммуникационная информация циркулирует в техничес-
ких средствах обработки и хранения информации, а также в кана-
лах связи при ее передаче. Носителем информации при ее обра-
ботке техническими средствами и передаче по проводным кана-
лам связи является электрический ток, а при передаче по радио- и
оптическому каналам — электромагнитные волны.
Источник информации может вырабатывать непрерывное со-
общение (сигнал), в этом случае информация называется непре-
рывной, или дискретное — информация называется дискретной.
Например, сигналы, передаваемые по радио и телевидению, а так-
же используемые в магнитной записи, имеют форму непрерывных,
быстро изменяющихся во времени зависимостей. Такие сигналы на-
зываются непрерывными, или аналоговыми сигналами. В противо-
51
положность этому в телеграфии и вычислительной технике сигналы
имеют импульсную форму и называются дискретными сигналами.
Непрерывная и дискретная формы представления информации
имеют особое значение при рассмотрении вопросов создания, хра-
нения, передачи и обработки информации с помощью средств
вычислительной техники.
В настоящее время во всех вычислительных машинах инфор-
мация представляется с помощью электрических сигналов. При
этом возможны две формы представления численного значения
какой-либо переменной, например X:
• в виде одного сигнала — например, электрического напря-
жения, которое сравнимо с величиной X (аналогично ей). На-
пример, при X=2003 единицам на вход вычислительного уст-
ройства можно подать напряжение 2,003 В (масштаб представ-
ления 0,001 В/ед.) или 10,015 В (масштаб представления 0,005
В/ед.);
в виде нескольких сигналов — нескольких импульсов напря-
жений, которые сравнимы с числом единиц в X, числом де-
сятков в X, числом сотен в X и т. д.
Первая форма представления информации (с помощью сходной
величины — аналога) называется аналоговой, или непрерывной. Ве-
личины, представленные в такой форме, могут принимать принци-
пиально любые значения в определенном диапазоне. Количество зна-
чений, которые может принимать такая величина, бесконечно вели-
ко. Отсюда названия — непрерывная величина и непрерывная ин-
формация. Слово непрерывность отчетливо выделяет основное свой-
ство таких величин — отсутствие разрывов, промежутков между зна-
чениями, которые может принимать данная аналоговая величина.
Вторая форма представления информации называется дискрет-
ной (с помощью набора напряжений, каждое из которых соответ-
ствует одной из цифр представляемой величины). Такие величи-
ны, принимающие не все возможные, а лишь вполне определен-
ные значения, называются дискретными (прерывистыми). В отли-
чие от непрерывной величины количество значений дискретной
величины всегда будет конечным.
Сравнивая непрерывную и дискретную формы представления
информации, нетрудно заметить, что при использовании непрерыв-
ной формы для создания вычислительной машины потребуется
меньшее число устройств (каждая величина представляется одним,
а не несколькими сигналами), но эти устройства будут сложнее (они
должны различать значительно большее число состояний сигнала).
52
Непрерывная форма представления используется в аналоговых
вычислительных машинах (АВМ). Эти машины предназначены в
основном для решения задач, описываемых системами дифферен-
циальных уравнений: исследования поведения подвижных объек-
тов, моделирования процессов и систем, решения задач парамет-
рической оптимизации и оптимального управления. Устройства для
обработки непрерывных сигналов обладают более высоким быст-
родействием, они могут интегрировать сигнал, выполнять любое его
функциональное преобразование и т. п. Однако из-за сложности
технической реализации устройств выполнения логических опера-
ций с непрерывными сигналами, длительного хранения таких сиг-
налов, их точного измерения АВМ не могут эффективно решать за-
дачи, связанные с хранением и обработкой больших объемов ин-
формации, которые легко решаются при использовании цифровой
(дискретной) формы представления информации, реализуемой
цифровыми электронными вычислительными машинами (ЭВМ).
Контрольные вопросы ~
1. Какие уровни проблем передачи информации Вы знаете?
2. Назовите меры информации синтаксического уровня.
3. Охарактеризуйте сущность понятия энтропии.
4. Как связаны между собой понятия количества информации и эн-
тропии ?
5. Что определяет термин «бит»? Приведите примеры сообщений,
содержащих один (два, восемь) бит информации.
б. Запишите формулы Хартли и Шеннона. При каком условии фор-
мула Шеннона переходит в формулу Хартли ?
7. Что такое абстрактный алфавит?
8. Дайте определение избыточности алфавита источника сообщений.
9. Какие меры информации семантического уровня Вы знаете?
10. Что такое тезаурус?
11. Какие меры информации прагматического уровня Вы знаете?
12. Дайте определение дезинформации.
13. Что такое качество информации?
14. Назовите основные составляющие качества информации.
15. Как Вы понимаете защищенность и содержательность информации ?
16. Чем достигается требуемый уровень защищенности информации?
17. Назовите основные классификационные признаки информации?
18. Какие виды и формы представления информации в информаци-
онных системах Вы знаете?
Тлава 3
Представление информации
в цифровых автоматах
3.1. СИСТЕМЫ СЧИСЛЕНИЯ
Система счисления — совокупность приемов и правил наимено-
вания и обозначения чисел, позволяющих установить взаимно одно-
значное соответствие между любым числом и его представлением
в виде конечного числа символов.
В любой системе счисления выбирается алфавит, представля-
ющий собой совокупность некоторых символов (слов или знаков),
с помощью которого в результате каких-либо операций можно
представить любое количество. Изображение любого количества
называется числом, а символы алфавита — цифрами (от лат. cifra).
Символы алфавита должны быть разными и значение каждого из
них должно быть известно.
В современном мире наиболее распространенной является де-
сятичная система счисления, происхождение которой связано с
пальцевым счетом. Она возникла в Индии и в XIII веке была пере-
несена в Европу арабами. Поэтому десятичную систему счисле-
ния стали называть арабской, а используемые для записи чисел циф-
ры, которыми мы теперь пользуемся, — 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 —
арабскими.
С давних времен для подсчетов и вычислений применялись раз-
личные системы счисления. Например, на Древнем Востоке доволь-
но широко была распространена двенадцатеричная система. Мно-
гие предметы (ножи, вилки, тарелки и т. д.) и сейчас считают дю-
жинами. Число месяцев в году — двенадцать. Эта система счисле-
ния сохранилась в английской системе мер (например, 1 фут = 12
дюймов) и в денежной системе (1 шиллинг = 12 пенсов). В Древ-
нем Вавилоне существовала весьма сложная шестидесятеричная
54
система. Она, как и двенадцатеричная система, в какой-то степе-
ни сохранилась и до наших дней (например, в системе измерения
времени: 1 ч = 60 мин, 1 мин = 60 с, аналогично в системе измере-
ния углов: 1° = 60 мин, 1 мин = 60 с).
Первые цифры (знаки для обозначения чисел) появились у егип-
тян и вавилонян. У ряда народов (древние греки, сирийцы, фини-
кияне) цифрами служили буквы алфавита. Аналогичная система
до XVI века применялась и в России. В Средние века в Европе
пользовались системой римских цифр, которые и сейчас часто при-
меняют для обозначения глав, частей, разделов в различного рода
документах, книгах, для обозначения месяцев и т. д.
Все системы счисления можно разделить на позиционные и
непозиционные.
Непозиционная система счисления — система, в которой симво-
лы, обозначающие то или иное количество, не меняют своего значения
в зависимости от местоположения (позиции) в изображении числа.
Запись числа А в непозиционной системе счисления D может
быть представлена выражением:
Ad = Z)j + + ••• + Dn = % D; f
где Ad — запись числа А в системе счисления D; Di — символы сис-
темы.
Непозиционной системой счисления является самая простая
система с одним символом (палочкой). Для изображения какого-
либо числа в этой системе надо записать количество палочек, рав-
ное данному числу. Например, запись числа 12 в такой системе
счисления будет иметь вид: 111111111111, где каждая «палочка»
обозначена символом 1. Эта система неэффективна, так как фор-
ма записи очень громоздка.
К непозиционной системе счисления относится и римская, сим-
волы алфавита которой и обозначаемое ими количество представ-
лены в табл. 3.1.
Таблица 3.1
Римские цифры I V X L С D М
Значение (обозначаемое количество) 1 5 10 50 100 500 1000
55
Запись чисел в этой системе счисления осуществляется по сле-
дующим правилам:
1) если цифра слева меньше, чем цифра справа, то левая цифра
вычитается из правой (IV: 1 < 5, следовательно, 5 — 1=4, XL: 10 < 50,
следовательно, 50 — 10 =40);
2) если цифра справа меньше или равна цифре слева, то эти
цифры складываются (VI: 5+1 =6, VIII: 5+14-1 + 1=8, XX:
10+10 = 20).
Так, число 1964 в римской системе счисления имеет вид
MCMLXIV (М — 1000, СМ — 900, LX — 60, IV — 4), здесь «девять-
сот» получается посредством вычитания из «тысячи» числа «сто»,
«шестьдесят» — посредством сложения «пятидесяти» и «десяти»,
«четыре» — посредством вычитания из «пяти» «единицы».
В общем случае непозиционные системы счисления характери-
зуются сложными способами записи чисел и правилами выполнения
арифметических операций. В настоящее время все наиболее распро-
страненные системы счисления относятся к разряду позиционных.
3.1.1. Позиционные системы счисления
Систему счисления, в которой значение цифры определяется ее
местоположением (позицией) в изображении числа, называют пози-
ционной.
Упорядоченный набор символов (цифр) fa0,a;,...,an7, используе-
мый для представления любых чисел в заданной позиционной си-
стеме счисления, называют ее алфавитом, число символов (цифр)
алфавита р = п + 1 — ее основанием, а саму систему счисления
называют р-ичной.
Основание позиционной системы счисления — количество различ-
ных цифр, используемых для изображения чисел в данной системе
счисления.
Самой привычной для нас является десятичная система счис-
ления. Ее алфавит — {0,1,2,3,4,5,6,7,8,9}, а основание р = 10, т. е. в
этой системе для записи любых чисел используется только десять
разных символов (цифр). Эти цифры введены для обозначения пер-
56
вых десяти последовательных чисел, а все последующие числа, на-
чиная с 10 и т. д., обозначаются уже без использования новых цифр.
Десятичная система счисления основана на том, что десять единиц
каждого разряда объединяются в одну единицу соседнего старшего
разряда, поэтому каждый разряд имеет вес, равный степени 10. Сле-
довательно, значение одной и той же цифры определяется ее мес-
тоположением в изображении числа, характеризуемым степенью
числа 10. Например, в изображении числа 222.22 цифра 2 повторя-
ется пять раз, при этом первая слева цифра 2 означает количество
сотен (ее вес равен 102); вторая — количество десятков (ее вес ра-
вен 10), третья — количество единиц (ее вес равен 10°), четвертая —
количество десятых долей единицы (ее вес равен 10 ’) и пятая циф-
ра — количество сотых долей единицы (ее вес равен 102). То есть
число 222.22 может быть разложено по степеням числа 10:
222.22 = 2х 102 + 2х 10* + 2х 10° +2 х 10 1 + 2 х 10’2.
Аналогично:
725 =7х 102 + 2х 10Ч-5х 10°;
1304.5 = 1 х 103 + Зх 102 + 0х 10Ч-4Х 10° + 5х 10';
50328.15 = 5х 104+0х 103 + Зх 102+2х 1О‘ + 8х 10°+1 х 1О‘ + 5х 102.
Таким образом, любое число А можно представить в виде поли-
нома путем разложения его по степеням числа 10:
А10 = аах 10" +ап1 х 10п1 + ... + а1 х 104-аох 10°-Та , х 10 * + ...+
+ а.тх 10т-Т..., (3.1)
последовательность из коэффициентов которого представляет со-
бой десятичную запись числа А10:
А,0 = апапл -а1а,-а.1-а.т- <3-2)
Точка, отделяющая целую часть числа от дробной, служит для
фиксации конкретных значений каждой позиции в этой последо-
вательности цифр и является началом отсчета.
В общем случае для задания р-ичной системы счисления необ-
ходимо определить основание р и алфавит, состоящий из р раз-
личных символов (цифр) a., i= 1,...,р.
За основание системы можно принять любое натуральное чис-
ло — два, три, четыре и т. д. Обычно в качестве алфавита берутся
57
последовательные целые числа от 0 до (р— 1) включительно. Для
записи произвольного числа в двоичной системе счисления ис-
пользуются цифры 0, 1, троичной — 0, 1,2, пятеричной — 0, 1, 2, 3, 4
и т. д. В тех случаях, когда общепринятых (арабских) цифр не хва-
тает для обозначения всех символов алфавита системы счисле-
ния с основанием р> 10, используют буквенное обозначение цифр
a,b,c,d,e,f.
Для примера в табл. 3.2 приведены алфавиты некоторых сис-
тем счисления.
Таблица 3.2
Основание Система счисления Алфавит системы счисления
2 Двоичная 0,1
3 Троичная 0,1,2
4 Четверичная 0,1,2,3
5 Пятеричная 0,1,2,3,4
8 Восьмеричная 0,1,2,3,4,5,6,7
10 Десятичная 0,1,2,3,4,5,6,7,8,9
12 Двенадцатеричная 0,1,2,3,4,5,6,7,8,9,А,В
16 Шестнадцатеричная 0,1,2,3,4,5,6,7,8,9, A,B,C,D,E,F
Таким образом, возможно бесчисленное множество позицион-
ных систем: двоичная, троичная, четверичная и т. д. Запись чисел
в каждой из систем счисления с основанием р означает сокра-
щенную запись выражения:
Ар = авхрп+ап_1хрЛ,+...+а1хр'+аохро+а_1хр-,+...+а тхрш =
п
= X акРк,
к=-т
(3.3)
где а( — цифры системы счисления; пит — число целых и дроб-
ных разрядов, соответственно, Ар— запись числа А в р-ичной сис-
теме счисления.
Изображением числа А в р-ичной системе счисления является
последовательность цифр ак.
Например, десятичное число 35 в системах счисления с основа-
нием Р будет иметь вид:
Р разряды 1 о
12 число 2 В12 = 2x12' +Вх12°
58
10
8
4
3
2
1 о
3 510= 3x10’+ 5x10°
1 о
4 38 = 4х8‘ + 3x8°
2 10
2 0 34 = 2х42 + 0x4* + 3x4°
3 2 10
1 0 2 23 = 1x3’ + ОхЗ2 + 2x3' + 2x3°
5 4 3 2 1 0
1 0 0 0 1 12 = 1х25 + 0х24 + 0х23 + 0х22 + 1х2‘+1x2°
Из приведенных примеров видно, что с уменьшением основа-
ния системы счисления уменьшается число используемых цифр,
но возрастает количество разрядов. Так, в двенадцатеричной, де-
сятичной и восьмеричной системах для записи числа 35 требова-
лось два разряда, в четверичной — три разряда, а в двоичной —
шесть разрядов.
Все известные позиционные системы счисления являются ад-
дитивно-мультипликативными. Особенно отчетливо аддитивно-
мультипликативный способ образования чисел из базисных вы-
ражен в числительных русского языка, например пятьсот ше-
стьдесят восемь (т. е. пять сотен плюс шесть десятков плюс во-
семь).
Арифметические действия над числами в любой позиционной
системе счисления производятся по тем же правилам, что и в де-
сятичной системе, так как все они основываются на правилах вы-
полнения действий над соответствующими полиномами. При этом
нужно только пользоваться теми таблицами сложения и умноже-
ния, которые имеют место при данном основании р системы счис-
ления.
Отметим, что во всех позиционных системах счисления с лю-
бым основанием Р умножения на числа вида Рт , где т — целое
число, сводится просто к перенесению запятой у множимого на т
разрядов вправо или влево (в зависимости от знака т), так же как
и в десятичной системе.
Рассмотрим в качестве примера выполнение арифметических
операций в троичной и пятеричной системах счисления, таблицы
сложения и умножения для которых представлены соответствен-
но на рис. 3.1 и 3.2.
59
+ 0 1 2
0 0 1 2
1 1 2 10
2 2 10 11
X 0 1 2
0 0 0 0
1 0 1 2
2 0 2 11
a)
б)
Рис. 3.1. Таблицы сложения (а) и умножения (б) в троичной системе счисления
+ 0 1 2 3 4
0 0 1 2 3 4
1 1 2 3 4 10
2 2 3 4 10 И
3 3 4 10 И 12
4 4 10 И 12 13
а)
X 0 1 2 3 4
0 0 0 0 0 0
1 0 1 2 3 4
2 0 2 4 11 13
3 0 3 11 14 22
4 0 4 13 22 31
б)
Рис. 3.2. Таблицы сложения (а)
и умножения (б) в пятеричной системе счисления
Пример 1. Выполните действия в троичной системе счисления:
а) 2113 + 1013; б) 2013 — 1223; в) 121зх 103.
Решение:
а> 2 1 1 б) __ 2 0 1 в) 12 1
1 0 1 1 2 2 Х 1 о
1 0 1 2 002 000
1 2 1
12 10
Пример 2. Выполните действия в пятеричной системе счисле-
ния: 3245 + 1025; 4315 - 1225; 142зх 135.
Решение:
а) 324 б) _ 4 з i в) 142
1 0 2 1 2 2 х 1 з
4 3 1 3 0 4 1 0 3 1
1 4 2
3 0 0 1
60
Системы счисления используются для построения на их осно-
ве различных кодов в системах передачи, хранения и преобразо-
вания информации.
Код (от лат. codex) — система условных знаков (символов) для пред-
ставления различной информации.
Любому дискретному сообщению или знаку сообщения можно
приписать какой-либо порядковый номер. Измерение аналоговой
величины, выражающееся в сравнении ее с образцовыми мерами,
также приводит к числовому представлению информации. Пере-
дача или хранение сообщений при этом сводится к передаче или
хранению чисел. Числа можно выразить в какой-либо системе
счисления. Таким образом будет получен один из кодов, основан-
ный на данной системе счисления.
Каждому разряду числа можно поставить в соответствие какой-
либо параметр электрического сигнала, например амплитуду. На
рис. 3.3 в качестве примера приведено изображение числа 35 в виде
импульсов длительностью т0 с разными амплитудами (при разных
системах счисления) [9].
Основание
системы
счисления
Запись
числа
{код числа)
Электри-
ческие
сигналы
(кодовая
комби-
нация)
Р= 12
2В
Р= 10
35
Р = 8
43
Рис. 3.3. Изображение числа 35 в виде сигналов при разных системах счисления
Анализ систем счисления и построенных на их основе кодов с по-
зиций применения в системах передачи, хранения и преобразования
информации показывает, что чем больше основание системы счис-
ления, тем меньшее число разрядов требуется для представления дан-
ного числа, а следовательно, и меньшее время для его передачи.
61
Однако с ростом основания существенно повышаются требо-
вания к аппаратуре формирования и распознавания элементарных
сигналов, соответствующих различным символам. Логические эле-
менты вычислительных устройств в этом случае должны иметь
большее число устойчивых состояний.
С учетом этих обстоятельств в качестве показателя эффектив-
ности системы может быть выбрано число, равное произведению
количества различных символов q на количество разрядов N для
выражения любого числа. Тогда наиболее эффективной будет си-
стема, обеспечивающая минимум значения данного показателя.
Обозначим произведение основания системы q на длину раз-
рядной сетки N, выбранную для записи чисел в этой системе, — С:
С= qxN. (3.4)
Если принять, что каждый разряд числа представлен не одним
элементом с q устойчивыми состояниями, a q элементами, каждый
из которых имеет одно устойчивое состояние, то показатель (3.4)
определит условное количество оборудования, которое необходи-
мо затратить на представление чисел в этой системе. В связи с этим
показатель (3.4) называют показателем экономичности системы.
Максимальное число, которое можно изобразить в системе с
основанием q:
A =qN — 1. (3.5)
Из (3.5) можно найти требуемую длину разрядной сетки:
N = ^gq(Amax+l). (3.6)
Тогда для любой системы счисления С = q logq(Aqmax + 1).
Допустим, что величина q является непрерывной величиной.
При этом будем рассматривать величину С как функцию от вели-
чины q. Теперь если за единицу измерения оборудования принять
условный элемент с одним устойчивым состоянием, то для срав-
нения двух систем счисления можно ввести относительный пока-
затель экономичности:
F = qlogq(Aqmax + 1)/[21од2(А2ш<а + 1)], (3.7)
позволяющий сравнить любую систему счисления с двоичной.
Из приведенного ниже соотношения видно, что функция F име-
ет минимум.
q 2 3 4 6 8 10
F 1,000 0,946 1,000 1,148 1,333 1,505
62
На рис. 3.4 представлена зависимость величины For основания
системы счисления q, если функция Fнепрерывна. Нижняя точка
графика соответствует минимуму функции F, определяемому из
условия dF/dq = 0, что соответствует значению q = е = 2,72.
Следовательно, с точки зре-
ния минимальных затрат услов-
ного оборудования наиболее
экономичной является система
счисления с основанием 3.
Незначительно уступают ей
двоичная и четверичная. Систе-
мы с основанием 10 и более су-
щественно менее эффективны.
Сравнивая эти системы с точки
зрения удобства физической ре-
ализации соответствующих им
логических элементов и просто-
ты выполнения в них арифмети-
ческих и логических действий,
Рис. 3.4. Зависимость относительного
показателя экономичности
от основания системы счисления
предпочтение в настоящее время отдается двоичной системе счис-
ления. Действительно, логические элементы, соответствующие
этой системе, должны иметь всего два устойчивых состояния. За-
дача различения сигналов сводится в этом случае к задаче обнару-
жения (есть импульс или его нет), что значительно проще. Ариф-
метические и логические действия также легче осуществляются в
двоичной системе.
3.1.2. Перевод чисел из одной системы счисления в другую
Рассмотрим задачу перевода числа из одной системы счисле-
ния в другую в общем случае [20]. Пусть известна запись числа А
в системе счисления с основанием р:
Ар = ап х р” + ап1 х р"1 +...+ а, хр1 + аох р° + а( х р1 +...+
п
+ axp'm = S а р ,
•Ш L— ...
«——т
(3.8)
где а. — цифры р-ичной системы (0 < а. £р-1)-
63
Требуется найти запись этого же числа А в системе счисления с
основанием d:
A=b xdn + b .х dnl +...+ b.xd1 + bnxd° + b .xd‘ + ... +
а П П-J J U -I
+ b xd^= X bKdK ,
k=-m
(3.9)
где b — искомые цифры d-ичной системы (0 < Ь <d-l}. При этом
можно ограничиться случаем положительных чисел, так как пере-
вод любого числа сводится к переводу его модуля и приписыва-
нию числу нужного знака.
При переводе чисел из р-ичной системы счисления в d-ичную
(Ар -> AJ нужно учитывать, средствами какой арифметики должен
быть осуществлен перевод, т. е. в какой системе счисления (р-ич-
ной или d-ичной) должны быть выполнены все необходимые для
перевода действия.
Пусть перевод Ар —>Ad должен осуществляться средствами d-ич-
ной арифметики. В этом случае перевод произвольного числа А, за-
данного в системе счисления с основанием р, в систему счисления
с основанием d выполняется по правилу замещения, предусматрива-
ющему вычисление полинома (3.8) в новой системе счисления. То есть
для получения d-ичного изображения выражения (3.8) необходимо
все цифры а и число р заменить d-ичными изображениями и выпол-
нить арифметические операции в d-ичной системе счисления.
Правило замещения чаще всего используется для преобразова-
ния чисел из любой системы счисления в десятичную. Правило
перевода для этого случая можно конкретизировать.
Перевод в десятичную систему числа А, записанного в р-ичной
системе счисления в виде А;) = (апап1 ... а0 , а_, а2 ... а т)р сводится
к вычислению значения многочлена А|о = ап р" + ап, р" ' + .. + аор° +
+ а,р'' + а2р-2 + ... + аш р” средствами десятичной арифметики.
Пример 3.
Разряды 3 2 1о -1
Число 10 11, 12 = 1х23 + 1x2'+ 1x2° + 1х2‘= 11,5](|.
6, 58 = 2х82 +7Х81 + 6x8° + 5х8> = 190,6251О.
31й = 1х162 +15Х161 + 3x16° = 499...
10 IV
64
При переводе следует придерживаться правила сохранения точ-
ности изображения числа в разных системах, причем под точностью
понимается значение единицы самого младшего (правого) разряда,
используемого в записи числа в той или иной системе счисления.
Пусть теперь перевод Ар —> Ad должен осуществляться сред-
ствами р-ичной арифметики. В этом случае для перевода любого
числа используют правило деления — для перевода целой части
числа, и правило умножения — для перевода его дробной части.
Перевод целых чисел. Выражения (3.8) и (3.9) для целых чисел
будут иметь следующий вид соответственно:
Ар = ап х р" + ап1 х р"1 +... + at х р' + а0, (3.10)
Ad = bnxd" 4-Ьп1хсГ‘+...+ b, х d1 4- Ьо, (3.11)
где а. — цифры р-ичной системы (0 < а< р-1) и Ь. — искомые циф-
ры d-ичной системы (0 < b. < d-1).
Так как А — А„, то можно записать:
р d'
Ар= bnxd"+ b^xd"' + ...+ b(xd’ + b0, (3.12)
где b. — искомые цифры в d-ичной системе счисления.
Для определения Ьо разделим обе части равенства (3.12) на число
d, причем в левой части произведем деление, пользуясь правилами р-
ичной арифметики (так как запись числа Ар в р-ичной системе счис-
ления известна). Выделим в частном [Ар/ d] целую и дробную части:
[Ap/d]= [Ap/d]4-HAp/d]A, (3.13)
где [Ар/ d]4 — целая часть частного — неполное частное;
остаток
<V
— дробная часть частного, остаток — оста-
ток от деления Ар на d.
Правую часть перепишем в виде:
[Ар/ d] =bnх d"1 + bnix dn2 +... + bi + b0/d. (3.14)
Учитывая, что b < d, приравняем между собой полученные це-
лые и дробные части равенства (3.14):
[Ар/ d]v = bnxdn l +bn.lxdn'2 +...+ br (3.15)
остаток
5 A-210
65
Таким образом, младший коэффициент Ьо в разложении (3.11)
определяется соотношением:
остаток
d
= остаток,
b0= dx
т. е. Ьд является остатком от деления Ар на d. Положим:
A1 = [A/d] =b xdnl+b ,xdn2 + ... + b,.
р 1 Р JI< П П-1 /
(3.16)
(3.17)
Тогда А1 будет целым числом и к нему можно применить ту же са-
мую процедуру для определения следующего коэффициента bt и т. д.
Этот процесс продолжается до тех пор, пока неполное частное
не станет равным нолю:
[А‘р/dj4 = 0. (3.18)
Поскольку все операции выполняются в системе счисления с
основанием р, то в этой же системе будут получены искомые ко-
эффициенты bt, поэтому их необходимо записать d-ичной цифрой.
Правило деления чаще всего используется для преобразования
целых чисел из десятичной в любую другую систему счисления.
Таким образом, правило перевода целых чисел из р-ичной сис-
темы счисления в d-ичную средствами р-ичной арифметики мо-
жет быть сформулировано в следующем виде.
Для перевода целого числа А из р-ичной системы счисления
в систему счисления с основанием d необходимо Ар разделить
с остатком («нацело») на число d, записанное в той же р-ичной сис-
теме. Затем неполное частное, полученное от такого деления, нужно
снова разделить с остатком на d и т. д., пока последнее полученное
неполное частное не станет равным нолю. Представлением числа Ар в
новой системе счисления будет последовательность остатков деления,
изображенных d-ичной цифрой и записанных в порядке, обратном
порядку их получения.
Пример 4. Переведем число А10 = 47 в двоичную систему с ис-
пользованием десятичной арифметики. Применяя формулы
(3.12)—(3.18) при d = 2, имеем:
47:2 = 23(1); м
23:2 = 11(1);
11:2 = 5(1);
5:2 = 2(1);
2:2 = 1(0);
1:2 = 0(1).
66
Поскольку числа ноль и единица в обеих системах счисления
обозначаются одинаковыми цифрами 0 и 1, то в процессе деления
сразу получим двоичные изображения искомых цифр: А~ 101111.
Пример 5. Переведем число А]0 = 75 в шестнадцатеричную си-
стему счисления с использованием десятичной арифметики. При-
меняя формулы (3.12)—(3.18) при d= 16, имеем:
75:16 = 4(11);
4:16 = 0(4).
Первый остаток 1110 в 16-ричной системе счисления обознача-
ется шестнадцатеричной цифрой В16, поэтому окончательно полу-
чим: А|6=4В.
Перевод правильных дробей. Выражения (3.8) и (3.9) для пра-
вильной дроби будут иметь следующий вид соответственно:
Ар = ал хр-‘ + а 2 хр2 +...+ а т хрт+..., (3.19)
Ad = b, х d1 + Ь 2 х d2 +...+ b ш х d* +..., (3.20)
где at — цифры р-ичной системы (0 < а( < Р-1) и bt — искомые циф-
ры d-ичной системы (0 < Ц < d-1).
При этом:
А = b.xd1 + b,xd'2 + ...+ b xdm. (3.21)
p -1 -2 -m ' •
определения b t умножим обе части равенства (3.21) на чис-
ло d, причем в левой части произведем умножение, пользуясь пра-
вилами р-ичной арифметики (так как запись числа Ар в р-ичной
системе счисления известна). Выделим в произведении [Арх d] це-
лую и дробную части:
[Ар х d] = [Ар х d]q+ [Ар х d]A, (3.22)
где [Ар х d]q — целая часть произведения;
[Ар х d]A — дробная часть произведения.
Правую часть перепишем в виде:
[Apxd]=b1 + b2xd1 + ... + bmxdm+1 + .... (3.23)
Учитывая, что 0<b.<d, приравняем между собой полученные
целые и дробные части равенства (3.23):
[ApXd]q=b1, (3.24)
[Axd] = b, х d1 +...+ b х d‘m+1 +....
i p лд -L -ХП
67
Таким образом, младший коэффициент b_t в разложении (3.21)
определяется соотношением:
b, = [A xd] .
-1 1 р
Положим:
А'р = [Apxd]4 = b2xd' + ... + bmxd“+1 +... . (3.25)
Тогда А' будет правильной дробью и к нему можно применить
ту же самую процедуру для определения следующего коэффици-
ента b 2 и т. д.
Этот процесс продолжается до тех пор, пока дробная часть про-
изведения не станет равной нолю:
[А‘рха]д=0, (3.26)
или не будет достигнута требуемая точность представления числа.
При переводе приближенных дробей из одной системы счисле-
ния в другую необходимо придерживаться следующего правила.
Если единица младшего разряда числа А, заданного в р-ичной
системе счисления, есть р*, то в его d-ичной записи следует сохра-
нить j разрядов после запятой, где j удовлетворяет условию:
d> > р к/2 > ,
округляя последнюю оставляемую цифру обычным способом.
Поскольку все операции выполняются в системе счисления с ос-
нованием р, то в этой же системе будут получены искомые коэффи-
циенты Ье поэтому их необходимо записать d-ичной цифрой. Прави-
ло умножения чаще всего используется для преобразования правиль-
ных дробей из десятичной в любую другую систему счисления.
Таким образом, правило перевода правильных дробей из р-ич-
ной системы счисления в d-ичную средствами р-ичной арифмети-
ки может быть сформулировано в следующем виде.
Для перевода правильной дроби Ар из р-ичной системы счисления в
систему счисления с основанием d необходимо Ар умножить на d,
записанное в той же р-ичной системе, затем дробную часть получен-
ного произведения снова умножить на d ит.д. до тех пор, пока дробная
часть очередного произведения не станет равной нолю, либо не бу-
дет достигнута требуемая точность изображения числа Ар в d-ичной
системе. Представлением дробной части числа Ар в новой системе
счисления будет последовательность целых частей полученных про-
68
изведений, записанных в порядке их получения и изображенных d-ичной
цифрой. Если требуемая точность перевода числа Ар составляет
j знаков после запятой, то предельная абсолютная погрешность при
этом равняется d ('+0 / 2.
Примерб. Переведем число А10 = 0.2 в двоичную систему счис-
ления с использованием средств десятичной арифметики. Приме-
нение формул (3.23)—(3.25) приводит к такой последовательности
действий:
0.2 х 2 = 0.4 = 0 + 0.4 => b , = 0;
0.4 х 2 = 0.8 = 0 + 0.8 => b 2 = 0;
0.8x2 = 1.6= 1 + 0.6 =>Ь3 = 1;
0.6 х 2 = 1.2= 1 + 0.2 => b . = 1 и т. д. ' ’
-4
Если десятичная дробь А)0=0.2 является точным числом, то в
результате перевода в двоичную систему счисления получена пе-
риодическая дробь А2 = 0.(0011) (в скобках указан период дроби).
Пример 7. Переведем число А10 = 0.36 в восьмеричную и шест-
надцатеричную системы счисления с использованием средств де-
сятичной арифметики. Применив формулы (3.23)—(3.25), получим:
0.36 х 8 = 2.88 = 2 + 0.88 => b , = 2;
0.88 х 8 = 7.08 = 7 + 0.08 => b 2 = 7;
0.08 х 8 = 0.64 = 0 + 0.64 => b 3 = 0 и т. д. ,,
Таким образом, А* = 0.270, при этом предельная абсолютная по-
грешность равна 8'4/2 = 213.
0.36 х 16 = 5.76 = 5 + 0.76 =>Ь4 = 5; I
0.76x8 = 12.16 = 12 + 0.16 => Ь2 = 12ит.д. |
Число 1210 в 16-ичной системе счисления обозначается цифрой
С16, поэтому окончательно получим А16 = 0.5С, при этом предель-
ная абсолютная погрешность равна 16V2 = 213.
Особого внимания заслуживает случай перевода чисел из од-
ной системы счисления в другую, когда основания данных систем
счисления pud связаны равенством р = dK, где К — целое положи-
тельное число. В этом случае перевод из d-ичной в р-ичную систе-
му счисления может быть осуществлен по следующему правилу.
69
В исходной, d-ичной, записи числа разряды объединяются впра-
во и влево отточки в группы длины К (добавляя в случае необходи-
мости левее старшей или правее младшей значащих цифр соот-
ветствующее количество нолей), и каждая такая группа записыва-
ется одной цифрой р-ичной системы счисления. Для обратного
перевода из р-ичной в d-ичную систему счисления — каждая циф-
ра числа, заданного в р-ичной системе счисления заменяется ее d-
ичным изображением. Например,
01 21 21 12 = 1996,,;
4 1о
1996, = 0001 1001 1001 ОНО,;
0 1 22.11 023 = 18.429;
5259 = 12 01 123.
3.1.3. Двоичная, восьмеричная и шестнадцатеричная
системы счисления
Примеры изображения чисел в данных системах счисления
представлены в табл. 3.3.
Таблица 3.3
Системы счисления
10-ичная 2-ичная 8-ичная 16-ичная
0 00000 0 0
1 00001 1 1
2 00010 2 2
3 00011 3 3
4 00100 4 4
5 00101 5 5
6 00110 6 6
7 00111 7 7
8 01000 10 8
9 01001 И 9
10 01010 12 А
10-ичная 2-ичная 8-ичная 16-ичная
И 01011 13 В
12 01100 14 С
13 01101 15 D
14 01110 16 Е
15 ОНИ 17 F
16 10000 20 10
17 10001 21 И
18 10010 22 12
19 10011 23 13
20 10100 24 14
70
Как было отмечено выше, в современной вычислительной тех-
нике, в устройствах автоматики и связи используется в основном
двоичная система счисления, что обусловлено рядом преимуществ
данной системы счисления перед другими системами. Так, для ее
реализации нужны технические устройства лишь с двумя устой-
чивыми состояниями, например материал намагничен или размаг-
ничен (магнитные ленты, диски), отверстие есть или отсутствует
(перфолента и перфокарта). Этот обеспечивает более надежное и
помехоустойчивое представление информации, дает возможность
применения аппарата булевой алгебры для выполнения логичес-
ких преобразований информации. Кроме того, арифметические
операции в двоичной системе счисления выполняются наиболее
просто.
Недостаток двоичной системы — быстрый рост числа разря-
дов, необходимых для записи больших чисел. Этот недостаток не
имеет существенного значения для ЭВМ. Если же возникает не-
обходимость кодировать информацию «вручную», например при
составлении программы на машинном языке, то используют
восьмеричную или шестнадцатеричную системы счисления. Чис-
ла в этих системах читаются почти так же легко, как десятичные,
требуют соответственно в три (восьмеричная) и в четыре (шест-
надцатеричная) раза меньше разрядов, чем в двоичной системе
(числа 8 и 16 — соответственно третья и четвертая степени числа
2), а перевод их в двоичную систему счисления и обратно осуще-
ствляется гораздо проще в сравнении с десятичной системой
счисления.
Перевод восьмеричных и шестнадцатеричных чисел в двоичную
систему осуществляется путем замены каждой цифры эквивален-
тной ей двоичной триадой (тройкой цифр) или тетрадой (чет-
веркой цифр) соответственно.
Например:
537,1 = 101 011 111,001,; 1 АЗ, F.= 1 10100011,1111,
ММ JM i i
5 3 7 1 1 А 3 F
Чтобы перевести число из двоичной системы в восьмеричную
или шестнадцатеричную, его нужно разбить влево и вправо от
запятой на триады (для восьмеричной) или тетрады (для шест-
надцатеричной) и каждую такую группу заменить соответству-
ющей восьмеричной или шестнадцатеричной цифрой.
71
Например:
10101001,10111, = 10 101 001, 101 110, = 251,56я
J, i 4- X
2 5 15 6
10101001,10111, = 1010 1001, 1011 1000, = А9,В81Й.
г г г г
А 9 В 8
Правила выполнения арифметических операций сложения, вы-
читания, умножения и деления в 2-, 8- и 16-ичной системах счисле-
ния, как было отмечено выше, будут такими же, как и в десятич-
ной системе, только надо пользоваться особыми для каждой сис-
темы таблицами сложения и умножения.
Рассмотрим примеры выполнения арифметических операций
в данных системах счисления.
Сложение
Таблицы сложения для 2-ичной, 8-ичнойи 16-ичной систем счис-
ления представлены на рис. 3.5.
Сложение
в восьмеричной системе
+ 0 1 2 3 4 5 6 7
0 0 1 2 3 4 5 6 7
1 1 2 3 4 5 6 7 10
2 2 3 4 5 6 7 10 11
3 3 4 5 6 7 10 11 12
4 4 5 6 7 10 11 12 13
5 5 6 7 10 11 12 13 14
6 6 7 10 11 12 13 14 15
7 7 10 11 12 13 14 15 16
Рис. 3.5. Таблицы сложения для двоичной, восьмеричной
и шестнадцатеричной систем счисления
72
Сложение
в шестнадцатеричной системе
+ 0 1 2 3 4 5 6 7 8 9 А В С D Е F
0 0 1 2 3 4 5 6 7 8 9 А В С D Е F
1 1 2 3 4 5 6 7 8 9 А В С D Е F 10
2 2 3 4 5 6 7 8 9 А В С D Е F 10 И
3 3 4 5 6 7 8 9 А В С D Е F 10 11 12
4 4 5 6 7 8 9 А В С D Е F 10 11 12 13
5 5 6 7 8 9 А В С D Е F 10 11 12 13 14
6 6 7 8 9 А В С D Е F 10 11 12 13 14 15
7 7 8 9 А В С D Е F 10 И 12 13 14 15 16
8 8 9 А В С D Е F 10 11 12 13 14 15 16 17
9 9 А В С D Е F 10 И 12 13 14 15 16 17 18
А А В С D Е F 10 11 12 13 14 15 16 17 18 19
В В С D Е F 10 И 12 13 14 15 16 17 18 19 1А
С С D Е F 10 11 12 13 14 15 16 17 18 19 1А 1В
D D Е F 10 И 12 13 14 15 16 17 18 19 1А 1В 1С
Е Е F 10 И 12 13 14 15 16 17 18 19 1А 1В 1С 1D
F F 10 11 12 13 14 15 16 17 18 19 1А 1В 1С 1D 1Е
Рис. 3.5. Таблицы сложения для двоичной, восьмеричной
и шестнадцатеричной систем счисления (окончание)
При сложении цифры суммируются по разрядам, и если при
этом возникает избыток, то он переносится влево.
Пример 8. Сложить десятичные числа 15 и 6 в 2-, 8- и 16-ичной
системах счисления.
Двоичная: 11112 + 1102 Восьмеричная: 17g + 68
ill 1
+ ИИ 17
ОНО _£
10101 25
73
Шестнадцатеричная: Fie + 6,6
1
+ F
15
Ответ: 15 + 6 = 2110 = 10 1 012 = 258 = 1516.
Проверка. Преобразуем полученные суммы к десятичному
виду:
101012 = 24 + 22 + 2° = 16 + 4 + 1 = 21,
258 = 2 81 + 5x8° = 16 + 5 = 21,
15,. = 1 х 16, + 5х 16 = 16 + 5 = 21.
1о 1 и
Пример 9. Сложить десятичные числа 141,5 и 59,75 в 2-, 8- и 16-
ичной системах счисления.
Двоичная: 10001101,12 + 111011,112
1111111
10001101,1
+ 111011,11
11001001,01
Восьмеричная: 215,48 + 73,68 Шестнадцатеричная: 8D,816 + ЗВ, С16
ill 1 1
, 215,4 , 8D,8
+ 73.6 ЗВ,С
311,2 С9,4
Ответ: 141,5 + 59,75 = 201,25, п = 11001001,01, = 311,2. = С9,4,,.
Проверка. Преобразуем полученные суммы к десятичному
виду:
1100 1001,012 = 27 + 26 + 23 + 2° + 2‘2 = 201,25;
311,28= Зх82+ 1 х 81 + 1 х 8° + 2х 81 = 201,25;
С9,4,„ = 12х 161 + 9х 16° + 4х 161 = 201,25.
1О
74
Вычитание
Пример 10. Вычесть единицу из чисел 102, 108 и 1016.
Двоичная: 102 — 12 Восьмеричная: 108 — 18
1 1 Заемы
_ 10 _ 10
____1 ___________________1
1 7
Шестнадцатеричная: 1016 — 116
1
_ 10
____1
F
Пример 10. Вычесть число 59,75 из числа 201,25.
Двоичная: 11001001,012 - 111011,112
1 1 1
11001001,01
00111011.11
10001101,10
Восьмеричная: 31 l,2g — 73,68 Шестнадцатеричная: С9,416 + ЗВ, С16
111
311,2
215,4
1 1
С9,4
ЗВ.С
8D,8
Ответ: 201,2510 - 59,7510 = 141,510 = 10001101,12 = 215,48 = 8D,816.
Проверка. Преобразуем полученные разности к десятичному
виду:
10001101,12 = 27 + 23 + 22 + 2° + 21 = 141,5;;
215,48 = 2-82+1-8’ + 5-8° + 4-81 = 141,5,•
8D,8,K = 8' 161 + D-16° + 8-161 = 141,5.
10
75
Умножение
Выполняя умножение многозначных чисел в различных позици-
онных системах счисления, можно использовать обычный алгоритм
перемножения чисел в столбик, но при этом результаты перемноже-
ния и сложения однозначных чисел необходимо брать из соответству-
ющих рассматриваемой системе таблиц умножения и сложения.
Таблицы умножения для 2-ичной, 8-ичной и 16-ичной систем
счисления представлены на рис. 3.6.
Умножение Умножение
в двоичной системе в восьмеричной системе
X 0 1
0 1 0 0 0 1
X 0 1 2 3 4 5 6 7
0 0 0 0 0 0 0 0 0
1 0 1 2 3 4 5 6 7
2 0 2 4 6 10 12 14 16
3 0 3 6 И 14 17 22 25
4 0 4 10 14 20 24 30 34
5 0 5 12 17 24 31 36 43
6 0 6 14 22 30 36 44 52
7 0 7 16 25 34 43 52 61
Умножение в шестнадцатеричной системе
X 0 1 2 3 4 5 6 7 8 9 А В С D Е F
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
1 0 1 2 3 4 5 6 7 8 9 А в с D Е F
2 0 2 4 6 8 А С Е 10 12 14 16 18 1А 1С 1Е
3 0 3 6 9 С F 12 15 18 1В 1Е 21 24 27 2А 2D
4 0 4 8 С 10 14 18 1С 20 24 28 2С 30 34 38 ЗС
5 0 5 А F 14 19 1Е 23 28 2D 32 37 ЗС 41 46 4В
6 0 6 С 12 18 1Е 24 2А 30 36 ЗС 42 48 4Е 54 5А
7 0 7 Е 15 1С 23 2А 31 38 3F 46 4D 54 5В 62 69
8 0 8 10 18 20 28 30 38 40 48 50 58 60 68 70 78
9 0 9 12 1В 24 2D 36 3F 48 51 5А 63 6С 75 7Е 87
А 0 А 14 1Е 28 32 ЗС 46 50 5А 64 6Е 78 82 8С 96
В 0 В 16 21 2С 37 42 4D 58 63 6Е 79 84 8F 9А А5
С 0 С 18 24 30 ЗС 48 54 60 6С 78 84 90 9С А8 В4
D 0 D 1А 27 34 41 4Е 5В 68 75 82 8F 9С А9 В6 СЗ
Е 0 Е 1С 2А 38 46 54 62 70 7Е 8С 9А А8 В6 С4 D2
F 0 F 1Е 2D ЗС 4В 5А 69 78 87 96 А5 В4 сз D2 Е1
Рис. 3.6. Таблицы умножения для 2-ичной, 8-ичной и 16-ичной систем счисления
76
Ввиду чрезвычайной простоты таблицы умножения в двоичной сис-
теме умножение сводится лишь к сдвигам множимого и сложениям.
Пример 11. Перемножим числа 5 и 6.
Двоичная: 1012 х 1102 Восьмеричная: 58 х 68
101 36
101
11110
Шестнадцатеричная: 516 х 616.
5
Х_6
1Е
Ответ: 5 х 6 = 30 = 11110 =36 = 1Е .
10 2 о 16
Проверка. Преобразуем полученные произведения к десятич-
ному виду:
111102 = 24 + 23 + 24- 21 = 30;
368 = 3 х 81 + 6 х 8° = 30;
IE, = 1 х 16’4-Ех 16°= 30.
1Ь
Пример 12. Перемножим числа 115 и 51.
Двоичная: 11100112 х 1100112 Восьмеричная: 1638 х 638
1110011 163
Х 110011 _£3
1110011 531
1110011 1262
1110011 13351
1110011
1011011101001
Шестнадцатеричная: 7316 х 3316
159
159
16Е9
77
Ответ: 115x51 = 5865 = 1011011101001 = 13351 = 16Е9,К.
Проверка. Преобразуем полученные произведения к десятич-
ному виду:
101101110 1 0012 = 212 4- 210 + 29 + 2’4- 26 4- 25 + 23 4- 2° = 5865;
133518 = 1х 84 4-3х 83 4-3х 82 4- 5 х8‘4-1х8° = 5865;
16Е9,, = 1 х 163 4- 6х 162 4- Ex 161 4- 9х 16° = 5865.
10
Деление
Деление в данных системах счисления, как и в любой другой
позиционной системе счисления, производится по тем же прави-
лам, как и деление углом в десятичной системе. В двоичной систе-
ме деление выполняется особенно просто, так как очередная циф-
ра частного может быть только нолем или единицей.
Пример 13. Разделим число 5865 на число 115.
Двоичная: 10110111010012: 11100112 Восьмеричная: 133518:1638
_10110111010011 1110011 1110011 110011 1000100 1110011 _10101100 3351 | 163 1262 63 531 531 0
1110011
_1110011
1114)011
0
Шестнадцатеричная: 16Е9: 73
_16Е91 73
159 33
_ 159
159
0
Ответ: 5865: 115 = 51, = 110011= 63 = 33,к.
1U 2 о 1о
Проверка. Преобразуем полученные частные к десятичному виду:
1100112 = 25 + 24 4- 21 4- 2° = 51;
638 = 6х8‘ 4- 3x8° = 51;
33,й = Зх 161 4- Зх 16° = 51.
ID
78
Пример 14. Разделим число 35 на число 14.
Двоичная: 1000112:11102 Восьмеричная: 438: 168
100011 |1110
' 1110 10,1
_ 1110
1110
0
43 |_lfi
34 2,4
70
‘ 2Q
0
Шестнадцатеричная: 23 : Е
_23 |Е
1С 2,8
70
23
0
Ответ: 35 : 14 = 2,51П = 10,1, = 2,4Я = 2,81К.
10 2 о 10
Проверка. Преобразуем полученные частные к десятичному виду:
10,12 = 21 + 21 = 2,5;
2,48 = 2x8° + 4x8* = 2,5;
2,8|К = 2х 16° + 8х 16'1 = 2,5.
10
3.1.4. Двоично-десятичная система счисления
Двоично-десятичная система счисления (ДДСС) широко ис-
пользуется в цифровых устройствах, когда основная часть опера-
ций связана не с обработкой и хранением вводимой информации,
а с ее вводом и выводом на какие-либо индикаторы с десятичным
представлением полученных результатов (микрокалькуляторы,
кассовые аппараты и т. п.) [6].
В двоично-десятичной системе десятичные цифры от 0 до 9 пред-
ставляют 4-разрядными двоичными комбинациями от 0000 до 1001,
т. е. двоичными эквивалентами десяти первых шестнадцатеричных
цифр (см. табл. 3.3). Преобразования из двоично-десятичной систе-
мы в десятичную систему счисления (ДСС) (и обратные преобра-
зования) не вызывают затруднений и выполняются путем прямой
замены четырех двоичных цифр одной десятичной цифрой (или об-
ратной замены). Например,
(ООП 0111)2_10
4, 4,
(3 -7)10
79
Две двоично-десятичные цифры составляют 1 байт. Таким об-
разом, с помощью 1 байта можно представлять значения от 0 до
99, а не от 0 до 255, как при использовании 8-разрядного двоичного
числа. Используя 1 байт для представления каждых двух десятич-
ных цифр, можно формировать двоично-десятичные числа с лю-
бым требуемым числом десятичных разрядов.
Так, если число
1001 0101 ООН 1000
рассматривать как двоичное, то его десятичный эквивалент
(1001 0101 0011 1000)2 — (38200) 10
в несколько раз больше десятичного эквивалента двоично-десятич-
ного числа
(1001 0101 ООП Ю00)2,10= (9538)10.
Сложение двоично-десятичных чисел, имеющих один десятич-
ный разряд, выполняется так же, как и сложение 4-разрядных дво-
ичных чисел без знака, за исключением того, что при получении
результата, превышающего 1001, необходимо производить коррек-
цию. Результат корректируется путем прибавления двоичного кода
числа 6, т. е. кода 0110. Например:
ДСС ДДСС ДСС ДДСС
, 4 0100 , 5 0101
+ 0101 + 9 1001
9 1001 14 1110
~г 0110 —коррекция
10 + 4 1 0100
ДСС ДДСС
, 9 , 1001
+ 9 + 1001
18 1 0010
0110 —коррекция
10 + 8 1 1000
Если первоначальное двоичное сложение или прибавление кор-
ректирующего числа приводит к возникновению переноса, то при
80
сложении многоразрядных двоично-десятичных чисел перенос
осуществляется в следующий десятичный разряд:
Дес ДДСС
1889 + £37£ 0001 + 1110 + 1000 ИШ + 1000 0111 + 1001 жш
8265 0111 1011 1111 1111
+__L Z 1000 + 4- оно 1 ' + < + 0110^ 1 1- оно 0101
г 0010 оно г
г г
8 2 6 5
3.2. ПРЕДСТАВЛЕНИЕ ЧИСЛОВОЙ ИНФОРМАЦИИ
В ЦИФРОВЫХ АВТОМАТАХ
Информация в памяти ЭВМ записывается в форме цифрового
двоичного кода. С этой целью ЭВМ содержит большое количество
ячеек памяти и регистров (от лат. regestum — внесенное, записан-
ное) для хранения двоичной информации. Большинство этих яче-
ек имеет одинаковую длину п, т. е. они используются для хране-
ния п бит двоичной информации (бит — один двоичный разряд).
Информация, хранимая в такой ячейке, называется словом. Дво-
ичное слово, состоящее из 2 байт, представлено на рис. 3.7 [6].
Рис. 3.7. Бит, байт и слово
Ячейки памяти и регистры состоят из элементов памяти. Каж-
дый из таких электрических элементов может находиться в одном
из двух устойчивых состояний: конденсатор заряжен или разря-
жен, транзистор находится в проводящем или непроводящем со-
стоянии, специальный полупроводниковый материал имеет высо-
кое или низкое удельное сопротивление и т. п. Одно из таких фи-
зических состояний создает высокий уровень выходного напря-
бА-210 81
жения элемента памяти, а другое — низкий. Обычно это электри-
ческие напряжения порядка 4—5В и ОВ соответственно, причем
первое обычно принимается за двоичную единицу, а второе — за
двоичный ноль (возможно и обратное кодирование).
На рис. 3.8 показан выходной сигнал такого элемента памяти
(например, одного разряда регистра) при изменении его состоя-
ний (при переключениях) под воздействием некоторого входного
сигнала. Переход от0к1иот1к0 происходит не мгновенно, одна-
ко в определенные моменты времени этот сигнал достигает значе-
ний, которые воспринимаются элементами ЭВМ как 0 или 1 [6].
Область
напряжений,
соответствующих
сигналу "1"
Идеальный
сигнал
Реальный
сигнал
Область
напряжений,
соответствующих
сигналу"О"
---►
t
Рис. 3.8. Графическое изображение двоичного сигнала
Память ЭВМ состоит из конечной последовательности слов, а
слова — из конечной последовательности битов, поэтому объем
представляемой в ЭВМ информации ограничен емкостью памяти,
а числовая информация может быть представлена только с опре-
деленной точностью, зависящей от архитектуры памяти данной
ЭВМ.
В вычислительных машинах применяются две формы представ-
ления двоичных чисел:
естественная форма, или форма с фиксированной запятой
(точкой);
82
• нормальная форма, или форма с плавающей запятой (точкой).
С фиксированной запятой все числа изображаются в виде пос-
ледовательности цифр с постоянным для всех чисел положением
запятой (точкой), отделяющей целую часть от дробной. В общем
случае разрядная сетка ЭВМ с фиксированной запятой имеет вид,
показанный на рис. 3.9.
Диапазон представления чисел по модулю для такой формы:
2r< |N| < 2п - 2 Г. (3.27)
Если в результате операции получится число, выходящее за до-
пустимый диапазон, происходит переполнение разрядной сетки,
что нарушает нормальное функционирование вычислительной
машины. В современных ЭВМ естественная форма представления
используется как вспомогательная и только для целых чисел.
С плавающей запятой каждое число изображается в виде
двух групп цифр. Первая группа цифр называется мантиссой,
вторая — порядком, причем абсолютная величина мантиссы
должна быть меньше 1, а порядок — целым числом. В общем
случае число в форме с плавающей запятой может быть пред-
ставлено в виде:
N=±Mp*s, (3.28)
где М — мантисса числа (|М|< 1);
s — порядок числа (s — целое число);
р — основание системы счисления.
При р = 2 и наличии п разрядов у мантиссы и г разрядов у по-
рядка (без учета знаковых разрядов) диапазон представления чи-
сел с плавающей запятой:
2 Лх2 (У ° <JV<(l-2 ")х2(2Г ° (3-29)
Нормальная форма представления является основной в совре-
менных ЭВМ.
83
3.2.1. Выполнение арифметических операций
над целыми числами. Прямой, обратный
и дополнительный коды
Целые числа могут представляться в компьютере без знака или
со знаком.
Целые числа без знака. Обычно занимают в памяти компьюте-
ра один или два байта (рис. 3.10). В однобайтовом формате принима-
ют значения от 000000002 до 111111112. В двубайтовом формате —
от 00000000 000000002 до 11111111 111111112.
Формат числа в байтах Диапазон
Запись с порядком Обычная запись
1 0 ... 28 - 1 0 ... 255
2 0 ... 216 - 1 0 ... 65535
Рис. 3.10. Диапазоны значений целых чисел без знака
Примеры:
а) число 72|0 — 10010002 в однобайтовом формате:
Номера разрядов 76543210
Биты числа |0 1 0 0 1 0 0 0
б) это же число в двубайтовом формате: Номера разрядов 15 14 13 12 И 10 9 8 7 6 5 4 3 2 1 0
Биты числа 0 0 0 0 0 0 0 0 0 1 0 0 10 0 0
в) число 65535 в двубайтовом формате: Номера разрядов 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
Биты числа 1111111 1 1 1 1 1111 _1
Целые числа со знаком: прямой, обратный и дополнительный
коды. Целые числа со знаком обычно занимают в памяти компью-
тера один, два или четыре байта (рис. 3.11).
84
Формат числа в байтах Диапазон
Запись с порядком Обычная запись
1 -27... 27 - 1 -128 ... 127
2 -215... 215 - 1 -32768 ... 32767
4 -231 ... 23' - 1 -2147483648 ... 2147483647
Рис. 3.11. Диапазоны значений целых чисел со знаком
В цифровых автоматах применяются три формы записи (коди-
рования) целых чисел со знаком: прямой код, дополнительный
код, обратный код.
Прямой код. Прямой n-разрядный двоичный код отличается от
двоичного тем, что в нем отводится один, как правило, самый стар-
ший разряд для знака, а оставшиеся п-1 разрядов —для значащих
цифр. Значение знакового разряда равно 0 для чисел Д2>0, и 1 —
для чисел А,<0 (рис. 3.12).
а)
Число 110 = 12
|0|0|0|0|0|0|0|1|
I Знак числа « + »
Число 12710= 111 11112
[о]Т|1|1|1|1|1|1|
Т Знак числа « + »
б)
Прямой код числа — 1
fl|O|O|O|O|Q|O|l|
f Знак числа « — »
Прямой код числа —127
ишшшшз
f Знак числа « — »
Рис. 3.12. Представление чисел в прямом коде:
а) положительных, б) отрицательных
Для прямого кода справедливо следующее соотношение:
<=о
(3.30)
где п — разрядность кода; азн — значение знакового разряда.
Например, десятичная запись числа, представленного в прямом
коде как 1101, будет иметь вид:
А10= (- 1)41 х 2° + 0 х 2>+ 1 х 22] = -5.
85
Дополнительный код. Использование чисел со знаком (прямо-
го кода представления чисел) усложняет структуру ЭВМ. В этом
случае операция сложения двух чисел, имеющих разные знаки,
должна быть заменена на операцию вычитания меньшей величи-
ны из большей и присвоения результату знака большей величины.
Поэтому в современных ЭВМ, как правило, отрицательные числа
представляют в виде дополнительного или обратного кодов, что при
суммировании двух чисел с разными знаками позволяет заменить
вычитание на обычное сложение и упростить тем самым конст-
рукцию арифметико-логического устройства компьютера.
Смысл перевода отрицательных чисел из прямого в дополни-
тельный и обратный коды поясним на примере с десятичными чис-
лами. Допустим, вычислительная машина, которая оперирует с
двухразрядными десятичными числами, должна сложить два чис-
ла: Х{ = 84 и Х2 = — 32. Заменим код отрицательного слагаемого Х2
егб дополнением до 100, так чтобы [Х2]доп = 100+ Х2 = 68. Сложив
числа X] + [Х2]доп, получим:
У= X, + [X,] = 84 + 68= 1 52.
1 1 2JAOn
Учитывая, что вычисления проводятся на устройстве с двумя
десятичными разрядами, конечный результат будет равен 52. Ра-
венство полученного результата истинному значению объясняет-
ся тем, что при формировании дополнительного кода к Х2 мы при-
бавляли 100, а затем из результата вычитали 100 отбрасыванием
старшего разряда:
Y = X, + [Х2]доп - 100 = X, + [Х2 + 100] - 100 =
= 84 + 1 — 32 +100] -- 100 = 52.
Операция вычитания 100 заключается в том, что не учитывает-
ся код третьего десятичного разряда.
Таким образом, дополнением М л-разрядного целого числа К
называют разность
М = рп — К, (3.31)
где р — основание системы счисления.
Так как количество различных целых n-разрядных чисел равно
рп (от 0 до рп — 1), то половину этих чисел рассматривают как по-
ложительные (от 0 до рп/2 — 1), а другую половину — как отрица-
тельные (т. е. как дополнения к первой половине чисел). Полный
же набор таких чисел называют числами, представленными в до-
полнительном коде (табл. 3.4) [6].
86
Дополнительные коды чисел
Таблица 3.4
Прямой код ряда 5-разрядных десятичных чисел Дополнительный код чисел
5-разрядных десятичных 4-разрядных шестнадцатеричных 16-разрядных двоичных
-50 000 50 000 —
-49 999 50 001 — —
-49 998 50 002 — —
-32 769 67 231
-32 768 67 232 8000 1 000 0000 0000 0000
-32 767 67 233 8001 1 000 0000 0000 0001
-3 99 997 FFFD 1 111 1111 1111 1101
-2 99 998 FFFF 1111 1111 1111 1110
-1 99 999 FFFF 1111111111111111
0 00 000 0000 0 000 0000 0000 0000
+ 1 00 001 0001 0 000 0000 0000 0001
+2 00 002 0002 0 000 0000 0000 0010
+3 00 003 0003 0 000 0000 0000 ООН
+32 766 32 766 7FFF 0 111 1111 1111 1110
+32 767 32 767 7FFF 0 111 1111 1111 1111
+32 768 32 768 — —
+49 998 49 998 — —
+49 999 49 999 — —
Легко проверить правильность получения дополнений (кодов
отрицательных чисел) в столбцах табл. 3.4. Для этого надо сложить
число из нижней половины таблицы с его дополнением, располо-
женным над кодом 0. Например:
а) для пятиразрядных десятичных чисел:
99999 + 00001 = 1 00000;
99998 + 00002 = 1 00000;
б) для четырехразрядных шестнадцатеричных чисел:
FFFF + 0001 = l 0000;
FFFE +0002=1 0000;
в) для шестнадцатиразрядных двоичных чисел:
1 111 1111 1111 1111 +0 000 0000 0000 0001 =
= 1 0 000 0000 0000 0000;
1 111 1111 1111 1110 + 0 000 0000 0000 0010 =
= 1 0 000 0000 0000 0000;
87
Как видно из примера, результатом такого суммирования бу-
дут числа 10s = ( 1 00 000) 10, 164 = (1 00 00) 16 и 216 = (1 0 000 0000 0000
0000)2. В связи с тем что разрядность чисел (см. табл. 3.4) ограниче-
на 5, 4 и 16 разрядами соответственно, единица в старшем разряде
полученных сумм не учитывается, так как она «выходит» за раз-
рядную сетку. Следовательно, все суммы равны нолю, т. е. правиль-
ному результату сложения двух одинаковых по величине чисел,
имеющих разные знаки.
Дополнения числа можно получить и без вычитания. Перепи-
шем формулу (3.31) в виде:
М = рп — К = ((рп-1) -К) +1.
(3.32)
Здесь число рп — 1 состоит из п цифр (р— 1), т. е. старших цифр
используемой системы счисления (для чисел в табл. 3.4 это 99 999,
FFFF или 1111111111111111).
Поэтому (рп — 1)—К можно получить путем образования допол-
нений до р—1 для каждой из цифр числа К в отдельности, а иско-
мое дополнение — суммированием этого числа с 1. Так как в дво-
ичной системе дополнения цифр до 1 соответствуют их инверс-
ным значениям (дополнение 0 равно 1, а дополнение 1— 0), то
можно дать простое правило для получения дополнения двоич-
ных чисел [6]:
1. Получить инверсию заданного числа (все его 0 заменить на 1,
а все 1 — на 0):
0 000 0010 1100 0101 число
1 111 11010011 1010 инверсия числа
2. Образовать дополнительный код заданного числа путем до-
бавления 1 к инверсии этого числа:
1 111 1101 ООП 1010 инверсия числа
________________1 слагаемое 1
1111 110100111011 дополнительный код числа
Проверим правильность перевода:
1 in ini ini nil
0 000 0010 1100 0101
1 111 1101 ООП 1011
10 000 0000 0000 0000
переносы
число
дополнительный код числа
0
88
(3.33)
где аы
Так как перенос из старшего разряда не учитывается, то резуль-
тат суммирования равен 0, что подтверждает правильность преоб-
разования.
Старший бит дополнительного кода двоичных чисел выполняет
функцию знака числа, т. е. равен 0 для положительных чисел и 1 —
для их дополнений (отрицательных чисел). При этом положитель-
ные числа в дополнительном коде изображаются так же, как и в
прямом, — двоичными кодами с цифрой 0 в знаковом разряде.
Для дополнительного кода справедливо следующее соотношение:
и-2
Ли=а,(-2-') + ^О?2'
1=0
0, для положительных чисел
1 д ; п — разрядность
1, для отрицательных чисел н
машинного слова.
Например, десятичная запись отрицательного числа, представ-
ленного в дополнительном коде как 1011, будет иметь вид:
А10 = lx (— 23) + [1 х2° + 1 х2’ + 0х22] = -8 + 3 = -5.
Обратный код. Для представления отрицательных чисел исполь-
зуется также обратный код, который получается инвертировани-
ем всех цифр двоичного кода абсолютной величины числа: ноли
заменяются единицами, а единицы — нолями. При этом, необхо-
димо помнить, что все операции с отрицательными числами вы-
полняются в формате машинного слова. Это значит, что к двоич-
ному числу слева дописываются ноли до нужного количества раз-
рядов. Например, для 8-разрядного машинного слова:
Число: — 1 Число: — 127
Код модуля числа: 00000001 Код модуля числа: 01111111
Обратный код числа: 11111110 Обратный код числа: 10000000
ПИЕИИИ
(3.34)
Для обратного кода справедливо следующее соотношение:
п-2
4о=«зи(-2'”* 1+1) + Х<2'.
i=0
0, для положительных чисел
, ч ; п — разрядность
1, для отрицательных чисел
машинного слова.
где азн
89
Например, десятичная запись отрицательного числа, представ-
ленного в обратном коде как 1010, будет иметь вид:
А)0 = 1 х (-23 + 1) + [0x2° +1x2' + 0х22] = -7 + 2 =-5.
Для положительных чисел ази = 0 и представление числа полнос-
тью совпадает с представлением в прямом и дополнительном кодах.
Таким образом, положительные числа в прямом, обратном и
дополнительном кодах изображаются одинаково — двоичными
кодами с цифрой 0 в знаковом разряде.
Обычно отрицательные десятичные числа при вводе в машину
автоматически преобразуются в обратный или дополнительный
двоичный код и в таком виде хранятся, перемещаются и участву-
ют в операциях. При выводе таких чисел из машины происходит
обратное преобразование в отрицательные десятичные числа.
Выполнение арифметических операций
Сложение и вычитание
В большинстве вычислительных устройств с целью упрощения
их конструкции операция вычитания не используется. Вместо нее
производится сложение обратных или дополнительных кодов
уменьшаемого и вычитаемого.
Сложение обратных кодов. В этом случае при сложении чисел
X и Y имеют место четыре основных и два особых случая:
1. Хи У положительные. При суммировании складываются все
разряды, включая разряд знака. Так как знаковые разряды поло-
жительных слагаемых равны нолю, разряд знака суммы тоже ра-
вен нолю. Например:
Десятичная запись Двоичные коды
3 0 0000011
+ _7 + 0 0000111
10 0 0001010
Получен корректный результат.
2. X положительное, У отрицательное и по абсолютной вели-
чине больше, чем X.
Например:
Десятичная запись Двоичные коды
3
nlQ
— 7
0 0000011
1 1110101
1 1111000
Обратный код числа — 10
Обратный код числа — 7
90
Получен корректный результат в обратном коде. При переводе
в прямой код биты цифровой части результата инвертируются:
1 0000111 = -710.
3. X положительное, Y отрицательное и по абсолютной вели-
чине меньше, чем X. Например:
Десятичная запись Двоичные коды
7
0 0001010
1 1Ш100
0 0000110
+1
0 0000111
Обратный код числа — 3
Компьютер исправляет полученный первоначально некоррек-
тный результат (6 вместо 7) переносом единицы из знакового раз-
ряда в младший разряд суммы.
4. X и У отрицательные. Например:
Десятичная запись Двоичные коды
-10
1 1111100
1 1111000
1 1110100
—
1 1110101
Обратный код числа — 3
Обратный код числа — 7
Обратный код числа — 10
Полученный первоначально некорректный результат (обрат-
ный код числа — 1110 вместо обратного кода числа — Ю10) компью-
тер исправляет переносом единицы из знакового разряда в млад-
ший разряд суммы. При переводе результата в прямой код биты
цифровой части числа инвертируются: 1 0001010 = — 101О.
При сложении может возникнуть ситуация, когда старшие разря-
ды результата операции не помещаются в отведенной для него обла-
сти памяти. Такая ситуация называется переполнением разрядной
сетки формата числа. Для обнаружения переполнения и оповеще-
ния о возникшей ошибке в компьютере используются специальные
средства. Ниже приведены два возможных случая переполнения.
5. X и У положительные, сумма Х+У больше либо равна 2"-1, где
п — количество разрядов формата чисел (для однобайтового фор-
мата п = 8, 2П-1 = 27 = 128). Например:
Десятичная запись Двоичные коды
65 01000001
+ 97 + 01100001
162 0 0100010 Переполнение
91
Семи разрядов цифровой части числового формата недостаточ-
но для размещения восьмиразрядной суммы (162]0 = 101000102),
поэтому старший разряд суммы оказывается в знаковом разряде.
Это вызывает несовпадение знака суммы и знаков слагаемых, что
является свидетельством переполнения разрядной сетки.
6. X и У отрицательные, сумма абсолютных величин X и У боль-
ше либо равна 2""1. Например:
Десятичная запись Двоичные коды
-63
' ^95
- 158
1 1000000 Обратный код числа —63
1 0100000 Обратный код числа — 95
0 1100000 Переполнение
Здесь знак суммы тоже не совпадает со знаками слагаемых, что
свидетельствует о переполнении разрядной сетки.
Сложение дополнительных кодов. Здесь также имеют место
рассмотренные выше шесть случаев. Примеры сложения целых чи-
сел X и У при 16-разрядном машинном слове сведены в табл. 3.5 [6].
В двух случаях (пятом и шестом) ограниченная разрядность чи-
сел приводит к искажению не только величины, но и знака ре-
зультата. Исправить положение можно, добавляя к результату (слу-
чай 5) или вычитая из него (случай 6) число 216= 65536.
Для обеспечения корректности вычислений перед суммирова-
нием необходимо анализировать знаки слагаемых и результата.
Разные знаки слагаемых или совпадение знаков слагаемых со зна-
ком суммы свидетельствуют о том, что результат будет коррект-
ным.
Таблица 3.5
Различные случаи сложения двоичных чисел со знаком
Случай Слагаемые и результат Комментарий
1 Х>0, Y>0, X+Y<2'5 0 000 0110 0011 1010 Х-+1594 + 0 100 0100 1001 1011 Y-+1756.3 0 100 1010 1101 0101 Z=+19157 Результат корректный
2 Х>0, Y<0, IX|<|Y| 0 000 0110 0011 1010 X=+1521 + 1 011 1011 01100101 Y--17563 1 100 0001 1001 1111 Z--15969 Результат корректный.
92
Окончание табл. 3.5
Случай Слагаемые и результат Комментарий
3 Х>0, У<(), |Х|>|У| 0 100 0100 1001 1011 Х-+17563 + 1 111 1001 1100 0110 Y=-159-1 1 0 011 1110 0110 0001 Z-+15969 Результат корректный. Перенос из старшего разряда не учитывается
4 Х<0, Y<0, |X|+|Y|<215 1 111 1001 1100 0110 X—1594 + 1011 10110110 0101 Y—1756.3 1 1 011 0101 0010 1011 Z—19157 Результат корректный. Перенос из старшего разряда не учитывается
5 X>0, Y>0, X+Y>2'5 0 100 0100 1001 1011 X-+17563 + 0 100 1010 1101 0101 Y-+19157 1 000 1111 0111 0000 Z--28816 При сложении положительных чисел получен отрицательный результат - ПЕРЕПОЛНЕНИЕ!
6 X<0, Y<0, |X|+|Y|>2‘5 1 011 1011 0110 0101 X--17563 + 1 011 0101 0010 1011 Y—19157 1 0 111 0000 1001 0000 Z-+28816 При сложении отрицательных чисел получен положительный результат — ПЕРЕПОЛНЕНИЕ!
Для контроля за выполнением арифметических операций в про-
цессоре ЭВМ (устройстве, в котором выполняются арифметичес-
кие операции) содержатся два индикатора — индикатор переноса
и индикатор переполнения. Каждый индикатор содержит 1 бит
информации и может иметь значение, равное 1 (индикатор уста-
новлен) или равное 0 (индикатор сброшен). Индикатор переноса
указывает на перенос из знакового бита, а индикатор переполне-
ния — на перенос в знаковый бит. Таким образом, после заверше-
ния операции, в которой происходит перенос в старший бит, про-
цессор устанавливает индикатор переполнения. Если такого пере-
носа нет, то индикатор переполнения сбрасывается. Индикатор
переноса обрабатывается аналогичным образом.
После выполнения операции процессором, ЭВМ сигнализирует о
состоянии индикаторов, и их можно проверить. Если состояние ин-
дикаторов указывает на неправильный арифметический результат,
то необходимо предпринять меры, исправляющие эту ситуацию,
т. е. пользователю ЭВМ предоставляется возможность контролиро-
вать правильность выполнения арифметических операций.
Операции сложения и вычитания являются основными опера-
циями в ЭВМ. Это объясняется тем, что они легко выполняются и
любые более сложные операции (умножение, деление, вычисле-
ние тригонометрических функций и т. д.) могут быть сведены к
многократным сложениям и вычитаниям. Так, во многих компью-
93
те pax умножение производится как последовательность сложений
и сдвигов, а деление реализуется путем многократного прибавле-
ния к делимому дополнительного кода делителя.
3.2.2. Смещенный код и код Грея
Смещенный код, или, как его еще называют, двоичный код с из-
бытком, используется в ЭВМ для упрощения операций над порядками
чисел с плавающей запятой. Он формируется следующим образом [4].
Сначала выбирается длина разрядной сетки — пи записываются пос-
ледовательно все возможные кодовые комбинации в обычной двоич-
ной системе счисления. Затем кодовая комбинация с единицей в стар-
шем разряде, имеющая значение 2n l, выбирается для представления
числа 0. Все последующие комбинации с единицей в старшем разряде
будут представлять числа 1,2,3,... соответственно, а предыдущие ком-
бинации в обратном порядке — числа —1, — 2, —3,.... Двоичный код
с избытком для 3- и 4-разрядных сеток представлен в табл. 3.6.
Таблица 3.6.
Номер кодовой комбинации Код с избытком 4 Десятичное значение Номер кодовой комбинации Код с избытком 4 Десятичное значение
7 111 3 15 1111 7
6 110 2 14 1110 6
5 101 1 13 1101 5
4 100 0 12 1100 4
3 011 -1 И 1011 3
2 010 -2 10 1010 2
1 001 -3 9 1001 1
0 000 -4 8 1000 0
7 0111 -1
6 ОНО -2
5 0101 -3
4 0100 -4
3 ООН -5
2 0010 -6
1 0001 -7
0 0000 -8
94
Так, числа 3 и — 3 в формате со смещением для 3-разрядной сет-
ки будут иметь представление 111 и 001 соответственно, в форма-
те со смещением для 4-разрядной сетки 1011и0101 соответствен-
но. Нетрудно заметить, что различие между двоичным кодом с из-
бытком и двоичным дополнительным кодом состоит в противопо-
ложности значений знаковых битов, а разность значений кодовых
комбинаций в обычном двоичном коде и двоичном коде с избыт-
ком для 3- и 4-разрядных сеток равна соответственно 4 и 8.
Например, кодовые комбинации 111 и 001 в обычном двоичном
коде имеют значения 7 и 1, а в двоичном коде с избытком: 3 и — 3
соответственно. Таким образом, разность значений кодовых ком-
бинаций в обычном двоичном коде и двоичном коде с избытком:
7—3 = 4 и 1—(—3) = 4.
Для 4-разрядной сетки кодовые комбинации 1011 и0101 в обыч-
ном двоичном коде имеют значения 11 и 5 соответственно а в двоич-
ном коде с избытком: 3 и — 3. Таким образом, 11 — 3 = 8и5—( — 3) = 8.
В связи с этим смещенный код для 3-разрядной сетки называют
двоичным кодом с избытком 4, для 4-разрядной — с избытком 8.
Смещенный код можно создать для любого значения п-разряд-
ности сетки. При этом он будет называться двоичным кодом с из-
бытком 2Л/.
Как было отмечено выше, смещенный код используется для уп-
рощения операций над порядками чисел с плавающей запятой. Так,
при размещении порядка числа в 8 разрядах используется двоич-
ный код с избытком 128. В этом случае порядок, принимающий
значения в диапазоне от — 128 до + 127, представляется смещен-
ным порядком, значения которого меняются от 0 до 255, что по-
зволяет работать с порядками как с целыми без знака.
Код Г рея широко используется в различных преобразовательных
устройствах (для кодирования положений валов, дисков и т. д.),
с тем, чтобы разрешить проблемы, связанные с возможностью од-
новременного изменения нескольких разрядов кодового слова.
Характерной особенностью кода Грея является то, что в нем
соседние кодовые слова различаются только в одном разряде.
Комбинации кода Грея, соответствующие десятичным числам от 0
до 15, приведены в табл. 3.7 [8].
Правила перевода числа из кода Грея в обычный двоичный код
сводятся к следующему:
1. Первая единица со стороны старших разрядов остается без
изменения.
95
2. Последующие цифры (0 и 1) остаются без изменения, если
число единиц, им предшествующих, четно, инвертируются — если
нечетно.
Число в десятичном коде Двоичный код Код Грея
0 0000 0000
1 0001 0001
2 0010 ООН
3 ООН 0010
4 0100 оно
5 0101 0111
6 оно 0101
7 0111 0100
Таблица 3.7.
Число в десятичном коде Двоичный код Код Грея
8 1000 1100
9 1001 1101
10 1010 1111
И 1011 1110
12 1100 1010
13 1101 1011
14 1110 1001
15 1111 1000
Пример 15. Выразим число 1011, записанное в коде Г рея, в обыч-
ном двоичном коде:
1. Первую слева цифру (1) переписываем — 1;
2. Вторую слева цифру (0) инвертируем, так как перед ней толь-
ко одна единица — 1;
3. Третью цифру (1) опять инвертируем, так как перед ней толь-
ко одна единица — 0;
4. Четвертую цифру (1) оставляем без изменений, так как пе-
ред ней две единицы — 1.
Таким образом, числу 1011 в коде Грея соответствует двоичное
число — 1101.
Код Грея широко используется для кодирования положений
валов, дисков и т. д., позволяя свести к единице младшего разряда
погрешность при считывании.
96
На рис. 3.12 представлен один из вариантов кодирующей мас-
ки, выполненной в виде диска с обычным двоичным кодом [8].
Внешняя дорожка диска соответствует младшему разряду. Каж-
дому дискретному значению угла
ставится в соответствие определенное
двоичное число. Для считывания с каж-
дого из разрядов могут использоваться
различные чувствительные элементы:
щетки, фотоэлементы и т. д. При ис-
пользовании такой маски с обычным
двоичным кодом в местах, где одно-
временно изменяется состояние не-
скольких чувствительных элементов,
при считывании могут возникать
значительные погрешности. Так,
если чувствительные элементы рас-
полагаются на границе между числом 7
(0111) и 8 (1000), то преобразователь
может выдать на выходе любое чис-
Рис. 3.12. Кодирующая
маска в виде диска
с двоичным кодом
ло от 0 до 15.
Указанный недостаток устраняется при использовании масок
с кодом Грея. Кодирующая маска в виде прямоугольной пластины
с кодом Грея изображена на рис. 3.13 [8].
Рис. 3.13. Кодирующая маска в виде прямоугольной пластины с кодом Грея
В коде Грея при последовательном переходе от числа к числу
изменяется только один разряд, поэтому погрешность при счи-
тывании не может превосходить единицы младшего разряда не-
зависимо от того, в каком разряде имела место неопределен-
ность.
7 А-210
97
Ъ.ЪЪ. Представление вещественных чисел
и выполнение арифметических операций над ними в ЭВМ
Любое вещественное число N, представленное в системе счис-
ления с основанием р, можно записать в виде:
N — ±М х р**,
где М — мантисса; к — порядок числа (целое число).
Например, десятичное число 234,47 или двоичное число 1011,01
можно представить следующим образом:
234,47 = 234470 х 103 = 23447 х 102 = 2344,7 х 101 = 234,47 х 10° =
= 2,3447 х 102 = 0,23447 х 103 = 0,023447 х 10\
1011,01 = 101101 х 10 10 = 1011,01 х 10° =10,1101 х 1010 =
= 0,101101 х 10100 = 0,0101101 х Ю101.
Такое представление чисел называется представлением с пла-
вающей запятой, где порядок определяет, на сколько разрядов не-
обходимо осуществить сдвиг относительно запятой.
Если «плавающая» запятая расположена в мантиссе перед пер-
вой значащей цифрой, то при фиксированном количестве разря-
дов, отведенных под мантиссу, обеспечивается запись максималь-
ного количества значащих цифр числа, т. е. максимальная точность
представления числа. Из этого следует то, что мантисса должна
быть правильной дробью (|М| < 1), у которой первая цифра а пос-
ле запятой отлична от ноля (|М|= 0,а... ). Для двоичной системы
счисления а = 1, поэтому |М| = 0,1... . Если это требование выпол-
нено, то число называется нормализованным. Нормализованная
мантисса в двоичной системе счисления всегда представляется
десятичным числом п, лежащим в диапазоне 0,5 < n < 1.
При написании вещественных чисел в программах вместо при-
вычной запятой принято ставить точку.
Примеры нормализованного представления:
Десятичная система Двоичная система
753.15 = 0.75315x10’; -101.01= -0.10101 х 1011 (порядок 112 = 310);
-0.000034= -0.34Х10Л 0.000011 = 0.11х101Ю(порядок -1002 = -41О).
Вещественные числа в компьютерах представляются, пак пра-
вило, в трех форматах — одинарном, двойном и расширенном,
имеющих одинаковую структуру вида рис. 3.14.
98
Рис. 3.14. Формат представления вещественных чисел
Здесь порядок n-разрядного нормализованного числа задается
смещенным кодом (см. п. 3.2.2), позволяющим производить опера-
ции над порядками как над беззнаковыми числами, что упрощает
операции сравнения, сложения и вычитания порядков, а также
операцию сравнения самих нормализованных чисел.
Чем больше разрядов отводится под запись мантиссы, тем выше
точность представления числа. Чем больше разрядов занимает по-
рядок, тем шире диапазон от наименьшего отличного от ноля чис-
ла до наибольшего числа, представимого в машине при заданном
формате.
Нормализованное число одинарной точности, представленное
в формате с плавающей запятой, записывается в память следую-
щим образом: знак числа (знак мантиссы) — в бите 15 первого слова
(О — для положительных и 1 — для отрицательных чисел); порядок
размещается в битах 7 — 14 первого слова, а мантисса занимает
остальные 23 бита в двух словах. При этом, хотя для мантиссы от-
ведены 23 разряда, в операциях участвуют 24 разряда, так как стар-
ший разряд мантиссы нормализованного числа не хранится (он
всегда равен 1), т. е. имеет место так называемый скрытый разряд,
который при аппаратном выполнении операций автоматически
восстанавливается и учитывается при выполнении операций. По-
рядок числа также учитывает скрытый старший разряд мантиссы.
Нормализованное число двойной точности представляет собой
64-разрядное нормализованное число со знаком, 11-разрядным
смещенным порядком и 53-разрядной мантиссой (размер поля,
выделенного для хранения мантиссы, составляет 52 разряда, а стар-
ший бит мантиссы не хранится).
Расширенный формат позволяет хранить ненормализованные
числа в виде 80-разрядного числа со знаком: 15-разрядным смещен-
ным порядком и 64-разрядной мантиссой.
99
Следует отметить, что вещественный формат с ш-разрядной
мантиссой дает возможность абсолютно точно представлять
m-разрядные целые числа, т. е. любое двоичное целое число, со-
держащее не более т разрядов, может быть без искажений пре-
образовано в вещественный формат.
Примеры представления чисел с плавающей запятой:
1) 0,110 = 0,000(1100)2 = 0,(1100)2 х 102(-3)10, при этом порядок
числа представляется двоичным кодом с избытком 128:
-310= (-3 4- 128)10 = 011111012.
fo o|l|l|l|l|l|o|l|l|o|o|l|l|ojo]
1 i|o|o|i|i|o|o i|i|o|o|i|i|o|i
Заметим, что в этом примере мантисса представлена бесконеч-
ной периодической дробью, поэтому последний учитываемый раз-
ряд мантиссы округляется.
2) -49,510 = - 110001,1002 = - 0,11000112 х 102|6Ч при этом по-
рядок числа:
610 =(6 4- 128)10 = 100001102.
11|1|о|о|о|о|1[Т о|1|о|о|о|1|1|о]
Выполнение арифметических действий
над нормализованными числами
При алгебраическом сложении и вычитании чисел, представ-
ленных в формате с плавающей запятой, сначала уравниваются
порядки слагаемых. В процессе выравнивания порядков мантисса
числа с меньшим порядком сдвигается в своем регистре вправо на
количество разрядов, равное разности порядков операндов. Пос-
ле каждого сдвига порядок увеличивается на единицу. В результа-
те выравнивания порядков одноименные разряды чисел оказыва-
ются расположенными в соответствующих разрядах обоих регис-
тров, после чего мантиссы складываются или вычитаются. В слу-
100
чае необходимости полученный результат нормализуется путем сдви-
га мантиссы результата влево. После каждого сдвига влево порядок
результата уменьшается на единицу. Ниже в примерах для упроще-
ния расчетов порядок представлен в обычной двоичной форме.
Пример 16. Сложите двоичные нормализованные числа
0.10111 х 10 1 и 0.11011 х 1010. Разность порядков слагаемых здесь
равна трем, поэтому перед сложением мантисса первого числа
сдвигается на три разряда вправо:
0.00010111 х 1010
+ 0.11011 хЮ10
0.11101111 х 1010
Пример 17. Выполним вычитание двоичных нормализованных
чисел 0.10101 х 1010и 0.11101 х 10’. Разность порядков уменьшаемо-
го и вычитаемого здесь равна единице, поэтому перед вычитани-
ем мантисса второго числа сдвигается на один разряд вправо:
_ 0.10101 хЮ10
0.011101 х 1Q10
0.001101 х Ю10
Результат получился не нормализованным, поэтому его мантис-
са сдвигается влево на два разряда с соответствующим уменьше-
нием порядка на две единицы: 0.1101 х 10°.
При умножении порядки складываются, а мантиссы перемно-
жаются.
Пример 18. Выполним умножение двоичных нормализованных
чисел:
(0.11101 х 10101) х (0.1001 х 10") = (0.11101 х 0.1001) х 10>101 + 11> =
= 0.100000101 х Ю1000.
При делении из порядка делимого вычитается порядок делите-
ля, а над мантиссами совершается обычная операция деления.
В случае необходимости полученный результат нормализуется, что
приводит к изменению порядков, так как каждый сдвиг на один
разряд влево соответствует уменьшению порядка на единицу, а
сдвиг вправо — увеличению его на единицу. Введение термина
«плавающая запятая» как раз и объясняется тем, что двоичный
порядок, определяющий фактическое положение запятой в изоб-
101
ражении числа, корректируется после выполнения каждой ариф-
метической операции, т. е. запятая в изображении числа плавает
(изменятся ее положение) по мере изменения данной величины.
Пример 19. Выполним деление двоичных нормализованных
чисел.
0.11 llxlO100: 0.101 хЮ11 = (0.1111 : 0.101) хЮ1100"111 =
= 1.1x10' = 0.11x10”.
32.4. Погрешности представления числовой информации в ЭВМ
Представление числовой информации в ЭВМ, как правило, вле-
чет за собой появление погрешностей (ошибок), величина кото-
рых зависит от формы представления чисел и от длины разрядной
сетки цифрового автомата [21].
Абсолютная погрешность Д [А] представления кода числа в раз-
рядной сетке ЭВМ определяется по формуле:
Д[А] = |А| - |А„|,
где |А| — модуль числа А, код которого требуется представить
в ЭВМ;
|Ам| — модуль числа Ам, код которого представлен в разрядной
сетке.
Относительная погрешность представления — величина
5[А]= Д[А]/|Аи|.
Для чисел с фиксированной запятой, представленных в форма-
те рис. 3.9, наибольшее значение абсолютной погрешности равно
весу младшего разряда разрядной сетки:
МА]тм = 2-1. (3.35)
Другими словами, максимальная погрешность перевода деся-
тичной информации в двоичную не будет превышать единицы
младшего разряда разрядной сетки автомата. Минимальная по-
грешность перевода равна нолю.
Отбрасывание младших разрядов кода числа, не вошедших в раз-
рядную сетку, может быть выполнено с округлением. В этом слу-
чае, если число ДА, код которого отбрасывается, меньше половины
веса младшего разряда разрядной сетки ЭВМ (ДА < 0,5x2'), то код
числа в разрядной сетке остается без изменений. В противном слу-
чае в младший разряд кода разрядной сетки добавляется единица.
102
Наибольшая абсолютная погрешность представления числа в
разрядной сетке с округлением равна:
= 0,5x2'.
Пределы изменения относительной погрешности при представ-
лении чисел с фиксированной запятой в ЭВМ с округлением оп-
ределяются по формулам:
= [А’]ти/|А|тах = 0,5х2'/(2п - 2-'); (3.36)
«ЯА1тах = A [A’U/HL = 0,5 х 2' / 2-' = 0,5. (3.37)
Из (3.37) видно, что погрешности представления чисел в форме
с фиксированной запятой могут быть значительными.
Для представления чисел в форме с плавающей запятой
(см. рис. 3.14) абсолютное значение мантиссы МЛ:
2'1 < |МД| < 1 - 2~т, (3.38)
где Л1 — количество разрядов, отведенных под мантиссу.
В этом случае, как и для формата с фиксированной запятой,
наибольшее значение абсолютной погрешности представления
мантиссы равно весу младшего разряда разрядной сетки, а наи-
большая абсолютная погрешность представления мантиссы в раз-
рядной сетке с округлением равна:
Д1М.1 = 0,5 х 2т.
Для нахождения погрешности представления числа Ат в форме
с плавающей запятой величину этой погрешности надо умножить
на величину порядка числа РА:
- 0.5 X 2- Р, / (2-РЛI - 2-;
4A.U-A|A.U'KI„“°.5x2-Pa/|(l -2-|Ра)-0,5х2-/(1 -2™).
где т — количество разрядов для представления мантиссы числа.
Для ЭВМ т > 16, тогда 1 — 2 “=/ и 5[Am]min = 0,5 х 2“ш.
Таким образом, относительная точность представления чисел
в форме с плавающей запятой почти не зависит от величины чис-
ла и определяется количеством разрядов, отведенных под ман-
тиссу.
103
3.3. ПРЕДСТАВЛЕНИЕ СИМВОЛЬНОЙ ИНФОРМАЦИИ В ЭВМ
Символьная (алфавитно-цифровая) информация хранится и
обрабатывается в ЭВМ в форме цифрового кода, т. е. каждому сим-
волу ставится в соответствие отдельное бинарное слово-код. При
выборе метода кодирования руководствуются объемом и спосо-
бами обработки символьной информации. Так как многие типы
информации содержат в значительном объеме цифровую инфор-
мацию, то применяются две системы кодирования: символьной
информации и десятичных чисел.
Необходимый набор символов, предусмотренный в конкретной
ЭВМ, обычно включает в себя:
буквенно-цифровые знаки алфавита (алфавитов);
• специальные знаки (пробел, скобки, знаки препинания и др.);
знаки операций.
Кроме того, в состав набора входят управляющие символы, со-
ответствующие определенным функциям.
Среди наборов символов наибольшее распространение полу-
чили знаки кода ASCII (ASCII — American Standard Code for
Information Interchange) — американский стандартный код обмена
информацией и кода EBCDIC (Extended Binary Coded Decimal
Interchange Code) — расширенный двоично-десятичный код обме-
на информацией. Набор EBCDIC используется главным образом
на «больших» машинах, тогда как набор ASCII, созданный в 1963 г. и
введенный в действие институтом стандартизации США (ANSI —
American National Standard Institute), находит наиболее широкое
применение в мини- и микроЭВМ, в том числе в персональных
компьютерах.
ASCII — это семиразрядный код, обеспечивающий 128 различ-
ных битовых комбинаций. Стандартный знакогенератор современ-
ного персонального компьютера IBM PC имеет 8-битную кодиров-
ку символов, состоящую из двух таблиц кодирования: базовой и
расширенной. Базовая таблица построена по стандарту ASCII и оди-
накова для всех IBM-совместимых компьютеров. Расширенная
относится к символам с номерами от 128 до 255 и может отличать-
ся на компьютерах разного типа (рис. 3.15).
Первые 32 кода базовой таблицы, начиная с нолевого, отданы
производителям аппаратных средств (в первую очередь произво-
дителям компьютеров и печатающих устройств). В этой области
104
размещаются так называемые управляющие коды, которым не со-
ответствуют никакие символы языков, и соответственно эти коды
не выводятся ни на экран, ни на устройства печати, но они могут
управлять тем, как производится вывод прочих данных.
Начиная с кода 32 по код 127 размещены коды символов анг-
лийского алфавита, знаков препинания, цифр, арифметических
действий и некоторых вспомогательных символов.
СО сч 5 8 176 О} см <35 208 224 1240
00 Е а til Г" и а = 00
01 U 2В i 1 1 т Р ± 01
02 ё А б 1 т тг г > 02
03 а О й 1 1 Ц я < 03
04 а О й 1 - ь X т 04
05 А 6 N I г о J 05
06 Ь U ас dl I- ГТ Ц “Г 06
07 С U О Tl II- 'Т 07
08 ё У 4 =1 S о 08
09 ё б 1— =11 If J 0 09
10 ё и —• II JT г S • 10
11 1 С Т1 Тг 1 б И
12 1 £ 'А JJ !г оо п 12
13 1 т JJ = 1 я6 X 13
14 А « =1 яг тг 1 е 14
15 А f » 1 "Г” п 15
Рис. 3.15. Стандартная кодировка фирмы IBM:
а) для кодов 1...127; б) для кодов 128...255
В расширенной таблице стандартной кодировки фирмы IBM три
смежные колонки (коды 176...223) занимают символы псевдогра-
фики, колонки с кодами от 128 до 175 и от 224 до 239 используются
для размещения некоторых символов национальных алфавитов
различных европейских языков, а последняя колонка (коды
105
240...255) — для размещения специальных знаков. С учетом этого
расположения символов разрабатывается подавляющее большин-
ство программ зарубежного производства.
Для представления букв русского алфавита в рамках ASCII
первоначально был разработан ГОСТовский вариант кодиров-
ки — КОИ-7 (код обмена информацией 7-битный). Расположе-
ние символов во второй половине таблицы этой кодировки рез-
ко отличается от принятого фирмой IBM, что затрудняет исполь-
зование зарубежного программного обеспечения на отечествен-
ных ЭВМ. В связи с этим он практически не применяется, а на
отечественных ПК введена так называемая ГОСТ-алыпернатив-
ная кодировка, главное достоинство которой — расположение
символов псевдографики на тех же местах, что и в кодировке
IBM (рис. 3.16).
00
01
02
03
04
05
06
07
08
09
10
И
12
13
14
15
СО-Ч'ФЮГЯСО’Ч'О
счч'ФГ'ФОСЧ'Ч'
— — CNCSC4
А -р а и “Г и р =
Б с б 1 1 т с
'В т в 1 т тт т >
Г У г 1 1 и У <
Д ф д i - 1= ф f
Е X е 1 + г X J
Ж ц ж 11 F ГТ Ц ч-
3 ч 3 т IF ч
И ш и т U. + ш о
Й щ й 41 (г Т Щ
К ъ к II X Г ъ •
Л ы л Т1 Тг ы
м ь м JJ lh ь п
н э н JJ г э к
о ю О =1 ГТГ" пг 7 ю
п я п 7 "Г W я
00
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
Рис. 3.16. ГОСТ-альтернативная кодировка
106
В настоящее время находят широкое применение и другие виды
кодировки [13].
Так, в связи с массовым распространением операционных сис-
тем и других продуктов компании Microsoft в нашей стране нашла
применение кодировка символов русского языка, известная как
кодировка Windows-1251 (рис. 3.17).
128 Ъ 144 $ 160 176 0 192 А 208 Р 224 а 240 р
129 Г 145 ‘ 161 V 177 ± 193 Б 209 С 225 б 241 с
130 , 146 ’ 162 у 178 I 194 В 210 Т 226 в 242 т
131 f 147 “ 163 J 179 i 195 Г 211 У 227 г 243 у
132 „ 148 ” 164 о 180 г 196 Д 212 Ф 228 д 244 ф
133 ... 149 • 165 Г 181 ц 197 Е 213 X 229 е 245 х
134 f 150 - 166 | 182 198 Ж 214 Ц 230 ж 246 ц
135 $ 151 — 167 § 183 • 199 3 215 Ч 231 з 247 ч
136 € 152 ~ 168 Ё 184 ё 200 И 216 Ш 232 и 248 ш
137 %о 153 ™ 169 © 185 № 201 Й 217 Щ 233 й 249 щ
138 Л> 154 л> 170 186 с 202 К 218 Ъ 234 к 250 ъ
139 < 155 > 171 « 187 » 203 Л 219 Ы 235 л 251 ы
140 Н» 156 н> 172 - 188 j 204 М 220 Ь 236 м 252 ь
141 К 157 к 173 - 189 S 205 Н 221 Э 237 н 253 э
142 Ъ 158 h 174 ® 190 s 206 О 222 Ю 238 о 254 ю
143 Ц 159 ц 175 I 191 Т 207 П 223 Я 239 п 255 я
Рис. 3.17. Кодировка Windows 1251
Эта кодировка используется на большинстве персональных
компьютеров, работающих на платформе Windows.
Другая распространенная кодировка носит название КОИ-8
(код обмена информацией восьмизначный) (рис. 3.18) — ее проис-
хождение относится ко временам действия Совета Экономичес-
кой Взаимопомощи государств Восточной Европы. Сегодня коди-
ровка КОИ-8 имеет широкое распространение в компьютерных се-
тях на территории России и в некоторых службах российского сек-
тора Интернета. В частности, в России она де-факто является стан-
дартной в сообщениях электронной почты и телеконференций.
107
128 144Ш 160 — 176 1 192 ю 208 п 224 Ю 240 П
129 I 145 И 161 Ё 177 1 193 а 209 я 225 А 241 Я
130 Г" 146 162 Г 178 -1 194 6 210р 226 Б 242 Р
131 1 147 f 163 ё 179 Ё 195 ц 211 с 227 Ц 243 С
132 L 148 164 г 180 ’I 196 д 212т 228 Д 244 Т
133 -1 149. 165 Г 181 -1 197 е 213у 229 Е 245 У
134 F 150 "V 166 1 182 т 198 ф 214ж 230 Ф 246 Ж
135-1 151 = 167 I 183 т 199 г 215в 231 Г 247 В
136 т 152 < 168 -| 184 т 200 х 216ь 232 X 248 Ь
137-L 153 > 169 L 185 -J- 201 и 217ы 233 И 249 Ы
138 + 154 170 1_ 186 -L 202 й 218з 234 Й 250 3
139- 155 J 171 L 187 J- 203 к 219 ш 235 К 251 Ш
140- 156- 172 -1 188 + 204 л 220 э 236 Л 252 Э
141 | 1572 173 -> 189 + 205 м 221 щ 237 М 253 Щ
142 1 158. 174 -> 190 + 206 н 222 ч 238 Н 254 Ч
143 1 159 + 175 h 191 ё 207 о 223 ъ 239 О 255 Ъ
Рис. 3.18. Кодировка KOH-8R
В последнее время все большее распространение получает уни-
версальная система кодирования текстовых данных — UNICODE.
В данной системе символы кодируются не восьмиразрядными дво-
ичными числами, а 16-разрядными числами. Шестнадцать разря-
дов позволяют обеспечить уникальные коды для 65536 различных
символов — этого достаточно для размещения в одной таблице всех
широкоупотребляемых языков.
В отличие от символьной для десятичной цифровой информа-
ции при байтовой организации в целях экономии памяти и удоб-
ства обработки используют специальные форматы кодирования
десятичных чисел — зонный и упакованный. При этом десятич-
ные числа рассматриваются как десятичные со знаком, имеющие
переменную длину.
108
В упакованном формате /ул каждой десятичной цифры отво-
дится по 4 двоичных разряда (полбайта), при этом знак числа ко-
дируется в крайнем правом полубайте числа (1100 — знак « + » и
1101 — знак « —»).
Структура поля упакованного формата1:
цф Цф Цф Цф ... цф знак
байт байт байт
Упакованный формат применяется обычно в ЭВМ при выпол-
нении арифметических операций: сложения, вычитания, умноже-
ния, деления и сравнения.
В зонном формате для каждой десятичной цифры отводится по
целому байту, при этом старшие полубайты (зона) каждого байта
(кроме самого младшего) заполняются кодом 1111, а в младших (ле-
вых) полубайтах обычным образом кодируются десятичные циф-
ры. Старший полубайт (зона) самого младшего (правого) байта ис-
пользуется для кодирования знака числа.
Структура поля зонного формата:
зона Цф зона Цф зона Цф знак Цф
байт байт байт байт
Зонный формат удобен для представления вводимой в ЭВМ де-
сятичной информации, когда каждая десятичная цифра вместе
с кодом зоны занимает целый байт.
Пример 20. Число —283(10) = —0010 1000 0011(210) в ЭВМ будет
представлено:
В упакованном формате 0010 1000 ООН 1101
В зонном формате 1111 0010 1111 1000 1101 ООП
1 Здесь и далее: цф — цифра; знак — знак числа.
109
3.4. ПРЕДСТАВЛЕНИЕ ГРАФИЧЕСКОЙ ИНФОРМАЦИИ
Современные компьютерные системы способны обрабатывать
не только простейшие текстовые и цифровые данные. Они позво-
ляют работать также с изображениями и с аудио- и видеоинфор-
мацией. В отличие от методов представления символьной и число-
вой информации, для представления изображений, аудио- и видео-
информации пока не существует общепризнанных стандартов.
Наиболее распространенные из существующих методов пред-
ставления изображений можно разделить на две большие катего-
рии: растровые методы и векторные методы.
При растровом методе изображение представляется как сово-
купность точек, называемых пикселями (pixel — сокращение от
picture element — элемент изображения). Поскольку линейные
координаты и индивидуальные свойства каждой точки (яркость)
можно выразить с помощью целых чисел, то можно сказать, что
растровое кодирование позволяет использовать двоичный код для
представления графических данных. Общепринятым на сегодняш-
ний день считается представление черно-белых иллюстраций в
виде комбинации точек с 256 градациями серого цвета, и, таким
образом, для кодирования яркости любой точки обычно достаточ-
но восьмиразрядного двоичного числа.
Для кодирования цветных графических изображений приме-
няется принцип декомпозиции произвольного цвета на основные
составляющие. В качестве таких составляющих используют три
основных цвета: красный (Red, R), зеленый (Green, G) и синий (Blue,
В). На практике считается, что любой цвет, видимый человечес-
ким глазом, можно получить путем механического смешения этих
трех основных цветов. Такая система кодирования называется
системой RGB (по первым буквам названий основных цветов).
Если для кодирования яркости каждой из основных составляю-
щих использовать по 256 значений (восемь двоичных разрядов), как
это принято для полутоновых черно-белых изображений, то на ко-
дирование цвета одной точки надо затратить 24 разряда (рис. 3.19).
• ОЛ Лыт _ ь.
Ч с- 1 UH1
Красный Зеленый Синий
8 бит 8 бит 8 бит
Рис. 3.19. Кодирование цветного изображения
ПО
При этом система кодирования обеспечивает однозначное оп-
ределение 16,5 млн различных цветов, что близко к чувствитель-
ности человеческого глаза. Режим представления цветной графи-
ки с использованием 24 двоичных разрядов называют полноцвет-
ным (True Color).
Графические файлы, в которых применяется цветовая система
RGB, представляют каждый пиксель в виде цветового триплета —
трех числовых величин (R, G, В), соответствующих интенсивнос-
тям красного, зеленого и синего цветов (рис. 3.20).
Голубой (0,255,255)
Рис. 3.20. Цветовая система RGB
Для 24-битового цвета триплетом (0, 0, 0) обычно представляет-
ся черный цвет, а триплетом (255, 255, 255) — белый. Если все три
величины RGB имеют одинаковые значения, например (63, 63, 63),
(127, 127, 127) или (191, 191, 191), то результирующим будет один
из оттенков серого цвета.
Кроме RGB, другими популярными системами кодирования
цветных изображений являются CMY и HSB.
CMY (Cyan-Magenta-Yellow — голубой-пурпурный-желтый) —
цветовая система, применяемая для получения цветных изображе-
ний на белой поверхности. Эта система используется в большин-
стве устройств вывода, таких как лазерные и струйные принтеры,
когда для получения твердых копий краски наносятся на белую
бумагу. При освещении каждый из трех основных цветов погло-
111
щает дополняющий его цвет: голубой цвет поглощает красный,
пурпурный — зеленый, а желтый — синий. Например, если увели-
чить количество желтой краски, то интенсивность синего цвета в
изображении уменьшится.
Новые цвета в системе CMY получают вычитанием цветовых
составляющих из белого цвета. Они имеют длину волны отражен-
ного света, не поглощенного основными цветами CMY. Например,
в результате поглощения голубого и пурпурного цветов образует-
ся желтый, т. е. можно сказать, что желтый цвет является резуль-
татом «вычитания» из отраженного света голубой и пурпурной
составляющих. Если все составляющие CMY будут вычтены (или
поглощены), то результирующим цветом станет черный. На прак-
тике же получить идеальный черный цвет без дорогостоящих кра-
сителей в системе CMYвесьма сложно.
Существует более практичный вариант CMY— система CMYK,
в которой символ К означает черный цвет. Введение в эту цвето-
вую систему черного цвета в качестве независимой основной цве-
товой переменной позволяет использовать недорогие красители.
Систему CMYK часто называют четырехцветной, а результат ее
применения — четырехцветной печатью. Во многих моделях точ-
ка, окрашенная в составной цвет, группируется из четырех точек,
каждая из которых окрашена в один из основных цветов CMYK.
Данные в системе CMYK представляются либо цветовым трип-
летом, аналогичным RGB, либо четырьмя величинами. Если дан-
ные представлены цветовым триплетом, то отдельные цветовые
величины противоположны величинам RGB. Так, для 24-битового
пиксельного значения триплет (255,255, 255) соответствует черно-
му цвету, а триплет (0, 0, 0) — белому. Однако в большинстве слу-
чаев для представления цветов в системе CMYK используется пос-
ледовательность четырех величин.
Как правило, четыре цветовые составляющие CMYK задаются
в процентах в диапазоне от 0 до 100.
Модель HSV (Hue, Saturation, Value — оттенок, насыщенность, ве-
личина) — одна из многих цветовых систем, в которых при представ-
лении новых цветов не смешивают основные цвета, а изменяют их
свойства. Оттенок — это «цвет» в общеупотребительном смысле этого
слова, например красный, оранжевый, синий и т. д. Насыщенность
(также называемая цветностью) определяется количеством белого
в оттенке. В полностью насыщенном (100%) оттенке не содержится
белого, такой оттенок считается чистым. Ча-стично насыщенный от-
112
тенок светлее по цвету. Красный оттенок с 50%-ной насыщенностью
соответствует розовому. Величина (также называемая яркостью) оп-
ределяет интенсивность свечения цвета. Оттенок с высокой интен-
сивностью является очень ярким, а с низкой — темным.
Модель HSV напоминает принцип, используемый художника-
ми для получения нужных цветов, — смешивание белой, черной и
серой с чистыми красками для получения различных тонов и от-
тенков [tint, shade и tone}. Оттенок tint является чистым, полнос-
тью насыщенным цветом, смешанным с белым, а оттенок shade —
полностью насыщенным цветом, смешанным с черным. Тон [tone] —
это полностью насыщенный цвет, к которому добавлены черный
и белый цвета (серый). Если рассматривать систему HSVс точки
зрения смеси этих цветов, то насыщенность будет представлять
собой количество белого, величина — количество черного, а отте-
нок — тот цвет, к которому добавляются белый и черный.
Режим, когда для кодирования цвета каждой точки использует-
ся 32 двоичных разряда, так же как и рассмотренный выше с ис-
пользованием 24 разрядов, называют полноцветным (True Color).
Если уменьшить количество двоичных разрядов, используемых для
кодирования цвета каждой точки, то можно сократить объем дан-
ных, но при этом диапазон кодируемых цветов заметно сокраща-
ется. Кодирование цветной графики 16-разрядными двоичными
числами называют режимом High Color.
При кодировании информации о цвете с помощью восьми бит
данных можно передать только 256 цветовых оттенков. Такой ме-
тод кодирования цвета называют индексным. Смысл названия со-
стоит в том, что, поскольку 256 значений недостаточно, чтобы пе-
редать весь диапазон цветов, доступный человеческому глазу, код
каждой точки растра выражает не цвет сам по себе, а только его
номер (индекс) в справочной таблице, называемой палитрой. Эта
палитра прикладывается к графическим данным.
Одним из недостатков растровых методов является трудность
пропорционального изменения размеров изображения до произ-
вольно выбранного значения. В сущности, единственный способ
увеличить изображение — это увеличить сами пиксели. Однако
это приводит к появлению зернистости — пикселизации.
Векторные методы позволяют избежать проблем масштабиро-
вания, характерных для растровых методов. В этом случае изобра-
жение представляется в виде совокупности линий и кривых. Вме-
8 А 210
ИЗ
сто того чтобы заставлять устройство воспроизводить заданную
конфигурацию пикселей, составляющих изображение, ему пере-
дается подробное описание того, как расположены образующие
изображение линии и кривые. На основе этих данных устройство
в конечном счете и создает готовое изображение. С помощью по-
добной технологии описываются различные шрифты, поддержи-
ваемые современными принтерами и мониторами. Они позволя-
ют изменять размер символов в широких пределах и по этой при-
чине получили название масштабируемых шрифтов. Например,
технология True Туре, разработанная компаниями Microsoft и Apple
Computer, описывает способ отображения символов в тексте. Для
подобных целей предназначена и технология PostScript (разрабо-
тана компанией Adobe Systems), позволяющая описывать способ
отображения символов, а также других, более общих графичес-
ких данных. Векторные методы также широко применяются в ав-
томатизированных системах проектирования, которые отобража-
ют на экране мониторов чертежи сложных трехмерных объектов
и предоставляют средства манипулирования ими. Однако вектор-
ная технология не позволяет достичь фотографического качества
изображений объектов как при использовании растровых мето-
дов.
Контрольные вопросы
1. Что такое система счисления?
2. В чем отличие позиционной системы счисления от непозиционной?
3. Что называется основанием системы счисления?
4. Что понимают под алфавитом системы счисления?
5. Сформулируйте правила выполнения арифметических действий
в позиционных системах счисления?
6. Что такое код?
7. Какие системы счисления являются более эффективными для ис-
пользования в цифровых автоматах?
8. Какие способы перевода чисел из одной системы счисления в дру-
гую Вы знаете?
9. В чем заключается преимущество использования восьмеричной и
шестнадцатеричной систем счисления?
10. Дайте определение двоично-десятичной системы счисления.
11. Что такое машинное слово?
12. Что представляет собой выходной сигнал элемента памяти ЭВМ?
114
13. Назовите формы представления двоичных чисел в ЭВМ.
14. Что такое прямой, обратный и дополнительный коды?
15. Сформулируйте правила, определяющие правильность выполне-
ния операций сложения чисел со знаком и без знака в ЭВМ.
16. Что такое смещенный код?
17. Что такое код Грея?
18. Как представляются вещественные числа в ЭВМ?
19. Чем определяется погрешность представления числовой инфор-
мации в ЭВМ?
20. Как представляются символьные данные в ЭВМ?
21. Какие системы кодировки символьной информации Вы знаете?
22. Какие системы кодирования графической информации Вы знаете?
Тлава У
Логические основы построения
цифровых автоматов
Основу любого дискретного вычислительного устройства со-
ставляют элементарные логические схемы. Работа этих схем ос-
нована на законах и правилах алгебры логики, которая оперирует
двумя понятиями: истинности и ложности высказывания.
Алгебра логики — раздел математики, изучающий высказывания,
рассматриваемые со стороны их логических значений (истинности или
ложности) и логических операций над ними.
Высказывание — некоторое предложение, в отношении которого
можно однозначно сказать, истинно оно или ложно.
Аппарат алгебры логики {булевой алгебры) создан в 1854 г. Дж.
Булем как попытка изучения логики мышления математическими
методами. Впервые практическое применение булевой алгебры было
сделано К. Шенноном в 1938 г. для анализа и разработки релейных
переключательных сетей, результатом чего явилась разработка ме-
тода представления любой сети, состоящей из совокупности пере-
ключателей и реле, математическими выражениями и принципов их
преобразования на основе правил булевой алгебры [1]. Ввиду нали-
чия аналогий между релейными и современными электронными схе-
мами аппарат булевой алгебры нашел широкое применение для их
структурно-функционального описания, анализа и проектирования.
Использование булевой алгебры позволяет не только более удобно
оперировать с булевыми выражениями (описывающими те или иные
электронные узлы), чем со схемами или логическими диаграммами,
но и на формальном уровне путем эквивалентных преобразований и
базовых теорем упрощать их, давая возможность создавать эконо-
мически и технически более совершенные электронные устройства
любого назначения. Операции булевой алгебры часто встречаются и
в программном обеспечении вычислительных устройств, где они ис-
пользуются для замены аппаратной логики на программную.
Аппарат булевой алгебры, как и любая другая формальная ма-
тематическая система состоит из трех множеств: элементов, опе-
раций над ними и аксиом.
116
Элементы. Схемы вычислительных устройств можно условно
разделить на три группы: исполнительные, информационные и
управляющие. Первые производят обработку информации, пред-
ставленной в бинарной форме; вторые служат для передачи би-
нарной формы информации; третьи выполняют управляющие
функции, генерируя соответствующие сигналы. Во всех случаях в
тпх или иных точках логических схем сигналы двух различных
уровней могут представляться бинарными символами {0,1} или
логическими значениями {Истина (True), Ложь (False)}. Поэтому
множество элементов булевой алгебры выбирается бинарным
В “ {0,1}, а сама алгебра называется бинарной, или переключатель-
ной. Ее элементы называются константами, или логическими 0 и
1, которым в ряде случаев соответствуют бинарные цифры, в дру-
гих случаях — логические значения, соответственно ложь (False) и
истина (True). В дальнейшем для обозначения булевых перемен-
ных будем использовать буквы латинского алфавита — х, у, z... .
Набор переменных х, у, z...может рассматриваться как п-разряд-
ный двоичный код, разрядами которого являются эти переменные.
Операции. Основными, или базовыми, операциями булевой
алгебры служат (табл. 4.1): И (AND), ИЛИ (OR) и НЕ (NOT). Опера-
ция И называется логическим умножением или конъюнкцией и
обозначается знаком умножения {•, л}. Операция ИЛИ называет-
ся логическим сложением или дизъюнкцией и обозначается знаком
сложения { +, v}. Операция НЕ называется логическим отрицани-
ям или инверсией (дополнением) и обозначается знаком {', —>}.
Таблица 4.1
Базовые логические операции
Операция Название операции Обозначение операции
И (AND) Логическое умножение — конъюнкция л
ИЛИ (OR) Логическое сложение — дизъюнкция + V
НЕ (NOT) Логическое отрицание — инверсия / —1
При выполнении операций применяются отношение эквивален-
тности « = » и скобки «()», которые определяют порядок выполне-
117
ния операций. Если скобок нет, то операции выполняются в сле-
дующей последовательности: логическое отрицание, логическое
умножение и логическое сложение.
4.1. ОСНОВНЫЕ ЗАКОНЫ
И ПОСТУЛАТЫ АЛГЕБРЫ ЛОГИКИ
Аксиомы (постулаты) алгебры логики
1. Дизъюнкция двух переменных равна 1, если хотя бы одна из
них равна 1:
0 + 0 = 0;
0+1 = 1;
1 + 0=1;
1 + 1 = 1.
2. Конъюнкция двух переменных равна 0, если хотя бы одна
переменная равна 0:
0x0 = 0;
0x1=0;
1x0 = 0;
1x1 = 1.
3. Инверсия одного значения переменной совпадает с ее дру-
гим значением:
1 = 0;
0 = 1.
Законы алгебры логики
1. Законы однопарных элементов:
а) универсального множества:
х + 1 = 1;
X • 1 = X.
б) нулевого множества:
х + 0 = х;
х-0 = 0.
2. Законы отрицания:
а) двойного отрицания: х = х
118
х + х = 1;
б) дополнительности: -
х • х = 0;
в) двойственности (де Моргана):---- — —
X, -Х2 =Х] +х2.
3. Комбинационные законы:
х + х = х;
а) тавтологии:
хх = х;
X] +х2 = х2 +Хр
б) коммутативные:
х, -х2 = х2 • х3;
х1+(х2+х3)=(х1+х2)+х3;
в) ассоциативные (сочетательные): / \ / \
X] (х2 x-J-lx, -х2) х3;
г) дистрибутивные (распределительные):
хг(х2+хз)7хГх2 + х1хз:
Xj +х2 -х3 = (х| +х2дх] +х3);
д) закон абсорбции (поглощения):
Xj+XjXj = х(.
х.^ + х^ = х);
е) склеивания:
X] -х2 +XjX2 = х,;
(х1+х2)(х1+х2) = х1.
Законы двойственности де Моргана были обобщены Шенноном
на произвольное количество двоичных переменных: инвертиро-
вание произвольной комбинации двоичных переменных, связан-
ных знаками дизъюнкции и конъюнкции, эквивалентно инверти-
рованию комбинаций переменных с одновременной заменой конъ-
юнкции на дизъюнкцию, и наоборот:
*1 ’ Х2 ’ Х3 ' ’ ’ Хп ~ Х1 + Х2 + Х3 + ’ ’ ’ + Хп •
X, + X, Ч---------F X = X, • X, • • Х„ .
1 Z п 1 1 п
119
Рассмотрим на примерах некоторые приемы и способы, при-
меняемые при упрощении логических формул:
1) х + у • (х • у )= х • у (х • у ) = х • х • у • у = 0 • у • у = 0 • у = О
(законы алгебры логики применяются в следующей последователь-
ности: правило де Моргана, сочетательный закон, законы допол-
нительности и нулевого множества);
2) х-у + х + у + х = х-у + х-у + х = х-(у + у) + х = х-1-х = 1
(применяется правило де Моргана, выносится за скобки общий
множитель, используется закон дополнительности);
3) xy + xyz + xz-p = х • (у • (1 + z) + z • р) = х • (у + z • р)
(выносятся за скобки общие множители; применяется закон уни-
версального множества);
4) Рассмотрим доказательство соотношения (хг + х2)(х! + х3) = х, +
-I- х2х3 (распределительный закон):
(х, +х,)(х, +х,) = х,х, +х,х, + х,х, +х,х = Х. + Х.Х. + Х-Х.+Х-Х =
' J Z* * 1 о* 11 1«5 Z 1 Z «5 1 1 и л. 1 Z О
= х) + х2х1+х2х3 = Х( (1+Х2) + Х2Х3 = xt+x2x3
(применяются законы тавтологии и универсального множества).
4. 2. ПРЕДСТАВЛЕНИЕ ФУНКЦИЙ АЛГЕБРЫ ЛОГИКИ
Булевой (переключательной, двоичной) функцией называется
двоичная переменная у значение которой зависит от значений дру-
гих двоичных переменных (х;, х? ...,хп), именуемых аргументами:
у = у(х,, х2.хп).
Задание булевой функции означает, что каждому из возмож-
ных сочетаний аргументов поставлено в соответствие определен-
ное значение у.
При п аргументах общее число сочетаний N = 2Л . Так как каж-
дому сочетанию аргументов соответствует два значения функции
(О, 1), то общее число функций F = 22”.
Булевая функция может быть задана на словах, таблично, ал-
гебраически или числовым способом.
В табл. 4.2 представлена функция одной переменной у = у(х). При
п = 1 существует 4 функции, каждая из которых имеет свое название.
120
Таблица 4.2
Табличное задание функции одной переменной
' у0 = 0 — const ноля, или генератор 0;
У] = х — повторитель;
у2 = х — инвертор;
у3 = 1 — const 1; или генератор 1.
Для алгебры логики установлено, что если у = у (zt,z^, где zt
и z2— двоичные функции, т. е. z; = z;fx;,x2), z2= z2(x3,x4), то
y = y(xt,x2lx3,x4).
Операцию замены одной функции другими функциями назы-
вают суперпозицией. Эта операция дает возможность с помощью
функций малых аргументов получить функции большего числа
аргументов. Так, при помощи суперпозиции можно получить фун-
кцию с требуемым числом аргументов, используя только функцию
двух аргументов.
Рассмотрим функцию двух аргументов.
По определению существует 16 функций двух аргументов (табл 4.3).
При помощи набора булевых функций двух аргументов можно
описать любую цифровую систему.
На практике используют не все функции, а лишь те из них, ко-
торые методом суперпозиции обеспечивают представление любой
другой функции. Набор таких функций называют функционально
полным набором (ФПН).
Существует несколько ФПН. В качестве ФПН применяются
дизъюнкция, конъюнкция и инверсия. Этот набор называют ос-
новным ФПН (ОФПН).
Кроме ОФПН, широкое применение получили:
функционально-полная система, включающая в себя только
одну функцию — функцию Пирса (ИЛИ-НЕ);
функционально-полная система, включающая в себя только
одну функцию — функцию Шеффера (И-НЕ).
При помощи этих функций можно построить любую цифровую
систему.
Синтез логических устройств в базисе ОФПН состоит из пред-
ставления этих функций в нормальных формах и минимизации.
121
Таблица 4.3
Табличное задание функции двух переменных
хх 0 1 0 1
х2 0 0 1 1
Уз 0 0 0 0 Const 0, - 0
У, 0 0 0 1 Конъюнкция: yt - х,х2
У2 0 0 1 0 Запрет по х,: у2-х,-х2
Уз 0 0 1 1 Повторитель х2: у3 - х2
У, 0 1 0 0 Запрет по х2: У<"*1 Л
Уз 0 1 0 1 Повторитель х,: ys - х,
Уз 0 1 1 0 Исключающее «или»: 1/б “ Xj • Х2 + Х| • х2, или сложение по модулю 2: Уз~хх®хг
У1 0 1 1 1 Дизъюнктор (или) У7 “ Х< + х2
Уз 1 0 0 0 Функция Пирса (или-не) % - х, + х2
Уз 1 0 0 1 Логическая равнозначность ^-x-Xj + x^-x;
1 0 1 0 Инвертор х,: ую -"х,
У» 1 0 1 1 Импликация от х2 к х,: Ун ~Хх + Х2
У\2 1 1 0 0 Инвертор х2: _у12 - х2
У\з 1 1 0 1 Импликация от х, к х2: У»-*! + Х2
У» 1 1 1 0 Функция Шеффера (и-не) У" ~Х,'Х2
У,з 1 1 1 1 Генератор 1: г/15 ~ 1
Нормальной формой считают представление этих функций по-
средством суперпозиций вспомогательных функций — минтермов
и макстермов.
122
Минтерном называют функцию, которая принимает 1 только при
одном значении аргументов и 0 — при других (иногда в литературе
используется термин «конституэнта единицы»).
Например, для функции двух аргументов имеем:
х2 С» С, сг С’з
0 0 1 0 0 0
0 1 0 1 0 0
1 0 0 0 1 0
1 1 0 0 0 1
Таким образом, для функции двух аргументов имеем четыре
минтерма:
Со = Х| • х2;
= Х1-х2;
с,1
С*
d
Макстермом называют функцию, которая принимает 0 только при
одном значении аргументов и 1 — при другом (иногда в литературе
используется термин «конституэнта ноля»).
Например, для функции двух аргументов имеем:
*1 х2
0 0 0 1 1 1
0 1 1 0 1 1
1 0 1 1 0 1
1 1 1 1 1 0
123
Таким образом, для функции двух аргументов имеем также че-
тыре макстерма:
Со =Х[ + х2;
С] = х, +х2;
С, = Х| +Х2>
С3 = X! + Х2.
^При этом, минтерм есть инверсия макстерма: С- =Cf, С? = С-.
Форму представления функций посредством суперпозиции их мин-
термов называют формой представления посредством совершенных
дизъюнктивных нормальных форм (СДНФ), а посредством суперпо-
зиции макстермов — посредством совершенных конъюнктивных нор-
мальных форм (СКНФ).
В общем случае форма представления функций посредством
суперпозиции их минтермов имеет вид:
у(х3х2...хя) = f у -с', N = 22".
1=1
Для функций одной переменной:
Я^) = У(1) -х, +у(0)-х, .
Для функций двух переменных:
у(х|,х2) = у(1,х2)х1 + у(0, х2) • х, =
= у(1,1) • х, • х2 + у(1,0) • х, х2 + у(0,1) • X] • х2 + у(0,0) Х| • х2
ИТ. д.
Аналогично алгебраическая запись СКНФ имеет вид:
Л-1 0
y(xjX2...xn)= П(у,+С,. ).
i=i
Любую функцию можно представить путем суперпозиции их
минтермов (СДНФ) или макстермов (СКНФ).
124
Пример. Представим функцию Шеффера путем суперпозиции
минтермов (СДНФ) и макстермов (СКНФ).
Табличное представление функции Шеффера имеет вид (см. табл. 4.3):
х, 0 1 0 1
х2 0 0 1 1
Ум 1 1 1 0
Тогда совершенная дизъюнктивная нормальная форма функ-
ции Шеффера будет иметь вид:
у14 = %! • Х2 + х1*2 + *1 ‘ *2'
Соответственно СКНФ функции Шеффера:
у14 =*1+Х2 •
Применив закон де Моргана, получим:
У14 =xt-x2.
Из примеров видно, что данная функция посредством СКНФ
представляется значительно проще, чем посредством СДНФ и, сле-
довательно, имеет меньшее число схем для реализации.
4.3. ЛОГИЧЕСКИЙ СИНТЕЗ ПЕРЕКЛЮЧАТЕЛЬНЫХ
И ВЫЧИСЛИТЕЛЬНЫХ СХЕМ
4.3.1. Синтез переключательных схем
В вычислительных и других автоматических устройствах ши-
роко применяются электрические схемы, содержащие множество
переключательных элементов: реле, выключателей и т. п. При раз-
работке таких схем с успехом может быть использован аппарат
алгебры логики.
125
Переключательная схема — схематическое изображение некото-
рого устройства, состоящего из переключателей и соединяющих их
проводников, а также входов и выходов, на которые подается и с кото-
рых снимается электрический сигнал.
Каждый переключатель имеет только два состояния: замкнутое
и разомкнутое. Переключателю X поставим в соответствие логи-
ческую переменную х, которая принимает значение 1 только в том
случае, когда переключатель X замкнут и схема проводит ток; если
же переключатель разомкнут; то переменная х равна нолю. При
этом два переключателя X и X связаны таким образом, что когда
X замкнут, то X разомкнут, и наоборот. Следовательно, если пе-
реключателю X поставлена в соответствие логическая переменная
х, то переключателю X должна соответствовать переменная х.
Всей переключательной схеме также можно поставить в соот-
ветствие логическую переменную, равную единице, если схема
проводит ток, и равную нолю — если не проводит. Эта перемен-
ная является функцией от переменных, соответствующих всем
переключателям схемы, и называется функцией проводимости.
Рассмотрим функции проводимости F некоторых переключа-
тельных схем:
а| о
о
Схема не содержит переключателей и проводит ток всегда, сле-
довательно, F= 1;
б)
О-------------------о
Схема содержит один постоянно разомкнутый контакт, следо-
вательно, F=0;
О--------х--------О
Схема проводит ток, когда переключатель х замкнут, и не про-
водит, когда х разомкнут, следовательно, F(x)=x;
г) О--------*--------О
Схема проводит ток, когда переключатель х разомкнут, и не
проводит, когда х замкнут, следовательно, F(x)= х;
126
Д) _ _
О--------х-------у О
Схема проводит ток, когда оба переключателя замкнуты, сле-
довательно, F(x)=х • у,
е)
Схема проводит ток, когда хотя бы один из переключателей зам-
кнут, следовательно, F(x) = х v у.
При рассмотрении переключательных схем решают, как пра-
вило, одну из основных задач: синтез или анализ схемы.
Синтез переключательной схемы по заданным условиям ее ра-
боты сводится к следующим трем этапам:
1. Составление функции проводимости по заданным условиям.
2. Упрощение этой функции.
3. Построение соответствующей схемы.
Анализ схемы характеризуется следующими этапами:
1. Определение значений функции проводимости при всех воз-
можных наборах входящих в эту функцию переменных.
2. Получение упрощенной формулы.
Рассмотрим примеры решения задач синтеза и анализа неслож-
ных переключательных схем.
Задачи синтеза.
1. Построим схему, содержащую 4 переключателя х, у, z и t, та-
кую, чтобы она проводила ток тогда и только тогда, когда замкнут
контакт переключателя t и какой-нибудь из остальных трех кон-
тактов.
Решение. Функция проводимости для данного случая имеет вид
F(x, у, z, t) = t (xv у vz), а схема имеет вид:
2. Построим схему с пятью переключателями, которая прово-
дит ток в том и только в том случае, когда замкнуты ровно четыре
из этих переключателей.
127
Решение:
F(a,b,c,d,e) =
= abcdevaB-cdeva-bcdeva-bcdevab-c-de
Схема имеет вид:
I
Задачи анализа.
3. Найдем функцию проводимости схемы:
Решение. Имеется четыре возможных пути прохождения тока
при замкнутых переключателях a, b, с, d, е: через переключатели
а, Ь; через переключатели а, е, d; через переключатели с, d и через
переключатели с, е, Ъ. Функция проводимости F(a, b, с, d, е) =
= a-b v a-e-d v c-d v c-e-b.
4. Упростим переключательные схемы:
а)
Решение:
F(x, у) = х • у v у • х = х • (у v у) = х -1 = х.
128
Упрощенная схема: О------х-------О
Решение:
F(x,y,z) = z (х v у) v (z v х • у) = 1.
Здесь первое логическое слагаемое z • (х v у) является отрицани-
ем второго логического слагаемого (z v х • у), а дизъюнкция пере-
менной с ее инверсией равна 1.
Упрощенная схема: О-------О
Анализ и синтез более сложных переключательных схем мо-
жет проводиться по тем же правилам, что и для вычислительных
схем.
4.3.2. Синтез вычислительных схем
Синтез вычислительных схем по заданным условиям работы
сводится к следующим трем этапам:
1. Образование СДНФ (СКНФ) функции по заданной таблице
истинности.
Таблица истинности — табличное представление вычислительной
(логической) схемы (операции), в котором перечислены все возмож-
ные сочетания значений истинности входных сигналов (операндов)
вместе со значением истинности выходного сигнала (результата опе-
рации) для каждого из этих сочетаний.
2. Упрощение этой функции (преобразованию СДНФ (СКНФ)
в формулу с наименьшим числом вхождений переменных);
3. Построение соответствующей схемы.
9а-210
129
Образование СДНФ функции по заданной таблице истиннос-
ти. Этот этап включает в себя следующие шаги:
1) в заданной таблице истинности выделяются наборы значе-
ний аргументов, при которых функция принимает единичное зна-
чение; '
2) для каждого выделенного набора образуется конституэнта
единицы (минтерм), принимающая единичное значение придан-
ном наборе значений аргументов;
3) составляется логическая сумма образованных конституэнт
единицы.
Для образования конституэнты единицы С'(, принимающей еди-
ничное значение при z-м наборе значений аргументов, необходи-
мо составить логическое произведение аргументов, в которое ар-
гументы, принимающие в z-м наборе единичное значение, входят
без знака отрицания, а аргументы, принимающие в z-м наборе но-
левое значение, входят со знаком отрицания.
При образовании совершенной конъюнктивной нормальной
формы (СКНФ) функции:
1) в таблице выделяются наборы значений аргументов, при ко-
торых функция принимает нолевое значение;
2) для каждого выделенного набора образуется конституэнта
ноля, принимавшая нолевое значение при данном наборе значе-
ний аргументов;
3) составляется логическое произведение образованных консти-
туэнт ноля.
Упрощение функции. При преобразовании СДНФ (СКНФ)
в формулу с наименьшим числом вхождений переменных (мини-
мизация формулы) используют следующие основные приемы:
вынос за скобки XYv XZ =_Х(YvZ);
• полное склеивание XY v XY = X;
• поглощение X v XY = X;
минимизация по методу Квайна;
* минимизация с использованием карт Карно или диаграмм
Вейча.
При минимизации по методу Квайна предполагается, что исход-
ная функция задана в СДНФ. Введем несколько определений.
Конъюнкция, получаемая в результате склеивания двух консти-
туэнт единицы, называется импликантой.
Импликанта поглощает конституэнты единицы, при склеивании
которых она образовалась.
130
Простая импликанта — импликанта, склеивание которой с дру-
гой импликантой невозможно.
Задача минимизации по методу Квайна состоит из следующих
шагов:
1) в СДНФ функции выполняются все возможные склеивания
конституэнт единицы и получаемых импликант, и выделяются все
простые импликанты;
2) из набора простых импликант выделяется наименьший по
числу импликант поднабор простых импликант, поглощающих
в совокупности наибольшее число конституэнт единицы;
3) образовывается логическая сумма простых импликант, во-
шедших в выделенный поднабор, и конституэнт единицы, не уча-
ствующих в склеивании.
Полученная таким образом формула называется минимальной
ДНФ функции.
Диаграмма Вейча или карта Карно — таблица, облегчающая на-
хождение склеивающихся конституэнт единицы и получение набора
простых импликант.
Таблица для функций п аргументов содержит 2“ клеток. Каждая
клетка соответствует одной определенной конституэнте единицы.
Соответствие клетки таблицы определенной конституэнте еди-
ницы устанавливается:
* для диаграммы Вейча с помощью обрамления таблицы, где
каждой клетке таблицы соответствует набор всех аргумен-
тов, в который каждый из аргументов входит или без знака
отрицания, или со знаком отрицания;
для карты Карно с помощью двух входов в таблицу, где ука-
заны две части набора значений аргументов, при котором со-
ответствующая конституэнта единицы принимает единичное
значение.
Карты Карно обычно используют для ручной минимизации бу-
левых функций при небольшом числе переменных (не более пяти).
На рис. 4.1 представлены карты Карно для трех переменных.
Каждая клетка соответствует логическому произведению прямо-
го или инверсного значения переменных, присвоенных столбцу
или строке, на пересечении которых она находится. Например,
клетка с номером 4 находится на пересечении строки со значени-
ем переменной xt и столбца со значениями переменных х2 и х3
131
и соответствует логическому произведению х15уг3. В картах Карно
значения переменных присваиваются таким образом, чтобы со-
седние клетки по строкам и столбцам отличались между собой зна-
чением только одной переменной, при этом обозначение значе-
ния логического произведения переменных соответствует .номе-
ру клетки, записанному в коде Грея (см. рис. 4.1).
Х2 Х2 Х2
4 (ПО) 5 (П1) 6 (101) 7 (100)
3 2 1 0
(010) (0П) (001) (000)
х3 хз хз х3
Х2 Х2 х2 х2
XjX2X3 Xj^2X3 XjX2X3
Л'|Х2Х3 XjX2X3
х3 Х3 хз
а)
б)
Рис. 4.1. Карты Карно для трех переменных:
а) с номером клетки (десятичным и в коде Грея);
б) с логическим обозначением клетки
На рис. 4.2 представлены аналогичные карты для четырех пе-
ременных.
Хз X) Х) Хз
12 (1010) 13 (ЮН) 14 (1001) 15 (1000)
И 10 9 8
(ИЮ) (1111) (1Ю1) (1100)
4 5 6 7
(ОНО) (ОШ) (0101) (0100)
3 2 1 0
(0010) (ООП) (0001) (0000)
Х4 Xf Xt
а) б)
Рис. 4.2. Карты Карно для четырех переменных:
а) с номером клетки (десятичным и в коде Грея);
б) с логическим обозначением клетки
132
При упрощении логических функций с использованием карт
Карно в ячейки карты записывают значения логических произве-
дений из таблицы истинности. Пусть, например, логическая фун-
кция трех переменных задана таблицей истинности (табл. 4.4).
х, х2 хз Y
0 0 0 0
0 0 1 0
0 1 0 0
0 1 1 1
Таблица 4.4
х. х2 хз Y
1 0 0 0
1 0 1 0
1 1 0 1
1 1 1 1
На рис. 4.3 представлена карта Карно, соответствующая дан-
ной логической функции.
х2 х2 х2 х2
illll Illll 0 0
0 яшш 0 0
Рис. 4.3. Карта Карно логической функции, заданной табл. 4.4.
Карта Карно позволяет легко выделить произведения, которые
можно упростить. Так, если произведения стоят в соседних клет-
ках, то из общего выражения можно исключить одну переменную.
В нашем случае элементы 2 и 5 клеток (см. рис. 4.1 а) можно преоб-
разовать к виду:
Х[Х2Х3 + Х]Х2Х3
= х2х3
Элементы 4 и 5 клеток — соответственно к виду:
Х]Х2Х3 +Х]Х2Х3 = х{х2
'2-
133
Таким образом, функция, представленная табл. 4.4, определя-
ется уравнением:
У = Х]Х2 + х2х3.
Построение схемы. В качестве примера логического синтеза
вычислительных схем рассмотрим построение одноразрядного
двоичного сумматора, имеющего два входа (х( и х2) и два выхода
(S и Р) рис. 4.4.
s — сумма
Р — перенос
в старший разряд
Рис. 4.4. Двоичный сумматор
Зададим таблицу истинности сумматора.
X, 0 0 1 1
х2 0 1 0 1
5-/,(х1,х2) 0 1 1 0
р “ /2(^'1» ^2) 0 0 0 1
Представим выходные функции S и Р в виде СДНФ:
5 = /1(х1,х2) = Х]Х2 + х1х2<
Р = f2(xitx2) = х}х2.
Логическая схема сумматора, реализующего данные функции,
представлена на рис. 4.5.
Для логических схем И, ИЛИ, НЕ существуют типовые тех-
нические схемы (логические элементы), реализующие их на по-
лупроводниковых структурах (см. п. 4.4.1).
134
X, хг
Рис. 4.5. Логическая схема сумматора
Логический элемент — часть электронной логической схемы, ко-
торая реализует элементарную логическую функцию.
Тогда структурная схема сумматора будет иметь вид, показан-
ный на рис. 4.6.
Рис. 4.6. Структурная схема сумматора
135
4.4. ОСНОВЫ ЭЛЕМЕНТНОЙ БАЗЫ
ЦИФРОВЫХ АВТОМАТОВ
4.4.1. Логические элементы
К основным логическим элементам современных вычислитель-
ных устройств относятся электронные схемы, реализующие опе-
рации И, ИЛИ, НЕ, И—НЕ, ИЛИ—НЕ и другие, а также триггер.
С помощью этих схем можно реализовать любую логическую
функцию, описывающую работу устройств компьютера. Обычно
у них бывают от двух до восьми входов и один или два выхода.
Входные и выходные сигналы, соответствующие двум логичес-
ким состояниям в логических элементах — 1 и 0 — имеют один из
двух установленных уровней напряжения. Например, +5 В и О В.
Высокий уровень обычно соответствует значению «истина»
(«1»), а низкий — значению «ложь» («О»),
Каждый логический элемент имеет свое условное обозначение,
которое выражает его логическую функцию.
Работу логических элементов описывают с помощью таблиц
истинности.
Схема И. Эта схема реализует конъюнкцию двух или более ло-
гических значений. Условное обозначение на структурных схемах
схемы И с двумя входами представлено на рис. 4.7.
X У хху
0 0 0
0 1 0
1 0 0
1 1 1
Рис. 4.7. Условное обозначение и таблица истинности схемы И
136
Единица на выходе схемы И будет тогда и только тогда, когда на
всех входах будут единицы. Когда хотя бы на одном входе будет
ноль, на выходе также будет ноль.
Связь между выходом z этой схемы и входами х и у описыва-
ется соотношением: z = х ху (читается как х и у). Операция конъ-
юнкции на структурных схемах обозначается знаком & (читается
как амперсэнд), являющимся сокращенной записью английского
слова and.
Схема ИЛИ. Эта схема реализует дизъюнкцию двух или более
логических значений. Когда хотя бы на одном входе схемы ИЛИ
будет единица, на ее выходе также будет единица.
Условное обозначение на структурных схемах схемы ИЛИ с
двумя входами представлено на рис. 4.8. Знак 1 на схеме соответ-
ствует обозначению, т. е. значение дизъюнкции равно единице,
если сумма значений операндов больше или равна 1. Связь между
выходом z этой схемы и входами х и у описывается соотношени-
ем: z = х v у (читается как х или у).
Рис. 4.8. Условное обозначение и таблица истинности схемы ИЛИ
Схема НЕ. Схема НЕ (инвертор) реализует операцию отрица-
ния. Связь между входом х этой схемы и выходом z можно запи-
сать соотношением z = х, где х читается как «не х» или «инвер-
сия х».
Если на входе схемы 0, то на выходе 1. Когда на входе 1, на вы-
ходе 0. Условное обозначение инвертора представлено на рис. 4.9.
137
X X
0 1
1 0
Рис. 4.9. Условное обозначение и таблица истинности схемы НЕ
Схема И—НЕ. Схема состоит из элемента И и инвертора и осу-
ществляет отрицание результата схемы И. Связь между выходом
z и входами х и у схемы записывают следующим образом: z = х X у,
где хху, читается как «инверсия х и у». Условное обозначение
на структурных схемах схемы И—НЕ с двумя входами представ-
лено на рисунке 4.10.
X У хху
0 0 1
0 1 1
1 0 1
1 1 0
Рис. 4.10. Условное обозначение и таблица истинности схемы И—НЕ
Схема ИЛИ—НЕ. Схема состоит из элемента ИЛИ и инвертора
и осуществляет отрицание результата схемы ИЛИ. Связь между
выходом z и входами х и у схемы записывают следующим обра-
зом: z = xv у, где xv у, читается как «инверсиях и у». Условное
обозначение на структурных схемах схемы ИЛИ—НЕ с двумя
входами представлено на рисунке 4.11.
138
X
У
X У xvy
0 0 1
0 1 0
1 0 0
1 1 0
Рис. 4.11. Условное обозначение и таблица истинности схемы ИЛИ НЕ
Триггер — (от англ, trigger — защелка, спусковой крючок) элект-
ронное устройство с двумя устойчивыми состояниями равновесия,
чередующимися под воздействием внешних сигналов, предназначен-
ных для записи и хранения 1 бита данных.
Для обозначения этой схемы в английском языке чаще употреб-
ляется термин flip-flop, что в переводе означает «хлопанье».
В отличие от рассмотренных выше логических схем, триггеры —
это логические устройства с памятью. Выходные сигналы тригге-
ров в общем случае зависят не только от их входных сигналов, дей-
ствующих в настоящий момент, но и от сигналов, действовавших
на входы до этого (рис. 4.12).
Рис. 4.12. Функциональная схема триггера
139
Триггер функционирует следующим образом. Устройство уп-
равления (УУ) преобразует входные сигналы так, что ячейка памя-
ти (ЯП) принимает одно из двух устойчивых состояний, в зависи-
мости от входных сигналов. Входные сигналы поступают на входы
S1 и R , преобразуются устройством управления (УУ) и поступают
на внутренние входы ячейки памяти (ЯП). В общем случае устрой-
ство управления может отсутствовать. Тогда сигналы подаются
непосредственно на входы RnS ячейки памяти.
В триггерах также может осуществляться синхронизация
приема информации с помощью входа С. При наличии входа С
триггер называют синхронным, в противном случае — асинх-
ронным. В асинхронных триггерах информация может записы-
ваться непрерывно. В этом случае она определяется информа-
ционными сигналами, действующими на входах в данный мо-
мент времени, т. е. изменение состояния ячейки памяти проис-
ходит мгновенно после изменения состояния информационных
входов.
В синхронном (или тактируемом) триггере информация зано-
сится только в момент действия так называемого синхронизирую-
щего сигнала. Синхронизация триггера может осуществляться как
импульсом (потенциалом), так и фронтом (перепадом потенциа-
ла) . В схемотехнике приняты следующие обозначения входов триг-
геров:
Q — прямой выход триггера;
Q — инверсный выход триггера;
S— раздельный вход установки в единичное состояние (напря-
жение высокого уровня на прямом выходе Q);
R — раздельный вход установки в нолевое состояние (напря-
жение низкого уровня на прямом выходе О);
D — информационный вход (на него подается информация,
предназначенная для занесения в триггер);
С — вход синхронизации;
Т — счетный вход.
В основе любого триггера находится кольцо из двух инверто-
ров (рис. 4.13). Это кольцо принято изображать в виде так называ-
емой защелки (рис. 4.14).
Однозначную запись 1 бита информации в защелку можно осу-
ществить, если снабдить ее цепями управления и запуска.
140
DD1 DD2
Рис. 4.13. Кольцо инверторов
DD1
DD2
Рис. 4.14. Элемент-защелка
DD2
Рис. 4.15.
Принципиальная
схема RS-триггера
Самый распространенный тип триггера — RS-триггер. Принци-
пиальная схема RS-триггера (рис. 4.15) содержит защелку (два эле-
мента И—НЕ или ИЛИ—НЕ), а также два раздель-
ных статических входа управления. В зависимости
от используемых элементов можно получить
триггеры с прямыми входами (за активный логичес-
кий уровень принимают уровень логической едини-
цы) — элемент ИЛИ—НЕ — или с инверсными вхо-
дами (за активный уровень принимается уровень
логического ноля). Эти входы управления называ-
ют R (reset — сброс) и S (set — установка).
По сути дела, RS-триггер, изображенный на
рис. 4.15, это триггер без устройства управления.
Для триггера с прямыми входами подача на вход
S -триггера логической единицы, а на вход R — ло-
гического ноля приведет к тому, что на выходе триг-
гера Q установится сигнал единицы и, наоборот,
при подаче на R единицы, а на S — ноля на выходе Q установится
сигнал ноля. Таким образом, таблица истинности для данного триг-
гера будет иметь вид, показанный в табл. 4.5.
Как видно из табл. 4.5, комбинация R = 1 и S = 1 является зап-
рещенной. После нее состояние выходов триггера становится нео-
пределенным. На выходе Q может установиться как состояние ло-
гического ноля, так и состояние логической единицы.
Иногда режим работы триггера, при котором R = 1, a S = О,
называют режимом очистки, при R = О, S = 1 — режимом записи,
а при R = О, S = 0 — режимом хранения, так как информация на
выходе триггера в этом случае не изменяется. Для триггера с ин-
версными входами таблица истинности имеет вид, представлен-
ный в табл. 4.6.
141
Таблица 4.5
Входы Выходы
R S Q Q
0 0 Без изменений
0 1 1 0
1 0 0 1
1 1 Не определено
Таблица 4.6
Входы Выходы
R 5 Q Q
0 0 Не определено
0 1 0 1
1 0 1 0
1 1 Без изменений
Поскольку один триггер может запомнить только один раз-
ряд двоичного кода, то для запоминания байта нужно 8 тригге-
ров, для запоминания килобайта соответственно 8x2'° = 8192
триггеров. Современные микросхемы памяти содержат милли-
оны триггеров.
4.4.2. Схемотехника логических элементов
По принципу построения базовые логические элементы делят-
ся на следующие основные типы: элементы диодно-транзисторной
логики (ДТЛ), резистивно-транзисторной логики (РТА), транзис-
торно-транзисторной логики (ТТЛ), эмиттерно-связанной логики
(ЭСЛ), элементы на так называемых комплементарных МДП-
структурах (КМДП). Элементы КМДП используют пары МДП-
транзисторов (со структурой металл—диэлектрик — полупровод-
ник) с каналами р- и п-типов. Базовые элементы остальных типов
выполнены на биполярных транзисторах. В основе построения
транзисторов и других полупроводниковых приборов лежат свой-
ства и характеристики электронно-дырочного перехода.
Образование и свойства электронно-дырочного перехода. Ос-
новой построения логических элементов являются полупроводни-
ковые структуры. Электрические свойства такой структуры опре-
деляются в первую очередь степенью связи носителей заряда с
атомами в кристаллической решетке. В полупроводниковой тех-
нике чаще всего используют четырехвалентные германий и крем-
ний — вещества кристаллической структуры с ковалентными меж-
атомными связями, при которых каждый атом связан с соседними
посредством восьми обобщенных электронов. Это обстоятельство
схематически отображено на рис. 4.16 а, где двойными линиями
142
показаны связи между соседними атомами в кристаллической
решетке, большими кружками обозначены четырехвалентные
атомы, а малыми кружками с горизонтальной чертой — элект-
роны.
Рис. 4.16. Схематичное изображение кристаллической структуры
с ковалентными межатомными связями (а)
и нарушения ее электрической нейтральности (б)
Такая связь весьма устойчива, и для ее разрыва требуется зат-
ратить определенную энергию. При разрывах ковалентных свя-
зей в полупроводнике появляются свободные носители заряда —
электроны и дырки, которые совершают хаотическое (тепловое)
движение в кристалле.
Появление дырок в полупроводнике и их перемещение в нем
связаны с возбуждением валентных электронов, когда в результа-
те поглощения энергии один из валентных электронов освобож-
дается от связи с атомом, становясь подвижным носителем заря-
да. Нарушение электрической нейтральности в месте разрыва ва-
лентной связи эквивалентно появлению там элементарного поло-
жительного заряда. Образовавшаяся вакантная связь может быть
заполнена электроном из соседней связи (рис. 4.16 б), так как та-
кой переход не связан с большими энергетическими затратами (все
валентные электроны в решетке взаимодействуют со своими ато-
мами примерно в одинаковой степени). Перемещение электрона
из одной связи в другую эквивалентно непрерывному перемеще-
нию подвижного положительного заряда — дырки.
143
Процесс возникновения свободных носителей заряда носит
название генерации. В процессе хаотического движения носите-
ли могут заполнять освободившиеся ранее связи, тогда происхо-
дит исчезновение двух носителей заряда — электрона и дырки, их
рекомбинация. Среднее число актов генерации и актов рекомби-
нации в единицу времени при постоянной температуре одинако-
во, поэтому среднее число дырок и электронов в кристалле при
данной температуре является вполне определенным. При этом
кристалл в целом электрически нейтрален.
Если к кристаллу приложить напряжение, то в образовавшем-
ся электрическом поле у электронов и дырок появляется состав-
ляющая дрейфовой скорости по силовым линиям. Электроны пе-
ремещаются к положительному полюсу, а дырки — к отрицатель-
ному. При этом полный ток равен сумме электронной и дырочной
составляющих.
Если в рассматриваемый кристалл с ковалентными связями вне-
сти примеси элементов III или V группы периодической системы
Менделеева, то относительное количество электронов и дырок изме-
нится. Процесс внесения примесей часто называют легированием.
Атомы примеси элемента V группы называют донорами. В неко-
торых узлах кристаллической решетки доноры замещают атомы ос-
новного вещества (рис. 4.17 а). Четыре валентных электрона донора
связываются в кристаллической решетке с соседними атомами, а
пятый электрон, оставшийся неиспользованным, оказывается слабо
связанным с атомом донора (лишь силами кулоновского притяжения).
При этом обеспечивается электрическая нейтральность атома.
а)
Рис. 4.17. Схематичное изображение замещения атомов
основного вещества: а) донорами; 6) акцепторами
б)
144
Для отрыва указанного электрона от атома достаточно затра-
тить небольшую энергию. Поэтому уже при комнатной темпера-
туре пятые электроны доноров оказываются свободными и могут
участвовать в создании тока через кристалл. Атомы примеси, ли-
шенные одного электрона, превращаются в положительные ионы,
расположенные в узлах кристаллической решетки. Следует особо
отметить, что появление свободного электрона в данном случае не
связано с появлением дырки, т. е. в кристалле с пятивалентной при-
месью ток будет иметь в основном электронную составляющую.
По этой причине полупроводник с донорной примесью называют
электронным, или полупроводником п-типа. В полупроводнике
n-типа также имеется и дырочная составляющая, но она значитель-
но меньше электронной. Наличие дырочной составляющей объяс-
няется разрывом отдельных связей атомов основного вещества с
образованием электронов и дырок.
Добавление в чистый полупроводник трехвалентных атомов
примеси, называемых акцепторами, приводит к замещению ими в
отдельных узлах решетки атомов основного вещества (рис. 4.17 б).
Трехвалентный атом примеси имеет на один электрон меньше того
числа электронов, которое требуется для образования устойчивых
ковалентных связей. Иными словами, при введении такого атома
примеси появляется вакантная связь, на которую может перейти
электрон из соседней связи. Необходимая для такого перехода
энергия весьма мала, и уже при комнатной температуре все сво-
бодные места у атомов примеси оказываются занятыми, а сами
атомы вследствие этого превращаются в отрицательные ионы. На
местах ушедших к этим атомам электронов образуются дырки,
которые хаотически перемещаются в кристалле и могут участво-
вать в создании тока через кристалл. Появление дырок не связано
с появлением свободных электронов, поэтому дырочная составля-
ющая общего количества подвижных носителей заряда в таком
полупроводнике преобладает над электронной составляющей. Рас-
смотренный полупроводник называют дырочным, или полупро-
водником р-типа.
Полупроводники п- и p-типа называют примесными, или легиро-
ванными. Носители заряда, однотипные с примесным полупровод-
ником, называют основными, а неоднотипные — неосновными.
В полупроводнике n-типа основными носителями являются электро-
ны, а неосновными—дырки, а в р-полупроводнике, наоборот, дырки
являются основными носителями, а электроны — неосновными.
10 А-210
145
Принцип действия большинства полупроводниковых приборов
и элементов интегральных схем основан на использовании свойств
электронно-дырочного перехода (р—п-перехода) — переходного
слоя между двумя областями полупроводника, одна из которых име-
ет электропроводность p-типа, а другая — n-типа. На рис. 4.18 а
показаны два образца полупроводника с различным типом элект-
ропроводности. В каждом полупроводнике подвижные носители
заряда (электроны и дырки) совершают хаотическое движение,
обусловленное их тепловой энергией. Неподвижные положитель-
ные и отрицательные примесные ионы обозначены знаками плюс
и минус соответственно, а дырки и электроны — теми же знаками
в кружках. Оба образца нейтральны, т. е. подвижные и неподвиж-
ные заряды в них взаимно скомпенсированы.
Р П
б)
Рис. 4.18. Проводники с различным типом электропроводности:
а) до соприкосновения, б) при соприкосновении
После приведения полупроводников в соприкосновение из-за
значительного различия в концентрациях подвижных носителей
заряда будет происходить диффузия электронов из n-области в
p-область и дырок из p-области в n-область, т. е. наблюдаться диф-
146
фузионный ток. Переход электронов из приконтактной области
Л-полупроводника в р-полупроводник нарушает электрическую
нейтральность указанной области. Заряды положительных ионов
примеси оказываются нескомпенсированными, т. е. со стороны
n-полупроводника у границы контакта появляется положительный
заряд (рис. 4.18 б). Появлению этого заряда способствует также
диффузия дырок из p-области и их рекомбинация с электронами
n-области, вследствие чего избыточный положительный заряд со
стороны n-области увеличивается.
Аналогично в слоях p-области, примыкающих к контакту, об-
разуется нескомпенсированный отрицательный заряд доноров,
вызванный уходом дырок в n-область и рекомбинацией дырок с
электронами, пришедшими из n-области. Появление противопо-
ложных по знаку зарядов по обе стороны контакта вызывает по-
явление электрического поля с напряженностью Е, направленно-
го из n-области в p-область (рис. 4.19).
Рис. 4.19.'Образование
р—п-перехода
Возникшее электрическое поле препятствует диффузии основ-
ных носителей заряда, но способствует перемещению неосновных
носителей заряда, т. е. электронов из p-области в n-область и ды-
рок из n-области в p-область, так как для них направление поля
является ускоряющим. Движение неосновных носителей заряда
под воздействием поля образует ток проводимости (дрейфа), на-
правленный противоположно току диффузии.
Состояние равновесия в структуре, очевидно, наступит тогда,
когда ток диффузии и ток проводимости сравняются. При этом в
области перехода установится некоторое значение напряженнос-
ти электрического поля, а между областями полупроводника —
разность потенциалов Vk (см. рис. 4.19).
147
Таким образом, вблизи границы двух полупроводников обра-
зуется слой, лишенный подвижных носителей заряда и поэтому
обладающий высоким электрическим сопротивлением, так назы-
ваемый запирающий слой. Толщина запирающего слоя обычно не
превышает нескольких микрометров.
Использование свойств р—n-перехода в полупроводниковых
приборах в большинстве случаев связано с приложением к пере-
ходу разности потенциалов. При этом в переходе возникает допол-
нительное электрическое поле, изменяется высота потенциально-
го барьера, а вместе с этим изменяются и потоки основных и нео-
сновных носителей.
Если к р—п-переходу приложить разность потенциалов таким
образом, чтобы плюс источника подключился к п-области, а ми-
нус — к p-области, то это приведет к увеличению потенциального
барьера в переходе на U, так как поле, обусловленное внешним
источником, добавляется к внутреннему полю, существующему в
переходе (рис. 4.20 а).
Увеличение напряженности электрического поля означает уве-
личение объемного заряда неподвижных ионов на участках, при-
легающих к контакту, а последнее может быть достигнуто только
за счет увеличения расстояния, на котором располагаются ионы с
нескомпенсированным зарядом, т. е. за счет толщины перехода. При
этом сопротивление р—л-перехода велико, ток через него мал — он
обусловлен движением неосновных носителей заряда. В этом слу-
чае ток называют обратным, а р—л-переход — закрытым.
Рис. 4.20. Электронно-дырочный переход во внешнем электрическом поле:
а) к р—n-переходу приложено обратное напряжение;
б) к р—n-переходу приложено прямое напряжение
148
При противоположной полярности источника напряжения
(рис. 4.20 б) внешнее электрическое поле направлено навстречу внут-
реннему полю в р—л-переходе, толщина запирающего слоя уменьша-
ется, и при напряжении 0,3...0,5 В запирающий слой исчезает. Сопро-
тивление р—n-перехода резко снижается, и возникает сравнительно
большой ток. Ток при этом называют прямым, а переход—открытым.
На рис. 4.21 показана полная вольт-амперная характеристика
открытого и закрытого р—п-переходов. Как видно, эта характери-
стика является существенно нелинейной. На участке 1 прямой ток
мал. На участке 2 внешнее электрическое поле больше внутренне-
го, запирающий слой отсутствует, ток определяется только сопро-
тивлением полупроводника. На участке 3 запирающий слой пре-
пятствует движению основных носителей, небольшой ток опреде-
ляется движением неосновных носителей заряда. Излом вольт-ам-
перной характеристики в начале координат обусловлен различны-
ми масштабами координатных осей при прямом и обратном на-
пряжении, приложенном к р—п-переходу. И наконец, на участке 4
происходит пробой р—л-перехода, и обратный ток быстро возрас-
тает. Это связано с тем, что при движении через р—л-переход под
действием электрического поля неосновные носители заряда при-
обретают энергию, достаточную для ударной ионизации атомов
полупроводника. В переходе начинается лавинообразное размно-
жение носителей заряда (электронов и дырок), что приводит к рез-
кому увеличению обратного тока через р—л-переход при почти
неизменном обратном напряжении. Этот вид электрического про-
боя называют лавинным. Обычно он развивается в относительно
широких р—л-переходах, которые образуются в слаболегирован-
ных полупроводниках.
Рис. 4.21. Вольт-амперная характеристика р—п-перехода
149
Закрытый р—л-переход обладает электрической емкостью С,
которая зависит от его площади и ширины, а также от диэлектри-
ческой проницаемости запирающего слоя. При увеличении обрат-
ного напряжения ширина р—n-перехода возрастает, и емкость
р—л-перехода уменьшается.
Свойства чистых и легированных полупроводников и р—л-пе-
рехода лежат в основе построения двухэлектродных полупровод-
никовых приборов — полупроводниковых резисторов и диодов.
В основе построения более сложных приборов — транзисторов —
лежат свойства и характеристики, определяемые взаимодействи-
ем нескольких р—п -переходов.
Биполярные и полевые транзисторы. Транзистором называ-
ют полупроводниковый прибор с тремя и более выводами, пред-
назначенный для усиления, генерирования и преобразования элек-
трических колебаний.
В зависимости от того, носители одного или обоих знаков уча-
ствуют в образовании тока, различают униполярные и биполяр-
ные транзисторы соответственно.
Основу биполярного транзистора составляет транзисторная
структура с двумя взаимодействующими р—п-переходами, обла-
дающая усилительными свойствами, обусловленными явлениями
инжекции и экстракции неосновных носителей заряда. На рис. 4.22
показана структура такого транзистора с выводами от каждой об-
ласти.
В зависимости от порядка чередования областей различают
транзисторные структуры р—п—р и л—р—л. На рис. 4.23 показаны
схемы и условные обозначения этих структур. Среднюю часть кри-
сталла с электрическим выводом называют базой, одну из край-
них — эмиттером, вторую — коллектором.
Рис. 4.22. Структура
биполярного транзистора
Рис. 4.23. Типы транзисторов (а)
и их условное обозначение (б)
a)
б)
150
Переход между эмиттером и базой обычно называют эмиттер-
ным, а между коллектором и базой — коллекторным. В зависимо-
сти от напряжения смещения переходов различают три режима
включения: активный, отсечки и насыщения.
В активном режиме один из переходов смещен в прямом на-
правлении, другой — в обратном. Если в прямом направлении
включен эмитгерный переход, то такой режим называют нормаль-
ным. Токи во внешних цепях в активном режиме определяются
высотой управляемого потенциального барьера открытого пере-
хода, т. е. способностью перехода инжектировать неосновные но-
сители в базу.
Режим отсечки имеет место в том случае, когда оба перехода
смещены в обратном направлении. В этом случае токи во внешних
цепях малы и соизмеримы с обратным током одного из переходов.
О транзисторе при этом говорят, что он заперт.
В режиме насыщения оба перехода открыты, в базу инжекти-
руются неосновные носители из области эмиттера и из области
коллектора. Так как оба перехода открыты, то на структуру падает
небольшое напряжение. По этой причине режим насыщения час-
то используют в тех случаях, когда транзистор выполняет роль клю-
ча, предназначенного для замыкания цепи. Размыкание цепи осу-
ществляется переводом транзистора в режим отсечки, при этом
транзисторная структура обладает большим сопротивлением.
Физические процессы в транзисторной структуре определяют-
ся состоянием эмиттерного и коллекторного переходов. При этом
все положения, рассмотренные ранее для единичного р—л-пере-
хода, справедливы для каждого из р—п-переходов транзистора.
В равновесном состоянии наблюдается динамическое равновесие
между потоками дырок и электронов, протекающими через каж-
дый р—n-переход, и результирующие токи равны нулю.
В активном нормальном режиме при подключении к электро-
дам транзистора напряжений U'^ и J7'6, как показано на рис. 4.24,
эмиттерный переход смещается в прямом направлении, а коллек-
торный — в обратном.
В результате снижения потенциального барьера дырки из об-
ласти эмиттера диффундируют через р—л-переход в область базы
(инжекция дырок), а электроны — из базы в область эмиттера.
Однако поскольку удельное сопротивление базы высоко, дыроч-
ный поток носителей заряда преобладает над электронным. Поэто-
151
му электронным потоком в первом приближении можно пренеб-
речь. Для количественной оценки составляющих полного тока р—
п-перехода используют коэффициент инжекции:
Л) ~ ^зр^зр "* ^зп) ~ Мз’
где I и /эп — дырочная и электронная составляющие тока эмиттерного
перехода; 1з — полный ток перехода.
Рис. 4.24. Токи в транзисторе
Вследствие разности концентраций инжектированные в базу
носители заряда диффундируют (в диффузионных транзисторах)
или движутся под действием поля (в дрейфовых транзисторах) в
глубь ее по направлению к коллектору. Так как ширина базы во
много раз меньше диффузионной длины, то большинство дырок,
инжектированных в базу, не успевает рекомбинировать в ней с
электронами и, попав вблизи коллекторного перехода в ускоряю-
щее поле, втягивается в коллектор (экстракция дырок). На воспол-
нение числа электронов, рекомбинированных с дырками, переме-
щающимися в базе, из внешней цепи по выводу в область базы
поступает такая же часть электронов, которая и создает ток базы
16. Таким образом, ток эмиттерного перехода несколько больше
тока коллекторного перехода. Относительное число неосновных
носителей заряда, достигших коллекторного перехода транзисто-
ра, характеризуется коэффициентом переноса:
= ^эр-
152
Если бы рекомбинация в базе отсутствовала, то все носители
заряда, инжектированные эмиттером, достигали бы коллекторно-
го перехода. В действительности только часть (у0) тока эмиттера
составляют дырки и только эта часть доходит до коллекторного
перехода. Поэтому ток коллектора равен:
где ад — коэффициент передачи эмиттерного тока, а0 = у080.
Кроме тока, вызванного инжектированными в базу неосновны-
ми носителями заряда, через р—л-переход, смещенный в обратном
направлении, протекает обратный ток 1кбо. Результирующий ток
в коллекторной цепи равен:
/ = aJ + К.
к 0 э кбо
Изменение напряжения, приложенного к эмиттерному переходу,
вызывает изменение числа инжектируемых в базу неосновных но-
сителей заряда и соответствующее изменение тока эмиттера и кол-
лектора. Следовательно, для изменения по определенному закону
коллекторного тока необходимо приложить к эмиттерному перехо-
ду напряжение, изменяющее по этому же закону ток эмиттера.
Поскольку сопротивление прямосмещенного эмиттерного пе-
рехода мало по сравнению с сопротивлением обратносмещенного
коллекторного перехода, то и мощность управления по входной
эмиттерной цепи оказывается намного меньше мощности, цирку-
лирующей в выходной цепи, содержащей коллекторный переход.
Именно с этим обстоятельством связаны в конечном итоге усили-
тельные свойства транзистора.
Полевой транзистор — полупроводниковый прибор, работа ко-
торого основана на модуляции сопротивления полупроводниково-
го материала поперечным электрическим полем, а усилительные свой-
ства обусловлены потоком основных носителей заряда одного знака,
протекающим через проводящий канал.
Управляющий электрод, изолированный от канала, называют
затвором. По способу изоляции затвора различают два типа поле-
вых транзисторов: с управляющим р—п-переходом, или с р—л-зат-
нором, и с изолированным затвором.
153
Транзистор с управляющим переходом представляет собой по-
левой транзистор, в котором проводящий канал изолирован от
подложки и затвора р—п-переходами, смещенными в обратном
направлении и расположенными вдоль базы (подложки) транзис-
тора. По каналу между электродами стока и истока протекает ток
основных носителей.
Истоком называется электрод, от которого начинают движение
основные носители заряда в канале. Электрод, к которому движут-
ся носители заряда, называется стоком. Управляющее напряже-
ние прикладывают к третьему электроду, называемому затвором.
Структура такого транзистора со схемой подачи напряжений и
направлений тока стока изображена на рис. 4.25.
Рис. 4.25. Полевой транзистор с управляющим переходом
Принцип работы полевого транзистора с управляющим пере-
ходом основан на изменении сопротивления канала за счет изме-
нения под действием обратного напряжения ширины области
р—п-перехода, обедненной носителями заряда. Так как во входной
цепи ток практически отсутствует, в такой структуре существует
возможность усиления по мощности.
Основными преимуществами полевых транзисторов с управ-
ляющим переходом являются высокое входное сопротивление, ма-
лые шумы, простота изготовления, отсутствие в открытом состоя-
нии остаточного напряжения между стоком и истоком открытого
транзистора.
Полевые транзисторы с изолированным затвором отличаются
от полевых транзисторов с управляющим р—n-переходом тем, что
электрод затвора изолирован от полупроводниковой области ка-
нала слоем диэлектрика. Эти транзисторы имеют структуру ме-
талл — диэлектрик — полупроводник и называются кратко МДП-
154
транзисторами. Если в качестве диэлектрика используется оксид
кремния, то их называют также МОП-транзисторами.
МДП-транзисторы могут быть двух видов: с индуцированным
каналом (канал наводится под действием напряжения, приложен-
ного к затвору) и со встроенным каналом (канал создается при из-
готовлении). МДП-транзисторы с индуцированным каналом изоб-
ражены на рис. 4.26 а. Они выполнены на основе кристалличес-
кой пластинки 1 слабо легированного п-кремния, называемого
подложкой П. В толще подложки созданы две сильно легирован-
ные области 2 с противоположным типом электропроводности р
(или р+). Металлические пластинки 5 над ними с проволочными
выводами являются электродами истока И и стока С. Поверхность
кристалла между указанными областями покрыта диэлектричес-
ким слоем диоксида кремния SiO2 3, который изолирует электрод
затвора 3 от области канала. На границе областей р у истока И —
стока С образуются р—n-переходы, один из которых при любой
полярности напряжения стока оказывается включенным в обрат-
ном направлении и препятствует протеканию тока 1с.
Рис. 4.26. Структуры МДП-транзисторов:
а) с индуцированным каналом; б) со встроенным каналом
В рабочем режиме транзистора канал 4 возникает (индуциру-
ется) под воздействием соответствующего напряжения на затво-
ре. При отрицательном напряжении затвора электрическое поле
через диэлектрик проникает в глубь подложки, выталкивает из нее
электроны и притягивает дырки (обогащает приповерхностный
слой). При некотором напряжении, называемом пороговым U ,
между стоком и истоком образуется проводящий канал, имеющий
такой же тип электропроводности, как и у стока и истока.
155
Толщина канала (инверсного слоя) незначительная, дырки ин-
дуцированного канала «сжаты» в приповерхностном слое. Дырки,
образующие канал, поступают в него не только из подложки, но
также из слоев p-типа стока и истока.
В транзисторах со встроенным каналом (рис. 4.26 б) ток в цепи
стока будет протекать и при нулевом напряжении на затворе.
В зависимости от полярности напряжения на затворе канал может
обогащаться дырками (сопротивление канала падает) либо обед-
няться, вплоть до прекращения тока ([7зи отс).
Полевые транзисторы успешно применяют в различных уси-
лительных и переключающихся устройствах, их часто использу-
ют в сочетании с биполярными транзисторами.
Схемотехника РТА и ДТЛ. На рис. 4.27 представлена принци-
пиальная схема трехвходового элемента, построенного по техно-
логии резисторно-транзисторной логики. Данная технология до-
вольно широко применялась в 60-х годах XX века при производ-
стве логических элементов.
Если на вход логического элемента (например, на вход А) по-
дать напряжение высокого уровня, то от положительного полюса
источника питания через резистор R1 и через базу транзистора
потечет насыщающий ток. Транзистор будет открыт, соответствен-
но на выходе логического элемента будет действовать сигнал ло-
гического нуля. Если на все входы подать напряжение низкого
уровня (заземлить), то транзистор VI'1 не будет получать открыва-
ющего тока и поэтому закроется. Таким образом, рассмотренный
элемент реализует логическую функцию ИЛИ—НЕ. Таблица ис-
тинности для данной функции имеет вид, показанный на рис. 4.11.
Рис. 4.27. Элемент РТА
156
Следующим этапом в развитии цифровой схемотехники стало
использование диодно-транзисторной логики, когда на входе вме-
сто резисторов использовались диоды.
Рассмотрим схемотехнику трехвходового логического элемен-
та И—НЕ (рис. 4.28), построенного по технологии ДТЛ. Таблица
истинности для функции И—НЕ имеет вид, представленный на
рис. 4.10.
Транзистор VT1 закрывается дополнительным внешним напря-
жением смещения. Элемент ДТЛ DD1 можно включить, если за-
землить один из его входов. Пусть это будет, например, вход А.
Тогда диод VD1 откроется, напряжение в точке схемы S понизится
до 0,7 В (это прямое падение напряжения на кремниевом диоде).
Отрицательное напряжение переведет транзистор VT1 в режим
отсечки. На выходе Q появится напряжение высокого уровня. От-
метим, что от входа логического элемента ДТЛ в это время стекает
на землю входной ток низкого уровня.
Рис. 4.28. Элемент ДТЛ
Когда на вход А будет подано напряжение высокого уровня,
диод закроется, и поэтому входной ток высокого уровня окажется
пренебрежимо малым. На выходе Q появится выходное напряже-
ние низкого уровня, так как транзистор VT1 получит от источника
питания через диод VD4 большой открывающий ток (учтем, что UK п
существенно превышает — Ц.м). Таким образом, в схеме ДТЛ база
ключевого транзистора VT1 непосредственно не связана с источ-
157
ником сигнала. Следовательно, транзистор не принимает многие
помехи от источника питания.
В элементе ДТЛ входным запускающим током служит ток низ-
кого уровня, для такой схемы активным является входное напря-
жение низкого логического уровня. Переход к низкому запускаю-
щему уровню оказался необходимым для обслуживания источни-
ков кодовых, цифровых, командных сигналов — кнопок, переклю-
чателей и контактов реле. Замыканию их контактов на провод с
нулевым потенциалом сопутствует гораздо меньше ложных им-
пульсов запуска (так называемый дребезг контактов), чем при их
замыкании на высокий потенциал.
Заметим, что если оставить все входы неподключенными
(«в воздухе»), это будет равнозначно подаче на них сигнала, соответ-
ствующего логической единице. Если при этом заземлен хотя бы один
из входов элемента, смена логических уровней на остальных входах
не влияет на выходное напряжение.
Схемотехника ТТЛ. После перехода к широкому выпуску интег-
ральных полупроводниковых микросхем ДТЛ довольно быстро вы-
яснилось, что для улучшения электрических параметров цифровых
микросхем выгоднее заменить матрицу диодов VD1—VD3 много-
эмиттерным транзистором (рис. 4.29). Поэтому название ДТЛтранс-
формировалось в ТТЛ, т. е. транзисторно-транзисторная логика.
Элементов ТТЛ на дискретных компонентах не было, так как мно-
гоэмиттерный транзистор разработали лишь на этапе интегральной
схемотехники. Три р—п-перехода транзистора VT1 образуют мат-
рицу диодов, соответствующую диодам VD1—VD3 элемента ДТЛ.
Рис. 4.29. Эквивалентная схема элемента ТТЛ
158
Логическую функцию И в элементе ТТЛ выполняет многоэмит-
терный транзистор (рис. 4.30).
Рис. 4.30. Элемент ТТЛ
Транзистор VT2 служит в качестве простого инвертора. Если
хотя бы один вход транзистора VT1 заземлить (сигнал логического
ноля), то соответствующий переход база—эмиттер транзистора от-
кроется. Появится входной стекающий ток /вх0 от источника пи-
тания через резистор R6 и переход база—эмиттер транзистора.
Силу базового тока нормирует резистор 7?в:
В этом случае переход база—коллектор транзистора УТ/ не
может открыться, на нем не создается избыточного напряжения
0,7 В как на переходе база—эмиттер. Транзистор VT2 в результате
будет закрыт. Соответственно на выходе появится высокий потен-
циал (логическая единица).
Будем теперь считать, что на все входы логического элемента
подан высокий потенциал (единица). В этом случае все переходы
база—эмиттер транзистора VT1 будут закрыты, так как нет разно-
сти потенциалов между базой и эмиттером, поскольку эти элект-
роды подсоединены к общему источнику питания +5 В. От поло-
жительного полюса источника питания на входы поступает лишь
входной ток утечки /вх, не превышающий при нормальной темпе-
ратуре нескольких наноампер. Направление этого тока будет про-
тивоположно проводимости транзистора. Потенциал базы тран-
159
зистора VT2 близок к нолю, а переход база — коллектор транзис-
тора VT1 открыт приложенным в прямом направлении напряже-
нием источника питания. Большой по силе ток базы теперь поте-
чет через открытый переход база—коллектор транзистора VT1 и
далее через переход база—эмиттер транзистора VT2, переводя его
в режим насыщения. На выходе в этом случае появляется низкий
потенциал (сигналлогического ноля).
Рис. 4.31. Схема работы элемента ТТЛ
Таким образом, видно, что сигнал ноля на выходе может быть
только при сигналах единицы на всех входах логического элемен-
та, что соответствует операции И—НЕ (рис. 4.31).
Схемотехника ЭСЛ. Цифровые микросхемы эмиттерно-связан-
ной логики (ЭСЛ) имеют наибольшее быстродействие, достигшее
в настоящее время субнаносекундного диапазона. Особенность
ЭСЛ заключается в том, что схема логического элемента строится
на основе интегрального дифференциального усилителя (ДУ),
транзисторы которого могут переключать ток и при этом никогда
не попадают в режим насыщения.
Дифференциальным усилителем называют усилитель, предназ-
наченный для усиления разности двух входных сигналов. При этом
полученное выходное напряжение не должно зависеть от абсолют-
ного значения входных сигналов, температуры окружающей сре-
ды и других факторов:
U = (U —U ,)К,
вых ' вх1 вх2' у’
где Ку — коэффициент усиления.
160
DD1
Рис 4.32. Схема простейшего дифференциального усилительного каскада
Базовая схема дифференциального усилителя приведена на рис.
4.32. Усилитель состоит из дифференциального каскада, выполнен-
ного на транзисторах VT1 и VT2. Базы транзисторов являются вхо-
дами усилителя, а выходное напряжение снимают с одного из кол-
лекторов транзисторов VT1 и VT2 (несимметричное подключение
нагрузки) или включают нагрузку между коллекторами двух тран-
зисторов.
Сумма токов, протекающих через эмиттеры транзисторов VT1
и VT2, не зависит от входных напряжений, а определяется режи-
мом генератора стабильного тока (ГСТ):
Ъ = 7о-
где /0 — ток генератора стабильного тока.
Если входным сигналом Д17вх открыть транзистор VT1, то через
него потечет весь ток /0. На коллекторе этого транзистора окажется
напряжение низкого уровня. В этот момент через транзистор VT2
ток не течет, транзистор вынужденно находится в состоянии отсеч-
ки. На его коллекторе присутствует напряжение высокого уровня.
Будем считать, что теперь на базу транзистора VT2 подано опор-
ное напряжение [7оп. Это напряжение будет фиксировать порог
срабатывания переключателя тока. Таким образом, дифференци-
альный усилитель выполняет функции логического элемента, у
которого два состояния выходов, переключающиеся только при
условиях Ubx < Uoa и UB* > Uon. Наличие генератора стабильного тока
принципиально: с его помощью строго фиксируются логические
уровни.
Отметим существенный недостаток данной схемы — выходное
сопротивление выходов велико, что не позволяет обеспечить вы-
1 1 А-210
161
сокое быстродействие схемы. Для снижения выходного сопротив-
ления к коллекторным выходам подключают эмиттерные повтори-
тели на транзисторах VT4 и VT5. Для получения нескольких логи-
ческих входов используют один пороговый транзистор и несколь-
ко параллельно включенных входных транзисторов (рис. 4.33).
Рис. 4.33. Базовая схема двухвходового элемента ЭСЛ
Нетрудно заметить, что данная схема реализует логические опе-
рации И, ИЛИ в зависимости от используемого выхода. Действи-
тельно, при подаче на один из входов элемента напряжения высо-
кого уровня соответствующий транзистор VT2 или VT3 откроется.
Через открытый транзистор будет протекать ток, который создаст
на резисторе R3 падение напряжения отрицательной относитель-
но корпуса полярности. Это напряжение низкого уровня (— 1,6 В)
через эмиттерный повторитель передается на выход Yr Порого-
вый транзистор вынужденно перейдет в режим отсечки, поэтому
на выходе У2 будет напряжение высокого уровня (логическая еди-
ница), равное —0,98 В. При наличии на входах X, иХ2 напряжения
низкого уровня транзисторы VT2 и VT3 закроются, а состояние
выходов изменится на противоположное. Таким образом, на вы-
ходе У, реализуется операция ИЛИ—НЕ, а на выходе У2 — опера-
ция ИЛИ (табл. 4.7).
Следует отметить очень важную черту элементов ЭСЛ. Все ло-
гические уровни ЭСЛ имеют место в отрицательной области по-
тенциалов. Такие уровни непосредственно не совместимы со схе-
мами ТТЛ и КМДП, что считается большим недостатком ЭСЛ.
162
Таблица 4.7
у. Y1
00 1 0
01 0 1
10 0 1
11 0 1
Рис. 4.34.
Ключевой
каскад
Элементы ЭСЛ отличаются повышенным быстродействием в
результате использования в них принципа переключения тока и
из-за отсутствия насыщения транзисторов. Но вместе с тем они
характеризуются повышенным энергопотреблением, низкой по-
мехоустойчивостью и повышенной чувствительностью к кратков-
ременным помехам.
Схемотехника КМДП. В основе всех цифровых микросхем
КМДП находятся три логических элемента: И, ИЛИ и коммутаци-
онный ключ (КК). С помощью КК реализуются выходы с третьим
состоянием очень большого выходного импеданса
Z (практически разомкнуто). Полевые транзисторы
можно соединять последовательно («столбиком»),
поэтому элементы И, ИЛИ строят по различным схе-
мам. В отличие от ТТЛ здесь не нужно переименовы-
вать логические уровни. Для КМДП принято, чтобы
единица отображалась высоким уровнем, а ноль —
низким.
Основу таких микросхем составляет ключевой
каскад на двух соединенных стоками МДП транзи-
сторах VT1 и VT2 (рис. 4.34). Данные транзисторы
имеют каналы с различными типами проводимости:
VT1 — канал с проводимостью п-типа; VT2 — канал с проводимос-
тью p-типа. На соединенные вместе затворы подается входной сиг-
нал. Напряжение питания положительной полярности может со-
ставлять от 3 до 15 В. Напряжение низкого уровня для микросхем
КМДП равно 0,001 В, а напряжение высокого уровня практически
равно напряжению питания.
При подаче на вход напряжения низкого уровня транзистор VT1
открывается, а транзистор VT2 закрывается. Напряжение источ-
ника питания через открытый транзистор VT1 подается на выход
163
каскада — это напряжение высокого уровня. При подаче на вход
напряжения высокого уровня транзистор VT1 закрыт, а транзис-
тор VT2 открыт. На выходе устанавливается напряжение низкого
уровня. Таким образом, данный ключевой каскад реализует логи-
ческую функцию НЕ.
Следует отметить одну важную особенность КМДП-ключа и
интегральных микросхем на его основе: в статическом режиме
потребляемая от источника питания мощность меньше на несколь-
ко порядков по сравнению с мощностью самых маломощных ло-
гических элементов ТТЛ и ТТЛШ. Это объясняется тем, что в ста-
тическом режиме один из транзисторов закрыт и, следовательно,
ток через ключ не проходит.
Схема логического элемента на основе КМДП-ключа приведе-
на на рис. 4.35. Если на оба входа подать сигналы низкого уровня,
то транзисторы VT3 и VT4 будут открыты, так как имеют канал с
проводимостью p-типа, а транзисторы VT1 и VT2 — закрыты, так
как имеют канал с проводимостью н-типа. Таким образом, на вы-
ходе установится напряжение высокого уровня (логическая еди-
ница). При подаче напряжения высокого уровня хотя бы на один
из входов соответствующий транзистор VT3 или VT4 закроется, а
транзистор VT1 или VT2 соответственно откроется. На выходе ус-
тановится напряжение низкого уровня (логический ноль). Видно,
что данная схема реализует логическую функцию ИЛИ—НЕ.
Устройство базового элемента И—НЕ как бы обратно устрой-
ству элемента ИЛИ—НЕ: параллельно соединены транзисторы с
каналами p-типа, а последовательно — с каналами n-типа (рис. 4.36).
Рис 4.35. Логический элемент ИЛИ—НЕ на основе КМДП-ключа
164
Работа данной схемы абсолютно идентична работе элемента
ИЛИ—НЕ с тем исключением, что напряжение низкого уровня на
выходе устанавливается только при одновременной подаче на оба
входа элемента напряжения высокого уровня, а во всех остальных
случаях на выходе будет присутствовать напряжение высокого уров-
ня. Действительно, при одновременной подаче на входы и Х2 на-
пряжения высокого уровня транзисторы VT1 и VT2 открываются, а
транзисторы VT3 и VT4 закрываются. На выходе устанавливается
напряжение низкого уровня (логический ноль). При подаче хотя бы
на один из входов напряжения низкого уровня один из параллельно
включенных транзисторов VT3 или VT4 открывается, а соответству-
ющий ему комплементарный транзистор (VT1 или VT2) закрывает-
ся. На вход в этом случае через соответствующий открытый тран-
зистор передается напряжение источника питания. На выходе ус-
танавливается напряжение высокого уровня (логическая единица).
Рис. 4.36. Логический элемент И—НЕ на основе КМДП-ключа
Чтобы построить логический элемент с тремя состояниями, с
выходом логического элемента нужно включить последовательный
двухполярный полевой ключ коммутации (рис. 4.37).
Затворы транзисторов VT1 и VT2 управляются сигналами с про-
тивоположными фазами <!>! и Ф2. При высоком уровне сигнала и
низком уровне S2 транзисторы VT1 и VT2 закроются, и ключ ра-
зомкнется. При обратной фазе сигналов Sj и S2 ключ будет открыт.
Когда ключ закроется, выходная цепь схемы станет высокоомной,
с очень большим сопротивлением Z. Сигналы от выхода логичес-
кого элемента не смогут пройти в выходной провод. Таким обра-
зом, выходы после ключа коммутации можно непосредственно
165
подключать к общей шине данных. При этом следует соблюдать
одно правило: при соединении нескольких элементов с третьим со-
стоянием сигналы разрешения должны быть сформированы так,
чтобы для соседних каналов они не перекрывались. Для формиро-
вания сигналов S, и S2 различного уровня (с различной фазой) мож-
но использовать один источник сигнала, при этом включив в схе-
му дополнительный инвертор.
Рис. 4.37. Двухполярный ключ коммутации
4.4.3. Элементы интегральных схем
Основными элементами полупроводниковых интегральных
схем (ИС) являются биполярные и полевые транзисторные струк-
туры. В схемах, как правило, применяют планарные транзистор-
ные элементы, у которых эмиттерные, базовые и коллекторные
области выходят на одну сторону подложки. На этой же стороне
подложки, на ее поверхности, располагаются и контактные выво-
ды от этих областей.
На рис. 4.38 показан разрез кристалла фрагмента интегральной
схемы. Транзисторы размещены в одной изолированной области
1, а резисторы — в области 2. Затемненными участками на повер-
хности кристалла обозначены металлизация, контактные площад-
ки и межсоединения. Транзисторы имеют общий коллектор.
Основой для изготовления ИС служит полупроводниковая пла-
стина кремния с проводимостью p-типа, на которую наносят тон-
кий эпитаксиальный слой n-типа. В этом случае протравливают
166
канавки для разделения отдельных элементов схемы. Путем диф-
фузии в эпитаксиальный слой под канавками вводятся примеси
p-типа, вследствие чего между созданной областью p-типа и при-
мыкающими к ней участками эпитаксиального слоя п-типа обра-
зуются р — n-переходы, служащие для изоляции отдельных элемен-
тов схемы. С этой целью при работе схемы на подложку подают
наибольший отрицательный потенциал, и р—п-переходы оказыва-
ются включенными в обратном направлении, т. е. между элемен-
тами отсутствует электрическая связь.
Рис. 4.38. Поперечное сечение фрагмента микросхемы
На оставшихся участках эпитаксиального слоя л-типа создают
необходимые структуры для получения активных и пассивных эле-
ментов. Так, путем двойной диффузии может быть создана пла-
нарная п—р—л-структура с выводами от всех электродов в одной
плоскости. При образовании полупроводниковой структуры боль-
шую роль играет пленка диоксида кремния, которая предохраня-
ет поверхности от внешних воздействий. В промежуточных опе-
рациях по изготовлению полупроводниковой структуры эта плен-
ка служит экраном, предохраняющим от диффузии примесей те
участки, в которых необходимо сохранить прежний тип проводи-
мости.
В процессе изготовления полупроводниковых ИС широко ис-
пользуют метод фотолитографии, сущность которого кратко сво-
дится к следующему. Поверхность пластины покрывают слоем
167
фоторезиста — материала, чувствительного к ультрафиолетовому
облучению. Затем пластину облучают через фотомаску, имеющую
рисунок, соответствующий последующей технологической опера-
ции. Облученные участки фоторезиста после операции закрепле-
ния полимеризуются, поэтому на них не действуют травители, с
помощью которых на необлученных участках удаляют слой диок-
сида кремния с фоторезистом. В дальнейшем производится диф-
фузия примесей в протравленные «окна», покрытие слоем диок-
сида кремния и, если необходимо, снова слоем фоторезиста с пос-
ледующим облучением через новую фотомаску и т. д.
В ходе изготовления интегральной схемы обычно приходится
использовать несколько фотомасок и выполнять соответственно
несколько по существу одинаковых технологических операций.
Однако число операций здесь примерно такое же, как и при изго-
товлении дискретного планарно-эпитаксиального транзистора, а
число одновременно изготовляемых из одной пластины схем мо-
жет быть достаточно велико, поэтому стоимость производства уни-
фицированных ИС сравнима со стоимостью производства диск-
ретных транзисторов.
Соединения между элементами в полупроводниковой ИС осуще-
ствляются путем вакуумного напыления металлических (обычно алю-
миниевых) пленок с использованием методов фотолитографии.
Транзисторный элемент отличается от обычного транзистора
тем, что содержит три р—n-перехода и четыре области. Переход,
образованный коллектором и подложкой, как уже отмечалось, ис-
пользуется для изоляции элементов схемы друг от друга. Однако
из-за наличия емкостей изолирующих переходов между отдель-
ными элементами схемы существует связь по переменному току.
Повышение эффективности изоляции элементов достигается
применением в качестве изолирующих материалов диэлектриков
(например, диоксида кремния) и воздушной изоляцией, частным
случаем которой является выращивание по технологии КНС (крем-
ний на сапфире) эпитаксиальных слоев кремния на изолирующей
подложке из сапфира, имеющего примерно такую же, как и крем-
ний, структуру кристаллической решетки, а также использовани-
ем комбинированных методов изоляции (например, сочетанием
смещенных в обратном направлении р—n-переходов с диэлектри-
ческой изоляцией, реализуемым по технологии, получившей на-
звание изопланарной, и др.). При этом удается уменьшить значе-
ние разделительной емкости между элементами схемы, повысить
168
напряжение пробоя изоляции и значительно уменьшить ток утеч-
ки изоляции.
В интегральных схемах используют вертикальные и горизонталь-
ные транзисторные элементы п—р—п- и р—п—p-типа, многоэмиттер-
ные и многоколлекторные элементы, транзисторные элементы с ба-
рьером Шотки и др. Наибольшее применение в ИС находят кремни-
евые транзисторные элементы п—р-н-типа, которые обладают луч-
шими по сравнению с р—п—p-элементами усилительными и частот-
ными свойствами. Показанные на рис. 4.39 н—р—n-элементы получи-
ли название вертикальных. В них основной поток электронов, инжек-
тируемых в базу, направлен вертикально по отношению к поверхно-
сти подложки. Эти элементы могут иметь очень тонкую базу.
Однако из-за планарного расположения контактного вывода
коллектора у таких элементов увеличивается последовательное
сопротивление коллекторного слоя в горизонтальном направле-
нии, и возрастает падение напряжения на нем, что ведет к увели-
чению энергетических затрат и ухудшению характеристик и
параметров элементов. Уменьшение этого сопротивления дости-
гается введением в нижнюю часть коллекторной области скры-
того низкоомного п+-слоя, через который и протекает основная
часть коллекторного тока.
Транзисторные элементы р—п—p-типа в ИС обычно не имеют
самостоятельного значения и применяются в сочетании с п-р—п-
элементами в одной и той же схеме, обеспечивая в ряде случаев
упрощение схемы и оптимизацию ее параметров. Транзисторные
элементы в таких схемах и сами схемы называют комплементар-
ными (дополняющими).
Многоэмиттерные транзисторные элементы (см. рис. 4.39 а) от-
личаются от обычных транзисторных элементов главным образом
наличием в базе нескольких эмиттеров. Для устранения взаимно-
го влияния эмиттеров последние располагают друг от друга на рас-
стоянии, превышающем диффузную длину носителя заряда.
В качестве эмиттерного слоя многоколлекторного транзистор-
ного элемента (рис. 4.39 б) используют эпитаксиальный n-слой, а
коллекторами служат низкоомные слои n-типа. Для увеличения
коэффициента передачи тока от эмиттера к каждому коллектору
скрытый п+-слой располагают в непосредственной близости от
базового слоя (или даже в контакте с ним), а сами коллекторы,
имеющие малые размеры, размещают на минимальном расстоя-
нии друг от друга.
169
Рис. 4.39. Транзисторный элемент:
а) многоэмиттерный; б) многоколлекторный
Важное место в производстве ИС занимает вопрос повышения
их быстродействия. Одним из путей улучшения частотных и вре-
менных свойств ИС является применение транзисторных элемен-
тов в сочетании с диодами Шотки. На рис. 4.40 а схематично пока-
зано устройство транзисторного элемента с диодом Шотки, а на
рис. 4.40 б—его эквивалентное представление. Диод Шотки обра-
зован алюминиевой полоской и n-слоем коллектора, при этом кон-
такт полоски с p-слоем базы выполняется невыпрямляющим.
Э |Б AI |К
б)
Рис. 4.40. Транзисторный элемент с диодом Шотки:
а) схематичное изображение; б) эквивалентное представление
При напряжении на коллекторном переходе, соответствующем
активному режиму или режиму отсечки транзисторного элемен-
та, диод Шотки находится под напряжением обратного смещения
и не влияет на работу элемента. При смене полярности напряже-
170
ния на коллекторном переходе диод Шотки открывается раньше
коллекторного перехода и, шунтируя его, предотвращает накоп-
ление неосновных носителей заряда в базе, что повышает быстро-
действие транзисторного элемента.
Одной из особенностей ИС является использование транзис-
торных элементов в диодном включении, обусловленное тем, что
при изготовлении ИС технологически проще получить одинако-
вые транзисторные структуры, чем специально диодные.
Существует пять основных вариантов схем диодного включе-
ния транзисторных элементов, используемых в ИС и отличающих-
ся друг от друга способом соединения электродов (рис. 4.41).
Рис. 4.41. Варианты схем диодного включения транзисторных элементов
Свойства полученных таким образом диодных элементов суще-
ственно различаются. Например, наибольшее напряжение пробоя
получается в схемах, использующих переход коллектор—база, а
наименьшее — в схемах, использующих переход эмиттер—база.
Схема с разомкнутой цепью коллектора обладает наименьшей ве-
личиной нежелательной емкости между коллектором и подлож-
кой.
Из полевых транзисторных элементов (ТЭ) наиболее широко в
интегральных схемах используют полевые ТЭ с изолированным
затвором. Их применение в интегральных схемах обусловлено осо-
бенностями МОП-элементов: высоким входным сопротивлением
(-1016 Ом); отсутствием необходимости в изоляции; возможностью
использования поверхности кристалла, созданной в результате
однократной диффузии, для стоков и истоков большой группы
транзисторных элементов; возможностью применения ТЭ в каче-
стве резисторов с высоким сопротивлением вследствие особенно-
сти входной характеристики; малой потребляемой и, следователь-
но, рассеиваемой мощностью; возможностью получения высокой
плотности элементов. Привлекательной стороной МОП-элементов
является также технология их изготовления, которая проще тех-
171
нологии изготовления биполярных ТЭ и во многом сходна с тех-
нологией получения пассивных элементов.
Основной недостаток полевых ТЭ в интегральных схемах зак-
лючается в относительно малом их быстродействии, обусловлен-
ном довольно высокими значениями емкостей затвор—исток и
затвор—сток.
МОП ТЭ имеют более низкое напряжение отсечки (или поро-
говое напряжение) по сравнению с аналогичными дискретными
компонентами. Это позволяет, в частности, снизить напряжение
питания ИС на полевых ТЭ до уровня напряжения питания ИС на
биполярных ТЭ и тем самым обеспечить условия для их совмест-
ного эффективного применения.
Внешне схема устройства МОП ТЭ практически не отличается
от схемы устройства дискретного полевого компонента. На рис.
4.42 показаны варианты МОП ТЭ со встроенным n-каналом и ин-
дуцированным p-каналом соответственно. Изоляция ТЭ от других
элементов ИС осуществляется путем смещения в обратном направ-
лении р—n-перехода, образуемого подложкой с областями истока
и стока.
В настоящее время в схемах с высокой степенью интеграции
интенсивно используются комплементарные МОП-элементы
(КМОП), обладающие рядом ценных свойств: малой потребляемой
мощностью в статическом режиме, относительно высоким быст-
родействием, хорошей помехоустойчивостью, большой нагрузоч-
ной способностью и высоким уровнем интеграции.
Рис. 4.42. МОП ТЭ:
а) со встроенным n-каналом; б) с индуцированным р-каналом
172
В КМОП ИС изоляция полевых элементов достигается как пу-
тем смещения в обратном направлении р—n-переходов, образуе-
мых подложкой с областями ТЭ (рис. 4.43 а), так и с помощью диэ-
лектрика, в частности воздуха (рис. 4.43 б), когда ИС изготовляет-
ся по упоминавшейся ранее технологии КНС.
|И|3|С
а)
Сапфир
PHUMI
б)
Рис. 4.43. Изоляция в КМОП ТЭ:
а) путем смещения р—n-переходов; б) с помощью диэлектрика
Схематическое устройство полевых ТЭ с управляющим р—п-пе-
реходом показано на рис. 4.44. Транзисторный элемент с п-кана-
лом (рис. 4.44 а) имеет скрытый р+-слой, предназначенный для
снижения напряжения отсечки элемента за счет уменьшения на-
чальной толщины канала. Транзисторный элемент с р-каналом
(рис. 4.44 б) содержит два затвора — верхний 3 и нижний 3', меж-
ду которыми и расположен p-канал. Затворы могут быть соедине-
ны друг с другом, что условно показано штриховой линией.
Рис. 4.44. Устройство полевых ТЭ с управляющим р—п-переходом:
а) ТЭ с n-каналом; б) ТЭ с р-каналом
173
Технология изготовлении ТЭ с управляющим р—п-переходом
хорошо согласуется с технологией биполярных ТЭ, поэтому они
часто изготовляются совместно на одной подложке.
Среди полевых ТЭ особое место занимают МНОП ТЭ (МНОП —
металл—нитрид—окись—полупроводник), у которых диэлектрик
затвора состоит из слоев нитрида и оксида кремния (рис. 4.45 а).
Характерной особенностью МНОП ТЭ является гистерезисная
зависимость порогового напряжения от напряжения затво-
ра. На рис. 4.45 б в качестве примера показана зависимость
[7зи пор(Ц,и) •Мя одного из МНОП элементов. Из рисунка видно, что
при подведении к затвору ТЭ напряжений, больших 30 В и мень-
ших —30 В, у ТЭ устанавливаются различные пороговые напря-
жения. В качестве управляющих сигналов обычно используют
импульсы напряжения длительностью около 0,1 мс. Так, при пода-
че импульса напряжения 17зи = 30 В устанавливается пороговое
напряжение Узи = — 5 В, которое сохраняется при работе ТЭ в
режиме малых сигналов. В таком режиме МНОП-элемент ведет
себя как обычный МОП ТЭ с индуцированным p-каналом. Если
теперь подать напряжение (7зи = — 30 В, то установится другое по-
роговое напряжение Ц, = —20 В и ТЭ окажется закрытым.
б)
Рис. 4.45. МНОП ТЭ:
а) схематичное изображение; б) гистерезисная характеристика
В основе работы МНОП ТЭ лежат процессы накопления носи-
телей заряда вблизи границы между нитридным и оксидным слоя-
ми. При напряжении затвора, превышающем 25 В, через слой диэ-
лектрика протекают токи проводимости, различные по значению
и зависящие от напряжения затвора (при малых напряжениях зат-
174
вора эти токи пренебрежимо малы). Локализация и соответствен-
но накопление носителей заряда происходят в слое нитрида крем-
ния. Накопленный заряд индуцирует на поверхности подложки
заряд противоположного знака, в результате чего изменяется по-
роговое напряжение. После снятия напряжения затвора заряд в
нитриде кремния может сохраняться в течение нескольких лет. Это
обстоятельство позволяет использовать МНОП ТЭ в запоминаю-
щих устройствах с неразрушаемой энергонезависимой памятью.
При относительно большом отрицательном напряжении затво-
ра ток проводимости, протекающий через слой окиси кремния,
превышает ток, протекающий через нитрид, что приводит к на-
коплению положительного заряда в слое нитрида и увеличению
отрицательного порогового напряжения. При относительно боль-
шом положительном напряжении затвора в слое нитрида накап-
ливается отрицательный заряд, что влечет за собой уменьшение
отрицательного порогового напряжения.
Для снятия накопленного заряда достаточно приложить к зат-
вору относительно высокое напряжение обратной полярности.
Контрольные вопросы
1. Что такое алгебра логики ?
2. Назовите области применения булевой алгебры.
3. Что такое элементы булевой алгебры?
4. Назовите базовые операции булевой алгебры.
5. Какие основные законы и постулаты алгебры логики Вы знаете?
6. Дайте определение булевой функции.
7. Перечислите булевые функции двух переменных.
8. Что такое функционально полный набор?
9. Какие функционально полные системы Вы знаете?
10. Дайте определение минтерма и макстерма.
11. Как называются формы представления функций посредством су-
перпозиции их минтермов и макстермов?
12. Что такое переключательная схема?
13. В чем состоит синтез переключательной схемы по заданным ус-
ловиям ее работы?
14. Что такое таблица истинности ?
15. Для чего применяют карты Карно?
16. Назовите основные этапы синтеза вычислительных схем.
17. Что такое логический элемент компьютера ?
175
18. Какие базовые логические элементы современных вычислитель-
ный устройств Вы знаете?
19. Что такое триггер?
20. Назовите основные свойства и характеристики электронно-ды-
рочного перехода.
21. Что такое транзистор ?
22. Какие типы транзисторов Вы знаете?
23. Назовите основные типы базовых логических элементов, их пре-
имущества и недостатки.
24. Что такое транзисторный элемент?
25. Назовите основные этапы процесса изготовления полупроводни-
ковых интегральных схем.
26. Какие типы транзисторных элементов, используемых в интеграль-
ных схемах, Вы знаете?
Тлава 5
Понятие алгоритма
и алгоритмические системы
Понятие алгоритма является одним из основных понятий совре-
менной информатики. Термин алгоритм (алгорифм) происходит
от имени среднеазиатского ученого IX века аль-Хорезми, который
разработал правила выполнения четырех арифметических дей-
ствий в десятичной системе счисления.
Вплоть до 30-х годов прошлого столетия понятие алгоритма но-
сило сугубо интуитивный характер и имело скорее методологичес-
кое, чем математическое значение. Общей теории алгоритмов
фактически не существовало, а под алгоритмом понимали конеч-
ную совокупность точно сформулированных правил, которые по-
зволяли решать те или иные классы задач. Основными свойства-
ми такого «интуитивного» понятия алгоритма являются [2]:
1. Массовость алгоритма. Подразумевается, что алгоритм позво-
ляет решать не одну конкретную задачу, а некоторый класс задач
данного типа. В простейшем случае массовость обеспечивает воз-
можность изменения исходных данных в определенных пределах.
2. Детерминированность алгоритма. Процесс применения пра-
вил к исходным данным (путь решения задачи) однозначно опре-
делен.
3. Результативность алгоритма. На каждом шаге процесса при-
менения правил известно, что считать результатом этого процес-
са, а сам процесс должен прекратиться за конечное число шагов.
В течение длительного времени пока дело касалось задач, име-
ющих положительное решение, математики довольствовались
этим определением. В этом случае достаточно и интуитивного по-
нятия алгоритма, чтобы удостовериться в том, что описанный про-
цесс решения задачи есть алгоритм. Совсем другое дело, когда за-
дача или класс задач могут и не иметь решения. В этом случае тре-
буется строго формализованное понятие алгоритма, чтобы иметь
возможность доказать его отсутствие.
В 20-х годах прошлого века задача такого определения понятия
алгоритма стала одной из центральных математических проблем.
Решение ее было получено в середине 30-х годов в работах извес-
12 А-210
177
тных математиков Д. Гильберта, К. Геделя, А. Черча, С. Клини,
Э. Поста и А. Тьюринга в двух эквивалентных формулировках: на
основе особого класса арифметических функций, получивших
название рекурсивных функций (Д. Гильберт, К. Гедель, А. Черч,
С. Клини) и на основе абстрактных автоматов (Э. Пост, А. Тью-
ринг) . Впоследствии в работах А. Маркова, Л. Калужнина появи-
лось толкование теории алгоритмов, поставившее в основу опре-
деление алгоритма как особого соответствия между словами в том
или ином абстрактном алфавите.
Таким образом, первоначально теория алгоритмов возникла
в связи с внутренними потребностями теоретической математи-
ки. Математическая логика, основания математики, алгебра, гео-
метрия и анализ остаются и сегодня одной из основных областей
приложения теории алгоритмов. Кроме того, теория алгоритмов
оказалась тесно связанной и с рядом областей лингвистики, эко-
номики, физиологии мозга и психологии, философии, естествоз-
нания. Примером одной из задач этой области может служить опи-
сание алгоритмов, реализуемых человеком в процессе умственной
деятельности.
Вместе с тем в 40-х годах прошлого века в связи с созданием
электронных вычислительных и управляющих машин возникла
область теории алгоритмов, тесно взаимодействующая с инфор-
матикой. Появление ЭВМ способствовало развитию разделов этой
теории, имеющих ярко выраженную прикладную направленность.
В настоящее время положения теории алгоритмов являются тео-
ретической основой таких составных частей современной инфор-
матики, как теории программирования, построения алгоритмичес-
ких языков и ЭВМ, анализа алгоритмов с целью выбора наиболее
рационального для решения на ЭВМ, анализа алгоритмических
языков и их синтаксического контроля при разработке трансля-
торов.
В общем случае при составлении алгоритма конкретной зада-
чи актуальное значение имеет такое представление алгоритма,
которое позволяет наиболее быстро реализовать его механизи-
рованным путем, и в частности с помощью ЭВМ. При этом для
решения задачи с помощью ЭВМ ее необходимо запрограмми-
ровать, т. е. представить алгоритм решения задачи в виде после-
довательности команд, которые может выполнять машина. Одна-
ко процесс записи алгоритма в виде последовательности машин-
ных команд очень длительный и трудоемкий. Его также можно
178
автоматизировать, если использовать для записи алгоритмов ал-
горитмические языки, представляющие собой набор символов и
терминов, связанных синтаксической структурой. С их помощью
можно по определенным правилам описывать алгоритмы реше-
ния задач. Алгоритмы, записанные в алгоритмическом языке, ав-
томатически самой ЭВМ с помощью специальной программы-
транслятора могут быть переведены в машинные программы для
конкретной ЭВМ.
Наиболее важными понятиями теории алгоритмов с точки зре-
ния информатики являются: алгоритм, алгоритмические системы,
а также системы и методы алгоритмизации.
5.1. ПОНЯТИЕ АЛГОРИТМА И ЕГО СВОЙСТВА
Алгоритм — конечный набор правил или команд (указаний), по-
зволяющий исполнителю решать любую конкретную задачу из неко-
торого класса однотипных задач.
Исполнителем может быть человек, группа людей, станок, ком-
пьютер и др. С учетом особенностей исполнителя составленный
алгоритм может быть представлен различными способами: с по-
мощью графического или словесного описания, в виде таблицы,
последовательностью формул, записанных на алгоритмическом
языке (языке программирования) и др. [2].
Язык — знаковая система (множество символов и правил) любой
физической природы, выполняющая познавательную и коммуникатив-
ную (общение) функции в процессе человеческой деятельности.
Язык может быть естественным и искусственным. Естествен-
ный язык — форма выражения мыслей и средство общения меж-
ду людьми. Искусственный язык — вспомогательный, созданный
на базе естественного языка людьми для каких-либо частных це-
лей.
Первоначально для записи алгоритмов пользовались средства-
ми естественного языка.
179
Словесный алгоритм — описание последовательных этапов обра-
ботки данных на естественном языке.
Уточним понятие словесного алгоритма на примерах сложения
п
п чисел а;, а2, ап, т. е. вычисления по формуле 5 = и нахож-
/=1
дения минимального числа х в массиве из п чисел а{, а? ап,.
В первом случае процесс может быть записан в виде следую-
щей системы последовательных указаний:
1. Полагаем S равным нолю и переходим к следующему указа-
нию.
2. Полагаем i равным единице и переходим к следующему ука-
занию.
3. Полагаем S равным S+a. и переходим к следующему указа-
нию.
4. Проверяем, равно ли i числу п. Если i = п, то вычисления пре-
кращаем. Если 1 < п, то увеличиваем i на единицу и переходим
к 3-му указанию.
Процесс нахождения минимального числа х в массиве из п чи-
сел а(, а? ад, осуществляется следующим образом. Первоначаль-
но в качестве числа х принимается а;, т. е. полагаем х = а/( после
чего х сравниваем с последующими числами массива, начиная с
а2. Если х < а2, то х сравнивается с а3, если х < а3, то х сравнивается
с а4, и т. д., пока не получим число а. < х. Тогда полагаем х = а. и
продолжаем сравнение с х последующих чисел из массива, начи-
ная с ai+), и так до тех пор, пока не будут просмотрены п чисел.
В результате просмотра всех п чисел х будет иметь значение, рав-
ное наименьшему числу из массива (г — текущий номер числа из
массива). Этот процесс может быть записан в виде следующей си-
стемы последовательных указаний:
1. Полагаем i = 1 и переходим к следующему указанию.
2. Полагаем х = а. и переходим к следующему указанию.
3. Сравниваем i с п, если i < п, то переходим к следующему ука-
занию, если i = п, процесс поиска останавливаем.
4. Увеличиваем i на единицу и переходим к следующему указа-
нию.
5. Сравниваем а. с х. Если at > х, то переходим к указанию 3,
если а, < х, переходим к указанию 2.
180
Алгоритмами в современной математике принято называть кон-
структивно задаваемые соответствия между словами в абстракт-
ных алфавитах [2].
Как было отмечено выше, под абстрактным алфавитом пони-
мают любую конечную совокупность объектов, называемых бук-
вами или символами данного алфавита. При этом природа этих
объектов не имеет значения. Символом абстрактных алфавитов
можно считать, например, буквы алфавита какого-либо языка,
цифры, любые знаки, рисунки и т. п.
Алфавит, как любое множество, задается перечислением его эле-
ментов, т. е. символов. Например, А = В = {п,6,с,Т, ?},
С = /х,у/.
Слово (строка алфавита) — любая конечная упорядоченная после-
довательность символов. Число символов в слове называют длиной слова.
Так, в алфавите А словами будут любые последовательности at,
ар* afl3a4, а4а4 и т. п., в алфавите С — х, у, ху, ух, хх, уу и т. п.
При расширении алфавита, т. е. при включении в его состав но-
вых символов, понятие слова может претерпеть существенное изме-
нение. Так, в алфавите А = {0,1,2,3,4,5,6,7,8,9} выражение «15+ 68»
представляет собой два слова, соединенные знаком суммы, а в алфа-
вите А' = {+, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9} это будет одно слово.
Алфавитным оператором, или алфавитным отображением на-
зывают всякое соответствие, сопоставляющее словам некоторого ал-
фавита слова в том же или в другом фиксированном алфавите.
При этом первый алфавит называется входным, второй — вы-
ходным алфавитом данного оператора.
В случае совпадения входного и выходного алфавитов говорят,
что алфавитный оператор задан в соответствующем алфавите.
Если а — слово в алфавите А, а /3 — слово в алфавите В, то алфа-
витный оператор Га = /3 «перерабатывает» входное слово а в вы-
ходное слово ft.
Буква Г в алфавитном операторе означает отображение. Если каж-
дому входному слову алфавитный оператор ставит в соответствие не
более одного выходного слова, то такой алфавитный оператор назы-
вают однозначным, в противном случае — многозначным.
181
Алфавитный оператор, не сопоставляющий данному входному
слову а. никакого выходного слова b, не определен на этом слове.
Совокупность всех слов, на которых алфавитный оператор оп-
ределен, называется его областью определения.
Наиболее простыми являются алфавитные операторы, осуще-
ствляющие посимвольные отображения. Посимвольное отображе-
ние состоит в том, что каждый символ s входного слова а заменя-
ется некоторым символом выходного алфавита В.
Большое значение имеют так называемые кодирующие отобра-
жения [2].
Кодирующее отображение — соответствие, сопоставляющее каж-
дому символу входного алфавита некоторую конечную последователь-
ность символов в выходном алфавите, называемую кодом.
Например, если заданы входной А = {а,Ь,с,(1} и выходной
В = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9} алфавиты, а также отображение симво-
лов А символами В (рис. 5.1), то для построения искомого кодиру-
ющего отображения достаточно заменить все символы любого сло-
ва а. в алфавите А соответствующими кодами алфавита В.
/7 ь. о? 7
(4 h 7Я
и ь. 454
с /)/??
и
Рис. 5.1. Пример кодирующего отображения
Так, для слова а = bccd имеем Га = 784564560123. Полученное
таким образом слово в алфавите В называется кодом исходного
слова а.
Процесс, обратный кодированию, т. е. замена в слове jB кодов
алфавита В символами из алфавита А, называется декодировани-
ем и обозначается Г1 ft. = а..
182
Например, для слова Д = 9314567878 в алфавите В декодирова-
ние Г'р дает слово а = acbb.
Кодирование называется обратимым, если при кодировании
слова а. получаем некоторое слово Д’, а декодирование дает исход-
ное слово а, (Га, = , Г1 Д;. = а).
В приведенном выше примере обратимость имеет место.
Пусть теперь имеем А = {а, Ь, с}, В = {0,1}, Га = О, ГЪ = 1, Гс —
01 и слово aabca в алфавите А. Тогда
ГааЬса = 001010 и
Г'001010 = aababa (либо одно из слов acaba, aabca, асса), т. е. об-
ратимость отсутствует.
Для обратимости кодирования должны выполняться следующие
условия:
1. Коды разных символов исходного алфавита А должны быть
различны.
2. Код любого символа алфавита А не может совпадать ни с ка-
ким из начальных подслов кодов других символов этого алфавита.
Слово р называется подсловом слова q, если слово q можно пред-
ставить в виде q = рг, где г — любое слово, в том числе и пустое,
т. е. не содержащее ни одного символа.
Второе условие выполняется в том случае, если коды всех сим-
волов исходного алфавита А имеют одинаковую длину.
Кодирование, при котором все коды имеют одинаковую длину, на-
зывают нормальным.
Кодирование позволяет сводить изучение произвольных алфа-
витных отображений к алфавитным отображениям в некотором
стандартном алфавите. Наиболее часто в качестве стандартного
алфавита выбирается двоичный алфавит, состоящий из двух сим-
волов, которые обычно отождествляют с цифрами 0 и 1: В = {0, 1}.
При этом, если п — число символов в алфавите А, то всегда
можно выбрать длину слова 1 так, чтобы удовлетворялось усло-
вие 2’ > п.
Поскольку число различных слов длины 1 в двоичном алфавите
равно 2’, то все символы в алфавите А можно закодировать слова-
ми длины 1 в алфавите В так, чтобы коды различных букв были раз-
ными. Любое такое кодирование будет нормальным и порождает
обратимое кодирующее отображение слов в алфавите А в слова в
алфавите В.
183
В общем случае к алгоритму сводятся любые процессы преоб-
разования информации, поэтому теория любых преобразователей
информации фактически сводится к изучению алфавитных опе-
раторов.
Наиболее явно это выражено при преобразовании лексической
или числовой информации. В этом случае как входная, так и вы-
ходная информация может быть представлена в виде слов, а пре-
образование информации сводится к установлению некоторого
соответствия между словами. Например, при переводе текстов
с одного языка на другой можно считать словами предложения или
отдельные абзацы книги, а задача перевода полностью сводится к
задаче установления соответствия между такими обобщенными
словами, т. е. процесс перевода с одного языка на другой может
трактоваться как процесс реализации некоторого алфавитного
оператора. При этом качественный и грамотный перевод допус-
кает, как известно, возможность известных модификаций пере-
водного текста, поэтому процесс перевода описывается не обыч-
ным однозначным алфавитным оператором, а многозначным.
Основой теории алфавитных операторов являются способы их
задания [2].
В случае если область определения алфавитного оператора ко-
нечна, оператор может быть задан простой таблицей соответствия,
связывающей все слова, входящие в область определения рассмат-
риваемого оператора (входные слова), и выходные слова, получа-
ющиеся в результате применения оператора к каждому входному
слову.
В случае бесконечной области определения алфавитного опе-
ратора задание его с помощью таблицы принципиально невозмож-
но. В этом случае оператор задается системой правил, позволяю-
щей за конечное число шагов найти выходное слово, соответству-
ющее любому наперед заданному входному слову из области оп-
ределения рассматриваемого алфавитного оператора.
Алфавитные операторы, задаваемые с помощью конечной системы
правил, называют алгоритмами.
Таким образом, всякий алфавитный оператор, который можно
фактически задать, обязательно является алгоритмом.
Однако между понятиями алфавитного оператора и алгорит-
ма существует различие. Так, в понятии алфавитного оператора
184
существенно лишь само соответствие, устанавливаемое между
входными и выходными словами, а не способ, которым это соот-
ветствие устанавливается. В понятии алгоритма, наоборот, основ-
ным является способ задания соответствия, устанавливаемого ал-
горитмом.
Алгоритм — алфавитный оператор вместе с правилами, определя-
ющими его действие.
Два алфавитных оператора считаются равными, если они име-
ют одну и ту же область определения и сопоставляют любому на-
перед заданному входному слову из этой области одинаковые вы-
ходные слова.
Два алгоритма считаются равными, если равны соответствую-
щие им алфавитные операторы и совпадает система правил, зада-
ющих действие этих алгоритмов на выходные слова.
Два алгоритма считаются эквивалентными, если у них совпада-
ют алфавитные операторы, но не совпадают способы их задания
(система правил).
Из свойства алгоритма результативности вытекает понятие об-
ласти применимости алгоритма под которой понимается множе-
ство строк, для которых алгоритм результативен.
Таким образом, эквивалентность алгоритмов может быть опре-
делена следующим образом: два алгоритма эквивалентны, если
совпадают их области применимости и результаты переработки
любого слова из этой области.
В общем случае различают случайные и самоизменяющиеся
алгоритмы [2]. Алгоритм называется случайным, если в системе
правил, описывающих алгоритм, предусматривается возможность
случайного выбора тех или иных слов или тех или иных правил.
Им соответствуют многозначные алфавитные операторы.
Алгоритм называется самоизменяющимся, если он не только
перерабатывает входные слова, но и сам изменяется в процессе
такой переработки. Результат действия самоизменяющегося алго-
ритма на то или иное входное слово зависит не только от этого сло-
ва, но и от истории предыдущей работы алгоритма.
В теории алгоритмов большое внимание уделяется общим спо-
собам задания алгоритмов, характеризующимся свойством универ-
сальности, т. е. таким способам, которые позволяют задать алго-
185
В общем случае к алгоритму сводятся любые процессы преоб-
разования информации, поэтому теория любых преобразователей
информации фактически сводится к изучению алфавитных опе-
раторов.
Наиболее явно это выражено при преобразовании лексической
или числовой информации. В этом случае как входная, так и вы-
ходная информация может быть представлена в виде слов, а пре-
образование информации сводится к установлению некоторого
соответствия между словами. Например, при переводе текстов
с одного языка на другой можно считать словами предложения или
отдельные абзацы книги, а задача перевода полностью сводится к
задаче установления соответствия между такими обобщенными
словами, т. е. процесс перевода с одного языка на другой может
трактоваться как процесс реализации некоторого алфавитного
оператора. При этом качественный и грамотный перевод допус-
кает, как известно, возможность известных модификаций пере-
водного текста, поэтому процесс перевода описывается не обыч-
ным однозначным алфавитным оператором, а многозначным.
Основой теории алфавитных операторов являются способы их
задания [2].
В случае если область определения алфавитного оператора ко-
нечна, оператор может быть задан простой таблицей соответствия,
связывающей все слова, входящие в область определения рассмат-
риваемого оператора (входные слова), и выходные слова, получа-
ющиеся в результате применения оператора к каждому входному
слову.
В случае бесконечной области определения алфавитного опе-
ратора задание его с помощью таблицы принципиально невозмож-
но. В этом случае оператор задается системой правил, позволяю-
щей за конечное число шагов найти выходное слово, соответству-
ющее любому наперед заданному входному слову из области оп-
ределения рассматриваемого алфавитного оператора.
Алфавитные операторы, задаваемые с помощью конечной системы
правил, называют алгоритмами.
Таким образом, всякий алфавитный оператор, который можно
фактически задать, обязательно является алгоритмом.
Однако между понятиями алфавитного оператора и алгорит-
ма существует различие. Так, в понятии алфавитного оператора
184
существенно лишь само соответствие, устанавливаемое между
входными и выходными словами, а не способ, которым это соот-
ветствие устанавливается. В понятии алгоритма, наоборот, основ-
ным является способ задания соответствия, устанавливаемого ал-
горитмом.
Алгоритм — алфавитный оператор вместе с правилами, определя-
ющими его действие.
Два алфавитных оператора считаются равными, если они име-
ют одну и ту же область определения и сопоставляют любому на-
перед заданному входному слову из этой области одинаковые вы-
ходные слова.
Два алгоритма считаются равными, если равны соответствую-
щие им алфавитные операторы и совпадает система правил, зада-
ющих действие этих алгоритмов на выходные слова.
Два алгоритма считаются эквивалентными, если у них совпада-
ют алфавитные операторы, но не совпадают способы их задания
(система правил).
Из свойства алгоритма результативности вытекает понятие об-
ласти применимости алгоритма под которой понимается множе-
ство строк, для которых алгоритм результативен.
Таким образом, эквивалентность алгоритмов может быть опре-
делена следующим образом: два алгоритма эквивалентны, если
совпадают их области применимости и результаты переработки
любого слова из этой области.
В общем случае различают случайные и самоизменяющиеся
алгоритмы [2]. Алгоритм называется случайным, если в системе
правил, описывающих алгоритм, предусматривается возможность
случайного выбора тех или иных слов или тех или иных правил.
Им соответствуют многозначные алфавитные операторы.
Алгоритм называется самоизменяющимся, если он не только
перерабатывает входные слова, но и сам изменяется в процессе
такой переработки. Результат действия самоизменяющегося алго-
ритма на то или иное входное слово зависит не только от этого сло-
ва, но и от истории предыдущей работы алгоритма.
В теории алгоритмов большое внимание уделяется общим спо-
собам задания алгоритмов, характеризующимся свойством универ-
сальности, т. е. таким способам, которые позволяют задать алго-
185
Используя данные функции в качестве исходных, путем при-
менения простых операций суперпозиции, примитивной рекурсии
и минимизации можно получить любую сколь угодно сложную
числовую функцию.
Операция суперпозиции функций заключается в подстановке
одних арифметических функций вместо аргументов других ариф-
метических функций.
Операция примитивной рекурсии позволяет строить функцию
от п + 1 аргумента по двум заданным функциям — функции п-го
аргумента и (п + 2)-го аргумента.
Функции, которые могут быть построены из элементарных
арифметических функций с помощью операций суперпозиции и
примитивной рекурсии, примененных любое конечное число раз
в произвольной последовательности, называются примитивно ре-
курсивными функциями.
Операции суперпозиции и примитивной рекурсии, будучи при-
менены ко всюду определенным функциям, дают в результате сно-
ва всюду определенные функции.
Большинство арифметических функций относятся к примитив-
но рекурсивным. Тем не менее примитивно рекурсивные функ-
ции не охватывают всех арифметических функций, которые мо-
гут быть определены конструктивно. При построении всех этих
функций используются другие операции, в частности операция
минимизации.
Операция минимизации позволяет определить новую арифме-
тическую функцию f(x, ..., xj от п переменных с помощью ранее
построенной арифметической функции g(xt,..., хп, у) от n + 1 пере-
менных. При этом оператор минимизации р определяется следу-
ющим образом.
Пусть (n+ 1) переменных функции g имеют неотрицательные
целые значения, тогда py(g(xI,x2,...,xn,y) = 0) образует наимень-
шее неотрицательное целое значение у, для которого
g(xl,x2,...,xn,y) = 0, при всех фиксированных значенияхх^х^...^.
Если у существует, то частичная функция f от п переменных мо-
жет быть определена из выражения g с помощью оператора ц:
/(xj, х2.хп) = ру (g(x,, х2.хп, у) = 0), в противном случаеf/x/,x2,...,xj
неопределима.
Например, для/(х) - ду(|2у-х| = 0) имеем Дх) = х/2 при всех
четных значениях х.
188
Арифметические функции, которые могут быть построены из
элементарных арифметических функций с помощью операций
суперпозиции, примитивной рекурсии и минимизации, называют-
ся частично рекурсивными функциями.
Частично рекурсивные функции представляют собой наиболее
общий класс конструктивно определяемых арифметических фун-
кций, а понятие частично рекурсивной функции является одним
из главных понятий теории алгоритмов.
Таким образом, каждая заданная частично рекурсивная функ-
ция вычислима путем определенной процедуры механического
характера, и наоборот, числовые функции, вычислимые посред-
ством алгоритмов, являются частично рекурсивными. В соответ-
ствии с тезисом Черча: класс алгоритмически (или машинно) вы-
числимых частичных числовых функций совпадает с классом всех
частично рекурсивных функций.
Этот тезис дает алгоритмическое толкование понятию частич-
но рекурсивных функций. Практически понятие частично рекур-
сивных функций используют для доказательства алгоритмической
разрешимости или неразрешимости проблем. Использование же
частично рекурсивных функций для представления того или ино-
го конкретного алгоритма практически нецелесообразно ввиду
сложности такого процесса алгоритмизации.
5.3. МАШИНЫ ТЬЮРИНГА
В 1936—1937 гг. независимо друг от друга и почти одновременно
с работами А.Черча и С. Клини было дано определение понятия ал-
горитма американским и английским математиками Э. Постом
и А.Тьюрингом. Их подход базируется на определении специальных
абстрактных (т. е. существующих не реально, а лишь в воображе-
нии) автоматов (машин). Основная мысль при этом заключалась
в том, что алгоритмические процессы — это процессы, которые мо-
жет совершать подходяще устроенная «машина». В соответствии
с этим ими с помощью точных математических терминов были описа-
ны классы машин, способные осуществить или имитировать все алго-
ритмические процессы, когда-либо описываемые математиками [2].
Машины, введенные Постом и Тьюрингом, отличались не очень
существенно и в дальнейшем стали называться машинами Тьюринга.
189
В общем случае такая машина состоит из следующих частей
(рис. 5.2):
1) информационной ленты, представляющей собой бесконеч-
ную (неограниченную) память машины. В качестве информацион-
ной ленты может служить магнитная или бумажная бесконечная
лента, разделенная на отдельные ячейки. В каждой ячейке можно
поместить лишь один символ, в том числе и ноль;
2) «считывающей головки» — специального чувствительного
элемента, способного обозревать содержимое ячеек. Вдоль голов-
ки информационная лента перемещается в обе стороны так, что-
бы в каждый рассматриваемый момент времени головка находи-
лась в одной определенной ячейке ленты;
3) управляющего устройства, которое в каждый рассматривае-
мый момент находится в некотором «состоянии». Предполагает-
ся, что устройство управления машины может находиться в неко-
тором конечном числе состояний. Состояние устройства управле-
ния часто называют внутренним состоянием машины. Одно из этих
состояний называется заключительным и управляет окончанием
работы машины.
Рис. 5.2. Состав машины Тьюринга
Рассмотрим алгоритмическую систему, предложенную Постом [2].
В алгоритмической системе Поста информация представляет-
ся в двоичном алфавите А = {1,0}. То есть в каждой ячейке инфор-
мационной ленты можно поместить либо 0, либо 1. Алгоритм пред-
ставляется в виде конечного упорядоченного набора правил, на-
зываемых приказами. Работа алгоритма начинается с некоторой
начальной ячейки, соответствующей первому приказу алгоритма.
Составляющие алгоритм приказы могут принадлежать к одному
190
из 6 приказов, выполняемых устройством управления машины
Поста:
1. Записать в рассматриваемую ячейку 1 и перейти к i-му при-
казу.
2. Записать в рассматриваемую ячейку 0 и перейти к i -му при-
казу.
3. Сдвинуть ленту вправо на одну ячейку и приступить к выпол-
нению i -го приказа.
4. Сдвинуть ленту влево на одну ячейку и перейти к выполне-
нию I -го приказа.
5. Если в рассматриваемой ячейке записана 1, то перейти к вы-
полнению j-ro приказа, а если записан 0, то перейти к выполне-
нию i -го приказа.
6. Окончание работы алгоритма, остановка.
Алгоритмы, составленные из любого конечного числа правил,
представленных приказами машины Поста, называются алгорит-
мами Поста.
Алгоритмы Поста сводятся к алгоритмам, реализуемым с помо-
щью частично рекурсивных функций, и наоборот, любая частич-
но рекурсивная функция может быть представлена алгоритмом
системы Поста.
В отличие от машины Поста машина Тьюринга может работать
в произвольном конечном алфавите и выполнять некоторое конеч-
ное число приказов. При этом машины Тьюринга, как и машины
Поста, могут сдвигать ленту на одну ячейку вправо или влево, ос-
тавляя содержимое ячеек неизменным, или могут изменять состо-
яние воспринимаемой ячейки, оставляя ленту неподвижной [2].
Машина Тьюринга называется стандартной, если она при сдвиге
ленты может предварительно изменять состояние воспринимае-
мой ячейки.
Пусть алфавит машины Тьюринга задан в виде множества А =
{So S;,..., Sгде So соответствует пустой ячейке, а число состояний
устройства управления задано в виде множества Q — {qtf qt, ..., qj,
где q0 соответствует заключительному состоянию.
Конечную совокупность символов алфавита, с которой работа-
ет машина, называют внешним алфавитом, конечную совокуп-
ность состояний устройства управления —внутренним алфави-
том.
Совокупность, образованную последовательностью состояний
всех ячеек ленты и состоянием устройства управления, называют
191
конфигурацией машины. Конфигурация задается в виде слова,
описывающего конкретное состояние машины.
Пусть в некоторый момент времени машина Тьюринга находит-
ся в состоянии, представленном на рис. 5.3.
Внешний
алфавит
Внутренний
алфавит
S
1 2
Рис. 5.3. Состояние машины Тьюринга
Конфигурация машины для данного случая будет представлена
в виде слова:
...S„S,S,...qS.k...S.Sn...,
О jl j2 ]к jr 0 '
где So — символ, обозначающий пустую ячейку;
г — число заполненных ячеек на ленте;
Sjt — состояние первой слева непустой ячейки;
Sk — состояние ячейки, просматриваемой в данный момент вре-
мени;
qt — состояние устройства управления.
Каждая конфигурация содержит лишь одно вхождение симво-
ла ф из внутреннего алфавита. Этот символ может быть в слове
самым левым, но не может быть самым правым, так как справа от
него должен помещаться символ состояния обозреваемой ячейки.
Если стандартная машина Тьюринга, находясь в состоянии q. и
воспринимая записанный на ленте символ Sk, переходит в новое
состояние q^ осуществляя при этом замену символа в рассматри-
ваемой ячейке на символ Sm и сдвиг ленты влево на одну ячейку, то
говорят, что машина выполняет команду qSk —>qSmA.
При манипуляциях с лентами используют следующие обозна-
чения:
Л — движение ленты влево;
П— движение ленты вправо;
С — нет движения ленты.
192
Команды стандартной машины Тьюринга могут задаваться на-
бором пятерок символов вида qsk qsmA, т. е. стрелка опускается.
Рассмотрим пример машины Тьюринга с алфавитами А = {0, 1},
Q = {qg qt} и командами qtl qt 1Л, qfi qg 1С.
Пусть на ленте имеется слово 11100. Головка стоит над первой
слева единицей (рис. 5.4). В результате работы машины Тьюринга
за 4 шага это слово превращается в 11110. По окончании работы
машины головка стоит над крайней правой единицей. Можно ска-
зать, что данная машина выполнила сложение в двоичной системе
десятичных чисел 28 + 2.
№ Конфигурация Исполняемые
шага команды (программа)
1 1 4- 1 0 0 <у,11100 <Т,Ч1Л
1 1 1 1 г 0 0 1g, 1100 <7,Ч1Л
2 1 1 1 0 4 0 11g, 100 д,1д,1Л
3 1 1 1 0 4 0 Illg,00 <?;Одо1С
4 1 1 1 1 0 Illg,10
а) б) в)
Рис. 5.4. Алгоритм работы машины Тьюринга
по переработке слова «11100» в слово «11110»
Совокупность всех команд, которые может выполнять маши-
на, называется ее программой [2].
Машина Тьюринга считается заданной, если заданы:
ее внешний и внутренний алфавиты;
программа;
• начальная конфигурация;
символы обозначающие пустую ячейку и заключительное
состояние.
13 А 210
193
Пусть машина Тьюринга задана внешним алфавитом А = {0, а,
Ь, с, d}, внутренним алфавитом Q = {g# q, q? q3, q4, qj и совокуп-
ностью команд:
<?oaqr;aA qobqobA, q2aqsdll, qocqocA, q,dq2cn, q3aq4dn, q4dq2cll.
Пустую ячейку обозначает символ S°, а заключительное состо-
яние — q5.
На рис. 5.5 представлен процесс переработки машиной Тьюрин-
га исходного слова bcadc в слово bcdcc. Начальная конфигурация
имеет вид qgbcadc.
№ шага Конфигурация Исполняемые команды (программа)
bqQcadc (<70b<70M)
1 bcqoadc (qocqocA)
2 bcaqtdc (qoaqtaA)
3 bcq2acc (4i<iq2cn)
4 bq5cdcc (q2aq5dn)
Рис. 5.5. Алгоритм работы машины Тьюринга
по переработке слова «bcadc» в слово «bcdcc»
Программа рассмотренной машины Тьюринга может быть пред-
ставлена в виде таблицы соответствия:
Q A S° a b c d
9» 9,аЛ qobJl qocA
- - - - 92M
92 - 954П - - -
- — - —
<?4 - - - <726П
9s Останов
Машины Тьюринга представляют собой универсальных испол-
нителей, с использованием которых можно имитировать все алго-
ритмические процессы, описываемые математиками. Было дока-
зано, что класс функций, вычислимых на этих машинах, точно со-
впадает с классом всех частично рекурсивных функций.
194
Таким образом, вопрос о существовании или несуществовании
алгоритма для задачи того или иного типа следует понимать как
вопрос о существовании или несуществовании машины Тьюрин-
га, обладающей нужным свойством.
В зависимости от числа используемых лент, их назначения и
числа состояний устройства управления определяются различные
модификации машин Тьюринга, например машина Тьюринга с дву-
мя выходами, многоленточная машина Тьюринга. При этом различ-
ные алгоритмы осуществляются на различных машинах Тьюринга,
отличающихся набором команд, внутренним и внешним алфавита-
ми. Но можно построить и универсальную машину Тьюринга, спо-
собную в известном смысле выполнять любой алгоритм [2].
В универсальной машине Тьюринга, как и во всякой тьюринго-
вой машине, информация изображается символами, расположен-
ными одновременно на магнитной ленте. При этом универсальная
машина Тьюринга может располагать лишь фиксированным ко-
нечным внешним алфавитом. Между тем она должна быть приспо-
соблена к приему в качестве исходной информации всевозмож-
ных состояний устройства управления и конфигураций, в которых
могут встречаться символы из разнообразных алфавитов со сколь
угодно большим числом различных символов.
Это достигается путем кодирования конфигурации и програм-
мы любой данной машины Тьюринга в символах входного (внеш-
него) алфавита универсальной машины. Само кодирование долж-
но выполняться следующим образом:
1) различные символы должны заменяться различными кодо-
выми группами, но один и тот же символ должен заменяться всю-
ду, где бы он ни встречался, одной и той же кодовой группой;
2) строки кодовых записей должны однозначным образом раз-
биваться на отдельные кодовые группы;
3) должна иметь место возможность распознать, какие кодовые
группы соответствуют различным сдвигам, т. е. каждой из букв Л,
П, Св отдельности, и различать кодовые группы, соответствующие
символам внутреннего алфавита и символам внешнего алфавита.
Рассмотрим пример такого кодирования для машины Тьюрин-
га Т, имеющей внешний алфавит А = fs(, s?..., sk} и внутренний ал-
фавит Q = {qt, q?..., qj.
Если внешний алфавит универсальной машины Тьюринга со-
стоит из символов А = {0, 1}, то эти условия будут выполнены при
следующем способе кодирования.
195
1. В качестве кодовых групп используются 3 + к + т различных
слов вида 100 ... 01 (между единицами — ноли), где к — число сим-
волов внешнего алфавита; т — число состояний устройства уп-
равления.
При этом разбивка строк на кодовые группы производится од-
нозначным образом путем выделения последовательностей нолей,
заключенных между двумя единицами.
2. Сопоставление кодовых групп с исходными символами внеш-
него и внутреннего алфавитов осуществляется согласно следую-
щей таблице кодирования:
Буква Кодовая группа
Л 101
п 1001
с 10001
(5, 100001 - 4 ноля
Внешний 10000001-6 нолей Четное
алфавит 2 число нолей,
больше
к 10...01 - 2(к +1) нолей) чем 2
1000001-5 нолей 1 Нечетное
Внутренний д 100000001 - 7 нолей числ0 нолей-
алфавит больше
(состояния) чем 3
flm 10...01 - 2(т +1) + 1нолей
Так, для машины Тьюринга, перерабатывающей слово bcadc в
слово bcdcc (см. рис. 5.5), входное слово в универсальной машине
Тьюринга с данным кодом будет представлено следующей строкой:
1000000110000000011000011000000000011000000001,
где 100001 — а, 10000001 — Ь, 1000000001 — с, 100000000001 — d.
Вся программа будет иметь вид:
(qobqobJl) 1000001 10000001 1000001 10000001 101
{qocqocJT) 1000001 1000000001 1000001 1000000001 101
(qoaqiaJI) 1000001 100001 100000001 100001 101
(qid2q2cll) 100000001 100000000001 10000000001 1000000001 10001
(q2aq5dFI) 10000000001 100001 100000000000001 100000000001 10001
196
Таким образом, если какая-либо машина Тьюринга Тп решает
некоторую задачу, то и универсальная машина Тьюринга Та спо-
собна решить эту задачу при условии, что кроме кодов исходных
данных этой задачи на ее ленту будет подан код программы маши-
ны Тп. Задавая универсальной машине Тьюринга Тц изображение
программы любой данной машины Тьюринга Тп и изображение
любого ее входного слова Хп, получим изображение выходного
слова Уп, в которое машина Тц переводит слово Хп.
Если же алгоритм, реализуемый машиной Тп, неприменим к сло-
ву Хп, то алгоритм, реализуемый универсальной машиной Ти так-
же неприменим к слову, образованному из изображения Хп и про-
граммы машины Тп.
Таким образом, машина Тьюринга Тп может рассматриваться
как одна из программ для универсальной машины Т.
При изучении моделей вычислений обычно проводят различие
между детерминированными и недетерминированными машинами
Тьюринга. В детерминированной машине Тьюринга общий ход вы-
числений полностью определяется машиной Тьюринга (программой),
начальным символом и начальными вводами с ленты. В недетерми-
нированной машине Тьюринга на каждой стадии вычислений суще-
ствуют альтернативы, т. е. она может работать в одном из несколь-
ких основных режимов. При этом класс задач, решаемых на детер-
минированных машинах Тьюринга за полиноминальное время, назы-
вают классом Р, а класс задач, решаемых на недертеминированных
машинах Тьюринга за полиноминальное время, — классом NP [2].
Современные электронные вычислительные машины строятся
как универсальные: в запоминающее устройство наряду с исход-
ными данными поставленной задачи вводится также и программа
ее решения. Однако в отличие от машины Тьюринга, в которой
внешняя память (лента) бесконечна, в любой реальной вычисли-
тельной машине она конечна.
Для сравнения структур различных машин и оценки их слож-
ности используют произведение числа символов внешнего алфа-
вита на число внутренних состояний, отличных от заключитель-
ного. В этом смысле представляет интерес задача построения уни-
версальных машин Тьюринга минимальной сложности. Здесь не-
обходимо отметить теоремы Ватанабе о существовании универ-
сальной машины с 5 символами и 6 состояниями, Минского о су-
ществовании машины с 4 символами и 7 состояниями и теорему
Триггера о существовании универсальной машины с 4 символами
и 6 состояниями.
197
5.4. НОРМАЛЬНЫЕ АЛГОРИТМЫ МАРКОВА
Как было отмечено выше, всякий общий способ задания алго-
ритмов называется алгоритмической системой. Алгоритмическая
система, основанная на соответствии между словами в абстракт-
ном алфавите, включает в себя объекты двух типов: элементарные
операторы и элементарные распознаватели [2].
Элементарные операторы представляют собой алфавитные
операторы, предназначенные для реализации алгоритмов в рас-
сматриваемой алгоритмической системе.
Элементарные распознаватели служат для распознавания на-
личия тех или иных свойств перерабатываемой алгоритмом инфор-
мации и для изменения, в зависимости от результатов распознава-
ния, порядка следования элементарных операторов.
Для указания набора элементарных операторов и порядка их
следования при задании конкретного алгоритма используют ори-
ентированные графы, называемые граф-схемами соответствую-
щих алгоритмов.
Граф-схема алгоритма представляет собой конечное множество
соединенных между собой вершин (или геометрических фигур),
называемых узлами граф-схемы. Каждому узлу, кроме особых уз-
лов, называемых входом и выходом, сопоставляется какой-либо
элементарный оператор (ЭО) или элементарный распознаватель
(ЭР). При этом из каждого узла, которому сопоставлен оператор, а
также из входного узла исходит по одной дуге, а из каждого узла,
которому сопоставлен распознаватель, исходит по две дуги. Из
выходного узла не исходит ни одной дуги. Число дуг, входящих
в узел граф-схемы, может быть любым.
Вариант такой граф-схемы представлен на рис. 5.6. Алгоритм,
определенный граф-схемой, работает следующим образом. Вход-
ное слово поступает на вход и двигается по направлениям, указан-
ным стрелками. При попадании слова в распознавательный узел
осуществляется проверка условия, сопоставленного этому узлу.
При выполнении условия слово направляется в операторный узел,
при невыполнении — к следующему распознавателю.
Если входное слово р, поданное на вход граф-схемы, проходя
через узлы схемы и преобразуясь, попадает через конечное число
шагов на выход, то считается, что алгоритм применим к слову р
(слово р входит в область определения этого алгоритма). Результа-
те
том воздействия на слово р будет то слово, которое оказывается на
выходе схемы. Если после подачи слова р на вход графа его преоб-
разование и движение по граф-схеме продолжается бесконечно
долго, не приводя на выход, считается, что алгоритм неприменим
к слову р, т. е. слово р не входит в область определения алгоритма.
Рис. 5.6. Вариант граф-схемы алгоритма
В нормальных алгоритмах в качестве элементарного оператора
используют оператор подстановки (ОП), а в качестве элементар-
ного распознавателя — распознаватель вхождения (РВ).
Распознаватель вхождения проверяет условие — имеет ли мес-
то вхождение рассматриваемого слова р{ в качестве подслова не-
которого заданного слова q.
Оператор подстановки заменяет первое слева вхождение слова
Р] в слово q на некоторое заданное слово р2. Оператор подстановки
задается обычно в виде двух слов, соединенных стрелкой р1—> р2.
Например, для слова 01230123применение подстановок 01—>32
и 23—>10 через четыре шага приводит к слову 32103210 (рис. 5.7):
01230123—>32230123—>32233223—>32103223—>32103210.
Последовательность слов pt, р?.рп, получаемых в процессе
реализации алгоритма, называется дедуктивной цепочкой, веду-
щей от слова pt к слову рп
Алгоритмы, которые задаются графами, составленными только
из распознавателей вхождения слов и операторов подстановки,
199
называют обобщенными нормальными алгоритмами. При этом
предполагается, что к каждому оператору подстановки ведет толь-
ко одна дуга, исходящая из соответствующего распознавателя.
ОП,
«01—>32»
оп2
«23—>10»
Рис. 5.7. Граф-схема алгоритма преобразования
входного слова «01230123» в слово «32103210»
Нормальными алгоритмами называют обобщенные нормаль-
ные алгоритмы, граф-схемы которых удовлетворяют следующим
условиям [2]:
1. Все узлы, соответствующие распознавателям, упорядочива-
ются путем их нумерации от 1 до п.
2. Дуги, исходящие из узлов, соответствующих операторам под-
становки, подсоединяются либо к узлу, соответствующему перво-
му распознавателю, либо к выходному узлу. В первом случае под-
становка называется обычной, во втором — заключительной.
3. Входной узел подсоединяется дугой к первому распознавателю.
Нормальные алгоритмы принято задавать упорядоченным мно-
жеством подстановок всех операторов данного алгоритма, назы-
ваемым схемой алгоритма. При этом обычные подстановки запи-
сываются, как и в обобщенных алгоритмах, в виде двух слов, со-
единенных стрелкой (pt—>р2), а заключительные подстановки обо-
значаются стрелкой с точкой (р:—> р2). Процесс выполнения под-
становок заканчивается лишь тогда, когда ни одна из подстановок
схемы не применима к полученному слову или когда выполнена
(первый раз) какая-либо заключительная подстановка.
Вариант граф-схемы нормального алгоритма в общем виде пред-
ставлен на рис. 5.8.
200
Рис. 5.8. Вариант граф-схемы нормального алгоритма
В качестве примера рассмотрим работу нормального алгорит-
ма А.А. Маркова, алфавит которого представлен алфавитом рус-
ского языка и задано множество подстановок:
1. Б—>В 4. 0->Х
2. Л->У 5. В->Я
3. С^М 6. Н—>А
Тогда, если на вход подать слово «СЛОН», то оно переработает-
ся алгоритмом в выходное слово «МУХА» (рис. 5.9):
«СЛОН» -»«СУОН» ->«МУОН» -^«МУХН» —>«МУХА».
На рис. 5.10 представлена граф-схема нормального алгоритма
А.А. Маркова, реализующего сложение единиц в непозиционной
системе счисления при заданном алфавите А = {+, 1} и системе
подстановок «1 + 1»—>' 1 Г, «1»—>•’ Г. При подаче на вход строки
’ 11 + 11 + Г она перерабатывается алгоритмом в строку «11 + 11
+ 1»—>'1111 +Г—>' 1111 Г—>'11И Г.
Наличие в нормальных алгоритмах подстановок двух видов —
заключительной и обычной — необходимое условие универсаль-
ности нормальных алгоритмов, т. е. возможности построения нор-
мального алгоритма, эквивалентного любому наперед заданному
алгоритму.
201
Новые алгоритмы могут быть построены из уже известных ал-
горитмов путем суперпозиции, объединения, разветвления алго-
ритмов и повторения (итерации).
В теории алгоритмов строго доказано, что по своим возможно-
стям преобразования нормальные алгоритмы эквивалентны маши-
не Тьюринга и другим моделям, уточняющим понятие алгоритма.
Рис. 5.9. Граф-схема алгоритма
преобразования входного
слова «СЛОН» в слово «МУХА»
Рис. 5.10. Граф-схема алгоритма
преобразования входного
слова «11 + 11 + 1» в слово «11111»
5.5. ОПЕРАТОРНЫЕ СИСТЕМЫ АЛГОРИТМИЗАЦИИ
Одной из особенностей рассмотренных выше алгоритмических
систем является неизменность набора допустимых средств, исполь-
зуемых для построения записи алгоритма. Например, все частич-
202
но рекурсивные функции получаются из некоторого фиксирован-
ного набора базисных функций с помощью трех операторов —
подстановки, примитивной рекурсии, минимизации. Элементар-
ные акты при вычислениях на машине Тьюринга ограничиваются
фиксированным набором операций, которые выполняет описыва-
емый класс машин и т. п.
В то же время при изучении конкретных алгоритмов желатель-
но, чтобы каждый алгоритм мог изучаться в терминах тех элемен-
тарных средств, которые наиболее удобны для его описания. На-
пример, алгоритмы линейной алгебры удобнее всего описывать
с помощью четырех арифметических действий, а алгоритмы вы-
числения функций алгебры логики — с помощью тех базисных ло-
гических операций, в терминах которых функции и записаны. По-
этому одним из требований, которое предъявляется к определе-
нию алгоритма при его практическом использовании, является то,
чтобы форма представления перерабатываемой информации и
средства ее переработки выбирались в зависимости от класса рас-
сматриваемых алгоритмов [2].
Кроме того, для классических алгоритмических систем харак-
терно, что в каждом алгоритме список предписаний о выполнении
элементарных актов — «команд» алгоритма фиксируется заранее
и явно указывается в записи алгоритма. Например, в нормальных
алгоритмах все применяемые формулы подстановки заранее ука-
заны в записи алгоритма. Список допустимых действий машины
Тьюринга при ее работе остается неизменным. Частично рекур-
сивная функция задается фиксированной последовательностью
уравнений. В то же время допущение формирования команд алго-
ритма в процессе его реализации приводит к существенному со-
кращению и упрощению записи алгоритма. В связи с этим следу-
ющим требованием, предъявляемым к понятию алгоритма, при его
практическом использовании является возможность формирова-
ния команд алгоритма в процессе его выполнения.
В общем случае все элементарные операции, производимые
в процессе выполнения алгоритмов, распадаются на две группы
операций, которые обычно называют арифметическими и логи-
ческими. Арифметические операции осуществляют непосред-
ственное преобразование информации. Логические операции оп-
ределяют дальнейшее направление счета, т. е. последовательность
выполнения арифметических операций. При этом во многих слож-
ных алгоритмах преобладают логические операции, в то время как
преобразование информации носит иногда очень простой характер.
203
Элементарные акты, аналогичные логическим операциям, в яв-
ном или неявном виде вводятся и при определении понятия вы-
полнения алгоритма в абстрактной теории алгоритмов. Например,
при выполнении нормального алгоритма после рассмотрения оче-
редной формулы подстановки осуществляется либо переход к сле-
дующей формуле подстановки, либо остановка, либо переход к
первой формуле подстановки схемы алгоритма. В машине Тьюрин-
га логической операцией можно считать движение ленты вправо
или влево в зависимости от состояния машины и прочитанного
символа.
Однако, как правило, логические операции в классических ал-
горитмических системах носят тривиальный характер. Во многих
случаях такая тривиальность логических операций сильно услож-
няет построение конкретных алгоритмов. В связи с этим следую-
щим требованием, которое предъявляется к определению алгорит-
ма при его практическом использовании, является допущение бо-
лее универсальных логических элементарных операций, нежели те,
которые имеются в абстрактной теории алгоритмов.
В той или иной мере этим требованиям отвечают так называе-
мые операторные алгоритмические системы [2].
5.5.1. Операторные алгоритмы Ван Хао
Операторный алгоритм Ван Хао задается последовательностью
приказов специального вида. Каждый приказ имеет определенный
номер и содержит указания: какую операцию следует выполнить
над заданным объектом и приказ с каким номером следует далее
выполнить над результатом данной операции. Общий вид такого
приказа:
CD а Р
где i — номер приказа;
со — элементарная операция над объектом;
а, Р — номера некоторых приказов.
В терминах машин Тьюринга номера приказов соответствуют
номерам конфигураций машины, а элементарная операция над
объектом — элементарному действию над конфигурацией при
некотором состоянии.
Выполнить приказ (5.1) над числом х в операторном алгоритме —
значит найти число со(х) и далее перейти к выполнению над й)(х)
204
приказа с номером а. Если же со(х) не определено, то перейти к
выполнению над числом х приказа с номером Д.
Заключительному состоянию машины Тьюринга в операторных
алгоритмах соответствует приказ вида:
i :|сшоп|,
который означает, что вычисления следует остановить. Число, над
которым следует выполнить этот приказ, есть результат вычисле-
ний.
Программой операторного алгоритма называется последова-
тельность приказов вида:
со, а.
ОДч-5 (Xi+s fli+s
стоп
i+n
где co/xj,coi+s(x) — заданные функции, определяющие элемен-
тарные операции над объектом х;
а , Д. — натуральные числа из последовательности i, i+l,
i -I- n.
Переработать x согласно данному операторному алгоритму —
значит выполнить над х последовательность следующих действий.
i-шаг. Находим со.(х). Если о\(х) определено, то результатом бу-
дет пара чисел [со(х),а]. Если со.(х) не определено, то результатом i-
го шага будет пара (х, Д.).
i+ 1-шаг, если результат предыдущего шага х, Д , где Д. = i + 1.
Находим coj+t (х). Если она определена, то результатом будет пара
[й)/+Дх/,а/+/], если не определена, то результатом будет пара (х, Д+1)
ИТ. д.
i+п-1 -шаг. Если в качестве результата на данном шаге получит-
ся пара, указывающая на заключительный оператор (z, i+п), то
процесс завершается и число z является результатом переработки
числа х согласно заданному алгоритму z = <о.+п ;(х).
Тип функций, вычисляемых посредством операторных алгорит-
мов Ван Хао, зависит от того, какие функции to. входят в записи
приказов.
205
5.5.2. Операторные алгоритмы Ляпунова
Алгоритмическая система отечественного ученого А.А. Ляпуно-
ва, предложенная им в 1953 г., является одной из первых, учитываю-
щих все требования, предъявляемые к конкретным алгоритмам. Она
возникла в связи с реализацией алгоритмов различных задач на ЭВМ.
Важнейшим понятием, введенным А.А. Ляпуновым, было поня-
тие оператора, являющегося одновременно и единицей действия,
и единицей конструирования программы. Как единица действия
оператор выполняет некоторое преобразование над информаци-
ей, а как единица конструирования программы — имеет некото-
рое обозначение, показывающее тип оператора, его место в про-
грамме и конкретное содержание оператора (спецификацию).
Важным свойством оператора было то, что трактовка операто-
ра как единицы действия носит относительный характер. Два опе-
ратора Ап В, выполненные друг за другом, осуществляют какое-то
совокупное преобразование информации, т. е. также образуют
некоторый оператор С. Для того чтобы операторы Ап В выполня-
лись подряд, их записывают один за другим: АВ, а связь с операто-
ром С выглядит как: С = АВ. Информация, например, о том, что
Ап В можно выполнять в любом порядке, получая один и тот же
результат, может быть выражена равенством А В = В А.
Выражаясь языком алгебры, можно сказать, что операторы про-
грамм образуют полугруппу, в которой могут существовать опре-
деляющие отношения. Изучение полугруппы операторов приоб-
рело фундаментальную роль в теоретическом программировании.
Аналогия двух рядом стоящих операторов АВ с произведени-
ем двух чисел делала понятными такие обозначения, введенные
А.А. Ляпуновым, как:
П^0)ВС(/)_
1=1
Эта запись обозначает n-кратное повторение операторов АВС,
причем символы A(i) и C(i) показывают, что спецификация этих
операторов зависит от значения индекса повторения I.
Для записи передач управления в зависимости от условий А.А. Ля-
пунов ввел понятие логических операторов:
i i
...г...р?...,
где Р — символ логического оператора;
ф — передающая и приемная стрелки соответственно.
206
Обозначение i используется, чтобы выделять пары соответству-
ющих друг другу приемных и передающих стрелок. При одном
значении Р управление передается на оператор, стоящий вслед за
передающей стрелкой I, а при другом — на оператор, стоящий
вслед за принимающей стрелкой i.
Запись алгоритма по А.А. Ляпунову состоит из двух частей. Пер-
вая часть — схема алгоритма — образована символами операто-
ров и показывает порядок расположения операторов в програм-
ме, а также направления передач управления. Вторая часть — это
спецификация всех операторов, образующих программу.
Рассмотрим пример записи операторного алгоритма Ляпунова для
решения 10 квадратных уравнений вида cz,x2 +bix + cj =0 (i = 1,...,10).
Для каждого уравнения, представив общую формулу решения
- b ± л/й2 — 4 ас J Ь2 - 4ас
Х\2=--------------- в виде р = -Ь/2а и q = --------------,
2а 2а
в зависимости от знака дискриминанта Ь2 — 4ас найдем для дей-
ствительного случая (призн = 1), корl=p+qn кор2 = p-q, для ком-
плексного — (призн = — 1), кор\ = у[р2 +q2 и кор2 = arcsin-у=г-
у1р2 + я2
Схема алгоритма:
2 1 2
4П Л2(0Л3Л4Р5?А6ТIА7 I AgA^i) 410 СТОП.
Спецификация:
At — ввод всех коэффициентов a., b., с. (I = 1,..., 10);
А2 — присвоение переменным а, b и с значений коэффициен-
тов а(, б,, с.;
А3—вычисление дискриминанта: tt = 2а, t2 — 2c, дискр = b2— ttt2\
А4—вычисление вспомогательных значений: р = —b/tt, q = ^дмск-р]//!;
Р5 — проверка условия: дискр < 0?;
Ag — вычисление модуля и аргумента комплексной пары кор-
ней:
t = р2 + q2, кор! = Vt, кор2 = arcsin (q/кор!);
207
А7 — вычисление пары действительных корней:
кор1= р + q, кор2 = р— q;
Ag — сохранение знака дискриминанта: призн = sign (дискр);
Ад — запоминание в массиве решений пары корней z-го урав-
нения;
А10 — печать всех решений.
На основе данного операторного метода в период 1955—1960 гг.
были созданы первые алгоритмические языки и трансляторы,
а также разработаны первые формализмы теоретического програм-
мирования.
5.5.3. Блок-схемный метод алгоритмизации
При блок-схемном методе алгоритмизации весь процесс реше-
ния задачи расчленяется на отдельные этапы-блоки. В блок-схеме
каждому типу действий (вводу исходных данных, вычислению зна-
чений выражений, проверке условий, управлению повторением
действий, окончанию обработки и т. п.) соответствует геометри-
ческая фигура, представленная в виде блочного символа, блоку при-
сваивается номер (метка), и он снабжается пояснительным текстом.
Направление процесса обработки в блок-схеме указывается путем
соединения отдельных элементов блок-схемы линиями переходов
(стрелками). В табл. 5.1 приведены наиболее часто употребляемые
символы.
Блок «Процесс» применяется для обозначения действия или
последовательности действий, изменяющих значение, форму пред-
ставления или размещения данных. Для улучшения наглядности
схемы несколько отдельных блоков обработки можно объединять
в один блок.
Блок «Решение» используется для обозначения переходов уп-
равления по условию. В каждом таком блоке должны быть указа-
ны вопрос, условие или сравнение, которые он определяет.
Блок «Модификация» используется для организации цикли-
ческих конструкций. (Слово модификация означает видоизме-
нение, преобразование.) Внутри блока записывается параметр
цикла, для которого указываются его начальное значение, гра-
ничное условие и шаг изменения значения параметра для каж-
дого повторения.
208
Таблица 5.1
Название символа Обозначение и пример заполнения Пояснение
Процесс I х = (а — b)/sin(l Вычислительное действие или последовательность действий
Решение Проверка условий
Модификация у I i-К i = 1,50,2 > 1 1 ' * Начало цикла
Предопределенный процесс - 1 II Расчет || параметров 1 Вычисления по подпрограмме, стандартной подпрограмме
Ввод-вывод / Ввод / / а,Ь, с / Ввод-вывод в общем виде
Пуск-останов С27началсГ^> Начало, конец алгоритма, вход и выход в подпрограмму
Документ 1 [Печать | уа, Вывод результатов на печать
Блок «Предопределенный процесс» используется для указания
обращений к вспомогательным алгоритмам, существующим авто-
номно в виде некоторых самостоятельных модулей, и для обраще-
ний к библиотечным подпрограммам.
При построении блок-схемы сложных вычислительных процес-
сов не всегда целесообразно дробить весь процесс решения зада-
чи на мелкие блоки. Иногда для большей обозримости соединяют
в один блок целую группу этапов, т. е. в зависимости от сложности
задачи необходимо составлять блок-схемы с различной степенью
детализации.
В качестве примера рассмотрим применение блок-схемного
метода алгоритмизации при решении двух задач: вычисления дей-
ствительных корней квадратного уравнения ах2+Ьх+с = 0 и на-
хождения максимального числа из массива целых чисел.
Блок-схема алгоритма вычисления действительных корней
квадратного уравнения показана на рис. 5.11.
14 А-210
209
Начало
Рис.5.11. Вычисление корней квадратного уравнения
В блоке 1 задаются исходные данные, в блоке 2 вычисляется зна-
чение дискриминанта d по заданным значениям а, b и с. В блоке 3
это значение проверяется: если оно меньше ноля, выдается сооб-
щение «Решения нет» (блок 5); если d больше или равен нолю, вы-
числяются квадратный корень из дискриминант, а затем — значе-
ния двух корней (х 1 и х2). В частном случае, если d = 0, получают-
ся два равных корня (х1 = х2 = -Ь/2а), и выводится значение ре-
зультата (блок 8).
На рис. 5.12 представлена блок-схема поиска максимального
числа из чисел a. (i = 1, 2, .... п).
Здесь сначала вводятся две дополнительные переменные: т —
значение максимального числа и i — порядковый номер (индекс)
числа в последовательности (i — 1, 2, ..., п). Присваивается т зна-
чение «ноль», a i — значение 1 (блок 3).
В блоке 4 сравнивается текущее значение т с очередным чис-
лом из заданной последовательности. Например, пусть в начале
210
последовательности указаны at = 3,
а3 = 6, а3 = 2, ... При первом выполнении
блока 4 проверяется условие а. > т (т. е.
3 > 0). В результате проверки переменной
т будет присвоено значение а. (т. е. т = 3).
Далее значение i увеличивается на едини-
цу (блок 6). Если i не больше п (блок 7), сно-
ва выполняется блок 4. На втором шаге а =
6, т. е. at > т, и т примет значение 6. На тре-
тьем шаге а = 2 (а.< ш), и т сохранит значе-
ние 6. Как только i превысит число элемен-
тов последовательности (все числа просмот-
рены), выполнение алгоритма заканчивает-
ся, а переменная т сохраняет значение мак-
симального числа последовательности.
Блок-схемным методом удобно пользо-
ваться при составлении сложных алгорит-
мов, в качестве предварительной проверки
и наглядного представления логики реше-
ния задачи.
В связи с возникновением ЭВМ и их ис-
пользованием для решения различных за-
дач возникла необходимость перевода алго-
ритмов, представленных аппаратом той или
иной алгоритмической системы, в команды
конкретной машины. Первоначально этот
перевод выполнялся вручную и требовал
много труда и времени. Для ускорения про-
Рис.5.12. Поиск
цесса перевода алгоритмов задач с языка ал- максимального числа
горитмической системы в язык машины
были разработаны специальные алгоритмические системы, полу-
чившие название алгоритмические языки программирования. В на-
стоящее время разработано и используется несколько сотен алго-
ритмических языков программирования. Строгая формализация и
однозначность описания алгоритмов в таких языках позволила пе-
реложить на машину и сам перевод с алгоритмического языка на
язык машины. Для этого ЭВМ снабжается так называемой програм-
мирующей программой — транслятором, которая, анализируя опи-
сание, сделанное на алгоритмическом языке, перерабатывает его в
программу, состоящую только из машинных команд.
211
5.6. МЕТОДЫ ОЦЕНКИ АЛГОРИТМОВ
И АЛГОРИТМИЧЕСКИ НЕРАЗРЕШИМЫЕ ПРОБЛЕМЫ
В теории алгоритмов понятие «алгоритм» обычно уточняется
посредством описания «математической модели» вычислительной
машины. При этом возможны два подхода в зависимости от того,
оценивается ли сложность алгоритма (машины, программы) или
сложность вычислительного процесса, протекающего в соответ-
ствии с алгоритмом [2].
В качестве меры сложности алгоритмов используется функци-
онал, соотносящий каждому алгоритму А некоторое число ц(А),
характеризующее (в подходящем смысле) его громоздкость, напри-
мер: число команд в А, длина записи А или какой-нибудь другой
числовой параметр, характеризующий объем информации, содер-
жащийся в А. Подобные функционалы применяются в теоретико-
кибернетических исследованиях схем, реализующих функции ал-
гебры логики, а также в вычислительной математике, где мощность
схемы, по которой вычисляется многочлен, измеряется числом
арифметических операций, фигурирующих в схеме.
В качестве меры сложности вычислений рассматривается фун-
кционал, соотносящий каждой паре (А, а), где А — алгоритм, а —
индивидуальная задача из того класса задач, которые алгоритм А
решает, некоторое число о(А, а). Это число характеризует слож-
ность работы алгоритма А применительно к исходным данным а до
выдачи соответствующего результата. Например, в качестве а(А, а)
можно брать число элементарных шагов, из которых складывает-
ся эта работа (иначе говоря, длительность процесса вычисления)
или объем памяти, который может понадобиться для реализации
всех выкладок по ходу данного процесса, и т. д. Поскольку для каж-
дого алгоритма А однозначно определен тот класс задач W, кото-
рый он решает (например, та функция f, значение которой он вы-
числяет), то можно считать, что в рассматриваемой ситуации каж-
дый алгоритм А характеризуется функцией переменного а
оА(а) = о(А, а). Иными словами, мерой сложности работы алгорит-
ма (вычисления) является оператор, сопоставляющий с каждым
алгоритмом А соответствующую функцию оА(а).
Введение некоторой меры сложности для алгоритмов (или вы-
числений) позволяет получить удобный инструмент для сравнения
алгоритмов, а также для оценки объективной трудности, прису-
212
щей различным вычислимым функциям. Обычно считают, что мера
сложности алгоритма принимает лишь натуральное значение, по-
этому для каждой вычислимой функции существует вычисляющий
ее алгоритм с минимальной сложностью.
Классификации по сложности обычно подвергаются задачи,
решаемые с помощью машины Тьюринга (МТ). В процессе вычис-
ления с помощью такой машины могут использоваться различные
ресурсы, например «пространство» и «время». Эти ресурсы фор-
мально могут быть определены следующим образом. Пусть зада-
ны программа М машины Тьюринга и входная цепочках, тогда вре-
менной ресурс Т(М,х) определяется как число шагов в вычислении
М на х до останова М. Время будет неопределенным (т. е. равным
бесконечности), если М не останавливается на х. Временная слож-
ность М определяется как целочисленная функция Тм, где TJn)=
e max (Т (М, х); | х | = п) для неотрицательного целого числа п.
Аналогичным образом, пространственный ресурс S(M,x) опре-
деляется как число ячеек ленты, используемых М на х, а простран-
ственная сложность Sm — как SM(n)= max (SfM, х); | х | = п). Чтобы
не путать пространство, необходимое для работы, с пространством,
выделяемым для входной цепочки х, предполагается, что машина
имеет ленту ввода, работающую только на считывание, a S(M,x)
определяется как число ячеек (куда можно записывать данные),
используемых М на х.
Алгоритм, для которого критерий сложности Тм(п) или Бм(п)
возрастает при увеличении п не быстрее, чем полином в п, назы-
вается полиномиально ограниченным; алгоритм, сложность кото-
рого возрастает по экспоненте, называется экспоненциально огра-
ниченным. При этом в обоих случаях подразумевается, что алго-
ритм завершается.
Одна из главных нерешенных в настоящее время задач теории
вычислительных систем — задача тождества Р = NP. Суть ее со-
стоит в следующем [2].
Р — класс задач полиномиального типа, или в терминологии
алгоритмической системы Тьюринга, — класс формальных язы-
ков, которые считаются распознаваемыми за полиномиальное вре-
мя. Язык L входит в Р, если существует программа М машины Тью-
ринга и некоторый полином р(п), при котором эта программа рас-
познает язык L, и для всех неотрицательных значений целых п со-
блюдается условие Тм (п) < р(п), где Тм является временной оцен-
кой сложности программы М. Если какой-либо язык не входит в Р,
213
то не существует алгоритма, который распознает его за полино-
миальное время.
NP — класс задач, имеющих недетерминированное решение с
полиномиально затрачиваемым временем на решение, или в тер-
минологии алгоритмической системы Тьюринга, — класс язы-
ков, распознаваемых за полиномиальное время недетерминиро-
ванной машиной Тьюринга. При этом PQNP, но вопрос тождествен-
ности до настоящего времени не решен, несмотря на интенсивные
исследования.
Успешное решение данной проблемы может иметь значитель-
ные последствия. Например, в криптографии, где надежность шиф-
ровальных систем основывается на нереальном времени, необхо-
димом для решения задачи расшифровки, решение данной про-
блемы может привести к компрометации шифровальных систем.
Таким образом, в зависимости от сложности практической ре-
ализации все алгоритмически разрешимые задачи подразделяют-
ся на задачи полиномиального типа и задачи неполиномиального
типа.
Одним из свойств алгоритма является его массовость. Это оз-
начает, что алгоритм представляет собой способ решения некото-
рой массовой проблемы, формулируемой в виде проблемы отобра-
жения не одного, а целого множества входных слов в соответству-
ющие им выходные слова. Таким образом, всякий алгоритм мож-
но рассматривать как некоторое универсальное средство для ре-
шения целого класса задач.
Однако существуют такие классы задач, для решения которых
нет и не может быть единого универсального приема — алгорит-
ма. Другими Словами, все задачи (проблемы) можно разделить на
алгоритмически разрешимые и алгоритмически неразрешимые.
В качестве примера доказательства алгоритмической нераз-
решимости рассмотрим проблему распознавания самопримени-
мости [2].
Существуют как самоприменимые, так и несамоприменимые
алгоритмы. Примером самоприменимого алгоритма является так
называемый тождественный алгоритм в любом алфавите А, содер-
жащем две или более двух букв. Этот алгоритм применим к любо-
му слову р в алфавите А и перерабатывает любое входное слово в
себя. Примером несамоприменимого алгоритма является так на-
зываемый нолевой алгоритм в любом конечном алфавите В. Этот
алгоритм задается схемой, содержащей единственную подстанов-
214
ку —>у (где у — любая буква алфавита В), и по своему определе-
нию он не применим ни к какому входному слову.
Проблема распознавания самоприменимости алгоритмов состо-
ит в том, чтобы найти единый конструктивный прием, позволяю-
щий за конечное число шагов по схеме любого данного алгоритма
узнать, является алгоритм самоприменимым или несамопримени-
мым.
Для доказательства алгоритмической неразрешимости данной
проблемы можно использовать алгоритмическую систему Тью-
ринга.
В терминологии машины Тьюринга проблема самоприменимо-
сти может быть сформулирована следующим образом. Пусть в
машине Тьюринга зафиксирована какая-нибудь конфигурация.
Возможны два случая:
1) машина применима к этой конфигурации, т. е. после конеч-
ного числа тактов (шагов) она останавливается в заключительной
конфигурации (самоостанавливающаяся программа);
2) машина неприменима к этой конфигурации, т. е. машина
никогда не переходит в заключительную конфигурацию, она впа-
дает в бесконечный процесс (несамоостанавливающаяся про-
грамма) .
Пусть на ленте машины Тьюринга изображен ее собственный
шифр (шифр таблицы соответствия и исходной конфигурации),
записанный в алфавите машины. Если машина применима к дан-
ной конфигурации, то будем называть ее самоприменимой, в про-
тивном случае — несамоприменимой.
Тогда проблема распознавания самоприменимости состоит в
следующем: по любому заданному шифру установить, к какому
классу относится машина — к классу самоприменимых или неса-
моприменимых?
Данная проблема распознавания самоприменимости алгорит-
мически неразрешима.
Доказательство проведем методом от противного, т. е. покажем,
что исходное предположение о распознавании самоприменимос-
ти приводит к противоречию, вследствие чего мы будем вынужде-
ны сделать вывод о неразрешимости проблемы распознавания са-
моприменимости. Предположим, что такая машина МТ существу-
ет. Тогда в МТ всякий самоприменимый шифр перерабатывается
в какой-то символ, например 1 (имеющий смысл утвердительного
ответа на поставленный вопрос о самоприменимости), а всякий
215
несамоприменимый шифр — в символ 0 (имеющий смысл отрица-
тельного ответа на поставленный вопрос).
В таком случае можно было бы построить и такую машину МГ;,
которая по-прежнему перерабатывает несамоприменимые шиф-
ры в 0, в то время как к самоприменимым шифрам МГ; уже непри-
менима. Этого можно добиться путем такого изменения схемы
машины (таблицы соответствия) МТ, чтобы после появления сим-
вола 1 вместо остановки машина стала бы неограниченно повто-
рять этот же символ.
Таким образом, получаем, что MTt применима ко всякому неса-
моприменимому шифру (вырабатывая при этом символ 0) и непри-
менима к самоприменимым шифрам. Однако это приводит к про-
тиворечию.
Действительно:
1) пусть машина MTt самоприменима, тогда она применима к
своему шифру М/ и перерабатывает его в символ 0, но появление
этого символа как раз и должно означать, что машина несамопри-
менима;
2) пусть MTt несамоприменима, тогда она применима к М/, что
должно означать, что Mt самоприменима.
Полученное противоречие доказывает теорему, т. е. наше пред-
положение о машине МТ неверно. Таким образом, мы показали,
что существуют алгоритмически неразрешимые задачи, т. е. зада-
чи, решение которых не может быть получено с помощью ЭВМ.
К типу алгоритмических проблем относится и теорема Геделя о
неполноте арифметической логики, утверждающая, что любая
адекватная непротиворечивая арифметическая логика неполна,
т. е. существует истинное утверждение о целых числах, которое
нельзя доказать в такой логике [2].
Под арифметической логикой понимается совокупность акси-
ом и правил вывода теорем в элементарной теории чисел (теории
положительных целых чисел). Логика называется полной, если в
ней можно доказать истинность или ложность каждого утвержде-
ния. Логика называется непротиворечивой, если она свободна от
противоречий. Гедель показал, что невозможно доказать непро-
тиворечивость арифметической логики (даже неполной) теми ме-
тодами, которые выразимы в самой этой логике.
Чтобы было понятно значение результатов, полученных Геде-
лем, вспомним, что первой аксиоматической системой была гео-
метрия Евклида (III век до н. э.). В основе евклидовой геометрии
216
лежит совокупность определений и аксиом, отражающих простей-
шие геометрические свойства, подтвержденные многовековым
человеческим опытом.
В число аксиом, которые в геометрии Евклида принимаются без
доказательств, входит и аксиома о параллельных линиях. Аксиому
о параллельных линиях нередко называли темным пятном в гени-
альном труде Евклида. Не была также доказана полнота и непро-
тиворечивость евклидовой геометрии. И очень рано начались упор-
ные попытки математиков очистить евклидову геометрию от вся-
ких пятен. С этой целью стремились доказать аксиому о параллель-
ных линиях. Пытались логически вывести ее утверждение из ос-
тальных аксиом Евклида. Такие попытки продолжались на протя-
жении двух с лишним тысячелетий. Почти все выдающиеся мате-
матики испытывали свои силы на решении этой проблемы (Декарт,
Лейбниц, Гаусс и др.).
Полную бесплодность попыток доказать аксиому о параллель-
ных линиях впервые строго научно установил великий русский
математик Я.И. Лобачевский в XVIII веке. Он доказал, что утверж-
дение этой аксиомы нельзя вывести из остальных аксиом Евкли-
да. Лобачевский постулировал особую неевклидову геометрию,
названную его именем. Она отвергала истинность следующей ак-
сиомы Евклида: «Если даны прямая и точка, не лежащая на ней, то
существует только одна прямая, которая проходит через данную
точку параллельно данной прямой». В геометрии Лобачевского па-
раллельных линий не существует. По отношению к этой новой гео-
метрии евклидова геометрия является только частным случаем.
Контрольные вопросы
1. Какие определения понятия алгоритма Вы знаете?
2. Назовите роль и место теории алгоритмов в современной инфор-
матике.
3. Чем вызвана необходимость формализации понятия алгоритма?
4. Какие способы представления алгоритма Вы знаете?
5. Что такое алфавитный оператор?
6. Дайте определение кодирующего отображения.
7. Назовите основные свойства алгоритма.
8. Что такое алгоритмическая система?
9. Что такое рекурсия?
10. Дайте определения вычислимой и частичной функций.
217
11. В чем состоит тезис Черча?
12. Назовите элементарные арифметические функции и операции.
13. Дайте определение частично рекурсивной функции.
14. Что такое абстрактные машины Поста и Тьюринга, для чего они
предназначены ?
15. Как «устроена» машина Тьюринга?
16. Перечислите приказы, выполняемые машиной Поста.
17. Что понимают под конфигурацией машины Тьюринга?
18. Каков принцип работы машины Тьюринга?
19. Что такое универсальная машина Тьюринга?
20. В чем различие между детерминированной и недетерминирован-
ной машинами Тьюринга?
21. Что такое граф-схема алгоритма?
22. Дайте определение нормального алгоритма Маркова.
23. Назовите основные требования, предъявляемые к определению
алгоритма при его практическом использовании.
24. Что представляет собой операторный алгоритм Ван Хао?
25. Назовите основные особенности операторных алгоритмов Ляпу-
нова.
26. В чем состоит особенность блок-схемного метода алгоритмиза-
ции?
27. Какие меры сложности алгоритмов Вы знаете?
28. Что такое полиномиально ограниченный алгоритм?
29. В чем состоит суть проблемы тождества PQNP1
30. Что означает алгоритмическая разрешимость или неразрешимость
задачи?
31. Приведите примеры алгоритмически неразрешимых задач.
Тлава 6
Обработка информации
6.1. КОМПЬЮТЕРНАЯ ОБРАБОТКА ИНФОРМАЦИИ
Обработка является одной из основных операций, выполняе-
мых над информацией и главным средством увеличения ее объе-
ма и разнообразия. Для осуществления обработки информации
с помощью технических средств ее представляют в формализован-
ном виде — в виде структур данных («информационных объек-
тов»), представляющих собой некоторую абстракцию фрагмента
реального мира. Абстракция (от лат. Abstraction — отвлечение)
подразумевает выделение наиболее существенных с точки зрения
задачи обработки свойств и связей. Так, например, информация
о студенте, необходимая для учета его успеваемости, может быть
представлена набором таких идентифицирующих данных, как фа-
милия, имя, отчество, номер учебной группы. При этом несуще-
ственные для данной задачи характеристики, например рост, вес,
цвет волос и т. п., не будут учтены.
Обработка информации — получение одних «информационных
объектов» (структур данных) из других путем выполнения некоторых
алгоритмов.
Исполнитель алгоритма — абстрактная или реальная (техни-
ческая, биологическая или биотехническая) система, способная
выполнить действия, предписываемые алгоритмом. Для механиза-
ции и автоматизации процесса обработки информации и вычис-
лений, выполняемых в соответствии с заданным алгоритмом, ис-
пользуют различные типы вычислительных машин: механические,
электрические, электронные (ЭВМ), гидравлические, пневмати-
ческие, оптические и комбинированные.
В современной информатике основным исполнителем алгорит-
мов является ЭВМ, называемая также компьютером (от англ.
computer — вычислитель).
219
ЭВМ — электронное устройство, предназначенное для автомати-
зации процесса алгоритмической обработки информации и вычислений.
В зависимости от формы представления обрабатываемой инфор-
мации вычислительные машины делятся на три больших класса:
цифровые вычислительные машины (ЦВМ), обрабатываю-
щие информацию, представленную в цифровой форме;
аналоговые вычислительные машины (АВМ), обрабатыва-
ющие информацию, представленную в виде непрерывно ме-
няющихся значений какой-либо физической величины
(электрического напряжения, тока и т. д.);
гибридные вычислительные машины (Г'ВМ), содержащие как
аналоговые, так и цифровые вычислительные устройства.
В основе функционирования АВМ заложен принцип модели-
рования. Так, при использовании в качестве модели некоторой
задачи электронных цепей каждой переменной величине задачи
ставится в соответствие определенная переменная величина элект-
ронной цепи. При этом основой построения такой модели является
изоморфизм (подобие) исследуемой задачи и соответствующей ей
электронной модели. Согласно своим вычислительным возможно-
стям АВМ наиболее приспособлены для решения математических
задач, содержащих дифференциальные уравнения, не требующие
сложной логики. В отличие от ЦВМ, точность которых определяет-
ся их разрядностью, точность вычислений на АВМ ограничена и
характеризуется качеством изготовления элементной базы и основ-
ных узлов. В то же время для целого класса задач скорость решения
задач на АВМ может быть значительно больше, чем на ЦВМ. Это
объясняется параллельным принципом решения задач на АВМ, ког-
да результат решения получается мгновенно и одновременно во всех
точках модели. Данная особенность обусловливает использование
АВМ в замкнутых системах автоматического регулирования и для
решения задач в режиме реального времени. Гибридные вычисли-
тельные машины, содержащие как аналоговые, так и цифровые
вычислительные устройства, совмещают в себе достоинства АВМ и
ЦВМ. В таких машинах цифровые устройства обычно служат для
управления и выполнения логических операций, а аналоговые уст-
ройства — для решения дифференциальных уравнений.
Поскольку в настоящее время подавляющее большинство ком-
пьютеров являются цифровыми, далее слово «компьютер», или
220
«ЭВМ», будем употреблять в значении «цифровой компьютер». Для
обработки аналоговой информации на таком компьютере ее сна-
чала преобразуют в цифровую форму (см. п. 6.2).
Современный компьютер (ЭВМ) как реальная система обработ-
ки данных имеет ряд общих черт с рассмотренной в предыдущей
главе абстрактной алгоритмической системой — машиной Тью-
ринга (МТ):
подобно МТ-модели ЭВМ располагает конечным множе-
ством команд, лежащих в основе реализации и выполнения
каждого алгоритма;
• подобно МТ-модели ЭВМ функционирует дискретно (потак-
тно) под управлением программы, хранящейся в оператив-
ной памяти;
устройство управления ЭВМ по назначению в общих чертах
аналогично устройству управления МТ-модели.
Однако ЭВМ имеют относительно МТ-моделей существенно
более сложную организацию и широкий набор более крупных ко-
манд, что позволяет эффективно представлять разнообразные ал-
горитмы решаемых задач. Более того, в предположении о возмож-
ности наращивания памяти в необходимых объемах каждая ЭВМ
может моделировать любую МТ, являясь потенциально универ-
сальной. Потенциальность объясняется тем, что ни одна ЭВМ не
может считаться универсальной в смысле вычислимости произ-
вольной, частично рекурсивной функции, т. е. для нее существует
класс нерешаемых задач при условии неизменности ее ресурсов
(в первую очередь памяти).
Основу современных компьютеров образует аппаратура
(Hardware) — совокупность электронных и электромеханических
элементов и устройств, а принцип компьютерной обработки ин-
формации состоит в выполнении программы (Software) — форма-
лизованном описании алгоритма обработки в виде последователь-
ности команд, управляющих процессом обработки.
Команда представляет собой двоичный код, который определя -
ет действие вычислительной системы по выполнению какой-либо
операции.
Операция — комплекс совершаемых технологических действий
над информацией по одной из команд программы.
221
Основными операциями при обработке информации на ЭВМ
являются арифметические и логические. Арифметические опера-
ции включают в себя все виды математических действий, обуслов-
ленных программой, над целыми числами, дробями и числами с пла-
вающей запятой. Логические операции обеспечивают действия над
логическими величинами с получением логического результата.
В вычислительных системах последовательность действий, состав-
ляющих задачу обработки информации, называют процессом.
Так, обработка некоторого текста программой-редактором явля-
ется процессом, а редактирование другого текста с помощью этой
же программы представляет собой другой процесс, даже если при
этом используется одна и та же копия программы. Процесс опреде-
ляется соответствующей программой, набором данных, которые в
ходе реализации процесса могут считываться, записываться и ис-
пользоваться, а также дескриптором процесса, который описывает
текущее состояние любого выделенного процессу ресурса ЭВМ.
Дескриптор процесса — совокупность сведений, определяющих
состояние ресурсов ЭВМ, предоставленных процессу.
Каждый сеанс пользователя с вычислительной системой, напри-
мер ввод-вывод данных в ЭВМ, также является процессом. В об- J
щем случае в вычислительной системе может одновременно су- |
ществовать произвольное число процессов, поэтому между ними j
возможна конкуренция за обладание тем или иным ресурсом, *
в первую очередь временем процессора — основного вычислитель- •
ного устройства ЭВМ. Это обусловливает необходимость органи-
зации управления процессами и их планирования. В современных
ЭВМ для решения данных задач служат операционные системы ।
(ОС), включающие совокупность программ для управления про- I
цессами, распределения ресурсов, организации ввода-вывода и
интерфейса с пользователем.
С точки зрения организации вычислительных процессов в ЭВМ
выделяют несколько режимов:
однопрограммный однопользовательский режим, в котором
вычисления носят последовательный характер, а ресурсы
ЭВМ не разделяются;
222
мультизадачный, когда несколько программ последователь-
но используют время процессора, при этом возможно раз-
деление как аппаратных, так и программных ресурсов ЭВМ;
многопользовательский, когда каждому пользователю выде-
ляется квант (интервал) времени процессора, при этом зада-
ча распределения ресурсов, в первую очередь времени про-
цессора и памяти, значительно усложняется;
мультипроцессорный, когда вычислительная система, вклю-
чающая несколько процессоров, позволяет выполнять реаль-
ные параллельные процессы, при этом распределение ресур-
сов носит наиболее сложный характер.
При выполнении задач обработки информации на компьютере
выделяют пакетный и интерактивный (запросный, диалоговый)
режимы взаимодействия пользователя с ЭВМ.
Пакетный режим первоначально использовался для снижения
непроизводительных затрат машинного времени путем объедине-
ния однотипных заданий. Его суть заключается в следующем. Зада-
ния группируются в пакеты, каждый со своим отдельным компиля-
тором. Компилятор загружается один раз, а затем осуществляется
последовательная трансляция всех заданий пакета. По окончании
компиляции пакета все успешно транслированные в двоичный код
задания последовательно загружаются и обрабатываются. Такой ре-
жим был основным в эпоху централизованного использования ЭВМ
(централизованной обработки), когда различные классы задач ре-
шались с использованием одних и тех же вычислительных ресур-
сов, сосредоточенных в одном месте (информационно-вычислитель-
ном центре). При этом организация вычислительного процесса стро-
илась главным образом без доступа пользователя к ЭВМ. Его функ-
ции ограничивались лишь подготовкой исходных данных по комп-
лексу информационно-взаимосвязанных задач и передачей их в
центр обработки, где формировался пакет заданий для ЭВМ.
В настоящее время под пакетным режимом также понимается
процесс компьютерной обработки заданий без возможности вза-
имодействия с пользователем. При этом, как правило, задания вво-
дятся пользователями с терминалов и обрабатываются не сразу,
а помещаются сначала в очередь задач, а затем поступают на обра-
ботку по мере высвобождения ресурсов. Такой режим реализует-
ся во многих системах коллективного доступа.
Интерактивный режим предусматривает непосредственное
взаимодействие пользователя с информационно-вычислительной
системой и может носить характер запроса (как правило, регла-
223
ментированного) или диалога с ЭВМ [12]. Запросный режим позво-
ляет дифференцированно, в строго установленном порядке предос-
тавлять пользователям время для общения с ЭВМ. Диалоговый режим
открывает пользователю возможность непосредственно взаимодей-
ствовать с вычислительной системой в допустимом для него темпе
работы, реализуя повторяющийся цикл выдачи задания, получения
и анализа ответа. При этом ЭВМ сама может инициировать диалог,
сообщая пользователю последовательность шагов (предоставление
меню) для получения искомого результата. Организация взаимодей-
ствия пользователя и ЭВМ представлена на рис. 6.1. Взаимодействие
осуществляется путем передачи сообщений и управляющих сигна-
лов между пользователем и ЭВМ. Входные сообщения генерируют-
ся оператором с помощью средств ввода: клавиатуры, манипулято-
ров типа мышь и т. п., выходные — компьютером в виде текстов, зву-
ковых сигналов, изображений и представляются пользователю на эк-
ране монитора или других устройствах вывода информации. Основ-
ными типами сообщений, генерируемыми пользователем, являются:
запрос информации, запрос помощи, запрос операции или функции,
ввод или изменение информации и т. д. В ответ со стороны компью-
тера он получает: подсказки или справки, информационные сообще-
ния, не требующие ответа, приказы, требующие действий, сообще-
ния об ошибках, нуждающиеся в ответных действиях и т. д.
I---------------------------------------------------------------------------------------------------------------------------------------!
I---------------------------------------------------------------------------------------------------------------------------------------1
Рис. 6.1. Организация взаимодействия пользователя и ЭВМ
224
Данный режим является основным на современном этапе разви-
тия компьютерных систем обработки информации, характерной чер-
той которого является широкое внедрение практически во все сфе-
ры деятельности человека персональных компьютеров (ПК) — одно-
пользовательских микроЭВМ, удовлетворяющих требованиям обще-
доступности и универсальности применения. В настоящее время
пользователь, обладая знаниями основ информатики и вычислитель-
ной техники, сам разрабатывает алгоритм решения задачи, вводит
данные, получает результаты, оценивает их качество. У него имеют-
ся реальные возможности решать задачи с альтернативными вари-
антами, анализировать и выбирать с помощью системы в конкрет-
ных условиях наиболее приемлемый вариант. Основные этапы ре-
шения задач с помощью компьютера представлены на рис. 6.2.
Практика применения персональных компьютеров в различных
отраслях науки, техники и производства показала, что наибольшую
эффективность от внедрения вычислительной техники обеспечи-
вают не отдельные ПК, а вычислительные сети — совокупность
компьютеров и терминалов, соединенных с помощью каналов свя-
зи в единую систему распределенной обработки данных.
6.1.1. Поколения электронных вычислительных машин
Развитие электронных вычислительных машин можно условно
разбить на несколько этапов (поколений ЭВМ), которые имеют
свои характерные особенности.
Первый этап (ЭВМ первого поколения) — до конца 50-х годов
XX века.
Точкой отсчета эры ЭВМ считают 1946 г„ когда был создан первый
электронный цифровой компьютер «Эниак» (Electronic Numerical
Integrator and Computer). Вычислительные машины этого поколения
строились на электронных лампах, потребляющих огромное количе-
ство электроэнергии и выделяющих много тепла.
Числа в ЭВМ вводились с помощью перфокарт и набора пере-
ключателей, а программа задавалась соединением гнезд на специ-
альных наборных платах. Производительность такой гигантской
ЭВМ была ниже, чем современного калькулятора. Широкому ис-
пользованию этих ЭВМ, кроме дороговизны, препятствовали так-
же низкая надежность, ограниченность их ресурсов и чрезвычайно
трудоемкий процесс подготовки, ввод и отладка программ, написан-
ных на языке машинных команд. Основными их пользователями
15 А-2Ю
225
1. Постановка задачи:
* сбор информации о задаче;
формулировка условия задачи;
определение конечных целей решения задачи;
определение формы выдачи результатов;
описание данных (их типов, диапазонов величин, структуры и т. п.).
I -
2. Анализ и исследование задачи, модели:
анализ существующих аналогов;
анализ технических и программных средств;
разработка математической модели;
разработка структур данных.
3. Разработка алгоритма:
• выбор метода проектирования алгоритма;
выбор формы записи алгоритма (блок-схема, псевдокод и др.);
выбор тестов и метода тестирования;
* проектирование алгоритма.
4. Программирование:
выбор языка программирования;
уточнение способов организации данных;
запись алгоритма на выбранном языке программирования
5. Тестирование и отладка:
синтаксическая отладка;
отладка семантики и логической структуры;
тестовые расчеты и анализ результатов тестирования;
совершенствование программы
--- I
6. Анализ результатов решения задачи и уточнение
в случае необходимости математической модели
с повторным выполнением этапов 2—5
I
7. Сопровождение программы:
доработка программы для решения конкретных задач;
составление документации к решенной задаче,
математической модели, алгоритму, программе, по их использованию
Рис. 6.2. Этапы решения задач с помощью компьютера
226
были ученые, решавшие наиболее актуальные научно-техничес-
кие задачи, связанные с развитием реактивной авиации, ракетос-
троения и т. д.
Среди известных отечественных машин первого поколения не-
обходимо отметить БЭСМ-1 (большая электронная счетная ма-
шина), Стрела, Урал, М-20. Типичные характеристики ЭВМ пер-
вого поколения (на примере БЭСМ-1, 1953 г.): емкость памяти —
2048 слов; быстродействие — 7000—8000 оп./с; разрядность —
39 разрядов; арифметика — двоичная с плавающей запятой; сис-
тема команд — трехадресная; устройство ввода — перфолента;
количество электронных ламп в аппаратуре — около 4000; вне-
шние запоминающие устройства — барабаны на 5120 слов; маг-
нитная лента — до 120 000 слов; вывод на быструю цифровую
печать — 300 строк в минуту. Отечественная ЭВМ М-20 (20 тыс.
оп./с) была одной из самых быстродействующих машин первого
поколения в мире.
Основной режим использования машин первого поколения со-
стоял в том, что математик, составивший программу, садился за
пульт управления машиной и производил необходимые вычисле-
ния. Чаще всего работа за пультом была связана с отладкой своей
собственной программы — наиболее длительным по времени про-
цессом. При этом класс математика-программиста определялся его
умением быстро находить и исправлять ошибки в своих програм-
мах, хорошо ориентироваться за пультом ЭВМ.
В этот период началась интенсивная разработка средств авто-
матизации программирования, создание входных языков разных
уровней, создание систем обслуживания программ, упрощающих
работу на машине и увеличивающих эффективность ее использо-
вания.
Второй этап (ЭВМ второго поколения) — до середины 60-х го-
дов XX века.
Развитие электроники привело к изобретению в 1948 г. нового
полупроводникового устройства — транзистора, который заменил
лампы (создатели транзистора — сотрудники американской фир-
мы Bell Laboratories физики У. Шокли, У. Браттейн и Дж. Бардин
за это достижение были удостоены Нобелевской премии). Появ-
ление ЭВМ, построенных на транзисторах, привело к уменьшению
их габаритов, массы, энергопотребления и стоимости, а также
к увеличению их надежности и производительности. Одной из
227
первых транзисторных ЭВМ была созданная в 1955 г. бортовая
ЭВМ для межконтинентальной баллистической ракеты ATLAS.
Если с технической точки зрения переход к машинам второго
поколения четко очерчен переходом на полупроводники, то со
структурной точки зрения ЭВМ второго поколения характеризу-
ются расширенными возможностями по вводу-выводу, увеличен-
ным объемом запоминающих устройств, развитыми системами
программирования.
В рамках второго поколения все более четко проявляется диф-
ференциация ЭВМ на малые, средние и большие, позволившая
существенно расширить сферу применения ЭВМ, приступить
к созданию автоматизированных систем управления (АСУ) пред-
приятиями, целыми отраслями и технологическими процессами.
Стиль использования ЭВМ второго поколения характерен тем,
что теперь математик-программист не допускается в машинный
зал, а свою программу, обычно записанную на языке высокого
уровня, отдает в группу обслуживания, которая занимается даль-
нейшей обработкой его задачи — перфорированием и пропуском
на машине.
Среди известных отечественных машин второго поколения не-
обходимо отметить БЭСМ-4, М-220 (200 тыс. оп./с), Наири, Мир,
МИНСК, РАЗДАН, Днепр. Наилучшей отечественной ЭВМ второ-
го поколения считается БЭСМ-6, созданная в 1966 г. Она имела
основную и промежуточную память (на магнитных барабанах)
объемами соответственно 128 и 512 Кбайт, быстродействие поряд-
ка 1 млн оп./с и довольно обширную периферию (магнитные лен-
ты и диски, графопостроители, разнообразные устройства ввода-
вывода).
В этот период появились так называемые алгоритмические язы -
ки высокого уровня, средства которых допускают описание всей
необходимой последовательности вычислительных действий в на-
глядном, легко воспринимаемом виде. Программа, написанная на
алгоритмическом языке, непонятна компьютеру, воспринимающе-
му только язык своих собственных команд. Поэтому специальные
программы, которые называются трансляторами, переводят про-
грамму с языка высокого уровня на машинный язык.
Появился широкий набор библиотечных программ для реше-
ния разнообразных математических задач. Были созданы монитор-
ные системы, управляющие режимом трансляции и исполнения
программ. Из мониторных систем в дальнейшем выросли совре-
228
менные операционные системы (комплексы служебных программ,
обеспечивающих лучшее распределение ресурсов ЭВМ при испол-
нении пользовательских задач).
Первые ОС просто автоматизировали работу оператора ЭВМ,
связанную с выполнением задания пользователя: ввод в ЭВМ тек-
ста программы, вызов нужного транслятора, вызов необходимых
библиотечных программ и т. д. Теперь же вместе с программой и
данными в ЭВМ вводится еще и инструкция, где перечисляются
этапы обработки и приводится ряд сведений о программе и ее ав-
торе. Затем в ЭВМ стали вводить сразу по нескольку заданий
пользователей (пакет заданий), ОС стали распределять ресурсы
ЭВМ между этими заданиями — появился мультипрограммный
режим обработки.
Третий этап (ЭВМ третьего поколения) — до начала 70-х годов
XX века.
Элементной базой в ЭВМ третьего поколения являются интег-
ральные схемы. Создание технологии производства интегральных
схем, состоящих из десятков электронных элементов, образован-
ных в прямоугольной пластине кремния с длиной стороны не бо-
лее 1см, позволило увеличить быстродействие и надежность ЭВМ
на их основе, а также уменьшить габариты, потребляемую мощ-
ность и стоимость ЭВМ.
Машины третьего поколения — это семейство машин с единой
архитектурой, т. е. программно-совместимых. Они имеют разви-
тые операционные системы, обладают возможностями мульти-
программирования, т. е. одновременного выполнения нескольких
программ. Многие задачи управления памятью, устройствами и
ресурсами стала брать на себя операционная система или же не-
посредственно сама машина.
Примеры машин третьего поколения — семейство IBM-360,
IBM-370, PDP-8, PDP-11, отечественные ЕС ЭВМ (единая система
ЭВМ), СМ ЭВМ (семейство малых ЭВМ) и др.
Быстродействие машин внутри семейства изменяется от не-
скольких десятков тысяч до миллионов операций в секунду. Ем-
кость оперативной памяти достигает нескольких сотен тысяч слов.
В этот период широкое распространение получило семейство
мини-ЭВМ. Простота обслуживания мини-ЭВМ, их сравнительно
низкая стоимость и малые габариты позволяли снабдить этими
машинами небольшие коллективы исследователей, разработчиков-
экспериментаторов и т. д., т. е. дать ЭВМ прямо в руки пользовате-
229
лей. В начале 70-х годов с термином мини-ЭВМ связывали уже два
существенно различных типа средств вычислительной техники:
универсальный блок обработки данных и выдачи управляющих
сигналов, серийно выпускаемых для применения в различных
специализированных системах контроля и управления;
универсальную ЭВМ небольших габаритов, проблемно-ори-
ентированную пользователем на решение ограниченного
круга задач в рамках одной лаборатории, тех. участка и т. д.,
т. е. задач, в решении которых оказывались заинтересованы
10—20 человек, работавших над одной проблемой.
В период машин третьего поколения произошел крупный сдвиг
в области применения ЭВМ. Если раньше ЭВМ использовались в
основном для научно-технических расчетов, то в 60—70-е годы все
больше места стала занимать обработка символьной информации.
Четвертый этап (ЭВМ четвертого поколения) — по настоящее
время.
Этот этап условно делят на два периода: первый — до конца 70-х
годов и второй — с начала 80-х по настоящее время.
В первый период успехи в развитии электроники привели к со-
зданию больших интегральных схем (БИС), где в одном кристалле
размещалось несколько десятков тысяч электронных элементов. Это
позволило разработать более дешевые ЭВМ, имеющие большую
память и меньший цикл выполнения команд: стоимость байта памя-
ти и одной машинной операции резко снизилась. Но так как затра-
ты на программирование почти не сокращались, то на первый план
вышла задача экономии человеческих, а не машинных ресурсов.
Разрабатывались новые ОС, позволяющие программистам от-
лаживать свои программы прямо за дисплеем ЭВМ, что ускоряло
разработку программ. Это полностью противоречило концепци-
ям первых этапов информационной технологии: «процессор вы-
полняет лишь ту часть работы по обработке данных, которую прин-
ципиально люди выполнить не могут, т. е. массовый счет». Стала
прослеживаться другая тенденция: «все, что могут делать маши-
ны, должны делать машины; люди выполняют лишь ту часть рабо-
ты, которую нельзя автоматизировать».
В 1971 г. был изготовлен первый микропроцессор — большая
интегральная схема (БИС), в которой полностью размещался про-
цессор ЭВМ простой архитектуры. Стала реальной возможность
размещения в одной БИС почти всех электронных устройств не-
сложной по архитектуре ЭВМ, т. е. возможность серийного вы-
230
пуска простых ЭВМ малой стоимости. Появились дешевые мик-
рокалькуляторы и микроконтроллеры—управляющие устройства,
построенные на одной или нескольких БИС, содержащих процес-
сор, память и системы связи с датчиками и исполнительными орга-
нами в объекте управления. Программа управления объектами вво-
дилась в память ЭВМ либо при изготовлении, либо непосредствен-
но на предприятии.
В 70-х годах стали изготовлять и микро-ЭВМ — универсальные
вычислительные системы, состоящие из процессора, памяти, схем
сопряжения с устройствами ввода-вывода и тактового генерато-
ра, размещенных в одной БИС (однокристальная ЭВМ) или в не-
скольких БИС, установленных на одной плате (одноплатная ЭВМ).
Примерами отечественных ЭВМ этого периода являются СМ-1800,
«Электроника 60М» и др.
Во втором периоде улучшение технологии БИС позволяло из-
готовлять дешевые электронные схемы, содержащие сотни тысяч
элементов в кристалле — схемы сверхбольшой степени интегра-
ции — СБИС.
Появилась возможность создать настольный прибор с габари-
тами телевизора, в котором размещались микро-ЭВМ, клавиату-
ра, а также схемы сопряжения с малогабаритным печатающим ус-
тройством, измерительной аппаратурой, другими ЭВМ и т. п. Бла-
годаря ОС, обеспечивающей простоту общения с этой ЭВМ, боль-
шой библиотеки прикладных программ по различным отраслям
человеческой деятельности, а также малой стоимости такой пер-
сональный компьютер становится необходимой принадлежностью
любого специалиста и даже ребенка. Кроме функций помощника
в решении традиционных задач расчетного характера, персональ-
ный компьютер (ПК) может выполнять функции личного секрета-
ря; помогать в составлении личной картотеки; создавать, хранить,
редактировать и размножать тексты и т. п.
С точки зрения структуры машины этого поколения представ-
ляют собой многопроцессорные и многомашинные комплексы,
работающие на общую память и общее поле внешних устройств.
Для этого периода характерно широкое применение систем управ-
ления базами данных, компьютерных сетей, систем распределен-
ной обработки данных.
Последующие поколения ЭВМ будут представлять, по-видимо-
му, оптоэлектронные ЭВМ с массовым параллелизмом и нейрон-
ной структурой — с распределенной сетью большого числа (десят-
231
ки тысяч) несложных процессоров, моделирующих структуру ней-
ронных биологических систем, произойдет качественный переход
от обработки данных к обработке знаний.
6.1.2. Классификация средств обработки информации
Существуют различные системы классификации электронных
средств обработки информации: по архитектуре, по производи-
тельности, по условиям эксплуатации, по количеству процессоров,
по потребительским свойствам и т. д. Один из наиболее ранних
методов классификации — классификация по производительнос-
ти и характеру использования компьютеров. В соответствии с этой
классификацией компьютерные средства обработки можно услов-
но подразделить на:
микрокомпьютеры;
• мэйнфреймы;
* суперкомпьютеры.
Данная классификация достаточно условна, поскольку интен-
сивное развитие технологий производства электронных компонен-
тов и значительный прогресс в совершенствовании архитектуры
компьютеров и наиболее важных составляющих их элементов при-
водят к размыванию границ между указанными классами средств
вычислительной техники. Кроме того, рассмотренная классифи-
кация учитывает только автономное использование вычислитель-
ных систем. В настоящее время преобладает тенденция объедине-
ния разных вычислительных систем в вычислительные сети раз-
личного масштаба, что позволяет интегрировать информационно-
вычислительные ресурсы для наиболее эффективной реализации
информационных процессов (рис. 6.3).
Вычислительная (компьютерная) сеть — комплекс территори-
ально рассредоточенных ЭВМ и терминальных устройств, соединен-
ных между собой каналами передачи данных.
Оценка производительности ЭВМ всегда приблизительна так
как при этом ориентируются на некоторые усредненные или, на-
оборот, на конкретные виды операций. Реально при решении раз-
личных задач используются и различные наборы операций. Поэто-
му для характеристики ЭВМ вместо производительности обычно
указывают тактовую частоту, более объективно определяющую
232
быстродействие машины, так как каждая операция требует для
своего выполнения вполне определенного количества тактов.
Такт — время однократного срабатывания логического элемента.
Во всех ЭВМ есть специальное устройство — генератор так-
товой частоты, которое выдает так называемые тактирующие
импульсы, инициирующие срабатывание схем. Т. е. прежде чем
логический элемент снова выполнит какую-либо минимальную
функцию — микрооперацию, должно пройти некоторое время, на-
зываемое тактом. Зная тактовую частоту, можно достаточно точ-
но определить время выполнения любой машинной операции.
Часто для оценки производительности ЭВМ используют некото-
рое число MIPS (Mega Instruction Per Second — миллион команд в се-
кунду) или число FLOPS (FLoating Operations Per Second — операций
над числами с плавающей запятой (точкой) в секунду). Например:
— запись 50 MIPS (МИПС) означает 50 миллионов команд в секунду;
— 100 MFLOPS (МФЛОПС) — сто миллионов (Меда) операций
над числами с плавающей запятой (точкой) в секунду;
— 100 GFLOPS (ГФЛОПС) — сто миллиардов (Giga) операций
над числами с плавающей запятой (точкой) в секунду.
Рис. 6.3. Классификация компьютерных средств обработки информации
Микрокомпьютеры. Первоначально определяющим признаком
микрокомпьютера служило наличие в нем микропроцессора,
т. е. центрального процессора, выполненного в виде одной микро-
схемы. Сейчас микропроцессоры используются во всех без исклю-
233
чения классах ЭВМ, а к микрокомпьютерам относят более компак-
тные в сравнении с мэйнфреймами ЭВМ, имеющие производитель-
ность до сотен МИПС.
Современные модели микрокомпьютеров обладают нескольки-
ми микропроцессорами. Производительность компьютера опре-
деляется не только характеристиками применяемого микропроцес-
сора, но и емкостью оперативной памяти, типами периферийных
устройств, качеством конструктивных решений и др.
Микрокомпьютеры представляют собой инструменты для ре-
шения разнообразных сложных задач. Их микропроцессоры с каж-
дым годом увеличивают мощность, а периферийные устройства —
эффективность.
Разновидность микрокомпьютера — микроконтроллер. Это ос-
нованное на микропроцессоре специализированное устройство,
встраиваемое в систему управления или технологическую линию.
Персональные компьютеры (ПК) — это микрокомпьютеры уни-
версального назначения, рассчитанные на одного пользователя и
управляемые одним человеком. В класс персональных компьюте-
ров входят различные вычислительные машины — от дешевых до-
машних и игровых с небольшой оперативной памятью, с памятью
программы на кассетной ленте и обычным телевизором в качестве
дисплея (80-е годы), до сверхсложных машин с мощным процессо-
ром, винчестерским накопителем емкостью в десятки гигабайт,
с цветными графическими устройствами высокого разрешения, сред-
ствами мультимедиа и другими дополнительными устройствами.
Персональные компьютеры можно классифицировать и по кон-
структивным особенностям (рис. 6.4).
Рис. 6.4. Классификация ПК по конструктивным особенностям
234
Переносные компьютеры обычно нужны руководителям пред-
приятий, менеджерам, ученым, журналистам, которым приходит-
ся работать вне офиса — дома, на презентациях или во время ко-
мандировок.
Laptop (наколенник, от lap — колено и top — поверх) по раз-
мерам близок к обычному портфелю. По основным характерис-
тикам (быстродействие, память) примерно соответствует настоль-
ным ПК. Сейчас компьютеры этого типа уступают место еще
меньшим.
Notebook (блокнот, записная книжка) по размерам ближе к кни-
ге крупного формата. Имеет вес около 3 кг. Помещается в порт-
фель-дипломат. Для связи с офисом его обычно комплектуют мо-
демом. Ноутбуки зачастую снабжают приводами CD-ROM.
Многие современные ноутбуки включают в себя взаимозаме-
няемые блоки со стандартными разъемами. Такие модули предназ-
начены для очень разных функций. В одно и то же гнездо можно
по мере надобности вставлять привод компакт-дисков, накопитель
на магнитных дисках, запасную батарею или съемный винчестер.
Ноутбук устойчив к сбоям в энергопитании. Даже если он получа-
ет энергию от обычной электросети, в случае какого-либо сбоя он
мгновенно переходит на питание от аккумуляторов.
Palmtop (наладонник) — самые маленькие современные пер-
сональные компьютеры. Умещаются на ладони. Магнитные дис-
ки в них заменяет энергонезависимая электронная память. Нет и
накопителей на дисках — обмен информацией с обычными ком-
пьютерами идет по линиям связи. Если Palmtop дополнить набо-
ром деловых программ, записанных в его постоянную память, по-
лучится персональный цифровой помощник (Personal Digital
Assistant).
Возможности портативных компьютеров постоянно расширя-
ются. Например, современный карманный компьютер iPAQ 3150
располагает всем необходимым для ведения списка задач, хране-
ния записок, включая аудиофайлы, работы с календарем, чтения
электронной почты, синхронизации с ПК, мобильным телефоном.
Помимо этого iPAQ позволяет проигрывать видео- и звуковые ро-
лики, работать с Интернетом, просматривать и редактировать до-
кументы и электронные таблицы, хранить файлы, искать в них сло-
ва, просматривать картинки, вести домашнюю бухгалтерию,
235
играть в игры, читать электронные книги с помощью Microsoft
Reader, полноценно работать с программным обеспечением.
Мэйнфреймы. Предназначены для решения широкого класса
научно-технических задач и являются сложными и дорогими ма-
шинами. Их целесообразно применять в больших системах при
наличии не менее 200—300 рабочих мест.
Централизованная обработка данных на мэйнфрейме обходит-
ся примерно в 5—6 раз дешевле, чем распределенная обработка
при клиент-серверном подходе с использованием микроЭВМ.
Известный мэйнфрейм S/390 фирмы IBM обычно оснащается
не менее чем тремя процессорами. Максимальный объем опера-
тивного хранения достигает 342 терабайт.
Производительность его процессоров, пропускная способность
каналов, объем оперативного хранения позволяют наращивать
число рабочих мест в широком диапазоне с помощью простого
добавления процессорных плат, модулей оперативной памяти и
дисковых накопителей.
Несколько мэйнфреймов могут работать совместно под управле-
нием одной операционной системы над выполнением единой задачи.
Суперкомпьютеры. Это очень мощные компьютеры с произво-
дительностью свыше 100 МФЛОПС. Они называются сверхбыстро-
действующими. Создать такие высокопроизводительные ЭВМ по
современной технологии на одном микропроцессоре не представля-
ется возможным ввиду ограничения, обусловленного конечным зна-
чением скорости распространения электромагнитных волн (300 000
км/с), так как время распространения сигнала на расстояние несколь-
ко миллиметров (линейный размер стороны МП) при быстродействии
100 млрд оп./с становится соизмеримым со временем выполнения
одной операции. Поэтому суперЭВМ создаются в виде высокопарал-
лельных многопроцессорных вычислительных систем (МПВС).
6.1.3. Классификация программного обеспечения
Под программным обеспечением (Software) понимается сово-
купность программных средств для ЭВМ (систем ЭВМ), обеспечи-
вающих функционирование, диагностику и тестирование их ап-
паратных средств, а также разработку, отладку и выполнение лю-
бых задач пользователя с соответствующим документированием,
где в качестве пользователя может выступать как человек, так и
любое внешнее устройство, подключенное к ЭВМ и нуждающее-
ся в ее вычислительных ресурсах [1].
236
Программное обеспечение (Software) — совокупность программ,
выполняемых вычислительной системой, и необходимых для их экс-
плуатации документов.
К программному обеспечению (ПО) относится также вся об-
ласть деятельности по проектированию и разработке ПО:
технология проектирования программ (например, нисходя-
щее проектирование, структурное и объектно-ориентиро-
ванное проектирование и др.);
• методы тестирования программ;
анализ качества работы программ;
документирование программ;
разработка и использование программных средств, облегча-
ющих процесс проектирования программного обеспечения,
и многое другое.
Все программы по характеру использования и категориям
пользователей подразделяют на два класса — утилитарные про-
граммы и программные продукты (изделия) [14J.
Утилитарные программы («программы для себя») предназначе-
ны для удовлетворения нужд их разработчиков. Чаще всего ути-
литарные программы выполняют роль сервиса в технологии обра-
ботки данных либо являются программами решения функциональ-
ных задач, не предназначенных для широкого распространения.
Программные продукты (изделия) предназначены для удовлет-
ворения потребностей пользователей, широкого распространения
и продажи.
Программный продукт — программа или комплекс взаимосвязан-
ных программ для решения определенной проблемы {задачи) массо-
вого спроса, подготовленные к реализации как любой вид промыш-
ленной продукции.
Программные продукты можно классифицировать по разным
признакам. Наиболее общей является классификация, в которой
основополагающим признаком служит сфера (область) использо-
вания программных продуктов:
аппаратная часть компьютеров и сетей ЭВМ;
технология разработки программ;
функциональные задачи различных предметных областей.
237
Исходя из этого выделяют три класса программных продуктов:
системное программное обеспечение;
инструментарий технологии программирования;
пакеты прикладных программ.
Системное программное обеспечение ЭВМ
Системное программное обеспечение управляет всеми ресур-
сами ЭВМ (центральным процессором, памятью, вводом-выводом)
и осуществляет общую организацию процесса обработки инфор-
мации и интерфейсы между ЭВМ, пользователем, аппаратными и
программными средствами. Оно разрабатывается так, чтобы ком-
пьютер мог эффективно выполнять прикладные программы.
ч _____________________________________________________
Системное программное обеспечение (System Software) — сово-
купность программ и программных комплексов для обеспечения ра-
боты компьютеров и сетей ЭВМ.
Системное ПО тесно связано с типом компьютера, является его
неотъемлемой частью и имеет общий характер применения, неза-
висимо от специфики предметной области решаемых с помощью
ЭВМ задач.
Структура системного программного обеспечения представле-
на на рис. 6.5.
Рис. 6.5. Классификация системного программного обеспечения компьютера
238
Системное ПО состоит из базового программного обеспечения,
которое, как правило, поставляется вместе с компьютером, и сер-
висного программного обеспечения, которое может быть приоб-
ретено дополнительно.
В базовое программное обеспечение входят:
» базовая система ввода-вывода (BIOS-Basic Input/Output System);
операционная система (сетевая операционная система);
операционные оболочки.
Базовая система ввода-ввода (BIOS) представляет собой набор
программ, обеспечивающих взаимодействие операционной сис-
темы и других программ с различными устройствами компьютера
(клавиатурой, видеоадаптером, дисководом, таймером и др.).
В функции BIOS входят также автоматическое тестирование ос-
новных аппаратных компонентов (оперативной памяти и др.) при
включении машины, поиск на диске программы-загрузчика опе-
рационной системы и ее загрузка с диска в оперативную память.
Програмные модули BIOS находятся в постоянном запоминаю-
щем устройстве — ПЗУ (см. п. 7.2.3), они имеют определенные ад-
реса, благодаря чему все приложения могут использовать их для
реализации основных функций ввода-вывода.
BIOS (Basic Input/Output System — базовая система ввода-вывода) —
совокупность программ, предназначенных для автоматического тес-
тирования устройств после включения питания компьютера, загрузки
операционной системы в оперативную память и обеспечения взаимо-
действия операционной системы и приложений с различными устрой-
ствами компьютера.
Операционная система предназначена для управления выпол-
нением пользовательских программ, планирования и управления
вычислительными ресурсами ЭВМ. Она выполняет роль связую-
щего звена между аппаратурой компьютера, с одной стороны, и
выполняемыми программами, а также пользователем — с другой.
Операционная система обычно хранится во внешней памяти
компьютера — на диске. При включении компьютера, как было
отмечено выше, она считывается с дисковой памяти и размещает-
ся в оперативном запоминающем устройстве.
Этот процесс называется загрузкой операционной системы.
В функции операционной системы входит:
осуществление диалога с пользователем;
239
ввод-вывод и управление данными;
планирование и организация процесса обработки программ;
распределение ресурсов (оперативной памяти, процессора,
внешних устройств);
запуск программ на выполнение;
всевозможные вспомогательные операции обслуживания;
* передача информации между различными внутренними ус-
тройствами;
программная поддержка работы периферийных устройств
(дисплея, клавиатуры, дисковых накопителей, принтера и др.).
Операционную систему можно назвать программным продол-
жением устройства управления компьютера. Она скрывает от
пользователя сложные ненужные подробности взаимодействия с
аппаратурой, образуя прослойку между ними. В результате этого
люди освобождаются от очень трудоемкой работы по организации
взаимодействия с аппаратурой компьютера. >
Операционные системы для компьютеров делятся на:
одно- и многозадачные (в зависимости от возможного числа
запускаемых и выполняемых прикладных процессов);
одно- и многопользовательские (в зависимости от числа
пользователей, одновременно работающих с операционной
системой);
• несетевые и сетевые, обеспечивающие работу в локальной
вычислительной сети ЭВМ.
Операционная система для компьютера, ориентированного на
профессиональное применение, должна содержать следующие
основные программные компоненты:
управление вводом-выводом;
управление файловой системой;
• планирование процессов;
* анализ и выполнение команд, адресованных операционной си-
стеме.
Каждая операционная система имеет свой командный язык,
который позволяет пользователю выполнять те или иные действия:
обращаться к каталогу;
" выполнять разметку внешних носителей;
* запускать программы и др.
Анализ и исполнение команд пользователя, включая загрузку
готовых программ из файлов в оперативную память и их запуск,
осуществляет командный процессор операционной системы.
240
В секторе программного обеспечения и операционных систем
ведущее положение занимают фирмы IBM, Microsoft, UNISYS,
Novell. Рассмотрим наиболее распространенные типы операцион-
ных систем.
Операционная система MS DOS (Microsoft Disk Operating
System) — самая распространенная ОС на 16-разрядных персо-
нальных компьютерах. Она состоит из следующих основных мо-
дулей (рис. 6.6):
• блок начальной загрузки (Boot Record);
модуль расширения базовой системы ввода-вывода (IO.SYS);
модуль обработки прерываний (MSDOS.SYS);
командный процессор (COMMAND.COM);
утилиты MS DOS.
Каждый из указанных модулей выполняет определенную часть
функций, возложенных на ОС.
MS-DOS
Блок начальной
загрузки
(Boot Record)
Модуль расширения
базовой системы
ввода/вывода
(Io. SYS)
Модуль обработки
прерываний MS-DOS
ввода/вывода
(MsDos. SYS)
Командный
процессор
(Command.COM)
Утилиты
Format.COM, Chkdsk.COM,
Mode. COM, Graphics. COM,
FDisk. COM,...
Рис. 6.6. Состав операционной системы MS-DOS
Блок начальной загрузки (или просто загрузчик) — это очень
короткая программа, единственная функция которой заключает-
ся в считывании с диска в оперативную память двух других частей
DOS — модуля расширения базовой системы ввода-вывода и мо-
дуля обработки прерываний.
Модуль расширения базовой системы ввода-вывода дает воз-
можность использования дополнительных драйверов, обслужива-
ющих новые внешние устройства, а также драйверов для нестан-
дартного обслуживания внешних устройств.
Модуль обработки прерываний реализует основные высоко-
уровневые услуги DOS, поэтому его и называют основным.
Командный процессор DOS обрабатывает команды, вводимые
пользователем.
<6а-2ю 241
Утилиты DOS — это программы, поставляемые вместе с опера-
ционной системой в виде отдельных файлов. Они выполняют дей-
ствия обслуживающего характера, например разметку дискет,
проверку дисков и т. д.
Долгое время эта операционная система была установлена на
подавляющем большинстве персональных компьютеров. Начиная
с 1996 г. MS DOS была заменена ОС Windows — 32-разрядной мно-
гозадачной и многопоточной операционной системы с графичес-
ким интерфейсом и расширенными сетевыми возможностями.
Операционные системы Windows. Windows 95 представляет со-
бой универсальную высокопроизводительную многозадачную 32-
разрядную ОС с графическим интерфейсом и расширенными се-
тевыми возможностями. Windows 95 — интегрированная среда,
обеспечивающая эффективный обмен информацией между от-
дельными программами и предоставляющая пользователю широ-
кие возможности работы с мультимедиа, обработки текстовой,
графической, звуковой и видеоинформации. Интегрированность
подразумевает также совместное использование ресурсов компь-
ютера всеми программами.
Эта операционная система обеспечивает работу пользователя
в сети, предоставляя встроенные средства поддержки для обмена
файлами и меры по их защите, возможность совместного исполь-
зования принтеров, факсов и других общих ресурсов. Windows 95
позволяет отправлять сообщения электронной почтой, факсимиль-
ной связью, поддерживает удаленный доступ.
Windows 98 отличается от Windows 95 тем, что в ней операцион-
ная система объединена с браузером Internet Explorer. Кроме это-
го, в ней улучшена совместимость с новыми аппаратными сред-
ствами компьютера, она одинаково удобна как для использования
на настольных, так и на портативных компьютерах.
Windows NT (NT— от англ. New Technology) — 32-разрядная ОС
со встроенной сетевой поддержкой и развитыми многопользова-
тельскими средствами. Она предоставляет пользователям много-
задачность, надежность, многопроцессорную поддержку, секрет-
ность, защиту данных и многое другое. Эта операционная система
очень удобна для пользователей, работающих в рамках локальной
сети, для коллективных пользователей, особенно для групп, рабо-
тающих над большими проектами и обменивающихся данными.
Семейство Windows 2000 — операционная система нового поко-
ления для делового использования на самых разнообразных компь-
ютерах — от портативных до серверов. Эта ОС является одной из
лучших для ведения коммерческой деятельности в Интернете. Она
242
объединяет присущую Windows 98 простоту использования с прису-
щими Windows NT надежностью, экономичностью и безопасностью.
Семейство Windows ХР обладает улучшенной защитой систем-
ных файлов, программное обеспечение, поддерживающее запись
СД и СД-RW, включено в состав самой ОС, имеет ряд новых драй-
веров устройств, полностью настраиваемый интерфейс, а также
множество новых программ и мультимедийных добавлений. По-
мимо 32-разрядного варианта ОС имеется и 64-разрядная модифи-
кация, предназначенная для установки на компьютеры, оснащен-
ные 64-разрядным процессором.
Packet (Windows СЕ) — операционная система для мобильных
вычислительных устройств, таких как карманные компьютеры, циф-
ровые информационные пейджеры, сотовые телефоны, мультиме-
дийные и развлекательные приставки, включая DVD-проигрывате-
ли и устройства целевого доступа в Интернет. Это 32-разрядная,
многозадачная, многопоточная операционная система, имеющая от-
крытую архитектуру, разрешающую использование множества уст-
ройств. Packet (Windows СЕ) позволяет устройствам различных кате-
горий «говорить» и обмениваться информацией друг с другом, свя-
зываться с корпоративными сетями и с Интернетом, пользоваться
электронной почтой. Она компактна, но высокопроизводительна. Это
мобильная система, функционирующая с микропроцессорами раз-
личных марок и изготовителей.
Операционная система Unix была создана в Bell Telephone
Laboratories. Unix — многозадачная операционная система, способ-
ная обеспечить одновременную работу очень большого количество
пользователей. Ядро ОС Unix написано на языке высокого уровня
С и имеет только около 10% кода на ассемблере. Это позволяет за
считанные месяцы переносить ОС Unix на другие аппаратные плат-
формы и достаточно легко вносить в нее серьезные изменения и
дополнения. UNIX является первой действительно переносимой
операционной системой. В многочисленные существующие вер-
сии UNIX постоянно вносятся изменения. С одной стороны, это
расширяет возможности системы, делает ее мощнее и надежнее,
с другой — ведет к появлению различий между существующими
версиями. В связи с этим возникает необходимость стандартиза-
ции различных свойств системы. Наличие стандартов облегчает
переносимость приложений между различными версиями UNIX
и защищает как пользователей, так и производителей програм-
много обеспечения. Поэтому в 80-х годах разработан ряд стандар-
тов, оказывающих влияние на развитие UNIX. Сейчас существу-
ют десятки операционных систем, которые можно объединить под
общим названием UNIX. В основном это коммерческие версии,
243
выпущенные производителями аппаратных платформ для компь-
ютеров своего производства. Основными факторами, обеспечива-
ющим популярность UNIX, являются следующие:
1. Код системы написан на языке высокого уровня С, что сдела-
ло ее простой для понимания, изменения и переноса на другие плат-
формы. При этом UNIX является одной из наиболее открытых си-
стем.
2. UNIX — многозадачная многопользовательская система.
Один мощный сервер может обслуживать запросы большого ко-
личества пользователей. При этом необходимо администрирова-
ние только одной системы. Кроме того, система способна выпол-
нять большое количество различных функций, в частности рабо-
тать, как вычислительный сервер, как сервер базы данных, как
сетевой сервер, поддерживающий важнейшие сервисы сети, и т. д.
3. Наличие стандартов. Несмотря на разнообразие версий UNIX,
основой всего семейства являются принципиально одинаковая
архитектура и ряд стандартных интерфейсов. Для администрато-
ра переход на другую версию системы не составит большого тру-
да, а для пользователей он может и вовсе оказаться незаметным.
4. Простой, но мощный модульный пользовательский интер-
фейс. Имея в своем распоряжении набор утилит, каждая из кото-
рых решает узкую специализированную задачу, можно конструи-
ровать из них сложные комплексы.
5. Использование единой, легко обслуживаемой иерархической
файловой системы. Файловая система UNIX — это не только дос-
туп к данным, хранящимся на диске. Через унифицированный
интерфейс файловой системы осуществляется доступ к термина-
лам, принтерам, сети и т. п.
6. Большое количество приложений, в том числе свободно рас-
пространяемых, начиная от простейших текстовых редакторов и
заканчивая мощными системами управления базами данных.
Операционная система Linux. Начало созданию системы Linux
положено в 1991 г. финским студентом Линусом Торвальдсом (Linus
Torvalds). В сентябре 1991 г. он распространил по Интернету пер-
вый прототип своей операционной системы и призвал откликнуть-
ся на его работу всех, кому она нравится или нет. С этого момента
многие программисты стали поддерживать Linux, добавляя драй-
веры устройств, разрабатывая различные приложения и др. Атмос-
фера работы энтузиастов над полезным проектом, а также свобод-
ное распространение и использование исходных текстов стали ос-
новой феномена Linux. В настоящее время Linux — очень мощная
система, и при этом она бесплатная (free).
244
Л. Торвальдс разработал не саму операционную систему, а толь-
ко ее ядро, подключив уже имеющиеся компоненты. Довольно ско-
ро другие программисты стали насыщать ОС утилитами и приклад-
ным ПО. Недостаток такого подхода — отсутствие унифицирован-
ной и продуманной процедуры установки системы, и это до сих
пор является одним из главных сдерживающих факторов для бо-
лее широкого распространения Linux.
Традиционные стадии жизненного цикла программного продук-
та таковы: анализ требований, разработка спецификаций, проек-
тирование, макетирование, написание исходного текста, отладка,
документирование, тестирование и сопровождение. Главное, что
отличает этот подход, — централизация управления разными ста-
диями и преимущественно «нисходящая» разработка (т. е. посто-
янная детализация). Однако Linux создавалась по-иному. Готовый
работающий макет постоянно совершенствовался и развивался
децентрализованной группой энтузиастов, действия которых лишь
слегка координировались. Налицо «восходящая» разработка: сбор-
ка все более крупных блоков из ранее созданных мелких. Здесь
можно отметить и другое. При традиционной разработке в основу
кладется проектирование и написание текстов, при разработке по
методу Linux — макетирование, отладка и тестирование. Первые два
этапа распараллелить сложно, а с отладкой и тестированием дело
обстоит полегче. Иными словами, разработка по методу Linux — это
метод проб и ошибок, построенный на интенсивном тестировании.
Сетевое программное обеспечение предназначено для органи-
зации совместной работы группы пользователей на разных ком-
пьютерах. Оно позволяет организовать общую файловую струк-
туру, общие базы данных, доступные каждому члену группы, обес-
печивает возможность передачи сообщений и работы над общи-
ми проектами, возможность разделения ресурсов.
Основными функциями сетевых ОС являются:
управление каталогами и файлами;
управление ресурсами;
коммуникационные функции;
• защита от несанкционированного доступа;
" обеспечение отказоустойчивости;
управление сетью.
Управление каталогами и файлами в сетях заключается в обеспе-
чении доступа к данным, физически расположенным в других узлах
сети. Управление осуществляется с помощью специальной сетевой
файловой системы. Файловая система1 позволяет обращаться к фай-
245
лам путем применения привычных для локальной работы языковых
средств. При обмене файлами должен быть обеспечен необходи-
мый уровень конфиденциальности обмена (секретности данных).
Управление ресурсами включает в себя обслуживание запросов
на предоставление ресурсов, доступных по сети.
Коммуникационные функции обеспечивают адресацию, буфе-
ризацию, выбор направления для движения данных в разветвлен-
ной сети (маршрутизацию), управление потоками данных и др.
Разграничение доступа — важная функция, способствующая
поддержанию целостности данных и их конфиденциальности. Сред-
ства защиты могут разрешать доступ к определенным данным толь-
ко с некоторых терминалов, в оговоренное время, определенное чис-
ло раз и т. п. У каждого пользователя в корпоративной сети могут
быть свои права доступа с ограничением совокупности доступных
директорий или списка возможных действий, например, может быть
запрещено изменение содержимого некоторых файлов.
Отказоустойчивость характеризуется сохранением работос-
пособности системы при воздействии дестабилизирующих фак-
торов и обеспечивается применением для серверов автономных
источников питания, отображением или дублированием инфор-
мации в дисковых накопителях. Под отображением обычно пони-
мают наличие в системе двух копий данных с их расположением
на разных дисках, но подключенных к одному контроллеру. Дуб-
лирование отличается тем, что для каждого из дисков с копиями
используются разные контроллеры. Очевидно, что дублирование
более надежно. Дальнейшее повышение отказоустойчивости обус-
ловлено дублированием серверов, что однако требует дополнитель-
ных затрат на приобретение оборудования.
Управление сетью связано с применением соответствующих
протоколов управления. Программное обеспечение управления
сетью обычно состоит из менеджеров и агентов. Менеджером на-
зывается программа, вырабатывающая сетевые команды. Агенты
представляют собой программы, расположенные в различных уз-
лах сети. Они выполняют команды менеджеров, следят за состоя-
нием узлов, собирают информацию о параметрах их функциони-
рования, сигнализируют о происходящих событиях, фиксируют
аномалии, следят за трафиком, осуществляют защиту от вирусов.
Агенты с достаточной степенью интеллектуальности могут участво-
вать в восстановлении информации после сбоев, в корректировке
параметров управления и т. п.
246
Программное обеспечение сетевых ОС распределено по узлам
сети. Имеется ядро ОС, выполняющее большинство из охаракте-
ризованных выше функций, и дополнительные программы (служ-
бы), ориентированные на реализацию протоколов верхних уров-
ней, выполнение специфических функций для коммутационных
серверов, организацию распределенных вычислений и т. п. К се-
тевому программному обеспечению относят также драйверы се-
тевых плат. Для каждого типа ЛВС разработаны разные типы плат
и драйверов. Внутри каждого типа ЛВС может быть много разно-
видностей плат с разными характеристиками «интеллектуальнос-
ти», скорости, объема буферной памяти.
Среди распространенных сетевых ОС необходимо отметить
UNIX, Windows NT/2000/XP и Novell Netware.
ОС UNIX применяют преимущественно в крупных корпоратив-
ных сетях, поскольку эта система характеризуется высокой надеж-
ностью, возможностью легкого масштабирования сети. В UNIX име-
ется ряд команд и поддерживающих их программ для работы в сети.
Во-первых, это команды, реализующие файловый обмен и эмуляцию
удаленного узла на базе протоколов TCP/IP. Во-вторых, команды и
программы, разработанные с ориентацией на асинхронную модем-
ную связь по телефонным линиям между удаленными Unix-узла-
ми в корпоративных и территориальных сетях.
ОС Windows NT включает в себя серверную (Windows NT Server)
и клиентскую (Windows NT Workstation) версии и тем самым обес-
печивает работу в системах «клиент-сервер». Windows NT обычно
применяют в средних по масштабам сетях.
ОС Novell Netware состоит из серверной части и оболочек, раз-
мещаемых в клиентских узлах. Предоставляет пользователям воз-
можность совместно использовать файлы, принтеры и другое обо-
рудование. Содержит службу каталогов, общую распределенную
базу данных пользователей и ресурсов сети. Эта ОС наиболее при-
менима в небольших сетях.
Операционные оболочки — специальные программы, предназ-
наченные для облегчения общения пользователя с командами опе-
рационной системы. Операционные оболочки имеют текстовый и
графический варианты интерфейса конечного пользователя.
Наиболее популярны следующие виды текстовых и графичес-
ких оболочек операционной системы Windows (MS DOS):
Norton Commander;
Far;
" Windows Commander;
247
XTree Gold 4.0;
Norton Navigator и др.
Эти программы существенно упрощают задание управляющей
информации для выполнения команд операционной системы, умень-
шают напряженность и сложность работы конечного пользователя.
Например, пакет программ Norton Commander обеспечивает:
• создание, копирование, пересылку, переименование, удале-
ние, поиск файлов, а также изменение их атрибутов;
отображение дерева каталогов и характеристик входящих
в них файлов в форме, удобной для восприятия человека;
создание, обновление и распаковку архивов (групп сжатых
файлов);
просмотр текстовых файлов;
• редактирование текстовых файлов;
выполнение из ее среды практически всех команд DOS;
запуск программ;
выдачу информации о ресурсах компьютера;
создание и удаление каталогов;
поддержку межкомпьютерной связи;
поддержку электронной почты через модем и др.
Сервисное программное обеспечение. Расширением базового
программного обеспечения компьютера является набор сервис-
ных, дополнительно устанавливаемых программ, которые можно
классифицировать по функциональному признаку следующим об-
разом [14]:
* программы контроля, тестирования и диагностики, которые
используются для проверки правильности функционирова-
ния устройств компьютера и для обнаружения неисправно-
стей в процессе эксплуатации; указывают причину и место
неисправности;
программы-драйверы, которые расширяют возможности
операционной системы по управлению устройствами ввода-
вывода, оперативной памятью и т. д.; с помощью драйверов
возможно подключение к компьютеру новых устройств или
нестандартное использование имеющихся;
программы-упаковщики (архиваторы), которые позволяют
записывать информацию на дисках более плотно, а также
объединять копии нескольких файлов в один архивный файл;
антивирусные программы, предназначенные для предотвра-
щения заражения компьютерными вирусами и ликвидации
последствий заражения вирусами;
248
программы оптимизации и контроля качества дискового про-
странства;
программы восстановления информации, форматирования,
защиты данных;
коммуникационные программы, организующие обмен ин-
формацией между компьютерами;
программы для управления памятью, обеспечивающие бо-
лее гибкое использование оперативной памяти;
программы обслуживания сети;
• программы для записи CD-ROM, CD-R и многие другие.
Эти программы часто называются утилитами. Они либо расши-
ряют и дополняют соответствующие возможности операционной
системы, либо решают самостоятельные важные задачи.
Утилиты (от лат. utilitas — польза) — программы, служащие для
выполнения вспомогательных операций обработки данных или обслу-
живания компьютеров (диагностики, тестирования аппаратных и про-
граммных средств, оптимизации использования дискового простран-
ства, восстановления разрушенной на магнитном диске информации
и т. п.).
Часть утилит входит в состав операционной системы, другая
часть функционирует независимо от нее — автономно.
Инструментарий технологии программирования
Инструментарий технологии программирования обеспечива-
ет процесс разработки программ и включает специализирован-
ные программные продукты, которые являются инструменталь-
ными средствами разработчика. Программные продукты данно-
го класса поддерживают все технологические этапы процесса
проектирования, программирования (кодирования), отладки и те-
стирования создаваемых программ. Пользователями технологии
программирования выступают системные и прикладные програм-
мисты.
Инструментарий технологии программирования — совокуп-
ность программ и программных комплексов, обеспечивающих техно-
логию разработки, отладки и внедрения создаваемых программ.
249
Выделяют следующие группы инструментальных средств тех-
нологии программирования (рис. 6.7) [14]:
• средства для создания приложений, включающие:
— локальные средства, обеспечивающие выполнение от-
дельных работ по созданию программ;
— интегрированные среды разработчиков программ, обес-
печивающие выполнение комплекса взаимосвязанных
работ по созданию программ;
CASE-технология (Computer-Aided System Engineering), пред-
ставляющая методы анализа, проектирования и создания про-
граммных систем и предназначенная для автоматизации про-
цессов разработки и реализации информационных систем.
Рис. 6.7. Классификация инструментария технологии программирования
Рассмотрим средства для создания приложений более подробно.
Локальные средства разработки программ наиболее представи-
тельны на рынке программных продуктов и состоят из языков и
систем программирования, а также инструментальной среды
пользователя.
Язык программирования — формализованный язык для описания
алгоритма решения задачи на компьютере.
250
Языки программирования, если в качестве признака классифи-
кации взять синтаксис образования его конструкций, можно ус-
ловно разделить на классы:
машинные языки (computer language) — языки программи-
рования, воспринимаемые аппаратной частью компьютера
(машинные коды);
• машинно-ориентированные языки (computer-oriented
language) — языки программирования, которые отражают
структуру конкретного типа компьютера (ассемблеры);
• алгоритмические языки (algorithmic language) — не завися-
щие от архитектуры компьютера языки программирования
для отражения структуры алгоритма (Паскаль, Фортран, Бей-
сик и др.);
• процедурно-ориентированные языки (procedure-oriented
language) — языки программирования, где имеется возмож-
ность описания программы как совокупности процедур (под-
программ);
проблемно-ориентированные языки (universal programming
language) — языки программирования, предназначенные
для решения задач определенного класса (Лисп, Симула
и др.);
интегрированные системы программирования.
Программа, подготовленная на языке программирования высо-
кого уровня, проходит этап трансляции.
Трансляторы реализуются в виде компиляторов или интерпре-
таторов. С точки зрения выполнения работы компилятор и интер-
претатор существенно различаются.
Компилятор (от англ, compiler — составитель, собиратель) читает
всю программу целиком, делает ее перевод и создает законченный ва-
риант программы на машинном языке, который затем и выполняется.
Интерпретатор (от англ, interpreter—истолкователь, устный пере-
водчик) переводит и выполняет программу построчно.
После того как программа откомпилирована, ни сама исход-
ная программа, ни компилятор более не нужны. В то же время
251
программа, обрабатываемая интерпретатором, должна заново пе-
реводиться на машинный язык при каждом очередном запуске
программы.
Откомпилированные программы работают быстрее, но интер-
претируемые проще исправлять и изменять.
Современные системы программирования обычно предостав-
ляют пользователям мощные и удобные средства разработки про-
грамм. В них входят:
компилятор или интерпретатор;
« интегрированная среда разработки;
средства создания и редактирования текстов программ;
« обширные библиотеки стандартных программ и функций;
отладочные программы, т. е. программы, помогающие нахо-
дить и устранять ошибки в программе;
«дружественная» к пользователю диалоговая среда;
многооконный режим работы;
мощные графические библиотеки;
« утилиты для работы с библиотеками;
встроенный ассемблер;
встроенная справочная служба и др.
При создании сложных прикладных систем часто возникает
необходимость использования машинно-ориентированных ассем-
блерных программ. При этом с целью повышения быстродействия
или сокращения требуемых объемов памяти на ассемблере иног-
да составляется значительное количество прикладных процедур
Помимо языка ассемблера, который дает возможность использо-
вать все особенности машины и потому может быть применен для
решения задач любого типа, существуют языки программирова-
ния высокого уровня, ориентированные на различные классы за-
дач. К ним относятся: Фортран, Паскаль и Си.
Язык Фортран — один из самых старых языков высокого уров-
ня, активно используется на персональных компьютерах. Приме-
няется он главным образом при разработке прикладных систем,
ориентированных на научные исследования, автоматизацию про-
ектирования и другие области, где уже накоплены обширные стан-
дартные библиотеки программ. Имеется несколько версий этого
языка, из которых наиболее популярна версия Фортран-90, отдель-
ные элементы которой реализованы в Microsoft Fortran, а в пол-
ном объеме — в Fortran PowerStation.
252
Язык Паскаль, выпущенный в 1969 г., — сегодня один из широ-
ко распространенных алгоритмических языков, компиляторы с
которого разработаны для компьютеров практически всех архи-
тектур. Существует несколько развитых диалектов языка, снаб-
женных разнообразными дополнительными инструментариями
и средствами поддержки разработки программного обеспечения.
В качестве примера можно назвать средства Borland для персо-
нальных компьютеров. Паскаль является классическим языком
программирования, который первоначально был создан как учеб-
ный язык и лишь позже стал применяться для решения научных
задач.
Язык Си, в отличие от Паскаля, с момента своего появления
(1972 г.) был ориентирован на разработку системных программ.
Он, в частности, послужил главным инструментом для создания
многих операционных систем и программных продуктов. В этом
языке имеются более гибкие средства для эффективного исполь-
зования особенностей аппаратуры, чем в Паскале. Благодаря это-
му порождаемые машинные программы, как правило, более ком-
пактны и работают быстрее, чем программы, полученные Пас-
каль-трансляторами. С другой стороны, синтаксис языка Си ме-
нее прозрачен, чем у Паскаля; возможностей для внесения оши-
бок больше; чтение текстов программ требует определенного
навыка. В связи с этим язык Си применяется главным образом
для создания системных и прикладных программ, в которых ско-
рость работы и объем памяти являются критическими парамет-
рами.
Несмотря на то что Паскаль представляется как ортодоксаль-
ный язык, а Си позволяет программисту точнее учитывать ап-
паратные особенности, в целом эти языки сравнимы. Основны-
ми достоинствами, необходимыми при построении больших про-
граммных систем, у этих языков являются возможность работы
с данными сложной структуры; наличие развитых средств для
выделения отдельных частей программ в процедуры, модуль-
ность, т. е. возможность независимой разработки отдельных
частей программ и последующего их связывания в единую сис-
тему.
Недостатками подхода, реализованного в процедурных языках,
выступают сложность организации процесса внесения в систему
изменений, обязательное последовательное выполнение всех эта-
253
пов разработки, несовместимость с эволюционным подходом и, как
следствие, слабая пригодность их для разработки сложных про-
граммных систем. Развитием процедурных языков является объек-
тно-ориентированный подход, впервые возникший в комплекте с
компилятором Turbo Pascal 5.5. Начиная с Turbo Pascal 6.0 в пакет
входит библиотека Turbo Vision, позднее перенесенная в среду
Turbo С + +. Данные библиотеки основаны на объектно-ориенти-
рованном программировании и принципах построения программ,
управляемых событиями. Объектно-ориентированный подход
представляет собой последовательный итеративный процесс, ко-
торый позволяет безболезненно вносить изменения в уже отла-
женный программный продукт и в котором результаты одного из
этапов могут влиять на решения, принятые на предыдущих.
Наиболее полное отражение концепция объектно-ориентиро-
ванного программирования и визуального подхода к построению
приложений нашла в языках для разработки Windows приложе-
ний: Visual Basic, Delphi, Си + +. Общим для них является про-
стота и наглядность процесса создания программ, основанных на
использовании технологий визуального программирования. Ком-
понентный подход позволяет легко и быстро создавать не только
интерфейс программ, но и достаточно сложные механизмы дос-
тупа к данным, а также проверять и тиражировать удачные про-
граммные решения. Несмотря на идентичность идеологии, зало-
женной в данных языках, в их применении имеются отличия. Со-
временные тенденции показывают, что Delphi ориентируется
фирмой Inprise (прежнее название — Borland) на создание пол-
ноценных распределенных корпоративных систем доступа к дан-
ным. Visual Basic (фирмы Microsoft) применяется в основном для
создания приложений и расширений для готовых программных
продуктов под Windows и Веб-приложения, a Visual Си+ +
(Microsoft) и Borland C++ Builder используется для разработки
интернет-обозревателей, корпоративных приложений и опера-
ционных систем.
Инструментальная среда пользователя представлена специаль-
ными средствами, встроенными в пакеты прикладных программ,
такими как:
• библиотека функций, процедур, объектов и методов обра-
ботки;
254
макрокоманды;
клавишные макросы;
языковые макросы;
программные модули-вставки;
конструкторы экранных форм и отчетов;
генераторы приложений;
языки запросов высокого уровня;
• языки манипулирования данными;
конструкторы меню и многое другое.
Дальнейшим развитием локальных средств разработки про-
грамм, которые объединяют набор средств для комплексного их
применения на всех технологических этапах создания программ,
являются интегрированные программные среды разработчиков.
Основное назначение инструментария данного вида — повыше-
ние производительности труда программистов, автоматизация со-
здания кодов программ, обеспечивающих интерфейс пользовате-
ля графического типа, разработка приложений для архитектуры
клиент-сервер, запросов и отчетов.
Пакеты прикладных программ
Пакеты прикладных программ (ППП) служат программным
инструментарием решения функциональных задач и являются са-
мым многочисленным классом программных продуктов. В данный
класс входят программные продукты, выполняющие обработку
информации различных предметных областей.
Пакет прикладных программ (application program package) — ком-
плекс взаимосвязанных программ для решения задач определенного
класса конкретной предметной области.
Единую классификацию ППП провести затруднительно ввиду
большого разнообразия решаемых на ЭВМ задач и соответствую-
щих им ППП. В общем случае ППП могут быть разделены на два
больших класса: общего назначения и специального назначения.
К ППП общего назначения можно отнести наиболее распрост-
раненные программные продукты, такие как текстовые и таблич-
ные процессоры, графические редакторы, системы управления
базами данных, различные интегрированные пакеты и др.
255
Текстовый редактор — программа, используемая специально для
ввода и редактирования текстовых данных.
Текстовые редакторы могут обеспечивать выполнение разно-
образных функций, а именно:
и редактирование строк текста;
возможность использования различных шрифтов символов;
• копирование и перенос части текста с одного места на дру-
гое или из одного документа в другой;
контекстный поиск и замена частей текста;
задание произвольных межстрочных промежутков;
автоматический перенос слов на новую строку;
автоматическая нумерация страниц;
обработка и нумерация сносок;
выравнивание краев абзаца;
создание таблиц и построение диаграмм;
проверка правописания слов и подбор синонимов;
• построение оглавлений и предметных указателей;
распечатка подготовленного текста на принтере в нужном
количестве экземпляров и т. п.
Возможности текстовых редакторов различны — от программ,
предназначенных для подготовки небольших документов простой
структуры, до программ для набора, оформления и полной подго-
товки к типографскому изданию книг и журналов (издательские
системы).
Наиболее известный текстовый редактор — Microsoft Word.
Графический редактор — программа, предназначенная для авто -
матизации процессов построения на экране дисплея графических
изображений.
Графический редактор предоставляет возможности рисования
линий, кривых, раскраски областей экрана, создания надписей
различными шрифтами и т. д. Большинство редакторов позволя-
ют обрабатывать изображения, полученные с помощью сканеров,
а также выводить картинки в таком виде, чтобы они могли быть
включены в документ, подготовленный с помощью текстового ре-
дактора.
256
Некоторые редакторы позволяют получать изображения трех-
мерных объектов, их сечений, разворотов, каркасных моделей
и т. п.
Пользуется известностью Corel DRAW— мощный графический
редактор с функциями создания публикаций, снабженный инст-
рументами для редактирования графики и трехмерного модели-
рования.
Табличный процессор — комплекс взаимосвязанных программ,
предназначенный для обработки электронных таблиц.
Электронная таблица — компьютерный эквивалент обычной
таблицы, состоящей из строк и столбцов, на пересечении которых
располагаются ячейки, содержащие числовую информацию, форму-
лы или текст.
Значение в числовой ячейке таблицы может быть либо введе-
но, либо рассчитано по соответствующей формуле; в формуле мо-
гут присутствовать обращения к другим ячейкам.
Каждый раз при изменении значения в ячейке таблицы в ре-
зультате ввода в нее нового значения с клавиатуры пересчитыва-
ются также значения во всех тех ячейках, в которых стоят величи-
ны, зависящие от данной ячейки.
Столбцам и строкам можно присваивать наименования. Экран
монитора трактуется как окно, через которое можно рассматри-
вать таблицу целиком или по частям.
Табличные процессоры представляют собой удобное средство
для проведения бухгалтерских и статистических расчетов. В каж-
дом пакете имеются сотни встроенных математических функций
и алгоритмов статистической обработки данных. Кроме того, име-
ются мощные средства для связи таблиц между собой, создания и
редактирования электронных баз данных.
Специальные средства позволяют автоматически получать и
распечатывать настраиваемые отчеты с использованием десятков
различных типов таблиц, графиков, диаграмм, снабжать их ком-
ментариями и графическими иллюстрациями.
Табличные процессоры имеют встроенную справочную систе-
му, предоставляющую пользователю информацию по конкретным
командам меню и другие справочные данные. Многомерные таб-
лицы позволяют быстро делать выборки в базе данных по любому
критерию.
17 А-210
257
Самые популярные табличные процессоры — Microsoft Excel и
Lotus 1—2—3.
В Microsoft Excel автоматизированы многие рутинные операции,
специальные шаблоны помогают создавать отчеты, импортировать
данные и многое другое.
Lotus 1—2—3 — профессиональный процессор электронных таб-
лиц. Широкие графические возможности и удобный интерфейс паке-
та позволяют быстро ориентироваться в нем. С его помощью можно
создать любой финансовый документ, отчет для бухгалтерии, соста-
вить бюджет, а затем разместить все эти документы в базах данных.
База данных — это один или несколько файлов данных, предназ-
наченных для хранения, изменения и обработки больших объемов вза-
имосвязанной информации.
В базе данных предприятия, например, может храниться:
вся информация о штатном расписании, о рабочих и служа-
щих предприятия;
сведения о материальных ценностях;
данные о поступлении сырья и комплектующих;
" сведения о запасах на складах;
данные о выпуске готовой продукции;
приказы и распоряжения дирекции и т. п.
Даже небольшие изменения какой-либо информации могут
приводить к значительным изменениям в разных других местах.
Базы данных используются под управлением систем управле-
ния базами данных (СУБД).
Система управления базами данных (СУБД) — система про-
граммного обеспечения, позволяющая обрабатывать обращения
к базе данных, поступающие от прикладных программ конечных
пользователей.
Системы управления базами данных дают возможность объ-
единять большие объемы информации и обрабатывать их, сорти-
ровать, делать выборки по определенным критериям и т. п. Совре-
менные СУБД дают возможность включать в них не только тек-
стовую и графическую информацию, но и звуковые фрагменты и
даже видеоклипы. Простота использования СУБД позволяет созда-
258
вать новые базы данных, не прибегая к программированию,
а пользуясь только встроенными функциями.
СУБД обеспечивают правильность, полноту и непротиворечи-
вость данных, а также удобный доступ к ним.
Популярные СУБД — FoxPro, Access for Windows, Paradox.
Для менее сложных задач вместо СУБД используются инфор-
мационно-поисковые системы (ИПС), которые выполняют следу-
ющие функции:
хранение большого объема информации;
быстрый поиск требуемой информации;
• добавление, удаление и изменение хранимой информации;
вывод ее в удобном для человека виде.
Интегрированные пакеты представляют собой набор нескольких
программных продуктов, объединенных в единый удобный инстру-
мент.
Наиболее развитые из них состоят из текстового редактора, орга-
найзера, электронной таблицы, СУБД, средств поддержки электрон-
ной почты, программы создания презентационной графики.
Результаты, полученные отдельными подпрограммами, могут
быть объединены в окончательный документ, содержащий таблич-
ный, графический и текстовый материал.
Интегрированные пакеты, как правило, включают в себя неко-
торое ядро, обеспечивающее возможность тесного взаимодей-
ствия между составляющими.
Наиболее распространенным интегрированным пакетом явля-
ется Microsoft Office. В этот мощный профессиональный пакет вош-
ли такие необходимые программы, как текстовый редактор
Win Word, электронная таблица Excel, программа создания презен-
таций PowerPoint, СУБД Access, средство поддержки электронной
почты Mail. При этом, все части этого пакета составляют единое
целое, и даже внешне все программы выглядят единообразно, что
облегчает как их освоение, так и ежедневное использование.
ППП специального назначения предназначены для решения за-
дач в некоторой предметной области.
Например, одним из наиболее эффективных и распространен-
ных программных средств моделирования сложных дискретных
систем на персональных ЭВМ является ППП GPSS (General Purpose
259
Simulating System). Он успешно используется для моделирования
систем, формализованных в виде систем массового обслуживания.
Язык GPSS построен на предположении, что моделью сложной дис-
кретной системы является описание ее элементов и логических
правил их взаимовлияния в процессе функционирования модели-
руемой системы. Далее предполагается, что для определенного
класса моделируемых систем можно выделить небольшой набор
абстрактных элементов, называемых объектами. Причем набор ло-
гических правил также ограничен и может быть описан неболь-
шим числом стандартных операций. Комплекс программ, описы-
вающих функционирование объектов и выполняющих логические
операции, является основой для создания программной модели
системы данного класса. Эта идея и была реализована при разра-
ботке языка GPSS.
На сегодняшний день среди широко известных программных
сред для проведения научно-технических расчетов можно выде-
лить: MathCad, MatLab и Mathematica. Важным достоинством сре-
ды MathCad является возможность записи алгоритмов в есте-
ственном научно-техническом виде. Данная среда на сегодняш-
ний день является одной из наиболее удобных сред для проведе-
ния математических расчетов. В последних реализациях MathCad
значительно облегчен ввод математических выражений, увели-
чено число встроенных процедур и приложений, расширены воз-
можности языка программирования, усовершенствованы сред-
ства обмена с Windows приложениями. Наглядность среды, а так-
же большое количество разнообразной литературы делают эту
среду весьма привлекательной для проведения имитационного
моделирования.
Среда MatLab (Matrix Laboratory — матричная лаборатория)
предложенная фирмой The MathWorks Inc. представляет собой
апробированную и надежную систему, рассчитанную на реше-
ние широкого круга инженерных задач с представлением дан-
ных в универсальной матричной форме. Благодаря интеграции
в ней среды Maple, разработанной фирмой Waterloo Maple
Software, так же как и в MathCad, среда MatLab позволяет при-
менять символьную запись математических выражений. Широ-
кому применению MatLab при имитационном моделировании
способствует не только разнообразный набор матричных и иных
операций и функций, но и наличие большого количества спе-
260
циализированных расширений. Так, версия MatLab 5.0/5.3 рас-
пространяется с 35 расширениями, самое мощное из которых
Simulink for Windows непосредственно предназначено для про-
ведения имитационного моделирования. Важным достоинством
системы является ее открытость и расширяемость, а также при-
способляемость к решению широкого класса задач. Расширяе-
мость достигается за счет встроенного языка программирова-
ния. При этом язык системы MatLab в части программирования
математических вычислений намного богаче большинства уни-
версальных языков программирования высокого уровня. Он
реализует почти все известные средства программирования, в
том числе объектно-ориентированное и визуальное программи-
рование. Расширения системы хранятся на жестком диске ком-
пьютера и вызываются в нужный момент без какого-либо пред-
варительного объявления или описания, необходимого в боль-
шинстве универсальных языков программирования. При этом
по скорости выполнения задач эта система превосходит другие
подобные системы.
Универсальная среда Mathematica разработана фирмой Wolfram
Relearch, является мощным средством для математических и дру-
гих вычислений и выполняет численные, аналитические и графи-
ческие операции. Ввод и представление информации, графичес-
кая оболочка среды, набор дополнительных библиотек — все со-
ответствует самым современным требованиям и тенденциям.
Встроенный, высокого уровня, язык программирования позволя-
ет быстро и качественно решать разнообразные инженерные за-
дачи, имеет богатые возможности для визуализации данных и ре-
зультатов расчетов. По богатству и разнообразию средств высо-
кого уровня данная среда уникальна. Пакет позволяет создавать
интерактивные документы, объединяющие в себе текст, анимацию
и активные формулы.
6.2. ПРЕОБРАЗОВАНИЕ АНАЛОГОВОЙ ИНФОРМАЦИИ
В ЦИФРОВУЮ ФОРМУ
При использовании ЭВМ для обработки информации от различ-
ных устройств (объектов, процессов), в которых информация пред-
ставлена непрерывными (аналоговыми) сигналами, требуется пре-
261
образовать аналоговый сигнал в цифровой — в число, пропорцио-
нальное амплитуде этого сигнала, и наоборот.
В общем случае процедура аналого-цифрового преобразования
состоит из трех этапов [8]:
дискретизации;
квантования по уровню;
* кодирования.
Под дискретизацией понимают преобразование функции непре-
рывного времени в функцию дискретного времени, а сам процесс дис-
кретизации состоит в замене непрерывной функции ее отдельными
значениями в фиксированные моменты времени.
г)
Рис. 6.8. Процесс аналого-
цифрового преобразования
Дискретизация может быть
равномерной и неравномерной.
При неравномерной дискрети-
зации длительность интервалов
между отсчетами различна. Наи-
более часто применяется равно-
мерная дискретизации, при кото-
рой длительность интервала меж-
ду отсчетами Тд постоянна. Пери-
од дискретизации Т непрерывно-
го сигнала u(t) (рис. 6.8 а) выбира-
ется в соответствии с теоремой
Котельникова:
Т=—, (6.1)
д 2Fe
где Fb — высшая частота в спектре
частот сигнала u(t) (рис. 6.8 б).
Под квантованием понимают
преобразование некоторой вели-
чины с непрерывной шкалой зна-
чений в величину, имеющую дис-
кретную шкалу значений.
Для этого весь диапазон значе-
ний сигнала u(t), называемый шка-
262
лой, делится на равные части — кванты, h — шаг квантования. Про-
цесс квантования сводится к замене любого мгновенного значе-
ния одним из конечного множества разрешенных значений, на-
зываемых уровнями квантования.
Вид сигнала u(t) в результате совместного проведения опера-
ций дискретизации и квантования представлен на рис. 6.8 в.
Дискретизированное значение сигнала u(t), находящееся меж-
ду двумя уровнями квантования, отождествляется либо с ближай-
шим уровнем квантования, либо с ближайшим меньшим (или боль-
шим) уровнем квантования. Это приводит к ошибкам квантования,
которые всегда меньше шага квантования (кванта), т. е. чем мень-
ше шаг квантования, тем меньше погрешность квантования, но
больше уровней квантования. Для ускорения процесса преобра-
зования, упрощения и удешевления преобразователя надо выби-
рать максимально допустимый шаг квантования, при котором по-
грешности еще не выходят за допустимые пределы.
Число уровней квантования на рис. 6.8 в равно 8. Обычно их
значительно больше. Можно провести нумерацию уровней и вы-
разить их в двоичной системе счисления. Д ля восьми уровней дос-
таточно трех двоичных разрядов. Каждое дискретное значение
сигнала представляется в этом случае двоичным кодом (табл. 6.1)
в виде последовательности сигналов двух уровней.
Таблица 6.1
Значение уровня Двоичное представление значения уровня
6 011
5 101
4 001
5 101
6 011
7 111
Наличие или отсутствие импульса на определенном месте ин-
терпретируется единицей или нолем в соответствующем разряде
двоичного числа. Цифровая форма представления сигнала u(t) по-
казана на рис. 6.8 г. Импульсы старших разрядов расположены
крайними справа.
Таким образом, в результате дискретизации, квантования
и кодирования аналогового сигнала получаем последовательность
263
n-разрядных кодовых комбинаций, которые следуют с периодом
дискретизации Т. При этом рациональное выполнение операций
дискретизации и квантования приводит к значительному эконо-
мическому эффекту как за счет снижения затрат на хранение и
обработку получаемой информации, так и вследствие сокращения
времени обработки информации.
Рассмотрим в качестве примера аналого-цифровое преобразо-
вание речевого сигнала при использовании его в цифровых систе-
мах передачи. Согласно рекомендациям Международного консуль-
тативного комитета по телефонии и телеграфии для передачи те-
лефонных сообщений достаточна полоса частот от 300 до 3400 Гц,
динамический диапазон — до 35 дБ. При этом слоговая разборчи-
вость, определенная экспериментально, составляет 90%. Так как
в реальном телефонном канале данная полоса частот выделяется
фильтром, имеющим конечный спад частотной характеристики,
в качестве расчетной ширины спектра стандартного телефонного
канала используют ширину полосы частот в 4 кГц.
Для дискретизации такого сигнала в соответствии с формулой
(6.1) частота дискретизации fg=2FB при FB=4 кГц равна 1=8 кГц, что
соответствует максимальному периоду дискретизации сигнала
Tg=l/f = 125 мкс. Данные период и частота дискретизации приня-
ты в качестве основы при разработке стандартов цифровых сис-
тем передачи.
Для кодирования квантованных значений амплитуды аналого-
вого сигнала используют, как правило, 7- или 8-битный двоичный
код, обеспечивающий соответственно N=2’= 128 или N=28 = 256
уровней квантования. Это гарантирует передачу качественного
речевого сигнала с динамическим диапазоном по амплитуде
D= 201g 128 = 42 дБ или D = 201g256 = 48 дБ соответственно. При
этом скорость передачи такого цифрового потока при 7-битном
кодировании равна 8 кГц х 7 бит = 56 кбит/с, при 8-битном коди-
ровании — 8 кГц х 8 бит = 64 кбит/с.
На практике преобразование аналогового сигнала в цифровую
форму осуществляется с помощью аналого-цифрового преобразо-
вателя (АЦП). Для решения обратной задачи преобразования чис-
ла в пропорциональную аналоговую величину, представленную
в виде электрического напряжения, тока и т. п. служит цифроана-
логовый преобразователь (ЦАП). В ЦАП каждая двоичная кодовая
комбинация преобразуется в аналоговый сигнал и на выходе со-
здается последовательность модулированных по амплитуде им-
264
пульсов с периодом Т . Восстановление аналоговой структуры про-
изводится при помощи специальных схем, обеспечивающих филь-
трацию либо экстраполяцию этих сигналов.
В основе построения ЦАП лежит принцип суперпозиции токов
(напряжений), каждый из которых пропорционален шагу кванто-
вания. При этом член суммы не равен 0, если соответствующий
разряд входного слова равен 1. На рис. 6.9 представлена одна из
наиболее простых схем ЦАП, включающая:
« источник опорного напряжения (ИОН), Е;
аналоговые ключи (АК);
цепи формирования выходных сигналов (резистивные цепи).
Рис. 6.9. Цифроаналоговый преобразователь с весовыми резисторами
На вход ЦАП поступает п-разрядный код преобразуемого чис-
ла X. Состояние электронного ключа определяется значением со-
ответствующего разряда преобразуемого числа, при этом, если
двоичный разряд числа равен единице, то соответствующий рези-
стор соединяется с источником опорного напряжения Е, в против-
265
ном случае ключ разомкнут. Сопротивления резисторов подбира-
ют следующим образом:
R0=2°R;
R1=2‘R;
Кп., = 2"^..
При этом на выходе ЦАП для каждого кода имеем:
Л-1 г Л-1
1=0 К i=0
где х. — значение /-го разряда входного двоичного кода.
Точность такого преобразования определяется разрядностью
ЦАП, а также точностью изготовления резисторов и стабильнос-
тью опорного напряжения Е. Для уменьшения количества номи-
налов резисторов используют цепную схему, составленную из
вдвое большего числа резисторов всего лишь двух номиналов —
Rn2R.
Цифроаналоговые преобразователи могут преобразовывать
в аналоговый сигнал лишь параллельные коды. При преобразова-
нии в аналоговый сигнал последовательных кодов их сначала пре-
образуют в параллельные.
Схема простейшего АЦП представлена на рис. 6.10. Она вклю-
чает в себя суммирующий счетчик, ЦАП, сравнивающее устрой-
ство (К-компаратор) и генератор тактовых импульсов (ГТИ).
По принципу действия такой АЦП называется последователь-
ным. Временные диаграммы на рис. 6.11 поясняют принцип его
работы. На один вход компаратора поступает входной сигнал Ubx.
На другой — формируемое ЦАП напряжение порога срабатыва-
ния компаратора. При достижении равенства данного напряже-
ния и напряжения входного сигнала на выходе компаратора появ-
ляется сигнал, останавливающий счет и суммирование тактовых
импульсов в суммирующем счетчике. Одновременно считывается
выходной цифровой код хдхг.лп.
Основной недостаток такой схемы — низкое быстродействие,
так как время преобразования Тпр пропорционально амплитуде
сигнала.
266
Рис. 6.10. Схема простейшего каскада АЦП
Значительно большим быстродействием отличаются АЦП па-
раллельного кодирования. В них для преобразования аналогового
сигнала в л-разрядный двоичный код используется 2П1 компарато-
ра. На один из двух дифференциальных входов каждого компара-
тора подается свое опорное напряжение, формируемое резистор-
ным делителем. Разность между опорными напряжениями двух
ближайших компараторов равна Е/2, где Е — опорное напряже-
ние, соответствующее максимальному значению преобразуемого
аналогового сигнала. Другие входы компараторов объединены, и
на них подается входной сигнал. Приоритетный шифратор фор-
мирует выходной цифровой сигнал, соответствующий самому
старшему сработавшему компаратору.
Способ параллельного кодирования (иногда он называется спо-
собом мгновенного кодирования) отличается наибольшим быст-
родействием. Время задержки при передаче сигнала от входа
к выходу равно сумме запаздываний компараторов и шифратора.
267
Ш1ШМ
Рис. 6.11. Временные диаграммы работы АЦП
В некритичных к быстродействию применениях используют
также преобразователи, построенные по методу двойного интег-
рирования. Такие преобразователи состоят из конденсатора (ин-
тегрирующий элемент), который в течение фиксированного про-
межутка времени заряжается током, пропорциональным входно-
му сигналу, после чего он разряжается до тех пор, пока напряже-
ние на нем не станет равным нолю. Время разряда конденсатора
пропорционально значению входного сигнала и используется для
подсчета тактовых импульсов фиксированной частоты при помо-
щи счетчика. Полученное число, пропорциональное входному
уровню, является выходным цифровым сигналом.
6.3. ФУНКЦИОНАЛЬНАЯ И СТРУКТУРНАЯ
ОРГАНИЗАЦИЯ ПРОЦЕССОРНЫХ УСТРОЙСТВ
ОБРАБОТКИ ИНФОРМАЦИИ
6.3.1. Общая структура процессорных устройств
обработки информации и принципы фон Неймана
Со времени появления в 40-х годах XX века первых электрон-
ных цифровых вычислительных машин технология их производ-
ства была значительно усовершенствована. В последние годы бла-
годаря развитию интегральной технологии существенно улучши-
268
лись их характеристики, значительно снизилась стоимость. Одна-
ко, несмотря на успехи, достигнутые в области технологии, суще-
ственных изменений в базовой структуре и принципах работы
вычислительных машин не произошло. Так, в основу построения
подавляющего большинства современных компьютеров положе-
ны общие принципы функционирования универсальных вычис-
лительных устройств, сформулированные еще в 1945 г. американ-
ским ученым Джоном фон Нейманом.
Согласно фон Нейману, для того чтобы ЭВМ была универсаль-
ным и эффективным устройством обработки информации, она
должна строиться в соответствии со следующими принципами:
1. Информация кодируется в двоичной форме и разделяется на
единицы (элементы) информации, называемые словами.
Использование в ЭВМ двоичных кодов продиктовано в первую
очередь спецификой электронных схем, применяемых для пере-
дачи, хранения и преобразования информации. Как уже отмеча-
лось, в этом случае конструкция ЭВМ предельно упрощается, и
ЭВМ работает наиболее надежно (устойчиво). Совокупности но-
лей и единиц (битов информации), используемые для представле-
ния отдельных чисел, команд и т. п., рассматриваются как само-
стоятельные информационные объекты и называются словами.
Слово обрабатывается в ЭВМ как одно целое — как машинный эле-
мент информации.
2. Разнотипные слова информации хранятся в одной и той же
памяти и различаются по способу использования, но не по спосо-
бу кодирования.
Все слова, представляющие числа, команды и прочие объекты,
выглядят в ЭВМ совершенно одинаково, и сами по себе неразли-
чимы. Только порядок использования слов в программе вносит
различия в слова. Благодаря такому «однообразию» слов оказыва-
ется возможным использовать одни и те же операции для обра-
ботки слов различной природы, например для обработки и чисел,
и команд, т. е. команды программы становятся в такой же степени
доступными для отработки, как и числа.
3. Слова информации размещаются в ячейках памяти машины
и идентифицируются номерами ячеек, называемыми адресами
слов.
Структурно основная память состоит из перенумерованных
ячеек. Ячейка памяти выделяется для хранения значения величи-
ны, в частности константы или команды. Чтобы записать слово
269
в память, необходимо указать адрес ячейки, отведенной для хра-
нения соответствующей величины. Чтобы выбрать слово из памя-
ти (прочитать его), следует опять же указать адрес ячейки памяти.
То есть адрес ячейки, в которой хранится величина или команда,
становится машинным идентификатором (именем) величины и ко-
манды. Таким образом, единственным средством для обозначения
величин и команд в ЭВМ являются адреса, присваиваемые вели-
чинам и командам в процессе составления программы вычисле-
ний. При этом выборка (чтение) слова из памяти не разрушает
информацию, хранимую в ячейке. Это позволяет любое слово, за-
писанное однажды, читать какое угодно число раз, т. е. из памяти
выбираются не слова, а копии слов.
4. Алгоритм представляется в форме последовательности управ-
ляющих слов, называемых командами, которые определяют наи-
менование операции и слова информации, участвующие в опера-
ции. Алгоритм, представленный в терминах машинных команд,
называется программой.
В общем случае алгоритм в ЭВМ представляется в виде упоря-
доченной последовательности команд следующего вида:
bb...b bb...b bb...b... bb...b.
t 1___ I 1 1 I
коп A, A2 Ak
Здесь b — двоичная переменная, принимающая значение 0 или
1. Определенное число первых разрядов команды характеризует
код операции (КОП). Например, операция сложения может пред-
ставляться в команде кодом 001010. Последующие наборы двоич-
ных переменных bb ... b определяют адреса А(,..., Ак операндов (ар-
гументов и результатов), участвующих в операции, заданной ко-
дом КОП.
На рис. 6.12 в общем виде представлен формат (структура) ко-
манды.
1 ...т 1...п 1...п_______________1 ...п
КОП Ai а2 Ак
Рис. 6.12. Общая структура команды
Составные части команды называют полями. Так, КОП, А/(..., Ак —
поля команды, представляющие соответственно код операции и
270
адреса операндов, участвующих в операции. Сверху указаны но-
мера разрядов полей: поле КОП состоит из т двоичных разрядов,
каждое поле А,,..., Ак содержит п двоичных разрядов. С учетом это-
го представленная на рис. 6.12 команда позволяет инициировать
одну из 2т операций, и каждый адрес может принимать до 2П раз-
личных значений, обеспечивая ссылку на любую из 2Л величин или
команд. Требуемый порядок вычислений предопределяется алго-
ритмом и описывается последовательностью команд, образующих
программу вычислений.
5. Выполнение вычислений, предписанных алгоритмом, сводит-
ся к последовательному выполнению команд в порядке, однознач-
но определяемом программой.
Первой выполняется команда, заданная пусковым адресом
программы. Обычно это адрес первой команды программы. Ад-
рес следующей команды однозначно определяется в процессе
выполнения текущей команды и может быть либо адресом сле-
дующей по порядку команды, либо адресом любой другой ко-
манды. Процесс вычислений продолжается до тех пор, пока не
будет выполнена команда, предписывающая прекращение вы-
числений.
Необходимо подчеркнуть, что вычисления, производимые ма-
шиной, определяются программой. Именно программа «настраи-
вает» ЭВМ на получение требуемых результатов. Замена програм-
мы приводит к изменению функций, реализуемых ЭВМ. Следова-
тельно, многообразие программ, которые могут быть выполнены
ЭВМ, определяет класс функций, который способна реализовать
данная ЭВМ.
Перечисленные принципы функционирования ЭВМ предпола-
гают, что компьютер должен иметь следующие устройства:
арифметико-логическое устройство (ААУ), выполняющее
арифметические и логические операции;
устройство управления (УУ), которое организует процесс
выполнения программы;
запоминающее устройство (ЗУ), или память для хранения
программ и данных;
* внешние устройства для ввода (устройства ввода) и вывода
(устройства вывода) информации.
При рассмотрении компьютерных устройств принято различать
их архитектуру и структуру.
271
Под архитектурой ЭВМ понимают ее логическую организацию,
состав и назначение ее функциональных средств, принципы кодиро-
вания и т. п., т. е. все то, что однозначно определяет процесс обработ-
ки информации на данной ЭВМ.
ЭВМ, построенные в соответствии с принципами фон Нейма-
на, называют фон-неймановскими, или компьютерами фон-ней-
мановской (классической) архитектуры.
Структура ЭВМ — совокупность элементов компьютера и связей
между ними.
Ввиду большой сложности современных ЭВМ принято пред-
ставлять их структуру иерархически, т. е. понятие «элемент» жес-
тко не фиксируется. Так, на самом высоком уровне сама ЭВМ мо-
жет считаться элементом. На следующем (программном) уровне
иерархии элементами структуры ЭВМ являются память, процес-
сор, устройства ввода-вывода и т. д. На более низком уровне (мик-
ропрограммном) элементами служат узлы и блоки, из которых
строятся память, процессор и т. д. Наконец, на самых низких уров-
нях элементами выступают интегральные логические микросхе-
мы и электронные приборы.
Несмотря на разнообразие современных компьютеров, обоб-
щенная структурная схема подавляющего большинства из них
может быть представлена схемой, изображенной на рис. 6.13.
Рис. 6.13. Обобщенная структурная схема ЭВМ
272
Все устройства ЭВМ соединены линиями связи, по которым
передаются информационные и управляющие сигналы, а синхро-
низация процессов передачи осуществляется при помощи такто-
вых импульсов, вырабатываемых генератором тактовых импуль-
сов (ГТИ).
Устройство управления и арифметико-логическое устройство
в современных компьютерах объединены в один блок — процес-
сор, предназначенный для обработки данных по заданной програм-
ме путем выполнения арифметических и логических операций и
программного управления работой устройств компьютера.
Процессор (центральный процессор, ЦП) — программно-управля-
емое устройство, осуществляющее процесс обработки цифровой ин-
формации, управление им и координацию работы всех устройств ком-
пьютера.
Процессор, построенный на одной или нескольких больших интег-
ральных микросхемах, называют микропроцессором.
Как было отмечено выше, микропроцессор включает в себя:
арифметико-логическое устройство (АЛУ), предназначенное
для выполнения всех арифметических и логических опера-
ций над числовой и символьной информацией. Для ускоре-
ния выполнения арифметических операций с плавающей
точкой к АЛУ подключается дополнительный математичес-
кий сопроцессор;
устройство управления (УУ) — формирует и подает во все
блоки машины в нужные моменты времени определенные
сигналы управления (управляющие импульсы), обусловлен-
ные спецификой выполняемой операции и результатами
предыдущих операций; формирует адреса ячеек памяти, ис-
пользуемых выполняемой операцией, и передает эти адреса
в соответствующие блоки ЭВМ; опорную последователь-
ность импульсов устройство управления получает от гене-
ратора тактовых импульсов (ГТИ).
Для кратковременного хранения, записи и выдачи информации,
непосредственно используемой в вычислениях в ЦП имеется про-
цессорная память (ПП), состоящая из специализированных ячеек
памяти, называемых регистрами.
18а-210 273
В общем случае регистры состоят из элементов памяти, каж-
дый из которых может находиться в одном из двух устойчивых со-
стояний: конденсатор заряжен или разряжен, транзистор находит-
ся в проводящем или непроводящем состоянии, специальный по-
лупроводниковый материал имеет высокое или низкое удельное
сопротивление и т. п. Одно из таких физических состояний созда-
ет высокий уровень выходного напряжения элемента памяти, а
другое — низкий. Например, электрическое напряжение порядка
5В может приниматься за двоичную единицу, а ОВ — за двоичный
ноль [6].
Регистры часто изображают так, как показано на рис. 6.14 а.
Регистр характеризуется единственным числом: количеством би-
тов, которые могут в нем храниться. Помещенная в регистр ин-
формация остается там до тех пор, пока она не будет заменена дру-
гой. Процесс чтения информации из регистра не влияет на содер-
жимое последнего, другими словами, операция чтения информа-
ции, хранимой в регистре, сводится к созданию копии его содер-
жимого, оригинал же сохраняется в регистре без изменений.
а) Номер бита 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
00001011 01000111
б)
Регистр
(источник информации)
в)
Регистр
(источник информации)
(приемник информации)
Рис. 6.14. Регистры, шины и вентильные схемы
274
Шина состоит из параллельных проводов, каждый из которых
предназначен для передачи соответствующего бита регистра (рис.
6.146). Если два 8-битовых регистра соединяются между собой ши-
ной из восьми проводов, то говорят, что ее ширина равна 8, или
восьмиразрядная шина. В действительности шина обычно содер-
жит несколько дополнительных проводов, используемых для пе-
редачи сигналов синхронизации и управления.
Шина служит для передачи информации лишь в направлении,
обозначенном стрелкой на шине (рис. 6.14 б, в). Такая однонап-
равленность передачи обусловлена не свойствами шины (прово-
да, из которых состоит шина, позволяют передавать сигналы в лю-
бом направлении), а характеристиками схем, соединяющих шину
с регистром или другими устройствами ЭВМ. Специальные схемы
дают возможность, например, в одни моменты времени передавать
информацию по шине в одну сторону, а в другие — в обратном
направлении, т. е. организовать двунаправленную шину. Такие
электронные ключевые схемы, предназначенные для управления
потоком информации из регистров в шины и обратно, называют
вентильными схемами. На рис. 6.14 в показано применение вен-
тильной схемы В. Такая схема имеет два входа и один выход. На
один вход подается информационный сигнал (данные с регистра),
а на другой — управляющий. Если управляющий сигнал равен еди-
нице, то данные проходят через схему, а если нолю — информация
через схему не пройдет. Таким образом, при подаче единичного
управляющего сигнала на вентильную схему В состояние регист-
ра приемника информации изменится с (00100110)2 на (10011101)2,
т. е. в него поступит копия содержимого регистра источника ин-
формации.
Простейшим вариантом организации взаимодействия между
процессором и любым другим устройством ЭВМ было бы исполь-
зование отдельного набора проводов для подключения данного
устройства к процессору. При этом количество проводов и разъе-
мов процессора было бы неимоверно большим. В большинстве
современных ЭВМ для организации процессов обмена информа-
цией между различными устройствами ЭВМ используется общая
шина (системная магистраль). Физически магистраль представля-
ет собой многопроводную линию с гнездами для подключения элек-
тронных схем. Совокупность средств сопряжения и связи уст-
ройств компьютера, обеспечивающая их эффективное взаимодей-
ствие, называют интерфейсом.
275
Системный интерфейс — набор цепей, связывающих процес-
сор с памятью и контроллерами внешних устройств, алгоритм пере-
дачи сигналов по этим цепям, их электрические параметры и тип
соединительных элементов.
Для согласования интерфейсов периферийные устройства подклю-
чаются к шине не напрямую, а через свои контроллеры (адаптеры).
Устройства ввода обеспечивают считывание информации (ис-
ходных данных и программы решения задачи) с определенных
носителей информации (клавиатур, магнитных лент или дисков,
датчиков состояний управляемых объектов и т. п.) и ее представ-
ление в форме электрических сигналов, воспринимаемых други-
ми устройствами ЭВМ.
Устройства вывода представляют результаты обработки инфор-
мации в форме, удобной для визуального восприятия (индикато-
ры, печатающие устройства, графопостроители, экран дисплея
ит. п.). При необходимости они обеспечивают запоминание ре-
зультатов на носителях, с которых эти результаты могут быть сно-
ва введены в ЭВМ для дальнейшей обработки, или передачу ре-
зультатов на исполнительные органы управляемого объекта (на-
пример, робота, станка с программным управлением и т. п.).
Память ЭВМ, или ЗУ, обеспечивает хранение команд и данных.
Это устройство состоит из блоков одинакового размера — ячеек
памяти, предназначенных для хранения одного слова информации
(рис. 6.15). В свою очередь, ячейка памяти включает в себя элемен-
ты памяти, состояние каждого из которых соответствует одной
двоичной цифре (0 или 1). Совокупность нолей и единиц, храня-
щихся в элементах одной ячейки, представляет собой содержимое
этой ячейки памяти [6].
Ячейки нумеруются числами 0, 1, 2, ... , называемыми адресом
ячеек. Запись в память слова осуществляется подачей на шину ад-
реса памяти сигналов, соответствующих адресу ячейки, в которую
надо поместить записываемое слово, и подачей самого слова на
шину записи (см. рис. 6.15). Память устроена так, что заданное сло-
во будет передано в ячейку с указанным адресом для хранения,
причем в любой момент, обратившись к памяти, можно получить
содержимое хранимого там слова. Для этого в память посылается
адрес, определяющий местоположение требуемого слова, и она
выдает по шине чтения копию слова.
276
Рис. 6.15. Организация памяти ЭВМ
При считывании содержимое ячейки остается без изменения,
так что, один раз записав слово, можно сколько угодно раз полу-
чать его копии. Это аналогично записи информации на магнито-
фонную ленту. Запись можно прослушивать с ленты (читать с лен-
ты) сколько угодно раз, но если на ее место записать другую ин-
формацию, то первая будет стерта. Однако время доступа к ин-
формации на магнитной ленте зависит от того, где записана эта
информация (иногда надо перемотать почти всю ленту, чтобы най-
ти нужную запись), тогда как время доступа к любой ячейке памя-
ти всегда одинаково (не зависит от ее номера).
На рис. 6.15 показана память, имеющая 4096 = 212 8-разрядных
слов, т. е. содержащая 4096 байт информации. При том же самом
числе запоминающих элементов можно было бы организовать па-
мять из 32 768 1-битовых слов; 2048 16-битовых слов, 1024 32-бито-
вых слов и т. д.
Тактовые импульсы вырабатываются генератором тактовых
импульсов ЭВМ и используются для синхронизации процессов пе-
редачи информации между устройствами ЭВМ. Необходимость
распределения во времени отдельных операций по передаче инфор-
мации в цифровых устройствах рассмотрим на примере работы
упрощенной модели школьного микрокалькулятора (рис. 6.16 а) [6].
277
Рис. 6.16. Структурно-функциональная схема микрокалькулятора и управляющие
сигналы: а) при вводе первой цифры слагаемого; б) при вводе второй цифры;
в) при нажатии клавиши « + »
В состав микрокалькулятора входят:
цифровая (0, 1,.... 9, «.») и функциональная (С, %, х,-*-, — , +,
=) клавиатуры;
основной регистр X, в который вводится операнд (набирае-
мое на клавиатуре число) и по окончании какой-либо опера-
ции засылается ее результат (сумма, разность и т. п.);
табло для индикации содержимого регистра X, т. е. вводимого
числа (в момент набора его на цифровой клавиатуре) или резуль-
тата вычислений (после нажатия функциональной клавиши);
вспомогательный регистр У, в который переписывается со-
держимое регистра X при вводе в последний нового операн-
да (это позволяет, например, сохранить в У значение преды-
дущего слагаемого или ранее накопленной суммы в момент
ввода в X нового слагаемого);
278
* арифметико-логическое устройство (АЛУ), предназначенное
для выполнения операций над содержимым регистров Хи У
(сложение, умножение, вычитание и деление) или только
регистра X (извлечение квадратного корня и нахождение
процентов), а также ряда служебных операций (например,
сдвига старших цифр числа при вводе его новой цифры);
• устройство управления вводом числа и выполнением опера-
ций, которое после любого нажатия цифровой или функци-
ональной клавиши вырабатывает определенную последова-
тельность управляющих сигналов (У.) для осуществления не-
обходимых пересылок информации между устройствами
микрокалькулятора и (или) перестройки АЛУ на ту или иную
операцию.
Рассмотрим работу микрокалькулятора при сложении чисел
27 + 48+129 + 36... [6]. При этом для удобства будем использовать
десятичное представление цифр в регистрах микрокалькулятора.
Начнем с момента нажатия клавиши « + », завершающей ввод пер-
вого слагаемого, т. е. с момента, когда в регистрах содержатся сле-
дующие числа:
Регистр У О
Регистр X 27
1 -й шаг. Ввод цифры 4 — старшей цифры второго слагаемого:
Регистр У 27
Регистр X 4
Содержимое регистра X переписалось для сохранения в регистр
У, регистр X был очищен и в его младший разряд записан код на-
жатой клавиши, т. е. цифра 4.
Рассмотрим последовательность управляющих сигналов У, вы-
рабатываемых при этом устройством управления.
Ввод первой цифры любого операнда (первое нажатие цифро-
вой клавиши после выполнения какой-либо операции) должен
инициировать перепись содержимого регистра X в регистр У,
т. е. выработку управляющего сигнала УЗ (рис. 6.16 а). Одновре-
менно с этим сигналом может быть выработан сигнал Уб, устанавли-
вающий 0 на выходе АЛУ. Теперь производятся очистка регистра X,
суммирование его содержимого с вводимой цифрой и перезапись
полученной суммы в регистр X. Для этого сначала подается сигнал
У2 (0 с выхода АЛУ переписывается в регистр X), затем одновре-
279
27
48
менно сигналы У7, У1 и У5 (У7 для настройки АЛУ на суммирова-
ние) и, наконец, сигнал У2.
2-й шаг. Ввод цифры 8 — младшей цифры второго слагаемого:
Регистр У
Регистр X
Число, содержащееся в регистре X, было сдвинуто влево на один
разряд, а в освободившийся младший разряд записан код нажатой
клавиши, т. е. цифра 8.
Рассмотрим последовательность управляющих сигналов У, вы-
рабатываемых устройством управления на втором шаге.
Ввод второй цифры (или любой из следующих) осуществляет-
ся путем умножения на 10 (сдвига влево на один десятичный раз-
ряд) содержимого регистра X и суммирования сдвинутого значе-
ния с вводимой цифрой. Для этого вырабатывается последователь-
ность управляющих сигналов, показанная на рис. 6.16 6 (сигнал У8
служит для организации сдвига).
3-й шаг. Нажатие клавиши « + »:
Регистр У 27
Регистр X 75
Зафиксировался ввод последней цифры второго слагаемого (48),
выполнились операция сложения содержимого регистров X и У
(48 + 27 = 75) и операция пересылки полученного результата в ре-
гистр X.
Суммирование содержимого регистров X и У (сигналы У7, У1 и
У4) и перезапись полученной суммы в регистр X (сигнал У2) иллю-
стрируются временной диаграммой на рис. 6.16 в.
4-й шаг. Ввод цифры 1 — старшей цифры третьего слагаемого:
Регистр У
Регистр X
Содержимое регистра X переписалось для сохранения в регистр
У, регистр X был очищен и в его младший разряд записан код на-
жатой клавиши, т. е. цифра 1. Дальнейшие шаги не представляют
интереса, так как в них будут повторяться ранее описанные опе-
рации.
Анализ временных диаграмм на рис. 6.16 а, б, в показывает, что
некоторые из управляющих сигналов вырабатываются одновре-
менно, а другие — через те или иные интервалы времени. Напри-
75
1
280
мер, нельзя при суммировании содержимого регистров X и У од-
новременно вырабатывать сигналы У1, У2, У4, У7, так как при од-
новременной выработке сигналов У1 и У2, а также при настройке
АЛУ на выполнение какой-либо операции с содержимым регист-
ра X возникает полная неопределенность: содержимое регистра X
попадает в АЛУ, через него обратно в регистр X и т. д. В то же вре-
мя, если при суммировании X и У не будет обеспечена одновре-
менная выработка сигналов У1, У4 и У7, то суммы не получится.
Минимальный промежуток времени Т между управляющими
сигналами, которые должны быть сдвинуты относительно друг
друга (например, промежуток времени между сигналами У1 и У2
на рис. 6.16 в), выбирается исходя из максимального времени пе-
реключения элементов цифрового устройства (пока, например, не
окончилось формирование суммы X+Y, бессмысленно подавать
управляющий сигнал У2 на перезапись этой суммы в регистр X).
Для задания нужных временных интервалов в управляющих уст-
ройствах ЭВМ устанавливаются генераторы тактовых импульсов
(ГТИ), синхронизирующие управляющие сигналы У .
Генератор тактовых импульсов генерирует последовательность
электрических импульсов, частота которых определяет тактовую
частоту ЭВМ. Промежуток времени между соседними импульса-
ми определяет время одного такта работы ЭВМ, или просто такт
работы ЭВМ. Частота генератора тактовых импульсов является
одной из основных характеристик компьютера и во многом опре-
деляет скорость его работы, так как каждая операция в ЭВМ вы-
полняется за определенное количество тактов.
6.3.2. Исполнение команд программы процессором
Первоначально команда ЭВМ содержала следующую информа-
цию (рис. 6.17 а) [6]:
1. Код операции, указывающий операцию, которую должна
выполнить ЭВМ (сложение, вычитание, умножение, сравнение,
изменение знака и т. п.).
2. Адреса двух операндов — аргументов операции, например
слагаемых, уменьшаемого и вычитаемого, сомножителей и т. п.
Если какой-либо из операндов является константой, то вместо его
адреса в команде может быть задано само значение операнда. Од-
нако это обстоятельство должно быть отражено в коде операции,
чтобы ЭВМ использовала соответствующую часть команды в ка-
281
честве операнда, а не адреса ячейки памяти, в которой хранится
этот операнд.
3. Адрес ячейки памяти, в которую должен быть помещен ре-
зультат операции.
4. Адрес следующей команды.
Такая команда, состоящая из пяти полей (код операции и четы-
ре адреса), может быть реализована процессорами самых разно-
образных структур.
а)
Рис. 6.17. Форматы команд:
а) четырехадресная; б) одноадресная; в) безадресная
Простейшая из этих структур (рис. 6.18) напоминает структуру
процессора микрокалькулятора, приведенную на рис. 6.16 [6]. Про-
цессор содержит устройство управления, АЛУ, регистр для разме-
щения исполняемой команды (регистр команд) и регистр для раз-
мещения одного из операндов или результата операции в процес-
се выполнения этой команды — аккумулятор (на рис. 6.16 а роль
аккумулятора выполнял регистр X). Рассмотрим, что происходит
в процессоре после того, как в его регистр команд была переписа-
на из памяти какая-либо команда, например команда вычитания.
Так как поле регистра команд, в котором хранится код опера-
ции, связано шиной с устройством управления, то последнее по-
282
лучит приказ на выполнение операции «вычитание» и перейдет
в режим генерации управляющих сигналов:
одновременной выработкой сигналов У1, У5, У10 и У8 обес-
печиваются пересылка из памяти численного значения
уменьшаемого, прохождение его через АЛУ (сигнал У10,/ и
запись в аккумулятор;
следующий тактовый импульс инициирует выработку сигна-
лов У2, У5, Уб и У11, что приводит к пересылке из памяти чис-
ленного значения вычитаемого, к выполнению операции вы-
читания этого значения (сигнал У11/ из содержимого аккуму-
лятора (из уменьшаемого); по сигналу У8 производится запись
полученной разности в аккумулятор вместо уменьшаемого;
затем сигналы УЗ и У9 обеспечат пересылку разности из ак-
кумулятора в ячейку памяти, на которую указывает предпос-
леднее поле команды;
* наконец, с помощью сигналов У4 и У7 будет произведена пе-
резапись в регистр команд следующей команды программы.
При такой структуре процессора и реализуемой им структуре
четырехадресной команды первый операнд приходится сохранять
в процессоре до момента получения следующего операнда, так как
нельзя одновременно получать из памяти оба операнда. Поэтому в
состав процессора включен аккумулятор (он назван так потому,
что может быть использован для накопления — аккумуляции —
слагаемых в процессе получения суммы многих слагаемых или
накопления результатов других вычислений).
Нужен и регистр для хранения в процессоре исполняемой ко-
манды (регистр команд), так как во время выполнения этой коман-
ды из нее должна выбираться различная информация, используе-
мая устройством управления и памятью.
Четырехадресная команда (см. рис. 6.17 а) длиной в 16 бит мо-
жет адресовать лишь 23 = 8 ячеек памяти. Современные же микро-
ЭВМ адресуются к памяти, содержащей не менее 216=65536 яче-
ек. Если создавать четырехадресную команду, работающую даже
с этим минимальным размером памяти, то на каждое адресное поле
команды придется отвести 16 бит, а на всю команду (при 16-бито-
вом коде операции) — 80 бит.
В связи с этим в современных ЭВМ практически не встречают-
ся четырехадресные команды. Мало и трехадресных команд, так
как результат операции почти всегда можно записать на место од-
ного из уже использованных операндов.
283
Рис. 6.18. Простой процессор, работающий с четырехадресной командой,
целиком выбираемой из одной ячейки памяти
Если команды программы размещать в памяти ЭВМ друг за дру-
гом (а не в произвольной последовательности), то адрес следую-
щей команды чаще всего будет отличаться от адреса исполняемой
команды (или ее последнего поля) лишь на единицу, а добавление
единицы к текущему адресу можно возложить на ЭВМ. Это по-
зволяет сократить длину команды (изъять из ее содержимого ад-
рес следующей команды), но приводит к необходимости исполь-
зования специальных команд перехода, размещаемых в тех мес-
тах программы, где может потребоваться изменение естественной
последовательности выполнения команд в зависимости от резуль-
тата вычислений. Обычно команды перехода — одноадресные ко-
манды (см. рис. 6.17 б), где код операции оговаривает проверяемое
условие (знак результата предыдущей операции, наличие перено-
284
са из старшего разряда и т. п.), а адрес — адрес команды, к кото-
рой нужно перейти, если условие выполняется (при невыполне-
нии условия выбирается команда, расположенная вслед за коман-
дой перехода).
Во многих случаях результат выполнения предыдущей коман-
ды используется как операнд в следующей. Если результат выпол-
нения команды не пересылать в память, а сохранять, например,
в аккумуляторе, то можно обойтись одноадресными командами:
арифметической (логической) обработки, которые дают
приказ на выполнение какой-либо арифметической или ло-
гической операции, используя в качестве операндов содер-
жимое аккумулятора и содержимое адресуемой ячейки па-
мяти (регистра данных, куда переписывается содержимое ад-
ресуемой ячейки);
пересылки, которые дают приказ на обмен информацией
между аккумулятором и памятью (через регистр данных),
т. е. на загрузку аккумулятора содержимым адресуемой ячей-
ки памяти или запись в эту ячейку содержимого аккумуля-
тора (результата вычислений);
передачи управления, обеспечивающими условный или бе-
зусловный переход к адресуемой ячейке памяти (т. е. к ко-
манде, которая должна быть помещена в процессор при вы-
полнении какого-либо условия или вне зависимости от ре-
зультата предыдущих вычислений), обращение к подпрог-
рамме и выход из нее;
ввода-вывода.
На рис. 6.19 представлена одна из возможных структур процес-
сора, реализующего программы из одноадресных и безадресных
команд. Он состоит из следующих устройств [6];
• арифметико-логического устройства, производящего опе-
рации над двумя величинами в целях получения результата
и выработки ряда признаков (результат меньше ноля, равен
нолю или больше ноля, был перенос из старшего разряда
результата);
регистра состояния, в котором хранятся признаки результа-
та последней операции, используемые командами перехода;
• аккумулятора — регистра, в котором размещаются подле-
жащие обработке данные или результат обработки;
• регистра команд —регистра, служащего для размещения ис-
полняемой команды;
285
регистра адреса — регистра, содержащего адрес ячейки па-
мяти, из которой будет считана команда (операнд) или запи-
сан результат обработки;
регистра данных — регистра, используемого в качестве бу-
фера между памятью и остальными регистрами процессора;
через него пересылаются в процессор команды (операнды)
и передаются в память результаты обработки;
счетчика команд — регистра, содержимое которого увели-
чивается на единицу в момент выборки из памяти исполняе-
мой команды и, если выбрана команда перехода, может быть
заменено на содержимое адресной части команды перехо-
да; в конце цикла исполнения команды в счетчике команд
всегда хранится адрес той команды, которая должна испол-
няться вслед за текущей, это может быть как следующая по
порядку команда, так и команда, к которой требуется перейти
при выполнении условий, заданных кодом операции коман-
ды перехода.
ПАМЯТЬ
26
41
77
102
134
135
136
137
Рис. 6.19. Простой процессор, работающий
с одноадресными и безадресными командами
286
Для решения задачи на такой ЭВМ необходимо:
1) через устройства ввода информации загрузить в память ЭВМ
программу решения задачи (алгоритм, написанный на языке
ЭВМ) и исходные данные; и программа, и данные могут быть раз-
мещены в любой области памяти, начиная с ячейки 0 или другой
ячейки с любым адресом (сначала программа, а затем данные, или
наоборот).
2) «сообщить» процессору адрес ячейки памяти, в которой раз-
мещена первая команда программы, для чего занести адрес этой
ячейки в счетчик команд;
3) нажать кнопку «ПУСК», что приведет к передаче в память
адреса первой команды программы и к пересылке ее содержимо-
го из памяти в регистр команд; с этого момента процессор начнет
выполнять последовательность достаточно простых операций, по-
казанных на схеме алгоритма выполнения команды (рис. 6.20).
Как видно из схемы алгоритма, два первых действия (блоки 1
и 2) выполняются для каждой команды. Эти действия (а также дей-
ствия по определению типа команды — блоки 3, 6 и 9) обычно на-
зывают «выборкой команды». Последующие действия алгоритма
(«Исполнение команды») полностью зависят от того, какая это ко-
манда.
Рассмотрим исполнение команды, расположенной в ячейке 135
на рис. 6.19 [6]. Оно начинается в момент, когда в аккумуляторе
хранится значение уменьшаемого, записанное туда при выполне-
нии предыдущей команды, а в счетчике команд — адрес 135.
1. Адрес, содержащийся в счетчике команд, переписывается
в регистр адреса и далее в память ЭВМ (сигнал У1), а оттуда счи-
тывается команда «Выч. 26», помещаемая в регистр команд (сиг-
нал У4).
2. Счетчик команд наращивается на единицу (сигнал +1), что-
бы он указывал на команду (адрес 136), расположенную в памяти
вслед за выбранной командой.
3. Устройство управления считывает из регистра команд код
исполняемой команды, выясняет, что это команда вычитания, и
переходит к ее выполнению.
4. Из регистра команд считывается (сигнал УЗ) и пересылается
в память (через регистр адреса) адрес вычитаемого (26), а из памя-
ти переписывается в регистр данных численное значение вычита-
емого.
287
Рис. 6.20. Схема алгоритма выполнения команд простого процессора
288
5. Выполняется операция вычитания содержимого регистра дан-
ных из содержимого аккумулятора (сигналы У5, Уб и У11), а затем
полученная разность переписывается с выхода АЛУ в аккумуля-
тор (сигнал У8_), заменяя значение уменьшаемого.
Таким образом, процесс выполнения команды сводится к опре-
делению последовательности открывания и закрывания вентиль-
ных схем. Описание того, какую вентильную схему и когда откры-
вать, составляет программу для машины, система команд которой
включает в себя команду «Открыть вентильную схему». Такой ма-
шиной и является устройство управления ЭВМ, в котором хранят-
ся программы реализации всех команд ЭВМ. Эти программы обыч-
но называются микропрограммами, а их команды — микроко-
мандами. Простейшая микрокоманда состоит из набора битов, каж-
дый из которых управляет одной из вентильных схем процессора:
единица означает, что вентильная схема открыта, ноль — закрыта.
В заключение отметим, что процессор, изображенный на рис.
6.19, не является единственно возможным процессором, исполь-
зуемым для реализации одноадресных команд. Так, сумму произ-
ведений ахв + схе + fxh + qxk +... лучше вычислять с помощью про-
цессора, имеющего два аккумулятора (один — для вычисления
произведений, а другой — для накопления суммы). Это позво-
лит исключить пересылку в память промежуточных результатов,
т. е. ускорить вычисления и уменьшить число используемых ячеек
памяти. Существуют и другие виды процессоров.
6.4. ОБЩАЯ СТРУКТУРА ЭВМ
6.4.1. Структурная схема ПЭВМ
Персональный компьютер (ПК), или персональная ЭВМ
(ПЭВМ) — электронная вычислительная машина, с которой мо-
жет работать пользователь, не являющийся профессиональным
программистом.
Она характеризуется развитым («дружественным») человеко-
машинным интерфейсом, малыми габаритами, массой, относитель-
но невысокой стоимостью и многофункциональностью (универ-
сальностью) применения.
Одним из основных достоинств ПЭВМ, обеспечивших им по-
трясающий успех, явился принцип открытой архитектуры, заклю-
19 А-210
289
чающийся в том, что при проектировании ПЭВМ регламентиру-
ются и стандартизируются только принцип действия компьютера
и его конфигурация (определенная совокупность аппаратных
средств и соединений между ними). Построение ПЭВМ не единым
неразъемным устройством, а на основе принципа открытой архи-
тектуры (модульности построения), обеспечивает возможность их
сборки из отдельных узлов и деталей, разработанных и изготов-
ленных независимыми фирмами-изготовителями. Кроме того, та-
кой компьютер легко расширяется и модернизируется за счет на-
личия внутренних расширительных разъемов, позволяющих
пользователю добавлять разнообразные устройства, удовлетворя-
ющие заданному стандарту, и тем самым устанавливать конфигу-
рацию своей ЭВМ в соответствии со своими личными предпочте-
ниями. Специалисты часто называют такие операции upgrade (рас-
ширить, обновить).
Упрощенная блок-схема, отражающая основные функциональ-
ные компоненты ПЭВМ в их взаимосвязи, изображена на рис. 6.21.
Конструктивно современный персональный компьютер состо-
ит из трех основных компонентов (рис. 6.22):
системного блока, в котором размещаются устройства обра-
ботки и хранения информации;
* дисплея — устройства отображения информации;
* клавиатуры — основного устройства ввода информации
вПК.
Для упрощения взаимодействия пользователя с ПК в тех или
иных случаях используют различные манипуляторы (мышь, трек-
бол, джойстик и др.).
Корпус системного блока может иметь горизонтальную (Desk-
Top) или вертикальную (Tower — башня) компоновку. В систем-
ном блоке размещаются основные элементы компьютера, необхо-
димые для выполнения программ:
* микропроцессор (МП), или центральный процессор (CPU, от
англ. Central Processing Unit) — основной рабочий компонент
компьютера, который выполняет арифметические и логичес-
кие операции, заданные программой, управляет вычисли-
тельным процессом и координирует работу всех устройств
компьютера;
" память (внутренняя — системная, включающая ОЗУ и ПЗУ и
внешняя дисковая). ПЗУ (от англ. ROM, Read Only Memory —
память только для чтения) служит для хранения неизменяе-
290
Рис. 6.21. Блок-схема ПЭВМ
291
Рис. 6.22. Состав
персонального компьютера
мой (постоянной) программной и справочной информации.
ОЗУ (от англ. RAM, Random Access Memory — память с про-
извольным доступом) предназначено для оперативной за-
писи, хранения и считывания информации (программ и дан-
ных), непосредственно участвующей в информационно-вы-
числительном процессе, выполняемом ПК в текущий пери-
од времени. Дисковая память относится к внешним устрой-
ствам ПК и используется для долговременного хранения
любой информации, которая может когда-либо потребо-
ваться для решения задач, в ней, в частности, хранится все
программное обеспечение компьютера. В качестве уст-
ройств внешней памяти, размещаемых в системном блоке,
используются накопители на жестких (НЖМД) и гибких
(НГМД) магнитных дисках, накопители на оптических дис-
ках (НОД) и др;
контроллеры (адаптеры) служат для подключения перифе-
рийных (внешних по отношению к процессору) устройств к
шинам микропроцессора, обеспечивая совместимость их
интерфейсов. Они осуществляют непосредственное управ-
ление периферийными устройствами по запросам микро-
процессора. Контроллеры реализуются, как правило, на от-
дельных печатных платах, часто называемых адаптерами
устройств (отлат. adapto — преобразовываю);
системная шина — основная интерфейсная система компь-
ютера, обеспечивающая сопряжение и связь всех его уст-
ройств между собой. Системная шина включает в себя: шину
данных (ТТТД), содержащую провода и схемы сопряжения для
параллельной передачи всех разрядов числового кода (ма-
шинного слова) операнда,
шину адреса (ША), состоя-
щую из проводов и схем со-
пряжения для параллельной
передачи всех разрядов кода
адреса ячейки основной па-
мяти или порта ввода-вывода
внешнего устройства, шину
управления (ШУ), содержа-
щую провода и схемы сопря-
жения для передачи инструк-
292
ций (управляющих сигналов, импульсов) во все блоки ком-
пьютера, и шину питания, имеющую провода и схемы со-
пряжения для подключения блоков ПК к системе энергопи-
тания. Системная шина обеспечивает три направления пе-
редачи информации: между микропроцессором и внутрен-
ней (основной) памятью, между микропроцессором и пор-
тами ввода-вывода внешних устройств, между внутренней
(основной) памятью и портами ввода-вывода внешних уст-
ройств (в режиме прямого доступа к памяти).
Устройства, непосредственно осуществляющие процесс обработ-
ки информации (вычисления), в том числе микропроцессор, опера-
тивная память и шина, размещаются на системной (материнской)
плате компьютера, на ней же располагается и контроллер клавиа-
туры. Схемы, управляющие другими внешними устройствами ком-
пьютера, как правило, находятся на отдельных платах, вставляемых
в унифицированные разъемы (слоты) на материнской плате. Через
эти разъемы контроллеры устройств подключаются непосредствен-
но к системной магистрали передачи данных в компьютере — шине.
Иногда эти контроллеры могут располагаться на системной плате.
Наборы микросхем, на основе которых исполняются системные
платы, называют чипсетами (ChipSets).
В системном блоке располагается также блок питания, преоб-
разующий переменное напряжение электросети в постоянное на-
пряжение различной полярности и величины, необходимое для
питания системной платы и других устройств компьютера, разме-
щенных в системном блоке. Блок питания содержит вентилятор,
создающий циркулирующие потоки воздуха для охлаждения сис-
темного блока, сетевого энергопитания ПК. Кроме сетевого, в ком-
пьютере имеется также автономный источник питания — аккуму-
лятор. К аккумулятору подключается таймер — внутримашинные
электронные часы, обеспечивающие при необходимости автома-
тический съем текущего момента времени (год, месяц, часы, ми-
нуты, секунды и доли секунд). Таймер продолжает работать и при
отключении компьютера от сети.
Важнейшую роль в работе ЭВМ играет контроллер прерываний.
Прерывание — временный останов выполнения одной программы
в целях оперативного выполнения другой, в данный момент более важ-
ной (приоритетной) программы.
293
Контроллер прерываний обслуживает процедуры прерывания,
принимает запрос на прерывание от внешних устройств, определя-
ет уровень приоритета этого запроса и выдает сигнал прерывания
процессору. Процессор, получив этот сигнал, приостанавливает
выполнение текущей программы и переходит к выполнению спе-
циальной программы обслуживания того прерывания, которое зап-
росило внешнее устройство. После завершения программы обслу-
живания восстанавливается выполнение прерванной программы.
6.4.2. Устройства ввода-вывода информации
Устройства вывода информации. Основным устройством вы-
вода информации в ПЭВМ является дисплей. Дисплей (монитор) —
устройство визуального отображения текстовой и графической
информации без ее долговременной фиксации.
Для обозначения этого типа устройств с учетом функций, вы-
полняемых ими в ПК, в английском языке используются как сино-
нимы термины monitor display, monitor, video monitor, video display.
Соответственно в русском переводе также в качестве синонимов
используется ряд терминов, таких как монитор, видеомонитор,
видеодисплей. Мониторы бывают алфавитно-цифровые и графи-
ческие, монохромные и цветного изображения.
В современных ПЭВМ в качестве устройств отображения ин-
формации наиболее широкое распространение получили цветные
графические дисплеи на базе электронно-лучевых трубок, газораз-
рядные и жидкокристаллические дисплеи.
Дисплей на базе электронно-лучевой трубки. Основной элемент
такого дисплея — электронно-лучевая трубка (рис. 6.23), а прин-
цип его работы аналогичен принципу работы телевизора. Форми-
рование изображения производится на внутренней поверхности
экрана, покрытого слоем люминофора — вещества, светящегося
под воздействием электронного луча, генерируемого специальной
«электронной пушкой» и управляемого системами горизонтальной
и вертикальной развертки.
Люминофор наносится в виде наборов точек трех основных цве-
тов — красного, зеленого и синего. Эти цвета называют основными,
потому что их сочетаниями (в различных пропорциях) можно пред-
ставить любой цвет спектра.
Наборы точек люминофора располагаются по треугольным три-
адам (рис. 6.24). Триада образует пиксель — (от англ, pixel — picture
element—элемент картинки) точку, из которых формируется изоб-
ражение.
294
Рис. 6.23. Схема электронно-лучевой трубки
Расстояние между центрами пикселей называется точечным
шагом монитора. Это расстояние существенно влияет на четкость
изображения. Чем меньше шаг, тем выше четкость. В современ-
ных цветных мониторах шаг составляет 0,24 мм и менее. При та-
ком шаге глаз человека воспринимает точки триады как одну точ-
ку «сложного» цвета.
На противоположной стороне трубки расположены три (по коли-
честву основных цветов) электронные пушки. Все три пушки «наце-
лены» на один и тот же пиксель, но каждая из них излучает поток
электронов в сторону «своей» точки люминофора. Чтобы электроны
беспрепятственно достигали экрана, из трубки откачивается воздух,
а между пушками и экраном создается высокое электрическое на-
пряжение, ускоряющее электроны. Перед экра-
ном на пути электронов ставится маска — тонкая
металлическая пластина с большим количеством
отверстий, расположенных напротив точек люми-
нофора. Маска обеспечивает попадание электрон-
ных лучей только в точки люминофора соответ-
ствующего цвета.
Величиной электронного тока пушек и, сле-
довательно, яркостью свечения пикселей, управляет сигнал, посту-
пающий с видеоконтроллера.
Отклоняющая система монитора обеспечивает прохождение
электронным лучом поочередно всех пикселей — строчка за строч-
кой от верхней до нижней, затем возвращается в начало верхней
строки и т. д. (рис. 6.25).
Рис. 6.24.
Пиксельные триады
295
Рис. 6.25. Ход электронного пучка по экрану
Количество отображенных строк в секунду называется строч-
ной частотой развертки. А частота, с которой меняются кадры изоб-
ражения, называется кадровой частотой развертки. Кадровая ча-
стота развертки должна быть такой, чтобы глаз человека не заме-
чал последовательной смены кадров. (Ассоциация видеоэлектрон-
ных стандартов (VESA — Video Electronics Standards Association}
рекомендует частоту не ниже 75 кадров в секунду).
Синхросигналы строчной и кадровой разверток, а также сиг-
налы управления яркостью лучей формируются видеоконтролле-
ром, часто называемым видеокартой, или видеоадаптером. Основ-
ным компонентом видеокарты (рис. 6.26) является память, где хра-
нятся передаваемые процессором числа, характеризующие каж-
дый пиксель монитора. Цифроаналоговые преобразователи пре-
образуют эти числа в аналоговые сигналы, необходимые для рабо-
ты монитора. Для ускорения процесса обработки видеоданных и
разгрузки при этом центрального процессора ЭВМ современные
видеокарты имеют свой собственный видеопроцессор.
Минимальный размер видеопамяти определяется количеством
цветов и разрешающей способностью монитора. Так, для представ-
ления на мониторе 16,7 млн цветов (цвет каждого пикселя задает-
ся 24-разрядным числом) с разрешающей способностью 640x480
пикселей необходимый объем видеопамяти равен 0,9 Мбайт, при
разрешающей способности 800x600 — 1,4 Мбайт.
Газоразрядные и жидкокристаллические дисплеи. Такие дисп-
леи часто называют панелями. Газоразрядную панель образуют два
плоскопараллельных стекла, между которыми размещены мини-
атюрные газоразрядные элементы. В инертном газе газоразрядного
элемента под действием управляющих сигналов, формируемых
296
микропроцессором устройства синхронизации и подаваемых на
прозрачные электроды одного или обоих стекол, возникает раз-
ряд с ультрафиолетовым излучением. Это излучение вызывает све-
чение нанесенного на переднее или заднее стекло люминофора
одного цвета черно-белой панели или люминофоров красного, зе-
леного или синего цветов цветной панели.
Рис. 6.26. Структура видеоконтроллера
Основой жидкокристаллической панели служат также две плос-
копараллельные стеклянные пластины. На одну из них нанесены
прозрачные горизонтальные и вертикальные токопроводящие
электроды. В местах их пересечения укреплены пленочные тран-
зисторы, два вывода которых соединены с электродами на стекле,
а третий образует обкладку конденсатора. Вторую пластину кон-
денсатора представляет прозрачный металлизированный слой на
второй стеклянной пластине, расположенной параллельно первой
на расстоянии, измеряемом микронами. Между пластинами поме-
щено органическое вещество (жидкий кристалл), поворачивающее
под действием электрического поля плоскость поляризации про-
ходящего через него света. С двух сторон панели укреплены поля-
роидные пленки, плоскости поляризации которых повернуты на
90° относительно друг друга (рис. 6.27).
297
Растр телевизионного изображения формируется сигналами,
генерируемыми устройством синхронизации и подаваемыми на
электроды стеклянных пластин. При подаче на эти электроды на-
пряжения в точке их пересечения конденсатор заряжается, и воз-
никает электрическое поле между соответствующими обкладка-
ми конденсатора. В зависимости от величины напряжения изме-
няется угол поляризации жидкого кристалла между обкладками
конденсатора. При отсутствии напряжения и соответственно элек-
трического поля жидкий кристалл поворачивает угол поляризации
света от лампы подсветки на 90°, в результате чего свет свободно
проходит через поляроидные пленки. В зависимости от напряже-
ния на обкладках конденсатора угол поляризации может изменять-
ся от 90° до 0°, а прозрачность ячейки панели — от максимальной
до непропускания света. Панель цветного дисплея содержит крас-
ный, зеленый и синий светофильтры, образующие триаду элемен-
та разложения изображения.
Плоские панели имеют преимущества перед вакуумными кинес-
копами по техническим параметрам, экологической безопасности
и сроку службы. Экран современных ЖК-мониторов (панелей)
с разрешением 1280x1024 имеет до 5 млн точек, каждая из которых
управляется собственным транзистором. Такие мониторы занима-
ют в 2—3 раза меньше места, чем мониторы с ЭЛТ и во столько же
раз легче; потребляют гораздо меньше электроэнергии и не излуча-
ют электромагнитных волн, воздействующих на здоровье людей.
Свет
Лампа
подсветки
Поляризующий
фильтр
Светофильтр
Поляри-
зующий
фильтр
Стеклянная
пластина
Жидкие
кристаллы
Стеклянная --------
пластина
Рис. 6.27. Жидкокристаллический дисплей
298
Сигналы, которые получает монитор (сигналы управления яр-
костью лучей и синхросигналы строчной и кадровой разверток),
формируются соответствующим контроллером, который называ-
ют видеокартой, или видеоадаптером. Монитор преобразует эти
сигналы в зрительные образы.
Другим широко распространенным устройством вывода тексто-
вой и графической информации, обрабатываемой ПЭВМ являет-
ся принтер.
Принтер — печатающее устройство для регистрации информации
на твердый, как правило, бумажный носитель.
Существует огромное количество наименований принтеров. Но
основных видов принтеров три: матричные (игольчатые), лазерные
и струйные.
Матричные принтеры. Их печатающая головка содержит не-
которое количество «иголок», которые под воздействием управ-
ляющих сигналов наносят удар по красящей ленте, благодаря чему
на бумаге остается отпечаток символа. Каждый символ, печатае-
мый на таком принтере, образуется из набора 9 или 24 игл, сфор-
мированных в виде вертикальной колонки. При использовании
многоцветной печатной ленты можно получить цветную печать.
Недостатками этих недорогих принтеров являются их шумная ра-
бота и невысокое качество печати.
Струйные принтеры. Печатное устройство этого принтера пред-
ставляет собой емкость со специальными чернилами, которые через
крошечные сопла под большим давлением выбрызгиваются на бума-
гу. Диаметр полученной таким образом точки на бумаге в десятки
раз меньше, чем диаметр точки от матричного принтера, что обеспе-
чивает значительно лучшее качество печати. Цветные струйные прин-
теры, кроме черного картриджа, дополнительно имеют картридж
с чернилами ярко-голубого, пурпурного и желтого цветов.
Лазерные принтеры. Основным печатающим устройством ла-
зерного принтера (рис. 6.28), так же как ксерокса, является валик-
«барабан», имеющий светочувствительное покрытие, изменяющее
свои электрические свойства в зависимости от освещенности.
Принцип работы лазерного принтера заключается в следующем.
Компьютер формирует в своей памяти «образ» страницы текста
и передает его принтеру. Информация о странице проецируется
с помощью лазерного луча на вращающийся барабан. После чего на
299
Рис. 6.28. Лазерный принтер
барабан, находящийся под электричес-
ким напряжением, наносится красящий
порошок — тонер, частицы которого на-
липают на засвеченные участки повер-
хности барабана. Принтер с помощью
специального горячего валика протяги-
вает бумагу под барабаном; тонер пере-
носится на бумагу и «вплавляется» в нее,
оставляя стойкое высококачественное
изображение. В отличие от лазерных
принтеров в светодиодных принтерах (которые часто также назы-
вают лазерными) информация на барабан проецируется не лазер-
ным лучом, а светодиодной матрицей. Из-за сложности техноло-
гии цветной лазерной печати цветные лазерные принтеры стоят
значительно дороже черно-белых.
Устройства ввода информации. Важнейшими устройствами
ввода информации, которыми укомплектован практически каж-
дый ПК, являются клавиатура и манипулятор типа «мышь».
Клавиатура — клавишное устройство для ручного ввода числовой,
текстовой и управляющей информации в ПК, оно обеспечивает диа-
логовое общение пользователя с ПЭВМ.
Клавиатура содержит стандартный набор клавиш печатной ма-
шинки и некоторые дополнительные клавиши — управляющие и
функциональные клавиши, клавиши управления курсором и ма-
лую цифровую клавиатуру. Все символы, набираемые на клавиа-
туре, немедленно отображаются на мониторе в позиции курсора
(светящийся символ на экране монитора, указывающий позицию,
на которой будет отображаться следующий вводимый с клавиату-
ры знак). В настоящее время наиболее распространена клавиату-
ра с раскладкой клавиш QWERTY (читается «кверти»), названная
так по клавишам, расположенным в верхнем левом ряду алфавит-
но-цифровой части клавиатуры.
Такая клавиатура имеет 12 функциональных клавиш, размещен-
ных вдоль верхнего края. Нажатие функциональной клавиши при-
водит к посылке в компьютер не одного символа, а целой совокуп-
ности символов. Функциональные клавиши могут программиро-
ваться пользователем. Например, во многих программах для полу-
300
чения помощи (подсказки) задействована клавиша F1, а для выхо-
да из программы — клавиша F10.
Название управляющих клавиш и их назначение представле-
ны в табл. 6.2.
Таблица 6.2
Название клавиши Назначение
Enter Клавиша ввода информации, служащая для завершения ввода очередной строки информации
Esc (Escape — выход) Отмена каких-либо действий, выход из программы, из меню и т. п.
Ctrl и Alt Самостоятельного значения не имеют, но при нажатии совместно с другими управляющими клавишами изменяют их действие
Shift Обеспечивает смену регистра клавиш (верхнего на нижний, и наоборот)
Insert Переключает режимы вставки (новые символы вводятся посреди уже набранных, раздвигая их) и замены (старые символы замещаются новыми
Delete Удаляет символ с позиции курсора
Back Space или <— Удаляет символ перед курсором
Home и End Обеспечивают перемещение курсора в первую и последнюю позицию строки соответственно
Page Up и Page Down Обеспечивают перемещение по тексту на одну страницу (один экран) назад и вперед соответственно
Tab Клавиша табуляции, обеспечивает перемещение курсора вправо сразу на несколько позиций до очередной позиции табуляции
Caps Lock Фиксирует верхний регистр, обеспечивает ввод прописных букв вместо строчных
Print Screen Обеспечивает печать информации, видимой в текущий момент на экране
Длинная нижняя клавиша без названия Предназначена для ввода пробелов
Клавиши Т, i, <— и Служат для перемещения курсора вверх, вниз, влево и вправо на одну позицию или строку
Малая цифровая клавиатура используется в двух режимах —
ввода чисел и управления курсором. Переключение этих режимов
осуществляется клавишей Num Lock.
301
Клавиатура содержит встроенный микроконтроллер (местное
устройство управления), который выполняет следующие функции:
последовательно опрашивает клавиши, считывая введенный
сигнал и вырабатывая двоичный скан-код клавиши;
осуществляет буферизацию (временное запоминание до 20
отдельных кодов клавиш на время между двумя соседними
опросами клавиатуры процессором);
управляет световыми индикаторами клавиатуры;
проводит внутреннюю диагностику неисправностей;
осуществляет взаимодействие с центральным процессором.
При поступлении любой информации в буферную память кла-
виатуры посылается запрос на аппаратное прерывание, иниции-
руемое клавиатурой. При выполнении прерывания скан-код пре-
образуется в ASCII и оба кода пересылаются в соответствующее
поле ОЗУ ЭВМ.
ч________________________________________________________
Манипуляторы (мышь, трекбол и др.) — специальные устройства
ввода и управления, облегчающие взаимодействие пользователя и
ПЭВМ.
Несмотря на большое разнообразие форм и размеров манипу-
ляторов типа мышь, они имеют единые принципы работы. При
перемещении мыши по поверхности это перемещение преобра-
зуется в последовательности импульсов, передаваемых в ПК. При
нажатии кнопок мыши их код также передается в ПК, где специ-
альная программа управления мышью (драйвер мыши) преобра-
зует последовательности импульсов и коды нажатия кнопок в оп-
ределенные действия. В зависимости от способа определения пе-
ремещения — механического, связанного с перемещением частей
устройства, или оптического, основанного на фиксации переме-
щения с помощью оптических приборов, различают соответствен-
но механические и оптические мыши.
На рис. 6.29 представлено устройство механической мыши.
Принцип ее работы заключается в следующем.
При перемещении мыши по поверхности расположенный в ее
основании шарик начинает вращаться, приводя в движение рас-
положенные внутри корпуса ролики. Эти ролики смонтированы
относительно друг друга под углом 90° и, соприкасаясь с шариком,
могут вращаться только по часовой или против часовой стрелки,
преобразуя произвольное движение шарика в движение в двух
302
взаимно-перпендикулярных направлениях (X и Y). При перемеще-
нии мыши строго горизонтально или строго вертикально приво-
дится в движение только один из роликов, показывающий движе-
ние либо в направлении X, либо Y соответственно. Электронные
схемы мыши преобразуют движения роликов в последовательно-
сти импульсов, передаваемые в ПЭВМ.
Переключатели
кнопок
К компьютеру
Кнопки
Корпус
Детектор
вращения
ролика
Два ролика,
смонтированных под углом 90°
друг к другу, вращающиеся
при перемещении шарика
Шарик, который
вращается
при перемещении
мыши
Схема,
которая передает
компьютеру информацию
о вращении роликов
и нажатии
переключателей
Рис. 6.29. Устройство механической мыши
Оптическая мышь, в отличие от механической, не имеет ника-
ких движущихся элементов, а для фиксации перемещения исполь-
зуются оптические приборы.
Трекбол по своему функциональному устройству аналогичен
механической мыши, с той лишь разницей, что вместо перемеще-
ния мыши для вращения шарика, пользователь вращает рукой сам
шарик, встроенный в верхнюю часть корпуса. В отличие от мыши,
трекбол не требует свободного пространства около компьютера,
его можно встроить в корпус машины.
303
Одним из широко распространенных манипуляторов, приме-
няемых в компьютерных играх, является джойстик. Обычно это
стержень-ручка, отклонение которой от вертикального положе-
ния приводит к передвижению курсора в соответствующем на-
правлении по экрану монитора. В некоторых моделях в джойстик
монтируется датчик давления. В этом случае, чем сильнее пользо-
ватель нажимает на ручку, тем быстрее движется курсор по эк-
рану дисплея.
Для ввода в ПЭВМ графической информации наиболее часто
используется сканер. Он создает оцифрованное изображение до-
кумента и помещает его в память компьютера. Существуют руч-
ные сканеры, которые прокатывают по поверхности документа
рукой, и планшетные сканеры (рис. 6.30), по внешнему виду напо-
минающие копировальные машины. Принцип работы сканера от-
носительно прост. Луч света (специальная лампа, расположенная
в корпусе сканера) «пробегает» по сканируемой поверхности, при
этом светочувствительными датчиками воспринимается яркость
Рис. 6.30. Планшетный сканер
и цветность отраженного света и
преобразуется в двоичный код.
Введенную с помощью сканера и
графическую, и текстовую ин-
формацию компьютер восприни-
маеткак «картинку», поэтомудля
преобразования графического
текста в обычный символьный
формат используют программы
оптического распознавания об-
разов.
6.4.3. Системная магистраль и шины ЭВМ
Отличительным признаком современных ПЭВМ, построенных
по модульному принципу, является единая системная магистраль
(шина), связывающая все входящие в систему модули [3]. Правила
подключения модулей к магистрали определяются системным
(внутренним) интерфейсом. Различают также внешние интер-
фейсы или интерфейсы периферийного оборудования, задаю-
щие правила сопряжения с устройствами ввода-вывода.
304
Под интерфейсом (interface) понимают совокупность информаци-
онно-логических, электрических и конструктивных требований, вы-
полнение которых обеспечивает работоспособное, с определенными
характеристиками сопряжение различных модулей (элементов, узлов,
устройств) системы.
Информационно-логические требования определяют структуру
и состав линий и сигналов, способы кодирования и форматы дан-
ных, адресов, команд, протоколы обмена для различных режимов и
фаз работы. Информационно-логические условия непосредствен-
но влияют на основные характеристики интерфейса — пропускную
способность, надежность обмена, аппаратурные затраты.
Электрические требования задают необходимые статические
и динамические параметры сигналов на линиях интерфейса: уров-
ни, длительности фронтов и самих сигналов, нагрузочные способ-
ности, уровни помех и т. п.
Конструктивные требования указывают на тип соединительно-
го элемента, распределение линий по контактам соединительного
элемента, допустимую длину линий, геометрические размеры пла-
ты, каркаса и других конструктивных элементов.
Системный интерфейс в целом существенно влияет на все ха-
рактеристики ЭВМ, особенно на производительность, так как
она может ограничиваться не быстродействием микропроцес-
сора, а возможностями магистрали по скорости передачи инфор-
мации.
Когда некоторый модуль выполняет обмен информацией с дру-
гим модулем или несколькими модулями, то первый называют ве-
дущим (master), а второй — ведомым (исполнителем, slave). Веду-
щий модуль управляет магистралью, т. е. генерирует определен-
ную последовательность сигналов, обеспечивающую выполнение
требуемой операции. Ведомый модуль посылает сигналы в магис-
траль только в ответ на соответствующие сигналы ведущего. Сиг-
налы между модулями передаются по линиям — электрическим
цепям, связывающим одноименные контакты на всех соедините-
лях (разъемах) магистрали. Как правило, линия и сигнал, который
по ней передается, называются и обозначаются одинаково. Сово-
купность линий, передающих сигналы одного функционального
назначения, называют шиной (bus). Отметим, что в англоязычной
литературе термин bus используется для обозначения и шины,
20 А-210
305
и магистрали. Различают следующие основные шины системной
магистрали:
• шину данных, предназначенную для передачи кодов данных
между модулями, характеризуется своей разрядностью, фак-
тически это количество линий в шине. Некоторые магистра-
ли допускают изменение разрядности передаваемых кодов
данных (но не шины) в процессе функционирования;
ш ину адреса, обеспечивающую выбор ведущим модулем тре-
буемого ведомого (передает адрес модуля), а внутри ведомо-
го модуля — выбор требуемого элемента, например ячейки
памяти (передает адрес ячейки) или регистра контроллера
ввода-вывода (передает адрес порта устройства ввода-выво-
да) . Адресная шина также характеризуется разрядностью —
количеством линий. В некоторых магистралях коды адреса
и данных передаются по одним и тем же линиям. Такую шину
называют мультиплексируемой шиной адреса/данных;
* шину управления, включающую в себя линии, по которым пе-
редаются сигналы управления обменом, запросы прерыва-
ния, сигналы синхронизации и т. п.;
* шину питания, подводящую питающие напряжения ко всем
потребителям, подключенным к магистрали.
Различают три фазы (режима) работы магистрали: обмена, ар-
битража, обработки прерываний [3].
В фазе обмена происходит передача информационного кода
между ведущим и ведомым модулями. В этой фазе выполняется
одна из двух операций: чтение, когда код данных передается из
ведомого модуля в ведущий, или запись, когда код данных переда-
ется из ведущего модуля в ведомый. Существуют два основных спо-
соба организации обмена — асинхронный и синхронный. Отли-
чительная особенность асинхронной организации заключается во
взаимной зависимости смены состояний ведущим и ведомым мо-
дулями (рис. 6.31 а). Ведущий модуль устанавливает на шине адре-
са код адреса модуля и элемента в модуле, из которого он хочет
получить информацию. Сигналом «Чтение» ведущий сообщает
всем модулям, что он начинает операцию чтения и что адрес уже
установлен на шине. Все модули, подключенные к магистрали, ана-
лизируют адрес. Однако активизируется только тот модуль, кото-
рому принадлежит установленный на шине адрес, он и становит-
ся ведомым. Этот модуль считывает код данных из требуемого эле-
мента (ячейки ЗУ или порта ввода-вывода) и выставляет его на
306
шину данных. Истинность кода ведомый подтверждает сигналом
готовности данных. Только получив сигнал готовности, ведущий
может принимать данные. Завершив прием, ведущий снимает ад-
рес и сигнал «Чтение». Теперь и ведомый может снять код данных
с шины и сбросить сигнал готовности. На этом фаза обмена завер-
шается. При такой организации не требуется никаких особых сиг-
налов синхронизации.
Шина
адреса
Истинный адрес
из ведущего
Чтение
Сигнал генерируется ведущим
Шина
данных
Данные
из ведомого
Сигнал генерируется
Готовность
данных
Рис. 6.31. Организация обмена в магистрали:
а) асинхронное чтение; б) синхронное чтение
307
При синхронном способе смена состояний модулей, участвую-
щих в обмене, происходит в строго оговоренные моменты времени,
определяемые специальным сигналом синхронизации. На рис. 6.31 б
показан пример синхронной организации обмена. Операция обя-
зана завершиться за три такта. Причем в первом такте ведущий
модуль должен выставить адрес и управляющий сигнал, определя-
ющий операцию, в рассматриваемом примере — низкий уровень
сигнала «Чтение». Ведомый модуль, распознав в первом такте, что
ведущий обращается к нему и желает прочитать содержимое неко-
торого элемента (ячейки ЗУ или порта ввода-вывода), должен во вто-
ром такте выбрать эту информацию и выставить ее на шину дан-
ных. Ведущий модуль всегда принимает код данных в начале тре-
тьего такта и затем снимает адрес и сигнал «Чтение». На этом опе-
рация завершается. Важно, что модули работают совершенно неза-
висимо и при выполнении всех временных требований нет необхо-
димости в сигнале подтверждения готовности данных от ведомого.
Считается, что асинхронная организация обмена упрощает сопря-
жение устройств с различной скоростью передачи данных, но сни-
жает пропускную способность магистрали. Синхронная организа-
ция позволяет достичь максимальных скоростей, но затрудняет
связь между устройствами, существенно различающимися по вре-
менным характеристикам. Для устранения последнего недостатка
в реальных синхронных магистралях так или иначе вводится под-
тверждение готовности ведомого к выполнению операции.
Возможны случаи, когда нескольким модулям одновременно не-
обходимо выполнить обмен. Но магистраль одна, и пользоваться ею
в каждый отдельный момент времени может только один ведущий.
Поэтому возникает необходимость в фазе арбитража, в которой
выбирается один модуль из всех, желающих стать ведущим. Выб-
ранному модулю и предоставляется право управления магистралью.
Существуют два принципиально различных способа арбитра-
жа [3]. Первый — централизованный, параллельный (рис. 6.32 а).
В этом случае к магистрали подключается специальный модуль —
арбитр (контроллер) магистрали, имеющий входы запроса и вы-
ходы разрешения. Каждый модуль, который пытается стать веду-
щим, формирует сигналы запроса магистрали (ЗМ) и передает их
арбитру. Последний по некоторому алгоритму выбирает модуль,
который должен стать ведущим в очередной фазе обмена, и сооб-
щает ему об этом, формируя сигнал разрешения (Р) на занятие
магистрали. Фаза арбитража на этом завершается и начинается
фаза обмена под управлением выбранного модуля.
308
Второй способ арбитража — последовательный (цепочечный,
daisy-chain). Все потенциально ведущие модули пронизывает линия
(цепочка) разрешения занятия магистрали (рис. 6.32 б). Так, пусть
модуль 2 пытается захватить управление. При этом в фазе арбитра-
жа он разрывает цепочку и анализирует состояние входа разреше-
ния. Если на входе установлена логическая единица, т. е. ни один
модуль, расположенный правее, не разорвал линию и, следователь-
но, не требует магистрали, то модуль 2 может ее занимать. Если на
входе разрешения отсутствует единичный сигнал, то какой-то мо-
дуль справа тоже стремится выполнить обмен, и управление шиной
получает он, а не модуль 2. Таким образом, между модулями уста-
навливается «географический» приоритет — чем правее, тем при-
оритетнее (для нашего примера), и никакого специального арбитра
не требуется. Фактически при последовательном способе арбитр
магистрали как бы распределяется между всеми модулями, в каж-
дом из которых есть схемы, выполняющие его функции.
б)
Рис. 6.32. Арбитраж магистрали:
а) централизованный параллельный арбитраж; б) последовательный арбитраж
309
И последовательный, и параллельный способы допускают час-
тичное или полное совмещение фазы обмена и фазы арбитража.
Это требует дополнительной регламентации и дополнительных
линий. Например, вводится линия «Занято», и модулям разреша-
ется запрашивать магистраль, только если она свободна (на линии
«Занято» низкий уровень). Получив управление шиной, ведущий
модуль переводит линию в единичное состояние. Следовательно,
пока ведущий модуль не завершит обмен, никакой другой, даже
старший по приоритету, не получит управление магистралью, но
и никаких специально выделенных тактов для арбитража не тре-
буется. К преимуществам параллельного арбитража относятся
малое время выбора ведущего, возможность программной на-
стройки системы приоритетов между модулями. Но количество
ведущих модулей, подключаемых к магистрали, ограничивается
количеством входов и выходов арбитра. И схемно, и организаци-
онно более прост последовательный способ, однако его эффектив-
ность снижается большими задержками в распространении сиг-
нала разрешения по длинной цепочке и невозможностью про-
граммного управления приоритетами модулей. Реальные магист-
рали допускают то или иное совмещение двух основных способов
арбитража, позволяющее сочетать достоинства каждого.
Фаза прерывания наступает, когда некоторый модуль стремит-
ся обратить внимание ведущего на свое состояние. Например,
принтер завершил печать сообщения и может печатать следующее,
контроллер должен сообщить об этом процессору. Или в процессе
передачи группы данных в память из дискового накопителя про-
изошла ошибка, канал прямого доступа должен немедленно поста-
вить в известность об этом процессор. Организация прерываний
в системных магистралях достаточно проста, пока допускается
только один обработчик прерываний, как правило, процессорный
модуль, а само количество запросов невелико. В шине управления
выделяется несколько линий, по которым запросы от всех уст-
ройств передаются обработчику. Получив запрос или запросы,
обработчик инициализирует на магистрали фазу прерывания, во
время которой происходит выделение наиболее приоритетного
запроса и идентификация модуля, который его выставил. Фаза
прерывания завершается передачей в процессор вектора преры-
вания — кода адреса программы, обслуживающей данное устрой-
ство. При росте числа источников запросов и ограниченном коли-
честве линий их передачи усложняется организация прерываний.
310
Вводятся, например, линии последовательной передачи запросов
типа daisy-chain и программный поиск в цепочке устройства, выс-
тавившего запрос. Если разрешается подключение к магистрали
нескольких обработчиков (мультипроцессорные системы), то орга-
низация прерываний еще более усложняется. Принципиальным
преодолением этих затруднений является введение виртуальных
прерываний — передачи сообщений специального вида между
модулями в стандартных фазах обмена. Виртуальные прерывания
полностью снимают проблемы количества запросов, их идентифи-
кации и множественности обработчиков. Однако реакция на зап-
росы при этом замедляется, что существенно при использовании
ЭВМ в системах реального времени.
В качестве системной магистрали в современных ПЭВМ исполь-
зуются:
шины расширений — шины общего назначения, позволяю-
щие подключать большое число самых разнообразных уст-
ройств;
локальные шины, специализирующиеся на обслуживании
устройств определенного типа.
Рассмотрим кратко основные из них [13].
ISA (Industry Standard Architecture — архитектура промышлен-
ного стандарта). Это 16-разрядная шина с 24 адресными линиями
(адресное пространство шины — 16 Мбайт), с 16 линиями аппа-
ратных прерываний и с 8 каналами DMA (Direct Memory Access,
прямого доступа к памяти). Несмотря на низкую пропускную спо-
собность (шина ISA работает асинхронно на частоте 8 МГц, ско-
рость обмена данными — до 5,5 Мбайт/с), эта шина продолжает
использоваться в компьютерах для подключения сравнительно
«медленных» внешних устройств, например звуковых карт и мо-
демов.
EISA. Расширением стандарта ISA стал стандарт EISA (Extended
ISA), имеющий 32-разрядную шину данных и 32-разрядную шину
адреса (адресное пространство шины — 4 Гбайт) и увеличенную
производительность (до 32 Мбайт/с). Как и ISA, в настоящее вре-
мя данный стандарт считается устаревшим.
VLB (VESA LocalBus — локальная шина стандарта VESA). Раз-
работана в 1992 г. Ассоциацией стандартов видеооборудования
(VESA— Video Electronics Standards Association), поэтому ее часто
называют шиной VESA. Понятие «локальной шины» впервые по-
явилось в конце 80-х годов XX века. Оно связано с тем, что при
311
внедрении процессоров третьего и четвертого поколений (Intel
80386 и Intel 80486) частоты основной шины (в качестве основной
использовалась шина ISA/EISA) стало недостаточно для обмена
между процессором и оперативной памятью. Локальная шина,
имеющая повышенную частоту, связала между собой процессор
и память в обход основной шины. Впоследствии в эту шину «вре-
зали» интерфейс для подключения видеоадаптера, который тоже
требует повышенной пропускной способности, — так появился
стандарт VLB, который позволил поднять тактовую частоту ло-
кальной шины и обеспечил пиковую пропускную способность до
130 Мбайт/с. В настоящее время данный стандарт не использует-
ся.
PCI (Peripheral Component Interconnect — стандарт подключения
внешних устройств). Шина PCI разработана в 1993 г. фирмой Intel.
По своей сути это тоже интерфейс локальной шины, связываю-
щей процессор с оперативной памятью, в которую врезаны разъ-
емы для подключения внешних устройств. Для связи с основной
шиной компьютера (ISA/EISA) используются специальные интер-
фейсные преобразователи — мосты PCI (PCI Bridge). В современ-
ных компьютерах функции моста PCI выполняют микросхемы
микропроцессорного комплекта (чипсета). Шина может работать
параллельно с шиной процессора, т. е. обмен данными процессор —
память и, например, видеоадаптер — память может осуществлять-
ся параллельно. Шина PCI является синхронной 32-разрядной или
64-разрядной шиной, работающей на частоте 33 или 66 МГц. Шина
PCI при частоте 33 МГц обеспечивает пропускную способность
132 Мбайт/с, при частоте до 66 МГц обеспечивают производитель-
ность 264 Мбайт/с для 32-разрядных данных и 528 Мбайт/с для
64-разрядных данных.
FSB. Шина PCI, появившаяся в компьютерах на базе процессо-
ров Intel Pentium как локальная шина, предназначенная для связи
процессора с оперативной памятью, недолго оставалась в этом ка-
честве. Сегодня она используется только как шина для подключе-
ния внешних устройств, а для связи процессора и памяти, начиная
с процессора Intel Pentium Pro применяется специальная шина,
получившая название Front Side Bus (FSB). Эта шина работает на
частоте от 100 МГц и выше. Пропускная способность шины FSB
при частоте 100 МГц составляет порядка 800 Мбайт/с.
AGPfAdvanced Graphic Port — усовершенствованный графичес-
кий порт). Видеоадаптер — устройство, требующее особенно вы-
312
сокой скорости передачи данных. Как при внедрении локальной
шины VLB, так и при внедрении локальной шины PCI, видеоадап-
тер всегда был первым устройством, «врезаемым» в новую шину.
Сегодня параметры шины PCI уже не соответствуют требованиям
видеоадаптеров, поэтому для них разработана отдельная шина,
получившая название AGP.
Другие локальные шины: IDE (Integrated Device Electronics), EIDE
(Enhanced IDE), SCSI (Smati Computer System Interface) используют-
ся чаще всего в качестве интерфейса только для внешних запоми-
нающих устройств.
6.4.4. Организация ввода-вывода информации в ЭВМ
В системах ввода-вывода большинства современных ЭВМ мож-
но выделить два уровня сопряжения внешних устройств (ВУ) с про-
цессором и памятью [6]. На первом уровне контроллеры ВУ сопря-
гаются с процессором и памятью через системный интерфейс
ЭВМ, который обеспечивает комплексирование отдельных уст-
ройств ЭВМ в единую систему. На втором уровне сопряжения кон-
троллеры посредством шин связи соединяются с соответствующи-
ми внешними устройствами ЭВМ.
На первом уровне сопряжения набор шин интерфейса ввода-
вывода и алгоритм его функционирования полностью определя-
ются системным интерфейсом ЭВМ. Несмотря на широкое раз-
нообразие системных интерфейсов ЭВМ, в общем случае можно
выделить два основных способа использования системного интер-
фейса для организации обмена информацией с ВУ: 1) с примене-
нием специальных команд ввода-вывода; 2) по аналогии с обраще-
ниями к памяти.
Рассмотрим, как используются для обмена информацией с ВУ
шины адреса и данных системных интерфейсов ЭВМ и какие не-
обходимы для этого управляющие сигналы [6].
При использовании для обмена с ВУ команд ввода-вывода ад-
рес (номер) ВУ передается по шине адреса. Однако по этой же шине
передаются и адреса ячеек памяти. Информация на шине адреса
имеет смысл адреса (номера) ВУ только при наличии специальных
управляющих сигналов. Такими сигналами могут быть, например,
«Ввод из ВУ» и «Вывод в ВУ» (рис. 6.33, а), инициируемые соответ-
ствующими командами ввода-вывода ЭВМ [6].
313
а) б)
Рис. 6.33. Простейшее сопряжение контроллера ВУ с системным интерфейсом:
а) с применением специальных команд ввода-вывода;
б) по аналогии с обращением к памяти
Для синхронизации работы процессора ЭВМ и контроллеров
ВУ, а точнее, для указания моментов времени, определяющих го-
товность данных в ВУ для передачи либо подтверждающих их при-
ем, может служить управляющий осведомительный сигнал «Готов-
ность ВУ».
Такого простого набора управляющих сигналов в общем слу-
чае достаточно для организации программно-управляемого обме-
на данными с ВУ на первом уровне (процессор — контроллер ВУ).
Порядок использования описанных выше управляющих сигналов
при выполнении операций ВВОД и ВЫВОД проиллюстрирован
рис. 6.34.
Операция ВЫВОД, инициируемая соответствующей коман-
дой микропроцессора, выполняется следующим образом. Мик-
ропроцессор выставляет на линиях адресной шины адрес (но-
мер) ВУ, на линиях шины данных — значения разрядов выводи-
мого слова данных и единичным сигналом по линии «Вывод
в ВУ» указывает тип операции. Адресуемый контроллер ВУ при-
нимает данные, пересылает их в ВУ и единичным сигналом по
линии «Готовность ВУ» сообщает процессору, что данные при-
няты ВУ и можно снять информацию с шин адреса и данных,
а также сигнал «Вывод в ВУ».
314
обмена *
Адрес
Ввод
из ВУ
Данные
Готовность
ВУ
а) б)
Рис. 6.34. Временные диаграммы операций для простейшего набора
управляющих сигналов: а) ВЫВОД; б) ВВОД
Выполнение операции ВВОД начинается с того, что микропро-
цессор выставляет на линиях адресной шины адрес (номер) ВУ
и единичным сигналом на линии «Ввод из ВУ» указывает тип вы-
полняемой операции. По сигналу «Ввод из ВУ» контроллер адре-
суемого ВУ считывает слово данных из ВУ, выставляет на линиях
шины данных значения разрядов считанного слова и единичным
сигналом по линии «Готовность ВУ» сообщает об этом процессо-
ру. Приняв данные из контроллера ВУ, процессор снимает сигна-
лы с шины адреса и линии «Ввод из ВУ».
При реализации в ЭВМ обмена с ВУ по аналогии с обращения-
ми к памяти отпадает необходимость в специальных сигналах, ука-
зывающих, что на шине адреса находится адрес ВУ. Для адресов
ВУ отведена часть адресного пространства ЭВМ, и в контроллерах
ВУ удается легко организовать селекцию адресов ВУ — выделение
собственного адреса ВУ из всего множества адресов, передавае-
мых по линиям адресной шины. Однако остается необходимость
передавать в ВУ приказ на ввод или вывод информации. Для этих
целей используются линии управляющей шины «Чтение» и «За-
пись», обеспечивающие обмен информацией микропроцессора
с модулями памяти (см. рис. 6.33 б).
315
Временные диаграммы операций ВВОД и ВЫВОД при органи-
зации обмена с ВУ по аналогии с памятью полностью соответству-
ют рассмотренным ранее (см. рис. 6.34).
Приведенный минимальный набор управляющих (осведомитель-
ных) сигналов позволяет организовать обмен с ВУ не только в асин-
хронном режиме, но и в режиме прерывания программы. Однако при
этом существенно усложняются алгоритмы использования управля-
ющих сигналов и, как следствие, аппаратура для их обработки. Более
рациональным оказывается увеличение числа управляющих сигна-
лов с тем, чтобы каждый режим обмена идентифицировался отдель-
ным сигналом или набором сигналов. Для этого в системных интер-
фейсах вводятся линии для передачи сигналов запроса на прерыва-
ние и предоставления прерывания, запроса на предоставление пря-
мого доступа к памяти и его предоставления и т. п.
Но в ЭВМ необходимо управлять еще и режимами работы кон-
троллеров разнообразных ВУ, многие из которых являются доста-
точно сложными устройствами. При этом каждый контроллер вос-
принимает определенный, присущий только данному ВУ набор
команд управления (приказов ВУ). Организовать в этом случае
передачу каждого приказа ВУ по отдельной линии системного ин-
терфейса не представляется возможным по двум причинам. Во-
первых, при разработке микропроцессора и системного интерфей-
са достаточно трудно предусмотреть все возможные применения
ЭВМ на его основе, а следовательно, и используемые в ЭВМ ВУ.
И во-вторых, для каждого дополнительного управляющего сигна-
ла потребуется отдельный вывод в БИС микропроцессора. Таким
образом, возникают чисто конструктивные ограничения на коли-
чество используемых в системном интерфейсе управляющих сиг-
налов, связанных с числом выводов в БИС микропроцессора [6].
Решение указанной проблемы осуществляется путем мульти-
плексирования шины данных, т. е. использования ее для обмена
с контроллерами ВУ как данными (в одни моменты времени), так и
частью управляющей информации (в другие моменты времени).
Однако пересылаемая информация должна размещаться в различ-
ных регистрах контроллера ВУ: данные — в регистре данных,
а управляющая информация — в одном или нескольких регистрах
состояния и управления (количество этих регистров возрастает
с увеличением сложности ВУ и уменьшением разрядности переда-
ваемых слов, т. е. разрядности шины данных). Это ставит новую за-
дачу — выбор одного или нескольких регистров контроллера ВУ.
316
Наиболее просто эта задача решается выделением каждому ре-
гистру контроллера собственного адреса в системе адресов ЭВМ.
В этом случае организация обмена информацией микропроцессо-
ра с регистрами контроллеров не потребует дополнительных ли-
ний системного интерфейса, так как для адресации регистров ис-
пользуется шина адреса. Таким образом, в ЭВМ каждому ВУ выде-
ляется столько адресов, сколько регистров в его контроллере.
Итак, подключение любого внешнего устройства к ЭВМ осуще-
ствляется через контроллер ВУ, при этом способы структурной и
функциональной организации контроллеров ВУ определяются дву-
мя основными факторами:
форматами данных и режимами работы конкретных ВУ;
типом системного интерфейса ЭВМ.
Влияние первого из этих факторов на организацию контролле-
ров ВУ достаточно очевидно. В самом деле, нерационально было
бы создавать единый универсальный контроллер, обеспечиваю-
щий, например, подключение к компьютеру простых устройств
типа цифровых индикаторов и сложных устройств типа накопи-
телей на магнитных дисках. Именно поэтому на практике приме-
няют самые разнообразные контроллеры ВУ: от простейших для
подключения к ЭВМ датчиков одиночных сигналов до очень слож-
ных, сравнимых по сложности с процессорами ЭВМ, например,
для сопряжения ЭВМ с аппаратурой видеозаписи.
Второй фактор — тип интерфейса — определяет способ орга-
низации электронных схем контроллеров ВУ, обеспечивающих
связь с шинами интерфейса, в первую очередь — схем распозна-
вания адресов ВУ.
Однако такое положение дел, когда для каждого типа ВУ требу-
ется уникальный контроллер, не устраивало ни разработчиков
средств вычислительной техники (ЭВМ и ВУ), ни ее пользовате-
лей. Наиболее перспективным оказался путь стандартизации на-
бора информационных и управляющих сигналов, которыми обме-
ниваются контроллер и ВУ. Так, для разных типов ЭВМ были раз-
работаны контроллеры, обеспечивающие связь с ВУ по стан-
дартному параллельному и по стандартному последовательному
каналам передачи данных.
Рассмотрим типичные структуры контроллеров ВУ, применяемых
в ЭВМ с различными системными интерфейсами [6]. На рис. 6.35 а
приведена блок-схема типичного контроллера ВУ, обеспечиваю-
щего программно-управляемый обмен информацией с ВУ (опера-
ции ВВОД и ВЫВОД).
317
Системный интерфейс Системный интерфейс
б)
Рис. 6.35. Блок-схема типичного контроллера ВУ для системного интерфейса:
а) с раздельными шинами адреса и данных;
б) с мультиплексированной шиной «адрес/данные»
318
Основу контроллера ВУ составляют несколько регистров, ко-
торые служат для временного хранения передаваемой информа-
ции. Каждый регистр имеет свой адрес, и часто такие регистры
называют портами ввода-вывода. Регистры входных и выходных
данных работают соответственно только в режиме чтения и толь-
ко в режиме записи. Регистр состояния работает только в режиме
чтения и содержит информацию о текущем состоянии ВУ (вклю-
чено/выключено, готово/не готово к обмену данными и т. п.). Ре-
гистр управления работает только в режиме записи и служит для
приема из ЭВМ приказов для ВУ. В контроллерах, используемых
для подключения достаточно простых ВУ (клавиатура, мышьит.п.),
удается совместить в один регистры состояния и управления, что
позволяет сократить количество используемых в контроллере пор-
тов ввода-вывода, а следовательно, и адресов, выделенных для дан-
ного ВУ.
Логика управления контроллера ВУ выполняет селекцию адре-
сов регистров контроллера, прием, обработку и формирование
управляющих сигналов системного интерфейса, обеспечивая тем
самым обмен информацией между регистрами контроллера и ши-
ной данных системного интерфейса ЭВМ.
Приемопередатчики шин адреса и данных служат для физичес-
кого подключения электронных схем контроллера к соответству-
ющим шинам системного интерфейса.
На рис. 6.35 б приведена блок-схема типичного контроллера ВУ
для системного интерфейса с мультиплексируемой шиной «адрес/
данные». Сравнение двух контроллеров показывает, что между
ними нет принципиальных различий в порядке использования ре-
гистров. Различия в структурах контроллеров, вызванные различ-
ной организацией системных интерфейсов, проявляются только в
построении логики управления (по-разному организованы прием
и селекция адресов) и способе подключения к шинам системного
интерфейса [6].
В настоящее время используются в основном программируемые
контроллеры, режимы работы которых устанавливаются специаль-
ными командами ЭВМ или определяются программами обмена с
ВУ. Программируемые контроллеры настраивают на конкретный
режим обмена данными, присущий ВУ: синхронный или асинхрон-
ный, с использованием сигналов прерывания или без их использо-
вания, на заданную скорость обмена и т. д.
319
Настройка таких контроллеров на требуемый режим обмена
производится программным путем с помощью специальных ко-
манд (управляющих слов), передаваемых из процессора в контрол-
лер ВУ перед началом обмена. Управляющее слово записывается в
специальный регистр и инициирует заданный режим обмена с ВУ.
Стандартизация интерфейсов ввода-вывода и использование
БИС для реализации логических схем интерфейсов и контроллеров
ВУ позволяет конструктивно реализовать контроллер (интерфейс
ввода-вывода) на материнской плате либо непосредственно в ВУ.
Такая реализация интерфейсов и контроллеров создает у пользова-
теля иллюзию их отсутствия и некоторую несогласованность
в структурных и функциональных схемах ЭВМ. Тем не менее в лю-
бой ЭВМ всегда можно достаточно четко выделить компоненты си-
стемы ввода-вывода, что крайне необходимо при изучение как ЭВМ,
так и способов их использования в различных системах.
Примерами контроллеров, как правило, располагаемых на ма-
теринских платах современных ПЭВМ, могут служить устройства
последовательного и параллельного интерфейсов, называемые так-
же последовательным и параллельным портами соответственно.
Контроллеры дисковых накопителей размещаются непосредствен-
но на диске, а контроллеры видеомонитора, называемые также
видеоадаптерами, — на отдельной плате (видеоплате).
6.5. СИСТЕМЫ ПАРАЛЛЕЛЬНОЙ ОБРАБОТКИ ДАННЫХ
Любая вычислительная система (будь то суперЭВМ или персо-
нальный компьютер) достигает своей наивысшей производитель-
ности благодаря использованию высокоскоростных элементов и
параллельному выполнению большого числа операций. Именно
возможность параллельной работы различных устройств системы
является основой ускорения основных операций.
Параллелизм — параллельное выполнение двух или более процес-
сов (программ).
Параллельное выполнение нескольких процессов может быть
реализовано путем следующих аппаратных решений:
многомашинности;
320
мультипроцессорности;
* однопроцессорности с несколькими исполнительными уст-
ройствами;
конвейеризации обработки данных.
Типичными примерами двух последних подходов являются спе-
циализированные векторные процессоры, использующие паралле-
лизм обработки, допускаемый векторно-матричными вычислениями.
Векторная обработка — единообразная обработка последователь-
ностей данных, встречающаяся, как правило, при манипулировании
матрицами (элементами которых являются векторы) или другими ин-
формационными массивами.
Векторные процессоры включают в свой состав векторные и
скалярные исполнительные устройства с быстрыми регистрами
и индексной арифметикой и имеют производительность почти на
порядок выше по сравнению с традиционными процессорами ска-
лярного типа. Конвейеризация обработки данных расширяет па-
раллелизм во времени вычислительного процесса за счет увеличе-
ния числа исполнительных устройств. Основу конвейерной обра-
ботки составляет раздельное выполнение некоторой операции
в несколько этапов. При этом, когда первый этап завершается, ре-
зультаты передаются на второй этап, на котором используются
другие аппаратные средства. Устройство, используемое на первом
этапе, используется для начала обработки новых данных.
Конвейерная обработка — вид обработки, при котором обработ-
ка в функциональном узле вычислительной системы разбивается на
несколько этапов.
Такая технология обеспечивает быструю обработку последова-
тельных процессов, но требует использования сложного управля-
ющего устройства, которое должно вести учет операций, выпол-
няемых одновременно. Производительность при этом возрастает
благодаря тому, что одновременно на различных ступенях конвей-
ера выполняются несколько операций. Конвейеризация эффек-
тивна только тогда, когда загрузка конвейера близка к полной,
а скорость подачи новых операндов соответствует максимальной
производительности конвейера. Если происходит задержка, то па-
21 А-210
321
раллельно будет выполняться меньше операций и суммарная про-
изводительность снизится. Идеальную возможность полной загруз-
ки вычислительного конвейера обеспечивают векторные операции.
В многомашинной вычислительной системе каждый компьютер,
входящий в систему, имеет классическую архитектуру. Такая сис-
тема применяется достаточно широко, однако эффект от ее при-
менения может быть получен только при решении задач, имею-
щих специальную структуру: она должна разбиваться на столько
слабо связанных подзадач, сколько компьютеров в системе.
В настоящее время существует ряд классификаций параллель-
ных архитектур вычислительных систем (Flynn, Share, структурная
и др.), однако они не охватывают всего спектра параллелизма и раз-
нообразия существующих и разрабатываемых параллельных струк-
тур. Все параллельные вычислительные системы являются мульти-
процессорными с различной архитектурой. При их описании часто
используют классификацию Флинна, в которой, определен парал-
лелизм потока команд и параллелизм потока данных в системе. Со-
гласно этой классификации системы делятся на четыре категории:
• SISD (Single Instruction Single Data) — система с одним пото-
ком команд и одним потоком данных;
SIMD (Single Instruction Multiple Data) — система с одним по-
током команд и несколькими потоками данных;
• MISD (Multiple Instruction Single Data) — система с несколь-
кими потоками команд и одним потоком данных;
MIMD (Multiple Instruction Multiple Data) — система с несколь-
кими по токами команд и несколькими потоками данных.
Первая из этих систем — SISD — представляет собой обычный
процессор последовательной обработки. Третья система—M1SD —
в существующих устройствах обработки данных практически не
встречается. Наибольший интерес для мультипроцессорных сис-
тем представляют две оставшиеся архитектуры. Система SIMD
пригодна для обработки данных, представленных в виде векторов
и матриц; здесь используется преимущество внутреннего парал-
лелизма данных такого типа. В качестве примера такой системы
можно привести матричный процессор.
Матричный процессор — ЭВМ или процессор со специальной ар-
хитектурой, рассчитанной на обработку числовых массивов, напри-
мер матриц.
322
Эта архитектура включает в себя матрицу процессорных элемен-
тов (например, 64x64), работающих одновременно. Каждый из них
обрабатывает один элемент матрицы, так что за одну операцию мо-
гут быть параллельно обработаны все элементы матрицы. Чтобы
получить тот же самый результат при использовании обычного про-
цессора, надо обрабатывать каждый элемент матрицы последова-
тельно, поэтому время вычислений значительно больше. Матрич-
ный процессор может быть выполнен в виде отдельного блока, под-
ключаемого к основному компьютеру через порт ввода-вывода или
внутреннюю шину. Это может быть также распределенный матрич-
ный процессор, обрабатывающие элементы которого распределе-
ны по всей вычислительной системе и тесно связаны с определен-
ной частью памяти ЭВМ. В отличие от ограниченного конвейерно-
го функционирования векторного процессора, матричный процес-
сор (синоним для большинства SIMD-машин) может быть значитель-
но более гибким. Обрабатывающие элементы таких процессоров -
это универсальные программируемые ЭВМ, так что задача, реша-
емая параллельно, может быть достаточно сложной и содержать вет-
вления. Матричные процессоры — очень мощное средство реше-
ния задач, характеризующихся высокой степенью параллелизма.
Однако они требуют другого подхода к программированию. Преоб-
разование обычных (последовательных) программ с целью их реа-
лизации на матричных процессорах представляет собой непростую
задачу, и часто приходится выбирать иной (параллельный) алгоритм,
который был бы пригоден для параллельной обработки.
Система MIMD представляет широкий диапазон архитектур —
от больших симметричных мультипроцессорных систем до неболь-
ших асимметричных миниЭВМ в комбинации с каналами прямо-
го доступа к памяти. В такой системе, как правило, каждый про-
цессорный элемент (ПЭ) выполняет свою программу достаточно
независимо от других процессорных элементов. В мультипроцес-
сорах с общей памятью (сильносвязанных мультипроцессорах)
имеется память данных и команд, доступная всем ПЭ. С общей
памятью ПЭ связываются с помощью общей шины или сети обме-
на. В противоположность этому варианту в слабосвязанных мно-
гопроцессорных системах (машинах с локальной памятью) вся па-
мять делится между процессорными элементами и каждый блок
памяти доступен только связанному с ним процессору. Сеть обме-
на связывает процессорные элементы друг с другом.
Базовой моделью вычислений на MIMD-мультипроцессоре яв-
ляется совокупность независимых процессов, эпизодически обра-
щающихся к разделяемым данным. Существует большое количество
323
вариантов этой модели. На одном конце спектра — модель распре-
деленных вычислений, в которой программа делится на довольно
большое число параллельных задач, состоящих из множества под-
программ. На другом конце спектра — модель потоковых вычисле-
ний, в которых каждая операция в программе может рассматривать-
ся как отдельный процесс. Такая операция ждет своих входных дан-
ных (операндов), которые должны быть переданы ей другими про-
цессами. По их получении операция выполняется и полученное зна-
чение передается тем процессам, которые в нем нуждаются.
Многопроцессорные системы за годы развития вычислитель-
ной техники претерпели ряд этапов своего развития. Историчес-
ки первой стала осваиваться технология SIMD. Однако в настоя-
щее время наметился устойчивый интерес к архитектурам MIMD.
Большинство самых быстрых вычислительных систем в мире мож-
но отнести к MIMD архитектуре, при этом их относительное коли-
чество увеличивается. Интерес к MIMD системам главным обра-
зом определяется двумя факторами:
Архитектура MIMD дает большую гибкость: при наличии адек-
ватной поддержки со стороны аппаратных средств и программно-
го обеспечения MIMD система может работать как однопользова-
тельская система, обеспечивая высокопроизводительную обработ-
ку данных для одной прикладной задачи, как многопрограммная
машина, выполняющая множество задач параллельно, и как неко-
торая комбинация этих возможностей.
Архитектура MIMD может использовать все преимущества со-
временной микропроцессорной технологии на основе строгого
учета соотношения стоимость/производительность. В действитель-
ности практически все современные многопроцессорные систе-
мы строятся на тех же микропроцессорах, которые можно найти
в персональных компьютерах, рабочих станциях и небольших од-
нопроцессорных серверах.
6.6. ПРОЦЕССОРЫ И ПРОЦЕССОРНЫЕ ЭЛЕМЕНТЫ
ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ
6.6.1. Микропроцессоры с расширенной
и сокращенной системой команд
В ходе выполнения заданной программы процессор обслужи-
вает данные, находящиеся в его регистрах, в поле оперативной
324
памяти, а также данные, находящиеся во внешних портах процес-
сора. Часть данных он интерпретирует непосредственно как дан-
ные, часть данных — как адресные данные, а часть — как коман-
ды. Совокупность всех возможных команд, которые может выпол-
нить процессор над данными, образует так называемую систему
команд процессора. Процессоры, относящиеся к одному семейству,
имеют одинаковые или близкие системы команд. Процессоры,
относящиеся к разным семействам, различаются по системе ко-
манд и являются невзаимозаменяемыми.
Если два процессора имеют одинаковую систему команд, то они
полностью совместимы на программном уровне. Это означает, что
программа, написанная для одного процессора, может исполнять-
ся и другим процессором. Процессоры, имеющие разные систе-
мы команд, как правило, несовместимы или ограниченно совмес-
тимы на программном уровне.
Группы процессоров, имеющих ограниченную совместимость,
рассматривают как семейства процессоров. Например, все процес-
соры Intel Pentium относятся к так называемому семейству х86.
Родоначальником этого семейства был 16-разрядный процессор
Intel 8086, на базе которого собиралась первая модель компьютера
IBM PC. Впоследствии сменилось восемь поколений процессоров
фирмы Intel: 8088, 80286, 80386, 80486, Pentium, Pentium II, Pentium III,
Pentium IV. В каждом поколении имеются еще и модификации,
отличающиеся друг от друга назначением и ценой. Все эти моде-
ли, и не только они, а также многие модели процессоров компа-
ний AMD и Cyrix относятся к семейству х86 и обладают совмести-
мостью по принципу «сверху вниз».
Принцип совместимости «сверху вниз» — это пример непол-
ной совместимости, когда каждый новый процессор «понимает»
все команды своих предшественников, но не наоборот. Благода-
ря такой совместимости на современном компьютере можно вы-
полнять любые программы, созданные для любого из предшеству-
ющих компьютеров, принадлежащего той же аппаратной плат-
форме.
Чем шире набор системных команд процессора, тем сложнее
его архитектура, тем длиннее формальная запись команды (в бай-
тах), тем выше средняя продолжительность исполнения одной ко-
манды, измеренная в тактах работы процессора. Так, система ко-
манд процессоров Intel Pentium в настоящее время насчитывает
порядка тысячи различных команд. При этом команды имеют длину
325
от 8 до 120 бит. Такие процессоры называют процессорами с рас-
ширенной системой команд — CISC-процессорами (CISC —
Complete Instruction Set Computer).
Лидером в разработке микропроцессоров с полным набором
команд (CISC) считается компания Intel со своей серией х86 и
Pentium. Эта архитектура является практическим стандартом для
рынка микрокомпьютеров. Для CTSC-процессоров характерно:
сравнительно небольшое число регистров общего назначения;
большое количество машинных команд, некоторые из которых
нагружены семантически аналогично операторам высокоуровне-
вых языков программирования и выполняются за много тактов и
методов адресации; большое количество форматов команд различ-
ной разрядности; преобладание двухадресного формата команд;
наличие команд обработки типа регистр-память.
Основой архитектуры современных рабочих станций и серве-
ров является архитектура компьютера с сокращенным набором
команд — (RISC — Reduce Instruction Set Computer), созданная
в середине 80-х годов XX века. Зачатки этой архитектуры уходят
своими корнями к компьютерам CDC6600, разработчики которых
(Торнтон, Крэй и др.) осознали важность упрощения набора ко-
манд для построения быстрых вычислительных машин. Эту тра-
дицию упрощения архитектуры С. Крэй с успехом применил при
создании широко известной серии суперкомпьютеров компании
Cray Research.
При такой архитектуре количество команд в системе намного
меньше, они имеют одинаковую длину и каждая из них выполня-
ется намного быстрее. В этих микропроцессорах на выполнение
каждой простой команды за счет их наложения и параллельного
выполнения тратится 1 машинный такт (на выполнение даже са-
мой короткой команды из системы CISC обычно расходуется
4 такта).
Таким образом, программы, состоящие из простейших команд,
выполняются этими процессорами намного быстрее. Оборотная
сторона сокращенного набора команд состоит в том, что сложные
операции приходится эмулировать далеко не эффективной после-
довательностью простейших команд сокращенного набора.
В 1980 г. в университете Беркли были изготовлены две маши-
ны, которые получили названия RISC-In RISC-П. Главными идеями
этих машин было отделение медленной памяти от высокоскорост-
ных регистров и использование регистровых окон. В 1981 г. выш-
326
ло описание стэндфордской машины MIPS, основным аспектом
разработки которой была эффективная реализация конвейерной
обработки посредством тщательного планирования компилятором
его загрузки.
Эти три машины имели много общего. Все они придерживались
архитектуры, отделяющей команды обработки от команд работы
с памятью, и делали упор на эффективную конвейерную обработ-
ку. Система команд разрабатывалась таким образом, чтобы выпол-
нение любой команды занимало небольшое количество машинных
тактов (предпочтительно один машинный такт). Сама логика вы-
полнения команд с целью повышения производительности ориен-
тировалась на аппаратную, а не на микропрограммную реализа-
цию. Чтобы упростить логику декодирования команд, использова-
лись команды фиксированной длины и фиксированного формата.
Среди других особенностей R/S'C-архитектур следует отметить
наличие достаточно большого регистрового файла, что позволяет
большему объему данных храниться в регистрах на процессорном
кристалле большее время и упрощает работу компилятора по рас-
пределению регистров под переменные. Для обработки, как пра-
вило, используются трехадресные команды, что, помимо упроще-
ния дешифрации, дает возможность сохранять большее число пе-
ременных в регистрах без их последующей перезагрузки.
Ко времени завершения университетских проектов (1983—1984 гг.)
обозначился также прорыв в технологии изготовления сверхболь-
ших интегральных схем. Простота архитектуры и ее эффектив-
ность, подтвержденная этими проектами, вызвали большой инте-
рес в компьютерной индустрии, и с 1986 г. началась активная про-
мышленная реализация архитектуры RISC. К настоящему време-
ни эта архитектура прочно занимает лидирующие позиции на ми-
ровом компьютерном рынке рабочих станций и серверов.
Развитие архитектуры RISC в значительной степени определялось
прогрессом в области создания оптимизирующих компиляторов.
Именно современная техника компиляции позволяет эффективно
использовать преимущества большого регистрового файла, конвей-
ерной организации и большей скорости выполнения команд. Совре-
менные компиляторы используют также преимущества другой оп-
тимизационной техники для повышения производительности, обыч-
но применяемой в процессорах RISC: реализацию задержанных пе-
реходов и суперскалярной обработки, позволяющей в один и тот же
момент времени выдавать на выполнение несколько команд.
327
Следует отметить, что в последних разработках компании Intel
(имеется в виду Pentium II и последующие поколения), а также ее
последователей-конкурентов (AMD Кб, Cyrix Ml, NexGen Nx686
и др.) широко используются идеи, реализованные в RISC-микро-
процессорах, так что многие различия между CISC и RISC стира-
ются. Однако сложность архитектуры и системы команд х86 оста-
ется и является главным фактором, ограничивающим производи-
тельность процессоров на ее основе.
6.6.2. Основные характеристики микропроцессоров,
используемых в ПЭВМ
Первый микропроцессор был выпущен в 1971 г. фирмой Intel
(США) — 4-разрядный Intel 4004. В настоящее время выпускается
несколько сотен различных микропроцессоров, но среди микро-
процессоров, используемых в ПЭВМ, наиболее популярными яв-
ляются микропроцессоры семейства х86.
Конструктивно современный микропроцессор представляет со-
бой сверхбольшую интегральную схему, реализованную на одном
полупроводниковом кристалле — тонкой пластинке кристалличес-
кого кремния прямоугольной формы площадью всего несколько
квадратных миллиметров. На ней размещены схемы, реализующие
все функции процессора. Кристалл-пластинка обычно помещается
в пластмассовый или керамический плоский корпус и соединяется
золотыми выводами с металлическими штырьками, чтобы его мож-
но было присоединить к системной плате компьютера.
С внешними устройствами, и в первую очередь с оперативной
памятью, процессор связан несколькими группами проводников,
называемых шинами. Основных шин три: шина данных, адресная
шина и командная шина.
Адресная шина. У большинства современных процессоров адрес-
ная шина 32-разрядная, т. е. состоит из 32 параллельных линий. В зави-
симости от того, есть напряжение на какой-то из линий или нет, гово-
рят, что на этой линии выставлена единица или ноль. Комбинация из
32 нолей и единиц образует 32-разрядный адрес, указывающий на
одну из ячеек оперативной памяти. К ней и подключается процессор
для копирования данных из ячейки в один из своих регистров.
Шина данных. По этой шине происходит копирование данных
из оперативной памяти в регистры процессора и обратно. В ком-
пьютерах, собранных на базе процессоров Intel Pentium, шина дан-
ных 64-разрядная, т. е. состоит из 64 линий, по которым за один
раз на обработку поступают сразу 8 байтов.
328
Шина команд. В большинстве современных процессоров шина
команд 32-разрядная, хотя существуют 64-разрядные процессоры
и даже 128-разрядные.
В процессорах семейства х86 различают реальный, защищен-
ный и виртуальный режимы работы.
Реальный режим соответствует возможностям первых процес-
соров 8086/8088, имеющих 20 разрядную адресную шину, позво-
ляя адресовать не более 1 Мбайт (220) памяти. Чтобы поддержать
совместимость с ранее разработанными программами, все после-
дующие процессоры поддерживают реальный режим, используя
при этом свои минимальные возможности.
Защищенный режим появился впервые в МП 80286. В этом ре-
жиме, если физическая память полностью загружена, «непоместив-
шиеся» данные МП располагает на винчестере. При этом он рабо-
тает не с реальными, а с виртуальными адресами, которые управля-
ются через специальные таблицы, с тем чтобы информацию можно
было найти (или снова записать). Эту память называют еще вирту-
альной памятью, так как фактически она не существует.
Кроме того, в защищенном режиме возможна поддержка муль-
тизадачного режима. При этом CPU может выполнять различные
программы в выделенные кванты времени, выпадающие на каж-
дую из программ (пользователю же кажется, что программы вы-
полняются одновременно).
Начиная с процессора 80386 его архитектура определяет четы-
ре уровня привилегий для защиты кода и данных системы от слу-
чайного или преднамеренного изменения со стороны менее при-
вилегированного кода. Такой метод выполнения кода называют мо-
делью защиты Intel. Уровни привилегий задаются от 0 до 3. Уровень
привилегий 0, отведенный под ядро операционной системы, —
режим ядра — максимальный. Уровень привилегий 3, или режим
пользователя — минимальный.
Виртуальный режим. Впервые, начиная с процессора 386, CPU
могут эмулировать работу нескольких процессоров 8086 и тем са-
мым обеспечить многопользовательский режим таким образом, что
на одном ПК могут быть записаны одновременно даже различные
операционные системы. Естественно, увеличивается и возможное
количество выполняемых приложений.
Основными параметрами процессоров являются: рабочее на-
пряжение, разрядность, рабочая тактовая частота, коэффици-
ент внутреннего умножения тактовой частоты и размер кэш-
памяти [13].
329
Рабочее напряжение процессора обеспечивает материнская
плата, поэтому разным маркам процессоров соответствуют разные
материнские платы (их надо выбирать совместно). По мере разви-
тия процессорной техники происходит постепенное понижение
рабочего напряжения. Ранние модели процессоров х86 имели ра-
бочее напряжение 5 В. С переходом к процессорам Intel Pentium
оно было понижено до 3,3 В, а в настоящее время оно составляет
менее 3 В. Причем ядро процессора питается пониженным напря-
жением 2,2 В и менее. Понижение рабочего напряжения позволя-
ет уменьшить расстояния между структурными элементами в кри-
сталле процессора до десятитысячных долей миллиметра, не опа-
саясь электрического пробоя. Пропорционально квадрату напря-
жения уменьшается и тепловыделение в процессоре, а это позво-
ляет увеличивать его производительность без угрозы перегрева.
Разрядность процессора показывает, сколько бит данных он
может принять и обработать в своих регистрах за один раз (за один
такт). Первые процессоры х86 были 16-разрядными. Начиная
с процессора 80386 они имеют 32-разрядную архитектуру. Совре-
менные процессоры семейства Intel Pentium остаются 32-разряд-
ными, хотя и работают с 64-разрядной шиной данных (разрядность
процессора определяется разрядностью внутренних регистров).
Рабочая тактовая частота и коэффициент ее внутреннего
умножения. В процессоре исполнение каждой команды занимает
определенное количество тактов. Тактовые импульсы задает одна
из микросхем, входящая в микропроцессорный комплект (чипсет),
расположенный на материнской плате. Чем выше частота тактов,
поступающих на процессор, тем больше команд он может испол-
нить в единицу времени, тем выше его производительность. Пер-
вые процессоры х86 могли работать с частотой не выше 4,77 МГц,
а сегодня рабочие частоты процессоров уже превосходят милли-
ард тактов в секунду (1 ГГц).
Тактовые сигналы процессор получает от материнской платы,
которая по чисто физическим причинам не может работать со
столь высокими частотами, как процессор. Сегодня ее предел со-
ставляет сотни МГц. Для получения более высоких частот в про-
цессоре происходит внутреннее умножение частоты на коэффи-
циент 3; 3,5; 4; 4,5; 5 и более. Например, частота МП 2,4 ГГц — это
частота системной шины в 400 МГц, умноженная на коэффици-
ент 6.
330
Обмен данными внутри процессора происходит в несколько раз
быстрее, чем обмен с другими устройствами, например с опера-
тивной памятью. Для того чтобы уменьшить количество обраще-
ний к оперативной памяти, внутри процессора создают буферную
область — так называемую кэш-память. Это как бы «сверхопера-
тивная память». Когда процессору нужны данные, он сначала об-
ращается в кэш-память, и только если там нужных данных нет, про-
исходит его обращение в оперативную память. Принимая блок
данных из оперативной памяти, процессор заносит его одновре-
менно и в кэш-память. Высокопроизводительные процессоры все-
гда имеют повышенный объем кэш-памяти.
В современных МП кэш-память распределяют по нескольким
уровням. Кэш первого уровня (L1) выполняется в том же кристал-
ле, что и сам процессор, и имеет объем порядка десятков Кбайт.
Кэш второго уровня (L2) находится либо в кристалле процессора,
либо в том же узле, что и процессор, хотя и исполняется на отдель-
ном кристалле. Кэш-память первого и второго уровней работает
на частоте, согласованной с частотой ядра процессора. Кэш-память
третьего уровня выполняют на быстродействующих микросхемах
и размещают на материнской плате вблизи процессора. Ее объе-
мы могут достигать нескольких Мбайт, но работает она на частоте
материнской платы.
Рассмотрим для примера основные характеристики некоторых
из процессоров семейства х86 [28].
Pentium. Начал выпускаться фирмой Intel в марте 1993 г. Имеет 32-
разрядную адресную и 64-разрядную внешнюю шины данных. Мик-
ропроцессор выполнен по 0,8-микрометровой технологии, имеет бо-
лее 3 млн транзисторов и работает на тактовых частотах 60 и 66 МГц.
Через год появилась следующая модель микропроцессора, выполнен-
ная по 0,5- (позднее по 0,35-) микрометровой технологии. Впервые
был применен раздельный 16-килобайтный кэш: 8 Кбайт для инст-
рукций и 8 Кбайт для данных. Тактовая частота была в пределах 75—
200 МГц, а тактовая частота системной шины — 50—66 МГц.
Pentium MMX — это версия Pentium с дополнительными муль-
тимедиа-инструкциями (добавлено 57 новых инструкций). Осно-
ва ММХ — технология обработки множественных данных одной
инструкцией (Single Instruction Multiple Data, SIMD). Кэш-память
увеличена до 32 Кбайт. Тактовая частота — 166—233 МГц. Частота
системной шины — 66 МГц.
Pentium Pro. Промышленный выпуск начался в ноябре 1995 г. Это
процессор, разработанный для 32-разрядных операционных систем.
331
Впервые в микропроцессоре вместе с кэш-памятью L1 (здесь объе-
мом 16 Кбайт) стали применять кэш-память второго уровня (L2),
объединенную в одном корпусе и оперирующую на частоте микро-
процессора. Выпускался сначала по 0,5-(позднее по 0,35-) микромет-
ровой технологии и имел в своем составе более 5 млн транзисторов.
кэш уровня L1 объемом 16 Кбайт. Кэш уровня L2 имел объем
256,512,1024 и 2048 Кбайт. Тактовая частота от 150 до 200 МГц. Че-
тырехканальная параллельная обработка данных. Частота систем-
ной шины 60—66 МГц. Pentium Pro поддерживал все инструкции
процессора Pentium, кроме ММХ, а также ряд новых инструкций.
Pentium II. Первая модель микропроцессора Pentium //впервые
появилась в мае 1997 г. Под этим общим именем выпускались мик-
ропроцессоры, предназначенные для разных сегментов рынка: для
недорогих компьютеров, для массового рынка ПК среднего уров-
ня, для высокопроизводительных серверов и рабочих станций.
Процессоры линейки Pentium II изготавливались по 0,35- и
0,25-микрометровой технологии. Диапазон тактовых частот от 233
до 533 МГц, дополнены ММХ-блоком.
Pentium III. Изготавливались по 0,18- и 0,13-микрометровой тех-
нологии, имеют расширенный набор MMX (ММХ2), в основе кото-
рого лежит технология SSE (Streaming SIMD Extentions), где техно-
логия SIMD расширена на числа с плавающей запятой. Добавлены
новые 128-разрядные регистры. Каждый регистр может обрабаты-
вать четыре числа с плавающей запятой. Усовершенствована тех-
нология поточного доступа к памяти, улучшающая взаимодействие
между кэш-памятью L2 и оперативной памятью. Дополнительные
инструкции называются инструкциями KNI (Katmai New Instruction).
Внедрение KNI предназначено для ускорения работы графических
приложений и ЗП-игр. Тактовая частота от 450 до 1000 МГц и выше.
Pentium IV. Отличительной особенностью этих процессоров
является наличие новой системы команд-инструкций, значитель-
но ускоряющих обработку мультимедийной информации (видео,
звука, графики) — SSE2.
6.6.3. Основные типы микропроцессоров, используемых
в высокопроизводительных вычислительных системах
Процессоры с архитектурой х86 находят широкое применение
и в высокопроизводительных вычислительных системах. Сейчас
различные модели этого семейства, кроме Intel, выпускают ком-
пании Advanced Micro Devices (AMD), Cyrix Corp.
332
В соответствии с системой команд, как было отмечено выше,
эти процессоры относятся к С/5С-архитектуре. Их главными осо-
бенностями с точки зрения использования в высокопроизводитель-
ных вычислительных системах, являются:
двухпотоковая суперскалярная организация, допускающая
параллельное выполнение пары простых команд;
наличие двух независимых двухканальных множественно-
ассоциативных кэшей для команд и для данных, обеспе-
чивающих выборку данных для двух операций в каждом
такте;
динамическое прогнозирование переходов;
конвейерная организация устройства плавающей точки
с 8 ступенями;
двоичная совместимость с существующими процессорами
семейства х86.
Процессоры с архитектурой SPARC компании Sun Microsystems.
Масштабируемая процессорная архитектура компании Sun
Microsystems (SPARC — Scalable Processor Architecture} является
наиболее широко распространенной R/SC-архитектурой, отража-
ющей доминирующее положение компании на рынке UNlX-рабо-
чих станций и серверов. Процессоры с архитектурой SPARC изго-
тавливаются несколькими производителями, среди которых сле-
дует отметить компании Texas Instruments, Fujitsu, LSI Logic, Bipolar
International Technology, Philips и Cypress Semiconductor. Эти ком-
пании осуществляют поставки процессоров SPARC не только са-
мой Sun Microsystems, но и другим известным производителям вы-
числительных систем, например Solbourne, Toshiba, Matsushita,
Tatung и Cray Research.
Процессоры РА-RISC компании Hewlett-Packard. Основой разра-
ботки современных изделий Hewlett-Packard выступает архитек-
тура РА-RISC. Она была разработана компанией в 1986 г. и с тех
пор прошла несколько стадий своего развития благодаря успехам
интегральной технологии от многокристального до однокристаль-
ного исполнения.
Особенностью архитектуры РА-RISC является внекристальная
реализация кэша, что позволяет реализовать различные объемы
кэш-памяти и оптимизировать конструкцию в зависимости от ус-
ловий применения. Хранение команд и данных осуществляется в
раздельных кэшах, причем процессор соединяется с ними с помо-
333
щью высокоскоростных 64-битовых шин. Кэш-память реализует-
ся на высокоскоростных кристаллах статической памяти (SRAM),
синхронизация которых осуществляется непосредственно на так-
товой частоте процессора.
Процессор МС88110 компании Motorola. Этот процессор отно-
сится к разряду суперскалярных RISC-процессоров. Основные его
особенности связаны с использованием принципов суперскаляр-
ной обработки, двух восьмипортовых регистровых файлов, деся-
ти независимых исполнительных устройств, больших по объему
внутренних кэшей и широких магистралей данных.
При построении многопроцессорной системы все процессо-
ры и основная память размещаются на одной плате. Для обеспе-
чения хорошей производительности системы каждый процес-
сор в такой конфигурации снабжается кэш-памятью второго
уровня емкостью 256 Кбайт. Протокол поддержания когерент-
ного состояния кэш-памяти (протокол наблюдения) базируется
на методике записи с аннулированием, гарантирующей разме-
щение модифицированной копии строки кэш-памяти только
в одном из кэшей системы. Протокол позволяет нескольким про-
цессорам иметь одну и ту же копию строки кэш-памяти. При
этом если один из процессоров выполняет запись в память (об-
щую строку кэш-памяти), другие процессоры уведомляются
о том, что их копии являются недействительными и должны быть
аннулированы.
Архитектура MIPS компании MIPS Technology. Архитектура
MIPS была одной из первых RISC-архитектур, получившей при-
знание со стороны промышленности. Она была анонсирована
в 1986 г. Первоначально это была полностью 32-битовая архитек-
тура, которая включала в себя 32 регистра общего назначения
длиною в 32 бит, 16 регистров плавающей точки и специальную
пару регистров для хранения результатов выполнения операций
целочисленного умножения и деления. Размер команд составлял
32 бит, в ней поддерживался всего один метод адресации, а ад-
ресное пространство также определялось 32 битами. В компью-
терной промышленности широкую популярность приобрели
32-битовые процессоры R2000 и R3000, которые в течение доста-
точно длительного времени служили основой для построения ра-
бочих станций и серверов компаний Silicon Graphics, Digital,
Siemens Nixdorf и др.
334
На смену микропроцессорам семейства R3000 пришли новые
128-битовые микропроцессоры R10000 и R12000. (MIPS была пер-
вой в компьютерной промышленности компанией, выпустившей
процессоры с 128-битовой архитектурой.) Набор команд этих про-
цессоров (спецификация MIPS IV) был расширен командами заг-
рузки и записи 128-разрядных чисел с плавающей точкой, коман-
дами вычисления квадратного корня с одинарной и двойной точ-
ностью, командами условных прерываний, а также атомарными
операциями, необходимыми для поддержки мультипроцессорных
конфигураций. В процессорах R10000 и R12000 реализованы 128-
битовые шины данных, а также метод удвоения внутренней так-
товой частоты.
Процессор R10000 допускает два способа организации много-
процессорной системы. Один из способов связан с созданием спе-
циального внешнего интерфейса для каждого процессора систе-
мы. Этот интерфейс обычно реализуется с помощью заказной ин-
тегральной схемы, которая организует шлюз к основной памяти и
подсистеме ввода-вывода. При таком типе соединений процессо-
ры не связаны друг с другом непосредственно, а взаимодействуют
через этот специальный интерфейс. Хотя такая реализация обще-
принята, ее стоимость достаточно высока.
Второй способ предназначен для достижения максимальной
производительности при минимальных затратах. Он подразумева-
ет использование от двух до четырех процессоров, объединенных
шиной Ciaster Bus. В этом случае необходим только один внешний
интерфейс для взаимодействия с другими ресурсами системы.
Архитектура Alpha компании DEC. Первым на рынке появился
64-разрядный микропроцессор Alpha (DECchip 21064). Он представ-
ляет собой R/SC-процессор в однокристальном исполнении, в со-
став которого входят устройства целочисленной и плавающей
арифметики, а также кэш-память емкостью 16 Кб. Кристалл про-
ектировался с учетом реализации передовых методов увеличения
производительности, включая конвейерную организацию всех
функциональных устройств, одновременную выдачу нескольких
команд для выполнения, а также средства организации симметрич-
ной многопроцессорной обработки.
Микропроцессор Alpha 21164 представляет собой вторую пол-
ностью новую реализацию архитектуры Alpha, обеспечивает про-
изводительность около 1200 MIPS и выполняет до четырех инст-
рукций за такт. На кристалле микропроцессора 21164 размещено
335
около 9,3 млн транзисторов, большинство из которых образуют
кэш. Кристалл построен на базе 0,5-микронной КМОП техно-
логии компании DEC. Он собирается в 499-контактные корпуса
(при этом 205 контактов отводятся под разводку питания и зем-
ли) и рассеивает 50 Вт при питающем напряжении 3,3 В на час-
тоте 300 МГц.
Ключевыми моментами для реализации высокой производи-
тельности является суперскалярный режим работы процессора,
обеспечивающий выдачу д ля выполнения до четырех команд в каж-
дом такте, высокопроизводительная неблокируемая подсистема
памяти с быстродействующей кэш-памятью первого уровня, боль-
шая, размещенная на кристалле, кэш-память второго уровня и
уменьшенная задержка выполнения операций во всех функцио-
нальных устройствах.
Архитектура POWER компании IBM и PowerPC компаний
Motorola, Apple и IBM. Архитектура POWER во многих отношени-
ях представляет собой традиционную 7?Г5С-архитектуру. Она при-
держивается наиболее важных отличительных особенностей RISC:
фиксированной длины команд, архитектуры регистр-регистр, про-
стых способов адресации, простых (не требующих интерпретации)
команд, большого регистрового файла и трехоперандного (нераз-
рушительного) формата команд. Однако архитектура РОWER име-
ет также несколько дополнительных свойств, которые отличают
ее от других RKC-архитектур. I
Во-первых, набор команд основан на идее суперскалярной об-
работки. Во-вторых, архитектура POWER расширена нескольки-
ми «смешанными» командами для сокращения времени выполне-
ния. Третий фактор, который отличает архитектуру POWER от
многих других R/SC-архитектур, заключается в отсутствии меха-
низма «задержанных переходов». Обычно этот механизм обеспе-
чивает выполнение команды, следующей за командой условного
перехода, перед выполнением самого перехода. Методика реали-
зации условных переходов, используемая в архитектуре POWER,
является четвертым уникальным свойством по сравнению с дру-
гими R/SC-процессорами.
По данным IBM, процессор POWER требует менее одного такта
для выполнении одной команды по сравнению с примерно 1,25 так-
та у процессора Motorola 68040, 1,45 такта у процессора SPARC
и 1,8 такта Hewlett-Packard. PA-RISC.
336
Подобно другим 64-битовым процессорам, PowerPC 620 содер-
жит 64-битовые регистры общего назначения и плавающей точки
и обеспечивает формирование 64-битовых виртуальных адресов.
При этом сохраняется совместимость с 32-битовым режимом ра-
боты, реализованным в других моделях семейства PowerPC.
В процессоре имеется кэш-память данных и команд общей ем-
костью 64 Кбайт, интерфейсные схемы управления кэш-памятью
второго уровня, 128-битовая шина данных между процессором и
основной памятью, а также логические схемы поддержания коге-
рентного состояния памяти при организации многопроцессорной
системы.
6.7. Сетевые технологии распределенной обработки данных
Современные сетевые технологии обработки данных основа-
ны на различных моделях архитектуры «клиент-сервер», появив-
шейся на этапе децентрализации архитектуры автономных вычис-
лительных систем и их объединения в компьютерные сети.
Сервер — приложение, обеспечивающее обслуживание запраши-
вающих приложений.
Например, сервер базы данных — приложение, отвечающее за об-
работку запросов к базе данных.
Клиент — приложение, посылающее серверу запросы на обслужи-
вание.
Одной из особенностей, отличающей клиента от сервера, является
то, что только клиент может начать транзакцию связи с сервером.
В распределенных локальных и глобальных вычислительных
системах компьютеры, предоставляющие те или иные общие ре-
сурсы, были названы серверами, а компьютеры, использующие
общие ресурсы, — клиентами (рис. 6.36). Компьютеры, исполняю-
щие роль клиентов, называют еще рабочими станциями сети.
В современных сетях серверы, как правило, выделяют в общее
пользование комплекс ресурсов — базы данных, файловые системы,
различные сервисы, предоставляемые выполняемыми на сервере
программами, а также внешние устройства, например принтеры.
Различают несколько моделей архитектуры «клиент-сервер»,
каждая из которых отражает соответствующее распределение
компонентов программного обеспечения между компьютерами
22 д-210
337
сети. Распределяемые программные компоненты могут быть раз-
делены по функциональному признаку на три группы [11]:
• функции ввода и отображения данных (интерфейс с пользо-
вателем);
" функции накопления информации и управления данными,
базами данных, файлами (СУБД).
прикладные функции, характерные для предметной облас-
ти конкретного приложения (приложение);
Рабочая станция
(клиент)
Рабочая станция
(клиент)
Рабочая станция
(клиент)
Рис. 6.36. Типовая архитектура «клиент-сервер»
В соответствии с этим различают четыре модели распределен-
ных вычислений:
файловый сервер (FS — File Server);
доступ к удаленным данным (RDA — Remote Data Access);
" сервер баз данных (DBS — Data Base Server);
• сервер приложений (ApS — Application Server).
Файловый сервер (FS). В этом случае на сервере расположены
только данные (рис. 6.37).
Рабочая станция
Компьютер-сервер
Интерфейс Приложение СУБД
Базы данных
Рис. 6.37. Модель распределенных вычислений FS
338
Данная модель является основной для ЛВС на персональных
ЭВМ. Здесь вся информация обрабатывается на рабочих станци-
ях, а файлы, содержащие эту информацию, для обработки долж-
ны быть переданы по сети с сервера. При этом возникает пробле-
ма корректного обновления файлов. Для ее решения все процес-
сы клиентов и серверов имеют маркеры, содержащие имя файла
и маску, в которой указаны права: только чтение атрибутов фай-
ла, только чтение самого файла, открытие файла, модификация
файла, удаление. Все обращения идут через менеджер маркеров,
который отслеживает соблюдение ограничений и разрешает кон-
фликты одновременного обращения для чтения и обновления фай-
лов. Основной недостаток модели FS — перегрузка сети из-за не-
обходимости передачи больших объемов данных.
Доступ к удаленным данным (RDA). В этом случае, кроме дан-
ных, на сервере расположен менеджер информационных ресур-
сов, например, система управления базой данных (СУБД) (рис.
6.38). Программные компоненты функции ввода и отображения
данных (интерфейс с пользователем) и прикладные функции, ха-
рактерные для предметной области конкретного приложения (при-
ложение), выполняются на компьютере-клиенте, поддерживаю-
щем как функции ввода и отображения данных, так и чисто при-
кладные функции.
Рис. 6.38. Модель распределенных вычислений RDA
Доступ к информационным ресурсам обеспечивается, как пра-
вило, операторами специального языка (например, языка SQL, если
речь идет о базах данных) или вызовами функций специализиро-
ванных программных библиотек. Запросы к информационным
ресурсам направляются по сети менеджеру ресурсов, который
обрабатывает запросы и возвращает клиенту блоки данных.
Главным преимуществом модели RDA перед моделью FS явля-
ется снижение объема информации, передаваемой по сети, так как
выборка требуемых информационных элементов из файлов вы-
полняется не на рабочих станциях, а на сервере.
339
Дальнейший переход к системе распределенных вычислений
приводит к перемещению прикладного программного обеспече-
ния или его части на сервер баз данных (DBS). В этом случае на
сервере сконцентрированы как данные и менеджер ресурсов, так
и основные прикладные компоненты (рис. 6.39). Процесс, выпол-
няемый на компьютере-клиенте, ограничивается лишь функция-
ми представления и некоторыми функциями индивидуальных для
каждого пользователя прикладных процедур. При этом в сравне-
нии с RDA снижается трафик, так как обмены по сети происходят
не для каждой операции с базой данных, а для каждой транзак-
ции, состоящей из нескольких операций.
Рис. 6.39. Модель распределенных вычислений DBS
При существенном усложнении и увеличении ресурсоемкости
прикладного компонента для него может быть выделен отдельный
сервер, называемый сервером приложений (ApS). Таким образом,
если модели FS, RDA, DBS являются двухзвенными, то модель ApS —
трехзвенной (рис. 6.40): первое звено — компьютер-клиент, вто-
рое — сервер приложений, а третье — сервер управления данными.
В рамках сервера приложений могут быть реализованы несколь-
ко прикладных функций, каждая из которых оформляется как от-
дельная служба, предоставляющая некоторые услуги всем про-
граммам, которые желают и могут ими воспользоваться. Серверов
приложения может быть несколько, каждый из которых ориенти-
рован на представление некоторого набора услуг.
Рис. 6.40. Модель распределенных вычислений ApS
340
Одной из основных проблем в такой модели является проблема
разделения серверных функций между многими рабочими стан-
циями. Эта проблема решается либо по схеме «один к одному»,
либо по многопотоковой схеме. В первой из них для каждого ак-
тивного клиента создается своя копия СУБД. Во второй СУБД дол-
жна обслуживать одновременно многих клиентов.
В начале 90-х годов в связи с развитием глобальной сети Интер-
нет появилась новая архитектура компьютерных сетей — интер-
нет-архитектура, обеспечивающая возможность обработки запро-
сов от клиентов, расположенных по всему миру. Одним из элемен-
тов данной архитектуры является Веб-технология, основанная на
передаче гипертекстовых документов. Веб — сокращенное назва-
ние World Wide Web (WWW— всемирная паутина) — гипертек-
стовая информационная система сети Интернет.
В соответствии с Веб-технологией на сервере размещаются так
называемые Веб-документы, которые визуализируются и интер-
претируются программой навигации, функционирующей на рабо-
чей станции. Программу навигации называют еще Веб-навигато-
ром или Веб-браузером Веб.
Логически Веб-документ представляет собой гипермедийный
документ, объединяющий ссылками различные Веб-страницы,
каждая из которых может содержать ссылки и на другие объекты.
Физически Веб-документ представляет собой текстовый файл спе-
циального формата, содержащий ссылки на другие объекты и Веб-
документы, расположенные в любом узле сети. Веб-документ ре-
ально включает только одну Веб-страницу, но логически может
объединять любое количество таких страниц, принадлежащих раз-
личным Веб-документам. Программа, связанная с Веб-страницей,
начинает автоматически выполняться при переходе по соответ-
ствующей ссылке или открытии Веб-страницы.
Получаемая таким образом система гиперссылок основана на
том, что некоторые выделенные участки одного документа, кото-
рыми могут быть части текста и рисунки, выступают в качестве
ссылок на другие логически связанные с ними объекты. При этом
объекты, на которые делаются ссылки, могут находиться на лю-
бом компьютере сети.
Передачу с сервера на рабочую станцию документов и других
объектов по запросам, поступающим от навигатора, обеспечивает
функционирующая на сервере программа, называемая Веб-серве-
ром. Из современных Веб-серверов можно отметить такие, как
Enterprise Server от корпорации Netscape, Internet Information Server
341
от Microsoft и Apache-сервер. Наиболее распространенными Веб-
навигаторами в настоящее время являются Netscape Navigator,
Internet Explorer и Opera.
Когда Веб-навигатору необходимо получить документы или дру-
гие объекты от Веб-сервера, он отправляет серверу соответствую-
щий запрос. При достаточных правах доступа между сервером и
навигатором устанавливается логическое соединение. Далее сер-
вер обрабатывает запрос, передает Веб-навигатору результаты об-
работки, например требуемый Веб-документ, и разрывает установ-
ленное соединение.
Веб-сервер выступает в качестве информационного концент-
ратора, который доставляет информацию из разных источников,
а потом однородным образом предоставляет ее пользователю. На-
вигатор, снабженный универсальным и естественным интерфей-
сом с человеком, позволяет последнему легко просматривать ин-
формацию вне зависимости от ее формата.
Таким образом, в рамках Веб-документа может быть выполнена
интеграция данных и программных объектов различных типов, рас-
положенных в совершенно разных узлах компьютерной сети. Это
позволяет рассредоточивать информацию в соответствии с естествен-
ным порядком ее создания и потребления, а также осуществлять
к ней единообразный доступ. Приставка Веб здесь, а также в назва-
нии самой технологии, переводимая как паутина, как раз и отражает
тот факт, что работа пользователя осуществляется на основе перехо-
да по ссылкам, которые как нити паутины связывают разнотипные
объекты, распределенные по узлам компьютерной сети.
Одной из главных особенностей интернет-архитектуры явля-
ется распределенная обработка информации на основе так назы-
ваемых мигрирующих программ:
Java-аплетов, подготовленных и используемых по техноло-
гии Java;
* программ, написанных на языке сценариев JavaScript,
VBScript (Visual Basic Scripting) или VRML;
программных компонент ActiveX Controls, соответствующих
технологии ActiveX.
Программа навигации, выполняемая на рабочей станции, мо-
жет не только визуализировать Веб-старницы и выполнять пере-
ходы к другим ресурсам, но и активизировать подобные програм-
мы на сервере, а также интерпретировать и запускать на выпол-
нение программы, относящиеся к Веб-документу, которые пере-
даются вместе с этим документом с сервера.
342
Говоря о сетевых технологиях обработки данных, необходимо от-
метить СОМ-технологии (COM, Component Object Model—компонен-
тная модель объектов) и технологии создания распределенных при-
ложений CORBA (Common Object Request Broker Architecture — общая
архитектура с посредником обработки запросов объектов). Эти тех-
нологии используют сходные принципы и различаются лишь осо-
бенностями их реализации.
Технология СОМ фирмы Microsoft является развитием техноло-
гии OLE I (Object Linking and Embedding—связывание и внедрение
объектов), которая использовалась в ранних версиях Windows для
создания составных документов. Технология определяет общую
парадигму взаимодействия программ любых типов: библиотек, при-
ложений, операционной системы, т. е. позволяет одной части про-
граммного обеспечения использовать функции (службы), предостав-
ляемые другой, независимо от того, функционируют ли эти части
в пределах одного процесса, в разных процессах на одном компью-
тере или на разных компьютерах. Модификация СОМ, обеспечива-
ющая передачу вызовов между компьютерами, называется DCOM
(Distributed COM — распределенная COM).
По технологии COM-приложение предоставляет свои службы,
используя специальные объекты — объекты СОМ, которые явля-
ются экземплярами классов СОМ. Объект СОМ, так же как и обыч-
ный объект, включает в себя поля и методы, но в отличие от обыч-
ных объектов каждый объект СОМ может реализовывать несколь-
ко интерфейсов, обеспечивающих доступ к его полям и функциям.
Технология CORBA, разработанная группой компаний OMG
(Object Management Group — группа внедрения объектной техно-
логии программирования), реализует подход, аналогичный СОМ,
на базе объектов и интерфейсов CORBA. Программное ядро CORBA
реализовано для всех основных аппаратных и программных плат-
форм и потому эту технологию можно использовать для создания
распределенного программного обеспечения в гетерогенной (раз-
нородной) вычислительной среде. Организация взаимодействия
между объектами клиента и сервера в CORBA осуществляется с
помощью специального посредника, названного VisiBroker, и дру-
гого специализированного программного обеспечения.
Контрольные вопросы — ~
1. Что понимается под обработкой информации ?
2. Что такое исполнитель алгоритма?
343
3. Какие типы вычислительных машин Вы знаете?
4. Что такое операция?
5. Охарактеризуйте основные режимы взаимодействия пользовате-
ля с ЭВМ.
6. Какие виды классификации средств обработки информации Вы
знаете? Охарактеризуйте основные из них.
7. Какие характерные признаки лежат в основе деления ЭВМ по
поколениям?
8. Дайте классификацию программных продуктов.
9. Что относится к системному программному обеспечению?
10. Для чего предназначены инструментальные средства технологии
программирования ?
11. Что такое прикладная программа?
12. Из каких этапов состоит процесс аналого-цифрового преобразо-
вания?
13. Сформулируйте принципы действия АЦП и ЦАП.
14. Перечислите принципы построения ЭВМ согласно фон Нейману.
15. Что такое архитектура и структура ЭВМ?
16. Назовите состав и функции блоков центрального процессора.
17. Что такое регистры? Для чего они предназначены?
18. Назовите состав и назначение основных элементов ЭВМ.
19. Поясните на примере модели микрокалькулятора необходимость
распределения во времени операций по передаче информации
в цифровых устройствах.
20. Какие бывают форматы команд?
21. Расскажите об особенностях работы простого процессора, ис-
пользующего четырехадресные команды, одноадресные и безад-
ресные.
22. Охарактеризуйте алгоритм выполнения команд процессором.
23. Что такое ПЭВМ? В чем отличие ПЭВМ от ЭВМ других классов?
24. Из каких устройств состоит системный блок? Каково их назна-
чение?
25. Какую роль в ЭВМ играют прерывания?
26. Охарактеризуйте основные устройства ввода/вывода информа-
ции в ЭВМ.
27. Объясните принцип работы монитора на основе электронно-лу-
чевой трубки. i
28. Как устроены газоразрядные и жидкокристаллические дисплеи?
29. Объясните систему шин ЭВМ.
30. Что такое интерфейс?
31. Какие способы арбитража магистрали Вы знаете? В чем их осо-
бенность?
32. Охарактеризуйте основные типы шин современных ПЭВМ.
33. Что представляет собой типичная схема контроллера внешних ус-
тройств?
344
34. Какие типы параллельных ЭВМ Вы знаете?
35. Что такое система команд процессора?
36. Охарактеризуйте архитектуры RISC и CISC- процессоров.
37. Назовите основные характеристики микропроцессоров.
38. Какие типы микропроцессоров, используемых в высокопроизво-
дительных вычислительных системах, Вы знаете?
39. Что представляет собой сетевая архитектура «клиент—сервер»?
40. Охарактеризуйте основные модели распределенных вычислений.
41. В чем особенность Web-архитектуры?
Тлава 7
Хранение информации
Хранение является одной из основных операций, осуществля-
емых над информацией, с целью обеспечения ее доступности
в течение некоторого промежутка времени.
Под хранением информации понимают ее запись в запомина-
ющее устройство (ЗУ) для последующего использования.
Запоминающее устройство (память) — устройство, способное
принимать данные и сохранять их для последующего считывания.
В компьютерных системах обработки информации выделяют
следующие основные типы памяти: регистровая память, основная
память, кэш-память и внешняя память. Кроме того, в ЭВМ могут
присутствовать различные специализированные виды памяти, ха-
рактерные для тех или иных устройств вычислительной системы,
например видеопамять.
Регистровая память, имеющаяся в составе процессора или дру-
гих устройств ЭВМ, предназначена для кратковременного хране-
ния небольшого объема информации, непосредственно участву-
ющей в вычислениях или операциях обмена (ввода-вывода).
Основная память предназначена для оперативного хранения и
обмена данными, непосредственно участвующими в процессе об-
работки. Конструктивно она исполняется в виде интегральных
схем (ИС) и подразделяется на два вида:
постоянное запоминающее устройство (ПЗУ);
оперативное запоминающее устройство (ОЗУ).
Кэш-память служит для хранения копий информации, исполь-
зуемой в текущих операциях обмена. Это очень быстрое ЗУ не-
большого объема, являющееся буфером между устройствами
с различным быстродействием. Обычно используется при обмене
данными между микропроцессором и оперативной памятью для
компенсации разницы в скорости обработки информации процес-
сором и несколько менее быстродействующей оперативной памя-
тью. Кэш-памятью управляет специальное устройство — контрол-
346
лер, который, анализируя выполняемую программу, пытается пред-
видеть, какие данные и команды вероятнее всего понадобятся
в ближайшее время процессору, и подкачивает их в кэш-память.
При этом возможны как «попадания», так и «промахи». В случае
попадания, т. е. если в кэш подкачаны нужные данные, извлече-
ние их из памяти происходит без задержки. Если же требуемая
информация в кэше отсутствует, то процессор считывает ее не-
посредственно из оперативной памяти. Соотношение числа попа-
даний и промахов определяет эффективность кэширования.
Внешняя память используется для долговременного хранения
больших объемов информации. В современных компьютерных
системах в качестве устройств внешней памяти наиболее часто
применяются:
накопители на жестких магнитных дисках (НЖМД);
накопители на гибких магнитных дисках (НГМД);
накопители на оптических дисках;
магнитооптические носители информации;
ленточные накопители (стримеры).
В отличие от элементов оперативной памяти с временем досту-
па к информации в пределах наносекунд (10‘9 с), время доступа к
информации для этих запоминающих устройств находится в об-
ласти миллисекунд (10'3 с).
МП не имеет непосредственного доступа к данным, находящим-
ся во внешней памяти. Для обработки этих данных процессором
они должны быть загружены в оперативную память (считаны в ОЗУ
с внешнего носителя данных).
7.1. КЛАССИФИКАЦИЯ ЗАПОМИНАЮЩИХ УСТРОЙСТВ
Основным классификационным признаком ЗУ является способ
доступа к данным. По этому признаку все ЗУ делятся на ЗУ с пря-
мым доступом (адресные) и ЗУ с последовательным доступом (пос-
ледовательные) (рис. 7.1) [24].
Прямой доступ реализует возможность непосредственного об-
ращения к элементам памяти, содержащим искомую информацию
или предназначенным для записи новой информации по адресу
этих элементов памяти.
347
Рис. 7.1. Классификация ЗУ
348
Последовательный доступ реализует последовательное счи-
тывание информации из ЗУ в порядке записи или в обратном по-
рядке.
Выделяют также ассоциативный доступ, реализующий поиск
информации по некоторому признаку, а не по ее расположению
в памяти (адресу — прямой доступ или месту в очереди — после-
довательный доступ). В этом случае все хранимые в памяти слова
одновременно проверяются на соответствие признаку, например
на совпадение определенных полей слов (тегов — от англ, tag) с
признаком, задаваемым входным словом (теговым адресом). На
выход выдаются слова, удовлетворяющие признаку. Дисципли-
на выдачи слов, если тегу удовлетворяет несколько слов, а также
дисциплина записи новых данных могут быть разными. Наибо-
лее часто ассоциативная память в современных ЭВМ использу-
ется при кэшировании данных.
К запоминающим устройствам с прямым доступом относятся
полупроводниковые ОЗУ и ПЗУ, а также дисковые ЗУ.
Оперативные запоминающие устройства (ОЗУ, или RAM,
Random Access Memory—память с произвольным доступом) пред-
назначены для хранения переменной информации: программ и
чисел, необходимых для текущих вычислений. По способу хра-
нения информации ОЗУ разделяют на статические (SRAM —
Static RAM) и динамические (DRAM — Dynamic RAM). В первом
случае запоминающими элементами являются триггеры, сохра-
няющие свое состояние, пока схема находится под питанием и
нет новой записи данных. Во втором — данные хранятся в виде
зарядов конденсаторов, образуемых элементами МОП-структур.
Саморазряд конденсаторов ведет к разрушению данных, поэто-
му они должны периодически (каждые несколько миллисекунд)
регенерироваться.
Постоянные запоминающие устройства (ПЗУ, или ROM, Read
Only Memory — память только для чтения) — энергонезависимая
память, используемая для хранения неизменяемых данных: под-
программ, микропрограмм, констант и т. п. Такие ЗУ работают
только в режиме многократного считывания. Постоянные запоми-
нающие устройства можно разделить по способу их программи-
рования на следующие категории:
масочные ПЗУ, т. е. программируемые при изготовлении.
Данная разновидность ПЗУ программируется однократно и
не допускает последующего изменения информации;
349
программируемые постоянные запоминающие устройства
(ППЗУ, или PROM—Programmable ROM) — постоянные за-
поминающие устройства с возможностью однократного
электрического программирования; они отличаются от ма-
сочных ПЗУ тем, что позволяют в процессе применения мик-
росхемы однократно изменить состояние запоминающей
матрицы электрическим путем по заданной программе;
репрограммируемые (перепрограммируемые) постоянные
запоминающие устройства (РПЗУ) — постоянные запомина-
ющие устройства с возможностью многократного электри-
ческого перепрограммирования. Стирание хранящейся
в РПЗУ старой информации перед процедурой записи новой
можно осуществлять по-разному. Это делают либо с помо-
щью электрических сигналов, снимающих заряд, накоплен-
ный под затвором (РПЗУ-ЭС — РПЗУ с электрическим сти-
ранием, EEPROM — electrically erasable PROM), либо с по-
мощью ультрафиолетового излучения (РПЗУ-УФ — РПЗУ
с УФ-стиранием, EPROM- electrically PROM). В последнем слу-
чае для этих целей в корпусе микросхемы предусматривают
окно из кварцевого стекла. К памяти типа EPROM относится
и Flash-память. Она подобна ей по запоминающему элемен-
ту, но имеет структурные и технологические особенности, по-
зволяющие выделить ее в отдельный вид.
Дисковые ЗУ, или накопители, представляют собой совокупность
носителя и соответствующего привода и предназначены для запи-
си, считывания и постоянного (длительного) хранения больших
объемов информации. Дисковые накопители являются энергонеза-
висимыми ЗУ.
В зависимости от типа носителя и принципов записи информа-
ции дисковые накопители подразделяются на магнитные, оптичес-
кие и магнитооптические ЗУ.
Основными представителями ЗУ с последовательным доступом
являются накопители на магнитных лентах, а также полупровод-
никовая память с дисциплиной «Первый пришел—первый вышел»
(буфер FIFO — Fist In — Fist Out), стековые ЗУ, реализующие дис-
циплину «Последний пришел — первый вышел» (буфер LIFO —
Last In — First Out), файловые и циклические ЗУ.
Разница между памятью FIFO и файловым ЗУ состоит в том, что
в FIFO запись в пустой буфер сразу же становится доступной для
чтения, т. е. поступает в конец цепочки. В файловых ЗУ данные
350
поступают в начало цепочки и появляются на выходе после неко-
торого числа обращений, равного числу элементов в цепочке. При
независимости операций считывания и записи фактическое рас-
положение данных в ЗУ на момент считывания не связано с ка-
ким-либо внешним признаком. Поэтому записываемые данные
объединяют в блоки, обрамляемые специальными символами кон-
ца и начала (файлы). Прием данных из файлового ЗУ начинается
после обнаружения приемником символа начала блока.
В циклических ЗУ слова доступны одно за другим с постоянным
периодом, определяемым емкостью памяти. К такому типу среди
полупроводниковых ЗУ относится видеопамять (VRAM).
В ленточных магнитных накопителях данные, содержащиеся
в произвольном участке ленты, могут быть считаны только после
ее перемотки к этому участку.
7.2. ОСНОВНАЯ ПАМЯТЬ
7.2.1. Характеристики запоминающих устройств
Конструктивно память (ЗУ) состоит из огромного числа запо-
минающих элементов (ЗЭ) памяти, каждый из которых может на-
ходиться в одном из двух состояний, кодируемых двоичной циф-
рой 0 или 1. ЗЭ группируются в запоминающие ячейки, предназ-
наченные для хранения слов, т. е. таких порций информации, ко-
торые могут одновременно пересылаться между памятью и про-
цессором и(или) обрабатываться последним. Поиск нужного сло-
ва памяти производится, как правило, по его адресу.
Запоминающие устройства имеют ряд показателей качества,
характеризующих их информационные и временные свойства.
Рассмотрим основные из них [6].
Информационная емкость — максимально возможный объем
хранимой информации. Емкость памяти выражается в количестве
битов, байтов или слов, состоящих из определенного числа бай-
тов.
Время доступа — временной интервал, определяемый от момен-
та, когда процессор выставил на адресной шине адрес требуемой
ячейки памяти и послал по шине управления приказ на чтение или
запись данных, до момента осуществления связи адресуемой ячей-
ки с шиной данных (рис. 7.2).
351
Цикл записи
Операция ЧТЕНИЕ
Операция ЗАПИСЬ
Рис. 7.2. Типичные временные диаграммы работы с памятью
При операции ЧТЕНИЕ содержимое шины данных может быть
переписано в соответствующий регистр процессора лишь после
завершения этого интервала времени. В связи с этим память, как
правило, информирует процессор о выдаче требуемых данных
посылкой сигнала ГОТОВО по шине управления.
При выполнении операции ЗАПИСЬ новое содержимое адре-
суемой ячейки памяти должно выставляться процессором на шину
данных до завершения времени доступа. Поэтому запись передан-
ного слова может выполняться памятью непосредственно за опе-
рациями по связи шины данных с адресуемой ячейкой.
Время записи — интервал времени, необходимый для переза-
писи содержимого шины данных в связанную с ней ячейку памя-
ти. Минимальная величина этого интервала определяется физи-
ческими свойствами элементов памяти. При изготовлении памяти
в нее включают схему, которая вырабатывает импульс записи нуж-
ной длительности. Сигнал на выработку импульса записи выдает-
ся в конце интервала доступа. После завершения импульса записи
352
память информирует процессор о выполнении операции ЗАПИСЬ
посылкой сигнала ГОТОВО по шине управления (см. рис. 7.2).
Цикл считывания и цикл записи определяются как время с мо-
мента выдачи процессором адреса требуемой ячейки памяти и сиг-
нала на считывание или запись (они могут выдаваться позднее ад-
реса) до того момента, когда заканчиваются все действия, связан-
ные с выполняемой операцией, и память будет готова реализовать
следующую операцию. Иногда, при совпадении продолжительнос-
ти этих циклов, используют обобщающий термин — цикл памяти.
Тип памяти — обозначает статическую или динамическую опе-
ративную память, или ПЗУ.
Структура — обозначает количество ячеек памяти и разряд-
ность каждой ячейки. Это дает информационную емкость ЗУ, од-
нако при одной и той же информационной емкости организация
ЗУ может быть различной.
Стоимость 1 бита определяется отношением стоимости памяти
к ее информационной емкости.
Кроме приведенных характеристик, довольно часто указыва-
ют и другие практически важные показатели качества ЗУ, напри-
мер потребляемую мощность, способ выборки информации и др.
7.2.2. Конфигурация запоминающих устройств
с прямым доступом
В настоящее время наибольшее распространение получили по-
лупроводниковые ЗУ, построенные на БИС (СБИС), каждая из
которых содержит большое число запоминающих элементов (ЗЭ).
Эти элементы обычно объединяются в М ячеек длиной N, при этом
N — кратно степени числа 2. Так, БИС, содержащие 2К (2048) за-
поминающих элементов, можно изготавливать для хранения 2К
1-битовых слов, 512 4-битовых слов или 256 8-битовых слов (2Кх 1,
512x4 или 256x8).
Существует два основных способа организации ячеек запоми-
нающих элементов внутри БИС и самих БИС в памяти ЭВМ: с од-
номерной адресацией и двумерной адресацией [6].
Рассмотрим в качестве примера кристалл ПЗУ 256x8 с одномер-
ной адресацией (рис. 7.3). Он содержит 256 (28) строк по восемь
элементов в каждой. При поступлении на его входы адреса выби-
раемой ячейки памяти на одном из 256 выходов дешифратора по-
является сигнал, который поступает на входы «Выбор элемента»
23 А-210
353
восьми запоминающих элементов (ЗЭ), подключенных к выходу
дешифратора. В зависимости от содержимого ЗЭ на его линии счи-
тывания может появиться сигнал, соответствующий 0 или 1. Та-
ким образом, на вертикальных линиях, соединяющих ЗЭ с усили-
телями считывания, появится код адресуемой ячейки, записанный
в нее при изготовлении ПЗУ.
А
Д
Р
е
с
я
ч
е
й
к
и
АО
А1
А2
АЗ
А4
А5
А6
А7
Содержимое ячейки
D7 D6 D5 D4 D3 D2 D1 DO
Рис. 7.3. ПЗУ 256x8 с одномерной адресацией 8-битовых слов
При реализации ЗУ с большим объемом памяти (большим числом
адресов) резко возрастает количество выходов дешифратора адресов.
Это усложняет изготовление БИС ЗУ. Для уменьшения числа выходов
дешифратора используют двумерную (матричную) адресацию.
Дешифратор строк ПЗУ 256x1 (рис. 7.4) имеет всего 16 выхо-
дов, каждый из которых соединен с шестнадцатью ЗЭ, составляю-
щими одну строку ПЗУ. Когда на одном из выходов дешифратора
появляется единичный сигнал, на 16 вертикальных линий (столб-
цов) выводится содержимое ЗЭ, расположенных в соответствую-
щей строке.
354
Рис. 7.4. ПЗУ 256x1 с двумерной адресацией 1-битовых слов
Электронный переключатель (мультиплексор) подключает
к усилителю считывания один из шестнадцати ЗЭ. Выбор этого эле-
мента осуществляется дешифратором столбцов, расположенным
в мультиплексоре. Для организации матричного ПЗУ 256x8 можно
использовать восемь ПЗУ 256x1, расположенных в одной или вось-
ми БИС. В одном из восьми ПЗУ 256x1 будут храниться биты с но-
мером 0, в другом — с номером 1 и т. д.
Содержимое всех восьми выходов этих ПЗУ будет аналогично
содержимому ПЗУ на рис. 7.3.
Интегральные микросхемы памяти реализуются, как правило,
в корпусах следующих типов:
DIP (Dual In line Package — корпус с двумя рядами выводов) —
классические микросхемы, применявшиеся в ранних моде-
лях ЭВМ, сейчас применяются в блоках кэш-памяти;
SIP (Single In line Package — корпус с одним рядом выводов) —
микросхема с одним рядом выводов, устанавливаемая верти-
кально.
При проектировании памяти микроЭВМ на БИС, как прави-
ло, не удается подобрать такую БИС, которая содержала бы нуж-
ное число слов заданной разрядности, поэтому память обычно со-
ставляют из нескольких однотипных БИС. В современных ком-
пьютерах оперативная память размещается на стандартных па-
355
нельках, называемых модулями. Модули оперативной памяти
вставляют в соответствующие разъемы на материнской плате.
Конструктивно модули памяти имеют два исполнения: SIMM
(Single In line Memory Module) — модуль памяти с одним рядом
контактов и DIMM (Dual In line Memory Module) — модуль памя-
ти с двумя рядами контактов.
7.2.3. Запоминающие элементы полупроводниковых ЗУ
По типу используемого для хранения информации запоминаю-
щего элемента все ОЗУ подразделяются на статические (SRAM —
Static RAM) и динамические (DRAM — Dynamic RAM) [6].
В статических ОЗУ каждую ячейку образует запоминающий эле-
мент в виде бистабильной схемы (схема с двумя устойчивыми со-
стояниями), называемой триггером. В БИС ОЗУ, построенных на
МОП-(металл-окисел-полупроводник) технологии, такие схемы
выполнены на шести МОП-транзисторах (рис. 7.5 а) с обязатель-
ным использованием внешнего источника питания (Епит). В них тран-
зисторы ТЗ и Т4 выполняют роль нагрузочных резисторов, а тран-
зисторы Т1 и Т2 всегда (кроме момента переключения) находятся
в противоположных состояниях. Когда один из транзисторов (на-
пример, Т2) открыт (проводит ток), то с него на другой транзистор
(Т1) поступает запирающий потенциал. В свою очередь, с закрыто-
го транзистора снимается потенциал, поддерживающий проводя-
щее состояние открытого транзистора.
а)
Рис. 7.5. Запоминающие элементы:
а) статического ОЗУ; б) динамического ОЗУ
б)
356
В таком устойчивом состоянии (которому при закрытом Т1 при-
своено значение 0) схема находится до тех пор, пока с помощью
отпирающего сигнала «Выбор элемента» не откроются транзисто-
ры Т5, Тб и через них на Т1 и Т2 одновременно не поступят с линий
(W/RJj и (W/R)o открывающий («1») и закрывающий («0») сигна-
лы. После переключения схема опять будет находиться в устойчи-
вом состоянии (которому присвоено значение 1) до нового разре-
шения (единичный сигнал «Выбор элемента») и записи ноля (0 на
линии (W/R)( и 1 на линии (W/R)o. Если же на элемент, сохраняю-
щий 1, будет подан набор сигналов, соответствующий записи 1, то
его состояние не изменится.
Современные запоминающие устройства статического типа
с произвольным доступом (SRAM) отличаются высоким быстро-
действием, но в микропроцессорных системах применяются ог-
раниченно из-за сравнительно высокой стоимости. В таких систе-
мах они используются только в качестве кэш-памяти. Cache (за-
пас) обозначает быстродействующую буферную память между
процессором и основной памятью, служащую для частичной ком-
пенсации разницы в скорости процессора и основной памяти:
в нее заносятся наиболее часто используемые данные. Когда про-
цессор первый раз обращается к ячейке памяти, ее содержимое
параллельно копируется в кэш, и в случае повторного обращения
может быть с гораздо большей скоростью из нее извлечено. При
записи в память информация попадает в кэш и одновременно ко-
пируется в память (схема Write Through — прямая или сквозная
запись) или копируется через некоторое время (схема Write Back
— обратная запись). При обратной записи, называемой также бу-
феризованной сквозной записью, информация копируется в память
в первом свободном такте, а при отложенной (Delayed Write) — ког-
да для помещения в кэш нового значения не оказывается свобод-
ной области; при этом в основное ОЗУ вытесняются сравнительно
редко используемые данные. Вторая схема более эффективна, но и
более сложна за счет необходимости поддержания соответствия со-
держимого кэша и основной памяти.
Динамический запоминающий элемент можно построить на
трех МОП-транзисторах (рис. 7.5 б). В нем информация запоми-
нается на паразитной емкости, всегда существующей между элек-
тродами транзистора (на схеме эта емкость показана в виде отдель-
ного конденсатора Сп). Хранение данных в таком запоминающем
элементе связано с состоянием проводимости Т2, которое опреде-
ляется зарядом конденсатора. Если заряд конденсатора обеспечи-
357
вает достаточный открывающий потенциал, то Т2 открыт. Это со-
стояние не является самоподдерживающимся, поскольку конден-
сатор постепенно саморазряжается. Если же заряд конденсатора
мал или отсутствует, то Т2 закрыт и это состояние является само-
поддерживающимся. Кроме Т2, в каждом запоминающем элемен-
те присутствуют два транзистора для подключения элемента к ли-
ниям «Запись» и «Чтение».
Из-за разряда запоминающих емкостей, вызванного током утеч-
ки, необходимо периодически подзаряжать емкости, хранящие за-
ряд. Упрощения выполнения такой задачи можно добиться органи-
зацией перезаписи содержимого каждого элемента. Тогда, связы-
вая между собой линии «Чтение» и «Запись» каждого столбца и по-
давая периодически сигналы на линии выбора строк (опрашивая по
линии «Выбор элемента») все элементы, расположенные в этой стро-
ке, обеспечивают перезапись каждого из элементов строки (содер-
жимое, появившееся на линии «Чтение» какого-либо столбца, по-
ступает через формирователь на линию «Запись» этого столбца и
далее в тот же элемент, с которого считывалась информация). Та-
кой процесс называется регенерацией памяти (Refresh).
Для регенерации всех элементов памяти модули динамической
памяти снабжают логической схемой регенерации, которая реа-
лизует наиболее приемлемую стратегию такого процесса. В про-
стейшем случае схема регенерации может выработать и подать на
дешифраторы строк БИС адрес первой строки, а также сигналы
«Выбор кристалла» всех БИС, т. е. одновременно регенерировать
элементы, расположенные в первых строках всех БИС модуля, за-
тем выработать аналогичные сигналы обращения ко второй стро-
ке всех БИС и т. д., пока не будут регенерированы все строки (все
элементы памяти). На регенерацию памяти затрачивается не бо-
лее 1—2% всего времени ее работы. Однако в процессе регенера-
ции память недоступна для других устройств, и поэтому, напри-
мер, исполнение запроса процессора на запись или чтение может
задержаться на несколько десятков микросекунд. Если такой ре-
жим работы нежелателен, то логическая схема регенерации снаб-
жается дополнительными блоками, позволяющими приостановить
процесс регенерации на время выполнения запроса процессора
или другого устройства, связанного с памятью.
В последнее время в качестве запоминающего элемента дина-
мических ОЗУ применяют однотранзисторные ЗЭ [24].
На рис. 7.6 представлена электрическая схема и конструкция
однотранзисторного ЗЭ.
358
лзс
Рис. 7.6. Запоминающий элемент динамического ЗУ:
а) схема; б) конструкция
Ключевой транзистор отключает запоминающий конденсатор
Сз от линии записи-считывания (АЗС) или подключает его к ней.
Сток транзистора не имеет внешнего вывода и образует одну из
обкладок конденсатора. Другой обкладкой служит подложка. Меж-
ду обкладками расположен тонкий слой диэлектрика — оксида
кремния SiO2. Затвор подключен к линии выбора элемента (АВ).
В режиме хранения ключевой транзистор заперт. При выборке
данного ЗЭ на затвор подается напряжение, отпирающее транзис-
тор. Запоминающая емкость через проводящий канал подключается
к линии записи-считывания и в зависимости от заряженного или раз-
ряженного состояния емкости различно влияет на потенциал линии
записи-считывания. При записи потенциал линии записи-считыва-
ния передается на конденсатор, определяя его состояние. В однотран-
зисторном ЗЭ конденсатор также неизбежно теряет со временем свой
заряд, и хранение данных требует их периодической регенерации.
Ячейки микросхем динамической памяти, как было указано
выше, организованы в виде прямоугольной матрицы; при обраще-
нии к микросхеме на ее входы вначале подается адрес строки мат-
рицы, сопровождаемый сигналом RAS (Row Address Strobe — строб
адреса строки), затем, через некоторое время — адрес столбца,
сопровождаемый сигналом С AS (Column Address Strobe — строб
адреса столбца). При каждом обращении к отдельной ячейке ре-
генерируются все ячейки выбранной строки, поэтому для полной
регенерации матрицы достаточно перебрать адреса строк.
Ячейки динамической памяти имеют сравнительно малое быстро-
действие (десятки-сотни наносекунд), но большую удельную плотность
(порядка нескольких Мегабайт на корпус) и меньшее энергопотреб-
ление. Динамические ОЗУ с запоминающим конденсатором наибо-
лее часто используются в современных микропроцессорных систе-
мах в качестве ОЗУ. Объем такого ОЗУ достигает 1 Гбайт и более.
359
ПЗУ в отличие от ОЗУ не теряют информации при выключении
питания и допускают только считывание информации. Все микро-
схемы ПЗУ можно разделить на два типа: программируемые единож-
ды и перепрограммируемые [6]. К первому типу относятся масочные
ПЗУ, программируемые в процессе изготовления микросхем, и ПЗУ,
программируемые пользователем при помощи плавких перемычек.
Накопитель ПЗУ обычно выполняют в виде системы взаимно
перпендикулярных шин, в пересечениях которых находится логичес-
кий элемент, связывающий две шины и определяющий записанный
в ячейку ноль или единицу. Выборка слов в ПЗУ осуществляется
с помощью дешифратора адреса. В масочных ПЗУ информация в мик-
росхему заносится при изготовлении построением одного из слоев
схемы при помощи фотошаблона, что и определяет их название.
На рис. 7.7 представлено масочное ПЗУ, запись в которое про-
изведена путем металлизации участков, соединяющих через дио-
ды соответствующие линии строк и столбцов.
СОДЕРЖИМОЕ ПЗУ
Адрес Сохраняемое значение
00 10011011 9В
01 11000100 С4
10 00101110 2Е
11 01110001 71
Рис. 7.7. ПЗУ емкостью 4 байта
360
Большее распространение получили микросхемы ПЗУ на осно-
ве плавких перемычек. В этих микросхемах элементом связи меж-
ду шинами является биполярный транзистор с выжигаемой пере-
мычкой (рис. 7.8).
Рис 7.8. Схема элемента памяти ПЗУ с плавкими перемычками
При программировании для записи ноля через соответствую-
щий переход транзистора пропускают импульс тока, необходимый
для удаления перемычки.
К репрограммируемым обычно относят микросхемы ПЗУ
с электрическим программированием и ультрафиолетовым стира-
нием и ПЗУ с электрическим программированием и электричес-
ким стиранием.
Организация РПЗУ отличается от организации ППЗУ тем, что
между линиями строк и столбцов установлены не диоды с плавки-
ми перемычками, а специальные МОП-транзисторы (с изолиро-
ванным затвором). После изготовления все МОП-транзисторы
обладают очень большим сопротивлением (т. е. закрыты). Пода-
чей импульса большой амплитуды МОП-транзистор переводится
в проводящее состояние, которое он может сохранять даже по ис-
течении 10 лет. Для возвращения МОП-транзисторов в исходное
(закрытое) состояние их надо подвергнуть длительному воздей-
ствию ультрафиолетовых лучей. Групповое облучение всех МОП-
транзисторов производится на специальных установках в течение
10—30 мин через прозрачное (кварцевое) окно в корпусе БИС.
После этого БИС РПЗУ оказывается в исходном состоянии и ее
можно снова программировать.
361
В ПЗУ с электрическим программированием и электрическим
стиранием после программирования можно вернуть в исходное
состояние (стереть) любой отдельно взятый МОП-транзистор. К это-
му типу перепрограммируемого ПЗУ относится и Flash Memory —
энергонезависимая память, допускающая многократную переза-
пись своего содержимого с дискеты.
Важнейшая микросхема постоянной или Flash-памяти в ЭВМ —
микросхема BIOS, содержащая программу начальной загруз-
ки ОС.
7.2.4. Основные типы памяти современных ПК
Как было отмечено выше, в современных микропроцессорных
системах в качестве ОЗУ чаще всего используются динамичес-
кие ОЗУ с запоминающим конденсатором. Такие ОЗУ часто на-
зывают асинхронными, так как установка адреса и подача управ-
ляющих сигналов могут выполняться в произвольные моменты
времени, необходимо только соблюдение временных соотноше-
ний между этими сигналами. В них включены так называемые
охранные интервалы, необходимые для установления сигналов.
Существуют также синхронные виды памяти, получающие вне-
шний синхросигнал, к импульсам которого жестко привязаны
моменты подачи адресов и обмена данными: они позволяют бо-
лее полно использовать внутреннюю конвейеризацию и блочный
доступ. Рассмотрим некоторые из них [24].
FPM DRAM (Fast Page Mode DRAM — динамическая память
с быстрым страничным доступом) отличается от обычной дина-
мической памяти тем, что после выбора строки матрицы и удер-
жания сигнала RAS допускает многократную установку адреса
столбца, стробируемого сигналом CAS, а также быструю регене-
рацию по схеме «CAS прежде RAS». Первое позволяет ускорить
блочные передачи, когда весь блок данных или его часть нахо-
дится внутри одной строки матрицы, называемой в этой системе
страницей, а второе — снизить затраты времени на регенерацию
памяти.
EDO (Extended Data Out — расширенное время удержания
данных на выходе) фактически представляют собой обычные
микросхемы FPM, на выходе которых установлены регистры-
защелки данных. При страничном обмене такие микросхемы
362
работают в режиме простого конвейера: удерживают на выхо-
дах данных содержимое последней выбранной ячейки, в то вре-
мя как на их входы уже подается адрес следующей выбираемой
ячейки. Это позволяет примерно на 15% по сравнению с FPM
ускорить процесс считывания последовательных массивов дан-
ных. При случайной адресации такая память ничем не отлича-
ется от обычной.
BEDO (Burst EDO — EDO с блочным доступом) — память на ос-
нове EDO, работающая не одиночными, а пакетными циклами чте-
ния/записи. Современные процессоры благодаря внутреннему и
внешнему кэшированию команд и данных обмениваются с основ-
ной памятью преимущественно блоками слов максимальной ши-
рины. При наличии памяти BEDO отпадает необходимость посто-
янной подачи последовательных адресов на входы микросхем
с соблюдением необходимых временных задержек, достаточно
стробировать переход к очередному слову отдельным сигналом.
SDRAM (Synchronous DRAM — синхронная динамическая па-
мять) — память с синхронным доступом, работающая быстрее
обычной асинхронной (FPM /EDO/ BEDO). Кроме синхронного
доступа, SDRAM использует внутреннее разделение массива па-
мяти на два независимых банка, что позволяет совмещать выбор-
ку из одного банка с установкой адреса в другом. SDRAM также
поддерживает блочный обмен. Основное преимущество SDRAM
состоит в поддержке последовательного доступа в синхронном
режиме, где не требуется дополнительных тактов ожидания. При
случайном доступе SDRAM работает практически с той же скоро-
стью, что и FPM/EDO.
При увеличении частоты процессорной шины с 66 до 100 МГц
вместо памяти SDRAM, работающей на частоте 66 МГц (PC 66),
стала использоваться более быстрая SDRAM, способная работать
на частоте 100 МГц. Эта память получила название PC 100 в соот-
ветствии со спецификацией фирмы Intel.
Следующий шаг по увеличению частоты процессорной шины
до 133 МГц привел к появлению модуля памяти PC 133 (разработ-
чик VIA Technologies).
VCM 133. Увеличение пропускной способности памяти — глав-
ный, но не единственный способ повышения ее производитель-
ности. Второй способ — уменьшение задержек (lattency) при об-
ращении к памяти. В памяти VCM SDRAM (Virtual Channel
363
Memory), разработанной фирмой NEC, уменьшение времени за-
держек достигается за счет организации одного или нескольких
виртуальных каналов доступа к памяти для каждого из обратив-
шихся устройств (процессор, графический адаптер, шина PCI и
др.). Чипы VCM по выводам полностью анологичны обычным
чипам SDRAM.
DDR SDRAM (DDR, Double Data Rate — удвоенная скорость пе-
редачи данных). В DDR SDRAM используется более точная внут-
ренняя синхронизация, которая фактически вдвое увеличивает
скорость доступа за счет возможности передачи данных на обеих
границах сигнала тактовой частоты. Так, при тактовой частоте 100
МГц она передает данные в два раза быстрее, чем обычная SDRAM
PC 100, поэтому и называется РС200. Отличия ее от SDRAM во внут-
ренней архитектуре очень незначительны, поэтому при производ-
стве и тестировании используется тот же технологический про-
цесс и то же оборудование.
Модуль памяти DDR SDRAM несколько отличается от обычно-
го модуля DIMM — число контактов увеличено со 168 до 184, а на-
пряжение питания уменьшено до 2,5 В. Поэтому прямого перехо-
да от SDRAM к DDR DRAM нет.
RDRAM. Память типа RDRAM (Rambus DRAM), разработан-
ная Rambus Inc, построена на базе специального интерфейса
Rambus Interface, которым снабжается как контроллер памяти,
так и каждая микросхема. Контроллер и микросхемы памяти (их
может быть до 32 штук) присоединяются непосредственно к спе-
циальной 33-проводной шине и образуют канал Direct Rambus
Channel. Таких каналов, работающих параллельно, может быть
несколько. Данные, адреса и управляющие сигналы передают-
ся по единой 16-разрядной шине. Уменьшение ширины слова
данных до 16 разрядов с избытком компенсируется более высо-
кой тактовой частотой передачи. Так, при тактовой частоте
400 МГц, за счет того, что данные передаются по обоим фрон-
там, реальная частота передачи составляет 800 МГц, а пропуск-
ная способность канала достигает 1,6 Гбайт/с. Сама же память
работает на частоте 100 МГц, но за счет многобанковой струк-
туры имеет-такую же пропускную способность — 1,6 Гбайт/с.
При использовании четырех каналов (общая ширина шины дан-
ных 64 разряда) пропускная способность достигает 6,4 Гбайт/с.
Таким образом, преимущества памяти RDRAM достигаются за
364
счет специального интерфейса, высоких скоростей передачи и
многобанковой структуры, обеспечивающей эффективную об-
работку перекрывающихся запросов.
Для использования в качестве оперативной памяти в компью-
терах память RDRAM выполняется в виде модулей типа RIMM, не-
сколько напоминающих обычные модули DIMM. Они имеют 184
позолоченных контакта. На модуле присутствует запоминающее
устройство EEPROM для реализации функции идентификации
параметров модуля системой SPD (Serial Presence Detect). Напря-
жение питания составляет 2,5 В.
Кроме основного ОЗУ, устройством памяти снабжается и уст-
ройство отображения информации — видеодисплейная система.
Такая память называется видеопамятью и располагается на плате
видеоадаптера.
Видеопамять служит для хранения изображения. От ее объема
зависит максимально возможное разрешение видеокарты —
АхВхС, где А — количество точек по горизонтали, В — по вертика-
ли, С — количество возможных цветов каждой точки. Например,
для разрешения 640x480x16 достаточно иметь видеопамять 256
Кбайт, для 800x600x256 — 512 КБ, для 1024x768x65536 (другое обо-
значение 1024x768x64k) — 2 Мбайт и т. д. Поскольку для хранения
цветов отводится целое число разрядов, количество цветов всегда
является целой степенью 2(16 цветов — 4 разряда, 256 — 8 разря-
дов, 64k — 16 и т. д.).
Основными типами видеопамяти, используемой в видеоадапте-
рах являются:
* FPM DRAM (Fast Page Mode Dynamic RAM — динамическое
ОЗУ с быстрым страничным доступом) — основной тип ви-
деопамяти, идентичный используемой в ОЗУ. Активно при-
менялась до 1996 г.;
VRAM (Video RAM — видео-ОЗУ) — так называемая двух-
портовая DRAM с поддержкой одновременного доступа со
стороны видеопроцессора и центрального процессора ком-
пьютера. Позволяет совмещать во времени вывод изображе-
ния на экран и его обработку в видеопамяти, что сокращает
задержки и увеличивает скорость работы;
EDO DRAM (Extended Data Out DRAM — динамическое
ОЗУ с расширенным временем удержания данных на вы-
ходе) — память с элементами конвейеризации, позволяю-
365
щей несколько ускорить обмен блоками данных с видео-
памятью;
SGRAM (Synchronous Graphics RAM — синхронное графи-
ческое ОЗУ) — вариант DRAM с синхронным доступом, ког-
да все управляющие сигналы изменяются одновременно
с системным тактовым синхросигналом, что позволяет
уменьшить временные задержки;
WRAM (Window RAM — оконное ОЗУ) — EDO VRAM, в ко-
тором окно, через которое обращается видеоконтроллер, сде-
лано меньшим, чем окно для центрального процессора;
MDRAM (Multibank DRAM — многобанковое ОЗУ) — вари-
ант DRAM, организованный в виде множества независимых
банков объемом по 32 Кбайт каждый, работающих в конвей-
ерном режиме.
Увеличение скорости обращения видеопроцессора к видеопа-
мяти, кроме повышения пропускной способности адаптера, позво-
ляет повысить максимальную частоту регенерации изображения,
что снижает утомляемость глаз оператора.
7.3. КОНТРОЛЬ ПРАВИЛЬНОСТИ РАБОТЫ
ЗАПОМИНАЮЩИХ УСТРОЙСТВ
Современные запоминающие устройства состоят из огромно-
го количества запоминающих элементов, каждый из которых хра-
нит бинарное значение — 0 или 1. Так, оперативная память емко-
стью всего в 1 Мбайт содержит 8 388 698 ЗЭ. При работе подоб-
ных устройств могут возникать ошибки, обусловленные воздей-
ствием различных факторов. В этом случае для повышения на-
дежности работы запоминающих устройств используют специ-
альные коды.
Различают коды, обнаруживающие ошибки, и корректирующие
коды, позволяющие обнаруживать место, где произошла ошибка, и
исправлять ее. Простейшим способом обнаружения ошибок явля-
ется проверка на четность. В этом случае к битам передаваемого или
хранимого М-разрядного слова добавляется еще один бит — бит
четности, значение которого подбирается таким образом, чтобы
среди получившихся N разрядов (N= М +1) обязательно было чет-
366
ное число единиц. Такой избыточный код позволяет лишь конста-
тировать факт наличия ошибки в слове даже без указания места,
где она произошла.
Для повышения надежности работы запоминающих устройств
используют корректирующие коды. Принцип построения коррек-
тирующих кодов заключается в том, что к каждому хранимому или
передаваемому М-разрядному слову добавляют К битов с соответ-
ствующим их расположением среди битов М-разрядного слова.
Подобные TV-разрядные коды (N=M + K) были впервые рассмот-
рены в 1948 г. Р. Хеммингом и с тех пор обычно называются кода-
ми Хемминга
Рассмотрим принцип построения кода Хемминга для 16-разрядно-
го слова данных (М = 16), исправляющего все одиночные ошибки {6].
Сначала определим необходимое число проверочных разрядов
К (K<=N-M) из соотношения:
2NM-1>7V.
Откуда для М= 16 находим N= 21 и К=5.
Верхние границы М и N для различных К представлены в табл. 7.1.
Таблица 7.1
К 1 2 3 4 5 6 7 8 9 10
м 0 I 4 11 26 57 120 247 502 1013
N 1 3 7 15 31 63 127 255 511 1023
Далее все биты TV-разрядного слова нумеруются слева направо
начиная с 1, при этом все биты, номера которых равны степени
числа 2, являются битами четности, а остальные — информацион-
ными. Полученный таким образом код Хемминга для 16-разрядно-
го слова данных представлен на рис. 7.9.
Нумерация битов кода Хемминга для 16-разрядного слова данных
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
|»|e|i}i|i|o|i'o|i|o|i|o|o|i|i!>1i|o|i|i|o~l
15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
Нумерация информационных битов 16-разрядного слова данных
Рис. 7.9. Код Хемминга для 16-разрядного слова данных
367
В 1, 2, 4, 8 и 16 разрядах данного кода располагаются биты чет-
ности, а в разрядах 3, 5, 6, 7, 9, 10, 11, 12, 13, 14, 15, 17, 18, 19, 20 и 21
биты данных слова 16-разрядного исходного слова.
Каждый бит четности используется для контроля лишь
определенных разрядов N-разрядного слова. Номера контролиру-
емых разрядов для каждого бита четности приведены в табл. 7.2.
Первый контрольный разряд контролирует разряды кода Хеммин-
га с номерами ax2J + а^х2'л +... + а2х22 + а}х2' + 1x2°, где j=log2N, а. —
произвольное значение. Таким образом, первый контрольный раз-
ряд контролирует все нечетные номера.
Второй контрольный разряд контролирует разряды кода Хем-
минга с номерами а.х2> + a.,1х2;1 +... + а2х22+ 1x2* + aflx2°.
Соответственно третий контрольный разряд контролирует раз-
ряды кода Хемминга с номерами ах2> + a 1x2J1 +... + 1х22 + a;x2‘ +
+ aflx2° и т. д.
Таблица 7.2
Номера битов четности и контролируемых ими разрядов слов
в коде Хемминга
Контрольный разряд/номер бита кода Хемминга Контролируемые разряды
1/1 1 3 5 7 9 И 13 15 17 19 21 23 25 27 29 31 33...
2/2 2 3 6 7 10 И 14 15 18 19 22 23 26 27 30 31 34...
3/4 4 5 6 7 12 13 14 15 20 21 22 23 28 29 30 31 36...
4/8 8 9 10 И 12 13 14 15 24 25 26 27 28 29 30 31 40...
5/16 16 17 18 1920 21 22 23 24 25 26 27 28 29 30 31 48...
6/32... 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48...
Как видно из табл. 7.2, в число контролируемых разрядов
включается и тот разряд, где расположен сам бит четности. При
этом содержимое бита четности устанавливается так, чтобы сум-
марное число единиц в контролируемых им разрядах было чет-
ным.
Таким образом в рассматриваемом примере (см. рис. 7.9):
1) первый контрольный разряд в коде Хемминга равен 0, так
как биты 3, 5, 7, 9, 11, 13, 15, 17, 19 и 21 содержат восемь единиц;
368
2) второй контрольный разряд равен 0, так как биты 3, 6, 7, 10,
11, 14, 15, 18 и 19 содержат шесть единиц;
3) четвертый контрольный разряд равен 1, так как биты 5, 6, 7,
12, 13, 14, 15, 20 и 21 содержат пять единиц;
4) восьмой контрольный разряд равен 0, так как биты 9, 10, И,
12, 13, 14 и 15 содержат четыре единицы;
5) шестнадцатый контрольный разряд равен 1, так как биты 17,
18, 19, 20 и 21 содержат три единицы.
Код, образованный значениями контрольных разрядов, назы-
вают дополнительным кодом. То есть для 16-разрядного кода дан-
ных 1101101001110110 дополнительный код равен 10100.
Дополнительный код можно также получить путем инвертирова-
ния результата поразрядного сложения (т. е. сложения по модулю 2)
номеров тех разрядов кода данных, значения которых равны 1.
В нашем случае для 1б-разрядного кода данных 1101101001110110
имеем:
0 0 0 0 1
0 0 0 1 0
0 0 10 0
0 0 10 1
0 0 110
0 10 0 1
0 10 11
0 110 0
0 1110
0 1111
0 10 11
После инвертирования имеем 10100, т. е. тот же проверочный
код, что и на рис. 7.9.
Предположим теперь, что из-за воздействия каких-либо возму-
щающих факторов исчезнет единица в девятом разряде кода Хем-
минга (одиннадцатом информационном бите 16-разрядного слова
данных) (рис. 7.10).
Нумерация битов кода Хемминга для 16-разрядного слова данных
1 2 3 4 5 6 7 8 9 10 И 12 13 14 15 16 17 18 19 20 21
I» lfl.ll 1*11 |0 11 |0 10 |0 I 1 Io |0 11 11 11.11 |0 11 И |0 I
15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
Нумерация информационных битов 16-разрвдного слова данных
Рис. 7.10. Код Хемминга для 16-разрядного слова данных
с искаженным девятым разрядом (11-информационным)
24 А-210
369
Проверка образовавшегося кода дает следующий результат:
бит четности 2, 4 и 16 правильны, а биты четности 1 и 8 — непра-
вильны.
Получение неправильного значения бита четности 1 указывает
на то, что ошибка должна быть в одном из контролируемых им
битов: 1,3, 5, 7, 9, 11, 13, 15, 17, 19 или 21. Поскольку бит четности 2
правилен, то правильны и контролируемые им нечетные биты 3, 7,
11, 15 и 19, так что ошибка произошла не в них. Правильность кон-
трольного бита 4 исключает возникновение ошибки в битах 5, 13 и
21, а правильность контрольного бита 16 — в бите 17. Следователь-
но, под подозрением остаются биты 1 и 9. Так как неправилен и
бит четности 8, который не контролирует бита с номером 1, но кон-
тролирует бит с номером 9, то можно сделать вывод об ошибочно-
сти бита 9. Инвертирование этого бита (изменение его значения
с 0 на 1) исправляет положение — все биты четности становятся
правильными.
Таким образом, номер искаженного разряда определяется сум-
мой номеров неправильных битов четности. В нашем примере биты
1 и 8 неправильны, следовательно, искаженный разряд—9 (9 = 1 + 8).
Определить номер искаженного разряда можно также следую-
щим способом.
После считывания информационного кода данных с искажен-
ным разрядом (в нашем случае 16-разрядного кода данных
1101001001110110, рис. 7.10), для него вновь рассчитывается допол-
нительный код и сравнивается с исходным. Фиксируется код срав-
нения (поразрядная операция отрицания равнозначности), и если
он отличен от ноля, то его значение и есть номер искаженного ин-
формационного разряда.
Тогда вновь рассчитанный дополнительный код:
0 0
0 0
0 0
0 0
0 0
0 1
0 1
0 1
0 1
0 0 1
0 1 0
1 0 0
1 0 1
1 1 0
0 0 1
1 0 0
1 1 0
1 1 1
0 0 0 0 0
370
То есть дополнительный код — 11111.
Поразрядная операция отрицания дает:
10 10 0
11111
0 10 11
Таким образом, код сравнения — 01011, что означает ошибку
в девятом разряде.
Применение корректирующего кода Хемминга означает, что
каждое слово памяти содержит не 16 бит, а 21 бит. Пять лишних
битов в каждом слове — это биты четности. Они недоступны
пользователю, так как зарезервированы для образования коррек-
тирующего кода.
7.4. ВНЕШНИЕ ЗАПОМИНАЮЩИЕ УСТРОЙСТВА
7.4.1. Накопители на гибких магнитных дисках
Дисководы (Floppy Disk Drive, FDD), или накопители на гиб-
ких магнитных дисках (НГМД), являются старейшими внешни-
ми ЗУ.
Принцип магнитной записи цифровой информации поясняет
рис. 7.11 [6]. Основу процесса магнитной записи составляет вза-
имодействие магнитного носителя информации (дискеты) и маг-
нитных головок: миниатюрных электромагнитов, располагаемых
у поверхности движущегося магнитного носителя с небольшим
зазором при бесконтактной записи или без зазора при контакт-
ной записи. Информация записывается на носителе вдоль дорож-
ки, проходящей под головкой, путем подачи на головку тока за-
писи, который создает магнитный поток, проходящий через за-
зор головки и частично через магнитный слой носителя. Измене-
нием направления сигнала в обмотке головки изменяют поляр-
ность намагничивания. Считывание информации производится
при прохождении под головкой дорожки носителя с записанной
информацией. Перемещение под зазором границы между участ-
ками с разной полярностью намагничивания создает в обмотке
импульс той или иной полярности.
371
Рис. 7.11. Магнитная запись цифровой информации
Конструктивно FDD состоит из большого числа механических
элементов и малого числа электронных, поэтому для надежной ра-
боты дисковода в значительной степени необходима устойчивая
работа механики привода. В дисководе имеются четыре основных
элемента:
" рабочий двигатель, который включается только тогда, когда
в дисковод вставлена дискета. Он обеспечивает постоянную
скорость вращения дискеты: для 3,5"FDD — 300 об./мин.
Для запуска двигателю необходимо время, в среднем равное
400 мс.
• рабочие головки, которыми оснащается дисковод для запи-
си и чтения данных и которые располагаются над рабочей
поверхностью дискеты. Так как обычно дискеты являются
двусторонними, т. е. имеют две рабочие поверхности, то одна
головка предназначена для верхней, а другая для нижней по-
верхности дискеты.
шаговые двигатели, предназначенные для движения и пози-
ционирования головок.
управляющая электроника, чаще всего размещаемая с ниж-
ней стороны дисковода. Она выполняет функции передачи
сигналов к контроллеру, т. е. отвечает за преобразование ин-
формации, которую считывают или записывают головки.
Чтобы не нарушалась постоянная скорость вращения привода,
он всегда должен работать только в горизонтальном или вертикаль-
ном положении.
В качестве носителя информации, как было отмечено, служит
дискета. Дискеты позволяют переносить документы и программы
372
с одного компьютера на другой, хранить информацию, не исполь-
зуемую постоянно на компьютере.
Дискета состоит из круглой полимерной подложки, покрытой
с обеих сторон магнитным окислом и помещенной в пластиковую
упаковку, на внутреннюю поверхность которой нанесено очища-
ющее покрытие. В упаковке сделаны с двух сторон радиальные
прорези, через которые головки считывания/записи накопителя
получают доступ к диску.
Дискета устанавливается в дисковод, автоматически в нем фик-
сируется, после чего механизм накопителя раскручивается до ча-
стоты вращения 300 об./мин. В накопителе вращается сама диске-
та, магнитные головки остаются неподвижными. Дискета враща-
ется только при обращении к ней. Накопитель связан с процессо-
ром через контроллер гибких дисков.
Для записи и чтения информации необходимо разбиение дис-
кеты на определенные участки. Если это разбиение выполняется
с помощью форматирования, то используются специальные коман-
ды: для DOS — это команда Format.
При этом дискета разбивается на дорожки (треки) и сектора
(рис. 7.12). Количество информации, которое может быть записано
в сектор, произвольно — для DOS эта величина составляет 512 байт.
Другие операционные системы устанавливают свои объемы сек-
торов. В настоящее время наибольшее распространение получили
3,5 дюйма (89 мм) дискеты высокой плотности DS/HD (double-side/
high-density — две стороны, высокая плотность). Для них число до-
рожек на одной стороне — 80, количество секторов на дорожках —
18, соответственно емкость диска 80 х 18x2x512 = 1474560 байт,
или 1474560/1048576 = 1,4 Мбайт.
Рис. 7.12. Поверхность магнитного диска
373
Обмен данными между НГМД и оперативной памятью осуще-
ствляется последовательно целым числом секторов.
Минимальная единица размещения информации на диске, состоя-
щая из одного или нескольких секторов дорожки, называется клас-
тером.
Кроме хранимых данных, на дискете имеется также и служеб-
ная информация.
На нолевой дорожке нолевой стороны размещается так назы-
ваемый Boot-сектор (загрузочный). В этом месте загрузочной (си-
стемной) дискеты, содержащей компоненты операционной систе-
мы, находится программа для загрузки системы.
Таблица размещения файлов FAT (File Allocation Table) помеща-
ется два раза подряд и требует также определенное количество сек-
торов. Эта таблица необходима для того, чтобы система могла узнать,
какая информация располагается на дискете и в каких областях она
находится. Таким образом, в FAT содержится как бы опись дискеты
и отмечается каждое изменение состояния данных дискеты.
Различные компьютеры могут использовать различные схемы
размещения этих дорожек на дискете. Поэтому производители
гибких дисков, вместо того чтобы выпускать большое количество
различных видов дискет, просто предоставили владельцам компь-
ютеров самостоятельно размечать дорожки на пустых дискетах.
Процесс разметки компьютером этих специальных дорожек и на-
зывается форматированием (или разметкой).
7.4.2. Накопители на жестких магнитных дисках
Рис. 7.13. Винчестерский
накопитель со снятой
крышкой корпуса
Накопитель на жестких магнитных дис-
ках (от англ. HDD — Hard Disk Drive), или
винчестер (рис. 7.13) — это запоминающее
устройство большой емкости, в котором
носителями информации являются круг-
лые жесткие пластины (иногда называе-
мые также дисками или платтерами), обе
поверхности которых покрыты слоем маг-
нитного материала. Винчестер использует-
сядляпостоянного (длительного) хранения
информации — программ и данных.
374
В принципе жесткие диски подобны дискетам. В них информа-
ция также записывается на магнитный слой диска. Однако этот
диск, в отличие от дискет, сделан из жесткого материала, чаще все-
го алюминия (отсюда и название Hard Disk). В корпусе объедине-
ны такие элементы винчестера, как управляющий двигатель, но-
ситель информации (диски), головки записи/считывания, позици-
онирующее устройство (позиционер) и микросхемы, обеспечива-
ющие обработку данных, коррекцию возможных ошибок, управ-
ление механической частью, а также микросхемы кэш-памяти.
Если дискета физически состоит из одного диска, то винчестер
состоит из нескольких одинаковых дисков, расположенных друг
под другом.
Головки чтения/записи соответствуют рабочим головкам дис-
ковода. Для каждого диска имеется пара таких головок, которые
приводятся в движение и позиционируются шаговым двигателем.
Все головки расположены «гребнем». Позиционирование одной
головки обязательно вызывает аналогичное перемещение и всех
остальных, поэтому, когда речь идет о разбиении винчестера, обыч-
но говорят о цилиндрах (Cylinder), а не о дорожках. Цилиндр —
это сумма всех совпадающих друг с другом дорожек по вертикали,
по всем рабочим поверхностям. Таким образом, количество цилин-
дров — это произведение числа дорожек на суммарное число ра-
бочих поверхностей, соответствующее числу магнитных головок
или удвоенному числу дисков в винчестере.
Общая емкость пакета дисков равна произведению количества
цилиндров, количества магнитных головок, количества секторов
на дорожке и числа 512 (размер сектора в байтах). Так, винчестер
емкостью 1,2 Гбайт содержит 2632 цилиндра с 16 магнитными до-
рожками на каждом цилиндре и с 63 секторами на дорожке.
Первый массовый НЖМД, выпущенный фирмой IBM еще
в 1973 г., вмещал 30 магнитных цилиндров по 30 дорожек на каж-
дом. Сходство этих цифр с маркой «30/30», соответствующей зна-
менитой винтовке «винчестер», и явилось причиной второго на-
звания НЖМД.
НЖМД помещен в почти полностью герметизированный кор-
пус. В отличие от НГМД, внутреннее устройство которого хорошо
видно, НЖМД изолирован от внешней среды, что предотвращает
попадание пыли и других частиц, которые могут повредить маг-
нитный носитель или чувствительные головки чтения/записи, рас-
375
полагаемые («плавающие») над поверхностью быстро вращающе-
гося диска на расстоянии нескольких десятимиллионных долей
дюйма.
Современные винчестерские накопители имеют очень большую
емкость: от 10 до 100 Гбайт. Кроме объема, другими основными
характеристиками производительности диска являются:
время доступа — интервал между моментом, когда про-
цессор запрашивает с диска данные, и моментом их выда-
чи. Время доступа изменяется в зависимости от располо-
жения головок и пластин под ними, поэтому для него да-
ются средние значения. В настоящее время средний пока-
затель — 7—9 мс;
" частота вращения — частота, с которой пластины диска вра-
щаются относительно магнитных головок (измеряется в об./
мин). У современных моделей скорость вращения шпинделя
(вращающего вала) обычно составляет 7200 об./мин;
средняя скорость передачи данных диском — определяется
временем для передачи данных после запуска операции чте-
ния. Эта скорость зависит также от канала ввода-вывода.
У современных моделей средняя скорость передачи данных
достигает до 60 Мбайт/с;
размер кэш-памяти. Все современные накопители снабжа-
ются встроенным кэшем (обычно 2 Мбайта), который суще-
ственно повышает их производительность.
Винчестерский накопитель связан с процессором через кон-
троллер жесткого диска.
7.4.3. Структура данных на магнитном диске
Наименьшей единицей хранения данных на магнитных дисках
является файл.
Файл (от англ, file — папка) — это именованная совокупность лю-
бых данных, размещенная на внешнем запоминающем устройстве и
хранимая, пересылаемая и обрабатываемая как единое целое. Файл
может содержать программу, числовые данные, текст, закодирован-
ное изображение и др.
Каждый файл на диске имеет свой адрес. Если процессору нуж-
на какая-то информация, размещенная на внешнем запоминаю-
376
щем устройстве, он находит на диске нужный файл, а потом байт
за байтом считывает из него данные в оперативную память, пока
не дойдет до конца файла.
Чтобы у каждого файла на диске был свой адрес, диск разбива-
ют на дорожки, а дорожки, в свою очередь, разбивают на секторы.
Размер каждого сектора стандартен и как правило равен 512 бай-
там. Разбиение диска на дорожки и секторы называется форма-
тированием диска (см. рис. 7.12), которые выполняют служебные
программы.
Адреса записанных файлов компьютер запоминает в специаль-
ной таблице — таблице размещения файлов (FAT-таблице). Таким
образом, когда компьютеру нужен какой-то файл, он по имени фай-
ла находит в этой таблице номер дорожки и номер сектора, после
чего магнитная головка переводится в нужное положение, файл
считывается и направляется в оперативную память для обработки.
При повреждении таблицы размещения файлов информация,
имевшаяся на диске, будет утрачена, так как к ней нельзя будет
обратиться. Поэтому таблица размещения файлов для надежнос-
ти дублируется. У нее есть копия, и при любых повреждениях ком-
пьютер сам восстанавливает эту таблицу.
Для записи в таблице размещения файлов адреса любого файла
может использоваться 16 битов, такую таблицу размещения файлов
называют FAT 16. С помощью 16 битов можно выразить 216 (65 536)
разных значений. Это значит, что файлам на жестком диске не мо-
жет быть предоставлено более чем 65 536 разных адресов (и самих
файлов соответственно не может быть более 65 536).
Современные жесткие диски имеют очень большие объемы и
им не хватает такого количества адресов. Если, например, размер
диска 2 Гбайт, то на каждый адрес (файл) приходится 2 Гбайт /
/ 65 536 = 32 Кбайт.
У современных дисков кластер намного больше сектора, кото-
рый равен 0,5 Кбайт. В одном кластере могут содержаться десятки
секторов, и, каким бы маленьким ни был файл, он все равно зай-
мет целый кластер, и все неиспользуемые секторы в нем просто
пропадут. Например, для жестких дисков, имеющих размер
2 Гбайт, как было показано выше, кластер равен 32 Кбайт. Пред-
положим, что нам надо записать на диск файл размером 35 Кбайт.
Для записи на диск файла такого объема потребуется 2 кластера —
64 Кбайта, т. е. 29 Кбайт памяти диска просто пропадают.
Если диск меньше, то и кластер у него тоже меньше (табл. 7.3).
377
Связь между размером жесткого диска
и размером кластера для FAT 16
Таблица 7.3
Объем диска Размер кластера
Менее 32 Мбайт 512 байт
32 Мбайт...64 Мбайт 1 Кбайт
64 Мбайт... 128 Мбайт 2 Кбайт
128 Мбайт...256 Мбайт 4 Кбайт
256 Мбайт.,.512 Мбайт 8 Кбайт
512 Мбайт... 1 Гбайт 16 Кбайт
1 Гбайт...2 Гбайт 32 Кбайт
В системе записи адреса файла на жестком диске FAT 32 адрес
записывается не двумя байтами, а четырьмя (32 бита). С помощью
32 битов можно выразить 232 (4 294 967 296) разных значений. Это
значит, что файлам на жестком диске не может быть предоставле-
но более чем 4 294 967 296 разных адресов (и самих файлов соответ-
ственно не может быть более 4 294 967 296). В этом случае размеры
отдельных кластеров становятся меньше, и в свою очередь намного
уменьшатся нерациональные потери дисковой памяти (табл. 7.4).
Таблица 7.4
Размеры кластеров для FAT 32
Объем диска Размер кластера
51.3 Мбайт... 8Гбайт 4 Кбайт
8 Гбайт... 16 Гбайт 8 Кбайт
16 Гбайт... 32 Гбайт 16 Кбайт
Более 32 Гбайт 32 Кбайт
Таким образом, чем больше жесткий диск, тем больше места на
нем тратится впустую из-за несовершенной системы адресации
файлов. Для борьбы с нерациональными потерями жесткий диск
разбивают на несколько разделов — логических жестких дисков.
378
Каждый логический диск имеет собственную таблицу разме-
щения файлов, поэтому на нем действует своя система адресации.
В итоге потери из-за размеров кластеров становятся меньше.
Каждому диску (физическому или логическому), присутствую-
щему на компьютере, присваивается уникальное имя. Имя диска
состоит из одной буквы английского алфавита и двоеточия, напри-
мер С: или F:.
Когда на компьютере устанавливается новый жесткий диск, он
получает букву, следующую за последней использованной буквой.
То же самое происходит и при создании нового логического диска
на уже установленном физическом диске.
Буквой А: общепринято обозначать дисковод для гибких дисков.
Буквой С: обозначается первый жесткий диск. Следующий диск
получает букву D:, потом Е: и так далее. (Буква В зарезервирована
на тот случай, что в компьютере может быть не один, а два диско-
вода гибких дисков.)
7.4.4. Накопители на оптических и магнитооптических дисках
Запись и считывание информации в оптических накопителях
производится бесконтактно с помощью лазерного луча. К таким
устройствам относятся, прежде всего, накопители CD-ROM, CD-R,
CD-RW, DVD и магнетический накопитель.
Устройства CD-ROM. В устройствах CD-ROM (Compact Disk
Read-Only Memory — компакт-диск только для чтения) носителем
информации является оптический диск (компакт-диск), изготав-
ливаемый на поточном производстве с помощью штамповочных
машин и предназначенный только для чтения.
Компакт-диск представляет собой прозрачный полимерный
диск диаметром 12 см и толщиной 1,2 мм, на одну сторону которо-
го напылен светоотражающий слой алюминия, защищенный от
повреждений слоем прозрачного лака. Толщина напыления состав-
ляет несколько десятитысячных долей миллиметра.
Информация на диске представляется в виде последовательно-
сти впадин (углублений в диске или питов) и выступов (их уровень
соответствует поверхности диска), расположенных на спиральной
дорожке, выходящей из области вблизи оси диска. На каждом дюй-
ме (2,54 см) по радиусу диска размещается 16 тысяч витков спи-
ральной дорожки. Для сравнения — на поверхности жесткого дис-
ка на дюйме по радиусу помещается лишь несколько сотен доро-
жек. Емкость такого CD достигает 780 Мбайт.
379
Компакт-диск (CD-ROM) обладает высокой удельной информа-
ционной емкостью, что позволяет создавать на его основе спра-
вочные системы и учебные комплексы с большой иллюстративной
базой. Один CD по информационной емкости равен почти 500 дис-
кетам. Считывание информации с CD-ROM происходит с доста-
точно высокой скоростью, хотя и заметно меньшей, чем скорость
работы накопителей на жестком диске. CD-ROM просты и удобны
в работе, имеют низкую удельную стоимость хранения данных,
практически не изнашиваются, не могут быть поражены вируса-
ми, с них невозможно случайно стереть информацию.
В отличие от магнитных дисков, компакт-диски имеют не мно-
жество кольцевых дорожек, а одну — спиральную, как у грампла-
стинок (рис. 7.14). В первых моделях дисководов скорость чтения
данных по всей дорожке была постоянной. В связи с этим угловая
скорость вращения диска линейно уменьшалась в процессе про-
движения читающей лазерной головки к краю диска. Этот метод
чтения назывался CLV — постоянная линейная скорость. Указан-
ная на дисководе скорость, например — 4х, означала, что данный
привод CD-ROM читает данные в четыре раза быстрее, чем самые
первые дисководы, скорость чтения которых составляла 150 кб/с,
150x4 = 600 кб/с. Более поздние модели стали поддерживать иную
технологию- постоянной угловой скорости, CAV. В этом случае
диск вращается с одинаковой скоростью на всем пути лазерного
луча, а скорость чтения данных меняется — на внутренних дорож-
ках она минимальна, а на внешний — максимальна. Указанная на
дисководе цифра и характеризует эту максимальную скорость.
Постоянная
угловая скорость
Рис.7.14. Вид дорожек на магнитном диске и CD-ROM
380
Записанная на компакт-диске информация в виде последова-
тельности углублений (питов) и выступов на его поверхности бес-
контактно считывается оптико-механическим лазерным блоком
(головкой), схема которого приведена на рис. 7.15. Основным эле-
ментом данной системы является маломощный лазер. Его луч про-
ходит через дифракционную пластину (на рисунке не показана),
что приводит к появлению (в дополнение к основному лучу) двух
боковых меньшей интенсивности. Они необходимы для работы ав-
томатической системы радиального отслеживания дорожки.
Далее луч проходит через коллиматор, который формирует па-
раллельный поток света, что облегчает в дальнейшем его точную
фокусировку. Затем луч проходит через разделительную призму.
Ее функция — пропустить поляризованный луч лазера к компакт-
диску, а затем, после его отражения от поверхности диска, напра-
вить на фотодиоды. Так как диаметр пятна луча лазера больше ди-
аметра пита, то луч лазера частично отражается от дна пита, час-
тично от прилегающей к нему поверхности диска. Глубина пита
(порядка 0,12 мкм) выбрана равной четверти длины волны лазер-
ного луча. Поэтому световые сигналы, отраженные от дна пита и
от соседних областей, сдвинуты по фазе относительно друг друга
на 180°. Это вызывает гасящую интерференцию между двумя со-
ставляющими отраженного луча, что в результате приводит к мо-
дуляции по интенсивности отраженного луча. Модулированный
световой сигнал с помощью оптической системы и считывающих
фотодиодов преобразуется в электрический сигнал.
Рис. 7.15. Схема оптико-механического лазерного блока
381
Фокусировка луча лазера на отражательной поверхности дис-
ка осуществляется с помощью объектива.
Таким образом, если в последовательных тактах считывания
длина пути света не меняется, то и состояние светодиода остается
прежним. В результате ток через светодиод образует последова-
тельность двоичных электрических сигналов, соответствующих
сочетанию питов (впадин) и выступов на дорожке (рис. 7.16).
Различная длина оптического пути луча света в двух последова-
тельных тактах считывания информации соответствует двоичным
единицам. Одинаковая длина соответствует двоичным нолям.
Накопители CD-R (CD-Recordable). Они позволяют наряду
с прочтением обычных компакт-дисков записывать информацию
на специальные оптические диски CD-R.
Запись на такие диски осуществляется благодаря наличию на
них особого светочувствительного слоя из органического матери-
ала, темнеющего при нагревании. В процессе записи лазерный луч
нагревает выбранные точки слоя, которые темнеют и перестают
пропускать свет к отражающему слою, образуя участки, аналогич-
ные впадинам.
Запись информации на диски CD-R представляет собой деше-
вый и оперативный способ хранения больших объемов данных.
Накопители CD-RW (CD-ReWritable). Дают возможность делать
многократную запись на диск, которая производится гораздо бо-
лее сложным способом. В этом случае применяется специальный
комбинированный слой красителя, который при нагреве лазерным
лучом способен многократно менять свои характеристики. Веще-
ство такого слоя при этом может многократно переходить из кри-
сталлического состояния в аморфное, и обратно.
Накопители DVD (Digital Versatile Disc, цифровой диск общего
назначения). Диски DVD имеют тот же геометрический размер,
что и обычные CD-ROM, но вмещают до 17 Гбайт данных. Это дос-
382
тигнуто благодаря уменьшению размеров углублений (питов) и
ровных участков, а также расстояния между дорожками, исполь-
зованию лазеров с меньшей длиной волны (635 нанометров про-
тив 780 у дисководов CD-ROM). Кроме того, DVD-диски могут
иметь два слоя информации, к которым можно обращаться, регу-
лируя положение лазерной головки.
Магнитооптический (МО) (Magneto-Optical — магнитоопти-
ческий) накопитель. В МО-носителе для записи и стирания ин-
формации используется специальный магнитный слой, который
реагирует как на оптическое, так и на магнитное воздействие.
Запись информации осуществляется с помощью лазера, нагре-
вающего отдельные участки слоя (соответствует питу в CD-ROM)
до температуры выше 150°С, при которой может изменяться ори-
ентация намагниченности. После этого магнитной головкой на
диск записываются данные. При считывании информации век-
тор поляризации лазерного луча, отраженного от слоя, меняет
свое направление в зависимости от ориентации намагниченного
участка.
Преимуществом магнитооптического метода записи по сравне-
нию с магнитным является независимость от внешних магнитных
полей при нормальных температурах, поскольку перемагничива-
ние возможно только при температуре выше 150°С.
Контрольные вопросы .— —
1. Что понимается под хранением информации?
2. Какие типы памяти выделяют в ЭВМ?
3. Охарактеризуйте способы доступа к данным в запоминающих
устройствах.
4. Дайте классификацию запоминающих устройств.
5. Назовите основные характеристики запоминающих устройств.
6. Расскажите об особенностях конфигурации запоминающих уст-
ройств с прямым доступом.
7. Объясните принцип функционирования запоминающих элемен-
тов статического и динамического ОЗУ.
8. Что представляют собой элементы памяти ПЗУ?
9. Охарактеризуйте основные типы памяти современных ПЭВМ.
10. Для чего используют корректирующие коды в запоминающих ус-
тройствах?
11. Объясните принцип построения кода Хемминга.
12. Для чего предназначены внешние запоминающие устройства?
383
13. Какие типы внешних запоминающих устройств Вы знаете ? Дайте
характеристику основным из них.
14. Что такое файл?
15. Что такое кластер?
16. Объясните структуру данных на магнитном диске.
17. В чем основное отличие между FAT 16 и FAT 32?
18. Какие виды накопителей на оптических дисках Вы знаете ?
19. Объясните принцип записи информации на оптические и магни-
тооптические диски.
Тлава 8
Передача информации
8.1. ОБЩАЯ СХЕМА СИСТЕМЫ ПЕРЕДАЧИ
ИНФОРМАЦИИ
Обобщенная структурная схема системы передачи информа-
ции (СПИ) изображена на рис. 8.1. В ее состав входят источник
сообщений и получатель сообщений, передающее и приемное ус-
тройства, линия связи. Воздействие помех условно на схеме
изображено в виде источника помех.
Принятый
первичный сигнал
Код
01011 ->«а»
Принятый сигнал
Декодированный
первичный сигнал
Рис. 8.1. Структурная схема СПИ
25 А-210
385
Передающее устройство обеспечивает преобразование сообще-
ния в сигнал, передаваемый по линии связи, в то время как прием-
ное устройство преобразует принятый сигнал обратно в переда-
ваемое сообщение. В современных цифровых системах связи ос-
новные функции передатчика и приемника выполняет устройство,
называемое модемом.
Линия связи — это среда, используемая для передачи сигналов
от передатчика к приемнику.
Такой средой могут быть кабель, волновод или область про-
странства, в которых распространяются электромагнитные волны
от передатчика к приемнику.
Система передачи информации — совокупность технических
средств (передатчик, приемник, линия связи), обеспечивающих воз-
можность передачи сообщений от источника к получателю.
Источник сообщений в общем случае образует совокупность
источника информации ИИ (исследуемого или наблюдаемого
объекта) и преобразователя сообщений (ПрС). Преобразователь
сообщений может выполнять две функции. Одной из этих функ-
ций является преобразование сообщения любой физической при-
роды (изображение, звуковой сигналит, п.) в первичный электри-
ческий сигнал S(t). Другая не менее важная функция ПрС — пре-
образование большого объема алфавита сообщений в малый объем
алфавита первичного сигнала (кодирование).
Например, 32 буквы русского алфавита передаются посред-
ством двух символов алфавита первичного сигнала — «О» и «1» или
«-1» и «1». В этом случае первичный сигнал, однозначно соответ-
ствующий сообщению, представляет собой код (кодовую комби-
нацию) из символов первичного сигнала.
Таким образом, преобразователь сообщений наряду с преобра-
зованием сообщения в электрический сигнал осуществляет и его
кодирование, поэтому ПрС иногда называют кодером (кодирую-
щим устройством) источника (КИ) .
В одних СПИ преобразователь сообщения выполняет обе фун-
кции (например, телеграфия) — преобразование и кодирование,
в других (например, телефония) — только преобразование сооб-
щения в электрический сигнал.
386
Передающее устройство осуществляет преобразование сооб-
щений в сигналы, удобные для прохождения по конкретной линии
связи. В его состав может входить устройство, обеспечивающее
помехоустойчивое кодирование. Это устройство называют коди-
рующим устройством (КУ) или кодером канала (КК).
Сущность помехоустойчивого кодирования состоит в том, что
в кодовую комбинацию первичного сигнала по определенному
правилу вводятся дополнительные, избыточные символы, которые
не несут информации о передаваемом сообщении. Однако исполь-
зование при передаче этих дополнительных символов позволяет
на приемной стороне обнаруживать и исправлять искаженные
помехами символы первичного сигнала, что увеличивает достовер-
ность передачи информации.
Первичный электрический сигнал, как правило, непосредствен-
но не передается по линии связи. В передатчике первичный сиг-
нал S(t) преобразуется во вторичный (высокочастотный) сигнал
u(t), пригодный для передачи по линии связи. Такое преобразова-
ние осуществляется посредством модулятора (М), который изме-
няет один из параметров высокочастотного колебания, генериру-
емого генератором высокой частоты, в соответствии с изменени-
ем первичного сигнала S(t).
В процессе передачи сигнала по линии связи он искажается
помехой и на входе приемника отличается по форме от передан-
ного. Приемное устройство обрабатывает принимаемый сигнал и
восстанавливает по нему переданное сообщение.
Принимаемый полезный высокочастотный сигнал фильтрует-
ся и усиливается линейными каскадами (ЛК) приемного устрой-
ства и поступает на демодулятор (ДМ), в котором высокочастот-
ный сигнал преобразуется в низкочастотный первичный сигнал.
В декодирующем устройстве (ДКУ) низкочастотный сигнал пре-
образуется в кодовую комбинацию символов первичного сигнала.
Одновременно в ДКУ осуществляются обнаружение и исправле-
ние искаженных символов первичного сигнала. Эта операция осу-
ществляется в случае использования на передающей стороне по-
мехоустойчивого кодирования. Таким образом, на выходе ДКУ
имеется кодовая комбинация символов первичного сигнала, соот-
ветствующая передаваемому сообщению.
Однако не следует думать, что демодуляция и декодирование —
это операции, обратные модуляции и кодированию. В результате
различных искажений и воздействия помех пришедший сигнал
387
может существенно отличаться от переданного. Поэтому всегда
можно высказать ряд предположений (гипотез) о том, какое сооб-
щение передавалось. Задачей приемного устройства является ре-
шение о том, какое из возможных сообщений действительно пе-
редавалось источником. Для принятия такого решения принятый
сигнал подвергается анализу с учетом всех сведений об источнике
(вероятность передачи того или иного сообщения), о применяемом
помехоустойчивом коде и виде модуляции, а также о свойствах
помех. В результате такого анализа принимается решение о том,
какое сообщение передано. Та часть приемного устройства, кото-
рая осуществляет анализ приходящего сигнала и принимает реше-
ние, называется решающей схемой.
В системах передачи непрерывных сообщений при аналоговой
модуляции решающая схема по пришедшему искаженному вто-
ричному сигналу определяет наиболее вероятный переданный пер-
вичный сигнал и восстанавливает его. В этих системах решающей
схемой является демодулятор, а декодирующее устройство в струк-
турной схеме приемника отсутствует.
В системах передачи дискретных сообщений решающая схема
состоит из двух частей — демодулятора и декодирующего устрой-
ства. Заметим, что в некоторых СПИ роль решающей схемы пол-
ностью или частично выполняет человек.
В общем случае на выходе ДКУ имеется кодовая комбинация
символов первичного сигнала, соответствующая определенному
сообщению.
Детектор сигнала (ДС) преобразует кодовую комбинацию сим-
волов первичного сигнала в соответствующее сообщение, которое
поступает на вход получателя информации (ПИ), которому была
адресована исходная информация. Если передача информации
между передатчиком и приемником осуществляется одновремен-
но в обе стороны, то такой режим называется дуплексным. При
полудуплексном режиме в каждый момент времени информация
передается только в одну сторону.
Меру соответствия принятого сообщения переданному называют
верностью передач, обеспечение которой — важнейшая цель СПИ.
Совокупность средств, предназначенных для передачи сообще-
ний, называют каналом связи. Для передачи информации от груп-
пы источников, сосредоточенных в одном пункте, к группе полу-
чателей, расположенных в другом пункте, часто целесообразно
использовать только одну линию связи, организовав на ней требу-
емое число каналов. Такие системы называют многоканальными.
388
8.2. ВИДЫ И МОДЕЛИ СИГНАЛОВ
8.2.1. Общие сведения о сообщениях и сигналах
В широком смысле слова под сигналом понимают материаль-
ный носитель информации. В современных системах передачи
информации используются электрические сигналы. Физической
величиной, определяющей такой сигнал, является ток или напря-
жение. Как лучше передать электрический сигнал? По физичес-
ким законам излучение электромагнитных волн эффективно, если
размеры излучателя соизмеримы с длиной излучаемой волны, по-
этому передача сигналов по радиоканалам, кабелям, микроволно-
вым линиям производится на высоких частотах (т. е. на весьма ко-
ротких волнах). Сигнал передается на «несущей» частоте. Процесс
изменения тех или иных параметров несущей в соответствии
с сигналом, передаваемым на этой несущей, называют модуляци-
ей.
На рис. 8.2 в качестве примера изображен электрический сиг-
нал в виде видеоимпульса единичной амплитуды, а также модули-
рованное по амплитуде этим сигналом синусоидальное колебание.
Данное колебание (радиоимпульс) можно записать в виде:
m(Z) = UrectT(t - At) sin(cat - <р0),
(8.1)
где U — амплитуда;.
Т — длительность;
At — временное положение;
<0 — частота;
<р0 — начальная фаза;
rectT— единичная прямоугольная функция (рис. 8.2 а).
rrectT(t-At) u(t)
б)
Рис. 8.2. Виды сигналов:
389
а) электрический сигнал; б) синусоидальное колебание
В общем случае у этого колебания (рис. 8.2 б) можно изменять в
соответствии с передаваемым сообщением любой из его парамет-
ров: при изменении амплитуды получаем амплитудно-модулиро-
ванный сигнал (AM), если изменить частоту или фазу, то соответ-
ственно частотно-модулированный (ЧМ) и фазо-модулированный
(ФМ) сигналы. При изменении длительности получим широтно-
импульсную модуляцию, изменяя временное положение — время-
импульсную модуляцию.
Наряду с понятием модуляции в теории передачи информации
существует понятие манипуляции. Манипуляция представляет
собой по своей сути дискретную модуляцию. При дискретной мо-
дуляции сообщение выступает как последовательность кодовых
символов (например, «О» и «1»), которым соответствуют импуль-
сы постоянного напряжения с одинаковой длительностью, но раз-
личной полярности. Эта последовательность импульсов посред-
ством манипулятора преобразуется в последовательность элемен-
тов сигнала. В этом случае можно получить амплитудную, частот-
ную и фазовую модуляции (манипуляции). На рис. 8.3 показаны
формы сигналов для двоичных символов при различных видах дис-
кретной модуляции. При AM символу «1» соответствует передача
колебания в течение времени т (посылка), символу «О» — отсут-
ствие колебания (пауза). При ЧМ передаче колебания с частотой
СО] соответствует символ «1», а с частотой соо — «О».
Рис. 8.3. Виды двоичных сигналов
390
Наиболее помехоустойчивой является фазовая модуляция или
манипуляция (ФМн). Это объясняется «амплитудным» характером
воздействующих помех, и такой параметр, как фаза несущей, ме-
нее других параметров подвергается этому воздействию.
При ФМн меняется фаза колебания на 180° при каждом пере-
ходе от символа «1» к «0» и от «0» к «1». В векторной форме это
можно изобразить так, как показано на рис. 8.4 а. Такое геометри-
ческое представление сигналов позволяет легко понять, почему
ФМн сигнал с двумя значениями фазы оказывается наиболее по-
мехоустойчивым. Дело в том, что приемник при приеме сигналов
решает задачу: в какой из областей решения находится сигнал
(верхней или нижней, рис. 8.4 а). В том случае, когда область приня-
тия решения состоит только из двух частей, вероятность ошибки
наименьшая. Однако если двухкратная манипуляция переносит
один сигнал, то 4-кратная переносит сразу два сигнала (рис. 8.4 б),
8-кратная — четыре сигнала (рис. 8.4 в).
Рис. 8.4. Фазовые диаграммы 2-кратной (а), 4-кратной (б)
и 8-кратной (в) фазовой манипуляции
Преобразование сообщения в электрический сигнал осуществ-
ляется с помощью различных датчиков, называемых преобразо-
вателями сообщений. Так, например, при передаче речи это пре-
образование выполняет микрофон, при передаче изображения —
электронно-лучевая трубка. Сигнал на выходе преобразователя
сообщения, как было отмечено выше, называют первичным сиг-
налом. В большинстве случаев первичный сигнал является низко-
частотным колебанием и не может быть передан на большие рас-
стояния. Поэтому для передачи первичного сигнала на большие
391
расстояния его преобразуют в высокочастотный сигнал. Для этой
цели в системах передачи информации предусмотрены специаль-
ные устройства — модуляторы.
Если бы передаваемое сообщение для получателя заранее было
известно с полной достоверностью, то передача его не имела бы
никакого смысла, как несодержащая информации. Сообщения, вы-
рабатываемые источником, следует рассматривать как случайные
события, а сигналы, соответствующие этим сообщениям, — как слу-
чайные функции. В процессе передачи сигнала он искажается слу-
чайной помехой. Все это обусловило необходимость в теории сис-
тем передачи информации использовать аппарат математической
теории вероятности.
Основными параметрами сигнала являются длительность сиг-
нала Т и ширина спектра. Любой сигнал имеет начало и конец.
Поэтому длительность сигнала определяет интервал времени Т,
в пределах которого сигнал существует.
Спектром сигнала как временной функции u(t) называется со-
вокупность его гармонических составляющих (гармоник), образу-
ющих ряд Фурье:
u(f) = — + Е (аьСоз2?гЮ + bksin2^4/iO, (8 2)
2 *=i
где fx — частота повторения сигнала (или частота первой гармоники);
к — номер гармоники.
Кроме ряда (8.2), широко используется ряд:
w(0 = ^ + ^Ckcos(2nkfxt + <pk), (8.3)
где Ск =]aj+bk2 (8.4)
— амплитуда;
<Pt =~arctg(bk/ak) (8.5)
— фаза гармоник (косинусоид). Применяются также ряды с си-
нусоидами под знаком суммы.
Коэффициенты Фурье определяются выражениями:
2 г
ак = — J u(t)cos2n!tf,tdt
То
(8.6)
392
2 т
bk = — \u(t)s\xilnkfxtdt,
To
(8.7)
где T= 1/fj — период повторения сигнала (периодической функ-
ции) u(t).
Для нахождения коэффициентов (8.6) и (8.7) используют фор-
мулы численного интегрирования:
2 N-1
ак = — £ ихсо52пк/х1^1,
N >=о
(8.8)
2 л-1
Ьк =— £ MjSin2n4^jA/
N i=o
(8.9)
где At= T/N — шаг, с которым расположены абсциссы u(t).
Рассмотрим в качестве примера сигнал в виде периодической
последовательности прямоугольных импульсов длительностью т и
амплитудой ид, следующих с частотой a)t = 2n/T(рис. 8.5). Отноше-
ние Т/т называется скважностью импульсов. Для данного сигнала
Т/т = 3.
Рис. 8.5. Сигнал в виде периодической последовательности
прямоугольных импульсов
Спектр такого сигнала содержит бесконечное количество убы-
вающих по амплитуде гармоник (рис. 8.6).
Он характеризуется следующими свойствами:
sinx
форма огибающей спектра описывается функцией
393
• амплитуда гармоник Ск имеет нолевое значение в точках
к/т, к= 1,2,...;
в области частот спектра от 0 до 1/т (Гц) располагаются 77т-1
гармоник;
постоянная составляющая сигнала равна иот/7".
Рис. 8.6. Спектр периодической последовательности прямоугольных импульсов
Диаграмма спектра фаз данного сигнала представлена на рис. 8.7.
2(0] 4(0] 5^ 4я
т т
Рис. 8.7. Диаграмма спектра фаз
Найденные по (8.8) и (8.9) коэффициенты Фурье приближают u(t)
рядом (8.2) или (8.3) с наименьшей среднеквадратической погреш-
ностью. На рис. 8.8. представлен сигнал (периодическая последова-
тельность прямоугольных импульсов со скважностью 77т = 2), по-
лученный путем суммирования нескольких первых членов ряда Фу-
394
иЮ
ujt)
U(t)
г\г
Рис. 8.8. Получение сигнала
путем суммирования его
гармоник
t
рье. Полученная последовательность
импульсов отличается от прямоу-
гольных в основном недостаточно
высокой крутизной фронтов. Кру-
тизна фронтов импульсов определя-
ется наличием в их спектре состав-
ляющих с частотами, многократно
превышающими основную частоту.
Таким образом, ширина спектра сиг-
нала дает представление о скорости
изменения сигнала.
Хотя спектр сигнала конечной
длительности неограничен, однако
для любого сигнала можно указать
диапазон частот, в пределах которо-
го сосредоточена его основная
энергия. Этим диапазоном и опре-
деляется ширина спектра сигнала.
Так, для импульсных сигналов боль-
шая часть энергии сосредоточена
в области частот от 0 до 1/т, поэто-
му ширина спектра ДР периодичес-
кого импульсного сигнала прибли-
зительно оценивается по формуле
ДЕ= 1/т (Гц). Для речевого сигнала
при телефонной связи ширина
спектра ограничивается полосой от
300 до 3400 Гц.
Объемом сигнала называют величину V = PAFT, где Р— мощность
сигнала, Вт; ДЕ—ширина его спектра, Гц; Т— время передачи сигна-
ла, с. Произведение длительности сигнала Тна его полосу ДР называ-
ют базой сигнала В: В = AFT. Если база сигнала порядка единицы, то
такие сигналы называют узкополосными. При В » 1 сигналы называ-
ют широкополосными.
Сигналы могут быть непрерывными (аналоговыми) и дискретны-
ми. Сигнал считают дискретным по данному параметру, если число
значений, которое может принимать этот параметр, конечно (или счет-
но) . Если параметр сигнала может принимать любые значения в неко-
тором интервале, то сигнал называют непрерывным по данному пара-
метру. Сигнал, дискретный по одному параметру и непрерывный по
другому, называют дискретно-непрерывным.
395
В соответствии с этим существуют следующие разновидности
математических представлений (моделей) детерминированного
сигнала:
непрерывная функция непрерывного аргумента, например
непрерывная функция времени (рис. 8.9 а);
непрерывная функция дискретного аргумента, например
функция, значения которой отсчитывают только в опреде-
ленные моменты времени (рис. 8.9 б);
дискретная функция непрерывного аргумента, например
функция времени, квантованная по уровню (рис. 8.9 в);
дискретная функция дискретного аргумента, например функция,
принимающая одно из конечного множества возможных значе-
ний (уровней) в определенные моменты времени (рис. 8.9 г).
Рис. 8.9. Виды сигналов
Так как источник сообщений выдает каждое сообщение с не-
которой вероятностью, то предсказать точно изменения значения
информативного параметра невозможно. Следовательно, сигнал
принципиально представляет собой случайное колебание и его ана-
литической моделью может быть только случайный процесс, оп-
ределяемый вероятностными характеристиками.
8.2.2. Сигнал как случайный процесс
Случайный процесс может быть задан ансамблем возможных его
реализаций (рис. 8.10) с вероятностью появления той или иной реа-
лизации. Каждая из п реализаций случайного процесса может быть
396
U(t)
ujt)
Ujt)
ujt)
Ujt)
сопоставлена сигналу, несущему
информацию об i-м сообщении
из п возможных сообщений, вы-
рабатываемых источником.
т *
Рис. 8.10.
Ансамбль реализации
случайного процесса
Значение случайного процес-
са в момент времени t = t, явля-
ется случайной величиной. Эту
случайную величину называют
сечением случайного процесса.
Возможные значения случайной
величины в сечении t = tt соот-
ветствуют мгновенным значениям сигналов в данный момент вре-
мени. Любая случайная величина характеризуется одномерной
плотностью вероятности W(u, tt) = WfuJ.
Одномерная плотность вероятности описывает вероятностные
свойства случайного процесса лишь для одного момента времени
и не несет никакой информации, например, о скорости измене-
ния случайного процесса, т. е. о связи между двумя случайными
величинами для сечений t = f, и t = t2.
Связь между значениями случайного процесса в моменты
времени tt и t2 учитывается двумерной плотностью вероятности
IV(u, tp и, t2) или WfU], u2). Наиболее полной характеристикой про-
цесса является л-мерная (при л —> °°) плотность вероятности Wifii,,
Нахождение л-мерной плотности для случайного процесса в боль-
шинстве случаев затруднено, поэтому на практике используют чис-
ловые характеристики случайного процесса — математическое ожи-
дание ти, дисперсию оц2 и корреляционную функцию К(т), где т =
= t2 — t, — интервал времени между сечениями случайного процесса.
Большинство случайных процессов являются стационарными
в том или ином смысле. Применительно к теории сигналов и по-
мех, действующих в радиотехнических системах передачи инфор-
мации, случайные процессы удовлетворяют условию не только
стационарности, но и эргодичности.
Для эргодического процесса характерно, что числовые харак-
теристики процесса (математическое ожидание, дисперсия, кор-
реляционная функция), вычисленные путем усреднения по ансам-
блю процесса и вычисленные по одной (любой) из его реализации
путем усреднения по времени, совпадают.
397
Если считать, что реализация случайного процесса соответству-
ет сигналу и представляет собой ток или напряжение, то:
а) математическое ожидание
---- 1
ти = = hm — (8.10)
Тс о ' 1
есть постоянная составляющая сигнала;
б)дисперсия
1 тс
° и = к(') - ти Г = 1™ — /(",(') - O2dt (8.11)
ГС^“ТС о
— это мощность переменной составляющей сигнала, выделяемая
на сопротивлении в 1 Ом, или удельная мощность переменной со-
ставляющей сигнала, в то время как величина
—2- 1 ‘с 2
w. (?) = lim — J и, (t)dt
тс~*°°Тс о
(8.12)
— это удельная мощность всего сигнала.
Корреляционная функция (КФ) рассматриваемого процесса мо-
жет быть вычислена в соответствии с выражением:
1 гс
Ки(т)= lim — J w(. (?)w( (? + т )dt
а центрированная КФ —
• 1 Тс
Ки(т)= hm — /(«,(?))(ui(t + г)- mu)dt
Тс^°°Т„ о
(8.13)
(8.14)
Из выражения (8.13) видим, что корреляционная функция при
т = 0 равна среднему квадрату сигнала, его удельной средней мощ-
ности, а центрированная Ки(о) — дисперсии сигнала оц2.
При т —> корреляционная функция Кц(°°)->ти2, Ки(р) —> 0 . На
практике часто используют нормированную корреляционную
функцию р(т), определяемую как
Аг) =——
°и
(8.15)
398
При ЭТОМ р(0) — 1,р(оо)=0.
Следует отметить, что корреляционная функция является фун-
кцией четной, т. е. р(т) = -р(-т). На рис. 8.11 показаны примеры
корреляционных функций.
Рис. 8.11. Корреляционные функции
Для сигналов как случайных процессов наряду с понятием кор-
реляционной функции широко используется понятие энергетичес-
кого спектра.
Отдельная реализация случайного процесса — конкретный сиг-
нал u.(t) есть детерминированная неслучайная функция времени.
Она имеет свой энергетический спектр Sut(f), физический смысл
которого — распределение удельной энергии сигнала в полосе ча-
стот сигнала.
Энергетический спектр случайного процесса связан с его кор-
реляционной функцией парой преобразований Фурье:
Su(a>) = °j Ku(T)e-J^di =2]ки(т)со&сотс1т; (8.16)
о
| оо ] ОО
Ки(т) =— JSu(a>)e>W<y =— J («) cos сип/со. (8.17)
2тс — п О
Заметим, что чем шире энергетический спектр, тем быстрее
флюктуирует случайный процесс, тем уже его корреляционная
функция. И наоборот, чем шире корреляционная функция, тем
медленнее флюктуирует процесс, тем уже его энергетический
спектр.
399
Средняя удельная мощность случайного процесса может быть
определена через корреляционную функцию и его энергетичес-
кий спектр:
u2(t) = Ku(0)= JSu((o)d<o (8.18)
—со
8.2.3. Математические модели сигналов и помех
Для получателя информации помеха — это случайное воздей-
ствие на передаваемый сигнал, приводящее к его изменению. По-
этому помеху рассматривают как случайный процесс, характери-
зующийся своим законом распределения и своим возможным ан-
самблем реализации.
Все помехи можно разделить на искусственные и естественные.
К искусственным помехам относятся промышленные помехи (ис-
крящие контакты), помехи от других радиотехнических систем,
работающих в данном диапазоне волн, организованные помехи,
генерируемые специальными техническими средствами.
Естественными помехами являются собственные шумы прием-
ных устройств радиотехнических систем передачи информации,
называемые внутренними помехами, и внешние помехи. Собствен-
ные шумы приемных устройств слагаются из тепловых шумов ре-
зисторов, дробовых шумов электронных ламп (до сих пор широко
используемых в передающих устройствах) и шумов полупровод-
никовых приборов.
Тепловой шум возникает в результате теплового хаотического
движения электронов в резисторе. В результате этого на концах
резистора возникает суммарное флюктуационное напряжение.
Дробовые шумы электронных ламп порождаются флюктуаци-
ей потока электронов, эмитируемых катодом и летящих к аноду
электронного прибора.
К внешним естественным помехам относятся шумы антенны,
грозовые помехи и космические шумы. По воздействию помех на
сигнал их можно разделить на аддитивные и мультипликативные.
Аддитивная помеха складывается с передаваемым сигналом, и
смесь полезного сигнала и помехи записывается в виде:
и(/) = ui(t) + n(t),
где n(t) — реализация помехи.
400
Действие мультипликативной помехи приводит к случайному
изменению во времени параметров канала, по которому переда-
ется сигнал.
Результат воздействия аддитивной или мультипликативной поме-
хи состоит в том, что сигнал изменяется случайным образом. Вслед-
ствие этого получатель сигнала не может точно определить, какой сиг-
нал передавался. Поэтому, наблюдая искаженный сигнал, получа-
тель в соответствии с определенным критерием принимает (с опре-
деленной вероятностью) решение о том, какой сигнал передавался.
Для теоретического рассмотрения процессов передачи инфор-
мации в радиотехнических системах широко используется мате-
матическое моделирование реальных сигналов и помех.
Математическая модель сигнала (помехи) — это математичес-
кая форма представления сигналов и помех. Модель должна быть
такой, чтобы она в наибольшей степени соответствовала реальным
сигналам. Например, для интервала времени 0<t<Tc математичес-
кой моделью конкретного i-го сигнала может быть выражение:
«,.(/) = Usin(a>ot + ф0).
В общем случае математическая модель конкретного сигнала
может быть записана в виде обобщенного ряда Фурье:
к=0
(8.19)
где Cjk — коэффициенты разложения;
т|*(0 — базисные функции разложения, удовлетворяющие ус-
ловию ортогональности:
о
С прик = е,
О при к *е.
Пример 1. При тригонометрическом базисе sin®At, cosco^t, когда
частоты кратны 2кя/Г (к= 1,2,...), получаем разложение в ряд Фу-
рье, см. (8.2) и (8.3).
Пример 2. Базис Котельникова — базис функций отсчетов. В
качестве базисных функций выступают функции вида:
26 А-210
401
Чк&=
sin(2^FB (/ - ЛА/))
2nFB (t — kAt)
(8.20)
1
где А/ =---;
2^в
FB — верхняя частота в спектре !-го сигнала. В рассматривае-
мом случае i-й сигнал запишется в виде:
д sin(2TtFH (t - kht))
Ut(t)= -------
k=o 2nFB(t-kt\t)
(8.21)
где u.(kAf) — значение сигнала в момент времени t= kAt, к=0,1 п.
Кроме рассмотренных базисов разложения, имеются и другие
ортогональные базисы, которые могут быть использованы для ма-
тематических моделей сигнала (помехи).
8.3. КАНАЛЫ ПЕРЕДАЧИ ДАННЫХ
И ИХ ХАРАКТЕРИСТИКИ
Каналом передачи информации называют совокупность техничес-
ких средств, обеспечивающую передачу электрических сигналов от
одного пункта к другому. Входы канала подключаются к передатчику,
а выходы — к приемнику. В современных цифровых системах связи
основные функции передатчика и приемника выполняет модем.
Одной из главных характеристик канала является скорость пе-
редачи информации.
Максимально возможная скорость передачи информации (дан-
ных) по каналу связи при фиксированных ограничениях называется
емкостью канала, обозначается через С и имеет размерность бит/с.
В общем случае емкость канала можно определить по формуле:
С=1/Т, (8.22)
где I— количество переданной за время Т информации.
В качестве меры количества информации возьмем меру Р. Харт-
ли определяемую как логарифм возможных состояний объекта L:
I = log2I. (8.23)
402
Для нахождения L воспользуемся теоремой Котельникова, ко-
торая доказывает, что сигнал, не содержащий в своем спектре ча-
стот выше F, может представляться 2F независимыми значениями
в секунду, совокупность которых полностью определяет этот сиг-
нал. Данная процедура, называемая аналого-цифровым преобра-
зованием, была рассмотрена в гл. 6. Она состоит из двух этапов —
дискретизации по времени, т. е. представлении сигнала в виде п
отсчетов, взятых через интервал времени t= 1/(2Е), и квантования
по уровню, т. е. представления амплитуды сигнала одним из т воз-
можных значений.
Определим количество различных сообщений, которое можно
составить из п элементов, принимающих любые из т различных
фиксированных состояний. Из ансамбля п элементов, каждый из
которых может находиться в одном из т фиксированных состоя-
ний, можно составить ш" различных комбинаций, т. е. 1= та. Тогда:
I = log2/nn = zilog2m. (8.24)
За время Тчисло отсчетов п= T/t—IFT.
Если бы шума не существовало, то число т дискретных уров-
ней сигнала было бы бесконечным. В случае наличия шума после-
дний определяет степени различимости отдельных уровней амп-
литуды сигнала. Так как мощность является усредненной характе-
ристикой амплитуды, число различимых уровней сигнала по мощ-
ности равно (Р.+Рш)/Рш), а по амплитуде соответственно:
т = у1(Рс+Рш)/Рш.
Тогда емкость канала:
— = —2P71og2
Т Т
= Hog2 1 + —
(8.25)
Итак, емкость канала ограничивается двумя величинами: ши-
риной полосы канала и шумом. Соотношение (8.25) известно как
формула Хартли-Шеннона и считается основной в теории инфор-
мации. Полоса частот и мощность сигнала входят в формулу та-
ким образом, что для С= const при сужении полосы необходимо
увеличивать мощность сигнала, и наоборот.
403
К основным характеристикам каналов связи относятся:
амплитудно-частотная характеристика (АЧХ);
полоса пропускания;
затухание;
• пропускная способность;
достоверность передачи данных;
помехоустойчивость.
Для определения характеристик канала связи применяется ана-
лиз его реакции на некоторое эталонное воздействие. Чаще всего
в качестве эталона используются синусоидальные сигналы разных
частот.
АЧХ показывает, как изменяется амплитуда синусоиды на вы-
ходе линии связи по сравнению с амплитудой на ее входе для всех
частот передаваемого сигнала.
Полоса пропускания — это диапазон частот, для которых отно-
шение амплитуды выходного сигнала к входному превышает неко-
торый заданный предел (для мощности 0.5). Эта полоса частот опре-
деляет диапазон частот синусоидального сигнала, при которых этот
сигнал передается по линии связи без значительных искажений.
Ширина полосы пропускания влияет на максимально возмож-
ную скорость передачи информации по линии связи.
Затухание — определяется как относительное уменьшение ам-
плитуды или мощности сигнала при передаче по линии связи сиг-
нала определенной частоты.
Затухание L обычно измеряется в децибелах (дБ) и вычисляет-
ся по формуле:
Z = 101og,„(P /Р ),
где Рвых — мощность сигнала на выходе линии;
Рвх — мощность сигнала на входе линии.
Пропускная способность линии (throughput) характеризует
максимально возможную скорость передачи данных по линии свя-
зи и измеряется в битах в секунду (бит/с), а так же в производных
единицах Кбит/с, Мбит/с, Гбит/с.
На пропускную способность линии оказывает влияние физи-
ческое и логическое кодирование. Способ представления дискрет-
ной информации в виде сигналов, передаваемых на линию связи,
называется физическим линейным кодированием. От выбранно-
го способа кодирования зависит спектр сигнала и соответственно
пропускная способность линии. Таким образом, для одного или
404
другого способа кодирования линия может иметь разную пропус-
кную способность.
Если сигнал изменяется так, что можно различить только два
его состояния, то любое его изменение будет соответствовать наи-
меньшей единице информации — биту.
Если сигнал изменяется так, что можно различить более двух со-
стояний, то любое его изменение несет несколько бит информации.
Количество изменений информационного параметра несущего
колебания (периодического сигнала) в секунду измеряется в бодах.
Пропускная способность линии в битах в секунду в общем слу-
чае не совпадает с числом бод. Она может быть как выше, так и
ниже числа бод, и это соотношение зависит от способа кодирова-
ния. Если сигнал имеет более двух различимых состояний, то про-
пускная способность в бит/с будет выше, чем число бод.
Например, если информационными параметрами являются
фаза и амплитуда синусоиды, причем различают 4 состояния фазы
(О, 90, 180 и 270) и два значения амплитуды, то информационный
сигнал имеет восемь различимых состояний. В этом случае модем,
работающий со скоростью 2400 бод (с тактовой частотой 2400 Гц),
передает информацию со скоростью 7200 бит/с, так как при од-
ном изменении сигнала передается три бита информации.
При использовании сигнала с двумя различными состояниями
может наблюдаться обратная картина. Это происходит, когда для
надежного распознавания приемником информации каждый бит
в последовательности кодируется с помощью нескольких измене-
ний информационного параметра несущего сигнала.
Например, при кодировании единичного значения бита импуль-
сом положительной полярности, а нолевого значения бита — им-
пульсом отрицательной полярности, сигнал дважды меняет свое
состояние при передаче каждого бита. При таком способе коди-
рования пропускная способность линии в два раза ниже, чем чис-
ло бод, передаваемое по линии.
На пропускную способность оказывает влияние логическое ко-
дирование, которое выполняется до физического и подразумевает
замену бит исходной информации новой последовательности бит,
несущей ту же информацию, но обладающей при этом дополнитель-
ными свойствами (обнаруживающие коды, шифрование).
При этом искаженная последовательность бит заменяется бо-
лее длинной последовательностью, поэтому пропускная способ-
ность канала уменьшается.
405
В общем случае связь между полосой пропускания линии и ее
максимально возможной пропускной способностью определяет-
ся соотношением (8.25).
Из этого соотношения следует, что хотя теоретического преде-
ла увеличения пропускной способности линии (с фиксированной
полосой пропускания) нет, на практике такой предел существует.
Повысить пропускную способность линии можно, увеличив мощ-
ность передатчика или уменьшая мощность помех. Однако увели-
чение мощности передатчика приводит к росту его габаритов и сто-
имости, а уменьшение шума требует применения специальных
кабелей с хорошими защитными экранами и снижения шума в
аппаратуре связи.
Емкость канала представляет собой максимальную величину ско-
рости. Чтобы достигнуть такой скорости передачи, информация дол-
жна быть закодирована наиболее эффективным образом. Утвержде-
ние, что такое кодирование возможно, является важнейшим резуль-
татом созданной Шенноном теории информации. Шеннон доказал
принципиальную возможность такого эффективного кодирования,
не определив, однако, конкретных путей его реализации. (Отметим,
что на практике инженеры часто говорят о емкости канала, подразу-
мевая под этим реальную, а не потенциальную скорость передачи.)
Эффективность систем связи характеризуется параметром, рав-
ным скорости передачи информации R на единицу ширины полосы
F, т. е. R/F. Для иллюстрации существующих возможностей по со-
зданию эффективных систем связи на рис. 8.12 приведены графики
зависимости эффективности передачи информации при различных
видах М-ичной дискретной амплитудной, частотной и фазовой мо-
дуляции (кроме бинарной модуляции используется также модуляция
с 4, 8, 16 и даже с 32 положениями модулируемого параметра) от от-
ношения энергии одного бита к спектральной плотности мощности
шума (Eo/No). Для сравнения показана также граница Шеннона.
Сравнение кривых показывает, в частности, что наиболее эф-
фективной оказывается передача с фазовой дискретной модуля-
цией, однако при неизменном отношении сигнал-шум наиболее
популярный вид модуляции 4ФМн в три раза хуже потенциально
достижимого.
Достоверней, передачи данных характеризует вероятность ис-
кажения для каждого передаваемого бита данных. Показателем
достоверности является вероятность ошибочного приема инфор-
мационного символа — Р .
ОШ
406
Рис. 8.12. Эффективность цифровых систем связи:
1 — граница Шеннона; 2 — М-ичная ФМн;
3 — М-ичная АМн; 4 — М-ичная ЧМн
Величина Рош для каналов связи без дополнительных средств
защиты от ошибок составляет, как правило, 10'4... 106. В оптоволокон-
ных линиях связи Рош составляет 10’9. Это значит, что при Рош = 104
в среднем из 10 000 бит искажается значение одного бита.
Искажения бит происходят как из-за наличия помех налинии, так
и из-за искажений формы сигнала, ограниченной полосой пропус-
кания линии. Поэтому для повышения достоверности передаваемых
данных необходимо повышать степень помехозащищенности линий,
а также использовать более широкополосные линии связи.
Непременной составной частью любого канала является линия
связи — физическая среда, обеспечивающая поступление сигна-
лов от передающего устройства к приемному. В зависимости от
среды передачи данных линии связи могут быть:
407
° проводные (воздушные);
кабельные (медные и волоконно-оптические);
радиоканалы наземной и спутниковой связи (беспроводные
каналы связи).
Проводные линии связи представляют собой проложенные
между опорами провода без каких-либо экранирующих или изо-
лирующих оплеток. Помехозащищенность и скорость передачи
данных в этих линиях низкая. По таким линиям связи передаются,
как правило, телефонные и телеграфные сигналы.
8.3.1. Кабельные линии связи
Кабельные линии связи представляют собой пучок проводов,
заключенных в одну или несколько защитных (электрическая, ме-
ханическая, электромагнитная и т. п.) трубок.
В современных системах связи применяют три основных типа
кабеля [18]:
а ) на основе скрученных пар медных проводов;
б ) коаксиальные кабели с медной жилой;
в ) волоконно-оптические кабели.
Скрученная пара проводов называется витой парой (twisted
pair). Скручивание проводов снижает влияние внешних помех на
сигналы, передаваемые по кабелю. Витая пара конструктивно мо-
жет быть:
неэкранированной (рис. 8.13 а) — Unshielded Twisted Pair, UTP;
экранированной (рис. 8.13 б) — Shielded Twisted Pair, STP.
Рис. 8.13. Типы кабелей:
а) неэкранированная витая пара;
б) экранированная витая пара; в) коаксиальный кабель
408
В случае экранированной витой пары STP каждая из витых пар
помещается в металлическую оплетку-экран для уменьшения из-
лучений кабеля, защиты от внешних электромагнитных помех и
снижения взаимного влияния пар проводов друг на друга. Экра-
нированная витая пара гораздо дороже, чем неэкранированная, а
при ее использовании необходимо применять специальные экра-
нированные разъемы, поэтому встречается она значительно реже,
чем неэкранированная.
Основные достоинства неэкранированных витых пар — про-
стота монтажа разъемов на концах кабеля, а также простота ре-
монта любых повреждений по сравнению с другими типами кабе-
ля. Все остальные характеристики у них хуже, чем у других кабе-
лей. Например, при заданной скорости передачи затухание сигна-
ла (уменьшение его уровня по мере прохождения по кабелю) у них
больше, чем у коаксиальных кабелей, поэтому линии связи на ос-
нове витых пар, как правило, довольно короткие (обычно в преде-
лах 100 м). В настоящее время витая пара используется для пере-
дачи информации на скоростях до 100 Мбит/с (ведутся работы по
повышению скорости передачи до 1000 Мбит/с).
Различают семь категорий кабелей на основе неэкранирован-
ной витой пары (UTP):
кабель категории 1 — это обычный телефонный кабель (пары
проводов не витые), по которому можно передавать только
речь;
кабель категории 2 — это кабель из витых пар для передачи
данных в полосе частот до 1 МГц;
кабель категории 3 — это кабель для передачи данных в по-
лосе частот до 16 МГц, состоящий из витых пар с девятью
витками проводов на метр длины;
° кабель категории 4 — это кабель, передающий данные в по-
лосе частот до 20 МГц;
кабель категории 5 — самый совершенный кабель в настоя-
щее время, рассчитанный на передачу данных в полосе час-
тот до 100 МГц. Состоит из витых пар, имеющих не менее 27
витков на метр длины (8 витков на фут);
кабель категории 6 — перспективный тип кабеля для пере-
дачи данных в полосе частот до 200 МГц;
кабель категории 7 — перспективный тип кабеля для пере-
дачи данных в полосе частот до 600 МГц.
409
Полное волновое сопротивление кабелей категорий 3, 4 и 5 со-
ставляет 100 Ом ± 15% в частотном диапазоне от частоты 1 МГц до
максимальной частоты кабеля. (Волновое сопротивление экрани-
рованной витой пары STP равно 150 Ом ± 15%.)
Второй важнейший параметр кабеля — максимальное затуха-
ние сигнала, передаваемого по кабелю, на разных частотах. Для
кабелей на основе витых пар эта величина очень значительна —
даже на небольших расстояниях (порядка сотен метров) сигнал ос-
лабляется в десятки и сотни раз.
Еще один важный параметр любого кабеля — скорость распро-
странения сигнала в кабеле, т. е. задержка распространения сиг-
нала в кабеле на единицу длины. Типичная величина задержки
большинства современных кабелей составляет 5 нс/м.
Коаксиальный кабель имеет симметричную конструкцию и со-
стоит из внутренней медной жилы (центральный проводник) и
внешнего экрана, отделенного от проводника слоем изоляции.
Применяется также внешняя защитная оболочка (рис. 8.13 в).
Коаксиальный кабель обладает более высокой помехозащи-
щенностью (благодаря металлической оплетке), а также более вы-
сокими, чем в случае витой пары, допустимыми скоростями пе-
редачи данных (до 500 Мбит/с) и большими допустимыми рас-
стояниями передачи (до километра и выше). К нему труднее ме-
ханически подключиться для несанкционированного прослуши-
вания сети, он также дает заметно меньше электромагнитных
излучений вовне.
Существует два основных типа коаксиального кабеля:
тонкий (thin), имеющий диаметр около 0,5 см, более гибкий;
толстый (thick), имеющий диаметр около 1 см, значительно
более жесткий. Он представляет собой классический вари-
ант коаксиального кабеля, который уже почти полностью
вытеснен более современным тонким кабелем.
Тонкий кабель используется для передачи на меньшие расстоя-
ния, чем толстый, так как в нем сигнал затухает сильнее.
Типичные величины задержки распространения сигнала в ко-
аксиальном кабеле составляют для тонкого кабеля около 5 нс/м, а
для толстого — около 4,5 нс/м.
В настоящее время считается, что коаксиальный кабель уста-
рел, в большинстве случаев его вполне может заменить витая пара
или оптоволоконный кабель.
410
Волоконно-оптический кабель (optical fiber) состоит из цент-
рального проводника света — стеклянного волокна, окруженного
другим слоем стекла — оболочкой, обладающей меньшим показа-
телем преломления, чем сердцевина (рис. 8.14).
Стеклянная Центральное
оболочка волокно
Внешняя
оболочка
Рис. 8.14. Структура оптоволоконного кабеля
Распространяясь по сердцевине, лучи света, отражаясь от обо-
лочки, не выходят из центрального проводника. В зависимости от
распределения показателя преломления и от величины диаметра
сердечника различают:
• многомодовое волокно со ступенчатым изменением показа-
теля преломления (рис. 8.15 а);
многомодовое волокно с плавным изменением показателя
преломления (рис. 8.15 б);
одномодовое волокно (рис. 8.15 в).
Понятие «мода» описывает режим распространения световых
лучей во внутреннем сердечнике кабеля.
В одномодовом кабеле (Single Mode Fiber, SMF ) используется
центральный проводник очень малого диаметра, соизмеримого с
длиной волны света — 5... 10 мкм. При этом практически все лучи
света распространяются вдоль оптической оси световода, не отра-
жаясь от внешнего проводника. Полоса пропускания одномодово-
го кабеля достигает сотен ГГц на километр.
В многомодовых кабелях (Multi Mode Fiber, MMF) применяют-
ся более широкие внутренние сердечники, которые легче изгото-
вить технологически.
Наиболее употребительными являются многомодовые кабели
с диаметрами центрального и внешнего проводника: 62,5/125 мкм
и 50/125 мкм соответственно.
411
Рис. 8.15. Типы оптических кабелей:
а) многомодовое волокно со ступенчатым изменением показателя преломления;
б) многомодовое волокно с плавным изменением показателя преломления;
в)одномодовое волокно
В многомодовых кабелях во внутреннем проводнике одновре-
менно существует несколько путей световых лучей, отражающих-
ся от внешнего проводника под разными углами.
В многомодовых кабелях с плавным изменением коэффициен-
та преломления режим распространения каждой моды определя-
ющие более сложным характером. Многомодовые кабели имеют
более узкую полосу пропускания — 500... 800 МГц/км. Сужение по-
лосы происходит из-за потерь световой энергии при отражениях,
а также из-за интерференции лучей разных мод.
Для одномодовых кабелей применяются в качестве источника
излучения света полупроводниковые лазеры. Для многомодовых
кабелей для этих целей используют более дешевые источники —
светодиодные излучатели.
В оптических волокнах передача информации возможна «в ок-
нах прозрачности» 1550 нм (1,55 мкм), 1300 нм (1,3мкм) и 850 нм
(0,85 мкм). Для других волн затухание в волокнах существенно
выше. В качестве источника света обычно используется лазер на
арсениде галлия с длиной волны излучения 0,84 мкм и средней мощ-
ностью от 1 до 10 мВт. Это излучение находится в невидимой части
спектра (видимый диапазон спектра занимает область от 0,4 мкм —
412
фиолетовый цвет, до 0,7 мкм — красный цвет). Кроме источника
света, в передающее устройство входит модулятор. На приемном
конце линии сигналы детектируются фотодиодом; для исключения
ошибок часто применяется помехоустойчивое кодирование.
Предельные расстояния для передачи данных по волоконно-
оптическим линиям связи (без ретрансляции) зависят от длины
волны излучения и достигают десятков километров.
8.3.2. Беспроводные линии связи
В беспроводных линиях связи передача информации осуществ-
ляется на основе распространения электромагнитных волн (радио-
волн). Наиболее освоенный диапазон длин волн находится в пре-
делах от 10 до 2 109 м.
Радиоволны, представляющие собой электромагнитные коле-
бания, являются совокупностью переменных электрического и
магнитных полей и характеризуются напряженностью электричес-
кого Е и магнитного Н полей.
Направление вектора напряженности электрического поля оп-
ределяет поляризацию волны. Различают линейную и круговую
поляризацию радиоволны. Линейная поляризация может быть го-
ризонтальной и вертикальной (относительно Земли), ажруговая
поляризация — правого или левого вращения вектора Е относи-
тельно направления распространения волны.
Распространение радиоволны определяется направлением век-
тора Пойнтинга П = Е х Н , указывающего направление распрос-
транения энергии.
Радиоволнам присущи следующие физические свойства:
преломление и отражение волны на границе перехода из од-
ной среды в другую;
рефракция (искривление траектории распространения) при
распространении в неоднородной среде;
дифракция — огибание волной препятствия, когда длина вол-
ны соизмерима с размерами препятствия.
По особенностям распространения в различных физических
средах спектр радиоволн делят на отдельные диапазоны. В соот-
ветствии с рекомендациями Международного консультативного
комитета по радио (МККР) принят десятичный принцип класси-
фикации радиоволн (табл. 8.1).
413
Таблица 8.1
Обозначение диапазонов радиочастот
Условное обозначение Наименование волн Границы диапазона Диапазон частот
ОНЧ (VLF) Мириаметровые 100—10 км 3...30 кГц
НЧ (LF) Километровые 10—1 км 30...300 кГц
СЧ (MF) Гектометровые 1000-100 м 300...3000 кГц
ВЧ (HF) Декаметровые 100-10 м 3...30 МГц
ОВЧ (VHF) Метровые 10-1 м 30...300 МГц
УВЧ, УКВ (UHF) Дециметровые 100—10 см 300...3000 МГц
СВЧ (SHF) Сантиметровые 10—1 см 3...30 ГГц
КВЧ (EHF) М ил лиметровые 10—1 мм 30...300 ГГц
Существенное влияние на распространение радиоволн оказы-
вают земная поверхность и атмосфера Земли, в особенности ее
нижняя область — тропосфера и верхняя — ионосфера.
Радиоволны, распространяющиеся вдоль поверхности Земли,
называют земными радиоволнами. Земная радиоволна (рис. 8.16)
как бы стелится вдоль поверхности Земли, огибая ее крупномасш-
табные неровности. Траектория радиоволны повторяет профиль
соответствующего участка гра-
ницы между земной поверхно-
стью и атмосферой Земли —
двумя областями с резко отли-
чающимися электрическими
параметрами. Таким образом,
пре-имущественно распростра-
Рис. 8.16. Земная радиоволна няются радиоволны, длина ко-
торых превышает 200—400 м.
Радиоволны, распространяющиеся в атмосфере Земли и за ее
пределами, где нет резко выраженных границ раздела, называют
пространственными.
Приземную область атмосферы, имеющую толщину 10—15 км,
называют тропосферой. Она неоднородна как по высоте, так и
вдоль земной поверхности. При этом электрические параметры
тропосферы существенно зависят от метеоусловий. Тропосфера
414
искривляет траекторию радиоволн (рефракция), рассеивает их
своими неоднородностями и ослабляет.
На рис. 8.17 а показаны возможные виды траекторий радиоволн,
распространяющихся в тропосфере. Эти радиоволны называют
тропосферными. Длина волны тропосферных радиоволн не пре-
вышает 5 м.
а)
Рис. 8.17. Траектории радиоволн:
а) в тропосфере; б) в ионосфере
б)
Область атмосферы, расположенную выше 60 км и простираю-
щуюся до 20000 км, называют ионосферой. Эта весьма разрежен-
ная область содержит значительное количество свободных элект-
ронов в единице объема. В ней выделяют области повышенной кон-
центрации электронов — слои Д, Е и F, оказывающих существен-
ное влияние на распространение радиоволн.
415
Ионосфера также искривляет траекторию радиоволн, рассеи-
вает их своими неоднородностями и ослабляет их. Искривление
траектории радиоволны в ионосфере иногда оказывается столь
значительным, что может рассматриваться как отражение радио-
волны от ионосферы. На рис. 8.17 б показаны возможные харак-
терные виды траекторий радиоволн, распространяющихся в ионос-
фере. Радиоволны, распространяющиеся путем отражения от
ионосферы или рассеивания на ее неоднородностях, называют
ионосферными радиоволнами. Такой характер распространения
присущ радиоволнам, длина которых превышает 5 м.
За пределами ионосферы плотность газа и концентрация элек-
тронов столь незначительны, что эта область практически может
рассматриваться как вакуум, а следовательно, радиоволны, вышед-
шие за пределы ионосферы, можно считать распределяющимися
прямолинейно.
Волны различных диапазонов имеют свои особенности распро-
странения.
Длинные (1—10 км) и сверхдлинные (свыше 10 км) волны рас-
пространяются земной и ионосферной волнами. Земная волна
может распространяться на расстояние до 300 км. Начиная с рас-
стояния 300—400 км, помимо земной волны, в точке приема при-
сутствует волна, отраженная от ионосферы.
На расстоянии свыше 3000 км длинные и сверхдлинные волны
распространяются только ионосферной волной.
Длинные и особенно сверхдлинные волны мало поглощаются
при их прохождении вглубь суши или моря. Этот диапазон волн
может быть использован для связи с погруженными подводными
лодками, а также для подземной связи. Дальность связи в этом ди-
апазоне может быть обеспечена на расстоянии более 20 000 км, но
для этого требуются мощные передатчики и большие антенны.
Средние волны (100—1000 м) обычно используются для веща-
ния и могут распространяться как земные и как ионосферные вол-
ны. Дальность распространения земной волны ограничена рассто-
янием 500—700 км. На большие расстояния радиоволны этого ди-
апазона распространяются ионосферной волной.
На условие распространения радиоволн среднего диапазона
существенно влияют время суток и время года. Так, в ночное вре-
мя средние волны распространяются за счет отражения от слоя F
ионосферы, в то время как в дневное время на пути волны возни-
кает слой D ионосферы, сильно поглощающий средние волны.
416
Поэтому в дневные часы распространение средних волн происхо-
дит практически только земной волной на сравнительно неболь-
шие расстояния (порядка 1000 км).
В диапазоне средних волн более длинные волны испытывают
меньшее поглощение. Поглощение увеличивается в летние меся-
цы и уменьшается в зимние. Этому диапазону волн присущ эф-
фект замирания волны. Так, в ночные часы на некотором расстоя-
нии от передатчика возможен одновременный приход земной и
ионосферной волн. В зависимости от разности фаз этих волн в точ-
ке приема может происходить усиление или ослабление принима-
емого сигнала. На значительных расстояниях от передатчика этот
эффект может возникнуть при взаимодействии волн, пришедших
в точку приема путем одного и двух отражений от ионосферы.
Диапазон коротких волн — земных и ионосферных находится
в пределах от 10 до 100 м. В этом диапазоне можно создать направ-
ленные антенны. Однако в нем поглощение земных волн сильно
возрастает, поэтому земные волны распространяются на расстоя-
ния, не превышающие нескольких десятков километров. Ионос-
ферной волной короткие волны могут распространяться на мно-
гие тысячи километров при сравнительно небольшой мощности
передатчиков.
Короткие волны распространяются на большие расстояния пу-
тем отражения от верхнего F слоя ионосферы и поверхности Зем-
ли, проходя при этом через слои D и Е, в которых они претерпева-
ют поглощение. В этом диапазоне также наблюдается эффект за-
мираний. Чаще всего причиной замирания служит приход в точку
приема двух волн, распространяющихся путем одного и двух от-
ражений от ионосферы.
Ультракороткими называются радиоволны короче 10 м. Диа-
пазон УКВ содержит четыре поддиапазона: метровый — от 10
до1 м, дециметровый — от 1 м до 10 см, сантиметровый — от 10
до 1 см и миллиметровый — короче 1 см. Диапазон метровых
волн используют в телевидении и вещании, дециметровый и сан-
тиметровый — в телевидении, радиолокации и многоканальной
связи.
Ультракороткие волны каждого из поддиапазонов имеют свои
особенности распространения. Однако на практике чаще рассмат-
ривают:
распространение УКВ на расстояния, не превышающие пре-
делов прямой видимости;
27 А-210
417
ионосферное распространение УКВ (расстояние свыше 1000км);
дальнее распространение УКВ с использованием искусствен-
ных спутников Земли.
Радиоволны УКВ диапазона в силу их малой длины плохо дифра-
гируют вокруг сферической поверхности Земли и крупных неров-
ностей земной поверхности и других препятствий. Поэтому при ра-
боте в диапазоне УКВ антенны стремятся расположить на значитель-
ной высоте над поверхностью земли, что позволяет увеличить рас-
стояние прямой видимости г0 (км), определяемое соотношением:
г0=3,75(Т^ + Т^) (8.26)
где Д, h2— высота соответственно передающей и приемных ан-
тенн, м.
Для организации связи на линии Земля—космос используют
волны в диапазоне от 3 м до 3 см. Волны этого диапазона практи-
чески не поглощаются в атмосфере. Они также не отражаются
ионосферой. Применяя спутники-ретрансляторы, можно обеспе-
чить глобальную связь в данном диапазоне волн.
8.3.3. Аппаратура линий связи
Аппаратура линий связи подразделяется на аппаратуру приема-
передачи данных, называемую аппаратурой окончания канала
данных (DCE — Data Circuit terminating Equipment), которая не-
посредственно связывает источник и получателя сообщения и про-
межуточную аппаратуру.
DCE работает на физическом уровне, отвечая за передачу и
прием сигнала нужной формы и мощности в физическую среду.
Примеры DCE: модемы, терминальные адаптеры сетей, оптичес-
кие модемы, устройства подключения к цифровым каналам.
Промежуточная аппаратура используется на линиях связи боль-
шой протяженности и решает две основные задачи:
• улучшение качества сигнала;
создание составного канала связи между абонентами в вы-
числительных сетях.
Промежуточная аппаратура может совсем не использоваться,
если протяженность физической среды — кабелей или радиоли-
нии позволяет осуществлять прием-передачу без промежуточно-
го усиления. В противном случае применяют специальные устрой-
ства — повторители.
418
Повторитель — устройство, обеспечивающее сохранение формы
и амплитуды сигнала при передаче его на большее, чем предусмотре-
но данным типом физической среды, расстояние.
Если требуется обеспечить качественную передачу сигналов на
большие расстояния, то необходимы усилители сигналов, установ-
ленные через определенные расстояния. В сетях передачи данных
используется также и другая промежуточная аппаратура:
мультиплексоры;
демультиплексоры;
коммутаторы.
Мультиплексор — устройство, обеспечивающее совмещение со-
общений, поступающих по нескольким каналам ввода, в одном выход-
ном канале.
Демультиплексор — устройство, выполняющее операцию, обрат-
ную мультиплексированию (уплотнению).
Коммутатор — комбинационная схема, коммутирующая один из
п входов с m выходами.
Эта аппаратура решает вторую задачу, т. е. создает между дву-
мя абонентами сети составной канал из некоммутируемых отрез-
ков физической среды. Промежуточная аппаратура канала свя-
зи прозрачна для пользователя, он ее не замечает и не учитывает
в своей работе.
Различают пространственные и временные коммутаторы [19].
Пространственный коммутатор размера NxM представляет
собой сетку (матрицу), в которой Nвходов подключены к горизон-
тальным шинам, а М выходов — к вертикальным (рис. 8.18).
Выходы
Рис. 8.18. Матрица пространственного коммутатора
419
В узлах сетки имеются коммутирующие элементы, причем в
каждом столбце сетки может быть открыто не более чем по одно-
му элементу. Если N < М, то коммутатор может обеспечить соеди-
нение каждого входа с не менее чем одним выходом; в противном
случае коммутатор называется блокирующим, т. е. не обеспечива-
ющим соединения любого входа с одним из выходов. Обычно при-
меняются коммутаторы с равным числом входов и выходов N х N.
Недостаток рассмотренной схемы — большое число коммути-
рующих элементов в квадратной матрице, равное N2. Для устране-
ния этого недостатка применяют многоступенчатые коммутаторы.
Например, схема трехступенчатого коммутатора 6x6 имеет вид,
представленный на рис. 8.19.
Рис. 8.19. Схема трехступенчатого пространственного коммутатора
Достаточным условием отсутствия блокировок входов являет-
ся равенство к > 2п-1. Здесь к — число блоков в промежуточном
каскаде; п = N/p; р — число блоков во входном каскаде. В приве-
денной на рис. 8.19 схеме это условие не выполнено, поэтому бло-
кировки возможны. Например, если требуется выполнить соеди-
нение —dv но ранее скоммутированы соединения а2—Ь2—с4—d3,
а,—Д—с,—(L, то для а, доступны шины Ь„ с. и с,, однако они не
ведут к dr
В многоступенчатых коммутаторах существенно уменьшено чис-
ло переключательных элементов за счет некоторого увеличения
задержки.
Временной коммутатор построен на основе буферной памяти,
запись производится в ее ячейки последовательным опросом вхо-
дов, а коммутация осуществляется благодаря считыванию данных
420
на выходы из нужных ячеек памяти. При этом происходит задер-
жка на время одного цикла «запись—чтение».
В зависимости от типа промежуточной аппаратуры все линии
связи делятся на:
аналоговые;
* цифровые.
В аналоговых линиях связи промежуточная аппаратура предназ-
начена для усиления аналоговых сигналов, которые имеют непре-
рывный диапазон значений. Такие линии связи традиционно при-
меняются в телефонных сетях для связи АТС между собой.
Для создания высокоскоростных каналов в аналоговых линиях
связи используется техника частотного мультиплексирования
(FDM), при которой в одном канале объединяется несколько низ-
коскоростных абонентских каналов.
В цифровых линиях связи передаваемые сигналы имеют конеч-
ное число состояний. С помощью таких сигналов передаются ком-
пьютерные данные, а также оцифрованные речь и изображение.
Промежуточная аппаратура образования высокоскоростных
цифровых каналов работает, как правило, по принципу временно-
го мультиплексирования каналов (TDM), когда каждому низкоско-
ростному каналу выделяется определенная доля времени высоко-
скоростного канала.
8.4. ИНФОРМАЦИОННЫЕ СЕТИ
В общем случае под телекоммуникационной сетью понимают си-
стему, состоящую из объектов, осуществляющих функции генера-
ции, преобразования, хранения и потребления продукта, называемых
пунктами (узлами) сети, и линий передачи (связи, коммуникаций,
соединений), осуществляющих передачу продукта между пунктами.
В зависимости от вида продукта — информация, энергия, мас-
са — различают соответственно информационные, энергетичес-
кие и вещественные сети [ 19]. Так, среди вещественных сетей мож-
но выделить транспортные, водопроводные сети и др.
Информационная сеть — коммуникационная сеть, в которой про-
дуктом генерирования, переработки, хранения и использования явля-
ется информация.
421
Традиционно для передачи звуковой информации используют-
ся телефонные сети, изображений — телевидение, текста — теле-
граф (телетайп). В настоящее время все большее распространение
получают информационные сети интегрального обслуживания,
позволяющие передавать в едином канале связи звук, изображе-
ние и данные.
Вычислительная сеть — информационная сеть, в состав которой
входит вычислительное оборудование.
Компонентами вычислительной сети могут быть ЭВМ и пери-
ферийные устройства, являющиеся источниками и приемниками
данных, передаваемых по сети.
8.4.1. Классификация вычислительных сетей
Вычислительные сети классифицируют по ряду признаков.
В зависимости от расстояния между узлами сети вычислитель-
ные сети можно разделить на три класса:
локальные (ЛВС, LAN — Local Area Network) — охватываю-
щие ограниченную территорию (обычно в пределах удален-
ности станций не более чем на несколько десятков или со-
тен метров друг от друга, реже на 1...2 км);
* корпоративные (масштаба предприятия) — совокупность
связанных между собой ЛВС, охватывающих территорию, на
которой размещено одно предприятие или учреждение в од-
ном или нескольких близко расположенных зданиях;
« территориальные — охватывающие значительное геогра-
фическое пространство; среди территориальных сетей мож-
но выделить сети региональные и глобальные, имеющие со-
ответственно региональные (MAN — Metropolitan Area
Network) или глобальные масштабы (WAN — Wide Area
Network).
Особо выделяют глобальную сеть Интернет.
Интернет — глобальная телекоммуникационная информацион-
ная сеть (мегасеть), объединяющая десятки тысяч сетей ЭВМ, охваты-
вающих более ста стран, миллионы подключенных узловых ЭВМ, де-
сятки миллионов пользователей.
422
Важным признаком классификации вычислительных сетей яв-
ляется их топология, определяющая геометрическое расположе-
ние основных ресурсов вычислительной сети и связей между ними.
В зависимости от топологии соединений узлов различают сети
шинной (магистральной), кольцевой, звездной, иерархической,
произвольной структуры.
Среди ЛВС наиболее распространены (рис. 8.20):
" шинная (bus) — локальная сеть, в которой связь между лю-
быми двумя станциями устанавливается через один общий
путь и данные, передаваемые любой станцией, одновремен-
но становятся доступными д ля всех других станций, подклю-
ченных к этой же среде передачи данных. Примером ЛВС
шинной структуры являются самые распространенные в на-
стоящее время сети Ethernet;
кольцевая (ring) — узлы связаны кольцевой линией переда-
чи данных (к каждому узлу подходят только две линии). Дан-
ные, проходя по кольцу, поочередно становятся доступны-
ми всем узлам сети. Примером ЛВС кольцевой топологии
является сеть Token Ring — вторая по степени распростра-
ненности после сетей Ethernet, а также высокоскоростная
сеть FDDI (Fiber Distributed Data Interface);
звездная (star) — имеется центральный узел, от которого рас-
ходятся линии передачи данных к каждому из остальных уз-
лов. Примером ЛВС звездной топологии является сеть Arcnet.
Топологическая структура сети оказывает значительное влия-
ние на ее пропускную способность, устойчивость сети к отказам
ее оборудования, на логические возможности и стоимость сети.
Рис. 8.20. Основные топологические структуры
локальных вычислительных сетей
423
В зависимости от способа управления различают сети:
«клиент-сервер» — в них выделяется один или несколько уз-
лов (их название — серверы), выполняющих в сети управляю-
щие или специальные обслуживающие функции, а остальные
узлы (клиенты) являются терминальными, в них работают
пользователи. Сети «клиент-сервер» различаются по характе-
ру распределения функций между серверами, т. е. по типам сер-
веров (например, файл-серверы, серверы баз данных). При
специализации серверов по определенным приложениям име-
ем сеть распределенных вычислений. Такие сети отличают так-
же от централизованных систем, построенных на мэйнфреймах;
" одноранговые — в них все узлы равноправны. Поскольку
в общем случае под клиентом понимается объект (устрой-
ство или программа), запрашивающий некоторые услуги,
а под сервером — объект, предоставляющий эти услути, то
каждый узел в одноранговых сетях может выполнять функ-
ции и клиента, и сервера.
В зависимости от того, одинаковые или неодинаковые ЭВМ
применяют в сети, различают сети однотипных ЭВМ, называемые
однородными, и разнотипных ЭВМ — неоднородные (гетероген-
ные). В крупных автоматизированных системах, как правило, сети
оказываются неоднородными.
В зависимости от прав собственности на сети последние могут
быть сетями общего пользования (public) или частными (private).
Среди сетей общего пользования выделяют телефонные сети
(PSTN — Public Switched Telephone Network) и сети передачи дан-
ных (PSDN — Public Switched Data Network).
Признаком различия сетей является также тип используемых
в них протоколов обмена информацией.
По способам коммутации данных различают вычислительные
сети с коммутацией каналов, сообщений и пакетов.
8.4.2. Методы передачи данных по каналам связи
Каналом связи называют физическую среду и аппаратурные сред-
ства, осуществляющие передачу информации между узлами коммутации.
В настоящее время в технике глобальных и региональных вы-
числительных сетей и телеобработки для передачи данных исполь-
зуют главным образом аналоговые каналы связи.
424
Передача дискретной (двоично-кодированной) информации по
аналоговым каналам связи осуществляется путем модуляцш в пе-
редающем пункте колебаний несущей частоты двоичными сигна-
лами передаваемого кода с последующей демодуляцией — восста-
новлением первоначальной формы сообщения в приемном пунк-
те. Операции модуляции и демодуляции выполняются в устрой-
ствах, называемых модемами.
Модем (модулятор-демодулятор) — устройство, выполняющее пре-
образование двоичных данных (потоков битов) в аналоговые сигналы,
пригодные для передачи по некоторому аналоговому каналу связи, и
принимаемые аналоговые сигналы обратно в цифровую форму.
Применяются три основных вида модуляции: амплитудная, ча-
стотная и фазовая. Способ образования дискретного канала пе-
редачи данных показан на рис. 8.21 [15].
Аналоговый канал
связи
К ЭВМ
Рис. 8.21. Дискретный канал передачи данных
Сама передача данных в канале связи может быть асинхрон-
ной и синхронной (рис. 8.22). При асинхронной передаче символы
передаются в свободном темпе независимо друг от друга, причем
каждый символ передается со своими сигналами Старт и Стоп,
указывающими на начало и конец передачи символа.
При синхронной передаче блок символов передается непрерыв-
но в принудительном темпе, синхронизация передающего и при-
нимающего устройств достигается посылкой специальных кодо-
вых комбинаций перед каждым блоком данных.
Асинхронная передача позволяет передавать информацию
с устройств, которые выдают ее асинхронно во времени. Однако
скорость передачи информации при асинхронном методе низка,
так как велика ее избыточность из-за большого числа служебных
сигналов. Синхронный метод обеспечивает большую скорость пе-
редачи данных из-за меньшей избыточности информации, но тре-
бует более сложной аппаратуры.
425
Буква В в 5-разрядном
телеграфном коде о
Старт
Буква М в коде
КОИ-8
о g
О О
8 элементов
1 элемент 2 элемента
Разные интервалы времени
5 элементов
1 символ
О 1
1 элемент
1,5 элемента
Э
В
Одинаковые интервалы времени
между символами
б)
Рис. 8.22. Передача данных:
а) асинхронная; б) синхронная.
Кодовая передача сообщений между накопителями, находящи-
мися в узлах информационной сети, называется телетексом
(в отличие от телекса — телетайпной связи), а факсимильная связь
называется телефаксом. Виды телетекса: электронная почта (Е-
mail) — обмен сообщениями между двумя пользователями сети,
обмен файлами, «доска объявлений» и телеконференции — ши-
роковещательная передача сообщений.
Установление соединения между отправителем и получателем
с возможностью обмена сообщениями без заметных временных
задержек характеризует режим работы on-line («на линии»). При
существенных задержках с запоминанием информации в проме-
жуточных узлах имеем режим off-line («вне линии»).
По возможным направлениям передачи информации различа-
ют каналы:
1) симплексные, позволяющие передавать данные только в од-
ном направлении;
2) полудуплексные, передающие данные в обоих направлениях,
но не одновременно;
3) дуплексные, позволяющие передавать одновременно данные
в обоих направлениях.
426
Помехи в каналах связи могут вызывать ошибки при передаче
информации. Достоверность передачи данных оценивается отно-
шением числа ошибочно принятых символов к общему числу пе-
реданных. Для телефонных коммутируемых каналов достовер-
ность передачи составляет 103. Такое низкое значение достовер-
ности передачи заставляет в ряде случаев применять специальные
методы (контроль по четности, контрольные суммы, циклические
коды) и средства контроля правильности передачи, автоматичес-
кого повторения передачи при появлении ошибки или автомати-
ческой коррекции.
Такие основные характеристики системы передачи информа-
ции, как пропускная способность, надежность передачи инфор-
мации, а также сложность аппаратуры напрямую зависят от вида
сигнала, используемого в системе передачи.
В настоящее время для кодирования информации широко ис-
пользуются коды NRZ (Non Return to Zero — без возврата к нолю),
RZ (Return to Zero — с возвратом к нолю), а также различные вари-
анты Манчестерского кода [18].
Код NRZ — это простейший код, представляющий собой
практически обычный цифровой сигнал (рис. 8.23). Логическая
1 (уровень Н — High) представляется положительным напряже-
нием высокого уровня, а логический 0 — низкого (уровень L —
Low), например ТТЛ-уровни: 2,4 В и 0,4 В. Основным достоин-
ством кода NRZ является его очень простая реализация (исход-
ный сигнал не надо ни кодировать на передающем конце, ни
декодировать на приемном конце). Самый большой недостаток
кода NRZ — это возможность потери синхронизации приемни-
ком при приеме слишком длинных блоков (пакетов) информа-
ции. Приемник может привязывать момент начала приема толь-
ко к первому (стартовому) биту пакета, а в течение приема па-
кета он вынужден пользоваться только собственным внутрен-
ним тактовым генератором. Если часы приемника расходятся с
часами передатчика в ту или другую сторону, то временной сдвиг
к концу приема пакета может превысить длительность одного
бита или даже нескольких бит. В результате произойдет потеря
переданных данных.
Чтобы решить задачу одинакового отсчета временных интер-
валов, нужно синхронизировать узлы сети (т. е. задать одинако-
вый отсчет времени для передатчика и приемника).
427
5В(1)—-------
О О
О В (О)-------
1 1 1
1
+ 12 В(Н)--
-12B(L)----
Рис. 8.23. Цифровое кодирование данных по методу NRZ
Один из способов синхронизации — посылка передающим узлом
сигналов тактовой частоты (рис. 8.24 а). Приемник в этом случае вы-
бирает сигнал данных в моменты появления тактовых импульсов
(рис. 8.24 б— синхронизация по уровню тактовых сигналов). Пере-
дача коротких тактовых сигналов, что необходимо для увеличения
скорости передачи, сталкивается с проблемой искажения сигналов
из-за затухания и с проблемами их кодирования-декодирования. По-
этому восприятие сигналов данных обычно происходит по фронту
(пусть и искаженного) сигнала тактовой частоты (рис. 8.24 в).
Линия сигнала данных
Передатчик
Линия сигнала тактовой частоты
Приемник
а)
Прямоугольный
тактовый сигнал
Рис. 8.24. Передача сигналов с синхронизацией
в)
428
Синхросигналы при использовании этих методов требуют от-
дельной линии связи в сетевом канале связи. При этом требуе-
мое количество кабеля увеличивается в два раза, то же проходит
и с количеством приемников и передатчиков. При большой дли-
не сети и большом количестве абонентов это оказывается невы-
годным.
В связи с этим код NRZ используется только для передачи
короткими пакетами (обычно до 1 Кбита). Для синхронизации
начала приема пакета применяется стартовый служебный бит,
чей уровень отличается от пассивного состояния линии связи
(например, пассивное состояние линии при отсутствии пере-
дачи — 0, стартовый бит — 1). Наиболее известное примене-
ние кода NRZ — стандарт RS232-C, последовательный порт пер-
сонального компьютера (рис. 8.25). На рисунке порт передачи
обозначен Т (Transmitter), порт приема — R (Reciever). Передача
информации в нем ведется байтами (8 бит), сопровождаемыми
стартовым и стоповым битами.
Интерфейс
Передаваемые Старт Стоп
биты сигнала Незанято) | 1 1 1 0 1 1 1 1 | | незанято
(+5В)1 --------- ------------ -------------------
Т
(О В) 0 — *—1
(+12 В) Н --- —
Передаваемый
сигнал
(-12 В) L —--------- *—--------- -------------------
Рис. 8.25. Линейные буферы RS-232 и кодирование NRZ
429
Код RZ — трехуровневый код, получивший такое название по-
тому, что после значащего уровня сигнала в первой половине пе-
редаваемого бита информации следует возврат к «нолевому» уров-
ню (например, к нолевому потенциалу). Переход к нему происхо-
дит в середине каждого бита. Логическому нолю, таким образом,
соответствует положительный импульс, логической единице — от-
рицательный (или наоборот) в первой половине битового интер-
вала [18].
Особенностью кода RZ является то, что в центре бита всегда есть
переход (положительный или отрицательный), следовательно, из
этого кода приемник может выделить синхроимпульс (строб).
В данном случае возможна временная привязка не только к нача-
лу пакета, как в случае кода NRZ, но и к каждому отдельному биту,
поэтому потери синхронизации не произойдет при любой длине
пакета. Такие коды, несущие в себе строб, получили название са-
мосинхронизирующихся.
Недостаток кода RZ состоит в том, что для него требуется вдвое
большая полоса пропускания канала при той же скорости переда-
чи по сравнению с NRZ (так как здесь на один бит приходится два
изменения уровня напряжения).
Код RZ применяется не только в сетях на основе электричес-
кого кабеля, но и в оптоволоконных сетях. Поскольку в них не
существует положительных и отрицательных уровней сигнала,
используется три уровня: отсутствие света, «средний» свет,
«сильный» свет. При этом, когда нет передачи информации, свет
все равно присутствует, что позволяет легко определить целос-
тность оптоволоконной линии связи без дополнительных мер
(рис. 8.26).
Рис. 8.26. Использование кода RZ в оптоволоконных сетях
430
Код Манчестер-!!, или манчестерский код, получил наибольшее
распространение в локальных сетях [18]. Он также относится к са-
мосинхронизирующимся кодам, но в отличие от кода RZ имеет не
три, а всего только два уровня, что способствует его лучшей поме-
хозащищенности. Логическому нолю соответствует положительный
переход в центре бита (т. е. первая половина битового интервала —
низкий уровень, вторая половина — высокий), а логической еди-
нице соответствует отрицательный переход в центре бита (или на-
оборот). Принцип формирования манчестерского кода представ-
лен на рис. 8.27.
Обязательное наличие перехода в центре бита позволяет при-
емнику кода Манчестер-П легко выделить из пришедшего сигнала
синхросигнал, что дает возможность передавать информацию
сколь угодно большими пакетами без потерь из-за рассинхрони-
зации. Допустимое расхождение часов приемника и передатчика
может достигать величины 25%. Как и в случае кода RZ, пропускная
способность линии требуется в два раза выше, чем при использова-
нии простейшего кода NRZ. Код Манчестер-П используется как
в электрических кабелях, так и в оптоволоконных кабелях (в пос-
леднем случае один уровень соответствует отсутствию света, а дру-
гой — наличию света).
н
L
н
L
н
L
Передаваемые
биты данных
Передаваемые
данные
Передаваемый
тактовый сигнал
Данные
в манчестерском
коде
Рис. 8.27. Принцип формирования манчестерского кода
Большое достоинство манчестерского кода — отсутствие посто-
янной составляющей в сигнале (половину времени сигнал положи-
тельный, другую половину — отрицательный). Это дает возможность
431
применять для гальванической развязки импульсные трансформа-
торы. При этом не требуется дополнительного источника питания
для линии связи (как в случае использования оптронной развязки),
резко уменьшается влияние низкочастотных помех, которые не
проходят через трансформатор, легко решается проблема согласо-
вания. Если же один из уровней сигнала в манчестерском коде но-
левой (как, например, в сети Ethernet), то величина постоянной со-
ставляющей в течение передачи будет равна примерно половине
амплитуды сигнала. Это позволяет легко фиксировать столкнове-
ния пакетов в сети (конфликт, коллизию) по отклонению величины
постоянной составляющей за установленные пределы.
Так же как и в случае кода RZ, при манчестерском кодирова-
нии очень просто определить, идет передача или нет, т. е. детекти-
ровать занятость сети или, как еще говорят, обнаруживать несу-
щую частоту. Для этого достаточно контролировать, происходит
ли изменение сигнала в течение битового интервала. Обнаруже-
ние несущей частоты необходимо, например, для определения
момента начала и конца принимаемого пакета, а также для пре-
дотвращения начала передачи в случае занятости сети (когда пе-
редачу осуществляет какой-то другой абонент).
Стандартный манчестерский код имеет несколько вариантов,
один из которых показан на рис. 8.28.
। । ।
।
Манчестер-Н
(вариант)
Рис. 8.28. Код Манчестер-11 и его вариант
Данный код, в отличие от классического, не зависит от переме-
ны мест двух проводов кабеля. Особенно это удобно в случае, ког-
да для связи используется витая пара, провода которой легко пе-
репутать. Именно этот код применяется в одной из самых извест-
ных сетей Token-Ring фирмы IBM.
Принцип данного кода прост: в начале каждого битового интер-
вала сигнал меняет уровень на противоположный предыдущему, а
в середине единичных (и только единичных) битовых интервалов
уровень изменяется еще раз. Таким образом, в начале битового
432
интервала всегда есть переход, который используется для самосин-
хронизации. Как и в случае классического кода Манчестер-!!,
в частотном спектре при этом присутствуют две частоты. При ско-
рости 10 Мбит/с это частоты 10 МГц (при последовательности од-
них единиц: 11111111...) и 5 МГц (при последовательности одних
нолей: 00000000...).
Все разрабатываемые в последнее время коды призваны найти
компромисс между требуемой при заданной скорости передачи
полосой пропускания кабеля и возможностью самосинхрониза-
ции. Разработчики стремятся сохранить самосинхронизацию, но
не ценой двукратного увеличения полосы пропускания [18].
Чаще всего для этого в поток передаваемых битов добавляют
биты синхронизации, например, один бит синхронизации на 4, 5
или 6 информационных битов или два бита синхронизации на 8
информационных битов. В действительности все обстоит несколь-
ко сложнее: кодирование не сводится к простой вставке в переда-
ваемые данные дополнительных битов. Группы информационных
битов преобразуются в передаваемые по сети группы с количе-
ством битов на один или два больше. Приемник, естественно, осу-
ществляет обратное преобразование, восстанавливает исходные
информационные биты.
Так, в сети FDD! (скорость передачи 100 Мбит/с) применяется
код 4Ь/5Ь, который 4 информационных бита преобразует в 5 пе-
редаваемых битов. При этом синхронизация приемника осуще-
ствляется один раз на 4 бита, а не в каждом бите, как в случае
кода Манчестер-!!. Требуемая полоса пропускания увеличивает-
ся по сравнению с кодом NRZ не в два раза, а только в 1,25 раза
(т. е. составляет не 100 МГц, а всего лишь 62,5 МГц). По тому же
принципу строятся и другие коды, например 5Ъ/6Ь, используемый
в стандартной сети 100VG-AnyLAN, или 8Ь/10Ь, используемый
в сети Gigabit Ethernet.
В сегменте 100BASE-T4 сети Fast Ethernet использован несколько
иной подход. Там применяется код 8Ь/6Т, предусматривающий па-
раллельную передачу трех трехуровневых сигналов по трем витым
парам. Это позволяет достичь скорости передачи 100 Мбит/с на де-
шевых кабелях с витыми парами категории 3, имеющих полосу про-
пускания всего лишь 6 МГц. Правда, это требует большего расхода
кабеля и увеличения количества приемников и передатчиков. К тому
же принципиально важно, чтобы все провода были одной длины, что-
бы задержки сигнала в них не различались на заметную величину.
28 А-210
433
Все упомянутые коды предусматривают непосредственную пе-
редачу в сеть цифровых двух- или трехуровневых прямоугольных
импульсов. Аналоговые сигналы с AM, ЧМ и ФМ используются при
передаче информации по каналу с узкой полосой пропускания,
например по телефонным линиям, и в локальных сетях применя-
ются редко из-за высокой сложности и стоимости как кодирую-
щего, так и декодирующего оборудования.
8.4.3. Способы коммутации данных
Под коммутацией данных понимается их передача, при кото-
рой канал передачи может использоваться попеременно для об-
мена информацией между различными пунктами информацион-
ной сети в отличие от связи через некоммутируемые каналы, обыч-
но закрепленные за определенными абонентами.
Различают следующие способы коммутации данных:
коммутация каналов (circuit switching);
коммутация сообщений (message switching);
коммутация пакетов (packet switching).
Коммутация каналов — образование непрерывного физичес-
кого канала из последовательно соединенных отдельных участков
сети. Установление связи между источником и адресатом произ-
водится путем посылки пунктом отправления сигнализирующего
сообщения, которое, перемещаясь по сети передачи данных от
одного узла коммутации каналов к другому и занимая пройденные
каналы, прокладывает путь от источника к пункту назначения. Этот
путь (составной канал) состоит из физических каналов, имеющих
одну и ту же скорость передачи данных. Об установлении физи-
ческого соединения из пункта назначения в источник посылается
сигнал обратной связи. Затем из источника передается сообщение
по установленному пути с одновременным использованием всех
образующих его каналов, которые оказываются недоступными для
других передач, пока источник их не освободит.
Отдельные участки сети (каналы) соединяются между собой
специальной аппаратурой — коммутаторами.
С целью увеличения пропускной способности линий связи ком-
мутаторы, а также соединяющие их каналы должны обеспечивать
мультиплексирование абонентских каналов.
В настоящее время для мультиплексирования абонентских ка-
налов используютсясАедующиетёхнологии:
434
частотное мультиплексирование {Frequency Division Multip-
lexing, FDM};
• временное мультиплексирование {Time Division Multiplexing,
TDM}.
Коммутация каналов на основе частотного мультиплексирова-
ния (FDM) была разработана для телефонных сетей, но применя-
ется в настоящее время и для других сетей (кабельное телевиде-
ние и др.).
Речевые сигналы имеют спектр шириной от 300 Гц до 20 кГц,
однако основные гармоники находятся в диапазоне 300...3400 Гц.
Таким образом, для качественной передачи речи между двумя со-
беседниками достаточно организовать канал связи с полосой про-
пускания 3,1 кГц. В то же время полоса пропускания кабельных
систем, соединяющих телефонные коммутаторы, составляет сот-
ни килогерц, что позволяет обеспечить одновременную передачу
сигналов нескольких абонентов методом переноса каждого або-
нентского канала в свой собственный ВЧ диапазон частот.
Принцип частотного мультиплексирования иллюстрирует рис. 8.29.
На входы FDM коммутатора поступают исходные сигналы от
абонентов телефонной сети.
60 кГц ... 108 кГц
Рис. 8.29. Коммуникация на основе частотного уплотнения
Коммутатор выполняет перенос частоты каждого канала в свой
диапазон ВЧ. ВЧ-диапазон делится на полосы, которые отводятся
для абонентских каналов. Чтобы спектральные составляющие або-
нентских сигналов не смешивались между собой, абонентские ка-
налы разделяют защитным промежутком в 900 Гц.
В канале между двумя FDM коммутаторами одновременно пере-
даются сигналы всех абонентских каналов, каждый из которых за-
нимает свою полосу частот. Такой канал называют уплотненным.
Выходной коммутатор выделяет модулированные сигналы каж-
дой несущей частоты и передает их на соответствующий выход-
ной канал, к которому подсоединен абонентский телефон.
435
В сетях на основе FDM коммутации принято несколько уров-
ней уплотненных каналов:
базовая группа каналов — первый уровень уплотнения,
12 абонентских каналов, занимающие полосу шириной
48 кГц (60 кГц... 108 кГц);
супергруппа каналов — второй уровень уплотнения, 5 базо-
вых групп, занимающих полосу шириной 240 кГц (312 кГц ...
552 кГц);
главная группа каналов — третий уровень уплотнения, 10 су-
пергрупп, занимающих полосу частот не менее 2520 кГц
(564 кГц ... 3084 кГц). Главная группа передает данные 600
абонентов и используется для связи между коммутаторами
на больших расстояниях.
Коммутаторы FDM могут выполнять как динамическую, так и
постоянную коммутацию.
При динамической коммутации один абонент инициирует со-
единение с другим абонентом, посылая в сеть номер вызываемого
абонента. Коммутатор выделяет данному абоненту одну из свобод-
ных полос своего уплотненного канала.
При постоянной коммутации за абонентом полоса в 4 кГц зак-
репляется на длительный срок путем настройки коммутатора по
отдельному входу.
Коммутация каналов на основе временного мультиплексирова-
ния (TDM) ориентирована на дискретный характер передаваемых
данных. Рис. 8.30 поясняет принцип коммутации на основе разде-
ления канала по времени.
Цикл работы оборудования TDM равен 125 мкс, что соответству-
ет периоду следования временных каналов в цифровом абонентс-
ком канале.
Каждому соединению выделяется часть времени цикла рабо-
ты аппаратуры, называемая также тайм-слотом. Длительность
тайм-слота зависит от числа абонентских каналов, обслуживае-
мых мультиплексором или коммутатором TDM. Мультиплексор
принимает информацию по N входным каналам от абонентов,
которые передают данные по абонентскому каналу со скоростью
64 кбит/с, т. е. 1 байт каждые 125 мкс. В каждом цикле мульти-
плексор обеспечивает:
прием от каждого канала очередного байта данных;
436
* составление из принятых байтов уплотненного кадра, назы-
ваемого также обоймой;
передачу уплотненного кадра на канал с битовой скоростью
Nx64 Кбит/с.
Порядок байт в обойме соответствует номеру входного канала,
от которого этот байт получен. Количество обслуживаемых муль-
типлексором абонентских каналов зависит от его быстродействия
(первые мультиплексоры, работающие по технологии TDM поддер-
живали 24 входных абонентских канала, создавали на выходе обой-
мы, передаваемые с битовой скоростью 1,544 Мбит/с).
Демультиплексор выполняет обратную задачу—разбивает бай-
ты уплотненного кадра и распределяет их по своим выходным ка-
налам, при этом он считает, что порядковый номер байта в обойме
соответствует номеру выходного канала.
Соединение 2 -1 Соединение 1 - 2
I_________________________________________________________________________I
Буферная память
Рис. 8.30. Коммутация на основе разделения канала по времени
Коммутатор принимает уплотненный кадр по скоростному ка-
налу от мультиплексора и записывает каждый байт из него в от-
дельную ячейку своей буферной памяти, причем в том порядке,
в котором эти байты были упакованы в уплотненный кадр. Д ля вы-
полнения операции коммутации байты извлекаются из буферной
памяти не в порядке поступления, а в таком порядке, который со-
ответствует поддерживаемым в сети соединениям абонентов.
437
Например, если первый абонент левой части сети на рис. 8.30
должен соединиться со вторым абонентом в правой части сети, то
байт, записанный в первую ячейку буферной памяти, будет извле-
каться из нее вторым. «Перемешивая» нужным образом байты
в обойме, коммутатор обеспечивает соединение любых абонентов
в сети. Выделенный номер тайм-слота остается в распоряжении пары
абонентов в течение всего времени существования этого соединения,
даже если передаваемый трафик является пульсирующим. Это озна-
чает, что соединение в сети TDM всегда обладает известной и фикси-
рованной пропускной способностью, кратной 64 Кбит/с.
Адресом каждого байта данных в сети TDM является номер
выделенного тайм-слота в мультиплексоре или коммутаторе, или
порядковый номер временного канала в кадре.
Сети, использующие технику TDM, требуют синхронности ра-
боты всего оборудования, что и определяет второе название этой
технологии — синхронный режим передачи (STM). Нарушение
синхронной работы всего оборудования разрушает требуемую
коммутацию абонентов, так как при этом теряется адресная ин-
формация.
Перераспределение тайм-слотов между разными каналами не-
возможно, даже если в каком-то цикле работы мультиплексора
один из временных каналов оказывается свободным (например,
абонент телефонной сети молчит).
Рассмотрим обеспечение дуплексной работы на основе техно-
логий FDM и TDM.
Наиболее простым вариантом организации дуплексного режи-
ма является использование двух независимых физических кана-
лов (две пары проводников в кабеле, каждый из которых работает
в симплексном режиме, т. е. передает данные в одном направле-
нии). Такая идея лежит в основе реализации дуплексного режима
во многих сетевых технологиях (например, ATM — асинхронный
режим передачи).
Если такое решение неэффективно (например, имеется только
один физический канал связи с АТС, а прокладывать второй неце-
лесообразно), то дуплексный режим работы может быть органи-
зован на основе разделения каналов на два логических подканала
с помощью технологии FDM или TDM.
При использовании технологии FDM модемы для организации
дуплексного режима работы на одной двухпроводной линии рабо-
тает на четырех частотах:
438
две частоты применяются для кодирования нолей и единиц
в одном направлении;
• две другие частоты используются для передачи данных в дру-
гом направлении.
При цифровом кодировании дуплексный режим на двухпровод-
ной линии организуется на базе TDM: часть тайм-слотов применя-
ется для передачи данных в одном направлении, а часть — в дру-
гом. Тайм-слоты противоположных направлений чередуются, из-
за чего такой способ называют «пинг-понговой» передачей.
Коммутация пакетов позволяет добиться дальнейшего увели-
чения пропускной способности сети, скорости и надежности пе-
редачи данных.
Суть метода заключается в следующем. Поступающее от абонен-
та сообщение подвергается пакетированию, т. е. разбивается на па-
кеты, имеющие фиксированную длину, например 1 Кбит (рис. 8.31).
Каждый пакет снабжается заголовком (3), в котором находится ад-
ресная информация, а также номер пакета, необходимый для сбор-
ки сообщения. Пакеты транспортируются сетью как независимые
информационные блоки.
Источник сообщения
Получатель сообщения
Заголовок
сообщения
Сообщение
aigjiEJi
П2ПЗП1
| Сеть передачи данных |
7тТ
П2
пз
_ Заголовок
сообщения
Сообщение
Рис. 8.31. Принцип коммутации пакетов
Коммутаторы сети принимают пакеты от конечных узлов и на
основании адресной информации передают их друг другу, а в ко-
нечном итоге получателю сообщения. Коммутаторы пакетной сети
отличаются от коммутаторов каналов тем, что имеют внутреннюю
буферную память для временного хранения пакетов, если выход-
ной порт коммутатора в момент принятия пакета занят передачей
другого пакета. В этом случае пакет находится некоторое время
в очереди пакетов в буферной памяти выходного порта, а когда до
него дойдет очередь, то он передается следующему коммутатору.
Такая схема передачи данных позволяет сглаживать пульсации
трафика на магистральных линиях между коммутаторами и тем
439
самым использовать их более эффективно для повышения пропус-
кной способности сети в целом. В пункте назначения из пакетов
формируется исходное сообщение.
Различают четыре режима передачи пакетов между двумя ко-
нечными узлами сети:
• дейтаграммный режим;
режим виртуального вызова;
метод коммутации пакетов с установлением виртуального
канала;
метод коммутации пакетов с виртуальным соединением.
Режим дейтаграмм допускает независимое перемещение по
сети пакетов сообщения (называемых в этом случае дейтаграмма-
ми) и не требует предварительного установления логического со-
единения, т. е. в виде дейтаграмм посылаются источником потре-
бителю без предварительного уведомления его о такой передаче.
Дейтаграмма (datdgram) — один пакет данных с сопутствующей
информацией о пункте назначения, передаваемый в сети с пакетной
коммутацией.
При этом пакеты одного и того же сообщения могут передавать-
ся по разным маршрутам. В качестве примера на рис. 8.32 показа-
на передача по сети связи сообщений С13 от абонента А1 абоненту
АЗ и С24 от абонента А2 абоненту А4.
Рис. 8.32. Передача пакетов
440
Основным достоинством этого режима является высокая сте-
пень использования линии связи, а также малое время передачи
сообщения за счёт параллельной передачи пакетов по различным
путям и начала связи без предварительного вхождения в связь
с потребителем информации.
Эти преимущества обеспечиваются независимой маршрутиза-
цией каждого пакета. При этом коммутатор — узел коммутации
(УК) — может изменить маршрут любого пакета в зависимости от
состояния сети — работоспособности каналов и других коммута-
торов, длины очереди пакетов в соседних коммутаторах и т. п.
Основные недостатки данного режима обусловлены следую-
щим:
из-за передачи пакетов одного сообщения по разным путям
к потребителю пакеты могут прийти не в той последователь-
ности и их придётся переставлять;
так как в абонентских пунктах не резервируется память для
приема сообщения, то может оказаться, что абонент не смо-
жет принять все пакеты сообщения. Это может привести
к перегрузке памяти входящего (ближайшего) узла коммута-
ции, который при этом откажет в приёме пакетов от других
узлов коммутации. В результате некоторые пакеты будут бло-
кироваться в сети и не смогут достичь пункта назначения;
на сети возможны «тупиковые ситуации», возникающие
в том случае, когда поступающий в сеть поток пакетов пре-
вышает допустимый. В результате сеть перегружается, в ней
непрерывно циркулируют пакеты, но ни один из них не пе-
редается потребителю, и сеть не принимает новых пакетов.
Режим виртуального вызова отличается от дейтаграммного тем,
что перед тем как передать пакеты сообщения в сеть (т. е. начать
сеанс связи), источник посылает специальный пакет (пакет вирту-
ального вызова) с информацией о том, что собирается передать
в данный абонентский пункт (приемнику сообщения) сообщение
с указанием его величины.
Получив пакет виртуального вызова, приемник резервирует
память для приема этого сообщения и посылает ответный пакет о
согласии приема. После поступления ответного пакета, источник
информации начинает сеанс связи. В случае если приемник не
имеет возможности принять данное сообщение он или передает
ответный пакет с отказом или ничего не передает, и сеанс связи
не начинается.
441
Таким образом, при дейтаграммном режиме с виртуальным
вызовом, когда резервируются ресурсы абонентского пункта (па-
мять) для приема пакетов всего сообщения, устраняется второй
недостаток, что приводит к уменьшению вероятности перегрузок
сети (уменьшается вероятность возникновения тупиковых ситуа-
ций) . Однако при этом увеличивается время передачи сообщения
и усложняется сам этот процесс.
Режим установки виртуального канала отличается от предыду-
щего не только резервированием ресурсов памяти приемника, но
и фиксацией маршрута передачи пакетов одного и того же сооб-
щения, т. е. пакеты, передаваемые в течение одного сеанса связи,
передаются по одному и тому же маршруту.
Виртуальный канал может быть динамическим или постоянным.
Динамический виртуальный канал устанавливается при пере-
даче в сеть специального пакета — запроса на установку соедине-
ния. Этот пакет проходит через коммутаторы и «прокладывает»
виртуальный канал, резервируя ресурсы (память) транзитных уз-
лов коммутации для приема следующих друг за другом пакетов
одного и того же сообщения.
Метод коммутации пакетов с виртуальным соединением
практически полностью устраняет недостатки метода с виртуаль-
ным каналом, а именно: из-за того, что ресурсы в линии и в уст-
ройствах коммутации не закрепляются за виртуальным каналом,
остается вероятность прихода пакетов (если не принять специ-
альных мер) к абоненту в перепутанной последовательности.
В последней модификации метода коммутации пакетов этого не
происходит.
Данная модификация метода коммутации пакетов близка по
организации связи методу коммутации каналов. Если принять, что
при вызове будут зарезервированы и временные интервалы
в транзитных линиях для передачи пакетов, то коммутация паке-
тов превратится в аналог коммутации каналов. Различия будут
состоять лишь в размерах пакета и в способе коррекции ошибок,
возникающих при передаче по сети пакетов. Так в сети коммута-
ции каналов проверка правильности передачи и коррекция воз-
никающих ошибок осуществляется обычно (но не обязательно)
на входящем абонентском пункте, в то время как в сети коммута-
ции пакетов — на каждом транзитном узле коммутации, причем
с повторной посылкой пакета с предыдущего узла коммутации
в случае обнаружения ошибок.
442
Коммутация сообщений. При этом методе физическое соеди-
нение устанавливается только между соседними узлами сети (на-
зываемыми центрами или узлами коммутации сообщений) и толь-
ко на время передачи сообщения. Каждое сообщение снабжается
заголовком и транспортируется по сети как единое целое. Посту-
пившее в узел сообщение запоминается в его буферном запоми-
нающем устройстве и в подходящий момент, когда освободится со-
ответствующий канал связи, передается в следующий, соседний
узел. Сообщение как бы прыгает от одного узла к другому, зани-
мая в каждый момент передачи только канал между соседними
узлами, при этом виртуальный канал между источником и адреса-
том может состоять из физических каналов с разной скоростью
передачи данных. Коммутация сообщений по сравнению с комму-
тацией каналов позволяет ценой усложнения аппаратуры узла ком-
мутации уменьшить задержку при передаче данных и повысить об-
щую пропускную способность сети передачи данных.
В компьютерных сетях под методом коммутации сообщений
понимают передачу единого блока данных между транзитными
компьютерами сети с временной буферизацией этого блока на
диске каждого компьютера.
Буферизация (buffering) — процесс использования буфера или бу-
феров для размещения передаваемых данных, например направляе-
мых в устройства ввода-вывода или из этих устройств.
Буфер —- место промежуточного хранения данных: зарезервиро-
ванная область памяти, в которой данные хранятся до их перемеще-
ния в запоминающее устройство или из него либо в другую область
памяти.
Сообщение в отличие от пакета имеет произвольную длину,
которая определяется не технологическими ограничениями, а со-
держанием информации, составляющей сообщение. Сообщением
может быть текстовый документ, электронное письмо и т. п. Тран-
зитные компьютеры могут соединяться между собой как сетью
с коммутацией пакетов, так и сетью с коммутацией каналов. Со-
общение хранится в транзитном компьютере на диске, причем вре-
мя хранения может быть достаточно большим, если компьютер
загружен другими работами либо сеть перегружена. По такой схе-
ме передают сообщения, не требующие немедленного ответа, чаще
всего сообщения электронной почты.
443
8.4.4. Эталонная модель взаимодействия открытых систем
и протоколы обмена
Задача согласованного взаимодействия различных ресурсов
сети (ЭВМ и периферийных устройств, являющихся источниками
и приемниками данных) решается с помощью системы специаль-
ных процедур, называемых протоколами.
Протокол — совокупность соглашений относительно способа
представления данных, обеспечивающего их передачу в нужных на-
правлениях и правильную интерпретацию данных всеми участника-
ми процесса информационного обмена.
Поскольку информационный обмен — процесс многофункци-
ональный, то протоколы делятся на уровни. К каждому уровню
относится группа родственных функций. Для правильного взаи-
модействия узлов различных вычислительных сетей их архитек-
тура должна быть открытой. Этим целям служат унификация и
стандартизация в области телекоммуникаций и вычислительных
сетей.
Наибольшее распространение получила в настоящее время эта-
лонная модель обмена информацией открытой системы OSI (Open
System Interchange). Под термином «открытая система» в данном
случае понимается незамкнутая в себе система, имеющая возмож-
ность взаимодействия с какими-то другими системами (в отличие
от закрытой системы).
Модель OSI была предложена в 1984 г. Международной органи-
зацией стандартов ISO (International Standards Organization). Как
и любая универсальная модель, OSI довольно громоздка, избыточ-
на и не слишком гибка, поэтому реальные сетевые средства, пред-
лагаемые различными фирмами, не обязательно придерживают-
ся принятого разделения функций.
Все сетевые функции в модели разделены на 7 уровней (рис. 8.33).
При этом вышестоящие уровни выполняют более сложные, гло-
бальные задачи, для чего используют в своих целях нижестоящие
уровни, а также управляют ими. Цель нижестоящего уровня — пре-
доставление услуг вышестоящему уровню, причем вышестояще-
му уровню не важны детали выполнения этих услуг. Нижестоящие
уровни выполняют более простые, более конкретные функции. В
идеале каждый уровень взаимодействует только с теми, которые
444
находятся рядом с ним (выше него и ниже него). Верхний уровень
соответствует прикладной задаче, работающему в данный момент
приложению, нижний — непосредственной передаче сигналов по
каналу связи.
Прикладной
Представительный
Сеансовый
Транспортный
Сетевой
Канальный
Физический
Рис. 8.33. Эталонная модель OSI
Функции, входящие в показанные на рис. 8.33 уровни, реализу-
ются каждым абонентом сети. При этом каждый уровень на од-
ном абоненте работает так, как будто он имеет прямую связь с со-
ответствующим уровнем другого абонента, т. е. между одноимен-
ными уровнями абонентов сети существует виртуальная связь.
Реальную же связь абоненты одной сети имеют только на самом
нижнем, первом, физическом уровне. В передающем абоненте
информация проходит все уровни, начиная с верхнего и заканчи-
вая нижним. В принимающем абоненте полученная информация
совершает обратный путь: от нижнего уровня к верхнему.
Ниже приведены номера уровней модели OSI, названия и вы-
полняемые функции.
7-й уровень — прикладной (Application): включает в себя сред-
ства управления прикладными процессами; эти процесы могут
объединяться для выполнения поставленных заданий, обменивать-
ся между собой данными. Другими словами, на этом уровне опре-
деляются и оформляются в блоки те данные, которые подлежат
передаче по сети. Уровень состоит например из таких средств для
445
взаимодействия прикладных программ, как прием и хранение па-
кетов в «почтовых ящиках» (mail-box).
6-й уровень — представительный (Presentation): реализуются
функции представления данных (кодирование, форматирование,
структурирование). Например, на этом уровне выделенные для
передачи данные преобразуются из кода EBCDIC в ASII и т. п.
5-й уровень — сеансовый (Session): предназначен для организа-
ции и синхронизации диалога, ведущегося объектами (станциями)
сети. На этом уровне определяются тип связи (дуплекс или полу-
дуплекс), начало и окончание заданий, последовательность и режим
обмена запросами и ответами взаимодействующих партнеров.
4-й уровень — транспортный (Transport): предназначен для уп-
равления сквозными каналами в сети передачи данных; на этом уров-
не обеспечивается связь между оконечными пунктами (в отличие от
следующего сетевого уровня, на котором обеспечивается передача
данных через промежуточные компоненты сети). К функциям транс-
портного уровня относятся мультиплексирование и демультиплекси-
рование (сборка-разборка пакетов), обнаружение и устранение оши-
бок в передаче данных, реализация заказанного уровня услуг (напри-
мер, заказанной скорости и надежности передачи). На транспортном
уровне пакеты обычно называют сегментами.
3-й уровень — сетевой (Network): на этом уровне происходит
управление передачей пакетов через промежуточные узлы и сети,
контроль нагрузки на сеть с целью предотвращения перегрузок,
отрицательно влияющих на работу сети, маршрутизация пакетов,
т. е. определение и реализация маршрутов, по которым передают-
ся пакеты. Маршрутизация сводится к определению логических
каналов. Логическим каналом называется виртуальное соединение
двух или более объектов сетевого уровня, при котором возможен
обмен данными между этими объектами. Понятию логического
канала необязательно соответствие некоего физического соеди-
нения линий передачи данных между связываемыми пунктами. Это
понятие введено для абстрагирования от физической реализации
соединения.
2-й уровень — канальный (Link, уровень звена данных): предо-
ставляет услуги по обмену данными между логическими объек-
тами предыдущего сетевого уровня и выполняет функции, свя-
занные с формированием и передачей кадров, обнаружением и
исправлением ошибок, возникающих на следующем, физическом
уровне. Кадром называется пакет канального уровня, поскольку
446
пакет на предыдущих уровнях может состоять из одного или мно-
гих кадров. В ЛВС функции канального уровня подразделяют на два
подуровня: управление доступом к каналу (МАС — Medium Access
Control) и управление логическим каналом (LLC — Logical Link
Control). К подуровню LLC относится часть функций канального
уровня, не связанных с особенностями передающей среды. На по-
дуровне МАС осуществляется доступ к каналу передачи данных;
1-й уровень — физический (Physical): предоставляет механичес-
кие, электрические, функциональные и процедурные средства для
установления, поддержания и разъединения логических соединений
между логическими объектами канального уровня; реализует функ-
ции передачи битов данных через физические среды. Именно на
физическом уровне осуществляются представление информации в
виде электрических или оптических сигналов, преобразования фор-
мы сигналов, выбор параметров физических сред передачи данных.
В конкретных случаях может возникать потребность в реали-
зации лишь части названных функций, тогда соответственно в сети
имеется лишь часть уровней. Так, в простых (неразветвленных)
ЛВС отпадает необходимость в средствах сетевого и транспортно-
го уровней.
Передача данных через разветвленные сети происходит при ис-
пользовании инкапсуляции/декапсуляции порций данных (рис. 8.34).
Уровни
модели Содержимое пакета
Порядок передачи
Рис. 8.34. Схема инкапсуляции передаваемого пакета
447
Так, сообщение, пришедшее на транспортный уровень, делится
на сегменты, которые получают заголовки и передаются на сетевой
уровень. На сетевом уровне сегмент может быть разделен на части
(пакеты), если сеть не поддерживает передачу сегментов целиком.
Пакет снабжается своим сетевым заголовком (т. е. происходит ин-
капсуляция сегментов в пакеты). При передаче между узлами про-
межуточной ЛВС может потребоваться разделение пакетов на кад-
ры (т. е. инкапсуляция пакетов в кадры). В приемном узле сегменты
декапсулируются и восстанавливается исходное сообщение.
Стандарты IEEE Project 802, разработанные Институтом инже-
неров по электротехнике и электронике 802.3, 802.4, 802.5, 802.12
прямо относятся к подуровню МАС второго (канального) уровня
эталонной модели OSI. Остальные 802-спецификации решают об-
щие вопросы сетей:
802.1 — объединение сетей;
802.2 — управление логической связью;
802.3 — локальная сеть с методом доступа CSMA/CD и топо-
логией «шина» (Ethernet);
802.4 — локальная сеть с топологией «шина» и маркерным
доступом;
* 802.5 — локальная сеть с топологией «кольцо» и маркерным
доступом;
802.6 — городская сеть (Metropolitan Area Network, MAN);
802.7 — широковещательная технология;
802.8 — оптоволоконная технология;
802.9 — интегрированные сети с возможностью передачи
речи и данных;
802.10 — безопасность сетей;
• 802.11 — беспроводная сеть;
802.12 — локальная сеть с централизованным управлением
доступом по приоритетам запросов и топологией «звезда».
Унификация и стандартизация протоколов выполняются рядом
международных организаций, что наряду с разнообразием типов
сетей породило большое число различных протоколов. Наиболее
широко распространенными являются протоколы, разработанные
для сети ARPANET и применяемые в глобальной сети Интернет,
протоколы открытых систем Международной организации по стан-
дартизации (ISO — International Standard Organization), протоколы
Международного телекоммуникационного союза (International
Telecommunication Union — ITU, ранее называвшегося CCITT) и
протоколы Института инженеров по электротехнике и электрони-
ке (IEEE — Institute of Electrical and Electronics Engineers).
448
Существует несколько стандартных наборов (называемых сте-
ками) протоколов, получивших сейчас наиболее широкое распро-
странение (табл. 8.2) [27]:
набор протоколов ISO/OSI;
IBM System Network Architecture (SNA);
Digital DECnet;
Novell NetWare;
набор протоколов глобальной сети Интернет, TCP/IP.
Таблица 8.2
Соответствие основных стеков протоколов модели ISO/OSI
Номер уровня Уровень модели OSI Стек протоколов
IBM/Microsoft TCP/IP Novell ISO/OSI
7 Прикладной SMB Telnet, FTP, SNMP, SMTP, WWW NCP, SAP X.400, X.500, FTAM
6 Представления SMB Telnet, FTP, SNMP, SMTP, WWW NCP, SAP Протокол представления OSI
5 Сеансовый NetBIOS TCP NCP, SAP Сеансовый протокол OSI
4 Транспортный NetBIOS TCP SPX Транспортный протокол OSI
3 Сетевой IP, RIP, OSPF IPX, RIP, NLSP ES-ES, IS-IS
2 Канальный Ethernet, Token Ring, FDDI, Fast Ethernet, SLIP, 100VG- AnyLAN, X.25,ATM, LAP-B, LAP-D, PPP Ethernet, Token Ring, FDDI, Fast Ethernet, SLIP, 100VG- AnyLAN, X.25, ATM, LAP-B, LAP-D, PPP Ethernet, Token Ring, FDDI, Fast Ethernet, SLIP, 100VG- AnyLAN, X.25, ATM, LAP-B, LAP-D, PPP Ethernet, Token Ring, FDDI, Fast Ethernet, SLIP lOOVG-AnyLAN, X.25, ATM, LAP-B, LAP-D, PPP
1 Физический Медный кабель, оптическое волокно
29 А-210
449
Стек коммуникационных протоколов — иерархически организо-
ванный набор протоколов, достаточный для организации взаимодей-
ствия узлов в сети.
Стек протоколов ISO/OSI. Стандартизация сетевых коммуни-
кационных протоколов — одно из важнейших направлений в об-
ласти вычислительных и телекоммуникационных сетей. Среди
большого количества стеков коммуникационных протоколов наи-
более распространенными являются стеки протоколов TCP/IP и
OSI. В большинстве из них на нижних уровнях модели OSI — фи-
зическом и канальном — используют одни и те же хорошо стан-
дартизованные протоколы Ethernet, Х.25, ATM и некоторые дру-
гие, которые позволяют применять в различных сетях один и тот
же тип аппаратуры. В противоположность этому на верхних уров-
нях модели OSI все стеки работают по своим протоколам, которые
часто не соответствуют рекомендуемому моделью ISO/OSI разби-
ению на уровни, в частности, функции уровня представления и
сеансового уровня и как правило, бывают объединены с приклад-
ным. Такое несоответствие связано с тем, что эталонная модель
OSI появилась как результат обобщения уже существующих и ре-
ально используемых стеков протоколов [27].
Следует различать эталонную модель OSI и стек протоколов
ISO/OSI. Модель определяет концептуально схему взаимодей-
ствия открытых систем, а стек представляет собой набор вполне
конкретных спецификаций протоколов. В отличие от других стек
ISO/OSI полностью соответствует модели OSI и включает в себя
спецификации протоколов для всех семи уровней ее взаимодей-
ствия.
На нижних уровнях стек ISO/OSI использует разработанные
вне стека протоколы нижних уровней модели OSI и поддерживает
протоколы Ethernet, Token Ring, FDDI, протоколы глобальных се-
тей Х.25, ATM, ISDN и др. Протоколы сетевого, транспортного и
сеансового уровней стека ISO/OSI специфицированы и реализо-
ваны различными производителями, но распространены пока мало.
Наиболее распространенными являются прикладные протоколы
стека ISO/OSI, к которым относятся протоколы передачи файлов
РТАМ, эмуляции терминала VTP, справочной службы Х.500, элек-
тронной почты Х.400 и др.
450
Протоколы стека ISO/OSI отличаются большой сложностью и
неоднозначностью спецификаций из-за их высокой универсаль-
ности применительно ко всем существующим и вновь появляю-
щимся сетевым технологиям. Из-за сложности они требуют боль-
ших затрат вычислительной мощности центрального процессора
и являются подходящими для рабочих станций, а не для сетей пер-
сональных компьютеров.
Стек протоколов ISO/OSI — это международный стандарт, не
зависимый от различных производителей сетевого оборудования.
Он популярнее в Европе, чем в США, так как там почти не оста-
лось старых сетей, работающих по собственным протоколам.
Стек протоколов TCP/IP был разработан по инициативе Мини-
стерства обороны США более 20 лет назад для связи эксперимен-
тальной сети ARPAnet с другими сетями как набор общих протоко-
лов для разнородной вычислительной среды. Этот стек используют
для связи компьютеров всемирной информационной сети Интер-
нет, а также в огромном числе корпоративных сетей. На нижнем
уровне стек поддерживает все распространенные стандарты физи-
ческого и канального уровней: для локальных сетей — это Ethernet,
Token Ring, FDDI, для глобальных сетей — протоколы работы на
аналоговых коммутируемых и выделенных линиях SLIP, PPP, про-
токолы сетей Х.25 и ISDN, ATM [27].
Основными протоколами стека, давшими ему название, явля-
ются IP и TCP, которые в терминологии модели ISO/OSI относят-
ся к сетевому и транспортному уровням соответственно. Прото-
кол IP передает пакеты по составной сети, а протокол TCP гаран-
тирует надежность их доставки.
Стек протоколов TCP/IP вобрал в себя большое число протоко-
лов прикладного уровня. К ним относятся такие, как протокол пе-
ресылки файлов FTP, протокол эмуляции терминала Telnet, почто-
вый протокол SMTP, используемый в электронной почте сети Ин-
тернет, гипертекстовые сервисы службы WWW и др. В настоящее
время стек протоколов TCP/IP — один из самых распространен-
ных стеков транспортных протоколов в вычислительных локаль-
ных и глобальных, а также магистральных телекоммуникационных
сетях. В сети Интернет объединено уже свыше 10 миллионов ком-
пьютеров по всему миру, которые взаимодействуют друг с другом
с помощью стека протоколов TCP/IP.
Стремительный рост популярности Интернета привел к тому,
что протоколы TCP/IP в значительной мере вытесняют стек про-
451
токолов IPX/SPX компании Novell, необходимый для доступа
к файловым серверам NetWare. Процесс становления стека про-
токолов TCP/IP в качестве стека номер один в любых сетях про-
должается, и сейчас любая промышленная операционная система
обязательно включает программную реализацию этого стека. На-
ряду с этим существует большое количество локальных, корпора-
тивных и территориальных сетей, непосредственно не являющихся
частями Интернета, в которых также используют протоколы ТСР/
IP. Чтобы отличать их от сети Интернет, эти сети называют сетя-
ми TCP/IP, или просто IP-сетями.
Протокол IP (Internet Protocol) работает на сетевом уровне. Это
дейтаграммный протокол, не ориентированный на установление
соединения. Пакеты IP называются также дейтаграммами IP.
В протоколе IP используется коммутация пакетов, а выбор марш-
рутов выполняется с помощью динамических таблиц маршрути-
зации, которые анализируются при прохождении каждого марш-
рутизатора. Пакеты, составляющие сообщение, можно маршрути-
зировать в интерсети в зависимости от состояния каждого сетево-
го сегмента. Например, если канал отключен или перегружен, то
пакеты направляются по другому маршруту.
К каждому пакету добавляется заголовок IP, включающий ин-
формацию об источнике и получателе. Если в сети возникает не-
обходимость разделить пакеты на части и собрать их при поступ-
лении к получателю или в промежуточной точке, то в IP применя-
ют последовательную нумерацию. Протокол IP контролирует
ошибки, анализируя контрольную сумму в заголовке.
Протокол TCP (Transmission Control Protocol) — протокол уп-
равления передачей относится к транспортному уровню стека
TCP/IP протоколов Интернета. Он обеспечивает адресацию служб
на сетевом уровне с помощью сервиса, а для протоколов высокого
уровня надежный дуплексный транспортный сервис, ориентиро-
ванный на установление соединения. Работает он совместно с про-
токолом IP и обеспечивает передачу пакетов в интерсети. Каждо-
му виртуальному каналу TCP присваивает идентификатор соеди-
нения (порт). Данный протокол предусматривает фрагментацию
сообщения и его сборку с помощью последовательной нумерации
фрагментов. Благодаря использованию подтверждений с помощью
протокола TCP лучше контролируются ошибки.
Протоколы стека TCP/IP верхнего уровня обычно реализуют при-
ложения или службы для работы в Интернете, например передачу
452
файлов или электронную почту. Протокол FTP (File Transfer Protocol)
применяется для передачи файлов между узлами интерсети. Кроме
этого, он позволяет пользователям взаимодействовать с удаленной
системой. Этот протокол работает на трех верхних уровнях модели
OSI. На сеансовом уровне он администрирует сеанс, устанавливает
соединение, передает файлы и закрывает соединение. На уровне
представления выполняет трансляцию файлов, на прикладном уров-
не предлагает сетевые службы, а именно, файловые и средства кол-
лективной работы. Протокол FTP одноранговый, позволяет переда-
вать файлы между разнородными узлами, поскольку использует об-
щую файловую структуру, не зависимую от операционных систем.
Протокол Telnet используют для эмуляции удаленных термина-
лов. Эта служба позволяет пользователям обращаться к приложени-
ям удаленной системы путем эмуляции одного из ее терминалов. Он
поддерживает соединение между различными операционными сис-
темами, работает на верхних трех уровнях модели OSI, а на сеансо-
вом уровне обеспечивает управление диалогом, используя полудуп-
лексный метод а на уровне представления он выполняет трансляцию,
используя последовательность байтов и коды символов. На приклад-
ном уровне предлагает функции поддержки удаленных операций.
Протокол SMTP (Simple Mail Transfer Protocol) — упрощенный
протокол электронной почты маршрутизирует почтовые сообще-
ния. Он работает на прикладном уровне и обеспечивает средства
обмена сообщениями. SMTP не предусматривает пользовательс-
кого интерфейса для приема и передачи сообщений, однако его
поддерживают многие приложения электронной почты Интернет.
Для передачи почтовых сообщений в интерсети SMTP использует
протоколы TCP и IP [27].
Поскольку стек TCP/IP изначально создавался для глобальной
сети Интернет, он имеет ряд преимуществ перед другими стеками,
когда речь заходит о построении сетей, включающих глобальные
связи. В частности, очень полезной является его способность фраг-
ментировать пакеты, что оказывается весьма привлекательным для
его применения в больших сетях, построенных по совершенно раз-
ным принципам. В каждой из таких сетей можно задать собствен-
ное значение максимальной длины единицы передаваемых данных
(кадра). В таком случае при переходе из одной сети, имеющей боль-
шую максимальную длину кадра, в сеть с меньшей возникает необ-
ходимость деления передаваемого кадра на несколько частей, что
весьма эффективно и обеспечивает протокол IP стека TCP/IP.
453
Другой особенностью технологии TCP/IP является гибкая сис-
тема адресации, позволяющая более просто по сравнению с дру-
гими включать в интерсеть сети других технологий. Это также спо-
собствует применению стека TCP/IP для построения больших ге-
терогенных сетей. В нем очень экономно используются возмож-
ности широковещательных рассылок. Это свойство крайне необ-
ходимо при работе на низкоскоростных каналах связи, которые
характерны для территориальных сетей.
Преимущества, которые дает стек протоколов TCP/IP для по-
строения сетей, неразрывно связаны с высокими требованиями,
предъявляемыми к ресурсам, и сложностью администрирования
IP-сетей. Мощные функциональные возможности протоколов сте-
ка TCP/IP требуют для своей реализации больших вычислитель-
ных ресурсов и затрат. Реализация гибкой системы адресации и
отказ от широковещательных рассылок приводят к наличию в IP-
сети различных централизованных служб типа DNS, DHCP и т. п.
Каждая из этих служб предназначена для облегчения админист-
рирования сети, включая конфигурирование сетевого оборудова-
ния.
Многочисленные преимущества Интернета сделали этот стек
широко используемым как в глобальных, так и в локальных сетях.
Стек протоколов IPX/SPX. Этот стек компании Novell разра-
ботан для сетевой операционной системы NetWare еще в начале
80-х годов. Протоколы сетевого и сеансового уровней Internetwork
Packet Exchange (IPX) и Sequenced Packet Exchange (SPX), кото-
рые дали название стеку. Популярность стека IPX/SPX связана
с популярностью операционной системы Novell NetWare [27].
Многие особенности стека IPX/SPX обусловлены ориентацией
ОС NetWare ранних версий на работу в локальных сетях неболь-
ших размеров, состоящих из персональных компьютеров со скром-
ными ресурсами, из-за чего протоколы стека IPX/SPX хорошо ра-
ботали в локальных и не очень хорошо в больших корпоративных
сетях, так как последние слишком перегружали медленные гло-
бальные связи широковещательными пакетами, которые интен-
сивно используются несколькими протоколами этого стека (напри-
мер, для установления связи между клиентами и серверами). Од-
нако с момента выпуска ОС версии NetWare 4.0 компания Novell
внесла и продолжает вносить в свои протоколы серьезные изме-
нения, направленные на их адаптацию для работы в больших кор-
поративных сетях. Сейчас стек протоколов IPX/ SPX реализован
454
не только в NetWare, но и в некоторых других популярных сете-
вых ОС, например SCO UNIX, Sun Solaris, MicrosoftWindows NT.
Стек протоколов NetBIOS/SMB широко используется в продук-
тах компаний IBM и Microsoft. На физическом и канальном уров-
нях в качестве протоколов этого стека применяются наиболее рас-
пространенные протоколы Ethernet, Token Ring, FDDI, NetBEUI и
SMB (верхние уровни) и др. [27].
Протокол этого стека NetBIOS (Network Basic Input/Output
System) появился в 1984 г. как расширение стандартных функ-
ций базовой системы ввода-вывода (BIOS) IBM PC для сетевой
программы PC Network компании IBM. В дальнейшем этот про-
токол был заменен протоколом расширенного пользовательско-
го интерфейса NetBEUI — NetBIOS Extended User Interface. Для
обеспечения совместимости приложений в качестве интерфей-
са к протоколу NetBEUI был сохранен интерфейс NetBIOS. Про-
токол NetBEUI разрабатывался как эффективный, потребляющий
немного ресурсов и предназначенный для сетей, насчитывающих
не более 200 рабочих станций. Этот протокол содержит много
полезных сетевых функций, которые можно отнести к сетевому,
транспортному и сеансовому уровням модели OSI, однако с его
помощью невозможна маршрутизация пакетов. Это ограничива-
ет его применение локальными сетями, не разделенными на под-
сети, и делает невозможным использование его в составных се-
тях. Некоторые ограничения NetBEUI снимаются реализацией
этого протокола NBF (NetBEUI Frame), которая включена в ОС
Microsoft Windows NT.
Протокол SMB (Server Message Block) выполняет функции уров-
ней представления и прикладного. На основе SMB реализуется
файловая служба, а также службы печати и передачи сообщений
между приложениями.
Стеки протоколов SNA компании IBM, DECnet корпорации
Digital Equipment и Apple-Talk/AFP компании Apple применяются
в основном в ОС и сетевом оборудовании этих компаний.
В табл. 8.2 показано соответствие некоторых, наиболее распро-
страненных стеков протоколов уровням модели OSI. Зачастую это
соответствие весьма условно, так как модель OSI — это только кон-
цептуальное руководство по взаимодействию систем, причем дос-
таточно общее. Конкретные протоколы различных сетевых техно-
логий разрабатывались для решения специфических задач, при-
455
чем многие из них появились до разработки модели OSI. Разра-
ботчики стеков отдавали предпочтение быстроте работы сети
в ущерб модульности, поэтому ни один стек, кроме ISO/OSI, не
разбит на семь уровней. Чаще всего в стеках протоколов явно
выделяются 3—4 уровня: уровень сетевых адаптеров, в котором
реализуются протоколы уровней физического и канального, се-
тевой уровень, транспортный и уровень служб, включающий
в себя функции сеансового уровня, уровня представления и при-
кладного. Важнейшим направлением стандартизации в области
сетевых технологий является стандартизация коммуникацион-
ных протоколов.
8.4.5. Методы доступа к среде передачи данных
Методы доступа регламентируют процедуры получения абонен-
тами доступа к среде передачи данных. Необходимость такой рег-
ламентации вызвана тем, что при одновременной передаче данных
несколькими абонентами возникает конфликтная ситуация — на-
ложение и взаимное искажение информации.
Управление доступом к среде — установление последовательности,
в которой узлы получают полномочия по доступу к среде передачи данных.
Под полномочием понимается право инициировать определенные
действия, динамически предоставляемые объекту, например станции
данных в информационной сети.
Методы доступа к среде передачи данных могут быть случай-
ными и детерминированными. Основным используемым методом
случайного доступа является метод множественного доступа с кон-
тролем несущей и обнаружением конфликтов CSMA/CD — Carrier
Sense Multiple Access / Collision Detection. Этот метод основан на
контроле несущей в линии передачи данных (на слежении за на-
личием в линии электрических колебаний) и устранении конфлик-
тов, возникающих из-за попыток одновременного начала переда-
чи двумя или более станциями. Устранение осуществляется путем
прекращения передачи конфликтующими узлами и повторением
попыток захвата линии каждым из этих узлов через случайный
отрезок времени.
Все узлы имеют равные права по доступу к сети. Узлы, имеющие
данные для передачи по сети, контролируют состояние линии пе-
456
редачи данных. Если линия свободна, то в ней отсутствуют электри-
ческие колебания. Узел, желающий начать передачу, обнаружив
в некоторый момент времени t( отсутствие колебаний, захватывает
свободную линию, т. е. получает полномочия по использованию ли-
нии. Любая другая станция, желающая начать передачу в момент
времени t2> t; при обнаружении электрических колебаний в линии,
откладывает передачу до момента t + td, где td — задержка.
В зависимости от загрузки сети могут применяться различные
варианты доступа CSMA/CD. Так при слабой загрузке сети попыт-
ка захвата канала может происходить сразу после его освобожде-
ния. При заметной загрузке сети велика вероятность того, что не-
сколько станций будут претендовать на доступ к среде сразу пос-
ле ее освобождения, и, следовательно, конфликты станут часты-
ми. Поэтому обычно используют вариант CSMA/CD, в котором
задержка td является случайной величиной.
При работе сети каждая станция анализирует адресную часть
передаваемых по сети кадров с целью обнаружения и приема кад-
ров, предназначенных для нее.
Параметром, характеризующим конфликты (столкновения)
в сети, является «окно столкновений» — интервал времени, необ-
ходимый для распространения сигналов по среде и обнаружения
его узлами сети. Например, если узлы в сети расположены на рас-
стоянии 1 км, то сигналу потребуется примерно 4,2 мкс, чтобы от
одного узла дойти до другого. Следовательно, в течение этого вре-
мени возможно возникновение конфликта, когда один узел уже
начал передачу, а другой узел «считает», что среда свободна. Это
одна из причин, ограничивающих длину кабеля в ЛВС на основе
метода CSMA/CD.
Метод CSMA/CD наиболее эффективен в условиях относитель-
но низкой загрузки среды (например, не более 30%). Если же в ЛВС
загрузка среды больше, то более эффективными будут детерми-
нированные методы доступа к среде, наиболее распространенны-
ми из которых являются маркерные методы доступа.
Маркерные методы основаны на передаче полномочий на пе-
редачу одному из узлов сети с помощью специального информа-
ционного объекта, называемого маркером.
Пусть, например, узлы сети А, В, С, D имеют однонаправленное
двухточечное подключение к среде через порты приема (R —
Reciever) и передачи (Т — Transmitter) (рис. 8.35).
457
A
С
Рис. 8.35. Структура физическогю кольца
На практике физическая кольцевая среда реализуется в виде
«звездно-кольцевой» топологии, когда узлы А, В, С, D соединяют-
ся через кабели с помощью специального концентратора сигна-
лов. Если один из узлов сети неисправен (например, узел С), то он
отключается от среды передачи данных так, как это схематически
показано на рис. 8.36.
Узлы в кольцевой среде играют активную роль. Во время пере-
дачи внутри узла сигналы могут анализироваться, усиливаться,
модифицироваться и т. д. Особенностью маркера является то, что
в нем отсутствует адресное поле. Маркер находится в одном из двух
состояний: занят или свободен. Если передача в кольце отсутству-
ет, то в каждый момент времени в нем циркулирует один свобод-
ный маркер (рис. 8.37 а). В момент прихода маркера передающий
узел меняет состояние маркера на занятое и присоединяет пакет
или фрейм (Frame) данных (рис. 8.37 б). Маркер с пакетом переда-
ется по кольцу. Теперь его состояние может изменить лишь узел,
передавший данные (рис. 8.37 в). Адрес принимающего узла нахо-
дится непосредственно в пакете. И этот узел копирует содержи-
мое пакета в рабочую станцию. Остальные узлы сети лишь рет-
ранслируют этот пакет.
458
Рис. 8.36. Звездно-кольцевая топология с передачей маркера
Рассмотрим более детально работу узлов сети. Каждом узлу
(и соответствующему устройству, например ПК, сетевом принтеру
и т. д.) с целью идентификации присвоен свой уникальный номер
(MAC address). Пакет, передаваемый в сети, содержит адреса как
передающего, так и принимающего узлов. Синхронизация переда-
чи данных в сети обеспечивается постоянной циркуляцией марке-
ра. Для того чтобы избежать ошибок при передаче данных, каждый
узел проверяет пакет. И если обнаружены какие-либо ошибки, то
проверяющий узел устанавливает специальный бит признака ошиб-
ки. Эта операция снижает загрузку активных узлов сети, так как
отмеченный пакет не обрабатывается другими узлами.
Рис. 8.37. Передача маркера (а) и пакета (б,в) в кольцевой сети
459
В процессе ретрансляции пакета каждый узел проверяет адре-
са источника и узла назначения и сравнивает его с собственным
адресом. Если собственный адрес совпадает с адресом назначения
и пакет не помечен как ошибочный, то узел копирует данные и
устанавливает в пакете специальные биты признаков: адрес рас-
познан (adress recognized, AR) и пакет скопирован (Frame copied,
FC). Если же в пакете содержатся ошибки, то узел не копирует
пакет, но устанавливает бит AR. Это позволяет проинформировать
передающий узел о том, что узел назначения присутствует в сети
и необходимо совершить повторную передачу.
Когда пакет достигает исходной точки и передающий находит
свой собственный адрес в поле «адрес источника» (Sourse addres,
SA), то пакет удаляется из сети. В процессе удаления анализиру-
ются биты AR и FC. Если бит FC не установлен, то узел пытается
сделать повторную передачу. Если же биты AR и FC установлены,
то в сеть регенерируется свободный маркер.
Протокол сети должен предусматривать восстановление мар-
кера в случае его потери при передаче и других сбоев в узлах.
Маркерный метод доступа используется и в сетях с шинной
архитектурой. В этом случае конфликт за доступ к среде исключа-
ется с помощью специального кадра (маркера), передаваемого
вдоль логического кольца узлов сети. Маркер содержит адрес узла
(MID). Причем каждому £-му узлу известен адрес (£+1)-го узла NID
(Next ID) (рис. 8.38). В обычном режиме работы сети основные со-
стояния узла: прослушивание, прием маркера, передача пакета и
передача маркера. В случае сбоя (например, потери маркера) или
реконфигурации сети (например, добавления узла) используются
состояния: бездействия и опроса.
Рис. 8.38. Логическое кольцо сети с шинной архитектурой
460
Так, если новый узел подключается к сети, то он сразу пере-
ходит в состояние сбоя. При этом в среду начинает передавать-
ся непрерывная сбойная последовательность (помехи). Помехи
приводят к потере маркера в среде и переходу к процедуре вос-
становления из состояния бездействия, в котором оказываются
все узлы сети, включая и новый. Узел с меньшим значением ID
возбуждается первым, поскольку время бездействия пропорци-
онально ID.
8=5. КОНТРОЛЬ ПЕРЕДАЧИ ИНФОРМАЦИИ
8.5.1. Методы повышения верности передачи информации
В системах передачи информации из-за воздействия различных
факторов (в первую очередь помех, действующих в канале связи)
прием сообщений происходит с ошибками, т. е. вместо, например,
символа «1» принимается символ «О», и наоборот. В то же время
к современным системам передачи данных предъявляются высокие
требования по верности передачи информации. Так, стандартами
международных организаций МККТТ и МОС установлено, что ве-
роятность ошибки при передаче данных не должна превышать 10'6 * В
на единичный элемент. Это означает, что не должно быть принято
более одного ошибочного символа на 106 двоичных элементов. На
практике допустимая вероятность ошибки при передаче данных
может быть еще меньше — 109. Для достижения требуемой вернос-
ти передачи информации применяют специальные методы, осно-
ванные на введении избыточности в передаваемый сигнал [9].
В общем случае увеличить избыточность или объем передавае-
мого сигнала можно за счет увеличения Р, ДГили Т ^объема сигна-
ла V—P AFT). Поскольку практические возможности увеличения
избыточности за счет мощности и ширины спектра сигнала в сис-
темах передачи дискретной информации по стандартным каналам
резко ограничены, то основное развитие получили методы повы-
шения верности приема, основанные на увеличении времени пе-
редачи. Эти методы реализуются системами без обратной связи и
системами с обратной связью. В системах без обратной связи (од-
нонаправленных системах) для повышения верности приема ис-
пользуются следующие основные способы:
1) многократная передача кодовых комбинаций;
461
2) одновременная передача кодовой комбинации по нескольким
параллельно работающим каналам;
3) использование корректирующих кодов, т. е. кодов, исправ-
ляющих ошибки.
Многократное повторение кодовой комбинации является са-
мым простым способом повышения достоверности и легко реали-
зуется, особенно в низкоскоростных системах передачи инфор-
мации. В этом случае за истинный сигнал принимают тот, кото-
рый большее количество раз появлялся в многократно повторен-
ной последовательности сигналов. Так, если при пятикратном по-
вторении символа «1» получена последовательность 11010, то при-
нимается решение в пользу символа «1». Существенным недостат-
ком такого способа является большое увеличение времени пере-
дачи и, следовательно, такое же уменьшение скорости. Если кодо-
вая комбинация повторяется п раз, то скорость снижается в п раз.
В то же время при оптимальном приеме повторение есть увели-
чение времени накопления сигнала, что, естественно, приводит
к лучшему усреднению флуктуационного шума канала связи.
Способ передачи одной и той же информации по нескольким
параллельным каналам связи аналогичен способу многократного
повторения. При приеме может быть использован мажоритарный
принцип (голосование). В этом случае необходимо иметь не менее
трех каналов связи, которые нужно выбирать таким образом, что-
бы ошибки в них были независимы. При двух параллельно работа-
ющих каналах в передаваемую информацию можно вводить из-
быточность, позволяющую обнаруживать ошибки. При обнаруже-
нии ошибки в одном канале информация может браться из друго-
го канала.
Более эффективным способом повышения верности приема
является использование корректирующих кодов, исправляющих
ошибки. При этом в кодовые комбинации вводится постоянная,
заранее рассчитанная избыточность (дополнительные элементы,
сформированные по известным правилам). Структура кода и его
исправляющие возможности рассчитываются для некоторого иде-
ализированного канала с известной статистикой ошибок. Однако
свойства реального канала непостоянны и могут резко отличаться
от выбранной модели. При этом могут быть ситуации, когда ошиб-
ки в канале отсутствуют и дополнительные избыточные разряды
вообще не нужны, а также ситуации, когда введенной избыточ-
ности оказывается недостаточно для исправления всех ошибок.
462
В этом случае повысить верность передачи без существенного сни-
жения пропускной способности можно, вводя переменную избы-
точность в сообщение в зависимости от состояния канала. Такие
системы являются адаптивными, т. е. приспосабливающимися к ус-
ловиям канала. Для их построения нужно уметь оценивать на при-
еме статистику ошибок в канале и передавать эти данные на пере-
дающую станцию. Таким образом, необходимо иметь дополнитель-
ный обратный канал от приемника к передающей станции и поэто-
му вся система связи оказывается системой с обратной связью.
Системы передачи данных с обратной связью делятся на три
большие группы: системы с решающей обратной связью (РОС),
системы с информационной обратной связью (ИОС) и системы
с комбинированной обратной связью (КОС). Характерной особен-
ностью используемых на практике подобных систем является по-
вторение переданной кодовой комбинации в случае обнаружения
ошибки [9].
В системах с РОС передаваемое сообщение кодируется обна-
руживающим ошибки кодом, на приемной стороне проверяется
наличие искажений в кодовой комбинации. Если ошибки обнару-
жены, то по обратному каналу посылается сигнал переспроса. По-
лучая этот сигнал, передатчик повторяет переданную комбинацию.
В случае отсутствия сигнала «переспрос» по обратному каналу
можно передавать полезную информацию в сторону передающей
станции.
В системах с ИОС решение о наличии ошибок (или ее отсут-
ствии) принимает передающая станция. Приемник по обратному
каналу передает либо принятую кодовую комбинацию, либо спе-
циальные сигналы, имеющие меньший объем, чем информацион-
ные, но характеризующие качество приема принятой полезной
информации. Эти сведения называются квитанциями. Таким об-
разом, в системах с ИОС по обратному каналу передается либо вся
полезная информация, либо информация о ее отличительных при-
знаках. Решение о правильности принятой комбинации принима-
ет передающая станция. Таким образом, специальное кодирова-
ние сообщений для обнаружения ошибок в системах с ИОС мож-
но не использовать, а переданные и принятые по каналу обратной
связи сообщения может сравнивать, например, оператор.
Системы с КОС представляют собой сочетание информацион-
ной и решающей обратных связей. В таких системах решение
о выдаче информации абоненту или о повторной передаче может
463
приниматься и в приемнике, и в передатчике, а канал обратной
связи может использоваться для передачи как квитанций, так и
решений о неправильно принятой кодовой комбинации. Системы
с КОС обладают высокой помехоустойчивостью.
В общем случае во всех системах с ОС для повышения вернос-
ти приема обычно используются корректирующие коды.
8.5.2. Принципы помехоустойчивого кодирования
В обычном равномерном коде число разрядов в кодовых ком-
бинациях определяется числом сообщений и основанием кода. Так,
если необходимо передать 32 буквы алфавита двоичным кодом, то
необходимая длина кодовой комбинации (число разрядов) опре-
деляется как п — 1од232 = 5. Любая из пятиэлементных кодовых ком-
бинаций представляет собой какой-то знак алфавита. Если в про-
цессе передачи такой кодовой комбинации произойдет одна ошиб-
ка, то принятая кодовая комбинация будет интерпретироваться
приемником как кодовая комбинация, соответствующая другому
знаку. Например, последняя буква алфавита «я» (11111) при иска-
жении 1-го разряда с 1 на 0 будет «прочитана» как буква «ю»
(11110). Таким образом, возникающие в кодовых комбинациях
ошибки обнаружить невозможно, поскольку нельзя отличить оши-
бочную комбинацию от безошибочной. Все 32 кодовые комбина-
ции разрешены, и возникающие ошибки просто переводят одну
разрешенную комбинацию в другую, также разрешенную. Обна-
ружить ошибку в данном случае может только получатель, прочтя
принятое текстовое сообщение. За счет огромной языковой и
смысловой избыточности текста можно легко восстановить пере-
данное сообщение. Это является одной из причин, по которым на
телеграфной сети общего пользования не применяется помехоус-
тойчивое кодирование, так как в данном случае «оптимальным»
декодером является сам получатель телеграммы [9].
Идея помехоустойчивого кодирования состоит в том, что в пе-
редаваемую кодовую комбинацию по определенным правилам
вносится избыточность (признаки разрешенной комбинации).
Правила внесения избыточности, т. е. признаки, должны быть из-
вестны как на передающей, так и на приемной стороне. Если на
приемной стороне эти признаки в кодовой комбинации не обна-
руживаются, то считается, что произошла ошибка (или ошибки).
В противном случае (при наличии признаков) считается, что кодо-
464
вая комбинация принята правильно (является разрешенной). Вне-
сение избыточности при использовании помехоустойчивых (кор-
ректирующих кодов обязательно связано с увеличением числа
разрядов (длины) кодовой комбинации — п. При этом все множе-
ство N0=2n комбинаций можно разбить на два подмножества: под-
множество разрешенных комбинаций, т. е. обладающих опреде-
ленными признаками, и подмножество запрещенных комбинаций,
этими признаками не обладающих. Корректирующий код отлича-
ется от обычного тем, что в канал передаются не все кодовые ком-
бинации (n0), которые можно сформировать из имеющегося числа
разрядов п, а только их часть N, которая составляет подмножество
разрешенных комбинаций: N<N0 [9].
Если в результате искажений переданная кодовая комбинация
переходит в подмножество запрещенных кодовых комбинаций, то
ошибка будет обнаружена. Однако если совокупность ошибок
в данной кодовой комбинации превращает ее в какую-либо другую
разрешенную, то в этом случае ошибки не могут быть обнаружены.
Поскольку любая из N разрешенных комбинаций может превра-
титься в любую из ^возможных, то общее число таких случаев рав-
но N Ng. Очевидно, что число случаев, в которых ошибки обнаружи-
ваются, равно N(N0~ N), где No~ N — число запрещенных комбина-
ций. Тогда доля обнаруживаемых ошибочных комбинаций составит:
N(N0-N) , N
77 = “7”' (8.27)
ХЛ0 No
Например, если N,==100, N=20, то ошибка обнаруживается в
80% случаев. Аналогичное рассуждение можно провести и для
случая исправления ошибок, если рассматривать код, исправля-
ющий ошибки. При использовании этого кода нужно произвес-
ти разбиение множества {Bj} (j= 1, 2, ..., Ng—N) всех запрещенных
комбинаций на N непересекающихся подмножеств {Мк}. Каждое
из подмножеств {Мк} приписывается одной из передаваемых ко-
довых комбинаций Ак. Способ приема состоит в том, что если
принята комбинация В. е Мк, то считается, что передана Ак т. е.:
если принятая кодовая комбинация осталась в том же подмноже-
стве, что и переданная, то принимается решение о приеме ком-
бинации Ак (рис. 8.39). На рис. 8.39 приняты следующие обозна-
чения: Ar..AN — множество разрешенных (передаваемых ком-
30 А-210
465
Рис. 8.39. Принцип
исправления ошибок
помехоустойчивым кодом
бинаций); Br.. BNoN — множество
всех возможных запрещенных ком-
бинаций, в которые в результате
различных ошибок могут перейти
комбинации {Ак}, Mt, М2 MN —
подмножества, на которые разбиты
запрещенные комбинации. Способ
приема состоит в том, что если при-
нимается кодовая комбинация (В , В2
или В3, принадлежащая подмноже-
ству Mt), то считается, что передава-
лась комбинация А, (показано на ри-
сунке стрелками). Если действитель-
но комбинация Bt (или В2, В3) обра-
зовалась из At, то ошибка исправле-
на. Если принятая кодовая комбина-
ция переходит в другое подмноже-
ство М? то декодер примет ошибоч-
ное решение о передаче комбина-
ции Ат Очевидно, что, каким бы образом ни разбивалось множе-
ство {В^ на подмножества fMK/, ошибка всегда исправляется в No—N
случаях. Способ разбиения на подмножества зависит от того, ка-
кие ошибки должны исправляться данным конкретным кодом.
Большинство разработанных до настоящего времени кодов
предназначено для корректирования взаимно независимых оши-
бок определенной кратности и пачек (пакетов) ошибок.
Кратностью ошибки называется количество искаженных символов
в кодовой комбинации.
При взаимно независимых ошибках вероятность искажения
любых г символов в n-разрядной кодовой комбинации составит [8]:
Рг = с£Рг(1- рГ-
Если учесть, что р«1, то в этом случае наиболее вероятны
ошибки низшей кратности, которые и должны быть обнаруже-
ны и исправлены в первую очередь. Кроме того, при взаимно
независимых ошибках наиболее вероятен переход в кодовую
466
комбинацию, отличающуюся от данной в наименьшем числе
символов.
Степень отличия любых двух кодовых комбинаций характери-
зуется кодовым расстоянием (расстоянием Хэмминга). Оно выра-
жается числом символов, в которых комбинации отличаются одна
от другой, и обозначается через d.
Чтобы получить кодовое расстояние между двумя комбинаци-
ями двоичного кода, достаточно подсчитать число единиц в сумме
этих комбинаций по модулю 2. Например:
а-Л001111101
^1100001010
0101110111 , d = 7.
Минимальное расстояние, взятое по всем парам кодовых раз-
решенных комбинаций кода, называют минимальным кодовым рас-
стоянием.
Декодирование после приема может производиться таким об-
разом, что принятая кодовая комбинация отождествляется с той
разрешенной, которая находится от нее на наименьшем кодовом
расстоянии. Такое декодирование называется декодированием по
методу максимального правдоподобия [8].
Очевидно, что при минимальном кодовом расстоянии d = 1 все
кодовые комбинации являются разрешенными.
Например, при п = 3 разрешенные комбинации образуют сле-
дующее множество: 000, 001,010,011, 100, 101, 110, 111.
Любая одиночная ошибка трансформирует данную комбина-
цию в другую разрешенную комбинацию. Это случай безызбыточ-
ного кода, не обладающего корректирующей способностью.
Если d = 2, то ни одна из разрешенных кодовых комбинаций
при одиночной ошибке не переходит в другую разрешенную ком-
бинацию. Например, подмножество разрешенных кодовых ком-
бинаций для п=3 может быть образовано по принципу четности
в них числа единиц:
000, 011, 101, ПО — разрешенные комбинации;
001, 010, 100, 111 — запрещенные комбинации.
Данный код обнаруживает одиночные ошибки, а также другие
ошибки нечетной кратности (при п = 3 тройные). В общем случае
при необходимости обнаруживать ошибки кратности до го вклю-
чительно должно выполняться условие:
d > r0 +1 .
467
Действительно, одновременная ошибка в го разрядах кода со-
здает новую кодовую комбинацию, отстоящую от первой на рас-
стоянии го. Чтобы она не совпала с какой-либо другой разрешен-
ной кодовой комбинацией, минимальное расстояние между дву-
мя разрешенными кодовыми комбинациями должно быть хотя бы
на единицу больше, чем г.
Для исправления ги-кратной ошибки необходимо, чтобы новая
кодовая комбинация, полученная в результате такой ошибки, не
только не совпадала с какой-либо разрешенной комбинацией, но
и оставалась ближе к правильной комбинации, чем к любой дру-
гой разрешенной. То есть должно выполняться соотношение [8]:
Учитывая, что ги и d целые числа, получаем:
d>2ru+\.
Так, для исправления одиночной ошибки расстояние Хэмминга
между разрешенными кодовыми комбинациями должно быть не
менее трех. При п = 3 за разрешенные комбинации можно, напри-
мер, принять ООО или 111. Тогда разрешенной комбинации ООО не-
обходимо сопоставить подмножество запрещенных кодовых ком-
бинаций 001, 010, 100, образующихся в результате возникновения
единичной ошибки в комбинации 000. Подобным же образом раз-
решенной комбинации 111 необходимо сопоставить подмножество
запрещенных кодовых комбинаций: 110, 011, 101, образующихся
в результате возникновения единичной ошибки в комбинации 111:
00Г
010
Разрешенные Г000^ 100 Запрещенные
комбинации ] 11 к 011 |комбинации
Xoi
110,
Таким образом, при п = 3 имеем Ng — 23 = 8 кодовых комбина-
ций, из которых только две N = 2 разрешенных. С использовани-
ем данного трехразрядного кода можно передать только два раз-
личных сообщения. Для передачи двух сообщений обычным непо-
мехоустойчивым способом достаточно было бы одноразрядных
комбинаций «0» и «1». То есть обеспечение возможности исправ-
468
ления одиночной ошибки в нашем случае связано с увеличением
длины кода на к = 2 разряда.
Величину w, равную отношению числа дополнительных провероч-
ных разрядов кода (к) к разрядности кода (п) называют избыточностью
корректирующего кода:
iv = к/п=(п—т)/п=1 — т/п, где т — число информационных симво-
лов корректирующего кода.
Величина m/n = 1 -wпоказывает, какую часть общего числа симво-
лов кодовой комбинации составляют информационные символы. Она
характеризует относительную скорость передачи. Так, если произ-
водительность источника информации равна R символов в секунду,
то скорость передачи после кодирования этой информации будет:
, т
R = R —,
п
поскольку в закодированной последовательности из каждых п сим-
волов только т символов являются информационными.
При построении корректирующих кодов возникает задача на-
хождения наибольшего числа N кодовых комбинаций п-значного
двоичного кода, расстояние между которыми не менее d. Общее
решение этой задачи неизвестно. Некоторые частные результаты
приведены в табл. 8.3.
Таблица 8.3
d N
1 2П
2 2я’1
3 2« 1 + и
4 < 2«-1 п
2/ + 1 < 2" “1 + С1+С2+...+ С'
469
Одними из первых математически обоснованных и практичес-
ки использованных корректирующих кодов были коды Хеммин-
га. В п. 7.1 рассмотрен принцип построения данных кодов для кон-
троля правильности работы запоминающих устройств. Коды Хем-
минга, представляющие собой просто совокупность перекрестных
проверок на четность/нечетность, являются одной из разновид-
ностей более широкого семейства корректирующих кодов — цик-
лических кодов.
8.5.3. Циклические коды
Основные свойства и само название циклических кодов связа-
ны с тем, что все разрешенные комбинации двоичных символов
в передаваемом сообщении могут быть получены путем операции
циклического сдвига некоторого исходного слова:
(«0 а! а2 ап-2 an-V
(а . а. а, a , a ,1
' п-1 0 1 п-3 n-2i
(ал-2 а , п-1 ао а„-4 ап-3‘
Обычно кодовые комбинации циклического кода рассматрива-
ют не в виде последовательности нолей и единиц, а в виде полино-
ма некоторой степени [9]. Любое число в любой позиционной сис-
теме счисления можно представить в общем виде как:
F(x) = an_tx"-1 + ап_2хп~2 +... + а^х + а0 ,
где х — основание системы счисления;
а — цифры данной системы счисления;
п—1, п—2, ... — показатель степени, в которую возводится ос-
нование, и одновременно порядковые номера, которые занимают
разряды. Для двоичной системы х=2, а а либо «О», либо «1». Напри-
мер, двоичную комбинацию 01001 можно записать в виде полино-
ма от аргумента х:
F(2) = 0«24 + l’23 + 0«22 + 0*24-l‘2°;
F(x)=0*x4 + 1«х3 + 0«х2 + 0*х-1-1*х0 = х3+1.
При записи кодовой комбинации в виде многочлена единица
в !-м разряде записывается членом х', а ноль вообще не записыва-
ется. Представление кодовых комбинаций в виде многочленов по-
зволяет установить однозначное соответствие между ними и свес-
ти действия над комбинациями к действию над многочленами. Так,
сложение двоичных многочленов сводится к сложению по моду-
лю 2 коэффициентов при равных степенях переменной.
470
Например,
х3 + х2 + 1
____________х + 1
X3 + X2 + X
1«х3 + х2 + 0*х + 1
О’х3 + 0*х2+ х + 1
х3 +х2 + х + О
Умножение производится по обычному правилу умножения
степенных функций, однако полученные коэффициенты при дан-
ной степени складываются по модулю 2. Например,
(х3+х2+0 + 1) (х+ 1) =х4+х3+0+х+х3+х2+ 0+1 =х4+х2+х+ 1.
Деление также осуществляется как обычное деление многочле-
нов; при этом операция вычитания заменяется операцией сложе-
ния по модулю 2:
х4+0 + х2 + х+ 1 |х + 1
®х4 + х3 х3 + х2+1
х^х2
„3 + у2
0
Как было отмечено выше, коды названы циклическими пото-
му, что циклический сдвиг ап 2, ап 3,..., разрешенной ком-
бинации ап t, ап 2,...,at,a0 также является разрешенной комбинаци-
ей. Такая циклическая перестановка при использовании представ-
лений в виде полиномов образуется в результате умножения дан-
ного полинома на х. Если V(x)=anlxn ,+ ап2хп2+...+ ар+а0, то
V(x)x = a jX” + + — + о,х2 + аох. Чтобы степень многочлена не
превышала п-1, член х" заменяется единицей, поэтому:
V(x)x = F(x) = an2xnl + ... + а[Х2+ а^х + ап1.
Например, имеем кодовую комбинацию 1101110-»х®+х5+х3+х2+х.
Сдвинем ее на один разряд. Получим:
1011101—>х6+х4+х3+х2 + 1.
Что то же самое, что и умножения исходного полинома на х:
х(х® + х5+х3 + х2 + х) = х6 + х4 + х3 + х2 + 1.
Теория построения циклических кодов базируется на разделах
высшей алгебры, изучающей свойства двоичных многочленов.
Особую роль в этой теории играют так называемые неприводимые
многочлены, т. е. полиномы, которые не могут быть представлены
в виде произведения многочленов низших степеней. Такой много-
471
член делится только на самого себя и на единицу. Из высшей ал-
гебры известно, что на неприводимый многочлен делится без ос-
татка двучлен х"+1. В теории кодирования неприводимое много-
члены называются образующими полиномами, поскольку они «об-
разуют» разрешенные кодовые комбинации (неприводимые поли-
номы табулированы, см. табл. 8.4) [9].
Идея построения циклического кода сводится к тому, что поли-
ном, представляющий информационную часть кодовой комбина-
ции, нужно преобразовать в полином степени не более п — 1, кото-
рый без остатка делится на образующий полином Р(х). Существен-
но при этом, что степень последнего соответствует числу разря-
дов проверочной части кодовой комбинации. В циклических ко-
дах все разрешенные комбинации, представленные в виде поли-
номов, обладают одним признаком: делимостью без остатка на об-
разующий полином Р(х). Построение разрешенной кодовой ком-
бинации сводится к следующему:
1. Представляем информационную часть кодовой комбинации
длиной к в виде полинома С?(х).
2. Умножаем Q(x) на одночлен xf и получаем О(х)хг, т. е. произ-
водим сдвиг A-разрядной кодовой комбинации на г разрядов.
3. Делим многочлен Q (х)хг на образующий полином Р(х), сте-
пень которого равна г.
В результате умножения О(х) на хг степень каждого одночлена,
входящего в О(х), повышается на г. При делении произведения
хгС?(х) на образующий полином степени г получается частное С(х)
такой же степени, что и О(х). Результаты этих операций можно
представить в виде:
= С(х;Ф (8 28)
Р(х)------------------------------Р(х) '
где 7?(х) —остаток от деления Q(x)x на Р(х). Поскольку С(х) имеет та-
кую же степень, что и Q(x), то С(х) представляет собой кодовую ком-
бинацию того же ^-разрядного кода. Степень остатка не может быть,
очевидно, больше степени образующего полинома, т. е. его наивыс-
шая степень равна г—1. Следовательно, наибольшее число разрядов
остатка не превышает г. Умножив обе части (8.28) на Р(х), получим:
Q(x)xr= С(х)Р(х)Ф/?(х) или
F(x) = С(х)Р(х) = Q(x)y®P(xj (8.29)
472
(знак вычитания заменяется знаком сложения по модулю 2). Оче-
видно, что Р(х) делится на Р(х) без остатка. Полином F(x) представ-
ляет собой разрешенную кодовую комбинацию циклического кода.
Из (8.29) следует, что разрешенную кодовую комбинации цик-
лического кода можно получить двумя способами: умножением
кодовой комбинации простого кода С(х) на образующий полином
Р(х) или умножением кодовой комбинации Q(x) простого кода на
одночлен хт к добавлением к этому произведению остатка Р(х),
полученного в результате деления произведения на образующий
полином Р(х). При первом способе кодирования информационные
и проверочные разряды не отделены друг от друга (код получается
неразделимым). Это затрудняет практическую реализацию про-
цесса декодирования. При втором способе получается разделимый
код: информационные разряды занимают старшие позиции, ос-
тальные п—к разряды являются проверочными. Этот способ ко-
дирования широко применяется на практике.
Пример 3. Дана кодовая комбинация 0111. Построим цикличес-
кий код с do= 3.
Решение. На первом этапе исходя из требуемого do= 3 опреде-
лим длину кода п и количество проверочных элементов к. Для это-
го воспользуемся таблицей 8.6.1. Для заданной четырехразрядной
кодовой комбинации N= 16. Тогда для d = 3 из соотноше-
2”
ния 16 <---(табл. 8.3) находим п = 7, соответственно, к = п — ш —
1 -(• п
= 7— 4 = 3. Следовательно, необходим код (7,4). По таблице обра-
зующих полиномов (табл. 8.4) при к = 3 определяем Р(х) = х3 + х2 + 1.
Далее:
1) для сообщения 0111 имеем О(х) =х2 +х+ 1;
2) умножаем Q(x) на х3 (так как г = 3):
Q(x) х3 = (х2 + х + 1) х3 =х5 + х4 + х3;
3) делим (Э(х)х3 на Р(х):
X5 + X4 -I- X3 | X3 + X2 + 1
X5 + X4 + X2 X2 + 1
X3 + X2
ф X3 + X2 + 1
1
Значит, Р(х) = 1 и Q(x)xr/P(x) = хг + 1®1/Р(х);
473
4) получаем:
F(x) = Q (x) x3 Ф R (x) = x5 + x4 + x3 + 1.
Этот полином соответствует кодовой комбинации:
0111 001
t J 1 - - I
к г
Таблица 8.4
Г Р(х) Двоичная запись многочлена Р(х)
2 х^+х+1 111
3 дЛьхМ . 1101
4 х4+х+1 10011
5 х5+хг+1 х5+х4+х3+хг+1 х5+Х1+х2+х+1 100101 111101 110111
6 x^+x+l x^+^+^+x+l 1000011 1100111
7 х’+хМ х7+х4+х2+х+1 х7+х4+х3+хг+1 10001001 10001111 10011101
8 х8+х7+х6+х5 +х2+х+1 ха+Х*+г'+х2+1 х8+х6+х5+х+1 111100111 100011101 101100011
9 ха+х5+х'+х2+1 х3+х*+х7+х6+х5+х3+1 1000101101 1111101001
10 xw+x4+x3+x+l x'°+xs+x6+xs+x4 +х3+х+1 10000011011 110011111111
И х" +х,0+х9+х8+х'+х+1 х|1+х8+х6+хг+1 111100001011 100101000101
12 х,2+х* 1+х8+ха+х7+х5+хг+х+1 х12+х®+х3+хг+1 1101110100111 1001000001101
Все указанные операции можно производить и над двоичными
числами:
1) Q(0, 1) = 0 1 1 1
2) Q(0, 1) х3 (0,1) = 0111000;
474
3) Q(0, 1) x3 (0,1) : P (0,1), т. e.
„0111000 I 1101
1101 101
„ 001100
(I J
1101
0001
101 -»x2 + 1; 1 —> R(0,l);
4) F(0,l) = Q(0,l)x3(0,l)®R(0,l) = 0111000®0001= 0111 001.
Построим теперь разрешенную кодовую комбинацию первым
способом: F(x)=C(x)P(x). Произведем умножение, представляя по-
линомы двоичными числами:
ОШ
1101
ф 0111
аш_____
0100011
F(0,1) = 0 1 000 1 1.
Видно, что в полученной кодовой комбинации нельзя выделить
информационные и проверочные разряды.
Обнаружение ошибок при циклическом кодировании сводит-
ся к делению принятой кодовой комбинации на тот же образую-
щий полином, который использовался при кодировании (его вид
должен быть известен на приеме). Если ошибок в принятой кодо-
вой комбинации нет (или они такие, что данную передаваемую
кодовую комбинацию превращают в другую разрешенную), то
деление на образующий полином будет выполнено без остатка.
Если при делении получится остаток, то это и свидетельствует о
наличии ошибки.
Пример 4. В качестве разрешенной кодовой комбинации
возьмем кодовую комбинацию, полученную в предыдущем при-
мере: F(x) = х5 + х4 + х3+1,а Р(х) = х3 +х2 +1, или в двоичном виде
F(0,1) = 0111001; Р(0,1) = 1101. Допустим, что в информационной
части произошла ошибка в старшем (7-м) разряде (разряды счита-
475
ем справа налево). Принятая кодовая комбинация имеет вид
1111001. Произведем операцию обнаружения ошибки:
1111001|1101
1101 1011
001000
® И01
оно
Наличие остатка 110 свидетельствует об ошибке.
Циклические коды находят большое применение в системах
передачи информации. Например, в широко распространенном
модемном протоколе V.42, для кодирования кодовых групп исполь-
зуется образующий полином д(Х) = Х':<’ + X12 4- Xs + 1, что эквива-
лентно коду 1 0001 0000 0010 0001, а также образующий полином
более высокого порядка д(Х) = X32 + X26 + X23 -1- X22 + X16 + X12 + X11
+ Х’° + X* 8 + Х> + X5 + X4 + X2 + 1.
8.6. СЖАТИЕ ИНФОРМАЦИИ
В общем случае под сжатием данных понимают процесс преоб-
разования большого объема данных в меньший объем. Существу-
ет большое количество методов сжатия. Для оценки их эффектив-
ности используют показатель — степень сжатия, определяющий
отношение объема несжатых данных к объему сжатых. Так, сте-
пень сжатия 10:1 характеризует в 5 раз более эффективное сжа-
тие, чем 2:1, и, например, для передачи сообщения, состоящего до
сжатия из 100 символов, после него потребуется всего лишь 10 сим-
волов.
Алгоритмы сжатия подразделяют на две категории: симметрич-
ные и асимметричные. Метод симметричного сжатия основан при-
мерно на тех же алгоритмах и позволяет выполнять почти такой
же объем работы, что и распаковка. В программах обмена данны-
ми, использующих сжатие и распаковку, обычно для большей эф-
фективности применяют именно симметричные алгоритмы.
При асимметричном сжатии в одном направлении выполняет-
ся значительно больший объем работы, чем в другом. Обычно на
сжатие затрачивается намного больше времени и системных ре-
сурсов, чем на распаковку. Так, при создании базы данных изоб-
476
ражений графические данные сжимаются для хранения всего од-
нажды, зато распаковываться с целью отображения данные могут
неоднократно. В этом случае большие затраты времени на сжатие,
чем на распаковку, вполне оправданы и такой алгоритм, можно
считать эффективным.
Алгоритмы, асимметричные «в обратном направлении» (т. е. когда
на сжатие затрачивается меньше времени, чем на распаковку),
применяются значительно реже. В частности, при резервном ко-
пировании информации, когда большинство скопированных фай-
лов никогда не будет прочитано, уместен алгоритм, выполняющий
сжатие значительно быстрее, чем распаковку.
Широко распространены методы сжатия данных, базирующи-
еся на словарях (когда для кодировки входных данных использу-
ются специальные словари). Среди данных методов выделяют адап-
тивные, полуадаптивные и неадаптивные.
Алгоритмы сжатия, спроектированные специально для обработ-
ки данных только определенных типов, называют неадаптивными.
Такие неадаптивные кодировщики содержат статический словарь
предопределенных подстрок, о которых известно, что они появля-
ются в кодируемых данных достаточно часто. Адаптивные кодиров-
щики не зависят от типа обрабатываемых данных, поскольку стро-
ят свои словари полностью из поступивших (рабочих) данных. Они
не имеют предопределенного списка статических подстрок, а, на-
оборот, строят фразы динамически, в процессе кодирования. Адап-
тивные компрессоры настраиваются на любой тип вводимых дан-
ных, добиваясь в результате максимально возможной степени сжа-
тия, в отличие от неадаптивных компрессоров, которые позволяют
эффективно закодировать только входные данные строго опреде-
ленного типа, для которого они были разработаны.
Метод полуадаптивного кодирования основан на применении
обоих словарных методов кодирования. Полуадаптивный кодиров-
щик работает в два прохода. При первом проходе он просматрива-
ет все данные и строит свой словарь, при втором — выполняет ко-
дирование. Этот метод позволяет построить оптимальный словарь,
прежде чем приступать к кодированию.
Наряду с методами сжатия, не уменьшающими количество ин-
формации в сообщении, применяются методы сжатия, основан-
ные на потере малосущественной информации.
Среди простых алгоритмов сжатия наиболее известен алгоритм
RLE (Run Length Encoding), позволяющий сжимать данные любых
477
типов. Этот алгоритм сжатия основан на замене цепочки из оди-
наковых символов символом и значением длины цепочки. Напри-
мер, символьная группа из 8 символов АААААААА, занимающая
8 байт, после RLE-кодирования будет представлена всего двумя
символами 8А и занимать, соответственно, два байта. При этом
будет обеспечена степень сжатия 4:1. Данный метод эффективен
при сжатии растровых изображений, но малополезен при кодиро-
вании текста.
При передаче информации широко используются и методы разно-
стного кодирования—предсказывающие (предиктивные) методы [19].
При методе разностного кодирования разности амплитуд от-
счетов представляются меньшим числом разрядов, чем сами амп-
литуды. Разностное кодирование реализовано в методах дельта-
модуляции и ее разновидностях. Предсказывающие (предиктив-
ные) методы основаны на экстраполяции значений амплитуд от-
счетов, и если выполнено условие A-Ap>d, то отсчет должен быть
передан, иначе он является избыточным; здесь Агп Ар — амплиту-
ды реального и предсказанного отсчетов, d — допуск (допустимая
погрешность представления амплитуд).
Иллюстрация предсказывающего метода с линейной экстрапо-
ляцией представлена на рис. 8.40. Здесь точками показаны пред-
сказываемые значения сигнала. Если точка выходит за пределы
«коридора» (допуска d), показанного пунктирными линиями, то
происходит передача отсчета. На рисунке передаваемые отсчеты
отмечены темными кружками в моменты времени t/r t? t4, tr Если
передачи отсчета нет, то на приемном конце принимается экстра-
полированное значение.
478
Методы MPEG (Moving Pictures Experts Group) используют пред-
сказывающее кодирование изображений (для сжатия данных о
движущихся объектах вместе со звуком). Так, если передавать
только изменившиеся во времени пиксели изображения, то дос-
тигается сжатие в несколько десятков раз. Данные методы стано-
вятся стандартами для цифрового телевидения.
Для сжатия данных об изображениях используют методы типа
JPEG (Joint Photographic Expert Group), основанные на потере ма-
лосущественной информации (не различимые для глаза оттенки
кодируются одинаково, коды могут стать короче). В этих методах
сжимаемая последовательность пикселей делится на блоки, в каж-
дом блоке производится преобразование Фурье и устраняются
высокие частоты. Изображение восстанавливается по коэффици-
ентам разложения для оставшихся частот.
Другой принцип воплощен в фрактальном кодировании, при
котором изображение, представленное совокупностью линий, опи-
сывается уравнениями этих линий.
Широко известный метод Хаффмена относится к статистичес-
ким методам сжатия. Идея метода — часто повторяющиеся сим-
волы нужно кодировать более короткими цепочками битов, чем
цепочки редких символов. Строится двоичное дерево, листья со-
ответствуют кодируемым символам, код символа представляется
последовательностью значений ребер (эти значения в двоичном
дереве суть 1 и 0), ведущих от корня к листу. Листья символов
с высокой вероятностью появления находятся ближе к корню, чем
листья маловероятных символов.
Распознавание кода, сжатого по методу Хаффмена, выполня-
ется по алгоритму, аналогичному алгоритмам восходящего грам-
матического разбора. Например, пусть набор из восьми символов
(А, В, С, D, Е, F, G, Н) имеет следующие правила кодирования:
А = 10; В = 01; С = 111; £>= 110;
E = 0001;F = 0000; G = ООН; Н = 0010.
Тогда при распознавании входного потока 101100000110 в стек
распознавателя заносится 1, но 1 не совпадает с правой частью ни
одного из правил. Поэтому в стек добавляется следующий символ
0. Полученная комбинация 10 распознается и заменяется на А.
В стек поступает следующий символ 1, затем 1, затем 0. Сочетание
110 совпадает с правой частью правила для D. Теперь в стеке AD
заносятся следующие символы 0000 и т. д.
479
Кодирование по алгоритму Хаффмена широко используется для
факсимильной передачи изображений по телефонным каналам и
сетям передачи данных. Этот алгоритм не является адаптивным.
В нем, как правило, применяется фиксированная таблица кодовых
значений, которые выбираются специально для представления
документов, подлежащих факсимильной передаче.
Кроме упомянутых методов сжатия, широкое распространение
получили адаптивные методы сжатия без потерь, основанные на
алгоритме LZ (Лемпеля —Зива). В частности, метод сжатия на ос-
нове LZ применен в модемном протоколе V.42bis.
В LZ-алгоритме используется следующая идея: если в тексте со-
общения появляется последовательность из двух ранее уже встре-
чавшихся символов, то эта последовательность объявляется новым
символом, для нее назначается код, который при определенных ус-
ловиях может быть значительно короче исходной последователь-
ности. В дальнейшем в сжатом сообщении вместо исходной после-
довательности записывается назначенный код. При декодировании
повторяются аналогичные действия и поэтому становятся извест-
ными последовательности символов для каждого кода.
Так, в модемном протоколе V.42bis заменяет конкретные, наи-
более часто встречающиеся последовательности символов (строк)
на более короткие кодовые слова. Алгоритм использует словарь
для сохранения наиболее часто встречающихся строк вместе
с кодовыми словами, которые их представляют. Словарь строится
и модифицируется динамически. Размер словаря может быть раз-
личным, стандартизировано только минимальное значение — 512
элементов (строк). Конкретное значение выбирается обоими мо-
демами при установлении соединения. Кроме того, согласовыва-
ется максимальная длина строки, которая может быть сохранена
в словаре, в диапазоне от 6 до 250 символов.
Словарь может быть представлен как набор (лес) деревьев,
в котором корню каждого дерева соответствует символ алфавита
и, наоборот, каждому символу соответствует дерево в словаре.
Каждое дерево представляет набор известных (уже встретивших-
ся) строк, начинающихся с символа, соответствующего корню.
Каждый узел дерева соответствует набору строк в словаре. И, на-
конец, каждый листьевой узел соответствует одной известной
строке. Так, набор деревьев на рис. 8.41 представляет строки А, В,
BA, BAG, BAR, BI, BIN, C, D, DE, DO и DOG. Каждый листьевой
узел — это узел, не имеющий подчиненных узлов и фактически
480
соответствующий последнему символу в строке. И наоборот, узел,
который не имеет родительского узла, соответствует первому сим-
волу в строке.
Рис. 8.41. Пример словаря в виде набора деревьев
В самом начале каждое дерево в словаре состоит только из кор-
невого узла, которому присвоено уникальное кодовое слово. При
поступлении нового символа выполняется процедура отождеств-
ления накопленной (отождествленной) к предыдущему шагу стро-
ки и текущего символа. Фактически эта процедура сводится к по-
иску строки, дополненной текущим символом, в словаре. Эта про-
цедура начинается с единственного символа и в этом случае все-
гда завершается успешно, так как в словаре всегда есть односим-
вольные строки, соответствующие каждому символу алфавита.
Если отождествленная на предыдущем шаге строка плюс символ
соответствует элементу словаря (найдена в нем), и этот элемент
не был создан при предыдущем выполнении процедуры отожде-
ствления строки, строка дополняется текущим символом и будет
использована при следующем вызове процедуры отождествления.
Процесс продолжается до тех пор, пока:
строка не достигает максимально возможной длины (согла-
I сованной модемами при установлении соединения);
| либо дополненная строка не найдена в словаре;
либо она была найдена, но этот элемент был создан при пре-
дыдущем вызове. В этом случае присоединенный к строке
символ удаляется из нее и называется «неотождествленным»,
строка кодируется кодовым словом, и на следующем шаге
будет состоять только из неотождествленного символа.
31 А-210
481
Во время процесса сжатия словарь динамически дополняется
новыми элементами (строками), которые соответствуют подстро-
кам, встречающимся в потоке данных. Новые строки образуются
добавлением неотождествленного символа к существующей стро-
ке, и это означает создание нового узла дерева. Например, в слу-
чае, если текущая отождествленная строка DO, а последнее пере-
данное кодовое слово соответствовало строке ВА, появление сим-
вола Т приводит к добавлению в словарь строки DOT (рис. 8.42).
На следующем шаге текущая строка соответствует неотождеств-
ленному символу Т.
Словари должны быть модифицированы в обоих модемах — пе-
редающем и принимающем. При этом передатчик всегда находит-
ся на один шаг (на одну строку) впереди приемника в цикле моди-
фикации словаря. Таким образом, в принимающем модеме первый
символ принятого кодового слова (который будет равен D) должен
быть использован для модификации словаря приемника. Приемник
V.42bis всегда полагает, что первый символ каждой строки (соот-
ветствующей принятому кодовому слову) должен быть использо-
ван для дополнения предыдущей строки и создания нового элемен-
та словаря. Состояние фрагмента словаря приемника после приема
кодового слова, соответствующего DO, при том что предыдущее
кодовое слово соответствовало строке ВА, показано на рис. 8.43.
Первый символ Т следующего кодового слова, принятого приемни-
ком, приведет его словарь к виду, изображенному на рис. 8.42.
узлы
Рис. 8.42 Изменения в части словаря передатчика
после последовательного получения от терминала символов ВА, DO и Т
узлы
482
Листьевые
узлы
Листьевые
узлы
Рис. 8.43. Состояние словаря приемника после приема слова ДО,
при том что предыдущее кодовое слово соответствовало строке ВА
Наиболее важными особенностями алгоритма, реализованно-
го в протоколе V.42bis являются следующие:
если в потоке данных часто встречаются те подстроки, кото-
рые уже есть в словаре, то новые элементы словаря созда-
ются редко и словарь переполняется медленно;
для представления максимального номера элемента (стро-
ки) словаря требуется 9 бит для словаря в 512 элементов,
10 — для словарей, содержащих до 1024 элементов, 11 —
до 2048 элементов и т. д. Однако не все номера должны
быть представлены максимальным количеством бит, и этот
механизм означает, что размер кодового слова увеличива-
ется с 9 до максимального значения по мере заполнения
словаря. Это уменьшает объем данных на первоначальных
этапах;
если на вход передатчика поступает хорошо перемешанный
(в статистическом смысле) поток символов, то высока веро-
ятность, что каждый следующий символ будет «неотожде-
ствленным» (такая же ситуация существует сразу после ини-
циализации словаря — он еще пуст). Для этого случая пред-
назначен прозрачный режим работы передатчика, т. е. режим
без сжатия, когда передача кодовых слов не осуществляет-
ся, а каждый приходящий на вход передатчика символ транс-
лируется в линию и далее в приемник.
483
Контрольные вопросы ..... —
1. Дайте определение системы передачи данных. Охарактеризуйте
ее основные элементы.
2. Что такое сообщение?
3. Что такое сигнал?
4. Какие виды и модели сигналов Вы знаете?
5. Назовите основные характеристики сигналов и помех.
6. Что понимают под каналом передачи информации?
7. Объясните формулу Хартли-Шеннона?
8. Назовите основные характеристики каналов связи.
9. Охарактеризуйте кабельные линии связи.
10. Какие типы кабелей Вы знаете?
11. Раскройте особенности беспроводных линий связи.
12. Назовите основные типы аппаратуры линий связи.
13. Дайте определение информационной сети.
14. Что такое вычислительная сеть?
15. По каким признакам осуществляется классификация сетей?
16. Охарактеризуйте методы передачи данных по каналам связи.
17. Какие виды сигналов используются в сетях передачи данных?
18. Охарактеризуйте способы коммутации данных.
19. Что такое протокол?
20. Что такое эталонная модель взаимодействия открытых систем?
21. Что понимается под стеком коммуникационных протоколов ? Оха-
рактеризуйте основные из них.
22. Объясните методы доступа к среде передачи данных.
23. Охарактеризуйте методы повышения верности передачи инфор-
мации.
24. Объясните принцип построения циклических кодов.
25. Перечислите основные методы сжатия информации. Расскажите
об их особенностях.
7ла£а 9
Контроль и защита информации
в автоматизированных системах
9.1. УГРОЗЫ БЕЗОПАСНОСТИ ИНФОРМАЦИИ
В АВТОМАТИЗИРОВАННЫХ СИСТЕМАХ
Эффективность любой информационной системы в значитель-
ной степени определяется состоянием защищенности (безопасно-
стью) перерабатываемой в ней информации.
Безопасность информации — состояние защищенности инфор-
мации при ее получении, обработке, хранении, передаче и использо-
вании от различного вида угроз.
Источниками угроз информации являются люди, аппаратные и
программные средства, используемые при разработке и эксплуа-
тации автоматизированных систем (АС), факторы внешней сре-
ды. Порождаемое данными источниками множество угроз безо-
пасности информации можно разделить на два класса: непредна-
меренные и преднамеренные.
Непреднамеренные угрозы связаны главным образом со стихий-
ными бедствиями, сбоями и отказами технических средств, а также
с ошибками в работе персонала и аппаратно-программных средств.
Реализация этого класса угроз приводит, как правило, к нарушению
достоверности и сохранности информации в АС, реже — к наруше-
нию конфиденциальности, однако при этом могут создаваться пред-
посылки для злоумышленного воздействия на информацию.
Угрозы второго класса носят преднамеренный характер и свя-
заны с незаконными действиями посторонних лиц и персонала АС.
В общем случае в зависимости от статуса по отношению к АС зло-
умышленником может быть: разработчик АС, пользователь, посто-
роннее лицо или специалисты, обслуживающие эти системы. Раз-
работчик владеет наиболее полной информацией о программных
и аппаратных средствах АС и имеет возможность осуществления
несанкционированной модификации структур на этапах создания
485
и модернизации АС. Он, как правило, не получает непосредствен-
ного доступа на эксплуатируемые объекты АС. Пользователь может
осуществлять сбор данных о системе защиты информации метода-
ми традиционного шпионажа, а также предпринимать попытки не-
санкционированного доступа к информации и внедрения вредитель-
ских программ. Постороннее лицо, не имеющее доступа на объект
АС, может получать информацию по техническим каналам утечки
и перехвата информации, а также осуществлять вредительские дей-
ствия методами традиционного шпионажа и диверсионной деятель-
ности. Большие возможности оказания вредительских воздействий
на информацию АС имеют специалисты, обслуживающие эти сис-
темы. Причем, специалисты разных подразделений обладают раз-
личными потенциальными возможностями злоумышленных дей-
ствий. Наибольший вред могут нанести работники службы безопас-
ности информации. Далее идут системные программисты, приклад-
ные программисты и инженерно-технический персонал.
Реализация угроз безопасности информации приводит к нару-
шению основных свойств информации: достоверности, сохран-
ности и конфиденциальности (рис.9.1). При этом объектами воз-
действия угроз являются аппаратные и программные средства,
носители информации (материальные носители, носители-сигна-
лы) и персонал АС. В результате воздействия угроз ухудшается
качество функционирования аппаратных средств и характеристи-
ки обрабатываемой информации, что в конечном итоге приводит
к ухудшению качества функционирования АС, снижению эффек-
тивности решаемых ею задач и тем самым к нанесению ущерба ее
пользователям или владельцам.
9.1.1. Непреднамеренные угрозы
Основными видами непреднамеренных угроз являются (см.
рис.9.1): стихийные бедствия и аварии, сбои и отказы техничес-
ких средств, ошибки в комплексах алгоритмов и программ, ошиб-
ки при разработке АС, ошибки пользователей и обслуживающего
персонала [10].
Стихийные бедствия и аварии. Примерами угроз этой груп-
пы могут служить пожар, наводнение, землетрясение и т. д. При
их реализации АС, как правило, подвергаются физическому раз-
рушению, при этом информация утрачивается, или доступ к ней
становится невозможен.
486
Угрозы безопасности информации в АС
Непреднамеренные угрозы ° Стихийные бедствия и аварии Сбои и отказы технических средств Ошибки при разработке АС Ошибки в комплексах алгоритмов и программ Ошибки пользователей и обслуживающего персонала Преднамеренные угрозы Шпионаж и диверсии Несанкционированный доступ к информации Съем электромагнитных излучений и наводок Несанкционированная модифи- кация структур Вредительские программы
Нарушение достоверности, сохранности (целостности, готовности)
и конфиденциальности информации
Объекты воздействия
Аппаратные
средства
Программные
средства
Носители информации
(материальные
носители,
носители-сигналы)
Люди —
носители
информации
Ухудшение качества
функционирования
аппаратных
средств
Ухудшение ТТХ
Ухудшение качества
программных
средств
Полное
или частичное
нарушение
работоспособности
средств
Невозможности
использования
программных
средств
Ухудшение
качественных
показателей
процесса
обработки
информации
Ухудшение
характе-
ристик
обрабаты-
ваемой
информации
у.
Ухудшение качества
(снижение эффективности)
решаемых задач
Ухудшение качества
(эффективности)
функционирования АС
Нанесение ущерба пользователям или владельцам системы
Рис. 9.1. Угрозы безопасности информации в АС и последствия их воздействия
487
Сбои и отказы технических средств. К угрозам этой группы
относятся сбои и отказы аппаратных средств ЭВМ, сбои систем элек-
тропитания, сбои кабельной системы и т. д. В результате сбоев и
отказов нарушается работоспособность технических средств, унич-
тожаются и искажаются данные и программы, нарушается алгоритм
работы устройств. Нарушения алгоритмов работы отдельных узлов
и устройств могут также привести к нарушению конфиденциаль-
ности информации. Вероятность сбоев и отказов (q) технических
средств изменяется на этапах жизненного цикла АС (рис. 9.2) [16].
средств технологические
ошибки
Рис. 9.2. Характер изменения вероятности отказов АС (7)
на этапах жизненного цикла АС
Ошибки при разработке АС и ошибки в комплексах алгорит-
мов и программ приводят к последствиям, аналогичным послед-
ствиям сбоев и отказов технических средств. Кроме того, такие
ошибки могут быть использованы злоумышленниками для воздей-
ствия на ресурсы АС.
Ошибки в комплексах алгоритмов и программ обычно класси-
фицируют на:
* системные, обусловленные неправильным пониманием требо-
ваний автоматизируемой задачи АС и условий ее реализации;
488
алгоритмические, связанные с некорректной формулиров-
кой и программной реализацией алгоритмов;
* программные, возникающие вследствие описок при програм-
мировании на ЭВМ, ошибок при кодировании информацион-
ных символов, ошибок в логике машинной программы и др.;
технологические, возникающие в процессе подготовки про-
граммной документации и перевода её во внутримашинную
информационную базу АС.
Вероятность данных ошибок изменяется на этапах жизненно-
го цикла АС (см. рис. 9.2).
Ошибки пользователей и обслуживающего персонала. По ста-
тистике на долю этой группы угроз приходится более половины
всех случаев нарушения безопасности информации. Ошибки
пользователей и обслуживающего персонала определяются:
• психофизическими характеристиками человека (усталостью
и снижением работоспособности после определенного вре-
мени работы, неправильной интерпретацией используемых
информационных массивов);
* объективными причинами (несовершенством моделей пред-
ставления информации, отсутствием должностных инструк-
ций и нормативов, квалификацией персонала, несоверше-
ниством комплекса аппаратно-программных средств, не-
удачным расположением или неудобной конструкцией их с
точки зрения эксплуатации);
• субъективными причинами (небрежностью, безразличием,
несознательностью, безответственностью, плохой организа-
цией труда и др.).
Ошибки данной группы приводят, как правило, к уничтожению,
нарушению ’’злостности и конфиденциальности информации.
Современная технология разработки аппаратных и программ-
ных средств, эффективная система эксплуатации АС, включающая
обязательное резервирование информации, позволяют значитель-
но снизить потери от реализации непреднамеренных угроз.
9.1.2. Преднамеренные угрозы
Угрозы этого класса в соответствии с их физической сущнос-
тью и механизмами реализации могут быть распределены по пяти
группам [10]:
шпионаж и диверсии;
несанкционированный доступ к информации;
489
• съем электромагнитных излучений и наводок;
несанкционированная модификация структур;
вредительские программы.
Шпионаж и диверсии. Традиционные методы и средства шпи-
онажа и диверсий чаще всего используются для получения сведе-
ний о системе защиты с целью проникновения в АС, а также для
хищения и уничтожения информационных ресурсов.
К таким методам относятся:
подслушивание;
наблюдение;
хищение документов и машинных носителей информации;
* хищение программ и атрибутов системы защиты;
подкуп и шантаж сотрудников;
сбор и анализ отходов машинных носителей информации;
поджоги;
взрывы.
Подслушивание — один из наиболее древних методов добыва-
ния информации. Подслушивание бывает непосредственное и
с помощью технических средств. Непосредственное подслушива-
ние использует только слуховой аппарат человека. В силу малой
мощности речевых сигналов разговаривающих людей и значитель-
ного затухания акустической волны в среде распространения не-
посредственное подслушивание возможно на небольшом рассто-
янии (единицы или в лучшем случае при отсутствии посторонних
звуков — десятки метров). Поэтому для подслушивания применя-
ются различные технические средства, позволяющие получать ин-
формацию по техническим каналам утечки акустической (рече-
вой) информации.
Технический канал утечки информации — совокупность объек-
та, технического средства, с помощью которого добывается информа-
ция об этом объекте, и физической среды, в которой распространяет-
ся информационный сигнал.
В зависимости от физической природы возникновения инфор-
мационных сигналов, среды распространения акустических коле-
баний и способов их перехвата технические каналы утечки акус-
тической (речевой) информации можно разделить на воздушные,
вибрационные, электроакустические и оптико-электронные [26].
490
В воздушных технических каналах утечки информации средой
распространения акустических сигналов является воздух, и для их
перехвата используются миниатюрные высокочувствительные
микрофоны и специальные направленные микрофоны. Автоном-
ные устройства, конструктивно объединяющие миниатюрные
микрофоны и передатчики, называют закладными устройствами
перехвата речевой информации, или просто акустическими зак-
ладками. Закладные устройства делятся на проводные и излучаю-
щие. Проводные закладные устройства требуют значительного
времени на установку и имеют существенный демаскирующий
признак — провода. Излучающие «закладки» («радиозакладки»)
быстро устанавливаются, но также имеют демаскирующий при-
знак — излучение в радио или оптическом диапазоне. «Радиозак-
ладки» могут использовать в качестве источника электрические
сигналы или акустические сигналы. Примером использования
электрических сигналов в качестве источника является примене-
ние сигналов внутренней телефонной, громкоговорящей связи.
Наибольшее распространение получили акустические «радиозак-
ладки». Они воспринимают акустический сигнал, преобразуют его
в электрический и передают в виде радиосигнала на определен-
ные расстояния. Из применяемых на практике «радиозакладок»
подавляющее большинство рассчитаны на работу в диапазоне рас-
стояний 50—800 метров.
В вибрационных технических каналах утечки информации сре-
дой распространения акустических сигналов являются конструк-
ции зданий, сооружений (стены, потолки, полы), трубы водоснаб-
жения, отопления, канализации и другие твердые тела. Для пере-
хвата акустических колебаний в этом случае используются кон-
тактные микрофоны (стетоскопы). Контактные микрофоны, соеди-
ненные с электронным усилителем называют электронными сте-
тоскопами. Такие микрофоны, например, позволяют прослуши-
вать разговоры при толщине стен до 50—100 см.
Электроакустические технические каналы утечки информации
включают перехват акустических колебаний через элементы, об-
ладающие микрофонным эффектом, а также путем высокочастот-
ного навязывания. Под микрофонным эффектом понимают эф-
фект электроакустического преобразования акустических коле-
баний в электрические, характеризуемый свойством элемента из-
менять свои параметры (емкость, индуктивность, сопротивление)
под действием акустического поля, создаваемого источником аку-
491
стических колебаний. Изменение параметров приводит либо
к появлению на данных элементах электродвижущей силы, изме-
няющейся по закону воздействующего информационного акусти-
ческого поля, либо к модуляции токов, протекающих по этим эле-
ментам, информационным сигналом. С этой точки зрения наиболь-
шую чувствительность к акустическому полю имеют абонентские
громкоговорители и датчики пожарной сигнализации. Перехват
акустических колебаний в данном канале утечки информации осу-
ществляется путем непосредственного подключения к соедини-
тельным линиям специальных высокочувствительных низкочас-
тотных усилителей. Например, подключая такие средства к соеди-
нительным линиям телефонных аппаратов с электромеханически-
ми вызывными звонками, можно прослушивать разговоры, веду-
щиеся в помещениях, где установлены эти аппараты.
Технический канал утечки информации путем высокочастот-
ного навязывания может быть осуществлен с помощью несанкци-
онированного контактного введения токов высокой частоты от со-
ответствующего генератора в линии (цепи), имеющие функцио-
нальные связи с нелинейными или параметрическими элемента-
ми, на которых происходит модуляция высокочастотного сигнала
информационным. В силу того, что нелинейные или параметри-
ческие элементы для высокочастотного сигнала, как правило, пред-
ставляют собой несогласованную нагрузку, промодулированный
высокочастотный сигнал будет отражаться от нее и распростра-
няться в обратном направлении по линии или излучаться. Для при-
ема излученных или отраженных высокочастотных сигналов ис-
пользуются специальные приемники с достаточно высокой чув-
ствительностью. Наиболее часто такой канал угечки информации
используется для перехвата разговоров, ведущихся в помещении,
через телефонный аппарат, имеющий выход за пределы контро-
лируемой зоны.
Оптико-электронный (лазерный) канал утечки акустической
информации образуется при облучении лазерным лучом вибри-
рующих в акустическом поле тонких отражающих поверхностей
(стекол окон, картин, зеркал и т. д.). Отраженное лазерное излуче-
ние (диффузное или зеркальное) модулируется по амплитуде и
фазе (по закону вибрации поверхности) и принимается приемни-
ком оптического (лазерного) излучения, при демодуляции которо-
го выделяется речевая информация. Причем лазер и приемник
оптического излучения могут быть установлены в одном или раз-
492
них местах (помещениях). Для перехвата речевой информации по
данному каналу используются сложные лазерные акустические
локационные системы, иногда называемые лазерными микрофо-
нами. Работают они, как правило, в ближнем инфракрасном диа-
пазоне волн.
При передаче информации по каналам связи возможен ее пе-
рехват.В настоящее время для передачи информации используют
в основном КВ, УКВ, радиорелейные, тропосферные и космичес-
кие каналы связи, а также кабельные и волоконно-оптические ли-
нии связи. В зависимости от вида каналов связи технические ка-
налы перехвата информации можно разделить на электромагнит-
ные, электрические и индукционные.
Высокочастотные электромагнитные излучения передатчиков
средств связи, модулированные информационным сигналом, мо-
гут перехватываться портативными средствами радиоразведки и
при необходимости передаваться в центр обработки для их раско-
дирования. Данный канал перехвата информации наиболее широ-
ко используется для прослушивания телефонных разговоров, ве-
дущихся по радиотелефонам, сотовым телефонам или по радиоре-
лейным и спутниковым линиям связи.
Электрический канал перехвата информации, передаваемой по
кабельным линиям связи, предполагает контактное подключение
аппаратуры разведки к кабельным линиям связи. Самый простой
способ — непосредственное параллельное подключение к линии
связи. Но данный факт легко обнаруживается, так как приводит
к изменению характеристик линии связи за счет падения напря-
жения. Поэтому средства разведки к линии связи подключаются
или через согласующее устройство, несколько снижающее паде-
ние напряжения, или через специальные устройства компенсации
падения напряжения. В последнем случае аппаратура разведки и
устройство компенсации падения напряжения включаются в ли-
нию связи последовательно, что существенно затрудняет обнару-
жение факта несанкционированного подключения к ней. Контак-
тный способ используется в основном для снятия информации
с коаксиальных и низкочастотных кабелей связи. Для кабелей, внут-
ри которых поддерживается повышенное давление воздуха, приме-
няются устройства, исключающие его снижение, в результате чего
предотвращается срабатывание специальной сигнализации.
В случае использования сигнальных устройств контроля целос-
тности линии связи, ее активного и реактивного сопротивления
493
факт контактного подключения к ней аппаратуры разведки будет
обнаружен. Поэтому наиболее часто применяют индуктивный ка-
нал перехвата информации, не требующий контактного подключе-
ния к каналам связи. В данном канале используется эффект возник-
новения вокруг кабеля связи электромагнитного поля при прохож-
дении по нему информационных электрических сигналов, которые
перехватываются специальными индукционными датчиками.
Индукционные датчики применяются в основном для съема ин-
формации с симметричных высокочастотных кабелей. Сигналы
с датчиков усиливаются, осуществляется частотное разделение ка-
налов, и информация, передаваемая по отдельным каналам, запи-
сывается на магнитофон или высокочастотный сигнал записыва-
ется на специальный магнитофон. Современные индукционные
датчики способны снимать информацию с кабелей, защищенных
не только изоляцией, но и двойной броней из стальной ленты и
стальной проволоки, плотно обвивающих кабель. Для бесконтакт-
ного съема информации с незащищенных телефонных линий свя-
зи могут использоваться специальные низкочастотные усилители,
снабженные магнитными антеннами. Некоторые средства бескон-
тактного съема информации, передаваемой по каналам связи, мо-
гут комплексироваться с радиопередатчиками для ретрансляции
в центр ее обработки.
Наблюдение предполагает получение и анализ изображения
объекта наблюдения (документа, человека, предмета, пространства
и др.). При наблюдении добываются, в основном, видовые призна-
ки объектов. Но возможно добывание семантической информа-
ции, если объект наблюдения представляет собой документ, схе-
му, чертежи т. д. Например, текст или схема конструкции прибо-
ра на столе руководителя или специалиста могут быть подсмотре-
ны в ходе их посещения. Также возможно наблюдение через окно
текста и рисунков на плакатах, развешанных на стене во время
проведения совещания.
Объекты могут наблюдаться непосредственно — глазами или
с помощью технических средств. Различают следующие способы
наблюдения с использованием технических средств [23]:
визуально-оптическое;
с помощью приборов наблюдения в инфракрасном (ИК) ди-
апазоне;
наблюдение с сохранением изображения (фото- и ки-
носъемка);
494
* телевизионное наблюдение, в том числе с записью изобра-
жения;
лазерное наблюдение;
радиолокационное наблюдение;
радиотеплолокационное наблюдение.
Визуально-оптическое наблюдение — наиболее древний спо-
соб наблюдения, со времени изобретения линзы. Современный со-
став приборов визуально-оптического наблюдения разнообразен —
от специальных телескопов до эндоскопов, обеспечивающих на-
блюдение скрытых объектов через маленькие отверстия или щели.
Так как человеческий глаз не чувствителен к ИК-лучам, то для
наблюдения в ИК-диапазоне применяются специальные приборы
(ночного видения, тепловизоры), преобразующие невидимое изоб-
ражение в видимое.
Основной недостаток визуально-оптического наблюдения
в видимом и ИК-диапазонах — невозможность сохранения изоб-
ражения для последующего анализа специалистами. Для сохране-
ния статического изображения объекта его фотографируют, для
сохранения изображения подвижных объектов производят кино-
или видеосъемку.
Наблюдение объектов с одновременной передачей изображе-
ний на определенные расстояния осуществляется с помощью
средств телевизионного наблюдения.
Возможно так называемое лазерное наблюдение в видимом и
ИК-диапазонах, в том числе с определением с высокой точностью
расстояния до объекта и его координат.
Радиолокационное наблюдение позволяет получать изображе-
ние удаленного объекта в радиодиапазоне в любое время суток и
в неблагоприятных климатических условиях, когда невозможны
другие способы наблюдения. При радиотеплолокационном наблю-
дении изображение объекта соответствует распределению темпе-
ратуры на его поверхности.
В целом дистанционное добывание информации в АС в резуль-
тате наблюдения малопригодно и носит, как правило, вспомогатель-
ный характер. Видеонаблюдение организуется в основном для вы-
явления режимов работы и расположения механизмов защиты ин-
формации. При этом из АС информация реально может быть полу-
чена при использовании на объекте экранов, табло, плакатов, если
имеются прозрачные окна и перечисленные выше средства разме-
щены без учета необходимости противодействовать такой угрозе.
495
Для вербовки сотрудников и физического уничтожения объек-
тов АС также не обязательно иметь непосредственный доступом
к объекту. Злоумышленник, располагающий доступом к объекту
АС, может использовать любой из методов традиционного шпи-
онажа.
Несанкционированный доступ к информации
Несанкционированный доступ (НСД) — доступ к информации, на-
рушающий установленные правила разграничения доступа, с исполь-
зованием штатных средств вычислительной техники или автоматизи-
рованных систем.
Под правилами разграничения доступа понимается совокупность
положений, регламентирующих права доступа лиц или процессов
(субъектов доступа) к единицам информации (объектам доступа).
Право доступа к ресурсам АС определяется руководством для
каждого сотрудника в соответствии с его функциональными обя-
занностями. Процессы инициируются в АС в интересах опреде-
ленных лиц, поэтому и на них накладываются ограничения по дос-
тупу к ресурсам.
Выполнение установленных правил разграничения доступа в АС
реализуется за счет создания системы разграничения доступа
(СРД) [10].
Несанкционированный доступ к информации возможен толь-
ко с использованием штатных аппаратных и программных средств
в следующих случаях:
" отсутствует система разграничения доступа;
сбой или отказ в АС;
ошибочные действия пользователей или обслуживающего
персонала АС;
ошибки в СРД;
фальсификация полномочий.
Если СРД отсутствует, то злоумышленник, имеющий навыки
работы в АС, может получить без ограничений доступ к любой
информации. В результате сбоев или отказов средств АС, а также
ошибочных действий обслуживающего персонала и пользовате-
лей возможны состояния системы, при которых упрощается НСД.
Злоумышленник может выявить ошибки в СРД и использовать их
для НСД. Фальсификация полномочий является одним из наибо-
лее вероятных путей (каналов) НСД.
496
Электромагнитные излучения и наводки. Процесс обработки
и передачи информации техническими средствами АС сопровож-
дается электромагнитными излучениями в окружающее простран-
ство и наведением электрических сигналов в линиях связи, сигна-
лизации, заземлении и других проводниках. Они полу1 шли назва-
ния побочных электромагнитных излучений и наводок (ПЭМИН).
Способы получения разведывательной информации с помощью
ПЭМИН называют техническими каналами утечки информации.
Такие каналы в зависимости от физической природы возникнове-
ния информационных сигналов, а также среды их распростране-
ния и способов перехвата, можно разделить на электромагнитные
и электрические [26].
К электромагнитным относятся каналы утечки информации,
возникающие за счет различного вида побочных электромагнит-
ных излучений технических средств переработки информации
(ТСПИ):
• элементов ТСПИ;
на частотах работы высокочастотных (ВЧ) генераторов
ТСПИ;
• на частотах самовозбуждения усилителей низкой частоты
(УНЧ) ТСПИ.
Совместно с ТСПИ могут использоваться и находиться в зоне
электромагнитного поля, создаваемого ими, технические средства
и системы, непосредственно не участвующие в обработке конфи-
денциальной информации (средства открытой телефонной, гром-
коговорящей связи, системы пожарной и охранной сигнализации,
электрификации, часофикации, электробытовые приборы и т. д.).
Такие средства называют вспомогательными техническими сред-
ствами и системами (ВТСС).
Электромагнитные излучения элементов ТСПИ. В ТСПИ носи-
телем информации является электрический ток, параметры кото-
рого (сила тока, напряжение, частота и фаза) изменяются по зако-
ну информационного сигнала. При прохождении электрического
тока по токоведущим элементам ТСПИ вокруг них (в окружаю-
щем пространстве) возникает электрическое и магнитное поле.
В силу этого элементы ТСПИ можно рассматривать как излучате-
ли электромагнитного поля, модулированного по закону измене-
ния информационного сигнала.
Электромагнитные излучения на частотах работы ВЧгенера-
торов ТСПИ и ВТСС. В состав ТСПИ и ВТСС могут входить раз-
32 А-210
497
личного рода высокочастотные генераторы. К таким устройствам
можно отнести: задающие генераторы, генераторы тактовой час-
тоты, генераторы стирания и подмагничивания магнитофонов, ге-
теродины радиоприемных и телевизионных устройств, генерато-
ры измерительных приборов и т. д.
В результате внешних воздействий информационного сигнала
(например, электромагнитных колебаний) на элементах ВЧ гене-
раторов наводятся электрические сигналы. Приемником магнит-
ного поля могут быть катушки индуктивности колебательных кон-
туров, дроссели в цепях электропитания и т.д. Приемником элект-
рического поля являются провода высокочастотных цепей и дру-
гие элементы. Наведенные электрические сигналы могут вызвать
непреднамеренную модуляцию собственных ВЧ колебаний гене-
раторов. Эти промодулированные ВЧ колебания излучаются в ок-
ружающее пространство.
Электромагнитные излучения на частотах самовозбуждения
УНЧ ТСПИ. Самовозбуждение УНЧ ТСПИ (например, усилителей
систем звукоусиления и звукового сопровождения, магнитофонов,
систем громкоговорящей связи и т. п.) возможно за счет случай-
ных преобразований отрицательных обратных связей (индуктив-
ных или емкостных) в паразитные положительные, что приводит
к переводу усилителя из режима усиления в режим автогенера-
ции сигналов. Частота самовозбуждения лежит в пределах рабо-
чих частот нелинейных элементов УНЧ (например, полупроводни-
ковых приборов, электровакуумных ламп и т. п.). Сигнал на часто-
тах самовозбуждения, как правило, оказывается промодулиро-
ванным информационным сигналом. Самовозбуждение наблюда-
ется, в основном, при переводе УНЧ в нелинейный режим работы,
т. е. в режим перегрузки.
Перехват побочных электромагнитных излучений ТСПИ осу-
ществляется средствами радио-, радиотехнической разведки, раз-
мещенными вне контролируемой зоны, т. е. зоны, в которой ис-
ключено появление лиц и транспортных средств, не имеющих по-
стоянных или временных пропусков.
Зона, в которой возможен перехват (с помощью разведывательного
приемника) побочных электромагнитных излучений и последующая
расшифровка содержащейся в них информации (т. е. зона, в пределах
которой отношение «информационный сигнал/помеха» превышает
допустимое нормированное значение), называется (опасной) зоной 2.
498
Причинами возникновения электрических каналов утечки
информации могут быть:
наводки электромагнитных излучений ТСПИ на посторон-
ние проводники (в том числе соединительные линии ВТСС),
выходящие за пределы контролируемой зоны;
• просачивание информационных сигналов в цепи электропи-
тания ТСПИ;
просачивание информационных сигналов в цепи заземления
ТСПИ.
Наводки электромагнитных излучений ТСПИ возникают при
излучении элементами ТСПИ (в том числе и их соединительными
линиями) информационных сигналов, а также при наличии галь-
ванической связи соединительных линий ТСПИ и посторонних
проводников. Уровень наводимых сигналов в значительной степе-
ни зависит от мощности излучаемых сигналов, расстояния до про-
водников, а также длины совместного пробега соединительных
линий ТСПИ и посторонних проводников.
ч____________________________________________________
Пространство вокруг ТСПИ, в пределах которого на случайных
антеннах наводится информационный сигнал выше допустимого (нор-
мированного) уровня, называется (опасной) зоной 1.
Случайными антеннами являются посторонние проводники,
способные принимать побочные электромагнитные излучения.
Случайные антенны могут быть сосредоточенными и распределен-
ными. Сосредоточенная случайная антенна представляет собой
компактное техническое средство, например телефонный аппарат,
громкоговоритель радиотрансляционной сети и т. д. К распреде-
ленным случайным антеннам относятся случайные антенны с рас-
пределенными параметрами: кабели, провода, металлические тру-
бы и другие токопроводящие коммуникации.
Просачивание информационных сигналов в цепи электропитания
возможно при наличии магнитной связи между выходным транс-
форматором усилителя (например, УНЧ) и трансформатором вып-
рямительного устройства. Кроме того, токи усиливаемых инфор-
мационных сигналов замыкаются через источник электропитания,
создавая на его внутреннем сопротивлении падение напряжения,
которое при недостаточном затухании в фильтре выпрямительно-
го устройства может быть обнаружено в линии электропитания.
499
Информационный сигнал может проникнуть в цепи электропита-
ния также в результате того, что среднее значение потребляемого
тока в оконечных каскадах усилителей в большей или меньшей
степени зависит от амплитуды информационного сигнала, что со-
здает неравномерную нагрузку на выпрямитель и приводит к из-
менению потребляемого тока по закону изменения информаци-
онного сигнала.
Просачивание информационных сигналов в цепи заземления.
Кроме заземляющих проводников, служащих для непосредствен-
ного соединения ТСПИ с контуром заземления, гальваническую
связь с землей могут иметь различные проводники, выходящие за
пределы контролируемой зоны. К ним относятся нулевой провод
сети электропитания, экраны (металлические оболочки) соедини-
тельных кабелей, металлические трубы систем отопления и водо-
снабжения, металлическая арматура железобетонных конструк-
ций и т. д. Все эти проводники совместно с заземляющим устрой-
ством образуют разветвленную систему заземления, на которую
могут наводиться информационные сигналы. Кроме того, в грунте
вокруг заземляющего устройства возникает электромагнитное
поле, которое также является источником информации.
Перехват информационных сигналов по электрическим кана-
лам утечки возможен путем непосредственного подключения
к посторонним проводникам, проходящим через помещения, где
установлены ТСПИ, а также к их системам электропитания и за-
земления. Для этих целей применяются специальные средства ра-
дио- и радиотехнической разведки, а также специальная измери-
тельная аппаратура.
Электромагнитные излучения используются злоумышленника-
ми не только для получения информации, но и для ее уничтоже-
ния. Электромагнитные импульсы способны уничтожить инфор-
мацию на магнитных носителях. Мощные электромагнитные и
сверхвысокочастотные излучения могут вывести из строя элект-
ронные блоки АС. Причем для уничтожения информации на маг-
нитных носителях с расстояния нескольких десятков метров мо-
жет быть использовано устройство, помещающееся в портфель.
Несанкционированная модификация структур. Большую угро-
зу безопасности информации в АС представляет несанкциониро-
ванная модификация алгоритмической, программной и техничес-
кой структур системы [10]. Несанкционированная модификация
структур может осуществляться на любом жизненном цикле АС.
500
Несанкционированное изменение структуры АС на этапах разра-
ботки и модернизации получило название «закладка». Алгоритми-
ческие, программные и аппаратные «Закладки» используются либо
для непосредственного вредительского воздействия на АС, либо
для обеспечения неконтролируемого входа в систему. Вредитель-
ские воздействия «закладок» на АС осуществляются при получе-
нии соответствующей команды извне (в основном характерно для
аппаратных «закладок») и при наступлении определенных собы-
тий в системе. Такими событиями могут быть: переход на опреде-
ленный режим работы (например, боевой режим системы управ-
ления оружием или режим устранения аварийной ситуации на
атомной электростанции т. п.), наступление установленной даты,
достижение определенной наработки и т. д.
Вредительские программы. Одним из основных видов угроз
безопасности информации в АС являются специальные програм-
мы, получившие общее название «вредительские программы».
В зависимости от механизма действия вредительские программы
делятся на четыре класса [10]:
«логические бомбы»;
«черви»;
«троянские кони»;
«компьютерные вирусы».
«Логические бомбы» — это программы или их части, постоянно
находящиеся в ЭВМ или вычислительных системах и выполняе-
мые только при соблюдении определенных условий. Примерами
таких условий могут быть: наступление заданной даты, переход АС
в определенный режим работы, наступление некоторых событий
установленное число раз и т. п.
«Червями» называют программы, которые выполняются каж-
дый раз при загрузке системы, обладают способностью переме-
щаться в системе и самовоспроизводить копии. Лавинообразное
размножение программ приводит к перегрузке каналов связи, па-
мяти и, в конечном итоге, к блокировке системы.
«Троянские кони» — это программы, полученные путем явного
изменения или добавления команд в пользовательские програм-
мы. При последующем выполнении пользовательских программ
наряду с заданными функциями выполняются несанкционирован-
ные, измененные или какие-то новые функции.
«Компьютерные вирусы» — это небольшие программы, кото-
рые после внедрения в ЭВМ самостоятельно распространяются
501
путем создания своих копий, а при выполнении определенных ус-
ловий оказывают негативное воздействие на АС.
Поскольку вирусам присущи свойства всех классов вредитель-
ских программ, то в последнее время любые вредительские про-
граммы часто называют вирусами.
9.2. ОБЕСПЕЧЕНИЕ ДОСТОВЕРНОСТИ ИНФОРМАЦИИ
В АВТОМАТИЗИРОВАННЫХ СИСТЕМАХ
Проблема обеспечения (повышения) достоверности информа-
ции (ОДИ) при ее обработке в АС заключается, главным образом,
в контроле правильности информационных массивов (ИМ), обна-
ружении ошибок и их исправлении на различных этапах обработ-
ки информации [16]. Исследование проблемы ОДИ в АС осуще-
ствляется на трех уровнях:
синтаксическом (связан с контролем и защитой элементар-
ных составляющих ИМ — знаков или символов);
и семантическом (связан с обеспечением достоверности смыс-
лового значения ИМ, их логичности, непротиворечивости и
согласованности)
прагматическом (связан с изучением вопросов ценности ин-
формации при принятии управленческих решений, её дос-
тупности и своевременности, влияния ошибок на качество и
эффективность функционирования АС).
На первом (синтаксическом) уровне в качестве показателя дос-
товерности можно использовать функцию верности D = 1 — д;,где
qt — вероятность ошибки, т. е. события, состоящего в том, что еди-
ничный правильный (верный) символ или знак заменяется в про-
цессе обработки другим, ошибочным.
Ошибки, возникающие в процессе обработки информации,
связаны с помехами, сбоями и отказами технических и программ-
ных средств, ошибками пользователей и обслуживающего персо-
нала, недостаточной точностью или ошибками в исходных данных,
округлением исходных, промежуточных и выходных данных, не-
адекватностью реализованных математических моделей реальным
процессам.
С целью обеспечения (повышения) достоверности в типовом
модуле обработки цикл обработки информации состоит, как пра-
вило, из трех операций (рис. 9.3): непосредственно логической (ма-
502
тематической) обработки, контроля и исправления ошибок. В этом
случае после исправления ошибочных информационных массивов
они вновь обрабатываются с последующим контролем и исправ-
лением, при этом фазы контроля и исправления ошибок могут по-
вторяться случайное число раз.
Рис.9.3. Структура типового модуля обработки информации в АС
В АС, как правило, добиваться теоретически максимальной до-
стоверности обработки информации нецелесообразно из-за рез-
кого повышения сложности, стоимости ее разработки, внедрения
и эксплуатации. Достаточно обеспечить требуемый (допустимый)
уровень достоверности D°. В реальных АС требуемая достовер-
ность устанавливается с учётом последствий, к которым могут при-
вести возникшие ошибки, и тех затрат (материальных, временных,
интеллектуальных и др.), которые необходимы для их предотвра-
щения.
Для достижения требуемой или максимальной достоверности
обработки информации в АС используются специальные методы,
основанные на введении в структуры обработки ИМ информаци-
онной, временной или структурной избыточности [16].
Информационная избыточность характеризуется введением
дополнительных разрядов в используемые ИМ и дополнитель-
ных операций в процедуры переработки ИМ, имеющих матема-
тическую или логическую связь с алгоритмом переработки,
обеспечивающих выявление и исправление ошибок определен-
ного типа.
503
Временная избыточность связана с возможностью неоднократ-
ного повторения определенного контролируемого этапа (фазы)
обработки информации.
Структурная избыточность характеризуется введением в состав
АС дополнительных элементов (резервирование ИМ, реализация
одной функции различными процедурами, схемный контроль и др.).
По виду реализации известные методы обеспечения (повыше-
ния) достоверности обрабатываемой информации в АС можно
разделить на две основные группы: организационные (системные
и административные) и аппаратно-программные (программные и
аппаратные) (рис. 9.4).
Системные и административные методы обеспечения дос-
товерности.
Методы обеспечения надежности АС включают в себя две боль-
шие группы методов обеспечения надежности комплекса аппарат-
ных и комплекса программных средств.
Надежность АС — свойство АС выполнять заданные функции, со-
храняя во времени значения установленных эксплуатационных пока-
зателей в заданных пределах, соответствующих заданным режимам и
условиям использования, технического обслуживания, ремонта, хра-
нения и транспортирования.
При наступлении отказа АС не может выполнять все предус-
мотренные документацией задачи, т. е. переходит из исправного
состояния в неисправное. Если при наступлении отказа АС спо-
собна выполнять заданные функции, сохраняя значения основных
характеристик в пределах, установленных технической докумен-
тацией, то она находится в работоспособном состоянии. С точки
зрения обеспечения безопасности информации необходимо сохра-
нять хотя бы работоспособное состояние АС. Для решения этой
задачи необходимо обеспечить высокую надежность функциони-
рования технических (аппаратных) и программных средств.
Надежность комплекса аппаратных средств определяется в ос-
новном случайными сбоями и отказами, а надежность комплекса
программных средств — наличием, как правило, систематических
ошибок, допущенных при его разработке. При этом отказ (сбой)
технического средства зависит от времени и не зависит от перера-
батываемой информации, а программные ошибки являются функ-
цией от текущей входной информации и текущего состояния АС.
504
Рис. 9.4. Классификация методов повышения достоверности обработки информации в АС
505
Для обеспечения достоверности в АС используются общие ти-
повые методы обеспечения надежности аппаратуры, целью кото-
рых служит поддержание характеристик аппаратных средств АС
в заданных пределах. Надежность технических (аппаратных)
средств достигается на этапах разработки, производства и эксплу-
атации. На этапе разработки выбираются элементная база, техно-
логия производства и структурные решения, обеспечивающие мак-
симально достижимую надежность АС в целом. На этапе произ-
водства главными условиями выпуска надежной продукции явля-
ются высокий технологический уровень производства и органи-
зация эффективного контроля качества выпускаемых техничес-
ких (аппаратных) средств. Удельный вес этапа эксплуатации тех-
нических средств в решении проблемы обеспечения надежности
АС в последние годы значительно снизился. Для определенных
видов вычислительной техники, таких как персональные ЭВМ,
уровень требований к процессу технической эксплуатации сни-
зился практически до уровня эксплуатации бытовых приборов. Тем
не менее, роль этапа эксплуатации технических средств в реше-
нии задачи обеспечения надежности сложных АС остается доста-
точно значимой [16].
Для программных средств рассматривают два этапа — этап раз-
работки и этап эксплуатации. Этап разработки программных
средств является определяющим при создании надежных компь-
ютерных систем. На этом этапе к основным направлениям повы-
шения надежности программных средств относятся [10]:
* корректная постановка задачи на разработку;
* использование прогрессивных технологий программирова-
ния;
* контроль правильности функционирования.
Корректность постановки задачи достигается в результате со-
вместной работы специалистов предметной области и высокопро-
фессиональных программистов. В настоящее время для повыше-
ния качества программных продуктов используются современные
технологии программирования (например, CASE-технология). Эти
технологии позволяют значительно сократить возможности вне-
сения субъективных ошибок разработчиков и характеризуются
высокой автоматизацией процесса программирования, использо-
ванием стандартных программных модулей, тестированием их со-
вместной работы. Контроль правильности функционирования ал-
горитмов и программ осуществляется на каждом этапе разработ-
506
ки и завершается комплексным контролем, охватывающим все
решаемые задачи и режимы. Основными методами контроля ка-
чества программных средств являются тестирование и отладка.
На этапе эксплуатации программные средства дорабатывают-
ся, в них устраняются замеченные ошибки, поддерживается цело-
стность программных средств и актуальность данных, используе-
мых этими средствами.
Оптимизация структур обработки информации состоит в вы-
боре технологической структуры переработки информации, обес-
печивающей максимизацию достоверности преобразования ин-
формации при заданных ограничениях на время и материальные
затраты. При этом для анализа и синтеза данных структур исполь-
зуется типовой модуль обработки информации (см. рис. 9. 3).
Системно-организационные методы дублирования информаци-
онных массивов рассматриваются в п. 9.3. Методы организации и
разграничения доступа к информационным ресурсам — в п. 9.4.
Оптимизация взаимодействия пользователей и обслуживающе-
го персонала с АС является одним из основных направлений обес-
печения достоверности информации в АС за счет сокращения чис-
ла ошибок пользователей и обслуживающего персонала. Основ-
ными направлениями при этом являются:
научная организация труда;
воспитание и обучение пользователей и персонала;
анализ и совершенствование процессов взаимодействия че-
ловека с АС.
Научная организация труда предполагает:
оборудование рабочих мест;
оптимальный режим труда и отдыха;
дружественный интерфейс человека с АС.
Рабочее место должно быть оборудовано в соответствии с ре-
комендациями эргономики. Освещение рабочего места; темпера-
турно-влажностный режим; расположение табло, индикаторов,
клавиш и тумблеров управления; размеры и цвет элементов обо-
рудования, помещения; положение пользователя (специалиста)
относительно оборудования; использование защитных средств -все
это должно обеспечивать максимальную производительность че-
ловека в течение рабочего дня. Одновременно сводится к мини-
муму утомляемость работника и отрицательное воздействие на его
здоровье неблагоприятных факторов производственного процес-
са. Для людей, работающих с ЭВМ, основными неблагоприятными
507
факторами являются: излучения мониторов, шумы электромеха-
нических устройств, гиподинамия, и, как правило, высокие нагруз-
ки на нервную систему. В связи с этим устанавливаются требова-
ния по организации работы труда и отдыха при работе с ЭВМ. При
этом выделяется 3 различных вида трудовой деятельности: А — ра-
бота по считыванию информации с экрана ЭВМ с предваритель-
ным запросом; Б — работа по вводу информации; В — творческая
работа в режиме диалога с ЭВМ. При выполнении в течение рабо-
чей смены работ, относящихся к разным видам трудовой деятель-
ности, за основную работу с ЭВМ следует принимать такую, кото-
рая занимает не менее 50% времени в течение рабочей смены или
рабочего дня.
Для видов трудовой деятельности устанавливается 3 категории
тяжести и напряженности работы с ЭВМ, которые определяются: для
группы А — по суммарному числу считываемых знаков за рабочую
смену, но не более 60 000 знаков за смену; для группы Б — по суммар-
ному числу считываемых или вводимых знаков за рабочую смену, но
не более 40 000 знаков за смену; для группы В —- по суммарному вре-
мени непосредственной работы с ЭВМ за рабочую смену, но не бо-
лее 6 часов за смену. В зависимости от тяжести работы устанавлива-
ется определенное время перерывов (табл. 9.1).
Таблица 9.1
Категория работы Уровень нагрузки за рабочую смену при видах работ с ЭВМ Суммарное время регламентированных перерывов, мин
группа А, кол-во знаков группа Б, кол-во знаков группа В, час при 8 часовой смене при 16 часовой смене
I до 20.000 до 15.000 до 2,0 30 70
II до 40.000 до 30.000 до 4,0 50 90
III до 60.000 до 60.000 до 6.0 70 120
Время перерывов дано при условии соблюдения санитарных
норм и правил, при их несоблюдении время перерывов следует
увеличить на 30%.
Во время регламентированных перерывов с целью снижения
нервно-эмоционального напряжения, угомления зрительного ана-
508
лизатора, устранения влияния гиподинамии и гипокинезии, пре-
дотвращения развития познотонического утомления целесообраз-
но выполнять комплексы упражнений для глаз, улучшения мозго-
вого кровообращения, снятия утомления с плечевого пояса и рук,
туловища и ног.
Прогресс в области электронной вычислительной техники (ЭВТ)
позволил значительно облегчить взаимодействие человека с ЭВМ.
Если на заре ЭВТ с компьютером мог работать только человек
с высшим специальным образованием, то теперь на ПЭВМ рабо-
тают дети дошкольного возраста. Дальнейшее развитие интерфей-
са человека с ЭВМ идет в направлении совершенствования про-
цессов ввода-вывода информации и управления вычислительным
процессом. Речевой ввод информации, автоматический ввод-вы-
вод видео- и аудиоинформации, работа с графикой, вывод инфор-
мации на экраны и табло создают новые возможности для обще-
ния человека с ЭВМ. Важным для обеспечения безопасности ин-
формации является совершенствование диалога пользователя
с АС. Наличие развитых систем меню, блокировок неправильных
действий, механизма напоминаний, справочных систем, систем
шаблонов существенно снимает нагрузку на нервную систему, со-
кращает число ошибок, повышает работоспособность человека и
производительность системы в целом.
Одним из центральных вопросов обеспечения достоверности
информации в АС является вопрос воспитания и обучения обслу-
живающего персонала и пользователей АС.
Важной задачей оптимизации взаимодействия человека с АС
является анализ этого процесса и его совершенствование. Анализ
должен проводиться на всех жизненных этапах АС и направлять-
ся на выявление слабых звеньев. Слабые звенья заменяются или
совершенствуются как в процессе разработки новых АС, так и
в процессе модернизации существующих.
Аппаратно-программные методы повышения достовернос-
ти перерабатываемой а АС информации представляют собой со-
вокупность методов контроля и выявления ошибок в исходных и
получаемых информационных массивах, ихлокализации и исправ-
ления [16]. Программные методы включают методы контроля
преобразований и защиты ИМ при переработке и методы контроля
и защиты информации, передаваемой в каналах связи. Программные
методы предусматривают дополнительные операции в процедурах
переработки информации, которые имеют математическую или
509
логическую связь с алгоритмом переработки (преобразования и пе-
редачи ИМ). Сравнение результатов этих дополнительных опе-
раций с результатами переработки информации дает возможность
установить с определённой вероятностью наличие или отсутствие
ошибок, а также исправить обнаруженную ошибку.
Аппаратные методы повышения достоверности выполняют
практически те же функции, что и программные методы, кроме
того, позволяют обнаруживать ошибки ближе к месту их возник-
новения, а также недоступные для программных методов (напри-
мер, перемежающиеся ошибки).
Наиболее распространенным аппаратным (схемным) методом
контроля преобразований информации является контроль по мо-
дулю. Он относится к неполному контролю, основанному на груп-
пировании чисел в классы эквивалентности. Если в случае возник-
новения ошибки число переходит в другой класс эквивалентнос-
ти, то ошибка легко обнаруживается, в противном случае — не об-
наруживается. Метод позволяет выявлять случайные и система-
тические ошибки. В один и тот же класс эквивалентности входят
числа, сравнимые по модулю.
Если целым числам Ли В соответствует один и тот же остаток
от деления на третье число р, то числа А и В равноостаточны друг
другу по модулю р или сравнимы по модулю р:
Я = 5(тос1р). (9.1)
Уравнения типа (9.1) называют сравнениями.
Различают числовой и цифровой контроль по модулю.
При числовом методе контроля определяется код заданного
числа как наименьший положительный остаток от деления числа
на выбранный модуль р:
гА= А-{а/р\р, (9.2)
где в фигурных скобках { } — целая часть от деления числа;
А — контролируемое число.
Величина модуля р определяет число классов эквивалентности
и существенно влияет на качество контроля. При этом, чем боль-
ше р, тем больше полнота контроля, поскольку чем больше клас-
сов эквивалентности, тем меньше мощность каждого класса и,
следовательно, меньше вероятность того, что в результате неко-
торой ошибки число А останется в том же классе эквивалентности
(и вследствие этого ошибка не обнаруживается).
510
Для числового метода контроля справедливы соотношения:
если А = гЛ(то4р); В = гв(тоф) > где0<гя<р-1; 0<гв < р-1;
то А + В = гл + rfl(modр) и
?а+в =гл + ^(modp). (9-3)
Кроме соотношения (9.3), используемого для числового конт-
роля по модулю выполнения операций сложения, используют срав-
нения вида:
гА-в - rA -^(modp); (9.4)
гав = глгв(тоАРУ < <9-5)
соответственно, для числового контроля по модулю выполнения
операций вычитания и умножения.
Пример. Для заданных чисел А — 125 и В =89 определим конт-
рольные коды самих чисел, их суммы и разности, если модуль р = 11.
Решение. Контрольные коды чисел определяем по формуле (9.2):
гА = 125 —{125/11^1 = 4; гв = 89-{89/11}11 = 1.
Аналогично находим контрольные коды для суммы и разности:
А + В = 214, гА+в= 214 - {214/11} 11=5;
А - В = 36, гАВ= 36 - {36/11} 11 = 3;
Проверку правильности определения контрольных кодов сум-
мы и разности можно провести на основании формул (9.3) и (9.4):
гА+в = 4 +1 s 5(modl 1); гА_в = 4 -1 = 3(modl 1).
Ответ:: rA=4; rB= 1; гд+в = 5; гА,в = 3.
При цифровом методе контроля контрольный код числа обра-
зуется как остаток от деления суммы цифр а. числа А на модуль р .
Например, если р = 5, А = 11101110, получим:
511
В частности, при использовании двоичной системы счисления
цифровой контроль по модулю 2 сводится к контролю на чет-
ность-нечетность. При этом в информационном массиве резер-
вируется один специальный бит чётности, значение («1» или «О»)
которого формируется всеми передающими информационные
массивы устройствами путём суммирования значений информа-
ционных битов и проверяется всеми принимающими информаци-
онные массивы устройствами. Несоответствие значения бита чет-
ности сумме значений информационных битов сигнализирует об
ошибке.
Методы контроля и защиты информации при передаче рассмот-
рены в п. 8.5.
9.3. ОБЕСПЕЧЕНИЕ СОХРАННОСТИ ИНФОРМАЦИИ
В АВТОМАТИЗИРОВАННЫХ СИСТЕМАХ
При эксплуатации АС существует возможность разрушения
информационных массивов (ИМ), которое приводит к появлению
ошибок в результатах, невозможности решения некоторых функ-
циональных задач или к полному отказу АС. Основными причина-
ми нарушения целостности и готовности ИМ в процессе их непос-
редственного использования или хранения на носителях являют-
ся ошибки и преднамеренные действия операторов и обслужива-
ющего персонала, деструктивные действия компьютерных виру-
сов, агрессивность внешней среды (температура, влажность и др.),
износ носителей информации, сбои и отказы АПС АС, приводя-
щие к разрушению информационных массивов или их носителей.
При этом на восстановление больших информационных массивов
требуются значительные временные, материальные, интеллекту-
альные и другие затраты. В критических ситуациях восстановле-
ние информационных массивов может оказаться вообще невоз-
можным.
Проблема обеспечения целостности и готовности информации
при эксплуатации АС заключается в разграничении доступа к ИМ
и программно-техническим ресурсам (см. п. 9.4), контроле правиль-
ности информационных массивов, обнаружении ошибок, резер-
вировании (дублировании, архивировании) и восстановлении ИМ
во внутримашинной информационной базе по зарезервированным
512
ИМ, т.е. в организации и применении мер, обеспечивающих со-
хранность информации [16].
Методы повышения сохранности информации в АС в зависи-
мости от вида их реализации можно разделлть на организацион-
ные и аппаратно-программные.
Организационные методы повышения сохранности состоят
в создании и использовании рациональной технологии эксплуата-
ции (хранения и применения) ИМ, предусматривающей профилак-
тические меры по снижению доли искажений ИМ до определен-
ного допустимого уровня и по обеспечению своевременного пре-
доставления необходимых аутентичных ИМ для автоматизирован-
ного решения задач АС. Основными из них являются:
* учет и хранение информационных масс ивов в базах данных АС;
контроль за качеством работы операторов и обслуживающе-
го персонала;
контроль износа и старения технических средств, функцио-
нирования АПС, а также правильности их эксплуатации;
профотбор, обучение и стимулирование персонала АС;
организация труда персонала АС, обеспечивающая умень-
шение возможностей нарушения им требований сохранно-
сти ИМ (минимизация сведений и данных, доступных пер-
соналу, минимизация связей (контактов) персонала, дубли-
рование контроля важных операций);
обеспечение противопожарной защиты и температурно-
влажностного режима.
Основными аппаратно-программными методами повышения
сохранности информации являются:
резервирование (дублирование) информации;
контроль, обнаружение и исправление ошибок ИМ;
контроль верности входных данных и защита от вредительс-
ких программ-вирусов;
блокировка ошибочных операций.
Резервирование информации является одним из самых эффек-
тивных методов обеспечения сохранности информации. Оно обес-
печивает защиту информации как от случайных угроз, так и от пред-
намеренных воздействий. В общем случае способы резервирования
ИМ с целью обеспечения сохранности информации включают:
оперативное резервирование — создание и хранение резер-
вных рабочих копий ИМ, используемых для решения функ-
циональных задач АС в реальном масштабе времени;
33 А-210
513
восстановительное резервирование — создание и хранение
дополнительных резервных (восстановительных) копий ИМ,
используемых только для восстановления разрушенных ра-
бочих копий ИМ;
• долговременное (долгосрочное) резервирование — создание,
длительное хранение и обслуживание архивов оригиналов,
дубликатов и резервных копий ИМ. При этом хранение ар-
хивной информации, представляющей особую ценность,
должно быть организовано в специальном охраняемом по-
мещении или даже в другом здании на случай пожара или
стихийного бедствия.
Одним из эффективных методов оперативного резервирования
является копирование информации на зеркальный диск. Зеркаль-
ным называют жесткий магнитный диск отдельного накопителя,
на котором хранится информация, полностью идентичная инфор-
мации на рабочем диске. Это достигается за счет параллельного
выполнения всех операций записи на оба диска. При отказе рабо-
чего накопителя осуществляется автоматический переход на ра-
боту с зеркальным диском в режиме реального времени. Инфор-
мация при этом сохраняется в полном объеме.
В настоящее время для повышения сохранности информации
в ЭВМ все чаще применяют системы дисковых массивов RAID —
группы дисков, работающих как единое устройство хранения дан-
ных, соответствующее технологии RAID (Redundant Arrays of
Inexpensive Discs). В технологии RAID предусмотрено 6 основных
уровней: с нолевого по 5-й, определяющих порядок записи на не-
зависимые диски и порядок восстановления информации. Различ-
ные уровни RAID обеспечивают различное быстродействие и раз-
личную эффективность восстановления информации.
Уровень 0 предполагает поочередное использование дисков
для записи файлов. Дублирование не используется. Преимуще-
ство подобного решения заключается в увеличении скорости
ввода-вывода пропорционально количеству задействованных
в массиве дисков. В то же время такое решение не позволяет
восстановить информацию при выходе из строя одного из дис-
ков массива.
RAID уровня 1 предусматривает зеркальное дублирование ин-
формации.
На уровне 2 биты информации поочередно размещаются на
дисках. Данные размещаются на дисках с дублированием.
514
На уровне 3 байты данных поочередно записываются на диски.
Для восстановления информации при выходе из строя какого-либо
из дисков используется не дублирование данных, а контрольная
информация, записываемая на специальный выделенный диск.
Уровень 4 предполагает поочередную запись на диски блоками
и допускает параллельное выполнение запросов на чтение, но за-
пись осуществляется последовательно, так как контрольная инфор-
мация записывается на один выделенный диск.
На уровне 5 осуществляется поочередная запись на диски как
блоков данных, так и контрольной информации. Этот уровень по-
зволяет осуществлять одновременно несколько операций чтения
или записи.
Реальные RAID системы поддерживают несколько уровней, ко-
торые выбираются с учетом требований, предъявляемых к вне-
шним запоминающим устройствам конкретной АС.
Для восстановительного и долговременного резервирования
используются, как правило, съемные машинные носители: гибкие
магнитные диски, жесткие съемные магнитные диски и магнит-
ные ленты, а также оптические диски.
Контроль, обнаружение и исправление ошибок ИМ реализу-
ются как в аппаратном варианте, так и в виде программных моду-
лей. Наиболее распространенными из них являются следующие [ 16 j.
Получение контрольных сумм. В качестве дополнительной из-
быточной информации для проверки целостности ИМ может ис-
пользоваться сумма всех символов (хранимая в конце ИМ), полу-
ченная циклическим сложением после обновления. Может также
применяться обратная величина контрольной суммы, при этом сум-
ма всей информации блока ИМ и обратной величины всегда рав-
на нолю. В случае воздействия различных дестабилизирующих
факторов (ошибок, сбоев, вирусов и др.) символ в ИМ может ис-
казиться, тогда соответствующая контрольная сумма изменится и
этот факт легко обнаружится при очередной контрольной провер-
ке. Для обнаружения простых перестановок символов в ИМ, при
которых контрольная сумма остается прежней, используют более
сложные алгоритмы подсчета контрольной суммы, например,
с учетом позиции символа. Кроме того, с целью скрытия конт-
рольной суммы она может подвергаться различным защитным
преобразованиям (см. п. 9.4).
Использование контрольных чисел. В качестве дополнительной
избыточной информации для проверки целостности ИМ может
515
использоваться цифра (хранимая в конце ИМ), связанная с симво-
лами ИМ некоторым соотношением. Например, контрольной циф-
рой может быть остаток от деления контрольного числа, если ис-
пользуется схема сравнения по модулю (см. п. 9.2).
Использование избыточных кодов, позволяющих выявлять и
автоматически исправлять имеющиеся в ИМ ошибки (см. п. 7.3).
Программная проверка по четности, обеспечивающая более
качественный контроль по сравнению со схемной проверкой чет-
ности для каждого бита (слова) за счет выявления ошибок в случае
четного количества неверных битов. Например, путем проверки
диагональной четности — биты четности соответствуют четности,
подсчитываемой по всем диагональным линиям.
Контроль верности входных ИМ. Алгоритмы, реализующие
данный метод, достаточно просты. Например, проверку значений
цифровых данных осуществляют на основе контроля допустимо-
го диапазона изменения некоторого показателя (вероятность не
может быть равна 1,5, скорость распространения радиосигнала не
может превышать ЗхЮ8 м/с и т. д.).
При увеличении масштабов и сложности АС возрастает доля
разрушения информации вследствие ошибок операторов и несан-
кционированных корректировок. Ошибки операторов на этапе
ввода и размещения исходных данных являются наиболее опас-
ными, поскольку часто их обнаружение становится возможным
спустя значительное время после их появления. Кроме того, опе-
раторы, имеющие доступ к информационным ресурсам АС, для их
искажения или разрушения могут использовать специальные вре-
дительские программы-вирусы.
Контроль верности входных данных и защита от вирусов. Ос-
новными задачами системы контроля и защиты информации от
компьютерных вирусов являются:
обнаружение вирусов в АС;
блокирование работы программ-вирусов;
устранение последствий воздействия вирусов.
Для решения данных задач используются специальные антиви-
русные средства.
Обнаружение вирусов должно осуществляться на стадии их
внедрения или до начала осуществления деструктивных функций
вирусов. При этом необходимо отметить, что не существует ан-
тивирусных средств, гарантирующих обнаружение всех возмож-
516
ных вирусов. Основными методами обнаружения вирусов явля-
ются [10]:
сканирование;
обнаружение изменений;
эвристический анализ;
использование резидентных сторожей;
вакцинация программ;
аппаратно-программная защита от вирусов.
Сканирование — один из самых простых методов обнаружения
вирусов. Сканирование осуществляется программой-сканером,
которая просматривает файлы в поисках опознавательной части
вируса — сигнатуры. Программа фиксирует наличие уже извест-
ных вирусов, за исключением полиморфных вирусов, которые
применяют шифрование тела вируса, изменяя при этом каждый
раз и сигнатуру. Программы-сканеры могут хранить не сигнатуры
известных вирусов, а их контрольные суммы. Данный метод при-
меним для обнаружения вирусов, сигнатуры которых уже выде-
лены и являются постоянными. Для эффективного использования
метода необходимо регулярное обновление сведений о новых ви-
русах. Самая известная программа-сканер в России — Aidstest
Д. Лозинского.
Метод обнаружения изменений базируется на использовании
программ-ревизоров. Эти программы определяют и запоминают
характеристики всех областей на дисках, в которых обычно раз-
мещаются вирусы. При периодическом выполнении программ-
ревизоров сравниваются хранящиеся характеристики и характе-
ристики, получаемые при контроле областей дисков. По результа-
там ревизии программа выдает сведения о предположительном
наличии вирусов. Обычно программы-ревизоры запоминают
в специальных файлах образы главной загрузочной записи, загру-
зочных секторов логических дисков, характеристики всех конт-
ролируемых файлов, каталогов и номера дефектных кластеров.
Могут контролироваться также объем установленной оператив-
ной памяти, количество подключенных к компьютеру дисков и их
параметры. Главным достоинством этого метода является возмож-
ность обнаружения вирусов всех типов, а также новых неизвест-
ных вирусов. Примером программы-ревизора является Adinf, раз-
работанная Д. Мостовым. Основным недостатком метода обнару-
жения изменений служит невозможность определения вируса
в ИМ, которые поступают в систему уже зараженными (вирусы
517
будут обнаружены только после размножения в системе), а также
вирусов в часто изменяемых ИМ (текстовых документах, табли-
цах и др.).
Эвристический анализ позволяет определять неизвестные ви-
русы, но при этом не требует предварительного сбора, обработки
и хранения информации о файловой системе. Его сущность зак-
лючается в проверке возможных сред обитания вирусов и выяв-
ление в них команд (групп команд), характерных для вирусов. При
обнаружении «подозрительных» команд в файлах или загрузоч-
ных секторах выдается сообщение о возможном заражении. Эв-
ристический анализатор имеется, например, в антивирусной про-
грамме Doctor Web.
Метод использования резидентных сторожей основан на при-
менении программ, которые постоянно находятся в оперативной
памяти ЭВМ и отслеживают все действия остальных программ.
В случае выполнения какой-либо программой подозрительных дей-
ствий (обращение для записи в загрузочные сектора, помещение
в оперативную память резидентных модулей, попытки перехвата
прерываний и т. п.) резидентный сторож выдает сообщение пользо-
вателю. Существенным недостатком данного метода является зна-
чительный процент ложных тревог.
Под вакцинацией программ понимается создание специального
модуля для контроля ее целостности. В качестве характеристики
целостности файла обычно используется контрольная сумма. При
заражении вакцинированного файла модуль контроля обнаружи-
вает изменение контрольной суммы и сообщает об этом пользова-
телю.
Самый надежный метод защиты от вирусов — использование
аппаратно-программных антивирусных средств. В настоящее вре-
мя для защиты ЭВМ применяются специальные контроллеры и их
программное обеспечение. Контроллер устанавливается в разъем
расширения и имеет доступ к общей шине. Это позволяет ему кон-
тролировать все обращения к дисковой системе. В программном
обеспечении контроллера запоминаются области надисках, изме-
нение которых в обычных режимах работы не допускается. При
выполнении запретных действий любой программой контроллер
выдает соответствующее сообщение пользователю и блокирует ра-
боту ЭВМ.
При обнаружении вируса необходимо сразу же прекратить ра-
боту программы-вируса, чтобы минимизировать ущерб от его воз-
518
действия на систему. Следующим шагом является устранение по-
следствий воздействия вирусов, включающее удаление вирусов и
восстановление (при необходимости) ИМ. При этом восстановле-
ние информации без использования дублирующей информации
может быть невыполнимым.
Для блокировки ошибочных операций (действий) используют-
ся технические и аппаратно-программные средства. Технические
средства применяются в основном для предотвращения ошибоч-
ных действий людей. К таким средствам относятся блокировоч-
ные тумблеры, защитные экраны и ограждения, предохранители,
средства блокировки записи на магнитные ленты, дискеты и т. п.
Аппаратно-программные средства позволяют, например, блокиро-
вать вычислительный процесс при нарушениях программами ад-
ресных пространств оперативной памяти. С их помощью может
быть заблокирована запись в определенные области внешних за-
поминающих устройств и некоторые другие операции. На про-
граммном уровне могут устанавливаться атрибуты файлов, в том
числе и атрибут, запрещающий запись в файлы. С помощью про-
граммных средств устанавливается режим обязательного подтвер-
ждения выполнения опасных операций, таких как уничтожение
ИМ, разметка или форматирование носителей информации и др.
9.4. ОБЕСПЕЧЕНИЕ КОНФИДЕНЦИАЛЬНОСТИ
ИНФОРМАЦИИ В АВТОМАТИЗИРОВАННЫХ
СИСТЕМАХ
В общей проблеме обеспечения защищенности информации
в АС особая роль отводится обеспечению требуемого уровня кон-
фиденциальности информационных массивов. Это обусловлено
тем, что возможное нарушение конфиденциальности ИМ и, как
следствие, раскрытие, модификация (с целью дезинформации),
случайное или преднамеренное разрушение, а также несанкцио-
нированное использование информации (НСИ) могут привести
к крайне тяжелым последствиям с нанесением неприемлемого
ущерба владельцам или пользователям информации.
Основными направлениями обеспечения конфиденциальности
информации в АС являются:
• защита информации от утечки по техническим каналам;
криптографическая защита ИМ;
519
защита объектов от несанкционированного доступа посто-
ронних лиц;
разграничение доступа в автоматизированных системах.
Всю совокупность мер и мероприятий по обеспечению конфи-
денциальности информации в АС можно условно разделить на две
группы [16]:
организационные (административные, законодательные);
инженерно-технические (физические, аппаратные, про-
граммные и криптографические).
Административные — комплекс организационно-правовых
мер и мероприятий, регламентирующих (на основе нормативно-
правовых актов: приказов, директив, инструкций и т. п.) процес-
сы функционирования АС, использование ее аппаратно-программ-
ных средств, а также взаимодействие пользователей и обслужи-
вающего персонала с АС с целью исключения возможности или
существенного затруднения НСД к ИМ. Административные меры
играют важную роль в создании надежной подсистемы защиты от
НСД и НСИ, обеспечивая организацию охраны, режима функци-
онирования объекта, работу с кадрами, документами, использова-
ние средств защиты, а также информационно-аналитическую де-
ятельность по выявлению угроз безопасности информации.
Комплекс законодательных мер определяется законами страны,
постановлениями руководящих органов и соответствующими по-
ложениями, регламентирующими правила переработки и исполь-
зования информации ограниченного доступа и ответственность за
их нарушение, препятствуя тем самым НСИ. Сюда же относятся
положения об охране авторских прав, о выдаче лицензий и т. п.
Комплекс физических мер и мероприятий предназначен для со-
здания физических препятствий (на основе применения различ-
ных специальных устройств и сооружений) для потенциальных
нарушителей на пути в места, в которых можно иметь доступ к за-
щищаемой информации. Они играют важную роль в комплексе
мероприятий по обеспечению конфиденциальности информации,
затрудняя использование прямых и косвенных каналов утечки
информации.
Аппаратные методы обеспечения конфиденциальности инфор-
мации — это комплекс мероприятий по разработке и использова-
нию механических, электрических, электронных и других уст-
ройств, предназначенных для защиты информации от несанкцио-
нированного доступа, утечки и модификации. Аппаратные реали-
520
зации методов широко применяются в современных АС благода-
ря, главным образом, их надежности, однако из-за низкой гибкос-
ти и адаптируемости к изменяющимся условиям эксплуатации АС
часто теряют свои защитные свойства при раскрытии их принци-
пов действия и в дальнейшем не могут быть использованы.
Программными решениями (методами) обеспечения конфиден-
циальности информации являются комплексы специальных про-
грамм и компонентов общего программного обеспечения АС, пред-
назначенных для выполнения функций контроля, разграничения
доступа и исключения НСИ. Программные методы обеспечения
конфиденциальности находят широкое применение вследствие их
универсальности, гибкости, возможности развития и адаптации
к изменяющимся условиям эксплуатации АС и т. п. Однако они
имеют ряд недостатков, таких как расходование ресурса процес-
сора на их функционирование, возможность несанкционирован-
ного изменения, невозможность их реализации там, где отсутству-
ет процессор, и др.
Криптографические методы обеспечения конфиденциальнос-
ти информации в АС — это комплекс процедур и алгоритмов пре-
образования информации, обеспечивающих скрытность смысло-
вого содержания ИМ. Они являются особенно эффективным сред-
ством против подслушивания нарушителем информации, переда-
ваемой по линиям связи, и внесения им не обнаруживаемых сред-
ствами контроля искажений в передаваемое сообщение. Криптог-
рафические методы защиты информации широко используются
также для защиты информации, обрабатываемой в ЭВМ и храня-
щейся в различного типа запоминающих устройствах.
9.4.1. Защита информации от утечки по техническим каналам
Защита информации от утечки по техническим каналам достига-
ется проектно-архитектурными решениями, проведением органи-
зационных и технических мероприятий, а также выявлением пор-
тативных электронных устройств перехвата информации (заклад-
ных устройств) [26].
К основным организационным мероприятиям относятся:
* привлечение к проведению работ по защите информации
организаций, имеющих лицензию на деятельность в облас-
ти защиты информации, выданную соответствующими орга-
нами;
34 А-210
521
категорирование и аттестация объектов ТСПИ и выделен-
ных для проведения закрытых мероприятий помещений по
выполнению требований обеспечения защиты информации
при проведении работ со сведениями соответствующего
уровня конфиденциальности;
» использование на объекте сертифицированных средств
ТСПИ и ВТСС;
установление контролируемой зоны вокруг объекта ТСПИ;
привлечение к работам по строительству, реконструкции
объектов ТСПИ, монтажу аппаратуры организаций, имею-
щих лицензию на деятельность в области защиты инфор-
мации;
* организация контроля и ограничение доступа на объекты
ТСПИ и в выделенные помещения;
введение территориальных, частотных, энергетических, про-
странственных и временных ограничений в режимах исполь-
зования технических средств, подлежащих защите;
отключение на период закрытых мероприятий технических
средств, имеющих элементы, выполняющие роль электро-
акустических преобразователей, от линий связи и т. д.
Техническое мероприятие по защите информации предусмат-
ривает применение специальных технических средств, а также
реализацию технических решений. Они направлены на закрытие
каналов утечки информации путем ослабления уровня информа-
ционных сигналов или уменьшением отношения сигнал/шум
в местах возможного размещения средств разведки до величин,
обеспечивающих невозможность выделения информационного
сигнала средством разведки, и проводятся с использованием ак-
тивных и пассивных средств.
К техническим мероприятиям с использованием пассивных
средств относятся:
контроль и ограничение доступа на объекты ТСПИ и в выде-
ленные помещения:
— установка на объектах ТСПИ и в выделенных помещени-
ях технических средств и систем ограничения и контро-
ля доступа;
локализация излучений:
— экранирование ТСПИ и их соединительных линий;
— заземление ТСПИ и экранов их соединительных линий;
— звукоизоляция выделенных помещений;
522
развязывание информационных сигналов:
— установка специальных фильтров во вспомогательных
технических средствах и системах, обладающих «микро-
фонным эффектом» и выходом за пределы контролируе-
мой зоны;
— установка специальных диэлектрических вставок в оплет-
ки кабелей электропитания, труб систем отопления, во-
доснабжения и канализации, имеющих выход за преде-
лы контролируемой зоны;
— установка автономных или стабилизированных источни-
ков электропитания ТСПИ;
— установка в цепях электропитания ТСПИ, а также в ли-
ниях осветительной и розеточной сетей выделенных по-
мещений помехоподавляющих фильтров.
К техническим мероприятиям с использованием активных
средств относятся:
пространственное зашумление:
— пространственное электромагнитное зашумление с ис-
пользованием генераторов шума или создание прицель-
ных помех (при обнаружении и определении частоты из-
лучения закладного устройства или побочных электромаг-
нитных излучений ТСПИ) с использованием средств со-
здания прицельных помех;
— создание акустических и вибрационных помех с исполь-
зованием генераторов акустического шума;
— подавление диктофонов в режиме записи с использова-
нием подавителей диктофонов.
линейное зашумление:
— линейное зашумление линий электропитания;
— линейное зашумление посторонних проводников и соеди-
нительных линий ВТСС, имеющих выход за пределы кон-
тролируемой зоны.
уничтожение закладных устройств:
— уничтожение закладных устройств, подключенных к ли-
нии, с использованием специальных генераторов импуль-
сов (выжигателей «жучков»).
Выявление портативных электронных устройств перехвата
информации (закладных устройств) осуществляется проведением
специальных обследований, а также специальных проверок объек-
тов ТСПИ и выделенных помещений.
523
Специальные обследования объектов ТСПИ и выделенных по-
мещений проводятся путем их визуального осмотра без примене-
ния технических средств. Специальная проверка проводится с ис-
пользованием технических средств. При этом осуществляется вы-
явление закладных устройств с использованием:
пассивных средств:
— установка в выделенных помещениях средств и систем об-
наружения лазерного облучения (подсветки) оконных
стекол;
— установка в выделенных помещениях стационарных об-
наружителей диктофонов;
— поиск закладных устройств с использованием индикато-
ров поля, интерсепторов, частотомеров, сканерных прием-
ников и программно-аппаратных комплексов контроля;
— организация радиоконтроля (постоянно или на время про-
ведения конфиденциальных мероприятий) и побочных
электромагнитных излучений ТСПИ.
* активных средств:
— специальная проверка выделенных помещений с исполь-
зованием нелинейных локаторов;
— специальная проверка выделенных помещений, ТСПИ и
вспомогательных технических средств с использованием
рентгеновских комплексов.
9.4.2. Криптографическая защита информации
Обеспечить конфиденциальность передачи информации меж-
ду абонентами в общем случае можно одним из трех методов [5]:
1. Создать абсолютно надежный, недоступный для других ка-
нал связи между абонентами.
2. Использовать общедоступный канал связи, но скрыть сам
факт передачи информации.
3. Использовать общедоступный канал связи, но передавать по
нему информацию в преобразованном виде, причем преобразо-
вать ее надо так, чтобы восстановить ее мог только адресат.
Первый вариант является практически нереализуемым из-за
высоких материальных затрат на создание такого канала между
удаленными абонентами.
Исследованием вопросов скрытия факта передачи информации
занимается стеганография. В настоящее время она представляет
524
одно из перспективных направлений обеспечения конфиденциаль-
ности хранящейся или передаваемой информации в компьютер-
ных системах за счет маскирования закрытой информации в от-
крытых файлах, прежде всего мультимедийных.
Разработкой методов преобразования (шифрования) информа-
ции с целью ее защиты от незаконных пользователей занимается
криптография (от греч. «криптос» —тайна и «графейн» — писать).
Криптографические методы и способы преобразования информа-
ции называют шифрами.
Шифрование — процесс преобразования открытого сообщения
в шифрованное сообщение (криптограмму, шифртекст) с помощью оп-
ределенных правил, сожержащихся в шифре.
Расшифрование— процесс, обратный шифрованию.
Правило зашифрования не может быть произвольным. Оно дол-
жно быть таким, чтобы по шифртексту с помощью правила расшиф-
рования можно было однозначно восстановить открытое сообще-
ние. Однотипные правила зашифрования можно объединить в клас-
сы. Внутри класса правила различаются между собой по значениям
некоторого параметра, которое может быть числом, таблицей и т.д.
В криптографии конкретное значение такого параметра обычно
называют ключом. По сути дела, ключ выбирает конкретное прави-
ло зашифрования из данного класса правил. Это позволяет, во-пер-
вых, при использовании для шифрования специальных устройств
изменять значение параметров устройства, чтобы зашифрованное
сообщение не смогли расшифровать даже лица, имеющие точно
такое же устройство, но не знающие выбранного значения пара-
метра, и во-вторых, позволяет своевременно менять правило зашиф-
рования, так как многократное использование одного и того же пра-
вила зашифрования для открытых текстов создает предпосылки для
получения открытых сообщений по шифрованным.
Используя понятие ключа, процесс зашифрования можно опи-
сать в виде соотношения:
/а(А) = В, (9.6)
где А — открытое сообщение; В — шифрованное сообщение; f —
правило шифрования; а — выбранный ключ, известный отправи-
телю и адресату.
525
Для каждого ключа а шифрпреобразование fa должно быть об-
ратимым, то есть должно существовать обратное преобразование
которое при выбранном ключе а однозначно определяет откры-
тое сообщение А по шифрованному сообщению В:
ga(B) = A. (9.7)
Совокупность преобразований Д и набор ключей, которым они
соответствуют, называют шифром.
Среди всех шифров можно выделить два больших класса: шиф-
ры замены и шифры перестановки [5].
Шифрами замены называются такие шифры, преобразования
из которых приводят к замене каждого символа открытого сооб-
щения на другие символы — шифробозначения, причем порядок
следования шифробозначений совпадает с порядком следования
соответствующих им символов открытого сообщения. Примером
простого преобразования, которое может содержаться в шифре
замены, является правило, по которому каждая буква исходного
сообщения заменяется на ее порядковый номер в алфавите. В этом
случае исходный буквенный текст преобразуется в числовой.
Шифрами перестановки называют шифры, преобразования из
кот чрых приводят к изменению только порядка следования сим-
волов исходного сообщения. Примером простого преобразования,
которое может содержаться в шифре перестановки, является пра-
вило, по которому каждая буква исходного сообщения, стоящая
в тексте на позиции с четным номером, меняется местами с пред-
шествующей ей буквой. В этом случае ясно, что и исходное, и шиф-
рованное сообщение состоят из одних и тех же букв.
Для осуществления обмена информацией отправитель и полу-
чатель информации используют один и тот же секретный ключ.
Этот ключ должен храниться в тайне и передаваться способом,
исключающим его перехват. При этом обмен информацией осу-
ществляется в 3 этапа:
отправитель передает получателю ключ;
* отправитель, используя ключ, шифрует сообщение, которое
пересылается получателю;
получатель получает сообщение и расшифровывает его.
Часто бывает так, что злоумышленнику становится известен
шифр, а использованный ключ — нет. Для определения исходного
текста по шифрованному при неизвестном ключе возможны два под-
526
хода: первый — определить ключ и затем найти исходное сообщение
расшифрованием; второй — найти исходное сообщение без опреде-
ления ключа. Получение открытого сообщения по шифрованному без
заранее известного ключа называется вскрытием шифра, или дешиф-
рованием, в отличие от расшифрования — когда ключ известен.
Под стойкостью шифра, как правило, понимается способность
противостоять попыткам провести его вскрытие. При анализе
шифра обычно исходят из принципа, сформулированного голлан-
дцем О. Керкгоффсом (1835—1903). Согласно этому принципу, при
вскрытии криптограммы противнику известно о шифре все, кро-
ме используемого ключа. Поскольку вскрытие шифра можно осу-
ществлять перебором всех возможных его ключей, одной из глав-
ных характеристик шифра является число его возможных ключей.
Иногда в литературе смешиваются два понятия: шифрование и
кодирование. В отличие от шифрования, для которого надо знать
шифр и секретный ключ, при кодировании нет ничего секретно-
го, есть только определенная замена букв или слов на заранее оп-
ределенные символы. Методы кодирования направлены не на то,
чтобы скрыть открытое сообщение, а на то, чтобы представить его
в более удобном виде для передачи с использованием технических
средств связи, для уменьшения длины сообщения, защиты от иска-
жений и т. д. В принципе, кодирование, конечно же, можно рассмат-
ривать как шифр замены, для которого «набор» возможных клю-
чей состоит только из одного ключа (например, буква «а» в азбуке
Морзе всегда кодируется знаками • — и это не является секретом).
В настоящее время для защиты информации в АС широко ис-
пользуются электронные шифровальные устройства. Важной ха-
рактеристикой таких устройств является не только стойкость реа-
лизуемого шифра, но и высокая скорость осуществления процес-
сов шифрования и расшифрования. Для создания и обеспечения
грамотной эксплуатации такой техники применяются достижения
современной криптографии, в основе которой лежат математика,
информатика, физика, электроника и другие науки.
Современная криптография бурно развивается. В ней появляют-
ся новые направления. Так, с 1976 г. развивается «открытая криптог-
рафия». Ее отличительной особенностью служит разделение ключей
для зашифрования и расшифрования. При этом ключ для зашифро-
вания не требуется делать секретным, более того, он может быть об-
щедоступным (открытым) и содержаться, например, в телефонном
справочнике вместе с фамилией и адресом его владельца.
527
Наиболее распространенной системой шифрования с открытым
ключом является RSA, названная так по начальным буквам фами-
лий ее изобретателей: Rivest, Shamir и Adieman. В основе ее постро-
ения лежит функция, обладающая следующими свойствами:
1) существует достаточно быстрый алгоритм вычисления зна-
чений f(x);
2) существует достаточно быстрый алгоритм вычисления зна-
чений f ‘(х);
3) функция f(x) обладает некоторым «секретом», знание кото-
рого позволяет быстро вычислять значения f ‘(х); в противном слу-
чае вычисление f‘(x) становится трудно разрешимой в вычисли-
тельном отношении задачей, требующей для своего решения столь
много времени, что по его прошествии зашифрованная информа-
ция перестает представлять интерес для лиц, использующих ото-
бражение /в качестве шифра.
Рассмотрим пример применения метода RSA для криптографи-
ческого закрытия сообщений. Алгоритм данной системы основан
на использовании операции возведения в степень модульной ариф-
метики: под результатом операции i mod j понимают остаток от
целочисленного деления i на j.
Чтобы использовать алгоритм RSA, надо сначала сгенерировать
открытый и секретный ключи, выполнив следующие шаги.
1. Выберем два очень больших простых числа р и q. Под про-
стым числом понимают такое число, которое делится только на 1 и
на само себя.
2. Определим п как результат умножения р на q (n = р х q).
3. Выберем большое случайное число d. Это число должно быть
взаимно простым с результатом умножения (р— 1) х (q— 1). Взаим-
но простыми числами называют такие числа, которые не имеют
ни одного общего делителя, кроме 1.
4. Определим такое число е, для которого является истинным
следующее соотношение (е х d) mod ((р—1) х (q— 1)) = 1.
5. Назовем открытым ключом числа е и п, а секретным ключом —
числа d и п.
Теперь, чтобы зашифровать данные по известному ключу {е, п},
необходимо сделать следующее:
* разбить шифруемый текст на блоки, каждый из которых мо-
жет быть представлен в виде числа М(1) =0, 1, .... п-1;
• зашифровать текст, рассматриваемый как последователь-
ность чисел M(i) по формуле C(i) = mod п.
528
Чтобы расшифровать эти данные, используя секретный ключ
{d, п}, необходимо выполнить следующие вычисления: M(i) = (C(i))
mod п. В результате будет получено множество чисел M(i), кото-
рые представляют собой исходный текст.
Рассмотрим в качестве простого примера использования мето-
да RSA для шифрования сообщения «ЭВМ». Для простоты будем
применять очень маленькие числа (на практике используются на-
много большие числа — от 200 и выше).
1. Выберем р = 3 и q = 11. Определим п = 3 х 11 = 33.
2. Найдем (р — 1) х (q— 1) = 20. Следовательно, в качестве d вы-
берем любое число, которое является взаимно простым с 20, на-
пример d = 3.
3. Выберем число е. В качестве такого числа может быть взято
любое число, для которого удовлетворяется соотношение (е х 3)
mod 20 = 1, например 7.
4. Представим шифруемое сообщение как последовательность
целых чисел в диапазоне 1... 32. Пусть буква Э изображается чис-
лом 30, буква В — числом 3, а буква М — числом 13. Тогда исход-
ное сообщение можно представить в виде последовательности чи-
сел 30 03 13.
5. Зашифруем сообщение, используя ключ {7, 33}.
6. Cl = (307) mod 33 = 21870000000 mod 33= 24,
С2 = (З7) mod 33= 2187 mod 33 = 9,
СЗ = (137) mod 33 = 62748517 mod 33 = 7.
Таким образом, зашифрованное сообщение имеет вид {24 09 07}.
Решим обратную задачу: расшифруем сообщение {24 09 07},
полученное в результате зашифрования по известному ключу, на
основе секретного ключа {3, 33}:
Ml = (243) mod 33 = 13824 mod 33 = 30,
М2 = (93) mod 33 = 739 mod 33 = 3,
М3 = (73) mod 33= 343 mod 33 = 13.
Таким образом, в результате расшифрования сообщения полу-
чено исходное сообщение «ЭВМ».
Криптостойкость алгоритма RSA основывается на предположе-
нии, что исключительно трудно определить секретный ключ по
известному, поскольку для этого необходимо решить задачу о су-
ществовании делителей целого числа. Данная задача является NP-
полной и, как следствие этого факта, не допускает в настоящее
время эффективного (полиномиального) решения. Более того, сам
вопрос существования эффективных алгоритмов решения NP-пол-
529
ных задач до настоящего времени открыт. В связи с этим для чи-
сел, состоящих из 200 цифр (а именно такие числа рекомендуется
использовать), традиционные методы требуют выполнения огром-
ного числа операций (порядка 1023).
9.4.3. Система охраны объекта
При защите объекта АС от несанкционированного доступа по-
сторонних лиц применяются те же средства и методы защиты, что
и для защиты других объектов, на которых не используются АС.
При этом объект, на котором производится работа с конфиденци-
альной информацией, имеет, как правило, несколько рубежей за-
щиты:
1 ) контролируемая территория;
2 ) здание;
3 ) помещение;
4 ) устройство, носитель информации;
5 ) программа;
6 ) конфиденциальная информация.
Система охраны объекта АС создается с целью предотвраще-
ния несанкционированного проникновения на территорию и
в помещения объекта посторонних лиц, обслуживающего персо-
нала и пользователей. В общем случае она включает в себя следу-
ющие компоненты [10]:
• инженерные конструкции;
охранная сигнализация;
средства наблюдения;
* подсистема доступа на объект;
дежурная смена охраны.
Инженерные конструкции. Инженерные конструкции служат
для создания механических препятствий на пути злоумышленни-
ков. Они создаются по периметру контролируемой зоны. Инже-
нерными конструкциями оборудуются также здания и помещения
объектов. По периметру контролируемой территории использу-
ются бетонные или кирпичные заборы, решетки или сеточные кон-
струкции.
В здания и помещения злоумышленники пытаются проникнуть,
как правило, через двери или окна. Поэтому с помощью инженер-
ных конструкций укрепляют, прежде всего, это слабое звено в за-
щите объектов. Надежность двери зависит от механической проч-
530
ности самой двери и от надежности замков. Чем выше требования
к надежности двери, тем более прочной она выполняется, тем выше
требования к механической прочности и способности противосто-
ять несанкционированному открыванию предъявляются к замку.
Вместо механических замков все чаще используются кодовые зам-
ки. Самыми распространенными среди них (называемых обычно
сейфовыми замками) являются дисковые кодовые замки с числом
комбинаций кода ключа в пределах 106 -107. Наивысшую стойкость
имеют электронные замки, на базе которых строятся автоматизи-
рованные системы контроля доступа в помещения. В каждый та-
кой замок вводятся номера микросхем, владельцы которых допу-
щены в соответствующее помещение. Может также задаваться
индивидуальный временной интервал, в течение которого возмо-
жен доступ в помещение. Все замки могут объединяться в единую
автоматизированную систему, центральной частью которой явля-
ется ПЭВМ.
Инженерное укрепление окон осуществляется путем установ-
ки оконных решеток или применением стекол, устойчивых к ме-
ханическому воздействию.
Охранная сигнализация. Охранная сигнализация служит для
обнаружения попыток несанкционированного проникновения на
охраняемый объект. Системы охранной сигнализации должны
отвечать следующим требованием:
охватывать контролируемую зону по всему периметру;
иметь высокую чувствительность к действиям злоумышлен-
ника;
надежно работать в любых погодных и временных условиях;
обладать устойчивостью к естественным помехам;
° быстро и точно определять место нарушения;
иметь возможность централизованного контроля событий.
Для формирования электрических сигналов тревоги использу-
ются различные датчики, которые по принципу обнаружения зло-
умышленников делятся на: контактные, акустические, оптико-
электронные, микроволновые, вибрационные, емкостные, телеви-
зионные.
Контактные датчики реагируют на замыкание или размыка-
ние контактов, на обрыв тонкой проволоки или полоски фольги.
Принцип действия акустических датчиков основан на исполь-
зовании акустических волн, создаваемых различными действия-
ми злоумышлинника.
531
Оптико-электронные датчики построены на использовании
инфракрасных лучей.
В микроволновых (радиоволновых) датчиках обнаружения
злоумышленников используются электромагнитные волны в СВЧ
диапазоне (9—11 ГГц).
Вибрационные датчики обнаруживают злоумышленника по
вибрации земли, заграждений, создаваемой им при проникнове-
нии на контролируемую территорию.
Принцип действия емкостных датчиков заключается в изме-
нении эквивалентной емкости в контуре генератора сигналов дат-
чика, которое вызывается увеличением распределенной емкости
между злоумышленником и антенной датчика.
Для контроля охраняемой зоны небольших размеров или от-
дельных важных помещении могут использоваться телевизионные
датчики, представляющие собой телевизионную камеру, которая
непрерывно передает изображение участка местности.
Средства наблюдения. Организация непрерывного наблюдения
или видеоконтроля за объектом является одной из основных со-
ставляющих системы охраны объекта. В современных условиях
функция наблюдения за объектом реализуется с помощью систем
замкнутого телевидения, называемых также телевизионными си-
стемами видеоконтроля.
Телевизионная система видеоконтроля обеспечивает:
автоматизированное видеонаблюдение за рубежами защиты;
контроль за действиями персонала организации;
видеозапись действий злоумышленников;
режим видеоохраны, при котором она выполняет функции
охранной сигнализации.
В общем случае телевизионная система видеоконтроля вклю-
чает в себя следующие устройства:
передающие телевизионные камеры;
мониторы;
устройство обработки и коммутации видеоинформации;
* устройства регистрации информации.
При наличии мониторов от четырех и более оператору сложно ве-
сти наблюдение. Для сокращения числа мониторов используются ус-
тройства управления. В качестве устройств обработки и коммутации
видеоинформации могут применяться следующие устройства:
коммутаторы;
квадраторы;
532
• мультиплексоры;
детекторы движения.
Коммутаторы позволяют подключить к одному монитору от 4
до 16 телекамер с возможностью ручного или автоматического
переключения с камеры на камеру.
Квадраторы обеспечивают одновременную выдачу изображе-
ния на одном мониторе от нескольких телекамер. Для этого экран
монитора делится на части по количеству телекамер.
Мультиплексор может выполнять функции коммутатора и квад-
ратора. Кроме того, он позволяет осуществлять запись изображе-
ния на видеомагнитофон с любой камеры. Мультиплексор может
включать в себя встроенный детектор движения.
Детектор движения оповещает оператора о движении в зоне
контроля телекамеры, подключает эту камеру для записи видео-
информации на специальный видеомагнитофон, обеспечивающий
гораздо большее время записи (от 24 ч до 40 суток), чем бытовой
видеомагнитофон. Это достигается за счет пропуска кадров, уп-
лотнения записи, записи при срабатывании детектора движения
или по команде оператора.
Подсистема доступа на объект. Доступ на объекты производит-
ся на контрольно-пропускных пунктах (КПП), проходных, через
контролируемый вход в здания и помещения. На КПП и проход-
ных дежурят контролеры из состава дежурной смены охраны. Вход
в здания и помещения может контролироваться только техничес-
кими средствами. Проходные, КПП, входы в здания и помещения
оборудуются средствами автоматизации и контроля доступа.
Одной из основных задач, решаемых при организации допуска
на объект, является идентификация и аутентификация лиц, допус-
каемых на объект [ 10]. Их называют субъектами доступа. Под иден-
тификацией. понимается присвоение субъектам доступа иденти-
фикаторов и (или) сравнение предъявляемых идентификаторов
с перечнем присвоенных идентификаторов, владельцы (носители)
которых допущены на объект. Аутентификация означает провер-
ку принадлежности субъекту доступа предъявленного им иденти-
фикатора, подтверждение подлинности.
Различают два способа идентификации людей: атрибутивный
и биометрический.
Атрибутивный способ предполагает выдачу субъекту доступа
либо уникального предмета (пропуска, жетона, ключей и т. п.), либо
пароля (кода), либо предмета, содержащего код. Пароль представ-
533
ляет собой набор символов и цифр, который известен только вла-
дельцу пароля и введен в систему, обеспечивающую доступ. Па-
роли используются, как правило, в системах разграничения дос-
тупа к устройствам АС. При допуске на объекты АС для открытия
кодовых замков чаще применяются коды. Наиболее перспектив-
ными являются идентификаторы, которые представляют собой
материальный носитель информации, содержащий идентифика-
ционный код субъекта доступа. Чаще всего носитель кода выпол-
няется в виде пластиковой карты, которые в зависимости от фи-
зических принципов записи, хранения и считывания идентифи-
кационной информации делятся на: магнитные, инфракрасные,
карты оптической памяти, штриховые, карты «Виганд», полупро-
водниковые.
Магнитные карты имеют магнитную полосу, на которой может
храниться информация, считываемая специальным устройством
при протаскивании карты в прорези устройства.
На внутреннем слое инфракрасных карт с помощью специаль-
ного вещества, поглощающего инфракрасные лучи, наносится
идентификационная информация. Верхний слой карт прозрачен
для инфракрасных лучей. Идентификационный код считывается
при облучении карты внешним источником инфракрасных лучей.
При изготовлении карт оптической памяти используется тех-
нология, которая применяется при производстве компакт-дисков.
Зеркальная поверхность обрабатывается лучом лазера, который
прожигает в нужных позициях отверстия на этой поверхности.
Информация считывается в специальных устройствах путем ана-
лиза отраженных от поверхности лучей.
В штриховых картах на внутреннем слое наносятся штрихи,
которые доступны для восприятия только при специальном облу-
чении лучами света. Варьируя толщину штрихов и их последова-
тельность, получают идентификационный код. Процесс считыва-
ния осуществляется протаскиванием карты в прорези считываю-
щего устройства.
Карточки «Виганд» содержат в пластиковой основе впрессован-
ные отрезки тонкой проволоки со случайной ориентацией. Благо-
даря уникальности расположения отрезков проволоки каждая кар-
та особым образом реагирует на внешнее электромагнитное поле.
Эта реакция и служит идентифицирующим признаком.
Полупроводниковые карты состоят из полупроводниковых мик-
росхем и могут быть контактными и бесконтактными. Наиболее
534
простыми полупроводниковыми контактными картами являются
карты, содержащие только микросхемы памяти, например карты
Touch Memory, содержащие постоянную память, в которой хра-
нится серийный номер Touch Memory. Полупроводниковые кар-
ты, имеющие в своем составе микропроцессор и память, называ-
ют смарт-картами. Кроме задач идентификации, такие карты ре-
шают целый ряд других задач, связанных с разграничением досту-
па к информации в АС. Бесконтактные карты имеют в своем со-
ставе энергонезависимую память, радиочастотный идентификатор
и рамочную антенну. Идентификатор передает код считывающе-
му устройству на расстоянии до 80 см.
Все атрибутивные идентификаторы обладают одним существен-
ным недостатком. Идентификационный признак слабо или совсем
не связан с личностью предъявителя.
Этого недостатка лишены методы биометрической идентифи-
кации [10]. Они основаны на использовании индивидуальных био-
логических особенностей человека. Для биометрической иденти-
фикации человека, как правило, используются: папиллярные узо-
ры пальцев, узоры сетчатки глаз, форма кисти руки, особенности
речи, форма и размеры лица, динамика подписи, ритм работы на
клавиатуре. Основным достоинством биометрических методов
идентификации является очень высокая вероятность обнаружения
попыток несанкционированного доступа. Но этим методам прису-
щи два недостатка. Даже в лучших системах вероятность ошибоч-
ного отказа в доступе субъекту, имеющему право на доступ, со-
ставляет 0,01. Затраты на обеспечение биометрических методов
доступа, как правило, превосходят затраты на организацию атри-
бутивных методов доступа.
Подсистема доступа на объект выполняет также функции ре-
гистрации субъектов доступа и управления доступом. Если на
объекте реализована идентификация с использованием автомати-
зированной системы на базе ПЭВМ, то с ее помощью может вес-
тись протокол пребывания сотрудников на объекте, в помещени-
ях. Такая система позволяет осуществлять дистанционный конт-
роль открывания дверей, ворот и т. п., а также оперативно изме-
нять режим доступа сотрудников в помещения.
Дежурная смена охраны. Состав дежурной смены, его экипи-
ровка, место размещения определяются статусом охраняемого
объекта. Используя охранную сигнализацию, системы наблюде-
ния и автоматизации доступа, дежурная смена охраны обеспечи-
535
вает только санкционированный доступ на объект и в охраняемые
помещения. Дежурная смена может находиться на объекте посто-
янно или прибывать на объект при получении сигналов тревоги от
систем сигнализации и наблюдения.
9.4.4. Разграничение доступа в автоматизированных
системах
Основными функциями системы разграничения доступа (СРД)
в АС являются [22]:
реализация правил разграничения доступа (ПРД) субъектов
и их процессов к данным;
реализация ПРД субъектов и их процессов к устройствам
создания твердых копий;
изоляция программ процесса, выполняемого в интересах
субъекта, от других субъектов;
управление потоками данных в целях предотвращения запи-
си данных на носители несоответствующего грифа;
реализация правил обмена данными между субъектами для
АС, построенных по сетевым принципам.
В АС, допускающих совместное использование объектов дос-
тупа, существует проблема распределения полномочий субъектов
по отношению к объектам. Наиболее полной моделью распреде-
ления полномочий является матрица доступа, возникшая как обоб-
щение создаваемых в 70-х годах механизмов защиты от НСД. Мат-
рица доступа представляет собой абстрактную модель для описа-
ния системы наделения полномочиями.
Строки матрицы соответствуют субъектам (s ), а столбцы —
объектам (о.); элементы матрицы характеризуют право доступа
(читать, добавлять информацию, изменять информацию, выпол-
нять программу и т. д.) (рис. 9.5). Чтобы изменять права доступа,
модель может, например, содержать специальные права владения
и управления. Если субъект владеет объектом, он имеет право из-
менять права доступа других субъектов к этому объекту. Если не-
который субъект управляет другим субъектом, он может удалить
права доступа этого субъекта или передать свои права доступа это-
му субъекту. Для того чтобы реализовать функцию управления,
субъекты в матрице доступа должны быть также определены в ка-
честве объектов.
536
О, 02 О3
Si orwe orw о: владеть
s2 orw re г; читать
s3 г e w: писать
rw rw e: выполнять
Рис. 9.5. Матрица доступа
Элементы матрицы установления полномочий (матрицы досту-
па) могут содержать указатели на специальные процедуры, кото-
рые должны выполняться при каждой попытке доступа данного
субъекта к объекту и принимать решение о возможности доступа,
основывающиееся на:
истории доступов других объектов;
динамике состояния системы (права доступа субъекта зави-
сят от текущих прав других субъектов);
значении определенных внутрисистемных переменных, на-
пример значений времени и т. п.
В наиболее важных автоматизированных системах целесооб-
разно использование процедур, в которых решение принимается
на основе значений внутрисистемных переменных (время досту-
па, номера терминалов и т. д.), так как эти процедуры сужают пра-
ва доступа.
Матрицы доступа реализуются обычно двумя основными спосо-
бами — либо в виде списков доступа, либо мандатных списков [22].
Список доступа приписывается каждому объекту, и он иденти-
чен столбцу матрицы доступа, соответствующей этому объекту.
Списки доступа часто размещаются в словарях файлов. Мандат-
ный список приписывается каждому субъекту, и он равносилен
строкам матриц доступа, соответствующей этому субъекту. Когда
субъект имеет права доступа по отношению к объекту, то пара
(объект — права доступа) называется мандатом объекта.
На практике списки доступа применяются при создании новых
объектов и определении порядка их использования или измене-
нии прав доступа к объектам. С другой стороны, мандатные спис-
ки объединяют все права доступа субъекта. Когда, например, вы-
полняется программа, операционная система должна быть способ-
на эффективно выявлять полномочия программы. В этом случае
35 д-210
537
списки возможностей более удобны для реализации механизма
предоставления полномочий.
Некоторые операционные системы поддерживают как списки
доступа, так и мандатные списки. В начале работы, когда пользова-
тель входит в систему или начинает выполнение программы, исполь-
зуются только списки доступа. Когда субъект пытается получить
доступ к объекту в первый раз, список доступа анализируется и про-
веряются права субъекта на доступ к объекту. Если права есть, то
они приписываются в мандатный список субъекта и права доступа
проверяются в дальнейшем проверкой этого списка.
При использовании обоих видов списков список доступа часто
размещается в словаре файлов, а мандатный список — в опера-
тивной памяти, когда субъект активен. С целью повышения эф-
фективности в техническом обеспечении может применяться ре-
гистр мандатов.
Третий способ реализации матрицы доступа — так называе-
мый механизм замков и ключей. Каждому субъекту приписывает-
ся пара (А, К), где А — определенный тип доступа, а К — доста-
точно длинная последовательность символов, называемая замком.
Каждому субъекту также предписывается последовательность
символов, называемая ключом. Если субъект хочет получить дос-
туп типа А к некоторому объекту, то необходимо проверить, что
субъект владеет ключом к паре (А, К), приписываемой конкрет-
ному объекту.
К недостаткам применения матриц доступа со всеми субъекта-
ми и объектами доступа можно отнести большую размерность мат-
риц. Для ее уменьшения применяют различные методы сжатия:
установление групп пользователей, каждая из которых пред-
ставляет собой группу пользователей с идентичными полно-
мочиями;
распределение терминалов по классам полномочий;
группировка элементов защищаемых данных в некоторое
число категорий с точки зрения безопасности информации
(например, по уровням конфиденциальности).
По характеру управления доступом системы разграничения
разделяют на дискреционные и мандатные [22].
Дискреционное управление доступом дает возможность кон-
тролировать доступ поименованных субъектов (пользователей)
к поименованным объектам (файлам, программам, томам и т. д.)
в соответствии с матрицей доступа.
538
Контроль доступа должен быть применим к каждому объекту и
каждому субъекту (индивиду или группе равноправных индивидов).
Механизм, реализующий дискреционный принцип контроля
доступа, должен предусматривать возможности санкционирован-
ного изменения правила разграничения доступа (ПРД), в том чис-
ле возможность санкционированного изменения списка пользова-
телей и списка защищаемых объектов. Права изменять ПРД долж-
ны предоставляться выделенным субъектам (администрации,
службе безопасности и т. д.).
Кроме того, должны быть предусмотрены средства управления,
ограничивающие распространение прав на доступ, и механизм,
претворяющий в жизнь дискреционные ПРД, как для явных дей-
ствий пользователя, так и для скрытых, обеспечивая тем самым
защиту объектов от НСД (т.е. от доступа, не допустимого с точки
зрения заданного ПРД). Под «явными» здесь подразумеваются дей-
ствия, осуществляемые с использованием системных средств —
системных макрокоманд, инструкций языков высокого уровня
и т. д., а под «скрытыми» — иные действия, в том числе с использо-
ванием собственных программ работы с устройствами. Дискреци-
онные ПРД являются как правило дополнением мандатных ПРД.
Для реализации мандатного принципа управления доступом
каждому субъекту и каждому объекту должны сопоставляться
классификационные метки, отражающие место данного субъекта
(объекта) в соответствующей иерархии. Посредством этих меток
субъектам и объектам должны назначаться классификационные
уровни (уровни уязвимости, категории секретности и т. п.), явля-
ющиеся комбинациями иерархических и неиерархических кате-
горий. Данные метки должны служить основой мандатного прин-
ципа разграничения доступа. При вводе новых данных в систему
должны быть получены от санкционированного пользователя клас-
сификационные метки этих данных. При санкционированном за-
несении в список пользователей нового субъекта должно осуще-
ствляться сопоставление ему классификационных меток. Внешние
классификационные метки (субъектов, объектов) должны точно
соответствовать внутренним меткам. Мандатный принцип конт-
роля доступа должен реализовываться применительно ко всем
объектам при явном и скрытом доступе со стороны любого из
субъектов:
субъект может читать объект, только если иерархическая
классификация в классификационном уровне субъекта не
539
меньше, чем иерархическая классификация в классифика-
ционном уровне объекта, и неиерархические категории
в классификационном уровне субъекта включают в себя все
иерархические категории в классификационном уровне
объекта;
субъект осуществляет запись в объект, только если класси-
фикационный уровень субъекта в иерархической классифи-
кации не больше, чем классификационный уровень объекта
в иерархической классификации, и все иерархические ка-
тегории в классификационном уровне субъекта включают-
ся в неиерархические категории в классификационном уров-
не объекта.
Реализация мандатных ПРД должна предусматривать возмож-
ности сопровождения изменения классификационных уровней
субъектов и объектов специально выделенными субъектами.
В СРД должен быть реализован диспетчер доступа, т. е. сред-
ство, осуществляющее перехват всех обращений субъектов к объ-
ектам, а также разграничение доступа в соответствии с заданным
принципом разграничения доступа. Во многих системах реализу-
ется как мандатное, так и дискреционное управление доступом.
При этом дискреционные правила разграничения доступа являют-
ся дополнением мандатных. В этом случае решение о санкциони-
рованности запроса на доступ должно приниматься только при од-
новременном разрешении его и дискреционными и мандатными
ПРД. Таким образом, должен контролироваться не только единич-
ный акт доступа, но и потоки информации.
Обеспечивающие средства для системы разграничения досту-
па выполняют следующие функции [22]:
идентификацию и опознавание (аутентификацию) субъек-
тов и поддержание привязки субъекта к процессу, выполня-
емому для субъекта;
регистрацию действий субъекта и его процесса;
предоставление возможностей исключения и включения
новых субъектов и объектов доступа, а также изменение пол-
номочий субъектов;
реакцию на попытки НСД, например, сигнализацию, блоки-
ровку, восстановление системы защиты после НСД;
тестирование всех функций защиты информации специаль-
ными программными средствами;
540
очистку оперативной памяти и рабочих областей на магнитных
носителях после завершения работы пользователя с защищае-
мыми данными путем двукратной произвольной записи;
учет выходных печатных и графических форм и твердых
копий в АС;
контроль целостности программной и информационной ча-
сти как СРД, так и обеспечивающих ее средств.
Для каждого события должна регистрироваться следующая ин-
формация: дата и время; субъект, осуществляющий регистрируе-
мое действие; тип события (если регистрируется запрос на доступ,
то следует отмечать объект и тип доступа); успешно ли осуществи-
лось событие (обслужен запрос на доступ или нет).
Выдача печатных документов должна сопровождаться автома-
тической маркировкой каждого листа (страницы) документа по-
рядковым номером и учетными реквизитами АС с указанием на
последнем листе общего количества листов (страниц). Вместе
с выдачей документа может автоматически оформляться учетная
карточка документа с указанием даты выдачи документа, учет-
ных реквизитов документа, краткого содержания (наименования,
вида, шифра, кода) и уровня конфиденциальности документа,
фамилии лица, выдавшего документ, количества страниц и копий
документа.
Автоматическому учету подлежат создаваемые защищаемые
файлы, каталоги, тома, области оперативной памяти ЭВМ, выде-
ляемые для обработки защищаемых файлов, внешних устройств и
каналов связи.
Такие средства, как защищаемые носители информации, дол-
жны учитываться документально, с использованием журналов или
картотек, с регистрацией выдачи носителей. Кроме того, может
проводиться несколько дублирующих видов учета.
Реакция на попытки НСД может иметь несколько вариантов
действий:
исключение субъекта НСД из работы АС при первой попыт-
ке нарушения ПРД или после превышения определенного
числа разрешенных ошибок;
работа субъекта НСД прекращается, а информация о несан-
кционированном действии поступает администратору АС и
подключает к работе специальную программу работы с на-
рушителем, которая имитирует работу АС и позволяет ад-
министрации сети локализовать место попытки НСД.
541
Реализация системы разграничения доступа может осуществ-
ляться как программными, так и аппаратными методами или их
сочетанием. В последнее время аппаратные методы защиты инфор-
мации от НСД интенсивно развиваются благодаря тому, что: во-
первых, интенсивно развивается элементная база, во-вторых, сто-
имость аппаратных средств постоянно снижается и, наконец,
в-третьих, аппаратная реализация защиты эффективнее по быст-
родействию, чем программная [22].
Когда какой-либо пользователь или программа (субъект) обра-
щается к ресурсам АС (объекту), необходимо провести идентифи-
кацию и аутентификацию участников процесса доступа. Задачи
идентификации и аутентификации в системах разграничения до-
ступа в АС аналогичны рассмотренным в п. 9.4.3. Среди применя-
емых в настоящее время принципов опознавания в АС наиболь-
шее применение получил метод паролей, который требует, чтобы
пользователь ввел строку символов (пароль) для сравнения с эта-
лонным паролем. Если пароль соответствует эталонному, то
субъект доступа может работать с АС и пользоваться всей инфор-
мацией, доступ к которой ему разрешен.
Важной характеристикой пароля является его длина. Чем боль-
ше длина пароля, тем большую безопасность будет обеспечивать
подсистема установления подлинности, так как потребуются зна-
чительно большие усилия для отгадывания пароля. Для определе-
ния необходимой длины пароля в случае, когда нарушитель может
вводить пароль через удаленный терминал, применяют формулу
Андерсена, или формулу безопасности:
4,32 104КГ/(ар)<Л', (9-8)
где А — число символов в алфавите, из которого составляется пароль;
s — длина пароля;
V— скорость передачи через линию связи (в символах/мин);
Т — период времени, в течение которого могут быть предпри-
няты систематические попытки отгадывания пароля (в месяцах при
работе 24 ч/день);
N — число символов в каждом передаваемом сообщении при
попытке получить доступ к системе;
Р — вероятность того, что соответствующий пароль может быть
раскрыт злоумышленником.
542
Задаваясь вероятностью Р, можно получить для заданных ха-
рактеристик АС значение длины пароля s, удовлетворяющее урав-
нению безопасности.
Для ввода пароля обычно используется клавиатура компьюте-
ра и специальный считыватель не нужен. Недостатком такой сис-
темы ввода информации является возможность выявления паро-
ля путем наблюдения процесса его набора санкционированным
пользователем, анализом загрязнений на клавиатуре и т. д. Кроме
того, длинные пароли, необходимые для предотвращения раскры-
тия нарушителем, плохо запоминаются пользователями и часто
записываются на бумаге, а иногда и прямо на клавиатуре, что де-
лает систему защиты бесполезной. Затрудняет запоминание паро-
лей и их частая смена [22].
С целью повышения надежности опознавания субъекта исполь-
зуют атрибутивный и биометрический способы идентификации
(см. п. 9.4.3).
Контрольные вопросы ~
1. Что такое безопасность информации?
2. Что понимается под угрозой безопасности информации?
3. Перечислите и охарактеризуйте случайные угрозы.
4. Дайте общую характеристику преднамеренных угроз.
5. К каким последствиям может привести реализация угроз безопас-
ности информации?
б. Дайте определение технического канала утечки информации.
1. Какие технические каналы утечки информации Вы знаете?
8. Дайте определение несанкционированного доступа к информации.
9. Что такое вредительские программы?
10. В чем заключается проблема обеспечения достоверности при об-
работке информации в АС?
11. Перечислите методы повышения достоверности информации в АС.
12. Охарактеризуйте особенности организационных методов повы-
шения достоверности информации.
13. Дайте определение операции сравнения чисел по модулю?
14. Какие виды контроля по модулю Вы знаете?
15. В чем заключается проблема обеспечения целостности и готовно-
сти информационных массивов в АС?
16. Перечислите методы повышения сохранности информации в АС.
17. Какие виды резервирования информации Вы знаете?
18. Дайте характеристику методов обнаружения вирусов.
543
19. Перечислите основные направления обеспечения конфиденци-
альности информации.
20. Охарактеризуйте методы и средства защиты информации от утеч-
ки по техническим каналам.
21. Что понимается под криптографической защитой информации?
22. Что такое шифр?
23. Какие шифры Вы знаете?
24. Какими свойствами обладает функция, лежащая в основе постро-
ения криптосистем с открытым ключом?
25. Назовите основные рубежи объекта, на котором производится ра-
бота с конфиденциальной информацией.
26. Охарактеризуйте составляющие системы охраны объекта.
27. Что понимается под идентификацией и аутентификацией?
28. Какие способы идентификации персонала АС Вы знаете?
29. Перечислите основные функции системы разграничения доступа
в АС.
30. Что представляет собой матрица доступа?
31. Какие способы реализации матрицы доступа Вы знаете ?
ЛИТЕРАТУРА
1. Аладьев В.З., Хунт Ю.Я., Шишаков М.Л. Основы информати-
ки: Учебное пособие. 2-е изд., перераб. и доп. — М.: Информ;
Издат. дом «Филин», 1999.
2. Алферова З.В. Теория алгоритмов.— М.: Статистика, 1973.
3. Ба шков Е.А. Аппаратное и программное обеспечение зарубеж-
ных микро ЭВМ: учебн. пособие. — К.: Высшая шк., 1990.
4. Брукшир Дж. Г. Введение в компьютерные науки: Пер. с англ. —
М.: Изд. дом «Вильямс», 2001.
5. Введение в криптографию / Под общей ред. В.В.Ященко. —
СПб.: Питер, 2001.
6. Введение в микроЭВМ/ С.А Майоров, В.В. Кириллов, А.А При-
блуда.— Л.:Машиностроение, 1988.
7. Герасименко В.А. Основы информационной грамоты. — М.:
Энерготомиздат, 1996.
8. Дмитриев В.И. Прикладная теория информации. — М.:
Высш, шк., 1989.
9. Емельянов Г.А., Шварцман В. О. Передача дискретной инфор-
мации: Учебник для вузов.— М.: Радио и связь, 1982.
10. Завгородний В.И. Комплексная защита информации в ком-
пьютерных системах: Учебное пособие. — М.: Логос; ПБОЮЛ
Н.А.Егоров, 2001.
11. Зима В.М., Молдовян А.А.. Молдовян Н.А. Безопасность гло-
бальных сетевых технологий. — СПб.: БХВ-Петербург, 2000.
12. Иванова Г.С. Технология программирования: Учебник для
вузов. — М.: Изд-во МГТУ им. Н.Э.Баумана, 2002 г.
13. Информатика: Базовый курс/Под ред. С.В. Симоновича. —
СПб.: Питер, 2002.
14. Информатика: Учебник. 3-е изд. перераб./Под ред. Н.В. Ма-
каровой. — М.: Финансы и статистика, 2000.
15. Каган Б.М. Электронные вычислительные машины и систе-
мы: Учеб, пособие для вузов. 3-е изд., перераб. и доп. — М.:
Энерготомиздат, 1991.
16. Ловцов Д.А. Контроль и защита информации в АСУ. В 2 кн. —
Кн. 1. Вопросы теории и применения. — М.: ВА им. Ф.Э. Дзер-
жинского, 1991.
545
17. Могилев А.В., ПакН.И., Хеннер Е.К. Информатика: Учеб, посо-
бие для студ. пед. вузов / Под ред. Е.К.Хеннера. 2-е изд. — М.:
Изд. центр «Академия», 2001.
18. Новиков Ю.В., Кондратенко С.В. Локальные сети: архитек-
тура, алгоритмы, проектирование. — М.: Изд-во ЭКОМ,
2001.
19. Норенков И.П., Трудоношин В.А. Телекоммуникационные
технологии и сети. 2-е изд., испр. и доп. — М.: Изд-во МГТУ им.
Н.Э Баумана, 2000.
20. Острековский В.А. Информатика: Учеб, для вузов. — М.:
Высшая школа, 2000.
21. Савельев А.Я. Основы информатики: Учебник для вузов. —
М.: Изд-во МГТУ им. Н.Э.Баумана, 2001.
22. Технические методы и средства защиты информации /
Ю.Н. Максимов, В.Г.Сонников, В.Г.Петров и др. СПб.:
ООО «Издательство Полигон», 2000.
23. Торокин А.А. Основы инженерно-технической защиты ин-
формации. — М.: Изд-во «Ось-89», 1998.
24. Угрюмов Е.П. Цифровая схемотехника. — СПб.: БХВ-Петер-
бург, 2002.
25. Федеральный закон «Об информации, информатизации
и защите информации, 1995.
26. Хорев А.А. Способы и средства защиты информации. — М.:
МО РФ, 1998.
27. Шмалько А.В. Цифровые сети связи: основы планирования
и построения. — М.: Эко-Трендз, 2001.
28. Экономическая информатика / Под ред. П.В.Конюховско-
го и Д.Н.Колесова. — СПб: Питер, 2001.
ОГЛАВЛЕНИЕ
Глава 1. Информация и информатика.....................4
1.1. Понятие информации.........................4
1.2. Информационные процессы и системы..........8
1.3. Информационные ресурсы и технологии.......14
1.4. Информатика и ее предыстория..............18
1.5. Структура информатики
и ее связь с другими науками.................24
Контрольные вопросы............................27
Глава 2. Количество и качество информации............29
2.1. Уровни проблем передачи информации........29
2.2. Меры информации...........................31
2.2.1. Меры информации синтаксического уровня ... 31
2.2.2. Меры информации семантического уровня ... 38
2.2.3. Меры информации прагматического уровня ... 40
2.3. Качество информации.......................42
2.4. Виды и формы представления информации
в информационных системах....................48
Контрольные вопросы ...........................53
Глава 3. Представление информации в цифровых автоматах .... 54
3.1. Системы счисления.........................54
3.1.1. Позиционные системы счисления........56
3.1.2. Перевод чисел из одной системы счисления
в другую.................................63
3.1.3. Двоичная, восьмеричная
и шестнадцатеричная системы счисления.......70
3.1.4. Двоично-десятичная система счисления.79
3.2. Представление числовой информации
в цифровых автоматах.........................81
3.2.1. Выполнение арифметических операций
над целыми числами. Прямой, обратный
и дополнительный коды................84
3.2.2. Смещенный код и код Грея...........94
3.2.3. Представление вещественных чисел
и выполнение арифметических операций
над ними в ЭВМ.........................98
547
3.2.4. Погрешности представления числовой
информации в ЭВМ....................................102
3.3. Представление символьной информации в ЭВМ .... 104
3.4. Представление графической информации.......ПО
Контрольные вопросы...................................114
Глава 4. Логические основы построения цифровых автоматов.... 116
4.1. Основные законы и постулаты алгебры логики.118
4.2. Представление функций алгебры логики.............120
4.3. Логический синтез переключательных
и вычислительных схем........................125
4.3.1. Синтез переключательных схем................125
4.3.2. Синтез вычислительных схем..................129
4.4. Основы элементной базы цифровых автоматов .... 136
4.4.1. Логические элементы.........................136
4.4.2. Схемотехника логических элементов.....142
4.4.3. Элементы интегральных схем..................166
Контрольные вопросы...................................175
Глава 5. Понятие алгоритма и алгоритмические системы...177
5.1. Понятие алгоритма и его свойства.................179
5.2. Рекурсивные функции..............................186
5.3. Машины Тьюринга..................................189
5.4. Нормальные алгоритмы Маркова.....................198
5.5. Операторные системы алгоритмизации...............202
5.5.1. Операторные алгоритмы Ван Хао...............204
5.5.2. Операторные алгоритмы Ляпунова..............206
5.5.3. Блок-схемный метод алгоритмизации...........208
5.6. Методы оценки алгоритмов
и алгоритмически неразрешимые проблемы.......212
Контрольные вопросы ..................................217
Глава 6. Обработка информации................................219
6.1. Компьютерная обработка информации................219
6.1.1. Поколения электронных вычислительных
машин......................................225
6.1.2. Классификация средств обработки
информации....................................232
6.1.3. Классификация программного обеспечения.... 236
6.2. Преобразование аналоговой информации
в цифровую форму.............................261
548
6.3. Функциональная и структурная организация
процессорных устройств обработки информации ... 268
6.3.1. Общая структура процессорных устройств
обработки информации и принципы
фон Неймана.............................268
6.3.2. Исполнение команд программы
процессором..............................281
6.4. Общая структура ЭВМ........................289
6.4.1. Структурная схема ПЭВМ................289
6.4.2. Устройства ввода-вывода информации....294
6.4.3. Системная магистраль и шины ЭВМ.......304
6.4.4. Организация ввода-вывода информации
в ЭВМ....................................313
6.5. Системы параллельной обработки данных.....320
6.6. Процессоры и процессорные элементы
вычислительных систем........................324
6.6.1. Микропроцессоры с расширенной
и сокращенной системой команд.........324
6.6.2. Основные характеристики
микропроцессоров, используемых в ПЭВМ.....328
6.6.3. Основные типы микропроцессоров,
используемых в высокопроизводительных
вычислительных системах..................332
6.7. Сетевые технологии распределенной
обработки данных............................337
Контрольные вопросы.............................343
Глава 1. Хранение информации .........................346
7.1. Классификация запоминающих устройств.......347
7.2. Основная память............................351
7.2.1. Характеристики запоминающих устройств.351
7.2.2. Конфигурация запоминающих устройств
с прямым доступом........................353
7.2.3. Запоминающие элементы
полупроводниковых ЗУ.....................356
7.2.4. Основные типы памяти современных ПК...362
7.3. Контроль правильности работы
запоминающих устройств......................366
7.4. Внешние запоминающие устройства............371
7.4.1. Накопители на гибких магнитных дисках.371
549
7.4.2. Накопители на жестких магнитных дисках .... 374
7.4.3. Структура данных на магнитном диске....376
7.4.4. Накопители на оптических
и магнитооптических дисках...............379
Контрольные вопросы..............................383
Глава 8. Передача информации............................385
8.1. Общая схема системы передачи информации....385
8.2. Виды и модели сигналов......................389
8.2.1. Общие сведения о сообщениях и сигналах ... 389
8.2.2. Сигнал как случайный процесс...........396
8.2.3. Математические модели сигналов и помех ... 400
8.3. Каналы передачи данных и их характеристики.402
8.3.1. Кабельные линии связи..................408
8.3.2. Беспроводные линии связи...............413
8.3.3. Аппаратура линий связи.................418
8.4. Информационные сети.........................421
8.4.1. Классификация вычислительных сетей.....422
8.4.2. Методы передачи данных по каналам связи ... 424
8.4.3. Способы коммутации данных..>...........434
8.4.4. Эталонная модель взаимодействия
открытых систем и протоколы обмена.............444
8.4.5. Методы доступа к среде передачи данных.456
8.5. Контроль передачи информации................461
8.5.1. Методы повышения верности передачи
информации.....................................461
8.5.2. Принципы помехоустойчивого кодирования... 464
8.5.3. Циклические коды.......................470
8.6. Сжатие информации...........................476
Контрольные вопросы..............................484
Глава 9. Контроль и защита информации
в автоматизированных системах...........................485
9.1. Угрозы безопасности информации
в автоматизированных системах.................485
9.1.1. Непреднамеренные угрозы................486
9.1.2. Преднамеренные угрозы..................489
9.2. Обеспечение достоверности информации
в автоматизированных системах.....................502
9.3. Обеспечение сохранности информации
в автоматизированных системах...............512
550
9.4. Обеспечение конфиденциальности
информации в автоматизированных системах......519
9.4.1. Защита информации от утечки
по техническим каналам...................521
9.4.2. Криптографическая защита информации.524
9.4.3. Система охраны объекта............530
9.4.4. Разграничение доступа
в автоматизированных системах............536
Контрольные вопросы ........................543
ЛИТЕРАТУРА........................................545
Учебник
Акулов Олег Анатольевич
Медведев Николай Викторович
ИНФОРМАТИКА
Главный редактор И.В. Кондаков
Редактор Ю.А. Серова
Корректор А.В. Бенецкая
Компьютерная верстка М.В. Сенотрусовой
Подписано в печать 25.03.04. Формат 60 х 90/16.
Печать офсетная. Бумага офсетная.
Гарнитура «Baltica». Печ. л. 34,5. Тираж 3000 экз.
Заказ А-210
ООО «Омега-Л»
125298, Москва, ул. Народного Ополчения, д. 40, к. 2., оф. 108
Тел., факс (095) 290-80-65
http://www.omega-l.ru
Отпечатано в типографии ОАО ПИК «Идел-Пресс»
в полном соответствии с качеством
предоставленных диапозитивов.
420066, г. Казань, ул. Декабристов, 2.
авторы
Кандидаты технических наук, доценты ка-
федры «Информационная безопасность» -
Николай Викторович Медведев 1954 года рож-
дения и Олег Анатольевич Акулов, 1966 года
рождения, работают в МГТУ им. Н.Э Баумана,
Николай Викторович - заведующий кафедрой,
Олег Анатольевич - сотрудник кафедры.
У них общая сфера научных интересов,
в которую входит изучение помехозащи-
щенных систем связи и систем автоматизи-
рованной обработки и защиты информации
Оба активно занимаются научной деятель-
ностью: у Николая Викторовича более 50 науч-
ных работ, у Олега Анатольевича - более 20.
Эта работа - результат их совместного
творчества.
о книге
Базовый курс, рассчитанный на студентов,
обучающихся по специальности «Информа-
тика и вычислительная техника», включает
описание структуры и общих свойств инфор-
мации, изложение общих принципов построе-
ния вычислительных устройств, представ-
ление числовой информации в цифровых
автоматах. В книге представлены основные
системы обработки, хранения и передачи
информации; вопросы контроля и защиты
информации в автоматизированных системах.
В учебнике даны четкие определения ключе-
вых понятий информатики и конкретные
вопросы по темам курса.