/
























































































































































































































































































































































































































































































































Author: Бабаш А.В. Шанкин Г.П.
Tags: системы письма графическое представление мысли логика криптография
ISBN: 5-93455-135-3
Year: 2007




Text
БАБАШ А. В.,
ШАНКИН Г. П.
КРИПТОГРАФИЯ
Под редакцией В.П. Шерстюка,
Э.А. Применко
Москва
СОЛОН-ПРЕСС
2007
УДК 003.26
ББК 87.4
Б121
Бабаш А.В., Шанкин Г.П.
Б121 Криптография. Под редакцией В.П. Шерстюка, ЭЛ. Применко /
А.В. Бабаш, Г.П. Шанкин. — М.: СОЛОН-ПРЕСС, 2007. — 512с.—
(Серия книг «Аспекты защиты»).
ISBN 5-93455-135-3
Книга написана в форме пособия, направленного на изучение «классиче-
ских» шифров, то есть шифров с симметричным ключом. После краткого исто-
рического очерка в ней рассмотрены вопросы дешифрования простейших
шифров, методы криптоанализа и синтеза криптосхем, вопросы криптографи-
ческой стойкости, помехоустойчивости и имитостойкости шифрсистем.
Архитектура пособия двухуровневая. Первый уровень предназначен для
студентов, изучающих дисциплины криптографии и компьютерной безопасно-
сти, читателей, впервые знакомящихся с учебными материалами по криптогра-
фии. Второй уровень — для аспирантов, преподавателей вузов соответствую-
щего профиля, для круга специалистов, чьей задачей является использование
криптографических средств защиты информации, для читателей, желающих
познакомиться с теоретической криптографией. На пособие получены поло-
жительные рецензии специалистов и организаций.
УДК 003.26
ББК 87.4
По вопросам приобретения обращаться: ООО «АЛЬЯНС-КНИГА КТК»
Тел: (495) 258-91-94, 258-91-95, www.abook.ru
Сайт издательства «СОЛОН-ПРЕСС»: www.solon-press.ru
E-mail: solon-avtor@coba.ru
книга - почтой
Книги издательства «СОЛОН-ПРЕСС» можно заказать наложенным платежом (оплата при получении)
по фиксированной цене. Заказ оформляется одним из двух способов:
I. Послать открытку или письмо по адресу: 123242, Москва, а/я 20.
2. Оформить заказ можно на сайте www.solon-press.ru в разделе «Книга — почтой».
Бесплатно высылается каталог издательства по почте.
При оформлении заказа следует правильно и полностью указать адрес, по которому должны быть вы-
сланы книги, а также фамилию, имя и отчество получателя. Желательно дополнительно указать свой те-
лефон и адрес электронной почты.
Через Интернет вы можете в любое время получить свежий каталог издательства
«СОЛОН-ПРЕСС», считав его с адреса www.solon-press.ru/kat.doc.
Интернет-магазин размещен на сайте www.solon-press.ru.
ISBN 5-93455-135-3
© А.В. Бабаш, Г.П. Шанкин, 2007
© Составление. Осипенко А.И., 2002
© Макет и обложка «СОЛОН-ПРЕСС», 2007
На учебное пособие получены положительные рецензии:
института информационных наук и технологий безопасности Россий-
ского государственного гуманитарного университета (РГГУ);
Московского института радиотехники электроники и автоматики (МИ-
РЭА);
кафедры информационной безопасности МГУ им. М.В. Ломоносова;
центрального банка Российской Федерации (ЦБ РФ);
заведующего кафедрой информационной безопасности Московского
государственного института электроники и математики (МИЭМ) кан-
дидата физико-математических наук, профессора Прокофьева И.В;
члена-корреспондента Академии криптографии, доктора физико-
математических наук, профессора Грушо А.А.;
профессора кафедры «Криптология и дискретная математика» Москов-
ского инженерно-физического института (МИФИ), доктора техниче-
ских наук, профессора Щербакова А.Ю;
члена-корреспондента Международной Академии Информатизации,
кандидата технических наук Шурупова А.Н.;
члена-корреспондента РАЕН, доктора физико-математических наук,
профессора Голованова П.Н.;
Авторы:
профессор ИКСИ Академии ФСБ РФ, доктор физико-
математических наук, профессор Александр Владимирович Бабаш;
профессор ИКСИ Академии ФСБ РФ, доктор технических наук,
профессор Генрих Петрович Шанкин.
Разрешение на открытое опубликование Академии ФСБ РФ от
08.12. 2000
4
Предисловие редакторов
Предлагаемое учебное пособие по криптографии содержит достаточно
большой фактографический материал, отражающий основные этапы развития
шифровального искусства и современной криптографии как отрасли науки.
Во введении авторами указана степень математической подготовленности чи-
тателя, необходимая для усвоения излагаемого в книге материала.
Книга состоит из семи глав. В первой и второй главах дается истори-
ческий очерк развития и практического применения криптографических ме-
тодов защиты информации. Понятие информации и ее свойства излагаются в
третьей главе. Теоретическая и практическая стойкость шифров представлены
в четвертой и пятой главах. Математические модели современных криптосХем
рассматриваются в шестой главе. В седьмой главе изучаются специальные
свойства шифров - имитостойкость и помехоустойчивость, а также сети за-
секреченной связи.
В целом книга содержит достаточно уравновешенный по глубине про-
работки материал по основным проблемам классической криптографии. Вме-
сте с тем недостаточно оправданным представляется включение в учебное
пособие раздела по стеганографии, не имеющей прямого отношения к крипто-
графии. В то же время незаслуженно мало места отведено шифрам с откры-
тым ключом.
В целом представляется, что книга, несомненно, может быть использована
в качестве учебного пособия, предназначенного для студентов, изучающих
вопросы информационной безопасности. Наряду с имеющейся учебной лите-
ратурой по данному Направлению, это учебное пособие поможет им более уг-
лубленно изучить основные вопросы классической криптографии. Книга бу-
дет полезна и для широкого круга специалистов, занимающихся разработкой
защищенных информационных технологий.
Член-корр. АК РФ В.П. Шерстюк,
кандидат физ.-мат. наук,
доцент Э.А. Применко
5
Предисловие авторов
Предлагаемое учебное пособие в первую очередь предназначено
для студентов, изучающих дисциИлины по защите информации по про-
граммам, утвержденным учебно-методическим объединением вузов
России (УМО):
1) по специальности 075500 - «Комплексное обеспечение информаци-
онной безопасности», квалификация - специалист по защите информа-
ции, ОПД.Ф. 13 - Криптографические методы защиты информации;
2) по специальности 075200 - «Компьютерная безопасность», квалифи-
кация - математик, ОПД.Ф. 13 - Криптографические методы защиты
информации;
3) по специальности 075600 - «Информационная безопасность теле-
коммуникационных систем», квалификация - специалист по защите
информации, ОПД.Ф. 03 - Криптографические методы защиты инфор-
мации;
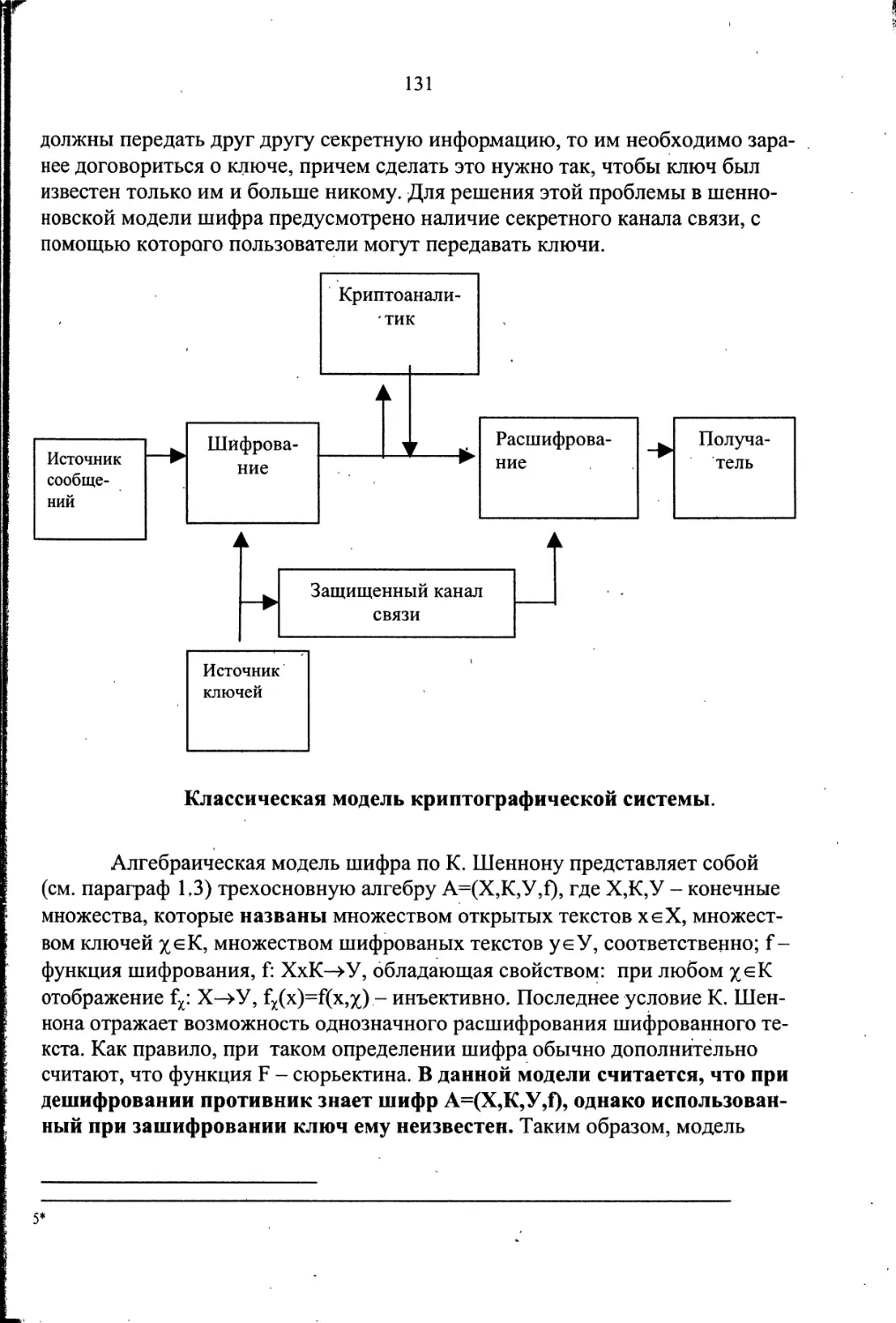
Пособие направлено на изучение шифров с симметричным клю-
чом. В настоящее время по шифрам с открытым ключом имеется мно-
го доступной информации.
Архитектура пособия двухуровневая. Первый уровень предна-
значен для читателей, впервые знакомящихся с учебными материалами
по криптографии. Второй уровень - для людей, знакомых с азами крип-
тографии. Собственно линия раздела материала достаточно условна, в
первую очередь она зависит от математической подготовки читателя.
Материал, излагающийся в начальных главах и в начальных царагра-
фах этих глав, относится к первому уровню познания классической
криптографии. Остальной материал относится ко второму уровню, в
частности, параграфы 5.5, 6.7, 6.9, 7.4, 7.5 предназначены для адъюнк-
тов и аспирантов. Необходимым условием освоения пособия является
знакомство читателя с двухсеместровым курсом теории вероятностей и
статистики. Авторы сознательно пошли на отчасти автономное изло-
жение материалов глав. Их связывающим началом являются началь-
ные параграфы глав 1, 2, 3, содержащие основные понятия криптогра-
фии, свойства шифров и открытых текстов.
В настоящее время развитие криптографии, и, в частности, ее
практические проблемы во многом определяют общее развитие мате-
6
матики. Этот тезис, исповедуемый авторами, определил и методологи-
ческий подход к форме подачи материалов пособия. Как правило, каж-
дая из обсуждаемых криптографических задач затем формализуется и
решается средствами математики. Кроме того, это положение отражено
и содержанием параграфов 5.5, 6.7, 6.9, 7.4, 7.5, где в явном виде пока-
зано значение результатов математических исследований в крипто-
графии, и влияние криптографии на направления развития математики.
Собственно, эти параграфы отчасти являются введением в теоретиче-
скую криптографию.
Большое значение мы придаем обучению студентов методикам
численного расчета параметров методов анализа и синтеза шифров.
При таком расчете, как правило, акцент делается на предварительный
математический расчет (расчет параметров «на уровне средних значе-
ний»), Такой подход особенно заметен в параграфе 2.2, где в разнооб-
разных вероятностных моделях подсчитывается среднее значение ис-
торически известного параметра текста - «индекса совпадения Фрид-
мана».
Основное внимание в пособии уделено криптоанализу шифров и
шифрсистем, что соответсвует направленности пособия - защите ин-
формации. Вопросам дешифрования шифров посвящена лишь глава 2.
Приведенная литература охватывает более широкий круг криптографи-
ческих проблем. Она может быть использована при написании курсо-
вых и дипломных работ.
Наряду с общей поддержкой коллег по кафедре криптографии
ИКСИ многие специалисты, понимая направленность, предназначен-
ность готовящегося учебного пособия по криптографии сочли необхо-
димым оказать действенную, реальную помощь.
Благодарим:
вице-президента Академии криптографии Российской Федерации Сач-
кова В.Н. (материалы к главе 6);
доктора физико-математических наук, профессора, Академика АК Рос-
сии Балакина Г.В (материалы к главе 5);
доктора физико-математических наук, профессора, Академика АК Рос-
сии Нечаева А.А (материалы к главе 6);
доктора физико-математических наук, профессора, Академика АК Рос-
сии Глухова М.М (материалы к главе 6);
7
профессора кафедры криптографии ИКСИ, доктора физико-
математических наук Проскурина Г.В. (материалы к главам 1, 2, 3);
доктора физико-математических наук, профессора по кафедре крипто-
графия Рязанова Б. А. (материалы к главе 5);
доктора физико-математических наук, старшего научного сотрудника
Малышева Ф. М (материалы к главе 5);
кандидата физико-математических наук, старшего научного сотрудника
Фомичева В. М. (материалы к главе 2);
кандидата физико-математических наук Максимова К.Н. (материалы к
главе 2);
Тришина А.Е. (материалы к главе 1).
Основой книги служат открытые публикации. Некоторые из них
использованы почти дословно. Такие параграфы помечены ссылками
на использованную литературу. В этом отношении обилием ссылок вы-
деляется пособие Г.В. Проскурина “Принципы и методы защиты инфо-
рмации”, Московский государственный институт электроники и мате-
матики. Выражаем сожаление о том, что нам не удалось использовать
материалы прекрасного учебного пособия “Основы криптографии” ве-
дущих специалистов в области криптографии: Алферова А.П., Зубова
А.Ю., Кузьмина А.С., Черемушкина А.В.
Настоящее пособие посвящается памяти замечательных крипто-
графов - математиков Степанова Вадима Евдокимовича и Горчинского
Юрия Николаевича. Многие их криптографические идеи и решения
сейчас можно встретить рожденными заново в ряде пособий, моногра-
фий и научных статей по криптографии. Ряд таких идей лежат в основе
и данной книги. С некоторыми работами упомянутых специалистов
можно ознакомиться: Степанов В.Е. - журнал «Теория вероятностей и
ее применения: 1957, т.2, N1; 1970, т.15, N2; 1972, т.17, N2; 1987, т.32,
N4; Горчийский Ю.Н. - Труды по дискретной математике тома 1
(1997), 2 (1998), 3 (2000), далее, предположительно, в томах 4, 5.
Авторы с благодарностью примут все предложения и замечания
по книге; их следует направлять по адресу: babash@yandex.ru.
8
Горчинский Юрий Николаевич (1929-1999)
Горчинский Юрий Николаевич (1929-1999) родился в Хмельницкой
области Украины. Полковник в отставке. В 1951 году закончил физико-
математический факультет Московского Государственного университета им.
М.В. Ломоносова. В 1956 году окончил аспирантуру НТС 8-го Главного
управления КГБ при СМ СССР. Доктор физико-математических наук. Про-
фессор. С 1951 по 1953 год сотрудник, старший сотрудник 2-го Управления
Главного управления Специальной службы при ЦК ВКП(б). С 1953 по 1961
год помощник руководителя группы, старший сотрудник 1 категории, руко-
водитель группы отдела 8-го Главного управления при СМ СССР. С 1961 по
1978 год начальник отделения, научный консультант отдела Спецуправления
8-го Главного управления КГБ СССР. С 1978 по 1993 год научный консуль-
тант Спецуправления 8-го Главного управления КГБ СССР. В сентябре 1993
года уволен на пенсию по возрасту. С 1993 академик — секретарь отделения
математических проблем криптографии Академии Криптографии РФ. Внес
большой вклад в подготовку научных и инженерных кадров. Награжден орде-
нами «Красная звезда» и «Знак. Почета» и многими медалями. Лауреат госу-
дарственной премии за 1975 год. Награжден знаком «Почетный сотрудник
госбезопасности».
9
Степанов Вадим Евдокимович (1929 - 1986)
Степанов Вадим Евдокимович (1929-1986) родился в городе Днепропетров-
ске. В 1951 году окончил МГУ им. М.В.Ломоносова. В 1956 году окончил ас-
пирантуру 8-го Главного управления. Доктор физико-математических наук.
Профессор. С 1951 по 1953 год работал лаборантом, младшим научным со-
трудником НИИ-1 ГУСС, с 1953 по 1959 год руководитель группы, замести-
тель начальника отделения, с 1959 по 1966 год старший научный сотрудник 8-
го Главного Управления КГБ. С 1966 по 1976 год научный консультант
Управления, а с 1976 по 1986 год начальник отдела. Внес большой вклад в
подготовку научных и инженерных кадров для Специальной службы. Награ-
жден орденом «Красная Звезда» и многими медалями, в .том числе медалью
«За боевые заслуги», Почетной грамотой Верховного Совета РСФСР, знаком
«Почетный сотрудник госбезопасности». Лауреат Государственной премии
СССР посмертно. Полковник.
10
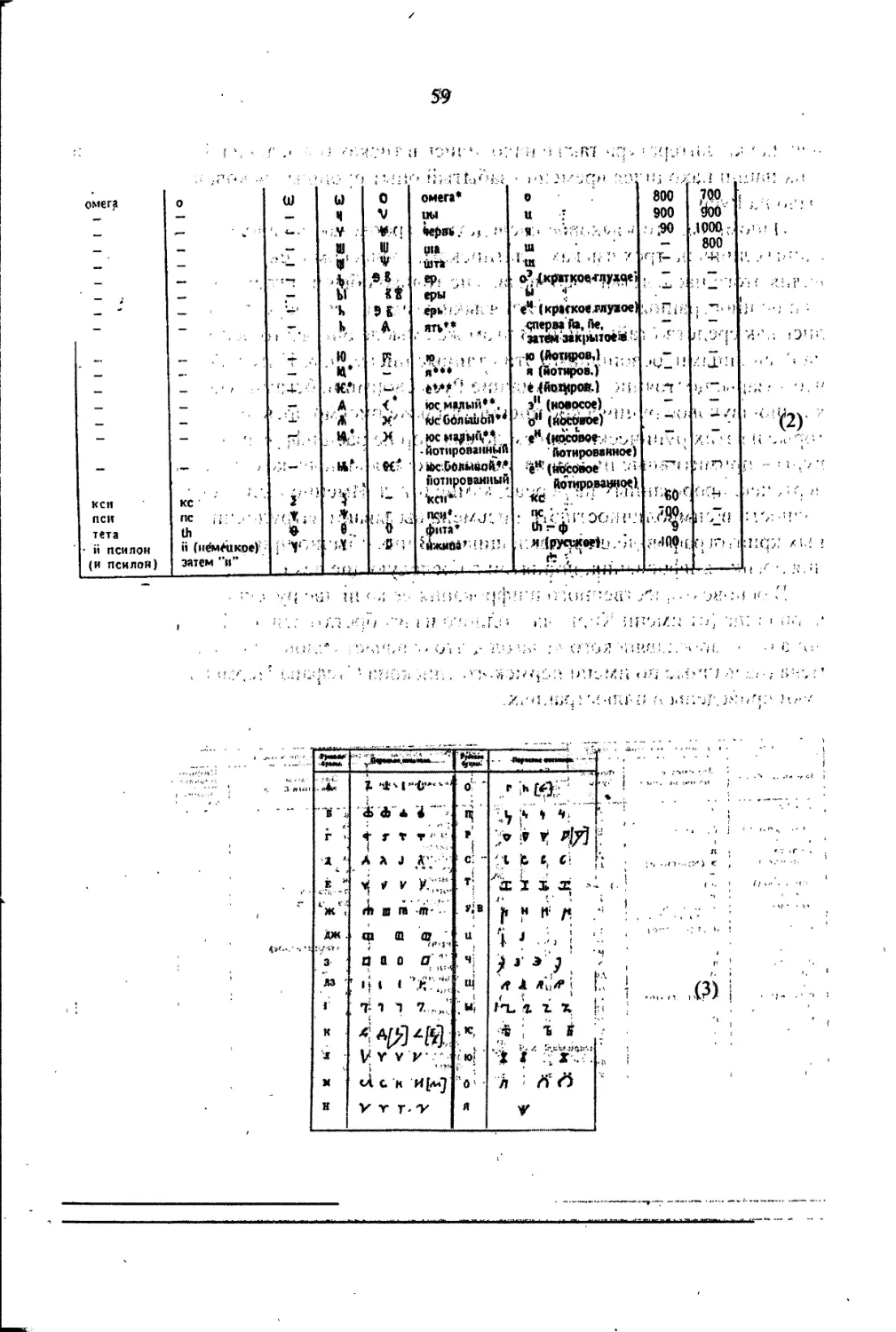
Основные обозначения
€ - принадлежит;
V - для любого;
3 - существует;
=> - тогда;
<=> - тогда и только тогда;
|К| - как правило, мощность множества К. В исключительных случаях,
абсолютная величина числа К;
(а,Ь) - как правило, общий наибольший делитель чисел а, Ь. Иногда
вектор с компонентами а, Ь, иногда семейство элементов (а,Ь,...с);
[а,Ь] - как правило, наименьшее общее кратное чисел а, Ь. Иногда ин-
тервал изменения переменной величины, иногда [ ] - квадратные
скобки, иногда целая часть числа;
а|Ь - а делит Ь;
I* - как правило, множество всех слов в алфавите I. В ряде случаев *
используется и в качестве индекса;
IL - множество всех слов в алфавите I длины L;
F2, GF(2) - Поле из двух элементов;
G(F(q)) - поле из q элементов;
ХхК - прямое произведение множеств X и К;
f: X—>У - отображение, функция;
{а,Ь,...,с} - множество;
11
ГЛАВА 1. ИСТОРИЧЕСКИЙ ОЧЕРК РАЗВИТИЯ
КРИПТОГРАФИЧЕСКИХ СРЕДСТВ И МЕТОДОВ ЗА-
ЩИТЫ ИНФОРМАЦИИ
Д. Канн: «... История криптографии ... - это история человечества».
Понятие «безопасность»охватывает широкий круг интересов как отдельных лиц,
так и целых государств. Во все исторические времена существенное внимание уделя-
лось проблеме информационной безопасности, обеспечению защиты конфиденциаль-
ной информации от ознакомления с ней конкурирующих групп. Недаром великий
психолог Вильям Шекспир в «Короле Лире» изрёк: «Чтоб мысль врага узнать, сердца
вскрывают, а не то что письма».
Параграф 1.1
Криптографические средства с древнего времени
Геродот
Существовали три основных способа защиты информации.
Первый способ предполагал чисто силовые методы: охрана документа
(носителя информации) физическими лицами, его передача специальным
курьером и т. д.
Второй способ получил название
«стеганография» и заключался в сокрытии са-
мого факта наличия секретной информации. В
этом случае, в частности, использовались так
называемые «симпатические чернила». При
соответствующем проявлении текст Становился
видимым. Один из оригинальных примеров
сокрытия информации приведён в трудах
древнегреческого историка Геродота. На голове
раба, которая брилась наголо, записывалось
нужное сообщение. И когда волосы его
достаточно отрастали, раба отправляли к адре-
сату, который снова брил его голову и считывал
полученное сообщение.
Идея экзотической защиты секретных текстов (в том числе и с применени-
ем симпатических чернил) дошла до наших дней. А. Толстой в известном
произведении «Гиперболоид инженера Гарина» описал способ передачи со-
общения путем его записи на спине посыльного - мальчика. Во время II Ми-
12
ровой войны таким же образом иногда передавались агентурные сообщения.
Секретные послания записывались симпатическими чернилами и на предме-
тах нижнего белья, носовых платках, галстуках и т. д.
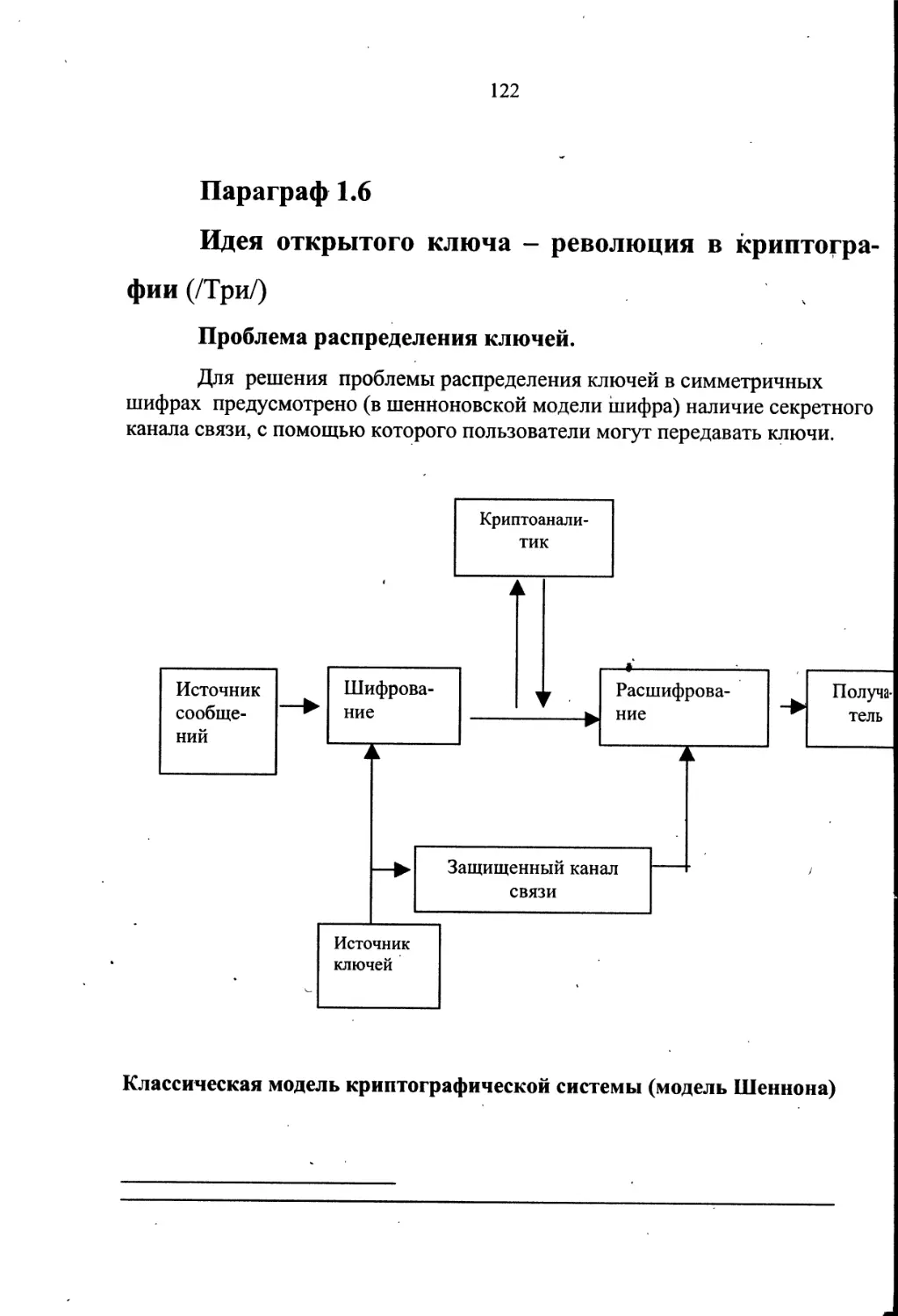
Третий способ защиты информации заключался в преобразовании смы-
слового текста в некий хаотический набор знаков (букв алфавита). Получа-
тель донесения имел возможность преобразовать его в исходное осмысленное
сообщение, если обладал «ключом» к его построению. Этот способ защиты
информации называется криптографическим.
По утверждению ряда специалистов, криптография по возрасту - ровесник
египетских пирамид. В документах древних цивилизаций - Индии, Египта,
Месопотамии - есть сведения о системах и способах составления шифрован-
ных писем.
1
ШИФР Гая Юлия Цезаря
\
В криптографии древних времен использовались два вида шифров: замена
и перестановка.
Историческим примером шифра замены является шифр Цезаря (I век до
н. э.), описанный историком Древнего Рима Светонием. Гай Юлий Цезарь ис-
пользовал в своей переписке шифр собственного изобретения. Применитель-
но к современному русскому языку он состоял в следующем. Выписывался
алфавит: А, Б, В, Г, Д, Е,...; затем под ним выписывался тот же алфавит, но с
циклическим сдвигом на 3 буквы влево:
АБВГДЕЁ^К^ИЙКЛМНОПРСТУФХЦЧШЩЫЪЬЭЮЯ
ГДЕЁЖЗИЙКЛ МНОП Р С Т У Ф X Ц ЧШ Щ ЫЪ Ь ЭЮЯАБВ
При зашифровании буква А заменялась буквой
Г, Б заменялась на Д, В - Е и так далее. Так, напри-
мер, слово «РИМ» превращалось в слово «УЛП».
Получатель сообщения «УЛП» искал эти буквы в
нижней строке и по буквам над ними восстанавливал
исходное слово «РИМ». Ключом в шифре Цезаря
является величина сдвига 2-й нижней строки
алфавита. Преемник Юлия Цезаря - Цезарь Август
использовал тот же шифр, но с ключом - сдвиг 1.
Слово «РИМ» он в этом случае зашифровал бы в
буквосочетание «СЙН»
Гай Юлий Цезарь
13
Естественное развитие шифра Цезаря очевидно: нижняя строка двух-
строчной записи букв алфавита может быть с произвольным расположением
этих букв. Если в алфавитном расположении букв в нижней строке существу-
ет*всего 33 варианта ключей (число букв в русском алфавите), то при их про-
извольном расположении число ключей становится огромным. Оно равно
33! (33 факториал), т.е. приблизительно десять в тридцать пятой степени.
Этот момент очень важен. Если противник догадался или получил сведе-
ния об используемом шифре (а шифры используются длительное время),
то он может попробовать перебрать все варианты возможных секретных
ключей при дешифровании перехваченной криптограммы. В современных
условиях такой перебор в шифре Цезаря доступен ученику 5-6 классов
средней школы. Но перебор 33! вариантов ключей занял бы даже при ис-
пользовании современных ЭВМ столетия. Едва ли найдется дешифро-
вальщик, который даже в наши дни выбрал бы этот путь дешифрования.
Однако во времена Цезаря, когда царила всеобщая неграмотность населе-
ния, сама возможность увидеть осмысленное сообщение за «абракадаб-
рой», даже составленной из знакомых букв, казалась неосуществимой.
Во всяком случае, древнеримский историк Светоний не приводит фактов
дешифрования переписки Цезаря. Напомним, что сам Цезарь всю жизнь ис-
пользовал один и тот же ключ (сдвиг - 3). Этим
шифром он пользовался, в частности, для обмена
посланиями с Цицероном.
В художественной литературе классическим
примером шифра замены является известный
шифр «Пляшущие человечки» (К. Дойля). В нём
буквы текста заменялись на символические фигур-
ки людей. Ключом такого шифра являлись позы
человечков, заменяющих буквы.
Цицерон
14
Фрагмент шифрованного послания имел следующий вид:
Соответствующий открытый текст: «Гт here Abe Slaney» («Я здесь Аб
Слени»), Использован шифр простой замены букв на фигурки людей; флажок
в руках означает конец слова.
ШИФР перестановки
Приведем пример второго исторического шифра - шифра перестановки.
Выберем целое положительное число, скажем, 5; расположим числа от 1 до 5
в двухстрочной записи, в которой вторая строка - произвольная перестановка
чисел верхней строки:
1 2 3 4 5
3 2 5 1 4
Эта конструкция носит название подстановки, а число 5 называется ее
степенью.
Зашифруем фразу «СВЯЩЕННАЯ РИМСКАЯ ИМПЕРИЯ». В этой фразе
23 буквы. Дополним её двумя произвольными буквами (например, Ь, Э) до
ближайшего числа, кратного 5, то есть 25. Выпишем эту дополненную фразу
без пропусков, одновременно разбив её на пятизначные группы:
СВЯЩЕ ННАЯР ИМСКА ЯИМПЕ РИЯЬЭ
Буквы каждой группы переставим в соответствии с указанной двухётроч-
ной записью по следующему правилу: первая буква встаёт на третье место,
вторая - на второе, третья - на пятое, четвёртая - на первое и пятая - на чет-
вёртое. Полученный текст выписывается без пропусков:
ЩВСЕЯЯННРАКМИАСПИЯЕМЬИРЭЯ
При расшифровании текст разбивается на группы по 5 букв и буквы пере-
ставляются в обратном порядке: 1 на 4 место, 2 на 2, 3 на 1,4 на 5 и 5 на 3.
Ключом шифра является выбранное число 5 и порядок расположения чисел в
нижнем ряду двухстрочной записи.
15
ПРИБОР Считала
Прибор Сцитала.
Упрощенное современное изобрете-
ние
нХо\в?о 16 \
OifliS'H Й|Е
' М I ff I a”; a e'i а *
Одним из первых физических приборов, реализующих шифр перестанов-
ки, является так называемый прибор Сцитала. Он был изобретён в древней
«варварской» Спарте во времена Ликурга (V в. до н. э.). Рим быстро восполь-
зовался этим прибором. Для зашифрования текста использовался цилиндр за-
ранее обусловленного диаметра. На цилиндр наматывался тонкий ремень из
пергамента, и текст выписывался построчно по образующей цилиндра (вдоль
его оси). Затем ремень сматывался и отправлялся получателю сообщения. По-
следний наматывал его на цилиндр того же диаметра и читал текст по оси ци-
линдра. В этом примере ключом шифра являлся диаметр цилиндра и его дли-
на, которые, по существу, порождают двухстрочную запись, аналогичную
указанной выше.
Шифр «Сцитала» реализует один из
вариантов так называемого сегодня
«шифра маршрутной перестановки».
Смысл этого шифра заключается в сле-
дующем.
Открытый текст выписывается в
прямоугольную таблицу из п строк и m
столбцов. Предполагается, что длина
текста t < n-m (в противном случае ос-
тавшийся участок текста шифруется
отдельно по тому же шифру). Если t
строго меньше n-m , то оставшиеся пустые
клетки заполняются произвольным
набором букв алфавита. Шифртекст
выписывается по этой таблице по заранее
оговоренному «маршруту» - пути, проходящему по одному разу через все
клетки таблицы. Ключом шифра являются числа n, m и указанный маршрут.
В такой трактовке шифр «Сцитала» приобретает следующий вид. Пусть
m - количество витков ремня на цилиндре, п - количество букв, расположен-
ных на одном витке. Тогда открытый текст, выписанный построчно в указан-
ную таблицу, шифруется путем последовательного считывания букв по
столбцам. Поскольку маршрут известен и не меняется, то ключом шифра яв-
ляются числа m и пт, определяемые диаметром цилиндра и длиной ремешка.
При перехвате сообщения (ремешка) единственным секретным ключом явля-
ется диаметр.
16
Изобретение дешифровального устройства - «Антисцитала» - приписыва-
ется великому Аристотелю. Он предложил использовать конусообразное «ко-
пьё», на которое наматывался перехваченный ремень; этот ремень передви-
гался по оси до того положения, пока не появлялся осмысленный текст.
Были и другие способы защиты информации, разработанные в античные
времена.
ДИСК Энея
Одно из первых исторических имен, которое упоминается в связи с
криптографией, это имя Энея - легендарного полководца, защитника Трои,
друга богатыря Гектора. Гомер в «Илиаде» (VIII век до н. э.) указывает, что
Эней был сыном богини Афродиты и смертного человека. В битве под Троей
Эней был тяжело ранен, и мать, спасая сына, также получила ранение. Пови-
нуясь долгу чести, Эней вступил в поединок с Геркулесом (Гераклом), хотя .
отлично понимал безнадежность этого поединка для себя. На этот раз его спас
от смерти союзник троянцев морской бог Посейдон.
Гомер дает следующую характеристику Гектору и Энею:
Гектор, Эней! На вас, воеводы, лежит наипаче
Бремя забот о народе троянском; отличны вы оба
В каждом намерении вашем, сражаться ли нужно, иль мыслить.
Согласно преданиям, Эней был посвящен в древнегреческую Мистерию.
При посвящении он спускался в ад; гарпии предсказали ему падение Трои.
В области тайнописи Энею принадлежат два изобретения.
Первое из них - так называемый «диск Энея». Его принцип был прос^.
На диске диаметром 10-15 см и толщиной 1-2 см высверливались отвер-
стия по числу букв алфавита. В центре диска помещалась «катушка» с намо-
танной на ней ниткой достаточной длины. При зашифровании нитка «вытяги-
валась» с катушки и последовательно протягивалась через отверстия в соот-
ветствии с буквами шифруемого текста. Диск и являлся посланием. Получа-
тель послания последовательно вытягивал нитку из отверстий, что позволяло
ему получать передаваемое сообщение, но в обратном порядке следования
букв. При перехвате диска недоброжелатель имел возможность прочитать со-
общение тем же образом, что и получатель. Но Эней предусмотрел возмож-
ность лёгкого уничтожения передаваемого сообщения при угрозе захвата дис-
ка. Для этого было достаточно выдернуть «катушку» с закреплённым на ней
концом нити до полного выхода всей нити из отверстий диска.
17
ЛИНЕЙКА Энея
Идея Энея была использована в создании
и других оригинальных шифров замены.
Например, в одном из вариантов вместо диска
использовалась линейка с числом отверстий,
равных количеству букв алфавита. Каждое
отверстие обозначалось своей буквой; буквы по
отверстиям располагались в произвольном
порядке. К линейке была прикреплена катушка с
намотанной на неё ниткой. Рядом с катушкой
имелась прорезь. При шифровании нить
протягивалась через прорезь, а затем через
отверстие, соответствующее первой букве
шифруемого текста, при этом на нити завязы-
вался узелок в месте прохождения её через
отверстие; затем нить возвращалась в прорезь и
аналогично зашифровывалась вторая буква текста
Инициация в Мистерию.
Эней в аду
ИТ. д.
После окончания шифрования
нить извлекалась и передавалась по-
лучателю сообщения. Тот, имея
идентичную линейку, протягивал
нить через прорези отверстий, опре-
деляемых узлами, и восстанавливал
исходный текст по буквам отверстий.
Это устройство получило название
«линейка Энея». Шифр, реализуемый
линейкой Энея, является одним из
примеров шифра замены: в нем бук-
вы заменяются на расстояния между
узелками на нитке. Ключом шифра
являлся порядок расположения букв
по отверстиям в линейке. Посторон-
ний, получивший нить (даже имея
линейку, но без нанесённых букв), не
сможет прочитать передаваемое со-
общение.
Жрица мистерий
18
УЗЕЛКОВОЕ письмо
Аналогичное «линейке Энея» так называемое «узелковое письмо» («ки-
пу») получило распространение у индейцев Центральной Америки. Свои со-
общения они также передавали в виде нитки, на которой завязывались разно-
цветные узелки, определявшие содержание сообщения.
КНИЖНЫЙ шифр
Заметным вкладом Энея в криптографию является предложенный им так
называемый книжный шифр, описанный в сочинении «Об обороне укреплён- '
ных мест». Эней предложил прокалывать малозаметные дырки в книге или в
другом документе над буквами секретного сообщения. Интересно отметить,
что в первой мировой войне германские шпионы использовали аналогичный
шифр, заменив дырки на точки, наносимые симпатическими чернилами на
буквы газетного текста.
Книжный шифр в современном его виде ймеет несколько иной вид. Суть
этого шифра состоит в замене букв на номер строки и номер этой буквы в
строке в заранее оговоренной странице некоторой книги. Ключом такого
шифра является книга и используемая страница в ней. Этот шифр оказался
«долгожителем» и применялся даже во времена второй мировой войны.
КВАДРАТ Полибия
Ещё одно изобретение древних греков - так называемый квадрат Поли-
бия, (Полибий - греческий государственный деятель, полководец, историк, III
век до н. э.). Применительно к современному латинскому алфавиту из 26 букв
шифрование по этому квадрату заключалось в следующем. В квадрат разме-
ром 5x5 клеток выписываются все буквы алфавита, при этом буквы I, J не
различаются (J отождествляется с буквой I):
А . в с D Е
А А в с D Е
В. F G н I к
с L м N О р
D Q R S т и
Е V W X Y Z
Шифруемая буква заменялась на координаты квадрата, в котором она за-
писана. Так, В заменялась на АВ, F на В A, R на DB и т. д. При расшифрова-
19
нии каждая такая пара определяла соответствующую букву сообщения. Заме-
тим, что секретом в данном случае является сам способ замены букв. Ключ в
этой системе отсутствует, поскольку используется фиксированный алфавит-
ный порядок следования букв.
Усложненный вариант шифра Полибия заключается в записи букв в квад-
рат в произвольном (неалфавитном) порядке. Этот произвольный порядок яв-
ляется ключом.
Здесь, однако, появилось и некоторое неудобство. Произвольный порядок
букв трудно запомнить, поэтому пользователю шифра было необходимо по-
стоянно иметь при себе ключ - квадрат. Появилась опасность тайного озна-
комления с ключом посторонних лиц. В качестве компромиссного решения
был предложен ключ - пароль. Легко запоминаемый пароль выписывался без
повторов букв в квадрат; в оставшиеся клетки в алфавитном порядке выписы-
вались буквы алфавита, отсутствующие в пароле. Например, пусть паролем
является слово «THE TABLE». Тогда квадрат имеет следующий вид:
т Н Е А В
L С D F G
I К М N О
Р Q R S и
V W X Y Z
Такой квадрат уже не нужно иметь при себе. Достаточно запомнить
ключ - пароль. Заметим кстати, что таким же образом можно запомнить поря-
док расположения букв при использовании «линейки Энея», а также шифра
обобщенной замены Ю. Цезаря (при произвольном расположении букв в
нижней строке). Интересное усиление шифра Полибия было предложено од-
ним криптографом-любителем уже в XIX веке. Смысл этого усложнения по-
ясним на примере.
Пусть имеется следующий квадрат Полибия:
1 2 3 4 5
1 Е / К т L В
2 Н I,j’ А D и
3 М S G С V
4 F р Q R W
5 О Y X Z N
Зашифруем по нему слово «THE APPLE». Получим шифрованный
текст:
13.21.11.23.42.42.14.11. (*)
20
На этом историческое шифрование по Полибию заканчивалось. Это был
шифр простой замены типа шифра Цезаря, в котором каждая буква открытого
текста заменялась на некоторое двухзначное десятичное число, и эта замена
не менялась по всему тексту. Количество ключей этого шифра равно 25! .
Усложненный вариант заключается в следующем. Полученный первичный
шифртекст (*) шифруется вторично. При этом он выписывается без разбие-
ния на пары:
1321112342421411 (**)
Полученная последовательность цифр сдвигается циклически влево на
один шаг:
3211123424214111
Эта последовательность вновь разбивается в группы по два:
32Л1.12.34.24.21.41.11.
и по таблице заменяется на окончательный шифртекст:
SEKCDHFE (***)
Количество ключей в этом шифре остается тем же (25!), но он уже значи-
тельно более стоек. Заметим, что этот шифр уже не является шифром простой
замены (буква Е открытого текста переходит в различные буквы: К, Е; буква Р
- в буквы D, Н).
Был подмечен и негативный момент. Если в шифре простой замены шиф-
ртекст будет написан с одной ошибкой (например, в тексте (*) вместо четвер-
той буквы 23 будет написано 32), то расшифрованный текст будет содержать
лишь одну ошибку: THE SPPLE, что легко исправляется получателем сооб-
щения.
Если же в тексте (***) будет искажена четвертая буква (буква С заменена,
например, на К), то в расшифрованном тексте будет уже два искажения: THE
HIPLE, что уже затрудняет восстановление исходного сообщения. Аналогич-
но обстоит дело с ошибками вида «пропуск букв». Пусть в тексте (***) про-
пущена буква С. Шифртекст примет вид: SEKDHFE, или
32.11.12.24.21.41.11.
После расшифрований получим: THE IPLE, то есть наряду с пропуском
буквы в расшифрованном тексте имеется и искажение другой буквы. При
пропуске в (***) первой буквы при расшифровании получим: ЕЕ APPLE.
ШИФР Чейза
В середине XIX века американец П. Э. Чейз предложил следующую мо-
дификацию шифра Полибия.
Выписывается прямоугольник размера 3x10; буквы латинского алфавита
дополняются знаком @ и греческими буквами X, <о <р:
21
12-34
IX и A C
2 В Y F M
3 D К S V
5 6 7 8
О N Z L
@ E G J
H R W T
9 0
P (p
Q co
I X
Ключом шифра является порядок расположения букв в таблице. При
шифровании координаты букв выписываются вертикально. Например, слово
PHILIP приобретает вид:
133131
9 5 9 8 9 9 (*)
• Чейз предложил ввести еще один ключ: заранее оговоренное правило пре-
образования нижнего ряда цифр. Например, число, определяемое этим рядом,
умножается на 9:
959899x9=8639091
получаем новую двухстрочную запись:
13 3 13 1
8 6 3 9 0 9 1
Эта двухстрочная запись вновь переводится в буквы согласно таблице;
при этом первое число (8) нижнего ряда определяет букву первой строки.
Шифртекст приобретает следующий вид:
L N S I <р IX (♦*)
Могут быть использованы и другие преобразования координат. Этот шифр
значительно сильнее шифра Полибия; он уже не является шифром простой
замены.
При расшифровании полученная последовательность (**) переводится в
двухстрочную запись:
(1) 13 3 13 1
8 6 3 9 0 9 1
Нижний ряд делится на 9:
8639091:9 = 9598 9 9,
образуется двухстрочная запись (*) и по ней согласно таблице читается от-'
крытый текст.
Однако предложение Чейза не нашло поддержки. Причины: заметное ус-
ложнение процесса шифрования - расшифрования, а также особая чувстви-
тельность шифра к ошибкам (искажениям в шифртексте). В этом читатель
сможет убедиться самостоятельно. Кроме того, использование в качестве
ключа любого числа (кроме 9) может порождать недоразумения как при шиф-
ровании, так и при расшифровании.
22
ТЮРЕМНЫЙ шифр
Интересно отметить, что в несколько изменённом виде шифр Полибия
дошёл до наших дней и получил своеобразное название «тюремный шифр».
Для его использования нужно только знать естественный порядок расположе-
ния букв алфавита (как в указанном выше примере квадрата Полибия для анг-
лийского языка). Стороны квадрата обозначаются не буквами (ABCDE), а
числами (12345). Число 3, например, передаётся путём тройного стука. При
передаче буквы сначала «отстукивается» число, соответствующее строке, в
которой находится буква, а затем номер соответствующего столбца. Напри-
мер, буква «F» передаётся двойным стуком (вторая строка) и затем одинар-
ным (первый столбец).
С применением этого шифра связаны некоторые исторические казусы.
Так, декабристы, посаженные в тюрьму после неудавшегося восстания, не
смогли установить связь с находившимся в «одиночке» князем Одоевским.
Оказалось, что князь (хорошо образованный по тем временам человек) не
помнил естественного порядка расположения букв в русском и французском
алфавитах (другими языками он не владел). Декабристы для русского алфави-
та использовали прямоугольник размера 5x6 (5 строк и 6 столбцов) и редуци-
рованный до 30 букв алфавит.
«Тюремный шифр», строго говоря, не шифр, а способ перекодировки со-
общения с целью его приведения к виду, удобному для передачи по каналу
связи (через стенку). Дело в том, что в таблице использовался естественный
порядок расположения букв алфавита. Так что секретом является сам шифр (а
не ключ), как у Полибия.
МАГИЧЕСКИЕ квадраты
Во времена средневековья европейская криптография приобрела сомни-
тельную славу, отголоски которой слышатся и в наши дни. Криптографию
стали отождествлять с черной магией, с некоторой формой оккультизма, аст-
рологией, алхимией, еврейской каббалой. К шифрованию информации призы-
вались мистические силы. Так, например, рекомендовалось использовать «ма-
гические квадраты».
В квадрат размером 4 на 4 (размеры могли быть и другими) вписывались
числа от 1 до 16. Его магия состояла в том, что сумма чисел по строкам,
столбцам и полным диагоналям равнялась одному и тому же числу - 34.
23
Впервые эти квадраты появились в Китае, где им и была приписана некоторая
«магическая сила». Приведем пример:
16 3 2 13
5 10 11 8 1
9 6 7 12
4 15 14 1
Шифрование по магическому квадрату производилось следующим обра-
зом. Например, требуется зашифровать фразу: «Приезжаю сегодня». Буквы
этой фразы вписываются последовательно в квадрат согласно записанным в
них числам, а в пустые клетки ставятся произвольные буквы.
16У ЗИ 2Р 13Д
53 10Е иг 8Ю
9С 6Ж * 7А 120
4Е 15Я 14Н 1П
После этого шифрованный текст записывается в строку:
УИРДЗЕГЮСЖАОЕЯНП
При расшифровывании текст вписывается в квадрат и открытый текст чи-
тается в последовательности чисел «магического квадрата». Данный шифр -
обычный шифр перестановки, но считалось, что особую стойкость ему прида-
ет волшебство «магического квадрата».
ИСТОРИЧЕСКИЕ КНИГИ по криптографии
В арабском мире в древние времена была создана одна из самых развитых
цивилизаций. Процветала наука, арабская медицина и математика стали ве-
дущими в мире. Естественно, что и наилучшие условия для развития крипто-
графии появились именно здесь. Одно из основных понятий криптографии -
шифр - имеет корни в арабском слове «цифра». Некоторые историки даже
считают, что криптография как наука зародилась именно в арабском мире. В
арабских книгах впервые были описаны содержательные методы криптоана-
24
лиза (дешифрования). Тайнопись и ее
значение упоминается в сказках «Тысяча
и одна ночь». Одна из первых крупных
книг, в которой содержательно
описывается криптография - это труд,
созданный Абу Вакр Ахмед бен Али бен
Вахшия ан-Набати - «Книга о большом
стремлении человека разгадать загадки
древней письменности». В ней описано
несколько систем шифров.
В 1412 году Шехаб аль Кашканди
напйсал 14-ти томную энциклопедию
«Шауба аль Аша». В этой работе имеется
раздел о криптографии «Относительно
сокрытия в буквах тайных сообщений».
Сцена из арабской жизни, XV век.
Мухаммед при осаде крепости
В нем дано систематическое описание различных шифров замены и переста-
новки. Здесь же приводится и криптоанализ этих шифров на основе подсчета
частотности букв в арабском языке по тексту Корана; развиваются методы'
дешифрования, базирующиеся на разночастотности букв. В работе Кашканди
предлагается семь систем шифрования (повторяющих неопубликованные
идеи его предшественника Ибн ад-Дурахийма):
- одна буква может заменять другую;
- можно писать слово в обратном порядке, например, слово «Мухаммед»
(МХМД - в арабском алфавите, состоящем из согласных) примет вид ДМХМ;
- можно переставлять в обратном порядке чередующиеся буквы слов;
- заменять буквы на цифры в соответствии с принятой заменой арабских
букв на числа. Тогда слово «Мухаммед» превращается в 40+8+40+4 (М=40,
Х=8, Д=4). При этом криптограмма выглядит как перечень каких-то цифр;
- можно заменять каждую букву открытого текста на две арабские буквы,
которые используются и в качестве чисел, и сумма которых равна цифровой
величине шифруемой буквы открытого текста;
+ 5 - г:'-'"'-' ’
W J ; » e f J S’ J
- можно заменять каждую букву
именем какого-либо человека;
- при шифровании можно
использовать словарь замены,
описывающий положения луны,
названия стран (в определенном
порядке), названия фруктов, деревьев
ит. д.
Арабский «давидовский» шифр замены ® этой же книге Кашканди пишет
о частотном методе дешифрования
25
шифра простой замены: «Если вы хотите разгадать сообщение, которое вы
получили в зашифрованном виде, то прежде всего начинайте подсчет букв, а
затем сосчитайте, сколько раз повторяется каждый знак, и подведите итог в
каждом отдельном случае...».
Арабы первыми обратили внимание на возможность использования стан-
дартных слов и выражений для дешифрования. Так, первый широко извест-
ный среди арабов филолог восьмого века Абу аль-Ахмади, дешифровав крип-
тограмму на греческом языке, которую переслал ему византийский император
с просьбой о дешифровании, так объяснил свой метод: «Я сказал себе, что
письмо должно начинаться со слов «Во имя Бога» или как-нибудь в этом роде.
Итак, я составил на основе этого первые буквы, и все оказалось правильным».
На основе открытого им метода дешифрования он написал книгу «Китаб аль-
Маумма» («Книга тайного языка»).
Однако в последующем столетии криптография у арабов деградировала. В
1600 году марокканский султан Ахмед аль-Мансур направил английской ко-
ролеве Елизавете посла с целью заключения союза против Испании. Посол
отправил султану зашифрованную депешу, которая попала в руки к арабам.
Ее дешифрование длилось 15 лет, и в связи с успешным завершением работы
арабы воздали хвалу Аллаху. Ибн ад-Дурахийм решил бы эту загадку за не-
сколько часов.
Выдающийся арабский ученый и философ XI-XII веков, поэт Омар Хайям
в своих произведениях нередко обращался к тайнописи. Вот одно из его про-
изведений («Рубаи»):
Все что видишь ты, - видимость только одна,
Только форма - а суть никому не видна.
Смысл этих картинок понять не пытайся -
Сядь спокойно в сторонке и выпей вина!
Здесь Хайям весьма пессимистично относится к попыткам проникнуть в
тайный смысл сообщений, скрывающийся за внешней формой их представле-
ния. Его современники - криптографы были настроены оптимистичнее.
В XIV-XV веках клерк тайной канцелярии папской курии Чикко Симо-
нетта написал книгу о тайнописи. В ней он изложил усовершенствованные
шифры замены, в том числе и шифр многозначной замены, в котором одной и
той же букве (гласной) соответствует несколько шифробозначений. Симонет-
та обслуживал герцогов Сфорца, олигархов Милана, дешифруя для них пере-
хваченные депеши. Он разработал 13 правил дешифрования шифров простой
замены, которые изложил в рукописи на трех кусках пергамента.
Секретарь антипапы Клемёнтия VII Габриель де Лавинда в XV веке напи-
26
сал «Трактат о шифрах» (первый европейский учебник по криптографии), в
котором изложил метод дешифрования шифров замены, основанный на под-
счете частот букв, и описал шифры пропорциональной замены. В последнем
шифре буквам алфавита ставилось в соответствие несколько шифробозначе-
ний, причем их количество было пропорционально частоте появления буквы в
текстах итальянского языка.
Первый из известных в Европе шифров омофонной (многознаковой) замены.
Италия, 1401 г.
Наиболее крупного успеха в развитии криптографии в то время достиг Ле-
он Альберти, человек универсального таланта, архитектор и математик. В
1466 году он представил в папскую канцелярию трактат о шифрах, написан-
ный по заказу папы римского, в котором провел анализ частот букв, исследо-
вал шифры замены и перестановки, затронул вопросы стойкости шифров. За-
меченная Альберти разночастотность появления букв в осмысленных текстах
дала толчок изучению синтаксических свойств письменных сообщений. При
этом основное внимание обращалось на наиболее часто встречающиеся бук-
вы. В русском языке первые десять наиболее частых букв породили несколько
неудобное для чтения слово «сеновалитр» (внутри этого слова частотные
«приоритеты» букв не соблюдаются). В английском языке из частых букв со-
ставлена фраза «а sin to егг» («грех ошибаться») В итальянском языке среди
наиболее частых букв встречаются в подавляющем большинстве гласные бук-
вы. Не в этом ли секрет «певучести» итальянского языка?
Полное же упорядочение букв литературного русского языка в порядке
убывания частот их появления в текстах имеет следующий вид:
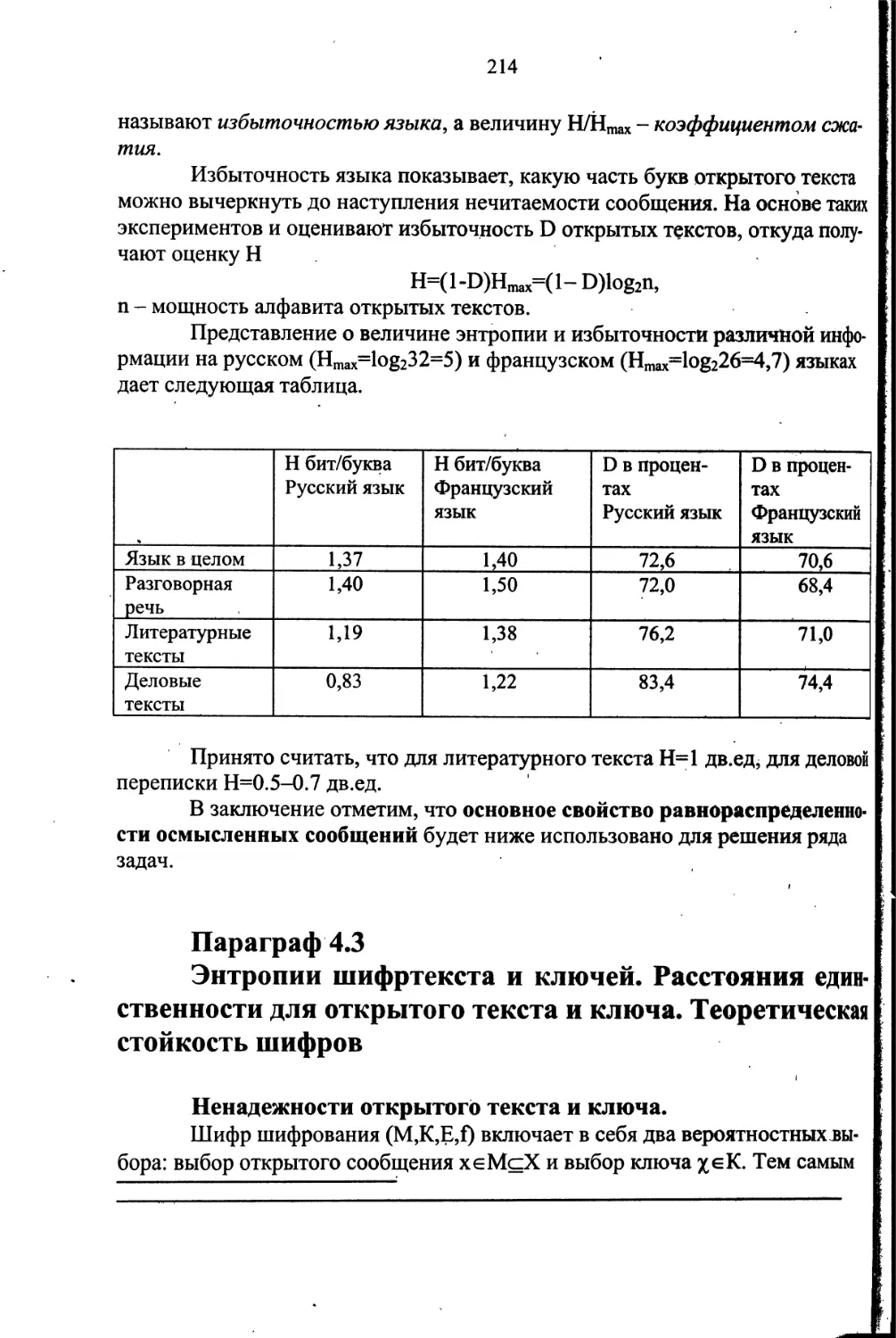
О,Е (Ё),А,И (Й),Т,Н,С,Р,В,Л,М, Ь,Д,П,У,Я,Ы,3,Ъ,Б,Г,Ч,К,Х,Ж,Ю,Ш,Ц,Щ,Э,Ф
ШИФР Аве Мария
В XV веке аббат Тритемий (Германия) сделал два новаторских предложения в
области криптографии: он предложил шифр «Аве Мария» и шифр, построенный на
27
основе периодически сдвигаемого ключа.
Шифр «Аве Мария» основан на принципе замены букв шифруемого текста
на заранее оговоренные слова. Из этих сообщений составлялось внешне «не-
винное» сообщение. Приведем пример.
Заменим буквы Е, Н, Т на следующие слова:
Е = «ЗЕЛЕНЫЙ», «ЖДУ», «МОЙ»; Н = «И», «Я», «ЗДЕСЬ»;
Т = «ДОМА», «ВЕЧЕРОМ», «ОКОЛО», «КЛЮЧ»
Фауст заклинает Мефистофеля
Тогда отрицательный секретный ответ «нет» на заданный вопрос может
иметь несколько «невинных» вариантов: «Я жду дома», «Я жду вечером»,
«Здесь мой ключ».
а Ж5еив b Creator с Condito? D jDpffex е jEsommus f Sominato? g jEonfblato? b arbiter a element b clemeHttTHmus c plus о piiflimus e magnus f excelfus g mjntm» b optimus
Первая страница шифра Тритемия «Аве Мария»
28
ТАБЛИЦА Тритемия
Наиболее серьезное предложение Тритемия по защите информации, до-
шедшее до наших дней, заключается в придуманной им таблице - «таблице
Тритемия». Приведем эквивалент для английского алфавита:
ABCDEFGHIJKLMNOPQRSTUVWXYZ
BCDEFGHIJKLMNOPQRSTUVWXYZA
CDEFGHIJKLMNOPQRSTU VWXYZ АВ
DEFGHIJKLMNOPQRSTUVWXYZABC
EFGHIJKLMNOPQRSTUVWXYZABCD
FGHIJKLMNOPQRSTUVWXYZABCDE
GHIJKLMNOPQRSTUVWXYZABCDEF
. HIJKLMNOPQRSTUVWXYZABCDEFG
IJKLMNOPQRSTUVWXYZABCDEFGH
JKLMNOPQRSTUVWXYZABCDEFGHI
KLMNOPQRSTUVWXYZABCDEFGHIJ
LMNOPQRSTUVWXYZABCDEFGHI JK
MNOPQRSTUVWXYZABCDEFGHIJKL
NOPQR.STUVWX YZABCDEFGHI J KLM
OPQRSTUVWXYZABCDEFGHIJKLMN
PQRSTUVWXYZABCDEFGHIJ KLMNO
QRSTUVWXYZABCDEFGHIJKLMNOP
RSTUVWXYZABCDEFGHIJKLMNOPQ
STUVWXYZABCDEFGHIJKLMNOPQR
TUVWXYZABCDEFGHIJKLMN OPQRS
UV WXYZABCDEFGHI JKLMNO PQRST
VWXYZABCDEFGHIJKLMNOPQRSTU
WXYZABCDEFGHIJKLMNOPQ RSTUV
XYZABCDEFGHIJKLMNOPQR S TUVW
YZABCDEFGHIJKLMNOPQRS TUVWX
ZABCDEFGHIJKLMNOPQRSTUVWXY
Здесь первая строка является одновременно и строкой букв открытого
текста.
Первая буква текста шифруется по первой строке, вторая буква по второй
и так далее после использования последней строки вновь возвращаются к
первой. Так слово «fight» (борьба) приобретает вид «fjikx».
Реализация таблицы Тритемия не требовала использования каких-либо
механических приспособлений; шифралфавит с каждым шагом шифрования
сдвигается на единицу влево. Однако в первоначальном варианте в шифре
29
Тритемия отсутствовал ключ. Секретом являлся сам способ шифрования. В
дальнейшем усложнения шифра пошли по двум путям:
- введение произвольного порядка расположения букв исходного алфавита
шифрованного текста вместо лексикографически упорядоченного алфавита;
- применение усложненного порядка выбора строк таблицы при шифровании.
Эти усложнения позволили применять ключевые множества значительно-
го объема. Отметим, что шифр простой замены является вырожденным случа-
ем шифра Тритемия: в нем все буквы шифруются по одной и той же строке
таблицы.
ШИФР Белазо
Следующий шаг в развитии предложенного Тритемием способа шифрова-
ния был сделан итальянцем Жованом Белазо. В 1553 году выходит в свет его
брошюра «Шифр синьора Белазо». В этом шифре ключом являлся так назы-
ваемый пароль - Легко запоминаемая фраза или слово. Пароль записывался
периодически над буквами открытого текста. Буква пароля, стоящая над соот-
ветствующей буквой открытого текста, указывала номер строки в таблице
Тритемия, по которой следует проводить замену (шифрование) этой буквы.
Так, если паролем является слово ROI, то при зашифровании слова FIGHT
получаем WWOYH. Аналогичные идеи шифрования используются и сегодня.
Изобретение книгопечатания Иоганном Гуттенбергом (1440, Германия,
г. Майнц) заметно повысило грамотность населения. Оживилась переписка,
возрос объем обмена секретной информацией. С другой стороны, доступные
всем книги сами по себе породили «книжные» шифры, используемые и в на-
стоящее время.
КНИЖНЫЙ шифр
Существует немало способов использования книги для тайного обмена
сообщениями. Например, если адресаты заранее договорились между собой
об использовании дубликатов одной и той же книги в качестве ключа шифра,
то их тайные послания могли бы состоять из таких элементарных единиц:
n/m/t, где п - номер страницу книги, m - номер строки, t - номер буквы в
строке; по этим буквам и читается тайное послание. Наряду с нумерацией
букв могут использоваться обозначения слов и даже целых фраз.
30
ФРЕНСИС Бэкон о шифрах
Крупнейший английский философ и ученый XVII века лорд-канцлер
Френсис Бэкон уделял серьезное внимание шифрам. Он выдвинул главные
требования к ним: «Они не должны поддаваться дешифрованию, не должны
требовать много времени для написания и чтения, и не должны возбуждать
никаких подозрений». Эти требования сохраняются и сегодня. Он также
предложил оригинальную идею стеганографической защиты информации, опи-
рающуюся, по существу, на двоичное кодирование букв алфавита и использование в
открытом тексте двух мало отличающихся шрифтов. Двоичное кодирование,
изобретенное Ф. Бэконом, по существу является современным кодированием
в двоичном алфавите. Вместо алфавита {0,1} он использовал алфавит {а,Ь}.
Код имел вид: А=ааааа - код 0, В=ааааЬ - код 1, С= aaaba - код 2, D=aaabb -
код 3-ки, E=aabaa - код 4-ки и т.д. Слово FUGE («бегите») кодировалось по
буквам:
F=5=aabab, U=19=baabb, G=6=aabba, E=4=aabaa. Кодированный текст имел
вид
aabab baabb baabb aabaa
Для зашифрования слова FUGE использовалось произвольное невинное со-
общение, например,
Manere te volo donee venero («оставайтесь до моего прихода») и два алфавита
А и В с близкими по начертанию буквами. Содержательном сообщение и ко-
дированный текст
Ma n е re te vol odoneevenero
аа b a bb аа bbb aabbaabaa
преобразовывались в то же содержательное сообщение, записанное в смешан-
ном алфавите, именно, буквы М,а записывались в алфавите А, п - в
алффвитё В, е - в А, г,е - в В и т.д.
Френсис Бэкон предупреждал о возможных негативных последствиях
ошибок в использовании даже весьма надежных шифров. Он писал: «В ре-
зультате неловкости и не искусности тех рук, через которые проходят вели-
чайшие секреты, эти секреты во многих случаях оказывались облеченными
слабейшими шифрами». Другими словами, даже сильный шифр в плохих ру-
ках не обеспечивает надежной защиты секретов. Надежность шифра заюпоча-
ется не только в самом шифре, но и в руках его пользователя. Последующие
века подтвердили этот тезис. Даже в XX веке ошибки в использовании шиф-
ров сводили «на нет» все усилия по защите информации. По справедливому
замечанию Д. Кана «ошибка шифровальщика порой является единственной
надеждой криптоаналитика».
31
а aAz//* ла- f Rda 6 fca-w faa.
t& -poto £iw fam'
Пример употребления двухшрифтового шифра Ф. Бэкона. Открытый текст
«Fuge» («Бегите» скрыт маскироввочным двухшрифтовым текстом, «Мапеге te
volo donee venero» (“Оставайтесь до моего прихода”). Пример принадлежит само-
му Ф. Бэкону
Интерес к криптографии про-
явили и представители высшей
знати. Так, в XVII веке Август И,
герцог Ганновера, под
псевдонимом Густав Селен опуб-
ликовал свою книгу «Секретные
сообщения и криптография».
Правда, в этой книге
пересказывались уже известные
идеи (в первую очередь - Три-
темия). Большое внимание
уделялось связи криптографии с
оккультизмом.
Не только государственные
деятели, но и различные тайные
общества использовали секретные
шифры.
Философ ордена Розенкрейцеров.
Ф. Бэкон был членом этого ордена
ШИФРЫ вольных каменщиков
Вспомним шифр «Братства Франкмасонов», или «Вольных каменщиков»,
который они использовали для общения между собой. По современным поня-
тиям и вопреки расхожему мнению он совершенно не стоек, но представляет
определенный интерес. Приведем небольшой пример (применительно к анг-
лийскому языку). Нарисуем три фигуры следующего вида:
32
А: В: С: J. к. L. S Т и
D: Е: F: м. N. О. V W X
G: Н: I: Р. Q- R. Y Z
В соответствии с этими фигурами буквы получают следующее геометри-
ческое представление:
А= : | , В= . [J , С= | : , J= . | , R= | . , S= _| и т. д.
Фраза «We talk about» при зашифровании принимает вид:
□ □Ld^JL-dLdCLLJ
Геометрическое представление может меняться, например:
Тогда А=
и т. д.
Интересно, что при походе на Россию Наполеон использовал в низших звень- {
ях своей связи подобные шифры. Они были раскрыты русскими специалистами, i
что оказало определенное влияние на ход боевых действий. *
33
ДИСК Альберти
Итальянец Альберти (XVI в.) впервые вы-
двинул идею «двойного шифрования» - текст,
полученный в результате первого шифрования,
подвергался повторному зашифрованию. В
трактате Альберти был приведен и его собст-
венный шифр, который он назвал «шифром,
достойным королей». Он утверждал, что этот
шифр недешифруем. Реализация шифра осу-
ществлялась с помощью шифровального диска,
положившего начало целой серии многоалфа-
витных шифров. Устройство представляло собой пару дисков - внешний, не-
подвижный {на нем были нанесены буквы в естественном порядке и цифры от
1 до 4) и внутренний - подвижный - на нем буквы были переставлены. Про-
цесс шифрования заключался в нахождении буквы открытого текста на внеш-
нем диске и замену ее на соответствующую (стоящей под ней) букву шифро-
ванного текста. После шифрования нескольких слов внутренний диск сдви-
гался на один шаг. Ключом данного шифра являлся порядок расположения
букв на внутреннем диске и его начальное положение относительно внешнего
диска.
Шифр, реализуемый диском Альберти, в наше время получил название
многоалфавитногр. Смысл этого названия заключается в следующем.
Вернемся к двухстрочной записи шифра
замены Ю. Цезаря. Назовем верхнюю строку
алфавитом открытого текста, а нижнюю -
алфавитом шифрованного текста
(шифралфавитом). Если в процессе
шифрования алфавит шифрованного текста
не меняется, то шифр носит название
одноалфавитного (или шифра простой
замены). Если этот алфавит меняется, то
шифр называется многоалфавитным. Таким
образом, шифр Цезаря - это шифр простой
замены, а в многоалфавитном шифре
Альберти количество алфавитов равно числу
Диск Альберти, использо-
ванный конфедератами во
время гражданской войны в
Северной Америке
2зи.5 ,
34
Модифицированный диск Альбер»
ти, использованный в начале ХЭД
века в США г
букв в алфавите открытого текста плюс четыре. Альберти - изобретатель мно-
гоалфавитных шифров, которые, в основном, используются и в наши дни. Од-
нако способ выработки последовательности алфавитов шифрованного текста
и их выбор существенно усложнен; у Альберти он определялся циклическим
сдвигом на единицу через заранее оговоренное количество шифруемых букв.
Таким образом, процесс шифрования стал «динамичным».
Второе изобретение Альберти -
буквенно-цифровой код (правда, малого
объема). Цифры на диске Альберти (1, 2, 3,
4) шифруются так же, как и буквы. Альберти
предложил использовать упорядоченные
двух-, трех- и четырех цифровые
комбинации в качестве кодообозначений для
букв, слов, и целых предложений (число
таких комбинаций равно 336). Не исключено,
что коды использовались и ранее, но в
исторических документах они связываются с
именем Альберти. Особо отметим, что
кодированные сообщения затем
перешифрорывались, то есть использовался код
с перешифровкой. Эта идея используется и в
наши дни.
ШВЙ»РЬ1 Ардженти
В XVI веке заметный вклад в развитие криптографии внес криптограф па-
пы римского Маттео Ардженти, унаследовавший искусство тайнописи от сво-
его дяди. Именно Ардженти предложил использовать слово^пароль для при-
данйя, алфавиту легко запоминаемого смешанного вида. Об этом уже говори-
лось’при рассмотрении усложненного шифра Полибия.
Ардженти рекомендовал не разделять слова, применять омофонные заме-
ны, вставлять в шифртекст большое количество «пустышек», устранять пунк-
туацию, не вставлять в шифртекст открытые слова («клер») и т. д. Для за-
труднения дешифрования шифров замены он предложил следующее: заменять
буквы либо на цифры (от 0 до 9), либо на числа (от 00 до 99), причем во избе-
жание путаницы при расшифровании цифры, используемые как самостоя-
тельные шифробозначения, не должны входить в двухзначные обозначения.
35
Поскольку однозначных обозначений оказывается сравнительно немного, то
чтобы не бросалась в глаза их малая частота появления в шифртексте, Ард-
жента рекомендовал придавать однозначные обозначения наиболее часто
встречающимся в открытом тексте буквам.
Приведем пример шифра замены Ардженти для итальянского языка. В
этой замене наряду с шифрованием используется шифрование - кодирование
некоторых 2-х, 3-х буквенных частых сочетаний.
А В С D Е F G Н I L М N
1 86 02 20 62,82 22 06 60 3 24 26 84
О Р Q R S Т и Z
9 66 68 28 42 80 46 88
ЕТ CON NON СНЕ ПУСТЫШКИ
08 64 00 44 5,7
Слово ARGENTI могло приобрести при зашифровании такой вид:
5128066284580377 или такой: 1772850682584780537.
Это было действительно серьезное усложнение шифра замены. Частотный
анализ дешифровальщиков существенно усложнялся. 1
Ардженти занимался также усложнением кодов (номенклаторов). В част-
ности, он впервые разработал буквенный код, в котором 1200 букв, слогов,
слов и целых фраз заменялись на группы из букв.
Результаты своих криптографических исследований Ардженти изложил в
пособии по криптографии, написанным уже после увольнения из канцелярии
папы в результате интриг внутри папской курии. Однако папа, признав Ард-
женти невиновным, назначил ему солидную пенсию.
Основная идея Тритемия о введении многоалфавитности шифрованного
текста была подхвачена итальянцем Жованом Батистой Белазо (середина XVI
века). В своей небольшой книжке «Шифр синьора Белазо» он предложил ис-
пользовать таблицу Тритемия'совместно с легко запоминаемым ключом, так
называемым паролем. Таким паролем могло бы служить, например, легко за-
поминаемое стихотворение. Буквы, входящие в стихотворение, последова-
2*
36
тельно определяют строки таблицы Тритемия, по которым шифруются буквы
открытого сообщения. Сам пароль стал ключом шифра.
В последующем идеи Тритемия и Белазо развил соотечественник Белазо
Джованни Батиста Порта. Он предложил отказаться от алфавитного порядка
следования букв в первой строке таблицы Тритемия и заменить этот порядок
на некоторый произвольный, являющийся ключом шифра. Строки таблицы
по-прежнему циклически сдвигались.
ШИФРЫ Порта
Основная книга Порта о тайнописи - это книга «О тайной переписке». Она
написана в жанре учебника. В ней Порта показал слабости широко распро-
страненных в то время шифров, в том числе и шифров масонов, которые он
назвал Щйфрами «сельских жителей, женщин и детей», и предложил так на-
зываемый биграммный шифр.
Этот шифр есть шифр биграммной (двухбуквенной) замены, в котором
каждому двухбуквенному сочетанию открытого текста в шифрованном тексте
соответствовал специально придуманный знак. Знаки шифртекста имели фо-
рму сймволико-геометрических фигур. По сути дела это был тот же шифр
простой замены, но на уровне двухбуквенных сочетаний. Криптографическая
стойкость при такой замене по сравнению с побуквенным шифрованием заме-
тно повышалась.
Порта также Предложил механизировать процесс шифрования по его таб-
лице. Он привел описание механического дискового устройства, реализующе-
го биграммную замену.
Порта также рекомендовал не использовать в переписке стандартных слов
и выражений; более того, он предлагал записывать открытый текст с ошибка?-
ми, чтобы затруднить работу дешифровальщика. Он писал: «... когда тема пе-
реписки известна, анализирующий может делать проницательные предполо-
жения относительно слов ...», что может существенно облегчить работу де-
шифровальщика.
: Порта видоизменил шифровальный диск Альберти, превратив алфавит
шифрованного текста в любимые им символико-геометрические фигуры. Ра-
зумеется, никакого усложнения при этом шифр Альберти не получил, добави-
лась лишь экзотика в шифрованном тексте.
37
Порта предложил некоторую модификацию шифра Белазо. В применении
к русскому языку он представляет собой прямоугольную таблицу из букв ал-
фавита в следующем порядке:
1 А Б а п б с в т г V д (Ь е X Ж тт 3 ч и ттт й ттт к ъ л ы м ь н 3 0 ю п я ,
2 В а б в г д е ж 3 и й к л м н 0 п
Г с т V <ь X тт ч ттт ттт ъ ы Б 3 ю я Р.г
3 д а б в г д е ж 3 и й к л м н О п
F. т V (h X тт ч ттт ттт Ъ ы Ь 3 то я П С .
4 Ж а б В г д е ж 3 и й к л м н IF
3 V (Ь X ,п ч ттт ттт ъ ы ь 3 то я п Q V
5 И а б в г д е ж 3 и й к л м н 0 п
и di, X тт ч ттт ттт ъ ы ь 3 то я п с т у
6 к а б в г д е ж 3 и й к л м н О п
л X тт ч ттт ттт ъ ы к 3 то я п с т V (h
7 м а 6 в г д е ж 3 и й к л м н о п
н тт ч ттт ттт ъ ы ь з то я п с т V di X
8 О а б в г д е ж 3 и й к л м н 0 п
п ч III ттт ъ ы ь з то я п с т V (Ь X п
9 р а б в г Д е ж 3 и й к л м н О п
с пт III ъ ы ь з то я п с т V ch X п ч
10 т а б в г Д е ж 3 и й к л м н 0 и
У ттт ь ьт ь з то я п с т V л ‘X тт ч П!
11 ф а б в г Д е ж 3 и й к л' м н о п
X ъ ы Ь з то я П с т V d) X тт ч пт тп
12 ц а б в г Д е ж 3 и й к л м н 0 п
ч ы ь з то я п с т V (Ь X тт ч ттт пт ъ
13 ш а б в г Д е ж 3 и й к л м н 0 п
пт ь 3 то я п с т V (Ь X тт ч ттт пт ъ м
14 ъ а б в г Д е ж 3 и й к л м н р ц
ы з ю я п с т V (Ь X тт ч ттт ттт ъ н к
15 ь а б в г Д е ж 3 и й к л м н р п
э ю я п с т V ch X тт ч ттт ш ъ ы Л,
16 ю а ь в г Д е Ж 3 и й . к л. м н о п
я я п с т V d» X тт ч ттт ттт ъ ы Ь Э JKL.
Шифрование производится при помощи секретного лозунга. Лозунг
периодически выписывается над открытым текстом, по первой букве лозунга
отыскивается алфавит (большие буквы в начале строк), в верхнем или нижнем
полуалфавите отыскивается первая буква открытого текста и заменяется соот-
ветствующей ей буквой из верхней или нижней строки. Аналогично шифру-
ются и другие буквы (интервалы между словами не учитываются). Приведем
пример:
38
Лозунг; ф ил о с о ф и я ф и л о с о ф и я ф и л о.
Открытый текст: периодическийшифр......'..
Шифртекот: щщ ляцытгфзюзр........
За этот шифр де ла Порту позднее назвали отцом современной криптографии,
йо в свое время этот шифр не нашел широкого применения. Причина этого - необ-
ходимость' постоянно иметь при себе указанную таблицу и сложность процесса
цшфровайия. Однако был дан импульс для появления других систем шифра (на-
пример, Шифра Виженера).
Йорта обладал игривым характером. В качестве упражнений в зашифрова-
нии и расшифровании он предлагал, например, такие тексты: «Сегодня ночью
я лишил Невинности предмет своей любви». Он увлекался магией, оккультиз-
мом, и это отражалось на его криптографических трудах. Тем не менее, его
вклад в криптографию настолько велик, что потомки назвали его «выдаю-
щимся криптографом Ренессанса», «гигантом, возвышающимся над совре-
менниками».
ШИФРЫ Кардано
В середине Xyi века в Италии появляется книга математика, врача и фи-
лософа Дж. Кардано «О тонкостях» с дополнением «О разных вещах», в кото-
ром имеются разделы, посвященные криптографии. В ней нашли отражение
новые идеи криптографии: использование части самого передаваемого откры-
того текста в качестве ключа шифра и новый способ шифрования, который
вошел в историй) как «решетка Кардано». Для ее изготовления брался лист из
твердого материка (картон, пергамент, металл), представляющий собой квад-
рат, в котором вырезаны «окна». При шифровании решетка накладывалась на
лист бумагЦ^т буквы открытого текста вписывались в «окна». При использо-
вании всех «окон» решетка поворачивалась на 90 градусов, и вновь буквы от-
крытого тексзОписывались в «окна» повернутой решетки. Затем вновь про-
изводился поворот на 90 градусов и т. д. В один «заход» решетка работала 4
раза. Если текст зашифрован не полностью, то решетка ставилась в исходное
положение и вся процедура повторялась. Это ничто иное, как шифр переста-
новки.
< . л.. .
39
Главное требование к решетке Кардано - при всех поворотах «окна»
не должны попадать на одно и то же место в квадрате, в котором образуется
шифртекст.
Если в квадрате после снятия решетки образовывались пустые места,
то в них вписывались произвольные буквы. Затем буквы квадрата выписыва-
лись построчно, что и было шифрованным текстом.
Жизнь Кардано была омрачена тяжелым и некрасивым спором - ссорой со
своим другом - математиком Тарталья. Кардано «позаимствовал» свою знамени-
тую «формулу Кардано» (решение уравнения третьей степени) у своего друга и
опубликовал ее под собственным именем. Этот факт вызвал весьма негативную
оценку со стороны современников Кардано и у последующих поколений матема-
тиков.
Судьба Кардано сложилась трагически. Как астролог, он заранее предска-
зал себе 75 лет жизни.
х 3 + рх + q = О
Формула Кардано в современной математической модели. Один из корней урав-
нения.
Квадрат Кардано
Чтобы не нарушать собственное предвидение, согласно легенде он
покончил с собой в отведенный им срок со словами: «Если и неверно, то
неплохо придумано». Перед смертью, находясь в религиозном экстазе, Кар-
дано сжег свои книги, усмотрев в них противоречие «с волей Божьей».
40
Предложенный Кардано «шифр-решетка» лежит в основе знаменитого
«шифра Ришелье», в котором шифрованный текст внешне имел вид «невинного
послания». Из плотного материала вырезался прямоугольник размером, на-
пример, 7 х 10; в нем проделывались окна (на рисунке они заштрихованы).
Кардинал Ришельё
-
I • L о V E • Y о и
I • H A V E • Y 0 и
D E E P • U N D E R
M Y • S к I N • M Y
L 0 V E • L A s T s
• F 0 R E V E R • I N
H Y p E R s p A c E
4
.. Секретный текст вписывался в эти окна, затем решетка снималась и
оставшиеся клетки заполнялись так, чтобы получалось «невинное» сообще-
ние. Суровую команду на английском языке: «YOU KILL AT ONCE» с помо-
щью решетки можно спрятать в «невинный» текст любовного содержания: «I
LOVE YOU. I HAVE YOU. DEEP UNDER MY SKIN. MY LOVE. LASTS
FOREVER IN HYPERSPACE».
41
Разумеется, использование этого шифра вызывает затруднения и тре-
бует соответствующего интеллекта.
Такого рода шифр использовал
известный русский писатель, обще-
ственный деятель и дипломат А.
С. Грибоедов. Будучи послом в Пер-
сии, он писал своей жене
«невинные» послания, которые,
попав в руки жандармерии, для
которой и были предназначены,
расшифровывались по
соответствующей «решетке» и
передавались царскому
правительству уже как секретные
сведения.
А.С. Грибоедов
Как математик, Кардано сумел вычислить количество квадратов-решеток
(ключей) заданного' размера NxN. Если N - четное число, то. это количество
2
равно 414 - . При N=10 оно имеет порядок десять в пятнадцатой степени.
Вместе с тем, Кардано ошибочно сводил стойкость всех шифров к количеству
возможных ключей. При таком подходе даже шифр простой замены должен
быть признан стойким, однако его научились дешифровать за несколько сто-
летий до Кардано. Не только количество ключей, но и сам способ (алгоритм)
шифрования при заданном ключе влияет на стойкость шифров. Даже при
N=10 шифр Кардано значительно более стоек, чем шифр простой замены, хо-
тя значительно уступает последнему по количеству ключей.
В то же время сами шифры Кардано составляют весьма незначительную
часть всех шифров перестановок» Так, например, при N=10 шифр Кардано пе-
реставляет буквы внутри блока, состоящего из 100 букв открытого текста.
Число ключей, как указывалось выше, имеет порядок десять в пятнадцатой
степени. Количество же ключей Шифра общей перестановки внутри блоков из
100 букв имеет порядок 100!, то есть примерно 10 |ф0 . Таким образом, шифры
Кардано составляют 10 '|45 часть от общего количества шифров перестано-
вок. Однако эффективно и быстро осуществлять произвольную перестановку
в блоках длиной в 100 знаков - достаточно трудная задача даже в наши дни.
Решетка Кардано позволяет осуществлять перестановку букв достаточно
просто.
42
Следует заметить, что подход Кардано к оценке стойкости шифров через
количество его ключей имеет положительный момент. Кардано в неявном ви-
де предполагал, что сам шифр может быть известен противнику, который мо-
жет попытаться дешифровать его путем перебора всех возможных ключей. В
явном виде требование обеспечения стойкости криптографической защиты
информации в условиях знания противником используемого шифра (но не
ключа!) было впервые сформулировано лишь в XIX веке.
Кардано выдвинул, но не сумел реализовать интересную идею. Он пред-
ложил использовать в качестве ключа шифра сам открытый секретный текст
(идея «самоключа»). Смысл его предложения можно проиллюстрировать сле-
дующим образом.
Пусть требуется зашифровать фразу:
SIC ERGO ELEMENTIS...
Ключ шифрования, опирающегося на таблицу Тритемия, образовывался
следующим образом: слово SIC шифрует само себя, то есть первый знак шиф-
ртекста стоит на пересечении строки и столбца, соответствующих букве S (S -
строка, S - столбец), второй знак шифртекста есть знак, стоящий на пересече-
нии строки I со столбцом I, третий - С-С и т. д. При зашифровании второго
слова (ERGO) к паролю SIC добавляется следующая буква открытого текста
(получается SICE); буква Е слова ERGO шифруется по строке S, следующая
буква - по строке I и так далее.
Разумеется такой шифр порождает проблемы расшифрования получателем
сообщения, который не знает исходного ключевого слова SIC открытого тек-
ста. Он вынужден перебирать все возможные варианты; аналогичным образом
действует и дешифровальщик.
Таким образом, идея «самоключа», выдвинутая Кардано в предложенном
им виде, не могла быть реализована. Но эта идея привела к появлению реаль-
но реализуемой системы шифрования. Два секрета («текст и ключ») на пере-
даче вступили в союз и породили новые шифры, получившие широкое рас-
пространение в XX веке. Первый шаг в этом направлении совершил сам Бел-
лазо (теперь он писал свою фамилию с двумя «л»). Он предложил шифровать
первую букву сообщения по первой строке таблицы Тритемия, вторую - по
шифрованной первой букве, и т. д. Именно эта идея получила поддержку в
современной криптографии. При этом выбор строки шифрования сложным
образом зависит уже от значительного количества предварительно зашифро-
ванных букв.
Предложив свой шифр перестановки («решетка Кардано») Кардано реко-
мендовал шифровать три раза подряд, т.е. предложил идею многократного
перещифрования. Эта идея дошла до наших дней. Многократное зашифрова-
ние (тем более на различных шифрах) значительно повышает надежность за-
щиты.
43
ШИФР Виженера
К
Посол Франции в Риме Блез де Виженер (XVI в.), познакомившись с тру-
дами Тритемия, Белазо, Кардано, Порта, Альберти, также увлекся, криптогра-
фией. В 1585 году он написал «Трактат о шифрах», в котором излагаются ос-
новы криптографии. В этом труде он замечает: «Все вещи в мире представля-
ют собой шифр. Вся природа является просто шифром и секретным письмом»^
Эта мысль позднее была повторена Блезом Паскалем - одним из основополо-
жников теории вероятностей, а в настоящее время и Норбертом Винером -
«отцом юбернетики». В этом трактате вновь появилась идея использования в
качестве ключа самого открытого текста. Заранее оговаривается одна ключе-
вая буква алфавита, и первая буква сообщения шифруется таблицей Тритемия
по строке, соответствующей этой букве. Вторая буква шифруется по строке,
соответствующей первой букве шифрованного сообщения, и так далее. Хаким
образом, была реализована идея, предложенная ранее Кардано. ‘
Очевидный недостаток этого шифра - его слабая стойкость: если .ис-
пользуемая таблица Тритемия известна, то для дешифрования достаточно оп-
робовать первую (ключевую) букву, и шифр «раскалывается».
Второй вариант использования таблицы Тритемия, предложейный Виже-
нером, заключается в применении лозунга. .
По сути дела Виженер объединил подходы Тритемия, Беллазо, Порта к
шифрованию открытых текстов, по существу не внеся в них ничего ориги-
нального.
v 1 : • с ' ' ’"l .. ‘ ч, • * '
В последующем «шифр Виженера» значительно упростил в смысле его
практического использования граф Гронсфельд - начальник первбго в Герма-
нии государственного дешифровального органа («криптографической лабора-
тории»), Его предложение по сути дела привело к появлению так называемого
в настоящее время шифра гаммирования - одного из самых распространенных
шифров в современной криптографии. Суть этого предложения заключается в
следующем. Выпишем латинский алфавит: > - . ;
ABCDEFGHIJKLMNOPQRSTUVWXYZ :
В качестве ключа - лозунга выбирается легко' запоминаемое число, йй-' Г
пример, 13579. Этот лозунг периодически выписывается над буквами откры-
того текста (одна цифра над буквой). При шифровании буква открытого тек-
ста заменяется на букву, стоящую от неё справа (циклически) в алфавите на
количество букв, определяемых соответствующей цифрой лозунга. Так, на-
пример, при указанном лозунге слово «THE TABLE» превращается в Шифро-
ванную последовательность: «UKJAJCOJ» . ; 1 > .
44
Дальнейшая модернизация привела в наше время к шифру модульного
гаммирования.
Пронумеруем буквы алфавита: А=01, В=02, С=ОЗ,..., Z=26.
Слово «THE TABLE» приобретает следующий вид:
20.08.05.20.01.02.12.05.
Применим операцию циклического (модульного сложения). От обычного
сложения эта операция отличается тем, что если сумма превышает число 26,
то из нее вычитается 26; обратная операция - вычитание - характеризуется
тем, что если в результате получается отрицательное число, то к нему прибав-
ляется 26.
Зашифрование проводится по операции модульного сложения. Выпишем
лозунг 13579 периодически под открытым текстом и сложим соответствую-
щие числа. Получим шифртекст: 21.11.10.01.10.03.15.10., что соответствует
сочетанию букв «UKJAJCOJ». При расшифровании лозунг вычитается из букв
шифртекста.
Астрологические увлечения Виженера привели его к шифру, в котором
шифрзнаками являются положения небесных тел в момент шифрования. Он
пытался перевести свои послания на «язык неба».
История иногда «забывается» на столетия. В наше время «шифр Вижене-
ра», состоящий в периодическом продолжении ключевого слова по таблице
Тритемия, вытеснил имена его предшественников. При этом сам этот шифр
часто примитизируется до элементарности, нанося оскорбление его автору. В
начале XX века один из популярных американских журналов преподнес весь-
ма упрощенную систему Виженера как шифр, который «невозможно
вскрыть!».
Шифры Виженера с коротким периодическим лозунгом используются и в
наши дни в системах шифрования, от которых не требуется высокая крипто- '
графическая стойкость. Так, например, они используются в программе - ар-
хиваторе «ARJ», в программе «Word for Windous» (версии 2, 6).
ШИФР Бофора
Шифр Виженера в дальнейшем модернизировался. Так, в XIX в. английс-
кий адмирал Бофор предложил использовать таблицу следующего вида:
45
ABC DE FGH IJ KLMNOPO RSTU V.WXY Z
AZYXWVUTSRQPONMLKJIHGFEDCBA
В AZ YX W VUTSRQ PONMLK JIHGFEDCB
C.BAZYX WVU TSRQPONMLKJ I HG FED C
DCBAZYXWVUTSRQPONMLKJIHGFE D
EDCBAZYXWVUTSRQPONMLKJI H G F E
FEDCBAZYXWVUTSRQPONMLKJIHG F
GFEDCBAZ YXWVUTSRQPONMLKJIHG
H.G F E D C BAZ YXWVUTSRQPO N-M L К J I H
I HGFEDCBAZYXWVUTSRQPONMLKJ.I
LI-HGFEDC BAZ YXWVUTSRQPONM L-KJ,
KJ.I HGFEDCBAZYXWVUTSRQPONMLK
L_K J.I HGFEDCBAZYXWVUTSR, QPONML
M LKJ I HGFEDCB AZ YXWVUTSRQPONM
N_M L.KJ.I HGFEDCB AZ Y*X WVUTSRQPO N
O_N MLKJ I HGFEDCBAZYXWVUTSRQP.O.
PONMLKJ I HGFEDCBAZYXWVUTSR QP
QP ON MLKJ I H G F E D CB AZ Y X W V U T S R Q
R.QPONMLKJ I HGFEDCBAZYXWVUTS R
S.RQP O_N M L К J I HGFEDCB AZ YXWVU T S
TSRQP O_N MLKJ I HGFEDCBAZYX WV U T
UTSRQP O_N MLKJ I HGFEDCB AZY XWVU
V U T S R Q P O_N MLKJ I HGFEDCB AZ Y X WV
WVUTSRQP O_N MLKJ I HGFEDCB A Z Y X W
XWVUTSRQP O_N MLKJ I HGFEDCB AZY X
Y X WVUTSRQP O_N M L К J I HGFEDCB A-Z Y
Z YXWVUTSRQP O_N M L К J I H G FE DC В A ;Z
У такой таблицы есть одно преимущество: правила зашифрования и рас-
шифрования по ней совпадают: и в том, и в другом случае буквы (шифруемые
и расшифруемые) извлекаются из верхнего алфавитного ряда. Это создает
определенные удобства при использовании шифров: не нужно запоминать два
различных правила (зашифрования и расшифрования).
Заметим, что с развитием математики отпала необходимость наличия таб-
лиц Виженера, Бофора при зашифровании и расшифровании. Если заменить
буквы на числа (как это делали еще арабы в средние века): А=1, В=2,..., Z=26
(0), то зашифрование и расшифрование сообщений легко выражается простой
математической формулой. В этом случае при'математической формализации
шифра Виженера используются две операции: сложение (при шифровании) и
вычитание (при расшифровании). Реализация шифра Бофора основывается
только на одной операции - вычитание.
46
Таким образом, при разработке шифров помимо проблемы обеспечения
надежности защиты информации возникает и проблема простоты и удобства
практической реализации шифров. Напомним, что эта проблема затрагивалась
ранее при описании древних шифров.
Ради исторической справедливости следует заметить, что таблица Бофора
была предложена значительно раньше. Еще в начале XVIII века с таким пред-
ложением выступил итальянец Дж. Сестри, но его имя в истории оказалось
забыто.
ЧЕРНЫЕ кабинеты. РОЛЬ КРИПТОГРАФИИ
В XVI веке в Европейских государствах появились первые специальные
органы дипломатической службы. Появление этих государственных органов -
спецслужб активно стимулировало развитие криптографии в этих государст-
вах.
XVII-XVIII века вошли в историю криптографии как эра «черных кабине-
тов» - специальных государственных органов по перехвату, перлюстрации и
дешифрованию переписки (в первую очередь, дипломатической).
В штат «черных кабинетов» входили криптографы - дешифровальщики,
агенты по перехвату почты, специалисты по вскрытию пакетов (не оставляющему
никаких следов), писцы - копировальщики, переводчики, специалисты - граверы
по подделки печатей, химики (для выявления «невидимых чернил»), специалисты
по подделки почерков и т. д. Таким образом, «черные кабинеты» состояли из высо-
коквалифицированных специалистов в различных областях деятельности. Эти спе-
циалисты ценились «на вес золота» и находились под особым покровительством
47
властей. От них требовалось строгое сохранение тайны и преданност?» монарху.
Предателей сурово наказывали. , > , . t
Представляет интерес следующая созвучная оценка роли криптографии, ''
высказывавшаяся уже в XX веке. Известный американский исследователь в ,
области истории спецслужб, Флетчер Прат, в книге «Секретно и срочно» ут-
верждает: «Престолы, королевства и битвы выигрывались или проигрывались
в зависимости от знания тайнописи». Здесь безусловно присутствует, элемент,,
преувеличения роли криптографии в развитии исторических событий, но фак-
том является то, что криптография играла и сейчас играет заметную ролВ’в
принятии государственных решений в области политики, дипломатии, воен- ,
ного дела и т. д. У Прата нашлись сторонники. Крупнейший исследователь
истории криптографии Д. Кан (США), иллюстрируя влияние криптографии на
развитие политических событий в мире, утверждает: «В самом деле, не будет
большим преувеличением заявить, что образование коммунистической дер-
жавы, а это является, пожалуй, самым главным событием coepeiMfeffifo^H^o-
рии, стало возможным в значительной степени в результате дешифрования
секретной переписки царской России». При этом имеются в,виду успехи не-
мецких дешифровальщиков. Германия была заинтересована в развале России
как главного противника в войне. Один из реальных путей достижения этой >
цели заключался в поддержке российских революционеров. Поэтому резуль-
таты дешифровальной работы использовались для поддержки российских
противников царского режима. Что же касается успехов немецких дешифро-
вальщиков, то министр иностранных дел Германии времен I Мировой войны
Циммерман вспоминал: «В те немногие мгновения дешифровальщики держа-
ли историю в своих руках». В наше время Д. Кан утверждает: «Крйптбграфйя'
является наиболее важной формой разведки в современном мире. Опа дает
намного больше и намного более достоверной информации, чем шпионаж...»
.1 z 1
ШИФР «Атбаш»
В Библии содержатся намеки на шифрование и дешифрование текстов.
Суть их заключается в следующем. i*' ;/ <
Древние евреи использовали несколько систем шифрования по принципу
Простой замены. Шифр «Атбаш» задавался (применительно к латинскому ал-
фавиту) следующим образом: . ,г , . ,
ABC...XYZ
ZYX...CB А
Заметим, что в этом шифре замена имеет симметричный вид:
(A-Z, Z-A), (B-Y, Y-В) и т. д.
48
Поэтому, как при шифровании, так и при расшифровании буквы открыто-
го и шифрованного текстов извлекаются из одной и той же Верхней строки
(как в таблице Бофора).
ШИФР «Альбам»
Шифр «Альбам» заключался в разбиении алфавита на две части и подпи-
сывания одной части под другой:
ABC...KL
MNO...YZ
Здесь замена также имела симметричный характер: ( А-^М, М-А), (B-N,
N-В) и т. д.
В «Ветхом Завете» слово «ВАВИЛОН» («BABEL») заменялось по шифру
«Атбаш» и имело вид: « СЕСАХ» (следует иметь в виду различный порядок
следования букв в латинском и еврейском алфавитах).
Второе применение шифра «атбаш» в Библии привело к появлению в ней
слова «ЛЕБ КАМАИ» («сердце моего врага») для замены слова «КАШДИМ»'
(«халдеи»), то есть в результате шифрования получилось осмысленное слово.
Смысл применения зашифрования в Библии до сих пор непонятен. Это
шифрование не носит характер засекречивания, поскольку из Дальнейшего
контекста становится понятным, о чем идет речь.
О дешифровании упоминается при описании «Валтасарова пира». Первым
библейским «дешифровальщиком» оказался пророк Даниил.
Во время пира чья-то таинственная рука написала на стене странную за-
пись «МЕНЕ, МЕНЕ, ТЕКЕЛ, УПАРСИН» (в латизированном варианте, про-
читанном по русски). Даниил расшифровал ее следующим образом: «Исчис-
лил Бог царство твое и положил ему конец; ты взвешен на весах и найден
очень легким; разделено царство твое и дано Мидянам и Персам». Й действи-
тельно, в ту же самую ночь Валтасар, царь Халдейский, был убит. Его госу-
дарство вскоре распалось. Однако за удачное «дешифрование» Валтасар ус-
пел щедро наградить Даниила: на него была возложена золотая цепь и он был
провозглашен третьим властелином в царстве. Справедливости ради отметим,
что критики библейских сказаний извлекли из той же самой надписи тексты,
которые пророк Даниил и не мог бы себе даже представить. Например, один
из вариантов дешифрования имел следующий вид: «Бог благословил твое
царство и дал ему вечную жизнь».
49
ШИФР Фальконера
В XVII веке Дж. Фальконер (Англия) выпустил книгу «Раскрытие секрет-
ных сообщений». В ней излагались некоторые разработанные им методы де-
шифрования. В частности, он предложил использовать перебор возможных
открытых слов по их длине, если в шифрованном тексте оставалась разбивка
на слова. , .
Представляет интерес предложенная Фальконером система шифрования,
объединяющая два шифра: вертикальной перестановки и гаммирования. При-
ведем пример. Выберем лозунг: «ЛИЛИПУТ». По этому лозунгу строится так
называемый номерной ряд по следующему правилу: буквы лозунга нумерую-
тся в алфавитном порядке, при этом одинаковые буквы получают последова-
тельные номера. Указанному лозунгу соответствует следующий номерной
ряд:3 1 42576.
А Б В Г Д Е Е Ж 3 И Й К Л М Н О П Р С Т У Ф X Ц Ч Ш Щ Ы Ъ Ь' Э Ю Я
1 3 5 6 7
2 4
Зашифруем фразу «ШИФР ВЕРТИКАЛЬНОЙ ПЕРЕСТАНОВКИ»; при
шифровании фраза выписывается в прямоугольник размера 4x7 без пробела
между словами. Столбцы отмечаются цифрами номерного ряда;
3 1 4 2.5 7 6 ’ 3 *
щ и ф р в е р
т и к а л ь н
О й п е р е с
т , а н о в к и
Первичный шифртекст образуется путем выписки букв по столбцам, а са-
ми столбцы следуют друг за другом в порядке, определяемом номерным ря-
дом. Получим:
. ИИЙАРАЕОШТОТФКПНВЛРВРНСИЕЬЕК
Затем этот первичный шифртекст шифруется вторично шифром модуль-
ного гаммирования, о котором упоминалось ранее. В результате получается
окончательный шифртекст.
Указанный шифр с различными модификациями использовался и в сере-
дине XX ве^ в Германии, Франции, СССР, Японии и др. странах.
L
$0
ДЕЗИНФОРМАЦИЯ под шифром
. В рассматриваемом историческом отрезке времеци использовалась так на-
зываемая «дезинформация под шифром» ГБвдв истории случай, когда фран-
цузы,наконёц,бсбзШйй/ чтоутечка дипломатической информации приводит
ктякейЫМ йбслёДстййкм дЛй кос^да}эётв£ СреЖ!п$йнятых ими мер заслужи-
вает внимания следующий шаг. Зная, что англичане дешифруют их секретную
переписку, они начали «подставлять» активно нападающей стороне дезинфо-
рмацию под видом «истинной» зашифрованнойдипломатической. почты. Ес-
тественно, что в этом случае истинная инфб^аШ&Шй&ЙЙ была передаваться
по каналам связи, недоступным для перехвата,англичанами.
?$ цдщд ддй дгр^.р^де^ицформ дцдд) под шифром хорошо описал драматург
ПитерУстиндввсвбёйпьесё«Роман6ви Жюльетта» (поставленной в Нью-
ЙЬркёв№51 'гдду);Вбт(ёйёйа'и'б:йТф6г,б.ЙпР’1 ”б!-'
Действукнциёлица:' :'о:' "
— Генерал, президент маленького государства в Европе;
Моулзуорт, американскийргосол в этой стране; ,
--Ромадрр^рв^скцйпосод, ,.И!.
Дочь Моулзуорта (Жюльетта) и сын Романова любят; друг друга и делятся
между собой семейными тайнами. /
Сцена в посольстве США. п * :
Генерал: «Кстати, вы знаете, что русские знают йаш шифр?»
Моулзуорт: «Мы Знаем, чт&они знают йаш шифр; Но сообщаем им только
ТО, ЧТО ХОТИМ, чтобы ОНИ узнади». ! ;
Генерал переходитвсоветское посольство! .
Генерал: «^Сстатц, америкайцН знают вщцтдифр»,, ,,
Романов: «Меня это ничутД нё удивляет, .ЭДы у?ке,в течение некоторого /
времени знаем, что онд знают раш шифр, и ведём' Себя соответствующим об-
разом - делаем вид, будто им удалось нас'одзфаййь». ' ; '
Генерал возвращается в американское посольство. • <
Генерал: «Кстати, вы знаете, что они знают, что вы знаете, что они знают,:
что вы знаете...» , ; г,--л.<
Моулзуорт: «Что? Вц уверены4?». ; .ч ..
Генррал: «Абсолютно».' . . , ....
Моулзуорт: «Благодарю вас! Благодарю! Я никогда не забуду об услуге,/
которую вы нам оказали». > ч .
Генерал: «Вы хотите сказать, что вы ничего не знали?».
Моулзуорт: «Нет». .
Эта сцена хорошо иллюстрирует ход размышления современного развед-
чика - аналн7и^д:<<О.н знает,чтр дзддю, что.он дд^рт
^^Предраедо, цедедал’^тдт,ртдлд,1^д1дендя, ангдиЙЯ^йи ррэт прошлого века
Кодендри,Паэд$р, Рдддхрдйтедьдрс^ьдерушдд.дрмрддтельствам ее по- г
клрннцддодрпдбдд.так:.,./..///",..1 -
51
Он думал, что уснула я
И все во сне стерплю,. .
Иль думал, что я думаю-
Что думал он: Я сплю!
Этот стиль напоминает размышления современного шахматиста - логика.
Таким образом, к ‘. концу XVHI века главными объектами деятельности
специальной, в том числе н • дешифровальной, службы Англии стали Франция
и Северная Америка, s : . о . •> ;•< .
ШИФРЫ и математики
Эйлер
Заметим, что в это же время криптографией интёресовалиськруПнейшие
математики. Так, например, великий немецкий математик К. Гаусс не обошел
своим вниманием и криптографию. Йе будучи знаком с ее историей, он само-
стоятельно разра- '• > гп.Н ; ' .л;'Л->. .Г .
ботал «недешифруемый» по его мнению шифр; который по существу являлся
ранее изобретенным шифром пропорциональнойзамейы и, Как оказалось,
вполне дешифруемым.
Ранее другой известный великий
математик - Л. Эйлер- «изобрел ,,
аналогичный шифр и также считал, .
его недешифруемым, хотя его друг
математик X. Гольбах в это же время
успешно дешифровывал гораздобо-
лее сильные шифры. Приведенные ; ‘ (
примеры говорят о том, что не всегда,
даже великие математики : ,
автоматически становятся хорошими:
криптографами. Это справедливо
особенно в наше время, когда
криптография стала серьезной .
самостоятельной наукой;
ШИФР Франклина
Посланник США во Франции, известный ученый, Дипломат, философ
Бенджамин Франклин для Связи сКонгрессом разработай свой собственный
шифр омофднной (^нЬгбзначйбй)' ^амейй..'ЙНтересеЙ Сай Способ составления
шифра. Он взял большой отрезок французского текста (682 буквы), пронуме-
52
ровал их, и каждой букве латинского
алфавита придал множество обозначений
(чисел) в пронумерованном тексте. При
шифровании буквы заменялись на
произвольно выбранные числа из
соответствующих множеств. В современ-
ном понимании он использовал шифр про-
порциональной замены, в котором
количество возможных шифробозначений
пропорционально частоте встречаемости
букв в открытом тексте. В этом случае все
знаки шифрованного текста появляются
примерно с одинаковыми частотами.
Однако англичанам удавалось прочитать
кое-что из переписки Франклина.
Разработав собственный шифр
Портрет Бенджамина Франклина
пропорциональной замены, Франклин ; .
воспроизвел идею шифра, предложенного Габриэлем де Лавинда еще в XV
веке.
К сожалению (для американцев) один из помощников Франклина Э. Банк-
рофт - был английским агентом. В результате Б. Франклин нередко отправлял
в Америку дезинформацию, поставляемую ему Банкрофтом.
Другой помощник Франклина, Артур Ли, пользовался своеобразным кни-
жным шифром. Открытый текст шифровался не побуквенно, а по словам.
Ключом шифра являлся заранее оговоренный словарь, слова заменялись на
соответствующие номера страниц и номера слов на странице. Этот шифр ока-
зался весьма неудобным в применении и в последующем не использовался.
СИМПАТИЧЕСКИЕ чернила
В Северной Америке в конце XVIII века симпатические чернила получили
широкое распространение^ Братья Калперы, один из которых являлся агентом
американцев в Лондоне, в своей переписке использовали невидимые чернила.
Эти уникальные чернила поставлял им врач из Лондона сэр Джеймс Джей -
брат первого главного американского судьи Джона Джея. Это стало первым в
исторйи США случаем широкомасштабного применения симпатических чер-
нил. Джеймс Джей много лет спустя рассказал историю с чернилами в одном
из своих писем; он описал созданный им способ составления невидимых чер-
нил для связи со своим братом Джоном в Нью-Йорке. В частности, он отме-
53
чал, что «этой жидкостью снабжали также генерала Вашингтона, и у меня
есть его письму ^.признанием ее большой пользы и с просьбами о дальнейших
посылках...» Такими чернилами Джеймс отправлял сообщения Б. Франклину,
С. Дину и другим. В июле 1779 года Вашингтон, отдававший должное защите
связи, в одном из своих писем писал: «Все белые чернила, которыми я распо-
лагал... отправлены полковником Уэббом в пузырьке № 1. Жидкость в пу-
зырьке № 2 является дополнением, которое делает первую жидкость видимой
при смачивании ею бумаги мягкой щеткой после того, как первая высохнет...
Я прошу ни при каких обстоятельствах никогда не говорить о получении вами
таковых жидкостей от меня или кого бы то ни было другого». Эта тайнопись
позволяла американцам успешно преодолевать английскую цензуру.
В это же время и англичане также широко использовали тайнопись. В час-
тности, в их агентурных посланиях использовалась галлодубильная кислота,
проявляемая сернокислым железом (этот рецепт был заимствован из книги
Дж. Порта «Магия естественная»).
ШИФРАТОР Джнфферсона
В конце XVIII века криптография обогатилась замечательным изобретени-
ем. Его автор - государственный деятель, первый государственный секретарь,
а затем и президент Америки Томас Джефферсон. Свою систему шифрования
он назвал «дисковым шифром». Этот шифр реализовался с помощью специа-
льного устройства, впоследствии названного шифратором Джефферсона.
Конструкция шифратора может быть вкратце описана следующим образом.
Деревянный цилиндр разрезается на 36 дисков (количество дисков может
быть и иным). Эти диски насаживаются на одну общую ось таким образом,
чтобы они могли независимо поворачиваться вокруг нее. На боковых поверх-
ностях дисков выписываются все буквы английского алфавита в произволь-
ном порядке. Порядок следования букв на различных дисках может быть раз-
личным. На поверхности цилиндра выделяется линия, параллельная его* оси.
При шифровании открытый текст разбивается на группы по 36 знаков, затем
первая буква группы фиксируется положением первого диска по выделенной
линии, вторая - второго диска и т. д. Шифрованный текст образуется путем
считывания последовательнорти букв с любой линии, параллельной выделен-
ной. При расшифровании на аналогичном шифраторе полученный шифр-
текст выписывается путем поворота дисков по выделенной линии, а открытый
текст отыскивается среди параллельных ей линий путем осмысленного проч-
тения возможных вариантов. При таком расшифровании принципиально воз-
можно появление различных вариантов открытого сообщения, но, как показал
54
накопившийся к томувремениопыт,этособытиевесьма маловероятно; ормыг
еденный текст.читался^толькопрод^йда.возможиыхлиншЬцги
. .ШифраторДжеффереона реализует ранее известный щифр;многоалфавит-
ной замены, а> егоключом является дарядоф расположения букв на каждом
диске, а такжйпорядок расположения, этих дисков-даобщей оси. Количество
ключей огромно: оно равно Зб! 26!, то есгь имеет порядок 1О60.
Это изобретениестал опредвестником появления так называемых диско-
вых! шифраторов^ нашедших широкое распространение в развитых странах в
ХХвеке.Щифратор,соверШенноаналогичный шифратору Джефферсона, ис-
пользовалеяв. армии СЩАврвремяПМировой ВОЙНЫ. Однако при жизни
Джефферсонасудьба его изобретения сложилась неудачно. ,
Будучи госсекретарему.еам Джефферсон продолжал использовать тради-
ционные' кода (нрменклаторы) и шифры типа шифра Виженера. Он очень
осторожно относился ксвсему изобретении)и считал, что его нужнооснова-
тельно проанализировать.. С этой целью л»длительное время поддерживал
связь «,'математшодматтерсоноц._в резжь^ате: обмен? информацией Пат-
терсонпредложил свой; собственный шифр, кохорый.цоего мнению, являлся
бол ее-надежным, чем шифр Джефферсона. Этот шифр представлял собой
шифр вертикальной лерестановки о введением «пустышек». По стойкости он
значительно устудал. шифру. Джефферсона,; однакоДжефферсон принял дово-
дысвоетокорреспондента и призцал его. шифр более приемлемым для испо-
льзования.Таким образом, Джефферсон самнеоценилдсейглубины своего
СОбСТВеННОГО ИЗОбретеНИЯ. : г. ,
XX веке криптоаналитикиСЩА признал ивысокуюстойкость шифра
Джефферсана. ОнИдажоназвалИ' его автора «отцом американского шифрова-
льного дела». ТШ1 ЙВДЮ i;uw. .
В связи с указанным эпизодом, можно особо выделить два момента. С од-
ной стороны, уже;бУдучи^ррзйфсцтбм1^ж^ФФё^сбй.’не' навязывал употребле-
ния изобретенного Им Шйфра. О другой стороны, поскольку orb изобретение
попало Д.архив,’оно'неи8бежно;повторшюсьвбудущем. До обнаружения «ар-
хивного шифра» Джефферсона новые криптографы самостоятельно изобрели
аналогичные шифры. В истории криптографии имеются многочисленные
примеры, иллюстрирующие забвение старых идей и попытки изобретения
«нового колеса». И в наши дни дилетанты от криптографии изобретают.свои
собственные «недешифруемые» шифры, которые на самом деле оказываются
легко раскрываемыми.
ИзобретеЖ^йЙфф%1^аЙ#!вг^ицё’^^в^Т1дй-орил француз Этьен Ба-
зери («цилиндр Базери»). Одноко и его устройство было отвергнуто иЗ-за
«чрезвычайной б^'жйбЬЫ»!кЙк?из1^бт6вйй1йЙ', ’iak'H в применении. Базери
ynpocrfin^cBdlo ’dkdTfeiiy^d&ibHSiS^iP^^^^ ^^dflbxtdriHB^yKB на дисках несе<-
кретным. Ключом шифра являлся лишь порядок расположения дисков. Поря-
55
док же расположения букв алфавита для удобства’ запоминания образовывался
из легко запоминаемых лозунгов - фраз для каждогодиска (таким же образом,
как ранее описанноеусложнениеквадратаПол ибия по лозунгу THE TABLE).
Однако, при таком упрощении шифрзначительно утратил свою Стойкость.
Маркиз де Виари показал пример дешифрования этого шифра. Упрощённый
вариант опять был отвергнутая Сам шифрвторично забыт.
В начале XX века трудами Паркера Хитта(США) идея дискового шифра-
тора была еще раз повторена.- При этомона’Приняла вид «полоскового шиф-
ра», значительно более простого в изготовлении. Полоски с удвоенным алфа-
витом, закрепленные в рамку; гораздо более технологичны, чем-Деревянные
диски с алфавитом. Смысл шифрования и расшифрования остался тем же, что
и в изобретении Джефферсона, однако сложные диски были заменены на лег-
ко воспроизводимые «полоски» из твердого материала (например, картона,
металла и т. д.). Значимость этого изобретения закл ючаетсянев появлении
новых криптографических идей, а втехнологической простоте их воплоще-
ния. В 20-х гОдак XX века шифр ДжефферосОна был изобретен В четвертый
раз. Это опять Произошло в США. Криптоаналитики; ловторившобретение,
пришли к выводу о достаточной стойкости и простоте этого шифра, и армия
США приняла его навооружение. Но самое главное последствие изобретения
Джефферсона - это появление вХХ Веке первых сложных электромеханичес-
ких устройств. Как уже отмечалось ранее, криптография носила не только го-
сударственный характер. Так, напримёр, шифры разрабатывались и широко
использовались масонами. ° r s . '; -
Итальянские карбонарии использовали своеобразный шифр простой заме-
ны. В основешифралежаллозунг («Счастливые друзья,пойдем на муки»
(AMlCiA...). Замена имела следующий вид:
abcde f gh i j k 1 m n о pq ir S t u v x у z
A MIС I2 A2L L2 'Is E <3 Ж E2 M Я Ь C A4 M2 Q Д5 L3 I/ A6>
t ' . f > J' , > '• "S ‘) • -' ,' ’ ' i1 i j .1 • :k). t ‘ i J '‘
Слово «carbonari» приобретало следующий вид: «IA A4 MNA3AA4I3».
б-i'; . 'f''' ?r; ; .’; ; ✓
, ШИФ^Ы К«иш|М1 м !"шпиЮ11 •
Аетрономы,вслед за Гал ил семи Кеплером,
1\СПЛСр
--------- ------' .г,- ..... i,,.-,! , - ....
56
Кристиан Гюйгенс, открыв кольца Сатурна, записал фразу: «Annulo cingiur
tenni piano, nusquem cohaerente, ad ecliptican inclinato» («Он окружен тонким
плоским кольцом, нигде не касающимся, наклоненным к эклиптике») в виде
ряда частот букв:
7А, 5С, ID, 5Е, 1G, 1Н, 71,4L, 2М, 9N, 40, 2Р, IQ, 2R, 1S, 5Т, 5U.
Заметим, что если Галилей в своем анаграммировании пытался переста-
вить буквы текста таким образом, чтобы полученная анаграмма имела «осмы-
сленный» вид (что было большим искусством), то его последователи исполь-
зовали простейший способ: указывали частоты букв в защищаемом тексте.
Так, фразу «ВСТРЕЧАЙ ЗАВТРА И КОЛЮ» Галлилей мог бы анаграмми-
ровать так: «ЗАВТРАК И ЧАЙ ЮРЕ В СТОЛ». Его последователи создали бы
такие упрощенные анаграммы:
«АААВВЕЗИЙКЛОРРСТТЧЮ»
«ЗА, 2В, 1Е, 13,1И^ 1Й, 1К, 1Л, 10,2Р, ГС, 2Т, 14,1Ю»
«А3, В2,Е*. З1, И1, И1, К1, Л1, О1, Р2, С1, Т2,.Ч1,Ю’» ‘
Анаграммирование можно рассматривать как упрощенный вариант шифра
перестановки. Хотя указанные преобразования открытых текстов по сути сво-
ей шифрованием не являются. И дело здесь не только в неоднозначности рас-
шифрования. Автор анаграммы, отсылая ее своим корреспондентам, не пред-
полагал ее расшифрования. Более того, он считал его практически невозмож-
ным. Действительно, восстановление открытого текста по частотам букв зада-
ча весьма сложная. Цель анаграммирования заключалась в защите «авторско-
го права» без публичного опубликования своих «еретических» идей. Записав
обычным текстом информацию о своем открытии, автор прятал эту бумагу в
надежном месте, а своему корреспонденту отсылал анаграмму. В сопроводи-
тельном тексте он сообщал о том, что ему удалось открыть удивительное яв-
ление, смысл которого скрывается за анаграммой. В случае необходимости
для подтверждения своего приоритета автор мог предъявить исходный текст.
Его истинность подтверждалась ранее высланной анаграммой. Эта идея в бо-
лее совершенном виде используется в наши дни. Для подтверждения подлин-
ности посылаемого шифрованного сообщения и отсутствия его подмены в
конце сообщения имеется ряд зашифрованных букв, достаточно сложным об-
разом полученных из открытого текста. На приемном конце после расшифро-
вания производится соответствующая проверка.
ШИФРОВАЛЬНОЕ устройство Уодстворта
Устройство состояло из большого диска с двумя кольцами, большим и ма-
лым. На большом кольце нанесен смешанный алфавит из 26 букв и 7 цифр
57
({2,3,...,8}), на малом кольце был нанесен смешанный алфавит из 26 букв.
Кольца могли вращаться с помощью двух шестерен. Для удобства определе-
ния взаимное положение колец имелась стрелка с двумя прорезями - верхней
и нижней. В ключ шифровального устройства включалось: смешанные алфа-
виты колец (порядки расположения букв), взаимное расположение двух ко-
лец. Для зашифрования первой буквы вращается большое кольцо, пока в
верхней прорези не покажется эта буква. Вращение верхнего кольца по шес-
теренкам передается внутрецнему кольцу, и оно, тоже вращается. В нижней
прорези напротив найденной.буквы читается первая шифрованная буква. Да-
лее процесс повторяется, вращается верхнее кольцо до проявления в верхней
прорези второй открытой буквы и т.д. Цифры верхнего кольца предназначены
для зашифрования кодовых слов, состоящих из цифр {2,3,.. .,8}.
Параграф 1.2.
История отечественной криптографии (/СОБ/).
Обратимся к истории отечественной криптографии.
До появления общегосударственной письменности не могла идти речи о
серьезном использовании криптографических методов защиты информации.
В этом смысле наше государство отстало от других развитых стран более чем
на тысячелетие. В IX веке болгары Кирилл и Мефодий разработали первую
русскую азбуку. Импульсом к этой работе послужило крещение Руси, в связи
с чем возникда необходимость написания на русском языке религиозных .
книг.
Грамотность на Руси прививалась с большим трудом. Князь Владимир I
после принятия на Руси христианства насильно привлекал детей своей «наро-
читой чади» (то есть детей своих придворных и феодальной верхушки) для
«обучения книжного», делая это нередко насильно. Исторические документы
свидетельствуют о том, что матери плакали о детях, направленных на обуче-
ние, как о покойниках. Неграмотность была всеобщей, и более того, сама
грамотность осуждалась в народе. Поэтому в IX-X веках вопрос о тайнописи
вообще не поднимался. Однако дальнейшее распространение письменности
естественным образом породило и вопрос о тайнописи как средстве защиты
секретов, доверяемых письму.
Древнейшие дошедшие до нас славяно-язычные рукописные книги дати-
руются серединой XI века: «Остромирово евангилие», «Изборник Святосла-
ва» и т. д. Именно такие рукописи активно способствовали развитию грамот-
ности, особенно среди священнослужителей. Напомнйм, что в это же время и
в Европе после крушения Римской империи под натиском германских пле-
58
мен, наука, литература также находились в тисках богословия. Но за плечами
этих наций находился временно забытый опыт прошлых веков, которого не
было на Руси. р
Напомним, что языковое наследство Европы заключалось в трудах, напи-
санных лишь На трех языках - латинском, греческой и еврейском. Для осоз-
нания этого наследства 'Требовалась не только обычная грамотность, но и
знание иностранных языков.-Эти языки сами по себе нередко воспринима-
лись как средство тайнописИ.В этом же смысле они часто использовались и
на Руси лицами, освоившими эти «тайные письмена». Интересно напомнить,
что хазары, постоянно тревожившие Русь своими набегами, употребляли бу-
квенно-звуковое руническое письмо, а также письмо древнееврейское. Неко-
торые из^этих рунических писем ДО сих пор не расшифрованы. Заметим, что
руны - примитивные письмена, обычно состоявшие из комбинаций прямых
черточек, прорезанный на дереве, камне и т. д. Именно в силу своей прими-
тивности и символичности эти письмена вызывают затруднения у современ-
ных криптографов-дешифровальщиков. В них обычно присутствуют наруше-
ния логики шифрования, принятой в последующие века.
В основе отечественного шифрования лежали две русские азбуки -
кириллица (от имени Кирилла - одного из изобретателей этой азбуки), глаго-
лица (от старославянского «глагол», что означает «слово») и пермские пись-
мена (названные по имени пермского епископа Стефана Пермского). Эти аз-
буки приведены в иллюстрациях.
Г рачесцма Gy Наэеання бума <^им*»«ч*а«мма Эаукоаш* бума Форма бука Форм ' Сд« • бума О«а«А«и« букам т- в Эоуаммаыа Цмфроама амачамня бт*са
тша глаго- лица - амача1Ш л бума> t : и» • кмрил- глаго-
альф* а А ’ А Ф. *3 В } г 5 t* s: ’
бета, (вита) 6. затем в В Б В Г V .Вуки • ' веди S -N • 2 2
гамма дельта э псилрн (дигамма) дзета эта (и та) г А з (краткое) (w) лэ ' э (долгое. Г А с. Z И Г •А . ~ » 1 И- А Л 3- X а & глаголь добро есть*** живете зело** земля*** йже*** А J А ' 3 • 4 & в 7 3 4 6 6 7 8 9
затем ••• & . ' 8 20
мота капля лам 6 да мм И (краткое) й л м 1 К А М t < Ь> к , А М • ж АГ А X дервь како люди мыслете к. й»< . .г (падаталъи) ‘ * • Я ?• 10 20 30 40 10 30 40 60 во
ни о микрон .и 6 (краткое) И ‘‘ б W 0 •г 7 маш*** он. о if Ь Й’.' 60 70 70
пн п 1 п п Г покой ' л 80 90
ро сигма Р с в с 0 с ъ я рам слово р r.v? .. С ’ . • * 100 200 ЮО 200
тау фи т т т Оу* ф (0 г ’ твердо Йрт 111 300 600 300 400 600
ХМ X X *-. ха X • * 600 600
(1)
S9
" ; . '“г /4 z * * ; • , r -. p \ * < f. * «,' t • '* ^г'.П t-.z н: ч/?;.г гт
омега о Ш ы О омега* О 800 Ж >
_ — ч иы U ; 900 <Ы
«— ' . 4- - ’ W! : л , л -ДО JW r, Ъ’Ч h
— — — и J0 W- J г ' и.ш . \ — 800
— 'Г'Г V Шта!:х * Л !> • Ji ’’ / нт- . i •' ‘ i ’ -a
- — ы Kt еры ’ыг ‘р " ’ ‘ .У. iiL'’,'- < Zhi’.
— .- ->4Л ь ЭК ' ’ерь'л?кГ.? <ч (краскоеглуаое) .'$>"} Hi ?: л> 4 i’i • •i '. '
_ _ W А - ять** t к• 1 Лперва йа, Ле, . *• 4-\; -IT
> ! . ;•. .-р: ' ^затей мкрытоей1- < \ 3 j •:>'!-
г -f- / ЛС‘-лгг ’ = . ТЮ (ЙОПфОВ,) , ; >5 .•uZ i! ZU»! 1
— И* я (йотиров.) ъ
— — ' . ‘ 1 ’ ’ -4- ' с;;:-' >?НЙ0Дф08.) Н л ’ ‘ h • i’ '
— А, ч IK МЦЛЫЙ*4. -> 0" (йЬёовое) 1•' — —-
_ — 'Ъ'-А 'гХх<'’ ^бдлыЬЬй** •' “• А 1' h -i/; ! -< !U2y
— — , ' • • Т' “ Ч .WCMafwW ) ч “ ч x i Г< с
-йотированной йотировайное) 1
— > — ,ЛЛ —‘ ' »' ,.;ыЛ. > «Осбслмйой** (ЙУсовое Н '..*< Urn f.' - : I'
KCH КС J/‘=) * йотированный > 1 ’ ’• -V 11' <', " fcCII*U r> f ftoTHpoBayiioe), i'W, z '.
пси ПС j i ' ‘ / г J U£ М ч ;ГЛ<(РУ«?Кв?Н?/;г,- r/W нгЛч ' ! * .• . U ’ ‘ <-
тета • й псилон th й (н4м4икре)Ч рТ~ " 0. 0 • .с ;; Лита* $ижмй4г‘П^Ь D q !П ;’l :nqz ХП
(И ПСИЛОЙ) затем ’и” г.-— -XLU- Л > и*ттЦ-т444^ч^ f i / 4 ;C. '
• Щ У.’ фр П ’; • ИГ • . - • < '?>/? М в’ ’ '
лкф/ и! ип.гп ’;гс ; < ч<\
' '- ( * i' У 1:; у; * v > 4 Z ф.» ‘. \ UU4 < < --U .И .* ‘ {’-•.’'
.Z/Ч JiXp'.MKf и h h^ZJ'.jZ’Zp1 h."'.'
60
A
aa
1
и
ижё
8
3
КСИ
60
У
УК
400
К
вёдп
2
фит4
9
О 1
он
70
ферт
500
глагбль
3
л
покой
80
600
Сла вл по-
А
добро
4
к
гсако
20
червь
90
qj
пси
700
е
есть
5
л
Л16 ди
30
Р
рцы
100
IU
S
аелб
6
м
мыслете
40
слово
200
3
зам л 4
н
яаоп
50
твердо
300
пы
900
кириллоаскпя цифровая система
800
Ю
X
Кириллица заметно схожа с греческим алфавитом, глаголица — с ви-
зантийской скорописью (стенографией) IX века. Алфавит кириллицы вклю-
чал 43 буквы, а глаголицы — 40 букв. Изобретение глаголицы связывают с
именем преемника Мефодия Горазда. Горазд видоизменил и усложнил фор-
му букв кириллицы с целью отдаления их графики от букв греческого алфа-
вита. С какой прагматической целью он это сделал, до сих пор неизвестно.
Некоторые исследователи русской письменности считают, что Горазд сделал
это с целью защиты секретных посланий. Напомним, что сам Горазд подвер-
гался репрессиям со стороны властей вплоть до изгнания из страны. Если ви-
доизменения графики букв действительно несут криптографическую нагруз-
ку, то Горазд стал первым изобретателем шифра простой замены на древ-
неславянском языке. Однако никаких серьезных исторических доводов в
пользу этой гипотезы не сохранилось.
61
<X> A
V* КУУЯ yZykmi ^ium
X&sVc Муян f^°ytd,y
y^K. 7^ RjljAy^A
oijAy^ /|лл1гог» 4IJ^llA
MAKA^OpA
<-fcT<54Obl£A4
ZPo onlo^irKfik
PuC. 2
С другой стороны, юго-западные славяне, перешедшие в католичест-
во, сознательно использовали глаголицу как свой «кастовый» язык, отличный
от латинского и кириллического письменных языков.
Помимо буквенных обозначений, элементы обеих азбук имели не
только звуковые обозначения, но и числовые эквиваленты.
Для того чтобы указать, что буква означает число, а не звук, над ней
ставился особый знак («титло»). При этом цифровые обозначения обычно име-
ли буквы, заимствованные из греческого алфавита вместе с их численным
значением.
Итак, первые упоминания о древнерусской тайнописи обнаруживаются
в средневековых документах. Среди средств тайнописи упоминаются так на-
зываемые «иные письмена». Этот способ тайнописи заключался в замене букв
кириллицы буквами других алфавитов: Глаголицы, греческого, латинского,
пермской азбуки.
В XV веке глаголиод уже действительно широко применялась как сред-
ство тайнописи. Образец такого письма приведен на рисунке; на втором рисун-
ке дан пример употребления букв греческого алфавита.
62
Таким образом, этобылишифрыпростойзамены. Напомним, что такие
же шифры господствовали в это время и в средневековой Европе.
Практиковалось также видоизменение знаков письма («вязь»), письме-
на типа стенографии. Применял иски специально придуманные для тайнописи
знаки. > - ; ; ••• ‘
В XVII веке начали применяться шифры типа масонской замены. Шиф-
ры замены подразделялись на особые классы: «простая литорея», «мудрая ли-
торея», «тайнопись в квадратах». . / <
«Простая литоредо заключалась лищь в замене согласных букв по дос-
таточно простомуправилу; гласные же буквы не изменялись. Первый десяток
согласных заменялся на второй десяток согласных (второй же на первый) по
следующей таблице:
г;/..,; ' ’ . , . . ", V i -
. • , . ' ч '-:Гг ’ (-. ' -
: Б В Г Д ж 3: К Л м н
i ; ЩШЧЦХФТСРП
Так, например, слово' ПСАЛТЫРЬ ' заменялось на буквосочетание
НЛАСКЫМЬ.; Шифрованный текст, «мацъ щыл томащсь нменсы шви нугипу
ромългую катохе и ниледь топгашви тьпичу лию, арипь» из одной из древне-
русских летописей следует читать так: «радь быс корабль преплывши пучину
морскую такоже и писецькончавшикнигу сию.аминъ».
В «мудрой литорее» все буквыкирилл ическойазбу ки заменялись на
другие буквы той же азбуки.
«Тайнопись в квадратах» - это шифры замены, где ключ - таблица за-
мены - представлен ввиде квадратной таблицы. ' i.
В XVI-XVII веках, использовалась цифровая система тайнописи, ее
называли «счетной» или «цифирной». Отождествление букв алфавита с числа-
ми было заимствовано у греков. Так, число 325 отождествлялось с сочетанием
ТКЕ (300 - Т, 20 - К, 5 - Ё); число6325отождествлялось с STKE (6 Заменя-
лось на S, шесть тысяч). Цифровая тайнопись реализовалась в различных вари-
антах.
В первом варианте каждая буква (она же и цифра) разбивается на не-
сколько букв-слагаемых (цифр); слагаемые представляются буквами. При
расшифровании группы букв-слагаемых представляются суммой цифр, их
сумма цифра-буква и есть значение зашифрованной буквы открытого текста.
Приведем простейший пример шифра такого рода. Пусть алфавит имеет вид:
А, Б, В, Г, Д, Е, Ж, и т.д. Положим А=1, Б=2, Г=3, Д=4, Е=5 и т.д. Тогда от-
63.
крытая буква Еможетбытьпредставленаг зашифрована р виде: ААЕмйи БГ
или АД. Таким образом; здесь имеет место уженепростая; амногозначная .к
(емофонная) замена;, но весьма простотодапа.1* ? /с. и пр л
Второй вариант, цифровойтайнопияиимеет дрейнегреческиекорни. i •.
Это так называемый описательный вид цифровой тайнописи. Примером может
служить следующий текст XV века:«Аще хощеши увед ати имяписавШего
книгу сию, и то ти написую: “Десятерицасугубая и пятерица четверицеюи *.•
еДинъ; десятерица дващи и един; десятая четыре сугубо и четырежди по пяти;
дващи два с единем; единица четверицеюсугубо; в семьименисловь седмери-
ца, три столпы и три души; царь. И< сегожечисла в семь имени РОЕ”». , : .
Имя писца расшифровывается следующим рбразом. Слово «сугубо»/ * > >
означает «дважды». Поэтому «Десятерица сугубая и пятерицачетверидею?.. .
есть 10x2+5 х4=40 - это буква М; «единъ» =1 (буква А), «десятерица дващи»
=10x2=20 (буква К); “един”=1 (А); «десятая четыре сугубо и четырежди по
пяти» =10x4x2 + 4x5 = 100 (буква ]?); «дващи Два О единем» = 2x2 + 1 = 5
(буква Е); «единица четвериЦию сугубо»=Гх4х2 = & (буква Й). Таким обра-
зом «имя писавшего книгу сию» есть МАКАРЕЙ. Последняя часть фразы: «в
семь имени словъ седмерица, три столпы и три души, царь. И сего же числа в
семь имени РОЕ» есть проверочный код, Он предназначен для проверки ре-
зультата расшифрования, РОЕ это 175 — сумма букв-цифр в слове МАКАРЕЙ,
7 букв которого содержат: Зглаеных, ЗсогласныхиоднуполуТласную^-(Й) ;
(«Три СТОЛПЫ И три души;, царь»). ЮЩ.ГИ И'.ГЮю
В древней Руси видоизменения письма иногд а носили игриво^ ! -
шуточный характер. Так; например, наберестяном обрывке ХШ века, обнару-
женного в Новгороде,имелась следующая запйаыз < лпогпг. ;; >qr.v -8
.Га <ОП: ЭЖ {ют Ы.’Ч .6 .гГ.
Н В Ж П С НД М'.к -мг.щ
/Е- Ъ Я И гА«Е;-¥:-’А..АА-Х<<О-1Е*И"А.и. >i77 - i / Z ?1
- ... - /Л • г/ п.> •. • к
’ . .<7 ’/Г''*' .('<•’т.. ''.’j.: t 4 u 1 J > £ * !’•
Прочтение по колонкам приводив'к фразе: :o - О! ч'- :г’«
: . . гл. щ-лоч ащщончг. мггл-ф Ч i .пг-лп г-Ъ а л-*.-.
у 1 '
НЕВЪЖЯПИСАНЕДУМАКАЗАЛХТОСЕЦИТА...
.. ' >.. • г г' r"< P.fmqrr . В
В более понятном сегодня изложении эта фраза приобретает вид: :
-Г. '!! а:./.ЛЙ'ЛПЫЛ г<!<1:!'г< ; ЩПЩЯОЩЩЩГМ-Х
НЕВЕЖДА ПИСАЛ НЕ: ДУМАВ*СКАЗАЛ А КТС0ИЕЯИТАЛ п.- т
4 .. Г ' Ь ‘.г« Ч ' г 7k f t ' Я кЧ
64
В это же время широкое распространение на Руси получил так назы-
ваемый тарабарский язык («тарабарщина»). Приведем пример. Фраза
ВОЗЬМИ СУМУ
звучала следующим образом: •
ТАРА - ВО - БАРА - ЗЬМИ - ТАРА - СУ - БАРА - МУ.
Арабские числа начали появляться на Руси с середины XVI века. Они
тут же стали использоваться в цифровой тайнописи. Вот фрагмент одного из
шифрованных документов XVII века:
3”ъ 3'171 49..
Правило шифрования простое. Буквы-цифры от 1 до 9 пишутся араб-
скими цифрами (А=1 и т. д.), цифры от 10 до 90 пишутся арабскими цифрами
со значками (3” =30), от 100 до 1000 - пишутся С другими значками (3'=300);
некоторые буквы не имеют цифрового значения и пишутся открыто, напри-
мер: ъ. Расшифрованный текст имеет вид «лъта7149...» (л=30=3”,т=300=3').
Имелись и другие системы тайнописи, Из них можно выделить моно-
кондил, то есть лигатуру - соединение в написании нескольких знаков-букв;
образное, аллегорическое письмо; акростих (“краегранесие”, “краёстрочие”) и
т.д.
Первые на Руси специалисты-тайнописцы, находящиеся на государст-
венной службе, появились в середине XVI века, В это время был создан орган
руководства внёшней политикой - Посольский приказ, прообраз современного
Министерства иностранных дел. На службе в Посольском приказе состояли и
специалисты-тайнописцы, создававшие шифры, которые В это время уже име-
ли названия: «цифирь», «цифры», «азбуки».
Царь Федор Иоаннович (1584-1598), сын Ивана Грозного, поручил по-
слу Николаю Воркачу «писать письма мудрою азбукою, чтоб оприч Царского
Величества никто не разумел». Это был шифр простой замены, в котором бук-
вы заменялись на причудливые знаки.
В 1619 году из польского плена возвратился отец царя Михаила Рома-
нова Федор, постриженный Борисом Годуновым в монахи под именем Филаре-
та. Став патриархом, он фактически управлял страной при больном и малоспо-
собном сыне. Он лично заведовал иностранными делами и сам разрабатывал
тайные азбуки. Шифры, используемые в это время, являлись шифрами простой
замены и перестановки. Сами перестановки были достаточно простыми. На-
65
пример, открытый текст разбивался на слоги, и в них осуществлялась переста-
новка букв. Так слово ПОВЕЛЕВАЮ превращалось в ОПЕВЕЛАВЮ.
На развитие средств и методов защиты письменной информации ока-
зывает состояние средств связи. В те времена это была почта.
До конца XV века послания отправлялись специальным курьером -
гонцом. С начала XVI века начала распространятьея так называемая ямская
гоньба, заимствованная у татаро-монголов. Тем не менее, тайные писания пе-
ресылались со специальными гонцами.
В одйой из обнаруженных в 1952 году в Новгороде грамот говорилось:
«... человиком грамотку пришли тайно...» Тайная переписка имела место в Ки-
евской Руси еще на рубеже XI-XII веков. Археологи находят во многих древ-
них городах печати с надписью «ДЬНЕСЛОВО», которое переводится как
скрытое, сокровенное, тайное слово. Такие печатй для защиты посланий ис-
пользовали киевские князья Святополк Изяславич и Мстислав Владимирович,'
князь Александр Невский и др.
В XV-XVI веках использовались возможности перехвата сообщений.
Так, во второй половине XV века новгородская знать вынашивала мысль от-
пасть от Москвы и признать над собой власть польского короля и литовского
великого князя Казимира IV. Тайно ковался союз Новгорода с Польшей. Не-
прерывно происходил обмен посланиями и гонцами. В 1470-147Ггг. бояре
подготовили проект договора с Казимиром IV. Однако гонец был перехвачен,
и грамота попала к великому князю Ивану III Васильевичу. Князь предъявил
Новгороду обвинение в йзмене и во главе своих войск двинулся разорять нов-
городские земли. Новгород вновь вернулся в состав единого Московского
княжества.
Первый международный акт о перевозке корреспонденции, подписан-
ный Россией - это соглашение между Москвой и Варшавой (1634 г.). По это-
му акту, в частности, гонцам обеих сторон разрешалось иметь при себе шес-
терых провожатых. В 1665 году была организована международная почтовая
линия между Москвой и Ригой. Несколько позднее аналогичное соглашение
было подписано со Швецией.
Организация международных почтовых связей потребовала более на-
дежной защиты информации. Начали широко применяться криптографиче-
ские методы («затейное письмо»). Одновременно активизировался и перехват
сообщений. Так, царь Алексей Михайлович заметил, что корреспонденция
его резидента в Варшаве очень сильно запаздывала. Причина выяснилась
3 Зак. 5
66
очень просто. Когда резидент В.М. Тяпкин явился с жалобой к королю Яну
Собескому, тот, в свою очередь, упрекнул резидента в том, что он писал
«ссорные и затейные письма к царю». Следовательно, поляки перехватывали
и дешифровали послания Тяпкина.
Большое внимание уделялось сохранению тайнописных секретов. Так,
в инструкции русскому агенту в Швеции Дмитрию Андрееву говорилось: «Ле-
та 7143 (1653 г.) декабря 15 день ... А про те тайные дела и про затейное пись-
мо подьячий Иван Исаков и иной никто отнюдь не ведал, и черные о сих тай-
ных делах тем же затейным письмом держать у себя бережно, чтоб о тех тай-
ных делах и про то затейное письмо оприч его, Дмитрия, подьячий Иван Иса-
ков и иной никто однолично не проведал».
Приведем выдержку из присяги переводчика - шифровальщика конца
XVII ве.ка: «...Ему всякие государственные дела переводить в правду, и с не-
приятелями государскими тайно никакими письмами не ссылаться и мимо
себя ни через кого не посылать, и в Московском государстве с иноземцами о
государственных делах, которые ему будут даны для перевода, ни с кем не
разговаривать».
Во внутренней переписке после создания ямской почты только особо
важные, особо срочные сообщения разрешалось посылать в Москву с нароч-
ными гонцами. Это было вызвано тем, что посыльный вез, как правило, толь-
ко одну грамоту. От такой «почты» государство получало только лишние
расходы. Поэтому правительство строго предупреждало нарушителей поряд-
ка доставки корреспонденции. Так, например, Новосильский воевода И.П.
Турский в 1637 году направил московскому царю грамоту со специальным
гонцом. Последовал «государев гнев»: «И ты б впредь с такими вестьми на-
рочных гонцов к нам не посылал не о скорых делах ... чтоб в том лишнего
расходу не было».
Во второй половине XVII века была организована первая общедоступ-
ная «правильная» почтовая гоньба в России. Основной вклад в ее становление
и развитие внес тогдашний глава русского правительства А.Л. Ордин-
Нащокин. Почтовая переписка заметно оживилась.
В XVI-XVII веках по уровню развития науки и образования Россия су-
щественно отставала от развитых государств Запада. И это не могло не ска-
заться на российской криптографии.
67
В это время, как и раньше, не существовало школы как государствен-
ного или общественного заведения. Русский человек образовывался самостоя-
тельно, и первыми его учебниками были книги Ветхого и Нового Завета, опуб-
ликованные сведения из греческой мифологии, из Илиады и Одиссеи Гомера,
эпизоды из истории Византии и т.д. Сами публикации (рукописные, а затем и
печатные) были очень малочисленны.
Естественные науки появлялись лишь в самом зародыше. Они заим-
ствовались из устаревшей Византии и не достигали уровня Древней Греции и
Древнего Рима. Сама система изображения цифр буквами алфавита противо-
действовала развитию эффективного десятичного исчисления. Арифметика
находилась в зачаточном состоянии. Из четырех правил арифметики основа-
тельно изучались лишь два: сложение и вычитание; умножение и деление из-
бегались. Дроби были почти повсеместно неизвестны и были сведены к не-
скольким типичным: половина (1/2 ), треть (1/3), четверть (1/4), полчетверти
(1/8), полтрети (1/6), полполчетверти (1/16), полполтрети (1/12), полполпол-
четверти (1/32), полполполтрети (1/24). И это все. Операции над дробями ос-
тавались неизвестными. Появившиеся в XVI веке польские учебники по
арифметике положения не изменили. Но знание даже такой арифметики вы-
зывало глубокое уважение.
Почетна была и геометрия, которая находилась в аналогичном со-
стоянии. Геометрия («помитр!я») понималась исключительно как землеме-
рие. Достижения Эвклида были забыты. Например, при измерении земельных
участков площадь всех треугольников определялась как площадь прямо-
угольного треугольника (произведение длины одного катета на половину
длины другого).
В астрономии господствовали идеи египетского монаха Козьмы Ин-
дикоплова: земля имеет форму четырехугольной плоскости, земную плос-
кость окружает океан и т. д.
В аналогичном состоянии находилась и медицина. В основе теории
древнерусской медицины лежало старинное учение о четырех основных жид-
костях человеческой природы, соответствующих четырем стихиям мира. Эти
стихии - земля, огонь, вода и воздух. Аналогично, человек, как малый мир, со-
3*
68
стоит из четырех вещей: крови, мокроты (или флегмы), красной желчи и чер-
ной желчи. Если эти четыре стихии находятся в равновесии - человек здоров.
Утверждалось, что «каждому возрасту и каждому времени года соответствуют
свои болезни ... У отроков пятнадцати лет «умножается кровь», то же состоя-
ние вызывает весна, потому что она тепла и мокра; в человеке тридцати лет
умножается красная желчь, как и летом, потому что оно тепло и сухо; в совер-
шенном муже, около 45 лет, умножается черная желчь, как и осенью, потому
что осень суха и студена; в старце умножается флегма, сиречь мокрота, как и
зимой, ибо она мокра и студена». Большое распространение получила астроло-
гическая медицина.
В истории господствовали такие изречения: «За что меч гнева Божия
так долго поражал Россию? За грехи царей, которые грешили, и за грехи наро-
да, который молчал, повиновался и не обличал грешных царей».
, Однако тяга к образованию была значительной. В 1687 году в Москве
была учреждена «Славяно-греко-латинская академия», в которой обучалось 99
учеников.
Таковы некоторые черты культурной жизни России накануне воцаре-
ния Петра I. Ему пришлось предпринять титанические усилия по выводу стра-
ны на уровень, хотя бы приближающийся к уровню развитых стран. В этих
усилиях он не забыл и криптографию.
Петр I был первым русским царем, осознавшим во всей глубине госу-
дарственную важность защиты информации. Именно уже в самом начале
XVIII века Петром Великим была создана Походная посольская канцелярия,
ведающая дипломатической перепиской. Уместно напомнить, что до учреж-
дения канцелярии Петр I имел возможность ознакомиться с постановкой ана-
логичного вопроса в европейских странах при своих «нелегальных» выездах
за рубежи Российского государства. В первые годы правления молодого царя
«цифирным» отделением канцелярии руководил первый «министр иностран-
ных дел» Петра I генерал-адмирал Ф.А. Головин. В 1710 году канцелярия пе-
реместилась в Петербург и стала называться короче - «Посольская канцеля-
рия». Канцелярия значительно укрепила и усилила свои возможности, ее
численный состав существенно возрос. Ф. А. Головина сменил канцлер Г.И.
Головкин, а затем вице-канцлер П.П. Шафиров. Они продолжали лично ку-
рировать шифровальную службу государства. Позднее Посольская канцеля-
рия была преобразована в Коллегию иностранных дел. К этому времени Рос-
сия уже имела ряд постоянных миссий в европейских странах. Все они имели
различные шифры для переписки с царем (но не между собой). Таким обра-
69
зом, царь получал всю шифрованную переписку своих дипломатических
представителей и держал ее под полным личным контролем.
Становлению криптографии в это время способствовало и развитие
печатного дела; начала издаваться первая общероссийская газета «Ведомо-
сти». При Петре I была напечатана первая в России книга по истории науки и
техники. В переводе ректора Московской духовной академии Феофилакта
Лопатинского вышла «Осмь книг об изобретении вещей» историографа из
Урбино (Италия) Полидора Вергилия.
Обратимся к шифрам, то есть к «цифирным азбукам», используемым
в начале XVIII века.
Главенствующее положение здесь занимали шифры простой замены.
Открытые тексты, подлежащие зашифрованию, писались не только на рус-
ском, но и на французском, немецком и даже на греческом языках. Буквы за-
менялись на буквы других алфавитов, на слова и даже на целые стандартные
выражения. Применялись и специально продуманные причудливые знаки,
символы. Например, использовались следующие символы для обозначения
планет и металлов.
\
Q — золото — Солнце
— серебро — Луна
d — железо — Марс
ртуть - Меркурий
— олово — Юпитер
Cf.— медь — Венера
- свинец - Сатурн
Особое место занимали шифры замены букв на арабские цифры. Еще в
начале XVIII века была выведена из употребления устаревшая буквенная ки-
риллическая нумерация, заимствованная у греков. Числовые эквиваленты букв
начали выбираться произвольно по ключу шифра. Применялись и элементы
простого кодирования.
В шифрованный текст часто вставлялись «пустышки» - знаки, ничего
не обозначающие. Вставлялся в шифрованный текст и «клер» - незашифро-
70
ванные слова и предложения. Это делалось в интересах облегчения процесса
зашифрования - «несекретные» слова и предложения могли не зашифровы-
ваться.
Несмотря на очевидную с позиций сегодняшнего дня слабость таких
шифров, они в то время оказались достаточно стойкими. Англичане, обладав-
шие в то время передовой дешифровальной службой, дешифровали первый
такой шифр лишь в 1725 году.
Типичный шифр простой замены того времени содержал таблицу заме-
ны букв, список пустышек, кодировочную таблицу. Кодировочная таблица
называлась «суплементом», она содержала правила замены имен собственных,
географических наименований, устойчивых словосочетаний йа условные обо-
значения.
Вот как выглядело письмо, лично зашифрованное Петром. _
s _____ _____ _______________
7S0X3SZ нъдь ЭЗ&5О 33iiiJ64-8Z)A‘'~C0Z0
ччнц ПН5Ь’
НАД.ГП'б/’! и 8 fl-т & 4-5" 3, И НАДЯ Т^^И, КО •
тррые. мзъ ныхъ е.с.ть пойманы,
85Л.429 7^O-9Z43A3935V7tf-:&V:X45V
а когда будешь 8 Ch 39^5 V, тогда Х-S’”'
2. Vxfr2ZL б' Xh Cd К и чтсхгз
, 11*4 ХНт 2 S Я~-Z Нт L. h 8 h 9 Ц и по совершеуи^
онс/чъ ксгда 7+f+3XhA V£L Ц Ш 4Х92Ж 7^-Х^ П. О
Z^Z-&2.93 такскз rt?2miXhUJV4 7&Х
ФД.ХО и протчымъ bhZ945V 6h(jJ4¥-3H
253 Пс сей 2 34VX'6ZTZ5’3
ДЗДЗ 7^09<ЧШО
Из Нарвы, в 28 д. июня 1708. Piter»
После расшифрования текст читается следующим образом.
«Поди къ Черкаскому и, сослався з губернаторомъ азовским, чини не-
медленно съ Божию помощию промысль надъ теми ворами, и которые изъ
нихъ есть пойманы, техъ вели вешать по украинским городамъ. А когда бу-
дешь в Черкаскомъ, тогда добрыхъ обнадежь и чтобъ выбрали атамана доброго
71
человека; и по совершении ономъ, когда пойдешь назадъ, то по Дону лежащие
городки такожъ обнадежь, а по Донцу и протчим речкам лежащие городки по
сей росписи разори и над людми чини по указу».
Сравнивая шифртекст с открытым текстом, можно частично восстано-
вить простую замену: П=7, О = +, Д=Х и т.д.
Приведем и другую разновидность шифра простой замены, использо-
ванную Петром I. Применительно к современному русскому алфавиту этот
шифр имеет вид:
А Б В Г Д Е Ж 3 И К л
ме ли ко ин зе жу НЮ О пы ра су
М Н О П Р С т У Ф X ы
ти У хи от ца чуше ам 3 ъ от
ц ч Ш щ ъ ы ь Ъ Ю Я
ь ъ ю я ф а бе ва гу ДИ
Например, слово ТЕБЕ приобретает вид ШЕЖУЛИЖУ
Отметим одну важную особенность этой замены. При ее применении
шифрованный текст писался слитно, и никаких затруднений при расшифро-
вании это не вызывало. Шифробозначения составлены так, что даже при их
слитном написании в шифрованном тексте в процессе расшифрования про-
блем с однозначным определением открытой буквы не возникает. Например,
пусть имеется шифртекст:
рахисухиууме
Расшифрование связано с разбиением текста на однобуквенные и
двухбуквенные сочетания. Однобуквенного сочетания «р» нет в ключевой
таблице, следовательно, следует расшифровывать сочетание «Ра», что соот-
ветствует букве открытого текста К. Аналогично замечаем, что буква «х» не
является самостоятельным обозначением в таблице; следовательно, нужно
расшифровывать сочетание «хи», что дает нам открытую букву О. Поступая
так и далее, получаем открытое слово КОЛОННА. Использованный прием
построения таблицы-ключа лежит в основе некоторых современных методов
экономичного кодирования информации. Одновременно отметим, что такой
метод шифрования чувствителен к ошибкам шифровальщика (как типа заме-
ны буквы на букву, так и типа пропуска-вставки букв в шифрованном тек-
сте). Разнозначность шифробозначений букв открытого текста используется и
в наши дни. Она существенно затрудняет работу дешифровальщика.
Петр I уделял особое внимание надежной рассылке шифров и ключей
к ним. Он писал одному из своих посланников: «При этом посылаем к Вам
ключ, и ежели посланный здорово с ним поедет, и о том к нам Отпиши, дабы
мы впредь нужные письма могли тем ключом писать и посылать». По указу
Петра I курьер должен был «как можно меньше знать, что он перевозит, и
72
быть очень довольным оплатой своего труда». Самому же курьеру приказы-
валось «... отнюдь ничьей грамотки не распечатывать и не смотреть».
Петр I лично проверял и надежность используемых шифров. По одно-
му из слабых шифров он дал такое заключение: «Сия цифирь зело к разобра-
нию легка».
Пересылка шифров и ключей к ним носила порой экзотический харак-
тер. Посланцы, передающие столь секретную информацию, иногда несли ее
спрятанной в одежде, каблуках и т.д. Одному из своих посланцев Петр I прика-
зал «заделать послание в пуговицы его сюртука».
Сам Петр I, получая от своих посланников предложения о необходимо-
сти введения новых шифров, писал: «Твое послание безопасно получено. Твой
шифр смотрел по печати гораздо исмотрительно».
Царь безусловно доверял неповрежденной государственной печати Рос-
сии, и, к сожалению, нередко ошибался. Подделка печатей к этому времени
достигла определенного совершенства.
.Большое внимание при Петре I уделялось и «режимным вопросам» ра-
боты шифровальных органов. Сотрудники этих органов изолировались от об-
щения с «несанкционированными» лицами и получали достаточное матери-
альное вознаграждение, охраняющее их от «соблазна».
В истории не сохранилось сведения о каких либо успехах русских де-
шифровальщиков в петровский период. По-видимому, криптографы того вре-
мени занимались в основном защитой собственной секретной информации.
«Черный кабинет» в России появился лишь при Елизавете.
При Екатерине I руководителем криптографической службы становится
канцлер А.И. Остерман. В эти годы разрабатываются новые шифры.
Появляются алфавитные, а затем и неалфавитные коды. Кодированию
подлежали фразы, слова, слоги и буквы. Суплемент в этих кодах включал в
себя замену имен, географических названий и т. д.
Начали активно применяться буквенно-цифровые шифры замены с
введением пустышек. Так, например, если 29 - шифробозначение буквы А, а
пустышками являются цифры 3 и 7, то при зашифровании буква А могла пре-
вратиться в любое число из: 29, 239, 729, 279, 293 и т. д. При расшифровании
пустышки вычеркивались, и полученное число 29 расшифровывалось в А. В
инструкции к такому шифру отмечалось «Сим образом на всяку литеру, по
малой мере, шесть номеров, которы знаемы будут токмо тому, кто ведает, что
3 и 7 ничего тут не значать. Следственно, яко оне бы не были, но едино 29
будет видеть».
Появились шифры омофонной (многозначной) замены. В первых та-
ких шифрах гласным буквам, как наиболее частым в тексте, придавалось по 6
шифробозначений, а согласным — по 2. Например,
73
А Б В Г д Е Ж 3 И К Л М Н
12 13 14 15 16 17 18 19 20 21 22 23
41 42 43 44 45 46 47 48 49 50 51 52 53
71 72 73
60 61 62
83 84 85
95 96 97
Очевидные закономерности в образовании замены существенно ос-
лабляли этот шифр.
Затем появилась идея придавать всем буквам одно и то же количество
шифробозначений, однако и здесь присутствовали закономерности, облег-
чающие пользование шифром и одновременно ослабляющие его.
Например, для латинского алфавита предлагалось использовать такую
омофонную замену:
А 11 12 13 14 15
В 16 17 18 19 20
С 21 22 23 24 25
Z 131 132 133 134 135
Агентурные шифры простой замены в интересах простоты запомина-
ния предлагались в вариантах, не требующих специальных документов.
Пусть, например используется латинский алфавит А, В, С,..., Z. Агенту
нужно запомнить лишь следующие правила:
буквы I и J, а также V и W не отличаются друг от друга и записываются
как I и V, соответственно;
- оставшиеся 24 буквы разбиваются на блоки длиной 7- 6-6-5;
- алфавит выписывается поблочно в обратном порядке, внутри каждого
блока естественный порядок букв.
Получаем:
STUVXYZ - MNOPQR - FGHIKL - ABCDE
Замена определена здесь следующим способом:
ABCDEF GHI KLMNOP QR STUVXYZ
S TUVX YZMNOPQ R F GH I KLA BCDE
Слово CONFIDENT зашифровывается в слово UFRYNVXRL.
74
Аналогичный шифр можно построить, запомнив числа 13 и 11 ,
13+11=24.
Таким образом, агентурные шифры тех времен являлись ослаблен-
ным вариантом шифров простой замены. Ослабление было вызвано необхо-
димостью легкого запоминания шифра. Такие шифры можно истолковывать
как некоторое усиление шифра Цезаря. Зато при захвате агента никаких ма-
териальных улик, свидетельствующих об использовании им шифрованной
связи, не обнаруживалось. Простота запоминания, безуликовость стали есте-
ственным требованием к агентурным шифрам, которые достигались за счет
снижения их криптографической стойкости.
В переписке 1735 года можно найти символические обозначения
имен, должностей и др., которые не зашифровывались при шифровании и
имели вид религиозно-мистических знаков. Например, зарубежные агенты
России обозначались знаками:
приятель &
приятель ®
приятель
приятель 0
Криптографические службы России в этот период работали в тесном
контакте с агентурно-разведывательными органами. Нередко агенты получа-
ли задание добывать шифры иностранных государств, а также перехватывать
их шифрованную переписку. Приведем один пример.
Командующий русскими войсками в Крыму и Бесарабии генерал-
фельдмаршал Г.Ф. Миних отправляет одному из своих агентов (поручику Ле-
вицкому) следующее послание: «Понеже из Швеции послан в турецкую сто-
рону с некоторой важной комиссией и с письмами майор Синклер, который
едет не под своим, а под именем одного, называемого Гогберг, которого ради
высочайших Ея Императорского Величества интересов всемерно потребно
зело тайным образом в Польше перенять и со всеми имеющимися при нем
письмами». Далее послание-приказ содержал инструкцию: добыть информа-
цию любым путем, вплоть до убийства гонца. Особое место в нем занимали
указания о сокрытии следов преступления. Это поручение агент выполнил
весьма профессионально. Однако исполнитель весьма деликатного дела был
сразу арестован по надуманному предлогу и сослан на 5 лет в Сибирь (для
75
более полного сохранения тайны). По окончании ссылки агент вернулся на
государственную службу и получил следующий воинский чин.
Окончательно «черный кабинет» был создан в России в конце XVIII
века при Екатерине И. Однако тайная государственная служба перехвата,
перлюстрации и дешифрования писем начала создаваться гораздо раньше,
еще в начале века.
В середине XVIII века, при царице Елизавете Петровне, была учреж-
дена секретная служба перлюстрации. Ее возглавил канцлер А.П. Бестужев-
Рюмин. Он был сторонником сближения России с Англией и Австрией, чем
вызвал, по отношению к себе, оппозицию со стороны сторонников связи Рос-
сии с Францией и Пруссией.
Дешифрованная корреспонденция докладывалась непосредственно
императрице, которая с большим вниманием относилась к этой стороне госу-
дарственной деятельности. Основной перехват почты осуществлялся через
почтамт Петербурга, руководителем которого был Ф. Аш. Этот почт-
директор подчинялся непосредственно Бестужеву-Рюмину.
Технические проблемы безуликовости вскрытия писем (депеш) были
весьма значительны. Так, Ф. Аш жаловался Бестужеву: «... Куверты не токмо
по углам, но и везде клеем заклеены, и тем клеем обвязанная под кувертом
крестом на письмах нитка таким образом утверждена была, что оный клей от
пара кипятка, над чем письма я несколько часов держал, никак распуститься
и отстать не мог. Да и тот клей который под печатями находился (кои я ис-
кусно снял) однако ж не распустился. Следовательно же, я к превеликому мо-
ему соболезнованию никакой возможности не нашел оных писем распечаты-
вать без совершенного разодрания конвертов. И тако я оные паки запечатал и
стафету в ея дорогу отправить принужден был...»
Возникали проблемы и с подделкой поврежденных печатей. В штате
ведомства' Аша имелся мастер «печатнорезчик», специалист своего дела. Но и
он не всегда умел справиться с возложенными на него обязанностями. Заме-
тим, что печати того времени были весьма «замысловатыми»; они отпечаты-
вались на красном сургуче. При появлении явных ошибок в подделывании
печатей Бестужев-Рюмин указывал, что «... оные печати вырезать с лучшим
прилежанием, ибо нынешняя нейгаузова не весьма хорошего мастерства».
Неудачным резчиком печатей оказался француз Купи, и Елизавета рекомен-
довала подобрать резчика «из российских такого мастера или резчика приис-
кать».
Значительные достижения российской дешифровальной службы свя-
зываются с именем известного математика Христиана Гольдбаха (1690-
1764). Этот немецкий ученый был приглашен Петром I в Россию в начале
XVIII века. Он прибыл в Россию в период организации Академии наук Рос-
сии и затем стал ее секретарем. Он работал вместе с видными учеными Рос-
76
сии: братьями Николаем и Даниилом Бернулли, Леонардом Эйлером и др.
Математическая специализация Гольдбаха - теория чисел и математический
анализ. В России Гольдбах сдружился с Эйлером, и именно в их переписке
возникли известные математикам «проблемы Гольдбаха», одна из которых
формулируется достаточно просто: Всякое число, большее или равное трем,
может быть представлено в виде суммы трех простых чисел.
По-видимому, именно Бестужев-Рюмин предложил привлечь Гольд-
баха в криптографическую службу России. Гольдбах стал первым профес-
сиональным дешифровальщиком в истории криптографической службы Рос-
сии.
Гольдбах быстро добился успехов в дешифровании иностранной пе-
реписки. Так, с июля по декабрь 1743 года им было дешифровано более 60
писем лишь «министров прусского и французского дворов». Среди прочих
дешифрованных им документов было письмо-послание посла Франции в Рос-
сии маркиза де ла Шетарди. Содержание письма было оскорбительным для
Елизаветы. Она характеризовалась как женщина, «находящаяся в плену сво-
их прихотей» и за которую ее фавориты решают государственные дела; она
является «довольно фривольной и распущенной женщиной» и т. д. Такие сло-
ва, естественно, не могли оставаться без последствий. В результате посол
Шетарди был выдворен из России.
Анализ материалов тех лет показывает, что до Гольдбаха перехвачен-
ные письма копировались на почте только по «клеру», то есть по кускам от-
крытого текста, содержащихся в письмах. Шифрованная часть не копирова-
лась. С момента появления Гольдбаха в «черном кабинете» России Бестужев-
Рюмин дал распоряжение Ашу копировать письма целиком. Аш старался вы-
полнить распоряжение, но у него постоянно возникали проблемы с бузулико-
востью вскрытия писем.
Гольдбах стремился разъяснить Бестужеву-Рюмину серьезные про-
блемы его работы по дешифрованию. Он, в частности, подчеркивал необхо-
димость абсолютно точного копирования перехваченных писем. Он просил
«каждое число или каждую цифру весьма прилежно свидетельствовать», по-
скольку ошибки копировальщика значительно затрудняют работу дешифро-
вальщика. Ранее уже .отмечались примеры влияния ошибок шифровальщика
на возможности расшифрования посланий. Еще большие сложности преодо-
левает дешифровальщик при наличии ошибок в шифртексте, допущенных
при копировании шифрованных сообщений.
Императрица высоко оценила труды Гольдбаха. Помимо больших де- .
нежных вознаграждений он получил очень высокое звание - тайный совет-
ник. Отметим, что знаменитый математик того времени Л. Эйлер, несмотря
на все его научные достижения, такого звания не получил.
77
Дешифрованные Гольдбахом материалы оказывали заметное влияние
на внутреннюю и внешнюю политику России.
Узнав об успехах русских дешифровальщиков, французы спешно ме-
няли шифры. Более того, иногда они предлагали перед зашифрованием изло-
жить сообщение на жаргонном коде. Так, посланец Людовика XV в Россию
Дуглас, приехавший под видом торговца мехами, использовал соответст-
вующий мехам код. В нем выражение «рысь в цене» означало успешное влия-
ние австрийцев при русском дворе; «соболь падает в цене» - падение влияния
австрийцев; «горностай в ходу» - усиление противников австрийской партии
ит.д.
Тем не менее, в конце XVIII века дешифровальная служба России
держала под контролем всю французскую дипломатическую переписку. Это
объяснялось как успехами в области аналитической разработки шифров, так и
активной агентурной работой по добыванию французских шифров, вербовкой •
агентуры в Министерстве иностранных дел. Франции.
Еще одной яркой личностью в истории российской криптографии яв-
ляется известный ученый, математик и физик, немец по национальности •
Франц Ульрих Теодор Эпинус (1724-1802). Его труды в области электриче-
ства и магнетизма известны современным специалистам. Он одним из первых
начал применять точные математические методы йри исследовании физиче-
ских явлений.
В середине XVIII века Эпинус был приглашен в Россию с целью про-
ведения криптографически-дешифровальных работ. Это приглашение напра-
вил руководитель Коллегии иностранных дел граф Н.И. Панин. Эпинус при-
глашение принял. Такие приглашения иностранных ученых на службу в Рос-
сию очень часто оправдывали себя. Собственных специалистов соответст-
вующего уровню Европы в России, к сожалению, не было, что можнообъяс-
нить предшествующей суровой историей нашего государства.
Эпинус был «пожалован статским советником и определен при Кол-
легии иностранных дел при особливой должности», то есть в должности де-
шифровальщика. За успешную работу он получил звание действительного
статского советника. К сожалению, фактических сведений о дешифровальной
деятельности Эпинуса, кроме упоминаний о том, что она была эффективной,
до сих пор не обнаружено.
В середине XVIII века появились первые отечественные криптогра-
фы. Среди них выделяются Ерофей Каржавин и его племянник Федор Каржа-
вин.
Ерофей Никитович Каржавин (1719-1772) родился в семье, занимав-
шейся мелкой торговлей в Москве. Он получил образование в Париже (в
Сорбонне), стал ученым - лингвистом. После возвращения в Россию он был
78
назначен на должность переводчика и составителя шифров в Коллегию ино-
странных дел.
Ерофей Каржавин впервые перевел на русский язык «Путешествия
Гулливера» Дж. Свифта, написал труд «Заметки о русском языке и алфавите».
Федор Каржавин (1745-1812) обладал хорошими способностями в изу-
чении иностранных языков, а также в физике. По возвращении из Парижа, где
проходил обучение, он, как и его дядя, Ерофей Каржавин, был назначен в Кол-
легию иностранных дел. Находясь в должности переводчика, он привлекался к
составлению шифров, а также участвовал и в дешифровальной работе.
Ф. Каржавин - современник и единомышленник Радищева, предшест-
венник декабристов, участник американской революции. Значительную по-
ложительную роль в его судьбе сыграл русский архитектор Баженов. Во вре-
мя обучения Ф. Каржавина во Франции посол России в Париже князь Голи-
цын так характеризовал российского студента: «Из сего молодого человека
может быть со временем искусный профессор». По возвращении в Россию
Каржавин работал учителем в семинарии при Троице-Сергиевой лавре. Нера-
дивым семинаристам он говорил: «Ты, малый, с ленцой, не пылаешь жаждой
знаний, ну и незачем тлеть».
Содержательный вклад Каржавиных в российскую криптографию до
сих пор не изучен: Ясно одно, Каржавины стали первыми отечественными
профессиональными криптографами и внесли свой весомый вклад в развитие
криптографической службы России.
С середины XVIII века в России стали использоваться новые шифры.
Их основные отличия от предшествующих шифров заключались в следую-
щем.
Во-первых, на русском языке начали активно применяться коды, ко-
торые тоже называли цифровыми азбуками (шифрами), на большое количе-
ство букв, слогов, слов, фраз и т. д.; их число уже достигало 1200. Как прави-
ло, это были алфавитные коды с цифровыми шифробозначениями. Наиболее
частым буквам, слогам, и т. д. придавалось несколько шифробозначений. Та-
ким образом, использовался шифр омофонной замены, но на уровне не толь-
ко букв, но и буквосочетаний. Коды менялись регулярно, поскольку ключом
такого шифра являлся сам код - таблица замены.
Во-вторых, увеличилось число «пустышек», вставляемых в шифро-
ванный текст. По этому поводу в одной из инструкций по пользованию шиф-
рами указывалось: «Пустые числа писать где сколько хочется, только чтобы
на каждой строке было сих чисел не меньше трех или четырех». Так обозна-
чался лишь нижний уровень количества вставок «пустышек», а верхняя гра-
ница не устанавливалась. И еще: «Не начинать пиесы (шифрованного посла-
ния) значащими числами, но пустыми ...» Тем самым начало истинного
79
шифрованного текста в послании скрывалось пустышками. Конечно, исполь-
зование пустышек усиливало шифр.
Определенной новостью в таких шифрах являлось вставление в их
кодовый сдоварь «особых чисел», шифробозначения которых определяло те
части шйфртекста, которые при расшифровании следует считать пустышкой.
Так, например, если при расшифровании появлялся знак + (ему, конечно, со-
ответствовало несколько шифробозначений), то это означало, что следующее
шифробозначение в шифрованном тексте йе следует принимать во внимание,
оно ничего не значит. Два ++ означали, что следует пропустить при расшиф-
ровании следующие две шифрвеличины. Три +++ — три шифрвеличины;
получение знака = при расшифровании означало, что следует не расшифро-
вывать все оставшиеся в строке шифробозначения. Некоторые знаки говори-
ли о том, что следует уничтожить некоторые ранее расшифрованные знаки и
т.д. ,•
Для затруднения опознавания типа шифра предлагались меры, маски-
рующие его. Например, для шифра, использующего трехзначные числа,
предлагалось произвольно переводить эти числа в четырехзначные, добавляя
произвольно первую цифру, означающую тысячи: 326 можно записать как
1326, или 5326 и т.д. Можно было вставлять и 0 в любое место трехзначного
числа и т. д.
Практиковался при написании секретного послания переход с русско-
го языка на другие (французский, немецкий). Для каждого языка использова-
лись свои собственные шифробозначения. В связи с чем статистический под-
счет частот появления знаков при дешифровании существенно затруднялся,
поскольку смешивались статистические характеристики различных языков.
В ряде случаев в шифрах использовалась замена не только букв, но и
биграмм, слов. В таких шифрах повторение в открытом тексте одного и того
же слова приводило к различным шифробозначениям в шифрованном тексте.
Большое внимание уделялось сохранению тайны шифра. В одной из
инструкций говорилось: «... Негь въ свете ни труда, ни прилежания, коими
бъ не должно жертвовать сохранению цыфръ, когда сему превращению вве-
ряются часто великие государственные тайности». Коллегия иностранных
дел постановила, что всем сотрудникам шифровальной службы «ни с кем из
посторонних людей об этих делах не говорить, не ходить на дворы к чуже-
странным министрам и никакого с ними обхождения и компании не иметь».
Коллегия иностранных дел внимательно следила за сохранностью
шифров. Когда стало известно, что один из канцелярских служащих при по-
сланнике России в Гданьске потерял шифр, руководители коллегии граф Н.
Панин и граф И. Остерман сделали посланнику России Волчкову строгое
предупреждение: «.. .Признано здесь за нужно подтвердить Вам в то же вре-
мя единожды навсегда, чтоб Вы сами впредь хранили у себя цифирные ключи
80
и заочно не выпускали их из рук, в чем и обязываетесь Вы Вашею присягою
верности Ея Императорскому Величеству».
Екатерина II лично уделяла большое внимание шифрованию сообще-
ний. Так, направляя Алексея Орлова в Европу с разведывательным заданием,
она снабдила его «нарочно сочиненным цифровым ключом», добавив, что
«этот ключ используется для корреспонденции вашей с Нами, которая по
важности предмета своего требует непроницаемой тайны». Орлову были да-
ны также отдельные шифры «на российском, немецком и французском язы-
ках для переписки при необходимости с русскими послами при государст-
венных дворах». Для обеспечения шифрованной переписки к Орлову были
прикреплены надежные и способные «служители канцелярские».
В эти же годы в России получили распространение «циркулярные
шифры», то есть общие шифры у послов и Коллегии иностранных дел, что
позволило оперативно передавать послам единые указания, установки и т. д.
Начало такой практики прослеживается с петровских времен.
Таким образом, создание сети общей шифрованной связи в России
можно отнести к середине XVIII века. Общий шифр получил название «гене-
ральная цифирь». Вместе с ним сохранились и «индивидуальные» шифры для
связи центра с корреспондентами сети. У каждого корреспондента, как пра-
вило, имелось несколько индивидуальных шифров.
При возникновении подозрений о попадании шифра к противнику он
тут же заменялся. Применение шифров рекомендовалось чередовать, указы-
вая использованный шифр специальным скрытым образом («маркантом») в
начале шифрованного послания. Маркант обычно запрятывался среди пус-
тышек.
Н.И. Панин рекомендовал в особых случаях использовать симпатиче-
ские чернила для записи шифрованного текста между строк видимого маски-
ровочного текста и отправлять эти письма специальным курьером, а не по
почте. Таким образом, здесь объединялись все три метода защиты информа-
ции: физическая защита носителя, стеганография и криптография. В одном из
писем в Берлин Панин писал: «Не имея под рукой симпатических чернил, к
помощи которых я обычно прибегаю, сегодня при написании прилагаемого
письма я использовал лимонный сок. Следовательно, при обработке не следу-
ет опускать его в азотную кислоту, а надо подогреть».
Русская разведка с середины XVIII века использовала интересный
прием для получения интересующей ее информации по линиям шифрованной
связи. Этот прием используется и в наши дни. В данном случае речь идет не о
«пассивном» дешифровании, а о побуждении противника к отправлению по
линии связи, находящейся под контролем разведки, интересующей информа-
ции. Эту идею можно проиллюстрировать следующим образом.
81
Пусть разведка Р контролирует, то есть перехватывает и дешифрует,
линию связи от корреспондента А к корреспонденту Б. Разведка, используя
свои возможности, побуждает А отправить Б информацию по интересующе-
му Р вопросу. Таким образом Р получает требуемую информацию. Побудить
А отправить нужное послание - дело непростое; успех зависит, в частности,
от возможностей Р влиять на А. Приведем примеры такого действий.
В самом начале XIX века из Петербурга русскому послу в Берлине
сообщили: «В нашем распоряжении есть шифры, с помощью которых пере-
писываются король Пруссии со своим поверенным в делах в России. В слу-
чае, если у Вас возникнут подозрения в вероломстве министра иностранных
дел Пруссии графа Кристиана фон Хаунвитца, то Ваша задача будет состоять
в том, чтобы под каким-то предлогом заставит его написать сюда письмо по
интересующему нас вопросу. И сразу же, как только будет дешифровано его
письмо или письмо его короля, я проинформирую Вас о содержании».
В XVIII веке криптографические методы защиты информации про-
никли и во внегосударственные сферы. Их стали применять различные тай-
ные организации, уголовный мир и т.д. В России появились ложи масонских
направлений, которые традиционно использовали криптографические мето-
ды. В связи с этим государственные криптографические органы России обра-
тили внимание и на эти организации.
Шифры, используемые этими организациями, как правило, не явля-
лись стойкими, что вполне объяснимо. Профессиональные криптографы по-
являлись в их среде крайне редко. Масоны, возродившиеся на Руси при Павле
Петровиче, использовали свои традиционные «экзотические» шифры простой
замены. Мать Павла, Екатерина II относилась к масонству крайне отрица-
тельно, но Павел, еще будучи великим князем, взял их под свое личное по-
кровительство. Екатерина II повелела взять переписку масонов под контроль.
Соответствующее указание она передала московскому почт-директору И.В.
Пестелю, отцу декабриста Павла Пестеля.
Итак, шифры масонов являлись недостаточно стойкими. Но следует
принять во внимание следующий факт. Само открытое сообщение масоны
формулировали в форме мистико-символического послания, истинный, смысл
которого был доступен лишь «посвященному». Здесь появляются так назы-
ваемые «семантические шифры», в которых заменяется не форма, а содержа-
ние послания; форма же остается вполне осмысленной для любого читателя, а
истинное содержание должен был понять лишь тот, кому сообщение направ-
лено. ’
Вольные каменщики придерживались следующего правила: «Символ
представляет мысли свободу; догмат сковывает, подчиняет. Язык в ложах
наших иносказательный». В одной из масонских инструкций указывалось:
«Каменщик должен всячески вникать в таинственные обряды наших лож, где
82
каждый предмет, каждое слово имеет пространственный круг значений и сие
поле расширяется, подобно как, всходя на высоту, по мере того как возвыша-
ется, то видимый нами горизонт расширяется».
В результате дешифрования масонской переписки был посажен в
Шлиссельбургскую крепость один из руководителей масонского движения в
России Н.И. Новиков - известный издатель, литератор и публицист. Позднее
другой масон, сенатор Й.В. Лопухин, жаловался: «Открывали на почте наши
письма, и всех моих писем копии, особливо к одному тогда приятелю, быв-
шему в чужих краях, отсылались к Государыне».
Таким образом, перехват и дешифрование повернулись внутрь страны
и стали эффективным оружием в борьбе с «инакомыслящими». Эта практика
в дальнейшем использовалась в России (как, впрочем, и в других странах)
весьма активно.
Параграф 1.3
Модели шифров по К. Шеннону. Способы представ-
ления реализаций шифров
Одним из первых ввел и систематически исследовал простую и есте-
ственную математическую модель шифра К. Шеннон. Эту модель можно най-
ти, например, в его книге «Работы по теории информации и кибернетике»,
1963 (раздел «Теория связи в секретных системах»). Он рассматривал так на-
зываемые «секретные системы», в которых смысл сообщения скрывается при
помощи шифра или кода, но само шифрованное сообщение не скрывается, и
предполагается, что противник обладает любым специальным оборудованием,
необходимым для перехвата й записи передаваемых сигналов.
Рассматривается только дискретная информация, то есть считается,
что сообщение, которое должно быть зашифровано, состоит из последова-
тельности дискретных символов, каждый из которых выбран из некоторого
конечного множества. Эти символы могут быть буквами или словами некото-
рого языка, амплитудными уровнями квантованной речи или видиосигнала.
Ядром секретной системы является собственно шифр.
Алгебраическая модель шифра.
Пусть X, К, У - некоторые конечные множества, которые названы, со-
ответственно, множеством открытых текстов (открытых сообщений), множе-
ством ключей и множеством шифрованных сообщений (криптограмм). На
прямом произведении ХхК множеств X и К задана функция (отображение) f:
83
ХхК—>У (f(x,%)=y, xgX, %gK, уеУ). Функции f соответствует семейство ото-
бражений fz: X—>У, хеК, каждое отображение задано так: для хеХ
t fz(x)=f(x,x).
Таким образом, fx - ограничение f на множестве Хх{х}. Здесь {х} -
множество,’ состоящее из одного элемента. Заметим, что задание семейства
отображений (fx)xeK , fx:X—>У однозначно определяет отображение f:XxK->y,
f(x,x)=fx(x).
Введенная четверка A=(X,K,y,f) определяет трехосновную универ-
сальную алгебру, сигнатура которой состоит из единственной функциональ-
• ной операции f.
Определение. Введенная тройка множеств Х,К,У с функцией
f:XxK—>У
A=(X,K,y,f), -
называется шифром (алгебраической моделью шифра), если выполнены два
условия: 1) функция f- сюрьективна (осуществляет отображение «на» У);
2) для любого Х*=К функция fx инъективна (образы двух различных
элементов различны).
Из 2) вытекает, что |Х|<|У|.
Запись f(x,x)=y называется уравнением шифрования. Имеется в виду,
что открытое сообщение х зашифровывается шифром на ключе х и получает-
ся шифрованный текст у. Уравнением расшифрования называют запись
fx’1(у)=х (f 1(у,х)=х)» подразумевая, что шифрованный текст y=f(x,x) расшиф-
ровывается на ключе х и получается исходное открытое сообщение х. Для
краткости, в ряде случаев используют и более простые обозначения уравне:
ний шифрования и расшифрования, а именно, соответственно: Хх=у и х’1у=х.
Требование инъективности отображений (fx)X€K в определении шифра
равносильно требованию возможности однозначного расшифрования крипто-.
граммы (однозначного восстановления открытого текста по известным шиф-
рованному тексту и ключу). Требование же сюрьекгивности отображения f не
играет существенной роли и оно обычно вводится для устранения некоторых
технических, с точки зрения математики, дополнительных неудобств, то есть
для упрощения изложения. В ряде случаев мы будем отказываться от этого
требования, если его наличие будет усложнять описание или анализ шифра.
Таким образом, наличие или отсутствие сюрьекгивности отображения f в ис-
пользуемом определении шифра будет следовать из текста.
Введенная модель шифра отражает лишь функциональные свойства
шифрования и расшифрования в классических (с точки зрения истории крип-
тографии) системах шифрования (в системах с симметричным ключом). В
этой модели открытый текст (или шифрованный текст) - это лишь элемент
абстрактного множества X (или У), не учитывающий особенностей языка, его
84
статистических свойств, вообще говоря, не являющийся текстом в его при-
вычном понимании. При детализации модели шифра в ряде случаев указыва-
ют природу элементов множеств.
Рассмотрим примеры.
Обозначим через I некоторый алфавит, а через I* - множество
всех слов в алфавите I, то есть множество конечных последовательностей
(ibiz,-•Ль), ij€l,je{l,...,L},Le{l,2,....}
Шифр простой замены. Пусть Х=М - некоторое подмножество из I*,
а К - множество всех подстановок на I (K=S(I) - симметрическая группа под-
становок на I). Для каждого geK определим fg , положив для б1Д2,...Дь) из М
fg( ibh,.- • -,iL)=g(ii),g(i2),- • -,g(ii.)- Положем дополнительно
f(ii,i2,...,iL,g)= fg( ii,i2,---,iL)
и y=f(M)={f(ii,i2,...,iL,g): geS(I), (ii,i2,...,ib)6M}. Таким образом, нами опреде-
лен шифр А=(М, S(I), У, f) простой замены, более точно: алгебраическая мо-
дель шифра простой замены с множеством открытых текстов Х=М. Иногда в
качестве шифра простой замены выступает шифр, в котором XaIuI2o...kJlL и
для шифрования открытых текстов длины к слов выбирается подстановка gk
из S(I).
Шифр перестановки. Положим X - множество открытых (содержа-
тельных) текстов в алфавите I длины, кратной Т. K=St - симметрическая
группа подстановок степени Т, для ge St определим fg> положив для
(11,12,---,1т)бХ
fg(ii ,i2, • • -,iT)=(ig(i),ig(2),- • -,ig(T));
доопределим fg на остальных элементах из X по правилу: текст хеХ делится
на отрезки длины Т, и каждый отрезок длины Т шифруется на ключе g по ука-
занному выше закону шифрования. Последовательность, составленная из букв
образов зашифрованных слов, является шифрованным текстом, соответсвет-
свующим открытому тексту х и ключу g. Таким образом, нами определена
функция ТХхК->У и шифр перестановки (X,Sj,y,f). Для шифрования текста
длины, не кратной Т, его дополняют буквами до длины, кратной Т.
Шифр гаммирования. Пусть буквы алфавита I упорядочены в неко-
тором естественном порядке. «Отождествим» номера этих букв с самими бу-
квами. То есть формально положим 1={1,2,...,п}, |1|=п. Положим, X - некото-
рое подмножество множества IL, KgIl.
Для ключа у=уьу2,...,уь из К и открытого текста х= ii,i2,...Ль их X, по-
ложим, fY(ii,i2,...,к)=У1 ,Уг,-• • ,Уь где yj=ij+yj mod(n), je {1,...,L}. Часто под шиф-
ром гаммирования понимают и следующие способы шифрования: yj=ij-yj;
УГУг ijmod(n).
85
Поточный шифр. Шифр поточной замены. Введем сначала вспомо-
гательный шифр (I,r,y,f) для шифрования букв алфавита I. Для ключа у( еГ,
и буквы (открытого текста) iel шифрованный текст имеет вид fY1(i)=y. Обо-
значим через К - множество ключей поточного шифра. Для натурального
числа L введем отображение Ф: К—>TL, для фиксированного ключа %еК по-
ложим Ф(х)=У1,У2>--->Уг- Поточный шифр (IL,K,F,y') для вспомогательного
шифра (X=I,K=r,y,f) шифрует открытый текст ii,12,- • - Jl на ключе %еК по
правилу
Fx(ii,i2,...,iL)= fT,(ii), fY2(i2),.• • > ^(k),
где fY(i)=f(i,y).
Поточным шифром замены мы называем поточный шифр, для кото-
рого опорный шифр имеет вид (X=I,K=r,y=I,f), a (fY)Yer - семейство подста-
новок на I. Примерами поточных шифров служат шифры гаммирования,
шифры простой замены. Поточный шифр с опорным шифром вида:
I=K={l,2,...,n}, f(i, y)=i+y mod |1| также называют шифром гаммирования.
При этом условно различают программный шифр гаммирования, в случае
|K|<|I|L, и случайный шифр гаммирования, в случае K=IL, Ф - тождественное
отображение. Более общее понятие поточного шифра состоит в том, что в ка-
честве множества открытых текстов рассматриваются все последовательности
алфавита I длины, не превосходящей некоторого L(0). Для шифрования тек-
стов длины L изпользуется гамма ФьСх^ьТг.-^Уь Таким образом, исполь-
зуются L функций Ф^ j g {1,... ,L(0)}.
Ряд специалистов, в частности Алиев Ф.К., считают, что приведенный
шифр следует называть поточным лишь в случае, когда существует ключ
Хе К, при котором не все функции fYi, fY2,..’., fYL одинаковы. В противном слу-
чае, шифр следует называть блочным шифром.
Произведение шифров.
Произведением шифров А1=(ХЬК1,У1,Г1), А2=(Х2,К2,У2,Г2), У,сХ2 на-
зывают шифр A=(X,,K|XK2,y2,f), для которого f(x,(xi,X2))=f2(fi(x,Xi),X2),
(Xi,X2)gK,xK2.
Транзитивность шифра.
Шифр A=(X,K,y,f) называют транзитивным, если при любых
хеХ и уеУ найдется %еК, при котором f(x,x)=y. Исходя из введенных
определений, легко доказывается, что для транзитивного шифра
|Х|<|У|<[К[.
Основные параметры шифра (/Про/ и др.). Ряд требований к шиф-
рам формулируется с использованием понятий, точное определение которых
будет дано позднее. Тем не менее, на качественном уровне понимания эти па-
раметры можно трактовать следующим образом.
86
Стойкость шифра. Ряд шифров являются совершенными в том смысле, что
положение противника, стремящегося к их дешифрованию, не облегчается в
результате перехвата шифртекста, то есть наличие криптограммы не умень-
шает неопределенности в возможном выборе открытого текста. Такие шифры
относят к так называемому классу теоретически стойких шифров. Ряд шиф-
ров, а это многие практически используемые шифры, таковы, что эта неопре-
деленность при перехваченной криптограмме полностью исчезает, то есть
с!ановится известным, что данная криптограмма может быть получена шиф-
рованием только единственного открытого текста (неизвестно только - како-
го). Уровень стойкости таких систем оценивается по затратам времени и сил,
необходимых для получения этого единственного открытого текста. При
больших затратах или малой вероятности успеха в дешифровании - говорят,
что шифр практически стойкий.
Объем ключа. Ключ шифрования (он же ключ расшифрования) должен быть
неизвестен* противнику и находиться как в передающем пункте связи, так и в
приемном пункте. Обычная практика использования ключа состоит в том, что
он используется как одноразовый шприц - единожды, при шифровании лишь
одного открытого текста. Для регулярной связи корреспондентов, следова-
тельно, надо иметь в их пунктах связи достаточно большое количество клю-
чей, то есть должна решаться задача секретной доставки ключей. Эта задача
решается более просто, если объем каждого ключа сравнительно небольшой.
Сложность выполнения операций шифрования и расшифрования. Эти
операции должны быть по способу выполнения по возможности простыми.
Если они выполняются вручную, то. их сложность приводит к большим затра-
там времени на их выполнение и появлению ошибок. При использовании
шифровальной аппаратуры возникают вопросы о простоте технической реа-
лизации аппаратуры, ее стоимости, а также о достижении необходимой ско-
рости выполнения операций, связанных с процессами шифрования и расшиф-
рования.
Разрастание числа ошибок. В некоторых типах шифров ошибка в одной бу-
кве, допущенная при шифровании, приводит к большому числу ошибок в
расшифрованном тексте. Такие ошибки разрастаются в результате операций
расшифрования, вызывая значительную потерю информации, и часто требуют
повторного зашифрования текста и передачи новой криптограммы. Естест-
венно, при выборе шифра для связи стараются минимизировать это возраста-
ние числа ошибок.
Помехоустойчивость шифра. При действии помех в линиях связи происхо-
дит искажение текста криптограммы, что приводит при расшифровании к ис-
кажениям открытого текста, а зачастую и к нечитаемости текста. Свойство
шифра противостоять разрастанию ошибок при расшифровании текстов .назы-
вают его помехоустойчивостью.
87
Имитостойкость шифра. К активным действиям противника в канале связи
относят его попытки навязать абоненту сети связи ложную информация путем
искажения шифрованного текста в канале связи, либо его замене на ранее
переданный шифртекст, а также и другие действия противника, ведущие к
принятию ложной информации. Шифры, обладающие свойством противосто-
ять таким попыткам навязывания ложной информации, называются имито-
стойкими.
Увеличение объема сообщения. Для некоторых шифров объем сообще-
ния увеличивается в результате операции шифрования. Этот нежелательный
эффект проявляется, например, при попытке выровнять статистику сообщения
путем добавления некоторых вспомогательных симолов («пустышек»), или
при рандомизации открытого сообщения, то есть, по сути, применения к нему
некоторого пропорционального кода.
Основные свойства модели шифра.
Важным классом шифров являются введенные выше так называемые
транзитивные шифры, то есть шифры, для которых уравнение Дх,х)=у раз-
решимо относительно %еК при любых парах (х,у)еХхУ и так называемые t -
транзитивные шифры, шифры, для которых система уравнений f(x(j),x)=y(j),
je {1,...,t} имеет решение относительно х^К для любых подмножеств
{x(l),x(2),...,x(t)}czX мощности t и любых подмножеств {у(1),у(2),...,у(0}сУ
мощности t.
Эндоморфный шифр.
Другой важный класс шифров представляют так называемые эндо-
морфные шифры (термин предложил К. Шеннон), то есть шифры (Х,К,У,1),
для которых множество открытых текстов X совпадает с множеством крипто-
грамм У. Для таких шифров (X,K,y,f) каждое преобразование fz, уеК являет-
ся биекцией X в X (подстановкой на X). Множество таких биекций обознача-
ют через II(K,f)={fx: Х*=К}, а сам эндоморфный шифр - через A=(X,II(K,f)) и
называют подстановочной моделью эндоморфного шифра.
При этом под ключом этого шифра понимают биекцию тгеП(К,Г). Уравнение
шифрования записывают в виде ях=у, уравнение-расшифования записывают
в виде 7г‘*у=х.
Групповой шифр.
Эндоморфный шифр, у которого множество подстановок n(K,f) является
смежным классом по некоторой подгруппе из S(X), называют групповым ,
шифром.
Транзитивный шифр, для которого |Х|=|К| называют минимальным
шифром.
88
Для эндоморфных шифров Ai=(X,II(K|,fi)) A2=(X,II(K2,f2)) используют
введенное ранее понятие произведения шифров А|-А2=(Х, П(К|,Г|)> n(K2,f2),
где II(Ki,fi)- II(K2,f2)={7ti7t2:7tiGlI(Ki,fi), ЛгбПСКгДг)}. Очевидно, произведение
эндоморфных шифров будет транзитивным шифром, если таковым яаляется
хотя бы один из них.
Эквивалентные ключи шифра.
Определение. Ключи %, %' шифра (Х,К,У,1) называются эквивалент-
ными, если при любом xgX
f(x,x)= f(x,x')-
Вероятностная модель шифра. Одно из важнейших предположений.
К.Шеннона при исследовании секретных систем состояло в том, что каждому
возможному передаваемому сообщению (открытому тексту) соответствует
априорная вероятность, определяемая вероятностным процессом получения
сообщения (см. ниже параграф 3.3 и главу 4) Аналогично, имеется и априор-
ные вероятности использования различных ключей шифра. Эти вероятност-
ные расределения на множестве открытых текстов и множестве ключей ха-
рактеризуют априорные знания криптоаналитика противника относительно
используемого шифра. При этом Шеннон предполагал, что сам шифр извес-
тен противнику.
Определение. Вероятностной моделью шифра называется его алгеб-
раическая модель с заданйыми дискретными независимыми вероятностными
распределениями Р(Х)-(р(х), хеХ), Р(К)=(р(х), хеЮ на множествах X и К .
Естественно, вероятностные распределения на X и К индуцируют ве-
роятностное распределение Р(У)=(р(у),уеУ) на У, совместные распределения
Р(Х,К), Р(Х,У), Р(У,К) и условные распределения Р(Х/у)=(р(х/у), xgX) и
Р(К/у)=(р(х/у),хеК).
Вероятностной модели шифра соответствует так называемая матрица
||р(у/х)|| размера |Х|х|У| переходных вероятностей шифра, составленная из
условных вероятностей р(у/х) - вероятности зашифрования открытого текста
х в криптограмму у при случайном выборе ключа х^К в соответствии с Р(К).
Совершенные шифры. При определении теоретической стойкости
шифра используют вероятностную модель шифра и следующие рассуждения.
Зная шифр и априорные вероятности открытых текстов и ключей, об-
ладая перехватом шифртекста уеУ, противник может вычислить условные
вероятности р(х/у) при всех xgX. Если при этом окажется, что один из эле-
ментов х(0) их X имеет значительную вероятность р(х(0)/у)=1-8, а все осталь-
ные элементы их X, вместе взятые, имеют вероятность р(х / у) = 8, то
х*х(0)
89
это означает, что с надежностью 1-е найдено истинное открытое сообщение. В
этом смысле говорят, что дешифрование сводится (равносильно) к вычисле-
нию апостериорных вероятностей р(х/у) при всех хеХ. Напротив, если ока-
жется, что при любом хеХ выполняется равенство р(х/у)=р(х), то перехвачен-
ная криптограмма у не несет никакой информации об открытом сообщении.
Если это равенство выполняется дополнительно и при любом уеУ, то это
свидетельствует о высокой способности шифра противостоять попыткам де-
шифрования, то есть о высокой криптостойкости шифра. Последние шифры
К. Шеннон назвал «совершенными» шифрами.
Определение. Шифр (X,K,y,f) с вероятностными распределениями
Р(Х)=(р(х), хеХ), Р(К)=(р(%), %еК) называется совершенным (при нападении
на хеХ по перехвату уеУ), если при любых хеХ и уеУ
р(х/у)=р(х).
Используя формулу условных вероятностей
Р(х,у)=р(у/х)р(х)=р(х/у)р(у),
легко показывается, что совершенность шифра равносильно условию
р(у/х)=р(у)
при любых х е X, у е У.
Несложно доказывается, что свойство совершенности шифра
(X,K,y,f), у которого |Х|=|К|=|У|, равносильно двум условиям: 1) р(х)=~~~ >
I К |
Хе К; 2) уравнение f(x,x)=y однозначно разрешимо относительно х^К при
любых хеХ и уеУ.
ЗАМЕЧАНИЕ. Заменив в рассуждениях, предваряющих определение совер-
шенных шифров, открытый текст х на ключ х> то есть считая, что противник,
зная криптограмму у, будет пытаться рассчитать вероятности р(х/у) для всех
ХеК мы аналогичным образом придем к классу шифров, обладающих свойст-
вом
р(х/у)=р(х)
при любых %еК, уеУ. Такие шифры, называют (х/у)-совершеннымш
Нетрудно показать, что для таких шифров |Х|=|У|. Шифр, у которого
|Х|=|У| с равновероятным распределением на множестве Х-открытых текстов
является (х/у)-еовершенным.
Одним из примеров совершенных шифров является шифр гаммирова-
ния X=y=K=IL с равновероятным выбором ключа - гаммы. В качестве со-
вершенных шифров выступают следующие шифры простой замены с множе-
ством ключей K=S(I) (S(I) - симметрическая группа подстановок на I) с рав-
новероятным выбором ключа: 1) Х=1 - алфавит текста; 2) X - множесво всех
слов алфавита I длины L, не содержащих одинаковых букв. Примером одно-
90
временно совершенного шифра и (%/у)-совершенного является'шифр гамми-
рования, в котором X=K=y=IL с равновероятными распределениями на X и К.
Возникают вопросы: если есть совершенные шифры, то зачем строить
новые, какие недостатки имеют совершенные шифры? Ответ следующий: ес-
ли шифр совершенный, то он транзитивен (это несложно доказывается). Сле-
довательно, |У|<|К|, откуда вытекает, что у совершенного шифра должна быть
большой «длина ключа»..Действительно, пусть, например, X=IL, Y=IT, K=Ik.
Тогда |Х|<| Y|<|K|, откуда k>L (длина ключа не меньше длины открытого тек-
ста). Чтобы уменьшить объем рассылаемых ключей, и строят другие несо-
вершенные шифры.
Способы представления реализаций шифров. В современном мире,
говоря о реализациях шифров, обычно употребляют термины: шифратор,
шифрсистема, алгоритм шифрования, программа шифрования. Последние два
понятия общеизветны и не требуют объяснений. Первый термин употребляет-
ся для указания собственно устройства, реализующего процесс шифрования и
расшифрования заданного шифра. Термин же шифрсистема используется в
более широком смысле, как обозначение всего устройства, включающего в
себя как устройства, предназначеннные для предварительной обработки шиф-
руемых «текстов», так и ряд других вспомогательных устройств ввода и вы-
вода информации. Термины же криптосхема, шифрующий автомат - явля-
ются специфическими и малоизвестными.
Криптосхема. Для записи законов функционирования шифратора используют
схемное описание, состоящее из прямоугольников с надписями узлов и бло-
ков шифратора. При заданном их математическом описании функционирова-
ния, описание функционирования шифратора задается указанием связей меж-
ду отдельными блоками и узлами. Совокупность блоков с заданными связями
и описанием функционирования каждого блока обычно и называют криптбс-
хемой шифратора. В таких описаниях преследуют цель указать принцип
функционирования шифратора и обычно не указывают конкретные, числен-
ные значения всех параметров узлов и блоков.
В таком виде может быть представлена принципиальная криптосхема
поточного шифратора.
91
Здесь управляющий блок предназначен для выработки управляющей
последовательности шифрующим блоком. Шифрующий блок предназначен
для зашифрования открытого текста с помощью управляющей последова-
тельности.
Ключом такой криптосхемы, например, может являться заполнение памятей
узлов и блоков, составляющих управляющий блок, а в ряде случаев, и закон
их функционирования.
Для описания функционирования дискретных устройств, реализую-
щих отдельные блоки шифратора, зачастую применяют язык теории авто-
матов.
Основные понятия теории автоматов.
Определение. Три конечных множества I,S,0 и два семейства ото-
бражений (8i)iei, (Pi)i6i, 5i:S->S, Pi: S—>0, iel называют конечным автоматом
(конечным автоматом Мили) и обозначают через A=(I,S,0,(5i)rei,(Pi)iSr).
Полагают, что автомат моделирует работу многих дискретных уст-
ройств, при этом множество I называют входным алфавитом автомата, S -
множеством состояний, О - выходным алфавитом автомата функции (5j)iSi,
(Pi)iei называют, соответственно, частичными функциями переходов и выхо-
дов автомата. Автомат А функционирует в дискретном времени te {1,2,...}.
При входной последовательности 3=i 1 ,i2,..., ij g I и начальном состоянии
s=S|sS автомат вырабатывает последовательность состояний Am(s,3)=S|,S2,...
(последовательно находится в; состояниях sbS2,...) и выходную последова-
тельность A(s,3)=yi,y2,.... Правила получения этих последовательностей та-
ковы:
s2=5iisi - образ s, при отображении 5л, Sj+i^SySj, je {1,2,...},
yi=PiiSi - образ si при отображении pib yj=PySj, j g {1,2,...},
В случае Pi=Pr для любых i,i' gI автомат А называют автоматом Му-
ра.
Автономным конечным автоматом называют двойку конечных мно-
жеств S,0 и два отображения: 6: S—>S и X:S—>0 и обозначают через
A=(S,O,8,X). В ряде случаев используют и другое определение: Автомат
A=(I,S,O, (8i)iei, (Pi)iei) называют автономным в случае, когда |1|=1.
Для автомата определяют его граф переходов: совокупность точек на
плоскости, обозначенных состояниями автомата, некоторые из которых со-
единены ориентированным ребром (стрелкой —>). На ребре, соединяющем
состояние s с s', ставятся две пометки: i/y, где i и у определены из соотноше-
ний 8jS=s', PiS=y. Переход из состояния в состояние по стрелкам называется
путем, в графе переходов автомата. Путь определяет последовательность со-
/
X \
92
стояний Am(s,3) и выходную последовательность A(s,3), отвечающую вход-
ной последовательности 3 автомата А и его начальному состоянию Si=seS.
Отметим, что задание семейства отображений (8j)iei, ((Pi)iei) равно-
сильно заданию отображения 5: Ix'S->S, 5(i,s)=8j(s) (аналогично, IxS-»O,
P(i,s)=Pi(s)). В связи с чем чаще автомат А определяют тремя множествами
I,S,O и двумя отображениями 8, 0: A=(I,S,0,8, Р).
Обозначим через I* множество всех слов конечной длины в алфавите
I. Автомат А с начальным состоянием s задает отображение (pA,s I*—>0*,
именно, для 3gI*
(Pa,s(3)=A(s,3).
Такие отображения называются конечно-автоматными или просто автомат-
ными.
При фиксированных множествах I, S, О автомат задается отображе-
ниями 8, р. При моделировани функционирования шифратора, или его крип-
тосхемы конечным автоматом начальные состояния автомата моделируют
в так называемые части ключа, иногда и весь ключ, заключенный в память
криптосхемы, часть же ключа «логики криптосхемы», иногда и весь ключ,
моделируется выбором функций 8, Р автомата. При этом полагают, что вход-
ными последовательностями автомата являются открытые тексты, подлежа- .
щир шифрованию, а выходные последовательности автомата трактуют как
шифрованные тексты, соответствующие открытым текстам и ключам.
Шифрующий автомат. Понятие шифрующего автомата трактуется
неоднозначно.
Первое определение состоит в том, что шифрующий автомат есть
множество автоматов A(r), reR с начальными состояниями s(r)eS(r). Такое
определение равносильно тому, что под шифрующим автоматом понимают
некоторое множество автоматных отображений множества открытых тек-
стов в шифрованные.
Второе определение шифрующего автомата состоит в том, что автомат
A=(I,S,O,(8i)i€i,(pi)iei) является шифрующим автоматом, если его автомат-
ные отображения <pA,s I*—>О* , являются инъективными отображениями.
Такое определение согласуется с определением шифра (X,K,Y,f) в том смысле
что в качестве отображений fx берутся автоматные инъективные отображения.
Для большей общности, иногда второе определение обобщают. Имен-
но, рассматривают автоматы, у которых 1=Гх@, где Г - алфавит внешней
• части ключа, часть ключа: y=yl,y2,...yL, yjeF; @ - алфавит открытого текста.
При фиксированы^ частях ключа уеГь и sgS требуют инъективность отобра-
жения @L в OL, то есть при входных различных последовательностях вида
93
3==(al,yl),(a2,y2),...(aL,yL) и 3'= (a'l,yl), (a'2,y2),...(a'L,yL) требуют, чтобы
A(s,3)*A(s,3') при любом натуральном L,
Выясним условия, при которых автомат A=(I,S,O,5,P) является шиф-
рующим автоматом, то есть автоматные отображения <pA>s, sgS явля-
ются инъективными отображениями. Для отображения Р: IxS—>0 обозначим
через ps отображение I в О: ps(i)=p(i,s). Через Ss обозначим множество состоя-
ний автомата А, содержащее s и все состояния s' gS, достижимые из s в графе
переходов автомата А, то есть для которых есть пути из s в s'. На множестве
Ss определен подавтомат As=(I,Ss,0,8,P) автомата А (здесь ограничения ото-
бражений 5, Р обозначены теми же буквами). С использованием введенных
определений несложно доказывается
УТВЕРЖДЕНИЕ. Автоматное отображение <pA,s , sgS являет-
ся инъективным тогда и только тогда, если при каждом состоянии s' из Ss
отображение р< инъективно.
В третьем определении под шифрующим автоматом понимают авто-
мат, моделирующий устройство шифрования, либо некоторого его блока. В
таком понимании устройство шифрования моделируют автоматом
A=(I,S,0,(5i)i€l,(pi)iei), у которого отображения (6j)iei S в S являются биекциями
S в S. Такие автоматы обычно называют перестановочными. Часто гам-
мообразующее устройство шифратора называют шифрующим автоматом.
Эквивалентность ключей шифрующего автомата.
Определение. Состояния s,s' автомата А называются неотличимыми,
если
A(s,3)=A(s',3)
при любом входном слове 3gI*.
Автомат А называется приведенным, если он не имеет различных
неотличимых состояний. I
Ключи s,s' шифрующего автомата А называются эквивалентны-
ми, если s,s' - неотличимые состояния автомата А.
Степенью различимости автомата А называется минимальное число R, при
котором для любых s, s' gS из равенств A(s,3)=A(s',3) для всех 3gIrследуют
равенства A(s,3')=A(s',3') для всех 3' gIRt!
Диаметром автомата А называют минимальное число D, при котором
для любого sgS каждое достижимое из s в графе перехоов автомата А состоя-
ние s', s Ф s', достижимо путем длины, не превосходящей D.
94
Параграф 1.4
Средства защиты информации в переходный пери-
од от древности к современности
Современные алгоритмы шифрования возникли на базе развития и
совершенствования простейших шифров, путем устранения имеющихся у
последних криптографических слабостей. Большинство современных шифров
можно рассматривать как усиление и модернизацию известных с древних
времен шифров простой замены, перестановки, о которых мы говорили в пре-
дыдущих параграфах этой главы.
Выше упоминалось о возможности дешифрования шифра простой за-
мены в случае, если достаточно велико соотношение между объемом мате-
риала и размером алфавита открытого и шифрованного текстов. Однако шифр
простой замены сложно вскрыть, если это соотношение мало. Отсюда и выте-
кает подход к усилению шифра: разрабатывают шифры, для которых это со-
отношение чрезвычайно мало. Делают это двумя способами: увеличивают ал-
фавит либо максимально уменьшают объем сообщения, шифруемого с помо-
щью одной и той же замены.
Первый путь (увеличения алфавита) реализован в шифрах многознач-
ной замены, в кодах и современных блочных шифрах.
По второму пути (уменьшение числа знаков, шифруемых по одной замене)
пошли при создании поточных шифров замены.
Шифры многозначной замены (/Про/).
Шифр многозначной замены задается таблицей,
А Б В Г д Е Ж ...
al 61 в1 г1 д1 el ж1
а2 62 в2 ж2
аЗ
...
в которой каждой букве отвечает несколько символов шифртекста. Алфавит
шифртекста по смыслу дела больше алфавита открытого текста. Шифроваль-
щик, зашифровывая открытый текст, должен выбрать для каждой буквы одно
Из обозначений - например, А зашифровывается в al, или в а2, и т. д. Данный
шифр при грамотном использовании может значительно выровнять диаграм-
95
му встречаемости символов в шифртексте. Какие-то остатки вероятностно-
статистических особенностей открытого текста в шифртекст все-таки прони-
кают. В шифртексте встречаются запретные биграммы. Например, за шиф-
робозначением символа «пробел» не может встретиться шифробозначение
символа Ъ или Ь. Далее, трудно проследить за тем, чтобы шифровальщик
равномерно использовал различные обозначения для наиболее частых букв.
Скорее всего, он будет использовать одну первую строчку и дело сведется к
чуть-чуть усложненному шифру простой замены.
Коды (/Про/). Идея увеличения алфавита открытого текста реализова-
на в кодах. Код представляет собой два словаря. Первый словарь предназна-
чен для зашифрования, а второй - для расшифрования. В словаре для зашиф-
рования в алфавитном порядке написаны символы алфавита открытого текс-
та: отдельные буквы, слова, целые предложения, и для каждого символа ука-
зано его кодообозначение. При шифровании шифровальщик каждый символ
(или слово, предложение) заменяет с помощью первого словаря на кодообо-
значение. Это преобразование неоднозначно. Слово можно заменить по бук-
вам или попытаться подобрать кодообозначение для целого слова или фразы.
При расшифровании используется второй слдварь, в котором в алфавитном
порядке записаны кодообозначения, и расшифрование сводится к замене их
на символы открытого текста. Словарь может состоять из тысяч, десятков ты-
сяч слов. Дешифровать код достаточно сложно. Для этого необходимо на-
брать достаточно много материала. Коды находят определенное применение.
Вы слышали, наверно, о военно-морских кодах, дипломатических кодах и т. п.
Недостаток этой системы шифрования - каждой код - это две книги, их надо
напечатать без ошибок, разослать всем участникам закрытой связи. Если одна
такая книга попадет злоумышленнику, то код надо срочно менять, а это хло-
потно, система достаточно инерционная.
Блочные шифры (/Про/). Промежуточным вариантом между простой
заменой и кодом является блочный шифр. В нем текст делится на блоки и
проводится простая замена блоков. Когда длина блока достаточно велика,
таблица замены становится необозримой и саму замену приходится задавать
не таблицей, а некоторым алгоритмом преобразования.
Блочный шифр «Два квадрата» (/Про/). Блочные шифры, в которых
заменялись пары букв, применяли во время второй мировой войны немцы в
низовых линиях связи. Они основаны на блочном шифре Плейфейра (у него
был один квадрат). При шифровании открытый текст разбивался на блоки по
две буквы
КР ИП ТО ГР АФ ИЯ
Ключом являлись два квадрата, в которых записывался алфавит в произволь-
ном порядке.
96
ы Щ э ю ь
м б г д е
в ж и з' к
л с н О п
а т р. . У.. ф.
X ц ч ш я
Ц ю э ч ь
е м н О ш
ж л к п' щ
б в а г д
р 3 и ф я
с т у X ы
Первая буква выбиралась в левом квадрате, вторая - в правом. Мысленно
строился прямоугольник и в шифртекст включались буквы из незанятых его
углов. Так в примере е на место К ставилась буква из соответствующего неза-
нятого угла прямоугольника второго квадрата Ж, а вместо Р ставилась Ф. Ес-
ли буквы оказывались в одной строке, то буква заменялась на букву той же
позиции, но из другого квадрата. Так в примере вместо И ставилась буква
этого же столбца второго квадрата К, а вместо. П - соответствующая буква
первого квадрата 3. Таким образом, слово криптография после зашифрования
имело бы вид
ЖФКЗФБЕРРУЩР
Шифры типа! «Два квадрата» советским криптографам в годы войны удава-
лось дешифровывать, но это требовало значительных усилий и опыта.
Преимуществом данных шифров перед кодами были.достаточная простота и
быстрота зашифрования и расшифрования, отсутствие потребности в слова-
рях, простота в смене ключевых квадратов. Практически шифр «Два квадра-
та» является забытым шифром англичанина Чарльза Уинстона (1854 г.), кото-
рый назывался «двойным квадратом».
Блочные шифры (Продолжение).
Блочные шифры - это шифры простой замены с большей мощностью
алфавита «открытого текста». Обычно к-граммы текста объявляются симво-
лами нового алфавита «открытого текста».
Многие блочные шифры используют в своем построении так называе-
мую идею X. Фейстеля, состоящую в реализации многих «раундов» шифрова-
ния, каждый из которых реализуется криптосхемой
97
идея которой заключается в том, что исходный блок длины 2k двоичной ин-
формации Be(F2)2k делится на два подблока L',RG(F2)k одинаковой длины,
(L,R)=B, которые преобразуются по правилу
(L,R)->(R, L+F(K,R)),
где Ke(F2)k - ключ раунда шифрования, + покомпонентное сложение векто-
ров по модулю 2, a F - произвольное фиксированное отображение (F2)2k в
(F2)k. Многие блочные шифры построены на этом принципе и отличаются
длиной к блоков, функцией F, числом раундов шифрования.
Блочный шифр DES (/Про/).
Блочный шифр DES (Data Encryption Standart) относится к числу наи-
более популярных. С точностью до перенумерации координат блоков откры-
того и шифрованного текста и ключа алгоритм DES имеет следующий вид.
Открытый текст представляется в виде последовательности бит-нулей и еди-
ниц. В вычислительной машине информация хранится в виде 8-мерных дво-
ичных векторов - байт и поэтому представление их в битовом виде не встре-
чает трудностей. В процессе шифрования открытый текст разбивается на
блоки по 64 бит и каждый блок заменяется по простой замене, т. е. если от-
крытый текст имеет вид: 0i,02,....,0t>.где 0t - 64-мерные вектора, то шифро-
ванный текст имеет вид: Zi Z2, ...., Zt> где Zt - тоже 64-мерные вектора, яв-
ляющиеся значениями взаимнооднозначной функции от открытого текста при
фиксированном ключе k, Z=Dk(Ot). Ключ шифратора DES - это последова-
тельность из 56 бит.
4 Зак. 5
98
Преобразование блока открытого текста в блок шифрованного текста
состоит из нескольких этапов. Прежде всего из ключа в 56 бит составляется
ключевая таблица из 16 строк по 48 бита в каждой строке. Эту таблицу мож-
но выписать в явном виде. Однако ее удобно получить с помощью следующе-
го алгоритма. Ключ из 56 бит разбивается на два блока по 28 бит (C(0),D(0)).
Далее строятся блоки (C(l), D(l)),....., (С(16), D(16)).
Каждый следующий блок получается циклическим сдвигом из предыдущего.
Сдвиг осуществляется на 1 или 2 шага влево. Так, если заполнение
(C(0),D(0)) обозначим через
С] С2, ...,С28 d],d2,...,d28 , '
то заполнение (C(1),D(1)) будет получено сдвигом на 1 влево
Т(С1С2, ...,С28)=(С2> Сз, .,C28,C1), T(did2>.......Д28)=№ йз,.....>d28,di). *
Таблица сдвигов является параметром алгоритма и имеет вид
1,1,2,2,2,2,2,2,1,2,2,2,2,2,2,1. j
Строка ключа K(i) получается из (C(i),D(i)) выбором некоторых 48 коорди- j
нат. Таблица выбора задана, она одна и та же для всех итераций. Таким обра- •
99
зом, на первом этапе из одного ключа в 56 бита получается 16 ключей К.1,
К2,..., К16 по 48 бит каждый. Эти ключи помещаются в ключевую таблицу К.
Замена вектора О из 64 битов открытого текста на вектор Z - 64 бита шифро-
ванного текста получается путем более простых замен.
Z=F(K16) F(K15)...F(K1) О.
.Отображение F О в Z удобно описать с помощью блок-схемы.
В схеме присутствуют накопители - фактически регистры, состоящие
из ячеек памяти, в них хранятся бинарные вектора. На регистре указана его
длина - размерность векторов.
Символом ® обозначим сумматор. На вход сумматора поступает два двоич-
ных вектора, а на выходе получается координатная сумма по модулю 2 этих
векторов. Суммой векторов 010010, 110100 будет вектор 100110.
В схеме DES есть три преобразования: Е, S и Р. Преобразование Е
расширяет 32-мерный вектор в 48-мерный. Оно задается некоторой таблицей.
4*
100
Фактически символы из R2 переписываются в R3, некоторые из них по 2
раза.
Преобразования SI, S2, ....,S8 (так называемые S-блоки) преобразуют 6-
битовые вектора в 4-х битовые вектора. Эти преобразования заданы 8 табли-
цами. В каждой таблице для всех 6-мерных 64 векторов указаны их образы 4-
мерные вектора - их образы при преобразовании S блока.
Обращаем внимание, что преобразование S не просто перестановка и
выборка координат, а достаточно произвольная замена. Так в S1 вектор
0=(0,0,0,0,0,0) переходит в вектор 14=(1, 1, 1,0), вектор 1=(0, 0, 0, 0, 0, 1) в
вектор 4=(0, 1,0,0), а 2=(0, 0, 0, 0, 1, 0) в 13=(1,0, 1, Г). То есть отображение
S - нелинейное.
Преобразование Р - это обычная перестановка координат 32-мерного
вектора. Оно тоже задано таблицей.
Таким образом, преобразование F(Ki) функционирует следующим об-
разом. Из накопителя R2 снимается заполнение, оно проходит через преобра-
зование Е, полученный в R3 48-мерный вектор суммируется с Ki. Результат
записывается в R4. Заполнение R4 проходит через преобразования S блоков,
перестановку Р, складывается с содержимым накопителя R1. Окончательный
результат преобразований записывается в R2, а предыдущее заполнение R2
выталкивается в первый регистр R1.
Далее процедура повторяется 16 раз, но каждый раз на вход поступает
новая ключевая последовательность.
Зашифрование блока О=(О1,О2) открытого текста можно описать
уравнениями шифрования
Z=(Z1,Z2)=(H17,HI6),
Ht+1=Ht_, ®F(Kt)H„
H0=Ol,Hi=O2.
Процедура расшифрования описывается уравнениямй
0=(01,02)=(Ho,H!),
Ht.I=H,+I®F(Kt)Ht,
Hi7=Zl,HI6=Z2.
Более удачное и подробное описание шифратора DES можно найти в книге
Ю.В. Романца, П.А. Тимофеева, В.Ф. Шаньгина «Защита информации в ком-
пьютерных системах и сетях. «Радио и связь», М., 1999 г.
Блочный шифр ГОСТ 28147 89 (/Про/). Российский аналог американско-
го стандарта шифрования DES - блочный шифр ГОСТ 2814789 имеет похо-
жую блок-схему
101
Ключом алгоритма является таблица К=(К1, К2,...,К8) из восьми 32-
мерных двоичных векторов. Основными узлами схемы являются накопители
(регистры Rl - R5) длины. 32, сумматор по модулю 232, сумматор по модулю 2
(такой же как в DES), S - блоки, подстановка сдвига Т. Подстановка Т в схеме
ГОСТ осуществляет сдвиг заполнения регистра по циклу.
Сумматор по модулю 232 рассматривает поступающие на его вход 32-х
битовое заполнение регистра R2 и 32 знака ключевой таблицы как два целых
числа (вектор трактуется как двоичная запись числа). С выхода сумматора
снимается 32-х разрядный вектор - двоичная запись суммы по модулю 232 ,
поступивших на вход сумматора чисел. Восемь преобразований S заменяют
поступающие на вход полубайты (4-х мерные вектора) йа другие полубайты
по заданным таблицам..
Процедура шифрования в ГОСТ осуществляется следующим образом.
Открытый текст разбивается на блоки по 64 бит. Каждый блок открытого тек-
ста О=(01,02) шифруется по Шифру простой замены
Z=(Z1,Z2)=T(K,O),
102
где преобразование Г задается рекуррентным соотношением
Ht+I=HM ® G(K|(t),Ht), t=l, 2,......................,32,
Н0=О1, Н,=О2,
© - покоординатное суммирование 32-мерных векторов в (F2)32.
(Z1,Z2)=(H33,H32),
l(t)=l, 2,8, 1, 2,8, 1, 2, ...,8, 8, 7,..., 1
G - преобразование (F2)32 —> (F2)32.
На вход преобразования в каждой итерации подается свой 32-мерный
ключевой вектор. Первые 24 цикла подаются в прямой последовательности,
а последние 8 циклов - в обратной. При преобразованиях G вектора
v=(vo,...,v3i) рассматриваются либо как последовательности из нулей и единиц,
либо как двоичная запись целого числа (при суммировании по модулю 232),
v=vo+2vi+22v2+ 2m''v3i.
Преобразование G (F2)32 -> (F2)32 имеет вид w=G(Kb и), где
w=TdS ((K|+u) mod 232), S - некоторое нелинейное преобразование V32 —>
V32, при этом преобразовании 32-мерный вектор и представляется в виде
восьми 4-х мерных векторов u=(ub ...., u8)
S(ui,..,u8)=(Si(ui),.., S8(u8))
Si : (F2)4 —> (F2)4 - задается таблицей из 24=16 значений,
Ts - подстановочная матрица типа сдвига
T(Uo,...,U3i)=(us(m0d32), Us+I(mod32),., U3i+S(mod 32))-
При каждой итерации преобразования G, как уже отмечалось выше, на
вход узла преобразования усложнения поступает 32 бита ключа. Поступают
они в следующем порядке:
в 1-ой итерации - 1-ая строка,
во 2-ой итерации - 2 строка,
в 8-ой итерации - 8 строка,
в 9-ой - 1 строка,
в 24-ой - 8 строка;
в 25-ой - 8 строка,
в 32-ой - 1 строка.
То есть строки 3 раза проходятся в прямом направлении (24 итерации)
и 1 раз - в обратном направлении (8 итераций). Результат этого преобразова-
ния записывается в регистры R1 и R2 и является шифртекстом.
Сравнивая схемы DES и ГОСТ, следует заметить, что они очень похо-
жи, но есть и отличия:
103
- в ГОСТе проводится в 2 раза большее число итераций, определяющих крип-
тографическую сложность результирующих преобразований;
- в ГОСТе существенно больше ключей (25б=6.41016 вариантов ключевых ус-
тановок в DES и 2256= 6.4-1076 ключевых установок в ГОСТ).
Обе схемы не являются теоретически стойкими. При достаточном ко-
личестве шифрованного текста тотальным методом, т. е. перебором всех клю-
чей, проведением пробного расшифрования и отсева по статистическим кри-
териям ложных вариантов получаемого открытого текста можно найти ключ
для обоих шифров.
Поточные шифры (/Про/).
Типичной областью применения средств криптографической защиты
информации является защита каналов связи. Канал закрытой связи между
двумя корреспондентами описывается следующей блок-схемой.
Открытый „ Шифра-
текст тор
Отправитель
Шифртеку_______Шифртекст^ Шифра-
тор
Канал связи -----—
Получатель
Защита информации в канале связи обеспечивается наличием шиф-
рующих устройств (шифраторов), преобразующих информацию. Особенно-
стью данного канала связи является необходимость последовательного закры-
тия потока сигналов, поступающих на шифратор. Конечно, можно и в этом
случае формировать из поступающих на вход символов блоки нужной длины
и применять для закрытия информации один из описанных выше блочных
шифров. Но более естественным представляется посимвольное шифрование
информации. Эти задачи решают так называемые поточные шифры.
Описание поточных современных криптосхем можно найти в пособии:
А.А. Варфоломеев, А.Е. Жуков, М.Ф. Пудовкина «Поточные криптосхемы.
Основные свойства и методы анализа стойкости. М., 2000, 243 с., а также в
гуляющей по Интернету одноименной книге.
Обычно поточный шифр удобно представить в виде трех блоков
104
Первый блок вырабатывает некоторую исходную последовательность, ко-
торая поступает на блок усложнения. Иногда эта последовательность выдает-
ся в канал связи. Обычно это делается в целях синхронизации работы аппара-
туры на передаче и приеме. Узел усложнения преобразует исходную последо-
вательность и в преобразованном виде передает ее на блок наложения шифра.
На вход блока наложения шифра поступает также открытый текст, который
преобразуется под управлением последовательности, идущей с блока услож-
нения, и в преобразованном виде выдается в канал связи. Иногда в схеме при-
сутствуют обратные связи, например, шифрованный текст может поступать не
только в линию, но и на узел выработки исходной последовательности.
Обычно первые два, а иногда и все три блока имеют внутреннюю память.
То, что получается на выходе, зависит не только от входа, но и от предысто-
рии, от внутреннего состояния.
Для математического описания работы узлов и блоков шифратора обычно
используется терминология теории автоматов, т. е. шифратор - это конечный
автомат.
Также как это было для блочных шифров, для поточных шифров можно
предложить массу способов конкретной реализации шифра. Функционирова-
ние одного или нескольких блоков криптосхемы обычно зависит от вводимых
ключей - секретных параметров, вводимых в устройство перед началом шиф-
рования. В общем случае можно сказать, что внутреннее состояние, функция
перехода и функция выхода шифрующего автомата зависят от ключа.
105
Иногда в схеме присутствуют и некоторые несекретные параметры,
называемые маркантами или синхропосылками. Делается это с той целью,
чтобы усложнить задачу дешифрования. Если бы функционирование схемы
зависело только от ключа, то все промежуточные последовательности (при
отсутствии обратных связей) при, скажем, двукратном использовании ключа
просто бы совпадали. Это - потенциальная криптографическая слабость. Тер-
мин «синхропосылка» обычно применяется для электронных шифраторов, а
«маркант» - для дисковых шифраторов, о которых пойдет речь ниже.
Дисковые шифраторы (/Про/).
Поточные шифры рассматривают как один из подходов к усилению
шифра простой замены. Известно, что шифр простой замены теряет стой-
кость, если объем шифрованного текста больше алфавита текста, подлежаще-
го шифрованию. Блочные шифры также рассматривают как один из подходов
к усилению шифра простой замены путем увеличения алфавита замены. Но
возможен и ещё один подход - сокращение объема открытого текста шиф-
руемого по простой замене. Наприм.ер, сокращают длину текста, шифруемого
с помощью одной простой замены, до одного знака. То есть применяют шифр
простой замены, для каждой очередной буквы. Например, зададим последова-
тельность подстановок
Pi, Р2,., Р„....
и шифрование открытого текста
ii,i2,... it, •••••••
будем проводить по правилу
У1 = Pi(ii),..,yt = Pt(it),.
В этом случае последовательность подстановок должна быть неиз-
вестной противнику. Для неограниченного по длине открытого текста ее
нельзя задать просто таблицей переходов, поэтому ее задают алгоритмом
шифрования. Именно эта идея реализована в дисковых шифраторах. Класси-
ческим примером является дисковый шифратор «Энигма».
«Энигма» (/Про/) в переводе означает «Загадка». Шифратор изобре-
тен в 1917 г. Эдваром Хеберном. Промышленная версия создана чуть позже
берлинским инженером Артуром Кирхом (некоторые называют его Артуром
Шербиусом). Активно шифратор «Энигма» и его модификации использова-
лись в годы второй мировой войны.
«Энигма» вначале представляла собой 4 вращающихся на одной оси барабана
- диска.
106
На каждой стороне диска по окружности располагалось 25 электриче-
ских контактов, столько же, сколько букв в алфавите. Контакты с обеих сто-
рон соединялись внутри диска достаточно случайным образом 25 проводами,
формировавшими замену символов. Диски складывались вместе и их контак-
ты, касаясь друг друга, обеспечивали прохождение электрических импульсов
сквозь весь пакет дисков на регистрирующее устройство. На боковой поверх-
ности дисков был нанесен алфавит. Перед началом работы диски поворачива-
лись так, чтобы установилось кодовое слово. При нажатии клавиши и кодиро-
вании очередного символа левый барабан поворачивался на один шаг. После
того как диск делал полный оборот, на один шаг поворачивался следующий
барабан - как в счетчике электроэнергии.
В процессе шифрования на один из контактов левого диска поступал
электрический импульс. Так как барабаны соприкасались контактами, то
электрический импульс попадал на выход, проходя через четыре диска и пре-
терпевая четыре простые замены. Исполняющее устройство (пишущая ма-
шинка или перфоратор) фиксировало знак шифрованного текста в соответст-
вии с тем, на какой контакт выходного диска поступал электрический им-
пульс. Поскольку в каждый такт шифрования сдвигался на один шаг хотя бы
один диск, подстановка - простая замена, по которой осуществлялось шифро-
вание, менялась для каждого символа открытого текста. Ключом шифратора,
который сменялся каждый сеанс, являлся набор начальных угловых положе-
ний дисков. Долговременным ключом, он менялся очень редко, служили ком-
мутации дисков - соединения проводов внутри дисков. Для затруднения рас-
шифрования диски день ото дня переставлялись местами или менялись, т.е. 4
диска выбирались из комплекта, состоящего из 10-20 дисков. Для того чтобы
не менять начальные установки на каждый сеанс связи, в некоторых сетях за-
крытой связ^ использовался маркант. Делалось это следующим образом:
шифровальщик выбирал какую-то случайную начальную установку дисков.
Далее шифровал на нем 4 заранее оговоренные буквы, например, АААА. По-
лученный шифрованный текст он не пересылал получателю, а использовал в
107
качестве начальной установки дисков прй шифровании. В начале шифрован-
ного текста проставлялся маркант - выбранные шифровальщиком случайные
начальные установки.
Блок-схемы поточного шифра для дискового шифратора имеет доста-
точно простой вид. Генератор исходной последовательности в данном слу-
чае — это обычный счетчик. С него снимаются угловые положения, в которые
надо установить диски для зашифрования очередного знака открытого текста.
Узел усложнения фактически отсутствует, а узел наложения шифра состоит
из четырех дисков, управляемых последовательностями, снимаемыми с блока
исходной последовательности. Уравнения шифрования, связывающие знаки
открытого и шифрованного текста, имеют вид
Zt=P1(t)P2([t/n]))P3([t/n2])P4([t/n3])0t,
где Pj(t) - подстановка, которая реализуется при повороте i-ro диска на t ша-
гов;
п - число символов в алфавите открытого текста;
[х] - целая часть х.
Очевидно, что Pj(t + n)=Pj(t), если п - алфавит открытого текста или, что
то же самое, число угловых положений диска.
Интересно вспомнить, что информацию, закрытую с помощью шифратора
«Энигма», в годы второй мировой войны удавалось дешифровать. Но более
сложные дисковые шифраторы - это достаточно надежные системы защиты.
Другое дело, что они сейчас устарели. Электромеханические системы не
очень надежны, довольно громоздки и, главное, весьма малоскоростные. На
смену им пришли электронные шифраторы - фактически специализирован-
ные ЭВМ.
Шифратор Хагелин.
В качестве иллюстрации механических машин мы обсудим машину С-
36 известного разработчика криптографических машин Бориса Хагелина. Она
известна также как М-209 Converter и использовалась в армии США еще в
начале пятидесятых годов. При описании шифратора Хагелин мы используем
следующие работы.
1. Саломаа А. Криптография с открытым ключом. Пер. с англ.
А.А. Болотова и И.А. Вихлянцева под редакцией А.Е. Андреева и А.А. Боло-
това. М.: Мир, 1996.
2. Barker, W.G. Cryptanalysis of the Hagelin Cryptograph, Aegean
Park Press, 1977.
3. Beker, Henry and Piper, Fred. Cipher Systems. The Protection of
Communications. Northwood Books, London. 1982.
108
4. D. Kahn, The Codebreakers: The Story of Secret Writing, New
York: Macmillan Publishing Co., 1967.
5. Technical Manual for Converter M-209. US War Department, 1942
(http://www.maritime.org/csp 1500.htm).
Hagelin M-209
Словесное описание механического устройства является крайне тяже-
лым, когда не доступен образец этого устройства. Маловероятно, что читатель
имеет под рукой машину С-36, поэтому мы опишем функционирование дан-
ного устройства в абстрактной форме. Машина изображена ниже.
Рейтеры Барабан с пронумерованными
подвижными комбинационными
линейками
Шестерня, продвигаемая
выдвинутыми комбинационными
линейками
Bt=
D
Нерабочие
и рабочие
штифты
Скошенная верхняя часть
промежуточного рычага
гаммообразующиего колеса
Воспроизводящий диск,
с которого считываются
получающиеся в результате
буквы
Гаммообразующее
колесо
Индикаторный диск,
на котором набираются
сводимые буквы
Комбинационная линейка,
сдвинутая влево и ставшая
зубцом шестерни
с переменным
числом зубцов
Кинематическая схема М-209
109
Ее основными компонентами являются шесть дисков, обычно назы-
ваемых роторами, и цилиндр, называемый клеткой.
Рассмотрим 6 х 27-матрицу М, элементами которой являются 0 и 1.
Потребуем также, чтобы в каждом из 27 столбцов матрицы М было не более
двух единиц. Такие матрицы называются кулачковыми матрицами. Матрица
000100001010001110000000001
100010001001100010010010100
000000000000000000000000000
М= 001100010100001001000111111
001010000001000100100000000
000000010010010000010001000
является примером кулачковой матрицы.
Очевидно, что если v является 6-разрядной строкой из нулей и единиц,
то vM (произведение вектора v на матрицу М) является 27-разрядной строкой
с элементами из множества {0,1,2}. К примеру, если v = (1, 0,1,1, 0, 0), то
vM = (0, 0, 1, 2, 0, 0, 0, 1, 1, 1,1, 0, 0, 0, 2, 1, 1, 1, 0, 0, 0, 1, 1, 1,1, 1,2).
(Здесь мы использовали матрицу М, написанную выше). Число эле-
ментов вектора vM, отличных от нуля, называется числом выталкиваний зуб-
цов v относительно М. В нашем примере оно равно 16. Обычно, данное число
является натуральным числом от 0 до 27
Пошаговая матрица конструируется следующим образом. Построим 6
последовательностей чисел из множества {0,1}. Эти последовательности
имеют соответствующие длины 17, 19, 21, 23,25, 26 и начинаются с одной
позиции.
К примеру,
0 1 1 000 1 0000000 1 1 0
01111100000000 0.0 000
001000001000000000000
00000000000100100010001
1010000000000000000000000
11000000000000100010000001
есть ступенчатая матрица. В отличие от кулачковой матрицы, для ступенчатой
матрицы нет ограничений на позиции единиц.
Пошаговая матрица генерирует бесконечную последовательность 6-
разрядных (строк) векторов следующим образом. Первые 17 векторов чита-
ются прямо из столбцов. Таким образом,
(0, 0, 0, 0, 1, 1) и (1, 1,0, 0,0, 1)
являются первыми двумя векторами, порожденными с помощью написанной
выше ступенчатой матрицы. Когда некоторая строка заканчивается, она стар-
тует с начала. Таким образом, векторами с 17-го по 47-й являются:
по
(О, О, О, О, О, О)
(0,1,0,0, 0,0)
(0,1,0,0, 0,0)
(О, 0, 0,0, 0, 0)
(1,0, 0,0,0, 0)
(1,0, О, 0, 0,0)
(1, 1,0, 0, 0, 1)
(О, 0,1,0, 0, 1)
(О, 0, 0, 0, 0, 0)
(О, 1, 0, 0, 0, 0)
(О, 0, 0,0,1, 1)
(О, 0, 1, 0, 0, 0)
(О, 0, 0, 0, 0, 0)
(О, 0, 0, 0, 0, 0)
(О, 1,0, 1,0, 0)
(О, 0, 0, 1, 0, 0)
(1,0,0, 1,0, 1)
(О, 1,0, 1,0, 0)
(О, 0, 0, 0, 0, 1)
(О, 0, 0, 0, 0, 0)
(О, О, 0, 1,0,0)
(О, 0,0, 1,0, 0)
(0,1, О, 0, 0, 0)
(О, 0, 0, 0, 0, 0)
(1,0,0,0, 0, 0)
(1, 1, 1,0, 0, 0)
(О, 0, 0, О, 1, 1)
(1,0, 0, 0, 0, 0)
(1,0, 0, 0, 0, 0)
(1,0, 0, 0, 0, 0)
(О, 1, 0, 0, 0, 0)
Имея определенные кулачковую и ступенчатую матрицы, мы те-
перь можем сказать, как получается шифртекст. Для букв используют число-
вые коды: А получает номер О, В получает номер 1 и т. д. Z получает номер
25. Сложение и вычитание чисел будет вестись по модулю 26.
' Обозначим через а i-ую букву исходного сообщения, а через h —
число выталкивании зубцов i-ro вектора, порожденного ступенчатой матри-
цей относительно кулачковой матрицы. Тогда а переводится в букву крипто-
текста
y=h-a-l.
Для примера рассмотрим исходное сообщение
GOVERNMENTOFTHEPEOPLEBYTHEPEOPLEANDFORTHEPEOPLE
для кулачковой и ступенчатой матриц, заданных выше. Числовое кодирование
данного сообщения будет следующим. (Мы используем его только для ясно-
сти).
6, 14,21,4,17, 13, 12, 4, 13, 19, 14, 5,19, 7,4, 15,4, 14,15, 11,4, 1,24,
19, 7,4, 15,4, 14, 15, 11,4, 0, 13, 3, 5, 14, 17, 19, 7, 4, 15,4, 14, 15, 11,4.
Длина сообщения равна 47. Вычисляется число выталкивании зубцов
для первых 47 векторов, Порожденных ступенчатой матрицей. Это делается
просто, так как первые 17 векторов можно увидеть непосредственно из этой
матрицы, а остальные уже найдены выше. Числа выталкивании зубцов равны:
10, 17, 16, 9, 9, 9, 7, 0, 0, 0, 0, 12, 0, 0, 18, 7, 0, 0, 18, 7, 9, 9, 19, 14, 9, 10,
5, 10, 0,0, 0, 7, 7, 0, 12, 7, 7, 12, 0, 9, 17, 19, 9,9, 5, 12, 0 .
По формуле y=h-a-l вычисляются числовые коды букв шифртекста:
3, 2, 20, 4, 17, 21, 20, 21, 12, 6, 11, 6, 6, 18, 13, 17, 21, 11, 2, 21,
4, 7, 20, 20, 1, 5, 15, 5, 11, 10, 14, 3, 6, 12, 8, 1, 18, 20, 6, 1,12, 3,
4,20, 15, 0, 21.
Поэтому мы получаем следующий шифртекст:
DCUERVUVMGLGGSNRVLCVEHUUBEPFLKODGMIBSUGBMD EUPAV.
Три появления PEOPLE в исходном тексте шифруются как RVLCVE,
PELKOD и DEUPAV, тогда как 3 появления THE шифруются как GSN, UBF и
GBM.
Дадим несколько дополнительных замечаний, касающихся машины С-
36. Роторы и клетки соответствуют ступенчатой и кулачковой матрицам. Лю-
бое переопределение ступенчатой матрицы осуществляется активизацией
подхо’дящих штифтов в роторах. Аналогично, любое переопределение кулач-
ковой матрицы получается позиционированием зубцов.
Ill
Кулачковая и ступенчатая матрицы образуют ключ для шифровки с
помощью С-36. Машина может быть рассмотрена как физическая реализация
криптосистемы, описанной выше: она оперирует с переопределенным ключом
после того, как активизируются подходящие штифты и позиционируются
подходящие зубцы. Уравнение y=h-a-l может быть записано также в виде
a=h-y-l. Это означает, что процесс шифрования и расшифрования иденти-
чен.
Читатель может захотеть найти число всех возможных ключей для
шифровки с помощью С-36. При этом должно быть учтено дополнительное
условие, налагаемое на кулачковую матрицу: не все возможные ключи явля-
ются хорошими с точки зрения обеспечения секретности.
Очевидно, что ступенчатая матрица генерирует векторы периодиче-
ски. Следовательно, шифровка с помощью С-36 может быть рассмотрена как
использование квадрата Бофора с ключевым словом. Но какова длина ключе-
вого слова? Обычно она намного длиннее любого допустимого сообщения.
Следовательно, периодичность в криптотексте может и не появиться.
Действительно, длины строк в ступенчатой матрице попарно взаимно
просты. Это означает, что только после
17-19-21-23-25-26 = 101.405.850
шагов мы можем быть уверены, что опять вернемся в исходное состояние. В
общем случае период не меньше данного числа, которое в действительности
превышает число символоЬ в достаточно объемной энциклопедии. Однако в
конкретных случаях период м.ожет быть короче. К примеру, если ступенчатая
матрица не содержит нулей, то генерируется только вектор (1,1,1,1,1,1), и,
следовательно, период равен 1. Период будет коротким, если в кулачковой
матрице имеется очень мало единиц или очень мало нулей в ступенчатой мат-
рице. Поэтому такого выбора ключа нужно избегать.
Для того факта, что ступенчатая матрица состоит из шести строк, нет
никаких математических оснований. Это число является компромиссом меж-
ду секретностью и технической реализуемостью. Конечно, в целом период
растет вместе с ростом числа строк. Число строк, очевидно, должно быть оди-
наковым в ступенчатой матрице и кулачковой матрице. Взаимная простота
длин строк в ступенчатой матрице гарантирует максимальный период. Все,
что еще является произвольным: длины строк в ступенчатой и кулачковой
матрицах, и дополнительное требование, накладываемое на кулачковую мат-
рицу. Физически это требование соответствует числу зубцов на шестерне в
цилиндре.
Теперь должно быть очевидно, что метод Казиского или любой другой
подобный подход неадекватен для криптоанализа С-36. Для изучения других
112
криптоаналйтических подходов читатель может обратиться к (Beker Н. &
Piper F. Cipher systems. Northwood Books, London, 1982).
Некоторые известные криптографические машины, такие как немец-
кая ENIGMA (описание приведено ранее), американская SIGABA и японские
RED и PURPLE времен второй мировой войны, являются электромеханиче-
скими. Основным блоком в них является диск в виде кодового колеса с про-
волочными перемычками внутри, называемый также ротором, по внешней и
внутренней поверхностям которого равномерно распределены электрические
контакты. Эти контакты позволяют объединять роторы. Как и для С-36, ре-
зультирующая подстановка может меняться от буквы к букве.
Ниже мы кратко обсудим роторные машины. Результирующие крип-
тографические отображения для них являются несколько более общими, чем
в случае С-36, по крайней мире с нашей точки зрения. Для более подробного
изучения читатель может обратиться к (Beker Н. & Piper F. Cipher systems.
Northwood Books, London, 1982).
Роторные машины.
В 20-х годах XX века были изобретены электромеханические устрой-
ства шифрования, автоматизирующие процесс шифрования для некоторых
поточных шифров. Принцип действия таких машин основан на многоалфа-
витной замене символов исходного текста по длинному ключу согласно вер-
сии Виженера (см. /РОМ/). Другими словами, эти устройства реализовывали
последовательность подстановок алфавита, с помощью которой шифровалась
последовательность букв открытого текста. Наверно первым примером ро-
торной машины служит шифратор Джефферсона, о котором уже говорилось в
параграфе 1.1. Кроме того, примерами таких устройств являются: описанный
выше шифратор Хагелин, немецкая машина «Энигма-ENIGMA», американ-
ская машина SIGABA (М-134), английская TYPEX, японская PURPLE и др.
Главной деталью таких машин являлся ротор. Ряд таких машйн (а именно
дисковые шифраторы) в роторах - дисках имели проволочные перемычки
внутри и контакты, расположенные по окружности двух сторон дисков. Каж-
дый контакт с одной стороны диска был соединен с одним контактом другой
стороны диска. Контакты отождествляются с буквами алфавита. В соответст-
вии с внутренним соединением контактов электрический сигнал, представ-
ляющий букву алфавита - номер контакта переставляется в соответствии с
тем, как он проходит через диск. Если П - подстановка букв, осуществляемая
диском в некотором фиксированном положении, то при повороте диска на j
шагов осуществляется новая подстановка TjnTj, где Т - подстановка цикли-
ческого вида k—>к+1 (mod |I|), I - алфавит текста.
113
Последовательное прохождение тока через контакты от первого диска
доп-го моделируется подстановкой - произведением подстановок П1П2...ПП;
соответствующих дискам Если же первый диск провернется Haji,
позиций, второй на j2 позиций,n-й на jn позиций, то реализуемая дисками
подстановка (схема токопрохождения) математически записывается в виде
подстановки Т’^'Г’1 Т2П2Т^2... Т’“ПП‘Г*П . Роторные машины-шифраторы от-
личались количеством дисков, их коммутацией, схемой совместного движе-
ния дисков.
Шифры гаммирования (/Про/).
Напомним, что в шифре гаммирования шифрование проводится сле-
дующим способом. Пусть алфавит открытого текста состоит из п символов,
включая пробел. Ключом системы является последовательность из некоторо-
го числа L символов. Под открытый текст подписывается ключ
io ii i2 ij is ie.;.
Yo Yi У2 Yo Yl-i Y0Y1...
Если длина ключа меньше длины открытого текста, то ключ периодически
повторяется. Каждому знаку открытого текста и ключа ставится в соответст-
вие некоторый вычет по модулю п, например, А=1, Б=2,.... Способ сопостав-
ления не является секретным. Шифрованный текст получается по правилу
, y(O=it+Yt (modn)
Таким образом, мы имеем перед собой шифр Цезаря с меняющимся
сдвигом нередко его называют и шифром ВИЖЕНЕРА.
Напомним, что суммирование по модулю часто называют гамми-
рованием, а саму ключевую последовательность - гаммой. Шифры, в ко-
торых узел наложения шифра представляет собой узел суммирования,
называются шифраторами гаммирования. Это очень распространенный
класс поточных шифров.
Гаммирование чаще всего осуществляется:
- по модулю 2, если открытый текст представляется в виде бинарной по-
следовательности;
- по модулю 256, если открытый текст представляется в виде последова-
тельности байтов;
- с помощью покоординатного суммирования двоичных векторов (опе-
рация Л в обозначениях языка программирования С или хог в обозначе-
ниях ассемблера);
- по модулю 10, если открытый текст представлен в виде последователь-
ности цифр, что иногда делается в ручных системах шифрования.
114
Блочные шифры как узлы усложнения поточных шифров (/Про/).
В типичном шифре гаммирования вместо случайной гаммы наложения
используется псевдослучайная последовательность, зависящая от ключа. В
этом случае шифр часто называют программным шифром гаммирования.
Псевдослучайная последовательность отличается от случайной тем, что она
разворачивается по некоторому регулярному закону, зависящему от ключа:
сначала вырабатывается исходная последовательность, потом она преобразу-
ется узлом усложнения. На выходе узла усложнения получается гамма, кото-
рая накладывается на открытый текст.
Способов конкретной реализации данной схемы существует очень много.
В качестве блока усложнения могут использоваться и блочные шифры. Так
шифраторы DES и ГОСТ могут использоваться и в режиме гаммирования.
Для подобной схемы исходный блок реалйзует некоторую рекуррентную по-
следовательность. Это может быть обычный двоичный счетчик (в каждый
такт к начальному разряду прибавляется единица). Снимаемый в данный такт
вектор поступает на DES, далее заменяется по преобразованию DES, а резуль-
тат используется в качестве гаммы наложения. Часто узел усложнения разби-
вается на ряд более простых последовательных блоков (это в чём-то напоми-
нает схему итераций в блочном шифре). Сам блочнйй шифр можно предста-
вить в виде последовательности блоков усложнения, в котором каждая итера-
ция реализуется с помощью своего оборудования. Такая реализация увеличи-
вает оборудование, но при этом увеличивает и скорость работы схемы.
Поточный шифр гаммирования RC4.
Выбор схемы шифратора как правило ориентирован на элементную ба-
зу, на которой предполагается осуществить ее реализацию. В качестве примера
современного шифра гаммирования, ориентированного на программную реа-
лизацию, приведем Алгоритм RC-4 (разработка RSA Security Incorporated).
Данный шифр применен, в частности, для защиты в распределенной базе дан-
ных Lotus Notus и в некоторых других программных продуктах.
Описание функционирования поточного шифра RC4 дается по работе
Йована Голича (ГОЛ. J. D. Golic, «Linear Statistical Weakness of Alleged RC4
Keystream generator», in Lecture Notes in Computer Science 1233; Advances in
Cryptology:: Proc. Eurocrypt '97, W. Fumy, Ed., May 1997, pp. 226-238, Berlin:
Springer-Verlag, 1997 ). Фактически, RC4 представляет собой семейство алго-
ритмов, задаваемых параметром п, который является положительным целым с
рекомендованным типичным значением и = 8. Внутреннее состояние генера-
тора RC4 в момент времени t состоит из таблицы St = (St (l))2^, содержа-
щей 2я «-битных слов и из двух «-битных слов-указателей i, и jt. Таким обра-
115
зом, размер внутренней памяти составляет М = и2" + 2п бит. Пусть выходное
и-битное слово генератора в момент t обозначается как Z(. Пусть начальные
значения i0 ~jo - 0- Тогда функция следующего состояния и функция выхода
RC4 для каждого t > 1 задается следующими соотношениями:
+ 1,
jt =jt -1 "* Sf. i(z'z),
S't(it) = St. St(jt) ~ St.
Zt^StiStiity + StQt)),
где все сложения выполняются по модулю 2". Подразумевается, что все слова,
кроме подвергаемых изменению по формулам, остаются теми же самыми.
Выходная последовательность n-битных слов обозначается как Z = (Zt)",.
Начальная таблица So задается в терминах ключевой последовательнос-
ти К = (A'/),=JI с использованием той же самой функции следующего состоя-
ния, начиная от таблицы единичной подстановки (О/=о * • Более строго, пусть
jo = 0 и для каждого 1< t < Т вычисляется jt = (jt. \ + 1) + Kt. i) mod 2", a
затем переставляются местами St.\(t - 1) и S(. jjt). На последнем шаге порож-
дается таблица, представляющая So- Ключевая последовательность К состав-
ляется из секретного ключа, возможно повторяющегося, и рандомизирующего
ключа, передаваемого в открытом виде в целях ресинхронизации. Шифрован-
ный текст получается сложением по модулю 2 двоичных векторов Ot длины п
(байтов при п=8) открытого текста с двоичными векторами Zt длины п.
Скремблеры (/Про/).
Примером шифратора со сложным узлом наложения шифра являются
скремблеры, предназначенные для защиты телефонных переговоров. Для об-
мена личной и отчасти коммерческой информации телефон является монопо-
листом. Его преимущества очевидны:
- относительно высокая скорость обмена информацией, т. к. этот вид связи
является двусторонним и сообщение принимается в реальном масштабе вре-
мени;
- уверенность корреспондента в том, что сообщение дошло до адресата, чего
не бывает, скажем, в случае отсылки письма или телеграммы;
116
- узнавание корреспондентами друг друга по тембру голоса, что бывает очень
важно при передаче конфиденциальной информации;
- меньшие затраты времени для передачи информации по сравнению с други-
ми видами связи;
- простота вхождения в связь и относительная дешевизна этого вида связи;
- широкая распространенность телефонных линий связи, станций и термина-
лов и т. д.
Особенностью телефонной связи является то, что акустический сигнал
в телефонном терминале преобразуется в электрический и затем после обра-
ботки и усиления передается по линиям связи. На приемном конце электриче-
ский сигнал снова преобразуется в акустический, при этом исходной форме
сигнала более или менее сохраняется. Акустический и соответственно элек-
трический сигнал характеризуется частотным спектром. Его можно рассмат-
ривать в развертке во времени и по спектру.
Известно несколько типовых преобразований аналогового сигнала,
которые могут быть легко реализованы инженерными методами. Укажем
главные из них.
ПЕРЕСТАНОВКА ЧАСТОТ. С помощью системы фильтров вся шири-
на полосы стандартного телефонного канала может быть разделена на некото-
рое число частотных полос, которые потом могут быть переставлены между
собой.
Перестановка частот
Простейший скремблер ограничивает защиту введением подобных
простейших частотных преобразований. Серийный скремблер переставляет
диапазон 250-675 Гц 675-1100 Гц 1100-1525 Гц 1950-2375 Гц. В данной
схеме на вход узла наложения шифра подается одно и то же управление, ор-
ганизующее перестановку.
ИНВЕРТИРОВАНИЕ СПЕКТРА. Более сложные скремблеры допол-
нительно проводят инвертирование спектра (см. рисунок).
117
Инвертирование спектра
ЧАСТОТНО-ВРЕМЕННЫЕ ПЕРЕСТАНОВКИ. Еще более сложные
системы разбивают сигнал на временном интервале 60-500 миллисекунд и на
каждом интервале используются в комбинации свои аналоговые преобразо-
вания. Сменой преобразований в разные временные интервалы управляет по-
следовательность, поступающая на узел наложения шифра из блока усложне-
ния. Тот, кто просто послушает дешифрованную аналоговым сигналом речь
услышит какое-то булькание, шум. О сложности задачи зашифрования и
расшифрования аналоговых сообщений писал Солженицын в своем «В круге
первом». Цитируем: «...Клиппирование, демпфирование, амплитудное сжа-
тие, электронное дифференцирование и интегрирование привольной челове-
ческой речи были таким же инженерным издевательством над ней, как если
бы кто-нибудь взялся расчленить Новый Афон или Гурзуф на кубики вещест-
ва, втиснуть в миллиард спичечных коробок, перевести самолетом в Нер-
чинск, на новом месте распутать, неотличимо собрать и воссоздать субтропи-
ки, шум прибоя, южный воздух и лунный свет. То же, в некоторых импуль-
сах надо было сделать и с речью, даже воссоздать ее так, чтобы не только все
было понятно, но Хозяин мог бы по голосу узнать, с кем говорит...» Конец
цитаты. «Хозяин» - это речь идет о Сталине. Также красочно и немного пре-
небрежительно Солженицын отзывался о самой работе по разработке отече-
ственных средств защиты телефонной информации. Однако здесь он был не
прав. По мнению высококвалифицированных специалистов из так называе-
мой шарашки в Марфино (настоящее название у нее другое, сейчас - это
НИИ в престижном районе Москвы) в то время работа шла очень целена-
правленно и аппаратуру на самом деле делали в срок. Это - аппаратура вре-
менной стойкости. При наличии спецтехники типа видимой речи содержание
переговоров удается восстановить. Еслизабыть про инверсии, то мы имеем
шифр перестановки. Аппаратура видимой речи сводит задачу дешифрования
к восстановлению некого рисунка, зашифрованного шифром перестановки.
Для гарантированного засекречивания телефонной речи ее сначала
оцифровывают - переводят в двоичную последовательность, а потом обраба-
118
тывают также как и любое текстовое сообщение. В практике используются
как аппаратура аналогового, так и цифрового засекречивания. Цифровая ап-
паратура обеспечивает гарантированную надежность защиты, но она более
дорогая, более привередливая к каналам связи. Аналоговая аппаратура менее
стойкая, но более дешевая, более портативная, менее требовательная к кана-
лам связи. Более подробно о шифровании в телефонии см. (Алферов А.П.,
Зубов А.Ю., Кузьмин А.С., Черемушкин А.В. «Основы криптографии» М.,
Гелиус АРВ, 2001- 480 с.), а также (Speech and Facemile scrambling and De-
coding. A cryptographic series, v.31,1981. Aegean Park Press).
Параграф 1.5
Стеганографические средства защиты информации
в переходный период от древности к современности
(/Про/)
Напомним, что под стеганографическими методами защиты инфор-
мации понимаются методы сокрытия самого факта наличия или передачи ин-
формации.
В первом параграфе этой главы отмечалось, что первые следы стега-
нографических методов теряются в глубокой древности. Например, мы ука-
зывали и такой способ сокрытия письменного сообщения. Голову раба брили;
на коже головы писали сообщение и после отрастания волос отправляли раба
к адресату. Отзвук этой истории можно встретить в «Гиперболоиде инженера
Гарина» Алексея Толстого, где текст нанесли на спину мальчика.
Тайнопись.
Сообщения симпатические, латентные или скрытые, могут быть сде-
ланы специальными техническими средствами, например, бесцветными чёр-
нилами, проявляющимися лишь после специального физического или хими-
ческого воздействия. Популярные исторические книжки сообщали, что рос-
сийские революционеры в тюрьмах использовали в качестве симпатических
чернил даже обычное молоко. При нагревании огнем или горячим утюгом та-
кие записки становились отчетливо видны. Литератор Куканов в своей повес-
ти о Ленине «У истоков грядущего» рассуждал так: «Молоко в роли чернил -
не самый хитрый способ тайнописи, но порой, чем проще уловка, тем она на-
дежнее». Однако если заглянуть в архивы российской охранки, то станет ясно,
что там было прекрасно известно о подобных уловках. Выявить и прочесть
эту тайнопись Департаменту полиции не составляло труда. Именно в России
были разработаны и развиты способы чтения скрытых и стертых текстов с
119
помощью фотографии и подбора освещения. Ими пользуются и поныне.
Позднее физик Роберт Вуд предложил использовать для чтения скрытых тек-
стов явление люминесценции.
Микроточки. Сокрытие текста достигло своих вершин после второй
мировой войны, когда распространились сверхминиатюрные фотографии.
Обычная точка текста могла содержать сотни страниц документов, и найти ее
в книге среднего формата было много сложнее, чем пресловутую иголку в
стоге сена.
Адвокат Рудольфа Абеля, известного разведчика в США, обмененного
в 1962 г. после 5 лет заключения из 30, на пилота-шпиона Пауэрса, хотел
продать его конфискованные картины с аукциона, чтобы поддержать своего
подзащитного, хотя бы материально. Однако этого не удалось сделать, т. к.
картины были написаны маслом с применением непрозрачных для рентгенов-
ских лучей красок. При поиске микроточек картины были бы разрушены, а
сам поиск занял бы годы кропотливой работы ЦРУ. Поэтому в тюрьме Абелю
пришлось подрабатывать, рисуя лишь прозрачные акварели. Сейчас нет тех-
нических проблем записать текст так мелко, что его вообще нельзя будет про-
честь оптическими средствами без применения электронного микроскопа.
Похожая технология используется при создании компьютерных микросхем
большой интеграции.
Маскировка среди другой информации. Акростих. Метод Грибое-
дова А.С. Другой подход - маскировка сообщения среди посторонней ин-
формации, которая как бы зашумляет его. Один типично стеганографический
прием тайнописи - акростих - хорошо известен знатокам поэзии. Акростих -
это такая организация стихотворного текста, при которой, например, началь-
ные буквы каждой строки образуют скрываемое сообщение. Ранее в парагра-
фе 1.1 мы отмечали, что стеганографический метод защиты информации ис-
пользовал А.С. Грибоедов в бытность послом России в Персии. Уже в Совет-
ское время некоторых его биографов смутил тот факт, что в отдельных пись-
мах из Персии жене нарушался характерный стиль и замечательный писатель
был не похож сам на себя. При исследовании оказалось, что эти письма со-
держали дипломатические послания Александра Сергеевича. Они были сде-
ланы через накладываемый на лист бумаги трафарет, в котором были выреза-
ны отдельные окошки под буквы. Написав донесение через трафарет, Грибое-
дов дописывал разбросанные по листу -буквы в связный текст так, чтобы он
содержал письмо жене, и отправлял его с обычной почтой. Российские сек-
ретные службы перехватывали это письмо или, как говорят, перлюстрирова-
ли, расшифровывали, а затем доставляли адресату. По-видимому, жена его не
догадывалась о двойном назначении этих посланий. Отметим большое остро-
120
умие применения защиты и хорошую надежность. Имея отдельное письмо,
вскрыть его содержание практически невозможно, а переписывание текста от
руки разрушало шифровку, поскольку буквы неизбежнЬ сдвигались по месту
расположения. Раскрыли эту систему очень просто. Сложили все листочки в
стопочку и просветили мощной лампой. Буквы на трафарете были на экране
более затемнены, т. к. лежали строго друг под другом.
Использование особенностей начертания символов. Могут быть
предложены различные способы реализации идеи сокрытия содержания среди
«шумовой» последовательности. При написании текста от руки человек ис-
пользует различные начертания для букв, например, «д» или «т». Если отпра-
витель и получатель договорятся, что только одно из возможных начертаний
принимается во внимание, то Вы получите способ маскировки сообщения.
Стеганографические способы маркировки очень любят фокусники и шарлата-
ны. Проскурин Г.В. сообщил авторам один карточный фокус с математиче-
ским и стеганографическим оттенком. Фокусник берет колоду карт, вынимает
часть из них, на остальные внимательно смотрит, как-то перекладывает, по-
том предлагает Вам вынуть одну карту из колоды, посмотреть на нее, и поло-
жить в колоду, можно положить на то же место. Далее он тасует Колоду,
предлагает потасовать Вам. Затем берет карты, просматривает их и угадывает
ту, что Вы выбрали. Секрет фокуса достаточно прост. У каждой карты можно
определить верх и низ по виду рисунка. Самый простой способ: сердечко чер-
вей должно быть ориентировано острым концом вниз, крест треф в правиль-
ном положении стоит на палочке - подставке, острый конец пики должен
быть направлен вверх. Симметричные карты фокусник откладывает. Остав-
шиеся карты он укладывает в установленном им нормальном положении вер-
хом вверх. Когда Вы вытаскиваете карту, его задача подставить колоду так,
чтобы Вы вложили карту кверху ногами. Стасовав колоду, не меняя при этом
ориентации карт, и просматривая картинки, он сразу видит карту, ориентиро-
ванную не так как остальные. Именно ее Вы и выбрали.
Использование особенностей поведения. Имея определенный навык
и хорошего помощника, фокусник легко найдет предмет, спрятанный в зале в
то время, когда его выгнали за дверь. Просто помощник своими ничего не
значащими для постороннего словами или внешним видом будет подсказы-
вать. Примеры подобного рода любят в детективах. Вспомните телефильм
«Вариант «Омега» (или его прообраз - книгу «Операция Викинг»), Совет-
ский разведчик, которого играл Олег Даль, вышел на прогулку без трости -
значит, надо было срочно приводить в исполнение приговор гитлеровскому
палачу.
121
Сокращение времени обмена информацией. Используются стегано-
графические методы и в серьезных делах. Как-то в прессе, достаточно давно,
сообщалось об аресте одного американского агента. Для связи ему было пере-
дано специальное устройство накопления информации и радиопередатчик уз-
ко направленного действия. Проезжая по Садовому кольцу мимо американ-
ского посольства, он направлял передатчик на здание посольства, нажимал
кнопку, и вся информация буквально за секунду выстреливалась в посольство
и перехватывалась специальными агентами. Машина даже не замедляла ход.
Постоянная работа системы передачи информации. Для сокрытия
интенсивности обмена информации в сети связи часто передатчики постоян-
но работают в режиме передачи информации. Если информации не цоступает,
то они передают сигнал - «нет сообщений». Этот сигнал закрывается крипто-
графическими методами, и по виду передаваемого текста нельзя определить,
что же передается.
Стеганографические приемы защиты программных продуктов.
Методы маскировки широко применяют в вычислительной технике. К ним
относится запись информации между дорожками на гибких магнитных дис-
ков, создание скрытых файлов. Это делается в целях защиты от копирования.
Если запускаемая программа не обнаружит меток на диске или нужного ей
скрытого файла, то она не будет работать. Когда Вы несанкционированно ко-
пируете программу, то едва ли скопируете скрытый файл, который может на-
ходиться совсем в другой директории.
Замаскированные закладки встречаются во встроенных системах
криптографической защиты некоторых широко известных программных про-
дуктов, в частности, в электронной почте Sprint Mail и в известной системе
управления базами данных Paradox.
В конце шифрованного файла Sprint Mail просто записывает в замас-
кированном виде введенный пользователем пароль, при этом способ маски-
ровки очень прост и легко восстанавливается стандартными методами анализа
программного обеспечения.
В СУБД Paradox устроено несколько подругому. Вводимый пароль
преобразуется по весьма сложному алгоритму. Провести обратные преобразо-
вания достаточно сложно. Для закрытия информации используется только
преобразованный пароль - рабочий ключ. Этот рабочий ключ разработчики
решили вписать в явном виде в заголовок файла таблицы базы данных. Вся-
кий знакомый с алгоритмом криптографических преобразований может из-
влечь рабочий ключ из заголовка и восстановить закрываемую информацию.
Пароль, введенный пользователем, он скорее всего никогда не узнает, но со-
держание таблицы восстановит в полном объеме при минимальных затратах.
122
Параграф 1.6
Идея открытого ключа - революция в криптогра-
фии (/Три/)
Проблема распределения ключей.
Для решения проблемы распределения ключей в симметричных
шифрах предусмотрено (в шенноновской модели шифра) наличие секретного
канала связи, с помощью которого пользователи могут передавать ключи.
Получа
тель
Классическая модель криптографической системы (модель Шеннона)
123
Но можно ли передавать ключи, если такого защищенного канала свя-
зи нет? Могут ли, например, два удаленных абонента обменяться секретными
сообщениями, пользуясь лишь таким средством связи, как электронная почта?
Проблема цифровой подписи.
Проблема цифровой подписи является не менее важной для обеспече-
ния безопасности связи, чем проблема рассылки ключей. Она состоит в том,
чтобы дать возможность получателю сообщения демонстрировать другим
людям, что полученное им сообщение пришло от конкретного лица, то есть,
фактически, обеспечить аналог обычной подписи. Иногда получателю доста-
точно удостовериться в том, что сообщение не было навязано (изменено или
имитировано) третьим лицом. Противодействовать данному типу угроз по-
зволяет обычная система обеспечения имитостойкости. Но она не может пре-
доставить получателю электронного сообщения юридическое доказательство
личности отправителя, то есть не может разрешить спор между отправителем
и получателем относительно того, какое было послано сообщение и было ли
оно послано вообще. Оказывается, обе эти проблемы могут быть решены, ес-
ли ввести в рассмотрение так называемые системы с открытым ключом.
Модель системы с открытым ключом
Модель системы с открытым ключом.
Считается, что криптография с открытым ключом родилась в 1976 го-
ду, когда была опубликована статья американских математиков У. Диффи и
М.Э. Хеллмана «Новые направления в криптографии». Эта публикация не то-
лько положила начало новому направлению науки о шифрах, но и послужила
124
импульсом к развитию новых направлений математики. Авторами данной ра-
боты и независимо от них Р. Мерклем было показано, что из классической
модели шифра можно исключить секретный канал распространения ключей, и
при этом все-таки обеспечить защиту при передаче сообщений без каких-либо
предварительных мероприятий.
В своей основополагающей работе Диффи и Хеллман ввели в рассмо-
трение понятие однонаправленной функции с лазейкой (или с секретом), ста-
вшее центральным в криптографии с открытым ключом. Оно является обоб-
щением известного до 1976 года понятия однонаправленной функции.
Определение 1. Функция F: X -> У называется однонаправленной
функцией (ОФ), если она обладает двумя свойствами:
1) функция F легко вычислима;
2) почти для всех yeY сложно найти такое хеХ, что F(x) = у.
Определение 2. Функция Fx: X —> Y, зависящая от параметра %gK, на-
зывается однонаправленной функцией с лазейкой (ОФЛ), если она обладает
тремя свойствами:
1) при любом % функция Fx легко вычислима; при неизвестном х почти
для всех уеУ сложно найти такое хеХ, что Fx(x) = у;
2) при известном х функцию Fx легко инвертировать (инвертировать -
значит решить уравнение Fx(x) = у относительно неизвестного х).
Второй пункт определения 1 означает, что почти для всех уеУ функ-
цию трудно инвертировать. Мы говорим «почти для всех», имея в виду, что
существует небольшое по мощности множество у-ов, для которых несложно
найти их прообразы при отображении F.
Замечание. Определения 1 и 2 являются математически нестрогими.
Точное определение однонаправленной функции читатель может найти во
многих изданиях по криптографии с открытым ключом. Математические
формализации понятий сложности и простоты алгоритмов можно найти в
книгах по сложности алгоритмов.
В настоящее время не построено ни одной функции, для которой было
бы доказано, что она является однонаправленной или однонаправленной
функцией с лазейкой. Более того, не доказано даже их существование. Для
практических целей криптографии построено несколько функций, которые
могут оказаться ОФЛ. Для них пока строго не доказано второе свойство - от-
сутствие полиномиального алгоритма их инвертирования, но считается, что
эта задача эквивалентна некоторой давно изучаемой трудной математической
проблеме. Одним из самых известных и широко используемых «кандидатов»
в однонаправленные функции с лазейкой является функция шифрования RSA.
Наиболее распространенным «кандидатом» в однонаправленные можно счи-
125
тать функцию возведения в степень в мультипликативной группе простого
поля, предложенную Диффи и Хеллманом для организации открытого рас-
пределения ключей.
Кроме возможности передачи секретной информации с использовани-
ем только открытых каналов связи, решающей проблему распределения клю-
чей, применение однонаправленных функций с лазейкой позволяет решить
проблему цифровой подписи, а также позволяет включить в задачу вскрытия
шифра трудную математическую задачу и тем самым повысить обоснован-
ность стойкости шифра.
Для решения проблемы распространения ключей было предложено
два основных подхода.
Первый - это открытое распределение ключей, с помощью которого
отправитель и получатель могут договориться р ключе, используемом в обыч-
ной криптографической системе. При этом пассивный перехватчик, прослу-
шивающий все переговоры, не будет в состоянии этот ключ определить.
Второй подход реализует криптографические системы с открытыми
ключами, в которых для зашифрования и расшифрования используются раз-
ные ключи. ь
Рассмотрим сначала второй подход. Причина, по которой ключи в
обычных криптографических системах должны тщательно защищаться, со-
стоит в том, что функции зашифрования и расшифрования в них нераздели-
мы. Любое лицо, имеющее ключ, использованный для зашифрования какого-
либо сообщения, может это сообщение расшифровать. В криптосистемах с
открытым ключом процессы зашифрования и расшифрования разделены и
зависят от различных ключей, причем по алгоритму зашифрования (опреде-
ляемому ключом зашифрования), практически невозможно восстановить ал-
горитм расшифрования. Это означает, что для восстановления алгоритма не-
обходимо провести такой объем вычислений, который можно считать практи-
чески неосуществимым. Поэтому стойкость таких систем не зависит от того,
знает противник ключ зашифрования или нет. Этот ключ не нужно держать в
секрете, его можно публиковать и передавать по незащищенному каналу свя-
зи. Отсюда название криптографических систем такого вида - «криптосисте-
мы с открытым ключом».
Принципы построения криптосистем с открытым ключом.
Опишем сначала принцип построения криптосистемы с открытым
ключом, предложенный Диффи и Хеллманом (W. Diffie, М.Е. Hellman, 1976).
Пользователь А, который хочет получать шифрованные сообщеяия, выбирает
однонаправленную функцию Fx: X—>Y с лазейкой, алгоритм вычисления зна-
чений Fz публикует, а % оставляет в секрете. Любой пользователе В, желаю-
126
щий послать А сообщение хеХ, вычисляет у = Fx(x) и посылает у по незащи-
щенному каналу связи. Из второго и третьего пункта определения 2 следует,
что только пользователь А может по у вычислить х, так как только А знает
секрет %.
Определение 3. Криптографической системой с открытым ключом
называется пятерка A=<X,K,Y,E,D>, где X,Y - конечные множества, соответ-
ственно, открытых и шифрованных текстов, К - множество ключей (откры-
тых и секретных), Е = {Ех}х€к , D = {Dx}xeK - семейства алгоритмов зашиф-
рования и расшифрования соответственно, определяющих отображения:
Ех: X->Y,
Dx: Y->X, *
такие что
1) для каждого хеХ" Dx обратно к Ех, то есть для любых у&К, хеХ
Рх(Ех(х)) = х>
2) для каждого хе^ функции Ех и Dx легко вычислимы;
3) для почти каждого вычислительно труднб по данному Ех найти
какой-либо легко вычислимый алгоритм, эквивалентный Dx;
4) по каждому заданному хе^ можно легко получить соответствую-
щую пару (EX,DX);
5) существует легко вычислимый алгоритм генерации ключей.
Поясним данное определение. В нем третье свойство можно сформу-
лировать по-другому: почти для каждого х^АГ вычислительно невозможно по
данному случайному у ё У определить хеХ, такой, что Ех(х)=у, то есть не су-
ществует полиномиального алгоритма (алгоритма со сложностью переделяе-
мой некоторым полиномом от размера входных данных), находящего какое-
либо решение х уравнения Ех(х)=у. Это свойство означает, что можно не засе-
кречивать алгоритм зашифрования Ех. При этом алгоритм расшифрования Dx
скомпрометирован не будет. Ясно, что алгоритм Dx имеет в качестве парамет-
ров элементы ключа х, не являющиеся параметрами алгоритма Ех (иначе по Ez
можно было бы восстановить Dx). Эти элементы ключа являются секретными
и образуют секретный ключ х? криптосистемы А. Остальные элементы ключа
X являются параметрами алгоритма Ех и образуют открытый ключ Xi крип-
тосистемы А.
Четвертое свойство гарантирует наличие практически реализуемого
пути вычисления пар алгоритмов зашифрования и расшифрования. На прак-
тике кроме эффективных реализаций этих алгоритмов криптографическое
оборудование должно включать и эффективную реализацию алгоритма гене-
рации ключей. Алгоритм генерации ключей общедоступен. Всякий желающий
127
может подать ему на вход случайную строку г (например, двоичную строку
достаточной длины) и получить ключ % и соответствующую этому ключу па-
ру (Ех, Dx). Строка г может также вырабатываться генератором случайных чи-
сел.
Замечание. Выше было определено, какие элементы ключа асиммет-
ричной криптографической системы называются открытыми, а какие секрет-
ными. Согласно этому определению далеко не во всякой криптосистеме с от-
крытыми ключами алгоритм расшифрования определяется только секретным
ключом Х2- То есть не всегда, зная лишь секретную часть ключа %, можно вос-
становить алгоритм Dx (например, этого нельзя сделать в криптосистеме Эль-
Гамаля). Существуют также и такие асимметричные криптосистемы, в кото-
рых знание хг позволяет восстановить весь ключ (например, RSA), а значит, и
алгоритм Dx. Будем в дальнейшем для удобства алгоритм зашифрования обо-
значать через Ехь а алгоритм расшифрования через DX2, где и %2 - Соот-
ветственно открытый и секретный ключи. При этом необходимо помнить, что
алгоритм Dx2 может иметь в качестве параметров элементы ключа %1- В от-
личие от него алгоритм зашифрования Exi всегда можно восстановить, зная
лишь xl-
Опишем теперь, каким образом два пользователя А и В могут с помо-
щью криптосистемы с открытым ключом организовать передачу секретных
сообщений. Пусть пользователь А хочет послать секретное сообщение поль-
зователю В. Для этого В строит ключ х = (%1> х2) и посылает xl пользователю
А. Получив хЕ пользователь А шифрует сообщение х с помощью алгоритма
Ехь Полученный шифртекст y=Exi(x) он посылает В. Используя алгоритм
расшифрования Dx2, пользователь В из полученного у вычисляет открытое
сообщение x=Dx2(y). Заметим, что только В может по у найти х, так как только
он знает секретный ключ. Криптоаналитику, в распоряжение которого попа-
дают %1 и у, для определения открытого сообщения необходимо решить урав-
нение Exi(x)=y. Но по третьему пункту определения 3 эта задача практически
неразрешима.
На первый взгляд может показаться, что описанный способ организа-
ции секретной связи идеально решает проблему распространения ключей. Но
на самом деле это не так. Отсутствие защищенного канала связи бесспорно
является значительным преимуществом этого способа над классическим. Од-
нако у него есть и существенный недостаток. Если криптоаналитик имеет во-
зможность осуществлять имитацию или подмену сообщений, то он может по-
лучить открытое сообщение, даже когда используемая криптосистема
128
обеспечивает стойкость. Криптоаналитик может построить свою пару ключей
Х'=(х' 1,Х 2) и послать А ключ х' 1 от имени пользователя В. Ничего не подо-
зревающий пользователь А зашифрует сообщение х, предназначенное для В,
на ключе криптоаналитика и затем, послав его, даст возможность последнему
без труда восстановить х.
Чтобы данная угроза не могла быть реализована, описанная схема ор-
ганизации секретной связи должна быть усовершенствована.. Пользователь А,
получив ключ пользователя В, должен иметь возможность убедиться в том,
что этот ключ прислал именно В, то есть необходимо обеспечить аутентифи-
кацию открытых ключей. Задача аутентификации открытых ключей может
быть решена методами криптографии с открытым ключом. Для ее решения в
сеть пользователей включают так называемый центр доверия, осуществляю-
щий сертификацию открытых ключей. При этом используются такие крипто-
графические механизмы как идентификация и цифровая подпись. Напомним
несколько понятий, играющих важнейшую роль при обеспечении безопаснос-
ти связи.
Определение 4. Аутентификация пользователя или идентификация - это
способ взаимодействия двух сторон, из которых одна сторона является поль-
зователем, позволяющий пользователю доказать другой стороне свою тожде-
ственность с лицом, за которое он себя выдает.
Определение 5. Аутентификация сообщения - это подтверждение под-
линности источника сообщения.
Определение 6. Цифровая подпись - это криптографическое средство,
дающее возможность получателю электронного сообщения не только убе-
диться в подлинности источника сообщения, но и уметь доказывать его под-
линность.
Схема цифровой подписи. Диффи и Хеллман предложили следующий
принцип построения схемы цифровой подписи. Пользователь А выбирает од-
нонаправленную функцию с секретом Fx: Y -> X, алгоритм вычисления зна-
чений Fx публикует, х оставляет в секрете. Для того чтобы подписать сообще-
ние хеХ, он находит такое уеУ, что Fx(y) = х, и посылает его вместе с х. По-
лучив пару (х,у), пользователь В проверяет равенство Fx(y) = х. Выполнение
этого равенства означает, что источником сообщения х является пользователь
А, владеющий секретом х-
Криптографические системы с открытым ключом обеспечивают реше-
ние проблемы цифровой подписи, если они удовлетворяют следующему усло-
вию:
129
Х=У и для каждого Ех обратно к Dx, то есть для любых хеХ
Ex(Dx(x)) = х-
\
Пусть пользователь А хочет послать подписанное несекретное сообще-
ние пользователю В. Для этого А строит ключ х=(%1,%2) и посылает %1 поль-
зователю В. Сообщение х пользователь А шифрует с помощью своего лично-
го ключа %2, получая таким образом подпись y=DX2(x), и посылает ее В. Ра-
ньше, когда при передаче информации требовалась только секретность, с по-
мощью алгоритма DX2 владелец ключа % расшифровывал получаемые им соо-
бщения, теперь же он использует этот алгоритм для зашифрования или по-
дписи. Используя алгоритм ЕхЬ пользователь В может вычислить х из полу-
ченного у и убедиться таким образом, что отправителем сообщения х является
А. Подпись у он сохраняет как доказательство того, что пользователь А при-
слал ему сообщение х. Если позднее А откажется от факта посылки этого соо-
бщения, то В может предъявить суду подпись у. Суд возьмет открытый ключ
Х1 пользователя А и установит, что Ех1(у) является осмысленным сообщени-
ем; Так как только А знает секретный ключ у 2, то только он может быть исто-
чником этого сообщения, поэтому А неизбежно придется отвечать за посылку
сообщения х.
Открытое распределение ключей Диффи-Хеллмана.
Рассмотрим теперь другой подход к решению проблемы распростра-
нения ключей, а именно: открытое распределение ключей. Под открытым
распределением ключей понимают последовательность действий двух или бо-
лее пользователей, в результате выполнения которой им становится доступна
некоторая общая секретная информация (ключ). При этом любой другой
пользователь, следящий за передаваемыми по каналу связи сообщениями, эту
секретную информацию определить не в состоянии. В работе /DH. W.Diffie,
М.Е. Hellman. New directions in cryptography, IEEE Transactions on Information
Theory, v.IT-22, N.6, November, 1976, рр.644-654/ был предложен так называе-
мый экспоненциальный ключевой обмен, который в настоящее время называ-
ется схемой открытого распределения ключей Диффи-Хеллмана. Данная схе-
ма основана на использовании функции возведения в степень в мультиплика-
тивной группе простого поля: f(x) = ах modp, где р - простое число, а -
примитивный элемент поля GF(p), 1<х< р - 1. Эта фукнция является канди-
датом в однонаправленные. Действительно, она легко вычислима, так как, ис-
пользуя метод квадратов, значения этой функции можно вычислять с полино-
миальной сложностью, оцениваемой величиной O((log р)3), в то время как об-
ратная задача - задача инвертирования функции - является сложной. Для ин-
5 Зак. 5
130
вертирования функции f(x) необходимо уметь решать уравнение
у = ах modp, то есть уметь решать задачу дискретного логарифмирования в
мультипликативной группе простого поля. В настоящее время не известно
достаточно эффективных (полиномиальных относительно logp) алгоритмов
дискретного логарифмирования в мультипликативной группе GF(p) поля.
Этот факт и лежит в основе стойкости данной схемы открытого распределе-
ния ключей. Опишем ее.
Пусть два пользователя А и В хотят выработать общий ключ. Для это-
го они заранее определяют элементы р и а, которые считаются общедоступ-
ными. Оба пользователя случайно выбирают по одному натуральному числу
хА и Хв: 1 < хА, хв < р - 1 и оставляют их в секрете. После этого выполняется
следующая последовательность шагов.
1) А вычисляет элемент уА = аХА modp и посылает его В;
2) В вычисляет элемент ув =аХв modp и посылает его А;
3) А вычисляет элемент ygA modp = (аХв ) А modp;
4) В вычисляет элемент УдВ modp = (аХд modp .
Таким образом, А и В. получают общий элемент поля GF(p), равный
ахлхБ modp, который и объявляется их общим ключом. Пассивный крипто-
аналитик получает в свое распоряжение величины р, а, аХд modp,
аХв modp и хочет определить аХдХв modp. Эта задача называется пробле-
мой Диффи-Хеллмана. В настоящее время не найдено более эффективного
решения этой проблемы, чем дискретное логарифмирование.
Параграф 1.7
Недостатки модели шифра Шеннона. Обобщенная
модель шифра
В классической модели шифра два абонента используют для связи
один ключ, хранящийся от всех других абонентов в секрете. Такой ключ на-
зывают секретным, а криптографические системы с секретными ключами на-
зывают еще одноключевыми или симметричными шифрами (криптосистема-
ми). При использовании симметричных криптосистем возникает проблема
рассылки ключей. Если два человека, которые никогда ранее не встречались,
131
должны передать друг другу секретную информацию, то им необходимо зара-
нее договориться о ключе, причем сделать это нужно так, чтобы ключ был
известен только им и больше никому. Для решения этой проблемы в шенно-
новской модели шифра предусмотрено наличие секретного канала связи, с
помощью которого пользователи могут передавать ключи.
Классическая модель криптографической системы.
Алгебраическая модель шифра по К. Шеннону представляет собой
(см. параграф 1,3) трехосновную алгебру A=(X,K,y,f), где Х,К,У - конечные
множества, которые названы множеством открытых текстов хеХ, множест-
вом ключей %еК, множеством шифрованых текстов уеУ, соответственно; f-
функция шифрования, f: ХхК—>У, обладающая свойством: при любом %еК
отображение fz: X—>У, fx(x)=f(x,%) - инъективно. Последнее условие К. Шен-
нона отражает возможность однозначного расшифрования шифрованного те-
кста. Как правило, при таком определении шифра обычно дополнительно
считают, что функция F - сюрьектина. В данной модели считается, что при
дешифровании противник знает шифр А=(Х,К,УД), однако использован-
ный при зашифровании ключ ему неизвестен. Таким образом, модель
5*
132
Шеннона предназначена для описания шифров с симметричным ключом (ши-
фров с неизвестным ключом шифрования).
Уравнение шифрования записывается в виде:
f(x,%)=y, или fz(x)=y, или %х=у.
Уравнение расшифрования записывается в виде:
fx ’(У)=х> или х1 У=х.
Достоинством данной модели шифра является ее универсальность.
Она описывает практически все известные шифры с симметричным ключом.
Недостатки математической модели заключаются в следующем.
1) Шифры с ассиметричным ключом (шифры с открытым ключом)
этой моделью не покрываются.
2) Даже при моделировании шифров с симметричным ключом отобра-
жение fx’’ задано не вполне корректно. Если элементу не принадлежит мно-
жеству fx(X)={y: y=fz(x), хеХ}, то значение fx’’(y) не определено.
3) Затруднительно определить понятая'«истинный» и «ложный» ключ
при дешифровании методом тотального перебора ключей. Действительно, ес-
ли f(x,%)=f(x,x'), где % - ключ шифрования, а х'~ опробуемый ключ, то как
называть ключ х', истинным или ложным?
3) Модель не учитывает наличие канала связи с помехами. Если прои-
зошло искажение передаваемого шифрованного текста y=f(x,x) и на прием
пришло сообщение у', то значение fx ’(y ) может быть не определено по при-
чине того, что у' не принадлежит fx(X), более того: это значение может не
принадлежать даже У.
4) Содержательная трактовка множества X в некоторых случаях вызы-
вает затруднение. По определению, это множество «текстов» х, для которых
определено значение f(x,x) при любом х^К, и они названы открытыми текс-
тами. Но тексты, которые могут быть зашифрованы, в общем случае делятся,
в свою очередь на «содержательные» (это подмножество ХссХ) и «бессодер-
жательные» («хаотические», это множество Х\ХС). Критерий истинности де-
шифрования, например, методом опробования ключей Xе К, обычно строится
в проверке условия fx''(y)eXc (критерий на содержательный текст). Если Х=ХС
(шифруются только содержательные текста), то критерий вырождается в кри-
терий: значение fx‘(y) определено или нет. Приведенные соображения говорят
о целесообразности наряду с множеством X ввести в модель и его подмножес-
тво Хс содержательных текстов.
j
133
Алгебраическая обобщенная модель шифра.
Целью данного пункта является описание новой модели шифра, уточ-
няющей модели К.Шеннона, Диффи и Хелмана и свободной от указанных
выше недостатков. Основная концептуальная идея построения такой модели,
на наш взгляд, естественна и очевидна. Она состоит во введении шифра шиф-
рования и шифра расшифрования, совокупность которых и составляет алгеб-
раическую модель шифров.
Шифром зашифрования (алгеброй зашифрования) назовем алгебру
АШ=(Х,ХС;КШ,У,УС,Ц, где XcczX, f: ХхКш->У - сюрьективное отображение,
причем для каждого х^Кш отображение fz:X—>У, fz(x)=f(x,x) инъективно, а
y^fpQxKuJ. Множество Хс трактуется как подмножество всех содержатель-
ных текстов из множества «открытых текстов» X. Последнее множество сос-
тоит из текстов х, которые могут быть зашифрованы шифром, то есть тех х,
для которых определено значение fx(x) для всех хеКш. Введение подмножес-
тва XcczX, как множества содержательных текстов, позволяет корректно вво-
дить критерии на содержательные тексты.
Таким образом, шифр зашифрования есть некоторое уточнение моде-
ли шифра Шенина А=(Х,КШ,У,Ц.
Шифром расшифрования (алгеброй расшифрования) для Аш назовем
алгебру АР=(У',КР,ХТ), где Ус;У', XczX', F: У'хКр—>Х' - сюрьективное отоб-
ражение, для которого выполняются следующие условия:
1) существует биекция (р: Кш—>КР;
2) для любых хеХ, х€Кш из условия f(x,x)=y вытекает F(y,cp(x))=x.
При отсутствии искажений в канале связи функция расшифрования F
полностью определена на всем множестве УхКр.
Введение множества Y' (а точнее, У'\У) обеспечивает возможность
описания реакции приемной стороны на поступление искаженного шифро-
ванного сообщения у' ёУ.
Введение множества Х'\Х обеспечивает возможность описания ре-
зультата расшифрования приемной стороной искаженного шифрованного со-
общения у'ёУ.
Отметим, что в определении шифра расшифрования не содержится
требований инъективности функции F по переменной ке Кр.
Алгебраической обобщенной моделью шифра назовем тройку (АШ,АР, ср).
Отметим следующие положительные свойства этой модели.
1 ь Возможность моделирования шифров с асимметричным ключом.
Здесь учитываются следующие соображения:
134
- ключ /еКш несекретен, а ключ к-(р(%)еКр является секретным;
- определение значения к связано с решением сложных проблем;
- синтез пар ключей (к, %) проводится достаточно просто.
Заметим, что здесь проявляется возможность классификации шифров
по параметру сложности вычисления значения ф(х) ключа расшифрования,
что определяет основной параметр криптографической стойкости шифров с
ассиметричным кдючом.
2. Возможность моделирования шифров с симметричным ключом.
Ниже используется как эта обобщенная модель шифра, так и модель шифра
по К. Шеннону,
ГЛАВА 2. ДЕШИФРОВАНИЕ ИСТОРИЧЕСКИХ
ШИФРОВ
Параграф 2.1
Дешифрование шифра простой замены, переста-
новки и некоторых шифров гаммирования (/Про/)
В параграфе 3.2 мы введем математические модели открытых текстов,
используемые при криптографичесом анализе шифров, а также укажем неко-
торые частотные свойства открытых текстов. В следующем пункте мы ис-
пользуем некоторые из этих свойств и акцентируем внимание на вероятност-
но-статистических закономерностях, присутствующих в открытом тексте, ко-
торые используются при дешифровании шифров простой замены и переста-
новки.
Устойчивые закономерности открытого текста и их использова-
ние при дешифровании шифров простой замены и перестановки. Воз-
можность дешифрования какого либо шифра в значительной мере зависит от
того, в какой степени криптографические преобразования разрушают вероят-
ностно-статистические закономерности, присутствующие в открытом тексте.
К наиболее устойчивым закономерностям открытого сообщения относятся
следующие.
1) В осмысленных текстах любого естественного языка различные буквы
встречаются с разной частотой, при этом относительные частоты букв в раз-
личных текстах одного языка близки между собой. То же самое можно сказать
и о частотах пар, троек букв открытого текста;
135
2) Любой естественный язык обладает так называемой избыточностью, что
позволяет с большой вероятностью «угадывать» смысл сообщения, даже если
часть букв в сообщении не известна.
В приводимой ниже таблицы указаны относительные частоты букв
алфавита русского языка.
1 а - 0,062 12 л - 0,035 23 ц - 0,004
2 б - 0,014 13 м - 0,026 24 ч- 0,012
3 в - 0,038 14 н - 0,053 25 ш - 0,006
4 г-0,013 15 о - 0,090 26 щ - 0,003
5 д - 0,025 16 п - 0,023 27 ы- 0,016
6 е,ё - 0,072 17 р - 0,040 28 ъ,ь - 0,014
7 ж - 0,077 18 с - 0,045 29 э - 0,003
8 з-0,016 19 т - 0,053 30 ю - 0,006
9 и - 0,062 20 у - 0,021 31 я-0,018
10 й-0,010 21 ф - 0,002 32 - 0,175
11 к - 0,28 22 х - 0,009
Подобные таблицы приводятся в разных книгах. Они получены на ос-
нове подсчетов частот на больших объемах открытого текста. Учитывая, что
для экспериментов берется различный исходный материал, значения вероят-
ностей несколько отличаются между собой.
Если упорядочить буквы по убыванию вероятностей, то Мы получим
вариационный ряд
' О,Е,А,И,Н,Т,С,Р,В,Л,К,М,Д,П,У,Я,3,Ы,Б,Ь,Г,Ч,Й,Х,Ж,Ю,Ш,Ц,Щ,Э,Ф.
Как запомнить первые 10 наиболее частых букв? Помните, как запо-
минают основные цвета в физике? Надо запомнить фразу Каждый охотник
желает знать, где живет фазан. Первые буквы слов фразы указывают на
основные цвета. В криптографии надо запомнить слово СЕНОВАЛИТР - в
нем все 10 наиболее частых букв.
Частотная диаграмма, конечно, зависит от языка. В нижеследующей таб-
лице приводятся в процентах относительные частоты наиболее употребляе-
мых букв некоторых языков.
Английский язык е-12,75 t - 9,25 г-8,50 i - 7,75 h - 7,75 о - 7,50
Французский язык е- 17,75 а - 8,25 s - 8,25 i - 7,25 n - 7,25 r - 7,25
Немецкий язык е-18,50 п- 11,50 i - 8,00 г-7,50 s - 7,00 a - 5,00
Арабский язык а-17,75 •
136
Греческий язык а-14,25
Японский язык р- 15,75
Латинский язык а - 11,00
Малайский язык а - 20,25
Санскрит а-31,25
Частоты знаков алфавита зависят не только от языка, но и от характера
текста. Так в тексте по криптографии будет повышена вероятность букв Ф, Ш
(из-за часто встречающихся слов «шифр», «криптография»), В математиче-
ском тексте скорее всего будет завышена частота буквы Ф (из-за слов «функ-
ция», «функционал» и т. п.).
В стандартных текстовых файлах наиболее частым был символ «про-
бел», в ехе-файлах наиболее часто встречается символ 0, в текстах, написан-
ных в текстовом процессоре ChiWriter, удобном для оформления математи-
ческих текстов, на первое место вышел символ “\” - backslash .
Частотная диаграмма является устойчивой характеристикой текста. Из
теории вероятностей следует, что при достаточно слабых ограничениях на
вероятностные свойства случайного процесса справедлив закон больших чи-
сел, т. е. относительные частоты ук знаков сходятся по вероятности к значе-
ниям их вероятностей р :
А "
Это верно для последовательности независимых испытаний, для ко-
нечной регулярной однородной цепи Маркова. Эксперименты показывают,
что это верно и для открытых текстов.
С позиций современной криптографии шифры перестановки и простой
замены обладают существенным недостатком - они не полностью разрушают
вероятностно-статистические свойства, имеющиеся в открытом сообщении.
При дешифровании текста, зашифрованного шифром простой замены,
используют частотные характеристики открытого текста. Именно, если под-
считать частоты встречаемости знаков в шифрованном тексте, упорядочить их
по убыванию и сравнить с вариационным рядом вероятностей открытого тек-
ста, то эти две последовательности будут близки. Скорее всего на первом мес-
те окажется пробел, далее будут следовать буквы О, Е, А, И.
Конечно, если текст не очень длинный, то не обязательно полное сов-
падение. Может оказаться на втором месте О, а на третьем Е, но в любом слу-
чае в первых и вторых рядах одинаковые буквы будут располагаться недале-
ко друг от друга, и чем ближе к началу (чем больше вероятность знаков), тем
меньше будет расстояние между знаками.
137
Аналогичная картина наблюдается и для пар соседних букв (биграмм)
открытого текста (наиболее частая биграмма русского открытого текста - СТ).
Однако для получения устойчивой картины длина последовательности долж-
на быть существенно больше. На сравнительно небольших отрезках открыто-
го текста эта картина как-то смазана. Более устойчивой характеристикой би-
грамм является отсутствие в осмысленном тексте некоторых биграмм, как го-
ворят, наличие запретных биграмм, имеющих вероятность, равную практиче-
ски 0.
Видели ли Вы когда-нибудь в открытом тексте биграммы ЪЬ, «глас-
ная» Ь, «пробел» Ь? Знание и использование указанных особенностей откры-
того текста значительно облегчает дешифрование шифра перестановки и за-
мены.
Дешифрование шифра простой замены. Рассмотрим пример дешифро-
вания шифра простой замены (Учебное пособие «Принципы и методы защиты
информации», Проскурин Г.В.). Пусть у нас имеется следующий шифртекст.
ДОЧАЛЬ ИЬЦИО ЛИОЙО ВНЫИЮШ ХЕМВЛНХЕИ ДОСОЛЬ ЧСО ИА
ТЬЖАТСР БАС АКЕИОЙО ДОКЩОКЗЖАЙО КПЗ РТАЩ ТПЬЧНАР ТДО-
ТОУН ХЕМВОРНИЕЗ ЕИМОВЛНЯЕЕ РЮУОВ БВЕД СОЙВНМЕЧАТБОГ
ТЕТСАЛЮ ЫНРЕТЕС ОС ОТОУ АИИОТСАГ ЕИМОВЛНЯЕЕ АА ЯАИИ-
ОТСЕ Е РОЫЛОЦИОТСАГ РПНКАПШЯАР ДО ЫНЖУСА ТРОАГ ЕИ-
МОВЛНЯЕЕ ДВАЦКА РТАЙО ДОКЧАВБИАЛ УОПШХОА ВНЫИООУ
ВНЫЕА РЕКОР ЫНЖЕЖНАЛОГ ЕИМОВЛНЯАА КОБЬЛАИСНПШИНЗ
САПАМОИИНЗ САПАРЕЫЕОИИНЗ БОЛДШЭСАВИНЗ БНЦКЮГ РЕК
ЕИМОВЛНЯЕЕ УЛААС ТРОЕ ТДАЯЕМЕЧАТБЕА ОТОУАИИОТСЕ Е ФСЕ
ОТОЧАИИОТСЕ ТЕПШИО РПЕЗЭС ИН РЮУОВ ЛАСОКОР ХЕМВОРНИЕЗ
ЕИМОВЛНЯЕЕ УОПШХОА ЫИНЧАИЕА ЕЛАЭС ОУЪАЛЮ Е
СВАУЬАЛНЗ ТБОВОТСШ ДАВАКНЧЕ ХЕМВОРНИИОГ
Работу следует начать с подсчета частот символов в шифрованном тексте.
После того как проведен подсчет, упорядочим символы по убыванию
частот.
bi b2 Ь3 Ь4 Ь5 .
Под ним стоит подписать вариационный ряд вероятностей знаков в
открытом тексте.
О ЕА ИНТСРВЛКМДПУЯЗЫБЬГЧЙХЖЮШЦЩЭФ
138
При достаточно большой длине шифртекста, для того чтобы из шиф-
рованного текста получить открытый, достаточно заменить bi на О, Ь2 на Е,
Ьз на А и т. д.
По крайней мере такая ситуация будет иметь место для наиболее веро-
ятных букв. У нас материала недостаточно. Посмотрев на шифртёкст после
такой замены, Вы видите, что он не читается, - значит, материала действи-
тельно мало.
Что нам остается - угадывать замену. При этом мы должны все-таки
учитывать статистические особенности открытого текста. В шифртексте через
пробел скорее всего обозначается пробел, через букву О скорее всего обозна-
чена О или А, через Е - О, Е, А, через А - Е, А или И и т.д.
Можно рекомендовать выписать шифртекст, а под ним в колонку
наиболее вероятные замены для этих букв. В нашем примере замена подобра-
на таким образом, что буква алфавита заменена как раз на наиболее вероятное
для нее обозначение. Поэтому сам шифртекст в данном примере выписывать
нет необходимости. Он совпадает со средней строкой последовательности ко-
лонок наиболее вероятных замен.
Чем реже встречается буква - тем большей глубины надо брать колон-
ку, чтобы была уверенность, что в колонке содержится знак открытого тек-
ста. В нашем случае колонки взяты одинаковой глубиной в 5 символов, но
выписаны они только для наиболее частых букв.
Таблица не приводится из-за своей громоздкости, она приведена в
Приложении 3.
При дешифровании без использования средств автоматизации дальше
надо угадывать замену. Если присмотреться к тексту, то сделать это не очень
трудно. В тексте есть слово АА из двух часто встречающихся букв. Что это
может быть за слово? В русском языке нет слов ОО, ИИ, НН и т. д. Так пере-
бирая возможные слова, мы обнаружим одно слово ЕЕ и прийдем к выводу, (
что буква Е была заменена на А. Очень часто в шифртексте слова кончаются
биграммами ЕЕ. В русском языке типичными окончаниями являются сочета-
ния ЕЕ; ИИ. Учитывая, что замену для буквы Е мы уже угадали, приходим к
выводу, что в шифртексте буква И заменена на Е. Теперь всюду в шифртексте
- можно провести обратную замену. Теперь мы уже можем угадывать отдель-
ные слова. Так, изрядно попотев, мы, как в игре «Поле чудес», в конце концов
восстановим весь текст.
В колонках наиболее вероятных замен буквы, отвечающие правиль-
ным обратным заменам, должны быть обозначены как заглавные. Прочитав
открытый текст, Вы убедитесь, что он представляет собой несколько предло-
жений из книги Дориченко С.А. и Ященко В.В. «25 этюдов о шифрах»,
М.,1994.
139
Для дешифрования в автоматизированном режиме прежде всего цадо
завести в память компьютера словарь русского языка.
Программа дешифрования должна, просматривая шифртекст, осущес-
твлять пробные обратные замены, предполагая, что на данном фиксированном
месте в открытом тексте находилось проверяемое слово. После каждой заме-
ны программа частично восстанавливает ключевую подстановку, частично
расшифровывает текст и отсеивает вариант подстановки, если в каком-то мес-
те восстановленного текста оказывается буквосочетание, которое не может
быть в открытом тексте. После восстановления некоторого числа замен в тек-
сте появляются участки, в которых определено значительное число букв. Ос-
тавшиеся буквы подбираются путем перебора словаря и подстановки в текст
слов, которые не противоречат восстановленным ранее заменам.
Следует отметить, что практические навыки по дешифрованию шифра
простой замены можно получить лишь после проведения самостоятельных
опытов по дешифрованию.
Дешифрование шифра перестановки. Для восстановления открыто-
го текста шифра перестановки нам необходимо переставить колонки таким
образом, чтобы в строках появился осмысленный текст.
Рассмотрим пример дешифрования шифра перестановки восьми
столбцов (Учебное пособие «Принципы и методы защиты информации», Про-
скурин Г.В.). Пусть шифртекст имеет вид
1 2 3 4 5 6 7 8
п а я В И м
О ч ш Г у е
е б ж л е о
м ч О т О я
е г е у с щ
а к ь 3 а т т
я р е е п ь
ю 3 в а н в
О й а в е ш л
е е я м п н
ь р р н 3 е е е
3 а м а н а к
ч с т а ь а н
О я л м а л
О ь ч X т а т
140
В е 0 а л е п
0 е р м т ь е
Д с г ы 0 а т
е б в н ы
а у и н 3 н л
г и а 0 к к Д
а 0 б Д г н
ж а У е д я Д
X л и е м 0 а
к р т д ь 0 е
ь X в т 0 н
р л е е д а ю
р 3 е в е д
ш в а е н е н
т и й е . в Д
в с д
Сопоставим перестановке столбцов таблицу 8x8, при этом поставим
на пересечении i-той строки и j-oro столбца единицу, если j-ая колонка после
обратной перестановки должна следовать за i-ой. Наша задача восстановить
таблицу, отвечающую правильной перестановке столбцов.
Давайте теперь попарно пристраивать один столбец к другому. Если
при этом в некоторых строках появляются запретные биграммы, то столбцы
не могут в открытом тексте следовать друг за другом, и соответствующая кле-
точка зачеркиваются. В нашем примере 6-ой столбец не может следовать за
4-ым, т. к. иначе в тексте в первой строке будет подряд два пробела. Посмот-
рим, например, 6-ую строку. Если бы 4-ый столбец следовал за 1-ым, то в тек-
сте были бы слова, начинающиеся с Ь. После просмотра всех строк мы полу-
чим таблицу. ,
1 2 3 4 5 6 7 8
1 X X X X X X
2 X X X
3 X X
4 X X X X X X
5 X X X X X
6 X X X X X
7 X X X X X X
8 X X X X X X
141
Если бы текст был бы подлиннее и строк было бы побольше, то в каж-
дой строке и в каждом столбце осталось бы ровно по одной не зачеркнутой
клеточке и перестановка была бы восстановлена.
В нашей таблице мы только можем утверждать, что 6-ой столбец сле-
дует за 3-им (обозначим это событие следующим образом 3 —> 6), если 6-ой
столбец не является последним. Для 6-го столбца может быть два варианта
продолжения
8
?
3 —6 —5
Нам надо рассмотреть оба и постараться отсеять ложный. Если отсеять
ложный не удастся, то надо продолжать оба варианта
8—> 4 1
t t
3-> 6—>5—>2 —>7
В итоге получаем некоторое дерево возможного следования столбцов в от-
крытом тексте.
7
т
3-> 6-> 5-> 2-> 8-> 4-> 1-> 7
Ф Ф Ф
8 4 1—>7
Ф Ф
4 1—> 7
Ф
5
г
2—>7
Ф
1—>7
Каждой ветви дерева соответствует некоторая перестановка столбцов.
Далее проверяем каждый вариант на осмысленность и получаем пра-
вильный вариант.
3->6->5->2-»8н>4н>1->7
Заметим, что не обязательно было строить дерево доусонца. Например,
ветвь 3—>6—>8—>4—>5 можно было отсеять сразу. Разве можно признать
осмысленным следующий фрагмент текста.
142
3 6 8 4 5
я м В
ш у е Г
ж е о л
ч т я О
г у щ е 3
к а т ь е.
е а т а
Такая процедура отсечения ветвей была бы просто необходима, если
бы строк было поменьше, и дерево было бы соответственно гораздо ветви-
стей. Предложенную процедуру легко автоматизировать и сделать пригодной
для реализации на ЭВМ. Алгоритм дешифрования должен состоять из сле-
дующих этапов.
1. Предварительная работа. Анализируя достаточно представительный объем
открытых текстов, построить множество запретных биграмм.
2. Предварительная работа. Составить словарь всевозможных v-грамм для
v=2,3,...,d, которые могут встретиться в открытом тексте. Число d выбира-
ется, исходя из возможностей вычислительной техники.
Построить таблицу 8x8. При этом перебираются последовательно все за-
претные биграммы и для каждой опробуемой биграммы - последовательно
все строки. Если хотя бы в одной строке первый символ биграммы встречает-
ся в i-том столбце, а второй в - j-ом, то клеточка i х j. таблицы зачеркивается.
3. Выбрать некоторый столбец в качестве исходного.
4. Начать процедуру построения дерева путем пристраивания к исходному
столбцу всех вариантов столбцов.
5. Для каждого полученного варианта добавить еще один из оставшихся
столбцов. Если хотя бы в одной из строк таблицы встретится 3-грамма, ко-
торая отсутствует в словаре размещенных 3-грамм, то вариант отсеивается.
6. Для каждого из не отсеянных вариантов добавляем еще один столбец и
проводим отсев ложных вариантов по словарю разрешенных 4-грамм.
Если словарь был построен только для d < 3 , то отсев проводится путем
проверки на допустимость 3-грамм, встретившихся в последних 3-х столбцах
каждой строки. Продолжаем этот процесс до получения полной перестановки.
Ниже приведен восстановленный для нашего примера текст.
143
1 2 3 4 5 6 7 8
1 Я в а м п И
2 ш У ч е г О
3 ж е б о л е
4 ч т О я м О
5 г У е щ е с
6 к а 3 а т ь т .
7 е п е р ь я
8 3 н а ю в в
9 а ш е й в о л
10 е м е н я п
11 р е 3 р е н ь е
12 м н а к а 3 а
13 т ь с н .а ч а
14 л а я м О л
15 ч а Т ь X О т
16 е л а п О в _е
17 р ь т е м О е
18 г о с т ы д а
19 в ы б н е
20 У 3 н а л и н
21 е к о г д а к
22 о г д а б н
23 а д е ж д у я
24 и м е л а X о
25 т ь р е д к о
26 X О т ь в н
27 е д' е л ю р, а
28 3 в д е р е
29 в н е н а ш _е
30 й в и Д е т ь
31 в а с
Замечание о степени неоднозначности восстановления открытого тек-
ста. В обоих примерах нам удалось, хотя и с трудом, восстановить открытые
тексты. Работа по дешифрованию значительно облегчается с увеличением
144
длины шифртекста (или, как говорят, имеющегося в распоряжении материала
перехвата). Если бы материал был увеличен в несколько раз, то во втором
примере в таблице 8x8 с большой вероятностью были бы зачеркнуты все кле-
точки, кроме отвечающих истинной последовательности следования друг за
другом столбцов в открытом тексте. В первом примере вариационный ряд
частот букв открытого текста почти целиком совпадал бы с вариационным
рядом вероятностей знаков открытого текста, и нам бы оставалось просто
подписать один вариационный ряд под другим и провести обратную замену.
Отдельные ошибки легко бы устранялись при первом же прочтении дешиф-
рованного варианта текста.
С другой стороны, при уменьшении материала задача дешифрования су-
щественно усложняется. Действительно, представьте себе, что Вам предложе-
но дешифровать зашифрованный с помощью простой замены шифртекст, со-
стоящий из одного первого слова нашего первого примера ДОЧАЛЬ. Для ка-
ждого слова из шести различных букв найдется простая замена, при примене-
нии которой мы получим данный шифртекст. Проблема заключается не в том,
чтобы найти ключевую подстановку, а в том, как выбрать из обширного мно-
жества вариантов восстановленных открытых текстов именно тот, который
был зашифрован. Таким образом, важной характеристикойэффекгивности
криптографической защиты является степень неоднозначности восстановле-
ния открытого текста по шифрованному. Эта характеристика шифра будет
изучена в главе 4. Сейчас же мы дадим качественное определение этого поня-
тия. Под степенью неоднозначности г естественно понимать математическое
ожидание числа вариантов открытых текстов, которые могут быть получены
при применении алгоритма дешифрования. Если предположить, что при слу-
чайном выборе ложного ключа (ключа, не совпадающего с истинным клю-
чом, с применением которого был получен шифртекст, восстановленный при
расшифровании) и расшифровании на этом случайном ложном ключе рас-
шифрованный текст не отличается от случайного текста, то вероятность того,
что полученный текст длины N будет осмысленным (по классическому опре-
делению вероятностей) равна отношению числа благоприятных исходов —
числа A (N) осмысленных открытых текстов длины N к общему числу текстов
длины N, которое равно, очевидно, nN, где п - число букв в алфавите откры-
тых текстов. Для того чтобы получить степень неоднозначности, необходимо
умножить полученное отношение на число К вариантов ключей. Откуда по-
лучаем формулу
r=r(N)=KA(N)nN (*)
для вычисления степени неоднозначности L восстановления открытого текста.
По смыслу дела шифрование обеспечивает надежную защиту сообще-
ния, если неоднозначность восстановления открытого текста по шифрованно-
му чрезвычайно велика.
145
Степень неоднозначности, как будет показано в главе 4, позволяет
классифицировать шифры по степени их криптографичесой стойкости. Каче-
ственные соображения здесь таковы. Если неоднозначность дешифрования
(возможное число получаемых открытых текстов) есть r(N), а цель дешифро-
вания определена получением открытого истиного текста, то вероятность по-
лучения именно его оценивается величиной l/r(N). Согласно /Про/, шифры
для которых r(N)=A(N) называются абсолютно (теоретически) стойкими (для
абсолютно стойкого шифра применение любого алгоритма дешифрования не
дает никакой информации об открытом тексте). К формуле (*), ее выводу и ее
тратовкам следует относиться весьма осторожно (см. параграф 4.3). Действи-
тельно, согласно /Про/, для получения абсолютной стойкости шифра доста-
N
точно иметь п ключей.
Шифры, не являющиеся теоретически стойкими, для которых надеж-
ность криптографической защиты обеспечивается чрезвычайно большой
сложностью реализации известных алгоритмов дешифрования, называют
практически стойкими (см. главу 5).
Согласно /Про/, шифры, не относящиеся к классам теоретически стой-
ких или практически стойких шифров, называют шифрами временной стойко-
сти.
Число осмысленных открытых текстов длины N для больших значе-
ний N обычно считается равным 2™, где Н - энтропия (в битах) на знак от-
крытого текста (см. главу 4). Для русского литературного текста, как показы-
вают экспериментальные расчеты, величина Н близка к единице. Для более
формализованных текстов (организационно-распорядительных писем, доку-
ментов и т. п.) величина Н заключена в пределах от 0.5 до 0.8.
Возвращаясь к анализу шифра простой замены, отметим, что степень
неоднозначности восстановления открытого текста для этого шифра согласно
/Про/ имеет вид
r(N)=n!2HN/nN,
где Н - энтропия на букву открытого текста.
Шифр простой замены является теоретически стойким при шифрова-
нии литературного русского текста (п=32) длины в одно-два слова и обеспе-
чивает только временную стойкость при большом объеме материала.
Эксперименты показывают, что практическое дешифрование шифра
простой замены для русского литературного текста возможно в случае, если
длина шифртекста в 2-3 раза превышает размер алфавита открытого текста,
т. е. равна 60-100 буквам.
Дешифрование шифра гаммирования при некачественной гамме.
Пусть I некоторый алфавит, буквы которого упорядочены в естествен-
ном порядке. Запись i+i'=i” будем понимать как модульное сложение номе-
146
ров букв из {1,2,.. .,|1|-1,0}по модулю |1|. То есть, записывая уравнения, свя-
занные с гаммированием, мы отождествляем буквы с их номерами в алфавите.
Предположим, что в качестве знаков гаммы в шифре гаммирования могут
быть лишь знаки i, Г el, то есть уравнения образования шифртекста bi,b2,...,
Ьт имеют вид aj+yj^bj, je {1,2,...,N} (можно сказать, что в данном примере ис-
пользуют всего 1 бит гаммы).
В этом случае восстановление открытого текста ai,a2,...i aN по шифр-
тексту bj не вызывает труда. Действительно, по известному шифртексту вы-
пишем колонки букв (переведя их в положительные вычеты)
bp i b2 —i ........................... bN -i
b] -i' b2 —i' ......................... bN -i'
Очевидно, что в каждой колонке содержится по одной букве открыто-
го текста. Этот текст можно попытаться восстановить, используя его избы-
точность. Делается это примерно так же, как и при дешифровании шифра
простой замены. Не вдаваясь в подробности, приведем один пример на чте-
ние в колонках.
к ш и П Ш О л ш А Э И Ж
в р А 3 т ж г р Ш Ф А Я
Прочитали слово КРИПТОГРАФИЯ?
Если бы для зашифрования использовалось 4 буквы, то глубина ко-
лонки была бы равна 4. Если используется полная гамма - для русского языка
все 32 знака, то глубина колонок равна 32, и Вы можете в ней прочитать лю-
бой текст.
Предположим, что гамма шифрования принимает все значения, но с
разными вероятностями. .В этом случае для дешифрования также существуют
определенные подходы. Один из них заключается в чтении в колонках, где
порядок (сверху вниз) в колонке возможных открытых букв ael определен
убыванием (точнее, не возрастанием) вероятностей
PW=P(a.b)/p(b)^ р(а)*Ь~а\
2Ха )q(b-a)
a'
при известной фиксированной букве b. Здесь (р(а),ае1) - вероятностное рас-
пределение букв открытого текста, (q(c), cel) - вероятностное распределение
на знаках гаммы.
147
Для дешифрования не требуется особых усилий, если открытая ин-
формация имеет высокую избыточность. Это характерно для фототелеграф-
ных изображений. Шифрование черно-белых картинок обычно осуществляет-
ся следующим образом. Картинка разбивается на квадратики. Квадратик за-
крашивается в черный цвет - 1, если большая его часть черная, и в белый цвет
-в противном случае. Таким образом, каждому изображению ставится в соот-
ветствие последовательность из 0 и 1. При шифровании на эту последователь-
ность накладывается гамма, снимаемая с шифратора.
Если посмотреть на изображение черного квадрата, зашифрованного
последовательностью, полученной по равновероятнстной схеме Бернулли
(полученной бросанием симметричной монеты), то мы увидим серый фон.
Если же гамма неравновероятностна, то на изображении проявляются конту-
ры фигур, и чем больше неравновероятность, тем контуры отчетливее. На
приводимых ниже рисунках приведено изображение черного квадрата на бе-
лом фоне, закрытое с помощью неравновероятнетной гаммы. Вероятность
единицы в гамме указана в процентах (0%, 42%, 50%, 70%).
148
В связи с вышеизложенным, обязательная составная часть крипто-
графии - это исследование вероятностно-статистических свойств выходных и
промежуточных гамм. Для этих целей можно использовать стандартные ста-
тистические критерии проверки качества псевдослучайных последовательно-
стей (см. Кнут, «Искусство программирования». Т. 2.) либо специально разра-
ботанные статистические процедуры.
Достаточно частой является ситуация, когда гаммы или открытый
, текст можно восстановить приближенно по побочным сигналам, сопрово-
ждающим работу криптотехники и оборудования. Представьте, например,
что открытый текст печатается на телетайпе. Каждый удар печатающего уст-
ройства вызывает шум, все телетайпы стучат, и стук немного отличается для
каждой буквы. Вопрос дЛя инженера - выявить эти отличия для разных букв.
Задача криптографа - оценка, насколько это опасно.
Для оценки используются методы теории информации. Самая грубая
оценка степени неоднозначности восстановления открытого текста длины N
для приведенного выше примера (шифрования гаммой, принимающей к зна-
чений) имеет вид
149
где n - мощность алфавита открытого (шифрованного текста), Н - энтропия
открытого текста на букву.
Таким образом, дешифрование принципиально возможно для литера-
турного открытого текста (Н=1), если шифрующая гамма принимает к<
возможных значений, т.е. к< 16 (положим п=32, Н=1, решая уравнение
nN
получим к=16).
Реальное дешифрование обычно удавалось провести при к < 8. Высо-
коклассные специалисты добивались дешифрования где-то при к=12.
Для шифрования не равновероятной гаммой оценки приобретают вид
2HyN2nh
г
где Ну - энтропия гаммы.
Дешифрование шифра гаммирования при перекрытиях.
Перекрытием шифра называется ситуация, при которой два открытых
текста шифруются с использованием одной и той же гаммы, управляющей
работой узла наложения шифра. Возникновение перекрытий - это опасная с
точки зрения надежности защиты ситуация. Особенно неприятна она для
шифраторов гаммирования. В этом случае в распоряжении противника оказы-
ваются два шифрованных текста вида
b1t=a1t+/t и b2t=a2t+/t, t=l,N.
Обращаем внимание, что открытый текст и шифрованный текст здесь разные,
а гамма одинакова. Злоумышленнику нетрудно из шифрованных текстов по-
лучить разность двух открытых текстов.
a' -a2 = bj -b2 = ct
и попытаться восстановить оба открытых текста. Это просто сделать, если
один из открытых текстов известен, в этом случае
aj=ct+a^
где ct иа^ -известны, a aj - легко восстанавливается. Открытый текст а ] -
может быть известен в случае, если аппаратура работала в линейном режиме
(постоянная связь между передатчиком и приемником), при этом в течение
некоторого времени содержательной информации не передавалось и шифро-
вался известный всем текст «нет информации».
150
Если шифруются обычные тексты и ни один из них не известен, то для
дешифрования используют стандарты.
Опробуют елово открытого'текста и пытаются восстановить второй
открытый текст Если вариант опробования-был выбран неправильно, то вто-
рой открытый текст будет бессмысленным, если правильно - то осмыслен-
ным, и так по частям мы восстановим оба открытых текста.
Например, предположим, что в один из текстов начинался со слова
«СЕКРЕТНО». В этом случае, подставив его на нужное место, мы восстано-
вим фрагмент второго текста, например,
СЕКРЕТНО
В О Е Н Н О-М
Угадав продолжение фрагмента второго текста, мы получаем продолжение
первого текста
СЕКРЕТНО СООБЩ
В О Е Н Н О-М ОРСКОЙ
Продолжая первый текст, получаем
СЕКРЕТНО СООБЩАЮ
В О Е Н Н О-М О Р С К О Й Ф
Снова обращаемся ко второму тексту
СЕКРЕТНО СООБЩАЮ ВАМ
ВОЕННО-МОРСКОЙ ФЛОТ
Таким образом, дешифровальщик восстанавливает оба текста.
Обращаем внимание на то, что наличие перекрытий шифра опасно и
для абсолютно стойкого шифра гаммирования. Перекрытия шифра - это одна
из самых больших неприятностей, которая практически может иметь место
для этих шифров. Для избежания перекрытий абсолютно стойких шифров
гаммирования обычно применяют организационно-технические методы, сво-
дящиеся к уничтожению гаммы наложения сразу же после первого использо-
вания.
151
-Параграф 2.2
Дешифрование шифра Виженера
Основное внимание в данной параграфе уделено вопросам определе-
ния периода гаммы наложения в шифре гаммирования по известному шифро-
ванному тексту. Основным инструментом решения этой задачи выступает ме-
тод Фридмана, основанный на введенном им понятии «индекса совпадения».
Введение. Проблеме определения периода гаммы в шифре гамммиро-
вания по шифрованному тексту посвящено много работ в открытой литерату-
ре, из которых мы отмечаем работы Уильяма Фрйдмана (W.F. Fridman). Це-
лью данного параграфа является математическая проработка открытых науч-
ных работ с единых методологических позиций. То есть доказательное изло-
жение известного материала с математической проработкой гипотез и приве-
денных там утверждений.
Краткий исторический очерк. Под шифром Виженера ниже понима-
ется шифр гаммирования с использованием периодической гаммы малого пе-
риода. Обычно ключ такого шифра выбирается с помощью легко запоминае-
мых приемов. Например, с помощью таблицы Виженера со стандартным рас-
положением алфавита.
A BCDEFGHI JKLMNOPQRSTUVWXYZ
A ABCDEFGHIJKLMNOPQRSTUVWXYZ
В BCDEFGHIJKLMNOPQRSTUVWXYZA
С CDEFGHIJKLMNOPQRSTUVWXYZAB
D DEFGHIJKLMNOPQRSTUVWXYZABC
Е EFGHI JKLMNOPQRSTUVWX YZABCD
F| FGHIJKLMNOPQRSTUVWXYZABCDE
Z Z A BCDEFGHIJKLMNOPQRSTUVWXY
Ключом шифра является последовательность букв у ь у 2,- • У j • При
шифровании открытого текста ai,a2.a<j каждая буква aj открытого текста оп-
ределяет номер столбца, а соответствующая буква ключа уj определяет но-
мер строки, на пересечении которых будет находится шифрованная буква bj.
Клюй (лозунг) - это, как правило, легко запоминаемая фраза. Последующий
152
отрезок длины d открытого текста шифруется на том же ключе. Отождествляя
буквы этого алфавита с их номерами (от 0 до 25) при расположении букв в
стандартном порядке
«А BCDEFGHIJKLMNOPQRSTUVWXYZ»,
уравнение шифрования j-той буквы представимо в виде bj=aj + у j mod 26,
je{l,2,...d}.
Напомним, что шифром Бофора (Beaufort) нередко называют шифр
гаммирования, использующий замену
bj=aj-/j mod26, je{l,2,...d},
то есть шифр «расшифрования» Виженера. Очевидно, шифр Бофора предста-
вим в виде шифра Виженера
bj=aj - у j = aj +(26- у j) mod 26.
Отметим, что по К. Шеннону (/Шен/ стр. 345-346) шифром Бофора
называется шифр с уравнением шифрования у j - aj = bj mod 26 и уравнением
расшифрования
/j-bj=aj mod 26.
Этот шифр также может быть представлен в виде шифра гаммирования для
зашифрования букв 26 - aj, j g {1,2,...}
Иногда используют усложненный шифр Виженера с перемешанным
исходным алфавитом первой строки (остальные строки - сдвиги первой стро-
ки, как и в исходном шифре Виженера). Перемешивание обычно производят с
помощью ключа - лозунга. Например, при ключевой фразе «WORLD TRADE
CENTER» образуют неповторяющуюся последовательность ее букв
«WORLDTAECN» и дополняют ее оставшимися не использованными буква-
ми по порядку «BFGH ... и т. д.». Затем выбирают число п, взаимно простое с
26 (числом букв алфавита), и образуют выборочную последовательность ша-
га п. Например, при п=3. из последовательности «WORLDTAECNBFGH ...»
получают выборочную последовательность «WLANG ...и т. д», которую и
используют в качестве нулевой строки (строки с номером А) в таблице
Виженера (остальные строки - сдвиги первой).
В 1920 году У. Фридман опубликовал результаты своих научных ис-
следований по дешифрованию шифров типа шифра Виженера. Затем появи-
лось достаточно много работ, уточняющих результаты Фридмана, расширяю-
щие границы их применимости (см. литературу к данной главе). Фридман
ввел в рассмотрение так называемый «индекс совпадения», на основе которо-
го он предложил алгоритм нахождения периода гаммы наложения по извест-
ному шифрованному тексту, полученному с помощью шифра Виженера. В
153
1950-х годах появились публикации, в которых излагались другие алгоритмы
определения периода гаммы по шифрованному тексту, так называемый метод
Казиского, разработанный им в 1863 году. Последний метод был заново от-
крыт и советским криптографом Михаилом Ивановичем Соколовым в районе
50-х годов. Для решения той же задачи позднее появился в печати и так назы-
ваемый метод Регрессии-Ковариации (Кэрол и Робинс, 1986 г.).
Понятие индекса совпадения.
Пусть I - некоторый конечный алфавит.
Определение 1. Индексом совпадения последовательности
J . .,1n g I называется величина
г N(N-V) ’
где Fj - частота встречаемости буквы i в последовательности 3 = ibi2,...,iN
(число мест, на которых стоит буква i).
Из данного определения следует, что индекс совпадения последова-
тельности 3 =i 1 ,i2,... Лы равен вероятности Р 3 (ij=if) совпадения букв данной
последовательности на случайно и равновероятно выбранных местах j,
j'el,N,j * j'.
Действительно, априори, буква ij=i может принимать любое значение
из I, следовательно, число F, (Fi—1) есть число возможных благоприятных
событий (ij=ij =i), aN(N-l) есть число всех возможных выборов пар упорядо-
ченных мест (j,j') в последовательности ii,i2,...Дм-.
Далее будем предполагать, что I - алфавит открытого текста некоторо-
го языка. При необходимости, в дальнейшем, мы отождествляем буквы этого
алфавита с их номерами (от 0 до |1|-1) при расположении букв в стандартном
порядке. Через P0=(Pi,P2>-• -,P|i|) обозначим вероятностное распределение на I,
где Pj- вероятность буквы ie I в содержательных открытых текстах; через
A(N)=ai,a2„..,aN будем обозначать реализацию случайной выборки объема N из
генеральной совокупности распределения Ро (далее будем говорить кратко -
выборка из распределения)
Покажем, что
I1! р. fp. _П Щ
lC(A(N))-yh'(h|
1 N(N-l) у
при N—> оо (сходимость по вероятности, см. параграф 2.1)
154
Докажем этот факт, предварительно уточнив обозначения. Именно
положим: Fj=Fj(N). Имеем
E(N)-1
-----------> П.В. -> Р: .
N 1
Второй сомножитель слагаемого в сумме может быть преобразован так
FjfN) F^N-iy + EjN)
N-l N-Ъ ’ .
где e(N) g {0,1}. Поэтому
E(N)
--------> П.В. —> Р; при N —> оо
N-1
откуда и вытекает указанное выше утверждение.
Аналогично, для реализации G(N) выборки объема N из равномерного
распределения на I
IC(G(N)) —> п.в. —> jyj при N —> оо.
Для фиксированного содержательного текста ai,a2j... aN мы полагаем,
что
E(N)
--------> П.В. —> Р: при N —> 00
N-------.
111
в связи с чем 1С(а,,а2.aN) —> п.в. —> У, Р; .
i=l
При случайном выборе последовательности 3=i|,i2,...,iN индекс
совпадения 1С( 5 ) является случайной величиной, и представляет интерес
подсчет его математического ожидания. При различных предположениях о
вероятностном распределении на множестве U возможных гамм ниже бу-
дет подсчитано среднее значение индекса совпадения шифрованного тек-
ста B(N)=B(A(N),G(N))=bi,b2j...bN, где bj=aj + /j (mod |I|), je \,N.
155
Среднее значение индекса совпадения для открытых текстов.
Обозначим через Е(1С(А)) математическое ожидание случайной вели-
чины IC(A(N)), вычисленной для случайной реализации A(N)=ai,a2.aN вы-
борки из вероятностного распределения P0=(Pi,P2,...,P|i|). Через P0(ij=ij ) обо-
значим вероятность совпадения букв в случайной выборке A(N)=ai,a2>... aN на
случайно и равновероятно выбранных местах j, j' е 1, N, j * j'. Здесь мы счита-
ем, что вероятностная мера задана на выборках A(N) и на парах j, j' е 1, N.
ЛЕММА 1. Справедливы равенства
Е(1С(А))=Р0(1Г1у)=2^Л
/
ДОКАЗАТЕЛЬСТВО. Вероятность совпадения двух букв в случайной
реализации выборки A(N)=ai,a2.aN из распределения Рона фиксированных
различных местах равна , и не зависит от выбора этих мест. Поэтому
I
Po(ij=ij )= •
i
С другой стороны,
Е(1С(А))= £lC(A)P(A) = 2 PJ(i]=ij-)P(A) =
a<=in а
Po(ij=ij)=Z^ •
i
Обозначим через E(IC(G)) математическое ожидание случайной величины
IC(G(N)), вычисленной для реализации G=G(N)=/1 ,у2 ,...,yN выборки из
равномерного вероятностного распределения на I, а через PG(=) - вероятность
совпадения букв в случайной выборке G(N)= у i, у 2,..., у N на случайно и
равновероятнстно выбранных местах j, j' е 1, N, j j'.
Аналогично доказательству леммы 1 легко доказывается равенство
E(IC(G))= PG(=)
156
Рассмотрим подмножество Хсвсех реализаций A(N)=ai,a2,„. аы выборки
из вероятностного распределения P0=(P|,P2,...,P|i|), состоящее из всех реализа-
ций A(N)=a1,a2>... aN, для которых частота Fj igI приблизительно равна NP,.
Таким образом, Хс состоит из наиболее вероятных реализаций. Здесь, как и
ранее, Fi=Fi(N) - частота встречаемости символа i el.
ЛЕММА 2. Для любой последовательности A(N)=ai,a2,,...,aN из Хс ве-
роятность Рс(=) совпадения двух случайно и равновероятно выбранных букв
последовательности A(N) (отметим, что индекс совпадения IC(A(N)) равен
Рс(=)) приблизительно равна
—X Pi2——•
N-l£ N-l
ДОКАЗАТЕЛЬСТВО. Имеем
IC,A,N))- F1(F1 ° ’ PIN(P'N~1) ~~
= —-—У i—У (/>2#-f;.)= ——Y Pi1 ——.
Отметим, что в формулировке леммы 2 множество Хс определено не-
строго, в связи с чем и приближенное равенство некорректно. Устранить оп-
ределенную некорректность можно, определив множество Хс как множество,
состоящее из всех реализаций A(N)=ai,a2..аы, для которых частоты Fj, igI
удовлетворяют неравенствам NPi - е < Fj < NPi +е. Утверждение леммы 2 в
этом случае будет состоять в указании верхней и нижней оценок IC(A(N)).
Так, например, несложно показывается, что
IC(A(N))< Р> +2e/N-1 +|I|e2-|I|e.
Пусть U - некоторое подмножество множества IN .Через P у обозна-
чим равномерное вероятностное распределение на U. Элемент множества U
будем обозначать через G(N)= у ।, у г,..., у N
157
Для G(N)= у i, у 2,..., у N из Uh A(N) из In образуем последователь-
ность
B(N>B(A(N),G(N))=bbb2....bN,
где bj=aj+ у j (mod|I|), j е 1, N. Последовательность B(N) будем трактовать
как шифрованный текст, полученный зашифрованием текста A(N) на клю-
че-гамме G(N) в шифре гаммирования
(X=IN,K= и,У= IN, f), f(a„a2,„ aN; у,, у 2,..у N)= bN.
Среднее значение индекса совпадения для шифрованных текстов.
Пусть (X=IN,K=U,y=IN,f) - шифр гаммирования. При заданных веро-
ятностных распределениях Ро, на I и Ру на UcIN на X индуцируется вероят-
ностное распределение и на У индуцируется вероятностное распределение Ру
и, следовательно, имеется и вероятностное распределение случайной величи-
ны 1С(В), где В - шифрованный текст, полученый в результате шифрования
случайного текста A(N) при случайном и равновероятном выборе ключа
G(N) из U. Обозначим через Еи(1С(В)) математическое ожидание случайной
величины 1С(В)- для случайного шифртекста В, а через Py(bj=bj) - вероят-
ность совпадения букв в шифртексте B(N)=f(A(N),G(N))=b|,b2,„. bN на случай-
но и равновероятнстно выбранных местах], j' е 1, N, j Ф j'.
ЛЕММА 3. Пусть U=IN. Тогда справедливы равенства
Еи(1С(В))=Ру(ЬГЬг)=^.
ДОКАЗАТЕЛЬСТВО. Справедливость утверждения леммы 3 вытекает из ин-
дуцированного на множестве шифртекстов равновероятного вероятностного
распределения и утверждения леммы 1.
Обозначим через R=(N|,N2,...,Nk) - произвольное разбиение множест-
ва {1,2,...,N}, а через П=(П (=),П(^)) разбиение множества пар
{l,2,...,N}x{l,2,...,N}, индуцированное разбиением R. Именно, {j,j'} еП(=),
тогда и только тогда, когда j и j' одновременно принадлежат одному классу
(блоку) разбиения R; {j j'} е П(^), когда] и]' принадлежат разным классам
разбиения R. Разбиению П поставим в соответствие подмножество и(П) мно-
жества ключей K=IN. Это подмножество и(П) определим так: последова-
тельность у 1, у 2,..., у n принадлежит и(П) тогда и только тогда, когда у j= у р
для любой пары {j,j'} е П (=).
158
ЛЕММА 4. Пусть последовательность у i, / 2,..., у N случайно и равно-
вероятно выбирается из множества и(П), Тогда: а) Р(у},= iг)=1/|1| для любо-
го je{l,...,N} и iel; б) P(Yj=Yj )=l/|I| для {jj'}G ПО)-
ДОКАЗАТЕЛЬСТВО. По определению, множество U(TI) состоит из
тех и только тех последовательностей у= / ь у 2,. , у n , для которых значения
элементов одинаковы на позициях, принадлежащих одному блоку разбиения
R. Таким образом, каждой такой последовательности у соответствует после-
довательность значений y(Nj) из I, то есть у - функция на множестве блоков
{Ni,N2,...,Nk}. Очевидно, что |и(П)|=|1|к и существует взаимно-однозначное
соответствие между последовательностями из и(П) и множеством всех слов
1к, откуда и вытекают утверждения леммы.
В множестве П (=) выделим подмножество П(=) всех пар различ-
ных элементов (j j'), j*j'.
Величина Р(П(=))= равна вероятности случайного и равно-
вероятного выбора пары индексов {jj'} из множества П(=), аналогично,
))= Равна вероятности случайного и равновероятного выбора
пары индексов (j,j') из множества П(^).
Теорема 1. Пусть шифртекст B=B(N) получается шифрованием слу-
чайного текста A(N) (выборки из распределения Ро) с помощью равноверо-
ятного выбора ключа G(N) из и(П). Тогда справедливы равенства
Eu(IC(B))= Py(bj=bj-)= । । УР. + । । .
J J N(N-Y) V 1 N(N-V) |Z|
ДОКАЗАТЕЛЬСТВО. Пусть B(N)=B(A(N),G(N))=bi,b2,...,bN. Ранее
отмечалось, что индекс совпадения IC(B(N)) последовательности Ь1,Ьг,...,Ьы
совпадает с вероятностью PB(bj=bj) совпадения шифрованных букв на слу-
чайно и равновероятно выбранных двух различных местах. Пользуясь опре-
делением математического ожидания случайной величины, получаем
E(IC(B(N))= P(A)P(G)PB(bj=bj).
AeIN,GeU
159
Последняя величина совпадает c Py(bj=bj ). Определим события С(1),
С(2). Событие С(1) состоит в выборе пары индексов (j, j') из П(=), а С(2) - в
выборе (j, j') из П( Ф ). Тогда
X Р(А)Р(О)РВ(Ь,=ЬГ)-
AelN,GeU
X P(A)P(G)[pB(bj =bj/C(l))P(C(l)) + P(bj = b у / С(2))Р(С(2))]=
AeIN,GeU
- X Р(А)Р(С)|рв(Ь; =by /С(1))Р(С(1))]+
AelN,GeU
+ X P(A)P(G)lpB(bj =ЬГ/С(2))Р(С(2))] =
AeIN,GeU
- Y P(A)P(G)|pB(aj+Yj = а,-+Yj-/C(l))P(C(l))]+
AeIN,GeU
+ £ P(A)P(G)[pB(aj+Yj =аг+уг/С(2))Р(С(2))]~
AeIN,GeU
= P(C(1)) 2 P(A)P(G)|pB(aj =а^/С(1))]+
AelN,GeU
+ P(C(2)) Y P(A)P(G)|pB(aj+Yj = aj-+ Yj-/C(2))j.
AeIN,GeU
Первое слагаемое преобразуем следующим образом:
Р(С(1)) X P(A)P{G)[pB(aj = aj-/С(1))]=
AelN,GeU
=Р(С(1» X X P(A)P(G)[pB(aj=aj-/C(l))]=
AeIN GeU
=P(C(1>) X Р(Л)[ра(а7 =flj-/C(l))]^/>(G) =
AeIN G^U
160
=Р(С(1)) X Р(Л)[р,(О; =Я//С(1))]«
AeIN
=Р(С(1))2 Р(Л)[р/лу =ау.)]=
AzIn
=Р(С(1)) •
iel
При получении последнего равенства использована лемма 1.
При случайном и равновероятном выборе G из U и выполнении усло-
вия С(2) значения /., в G случайны и равновероятны (см. лемму 4). С
учетом этого факта преобразуем теперь второе слагаемое.
Р(С(2)) £ P(A)P(G)|pB(aj+Tj =aj+yj./C(2))]=
AeIN,GeU
= Р(С(2)) P(A)P(Yj>YjO[PB(aj +Yj =aj'+Yj')]=
AGlN,Yj,yjGlxI
= P(C(2)) 2 P(A)Z P(Yj,Yj')|PB(aj+Yj =aj +Yj)]=
AeIN, Yj,Yj-
= P(C(2)) P(A)[p(aj +Yj =ar + yf)J,
AeIN,
где P(ctj + уj- = aj- + у j) вероятность события
(aj + уj- = ay. + 7..) при случайном и равновероятном выборе
Yj>Yr-
Следовательно,
Р(С(2)) £ Р(Л)[р(ау + Yj =ar+yr}}=
Ael\
= P(C(2))-J- 2 Р(Л)=Р(С(2))-4-.
I 7 I Ael", Г7 I
Объединяя результаты преобразований двух слагаемых, получаем
161
Eu(IC(B))=Py(bj=bj)= |Л( ^P,2 .
J J N(N-T) T ' N(N-T) |Z|
Укажем и второй способ доказательства теоремы 1. Представим ве-
роятность Py(bj=bj ) в следующем виде:
py(bj=bj)=
Y,Py(bj =ЬГ/= 1—ру(а.+г.=аг+Гг)-
=-------- У Pv (а, + у, = а+ у) +
+-------- У Ру(а, +у, = аг +/,) =
=-------- У Pv(aj=ar) +------------ У Pv(a,+/, =а,-+/,).
w-i)y,/4=) J 7 w-i)AAo 7 7 7 7
Используя теперь технику доказательства леммы 1, предыдущее вы-
ражение преобразуется к виду
I П(=) | ур2 | |(77(*)Ь 1
ЛГ(ЛГ-1) У ' N(N-l) |Z|’
СЛЕДСТВИЕ ТЕОРЕМЫ 1. Если R - разбиение множества {1,2,.. .,N} на од-
ноэлементные подмножества (k=N, |П(=)| = 0), то есть рассматривается мно-
жество U(TI)=IN, то
Eu(IC(B))=Py(bj=bj)=jyj.
Если R - одноэлементное разбиение (к=1), то
Еи(1С(В))=Ру(ЬГЬг)=2Л2-
‘ i
Утверждения следствия вытекают из теоремы 1; они также могут быть
доказаны исходя из утверждений лемм 3, 1. 6
6 Зак.5
162
Среднее значение индекса совпадения шифрованных текстов в
шифре Виженера. Напомним, что шифром Виженера называют шифр
гаммирования, множеством ключей которого являются коротко-
периодические лозунги. Имея дело с гаммами конечной длины, понятие пе-
риодичности конечной последовательности и ее периода требует математиче-
ской формализации.
Определение 2. Назовем конечную последовательность i 1,12,...,iwло-
кально-периодической (или, кратко-периодической), если найдется натураль-
ное число d, 2d <N, при котором для любого j, в случае j+d <N, выполняется
равенство ij =ij+(j. Число d с указанным свойством назовем локальным перио-
дом, или, короче, периодом данной последовательности. (Период конечной
последовательности определен данным определением, вообще говоря, неод-
нозначно).
Говоря ниже о том, что некоторая последовательность имеет локаль-
ный период мы, не оговаривая это, считаем, что рассматриваемая последова-
тельность локально-периодическая.
Обозначим через INd - множество всех локально-периодических
последовательностей периода d, N=Kd+r и рассмотрим разбиение
R<i=(Ni,N2,...,Nd) множества номеров {1,2,...,N}, где
N,={1, 1+d, ... ,1+kd}
N2={2, 2+d, ... ,2+kd}
Nr={r, r+d, .... ,r+kd}
N.+Hr+I.r+l+d, .... , r+l+(k-l)d}
Nr+2={r+2, r+2+d, ..., r+2+(k-l)d}
Nd={d, 2d, ... ,d+(k-l)d}.
Любая последовательность из INd такава, что ее элементы, стоящие на
местах с номерами из одного блока номеров, одинаковы. Разбиению Rj соот-
ветствует рзбиение nd =( П d (=),nd (^ )) множества различных пар номеров.
При этом ясно, что / ^=и(П), так как, очевидно, любую последовательность
длины N с периодом d можно получить случайно и равновероятно, выбирая
d-грамму в алфавите I и повторяя ее необходимое число раз до получения по-
следовательности длины N. Следовательно, | INd |=|I|d, и для подмножества nd
(=) пар различных элементов из П d(=) получаем
163
|nd(=)|= (k+l)kr + k(k-l)(d-r),
где к и г определены равенством N=kd+r (г - остаток от деления N на d). Ис-
пользуя последнее равенство, получаем
|IIdO )|=N(N-1) - (k+l)kr - k(k-l)(d-r).
Из полученных значений мощностей |nd (=)| и |nd ( Ф )| и утверждения
теоремы 1 непосредственно вытекает
СЛЕДСТВИЕ 2 ТЕОРЕМЫ 1. Пусть шифртекст B=B(N) получается
шифрованием случайного текста A(N) (выборки из распределения Ро) с по-
мощью равновероятного выбора ключа G(N) из множества 1 Nd всех периоди-
ческих последовательностей периода d, bJ=kd+r. Тогда справедливы равенства
' Еи(1С(В))=Ру(ЬГЬг)=
_ (k + l)kr + k(k-V)(d-г) ур2 (k + V)kr + k(k-V)(d-г) 1
N(N-1) V ' +( N(N-r) VI’
В частности, при г=0
Eu(IC(B))= Py(bj=bj-)=
_ k(k-V)d ур2 k(k-V)d 1 _ N — d ур2 }N(d-\) 1
N(N—1) ‘ 1 ' N(N-1)J| 11 d(N-\)£t ‘ (N-V)d\I\'
Среднее значение индекса совпадения шифрованных текстов, за-
шифрованных почти периодическими гаммами.
Определение 3. Назовем конечную последовательность ii,i2,.. -Jn К -
приближенной к локально-периодической последовательности if, i2,..., i*N пе-
риода d, если расстояние Хэмминга р (ii,i2,...4n; if, i2,• • •, i*N) между данными
последовательностями равно К. Последовательность ii,i2,...,iN назовем после-
довательностью с К-приближенным периодом d, если она является К-
приближенной к некоторой локально-периодической последовательности пе-
риода d.
ЗАМЕЧАНИЕ 1. Пусть I=Z/|I| - кольцо вычетов по модулю |1|. Из оп-
ределения следует, что каждую последовательность i*,i*2y->iN с
6*
164
К-приближенным периодом периодом d можно представить в виде суммы по
модулю |1| некоторого вектора - последовательности i i Лг» - • -Jn периода d из
компонент, принадлежащих Z/|I|, и некоторого вектора «помех»
C(N,K)=Ci,C2,...,cn с числом К ненулевых компонент. Очевидно, верно и об-
ратное утверждение: сумма такого вида будет последовательностью с К-
приближенным периодом d.
Следовательно, процесс шифрования открытого текста A(N)=ai,a2„.. аы гаммой
G(N)= z'] ,i2 N с К-приближенным периодом d можно представить в виде
последовательного выполнения двух процессов: наложения на открытый
текст A(N) вектора помех C(N,K) и затем зашифрования результата гаммой
ii,i2,...,In периода d.
ЛЕММА 5. Пусть ai,a2.aN- выборка из распределения
P0=(Pi,P2,...,P|i|), a C(N,K)=Ci,c2,. . .,cN - равновероятно выбранный вектор из
множества всех векторов, имеющих ровно К ненулевых компонент. Тогда по-
следовательность а'1,а'2,„. а'ы.где a'j =aj +Cj (mod(|I|) является выборкой из рас-
пределения Р'0=(Р' |,Р'2,.. .,Р'|1|),
где
р,=р,(1_____“—ш-)+—!------------------“—.
WGV-tf + l) (|Z|-1) |Z|-1 N(N-K + V)
ДОКАЗАТЕЛЬСТВО.
P(aj +Cj=i) = P(aj =i/Cj=O)P(Cj=O) + P(aj +Cj=i/Cj O)P(cj * 0)=
Pi (1 - ^L) + P(aj +Cj=i/Cj * 0, aj * i )Р(с; * 0) P(aj * i) =
=pi (1--^-)+
----------)+----------------- (l.p):
N(N-K + 1) |Z|-1 N(N-K + T)
165
=pi(l-—^)- -J—
N(N-K + 1) |Z|-1 N(N-K + 1)
1 ‘ К
| Z |-1 N(N-K + \)
=pi(l___*-------1—*—
N(AT-tf + l) |Z|-1 N(N-K + 1)
! 1 К
|Z|-1 N(N-K + 1)
=p,<i-------4---------l£L) + _!-----------«------
N(N — K + \) (|Z|-1) |Z|-1 N(N-K + 1)
Пусть последовательность а'ьа'2.... а'ы, получена зашифрованием слу-
чайной выборки из распределения Po=(Pi,P2,...,P|i|) наложением случайно и
равновероятно выбранной гаммы из множества всех гамм с К-приближенным
периодом d.
Замечание 1 и утверждение данной леммы сводит задачу подсчета ве-
роятности совпадения двух букв на случайно и равновероятно выбранных
различных местах в случайной последовательности a'i,a'2 ,.a'N к аналогичной
решенной задаче для гаммирования случайной последовательностью
периода d.
Среднее значение индекса совпадения для шифра Виженера с
фиксированным ключом.
Теорема 2. Пусть шифртекст B=B(N) получается шифрованием слу-
чайного текста A(N) (выборки из распределения P0=(Pi,P2,...,Pn)) с помощью
фиксированного ключа G(N)=/l,/2,...,/yv. Тогда среднее значение Е(1С(В))
индекса совпадения случайного шифртекста совпадает с вероятностью
P(bj=bj ) совпадения букв на случайно выбранных различных местах в случай-
ном шифртексте, и это значение равно
1 П(=) 1 у р; +—1— у у р,р,„_...
N(N -1)
где П(=) - множество всех различных позиций], j', для которых у. = у ~, а
П( Ф) - множество всех остальных позиций (операции в индексах по
модулю |1|).
166
ДОКАЗАТЕЛЬСТВО.
P(bj=bj)=E(IC(B))=
SP (bj =/,../;,/)Р(;,/)=_P(aJ +Yj=ar +Гг) =
--------- У P (at +Yi =ar + /,•) +
w-ib4(=> J J 11
+-------- У P(a, + y, =ar +r,.)=
W-l) л/few ' ’
=-------- У P{a.=aj.')+.----------- У P (a.+/ =«,.+/ ).
Вероятность P (dj + у} = а~ +уг) представляется в виде
Р (ау. +у. =аг + /у.) = У PiPi+/7 "Г;-.
/е/
властности, Р (dj = а,..) = У Р^.2 • Поэтому
iel
P(bj=bj)=E(IC(B)= У Р2 +---------- У У р,^+г_г..
Задача определения периода гаммы в шифре гаммирования по задан-
ному шифртексту.
Пусть (X=IN,K= и,У= IN, f), U С IN - шифр гаммирования
f(ai,a2.aN; /i,/2,-.-,/n)= bi,b2„..bN.
Здесь A(N)= ai,a2 aN - открытый текст, G(N)=/1 ,/2N - гамма из U, B=
ЬьЬ2.bN - шифрованный текст.
Задача состоит в определении периода гаммы по известному шиф-
ртексту (либо установления факта ее непериодичности).
Статистические методы.
Определение статистическими методами периода гаммы в шифре гам-
мирования по заданному.шифртексту основано на переборе возможных зна-
чений периода и решения для каждого значения периода задачи «о перекры-
167
тии» - установления факта того, что два заданных шифртекста получены за-
шифрованием двух открытых текстов одной гаммой.
Пусть bi,b2,... ,bN - известный шифртекст, полученый зашифрованием
неизвестного открытого текста ai,a2,.. .,ац на ключе - гамме yi,y2,.. .,Yn- Для
проверяемого периода d образуется вспомогательная последовательность
bi-b|+d, b2-b2+d,...,bj-bj+d,...,b(k-1 )d+r-bkd+r , N=kd+r.
Напомним, что вычитание и сложение проводится по модулю |1| номе-
ров букв, упорядоченных в естественном расположении. Так как bj=aj+yj, то, в
случае истинного периода d гаммы, получаем
bj-bj+d aj-aj+d
для любого j g {1,... ,(k-1 )d+r}, то есть вспомогательная последовательность
является, как говорят, «разностью двух открытых текстов». При случайном
выборе этих “открытых текстов” вспомогательная последовательность тоже
является случайной, вероятностное распределение букв (номеров), которой
равно Р =(pi,p2,...,Р[![) (ГИПОТЕЗА Н(0)), где р,= УРСРС- > сумма берется по
c-c'=j
всем с,с': c-c'=j (mod |I|) .
Если d не является истинным периодом гаммы, то
bj-bj+d=aj+yj-aj+d-yj+d.
Естественно предположить, что знаки Yj,Yj+d выбирались при шифро-
вании независимо. Вспомогательная последовательность в этом случае не яв-
ляется «разностью двух открытых текстов». При случайном выборе открытых
текстов ai,a2,..., a(k.i)d+r; ai+d,a2+d,...,akd+r нередко предполагают, что вспомога-
тельная последовательность является случайной независимой выборкой из
равновероятного распределения на I (ГИПОТЕЗА Н(1)).
Относительно вспомогательной последовательности решают стати-
стическую задачу - принятия гипотезы Н(0) или Н(1). Принятому решению в
статистической задаче соответствует решение криптографическое: истинным
периодом является d или d - не истинный период. Основными характеристи-
ками изложенного метода являются: N и ошибки критерия.
Метод Фридриха Казиского. Метод Фридриха Казиского, представ-
ленный в 1863 году, анализирует повторения в шифртексте. Этот же метод
независимо от Казиского был разработан советским криптографом Соколо-
вым. Метод основан на том, что если гамма локально периодическая, то две
одинаковые m-граммы открытого текста, отстоящие друг от друга на рас-
стояние, кратное периоду гаммы, будут одинаково зашифрованы в некоторые
одинаковые m-граммы, находящиеся на том же расстоянии друг от друга. По-
явление же одинаковых m-грамм в шифрованном тексте по другим причинам
маловероятно (при некоторых разумных ограничениях на величину m и на
168
длину шифртекста N). Следовательно, большинство расстояний между одина-
ковыми m-граммами шифртекста делится на минимальный период. Поэтому
на практике в качестве предполагаемого периода гаммы рассматривают наи-
больший общий делитель длин большинства расстояний между повторениями
m-грамм. Эксперименты показали хорошую надежность этого метода, если в
шифртексте имеются повторения триграмм и m-грамм при т, большим трех.
Первый метод Уильяма Фридмана. Первый метод Уильяма Фрид-
мана состоит в том, что для данного шифртекста В вычисляют индекс совпа-
дения 1С(В) и сравнивают его с величинами
N-d
d(N
При достаточной близости 1С(В) к одной из этих величин при некото-
ром d, предполагают, что период равен этому d. Согласно открытым публика-
циям (см., например, John С. King. 1994. An Algorithm for the Complete Auto-
mated Criptanalysis of Periodic Polyalphabetic Substitution Ciphers. Cryptologia.
18 (4), 332-355) данный метод удовлетворительно работает при использова-
нии для зашифрования локально-периодических последовательностей перио-
да не более 5. С точки зрения обоснованности применения данного метода
лучше сравнивать 1С(В) с более точным выражением
Еи(1С(В))=Ру(ЬГЬг)=
(k + l)kr + k(k-l)(d-r) ур2 (k + l)kr + k(k-l)(d-г) 1
N(N-V) / + _ N(N-l) VI’
полученным ранее для N=kd+r и представленным в начале формулировки
следствии 2 теоремы 1.
Слабая эффективность этого метода объясняется, тем обстоятельст-
вом, что значение
N-d ур2 ^(d-1) 1
d(N-l)% ‘ (N-T)d\l\
математического ожидания индекса совпадения шифрованного текста для
класса U периодических гамм фиксированного периода d совпадает со значе-
нием целого ряда различных классов гамм. Это следует из теоремы 1, где до-
казано, что это среднее значение
Eu(IC(B))= Py(bj=bj )= । । + । । — •
J J N(N-1) V N(N-V) |Z|
169
определено разбиением R=(N!,N2,...,NC) множества 1,2V. В частности, из это-
го факта следует, что значение Eu(IC(B))= Py(bj=bj) для класса гамм периода d
остается инвариантным относительно одновременной перестановки знаков во
всех периодических гаммах - ключах.
Второй метод Уильяма Фридмана.
Второй метод Уильяма Фридмана также основан на вычислении ин-
декса совпадения. Он состоит в опробовании возможных периодов по сле-
дующей схеме. Для предполагаемого периода d выписываются d подпоследо-
вательностей
b|,bi+d,bi+2d,-..
b2,b2+d,b2+2d>- • •
bd,bd+d?l^d+2d? • • •
Для каждой подпоследовательности подсчитывается ее индекс совпадения.
Если все индексы совпадения в среднем близки к значению
то есть к среднему значению индекса совпадения случайных шифртекстов,
полученных с помощью гамм периода 1 (см. следствие 2 теоремы 1), то при-
нимают величину d за истинный период, в противном случае опробуют сле-
дующую величину периода. Приведенный способ нахождения периода гаммы
по шифрованному тексту удовлетворительно работает для периодов, не пре-
вышающих 30.
Метод БШ.
Предлагаемый метод определения периода гаммы в шифре гаммиро-
вания по известному шифртексту В= b|,b2.bN состоит в следующем.
Выписываются все пары номеров j, j', для которых bj = by. Пусть
П(В,=) - множество таких пар. Очевидно, |П(В,=)|= Fj (Fj — 1), где Fj - час-
isl
тота встречаемости буквы i в шифртексте В.
Каждой паре (j, j') из П(В,=) ставится в соответствие расстояние p(jj'),
равное абсолютной величине разности между] и]'. Ищется максимальное по
мощности подмножество П(В,б,=) пар в П(В,=) такое, что их расстояния p(j,j')
имеют некоторый общий наибольший делитель d, отличный от 1. Подсчиты-
вается величина
170
иБШ(в,а) = !П(в,а’
N(N-l)
и сравнивается с величиной
Еи(ИБШ(в.а))= + z
где к, г определены равенством N=kd+r. Если эти величины близки, принима-
ется гипотеза о том, что шифрование проводилось гаммой периода d. В про-
тивном случае, эта гипотеза отвергается.
Обоснование метода БШ.
Для шифрованного текста В= Ь],Ь2,...Ьн величина
иБШ(в,а) = |п(в,а,=)|
N(N-l)
равна вероятности PB(bj=by, d) того, что при случайном и равновероятном вы-
боре различных позиций j и j' с расстоянием, кратным d элементы bj и by сов-
падут. Действительно, по определению множества II(B,d,=), ему принадлежат
те и только те пары (j, j'), при которых d|p(j,j') ц bj = by , a N(N-1) - число всех
пар различных позиций в последовательности В= Ь1,Ь2„...Ьм.
Обозначим через I% множество всех локально-периодических после-
довательностей периода d.
Теорема 3. Пусть шифртекст B=B(N)=bi,b2,...bN получается шифрова-
нием случайного текста A(N) (выборки из распределения Ро) с помощью
равновероятного выбора ключа G(N) из . Тогда вероятность Py(bj=bj,d)
того, что при случайном и равновероятном выборе различных позиций j и j' с
расстоянием, кратным d, элементы bj и bj- случайного шифртекста В совпадут
(имеется в виду вероятность совместного события: равенство букв на местах],
j' и кратность расстояния между ними величине d), равна величине
(k + V)kr + k(k-V)(d-г) ур2
N(N-l) V ' ’
При указанной вероятностной модели получения шифртекста данная
вероятность совпадает с математическим ожиданием Е(ИБШ(ВД)) случайной
величины ИБШ(ВД).
ДОКАЗАТЕЛЬСТВО. Множеству Z^=U соответствует разбиение
R(d)=(Nb N2,...,Na) множества {1,2,...,N}, где Nj={jj+dj+2d,...}, je{l,2,..,.,d}.
171
Пусть II(d)=( П (d,=),II(d,( Ф)) - разбиение множества пар
{l,2,...,N}x{l,2,...,N}, индуцированное разбиением R(d). Введем обозначе-
ние: n(d,=)= |{(jj'}еП(d,=), >j'}|.
Положим, P(n(d,=))= ~ вероятность случайного и равнове-
роятного выбора пары индексов {j j'}h3 множества n(d,=).
Ранее отмечалось, что величина HBIII(B(N)) последовательности
bi,Ьг,...,Ьи совпадает с вероятностью PB(bj=bj-,d) совпадения шифрованных
букв на случайно и равновероятно выбранных двух различных местах, рас-
стояние между которыми кратно d. Поэтому
E(HBm(B(N)) = Py(brbj,d)= P(A)P(G)PB(bj=br,d) =
AeIN,GeU
= X Р(А)Р(О)[рв(Ь; =bf/d|P(j,j'))P(d|p(j,j')J-
AeIN,GeU
- X P(A)P(G)[pB(aj+7j =aj +Yj./d|p(j,j'))P(d|p(j,j'))J-
AeIN,GeU
I
= P(d|p(j,j)) L P(A)P(G)[pB(aj=aj/d|p(j,j-)]=
AeIN,GeU
= P(d(p(jj')) £ £ P(A)P(G)[pB(ai=aj /d|p(j,j')]-
AelN GeU
-P(d|pOJ-)) X P(A)lPB(aj=aj /d|p(ij')]S P(G)-
AeIN GeU
= P(d|p0J')) Р<Л)|А(а; = ar ld I Р(Л/)]=
AeIn
= P(d|p(jj')) Z р(Л)[Ря(а; = a,..)]=
AeIN
' Z- . N(N-l) V '
Теорема доказана.
172
Обозначим через R'=(N'i,N'2,...,N\) - произвольное разбиение мно-
жества {1,2,...,N}, а через П(И')=(П (R',=),II(R-,^)), разбиение множества
пар (1.2...N}x(1.2....N). индуцированное разбиением R' (данное понятие
определено выше). Разбиению II(R') поставим в соответствие подмножество
U(II(R')) множества ключей K=IN. Последовательность /1, / 2, • • • > / n из IN
принадлежит U(n(R')) тогда и только тогда, когда для любой пары
{j j'} е П (R',=). Рассмотрим пересечение R' n R(d) разбиения
R'=(N'i,N' 2,...,N\) и введенного при доказательстве теоремы 3 разбиения
R(d)=(N। ,N2,... ,Nd) множества {1,2,... ,N}, где Nj= {j j+d j+2d,...}, j g {1,2,... ,d}.
Разбиение R' ГУ R(d)=(ni,n2,...,nt) состоит из непустых блоков вида N'j- ГУ Nj,
где j' g {1Д... ,k}, j g {1,2,... ,d}. Этому разбиению соответствует разбиение
n(R' ГУ R(d))=(n((R' n R(d),=)),n((R' ГУ R(d),^)) множества пар
{l,2,...,N}x{l,2,...,N}\{(j j):jG 1,N}. Напомним, что разбиению R(d) соответ-
ствует n(d)=(n(d,=),n(d,( =£)) - разбиение множества пар
{l,2,...,N}x{l,2,...,N}\{(j,j):jG 1, N}, индуцированное разбиением R(d).
Положим Р(П(б,=))=^-^^—— = У
|ЛГС| W-!)
w(w-i)
вероятность случайного и равновероятного выбора пары индексов {j j'}H3
множества n(d,=), a е 77(R'ryR(tZ) = У
|пс 1(1”с 1-1)
N(N-l)
Пусть шифртекст B=B(N) получается шифрованием случайного текста
A=A(N) (выборки из распределения Ро) с помощью равновероятного выбора
ключа G=G(N) из U(n(R')). Подсчитаем вероятность Py(bj=bj,d) совместного
события: при случайном и равновероятном выборе различных позиций) и)' с
расстоянием, кратным d, элементы bj и bj- случайного шифртекста В совпадут.
Имеем
Е(ИБШ(В(М)) = Py(bj=bj,d) = У P(A)P(G)PB (bj = b f, d),
AeIN,GeU-
где PB(bj,bj-,d) - вероятность совпадения шифрованных букв bj,bj- в шифртек-
сте В=Ь1,Ь2,...,Ьы, на случайно и равновероятно выбранных двух различных
местах jj', расстояние между которыми кратно d. Шифртекст В получен из
открытого текста А с помощью гаммы G.
Последние равенства можно продолжить:
X P(A)P(G)PB(bj=bj.,d) =
AeIN,GeU
173
- Y Р(А)Р(О)РВ(Ь^Ъ; Д(И)еП(Д>)) +
AeIN,GsU
+ Y P(A)P(G)PB(bj =bj',d,(j,j’)eII(R',#))s
AeIN,GeU
£ Р(А)Р(0)Рв(Ь3=Ь£<1|р(),Г),а]')еП(К-,=))Р(<1|р().Г),О.Г)еЦК-,=))+
AeIN,G6U
+ £ /тед =bf/d\
AslN,GdJ
Напомним, что bj=aj+yj, bj—aj+yj- и при выполнении условия
(jj')G n(R',=) все ключи - гаммы из U(II(R')) таковы, что Yj=7j-. Следователь-
но, первую сумму предыдущего выражения можно преобразовать так:
P(A)P(G)PB(aj =af /d|p(j,j'),Gj')en(R\=))P(d|p(j,j'),Gj')en(R',=))=
AeIN,GeU
=Л^| )еЛ(Л-,=))£ =«; /</|А/-,7"),а/)еМЯ',=))=
AsIn
‘P(d I p(j.j-),(J,/)s Л(Я»)£ Р/.
i<=!
Для случайно и равновероятно выбранной гамме из U(II(R')) вероятность со-
бытия
(yj=i, Yj =i') равна P(yj=i)P(yj =i') для любых i,i', причем P(Yj=i)=j“ для
любого i е I (см. лемму 4). Поэтому вторую сумму рассматриваемого выра-
жения можно привести к виду
ВД|рЩМы)еЦК,#)) £ RA)P(G)PB(aj+Yj=aj.+7J/d№j')fij')eIXR',#)).
AdN,GeU
.Get/
-P(d | p(j,D,(j,j') e Л(Л',#))-4-.
174
Получаем промежуточный результат:
Е(ИБШ(В(Ы)) = Py(bj=bj,d)= P(d | p(j, J'),(J, J') e 77(7?',=))^ T^.2 +
iel
+ Л*|р(ЛЛ.(ЛЛеЛ(Я>))ууу.
Продолжим выкладки:
P(d I PUJ'MJ.J") e Я(й-,=))-Р((л/е Я(Я'пЛ(</),=)))-
_ KI(KI-I)
it N(N-l)
Для подсчета вероятности P(d | p(j, > J) e 77(7?',*)) переобо-
значим разбиение R'nR(d)= (ni,n2,...,nt), состоящее из непустых блоков ви-
да N\nNj, где)'е{1,2,...,к}, je{l,2,...,d}. Именно, пусть ,...,и/(7))-
семейство непустых блоков nm> из системы (ni,n2,...,nt)входящие в блок N,,
je {1,2,...,d}. Тогда .
P(d | p(j,j'),U,J') e 77(7?',*))=P((j,j')en(R(d),=), (j j')en(R',*))=
1 d ( t(j> • 4
Окончательно получаем
E(HBm(B(N))-py(bJ-bj,d)= P(d|p(j,j-),<j,j')en(R-,=){^ р^+
_1
11\ W-I)
N(N-l) 1
‘ f, ( )•
175
Таким образом доказана
Теорема 4. Пусть шифртекст B=B(N) получается шифрованием слу-
чайного текста A=A(N) (выборки из распределения Ро) с помощью равнове-
роятного выбора ключа G=G(N) из U(n(R')). Тогда вероятность Py(bj=bj,d)
того, что при случайном и равновероятном выборе различных позиций] и]' у
них расстояние будет кратно d и элементы bj и bj- случайного шифртекста В
совпадут, равна величине
у1 I I (I I ~1) / у р2 V
% W-1) -
1 1 d t(j)
+----------У( (NAN,. -1) ).
|Z| N(N-V)^ J 1
При указанной вероятностной модели получения шифртекста данная вероят-
ность совпадает с математическим ожиданием Е(ИБШ(В,д)) случайной вели-
чины ИБШ(В^).
Из полученного выражения для вероятности Py(bj=bj,d) следует, чт;о
она зависит не только от мощностей блоков разбиения R' (как это имело ме-
сто для вероятности Py(bj=bj)), но и от мощностей блоков пересечения разбие-
ний R' и R(d). Поэтому такая большая многозначность определения периода в
шифре гаммирования по шифртексту, как в первом методе Вольфа Фридмана,
в предлагаемом методе БШ отсутствует.
WV-1) '
В случае R'=R(d) имеем k=d=t, N'j=Nj=nj, tj=l. Формула для Py(bj=bj,d)
принимает вид
Р<ъ-Ь<п- У I I« I -Ц (У
Py(bj bj,a) 2^ v 2L
zt w(w-i) “Г
(k + \)kr + k(k-V)(d-r) у-.в2
--------₽------------- Z 1 • 9
AT(W-l) т
где N=kd+r. Ранее эта формула была получена в теореме 3.
Возможности использования m-грамм шифрованного текста.
Основная идея одного из направлений повышения надежности пред-
ставленных методов определения периода гаммы в шифре гаммирования со-
стоит в представлении последовательностей алфавита I в виде последователь-
ностей m-грамм алфавита I.
176
Через P0(m) обозначим вероятностное распределение на Im, опреде-
ленное вероятностями P(iiДг,- • .,im) появления т-грамм i|,i2,.. .,im =М в со-
держательных открытых текстах; через A(N,m)=Mi,M2....MN будем обозначать
реализацию случайной выборки объема N из распределения Ро(т). Последо-
вательность m-грамм М],М2...MN при необходимости мы будем рассматри-
вать и как последовательность A(Nm)=MiM2„ MN=ai,a2,...,aNmсимволов алфа-
вита I длины Nm (MjMj+i - конкатенация слов Mj и Mj+i). Пусть
B(N)=B(A(N),G(N))=bi,b2>...bNm,
rflebj=aj + /j (mod |I|), je{l,2,...,Nm}.
Последовательность B(N) будем трактовать как шифрованный текст,
полученный зашифрованием текста A(N) на ключе-гамме G(N) в шифре гам-
мирования (X=INm,K= и,У= INm, f),
f(aba2,... ,aNm; Y b Y 2v • •>/Мт)=Ь|,Ь2,... bblm.
Представляя гамму G(Nm)= у ь у 2,. , Y Nm как последовательность ш-
грамм Г1,Г2,...,ГК, а шифртекст bi,b2.. bNm как последовательность т-грамм
Bi,B2,...,Bn, можно говорить теперь о том, что мы зашифровали выборку
М„м2,... MN на ключе ГЬГ2,.. .,ГЫ, получив шифрованный текст - последова-
тельность m-грамм Bi,B2,...,BN. Задача определения периода последователь-
ности m-грамм Г=Гi,r2,...,rN может решаться теперь полностью аналогично
рассмотренной ранее задаче определения периода гаммы при ш=1. При этом
надо иметь в виду, что если период последовательности Г равен D, то период
d последовательности G(Nm) является делителем числа mD.
Очевидно, модель получения содержательных текстов в виде выборки
m-гамм является значительным уточнением начальной модели получения со-
держательных текстов. Но надо иметь в виду, что, имея текст длины N (вы-
борку объема N) в алфавите I, при переходе к m-граммам нам приходится ра-
ботать с длиной текста N/m (объем выборки уменьшается в m-раз) и, следова-
тельно, уменьшается степень приближения значения индекса совпадения (ин-
декса БШ) шифртекста к значениям теоретических расчетов (аналогично тому
как уменьшается точность приближения относительной частоты встречаемо-
177
сти буквы в содержательном тексте к ее вероятности с умейыпением длины
текста).
Определенным выходом из этой ситуации является рассмотрение всех
m-грамм ij,ij+i,...,ij+(m-i) последовательности ibi2,.• -Зы длины N в алфавите I
(таких m-грамм всего N-(m-l). При этом нам ниже придется проводить расче-
ты в предположении, что эти m-граммы получены независимо друг от друга,
что не соответствует действительности (например, очевидно, что т=граммы
ij,ij+i,...,ij+(m-i)и ij+i,...,ij+(m-i),ij+m зависимы). Тем не менее, такая неразумность
объяснима тем, что при большом N и небольшом ш большинство пар т-грамм
состоит из независимых m-грамм. И остается надежда, что такой слабой зави-
симостью можно пренебречь. Проверка же применимости получаемых при
этом предположении теоретических результатов осуществляется в таких слу-
чаях экспериментальным путем.
Обозначим через Ij множество всех локально периодических после-
довательностей периода d.
Теорема 3'. Пусть шифртекст B=B(m,N) получается шифрованием
случайного текста A=A(N)=ai,a2,...,aN, m-граммы которого являлись выбор-
кой из распределения Р0(ш), с помощью равновероятного выбора ключа
G=G(N) из Ij . Причем, d>m. Тогда вероятность
Py(bjbj+i,...,bj+m=bj bj +i,...,bj-+m;d) того, что при случайном и равновероятном
выборе различных позиций) и)' с расстоянием кратным d m-граммы
bjbj+i,...,bj+m; bj bj +i,...,bj +m случайного шифртекста В совпадут, равна вели-
чине
N(N-Y)
(к+ V)kr + k(k-l)(d-г) v 2
Zj Р (al>a2>—>am) •
(aba2,...,am)elm
При указанной вероятностной модели получения шифртекста данная
вероятность совпадает с математическим ожиданием Е(ИБШ(В(т,М)) слу-
чайной величины ИБШ(В(т,Ы).
ДОКАЗАТЕЛЬСТВО. Множеству Ij =U соответствует разбиение
R(d)=(Nb N2,...,Nd) множества {1,2,...,N}, rfleNj={j,j+dj+2d,...}, je{l,2,...,d}.
Пусть n(d)=(n(d,=),n(d,( Ф)) - разбиение множества пар
{l,2,...,N}x{l,2,...,N}\ {(j,j), je 1, N}, индуцированное разбиением R(d).
178
Положим, Р(П(<1,=))=-^^—— - вероятность случайного и равнове-
роятного выбора пары индексов {j,j'} из множества П(б,=).
Ранее отмечалось, что индекс BIII(B(m,N)) последовательности
bi,ba,...,bN совпадает с вероятностью PeCbjbj+i,...,bj+m=bj bj +i,...,bj+m;d) совпа-
дения шифрованных букв на случайно и равновероятно выбранных двух раз-
личных местах, расстояние между которыми кратно d. Поэтому
E(HBIII(B(m,N)) = Py(bjbj+1,...,bj+(m.i)=bjbj+i,...,bj+(m.|);d) =
- Y P(A)P(G)PB(bj,...,bj+(m-i)=bf,..,bj+(m-i),d),
AeIN,GeU
где PB(bjbj+i,... ,bj+m = bj bj +i,... ,bj +m >d) - вероятность совпадения шифрованных
m-грамм в шифртексте B=bi,b2,.. .,Ьи на случайно и равновероятно выбран-
ных двух различных местах j,j', расстояние между которыми кратно d. Шиф-
ртекст В получен из открытого текста А на ключе - гамме GeU=Z^.
Последние равенства можно продолжить:
X Р(А)Р(О)Рв(Ь,,...,ЪМт-1) =br,...,bj+(m-i).<l)-
AeIN,GeU
X P(A)P(G)PB(bj,...,bWn^1) =bi,...,bjx^l),/<l|p(j,j'))₽(d|p(j,j')=
AeIN,GeU
p(d|p(j,j') S p(A)p(G)PA(aj,...,aj4<m_i)=aj,...,aj+(m_i),/d|p(j,j'))=
AeIN,GeU
Aef" G<=U
Так как по условию d > m то при случайном выборе m-грамм
X р(л)р/а;’-,ау+(т_1) = ay.,...,a/+(m_1),/J|p(j,/)) =
AtlN,
22 Р(А)Ра (а j+(m-l) — а “ 22 P (a12>a2»->am)
AgIn, (ai2,a2,.--,am)Glm
Следовательно,
179
Py(bjbj+i,...,bj+(m-i) bjbj'+i9• •
,m <‘l2'‘2.....
(ai2,a2,-,am)Gl
(k + V)kr + k(k-l)(d-r)
N(N-i)
У\ P2(a>2,“2,•
(a12>a2>—<am^m
Доказательство теоремы 3' закончено.
Возможности переноса изложенных результатов на шифры поточ-
ной замены (ПЗ).
В данном пункте, как и ранее, под открытым текстом мы будем пони-
мать выборку из распределения P0=(Pi,P2,-..,P|i|), где Pj - вероятность буквы]
(ее номера) в содержательном тексте.
Пусть К - некоторое множество подстановок на I. Рассмотрим шифр
ПЗ (X=IN, KN, У, f), где шифрованный текст B=(bbb2,...,bN)=f(A,CT) получается
из открытого текста А=аьа2,.. .,аы с помощью ключа ct=ctj,CT2,. • .,ctngKn сле-
дующим образом:
bj=cj(aj),j6{l,...,N}.
Пусть d - период последовательности ст=СТ1,СТ2,.. • Лы (см. определение 2), в
случае ее локальной периодичности. Задача состоит в определении периода d
последовательности о или же установления его отсутствия по известному
шифрованному тексту В. Легко проверить, что значение индекса совпадения
(IC) последовательности 3 = ibi2,...,1n е IN •
N(N-Y) ’
(Fj - частота встречаемости буквы i в последовательности 3 == i|,i2,...,iN)
совпадает с индексом совпадения последовательности
ст(3 )=CT(i|),cr(i2),...,CT(iN) при любой подстановке ст на I. Предположим допол-
нительно, что |К|=|1| и нижние строки множества К подстановок образуют ла-
тинский квадрат, т. е. множества переходов любых двух различных подстано-
вок не пересекаются (это условие обеспечивает несложное доказательство
аналога леммы 4 для рассматриваемого здесь шифра). Тогда полученные ра-
нее результаты по применению индекса совпадения для определения периода
гаммы шифра гаммирования полностью переносятся и на рассматриваемый
шифр поточной замены. Несложно проверяется и совпадение индекса БШ по-
следовательности 3 =i 14г,... 4n с индексом БШ последовательности
180
o(3 )=o(ii),o(i2),...,CT(iN), откуда следует справедливость полученных ранее
утверждений для индекса БШ и для шифра ПЗ. Трактуя уравнение а+у=Ь как
уравнение TY(a)=b, где Т - подстановка вида T(j)=j+1 (mod(|I|), заключаем, что
шифр гаммирования является частным случаем шифра ПЗ с множеством клю-
чей KN, где К=(Т, Т2,...,Т1'1), Т1’1 - тождественная подстановка на I.
Задача дешифрования шифра поточной замены при известном пе-
риоде ключевой последовательности.
Рассмотрим шифр ПЗ (X=IN,KN,y,f), где шифрованный текст
B=(b|,b2,...,bN)=f(A,cr) получается из открытого текста А=Э1,а2,...,аы с помо-
щью ключа - последовательности o=oi,G2>- • -><7n периода d. Мы будем пред-
полагать, что нижние строки множества К подстановок образуют латинский
квадрат |К|=|1|. Задача состоит в определении открытого текста А по извест-
ному шифрованному тексту В и известному периоду d ключа о.
Метод протяжки вероятного слова. Пусть bi,b2,...,bN - известный
шифртекст, N=kd+r. Рассмотрим две его подпоследовательности.
Ь|, Ь2... , bj,... ,b(k-i)d+r,.
bi +d, b2+d,-. bj+d,... , bkd+r
Выберем так называемое «множество вероятных слов» - слова, кото-
рые по нашему мнению, могут быть началом искомого открытого текста. Для
опробуемого такого слова а'|,а'2,.;.,а\, предполагая, что оно является нача-
лом искомого открытого текста, находим первые O|,a2>---,crt подстановок
ключа (пользуясь тем, что множество К известно и тем, что нижние строки
этого множества образуют латинский квадрат. Действительно, уравнение
ст(а)=Ь при известных а и b однозначно разрешимо относительно о из К. Пра-
вильность угадывания вероятного слова a'i,a'2,...,a't проверяется теперь на
«читаемости» расшифрованного текста
oi_1(b|+d), crf’Cbz+d),..., *(bt+d).
Если последовательность этих букв принимается как случайный (не-
читаемый) текст, то опробуется следующее вероятное слово. В случае же «чи-
таемости» этой последовательности полагают, что
c»i(bi+d)9 c»2(b2+d)9-• nt(bt+d)= ai+d, a2+d?---9 at+d? -
и стараются построить возможные продолжения at+d+i,...,at+d+cэтого отрезка
открытого текста по смыслу первых его t букв ai+d, a2+d?-.-, at+d. Затем опробо-
вать каждое такое продолжение at+d+b---A+d+c,т. е- найти с помощью
bt+d+i,-•-,bt+d+cи этого продолжения последовательность подстановок
' Qt+b- • -jCFt+c, а затем для нее и расшифрованный отрезок текста
181
<^t+i *(bt+i), c?t+2 (bt+2),..., CTt+c '(bt+c)— a t+i, a a t+c.
Если текст а' 1,а'г,.. .,a't, a't+i, a't+2,..a't+c «нечитаемый» (он может
быть таким за счет его окончания a't+1, а\+2,..., а\+с.), то продолжение
at+(|+|,.,.,al+d+c отбрасывается. Если же текст a'i,a'2,...,a\, a't+i, а\+2,..., a't+c
«читаемый», то ищут его возможные продолжения и т. д. Очевидно, поиск
продолжений заканчивается по прочтению первых d букв открытого текста.
Так как в этом случае найден отрезок ключа на d первых знаков и, следова-
тельно, определен весь ключ. Оставшаяся часть не найденного открытого тек-
ста читается расшифрованием на найденном ключе.
Мы привели последовательность действий в методе протяжки вероят-
ного слова исходя из предположения, что выбранные нами наиболее вероят-
ные слова являются началом открытого текста. Обычно подбирают наиболее
вероятные слова и для других позиций открытого текста. В этом случае начи-
нают опробовать эти вероятные слова, естественно, не сначала текста, а при-
вязываясь к их возможному месторасположению. При этом, конечно, видоиз-
меняется и приведенный алгоритм «протяжки вероятного слова».
Метод чтения по колонкам. Пусть bi,b2,...,bN - известный шифр-
текст,^ - период ключевой последовательности. Рассмотрим две его подпос-
ледовательности.
bi, b2... ,bj,... ,b(k.|)d+r, N=kd+r.
Ьl+d, b2+d,..., bj+d ,... , bkd+r
Для изложения «метода чтения по колонкам» введем предварительно
необходимые обозначения. Будем предполагать, что открытыми текстами,
подлежащими шифрованию, являются содержательные тексты с вероятностя-
ми PbP2,...,P|i| букв алфавита I, Pj- вероятность буквы с номером] в содержа-
тельных текстах. Пусть на множестве ключей KN задано равномерное распре-
деление (ключом является реализация выборки объема N из равномерного
распределения на К). Тогда вероятность P(aj=i, aj+d=i7cj(aj)=bj, <Tj(aj+d)=bj+d))
того, что j-тая и j+d-тая буквы открытого текста были равны, соответственно,
i и Г при условии, что j-тая и j+d-тая буквы шифрованного текста равны bj и
bj+d выражается формулой
P(aj=i,aj+d=i7oj(aj)=bj,Oj(aj+d)=bj+d)=
_ Р(а j = i, a j+d = Г; (а;) = Z+,.ау (a J+d) = bJ+d)
Р(сгу {a j ) = bj, a j (ai+d ) = bj+d )
182
Напомним, что мы рассматриваем шифр, множество ключей которого
задано латинским квадратом, следовательно, используемый ключ о однознач-
но определен любым переходом в этой подстановке. Поэтому если числитель
последнего выражения не равен нулю, то
Р(а j = i, a j+d = Г; (ау ) = £,-, (a.+d ) = bJ+d ) _
Р(сту (aj ) = bj, a j (aj+d) = bj+d)
' _P(aj = i’aW = = = PjPr
^aJ(aJ) = bj,aj(aj+d) = bj+d) '
Для рассматриваемых букв шифрованного текста bj и bj+d упорядочим
в соответствии с невозрастанием полученных значений условных вероятно-
, z
стеи и запишем в вертикальную колонку пары букв открытого текста —, при
Г
этом верхние пары будут иметь большую условную вероятность, чем нижние.
Построив такие колонки для каждого je {1,...,N} и расположив их по порядку
слева направо, можно утверждать, что пары
а, а2 а3 а4 .
a\+d a2+d a3+d a4+d a J+d
букв искомого читаемого содержательного текста будут находиться, соответ-
ственно, в первой, второй, и т. д. колонках, и наша задача состоит в подборе
пар букв в каждой колонке так, чтобы получить читаемые тексты как по пер-
вым позициям пар, так и по вторым. При этом большинство истинных пар бу-
дет находиться ближе к верхнему краю колонок. Конечно, не исключен слу-
чай и получения нескольких начальных читаемых пар текстов на небольшой
длине.
Метод дешифрования с использованием взаимного индекса сов-
падения.
Пусть 3=ii,i2,...,iN; 3'=i'i,i'2,...,i'N- - последовательности длины, соот-
ветственно, N и N' букв алфавита I.
ОПРЕДЕЛЕНИЕ. Взаимным индексом совпадения последовательно-
стей 3, 3' называется величина
183
м«3’3'>-^г~-
где F, (F\) - частота встречаемости буквы i в последовательности 3 (За-
данная величина совпадает с вероятностью совпадения букв в последователь-
ностях 3, 3' при случайном независимом и равновероятном выборе позиций
этих букв последовательностях 3, 3'.
Пусть 3 - случайная выборка объема N из некоторого распределения
P=(Pi)iei, а 3' - случайная выборка объема N'=N из распределения P'=(P'j)iei.
Тогда, очевидно, величина
М1С(Р,Р')=£/>Р\.
iel
совпадает с вероятностью P(ij=i'j ) события (ij=i'j ) при случайном и равнове-
роятном выборе выборе] и]' в случайных последовательностях 3, 3'.
Очевидно, для реализаций выборок 3, 3' длины N=N' из распределе-
ний Р, Р' справедлив предельный переход по вероятности
Хг.Г',
Mic(5,3)--^——>п.в.-»У р,р; = м1с(р,р-)
NN %
при N—> оо. Поэтому при достаточно большом N пользуются с некоторой на-
дежностью приближением
М1с(3,3')= " MWP')- (.)
1У1У
Пусть, как и ранее, Р=(Р],Р2,.. -,Рщ) вероятностное распределение букв содер-
жательных текстов, а Р'=(Р' i,P'2,...,Р'щ) - неизвестное распределение на I,
принадлежащее множеству Р(Оек) распределений вида:
P(Q4HPa1(1),Pa-,(2),-,Pa-,(|lW,
где о принадлежит множеству К подстановок на I (Ро4ф - вероятность j-той
буквы, для ее расчета исходя из набора (Р1,Р2,...,Рц|) необходимо найти -
образ буквы j при подстановке а"1).
Предположим, что множество К подстановок таково, что при любых
различных ст,о',ст*еК величины MIc(P(o l),P(cf4))= 5Z-Ч.Л-«>»
iel
М1с(Р(о’1),Р(о*1))=^Рг_1(.)РстШ_|(.) достаточно сильно различаются, то есть
iel
184
различаются так, что различаются и взаимные индексы совпадения М1с(3(ст),
3(ст')), М1с(3(ст),3(ст*)) для выборок 3(ст), 3(ст'),3(ст*) из распределений
Р(ст'), Р(ст'-1), Р(о*-‘).
Приведенное выше приближенное равенство (,) является основным
средством решения следующей задачи. При известных значениях М1с(Р(ст’'),
Р(ст'*)), М1с(Р(о |),Р(о*1)) и известной подстановке о найти ст' и ст* по реали-
зациям выборок: 3(ст), З(ст'), 3(ст*) из распределений
Р(ст '), Р(ст'-'), Р(ст*‘).
Для решения этой задачи подсчитывают взаимные индексы совпаде-
ния М1с(3(ст),3(ст')), М1с(3(ст),3(ст*)) выборок 3(ст), З(ст') и 3(ст), 3(ст*) и.
определяют по ним приближенные значения величин М1с(Р(ст’|),Р(ст'1)) и
М1с(Р(ст‘|),Р(ст*1)). Откуда узнают и неизвестные ст' и ст*.
Метод Симпсона.
Перейдем теперь к изложению метода дешифрования шифра последо-
вательной замены при известном периоде ключевой последовательности.
Пусть bi,b2,...,bN - известный шифртекст, d - период ключевой после-
довательности.
Для всех возможных пар (ст,ст') из КхК подсчитывается значение веро-
ятности М1с(Р(ст’'), Р(ст'‘*)). Проводится разбиение множества К на классы
kczK эквивалентности так, что пары из одного класса имеют одинаковое зна-
чение вероятности, а из разных классов к, к' - разное значение вероятности.
Выписывают шифртекст в следующем виде:
3(1) bi, bj+d, bi+2d,. • .,b]+j<j,...
3(2) b2, b2+d, b2+2d,... ;b2+jd,...
3(d) bd, bd+d, bd+2dj. • -,bd+jd- • •
Пусть Ст1,ст2,...,CTd - начальный отрезок неизвестной ключевой после-
довательности. Тогда первая строка букв - последовательность 3(1) результат
шифрования букв открытого текста по простой замене сть вторая - 3(2) - по
ст2, ...d-тая - по CTd. Далее предполагают, что каждая последовательность 3(j)
является реализацией выборки из неизвестного вероятностного распределения
Р(сгТ1). Подсчитываются значения взаимных индексов совпадения
MIc(3(l),3(j)), je{l,...,d}. Опробуют в качестве неизвестной подстановки Ст]
все подстановки ст из К. Для опробуемого варианта ст при каждом фиксиро-
ванном je {l,...,d} проводят сравнение значения взаимного индекса совпаде-
ния MIc(3(l),3(j)) с вероятностями: М1с(Р(ст ’),Р(ст'1)), ст'еК. Для каждого
je {l,...,d} находят наиболее близкое значение М1.с(Р(ст’1),Р(ст'’1)). Этому зна-
185
чению отвечает некоторый класс эквивалентности k(j). Опробуемому вариан-
ту о ставят в соответствие множество {ст,к(2),...,к(б)| значений вариантов на-
чального отрезка Ст1,ст2,...,ста ключевой последовательности. Первый элемент
любого такого варианта есть ст, второй - произвольный элемент из класса к(2),
и т. д. Промежуточным этапом решения задачи является получение объеди-
нения множеств вариантов по всем стеК. Далее поставленная задача дешиф-
рования решается опробованием вариантов этого множества.
Отметим, что опробование неизвестной подстановки Ст1 диктуется не-
однозначностью решения уравнения = Р относительно пары
zeZ
подстановок (ст,ст*). Так, если (ст,ст*) - решение этого уравнения, то пара
(остЛ,ст*стЛ) также будет решением рассматриваемого уравнения при любой
подстановке стл. Если >ке ищутся решения (ст,ст*) с заданной первой компонен-
той ст, то неоднозначность решения значительно уменьшается.
Модернизированный метод Симпсона.
Если известно, что первая подстановка cti начального отрезка
01 ,о2,...,CTd ключевой последовательности равна тождественной подстановке,
то 3(l)=bi, bi+a, bi+2d,...,b|+jd является выборкой из неизвестного открытого
текста и, по предположению, она трактуется как выборка из распределения
Ро. В этом случае по значениям вероятностей М1с(Ро,Р(ст-1)), стеК с помощью
вычисленных значений взаимных индексов совпадения MIC(3(1), 3(j)),
jG{l,...,d } определяются остальные значения ключевой последовательности.
При неизвестной же первой подстановке в качестве выборки из неиз-
вестного открытого текста (выборки из распределения P0=(Pi,P2,...,P|i|)) может
быть взят произвольный содержательный текст 3(0), т. е. можно ввести до-
полнительную вспомогательную последовательность 3(0) и считать, что ее
буквы шифровались по тождественной подстановке. Следовательно, в общем
случае имеется возможность сведения данной задачи к задаче дешифрования
при известной первой подстановке. Практически же предлагается провести
вычисления модернизированного взаимного индекса MB3(P0,3(j)) по формуле
B3(P0,3(j))=£/>^
/е/ ZV j
где Nj - длина последовательности 3(j), F/ - частота буквы i в 3(j). В качестве
искомой подстановки <jj предлагается брать подстановки ст, для которых
B3(P0,3(j))= ^^«МЦРо^СТ^ '
zeZ j iel
186.
ГЛАВА 3. ИНФОРМАЦИЯ, ЕЕ СВОЙСТВА
Параграф 3.1
Общее понятие информации. Способы представле-
ния информации, подлежащей шифрованию. Дискрети-
зация непрерывных сигналов
Объектом криптографии является информация (содержание сообще-
ний) в процессе ее передачи по каналу связи. Поэтому, как правило, изучение
криптографии как науки начинают с изучения свойств открытой информа-
ции. Криптографы дают следующее определение открытой информации: «не-
засекреченная (незашифрованная) информация, предназначенная для переда-
чи по каналу связи». Открытая информация обязательно должна быть зафик-
сирована на каком-либо материальном носителе (на бумаге, фотопленке, пер-
фоленте и т. д.) Открытую информацию, зафиксированную на некотором ма-
териальном носителе, принято называть открытым сообщением.
Открытая информация обладает свойством инвариантности относи-
тельно материального носителя и заранее оговоренной формы ее представле-
ния (например, в естественной форме - в виде текста на каком-либо языке,
либо в искусственной форме, например, в виде двоичной последовательности,
последовательности физических сигналов и т .д.).
Общеизвестно, что имеется возможность представления непрерывных
сигналов ограниченного спектра в виде последовательности дискретных сиг-
налов без потери информации.
Теорема Котельникова В.А.
Непрерывная функция S(t), спектральная плотность которой отлична
от нуля только в интервале (-F,F), полностью определяется своими значения-
1
ми, отсчитанными в дискретных точках через интервал At=—, где F - мак-
симальная частота спектра (равная ширине спектра в случае, если он начина-
ется от нуля). Значения функции S(t) в любой точке t выражается формулой
/ч v о/ » ч sin2nF(t - KAt)
S(t)= X S(KAt) ' /,
KZc 2nF(t-KAt)
где S(icAt) - отсчеты непрерывной функции в дискретных точках t=KAt.
187
Обычно реальные непрерывные сообщения и сигналы приблизительно
можно рассматривать как функции с ограниченным спектром. Поэтому в силу
теоремы Котельникова вместо непрерывных сообщений можно рассматривать
соответствующие им дискретные (без потери информации). Процедура пред-
ставления непрерывного сообщения в дискретную форму называется кванто-
ванием сигнала во времени (дискретизацией). В связи со сказанным выще
особое значение приобретает изучение свойств дискретных сообщений. Далее
основное внимание будет уделено именно им. При этом основное внимание
будет сосредоточено на изучении свойств так называемых открытых текстов.
Читателю, интересующемуся цифровой обработкой сигналов, реко-
мендуем прочесть ПРИЛОЖЕНИЕ 1 и книги: А.В. Оппенгейм, Р.В. Шафер
«Цифровая обработка сигналов», М., Связь, 1979,416 с.; Л.М. Гольденберг,
Б.А. Матюшкин, М.Н. Поляк «Цифровая обработка сигналов», М., Связь,
1990.
Параграф 3.2
Открытые сообщения и их характеристики (/Фом/)
Понятие открытого сообщения в криптографической литературе
понимается двояко: либо это содержательный текст, поддающийся смы-
словому чтению, либо это текст, подлежащий зашифрованию,- в последнем
случае, вообще говоря, это текст, возможно, и не читаемый, например,
шифрованный текст в случае двойного перешифрования.
В данном параграфе под открытым текстом, как правило, мы понима-
ем содержательный читаемый текст на каком либо языке.
Модели шифров, криптосхем, шифраторов, модели ключевых систем
шифров строятся с использованием моделей открытого текста (или моделей
источника открытых сообщений). Все модели, в том числе и модели открытых
сообщений, обычно делятся на два класса: детерминированные и вероятно-
стные.
Детерминированный источник сообщений.
В этой модели открытые тексты (как и шифрованные) дредставляют
собой последовательности символов, взятых из конечного множества симво-
лов, называемого алфавитом открытого текста. Например, алфавит русского
языка, алфавит английского языка.
Число символов в алфавите математики называют мощностью алфа-
вита. Например, алфавит A(1)={A,B,C,D,.. .,X,Y,Z} - прописные буквы анг-
i лийского языка. Мощность алфавита 26 (иногда вместо пробела используют
188
букву Z). Алфавит А(2)= {A,B,C,D,... ,Х,Y,Z, a,b,c,..., x,y,z, 0,1,2,... ,9, □ , .
« » ? !}- мощность алфавита 70. Алфавит А(3)={0,1} - мощность 2. Часто
используются алфавиты, представляющие собой двоичные наборы длины п
(как правило 5<п<8) или двоичные коды, например, международный теле-
графный код (МТК-2). Полный русский алфавит состоит из 33 букв:
АБИГДЕЕЖЗИЙКЛМНОПРСТУФХЦЧШЩЬЫЪЭЮЯ,
пробела, точки,запятой.
Отождествляют: в ряде случаев Е и Ё, иногда И и И, а иногда Е и Э,
часто отождествляют Ь и Ъ. Добавляя пробел, говорят, что алфавит состоит из
34 букв, а с некоторыми отождествлениями букв алфавит содержит от 28 до
33 букв.
Пусть I - некоторый алфавит, мощности |1|. Текст, записанный в алфа-
вите I, имеет длину - число символов в соответствующей последовательно-
сти. Последовательность к символов называют к-граммой в алфавите I. Мате-
матики, как правило, под последовательностью обычно понимают бесконеч-
ную последовательность символов алфавита I, конечную же последователь-
ность называют словом в алфавите I. Двоякое использование терминов мы, по
возможности, будем отмечать и далее во всей книге.
Собственно источниками открытого текста является отдельный чело-
век или группа людей, радиопередающие станции, пункты телеграфной и те-
лефонной сети и т. д. Каждый источник открытого текста (сообщений) харак-
теризуется своими особенностями: используемым алфавитом, например, рус-
ским алфавитом; определенной структурой тематики сообщений, например, о
погоде, о политике; математический текст, физический и т. д.; частотными
характеристиками сообщений и другими особенностями, например, так назы-
ваемыми вероятными словами: «Сообщаю Вам», «Докладываю», «На Ваш
номер «...» сообщаю», «старший оперуполномоченный провинции Логар
майор Тарасов», и т. д. Сообщения на английском язык,е передаваемые по
телетайпу, скорее всего используют алфавит А(2). Частный корреспондент,
намеревающийся шифровать свои сообщения, во многих случаях предпочтет
использовать алфавит А(1). Данные, передаваемые при межмашинном обме-
не, удобнее отображать с использованием алфавита А(3) (см. В.М. Фомичев,
«Симметричные криптосхемы», М., 1995).
Каждый источник сообщений порождает тексты в соответствии с пра-
вилами грамматики, что находит отражение и в других характеристиках со-
общений. Например, в содержательных текстах на английском языке за бук-
вой «q» всегда следует буква «и», в русских текстах буквы «ь» и «ъ» никогда
не располагаются рядом и не следуют за гласными буквами. Всякий источник
сообщений можно моделировать списком допустимых (т.е. встречающихся в
189
каких-либо текстах) k-грамм при к= 1,2,3,... Если к-грамма не является допус-
тимой, то ее называют запретной или запрещенной.
Разделение множества к-грамм на допустимые и запретные опре-
деляет детерминированную модель источника открытых сообщений. В
такой модели открытый текст рассматривается как последовательность сим-
волов некоторого алфавита, не содержащую запретных к-грамм.
Построение детерминированной модели исследуемого источника от-
крытых сообщений можно реализовать в результате статистической обработ-
ки генерируемых им текстов. Для этого следует «просмотреть» достаточно
большое количество текстов, сгенерированного данным источником, и все не
встретившиеся k-граммы отнести к множеству запретных k-грамм источника.
Естественно, чем большее количество материала отработано, тем эффектив-
нее применение прстроенной модели сообщений на практике для решения х
различных криптографических задач.
В ряде криптографических задач данная модель источника сообщений
используется для различения открытых текстов от случайных последователь-
ностей с помощью вычислительной техники.
Источник передачи данных.
Появление систем телеобработки привело к появлению нового вида
электрической связи, так называемого «передача данных». Целью передачи
данных является передача информации для обработки ее вычислительным
машинам или же выдача ее этими машинами. Принципиальная новизна вида
связи - передачи данных - состоит в том, что эта связь осуществляет обмен
информацией между ЭВМ, а так же между ЭВМ и человеком. Данные, пред-
назначенные для машин, называют «формализованным языком», языком ма-
шин. Этим подчеркивается, что они не предназначены непосредственно для
восприятия человеком. Эти данные передаются в цифровом виде (часто в виде
двоичной последовательности). Осмысливание их человеком может происхо-
дить только после их представления в соответствующей форме. В криптогра-
фических терминах понятия формализованного языка представляют собой
словарные величины, а их условные формы - кодобозначения, последние изо-
бражаются в виде буквенных, цифровых и смешанных групп различной дли-
ны (разрядности). Формализованный документ оформляется в виде так назы-
ваемого «формата», т. е. формы, в которой размещение данных осуществляет-
ся по некоторым жестким правилам на местах, определяемых для данного
формата шаблоном. Таким образом, для чтения таких документов необходи-
мо знать формальный язык и форматы документов. Можно сказать, что фак-
тически открытое сообщение в формализованном языке представляет собой
кодограмму, а перевод открытого сообщения в формализованный язык есть
позиционное кодирование смысловых сообщений нескольких языков, каждый
190
из которых кодируется своим кодом и располагается на определенном месте
формата сообщения. Таким образом, для формализованных сообщений исче-
зает понятие открытого текста в общепринятом его понимании «читаемого»
текста.
Признаками «открытого текста» текста формализованного являются
не его читаемость, а различные его детерминированные и статистические при-
знаки, связанные с применяемыми способами сжатия и кодирования в систе-
мах дискретного фототелеграфа, телевидения, ЭВМ.
Вероятностные источники сообщений.
В этих моделях источник открытого текста рассматривается как ис-
точник случайных последовательностей. Считается, что источник генерирует
конечную или бесконечную последовательность случайных символов
х(1),х(2),...,х(п) из алфавита!. Вероятность случайного сообщения
«i(l),i(2),..., i(n)» определяется как вероятность совместного события
P(i(l),i(2),...,i(n))=P(x(l)=i(l),x(2)=i(2),...,x(n)=i(n))).
При этом, естественно, требуют выполнения условий:
1) для любого случайного сообщения «i( 1),i(2),..., i(n)»
P(i(l),i(2),...,i(n))>0;
2) £P(i(l),i(2),...,i(n))=l;
i(i),i(2),.:.,i(h)
3) для любого случайного сообщения «i( 1),i(2),..., i(n)»
P(i(l),i(2),..„ i(n))= £P(i(l),i(2),...,i(s)), s>n+l.
i(l),i(2),...,i(s)
Смысл последнего условия состоит в том, что вероятность всякого
случайного сообщения длины п есть сумма вероятностей всех «продолжений»
этого сообщения до длины s>n (некоторый вариант аксиомы Колмогорова).
Текст, порождаемый таким источником, является вероятностным ана-
логом языка. Он обладает одинаковыми с языком частотными характеристи-
ками k-грамм. Задавая конкретное вероятностное распределение на множестве
открытых текстов, мы задаем соответствующую модель источника сообще-
ний. Рассмотрим некоторые частные случаи этой общей модели.
Стационарный источник независимых символов алфавита.
ZB этой модели предполагается, что вероятности сообщений полностью
определяются вероятностями отдельных символов алфавита:
п
P(i(l),i(2),..., i(n))=JJP(x(j) = i(j)) и P(x(j)=i)>0, ^P(x(j) - i) = 1.
j=l iel
191
Под открытым текстом понимается реализация последовательно-
сти независимых испытаний в полиномиальной вероятностной схеме с
числом исходов |I|=m. Исходу взаимно однозначно соответствует символ ал-
фавита I. Эта модель позволяет разделить буквы алфавита на классы высокой,
средней и низкой частот использования. Ниже приводятся буквы высокой
частоты использования для некоторых европейских языков (частота указана в
процентах). __________________'_____________________________________
[язык Буквы алфавитов и частоты их использованйя в текстах
1 Английский Е 12,86 Т 9,72 А 7,96 I 7,77 N 7,51 R 7,03
[Испанский Е 14,15 А 12,9 О 8,84 S 7,64 I 7,01 R 6,95
| Итальянский I 12,04 Е 11,6 А П,1 о 8,92 N 7,68 т 7,07
I Немецкий Е 19,18 N 10,2 I 8,21 S 7,07 R 7,01 т 5,86
[Французский Е 17,76 S 8,23 А 7,68 N 7,61 Т 7,30 I 7,23
[Русский О 11,0 И 8,9 , Е 8,3 А 7,9 Н 6,9 т 6,0
Для сравнения частот редких букв и букв, приведенных в таблице,
укажем, что, например, в английском языке редкими буквами являются буквы
J,Q,Z, а их частоты в процентах оцениваются величинами 0,13, 0,12, 0,08,
соответственно. Из этой таблицы видно, что не случайно итальянский и ис-
панский языки считаются певучими: на долю гласных приходится около по-
ловины всех букв.
Самыми частыми биграммами в русском языке являются (в процен-
тах) СТ (1,74), НО (1,29), ЕН (1,23), ТО (1,21), НА (1,20), ОВ (1,16), НИ (1,15),
РА (1,14), ВО (1,08), КО (1,07).
Наиболее частые триграммы: СТО, ЕНО, НОВ, ТОВ, ОВО, НАЛ, РАЛ,
НИС.
Рассматриваемая модель открытого текста весьма просто строится для
любого источника открытых сообщений с использованием относительно не-
большого количества материала и удобна для практического применения. В
тоже время, некоторые свойства модели противоречат свойствам языков. В
частности, согласно этой модели любая k-грамма, к>1, имеет ненулевую веро-
ятность появления в сообщении.
Стационарный источник независимых биграмм.
Открытый текст такого источника является реализацией последовательности
независимых испытаний в полиномиальной вероятностной схеме с числом
исходов равным т2, где т - мощность алфавита I. Для простоты мы отожде-
ствим алфавит с множеством чисел {0,1,...,ш-1} (обычно буква отождествля-
ется с ее номером в естественно упорядоченном алфавите). Множество исхо-
192
дов взаимнооднозначно соответствует множеству всех биграмм алфавита. Эта
модель характеризуется следующим равенством:
п
P(i(l),i(2),..., i(2n))=PJP(x2j_i =i2j-i,x2j =i2j),
j=l
где P(x2j.i=i,X2j=i')^0, для всех i,i'e {0,1,...,m-1}, a
Xp(x2j-i =i,P(x2j =i') = l-
i,i'
В качестве оценок вероятностей биграмм используются относительные
частоты их появления в открытом тексте, которые вычисляются эксперимен-
тально на большом текстовом материале. Вероятности биграмм в алфавите
{0,1,...,ш-1} могут быть сведены в матрицу размера mxm:
Р11 Р12 ... Р1т
Р21 Р22 Р2т
... ... ...
Рт1 Рт2 Ртт
где pjk - вероятность биграммы (jk). Из матрицы вероятностей биграмм де-
шифровальщик может извлечь ряд полезных особенностей, свойственных ис-
точнику сообщений и языку в целом. Например, в английском языке все би-
граммы вида (q,...) имеют нулевую вероятность за исключением биграммы
(q,u), вероятность которой равна приблизительно 0,0011. Биграммы вида
(а,...) имеют ненулевую вероятность за исключением биграммы (a,q).
Данная модель точнее по сравнению с предыдущей отражает особен-
ности языков и источников сообщений. В частности, согласно этой модели
всякое сообщение, у которого на нечетном месте x2j-i,X2j располагается за-
претная биграмма (i,i'), имеет нулевую вероятность. В то же время, моделью
игнорируется свойственные языкам зависимости между соседними биграм-
мами. Например, вероятность слова «ququ» в данной модели английского
языка оценивается величиной 1,21 10‘6, хотя в языке оно не встречается. В
меньшей степени указанные недостатки присущи следующей модели.
Стационарный источник марковски зависимых букв.
Открытый текст такого источника является реализацией последова-
тельности испытаний, связанных простой однородной цепью Маркова с m
состояниями. Данная модель (как и соответствующая цепь Маркова) характе
ризуется матрицей П переходных вероятностей: II=||p(s/t)||, s,t из алфавита
{0,1,... ,m-1} и стационарным распределением вероятностей Р=(р( 1),..., р(т'
193
на алфавите (на состояниях цепи Маркова). Вероятность случайного сообще-
ния выражается формулой
п-1
, P((i( 1 ),i(2),..., i(n))=p(i( 1))• p(i(j +1) I i(j).
j=l
Переходные вероятности и стационарное распределение удовлетворяют усло-
виям:
p(s/t)>0, p(t) >0, t,sе {0,1,... ,m-1};
m-1
£p(s /1) = 1,
s=0
m-1
P(s)= X P(l)p(s/t), S e {0,1,... ,m-1}.
t=o
В данной модели вероятность появления в тексте каждой последую-
щей буквы зависит от значения предыдущей буквы. Согласно модели всякое
сообщение, содержащее где-либо запретную биграмму, имеет нулевую веро-
ятность. Стационарное распределение Р является решением следующей сис-
темы линейных уравнений, записанных в матричной форме: РП=Р.
Стационарный источник независимых k-гамм, к>2.
К этому разделу относится класс моделей, в условиях которых всякое
сообщение является реализацией последовательности испытаний в полиноми-
альной вероятностной схеме с числом исходов равным mk. Эти модели адек-
ватно отражают межсимвольные зависимости внутри каждой k-граммы, но
игнорируют межсимвольные зависимости соседних к-грамм. Чем больше к,
тем, с одной стороны, точнее рассматриваемые модели отражают свойства
языков и источников сообщений и, с другой стороны, тем они более громозд-
ки и неудобны для практического использования. Поэтому выбор подходящей
модели для исследования источника сообщений носит, как правило, компро-
миссный характер и осуществляется дешифровальщиком с учетом свойств
конкретного шифра.
Стационарный источник зависимых k-грамм к>2.
Эти модели характеризуются не только размером к рассматриваемых
мультиграмм (символов, генерируемого сообщения), но и глубиной межсим-
вольной зависимости. Глубина зависимости определяется как размер h муль-
тиграммы (составленной из k-грамм), от значения которой зависит вероят-
ность появления в сообщении следующей за мультиграммой k-граммы. Во
всех языках зависимость вероятности k-граммы от последнего символа h-
7 Зак.5
194
гаммы с ростом h заметно убывает, поэтому подобные модели используются
на практике при небольших значениях h, тем более что с ростом h эти модели
становятся весьма громоздкими.
Нестационарные источники сообщений.
Каждой модели из предыдущих классов можно поставить в соответст-
вие семейство нестационарных моделей, которые отличаются от стационар-
ной модели тем, что вероятности появления по крайней мере некоторых к-
грамм зависит от их места в сообщении. Нестационарные модели можно рас-
сматривать как уточнение стационарных моделей, в которых учтена, в той или
иной мере, структура сообщения. Например, если источником сообщений яв-
ляется премьер-министр, а получателем сообщений - король, то с большой
вероятностью все сообщения будут начинаться со слов «Ваше Величество!..».
Подобные стандарты играют важную роль в криптографическом анализе.
Теоретико-информационная модель источников сообщений.
В данном разделе мы кратко охарактеризуем теоретико-
информационную модель открытых сообщений. Более подробно эта модель
будет изложена в главе 4. Здесь будут использованы понятия «энтропия веро-
ятностной схемы», «собственная информация сообщения» и другие понятия
теории информации.
В данной модели предполагается, что открытые сообщения реализу-
ются некоторым стационарным эргодическим источником сообщений. Для
такого источника определена предельная энтропия Н: HL—>Н, при L—> -яс, где
HL - энтропия на один знак сообщения длины L. Таким образом, Н - энтропия
открытого текста на один знак.
Пусть P(Cl) - вероятность реализации источником сообщения Cl дли-
ны L, I(CL)=loga —- собственная информация сообщения Cl. Тогда по
теореме Макмиллана при L—>ос справедливо асимптотическое равенство
I(Cl)«LH, .
откуда получаем, что для всех вероятностей P(CL):
P(CL)«aLH,
где а - основание логарифма, по которому вычисляется Н. В частности, число
открытых текстов длины L (при большом L) приблизительно равно aLH. Для
литературных текстов на русском, английском языках Н=1 бит. Бели N - чис-
ло букв алфавита, то D=l- H/logaN называют избыточностью языка, она дока-
зывает часть букв открытого текста, которую можно пропустить без потери
содержания текста. Для русского и английского языков D=O,5-O,8. , f .j .
195
Параграф 3.3
Критерии на осмысленные сообщения
Важнейшей задачей криптографии является задача распознавания-от-
крытых текстов. .Имеется некоторая последовательность знаков, записанная в
алфавите!: .
3=ibi2,...iL, ijSl, je{l,2,...,L}.
Требуется построить некоторый алгоритм, который Позволял бы вы-
яснить, является 3 открытым текстом или нет.
Формальное правило, которое позволяет ответить на данный вопрос,
называется критерием на открытый текст. При построении таких критериев
обычно ограничиваются использованием моделей открытых текстов (см. па-
раграф 2.3.) При этом множество X открытых текстов заменяется на некото-
рое другое множество, тексты которого формально считаются открытыми
текстами в этой модели.
В терминах математической статистики можно сказать, что ряд таких
критериев позволяет различать две гипотезы: НО - последовательность 3 -
открытый текст (в принятой модели); Н1 - последовательность 3 - случайная
равновероятная последовательность знаков. Любой статистический критерий
различения двух простых гипотез, в частности, ряд критериев на открытый
текст может допускать ошибки двоякого рода:
ошибка первого рода - имеет место гипотеза НО, а критерий принима-
ет гипотезу Н1, то есть отбраковывается открытый текст;
ошибка второго рода - имеет место гипотеза Н1, а критерий принима-
ет гипотезу НО, то есть за открытый текст принимается случайный набор зна-
ков.
Вероятности этих ошибок
а=Р(Н1/Н0), р=Р(Н0/Н1)
являются основными параметрами критерия. Важным параметром является и
значение среднего числа знаков, на котором критерий отбраковывает случай-
ный текст.
Существует много разнообразных статистических критериев различе-
ния двух простых гипотез, каждый из которых может быть реализован при
решении криптографической задачи: определения открытого текста по задан-
ной последовательности знаков алфавита. Естественно, прежде всего следует
назвать наиболее мощный критерий (критерий Неймана-Пирсона), а также
последовательные критерии (критерии Вальда). Мы же ограничимся рассмот-
7»
196
рением возможностей применения критериев запретных знаков и запретных
биграмм.
Критерии запретных знаков и запретных биграмм.
Один из простых в реализации критериев использует ту особенность
открытого текста, что некоторые m-граммы алфавита появляются в нем очень
редко.
Итак, предполагают, что заданная последовательность знаков есть
реализация некоторого случайного процесса. Примем следующую вероятно-
стную модель.
«Открытый текст» (далее ОТ) 3 получается в результате выборки т-
грамм алфавита I из заданного вероятностного распределения на них: .
{P(ai,a2,.,am), (ai,a2,.,am)6lm } - гипотеза НО. Причем данные значения вероят-
ностей соответствуют вероятностям их появления в открытом тексте (они по-
лучены путем маркировки достаточно длинного открытого текста).
Гипотеза Н1 - текст 3 получен выборкой его m-грамм из вероятност-
ного равномерного распределения на Im , вероятность появления любой т-
граммы есть l/|I|m.
Отберем h самых редких m-грамм и назовем их запретными. Поло-
жим, р=р(з) - суммарная вероятность их появления в ОТ. Остальные ш-
граммы назовем незапретными. Положим, р(н)=1-р(з) — суммарная вероят-
ность незапретных m-грамм. Суммарная вероятность появления в случайном
тексте запретной m-граммы равна Q=h/|I|m.
Критерий запретных m-грамм состоит в поиске в последовательности
3=ii,i2,...iL запретной m-граммы. Для этого просматривается первая tri-грамма
ii,i2,.. .im, вторая - i2,.. .im+i и т.д. Если запретная m-грамма отсутствует в 3, то
принимается гипотеза НО - считается, что текст открытый. Если нашли за-
претную m-грамму, то принимается гипотеза Н1 - текст считается случайным.
Всех m-грамм в тексте 3 есть L-(m-l). В случае т>1 т-граммы оче-
видно зависимы. Но далее, как мы увидим, расчеты ошибок критерия провЪ-
дятся в предположении их независимости.
Рассчитаем ошибку а критерия
а=Р(Н1/Н0)=Р(н,н,.. .,з,.. ,н),
где Р(н,н,...,з,...н) - вероятность появления запретной m-граммы (хотя бы
один раз) в выборке длины L-(m-l) из распределения
{P(ai,a2,.,am),(ai,a2,.,am)elm }. Имеем
а=Р(Н1/Н0)=Р(н,н,. .'.,з,.. .H)=l-(l-p)Lm+1.
Случай запретных знаков, ш=1.
В этом случае a=l-(l-p)L, a p=P(HO/Hl)=(hQ)L=(l-h/|I|)L.
197
Случаи запретных биграмм, m=2. Пусть m=2. Тогда а=1-(1-р)ь*.
Проведем расчет 0=Р(НО/Н1). Обозначим через \|/(L) число всех по-
следовательностей в алфавите I длины L, не содержащих запретных биграмм.
Тогда
₽=P(H0/H1)=\|/(L)/|I|l.
Положим, I={ 1,2,.. .,п}. Для подсчета xj/(L) обозначим через \|/j(L) -
число последовательностей в алфавите I длины L, не содержащих запретных
биграмм и оканчивающихся буквой j . Тогда для j е {1,2,.. .,п} имеют место
рекуррентные соотношения
\|/j(L+l)=\|/i(L)bij+\|/2(L)b2j+.. .\|/n(L)bnj,
где bg =0, если биграмма rj - запретная и brj =1 в противном случае. Рассмот-
рим матрицу В=( brj) размера пхп и вектор
^(LHVi(L),X|/2(L),...,i|/n(L)).
Предыдущие рекуррентные соотношения можно записать в виде
V“>(L+1)=V‘*(L)B.
Элементы L-ой степени BL матрицы В запишем в виде brj(L), BL=(brj(L)). Пре-
дыдущее равенство может быть продолжено так
\|/^(L+1)= \|T(L)B=v^(L+l)= v^(2)BL1
или
Vj(L+l)=Vi(2)blj(L-l)+v2(2)b2j(L-l)+.. ,x|/n(2)bnj(L-l),
где je{l,...,n}, v|/r(2) - число незапретных биграмм оканчивающихся на г,
b^L-l) - число текстов длины L-1 в алфавите I, начинающихся с г, оканчи-
вающиеся на j и не содержащих запретных биграмм. Расчет величин Vr(2)
проводится непосредственно. Таким образом, расчет ошибки 0 сводится к
расчету значений элементов матрицы BL'2. Для подсчета этих значений ис-
пользуют асимптотические результаты. Один из подходов к их вычислению
состоит в использовании теоремы Фробениуса и формулы Перрона.
Часть теоремы Фробениуса (см. /41, стр. 323/).
Если матрица В неотрицательная и неразложимая, то среди ее харак-
теристических чисел есть простой корень X, причем все остальные корни по
модулю строго меньше X.
Неотрицательность матрицы В запретных биграмм очевидна.
Напомним, что матрица называется неразложимой, если ее путем пе-
рестановки строк и столбцов с одинаковыми номерами нельзя привести к ВИ-
ДУ
<Р 0>
J R>
198
где Р и R - квадратные ненулевые матрицы, а элементы подматрицы Т могут
быть произвольными. Неразложимость матрицы В следует из ее связи с от-
крытым текстом. Степень разложимой матрицы имеет аналогичный вид. Если
бы матрица В была разложима то нашлись бы bg(L), которые равнялись бы
нулю при любом L, то есть переход от знака г к знаку] невозможен ни за ка-
кое число шагов L. Это обстоятельство, очевидно, не соответствует природе
открытого текста, и поэтому матрицу В можно считать неразложимой.
Таким образом, матрица В удовлетворяет всем условиям теоремы
Фробениуса и, следовательно, имеет простое максимальное по модулю харак-
теристическое число X.
Матрица называется ациклической, если ее путем перестановки строк
и столбцов с одинаковыми номерами нельзя привести к виду
' О Т1,2 0 '
О . о
О . . Тг-1,г ’
Jr,l 0.0/
где все диагональные элементы - нулевые квадратные подматрицы, а все мат-
рицы Т1,2; Т2,3;..., Тг-1,г; Тг,1, стоящие над’главной диагональю, - ненуле-
вые. В противном случае, матрица называется циклической. Цикличность
матрицы В влечет наличие таких знаков г и], что переход из г в] в открытом
тексте возможен лишь за число шагов, кратное г. Последнее не характерно для
открытого текста, в связи с чем матрицу В считают ациклической.
Из формулы Перрона (см., например, Романовский В.И., «Дискретные
цепи Маркова») следует, что асимптотически при L—>ос имеет место соотно-
шение
bg(L)= с/, гj е {1,2,... ,п},
где Сд от L не зависят. Воспользуемся этим соотношением для получения при-
ближенного значения v|/(L). Так как
y(L)= Vi(L)+\|/2(L)+. .-Vn(L),
то при L—>сс
п п п п
V(L)=££v,(2)cdXL-2=XL-2 ££ч>г(2)Сг;-
j=l r=l j=l r=l
Двойная сумма не зависит от L, поэтому, обозначив ее через С, получим
\|/(L)«CA,l'2,
откуда следует, что
199
.. V(L+1)
lim ---------'—x.
L->co V(L)
Таким образом, вычисляя непосредственно числа \р(2), \р(3),... и рас-
сматривая их последовательные отношения, можно вычислить X с любой сте-
пенью точности. Пусть для достижения нужной степени точности пришлось
подсчитать у(2), \р(3),..., 1|/(к). Тогда для L>k имеем приближенную формулу
V(L)«v(k)XLk.
Разделив полученное число на nL, получим приближенное значение вероятно-
сти (3-ошибки 2-го рода.
При произвольном значении m метод подсчета вероятности р полно-
стью аналогичен предыдущему. С ростом m резко возрастает объем вычисли-
тельной работы, связанной с определением числа X, так как порядок матрицы
запретных m-грамм с ростом m возрастает по показательному закону.
ПРИМЕР. Пусть для русского языка запретными буквами выбраны:
Ф,Ц,Щ, Э. Тогда р®0,01. Q=h/N=4/30®0,133. При L=100 получим а»0,64,
Р»0,63-10'6. При L=50 получаем а«0,40, р«0,79-10’3. Заметим, что в итальян-
ском языке очень редко используются 5 знаков латинского алфавита:
J,K,W,X,Y, суммарная вероятность которых р«0,003, в то время как
Q=5/26«0,192. Для этого случая критерий работает намного лучше. Если для
русского языка выбрать 376 самых редких биграмм то их суммарная вероят-
ность составит р«0,0093, при этом Q=376/900«0,416. Непосредственный под-
счет дает у(2)=524, \р(3)=10416,\|/(4)=203587 и т.д. Последовательные при-
ближения, значения X имеют вид
19,8778, 19,5456, 19,6030.
Положив Х= 19,60 получаем при L=100
а»0,61, р»4,45-10’17.
Среднее число знаков, на котором срабатывает критерий.
Рассмотрим критерий запретных знаков, ш=1. Пусть £, - случайная ве-
личина, принимающая значения номера знака, на котором сработал критерий
при проверке случайного текста, % g {1,2,... ,L}. Событие ^=к означает, что на
первых к-1 местах в случайном тексте имеются незапретные знаки, а на к-ом
месте впервые появился один из запретных знаков. Учитывая независимость
знаков случайного текста, получим
P(£=k)=(1-Q)k1Q, k<L.
200
Согласно правилу, определяющему действие критерия, его работа заканчива-
ется на L-ом шаге принятием гипотезы НО или Н1, если на первых L-1 местах
стояли незапретные знаки. Следовательно,
P(^=L)=(1-Q)l1.
Математическое ожидание Efi, случайной величины 4 подсчитывается
непосредственно
Е^= ]Tk(1-Q)k-1Q +L(1-Q)l1.
K=1
Используя обозначение (1-Q)=x и формулы
l-xL . .t 5 fl-xL>| -Lxl'1(1-x) + (1-xl)
------= l+x+...+x и -— ------- =--------i-------------
1-x 5x 1-x J (1-x)2
получаем
ГЛАВА 4. ТЕОРЕТИЧЕСКАЯ СТОЙКОСТЬ
ШИФРОВ. ТЕОРЕТИКО-ИНФОРМАЦИОННЫЕ МО-
ДЕЛИ ШИФРОВ
Возникновение современной математической теории информации связано
с работами К. Шеннона (см. /Шен/). В основу этой теории положено количе-
ственное определение информации через вероятностные характеристики про-
цесса образования данного вида информации. Наиболее важные практические
приложения теории информации заложены в определении пропускной спо-
собности канала связи с шумом. Понимая под шифрованием передачу откры-
того сообщения по некоторому каналу связи с шумом, можно использовать
ряд общих результатов теории информации (относящихся к вычислению про-
пускной способности канала связи) в оценке возможности восстановления
этого сообщения по шифрованному тексту.
201
Параграф 4.1
Основные понятия и теоремы математической тео-
рии информации
Ограничимся случаем дискретной информации, где сообщение, по-
длежащее передаче через канал связи, состоит из последовательности дискре-
тных символов, каждый из которых выбран из некоторого конечного множес-
тва (алфавита) букв сообщения. В случае непрерывной информации рекомен-
дуем прочитать пособие Ю.С. Харина, В.И. Берника, Г.В. Матвеева «Матема-
тические основы криптологии», Минск, БГУ, 1999, 319 стр.
Энтропия конечной вероятностной схемы
Пусть задана конечная вероятностная схема
J 1 2 ... п Л
1р(1) Р(2) - Р(п)/
1,2,.. ., а,..., п - исходы (буквы, сообщения) вероятностной схемы из множес-
тва (алфавита) А= {1,2,..., а,..., п}, р(1), р(2),..., р(а),..., р(п) - вероятности
п
этих сообщений, 2>)=i.
а=1
Основоположником теории численной оценки меры неопределенности
вероятностных схем является американский инженер и математик Клод
Шеннон. Ниже приводятся его основные идеи в решении данной задачи. .
, Если имеется такая мера (обозначим ее через Н=Н(А)=
=Н(р(1),р(2),...,р(а),...,р(п)), то разумно аксиоматически потребовать, чтобы
она обладала следующими свойствами:
1) Н должна быть непрерывной относительно р(а), аеЛ;
2) Н должна быть симметрична относительно своих аргументов (т. е.
Н(р(1),р(2),..., p(n))= H(p(ii),p(i2),..., p(in)) для любой перестановки индексов);
3) если выбор распадается на два последовательных выбора, то первона-
чальная Н должна быть взвешенной суммой индивидуальных значений Н, т. е.
при р(1)+р(2)>0 справедливо тождество:
Н(р(1),р(2),..., р(п))=
=Н(р(1)+р(2),р(3),...,р(п))+ (р(1)+р(2)) Н( Р(1) , - )
р(1) + р(2) р(1) + р(2)
Смысл третьего свойства иллюстрируется на следующем рисунке:
202
1/3 2/3
Т Т .
•-> 1/6 • -> 1/2 *->1/3
Ф ф
1/2 1/2
Слева имеются три возможности р( 1 )= 1/3, р(2)=1 /6, р(3)=1/2. Справа
проводится выбор сначала между двумя возможностями, причем каждая име-
ет вероятность 1/2, и в случае осуществления первой возможности производи-
тся еще один выбор между двумя возможностями с вероятностями 2/3 и 1/3.
Окончательные результаты имеют те же самые вероятности: р(1)=1/2х2/3=1/3,
р(2)=1/2х1/3=1/6, р(3)=1/2, как и прежде. В этом конкретном случае по свойс-
тву 3 требуют, чтобы
Н(1/3,1/6,1/2)=Н(1/2,1/2) + у Н(2/3,1/3).
Весовой множитель 1/2=(р(1)+р(2)) введен из-за того, что второй выбор осу-
ществляется в половине случаев.
Оказывается, что приведенные три условия с точностью до постоянно-
го коэффициента «с» определяют функцию Н(р(1),р(2),..., р(п)):
п
Н(р(1),р(2),..., р(п))= -с ^р(а) logd р(а),
а=1
где c=const>0. Выбор константы равносилен выбору основания d логарифма, а
ее значение и значение основания можно трактовать как определение масшта-
ба единицы количества неопределенности. Таким образом, окончательное вы-
ражение для Н имеет вид
Н(р(1),р(2),..., р(п))= - ^р(а) l°gp(a) >
а=1
при оговоренном основании логарифма.
Определение. Количеством информации (неопределенности) в со-
общении а gA называется число h(a), определяемое соотношением
h(a)= - log р(а).
Определение. Среднее значение количества информации
п ’ .
Н(А)—£p(a)logp(a) (1)
а=1
называется энтропией конечной вероятностной схемы.
Термин количество информации Н применяют исходя из предположе-
ния, что произошла реализация (некоторый исход) в вероятностной схеме, в
203
результате чего мы получаем информацию об исходе реализации вероятност-
ной схемы, мера неопределенности Н употребляется в связи с измерением
неопределенности возможных не реализованных исходов вероятностной схе-
мы. Не придавая житейского смысла этой величине, а имея в виду математи-
ческую формализацию Н, говорят об энтропии вероятностной схемы.
Отметим, что при использовании десятичных логарифмов, что обеспе-
чивает удобство расчетов с помощью таблиц, в качестве единицы количества
информации (неопределенности) принимают энтропию равновероятной схе-
мы с 10 исходамй (р(а)= 1/10, ае 1,10), так как
10 1 1
Н=-У—1g—=1.
at! ю ю
Чаще за единицу неопределенности принимают неопределенность, со-
держащуюся в альтернативном ответе «да-нет», соответствующему вероятно-
стной схеме (р(1)=1/2, р(2)= 1/2). В этом случае основание логарифма должно
быть равно двум:
H=-<ilog2|+i log2i)=1'
Эту единицу называют «битом», она в 3,32=log210 раза меньше деся-
тичной единицы измерения информации.
Из определенйя энтропии конечной вероятностной схемы следует, что
она всегда неотрицательна: Н(р(1),р(2),..., р(п))>0. Важное свойство энтропии
конечной вероятностной схемы (р(1),р(2),..., р(п)) заключается в том, что она
максимальна й равна logn при р(а)=1/п, ае 1,п. Минимального значения
энтропия достигает на вероятностной схеме, где имеется сообщение с вероят-
ностью, равной единице.
Неравенство (k£H(A)£logn позволяет качественно толковать понятие
,энтропия как. меру неопределенности в эксперименте с возникновением того
или иного случайного сообщения.
Использование численной меры неопределенности Н(р(1),р(2),..., р(п))
вероятностной схемы оказалось очень удобным для весьма многих целей. От-
метим, однако, что эта мера не претендует на полный учет всех факторов, оп-
ределяющих «неопределенность опыта» в любом практическом смысле, так
как приведенная мера неопределенности зависит лишь от значений вероятно-
стей р(1),р(2),..., р(п) различных исходов, но вовсе не зависит от того, каковы
сами эти исходы - являются ли они в некотором смысле «близкими» один к
другому или очень «далекими», насколько различны или одинаковы послед-
ствия этих исходов.
204
Ранее мы отмечали, что Основание, по которому берется логарифм в
определении энтропии, влияет на единицу измерения количества информа-
ции.
Всюду ниже, если не оговорено противное, будут использоваться
двоичные логарифмы.
Объединенная энтропия двух конечных схем. Условная энтропия.
Рассмотрим наряду со схемой
fl 2 - п
А 1р(1) Р(2) - p(n)J’
схему
fl 2 ... m
В=
lq(i) q(2) ... q(m)J
Схемы А и В могут быть зависимы между собой в том смысле, что для
вероятности р(а,Ь) одновременного выполнения событий а, b выполняется не-
равенство: p(a,b)^p(a)q(b). Рассмотрим объединенную схему С=АВ вида
Г (11) (12)... (ab)
tp(ll) р(12)... p(ab)
(пт) Л
Р(пт)>
Р(а)= X Р(аЬ) ’ Ч(ь)= 2 Р<аЬ) •
Ь=1 а=1
Определение. В соответствии с определением (1), энтропия
Н(АВ)= - £ p(ab) log p(ab)
а,Ь
называется энтропией объединенной схемы АВ.
Обозначая через p(b/a)=p(ab)/p(a), ЬеВ условные вероятности сообще-
ний схемы В при условии сообщения а, можно рассмотреть ряд «условных»
вероятностных схем
( 1 2 ... m
В/а 1р(1/а) р(2/а) ... p(m/a)J‘
Для каждой из этих схем согласно (1) можно определить энтропию
H(B/a)=-^p(b/a)log p(b/a).
Ь=1
Определение. Среднее значение
Н(В/А)=^р(а)Н(В/а) = -^р(а) ]£p(b/a)logp(b/a) (2)
а=1 а=1 Ь=1
называется условной энтропией схемы В при условии схемы А.
Взаимная информация между вероятностными схемами.
Исходя из установленного выше понятия энтропии как меры неопре-
деленности случайного сообщения, введем меру количества информации о
сообщении «а», содержащемся в сообщении «Ь», как разность между количе-
ством неопределенности (априорной) в сообщении «а» и количеством не-
определенности в сообщении «а» при известном сообщении «Ь».
Определение. Количеством информации о сообщении «а», содер-
жащемся в сообщении «Ь», называется величина
i(ab)=h(a)-h(a/b)=log2p(a/b)/p(a).
Определение. Среднее значение
1(АВ)= 22 p(ab)i(ab) = 22 P(ab) log2 (р(а / Ь) / р(а)).
а>ь а,Ь
называется взаимной информацией между А и В.
Введем в рассмотрение вероятностную схему В с вероятностями исхо-
дов
q(b)=22p(a)p(b/a)
а \
Тогда величину 1(АВ) можно выразить через энтропийные характеристики
следующим образом:
1(АВ)=Н(А)-Н(А/В)=Н(В)-Н(В/А).
Свойства энтропии.
1. Н(В/А)= Н(АВ) - Н(А). (3)
Действительно,
Н(В/А)=
~£р(а)р(ь/а) log2[p(b / а)р(а)р-1 (а)]=- 22 Р(Ь / а)р(а) log2 p(b / а)р(а) +
а,Ь а,Ь
+ 22 P(ab) log 2 р(а) =Н(АВ) - Н(А).
а,Ь
2. Н(В/А)<Н(В), (4)
Нетрудно показать, что выполняется неравенство 1пх-х+1<0. Действи-
тельно, для функции f(x)=lnx-x первая производная f '(х) = 1 / х -1 обращает-
ся в 0 в точке х=1, причем f(l)=0, a f "(х) = —1 / х2 <0 для всех х>0. Следова-
206
тельно, f(x) имеет единственную! точку максимума при х=1. Для двоичного
логарифма имеем:
log2X=lnx/ln2=(x-1 )log2e.
Тогда
m
H(B/A)-H(B)=-^pid log2 p(j/i) + £qj log2 qj =
i.j j=l
“ZPm 1о^2 P0Z + 1o§2 % =
i,j
i.j
p^-1
ln2 e = 0
=Lpi,jlog2 .....
P(j/O
3. Пусть на алфавите А вероятностной схемы А задано отображение
ф(.) в множество С. Это отображение определяет вероятностную схему С с
алфавитом С, для которой р(с)= У*р(а). Тогда выполняется неравенство
а:<р(а)=с
Н(С)<Н(А), и знак равенства имеет место в том случае, когда отображение
ср(.) обратимо.
Легко видеть, что условное распределение р(с/а)=1, если ф(а)=с и
р(с/а)=0 в противном случае. Следовательно, Н(С/А)=0. Далее, нетрудно про-
верить, что
Н(С)-Н(С/А)=Н(А)-Н(А/С) ... :
и, следовательно,
Н(С)+Н(А/С)=Н(А)+Н(С/А).
Тогда,
Н(С)< Н(С)+Н(А/С)=Н(А)+Н(С/А)= Н(А)
и равенство имеет место в том случае, когда отображение ф(.) обратимо и
Н(А/С)=0, Н(С)=Н(А).
4. Н(АВ)<Н(А)+Н(В), причем равенство достигается в том и только в
том случае, когда А и В независимы. Это свойство непосредственно следует
из свойств 2 и
Если мы имеем A(L-AjA2...Al- m независимых объединений схемы
А, то
H(A(L))=- £p(a1a2...aL)log2 p(a1a2...aL) =
ata2...aL
=" Z P(ai)P(a2) -P(aL)Z log2 p(ak)=LH(A)
&ia2...aL k
и в этом случае
207
-H(A(L)) = H(A).
L
Смысл введенного понятия энтропии становится ясен из следующих
двух теорем Шеннона, относящихся к созданию сообщений с помощью неза-
висимых испытаний из конечной вероятностной схемы А.
Теоремы Шеннона.
Обозначим через Al последовательность aja2...aL, полученную с по-
мощью независимых испытаний из конечной вероятностной схемы
(12 •" п
А 1р0) Р(2) - P(n)J’
P(Al)= р(а। )р(а2 )...p(aL) - вероятность последовательности AL. Оказывает-
ся, что при больших L все последовательности (за исключением сколь угодно
малой их доли) имеют приблизительно одинаковую вероятность, величина
которой зависит от энтропии Н(А). Качественное объяснение этого факта дос-
таточно простое. Так как символы в последовательности AL независимы, то
п
энтропия на символ текста равна Н(А)= -^р(а) log2 р(а). Предположим,
а=1
что рассматривается длинное сообщение, то есть L велико. Тогда последова-
тельность Al будет, так сказать, «с большой вероятностью содержать p(a)L
раз» символ ае 1,п . Вероятность конкретной последовательности AL есть
P(Al) = Пр(а)''
а=1
где va - частота буквы «а» в последовательности AL. Заменяя va на p(a)L, по-
лучаем «приближенное равенство»
п
P(AL)£[[p(a)W,
а=1
п
a log2 P(Al) =L ^2 Р(а) l°g2 Р(а) =-LH(A), откуда
а=1
1
Н(А>-----
Это приближенное равенство остается верным и для любого стацио-
нарного источника (стационарной последовательности). Распространение ука-
208
занного утверждения на цепь Маркова осуществил Хинчин А.Я., а на произ-
вольный стационарный источник - Макмиллан. Пусть, как и прежде,
А={1,2,...а,...п} - конечное множество исходов, соответсвующее вероятнос-
тной схеме
( 1 2 ... п
А 1р0) Р(2) - р(п)>
Первая теорема Шеннона.
Для любых £ > 0, д > 0 существует Ц такое, что при любом L > Lo
множество Al всех последовательностей длины L алфавита А разбиваются на
группы (Al)* и (Al)“ такие, что
1) для любой ALe(AL)*
r10gj?(b'H(A)<,1;
2) £P(AL)<6.
ALe(ALr
ДОКАЗАТЕЛЬСТВО.
Нетрудно видеть, что
P(Al) = Пр(а)'-,
а=1
где va - частота буквы «а» в последовательности AL. Отнесем к первой группе
(Al)* те и только те последовательности AL, в которых
|v,-Lp(a)|<L8
для некоторой 5>0. Ко второй группе отнесем все остальные последователь-
ности.
Покажем, что при достаточно большом Lo это разбиение удовлетворя-
ет обоим условиям теоремы. Действительно, для AL е (AL)*
P(Al) = flPW1'1*” +LS0‘. |®а| < 1. a = Ci.
a=l
Отсюда нетрудно показать, что
Tlog2 - Н(А) = 0а log2 р(а).
Ь а=1
209
Следовательно,
Г|<>8=йЬ’Н<А,1<8?;'08’^)'
Полагая
5 = n
к
получаем первое утверждение теоремы.
Рассмотрим вторую группу (AL)**. Нетрудно видеть, что вероятность
P((AL)") = P(Ujv. -Lp(a)| > LS}) < £p(|v„ -Lp(a)|> L8).
a=l a=l
По неравенству Чебышева
оЛ т ( чК т sn LP<a)(l - Р(а))
P(|Vi - Ьр(а)| > L5) <--------,
откуда следует, что
P((Al)")<-^-.
L62
Полагая L0=n/82£, получаем второе утверждение теоремы.
Следствие. Если L>L0, то для любой Alg(Al)* выполняется неравенс-
- L(H(A) + Л) < log, P(AJ < -L(H(A) - n).
Таким образом, при достаточно больших L вероятность каждой по-
следовательности из (AL)* (за исключением последовательностей весьма ма-
ловероятного класса) заключена между 2'L(H+>1> и 2'цн'>1>.
Важно бывает знать мощности обоих групп последовательностей (см.
первую теорему Шеннона). В частности, возникает вопрос о числе «наиболее
вероятных» последовательностей, вероятности которых приблизительно рав-
ны 2“LH(A).
Занумеруем все последовательности AL в порядке убывания их вероя-
тностей:
Р(А^) > Р(А[2)) >... > P(A[N)), N = nL.
Выберем X, 0<Х<1. Пусть NL(X) - число последовательностей, опре-
деляемых из неравенства
Nl(X)-1 Nl(X) •
Z Р(А“)<Х< 2>(А<»),
к=1 к=1
210
В это число войдет некоторое число последовательностей Al второй
группы, у которых P(Al)>2L(H(A)-t|), но в основном оно определяется после-
довательностями первой группы.
Вторая теорема Шеннона.
Для любого фиксированного значения X, 0<Х<1 справедливо соотно-
шение
lim£log2NL(X) = H(A).
ИМЕННО В ЭТОМ СМЫСЛЕ ПИШУТ, что NL(X)=2LH(A). Как следует
из формулы, этот предел не зависит от X и поэтому можно полагать X сколь
угодно близким к 1, Х=1-Д и тогда nL-NL(l-A) есть число последовательнос-
тей, вероятность появления которых в результате реализации нашего случай-
ного процесса получения последовательностей пренебрежимо мала, то есть
практически невозможных последовательностей.
Доказательства приведенных теорем обычно даются в курсе матема-
тической теории информации.
Таким образом в .первой и второй теоремах Шеннона устанавливаете!
замечательное свойство «равнораспределенности» длинных сообщений, по-
рождаемых независимыми испытаниями схемы А.
Это свойство устанавливает, грубо говоря, тот факт, что всего та-
ких сообщений
Nl«2LH(A)
и все они приблизительно равновероятны.
Можно ли установить похожее свойство для осмысленных сообщений,
которые, очевидно, не порождаются независимыми испытаниями?
Для этого необходимо,, во-первых, ввести математическую модель ос-
мысленных сообщений, а во-вторых, определить, в соответствии с (1), энтро-
пию на одну букву осмысленного сообщения. В качестве математической мо-
дели осмысленных сообщений обычно рассматривают последовательности,
получаемые с помощью так называемых марковских процессов. Среди таких
процессов имеется важная группа процессов называемая стационарными эр-
годическими процессами. В таких процессах каждая создаваемая процессом
последовательность имеет одни и те же статистические свойства. Поэтому
относительные частоты различных комбинаций исходов (букв, биграмм и
т. п.), полученные из частных последовательностей будут стремиться с увели-
чением длин последовательностей к определенным пределам, не зависящим
от этих частных последовательностей. Таким образом, для эргодического
процесса возможно отождествление средних значений различных комбинаций
исходов вдоль некоторой последовательности со средними значениями по ан-
211
самблю возможных последовательностей (причем вероятность расхождения
равна нулю).
Параграф 4.2
Стационарные эргодические, модели содержатель-
ных сообщений
В этой модели открытые (содержательные) сообщения AL= a t а 2... a L
представляются отрезками реализаций стационарной эргодической случай-
ной последовательности. Случайная последовательность называется стацио-
нарной, если распределение вероятностей отрезка этой последовательности
ai+iai+2---ai+k не зависит от i при любом конечном значении к. Если на отк-
рытые сообщения не накладывается никаких регламентирующих ограниче-
ний, то с большой уверенностью можно считать, что указанное свойство бу-
дет для них выполняться. Эргодичность случайной последовательности, пред-
ставляющей осмысленное сообщение, означает, что для любых двух отрезков
текста осмысленного содержания в потоке осмысленных сообщений найдется
сообщение, которое содержит в себе оба этих отрезка. Это свойство также не
противоречит нашим представлениям о характере взаимосвязей в последова-
тельности знаков осмысленных сообщений.
Зададим распределение вероятностей P(Al) на последовательностях
AL=a,a2 ...aL для всех L>0 с учетом заданных условных вероятностей
Р(а/Аы)=Р(АЬ1а)/Р(Аы).
В соответствии с формулами (1) и (2) (см. параграф 4.1) можно ввести
в рассмотрение энтропию объединенной схемы А^ A j А 2... A L
H(A(L>)=-£P(AL)log2P(AL),
al
которую называют энтропией отрезка последовательности длины L.
Из рассмотренных ранее свойств энтропии имеем
0< Н( A(L) )<log2nL=Llog2n.
Отношение Н( A(L) )/L называют средней энтропией, приходящейся на
одну букву набора а ] а 2... a L. При этом всегда 0< Н( A(L) )/L<log2n
ДОКАЖЕМ теперь, что существует предел
' r H(A) = lim~H(A(L)).
L—>°о L
212
Рассмотрим условную энтропию
Н(А/А|М )= - 2Р(А, )£р(а/ AL1)log2 Р(а/ At_,).
AL-i а
Аналогично доказательству неравенства (3) (параграф 4.1), можно по-
казать, что для любого L
H(A/A(L))<H(A/A(L-1)).
Далее, легко убедиться, что
Н( A(L+1) )=Н( A(L) )+Н(А/A(l) )<Н( A(L) )+Н(А/A(L-1))
И
Н( A(L) )=Н( А1)+Н(А/А1)+Н(А/А1А2)+...+Н(А/ A(L-I) )> LH(A/A(L-1)).
Отсюда следует, что
и
Таким образом, последовательность y H(A<L))npH L—>оо является
невозрастающей последовательностью, ограниченной снизу нулем. Следова-
тельно, существует предел Н(А) =? lim — Н( A(L)).
L->°° L
Определение. Предел
Н(А) = 1шД H(A(L)).
L—>ао L
называется энтропией эргодического источника сообщений на одну букву
или энтропией, приходящейся на одну букву в бесконечных наборах (с уче-
том стационарной эргодичности их получения).
Свойство «равнораспределенности» для эргодических источников.
Это свойство формулируется следующим образом.
Для любого 8>0
Р
7 log 2 P(Al)-H(A)
JL/
> е I —> 0 при L —> оо.
213
Иными словами, утверждается, что при больших L все множество по-
следовательностей AL, также, как и в независимом случае, можно разбить на
два непересекающихся подмножества (AL)* и (AL)“, которые обладают сле-
дующими свойствами: . _
- для любой Alg(Al)* вероятность P(Al)«2‘l Н(А),
- суммарная вероятность P((AL)*‘)—> 0 при L —> оо.
Таким образом, распределение P(AL) оказывается фактически сосредо-
точенным лишь на множестве (AL)*, причем входящие b_(Al)* последователь-
ности почти равновероятны, а их число почти равно 2L ^(А)
Отдельно стоит вопрос об оценке величины Н(А) . В некоторых уче-
бных курсах теории информации доказывается, что для стационарных слу-
чайных последовательностей предел Н(А) совпадает с условной энтропией
знака последовательности, при условии, что известна вся предыдущая после-
довательность, то есть с «неопределенностью» очередной буквы последова-
тельности. Формально, последняя неопределенность записывается как
lim H(aL/ai,a2,...,aL-i) при L->oc.
Все вышеизложенное (в частности, формулы) для абстрактной ста-
ционарной последовательности ИСПОЛЬЗУЕТСЯ для последовательности
букв открытых (содержательных) текстов. При этом не учитываются неста-
ционарности в их началах и концах. Из вероятностных свойств открытых тек-
стов следует, что непосредственный расчет значений Н( A(L)) и
H(aL/ai,a2,...,aL.i) возможен для небольших значений L. Для больших значений
L известны лишь косвенные методы их оценок. Например, К. Шеннон предла-
гал метод оценки H(at/ai,a2,...,ац) основанный на задании случайно выбран-
ных L-значных отрезков открытого текста и отгадывании L+1 буквы. При
этом замечено, что с увеличением L до 20-30 величина H(aL/ai,a2,...,aL-i) за-
метно убывает. Другой метод оценки предельной энтропии связан с некото-
рой характеристикой языка, называемой его избыточностью. Этот термин
возник в связи с тем, что каждая буква сообщения, при условии что буквы по-
являются в нем случайно, равновероятно, независимо могла бы нести инфор-
мацию, равную Hmax=log2n, где п - число букв в алфавите. В это же время сре-
дняя энтропия Н буквы в обычном открытом тексте, как показывают экспери-
ментальные расчеты, значительно меньше, и, следовательно, величина Нтах -
Н характеризует неиспользованные возможности в «сжатии» информации,
содержащейся в открытом тексте. Величину
Нтах-Н , Н
КЧ_ Шал______ __ 1_______
ТТ TJ
Г1тах птах
214
называют избыточностью языка, а величину Н/Нщах - коэффициентом сжа-
тия.
Избыточность языка показывает, какую часть букв открытого текста
можно вычеркнуть до наступления нечитаемости сообщения. На основе таких
экспериментов и оценивают избыточность D открытых текстов, откуда полу-
чают оценку Н
H=(l-D)Hmax=(l-D)log2n,
п - мощность алфавита открытых текстов.
Представление о величине энтропии и избыточности различной инфо-
рмации на русском (Hmax=log232=5) и французском (Hmax=log226=4,7) языках
дает следующая таблица.
Н бит/буква Русский язык Н бит/буква Французский язык D в процен- тах Русский язык D в процен- тах Французский язык
Язык в целом 1,37 1,40 72,6 70,6
Разговорная речь 1,40 1,50 72,0 68,4
Литературные тексты 1,19 1,38 76,2 71,0
Деловые тексты 0,83 1,22 83,4 74,4
Принято считать, что для литературного текста Н=1 дв.ед, для деловой
переписки Н=0.5-0.7 дв.ед.
В заключение отметим, что основное свойство равнораспределенно-
сти осмысленных сообщений будет ниже использовано для решения ряда
задач.
Параграф 4.3
Энтропии шифртекста и ключей. Расстояния един-
ственности для открытого текста и ключа. Теоретическая
стойкость шифров
Ненадежности открытого текста и ключа.
Шифр шифрования (M,K,E,f) включает в себя два вероятностных вы-
бора: выбор открытого сообщения хеМсХ и выбор ключа х^К. Тем самым
215
определена вероятностная модель шифра шифрования. Количество информа-
ции, создаваемой при выборе открытого сообщения, измеряется величиной
Н(М)=- ^p(m)log2p(m).
meM
Аналогично, неопределенность, связанная с выбором ключа, дается выраже-
нием
H(K)=-2}p(x)log2p(x).
ХеК
Неопределенность сообщения, так же как и неопределенность ключа
могут изменяться, когда имеется возможность наблюдать криптограмму -
шифрованный текст ееЕ=£(МхК)сУ (Е - образ МхК при отображении f) . Эту
условную неопределенность естественно измерять условной энтропией.
Н(М/Е)= - p(m, е) log2 р(т / е),
(т,е)еМхЕ
Н(К/Е)=- Xp(e,x)l°g2P(x/e)-
(е,х)еЕхК
Введенные условные энтропии Шеннон назвал ненадежностью от-
крытого сообщения и ключа. Эти ненадежности используются в качестве
теоретической меры секретности. В качестве обоснования такого использо-
вания можно привести следующие рассуждения. Если ненадежность сообще-
ния (ключа) равна нулю, то отсюда следует, что лишь одно сообщение (один
ключ) имеет единичную апостериорную вероятность, а все другие - нулевую.
Этот случай соответствует полной осведомленности дешифровальщика о со-
общении (ключе). Действительно, пусть
Н(М/Е)=- ^p(m,e)log2p(m/e) =0.
(ш,е)еМхЕ
Тогда при любых (т,е) е МхЕ
p(m,e)log2p(m/e)=0.
Выберем такие (т,е) для которых существует ключ Х(т,е)=Х6К такой,
что хт=е. Для таких пар имеем р(т,е)>0, следовательно, из предыдущего ра-
венства получаем log2p(m/e)=0, то есть р(ш/е)=1. Таким образом, по шифртек-
сту ш открытый текст е восстанавливается однозначно.
Приведем некоторые формулы для ненадежности ключа и открытых
сообщений. Рассмотрим вероятностные схемы, определенные на М, К, Е и
совместную энтропию Н(М,К,Е). По правилам сложения энтропий имеем
Н(М,К,Е)=Н(М,К)+Н(Е/М,К)=Н(Е,К)+Н(М/Е,К).
216
Но Н(Е/М,К)=0, так как условия полностью определяют событие Е. Кроме
того, Н(М/Е,К)=0, так как в шифре выполняется свойство однозначного рас-
шифрования. В связи с чем
Н(М,К,Е)=Н(М,К)=Н(Е,К).
Так как ключ и открытое сообщение в вероятностной модели шифра выбира-
ются независимо, получаем
Н(М,К)=Н(М)+Н(К).
Кроме того,
Н(Е,К)= Н(Е)+Н(К/Е).
Отсюда получаем формулу для ненадежности ключа
Н(К/Е)=Н(М)+Н(К)-Н(Е).
Из этой формулы следует: если Н(М)=Н(Е), то Н(К/Е)=Н(К) и наобо-
рот. Формула для ненадежности сообщения получается аналогичным образом.
Именно, имеем
Н(М,Е)= Н(Е)+Н(М/Е)=Н(М)+Н(Е/М),
откуда
Н(М/Е)=Н(М)+Н(Е/М)-Н(Е).
Используя тот факт, что уменьшение объема известных сведений мо-
жет лишь увеличить неопределенность, получаем соотношения
Н(М/Е)<Н(М,К/Е)=Н(К/Е)+Н(М/Е,К)==Н(К/Е)<Н(К).
В последнем равенстве Н(М/Е,К)=0.
Ниже мы покажем, что для совершенных шифров, то есть шифров, для
которых p(m/e)=p(m) при любых (т,е) (см. параграф 1.3) выполняется равен-
ство Н(М/Е)=Н(М), и полученное выше неравенство говорит о том, что для
них неопределенность секретного ключа всегда не меньше неопределенности
шифруемого текста.
Учитывая связь Н(К) с возможностью кодировки множества клюйей,"
заключаем, что для совершенных шифров средний «размер» секретного клю-
ча не может быть меньше «размера» открытого текста. Следовательно, для
таких шифров число ключей растет вместе с ростом длины передаваемых со-
общений.
Напомним, что примером совершенного шифра является шифр гам-
мирования. При шифровании двоичного сообщения m=mi,m2,...,mLnpH слу-
чайном и равновероятном выборе ключа - двоичной гаммы длины L имеем
p(m/e)=2'L при всех т,е.
Теорема. Шифр (M,K,E,f), где E=f(MxK) является совершенным тогда
и только тогда, когда Н(М/Е)=Н(М).
ДОКАЗАТЕЛЬСТВО. Имеем
Н(М/Е)-Н(М)= - p(m, e)log2p(m / е) + £ p(m)log2p(m) =
т,е т
217
= -SP(m’e)log2P(m/e) + X Ep(m’e> log2p(m) =
m,e m L e
= - S P(m’ e)log2P(m / e) + 2 E P<m’ e)loS2P(m) =
m,e m e
= - S E P(m’ e)(log2 p(m / e) - lo§2 p(m)) =
m e
=E E p(m’ e)( log2 p(m» - lo§2 p(m / e))=
m e
=SEp(m>e)log2(-777)= E p(m,e)log2^^-.
. p(m/e) (m>e):J^>e)*0 p(m/e)
Если шифр совершенный, то p(m/e)=p(m) при всех парах (ш,е). В част-
ности, для пар (т,е), при которых р(т,е)*0, выполняется равенство
log2_E<5L = o.
p(m/e)
Следовательно, Н(М/Е)=Н(М). .
Предположим теперь, что Н(М/Е)=Н(М), то есть
2 P(m,e)log2 ^\=0-
(m,e):p(m,e)*0 р(ш/е)
Тогда
p(m)=p(m/e) для пар (m,e): р(т,е)^0.
Для доказательства совершенности шифра достаточно показать, что р(ш,е)?Ю
при любой паре (ш,е)еМхЕ. Докажем это. Для любого теМ найдется е=е(т)
с условием р(т,е)*0. Имеем
р(т) = j} р(т, е) = р(е)р(т / е) = Р(е)р(т/е) =
е е е:р(т,е)*0
e:p(m,e)*O
так как p(m)=p(m/e) для пар (m,e): p(m,e)#O. Откуда получаем:
EP(e)=i . Это равенство возможно лишь при суммировании по всем
е:р(т,е)*0
ееЕ, так как, по условию теоремы: E=f(MxK), и поэтому р(е)*О при любом
ееЕ.
218
Следовательно, р(ш,е)*0 при всех ееЕ, а так как m выбиралось про-
извольным, то р(т,е)*0 при любой паре (т,е)еМхЕ, что и оставалось нам
показать для завершения доказательства необходимости условий теоремы.
Расстояния единственности для открытого текста и ключа.
Ниже в данном разделе будут рассматриваться лишь поточные
шифры (M,K,E,f) с заданными вероятностными распределениями на М и К.
Напомним, что поточный шифр определен опорным шифром и соот-
ветствием между ключами и ключевыми последовательностями. Будем пред-
полагать. что M=IN, где I - алфавит открытого текста, a f; МхК->Е - сюрьек-
тивное отображение EcOL. где О - алфавит шифрованного текста.
Наряду с текстом теМ длины N и шифрованным текстом ееЕ длины
N мы будем рассматривать их начальные отрезки тг_ и eL длины L<N. Будем
считать, что вероятностное распределение на множестве М индуцирует веро-
ятностное распределения на начальных отрезках mLeML сообщений m из М.
Последнее распределение и вероятностное распределение на ключах К инду-
цируют вероятностные распределения на начальных отрезках eLeEi крипто-
грамм е из Е и другие совместные и условные распределения. При изучении
свойств рассматриваемого шифра будем считать, что N всегда больше рас-
сматриваемых нами значений L.
В связи со сказанным выше корректно введение и соответствующих
энтропий:
H(Ml/El)=- £p(mL,eL)log2p(mL/eL),
mL’eL
H(K/El)= - £ p(eL, X) log2 P(X / eL).
eL>X
Эти энтропии также трактуются как ненадежности части сообщения и
ключа. Отметим, что в поточном шифре множество ключей не зависит от
длины L сообщения.
Теорема Шеннона.
1. Ненадежность ключа H(K/EL) есть невозрастающая функция от L, то
есть при любом L'>L
H(K/El)> H(K/El).
2. Ненадежность первых к букв сообщения является невозрастающей
функцией от L, то есть при L'>L
H(Mk/EL)>H(Mk/EL).
3. При любом L
H(K/El)>H(Ml/El).
219
Справедливость утверждений теоремы вытекает из свойств условных
энтропий.
Напомним, что во второй части параграфа 3.1 мы обсуждали проблему
многозначности дешифрования поточных шифров. В данном пункте речь
пойдет об условиях однозначного дешифрования шифров.
На качественном уровне, под расстоянием единственности шифра по
открытому тексту понимают минимальное натуральное число L, при котором
по известному шифртексту eL длины L однозначно восстанавливается соот-
ветствующее ему открытое сообщение mL. Аналогично, под расстоянием
единственности шифра по ключу понимают минимальное L, при котором по
известному шифртексту длины L однозначно восстанавливается использован-
ный ключ.
Такие качественные понятия не вполне точны. Действительно, видимо
минимальное L, о котором идет речь (если оно существует), зависит от кон-
кретного шифртекста е,' L=L(e). Следовательно, видимо речь должна идти о
среднем значении таких минимальных L(e). С другой стороны, для каждого eL
можно определить все множество сообщений шь, которые могут быть зашиф-
рованы шифром в криптограмму eL. Расстояние единственности шифра по
открытому тексту можно определить теперь как минимальное L, при котором
среднее значение мощностей этих множеств равно единице.
Первое определение Шеннона расстояний единственности шифра.
Ранее было показано, что энтропия характеризует некоторый источник
информации, в частности, вероятностные модели получения открытых (со-
держательных) текстов. Число открытых текстов и их вероятности оценива-
ются по фундаментальным теоремам теории информации, теоремам Шеннона,
Хинчина, Макмиллана.
Аналогичную роль играет и условная энтропия H(ML/EL) - ненадеж-
ность части сообщения в вероятностной модели шифра. Она характеризует
среднее число текстов длины L, которые могут соответствовать известному
отрезку eL шифрованного текста. Именно, Шеннон полагал, что среднее число
текстов Шь, которые могут быть зашифрованы в заданный шифртекст, равно
R(L)=2 Н(МЛ>,
где 2 - основание логарифма в выражении энтропии.
Аналогично среднее число (по всем eL) ключей, при которых
получается отрезок шифрованного текста (при подходящих выборах mL из М).
Согласно, пункту 1 теоремы Шеннона второе из этих значений с рос-
том L не возрастает и, в случае существования минимального L, при котором
; это значение становится равным единице, такое L называют расстоянием
. единственности шифра по ключу. Аналогично определяют расстояние един-
220
ственности шифра по открытому тексту, именно, как минимальный корень
уравнения R(L)=2 Таким образом, расстояния единственности шиф-
ра это минимальные корни уравнений
R(L)=2 “'“ДЧ,
2h(k/ej=1
относительно L (если такие корни существуют).
Некоторые шифры устроены так, что их количество ключей растет с
ростом длины L сообщений, например, шифр гаммирования. В этом случае
возможна ситуация, когда R(L)—>ос с ростом L. Такие шифры называют асим-
птотически стойкими. Для таких шифров при достаточно большом L вели-
чина R(L) становится большой и среди R(L) возможных текстов выбрать
текст, который был действительно зашифрован в заданную криптограмму,
становится невозможным.
Второе определение Шеннона расстояний единственности шифра
(модель случайного шифра). ,
Прямой подсчет расстояний единственности шифра (по открытому,
тексту и ключу), как правило, затруднителен. В связи с чем для их подсчета
используют модель «случайного шифра». Пусть (E,K,X,F) - шифр расшифро-
вания для шифра зашифрования, МсХ, где М - все множество содержатель-
ных открытых текстов длины N в алфавите I (|1|>2).
Предполагается (в этом и заключается случайность модели шифра),
что при случайном и равновероятном выборе ключа %еК и расшифровании на
нем криптограммы et (L<N) вероятность получить содержательный текст рав-
на
2hl
|I|L’
где Н - энтропия на букву содержательного текста в алфавите I, 2 - основание
логарифма в выражении энтропии. Это число «почти» совпадает с вероятно-
стью выбора открытого текста длины L при случайном и равновероятном вы-
боре последовательности длины L букв алфавита (2HL - приближенное значе-
ние количества открытых текстов). Тогда при расшифровании шифртекста
длины L на всех ключах из К мы получим в среднем
2hl
|К|—r-=r(L)
IHL
открытых текстов. Так как H<logi|I|, то отсюда следует, что г(Е)->0 с ростом
L. Решая теперь уравнение '
221
2HL
относительно L, получаем решение
L log2|K| log2|K|
° log, |I|-H Dlog2 |I| ’
„ , H
где --------— - избыточность открытого текста.
ЗАМЕЧАНИЕ. Величина
9hl
|К|77^
t(L) может стремится к бесконеч-
ности с ростом L лишь в случае, когда число ключей |К| растет вместе с L, на-
пример, для случайного шифра гаммирования (K=IL).
Аналогично вычисляется расстояние единственности для ключа.
Множество ключей, при которых может быть получен Шифртекст eL, при ус-
ловии что мы шифровали лишь открытые сообщения (М - множество откры-
тых текстов), совпадает с множеством ключей, расшифровывающих eL в от-
крытый текст, вероятность такого расшифрования и, следовательно, вероят-
ность получения нужного ключа при опробовании, как было замечено ранее,
2hl
равна ;——. Следовательно, величина
IIIL
2hl
одновременно является и средним числом ключей, соответствующих крипто-
грамме длины L. Решение этого уравнения с правой частью r(L)=l относи-
тельно L называется расстоянием единственности шифра по ключу.
Так как введенные расстояния единственности шифра по открытому
т log2|K| log2|K|
тексту и по ключу совпадают, то величину Lo=----— = ——- на-
log2|I|-H Dlog2|I|
зывают расстоянием единственности шифра.
Отметим определенную некорректность во введении понятия рас-
стояния единственности во втором определении Шеннона. Число содержа-
тельных открытых текстов приблизительно равно 2HL, это число получено в
предположении, что рассматривается достаточно больше число L. В связи с
этим предыдущие равенства следует рассматривать как приближенные. Не-
222
коректность же заключается в том, что одновременно при нахождении рас-
стояния единственности (корня уравнения) ищется по существу минимальное
L (оно, возможно, будет и небольшим), и тогда нельзя пользоваться прибли-
женной формулой 2hl для числа открытых текстов.
Второе сомнение в корректности такой формализации понятия рас-
стояния единственности шифра может возникнуть из следующих соображе-
ний. По логике рассматриваемого подхода «случайного шифра» расшифрова-
нию подлежит криптограмма, полученная при некотором открытом тексте и
некотором истинном ключе %0. Следовательно, предположение о случайном
расшифровании можно относить к ключам из множества К\{%о}» й тогда,
имея в виду, что уже имеется один истинный ключ, заведомо дающий откры-
тый текст, для среднего значения числа открытых текстов получаем выраже-
ние
2hl
rXL^l+IK-ll-j-.
Следовательно, r'(L) si при
2 HL
|К-1|—г=о.
HIL
Если |К|>2, то это приближенное равенство справедливо лишь для достаточно
больших L (чем лучше приближение, тем больше Lo). Тем не менее, расчеты
показывают, что значения корней уравнений r(L)=l, r'(L) si приблизительно
равны.
Приведем пример. Пусть |К|=2100, |1|=32, Н=1 бит. Тогда r(L)=l при
LO=25. Если |К|=2104, то r(L)=l при LO=261 Откуда следует, что для 2100<|К|<21<м
величина Lo будет находится в пределах 25<LO<26. В частности, в этих грани-
цах будет находится и Lo для |К|=2100+1. Рассчитаем теперь для этого |К| вели-
чину L'0(t), при которой r'(L)=-^-, то есть решим уравнение
9HL
|К-1|—г-
IIIL
1
2‘ *
Имеем
21оо 2'4L— 1
100 + t
откуда t=4L-100. Окончательно получаем L'o(t)=>,—-—. При t=4 получаем
223
L'O(4)=26. Следовательно, для |К|=2100+1 имеем L'O(4)<26. При t=20 получаем
L'o(20)=30. Уже есть повод задуматься и предложить другие подходы к под-
счету расстояний единственности шифра.
Третий подход к формализации понятий расстояний единственно-
сти шифра.
Рассмотрим уравнение шифрования поточного шифра (M,K,E,f), МсХ,
E=f(MxK)
f(mL,x)=eL.
Пусть I - алфавит открытого Текста, О - алфавит шифрованного текста, mL, eL
-начальные отрезки Шифруемого текста m и шифрованного текста е, соответ-
ственно. Множество всех возможных отрезков mL обозначим через ML, а
множество всех возможных отрезков eL обозначим через EL. В случае
|Ol|<|Ml||K| всегда найдется eL, при котором число решений уравнения шиф-
рования относительно неизвестной пары (mL,x) больше единицы. За расстоя-
ние единственности шифра примем минимальное L, если оно существует, при
котором |OL|==|ML||K| (имеется в виду приближенное равенство).
Рассмотрим пример. Пусть М - множество содержательных откры-
тых текстов, |К|=2100, |1|=|О|=32, Н=1, тогда |ML|=2HL и решение уравнения
|0L|=|ML||K| относительно L дает: 25Ls2L2100, 5LSL+100, то есть L=25. Сравните
с приведенным выше примером.
Одна трактовка второго определения Шеннона расстояний един-
ственности шифра.
Попытаемся уточнить использованное Шенноном предположение о
случайности расшифрования криптограммы. Предположим, что шифр
(M,K,E,f), E=f(MxK), ЕсУ выбирается случайно и равновероятно из множест-
ва всех шифров такого вида. То есть при фиксированных множествах М -
сообщений, У- шифробозначений, из множества всех биекций М в У случай-
но и равновероятно выбираются (с возвращением) |К| инъекций {fx :М->У,
1еК). Тем самым случайно выбран шифр A=(M,K,E,f).
Для произвольного шифробозначения уеУ и шифра А обозначим че-
рез F(A,у) множество всех сообщений теМ, для которых существует х, при
котором, Дт,х)=у. При фиксированном уеУ заданное вероятностное распре-
деление на шифрах индуцирует вероятностную меру на множестве мощно-
стей |F(A,y)|.
Утверждение. Среднее значение случайное величины |F(A,y)| равно
|кцм|
|У|
224
ДОКАЗАТЕЛЬСТВО. Докажем сначала очевидное на интуитивном
уровне вспомогательное утверждение: при случайном и равновероятном вы-
боре инъективного отображения fx:M—>У вероятность того, что элемент у бу
дет принадлежать образу отображения fx, равна •
Действительно, число возможных различных образов (Об) инъектив-
ного отображения: М-»У равно Cjу|, каждый из таких образов равновероя-
тен. Число образов Об(у), содержащих элементу, равно
С|у(Ц .Следовательно,
P(yefx(M))=£P(y е fx(M)/fx(M) = O6)P(fx(M = Об) =
Об
е = Об) У'-,',
С|У| Об С|У|
так как вероятность P(yefx(M)/ fx(M)=O6) равна либо единице либо нулю.
Раскроем последнее выражение
1 CIM!-I |М|!(|¥|-|М|)! (|У|—1)! =|М|
(ЭД |УН |У|! (| М |-1)!(| Y |-1-| М |+1)! |У|
Среднее значение случайной величины |F(A,y)| определяется числом
испытаний |К| и вероятностью «успеха» P(yefx(M))= . Среднее значение
|F(A,y)| равно
|К||М|
|У|
Беря в качестве М - множество содержательных открытых текстов и
полагая |М|=2Н\, а в качестве У беря OL, получаем, что среднее значение слу-
чайной величины |F(A,y)| - числа прообразов шифртекста у равно
2hl
Из уравнения
?HL
|К|-----=1
|O|L
225
находим «новое» расстояние единственности шифра по открытому тексту.
Напомним, ито по второму определению Шеннона расстояния единст-
венности шифра по открытому тексту для числа открытых текстов мы имели
выражение
2hl
|K|RTr(L)'
Четвертый подход к оценке расстояний единственности шифра.
Вернемся к началу раздела, посвященному расстояниям единственно-
сти шифра по открытому тексту и ключу. Там отмечалось, что расстояния
единственности шифра - это, соответственно, целочисленные минимальные
корни уравнений
2^^=!,
2H(K/EL)=1;
то есть корни уравнений H(Ml/El)=0 и H(K/El)=0, если они существуют. В
разделе «Второе определение Шеннона ...» говорилось о том , что прямой
подсчет расстояний единственности шифра, как правило, затруднителен, в
связи с чем выше были рассмотрены и другие формализации понятий рас-
стояний единственности по открытому тексту и ключу.
Ниже, на основе результатов Ю.С. Харина (Ю.С. Харин, В.И. Берник,
Г.В. Матвеев «Математические основы криптологии», Минск, БГУ, 1999)
даются верхние приближенные оценки указанных корней.
Пусть Lo - минимальное натуральное число, при котором H(Ml/El)=0.
Имеем
H(El,Ml,K)=H(El)+H( Ml/ El)+H(K/Ml,El),
H(El,K,Ml)=H(El)+H(K/ EL)+H(Mt/K,EL).
Так как при известном шифрованном тексте и известном ключе от-
крытый текст восстанавливается расшифрованием однозначно, то
H(Ml/K,El)=0. С учетом этого из данных уравнений находим
Н( Ml/El)=H(K/El)-H(K/Ml,El)
и заключаем, что
H(Ml/El)<H(K/El).
Следовательно, любая верхняя оценка минимального корня уравнения
H(K/El)=0 (расстояния единственности по ключу) будет верхней оценкой и
8 Зак. 5
226
для Lo - расстояния единственности по открытому тексту. Для получения та-
кой оценки используем формулу для ненадежности ключа:
H(K/EL)=H(ML)+H(K)-H(EL).
Найдем одно из натуральных чисел L, при котором
H(K/El)=H(Ml)+H(K)-H(El)=O.
Имеем H(Mt)^log2|ML| (энтропию измеряем в битах) и H(K)=log2|K|
при равновероятном распределении на множестве ключей К. При рассматри-
ваемых условиях справедливо неравенство
H(Ml)+H(K)-H(El)< log2|ML|+log2|K|-H(EL).
Искомую верхнюю оценку величины Lo теперь можно получить, если решить
уравнение
log2|ML|+log2|K|-H(EL)=0
относительно L.
Введем дополнительные предположения относительно рассматри-
ваемого шифра. Предположим, что
1) Значение L достаточно велико, именно - оно таково, что мощность
. |ML| множества открытых текстов приблизительно равна 2HL и они
все равновероятны (см. теоремы Шеннона., Н - энтропия на букву).
2) Вероятностные распределения на Ml и К индуцируют равномер-
ное распределение на множестве ElcOl (О - алфавит шифрован-
ных текстов.
Из предположения 1) вытекает, что
log2|ML|=LH,
а из 2) получаем
H(EL)=log2|EL|.
Уравнение
log2|ML|+log2|K|-H(EL)=0
теперь можно переписать в виде
LH+log2|K|-log2|EL|sO.
Представим |EL| в виде |El|=Vl, где V зависит от L, V=V(L). Тогда
уравнение принимает вид
LH+log2|K|-Llog2VsO.
Откуда получаем искомую верхнюю приблизительную оценку расстояний
единственности шифра
_Н2_|К|_
log2V-H
В случае H(Ml)=LH, H(K)=log2|K|, H(El)=L log2|V| имеем L0=L'.
227
При отказе от предположения 2) для вычисления L' используют в ряде
публикаций неравенство
LH+log2|K|-H(EL)>LH+log2|K|-Llog2V
с последующим определением L' как корня уравнения LH+log2|K|-Llog2V=0,
который, вообще говоря, не обязан быть в случае строгого неравенства оцен-
кой искомого корня Lo уравнения LH+log2|K|-H(EL)=0.
В заключение отметим, что мы рассматриваем поточные шифры, для
которых существуют расстояния единственности. Очевидно, например, для
шифров с эквивалентными ключами расстояние единственности по ключу
отсутствует.
Теоретическая стойкость шифров.
Понятие теоретической стойкости шифров обычно ассоциируется с
понятием совершенного шифра по К. Шеннону.
Определение. Шифр (X,K,y,f), Y=f(XxK) с заданными вероятностны-
ми распределениями Р(х), хеX на X и Р(%), уеК называют теоретически
стойким, если он совершенный по Шеннону, то есть при любом уеУ
Р(х/у)=Р(х)
при любом хеX.
Таким образом, теоретическая стойкость шифра (его совершенность)
состоит в том, что знание шифрованного текста, не влечет перераспределения
вероятностей на множестве шифруемых текстов X.
При изучении энтропий открытых и шифрованных текстов ранее было
показано, что условие совершенства шифра (Х,К,У,1) равносильно условию:
Н(Х/У)=Н(Х).
В ряде случаев понятие теоретической стойкости шифра трактуют
и по другому.
Теоретически стойкими шифрами относительно криптографических
методов определения открытых текстов считаются те шифры, для которых эти
методы приводят к неоднозначному определению открытых (содержатель-
ных) текстов. Например, теоретически стойкими шифрами относительно ме-
тодов, приводящих к чтению текстов в колонках, считаются шифры, для ко-
торых доказана неоднозначность такого чтения.
Теоретически стойкими шифрами относительно теоретико-
информационного представления шифра в виде канала связи без памяти счи-
таются шифры, для которых средняя вероятность правильного декодирования
открытого сообщения с заданной многозначностью по шифрованному тексту
стремится к нулю с ростом длины сообщений.
8*
228
ГЛАВА 5. ПРАКТИЧЕСКАЯ СТОЙКОСТЬ ШИФРОВ
«Надежна ли шифрсистема,
если криптоаналитик располагает
ограниченным временем и ограни-
ченными вычислительными воз-
можностями для анализа перехва-
ченных криптограмм?»
К. Шеннон
Параграф 5.1
Понятие практической стойкости шифров
(/Про/,/Фом/)
Правила криптоаналйза были сформулированы еще в конце XIX века
преподавателем немецкого языка в Париже голландцем Керкхофом в книге «La
Cryptographic militare». Согласно одному из этих правил разработчик шифра
должен оценивать криптографические свойства шифра в предположении, что
не только шифртекст известен противнику (криптоаналитику цротивника), но
известен и алгоритм шифрования, а секретным для него является лишь ключ.
Основными количественными мерами стойкости шифра служат так на-
зываемые «трудоемкость метода криптографического анализа» и «надежность
его». Обозначим через А - класс применимых к шифру алгоритмов дешифро-
вания и через Т(<р) - трудоемкость реализации алгоритма ф на некотором вы-
числительном’устройстве.
Трудоемкость дешифрования. Данная трудоемкость обычно измеряется
усредненным по ключам шифра и открытым текстам количеством времени или
условных вычислительных операций, необходимых для реализации алгоритма.
За трудоемкость дешифрования принимают величину
пмпЕТ(ф).
(реА
Последняя величина (по определению) совпадает со средней трудоемкостью
ЕТ(ф) лучшего из известных и применимых к шифру алгоритмов. При попытке
практического использования этой формулы выявляются некоторые проблемы.
229
Поясним более подробно введенное понятие. Алгоритмы дешифрова-
ния применяются обычно к входным данным. В нашем случае это шифрован-
ный текст «у» и шифр. Следовательно, результатом применения алгоритма до-
лжен быть открытый текст. Наша же цель состоит в определении трудоемкости
- времени Т(ср), требуемого на реализацию алгоритма. Возможно, что Т(ср) бу-
дет зависеть от ряда дополнительных параметров, например, от шифртекста
«у» и от порядка опробования ключей в алгоритме. Криптоанализ проводится,
как правило, без наличия конкретного шифртекста и без прямой реализации
алгоритма. Сам алгоритм в ряде случаев становится вероятностным алгорит-
мом, в его фрагментах используются вероятностные правила принятия реше-
ния о выполнении последующих действий, например, опробование ключей.
Таким образом, умозрительное построение процесса нахождения открытого
текста шифра скорее всего следует назвать методом (криптографическим ме-
тодом) решения задачи. В предположении о вероятностных распределениях
случайных действий алгоритма и неизвестных нам входных данных алгоритма,
а также вероятностных характеристик выбора ключа в шифре при зашифрова-
нии случайного открытого текста подсчитывается среднее число операций
(действий) алгоритма, которое и называется трудоемкостью метода криптоа-
нализа. При фиксации в предположениях вычислительных способностей про-
тивника (производительность ЭВМ, объем возможных памятей и т. д.) это сре-
днее число операций адекватно переводится в среднее время, необходимое для
дешифрования шифра.
Второй количественной мерой стойкости шифра относительно метода
криптоанализа является надежность метода л(ф) - вероятность дешифрования.
Раз метод несет в себе определенную случайность, например, не полное опро-
бование ключей, то и положительный результат метода возможен с некоторой
вероятностью. Блестящим примером является метод дешифрования, заключа-
ющийся в случайном отгадывании открытого текста. В ряде случаев представ-
ляет интерес и средняя доля информации, определяемая с помощью метода. В
методах криптоанализа с предварительным определением ключа можно пола-
гать, что средняя доля информации - это произведение вероятности его опре-
деления на объем дешифрованной информации.
Конечно, используют и другие характеристики эффективности методов
криптоанализа, например, вероятность дешифрования за время, не превосхо-
дящее Т. -
Под количественной мерой криптографической стойкости шифра понима-
ется наилучшая пара (Т(ф),л(ф)) из всех возможных методов криптографичес-
кого анализа шифра. Смысл выбора наилучшей пары состоит в том, чтобы вы-
брать метод с минимизацией трудоемкости и одновременно максимизацией его
надежности.
230
Предположения о возможностях противника.
Криптограф, оценивая стойкость шифра, как правило, имитирует атаку
на шифр со стороны криптоаналитика противника. Для этого он строит модель
действий и возможностей противника, в которой максимально учитываются
интеллектуальные, вычислительные, технические, агентурные и другие возмо-
жности противника. Примером такого подхода может служить случай в США в
конце 70-х годов, Криптографы не нашли практически приемлемого алгоритма
дешифрования «DES-алгоритма». Но небольшой размер ключа DES-алгоритма
не позволил прогнозировать его практическую стойкость как достаточную на
длительный срок, что привело к решению отказаться от использования DES-
алгоритма в государственных учреждениях для защиты информации.
Учет интеллектуальных возможностей противника нередко прояв-
ляется в постановках задач криптоанализа шифра. В шифрах гаммирования не-
редко оценивают трудоемкости и надежности методов определения открытого
текста по параметрам эффективности методов определения ключа по известной
гамме наложения (или, что то же самое, по известным открытому и шифрован-
ному текстам). Аналогично иногда поступают и с другими поточными шифра-
ми, например, при анализе шифров поточной замены переходят к решению за-
дачи определения ключа по известной управляющей последовательности шиф-
рующего блока. В задачах чтения открытого текста по шифрованному тексту
иногда «добавляют» и другой известной информации, облегчающей нахожде-
ние решения задачи. Таким образом, учет интеллектуальных возможностей
противника проводится путем постановки и решения «облегченных» задач
криптоанализа. При этом полагают, что криптографическая стойкость шифра,
вычисленная по таким «облегченным» задачам, не превышает стойкости шиф-
ра, анализируемого в реальных условиях эсплуатации. Нередко в качестве та-
ких задач выделяют задачи, возникающие на промежуточных этапах анализи-
руемого метода криптоанализа. Примерами таких задач являются разнообраз-
ные математические задачи, к которым сводится метод криптоанализа, напри-
мер, задача решения систем нелинейных уравнений в разнообразных алгебраи-
ческих структурах, определение начального состояния автомата По его выход-
ной и входной последовательностям, определение входной последовательнос-
ти автомата по его начальному состоянию и выходной последовательности и
др. Нахождение эффективных алгоритмов решения какой-либо из этих матема-
тических задач может значительно понизить криптографическую стойкость
многих шифров.
Учет старения дешифруемой информации. Что лучше? Дешифровать
за 5 лет 5 телеграмм или за один год одну телеграмму? Ответ на этот вопрос
неоднозначен. Конечно, чем больше дешифрованной информации, тем лучше,
231
но хороша ложка к обеду! В ряде случаев не полученная вовремя информация
теряет свою ценность. Так, сведения о погоде, о временных дорогах и перепра-
вах и т. д. теряют свою ценность по истечении определенного времени. Учет
«старения информации» может быть проведен аналогично учету порчи про-
дуктов питания на овощных и продовольственных складах, аналогично учету
старения словарей, т. е. учету не используемых слов из старых словарей. Такой
учет может проводится по так называемому правилу «постоянного процента»,
U(t)=U(0)e‘Xt, здесь U(0) - начальное количество «продукта», U(t) - количество
«продукта» через t единиц времени. Эту же формулу иногда записывают в виде
U(t)=U(0)(l- а)‘, а - коэффициент старения 0<а<1.
Параграф 5.2
Принципы построения методов определения ключей
шифрсистем .
Пусть (Х,У,К,1) - модель шифра по К. Шеннону. Рассмотрим задачу
определения ключа %еК по известным открытому х и соответствующего ему
шифрованному у текстам, то есть задачу нахождения решения % уравнения
f(x,X)=y
Частным случаем этой задачи является задача определения ключа % по
известной выходной последовательности у автономного шифрующего автомата
А, которая сводится к нахождению решения уравнения
А(х)=у.
К решению уравнения вида
Ф(х)=У>
(где Ф: К—>У), сводится и первая поставленная задача. Действительно, так как
f: ХхК—>Y, то при фиксированном хеХ индуцируется отображение O=fx: K->Y,
Ф(х)=^х,х).
Итак, задача определения ключа по открытому и шифрованному текс-
там и задача определения ключа по выходной последовательности шифрующе-
го автомата сводятся к решению уравнений вида
Ф(Х)=У-
В ряде случаев такие уравнения записываются в «координатной фор-
ме»:
Ф1(ХьХ2,..-,Хп)=У., tG{l,...,T}.
Здесь: Ф,, te {1,...,Т} - координатные функции функции Ф, Х=(ХьХ2,--->Хп),
У=(УьУ2,..-,Ут).
232
Общая концепция решения указанной задачи состоит в сведении ее
к более простым задачам, решаемым известными («базовими») алгорит-
мами.
Ниже дается краткое описание базовых алгоритмов и методов сведения
к ним.
Базовые алгоритмы: алгоритмы поиска, алгоритмы решения систем
линейных и нелинейных уравнений над различными алгебраическими структу-
рами (поля, кольца и т. д.), итерационные методы.
Каждый базовый алгоритм, как и метод сведения к нему, содержит ши-
рокий круг разнообразных методов, связанных собственной «иерархией». Ниже
приводится их краткая характеристика.
Алгоритмы поиска. Любой алгоритм нахождения решения %' уравнения
Ф(х)=У
представляет собой последовательность действий на основе системы тестов и
может быть описан как алгоритм поиска элемента %' в массиве К. В криптогра-
фической литературе под алгоритмами поиска нередко понимают узкий класс
алгоритмов поиска - метод последовательного перебора (метод тотального
опробования), в соответствии с которым опробуются поочередно в некотором
порядке элементы % множества К. Для каждого опробуемого варианта % вычи-
сляется ух=Ф(%) и сравнивается с у по критерию на совпадение. При принятии
решения о несовпадении ух с у опробуемый вариант % отбраковывается. При
известной структуре (частичной структуре) множества К применяют «упорядо-
ченный», «направленный» перебор элементов из К. Так, например, при струк-
туре множества «больше - менше»:
У1<У2<...<У|К|
для нахождения номера заданного элемента у сравнивают у со «средней точ-
кой» y[|Q|/2] массива и выбирают ту половину его, в которой лежит у, затем •
сравнивают у со «средней точкой» выбранного «половинного массива» и так
далее до идентификации элемента у. Число операций такого способа оценива-
ется величиной log2K. Иногда удается сгруппировать элементы массива в «лег-
ко различимые» между собой группы и вначале определять номер группы, в .
которой лежит у, а затем определять номеру, ведя поиску в этой выделенной
группе. Сократить число операций при структуре ключей «больше - меньше»
возможно, если использовать предварительную кодировку у-ов и «удобно»
расположить у-ки в соответствии с их адресами (см. Зубков А.М., Клыкова
Н.В. Построение баз данных с ограниченным временем поиска. Симпозиум по
прикладной и промышленной математике. Тезисы доклада. 2001 г., стр. 185-
186).
233
Характерной особенностью алгоритмов поиска является то, что струк-
тура отображения Ф фактически не учитывается (возможно учитывается лишь
для предварительного группирования элементов массива Y).
Алгоритмы решения систем линейных и нелинейных уравнений над раз-
личными алгебраическими структурами (поля, кольца и т.д.). Для решения си-
стем линейных уравнений в этих структурах существует широкий круг извест-
ных «стандартних» алгоритмов, таких как - алгоритмы Гаусса, Штрассена, Ко-
новальцева для решения общих систем линейных уравнений над конечными
полями и кольцами; алгоритмы решения некоторых специальных систем ли-
нейных уравнений - например, ганкелевых систем или систем с разреженной
матрицей. Из алгоритмов решения систем нелинейных уравнений отметим ал-
горитм Лазера.
Итерационные методы. Эти методы значимы при решении уравнений в
области действительных чисел и в функциональном анализе. Они же стали раз-
виваться, модернизироваться и для решения дискретных задач криптографии.
Методы частичного опробования. В методах этого класса пытаются
«разбить» ключ % на две части хьХг и представить его в виде х=(ХьХг) таким
образом, чтобы при каждом варианте Xi уравнение Ф(ХьХг)=У относительно Хг
решалось достаточно «просто», например, с трудоемкостью меньщрй, чем по-
лный перебор возможных значений хг- При выполнении этих условий решают
уравнение Ф(ХьХ2)=У перебором возможных вариантов x'i с последующим ре-
шением уравнения Ф(х'ьХг)=У для каждого опробуемого варианта х'ь Приме-
ром такого метода служит метод решейия нелинейных булевых уравнений пу-
тем линеаризации за счет опробования части переменных.
Методы последовательного опробования. Этот метод является развити-
ем метода частичного опробования. В этом методе также пытаются «разбить»
ключ х на две части хьХг и представить его в виде х=(ХьХ2) таким образом,
чтобы при каждом варианте Xi для уравнения Ф(хьХ2)=У относительно Хг до-
статочно «просто» устанавливалось, разрешимо оно или нет. Если при варианте
X i оно неразрешимо относительно Хг> то вариант х' i отбраковывается и опро-
буется следующий вариант. В случае же положительногр ответа уравнение
Ф(Х ьХг)=У пытаются решить всеми возможными средствами, например, пы-
таются применить метод частичного опробования для части Хг> всего ключа х-
В последнем случае и говорят о применении метода последовательного опро-
бования.
234
Методы сведения к базовым алгоритмам основаны:
— на преобразовании как уравнений, так и множества неизвестных; на исполь-
зовании различных моделей алгебраических структур (гомоморфные образы
автоматов, алгебр, их приближенные модели и т. д.);
— на использовании частичного и последовательного опробования.
Неизвестные параметры ХьХ2,--->Хп - части ключа %, относительно ко-
торых решается уравнение, могут быть заданы в различной форме, влияющей
как на выбор способов решения уравнения, так и на их сложность. Так, напри-
мер, подстановка может быть задана в обычной двухстрочной форме, или в ма-
тричной форме; двоичная функция может быть задана таблично, в виде много-
члена Жегалкина, в виде вектора ее коэффициентов Фурье по любому базису п-
мерного векторного пространства над полем вещественных чисел или над ко-
нечным полем и т. д. Собственно сам метод сведения к базовым алгоритмам и
состоит в выборе способа представления, «кодирования» частей ключа.
Преобразования уравнений шифрования. Многие методы преобразова-
ния системы уравнений шифрования нацелены на получение уравнений - след-
ствий, которые могут быть решены известными способами. Например, подби-
рают множество У' совместно с отображением ср: Y-»Y' так, чтобы новое
уравнение-следствие
ф( ф(х))=ф(у)
решалось достаточно просто. Найдя все множество М решений этого уравне-
ния, решают, относительно х^М, начальное уравнение Ф(х)=У, например, оп-
робуя элементы множества М. К таким методам относятся так называемые
«методы сведения»: выделение из системы уравнений
<I>t(XbX2,...,Xn)=yt, tG{l,...,T}
«хороших уравнений», например линейных, или выделение уравнений, из ко-
торых можно составить систему уравнений «треугольного типа» и т. д.
Преобразование неизвестных. Один из способов преобразования неиз-
вестных состоит в поиске нового множества К' и отображений ср: К->К', у:
К'—>Y так, чтобы Ф(х)=ф(ф(х))- В этом случае задача поиска решения уравне-
ния Ф(х)=У сводится к решению двух уравнений
ф(х')=у>
ф(х)=х'-
При таком сведении задачи поступают следующим образом. Находят все реше-
ния %' первого уравнения, а затем решают второе уравнение для каждой правой
части %', найденной ранее. Типичным примером преобразования неизвестных
при решении системы нелинейных уравнений является введение новых пере-
менных, приводящих систему уравнений относительно этих новых переменных
к системе линейных уравнений.
235
Методы использования гомоморфизмов. Итак, мы изучаем возможно-
сти определения прообраза % отображения Ф: К—>У по известному образу
У=Ф(Х)-
Ищутся такие подходящие множества К' и У’ и отображения <р: К-»К',
у:У->Y', f:K'—>Y', чтобы была коммутативна следующая диаграмма:
Ф
К -> У
ф Ф ф
К' -> Y'
f
Сначала решается уравнение f(x )=У > относительно еК' при у'=у(у).
Это уравнение называют гомоморфным образом уравнения Ф(%)=у.
Затем для каждого найденного решения х' решается уравнение ф(х)=Х • Обоз-
начим через М все найденные таким образом решения (объединение всех ре-
шений уравнения ф(х)=х' по всем решениям х' уравнения f(x')=y')- Далее
решают начальное уравнение Ф(х)=У относительно х^М.
Метод гомоморфизмов представляет собой комбинацию методов пре-
образования уравнений и преобразования множества ключей и включает их как
частные случаи.
Наряду с использование базисных алгоритмов и методов сведения к
ним при решении задачи определения ключа нередко используют и дополните-
льные предположения, облегчающие расчет параметров эффективности испо-
льзуемого метода решения. Например, предполагают, что решение уравнения
Ф(х)=У единственно, в частности, используемый шифр не имеет эквивалентных
ключей, объем Т материала больше расстояния единственности шифра.
Параграф 5.3
Методы опробования
Тотальный метод
Пусть А - шифр с алгеброй шифрования (Х,КШ,У,£), алгеброй расшиф-
рования (y,Kp,X,F) и уеУ - известный шифрованный текст, полуденный при
зашифровании некоторого содержательного открытого текста х0 при неизвес-
236
тном ключе %оеКш. Задача состоит в нахождении открытого текста х0, т.е. в
решении уравнения £(хо,Хо)=У относительно х0 при известном у и известном
шифре А. Одним из методов решения этого уравнения для известного симмет-
ричного шифра является опробование пар элементов (х',х) из ХхКш. Для каж-
дой пары (х',х) вычисляется значение f(x',xи сравнивается усу'. Для
несимметричного шифра (шифра с открытым ключом) проводится опробова-
ние х' еХ. В этом случае проводится сравнение значения f(x',x0)=y' с у. Откры-
тый текст х, при котором у=у', считается решением задачи. Как правило, при
надежном шифре А такой способ дешифрования неэффективен из-за большого
числа опробований, необходимых для определения открытого текста. Сокра-
тить число опробований можно путем опробования ключей х*^Кр ПРИ исполь-
зовании алгебры расшифрования шифра с последующим применением крите-
рия на открытый текст к получаемому расшифрованному тексту F(y,x*). Имен-
но этот метод дешифрования и получил название «тотальный метод».
Таким образом, тотальный метод заключается в случайном опробова-
нии ключей х* из Кр. При каждом опробуемом ключе х* проводится расшиф-
рование шифрованного текста и проверка полученного текста F(y,x*) на при-
надлежность к множеству содержательных текстов.
Предполагается, что проверка на принадлежность расшифрованного те-
кста множеству содержательных текстов проводится с помощью некоторого
«гипотетиченского статистического критерия на содержательные тексты»,
имеющего ошибки первого и второго рода: а - вероятность отбраковки содер-
жательного текста (в т^р^инах статистического критерия - отбраковки гипоте-
зы Н(0), отвечающей вероятностному распределению Р(0)); р - вероятность
принять несодержательный текст за содержательный текст (принять гипотезу
Н(0), когда верна гипотеза Н(1) - выборка из распределения Р(1), отвечающего
нечитаемым текстам). Далее везде Р5* 1.
Предполагается также, что опробование ключей заключается в после-
довательном случайном и равновероятном опробовании без повторений г клю-
чей из Кр. Процесс опробования заканчивается при опробовании S, ключей; £=j
- номер первого ключа (1<)<г), при котором соответствующий расшифрован-
ный текст будет признан критерием за содержательный текст, или £=г, если
такое событие не произойдет при любом j<r.
Основными характеристиками криптографической стойкости шифра
относительно тотального метода решения задачи являются:
трудоемкость Е“,₽(г) метода - среднее число опробуемых ключей (математиче-
ское ожидание случайной величины %).
Надежность ла₽(г) метода - вероятность определить истиный содержа-
тельный текст.
237
Расчет этих характеристик тотального метода будем проводить при
следующих предположениях: при расшифровании шифртекста^ на всех клю-
чах %* из Кр среди расшифрованных текстов {F(y,x*):x*eKp} содержится един-
ственный содержательный текст - истинный текст х0; в множестве Кр сущест-
вует единственный ключ х*о, при котором F(y,x*0)=x0. Эти предположения по-
зволяют трактовать использование гипотетического статистического критерия
на содержательный текст, как критерий проверки опробуемого ключа х* на его
совпадение с неизвестным истинным ключом х*0- С вероятностью а истинный
ключ будет признан ложным (при выполнении гипотезы Н(0) критерием будет
принята Н(1)), а с вероятностью Р ложный ключ будет признан истинным (при
выполнении гипотезы Н(1) будет принята Н(0)). Процесс опробования ключей
закончится при опробовании % ключей; £=j - номер первого ключа (l<j<r), ко-
торый будет признан статистическим критерием за истинный ключ, или £,=т,
если такое событие не, произойдет при любом j<r.
Проведем сначала расчет трудоемкости Е^г) тотального метода. Да-
лее для краткости положим КР=К
Пусть Bt — событие, состоящее в том, что в схеме последовательного
опробования ключей без возвращения t-ый ключ является истинным,
te{l,...,|K|};
- E“’p(r,t) - среднее значение £, при условии Bt;
- Eap(t<r) - среднее значение S, при условии, что истинный ключ находится сре-
ди первых г опробуемых ключей;
E ap(t>r+1) - среднее значение £, при условии, что истинный ключ не содержится
среди первых г опробуемых ключей.
По формуле условного математического ожидания получаем
Ea’p(r)= щ Ea₽(t<r) + । Ea,p(t>r+1).
Для подсчета величины Ea,p(t<r) предварительно подсчитаем Ea ₽(r,t) при t<r.
. Г
Ea’p(r,t)=^m(l - Д)1"’1 р + tCl-P/'Cl-a) + ^m«(l - Р)т'2 ft + ra(l-₽)rl.
m=l m=t+l
Первое слагаемое отвечает окончанию опробований на каком то к-ом
ключе, где K<t-1 (напомним, что истиный ключ опробуется при t-ом опробова-
нии). Второе слагаемое отвечает определению истинного ключа при t-ом опро-
бовании. Третье слагаемое отвечает ситуации аналогичной первой для K>t+1.
Четвертое слагаемое отвечает ситуации, когда при каждом из первых г опробо-
ваний критерий принимал гипотезу Н(1).
238
Если истинный ключ находится среди первых г опробуемых ключей, то
он может с вероятностью - появиться при любом t-ом опробовании,
г
te{l,...,r}. Поэтому E“’₽(t<r)==^Ea’P(r,t)p(Bt) ,
t=l
Е"’(кг)«-Х(Ет(1-₽)п>1₽+ t(l-3)''(l-«) + Y,moiy-pr2p + ra(l-₽y')=
Г t=l m=l m='+1
+—Ё‘(1-лы
Гни г 77 г(1-/?)м,7и
Нам предстоит теперь изменить порядок суммирования в двойных
суммах. С этой целью выпишем отдельно слагаемые первой и второй двойных
сумм:
Слагаемые первой суммы:
t=l
t=2 1
t=3 1 +2(1-р)
t=4 1 +2(1-р) +3(1-р)2
t=r-1 ................................
t=r 1+2(1-р)+3(1-р)2 +...+(r-l)(l-p)r’2
Слагаемые второй суммы:
2(1-Р)+3(1-Р)2+...+г(1-Р)г‘1
3(1-Р)2+...+г(1-Р)г-’
г(1-р)г-'
Меняя порядок суммирования в двойных суммах, получим, что
Ea,|3(t<r)=
+ra(l-/7)rJ
Г 77 г
Дополняя первую сумму слагаемым при j=r, а вторую слагаемым при
i=l (равными нулю) и меняя везде индекс суммирования на «к», объединяя
первые три слагаемые в одно слагаемое, получим
E“ ’(t<r). -£к( I - РГ' Р(т - к) + (к -1) + (1 - а)
1-Д
+ га(1-Р)г1.
239
В том случае, когда истинный ключ не находится среди первых г опро-
буемых ключей, среднее число опробуемых ключей равно
E“’₽(t>r+l)=^K(l-P)K"1p + г(1-р)г.
к=1
Последнее слагаемое отвечает ситуации, когда при всех опробуемых ключах
критерий принял гипотезу Н(1). Для получения окончательной формулы трудо-
емкости Еа,₽(г) тотального метода подставим полученные выражения Ea,|J(t<r),
E^ferH) в начальную формулу:
Ea>₽(r)= — Ea’₽(t<r)+ ffl^Ea’₽(t>r+l).
|^| |К|
Е“’₽(г)= 7777 Аг-к)+-^(к-1) + (1-а) + rad-Pf1 +
I I *=i L *" Р J I I
(2>о-Д)"'Д +r(i-₽)r).
1*4 №1
Приведем формулы для расчета среднего числа Е“’₽(г) опробуемых
ключей в некоторых частных случаях.
Если положить г=|К|, то мы получим формулу для среднего числа опро-
бований в тотальном методе при условии, что опробуются все ключи.
В"'(|К|)= -±- f>(l - /?Г' Д| КI -к)+(к -1) + (1 - а)
I I k=i L 1 “ р
+ |К|а(1-рГ1.
Положим, г=|К| и а=р=0, то есть рассмотрим случай, когда в тотальном методе
опробуются все ключи и критерий отбраковки текстов работает без ошибок.'
В случае r=|K|, а^О, Р=0, то есть при использовании процедуры, не допускаю-
щей принятия ложного ключа за истинный, но допускающей невыявление ис-
тинного ключа, имеем
1 Ж г
Е“’°(|К|)=—-+|К|сс =
I I К=1
Jl-tt)(|7<|+l)|j<l+|K|^W±l(1 _ a)+| ,q а
21К | 2
Если положить г=|К|, а=0, Р^О, то есть рассматривать процедуры принятия ре-
шения, при которых невозможна потеря истинного ключа, то
240
E4(|K|)= -i- § к(1 - /?)’-' </?(| К | -к) + 1) -
I I №1
'7^ fzO - (Al * I-*) +1)=
II K=0
1*4 £ 1Л5
Для вычисления входящих в последнее выражение сумм рассмотрим функцию
|К| 1 _ vx+l
ф(х)=2>к.=——.
R-=0 1 — Л
\К\
2>'”
R-0
= Ф'(Х)
-(|А’|+1)х|*|(1-х)4-1-х|АГ|+|
(1-х)2
|К| |К| |К|
Х^2хк-' =^к(к-1)хк-1 ч-^кх^-1 = хФ"(х) + Ф'(х).
к=0 к=0 /с—0
В то жеъремя
ф.. (х) = -flKMW/” + 2Ф'(х)
1-х 1-х
Отсюда
|К|
У к2хк~х = + 121±Ф'(Х).
1-х 1-х
Используя полученные соотношения при х=1-р для ЕО,Р(|К|) будем иметь
Е°’р(|К|)=^|7<|+1ФЧ1 - р) + (IКI +1)(1 - - ^-^Ф'(1 - /?),
где
ф.(1 _ д = -(|У|4-1)(1-/?Г'/? + 1-(1-А№1
Подставляя последней выражение в формулу для Е°’Р(|К|) и проводя
элементарные преобразования получаем
Е„,,К|> [1 - (I - /?)№1 - (IКI +1X1 - /?)|У| /?]- Lg(i /с I +1) -1]
м • IКI р1
Несложный анализ показывает, что при |К|—> оо
241
Е°’₽(|К|)->-^-.
Н
Следовательно, при больших значениях |К| можно пользоваться приближенным
равенством E0,p(|K|)s—.
Перейдем теперь к расчету надежности метода тотального опробования
ключей, то есть вероятности Р(г,а,Р) определить истинный ключ этим методом.
Пусть С - событие, состоящее в определении истинного ключа при оп-
робовании г ключей. Используем введенные ранее события Bt, te{l,...,|K|}. Со-
бытия Bt несовместны, в связи с чем событие С представимо в виде
C=[J (С П Bt). Отсюда
к
Р(г,а,|3)»Р(С)-£ Р(С п В,) = £ Р(В, )Р(С/В,) = Р(С/В,),
/=1 /-1 1^1 /=1
так как P(Bt) = ——. В то же время Р(С / Bt) = (1 — (1 - а) . Следова-
|К|
тельно,
Последнее равенство выписано в предположении: РХ).
Методы использования эквивалентных ключей
Пусть А=(Х,К,У,1) - алгебра зашифрования шифра. Напомним следую-
щее
Определение. Ключи %,%' называются эквивалентными, если
f(x,x)=f(x,x') при любом хеХ.
Ключи х»Х называются эквивалентными относительно подмноже-
ства Х'сХ, если
f(x,X)=f(x,X')
при любом хеХ'. Введенное бинарное отношение о(Х') на множестве ключей
К является бинарным отношением эквивалентности (выполнены свойства реф-
лексивности, симметричности и транзитивности). Поэтому все множество клю-
чей К разбивается на классы эквивалентности бинарного отношения а(Х').
242
£(%•)
Обозначим это разбиение через R(o(X'))= [J/C* • Очевидно, что из эквива-
;=1
лентности ключей %,%' еК относительно X' следует их эквивалентность и отно-
сительно любого подмножества X" множества X'. Откуда вытекает, что любой
класс К* содержится целиком в некотором классе К*. эквивалентности от-
/
носительно подмножества X" множества X'. Каждый класс К* состоит из
объединения некоторых классов К* . В частности, L(X")<L(X'), а классы
Kj «мельче» классов К* .
Рассмотрим задачу определения ключа % по заданным открытому х
и шифрованному / текстам, т. е. задачу решения уравнения f(x,x)=y относи-
тельно К. Под решением задачи будем понимать нахождение произвольного
решения х данного уравнения. В принятой выше терминалогии данная задача
состоит в нахождении ключа (решения уравнения) с точностью до эквивалент-
ности относительно множества, состоящего из одного элемента х.
Обозначим через Ki,K2,...,KL классы эквивалентности относительно
элемента хеХ. В дальнейшем, для краткости, эти классы мы будем называть
просто классами эквивалентности ключей, хотя более содержательное их на-
звание, на наш взгляд, состояло бы в названии их «классами слабой эквива-
лентности ключей».
Будем решать поставленную задачу при различных возможных допол-
нительных данных.
1. Известны представители ХьХг,- • ->Хь классов Ki,K2,..,,KL эквивалентных
ключей. В этом случае проводится опробование без возвращения предста-
вителей до первого успеха (до получения представителя класса эквивалент-
ности, в котором лежит искомый ключ). То есть для каждого опробуемого
ключа х вычисляется f(x,x)=yx и сравнивается ух с заданным у. Процесс оп-
робования заканчивается при получении равенства ух=у. Трудоемкость Т в
опробованиях такого метода совпадает с трудоемкостью тотального метода
при r=|K|=L и нулевых ошибках статистичечкого критерия:
2
Надежность метода л=1.
2. Известны мощности классов эквивалентных ключей и представители этих
классов.
Упорядочим Xi(i),Xi(2)> - • - ,Xi(L) известные нам представители в соответст-
вии с мощностями классов эквивалентных ключей:
243
|Ki(1)|>|Ki(2)| >...>|Ki(L)|
и опробуем их в соответствии с этим порядком Xi(i),Xi(2),-.--,Xi(L), L . Алго-
ритм прекращает свою работу, если найден искомый ключ (с точностью до эк-
вивалентности), либо проведено г опробований.
Если ключ шифра выбирался случайно и равновероятно из К, то веро-
|Я, I
ятность выбора ключа из класса Kj равна------------------. Поэтому среднее число Тг оп-
.1^1
робуемых при реализации алгоритма ключей равно
а надежность метода
При r=L имеем
3. Известны Только мощности |К]|, |К2|,...,|Kl| классов эквивалентных ключей.
Проведем опробование без возвращения ключей х^К до получения ис-
тинного ключа с точностью до эквивалентности.
Если ключ шифра выбирался случайно и равновероятно из К, то веро-
| /С • |
ятность выбора ключа х из класса Kj равна -------. Обозначим через T(j)
1-^1
среднее число опробований алгоритма, при условиии что искомый ключ
ХеКг Тогда
1^1+1
1^1+1
и общее среднее число опробований алгоритма
% iki ^|/су|+1
Надежность метода тс=1.
Отметим, что если в данном методе опробование проводить с возвра-
щением, то среднее число опробований алгоритма будет равно
244
У |К| 1 1 = £.
STIKjlW
Следовательно, в условиях третьей задачи всегда T<L.
Очевидно,
2
при этом нижняя оценка достигается при L=l, |Kj|=|K|, а верхняя при L=|K|,
|Kj|=l. Если известны оценки мощностей классов эквивалентных ключей
Cj^Kj|<Cj, jel,L,
ТО
I к I +1 у» cj <т< I К I 4-1 у Cj
|К| £cj+r.’ |К| ^Cj+1'
4. Известно число L классов эквивалентных ключей. Проводя метод пункта 3,
для трудоемкости метода получаем оценку T<L.
Обратим Ваше внимание на то обстоятельство, что изложенные методы
• базировались на эквивалентности ключей относительно заданного хеХ («сла-
бой эквивалентности ключей»). Обычно точный расчет мощностей классов та-
ких эквивалентностей затруднителен, в связи с чем пользуются эквивалентно-
стью ключей относительно всего множества X. В этом случае несложно полу-
чаются нижние оценки мощностей классов использованных нами слабых экви-
валентностей. Прямое использование мощностей классов эквивалентных клю-
чей относительно всего множества X в методах 1-4 дает верхние оценки тру-
доемкостей изложенных выше методов «слабых эквивалентностей».
Метод опробования с использованием памяти
Пусть известны: A=(I, S, О, (5i)iei, (Pi)iei) - конечный автомат и его N
вход-выходных последовательностей 3J=ij(l),ij(2),..., t*(L); W=yi(l),yi(2),..., y'(L),
где ij(k)el, у’(к)еС), je 1,N .Требуется найти произвольное состояние seS, при
котором A(s,3j)=91j при некотором je 1,N. Напомним, что A(s,3j) — выходная
последовательность автомата А с начальным состоянием seS при входном сло-
ве ,3\
Метод состоит из двух этапов.
245
На первом этапе проводится заполнение памяти (таблицы), содержащей
|0|‘ ячеек (строк), где t - параметр метода, t<L. Фиксируется некоторое слово
ii,i2,...,it из I*. Для заполнения памяти опробуются все последовательности
(5j,9?j), j е 1, N. Для j-той пары проверяется условие
(f(l),P(2),.„, ij(t))=(ii,i2,...,it).
Если равенство выполнено, то пара (3J,W) записывается в ячейку
(строку) с адресом у’(1),у’(2),..., y*(t).
На втором этапе проводится опробование состояний sgS (опробование
поурновой схеме без возвращения^. Пусть A(s,ii,i2,...,it)= ys(l),ys(2),..., ys(t)-
выходное слово автомата А, определяемое начальным состоянием sgS и вход-
ным словом ii,i2,...,it. Тогда проводится обращение к ячейке (строке таблицы) с
адресом ys(l),ys(2),..., ys(t). Если ячейка оказалась пустой, опробуется следую-
щее состояние автомата. В противном случае, проверяется, удовлетворяет ли
состояние s улоЬиям задачи относительно одной из пар (3J,5RJ), записанных в
этой ячейке, то есть перерабатывает ли автомат А с начальным состоянием s
входное слово 3J в выходное слово пара W. Если состояние s таково, что A(s,
3J)= 9lJ, реализация алгоритма заканчивается. В противном случае (после опро-
бования всех пар из ячейки на состоянии s) опробуется следующее состояние
из S.
Очевидно, надежность метода равна единице. Рассчитаем его трудоем-
кость. Пусть Ni - число пар из всех (3\9Р), je 1,N, для которых
(^ОЗЧг),...,^))^!^,...,^).
, Трудоемкость первого этапа метода имеет вид: T|=N+Nb где N - число
опробований на предмет поиска пар с началом (цЗг,...,it), a Ni - число обраще-
ний к памяти для записи в память пар с этим началом. Здесь и далее мы «сум-
мируем различные операции», молчаливо предполагая, их приблизитель-
ную равноценность по скорости выполнения.
В качестве трудоемкости второго этапа метода берут величину
rr_|S|+l , |S|+1 Ni
1 2---------1 ,
Nj+1 Ni+1 |О|‘
246
где ---------среднее число опробуемых состояний на втором этапе метода,
Nj +1
|S|+1 Ni
--------------среднее число опробовании второго этапа метода, совершаемых
Nj+1 | О |‘
N
после обращения к памяти (—-— среднее число пар в ячейке памяти).
|ор
При получении этой формулы использовано следующее предположе-
ние: для каждой пары (3J,9?) существует единственное состояние, при котором
A(s,3j)=
Первое слагаемое в формуле для Т2 - это среднее число операций вы-
числения выходного слова A(s,ii,i2,...,it)= ys(l),ys(2),..., ys(t) с последующим об-
ращением в память по адресу ys(l),ys(2),..., ys(t). Второе слагаемое - это среднее
число операций вычисления выходного слова A(s,3j) с последующим сравне-
нием его с 9V.
При необходимости проводят усреднение общей трудоемкости Ti+T2 по
возможным значениям N! и оптимизацию метода по параметру t, а также его
модернизацию, ограничивая себя в возможном числе опробований. В послед-
нем случае рассчитывают и надежность метода.
Остановимся на одной модификации приведенного метода упорядо-
ченного опробования.
На первом этапе наряду с фиксацией начала ii,i2,...,it входных слов ав-
томата фиксируют и некоторое начало уьу2,.. .,yt его выходных слов и отбира-
ют пары вход-выходных последовательностей 3]=Г(1)Д\2),..., P(L);
W=yi(l),yi(2),..., y’(L) автомата удовлетворяющие условию
iJ(l),iJ(2),..„ iJ(t)= ibi2,..:,it, ^(l),^),..., y*(t)= yi,y2,...,yt
Обозначим через M - множество отобранных пар.
На втором этапе метода проводится опробование состояний sgS и от-
бор таких s, при которых A(s, it,i2,..,,it)= yi,y2,...,yt.
На третьем этапе проверяют, удовлетворяет ли s, отобранное на втором
этапе, хотя бы одной паре (3j,W) из множества М, то есть выполняется ли ра-
венство A(s,3j)=W. В процессе реализации метода второй и третий этапы че-
редуются: как только на втором этапе найдено состояние s автомата, при кото-
ром A(s, i|,i2,...,it)= yi,y2,...,yt, - так оно опробуется на третьем этапе. Перебор
проводится до появления искомого состояния.
Число операций первого этапа равно N (операции нахождения пар, при-
надлежащих множеству М). Для подсчета трудоемкостей второго и третьего
этапов метода примем предположения, указанные выше.
247
Пусть £ - число опробуемых состояний на втором этапе метода, £ - чи-
сло опробуемых состояний на третьем этапе метода. За операцию примем по-
лучение выходного слова автомата при заданных начальном состоянии и вход-
ном слове. Тогда общее число операщй, выполненых на втором и третьем ета-
пах, составит %+£, |М|, при этом и - случайные величины. Среднее значение
Т2,з величины %+S, |М| имеет вид
Т2,з = Е(^'|М|)= Е(^)+Е(^)|М|.
По предположению распределение £, есть распределение числа испыта-
ний по урновой схеме без возвращения с |8|-исходами до появления одного из
|М|-исходов. Поэтому Е(^)= . Далее,
| М | +1
|5|ЧМ|+1
Е(^)= £E(^ = y)p(£ = v).
У=1
Предположим дополнительно, что вероятность события A(s, it,
i2,...,it)= yi,y2,.--,yt при случайном и равновероятном выборе sgS равна |О|'‘. То-
гда Е(£, 4=v)=v|Or* и
|S|-|M|+i
X v|or‘ pft = v)=|or' Е©.
V=1
Таким образом,
Tz _ |S|+1 t |M|(|Sj+l)
2,3 IM I +1 (I MI +1) IО |‘ ’
В ряде случаев, при необходимости, проводят усреднение трудоемкости
метода по |М| и ее оптимизацию.
Метод расшифровки черного ящика
Пусть для начального состояния seS и каждого входного слова 3 g IL
известно выходное слово A(s,3)= 9?=у(1),у(2),..., y(L). автомата А. Требуется
найти частичные функции переходов и выходов автомата А.
Обозначим через A(s) - подавтомат автомата A=(I, S, О, (5i)jei, (₽i)iei),
порожденный состоянием s. Состояниями этого подавтомата являются: само s
и все состояния, достижимые в автомате А из s. Уточненная задача, решаемая
ниже, состоит в построении графа переходов автомата A(s), что равносильно
нахождению его функций переходов и выходов. При этом мы будем предпола-
гать, что автомат A(s) является приведенным и L>R+D+1, где R - степень раз-
248
личимости автомата, D - его диаметр (здесь использована терминология теории
автоматов.
Метод состоит в последовательном проведении двух этапов (использу-
ется терминология теории графов).
На первом этапе по набору входных и выходных слов строится дерево
высоты L, из каждой вершины которого' исходит |1| ребер. Каждое ребро, исхо-
дящее из каждой вершины дерева, помечается одним из символов входного ал-
фавита I, точнее говоря, устанавливается взаимно-однозначное соответствие
между элементами из I и ребрами, исходящими из каждой вершины. Для
1={0,1}, L=2 полученное таким образом дерево изображается на приводимом
ниже рисунке (левая стрелка - 0, правая - 1)
Далее проводится «разметка» дерева выходными символами уеО авто-
мата A(s) по следующему правилу. Пусть ребро v является концом пути, кото-
рый начинается в корне и ребрам которого соответствует входное слово
ii,i2,...,it, t<L; если A(s) преобразует его в выходное слово У1,У2,--.,Уь то ребро v
помечается выходной буквой yt. В результате получается дерево V, каждому
ребру которого поставлено в соответствие входной и выходной символы.
На втором этапе осуществляется операция «свертывания» дерева V, то
есть получение из дерева V графа переходов автомата A(s). Занумеруем все ве-
ршины дерева V следующим образом: припишем номер 1 корневой вершине,
затем нумеруем слева направо все вершины первого яруса, второго и так далее
до D+1 яруса включительно. Назовем вершину с номером) базисной, если по-
ддерево V(j) дерева V высотой R с корнем в вершине с номером) отлично от
любого поддерева V(f) дерева V той же высоты с корнем в вершине с номером
j' - такой, что j'<j.
Свертывание дерева V проводится следующим образом. На первом ша-
ге поддерево V(2) сравнивается с поддеревом V(l). Если V(2) отлично от V(l),
то вторая вершина базисная и на следующем шаге сравнивается V(3) с подде-
ревьями V(l) и V(2). Если же V(2) совпало с V(l), то из дерева V удаляется все
его поддерево (высоты L-1) с корнем во второй вершине; ребро, входившее во
вторую вершину, присоединяется к первой вершине, то есть проводится пере-
ориентация ребра (с его пометками), и на следующем шаге сравнивается V(3) с
V(l). Вообще на k-ом шаге последовательно сравнивается некоторое поддерево
249
V(jk) с поддеревьями V(j), где j<jk и j - номер базисной вершины. Если V(jk)
совпало с некоторым V(j');TO все поддерево дерева V с корнем в вершине с
номером jk удаляется из V (удаленные таким образом вершины в дальнейшем
не рассматриваются), ребро, входившее в вершину jk, присоединяется к верши-
не]', то есть переориентируют ребро. На (к+1)-ом шаге проводят сранение по-
ддерева V(jk+i), где jk+i минимальный номер вершины такой, что jk+i> jk и вер-
шина с этим номером осталась в дереве после проведения k-го шага. Алгоритм
заканчивает свою работу после того, как проведено сравнение последней не
удаленной вершины (D+l)-ro яруса дерева V.
' Расчет параметров метода расшифровки «черного ящика». Надежность
метода очевидно равна единице, а общая трудоемкость Т метода есть сумма
трудоемкостей Tt и Т2 первого и второго этапов. Подсчитаем величину Ть Чис-
11 |L
ло дуг дерева V равно ——-111, поэтому для реализации первого этапа требу-
II |L |I|L
стоя память объема ——j-111 ячеек и для ее «разметки» ——-111 обращений
к памяти, то есть трудоемкость первого этапа можно положить равной
|I|L
Т|=——j-111 обращений к памяти.
Точный расчет трудоемкости второго этапа метода достаточно сложен,
в связи с чем мы его не приводим.
Метод упорядоченного опробования в задаче оп-
ределения входного слова автомата
Пусть A=(I,S,O,5,P) - автомат, для которого 1=АхХ, О=А, функция пе-
реходов 8(a,x,s), (а,х)е АхХ при каждом seS зависит лишь от хеХ, то есть
6(a,x,s)= 8(x,s), а функция р при каждом seS зависит лишь от аеА, то есть
P(a,x,s)=P(a,s), и при каждом seS эта функция.осуществляет биективное отоб-
зажение А в О= А.
Рассматриваемая задача состоит в определении входной последователь-
ности Xq,xi,...,xk при известных данных: автомат А, выходная последователь-
ность уо,У1,...,Ук> отвечающая выходной последовательности
ao,xo),(ai,xi),...,(aK,xk) и начальному состоянию So автомата А.
Обозначим через WK+i множество входных последовательностей
xo,X],...,xkgXk+1, являющихся решениями задачи, а через SK+k множество заклю-
чительных состояний автомата А, отвечающих его входным последовательнос-
тям вида (ao,Xo),(a],Xi),...,(alc,xlc), х0,Х1,...,хкеХк+1. Множество WK+i искомых по-
250
следовательностей может быть разбито на непересекающиеся подмножества
WK+i>s, seSK+i, где WK+i,s - множество последовательностей xo,xi,...,xK, являю-
щихся решениями задачи, и при которых автомат А с начальным состоянием So
переходит в заключительное состояние s. Таким образом, задача сводится к
нахождению множества Sk+i и соответствующих его элементам sgSk+i мно-
жеств Wk+i,s. Для нахождения этих параметров предлагается следующий алго-
ритм, состоящий в последовательном построении множеств Sj, WjiS, seSj по на-
чалам ao,ai,...,aj-i, уо,У1,...,ун известных последовательностей xo,Xi,...,xK,
Уо,У1,-..,Ук-
Положим, So={so,}, Wo s =х. В качестве множества Si выберем все со-
стояния s вида s=8(x,s0), xgX, для которых P(ai,s)=yi, а в качестве множества
Wi>s, sgSi выберем все элементы xqgX, для которых 8(xo,so)=sgSi. Пусть для j-
го шага построены: множество состояний Sj и множества Wj S, seSj входных
слов длины] в алфавите X. Тогда множество Sj+i строится исходя из следующе-
го правила: Sj+i gSj+i тогда и только тогда, если для некоторых SjGSj и XjGX
8(xj,Sj)=Sj+I и P(aj+i,Sj+i)=yj+i. Если Sj+tGSj+i, то множество W]+j s. состоит из
всех слов вида x0,xi,...,Xj.i,Xj, где x0,X|,...,Xj.iG Wj s и 8(xj,Sj)=Sj+i. Алгоритм за-
канчивает свою работу при j=k, и множество WK S представляет собой
множество решений рассматриваемой задачи, так как k+1-e элементы хк в ре-
шениях произвольны (это следует из законов функционирования автомата А).
Трудоемкость алгоритма совпадает с трудоемкостью предложенного
метода построения множеств So, Si,;.., SK. Она определяется величиной
к
T=|X|=|Sj|.
j=0
Здесь за операцию принято вычисление 8(x,s) при заданных (x,s)gXxSh
проверка равенства P(a,s)=y для заданных (a,s,y)G AxSxO.
Предположим, что автомат А выбирается случайно и равновероятно из
класса всех автоматов рассматриваемого типа с заданными алфавитами S, X, А.
Это означает, что 5 является случайным равновероятным отображением мно-
жества XxS во множество S, а Р выбирается случайным равновероятным обра-
зом из класса всех отображений множества AxS во множество О=А, индуци-
рующих при любом фиксированном sgS подстановку множества А. В приве-
денных предположениях |Sj| являются случайными величинами, в связи с чем
представляет интерес
251
к
ET=|X|£E|Sj|,
j=0
связанных с проведением алгоритма. Для этого достаточно оценить средние
значения E|Sj|.
Для произвольного целого числа t>0 выделим в графе переходов авто-
мата А все пути длины t, исходящие из вершины so (отождествляя все дуги вида
(х,а), абА). Таким образом мы получим некоторый мультиграф T(t).
Обозначим через B(t) событие, заключающееся в том, что мультиграф
Г(1) будет деревом, а через
w(t)=
| X |t+1 -1
|Х|-1
число вершин дерева высоты t. Тогда
(|S|-l)(|S|-2)...(|Sbw(t)4-l) Isr^-CISf-W'2
1 | S|w(t)-1 | s |w(t)-i
и при |S|—><ю и фиксированных значениях остальных пааметров получаем
P(B(t)=l-O(-^-).
Откуда
E(|St|)=P(B(t))E(||St|/B(t))+P( B(t) )E(|St|/ B(t) )=
=(l-O(-^-))E(||St|/B(t))+O(-|-)E(|St|/B(t)).
I Ь I I O I
Здесь через B(t) обозначено событие, состоящее в том, что мультиграф Г, не
будет деревом.
Заметим теперь, что при фиксированном t с ростом |S| величины
E(||St|/B(t)), E(|St|/B(t) ) ограничены (например, числом вершин на уровне t де-
рева). Поэтому из предыдущей формулы вытекает
E(|St|)= E(|St|/B(t))+О(-^—).
' |S|
По формуле условных математических ожиданий при любом t>l, t<k
имеем
E(|[S,|/B(t))=£P(| S,_, 1= j/B(t))E(| S, I /B(t),I S,_1 h j) •
j
252
Расчет E(|St|/B(t),|St-i|=j) проводится из следующих соображений. Каж-
дое состояние stGSt является приемником некоторого состояния st.i из St.i. Чис-
ло приемников состояний из St.i равйо j|X|, при этом один из таких приемников
по условию задачи заведомо принадлежит St, t<K. На каждом из остальных j|X|-
1 приемниках имеется нужное нам значение «у» с вероятностью | А|'*, то есть с
вероятностью |А|'* каждый из j|X|-l приемников принадлежит множеству St.
Следовательно,
E(|St|/B(t),|St.,|=j)=l+(j|X|-l) I Ар1
и
E(||St|/B(t))= £Р (ISmH/BO)) (1+61X1-1) I А|-*)=
j '
1+|Х| I Аг1 £р (|St.i|=j/B(t))j -1 Аг’=
j
1+1ХЦ Аг1 £p(|s,i|=j/B(t-i))j -I Аг1.
j
Таким образом,
E(||St|/B(t))= (I A|-iI) |А|-‘ +|Х|| А|-‘ E(||st.i|/B(t-i)). .
Это равенство справедливо и при t=l, если положить E(||So|/B(O))=
E(||SO|)=1. Умножим обе части равенства на (|Х|’’|А|)‘
(|х||АГ)‘ E(||st|/B(t))= (I A|-i I) |Аг1(|хг1|А|)‘+ (|хг,|А|)‘'1 echs^/bc-i)).
Суммируем последнее соотношение по t от 1 до j и учитывая, что
E(||So|/B(O))=l, имеем
Я . ...
£| А|‘|Х|-‘ E(||St|/B(t))+ IA|J|X|-J E(||Sj|/B(j))=
t=l
< z j , H
=(l A|-11) |Ar £l X |A|)‘+ E(||So|/B(O))+ £| x p‘ |A|)‘ E(||st|/B(t)).
t=l t=l
Откуда
вд|/в(П)=|хН|АГ[(| A|-i I) | Ar12l x r‘ |A|‘+r]=
t=l
=|xn Arj+(l A|-i|) |Ar* £| x rt+j |A|‘-j=
‘ t=l
253
=|хиА|-ч (I А|-1|) |А|-1[|хиА|<1] lAr'dxnAr1-!)-1.
Таким образом,
EdSjDHXHAr^ (| A|-i|) |Аг'[|хпАр-1] |Аг*(|Х|| Ar’-iy'+odsr1).
Окончательный результат получается подстановкой этого значения в
полученную ранее формулу
к
' ET=|X|^E|Sj |. .
j=0
Опробование в методе использования гомомор-
физмов
Напомним сначала основйые понятия, связанные с определением гомо-
морфизма автоматов.
Пусть A=(Ia,Sa,Oa, (5iA)iel,(PiA)id) и B=(Ib,Sb,Ob, (3iB)ieI>(PiB)iel) Два
автомата. Тройку сюръективных отображений (\р,ф,т|)
ip: 1А—>1в> Ф-’Sa->Sb; t|:Oa->Ob
называют гомоморфизмом автомата А на автомат В, если для любых ieIA, seSA
выполняются следующие равенства:
<p5iAs=5ViB<ps,
T]PiAs=PviB<ps.
Автомат В в этом случае называют гомоморфным образом автомата А. Если
отображения (ф,ф,г|) биективны, то гомоморфизм называют изоморфизмом ав-
томата А на автомат В.
Следующее, легко проверяемое исходя из определения гомоморфизма,
утверждение является основой для построения методов определения начально-
го состояния автомата А по его входной й выходной последовательностям.
УТВЕРЖДЕНИЕ. Пусть 3=i(l),i(2),...,i(L) - произвольная входная по-
следовательность автомата A, s - произвольное его начальное состояние,
A(s,5)=y=y(l),y(2),...,y(L) - выходное слово автомата А, отвечающее его на-
чальному состоянию seSA и входному слову 3, а (ф,ф,т|) - гомоморфизм А на
В. Тогда выходное слово B(cps,4|/3) автомата В, соответствующее его начально-
му состоянию <pseSB и входному слову \p3=i|/i(l),vpi(2),...,\|/i(L) есть
B((ps,\|/3)= т)у(1), т]У(2),--->.ПУ(Ь)
Рассмотрим задачу определения начального состояния s автомата А по
известным входному слову 3eIL и выходному слову A(s,3)=y, то есть задачу
нахождения решений seSA уравнения A(s,i(l),i(2),...,i(L))=y(l),y(2),...,y(L).
х£54
При этом предполагаются известными автоматы А, В и гомоморфизм (\|/,<р,т|) А
на В.
На основании сформулированного выше утверждения исходную задачу
для автомата А можно редуцировать в аналогичную задачу для автомата В,
именно будем искать все решения cpseSe уравнения
B(<ps, V|/i(l),V|/i(2),...,i|/i(L)= цу(1), т|у(2)>..., т|У(Ь).
Цель такой редукции заключается в том, что автомат В может иметь
более простое строение, чем автомат А (например, иметь меньшее число со-
стояний, или быть линейным). Поэтому для него задача определения начально-
го состояния может решаться проще (с меньшей трудоемкостью), нежели ис-
ходная задача. Однако при такой редукции теряется часть первоначальной ин-
формации, так как произошла замена последовательностей 3, У на последова-
тельности \уЗ, т]У. В этой связи в результате редукции йсходная задача реша-
ется с дополнительной многозначностью, то есть получаются лишние решения.
Для того чтобы их отбросить, надо снова использовать первоначальную ин-
формацию. Поэтому, найдя все решения 8(\|/3,г]У) уравнения
B(cps,\|/i(l),i|/i(2),...,V|/i(L)=T]y(l), т|у(2),..., r|y(L), а затем все состояния sgSa, для
которых <р5е8(\|/3,г]У), следует проверить, какие из этих состояний являются
решениями первоначального уравнения
A(s,i(l),i(2),.. .,i(L))=y(l),y(2)„. ,,y(L).
При расчете трудоемкости данного метода будем использовать сле-
дующие предположения: каждое из рассматриваемых уравнений
A(s,i(l),i(2)„. .,i(L))=y(l),y(2)„. ,,y(L),
B(<ps, i|/i(l),\|/i(2),...,\|/i(L)= цу(1), цу(2),..., цу(Ь)
имеет единственное решение; нахождение решения второго уравнения прово-
дится тотальным методом; не учитывается трудоемкость определения всех ре-
шений <p’’sB уравнения <ps=sB, а последующий отсев этих решений проводится
тотальным методом в автомате А.
Трудоемкость метода гомоморфизма слагается из трудоемкости опре-
деления решения sB уравнения
B(q>s, \|/i(l),\|/i(2),...,\|/i(L)= ПУ(1), ПУ(2),---, ПУ(Ь),
|SB|+1
которая равна —-----------(среднее число опробований) и среднего числа опробо
2'1
ваний состояний sgcp ’sb в уравнении
A(s,i(l),i(2),.. .,i(L))=y(l),y(2)„. ,',y(L),
которое равно —(19 ’88+ 1|).
255
При необходимости общую трудоемкость метода усредняют по воз-
можным значениям Icp ’sel, а также рассчитывают ее в менее жестких предпо-
ложениях.
. Опробование в методе встречных атак для опре-
деления начального состояния последовательного
соединения автоматов
Рассмотрим задачу определения состояний Si,S2 последовательного сое-
динения двух автоматов Ai=(I(l),S(l),O(l),81,|31) и A2=(I(2),S(2),O(2),82,p2),
0(1)=1(2) по известному входному слову 3gI(1)l и выходному слову YgOl,
0(2)=О.
Будем предполагать, что автомат А(2) обратим, то есть по его началь-
ному состоянию и выходному слову можно однозначно определить его входное
слово.
Разобьем слова 3=ii,i2,...,ib У=УьУ2,--.,Уе на отрезки длины t, v, L-t-v.
3=3(1 )3(2)3(3); 3(1)gI(1)‘, 3(2)gI(1)v, 3(3)gI(1)l-, v;
У=У(1),У(2),У(3); У(1)еО‘, У(2)еО\ y(3)6OL’,’v.
Алгоритм решения задачи состоит из трех этапов, которые проводятся
для каждого слова W(l)=zi,z2,.. .,zt из 0(1)'.
На первом этапе для слова Z( 1 )=Zi ,z2,... ,zt и каждого j g 1, t последовате-
льно строят множества Si(ii,i2,...,ij;zbz2,...,Zj)={s(l): s(1)gS(1), Ai(s(1),
il,i2,...,ij)=ZbZ2,...,Zj}.
Для чего при слове zbZ2,...,zt проводят последовательное опробование
s(1)gS(1). Опробуя все состояния s(1)gS(1), находят множество Si(ii;zi), опро-
буя состояния из Si(ii;zi), находят S|(ij,i2;zbZ2) и так далее до определения
множества Si(3(1 ),Z(1)), для чего требуется провести
Ti(A])= |S(l)|+|S1(i1;z1)|+...+ |S1(il,..„it.1;z1,...,zt.l)|
опробований (на один такт работы автомата). Далее для каждого
seSi(3(l),Z(l)) при данном Z(l) вычисляют Z(2)gO(1)v, именно
AI(s,3(l),3(2))=Z(l),Z(2)
и по адресу Z(2) записывают s в память П. Трудоемкость этой части алгоритма
есть
T2(Ai)=|Si(3(l),Z(l))|(t+v)+|Si(3(l),Z(l))|,
где первое слагаемое является трудоемкостью вычисления адресов, а второе -
число обращений к памяти П. Поэтому для фиксированного z(l) общая трудое-
мкость первого этапа алгоритма есть величина Тi= Tj(Ai)+ T2(Ai).
256
Второй этап аналогичен первому. Для данного слова Z(l)=zi,z2,...,zt по-
следовательно находят множества
S2(Z|;yi), S2{zbz2,y\,y2),..., S2(Z(1);Y(1)),
где S2(zi,...,zj;y1,...,yj)={s(2):s(2)GS(2),A2(s(2),zi,...,Zj)=y1,...,yj}. Для нахожде-
ния этих множеств потребуется провести
T,(A2)=|S(2)|+| S2(zi;y,)|+...+|S2(zi,...,zt.i;yi,...,yt.i)|
опробований на один такт работы автомата А2. Для каждого s(2)gS2(Z(1);Y(1))
вычисляют Z(2)
A2(s(2),Z(l),Z(2))=y(l),Y(2),
что можно сделать в силу обратимости автомата А2. По адресу Z(2) записывают
s(2) в память П. Точнее говоря, по адресу Z(2) находят все s(1)gS(1), содержа-
щиеся в ячейке с адресом Z(2) и образуют пары (s(l),s(2)). Трудоемкость этой
части алгоритма (при фиксированном Z(l)) есть
T2(A2)=|S2(Z(l);y(l)|(t+v)+|S2(Z(l);y(l))|,
и суммарная трудоемкость второго этапа есть Т2= Т|(А2)+ Т2(А2).
На третьем этапе совокупность пар (s(l),s(2)), содержащихся в каждой
адресной ячейке «согласуют» на оставшемся материале. Именно, для каждой
пары (s(l),s(2)) опробованием проверяют выполнение равенства
A(s(l),s(2), 3(1),5(2),3(3))=У(1),У(2),У(3),
которое по определению пар (s(l),s(2)) может не выполняться лишь на послед-
них L-t-v тактах работы последовательного соединения A=Ai->A2 автоматов
Ai, А2. Трудоемкость такой проверки в числе опробований (на один такт) равна
T3=|S(3(l),3(2);y(l),y(2))|(t+v+l)+|S(ii,...,it+v+i;y1,...,yt+v+i)|+...
.. .+|S(i„. ..,iL.,;y„.. .,уы)|+|5(3(1), 3(2);У(1),У(2))|,
где S(ii,...,ij;yi,...,yj) - множество пар (s(1),s(2))gS(1)xS(2), для которых
A(s(l), s(2),i,,..., ij)=y...
Последнее слагаемое в формуле для Т3 учитывает обращения в память П.
Общая трудоемкость трех этапов при фиксированном Z(1)gO(1)‘ есть
T(Z(l))=Ti+T2+T3. Все три этапа алгоритма проводятся для каждого Z(l)6 0(1)'.
Поэтому общая трудоемкость метода есть
T=|O(1)|‘T(Z(1)).
При необходимости оценивают среднее значение Т, исходя из возмож-
ных значений параметров Si(ibi2,...,ij;zbz2,...,Zj), S2(zl5...,Zj;yi,...,yj),
S(ib...,ij;yi,...,yj).
257
Параграф 5.4
Принципы построения статистических методов
криптоанализа.
Принципы построения статистических методов криптоанализа весьма
многообразны. В данном параграфе мы сформулируем ряд таких принципов,
которые используются в известных статистических методах определения клю-
чей шифрсистем.
Ниже под моделью А* автомата А мы понимаем некоторый новый ав-
томат, позволяющий с помощью А* решать поставленную для А задачу. Обыч-
но эти автоматы зависимы и А* имеет некоторые количественные характерис-
тики «похожести» на А.
1. Рассмотрим задачу восстановления ключа х=(ХьХ2) по известной выходной
последовательности А(х)=уьУ2>---Уь--- шифрующего автомата А с помощью
построения его модели А*.
Пусть модель А* шифрующего автомата А такова, что ее выходная по-
следовательность при произвольном ключе Х=(Х1 »Хг) зависит только от первой
части Xi ключа и при случайно и равновероятно выбранном ключе Х=(ХьХ2)
между последовательностями
А(Х1,Х2)=У1,У2,.--,Ут,
А*(Х1) =У*ьУ*2,-.-,У*т
имеется кореляционная связь, а при ключах вида X=(Xi5X2) и X i*Xi такой связи
в последовательностях
А(хьХ2)=УьУ2,...,Ут,
А*(Х1) =УьУ'2,...,У'т
не проявляется.
а) . Один из способов нахождения истиной части Xi ключа х по выходной по-
следовательности А(Х1,Хг) состоит в опробовании вариантов х' i в А*, т. е. вы-
числении последовательности А*(х'1)=у'|,у'г,...,у'т для каждого варианта x'i и
в выявлении статистическим методом корреляционой зависимости между
А(хьХг) и А*(х0 при истинном варианте Хь
б) . Пусть при истиной части Xi ключа х=(ХьХг) последовательности А(Х1,Хг),
A*(Xi) близки по Хэммингу. Предполагаем, что такой близости нет при ложной
части Xi ключа х=(ХьХг)- В этом случае задачу определения истиной части Xi
ключа можно свести к решению уравнения A*(xi) =у*1,у*2>--,у*т с искажен-
ной правой частью, а записав это уравнение в координатной форме, - к реше-
нию системы уравнений
9 Зак. 5
258
®*t(Xi)=y*t, te{l,...,T}
с искаженной правой частью уьу2,...,ут(см.параграф 5.5).
2. Рассмотрим задачу определения части %| ключа х=(у1,х2)еК|хК2 из уравне-
ния Ф(Х1,%2)=у, где Ф: KjxK2—>У, уеУ. Предположим, что она решается мето-
дом частичного опробования. Именно, опробуются все варианты %'i еК( и для
каждого варианта проверяется разрешимость уравнения Ф(х ьХ2)=У относите-
льно хг-
Положим: У'(Х1)={У=Ф(ХьХ2)-’ (ХьХг)е {Xi}хКг) и введем индикаторную
функцию:
... ч (1, если, уеУ'(Т1)
Ь(ХьуН Л1 ,
О, если уёУ'(Х1)
определенную на К]хУ'.
В этих обозначениях критерий разрешимости уравнения Ф(х ьХг)=У
относительно %2 описывается логическим правилом
А'(хьУ)=0 => Xi “ ложный вариант,
Х'(ХьУ)=1 Xi _ истиный вариант.
Поиск эффективного критерия разрешимости уравнения Ф(х ьХг)=У в
веденных терминах сводится к поиску «легко» реализуемых алгоритмов вы-
числения индикаторной функции или, что то же самое, к конструктивному
описанию множеств У'(Xi)> Х1еКь
Нередко, ввиду сложности отображения Ф, найти индикаторную функ-
цию не удается, т.е. не удается конструктивно описать множества У'(х>),
Xi еКь Чтобы обойти эту трудность, обычно пытаются аппроксимировать мно-
жества У'(Х1)> Xi некоторыми «хорошими» множествами У(хд, Xi еК» Если
такие множества найдены, то опробование вариантов %] еК] проводят на основе
вычисления значения новой индикаторной функции
МХ..У>-{ ’’ eCM’ysV(Zi).
О, если уёУ(Х1)
Естественно, при использовании аппроксимаций в принятии решения по пра-
вилу
X(Xi,y)=O => Xi _ ложный вариант,
X(xi,y)=l => Xi _ истиный вариант, -
могут возникать ошибки. Далее процедуры такого вида будут называться X-
процедурами (Х-критериями).
Характеристики Х-процедур. Пусть значение у(0)=Ф(%(1),%(2)) полу-
чено при неизвестном ключе (х(1)>х(2))- Будем определять часть ключа %(1) с
помощью Х-процедуры. Оценим эффективность метода определения части
259
ключа Хь В качестве меры эффективности можно рассматривать следующие
параметры.
1. Трудоемкость вычисления функции X (аппроксимирующей функции индика-
торной функции).
2. Средняя мощность множества {хь X(xi,y(O))=l} ПРИ случайном и равноверо-
ятном выборе ключа (x(l),x(2))eKixK2=K. Эта величина характеризует число
вариантов первой части ключа, оставшихся для дальнейшей обработки с целью
определения использованного полного ключа (х( 1 ),х(2))-
3. Вероятность не потерять истиный вариант части ключа
Р(х(1)е{хь Х(хь у(0))=1}).
Описание последних двух параметров на языке математической
статистики.
Введем в рассмотрение множество пар
Т={т=(Хь X): XieKh Х=(х(П,Х(2))еК}
и зададим на этом множестве меру Рт(т)=р(Х1)Р(х)> геТ, где р - равномерная
мера на множестве Ki, а Р - некоторая вероятностная мера на множестве клю-
чей К.
Рассмотрим следующие подмножества множества Т.
Т(0) = {т=(Хь Х): Х>еКь Х=(х(1),Х(2))еК, Х1=х(1)},
Т(1)= {т=(Хь X): XieKb Х=(х(1),Х(2))еК, Xi*X(l)}-
Введенная основная мера Рт индуцирует на этих подмножествах соот-
ветствующие условные распределения
Рт(0)= Рт{т4еТ(0)} и Рт(1)= Рт{УтеТ(1)}.
Если исходная мера Р равномерна, то эти условные распределения представля-
ют собой равномерные распределения на соответствующих множествах Т(0),
Т(1).
На первом этапе решения задачи определения части ключа Xi из урав-
нения у(0)=Ф(х(1),х(2)) нас интересует только один вопрос: в каком из мно-
жеств Т(0), Т(1) лежит соответствующее t=(Xi>(x(D>X(2)))- Отождествим эту
задачу с задачей разделения с введенных на Т(0), Т(1) распределений РТ(0), Рт<1)
и посмотрим на Х-процедуру как на статистический критерий разделения этих
двух распределений (двух гипотез Т(0), Т(1)). Этот критерий, обозначим его
символом (Т(0),Т(1),Х), в общем случае допускает ошибки с соответствующими
вероятностями - ошибками критерия:
а= РТ(О){Х(Х1, у(0))=0}-
вероятность события Xi=xG )> ПРИ условии X(xi, у(0))==0 и
Р= Рт(1){Х(хь у(0))=1}-
вероятность события Xi*X(l)> ПРИ условии X(xi,y(0))=l, где у(0)=Ф(х(1),х(2))-
9*
260
Теорема. При любой Х-процедуре и любой мере Р на К параметры
л=Р{(%(1)б {Хь МХь у(0))=1} - надежность Х-процедуры и ЕХ- средняя мощ-
ность множества {%ii Х(хь у(0))=1} при случайном и равновероятном выборе
части ключа х(1)еК] выражаются через ошибки аир критерия (Т(0),Т(1),Х)в
виде
л=1-а,
Е(Х)=|К1|[(1-а)|К1Г1+р(1-|К1Г1)].
ДОКАЗАТЕЛЬСТВО. Функция
ч ( 1, если,уеУ(Х1)
^(Х1,У)=| у 1
0, если уёУ(Х1)
представляет собой индикатор события
Х1£{Х ь Х(х'ь у(0))=1}
и поэтому л=1-а.
Далее заметим, что
|{Хь X(X1, У(О))=1}|=|{Х1: Х(х„ Ф(х(1),х(2)))=1}|=£ Х(Хь Ф(х(1),х(2)))=
Х1
=|Ki| E(xi)( X(xi, Ф(Х(1),Х(2)))),
I I
где Е(Х1)(Х(Х1,Ф(хО),Х(2)))) - среднее значение случайной величины
Х(хьФ(х(1),Х(2)) по возможным значениям Xi gKj при равномерной мере на К!
(вероятность события: Х(Х1,Ф(х( 1)»Х(2)))=1 при случайном равновероятном вы-
боре Xi ?Kj при фиксированном (х(1),х(2))еК).
Усредним теперь значения |Ki|E(xi)( X(xi, Ф(х(1),х(2))) по всем
(х(1),х(2))еК. Получим (будет использована теорема Фубини):
Ц(Х)=Е (|{х,: Х(хь у(0)У=1}|)=|К,| Е(хьХ(1),Х(2))(Х(х.,Ф(х(1),Х(2)))),
где E(xi,x(l)»X(2))(X(xi,Ф(х( 1),Х(2)))) - среднее значение случайной величины
(Х(Х1,Ф(хО)>Х(2))) при равновероятном выборе XigKi и случайном выборе
(х(1),х(2))еК с распределением Р(х), хеК1хКг. Другими словами, величина
Е(Х1,%(1),х(2))(Х(хьФ(х(1),Х(2))))
есть вероятность Р события: Х(хьФ(х(1)>х(2)))=1 • Из определений ошибок а, 0
по формуле полной вероятности непосредственно получаем
PKl-aW1 + р(1-|К1Г').
Таким образом, Х-процедуры можно описывать на языке математиче-
ской статистики.
Построение таких статистических процедур нахождения части ключа
Х(1) из уравнения у(0)=Ф(х(1), х(2)) нередко проводят по следующей общей
схеме.
261
Во множестве ключей К выбирают «часть» Ki ключей, то есть предста-
вляют К в виде K=KixK2,a для основного отображения Ф: К|хК2—>У подбирают
некоторое вспомогательное отображение Ф*: К1->У*. На множестве У*хУ за-
дают некоторый функционал Ф:У*хУ->К| и строится статистика
ф(Хь(х(1)»Х(2)))- Эта статистика и меры Рт(о)=Рт{т/теТ(О)}, Рт(1)=Рт{т/теТ(1)}
индуцируют на борелевских множествах В числовой прямой два распределе-
ния
Рт(0)( ф(Хь (х(1),х(2)))еВ) и Рт(1)( Ф(х., (Х(1),х(2)))еВ). •
Цель построения общей схемы состоит в подборе четверки Кь У*, Ф*
и (р так, чтобы приведенные выше распределения «хорошо различались», то
есть чтобы эти распределения были в основном сосредоточены на некоторых
непересекающихся множествах В(0), В(1). Если такую четверку подобрать уда-
ется, то в качестве решающей функции X берется индикаторная функция
k(Xi, У(0))=1, если <p(xi, (Х(1),х(2)))еВ(0),
*(Хь У(0))=0, если ф(хь (х(1),х(2)))£ В(0).
Ошибки а, Р получаются из соотношений 1-а=РТ(0)( Ф(хь (х(1)>Х(2)))еВ(0)),
Р=Рт(1)(ф(Хь,(х(1),Х(2)))еВ(0)).
Принцип «удобного» разбиения множества ключей.
Пусть I, Q, О — конечные множества, IxQ—>0. Задача состоит в на-
хождении решения со(0) системы уравнений
\|/(11,<»)=У1
V(i2,o))=y2
ф(1ы,со)=уы
относительно неизвестного параметра <oeQ.
Пусть ф*:1х£1—>0* - некоторое вспомогательное отображение, где О* -
некоторый новый алфавит. Рассмотрим последовательность у*ь у*2,..., y*N,
где
v|/*(ii,co*)=y*i
ф*(12,СО*)=У*2
V*(iN,(0*)=y*N
для<о*еП.
Предположим, что на I задано вероятностное распределение. Обозна-
чим через Рш,а>»(к|/,к|/*) - совместное распределение пары (y(i,<o),y*(i,«>*)), ин-
дуцированное распределением на I. Для заданной функции у* проведем разби-
ение множества параметров Q на классы: Q1,Q2,...,QL так, что при любых
262
j,ke 1,Ьбыло верно утверждение: если со,со' принадлежат Qj, а со*,со** принад-
лежат Qk, то _то есть распределение пары постоян-
но на введенных классах:
Pnj,nk= P«mo*(4',4'*)=f Pe»‘‘(Y,4'*).
Если это условие выполняется, то будем говорить, что функция \|/* согласована
относительно разбиения множества Q на классы: Q1,Q2,...,QL.
Отметим, что можно действовать, исходя из разбиения множества Q.
Именно, искать согласованную функцию для заданного разбиения. Задача
определения решения со(О) приведенной выше системы уравнений может быть
решена путем предварительного определения класса Qj, которому принадле-
жит искомое решение. Задача же определения класса Qj может быть решена
следующим образом. Опробуя представителей a>l,<o2,...,a>L классов
Q1,02,.. ,,QL и вычисляя для всех j е 1, N значения \|/*(ij,(cok), ke 1, L, опреде-
ляем значения выборок из распределений Pnk.o>(0)('K,V*)> ke 1,L (при этом по-
следовательность ii,i2,.. .,iN рассматриваем как выборку из заданного распреде-
ления на I).
Если при любых m^n, m,ne 1,L последовательности распределений
P<o(0)ni(V,v4P<o(0)a2(w*X- • .,Р<В(0)П1.(Ч',Ч'*), co(0)eQn,
Pox0)qi(V,V*),PoX0)Q2('F,'I/*),---,Po>(0)ql('V,4/*), (o(O)eQm
не совпадают, то пб значениям выборок из распределений
Р<о(0)01('|/,'И*),Ро>(0)02('|/,'1/*), --,Рсо(0)пе('И,'1/*) можно статистическими критериями
определить с некоторой надежностью класс Qj, которому принадлежит иско-
мое решение со(О).
Частный случай «удобного» разбиения.
Для вышеизложенной идеи «удобного» разбиения возможен частный
случай, когда Ряк,ок('|/,'И*)==Р('И,'|/*) при любом ke 1, L, и РаьЯк('|Л'И*)*Р('|ЛУ*)
при любых j^k. Тогда, опробуя представителей классов Qj, je 1,L, пользуясь
статистическими критериями, можно с некоторой надежностью определить
искомый класс.
2). Другой подход к решению поставленной задачи поиска решения <о(0) сис-
темы уравнений
i|/(ii,<o)=y,
Х|/(12,СО)=У2
V(iN,®)=yN
263
состоит в поиске функции для которой существует разбиение множес-
тва Q на классы Q1,Q2,...,QL, такое, что элементы со, со' принадлежат одному
классу тогда и только тогда, когда совпадают распределения Р<о(ф,0 пары
(\|/(i,co),t(i)) и Рю (\|/Д) - пары (v|/(i,co'),t(i)), индуцированные заданным распреде-
лением на I. В этом случае наблюдаемость пар (\|/(ij,co(0)),t(ij)), j е 1,N позволя-
ет по выборке из распределения Ри(о)(y,t) статистически определить класс, в
котором содержится искомое решение со(0).
Примеры статистических методов анализа
Пример 1. Метод статистических аналогов.
Пусть, как и ранее, ф: IxQ—>0. Рассмотрим поставленную выше задачу
нахождения решенйя со(0) системы уравнений
\|/01,Ю)=У!
v|/(i2,co)=y2
\|/(iN,<o)=yN
относительно неизвестного параметра coefl. Эту систему уравнений можно за-
писать в виде
X,(i,)=yi
X(i2)=y2
^•бм)=Уы
и решать ее относительно неизвестного отображения 1:1—>0, Хе{фю, coeQ},
Y<»(i)=\|/(i,a>).
Пусть существует функция <р:1—>О, характеризуемая тем, что для всех
функций Л. из некоторого подмножества М всех возможных функций
{фи:сое£2} и только для них вероятность совпадения их значений со значе-
ниями функции ф (при случайном и равновероятном выборе iel) имеет нену-
левое преобладание Аф
Р(ф(О= X(i))> j-^j+Дф, дляХеМ
и Р(ф(О= X(i))=—для Л.£М.
264
Функцию ср, обладающую таким свойством, называют статистическим анало-
гом подмножества М функций или просто статистическим аналогом.
Зная последовательности 3=цд2,...йы и У1,Уг,...,Уы и вычисляя значения
функции ф на элементах известной последовательности 3
ф(й)=у' ь ф(12)=у'2,• • .,фбм)=у'ы,
сравнивают на совпадение последовательно первые, вторые и т. д. элементы
последовательностей У1,у2,---,Уы и у'1,у'г,...,у'ы- Наличие ненулевого преобла-
дания Дф в предположении, что ibi2,...,iN является выборкой из равновероятно-
го распределения на I, дает возможность строить статистический критерий, по-
зволяющий для достаточно длинных последовательностей с заданными ошиб-
ками первого и второго рода принять или опровергнуть гипотезу: искомое ото-
бражение X принадлежит множеству М. В общем случае множество возможных
функций X, как правило, разбивают на непересекающиеся подмножества, объе-
динение которых дает все множество функций. Для каждого подмножества
строят свой статистический аналог, вычисляют значения у'ьУ 2,---,У n и ис-
пользуют свой статистический критерий (со своим преобладанием) для провер-
ки принадлежности искомой функции X своему подмножеству. Затем оцени-
вают трудоемкость и надежность метода. Для более углубленного изучения
способов построения статаналогов функций рекомендуем статью Сидельникова
В.М. «Быстрые алгоритмы построения набора маркировок дискретных масси-
вов информации». Труды по дискретной математике, Т.1, ТВП, М., 1977,
стр.251-264.
Пример 2. Статистический метод определения пары: входного сло-
ва и начального состояния конечного автомата.
Пусть A=(I,S,O,8,P) - автомат и A(s,3)=yl,y2,... ,yL - его выходная по-
следовательность, отвечающая начальному состоянию seS и входной последо-
вательности 3=il,i2,...,iL. Задача состоит в нахождении входной последова-
тельности 3 и начального состояния seS при известных A(s,3) и множестве
McIL, содержащем 3.
Пусть h - некоторое натуральное число и L=kh. Обозначим через р(У/3)
- вероятность получения выходной последовательности У бОь с автомата А при
входном слове 3elh и случайно и равновероятно выбранном начальном состо-
янии sgS, а через р(У) - безусловную вероятность получения У, при случайно
и равновероятно выбранном начальном состоянии sgS и случайном и равнове-
роятном выборе входного слова 3e!h. Для автомата А определим два случай-
ных процесса и соответствующие им две гипотезы Н(0) и Н(1) получения пары:
входное слово 3'=31,32,...,3к (в алфавите I) длины L=kh, 3jelh и выходное
слово У автомата А.
265
Н(0) - последовательность слов длины h: 31,32,.. .,3к есть реализация выбор-
ки из равновероятного распределения на 3h; последовательность
(у1,у2,...уЬ)=(У1,У2,...,Ук), yj=y(j-l)h+l,...,yjh, je{l,...,k} получена последо-
вательной переработкой (A(Sj,3j)=yj) автоматом А входных слов 31,32,...,3к
при случайном и равновероятном выборе (для каждого слова 3j) начального
СОСТОЯНИЯ (Sj) из S.
Н(1) - последовательность слов длины h: 31,32,.. .,3к есть реализация выбор-
ок
ки из равновероятного распределения на 3 ; последовательность
(у1,у2,...уЬ)=(У1,У2,...,Ук), есть реализация выборки из распределения
(р(У),УеОь).
Решение поставленной задачи проводится путем перебора возможных
последовательностей (i 1 ,i2,... ,iL)=(31,32,.. .,3к) из множества М и использо-
ванием статистической процедуры принятия одной из гипотез Н(0) или Н(1)
для каждой пары слов (31,32,...,3k; У1,У2,...,Ук). Все не отбракованные вхо-
дные последовательности 3', то есть 3', для которых принимается гипотеза
Н(0), совместно с каждым состоянием sgS опробуются на предмет выполнения
равенства A(s,3')=yhy2,... yL.
Пример 3. Метод разностного анализа определения входного слова
конечного автомата.
Пусть A=(I,S,O,(8j)iei,(Pi)iei) - автомат, 3=il,i2,.. .,iL - его входное слово,
s=S| - его начальное состояние, a s(3)=SL+i=8ii.8iL+i--.5i28iiS - его заключитель-
ное состояние, полученное после воздействия входного слова 3 на автомат А с
начальным состоянием sgS. Задача состоит в определении входного слова 3
автомата А по некоторому множеству МП пар (начальное состояние s; заклю-
чительной состояние s(3)), полученном при входном слове 3.
Обозначим через Am(s!,3)=Si,S2,...,Sl+i - последовательность состояний
автомата А, отвечающую его входному слову 3 и начальному состоянию s=s i.
Обозначим аналогично Am(s'i,3)=s'i,s'2,...,s'l+i- На множестве SxS определим
некоторую функцию Ф со значениями в некотором множестве D. Для началь-
ных состояний S] и s'i автомата А определим последовательность
<D(S,,S'i),O(S2,S'2),..., O(SL+1,S'L+|).
Примем следующую вероятностную модель. Задано равномерное веро-
ятностное распределение на I. Оно индуцирует равномерные вероятностные
распределения на IJ, j g {1,... ,L}. Задано также вероятностное рапределение на
SxS. Вероятностные распределения индуцируют вероятностные распределения
на значениях O(si,s'1),O(s2,s'2),..., O(sl+i,s'l+i), в связи с чем корректно опреде-
ляются условные вероятности
P(j,Y /А) =p(O(Sj,s'j)= y/O(s,,s' i)= A), jg {1,.. ,,L+1}.
266
Поставленную задачу определения входного слова 3 автомата А реша-
ют в два этапа.
На первом этапе находят возможные значения последнего символа it в
3. Выбирают пару (А,у), для которой величина P(L,y/A) принимает максималь-
ное значение. Выбирают из первых компонент множества МП (из множества
известных начальных состояний автомата) состояния, точнее, пары состояний
вида: (sj,s'i), O(si,s' |)= А и из уравнений
SilSiL-1 •.. 3i2Sj 1S1 =Sl+1
5il5iL-l---8i28ilS 1=S'l+1
Ф(8н.-1-.-8i25iiSi, 5iL-i...8i28jis'i)= у
определяют множество I(si,s'i) возможных значений первой переменной iL.
Для достижения эффективности метода функцию Ф обычно выбирают (если
это возможно) таким образом, чтобы предыдущая система уравнений, запи-
санная в форме
8jLSL=SL+l
8iLS'L=S'L+i
Ф(8Ь S'L)=y,
при известных значениях правых частей решалась относительно iL с достаточ-
но малой трудоемкостью. В литературе это предположение формулируется как
предположение о слабом криптографическом преобразовании 8^.
Для сокращения мощности найденных возможных вариантов перемен-
ной iL, эту процедуру проводят для нескольких пар начальных состояний со
значением А функции Ф и выбирают общие решения относительно iL.
Второй этап решения задачи зависит, к&к правило от конкретных осо-
бенностей исследуемого автомата. Входные знаки il,i2,...,iL-l, теперь находят
либо с предварительным определением состояний вида (sl,s'l) и использова-
нием алгоритма первого этапа, либо перебором всех вариантов укороченной
последовательности il,i2,...,iL-l, либо другими способами.
ЗАМЕЧАНИЕ. При решении задачи неизвестная последовательность 3
фиксирована, а вероятности P(j,0/A) рассчитываются при случайном выборе
входных последовательностей автомата. Для корректности вычислений пара-
метров метода обычно используют предположение о том, что эти вероятности
близки к вероятностям, полученным при фиксации последовательности 3 и
случайном выборе начальных состояний seS. Для более детального ознаком-
ления с примерами применения разностного метода криптоанализа рекоменду-
ем книги: Грушо А.А., Тимониной Е.Е., Применко Э.А. «Анализ и синтез крип-
267
тоалгоритмов», 2000, 108 стр; А.Л. Чмора «Современная прикладная крипто-
графия», М., Гелиус АРВ, 2001, 244 стр.
Пример 4. Метод линейного криптоанализа определения входного
слова автомата. Рассмотрим идейную сторону метода линейного криптоана-
лиза на примере конечного автомата A=(I,S,O,(8i)iei,(Pi)iei) вида I=F2, S=F2 ,
моделирующего функционирование блочного шифра (например, шифра Фейс-
теля), 3=il,i2,...,iL - его входное слово, s=si - его начальное состояние, а
s(3)=SL+i=8iL8iL+i...8,28,18 его заключительное состояние, полученное после воз-
действия входного слова 3 на автомат А с начальным состоянием seS. Задача
состоит в определении входного слова 3 автомата А по некоторому множеству
МП пар (начальное состояние s; заключительное состояние s(3)), полученном
при входном слове 3. Рассмотрим выражение вида:
(p(s)©\|/(sL+i) ®х(3)=е,
где - фиксированные произвольные двоичные линейные функции на
соответствующих пространствах F” и F^, 8GF2, © - сложение по mod 2. Пусть
PL - вероятность выполнения этого равенства при случайном и равновероятном
выборе s и 3. Преобладание Pl-1/2 характеризует эффективность выбранного
соотношения. Чем больше преобладание, тем успешнее работает метод линей-
ного криптоанализа, точнее говоря, лучше работает критерий на отсев ложных
вариантов.
Данное выше линейное уравнение позволяет определить (с некоторой
надежностью) значение одной координаты входного бинарного вектора 3 ав-
томата А.
В ряде методов, эксплуатирующих такие выражения (линейные статис-
тические аналоги), поступают следующим образом. Выписывают аналогичное
равенство для промежуточного состояния Sj+ь
<p(s)©\|/(Sj+i) ©%(il,i2,...,ij)=E, (*)
выполняющееся с вероятностью Pj.
Затем стараются выразить v|/(sj+i) через sL+i, и вектор (ij+l,ij+2,...,iL) в
виде \|/(Sj+i)=4>'(sL+i) ®x'(F(sL+i,(ij+l,ij+2,...,iL)), где у', %’ - линейные функ-
ции, a F - некоторая функция, принимающая значения на векторном простран-
стве над полем F2. Подстановка выражения для v|/(sj+i) в уравнение (*) дает ли-
нейное соотношение
<p(s)® \|/'(sl+i) ®X'(F(sL+i,(ij+l,ij+2,..,,iL))) ®x(il,i2,...,ij)=e, (**)
выполняющееся с той же вероятностью Pj при случайном и равновероятном
выборе s и 3. Предполагают, что это равенство будет выполняться приблизи-
тельно с вероятностью Pj и при фиксированной последовательности 3. В связи
268
с чем, при имеющихся парах (s,Sl+i), полученных при одной и той же последо-
вательности 3, статистическими методами отсеивают ложные кандидаты в
часть ключа (ij+l,ij+2,...,iL). При переборе варианов части ключа учитывают
несущественную зависимость некоторых переменных, входящих в функции
использованные в равенстве (**).
Пример 5. Вариация статистического метода с методом координат-
ного спуска (/Про/).
В качестве примера применения статистического метода рассмотрим
задачу дешифрования алгоритма криптографической защиты Gamma-З. Про-
грамма шифрования запускается командной строкой DOS. При запуске про-
, граммы проверяется санкционированность доступа, а именно наличие в диско-
воде защищенной дискеты и определенных записей на ней. Дискета имеет не-
стандартный формат. (В процессе экспертизы защита от копирования была до-
статочно быстро снята, и здесь идет речь о немодернизированном варианте
программы.)
При удачной проверке программа запрашивает ключ для обработки
файлов. Этот ключ дважды вводится с клавиатуры пользователем и представ-
ляет собой последовательность из L (от 1 до 32) символов из латинских букв,
русских заглавных букв и 22 служебных символов (пробел, равенство, звездоч-
ка, знаки препинания и др.). Далее программа автоматически дополняет введе-
ние L символов пароля до длины пароля в 32 байта и на основе этого дополне-
ния пароля строит бинарный (рабочий) ключ х = (хь ...., хп) Длиной n=31
бит и формирует начальное заполнение регистра w = wt, w2,...., wL, L = 39.
Открытый текст Ot и шифрованный текст IHt представляются в виде после-
довательности бит. Уравнения шифрования имеют вид
Zt+i = Ot+i Ф H(xj + wt+b х2 + wt+i,., х31 + wt+i)
Wt+40 = Шж,
где суммирование осуществляется по модулю 2, а пороговая функция, опре-
деляющая гамму наложения, H(v(,..., v3|)=h(vi+ ...+v3|) равна 0, если Vi+...
+V3i<16, и равна 1, если vi+... +V3i>l5. Общее число паролей, допустимых для
использования в системе защиты, равно К = т32 +. т31 + ....+ т, где т=116 -
число допустимых для ввода с клавиатуры символов. Таким образом, общее
число паролей k> 1064 достаточно велико. Блок-схема алгоритма шифрования
имеет вид:
269
------------------------►
Открытый текст
Криптосхема имеет достаточно большое число ключей, в ней использо-
ваны нелинейные схемы преобразований. С другой стороны, в алгоритме при-
сутствуют и криптографические слабости.
Прежде всего отметим, что в процессе зашифрования используется то-
лько рабочий ключ длиной 31 бит и начальное заполнение регистра длины 39
бит (общее число вариантов ключевых установок равно 270«2-1021), а в процессе
расшифрования при известном шифрованном тексте для расшифрования всех
знаков, кроме первых 4 байт используется только рабочий ключ в 31 бит (об-
щее число вариантов равно 231«2-109).
Для системы защиты данных Gamma-З , если ориентироваться на рас-
шифрование текста, начиная с 5-го байта, число неэквивалентных рабочих
ключей, т. е. число ключей, дающих разные алгоритмы дешифрования, таким
образом, равно 2-109. Это число, по меркам криптографии, невелико. На совре-
менной cyrtep-ЭВМ ключ может быть найден методом тотального опробования
всех вариантов ключей, путем проведения пробного расшифрования и отсева
ложных вариантов открытого текста по его статистическим свойствам.
Используемая в процедуре шифрования пороговая функция Н обладает
существенными криптографическими слабостями. Главная слабость заключае-
тся в том, что для многих пар близких (в смысле расстояния Хэмминга) аргу-
ментов значения функции совпадают. Это приводит к повышенной вероятности
совпадения гамм наложения шифра, полученных с помощью системы Gamma-3
на близких рабочих ключах.
270
Действительно, рассмотрим два рабочих ключа x=(xi,X2,...,X3i) и
у=(уьУ2,...,Уз 1), отличающихся одним битом, т. е. находящихся на расстоянии
Хемминга друг от друга, равном 1. Для определенности будем считать, что
Х1=У1,... .,хзо=Узо, Хз1=уз1+1 (mod 2). Сумма знаков гамм наложения, получен-
ных на этих ключах в один и тот же такт работы криптосхемы, имеет вид
H(w( ф X1,...,W3O® X30.W31 Ф Х31)ф H(W1 Ф У1,...,3¥зоФ y3O,W31 ф Уз1)=
=H(W] ф X1,...,W3O© X3O,W3I Ф Х31)ф H(W1 Ф Х1,...,\УзОф X3O,W31 ф Хз1 Ф 1)=
=h(v+(w3i Ф Х31)) Ф h(v+(w3i Ф Хз! Ф 1)).
Здесь через Ф обозначено суммирование по модулю 2 и
V=(W1 ф Xi)+...+(w3o Ф Хзо).
Обращаем внимание, что, если v<15 или v>15, то знаки гамм при обоих
ключах совпадают.
При естественном предположении, что последовательность wj, W2,.... по
своим вероятностным свойствам близка к равновероятной схеме Бернулли (ма-
тематическому аналогу последовательности независимых бросаний симметри-
чной монеты), можно считать что, величина v распределена по равновероятной
биномиальной схеме с 30 испытаниями.
Отсюда получаем, что вероятность совпадения знаков гамм для рабочих
ключей, отличающихся одним битом, равна 1- (
30
15
) 2’30.
Расчеты показывают, что для рабочих ключей, находящихся на рассто-
янии Хэмминга, равным единице, совпадают в среднем 85 % знаков гаммы, для
ключей на расстоянии 5-75%, на расстоянии 10-62%, на расстоянии 15-50%.
Для ключей, находящихся на большем расстоянии, знаки гамм будут в боль-
шинстве случаев отличаться инверсией, единице в одной гамме чаще будет со-
ответствовать ноль в другой гамме. Это'также является недостатком (для наде-
жных криптосхем гаммы, снимаемые при любых двух несовпадающих ключах,
должны отличаться друг от друга в среднем в половине случаев).
С учетом отмеченных выше слабостей криптосхемы Gamma-З был раз-
работан алгоритм нахождения рабочего ключа, основанный на идее координат-
ного спуска. Метод координатного спуска относится к методам направленного
перебора ключей и может рассматриваться как дискретный аналог известного
метода градиентного спуска.
Метод координатного спуска.
В применении к решению системы булевых уравнений
f(x)=a
от п неизвестных метод заключается в следующем.
271
На первом этапе случайно выбирается начальный вектор у0 и вычисляе-
тся значение p(f(y°) Ф а), равное числу несовпадений значений вектора f(y°) с
правой частью системы уравнений и называемое уровнем вершины. Далее рас-
сматриваются все вектора у°( 1), у°(2),...,у°(п), отличающиеся от у0 одной коор-
динатой, вычисляются их уровни и в качестве у1 выбирается вершина минима-
льного уровня. Далее повторяется первый этап с заменой у0 на у1.
Процедура продолжается до возникновения ситуации, когда y-yt+1. В
этом случае, как говорят, мы пришли в локальный минимум поверхности уров-
ней вершин.
При попадании в локальный минимум производится анализ полученно-
го значения у\ Если по принятым критериям найденный вариант признается
решением, то на этом процедура поиска заканчивается. В противном случае
случайно выбирается новая начальная точка у0 и алгоритм повторяется.
Таким образом, метод координатного спуска заключается в выборе на-
чального значения переменных, переборе всех соседних с ним элементов и
движении по направлению снижения уровня. Отсюда следует и название «ме-
тод координатного спуска».
Метод координатного спуска может быть применен и в случае, когда
гамма наложения известна с отдельными искажениями, в частности, в задаче
дешифрования по известному шифртексту. При этом гамма рассматривается
как некоторый шум, наложенный на открытый текст. Наличие шума, конечно,
снижает эффективность метода. Слабая чувствительность алгоритмов дешиф-
рования к искажениям в имеющемся в распоряжении аналитика материале яв-
ляется важной характерной особенностью и других статистических методов
нахождения ключей.
Удачно подобранные примеры применения статистических методов
криптоанализа и расчета их трудоемкости содержатся в книге Грушо А.А., Ти-
мониной Е.Е., Применко Э.А. «Анализ и синтез криптоалгоритмов», 2000,
108 стр. Для изучения методов криптоанализа, созданных на основе теории ста-
тистических решений, рекомендуем книгу /25/.
Параграф 5.5
Введение в теорию случайных систем уравнений
Материалы данного параграфа базируются на статье Г.В. Балакина «Введение
в теорию случайных систем уравнений» Труды по дискретной математике. Том 1, стр.
1-18 (Под ред. В. Н. Сачкова и др.) Научное издательство «ТВП», 1997 г.
1. Примеры случайных систем уравнений.
В параграфе рассматриваются системы уравнений
fi(xl,...,xn) = ai, i = (1)
272
в которых
' х,. е N-, |#| = q, а, еЛ/, i =
N,M - некоторые множества, например, N = {0,1,...,<? - 1},М = (0,1,...,т- 1).
Каждая функция, задает отображение N” в М.
Если система (1) рассматривается над конечным полем GF(g), то т = q и
элементы поля для удобства будем отождествлять с наименьшими
неотрицательными вычетами по модулю q. При т = q = 2 система (1)
называется булевой. Особое промежуточное положение занимают так
называемые псевдобулевы системы, для которых неизвестные х, ,...,х„ булевы,
т. е. принимают только два значения 0 и 1, а функции fx задают
отображения булевых векторов в поле вещественных чисел R. В криптографии
неизвестные - элементы ключа, а система уравнений (1) называется системой
уравнений гаммообразования.
Одним из подходов к анализу свойств систем уравнений вида (1)
является задание вероятностной меры на множестве таких систем и изучение
получающихся при этом случайных характеристик систем, например, среднего
числа решений, структуры решений, распределения числа решений, числа
уравнений, необходимого для однозначного определения решения системы
либо для ее несовместности (отсутствия решений). Характеристики,
усредненные по всему рассматриваемому классу систем уравнений, дают
предварительные ориентиры при анализе любой конкретной системы из
данного класса систем. Заметим, что в некоторых случаях случайность системы
уравнений естественно порождается физической природой рассматриваемой
задачи.
Приведем примеры возникновения систем уравнений с
целочисленными неизвестными.
Конечные автоматы, «черный ящик». В этом случае системой (1)
задается функционирование автомата. Входом являются неизвестные хх,...,хп,
выходом - правая часть а1,...,а1 (Как правило, все функции fx,...,ft
одинаковы и отличаются друг от друга только выбором аргументов. Например,
если функция f = fj, (i = l,...,t) принадлежит некоторому множеству
многочленов от целочисленных переменных, то, зная вход и выход автомата,
приходим к необходимости решения системы линейных уравнений
относительно коэффициентов этого многочлена. При неизвестном входе
273
возникает сложная задача определения закона функционирования автомата
(проблема «черного ящика»)
Передача сигналов по каналу связи. Пусть сигнал хх,...,хп кодируется
системой функций fx и на принимающее устройство поступают значения
<?, = /^(х, ,...,хя ), i = , причем некоторые из них случайным образом
искажаются. Функции fx,...,ft могут выбираться случайно из некоторого .
множества функций (случайный блоковый код). Например, передаем г -набор
из значений неизвестных хх ,...,хп, а на приемном конце принимаем, помимо
переданного истинного т -набора, еще несколько ложных т-наборов (шум).
Здесь необходимо определить, сколько и каких т-наборов надо передать для
правильного однозначного декодирования, т. е. для восстановления истинных
значений х1 ,...,хп.
Классификация и распознавание образов. Очевидно, что задача решения
системы уравнений (1) сводится к задаче классификации (распознавания)
неизвестных х, ,...,хп, т. е. к определению множеств неизвестных,
принимающих заданное значение seN,s = 0,...,q- 1. Если решение исходной
системы единственное, то и решение задачи классификации тоже
единственное. На систему уравнений (1) можно посмотреть и с другой
стороны. Каждая функция из fx,...,ft характеризует некоторые свойства
наблюдаемых объектов (аргументов), и по значениям функций (правым частям
системы ах ) и набору свойств следует провести классификацию объектов
(неизвестных х1 ,...,х„).
Для простейшего случая, когда fk ( х ) = f{xik,xjk ), системе (1) •
ставится в соответствие ориентированный граф по следующему правилу:
вершина xik соединяется с вершиной х^ дугой ик веса
v(uk ) = ак = J\xit ,Xjk ). Функция /(х,-,ху ) может характеризовать близость
по какому-то свойству между объектами х7 и ху., например, расстояние между
ними. Здесь возникает много интересных задач по изучению различных
характеристик графов.
Линейный случайный код. Рассмотрим случайный код, реализации
которого представляют собой линейный код над GF(<?). В этом случае
кодирующая матрица А кода есть случайная матрица, х = (х, ,...,хя ) есть
274
входное слово, a =(ai,...,al ) есть кодовое слово, х^а^ gGF(<?),
i = > n. Входное слово преобразуется в кодовое слово с
помощью матрицы А:
хА = а
Эта система является (в силу случайности матрицы А) случайной
системой линейных уравнений над GF(g).
2. Классификация систем уравнений.
Вначале выделим важный класс случайных систем уравнений. В общем
случае случайная система уравнений
^,.(х1,...,х„ ) = с,. i = (2)
по некоторому вероятностному закону выбирается из некоторой совокупности
систем уравнений Q. Здесь под элементарным событием а> = {f <ogQ мы
подразумеваем конкретную реализацию системы уравнений (2)
) = f = ), с = (с, ) = а = (ах )}.
Каждому элементарному событию а приписывается вероятность
p(<y)>0, 2X®)=1-
При построении случайной системы независимых уравнений выбор
уравнений в системе осуществляется по некоторым вероятностным законам
последовательно и независимо из соответствующих совокупностей уравнений.
Как правило, совокупность уравнений и вероятностный закон одни и те же для
всех уравнений. В случайной системе независимых уравнений возможны
повторы уравнений и появление двух уравнений с одинаковой левой частью, но
с разными правыми частями. Во втором случае, система не имеет решений, и
мы будем говорить, что эта система несовместна. Случайная система
независимых уравнений, как легко видеть, является частным случаем
рассмотренной выше случайной системы, которая выбирается вся целиком.
Очевидно, что для случайной системы независимых уравнений при
любом со е Q
pW=Пл (<*>. )> = (Z Л )> ® = (®1 ),
7 = 1
где р{ — вероятностная мера на множестве возможных реализации z-ro
уравнения системы.
Классификацию систем уравнений можно проводить по трем
параметрам:
1) характер зависимости правых и левых частей в системе;
2) алгебраический вид левых частей;
3) способ задания правых частей.
По характеру зависимости правых и левых частей системы уравнений
могут быть полуслучайными, случайными и заведомо совместными
случайными. Приведем соответствующие определения.
Определение 2.1. Система уравнений называется полуслучайной, если
либо ее левая часть случайна, т. е. выбирается по некоторому вероятностному
закону, а правая часть фиксированна, либо ее правая часть случайна, а левая
часть фиксированна.
Определение 2.2. Система (2) называется случайной системой уравнений
с независимыми частями, если ее левая часть ip = (^ ,...,$>,) не зависит от
правой части с = (c‘j )
По сути дела, введенные в определениях 2.1 и 2.2 понятия относятся не
столько к вероятностной структуре случайной системы, сколько к форме ее
записи. Например, в любой системе можно перенести правые части в левые,к
сделав ее полуслучайной.
Для случайной системы уравнений с независимыми частями выполняется
равенство
/?(«) = «о = (/,а)еО
где и 'р - вероятностные меры на множествах значений левой и
правой частей случайной системы уравнений, соответственно. Заметим, что
случайная система может оказаться полуслучайной, если /»(су) = /(/) или
р(й>) = р(я)-
Таким образом, случайные системы уравнений включают в себя как
частные случаи полуслучайные системы уравнений, случайные системы
независимых уравнений, случайные системы уравнений с независимыми
частями. В дальнейшем изложении мы будем говорить о случайных системах
276
уравнений, лишь иногда оговаривая особенности рассматриваемых систем.
Обозначим число решений случайной системы из t уравнений.
Выделим еще один важный для практики класс случайных систем
уравнений. В рассмотренных в пункте 1 примерах мы имели дело с системами
уравнений следующего вида:
/(*)=«<> at = /(х0), z = l,...,/, (3)
где х° = (х° ,...,х° ) есть некоторый вектор, называемый обычно истинным
решением. Эта система отличается от системы (2) тем, что правые части
системы (3) всегда (при любом числе уравнений) удовлетворяют условиям
ai = ft (*° )»z - 1 • Вероятность того, что случайная система с независимыми
частями (2) несовместна, как правило, стремится к 1 при t->оо.
Определение 2.3. Система уравнений (2) называется заведомо
совместной случайной системой уравнений, если
РК eUM*)}f = 1
(4)
Таким образом, истинное решение х° удовлетворяет системе (3) при
любом ее расширении (добавление уравнений). Ложное решение может не
удовлетворить некоторому уравнению при расширении системы. Как правило,
будем считать, что система допускает только одно истинное решение, другие
случаи будут особо оговариваться. Обозначим через T]t число решений
заведомо совместной случайной системы из / уравнений. Очевидно, что > 1.
В заведомо совместную систему случайность может быть введена
разными способами. Первый способ, как и для случайных систем, связан со
случайным выбором функций fx . В этом случае левая часть системы (3)
случайная, а правая часть однозначно задается левой частью и вектором х°.
При другом способе левая часть системы (3) фиксирована, а правая часть
становится известной только после случайного выбора истинного решения х°.
В обоих случаях правая часть случайная, так как зависит от выбора либо левой
части, либо х°. В последнем случае мы имеем дело с полуслучайными
заведомо совместными системами уравнений.
277
При случайном выборе функций и истинного решения х°
заведомо совместная система становится как бы полностью случайной.
Действительно, в этом случае случайны левая часть (в силу условия) и правая
часть (из-за случайного выбора х° ), однако связь между левыми и правыми
частями сохраняется:
Заметим, что так определенная заведомо совместная система в отличие от
случайной системы уравнений не может быть заведомо совместной системой
случайных уравнений с последовательным и независимым выбором уравнений
системы, так как правые части зависимы между собой из-за наличия такого
о
вектора х , для которого
Системы уравнений различаются также по алгебраическому виду левых
частей. Системы уравнений могут рассматриваться над конечным полем GF(<?),
кольцом, группой или над полем вещественных чисел. Системы уравнений над
R обычно называются целочисленными. В частности, системы могут быть
булевыми или псевдобулевыми. Возможны и смешанные системы уравнений,
когда часть уравнений, к примеру, булевы (т. е. над GF(2)), а часть уравнений
псевдобулевы (т. е. над R). Кроме того, системы уравнений могут быть
линейными и нелинейными, с фиксированным или со случайным числом
неизвестных в каждом уравнении, и т.д.
В заключение кратко скажем о наиболее типичных способах задания
правых частей в системах уравнений. Системы могут иметь точно известную
правую часть, правую часть, известную в вариантах, и искаженную правую
часть. Заметим, что для заведомо совместной системы уравнений ее истинная
правая часть обязательно содержится среди возможных вариантов правых
частей, а при наличии искажений система может оказаться несовместной. В
последнем случае иногда в правую часть вводят так называемые мешающие
параметры (см. Балакин Г. В. Системы уравнений с мешающими параметрами.
-В сб.: Всероссийская школа-коллоквиум по стохастическим методам
геометрии и анализа. Тезисы докладов. М.: ТВП, 1994, с. 11-12),
характеризующие искажения, и система уравнений остается заведомо
совместной, т. е. имеет истинное решение х° при некоторых истинных
значениях мешающих параметров (искажений).
278
Для краткости в дальнейшем изложении случайные системы уравнений с
независимыми частями будем называть случайными системами, а заведомо
совместные случайные системы уравнений — заведомо совместными
системами. Напомним еще раз, что для заведомо совместных систем, в отличие
от случайных систем, выполняется равенство (4), которое указывает на
существование зависимости между левыми и правыми частями системы.
3. Задачи анализа систем уравнений.
Основная задача для случайных систем - определить или оценить
величину Р{<^, > О} - вероятность совместности системы. Представляют
интерес также среднее число решений и структура множества решений. Более
сложная задача - найти распределение числа решений . Ясно, что последняя
задача содержит в себе нахождение вероятности совместности и среднего
числа решений.
Зная функциональную зависимость среднего числа решений случайной
системы от числа уравнений, нетрудно оценить так называемый «порог
единственности» - минимальное число уравнений /0, при котором среднее
число решений случайной системы не превосходит 1:
• Е^,о<1, Е£о_,>1.
Очень важно для случайной системы оценить момент t* - «порог
несовместности», когда система становится несовместной:
^,.=0.
Найти распределение этого момента /*, как правило, очень трудно. Для
линейных систем над полем GF(^) он связан с появлением линейных
зависимостей между строками матрицы системы.
При изучении заведомо совместных систем основная задача - найти
распределение числа решений и структуру множества решений. Более
простыми задачами могут оказаться оценка среднего числа решений и
вероятностных характеристик числа уравнений, при котором заведомо
совместная система с заданной вероятностью имеет только одно решение. Для
линейных заведомо совместных систем над полем GF(<y) с матрицей At
распределение числа решений определяется рангом r(At) случайной матрицы
4
Р{'7,=‘7""и1}=1. Р{>7,=1)=РИИ,)=П}
279
По аналогии со случайными системами определим «порог
единственности» для заведомо совместной системы равенством
= min{r: Efe -1) < 1, E(ql_l -1) > 1},
т. е. /0 - минимальное число уравнений, при котором среднее число
ложных решений заведомо совместной системы не превосходит 1;
' =min{z:77,_1 >2,7/, =1},
т.е. t* - минимальное число уравнений, при котором заведомо
совместная система имеет единственное решение. Ложные решения при
t > t* отсутствуют.
Предположим, что во всех t уравнениях заведомо совместной системы
левые части не зависят от V, неизвестных. Тогда очевидно, что в заведомо
совместной системе rjt >qv'. Здесь возникает, как правило, комбинаторная
задача нахождения распределения случайной величины v,. Например, оценка
такого момента t, что v,_] > 0, a v, = 0.
Очень существенным моментом для заведомо совместной системы
является изучение структуры множества возможных решений, связи ложных
решений с истинным решением. Например, если с вероятностью, стремящейся
к 1 при t, п —> оо, ложные решения отличаются от истинного решения х не
более чем к(п) координатами, к(п) = о(п), то первое же найденное решение
системы будет либо истинным, либо даст существенную информацию об
истинном решении, которая может быть использована при поиске остальных
решений системы.
Заметим, что при анализе числа решений, их структуры, связи с
истинным решением обычно удается выделить такие события, которые в
основном и определяют поведение отмеченных параметров и наличие свойств.
При разработке эффективных методов решения такие результаты могут
оказаться полезными и подсказать исследователю способ решения задачи.
4. Сравнение случайных систем с независимыми частями и
заведомо совместных случайных систем уравнений.
По определению в случайных системах с независимыми частями
совокупность левых частей не зависит от совокупности правых, а в заведомо
совместных случайных системах уравнений правая часть есть результат
280
подстановки в левую часть некоторого вектора. Поэтому случайная система
может оказаться несовместной.
Если случайная система имеет решения, то различия между случайной
системой и заведомо совместной системой следует искать в числе решений и в
их структуре. Для заведомо совместной случайной системы уравнений решения
могут оказаться в каком-то смысле близкими к истинному, отражать его
структуру. У случайной же системы все решения как бы равноправны, так как
любое решение может, в принципе, отсеяться при добавлении уравнений к
системе.
Рассмотрим связь между распределениями числа решений £ случайной
системы уравнений с независимыми частями и числа решений 7 заведомо
совместной случайной системы.
Согласованные системы уравнений.
Пусть в системе уравнений
= i = (5)
функции <px,...,<pt задающие отображение в М, по каким-то
вероятностным законам выбираются из некоторых множеств функций
Фр...,Ф,, соответственно, неизвестный вектор х может принимать qn
возможных значений х(1),...,х(д"), а значения с,,...,с, правой части в одном
случае по некоторому вероятностному закону независимо от левой чарги
выбираются из множества М‘, а в другом случае есть результат
подстановки в левую часть системы некоторого фиксированного значения
х = х(у). Распределения левых частей в обоих случаях одинаковы.
Обозначим множество возможных реализаций случайных систем
уравнений с независимыми частями символом Q, подразумевая под
элементарным событием со = cog О конкретную систему уравнений (5) с
= f = (Z>-,/г ),с = а=(ах
Пусть, далее, - множество реализаций случайной системы (5),
которым удовлетворяет значение х = x(i\ i = \,...,q"; - множество
несовместных систем уравнений; р(<®) = У>(/)р(а) есть вероятность
281
конкретной реализации co = \f,a) случайной системы (4.1); Q(j) -
множество реализаций заведомо совместной системы (4.1) с истинным
решением х = х(у }, - число решений заведомо совместной системы с
истинным решением х(у).
Очевидно, что
ч' ?*
O=(jn„ U(n«nn.)=0- Un>=lJnW
1=0 1=1 i=l ;=1
Определение 4.1. Назовем случайную систему уравнений с
независимыми частями и заведомо совместную случайную систему уравнений
вида (5) согласованными, если для любого i = l,...,q
1)Q,. =Q(zj;
2) p(f)= ), co = (/,/(x(z)))e Q,;
3) распределение tj(i) не зависит от номера z.
Лемма 4.1. Если правая часть случайной системы уравнений с
независимыми частями (5) имеет равномерное распределение на множестве
допустимых правых частей, то первое и второе условия согласованности
выполняются.
ДОКАЗАТЕЛЬСТВО. В элементарное событие со включаются
конкретная левая часть системы f = (/],...,/,) и конкретная правая часть
системы а = (a15...,az). Поэтому для случайной системы с независимыми
частями
pW=p(/)p(«)
а для заведомо совместной системы с истинным решением х(у) и а = /(х(у))
вероятность этого события* равна вероятности появления левой части так
как правая часть однозначно определяется левой частью.
Первое условие согласованности выполняется, поскольку в случайной
системе правые части могут принимать все возможные значения. Для второго
282
условия находим, учитывая, что Q, содержит ровно одно элементарное
событие а> = (/,а) при каждой левой части f:
p(Q/)=LX/W(M0))=
f
p(<y)/p(Q,.) = p(f )p(a )/ q" = p(f}
Лемма доказана.
Замечание. Лемма 4.1 верна и при более слабом ограничении на
распределение правых частей. Действительно, для выполнения первого условия
согласованности Q- =Q(z) достаточно потребовать выполнения неравенства
р(7(*(0)) > ° при р(7) > ° >
а второе условие согласованности
указывает на одинаковые значения вероятности появления правых частей для
систем уравнений из .
Приведем несколько простейших примеров согласованности случайной
системы и заведомо совместной системы.
а) Линейная система уравнений над полем GF(<y) с независимыми и
равномерно распределенными в GF(^) коэффициентами и правыми частями:
+ + = Z>z, i = 1,...,Z (6)
Покажем, что случайная система (6) согласована с заведомо совместной
системой
ЗД +--- + ainxn =bt = ад1°+--- + ад„°, i = (7)
коэффициенты которой имеют такое же распределение, как и в случайной
системе (6).
Действительно, в силу равновероятности правых частей линейных
уравнений системы (6) по лемме 4.1 выполнены первое и второе условия
согласованности. Далее, число решений заведомо совместной системы (7)
равно числу решений соответствующей однородной системы уравнений
283
ЗД+Л +ainyn =0, i =
у i = Xj + x,°, i =
или, что то же самое, числу решений заведомо совместной системы (7) с
истинным решением х° = (0,0,...,0}
Следовательно, распределение числа решений системы (7) не зависит от
вида истинного решения, и системы (6) и (7) согласованны.
б) Рассмотрим систему уравнений (5) с целочисленными неизвестными
xit...,x„ еЛГ,|У| = ?:
^,.(х1,...,хя) = с,., г = 1,../. (8)
Пусть функции (px,...,(pt - независимые случайные величины, имеющие
равномерное распределение на множестве всех возможных.функций,
отображающих множество N" в множество М , |Л/| = т . Всего таких функций
тч . Правая часть с не зависит от левой части .
Соответствующая заведомо совместная система имеет вид
(pi(xl,...,x„) = <pi(xf,...,x°„), i = ’ (9)
Так как случайные функции имеют равномерное распределение, то число
решений одного уравнения из системы (9) не зависит от истинного решения
х°. В силу независимости выбора уравнений этот факт имеет место и для всей
системы уравнений.
Следовательно, если в случайной системе (8) с1,...,с1 - независимые
случайные величины, имеющие равномерное распределение на множестве М,
то системы уравнений (8) и (9) согласованны.
в) Псевдобулева система уравнений
/.(х) = а,., i = l,...L
с линейным псевдобулевым ограничением на неизвестные
х. + х, +Л +х„ =п.
1 z п 1
284
Пусть в указанной системе уравнений
/.(x)=/.(xS(i,...,x,J,
где Sj = (sn,...,sir) при любом i = есть выборка без возвращения объема г
из совокупности {1,2,...,и}, все выборки независимы и равновероятны.
Для заведомо совместных систем этого вида с истинным решением х°,
удовлетворяющим условию х, + х2 +Л + х„ = щ , распределение числа
решений не зависит от х°, что следует из симметрии и равновероятности
выборок неизвестных. Поэтому случайная система и заведомо совместная
система согласованны при выполнении условий леммы 4.1.
Связь между распределениями чисел решений согласованных
случайных и заведомо совместных случайных систем уравнений.
Теорема 4.1> Если случайная система уравнений с независимыми
частями и заведомо совместная случайная система уравнений согласованны, то
между распределениями их чисел решений % и Т] существует следующая
связь:
) (10)
Pfe = £} = E£Pi7~^, k>\.
ДОКАЗАТЕЛЬСТВО. Представим случайную величину £ в виде суммы
индикаторов
£ = £+Л+^,
полагая = 1, если вектор х(у) удовлетворяет случайной системе,
j = K..,qn.
Рассмотрим моменты сдучайной величины £:
В силу согласованности систем уравнений
285
е(Г'/£, =!)=£//-'.
Отсюда следует основное соотношение для моментов случайных
величин g и rj
Е^к =Е^Ет|к-1, к>1.
Очевидно,
' tk
Ее‘< Т,
£>0 к>0 К-
Но в силу формулы Е£,к = Е£,Ет]к -1, к > 1 находим
к
2X^=i+Efj
*>о к- о v>o к\ J
Следовательно,
к>0
о \teO
В это равенство введем новые переменные х = ег, y = ez. Получим
соотношение между производящими функциями
A Yk —1
= к}х‘ = 1 + Е£J Xrfo = i}/-' U = 1 + EfУ Pfc = 1
k>0 1 \ k>\ J &>1
Сравнивая коэффициенты при одинаковых степенях х, приходим к
формулам (10). Теорема доказана.
Следствие 4.1. Для вероятности совместности случайной системы
уравнений с независимыми частями имеет место оценка
Pfe>O) = E^l-e(E^-l)l
где 0 < 0 < 1.
ДОКАЗАТЕЛЬСТВО. Из формул (10) следует:
Р{£ > 0} = Е^У-fe—< Eg
ш к
286
Очевидно, что P{r] > 1}< Erj-1. Отсюда получаем неравенство
Pfe>0}>E^P{77 = l}>E^2-E7)
из которого следует требуемое равенство.
Лемма 4.2. Пусть случайная система уравнений и заведомо совместная
система уравнений согласованны. Тогда Р{£ > 1} (вероятность совместности
случайной системы) и Р{^ = 1} (вероятность единственности решения заведомо
совместной системы) связаны следующими неравенствами и соотношениями:
pfeal}=E41-«(i-p{7 = i})J |<0<1
ДОКАЗАТЕЛЬСТВО. Из формул (10) находим
Pfcil} = El£5fc^<
к>1 К
= црй—О=i-l(i-p{n=i))
Нижняя оценка для Р{£ > 1} очевидна:
Pfe > 1} > Pfe = 1} = Е£Р{7 = 1} = Е£[1 - (1 - Pfe = 1})J
Докажем верхнюю оценку для Р{£ > 1}. Легко проверить, что
у P{rf < р{ = 1)|Р{7 = 2}|1-Р{7 = 1}-Р{7 = 2} = 2+4Pfa=l}+PM
Ь к W J 2 3 6
Ет7>Р{7 = 1}+2Р{7 = 2}, Pfa = 2}<
287
Отсюда и следует верхняя оценка для Р{£ > 1}, приведенная в утверждениии
леммы 4.2.
Лемма 4.3. Для согласованных случайной системы уравнений и
заведомо совместной системы уравнений выполняется неравенство
Р{£>1}>^-
Ет;
ДОКАЗАТЕЛЬСТВО. Рассмотрим выражение
Е£ tai к (>]
, . Ef
Неравенство Р{£ > 1} >- следует из соотношения
так как z + z 1 > 2 при z > 0.
Найдем условное распределение £ при условии % > 1. Очевидно, что
Р^=Л/^>1}=-РХ=-^р k>i;
( /Ъ J 1-Р{£ = 0}
Е(£/£>1) =---—г.
V ’ 1-Р{£ = 0}
Поэтому из (10) следует, что
к
При к < > 1)
Л>Р{т7 = £},
апри А:>Е(^/^>1)
Рк <?{ri = k}.
288
Следовательно, по числу решений можно статистически различать заве-
домо совместную систему и случайную систему, имеющую решения.
В заключение отметим, что связь (10) имеет место и в том тривиальном
случае, когда все индикаторы независимы и одинаково распределены:
pfc = i}=p, Pfe =0}=1-Л
и случайная величина г] имеет такое же распределение, как и
б+А+^.,+1.
Действительно, для к > 1 в этом случае
pfe=*}=с;. рЧ1
К К,
5. Системы уравнений с искаженной правой частью.
Рассмотрим систему булевых уравнений (1)
7(х)=&, ап
в которой Ъ = а®с,а= /(х0), £ =(е1,...,£1>) есть вектор ошибок, не
зависящий от левой и правой частей исходной системы уравнений. Такие
системы уравнений (5.1) называются системами уравнений с искаженной
правой частью. Обычно координаты вектора ошибок £1,...,£1 - независимые
случайные величины и I
Р^.=1} = Л<|, i = (12)1
Система (11) при pi = 1,.•.Аявляется случайной системой |
уравнений с независимыми частями, а при = 0 (z = - заведомо I
совместной системой. I
~ —о I
Ставится задача статистической оценки вектора х по реализации I
системы (11). " I
Каждому вектору х соответствует вектор ошибок I
289
f(x) = f(x)®b ,
который определяется подстановкой вектора х в левую часть системы (11).
Вероятность появления такого вектора ошибок при условии (12) есть
Р{г, = s,(x),=^(х)} = Пр?И(1-Р,ГИ.
/=1
Если вектор х°, по которому строится правая часть (11), случаен, не
зависит от/ и ё и имеет равномерное распределение на множестве
возможных решений X, то вектор х*, удовлетворяющий условию
max₽{f = ё (х)} = р{г = <f(x*)}
естественно считать максимально правдоподобным.
Такой способ построения оценки вектора х° называется методом
максимума правдоподобия (ММП). В теории кодирования аналогичная
процедура, применяемая при pt = p,i = , для декодирования блоковых
кодов, задаваемых преобразованием
(х,,..., хп) —> (/ (х,,..., х„),..., ft (xj,..., х„)),
называется методом декодирования в ближайшее кодовое слово.
Основной задачей анализа систем уравнений с искаженной правой
частью является оценка величины р|х‘ = х0}, которая характеризует
надежность метода максимума правдоподобия. Приведем оценки р{х‘ = х° }
для случаев фиксированной и случайной левых частей системы.
Если = p,i = , то каждому вектору х соответствует «невязка»
?(*)=
i=i
т. е. число уравнений в системе (11) которым не удовлетворяет вектор х . При
этом для истинного решения
s(x°)= +Л + st,
10 Зак.5
290
где £x,...,£l - биномиально распределенные случайные величины с
P{f, = 1} — р = 1 - P{<s; = О}, i = 1,...,/, а для ложного решения х Ф х°
5(*) = S ei (*) = SI/ (*) ® Z (*° )® £< 1
i=i /=1
Таким образом, если левая часть системы (11) фиксированна, то
p{^)=i}={/ при
(1-р при fXx^fXx )
Во втором случае при случайном выборе функций в системе уравнений
Т{г,(х) = 1} = р{/(х)® с, = 1}= 1 + (1 - 2р'р>’/; (х) = /,(х“)}-|
В силу того, что
5(х*)=тт5(х),
вероятность ошибки при решении задачи ММП можно оценить следующим
образом:
-I, m
Теорема 5.1. Пусть pt = р <A/2,i = , и выполняются следующие
условия:
1) функции независимо выбираются из некоторого множества
функций Ф;
2) р{^.(х)^ Дх°)}> р для любого х *х°,0 <р <1;
3) если Т] —> оо, |х| —> оо, и
t =
In
pYf i-p
291
rolim^^ >0.
Тогда построенная методом максимума правдоподобия оценка решения
х° состоятельна:
р{г=х0}->1, П—>00.
ДОКАЗАТЕЛЬСТВО. Положим в правой части (13)
c = pt + ux_a^tp^-p\
где их_а - квантиль нормального распределения с уровнем значимости
1-а. Тогда при достаточно больших t
c = pt + их_афр(1 -р)< t(p + Д(1 - 2/?)).
Используя нормальное приближение для распределения случайной
величины s(x°), находим, что при п —> оо и а = const
Для х Ф х°
Д(х) = P{S(x) = е,(х)+А + et(х) < с} < £ С‘(р*)'(1 - р',
i<c
так как
pk(*)=z(*°)®Z(*)®3=1}=р+(1-2р)р{/;(х0)*/;(х)}>р+(1-2р)д=/
Согласно известной оценке Чернова (см. /Месси Дж.. Пороговое
декодирование. М.: Мир, 1962/) для Р° ~ “ Р
Е С< G7*) 0 “ Р* У' ~ ехр{“ (Ро )~Н(Ро )Ц
i<c=pQt
где
Н(р) = - 1п[р"(1 - р}'-" J г. (р) = -ф7(1 -р )’' ].
10*
292
Поэтому
'хеАЛ
т,.Ы-нМ
Т.(р^Н(р)
Заметим, что р0 —> р при п —> оо,р* > р, и, значит,
lim |г.(р,)- н(р,)]= т. (р)-я(р) * о.
По условию теоремы limzi^x вп > 0,]х| —> со при и —> оо,
следовательно, Q = 6(l);
р{х* 5* х°}< а + о(1)
В силу произвольности а отсюда вытекает утверждение теоремы.
Следствие 5.1. Если в условиях теоремы р = l/2,|Aj = 2" ,то при
t = 0 + еп)«/ 1оё2 (2Р Р 0 - рГР )> lim^oo £п >0 оценка х* истинного решения
—о
х состоятельна.
ДОКАЗАТЕЛЬСТВО непосредственно следует из того, что р* = 1/2.
Пусть J\ (х),...,У;(х) - известные фиксированные функции и pt = р, i = 1,...,/.
Разобьем множество И” всех n-мерных двоичных векторов на классы
В связи с тем, что fi(x) - фиксированная функция,
Таким образом, для любого к е {О,...,?} распределение случайной
величины
S(x) = £{ (x)+t->+et (х)
\
293
- одно и то же при всех х е Хк и совпадает с распределением случайной
величины
(f, Ф1)+н^+(^ ®l)+fi+1 +i->+£, = к-ех -\-+-£к +£к+х +н»+£,
Положим Sk = S(x),x е Хк . Набор чисел (|Х0|,...,|Л'/|) естественно
назвать спектром расстояний системы (11) относительно решения х0 (по
аналогии со спектром расстояний кода, задаваемого соответствующим
преобразованием f).
Теорема 5.2Л Пусть левая часть системы (11) фиксированное
спектр расстояний системы (11)
относительно истинного решения х0; тогда вероятность того, что метод
максимума правдоподобия дает правильное решение системы (11),
удовлетворяет неравенству
р{х ’ = х° } > 1 - = | |р(&), где
tei
р(к) = = с‘кр‘0 - рТ‘ уМ^-р)
i-zk/2
ДОКАЗАТЕЛЬСТВО. Нетрудно проверить, что
k=lxeXk
>l-=|Xk|p{Sk <s„).
k=l
Разность Sk - SQ имеет такое же распределение, как и случайная
величина = к - 2(f, +1-»+ £к ), поэтому при 0 < р < 1/2
294
к
2
= Z с‘кР‘0 - pt~l =
i>kl2
=М1-р)ГТяЛ ^‘М-рГ-
M/2 U-Pj
Следствие 5.2. Если — р)У = о(1) при n,t —>00
вероятность правильного решения системы (11) методом максимума
правдоподобия стремится к 1:
р{х*=х°}->1, п—>оо.
Дополнительные сведения о тематике случайных систем уравнений
читатель может найти в работах:
Балакин Г. В. О распределении числа решений систем случайных
булевых уравнений. - Теория вероятн. и ее примен., 1973, т XVIII, в. 3, с. 627-
632.
Коваленко И. Н., Левитская А. А., Савчук М. Н. Избранные задачи
вероятностной комбинаторики. Киев: Наукова думка, 1986, 224 с.
Balakin G. V. On the number of solutions of systems of pseudo-boolean
random equations. - В сб.: Вероятностные методы дискретной математики.
Труды третьей Петроза-водской конференции / Под ред. В. Ф. Колчина и др.
Москва/Утрехт: ТВП/VSP, 1993, с. 71-98.
Параграф 5.6
Аналитические методы криптоанализа
Имеется достаточно обширная литература по алгоритмам решения сис-
тем уравнений в разнообразных алгебраических структурах. В учебных целях
мы сосредоточимся на алгоритмах решения систем линейных и нелинейных
уравнений над полем F2, состоящим из двух элементов.
Линейные системы.
Пусть система линейных уравнений над полем F2 имеет вид
anXi+ai2X2+....+alnXn=bi
a2ixI+a22X2+.. ..+a2nXn=b2
amixi+am2x2+....+amnxn bm
295
а^еР2, bjG F2, je l,m, ie l,n.
Положим,
Тогда рассматриваемая система принимает вид А х=Ь.
Метод Гаусса.
Как известно из курса линейной алгебры, данный метод основан на по-
следовательном исключении неизвестных в уравнениях системы. В терминах
матриц исключение неизвестных равносильно выполнению операций сложения
в поле F2 строк матрицы А. Например, пусть первые два уравнения системы
имеют вид
Xi+ai2x2+....+alnxn=bi
х,+а22х2+... .+a2nxn=b2
Выражая Xi из первого уравнения (операция + в поле F2) и, подставляя его во
второе уравнение, получаем уравнение
(а!2 +а22)х2+.. ..+(aln+a2n)xn=b|+b2,
исключив таким образом неизвестное Х]. Такое преобразование соответствует .
замене в матрице
а11 ....... aln bl
................. .. =(А,Ь)
aml .................. amn bm
второй строки на сумму первой и второй строк.
Определим следующие элементарные преобразования над матрицами:
1) прибавление одной строки матрицы к другой строке;
2) перестановка строк матрицы;
3) перестановка столбцов.
Отметим, что при перестановке строк матрицы (А, b) система уравне-
ний не изменится, а при перестановке столбцов матрицы А произойдет перену-
мерация неизвестных.
Как известно, метод Гаусса заключается в следующем. На первом шаге
матрица (А, b) преобразуется в матрицу (А1, b '), у которой первый столбец
совпадает с первым столбцом единичной матрицы. Для этого необходимо най-
296
ти строку, в которой первый элемент равен единице (если такой нет, то надо
переставить столбцы) и прибавить ее к другим строкам, содержащим единицу в
первом столбце. На втором шаге выполняется это же преобразование над под-
матрицей матрицы (А',Ь *), полученной удалением первой строки и первого
столбца. Продолжая этот процесс, матрицу приводят к виду
Теперь система уравнений А' х = b' (имеет то же множество решений,
что и исходная, возможно с измененным порядком нумерации переменных).
Если некоторые из элементов b'K+i,...,b'm отличны от нуля, то система линей-
ных уравнений не имеет решений. Если b'iH.i=...=b'm=0, то система имеет 2ПК
решений. Для их нахождения фиксируют произвольным образом переменные
Хц+i, ...,хп (2П-К способов), а затем находят значение переменной хк из к-го урав-
нения, значение xK.i из (к-1)-го, и т. д. Так находят все решения исходной сис-
темы уравнений.
Подсчитаем трудоемкость этого метода. На первом шаге выполняется не
более (n+l)(m-l) операций сложения, на втором - не более n(m-l) и т. д. Сле-
довательно, трудоемкость преобразования матрицы (А,b) к виду (А', b') оце-
нивается величиной
min(ffl,w)
Ti< 2 (и + 2-у)(/и-у) =
;=1
О(и2ти), .п < т,
- О(п3),. т = п,
О(пт2),. гп <п,
или иначе
Т i<O((min(m,n))2max(m,n).
При m=n данная оценка принимает вид
297
n n-1 n-1 n-1
, T,S £ (n + 2 - j)(n - j) = £ j( j + 2) = L j2 + J -
j=l j=0 j=0 j=0
_(n-l)n(2n-l) n(n - l)(2n +5) _ r?
6 ' ’ 6 ' 3 '
Несложно показывается, что для нахождения каждого из решений тре-
буется не более
Т2=2(п-к)+2(п-к+1)+. . .+2(п-1)<2(1+2+.. .+п)=п(п-1)
операций сложения. Таким образом, поскольку Т2< Ть общая трудоемкость ме-
тода Гаусса оценивается величиной Ть
LUR-разложение матриц.
Если приходится решать не одну систему линейных уравнений, а много
таких систем с одинаковой левой частью и разных правых частях, то исполь-
зуют зачастую следующую модификацию метода Гаусса.
Сначала заметим, что метод Гаусса фактически заключается в приведе-
нии матрицы (А,Ь ) с помощью элементарных операций к верхнетреугольному
виду. Каждая из элементарных операций эквивалентна умножению матрицы
(А, b ) на некоторую матрицу:
1) при i<j прибавление i-й строки к j-й осуществляется умножением слева на
матрицу 1 i
0 0
1 Ljj
1 0 1 1 j
размера mxtn;
2) перестановка i-й и j-й строк (i<j) эквивалентно умножению слева на матри-
цу
1 1
1
=Ri
0 1 i '
1
1
1 0 j
размера тхш.
298
3) перестановка i-ro и j-ro столбцов эквивалентна умножению справа на мат-
рицу Ry размера (п+1)(п+1).
Выделим особо случай, когда можно ограничиться выполнением только
элементарных операций первого типа.
Обозначим через
а11 • • а1к
ак1 • • акк
главные миноры матрицы А.
Справедливы следующие теоремы.
Теорема. Если все главные миноры матрицы А отличны от нуля, то до-
статочно использовать только операции первого типа.
Доказательство теоремы проводится индукцией по к.
Теорема. Для любой матрицы А размера пхщ с ненулевыми главными ми-
норами найдутся невырожденные нижнетреугольная матрица L размера пхп и
верхнетреугольная матрица U размера nxm такие, что A=LU.
Теорема. Невырожденную матрицу А размера пхп можно перестановкой
только строк (или только столбцов) перевести в матрицу, у которой все глав-
ные миноры отличны от нуля.
В качестве следствия из этих теорем можно получить утверждение: всякую
невырожденную матрицу А можно привести к виду A=LUR=R'L'U', где R,R' -
подстановочные матрицы, a L,L' и U,U', соответственно, нижние и верхние
треугольные матрицы. На основании этого утверждения доказывается, что раз-
ложение матрицы А, указанное выше, находятся за О(п3) операций, а после то-
го как оно найдено, решение каждой системы (со своей правой частью) нахо-
дится за О(п2) операций.
Метод И.В. Коновальцева.
Изложение данного метода мы проведем на основе работы И.В. Коно-
вальцева «Об одном алгоритме решения систем линейных уравнений в конеч-
ных полях», Проблемы кибернетики, вып. 19, 1967 г.
Итак, задача состоит в нахождении решений системы линейных урав-
нений
ацХ1+...а|Пхп ain+i
3niX]"i".. .annxn an>n+i
299
в случае, когда элементы матрицы А данной системы принадлежат конечному
полю из q элементов. Алгоритм И.В. Коновальцева состоит в следующем.
Первые г элементов i-той строки матрицы А назовем кортежем Cj.
Перебирая последовательно строки матрицы А, находят первый кортеж
С, отличный от (0,0,.. .,0), и ставят его на первое место. В полученной матрице
сравнивают кортеж С]^(0,0,...,0) с кортежем С2. Если Ci=C2, то вычитают из
второй строки первую, после чего кортеж второй строки станет нулевым. Если
С|*С2, то сравнивают С] с Сз и поступают аналогично предыдущему. На по-
следнем этапе сравнивают кортежи Ci и Сп и выполняют соответствующие
операции. Отметим, что в полученной матрице кортеж Ci^(0,0,...,0) и среди
кортежей С2,.. .,СП нет равных С|. Рассматривают строки 2,.. .,п полученной
матрицы, находят первый ненулевой кортеж, меняют его местами с кортежем
С2 (переставляя соответствующие строки) и повторяют процедуру, описанную
выше. Если число различных ненулевых кортежей равно v, то после v шагов
матрица А системы линейных уравнений принимает вид
где матрица А' имеет v строк и г столбцов. Алгоритмом Гаусса приводят мат-
рицу А' к верхнетреугольному виду. В случае, когда определитель матрицы А
отличен от нуля полученная матрица принимает вид
>
*
0 1
к 0 Ап- г>
Если же на этом этапе выяснится, что detA=0, то процесс заканчивается.
Этот этап применяется t раз, где t выбирается исходя из условий
qr<n-(t-l)r,
но
qr>n-tr.
В результате матрица А принимает вид
300
<1 * >
*
0 1
< 0 ^n-tr)
„ I
Преобразование подматрицы An.tr к треугольному виду осуществляется ме-
тодом Гаусса. В результате матрица А преобразуется в матрицу треугольного
вида с единичными элементами на главной диагонали (если detA#0). Затем ре-
шается система линейных уравнений с треугольной матрицей коэффициентов.
В цитированной выше работе И.В. Коновальцева доказывается, что число всех
операций (арифметических и вспомогательных) данного алгоритма не превос-
ходит величины
В заключение отметим, что для уравнений с невырожденной матрицей
log? 7
Штрассеном был предложен алгоритм со сложностью О(п ) операций. По-
нижение оценки сложности в нем достигнуто благодаря использованию памяти
ЭВМ.
Методы решения систем нелинейных уравнений
Метод решения системы нелинейных уравнений над полем F2, ос-
нованный на приведении ее к трапецеидальному виду.
Приведем сначала метод решения системы нелинейных уравнений, уже
имеющий трапецеидальный вид:
fi(x(l),...,x(ji))=yi
f2(x( 1),...,x(j2))=y2
fm.i(x(l),...,x(jm.i))=ytn.1
fm(x(l),...,x(n))=ym,
где l<ji<j2<...<jm.i<n. Такую систему уравнений называют системой трапе-
цеидального вида. Решают эту систему уравнений следующим образом.
Опробованием 2Jl векторов (х( 1),... ,x(j ,)) е F находят все решения
первого уравнения. Затем во второе уравнение подставляют (опробуют) все
301
вектора (х( 1),...,x(j2)) - такие, что начальный подвектор (х( 1),. ?.,x(j 1)) является
решением первого уравнения и т.д.
В предположении, что число решений каждого уравнения составляет в
среднем половину опробуемых векторов (то есть половина опробуемых векто-
ров каждого уравнения составляет множество его решений), трудоемкость дан-
ного метода (в опробованиях) составляет ( 2 + 2 ^2-1 + 2"-2 +...).
Алгоритм приведения произвольной системы нелинейных уравнений
над полем F2
fj(x(l),...,x(n))=yj, jel,m
к трапецеидальному виду относится к алгоритмам частичного перебора функ-
ций fj Je l,m и является достаточно очевидным и трудно формализуемым.
Трудоемкость приведения системы к трапецеидальному виду Оценивается ве-
личиной m2n.
Нахождение решений системы нелинейных уравнений специально-
го вида методом встречных атак.
Рассмотрим некоторый класс систем уравнений, нахождение решений
которых проводится с использованием идей согласования (встречных атак).
Пусть система уравнений имеет вид
<Pj(x(l),..., x(r),x(r+-l),..., x(r+v))+\|/j(x(l),..., x(r),x(r+v+l),..., x(n))=0, je l,m,
где (pj и ц/j, j e 1, m- двоичные функции, “+” - в поле F2. Требуется найти все
решения данной системы уравнений. Предлагается следующий алгоритм нахо-
ждения всех решений.
Проводится перебор всех двоичных векторов E=si,g2,...er. Для каждого
фиксированного набора e=£i,£2,..;er выполняется процедура: для каждого набо-
ра бг+ь-.-Д+уе Fj вычисляются значения (pj(fii,£2,...£r Д+i,..., 8l+v)=aj и по адре-
су ai,.. .,am записывают набор 5=8^1,..., 8ц.у в память П. После заполнения памя-
ти элементами из F\, для каждого набора у=Уг+у+1,.• .,ynGF "_r-v вычисляют
значения \|/j(£i, • • • > Br,Yi+v+b • • •, yn)=bj и по адресу b (,... ,bm обращаются в память
П. Вариант е, 8',у, гДе б'=б'г,,..Дц.у набор, содержащийся в П по адресу
bj,...,bm, является решением рассматриваемой системы.
Объем адресной части памяти есть 2тш бит, а число наборов 8, записы-
ваемых в память П, есть 2V, поэтому необходимый объем памяти не превосхо-
дит величины 2mm+2vv бит.
Пусть С - трудоемкость вычисления значения функции q)j или \|/j на
фиксированном наборе переменных. Тогда трудоемкость вычисления функций
302
равна величине 2r(mC2v+mC2n v r). Число обращений к памяти равно величине
2r(2v+2n’v'r), поэтому общая трудоемкость метода есть
Т= mC(2v+r+2n’v)+2v+r+2n’v.
Надежность метода равна единице.
Метод решения системы нелинейных уравнений над полем F2, ос-
нованный на линеаризации путем введения новых переменных.
Пусть задана система нелиненых уравнений над полем F2.
f,(x(lx(n))=yi
f2(x(lх(п))=у2
,fm(x(lх(п))=Ут
относительно двоичных переменных х(1),...,х(п). Предполагается, что функции
fj(x(l),...,х(п)), j е 1, mзаданы в виде полиномов Жегалкина.
Метод решения системы уравнений заключается в замене каждого не-
линейного члена x(ii)x(i2)...x(iK) на новое неизвестное u(iji2...iK) и решении по-
лучившейся линейной системы уравнений относительно новых переменных, с
последующим нахождением решений первоначальной системы путем решения
систем специального вида x(ii)x(i2)...x(iK)= u(iii2...iK) для каждого решения
{u(iii2.. .iK)} линейной системы.
Если степень нелинейности каждого уравнения не превосходит величи-
ны г, то число переменных полученной системы линейных уравнений не пре-
восходит величины Кп,г =С n +С 2 +.. .+С п Так как трудоемкость нахождения
решений такой системы линейных уравнений (если пользоваться алгоритмом
Гаусса) оценивается величиной О(КП?Г)3, то, пренебрегая трудоемкостью реше-
ния указанных систем специального вида, трудоемкость метода оценивают ве-
личиной О(Кп,г)3.
Метод решения системы нелинейных уравнений над полем F2, ос-
нованный на линеаризации путем опробования части неизвестных.
Пусть дана система нелинейных уравнений над полем F2, левые части
которых записаны в виде полиномов Жегалкина
fi(x(l),...,x(n))=yi
f2(x(lx(n))=y2
fm(x(lx(n))=ym.
Алгоритм определения всех решений рассматриваемой системы состоит
в следующем. Находят минимальное число v - такое, что существует набор пе-
303
ременных Xv={x(i]),...,x(iv)}, ije 1,n, je 1, v, что для любого набора
bj,b2,-. .,bveF 2 при фиксации переменных
x(i|)=bi,x(i2)=b2,.. .,x(iv)=bv
указанная система становится линейной. Полученную систему линейных урав-
нений (при каждой фиксации переменных x(i]x(iv)) решают одним из из-
вестных способов (например, методом Гаусса).
Пусть Mv - трудоемкость нахождения искомых номеров ib.. ,,iv, С - тру-
доемкость получения из системы нелинейных уравнений системы линейных
уравнений указанным способом задания значений фиксированных переменных,
М(л) - трудоемкость решения получившейся системы линейных уравнений.
Тогда трудоемкость данного метода есть MV+(C+ М(л))2\
Основной интерес для оценки сложности реализации данного алгорит-
ма представляют оценки величин v и Mv. Для их нахождения решают некото-
рые специальные задачи из теории графов.
Метод решения системы нелинейных уравнений над полем F2, ос-
нованный на линеаризации с помощью редкого события.
Рассмотрим еще один алгоритм решения системы нелинейных уравне-
ний над полем F2, левые части которых заданы в виде многочленов Жегалкина:
fi (х(1),...,x(n))=yi
f2(x(lх(п))=у2
fm(x(l),..., x(n))=ym.
Предполагается, что данная система имеет единственное решение.
Находят минимальное число v, при котором существуют наборы
x(ii),.. .,x(iv) и bj,b2,.. .,bveF 2 - такие, что при фиксации
x(ii)=bi,...,x(iv)=bv
каждая конъюнкция ранга больше единицы рассматриваемой системы уравне-
ний становится конъюнкцией ранга не более чем единица. Полученную таким
образом систему уже линейных уравнений решают одним из известных мето-
дов.
Трудоемкость указанного метода решения системы нелинейных урав-
нений слагается из трудоемкостей: 1) Mv - нахождения необходимых наборов
x(ii),...,x(iv) и bi,b2,...,bvJ 2) трудоемкости построения линейной системы урав-
нений указанным способом; 3) трудоемкости нахождения решения этой линей-
ной системы уравнений, либо установления факта ее несовместности.
304
Если считать, что единственным решением исходной системы нелиней-
ных уравнений априори может быть с одинаковой вероятностью любой вектор
из F ”, то надежность (вероятность нахождения решения) данного метода
1
есть —.
2V
Основной интерес представляют попытки получения оценок для Mv,
которые ранее проводились в случае специального выбора bi,b2,...,bv, а именно
bi=0, b2=0,..., bv=0.
В этом случае нахождение искомых номеров ii,...,iv и даже значения v (естест-
венно минимального значения) сводятся, соответственно, к задаче нахождения
наименьшего покрытия множества его подмножествами и задаче определения
поперечника наименьшего покрытия гиперграфа.
Удачно подобранные примеры применения аналитйческих методов
криптоанализа и расчета их трудоемкости содержатся книге Грушо А.А., Ти-
мониной Е.Е., Применко Э.А. «Анализ и синтез криптоалгоритмов», 2000 г.,
108 стр.
ГЛАВА 6. ВОПРОСЫ СИНТЕЗА ШИФРОВ И ИХ
КРИПТОСХЕМ
Параграф 6.1
Шифры, близкие к совершенным
Пусть А=А1-А2=(Х1,К1хК2,У2,1) - произведение шифров
Ai=(Xi,Kl,yi,fi) А2=(Х2,К2У2,₽2), У1=Х2 (см. параграф 1.3). Исходя из опреде-
ления совершенности шифра:
р(х/у)=р(х) при любых х, у,
несложно доказывается следующее
УТВЕРЖДЕНИЕ. Шифр A=Ai-A2=(Xi,KixK2,y2,f) является соверше-
ным, если таковым является хотя бы один из сомножителей.
Произведение шифров, не являющихся совершенными может дать
шифр «близкий» к совершенному шифру.
Действительно, пусть (X,K,y,f) - шифр модульного гаммирования
(Х=У) и распределение вероятностей Р(К)=(р(%), Xе К) такое, что р(х)>0> для
каждого Xе К. Тогда квадратная матрица условных вероятностей М = ||р(у/х)||
305
является дважды стохастической и, следовательно, как известно из курса ал-
гебры существует предел
Л1 .1 . Р
1 . . 1
В частности, к-тая степень (Х,К,У,1)К шифра представляет собой шифр, пере-
ходные вероятности которого стремятся к величине 1/||Х| при к—>ос, то есть
шифр (X,K,y,f)K близок к совершенному шифру при достаточно большом к.
Оказывается, что даже произведение конечного числа шифров, не яв-
ляющихся совершенными, может дать совершенный шифр.
Пусть Х= {0,1,...,п-1}. Обозначим через Т=
j + 1J
подстановку сдвига
из симметрической группы подстановок Sn; наряду с Т будем рассматривать и
ее степени Т“(|), в частности, единичную подстановку Е. Рассмотрим m эндо-
морфных шифров AK=(X,n(KK,fic), ке 0,m -1, где П(Кк,Гк)=Пк={Е, Т“(к)}. На
множестве Пк ключей - подстановок задано вероятностное распределение
Р(Пк)=(рк(Е), рк(Та(к))), рк(Е)+рк(Т'“(к))=1.
Теорема. Шифр A=(X,n(K,f))=AoAi...Am.i, являющийся произведением
шифров Ак, явлется совершенным шифром тогда и только тогда, когда выпол-
няются условия
1) |Х|=2‘, t - натуральное число;
2) m>t;
3) среди шифров Ак имеется t сомножителей Aj^j, для которых
aj(i)=P j(i)-2‘, ie 0, t -1, Р j(ij - нечетные числа;
4) для чисел j(i) из 3) выполняются равенства
. Pj(i)(E)= Pj(i)(T-“j(i))=l/2, ieO,t-l.
ДОКАЗАТЕЛЬСТВО. Докажем сначала необходимость условий 1)-4).
Предварительно сформулируем и докажем вспомогательную лемму.
Лемма. Если шифр А совершенный, то |К|=|Х| и индуцированное, веро-
ятностными распределениями Р(ПК) на ключах шифров Ак, вероятностное рас-
пределение Р(К) на ключах шифра А является равномерным.
ДОКАЗАТЕЛЬСТВО. Так как А - совершенный шифр, то он транзи-
тивный, поэтому |К|>|Х|. С другой стороны, множество его ключей П(К,1) явля-
306
ется подмножеством в группе <Т> подстановок, порожденной подстановкой Т.
Поэтому |К|<|Х|. Следовательно, |К|=|Х|. Откуда следует, что n(K,f)=<T>.
Покажем теперь, что р(%)= 1/|П(К,1)|, для любого /еК. Имеем
Р(у/х)= Р(%) >0’ УеУ’ хеХ’ <х=у)
ха*=у
и, в силу транзитивности А и равенства |К|=|Х|, существует единственный ключ
Х=Х(х):%х=у. Откуда: р(у/х)=р(%(х)). С другой стороны,
£р(у/х) = £р(у) =| X | р(у).
X X
Следовательно,
ХР(У/Х) = £р(х(х)) = 1 =|Х|р(у),
• X X
поэтому р(у/х)= р(%(х))=р(у)=1/|Х|= 1/|К|, что и требовалось доказать.
Покажем теперь необходимость условия 1): |Х|=2‘.
Любой элемент леП(К,£) имеет вид Ту, где у - определяется значением
случайной величины ^(ш), представляющей собой сумму независимых случай-
ных величин
' ( 0 аЛ
lqj Pjj
где pj= pj(T'a(i)), jе 0, m -1. Это следует из того, что 7t=7t0-7t|.. .тст.|, где 7tj= Т .
Пусть P(^(m))=(p(0),p(l),...,р(|Х|-1)) распределение вероятностей случайной
величины <^(т). Ранее мы показали, что при любом j е 0, m — 1
p(j)=l/|X|.
Используем это равенство для доказательства того, что |Х|=2*. Введем аппарат
характеристических чисел величины
„7 ... ’ v 27TKV . . 2лКУ
NK(j)=qj+PjeK , где sK =cos-j^—
Напомним, что если f(x)=Me'x^ - характеристическая функция случай-
, „ 2лк
нои величины q, то ее значение f( । р называется к-ым характеристическим
числом для Поскольку случайные величины независимы, то характери-
стическая функция для <^(т) равна произведению характеристических функций
для
307
m-1
<X>=]Jfj(x).
j=°
_ ~ 2лк
Полагая в последней сумме х=---получаем формулу для к-того характери-
I X |
стического числа NK:
|Х|-1
NK=NK(0)-...-NK(m-l)= 2>(j)£JK.
j=0
Выразим для фиксированного г вероятность р(г) из предыдущего равенства че-
рез NK, ке 0, | X | -1. Для этого умножим это равенство на £~г и просуммируем
по kg 0,| X | —1. В левой части равенства получим
|Х|-1 |Х|-1
£eKrNK=EorNo+ £eKrNK
к=0 к=1
а в правой части получим
|Х|-1 ( |Х|-1 . А 1X1-1
Ёекг ЁрО')£к = £
к=0 j=0' J к=б
|Х|-1 |х\-1 <|Х|-1 . Л
= £р(г)+ £ P(j) Еек"Г
к=0 j=0 V к=0 >
|Х|-1
р(04 + £ р0')£к
j=0
=р(г)|Х|.
>г
В итоге получаем
. |Х|-1
1+ £ =р(т)|Х|:
к=1
Откуда
|ХН .
l .+ ££;rNK .
к=1 )
Из этого равенства заключаем, что из условия р(г)=1/|Х| вытекает
р(г)=—
1X1
ПХН >
£ s/Nk
\ К=1 )
=0.
308
t
Следовательно наша задача свелась к доказательству того, что из ра-
венств
№
Z s;fnk
=0, re 1,| X |-1
вытекает |Х|=2‘.
Рассмотрим предыдущие равенства как систему лйнейных уравнений
относительно величин NK. Определитель этой системы равен
А=£| 1£2’1...£|Х|-1
где А' - определитель Ванндермонда:
Отсюда следует, что рассматриваемая система линейных уравнение относи-
тельно величин NK имеет единственное решение:
Ni= N2=...=N|x|-i=0.
Выясним, чему равносильна данная цепочка равенств. Из того, что
NK=NK(0)-„. -NK(m-l)=0
следует, что для некоторого]
NK(j)=O.
Рассмотрим модуль комплексного числа NK(j). По определению
|NK(j)|=|qj+pjCOS
2 лк . . 2 лк ,
а,+ ipjSin------а, =
|Х| J J |Х| J
J. 2лк .2 2 2 2лк
(qi+PiCOS---ОС;) +Pi sin ---0С: =
J Fj |X| J’ |X| J
2 2 2 2лк _ 2лк 2 • 2 2лк
= qi+PiCos -----a; + 2p:q:cos---а;+р;8ш -------a.=
i vi J rJnJ I Yi J i vi J
2 2 n 2ЛК , _ .. 2лк .
=Jq j+Pj + 2Pj-q j cos—aj =1 - 2pjqj(l - cos—aj) =
Л . 2 ЛК
— aj.
309
Еслир^о,, TOpjqj<l/4, и поэтому
7TK
NK(j)>|eos—-aj |>0.
I -X I
Значит NK(j)=O лишь в случае, когда pj=qj=l/2, при этом из последнего равенст-
ва для NK(j) получаем
7СК
| NK(j)|=|cos—— aj|=0,
откуда
ЯК 71 п
------------------------а: = —В:,
|Х| J. 2 J
где Pj - некоторое нечетное число. Тогда
2ка:
4 ' 1х1=^-
Пусть t - максимальная степень числа 2, при которой 2* делит число
|Х|: |Х|=2*р0, где Ро - нечетное число. Тогда
J 2 к
к
Покажем, что р0= 1. В самом деле, если р0=2+у>3, то
|Х|-1=2‘Ро-1=2‘(2+у)-1>2‘+1.
Номера к в NK(j) изменяются в пределах от 0 до |Х|-1.. При к=2‘+| (что меньше
IVI PoPj
|Х|—1) из последнего равенства для aj получаем aj=—-—. Это не целое число,
то есть получили противоречие, означающее, что Ро=1, откуда получаем |Х|=2‘.
Необходимость условия 1) доказана.
Для доказательства остальных условий теоремы вернемся к анализу
полученных ранее условий:
NK=NK(0)-... NK(m-l)=0.
Разобьем множество {NK, kg 0, | X | — 1} на непересекающиеся подмно-
жества: Go,...,Gt-i, где GV={NK, k=2vuv, uv - нечетное число}.
Покажем, что если аргумент a.j, j g 0, m -1 обнуляет элементы одного
из множеств Gv, то этот аргумент не обнуляет ни один элемент из G< , v^v'. Тем
самым, для того чтобы обнулить по одному элементу из каждого Gv и, таким
образом, добиться выполнения равенств: NK= NK(0)-... •NK(m-l)=0, необходимо
условие m>t.
Итак, ранее было доказано, что
310
то есть
Если к=2гиг (т.е. NKGGr), то Oj=2t r lu'j, где u'j - нечетно. Такой аргумент обра-
щает в ноль лишь Gr. В самом деле, если г/т', то из ранее полученного равенст-
71K Я о
ва ----а. = — [3: следует
|Х| J 2J
лк л2 ur' _ +_1 л л л
---а,=-------— 2 r \=л2г r u ru и,
|X|J 2*------J J 2
и поэтому NK^0 при NKeGf. Таким образом, необходимость условия 2) доказа-
на. Необходимость условий 3) и 4) бала получена попутно (из равенства
|NK(j)|:=O и определения множеств Gv).
Доказательство достаточности условий 1)-4) можно получить, просле-
живая проведенные рассуждения в обратную сторону.
Развитие и обобщение данной теоремы содержится в статье Б.В. Ряза-
нова, Т.П. Шанкина «Критерий равномерности распределения суммы незави-
симых случайных величин на примаркой циклической группе». Дискретная
математика. Т. 9, е?ып. 1, 1997, стр 95-102.
Параграф 6.2
Гомоморфизмы и конгруэнции шифров
Ряд методов криптоанализа шифров основан на наличии гомоморфного
образа изучаемого шифра. С точки зрения синтеза шифров представляют инте-
рес шифры, не имеющие нетривиальных гомоморфных образов.
Понятие гомоморфизма алгебраической модели шифра сводится к по-
нятию гомоморфизма произвольной алгебры. Рассмотрим сначала частное по-
нятие гомоморфизма шифров по ключам.
Пусть имеются две алгебры A=(X,K,Y,f), А'=(Х, К',У, f). Отображение
<р: К-»К' со свойством: при любых хеХ, /еК
f(x,x)=f(x,<p%)
называется гомоморфизмом алгебры А в А' по множеству К (гомоморфизмом
алгебры А на А', если ф - сюрьективное отображение К в К'). Алгебру А' на-
311
зывают образом А при гомоморфизме ф. Если ф - биекция, то ф называют изо-
морфизмом алгебр А, А' по множеству К.
Очевидно, что если А - шифр, и ф - гомоморфизм шифра по К, то
классы эквивалентных ключей шифра А являются объединением некоторого
числа прообразов отображения ф.
Ниже нам необходимо рассматривать бинарное отношение эквива-
лентности £ на К (т. е. бинарное отношение на К со свойствами рефлексивно-
сти, симметричности, и транзитивности). Факт того, что элементы %, %' нахо-
дятся в отношении £, будем записывать в виде %£%'. Напомним, что любое от-
ношение эквивалентности на множестве К задает разбиение этого множества,
то есть задает совокупность попарно непересекающихся подмножеств (бло-
ков) множества К, объединение которых дает К. Обратно, любое разбиение
множества К задает бинарное отношение эквивалентности (элементы, лежащие
водном блоке разбиения, эквивалентны).
Конгруэнцией на множестве К алгебры А называют бинарное отноше-
ние эквивалентности £ на К, согласованное с операцией f, то есть из условия
Х^Х' Для некоторых х,у' еК следует f(x,x)= f(x,x') при любом хе’Х,
Совокупность блоков К], Кг,..., Kl отношения эквивалентности £ (конгруэнции
с) на К называют фактормножеством и обозначают через К/е.
Факторалгеброй алгебры А=(Х,К,У,1) по конгруэнции £ на К называют
алгебру А/е=(Х,К/е,У,Г), где f :ХхК/е-»У, именно, для хеХ: f(x,Kj)=y,
je{l,...,L}, если при %eKj f(x,x)=y.
Гомоморфизм ф алгебры А на А' индуцирует конгруэнцию £ф на К,
именно Х1£<Д2 тогда и только тогда, если эти элементы одновременно принад-
лежат некоторому прообразу ф’*(х ), X • Обратно, для любой конгруэнции £
на К алгебры А строится отображение фе: К—>К/е, именно фе(х)= Kj, если Xе К).
Легко проверяется, что фе - гомоморфизм А на А/е=(Х,К/е,У,Г) по множеству
К. При этом, конгруэнция на К, соответствующая гомоморфизму фе, совпадает
с конгруэнцией £. Гомоморфизм фе алгебры А на факторалгебру А/в=(Х, К/£,
У, Г) по множеству К называют естественным гомоморфизмом.
Очевидно, что при гомоморфизме ф алгебры А на А' факторалгебра
А/еф изоморфна алгебре А' при изоморфизме ф '(х )^Х , X (ф '(х )_ класс
эквивалентности бинарного отношения эквивалентности £ф).
В общем случае под гомоморфизмом алгебр A=(X,K,y,f), А'=(Х',
К ,У', Г) понимают тройку отображений Т=(ф,ф,т|), соответственно X—>Х',
К-ЯС,У->У' со свойством: f (ф(х),фх)= r|(f(x,x)), хеХ, х^К.
Это свойство обычно записывают в виде коммутативной диаграммы:
312
f
--------►
XxK У
Ф 4<ср Ф
Х'хК' У'
f
При сюръективных отображениях тройку (ф,ф,т|) называют гомомор-
физмом А на А' (в противном случае - гомоморфизм А в А'). Если отображе-
ния биективны, то говорят, что А и А' изоморфны.
В общем случае конгруэнцией алгебры А называют тройку бинарных
отношений эквивалентностей (С8Л) определенных, соответственно, на X, КД
согласованных с операцией f, то есть из соотношений
Х^х2,
следует
f(Xi,Xl) £ f(x2,X2>.
Аналогично тому как ранее было введено фактормножество К/е, вво-
дятся фактормножества Х/£, У/£ и факторалгебра
А/(С еЛ)=(Х/^ К/е,У/^,^£Л).
Гомоморфизму (\|/,ср,т)) алгебры А на А' соответствует конгруэнция
£Ф4Л), для которой факторалгебра A/(£v,£94n) изоморфна алгебре А'. Ана-
логично тому как это сделано ранее для гомоморфизма ф, строится естествен-
ный гомоморфизм алгебры А на А/(^ф,Еф4п).
Отметим, частный случай гомоморфизма алгебры A=(X,K,y,f) на ал-
гебру А=(Х,К,У',Г ) — гомоморфизм вида (Е,Е,Ф), где Ф:У—>У ', Е - тождест-
венное отображение.
Все возможные гомоморфизмы и соответсвующие им гомоморфные об-
разы алгебры A=(X,K,y,f) можно получить следующим образом.
Зададим на множествах X, К произвольные разбиения Rx и Rk. Им от-
вечают бинарные отношения эквивалентности С,, е. Определим на У бинарное
отношение эквивалентности S, положив: уiS,y2, если найдутся хьх2еХ, ХьХг6К
для которых
Х1£х2,
Х16Х2,
f(xi,Xi)=yb
f(X2,X2)=y2-
Легко проверяется, что (£,£,£) - конгруэнция на алгебре А. Строя по этой кон-
груэнции естественный гомоморфизм (ф^фсЦ^) и соответсвующую факторал-
гебру А/(£,8,£), мы получаем гомоморфный образ F(Rx,Rk)=A/(^,£4) алгебры А
313
Теперь несложно доказывается, что любой гомоморфный образ алгебры А (с
точностью до изоморфизма) является гомоморфным образом при гомоморфиз-
ме вида (Е,Е,Ф) некоторой факторалгебры F(Rx,Rk)=A/(£,e4).
ЗАМЕЧАНИЕ. Как правило, шифр реализуется некоторым шифрато-
ром. Если функционирование этого шифратора моделируется конечным авто-
матом, то представляет интерес описание его (автомата) гомоморфных образов.
Решение этой задачи широко известно, оно содержится во многих книгах по
теории автоматов. Одно из обобщений понятия гомоморфизма шифра заключа-
ется в следующем. Пусть на множествах X, К заданы вероятностные распреде-
ления. Тогда для шифров A=(X,K,y,f), A'=(X',K',y',f) и тройки отображений
Т=(у,<р,г|): \|/:Х—>Х', ср:К->К', т|:У->У' при случайном выборе (х,х)еХхК опре-
делена вероятность события: f (1|/(х),фх)= r](f(x,x)). Тройку отображений с
максимальной вероятностью иногда называют наилучшим вероятностным го-
моморфизмом шифра.
Параграф 6.3
Групповые шифры. Обратимые групповые шифры
Групповые минимальные шифры.'
Ниже нам потребуется так называемое табличное задание шифра
A=(X,K,y,f). Это таблица размера |Х|х|К|
х
Ф •
У(А)=Х ->/(х,/). ,
к 7
столбцы которой пронумерованы элементами х из X, а строки - элементами х
из К. На пересечении столбца с номером х и строки с номером х стоит элемент
y=f(x,x) из У. Отметим некоторые свойства табличного задания шифра:
1) в У(А) нет пустых строк;
2) объединение всех f(x,x) дает У;
3) каждая строка таблицы не содержит одинаковых элементов.
Если шифр А транзитивен, то, очевидно, |Х|<|У|<|К|.
Шифр А=(Х,К,У,1) называют минимальным шифром, если он транзи-
тивен и |Х|=|У|=|К|.
314
Напомним, что эндоморфными шифрами называются шифры
А=(Х,К,У,1), у которых Х=У. Для таких шифров ранее нами вводилась подста-
новочная модель эндоморфного шифра А - обозначение А=(Х, II(K,f)), где
II(K,f)={fz: %еК} - множество всех биекций X в X шифра-А. Уравнение шиф-
рования записывалось в виде: лх=у, л - ключ шифра - взаимно однозначное
преобразование множества X, тгеП(К,1). Уравнение расшифрования записыва-
лось в виде: л'1у=х.
Если множество П(К,1) подстановок на X является смежным классом по
некоторой подгруппе в симметрической группе S(X) подстановок на множестве
X, то эндоморфный шифр А=(Х, П(К,1)) называется групповым (по К. Шенно-
ну - «чистым»).
Для эндоморфного шифра его табличное задание У (А) представляет со-
бой таблицу, строки которой пронумерованы элементами л из H(K,f), а сами
строки представляют собой нижние строки подстановок л на X.
Напомним, что латинским квадратом над алфавитом X называют
квадратную таблицу размера )Х|х|Х| с элементами из X, такую, что в каждой
строке таблицы и в каждом столбце таблицы нет одинаковых элементов, то
есть каждая строка, как и каждый столбец такой таблицы, представляет собой
нижнию строку некоторой подстановки на X.
Напомним, что квазигруппой (Х,«) называют множество X с операци-
ей • для которых уравнение х*х'=х” однозначно разрешимо: 1) относительно
х' при любой фиксации хих" из X; 2) однозначно разрешимо относительно х
при любой фиксации х' их” из X. Таким образом, любая квазигруппа на X
может быть задана некоторым отображением F: ХхХ-»Х, инъективным по ка-
ждой переменной, либо латинским квадратом, на пересечении строки с номе-
ром х и столбца с номером х' которого стоит элемент x*x'=x”=F(x,x'). В свою
очередь, каждый латинский квадрат или функция ХхХ—>Х, инъективная по ка-
ждой переменной, задает квазигруппу на X. Частным примером квазигруппы
служит группа (X, •) - квазигруппа, где каждый элемент х имеет обратный х1,
х- х '=Е, EgX, x 'gX, Е - единичный элемент группы X.
Необходимость введения понятий латинского квадрата и квазигруппы
диктуется тем, что табличное задание У (А) минимального эндоморфного шиф-
ра, А=(Х, П(К,1)) очевидно, представляет собой латинский квадрат (в силу
транзитивности такого шифра) и ему соответствует квазигруппа (X, •).
Именно, пронумеруем подстановки тгхеП(К,1): n(K,f)={7ti,....7tn},
n=|X|=|K|=|II(K,f)| и элементы из X: X={xi,...,xn}.
315
На множестве X определим операцию •, положив Xj«x= я3х. Тогда под-
( X
становка itj может быть записана в виде
, хеХ
X: • X
Пусть (X,*) и (!,♦) квазигруппы. Тройка биекций (a, Р, у) множества X
в I называется изотопией квазигруппы (X,*) в (на) (I, ♦), если
у(х*х')=а(х)*Р(х') при любых х, х'еХ.
X. Имеем изотопию (а,р,у): y(xj*x)=a(xj)P(x) и подстановку л;=
Теорема. Минимальный эндоморфный шифр A=(X,II(K,f)) является
групповым тогда и только тогда, когда соответствующая ему квазигруппа (Х,«)
изотопна группе (X,-).
ДОКАЗАТЕЛЬСТВО. Пусть (Х,«) изотопна группе (X, ). Покажем, что
II(K,f) - смежный класс по некоторой подгруппе в симь^трической группе на
х А
. Рас-
X: «X
смотрим суперпозицию rtjy отображений 7tj и у (на элемент хеХ сначала дейст-
вуем Ttj, а затем у)
( х
7tjy=
X; *Х
где g=
х 1
у(х j • х^
Г х'
4a(xj)-x
X
a(xj)-p(x)
X
р(х)
=₽g>
- элемент группы (группы подстановочного пред-
Г Р(х)
(a(xj)-P(x)
х'
a(xj)-x'
ставления группы (X,-)). Откуда получаем 7tj=Pgy’1=PgP lpy l. Следовательно,
II(K,f)= рор^Ру1, где G - некоторая группа подстановок на X. Далее n(K,f)=
pGp 'Py’^G'h, где G'=PGP'’ - некоторая группа подстановок на X, а h=Py"' -
подстановка на X. Таким образом, n(K,f) - смежный класс.
Обратно, пусть n(K,f) - смежный класс по некоторой подгруппе G в
симметрической группе S(X), n(K,f)=Gh.
Рассмотрим для группы G={gi,...,gn} (n=|II(K,f)|=|G|) латинский квад-
рат, строка с номером j которого определяет нижний ряд подстановки
316
х
. Для шифра A=(X,II(K,f)) строка с номером j его латинского квад-
рата определяет подстановку 7tj=gjh=
х
X : • X
J 7
Имеем
gjh=
' х Y 4
^(хф1(^(х))у
^(хрх);
Откуда получаем
Xj*x=h(xj-x),
или
h’1(xj*x)=xJ-x
при любых Xj,xeX.
Следовательно, тройка биекций (а=Е, Р=Е, у=Ь‘‘) множества X в X (Е -
тождественное отображение) осуществляет изотопию квазигруппы (X,*) на
(X,-).'
Эндоморфный шифр называется обратимым, если каждая его подста-
новка 7teII(K,f) есть инволюция: л2 =Е (Е-тождественная подстановка).
Напомним, что шифр A=(X,H(K,f)) называется транзитивным, если для
любых х,х' еХ, (х^х') найдется ключ леП(К,£), при котором ях=х'.
Групповые, транзитивные, обратимые шифры.
Напомним некоторые необходимые нам понятия из теории конечных
групп подстановок.
Пусть G - подгруппа S(X), G<S(X). Группа подстановок G называется
регулярной, если стабилизатор любого элемента хеХ совпадает с единицей «е»
группы G, то есть {g: g(x)=x}={e}. Ниже будут использоваться следующие из-
вестные свойства регулярной группы G.
1). Транзитивная группа подстановок G регулярна тогда и только то-
гда, когда |G|=|X|.
2). Транзитивная, абелева группа подстановок G регулярна.
Лемма. Пусть H=Gt, G<S(X), teS(X). Если Н - транзитивное множест-
во инволюций, то G - регулярная абелева группа.
ДОКАЗАТЕЛЬСТВО. Так как Н - транзитивное множество подстано-
вок на X, то группа G транзитивна. Для доказательства ее регулярности, со-
317
гласно 2), достаточно доказать ее абелевость. Докажем это. При любых heH и
geG имеем
h=h'*, ghgh=e,
h‘1gh=g’1g h'‘gh= g‘‘g hgh=g’’.
Следовательно, для g=gig2, gi,g2^G имеем
h’'gig2h=(gig2)'-g2’1gi‘1,
h’lgig2h= h'1gihh'1g2h=g1‘lg2'1,
„ -L -I— „ -1„ -1
g2 gl ~gl g2 ,
то есть группа G абелева.
Теорема. Групповой, транзитивный шифр А=(Х,П(К,Г) является обра-
тимым тогда и только тогда, если 1) А - минимальный шифр; 2) латинский
квадрат, соответствующий табличному заданию шифра, таков, что определяе-
мая им квазигруппа (X, •) изотопна абелевой группе (X, +). Для любых элемен-
тов а,ЬеХ изотопия определяется равенствами a*b=c-(a+b), где с - фиксиро-
ванный элемент из X.
ДОКАЗАТЕЛЬСТВО. Необходимость условий. Шифр А групповой,
транзитивный. Положим n(K,f)=Gt=H. Шифр обратим. Следовательно, по лем-
ме, G - абелева группа. Она транзитивная группа, так как Н - транзитивное
множество подстановок. Тогда (см. свойство 2 перед леммой) |G|=|X| и поэтому
|Н|=|Х|, то есть транзитивный шифр А является минимальным.
Рассмотрим латинский квадрат для группы G={gi,...,gn}, n=|X|=|G|.
Пусть его строка с номером j определяет нижний ряд подстановки
в этой записи мы использовали абелевость группы G- Латинский
квадрат шифра А таков, что его j -тая строка есть нижний ряд подстановки
, при этом Xj*x=t(gj(x)). Шифр А обратимый, то есть
gjt gjt=E
при любых je{l,...,n}. В частности, для тождественной подстановки g=E, EgG
имеем t2=E, откуда получаем
, t=t‘l
gjt =(gjt)'-f’gfMgj’1,
ИЛИ
318
X: + X
к J 7
Xj + X
?(Xj+X\
X V t(x)
t(x)J l^-Xj+Ux),
Следовательно, для любого xgX и любого Xj g X
t(Xj+x)=t(x)-Xj,
а, в силу симметричности вхождения в равенство х и Xj, получаем и равенство
t(x+Xj)=t(Xj)-X.
Так как t(xj+x)= t(x+Xj), то
t(x)-Xj= t(Xj)-X.
Следовательно, t(xj)= t(x)-Xj+x при любом xgX. Поэтому t(x)+x=const=c, cgX.
И
t(Xj)= C-Xj, XjGX={Xi,...,Xn}.
Возвращаясь к равенству Xj.x=t(gj(x)) получаем
Xj.x=t(gj(x))=t(xj+x)=c-(Xj+x).
Перейдем к доказательству достаточности условий теоремы.
Итак, шифр А групповой минимальный и (X,*) изотопна (Х,+), при этом
'Xj.x = c-(xj+x) при любых x,xjgX. Надо доказать, что шифр А обратим, то есть
gjt gjt=E
при любых je{l,...,n}. То есть надо показать, что
Проверим этот факт непосредственно: х по первой подстановке перейдет в Xj»x,
a Xj«x по второй подстановке перейдет в Xj*( Xj«x). Используем соотношение
xj*x=c-(xj+x) справедливое при любых х, xjgX. Имеем
Xj*(Xj*x)=C-(Xj+ Xj*x)= C-(Xj+ (c-(Xj+x))= C-Xj-C+Xj+x=X.
Таким образом, при действии подстановки gjt gjt элемент xgX перейдет в х, что
и требовалось доказать.
Параграф 6.4(
Инварианты шифров
Пусть A=(X,K,Y,f) - шифр, О - некоторый алфавит, а \у:Х—>О и г]:У->0
- отображения, при которых при любых xgX и %gK выполняется равенство
i|/(x)=Ti(f(%,x)).
319
Такие функции (у,г|) (в случае, когда они не являются константами) называют-
ся инвариантом шифра А. Для эндоморфного шифра иногда рассматривают
частный случай инварианта (\р,т|), именно, случай \|/=т|.
Иногда под инвариантом эндоморфного шифра А понимают и некон-
стантную функцию \|/:УхУ->0, обладающую свойством
V(XX,xx')=v(x'x,x'x')
при любых х,х' еХи х,Х еК-
Инварианты специального типа. Ниже мы укажем путь к описанию
транзитивных эндоморфных шифров, обладающих инвариантом инъектив-
ным по обеим переменным. Для этого приведем один известный результат из
теории квазигрупп. Пусть (X,*) - некоторая квазигруппа на X. Подстановка
geS(X) называется средней регулярной подстановкой квазигруппы (X,*), если
найдется подстановка g' eS(X), для которой равенство
g(x)*x'=x*g'(x')
выполняется при любых х,х' еХ. В книге Белоусова В.Д. «Основы теории ква-
зигрупп и луп». Кишенев, 1969 г., в теореме 2.5 доказано утверждение о том,
что множество М всех средних регулярных подстановок квазигруппы (X.*) яв-
ляется группой и мощность |М| множества М делит |Х| (|М|||Х|). С помощью
этого результата несложно получается описание эндоморфных транзитивных
шифров А=(Х,П(К,1) обладающих инвариантом \|/:УхУ-»О
Mxx^Xx'^vCx х,х'х ) при любых х,х' еХ и х,Х еК) инъективным по обеим
переменным.
Инварианты общего типа. Пусть А=(Х,К,У,1) - шифр. Укажем усло-
вия наличия для шифра А инвариантов общего типа, то есть наличия некон-
стантных функций \|/:Х—>0 и т|:У->О (О - некоторый алфавит), при которых
при любых хеХ и уеК выполняется равенство
V(x)=t](f(x,x)).
Введем на множестве X бинарное отношение ст, положив: хстх', если
найдутся % и %' из К, при которых f(x,x)= f(x',x )• Если некоторые функции \р,
1] являются инвариантами шифра, то, очевидно, функция принимает одина-
ковые значения на х и х'. Пусть ст* - транзитивное замыкание бинарного отно-
шения отношения ст, то есть X]CT*xn, если найдутся x2,...,xn.i из X, при которых
XiCTX2CT...CTXn-1CTXn.
Как известно, ст* - будет бинарным отношением эквивалентности на X.
Из сказанного выше следует, что функция инварианта (\р,г|) шифра А посто-
янна на классах бинарного отношения эквивалентности ст*.
320
Перейдем к изучению свойств функции q инварианта (1|/,т|). На множе-
стве У введем бинарное отношение, г положив: угу', если найдутся х из X и
ключи %, х\ при которых f(x, х)=у и f(x,x')=y'. Для инварианта (у,г)) должно
очевидно выполняться т|(у)=т](у'). В связи с чем, функция т| должна принимать
одинаковые значения на классах эквивалентности бинарного отношения экви-
валентности г* - транзитивного замыкания бинарного отношения е. Легко по-
казывается, что между фактормножествами Х/о* и У/е* существует биекция т,
устанавливаемая с помощью равенства f(x, х)=У- Положим X/o*={Xi,...,Xl},
У/е*={Уь...,УЕ}, где t(Xj)=yj, je Произвольные неконстантные
функции \р:Х—>О и т|:У->О являются инвариантом шифра A=(X,K,y,f),
если они постоянны на соответствующих классах Xj,yj из Х/о*, У/е* и их
значения одинаковы на каждом j -ом блоке, у(х)= т|(у), при xeXj, уеУр
je{l,...,L}.
ЗАМЕЧАНИЕ. Аналогичным образом вводятся понятие инварианта ав-
томата (шифрующего автомата). При этом инварианты зависят от длины к рас-
сматриваемых входных и выходных слов автомата. Поэтому встает вопрос о
существовании минимального к, при котором для заданного автомата сущест-
вует инвариант и проблема о существовании такого к для заданного автомата.
Эти проблемы в настоящее время полностью решены одним из авторов посо-
бия. Одно из обобщений понятия инварианта шифра состоит в следующем. На
множествах X и К вводится вероятностные распределения. Для заданных
функций 1|/:Х—>О и т):У—>0 рассматривается вероятность события:
\|/(x)=r](f(x,x)). Ставится вопрос о нахождении функций, для которых вероят-
ность данного события максимальна.
Параграф 6.5
Введение в вопросы синтеза криптосхем
(
В настоящее время в открытой литературе много внимания уделяется
вопросам синтеза и анализа криптосхем. В связи с чем дать полный обзор ти-
повых криптосхем или их блоков в рамках учебного пособия достаточно
сложно. Прежде всего отметим, что описание наиболее популярного блочного
шифра DES (Data Encryption Standart) было дано в параграфе 1.4. Там же со-
держатся: описание блочного шифра ГОСТ 28147-89 - российского аналога
американского стандарта шифрования DES; описание современного шифра
гаммирования, ориентированного на программную реализацию - Алгоритм
RC-4 (разработка RSA Security Incorporated). Более подробное и прекрасное
описание шифров DES, IDEA, Гост28147-89 содержится в книге Ю.В. Роман-
321
ца, ПА. Тимофеева, В.Ф. Шаньгина. Защита информации в компьютерных сис-
темах и сетях. Радио и связь, М., 1999, 328 стр. В отношении учебной литера-
туры по данному вопросу мы отмечаем: 1) прекрасное описание шифратора
«Хагелин», данное А.'Соломаа в его книге «Криптография с открытым клю-
чом» и 2) изданные Московским Государственным инженерно-физическим ин-
ститутом учебные материалы по криптографии.
Следует отметить глубину математических исследований в области
синтеза криптосхем Ю. С. Харина, В.И. Берника, Г.В. Матвеева в их книге
«Математические основы криптологий», Минск, БГУ, 1999, стр. 319.
Многа конкретных алгоритмов блочного шифрования приведено в
книгах Молдовяна Н.А. (Н. А. Молдовян, «Проблемы и методы криптогра-
фии», С.-П. 1998; Н.А. Молдовян, «Скоростные блочные шифры», С.-П., 1998).
В отношении поточных шифров мы рекомендуем читателю
(http:/ns.ssl.neva.ru/psw/ciypto/potok/str-ciph.htm, 1997). Нельзя пройти мимо хо-
роших книг:
АА. Варфоломеев, А.Е. Жуков, М.А. Пудовкина. Поточные криптосхемы. Ос-
новные свойства и методы анализа стойкости. МГИФИ, 2000, 243 стр.;
Грушо А.А., Тимонина Е.Е., Применко Э.А. «Анализ и синтез криптоалгорит-
мов», 2000, 108 стр.;
АЛ. Чмора «Современная прикладная криптография». М., Гелиус АРВ, 2001,
244 стр.
Естественно, мы не касались здесь книг, посвященных главным образом
-«криптографии с открытым ключом» и монографий по теоретическим пробле-
мам криптографии. /
Криптосхемы шифраторов, как и сами шифраторы, принято клас-
сифицировать на криптосхемы блочного шифрования и криптосхемы по-
чинного шифрования.
Условно большую часть криптосхем поточного шифрования можно
схематически представить в виде последовательного соединения двух блоков:
управляющего блока (УБ) и шифрующего блока (ШБ).
11 Зак. 5
322
Управляющий блок предназначен для выработки управляющей после-
довательности шифрующего блока. Эта последовательность должна быть
«псевдослучайной» последовательностью, то есть по своим статистическим
характеристикам она должна быть «близка» к случайной и равновероятной по-
следовательности элементов некоторого алфавита. Нередко криптосхемы
управляющих блоков шифраторов представляют собой последовательное со-
единение линейного регистра сдвига (ЛРС) с некоторым узлом усложнения,
функционирование которого моделируется либо функцией, определенной на
последовательных отрезках выходной последовательности ЛРС, либо более
сложным устройством с памятью, моделируемым некоторым конечным авто-
матом, выходная последовательность которого и является управляющей после-
довательностью шифрующего блока. В ряде случаев вместо ЛРС используют
параллельное соединение нескольких ЛРС. Для таких управляющих блоков
центральными направлениями их синтеза (получения псевдослучайных после-
довательностей) являются решения следующих математических задач.
1) Построение статистических аналогов двоичных функций и ав-
томатов.
2) Построение линейных рекуррентных последовательностей мак-
симального периода.
3) Построение автоматов с гарантированными периодами выход-
ных последовательеностей.
Основными элементами управляющих блоков криптосхем являются
устройства, реализующие лийейные рекуррентные последовательности элемен-
тов конечного поля-или кольца вычетов по некоторому модулю, К-значные
функции (в частности, двоичные функции), коммутаторы, регистры сдвига и
ряд других устройств, функционирование которых моделируется конечными
автоматами и многоосновными алгебрами.
Шифрующий блок предназначен для последовательного шифрования
букв открытого текста с помощью управляющей последовательности. Многие
шифрующие блоки, как сами шифраторы, делятся в основном на два класса-
шифрующие блоки гаммирования и блоки реализации замены.
В первом классе криптосхем управляющая проследовательность шиф-
рующего блока является, собственно, гаммой наложения шифра гаммирования.
Второй класс криптохем - класс криптосхем шифров последовательной заме-
ны - таков, что шифрующий блок под воздействием управляющей последова-
тельности вырабатывает последовательность подстановок
ТМТьПг,...,Пр...алфавита открытого текста, при этом элемент П, этой после-
довательности используется для зашифрования j-ой буквы a(j) открытого текс-
та, именно, j-ая шифрованная буква b(j) является образом буквы a(j) для под-
становки Ц: Ь(р=Ша())). Процесс зашифрования в ряде случаев моделируется
323
функционированием некоторого перестановочного автомата (см. параграф 1.3)
с множеством состояний, совпадающим с алфавитом открытого текста. В этом
случае управляющая последовательность 3=ii,i2,... шифрующего блока пред-
ставляется конкатенацией 3=3(1),3(2),..., 3(к),... своих последовательных h-
грамм
3(k)=i(k.i)h+l,i(k-l)h+2>- • -,i(k-l)h+h-
При начальном состоянии а(1) под воздействием входного слова 3(1)
автомат переходит в состояние Ь(1), второй знак Ь(2) шифрованнгого текста
является заключительным состоянием автомата при подаче входного слова
3(2) на автомат с начальным состоянием а(2) и т. д. В других случаях шифру-
ющие блоки реализуются на базе регистров сдвига или с помощью конструк-
ции Фейстеля. Центральными вопросами синтеза шифрующих блоков последо-
вательной замены являются известные математические задачи изучения строе-
ния групп подстановок, заданных своими образующими подстановками (см.
литературу).
В параграфах 6.6, 6.7 этой главы приводятся основные результы по за-
дачам, поставленнйм выше для управляющих блоков шифраторов.
Параграф 6.6
Статистическая структура двоичной функции
В этом параграфе мы приводим ряд известных результатов по вопро-
сам построения линейных статистических аналогов двоичных функций.
Рассмотрим двоичную функцию y(xi,...,x„): F" —> F2, будем считать,
что ее переменные являются независимыми случайными величинами с распре-
делениями: p{xt — 1) = р(х, = 0) = —, i = 1, п .
Тогда для любого набора а = (at ,К ,ап ) е F2 выполняется равенство
р((Х] ,К , х„ ) = (й] ,К , ап )) = , кроме того
' II = ^2 ,
п
р(/(х,,К,хл) = 1) = ^ = ^-;—, где х = (х1?К,х„).
1 Z*
II*
324
Здесь через ||f|| обозначен вес функции f - число двоичных наборов,на,
которых она принимает.значение, равное единице.
Определение. Двоичная функция g(x) называется статистическим ана-
логом функции/(х), если p(f(x) = g(x)) > у. Здесь p(f(x) = g(x)) - вероя-
тность совпадения значений функций f и g при случайном и равновероятном
выборе набора х е .
Ь(х)
1 ------------------ 1 '
Очевидно свойство: если p(J(x) = й(х)) < *-, то p(f(x) = h(x)) > —. Здесь
2 2
и далее h(x) =h(x) Ф 1.
На использовании статистических аналогов двоичных функций основан
целый ряд статистических методов анализа криптосхем. Основная идея этих
методов заключается в замене «сложной» функции f (х), используемой в исс-
ледуемой схеме, на один из ее статистических аналогов более простого вида,.
причем этот аналог g(x) выбирают так, чтобы вероятность p( f(x') - g(x)) ,
была максимальной. В этом случае функция g(x) будет нести информацию о
многих свойствах исследуемой функции, однако за счет отличия значений фу*
нкций f (х) и g(x) на некоторых наборах задача из детерминированной стано-
вится вероятностной, для решения которой используются статистические мето-
ды.
Наиболее изученным классом двоичных функций, для которых имеют-
ся достаточно эффективные методы решения систем уравнений, является класс
линейных функций. Поэтому при анализе зачастую используют линейные ста-
тистические аналоги функций.
Пусть (а,х) = tz1x1 ФК Ф апхп - некоторая линейная функция. Опре-
1 Д'
делим параметр равенством: р(/(х) = (а,х)) = —+ -^-.
Определение. В приведенных выше обозначениях Д^ называется коэ-
ффициентом статистической структуры функции f
Получим формулу для вычисления коэффициентов статистической
структуры:
325
Х/(х) = g(x)) = p(f(x) ® g(x) = 0) = 1 - p(f(x) Ф g(x) = 1) = 1 -
Тогда ±= 1 - . Следовательно Д{ = 2"-1 -1|/(x) ® (a,x)||.
Определение. Множество {Д£ : a e F? } называется статистической
структурой функции f.
Связь между коэффициентами статистической структуры и коэф-
фициентами Фурье двоичной функции f.
Через С| обозначим коэффициент Фурье двоичной функции f . (Более
подробно, см. параграф 6.7.)
Сначала рассмотрим случай а = 0:
^=±.2/(х) = 11М,У,=2-'-|Лх)||,
Z xeF] Z
поэтому Д{= 2я"1-2й-Co7.
Теперь пусть а * 0:
С.' ЕЛЖГ =^-| .
Z X€F2" Z \(л,х)=0 (л,х)=1 у
= 2' - Il/М Ф (а, х)|| = 2-'X (Л х) ® (а, х)) =
=2-'- хлх)- £7Л)= E/w- E/w-
(а,х)=0 (а,х)=1 (а,х)=1 (а,х)=0
Поэтому Д{ = -2” • С/.
Полученные результаты можно использовать для нахождения статисти-
ческой структуры функции по ее разложению в ряд Фурье, и наоборот.
Кроме того, становится очевидным следующее представление двоичной
функции через коэффициенты ее статистической структуры:
/(х) = |-7Л IX-t-1)'"’'
Z Z аеГ2"
Отсюда следует, что статистическая структура однозначно определя-
ет двоичную функцию.
326
Индуктивный метод поиска статистической структуры двоичной
функции.
Выведем формулы, связывающие коэффициенты статистической струк-
туры функции fix....х„) и ее подфункций /0(х2,...,х„) = /(0,х2,К ,х„) и
/,(х2....х,) = /(1,х2,К , хя). Для удобства положим х1 = (х2,...,хп) и
а1 = (а2,...,ап), при этом получаем, что„
(a,x) = alxl ®'^jaixj =а1х1 ©(а1,*1)
Утверждение. В приведенных ввйце обозначениях верны равенства:
= Да°' +
ДОКАЗАТЕЛЬСТВО,
1-й случай: а, = 0. а =0
। = Г' = 2-' -||/’(х)Ф(£1',х,)||
= 2"-1-]/0(х')ф(а|,х')|-||/(хЬ®(<1|,х'}| = д5 +У;
2-й случай: а, =1.
Д-f , = 2"”’
-||/(х)Ф(а,х)| °= 2
Ф(а‘ х’)| - 2"-2- /
Утверждение доказано.
Из доказанного утверждения следует, что статистическую структуру
функции f (Х|,..., хя) можно вычислить по статистическим структурам ее по-
дфункций /0(х2,...,хя) й /](х2,...,хя) следующим образом:
Пусть (До°..ОО>ДО...О1» •" ’ ДЕ..1к) = ^0 И (Д0...00’ Д0...01> ••• >ДЕ..ц) = ’ тог"
Да (Д00...00’Д00...01»’"’ Д01..11> Д1О...ОО’ Д10...01> ••• ’Д11...11) = (Q ~ ^1)‘
На этом основан индуктивный алгоритм поиска статистической струк-
туры двоичной функции f (x|v..,xn).
Сначала определяем статистические структуры всех подфункций
f (а{,хя), зависящих от одной переменной. Для этого удобно исполь-
зовать следующую таблицу:
f ^0 д.
0 1 0
X 0 1
X 0 -1
1 -1 0
- вспомогательная таблица
327
, Затем, по доказанной формуле находим статистические структуры фун-
кций f (а1,..., ап_2, хп_х, хп) для всех наборов а„_2) е F2~2. Потом ищем
статистические структуры функций f и так далее, до
получения статистической структуры функции f (хх,...,хп).
Схема алгоритма и пример его использования для функции от 4-х пере-
менных приведены ниже.
Оценим трудоемкость этого метода. Для его реализации необходимо
проделать п этапов, на каждом из которых подсчитать 2" коэффициентов. По-
этому Т = О(п • 2”).
Индуктивный метод поиска статистической структуры двоичной
функций.
Случай функции от четырех переменных.
XIX2X3X4
f(Xl,X2, Хз,Х4) fo(X2,X3, х4) /оо(хз,х4) joooM 0000 Aq00~ (^Д000) Boo~(Aooo+ Aooi, A000-A001) Co=(Boo +Boi, Boo-Bot) D (Co+Ci, Cq-Ci)
000 1
foot (*4) 00 1 0 A ooi ~
00 1 1
foi(x3,x4) foiofa) 0 100 Aoio~ •Boi=(Aoio+ Aon, A010-A011)
0 101
fo'llfa) 0 110 Aou= (4"Д°")
0 111
fl(X2,X3, х4) fio(x3>x4) fioofa) 1000 A ioo= (Д»Д°о) Bio~(Aioo+ A101, A^txrAioi) Ct=(Bio +Bn, BiorBu)
100 1
fioifa) 10 10 A ioi~ (4°'До1)
10 11
fu(x3,X4) fliofa) 1 100 Ацо~ (ДоДо) Bn~(Ano+ Аш, Апо-Ат)
110 1
flllfa) 1110 Лиг
1111
328
Получаем!) (Дооо^,^oooi’^оою’^ооп’ •••»п)
Пример, использования индуктивного метода поиска статистической
структуры двоичной функции.
XIX2X3X4 f
0000 1 1 Аооо - (-1.0) Воо- (-1,1.-1.-1) Со =(0,2, 0,-2,-2,0, -2, 0) D = (0, 0,0, 0,-2,-2,-2,-2, 0,4, 0,-4,-2, 2,-2,2)
000 1 1
оою 0 X Aooi = (0,1)
0011 1
0 1 00 0 0 Аою = (1,0) Boi= (1,1,1,-1)
0 10 1 0
0 110 0 X Aon = (0, 1)
0 111 1
1000 1 X А10о = (0,-1) Вю = (0,-2,0, 0) Ci = (0,-2, 0, 2, 0,-2, 0,-2)
100 1 0
10 10 1 X Aioi= (0,-1)
10 11 0
1 100 0 X Ацо = (0,1) вн- (0,0,0,2)
110 1 1
1110 1 X Ац| = (0,-1)
1111 0
О' (Доооо’^oooi’ Аоою’^ooii\-" ’^iiii) (О’ 0» 0, 0,-2,-2,-2,-2, 0, 4, 0,-4,-2, 2,-2,2)
Среди координат вектора D наибольшие по модулю значения (4 и -4)
имеют 10-я и 12-я соответственно, т.е. Д^ = 4, а д{0|1 = -4. Поэтому
наилучшими линейными статистическими аналогами функции f являются фун-
КЦИИ£1 = Х1Ф%4 И g2=Xi®X3®X4® 1.
При ЭТОМ Р(Дх) = Х| ® Х4) =Р(/(х)= xj ® х3 Ф х4 Ф 1)=
1 4 3
ч--— — —.
2 24 4
+
2
Параграф 6. 7
Математические основы синтеза булевых функций с
гарантированными криптографическими свойствами
Введение. При написании данного параграфа использована начальная
часть работы В.Н. Сачкова, В.И. Солодовникова, М.В. Федюкина «Дискретные
329
функции, используемые в криптографи», М., 1998 г., любезно предоставленная
ими авторам данной книги. Здесь рассматриваются основные свойства матриц
Сильвестра-Адамара, с использованием которых вводятся преобразования Уо-
лша-Адамара и Фурье булевых функций. Приводится схема Грина быстрых
преобразований Уолша-Адамара и Фурье. Определяются критерии нелиней-
ности булевых функций, инвариантные относительно групп преобразований
переменных, являющихся подгруппами группы всех аффинных преобразова-
ний. Вводятся понятие линейной структуры булевой функции и понятие расс-
тояние булевой функции до множества функций, имеющих линейные структу-
ры. Определяется порядок нелинейности булевой функции являющейся од-
ним из критериев нелинейности булевой функции. Булева функция, имеющая
максимальное расстояние до линейных структур, называется совершенной не-
линейной функцией. Оказывается, что эти функции находятся также на макси-
мальном расстоянии и от аффинных функций. Класс совершенно нелинейных
функций совпадает с классом так называемых «бент-функций», у которых мо-
дуль преобразования Уолша-Адамара, принимает единственное значение.
1. Матрицы Адамара и их свойства.
Определение. Матрица Н=(Ьу), i,j е {1,2,... ,п} такая, что hij е {1,-1}, на-
зывается матрицей Адамара, если имеет место равентво
ННт=пЕ,
где Нт- транспонированная матрица Н и Е - единичная матрица.
Матрица Адамара обладает следующими свойствами.
и/
I. det(7/) = пл .
2. ННТ = НТН .
Имеем ННТ = Н 'ННтН=пЕ.
3. Если Н|,.. .,НП- строки, Н(1),.. .,Н(п) - столбцы матрицы Н, (Hj,Hj) и
(Н^Н^) - скалярные произведения соответствующих векторов, то
Отметим, что каждое из четырех условий при Ьу= ± 1 является характе-
ристическим, т. е. определяет все остальные свойства и, стало быть, определяет
матрицу Адамара.
330
4. Перестановка строк или столбцов, умножение на -1 строк или столб-
цов переводят матрицу Адамара снова в матрицу Адамара.
5. Для существования матрицы Адамара порядка п, необходимо, чтобы
либо и = 1,2 , либо n%0(mod 4).
При п=1 и п=2 матрицы Адамара существуют и имеют вид
с точностью до перестановки строк, столбцов и умножения их на -1.
Используя свойство 4, любую матрицу Адамара порядка п можно при-
вести к нормализованному виду, при котором матрица Адамара имеет первую
строку и первый столбец, состоящие только из единиц. Рассмотрим первые три
строки матрицы Адамара Н, приведенной к нормализованному виду. Соот-
ветствующая подматрица Зхп матрицы Н имеет столбцы вида
x,y,z. Если число таких столбцов в подматрице Зх п равно соответственно w, то
имеют место следующие соотношения
x+y+z+w=n
x+z=y+w
x+y=z+w
x+w=y+z.
Первое равенство означает, что общее число столбцов равно п. После-
дующие равенства следуют из ортогональности 1 и 2 строк, 1 и 3 строк, 2 и 3
строк подматрицы Зхп. Нетрудно убедиться (например, приведением матрицы
системы к треугольному виду методом Гаусса), что детерминант приведенной
системы линейных уравнений относительно неизвестных х, у, z, w отличен от
нуля и, стало быть, эта система имеет единственное решение: x=y=z=w=n/4.
Следовательно, n=0(mod 4).
Кронекеровское произведение матриц A=(aij), ij=l,2,...,n; B=(bij),
ij=l,2,...,m определяется равенством
331
ацВ #12-S .... а,
а->,В а,,В а->„В
А® В = 21 2.L £П
, a ,B a ,B .... а В
\ л 1 nl nn j
6. Если Hm и Hn - матрицы Адамара, то их
Н ®Н
ние т " - снова матрица Адамара.
кронекеровское произведе-
Из свойств кронекеровского произведения следует, что элементы матрицы
„ , , Т7.
т п равны ± 1. Кроме того,
(Нга®Ц1)(Нп®Н,„)т=(Н,п®Нп)(Нпт®Цпт)=
где Ет - единичная матрица порядка т.
2. Матрицы Силъвестра-Адамара их свойства.
Ма трицы Сильвестра-Адамара имеют порядок п, где n=2k, k=l, 2,..., n
и определяются рекурретным соотношением
я^=я2®я.1?
? 1 2 ’к=1,2,... ,
где
П 1
я1=(1), н2 = _1
V V
Матрица Сильвестра-Адамара обладает свойством симметричности, а
именно
Я/ =Н1к
что следует из ее определения.
332
Независимо от свойства 6 можно убедиться, что матрица Н2к действи-
тельно является матрицей Адамара. Доказательство можно провести индукци-
ей по к. Имеем: Н2 - матрица Адамара,
В силу равенства
H2k2=2kE2k
для обратной матрицы имеем выражение
Рассмотрим совокупность всех двоичных m -мерных векторов V0,
VI,..., V2m-1, координаты которых принимают значения 0 или 1. Будем пред-
полагать, что эти векторы расположены в порядке возрастания чисел, для кото-
рых они являются двоичными представлениями. Для векторов
Vi=(Vi(l),...,Vi(m)), Vj=(Vj(l),...,Vj(m)) будем рассматривать их скалярные
произведения
. \ т
o<ij<2"-l,
r=l
где сложение ведется по модулю 2. Покажем, что матрица
Н2„ =((-l)(viVi)), i,j = o,l,2>...2m-l
есть Матрица Сильвестра-Адамара. Доказательство проведем индукцией по п>.
При ш=1 утверждение верно, так как матрица Н2 имеет вид
Введем обозначения
333
Матрицу Н2т+| представим в виде
2т
2т
^т+о
>
2т
где
ХЕ,.,ГУ)+(О,1)
2
х х 2^ W ж / / > 2W у\ А / /?
где (0,0), (0,1), (1,0), (1,1) - скалярные произведения векторов размерности еди-
ница, 0<i,j<2m -1. Очевидно,что
2т
2т
2т
2^и 5 х 2w
2т >
где Н2„ - матрица Сильвестра-Адамара порядка 2т . Следовательно,
и ^2и - матрица Сильвестра-Адамара порядка 2m+1.
г.. 3.-Преобразования Уолша-Адамара булевых функций.
Булеву функцию f определим отображением
f: [GF(2)]n-> GF(2),
где GF(2) есть n-я декартова степень множества GF(2).
Пусть [GF(2)]n = (v0, Vi,...,V2m |, где векторы расположены в поряд-
3,34
ке возрастания чисел, для которых они являются двоичными разложениями.
Вектор
f = (f(V0),f(V1),...,f(V22 _]))
называется таблицей истинности булевой функции f .
Вектор
F = (F(V0),...,F(V )) =
2 1 \ J
называется характеристической последовательностью булевой функции f.
Преобразованием Уолша-Адамара булевой функции f называется век-
тор
F = (F(U0),...,F(U2m_1)).
координаты которого для всех двоичных векторов Uo,.. .ЛЬ1”-! определяются
равенством
F(U)= £F(V)(-1)(V’U)
VeY
v *= m
где Ym = |v0, V]1 и скалярное произведение вычисляется по моду-
лю 2.
Из этих определений и записи матрицы Сильвестра-Адамара Н порядка
2 м следует, что
F=F-H. а,
ТТ 1 тт
Из этого равенства и равенства £12k к П1к следует, что
335
F = FH~' = —FH
2”
Следовательно,
F(U) = i LF(vX-!)(V’U)
2 vgy
v im
для любого двоичного вектора U размерности m. Это равенство определяет об-
ратное преобразование Уолша-Адамара.
Для булевой функции f(V), множество
{tfWXC/eYj
называют весовым спектром функции.
Пусть булевы функции f и g связаны равенством
g(y) = f(AV + b),V<=Ym,
где А - обратимая двоичная матрица т х т и b двоичный вектор размерно-
сти т . В этом случае говорят, что функция g(K) получается из функции
/(И) аффинным npeo6pai3oeaHHeM переменных. Имеем
F(U) = £f(V)(-1)(v’u) G(U)= £G(V)(-l)(v’u)
VeYm ' VeYm
где F(V) = (- 1)/(И, G(F) = (- 1)8(Г), V e Ym .Покажем,
что в этом случае весовые спектры функций f(V) и g(V) совпадают.
Положим V=A‘1w+A’1b. Тогда
336
G (U ) = X (- 'Г Л >^ (ЛГ + В ) =
W e Гм
где U-UA’1 для всех U E.Ym,
Равенство Парсеваля
KeY
r m
следует из цепочки равенств
у € Y V е Y
Г е A w г 4Z ± т
Аналогичным образом из равенств
FFT = (#,#)= ^F2(K)=2m(F,F)=22'"
j/eY
' m
вытекает равенство Парсеваля для векторов
Для преобразований Уолша-Адамара имеет место соотношение ортого-
нальности
22т, 7^0
О , Г = 0
£#([/)#([/+к) =
(J
337
ДОКАЖЕМ этот факт. Действительно,
, X f(u)f(u +v) =
U € Y т
= Z [ I f X-iF't,,Yx г(хХ-|^;’»
UeYn[weYn A^eY«
= Z (-1 <У )f (*)£(-! У"" ’ =
^^€Ym UeYm
= ЕС-1 )(хИ >F )F Iх )2 т s (W , х ) =
W ,х € Ym
= 2т X (-\)(w'v)F2(W )= 2” % (-1)(г'г) =
T«Y. 1У<=Хт
= 22т Sty ,0)
где -fW,x) - символ Кронекера.
Из доказанного равенства при V=0 следует равенство Парсеваля
FeY
г 1 т
2т
В заключение данного пункта изложим трактовку значений F(U) пре-
образования Уолша-Адамара, связанную с понятием расстояния Хэмминга
между функциями.
EcnHU=(Ui,U2,...,Um),
V=(V 1 ,V2,... ,Vm), то скалярное произведение
т
(U,V) = XuiVi=(V,U)
i=l
представляет собой линейную функцию U от переменных xi=Vi, x2=V2,...,
Хт=Ут. В силу равенства
#([/)= £(_1)ЛП+(слп (<)
KgY
г х/и
с учетом того, что
338
преобразование Уолша-Адамара F(U) определяет разность между числом
совпадений и несовпадений булевой функци и f(V)=f(xb x2,...,Xm) с линейной
фикцией
т
Расстояние Хэмминга между функциями f и g определяется равенством
d(f,g)=
Нетрудно проверить, что d является метрикой на множестве булевых
функций.
/(F)+(t7,K)
F(U)= £(-1)
Из равенства
KeY
г т
имеем
F(U) = (2" - d(f,(U,К))-d(f, (U, V))).
Поэтому
d(f,(U,V)) = 2- +р(С/).
Аналогичным образом следует, что если (с/, V j есть дополнение линейной
функции (U, И), т. е. аффинная функция, то
d(f,(U, V ))= 2”-1 + р(^).
Л*
Таким образом, расстояние функции f до линейной или аффинной функции
является минимальным тогда и только тогда, когда величина
#(у)
достига-
ет максимального значения.
4. Преобразование Фурье булевой функции. Для булевой функции f(V),
имеющей таблицу истинности f=(f(Vo),...,f(V2m.i)), где векторы Vo,...,V2m-i
339
расположены в порядке возрастания чисел, для которых они являются двоич-
ными разложениями, преобразование Фурье определяется как вектор
CKCfCUo), Cf(U1),..: .Cf(U2m1)),
где {Uo, Ui,..., U2m-i} совокупность всех двоичных векторов, а координаты
Cf(U) определяются равенством
f(U)= X Cf (uX-i)(V’U),
Ve Y
v c i m
где, как и ранее, скалярное произведение (U,V) вычисляется по модулю 2.
Числа Cf(U) называются коэффициентами Фурье булевой функции f.
Из последнего равенства следует, что
/ = СГЯ, (2)
где Н - матрица Сильвестра-Адамара порядка 2т. А так как из соотношения (2)
следует, что
то для коэффициентов Фурье получаем следующую формулу
Сг(и)=75Г Zf(VM-D(V’U).
2 Ve Y
v 1 m
Рассмотрим некоторые свойства коэффициентов Фурье булевой функ-
ции.
где Cf(O) - значение коэффициента Фурье булевой функции f для нуле-
вого вектора, а ||У|| вес булевой функции f, т. е. число таких значений
К е , Для которых f(V)=l.
Из свойства 1° следует, что булева функция f является сбалансирован-
ной (равновероятной) тогда и только тогда, когда для нулевого коэффициента
Фурье имеет место равенство
340
2°. Для любого вектора
имеет место равенство
с,(^)=тЦ Е ЛО- Z /<У)
z \V:(U,V)=0 И:({/,И>1 J
3°. Для любого вектора и *0 имеет место соотношение
С,(И = у-ЛЛП = (C/.F)) ,
где P(f(V)=(U,V)) - вероятность совпадения значений булевой функции с ли-
нейной функцией (U,V) при случайном равновероятном выборе вектора
V е Ym , скалярное произведение (U,V) вычисляется по модулю 2.
ДОКАЖЕМ 3°. Действительно, имеем
p(f(v)= (u,v)) =
1
2m
X p(f(v) = (U, V ))
lV6Ym )
f \
£f(v)+ £(i-f(v)) =
VeY yeY
t(U,V>l (U,V>0 )
£f(V)+ Xf(v)+2m+l
yeY yeY
V(U,V>1 (u,v)=o J
1
2 m
£ p(f(v)= (u,v)) =
P(f(V )= (U,V )) =
veil
(u , V > 0
Z (1- f(v)) =
Vs Y.
(u,v)=0 J
2 m +1
-Cf(u)+y.
341
Таким образом,
P(f(v)=(u,v))=-cf(u)+|.
Отсюда вытекает требуемое равенство из свойства 3° .
В криптографических исследованиях иногда используют вектор
координаты которого связаны с коэффициентами Фурье равенством
Д/(ц) = -2"С/(ц), U *0.
Вектор f называется статистистической структурой булевой
функции, а его координаты — у fai )>•••>— у fa " коэффициентами стати-
стической структуры этой функции. Для U=0 полагают
Д/(0)=2”-‘-2”С/(0).
4°. Для коэффициентов Фурье булевой функции имеет место соотноше-
ние
cf(o)= Хс?М
VgY
ДОКАЖЕМ это равенство, действительно, из равенства (2) следует, что
£сДк)=±£Лк)=И=С/(о)
KeYm 2 KeYm 2
Из доказанного сейчас равенства для коэффициентов статистической
структуры вытекает равенство Парсеваля
^Д2/(г)=22(”"1)
342
И,формул C/(0) = |-P(f(K)=(l/,K))„
Af (и) =-2n'Cf (и),
и*о для коэффициентов Фурье булевой
функции получаем, что для и Ф и
Р(/(и)=(и,к))=1+^р.
Из равенств
сле-
дует, что
Д/(0)+2"С/(0)=2"“1.
Для коэффициентов статистической структуры имеют место нера-
венства
22 <дД/)<2"'Л
Оценка сверху для Ду следует из равенства
P(f(V = (u,v =|+^.
Оценка снизу вытекает из равенства Парсеваля . Действительно, до-
---1
пустим, что А (и)<2
Тогда
£Д2/(г)<22(т’|),
г А т
что противоречит равенству Парсеваля.
343
5. Схема Грина быстрых преобразований Уолша и Фурье.
Для матриц Сильвестра-Адамара Н m имеет место следующая фак-
торизация (разложение матрицы в произведение матриц)
н2. = к ,
где М<” = Е2гаЧ ® Н2, М(”> = Н2 ® Е2т.,,
М*” = E2rn-i ® Н2 ® Е2„_; , 2 < i < Ш-1.
- единичная матрица порядка к.
ДОКАЖЕМ указанную факторизацию индукцией по т.
При т=1 имеем
Mi,” =Е, ®Н2 =Н2,
т. е. указанная факторизация справедлива.
Так как E^m-i+l = Е2 ® E^m-i , то можно записать, что
М<” , = Е ®М<” ( = 1,2,...,т.
Z • Z
М(^11)=НО ®Е m
2П1+1 2 2
С учетом этих равенств имеем
=(е2 ®м%)...(е2 ®м^)(н2 ®е2.)=н2®м^..м{;}
Так как по предположению индукции верно равенство
Н2. =М^М™КМ™ ,то
к м<,"> м'::1»=я2„,
и факторизация доказана.
344
Например, при га =2 факторизация имеет вид
Я4=МУХ2,,где
Г1 1 о (Г
м9} = е2 ®н2 = 1 -10 0 -
4 z z 0 0 1 1 9
0 1 -1? *
Г1 0 1 ол
М<2) =Н2 ®Е 9 == 0 1 0 1
1 0 -1 0
ч0 1 0 -1,
Из равенств ~ ^2т-’ ^2 ® ^2т-’ ’ — — П1-1
следует, что матрица 2m > , содержит в каждой строке и в каждом
столбце ровно два ненулевых элемента, равных либо 1, либо -1. Следователь-
но, умножение любой вектор-строки размерности 2т на столбец матрицы
М(') „
2 и связано с одной операцией сложения или вычитания компонент данной
вектор-строки, а общее число таких операций при умножении вектора-строки
на матрицу М<2 равно 2т . Так как умножение вектора-строки на матрицу
11 можно свести к последовательному умножению на матрицы
лСС.к.с , то общее число операций при таком умножении ра-
вно ш2т.
Отметим, что число умножений вектора-строки на матрицу Н по-
рядка 2т без применения схемы быстрого, умножения требует 22т операций.
Способ быстрого умножения вектор-стрбки на матрицу ^Сильвестра-Адамара с
использованием приведенной факторизации обычно называют схемой Грина.
345
Применение этой схемы к равенствам (1) и (2) называют, соответствен-
но, быстрым преобразованием Уолша-Адамара и быстрым преобразованием
Фурье.
6. Критерий нелинейности булевых функций.
В соответствии с принципами, сформулированными К. Шенноном, при
синтезе криптографических систем выдвигаются два требования, которые
обычно называются требованием перемешивания и требованием рассеивания.
Для обеспечения выполнения требования перемешивания для осуществления
криптографических преобразований используются нелинейные функции. Та-
ким образом, требование нелинейности для дискретных функций является
весьма существенным для обеспечения криптографической стойкости шифрси-
сгем.
В этой связи необходимо иметь критерий, определяющий меру нели-
нейности криптографических функций. Такой критерий должен учитывать из-
вестный в криптографии принцип, заключающийся в том, что функция являет-
ся неприемлемой с криптографической точки зрения, если она простыми пре-
образованиями приводится к функции, не обладающей хорошими криптогра-
фическими качествами. Поэтому критерий нелинейности должен быть инвари-
антен относительно некоторой группы преобразований, переводящих одну
функцию в другую.
Действительно, например, булева функция
/(х,хп) = (1 + х, )(1 + х2)...(1 + х„)
содержит все нелинейные члены после перемножения. Однако функция
g(xb...,xn) = f(xb...,xn) = X!X2...Xn состоит из одного члена и
является криптографически неприемлемой.
Как и ранее, ниже для различения обозначений F - функция, a F2 -
конечное поле из двух элементов, для поля будем использовать обозначение
GF(2), столь же общепринятое, как и F2. Для множества всех двоичных наборов
длины к (координатного векторного пространства над полем GF(2)) используем
обозначение [GF(2)]k.
Критерий нелинейности булевых функций.
В криптографических приложениях часто используются функции вида
S : [GF (2)]п-> [GF (2)]т.
346
Например, преобразования S-блоков шифрсистемы DES (см. пара-
граф 1.4) определяются функцией
S : [GF(2)]6 —> [GF(2)]4
Вместе с тем, критерий нелинейности удобно сводить к критериям не-
линейности булевых функций вида
f: [GF(2)]n GF(2)
В этих целях используется понятие линейной структуры. Говорят, что
функция 8: [GF(2)]" -> [GF(2)]m та,ттнейную
структуру, если существует такой ненулевой вектор а и
нетривиальное линейное отображение
Т . Г И к \
такое, что сумма
LS(x +a) +LS(x)
принимает одно и то же значение, равное 0 или 1, для всех х е эта
С
линейная структура ° может быть выражена через линейные структуры буле-
вой функции . По этой причине основное внимание будет уделено критери-
ям нелинейности булевых функций f. В этих целях будет использоваться алгеб-
раическая нормальная форма функции f, имеющая вид:
/(xi,...,x„) = ao +... + ап пхх...хп
По определению считаем, что функция f нелинейна, если ее алгебраи-
ческая нормальная форма (многочлен Жегалкина) содержит члены степени
выше первой. Расстояние функции f до ближайшей аффинной функции L опре-
делим равенством
(/)= mm d(f,L)
LeA(n)
где - расстояние Хэмминга между f и L и А(п) - множество всех аф-
финных фуНКЦИЙ ’••"’Хп) ~ а0 + а1Х1 +"- + апГХт
347
Для исследования - расстояния функции f до множества А(п)
рассмотрим - группу всех обратимых преобразований пространства
[GF(2)] в это~ рруППе рассмотрим подгруппу AGL(n) всех аффинных пре-
образований. Известно, что любой элемент ® AGL(n) может быть
а(х) = Ах + а . ,
записан в виде v 7 , где А - регулярная (невырожденная) матрица
Ихп и a^[GF{q)]m
Положим,
0(n) = {/-;[(zF(2)]"->GF(2)}
множество всех булевых функций от п переменных.
Действие группы на множество определим равенством
« /W = /(«(х))
/еФ(и)10!еОД,-хё[СГ(<
В этих терминах описание критериев нелинейности функций можно
сделать более общим и более точным. Любой такой критерий определяется
функцией D
D: Ф(и) -> W
которая принимает значения из соответствующего множества W.
Функция f удовлетворяет критерию нелинейности, если D(f))eWl,
WlcW - соответствующим образом определенное подмножество. Существен-
но, чтобы значения D были инвариантны при таких преобразованиях из ,
которые переводят функцию f в другую функцию g , не удовлетворяющую
криптографическим требованиям. В совокупность таких преобразований обыч-
но включают аффинные преобразования.
Для определения критерия рассмотрим максимальную подгруппу
, которая оставляет D инвариантным, т. е.
J(D} = {а: П(а /) = £>(/), f е Ф(п), а е «(»)}
Группу будем называть группой симметрий D. Исследование
критериев нелинейности связано с описанием группы симметрий.
348
Прежде всего покажем, что расстояние и до ближайшей аффинной
функции инвариантно относительно операции действия аффинной группы
AGL61)
' . Этот результат получим в качестве следствия из теоремы, сформу-
лированной ниже.
„ Н cl Ф(п) f <=Ф(п) R
Пусть — ' 7 и для 7 ' 7 обозначим
(f) = mind(f,H); £1(п) - группа всех обратимых преобразований
heH
[f (2)]m
Положим,
: a-h е Н для всех h е Н, а е Q(n)}.
Будем называть
Оя(и)
группой симметрий множества Н.
Теорема 1. Для любого подмножества — ' 7 группа симметрий
d
1 совпадает с группой симметрий Н, т. е.
J(dm') = Q.m(n)
ДОКАЗАТЕЛЬСТВО состоит из двух пунктов.
чтт О'” (и) С Jtd".') n с/<=ОНГгйт
а) Покажем, что v 7— v т 7 . Возьмем СС G ь L и
/еФ(л)п- ЛУЯ = т а
J v . Пусть ri такое, что н \ j j \j ? / . Тогда
dH(f} = d(f\H} = d(a- f,a-h) ~ Q(«)
hw / \J ’ / v J ’ 7, так как операция действия v ’
на Ф(п) оставляет инвариантным расстояние Хэмминга. Из определения
Г2я(и) a-heH
v 7 следует, что ** 7 и, следовательно,
d(a- f,a-h)> dJa-/) т д J„(/) > dH(a •/)
v ’ 7 J 7. Таким образом, H 7 н v 7 7 при
любом a.
т £!"(«) П(й)
Так как v 7 есть подгруппа группы 7 , то существует oo-
zy"1
ратный элемент . Действуя этим элементом, получаем, что
349
dH(f) = dH(a-f) и П WcA^.),
~ n J(dm ) C (П) Q Я
б) Покажем, что v m 7 — v 7 . Заметим, что для любого
(Z $2 (ri) hy\H n h ct W
v 7 существует такое , что QI • П ft Jtl и, следовательно,
d„(a-h) Ф О г .. б/ (Г) = 0 п & т/н
н v 7 .С другой стороны, так как н 7 , то ОС £ J WH ) -
получили Противоречие-
Следствие 1. Группа симметрий J(8) для минимума расстояний 8 до
множества аффинных функций L есть аффинная группа AGL(n)
г 1 ПЯ(и) жж
С учетом теоремы 1 остается показать, что v 7 - аффинная груп-
n AGL(n) с= Ол(и)(и) „
Очевидно, что ' 7 — х 7. Кроме того, для любого
аеП(п)\ ЛС£(и) ...
v ' v 7 существует такой индекс 1, что 1 -я компонента
di(xl,...,xn) вектора ах не является аффинной. Тогда, если g(xl,...,xn)= xi, то
функция ag(x 1,... ,xn)=aj(x 1,... ,xn) ' J . Отсюда следует, что
7. Расстояние до линейных структур.
Линейная структура булевой функции
г
1 , что выражение
определяется существованием такого вектора
w \ х е fc*F(2)T
i(x+a)+f(x) принимает для всех L v 7J одно и то же значение, равное О
или 1. Обозначим через LS(n) множество булевых функций, имеющих линей-
ные структуры. Заметим, что Ь8(п)содержит в себе множество А(п) всех аф-
финных функций. Для булевой функции f определим расстояние до линейной
структуры как расстояние f до множества LS(n):
d(f) = d(f,LS(n))= min d(f,s)
seLS(n)
350
Расстояние до линейной структуры может быть одним из критериев не-
линейности булевой функции. Это вытекает, в частности, из следствия из тео-
ремы 1.
Следствие 2. Для группы J(ct) симметрий расстояния до линейной
AGLfn) = J(ct)
структуры о имеет место включение z .
э AGL(n)
Применим теорему 1 и покажем, что ' '
a G [GF(2)p
и пусть L v есть линейная структура
f, т.е. для всех “ v / J выполнено равенство f(x+a)+f(x)=C, где посто-
CeGF(2)_ a<=AGL(n)
янная v 7. Тогда для равенство
Пусть
выполняется для всех
Г
' . Это означает, что а ’(а) есть линейная
г гл ос е
структура а-f. Отсюда следует, что
8. Порядок нелинейности.
f=<£(n)
Для булевой функции J ' z обозначим через O(f) - степень
члена в алгебраической нормальной форме, имеющего наивысший порядок.
Величину 0(f) будем называть порядком нелинейности булевой функции. По-
. О:Ф(п)->{0,1,К>И},
рядок нелинейности, определяемый функцией v z v ’
удовлетворяет требованиям критерия нелинейности в силу следующей теоре-
мы.
Теорема 2. Группа симметрий функции 0 совпадает с аффинной
группой AGL(n).
ДОКАЗАТЕЛЬСТВО содержит два пункта.
а) Покажем, что пусть % е AGL(ri) и выдрана Пр0.
извольная функция f е Ф(«) Вычислим алгебраическую нормальную форму
для % f, используя ее связь с . В некоторые нелинейные
члены могут исчезать, а некоторые - появляться как новые. Однако чле-
351
ны некоторой степени в J '%7 не могут в порождать члены степени
выше, чем . Отсюда следует, что
О{а • /) < О(/)
Эту формулу применим к случаю, когда действие определяется а .
Имеем
O(f) = O(a'-(af»<O(a-f)
Из приведенных формул следует, что
о(«-Л = о(Л
Следовательно, а е .
б) Покажем теперь, что — AGLfri)
Пусть а е т0Гда при действии а на (х,хп ) имеем не-
w сс (х X } f (X X — X
линейную компоненту z v 1 п 7 «и из J v 1 п 1 следует, что
. Стало быть > 1, в то время как 0(f)= 1. Отсюда вытекает,
товйЛО),
9. Совершенно нелинейные функции.
к ж f '-\GF(2)'\n ->GF(2)
Ьулева функция 7 L v 7J v 7 называется совершенно
\ .. . ae[GF(2)]n
нелинейной функцией, если для каждого ненулевого вектора L v 7J
значения функции f(x+a) и f(x) совпадают точно для половины векторов
xe[GF(2)]”
пег П(«) CZ Ф(и)
Обозначим через v 7 — v 7 множество всех совершенно нели-
нейные функций и покажем, что для этих функций достигается оптимум
расстояния до линейных структур.
352
Для произвольной функции f * [^7** (2)] ~CzF(2) расстояниедо
линейных структур можно вычислить следующим образом. Пусть
яе[№(2)]' . т [GF(2)]'
L \ /j - ненулевой вектор. Тогда пространство L х 7J можно
разбить на 2 неупорядоченных пар вида (х, х+а). Обозначим через И° чис-
W
ло элементов множества 0 пар вида (х, х+а), для которых f(x)=f(x+a), а через
7/ w. f(x)^f(x + а)
4 - число таких пар множества <, что J v 7 J v 7 .
Любая булева функция может быть получена из функции f путем изме-
нения соответствующего множества е-значений. Таким способом функцию f
можно преобразовать в функцию с линейной структурой, изменяя значения ли-
eW • .
бо для х, либо для х+а для пары (х, х+а) 0, или путем изменения 1-значений,
либо х, либо х+а для пары (х, х+а) е . Таким образом, П° значений можно
изменить так, чтобы получить функцию g с линейной структурой такой, что
g(x) Ф g(x 4- а) для всехх, а значений изменить так, что получить фун-
кцию g с линейной структурой такой, что g (х) = g(x + а) для всех х. Для
того чтобы получить любую другую функцию с такой же линейной структурой
необходимо изменить по крайней мере min(w0, п}) значений. Следовательно,
П = Ш1п(ио, Щ) есть расстояние функции f до ближайшей функции с ли-
нейной структурой а. Заметим, что и зависит от вектора d , то есть
л = «/(a) = min(n0(a),n1(a))_
Отсюда расстояние до линейных структур определяется формулой
a(f) = min п f (а) .
а*0 J
„ пЛа) + пАа) = 2"“'
Так как и 7 1X7 , то из этой формулы следует, что
nf(a)<2n~2 п п
J для всех ' . Максимум расстояния достигается для со-
„ п0(а) = п1(а) = 2”~2
вершенно нелинейной функции и в этом случае и 1 для
” или, что эквивалентно, . Таким образом доказана сле-
дующая
353
Теорема 3. Класс х '•л' совершенно нелинейных функций совпадает с
классом функций, имеющих максимальное расстояние до линейных структур,
равное 2П'2.
f(x\ F(x) = (~1V(X)
Если J v 7 - совершенно нелинейная функция и v ' v 7 , то из
определения совершенной нелинейности следует, что для любого ненулевого
ae[GF(2)]"
вектора L v 7J имеет место равенство
£ F (x~)F (х + а) = О
X е [ GF ( 2 )] т
Рассмотрим преобразование Уолша-Адамара для совершенно нели-
нейной функции /(%) . По определению имеем: •
F(u)= £ F(x)(-1)<“'*>
хe[GF (2)]л
Из этого равенства следует, что
F2(m) = 2"+ XC-i)*"’0’ ^F(x)F(x + a)
ае[С^(2)]ш X6[GF(2)]m
Пользуясь этими равенствами, с учетом соотношения
£ F (x)F (х + а) = О
хе [GF (2 )] т ' '
находим, что
п
F (и) = 2^ . Г)
Теорема 4. Булева функция f (х) является совершенно нелинейной то-
гда и только тогда, когда матрица
, строки и столбцы которой
помечены 2П векторами пространства [Я (2)]” и элементы имеют вид
К,
п
2 1
является матрицей Адамара.
12 Зак. 5
354
Из равенства (*) следует, что nuv — ± i. Кроме того, скалярное произ-
ведение и -й и w -й строк удовлетворяет равенствам
1 V'1 г?/ \ г?/ \ 2 , W = W
— £ F(t/ + v)F(w + v) =
ve[GF(2)]" О, W W
в силу соотношения ортогональности для преобразований Уолша-Адамара. Так
как ортогональность строк, выраженная предыдущим равенством, является ха-
рактеристическим свойством для матриц Адамара, то достаточность теоремы 4
доказана.
п
Обратно, если huv = +1 f то F ( W + V ) = + 22 т. е. функ-
ция f является совершенно нелинейной. Ортогональность строк матрицы
Адамара сводится к соотношению ортогональности для преобразований Уол-
ша-Адамара.
Функция , для которой преобразование Уолша-Адамара удовле-
творяет условию (*), называется бент-функцией. Таким образом, справедлива
следующая
Теорема 5. Класс совершенно нелинейных функций совпадает с клас-
сом бент-функций.
Из равенства (♦) следует, что бент-функций могут существовать только
для четных п. Из свойств совершенно нелинейных функций следует, что поря-
док нелинейности бент-функции не превосходит п/2.
10. Расстояние до аффинных функций и корреляция.
Пусть Lw(x) = (w,x) - произвольная линейная функция и
(х) “ (—1)(м,х\ Тогда из определения преобразования Уолша-Адамара
следует, что
F(w) = |{х : /(х) = Lu (х)}| - |{х : /(х) Ф Lu (х)}|
Отсюда следует, что
d(f,L„) = 2-1 -|#(«) ,
355
где d означает расстояние Хэмминга. Расстояние до соответствующей аф-
финной функции L'u = Lu +1 вычисляется по формуле
-F(w)
2
d {f ,L'U} = 2п~х
так как в этом случае преобразование Уолша-Адамара равно F .
Формула d(f,Lu) = 2 — F(u) может быть использо-
вана для отыскания наилучшей аппроксимации булевой функции f с помо-
щью линейной функции (и, х) путем отыскания для данной функции f такого
и, что Г0-0 достигает максимума, т. е.
ад = 2п-‘-|тахВД .
Z U
Из равенства (*) следует, что для совершенно нелинейных функций
-1 ~-1
расстояние d(f) до ближайшей аффинной функции равно d(f)= 2п -22
Если у' не является совершенно нелинейной функцией, то из равенства
п
Парсеваля У F (W ) — 2 следует, что Црп F(u) ®2 .
“ U
-1
Следовательно, в этом случае d(f)< 2П — 2 2 и, стало быть, эта фун-
кция ближе к множеству аффинных функций, чем совершенно нелинейная фу-
нкция. Это показывает, что для класса совершенно нелинейных функций до-
стигается оптимум не только по отношению к расстояниям до линейных струк-
тур, но по отношению к расстояниям до всех аффинных функций.
Итак, доказана следующая теорема.
Теорема 6. Класс П(7^ совершению нелинейных функций совпадает
с классом функций, для которых достигается максимум расстояния до аффин-
т- 1 —- 1
ных функций, равный 2 — 2 2
12*
356
В начале пункта 10 указывалась формула
</(/,£„) = 2-
Li
Из этой формулы следует, что расстояние совершенно нелинейной фу-
нкции f до любой аффинной функции равно либо 2 т 4- 2 2 ,
либо 2 — 2 2 . Этот факт можно выразить с использованием по-
нятия корреляции функций.
Корреляция C(f, g) для булевых функций fug определяется равенс-
твом
2“ С(/, g) = |{х: /(х) = g(x)}| - |{х: /(х) * g(x)}|.
Для g — Lu в соответствии с равенством
— L F(u + v)F(w + v) = \
ve[GF(2)]n [ V, U Ф W
имеем
Из этого равенства и (*) следует, что абсолютная величина корреляции
между совершенно, нелинейной функцией и любой аффинной функцией пред-
т
ставляет собой постоянную, равную 2 2.
Если, же функция g не является совершенно нелинейной, то ее корре-
т
ляция C(g, L) с аффинной функцией L больше 2 2 по абсолютной величине.
Отсюда вытекает следующая
Теорема 7. Класс совершенно нелинейных функций совпадает с клас-
сом функций, для которых корреляция со всеми аффинными функциями дости-
гает минимума.
Отметим, что корреляция С(/,0) булевой функции f с нулевой фун-
кцией определяет степень сбалансированности f. Ясно, что совершенно нели-
357
нейная функция никогда не может быть сбалансированной. Вместе с тем, отме-
т
там, что ее отклонение от сбалансированности, равное 2 2 быстро стремится к
нулю, когда п неограниченно возрастает. То же самое имеет место и для корре-
ляции f с любой другой аффинной функцией.
11. Булевы функции от нечетного числа аргументов.
Совершенно нелинейные функции существуют только для четного чис-
ла аргументов. Для этих функций преобразование Уолша-Адамара имеет по
абсолютной величине постоянное значение. По аналогии с этим свойством да-
дим способ построения булевых функций от нечетного числа аргументов, когда
абсолютное значение преобразования Уолша-Адамара принимает по абсолют-
ной величине два значения.
При нечетном п для булевой функции f е Ф(и) рассм0ТрИМ функции
/0,£ еФ(я-1) /0(х,,...,х„.,) = /(0,х.,...,х„.,)
J и “ J I к. * такие ЧТО * 5 " nt-l ' j х з, 1" nt-1 / л
f (х х 3= f(1 х х 3 F
Ji\ !’•••> m-i j !>•••» m-i . Обозначим через 0 и 1 - преобразования
f (х х 1 f (х X 1
Уолша-Адамара функций J 0 v т’1/ и J1V т~1'' соответственно. Для
_ v * F (и) х f w = (ип,и.,...,ит_.)
преобразования Уолша-Адамара функции J при и 1
F^(u) = F (и) ип=0 F{(u) = F(u) u0=l - я
положим и при 01 и 1 при 0 . Таким обра-
зом F = (Fj, Fo ). Тогда имеют место равенства: Fq = Fq + Fj,
FI = FO-F1.
Теперь, если и - совершенно нелинейные функции, то
п-1
F0(u) = F1(u) = ±2^_
Следовательно, F'0(u) « F'((u) могут принимать точно два зна-
£-1
чения 0 или •> 2 . Стало быть и F(u)
принимает эти же два значения. Ис-
пользуя равенство Парсеваля, можно показать, что ровно половина значений
358
к-1
F равна 0, а другая половина равна , 2 . Можно также показать, что для
класса функции П (и) , для которого преобразование Уолша-Адамара входя-
к-1
щих в него функций принимает два значения 0 и , 2 , порядок нелинейности
к-1
функции f Е П (и) не превосходит \ 2 , а расстояние до аффинных
функций определяется величиной
П +1 j
c(f) = 2П-1 - 2^
Таким образом, при п нечетном функция f G П (и) является при-
мерно так же далекой от аффинных функций, как и совершенно нелинейные
функции при п четном.
Параграф 6.8
Регистры сдвига, одноканальные линии задержки
Линейным регистром сдвига (ЛРС) называют устройство - регистр
сдвига с линейной обратной связью и линейной функцией выхода. Получаемая
с ЛРС последовательность является линейной рекуррентной последовательнос-
тью. Ниже приводится основные понятия и широко известные основные алгеб-
раические результаты по изучению свойств таких последовательностей. Изло-
жение материала основано на книге (М.М. Глухов, В.П. Елизаров, А.А. Нечаев
«Алгебра. Часть II», Москва, 1991).
Читателю, желающему познакомиться с этими результатами более де-
тально, рекомендуем прочесть Приложение 2.
Далее R - коммутативное кольцо с единицей е, N — множество нату-
ральных чисел, Nj =NoO, Z - множество целых чисел, GF(q) - поле из q эле-
ментов.
Определение 1. Последовательностью над R назовем любую функцию
u : Nj —> R, при этом для каждого ie Nj элемент u(i) назовем i-м членом после-
довательности и. Множество всех последовательностей над R обозначим R°°.
359
Для наглядности последовательность ue R” можно записать в виде бес-
конечного вектора
u=(u(0), u(l),...,u(i),...). (1)
Последовательность (О, О,...,О,...) будем называть нулевой, и обо-
значать через (0).
Определение 2. Последовательность ueR°° называют линейной рекур-
рентной последовательностью (ЛРП) порядка ш>0 над R, если существуют
константы f0, fj,.. ,,fm.i eR - такие, что любого ie Nj
u(i+m)= fm.iu(i+m-l)+...+ f|U(i+1)+ fou(i). (2)
В этом случае соотношение (2) называют законом рекурсии ЛРП и,
многочлен F(x)=xm - fm-ixm l fix'- fo - характеристическим многочленом
ЛРП и, а вектор u(0,...m-l)=(u(0),...,u(m-l)) - ее начальным вектором. После-
довательность (0) считается по определению единственной ЛРП порядка 0 с
характеристическим многочленом F(x)=e.
Пример 1. (Последовательность Фибоначчи). Эта последовательность
была придумана для решения следующей задачи, называемой задачей о разм-
ножении кроликов. Допустим, что каждая пара зрелых кроликов чрез месяц
рождает новую пару кроликов, которая еще через месяц достигает зрелости.
Сколько всего пар кроликов можно получить от одной зрелой пары за i меся-
цев? Если обозначить искомую величину через u(i), то нетрудно увидеть, что
ц(0)=1, u(l)= 1 и u(i+2)=u(i+l)+u(i) для ieN. Таким образом, и - ЛРП над Z
(кольцом целых чисел) с характеристическим многочленом F(x)= х2 -х -1 и на-
чальным вектором и(0,1)=(1,1).
Арифметическая последовательность. Для любых элементов a, d из
кольца R последовательность v с общим членом v(i)=a+di, ie {0,1,...} есть ЛРП
порядка 2 с характеристическим многочленом F(x)=x2-2x+e=(x-e)2 и начальным
вектором (a,a+d).
Геометрическая последовательность. Для любых элементов a, q из
кольца R последовательность a,aq,.. ,,aq',... есть ЛРП порядка 1 с характери-
стическим многочленом F(x)=x-q и начальным вектором а.
Конгруэнтная последовательность. Для любых элементов q, d из
кольца R последовательность w(0),w(l),...,w(i),..., определяемая соотноше-
ниями w(0)=a, w(i+l)=qw(i)+d, ieN0 есть ЛРП порядка 1 с характеристическим
многочленом F(x)=(x-e)(x-q) и начальным вектором w(0,l)=(a,aq+d). Арифме-
тическая прогрессия есть частный случай конгруэнтной последовательности
при q=e.
Пример 2. Линейный регистр сдвига с характеристическим многочле-
ном F(x)=xm - fm.ixm-1 -...- fix - fo - это конечный автомат вида
360
Здесь g(i) -ячейка памяти, содержащая элемент |1(s)gR ; fs - узел, осу-
ществляющий умножение на fs; знак + обозначает узел, осуществляющий
сложение в R. В начальный такт работы в ячейках памяти регистра записан на-
чальный вектор ц(0,..., m-1) = (ц(0),... ,ц(т-1)) ЛРП . Такой регистр схе-
матически обычно изображается следующим образом.
Заметим, что заполнение p(i,..., i+m-l) регистра в i-й такт работы вы-
ражается через его начальное заполнение ц(0,..., m-1) формулой
p(i,... , i+m-l) = и(0,..., m-1)- S(F)\
где '
- сопровождающая матрица для унитарного многочлена F(x).
361
Напомним, что унитарным многочленом называется многочлен со
старшим коэффициентом равным единице. Зафиксируем унитарный многочлен
F(x)=xm - fm.ixm’' f]X - f0 gR[x] степени m>0 и обозначим через Lr(F) се-
мейство всех ЛРП над R с характеристическим многочленом-Р(х). Тогда непос-
редственно из определения 2 вытекает
Утверждение 1. Любая ЛРП ugLr(F) однозначно задается своим нача-
льным вектором u(0,...,m-l). Если |R| < оо, то | LR(F)| = |R|m.
При исследовании свойств ЛРП весьма плодотворным оказывается ал-
гебраический подход, связанный с введением на R” различных операций.
Определение 3. Суммой последовательностей u,v g R" и произведени-
ем и на константу re R называют, соответственно, последовательности w = и +
v и z = г • и, определяемые соотношениями
w(i) = u(i) + v(i),
z(i) = r-u(i),ie Nj.
Очевидно, что группоид (R°°, +) есть абелева группа с нулем (0) и для
любых а, b 6 R, u, v 6 R00 справедливы соотношения
(ab) • и = а • (Ь • и), (а+Ь) • и = а • и + b • и,
a(u+v)=au+av, еи=и. (3)
В частности, если Р - поле, то определенные выше операции задают на
Р00 структуру левого векторного пространства РР°°, имеющего, очевидно, беско-
нечную размерность. Из определений 2, 3 легко следует
Утверждение 2. Для любого унитарного многочлена F(x)eR[x] подм-
ножество Lr(F)czR”°- есть подгруппа группы (R°°,+), выдерживающая умноже-
ние на элементы из R. Если Р - поле и F(x)eP[x], то LR(F) - подпространство
пространства Р°°.
Таким образом, в случае, когда Р - поле, можно говорить о базисе про-
странства Lr(F). Мы, однако, не будем рассматривать эту простейшую ситуа-
цию отдельно, а введем и изучим аналог понятия базиса пространства для про-
извольного семейства LR(F).
Определение 4. Для унитарного многочлена F(x)eR[x] степени т>0
систему последовательностей Ui,...,umGLR(F) назовем базисом семейства LR(F),
если для любой последовательности ugLr(F) существует единственный набор
констант C|,...,cmeRTaKofi, что
U=C|Ui+.. .+cmum.
Доказательство существования и описание базисов семейства LR(F)
дает
Утверждение 3. В обозначениях определения 4 система последовате-
льностей ui,...,umGLR(F) есть базис LR(F) тогда и только тогда, когда состав-
ленная из начальных векторов этих последовательностей матрица
362
u= ......
um(0,w-l)^
обратима над кольцом R.
ДОКАЗАТЕЛЬСТВО. Если U - обратимая матрица, то для любой по-
следовательности ugLr(F) единственный набор (ci,C2,.-..,cm)GRm такой, что
u(0,1,... ,m-1 )=(с 1 ,с2,... ,ст) U.
Рассмотрим последовательность v=CiU|+...+cmum. По утверждению 2
vgLr(F). Кроме того, очевидно, что v(0,...,m-l)=(C|,C2,...,cm)-U=u(0,l,...,m-l).
Поэтому в силу утверждения 1 v=u, то есть сраведливо равенство
U=C]Ui+...+CmUm.
Единственность представления последовательности и в этом виде сле-
дует из того, что это равенство влечет: u(0,l,...,m-l)=(Ci,c2,...,cm)*U. Таким об-
разом, ui,._. .,um - базис Lr(F).
Наоборот, пусть U|,...,um - базис Lr(F). Определим для каждого
ке{1,...,ш} ЛРП е/бЕк(Р) начальным вектором: ekF(0,...,m-l)-k-ofi строкой
единичной матрицы Е размера mxm. По предположению каждая из последова-
тельностей представляется в виде
вк — Ck|U,+.. .+CkmUm-
Но тогда для матрицы C=(Ckj) размера mxm справедливы равенства
ei(0,...m-l)
C-U= ............. = Е.
Следовательно, U - обратимая матрица.
Следствие. Для унитарного многочлена F(x) над полем Р размерность
пространства Lp(F) равна степени многочлена F(x).
Определим на R°° внешнюю операцию умножения слева на многочлены
из R[x]. Для любых keNj и ugR00 положим
xk-u=v,
где v(i)=u(i+k), для iG Nj.
Другими словами умножение на хк есть сдвиг последовательности и на
к шагов влево, или вычеркивание из и первых к членов
хк (и(0), и(1),...)=(и(к), и(к+1),...).
363
т
Определение 5. Произведением многочлена А(х) = У'акхк
к=0
на последовательность ueR°° называется последовательность A(x)ueR”° вида
т
А(х)и = У.а* (хк • и).
к=0
т
То есть A(x)u=w, где w(z) = ^ак • u(i + к) для ieN2.
к=0
Теорема 1. Для любых A(x),B(x)eR[x] и u,v6R°° справедливы равенства
1. A(x)-(u+v)=A(x)-u+A(x)-v
2. (A(x)+B(x))u=A(x)-u+B(x)-u
3. (A(x)-B(x))-u=A(x) (B(x)-u)
Первые два равенства легко выводятся из определения 5. Для доказа-
тельства последнего равенства заметим, что для любых a,beR и k,je N2 из вве-
денных определений легко следует равенство axk-(bxj-u)=abxk+j-u. Поэтому, если
А(х) = £akxk, В(х) = £bjXJ,
k>0 j>0
то из первых двух равенств, указаных в теореме, следуют равенства
(A(x)B(x))u= ]£akbjXk+j u = ^akxk(bjXj-u) =
^k,j>°
k,j>0
= Zakxk(B(x)-u)=A(<HB(x)u))-
k>0
Следствие. Любая ЛРП u над кольцом R имеет бесконечно много хара-
ктеристических многочленов.
Определение 7. Характеристический многочлен ЛРП и, имеющий наи-
меньшую возможную степень, называется ее минимальным многочленом, а его
степень называется рангом ЛРП и и обозначается через rang и.
Очевидно, что ранг ЛРП определяется однозначно. В то же время, ми-
нимальных многочленов у одной ЛРП может быть несколько, и даже бесконеч-
но много.
Определение 8. Аннулятором последовательности ueR°° называется
множество
364
Ann(u)={H(x)eR[x] : H(x)u=(O)}.
Очевидно, что Ann(u) - идеал кольца R[x], последовательность ugR00
есть ЛРП над R тогда и только тогда, когда в этом идеале есть унитарные мно-
гочлены, и минимальный многочлен ЛРП и есть любой унитарный многочлен
наименьшей степени из Ann(u).
Теорема 2. Любая ЛРП и над полем Р имеет единственный минималь-
ный многочлен G(x)gP[x] и он удовлетворяет равенству
Ann(u)=P[x]G(x).
ДОКАЗАТЕЛЬСТВО. Так как Р[х] - кольцо главных идеалов, то суще-
ствует единственный унитарный многочлен G[x] gP[x] такой, что
Ann(u)=P[x]G(x). Откуда следует, что G(x) - характеристический многочлен
ЛРП и, на который делится любой другой ее характеристический многочлен.
Следовательно, G(x) - единственный минимальный многочлен ЛРП и.
В дальнейшем минимальный многочлен ЛРП и над полем будем обо-
значать через ши(х).
Теорема 3. Для любого унитарного многочлена G(x)gR[x] и любой по-
следовательности ugR°° следующие утверждения эквивалентны
(а) и - ЛРП с единственным минимальным многочленом G(x);
(б) Ann(u)=R[x]-G(x).
ДОКАЗАТЕЛЬСТВО. Покажем, что из (а) следует (б). Так как
G(x) u=(0), то R[x]- G(x)cAnn(u). Наоборот, пусть H(x)eAnn(u). Разделим Н(х)
с остатком на G(x):
H(x)=Q(x)-G(x)+A(x), degA(x)<degG(x).
Тогда A(x)eAnn(u), так как H(x)u=G(x)u=(0). Следовательно,
Gi(x)=G(x)+A(x) - унитарный многочлен из Ann(u) той же степени, что и G(x),
то есть G|(x) - минимальный многочлен ЛРП и. Но тогда ввиду условия (а)
Gi(x)= G(x), то есть А(х)=0 и H(x)g R[x] G[x]. Импликация (б)=>(а) доказыва-
ется так же, как и в теореме 2.
Определение 9. Для элемента aeR\0 и любого keNj последователь-
ность a[k] gR” элементов вида
a[k](i) = P\a1, igN0
J
называется биномиальной последовательностью порядка к+1 с корнем а.
Теорема 4. Пусть многочлен F(x)gP[x] раскладывается над полем Р на
линейные множители и имеет каноническое разложение вида
F(x) = (х-а|/|+1 -К •(x-ar)kt+', as ^Q,ks > 0, дляs el,г.
365
Тогда базисом пространства Lp(F) является система биномиальных по-
следовательностей
аМ.Ка'Ч
Эта теорема позволяет находить произвольный u(i) ЛРП и над полем,
заданной своим характеристическим многочленом f(x) и начальным вектором
u(0, ...,т-1)
Пример. u(i+4)=2u(i+3)+2u(i+2)+2u(i) над GF(5). Начальный вектор
и(0,...,3)=(0,3,0,2). Найти и(999). .
1) Раскладываем f(x) на линейные множители (переходим, если
нужно к полю разложения).
f(x)=(x-2)3(x-l).
2) По теореме 4 ЛРП и представляется в виде линейной комбина-
ции 3-х биномиальных последовательностей с корнем 2 и одной с корнем 1.
и = с02[0]+С]2[|]+с22[2]+с31[0] ИЛИ
3) Используя известный начальный вектор и(0,.. .,3) составляем
систему линейных уравнений. Полагаем i=0,1,2,3.
i = 0 с0 + с3 = 0 с0 =3
z = l z=2 2с0 + С] + с3 =3 4с0 + 4cj + с2 + с3 =0 с( = 0 с2 = 1
z = 3 8с0 + 12с, + 6с2 + с3 = 2 с3 = 2
4) Записываем ответ:
Z 1 • э
u(z) = 3-2 + -2'“2+2, z>0.
\2)
Теперь вычислим и(999). Имеем ач’*=е, aeGF(q), у нас а4=1, 24=1. Получим
и(999) = 3 • 2999 +f"9>| • 2997 + 2 = 3 • 23 + 999 "8.2‘ +2 = 4.
2 ) 2
1
366
Напомним следующее понятие.
Определение 10. Последовательность ugQ” над множеством Q называ-
ется периодической, если существуют числа XgNj, teN, такие что для
любого i > А
u(i+t)=u(i). (*)
Длиной подхода Л(и) называется наименьшее AeNj, для которого су-
ществует teN, такое что выполняется (*).
Периодом Т(и) называется наименьшее teN, такое, что существует
AeNj, для которого выполняется (*).
Все Ant, удовлетворяющие (*), описываются 'следующим утверждени-
ем.
Утверждение 4. Числа AeNj и teN, удовлетворяют (*) тогда и только
тогда, когда A>A(u), T(u)| t.
Утверждение 5. Всякая периодическая последовательность над полем
Р является ЛРП. Если Р - конечно, то верно и обратное.
Определение 11. Периодическая последовательность и называется чис-
то периодической или реверсивной, если Л(и)=0, и вырождающейся, если для
любого i>A(u): u(i)=0.
Утверждение 6. Любая периодическая последовательность и над полем
Р однозначно представляется в виде u=u0+ui, где ио - вырождающаяся, щ - чис-
то периодическая, при этом A(u)=A(u0), T(u)=T(u,).
Определение 12. Многочлен f(x) над Р называется периодическим, если
существует AgNj, teN: f(x) | хх(х‘-е) (**).
Длиной подхода A(f) называется наименьшее AeNj, для которого 3 teN,
такое что выполняется (*). • ;
Периодом T(f) называется наименьшее teN, такое что существует
AeNj, для которого выполняется (*).
Утверждение 7. Пусть и - ЛРП над полем Р с минимальным многочле-
ном mu(x), тогда и - периодична тогда и только тогда, когда многочлен mu(x) -
периодичен. При этом T(u)=T(mu(x)), A(u)= A(mu(x)).
Утверждение 8. Пусть f(x) - унитарный многочлен над полем P=GF(q),
характеристики р, с каноническим разложением
f(x) = xLg,(x)kl ,К gs(x)k>, L>0, kj >1,
Тогда
A(f)=l,
т(0=[Т(ё1),...,т(&)].рс,
367
где c=constGNj, определяемая соотношением
pc l <k=max{ki,.. .,ks}< pc.
To есть нахождение периода многочлена над конечным полем сводится к на-
хождению неприводимого многочлена неравного многочлену х.
'.Определение 13. Многочлен f(x) над полем Р называется регулярным,
если f(0)X).
Утверждение 9. Пусть f(x) - неприводимый, регулярный степени ш над
P=GF(q), тогда T(f) равен порядку его произвольного корня а в поле разложе-
ния P’=GF(qm). При этом выполняется соотношение : T(f)|qm-1 ; для любого
r=l,...m-l : T(f) не делит q-l.
Пример, найти период f(x)=x4+x+e над GF(2).
1) qm-l=24-1=15=5-3
te {1,3,5,15}, 1 и 3 - не подходят, так как 3|q-1 при г=2.
te {5,15}.
2) Проверим x5se (mod f(x)):
x5s x4-x (mod f(x))=(x+e)-x= x2+x - несравнимо c e (mod f(x)).
Значит период многочлена f(x) равен 15.
Определение 14. Регулярный многочлен f(x) степени m > 1 над полем
P=GF(q) называется многочленом максимального периода или примитивным
многочленом, если T(f)= qm-l. ЛРП и над полем P=GF(q), имеющая ранг m > 1
и период qm-l называется ЛРП максимального периода над Р.
Утверждение 10. Пусть и - ЛРП над полем P=GF(q) с регулярным ми-
нимальным многочленом mu(x)=f(x) степени m и пусть qm>2, тогда эквивалент-
ны следующие утверждения:
(а)и-ЛРПМП;
(б) любая ЛРП vgLp(1)\{0} является сдвигом ЛРП и, то есть
v=xku для некоторого keN0;
(в) f(x) - неприводим над Р и его корень а (в поле разложения
P’=GF(qm) многочлена f(x) над Р) является примитивным элементом Р’;
(г) f(x) - многочлен максимального периода над Р.
Следствие. Если f(x) - многочлен максимального периода над P=GF(q),
то любая ненулевая ЛРП ueLP(f) является. ЛРПМП.
Зафиксируем ao,...,ar.ieP и обозначим Nuffi) = М/(а0,К ,аг_х)число
и(0 = а0
решений системы уравнений : < u(i +1) = а.
К
u(i + г -1) = ак_\
368
Величина Nu(a) называется числом появлений вектора а на цикле
ЛРП и.
Утверждение 11. Пусть и - ЛРПМП ранга m над P=GF(q) и пусть г<ш,
тогда
для любых ао,
Nu(a) = -
• •A-isP:
цт-г,если (a0,...ar_[) 7b (0,...,0)
qm-r _ j, иначе.
Следствие. Если и - ЛРПМП ранга m над GF(q), тогда каждый ненуле-
вой элемент поля встречается на цикле ЛРП u q"1’1 раз, а нулевой элемент qm'’-l
раз.
Подробное изложение данного материала с доказательствами всех ут-
верждений содержится в ПРИЛОЖЕНИИ 2.
Параграф 6.9
Вопросы гарантирования периодов выходных после-
довательностей автоматов при заданной входной последо-
вательности
Основным результатом по оценке снизу периодов выходных последо-
вательностей конечных автоматов, отвечающих их начальным состояниям и
входным периодическим последовательностям является результат, представ-
ленный в теореме 2.2. работы: Трахтенброт Б.А., Барздинь Я.М. Конечные ав-
томаты (поведение и синтез). «Наука», М., 1970 г., й состоящий в том, что ми-
нимальный период W выходной последовательности автомата не превосходит
величины ксо, где к - число состояний автомата, а со - минимальный период
входной последовательности. В работах: Беркс А.В., Райт Д.Б. Теория логиче-
ских сетей. «Кибернетический сборник» вып;4, ИЛ, 1962; Кобринский Н.Е.,
Трахтенброт Б.А., Введение в теорию конечных автоматов. М., 1962 г., приве-
дены утверждения, суть которых состоит в том, что W является делителем
числа к'со при некотором к' <к.
В связи с большой сложностью проблемы нижней оценки периодов вы-
ходных последовательностей конечных автоматов при заданных начальном
состоянии и входной периодической последовательности естественным подхо-
дом к ее удовлетворительному решению является выделение тех или иных
классов автоматов в качестве объектов исследований. Например, ряд работ по-
369
священ вопросам периодичности выходных последовательностей линейных
автономных автоматов, в частности, здесь выделяются работы, в которых ука-
зываются способы построения линейных рекуррентных последовательностей
максимального периода в разнообразных алгебраических структурах.
В настоящем параграфе используется другой подход к решению по-
ставленной проблемы, заключающейся в предварительном решении промежу-
точной задачи - оценки снизу периода последовательности состояний автома-
та, отвечающей его начальному состоянию и входной периодической последо-
вательности. Эта задача решается в более общёй постановке, а именно, речь
идет об оценке характеристик почти периодичности последовательностей со-
стояний конечных автоматов.
Для периодической последовательности 3 периода <о элементов конеч-
ного алфавита I вводится понятие меры ц(3, d) приближенного периода d. Ка-
чественно, p(3,d) трактуется как минимальная часть знаков последовательно-
сти 3, которые необходимо изменить для получения из 3 последовательности
периода d.
Основным результатом является теорема 1, дающая нижние оценки мер
приближенных периодов последовательности состояний автомата, отвечающей
его начальному состоянию и входной периодической последовательности.
Следствие 1 дает нижние оценки периодов этих последовательностей. В след-
ствии 2 указываются нижние оценки мер приближенных периодов выходной
последовательности регистра сдвига, отвечающей его начальному состоянию и
входной периодической последовательности.
Обозначения, основные понятия, вспомогательные результаты.
I, S, О - произвольные непустые конечные множества с мощностями
|1|>2, |О|>2;
A=(I,S,O, (5,)jej, (P)i<=[) - автомат с входным алфавитом I, мно-
жеством состояний S, выходным алфавитом О, частичными функциями пере-
ходов (z, ),e/ и выходов (P)ieI;
N - множество натуральных чисел Nuo=No;
- I* - множество всех слов в алфавите I;
- 1^ - множество всех смешанно-периодических последовательностей
в алфавите I. Напомним, что последовательность 3 из называется чисто-
периодической, если длина L ее предпериода равна нулю. Под периодом после-
довательности у здесь и далее будет пониматься ее минимальный период.
- In W - множество всех последовательностей из I* периода W
370
- AM(s,3) = Si,s2,...,Sj,... - последовательность состояний автомата А;
- A(s,3) =у। ,у2,... ,yj,... - выходная последовательность автомата А;
- для 3=ii,i2,...,ij,... иseS
Sj =5iji...5iis, yj =Pi.Sj , sI=s;
- p(3,3') - расстояние Хемминга между словами 3, 3' одинаковой дли-
ны из I*;
- рк(3,3') - расстояние Хемминга между начальными словами длины к
последовательностей 3, 3' из 7” ;
- (со,со') - наибольший общий делитель чисел со, со';
- [со,со'] - наименьшее общее кратное чисел со, со';
- D| со - D делит со;
- 191| - мощность множества 9?.
Для 3=ii,i2,...,ij,...H3 1д положим:
> 'З -3, • *,ij+k-i»
COD(3)={ieI: 3 jeN, ij=i}.
Последнюю величину мы называем «содержанием» последовательно-
сти 3. Если понимать под последовательностью 3 элементов алфавита I ото-
бражение 3: N—>1, то содержание 3 равно образу множества N.
Пусть 3, 3' - произвольные последовательности из 7” с длинами под-
ходов L, L' и периодами со, со', соответственно. Легко доказывается следующее
утверждение.
УТВЕРЖДЕНИЕ 1. При к->оо предел
IimTPk(3’3')
к
существует и равен величине
Р(3,3')=-^— p[(a,(0-](3maX(L-L' )+l)j3-ax(L,L- )+I)
[со, СО ]
Данное утверждение является частным случаем следствия 1 работы:
Бабаш А.В. Приближенные модели перестановочных автоматов. Дискретная
математика. Т.9, вып. 1, 1997 г.
Определение 1. Приближенным периодом последовательности Зе 7“
называется любое число W из N. Величина p(3,W)=infp(3,3'), где нижняя
грань берется по всем последовательностям 3' e I^w, называется мерой при-
ближенного периода W (мерой приближения приближенного периода W) по-
следовательности 3.
371
Из утверждения 1 следует, что величина ц(3,3') определена периоди-'
ческими частями Зк, З'к последовательностей 3, 3' при k>max(L,L')+l.
Мощность множества всех чисто-периодических последовательностей
периода W элементов алфавита I конечна. Поэтому infp(3,3')=minp(3,3') по
всем 3' из множества чисто периодических последовательностей фиксирован-
ного периода.
Пусть N' - конечное подмножество N.
Определение 2. Наилучшей мерой приближения приближенных перио-
дов из множества N' последовательности 3 называется величина minp(3,W'),
где минимум берется по всем W' gN'.
Определение 3. Наилучшим приближенным периодом W среди перио-
дов из N' последовательности 3 называется минимальное число WgN', при
котором p(3,W)= minp(3, W'), W' gN'.
Определение 4. Наилучшей приближенной последовательностью
НПП(3, In,w') из множества [J I^w' к последовательности 3 называ-
W'eN' W'eN'
ется произвольная последовательность 3'g (J I“w-, для которой
W'eN'
р(3,3')= min (3,W')
W'eN'
Для формулировки приводимых ниже вспомогательных утверждений
введём дополнительные обозначения.
1 Для чисто-периодической последовательности 3=ii,i2,... из , D| со и
je l,D обозначим через Vj(i) - частоту встречаемости символа i слове ij,ij+D,
•••3j+TD , Т=(— - 1)D, а через I(j) - множество всех iel, для которых Vj(i)=
max Vj(i). Отметим, что | I(j)|>l.
16/
Через 9U3.D) обозначим множество всех последовательностей
3"=if вида:
»j=ij+o, jeN,_
ikGl(k), kGl,D .
Последние соотношения определяют 3" однозначно лишь в случае
|I(k)|=l, kc \,D . Очевидно, что COD(3")cCOD(3) для любой последователь-
ности 3" из 91(3 ,D), а период каждой последовательности из 91(3,D) является
делителем числа D.
372
Лемма 1. Для Зе 1„ ш, 3'g D=(co,co') величина ц(3,3") не зави-
сит от выбора 3" из 9?(3,D) и
1) ц(3,3'')< Ц(3,3'),
2) ц(3,3")<ц(3,со').
.ДОКАЗАТЕЛЬСТВО. Из утверждения 1 следует, что для доказательст-
ва леммы 1 достаточно доказать ее для чисто-периодических последовательно-
стей 3, 3'. Пусть 3,3' - чисто-периодические последовательности.
При (со,со')=<в утверждение леммы очевидно, так как множество 9?(3,D)
состоит из последовательности 3"=3.
Пусть (co,co')=D^co, 3=ii,i2,... , 3'=i'i,i'2,.... По утверждению 1 имеем
1 1
ц(з,з )=7 ГГР[со,(о ](^>^ ) = 7 S P(ij’ij) =
7 [со, СО ] [(0,(0 ]
[<»,«> ] !
| <»' со'
7^2 Ер(>' j’ij+kco').
[ю.®]н к=0
Заметим, что — 1 = — -1, а слова
X' D
со
ij, ijWv.Jj+сш Л ij+D,...,ij+cD,rae С= — “1, получаются друг из
друга перестановкой символов, в связи с чем справедливо равенство
D D
j ’ ij+ka/' ) = ’Ц+kD ) .
£=0 *=0
Поэтому
, — -1
I co D
Ер(чЛ+ко)=
[(0,(0 J j=1 k=0
373
1 D
-i- у
—-1 --1
D D
m=0 k=0
’ Для произвольной последовательности 3"=i|",i2",... из 9?(3,D) имеем
Р[со,со'](3^
[со,®]
1
СО
, —-1
1 со D
б
к=0
^-1
D D D
г уз Zj ’ Z j к \ ItIIIU “ ItKU z .
[®,co]j=i m=0 k=0
Из этого равенства, во-первых, вытекает независимость значения
ц(3,3") от выбора 3" из 9?(3,D) и, во-вторых, то, что при любых je 1, D,
п со' Л
те 0,— — 1 справедливо неравенство
D D
P(i j+md ’ i j+kD ) — ^2 P(i j+md > i j+kD ) .
k=0 k=0
Следовательно, ц(3,3")<ц(3,3'). Откуда получаем неравенство
ц(3,3")<ц(3,со'). Лемма 1 доказана.
УТВЕРЖДЕНИЕ 2. Пусть Зе 1“ю, со' gN. Наилучшая мера приближе-
ния min ц(3,сГ) приближенных периодов из множества {d':d'|co'} последо-
вате^Йс^ти 3 равна величине ц(3,3"), где 3"g9?(3,D) при D=(co,co').
ДОКАЗАТЕЛЬСТВО. Пусть min p(3,d')=p(3,d'o), а 3' =
d':d'|c»'
Hnn(3,Z“rf ) ) - наилучшая приближенная последовательность из множества
к последовательности 3. Тогда p(3,3')=p(3,d'o). По лемме 1 заключаем,
что найдется 3"e$R(3,D0), периода d", d"|Do, D0=(d'0,co), для которой
374
ц(3,3")<ц(3,3'). Так как Р0|оэ', то d"|<о'. Из определения p(3,d'o) и предыду-
щего неравенства получаем
p(3,3")=p(3,d'o) =ц(3,3').
Очевидно, что p(3,d'o) является наилучшей мерой приближения при-
ближенных периодов и из множества {d':d'|D} последовательности 3. Откуда
вытекает, что 3" g 9?(3,D).
2. Нижние оценки мер приближенных периодов последовательно-
стей состояний автомата, отвечающих его начальным состояниям и вход-
ным смешанно-периодическим последовательностям.
Пусть 3=ij,i2,... - входная смешанно-периодическая последователь-
ность автомата A=(I,S,O, (Sj )ieI, (P)iej), a a - бинарное отношение эквивалент-
ности на СОД(З) удовлетворяющее условию: произвольные элементы i, Г из
разных классов эквивалентности таковы, что частичные функции переходов 6,
8р автомата А не имеют общих переходов, т.е. SiS^ Sj-s при любом sgS. Класс
эквивалентности отношения а, содержащий элемент i, обозначим через a(i).
Теорема 1. Пусть 3=ibi2,... - входная смешанно-периодическая после-
довательность автомата A, a(3)=a(i|),a(i2),...- соответствующая ей последова
тельность периода <»(а) классов эквивалентности отношения а на СОД(З);
AM(s,3) - последовательность состояний автомата А, отвечающая его началь-
ному состоянию sgS и входной последовательности 3; х' - приближенный пе-
риод последовательности AM(s,3) с мерой приближения p(AM(s,3),x'), причем
(x',co(a))=t^ <в(а). Тогда
ц( Am(s,3),x')>t- min p(a(3),d).
2 d:d|t
ДОКАЗАТЕЛЬСТВО. Пусть НПП (AM(s,3), /“r-)=s'f,s'2,...-наилуч-
шая приближенная последовательность периода х' из множества 7"г. к после-
довательности Am(s,3)= si,S2,... периодах, s=sb Определим вспомогательные
последовательности
(Am(s,3))2=SiS2,S2S3,. . .,SjSj+i,... ,
(НПП (AM(S,3), /“r.))2=S'iS'2,S'2S'3,...,S'jS'j+i,... .
Очевидно, периоды этих последовательностей равны х, х', соответст-
венно. Непосредственно проверяется, что
P((Am(s,3))2,x') < p((AM(s,3))2,(Hnn(AM(s,3), I* т- ))2) <
375
<2g(AM(s,3),Hnn(AM(S,3),/;r. ))=2p( Am(s,3),t ).
По утверждению 2 найдется последовательность Р" периода do" из
$(Am(s,3)2,D), D=(t,t'), для которой d0"|D и выполняются соотношения
|i(( AM(s,3)2,d0")=H(( Am(s,3)2,P") < ц(( Am(s,3)2,t'),
Отметим, что СОД(Р")сСОД(( AM(s,3)2)).
На множестве СОД((Ам(з,3)2)) определим функцию f. Для ss' из
С0Д(Ам(б,3)2) положим f(ss')=a(i), если 8jS=s'. Рассмотрим последовательно-
сти
F(( AM(s,3.)2))=f(s1S2),f(s2s3),.. .,f(sjSj+1),... ,
F(P")=a(i1"),a(i2"),-.
Очевидно, что Р((Ам(з,3)2))=а(3). Напомним, что период последова-
тельности а(3) равен со(а). Обозначим через <о"(а) период последовательности
F(P"). Ясно, что co"(a)|d0". Так как (ш(ос),тЭ=^а>(а), то (a>(a),a>"(a))=d, где d|t.
Очевидно, что
р(а(3)ДР”)<р(( Am(s,3))2),P”).
Используя утверждение 2, получаем
min p(a(3),d)< p(a(3),F(P").
d:d|t
Следовательно,
min p(a(3),d) < p(( Am(s,3))2),t')^ 2p( AM(s,3),<),
d:d|t
Что и требовалось доказать.
Эффективность теоремы 1 (рамки ее применения) определены условием
<в(а)>1. Таким образом, для нахождения нижней оценки меры приближенного
периода последовательности Am(s,3) состояний автомата А с помощью теоре-
мы 1 необходимо предварительно построить какое либо бинарное отношение
типа а. В ряде случаев удобно сначала пытаться строить бинарное отношение
эквивалентности ст* на СОД(З) следующим образом. Определяем бинарное
отношение ст на СОД(З): i находится в отношении ст с Г тогда и только тогда,
если найдется seS, при котором 5jS= 8j-s. В качестве ст* берем транзитивное за-
мыкание отношения ст. Для повышения эффективности теоремы 1 удобно
предварительно определить компоненту связности As автомата А, содержащую
начальное состояние s, а затем проверять выполнение условий теоремы для
автомата As.
Следствие 1. Пусть 3=ii,i2,... - входная смешанно-периодическая ос-
ледовательность автомата A, a(3)=a(ii),a(i2),...- соответствующая ей после-
довательность периода <о(а) классов эквивалентности отношения а на СОД(З).
376
Тогда период т последовательности AM(s,3) состояний автомата А, отвечаю-
щей его,начальному состоянию seS и входной последовательности 3 кратен
со(а).
ДОКАЗАТЕЛЬСТВО. Предположим, что (т,ю(а))=Ьчо(а). В качестве
приближенного периода т' последовательности AM(s,3) рассмотрим период т
последовательности AM(s,3). Тогда по теореме 1
ц( Am(s,3),t)> у min Ц (a(3),d)
2 d:d|t
Так как Ьчо(а), то очевидно, что правая часть неравенста больше нуля.
Поэтому p(Am(s,3),t)>0, что противоречит тому, что т - период последователь-
ности AM(s,3). Таким образом, т кратен со(а).
Утверждение следствия 1 позволяет строить автоматы и с гарантиро-
ванными периодоми последовательностей состояний, отвечающих их началь-
ным состояниям и входным смешанно-периодическим последовательностям.
Так, в частности, выбор частичных функций переходов автомата так, чтобы они
попарно не имели общих переходов, гарантирует кратность периода последо-
вательности его состояний величине периода входной последовательности при
любом его начальном состоянии.
Следующие две леммы, предстабляющие и самостоятельный интерес,
являются вспомогательным инструметом для доказательства иной (чем в тео-
реме 1) нижней оценки меры приближенного периода последовательности со-
стояний автомата, отвечающей его начальному состоянию и входной смешан-
но-периодической последовательности.
Лемма 2. Пусть 3g 1п)(0, 3' g 1“^,-, (a>,co')=d; L, L' - предпериоды
последовательностей 3, 3', соответственно; M=max (L,L'). Тогда
|i(3,3')=p(3M+j, 3'M+j)= p(3M+j+cd, 3'M+j),
где je’N, cgN0.
ДОКАЗАТЕЛЬСТВО. Так как (oj,a>')=d, то найдутся kb k2, при которых
K2co'-kico=d. По утверждению 1 имеем
И(3,3>-^— (З^'.З'"*1).
Очевидно, что при любом jeN и cgN0 справедливы равенства
377
1 r> z«M+l e-pM+l\_ 1 л Z^M+i
7 77P[<o,<£>] t'5 )- “ -1Р[ю,Ю’]('5 )“
[(0, CO ] [(0, CO ] L J
1 л zeyM+j+ck <a oy'M+j\ 1 „ /crM+i+ck <o+cd ry'M+h
7-----ТТРЬйХР'5 2 J-7-----TTPtoMo'Jb5 1 I'5 )-
[co, co ] [co, co J 1 J
Несложно доказывается следующая
Лемма 3. Для любых 3, 3',3" g/“ справедливо неравенство
ц(3,3')+ц(3',3")>ц(3,3").
На множестве чисто-периодических последовательностей функция ц
является метрикой.
Теорема 2. Пусть Пусть 3=i|,i2,... - входная смешанно-периодическая
последовательность автомата A, a(3)=a(i]),a(i2),...- соответствующая ей по-
следовательность периода со(а) классов эквивалентности отношения а на ‘
СОД(З); Am(s,3) - последовательность периода т состояний автомата А, отве-
чающая его начальному состоянию sgS и входной последовательности 3; т' -
приближенный период последовательности AM(s,3) с мерой приближения
p(AM(s,3),x'), причем (т', z))=d^ co(a). Тогда при любом jgN
^p(a(3y,a(3fcd)< p(AM(s,3),T').
. 4
ДОКАЗАТЕЛЬСТВО. Пусть НПП(АМ(§,3),I”T')=Si',S2',... - наилучшая
приближенная последовательность из множества последовательностей периода
т’ к последовательности AM(s,3)= Si,S2,... . Обозначим через Р - максимальную
длину из длин подходов последовательностей НПП(АМ(8,3), I” т~) и
AM(s,3). Тогда последовательности (Hnn(AM(s,3), 1“ T ))P+1, (AM(s,3))p+1
- чисто-периодические и первая последовательность является наилучшей при-
ближенной последовательностью из множества последовательностей периода
т' ко второй последовательности. Пользуясь сначала утверждением 1, а затем
леммой 2 для j g N, с g No получаем
p(AM(s,3),<)= p((AM(s,3),T')P+l,T')=p( (Am(s,3))p+1,
(Hnn(AM(s,3),l”T.))p+>
p( (AM(s,3))p+j+cd, (Hnn(AM(s,3), I„,T ))P+j).
378
Для с и с' из No по лемме 3 имеем
ц( (AM(s,3))p+j+cd, (AM(s,3))p+j+cd))<2H(AM(s,3)),T').
Для последовательностей
(Am(S,^)) j Sp+j+cd,Sp+j+cd+i,... , j )~Sp+j+c'djSp+j+c'd+l?• • •
построим вспомогательные последовательности
((AM(S,3))P j cd)2= Sp+j+cdSp+j+cd+b Sp4j+cd+lSp+j+cd+2, •••
)2 Sp+j+c'dSp+j+c'd+b Sp+j+c'd+lSp+j+c'd+2, •••
и функцию f на COfl(((AM(s,3))p+j+cd)2) положив
f(Sk,Sk+i)=a(i),
если 5jSk=Sk+i. Из законов функционирования автомата А следует, что последо-
вательности
F((AM(S,3))P j cd)2~ f(Sp+j+cdsP+j+cd+l)?f(sP+j+cd+lSp+j+cd+2), •••
F((Am(S,«k5)) j )2 f(Sp+j4-c'dSp+j4-c'd+l)>f(Sp+j+c'd+lSp+j4-c'd+2), •••
равны, соответственно, последовательностям
a(3)p+j+cd=a(i1+j^d),a(i2+j+Cd)
j “^(il+j+c'd),j^(i2+j+c'd)>* • •
Очевидно, что
и (F((AM(s,3))p+j+cd)2, F((AM(s,3))p+j+cd)2)< p(((AM(s,3))p+j+.cd)2,
((AM(s,3))p+j+cd)2) <
< 2ц ((AM(s,3))p+j+cd, (AM(s,3))p+j+c d).
Из полученных оценок вытекает, что
g(a(3)p+j+cd, a(3)p+j+cd) <2ц ((AM(s,3))p+j+cd, (AM(s,3))p+j+c'd)
<4n(AM(s,3)),r).
Доказательство закончено.
Теорему 2 мбжно использовать и для оценки периода т последователь-
ности Am(s,3) состояний автомата А. Анализ доказательств теорем 1,2 показы-
вает, что данные в них оценки меры ц(Ам(з,3),т') приближенного периода т'
последовательности Am(s,3) несравнимы. На практике, для получения опти-
мальной оценки следует использовать утверждения обеих теорем.
3. Нижние оценки мер приближенных периодов выходных последова-
тельностей регистров сдвига, отвечающих его начальным состояниям и вход-
ным смешанно-периодическим последовательностям.
Рассмотрим регистр сдвига то есть автомат A=R((p,I)=(I,S,O,(5i)iei,(Pi)iei)
вида S=In, 0=1; для iel и i(n),i(n-l),...,i(l)eln
5i(i(n),i(n-1),... ,i( 1 ))=(cp(i, i(n),i(n-1),... ,i( 1)), i(n),i(n-1),... ,i(2)),
где <p - функция: In+1 ->I; 0j=X, iel,
379
X(i(n),i(n-1),...,i(l))=i(k)
для некоторого ke {1,... ,n}.
Пусть 3 - входная смешанно-периодическая последовательность авто-
мата A=R(cp,I). Период выходной последовательности A(s,3) автомата R(<p,I)
совпадает с периодом его последовательности состояний AM(s,3), в связи с чем,
следствие 1, теорема 2 дают нижние оценки периода выходной последователь-
ности A(s,3) автомата R(<p,I).
Рассмотрим вопрос о связях мер приближенных периодов последова-
тельностей AM(s,3) и A(s,3).
УТВЕРЖДЕНИЕ 3. Для любого x' eN справедливо неравенство
пр (A(s,3), т')>р (AM(s,3), т )
ДОКАЗАТЕЛЬСТВО. Без ограничения общности доказательства будем
предполагать, что входная последовательность 3 и выходная последователь-
ность регистра сдвига A(s,3)=i(k),i(k+1),...,i(k+j),.... чисто-периодические по-
следовательности (см. утверждение 1). Последовательность AM(s,3) можно
записать в виде
AM(s,3)=(i(n),i(n-l),...,i(l)), (i(n+l),i(n),...,i(2)),..„ (i(n+j),...,i(j+l)),... .
Несовпадение состояний - слов (i(n+j),...,i(j+l)), (i'(n+j),...,i'(j+l)),
обуславливается несовпадением их компонент. Для последовательности
A(s,3)=i(k),i(k+1),.. .,i(k+j),... и чисто-периодической последовательности
3'=i'(k),i'(k+l),...,i'(k+j),... периода т' неравенство i(k-bj) i'(k+j) для j>k-l
влечет п неравенств
(i(k+j),i(k+j-l),...,i(k+j-n+l))* (i'(k+j),i'(k+j-l),...,i'(k+j-n+l))
(i(k+j+l),i(k+j),...,i(k+j-n+2))* (Г(k+j+1 ),i'(k+j),.. ,,i'(k+j-n+2))
(i(k+j+n-l),i(k+j+n-2),...,i(k+j)* (i'(k+j+n-1 ),i'(k+j+n-2),.. ,,i'(k+j)).
Поэтому для последовательностей A(s,3) периода т и 3' перио-
да т' справедливы соотношения
np(A(s,3),3')=—ргт.т'1 (A(s,3),3')>—Ргт,т] (AM(s,3),R(3))=
[т,т ] [т,т ]
=р( AM(s,3),R(3)),
где R(3')=(i'(k),i'(k+l),...,i'(k+n-l)), (i'(k+l),i'(k+2),...,i'(k+n)),...
Имеем
р( AM(s,3),R(3))>p( AM(s,3),x'))
Следовательно, взяв в качестве 3' наилучшую приближенную
последовательность периода т' к A(s,3), получаем требуемое неравенство
пр (A(s,3), т')= np(A(s,3),3') >р( AM(s,3),R(3))>p( AM(s,3),x')-
380
Из теорем 1, 2 и утверждения 3 вытекает
Следствие 2. Пусть 3 - входная последовательность регистра сдвига
R(<p,I), а(3) - соответствующая ей последовательность периода а(со) классов
эквивалентности бинарного отношения а на СОД(З); W' - приближенный пе-
риод выходной последовательности A(s,3) периода W регистра сдвига R(<p,I).
1. Если (W,W')=d Ф а(а>), то при любом j eN, сgN0
-^-p(a(3)’,a(3)’+cd)< p(A(s,3),W'); .
4
2. Если (a(w),W')=t^ a(<o) nd- наилучший приближенный период
последовательности a(3) среди приближенных периодов из множества {d':
d|'t}, то
-^-p(a(3),d)<p(A(s,3),W').
2и
ГЛАВА 7. ИМИТОСТОЙКОСТЬ ШИФРОВ. ПО-
МЕХОУСТОЙЧИВОСТЬ ШИФРОВ. СЕТИ ЗАСЕКРЕ-
ЧЕННОЙ СВЯЗИ
Параграф 7.1
Имитостойкость шифров в модели К. Шеннона
Классическая триада основных требований к шифрам состоит из соста-
вляющих:
- криптографическая стойкость;
- имитостойкость;
- помехоустойчивость.
Имитостойкость шифров (в модели Шеннона).
Предположим, что имеется связь между абонентами А и В. Абонент А
может в определенный момент времени отправить абоненту В сообщение «у» -
криптограмму, зашифрованную шифром (X,K,Y,f) на ключе %gK (здесь в рас-
суждениях мы используем модель шифра Шеннона, где под X понимается
множество открытых (содержательных) текстов). До момента передачи уеУ
канал связи «пуст», но в шифратор абонента В введен ключ % в ожидании по-
лучения сообщения от абонента А.
381
Возможные действия противника сформулируем в виде предположений
о его возможностях: -
- он знает действующий шифр;
- он имеет доступ к каналу связи ;
- он может считывать из канала любое сообщение;
- он может формировать и вставлять в канал связи любое сообщение;
- он может заменять передаваемое сообщение на любое другое сообщение;
- все указанные действия он может совершать «мгновенно» (располагая соот-
ветствующими техническими средствами);
- он не знает действующего ключа шифра.
Ниже используется обобщенная модель шифра, введенная ранее в главе
1. Именно, пусть (У,К,Х',Х,Ф) - шифр расшифрования, X - множество содер-
жательных открытых текстов, ХеХ'. Уравнение расшифрования уеУ при
ключе %еК будет записываться в виде %‘1у=х, хеХ'.
Имитация при пустом канале. Пусть канал связи «пуст» и противник
вставляет в канал связи некоторое шифрованное сообщение - элемент уеУ.
При действующем ключе х абонент В расшифрует у.
Априори возможны два исхода:
1) он получит х ’уйХ, то есть абонент В не прочтет сообщение и сочтет
его за ложное сообщение (напомним, что в качестве X выступает множество
всех содержательных текстов);
2) х 'уеХ. В этом случае В получит открытое ложное сообщение х=х *У
и действуя в соответсвии с этим сообщением может нанести себе ущерб.
Заметим, что при таком «навязывании» ложной информации противник
не знает какое именно сообщение хеХ (во втором случае) он «навязал» або-
ненту В. Такое навязывание ложной информации можно назвать навязыванием
«наугад». При случайно выбираемом ключе х событие: х’*уеХ имеет свою
вероятность
Рн(у)=Р(х'убХ),
называемую вероятностью навязывания криптограммы у. Считается естествен-
ным, что противник выберет навязываемый уеУ так, чтобы максимизировать
вероятность Рн(у). Защищающаяся сторона, в свою очередь, зная о возможных
действиях противника, будет выбирать такой шифр, в котором максимальное
значение вероятностей навязывания Рн=тахР(х’*уеХ) минимально.
уеУ
Величина 1/Рн можно назвать коэффициентом имитозащиты в пустом
канале. При навязывании противником «наилучших» криптограмм у': Рн(у')=
Рн величина 1/Рн характеризует среднее число попыток противника до навязы-
382,
вания ложной информации (предполагается случайный выбор ключей при ка-
ждой попытке).
Противник может ужесточить свои действия: пусть х(0)еХ - сообщение,
которое наносит максимальный ущерб абоненту В; противник может попы-
таться навязывать такое сообщение уеУ, при котором вероятность Р(х''у=х(0))
максимальна. Такой способ навязывания можно назвать целевым (прицель-
ным).
Имитация при передаваемом сообщении. Аналогичные ситуации возни-
кают и при навязывании путем подмены передаваемого сообщения уеУ на
у'еУ, у*у'.
Имитация при знании открытого текста. Противник может обладать и
дополнительной информацией (не отраженной выше в перечне его возможнос-
тей). Например, может знать открытый текст х&Х, который скрывается за кри-
птограммой у в канале связи. В этой ситуации аналогично вводится величина
max Р(х~1у'G % /= у) •> характеризующая стремление противника макси-
У* € У ,у’ * у
мизировать условную вероятность навязывания, а защищающаяся сторона
стремится минимизировать этот максимум.
Общая задача защищающийся стороны состоит в выборе такого шифра,
который минимизирует ущерб от имитационных действий противника во всех
реально возможных ситуациях.
Замечание. К имитации в широком смысле относятся и некоторые дру- I
гие действия противника . Во-первых, противник может переадресовать сооб- I
щение у, идущее от А к В, другому абоненту С. Такая переадресация (со сры- j
вом сообщения абоненту В или без срыва) может привести к негативным по-
следствиям для защищающейся стороны. Следовательно, абонент С, получив j
шифрованное сообщение уеУ, должен быть уверен в том, что это сообщение 1
предназначено именно ему. Во-вторых, противник может изменить «подпись» j
абонента А, передающего «у» абоненту В (заменив каким-либо способом в от-
крытом тексте адрес отправителя сообщения А на адрес другого абонента A'), j
Поэтому абонент В, приняв сообщение, должен быть уверен, что это сообще- \
ние передано ему именно абонентом А. В-третьих, противник, перехватив уеУ,
может задержать это сообщение и вставить его в канал связи в другое время.
Следовательно, абонент В, получая^, должен быть уверен в том, что сообще-
ние он получил вовремя.
Рассмотрим один из вопросов, связанных с возможностью подмены со-
общения, зашифрованного шифром поточной замены, при условии, что проти- ’
вник может заменять любую букву шифрованного сообщения по своему усмо-
трению. Пусть буквы открытого сообщения шифруются с помощью последова-
тельности подстановок, взятых из некоторого множества G. Пусть некоторая
383
буква «а» открытого текста переходит в букву «Ь» шифрованного текста при
действии подстановки geG: g(a)=b. Для того чтобы заменить букву «а» откры-
того сообщения на букву aVa, противник должен заменить букву «Ь» шифрте-
кста такой буквой Ь', чтобы g(a')=b'. Поскольку подстановка g противнику не-
известна (а все множество G известно), то неоднозначность выбора Ь' можно
охарактеризовать величиной 0G(a,b,a')=| {g(a'): geG, g(a)=b}|, а в качестве меры
имитостойкости шифра использовать величину
!----- Уе0(а,Ь,а-).
|1|2 (|1|-1)аЛ%-
Перейдем к математической постановке и решению задач крипто-
графии, связанных с имитационными действиями противника в канале связи в
узком смысле, то есть навязывания ложных сообщений.
Навязывание в пустом канале. При фиксированном уеУ и при слу-
чайном и равновероятном выборе ключа % в шифре (X,K,Y,f) для зашифрова-
ния открытых сообщений
Рн(У)=Р(Х1уеХ)=|К(у,Х)|/|К|,
где К(у,Х) ={%еК: /’’уеХ}. Несложно доказывается следующая основная фор-
мула
5}[К(у,Х)|=|Х||К| .
уеУ
Отсюда следует, что max | К(у,Х) |>--------, причем равенства достигается в
УеУ I У |
том и только в том случае, если для любого уеУ
|К(У,Х)|=
Наилучшая стратегия противника состоит в выборе для навязывания
у'еУ, при котором вероятность навязывания Рн(у')=Р(х’1у'^Х)=|К(у',Х)|/|К|
максимальна. Наилучшая стратегия защиты состоит в минимизации по возмо-
жным шифрам максимальной вероятности . Шифр, при котором эта цель до-
стигается, можно назвать наилучшим по имитозащите в «пустом» канале. Из
приведенных формул следует
УТВЕРЖДЕНИЕ. Шифр является наилучшим по имитозащите в пустом
канале в том и только в том случае, если для любого уеУ
|№1ВД,
|У|
СЛЕДСТВИЕ. 1) Для наилучшего по имитозащите в пустом канале
шифра f
384
при любом уеУ.
2) Для выполнения условия Рн(у)<е, о<е<1 достаточно, чтобы шифр был наи-
лучшим по имитозащите в пустом канале и удовлетворял условию
|Х|<8|У|.
3) Для наилучшего по имитозащите в пустом канале шифра из условия Рн(у)<£,
о<е<1 вытекает |К|>1/е.
Утверждение пункта 3 следует из определения шифра (сюръективность
функции f), из которого следует неравенство |X||K|^|Y|.
Неравенство Рн(у)<е, о<£<1 говорит об уровне имитозащиты в пустом
канале при наилучшем шифре.
Для наилучшего шифра по имитозащите в пустом канале коэффициент
|У I
эмитозащиты 1 /Рн равен---. Он совпадает со среднем числом попыток про-
|Х|
тивника «наугад» (случайно и равновероятно) навязывания у<=У до получения
«успеха» - навязывания ложной информации (предполагается, что при каждой
попытке ключ наилучшего по имитозащите в пустом канале шифра выбирается
случайно и равновероятно).
ЗАМЕЧАНИЕ. Пусть задано некоторое вероятностное распределение на
множестве ключей К шифра (X,K,y,f). Обозначим через 1(У,К) - взаимную ин-
формацию между У и К, то есть 1(У,К)=Н(У)-Н(У/К). Имеет место достижимая
оценка
log (max Рн(у))>-1(У,К).
уеУ
Имитация при передаваемом сообщении (имитация путем подме-
ны). Пусть по каналу связи передается уеУ. Противник заменяет его на у',
У>У-
Положим К(у,у')=К(у,Х) п К(у',Х)={%еК: %*’у, х‘’у'еХ}. Заметим, что
Хк<У.У')=|К(у,Х)|(|Х|-1).
у'еУ,у'*у
Отсюда следует, что
|т„ пк |К(у,Х)|(|Х|-1)
max|К(у,у )|> v^yl|_1--------,
причем равенство достигается в том и только в том случае, если для любого
у'еУ, yVy
385
|К(У,У>|К(У’Х)|(|ХЬ1).
1 I У |-1
При фиксированном уеУ и при случайном и равновероятном выборе ключей в
шифре (X,K,y,f) для зашифрования открытых сообщений под вероятностью
Рн(у',у) навязывания ложного открытого текста путем замены у на у' понимают
вероятность
Р(хУеХ/%х=у,хеХ)=|К(у,у )|/|К(у,Х)|.
Наилучшая стратегия противника состоит в выборе для навязывания
у'еУ, при котором вероятность навязывания Рн(у,у')= |К(у,у'|/|К| максимальна.
Наилучшая стратегия защиты состоит в минимизации по возможным шифрам
максимальной вероятности при каждом уеУ. Шифр, при котором эта цель до-
стигается можно называть наилучшим по имитозащите путем подмены. Из
приведенных формул следует
УТВЕРЖДЕНИЕ. Шифр является наилучшим по имитозащите путем
подмены в том и только в том случае, если для любых у,у'еУ
. |К(У,уэ|-мт.
1X1—1
В этом случае Рн(у\у)= -.
СЛЕДСТВИЕ. Шифр одновременно обеспечивает наилучшую имито-
защиту в пустом канале и наилучшую имитозащиту путем подмены в том и
только в том случае, если для любых у,у' ёУ
|К(у,Х)|=
|К(у,у')|=| К |
Для шифра Ш(2), обеспечивающего наилучшую имитозащиту путем
подмены, имеем
откуда | К |
|К(у,у')£1,
>1, |К|> । У У ।—11 для шифра Ш(1), обеспечи-
вающего наилучшую имитозащиту в пустом канале (как и для любого шифра)
I УI
имеем |К|^ -—1. Если ключи в шифре задаются множеством Г и |К|» 1 (|К|
13 Зак. 5
386
много больше 1), то длина ключа шифра Ш(2) почти, вдвое больше длины клю-
ча шифра Ш(2).
Имитация при наличии открытого и шифрованного текстов. Пред-
положим, что противник знает открытый текст хеХ, соответствующий пере-
хваченной криптограмме уеУ. Он навязывает в канал у', заменяя у. Положим,
К(у,х)={хеК:%х=у}, К(у,у',х)={хеК(у,х):х'у'еХ}. Вероятностью Рн(у',у,х)
навязывания путем замены при наличии открытого текста можно назвать вели-
чину
Р(%х=у, х’у' еХ)= 1.
|К(у,х)|
Заметим, что
£| К(у,у',х) =(|Х|-1)||К(у,х)|.
у\у'*у
Таким образом, максимальная (по у'), вероятность навязывания минимальна в
том и только в том случае, если для шифра выполняется условие
|К(у,у',х)|=(|Х|-1)|К(у,х)|/(|У|-1).
Аналогично предыдущим случаям вводится понятие наилучшего шиф-
ра по эмитозащипге путем навязывания с известным открытым текстом. Из
приведенных формул вытекает
УТВЕРЖДЕНИЕ. Шифр обеспечивает наилучшую имитозащиту путем
навязывания с известным открытым текстом в том и только в том случае, если
для любых хеХ, у,у' еУ, yVy выполняется равенство
|К(у,у',х)|=(|Х|-1)|К(у,х)|/(|У|-1).
В этом случае для любого у' еУ, у Vy вероятность навязывания Рн(у,у'х) есть
Рн(У,У'х)=(|Х|-1)/(|У|-1).
Покажем, что для шифра, обеспечивающего наилучшую имитозащиту
путем навязывания с известным открытым текстом выполняется неравенство
|K|>|Y|(|Y|-1)/(|X|-1). .
Действительно, из неравенства К(у,у', х)>1 следует
|К(у,х)| >(|Y|-1)/(|X|-1),
Поскольку
£|К(у,х)|=|К|,
У
то |K|>|Y|(|Y|- 1)/(|Х|—1), То есть длина ключа возрастает по сравнению с клю-
чами шифра Ш(2).
УТВЕРЖДЕНИЕ. Шифр Ш(3), обеспечивающий наилучшую имитоза-
щиту путем навязывания с известным открытым текстом, является шифром,
обеспечивающим наилучшую имитозащиту путем замены.
387
Действительно, имеем
]Г|К(у,у',х)|=|К(у,у')|,
хеХ
Для шифра Ш(3) по условию имеем |К(у,у',х)|=(|Х|- 1)|К(у,х)|/(|У|-1) (см. пред-
ыдущее утверждение). Следовательно,
Е | К(у, у-, х) I = £ I К(У, х) |=К(у, X) =|К(у,у’)|.
хеХ I У I 1 хеХ I У I 1
Из последнего равенства и приведенного выше критерия о шифре с наилучшей
имитозащитой по замене и следует данное утверждение.
Целевая имитация в пустом канале. Пусть противник стремится на-
вязать конкретный открытый текст хеХ. Он вставляет в пустой канал сообще-
ние уеУ.
Используем введенные ранее обозначения: К(у,х)={%еК:%х=у}. Веро-
ятность целевого навязывания хеХ в пустом канале можно определить вели-
чиной
Рнц(х/у)= |К(у,х)|/|К|.
Напомним, что
£|К(у,х)|=|К|.
У
Тогда минимальное значение вероятности целевого навязываний достигается в
том и только в том случае, когда для любых хеХ и уеУ
|К(у,х)|=|К|/|У|.
В этом случае она равна 1/| У|.
УТВЕРЖДЕНИЕ. Шифр обеспечивает наилучшую имитозащиту от це-
левого навязывания в пустом канале в том и только в том случае, если для лю-
бых хеХ и уеУ выполняются условия
|К(у,х)|=|К|/|У|.
В этом случае для любых хеХ и уеУ
Рнц(х/у)=1/|У|,
а |К|>|У|.
Из условия |К(у,х)| >1 вытекает
СЛЕДСТВИЕ. Наилучший по указанной имитозащите шифр по необхо-
димости является транзитивным (см. параграф 1.3).
Из равенства К(у,х) | =}К| и предыдущего УТВЕРЖДЕНИЯ полу-
у
чаем
13*
388
СЛЕДСТВИЕ. Если шифр является наилучшим по имитозащите при це-
левом навязывании в пустом канале, то он является наилучшим и при общем
навязывании в пустом канале.
Параграф 7.2
Примеры имитации и способы имитозащиты
Обозначим через А множество информационных сообщений, передава-
емых по каналу связи от передающего устройства к приемному устройству.
Предполагается, что противник «контролирует» канал связи и может заменить
передаваемое сообщение ас А (истинное сообщение) на сообщение а' е А (лож-
ное сообщение). Под обеспечением имитостойкости приемного устройства
понимается его защита от навязывания информации, поступающей в результате
воздействия противника на передаваемую по каналу связи информацию, а так-
же и на «пустой канал». Ложная информация считается навязанной, если она
принята приемным устройством к исполнению (то есть принята также как при-
нимается истинное сообщение). Воздействие помех в канале связи на передава-
емую информацию также трактуется как попытка навязывания ложной инфор-
мации.
Для узнавания факта навязывания информации и предусмотрена ими-
тозащита. Существуют много способов имитозащиты, позволяющих устано-
вить приемному устройству вмешательство противника (или помех) в процесс
передачи по каналу связи истинного сообщения аеА. Как правило, такие спо-
собы имитозащиты основаны на использовании шифров и не обеспечивают
стопроцентную гарантию защиты от навязывания ложной информации, (см.
предыдущий параграф).
Рассмотрим некоторые варианты навязывания информации и способы
имитозащиты от них.
1. Пусть А=У и передаются шифрованные сообщения уеУ. Противник пере-
хватывает передаваемое сообщение «у» и через определенный промежуток
времени посылает его в канал связи. Если за этот промежуток времени не ме-
нялся ключ на приемном и передающем устройстве, то приемное устройство
повторно воспримет ранее переданную информацию. Для защиты от таких
действий противника используют метки времени (проставляя время отправле-
ния в открытом сообщении хеХ). В случае, когда отмеченное время отличается
от времени принятия сообщения у на величину, превышающую некоторый до-
пустимый предел, приемное устройство делает вывод о принятии ложного соо-
бщения. В некоторых случаях используют секретный алгоритм изменения
389
I.
ключа шифра через короткие промежутки времени. Если задержка в приеме
превышает величину этого промежутка, то приемник не расшифрует навязыва-
емое сообщение.
2. Пусть множество возможных сообщений А является множеством F2 дво-
ичных наборов длины к. Противник посылает сообщение а' в канал связи и
приемное устройство принимает его. Для обеспечения защиты от навязывания
сообщения а' применяют кодирование векторов двоичными векторами
длины п>к. В этом случае множеством передаваемых сообщений становится
некоторое неизвестное противнику подмножество М мощности 2К векторов из
F2\ При случайном и равновероятном выборе противником вектора а' из F2"
и его передачи по каналу связи вероятность принятия ложного сообщения а'
совпадает с вероятностью Р события: а' еМ, очевидно, Р=
2К
2”
= 2К‘П
3. Противник знает передаваемое сообщение «а» и может заменить его на
а' бА.
Для обеспечения имитостойкости в этом случае используют имитовс-
тавки. Предполагается, что приемное и передающее устройства снабжены ши-
фром зашифрования, позволяющим им на ключах шифра вырабатывать одина-
ковые гаммы . Через Г обозначим множество всех возможных гамм шифра. На
АхГ определяется функция F: Axf->Z, где Z - некоторое множество называе-
мое множеством проверочных символов (кодов имитозащиты). Для передачи
сообщения аеА (на передающем устройстве) вырабатывают гамму Ye Г и по
каналу связи передают пару (a,z), где z=F(a,Y). На приемном устройстве с по-
мощью шифра вырабатывается та же самая гамма Y и проверяется для приня-
той из канала пары (a',z') совпадение значения F(a',Y) со значением z'. При
совпадении значений делается вывод о приеме истинного сообщения. В проти-
вном случае, делается вывод о приеме ложного сообщения. Предполагается,
что на приёмное устройство противник может послать произвольную пару
(a',z') из AxZ, для которой а^а'. В предположении, что выбор гамм Те Г про-
водится случайно и равновероятно, из Г вероятность P((a',z'),(a,z)) навязывания
приемному устройству сообщения а' совпадает с вероятностью P(z'=F(a',Y),
z=F(a, Y)) события:
z'=F(a',Y), z=F(a, Y).
Численное значение имитостойкости в рассматриваемом случае можно охарак-
теризовать величиной:
Р(имит)= max Р((а',z'),(a,z))=max P(z'=F(a' ,х), z=F(a,x)),
где максимум берется по всем наборам (a' ,z', a,z), а^а'.
390
Величину Р(имит) можно преобразовать к виду
Р(имит)=шах P(z'=F(a',Y), z=F(a, Y))=max max P(z'=F(a',Y), z=F(a, Y)),
a,a z,z
откуда вытекает, что минимально возможное значение величины Р(имит) равно
|r|/|Z|2|F|=l/|Z|2, причем оно достигается для тех и только тех функций, для ко-
торых при любых а, а', а^а' число решений 4(F, a^a',z,z') (относительно Y) си-
стемы уравнений
F(a',Y)=z'
F(a, Y)=z
не зависит от выбора значений (z',z) правой части уравнений, то есть
4(F,a^a' ,z,z' )=|Г|/|Z|2. Действительно,
P(z =F(a',Y),z=F(a,Y))=4(F,a*a' ,z,z )/|Г|.
Далее,
22 4(F,a^a',z,z')=|F|,
z,z'
откуда вытекает, что величина maxP(z'=F(a',Y),z=F(a,Y)) минимальна при
z,z
4(F,a*a',z,z')=|r|/|Z|2. Этот вывод справедлив для любых пар (а,а').
4. Предположим, что канал связи используется для передачи шифрованных со-
общений с использованием шифра гаммирования. Противник знает передавае-
мое открытое сообщение хеХ, знает шифртекст уеУ и, узнав по этим данным
гамму наложения, может заменить открытое сообщение х на другое х' еХ пу-
тем наложения гаммы на сообщение х'.
Для борьбы с таким навязыванием информации используют узлы имитозащи-
ты, функционирование которых описывается конечными автоматами А=
(IxG,S,I,8,X) с входным алфавитом IxG, где! - алфавит открытого текста, G -
алфавит гаммы. Выходные последовательности таких автоматов при заданных
входной последовательности и начальном состоянии sgS являются крипто-
граммами. Основное свойство автоматов состоит в возможности «снять имито-
защиту», то есть в возможности легко определить открытый текст по извест-
ным шифртексту, начальному состоянию, и гамме. ’,, .
Приведем несколько примеров узлов имитозащиты. Положим 1=6= F2 -
поле из двух элементов, S=F п2 , f: F" —> F2 - двоичная функция. При
s=(xl,x2,...,xn), iel, geG
1) S(i,g, s)=( x2,...,xn,i+f(s)+g),
X( i,g, s)= i+f(s).
2) 5(i,g, s)=( x2,...,xn,i+f(s)+g),
X( i,g, s)= i+f(s)+g.
391
3)G=F2-l,S=F2,
5(i,g, s)=f(g,s)+i,
Z,( i,g, s)= f(g,s)+i.
Здесь + означает сложение no mod2.
Параграф 7.3
Помехоустойчивые шифры
Общие понятия и определения. В последующих рассуждениях будет
использована уже известная читателю модель эндоморфного шифра (см.
параграф 1.3)
А= (X,n(K,f))
со следующими уравнениями зашифрования, расшифрования
у=7ГХ, х = л-1у, хеХ, уеУ.
Здесь у - шифрованный текст; в последующем будет использовано
обозначение Y для множества шифрованных текстов (Y = X); это делается
для удобства различения открытых и шифрованных текстов.
В дальнейшем, для определенности, будем считать, что множество X -
это множество текстов одной и той же длины L в некотором алфавите Q,
X = Ql.
Прежде всего формализуем понятие «искажение сообщения при его
передаче по каналу святи».
Под искажением сообщения при его передаче по каналу связи
понимается замена шифрованного сообщения уеУ на некоторое другое - у*,
у*еУ*. Характер (правило) замены уеУ на у*е У* определяется физическим
состоянием как самого канала связи, так и окружающей его Среды, У< У*.
Примером искажений являются так называемые искажения типа
замены. Передаваемое по каналу связи сообщение y=bi,b2,.-->bL заменяется на
сообщение y'=b'i,b'2,...,b'L. Имеется в виду, что исказиться может любая буква
bj сообщения у, при этом искажении она заменится на букву b'j.
Примерами других искажений являются искажения типа «пропуск»,
«вставка». Искажение типа пропуска букв состоит в том, что из сообщения
у=Ь1,Ь2,Ьз,.г.,Ьь пропадут одна или несколько букв, стоящих на некоторых
местах. Так при пропадании второй буквы Ь2 из канала связи на
расшифрование придет сообщение y=bi,b3,...,bL длины L-1. Искажение типа
вставки состоит в добавлении одной или нескольких букв алфавита Q в
сообщение y=b i ,b2,b3,.. .,Ьь
392
При рассмотрении шенноновской модели шифра для указанных
искажений может оказаться, что при некоторых л из П(К,1) и выражение л''у*
может быть не определено. Это означает, что на приемной стороне сообщение
у* не будет расшифровываться. В дальнейшем будем рассматривать лишь
* *
такие щифры и искажения, при которых для любого yeY преобразование
л’у* определено при всех леП(К,£).
Пусть на множестве X=Y задана некоторая метрика D. Напомним,
что, по определению, это функция на ХхХ со свойствами:
a) D(x, х') = 0 в том и только в том случае, когда х = х',х,х' е X;
b) D(x,x') = D(x',x) для любых х, х'еХ;
в) D(x,x') + D(x',x") > D(x,x")
для любых х,х',х*еХ.
Примером метрики на X может служить расстояние Хэмминга р.
Пусть х = (aj,a2,..,aL), х'= (aj ja'2,...,a'L), а^а-бЦ i = l,L.
Напомним, что p(ai,...,aL, а'|,...,а\) равно числу позиций], для которых a^a'j.
В дальнейшем, исследуя свойство помехоустойчивости шифров, мы
будем сравнивать между собой значения метрики вида:
(-1 * — 1 \
71 у ,7Г у) И Щу ,yj,
где у* - искаженное сообщение у.
Докажем следующее утверждение.
Лемма 1.1. Если для любых у', у" g Y, 71 е П(К,£) справедливо:
в(я_1у';я’’1у'г)< D(y',y"), то
в(л-1 у', л-1 у") = D(yу")
для любых у', у" е Y, л g II(K,f). ,
ДОКАЗАТЕЛЬСТВО следует из очевидного равенства
y'.y'eY y',y'eY
ИЛИ
|р(л~1у',л~1у'')-В(у',у")]= О
y'.y'eY
при любом леП(К,1).
393
Шифр Л называется шифром, не размножающим искажений (в
*
метрике D), если для любых у, у е Y, л е л(К, f) выполняется равенство
(_] _i * \ / *\
71 УЛ У /=Dly,y }
В некоторых случаях приходится вводить понятие шифра, не
размножающего искажений не через метрику, а через определенное бинарное
отношение на множестве X. Пример такого подхода будет приведен ниже.
Рассмотрим произведение А=А'-А"шифров (см. параграф 1.3). Ясно,
что если А' и А" не размножают искажений (в метрике), то А также не
размножает искажений (в той же метрике).
Шифры, не размножающие искажений типа
«замена»
В данном пункте метрика D - это расстояние Хэмминга; искажения
в канале связи - это искажение типа «замены», слово a],a2,...aL
искажается, каждая буква aj может замениться на другую букву a'j, aj,
a'jeQ.
Пусть njt j есть преобразование X, осуществляющее перестановку
элементов в словах из X=QL, то есть
П; : :аь...,ат а а, ,...,а; ; i;el,L, j: * jr (i * г)
Пусть Rj, i g 1,L - набор подстановок на Q и R = (Rj,...,RL) подстановка
Ha£lL:
R:ai,...,aL <x Ri(ai),...,RL(aL).
Очевидно, что элементарные шифры, построенные на отображениях типа
п j jl и R, не размножают искажений типа замены (не размножают
искажения в метрике Хэмминга). Оказывается, что кроме композиции этих
отображений других отображений, не размножающих искажений, не
существует. Впервые это свойство было обнаружено А.А. Марковым.
Теорема (А.А. Марков). Любой шифр, не размножающий искажений в
метрике Хэмминга, представим в виде композиции шифров многозначной
замены и перестановки.
Данное утверждение адекватно следующему утверждению.
394
Теорема. Взаимно однозначное преобразование X=QL, не
размножающее искажений типа замены в метрике Хэмминга, представляется в
виде композиции перестановки ) и многозначной замены R на QL.
Доказательство. Достаточность условий теоремы очевидна. Докажем
их необходимость. Возьмем произвольную изометрию л е S(X) и
зафиксируем произвольное слово a j, а 2,..., a l • Обозначим через
a1,a2,...,ai_1Qai+i,...,aL множество слов
{a1,...,ai_1bai+1,...,aL :beQ}.
Если л(а!„..,aL) = (ci,...,cL), то для любого iel,L существует],
такое что
n(a1,...,ai_1,Q,ai+1,...,aL) = (c1,...,cj_1,Q,cj+1,...,cL). (*)
Действительно, для любых слов Xj^x2, х1?х2 е n(ai,...,ai,Q,ai+j,...,aL)
имеем p(xi,'x2) = 1. Если бы среди слов K(ai,...,aj_j,Q,ai+i,...,aL) имелось
бы слово С , которое с разными словами Ci и С 2 из того же множества
различалось бы в разных позициях, то р(С1, С 2 ) = 2, что противоречило бы
инвариантности п относительно р. Заметим, что если преобразование п
инвариантно относительно р, то и л'1 обладает этим же свойством. Из
инвариантности л-1 относительно р следует, что существует
взаимнооднозначное соответствие в (*) между номерами i и j, то есть
отображение л на словах рассматриваемого вида порождает подстановку
п; : . С другой стороны, для каждого i порождается подстановка R и на
Q, такая что
л(а1,...,ам,а,аИ1,...,аЕ) = (с1,...,с]._1,К]. (а),с^._15...,сЕ),
а также преобразование R = (Ri,...,Rl) множества OL.
Обозначим:
Oi(ai,...,aL)={XGQL: р(х,(аь...,aL)<l.
Очевидно, что
L
’ O1(a1,...,aL) = (J(a1,...,ai_1,n,ai+1,...,aL).
i=l
Здесь и далее при объединении множеств и, в частности, одноэлементных
множеств, то есть слов, знаки {...} множества мы опускаем.
395
Таким образом, получаем, что отображение <p = R jL ) 1 л есть
тождественное отображение множества O](aj,...,aL).
Покажем, что ср будет тождественным и на всем множестве QL.
Возьмем произвольное слово (b j,..., b L ) и рассмотрим множества
Во = Oi(ai,...,aL), Bj = O](bi,a2,...,aL),
В2 = O1(b1,b2,a3,...,aL),...,BL =O1(^1,...,bL_1,bL).
Если мы покажем, что ограничение отображения ср на каждое из этих
множеств есть тождественное отображение, то тем самым мы докажем и
утверждение теоремы.
Доказательство проведем методом индукции по j, j=0, 1,....
Для множества Во утверждение выполняется. Допустим, что оно верно
для Bj. Покажем, что оно тогда верно и для Bj+i. Возьмем слова
d = (bi,...,bj,aj+1,...,aL)eBj и xeBj+1.Ecnn p(x,d)=l,To <р(х) = х (по
предположению индукции). Пусть х есть произвольное еловое p(x,d)=2.
Без ограничения общности положим
x = (c1,c2,b3,...,bj,aj+1,...,aL^ Cj *bls c2*b2.
Из последующего изложения станет ясно, что основные выводы не
изменятся, если искаженные знаки (сьСг) стоят на произвольных местах ji,
Имеем:
(c1,b2,b3,...,bj,akl,...,aL)eO1(b1,b2,b3,...,bj,aj+1,...,aLJ
(b1,c2,b3,...,bj,aj+1,...,aL)eO1(b1,b2,b3,...,b;,aj+1,...,aLJ
<p(ci,b2,b3,...,bj,aj+1,...,aL)=(c1,b2,...,bj,aj+1,...,aL}
<p(bi,c2,b3,...,bj,aj+1,...,aL)=(b1,c2,...,bj,aj+1,...,aL^
<p(ci,c2,b3,...,bj,aj+I,...,aL)=(px.
При этом
p(<px,(bj,c2,b3,...,aL) = 1,
p(q>x,(c1,b2,b3,...,aL)= 1.
Отсюда следует, что фх совпадает либо с d = (bi,b2,b3,...,aL), либо с
х = (c!,c2,b3,...,aL). Но так как по условию индукции 9d = d, то, в силу
взаимнооднозначности преобразования <р,
396
срх ф d (х * d),
отсюда следует, что фх=х. В частности, ф(х)-х и для xeBJ+1. Теорема
доказана.
Шифры, не размножающие искажений типа «пропуск». Пусть
множество открытых текстов в модели эндоморфного шифра A=(X,K,Y,f), Х=У
имеет следующий вид:
L
X = (jQk=QL,
k=l
то есть включает все слова над Алфавитом £1 длины от 1 до L. Тогда
искажение типа «пропуск» приводит к тому, что искаженный текст у*
принадлежит У=Х (при естественном условии, что искажение не приводит к
полному «уничтожению» слова, то есть к слову длины 0).
Заметим, что шифры, не размножающие искажений типа «замены» в
метрике р при X=QL, сохраняют это свойство и при X = QL (имея в виду
использование указанных в теореме своих преобразований множества Qk
при каждом к).
L
На множестве ~ определим бинарное отношение е: слово
к=1
а = (ai,a2,...,ak), к>2 находится в отношении е со словом
а'= (a'i,...,ak_i), если найдется jel,k, при котором
а = (aj,...,ak_j)=(ai,...aj.i,aj+i,...aL)
Таким образом, слово.а находится в отношении е со словом а', если а'
получается из а вычеркиванием (пропаданием) одного какого-то знака (то
есть одним искажением). Для обозначения данного события будем
использовать запись
(ai,...^^^....^-!),
или
аеа', aeQk, a'ef?’1.
Будем также использовать обозначение аеС, где С - множество слов,
если а находится в отношении £ с каждым словом а' из С.
397
На множестве QL определим также отношение е} ,j=l,2,..., положив
е'=е, а для]>2: asJa' тогда и только тогда, когда найдутся слова ai,...,aj-i из
для которых aeaj, a1£a2,...,aj-2eaj-i, aj-iea'. Очевидно, что s'=£h
£J 0, j е 1,L —1; eL = 0. Таким образом, запись* ае1 а' означает, что слово
а' получается их а вычерчиванием j букв, то есть j искажениями.
Как и ранее, под длиной произвольного слова а из будем понимать
число входящих в него букв и будем обозначать ее через |а|. Множество всех
слов длины к-1, с которыми слово а , (|а| = к, к > 2^ находится в отношении
е, назовем содержанием слова а. Содержание слова а = (aj,...,ac) будем
обозначать через с(а)= C(aj,...,ac).
Если а'= (a'|,...,a'r), а" = (aj,...,a" ), a W - некоторое множество
слов, то через а'а" будем обозначать слово (a'j,...,a'r,aj,...,an), а через aW
множество слов вида а а \ а' е W.
Лемма 1. Содержание произвольного слова длины к > 3 однозначно
определяет само слово.
Доказательство проводится индукцией по длине слова. При к=3
данное утверждение проверяется непосредственно. Пусть оно справедливо для
слов длины к < £. Пусть а = (ai,...,a^+1) - произвольное слово длины £ +1.
Если а^ = а2 =... = а^+1, то справедливость утверждения очевидна. В
противном случае, пусть] - наименьший номер, при котором Д[ Ф aj. Тогда,
положив aj = а , слово а можно представить в виде
(a,...,aj_1aj,aj+1,...,a^+1), aj * а.
Во введенных обозначениях имеем
c(a,...,a,aj,aj+1,...,a^+1)= (a^a^c(aj,...,a^+1][J((a^a^aj,...,a^+i), j>2.
"ТТ "ТТ
Возможны три случая. Если j < £ — 1, то по содержанию C(aj,...,a^+1) в
соответствии с допущением однозначно восстанавливается слово (aj,...,a^+1).
398
Для этого собираем все слова из множества C^a,a,...,a,aj,aj+1,...,a^+j J с
началом а,а,...,а; нетрудно заметить, что «хвосты» у этих слов - одинаковы, и
равны слову (aj,...,a^+i). Добавляем к этому слову j-1 раз букву а (в его
начало), однозначно получаем слово (a,...,a,ajaj+1,...,a^+j).
Если j = I,то
С(а,...,а,ае,ам) = )[J (а 67,67 , 67^+1)
6И 6-1 ' 6-1 6-2
По последнему слову определяем (а^, а^+1); добавляя к нему I — 1 раз букву
а, однозначно получаем слово (а,...,а,а^,а^+1). Если j = I +1, то
С(а^а,а^+1) = (a^)J(a^,a€+1)
t I £-\
и однозначность определения слова по содержанию очевидна.
Лемма доказана.
Будем говорить, что произвольное бинарное отношение 8 на
множестве ^коммутирует с отношением £, если для любых слов
a,a\a”,aw h3Ql из a£ar,a8a",a'8aw вытекает a*8aw.
Заметим, что любое отображение ср: QL —> может
рассматриваться как некоторое отношение ф на QL? именно: a<par, a,a' g QL
тогда и только тогда, когда ф(а) = а'. В связи с этим можно говорить о
коммутирумости отображения ф : с отношением 8, если ф
коммутирует с 8. Будем говорить, что отображение не размножает искажений
типа пропуск, если для любых у,у g Y = flL из условия y8Jy , je{l,...,L-}
следует (фу)е^(фу )•
Легко видеть, что взаимно однозначное отображение <p: QL —> ’ не
распространяющее искажения типа пропуск, должно коммутировать с
отношением е.
Это утверждение иллюстрируется коммутативной диаграммой:
гУ~К~^У\
Х(у)—^->Х(У*)
Обозначим через М(е), множество всех взаимно однозначных
399
отображений ф: £1L > коммутирующих с б. В принятых определениях и
' обозначениях наша задача состоит в описании этого множества. Для этого
рассмотрим некоторые свойства отображений из M(g). >
Лемма 2. Произведение отображений из М(б) также принадлежит М(б)
(то есть М(е) есть подгруппа симметричной группы S(Qk ) )•
Действительно, пусть ф),ф2 - некоторые взаимно однозначные
отображения QL в QL, коммутирующие с б, то есть из
aj 8&2 £34 ,аj g »i= 1, L
следует ф1(а1)£ф1(а2),92(33)892(34). Так как 91(a)) е QL и Ф2^М(б), то
Аналогично имеем 91ф2 (33)89192(^4)- Таким образом,
произведение отображений из М(б) также коммутирует с б. Отсюда, в
частности, следует, что если 9 gM(e), то и 9"1 еМ(е).
Лемма 3. Любое отображение из М(е) сохраняет длины слов.
Действительно, пусть 9 е М(е), а = (a j ,..., a j) е
|a| = j, \|/(a) = (a'1,...,a})eQL, |ф(а)| = )'.
Покажем, что j'=j. Для любого kel,j и г el,/имеем
a£J-1ak, 9(3 )eJ -1ar. Отсюда, так как 9,9-1 еМ(е), получаем,
соответственно,
9(а>г19(ак), a£J_19-1(ar),
откуда вытекает
|ф(а)| = j'> j-1, |а| = j> j'-l.
Следовательно, j'=j. Так как это верно для любого j < L, то справедливо
утверждение'леммы.
Таким образом, для \|/ еМ(е)
то есть множество , к = 1,L инвариантно относительно действия
\|/ еМ(е).
Примером отображения, принадлежащего множеству М(б), является
отображение 9 :Qm —> Qm, определяемое соотношением
400
Такое отображение является частным случаем перестановки, которую назовем
обращением. Легко показать, что 0 коммутирует с е. Кроме того, отметим,
что 99(a) = а при любом а, то есть = Е, где Е - тождественное
отображение, и & = Э-1.
Так как \|/ gM(e) сохраняет длину слова, то его проекция на Q есть
подстановка на О. Обозначим ее через л и рассмотрим отображение л^
—>£1l, определяемое следующим образом:
7tL :(a1,...,aj)i->(7t(a1),...,n(aj)) (2)
для любого слова (а],...,apeQl- Таким образом, отображение ль есть простая
замена в алфавите О.
Для любой подстановки л отображение ль вида (2) коммутирует с £.
Действительно, пусть
Тогда очевидно,
[л(а1),...,л(а]))е(л(а1),...,л(а^_1),л(а^+1),...,л(а])).
Таким образом, ль £=£Ль для любой подстановки л на Q. Из Леммы 2 следует,
что Зл^ также принадлежит множеству М(е). Легко видеть, что
Зль = ль3 (3)
Пусть \|/ - произвольное отображение из множества М(е), л - его
проекция на й и Ль - порожденное им отображение Ql в ^l, определяемое
соотношением (2). Рассмотрим отображение л£'\|/ gM(e). Очевидно
следующее утверждение
Лемма 4. Проекция на Q отображения л£'\у • является
тождественным отображением, то есть
л£*\|/(а) = a, a g Q.
Обозначим алфавит из букв а,а' е I) через Q(a,а') = {а, а'}, 0 Ф О', а
множество всех слов длины к алфавита П(а,а') через £2^(а,а'), и
положим
L
QL(a,a') = |J Q(k)(a,a').
к=1
401
Лемма 5. Множество Q^k\a,a'), kel,L, а, а'е Q инвариантно
относительно л£'<|/.
Возьмём произвольное слово (а ।,..., а к ) е Q ^к\а, а') • Рассмотрим
произвольное г el,к и
n[1v(ai,...,ak)= (bj,...,bk), (^,...^>^4.
Применим обратное отображение к обеим частям последнего отношения
(а1,...,ак>к-1у-1ль(Ьг).
Но <|/-1лт(Ьг) = Ьг (см. лемму 4) и, следовательно, br е Q(a,a'). Так как
это верно для любого г е 1, к, то
v(aiак ) е Q(k) (а, а'),
то есть множество Q^k\a,a') инвариантно относительно л^'у •
Следствие. Для любых a15a2eQ
7t£1v(ai,a2)e{(a1,a2),(a2,a1)} .
В введенных нами обозначениях и терминах основное утверждение
данного раздела теперь можно сформулировать в виде теоремы.
Теорема. Взаимно однозначное отображение \|/ : QL “*
коммутирует с отношением е (то есть не размножает искажений типа
«пропуск») тогда и только тогда, когда = ль3 или \|/ = лЕ ПРИ некоторой
подстановке л на Q, где отображение Э и лк определяются соотношениями
(1),(2), L>2, |Q|>2.
ДОКАЗАТЕЛЬСТВО. Ранее было показано, что преобразования
множества QL вида лк и коммутируют с £ при произвольной
подстановке л; при этом выполняется соотношение (3).
Допустим теперь, что некоторое взаимно однозначное отображение \|/
коммутирует с <е. Покажем, что, либо \|/ = лк&, либо \|/ = лк , то есть что
л^у совпадает с отображением &, либо с тождественным отображением Е.
Вначале покажем справедливость утверждения для проекции
отображения л£*\|/на множество QL(aj,a2) для любых а15а2бО и
т>2.
402
2)
Из. вяедСтвия к лемме 5 следует, что проекция Kl'v на Q^2^(aj
для любых а}, а2 е О, aj ф а2 осуществляет отображение
n«2»(a1,aJj)->n<2>(a,,a2) в одном из следующих двух вариантов:
-*l v(ai,a2) = (ai,a2), я£1у(а1,а1) = (a^aj
- V(a2’al)=(a2»al)’ nLV(a2’a2)=(a2>a2)-
ЖМа1>а2) = (а2>а1)> чМа2>а1)=(аЬа2)>
CMabal)=(al>ai)
В первом случае проекция на (aj,a2) является
тождественным отображением, во втором случае она совпадает с проекцией 3
ria ri^'fa^a^. Если во втором случае вместо отображения \|/
рассматривать 3-ц/, то его проекция на QL(al>a2)> L > 2 также будет
тождественным отображением.
Обозначим через Ф отображение —> Ql из множества М(е),
проекция которого на Q^2^(aj,a2) является тождественным отображением.
Покажем, что тогда проекция Ф на QL(a, ,а2), L>2 есть также
тождественное отображение.
Доказательство проведем индукцией по L. Для L=2 это верно по
определению Ф. Допустим, что при некотором к > 2 отображение Ф
тождественно на (a j, а 2 ). Покажем, что оно будет тождественным и на
Q<k+l5aj,a2).
Для любого слова (a!,...,ak+i)e Q^k+1^(a15a2) имеем
(a1,...,ak+1)eC(a1,...,ak+1),
где C(ai,...,ak4.]) - содержание слова (ai,...,ak+i). Напомним, что
предыдущая запись означает, что слово ai,...ak+i находится в отношении е с
каждым словом из множества C(ai,...ak+i).
Поскольку Ф gM(e), то
ф(а1,...,ак+1>Ф(с(а1,...,ак+1)),
где Ф(С(аь. .'.,ак+|)) - множество образов из С(аь.. .,ak+i) при отображении Ф.
Но С(й|,...,ак+1) состоит из слов длины к, и по предположению Ф есть
тождественное отображение на словах длины к, поэтому
403
Ф(С(а1,...,ак+|) = С(а],...,ак+]) . Так как (по лемме 1) содержание
С(а15...,ак+1) однозначно определяет слово, то O(ai,...,a]c+i) = и
тем самым Ф - тождественное отображение на Q^k+1^(a1,a2), что и
требовалось доказать.
Из доказанного следует, что проекция отображения на
^ь(а1»аг) для любых ai»a2 е Ф а1 а2 совпадает либо с
соответствующей проекцией отображения &, либо тождественного
отображения Е.
Рассмотрим теперь проекцию отображения л^у на (а i а 2 >а 3 )
для произвольных различных af, а2, аз е Q. Применяя следствие из леммы 5
теоретически можно представить следующие типы отображений
Q(2)(a1,a2,a3)^Q(2)(a1,a2,a3) , осуществляемых ц/ (с точностью до
обозначения букв):
I.Kl \|/(a,b) = (b,a) 2.Kl \|/(a,b) = (b,a)
TTL1\|/(a,c) = (a,c) л^х^с) = (c,a)
7tLV(b,c) = (b,c) л£1\|/(Ь,С) = (Ь,С)
З.л^уСа.Ь) = (b,a) 4.7tL1i|/(a,b) = (a,b)
7Tl y(a,c) = (c,a) л^1 y(a,c) = (a,c)
7tL\|/(b,c) = (c,b) Kl v(b,c) = (b,c)
Здесь a, b, с - набор различных букв из Q(a],a2,a3). На словах из
одинаковых букв во всех случаях имеет место тождественное отображение
(или совпадающее с ним на таких словах отображение 9).
Разберем в отдельности каждый случай.
Если бы имело место первое отображение, то для слова (а,с,Ь) получили
бы
(а, с, b)s{(a, Ь), (а, с), (с, Ь)}.
404
Применяя к обеим частям этого отношения отображение Л[/ф получим:
Но такое отношение невозможно, так как никокое слово длины 3 не может
иметь своим содержанием множество {(b,a),(a,c),(c,b)} . Таким образом, случай
1 невозможен. •
Такие же рассуждения относительно второго отображения,
примененные к слову (с,а,Ь), приводят к заключению о его невозможности.
' Действительно,
(с, a, b)e{(c, а), (а, Ь), (с, Ь)}
приводит к отношению
7Cl \|/(с, a,b)e{(a, с),(Ь, а), (с,Ь)},
что невозможно.
В третьем случае проекция отображения л^у на (а 1 »а 2 >а 3 ) есть
отображение 3, а в четвертом случае совпадает с тождественным
отображением, то есть ведет себя так же, как на (aj, а2 ).
Отметим, что проекция отображения л^ф на ^^2^(аьа2»аз) либ° не
переставляет буквы ни в каких словах, либо переставляет их во всех словах.
Применяя рассуждения, аналогичные предыдущему, с использованием
леммы 1 получим, что проекция л^у на О^2^(а],а2,аз) совпадает либо с 3,
либо с тождественным отображением Е.
Из приведенных утверждений следует справедливость теоремы для
алфавитов О мощности 2 и 3. Теперь мы можем доказать ее справедливость
для слов любого алфавита Q, |Q| 4.
Разобьем множество букв алфавита Q на,подмножества aj,...,a^,
обладающие следующими свойствами:
___ - I _____
|<Xj|.= 3, j = l,i-^Uaj =Q; |ajQaj+I| = 2; j = l,i-4-l.
j=i
На каждом QL (a j), j = 1,1—эпо доказанному ранее проекция отображения
л£*у совпадает либо с 3, либо с тождественным отображением Е. По
построению подмножеств aj и aj+i множества Q^(aj) и П(2,(ам) имеют
общее слово длины 2. Поэтому проекция отображения как на (a j),
405
так и на Q 2 \а j+1) одновременно либо совпадает с Э, либо с Е. Так как это
имеет место для всех j = 1,Х— 1, то это верно и для Q(2). Применяя лемму 3 и
метод индукции, отсюда получаем, что на совпадает либо с
отображением 3, либо является тождественным отображением Е. Теорема
доказана.
Содержание теоремы другими словами можно сформулировать
следующим образом: всякий шифр, не размножающий искажений типа
пропадания букв в шифрованном тексте, есть либо шифр простой замены,
либо произведение шифра простой замены и частного вида шифра
перестановки, заключающегося в инверсной записи текста (справа
налево).
Заметим, что результат не изменится, если искажения будут выражаться
в появлении лишних знаков в шифрованном тексте. Таким образом, сложные
шифры (отличные от указанных выше простых шифров) распространяют
искажения типа пропуска-вставки знаков в канале связи. Это означает, что в
данном случае борьба с такими искажениями криптографическими методами
невозможна и, следовательно, необходимо применять иные способы
повышения помехоустойчивости (например, введением избыточности).
Параграф 7.4
Помехоустойчивые шифрующие автоматы
Пусть A=(X,S,O, (Si)iei, (Pi)iei) - конечный автомат с входным алфави-
том I, множеством состояний S, выходным алфавитом О, частичными функ-
циями переходов (5i)jei и выходов (Pi)ieI. Предположим дополнительно, что ав-
томат А является шифрующим автоматом (по второму определению, см пара-
граф 1.3), то есть его автоматные отображения <Pa,s I*—>О* , sgS являются
инъективными отображениями. v
Напомним (см. параграф 1.3) условия, при которых автомат А является
шифрующим автоматом. Обозначим через ps отображение I в О: ps(i)=Pi(s). Че-
рез Ss обозначим множество состояний автомата А, содержащее s и все состоя-
ния s' eS, достижимые из s в графе переходов автомата А, то есть для которых
есть пути из s в s'. На множестве Ss определен подавтомат
As=(I,Ss,0,(5i)iel,(Pi)jei) автомата А (здесь ограничения отображений (5j)iei, (Pi)iei
обозначены теми же буквами). Состоянию seS автомата А соответствует ото-
406
браЖение <pAs:I*—>0*, именно, для 3gI*: q>AiS(3)=A(s,3), где A(s,3) - выходное
слово автомата А, отвечающее входному слову 3 и начальному состоянию s
автомата А.
В параграфе 1.3 нами приведено
УТВЕРЖДЕНИЕ: автоматное отображение q)AjS I*—>0* , sgS является
ййъектийййм тогда и только тогда, если при каждом состоянии s'из Ss отобра-
жение-ps' инъективно.
Наша задача состоит в описании помехоустойчивых шифрующих автома-
тов. Предварительно введем необходимые понятия и докажем вспомога-
телъвыеутверждения.
Определение. Автоматное отображение <pA,s: I*—>О* называется не
размножающим искажений типа замены букв, если для любых слов 3,3' gI*
одинаковой длины выполнятся условие: p(3,3')>p(q>A>s (3),<pA>s (3')).
Определение. Автомат Ai=(I,Ss,0»(8i)iei»(Pi)iei) называется внутренне ав-
тономным, еОли
8iS'=5jS'
при любых s'gSs и i,i'gI.
Ниже используется понятие приведенного автомата, определение кото-
рого, дано в заключение параграфа 1.3.
Теорема. Пусть А - приведенный автомат и <рА s - инъективное отобра-
жение. Отображение <pA,s не размножает искажения типа замейы букв тогда и
только тогда, если автомат As внутренне автономен.
Достаточность условий теоремы очевидна.
ДОКАЖЕМ их необходимость. Для любых слов 3, 3' из 3* одинако-
вой Длйны имеем
./J p(3,3')>p(A(s,3),A(s,3')).
В частности, Для слов вида 3=i,i2,...,iL, 3'=i',i2,...,ib i*i' получаем
' ';' l=p(3,3')>p(A(s,3),A(s,3')).
Так как <pAiS - инъективное отображение, то ps - инъективное отображение I в
О. ’Следовательно,
A(5jS, i2,... ,iL)= A(8j-s, i2,... ,iL)
при любом слове ii,...,k из I*. Из приведенности автомата А получаем, что для
дащюго s
8iS=6i-s
при любых i,i'Gl. ’
Покажем, что q>A,S” не размножает искажения типа замены букв при лю-
бом s”gSs. По определению множества Ss, для любого s” из Ss найдется
407
3”=i”l,i”2,...,i”k, при котором 8^... ,5r2,8j”is= s”. Тогда для слов одинаковой
длины вида 3”3, 3”3' получаем
p(3”3,3”3')>p(A(s,3”3),A(s,3”3')),
откуда следует
p(3,3')>p(A(s”,3),A(s”,3'))
для любых слов 3,3' одинаковой длины. То есть (pA>S" не размножает искажения
типа замены букв. По доказанному выше заключаем, что
5iS”=8i-s”
при любых i,i' el. Следовательно, автомат As внутренне автономен.
Для формулировки приводимого ниже следствия доказанной теоремы
нам потребуются некоторые понятия теории автоматов. Напомним их форму-
лировки. Автоматы А, А' с множествами состояний S, S', соответственно, с
одинаковыми входным и выходным алфавитами I, О называются неотличимы-
ми, если для любого состояния seS найдется неотличимое от него состояние
s'e S' автомата А' и наоборот, для любого s' eS' найдется неотличимое от него
состояние sgS. Состояния s, s' считаются неотличимывми, если A(s,3)=A(s',3)
при любом Зб1*. В приводимом ниже следствии под приведенной формой ав-
томата А понимается любой неотличимый от него приведенный автомат.
Следствие. Отображение <pA,s автомата А инъективно и не размножает
искажения типа замены букв тогда и только тогда, если приведенная форма
As/=(I,S/,0,8/,p/) автомата As является внутренне автономным автоматом и при
любом s/gS/ отображение инъективно.
Вернемся к исходной цели данного параграфа - описанию помехо-
устойчивых шифрующих автоматов.
Пусть A =(I,S,O,(8i)iei,(Pi)iei) - шифрующий автомат (отображения ps
sgS - инъекгивны). Будем предполагать, что 1=0 (ниже для различения эле-
ментов входного и выходного алфавитов мы сохраним различные их обозначе-
ния).
Определим для автомата А так называемый обратный автомат: А'1 =
=(O,S,I, (8y)yeo,(Py)ieo) положив: О - входной алфавит, I - выходной алфавит,
частичную функцию переходов 8У определим так: для sgS
8y(s)=8i(s),
где i=ps ‘(y), а частичную функцию выходов РУ определим положив
Py(s)=ps’‘(y).
Приведенные выше математические утверждения можно трактовать теперь
следующим образом. Отображения входных слов в выходные слова обратного
автомата А1, получаемые при его начальных состояниях (ключах) осуществ-
ляют расшифрование выходных слов шифрующего автомата А, полученных на
тех же состояниях. Требование помехоустойчивбсти к автомату А"*1 по отноше-
408
нию к помехам типа замены букв в канале связи (не размножения искажений
типа замены букв его всеми отображениями) состоит в том, что приведенная
форма автомата А должна быть внутренне автономным автоматом.
Перейдем к изучению помехоустойчивости шифрующих автоматов
к помехам типа пропуска букв в канале связи.
Пусть е - бинарное отношение на множестве слов некоторого конечно-
го алфавита D. Для слов Р и Q из Q* отношение PsQ ,будет означать, что слово
Q получено из Р удалением некоторой его буквы; е' - t-ая степень бинарного
отношения 8.
Определение. Автоматное отображение <pA,s I*—>0* , sgS называется не
размножающим искажения типа пропуска букв, если для любых слов 3, 3' gI*
одинаковой длины 5(3) =5(3') и любого kG {1,..., 5(3)} найдется число
me {1,...,к}, такое, что выполняется импликация:
3Ek3 '=>cpA,s (3)Emq>A,s (3')-
Теорема. Инъективное отображение <pA,s автомата
A=(X,S,0,(5i)iei,(Pi)ieI), |1|=|О| не размножает искажений типа пропуска букв то-
гда и только тогда, если для автомата As=(I,Ss,O,(8i)jei,(Pi)iei) при любом s' gSs
отображение ps- не зависит от выбора s'из Ss.
ДОКАЗАТЕЛЬСТВО. Пусть инъективное отображение cpA,s не размно-
жает искажения типа пропуска букв. В силу инъективности <pA,s и равенства
|1|=|О|, для любого усУ существует слово вида 3=ii,i2, при котором A(s,3)=yy.
Для слов 3 и i2 имеем Зг12. Следовательно, A(s,3)sA(s, i2). Поэтому A(s, i2)=y, в
частности, PsCij^PXh)/откуда следует: ii=i2. Таким образом, при т' имеем
A(s,ii')=yy',
гдеу^у'.
Покажем, что при любом icl и s”=8jS отображение (pA,s” не размножает
искажения типа пропуска букв. Действительно, при любых igI, 3gI* (3 - не
пустое слово) и 3', для которого ЗеЗ', справедливы отношения
i3ei3', A(s,i3)eA(s,i3').
Учитывая, что первые символы в словах A(s,i3), A(s,i3') равны, получаем
A(8iS,3)EA(8iS,3').
Из сказанного выше следует, что любое отображение <pA,s'> s' gSs не размножает
искажения типа пропуска букв.
Для кеГ из I имеем: ii'ei', A(s,ii')=yy', где у^у', yy'sA(s,i'), откуда выте-
кает, что ps(i')=y'. Поэтому при sA=8jS
Ps4i')=y'=₽s(i')
для всех Гиз I, не равных i. Следовательно, для всех s(i)= 8iS, igI
409
' Ps Ps(i)-
А так как каждое отображение срA1S-, s' gSs не размножает искажения типа про-,
пуска букв, получаем: ps=ps- при любом s'gSs.
Достаточность условий теоремы очевидна.
Следствие. Если |I|=|O|, As=(I,Ss,0,(5i)iei,(Pi)jei) - приведенный автомат
и инъективное отображение <pAs не размножает искажения типа пропуска букв,
to|Ss|=1.
С точки зрения шифров, последние математические утверждения гово--
рят о том, что обратный к автомату А автомат А1, в случае его приведенности,
будет не распространять искажения типа пропуска букв' лишь в случае, когда
он имеет одно состояние, то есть шифрующий автомат А должен реализовы-
вать шифр простой замены.
ЗАМЕЧАНИЕ. Утверждение теоремы об инъективном отображении <pA>s
автомата A=(X,S,O, (8i)iei, (Pi)iei), |1|=|О|, не размножающим искажений типа
пропуска букв, остается верным и при отказе от условия: |1|=|О|.
/
Параграф 7.5
Общие математические задачи, связанные с пробле-
мой построения помехоустойчивых шифров
Основные положения данного параграфа опубликованы в журнале Дис-
кретная математика. Т. 9, вып. 3, 1977, в статье Бабаша А.В., Глухова М.М.,
Шанкина Г.П. «О преобразованиях множества слов в конечном алфавите, не
размножающих искажений».
Введение. Пусть (Аш,Ар,ср) - алгебраическая обобщенная модель шиф-
ра (см. параграф 1.7); АШ=(Х,КШ,У,1) - шифр шифрования (f: ХхКш—>У - сюрье-
ктивное отображение, причем для каждого %еКш отображение fx:X->y,
fx(x)=f(x,x) инъективно), а АР=(У',КР,Х',Г) - шифр расшифрования (УсУ',
ХеХ', Г:У'хКр-»Х' - сюрьективное отображение); ср: Кш—>КР - биекция, для
которой при любых хеХ, /еКш из условия f(x,%)=y вытекает F(y,cp(x))=x.
Будем предполагать, что открытый текст х шифруется на некотором
ключе х, а шифртекст у= fx(x)ey передается по каналу связи с помехами. По-
лучатель шифртекста принимает «искаженный» текст у' еУ'. При расшифрова-
нии шифртекста у получается открытый текст F(y,cp(x))=x, а при расшифрова-
нии текста у' получается текст F(y',cp(x))=x'. При наличии канала связи с по-
мехами возникает естественное желание использовать «помехоустойчивые
410
шифры» - шифры, для которых при малом искажении шифртекстау в резуль-
тате расшифрования принимаемого текста у' получают малое искажение от-
крытого текста х.
Пусть «мера искажения» шифртекста уеУ определяется с помощью
значения Фу(у,у') некоторой функции Фу, определенной на множестве УхУ'со
значениями в области действительных чисел (чем меньше значение функции,
тем менее искажено у), а «мера искажения» открытого текста хеХ определяет-
ся с помощью значения Фх(х,х'), (х,х')е ХхХ' некоторой функции Фх, опреде-
ленной на множестве ХхХ'со значениями в области действительных чисел.
1. Шифр (Аш,Ар,(р) называется не распространяющим искажения более
чем в к раз (относительно «функций искажения» Фх, Фу), если при любых
хеХ, у' еY' и любом ключе хе^ш выполняется неравенство
кФу(Гх(х),у')> Фх(х, F(y',cp(x)).
При выполнении этого условия для к=1 шифр называют не распростра-
няющим искажений (относительно функций Фх, Фу).
Обычно понятие помехоустойчивости шифров вводят в следующем
усиленном варианте. Предполагают, что функции искажений Фх, Фу определе-
ны на множествах Х'хХ', Y'xY', соответственно.
2. Шифр (АШ,АР, %) называется не распространяющим искажения бо-
лее чем в к раз (относительно «функций искажения» Фх, Фу), если при любых
у", у'eY' и любом ключе хеКш выполняется неравенство
кФу(у",у')> Фх(Р(у",<р(х), F(y',q>(x)).
При выполнении этого условия для к=1 шифр называют не распростра-
няющим искажений (относительно функций Фх, Фу).
Общая математическая задача описания шифров, не распростра-
няющих искажения (относительно «функций искажений» Фх, Фу), форму-
лируется следующим образом. Описать отображения (p:Y'->X', для кото-
рых при любых у", y'eY' выполняется неравенство
Фу(у'\у')^Фх(ф(у"),ф(у'))-
Описаниие таких отображений позволяет строить шифры расшифрова-
ния, не размножающие искажений, а затем строить и соответствующие им
шифры зашифрования. ‘ ,
Обычно уточняют структуру абстрактных множеств Y', X', а также
уточняют определение искажений в канале связи, то есть конкретизируют
«функции искажений» Фх, Фу.
Ниже приводится такие конкретизации и уточнения для описания
помехоустойчивых шифров расшифрования в случае Х= Х'=¥'=У= Q*,
где О - конечный алфавит. При этом (в условиях эндоморфных шифров) ма-
тематическая задача описания помехоустойчивых шифров сводится к задаче
411
описания инъективных отображений Q* в- Q*, не размножающих искажений
определенных типов.
Приводимые ниже результаты инициированы одним полученным в
1956 году результатом А. А. Маркова о биективных преобразованиях (р
множества слов Q в конечном алфавите Q, сохраняющих длины слов и не
увеличивающих расстояния Хемминга между словами одной длины, то есть, не
размножающих искажений типа замены букв в словах.
Рассмотренная А. А. Марковым задача имеет много различных вариа^
ций. В частности, представляют интерес не только биективные но и инъектив-
ные отображения, наряду с искажениями типа замены букв могут происходить?
искажения других типов, например, пропуски букв, по разному может опреде-
ляться понятие близости слов и т. д. Некоторые из таких вариаций и.рассмат-
риваются ниже. В пункте 3 на основе идей А. А. Маркова описано множество
G(Q, р) всех инъективных отображений (р: £1* —> Q*, сопоставляющих сло-
вам одинаковой длины слова также одинаковой длины и не увеличивающих
расстояние Хемминга р между словами. В качестве следствия этого описания
получается и упомянутый выше результат А. А. Маркова. В пункте 4 рассмат-
ривается задача описания множества G(£l, е) инъективных отображений
(р: Q* —> Q*, не размножающих искажений типа пропуска букв. Однако из
них полностью описаны лишь биективные преобразования. В пункте 5 полнос-
тью описано пересечение G(Q.,p,s) множеств G(Q, р) и G(Q, е). В пункте
6 в качестве меры близости произвольных слов (а не только словодииаковой
длины) рассматривается обобщенное расстояние Хемминга, функция , совг
падающая с р на парах слов одинаковой длины и принимающая значение К
на парах, в которых одно слово получается из другого удалением к букр. До?
называется, что при |£1| > 3 множество всех G(Q,p') инъективных отображе-
ний, не увеличивающих значений функции р', совпадает с пересечением мно-
жеств G(Q.,p) и G(Q, г), хотя непосредственно из определений вкдвдепИ^.
G(Q, р') в каждое из этих множеств не усматривается. Заметим, что функция
р' не является метрикой: она не удовлетворяет известному свойству треуголь-
ника.
2. Основные понятия и обозначения.
Мы будем придерживаться следующих обозначений.
N - множество натуральных чисел;
No - множество целых неотрицательных чисел;
412
[s,/] = {s,s + l,...,?}, где s,t e N0,s < t
fl- конечный алфавит из n букв n > 2; буквы алфавита fl и слова в алфави-
те Q будут обозначаться соответственно малыми и большими латинскими бу-
квами (с индексами и без индексов);
P = Q - графическое равенство слов Р и Q;
2 - пустое слово;
д(Р) - длина слова Р;
Q' - множество всех слов длины t е No в алфавите Q, в частности,
£1°={я};
fl* = l^Jfl* - обозначает множество всех слов в алфавите fl;
PQ - произведение (конкатенация) слов Р, Q;
Р1 - t -я степень слова Р (при любом t & No) причем Р° = Л для любого
РеО‘;
MH = {PQ:PeM,Q е Н} - произведение множеств слов М и Н;
Р(,) - z -я буква слова Р при естественном упорядочении всех букв слова Р
от его начала к концу;
P(i —> а) - слово, полученное из Р заменой его i -й буквы на букву а;
P(i —А) - слово, полученное из Р удалением его i -й буквы;
P(i -+M)={p(i->a):aeM} - для любого подмножества М из fl;
p(i Фа) - слово, полученное вставкой буквы а после i -й буквы слова Р при
i е [1, б(Р)] и перед первой буквой слова Р при i = 0;
p(z4a/)={p(z4 а): а е М} - для любого подмножества М из Q;
р(Р,О) - расстояние Хемминга между словами Р, Q (одной длины), слова Р
и Q, для которых р(Р, Q) = 1, будем называть соседними;
£ - бинарное отображение на множестве fl , PeQ означает, что слово Q по-
лучено из Р удалением одного вхождения некоторой его буквы;
£' - t -я степень бинарного отношения £;
£(p) = ^sQ*:P£Q}-,
z - особая буква, не содержащаяся в fl;
р (Р,С?) - обобщенное расстояние Хемминга между словами Р и Q, опреде-
ляемое как р(р,е)пРи а(р)=з(е) и как min /?(Р, Qi ) при д(р)> д(0) , где
413
минимум берется по всем словам Qt, полученным вставками в Q ровно
д(Р)-вхождений особой буквы z (предполагается также, что ,
p'(P,Q)=p'(Q,P)-,
0>(р) - образ слова Р при отображении ср : Q* —> Q*;
р(м)={р(р):РеЛ/} - для Любого подмножества слов М множества Q’;
S{M) - симметрическая группа подстановок множества М относительно
умножения подстановок, так что для g,he S(m) к хеМ
gh(x) = h(g(x));
р- оператор обращения слов, то есть р(Р) = акак_х...ах для слова
Р = ах...ак_хак;
РК - для слова Р = ах...ак_хак и подстановки <т е S(Q) обозначает слово
S, - симметрическая группа подстановок множества [1, f].
Определение 1. Отображение ср : Q —> Q называется не размножа-
ющим искажений типа замены букв, если для любых слов P,Qe£l выполня-
ются условия
8(p)=a(e)=>aMp))=a(v>(e)), <р
р(р,0)>р(<р(р\ч>(0»- (2)
Определение 2. Отображение (р : Q —> Q называется не размножа-
ющим искажений типа пропуска букв, если для любых слов P,Qeti и любо-
го к е [1,д(Р)] найдется число т е [1, Аг] - такое, что выполняется импликация
. (3)
Множество всех инъективных отображений ср: £1 —> £1 , не размно-
жающих искажений типа замены букв, обозначим через G(£l, /?), а множество
всех инъективных отображений £1* в £1*, не размножающих искажений типа
пропуска букв, обозначим через G(£l, £). Положим
G(Q, р, £) = G(Q, р)Г| G(Q,f).
Очевидно, что множества <j(Q, р) и G(Q., е) являются подполугруп-
пами полугруппы = (Q*) всех отображений Q* в Q*. Из них естественно
414
выделить подгруппы биективных отображений. Обозначим их, соответственно,
через О, (Q, р) и G2 (О, г).
Определение 3. Отображение ср : Q —> Q называется не увеличива-
ющим обобщенного расстояния Хемминга между словами, если для любых
P,Qe О’
Множество всех инъективных и биективных от ображений - не увеличиваю-
щим обобщенного расстояния Хемминга между словами обозначим соответст-
венно через G(Q,-p') и Gx(£).,p'}.
3. Описание полугруппы G(Q, р). Так как преобразование
<р е G(Q,p) инъективно и удовлетворяет условию (1), при любом t е No оно
отображает множество Q' в при некотором Д(/) е No. Кроме того, из
инъективности (р следует, что для (р выполняется условие: для любых
Z + A0 = .s + A(.s)=>^(Q')p]^(Qs)=0. (4)
Таким образом, описание полугруппы <7(£1, р) сводится к описанию
инъективных отображений <pt: О! —> е No, удовлетворяющих услови-
ям (2) и (4).
Опишем сначала инъективные отображения (р : Q' —> О'+д, Д е No, с
условием (2).
, Теорема 1. Инъективное отображение <р :£1‘ —> Г2,+Л удовлетворяет
условию (2) (не размножает искажений типа замены букв) тогда и только тогда,
когда оно имеет вид: для любого слова Р е О!
^(р)=4<t1(pW1)))^2(^(2)))--4^(^(')))4+u (5)
при фиксированных (не зависящих от слова Р) словах 4>—4+1 е О суммар-
ной длины 5(4-4+)) = Д, подстановках сг,,...,<т, е s(n) и подстановке
geS,.
ДОКАЗАТЕЛЬСТВО. Очевидно, что любое отображение
(р: Q' —> £2,+д вида (5) инъективно и обладает свойством (2). Докажем обрат-
ное утверждение. Пусть <р инъективно и удовлетворяет условию (2). Зафикси-
415
руем слово Р е Q' и рассмотрим множество слов P(i —> Q), i е [1, f]. Так как
при а Ф b
p(P(i —> а\ P(i —> b)) = 1,
в силу инъективности (р и свойства (1)
pM.P(i a)\(p(P(i 5))) = 1
и поэтому
^(p(z-» а)) = ^(p(t(z)—> Л,.(а))) (6)
при некоторых t(z')g [1,^ +Д] и /г, е $(П).
Ясно, что P(i —> Q) P(j —> £1) при i Ф j и
p(P(r(i) -> £})) = ^(p(t(j) -> £1)) при t(z) = t(j) . Отсюда и из инъективности
<р получаем, что г есть инъективное отображение множества [1,1] в [1,Г + 1].
Таким образом, по отображению <р каждому слову Р g £1' сопоставлен набор
подстановок hx,...,ht g S(£l) и инъективное отображение г: [1,?]-4к[1,/ + 1],
так что для всех a g £1 и i G [1, /] выполняется равенство (6). Подставляя
а = Р^ в (6), находим, что
p(p)W')) = h{p^\i е [1,/]. (7)
Упорядочив числа r(z), i g [1, t + Д], в порядке возрастания
r(zj) < r(z2)<... < r(z;), мы можем записать слово ?>(Р) в виде
где йу(Р^) есть т(у)-я буква слова <p(P\j g [1,/], a AlA2...Al+l - слово, полу-
ченное из <р(Р) удалением букв с Номерами т(г‘]),..., t(z',) . Из формулы (6) сле-
дует также, что формула (8) остается верной при замене слова Р дюбым из
слов множества P(z —> £1) при любом i g [l,f]. Подчеркнем еще, чтопри изме-
нении в Р буквы с номером j в слове <р(Р) изменится лишь букра с номером
4/)- ' ' ".
Теперь докажем, что подстановки hx,..., ht, отображение г и
, ?12,..., Аг+1 не зависят от выбора Р из О.'.
Так как к любому слову Q g О! можно перейти от Р, меняД последо-
вательно лишь по одной букве, указанный факт достаточно доказать лишь для
416
соседних с Р слов. Пусть Q&Q.', p(P,Q)=\ и сходное с (8) представление
слова Q имеет вид
v(Q}=.в,л;(еш)вм. ст
где есть г'(г)-я буква слова <р(@) и отображение г': [1,/]—> [1,/ +Д]
определяется равенствами
(p{Q(i -> а)) = ^(c(r'(z)-> A;(a))),z е[1,4« е • (Ю)
Так как p(P,Q) = 1, существует единственное число к е [1, f] - такое, что
р(*) .£ q^) Следовательно, Р{к —> а) = Q(k —> а) при любом а е £2. Отсюда
и из равенств (6), (10), учитывая, что p(ff>(P), ^(С)) = 1 > получаем, что
г'Щ=^)ил; = hk для указанного к. Далее рассмотрим слова
P{ja),Q(jа) при j * к. Очевидно, что p(P(j —> а\Q(j —> а)) = 1, а
поэтому и p(<p{P(j afy,(p(Q(j —> а))) = 1. Согласно формулам (8), (9) при
изменении j -й буквы в словах P,Q будут меняться соответственно по подс-
тановкам hj,h'j только т(у)-яи т'(у)-я буквы слов <р{Р\ <p(Q). Отсюда легко
следует, что г'(у) = т(у),Л' = hj и Д. = Btp е [1,Z +1]. Этим и доказано утве-
рждение о независимости подстановок , отображения г и слов
Ах, А2А1+1 от выбора слова Р из £2'Таким образом, равенство (8) верно
для всех Р 6 £2'. Введя переобозначения Л, = <Js,is = g(s)> мы получим из (8)
требуемую формулу (5). Теорема доказана.
Из всего вышесказанного в данном пункте следует, что для построения
любого отображения из G(£l, р) можно выбрать произвольную последовате-
льность д(0),д(1),... чисел из No и для каждого t из No задать указанным в
теореме 1 способом отображение (pt :О.' —> £2'+4^ так, чтобы выполнялось
условие (4). Если это возможно для выбранной последовательности
д(о),д(1),... , то последовательность ^>0,^>|5... определит отображение <р из
С7(£2, р), для которого ограничение <р | £2' совпадает с (pt.
Покажем, как можно удовлетворить условие (4) при определении отоб-
ражений для заданной последовательности (рй,(рх,... чисел из No.
Для этого заметим сначала, что номера букв слова ф(Р) из формулы (8) делят-
ся на два класса: - множество номеров,букв, изменяющихся при замене
417
слова Р другими словами из Q' ,М2 (<р) - множество остальных номеров (но-
меров неизменяющихся букв. Точнее,
Из формулы (8) видно, что выбирая подходящим образом слово Р, мы можем
получить в качестве b -й буквы в слове ^>(р) любую букву из Q. С другой
стороны, для любого к е M^tp) буква (р(Р)^ является постоянной, независи-
мой от выбора слова Р (это буква слова А^А^.А^ ). Следовательно, справед-
лива следующая теорема.
Теорема 2. Отображение —>Q* принадлежит G(£l, р) тогда и
только тогда, когда
(1) ограничения (pt = ср | определен^! согласно теореме 1 для
некоторых Д(?), t е No;
(2) для любых t, s е No, при которых t + A(z) = s + Д($), существу-
ет такое к М 2(<р М 2((р} что
где Р е Q(, <2 е Q4 s.
Отметим, что условие 2 данной теоремы вполне конструктивно.
В частном случае, когда все числа Д(^) равны нулю, получается следу-
ющая теорема А. А. Маркова.
Теорема 3. Биективное отображение ф'.О. —> Q не размножает ис-
кажений типа замены букв в словах тогда и только тогда, когда для любого
слова Р е Q', t е N, оно задается формулой
<р(Р) = alt (р(г‘(1)))..<т„ (P(gt(,))),
где '.i<EN,je. [1,- любой набор подстановок из S(Q), a g,,g2- лю-
бой набор подстановок, соответственно, из 5,,52,...
4. Описание группы G,(Q,6'). Напомним, что <j](Q,f) есть множест-
во всех биективных отображений (р : Q —> Q , удовлетворяющих условию
14 Зак. 5
418
(3) . Докажем сначала несколько общих утверждений о преобразованиях из по-
лугруппы G(Q,f).
Предложение 1. Для любого ф е , любых слов P,Q е Q* и
числа к е N справедлива импликация
' рг*е=>?(р>ме)- со
ДОКАЗАТЕЛЬСТВО. Согласно определению степени £к бинарного
отношения £, соотношение PskQ означает существование последовательно-
сти Р — Рх, Р2,..., Pk+l = Q - такой, что Р^£ Рг£... £ Рм . Отсюда и из условия
(3), учитывая инъективность отображения ф, получаем, что
^(/»)^(P2)f ...^(Pt+1),
что означает ф (Р) £кф (Q).
Предложение 2. Для любого ф eG(Q,f) существует . А = Д(^>) eN0
такое, что при каждом t е Ао
ДОКАЗАТЕЛЬСТВО. Пусть <р ^G(Q.,£), ф(Х) = Ри ^Р) = Д. Тогда
для любого слова A eQ! при t > 1 имеем Ае‘ А и в силу (11) получаем, что
(р{А)£‘ Р. Отсюда видно, что д(ф(А}) = t + д(Р) = д{А) + & . Следовательно,
да')^'+А-
Предложение 3. Отображение (р из G(£l, £) биективно тогда и только
тогда, когда оно сохраняет длины слов.
ДОКАЗАТЕЛЬСТВО. Если ф eG(Q, £) сохраняет длины слов, то бие-
ктивность (р следует из его инъективности. Если же оно биективно, то указан-
ное в предложении 2 число Д(^) равно нулю, а это и означает, что ф сохраня-
ет длины слов.
Предложение 4. Множество всех биективных отображений из
G(Q, £) является группой.
ДОКАЗАТЕЛЬСТВО. Замкнутость множества относительно
операции умножения отображений очевидна. Поэтому достаточно показать,
что
Ф е G( (Q, £) => ф~' е Gx (Q, £)
419
то есть
PsQ^<p-\P)£(p-\Q)
для любых Р, Q eQ .Из условия сохранения длин слов (предложение 3) отоб-
ражением ср следует, что для слов Р, Q найдется натуральное число m - такое,
что <рт{Р) = Р ,(p"\Q) = Q.K>w <р~\Р) = <рт~\Р), <р~\О) = (рт~\О),п
доказываемая импликация является следствием замкнутости множества
(£1, £) относительно произведения отображений.
Из предложений 1 и 4 следует, что любое отображение ф е G{ (£2, £)
перестановочно с отношением £, то есть для любого Р е £1*
^О(Р)) = £(Ф(Р)) • (12)
В дальнейшем нам понадобятся еще некоторые чисто технические
утверждения о словах из £2*.
Лемма 1. Если Р & Q!, a,b е£2 и аР=РЬ, то а=Ь и Р = а'.
Для ДОКАЗАТЕЛЬСТВА леммы 1 достаточно провести побуквенное
сравнение слов аР и РЬ.
Лемма 2. Если Р G Q', a,b е О. и
р(аР,РЬ) = 1 (13)
то а b и Р — акЬт при некоторых к,т е No.
ДОКАЗАТЕЛЬСТВО. Из условия (13) следует существование единст-
венного значения i е[1,( +1], при котором (аР)(,) Ф (РЬ)^. Пусть (аР)(,) = с,
(РЬ)(,) = d . Тогда при 1>1слово Р имеет вид PxcdP2, и из (13) получаем, что
аРх - Р\С, dP2 = Р2Ь.
Отсюда и из леммы 1 следует утверждение леммы 2.
Лемма 3. Любое слово Р длины г?(Р) > 3 однозначно определяется
множеством слов f(P) .
ДОКАЗАТЕЛЬСТВО. Для слова Р возможны три варианта:
Р = а‘-,
Р = акЬР1-,
Р — аЬР2,
где е£2, a^b, РХ,Р2 е£1*, Р2Ф Л, t>3, к>2. Они характеризуются
следующими свойствами множества £•( Р) .-
14*
420
в первом случае £(Р) состоит из одного слова а1 1;
во втором случае все слова из <s'( Р) начинаются с буквы а, при-
чем одно из них есть ak~lbPi, все другие имеют начало ат,т > к;
в третьем случае £ ( Р) содержит слова аР2, ЬР2, а все остальные
слова, если они есть, имеют начало ab, при этом таких слов может не быть
лишь в том случае, когда Р2 = Ьг.
Очевидно, что по указанной информации легко не только различить эти
три варианта, но и однозначно найти слово Р.
Из леммы 3, в частности, следует, что для любых слов P,Q eQ длины
t > 3 выполняется импликация
f(P) = f(2)=> p = Q. (14)
Л емма 4. Если для некоторых слов , Р2, Q е О. и различных букв
a,b е Q выполняются соотношения
PxaP2£Q, PxbP2£Q,
т о Q=pxp2:
ДОКАЗАТЕЛЬСТВО. По условию слово Q получено удалением по од-
ной букве из слов PvaP2, Р\ЬР2. Если удалялось выделенное вхождение буквы а
и слова Рх.аР2 или буквы b из РХЬР2, то утверждение верно. Кроме того, поско-
льку а *Ь, слово Q не "могло получиться удаление из слов Рх.аР2, РХЬР2 по од-
ной букве из Рх или по одной букве из Р2. Следовательно, возможна лишь
ситуация,где
Рх=Рх'сР”, P2^P2'dP2"
и либо
Q=Px'P”aP2 = Р1ЬР2'Р2",
либо
Q=Pl,P"bP2=PlaP2'P2n.
В силу симметрии достаточно рассмотреть один из указанных случаев.
Пусть имеет место первый случай, то есть
Q= Px'P”aP2'dP2" = Рх cP"ЬР2 Р2".
Тогда Рх"аР2*d = сР"ЬР2 , в частности Р"а = сР", Рх'd = ЬР2 . От-
сюда по лемме 1 получаем, что а=с, Р"=ак ,d=b, P2=dm. Следовательно,
0 = P'akadmdP" = P'aakddmP"
1 Z 1 Z ’
421
Px = Pxaak, P2=dmdP2",
откуда получаем, что Q = РХР2 н лемма доказана.
Теперь можно перейти к формулировке и доказательству основ-
ного результата данного пункта.
Теорема 4. Отображение (р: О. * —> О' содержится в группе
(7, (£!,£) тогда и только тогда, когда (р (Р) для любого Р еО’ имеет вид
<р(Р}=Р° (15)
или
^(Р) = //(РСТ) (16)
где <т-фиксированная для данного (р подстановка из S(Q),a ц - оператор
обращения слов.
ДОКАЗАТЕЛЬСТВО. Очевидно, что отображения (15), (16) содержать-
ся в (7,(0,^). Докажем обратное утверждение. Пусть £1= {ах,...ап} и
<р е О, (Q, <?). Так как (р биективно, оно по предложению 3 сохраняет длины
слов, в частности, р(Л) = Л и (р(ах) = е[1,и], для некоторой подс-
тановки сг eS(Q). Покажем, что при этой подстановке ст отображение дей-
ствует, как в (15) или как в (16), на всех словах Р длины 2.
Для п < 2 этот факт следует непосредственно из (12), биективное™ <р
и сохранения им длин слов.
Пусть п > 3. Обозначим для краткости сг(а( ) = 6,, i е[1,и]. Так как
е(аха Л) = {ах,аj} при i j, в силу (12)
f(^(a,.ay)) = {р(а,.),^(ау)} = {&,.,6у} .
Отсюда, учитывая биективность (р, находим, что
(p{aiaj) = bibj, <p{ajai) = bjbi (17)
ИЛИ
^(а,.ау) = Ь& , <р(а}аЛ) = Ь^ (18)
Докажем, что при выполнения условия (17) для некоторых фиксиро-
ванных различных i,j е[1,и] необходимо выполняются равенства
(p{alak) = bibk (19)
422
при любом к i. Допустим. Что при некотором к , к* j справедливо ра-
венство <p(afak) = ЬкЬ(п, значит (р(ака^ = btbk. Рассмотрим слово
Q = aiajak. Так как s(Q) = {apij ,atak ,0^0.к} , в силу (12)
£(^(2)) = {Ь^^Ь^а^)} .
Отсюда однозначно находим, что
^(2) = b&bj, (р{а^к) = bkbj <р(ака^ = bjbk.
Теперь для слова Q = atakaj
£(2i) = {a(ak,aiaJ.,akaJ}
и в силу (12) получаем, что
£(т))НМ;ЛМД}-
Однако нетрудно видеть, что слова Qx, удовлетворяющего последнему
условию, не существует (так как ни одна из букв bt, bj, bk не может быть пе-
рвой буквой в слове <p(Qi) ). Значит, наше допущение невозможно, то есть
верно (19). Из доказанного легко следует, что если равенства (17) выполняются
для некоторых фиксированных различных i, j, то они выполняются для произ-
вольных i,j е[1,и]. Из соображений симметрии то же самое верно и относите-
льно условия (18). Заметим еще, что теперь равенства
q)(aiai) = bibi, i е[1,и],
следуют непосредственно из условия (12).Таким образом, (р действует по пра-
вилу (15) или по правилу (16) на всех словах длины Л < 2 .
Допустим, что последнее утверждение верно для всех слов длины
L < t и докажем его для всех слов t+1.
Пусть <р(Р) = Ра для всех Р e fl', a Q - любое слово длины Z+/. Тог-
да, используя (13) и очевидное равенство (f(£?))<T = £’(2<т) , получим, что
£(^(2)) = ^>(£(2)) = (£(2))ст = £(2ст) •
Отсюда, в силу (14), (р ( Q ) = Q а .
Если же ^>(Р) = /1{Ра) для всех Р , то аналогично, используя
перестановочность преобразования д с отношением £ и преобразованием
Р Ра, получим, что
?(2) = д(2ст)
для любого слова Q eQ'.
Теорема доказана.
423
Непосредственно из теорем 1, 3 получается следующее утверждение.
Следствие 1. Справедливо включение
<^(£2,6') с Gx(Q.,p).
5. Описанйе полугруппы G (£2, р, s) .
Теорема 5. Инъективное отображение (р: £2 —> £2 содержится в
полугруппе G (£2, р, е) тогда и только тогда, когда для любого Р е£2* отоб-
ражение (р(Р) имеет вид
(р{Р) = АРа В (20)
или
<р(Р) = Ар(Р°)В (21)
при фиксированных для заданного (р словах А, В е£2 и подстановке
o-eS(Q).
ДОКАЗАТЕЛЬСТВО. Непосредственно из теорем 1- 4 видно, что отоб-
ражения вида (20) и (21) содержаться в полугруппе
G(£2 ,p,s) = G(£2, р) I G (£2, £•) . Докажем обратное утверждение. По
предложению 2 для любого <р eG((2,f) существует число ДеА -такое,
что для любого teN справедливо включение <p(Q! ) a £2'+л . Если Д = 0, то
<р биективно, и по теореме 3 имеет требуемый вид (20) или (21) при А = ВЛ.
Пусть Д > 1. Согласно теореме 1 (при t=l) (p(at) = Aa(a/)B для лю-
бой буквы at из £2, где А, В- фиксированные слова, ст - фиксированная по-
дстановка из S(£2). Так как atsA , то ^(а^Сф^Л) , i е[1,и]. Отсюда, учиты-
вая, что |£2|= п > 2 , по лемме 4 получаем, что ф{Л) = АВ. Таким образом,
доказываемое относительно <р утверждение верно для всех слов Р длины
L < 1. Для общего индуктивного перехода нам понадобиться доказать его и
для слов длины 2, поскольку на словах длины L < 1 преобразования ф, опре-
деляемые формулами (20) и (21), действуют одинаково. По теореме 1 (при 1=2)
образ ф( Р) любого слова Р длины 2 находится по формуле
ф(Р) = A^(P(g(l)))A2cr2(P(s(2)))A3
при некоторых At, А2, А3 е £2*, сг,, <у2 е 5(£2), g е S2. В зависимости от подс-
тановки g возможны два случая:
р(Р) = A,v,(Pm)A2a2(Pm)A,-,
р(Р)=А,а1(Рт)А2а2(Рт)А1.
424
В первом случае
«9(Р(1 -А а)) = А1а1(аУА1а2(РтуА3,
9>(Р(2 -> а)) = Л^Р^Л^аУА,.
Так как P(i —> a)s P(i —> Л) ,то
(р ( Р (z —> а)) £<р (P(i —> Л )) . Отсюда, учитывая, что п > 2, по лемме 4
получаем,что ^(Р(1—> Л)) = AtA2cr2(P(2)) А3
р(Р(2-> ЛУУ = А,<7,(Р1'>УА2А,.
с другой стороны по доказанному для Г=1
-> Л)) = Аа(Р(2))В ,
Ф(Р(2 -+ Л)) = Аа(Р(1))В .
Приравнивая правые части соответствующих приведенных выше ра-
венств, получим, что At — А, А2 = Л, А3 = В , CTj = ст2 = ст и, значит,
<р(Р)=АРкВ.
Аналогично во втором случае получим, что
<р{РУ= А/АР'УВ.
Далее в индуктивном переходе необходимо рассмотреть два случая, ко-
гда для всех слов длины t < L, где L > 3, действие отображения <р задается
соответственно формулами (20), (21). В обоих случаях при рассмотрении слов
длины L повторяются те же рассуждения, что и выше при t=2. А именно, срав-
ниваются значения слова Р (z —> Л ) , найденные по лемме 4 с использовани-
ем формулы (5) и по предположению индукции (при всех возможных Р gQ',
i e[l,f]). В обоих случаях получим, что
Л, = А, А2 = А3 =...= At - Л, At+l = В, CTj = ст2 =...= ст, = ст,
а подстановка g в первом случае будет тождественной, а во втором она равна
2 - Z-1 Л
t-1 - 2 1/
Отсюда следует, что утверждение теоремы справедливо для всех слов
длины L<t, t > 3. Теорема доказана.
Описание полугруппы G ( Q , р ' ) . Заметим, что хотя значение
р ' на парах слов одной длины совпадает со значением р, включение
G ( Q , р ') cz G(Q,p) непосредственно из определений 1,3 не еле-
425
дует, поскольку при определении множества G(£2,p) на отображения
(р: £2, * —> £2 * налогалось дополнительное требование (1). Кроме того, непо-
средственно из определений G (£2, р') и G(£2, е) не следует также, что
G ( £2 , р') cz G ( £2 , е ) . Дело в том, что из Ps Q следует, что
Р’(Л0) = 1 , однако обратная импликация неверна. Вместе с тем, имеет место
следующее утверждение.
Теорема б. Если |£2| = п > 3,то <7(£2,р)ПС(£2,£’).
Для ДОКАЗАТЕЛЬСТВА теоремы 6 введем некоторые дополнительные
понятия и обозначения.
Пусть Р - фиксированное слово из £2 . Множество слов М <z £2 на-
зовем Р- системой, а слова из М назовем1 Р - совместимыми, если для лю-
бых А,В е М
0(А,В} =/3(Р,А)=\.
Р- систему назовем максимальной, если она не входит ни в какую от-,
личную от нее Р-систему.
Опишем максимальные Р— системы. Для Р - Я единственной такой
системой является. £2. Пусть Р е£2‘, t > 1. В этом случае множество
содержащее все Р- системы, представляется в виде объединения
О(Л=£(Ли |JP(i4£2)Ul(JP(i->£2)\P(Ol .
М-1 М=1
Выясним вопрос о совместимости слов из различных компонент этого
объединения.
Лемма 5. Пусть А,В - два различных Р-совместимых слова для
слова Р* Л.
Тогда
(1) A Gf(P)=>PgP(z4£2), ze[O,r];
(2) А еЕ(Р\В eP(iР = РхаР2, А = РХР2,В = РХЬР2 при
некоторых Рх ,Р2 е£2*, aj) е£2, а Ф b;
(3) А,В gР) => Р = РхаЬР2,А-РХР2,В- РХЬР2 при некоторых
РХ,Р2 g£2*,a,b е£1,а*Ь;
(4) если некоторое слово С совместимое А,В и А,В,С gs(P), то
С = А или С = В;
426
(5) A € P(z4 Q), В g P(jQ) => P = PxbP2, A = PxabP2, В = PxaP2
или A = PxbaP2,В = PxaP2,a*b;
(6) если A eP(iiQ),В gP( jIQ) , то существует r g[0,/], при
котором А,В g P(r>kQ);
(7) A g P(z —> Q)=> В £ P{j —> Q) для j .
ДОКАЗАТЕЛЬСТВО. 1. Если A g s(P), В g P(z4 Q), to
c\JB) — d(A) = 2 . Поэтому 0(A,B)>2 и ЛОВ не могут быть Р-совмести-
мыми.
2. Пусть А = P(J —> Л), В g P(i —> b). Если z = j, то утверждение ве-
рно. Пусть z < j. Тогда
Р = Р|аЛ2сЛ3, А = RxaR2R3, В = RxbR2cR3, а фЬ.
Так как <Я(Л) = <?( В ) - 1, при нахождении /3(А,В} в слово А долж-
на вставляться особая буква z так, чтобы для полученного слова А выполня-
лось условие р( А ,В) = 1. Так как а *Ь, буква z может быть вставлена толь-
ко в Rx. Значит, А = Rx zx' aR2R3 и из условия /X А ,В ) = 1 получаем, что
ptzR" ,R"b) = 1, p(aR2,R2c) = 0.
Отсюда, используя леммы 1 и 2, находим, что а = с, Р2 = ак, R = bm.
Поставляя найденные результаты в PQ4 и В, замечаем, что утверждение 2
выполняется при Рх = Rx, Р2= R2cR3. Справедливость утверждения 2 при
z > J устанавливается аналогично.
3. Пусть A = P(i—>2), В = P(J —> Л). Так как А^В,то
A j. Пусть z < j.
Тогда
Р = RxaR2bR3, А = RxR2bR3, В = RxaR2R3
Так как А) = <%В), то /У (А,В) = р(А,В) , и из условия
р( А ,В ) = 1 получаем, что р( R2baR2) = 1. Отсюда по лемме 2 находим, что
a^b, R2= akbm. Следовательно, утверждение 3 выполняется при Рх = Rxak,
P2=bmR3.
4. Допустим, что А, В ,С попарно различны. В силу симметричности
условий для слов А, В, С, не теряя общности, можно считать, что
Р = RxaR2bR3cR^, А = RxR2bR3cR4, В = RxaR2R3cR4, С = RxaR2bR3R4.
427
Применяя утверждение 3 к парам слов ( А,В), ( В,С), ( А,С), полу-
чим равенства Р2 = akbm, R3 = brcs, R2bR3 = арсч.
Отсюда видно, что Ь- а или b = с. В первом случае А = В, во втором
В= С. Получим противоречие.
5. Это утверждение доказывается так же, как утверждение 2, с рассмот-
рением двух подслучаев i < j, и i> j.
6. Пусть. А = P(i Фа) , В е Р(у Ф Ь} и i < j. Тогда
Р = RlR2R3, А = RiaR1R3, В = RlR2bR3.
Отсюда и из условия /X А,В) = 1 по лемме 2 получаем, что R2 = akbm,
а*Ь,и утверждение 6 выполняется при = Riak, Р2 = bmR2.
7. Если А е P(z —> Q), В е Р( j —> Q), то очевидно, что при i Ф j
справедливы равенства р)(А,В) = р(А,В) = 2 и получаем противоречие.
Лемма доказана.
Лемма 6. Если Р е Q', |О| = и > 3 и t > 1, то максимальные по мощ-
ности Р-системы слов исчерпываются множествами вида
(а) Р(/ФО), i е[0,/];
(b) P(z->(Q\{p0)}y{P(z^2)}, i e[l,r];
ДОКАЗАТЕЛЬСТВО. Используем утверждения 1-7 леммы 5. Очевид-
но, что Р-системы типа (а) и (Ь) содержат по п элементов. Покажем, что лю-
бая другая Р -система слов содержит менее п элементов. Пусть Р е Q', t > 1
и М - максимальная по мощности Р -система. По утверждению 4 леммы 5
М содержит не более двух различных слов из Р( е). В связи с этим возможны
три случая.
1. А,В еМ1 £(Р), А Ф В. Тогда согласно утверждению 3
Р = Р{аЬР2, А = РхаР2, В = РХЬР2, а ФЬ.
Кроме того, согласно утверждению 1 Ml Р(/ФО) = 0, z е[0,/],ав
силу утверждения 7 может существовать лишь единственное значение i, при
котором МI P(z —> Q) Ф 0. Пусть С е Ml P(i Ф Q). Тогда в силу утверж-
дения 2
С = PlacP2 = PxdbP2, с Ф b, dta.
Получили противоречие. Значит, в этом случае М = 2 < п.
2. Ml г(Р)= {Л}. Здесь, как и выше, из утверждений 1 и 7 получим,
что М может содержать слова лишь из P(z—>Q) при некотором одном зна-
428
чении i e[l,z]. В последнем случае, согласно утверждению 2, Р = Р\аР2, и М
состоит из слов PiP2, РХЬР2, b а, то есть М - Р-систематипа(Ь).
3. Ml г(Р) = 0 для всех i е[1,/]. Здесь согласно утверждению 7
возможны два подслучая.
3.1 P(z‘ —> Q)I М = 0 для всех i е[1,/]. Тогда в силу утверждения 6
М gP(j‘4<Q) для некоторого j e[0,f] и значит, М есть Р-система типа (а).
3.2 Существует единственное значение z , при котором
P(z —> Q)I М Ф 0. Если М с: P(z —> Q), то |Л/| < п. В противном случае
согласно утверждению 6 существует единственное значение j e[0,f] такое,
что Ml P(j 4< Q) 0 . Тогда согласно утверждению 5 справедливо представ-
ление Р = Р,ЬР2, и М может содержать лишь слова вида Р{аР2, РхаЬР2 или
РхаР2, РхЬаР2, а Ф b. Так как при различных а,Ь,с
pf(PlabP2,PlcP2) = 2,
М не может содержать более двух слов, и поэтому |Д/| < п. Лемма доказана.
ДОКАЗАТЕЛЬСТВО ТЕОРЕМЫ 6. Из теоремы 5 следует, что
G(Q,p)I G(Q,f)cG(Q,/y).
Докажем обратное включение. Пусть (р е G(Q,/7 ). Так как <р инъек-
тивно и не увеличивает значений функций f) , то (р любую Р -систему слов
переводит в <£>( Р) -систему для любого Р е Q*. В частности, максимальные
Р-системы типов (а) и (Ь) переводится отображением (р в <р(Р) -системы ти-
пов (а) и (Ь).
Докажем, что Р -система типа (а) может отображаться лишь в <р( Р) -
систему типа (а) для любого слова Р е Q*.
Допустим, что для некоторого слова Р некоторая его Р-система М
типа (а) отображается в <р( Р) -систему типа (Ь). Тогда
Р = РЛ- И = {faP,-I «(».«]} «</’)= йа.й •
р(М) = {ай} у{2АЙ; i e[l,n],l * т}
и для фиксированного h е[1,п]
(К Ъ ai, Р2 ) = Q,Q2 , <р( РхсчР2) = <2хЬ£2, i е[1,л], i*h. '
Заметим, что в последнем равенстве при изменении буква bt прини-
мает все значения из Q\ |. Рассмотрим еще Р{агР2- систему типа (а)
429
ЛГ = {р(araiP2: i е[1,л]}
при фиксированном г е[1,л] г * h . Для нее возможны два случая.
В первом случае ЛГ ) есть (р{ Рх агР2 ) -система типа (а). Тогда
а=а' а". мадз)=аш1 < «[•,«]
ИЛИ
а=а1 а". «АЛ)=а'с.а" <>,а.; s It"]
в обоих вариантах имеем противоречие с определением (р, поскольку
0 (Рх ah Р2, arah Р2) = 1, (5 ((р{ Рх ah Р2 ),^( Р{ arah Р2)) = 2.
Во втором случае <р( М ) есть <р( Рх агР2 ) -система типа (Ь). Тогда в
силу симметрии можно считать, что Qx = Qx cQ" и при некотором фиксиро-
ванном s е[1,п]
<p(PlarasP2) = Qi,Ql"brQ2, (p[PlarajP2)=Ql'CjQ”brQ2, J е[1,л],
j Ф S , С; * С .
J J ,
Докажем, что h — s. Допустим, что это не так. Тогда из условия
0 ( R arah^2> ah^2 ) ~ 1
получаем, что
^(Q'c^b^^'cQ-Q,)^!
Отсюда точно так же, как в доказательстве утверждения 2 леммы 5, из
условия () (А,В) ъ 1 получим, что Ьг = с и Q}" = ск при некотором к eN0.
Используя эти равенства, приходим к соотношениям
НР\arasP2) = 2,' ckcQ2, (p{P{ahP) = QJ cckQ2,
противоречащим инъективности (p. Таким образом, h — s^r ив силу условия
п > 3 найдется J е[1,и], J Ф h,s,r. Тогда
fl(PlalP1,PlaralP2)=l,
MP^P^P^P^/HQ^Q^b^Q^^'^Q^l
что противоречит инъективности <р.
Итак, во всех логически возможных случаях наше допущение ведет к
противоречию. Значит (р переводит Р-системы типа (а) в ^>(Р)-системы типа
(а) и Р -системы типа (Ь) в <р( Р) -системы типа (Ь) для любого слова Р е Q .
Теперь, используя этот факт, покажем, что ^>( Р) е G(Q,f). Пусть для
некоторых слов P,Q eQ выполнено соотношение PsQ, то есть Р, Q име-
ют вид
430
P=PiaP2,Q=PlP2
при некоторых РХ,Р2 gQ , a gQ. Рассмотрим Р-систему типа (Ь)
M = {PiP2}{j[PlaiP2:ai^a}.
По доказанному (р переводит ее в ^?( Р) систему типа (Ь). Это означа-
ет, что ср( Р) = R = RxbR2, ^(M)={P1P2}U{P16;P2:Z’J,*b]
Если при этом <р( PlP2) * R{R2, то
<Р( Л Р2 ) = Ri bsR2, (р( Р, а, Р2 ) = Я, R2
при некоторых bs Ф b, а аг Ф а.
Отсюда, учитывая, что (р( Р, arP2 ) = R^bR2, получаем, что <р перево-
дит Р}Р2-систему ^PiajP2:aj gQ| типа (а) в <р(Р{Р2 )-систему типа (Ь). Полу-
ченное противоречие доказывает, что <р(Р,Р2)- Р,Р2, то есть <р( Q) = R{R2.
Следовательно, верно соотношение <p(P)£<p(Q) , и поэтому (р &G{Q.,s).
Отсюда и из предложения 2 следует, в частности, что (р удовлетворяет
условию (2). А так как на словах одной длины функция /У совпадает с р, то *
(р e.G(Q.,p). Таким образом, <р еС(О,р)П<7(О,^ ), и теорема доказана.
Замечание 1. В практических приложениях криптографии представляет
интерес рассмотрение биективных отображений конечного множества
Q° UO. • -UQ£ в себя, не распространяющих искажений.
Из доказательств приведенных утверждений легко видеть, что и в этом
случае вид таких отображений остается таким же (см. параграф 7.3).
Параграф 7.6
Основные понятия сетей засекреченной связи. Ком-
прометация абонентов
Под сетью засекреченной связи, далее более коротко, под сетью связи
(СС) подразумевают совокупность объектов: шифр, используемый в сети, мно-
жество А абонентов сети, правила (протоколы) распределения ключей шифра
между абонентами сети, правила (протоколы) вхождения в связь, протоколы
восстановления СС после компрометации абонентов, протоколы синхрониза-
ции шифраторов в СС.
431
Любое подмножество А' множества абонентов А с введенными прави-
лами функционирования сети называют подсетью СС. Говорят, что подсеть А'
обладает конференц-связью (селекторной связью) если все абоненты подсети
могут одновременно войти в связь. Очевидно, необходимым условием этого
является наличие у всех абонентов аеА' общего ключа шифра.
Далее мы ограничимся рассмотрением так называемой двухсторонней
сети связи, то есть сети, в которой каждая пара абонентов может войти в
связь.
Обозначим через К(а) - множество ключей шифра абонента аеА. Мно-
жество К(С)={К(а), аеА} - назовем структурой сети С. Различают следую-
щие два способа ее формирования.
1. Прямое распределение ключей. В этом случае множества К(а), аеА созда-
ются в центре организации сети засекреченной связи и рассылаются по закры-
тыми каналам абонентам сети, например, в виде ключевых блокнотов для связи
с абонентами.
2. Функциональное распределение ключей. В центре организации СС опре-
деляют для каждого абонента аеА некоторую базисную информацию U(a)eU
(U={U(a),aeA} и передают ее абоненту «а» по закрытым каналам. Выбирают
функцию Ф: AxU->K, удовлетворяющую условию: для любых а,Ь из А, а*Ь
Ф(Ь,и(а))= Ф(а,и(Ь)).
Для связи абонента «а» с абонентом «Ь» формируют ключ %(а->Ь)=Ф(Ь,и(а)),
абонент же b - ключ %(Ь—>а)=Ф(а,и(Ь))= Ф(Ь,и(а))=х(а—>Ь). Положим
Ф(а,и(Ь))=Фа(и(Ь)).
Для описания общей схемы функционального распределения ключей
введем дополнительные обозначения и понятия. Обозначим через W некоторое
конечное множество, которое назовем исходным множеством сети и введем
функцию f: AxW—>U, где U - конечное множество, которое назовем базисной
информацией сети. Положим f(a,w)=fa(w).
В центре организации СС в соответствии с абонентами сети аеА фор-
мируется базисная информация абонентов U(a), аеА. Именно, для некоторого
weW и всех аеА вычисляют U(a)=f(a,w). Таким образом, получение абонента-
ми ключей базируется на двух функциях f, Ф, которым соответствуют два се-
мейства функций fa: W—>U, аеА и Фа: U->K, аеА. При анализе такой СС естес-
твенным представляется предположение: на исходном множестве сети W за-
дано равномерное распределение вероятностей. Это распределение индуцирует
с помощью функций fa, аеА вероятностные распределения на множестве бази-
сных множеств абонентов {fb(w)=U(b):beA}, weW. Последние распределения,
в свою очередь, индуцируют вероятностное распределение на множестве клю-
чей абонентов {%(а—>b), a,beA}. С точки зрения синтеза СС естественным тре-
432
бованием является равномерность указанных распределений, что достигает-
ся соответствующим выбором функций fa, Фа,ае А. Именно, легко показывает-
ся, что такая равномерность достигается лишь при «равновероятных» функци-
ях fa, Фа, аеА, то есть таких функциях, при которых число решений каждого из
уравнений
fa(w)=U(b), Фа(и(х)=Х,
не зависит от выбора значения правой части. (Здесь через U(x) - произволь-
ный элемент из U, хе А, %еК). Таким образом, справедливо
Утверждение. Структура СС с функциональным распределением клю-
чей обеспечивает равновероятность базисной информации абонентов и равно-
вероятность ключей шифрования в том и только в том случае, когда функции
fa, Фа, ае А равновероятны.
Замечание. Из изложенного выше можно сделать вывод о том, что при
повторном вхождении в связь абоненты «а», «Ь» вырабатывают тот же самый
ключ х(а, Ь). Негативные последствия передачи шифрованных сообщений, по-
лученных на одном ключе, читателю уже известны. В целях предотвращения
повторного использования одного и того же ключа используют так называемый
процесс выработки рабочего ключа с помощью служебных посылок. Пусть М -
множество служебных посылок, передаваемых по открытым линиям связи.
Ключ Хш(а,Ь) для каждого сеанса связи абонентов «а», «Ь» вырабатывается с
помощью функции (р (вспомогательного алгоритма ф), ф(х(а—>Ь),т)=хш(а,Ь);
служебная посылка шеМ вырабатывается абонентом «а» и передается в откры-
том виде абоненту «Ь».
Расход ключевой информации сети. Будем предполагать, что все
множества, характеризующие сеть, заданы в виде множеств слов над некото-
рым алфавитом I. Одной из основных характеристик СС является объем R(C)
(число символов алфавита) базисной информация абонентов, рассылаемый
центром организации СС своим абонентам по закрытым каналам связи («рас-
ход ключевой информаций»). Пусть множество ключей К шифра имеет вид
K=IL, а множество U=Ir. .
В сети с прямым распределением ключей имеем расход базисной ин-
формации R„(C):
Rn(C)=L|A|t,
где t=|Ka|, аеА, L=logn|K.
Оценим величину г в случае, когда функции fa, Фа, аеА равновероятны.
433
Обозначим а - число решений уравнения fa(w)=U(b); в нашем случае
IFFI 1^1
a- при любом be А. Аналогично, 0= - число решений уравнения
Фа(и(х))=% при любом %бК. Поскольку |U|=|I|r, |K|=|I|L, то
r=L+log|i|0.
В сети с функциональным распределением ключей при равновероят-
ных функциях Фа, аеА имеем |Фа'‘(х)|=|и|/|К| = |I|r’L. Откуда г=Ь+1о§1||Фа'’(х)|,
(Фа '(х) - прообраз х)- Для расхода ключевой информации Иф(С) получаем
Кф(С)=г|А|.
При 0=1, |К(а)|=1, аеА.имеем
Иф(С)= Rn(C)=L|A|,
причем в этом случае множество ключей шифра, вырабатываемых самим або-
нентом аеА, есть Ка={х(а—>Ь), ЬёА, Ь*а}, то есть | Ка|=|А|-1.
Следовательно, переход к косвенному распределению ключей в данном
случае видимых преимуществ по расходу ключевой информации не дает. Более
того, косвенное распределение ключей выглядит более громоздким, сложным.
Однако его преимущества проявляются при учете нового фактора - компроме-
тации абонентов сети связи. Предварительно отметим, что при |К(а)|=1 все або-
ненты сети связи с прямым распределением ключей должны иметь один и тот
же ключ; при функциональном распределении ключевая информация абонен-
тов разная. Один уже этот факт защищает абонентов а,ЬеА от случайного по-
дслушивания со стороны других абонентов сети. При преднамеренном подс-
лушивании ситуация меняется.
Компрометация абонентов сети связи.
Предполагается, что априорными сведениями противника о СС являет-
ся знание им используемого в сети шифра, множеств: А и номеров абонентов
N(a), аеА; исходного базисного множества сети W; функций f, Ф. Он имеет
возможность перехвата сообщений абонентов’. С учетом указанных выше
свойств функций f, Ф, априорные распределения вероятностей на W, U и К для
противника равновероятны.
Под компрометацией абонентов сети засекреченной связи понимается
ситуация, при которой вся информация этих абонентов становится извест-
ной противнику. При компрометации абонента «с» противнику становится из-
вестен базисный элемент U(c) и, следовательно, и все ключи, связывающие «с»
со всеми другими абонентами. Это дает возможность противнику перераспре-
делить вероятности ключей на не скомпрометированных линиях связи. Задача
состоит в построении функций f, Ф таким образом, чтобы априорные и апосте-
434
риорные распределения вероятностей на ключах не скомпрометированных ли-
ний связи совпадали.
Методологически это требование совпадает с концептуальным требова-
нием К. Шеннона, выдвинутым им при определении совершенных (идеальных)
шифров.
Пусть априорное вероятностное распределение на U равномерное:
P(U(b)=cu)=l/|U|, ugU. Найдем апостериорное распределение на U при условии,
что U(c)=u' (P(U(a)=u/U(c)=u'), то есть при компрометации абонента «с».
Имеем
P(U(a)=u/U(c)=u')=P(f(a,w)=u/ f(c,w)=u')-
Обозначим через 4(f,a,c,u,u') число решений системы уравнений
f(a,w)=u
f(c,w)=u',
а через 4(f,c,u') - число решений последнего уравнения. Тогда в силу равноме-
рного вероятностного распределения на W получаем
,. P(U(a)=u/U(c)=u')=4(f,a,c,u,u')/4(f,c,u').
Назовем функцию f 2-равновероятной, если число решений указанной
выше системы двух уравнений при любом выборе а, с (а^с) не зависит от зна-
чений правой части системы (т.е. 4(f,a,c,u,u')=|W|/|U|2).
Утверждение (критерий устойчивости базисной информации). Ра-
венство априорных и апостериорных вероятностей
P(U(a)=u/U(c)=u')=P(U(a)=u)=l/|U|
при Любых а, с (а*с), и, и' и равновероятных функциях fa, ае А выполняется в
том и только в том случае, если функция f 2-равновероятна.
ДОКАЗАТЕЛЬСТВО. Пусть f 2-равновероятна. Тогда
P(U(a)=u/U(c)=u')=P(U(a)=u,U(c)=u')/ P(U(c)=u')=
(4(f,a,c,u,u')/|W|) P(U(c)=u')=(l/|U|2)P(U(c)=u').
Заметим, что P(U(a)=u)= P<SJJ(я) = u,U(с) = и\ )=|U|/|U|2=1/|U|.
ul
Следовательно, P(U(a)=u/U(c)=u'>(l/|U|2)P(U(c)=u')=(l/|U|2)/( 1/|U|)=1/|U|,
то есть функция f 2-равновероятна. Докажем обратное утверждение. Пусть
функции. fa, аеА равновероятны и P(U(a)=u/U(c)=u')=P(U(a)=u). Поэтому имеем
P(U(a)=u,U(c)=u')= P(U(a)=u) P(U(c)=u )=1/|U|2= 4(f,a,c,u,u')/|W|.
Откуда 4(f,a,c,u,u')=|W|/|U|2, то есть функция f 2-равноверооятна.
Данное утверждение составляет критерий устойчивости базисной
информации абонентов сети к компрометации одного абонента сети.
Назовем функцию f t- равновероятной, если для любого подмножества
{al, а2,...,аГ{мощности t'<t множества А число решений системы уравнений
435
f(al,w)=ul
f(a2,w)=u2
f(at',w)=ut'
не зависит от выбора значений правой части. Аналогично доказательству при-
веденного выше утверждения доказывается, что СС устойчива к компромета-
ции t абонентов сети тогда и только тогда, если функция f t+1-равновероятна.
Заметим, что при равновероятной функции Ф равновероятность базис-
ной ключевой информации U(a), аеА, обеспечивает равновероятность ключей
у всех абонентов сети. Однако из ключевой равновероятности сети в общем
случае не следует равновероятность базисной ключевой информации. Поэтому
представляет интерес вопрос о ключевой равновероятности сети связи.
Пусть априорное вероятностное распределение на К равномерное,
Р(х(а,Ь)=%)=1/|К| для любых а^в. Найдем апостериорное распределение
(Р(х(а,Ь)=х/х(а,с)=Х ) на К, при условии, что х(а,с)=хто есть при компромета-
ции абонента «с» (напомним, что х(а,с)=х(с,а). Рассмотрим систему уравнений
Ф(Ь, U(a)) =х(а,Ь)=х
Ф(с,и(а))= х(а,с)=х'
Обозначим через Ч(Ф,а,с,Ь х,Х ) число решений этой системы уравне-
ний, а через Ч(Ф,с,а,и') - число решений последнего уравнения. Тогда в силу
равномерного вероятностного распределения на U получаем
Р(х(а,Ь)=х/х(а,с)=х' )=Ч(Ф,а,с,Ь,х,х' )/Ч(Ф,с,а,х' )•
Аналогично доказательству критерия устойчивости базисной ключе-
вой информации доказывается
Утверждение (критерий устойчивости ключей).
Равенство априорных и апостериорных вероятностей
P(x(a,b)=x/x(a,c)=x' )=(P(x(a,b)=X)= 1 /|К|
при любых а, с, b (a^cf, b^c), х>Х и равновероятных функциях Фа, аеА выпол-
няется в том и только в том случае, если функция Ф 2-равновероятна (то есть
при любых различных а,с,Ь число решений Ч(Ф,а,с,Ь Х>Х) не зависит от выбора
правой части х,Х рассматриваемой системы уравнений).
В случае К= IL, U=Ir и устойчивости ключей к компрометации одного
абонента сети, полагая т|=Ч(Ф,а,с,Ь,х,х )> получаем
|U|=n|K|2,
откуда следует
r=2L+log|i| т].
Следовательно, расход ключевой информации в нашем случае есть
Кф(С)= |A|(2L+log|I|n). (*)
436
Ясно, что уже при t=l скомпрометированных абонентов устойчивая
сеть с прямым распределением ключей должна иметь следующую ключевую
структуру: множество К(а) для любого аеА должно включать в себя ключи ви-
да х(а->Ь)*х(а->с) при Ь^с. Таким образом, величина |К(а)| кратна |А|-1, то
есть
|К(а)|=к(|А|-1), к>1,
а общий расход ключей равен
R„(C)=kL|A|(|A|-1). (**)
Сравнивая выражения (*) й (**), приходим к следующему выводу.
При |А|>3 минимальный расход ключей (т|=1) в 1-устойчивой сети связи
с функциональным распределением ключей меньше минимального (|К(а)|=1)
расхода в такой же сети при прямом распределении ключей, и этот разрыв уве-
личивается с ростом |А|.
Заметим, что из приведенного выше критерия t-устойчивости сети сле-
дует, что расход ключевой информации в этом случае при функциональном
распределении ключей равен
R^(CHA|((tH)L+log|I|Y),
где у - число решений системы уравнений
f(al,w)=ul
f(a2,w)=u2
f(at,w)=ut,
то есть |U[=y|K|t+1.
Заметим, что при прямом распределении ключей 1-устойчивая сеть яв-
ляется t-устойчивой при любом t<|A|-2, то есть
R„XC)=kL|A|(|A|-1)
при любом t.
Минимальные расходы ключей в t-устойчивой сети имеют рид
тКф.,(С)=|А| (t+l)L, mRn.,(C)= L|A|(|A|-1).
Назовем величину 8(t)=mR„it(C)/ mR^t(C) показателем эффективности перехода к
функциональному распределению ключей.
В рассматриваемом нами случае
t 4-1
Таким образом, 8(t) есть функция, убывающая по t и лежащая в пределах
1 <S(t) <0,5(|А|-1).
437
Параграф 7.7
Перекрытия в сетях засекреченной связи
В процессе образования ключей для связи абонентов сети друг с дру-
гом может возникнуть ситуация, когда ими получены одинаковые ключи, на
которых шифруются открытые тексты. Такая ситуация является частным слу-
чаем так называемого «перекрытия ключей». В связи с этим рассмотрим вопрос
о выборе периодов исходных гамм шифраторов, обеспечивающих заданную
вероятность неперекрытия. Будем моделировать датчик исходных гамм авто-
номным полноцикловым автоматом (граф переходов автомата состоит из одно-
го цикла длины Т). Предположим, что ключами шифратора являются началь-
ные состояния автомата А, выбираемые для каждого сообщения случайно и
равновероятно. Условимся говорить, что два сообщения длин L(l), L(2) имеют
перекрытие, если последовательности состояний AM(s), AM(s') длин L(l), L(2)
автомата А, отвечающие ключам шифрования s, s', имеют хотя бы одно общее
состояние.
Предположим, что передается г сообщений длин L( 1), L(2),...,L(r). Пе-
рекрытие отсутствует, если все пары сообщений не имеют перекрытий.
Теорема. Вероятность неперекрытия г сообщений длин L(l), .
L(2),...,L(r),
Г
L(j) = L при цикле длины Т автомата А равна
7=1
(г-1)!Сг~'т-ь+,-1
qp Г-1
ДОКАЗАТЕЛЬСТВО. Положение каждого отрезка на цикле автомата
определяется" его начальным состоянием, поэтому общее число расположений г
отрезков на цикле длины Т равно Тг.
Найдем число раположений, при которых никакая пара отрезков не
имеет общих состояний. Формула для числа возможных таких расположений
приведена в работе (Носов В.А. Специальные главы дискретной математики.
Учебное пособие. М., 1990, теорема 6, стр. 116). Ее доказательство, сообщен-
ное авторам Носовым В.А., приводится ниже.
Каждому расположению отрезков поставим в соответствие следующий
набор из трех параметров: начало первого отрезка (Т вариантов начал), поря-
док, в котором следуют отрезки после первого отрезка ((г-1.)! порядков), длины
промежутков между отрезками x(l),x(2),...,x(r), x(j)>0, je {1,...,г}. Введенные
числа удовлетворяют равенству
438
X-v(7) +
;=i j-\
а х(1),х(2),...,х(г) уравнению
^х(Л = Т-£.
;=i
Общее число расположений отрезков на цикле при фиксированном по-
рядке и фиксированном положении Первого отрезка равно числу решений по-
следнего уравнения. Это число равно числу способов, которыми можно распо-
ложить Т-L предметов по г ящикам, или равно числу различных расстановок
г-1 перегородок между Т-L предметами (о...о|о...о|...|о...о). Последнее число,
очевидно, равно C^~lL+r_!. Поскольку введенный выще набор параметров взаи-
мно однозначно определяет каждое расположение отрезков, при котором от-
сутствуют перекрытия, то
r(r-i)!ca„.,r (r-Dic'-^-L*,-.
Р----------------------- -----------:-------.
Г тг-1
По указанной в теореме формуле, при заданных вероятности перекры-
тия (1^-Р), среднему числу сообщений г и среднему объему L переданной инфо-
рмации, можно вычислить необходимую минимальную длину Т цикла автома-
та.
При г=2 формула для вероятности перекрытия имеет достаточно прос-
той вид:
4
439
ЛИТЕРАТУРА
Основная литература
1. /Шен/ -Шеннон К. Работы по теории информации и кибернетике. - М., ИЛ, 1963. -
830 с. (Раздел - Теория связи в секретных системах.)
2. /Соб/ - Соболева Т. Тайнопись в истории России. М., 1994, 380с.
3. /Про/ - Проскурин Г.В. Принципы и методы защиты информации. (Учебное пособие)
Московский государственный институт электроники и математики. 1977.
4. /Фом/- Фомичев В.М. Симметричные криптосхемы. Краткий обзор криптологии для
шифрсистем с секретным ключом: Учебное пособие: М., МИФИ, 1995. -44с.
5. /Три/ -. Тришин А.Е. Криптографические системы с открытым ключом (курс лекций)
М., 2000, 122с.
6. Бабаш А.В., Глухов М.М., Шанкин Г.П. О преобразованиях множества слов в конеч-
ном алфавите, не размножающих искажений. Дискретная математика. Т. 9, вып. 3,
1977, С.3-19.
7. Варфоломеев А.А., Пеленицын М.Б. Методы криптографии и их применение в бан-
ковских технологиях. М.,МИФИ, 1995, 116 с.
8. Варфоломеев А.А., Домнина О.С., Пеленицын М.Б. Управление ключами в системах
криптографической защиты банковской информации. М., МИФИ, 1996.
9. А.А. Варфоломеев, А.Е. Жуков, М.А. Пудовкина. Поточные криптосхемы. Основ-
ные свойства и методы анализа стойкости. МГИФИ, 2000, 243 стр.
10. Ведение в криптографию. Под общей редакцией Ященко В.В.// М., МЦНМО -ЧеРо,
1998, 271с.
11. Глухов М.М., Елизаров В.П., Нечаев А.А. Алгебра. Часть 2. М..1991, 475с.
12. Грушо А.А., Тимониной Е.Е., Применко Э.А. Анализ и синтез криптоалгоритмов,
2000, 108 стр.
13. Диффи У., Хеллман М. Защищенность и имитостойкость. Введение в криптогра-
фию. ТИИИЭР, т.64, N3, 1979, с 71-109.
14. Дориченко С.А., Ященко В.В. 25 этюдов о шифрах. М.,Теис, 1994, 64с.
15. Зубков А.М., Клыкова Н.В. Построение баз данных с ограниченным временем по-
иска. Симпозиум по прикладной и промышленой математике. Тезисы доклада. 2001г.
стр. 185-186.
16. Кнут. Д. Искусство программирования для ЭВМ. Т.2, М.: Мир, 1977.
17. Н.А. Молдовян. Скоростные блочные шифры. - СПб, СПбГУ, 1998. - 230 с.
18. Н.А. Молдовян. Проблематика и методы криптографии. - СПб, СПбГУ, 1998. -
212 с.
19. Ю.В. Романец, П.А. Тимофеев, В.Ф. Шаньгин. Защита информации в компьютер-
ных системах и сетях. Радио и связь, М., 1999, 328 стр.
20. Саломаа А. Криптография с открытым ключом. М., 1997, 324с.
21. Сачков В.Н., Солодовников В.И., Федюкин М.В. Дискретные функции, используе-
мые в криптографии. М., 1998.
22. Труды по дискретной математике. Том 1, «ТВП», 1997г.
23. Труды по дискретной математике. Том 2, «ТВП», 1998г.
24. Труды по дискретной математике. Том 3, ФИЗМАТЛИТ, 2000..
440
25. Ю. С. Харин, В.И. Берник, Г.В. Матвеев, Математические основы криптологии.
Минск, БГУ, 1999, стр 319.
26. Хоффман Л. Современные методы защиты информации. Пер. с англ. - М. Сов. ра-
дио. 1980. -264 с.
27. А.Л. Чмора Современная прикладная криптография. М., Гелиус АРВ, 2001,244с.
28. Шнайер Б. Прикладная криптография. 2-е издание. Протоколы, алгоритмы и ис-
ходные тексты на языке С.
29. Speech and Facsemile scrambling and Decoding. A cryptographic series, v.31,1981. Ae-
gean Park Press.
30. Егоров Б.А., Прокофьев И.В. Исследование возможности построения шифров с рас-
стоянием единственности, существенно большим, чем для случайных шифров. Безо-
пасность информационных технологий. N 1, 1995, стр 24-25.
31. Введение в криптографию. Под общей редакцией В.В. Ященко. М., ЧеРо, 1998,271
стр.
32. Б.В. Рязанов, Г.П. Шанкин. Критерий равномерности распределения суммы цезави-
симых случайных величин на примарной циклической группе. Дискретная математика.
Т. 9, вып. 1, 1997, стр. 95-102.
33. Бабаш А.В. О периодичности последовательности состояний автомата, отвечающей
его начальному состоянию и входной периодической последовательности. Передана
для опубликования в журнал «Дискретная математика», 2001.
34. Бабаш А.В. О некоторых инвариантах конечного автомата. Обозрение прикладной и
промышленной математики. Пятая Международная Петрозаводская конференция. Те-
зисы докладов. Т.7, вып.1, М.:ТВП, 2000, стр.86-87.
35. А.А. Молдовян, Н.А. Молдовян, Б.Я. Советов. Криптография, Санкт-Петербург,
2000,218 стр.
36. Герасименко В.А. Защита информации в автоматизированных системах обработки
данных. В 2-х книгах, М., Энергоатомиздат, 1994. 576 стр.
ГОСТ 28147-89. Системы обработки информации. Защита криптографическая. Алго-
ритм криптографического преобразования, М. Госстандарт СССР.
37. Андреев Н.Н. О некоторых направлениях исследований в области защиты инфор-
мации. Международная конференция «Безопасность информации». Москва, 14-18 ап-
реля 1997. Сборник материалов. М., 1997. стр. 94-97.
38. Алферов А.П., Зубов А.Ю., Кузьмин А.С., Черемушкйн А.В. Основы криптографии:
Учебное пособие. М., Гелиос АРВ, 2001, 480 стр.
39. Александр Бабаш, Генрих Шанкин. Под небом нет ничего, что может скрыться
(криптография). Разведчики и шпионы. Серия «Секретные службы». М., XXI ВЕК-
СОГЛАСИЕ, 2000, стр.270-285.
40. Генрих Шанкин. Тысяча и одна ночь в криптографии. Тайные страницы истории.
Серия «Профессиональные секреты спецслужб», М., «ЛГ Информэйшн» ACT, 2000,
стр. 99-106.
40. Носов В.А. Специальные главы дискретной математики. Учебное пособие. М., 1990,
156 стр.
41. Гантмахер Ф.Р. Теория матриц. М., 1954.
42. Романовский В.Ц. Дискретные цепи Маркова. Ленинград, 1949 г.
441
Вспомогательная литература
Анохин М.И., Варнавский Н.П., Сидельников В.М., Ященко В.В. Криптография в бан-
ковском деле. Московский государственный инженерно-физический институт. М.,
1997.
Биллингслей П. Эргодическая теория и информация. М., МИР, 1969.
Брассар Ж. Современная криптология. М., Полимед, 1999.
Гайкович В., Першин А. Безопасность электронных банковских систем. М., Единая
Европа, 1994.
Л.М. Гольденберг, Б.А. Матюшкин, М.Н. Поляк «Цифровая обработка сигналов», М.,
Связь, 1990.
Кнут Д. Искусство программирования на ЭВМ. Т.2, М., МЦР, 1977.
Кнут Д. Искусство программирования на ЭВМ. Т.З, М., МИР, 1978.
Р.Галлагер. Теория информации и надежная связь. М.: Сов. Радио, 1974.
Жуков А.Е. Современные методы анализа систем блочного шифрования. (Обзор), М.,
МИР АН, 1994.
Жуков А.Е. Системы блочного шифрования. Методы анализа и результаты. (Обзор),
М., МИР АН, 1992.
Жуков А.Е. Системы блочного шифрования. Методы анализа и результаты II. (Обзор),
М., МИР АН, 1994.
И.В. Коновальцев «Об одном алгоритме решения систем линейных уравнений в конеч-
ных полях», Проблемы кибернетики, вып. 19,1967.
Лебедев А.Н. Открытые системы "‘закрытой” информации И Открытые системы, 3, лето
1993, с 20-34.
Максимов В.А. Защита информации от утечки по каналу побочных электромагнитных
излучений. И Защита информации, 1. 1992. С. 117-120.
Мафтйк С. Механизмы защиты в сетях ЭВМ. Пер. с англ. - М., Мир. 1993. - 216 с.
Месси Дж. Л. Введение в современную криптологию//ТИИЭР. 1988, Т. 76, N5.
Моисеенков Их Безопасность компьютерных систем. Компьютер-Пресс NN 10/91 стр.
19-24, 11/91 стр. 7-21, 12/91 стр. 57-67.
Николаев А.Г.. Перцов С.В. Радиотеплолокация (пассивная радиолокация). М., “Совет-
ское радио”, 1964.
Нечаев В.И. Элементы криптографии. Основы теории защиты информации. М., Выс-
шая школа, 1999.
Орлов В.А., Петров В.И. Приборы наблюдения ночью и при ограниченной видимости.
М., Воениздат, 1989.
Ошкин И.Б., Проскурин Г.В. Нижние оценки вероятности различения подмножеств
единичного куба. Проблемы передачи информации, т.30, вып.З, 1994.
А.В. Оппенгейм, Р.В. Шафер «Цифровая обработка сигналов», М., Связь, 1979,416с.
Палий А.И. Радиоэлектронная борьба. М., Воениздат. 1989.
Першин А. Организация защиты вычислительных систем. Защита информации. 1, 1992,
стр. 81-112., Компьютер Пресс NN 10/92 стр. 35-36,45-48,50, 11/92 стр. 33-38.
Петров А.А. Криптографические методы защиты. М., ДМК, 2000.
А.А.Пиотровский, Р.Г.Пиотровская, К.А.Разживин. Энтропия русского языка. Вопросы
языкознания, №6, т. II, 1962.
442
Пискарев А.С. Обеспечение качества продукции и услуг в области защиты информа-
ции. “Безопасность информационных технологий”, вып. 3, 1995.
Поляков В.Т. Посвящение в радиоэлектройику. М., “Радио и связь”, 1989.
Правиков Д.И. Ключевые дискеты. Разработка элементов систем защиты от несанкцио-
нированного копирования. М.: Радио и связь, 1995, 128 с.
Предпринимательство и безопасность. Сборник (3 книги в 2-х томах). М., “Универ-
сум”. 1991.
Прелов А.В. Проблемы защиты обрабатываемой средствами ЭВТ информации об утеч-
ке за счет перехвата побочных электромагнитных излучений и наводок и общие пути *
их решения. М., НИИ “Квант”, 1995.
Прокофьев И.В. Криптографические исследования системы защиты информации
GAMMA-3. Безопасность информационных технологий, 1,1995.
Проскурин Г.В. Задача различения гипотез о параметрах процесса обобщенного сколь-
зящего суммирования. Дискретная математика, т.5, вып. 3, 1993, стр. 44-63.
Проскурин Г.В. Способ генерации бинарного ключа на базе испытаний Бернулли с не-
известной вероятностью успеха. М., МГИЭМ, 1996.
Проскурин Г.В. Способ внедрения криптографической закладки в программные средс-
тва защиты информации, запускаемые командной строкой DOS. М., МГИЭМ, 1996.
Проскурин Г.В., Проскурина Л.С. Методы анализа средств криптографической защиты
в базах данных на примере СУБД Paradox (версия 3.5) М., МГИЭМ, 1994.
Проскурин Г.В., Проскурина Л.С. Экспертные криптографические исследования сис-
темы защиты данных GAMMA-3. М., МГИЭМ, 1994.
Проскурин Г.В., Проскурина Л.С. Метод координатного спуска и его применения к
решению криптографических задач. М., МГИЭМ, 1994, Безопасность информационных
технологий 1, 1995.
Проскурин Г.В., Проскурина Л.С. Обзор некоторых программных средств криптогра-
фической защиты информации. М., МГИЭМ, 1995.
Пярин В.А. Генерация, распределение и использование ключей. Защита информации, 1,
1992, стр. 157-184.
Расторгуев С.П. Программные методы защиты информации в компьютерных сетях. -
М: Яхтсмен, 1993, - 188 с.
Расторгуев С.П., Дмитриевский Н.Н. Искусство защиты и “раздевания” программ.
М.,”СовМаркет”, 1991 г.
Старовойтов А.В. Правительственная связь и актуальные проблемы развития защи-
щенных информационно-коммуникационных систем россии// Безопасность информа-
ционных технологий. 1994. Вып. %. С.6-20
Статистика речи и автоматический анализ текста. (Под редакцией Р.Г.Пиотровской.)
Л.: Наука, 1971.
О.Л.Смирнов, А.В.Екимов. Энтропия русского телеграфного текста. Труды Ленинград-
ского института авиационного приборостроения, №56, 1967.
Сидельников В.М., Приходов О.Ю. О методах генерации ключей, устойчивых к комп-
рометациям. (в печати).
443
Сидельников В.М. «Быстрые алгоритмы построения набора маркировок дискретных
массивов информации». Труды по дискретной математике, Т.1, ТВП, М.,1977, стр.251-
264.
Спановский В.А. Безопасность обмена банковскими сообщениями в СВИФТ.// Защита
информации, 1, 1992. С. 185-193.
Спесивцев-А.В., Вегнер В.А., Крутиков А.Ю., Серегин В.В., Сидоров В.В. Защита ин-
формации в персональной ЭВМ. - М. Радио и связь, МП Веста, 1992. 192 с.
Тимофеев Ю.А. Комплексный подход к защите информации (Почему и как надо защи-
щать компьютерные системы).// Защита информации, 1, 1992. С. 62-80.
Уокер Ф. Электронные системы охраны. “За и против”. 1991.
8. Р.Фано. Передача информации. Статистическая теория связи. М.: Мир, 1965.
Халяпин Д.Б., Ярочкин В.И. Основы защиты промышленной и коммерческой инфор-
мации. Термины и определения (словарь). М., ИПКИР, 1992.
Халяпин Д.Б. Технические средства, используемые для промышленного шпионажа.
Учебное пособие, ч. 1,М., РГГУ, 1993.
Хоффман Л. Современные методы защиты информации. М., Радио и связь, 1980.
Хижняк П.Л. Пишем вирус и ... антивирус. - М.: ИНТО, 1991, - 90 с.
Щербаков А. Разрушающие программные воздействия. М.: - Эдель, 1993, - 64 с.
Щербаков А. Защита от копирования. М.: - Эдель, 1992 - 80 с.
Ярочкин В.И. Лазерные системы подслушивания. Учебное пособие М., РГГУ, 1993.
Ярочкин В.И. Технические каналы утечки информации. М., ВИНИТИ, 1994.
Ярочкин В.И. Подслушивание телефонных переговоров и меры борьбы с подслушива-
нием. Учебное пособие. М., РГГУ, 1993.
Ярочкин В.И. Радиосистемы акустического подслушивания. Учебное пособие. М.,
РГГУ. 1993.
Ярочкин В.И. Способы несанкционированного доступа к объектам и источникам кон-
фиденциальной информации. М., РГГУ, 1993.
Ярочкин В.И., Халяпин Д.Б. Основы защиты информации. Служба безопасности пред-
приятия. М., ИПКИР, 1993
http.7ns.ssl.neva.ru/psw/crypto/potok/str-ciph.htm
Adams С.М. On immunity against Biham and Shamir's «differential cryptanalysis». Infor-
mation Processing Letters, v.41, N2, 1992, p.77-80.
Biham E. On Matsui's linear cryptanalysis. Pre-proceedings of Eurocrypt-94. May 9-12,
1994. University of Perugia, Italy. A workshop on the theory and applications of crypto-
graphic technicues. Scuola Superiore Guglielmo Reiss Romoli, 1994, p.349-361.
R. Anderson. "Solving a class of stream ciphers", Cryptologia, 14(3):285-2&8,1990.
R. Anderson. "Faster attack on certain stream ciphers", Electr. Lett,, 29(15):i322-1323, July
1993.
R. Anderson, post to Newsgroups: sci.crypt (from rjal4@cl.cam.ac.uk), 17 Jun 1994, Sub-
ject: A5
H. Beker and F. Piper, Cipher Systems: the Protection of Communications, London: North-
wood Books, 1982.
E. Biham and A. Shamir. Differential Cryptanalysis of the Data Encryption Standard.
Springer-Verlag, New York, 1993.
444
Biham E., Shamir A. Differential cryptanalysis of DES-like cryptosystems. Proc. Crypto-90,
L.N. Cbmp.Sci.,v.537, 1991, p.2-21.
W. Blaser and P. Heinzmann, ’’New cryptographic device with high security using public key
distribution,” Proc. IEEE Student Paper Contest 1979-80, pp. 145-153,1982.
V. Chepyzhov and B. S meets. On a fast correlation attack on certain stream ciphers. In D.W.
Davies, editor, Advances in Cryptology - Eurocrypt ’91, pages 176-185, Springer-Verlag,
Berlin, 1991.
Crypto 84: Lecture Notes in Computer Science, 1984, p 10-19.
Computer Security Handbook. Printed by MacDonnell Printers of Massachusets. Inc. 1987
Departament of Defence trusted computer system evaluation criteria. 1985.
Cryptology and Computational Number Theory (Carl Pomerans,Editor). Proceedings of
symposia in applied mathematics, vol. 42, 1989.
J. Daemen, R. Govaerts, and J. Vandewalle. ’’Resynchronization weakness in synchronous
stream ciphers”. Advances in Cryptology - Eurocrypt '93, LNCS vol 765, pages 159-167?
Springer-Verlag, 1994.
Departament of defence trusted computer system evaluation criteria. 1985.
T.E1 Gamal A Public Key Cryptosystem and a signature scheme. Proceedings of
Conference. Petrozavodzk, Russia, May 12-15, 1992 - Moscow/Utrecht: TVP/VSP, 1993,
pp366-375.
E. Dawson and A.Clark, "Discrete Optimisation: A Powerful Tool for Cryptanalysis?”, in
Proceedings of the 1st Int. Conference on the theory and Applications of Cryptology, Pragoc-
rypt '96, CTU Publishing House, 1996, pp 425-450.
C Ding, G Xiao, W Shan, "The Stability Theory of Stream Ciphers" , Springer LNCS v 561
(1991)
C. Ding, ’’The Differential Cryptanalysis and Design of Natural Stream Ciphers”. In Fast
Software Encryption, Cambridge Security Workshop, December 1993, pages 101-115,
Springer-Verlag, Berlin, 1994*
J. Golic and M. V. Zivkovic, "On the linear complexity of nonuniformly decimated pn-
sequences," IEEE Trans, inform. Theory, vol 34, pp. 1077-1079, Sept. 1988.
J. Golic, "On the security of shift register based keystream generators". In Fast Software En-
cryption, Cambridge Security Workshop, December 1993, pages 90-100, Springer-Verlag,
Berlin, 1994.
J. Golic, Linear cryptanalysis of stream ciphers. In Fast Software Encryption - Second Inter-
national Workshop, LeuVen, December 1994, Springer-Verlag, Berlin, 1995.
D. Gollmann and W. G. Chambers, "Clock-controlled shift registers: A review," IEEE J.
Selected Areas Commun., vol. 7, pp. 525-533, May 1989.
DJC MacKay, "A Free Energy Minimization Framework for Inference Problem in Modulo 2
Arithmetic". Fast Software Encryption - Second International Workshop, Leuven, December
1994, Springer-Verlag, Berlin, 1995, pp 179-195.
Golomb A.W. Shift Register sequences. Aegean Park Press, 1982.
Hall of Australia, New York, London, Toronto, Sydney, Tokio, 1989.
Konheim A.G. A Primer Cryptography, John Wiley&Sons, 1981.
W. Meier and O. Staffelbach, "Fast correlation attacks bn certain stream ciphers," Journal of
Cryptology, vol. I, no. 3, pp. 159-176, 1989.
445
W. T. Penzhom, "Correlation Attacks on Stream Ciphers: Computing Low-Weight Parity
Checks Based on Error-Correcting Codes". In Fast Software Encryption - Third International
Workshop, Cambridge, February 1996, pp. 159-172, Springer-Verlag, Berlin, 1996.
B. Preneel, "Introduction". Fast Software Encryption - Second International Workshop,
Leuven, December 1994, Springer-Verlag, Berlin, 1995, pp 1-5.
J. L. Massey, "Probabilistic encipherment," Elektrotechnik und Maschinenbau, vol. 104, no.
12, Dec. 1986.
Norbert Ryska, Sciegfried Herda. Kryptographiske Vervaren in dateenverarbeitung.
Springer-Verlag. Berlin, Heidenberg, New York,1980.
An Introduction to Computer Security. Prentice Proskurin G.V. On a Nonlinear Generaliza-
tion of Occupancy Problem // Probabilitic methods in discrete Mathematics. Proceeding of the
Third International Petrozavodsk Sebery J., Pieprzyk J. Cryptography.
B. Schneier, Applied Cryptography, 2nd edition, John Wiley & Sons, New York, 1996.
Siegenthaler, "Correlation-immunity of nonlinear combining functions for cryptographic
applications," IEEE Trans, Inform, Theory, vol. IT-30, pp. 776-780, Oct. 1984.
34. K. Zeng and M. Huang, "On the linear syndrome method in cryptanalysis," in Lecture
Notes in Computer Science 403; Advances in Cryptology: Proc,
Crypto'88, S. Goldwasser, Ed., Santa Barbara, CA, Aug. 21-25, 1987, Berlin: Springer-
Verlag, 1990.
Дополнительная литература по специальным вопросам
Криптографические средства с древнего времени
Kahn D. The Codebreakers. N-Y, 1967.
Соболева T. Тайнопись в истории России. М., 1994.
Бол У., Кокстер Г. Математические эссе и развлечения. М:, 1986.
Вигилев А. История отечественной почты. М., 1977.
Под редакцией Сухова А. Свободомыслие и атеизм в древности, средние века и в эпоху
возрождения. М., 1986.
Кэролл Л. Алиса в Стране чудес. Алиса в Зазеркалье. М., 1979.
Демурова Н. Льюис Кэролл. Очерки жизни и творчества. М., 1979.
Никифоровский В. Из истории алгебры XVI-XVIIb.b. М., 1979.
Моргенштерн И. Психографология. СПб., 1994.
Роуан Д. Очерки секретной службы. Спб., 1992.
Василевский А. Хиромантия. Вильнюс, 1990.
Мазер И. Дипломаты и дипломатия. За рубежом, № 17, 1993.
Ронге М. Разведка и контрразведка. М., 1937.
Фролов Г. Тайны тайнописи. М., 1992.
Черняк Е. Пять столетий тайной войны. М., 1991.
Черняк Е. Секретная дипломатия Великобритании. М., 1975.
Kahn D. Kahn on codes. N-Y, 1983.
Миллер Г. Толкование десяти тысяч снов. М., 1994.
Гарднер М. От мозаик Пецроуза к надежным шифрам. М., 1993.
446
Бекль М. Нострадамус. М., 1995.
Зима Д., Зима Н. Расшифрованный Нострадамус. М., 1998.
Краснобаев Б. Очерки истории русской культуры XVIII века. М., 1977.
Записки сенатора И.В. Лопухина. М., 1990.
Морамарко М. Масонство в прошлом и настоящем. М., 1990.
Холл М. Энциклопедическое изложение масонской, герметической, каббалистической
и розеркрейцеровской символической философии. Новосибирск, 1992.
Берберова Н. Масонство в России. М., 1998.
Мамин-Сибиряк Д. Сибирские рассказы. М., 1958.
Давыдов Ю. Неунывающий Теодор. М., 1986.
Князьков С. Очерки из истории Петра Великого и его времени. Спб., 1914.
Косидовский 3. Библейские сказания. М., 1990.
Зелинский Ф. Сказочная древность Эллады. М., 1993.
Фрейд 3. Психология бессознательного. М., 1990.
Быков В. Русская феня. Смоленск, 1994.
Жельников В. Криптография от папируса до компьютера. М., 1996.
Саломаа А. Криптография с открытым ключом. М., 1997.
Светоний Г.Т. Жизнь двенадцати цезарей. М., 1966.
Легенда о докторе Фаусте. М., 1978.
Гомер. Илиада. М., 1984.
Йистунова А. Прикасаясь к книге. М., 1973.
Гегель. Соч., ч.П, параграф 325. М.-Л., 1934.
Соболев Л. Морская душа. М., 1977.
Горбовский А. Загадки древнейшей истории. М., 1971.
История дипломатии, Т. 1. М., 1959.
Свифт Дж. Избранное. Л., 1987.
Колгушкин А. Лингвистика в военном деле. М., 1970.
Гадамер Г. Актуальность прекрасного. М., 1988.
“Последние Новости”, № 35,3.10.97.
Лавровский П. Старо-русское тайнописание. “Древности”, т. III, вып. I, М., 1870.
Помяловский Н. Очерки бурсы. М., 1954.
Записки Императорского Археологического Общества. T.V. СПб, 1853.
Энциклопедия славянской филологии. Т.4. М., 1929.
История дипломатии. Т. 1. М., 1941.
Устрялов Н. История царствования Петра Великого. СПб, 1859.
Покровский М. Избранные сочинения. Т. 1,4, М., 1967.
Ключевский В. Сочинения. Т.З, М., 1957.
Соловьев С. История России с древнейших времен. Т. 4-9, М., 1959.
Фролов Г. Тайны тайнописи. - М. A/О Безопасность и фирма Инфосервис Экспресс,
Лтд. 1992- 124 с.
Бабаш А.В. Зарождение криптографии (материалы к лекции), http:www.fssr.ru/
ices/1251/babash_articZe.htm/ 1998.
Бабаш А.В., Шанкин Г.П. Средневековая криптография (лекция с учебно-наглядными,
иллюстративными материалами), http://www.fssr.ru/iccs/1251/babashl. htm/ 1998.
447
Бабаш А.В., Шанкин Г.П. Рядом с криптографией (лекция с учебно-наглядными, ил-
люстративными материалами), http://www.fssr.ru/iccs/1251/babash2_l/htm/ 1998.
Ю. Полунов. Кто изобрёл колесо? Журнал «Подводная лодка», N 2, 1998, £тр 86-90.
А. Бабаш. Тайна головы раба. Мир и безопасность № 4, 1997, стр. 15-17; Служба безо-
пасности - новости разведки и контрразведки. № 3-4, 1996, стр. 73-75.
Г. Шанкин. Тысяча и одна ночь криптографии Служба безопасности - новости развед-
ки и контрразведки. № 1-2, 1997, стр. 76-78.
А. Бабаш, Г. Шанкин. Тайна смерти Марии Стюарт. Служба безопасности - новости
разведки и контрразведки. № 3-4, 1998, стр. 73-75.
А. Бабаш, Г. Шанкин. «Под небом нет ничего, что может скрыться от твоих глаз...»
Служба безопасности - новости разведки и контрразведки. № 5-6, 1998, стр. 75-78.
А. Бабаш, Г. Шанкин. Шифр, достойный королей. Служба безопасности - новости раз-
ведки и контрразведки. № 1-2, 1998, стр. 75-77.
А. Бабаш, Г. Шанкин. «Медленно, не спеши...» Служба безопасности - новости раз-
ведки и контрразведки. № 1, 1999, стр. 76-79.
Дешифрование шифра Виженера
Carroll, J.,S. Martin. 1986. The Automated Cryptanalysis jf Substitution Ciphers: Cryptolo-
, gia. 10 (4): 193-209.
Carroll, J., J. Robbins. 1989. Comhuter Cryptanalysis of Product Ciphers. Cryptologia.13 (4):
303-326.
Denning, D. 1982. Cryptography and Data Security. Reading MA: Addison-Westly.
Friedman, W.F. 1917. A Method of Reconstructing the Primari Alphabet from a Single One
Of the Series jf Secondary Alphabets. Riverbank Publication No. 15. Gentva IL: Riverbank
Labs.
Friedman, W.F. 1920. The Index of Coincidence and Its Application in Cryhtography. River-
bank Publication No. 22. Geneva IL: Riverbank Labs.
Gaines, H. 1956. Cryptanalysis; A Study of Ciphers and Their Solutions. New York NY: Do-
ver. Originally published as Elementary Cryptanalysis, 1939.
Kahn, D. 1967. The Codebreakers. New York NY: Macmillan Co.
King, J., D. Bahler. 1992. An Implementation of Probabilistic Relaxation in the Cryptanalysis
of Simple Substitution Ciphers. Cryptologia. 16 (3): 215-225.
Matthews, R. 1988. An Empirical Method for Finding the Keylength of Periodic Ciphers.
Cryptologia. 12 (4): 220-224. .
Melville, H. 1851/ Moby Dick. Project Gutenberg. Available anonymous FTR from
mrcnext.cso.uiuc.edu/etext.
Peleg, S., A. Rosenfeld. 1979. Breaking Substitution Ciphers Using a Relaxation Algorithm.
Communications jf the ACM. 22 (11): 589-605.
John C. King. 1994. An Algorithm for the Complete Automated Criptanalysis of Periodic
Polyalphabetic Substitution Ciphers. Cryptologia. 18 (4): 332-355.
448
Избранные вопросы синтеза криптосхем поточных шифров
Случайные системы уравнений
Закревский А. Д. Логические уравнения. Минск: Наука и техника, 1975
Ivanescu Р. L., Rudeanu S. Pseudo-Boolean Methods for Bivalent Programming (Lecture
Notes in Mathematics Vol. 23.) Berlin-Heidelberg Springer-Verlag, 1966.
Корбут А. А., Финкельштейн Ю. Ю. Дискретное программирование. M.: Наука, 1970.
Питерсон У. Коды, исправляющие ошибки. М.: Мир, 1964.
Гилл А. Введение в теорию конечных автоматов. М.: Наука, 1966, 272 с.
Колчин В. Ф. Системы случайных уравнений. М: МИЭМ, 1988, 80 с.
Балакин Г. В. Графы систем двучленных уравнений с булевыми неизвестными. — Тео-
рия вероятн. и ее примен.,, 1995, т 40, в. 2, с. 241—259.
Балакин Г. В. Системы уравнений с мешающими параметрами. — В сб.: Всероссийская
школа-коллоквиум по стохастйческим методам геометрии и анализа. Тезисы докладов.
М.: ТВП, 1994, с 11-12.
Балакин Г. В. Об одной возможности различия случайного и закономерного. — В сб.
Вероятностные методы в дискретной математике. Петрозаводск: Карельский филиал
АН СССР, 1988, с 10-11.
Месси Дж. Пороговое декодирование. М.: Мир, 1962
Балакин Г. В. О распределении числа решений систем случайных булевых уравне-
ний. — Теория вероятн. и ее примен., 1973, т XVIII, в. 3, с. 627-632.
Коваленко И. Н., Левитская А. А., Савчук М. Н. Избранные задачи вероятностной ком-
бинаторики. Киев: Наукова думка, 1986, 224 с.
Balakin G. V. On the number of solutions of systems of pseudo-boolean random equa-
tions. — В сб.: Вероятностные методы дискретной математики. Труды третьей Петроза-
водской конференции / Под ред. В. Ф. Колчина и др. Москва/Утрехт: ТВП/VSP, 1993, с.
71-98.
Балакин Г.В. Системы случайных булевых уравнений со случайным выбором неиз-
вестных в каждом уравнении. Труды по дискретной математике. Том 3, стр. 21-29
ФИЗМАТЛИТ, 2000.
Балакин Г.В. Системы случайных уравнений над конгечным полем. Труды по дискрет-
ной математике. Том 2, стр. 21-38 Научное издательство «ТВП», V997r.
Статистические свойства последовательностей
M.J.B. Robshaw. Stream Ciphers. Technical Report TR - 401, RS A Laboratories, revised
July 1995.
V
449
G.J. Simmons, editor. Contemporary Cryptology, The Science of Information Integrity. IEEE,
New York, 1992.
S. W. Golomb, Shift Register Sequences, San Francisco: Holden Day, 1967. (and also reprint:
Aegan Park Press, 1982)
E.D. Eridmann. Empirical Tests of Binary Keystreams. Master’s thesis, University of London,
1992.
E.D. Eridmann. Empirical Tests of Binary Keystreams. Master’s thesis, University of London,
1992.
E.D. Eridmann. Empirical Tests of Binary Keystreams. Master’s thesis, University of London,
1992.
D.E. Knuth. The Art of Computer Programming. Volume 2, Addison-Wesley, Reading,
Mass., 2nd edition, 1981.
H.M.Gustafson, E.P.Dawson and J.Dj.Golic, ’’Randomness Measures Related to subset oc-
curence”, in Lecture Notes in Computer Science 1029; Advances in Cryptology: Proc. Cryp-
tography: Policy and Algorithms, Ed Dawson, J.Golic (Eds.), Brisbane, Queensland, Austra-
lia, July 1995, pp. 132-143. Berlin: Springer-Verlag, 1996.
M. A. Stephens and R.B.D. D’Agostino, Tests Based on EDF Statistics, Goodness of Fit
Techniques, Statistics, Textbooks and Monographs, 68, Marcell Dekker Inc., 1986, 97-193.
Алгебраические свойства регистров сдвига с линейной обратной связью
Кузьмин А.С., Куракин В.Л., Нечаев А.А. Псевдослучайные и полилинейные последо-
вательности. Труды по дискретной математике, том 1. М.: ТВП, 1997. 139-202.
Куракин В.Л. Алгоритм Берлекэмпа-Месси над конечными кольцами, модулями и
бимодулями. Дискрет, мат. 1998, N. 4, 3-34.
Куракин В.Л. Полиномиальные преобразования линейных рекуррентных последова-
тельностей над конечными коммутативными кольцами. Дискрет, мат. 2000, N 3, 3-36.
Нечаев А.А. Код Кердока в циклической форме. Дискрет, мат. 1989, N 4, 123-139.
Нечаев А.А. Линейные рекуррентные последовательности над коммутативными коль-
цами. Дискрет, мат., 1991, N4, 107-121.
Нечаев А.А. Конечные квазифробениусовы модули, приложения к кодам и линейным
рекуррентам. Фундаментальная и прикладная математика. ЦНИТ МГУ, 1995, N 1,
229-254.
Нечаев А.А., Кузьмин А.С., Куракин В.Л. Структурные, аналитические и статистиче-
ские свойства линейных и полилинейных рекуррент. Труды по дискретной математике,
том 3. М.: ТВП, 2000. 155-194.
Нечаев А.А., Кузьмин А.С., Марков В.Т. Лйнейные коды и полилинейные рекурренты.
Фундаментальная и прикладная математика, 1996, N 3, 195-254.
Лидл Р., Нидеррайтер Г. Конечные поля. Т. 1, 2. М.: Мир, 1988.
Куракин В.Л. Линейная сложность полилинейных последовательностей. Дискретная
математика, 2001.
15 Зак. 5
450
Kurakin V.L., Kuzmin A.S., Markov V.T., Mikhalev A.V., Nechaev A.A. Linear codes and
polylinear recurrences over finite rings and modules (a survey). 13th Intern. Symp.,
AAECC-13, Honolulu, Hawaii, USA, November 15—19, 1999.
Algebra IL Proceedings. Lecture Notes Comput. Sci.}, 211—220. Springer, Berlin, 1997.
V.L. Kurakin, A.S. Kuzmin, A.V. Mikhalev, and A.A. Nechaev. Linear recurring sequences
over rings and modules. (Contemporary MathA and its Appl. Thematic survays. Vol.~10. Al-
gebra-2. Moscow, 1994.) of MathA Sciences, 1995, N 6, 2793—2915.
Kurakin V.L., Mikhalev A.V., Nechaev A.A., and Tsypyschev V.N. Linear and polylinear
recurring sequences over abelian groups and modules, of MathA Sciences, 2000, N 6,4598-
-4627.
R.E. Blahut. Theory and Practice of Error Control Codes. Addison-Wesley, 1983.
A. Klapper and M. Goresky. Feedback Shift Registers, 2-Adic Span, and Combiners with
Memory, Journal of Cryptology (1997) 10: 111-147
S. W. Golomb, Shift Register Sequences, San Francisco: Holden Day, 1967. (and also reprint:
Aegan Park Press, 1982)
R. Lidl and H. Niederreiter, ’’Finite Fields,” in Encyclopedia of Mathematics and Its Applica-
tions, Vol. 20, Reading, MA: Addison-Wesley, 1953.
R. Lidl and H. Niederreiter, Introduction to Finite Fields and Their Applications, London,
Cambridge University Press, 1986.
H. Krawczyk. ’’The Shrinking Generator: Some Practical Considerations”, Fast Software En-
cryption, Cambridge Security Workshop Proceedings, Springer-Verlag, 1994, pp. 45-46
D.E. Knuth. The Art of Computer Programming. Volume 2, Addison-Wesley, Reading,
Mass., 2nd edition, 1981.
E. R. Berlekamp, Algebraic Coding Theory, New York: McGraw-Hill, 1968.
M. Ben-Or, Probabilistic algorithms in finite fields, Proceedings of the 22nd IEEE
Foundations of Computer Science Symposium. 1981. Pp. 394-398
T. Ritter. The Efficient Generation of cryptographic Confusion Sequences. Cryptologia, 1991,
15(2): 81-139
M.J.B. Robshaw. Stream Ciphers. Technical Report TR - 401, RS A Laboratories, revised
July 1995.
W.H.Press, B.P.Flannery, S.A. Teukolsky and W.T. Vetterling, Numerical Recipes in C: The
Art of Scientific Computing, Cambridge University Press, 1988.
W.H.Press, B.P.Flannery, S.A. Teukolsky and W.T. Vetterling, Numerical Recipes in C: The
Art of Scientific Computing, Cambridge University Press, 1988.
E. S. Selmer, Linear recurrence relations over finite fields. Lecture Notes, University of Ber-
gen, Bergen, Norway, 1966.
N. Zierler, ’’Linear recurring sequences,” J. Soc. Indust. Appl. Math., vol. 7, no.l, pp. 31-48,
March 1959.
N. Zierler, ’’Primitive Trinomials Whose Degree Is a Mefsenne Exponent,” Information and
Control, vol. 15, pp. 67-69, 1969.
Линейная сложность последовательностей и преобразований
J. L. Massey, ’’Cryptography and System Theory," Proc. 24th Allerton Conf.Commun., Con-
trol, Comput., Oct. 1-3, 1986.
451
J. L. Massey, “Shift-register synthesis and BCH decoding,” IEEE Trans. Inform. Theory, vol.
IT-15, pp. 122-127, Jan. 1969.
F. Piper, “Stream ciphers,” Elektrotechnik und Maschinenbau, vol. 104, no. 12, pp. 564-568,
1987.
B. Smeets, “The linear complexity profile and experimental results bn a randomness test of
sequences over the field Fq, "IEEE Int. Symp. Inform. Theory, Kobe, Japan, June 19-24,
1988.
T. Schaub, A linear complexity approach to cyclic codes, Ph.D. thesis, Swiss Federal Institute
of Technology, Zurich, 1988.
Zong-duo Dai, “Proof of Rueppel’s linear complexity conjecture,” IEEE Trans, inform. The-
ory, vol. 32, pp. 440-443, May 1986.
H. Niederreiter, “Continued fractions for formal power series, pseudorandom numbers, and
linear complexity of sequences,” contributions to General Algebra 5, Proc. Conf. Salzburg,
Teubner, Stuttgart, 1986.
H. Niederreiter, “Sequences with almost perfect linear complexity profile,” in Lecture Notes
in Computer Science 304; Advances in Cryptology: Proc. Eurocrypt'87, D. Chaum and W. L.
Price, Eds., Amsterdam, The Netherlands, April 13-15, 1987, pp. 37-51. Berlin: Springer-
Verlag, 1988.
H. Niederreiter, “Keystream sequences with a good linear complexity profile for every start-
ing point," in Lecture Notes in Computer Science 434; Advances in Cryptology; Proc.
Eurocrypt'89, J.-J. Quisquater and J. Vandewalle, Eds., Houthalen, Belgium, April 10-23,
1989, pp. 523-532. Berlin: Springer-Verlag, 1990.
M. Wang, "Linear complexity profiles and continued fractions,” in Lecture Notes in Com-
puter Science 434; Advances in Cryptology; Proc. Eurocrypt'89, J.-J. Quisquater and J.
Vandewalle, Eds., Houthalen, Belgium, April 10-23, 1989, pp. 571-585. Berlin: Springer-
Verlag, 1990.
R. A. Rueppel, “Linear complexity and random sequences,” in Lecture Notes in Computer
Science 219; Advances in Cryptology: Proc. Eurocrypt'85, F. Pilcher, Ed., Linz, Austria,
April 1985, pp. 167-188. Berlin: Springer-Verlag, 1986.
F. Piper, "Stream ciphers,” Elektrotechnik und Maschinenbau, vol. 104, no. 12, pp. 564-568,
1987.
J. L. Massey, “Delayed-decimation/square sequences," Proc. 2nd Joint Swedish-Soviet
Workshop on Information Theory, Granna, Sweden, Apr. 14-19, 1985.
H. Niederreiter, "Sequences with almost perfect linear complexity profile,” in Lecture Notes
in Computer Science 304; Advances in Cryptology: Proc. Eurocrypt'87, D. Chaum and W. L.
Price, Eds., Amsterdam, The Netherlands, April 13-15, 1987, pp. 37-51. Berlin: Springer- x
Verlag, 1988.
H. Niederreiter, "Probabilistic theory of linear complexity,” in Lecture Notes in Computer
Science 330; Advances in Cryptology: Proc. Eurocrypt'88, C. G. Gunther, Ed., Davos, Swit-
zerland, May 25-27, 1988, pp. 191-209. Berlin: Springer-Verlag, 1988< [379]
H. Niederreiter, “Keystream sequences with a good linear complexity profile for every start-
ing point," in Lecture Notes in Computer Science 434; Advances in Cryptology; Proc.
Eurocrypt'89, J.-J. Quisquater and J. Vandewalle, Eds., Houthalen, Belgium, April 10-23,
1989, pp. 523-532. Berlin: Springer-Verlag, 1990.
15*
452
В. Smeets, ’’The linear complexity profile and experimental results on a randomness test of
sequences over the field Fq, "IEEEInt, Symp. Inform. Theory, Kobe, Japan, June 19-24,
1988.
R. A. Rueppel and J. L. Massey, ’’The knapsack as a nonlinear function," IEEE Int. Symp.
Inform. Theory, Brighton, UK, May 1985.
J.A. Reeds and N.J.A. Sloane. Shift register synthesis (modulo m). SIAM Journal on
Computing, 14(3):505-513, 1985.
Zong-duo Dai and Kencheng Zeng, "Continued Fractions and the Berlekamp-Massey Algo-
rithm," In J. Seberry and J. Pieprzyk, editors, Advances in Cryptology - Auscrypt '90, pages
24-31, Springer Verlag, Berlin, 1990.
R. A. Rueppel, "Stream ciphers," in G.J. Simmons, editor. Contemporary Cryptology, The
Science of Information Integrity', pp 65-134. IEEE Press, New York, 1992.
R. A. Rueppel, Analysis and Design of Stream Ciphers, Berlin: Springer-Verlag, 1986
R.A. Rueppel. New Approaches to Stream Ciphers. PhD thesis, Swiss Federal Institute of
Technology, Zurich, 1984.
R. E. Blahut, '"Transform techniques for error-control codes," IBM J. Res. Develop, vol. 23,
pp. 299-315, 1979.
J. L. Massey and M. Z. Wong, "The characterization of all binary sequences with perfect lin-
ear complexity profiles," in Abstracts of Papers, Eurocrypt'86, Linkoping, Sweden, May 20-
22, 1986, pp. 3-4A-3-4B.
C. J. Jansen, "Investigations on nonlinear stream cipher systems: Construction and evaluation
methods", Ph.D. thesis, Eindhoven University of Technology, The Netherlands, 1989.
R. A. Rueppel, "Linear complexity and random sequences," in Lecture Notes in Computer
Science 219; Advances in Cryptology: Proc. Eurocrypt'85, F. Pilcher, Ed., Linz, Austria,
April 1985, pp. 167-188. Berlin: Springer-Verlag, 1986.
B. Smeets, "The linear complexity profile and experimental results on a randomness test of
sequences over the field Fq, "IEEEInt. Symp. Inform. Theory, Kobe, Japan, June 19-24,
1988.
Z. Wong, "The characterization of all binary sequences with perfect linear complexity pro-
files," in Abstracts of Papers, Eurocrypt'86, Linkoping, Sweden, May 20-22, 1986, pp. 3-
4A-3-4B)..
J. Jansen, "Investigations on nonlinear stream cipher systems: Construction and evaluation
methods", Ph.D. thesis, Eindhoven University of Technology, The Netherlands, 1989.
«Криптографические» функции
W. Blaser and P. Heinzmann, "New cryptographic device with high security using public key
distribution," Proc. IEEE Student Paper Contest 1979-80, pp. 145-153,1982.
T. Siegenthaler, "Correlation-immunity of nonlinear combining functions for cryptographic
applications," IEEE Trans. Inform. Theory, vol. IT-30, pp. 776-780, Oct. 1984
R. Yarlagadda and J.E.Hershey, "Analysis and synthesis of bent sequences," Proc. IEE, vol.
136, pt. E., pp. 112-123, March 1989.
P.Camion, C. Carlet, P. Charpin and N. Sendrier, "On correlation-immune functions," in Lec-
ture Notes in Computer Science vol.576; Advances in Crypology: Crypto '91 Proc., pp 87-
100. Berlin: Springer-Verlag, 1991.
453
J. Seberry, X.M. Zhang and Y. Zheng, “On Constructions and Nonlinearity of Correlation
Immune Functions” In T. Helleseth, editor, Advances in Cryptology - Eurocrypt ’93, pages
181-199, Springer-Verlag, Berlin, 1994.
R. A. Rueppel, “Correlation immunity and the summation combiner,” in Lecture Notes in
Computer Science 218; Advances in Cryptology: Proc. Crypto'85, H. C. Williams Ed., Santa
Barbara, CA, Aug. 48-22, 1985, pp. 260-272. Berlin: Springer-Verlag, 1986.
W. Meier and O. Staffelbach, “Correlation properties of combiners with memory in stream
ciphers,” in Lecture Notes in Computer Science 473; Advances in Cryptology: Proc.
Eurocrypt'90, I. Damgard, Ed., Aarhus, Denmark, May 21-24. 1990, pp. 204-213. Berlin:
Springer-Verlag.
J. F. Dillon, ”A survey of bent functions", The NSA Technical Journal (1972), pp 191-215
(unclassified).
J. F. Dillon, “Elementary Hadamard difference sets”, Ph..D. Thesis, University of Maryland,
1974.
J. F. Dillon, “Elementary Hadamard difference sets,” Proc. 6th Southeastern Conf. Combina-
torics, Graph Theory, and Computing, Boca Raton, FL, pp. 237- 249, 1975; in Congressus
Numerantium No. XIV, Utilitas Math., Winnipeg, Manitoba, 1975.
R. L. McFarland, “A family of difference sets in non-cyclic groups," J. Combinatorial The-
ory, Ser. A, 15, pp. 1-10, 1973.
K. Nyberg, “Perfect Nonlinear S-boxes“ in Lecture Notes in Computer Science 547; Ad-
vances in Cryptology:Proc. Eurocrypt'91, Springer-Verlag, 1992.
B. Carlet, “Two New Classes of Bent Functions”, in Lecture Notes in Computer Science
vol.765; Advances in Crypology: Eurorypt '93 Proc.,Springer-Verlag 1994, pp. 77-101.
J. F. Dillon, "Elementary Hadamard difference sets", Ph..D. Thesis, University of Maryland,
1974.
H. Dobbertin, "Construction of Bent Functions and Balanced Boolean Functions with High
Nonlinearity", Fast Software Encryption - Second International Workshop, Leuven,
December 1994, Springer-Verlag, Berlin, 1995, pp 61-74.
A. F. Webster and S. E. Tavares, “On the design of S-boxes,” in Lecture Notes in Computer
Science 218; Advances in Cryptology: Proc. Crypto'85, H. C. Williams, Ed., Santa Barbara,
CA, Aug. 18-22, 1985, pp. 523-534. Berlin: Springer-Verlag, 1986.
R. Forre, “The strict avalanche criterion: Spectral properties of boolean functions and an ex-
tended definition,” in Lecture Notes in Computer Science 403; Advances in Cryptology: Proc.
Crypto '88, S. Goldwasser, Ed., Santa Barbara, CA, Aug. 21-25, 1987, pp. 450-468. Berlin:
Springer-Verlag, 1990.
С. M. Adams and S.E. Tavares, “The use of bent sequences to achieve higher-order strict
avalanche criterion", Technical Report, TR 90-013, Departament of Electrical Engineering,
Queen’s University, 1990.
X.-M. Zhang and Y.Zheng, “Cryptographically resilient functions," IEEE Transactions on
Information Theory, September 1997 (to appear).
B. Chor, O. Goldreicfi, J. Hastad, J. Friedman, S. Rudich and R. Smolensky. "The bit extac-
tion problem or t-resilient functions," IEEE Symposium on Foundations of Computer Science,
vol. 26, pp. 396-407, 1985.
C.H. Bennett, G. Brassard and J.M. Robert, "Privacy amplification by public discussion",
SIAM J. Computing, vol. 17, pp. 210-229, 1988.
454
R. A. Rueppel, “Stream ciphers,” in G.J. Simmons, editor. Contemporary Cryptology, The
Science of Information Integrity', pp 65-134. IEEE Press, New York, 1992.
R. A. Rueppel, Analysis and Design of Stream Ciphers, Berlin: Springer-Verlag, 1986
J. Seberry, X.-M. Zhang and Y Zheng, “Nonlinearity and Propagation Characteristics of Bal-
anced Boolean Functions”, Information and Computation, VoL 119, No 1, pp 1-13, 1995.
J. Seberry, X.M. Zhang and Y. Zheng, “On Constructions and Nonlinearity of Correlation
Immune Functions” In T. Helleseth, editor, Advances in Cryptology - Eurocrypt ’93, pages
181-199, Springer-Verlag, Berlin, 1994.
L. Brynielsson, “Below the unicity distance,” Workshop on Stream Ciphers, Karlsruhe,
Germany 1989.
C. Carlet, “Hyper-bent functions”, in Proceedings of the 1st Int. Conference on the theory and
Applications of Cryptology, Pragocrypt '96, CTU Publishing House, 1996, pp 145-155.
D. Chaum and J. H. Evertse, “Cryptanalysis of DES with a reduced number of rounds,” in
Lecture Notes in Computer Science 218; Advances in Cryptology: Proc. Crypto '85, H. C.
Williams, Ed., Santa Barbara, CA, Aug. 18-22, 1985, pp. 192-211. Berlin: Springer-Verlag,
1986.
P. V. Kumar, R. A. Scholtz, and L. R. Welch, “Generalized bent functions and their proper-
ties,” J. Combinatorial Theory, Ser. A 40, pp. 90-107, 1985.
W. Meier and O. Staffelbach, “Correlation properties of combiners with memory in stream
ciphers,” in Lecture Notes in Computer Science 473; Advances in Cryptology: Proc.
Eurocrypt'90, I. Damgard, Ed., Aarhus, Denmark, May 21-24. 1990, pp. 204-213. Berlin:
Springer-Verlag.
K. Nyberg, “Construction of bept functions and difference sets,” in Lecture Notes in Com-
puter Science 473; Advances in Cryptology:Proc. Eurocrypt'90,1. Damgard, Ed., Aarhus,
Denmark, May 21-24. 1990, pp. 151-160. Berlin: Springer-Verlag.
J. H. Evertse, “Linear structures in block cyphers,” in Lecture Notes in Computer Science
304; Advances in Cryptology: Proc. Eurocrypt '87, D. Chaum and W. L. Price, Eds., Amster-
dam, The Netherlands, April 13-15, 1987, pp. 249-266. Berlin: Springer-Verlag, 1988.
B. Preneel, W. Van Leekwijck, L. Van Linden, R. Govaerts; and J. Vandewalle, “Propagation
characteristics of boolean functions,” in Lecture Notes in Computer Science 473; Advances in
Cryplology: Proc. Eurocrypt'90, 1. Damgard, Ed., Aarhus, Denmark, May 21-24. 1990, pp.
161-173. Berlin: Springer-Verlag.
B. Preneel, R. Govaerts, and J. Vandewalle, “Boolean functions satisfying higher order
propagation criteria” in Lecture Notes in Computer Science 547; Advances in Cryplology:
Proc. Eurocrypt'91,\991,pp. 141-152. Berlin: Springer-Verlag.
G. Z. Xiao and J. L. Massey, “A spectral characterization of correlation-immune functions,”
IEEE Trans. Inform. Theory, vol. 34, no. 3, pp. 569-571, May 1988.
k. Yarlagadda and J.E.Hershey, “Analysis and synthesis of bent sequences," Proc. IEE, vol.
136, pt. E., pp. 112-123, March 1989.
Метод статистических аналогов
C. Adams, S. Tarares. The Structured Design of Cryptographyicaly Good S-Boxes. J. of
Cryptology, v.3,Nl,1990, p. 27-41.
Biham E. On Matsui's Linear Cryptanalysis, Eurocrypt' 1994, p. 349-360.
455
Biham E. Biryukov A. Shamir A. Cryptanalysis of Skipjack Redmed to 31 Rounds using
Impossible Differential. Technion. Computer Science Departament. Technical Report.
CS0947, 1998.
Biham E, Shamir A. Differential Cryptanalysis of Snefru. Khafre, Redoc-II, LOCI an
Lucifer. Crypto 91,1992, p. 156-171.
Biham E, Shamir A. Differential Cryptanalysis of Feal and N-Hash Eurocrypt'91, p. 1-16.
Biham E, Shamir A. Differential Cryptanalysis of DES - like Cryptasystems (Extended
Abstract). Proc. Crypto-90, L.N. Comp. Sci. V-537, 1991, p.2-21.
G. Caronni, M. Robshaw. How Exhansting is Exhanstive Search. Crypto Bytes, RSA
Laboratories, 1997.
Chabaud F., Vaudenay S. Links between differential and linear cryptanalysis. Eurocrypt,
1994, p. 363-374.
M. Matsui. Linear Cryptanalysis Method for DES. Eurocrypt, 1993, p. 24-27.
M. Matsui. On correlation between the order of S-boxes and the strength of DES. Eurocrypt,
1994, p. 375-387.
M. Matsui. T he First Experimental Cryptanflysis of the data Encryption Standard. FSIA
CRYPT'94, p. 1-11.
K. Ohta, S. Moriai, K. Aoki. Improving the Search Algorithum for the Best Liilear
Expression.
T. Tokita, T. Sorimachi, M. Matsui. Linear Cryptanalysis of LOKI, DES. FSIA CRYPT'94,
p. 246-256.
Системы образующих групп подстановок
Артин Э. Геометрическая алгебра; Наука, М., 1969.
Байрамов Р.А. К проблеме полноты в симметрической полугруппе. Дискретный анализ,
8, Новосибирск, 1966, 3-26.
Байрамов Р.А. Критерии фундаментальности групп подстановок и полугрупп отобра-
жений. ДАН СССР, 189, 3,1969.
Бижев Г.Т., Касабов Н.К. Минимальное представление Sn, близкое к предельно ком-
пактному. Кибернетика, 3, 1980, 135-136.
Биндер Г.Я. О вложении элементов симметрической группы в систему образующих из
двух элементов. Сборник аспирантских работ изд-ва Казанского университета, 1965,
3-5.
Биндер Г.Я. О базисах симметрической группы. Изв.ВУЗов, Математика, 11, 1968,
19-25.
Биндер Г.Я. О двухэлементных базисах симметрических групп. Изв. ВУЗов, Мате-
матика, 1,1970,9-11. .
Биндер Г.Я. Некоторые полные множества дополняющих симметрической и знакопе-
ременной группы П — той степени. Мат. заметки, 7, 2, 1970, 173-180.
Битюцкий В.П., Чистов В.П. Функциональная полнота в ленточных однородных струк-
турах. Изв. АН СССР, Техническая кибернетика, 3, 1971, 116-121.
Битюцкий В.П., Чистов В.П. Простейшие ленточные структуры. Изв. АН СССР, Тех-
ническая кибернетика, 6, 1971, 126-130.
456
Битюцкий B.IL Итеративные процедуры разложения элементов симметрической полу-
группы. Кибернетика, 5,1975,49-50. >
Бондарев В.Г. Алгоритм разложения в конечных симметрических полугруппах. Кибер-
нетика, 4,1970,24-28.
Бурбаки Н. Группы и алгебры Ли; Мир, М., 1972.
Вавилов Е.Н., Вичев В.П., Осинский Л.М. Оценка длины микропрог- рамм для автома-
тов. Изв. АН СССР, Техническая кибернетика, 6, 1972, 160-165.
Ганов В.А. Верхняя оценка меры информационной избыточности симметрической по-
лугруппы. Кибернетика, 6, 1970, 63-65.
Глухов М.М. О числовых параметрах, связанных с заданием конечных групп система-
ми образующих элементов. РАН, АК РФ. Труды по дискретной математике, Том I; изд-
во ТВП, М., 1997,43-66.
Глушков В.М. О полноте систем операций в электронных вычислительных машинах.
Кибернетика, 2, 1968, 1-5.
Годлевский А.Б., Шевченко В.П. К вопросу оценки меры информационной избыточно-
сти микропрограммной алгебры. Труды “Теория автоматов”, АН УССР, Институт ки-
бернетики, 1969,’ 5,37-39.
Голунков Ю.В. Полнота систем микроопераций и сложность микропрограмм I. Изв. АН
СССР, Техническая кибернетика, 3, 1976, 117-123.
Голунков Ю.В. Реализация микропрограммных базисов на регистрах сдвига. Киберне-
тика, 3, 1975, 33-39.
Голунков Ю.В. О сложности представления подстановок симметрической полугруппы
через элементы систем образующих. Кибернетика, 1, 1971, 43-44.
Голунков Ю.В. Несколько замечаний об однородных ленточных структурах. Изв. АН
СССР, Техническая кибернетика, 6, 1972, 176-180.
Голунков Ю.В. Алгоритмическая полнота и сложность микропрограмм. Кибернетика,
3, 1977, 1-15.
Голунков Ю.В. Программно-автоматная реализация подстановок симметрической по-
лугруппы L, Кибернетика, 5, 1971, 6-12.
Голунков Ю.В. Программно-автоматная реализация подстановок симметрической по-
лугруппы II., Кибернетика, 5, 1975, 35-42.
Голунков Ю.В. Функциональная полнота ленточных структур из простейших однонап-
равленных каскадов. Изв. АН СССР, Техническая кибернетика, 2, 1973, 96-101.
Гольдберг М.К. Управляемые системы, вып. 2, Новосибирск, 1969, 92.
Дьедонне Ж. Геометрия классических групп; Мир, М., 1974.
Зайченко В.А., Клин М.Х., Фараджев И.А. О некоторых вопросах, связанных с пред-
ставлением групп подстановок в памяти ЭВМ. В сб. “Вычисления в алгебре, теории
чисел и комбинаторике” (под ред. Калужнина Л.А.). Киев, 1980, 3-19.
Земляченко В.Н., Корнеенко Н.М., Тышкевич Р.И. Проблема изоморфизма графов. В
сб. “Теория сложности вычислений” (под ред. Д.Ю.Григорьева и А.О. Слисенко.); Нау-
ка, Ленинградское отд-е, 1982, 83-158.
457
Зубов А.Ю. О диаметре группы S относительно системы образующих, состоящей из
полного цикла.и транспозиции. РАН, АК РФ. Труды по дискретной математике, Том П;
изд-во ТВП, М., 1998, 112-150.
Зыков А.А. Теория конечных графов. Новосибирск, 1969.
Капельмахер В.Л., Лисовец В.А. Последовательное порождение перестановок с помо-
щью базиса транспозиций. Кибернетика, 3, 1975, 17-21.
Капитонова Ю.В. К вопросу оценки длины микропрограмм в одной микропрограммной
алгебре. Кибернетика, 1, 1969, 101-102.
Касабов Н.К. О порождении симметрической группы. Годишн. вист, учебни завед.,
Прилож. мат., 10, 3, 1974, 55-59.
Клевачев В.И. О критериях полноты систем подстановок, содержащих транспозиции.
Кибернетика, 6, 1972.
Piccard S. Sur les bases des groupes d’ordre fini. Neuchatel, 1957..
Criscuolo G., Chung-Mo K. The group and the minimal polinomial of a graph. Journal of
comb, theory, B29, 3,1980, 293-302.
Коксетер Г.С.М., Мозер У.О.Д. Порождающие элементы и определяющие соотношения
дискретных групп; Наука, М., 1980.
Коршунов А.Д. О диаметре графов. ДАН СССР, т.196, 5, 1971, 1013-1015.
Кратко М.И., Плесневич Г.С. Об одной задаче В.М.Глушкова. Кибернетика, 2,
1969, 97.
Лазарев А.Г. Практические результаты изучения порождения симметрической группы
системами образующих. Кибернетика и системный анализ, 6, 1992, 39-47.
Марков А.А. Основы алгебраической теории кос. Труды матем. инст-та им.
В.А.СтеклоЬа, XVI, 1945, 1-53.
Нечаев А.А. Критерий полноты систем функций р " — значной логики, содержащих
__п
операции сложения и умножения по модулю р • Методы дискретного анализа в ре-
шении комбинаторных задач. Сборник трудов, 34, Новосибирск, 1980, 74-87.
Орэ О. Теория графов; Наука, М., 1968.
Петров Н.Т. О длине простых групп. ДАН СССР, 208, 3, 1973, 537-540.
Пикар С. О базисах симметрической группы. Кибернетический сборник, новая серия,
вып.1, 1965, 7-34.
Погорелов Б.А. Примитивные группы подстановок, содержащие 2"1 — цикл. Алгебра
и логика, 19, 2, 1980, 236-247.
Погорелов Б.А. Об одной задаче В.М.Глушкова. Кибернетика, 5, 1973, 141-144.
Рубцов В.А. О некоторых оценках меры информационной избыточности систем обра-
зующих, порождающих симметрическую группу подстановок. Кибернетика, 5, 1975,
51-55.
Сущанский В.И., Восканян Р.А. О системах порождающих симметрических и знакопе-
ременных групп, состоящих из циклов одинаковой длины. В сб. “Вопросы теории
групп и гомологической алгебры”, Ярославль, 1985, 43-49.
458
Симс Ч. Вычислительные методы в изучении групп подстановок. В сб. “Вычисления в
алгебре и теории чисел” (под ред. А.Н.Колмогорова и П.С.Новикова); Мир, М., 1976,
129-148.
Хоффман Л.Д. Современные методы защиты информации. Советское радио; М., 1980.
Babai L., Seress A. On the diameter of Cayley graphs of the simmetric group. Journal of
comb, theory, A49, 1988, 175-179.
Babai L. Spectra of Cayley graphs. Journal of comb, theory, B27, 1979, 180-189.
Baginski C. On sets pf elements of the some order in the alternating group A . Publ. Math.,
V34, 3-4,1987,313-316.
Batler G. Fundamental algorithms for permutation groups. Springer-Verlag; 1991.
Beasby L.B., Brenner J.L., Erdes P., Szalay H., Williamson A.G. Generation alternating
groups by conjugates. Period Math. Hung. 18, 4, 1987, 259-269.
Bertram E. Even permutation as a product of two conjugate cycles. Journal of comb, theory»
A12, 1972,368-380.
Bertram E.A., Wei V.K. Decomposing a permutation into two large cycles: A
enumeration. SIAM J. Algebraic and discrete metods, 1, 1980, 105-134.
Biggs N. Algebraic graph theory. Cambridge University press, 1974.
Boccara G. Nombre de representation d’une permutation coriime produit de deux cycles de
longueurs donnees. Discrete math. 29, 1980, 105-134.
Bovey J.D. The probability that some power of a permutation has small degree. Bull. bond,
math, soc., 12, 1,1980,47-51.
Brenner J.L., Evans R.J. Even permutations as a product of two elements of order five.
Journal of comb, theory, A32, 1987, 196-206.
Brenner J.L., Randall M., Riddell J. Covering theorems for finite non-abelian simple groups.
I. Coll, math,, V32, 1974, 39-48.
Brenner J.L., Wiegold J. Two-generator groups. I. Michigan math. J., 22, 1975, 53-64.
Brenner J.L. Group theory reseach problems. Bull. Amer. math. soc. 66, 4, 1960, 275.
Brenner J.L. Covering theorems for finite non-abelian simple groups. II. Journal of comb,
theory, A14, 2, 1973, 264-269.
Brenner J.L., Granwell R.M., Riddell J. Covering theorems for finite non-abelian simple
groups. Pasif. math., 58, 1, 1975, 55-60.
Brenner J.L. Covering theorems for non-abelian simple groups. VIII. J. Austral, math, soc.,
A25, 2,1978,210-214.
Brenner J.L., Riddell J. Noncanonical factorization a permutation. Amer. math, mon., 84, 1,
1977, 39-40.
Brenner J.L., Wiegold J. Two-generator groups. I. Bull. Austral, math, soc., V22, 1980, 113-
124.
Campbell K.W., Wiener M.J. DES is not a group. Adv. in cryptology CRYPTO’90. Leet,
notes in comp, sci., 740, 512-520.
Carlitz L.A. Permutations in a finite field. Proc. Amer. math, soc., VI1, 1960, 456-459.
Carmichael R.D. Abstract definitions of the symmetric and alternating groups and jther
permutations groups. Quart. J. of pure and appl. math., Cambrigge, 1923, 226-283.
459
Conder M.D.E. Generators for alternating and symmetric groups. J. bond. math, soc., 22, 1,
1980, 75-86.
Copersmitt D., Grossman E. Generators for certain alternating groups with applications to
criptography. SIAM J. appl. math., 29, 4, 1975, 624-627.
Craig W. A presentation of the symmetric group based on unique irredundant nondecreasing
factorisation. J. Pure and apple, algebra. 13, 2, 1978, 165-168. ,
Criscuolo G., Chung-Mo K. The group and the minimal polinomial of a graph. Journal of
comb, theory, B29, 3, 1980, 293-302.
Denes J. The representation of a permutation as the product of a minimal number of
transpositions and its connection with the theory of graphs. PubL Vath. inst. Hungar. acad.
sci., 4, 1959,63-70.
Dey M.S., Wiegold J. Generators for altamating and simmetric groups. J. Aust. math, soc.,
12, 1971,63-68.
Dittmar R., Hoemaner G., Wemsdorf R. SAFER, DES and FEAL: algebraic properties of
two round functions. Pragocrypt 96, 55-66.
Dixon J.D. A finite analoque of the Goldlech problem. Canad. math, bull., V3, 1960, 121—
126.
Dixon J.D. Problems in group theory. Dover publications, 1973.
Dixon J.D. The probability of generatig the symmetric group. Math. Z. 110, 1969, 199-205.
Driscoll J.R., Furst M.L. On the diameter of permutations groups. 15-th STOC, 1983, 152-
162.
Driv Y. Covering properties of permutation groups. Leet, notes math., v.l 112, 1985, 197-
221.
Even S., Goldreich O. The minimum-lenth generator sequence problem is NP-hard. J.
Algorithms, 2,1981,311-313.
Even S., Goldreich O. DES-like functions can generate the alternating group. IEEE
Transactions of inform, theory, IT-29, 6, 1983, 863-865.
Festracts A. Sur les involutions du groupe alterne d’un ensemble fini. Acad. rog. Bull. el.
Sci., 1964, 50, 3.
Frucht W. Un problema combinatorique interesa en la teoria ole los grupos ole permu-
taciones. Scientia (Chil.), 29, 117, 1962, 39-49.
Hamidonne Y.O. Factorisations courtes dans un groupe fini. Discrete appl. math., 24, 1989,
153-165.
Herzog M., Reid K. Permutation groups generated by cycles of fixed lenth. Isr. J. math., 26,
3-4, 1977, 221-231.
Huang J.-C. Universal cellular array. IEEE Trans, on computers, 3, 1971, C-20.
Husemuller D.H. Ramified coverings of Riemann surfaces. Disc. math. J., 29 1962, 167-174.
Ito N. A theorem on the alternating group A , (ll > 5). Math. Japon, 2, 1951, 59-60.
Jackson D.M. Counting cycles in permutations by group characters, with an application to a
topological problem. Trans. Amer. math, soc., V299, 2, 1987, 785-801.
Jerrum M. A compact representation for permutation groups. 23-th Amm. sump, found,
comput sci. Chicago, 3-5 Nov., Silver Spring, 1982, 126-133.
460
Jerrum M. The complexity of finding minimum length generator sequences. Theor. compiit.
sci., 2-3,1985, 265-289.
Johonson S.M. Generation of permutations by adjacent transpositions. Math. comp. 17, 83,
1963,282-285.
Kalisky B.S., Rivest R.L., Sherman A.T.. Is the DES a group ? Journal of cryptology, 1, 1,
1988,3-36.
Knuth D.E. Efficient representation of permutation groups. An international Journal on comb,
and the theory of comp., VI1, 1, 1991, 33-43.
Komhauser D., Miller G., Spirakis P. Coordinating pebble motion on graphs, the diameter of
permutations groups, and applications. Proc. 25 IEEE FOCS, 1984, 241-250.
Leon J.S. On an algorithm for finding a base and a strong generating set for a group given by
generating permutations. Math, of comp., V35, 151, 1980, 941-974.
Lewin M. Generating the alternating group by cycles triples. Discrete math., 11, 1975, 187-
189.
Luby M., Rackoff C. How to Construct Pseudorandom Permutations From Pseudorandom
Functions. SIAM J. Comput., 1988, Vol. 17, №2, pp. 373-386.
Luce R.D. Psychometrika, 15, 1950, 169.
Lynn M.S. Canad. J. math., 20, 3,1968,749.
McKenzie P. Permutations of bounded degree generate groups of polinomial diameter
(manuscript). Inf. Process Lett., 19, 5, 1984, 253-254.
Moon J.W. On the diameter of a graph. Michigan math. J., 12, 3, 1965, 349-351.
Moran G. Permutations as products of к conjugate involutions. J. of comb, theory, A19,
1975, 240-242.
Moran G. The bireflections of a permutation. Discrete math., 15, 1976, 55-62.
Moran G. The product of two reflection classes of the symmetric group. Discrete math., 15, ,
1976,63-77.
Piccard S. Sur les bases des groupes d’ordre fini. Neuchatel, 1957.
Pieprzyk , Zhang . Permutations generators of alternating groups. Proc. AUSCRYPT’90;
Leet, notes in comp, sci., 453, 1990, 237-244.
Rapaport E.S. Cayley color groups and Havilton lines. Scripta math., 24, 1, 1959.
Rothaus O.S. Asymptotic properties of group generation. Pacif. J. of math., 17, 2, 1966,
312-322.
Rowlinson P., Williamson A. On primitive permutation groups which contain a cycle. Bull.
Austral, math, soc., 15, 1, 1976, 125-128.
Rowlinson P. Primitive permutation groups containing a 2-cycle. J. Lond. math, soc., 10, 2,
1975,225-227.
Sims C.C. Computation with permutation groups. Proc. 2-nd Symp. simbolic and algebraic
manipulation, Assoc, comp, math.,4, N.Y., 1971.
Stanley R. On the number of redued decompositions of elements of coxeter groups. Eur. J.
Comb., 1985,5, 4,359-372.
Stanley R. Factorizatiop of permutations into П — cycles. Discrete math., 37, 1981, 255-
262.
461
Van Nuttelen C. Rank and diameter of a graph. Bull. soc. math. Belgium, B34, 1, 1982,
105-111.
Walkup D.W. How many ways can a permutation be factored into two П — cycles. Descrete
math., 28, 1979,315-319.
Wang Efang. The conditions and methods about expressing permutations as a product of two
cycles. Бэйцзин дасьюэ сюэбао, 5, 1986, 26-36.
Wemsdorf R. The one-round functions of the DES generate the alternating group. Proc.
Eurocrypt-92, Leet, notes in comp, sci., V658, 1993, 99-112.
Wilandt H. Finite permutation groups. Acad. Press, N.Y., 1964.
Wilson R.M. Graph puzzles, homotopi, and the alternating group. Journal of comb, theory, f
B16, 1974, 86-96.
Xu Cheng-Hao. The commutators of the alternating group. Scientia Siniqa, 14, 3,1965,
339-342.
Zieschang T. Combinatorial properties of basic encryption operations. Adv. in cryptology
EUROCRYPT’97. Leet, notes in comp, sci., V1233, 1997, 14-26.
Теоретические основы квантовой криптографии
С.Н. Bennett, Quantum criptography using any two nonortogonal states, Physical Reviev
Letters, v. 68, № 21, p.3121, 1992.
C.H. Bennett, F.Bessette, G.Brassard, L.Salvail, J.Smolin, Experimental quantum cryptogra-
phy, Journal of Cryptology, v.5, №1, 1992, pp. 3-28.
R.J. Hughes et al., Quantum criptography over underground optical fibers, Proceedings
CRIPTO’96, p.329, 1996.
Р.Фейман, Р.Лейтон, М.Сэндс, Феймановские лекции по физике. Квантовая механика,
т.8, М.: Мир, 1967.
К. Хелстром, Квантовая теория проверки гипотез и оценивания, М.: Мир, 1979.
462
ПРИЛОЖЕНИЕ! '
Классификация сигналов. Пояснения к выводу теоремы Котельникова
Классификация сигналов.
Физически сигнал реализуется в виде некоторого модулированного ко-
лебания. Если значения сигнала можно точно предсказать в любой момент
времени, то он называется детерминированным. Примером непрерывных де-
терминированных сигналов являются импульсы или пачки импульсов, форма,
амплитуда и положение во времени которых точно известны.
Все детерминированные процессы можно разделить на два класса: пе-
риодические и непериодические. Процесс S(t) считается периодическим, если
его значения точно повторяются через одинаковые отрезки времени Т, величи-
на которых называется периодом:
S(t) = S(t + nT); и = 1,2,3,..
Если такого отрезка времени нельзя указать, то процесс является непе-
риодическим. Периодические процессы делятся на гармонические и полигар-
монические. Класс непериодических процессов состоит из почти периодиче-
ских процессов и переходных процессов. Реально могут существовать любые
комбинации этих процессов. Рассмотрим методы представления сигналов этих
классов.
В качестве носителя сигналов часто рассматривается гармоническое ко-
лебание, изменяющееся в соответствии с выражением S(f) = Sm cos(<yZ + (р),
где: Sm - амплитуда; со- круговая частота; со = 2 л/;/- частота в герцах; <р- на-
чальная фаза. Это колебание является периодической функцией с периодом Г=
/”’. Частным случаем гармонического сигнала (при частоте а>= 0) является по-
стоянный уровень. Гармонические колебания - это наиболее простой вид не-
прерывных периодических процессов. Сам по себе бесконечный во времени
гармонический процесс не является сигналом и не несет информации. Носите-
лем информации он становится после модуляции одного или нескольких его
параметров другим процессом, связанным с сообщением.
Полигармонические сигналы образуются любыми периодическими
процессами, отличными от гармонических. Если некоторый процесс S(t) с пе-
риодом Т удовлетворяет условиям Даламбера, т. е. является непрерывным вез-
де, кроме, может быть, счетного множества точек разрыва 1 рода, и имеет ко-
нечное число экстремумов, то он может быть представлен на интервале перио-
да [0,7] совокупностью базисных функций в виде суммы
5(') = ХСЛ('). С)
*=о
463
где: ^(0 - k-я базисная функция; Ск - весовые коэффициенты. При
этом предполагается, что
Г/2
' -Г/2
т. е. никакая из функций базисной системы не равна тождественно нулю на ин-
тервале периода [0,7]". Система функций {^(0} называется ортогональной, ес-
ли для любой пары к и I, исключая к=Ц выполняется равенство
Г/2
(2)
- Г/2
Если, при /= к
Т!2
\(pl{t)dt = pk^Q, (3)
- Г/2 __
то величина */** называется нормой функции <p^t) и обозначается ||^*||- Если
норма функций ортогональной системы равна 1, то такая система функций на-
зывается ортонормированной. Для определения коэффициентов Ск в разложе-
нии функции S(t) в ортогональном базисе рассмотрим выражение
Г/2
- Г/2
Представив в подынтегральном выражении S(t) в виде его разложения
(1) и учитывая (2) и (3), получим:
Т/2 оо
J (ECr<pr(t))<pk(t)dt = Ct||<pk||2.
- Т/2 г=0
Из последнего выражения находим значение коэффициента Ск:
Сумма (1) с коэффициентами, определяемыми по (4) называется обоб-
щенным рядом Фурье по данной системе базисных функций {(pk(t)}. Обобщен-
ный ряд Фурье обладает важным свойством: при заданной системе базисных
функций и фиксированном числе N его слагаемых он обеспечивает наилучшую
аппроксимацию (в смысле среднеквадратической ошибки) заданной функции
S(f). При заданной системе базисных функций {</%(/)} сигнал S(f) полностью
определяется набором весовых коэффициентов Ск. Этот набор называется дис-
кретным спектром сигнала.
464
Для любой ортогональной системы справедливо неравенство Бесселя
кыче
к=0
Ортогональная система называется полной, если увеличением числа N
членов ряда среднеквадратическую ошибку аппроксимации можно сделать как
угодно малой. Условие полноты может быть представлено в виде выражения
йыче
к=0 I
Величину ||5(^|2 = Qs называют энергией сигнала. Для энергии
сигнала получаем
е, = Ёс>4||2 (5)
Л = 0
или для ортонормированной системы базисных функций
е.=Ёсг
*=0
Пояснения к выводу теоремы Котельникова.
Как отмечалось выше в теории анализа сигналов и технике связи широ-
кое применение находит теорема Котельникова (теорема отсчетов), в соответ-
ствии с которой функция S(t) полностью определяется последовательностью
своих значений в моменты времени, взятые с интервалами не более продолжи-
тельными, чем 1/2у«, если наибольшая частота в спектре этой функции меньше
fe. В этом случае функция S(t) может быть представлена выражением
S0 = (t) - XSm 2^‘ , (6)
2xfe(t-k&t)
где A? = 1 / 2fe - интервал времени между двумя соседними отсчетами
сигнала S(f), a S(k4f) - отсчеты функции S(f) в моменты времени t = k&t,
' Функции вида (рк (?) встречаются при исследовании спектра одиночно-
го прямоугольного импульса. Эти функции образуют систему ортогональных
функций с интервалом ортогональности, равным бесконечности, и нормой
к»2 г sin2 a>(t -kAt) , 1 fsin2(x), л . .
J = ------•
465
Покажем, что разложение сигнала S(t) в этом базисе дает спектр, дейст-
вительно состоящий из отсчетов сигнала S(kAt). Предварительно условимся,
что энергия сигнала конечна, т. е. S(f) является квадратично-интегрируемой
функцией. Кроме того, отметим, что <рк(k&t) = ^.(0) = 1, (рк (n&t) = 0 при п*к.
Напомним, что понятие спектральной плотности сигнала S(t) опреде-
ляют с помощью преобразования Фурье S(<o)= J S(t)e *cot dt, где
—00
e~l<ot=cosa>t-isina>t. S(a>) называют спектральной плотностью сигнала S(t) (в
общем случае это копплексное число). Спектральная плотность одиночного
оо t2
импульса Si(t) на частоте <b=kcdi равна Si(a>)= |Sj(t)e~itotdt = j*Sj(t)e—1K<Oltdt,
-00 t|
интервал существования импульса. Выражение
где [tbt2]
1 00
S(t)=— Г S(®)e-,<otd(O называют обратным преобразованием Фурье.
2л J ,
-00
Спектральная плотность функции ^(/) равна
-J_e-ikAt® = Ate-ikAt
при|со|<сов
О при|со|>сов.
Отсюда следует, что модуль спектральной плотности любой базисной
функции фк (t) в полосе частот |й>| < а>в имеет постоянное значение, равное
ДГ = 1/2Д =л1о)в.
Определим значения коэффициентов разложения, примеряя формулу
(4):
(7)
С к =~ \s{t}(pk{t)dt.
-оо
Для вычисления интеграла в этом выражении воспользуемся известным
соотношением, устанавливающим связь между произведением двух функций
Д/) и g(t)a произведением их спектров плотностей F(<y) и G(<o)
j = ^j F(«)G* ,
466
где G*(ty) - функция комплексно-сопряженная к G(<y). В соответствии с этцм
свойством
00 сов -• 1 сов
js(t>Pk(t)dt=— Js(co>k(®)ico = —js(co)e,kAt®d© = AtS(kAt),
J 2л J 2fR 2л J
-оо ' -<ав в -coB
где пределы интегрирования берутся равными граничной частоте а)в спектра
сигнала и базисных функций. Подставляя полученное значение интеграла в (7),
имеем окончательное выражение для коэффициента разложения
c,=s(M/)=st,
т. е. коэффициентами ряда Котельникова являются отсчеты сигнала в моменты '
времени t = kAt, как это было определено в (6). Ряд (6) сходится к функции
S(f) при любых значениях времени t, т. к. вследствие ограниченности верхней
частоты сигнала он является непрерывным. /
Если отсчеты сигнала S(f) берутся с интервалами Д^ = 1 / 2fe, то шири-
на спектра базисных функций <pk(t) совпадает с шириной спектра сигнала и
представление сигнала соответствует (6). Если взять интервал между отсчетами
равнымД/ < Д£, то ширина спектра соответствующих базисных функций бу-
дет превышать спектр сигнала S(f), что повышает точность представления этого
сигнала. При этом исключается возможность отбрасывания «хвостов» спектра
S(<y) вне граничных частот. Если интервал Д/ > Д?, то спектр соответствую-
щей базисной функции становится уже спектра сигнала S(f) и коэффициенты Ск
в выражении (7) становятся отсчетами не этого сигнала S(t), а некоторого дру-
гого сигнала, спектр которого ограничен другой частотой fe < fe.
Решение реальных задач связано с сигналами, одновременно ограни-
ченными и по частоте и по времени. Теоретически эти условия являются несо-
вместимыми. Практически эти ограничения определяют таким образом, , чтобы
основная часть энергии сигнала была заключена в пределах выбранной дли-
тельности этого сигнала и ширины его спектра, а на долю «хвостов» приходи-
лась бы только незначительная ее часть. При таком подходе для сигнала дли-
тельностью Т и верхней частотой полосы пропускания fe число независимых
отсчетов, необходимое для полного задания сигнала, равно
Т
N=— = 2fT.
At
В этом случае ряд (6) может быть представлен следующим образом
л=о
467
Число N называют базой сигнала или числом степеней свободы сигнала.
Учитывая (5), можно представить энергию и среднюю мощность сигнала через
последовательность его отсчетов
N . N
а=2с.2Ы =Д'Ё52(И').
*=0 к=0
1 1 к=0 Л k=0
Последнее выражение показывает, что средняя мощность непрерывного
сигнала на интервале Т равна среднему квадрату отсчетов, умещающихся на
этом интервале через промежутки l/2fe.
ПРИЛОЖЕНИЕ 2
Линейные рекуррентные последовательности над конечным полем
Излагаемый материал основан на книге /М.М. Глухов, В.П. Елизаров, А.А. Не-
чаев “Алгебра. Часть И”, Москва, 1991/. Далее: R - коммутативное кольцо с единицей
е, N - множество натуральных чисел; No =NuO, Z - множество целых чисел; GF(q) -
поле из q элементов; (а, Ь) - наибольший общий делитель а, Ь; [а, Ь] - наименьшее об-
щее кратное a, b; а | b - а делит b; V - для любого.
Основные определения.
Определение 1. Последовательностью над R назовем любую функцию
u : No—> R, при этом для каждого ie ^элемент u(i) назовем i-м членом после-
довательности и. Множество всех последовательностей над R обозначим R00.
Для наглядности последовательность ug R00 можно записать в виде бес-
конечного вектора
u=(u(0), u(l),...,u(i),...).
Последовательность (0, 0,...,0,...) будем называть нулевой, и обозна-
чать через (0).
Определение 2. Последовательность ugR”° называют линейной рекур-
рентной последовательностью (ЛРП) порядка ш>0 над R, если существуют
константы fo, fi,...,fm_ieR такие, что V ie No
u(i+m)= fm_|U(i+m-l)+...+ f|U(i+l)+ fou(i):
В этом случае это соотношение называют законом рекурсии ЛРП и,
многочлен F(x)=xm - fm-ix"1'1 fix - fo - характеристическим многочленом
ЛРП и, а вектор u(0,...m-l)=(u(0),.. .,u(m-l)) - ее начальным вектором. После-
довательность (0) считается по определению единственной ЛРП порядка 0 с
характеристическим многочленом F(x)=e.
468
Пример 1. (Последовательность Фибоначчи). Эта последовательность
была придумана для решения следующей задачи, называемой задачей о разм-
ножении кроликов. Допустим, что каждая пара зрелых кроликов через месяц
рождает новую пару кроликов, которая еще через месяц достигает зрелости.
Сколько всего пар кроликов можно получить от одной зрелой пары за i меся-
цев? Если обозначить искомую величину через u(i), то нетрудно увидеть, что
u(0)=l, и(1)=1 и u(i+2)=u(i+l)+u(i) для ieN. Таким образом, и - ЛРП над Z
(кольцом целых чисел) с характеристическим многочленом F(x)= х2 -х -1 и на-
чальным вектором u(0,1 )=( 1,1).
Арифметическая последовательность. Для любых элементов a, d из
кольца R последовательность v с общим членом v(i)=a+di, ie {0,1,...} есть ЛРП
порядка 2 с характеристическим многочленом F(x)=x2-2x+e=(x-e)2 и началь-
ным вектором (a,a+d).
Геометрическая последовательность. Для любых элементов a, q из
кольца R последовательность a,aq,.. .,aq',... есть ЛРП порядка 1 с характерис-
тическим многочленом F(x)=x-q и начальным вектором а.
Конгруэнтная последовательность. Для любых элементов q, d из
кольца R последовательность w(0),w( 1),... ,w(i),..., определяемая соотношени-
ями w(0)=a, w(i+l)=qw(i)+d, ieN0 есть ЛРП порядка 1 с характеристическим
многочленом F(x)=(x-e)(x-q) и начальным вектором w(0,l)=(a,aq+d). Арифме-
тическая прогрессия есть частный случай конгруэнтной последовательности
при q=e.
Пример 2. Линейный регистр сдвига с характеристическим многочле-
ном F(x)=xm - fm-ix1”-1 -...- fix - f0 - это конечный автомат вида
Здесь p(i) - ячейка памяти, содержащая элемент p(s)eR; fs - узел,
осуществляющий умножение на fs; знак + обозначает узел, осуществляющий
сложение в R. В начальный такт работы в ячейках памяти регистра записан на-
чальный вектор ц(0,..., т-1) - (ц(0),... ,ц(т-1)) ЛРП . Такой регистр схе-
матически обычно изображается следующим образом.
469
Заметим, что заполнение p(i,, i+m-l) регистра в i-й такт работы вы-
ражается через его начальное заполнение ц(0,..., ш-1) формулой
p(i,..., i+m-l) = р(0,..., m-1)- S(F)\
где
- сопровождающая матрица для унитарного многочлена F(x).
Напомним, что унитарным многочленом называется многочлен со ста-
ршим коэффициентом равным единице. Зафиксируем унитарный многочлен
F(x)=xm - fm^|Xm“' -...- fix - f0 gR[x] степени m>0 и обозначим через LR(E) се-
мейство всех ЛРП над R с характеристическим многочленом F(x). Тогда непос-
редственно из определения 2 вытекает
Утверждение 1. Любая ЛРП ugLr(F) однозначно задается своим нача-
льным вектором u(0,.. .,т-1). Если |R| < оо, то | LR(F)| = |R|m.
При исследовании свойств ЛРП весьма плодотворным оказывается ал-
гебраический подход, связанный с введением на R00 различных операций.
Определение 3. Суммой последовательностей u,v g R°° и произведени-
ем и на константу fg R называют, соответственно, последовательности w = и +
v и z = г • и, определяемые соотношениями
w(i) = u(i) + v(i),
z(i) = г • u(i), iG No.
Очевидно, что группоид (R”°, +) есть абелева группа с нулем (0) и для
любых a, b g R, u, v g R°° справедливы соотношения
(ab) • и = а • (Ь и), (а+Ь) • и = а • и + b ц,
a(u+v)=au+av, е-и=и.
470
В частности, если Р - поле, то определенные выше операции задают на
Р°° структуру левого векторного пространства РР°°, имеющего, очевидно, беско-
нечную размерность.
Из определений 2, 3 легко следует
Утверждение 2. Для любого унитарного многочлена F(x)gR[x] подм-
ножество Lr(F)czR“:’- есть подгруппа группы (R”°,+), выдерживающая умноже-
ние на элементы из R. Если Р - поле и F(x)gP[x], то Lr(F) - подпространство
пространства Р°°.
Таким образом, в случае, когда Р - поле, можно говорить о базисе про-
странства Lr(F). Мы, однако не будем рассматривать эту простейшую ситуа-
цию отдельно, а введем и изучим аналог понятия базиса пространства для про-
извольного семейства LR(F).
Определение 4. Для унитарного многочлена F(x)gR[x] степени т>0
систему последовательностей ui,...,umGLR(F) назовем базисом семейства LR(F),
если для любой последовательности ugLr(F) существует единственный набор
констант ci,...,cmGR такой, что
. U=C|U|+...+CmUm
Доказательство существования и описание базисов семейства Lr(F)
дает
Утверждение 3. В обозначениях определения 4 система последователь-
ностей ui,...,umeLR(F) есть базис Lr(F) тогда и только тогда, когда составленная
из начальных векторов этих последовательностей матрица
wm(0,w-l)
k mV ’ ’)
обратима над кольцом R.
ДОКАЗАТЕЛЬСТВО. Еслц U - обратимая матрица, то для любой по-
следовательности ugLr(F) единственный набор (С|,с2,...,ст)еКттакой, что
u(0,1,... ,m-1 )=(с 1 ,с2,... ,cm)-U.
Рассмотрим последовательность v=C|U|+...+cmum. По утверждению 2
vgLr(F). Кроме того, очевидно, что v(0,...,m-l)=(cI,c2,...,cm)-U=u(0,l,...,m-l).
Поэтому в силу утверждения 1 v=u, то есть сраведливо равенство
u=ciU|+...+cmum. Единственность представления последовательности и в этом
виде следует из того, что это равенство влечет: u(0,l,...,m-l)=(ci,c2,...,cm)-U.
Таким образом, щ,.. .,um - базис LR(F).
Наоборот, пусть ui,...,um - базис LR(F). Определим для каждого
ке{1,...,ш} ЛРП ekFGLR(F) начальным вектором: е/(0,...,т-1) - k-ой строкой
471
единичной матрицы Е размера mxm. По предположению каждая из последова-
тельностей ej представляется в виде
—CklUi+.. .+CkmUm.
Но тогда для матрицы C=(Ckj) размера mxm справедливы равенства
eiF(0,..jn-l)
Следовательно, U - обратимая матрица.
Следствие. Для унитарного многочлена F(x) над полем Р размерность
пространства LP(F) равна степени многочлена F(x).
Умножение последовательности на многочлен.
Определим на R90 внешнюю операцию умножения слева на многочлены
из R[x]. Для любых keNo и ueR" положим
xk-u=v,
где v(i)=u(i+k), для ie No.
Другими словами умножение на хк есть сдвиг последовательности и на
к шагов влево, или вычеркивание из и первых к членов
хк-(и(0), и(1)„. .Ни(к), и(к+1)„..).
т
Определение 5. Произведением многочлена А(х) = У^акхк
к=0
на последовательность ugR00 называется последовательность A(x)ueR°° вида
т
А(х)и = ^ак(хк-и).
к=0
т *
То есть A(x)u=w, где w(z) = ^\ik • u(i + к) для ieN0 .
к=0
Несложно доказывается
Утверждение 4. для.любого многочлена F(x)eR[x]
Lr(F)={ug R”°: F(x)u=(0)}.
У
Теорема 1. Для любых A(x),B(x)gR[x] и u,vgR" справедливы равенства
1. A(x)-(u+v)=A(x)-u+A(x)-v
2. (A(x)+B(x))u=A(x)-u+B(x)-u
3. (A(x) B(x)) u=A(x)-(B(x) u)
472
Первые два равенства легко выводятся из определения 5. Для доказа-
тельства последнего равенства заметим, что для любых a,beR и k,je N« из вве-
денных определений легко следует равенство axk-(bxJ-u)=abxk+i-u. Поэтому, если
А(х) = akxk , В(х) = 22 bjXJ,
k>0 j>0
то из первых двух равенств, указаных в теореме, следуют равенства
(А(х)В(х))и=
2akbjXk+J
4k,j>0
u = £ak*k(bjXJ-u) =
k,j>0
= Sakxk(B(x)u) = A(x)-(B(x)-u)).
k>0
Следствие. Любая ЛРП u над кольцом R имеет бесконечно много хара-
ктеристических многочленов.
Для унитарного многочлена F(x)gR[x] степени т>0 через eF обозначим
ЛРП из Lr(F) с начальным вектором eF( 0, m — 1 )=(0,0,.. .0,е).
Справедлива /11/ 1
Теорема 2. Пусть F(x)= xm-fm_ixm-1 -...-f0 gR(x), m>0. Тогда для любой
ЛРП ugLr(F) существует единственный многочлен ф(х)ёВ(х) степени меньшей
m такой, что
и=ф(х)- eF
и этот многочлен имеет вид
m-1
• ф(х)=и(0)хт~| + 22 (u(k)-fm-iu(k-l)-...-fm_ku(O))xm-1-k.
. k=l
Замечание 1. В случае когда R=P - поле, теорема 2, по сути дела, утве-
рждает, что Lp(F) - подпространство пространства Рк, не только инвариантное
относительно преобразования ст, определяемого условием: для любого ug Рж
ct(u)=x-u, но и циклическое относительно ст, причем eF - вектор, порождающий
подпространство Lp(F).
Определение 6. Многочлен ф(х), удовлетворяющий условию
и=ф(х)- eF
называется генератором ЛРП и относительно ее характеристического
многочлена F(x).
473
Определение 7. Характеристический многочлен ЛРП и, имеющий наи-
меньшую возможную степень, называется ее минимальным многочленом, а его
степень называется рангом ЛРП и и обозначается через rang и.
Очевидно, что ранг ЛРП определяется однозначно. В то же время, ми-
нимальных многочленов у одной ЛРП может быть несколько, и даже бесконеч-
но много.
Определение 8. Аннулятором последовательности ugR°° называется
множество
Ann(u)={H(x)eR[x]: H(x) u=(0)}.
Очевидно, что Ann(u) - идеал кольца R[x], последовательность ugR00
есть ЛРП над R тогда и только тогда, когда в этом идеале есть унитарные мно-
гочлены, и минимальный многочлен ЛРП и есть любой унитарный многочлен
наименьшей степени из Ann(u).
Теорема 3. Любая ЛРП и над полем Р имеет единственный минималь-
ный многочлен G(x)gP[x], и он удовлетворяет равенству
Ann(u)=P[x]G(x).
ДОКАЗАТЕЛЬСТВО. Так как Р[х] - кольцо главных идеалов, то сущес-
твует единственный унитарный многочлен G[x]gP[x] - такой, что
Ahn(u)=P[x]G(x). Откуда следует, что G(x) - характеристический многочлен
ЛРП и, на который делится любой другой ее характеристический многочлен.
Следовательно, G(x) - единственный минимальный многочлен ЛРП и.
В дальнейшем минимальный многочлен ЛРП и над полем будем обоз-
начать через ши(х).
Теорема 4. Для любого унитарного многочлена G(x)gR[x] и любой по-
следовательности ugR00 следующие утверждения эквивалентны
(а) и - ЛРП с единственным минимальным многочленом G(x);
(б) Ann(u)=R[x]G(x).
ДОКАЗАТЕЛЬСТВО. Покажем, что из (а) следует (б). Так как
G(x)-u=(0), то R[x]- G(x)czAnn(u). Наоборот, пусть H(x)eAnn(u). Разделим Н(х)
с остатком на G(x):
H(x)=Q(x) G(x)+A(x), degA(x)<degG(x).
Тогда A(x)GAnn(u), так как H(x)u=G(x)u=(0). Следовательно,
Gi(x)=G(x)+A(x) - унитарный многочлен из Ann(u) той же степени, что и G(x),
то есть Gi(x) - минимальный многочлен ЛРП и. Но тогда ввиду условия (а)
Gi(x)= G(x), то есть А(х)=0 и H(x)g R[x] G[x]. Импликация (б)=>(а) доказывае-
тся так же, как и в теореме 2.
Несложно доказывается
Утверждение 5. Пусть F(x)gR(x) - унитарный многочлен степени т>0,
ugLr(F) и
474
u(O,m -1)=(0,0,...,а), где aeR-элемент, не являющийся делителем нуля. Тог-
да F(x) - единственный минимальный многочлен ЛРП и.
Следствие. Для любого унитарного многочлена F(x) е R[x]
?tnn(eF)=R[x]F(x).
Определение 9. Для элемента а е R\0 и любого к е N 0 последователь-
ность а ^6 R“ элементов вида
a W(i)=|1 j-a‘,i е No
I к J
называется биномиальной последовательностью порядка к+1 с корнем а.
Утверждение 6. Если элемент а е R не является делителем нуля, то
а -ЛРП с единственным минимальным многочленом G(x)=(x-a)k+1.
ДОКАЗАТЕЛЬСТВО. Докажем индукцией по к включение
a М g Lr ((х - a)k+1). При к=0 оно очевидно. Пусть к>0 и
a [к*^ е Lr ((х - а)к ). Тогда используя известное равенство
(i +(i А ( i гк1
— = , получаем (x-a) a1 J =v, где
v(i)=( Р+ |-f | )a,+1=a-f * |-a‘=a-cJk’1l(i),
4 k Ik lk-1)
МГ k-l I
z - tx • a1 J. Отсюда, пользуясь предположением индукции
имеем (x-a)k+1 • = a • (x - a)k • a^k'^ = (0).
Остается заметить, что a^(( 0,1 ) = (0,...,0,ak )) , и так как ak- не
делитель нуля в R, то по утверждению 5 характеристический многочлен (х-
a)k+1 ЛРП a является ее единственным минимальным многочленом.
Простой способ вычисления минимального многочлена ЛРП над полем
дает
Теорема 5. Пусть и - ЛРП над полем Р с характеристическим многоч-
леном F(x) и генератором ф(х). Тогда
475
(a) Mu(x)=---;
(F(x),<Kx))
(б) если v=H(x)-u для некоторого H(x) e P[x], то
М (х) =----Мц(х) '
(H(x),Mu(x))
ДОКАЗАТЕЛЬСТВО, (а) По определению генератора справедливо ра-
венство и=ф(х)-ер, и так как по следствию утверждения 5 MeF (х) = F(x), то (а)
следует из (б).
(б) Достаточно заметить, что по теореме 2 для любого А(х)еР[х] спра-
ведливы соотношения
A(x)-v=(0) <=>A(x)H(x)u=(0) <=> —Tvff . •• |А(х).
(H(x),Mu(x))
Следствие. Минимальный многочлен ЛРП ueLp(F) равен F(x) тогда и
только тогда, когда ее генератор относительно F(x)- взаимно прост с F(x). В час-
тности F(x) является минимальным многочленом для любой ненулевой ЛРП из
LP(F) тогда и только тогда, когда F(x) неприводим над Р.
Для линейных рекурент кольцом над теорема 5(a) может быть обобщена
следующим образом.
Утверждение 7. Если и - ЛРП над кольцом R с характеристическим
многочленом F(x) и генератором ф(х), то
Апп(и)= {А(х) g R[x]: F(x)| А(х)ф(х)}
ДОКАЗАТЕЛЬСТВО. Так как п=ф(х) ер, то по следствию утверждения 5
А(х)и=(0) <=> А(х) -ф(х) -eF <=> F(x)| А(х) -ф(х)-
Соотношения между семействами ЛРП с различными характеристиче-
скими многочленами.
Утверждение 8. Для любых унитарных многочленов F(x),G(x)e R[X]
(Lr(G)cz LR(F)) о (G(x)|F(x)).
ДОКАЗАТЕЛЬСТВО. Пусть G(x)|F(x). Тогда
ugLr(G) => G(x) u=(0) => F(x) u=(0) => ugLr(F).
476
Пусть Lr(G)cz Lr(F). Тогда eGe LR(F), F(x)-eG=(0) и по следствию
утверждения 5
G(x)|F(x).
Определение 10. Многочлены F (x), G (x) g R [x] называют взаимно
простыми, если R[x]-F(x)+R[x]G(x)=R[x], т. е. A(x)F(x)+B(x)G(x)=e для неко-
торых А(х), B(x)gR[x]. В этом случае пишут (F (х), G (х))=е.
С использованием этого определения несложно, аналогично тому как
это делается для многочленов над полем, доказывается
Утверждение 9. Для любых многочленов F(x), G(x), H(x)gR[x]
справедливы импликации
(a) ((F(x), G(x))=e, (F(x), Н(х))=е) => (F(x), G(x) • H (x))=e;
(6) ((F(x), G(x))=e, F(x) | G(x) • H(x)) => F(x) | H (x);
(в) ((F(x),G(x))=e, F(x) | H(x), G(x) | H(x)) => F(x)G(x) | H(x).
Теорема 6. Пусть Fo(x),F|(x)gR[x]-унитарные взаимно простые
многочлены и F(x)=Fo(x)-F](x).
Тогда
Lr(F)=Lr(F0) +Lr(F()
Если R - поле и последовательность ugLr(F) представлена в виде
U=Uo+Ui, usgLr(Fs), sg 0,1, то
(Mu0(x),Mui(x))=e, Mu(x)= Mu0(x)-Mui(x).
ДОКАЗАТЕЛЬСТВО. По утверждению 8 LR(Fs)cz LR(F) для sg 0,1 и по
утверждению 2
Lr(F)z>Lr(Fo) + Lr(Fi)
Так как по условию Ao(x)Fo(x)+A[(x)Fi(x) =е для подходящих
Ao(x),A](x)gR[x], то любая последовательность ugLr(F) представляется в
виде
u=uo+ui,
raeus=AI_s(x) Fi_s(x)-u для sg0,1.
Очевидно, что Fs(x)-us= A|_s(x)-F(x)-u=(0), т. е. usgLr(Fs). Отсюда и из
Lr(F) z> Lr(F0) + Lr(Fi) следует равенство Lr(F)=Lr(F0) + Lr(Fi). Если
ugLr(Fo)oLr(F|), то Fs(x)u=0 для sg 0,1, и потому в приведенном выше равенс-
тве u=uo+ui выполняются соотношения: uo=ui-(O), то есть и=(0). Требуемое в
теореме 6 равенство доказано.
477
Если R - поле, и u= u0+ui, use Lr(Fs), se 0,1, то по теореме 3
M Us (x)|Fs(x), и потому (M Uo (x), M U) (x)) =e.
Теперь для доказательства равенства Mu(x)=Muo(x)-Mui(x) остается за-
метить, что MUj (х) есть минимальный многочлен вектора usg Lr(F) относи-
тельно линейного преобразования а=ст| LR(F) (см. замечание 1), и воспользо-
ваться известными утверждениями о минимальных многочленах векторов от-
носительно линейных преобразований векторных пространств.
Для ЛРП над полем первое утверждение теоремы 6 может быть сущест-
венно усилено.
Теорема 7. Для любых унитарных многочленов F(x) и G(x) над по-
лем Р справедливы равенства
LP(F) n LP(G)= Lp(D), где D (x)=(F (х), G (х));. (1)
Lp(F) + LP(G)= LP(H), где H(x)=[F(x),G(x)].
ДОКАЗАТЕЛЬСТВО. По утверждению 8 L (D)c L (F) n L (G). С дру-
гой стороны, так как D(x)=A(x)F(x)+B(x)G(x) для подходящих А(х),
В(х)еР[х], то для любой ЛРП ueLp(F)nLp(G) справедливы равенства
D(x)-u=A(x)F(x)-u+B(x)G(x)u=(0)+(0)=(0), т. е. ugLp(D) Равенство (1) доказано.
Из утверждения 8 следует также включение LP(F)+Lp(G) с
ЬР(Н).Остается заметить, что по следствию утверждения 3 и в силу (25)
dim (Lp(F)+LP(G)j =dim UW+dirn LP(G)-rffm(LP(F) n LP(G)) =
=deg F(x)+deg G(x)-deg D (x)=deg H (x)=dzm LP(H). □
Биномиальный базис пространства ЛРП над полем.
Все рассмотренные до сих пор базисы пространства LP(F) не давали
способов представления общего члена u(i) произвольной ЛРП ugLp(F) в виде
просто вычисляемой и записываемой явной формулой функции от параметра i.
Опишем важный частный случай, когда такой способ существует.
Теорема 8. Пусть многочлен F(x) g Р [х] раскладывается над по-
лем Р на линейные множители и имеет каноническое разложение вида
F(x) = (x-at)k,+1-...•(x-ar)kr+‘, as *0, ks>0, длявб1,г. (2)
Тогда базисом пространства LP(F) является система биномиальных по-
следовательностей
478
„ [0] „ [1] „ [к,]
otj ,ai 5 9
[0] [1] [к2]
a2l J,a,2 J,...,a2l
„ [0] [1] [kJ
(см. определение 9).
ДОКАЗАТЕЛЬСТВО. По теореме 6 пространство LP(F) есть прямая су-
мма подпространств
LP(F)=Lp((x-a1) kl+1)+.. .+LP((x-ar) k'+1).
Остается доказать, что система последовательностей
as[01,aslI1,...,astksJ есть базис пространства Lp((x-as)k’+1). Включения
asf11 е Lp ((х - as )ks+l) для 1g 0, ks следуют из утверждения 6. Теперь достато-
чно заметить, что система из ks +1 векторов длины ks +1:
a[sO](ojr)=(e,,
а^^1Г)=(0,е,*,...,*),
a^s](0,ks)=(0,....,0,e)
линейно независима над Р и воспользоваться утверждением 3.
Следствие 1. При условии (2) для каждой ЛРП ugLp (F) существует
единственный набор коэффициентов
а10,ан,...,а ,a20,...,a2k ,...,аА еР
1К| г
такой, что для каждого i g N выполняется равенство
479
u(i) = a10aj +ан
+ a20a2 +
+aX +
(3)
+ arkr
ДОКАЗАТЕЛЬСТВО. Нужные коэффициенты a S>1 суть коэффициенты
в разложении вектора u е LP
u = SEasia'"-D
s=l 1=0
по базису
a2[0],a2[11,...,a2[k2],
а Да/’1,..., a/Ч
По разложению (3) последовательности и можно легко построить ее
минимальный многочлен и найти rang и. Мы рассмотрим здесь наиболее прос-
той и важный частный случай.
Следствие 2. Если вц,..., ar - попарно различные элементы Р\0, то
для любых аь ..., аг 6 Р последовательность u е Р“ элементов вида
u(i) = a,a; +... + ara'r*
есть ЛРП с характеристическим многочленом F(x)= (x-ai )•...• (x-ar) При этом
ранг последовательности и равен числу ненулевых коэффициентов среди аь ...,
£ £ --------------------------------------------
аг и Ми(х)= (х - о.]) 1-...-(х-а^.) г ,где для s е 1,г
1, если as ф О,
£, = <
[О, если as = 0.
480
ДОКАЗАТЕЛЬСТВО. Включение u g Lr(F) очевидно. Тогда Mu (х) | F
(х), т. е. Ми (х) - произведение некоторых одночленов из (х-0С])-...-(х-аг)
. Упрощая обозначения, допустим, что
Mu(x) = (x-a1)-...-(x-at), l<t<r.
Тогда по следствию 1 существуют ci,..., ct е Р такие, что
V ieN0: u(i) = c1a'1 +... + cta{.
Отсюда, пользуясь единственностью представления (3), получаем
ai=Ci,..., at=ct, at+i =.. .=аг=0. Остается заметить, что все коэффициенты сь...,
ct отличны от нуля. Действительно, если например ct =0, то ugLp ((х-а|)-...-(х-
at_j)), что противоречит допущению о виде Мч(х).
Замечание 2. Пусть в обозначениях теоремы 8 m=deg F(x)=
(ki+l)+...+ (kr+l). Тогда каждая ЛРП ug Lp (F) однозначно определяется своим
начальным вектором и (0, m — 1), и для нахождения коэффициентов as>t в раз-
ложении (3) достаточно составить систему m линейных уравнений с ш неизвес-
тными {xs t; s е 1, г, t е 0, ks}, которая в векторной форме имеет вид
u(0, m -1) = x-st<4t] (0, m -1).
Однозначная разрешимость этой системы следует из линейной незави-
симости системы векторов |a^(0,m-l) :S,e l,r, teO,ks|
(см. теорему 8 и утверждение 3).
Примере. Пусть и - ЛРП над полем Р = Z5. с характеристическим
многочленом F(x) = x6-2х3 + х2+3х-2 и. начальным вектором
и(0,5 )= (0, е, е, 0, 3, е, е). Требуется найти и (1986).
Перебором элементов поля Р убеждаемся, что многочлен F(x) имеет в Р
корни <Х| = е, а2 = 2е, а3 = Зе, и его каноническое разложение над Р .имеет
вид
F(x) = (х - е)3 • (х - 2е)2 • (х - Зе).
481
Следовательно, F(x) удовлетворяет условию (2) теоремы 8 и последова-
тельность и однозначно представляется в виде
u — 3|Q<X| ] + а,]<Х[ ] + а12ос-] + ^20^2] ^21^21 + а30а3 •
Выражение (3) для i-ro члена этой последовательности имеет в рассма-
триваемом случае вид
u(i) = а10е' + aHi -е1 + а|2
е‘ + а20(2е)' +a21i(2e)' +азо(3е)‘
+ a21i)-(2e)' + азо(3е)‘,
а система линейных уравнений
u(0, m -1) = 2=1 Zt=o xsta[s] (°’m “
для определения коэффициентов в этом представлении выглядит следующим
образом: Ге° 0е° (0е)°(2е)° 0-(2е)° (Зе)° Л \
• е1 е1 0е’(2е)‘ . 1 • (2е)‘ (Зе)1 хн е е2 2е2 1е2(2е)2 2-(2е)2 (Зе)2 х12 _ е е3 Зе3 3-е3(2е)3 3 • (2е)3 (Зе)3 х20 " 0 е4 4е4 6е4(2е)4 4-(2е)4 (Зе)4 x2i Зе е5 5е5 10е5(2е)5 5 • (2е)5 (Зе)5 ) Ы Iе )
После преобразований в арифметике поля Z5 эта система принимает вид
'е 0 0 е 0 е <х Л10 <°
е е 0 2е 2е Зе Х11 е
е 2е е 4е Зе 4е Х12 е
е Зе Зе Зе 4е 2е Х20 0
е 4е е е 4е е Х21 Зе
0 0 2е 0 Зе> \хзо>
Решая ее, получаем: (а^аца^агоаз^зо) =(ё, е, е, 2е, 2е, 2е), т. е. для
всех i g N справедливо равенство
163ак. 5
482
i
2
u(i)= l + i +
е + (2 + 2i)(2e)'+ 2(3е)'
Отсюда, при i = 1986 находим
и(1986)=2е+4-(2е)449Ш + 2 • (3e)449(W =2е+4-(2е)2 +2(3е)2 =2е+е+3е = е
Замечание 3. Теорема 8 может быть использована для описания общего
члена ЛРП ugLp (F) и в случае, когда многочлен F(x) не раскладывается над
полем Р на линейные множители. В этой ситуации рассматривается поле раз-
ложения Q многочлена F(x) над полем Р и каноническое разложение (2) F (х)
над Q. Так как ugLq(F), то можно утверждать, что общий член u(i) последова-
тельности и имеет вид (3) где ask некоторые коэффициенты из расширения
Q поля Р. Следует заметить, однако, что при сделанных предположениях в
виде (3) представляется общий член любой ЛРП ugLq(F). Поэтому дополни-
тельное условие u g LQ(F)nPx накладывает некоторые ограничения на набор
коэффициентов ask g Q. Смысл этих ограничений в случае, когда Р - конечное
поле можно будет уяснить из результатов следующего параграфа.
П р и м е р 9. Вычислим над полем Р = Z2 значение определителя
2 2 0 0 ... О
О 1 2 2 0 ... О
J 0 1 2 2 ... О
а =
О ... О 1 2 2
Как отмечено в примере 5, d -есть член А(11) ЛРП Д над Р с характери-
стическим многочленом F(x) = х2 - 2х + 2 и начальным вектором Д (0,1)=(2,
2).
Многочлен F(x) не имеет корней в Р и потому ввиду условия <ZegF(x)=2,
он неприводим над Р, а его минимальное поле разложения Q есть Q = GF(32).
В поле Q многочлен F(x) имеет 2 разных корня: а0 и а,, удовлетворя-
ющих соотношению а© +оц =2.
По следствию теоремы 8 общий член ЛРП Д имеет вид
A(i) = соа{) + с,а], где коэффициенты с0 и С] системы линейных уравнений •
483
соа®+с,а®=А(О)
соа* + с,а} = А(1).
Подставляя сюда значения начального вектора, получаем
с0 + Ci =2
Coao+c.ct] =2
Пользуясь условием а0 + cq = 2, находим с0 = с, = 1 и
A(i) = а}, + а}.
В частности, d = А (11) = а" + а}1 . Так KaKaseGF(32), то а’ = ав,для
s е 0,1. Поэтому а” = а„+2 + а’+2 = а^ + а2. Так как а2 = 2as - 2, то
а2 = 2а2 - 2а. = а -1 - 2а, = 2а, -1 для s е 0,1.
Окончательно получаем:
d = (2a0 -l)+(2a! -1) = 2(a0 + aJ-2 = 2.
Представление ЛРП над конечным полем с помощью функции
"след”.
Пусть Р = GF(q) - конечное поле характеристики р и Q = GF(qm) - его
расширение степени т.
Определение 11. Следом из поля Q в поле Р называется отображение
tr,? : Q —> Р, ставящее в соответствие произвольному элементу a е Q элемент
tr^(a) = a + a4+... + aq,n 1 .
О am
Функция tTp (х) иногда обозначается также через trq (х) (если
достаточно акцентировать внимание лишь на мощностях рассматриваемых по-
лей) или просто — через tr (х) (если из контекста ясно, какие поля имеются в
виду).
Отметим сразу, что отображение tr^ определено корректно, т. е.
для - любого
16*
484
a g Q выполняется включение tr^ (a) g P, поскольку очевидно,
что tr (a)4 = tr^ (a). Основные свойства функции "след" перечисляет
Теорема 9. (а) Функция tr^ есть линейное отображение пространства
Qp на пространство РР .
(б) Если дана башня полей Q = GF(qm) GF(qk) о Р, то для любого a g
Q справедливо равенство
trq4 (a) = trq4 (tr’k (a)]
(в) Если минимальный многочлен элемента a g Q над полем Р имеет
вид ца р (х) = хк - ск_1хк-1 -... - с0 , то к | ш и
<(а) = ^ск_,
К.
ДОКАЗАТЕЛЬСТВО, (а) Для любых а,Ь g Р и a,0 g Q из известного
равенства (аа + pb)4 = ача + рчЬ и определения 11 следует равенство
tr^ (аа + pb) = tr(a) - а + tr(P) • b. Следовательно, trj? - линейное отобра-
жение QP в Рр. Так как dim Рр =1, то либо tr (Q) = Р, либо tr (Q) = 0. Послед-'
нее равенство невозможно, так как оно означает, что все qm элементов поля Q
являются корнями многочлена х + хч + ... + хч степени q”*-1. Следовательно,
tr (Q) = Р, т. е. tr - отображение Q на Р.
(б) Из условия теоремы й свойств конечных полей следует, что k | т.
Пусть m = к-n. Заметим, что справедливо равенство {0, 1,..., m-1} = {ks+1:
sg 0, n-1, 1g 0, к-1}. Теперь утверждение (б) доказывается следующим об-
разом:
=ф>(’*9’' -
=iXfe'к?" <а))
(в) Рассмотрим расширение Р(а) поля Р в Q. Так как (P(a) : Р] =
485
=deg,jia>p(x),=. к, то P(a) = =GF(qk) и k|m, т.е. m = kn для подходящего n e N.
tt qk
Поскольку при сделанных предположениях a4 = а, то справедливы равенства
am Qk(n-1)
tr4k (a) = a 4- a4 +... + a4 = a + a +... + a = n • a.
Из свойств неприводимых многочленов над конечным полем следует
равенство
Ma,p(x) = xk -ck_lxk"' - ,..-с0 =(x-a)(x-aq)•...• (х-a4"’1),
которое дает соотношение
trqqk (a) = a + aq +... 4- aqk ’ = скЧ .
Отсюда, пользуясь утверждениями (б) и (а), получаем
t< (a) = trqk (try (a)) = trqqk (na) = n • trqqk (a) = n • ck_t = ck_,.
К
Основной результат, позволяющий описывать любую ЛРП над конеч-
ным полем с помощью функции "след", состоит в следующем.
Теорема 10. Пусть Р = GF(q), G(x) - неприводимый многочлен степени
m над Р, Q=?GF(qm) - минимальное поле разложения G(x) над Р и a - корень
G(x) в Q. Тогда для любой ЛРП u е Lp(G(x)k+l), k е N, существует единствен-
ный набор констант ао,..., ак е Q такой, что
VieN0
u(i) = trpQ(aoa') + l JtrpQ(а^1 ) + ...+
trp (aka')
(4)
Любая последовательность u g Р00 вида (4) принадлежит LP(G(x)k+1).
ДОКАЗАТЕЛЬСТВО. При доказательстве данной теоремы мы исполь-
зуем следующее известное из теории конечных полей вспомогательное утве-
рждение.
Пусть f(x) - неприводимый многочлен степени п над полем P=GF(q),
q-p , и А =Р(а) -расширение поля Р, порожденное корнем а многочлена f(x).
Тогда справедливы следующие утверждения:
a) F - минимальное поле разложения многочлена f(x) над Р, причем f(x)
имеет в Fровно п различных корней
486
_n-l
a, cP, .... а4
пп-1
6)f(x)\ xq -х.
Пространство LP(G(x)k+1) имеет над Р размерность т(к+1) и потому сос-
тоит ровно из qm(k+l) последовательностей. Число различных наборов (ао,Эк)
элементов из Q также равно qm(k+1). Поэтому для доказательства теоремы доста-
точно показать, что любая последовательность вида (4) принадлежит
LP(G(x)k+1) и различным наборам коэффициентов (ао,..., ak) е Q(k+I) соответст-
вуют различные последовательности вида (4).
Любая последовательность и, удовлетворяющая условию (4) при неко-
торых ао,... ,ak е Q, есть сумма последовательностей и = и© + Ui + ... + Uk, где
для г е 0, к последовательность иг, задается равенствами
Введем обозначения а0 = а, oq = ач,...,ат_! = aq . Тогда по
определению 11
tr^ara’j^aja}) +aqaj + ... + aq а^.
ttp* (ara* J i e No., пользуясь обоз-
Отсюда и из равенств ur(i) =
качениями определения 9, получаем
ur = ara[or] + aqair] +... + af * ,
И В силу U = Uo + U1 + ... + Uk,
k m-1 .
U = SEa?asr]- (5)
r=0 s=0
Теперь заметим, что (по приведенной в начале доказательства вспомо-
гательной теореме) а0,..., otm-i - суть все различные корни в Q неприводимого
над Р многочлена G(x), т.е. G(x) = (х - ao)-...-(x - ctm-i), и каноническое разло-
жение над Q многочлена G(x)k+1 имеет вид G(x)k+1 = (х - a0)k+1 •...• (х - a,m-i)k+I.
Поэтому из (5) и теоремы 8 следует, что u е Lq(G(x)k+1). Так как, кроме того, и
е Р°° ввиду (4), то ие LQ(G(x)k+1)r)P”° = LP(G(x)k+1). Наконец, так как элементы
ао,..., ащ-1 g Q попарно различны и отличны от нуля, то по теореме 8 система
487
последовательностей : s g 0, m — 1, г g 0, к| линейно независима над Q.
Поэтому различным наборам коэффициентов (ао,ak) g Q(k+1) соответствуют
различные последовательности вида (5).
Замечание 4. Из доказательства теоремы 10 вытекает следующий спо-
соб представления знаков ЛРП u 6 Lp(G(x)k+1) в виде (4). Так как ug LQ(G(x)k+l),
то и однозначно представляется в виде
m-1 к _______ ________
u = где asr gQ,sg0,di-1, гс0,к. (6)
s=Or=O
Коэффициенты as) в этом представлении находятся путем решения сис-
темы линейных уравнений над Q (см. замечание 3). Из единственности пред-
ставления (6) и существования для и представления вида (5) следует, что коэф-
фициенты asr в (6) удовлетворяют соотношениям
2 ш-1 ----
а1г = а0Г’а2г = а0г ’•"’ат-1г = а0г Д™ г е °,к,
и искомые коэффициенты ао,..., ак в разложении (4) суть ао = аоо, ai = aoi,...,
ак= аок- Указанные соотношения и представляют собой упомянутые в замеча-
нии 4 ограничения на коэффициенты а«1 разложения (6) произвольной ЛРП
u G LQ(G(x)k+l), которые накладываются условием u G Р°°.
Пример 10. Пусть и - ЛРП над полем Р = Z5 с характеристичес-
ким многочленом (х2 - 2х - 2)2 и начальным вектором и( 0,3 ) = (0, 0, 0, 1). Тре-
буется представить общий член этой ЛРП с помощью функции "след" и вычис-
лить и(37). Непосредственной проверкой убеждаемся в том, что многочлен
G(x) = х2 - 2х - 2 не имеет корней в Р и потому неприводим. Пусть Q = GF(52) -
минимальное поле разложения G(x) над Р и a g Q - корень G(x). Тогда согласно
теореме 10 общий член u(i) ЛРП и однозначно представляется в виде
u(i) = tr(aoa‘) + itr(ai<x').
Для отыскания коэффициентов ао, ai в этом представлении ищем коэф-
фициенты аоо, зоь Зю, аи с Q, удовлетворяющие равенству (6), которое в дан-
ном случае имеет вид:
u = аоо^о 1 + ао1ао] аюа1 ан®1
где 0L = а5 ,а<°3 = (...,а',...1а^ = (...,ia‘,...) дляв g 0,1. Согласно
замечанию 4 ао = аоо, =<*oi- Коэффициенты asi находятся из системы ли-
нейных уравнений
488
и(оз)=а„ат(оз)+а01а'||(оз)+а,Х1(о.з)+а||а|,'Н
которая в рассматриваемом случае имеет следующую матричную запись:
fl 0 1 0 > аоо Г(Л
а а а5 а5 а01 0
а2 2а2 а10 2а'° а10 0
У За3 а15 За15, ка11> <1,
Составим расширенную матрицу системы
и упростим ее элементарными преобразованиями строк. Вычитая последовате-
льно из 4-й, 3-й, 2-й строк матрицы А предыдущую строку, умноженную на а,
получаем
'1 0 1 0 (Р
0 а а5 - а а5 0
А~ В =
0 а а - а 2а - а 0 '
П О „.15 ^0 а а — а За — 2а b
Повторяя ту же процедуру с 4-й и 3-й строками В, получаем
489
0. 1 0 (?
0 а а5 - а а5 0
в~с = 0 0 а10 - 2а6 + а2 2а10-2аб 0
ч0 0 а15-2ап+а7 За15-4а11+а7 1^
С~
Вычитая из 4-ой строки матрицы С 3-ю, умноженную на а5, находим
'1 0 1 0 0
0 а а5 - а а5 0
D = 0 0 а10 -2а6 + а2 2а10-2аб 0
<0 0 0 а15 - 2а“ + а7 1
Так как а - корень многочлена х2 - 2х - 2, то справедливы соотношения
а2=2а+2 а5=4а+2 а10=За+1
а3=а+4 а6=3 а”=2а+1
а4=а+2а7=3а а|5=4а+1,
пользуясь которыми матрицу D можно записать в виде
1 0 1 0 0
0 а За+ 2 4а + 2 0
0 0 2 а + 1 0
0 0 0 За + 4 1
Так как (За+4) 1 = а, то, вычитая из 3-й строки матрицы D ее 4-ю стро-
ку, умноженную на а(а+1), получаем
Г1 0 1 0 0
0 а За+ 2 4а+ 2 0
и ~ 0 0 2 0 2а+ 3
1° 0 0 За + 4 1 J
490
Теперь, как нетрудно видеть, в исходной системе линейных уравнений
выделяется подсистема
1 lY’cVr о 'I
0 2j<a10> . к2а + 3^
из которой находим аю = a + 4, аоо = 4a + 1 и ао = a^ = 4a+l. (Для проверки,
заметим, что = (4a +1)5 — 4a5 +1 = 4(4a + 2) + 1 = а + 4 = а10). Отсюда
для отыскания переменных аю, ан получаем следующую систему
a 4a + 2Ya0IA (-(3a + 2)(a + 4)A (1
0 За + 4^ан^ 1 J v
Решая ее, находим ап = (3a+4)-1 = a, aoi = a”’(l - a(4a + 2)) = 3a-1 =
3(3a + 4) = 4a + 2 = и a,= aoi = 4a+2.
Окончательно получаем, что искомое представление знаков ЛРП и име-
ет вид
w(z) = tr((4x+l)./)+itr((4x+2).x‘)
для i е Nq.
Теперь значение и(37) можно вычислить следующим образом.
Так как а24= а25-1 =1, то а37 = а13 = а3а10 = (а+4)(За+1) = 4а. Отсюда
u=tr((4a+l)-4a)+37tr((4a + 2)- 4а) = =tr(((4a+l) + 2(4а + 2))-4а) = tr(3a2) = tr(a
+1) = tr(a) + tr(l).
Так как a - корень неприводимого многочлена х2 - 2х - 2, то по теореме
9 (в) tr(a)= 2 и tr(l)=2. Отсюда и (37) = 4.
. Замечание 5. Теорема 10 позволяет вычислять с помощью функции
«след» знаки линейной рекурренты не только с примарным, но и вообще с лю-
бым характеристическим многочленом F(x), таким, что F(0)^0. Для этого до-
статочно найти каноническое разложение F(x) и представить исходную ЛРП в
виде суммы ЛРП с примарными характеристическими многочленами, пользу-
ясь теоремой 6.
491
Периодические последовательности.
1. Пусть Q - произвольное множество.
Определение 12. Последовательность ugQ°° называется периодичес-
кой. если существуют параметры XeN0, teN и такие, что
V i > X: u(i+t) « u(i).
Для наглядности, периодическую последовательность и, удовлетворя-
ющую указанному условию можно изобразить графически следующим образом
и(Х+1)->.
u(0)—>и(1) —♦...—»и(Х-1)__►/u(X)=u(X+t)
u(X+t-l)
u(X+j)=u(X+j+t)
Заметим, что если и - последовательность над кольцом R, то условие V
i > X: u(i+t) = u(i) эквивалентно условию
x’(x'-e)u=(0).
В дальнейшем этот факт используется без дополнительных оговорок. В
частности, отсюда следует t
Утверждение ГО. Любая периодическая последовательность над ко-
льцом R есть ЛРП.
. Если ие£2°° - периодическая последовательность, то набор параметров
(X,t)eNoxN, удовлетворяющий условию V i > X: u(i+t) = u(i), определен неодно-
значно. Для описания всех таких наборов введем
Определение 13. Если и е£2°° — периодическая последовательность,
то наименьшее число teN, для которого существует XeN0 такое, что V i > X:
u(i+t) = u(i), назовем периодом последовательности и и обозначим через Т(и).
При этом наименьший параметр XeN0 - такой, что
V i > X: u(i+T(u)) = u(i),
назовем длиной подхода последовательности и и обозначим через Л(и).
Теорема 11. Если и - периодическая последовательность элементов
множества £2, то числа XeNo, teN удовлетворяют условию
V i > X: u(i+t) = u(i)
492
тогда и только тогда, когда
X>A(u), T(u)|t.
ДОКАЗАТЕЛЬСТВО. Введем, для краткости, обозначения: Л(и)=Хо,
T(u)=t0. Пусть М - множество всех различных элементов из Q, встречающихся
в последовательности и. Так как и - периодическая последовательность, то М -
конечное множество: |М| < X0+t0. Выберем произвольно поле Р такое, что |Р| >
|М|, зададим инъективное отображение %:М—>Р и определим последователь-
ность и еР°° условием u(i)=^(u(i)) для ieNo. Ввиду инъективности отображе-
ния % очевидно, что для фиксированных XeN0 и teN условие V i > X: u(i+t) =
u(i) равносильно условию
хх(х‘-е) = (0).
Отсюда и из условия теоремы следует, что и - периодическая последо-
вательность, причем Т( u )=to, Л( и )=Х0 и нам достаточно доказать, что указан-
ное условие равносильно условию
X > Хо, to | i.
Так как по определению 13
ххо(х,о-е)й=(О)
и из X > Хо, to | i следует, что ххо(х‘°-е) | хх(х‘-е), то из X > Хо, to | i следует
х\х'-е) = (0).
Наоборот, допустим, что параметры XgN0, teN удовлетворяют условию
х\х'-е) = (0), и докажем выполнение условий X > Хо, to | i. Покажем, что спра-
ведливо равенство
(х\х'-е), xX0(xt0-e))=xk(xd-e), где к=лпи{Х, Хо}, d=(t, to).
Действительно, очевидно, что (х\х‘-е), ххо(х‘°-е))=хк(х,-е, х,0-е) и так
как по определению 14 t > to, то х‘-е=х‘ч0(х,0-е)+(х‘"‘°-е), откуда (х‘-е, х‘°-е)=(х,‘
ю-е, х,0-е). Теперь исследуемое равенство легко доказывается индукцией по
t+to. '
493
Так как многочлен xk(xd-ie) есть линейная комбинация многочленов
хх(х‘-е) и ххо(хю-е), то из х^(х'-е) = (0) и равенства ххо(х‘°-е) и =(0) следует, что
xk(xd-e)u=(0).
Отсюда по определению параметра to=T(u) следует, что d > to, а так как
d=(t, to) | to, то d=to, to 11 и справедливо равенство x’(x,o-e)u=(O). Но тогда по
определению параметра Хо=Л(и) справедливо неравенство к > Хо, то есть верны
условия X > Хо, to | i. Теорема доказана.
Следствие 1. Если и - периодическая последовательность, то Л(и)
есть наименьшее XeN0, для которого существует teN со свойством
V i 2 X: u(i+t) = u(i).
Следствие 2. Если и — периодическая последовательность над коль-
цом R, то для любого многочлена H(x)gR[x] последовательность v=H(x)-u -
также периодическая, причем A(v) < Л(и), Т(у) | Т(ц).
ДОКАЗАТЕЛЬСТВО. Достаточно заметить, что если A(u)=Xo, T(u)=to,
то
xk0(x*°—e)’V = Н(х)хх°(х‘°-е)-и=(0).
В качестве важного приложения теоремы 11 докажем
Утверждение 11. Если u,vgR°°, - периодические последовательно-
сти, то w = u+v периодическая последовательность и
A(w) < max{A(u), A(v)}, T(w) | [T(u), T(v)].
При этом
(а) если A(u)^A(v), то
A(w)=max{A(u), A(v)};
(б) если (T(u), T(v))=l, то
T(w)=[T(u), T(v)];
(в) если u и v - ЛРП, для которых можно указать взаимно простые хара-
ктеристические многочлены, то справедливы равенства T(w)=[T(u), T(v)] и
T(w)=[T(u), T(v)].
494
ДОКАЗАТЕЛЬСТВО. Пусть X=max{A(u), A(v)}, t=[T(u), T(v)]. Тогда по
теореме 11
х\х‘-е)и=(0) и xx(x‘-e)v=(0)
и, следовательно, хх(х'-е)ш=(0). Отсюда, опять по теореме 11, следуют
соотношения
A(w) < max{A(u), A(v)}, T(w) | [T(u), T(v)].
(а) . Если, например, A(u) < A(v), to X=A(v). Допустим, что A(w) < X. То-
гда многочлен х^*(х‘-е) аннулирует последовательности и и w, а значит и по-
следовательность v=w-u. Но тогда по теореме 11 A(v) < Х-1, что невозможно.
Следовательно, A(w)=X, т. е. верно равенство T(w)=[T(u), T(v)].
(б) . Пусть (T(u), T(v))=l и T(w)=t. Заметим, что [х, Т(и)]= х-к, где
к=Т(и)/( х, T(u)) > 1, и так как х | хк и Т(и) | тк, то по теореме 11 x\xkT-e)w=(0),
x\xTk-e)u=(0). Но тогда xx(xTrk-e)v=(0), и по теореме 11 T(v) | тк, а поскольку
(T(v), k)=l, то T(v) | т. Аналогично доказывается, что Т(и) | т. Следовательно,
T(u)-T(v) | T(w). Теперь равенства T(w)=[T(u), T(v)] следует из соотношений
A(w) < max{A(u), A(v)}, T(w) | [T(u), T(v)].
(в) . Пусть ugLr(F), vgLr(G) и (F(x), G(x))=e. Тогда wgLr(F-G) и
Lr(F-G)=Lr(F)+Lr(G). Отсюда, учитывая, что для любых X|gN0, tisN справед-
ливы соотношения
xxi(xtl-e)w=xxi(x,1-e)u+xkl(x“-e)v, xxl(x“-e)uGLR(F), xxl(x,1-e)vGLR(G)
получаем:
V X] gN0, ti gN: (xkl(xtl-e)w=(0)) (х^х^-еЭи^О), xxl(x,1-e)v=(0)).
Теперь соотношения A(w) < max{A(u), A(v)}, T(w) | [T(u), T(v)] и ра-
венство T(w)=[T(u), T(v)] следуют из теоремы 11. Утверждение доказано.
Определение 14. Периодическая последовательность и над коль-
цом R называется чисто периодической, если А(и)=0 и вырождающейся, если
u=(u(0),..., u(X-l), 0, 0,..., О,...) для некоторого XgN0.
Очевидно, что и - чисто периодическая последовательность тогда и то-
лько тогда, когда UGLR(x‘-e) для некоторого teN, и и - вырождающаяся после-
довательность тогда и только тогда, когда ugLr(xz) для некоторого XgN0.
Единственная одновременно чисто периодическая и вырождающаяся последо-
вательность - нулевая: А((0))=0, Т((0))=1.
Теорема 12. Любая периодическая последовательность ugR00 одно-
значно представляется в виде суммы
495
U=Uo+Ui,
где Uo - вырождающаяся, щ - чисто периодическая последовательности. При
этом
Л(и)=Л(ио), T(u)=T(U1).
ДОКАЗАТЕЛЬСТВО. Пусть A(u)=X, T(u)=t. Тогда ueL^x’Xx-e)). Из
очевидного соотношения (х, х‘-е)=е в силу утверждения 9 (а) следует соотно-
шение (хх,х‘-е)=е. Отсюда, пользуясь теоремой 6, получаем, что
и последовательность и единственным образом представляется в виде
u=uo+ui, uogLr(xx), uiGLR(x‘-e).
Это и есть искомое разложение u=uo+ui. Равенства A(u)=A(uo),
T(u)=T(ui) легко следуют из утверждения 11.
Пусть имеется еще одно разложение u=vo+vi, где v0, Vi - соответственно
чисто периодическая и вырождающаяся последовательности. Тогда по утверж-
дению 11 A(v0)=A(u)=X, T(vi)=T(u)=t. Следовательно, voeLR(x'), Vi GLR(x‘-e) и
ввиду LR(xx(x,-e))=LR(xx)+LR(x‘-e) справедливы равенства v0=Uo, Vi=ui. Теорема
доказана.
Замечание 6. На практике, для представления последовательности
uGLR(x\x,-e)) в виде u=uo+ui, достаточно подобрать keN такое, что tk > X. Тог-
да x,kuo=(0) и из указанного вида и следует, что x,ku=xtkui=ui. Теперь последова-
тельность ио находится из равенств uo=u-ui=u-xtku. Например, для последова-
тельности
u=(002 2 1 3 1 203 1 20...)
над Z4 справедливы соотношения A(u)=X=5, T(u)=t=4, t-2=8 > X. Следо-
вательно,
U!=x8 u=(0 3 12 0 3 12...),
Uo=u-ui=(O 1 10100 0...).
496
Периодические многочлены. Периодичность ЛРП над конечным
кольцом.
Для кольца R через R* обозначим множество (группу) всех его обратимых
элементов.
Заметим, что если R - произвольное кольцо, то не любая ЛРП над R периоди-
чна, т. е. обращение утверждения 10 неверно. Простейший пример:
ЛРП u==(0, 1, 2, 3, ...)eLz((x-l)2).
Однако, если R - конечное кольцо, то обращение утверждения 10 верно. Дока-
зательство этого факта и методика расчета периода ЛРП над конечным кольцом опи-
раются на следующие результаты.
Определение 15. Многочлен F(x)gR[x] назовем периодическим, если суще-
ствуют параметры XeN0, teN такие, что
F(x) | х\х'-е).
При этом наименьшее teN, для которого существует XgNo, удовлетворяющее
условию F(x) | х\х-е), обозначим через T(F) и назовем периодом многочлена F(x), а
наименьшее XgN0, такое, что F(x) | x\xT(F)-e) обозначим через A(F). Унитарный пери-
одический многочлен F(x) со свойством A(F)=0 назовем регулярным.
Связь введенных понятий с понятием периодической последовательности
устанавливает
Утверждение 12. Унитарный многочлен F(x)eR[x] является
периодическим тогда и только тогда, когда периодична ЛПР eF g Lr(F). Если F(x) -
периодический многочлен, то
A(F)= A(eF), T(F)=T(eF)
и любая ЛПР ugLr(F) есть периодическая последовательность, для которой
A(u)<A(F), T(u)|T(F).
ДОКАЗАТЕЛЬСТВО. Так как по следствию утверждения 5 y4w!(eF)==R[x]-F[x],
то
VXgNo, VteN: (х\х1-е)ер=(0)«Р(х) | х\х1-е). .
Отсюда следуют первая часть утверждения 12 и соотношения A(F)= A(eF),
T(F)=T(eF). Пусть ugLr(F). Тогда F(x)u=(0), и так как
F(x) | xA(F)( xT(F)-e), то xA(F)( xT(F)-e)u=(0).
Следовательно, u - периодическая последовательность, и по теореме 11 верно
A(u)<A(F), T(u)|T(F).
497
Следствие 1. Если F(x) eR[x] - унитарный периодический многочлен, то
VXeN0) VteN: (F(x) I (x\x*-e)) (X > A(F), T(F) 11).
ДОКАЗАТЕЛЬСТВО. Достаточно воспользоваться соотношениями:
VXeNo, VteN: (x\x'-e)eF=(0)<=>F(x) | xz(x‘-e);
X
A(F)=A(eF), T(F)=T(eF)
и теоремой 11.
Следствие!. Если F(x), G(x) eR[x] унитарные периодические взаимно прос-
тые многочлены, то Н(х)= F(x) G(x) - периодический многочлен, причем
A(H)=wax{A(F),A(G)}, T(H)=[T(F),T(G)].
ДОКАЗАТЕЛЬСТВО. Пусть X=wox{A(F),A(G)}, t =[T(F),T(G)]. Тогда по
следствию 1 многочлен х;(хг-е) делится на F(x) и G(x), и по утверждению 9(в) Н(х) |
(х\х1-е)). Таким образом, по определению 15 Н(х) - периодический многочлен, и по
следствию 1 А(Н) < X и T(F) I Т(Н), T(G) | Т(Н), т. е. 11 Т(Н).
Замечание 7. Если R - произвольное бесконечное кольцо, и F(x), G(x) gR[x]
унитарные периодические, но не взаимно простые многочлены, то многочлен
Н(х)= F(x) G(x) может быть не периодическим. Например, если R=Q, F(x)=G(x)=x-1,
то Н(х)=(х-1)2 - многочлен с кратным корнем 1 и потому о не делит ни одного из мно-
гочленов х-1, teN. Иная картина имеет место, если R - конечное кольцо.
Теорема 13. Пусть F(x) - унитарный многочлен степени т>0 над конечным
кольцом R. Тогда
(a) F(x) - периодический многочлен, причем если | R | т>2, то
A(F)+T(F)<|R|m-l;
(б) F(x) - регулярный многочлен в том и только том случае, если F(0)gR*.
ДОКАЗАТЕЛЬСТВО, (а) Рассмотрим факторкольцо S=R[x]/F(x) и последо-
вательность над S:
[e]F,[x]F, ...,МЬ ....
Так как S - конечное кольцо: | S | = IR |т - то в указанной последовательности
есть повторения, т. е.
498
[xX]f=[xX+,]f
для некоторых XgN0, teN. Но это равенство, очевидно, эквивалентно условию
F(x) | х\х-е).
Следовательно, F(x) - периодический многочлен. Более того, из следствия
утверждения 12 и равносильности условий [xx]F = [xUt]F и F(x) | х\х*-е) следует, что
A(F)+T(F)=k - наибольшее натуральное число, такое, что элементы кольца S
[e]F,[x]F, ...,[xk-1]F
попарно различны. Поэтому всегда A(F)+T(F) < | S | +1RIm.
Покажем, что если | S | >2, то k < I S | - 1. Допустим, что к> I S | - 1. Тогда
к= I S | и, и так как элементы [e]F,[x]F,.. .,[xk-l]F попарно различны, то
S={[e]F,[x]F,...,[x]k-1F}.
Поскольку [0]fgS, то из последнего равенства для S следует, что
[0]F = [x]k-1, [x]F - делитель нуля в S и [e]F - единственный обратимый элемент в S. Но
[e-x]F- также обратимый элемент в S, поскольку [e-x]F-[e+x+...+xk"1]F=[e-xk]F=[e]F,
Следовательно [e-x]F=[e]F , [0]F= [x]F и ввиду равенства S = {[e]F,[x]F, ...,[x]k-1F} име-
ем S={[e]F, [0]F }, т. е. | S | = 2, что противоречит условию.
(б) . Если F(x) - регулярный многочлен, То х T(F)-e=F(x)-G(x) для подходящего
G(x)gR[x]. Но тогда F(0) (-G(0))=e и поэтому F(0)gR*. Наоборот, так как F(x) имеет
вид F(x)-F(0)+x-U(x), то из условия F(0)gR*, очевидно, следует, что (F(x),x)=e, и по
утверждению 9(a) (Р(х),хх)=е, для любого XgN. Тогда так как F(x) I xA(F) -(х T(F)-e), то по
утверждению 9(6) F(x) | х T(F)-e, т.е. F(x) - регулярный многочлен.
Следствие. Если и - ЛРП порядка m над конечным кольцом
Rn|R|m>2, то
А(и)+Т(и) < |R|m-l.
ДОКАЗАТЕЛЬСТВО. Если ugLr(F) , deg F(x)=m, то нужное неравенство сле-
дует из A(u) < A(F), T(u) | T(F) и A(F)+T(F) < I R | m-l (см. теорему 13).
Замечание 8. При условии |R|m=2 существует единственный пример, опровер-
гающий неравенство A(F)+T(F) < | R | т-1 и последнее следствие: R=Z2, F(x)=x,
u=(l,0,0,...). В этой ситуации A(F)=A(u)=l и T(F)=T(u)=l.
499
Вычисление периода и длины подхода ЛРП над конечным полем.
Прежде всего сведем поставленную задачу к изучению минимального многоч-
лена ЛРП.
Утверждение 13. Если и - ЛРП над конечным полем, то
А(и)==А(Ми(х)), Т(и)=Т( Ми(х)).
ДОКАЗАТЕЛЬСТВО. Достаточно заметить, что в силу теоремы 3
V XeNo, teN : (х<( x'-e)u=(0)>» (Mn(x) I хх-(х*-е)).
Описание параметров A(F) и T(F) для произвольного унитарного многочлена
F(x) над конечным полем сводится к построению его канонического разложения и вы-
числению периода неприводимых сомножителей. Пусть P=GF(q), q=pn, р - простое.
Для произвольного F(x)gP[x] определим параметр 0(F) как наименьшее общее кратное
(НОК) порядков всех ненулевых корней F(x) в его поле разложения над Р и положим
O(F)=1, если F(x)=xk , keN.
i
Утверждение 14. Если F(x)eP[x] - регулярный неприводимый многочлен
степени т, то
1)T(F)=O(F);
2)T(F)|qm-l и T(F) не делит многочлены (qk- 1 ) для к е {1,2,...,т-1};
3) в частности, (T(F),p)=l.
ДОКАЗАТЕЛЬСТВО.
* Пусть Q-минимальное поле разложения F(x) над Р.
Тогда Q=GF(qm) (по известным утверждениям описывающих строение простых
расширений полей), и если a-корень F(x) в Q, то O(F)=ord а (следствие утверждений
описывающих строение простых расширений полей). Так как F(x) | xT(F)-e, то aT(F)=e и
0(F) | T(F). С другой стороны, a0(F)=e и (F(x),x0(F-е)^е. Поскольку x0(F)-e е Р[х] и F(x)
неприводим над Р,отсюда следует, что F(x) | x0(F)-e, т.е. T(F) 10(F) и T(F)=O(F).
Т.к. a g Q*, то ord а I qm-l,T.e. T(F) | qm-l. Наконец, если . T(F) I qk-l, где l<k<m, то
а4 = е и а4 = а , что известным утверждениям описывающих строение прос-
тых расширений полей. Доказательство окончено.
Из пункта 2) утверждения 14 вытекает следующий способ вычисления периода
регулярного неприводимого многочлена F(x) е РГх] степени т>0.
1. Перебрать все делители t числа qm-l, не являющиеся делителями чисел
q-l,...,qm-l.
2. Для каждого выбранного t проверить условие
х =е (mod F(x)).
Наименьшее из таких t, для которых это условие выполнено, есть T(F).
500
Пример 11. Вычислим период многочлена F(x)=x4+x+l над P=Z2. Так как
F(x) неприводим, то можно применить описанный выше алгоритм. Поскольку
24-1=15=3-5 и 3 122-1, то нужно проверить условие х=е (mod F(x)) лишь для
te {5,15}. Так как х4=х+1 (mod F(x)) и xV 1 (mod F(x)). Следовательно, T(F)=15.
Теорема 14. Если P=GF(q) - поле характеристики р, унитарный многочлен
F(x)gP[x] имеет каноническое разложение
F(x)=x' G1(x)4‘
и
k=max{ki ,...ks},
то справедливы равенства
A(F)=1, T(F)=[T(G1),...,T(GS)] • рс =O(F). рс,
где параметр с g No находится из условия
рс-'<к<рс,
т. е. c=]logpk [ - целая часть числа logpk.
ДОКАЗАТЕЛЬСТВО. Пусть Н(х) = G,(x)k| К Gs(x)k‘. Тогда по тео-
реме 13 Н(х) - регулярный многочлен и по следствию 2 утверждения 12 A(F) = А(х') =
1, T(F)=T (Н). Пусть G(x)=G!(x)-... Gs(x). Тогда очевидно, что O(F)=O(G)= [О (G0.О
(Gs) ] и по утверждению 14 и следствию 2 утверждения 12 [О (Gj),..., O(GS) ] = [Т
(Gt),..., T(GS) ] =T(G). Теперь остается доказать равенство T(H)=T(G) рс.
Так как G(x) | xT(G)-e, то в силу k=max{k!„..kJ. получаем Н(х) | (xT(G)-e)k и в
силу условия pc'l<k<pc имеем Н(х) (xT(G) — е)р . Отсюда, пользуясь равенством
(xT(G) — е)р = xT(G)p — е, получаем Т(Н) j T(G) • рс. Более того, так как T(G) | Т(Н)
(поскольку G(x)|H(x)), то
Т(Н) = T(G) pd, где d < с. Заметим теперь, что (T(G), р)= 1, поскольку по
утверждению 14 (T(Gj), р)=1 для i е 1, s . Следовательно, многочлен xT(G)-e над Р
взаимно прост со своей производной и потому не имеет кратных множителей в канони-
ческом разложении над Р.
Поэтому каждый неприводимый делитель многочлена хТ(Н)-е = (х1^ — е/* име-
ет в его каноническом разложении кратность pd, и так как Н(х) I хТ(Н)-е, то ввиду
k=max{kiks} имеем k < pd и ввиду рсЧ< к < рс получаем d>c.
Следовательно, d=c, т. е. Т (Н)=Т (G) • рс.
Пример 12. Пусть P=GF (рп) и а - элемент из Р* порядка L Вычислим период и
длину подхода биномиальной последовательности a[sl. По утверждению 6 ее минима-
501
льный многочлен равен (х -a)s+1. Следовательно, по утверждению 13 a[s] - чисто пери-
одическая последовательность и Т (a[s]j = Т((х -a)s+1). Так как T((x-a))=t, то по теореме
14 Т ((х -a)s+1) = t • рс, где c=]/tfgp(s+l)[. В частности, для последовательности а[0] =
(е, а, а2,...,) справедливо равенство Т( а101) = orda = t, а для последовательности би-
T(etsl) = p]logp(s+1)[.
Пример 13. Найдем период и длину подхода ЛРП и над Z2, с характеристичес-
ким многочленом
F(x)=x8 + х5 + х3 + х2 +х и начальным вектором и (0,7) = (00001010).
По формуле (16) находим генератор и отйоситёльно F(x): ^(х)=х3+х+1 и по те-
ореме 5 (а) - ее минимальный многочлен:
Ми(х) =------------= х5 +х3 + х = х(х2 + х +1)2.
u (Р(Х),Ф(Х))
Так как х2+х+1 - неприводимый многочлен над Z2 и Т(х2+х+1)=3, то по теоре-
ме 14 А (Ми(х))=1 и Т (Ми(х))=3 • 2,=6. Таким образом, по утверждению 13 А(и)=1,
Т(и)=6. .
ЛРП максимального периода над конечным полем.
1. Пусть P=GF(q) й и - ЛРП ранга m над Р (определение 8). Тогда, согласно
теореме 13 и утверждению 13, при условии qm > 2 период и длина подхода последова-
тельности и удовлетворяют неравенству A (u)+T (u) < qm -1. В связи с этим представля-
ет естественный интерес изучение следующих последовательностей.
Определение 16. Последовательность и над полем P=GF(q) называется
линейной рекуррентной последовательностью максимального периода над Р, если для
некоторого meN и - есть ЛРП ранга m и периода qm -1.
Очевидно, что при qm > 2 ЛРП максимального периода qm -1 есть чисто пери-
одическая последовательность, т.е. ее минимальный многочлен регулярен.
Теорема 15. Пусть и - ЛРП над полем P=GF(q) с регулярным минимальным
многочленом Mu (x)=^F(x) степени m и qm > 2. Тогда следующие утверждения
эквивалентны:
(а) и - ЛРП максимального периода над Р;
(б) Любая ненулевая ЛРПуеЬр(Р) есть сдвиг последовательности и, т. е.
v=xku для некоторого k е N;*
(в) Многочлен F (х) неприводим над Р и его корень а в минимальном поле раз-
ложения Q=GF(qm) над Р есть примитивный элемент поля Q;
; (Г) Т (F)= qm-l. ’
502
ДОКАЗАТЕЛЬСТВО. (а)=>(б). Так как T(u) = qm-l, то все последовательности
и, хи,..., хтЛ, гдет = дт-1,
различны и принадлежат Lp(F)\{(0)}. Поскольку |Lp(F)\{(0)}| = qm-l= т, то указанная
система последовательностей исчерпывает все множество Lp(F)\{(0)}, Следовательно,
ей принадлежит и последовательность v.
(б) => (в). Так как ненулевая ЛРП v е Lp (F) имеет вид v=xku и по условию (Ми
(х), х) =е, то по теореме 5 (б) Mv (х)= Ми (х). Таким образом, минимальный многочлен
любой ЛРП v gLp (F)\{(0)} равен F(x), и по следствию теоремы 5 F(x) неприводим над
Р. Тогда по утверждению 14 T(F)=O(F)=orJa; и из равенств T(F)=T(u)= qm-l сле-
дует, что а — примитивный элемент поля Q.
(в) => (г). При условии (в) по утверждению 14 T(F)=orJa= qm-l. Импли-
кация (г) => (а) очевидна.
Замечание 9. Если и - ЛРП максимального периода qm-l над полем P=GF(q) и
Р < Р’ = GF(ql), то при t > I последовательность и уже не является ЛРП максимального
периода над Р’, поскольку T(u) < q^-l.
2. Следующее важное для практических приложений свойство ЛРП и максима-
льного периода т— qm—1 над P=GF(q) показывает, что она в некотором смысле хорошо
’’имитирует” случайную последовательность элементов поля Р, в которой все элементы
1 :
из Р встречаются с одинаковой вероятностью —.
_______q
Зафиксируем числа ib ..., ir е 0, Т — 1 и элементы аь ..., ar е Р
и обозначим через 91 u
аиК ,аг
число решений i, i е 0, Т — 1,
системы уравнений
u(i+ii)=ai u(i+i2)=a2, ..., u(i+ir)=ar.
Отметим, что если бы последовательность и была описанной выше случайной
последовательностью, то при достаточно большом т должно было бы выполняться
приблизительное равенство
чР”кл VPY
т Va,,K,aJ
Оказывается, это равенство (при некоторых ограничениях) выполняется и для
ЛРП и.
Теорема 16. Пусть и - ЛРП максимального периода x=qm -1 над полем
P=GF(q) и 0 < i, < i2 < ... < ir < m -1. Тогда для любых Я), ...,я, еР справедливы ра-
qm~r, если (а!,...,аг)*К
qm"r-l, если (а15...,аг) = 8
венства: 9?и
арК ,а
503
ДОКАЗАТЕЛЬСТВО. Так как и - ЛРП ранга m и периода т, то система векто-
ров
и(о,т-1),и(1,т)к ,и(т-1,т + т-2)
не содержит одинаковых векторов и нулевого вектора, следовательно, она совпадает
с множеством р(т) \{К>. Теперь легко видеть, что число решений i е 0, т — 1
системы уравнений u(i+ii)=ai u(i+i2)=a2,..., u(i+ir)=ar. равно числу ненулевых векторов
из Р(т), у которых координаты с номерами h ,...,нравны, соответственно, аь ...,
аг. Это число, очевидно, описывается равенствами указанными в формулировке те-
оремы 16.
3. Согласно теореме 15, задача построения ЛРП максимального периода
qm -1 над полем P=GF(q) сводится к построению регулярного многочлена F(x)gP[x],
удовлетворяющего условиям пункта (г) этой теоремы.
Определение 17. Регулярный ’ многочлен F(x) над полем P=GF(q), имеющий
степень m и период qm — 1, называется многочленом максимального периода (или
примитивным многочленом) над полем Р.
Заметим, что ввиду эквивалентности утверждения (в) и (г) теоремы 15, любой
многочлен, удовлетворяющий условиям определения 17, имеет в поле Q=GF(qm) m ко-
рней, каждый из которых есть примитивный элемент Q, и число многочленов максима-
льного периода qm -1 над Q равно —(p(qm “ 1) (где ср —функция Эйлера).
т <
Построение многочлена максимального периода над полем Р осуществляется,
как правило, путем построения неприводимого многочлена F(x) степени m над Р с про-,
веркой условия T(F)= qm -1 по следующему критерию.
Утверждение 15. Неприводимый многочлен F(x) е Р[х] степени m > 1 являет-
ся многочленом максимального периода над полем Р тогда и только тогда, когда F(x) ф
х и для каждого собственного простого делителя р числа qm -1 выполняется условие:
Г~1
F(x) не делит X р -е.
ДОКАЗАТЕЛЬСТВО. Пусть T(F)=t. Так как F (х) неприводим над P=GF(q), то t
| qm -1 и условие t < qm -1 равносильно тому, что для некоторого собственного просто-
го делителя р числа qm -1 выполняется соотношение t
т. е. не выполняется
5
Р
Г-1
условие: F(x) не делит X р -е.
Следствие. Если 2m -1 - простое число, то любой неприводимый над GF (2)
многочлен степени m есть многочлен максимального периода.
Пример 14. Рассмотрим многочлен F (х)'=х3 -х-2 над P=GF(3). Так как F(x) не
имеет корней в Р, то он неприводим. Число qm -1=33 —1=26 имеет простые делители 2 и
13. Очевидно, что
504
з3 -1
х 13 = х2 Ф l(modF(x)).
' Далее, из сравнений по модулю F(x)
х3 = х + 2, х4 = х2 + 2х, х8 = (х2 + 2х)2 = 2х2 + 2
находим .
З3 -1 . ; , ...
х 2 =х13 =хх4-х8 =х(х2 +2х)(2х2 +2)=2х2(2х2 +2x+1)sx4 +х3 +2х2 =2^1.
Следовательно, х3 -х-2 - многочлен максимального периода над GF(3).
Пример 15. Числа 22 — 1 = 3, 23 — 1 = 7, 25 —1 = 31 - простые. Следова-
тельно, все неприводимые многочлены степеней 2, 3, 5 над GF (2) являются многочле-
нами максимального периода. Например, такими будут
X2+Х + 1, х3+х + 1, х3+х2+1, х5+х2+1.
Последний многочлен неприводим, потому что он не имеет корней в GF(2) и
не делится на единственный неприводимый над GF(2) многочлен второй степени х2
+Х+1. г ’ ' . / , -
Напомним читателю, что простые числа вида 2т-1 называются числами Мер- .
сенна. Таковы, например, числа 2т-1 приJ.тЕ {2, 3,5, 7,13, 17, 19, 31, 127}. До
сих пор неизвестно — конечно ли множество чисел Мерсенна? ч
505
ПРИЛОЖЕНИЕ 3 (к стр. 138)
о р е е Р е
е в а а в а
д О Ч А Л Ь И Ь Ц И О Л И О Й О
е и к н н е к н е е
а н м т т а м т а а .
почему нужно мно го
с а е с р а е
Р и а о Р в и О а
В Н Ы И Ю Ш X Е М В л Н X Е И
л т н а л к т а н
к с ST и К м с и т
ра з н ' ы х щи ф р маш и н
н Р н е О
' т в т а е
д О С О Л Ь Ч С О И А
е Р е к Р е н и
а в а м в а. т н
потому что не
и о и н т О н О е
н е н т с е т е О д
Т Ь Ж А Т С р Ь А С А К Е И О Й О
с и с Р в и Р и а н е е
_Е_ и в л н в и и т а а
суще ст в у е т е . д и н г о
о т и о
е с н е
Д О К Щ О К 3 Ж А й о К П 3 Р Т А Щ
е е и е в с и
а а н а а н
подходящего для всех
и а О т и а
н и е с н и
Т П Ь Ч Н А р т Д О Т О У Н
с т и в с е с е т
р с н л а а с
случаев способа
с т а е е с р а
о Р с и а О о а Р в и О о
X Е М В О р Н И Е 3 Е И М О В Л Н Я Е Е
а л е в т н а а н е л к т а а
и к а л с т и и т а к м с и и
шиф ров а н и ' я ин форма ц. и и
506
т с с
с Р Р О
р Ю У О В Б В Е д
в е л л а
л а к к и
выбор крип
н с а о и и и н О ' р
т Р ч О е н • н о н т е в
С О Й В Н М Е Ч А Т Б О Г Т Е Т С А Л Ю
Р е л т а и с е с а с Р и к
в а к с и н Р а и _Е__ в н м
тографической с ис темы
а т и н н и
и с О н о т т н
Ы Н р Е Т Е С О С О Т О У
т в а с а Р е в е с е
с л и и в а в а р а
зависит от особ
о е е и н О е с Р а
е д д н т е О д р в и о о
А И И О Т С А Г Е И М О В Л Н Я Е Е
и н н е с Р и а н е л к т. а а
н т т а в н и т а к м с и и
енносте й информа ции
о О О е е и н
е е е д д н т О
А А Я А И И О Т С Е Е
и и и н н е с Р а
н н н т т а в и
ее ценности и
т Р е и н О
с в а н т е
Р О Ы Л О Ц И О Т С А Г
в е к е н е с Р и
л а м а т а JL- о н
во зможностей
т а О о т а н О
с и е е с и О т е
р П Н К А П Ш Я А р Д О Ы Н Ж У С А
в т и и в е т а Р и
л с н и л а с и в н
владельцев по защите
507
nr
И т о -е с р а
н с е О а Р в и О о
Т р О А Г Е И М О В Л Н Я Е Е
с в е и а н е л к т а а
л а н и т а к м с и и
своей информации
с О О т и О
р е е с н е
д В А ц к А р т А и- о
л и и в с и е
к н н л н а
прежде все го
о с е О р О
е р а е в е
Д' о К Ч А В Б И А Л У О П Ш X О А
е и л н и к е е и
а н к т и м а а н
подчер кием большое
с а е с а о т 0 т
р и д Р и О е с О с
В Н Ы И О О У В Н Ы Е А р Е К О Р
л т н е е л т а и в а е в
к с т а а к с и н л и а л
р а знообра зие видов
а а О р е с р а О О
и О и е в о а Р в и е е
Ы Н Ж Е Ж Н А Л О Г Е 'и М 0 В Л Н Я А А
т а т и к • е а н е л к т и и
с и с н м а и т а к м с н н
защищаемой информации
Р О е н а е а
в е а т и а и
К О б Ь Л А И С Н П Ш И Н 3
е к и н Р т н т
а м н т в с т с
документа льная
н О О е е а
т е е а а и
С А П А М О И И Н 3
Р и и е н н т
в н н а т т с
т еле фонная
L
508
н О О т е е А •
т е е с О 0 а а и ‘
С А П А р Е Ы Е О и И Н 3
Р и и в а а е н и т
в н н л и и а т т с
те л е в и з и о нн. ая
н о с е а а
т е р а и и
Б О Л д ’ ш э С А В И Н 3 Б Н и К Ю Г
е к Р й л н т т
а м в н к т с с
компьют ерная каждый
т е - с р а P О О н
с 0 о а Р в и О о о в е е , т
р Е К Е И М’ О В Л Н Я Е Е У Л А А . С
в а а н - е л ; к т а а а к и и Р
л и и т а к м с и и и . м н н в
вид и нформа ци и имеет
и т и О о и о
н с о н е о О е н о е
Т р О Е Т д А Я Е м. Е' Ч А Т 5, Е А
с в. е а с а а и с< а и
-Ё— л а и _Ё_ н и и и -Ё— И ' н
св ои с п е циф ические
и о е е' и н н
н е а а н , т О о Т О
О Т О ' У А И и 6 ; Т С ё ; Е Ф с: Е f
е с е и н н е с Р а • а р а
а а н т т , а _Ё__ в и и в и
осо бенн ое ти и эти
и о е е и н и е
н е а а н т О н о а
О Т О Ч А И И О Т С Е Т Е П Ш И О
е с е и н н е с Р а с а н е
а а н т т а Р в и _Ё__ и т а
о со бенности сил ьн о
т н е а т с
с О т а и с р
Р П Е 3 Э С И Н р Ю У О В
в а Р н т в е л
л и в т с л а к
влияют' на выбор
509
р О н т с т а е
в е т с О Р с и а О
Л А С О К О р X Е М В О Р Н И Е 3
к и Р е е в а л е в т н а
м н в а а л и к а л с т и
м е т о д ов ши фро ва н ия
е с Р а О
о а Р в и о О е
Е И М О В Л Н( Я Е Е У О П Ш X О А
а н е л к т а а е е и
и т а к м с и и а а н
и н ф о р м а Ц н и б о л ь ш о е
е а О е О Р О н О Р
д и е а о е о в е т е в
ы и н е а и е а е л а э с 9 о У ъ а л ю
Ы И Н Ч А И Е А Е Л А Э С О У Ъ А Л Ю
т с и т и н и м н в а н м
н т и н а и а к и р е и к
3 н а ч е н и е • и м е ю т о б ъ е м ы
н с О о р а н с и н
О т р е е в и н Р н т
Е С В А У, Ь А Л Н 3 Т Б О В О Т С Ш
а р л и и к т с е л е с Р
и в к н н м с а к а Р в
и требуемая скорость
О с О а с т а е е
е р е и О о Р с и а ' а
д А В А Л Н Ч У X Е М В О Р Н И И О
и л и т а а л е в т н н е
н к н с и и к а л 0 т т а
передачи шифрова иной
и так далее!
510
СОДЕРЖАНИЕ
Предисловие редакторов.....................................4
Предисловие авторов........................................5
Основные обозначения.........................................10
ГЛАВА .1. ИСТОРИЧЕСКИЙ ОЧЕРК РАЗВИТИЯ КРИПТОГРАФИЧЕ-
СКИХ СРЕДСТВ И МЕТОДОВ ЗАЩИТЫ ИНФОРМАЦИИ
Параграф 1.1. Криптографические средства с древнего времени..11
Параграф 1.2. История отечественной криптографии.............57
Параграф 1.3. Модели шифров по К. Шеннону.
Способы представления реализаций шифров....................82
Параграф 1.4.Средства защиты информации в переходный
период от древности к современности........................94
Параграф 1.5. Стеганографические средства защиты информации
в переходный период от древности к современности...........118
-Параграф 1.6. Идея открытого ключа -
революция в криптографии...................................122
Параграф 1.7. Недостатки модели шифра Шеннона.
Обобщенная модель шифра....................................130
ГЛАВА 2. ДЕШИФРОВАНИЕ ИСТОРИЧЕСКИХ ШИФРОВ
Параграф 2.1. Дешифрование шифра простой замены,
перестановки и некоторых шифров гаммирования.............134
Параграф 2.2. Дешифрование шифра Виженера...................151
ГЛАВА 3. ИНФОРМАЦИЯ, ЕЕ СВОЙСТВА
Параграф 3.1. Общее понятие информации. Способы
представления информации, подлежащей
шифрованию. Дискретизация непрерывных
сигналов...................................................186
Параграф 3.2. Открытые сообщения и их характеристики.'......187
Параграф 3.3. Критерии на осмысленные сообщения.............195
ГЛАВА 4. ТЕОРЕТИЧЕСКАЯ СТОЙКОСТЬ ШИФРОВ. ТЕОРЕТИКО-
ИНФОРМАЦИОННЫЕ МОДЕЛИ ШИФРОВ
Параграф 4.1. Основные понятия и теоремы математической
теории информации..........................................201
Параграф 4.2. Стационарные эргодические модели
содержательных сообщений.....................................211
Параграф 4.3. Энтропии шифртекста и ключей. Расстояния
единственности для открытого текста и ключа.
Теоретическая стойкость шифров. ................214
511
ГЛАВА 5. ПРАКТИЧЕСКАЯ СТОЙКОСТЬ ШИФРОВ
Параграф 5.1. Понятие практической стойкости шифров........228
Параграф 5.2. Принципы построения методов определения
ключей шифрсистем........................................231
Параграф 5.3. Методы опробования......................... 235
Параграф 5.4. Принципы построения статистических
методов криптоанализа....................................257
Параграф 5.5. Введение в теорию случайных систем уравнений.271
Параграф 5.6. Аналитические методы криптоанализа...........294
ГЛАВА 6. ВОПРОСЫ СИНТЕЗА ШИФРОВ И ИХ КРИПТОСХЕМ
Параграф 6.1. Шифры, близкие к совершенным.................304
Параграф 6.2. Гомоморфизмы и конгруэнции шифров........... 310
Параграф 6.3. Групповые шифры. Обратимые групповые шифры...313
Параграф 6.4. Инварианты шифров. ..........................318
Параграф. 6.5. Введение в вопросы синтеза криптосхем.......320
Параграф 6.6. Статистическая структура двоичной функции....323
Параграф 6.7. Математические основы синтеза булевых
функций с гарантированными
криптографическими свойствами............................328
Параграф 6.8. Регистры сдвига, одноканальные линии задержки.358
Параграф 6.9. Вопросы гарантирования периодов выходных
последовательностей автоматов при заданной
входной последовательности...............................368
ГЛАВА 7. ИМИТОСТОЙКОСТЬ ШИФРОВ. ПОМЕХОУСТОЙЧИВОСТЬ
ШИФРОВ. СЕТИ ЗАСЕКРЕЧЕННОЙ СВЯЗИ
Параграф 7.1. Имитостойкость шифров в модели К. Шеннона....380
Параграф 7.2. Примеры имитации и способы имитозащиты.......388
Параграф 7.3. Помехоустойчивые шифры........................391
Параграф 7.4. Помехоустойчивые шифрующие автоматы...........405
Параграф 7.5. Общие математические задачи, связанные
с проблемой построения помехоустойчивых шифров..........409
Параграф 7.6. Основные понятия сетей засекреченной связи.
Компрометация абонентов..................................430
Параграф 7.7. Перекрытия в сетях засекреченной связи.......437
ЛИТЕРАТУРА.../............................................ 439
ПРИЛОЖЕНИЕ 1............................................. 462
. ПРИЛОЖЕНИЕ 2.............................................467
ПРИЛОЖЕНИЕ 3............................................. 505
1
Научно-популярное изданиеА
Серия книг «Аспекты защиты»
Бабаш Александр Владимирович
Шанкин Генрих Петрович(
Криптография
Под редакцией В.П. Шёрстюка,
Э.А. Применко
Редактор
А. Борисов
Верстка
Н. Нечаева
Обложка
Е. Жбанов
Изд. лиц. ЛР № 066584 от 14.05.1999 г. Подписано в печать 13.11.01 г.
Формат 70X100/16. Печать офсетная. Кол-во п. л. 32. Тираж 2000 экз.
ООО Издательство «СОЛОН-Р»
Москва, ул. Тверская, д. 10, стр. 1, ком. 522.
Типография АООТ «Политех-4»
Москва, Б. Переяславская, 46
Заказ № 5
Уважаемый читатель!
Если вы:
специалист по "железу";
профессионал в области
программного обеспечения;
эксперт по компьютерным сетям -
поделитесь своими знаниями, напишите книгу!
Издательство "СОЛОН-Р" предлагает сотрудничество
как опытным авторам,
так и тем, кто только пробует свои силы.
Ждем ваших предложений!
103001, Москва, а/я 82
e-mail: Solon-Avtor@coba.ru