/



















































































































































































































































































































































































Author: Нильсон Н.
Tags: инженерное дело техника в целом информатика искусственный интеллект
Year: 1985




Text
анильсон
Принципы
искусственного
интеллекта
Principles
of
Artificial Intelligence
NILS J. NILSSON
SRI International
s
tfoga
paBLfsbing
company
paLo aLto,
ca LifoRnfa
н.нильсон
Принципы
искусственного
интеллекта
Перевод с английской)
Р. М. Абдусаматова
и Ю.И. Крюкова
Под редакцией
В.Л. Стефанюка
Ε
Москва «Радио и связь»
1985
УДК 62.506.222.001.57
Нильсон Η. Принципы искусственного интеллекта: Пер. с англ. — М.: Радио и связь,
1985. - 376 с, ил.
Описаны фундаментальные вопросы из области искусственного интеллекта, лежащие
в основе многих приложений к обработке естественного языка, автоматическому
программированию, "интеллектуальным" системам извлечения информации, экспертным
системам и планированию действий. Показано, что большинство современных систем
искусственного интеллекта (ИИ) может быть описано в виде глобальной базы данных,
к которой применяются правила продукций под контролем некоторой управляющей
системы. Выделение базы данных, правил продукций и блока управления в системе
ИИ дает возможность изучения разнообразных механизмов использования в
вычислительном процессе дополнительной информации о предметной области, обеспечивающих
в конечном счете эффективное решение задач реальной сложности. Приводятся
многочисленные примеры и программы, поясняющие и детализирующие общий подход к
максимальному использованию знаний при решении задач.
Автор книги — известный американский ученый, руководитель работ по
искусственному интеллекту в Станфордском исследовательском институте, разработчик
системы STRIPS, предназначенной для управления автономным роботом.
Для научных работников, специализирующихся в области искусственного
интеллекта.
Табл. 4. Ил. 142. Библиогр. 410 назв.
Редакция переводной литературы
„ 1502000000-055 с, ол
Η 53—84
046 (01)-85
» 1980 by Tioga Publishing Co. P. O. Box 98, Palo Alto, CA 94302
) Перевод на русский язык, предисловие редактора перевода,
примечания редактора перевода и переводчиков,
дополнительный список литературы. Издательство "Радио и связь", 1985
ПРЕДИСЛОВИЕ РЕДАКТОРА ПЕРЕВОДА
В предисловии к русскому изданию в 1973 г. книги "Искусственный
интеллект. Методы поиска решений" (по-английски она называлась "Problem-
Solving Methods in Artificial Intelligence") Η. Нильсон отмечал, что вопросы
эвристического поиска перестали быть в центре внимания в исследованиях по
искусственному интеллекту (ИИ). Для этого имелись две причины: с одной
стороны, эта область уже достаточно разработана, так что не следует ожидать
существенного повышения эффективности поиска, а с другой — одних
эффективных методов поиска (перебора), как показал опыт, недостаточно
для решения по-настоящему сложных задач. Он говорил, что хорошо бы
написать книгу под названием "Как вкладывать знания в программы для ЭВМ"
или "Как ЭВМ могут усваивать знания".
Тем не менее эта небольшая книга Н. Нильсона, посвященная в основном
эвристическому поиску и доказательству теорем методом резолюции, сыграла
свою важную роль, став настольной книгой по теории искусственного
интеллекта — направлению, которое Н. Нильсон относит к числу инженерных
дисциплин, "поскольку его первоначальной целью является создание
конструкций".
Сегодня советскому читателю предлагается перевод новой книги Н.
Нильсона, которая просто называется "Принципы искусственного интеллекта".
Она вышла сначала в США в 1980 г., а затем была переиздана в Западной
Европе и сейчас является одним из наиболее популярных пособий (в ряде
учебных заведений — обязательным) для студентов и аспирантов,
специализирующихся в области искусственного интеллекта.
Отвечает ли эта книга на вопрос о том, как вкладывать знания в
программы для ЭВМ?
Дело в том, что последние десять лет вопрос представления знаний в ЭВМ
был практически основным, над которым работали во всех ведущих
научных центрах. В широком смысле это вопрос о том, как усваивать, хранить,
обновлять и обрабатывать большие объемы данных, имеющих развитую
внутреннюю структуру. В ходе этих работ был получен целый ряд важных
результатов "инженерного свойства" — создание экспертных систем и
богатых баз знаний в разнообразных проблемных областях, разработка
эффективных методов программирования задач искусственного интеллекта и
соответствующих языковых средств, разработка новых структурных схем
хранения и использования знаний (фреймов и т. п.), создание систем
планирования порядка выполнения действий в сложной ситуации (например,
для робота), гетерархических систем анализа сцен, восприятия речевых,
письменных и других сообщений и т. д.
За это время значительно изменился и характер вычислительных машин.
С одной стороны, они стали более производительными и располагают боль-
5
шим объемом памяти. С другой стороны, мы являемся свидетелями
наступления эры персональных ЭВМ, обладающих хорошими вычислительными
параметрами, при этом достаточно дешевых, чтобы стать массовыми.
Указанным выше работам в значительной степени обязано и появление проектов
создания вычислительных машин пятого поколения (что, в свою очередь,
"подогрело" интерес к искусственному интелекту у более широкой
аудитории) .
Следует, однако, признать, что и сегодня наиболее развитыми являются
вопросы эвристического поиска и формально-логического вывода на ЭВМ,
для которых обнаруживаются все новые приложения, подтверждающие
то, что эти вопросы образуют фундамент любой системы ИИ.
Что же касается представления знаний (в широком смысле) в
вычислительной машине, то из потока работ в этом направлении лишь какую-то часть
удается подвергнуть теоретическому осмыслению и систематизации.
Именно эту задачу возложил на себя крупный специалист по искусственному
интеллекту Н. Нильсон, руководитель Центра искусственного интеллекта Стан-
фордского исследовательского института в США. Видимо, свою роль
сыграло то обстоятельство, что по общему мнению Н. Нильсон является одним из
самых информированных ученых в области ИИ и, кроме того, обладает
необходимым вкусом и способностями к теоретическому обобщению.
В новой книге не дано окончательного решения вопроса работы со
знаниями, как на сегодня нет и ни одной действующей системы, достаточно
свободно оперирующей знаниями в широкой предметной области. (Даже в так
называемых экспертных системах знания пока что относятся к некоторой
сравнительно узкой и четко очерченной предметной области.) Однако в ней
собраны те достижения в области представления знаний, без ознакомления с
которыми нельзя добиться успеха при создании систем искусственного
интеллекта. Попытаемся их перечислить, следуя плану построения книги
Н. Нильсона.
Результатом большого числа экспериментов является понимание важной
роли систем продукций. По Н. Нильсону все данные в системе ИИ
организованы в виде глобальной базы данных, к которой под контролем некоторой
системы управления применяются операции — продукции, переводящие
глобальную базу данных в новое состояние. В гл. 1 обсуждаются и задача
построения эффективной системы управления, и вопросы выбора удобного
представления для задач — обстоятельства, подчас полностью определяющего
трудность их решения. Исследование вопросов эффективности работы ведет
к рассмотрению прямой, обратной и комбинированной систем продукций,
а также к важным понятиям коммутативности и разложимости глобальной
6а?ы данных.
Таким образом, центральная проблема, рассматриваемая в этой книге,
состоит в том, как, основываясь на знаниях о задаче, наилучшим образом
организовать декларативную (глобальную базу данных), процедурную
(продукции) и управляющую комопоненты всей системы продукций.
В гл. 2 и 3 рассматриваются стратегии поиска для систем продукций —
это по существу некоторая обработка результатов предыдущей книги
автора, относящихся к эвристическому поиску. В них обсуждается широкий
спектр задач эвристического поиска, обусловленный различной степенью ин-
6
формированности алгоритма поиска в рамках конкретных свойств
решаемой задачи.
Главы 4 и 5 книги также являются результатом переработки
соответствующих глав предыдущей книги автора. Следует отметить, что и при
применении в системе других формальных языков знакомство с методами
использования исчисления предикатов первого порядка является совершенно
необходимым. Так, необходимый для резолюции алгоритм унификации
является весьма универсальной процедурой. Имеются все основания считать,
что унификация, которая буквально пронизывает все главы книги Н. Ниль-
сона, является важнейшей компонентой любой системы ИИ.
В изложении метода резолюции большое внимание уделено
использованию в процессе вывода всевозможных дополнительных знаний. Особый
интерес, в частности, представляет использование "присоединенных процедур",
когда истинность отдельных литералов проверяется некоторым внешним
для резолюции образом (например, проведением непосредственного
измерения или обращением к заранее запасенному табличному файлу).
Хорошо известно, что попытки непосредственного применения метода
резолюции оказались неудачными вследствие того, что это приводит к
быстрому "размножению" промежуточных результатов, и часто при очевидном
существовании доказательства на практике при заданных объеме памяти
и быстродействии невозможно дождаться конца доказательства. Поэтому
в гл. 6 автор переходит к рассмотрению систем дедукции с использованием
правил, представимых в виде импликаций, не преобразуя все формулы в
форму предложений, как это принято в методе резолюции. В этом случае
все правильно построенные формулы разбиваются на такого рода правила
и факты (последние не выражаются в форме импликаций). Такие системы
непосредственного логического вывода оказываются более
эффективными, и, во всяком случае, более понятным становится сам ход вывода.
При таком подходе, позволяющем учесть при логическом выводе
проблемно-специфическую информацию, рассматриваются прямая и обратная
системы, причем обратная система (от цели) напоминает работу
интерпретатора языка ПРОЛОГ, но является более общей по сравнению с ним
системой.
Если в гл. 5 и 6 показано, как можно решать широкий круг задач с
применением коммутативных систем продукций, то в гл. 7 и 8 речь идет о задачах
планирования, в которых наиболее естественной является формализация,
связанная с некоммутативными системами, когда использование некоторого
правила изменяет, вообще говоря, необратимым образом глобальную базу
данных.
Здесь автором подробно описана работа таких систем, как STRIPS и
RSTRIPS, в создании которых он принимал непосредственное участие, а
затем рассматриваются вопросы иерархического планирования и построения
постепенно улучшаемых планов. Особое внимание уделено разрешению
совокупности конфликтных целевых условий.
Приводится также описание других подходов и формализации в задаче
планирования.
С точки зрения теории очень интересным, хотя и на первый взгляд
сложным, является механизм регрессии целевого условия. Необходимость в нем
7
возникает потому, что в обратной системе продукций приходится,
разумеется, использовать "прямые" правила, каждое из которых определяется
предусловием и списком добавлений и изъятий данных в глобальной базе данных
(например, правило "взять данный кубик").
Наконец, в гл. 9 рассматриваются вопросы представления знаний в виде
блоков (или фреймов, сценариев и т.п.) и связанные с этим вопросы
организации работы системы в целом. Показано, что при блочном описании
установление соответствия играет роль, аналогичную унификации.
Рассматриваются методы использования блоков, отвечающих присоединенным
процедурам, использования сетевых описаний, включения рекомендаций по
применению данного правила. Затрагивается проблема неточной и
противоречивой информации.
В целом книга Н. Нильсона ценна не только тем, что в ней систематически
описан тщательно отобранный материал по вопросу представления знаний и
их обработке, характеризующий область ИИ на 1980 г., но и тем, что в
библиографических разделах каждой главы автор рисует весьма широкую
картину состояния проблематики, указывая на источники информации, как
подкрепляющие его точку зрения, так и значительно от нее отклоняющиеся.
Безусловно, читателей заинтересует также небольшая гл. 10, в которой
перечисляются определенные "горячие точки" в области ИИ, являющиеся
очень важными для дальнейшего прогресса в этой области.
Таким образом, новая книга Н. Нильсона содержит богатый материал
по искусственному интеллекту и, несмотря на значительный объем,
читается довольно легко, если не считать некоторых разделов, носящих более
технический характер. Во всяком случае, читателю не потребуется
обращаться к другим материалам за справками — все необходимые сведения из
самых различных областей, затрагиваемых в книге, изложены в ней самой.
Кристине и Ларсу
ПРЕДИСЛОВИЕ
Обычно искусственный интеллект (ИИ) рассматривают в соответствии с
основными областями его применения - такими, как обработка
естественного языка, автоматическое программирование, управление роботами,
машинное зрение, автоматическое доказательство теорем, разумные системы
извлечения информации и т.д. Основная трудность при таком подходе
состоит в том, что указанные области применений настолько обширны, что
каждая в самом лучшем случае лишь весьма поверхностно может быть
изложена в книге нормального объема. Вместо этого я предпринял попытку
описать здесь фундаментальные идеи из области искусственного интеллекта,
лежащие в основе таких применений. Эти идеи, таким образом,
упорядочены мною не на основе тех областей, в которых они находят применение, а
на основе общих вычислительных концепций, включающих типы
используемых структур данных, типы выполняемых над ними операций и
свойства стратегий, используемых системами ИИ. В частности, мною выделено
то важное значение, которое в искусственном интеллекте имеют обобщенные
системы продукций и исчисление предикатов.
Мысли, на которых базируется настоящая книга, развились в ходе
семинаров и чтения учебных курсов в Станфордском университете и
Университете шт. Массачусетс, г. Амхерст. Хотя в ней охвачены и некоторые
вопросы, которые вошли в мою предыдущую книгу "Искусственный интеллект.
Методы поиска решений" [275], предлагаемый материал содержит
множество дополнительных вопросов. Обсуждаются системы, основывающиеся на
правилах, системы решения задач роботами и представления для
структурированных объектов.
Одна из задач этой книги — заполнить брешь, образовавшуюся между
теорией и практикой. Теоретики искусственного интеллекта не испытывают
больших затруднений в общении друг с другом, и книга не нацелена на то,
чтобы внести вклад в это общение. Но она не представляет собой и
справочника по современной технологии программирования в области
искусственного интеллекта — для этого имеются другие источники информации. В
настоящем своем виде книга может быть дополнена либо более глубоким
теоретическим анализом определенных предметов при прочтении курсов по
теории искусственного интеллекта, либо выполнением научного проекта
или лабораторных работ, если учебный курс в большей степени имеет
практическую ориентацию.
Книга задумана как учебник для студентов старших курсов
университета или первого года обучения в аспирантуре по специальности
"Искусственный интеллект". Предполагается при этом, что читатель имеет хорошую
подготовку в области основ вычислительной науки. Знание какого-либо
языка по обработке списков, такого как ЛИСП, было бы полезным. Курс
9
на основе данного учебника без напряжения может занять один семестр. Если
же добавляется отдельный материал практической или теоретической
ориентации, то может потребоваться и весь учебный год. Полусеместровый курс
будет слишком напряженным, если только не опустить какую-то часть
материала книги (возможно, некоторые разделы гл. 6 и 8).
Упражнения в конце каждой главы должны побудить к
самостоятельному размышлению. В тексте упоминаются также отдельные более общие
подходы к рассматриваемым вопросам. Для преподавателей может
оказаться целесообразным использование выборочных упражнений в качестве
основы для проведения дискуссии на семинарах. В конце каждой главы кратко
обсуждаются литературные ссылки, которые могут служить для активно
интересующегося студента адекватными стартовыми точками к большей
части наиболее важной литературы в области искусственного интеллекта.
Я рассчитываю однажды подвергнуть ревизии свою книгу: исправить
неизбежные ошибки и осветить новые результаты и свежие точки зрения. Имея
это в виду, я надеюсь услышать соответствующую реакцию читателей.
НилсДж. Нильсон
ВЫРАЖЕНИЕ БЛАГОДАРНОСТИ
Несколько организаций оказывало моральную и финансовую поддержку в тех
исследованиях, учебных курсах и дискуссиях, которые привели к созданию этой книги.
По программе информационных систем управления научно-исследовательскими
работами ВМС (директор Марвин Деникофф) было обеспечено финансирование научных
исследований по контракту № 00014-77-С-0222 с Международным Станфордским
исследовательским институтом. В академическом 1976/77 г. я по совместительству был
приглашенным профессором на факультете вычислительных наук Сганфордского
университета. С сентября 1977 по январь 1978 г. я вел зимний семестр на факультете
вычислительных и информационных наук в Университете шт. Массачусетс г. Амхерста.
Студенты и преподаватели этих факультетов оказали мне неоценимую помощь на этапе
формирования книги.
Я хотел бы выразить особую благодарность моей организации - Международному
Станфордскому исследовательскому институту — за предоставленные мне условия и
либеральное отношение к написанию книги. Я также хотел бы поблагодарить моих
друзей и коллег по Центру искусственного интеллекта Сганфордского исследовательского
института. Трудно себе представить более динамичную, интеллектуально
стимулирующую и конструктивно критическую обстановку для работы.
Хотя у настоящей книги указан лишь один автор, она была написана под влиянием
нескольких людей. Мне доставляет удовольствие поблагодарить здесь всех, кто
направлял меня в отношении лучшего представления результатов. Вот некоторые из
тех, чьи предложения были особенно подробными и обширными: Дуг Эппелт, Майкл
Арбиб, Вольфганг Бибел, Вуди Бледсоу, Джон Браун, Лу Крири, Рэнди Дэвис, Эд Фей-
генбаум, Ричард Файкс, Нортран Фаулер, Питер Фридленд, Энн Гарднер, Дэйвид Гель-
перин, Питер Харт, Пэт Хейес, Гери Хендрикс, Дуг Ленат, Вик Лессер, Джон Лоуренс,
Джек Минкер, Том Митчел, Боб Мур, Аллен Ныовелл, Эрл Сейсердоти, Лен Шуберт,
Херб Саймон, Рид Смит, Эллиот Солоуэй, Марк Стефик, Мэбри Тайсон и Ричард Уолдин-
гер, Джон Доил.
Я также хотел бы поблагодарить Робин Рой, Джуди Фетлер и Джорджию Наварро за
терпеливую и аккуратную машинописную работу, Салли Сейтц за размещение в тексте
инструкций для наборной машины и Хелен Тогнетти за творческое редактирование.
И что важнее всего, мои усилия вовсе не соответствовали бы поставленной задаче,
не получи они добрую поддержку, одобрение и понимание со стороны моей жены Карен.
Рукопись этой книги была подготовлена в Международном Станфордском
исследовательском институте на ЭВМ KL-10 фирмы Digital Equipment Corp. Соответствующий
машинный файл был обработан для автоматического фотонабора с помощью системы
TYPETB. А. Барретта на ЭВМ Hewlett-Packapd 3000.
Ответственные за оформление книги - Иан Бастельер, обложки - Андреа Хендрик;
иллюстрации Марлы Мастерсон.
Подготовка рукописи к набору: система Vera Allen Composition, Castro Valley, CA;
наборная система Typothetal, Palo Alto, CA; печать и переплет R.R. Donnelley and Sons
Company.
ПРОЛОГ
Многие виды умственной деятельности человека: такие, как написание
программ для вычислительной машины, занятие математикой, ведение
рассуждений на уровне здравого смысла и даже вождение автомобиля, — как
говорят, требуют "интеллекта". На протяжении последних десятилетий
было построено несколько систем на вычислительных машинах, способных
выполнять задачи, подобные этим. В частности, имеются системы,
способные диагностировать заболевания, планировать синтез сложных
органических соединений в химии, решать дифференциальные уравнения в
символической форме, анализировать электронные схемы, понимать ограниченный
объем человеческой речи и естественного языкового текста или написать
небольшую программу для вычислительной машины, удовлетворяющую
определенным формальным требованиям. Мы могли бы сказать, что такие
системы обладают в некоторой степени искусственным интеллектом.
Работа по построению такого рода систем проводится, главным образом,
в области, получившей название искусственный интеллект. Эта работа в
значительной степени имеет эмпирическую и инженерную ориентации.
Отталкиваясь от плохо структурированного, но все время увеличивающегося
объема вычислительных приемов, системы ИИ испытываются и
совершенствуются в экспериментальных ситуациях. В результате было разработано и
выделено несколько принципов искусственного интелекта, получивших
широкое применение.
Настоящая книга посвящена некоторым наиболее важным или
центральным идеям ИИ. В ней мы останавливаемся на тех, которые используются в
нескольких различных проблемных областях. Чтобы подчеркнуть широкую
применимость этих принципов, они поясняются на абстрактном уровне, а не
рассматриваются в рамках конкретных приложений. Приводится несколько
простых примеров, но подробного анализа конкретных широкомасштабных
применений не дается. (Для детального анализа каждого из таких
применений потребовалась бы отдельная книга.) Понимание основных идей на
абстрактном уровне должно облегчить понимание конкретных систем ИИ
(включая их сильные и слабые стороны), а также послужить прочной основой при
разработке новых систем.
Искусственный интеллект ставит перед собой и более серьезную задачу
построения теории интеллекта, базирующейся на обработке информации.
Если бы такую теорию интеллекта можно было создать, то с ее помощью
можно было бы направленно вести разработку интеллектуальных машин.
Кроме того, можно было бы прояснить детали интеллектуального поведения,
проявляющегося у людей и животных. Поскольку построение такой общей
теории пока остается в значительной степени нерешенной задачей, стоящей
12
перед ИИ, то мы сконцентрируем внимание на тех принципах, которые
касаются инженерной задачи построения интеллектуальных машин. И даже при
таком ограниченном подходе наше обсуждение идей ИИ может представить
интерес для психологии познания и других областей, нацеленных на
понимание естественного интеллекта.
Методы и приемы ИИ, как мы уже говорили, нашли применение в
нескольких проблемных областях. Чтобы облегчить мотивирование нашего
дальнейшего анализа, перейдем к описанию некоторых таких приложений.
0.1. НЕКОТОРЫЕ ПРИЛОЖЕНИЯ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА
0.1.1. ОБРАБОТКА ЕСТЕСТВЕННОГО ЯЗЫКА
Когда люди общаются друг с другом с помощью языка, они практически
без всяких усилий используют чрезвычайно сложные и пока еще мало
понятные процессы. Оказалось, что построить вычислительные системы, способные
генерировать или "понимать" хотя бы фрагменты такого естественного
языка, как английский, чрезвычайно трудно. Одной из причин этого является
то обстоятельство, что язык возник как средство общения
интеллектуальных существ. В первую очередь он используется для передачи некоторой
порции "умственной структуры" от одного мозга к другому в услових, в
которых каждый мозг располагает большими весьма подобными друг другу
"умственными структурами", служащими в качестве общего контекста.
Более того, часть этих схожих контекстуальных "умственных структур" дает
возможность каждому партнеру знать, что другой также располагает этой
общей структурой и может и будет выполнять определенные процессы в ходе
актов общения. В процессе эволюции применения языка была, очевидно,
учтена потенциальная возможность участников разговора использовать
значительные вычислительные ресурсы и совместные знания для создания
и восприятия чрезвычайно сжатых сообщений: мудрому человеку
достаточно услышать от мудрого одно слово. Таким образом, образование и
понимание фразы — чрезвычайно сложная проблема кодирования и
декодирования.
Вычислительная система, способная понимать сообщение на естественном
языке, нуждалась бы, по-видимому, не в меньшей степени, чем человек, как
в контекстуальных знаниях, так и в процессах, обеспечивающих тот
логический вывод (из контекстуальных знаний и сообщения), наличие которого
предполагает генератор сообщений. В направлении создания
вычислительных систем такого рода, предназначенных для понимания письменных и
устных фрагментов речи, был достигнут некоторый прогресс. При
построении систем существенными оказались некоторые представления из области
ИИ о структурах представления контекстуальных знаний и некоторых
методах логического вывода из знаний такого типа. Хотя проблему
обработки языка как таковую мы в этой кйиге не рассматриваем, тем не менее мы
описываем некоторые важные методы представления и обработки знаний,
которые и в самом деле находят применения в системах, предназначенных
для обработки языка.
13
0.1.2. ИЗВЛЕЧЕНИЕ ИНФОРМАЦИИ ИЗ БАЗ ДАННЫХ
Системы баз данных представляют собой вычислительные системы, в
которых хранятся большие объемы фактов, относящихся к некоторой области,
причем в таком виде, чтобы их можно было использовать при ответах на
вопросы, касающиеся этой предметной области. Чтобы дать конкретный
пример, предположим, что такими фактами являются личные дела
сотрудников какой-то большой корпорации. Тогда примерами элементов базы
данных могли бы служить представления для таких фактов, как "Джо Смит
работает в отделе закупок", "Джо Смит был взят на работу 8 октября 1976
года", "В отделе закупок 17 сотрудников", "Джон Джонс является главой
отдела закупок" и т. д.
Разработка систем баз данных — один из важных разделов области
вычислительных наук (computer science), в рамках которого были предложены
разнообразные приемы, дающие эффективное представление, хранение и
извлечение из памяти большого числа фактов. С нашей точки зрения этот
предмет становится действительно интересным, когда мы хотим извлечь
ответ на вопрос, для которого необходимо провести дедуктивное
рассуждение с фактами из базы данных.
Конструктор такой интеллектуальной системы извлечения информации
сталкивается с несколькими проблемами. Во-первых, имеется гигантская
проблема построения системы, которая могла бы понимать запросы,
сформулированные на естественном языке1. Во-вторых, даже в случае, если задачу
понимания языка удается обойти, определив для этого некоторый
формальный понятный машине язык запросов, проблема того, как логически
вывести ответы, исходя из хранящихся фактов, остается. В-третьих, для
понимания запроса и вывода ответа может потребоваться информация,
выходящая за рамки информации, явным образом представленной в базе данных
для предметной области. Часто бывают необходимы широко известные
сведения, которые обычно опускаются в базе данных, характеризующей
проблемную область. Например, из фактов, касающихся упомянутых
нами личных дел, интеллектуальная система должна логически вывести
ответ "Джон Джонс" при поступлении запроса "Кто является боссом Джо
Смит?". Такая система должна каким-то образом знать, что глава
некоторого отдела является боссом для людей, работающих в этом отделе. То,
каким образом обыденные знания следовало бы представлять и
использовать, является одной из задач, возникающих при разработке систем, для
решения которых могут быть привлечены методы искусственного
интеллекта.
0.1.3. ЭКСПЕРТНЫЕ КОНСУЛЬТИРУЮЩИЕ СИСТЕМЫ
Методы ИИ нашли также применение при разработке автоматических
консультирующих систем. Такие системы обеспечивают пользователя
компетентными заключениями, касающимися определенных предметных областей.
Были созданы автоматические консультирующие системы, способные
диагностировать заболевания, оценивать потенциальные золотоносные месторож-
1 Читателю можно рекомендовать весьма информативную книгу [3*], в которой
подробно освещаются разнообразные аспекты этой проблемы. - Прим. ред.
14
дения, предлагать варианты возможных структур для сложных органических
химических элементов и даже давать советы о том, как пользоваться
другими вычислительными системами.
Ключевая проблема при построении экспертных консультирующих систем
состоит в том, как представлять и использовать знания, которыми,
очевидно, располагают и пользуются люди, являющиеся экспертами в этих
областях. Эта проблема осложняется еще тем фактом, что экспертные знания
во многих важных областях часто являются неточными, неопределенными
или анекдотическими (хотя эксперты пользуются такими знаниями, выводя
полезные для дела заключения) [4*].
Во многих экспертных консультирующих системах применяется метод
ИИ, связанный с логическим выводом, основанным на правилах. В таких
системах экспертные знания представлены в виде большого множества
простых правил, которые применяются при организации диалога между
системой и пользователем, а также для вывода заключений. Дедукция,
основанная на правилах, является одним из главных вопросов, затрагиваемых в
настоящей книге.
0.1.4. ДОКАЗАТЕЛЬСТВО ТЕОРЕМ
Поиск доказательства (или опровержения) для некоторой
математической теоремы, несомненно, может быть рассмотрен, как пример
интеллектуальной задачи. Не только потому, что для этого требуется способность
произвести дедукцию, исходя из гипотез, но и потому, что для нее необходимы
интуитивные навыки, такие, как построение догадки о том, какие
промежуточные леммы следует доказать, чтобы способствовать доказательству
основной теоремы. Опытный математик опирается на то, что он, возможно,
назовет суждением (основанным на большом объеме специальных знаний),
чтобы высказать точную догадку, какие из ранее доказанных теорем в
рассматриваемой предметной области будут полезны для искомого доказательства,
и чтобы выделить в главной проблеме подзадачи, над которыми можно
работать независимо друг от друга. Было разработано несколько программ
автоматического доказательства теорем, которые до какой-то степени обладают
некоторыми из таких способностей.
Изучение приемов доказательства теорем сыграло большую роль в
развитии методов ИИ. Формализация дедуктивного процесса с использованием
языка логики предикатов, например, помогает глубже понять некоторые
компоненты рассуждения. Многие неформальные задачи, включая
медицинскую диагностику и извлечение информации, допускают их формализацию
как задачу на доказательство теорем. По этим причинам доказательство
теорем является чрезвычайно важной областью при изучении методов ИИ.
0.1.5. РОБОТИКА1
Может показаться, что управление физическими действиями подвижного
робота не требует большого интеллекта. Даже маленькие дети способны ус-
1 Роботика (Robotics) - молодая наука, выделившаяся в рамках искусственного
интеллекта. Ее задачей является решение теоретических и практических вопросов
организации целесообразного поведения подвижного робота, снабженного сенсорными и зф-
фекторными (исполнительными) механизмами. Перед таким роботом, как правило,
15
пешно находить дорогу в окружающей их обстановке и манипулировать
такими предметами, как выключатели света, игральные кубики,
приспособления для еды и т.д. Однако некоторые из этих задач, практически
бессознательно выполняемые людьми, требуют для их решения тех же многих
способностей, которые необходимы для решения проблем, нуждающихся в
большем интеллекте.
Исследования по роботам и роботике оказали помощь при развитии
многих идей ИИ. Они привели к созданию нескольких методов моделирования
состояний мира и описания процесса изменения одного состояния внешнего
мира на другое. Они привели к лучшему пониманию того, каким образом
строить планы для последовательности действий и как управлять
выполнением этих планов. Сложные задачи управления роботом заставили нас
развить методы планирования, осуществляемого на высоком уровне
абстракции, опуская детали, с последующим переходом к планированию на все
более низких уровнях, на которых детали становятся важными. В настоящей
книге у нас будет много случаев использовать примеры из области решения
задач роботом для иллюстрации важный идей.
0.1.6. АВТОМАТИЧЕСКОЕ ПРОГРАММИРОВАНИЕ
Задача написания программы для вычислительной машины связана как с
доказательством теорем, так и с роботикой. Большая часть основных
исследований по автоматическому программированию, доказательству теорем и
решению проблем роботом перекрывается друг с другом. Существующие
компиляторы уже осуществляют в некотором смысле "автоматическое
программирование". Они воспринимают полную спецификацию во
входном коде того, что программа должна делать, и пишут программу в
объектном коде, которая это делает. То, что мы здесь подразумеваем под
автоматическим программированием, может быть описано как
"суперкомпилятор", или программа, которая могла бы воспринимать описание на очень
высоком уровне того, что требуется от искомой программы. Указанное
описание на высоком уровне могло бы быть точным утверждением в
некотором формальном языке, таком, как исчисление предикатов, или же быть
приблизительным описанием, скажем, на английском языке, которое
потребовало бы проведения дополнительного диалога между системой и
пользователем для исключения неоднозначностей.
Задача автоматического написания программы для достижения заданного
результата тесно связана с задачей доказательства того, что программа
достигает этого результата. Последняя получила название задачи
верификации программы. Многие системы автоматического программирования
включают верификацию выходной программы в качестве некоторой
дополнительной возможности.
ставится определенная глобальная задача, оДнако предполагается, что заранее
невозможно полностью предсказать реакции со стороны окружающей его среды, поэтому
такую проблему, как, например, планирование порядка выполнения действий, робот
должен решать самостоятельно, сообразуясь с конкретными условиями, используя
для этого "бортовую" ЭВМ. Именно эта проблема является предметом исследования
настоящей книги в той ее части, которая касается роботов. - Прим. ред.
16
Одним из важных вкладов исследования в автоматическое
программирование явилось представление об отладке как стратегии решения проблем.
Установлено, что часто более эффективным оказывается создание
недорогого, полного ошибок решения задачи написания программы или управления
роботом с его последующей модификацией (добиваясь нужного результата),
а не поиск с самого начала такого решения, которое было бы свободно от
дефектов.
0.1.7. КОМБИНАТОРНЫЕ ЗАДАЧИ И СОСТАВЛЕНИЕ РАСПИСАНИЙ
Интересный класс проблем связан с поиском оптимальных расписаний и
комбинаторикой. Многие из них могут быть исследованы методами,
обсуждаемыми в этой книге. Классическим примером является задача
коммивояжера, в которой требуется найти маршрут минимальной длины в пределах
нескольких городов, начиная от некоторого исходного города, посещая
каждый город один раз и возвращаясь в исходный город. Эта задача
допускает обобщение как задача поиска пути минимальной стоимости по дугам
графа, содержащего η вершин, такого, что этот путь проходит каждую из
η вершин в точности один раз.
Многие головоломки носят такой же общий характер. Еще одним
примером является задача о восьми ферзях, которая состоит в том, что восемь
ферзей надо разместить на обычной шахматной доске таким образом, чтобы
ни один из них не атаковал другого. Иными словами, на каждой вертикали,
горизонтали и диагонали должно быть не более одного ферзя. В большинстве
задач такого типа область возможных комбинаций или последовательностей,
из которых предстоит выбирать ответ, чрезвычайно велика. Простые
попытки решения задач такого типа вскоре порождают комбинаторный взрыв
вариантов, которые быстро исчерпывают возможности больших
вычислительных машин.
Некоторые из этих задач (включая задачу коммивояжера) относятся к
задачам, которые теоретики-вычислители называют NP-полными. При этом
трудности различных задач упорядочиваются по тому, как при применении
теоретически лучшего метода решения в худшем случае растет время (или
число шагов), по мере роста некоторой характеристики объема задачи.
(Например, характеристикой объема задачи о коммивояжере может служить
число городов.) Таким образом, сложность задачи может расти линейно,
полиномиально или экспоненциально, например, с увеличением объема
задачи.
Время, необходимое при использовании наилучшего из известных
методов для решения ΝΡ -полных задач, растет экспоненциально с
увеличением объема задачи. Пока еще не установлено, существуют ли более быстрые
методы (дающие, скажем, лишь полиномиальное время), но было
доказано, что если более быстрый метод существует для одной из ΝΡ-полных
задач, то он может быть преобразован в аналогичные быстрые методы для
всех остальных ΝΡ-полных задач. А пока что мы должны обходиться
методами, обеспечивающими экспоненциальный рост времени решения.
Исследователи в области ИИ работали над методами решения нескольких
типов комбинаторных задач. Их усилия были направлены на то, чтобы
кривая, отражающая зависимость времени от объема задачи, росла возможно
17
медленнее,даже когда она должна расти экспоненциально. Несколько
методов было развито для того, чтобы задержать и несколько "умерить"
неизбежный комбинаторный взрыв. И снова знания о проблемной области
являются ключевыми для создания более эффективных методов решения.
Многие из методов, созданных для работы с комбинаторными задачами, также
полезны и в других задачах, не носящих чисто комбинаторного характера.
0.1.8. ПРОБЛЕМЫ ЗРИТЕЛЬНОГО ВОСПРИЯТИЯ
Были предприняты определенные попытки снабдить вычислительные
системы телевизионными входами, что позволяет им "видеть" окружающую
среду, или же микрофонными входами, что позволяет им "слышать" голоса
говорящих. Эти эксперименты показали, что для полезной обработки
сложных входных данных необходимо "понимание" и что для такого понимания
необходима большая база знаний о воспринимаемых вещах.
Процесс восприятия, изучаемый в искусственном интеллекте, обычно
опирается на некоторое множество операторов. Скажем, зрительная сцена
кодируется сенсорами и представляется в виде матрицы интенсивно'стей.
Последние обрабатываются детекторами, которые осуществляют поиск таких
элементарных компонент изображения, как отрезки линий, простые кривые,
углы и т. п. А они, в свою очередь, подвергаются обработке для выведения
информации о трехмерном характере сцены в терминах поверхностей и
форм. Конечной целью является представление сцены с помощью некоторой
подходящей модели. Эта модель может сводиться к описанию на высоком
уровне, например: "Холм, на вершине холма дерево, у которого пасется
корова".
Смысл всего процесса восприятия состоит в создании сжатого
представления, в замене "сырой" входной информации, с которой невозможно
работать из-за ее громадного объема. Очевидно, что характер и качество
окончательного представления зависят от целей воспринимающей системы. Если
важны цвета, то на них следует обратить внимание; если важны
пространственные соотношения и размеры, то их нужно установить аккуратно. Перед
различными системами ставятся различные задачи, но во всех случаях
громадный объем входных сенсорных данных должен быть сведен к
приемлемому и осмысленному описанию.
Основную трудность при восприятии сцены составляет невообразимое
число возможных описаний-кандидатов, которые могли бы представить
интерес для системы. Если бы не этот факт, то можно было бы построить ряд
детекторов, чтобы решить, к какой категории принадлежит сцена.
Например, не исключено, что можно построить детектор, который мог бы
проверять сцену на принадлежность к категории: "Холм, на вершине холма
дерево, у которого пасется корова". Но почему следует брать такой детектор,
а не какой-нибудь другой из несчетного числа детекторов, которые могли
бы быть использованы?
Стратегия, которая, по-видимому, дает подход к решению этой задачи,
состоит в построении гипотез на различных уровнях описания и
последующей проверке таких гипотез. Были построены системы, обрабатывающие
подходящие представления сцены, чтобы высказать гипотезы относительно
наличия компонент некоторого описания. Затем эти гипотезы проверяются
18
детекторами, специально предназначенными для таких описаний компонент.
Результаты проверок, в свою очередь, используются для построения лучших
гипотез и т. д.
Парадигма вида гипотеза и проверка применяется на многих уровнях
процесса восприятия. Несколько расположенных в линию отрезков
наводят на мысль о некоторой прямой линии; детектор линии может быть
использован для проверки такой гипотезы. Примыкающие друг к другу
прямоугольники наводят на мысль о том, что это — стороны некоторого
твердого призматического предмета; детектор объектов может быть
использован для проверки.
Процесс формирования гипотез нуждается в большом объеме знаний о
сценах, которые ожидается увидеть. Некоторыми исследователями в
области ИИ высказывалось предположение, что это знание может быть
организовано в виде специальных структур, называемых фреймами, или схемами1.
Например, когда робот входит в комнату через дверной проем, он
активирует схему комнаты и рабочая память загружается "ожиданиями",
касающимися того, что может быть в дальнейшем увидено роботом. Предположим, что
роботом воспринимается какая-то прямоугольная форма. Эта форма в
контексте схемы комнаты может навести на мысль об окне. Схема окна может
содержать знание о том, что обычно окно с полом не соприкасается.
Специальный детектор, примененный к сцене, подтверждает это ожидание,
повышая таким образом степень доверия к гипотезе о наличии окна. В
дальнейшем мы будем обсуждать фундаментальные идеи использования
представлений на основе фреймовых структур и процессов логического вывода.
0.2. СОДЕРЖАНИЕ КНИГИ
Книга содержит девять глав и проспект. В гл. 1 вводится понятие
обобщенной системы продукций и указывается на ее важную роль как
основного строительного блока систем ИИ. Приводится несколько систем
продукций с различными стратегиями управления. Выделенные различия
используются в ходе изложения для классификации систем ИИ*
Основное внимание в гл. 2 и 3 уделяется стратегиям поиска (перебора),
полезным при управлении работой системы ИИ. Глава 2 посвящена
эвристическим методам поиска на графах, которые неявным образом вводятся во
многих системах ИИ. Эти методики поиска обобщаются в гл. 3 на случай
развернутых вариантов таких графов, называемых графами типа И/ИЛИ,
и на случай графов, возникающих при анализе некоторых игр.
В гл. 4 вводится исчисление предикатов и описывается важная роль,
которую оно играет в системах ИИ. Обсуждаются различные правила
логического вывода, включая резолюцию. Системы доказательства теорем с
использованием резолюции обсуждаются в гл. 5. Показывается, как несколько
проблем различного типа может быть сформулировано в виде задач на
доказательство теорем.
В гл. 6 исследуются некоторые недостатки простых систем резолюции и
описываются альтернативы, называемые системами дедукции, основанны-
1 Первой и самой общей работой, в которой проблема таких специальных структур
нашла глубокое обсуждение, была статья М. Минского [397]. - Прим. ред.
19
ми на использовании правил, которые для многих приложений
искусственного интеллекта оказываются более подходящими. Для иллюстрации
приводятся примеры, включающие извлечение информации и автоматическое
программирование.
В гл. 7 и 8 представлены методы синтеза последовательностей действий
при достижении предписанной цели. Для иллюстрации этих методов
рассматриваются простые задачи планирования для робота и задачи
автоматического программирования. В гл. 7 вводятся некоторые основные идеи,
а в гл. 8 подробно обсуждаются вопросы сложного взаимодействия целей
и иерархического планирования.
В гл. 9 описываются некоторые формальные схемы представления, в
которых сама структура представления используется в помощь процессу
извлечения и делает некоторые обычные логические выводы практически
мгновенными. Примерами служат семантические сети и так называемые
представления на основе фреймов. Наша позиция по отношению к таким
представлениям состоит в том, что лучше всего их понимать как некоторую
форму исчисления предикатов.
Наконец, в проспекте дается обзор некоторых замечательных задач
искусственного интеллекта, которые еще не настолько хорошо понятны, чтобы их
можно было включить в основной текст учебника. Надеемся, что
обсуждение этих проблем укажет на перспективу в отношении текущего состояния
области исследований и даст полезные указания относительно будущих
исследований.
0.3. БИБЛИОГРАФИЧЕСКИЕ И ИСТОРИЧЕСКИЕ ЗАМЕЧАНИЯ
В этом и в подобных разделах в конце каждой главы очень кратко
обсуждается относящаяся к делу литература. Цитируемый материал
перечислен в алфавитном порядке по имени первого автора в библиографическом
списке в конце книги. Многие ссылки будут полезны тем читателям,
которые захотят более глубоко заняться теоретическими или прикладными
вопросами. Для полноты иногда дается ссылка на неопубликованные отчеты
и сообщения. Авторы (или учреждения, с которыми они связаны) иногда
смогут по заявке выслать копию таких материалов.
Об искусственном интеллекте и его применениях было написано
несколько книг. В книге Слейгла [342] описываются многие ранние системы ИИ.
Нильсон в книге, посвященной решению проблем в искусственном
интеллекте, сосредоточивает внимание на методах поиска (перебора) и
применениях доказательства теорем методом резолюции [273]. Джексон в
книге,являющейся введением в ИИ, также рассматривает эти идеи решения проблем
и описывает приложения к обработке естественного языка и анализу
изображений [164]. Хант уделял внимание изучению распознавания образов, а
также другим вопросам ИИ [163]. Вводные статьи о предметах
искусственного интеллекта опубликованы в книге под редакцией Барра и Фейгенбаума
[14]. В обзоре Нильсона охарактеризовано положение в области
искусственного интеллекта в начале 70-х годов и содержится множество ссылок на
работу [275]. Мичи опубликовал несколько статей по искусственному
интеллекту в книге [238].
Книги Рафаэла [294] и Уинстона [399] представляют собой легко
читаемые элементарные рассмотрения идей ИИ. Вторая содержит блестящее вве-
20
дение в методы программирования ИИ. В книге под редакцией Банди [43]
представлен материал, использованный в вводном курсе по искусственному
интеллекту, прочитанном в Эдинбургском университете (Шотландия).
Общее обсуждение ИИ и его взаимоотношения с интеллектом человека
содержится в книге Боден [37]. Маккордак написал интересную книгу по
истории искусственного интеллекта [211]. Эссе Марра [223] и книга Саймона
[335] посвящены исследованиям по искусственному интеллекту как
научному направлению. Коэн проследил взаимосвязь между художественным
воображением и зрительным восприятием [54].
Наиболее авторитетное и полное изложение механизмов решения
человеком проблем с позиции ИИ содержится в книге Ньювелла и Саймона [269].
В сборнике под редакцией Нормана и Румельхарта рассматриваются
машинные модели памяти человека; учебник психологии Линдсея и Нормана
написан с позиции обработки информации [194]. В журнале широкого профиля
Cognitive Science публикуются статьи по информационной обработке,
характерной для человеческого понимания, восприятия и использования языка.
0.3.1. ОБРАБОТКА ЕСТЕСТВЕННОГО ЯЗЫКА
Грож дал хороший обзор современных методов и проблем обработки
естественного языка [132]. Совокупность важных статей по этому
предмету имеется в книге под редакцией Растина [314]. Одна из самых первых
успешных систем ИИ, предназначенная для понимания ограниченных
фрагментов естественного языка, описана Виноградом [392].
Задачи пятилетнего научно-исследовательского проекта построения
системы понимания речи освещены в книге Ньювелла и соавторов [270].
Основные результаты этого предприятия описаны в статьях Медресса и соавторов
[231], Клэтта [169], в отчетах Редди и соавторов [297], Вудса и соавторов
[405], Бернстейна [21] и в книге Уолкера [373].
Основы вычислительных механизмов, участвующих в обработке
естественного языка, представлены Виноградом [394]. Некоторые системы
интерфейса для подмножеств естественного языка описаны в статье под
редакцией Уолтца [375].
Несколько важный статей содержится в трудах проходящей каждые два
года конференции "Теоретические вопросы обработки естественного языка"
(TINLAP). Исследования в области обработки языка ведутся и в рамках
других, отличных от ИИ, научных направлений, при этом наиболее
выделяются вычислительная лингвистика, философия и психология понимания.
0.3.2. ИЗВЛЕЧЕНИЕ ИНФОРМАЦИИ ИЗ БАЗ ДАННЫХ
По системам баз данных опубликованы прекрасные книги Дейта и Видер-
холда [64], [386]. В важной статье Кодда [52] дается формализация
реляционной модели для управления базой данных. Различные применения
ИИ и логики к организации баз данных и извлечению сведений из нее
обсуждаются в книге под редакцией Галлаира и Минкера [113]. Несколько
описаний систем запросов для баз данных с использованием упрощенного
естественного языка приводится в статье под редакцией Уолтца [375].
21
0.3.3. ЭКСПЕРТНЫЕ КОНСУЛЬТИРУЮЩИЕ СИСТЕМЫ
Были построены экспертные консультирующие системы для самых
различных областей. Идеи ИИ нашли наиболее развитые применения в
медицине: для лечения внутренних органов [286], глаукомы [382], диагностики и
лечения инфекционных заболеваний [65, 330].
Консультирующая система для оказания помощи геологу при оценке
потенциальных запасов залежей полезных ископаемых представлена в работах
Дуда и соавторов [81—83]. Краткое описание нескольких экспертных
систем, разработанных в Станфордском университете, дано в статье Фейгенба-
ума [198]. Самая развитая из систем — DENDRAL — вычисляет структурные
описания сложных органических химических соединений, опираясь на масс-
спектрографию и другие данные, например приведенные в работе [41].
Другими важными примерами экспертных систем являются система,
предложенная Сассманом и Столлманом [355] для анализа работы
электронных схем (см. также [350]), и система [122, 123] оказания поддержки
неопытному пользователю системой манипулирования математическими
формулами MACSYMA [229].
0.3.4. ДОКАЗАТЕЛЬСТВО ТЕОРЕМ
Первые приложения ИИ к доказательству теорем были сделаны Гелэнте-
ром для геометрии на плоскости [119] и Ньювеллом, Шоу и Саймоном для
препозициональной логики [265]. Принцип резолюции Робинсона
значительно ускорил работу по автоматическому доказательству теорем [306] ·
Доказательство теорем с помощью резолюции подробно описано в книгах
[48, 198, 307].
Бледсоу с сотрудниками создали весьма впечатляющие системы для
математического анализа [12], топологии [28] и теории множеств [26]. Вое
с сотрудниками добился блестящих результатов в системах, основанных на
принципе резолюции [39, 210, 390, 391]. Бойер и Мур построили систему
доказательства теорем о рекурсивных функциях, опираясь на индукцию
[39].
По автоматической дедукции проводятся регулярные совещания.
Неформальный сборник трудов был выпущен для четвертого совещания (см.
Труды конференций, WAD).
0.3.5. РОБОТИКА
Большая часть теоретических исследований по роботике проводилась в
связи с проектами создания роботов в Массачусетском технологическом
институте, Станфордском университете, Станфордском исследовательском
институте и Эдинбургском университете в конце 60-х и начале 70-х годов.
Эта работа описана в нескольких статьях и отчетах, в частности в хороших
отчетах Уинстона по Массачусетсе ому технологическому институту [396],
Рафаэла с соавторами [295] и Рафаэла [294] — по Станфордскому
исследовательскому институту; Маккарти с соавторами [208] — по
Станфордскому университету и Амблером с соавторами [8] — по Эдинбургскому
университету.
Практические применения роботики для промышленной автоматизации
становятся обычным делом. В системе-роботе для сборки небольших элек-
22
трических моторов, разработанной Абрахамом, манипулирование деталями
контролируется с помощью автоматического зрительного воспринимающего
устройства с применением телевизионной камеры [1]. В книге Розена и Нит-
зана обсуждается использование зрения и других сенсорных систем в
промышленной автоматизации [308]. Примеры развитых исследований по
применениям роботов можно найти у Нитзана, Бинфорда с соавторами, Невин-
са и Витнея, Уилла и Грошмана, Такеуси с соавторами, Охоцимского с
соавторами и Кассиниса [24, 46, 261, 277, 357, 389]. Регулярно проводятся
международные симпозиумы по промышленным роботам.
0.3.6. АВТОМАТИЧЕСКОЕ ПРОГРАММИРОВАНИЕ
Одна из первых попыток использования идей ИИ для автоматического
синтеза программ вычислительной машины принадлежит Саймону [334,
337]. В пионерских статьях Уолдингера и Ли [370], Грина [127] показано,
как небольшие программы могли бы быть синтезированы с помощью
доказательства теорем методом резолюции.
В обзорах Брамана [23], Хаммера и Рата [135] обсуждаются различные
подходы к автоматическому программированию. Проект PST Грина [129]
включает несколько компонент, одной из которых является основанная на
правилах система синтеза программ с использованием описания
абстрактных алгоритмов [16]. Система ученика-программиста для помощи
программисту-человеку описана Ричем и Шроубом [301] ·
Связанные с этим вопросы верификации программ обсуждаются
Лондоном [197] (см. также [58]). Ранее формальная верификация свойств
программ обсуждалась в теории вычислений Голдстайном и фон Нейманом
[125], Тьюрингом [360]. Верификация программ упоминалась Маккарти
[204] как одно из применений предполагавшейся математической теории
вычислений. В работах Флойда [109] и Нора [259] в явном виде
высказывалась идея инвариантных утверждений. В сборнике статей под редакцией
Манна и Уолдингера [219] описываются основанные на математической
логике методы верификации, синтеза и отладки программ.
0.3.7. КОМБИНАТОРНЫЕ ЗАДАЧИ И ЗАДАЧИ СОСТАВЛЕНИЯ
РАСПИСАНИЙ
Задачи составления расписаний обычно изучаются в исследовании
операций. В качестве хороших общих литературных ссылок следует указать на
работы Вагнера [368], Хиллиера и Либермана [158]. Обсуждение
NP-полных задач и других вопросов математического анализа алгоритмов можно
найти у Хопкрофта и Ульмана [3]. Вычислительный язык и система для
решения комбинаторных задач с использованием методов ИИ описан Лурье
[186].
0.3.8. ПРОБЛЕМЫ ЗРИТЕЛЬНОГО ВОСПРИЯТИЯ
Множество хороших работ по проблемам зрительного восприятия
содержится в гомах по*д редакцией Хансена и Райзмена [136], Уинстона [397].
В число представительных систем обработки зрительных образов входят
системы, описанные Барроу и Тененбаумом [15], Сираи [329]. В важной
23
статье Марра приводятся теоретические соображения о механизмах
вычисления и представления в зрительной системе человека [222]. Канейд
представил обзор некоторых важных общих аспектов зрительных систем [166], а
Эйгин остановился на некоторых вопросах применения зрительных систем
при промышленной автоматизации [2].
Некоторые фундаментальные вопросы машинного зрения описали Дуда
и Харт [79]. Регулярно проводится Международная объединенная
конференция по распознаванию образов, труды которой публикуются
Институтом инженеров по электротехнике и радиоэлектронике. Отдел методов
обработки информации в Управлении перспективных исследований МО США
финансируют проведение Совещаний по пониманию изображений.
0.3.9. ДРУГИЕ ПРИЛОЖЕНИЯ
Идеи искусственного интеллекта нашли применение также и в других
областях: Латомб [185] и Сассман [354] описали системы автоматического
конструирования, Браун предложил использовать их в педагогике [40],
Гелэнтер с соавторами [120] и Випке, Оуши, Кришнан создали системы
для синтеза в органической химии [402].
0.3.10. ДРУГИЕ ВАЖНЫЕ ИСТОЧНИКИ ИНФОРМАЦИИ
В добавление к уже упомянутым книгам, некоторые сборники статей
перечислены в начале даваемой нами библиографии. В их числе серия из
девяти томов1 под названием Machine Intelligence и книга "Вычислительные
машины и мышление" под редакцией Фейгенбаума и Фельдмана,
содержащая первые важные работы в этой области [100].
Международный журнал Artificial Intelligence является основным
печатным органом в области искусственного интеллекта. Статьи по ИИ
публикуются также в журнале Journal of the Association for Computing Machinery (JACM),
в сообщениях Communication of the Association for Computing Machinery (CACM)
и в различных публикациях Института инженеров по электротехнике и
радиоэлектронике (США).
Каждые два года, начиная с 1969-го, проводится Международная
объединенная конференция по искусственному интеллекту2. Ассоциация по
вычислительным машинам (АСМ) выпускает бюллетень писем по искусственному
интеллекту SIGART Newsletter. В Великобритании Общество по изучению
искусственного интеллекта и моделированию поведения выпускает
бюллетени AISB Quarterly, а также проводит раз в два года конференции.
Канадское общество по вычислительному анализу интеллекта (CSCSI/SCEIO)
публикует время от времени научные бюллетени.
Неоторые вопросы, рассматриваемые в настоящей книге, предполагают
определенное знакомство с языком программирования ЛИСП. Легко
читаемое введение в ЛИСП можно найти в книге Вейсмана [383]. Довольно
привлекательное руководство по программированию дал Фридман [112]. Более
техническое изложение содержится у Аллена [4].
1 Десятый том вышел в 1982 г. Он посвящен вопросу экспертных систем. - Прим.
ред.
2 С ней чередуется весьма представительная Европейская конференция по
искусственному интеллекту; последняя состоялась в 1984 г. в г. Пиза (Италия). - Прим.
ред.
24
ГЛАВА 1
СИСТЕМЫ ПРОДУКЦИЙ И ИСКУССТВЕННЫЙ ИНТЕЛЛЕКТ
В большинстве систем искусственного интеллекта наблюдается более или
менее постоянное разделение между стандартными вычислительными
компонентами: данными, операциями и управлением. Иными словами, если эти
системы описаны на подходящем уровне, часто удается выделить некоторую
центральную структуру, которую можно назвать глобальной базой данных;
действия с ней выполняются с помощью известных четко определенных
операций, причем управление этим процессом происходит в соответствии с
некоторой глобальной стратегией управления. Подчеркнем важность определения
подходящего уровня описания; вблизи уровня машинного кода любое
четкое разложение на отдельные компоненты может оказаться неоправданным;
на наиболее высоком уровне полная система ИИ может состоять из
нескольких модулей база данных—операции—управление, взаимодействующих по
слишком сложным законам. Наша точка зрения заключается в том, что
система, допускающая выделение базы данных, операций и управляющих
компонент, представляет собой подходящий метафорический строительный блок
для составления ясного описания систем ИИ.
Ы. СИСТЕМЫ ПРОДУКЦИЙ
Разнообразные обобщения вычислительного формализма, известного
под названием система продукций, содержат четкое разделение упомянутых
вычислительных компонент и, видимо, вследствие этого отражают суть
работы многих систем ИИ. Основными элементами системы продукций
искусственного интеллекта являются глобальная база данных, множество правил
продукции и система управления.
Глобальная база данных — центральная структура данных, используемая
системой продукции ИИ. В зависимости от конкретной задачи эта база
данных может быть простой, как обычная матрица чисел, или сложной, как
большая реляционная индексированная файловая структура. (Читателю
не следует путать выражение "глобальная база данных" в том смысле, как
оно понимается в этой книге, с базами данных систем баз данных).
Правила продукций применяются к глобальной базе данных. Для
каждого правила имеется предварительное условие, которому эта база данных
либо удовлетворяет, либо нет. Если предварительное условие выполняется, то
правило может быть применено. Применение этого правила изменяет базу
данных. Система управления выбирает, какое именно применимое правило
следует использовать, и прекращает вычисления, когда глобальная база
данных удовлетворяет терминальному условию (или условию остановки).
25
Имеются некоторые различия между структурой такой системы
продукций и традиционными вычислительными системами с иерархически
организованными программами. Глобальная база данных доступна для всех
правил продукций; ни одна ее часть не ориентирована преимущественно на
какое-либо из них. Одни правила не "вызывают" другие; связь между
правилами осуществляется только через глобальную базу данных. Эти свойства
систем продукции находятся в согласии с эволюционным характером
разработки больших систем ИИ, предполагающих наличие весьма обширных
объемов знаний.
Одно из затруднений, связанных с использованием обычных систем
иерархически организованных программ в приложениях искусственного
интеллекта, состоит в том, что добавления или изменения в базе знаний могут
вызывать большие изменения в уже существующих программах,
структурах данных и организации подпрограмм. Конструкция системы продукций
в гораздо большей степени является модульной, и изменения в базе данных,
системе управления или правилах могут проводиться относительно
независимо.
Будем различать несколько видов систем продукций. Они отличаются
типами используемых ими систем управления, свойствами правил и баз
данных, а также способами их применения к конкретным задачам.
В качестве простого примера того, что мы понимаем под системой
продукций в искусственном интеллекте, покажем, как такая система может
использоваться для решения одной простой головоломки.
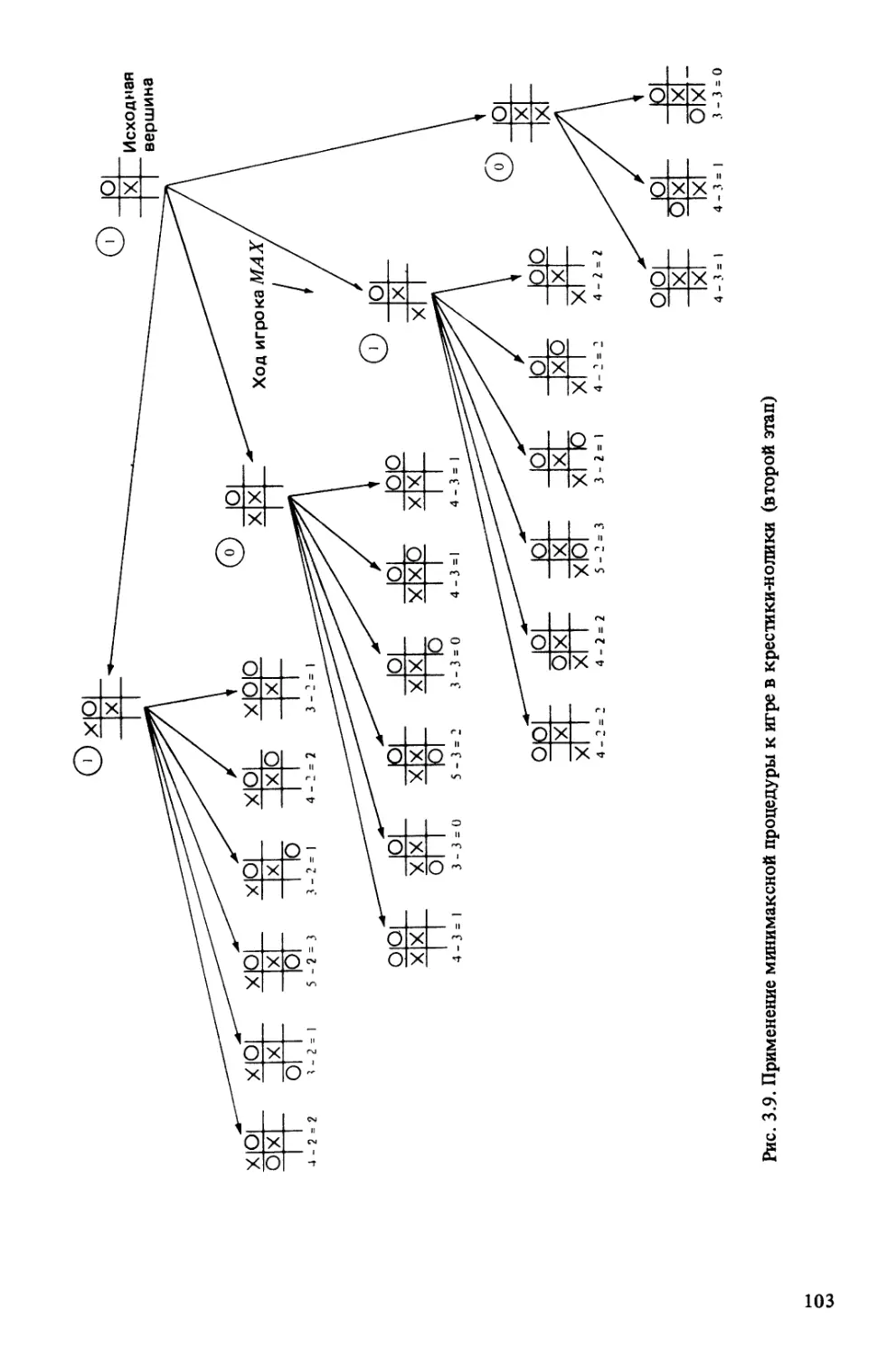
1.1.1. ИГРА В ВОСЕМЬ
Многие приложения ИИ связаны с построением последовательности операций.
Можно привести два примера: управление действиями робота и автоматическое
программирование. Простой и, наверное, известной задачей подобного типа, полезной для
иллюстрации основных идей, является игра в 8. В ней используются 8 пронумерованных
подвижных квадратных фишек, помещенных на поле размерами 3X3 клетки. Одна
клетка поля всегда свободна, что дает возможность перемещать в нее соседнюю
нумерованную фишку или, по-другому, перемещать пустую клетку. Эту игру иллюстрирует рис. 1.1,
где приводятся две конфигурации фишек. Рассмотрим задачу преобразования
начальной конфигурации в указанную целевую. Решением служит правильная
последовательность ходов, например передвинуть фишку 6 вниз, передвинуть фишку 8 вниз, ...
и т. д.
гу
1
7
8
6
3
4
11
Исходная
1
8
и
2
6
3
4
5]
Целевая
Рис. 1.1. Исходная и целевая
конфигурация для игры в 8
Для решения задачи с помощью системы продукций мы должны определить
глобальную базу данных, набор правил и задать стратегию управления. В области ИИ
преобразование исходной формулировки задачи в такие три компоненты некоторой системы
продукций часто называется проблемой представления. Обычно существует несколько
способов такого представления задачи. Искусство выбора хорошего представления
очень существенно для применения методов ИИ к практическим задачам.
26
Для игры в 8 и других задач можно легко определить элементы задачи,
соответствующие указанным трем компонентам, - состояния, ходы и цель задачи. В игре в 8
каждая конфигурация фишек является состоянием задачи. Множество всех возможных
конфигураций образует пространство состояний задачи, или пространство задачи.
Многие задачи, представляющие для нас интерес, имеют пространство очень большого
размера. У игры в 8 оно относительно невелико: имеется только 362 880 (т.е. 9!)
различных конфигураций восьми фишек и пустой клетки. (Оказывается, это пространство
разделяется на два непересекающихся подпространства из 181440 состояний каждое.)1
Определив на смысловом уровне состояния задачи, мы должны сконструировать их
машинное представление, или описание, которое затем используется как глобальная
база данных системы продукций. Для игры в 8 простым описанием является сам массив
или.матрица чисел размерами 3X3. Исходная глобальная база данных будет описанием
начального состояния задачи. В сущности, любую структуру данных можно
использовать для описания состояний. Сюда относятся строки символов, векторы, множества,
массивы, деревья и списки. Иногда, как в нашей игре в 8, вид структуры данных несет
на себе явный отпечаток физических особенностей решаемой задачи.
Каждый ход преобразует одно состояние задачи в другое. Удобно интерпретировать
игру в 8 как игру, в которой имеется четыре хода: передвижение пустой клетки
(пробела) налево, передвижение пробела вверх, передвижение пробела направо и
передвижение пробела вниз. Эти ходы моделируются правилами продукции, которые
соответствующим образом применяются к описаниям состояний. У каждого правила есть
предварительные условия, которым должно удовлетворять описание состояния, чтобы
правила были применимы к этому описанию состояния. Так, предварительное условие для
правила, соответствующего передвижению пробела вверх, вытекает из требования,
чтобы пустая клетка уже не находилась в верхнем ряду.
В игре в 8 нам необходимо достичь особого состояния задачи, а именно - целевого
(см. рис. 1.1). Можно также рассматривать задачи, для которых целью является
достижение любого из явно указанных состояний задачи. Некоторое дальнейшее обобщение
состоит в том, чтобы установить для состояний некоторое условие
истинности/ложности, которое будет служить целевым условием. Тогда целью было бы достижение
любого состояния, удовлетворяющего этому условию. Такое условие неявно определяет
некоторое множество целевых состояний. Например, в игре в 8 мы могли бы
стремиться прийти к любой конфигурации фишек, для которой сумма номеров фишек в первом
ряду равна 6. На нашем языке состояний, ходов и целей решением задачи является
последовательность ходов, которая переводит исходное состояние в целевое.
Целевое условие задачи служит основой для терминального условия системы
продукций. В соответствии со стратегией управления правила последовательно
применяются к описаниям состояний до тех пор, пока не будет получено описание целевого
состояния. При этом сохраняется информация о сделанных ходах с тем, чтобы иметь
возможность объединить их в последовательность, представляющую решение задачи.
В некоторых задачах нам нужно, чтобы решение подчинялось определенным
дополнительным ограничениям. Например, можно потребовать, чтобы решение задачи об
игре в 8 достигалось за минимальное число ходов. В общем случае мы приписываем цену
каждому ходу и затем пытаемся найти решение, имеющее минимальную цену. С этими
усложнениями легко справиться с помощью методов, которые мы опишем.
1.1.2. ОСНОВНАЯ ПРОЦЕДУРА
Основной алгоритм системы продукций для решения задачи типа игры в 8 можно
записать в недетерминированной форме:
1 Это два класса не переводимых друг в друга конфигураций фишек. — Прим. ред.
27
Procedure PRODUCTION
1 DA ТА «— исходная база данных
2 until DA ТА удовлетворяет терминальному условию, do.
3 begin
4 select (выбрать) некоторое правило Π в множестве
правил, которые можно применить к DA ТА
5 DA ТА <— результат применения Π к DATA
6 end
1.1.3. УПРАВЛЕНИЕ
Приведенная процедура является недетерминированной, поскольку мы
до сих пор не дали точного определения, как мы собираемся выбрать
применимое правило на шаге 4 этой процедуры. Правила вывода и запоминания
уже опробованных последовательностей правил и баз данных, порожденных
их применением, образуют то, что мы называем стратегией управления для
систем продукций. В большинстве приложений ЙИ информация, доступная
стратегии управления, недостаточна для того, чтобы выбрать наиболее
подходящее правило при каждом обращении к шагу 4. Поэтому работу систем
продукций в искусственном интеллекте можно охарактеризовать как процесс
поиска, в котором правила подвергаются испытанию до тех пор, пока не
обнаружится, что некоторая их последовательность порождает базу данных,
удовлетворяющую терминальному условию. Эффективные стратегии
управления предполагают наличие достаточной информации о решаемой задаче,
чтобы то правило, которое будет выбрано на шаге 4, с большой вероятностью
было наиболее подходящим.
Мы различаем два основных типа стратегий управления: безвозвратный и
пробный. В безвозвратном режиме управления выбирается применимое
правило и используется необратимо, без возможности пересмотра в дальнейшем.
В пробном режиме управления выбирается применимое правило (либо
произвольно, либо, возможно, на каком-то разумном основании); это
правило используется, но резервируется возможность впоследствии заново
вернуться к этой ситуации, чтобы применить другое правило.
Далее различаем два типа пробных режимов управления. В первом,
который называем режимом с возвращением, при выборе правила
определяется некоторая точка возврата. Если последующие вычисления приведут к
трудностям в построении решения, то процесс вычисления переходит к
предыдущей точке возврата, где теперь применяется другое правило, и процесс
продолжается.
Во втором типе пробного режима управления, который мы называем
управлением с поиском на графе, предусмотрено запоминание результа-
28
тов применения одновременно нескольких последовательностей правил.
Здесь используются различные виды графовых структур и процедур поиска
на графе.
1.1.4. ПРИМЕРЫ РЕЖИМОВ УПРАВЛЕНИЯ
1.1.4.1. Безвозвратный режим. На первый взгляд может показаться, что
безвозвратный режим управления не подходит к системам продукций для решения задач, где
требуется процесс поиска. Например, методы проб и ошибок представляются
естественными при решении головоломок. Можно возразить, что если стратегия управления
системы продукций располагает достаточной информацией о головоломке для
окончательного выбора подходящего правила, чтобы применить его к описанию каждого
состояния, то решение головоломки фактически заложено в этой стратегии. В таком случае
вряд ли можно говорить о том, что эта стратегия "решает" головоломку, так как ее
решение уже было известно. Подобная аргументация не делает различия между явной
локальной информацией о том, как двигаться к цели из любого состояния, и неявной
глобальной информацией о полном решении. Когда имеется достоверная локальная
информация, безвозвратная система продукций может использовать ее для построения
явной глобальной информации о решении (не имея исходно явной глобальной
информации).
Одним из наиболее известных примеров применения локальной информации для
построения глобального решения, лежащим вне области искусственного интеллекта,
является процесс "подъема на гору" при поиске максимума функции. В любой точке
мы движемся в направлении наибольшей крутизны (локальная информация), чтобы
в конечном счете найти максимум функции (глобальная информация). Для
определенного класса функций (а именно имеющих единственный максимум и обладающих
некоторыми другими свойствами) знания направления наиболее крутого подъема
достаточно, чтобы найти решение.
Мы можем непосредственно применить процесс "Подъема на гору" в безвозвратной
системе продукций. Нам нужна только некоторая действительная функция,
определенная на глобальных базах данных. Стратегия управления использует эту функцию для
выбора правила. Она выбирает (безвозвратно) применимое правило, которое порождает
базу данных, дающую наибольшее увеличение значения этой функции. Наша функция
"подъема на гору" должна быть такой, чтобы ее максимальное значение
соответствовало той базе данных, которая удовлетворяет терминальному условию.
Применяя метод "подъема на гору" к игре в 8, мы можем использовать в качестве
функции от описания состояния (взятое с отрицательным знаком) число фишек,
находящихся "не на месте", по сравнению с расположением фишек в описании целевого
состояния. Например, значение этой функции для исходного состояния на рис. 1.1 равно
-4, а значение ее для целевого состояния - 0. Нетрудно вычислить значение этой
функции для описания любого состояния.
Начиная с указанного исходного состояния, мы достигаем максимального
увеличения значения данной функции путем перемещения пробела вверх и поэтому наша
система продукций выбирает соответствующее правило. На рис. 1.2 показана
последовательность состояний, через которые проходит система продукций при решении этой
головоломки. Значение нашей функции "подъема на гору" для описания каждого
состояния заключено в кружок. Из рисунка видно, что одно из применений правила не
привело к увеличению значения функции. Если ни одно из применимых правил не
обеспечивает увеличения значения функции, то выбирается (произвольно) то правило,
которое не уменьшает ее значения. Если таких правил нет, то процесс прекращается.
Для конкретного примера игры в 8 (см. рис. 1.2) стратегия "подъема на гору"
позволила нам найти путь к целевому состоянию. В общем случае подобные функции
могут иметь много локальных максимумов, что делает метод "подъема на гору"
несостоятельным. Пусть, например, целевым состоянием является
29
Θ
η
Λ
\Σ
8
6
3
4
5
®
Π"
8
[1
2
'
6
3
4
5
Θ
2
1
7
8
6
3
4
5
Θ
1
7
2
8
6
3
4
5
Θ
2Γ
ψ
7|(
Θ
Ι ^
Ш
Тз]
Ч4
s 151
f
-I3
44
7|б|5|
Рис. 1.2. Значения функции "подъема на гору" для состояний игры в 8
и исходным -
Любое допустимое правило, примененное к описанию начального состояния,
уменьшает значение нашей функции "подъема на гору". В данном случае описание исходного
состояния находится в локальном (но не глобальном) максимуме функции.
Бывают и другие случаи бесперспективности "подъема на гору": процесс может
попасть на "плато" или "хребет". Конечно, эти трудности разрешились бы, если бы мы
смогли построить более удачную функцию "подъема на гору", например такую, у
которой есть только один глобальный максимум и нет "плато". Легко вычислимые
функции в задачах искусственного интеллекта обычно обладают некоторыми упомянутыми
недостатками. Таким образом, использование методов "подъема на гору" для
управления выбором правила в безвозвратных системах продукций ограничено.
Даже в тех ситуациях, когда стратегия управления не может всегда выбирать
наилучшее правило для применения на любой стадии, бывают случаи, в которых
безвозвратный режим приемлем. Например, если применение какого-либо "сомнительного"
правила не делает невозможным впоследствии применение другого, подходящего, мы
ничем не рискуем, необратимо применяя правило (за исключением того, что будут
сделаны лишние операции). В дальнейшем мы познакомимся с некоторыми примерами
подобных ситуаций.
1.1.4.2. Режим с возвращением. Во многих содержательных задачах применение
неподходящего правила может воспрепятствовать успешному завершению процесса
решения или существенно задержать его. В этих случаях для нас предпочтительнее
стратегия управления, способная испытать какое-либо правило, и если впоследствии
окажется, что это правило было неподходящим, вернуться назад и испробовать вместо него
какое-нибудь другое.
Процесс возвращения является одним из способов построения пробной стратегии.
Выбирается некоторое правило, и если оно не ведет к решению, то последующие шаги
"забываются", а вместо него выбирается другое правило. С формальной точки зрения
30
стратегию возвращения можно использовать независимо от того, насколько полной
информацией, имеющей отношение к выбору правила, мы располагаем. Если такая
информация вообще отсутствует, можно выбирать правила в соответствии с некоторой
произвольной схемой. В конечном счете в управлении предусмотрено возвращение,
позволяющее выбрать подходящее правило. Очевидно, если можно использовать достаточно
достоверную информацию о том, как выбирать правила, возвращения для рассмотрения
альтернативных правил будут реже и процесс в целом окажется более эффективным.
Для иллюстрации применим стратегию возвращения к примеру игры в 8,
приведенному на рис. 1.1, на кото ром правила выбираются в соответствии с произвольным
порядком: сначала пробуем передвинуть пустую клетку влево, затем вверх, затем направо,
затем вниз. Возвращение будет происходить каждый раз, когда: а) порождается
описание состояния, которое уже встречалось на пути назад к описанию исходного состояния;
б) было применено некоторое произвольно выбранное число правил, но описание
целевого состояния не было построено или в) более не существует применимых правил.
В случае б) выбранное число представляет собой границу глубины данного процесса
с возвращением.
На рис. 1.3 для иллюстрации того, как можно применить стратегию с возвращением
к игре в 8, показана последовательность пробных применений правил и возвращений.
Каждое описание состояния помечено номером (в кружке), обозначающим его
порядок в последовательности описания состояний, порождаемых системой продукций.
Мы не имеем возможности полностью привести на рисунке процесс поиска решения —
это заняло бы слишком много места. Тем не менее, в конце концов решающая
последовательность ходов будет обнаружена, так как будут исследованы все возможные
пути (длиной менее 6). Заметим, что если граница глубины установлена слишком
малой, то процесс решения может не достичь цели.
Процесс с возвращениями будет более эффективным, если выбор правила
осуществляется не произвольно, а направляется с помощью информации о том, каким мог бы
быть наилучший ход. Если есть основания доверять этой информации, тогда обычно
отбирается подходящее правило и необходимость в возвращениях практически отпадает.
В игре в 8, например, мы могли бы использовать некоторую функцию для метода
"подъема на гору" как средство выбора правила. В то время, как "подъем на гору"
при безвозвратном режиме управления может, в принципе, застревать в локальных
максимумах, механизм возвращения оставляет возможность для исследования
альтернативных путей.
1.1.4.3. Поиск на графе. Графы (или, более точно, деревья) являются чрезвычайно
полезными структурами для сохранения информации о результатах применения
нескольких последовательностей правил. Здесь приведем лишь пример их использования;
более подробно эти структуры будут обсуждаться в гл. 2 и 3.
Допустим, мы решили использовать режим управления с поиском на графе при
решении игры в 8, показанной на рис. 1.1. Мы можем запомнить различные примененные
правила и соответственно порожденные базы данных с помощью структуры, называемой
деревом поиска. Пример такого дерева приведен на рис. 1.4. Наверху, или в корне
дерева находится описание исходной конфигурации. Различные правила, которые здесь
можно применить, соответствуют связям или направленным дугам, идущим к верши-
нгм-преемникам, представляющим те состояния, которые можно достичь из исходного
состояния за один ход. Стратегия управления с поиском на графе наращивает такое
дерево до тех пор, пока не будет порождена база данных, удовлетворяющая
терминальному условию.
На рис. 1.4 показаны все возможные здесь правила, примененные к каждому
описанию состояния. Такого рода "нерешительность" со стороны системы управления
обычно обусловливает ее чрезвычайную неэффективность, поскольку результирующее
дерево растет слишком быстро. Разумная стратегия управления давала бы гораздо более
узкое дерево при использовании некоторых специфических для задачи знаний, чтобы
31
Ц813
1
7
ш
&
2 8 3
Ш
\2
1
8
6
7
У|
4
11
11715
11715
|8
2
Li
6
7
11
4
iJ
2,
£
8
/
7
^
4
ll
ях
|8
2
1
6
7
~зП
4
1J
8
[8
|2
LL
I
3
6
7
4
1J
£U-
Г8
2
_7_
4
111
Опять повторяется одно
из пройденных состояний,
поэтому берем назад
последний ход и вместо
него применяем
к состоянию ® правило
"передвинуть пробел вниз".
Продолжение в следующей
колонке.
Это состояние имеется на пути
назад к исходному состоянию,
поэтому берем назад последний
ход и вместо него применяем к
состоянию О правило "передвинуть
пробел вправо". Продолжение в
следующей колонке.
&
Г8
2
LL
3
6
7
4
iJ
Ф\
[8
2,
\£
3
/
А
iJ
Мы шесть раз применили
правила и не достигли цели,
поэтому берем назад
последний ход. Все правила,
которые можно применить к
предыдущему состоянию
(номер © ), уже испробованы,
поэтому берем назад и
предпоследний ход
и применяем к состоянию (5)
"передвинуть пробел вниз".
Продолжение в следующей
колонке.
Φ
8
2 ί
111*3
1 з 1
Μ4
' 5
® 1
|8|<
2
hi'
> Ι з Ι
4
Μ 51
ρ, ι
|8|ι
Ut
5И
2Ί4
71S1
Опять после шести
применений правил
цель не достигнута,
поэтому—
Рис. 1.3. Применение к игре в 8 стратегии управления с возвращением
32
~\ ■ ч
χ -ζ «-
го О Ч
Χ ■ w>
У
/
\
\
Ό О Ч
■ X w>
гО О Ч
X — »/->
(M|h
[2 8 3|
|7 6 5|
<
ГО СО ■
X Ч «3
г\| — г~
■ го «Л
X Ч О
X Ч ■
■ ч «
|гО Ч */">
■ X £
И
Iе 2 3I I2 3 "1
II 8 4 1 8 4
|7 ft 51 I 7 ft 5 I
ч ■ »/->
го Χ Ο
(S4 — Г-
го Ч «Л
<Ν Χ nC
Ζ
— г- ■
ГО Ч */">
СЧ ■ >С
— ос г-
с;
ω
ΖΓ
X — sC
сч г- ■
X — ■
<
2 8 3
ft 5 ■
го Ч >л|
X ■ —
rj Г~ -С
2 8 3
■ 1 4
7 ft 5
/
го Ч */">
X — Л
f, f 1Л
<
го Ч «л]
— ■ nC
X ги г~ j
■' Ч >л|
го — «С
X Р^ Г-
Ιχ г- ■ 1^
го
,00
ч
г-
*е
•
>л|
—
оо
«м
ч
г-
·£
<л
—
■
х >с г-
;М ■ -
2 8 3
ft ■ 4
1 7 5
г-, ■ »/->
X Ч Г-
«VJ >5 —
s
У
с
\
го «Л ■ I
X Ч Г~
CJ >С —
■ го >/".
х ч г-
г*\ ч· w
X О 1-
■ СМ —
Ό Ч «~
■ X г-
<М Ό —
><
С
гг, X Г- |
гг *J- 1/-
CslOC Г-
■ О —
Ό Ч "">
■ «^
οοιν —
<
гл Ч U-
1£J ■ Г~
■ Т"5
Х>см —
л
о.
о
в
о
η
33
сфокусировать его рост в направлении, более близком к цели. В гл. 2 мы обсудим
несколько методов для достижения фокусирования.
Хотя мы и пользуемся графами такого вида только в режиме управления с поиском
на графе, полезно отметить, что безвозвратному режиму управления соответствует
прослеживание только одного пути вниз через дерево поиска. (Мы уже видели, что такая
простая стратегия иногда может успешно работать.) Режим с возвращениями не
запоминает целиком дерево поиска, он просто сохраняет информацию о текущем пути,
при необходимости изменяя его.
1.1.5. ЗАДАЧИ ПРЕДСТАВЛЕНИЯ
Для эффективного решения задачи недостаточно иметь только
эффективную стратегию управления. Требуется найти хорошее представление для
состояний задачи, ходов и целевых условий. Представление задачи в очень
большой степени определяет усилия, необходимые для ее решения.
Предпочтительны, очевидно, представления с малыми пространствами состояний.
Есть много примеров трудных на первый взгляд головоломок, для которых
удачное представление позволяет получить тривиально малое пространство
состояний. Иногда имеющееся пространство состояний можно сократить,
заметив, что ряд правил можно отбросить или что некоторые правила можно
объединить, образуя более мощные. Даже если такие простые
преобразования невозможны, то не исключено, что в результате полной
переформулировки задачи (например, изменения самого понятия о том, что такое состояние)
мы придем к меньшему пространству.
Мы все еще плохо разбираемся в том, что нужно для построения
первоначального представления задач и улучшения данных представлений.
Кажется, что полезные изменения в некотором данном представлении задачи
зависят от опыта, накопленного в попытках решить ее в этом представлении.
Этот опыт позволяет обнаружить существование упрощенных
усовершенствований — таких, как использование симметрии, или удачных
последовательностей правил, которые следует объединить в макроправила. Например,
первоначальное представление игры в 8 может определить 32 правила,
соответствующих: передвижению фишки 1 влево, затем вправо, затем вверх,
затем вниз, передвижению фишки 2 влево и т.д. Конечно, многие из этих
правил никогда не применяются для любого данного описания состояния.
Как только это станет очевидно тому, кто решает эту задачу, он, возможно,
натолкнется на лучшее представление, использующее перемещение просто
пустой клетки.
Далее мы разберем еще два примера, чтобы пояснить, как их можно
было бы представить для решения системой продукций.
1.1.6. HEKOTOPblE ПРИМЕРЫ ПРЕДСТАВЛЕНИЯ ЗАДАЧ
Метод системы продукций позволяет заняться решением широкого круга задач.
Используемые нами формулировки не претендуют на указание единственных путей
решения этих задач. Читатель вправе искать хорошие альтернативы.
1.1.6.1. Задача о коммивояжере. Торговец должен побывать в каждом из пяти
городов, обозначенных на карте (рис. 1.5). Каждая пара городов соединена дорогой с
указанием ее длины. Задача состоит в том, чтобы, начиная, например, с города Л, найти
минимальный путь, проходящий через все остальные города только один раз и
приводящий обратно в А.
Чтобы поставить эту задачу, определим следующее.
34
в
Рис. 1.5. Карта к задаче о коммивояжере
Глобальная база данных будет списком городов, посещенных к данному моменту.
Таким образом, исходная база данных является списком (Л). Не допускается
появление списков, содержащих название любого города более одного раза, кроме случая,
когда после внесения в список названий всех городов А упоминается в нем вторично.
Правила соответствуют решениям: а) идти в город Л, б) идти в город 5,. .. , и д)
идти в город Е. Правило не применимо к базе данных, если оно не преобразует ее в какую-
либо допустимую базу данных. Следовательно, правило, соответствующее тому, чтобы
"идти в город А", не применимо к любому списку, в который еще не внесены все
города.
Любая глобальная база данных, начинающаяся и заканчивающаяся названием
города Л и содержащая название всех других городов, удовлетворяет терминальному
условию. Заметим, что можно использовать схему расстояний на рис. 1.5 для вычисления
общей протяженности любого маршрута. Путь, предлагаемый в качестве решения,
должен иметь минимальную длину.
На рис. 1.6 показана часть дерева поиска, которое при решении этой задачи может
породить стратегия управления с поиском на графе. Числа около ребер дерева
показывают, насколько увеличивается длина пути при применении соответствующего правила.
1.1.6.2. Задача синтаксического анализа. Другая задача, которую можно
попытаться решить с помощью метода систем продукций, - определение того, является ли
произвольная последовательность символов предложением языка, т. е. могла ли
грамматика породить ее. Решение о том, образует ли строка символов предложение, назвали
задачей грамматического разбора, и для этого разбора можно использовать системы
продукций.
Пусть имеется контекстно-свободная грамматика, определяющая язык. Для
примера, пусть эта грамматика содержит терминальные
of approves new president company sale the
и нетерминальные
S NP VP PP Ρ V DNP DET A N
символы.
Грамматика определяется следующими правилами переписывания:
ONP VP — S
у DNP -> VP
Ρ DNP -^ РР
of -^ Ρ
approves —► V
DET NP — DNP
35
DHP pp _^ DNP
A NP -> NP
N -> NP
new —» y4
president —► N
company —► N
sale —» N
the -» Ζ)£Γ
t · ·
A /v /\
/ \ / \ / \
/ \ / \ / \
/ \ / \ / \
\
(ACDEB)
}
(ACDEB4)
Целевая
Рис. 1.6. Дерево поиска для задачи о коммивояжере
Эта грамматика слишком проста, чтобы быть полезной для анализа большинства
предложений английского языка, но ее можно расширить и тем самым сделать
несколько более реалистичной.
Допустим, мы хотим определить, является ли строка символов предложением этого
языка:
The president of the new company approves the sale
(президент новой компании санкционирует продажу) .
Чтобы поставить эту задачу, определим следующее.
Глобальная база данных будет состоять из строки символов. Исходной базой данных
является указанная строка символов, которую мы хотим исследовать.
Правила продукций выводятся из правил переписывания для данной грамматики.
Правая часть грамматического правила во всех случаях может заменить в базе данных
его левую часть. Например, грамматическое правило DNP VP-+ S используется для из-
36
Исходная
The president of the new company approves the sale
I Эта последовательность
t правил замещает
! терминальные символы
1 нетерминальными
DET Ν Ρ DET А N V DET N
I Другая последовательность
j дает следующую строку:
DNP Ρ S
С этой строкой
I
нельзя сделать
DNP РР VP\
ι
DNP VP ]
\
f
S
Цел
Рис. 1.7. Дерево поиска для задачи синтаксического анализа
менения любой базы данных, содержащей последовательность DNP VP, на такую, в
которой эта подпоследовательность заменена на S. Правило неприменимо, если база данных
не содержит левой части соответствующего грамматического правила. Кроме того,
правило можно применять к базе данных различными способами в соответствии с
различными вхождениями левой части этого грамматического правила в базу данных.
„ Терминальному условию удовлетворяет только база данных, состоящая из
единственного символа S.
Часть дерева поиска для этой задачи показана на рис. 1.7. В этом простом примере
ветвление дерева очень незначительно, если не учитывать различные выборы порядка
применения правил.
1.1.7. ОБРАТНЫЕ И ДВУСТОРОННИЕ СИСТЕМЫ ПРОДУКЦИЙ
Мы могли бы сказать, что наша система продукций для решения игры в 8
работала непосредственно от исходного состояния к целевому.
Следовательно, ее можно назвать прямой системой продукций. Мы также могли бы
решать задачу в обратном направлении, применяя обратные ходы и
продвигаясь от целевого к исходному состоянию. Каждый обратный ход породил бы
подцелевое состояние,шз которого нецосредственно первоочередное целевое
состояние можно достичь за один ход вперед. Система продукций для
решения игры в 8 таким способом просто изменила бы назначения состояний и
целей и использовала бы правила, соответствующие обратным ходам.
Построение обратной системы продукций для игры в 8 не представляет
трудности, поскольку цель описана явно заданным состоянием. Можно оп-
37
ределить обратную систему продукций и в случае, когда цель описана
заданием условия. Мы рассмотрим эту ситуацию после введения подходящего
языка (логики предикатов), для того чтобы говорить о целях, заданных
условиями.
Хотя между системами продукций, работающими над решением задачи
в прямом и обратном направлениях, нет формального различия, часто
оказывается удобным ввести его в явном виде. Если в задаче можно выделить
четкие, на интуитивном уровне, состояния и цели и если мы приняли решение
пользоваться описаниями этих состояний как глобальной базой данных
системы продукций, мы называем эту систему прямой системой продукций.
Правила применяются к описаниям состояний для порождения новых
состояний, и эти правила называются П-правилами. Наоборот, если используются
описания целей задачи как глобальная база данных, будем называть эту
систему обратной системой продукций. Тогда правила применяются к
описаниям целей для порождения описания подцелей, и эти правила называются
О-правилами.
Для игры в 8, где начальное и целевое состояния единственны,
безразлично,' решается задача в прямом или обратном направлении. Вычислительные
затраты одинаковы для обоих направлений. Есть, однако, случаи, когда при
решении задачи одно направление более предцочтительно. Предположим,
например, что существуют большое число явно заданных целевых состояний и
одно исходное. Не очень эффективной была бы попытка решить такую
задачу в обратном направлении; априори мы не знаем, какое именно целевое
состояние является "ближайшим" к исходному, и нам пришлось бы
начинать полный перебор состояний. Вообще наиболее эффективное направление
решения определяется структурой пространства состояний.
Часто удачной является попытка решить задачу путем двухстороннего
поиска (в прямом и обратном направлениях одновременно) . Этого также
можно достичь с помощью систем продукций.
Для этого следует включить в глобальную базу данных описания как
состояний, так и целей. К части описания состояний применяются П-правила,
а к части описания целей — О-правила. При поиске такого типа терминальное
условие для управляющей системы, которое позволяет сделать вывод о том,
что задача решена, должно быть определено как разновидность условия
соответствия между частью описания состояний и частью описания цели в
глобальной базе данных. Управляющая система должна также на каждой
стадии принимать решения об использовании применимого П- либо
О-правила.
1.2. СПЕЦИАЛИЗИРОВАННЫЕ СИСТЕМЫ ПРОДУКЦИЙ
1.2.1. КОММУТАТИВНЫЕ СИСТЕМЫ ПРОДУКЦИЙ
При определенных условиях порядок, в котором множество применимых
правил используется в базе данных, несуществен. Когда эти
условия'удовлетворяются, эффективность работы системы продукций можно повысить,
отказываясь от исследования излишних путей решения, j Бивалентных во
всем, кроме очередности правил.
На рис. 1.8 рассматриваются три правила — ΠΙ, Π2 нПЗ, — которые
применимы к базе данных, обозначенной SO. После использования любого из этих
38
правил каждое по-прежнему является применимым к результирующим
базам данных; после использования двух правил подряд все три остаются
применимыми. На рис. 1.8 показано также, что одна и та же база данных,
а именно SG, формируется независимо от последовательности применения
правил из множества {171,772, ПЗ ).
Мы говорим, что система продукций коммутативна, если она обладает
следующими свойствами по отношению к любой базе данных D:
а. Каждое из множества правил, применимое к D, применимо к любой
базе данных, полученной при использовании применимого правила к D.
б. Если целевое условие удовлетворяется базой D, то оно также
удовлетворяется любой базой данных, полученной при использовании любого
применимого правила к D.
в. База данных, полученная в результате применения к D любой
последовательности применимых к D правил, инвариантна относительно
перестановок к этой последовательности.
Процесс применения правил, показанный на рис. 1.8, обладает этим
свойством коммутативности. При получении базы данных, обозначенной через
SG на рис. 1.8, нам, очевидно, следует рассмотреть только один из многих
приведенных путей. Методы исключения из рассмотрения избыточных путей,
очевидно, очень важны для коммутативных систем.
Заметим, что коммутативность системы не означает, что всю
последовательность правил, использованных для преобразования исходной базы
данных в ту, которая удовлетворяет определенному условию, можно
переупорядочить. После того, как некоторое правило было применено к базе данных,
применимыми могут стать дополнительные правила. Только те правила,
которые изначально применимы к базе данных, можно объединить в
произвольную последовательность и применить к этой базе данных, чтобы
получить результат, не зависящий от порядка. Подчеркнем существенность этого
различия.
Коммутативные системы продукций представляют собой важный
подкласс, обладающий особыми свойствами. Например, в коммутативных
системах всегда можно использовать безвозвратный режим управления,
поскольку применение правила никогда не приводит к необходимости его
отмены. Любое правило, которое было применимо к возникавшей ранее базе
данных, применимо и к имеющейся в настоящий момент. Нет необходимости
вводить механизм применения различных последовательностей правил.
Применение неудачного правила отсрочивает, но не делает невозможным
завершение процесса; после решения задачи можно удалить лишние правила из
решающей последовательности. В дальнейшем у нас еще будет возможность
более детально исследовать коммутативные системы.
Интересно отметить, что существует простой способ преобразования
любой системы продукций в коммутативную. Допустим, мы осуществили
представление задачи для решения с помощью системы продукций. Пусть в этой
системе имеются глобальная база данных, правила, которые могут
модифицировать ее, и стратегия управления с поиском на графе, которая
порождает дерево поиска глобальных баз данных. Рассмотрим теперь другую систему
продукций, глобальной базой данных которой является полное дерево
поиска первой. Правила новой системы продукций представляют собой
различные способы, позволяющие преобразовать дерево поиска с помощью стра-
39
Рис. 1.8. Эквивалентные пути на графе
Исходная
(Β.Μ,Β.Ζ)
пз
1
'
(Μ.Μ,Μ.Β.Ζ)
пз
г
(Μ,Μ,Μ,Μ.Μ.Ζ)
П4
г^— """"
(ММММ.М.В.ВМ) \
пз
г
ШММММММВМ) 1
пз
г Целевая
VxtM.MMM М.М,МММ)\
(С.В.В.В.М)
(Β,Μ,Β,Β,Β.Μ)
пз
{ММ.М.В.ВЛМ)
пз
(D,L,B.Z)
пз\ ""**
{D,L.M,M,Z)
П4
г
(D,L,M,M,B,B,M)
ПЗ
г
(D,L,M,M,M,M,B,M)
ПЗ
f
Ι (ΡΧΜΝΜΜΜΜΜ)
Рис. 1.9. Последовательности решения для задачи переписывания
тегии управления первой системы продукций. Ясно, что любые правила
второй системы, применимые на любом этапе, остаются применимыми и
в дальнейшем. Коммутативные свойства второй системы явным образом
реализуют недетерминированную возможность проб, которой мы наделили
стратегию управления первой системы. Использование этого преобразования
40
приводит к более сложной глобальной базе данных и множеству правил,
но допускает более простой режим управления (безвозвратный) . Это
изменение представления просто переводит описание системы на более низкий
уровень.
1.2.2. РАЗЛОЖИМЫЕ СИСТЕМЫ ПРОДУКЦИЙ
Коммутативность — не единственное условие, выполнение которого
дает определенную свободу выбора очередности применяемых правил.
Рассмотрим, например, систему с исходной базой данных (С, В, Z),
правила продукции которой основаны на следующих правилах переписывания
Ш ;C->(i),L); П2:С^(В,М);
ПЗ :В^(М,М); Л4 : Ζ ^(Β, Β, Μ),
а терминальное условие состоит в том, что эта база данных должна
содержать только символы М.
В режиме управления с поиском на графе можно было бы исследовать
много эквивалентных путей получения базы данных, содержащей только
М. Два из них показаны на рис. 1.9. Наличие лишних путей может привести к
снижению эффективности системы — стратегия управления предусматривает
возможность рассмотрения их всех или, что еще хуже, прохождения путей,
не приводящих к успеху, и система совершает большую работу, которая в
конечном счете пропадает впустую. (Многие из применений правил на
правой ветви дерева на рис. 1.9 являются как раз такими, которые нужны
для решения.)
Избежать рассмотрения лишних путей можно, например, если заметить,
что исходная база данных может быть размещена или разбита на отдельные
компоненты, которые можно обрабатывать независимо. В нашем примере
исходная база данных разлагается на составляющие С, В и Ζ. Правила
продукций применимы независимо к каждой составляющей (возможно,
параллельно) ; результаты этих операций также подвергаются декомпозиции и так
далее, пока каждая компонента базы данных не будет содержать только
символы М.
В искусственном интеллекте базы данных систем продукций часто
допускают подобное разбиение. Образно говоря, можно представить себе такую
глобальную базу данных, как "молекулу", состоящую из отдельных
"атомов", объединенных тем или иным способом. Если условия применимости
правил предусматривают проверку только отдельных атомов и если
результатом применения этих правил будет замена каждого рассматриваемого
атома на некоторую новую молекулу (которая, в свою очередь, состоит из
атомов) , то мы точно так же могли бы разбить эту молекулу на ее атомные
компоненты и независимо работать с каждой частью. Каждое применение
правила воздействует только на ту компоненту глобальной базы данных,
которая используется для проверки выполнения соответствующего
предварительного условия этого правила. Поскольку некоторые из правил
применяются, по существу, параллельно, их порядок не имеет значения.
Чтобы разложить базу данных, мы должны уметь разложить и
соответствующее терминальное условие. Это значит, что, если мы занимаемся
каждой составляющей отдельно, мы должны суметь выразить глобальное тер-
41
минальное условие через терминальные условия каждой составляющей.
Наиболее важный случай: глобальное терминальное условие можно выразить
как конъюнкцию того же терминального условия для каждой составляющей
баз данных. В дальнейшем всегда подразумевается этот случай, если не
оговорено обратное.
Системы продукций, глобальные базы данных и терминальные условия
которых допускают декомпозицию, называются разложимыми. Основная
процедура для разложимой системы продукций может иметь, например,
следующий вид:
Procedure SPLIT
1 DA ТА 4- исходная база данных
2 { Di} <— декомпозиция базы DATA; теперь каждая D.
рассматривается как отдельная база данных 1
3 until все {/λ} удовлетворяют терминальному условию, do :
4 begin
5 select £>* (выбрать) из тех {£>.}, которые не
удовлетворяют терминальному условию
6 удалить/)* из {/λ}
7 select некоторое правило Π из множества правил,
которое можно применить к D*
8 D <— результат применения Π κ Ζ>*
9 {di} 4— декомпозиция D
Ю добавить {d.} κ{/λ}
11 end
Стратегия управления для процедуры SPLIT должна на шаге 5 выделить
одну из составляющих баз данных D* и на шаге 7 — правило Π и применить
его. Независимо от формы этой стратегии для выполнения условия на шаге 3
она должна, в конце концов, выбрать все элементы из {Ьг· }. Для любого
отобранного D*, однако, необходимо выделить только одно применимое
правило.
Несмотря на то, что возможна параллельная обработка составляющих
баз данных, мы обычно ищем стратегию управления, которая обрабатывает
их в некотором последовательном порядке. Существуют два основных
способа упорядочения этих компонент: их можно или а) расположить в ка-
42
ком-то определенном жестком порядке в момент их порождения, или б)
динамически переупорядочить в ходе обработки.
В первом случае полностью обрабатывается каждая составляющая и
только после этого обрабатывается следующая. Конечно, когда правило
продукции применяется к составляющей, может возникнуть база данных, которую
также можно разложить. Компоненты этой базы данных также
обрабатываются по очереди. Обычно для отбора правил используется стратегия с
возвращением совместно со стратегией жесткого упорядочения для обработки
компонент.
Более гибкие стратегии управления для разложимых систем продукций
допускают динамическое переупорядочение составляющих баз данных в
ходе обработки. Для описания работы систем продукций в этом режиме
полезны структуры, называемые графками типа И)ИЛИ. На рис. 1.10
приведен пример дерева типа И/ИЛИ для нашей задачи переписывания. Как и в
случае обычных графов, граф типа И/ИЛИ состоит из вершин, помеченных
глобальными базами данных. Вершины, помеченные составными базами
данных, имеют множества вершин-преемников, каждая из которых
помечена одной из составляющих. Эти вершины-преемники называются
вершинами типа И, так как для полной обработки составной базы данных все
составляющие базы данных должны быть обработаны полностью. Множества
вершин типа И на наших рисунках обозначаются специальной отметкой,
объединяющей входящие в них дуги графа.
К составляющим базам данных можно применять правила. Вершины,
помеченные этими составляющими базами данных, имеют вер шины-преем-
11 — 11
\\м\\
и
r-S-,,-ΖΧ
и
0
и
и
Рис. 1.10. Дерево типа И/ИЛИ для задачи переписывания
43
ники, которые помечены базами, полученными в результате применения
правил. Эти вершины-преемники называются вершинами типа ИЛИ,
поскольку для полной обработки составляющей базы данных полностью
должна быть обработана база данных, порожденная в результате
применения лишь одного из правил.
На рис. 1.10 все вершины, соответствующие какой-либо составляющей
базе данных, которая удовлетворяет терминальному условию (в данном
случае состоящей из символов М), заключены в двойную рамку. Такие
вершины называются терминальными. (Мы могли бы нарисовать дерево
рис. 1.10 в виде графа; например, база данных (Μ, Μ) соответствует
четырем вершинам рис. 1.10, и их можно было бы объединить в одну.)
Решение этой задачи переписывания можно проиллюстрировать
подграфом данного графа типа И/ИЛИ Такой подграф решения показан на рис. 1.10
жирными линиями. Это — граф, в котором "конечные вершины"
соответствуют базам данных, каждая из которых удовлетворяет терминальному
условию. В гл. 3 мы обсудим стратегии поиска графов решения на графах
типа И/ИЛИ
Далее мы на примерах покажем, как применяются разложимые системы
продукций.
1.2.2.1, Порождение химических структур. Одна из важных проблем органической
химии - определение структуры сложного органического соединения на основании
определенных экспериментальных данных - таких, как масс-спектрограмма образца
этого соединения. Большая система ИИ под названием DENDRAL способна
предложить вероятные структуры для достаточно сложных соединений. Важным аспектом
работы системы DENDRAL является порождение при заданной химической формуле
соединения вариантов соответствующих структур. Полное описание того, как
порождаются эти структуры-кандидаты, выходит за рамки нашей книги. Приведем здесь лишь
краткое описание того, как это происходит для простого углеводородного соединения.
Систему для порождения вариантов структур можно рассматривать как систему
продукций. Глобальной базой данных является "частично структурированное"
соединение. Система продукций оказывает воздействие на эту базу данных с тем, чтобы
повысить степень ее структурности: вначале в базе данных нет описания химической
структуры, а записана лишь химическая формула; на промежуточных этапах база
данных описывает некоторые фрагменты структуры соединения; после завершения этого
процесса в базе данных содержится представление всей структуры соединения.
Для этой задачи можно использовать разложимую систему продукций, поскольку
здесь базы данных можно разложить на сегменты, некоторые из которых
представляют собой неструктурированные химические формулы части исходного соединения.
Правила продукции - правила "выдвижения структур", которые преобразуют базы
данных, соответствующие неструктурированным химическим формулам, в базы
данных, представляющие частичные структуры. Любая база данных, не содержащая
неструктурированные формулы, удовлетворяет терминальному условию.
Мы можем кратко проиллюстрировать работу правил выдвижения структур на
простом примере соединения, химическая формула которого С5Н12. Наша система
продукций предлагает для этого соединения несколько вариантов структур. (Не все из
них возможны с точки зрения химии; на данном этапе процесса мы просто описываем,
как можно было бы породить правдоподобные структуры, основываясь только на
простом рассмотрении валентных связей. Реальная система DENDRAL заметно
сокращает число кандидатов, используя знания других химических закономерностей, а также
особенности масс-спектрограмм.)
Исходной базой данных служит формула С5Н12. В этом случае правила дают
следующие частичные структуры:
44
К2н7|
Η
I
c = c
I
Η
C-H
I
Η
Η
I
H-C- Η
I
|с2н6| = с
H — C-H
I
Η
Η
I
H-C-H
|с2н5|-с-н
H — C — Η
I
Η
Η
I
н-с —η
Η
|C2HS|-C-|C2HS|
Η
Η
I
Η
I
н—с—с—с-н
I
Η
I
Η
н-с-н
I
Η
В рассмотренных частичных структурах формулы, ограниченные вертикальными
линиями (I I), не структурированы. Их можно отделить от структурированной части
базы данных, и применить соответствующие правила выдвижения структур независимо к
каждой из них. Например, для формулы IC2HS I эти правила дают структуру
Η Η
I I
н-с-с-
Η Η
Часть дерева типа И/ИЛИ для нашей задачи о CsHj 2 показана на рис. 1.Ц. Каждое
дерево решения соответствует структуре-кандидату. То, которое выделено жирными
линиями, соответствует структуре
Η Η Η Η Η
Ι Ι Ι Ι !
H-C-C-C-C-C-H (пентан)
ι ι ι ι ι
Η Η Η Η Η
1.2.2.2. Символьное интегрирование. В задаче о символьном интегрировании нам
нужен автоматический процесс, который может воспринимать в качестве входного
сигнала любой неопределенный интеграл, например fx sin Ъхdx, и давать на выходе решение
1/9 sin Ъх -1/Ъх cos Ъх. Считаются известными простые табличные интегралы типа
f иdu =м2/2, /sin иdu =-cosi/, /0м du =au logfle и т. д.
Решение задачи о символьном интегрировании можно искать с помощью системы
продукций, которая преобразует интеграл в выражения, включающие только частные
случаи табличных интегралов.
Правила продукций могут основываться на правилах интегрирования по частям,
разложения интеграла в сумму и других правилах преобразований, в том числе и тех, в ко-
45
Η
I
н - с-н
I
- с-н
I
н - с-н
I
Η
Правило
н -
Η Η
ι ι II
с - с -
II
Η Η
Терминальная
Терминальная
Терминальная
Рис. 1.11. Дерево типа И/ИЛИ для задачи о химической структуре
торых используются алгебраические и тригонометрические подстановки. Правило
продукций, основанное на интегрировании по частям, преобразует выражение fudv в
выражение и fdv - fv du. Если существуют возможности выбрать одну часть исходного
подынтегрального выражения в качестве и, а другую - в качестве ν, то специальное
правило перебора этих возможностей обеспечивает рассмотрение каждого случая.
Правило разложения устанавливает, что интеграл суммы можно заменить суммой
интегралов от слагаемых подынтегрального выражения. Другое правило, называемое
правилом вынесения множителя, позволяет заменять выражение fkf(x)dx на
выражение к/ f(x) dx. Другие правила основаны на следующих действиях:
Алгебраические постановки
Пример
х2 dx 1
/ — -+ / - {ζ6 -4ζ3 +4) dz, используя ζ2 = (2+Зх)2/*.
(2+Зх)2/3 9
Тригонометрические подстановки
Пример
dx 5 , 4 . Л
/ —— -► / —— ctg θ cosec θ de, используя χ = -ξ tg θ.
16 ^
χ2ν/25χ2+16
46
Деление числителя на знаменатель
Пример
, z4dz
z2 + l
Выделение полного квадрата
Пример
/■
dx
>f (*2-1+— ) dz.
1+z2
dx
(x2-4x+13)2 [(x-2)2+9]2
Любое выражение, содержащее сумму интегралов, можно разбить на отдельные
интегралы, причем каждый можно обрабатывать отдельно. Следовательно, наша система
продукций является разложимой.
Применимость указанных разнообразных правил сильно зависит от формы
подынтегрального выражения. В системе символьного интегрирования, названной SAINT [340],
эти выражения классифицировать в соответствии с теми свойствами, которыми они
обладали. Для каждого класса подынтегральных выражений подбирались различные
правила с учетом их применимости с эвристической точки зрения.
На рис. 1.12 показано дерево типа И/ИЛИ, которое демонстрирует возможный про-
J (1 -χ2Ϋ
dx
***t
ec*°e
I
/
sin" у
cos4 у
dy
г° ^-~Т^>с^° ческое тождество ^-</</
^V^^^^*pPc* ческое тождество
-со'
|/ctg 4 yd}
ι
;
z=c\gy
Г- * !
J г4( 1 + .-г)
\/~ !
1
Г
иИ
L
I tg4 у dy
1
/*32 ^ «fc
J (1+Ζ2)(Ι -Γ2)4
г= \%у
J 1 + ζ2
Деление числителя на знаменатель
1
\
| A-l+*I + ih)« ]
1
/**
ζ =tgw
/
ί/Η
Рис. 1.12. Дерево типа И/ИЛИ для задачи интегрирования
47
цесс поиска, выполняемый разложимой системой продукций. Задача состоит в том,
чтобы вычислить интеграл / — 2 s,2 dx. Вершины этого дерева представляют собой
выражения, которые необходимо проинтегрировать. Те выражения, которые
соответствуют основным табличным интегралам, удовлетворяют терминальному условию и
заключены в двойные рамки. Жирно выделенные дуги показывают дерево решения
для этой задачи. Используя это дерево и табличные интегралы, вычислим ответ:
arcsin χ + -~ tg3 (arcsin χ) - tg (arcsin x).
1.3. КОММЕНТАРИИ К РАЗЛИЧНЫМ ТИПАМ СИСТЕМ ПРОДУКЦИЙ
В заключение обсудим два главных типа систем продукций ИИ, а именно
обычный тип, описываемый процедурой PRODUCTION, и разложимый,
описываемый процедурой SPLIT. В зависимости от способа представления
задачи любой из этих типов можно использовать в прямом или обратном
направлении. Системами можно управлять в безвозвратном или пробном
режиме. Классификация систем продукций, основанная на этих различиях,
принесет большую пользу при организации различных систем и понятий
искусственного интеллекта в единую согласованную структуру.
Важно отметить, что мы устанавливаем различия только между разными
типами систем искусственного интеллекта; мы не делаем различий между
разными видами задач. В дальнейшем на примерах мы увидим, как одну и
ту же задачу можно представить и решить с помощью совершенно разных
типов систем.
Мы приведем еще очень много других примеров представления задач.
Определение глобальных баз данных, правил и терминальных условий для
любой задачи пока что остается своего рода искусством, и обучать этому
лучше всего на примерах. Поскольку большинство исследованных до сих
пор примеров было связано с элементарными задачами и головоломками,
читатель вправе поинтересоваться, действительно ли системы продукций
достаточно мощны, чтобы стать основой интеллектуальных систем. Далее
мы рассмотрим некоторые более реальные и трудные задачи, чтобы
показать, как широка область использования этих систем.
Эффективные системы ИИ должны располагать знаниями о
предметной области решаемой задачи. Вполне естественно представить эти знания в
виде трех обширных категорий, соответствующих подсистемам глобальных
баз данных, правил и управления в системах продукций. Сведения о задаче,
которые представлены в глобальной базе данных, иногда называются
декларативными знаниями. Например, в интеллектуальной системе
информационного поиска (ИСИП) декларативные знания включали бы в себя основную
базу, содержащую данные о конкретных фактах. Знания, касающиеся какой-
либо задачи, которые представлены в правилах, часто называются
процедурными. В ИСИП процедурные знания включали бы сведения, дающие нам
возможность работать с декларативными знаниями. Знания о задаче,
представленные в стратегии управления, часто называют управляющими. Она
включает данные о множестве процессов, стратегий и структур, используемых для
координации процесса решения задачи в целом. Центральная проблема,
рассматриваемая в этой книге, такова: как, основываясь на знании о задаче,
48
наилучшим образом организовать его декларативную, процедурную и
управляющую компоненты для использования в системах продукции ИИ. Первым
объектом нашего изучения, который достаточно подробно будет
рассматриваться в следующих двух главах, является управление, в особенности
режимы управления с поиском на графе. Затем мы обратимся к использованию
в ИИ исчисления предикатов.
1.4. БИБЛИОГРАФИЧЕСКИЕ И ИСТОРИЧЕСКИЕ ЗАМЕЧАНИЯ
1.4.1. СИСТЕМЫ ПРОДУКЦИЙ
Термин система продукций достаточно широко использовался в ИИ,
хотя он относился к более специализированным типам вычислительных
систем по сравнению с теми, о которых идет речь в этой книге. Системы
продукций произошли из вычислительного формализма, предложенного Постом
[288]; он был основан на правилах замены строк символов. Близка к
нему идея алгоритма Маркова [114, 221], связанная с установлением
порядка правил замены и с использованием этого порядка для принятия решения
о том, какое из правил применять на очередном шаге. Правила продукции
преобразования строк в сочетании с простой стратегией управления были
применены Ньюэллом и Саймоном для построения моделей определенных
типов человеческого поведения при решении задач [269] (см. также [264]) .
Ричнер предложил высокоуровневый язык программирования, основанный
на правилах продукций для преобразования строк [315] *.
Обобщения этих формализмов систем продукций использовались в ИИ и
получали различные названия — системы продукций; системы, основанные
на правилах; системы "классной доски'* и системы "вывода по образцу".
Много примеров систем такого рода приведены в книге [380] (см. также
[147]). В статье Дэвиса и Кинга подробно рассмотрены системы продукций
в ИИ [67].
Наше представление о системах продукций не связано ни с какими
ограничениями на форму глобальной базы данных, правил и стратегии
управления. Мы вводим идею пробных режимов управления, чтобы сделать
возможной какую-либо форму управляемого недетерминизма в порядке
применения правил. При таком обобщении системы продукций можно использовать
для описания работы многих важных систем ИИ.
Наша мысль о том, что порядок применения правил может быть
несущественным в коммутационных и разложимых системах продукций, связано с
теоремами Черча-Россера в абстрактной алгебре (см., например, [87, 88,
309]).
Понятие разложимых систем продукций включает в себя метод, в
искусственном интеллекте часто называемый сведением задачи к подзадачам
[273]. Идея сведения задачи к подзадачам обычно состоит в замене цели
задачи множеством таких подцелей, что если эти, подцели достигнуты, то
задача решена. Объяснение сведения задачи к подзадаче в терминах
разложимых систем продукций позволяет нам не определять, производим мы деком-
1 В нашей стране хорошо известен такой язык программирования, как РЕФАЛ. В
его основу положена некоторая реализация алгоритма Маркова. — Прим. ред.
49
позицию целей или состояний задачи. Слейгл, занимаясь декомпозицией
задач, использовал структуры, которые он называл деревьями целей типа
И/ИЛИ [340]. Сходные структуры предложены в статье [6]. С тех пор
деревья и графы типа И/ИЛИ часто использовались в искусственном
интеллекте. Дополнительные ссылки на литературу по методам графов типа И/ИЛИ
имеются в гл. 3.
Проблема нахождения хороших представлений задач исследовалась лишь
немногими учеными. Амарель написал классическую статью на эту тему [7],
в которой продемонстрирована серия последовательно улучшающихся
представлений для задачи о миссионерах и людоедах [см. упражнение 1.1].
Саймон описал систему под названием UNDERSTAND для преобразования
описаний задач на естественном (английском) языке в представления, удобные
для решения задач [338].
1.4.2. СТРАТЕГИИ УПРАВЛЕНИЯ
Подъем на гору используется в теории управления и системном анализе
в качестве одного из методов поиска максимума (наискорейший подъем)
или минимума (наискорейший спуск) функции (подробнее см. [10]). В
области вычислительных наук Голомб и Баумерт предложили возвращение
в качестве механизма выбора [126]. В различных языках
программирования искусственного интеллекта возвращение используется как
"встроенная" стратегия поиска [31]. Имеется обширная литература по
эвристическому поиску на графе; некоторые источники упоминаются в следующих двух
главах.
1.4.3. ПРИМЕРЫ ЗАДАЧ
Методы, используемые в программах решения задач, отработаны на
многих играх и головоломках. Несколько хороших книг общего плана,
посвященных головоломкам, принадлежит Гарднеру [115, 116], который
является редактором отдела головоломок в журнале Scientific American1.
Можно прочитать также книги Дадни — известного изобретателя головоломок
[84, 85], книги [346] о логических головоломках и Уикемрена [385] о
том, как решать задачи. Игра в 8 — это уменьшенный вариант игры в 15,
рассмотренный Гарднером [117] и Боллом [11].
Задача коммивояжера возникла в исследовании операций [158, 368].
Метод нахождения оптимальных маршрутов предложили Хелд и Карп [148,
149], метод нахождения "приблизительно" оптимальных маршрутов описан
Лином [193].
Хорошим общим справочником по формальным языкам, грамматикам и
синтаксическому анализу является книга Хопкрофта и Ульмана [161].
Метод, предложенный для химических структур, основан на системе
DENDRAL Фейгенбаума и др. [99], пример символьного интегрирования —
на системе SAINT Слейгла [340]. Более мощная система символьного
интегрирования SIN была разработана Мозесом позднее [255]. В книге [256]
обсуждается история методов символьного интегрирования.
1 Журнал выходит в переводе на русский язык под названием "В мире науки";
издается с 1983 г. М.: Мир. - Прим. ред.
50
Упражнения
1.1. Определите глобальную базу данных, правила и терминальное условие для
системы продукций применительно к решению задачи о миссионерах и людоедах.
Три миссионера и три людоеда подошли к реке. У них есть лодка, в которую могут
поместиться не более двух человек. Как им воспользоваться этой лодкой и
переправиться через реку, чтобы при этом людоеды ни на каком берегу численно не превосходили
миссионеров?
Определите функцию подъема на гору для глобальных баз данных.
Проиллюстрируйте, как безвозвратная стратегия управления и стратегия управления с возвращением
использовали бы эту функцию при решении данной задачи.
1.2. Определите глобальную базу данных, правила и терминальное условие для
системы продукций применительно к следующей задаче о кувшинах с водой.
Имеются пятилитровый кувшин, наполненный водой, и пустой двухлитровый. Как
можно налить ровно один литр в двухлитровый кувшин? Воду можно либо выливать,
либо переливать из одного кувшина в другой, при этом весь запас воды ограничен
исходными пятью литрами.
1.3. Покажите, как правила переписывания из подразд. 1.1.6 можно применить в
системе продукций, которая порождает предложения. Каковы глобальная база
данных и терминальное условие для такой системы? Используйте эту систему для
порождения пяти грамматически верных (хотя и не обязательно имеющих смысл)
предложений.
1.4. Мой друг Том претендует на то, что он - потомок Пола Риверы. Каким
способом было бы легче проверить это: показать, что Ривера - один из предков Тома, или
показать, что Том - один из потомков Риверы? Почему?
1.5. Пусть некоторое правило Π коммутативной системы продукций применено к
базе данных D, что дает D' . Покажите, что если для Я имеется обратное правило, то
множество правил, применимых к D' , идентично множеству правил, применимых kD.
1.6. В некоторой системе продукций глобальной базой данных является множество
целых чисел. Базу данных можно преобразовать, добавив к этому множеству
произведения любых двух его элементов. Покажите, что эта система продукций
коммутативна.
1.7. Покажите, как систему продукций можно использовать для перевода
десятичного числа в двоичное. Для иллюстрации ее работы преобразуйте число 141.
1.8. Критически рассмотрите следующее утверждение: стратегия управления с
возвращением (или поиском на графе методом перебора в глубину) должна
применяться, когда между состояниями задачи существует много путей, так как тенденция этих
стратегий - избежать рассмотрения всех возможных путей.
1.9. При использовании стратегии возвращения с процедурой SPLIT должен ли
выбор, происходящий на шаге 5, быть точкой возврата? Обсудите это. Если шаг 5 не
является точкой возврата, то есть ли различия между процедурами SPLIT в режиме
возвращения и PRODUCTION в режиме возвращения?
ГЛАВА 2
СТРАТЕГИЯ ПОИСКА ДЛЯ СИСТЕМ ПРОДУКЦИЙ
ИСКУССТВЕННОГО ИНТЕЛЛЕКТА
В этой главе мы исследуем некоторые стратегии управления для систем
продукций ИИ. В соответствии с основной процедурой для систем
продукций (см. подразд. 1.1.2) главная задача управления состоит в выборе
применимого правила для использования на шаге 4. Для разложимых систем
продукций (см. подразд. 1.2.2) задача управления состоит в отборе составля-
51
ющей базы данных на шаге 6 и применимого правила для использования на
шаге 8. Другие вспомогательные, но важные задачи, стоящие перед системой
управления, включают проверку условий применимости правил, проверку
завершения и запоминания результатов.
Важной характеристикой вычислительного процесса для выбора правил
является объем имеющейся информации, или "знаний" о задаче, который
используется при вычислениях. В ситуации полной неинформированности
выбор делается абсолютно произвольно, без учета какой-либо имеющейся
о данной задаче информации. В ситуации полной информированности
стратегия управления руководствуется достаточно большим знанием, чтобы
каждый раз выбирать "верное" правило.
В целом вычислительная эффективность системы продукций ИИ зависит
от того, в каком положении между этими двумя крайними случаями
находится данная стратегия управления. Мы можем разделить вычислительные
затраты в системе продукций на две главные категории: затраты на
применение правил и на управление. Полностью неинформированная система
управления несет лишь небольшие расходы на стратегию управления, поскольку
чисто произвольный выбор правила не требует больших вычислений. Такая
стратегия, однако, приводит к большим расходам, связанным с применением
правил, так как она обычно должна перепробовать много правил, чтобы
найти решение. В искусственном интеллекте введение в управляющую
систему полной информации об области рассматриваемой задачи обычно
связано с использованием дорогостоящей — за счет необходимых вычислений
и объема занимаемой памяти — стратегии управления. Однако стратегии
управления с полной информацией требуют минимальных затрат на
применение правил; они ведут систему продукций непосредственно к решению.
Эти тенденции качественно отражены на рис. 2.1.
Общая стоимость вычислений в системе продукций ИИ складывается
из стоимостей применения правил и стратегии управления. Умение проекти-
"Информированность" Полная
Рис. 2.1. Затраты на вычисления в системах продукции ИИ:
1 — стоимость применения правил; 2 — стоимость стратегии управления; 3 — полная
стоимость
52
ровать эффективные системы искусственного интеллекта состоит отчасти в
установлении пропорции между этими двумя стоимостями. Для любой
конкретной задачи оптимальную эффективность системы продукций
можно было бы получить при стратегиях управления, вовсе не являющихся
полностью информированными. (Стоимость полностью информированной
стратегии может оказаться слишком высокой.)
Другой важный аспект проектирования систем искусственного
интеллекта связан с применением методов, дающих стратегии управления
возможность пользоваться большим объемом информации о задаче, избегая при
этом чрезмерных затрат на управление. Такие методы помогают уменьшить
наклон кривой стоимости стратегии управления (см. рис. 2.1), снижая
общие затраты системы продукций.
Поведение системы управления в то время, как она выбирает правила,
можно рассматривать как процесс поиска. Некоторые примеры того, как
система управления может осуществлять поиск решения, приведены в гл. 1.
Там мы говорили о методе "подъема на гору" для безвозвратного выбора
правил при поиске максимума на некоторой поверхности и о режимах
с возвращениями и поиска на графе — процессах поиска, допускающих
пробный выбор правил. Основная тема настоящей главы — пробные
режимы управления, хотя и у безвозвратных режимов есть важные приложения,
особенно для коммутативных систем продукций. Некоторые методы
поиска, разрабатываемые нами для пробных режимов управления, можно
приспособить для определенных типов коммутативных систем продукций,
применяющих безвозвратные режимы управления. Начнем обсуждение управления
с пробами описанием возвратных методов.
2.1. СТРАТЕГИИ С ВОЗВРАЩЕНИЕМ
В гл. 1 приведено общее описание стратегии управления с возвращением
и проиллюстрировано ее использование на примере игры в 8. Для задач,
где необходим лишь небольшой объем поисковой работы, стратегии
управления с возвращением часто оказываются вполне адекватными и
эффективными. По сравнению с режимами управления с поиском на графе стратегии
с возвращением обычно проще реализуются и требуют меньшего объема
памяти.
Суть работы системы продукций при управлении с возвращением может
быть отражена в простой рекурсивной процедуре. В этой процедуре, которую
мы назовем BACKTRACK, используется единственный аргумент DATA,
который вначале полагаем совпадающим с глобальной базой данных системы
продукций. При успешном срабатывании эта процедура дает на выходе
(с помощью команды return) список правил, последовательное
применение которых к исходной базе данных порождает базу данных,
удовлетворяющую терминальному условию. Если процедура прекращает работу, не
обнаружив такого списка правил, то дается ответ FAIL (^неудача) .
Процедура BACKTRACK определяется следующим образом:
53
Recursive procedure BACKTRACK( DA ТА )
1 if TERM(Z)/17>1), return JV/L; TERM
— предикат, принимающий значение "истина" для
аргументов, удовлетворяющих терминальному
условию системы продукций. При успешном
срабатывании на выходе дается пустой список
NIL.
2 if ΌΕΑΌΕΝΌ( DATA), return FAIL; DEADEND
— предикат, принимающий значение "истина" для
аргументов, о которых известно, что они
не встречаются на пути, ведущем к решению. В этом
случае иа выходе появляется символ FAIL.
3 RULES*- APPRULES(Z>/17/0; APPRULES
— функция, которая определяет правила,
применимые к ее аргументу, и упорядочивает их
(либо произвольно, либо в соответствии с их
эвристическим качеством).
4 LOOP: if N\JLL(KUL£S), return FAIL;
если не имеется (более) применимых правил,
то процедура фиксирует неудачу.
5 Л «- FIRST(RULES); выбирается наилучшее
из применимых правил.
6 RULES *-TAHj(RULES); список
применимых правил сокращается — из него
удаляется только что выбранное правило.
7 RDA ТА 4- R( DA ТА ); применяется
правило R и порождается новая база данных.
8 PATH 4- В ACKTRACK( RDA ТА ); BACKTRACK
рекурсивно вызывается для новой базы данных.
9 if PATH = FAIL, go LOOP; если рекурсивный
вызов неудачен, попробовать другое правило.
10 return CONS(R, PATH); на выходе дается
список правил, начинавшийся с R и обеспечивший
успешное решение
Можно дать несколько комментариев к этой процедуре. Прежде всего
процедура успешно завершает работу (на шаге 1), только если
порождается база данных, удовлетворяющая терминальному условию. Список правил,
использованных при формировании базы данных, составляется на шаге 10.
54
Неудачное завершение процесса может произойти на шагах 2 и 4, но если оно
происходит во время рекурсивного вызова, то процедура возвращается на
более высокий уровень. На шаге 2 проверяется возможность достижения
решения для рассматриваемой базы данных. На шаге 4 процедура
фиксирует неудачу, если все применимые правила уже опробованы.
В процедуре BACKTRACK может и не быть остановки; она может либо
бесконечно порождать новые нетерминальные базы данных, либо
зацикливаться. Оба случая можно произвольным образом предотвратить, вводя
ограничение на глубину рекурсии. Любой рекурсивный вызов является
неудачным, если его глубина превышает эту границу. Зацикливания можно
избежать с помощью более прямолинейного способа — ведения списка уже
порожденных и проверки новых баз данных на совпадение с имеющимися
в этом списке. В дальнейшем укажем несколько более сложную процедуру,
осуществляющую эти проверки.
На шаге 3 процедура упорядочивает применимые к рассматриваемой
базе данных правила. Здесь используется любая имеющаяся эвристическая
информация об области, к которой относится задача. Эти правила
"угадываются" с учетом эвристической информации, причем наиболее подходящие
для исследуемой базы данных правила в процессе упорядочения занимают
первые места. Применимые правила могут упорядочиваться произвольно,
если полезная информация отсутствует, хотя в этом случае из-за
многочисленных возвращений процедура может оказаться неэффективной и
нецелесообразной. По определению, если "верное" правило в процессе
упорядочения всегда оказывается на первом месте, никаких возвращений не
произойдет.
Мы использовали процедуру BACKTRACK для того, чтобы пояснить, как
работают стратегии управления с возвращением. Некоторые потребности
практики — такие, как стремление избегать размножения больших,
сложных баз данных, диктуют необходимость более эффективных, чем эта
процедура, реализаций стратегии с возвращением.
Возможно, окажется полезным еще один пример того, как стратегия с
возвращением применяется для решения простой задачи. Представим, что
дана задача: расставить на шахматной доске размерами 4X4 четыре ферзя
так, чтобы они не били друг друга. Для нашей глобальной базы данных
используем массив 4X4 с помеченными клетками, соответствующими полям,
занятым ферзями*. Терминальное условие, выраженное предикатом TERM,
удовлетворяется для какой-либо базы данных в том и только в том случае,
если она содержит ровно четыре ферзевых метки и эти метки
соответствуют ферзям, которые стоят так, что не могут взять друг друга.
Существует много допустимых альтернативных формулировок для
правил продукций. Формулировка, полезная для наших целей, включает
следующую схему правил для 1<ί, у <4:
пп
Предусловие:
ί = 1: в массиве нет ферзевых меток.
К ί <4: в (ί — 1)-й строке массива есть ферзевая метка.
Действие:
ферзевая метка ставится в ί-ю строку, j -й столбец
массива.
55
Таким образом, первая ферзевая метка, занесенная в массив, должна быть
в первой строке, вторая — во второй и т.д.
Чтобы применить процедуру BACKTRACK для решения задачи о четырех
ферзях, нам остается определить предикат DEADEND и упорядочивающее
отношение для применимых правил. Допустим, что при таком упорядочении
мы произвольно устанавливаем, что /7Z·,· стоит раньше, чем П^, только если
j <k. Предикат DEADEND можно было бы определить так, чтобы он
удовлетворялся для баз данных, где невозможность решения очевидна; например,
конечно, не может быть решения для любой базы данных, содержащей
метки двух ферзей в позиции, где они атаковали друг друга. (Читателю
предлагается попробовать проделать процедуру BACKTRACK вручную, используя
для DEADEND этот простой тест.) Алгоритм возвращается в общем 22 раза
перед тем, как найдет решение; даже самое первое примененное правило,
в конце концов, приходится сменить.
Более эффективный алгоритм (с меньшим числом возвращений) можно
получить, если использовать упорядочение правил при большей
информативности. Один простой, но полезный способ упорядочения для
рассматриваемой задачи связан с использованием функции diag (U УЛ значением которой
для клетки (i,j)является длина наибольшей диагонали, проходящей через
нее. Пусть при упорядочении Я/;· будет перед ПтП9 если diag (i, j)< diag(m9 n).
(Для равных значений diag используется тот же порядок, что и ранее.) При
использовании этого отношения порядка правила, применимые к исходной
базе данных, упорядочиваются следующим образом: (Я12, Я13,ЯИ ,Я14).
Читатель может проверить, что эта схема упорядочения решает задачу о
четырех ферзях с всего лишь двумя возвращениями.
Как уже отмечалось, чтобы избежать зацикливания, требуется несколько
более сложный алгоритм. Все базы данных на обратном пути к исходной
базе необходимо проверить, чтобы не было повторений. Для реализации
такой стратегии с возвращением в виде рекурсивной процедуры аргументом
этой процедуры должна быть вся цепочка баз данных. И здесь в
практических реализациях систем продукции ИИ с возвращением применяются
различные способы, позволяющие избежать явного перечисления всего
множества баз данных.
Назовем наш алгоритм, избегающий циклов, BACKTRACK 1. Его
аргументом служит список баз данных; когда вызывается первая база данных,
в этом списке имеется только один элемент — исходная база данных. После
успешного срабатывания BACKTRACK 1 выдает последовательность правил,
которую можно применить к исходной базе данных для получения базы
данных, удовлетворяющей терминальному условию. Алгоритм BACKTRACK 1
определяется следующим образом:
Recursive procedure BACKTRACK1( DA ТА LIST)
1 DA ТА 4- FIRST( DA ТА LIST); DA ТА LIST
— список всех баз данных на обратном пути
к исходной базе. DATA — последняя порожденная
база данных.
56
2 if MEMBER( DA ТА, TAIL( DA ТА LIST)\ return
FAIL; неудача, если процедура приходит
к уже встречавшейся ранее базе данных.
3 if TERM(DATA), return NIL
4 if DEADEND( DA ТА ), return FA IL
5 if LENGTH( DA ТА LIST)> BO UND, return
FAIL; неудача, если было применено
слишком много правил. BOUND —
глобальная переменная, определенная до
первого вызова этой процедуры.
6 RULES <-\PPRVLES(DATA)
7 LOOP: if NVLL(RULES\ return FAIL
8 R*-F1RST(RULES)
9 RULES *-T\\L(RULES)
10 RDATA*-R(DATA)
11 RDATALIST4-CONS(RDATA,DATALIST);
к списку баз данных, встретившихся к
следующему моменту, добавляется
RDATA.
12 РА ТН 4- BACKTRACKSRDATALIST)
13 if ΡΑ ΤΗ = FAIL, go LOOP
14 return CONS(Я, PATH)
В примере возвращения для игры в 8 (см. гл. 1) использовалось BOUND =7
и проводилась проверка — встречалась ли ранее конфигурация фишек.
Заметим, что этот рекурсивный алгоритм не запоминает всех встретившихся
ранее баз данных. Возвращение предусматривает "забывание" всех баз
данных на путях, приводящих к неудаче. Этот алгоритм запоминает
только те базы данных, которые находятся на текущем обратном пути к
исходной базе данных.
Только что описанные стратегии с возвращением при неудаче каждый раз
"отходят" на один уровень. Если рекурсивный вызов процедуры BACKTRACK
η-го уровня терпит неудачу, управление возвращается к (п - 1)-му уровню,
где пробуется другое правило. Однако иногда можно проследить, что
причина этого или ответственность за неудачу на n-м уровне связана с выборами
57
правил, сделанными на много уровней выше. Тогда, очевидно, бесполезно
пытаться выбрать другое правило на (лЧ)-м уровне; можно предсказать,
что здесь любой такой выбор снова приведет к неудаче. В этом случае
требуется найти какой-либо способ "перепрыгнуть" сразу через несколько
уровней, вернуться сразу к тому уровню, где иной выбор правила обеспечит
существенное изменение.
В качестве примера многоуровневого
возвращения рассмотрим использование
процедуры BACKTRACK для решения задачи с
восьмью ферзями. На доске 8X8 нужно
расставить восемь ферзей так, чтобы они не
атаковали друг друга. Допустим, мы
находимся на той стадии работы этого алгоритма,
когда только что порожденная база данных
описывается массивом, показанным на рис.
2.2. (На самом деле, алгоритм BACKTRACK
породил бы в точности эту базу данных при
использовании произвольного упорядочения
правил, которое мы рассмотрели в самом
начале.) Теперь алгоритм должен
попытаться поместить ферзя в шестом ряду (строке).
Заметим, что ни одна клетка в этом ряду не подходит, и любая попытка
поместить ферзя в шестом ряду окончилась бы неудачей. В такой ситуации
алгоритм BACKTRACK попытался бы перемещать ферзя, находящегося в
пятом ряду, приводя его в конечном счете в восьмой столбец. Однако более
детальный анализ причин неудач при размещении ферзя в шестом ряду
показал бы, что они все же возникали бы независимо от положения ферзя в
пятом ряду. Неудачи в шестом ряду предопределены позициями первых
четырех ферзей. Поэтому раз нет смысла в перемещении ферзя 5, можно
перепрыгнуть через один уровень рекурсии к шагу, где мы выбирали позиции в
четвертом ряду. Некоторые системы искусственного интеллекта используют
стратегии с возвращением, способные таким образом анализировать неудачи
и возвращаться к нужному шагу.
X
X
X
X
X
Рис. 2.2. Позиции ферзей на этапе
работы алгоритма BACKTRACK
2.2. СТРАТЕГИИ ПОИСКА НА ГРАФЕ
П1
Dili
/
1)112
пз
1
'
Dili
Рис.
дан!
2
.3
/\
S
П2
DM
. Дерево баз
В стратегиях с возвращением управляющая
система забывает все пробные пути, окончившиеся
неудачей. В явном виде в памяти хранится лишь
путь, по которому идет процесс в данный момент.
Более гибкой была бы процедура, обеспечивающая
явное запоминание всех пробных путей с тем, чтобы
любой из них мог быть кандидатом на дальнейшее
продолжение.
Например, на рис. 2.3 показана исходная база
данных DB1, к которой применимы, скажем, правила
171 а П2. Пусть система управления отбирает и
применяет П1У порождая базу данных DB2\ пусть затем
система управления отбирает применимое правило
58
ПЗ и применяет его к DB2, получая DB3. Допустим, в данный момент
система управления решила, что этот путь не является перспективным, и
вернулась назад, чтобы применить к DB1 правило П2, получая базу данных DB4.
Как указано, стратегия с возвращением стерла бы записи о DB2 и DB3.
Но если бы система управления сохранила эту запись, то в случае,если бы
путь через DB4 не привел к успеху, она могла бы возобновить работу сразу
с DB2 или DB3. Чтобы обладать такой гибкостью, система управления
должна сохранять в явном виде запись графа баз данных, соединенных в
результате применения правил. Мы говорим, что система управления, работающая
таким образом, использует стратегии поиска на графе.
При обсуждении стратегий поиска на графе считаем, что различные базы
данных, полученные в результате применения правил, реально представлены
(каждая во всей полноте) в виде вершин графа или дерева. Поскольку эти
базы обычно являются очень большими структурами, было бы очень
непрактично запоминать каждую из них в явном виде. К счастью, имеются способы
получения эффекта явного запоминания всех достижимых баз данных путем
явного запоминания только исходной базы данных и записей
увеличивающихся изменений, на основании чего можно быстро вычислить любую другую
базу данных.
2.2.1. ЗАПИСЬ НА ЯЗЫКЕ ГРАФОВ
Мы можем рассматривать стратегию управления с поиском на графе как
средство нахождения пути на графе от вершины, представляющей исходную
базу данных, к вершине, представляющей базу данных, которая
удовлетворяет терминальному условию системы продукций. Таким образом,
алгоритмы поиска на графе представляют для нас особый интерес. Перед тем,
как описать эти алгоритмы, рассмотрим термины из теории графов.
Граф состоит из множества (не обязательно конечного) вершин.
Определенные пары вершины соединены дугами, и эти дуги направлены от одного
элемента пары к другому. Такой граф называется направленным. Для наших
целей вершины помечены базами данных, а дуги — правилами. Если дуга
направлена от вершины ni к вершине η,·, то говорят, что вершина nj
является преемником вершины пг·, а п^ — родителем вершины п.-. В графах,
представляющих для нас интерес, у любой вершины может быть лишь
конечное число преемников. (У наших систем продукций имеется лишь
конечное число применимых правил.) Обе вершины в паре одновременно могут
быть преемниками друг друга; в этом случае пара направленных дуг
иногда заменяется ребром.
Дерево — частный случай графа, в котором каждая вершина имеет не
более одного родителя. Вершина дерева, не имеющая родителя, называется
корневой, а не имеющая преемников — концевой. Мы говорим, что корневой
вершине соответствует глубина, равная нулю. Глубина любой другой
вершины дерева определяется как глубина предшествующей вершины плюс 1.
Последовательность вершин rijj, ni2> · · · >nik> гДе каждая п^ является
преемником п^,}- _^ для / =2, . . . , к, называется путем длиной к от nix к
nikl. Если существует путь от вершины мг· к вершине η,· , то говорят, что
1 Таким образом, автор называет путем не последовательность дуг или ребер, а
последовательность вершин. - Прим. ред.
59
вершина м.· достижима из вершины ni. В этом случае п.- является потомком
вершины ηζ· и ηζ· — предком вершины п.-1.
Ясно, что задача нахождения последовательности правил, преобразующих
одну базу данных в другую, эквивалентна задаче отыскания пути на графе.
Часто оказывается удобным приписать положительные стоимости дугам,
чтобы отразить таким образом стоимость применения соответствующего
правила. Мы используем обозначение c(nz·, nА для стоимости дуги,
направленной от вершины ηζ· к вершине м.·. (Для некоторых дальнейших
рассмотрений важно, чтобы все они были больше некоторого произвольно малого
положительного числа е.) Стоимость пути между двумя вершинами равна
сумме стоимостей всех дуг, соединяющих вершины, лежащие на этом
пути. В некоторых задачах мы хотим найти путь между двумя вершинами,
имеющий минимальную стоимость.
В задаче простейшего типа ищем путь (возможно, имеющий
минимальную стоимость) между вершиной s, представляющей исходную базу данных,
и известной вершиной ί, представляющей другую базу данных. Чаще,
однако, встречается ситуация, где требуется найти путь между вершиной s и
любой вершиной из множества {ίζ· j. , представляющего базы данных,
удовлетворяющие терминальному условию. Это множество {ίζ \ называют
целевым и каждую вершину ί в {ίζ·} - целевой.
Граф можно определить либо явно, либо неявно. При явном определении
вершины и дуги (с соответствующими стоимостями) явно задаются
таблицей. В этой таблице могут перечисляться все вершины графа, их преемники
и стоимости соответствующих дуг. Очевидно, явное задание непрактично для
больших графов и невозможно для тех, в которых имеется бесконечное
множество вершин.
В наших практических примерах стратегия управления порождает
(определяет явно) часть неявно заданного графа. Это неявное описание дается
с помощью начальной вершины s, представляющей исходную базу данных,
и правил, изменяющих базы данных. Удобно ввести понятие оператора
построения преемников, применение которого к некоторой вершине
выявляет всех преемников этой вершины (и стоимости соответствующих дуг).
Этот процесс применения оператора преемников к вершине называют
раскрытием этой вершины. Оператор построения преемников очевидным
образом зависит от соответствующих правил. Раскрытие вершин s, преемников
s и так далее дает в явном виде граф, неявно определенный через s и
оператор построения преемников. Следовательно, стратегию управления с
поиском на графе можно рассматривать как процесс выявления части неявного
графа, содержащей целевую вершину.
2.2.2. ОБЩАЯ ПРОЦЕДУРА ПОИСКА НА ГРАФЕ
Процесс явного порождения части неявно заданного графа можно
неформально определить следующим образом.
Procedure GRAPHSEARCH
1. Создать граф поиска G, состоящий лишь из начальной вершины s.
1 Иногда будем говорить, что rij предшествует л,· и что л,· следует за п^ и т. д. -
Прим. ред.
60
Занести s в список, названный OPEN.
2. Создать список, названный CLOSED, который вначале пуст.
3. LOOP: если OPEN пуст, то неудача, окончание работы.
4. Выбрать первую вершину в OPEN, убрать ее из OPEN и поместить в
CLOSED. Обозначить эту вершину через п.
5. Если η — целевая вершина — успех, окончание работы с решением,
полученным в результате прослеживания пути в G вдоль указателей от η
к s. (Указатели определены на шаге 7.)
6. Раскрыть вершину п, порождая множество Μ ее преемников, не
являющихся предками п. Поместить в G эти элементы множества Μ как
преемники п.
7. Ввести указатель к м от тех элементов из М, которые еще не были в G
(т.е. ни в OPEN, ни в CLOSED). Добавить эти элементы в OPEN. Для
каждого элемента из Л/, который уже был в OPEN или CLOSED, решить, нужно
ли переориентировать указатель на η (см. текст). Для каждого элемента из
М, уже находящегося в CLOSED, принять решение относительно каждого
его потомка в G — нужно ли переориентировать его указатель (см. текст).
8. Переупорядочить список OPEN в соответствии либо с некоторой
произвольной схемой, либо с эвристической значимостью.
9. Перейти к метке LOOP.
Эта процедура имеет достаточно общий характер и заключает в себе
большое разнообразие отдельных алгоритмов поиска на графе. Процедура
порождает в явной форме граф G, называемый графом поиска, и подмножество Τ
графа G, называемое деревом поиска. Каждая вершина из G содержится
также в Т. Дерево поиска определено указателями, которые
устанавливаются на шаге 7. Каждая вершина (за исключением s) в G имеет указатель,
направленный только к одному из его родителей в G, который определяет
ее единственного родителя в Т. Этот граф поиска производит частичное
упорядочение, поскольку ни одна вершина в Сне является своим
собственным предком (шаг 6). Каждый возможный путь к какой-либо вершине,
открытой этим алгоритмом, хранится в явном виде в G; один выделенный
путь к любой вершине определен в дереве Т. Грубо говоря, вершины в
списке ОТКРЫТ (OPEN) являются концевыми вершинами дерева поиска, а в
списке ЗАКРЫТ (CLOSED) — неконцевыми. Точнее, на шаге 3 процедуры
вершины в списке ОТКРЫТ являются теми (концевыми) вершинами
дерева поиска, которые еще не выбирались для раскрытия. Вершины в списке
ЗАКРЫТ являются либо концевыми, выбранными для раскрытия,
которое не порождает преемников в графе поиска, либо неконцевыми
вершинами дерева поиска.
Эта процедура на шаге 8 упорядочивает вершины в списке ОТКРЫТ
так, чтобы "лучшая" из них была выбрана для раскрытия на шаге 4. Это
упорядочение может основываться на разных эвристических идеях (их мы еще
обсудим) или на произвольных критериях. Всякий раз, когда вершиной,
выбранной для раскрытия, оказывается целевая вершина, процесс успешно
завершается. Решающий путь от исходной вершины к целевой можно затем
восстановить, прослеживая (в обратном порядке) указатели от целевой
вершины к s. Процесс заканчивается неудачей, когда на дереве поиска не
остается концевых вершин, еще не выбиравшихся для раскрытия. (У
некоторых вершин может вообще не быть преемников, поэтому может случиться,
61
что список ОТКРЫТ, в конце концов, окажется пустым.) Если процесс
завершился неудачей, то целевая вершина (вершины) не может быть
достижима из исходной.
Шаг 7 процедуры нуждается в дополнительном пояснении. Если бы неявно
заданный граф, на котором ведется поиск, был деревом, мы могли бы быть
уверенными в том, что никакой из преемников, порожденных на шаге 6,
не порождался ранее: каждая вершина (за исключением корневой) дерева
является преемником только одной вершины и поэтому порождается
один раз — когда раскрывается его единственная вершина-родитель.
Следовательно, в этом частном случае элементы множества Μ на шагах 6 и 7 уже
не содержатся ни в списке ОТКРЫТ, ни в списке ЗАКРЫТ, причем каждый
элемент из Μ добавляется к списку ОТКРЫТ и помешается в дерево поиска
как преемник вершины п. Граф поиска совпадает с деревом поиска на
каждом этапе работы этого алгоритма, и нет необходимости менять родителей
вершин в подмножестве Т.
Если же рассматриваемый неявно заданный граф не является деревом,
то возможно, что некоторые элементы из Μ уже порождались, т.е. они уже
могут быть в списке ОТКРЫТ или ЗАКРЫТ. Задача определения того,
совпадает ли вновь порожденная база данных с какой-либо порожденной ранее,
может требовать большой вычислительной работы. По этой причине в
некоторых процессах поиска такая проверка не проводится; в результате может
оказаться, что в дереве поиска имеется несколько вершин, помеченных
одной и той же базой данных. Конечно, повторное появление этих вершин
приводит к излишней обработке вершин-преемников. Таким образом, имеется
выбор между вычислительными затратами проверки на совпадение баз
данных и вычислительными затратами, связанными с порождением большего
дерева поиска (содержащего множественные вершины, помеченные
идентичными базами данных). На шагах 6 и 7 процедуры GRAPHSEARCH
предполагаем, что предпочтительнее проверять вершины на идентичность.
Когда процесс поиска порождает вершину, уже возникавшую ранее, он
находит другой путь к ней (возможно, лучший), чем тот, который уже
зафиксирован в дереве поиска. Желательно, чтобы дерево поиска сохраняло
тот из найденных путей от s к любой другой его вершине, стоимость
которого минимальна. (Стоимость пути от s к η в дереве поиска можно вычислить,
суммируя стоимости дуг, встретившихся на дереве при обратном движении
от η к s. В задачах, где не указаны стоимости дуг, считаем, что их стоимость
равна единице.) Если вновь найденный путь дешевле прежнего, дерево
поиска преобразуется — родительские функции утверждаются за последним
родителем снова полученной вершины.
Если в Τ заменен родитель вершины п, находившейся в списке ЗАКРЫТ,
то найден путь к п, имеющий меньшую стоимость. Этот менее дорогой путь
может быть частью менее дорогих путей к некоторым преемникам вершины
η в графе поиска G; в этом случае возможно изменение в порядке родитель-
ства в подмножестве Τ преемников η в G. Поскольку G конечен и на его
вершинах имеется частичное упорядочение, процесс распространения
стоимостей новых путей вниз к преемникам η в графе G является прямым и
конечным. После такого пересчета дерево поиска подготовлено к записи,
если эти пути необходимы.
62
Рис. 2.4. Граф поиска и дерево
поиска перед раскрытием узла 1
Простой пример послужит иллюстрацией того, как совершаются такие
коррекции дерева поиска. Допустим, процесс поиска породил граф поиска и
дерево поиска, показанные на рис. 2.4. Жирные стрелки вдоль некоторых
дуг в этом графе поиска являются указателями, определяющими
родителей вершины в дереве поиска. Зачерненные вершины находятся в списке
ЗАКРЫТ, а остальные — в списке ОТКРЫТ в момент, когда алгоритм
выбирает вершину 1 для раскрытия. (Считаем, что стоимости дуг равны единице.)
Когда вершина 1 раскрыта, то порождается ее единственный преемник—
вершина 2. Но вершина 2, как и ее родитель на дереве поиска — вершина 3,
уже порождалась и находится в списке ЗАКРЫТ со своими
вершинами-преемниками 4 и 5. Заметим, однако, что родителем вершины 4 в дереве
поиска является вершина 6, поскольку кратчайший (наименее дорогой) путь
от $ к вершине 4 в графе поиска проходит через вершину 6. Так как теперь
алгоритм обнаружил путь к вершине 2 через вершину 1, стоимость
которого меньше стоимости предыдущего пути через вершину 3, то родителем
вершины 2 в дереве поиска становится вместо вершины 3 вершина 1.
Стоимости путей к потомкам вершины 2 на дереве поиска (а именно, путей к
вершинам 4 и 5) пересчитываются. Эти стоимости теперь меньше, чем ранее, и,
таким образом, родителем вершины 4 вместо вершины 6 становится
вершина 2. Скорректированное дерево поиска определено указателями, у дуг
графа поиска на рис. 2.5.
~' Рис. 2.5. Граф поиска и дерево
поиска после раскрытия узла 1
63
Как уже говорилось, алгоритм GRAHSEARCH порождает сразу всех
преемников вершин. Можно изменить этот алгоритм так, чтобы при выборе
вершины для раскрытия и порождении преемников в каждый момент
рассматривалась только одна вершина (см., например, [239]).
Модифицированный алгоритм не помещает вершину в список ЗАКРЫТ до тех пор, пока
не будут созданы все ее преемники. Поскольку процесс применения
правил к базе данных для порождения новых баз данных обычно требует
больших вычислительных затрат, модифицированный алгоритм часто
предпочтительнее даже с учетом того, что его несколько труднее описать. Чтобы
облегчить изложение некоторых общих свойств процедур поиска на графе,
будем и далее пользоваться тем вариантом алгоритма, в котором все
преемники порождаются одновременно.
2.3. НЕИНФОРМИРОВАННЫЕ ПРОЦЕДУРЫ ПОИСКА НА ГРАФЕ
Если при упорядочении вершин в списке ОТКРЫТ не используется
никакая эвристическая информация об области задачи, на шаге 8 алгоритма
должна применяться какая-либо произвольная схема. Получающаяся в
результате процедура поиска называется неинформированной. В искусственном
интеллекте мы обычно не интересуемся неинформированными процедурами,
но здесь для сравнения привфщм два типа: поиск в глубину и поиск в
ширину.
Первый тип неинформированного поиска располагает вершины списка
ОТКРЫТ в порядке убывания их глубины в дереве поиска. Наиболее
глубокие вершины помещаются в списке на первое место. Вершины,
расположенные на одинаковой глубине, упорядочиваются произвольно. Процесс поиска,
являющийся результатом такого упорядочения, называется поиском в
глубину, поскольку для раскрытия всегда выбирается наиболее глубоко
расположенная вершина дерева поиска. Для предупреждения неограниченного ухода
процесса поиска по бесперспективному пути вводится ограничение на
глубину. Вершины, глубина которых на данном дереве поиска превышает эту
границу, вообще не порождаются. (Можно добиться, чтобы этот процесс
завершался, как только порождается целевая вершина при помещении
целевых вершин в начало списка ОТКРЫТ; но, конечно, эта процедура
потребовала бы проверки достижения цели на шаге 8 процедуры GRAPHSEARCH.
Если результат запоминается, то при проверке достижения цели на шаге 5
достаточно только считать результат, а не повторять вычисления, возможно,
трудоемкие.)
Процедура поиска в глубину порождает новые базы данных в порядке,
подобном тому, в котором они порождались управляющей стратегией с
возвращением, не располагающей информацией. Аналогия была бы полной,
если бы процесс поиска на графе порождал в каждый момент только
одного преемника. Обычно варинат GRAPHSEARCH с поиском в глубину
предпочитают варианту с возвращением, поскольку возвращение проще
реализуется и требует меньшего объема памяти. (Стратегии с возвращением
запоминают только один путь к целевой вершине; они не хранят полной
записи процесса поиска, как это делают стратегии поиска на графе методом
поиска в глубину.)
Дерево поиска, порожденное процессом поиска в глубину в задаче об игре
64
в 8, показано на рис. 2.6. Вершины помечены соответствующими им базами
данных и пронумерованы в порядке, согласно которому они выбраны для
раскрытия. Пусть граничная глубина равна 5. Путь, выделенный жирной
линией, указывает решение, содержащее пять применений правил. Видно, что
процесс поиска в глубину распространяется вдоль одного пути, пока он не
достигнет границы, затем рассматриваются альтернативные пути той же или
меньшей глубины, отличающиеся только последним шагом, затем пути,
отличающиеся двумя последними шагами, и т. д.
Второй тип неинформированной процедуры поиска располагает вершины
списка ОТКРЫТ в порядке возрастания их глубины в дереве поиска. (И здесь
для скорейшего завершения целевые вершины следует сразу помещать в
начало списка ОТКРЫТ.) Процесс поиска, являющийся результатом такого
упорядочения, называется поиском в ширину, поскольку раскрытие
вершины в дереве поиска происходит вдоль "уровня" на одинаковой глубине.
На рис. 2.7 показано дерево поиска, порожденное поиском в ширину для
задачи об игре в 8. Числа около каждой вершины указывают порядок, в
котором вершины выбираются для раскрытия. Заметим, что целевая
вершина выбирается сразу после того, как она будет создана.
В дальнейшем покажем, что поиск в ширину гарантирует нахождение
кратчайшего пути к целевой вершине при условии, что такой путь вообще
существует. (Если такого пути нет, то данный метод закончит работу
неудачно в случае конечных графов или никогда не завершит в случае
бесконечных графов.)
2.4. ЭВРИСТИЧЕСКИЕ ПРОЦЕДУРЫ ПОИСКА НА ГРАФЕ
Методы поиска без информации, будь то поиск в ширину или в глубину,
являются методами перебора для нахождения путей к целевой вершине.
В принципе эти методы дают решение задачи отыскания пути, но зачастую
они не пригодны для использования при управлении системами продукции
ИИ, поскольку здесь в процессе поиска до нахождения требуемого пути
раскрывается слишком много вершин. Вследствие того, что на практике
всегда существуют ограничения на время и память, которыми мы располагаем
для реализации этого процесса, необходимо найти более эффективные
альтернативы неинформированному поиску.
Для многих задач имеется возможность использовать некоторую
информацию, относящуюся к рассматриваемой задаче, чтобы содействовать
сокращению поиска. Информацию такого рода обычно называют эвристической,
а процедуры поиска, использующие ее, — методами эвристического поиска.
Часто можно определить эвристики, уменьшающие затраты на поиск (по
сравнению, например, с методом поиска в ширину), но не ценой лишения
гарантии того, что путь с минимальной длиной будет найден. Некоторые
эвристики очень существенно уменьшают затраты на поиск, но не гарантируют
нахождения пути минимальной стоимости. В большинстве практических задач
мы стремимся к тому, чтобы минимизировать некоторую комбинацию
стоимости пути к цели и стоимости поиска, необходимого для нахождения
этого пути. Более того, нас обычно интересуют такие методы поиска, которые
минимизируют эту комбинацию, усредненную по всем ожидаемым задачам.
Если усредненная стоимость комбинации для первого метода поиска мень-
65
[ro Tf wol
j ГЧ ОО О Lm
jro тг wo 1 ^/*
ro
tvj 00 О
— г- ■
ro тГ wo
r>J ■ О
— 00 Г-
si
I*
ro Tf W>
00 — sO
wo
ГО Tf W0
00 — ■
Г-J Г- sO
26 / \ 2"
го тГ ■
oo — wo
го ^- wo
00 ■ ~
ГЧ1 Г- чС
|ro Tt "->
00 — «О
■ ГМ Г-
-
го тГ wo
■ — vC
00 ГЧ1 r»
K
ГМ
— ■ чС
■ ТГ wo
3C (N r-
ro rf wo
00 Г- ■
ГЧ1 чО ~
^
с
\
vC
rO ТГ ■
00 Г- WO
гл тГ w-,
X Г- —
OD ■ r-
\ ^
ro ■ WO
эс тГ r-
Cvl О —
с
ro
rO WO ■ 1
ОС *Г Г-
CO t Г-
roi Τ w-j
■ X r-
CM О —
10 / \ II
r*-> оо г- :
rs4 О — '
" Τ w 1
■ ·.£> —
~> 9 *Λ
«a «c r-
■ cv —
19 «■
4? ■ rV
<a© <vj —
■ 4· «"*
ΙΛ·βΝ
OO Ν —
to
>»
К
η
о
υ
§
и
о
о
и
s
о
с
о
η
«£
66
со о >/>
[с4 — г-
х "ч τΊ
■ «0<л
С4 — г-
X >/; ■
Ό ■ Τ
-
Ό Ο rf
Χ ■ «Л
^
\
Ό VO ·*
■ х <л
Ό «О·*
х — «л
Μ ■ г-
Ό «Λ ■
X ·* О
[OJ —
ΓΙ ■ ГО «Л
X 1- sC
[гы — г-
X ТГ ■
<\» — г-
X ГО <Л
■ ТГ >С
<М — Г-
го ^Г <л
lг,-'"
-
^
тг
■ ТГ «Л
2 3||2 3
8 4 1 8
6 5||7 6
■ — г-
о
ТГ ■ <Л
ГО X О
гм — г-
— ■ г-
к^
Pi
ЪГ,„\
— г- ■ |
— X Г-
0> 3
ΖΓ m
«л гм г- ОР^Ч. |ό тг <л|
~1 1 "XL.J
1сО ^" «Л
гх ■ г-
Η
со ·* <Л
■ гм г-
41·
ГО ^" <Л
X ГМ Г-
к
со ^- <л|
— ш о\
0ONM
Ό — >0
χ сц г-
■ ОГ-
«Ν-
.
^
X
X
"·> τ V-
VO ■ г-
Х>С* —
I
I
I
г4
67
ше, чем для второго, то говорят, что первый метод поиска имеет большую
эвристическую силу, чем второй. Заметим, что из нашего определения не
следует, что метод поиска, обладающий большей эвристической силой,
гарантирует нахождение пути минимальной стоимости.
Усредненные стоимости комбинаций в действительности никогда не
вычисляются и потому, что трудно принять решение, каким образом
комбинировать стоимость пути и стоимость поиска, и потому, что было бы трудно
определить распределение вероятностей на множестве задач, с которыми
придется столкнуться. Поэтому вопрос о том, обладает ли один метод
поиска большей эвристической силой но сравнению с другим, обычно
решается на основе интуиции, накопленной в процессе работы с этими методами.
2.4.1. ПРИМЕНЕНИЕ ОЦЕНОЧНЫХ ФУНКЦИЙ
Эвристическую информацию можно использовать для упорядочения
вершин в списке ОТКРЫТ на шаге 8 процедуры GRAPHSEARCH таким
образом, что процесс поиска будет распространяться по тем участкам границы,
которые представляются наиболее перспективными. Чтобы применить такую
процедуру упорядочения, нужен метод вычисления "перспективности"
вершины. В одном важном методе используется функция, принимающая на
вершинах действительные значения и называемая оценочной. В основе
оценочных функций лежат самые разнообразные идеи: делались попытки
определить вероятность того, что некоторая вершина принадлежит наилучшему
пути; предлагались меры расстояния или различия между произвольной
вершиной и целевым множеством; кроме того, в настольных играх или
головоломках для рассматриваемой конфигурации часто подсчитывается
число очков — на основании тех ее особенностей, которые, видимо, связаны с
ее перспективностью.
Обозначим оценочную функцию символом /. Тогда /(п) дает значение
этой функции в вершине п. Пусть пока / — любая произвольная функция;
в дальнейшем предположим, что она является оценкой стоимости пути
минимальной стоимости от исходной вершины к целевой при ограничении, что этот
путь проходит через узел η.
Используем функцию / для упорядочения вершин в списке ОТКРЫТ на
шаге 8 процедуры GRAPHSEARCH. Условимся, что вершины в списке
ОТКРЫТ расположены в порядке возрастания соответствующих им значений
функции /. При совпадениях значений/ упорядочение осуществляется
произвольно, но целевым вершинам всегда отдается предпочтение. Считаем,
что вершина, имеющая меньшую оценку, с большей вероятностью окажется
на оптимальном пути.
Способ, с помощью которого оценочная функция используется в
процедуре GRAPHSEARCH для упорядочения вершин, можно пояснить, снова
рассмотрев пример игры в 8. Возьмем простую оценочную функцию
f(n)=d(n)+W(n),
где d(n) — глубина вершины η на дереве поиска nW(n) - число
находящихся не на нужном месте клеток в базе данных, связанной с вершиной п. Таким
образом, конфигурация исходной вершины
68
2 8 3
1 6 4
7 5
имеет/= 0 + 4 = 4.
Результаты применения
процедуры GRAPHSEARCH к игре
в 8 с использованием такой
оценочной функции приведены
на рис. 2.8. Значения / для
каждой вершины заключены в
кружок; отдельно выписанные
числа указывают на порядок,
в котором раскрывают
вершины. Видно, что здесь найден
тот же решающий путь, что и с
помощью других методов
поиска, хотя использование
оценочной функции позволило
раскрыть значительно меньше
вершин. (Если применить
оценочную функцию, равную просто
/(и) = d(n), то получаем
процесс поиска в ширину.)
Выбор оценочной функции
в значительной степени
определяет результаты поиска.
Использование оценочной
функции, которая не может
различить среди нескольких вершин
действительно перспективную,
может дать пути, стоимости
которых превышают минимальную; в то же время использование функции,
переоценивающей перспективность всех вершин (такой, как оценивающая
функция, дающая поиск в ширину) , приводит к раскрытию слишком многих
вершин. В следующих разделах содержатся некоторые результаты
теоретического исследования работы процедуры GRAPHSEARCH при
использовании определенного типа оценочной функции.
2.4.2. АЛГОРИТМ А
Определим оценочную функцию / так, чтобы ее значение /(и) для любой
вершины η оценивало сумму стоимости пути минимальной стоимости от
исходной вершины s к вершине η и стоимости аналогичного пути от
вершины η к целевой. Это значит, что /(и) является оценкой стоимости пути
минимальной стоимости при условии, что он проходит через вершину п. Та
вершина в списке ОТКРЫТ, для которой значение / наименьшее, считается
вершиной, дающей наименее жесткое ограничение, следовательно, ее
целесообразно взять для очередного раскрытия.
Перед тем, как продемонстрировать некоторые свойства этой оценочной
69
ф[
X
ф|
φ
/
,■8 3
2 1 4
17 6 5,
з ^
2 8 3
α 1 4
7 6 5
А
ш
2 8 3|
1 6 4
■ 7 5|
Φ
1 ·
\
2 8 3
7 1 4
■ 6 5
W
Целевая а.
вершина чВг
Φ
[l 23
8 ■ 4
[7 6 5
2 8 3]
1 6 4
7 · S|
Χ
2 8 3 Ι
1 ■ 4
7 6 5 I
Τ
2 ■ 3
1 8 4
7 6 5
5 I
■ 2 3
1 8 4
7 6 5
6
11 г з
■ 84
[7 6 5
]Ф
Исходная
вершина
\
Ф\
Χ
2 8 3
1 6 4
7 5 ■
Φ
Φ
ll 2 3
7 8 4
|· 6 5
2 3 ■
1 8 4
7 6 5
2 8 3
1 4 ■
7 6 5]
Рис. 2.8. Дерево поиска с использованием
оценочной функции
функции, введем ряд полезных обозначений. Пусть функция к(щ, iy)
выражает реальную стоимость пути минимальной стоимости между двумя
произвольными вершинами щ и и.·. (Функция к не определена для вершин,
между которыми нет пути.) Стоимость такого пути от вершины η к
некоторой конкретной целевой вершине щ в этом случае равна к (и, f г·). Пусть
h *(п) — минимум всех значений к (и, ίζ·) на полном множестве целевых
узлов {f /}. Таким образом, h *(n) — стоимость пути минимальной
стоимости от вершины η к целевой вершине и любой путь от вершины η к целевой,
для которой достигается h *(п), является оптимальным путем от η к цели.
(Функция h * не определена для любой вершины и, не имеющей доступа ни
к одной целевой вершине.)
Часто нас интересует стоимость k(s, n) оптимального пути от заданной
исходной вершины s к некоторой произвольной вершине и. Чтобы
несколько упростить наши обозначения, введем новую функцию g*(n) = k(s, ή)
для всех η, доступных из s.
Далее, определим функцию /* так, чтобы ее значение /*(я) для любой
вершины η было бы реальной стоимостью оптимального пути от вершины
s к вершине η плюс стоимость оптимального пути от вершины η к целевой:
f*(n)=g*(n)+h*(n).
Функция /*(«), следовательно, равна стоимости оптимального пути при
условии, что он проходит через вершину и. (Заметим, что f*(s) = h *(s) —
это реальная стоимость оптимального пути от s к цели в отсутствие
ограничений.)
Мы хотим, чтобы наша оценочная функция / была оценкой /*. Эта
оценка дается соотношением
f(n)=g(n)+h(n),
где g — оценка g* и h — оценка h *. Очевидно, в качестве g (n) можно
выбрать стоимость пути на дереве поиска от s к п, которая получается в
результате суммирования стоимостей дуг, вычисленных при отслеживании
указателей от л к «. (Этот путь является путем самой меньшей стоимости
от s κ п, найденным до сих пор алгоритмом поиска. Значение g (ή) для
некоторых вершин можно уменьшить, если дерево поиска видоизменяется на
шаге 7.) Заметим, что такое определение подразумевает g(n) **g*(n). При
установлении h (ή) — оценки h *(n) — исходим из эвристической информации
об области задачи. Эта информация может быть сходна с той, которая
использовалась в функции W(n) примера игры в 8. Назовем h эвристической
функцией и позднее рассмотрим ее более подробно.
Итак, пусть в качестве оценочной функции имеем
f(n)=g(n)+h(n).
Назовем алгоритм GRAPHSEARCH, использующий эту оценочную
функцию для упорядочения вершин, алгоритмом А. Отметим, что, когда Л = 0и
g =d (глубина вершины на дереве поиска), алгоритм А идентичен поиску в
ширину. Ранее мы утверждали, что алгоритм поиска в ширину с гарантией
находит путь к цели, имеющий минимальную длину. Покажем теперь, что
если h является нижней границей h *(h (ή) <h *(и) для всех вершин ή),
то алгоритм А находит оптимальный путь к цели. Когда алгоритм А исполь-
70
зует функцию h , являющуюся нижней границей h *, то называем его
алгоритмом А* (читается "А со звездочкой"). Поскольку h = О несомненно
является нижней границей h*, тот факт, что алгоритм поиска в ширину
обнаруживает кратчайшие пути, подтверждается сразу как частный случай более
общего результата, относящегося к алгоритму А*.
2.4.3. СОСТОЯТЕЛЬНОСТЬ АЛГОРИТМА А*
Будем говорить, что алгоритм поиска состоятелен, если для любого
графа он завершает работу, получая оптимальный путь от s к целевой вершине,
при условии, что путь от 5 к целевой вершине существует. В этом
подразделе приведем неформальное доказательство того, что А* состоятелен.
Для подтверждения состоятельности какого-либо алгоритма необходимо
по меньшей мере показать, что он завершит работу, если целевая вершина
достижима. Алгоритм GRAPHSEARCH останавливается (если это вообще
случается) на шаге 3 или 5. Заметим, что при каждом повторении цикла
алгоритма вершина удаляется из списка ОТКРЫТ и только конечное число
новых преемников добавляется в этот список. Для конечных графов мы
рано или поздно истощим запас новых преемников, и, следовательно, если
этот алгоритм не завершит успешно работу на шаге 5, придя к целевой
вершине, то он остановится на шаге 3, исчерпав, в конце концов, список
ОТКРЫТ Итак,
RESULT 1: процедура GRAPHSEARCH всегда завершает работу
на конечных графах.
Теперь покажем, что если путь от s к целевой вершине существует, то
окончание работы А* наступит даже для бесконечных графов. Для этого
допустим обратное, что А* никогда не остановится. Работа не завершится до
тех пор, пока новые вершины будут постоянно добавляться в список
ОТКРЫТ Но в этом случае можно показать, что даже наименьшее из значений
/ для вершин в списке ОТКРЫТ будет расти до нереально больших значений.
Пусть d* (и) — длина самого короткого пути в рассматриваемом неявном
графе от s до любой вершины η на дереве поиска, порожденном
алгоритмом А*. Тогда поскольку стоимость каждой дуги в этом графе является
по крайней мере малым положительным числом е, то g*(n) > d*(n)e.
(Напомним, что g* (и) — стоимость оптимального пути от s к п, g (η) —
стоимость пути на дереве поиска от s к вершине п.) Ясно, что g (/ι) > g* (и) и,
следовательно, g (η) > d*(n)e. Если h (и) > О (это будем предполагать и в
дальнейшем), /(/г) > g(n) и, значит, f(n) > d*(n)e. В частности, для каждой
вершины в списке ОТКРЫТ его функция / равна по меньшей мере d*(ri)e.
И хотя А* выбирает для раскрытия ту вершину в списке ОТКРЫТ, для
которой / является наименьшей, эта выбранная вершина будет в конечном
счете иметь сколь угодно большое значение с?*, и следовательно, также /,
если А* не останавливается.
Теперь, чтобы показать, что А*, в конце концов, должен завершить работу,
покажем, что до момента остановки А* в списке ОТКРЫТ всегда есть какая-
либо вершина и, для которой /(п) </*(s). Пусть упорядоченная
последовательность (s - по, ηΪ3 . . . , nk) будет оптимальным путем от s к целевому
узлу nk. Тогда для любого момента до завершения работы А* считаем, что
71
η — первая вершина из этой последовательности, которая находится в
списке ОТКРЫТ. (Там должна быть по крайней мере одна такая вершина,
так как s находится в списке ОТКРЫТ в самом начале, и если п^ помещена
в списке ЗАКРЫТ, то А* закончил работу.) По определению / для А* имеем
f(n)=g(n')+h(n').
Известно, что А* уже нашел оптимальный путь к η , так как вершина
η находится на оптимальном пути к цели и все ее предшественники на этом
пути уже помещены в список ЗАКРЫТ Следовательно, g(n) = g*(n) и
/(и) =«*(«') + Л (»')·
Поскольку мы предполагаем, что h (η1) <Л *(л') , можно записать
/о») <**(»')+**(»')=/*(»').
Но /* для любой вершины на оптимальном пути равна /* (s) — минимальной
стоимости, поэтому/(п') </*(«). Итак, имеем
RESULT 2: В любой момент до завершения работы А*
в списке OPEN существует вершина η
такая, что она находится на оптимальном
пути от s к целевой вершине и f(n) ^f*(s).
Сопоставление полученного результата с предыдущим утверждением
о том, что даже самые малые / для вершин в списке ОТКРЫТ в случае
неостанавливающегося алгоритма А* становятся неограниченными,
показывает, что А* должен закончить работу даже для бесконечных графов.
Итак,
RESULT 3: Если путь от s к целевой вершине
существует, то А* завершает работу.
РЕЗУЛЬТАТ 3 имеет интересное следствие — любая вершина η из списка
ОТКРЫТ, для которого f(n)<f*(s), будет рано или поздно выбрана
алгоритмом А* для раскрытия. Доказательство этого оставляем читателю в
качестве упражнения.
Теперь уже совсем просто показать, что А* состоятелен. Во-первых,
отметим снова, что алгоритм А* может остановиться при достижении целевой
вершины либо на шаге 3 или 5, исчерпав список ОТКРЫТ. Но список
ОТКРЫТ никогда не оказывается пустым до завершения работы, если
существует путь от s к целевой точке; причина состоит в том, что в соответствии
с РЕЗУЛЬТАТОМ 2 в списке ОТКРЫТ (и на оптимальном пути) всегда
имеется какая-либо вершина. Следовательно, А* должен завершить работу
после обнаружения целевой вершины.
Далее нужно показать, что А* заканчивает работу, только найдя
оптимальный путь к целевой вершине. Представим себе, что А* остановился, придя к
некоторой целевой вершине ί, но не нашел оптимального пути, т.е. /(f) =
= g(t) >,/*(?)· Но в соответствии с РЕЗУЛЬТАТОМ 2 непосредственно перед
завершением работы существует вершина η в списке ОТКРЫТ и на
оптимальном пути такая, что /(п) </*(s) </(t). Следовательно, на этом
этапе алгоритм А* отобрал бы для раскрытия η , а не ί, что противоречит
нашему допущению об окончании работы А*. Следовательно, в конечном счете
получаем
72
RESULT 4: Алгоритм А* состоятелен. (Иными
словами, если существует путь от s к целевой
вершине, то А* заканчивает работу, найдя
оптимальный путь.)
Каждая вершина, выбранная алгоритмом А* для раскрытия, обладает
интересным свойством, которое следует непосредственно из РЕЗУЛЬТАТА 2:
функция / для него никогда не превышает стоимости f*(s) оптимального
пути. В дальнейшем это обстоятельство будет для нас важно. Для
доказательства обозначим через η произвольную вершину, выбранную алгоритмом А*
для раскрытия. Если η — целевая вершина, то в соответствии с
РЕЗУЛЬТАТОМ 4 /(и) =/*(«), поэтому считаем, что η — нецелевая вершина. Далее А*
выбирает η до завершения работы, следовательно, в этот момент (в
соответствии с РЕЗУЛЬТАТОМ 2) мы знаем, что в списке ОТКРЫТ имеется
некоторая вершина η , находящаяся на оптимальном пути от s к цели, для
которого /(и ) <jf*(s) · Если η = η , то получаем наш результат. В противном
случае, как известно, А* выберет для раскрытия п, а не п; следовательно, это
должен быть случай, когда
/00 </(в') </*(,).
Итак, имеем
RESULT 5: Для любой вершины п, выбранной
алгоритмом А* для раскрытия,/(м) </*(«).
2.4.4. СРАВНЕНИЕ ВАРИАНТОВ АЛГОРИТМА А*
Точность кашей эвристической функции h зависит от того, насколько
велико заложенное в ней эвристическое знание об области задачи. Ясно,
что использование h (η) = О свидетельствует о полном отсутствии какой-
либо эвристической информации о данной задаче, несмотря на то, что
такая оценка является нижней границей h*(n) и, следовательно, приводит к
состоятельному алгоритму.
Сравним два варианта А*, а именно Ах и А2, использующие оценочные
функции:
/ι О) = £ι(Ό+Λι(Ό; /2 О) =g2(n)+h2(n),
где и h χ и h 2 — нижние границы для h*. Считаем, что алгоритм А2 является
более информированным, чем Ах, если для всех нецелевых вершин η имеем
h 2 (η) > h χ (η). Это определение кажется интуитивно разумным, поскольку
h ограничено сверху h*, обеспечивающей состоятельность алгоритма, и
можно ожидать, что использование больших значений h (и приближающихся,
следовательно, к h*) требует более точной эвристической информации.
В качестве примера рассмотрим игру в 8, решение которой приведено на
рис. 2.8. Там использовалась оценочная функция /(n) = d(n) + W (η). Мы
можем интерпретировать процесс поиска в этом примере как применение
алгоритма А* с h (и) = W (п) и единичными стоимостями дуг. (Заметим, что
W(n) является нижней границей числа шагов, оставшихся до достижения
цели.) Разумно считать, что алгоритм А* с h(n) =W(n) более информирован,
чем поиск в ширину, для которого h (η) ^0.
73
Интуитивно можно ожидать, что более информированному алгоритму
для нахождения пути минимальной стоимости нужно будет раскрыть, как
правило, меньшее число вершин. Для случая игры в 8 это наблюдение
подтверждается при сравнении рис. 2.7 и 2.8. Конечно, то, что один алгоритм
раскрывает меньше вершин, чем другой, не означает, что он является более
эффективным. В действительности может случиться так, что более
информированный алгоритм будет осуществлять более трудоемкие вычисления,
что понизит его эффективность. Тем не менее число вершин, раскрываемых
алгоритмом, — один из факторов, определяющих его эффективность, и этот
фактор позволяет проводить простые сравнения.
Допустим, что алгоритм А2 более информирован, чем Αχ, и что оба они -
варианты алгоритма А*. Пусть Ах и А2 используются для поиска на неявно
заданном графе, имеющем путь от вершины s к целевой вершине. Оба,
разумеется, завершат работу, найдя оптимальный путь. Покажем, что к
моменту окончания всякая вершина π в С, раскрытая алгоритмом А2,
раскрывалась также и алгоритмом Ах. Таким образом, Ах всегда раскрывает по
меньшей мере столько же вершин, сколько и более информированный
алгоритм А2.
Докажем этот результат, используя индукцию по глубине вершины на
дереве поиска по окончании работы алгоритма А2. Сначала докажем, что если
А2 раскрывает вершину п, имеющей нулевую глубину в ее дереве поиска,
то это сделает и Ах. Но в данном случае η = s. Если s представляет собой
целевую вершину, то ни один алгоритм не раскрывает ни одну вершину. Если
s — нецелевая вершина, то оба алгоритма раскрывают вершину s.
Продолжая доказательство до индукции, допустим (гипотеза индукции), что Ах
раскрывает все вершины, раскрываемые алгоритмом А2, имеющие на дереве
поиска А2 глубину к или менее. Теперь следует доказать, что любая вершина
и, раскрытая алгоритмом А2 и имеющая глубину к + 1 на дереве поиска
алгоритма А2, будет также раскрыта и алгоритмом Ах. По гипотезе индукции
любой потомок вершины η в дереве поиска А2 раскрыт также алгоритмом
Ах. Следовательно, вершина η находится на дереве поиска Ах и существует
путь от 5 к η в этом дереве поиска, причем стоимость пути не выше, чем
стоимость пути от s κ η в дереве поиска алгоритма А2, т. е. g ι (η) <g2 (n).
Допустим противоположное тому, что мы хотим доказать, а именно
что At не раскрыл вершину и, раскрытую алгоритмом А2. После окончания
работы Αχ вершина η должна быть в списке ОТКРЫТ алгоритма Αχ,
поскольку Aj раскрыл родительскую вершину для п. Так как Аг завершил работу,
найдя путь минимальной стоимости, не раскрывая вершину п, то известно,
что
Л 00 >/*(»).
следовательно,
*ι(»)+ΜΌ>/*(0.
Поскольку было показано, 4TOgx (n) <g2 (n), το
hl(n)>f*(s)-g2(n).
Но раз в соответствии с РЕЗУЛЬТАТОМ 5 алгоритм А2 раскрыл вершину
п, получим
74
/а (в) </·(«).
или
или
ft2 («)</·(.) -*,(»)·
Сравнение этого неравенства для Л 2 (и) с более ранним для /ι j (η) (Л t (и) >
^ f*(s) ~g2 (Ό) дает, что по крайней мере в вершине η h г должно
равняться h 2, однако это противоречит допущению, что А2 более информирован,
чем Ах. Итак, имеем
RESULT 6: Если At и А2 — два варианта А* такие,
что А2 более информирован, чем Aj, то
к окончанию процессов поиска на любом
графе, имеющем путь от s к целевой
вершине, каждая вершина, раскрытая
алгоритмом А2, раскрыта также и
алгоритмом Aj. Следовательно, Ах раскрывает
по меньшей мере столько же вершин,
сколько и А2.
2.4.5. МОНОТОННОЕ ОГРАНИЧЕНИЕ
При описании процедуры GRAPHSEARCH мы отметили, что в случае
раскрытия какой-либо вершины η некоторые ее преемники могут уже
находиться в списке ОТКРЫТ или ЗАКРЫТ. При этом, возможно, потребуется
скорректировать дерево поиска так, чтобы оно определяло пути наименьших
стоимостей в G от вершины s к потомкам вершины п. Дополнительно к
затратам на корректировку дерева поиска часто приходится проводить
большую вычислительную работу, связанную с проверкой того, не порождалась
ли та или иная вершина раньше. Покажем, что при достаточно слабых и
разумных ограничениях на h алгоритм А* при выборе вершины для
раскрытия уже находит оптимальный путь к ней. Таким образом, при этих
ограничениях нет необходимости для А* проверить, находится ли только что
порожденная вершина уже в списке ЗАКРЫТ и не нужно ли менять
родительские отношения на дереве поиска для любого преемника этой вершины в
графе поиска.
Говорят, что эвристическая функция h удовлетворяет монотонному
ограничению, если для всех вершин щ и ги таких, что ги является
преемником η^,Η (η) —h (гь) <с(ηζ·,м ) , причем h (t) =0.
Если записать это монотонное ограничение в форме
h (ni)<h(nf) +с(м/,м/),
то можно заметить его сходство с неравенством треугольника. Оно
устанавливает, что оценка оптимальной стоимости пути от вершины щ к цели не
должна превышать сумму стоимости дуги от щ к п.- и оценки оптимальной
стоимости пути от иу к цели. Можно сказать, что это монотонное
ограничение накладывает достаточно разумное условие — эвристическая функция
должна локально согласовываться со стоимостями дут.
75
Для игры в 8 легко проверить, что h (n) =W(n) удовлетворяет
монотонному ограничению. Если же функция h каким-либо образом изменяется
в ходе процесса поиска, то это монотонное ограничение может не
удовлетворяться.
Теперь покажем, что при таком монотонном ограничении алгоритм А*,
раскрывая вершину, находит оптимальный путь к ней. Пусть η — любая из
вершин, выбранных для раскрытия алгоритмом А*. Если n=s, то нахождение
А* оптимального пути к s тривиально; поэтому считаем, что η не совпадает
с s. Пусть последовательность Ρ = (s = п0, щ , п2, . . . , п% = п) представляет
собой оптимальный путь от 5 к п. Пусть вершина щ — последняя из этой
последовательности, которая находится в списке ЗАКРЫТ в то время, как
А* выбирает η для раскрытия. (Вершина s находится в списке ЗАКРЫТ, а
nk не находится, потому что она именно сейчас выбирается для раскрытия.)
Следовательно, вершина щ + х в последовательности Ρ находится в списке
ОТКРЫТ в то время, как А* выбирает вершину п.
Используя монотонное ограничение, имеем
g4ni)+h(ni)<g*(ni)+c(ni9ni+l)+h(ni+l).
Поскольку щ и щ+ х находится на оптимальном пути,
то
ЬЧп,) +Л (щ)) < Ь*(п,+ 1) +Λ(4 + ι)]·
В силу транзитивности имеем
g*(nl + l) +h (n7 + 1) <g*(nk) +h (nk)
или
/ta + i) <*·(")+* 00·
Следовательно, в то время, как А* выбирает вершину п, предпочитая
вершине п/ + 1, должно выполняться g(n) <;g*(ri), иначе f(n) была бы больше
f(n + \)9 Поскольку g(m)> g*(m) для всех вершин т на дереве поиска,
получаем
RESULT 7: Если удовлетворяется монотонное
ограничение, то алгоритм А* автоматически
обнаруживает оптимальный путь к лю-
бойвершине, выбранной им для
раскрытия. Другими словами, если А*
выбирает η для раскрытия и если
удовлетворяется монотонное ограничение, то
*(»W(n)·
С монотонным ограничением связан также еще один интересный
результат — значения функции / для последовательности вершин, раскрытых
алгоритмом А*, образуют неубывающую последовательность. Пусть вершина
щ раскрывается сразу после вершины пг. Если п2 находится в списке
ОТКРЫТ в то время, как раскрывается пг, получаем (тривиально),что/(щ) <
^/("з) · Пусть пг не содержится в списке ОТКРЫТ, когда раскрывается щ.
(Вершина щ не содержится и в списке ЗАКРЫТ, поскольку предполагаем,
что она еще не раскрывалась.) Тогда если п2 раскрывается сразу после пх,
76
то она должна добавляться в список ОТКРЫТ в процессе раскрытия
вершины щ. Поэтому п2 является преемником щ . При этих условиях в момент,
когда п2 выбирается для раскрытия, имеем
/О2) =g(n2) + h(n2) =
= g*(n2) + h (n2) = (РЕЗУЛЬТАТ 7)
= g*Oi) +c(mi,m2) +h(n2) =
= g ("1) + с ("ι, n2 ) + h (n2 ) (РЕЗУЛЬТАТ 7).
Поскольку монотонное ограничение означает, что
с Oh , п2 ) + /ι (м2 ) > + Λ (μι ) ,
получаем
/Ы>ЙГ(»1)+Л(Я1) =/0ч)·
Так как этот факт верен для любой пары соседних вершин в
последовательности вершин, раскрытых алгоритмом А*, имеем
RESULT 8: Если удовлетворяется монотонное ограничение,
значения / для последовательности вершин,
раскрытых алгоритмом А* не убывают.
Если монотонное ограничение не удовлетворяется, возможно, что какая-
либо вершина при раскрытии имеет значение /, меньшее, чем для
предыдущей раскрытой вершины. Мы можем использовать это обстоятельство,
чтобы улучшить эффективность А* при таком условии. В силу РЕЗУЛЬТАТА 5,
когда вершина η раскрыта, /(и) </*(«). Пусть в ходе работы алгоритма А*
сохраняется глобальная переменная F — максимум / для всех до сих пор
раскрытых вершин. Ясно, что в каждый момент F </*($). Если для какой-
либо вершины и, находящейся в списке ОТКРЫТ, f(n) <F, то, как следует
из РЕЗУЛЬТАТА 3, она, в конце концов, будет раскрыта. В
действительности, возможно, есть несколько вершин в списке ОТКРЫТ, для которых
/ строго меньше F. Вместо того, чтобы выбирать среди них ту вершину,
для которой / минимальна, мы могли бы выбрать вершину с наименьшим
значением функции g. (В любом случае все они в конечном счете должны
быть раскрыты.)
Смысл этого измененного правила выбора вершин в том, чтобы увеличить
вероятность того, что первый обнаруженный путь к какой-либо вершине
будет оптимальным. Таким образом, даже если монотонное ограничение не
удовлетворяется, эта перестройка уменьшает необходимость в
переориентации указателей на шаге 7 алгоритма. (Заметим, что, когда монотонное
ограничение удовлетворяется, РЕЗУЛЬТАТ 8 означает, что в списке ОТКРЫТ
никогда не будет вершины, для которой /< F.)
2.4.6. ЭВРИСТИЧЕСКАЯ СИЛА ОЦЕНОЧНЫХ ФУНКЦИЙ
Выбор эвристической функции имеет критическое значение при
определении эвристической силы алгоритма поиска А. Использование h ^0
гарантирует состоятельность, но приводит к поиску в ширину и, таким образом,
обычно является неэффективным. Установление h равным наибольшей
возможной нижней границе h * обеспечивает раскрытие наименьшего числа
вершин, не нарушающих состоятельности алгоритма.
77
Часто можно выиграть в эвристической силе за счет состоятельности
путем использования некоторой функции для h , не являющейся нижней
границей Л*. Эта добавочная эвристическая сила дает нам возможность решать
гораздо более трудные задачи. В игре в 8 функция h (η) = W{n) (W(n) —
число фишек, находящихся не на своем месте) является нижней границей
h * (и), но не обеспечивает очень хорошей оценки трудности позиций
(выраженной числом шагов до цели) для данной конфигурации фишек. Более
хорошей оценкой будет функция h (η) =Р(и), где Р(п) — сумма расстояний
каждой фишки от ее места в целевой конфигурации (при этом
игнорируются мешающие фишки). Даже эта оценка, однако, является слишком
грубой, так как она не дает точного учета того, насколько трудно поменять
местами две соседние фишки.
Достаточно хорошей оценкой для игры в 8 будет
h(n) = i?(n)+3S(n).
Величина S (и) - счет последовательности, получаемый последовательной
проверкой нецентральных клеток, причем за каждую фишку, если после
нее стоит не та, которая соответствует правильному порядку, добавляется 2
или 0 в противном случае; за фишку, стоящую в центре, добавляется 1.
Отметим, что такая функция h не дает нижней границы h*. С помощью этой
эвристической функции, используемой в оценочной функции /(и) =g(n) +
+ h (м), можно легко решать гораздо более трудные случаи игры в 8, чем
тот, который был решен ранее. На рис. 2.9 показано дерево поиска,
получающееся в результате применения Процедуры GRAPHSEARCH с этой
оценочной функцией к задаче преобразования
2 16 12 3
4 8 в 8 4
7 5 3 7 6 5.
На этом рисунке значения / для каждой вершины, как и ранее,
заключены в кружок, а отдельно стоящие числа показывают порядок, в котором
раскрываются вершины. (В процессе поиска случай равенства
минимальных значений / разрешается выбором наиболее глубокой вершины на
дереве поиска.) Найденный решающий путь, как оказалось, обладает
минимальной длиной (18 шагов), несмотря на то, что, поскольку функция h
не является нижней границей h*, у нас не было гарантии найти оптимальный
путь. Заметим, что функция h приводит к "сфокусированному" поиску,
направленному к цели; возникает только очень ограниченное разветвление
в начале поиска.
Другим фактором, определяющим эвристическую силу алгоритмов
поиска, является трудоемкость вычисления эвристической функции.
Наилучшей функцией была бы та, которая точно совпадала бы с Л*, w"
обеспечило бы абсолютный минимум числа раскрытий вершин. (Такую
функцию h можно было бы, например, определить в результате отдельного
полного поиска с участием каждой вершины, но, очевидно, это не снизило бы
общей трудоемкости вычислений.) Иногда функцию h , не являющуюся
нижней границей Л*, легче вычислить, чем ту, которая представляет собой
нижнюю границу. В этих случаях эвристическую силу можно увеличить
78
Исходная вершина
Целевая
вершина
Рис. 2.9. Дерево поиска для игры в 8
вдвое, поскольку можно уменьшить как общее число раскрытых вершин (за
счет состоятельности), так и трудоемкость вычислений:
В определенных случаях эвристическую силу эвристической функции
можно увеличить просто умножением на некоторую положительную констан-
79
ту, превышающую единицу. Если константа очень велика, возникает
ситуация, как в случае g (л) = 0. Во многих задачах мы всего лишь хотим найти
какой-нибудь путь к цели и не беспокоимся о стоимости полученного пути.
(Конечно, нас заботит трудоемкость поиска, необходимого для нахождения
пути.) В подобных ситуациях мы могли бы считать, что значение g можно
вообще не принимать во внимание, так как на любом этапе поиска для нас
несущественны стоимости уже пройденных путей. Нас интересуют только
остающиеся затраты на поиск, необходимые для нахождения целевой вершины.
Эти затраты на поиск, хотя, возможно, и зависят от значения h для вершин,
находящихся в списке ОТКРЫТ, представляются не зависимыми от значений
g для вершин. Следовательно, для таких задач мы могли бы использовать в
качестве оценочной функции / = h .
Чтобы гарантировать, что хоть какой-нибудь путь будет, в конце концов,
найден, g должна быть включена в /, даже если для нас несущественно
нахождение пути с минимальной стоимостью. Такая гарантия необходима, если h
не является точной оценкой; если бы всегда раскрывались вершины с
минимальной h , процесс поиска мог бы все время раскрывать ложные вершины
и даже не достичь целевой вершины. Включение g приводит к добавлению
в этот процесс составляющей поиска в ширину и, следовательно,
гарантирует, что никакая часть неявно заданного графа не будет постоянно
оставаться необследованной.
Относительные веса функций g и h в оценочной функции можно
варьировать, используя f=g + wh, где w — положительное число. Очень большие
значения w придают слишком большое значение эвристической компоненте,
а очень малые значения w придают поиску преимущественный характер
поиска в ширину. Опыт подсказывает, что эффективность поиска часто
возрастает, если допустить изменение w в обратной зависимости от глубины
вершины на дереве поиска. При небольших глубинах поиск направляется в
основном эвристической компонентой, в то время как при возрастании
глубин он все больше похож на поиск в ширину, чтобы гарантировать, что
какой-либо путь к цели в конечном счете будет найден.
Итак, имеются три важных фактора, влияющих на эвристическую силу
алгоритма А: а) стоимость пути, б) число вершин, открытых при
нахождении пути, и в) трудоемкость вычислений, необходимых для подсчета h .
Выбор удобной эвристической функции дает возможность уравновесить
эти факторы, чтобы достичь максимума эвристической силы.
2.5- ДРУГИЕ АЛГОРИТМЫ
2.5.1. ДВУНАПРАВЛЕННЫЙ ПОИСК
Некоторые задачи можно решить, используя системы продукций,
правила которых можно применять либо в прямом, либо в обратном направлении.
Интересной представляется возможность проводить поиск одновременно
в обоих направлениях. Поиск на графе, моделирующий такую
двунаправленную систему продукций, можно рассматривать как процесс, при котором
поиск осуществляется одновременно из исходной вершины и множества
целевых вершин. Процесс заканчивается, когда (и если) два фронта поиска
подходящим образом встречаются. Сравнение вариантов метода поиска в
ширину показывает преимущество двунаправленного Поиска на графе перед
80
однонаправленным поиском в ширину. На рис. 2.10 сопоставлены два
процесса поиска на двумерной сетке вершин. Видно, что двунаправленный
поиск раскрывает намного меньше вершин, чем однонаправленный.
Фронт однонаправленного
поиска в момент окончания
Целевая
^^ вершина
Фронты
двунаправленного
поиска в момент
окончания
Рис. 2.10. Двунаправленный и однонаправленный процессы поиска в ширину
Фронт обратного поиска
Исходная вершина
Целевая вершина
Фронт прямого поиска
Рис. 2.11. Прямой поиск не встречается с обратным
Ситуация становится более сложной при сравнении двунаправленного
и однонаправленного эвристических поисков. Если эвристические функции,
используемые двунаправленным процессом, окажутся хоть в незначительной
степени неточными, два фронта поиска могут разойтись, не пересекаясь. В
таком случае двунаправленный процесс поиска может раскрыть в два раза
больше вершин, чем это сделал бы однонаправленный процесс. Эту ситуацию
иллюстрирует рис. 2.11.
81
2.5.2. ПОЭТАПНЫЙ ПОИСК
Как уже говорилось, использование эвристической информации может
существенно уменьшить объем поисковой работы, требуемой для
обнаружения приемлемых путей. Следовательно, можно также осуществлять поиск
на гораздо больших графах, чем в отсутствие этой информации. Но и здесь
может случиться, что имеющиеся ресурсы будут исчерпаны до нахождения
удовлетворительного пути. Тогда вместо того, чтобы полностью
прекратить процесс поиска, возможно, целесообразно сократить граф поиска,
чтобы освободить необходимое пространство для углубления поиска.
Таким образом, процесс поиска может осуществляться по этапам,
разделенным операциями сокращения (графа), позволяющими освободить
пространство в памяти. В конце каждого этапа некоторое подмножество
вершин в списке ОТКРЫТ, имеющих, например, наименьшие значения /,
отмечается и сохраняется. Наилучшие пути к этим вершинам
запоминаются, и остаток графа отбрасывается. Затем поиск возобновляется из этих
наилучших вершин. Процесс продолжается до тех пор, пока не будет
найдена целевая вершина или не иссякнут ресурсы. Разумеется, теперь, даже
если мы на каждом этапе используем алгоритм А* и если весь процесс
поиска заканчивается после нахождения пути, нет гарантии, что этот путь
является оптимальным.
2.5.3. ОГРАНИЧЕНИЕ ЧИСЛА ПРЕЕМНИКОВ
Существует способ, который может дать экономию затрат на поиск:
это отбрасывание сразу после раскрытия всех преемников, за исключением
небольшого числа имеющих наименьшие значения /. Конечно, отброшенные
вершины могут находиться на лучших (или на единственном!) путях к цели,
поэтому целесообразность любого такого метода сокращения для
конкретной задачи можно определить только опытным путем.
Иногда достаточно иметь значения в области задачи, чтобы установить,
что некоторые вершины, вероятно, не могут находиться на пути к целевой
вершине. (Такие вершины удовлетворяют некоторому предикату,
подобному DEADEND, использовавшемуся в алгоритме с возвращениями.) Эти
вершины можно удалить из графа поиска, модифицировав алгоритм А
соответствующим образом. Другой способ — приписать этим вершинам очень
большое значение h , чтобы никогда не выбирать их для раскрытия.
Существуют также задачи поиска, для которых можно указать
преемники какой-либо вершины и вычислить для них значения h до того, как
соответствующие базы данных сами будут получены в явном виде. Более
того, может оказаться выгодным отложить вычисление базы данных,
ассоциированной с вершиной, до того, как она будет раскрыта, тогда процесс
поиска никогда не будет производить расчеты для преемников, не
раскрытых этим алгоритмом.
2.6. РАЗЛИЧНЫЕ МЕРЫ КАЧЕСТВА РАБОТЫ
Эвристическая сила метода поиска существенно зависит от отдельных
факторов, специфичных для данной задачи. Оценивание эвристической
силы связано с суждениями, основанными скорее на опыте, чем на расчете.
82
Однако некоторым мерам качества работы можно дать количественное
выражение, и, хотя они могут неполностью определять эвристическую силу,
все же они полезны для сравнения различных методов поиска.
Одна из таких мер называется направленностью. Направленность поискаР-
это степень, в которой поиск является сфокусированным в направлении
цели, а не блуждает по бесперспективным направлениям. Она
определяется просто как
P = L/T,
где L — длина найденного пути к цели; Τ — общее число вершин,
порожденных в ходе поиска (включая целевую вершину, но без учета исходной).
Например, если оператор построения преемников настолько точен, что
порождаются лишь вершины, находящиеся на пути к цели, Ρ достигает
своего максимального значения 1. Поиск без информации характеризуется
Р<\. Итак, направленность измеряет степень, в которой дерево,
порожденное поиском, является скорее "удлиненным", чем "пышным".
Направленность поиска зависит от трудности задачи, решаемой поиском,
а также от эффективности используемого метода поиска. Значение
направленности избранного метода поиска может быть большим, когда
оптимальный решающий путь короткий, и значительна меньшим для длинного пути.
(Возрастание длины L решающего пути обычно приводит к еще более
быстрому возрастанию Т.)
Другая мера — показатель эффективности ветвления В —в большей
степени не зависима от длины оптимального решающего пути. Основой для его
определения является дерево, имеющее а) глубину, равную длине пути, и
б) общее число вершин, равное числу вершин, порожденных в ходе поиска.
Показатель эффективности ветвления есть постоянное число преемников,
которыми могла бы обладать каждая вершина в таком дереве.
Следовательно, показатель В связан с длиной пути L и общим числом порожденных
вершин выражениями:
B+B2 + ...+BL = Г; [BL -\) В/(В-1) = Т.
Хотя В нельзя записать в явном виде как функцию L или Г, представим
на рис. 2.12 диаграмму для В в зависимости от Τ при различных значениях
L. Значения В, близкие к единице, соответствуют поиску, в высокой
степени сфокусированному в направлении цели, с очень незначительным
ветвлением в других направлениях. С другой стороны, "пышный" граф поиска
имел бы большое значение В. Направленность можно связать с В и длиной
пути соотношением Ρ = L (B—l)jB [BL —1]. На рис. 2.13 показано, как
направленность изменяется с длиной пути для различных значений В.
В той степени, в какой показатель эффективности ветвления разумно
считать не зависимым от длины пути, он может использоваться для
предсказания того, сколько вершин может быть построено при поисках с
различными длинами. Например, можно воспользоваться рис. 2.12, чтобы
подсчитать, что применение оценочной функции f = g+P + 3S дает 5=1,08
для примера игры в 8 (см. рис. 2.9). Допустим, требуется оценить,
сколько вершин было бы порождено при использовании этой же оценочной
функции для решения более трудной конфигурации игры в 8, например,
требующей 30 шагов. Из рис. 2.12 видно, что для 30-шаговой задачи понадобилось
83
η
10 Ю2
. Зависимость В от Т для различных L
104Г
бы породить около 120 вершин при
условии, что показатель ветвления
постоянен. Эта оценка, кстати, не
противоречит результатам,
полученным для широкого разнообразия
задач об игре в 8 [77].
_ Рис. 2.13. Зависимость Ρ от L для различ-
8 10 12 14 16 18 20L ных£
2.7. БИБЛИОГРАФИЧЕСКИЕ И ИСТОРИЧЕСКИЕ ЗАМЕЧАНИЯ
В работе Хоровица и Сахни [162] подробно обсуждается поиск с
возвращениями и другие методы. Результаты экспериментального сравнения
алгоритмов с возвращениями и им подобных приводятся в отчете Гашни
[118]. В некоторых задачах, где требуется выполнение ограничений,
можно для уменьшения трудоемкости поиска использовать релаксационные
методы, рассмотренные Маквортом [218], Монтанари [248] и Уолцем
[374].
Процедуры поиска на графе того типа, которые мы назвали
неинформационными, имели разнообразных предшественников. Дейкстра [75] и Мур
[254] предложили, по существу, процедуры поиска в ширину. Динамичес-
84
кое программирование является разновидностью процесса поиска в ширину
[18]. Наша процедура GRAPHSEARCH отличается от многих предыдущих
тем, что мы не переводим вершины из списка ЗАКРЫТ обратно в список
ОТКРЫТ, когда они повторно встречаются. (Вместо этого мы
переориентируем указатели На дереве поиска.)
Использование эвристической информации для повышения
эффективности поиска изучалось как и в искусственном интеллекте, так и в исследовании
операций. В области ИИ эвристический поиск был главной темой работы Нью-
элла, Шоу и Саймона [265, 267]. Использование оценочных функций для
того, чтобы направлять поиск на графах, было предложено Дораном и Мики
[77], у них же заимствованы примеры игры в 8.
Общая теория использования оценочных функций для управления
поиском была дана в статье Харта, Нильсона и Рафаэла [138], на которой
основано наше описание алгоритма А* и его свойств. Тот факт, что А*
раскрывает не больше вершин, чем другие алгоритмы, располагающие не большей,
чем А*, информацией, вначале ошибочно связывался с существованием
ограничения, сходного с монотонным ограничением. Эта ошибка, на которую
указал впервые Р. Коулман, была исправлена Хартом, Нильсоном и Рафаэ-
лом [139]. Исправления и усовершенствования предложены также Голь-
периным [121]. Ван дер Браг дал интересную геометрическую
интерпретацию эвристических процессов поиска [363].
Пол предложил несколько обобщений А*, включающих схему
двунаправленного поиска [283], и метод, с помощью которого в ходе поиска
изменяются относительные веса h и g [284]. Использование нами монотонного
ограничения основано в работе [285]. (Прежнее согласованное
ограничение Харта, Нильсона и Рафаэла является более сильным, чем необходимо,
и его труднее выполнить, чем монотонное ограничение.) Пол [282, 285]
и Харрис [137] проанализировали некоторые последствия для поиска
ошибок в эвристической функции, а Мартелли исследовал сложность
эвристических алгоритмов поиска [224]. (Правило выбора вершины, описанное на
с. 77, основано на статье Мартелли [224].) Саймон и Кадан описали
методы поиска, созданные скорее для нахождения любого решения, чем
стремящиеся к оптимальным решениям [339]. Мики и Росс рассмотрели
процесс эвристического поиска, порождающий в каждый момент только одного
преемника [239].
Вариант поэтапного поиска исследовался Дораном и Мики [76, 77].
Процесс с использованием поэтапного поиска довольно эффективно
применялся в системах понимания речи [200] и интерпретации визуальных сцен [311].
Джексон [164, с. 104] описал приложение к игре в 15 интересного,
процесса поиска, использующего "вехи" (А. К. Чандра).
Доран и Мики предложили меру направленности для оценки
эффективности процесса поиска [77]; Слейгл и Диксон предложили другую меру,
которую они называли "отношением глубины" [343]. Идея нашего
"показателя эффективности ветвления" была навеяна этими более ранними
мерами.
Эвристический поиск находит много применений иногда и вне сферы
традиционных систем ИИ. Эвристический поиск Монтанари использовал для
сравнения хромосом [247]; Канэл рассмотрел его приложение к задаче
классификации образов [167].
Упражнения
2.1. Рассмотрите задачу о блоке подвижных фишек, находящихся в следующем
исходном состоянии:
в
в
в
W \ W
w \ Е\
Имеются три черные (В), три белые (W) фишки и одна пустая клетка (Е). В этой
игре возможны следующие ходы:
а) фишка может перемещаться в соседнюю пустую клетку; стоимость хода равна 1;
б) фишка может перепрыгивать не более чем через две другие, попадая в пустую
клетку; стоимость хода равна числу перепрыгнутых фишек.
Цель игры - переместить все белые фишки налево от всех черных (положение
пустой клетки не имеет значения).
Определите эвристическую функцию h для этой задачи и покажите дерево поиска,
которое дает алгоритм А, использующий эту эвристическую функцию. Удовлетворяет
ли ваша функция h монотонному ограничению? Удовлетворяет ли она монотонному
ограничению на узлах вашего дерева поиска?
2.2. Предложите две (ненулевые) функции h для задачи коммивояжера из под-
разд. 1.1.6. Является ли какая-нибудь из этих функций h нижней границей для Л*?
Как вы считаете, которая из них обеспечит более эффективный поиск? Примените
алгоритм А с этими функциями h к задаче о пяти городах (см. рис. 1.5).
2.3. Присвойте единичные стоимости каждому применению правила в
формулировке задачи с четырьмя ферзями, приведенной в разд. 2.1. Опишите общие свойства
функции И* для этой задачи. Можно ли придумать какую-либо функцию Л, которая была
бы полезна для управления поиском?
2.4. Опишите, как видоизменить процедуру GRAPHSEARCH, чтобы на шаге 6 в
каждый момент около вершины порождался только один преемник. Модифицированная
процедура должна делать два выбора: какую вершину раскрыть и какой преемник
породить. (При управлении системой продукций эта модифицированная процедура
должна выбирать базу данных и применимое правило.)
2.5. Докажите, как следствие РЕЗУЛЬТАТА 3, что любая вершина η из списка
ОТКРЫТ с /(л) < /*(s) будет в конечном счете выбрана алгоритмом А* для раскрытия.
2.6. Объясните, почему алгоритм А* останется состоятельным, если он будет
удалять из списка ОТКРЫТ любую вершину л, для которой f{n)>Fy где F - верхняя
граница для/*(s).
2.7. Примените оценочную функцию /(«) =d(n) + W(n) (определенную в подразд.
2.4.2) с алгоритмом А для обратного поиска от целевой вершины на рис. 2.8 к
исходному. Где обратный поиск встретится с прямым поиском?
2.8. Рассмотрите способы улучшения функции h β процессе поиска.
ГЛАВА 3
СТРАТЕГИИ ПОИСКА ДЛЯ РАЗЛОЖИМЫХ СИСТЕМ ПРОДУКЦИЙ
В гл. 1 были введены разложимые системы продукций, а также
структуры, названные деревьями типа И/ИЛИ и предназначенные для управления
их действиями. В этой главе описываются некоторые эвристические
стратегии поиска на графах и деревьях типа И/ИЛИ. Обсуждаются также
некоторые методы поиска для графов, применяемые в игровых системах.
3.1. ПОИСК НА ГРАФАХ ТИПА И/ИЛИ
Напомним, что метки И либо ИЛИ, приписанные вершине дерева типа
И/ИЛИ, определяются отношением этой вершины к своему родителю. В пер-
86
вом случае родительская вершина, помеченная некоторой составной базой
данных, обладает множеством дочерних вершин типа И, каждая из которых
помечена одной из составляющих баз данных. Во втором случае
родительская вершина, помеченная некоторой составляющей базой данных, обладает
множеством дочерних вершин типа ИЛИ, каждая из которых помечена в
соответствии с базой данных, получающейся при применении
альтернативных правил к упомянутой составляющей базе данных.
Нас в основном будут интересовать графы типа И/ИЛИ, а не частный
случай деревьев, поскольку одинаковые базы данных могут быть порождены
разными последовательностями применения правил. Например, некоторая
вершина может быть помечена составляющей базой данных, которая могла
получиться в результате как расщепления составной базы данных, так и
применения правила к другой составляющей базе данных. В этом случае наша
вершина может быть названа вершиной типа ИЛИ по отношению к одному
родителю и вершиной типа И по отношению к другому. По этой причине
мы, как правило, не называем вершины графа типа И/ИЛИ вершинами
типа И или вершинами типа ИЛИ; вместо этого мы вводим некоторое более
общее обозначение, подходящее для графов. Однако мы продолжаем
называть эти структуры графами типа И/ИЛИ, а при обсуждении деревьев типа
И/ИЛИ используем термины "вершина И" и "вершина ИЛИ".
В этом месте мы определим графы типа И/ИЛИ как гиперграфы. В них
вместо дуг, соединяющих пары вершин, имеются гипердуги, соединяющие
родительскую вершину с множеством дочерних. Эти гипердуги называются
связками. Каждая k-связка направлена от родительской вершины к
множеству к дочерних вершин. (Если все связки являются 1-связками, то как
частный случай получаем обычный граф.)
На рис. 3.1 показан пример
графа типа И/ИЛИ. Заметим,
что вершина п0 имеет
1-связку, направленную к потомку
щ, и 2-связку, направленную
к множеству потомков м4, п5.
При к> 1 ^-связки
обозначены с помощью перемычки
между дугами, идущими из
вершины-предка к элементам
множества потомков.
(Используя введенную ранее
терминологию, можно
рассматривать вершины щ и п5 как
множество вершин И, а пх —
как вершину ИЛИ по
отношению к их общему предку
щ\ заметим, однако, что
вершина м3, например, по
отношению к своему предку п5
является одной из вершин п7®
типа И, но по отношению к Рис. 3.1. Граф типа И/ИЛИ
87
предку щ — вершиной типа ИЛИ.) На дереве типа И/ИЛИ каждая вершина
имеет не более одного предка. Вершина графа или дерева, не имеющая
предка, называется корневой. Вершина, не имеющая потомков, называется
концевой.
Разложимая система продукции определяет неявный граф типа И/ИЛИ.
Исходная база данных соответствует выделенной вершине графа,
называемой исходной вершиной. В исходной вершине начинается связка,
соединяющая ее с множеством дочерних вершин, помеченных компонентами
исходной базы данных (если она разложима). Каждая продукция
соответствует связке в этом неявном графе. Вершины, в которые входит эта связка,
помечены составляющими базами данных, получающимися в результате
применения правила с последующим разложением на компоненты. В
неявном графе имеется набор терминальных вершин, соответствующих базам
данных, удовлетворяющим условию остановки для системы продукций.
Можно считать, что задача системы продукций состоит в прослеживании
графа решения от исходной к терминальным вершинам.
Попросту говоря, граф решения, связывающий вершину η с множеством
вершин N в графе типа И/ИЛИ, аналогичен пути в обыкновенном графе.
Граф решения можно получить, если отправиться из вершины η и выбрать
ровно одну исходящую связку. Для каждой дочерней вершины, в которую
входит эта связка, по-прежнему выберем одну исходящую связку и т.д.
Продолжаем поступать таким же образом, пока, в конце концов, каждая
полученная дочерняя вершина не станет элементом множества Аг. На рис. 3.2
показаны два разных графа решений, связывающих вершину м0 с
множеством вершин { п7, и8} в графе, изображенном на рис. 3.1.
м к
п7 *8 п7 п8
Рис. 3.2. Два графа решений
Можно дать точное рекурсивное определение графа решения. В этом
определении подразумевается, что в рассматриваемых нами графах типа И/ИЛИ
нет циклов, т. е. нет вершин, обладающих таким потомком,который был бы
также и их предком. При принятии этого предположения вершины образуют
частично упорядоченное множество, что гарантирует завершение
применяемой процедуры. В силу изложенного мы принимаем предположение об
ацикличности.
Обозначим через G' граф решения, связывающий вершину η с
множеством вершин N графа G типа И/ИЛИ; G' является подграфом графа С
Если η — элемент N,toG' состоит из единственной вершины п.
88
Если η φ N и если из п исходит связка А*, направленная на вершины {щ ,...
. . . , пк } , причем существует граф решения, идущий в N из каждой щ (i =
= 1, ... , к), то G' состоит из вершины и, связки К, вершин [п1у.. ., пк } и
графов решения, идущих в ]Уиз каждой вершины множества {πι,.. . , пк } .
Если не выполнены оба условия, то графа решения, связывающего η с Ν>
не существует.
Зачастую связкам в графах типа И/-ИЛН бывает полезно приписать
некоторые значения стоимости подобно тому, как в обыкновенных графах
применяются значения стоимости его дуг. (Эти стоимости являются моделью
стоимости применения правил; здесь нам опять надо принять
предположение о том, что каждая стоимость больше некоторого малого
положительного числа е). Эти стоимости связок можно потом использовать для
вычисления стоимости графа решения. Обозначим стоимость графа решения,
связывающего некоторую вершину η с Ν, через к (η, Ν). Стоимость к (η, Ν) может
быть вычислена рекурсивно: 1) если η — элемент Ν, то к(п, Ν) = 0; 2) если
η ^ Ν, то из η исходит связка, направленная на множество дочерних вершин
{ пг, . . . , πι } в графе решения. Пусть стоимость этой связки равна сп.
Тогда
fc(n,iV) =cn + k(nliN) +... + /с(^.5Лг).
Таким образом, стоимость графа решения G\ связывающего η с Ν, равна
стоимости связки, исходящей из η (в пределах G'), плюс сумма
стоимостей графов решения, связывающих потомков η (в пределах G1) с N. Это
рекурсивное определение корректно, поскольку мы рассматриваем
ацикличные графы.
Заметим, что при нашем определении в процессе подсчета стоимости
самого графа решения стоимости некоторых его связок могут учитываться
более одного раза. В общем случае при подсчете стоимости графа решения,
связывающего η с Ν, стоимость' связки, исходящей из некоторой вершины
т, учитывается столько раз, сколько путей ведет из м в пг в графе решения.
Таким образом, стоимости двух графов решения, приведенных на рис. 3.2,
составляют 8 и 7 единиц при условии, что стоимость каждой fe-связки
составляет к единиц.
Можно искать не произвольный граф решения, идущий из исходной
вершины в множество терминальных вершин, а тот, который обладает
минимальной стоимостью. Такой граф решения будем называть оптимальным.
Стоимость оптимального графа решения, связывающего η с множеством
терминальных вершин, обозначим h*(n) .
3.2. АО* - ЭВРИСТИЧЕСКАЯ ПРОЦЕДУРА ПОИСКА НА
ГРАФАХ ТИПА И/ИЛ И
Как и в случае обыкновенных графов, определим процесс раскрытия
вершины как применение оператора порождения, который порождает всех
потомков данной вершины (по всем исходящим из нее связкам). Теперь
можно дать определение алгоритма поиска в ширину, предназначенного
для отыскания графов решения на неявных графах типа И/ИЛИ. Процедуры
поиска в ширину недостаточно эффективны в приложениях искусственного
интеллекта из-за отсутствия учета в них конкретной проблемной области.
89
Естественно при этом задаться вопросом: можно ли и для графов типа
И/ИЛИ разработать какую-то процедуру поиска с использованием оценочной
функции, содержащей эвристическую компоненту?
Опишем процедуру поиска с использованием эвристической функции
h (и), представляющей собой оценку функции h*(n) — стоимости
оптимального графа решения, связывающего вершину η с множеством терминальных
вершин. Как и в процедуре GRAPHSEARCH, формулировка процедуры^
допускает упрощения, если h удовлетворяет определенным условиям.
Наложим на h условие монотонности, т.е. будем считать, что в неявном
графе для каждой связи, направленной из вершины η к ее потомкам щ , . ..
..., ид., имеет место неравенство
h (и) < с + h (м!) + . . . +Λ (nk) ,
где с — стоимость связки. Это условие аналогично условию монотонности,
накладываемому на эвристическую функцию в обыкновенных графах.
Если h (м) =0 для некоторого η из множества терминальных вершин, то
условие монотонности означает, что h есть нижняя граница для Λ*, т.е.
h (η) < h * (η) для всех вершин п.
Теперь можно сформулировать нашу эвристическую процедуру поиска
на графах типа И/ИЛИ:
Процедура АО*
1 Создать граф поиска G, состоящий из единственной исходной
вершины s. С вершиной s свяжем стоимость q (s) =h (s). Если
s — терминальная вершина, то присвоим ей метку SOLVED.
2 until s не получит метку SOLVED, do:
3 begin
4 Вычислить частичный граф решения G' в G, спускаясь в пределах
G по отмеченным связкам, идущим из s. (Связки в G будут
отмечены на следующем шаге)
5 select любую нетерминальную концевую вершину η в G.
(Далее обсудим способ этого выбора.)
6 Раскрыть вершину п, породив всех ее потомков, и назначить их
дочерними вершинами η в G. С каждым потомком ги, еще не
появлявшимся в G, связать стоимость q (ги ) = h (ги). Тем из
дочерних вершин, которые являются терминальными,
присвоить метку SOLVED. (См. в тексте рассмотрение того случая,
когда у вершины η нет ни одного потомка.)
90
7 Создать одноэлементное множество вершин S, содержащее
единственную вершину м.
8 until 5 не станет пусто, do:
9 begin
10 Удалить из S вершину т, у которой в G нет потомков,
принадлежащих S.
11 Пересмотреть стоимость q(m) вершины т следующим образом:
для каждой связки, исходящей из т в множество вершин
{ nii, .. . , Ufa } f вычислить qi (m) = cf +д(яи-+...
• · · + Я (nki) · (Значения q (nj() либо уже вычислены в
предыдущем проходе через этот внутренний цикл, либо, если этот
проход первый, они берутся из шага 6.) Найти минимум д,· (т)
на множестве всех исходящих связок; это минимальное
значение присвоить q (т ), а связку, на которой достигается
минимум, пометить, удалив старую пометку, если она
отличается от новой. Если вершина, на которую эта связка
указывает, и все ее дочерние вершины имеют метку SOLVED,
то присвоить метку SOL VED и вершине т.
12 Если т имеет метку SOLVED или если новая стоимость т
отличается от предшествующей, то включить в множество S все
те родительские вершины т , для которых т является одним
из потомков в ветви, начинающейся помеченной связкой .
13 end
14 end
Процедуру АО* лучше всего представлять себе как повторение двух
основных операций. Первая операция (шаги 4—6), направленная сверху вниз
(в направлении роста графа), прослеживает граф по отмеченным связкам и
отыскивает наилучший частичный граф решения. Пометки на связках,
нанесенные ранее, в каждой вершине графа поиска выделяют наилучший в
данный момент частичный граф решения. (До того, как алгоритм закончил
работу, не все концевые вершины наилучшего частичного графа решения
являются для него терминальными, потому этот граф назьюается
частичным.) Одна из концевых вершин наилучшего частичного графа решения, не
являющаяся терминальной, подвергается раскрытию, и ее потомкам
приписывается некоторая стоимость.
91
Вторая основная операщш в процедуре АО* направлена снизу вверх и
представляет собой процедуру пересмотра стоимостей, разметки связок
и присвоения метки SOLVED (шаги 7—12). Начиная с той вершины,
которая подверглась раскрытию последней, эта процедура изменяет ее стоимость
(используя при этом заново вычисленные стоимости ее потомков) и
помечает исходящие из нее связки на том пути к терминальным вершинам,
который оценивается как "наилучший". Эта измененная оценка стоимости
переносится вверх по графу. (Нецикличность рассматриваемых нами графов
обеспечивает отсутствие петель при таком переносе вверх.) Измененная
стоимость q(n) является уточненной оценкой стоимости оптимального
графа решения, связывающего η с множеством терминальных вершин.
Стоимости могут быть изменены только у тех вершин, которые
являются потомками вершин с измененной стоимостью, так что только такие
вершины и надо рассматривать. Поскольку мы приняли условие монотонности
h , то изменения стоимости могут заключаться только в ее увеличении.
Следовательно, изменять стоимость надо не у всех дочерних вершин, а лишь у
тех, чьи наилучшие частичные графы решения содержат потомков с
измененной стоимостью (отсюда вытекает шаг 12) .
Если граф типа И/ИЛИ является деревом, то вторую операцию можно
несколько упростить за счет того, что у каждой вершины тогда будет
только один родитель.
Чтобы не усложнять и без того сложный алгоритм АО*, мы на шаге 6
пренебрегли возможностью того, что у вершины, выбранной для раскрытия,
может не оказаться ни одного потомка. Эту трудность легко обойти на шаге
11, приписав очень большую стоимость q всякой вершине /п, не имеющей
потомков (или в более общем случае всякой вершине, которая окажется
не принадлежащей никакому графу решения). Тогда вторая из описанных
операций перенесет эту большую стоимость вверх по графу, чем исключит
всякую возможность выбора графа, содержащего эту вершину, в качестве
предполагаемого наилучшего графа решения.
Пусть некоторая вершина η обладает конечным числом потомков в
неявном графе типа И/ИЛИ и пусть они не образуют графа решения, идущего из
вершины η в множество терминальных вершин. Тогда после всех изменений
значение стоимости q(n) вершины η будет очень большим. Следовательно,
приписывание исходной вершине очень большой стоимости q(s) можно
использовать как указание на то, что из нее не исходит ни один граф решения.
Можно показать, что если существует граф решения, связывающий данную
вершину с множеством терминальных вершин, и если для всех вершин
выполняется неравенство h(n) <h*(rc), а функция h подчиняется условию
монотонности, то после окончания работы алгоритма АО* будет получен
оптимальный граф решения. (После окончания работы АО* этот граф можно
получить с помощью спуска из вершины 5 по отмеченным связкам.
Стоимость оптимального графа решения будет равна q (s) после окончания
работы АО*.) Таким образом, можно сказать, что алгоритм АО* при указанных
ограничениях приемлем для решения поставленной задачи. Здесь мы
опускаем доказательство этого факта, читатель может найти его в книге Мартел-
ли и Монтанари [225].
Алгоритм поиска в ширину можно получить из алгоритма АО*,
положив в последнем h =0. Поскольку такая функция удовлетворяет условию
92
монотонности (и является нижней границей h *), то использующий ее
алгоритм поиска в ширину тоже приемлем.
В качестве примера применения алгоритма АО* рассмотрим снова граф
на рис. 3.1. Предположим, нам известно, что
Л (по) =0Д(м1) =25Л(м2) =4,Л(м3) = 4,Л(л4) =1,
h(n5) =1,Л(мб) =2,Λ(ιΐ7) =0,/ι(η8) =0.
Пусть терминальными вершинами будут вершины щ и м8, а стоимость
каждой fc-связки составляет к единиц. Заметим, что функция h в данном
примере является нижней границей для h* и удовлетворяет условию
монотонности.
На рис. 3.3 показаны графы поиска, полученные после различных
проходов по внешнему циклу алгоритма АО*. На каждом графе около
каждой вершины указаны измененные значения q\ помеченные связки
изобаз О "5 1
1
После одного цикла После двух циклов
После трех циклов п7 Фо После четырех циклов
Рис. 3.3. Графы поиска после прохождения процедурой АО* разного числа циклов
93
ражены жирными стрелками, а вершины, имеющие метку SOLVED, —
сплошными кружками. При первом проходе раскрытию подвергается вершина
до, при следующем — nls затем и щ. После того, как раскрыта вершина щ,
вершина п5 получает метку SOLVED. Граф решения (с наименьшей
стоимостью, равной 5) получается при прохождении графа по связкам с меткой.
Надо еще рассмотреть вопрос о том, как на шаге 5 алгоритма АО* в
частичном графе решения, считающемся наилучшим, выбирается та
концевая нетерминальная вершина, которая подлежит раскрытию. По-видимому,
концевую вершину стоит выбирать так, чтобы с наибольшей вероятностью
изменить оценку наилучшего частичного графа решения. Если ни при каком
выборе эта оценка не изменяется, то АО* должен произвольным образом
подвергнуть раскрытию все Концевые вершины этого графа, не
являющиеся терминальными. Если, однако, эта оценка может быть изменена в сторону
большей оптимальности графа, то чем скорее АО* это изменение
произведет, тем лучше. Может оказаться, что раскрытие концевой вершины с
наибольшим значением h скорее всего приведет к получению измененной
оценки.
Алгоритм АО*, как и алгоритмы А и А* для обыкновенных графов,
можно разными способами видоизменять, чтобы в конкретных ситуациях
он становился более эффективным. Можно, во-первых, не находить новый
считающийся наилучшим частичный граф решения после каждого
раскрытия вершин, а сразу подвергнуть раскрытию одну или несколько концевых
вершин и некоторое число их потомков, а затем заново найти наилучший
по оценке частичный граф решения. Такая стратегия уменьшает "накладные
расходы" на часто встречающиеся операции прохождения графа снизу вверх,
но здесь возникает риск, что некоторые раскрытия вершин могут и не
принадлежать наилучшему графу решений.
Для графов типа И/ИЛИ можно также применить стратегию поэтапного
поиска. Для ее реализации надо периодически изменять запрос на
требующийся объем памяти, стирая для этого некоторые из графов поиска типа И/ИЛИ.
Можно, например, выявить в пределах всего графа поиска несколько
частичных графов решения, имеющих наибольшие оценки стоимости. Их и нужно
периодически удалять (рискуя, конечно, стереть граф, который может
оказаться верхней частью оптимального графа решения).
3.3. НЕКОТОРЫЕ СООТНОШЕНИЯ МЕЖДУ РАЗЛОЖИМЫМИ И
КОММУТАТИВНЫМИ СИСТЕМАМИ
В гл. 1 упомянуто о том, что некоторые задачи могут быть решены
системами продукций, работающими либо в прямом, либо в обратном
направлении. (Называть ли данное направление прямым или обратным, часто
зависит от произвольного выбора.) В этом разделе покажем, что определенные
типы коммутативных систем, работающих в прямом направлении,
двойственны разложимым системам, работающим в обратном направлении.
Пусть дана система продукций, основанная на следующих правилах
подстановки:
П1 : Т-+А, В,
П2 : Т-+В, С,
ПЗ :A-+D9
94
Π4 :B-+E,F,
Π5 :B-+G,
Π6 :C-+G.
Эти правила должны применяться к глобальной базе данных, состоящей
из строки символов. Данное правило является применимым, если
глобальная база данных содержит символ, стоящий в левой части этого правила.
Результатом применения правила является замена в глобальной базе данных
символа из левой части правила подстановки на ее правую часть.
Системы продукций,
использующие такие
контекстно-свободные правила подстановки с
односимвольными левыми
частями, являются разложимыми.
Граф поиска типа И/ИЛИ,
полученный в результате
применения правил подстановки к
глобальной базе данных,
состоящей из единственного символа
Г, показан на рис. 3.4.
Правила подстановки из
нашего примера можно интерес-
Рис. 3.4. Граф поиска
ным способом применить в обратном направлении. Будем говорить, что
такое обратное правило является применимым, если глобальная база данных
содержит символы, соответствующие всем символам правой части правила.
Действие правила состоит в добавлении к глобальной базе данных
символов из левой части правила (но не в замене на них символов из правой
части). На рис. 3.5 приведен пример, в котором некоторые правила подста*
новки (в обратном направлении) применены к исходной глобальной базе
данных, состоящей из символов D,E, F, G. (Применение П-правила в
обратном направлении обозначим Ft.) Заметим, что система продукций,
получающаяся при применении этих правил подстановки в обратном направлении
(описанным выше способом), является коммутативной. Таким образом,
[D,E,F,G]
{D,E,F,G,A\
{D,E,F,G,C}
{D,E,F,G,B}
Рис. 3.5.
Использование пряник
подстановки в обратном
направлении
95
го'
D
W^
./.
I E
Τ
Τ f*
в
П41
П21
Nj75
1F
П6'
Рис. 3.6. Граф вывода
как об этом говорилось в гл. 1, можно использовать неотменяемый (или
безвозвратный) режим управления, не боясь подвергнуть исключению
какое-либо из возможных применений правил подстановки.
Если продолжить применение (в неотменяемом режиме) обратных
правил подстановки Ш' , . . . , Пб' к базе данных, изначально состоящей из
символов D, Е, F, G, и к ее потомкам, то в конечном счете получим множество
{. D, Е, F, G, А, В, С, Г } .С помощью особой структуры, называемой графом
вывода, можно сохранить следы применений правил подстановки, а также
результирующие глобальные базы данных. Этот граф представляет собой
способ структурирования глобальной базы данных на любом этапе процесса
порождения системы продукций, так что он несет в себе некоторую
информацию об истории применения правил подстановки.
Граф вывода для нашего
примера показан на рис. 3.6.
Глобальная база данных
состоит из графа вывода. То, откуда
получено каждое из выражений
на графе, заключенных в
рамку, указывается набором
входящих дуг, помеченных
обратными правилами подстановки.
Ясно, конечно, что
структуры на рис. 3.4 и 3.5 идентичны
во всем, кроме направлений
дуг. Во многих интересующих
нас задачах изменение
направления коммутативной системы продукций дает разложимую систему
продукций. Часто, используя правила подстановки коммутативной системы, будем
представлять ее направление прямым, а используя обратные правила
разложимой системы — обратным.
Для управления работой коммутативных систем продукций этого типа
можно использовать оценочную функцию в сочетании с графами вывода.
Любое правило подстановки, примененное к графу вывода, можно
рассматривать как средство создания нового графа вывода. Применение правила
приводит к добавлению в структуру одной новой вершины. Так, на рис. 3.6
правило ПГ добавляет вершину, помеченную Т. Стоимость вывода с
помощью данного правила подстановки можно определить как стоимость
самого правила плюс стоимости самых "дешевых" графов (или подграфов,
вывода, связанных с теми вершинами, которые для данного правила
являются "входами". Такое определение стоимости совершенно аналогично
рекурсивному определению стоимости графа решения типа И/ИЛИ.
Стоимость графа вывода можно рассматривать как средство вычисления
функции g для коммутативной системы продукций. Существует несколько
альтернативных правил подстановки, которые можно применить к любому
графу вывода. Каждое из них связывает с этим графом значение функции g,
вычисленное описанным способом. Над множеством графов вывода можно
определить также эвристическую функцию h. Такая функция оценивает
дополнительную стоимость всех последующих применений правил к этому
графу вывода и к его потомкам на оптимальном пути к окончанию. При оп-
96
ределении стоимости альтернативных правил принимаем, что h для
применения данного правила равно значению, полученному с помощью этой
эвристической функции для графа вывода после того, как данное правило
к нему применено. Теперь можно сложить значения g и h для применения
некоторого правила и получить оценочную функцию /, предназначенную
для оценки правил подстановки. Для неотменяемого (безвозвратного)
применения отбирается применимое правило подстановки с наименьшим
значением /.
Работа коммутативной системы продукций с неотменяемой
(безвозвратной) стратегией управления может направляться процессом, очень
напоминающим процесс, используемый алгоритмом А при поиске на графах. Если
принять, что h является нижней границей Λ*, то можно показать, что такая
стратегия обеспечивает выводы минимальной стоимости и что функция h ,
более полно отражающая информацию о специфике задачи, обходится
меньшим числом применений правил подстановки.
3.4. ПОИСК НА ИГРОВЫХ ДЕРЕВЬЯХ
При нахождении игровых стратегий для определенных видов игр можно
использовать методики поиска, подобные рассмотренным. Обсуждаемые
здесь игры являются играми двух лиц с полной информацией. Оба игрока
делают ходы по очереди. Каждый из них полностью осведомлен о том, как
каждый поступил и как мог бы поступить. Нас будут интересовать те игры,
в которых либо один игрок выигрывает (а другой проигрывает), либо
между ними заключается ничья. Таковы игры в шашки, крестики-нолики,
шахматы, го и ним. Мы не будем рассматривать игры, исход которых, хотя бы и
отчасти, определяется случаем, например, игры в кости и карты. (Можно,
однако, обобщить наше исследование так, чтобы оно включало в себя и
некоторые стохастические игры.)
Для анализа игр можно использовать системы, во многом похожие на
системы продукций. Например, в шахматах глобальная база данных должна
содержать информацию о положении на доске всех фигур. Правилами
вывода моделируются допускаемые ходы. Применение этих правил к исходной
базе данных и к результирующим базам данных приводит к игровому графу
(или дереву).
Эти идеи можно проиллюстрировать на примере следующей игры. Перед двумя
игроками в одну кучку сложены некоторые предметы, скажем монеты. Первый игрок
делит исходную кучку на две, обязательно неравные. Далее игроки по очереди делят
какую-нибудь из получающихся кучек (выбирая ее каждый раз по своему усмотрению).
Игра продолжается до тех пор, пока во всех кучках не окажется по одной или по две
монеты, после чего продолжение игры станет невозможным. Проигрывает тот, кто
первым не сможет сделать свой ход. Назовем наших игроков МАХ и MIN, и пусть первый
ход делает MIN.
Начнем со случая, когда в кучке семь монет. Для этой игры база данных состоит
из неупорядоченной последовательности чисел, представляющих число монет в разных
кучках, а Также из указания на то, чей ход следующий. Так (7, MIN) - это исходная
конфигурация. В ней MIN имеет три различных хода, приводящих к конфигурации
(6,1 МАХ), (5,2 МАХ) или (4,3 МАХ). Полный граф этой игры, полученный
применением ко всем базам данных всех применимых к ним правил, показан на рис. 3.7. Все
концевые вершины соответствуют позициям, проигрышным для игрока, делающего
следующий ход.
97
4, 1. 1. \ЩМАХ)\ \(3,2.\,\,МАХ)\ (2, 2, 2, 1, МАХ)
Рис. 3.7. Пример игрового графа
С помощью этого игрового графа можно показать, что независимо от поведения
игрока MIN игрок МАХ всегда может выиграть. На рис. 3.7 выигрышная стратегия
показана жирными линиями. Для каждой вершины, соответствующей позиции, в
которой следующий ход за игроком MIN, нам надо доказать, что игрок МАХ может
выиграть при любом ходе MIN. Для каждой вершины, соответствующей позиции, в
которой следующий ход за игроком МАХ, нам надо доказать, что МАХ может достичь
выигрышной ситуации, исходя хотя бы из одной из тех позиций, в которые он может
перевести игру, сделав свой ход.
Укажем на сходство между выигрышной стратегией игрока МАХ, показанной на
рис. 3.7, и графом решения в графе типа И/ИЛИ. У вершин, соответствующих
следующему ходу MIN, есть потомки, подобные вершинам типа И. С точки зрения интересов
игрока МАХ решение (т. е. выигрыш) должно быть достижимо из всех этих дочерних
вершин. Вершины, соответствующие следующему ходу МАХ, имеют потомков,
схожих с вершинами типа ИЛИ. С позиции интересов опять-таки игрока МАХ выигрыш
должен быть достижим из хотя бы одной дочерней вершины. Терминальные вершины
на графе - это вершины, соответствующие победе игрока МАХ.
Говоря об играх, мы условились, чтр пытаемся найти выигрышную стратегию для
МАХ. Первым ходит МАХ, а затем игроки по очереди делают по одному ходу.
Рассматривая в дальнейшем рисунки игровых графов и деревьев, мы при таких
предположениях можем явно не указывать, чей ход следующий. Вершины на четных уровнях
соответствуют позициям, в которых ход за игроком МАХ; назовем их Л/ЛХ-вершинами.
Вершины на нечетных уровнях соответствуют позициям, в которых ход за игроком MIN;
это - MIN-веритны. Терминальной является любая вершина, соответствующая
выигрышной для МАХ позиции. (Самая верхняя вершина игрового графа лежит на нулевом,
т. е. четном, уровне.)
98
3.4.1. МИНИМАКСНАЯ ПРОЦЕДУРА
Методы поиска, аналогичные применявшимся для находения графов решения типа
И/ИЛИ, могут быть применены и ко многим простым играм, а также к некоторым
окончаниям более сложных игр. При этом графом решения представлена полная
игровая стратегия. Вышеописанная игра, крестики-нолики, разные варианты нима и некото*
рые окончания в шахматах и шашках дают примеры Простых игр, в которых
физически реален поиск завершения с помощью графов типа И/ИЛИ. Грубую оценку размеров
игрового дерева, например для крестиков-ноликов, можно получить, исходя из того,
что у исходной вершины имеется 9 дочерних, у каждой из них - по 8 дочерних и т. д.,
что дает на нижнем уровне дерева! = 362 880 вершин. Однако многие пути в этом
дереве оканчиваются на терминальных вершинах более высокого уровня, а если принять во
внимание симметрию позиций игры, то можно еще уменьшить размеры дерева.
Поиск на графе типа И/ИЛИ выигрышной стратегии в более сложных играх — таких,
как шахматы или шашки, для целиком взятой партии является совершенно не
реальным. Известны оценки, утверждающие, что игровое дерево партии в шашки содержит
около 1040 вершин, а в шахматы - около 10120 вершин. (Если даже порождение
дочерней вершины занимало бы 1/3 не, то порождение всего игрового дерева для шашек
все равно заняло бы около 1021 веков.) К тому же и методы эвристического поиска
не снижают коэффициента ветвления до такой степени, чтобы спасти ситуацию.
Поэтому в случае сложных игр приходится мириться с тем, что поиск окончания
невозможен, т.е. приходится отказаться от идеи использования этого метода для
доказательства достижимости победы или ничьей (кроме того, может быть, случая, когда
игра уже находится в стадии завершения).
Однако наша цель поиска на игровом дереве может состоять просто в отыскании
хорошего первого хода. После этого можно сделать найденный ход, подождать
ответного хода противника и снова начать поиск хорошего первого хода. Можно применить
или поиск в ширину, или поиск в глубину, или эвристические методы, при этом
следует лишь видоизменить условия остановки. Надо ввести несколько искусственных
условий остановки, основанных на таких факторах, как ограничения на время и объем
памяти или наибольшая допустимая глубина вершин в дереве поиска. Кроме того, в
шахматах обычно не делается остановка, если все концевые вершины представляют
позиции, в которых возможен немедленный и выгодный размен фигур.
По окончании поиска надо выделить на графе поиска претендента на "наилучший"
первый ход. Претендента можно найти, применив к концевым вершинам графа поиска
статическую оценочную функцию. Эта функция измеряет "ценность" позиции,
представленной концевой вершиной. Вычисление ценности основано на учете свойств,
которые, как считается, оказывают на эту ценность влияние. В шашках, например,
полезными признаками являются относительный перевес в фигурах, контроль над центром,
контроль дамок над центром и т. д. При анализе игровых деревьев обычно принимают
соглашение, πα которому позиции, выгодные для игрока МАХ, сообщают оценочной
функции положительное значение, а позиции, выгодные для ΜΙΝ, - отрицательное.
Значения оценочной функции, близкие к нулю, соответствуют тем позициям, которые
не особенно выгодны ни МАХ, ни ΜΙΝ.
Хороший первый ход может быть найден с помощью процедуры,называемой
минимаксной. (Для простоты будем объяснять работу этой процедуры и других, от нее
зависящих, так, словно граф игры является деревом.) Будем считать, что если бы
игроку МАХ был предоставлен выбор концевых вершин, то он бы выбрал ту, на которой
значение оценочной функции наибольшее. Следовательно, родителю концевых ΜΙΝ-
вершин (который сам является МАХ-ъерипшой) присваивается возвращенное
значение, равное максимальному значению оценочной функции на концевых вершинах.
С другой стороны, если игроку ΜΙΝ надо выбирать среди концевых вершин, то он
скорее всего выберет ту, на которой значение оценочной функции наименьшее (т.е.
наибольшее по модулю отрицательное число). Следовательно, родителю концевых
99
МАХверитн (который сам является MIN-вершиной) присваивается возвращенное
значение, равное минимальному значению оценочной функции на концевых вершинах.
После присвоения возвращенных значений всех концевых вершин строятся
возвращенные значения на следующем уровне, причем считается, что игрок МАХ предпочитает
выбирать вершины с наибольшим возвращенным значением, а игрок MIN — с
наименьшим.
Так, уровень за уровнем значения "возвращаются" до тех пор, пока, наконец,
возвращенные значения не будут присвоены непосредственным потомкам исходной
вершины. Мы условились, что первым ходит игрок МАХ, поэтому МАХ должен выбирать
в качестве первого хода тот, который соответствует дочерней вершине с наибольшим
возвращенным значением.
Полезность этой процедуры в целом основана на предположении, что
возвращенные значения для потомков исходной вершины более надежны в качестве оценок
окончательной относительной ценности соответствующих им позиций, нежели значения,
которые можно было бы получить непосредственным применением к этим позициям
статической оценочной функции. В конечном итоге возвращенные значения основаны
на "просмотре вперед" по игровому дереву и потому зависят от свойств,
проявляющихся ближе к окончанию игры.
Проиллюстрируем минимаксный метод на простом примере игры в
крестики-нолики. Пусть игрок МАХ ставит крестики, a MIN - нолики,и пусть первый ход делает МАХ.
Проведем поиск в ширину, пока не получим все вершины второго уровня, а затем к
позициям, соответствующим этим вершинам, применим статическую оценочную
функцию. Пусть для позиции ρ наша оценочная функция е (р) задается следующими тремя
условиями:
1. Если в позиции ρ не выигрывает ни один из игроков, то е (р) - (число строк,
столбцов и диагоналей, на данный момент целиком свободных для игрока МАХУ - (число
строк, столбцов и диагоналей, на данный момент целиком свободных для игрока ΜΙΝ).
2. Если в позиции ρ выигрыш получает игрок МАХ, то е (р) = «>, где °° обозначает
очень большое положительное число.
3. Если в позиции ρ выигрыш получает игрок ΜΙΝ, тое(р) = - °°.
Таким образом, если ρ такова:
о
X
тое(р) =6-4 = 2.
При порождении дочерних позиций используются свойства симметрии, так что
позиции
X
о
X
о
о
X
рассматриваются нами как идентичные. (В начальной стадии игры в крестики-нолики
коэффициент ветвления игрового дерева поддерживается на низком уровне
вследствие симметрии позиций, а на более поздних стадиях игры он остается малым
вследствие уменьшения числа свободных клеток на доске.)
На рис. 3.8 показано дерево, полученное в результате поиска на глубину 2. Под
концевыми вершинами указаны значения статической оденочной функции, а в кружках
помещены возвращенные значения.
1 Т.е. число строк, столбцов и диагоналей на игровой доске из 3X3 клеток, в которых
игрок MINne поставил пока ни одного своего знака. — Прим. перев.
100
χίδΐ
101
Поскольку наибольшим возвращенным значением обладает позиция
то она выбирается в качестве результата первого хода. (В соответствии с тем, что было
сказано ранее, это наилучший первый ход игрока МАХ.)
Предположим теперь, что МАХ сделал этот ход, slMINb ответ поставил нолик прямо
над крестиком МАХ (для MIN'это плохой ход, но он не обязан придерживаться
хорошей стратегии поиска). Затем из сложившейся конфигурации игрок МАХ
осуществляет поиск на два уровня вниз. Получается дерево поиска, показанное на рис. 3.9. Теперь
уже имеется два возможных "наилучших" хода. Предположим, что МАХ делает тот
ход, который указан на рисунке. Тогда MIN делает ход, позволяющий ему избежать
немедленного поражения. Получается позиция
О
ю
Игрок МАХ вновь проводит поиск и получает дерево, представленное на рис. 3.10.
На этом дереве некоторые концевые вершины (например, отмеченная буквой А)
соответствуют позициям, выигрышным для MIN, и поэтому оценочная функция на них
равна — °°. После возвращения этих значений оценочной функции видим, что лучший
ход для МАХ — тоже тот,, который позволяет ему избежать немедленного поражения.
Теперь MIN может убедиться, что на следующем ходу МАХ выигрывает, после чего
MINc достоинством сдается.
3.4.2. АЛЬФА-БЕТА ПРОЦЕДУРА
В только что описанной процедуре поиска процесс порождения дерева поиска и
процесс оценки позиции полностью отделены друг от друга. Оценка позиции может
начаться только после завершения порождения дерева поиска. Случается, что такое
разделение приводит к реализации крайне неэффективной стратегии. Если же оценивать
концевые вершины и вычислять возвращенные значения по мере порождения дерева, то для
нахождения столь же хорошего хода длительность требующегося на это поиска можно
заметно сократить, порой даже на много порядков.
Рассмотрим дерево поиска, изображенное на рис. 3.10 и представляющее собой
последний этап поиска для игры в крестики-нолики. Пусть всякая концевая вершина
оценивается сразу же после возникновения. Тогда после порождения вершины,
помеченной на рисунке буквой Л, и ее оценивания уже нет смысла порождать и оценивать
вершины В, С и D. Иными словами, поскольку вершина А достижима для игрока MIN и
посокльку MIN ни одну вершину не предпочтет вершине Л, то MIN заведомо
выберет вершину А. Тогда можно присвоить родителю вершины А возвращенное значение
- °° и продолжить поиск, сэкономив на порождении и оценивании вершин B,CmD.
(Если бы нам надо было проводить поиск на большую глубину, то экономия была бы еще
больше, поскольку не надо было бы порождать и вершины, дочерние вершинам В, С и
D.) Важно понимать, что непорождение вершин В, С и D никак не может повлиять на
то, каким окажется наилучший первый ход игрока МАХ.
В этом примере экономия в поиске была обусловлена тем, что вершина А
соответствовала выигрышной для MIN позиции. Однако примерно такой же экономии можно
добиться даже в том случае, когда ни одна позиция на дереве поиска не является
выигрышной ни для МАХ, ни для MIN.
Рассмотрим первый этап игры в крестики-нолики, показанный на рис. 3.8. Часть
этого дерева повторена на рис. 3.11. Считаем, что поиск ведется в глубину и что как
102
о
8
I
л
Χ
8.
ex
й
о
&
«
о
I
103
СП
в
S
О
Я
о,
л
о,
о
2
S
2
X
(X
с
104
альфа =-1 ~Н~ Исходная
| | вершина
бета = — 1
Рис. 3.11. Фрагмент игрового дерева в крестики-нолики на первом этапе
только порождается концевая вершина, тут же вычисляется ее статическая оценка.
Будем также считать, что возвращенное значение приписывается позиции сразу же,
как только это значение становится возможным вычислить. Рассмотрим теперь
ситуацию, возникающую на этом этапе поиска в глубину непосредственно после
порождения вершины Л и ее дочерних вершин, но до порождения вершины В. Вершине А
присваивается возвращенное значение —1. С этого момента нам становится известно, что
возвращенное значение исходной вершины ограничено снизу значением —1. Окончательное
возвращенное значение исходной вершины, зависящее от возвращенных значений
других ее потомков, может быть больше -1, но меньше быть не может. Это нижняя
граница называется значением альфа для исходной вершины.
Пусть теперь поиск в глубину продолжается до тех пор, пока не будут порождены
вершины В и ее первая дочерняя вершина С. После этого вершине С приписывается
статическое значение -1. Теперь мы знаем, что возвращенное значение вершины В
ограничено сверху значением -1. Окончательное возвращенное значение вершины £,
зависящее от статических значений остальных ее потомков, может быть меньше -1,
но больше быть не может. Эта верхняя граница называется значением бета. Заметим,
что окончательное возвращенное значение вершины В не может превысить значения
альфа исходной вершины, и поэтому поиск на поддереве, идущем из вершины 2?, можно
не проводить: вершина В заведомо не окажется более предпочтительной, чем вершина Л.
Такая экономия при поиске была достигнута благодаря учету тех границ, в которых
заключены возвращенные значения. В общем случае эти границы для данной вершины
могут быть изменены после присвоения возвращенных значений ее потомкам. Отметим,
однако, что: а) значение альфа для МАХ-веришн (в том числе и для исходной) не могут
уменьшаться; б) значения бета для МШ-веришя не могут увеличиваться. Благодаря
этим ограничениям можно сформулировать следующие правила прекращения поиска:
1. Можно не проводить поиска на поддереве, растущем из всякой ЛЯЛТ-вершины,
бета-значение которой не превышает альфа-значения всех ее родительских Л£4Л!-вер-
шин. При этом окончательное возвращенное значение для этой МШ-веримны можно
положить равным ее бета-значению. Это возвращенное значение не обязательно равно
значению, получаемому в результате полного минимального поиска, однако
использование этого возвращенного значения приводит к выбору того же наилучшего хода.
2. Можно не проводить поиска на поддереве, растущем из всякой МАХ-вершты,
альфа-значение которой не меньше бета-значения всех ее родительских .ШУУ-вершин.
105
При этом окончательное возвращенное значение для этой Л/ЛХ-вершины можно
положить равным ее альфа-значению.
В процессе поиска значения альфа и бета вычисляются по следующим правилам:
а) у МАХ-въритны значение альфа принимается равным наибольшему (в данный
момент) значению среди окончательных возвращенных значений для ее дочерних вершин;
б) yAf/ЛГ-вершины значение бета кладется равным наименьшему (в данный момент)
значению среди окончательных возвращенных значений для ее дочерних вершин.
Если поиск прекращен в силу первого из перечисленных правил, то будем говорить,
что произошло альфа-отсечение, если в силу второго — то бета-отсечение. Весь же
процесс учета альфа- и бета-значений по мере прохождения дерева и произведение
отсечений при первой возможности обычно называются альфа-бета процедурой. Эта
процедура завершается тогда, когда окончательные возвращенные значения присвоены всем
потомкам исходной вершины. Тогда наилучший первый ход определяется как ход,
приводящий к позиции с наибольшим возвращенным значением. Применение этой
процедуры всегда приводит к нахождению столь же хорошего хода, как и ход,
который можно было бы найти с помощью простого минимаксного метода поиска на ту же
глубину. Единственное различие состоит в том, что альфа-бета процедура обычно
находит наилучший первый ход гораздо быстрее.
Применение альфа-бета процедуры проиллюстрировано на рис. 3.12. Там показано
дерево поиска, порожденное до шестого уровня1. (Мы условились порождать вершины
одного уровня слева направо.) Статические значения концевых вершин приведены на
рисунке. Проведем теперь поиск в глубину с использованием альфа-бета процедуры.
Поддерево, порожденное альфа-бета процедурой, отмечено жирными дугами с
зачерненными вершинами. Вершины, в которых происходит отсечение, перечеркнуты
крестиком. Значение оценочной функции приходится вычислять только для 18 из 41
исходной концевой вершины. (Читатель может проверить свое понимание работы этой
процедуры, попытавшись воспроизвести альфа-бета-поиск в этом примере.)
3.4.3. ЭФФЕКТИВНОСТЬ ПОИСКА С ПОМОЩЬЮ АЛЬФА-БЕТА ПРОЦЕДУРЫ
Чтобы можно было провести альфа-бета отсечения, хотя бы часть дерева
поиска должна быть порождена на максимальную глубину, так как
вычисление альфа и бета должно основываться на статических значениях
концевых вершин. Поэтому при использовании альфа-бета процедуры обычно
применяется некоторая методика поиска в глубину. Кроме того, число
отсечений, которые могут быть проведены в процессе поиска, зависит от
того, в какой мере первоначальные значения альфа и бета близки к
окончательным возвращенным значениям.
Окончательное возвращенное значение для исходной вершины совпадает
со статическим значением для одной из концевый вершин. Если при поиске
в глубину удается достичь этой вершины первой, то число отсечений будет
наибольшим. Если же число отсечений максимально, то порождать и
оценивать приходится минимальное число концевых вершин.
Пусть глубина дерева равна!), а каждая вершина (кроме концевой) имеет
ровно В дочерних. В таком дереве содержится в точности BD концевых
вершин. Положим, что альфа-бета процедура порождает дочерние вершины в
очередности, определяемой их истинными возвращенными значениями:
для MiiV-вершин первыми порождаются потомки с наименьшими
возвращенными значениями, а для МАДГ-вершин — с наибольшими. (Конечно, эти воз-
1 Напомним, что исходная вершина — это нулевой уровень. — Прим. перее.
106
-D7
о ^
С£ ..
107
вращенные значения, как правило, неизвестны в момент порождения
дочерней вершины, так что указанная очередность никогда не соблюдается, разве
что только случайно.)
Таким образом, такая очередность максимизирует число будущих
отсечений и минимизирует число порождаемых концевых вершин. Обозначим это
наименьшее число концевых вершин через ND. Можно показать, что
Г 2В°12 - 1, если Dчетно;
ND~ [ B(DH)I2+B(D-1)I2_ ι, еслиDнечетно.
Это означает, что при оптимальном альфа-бета поиске на уровне D
порождается примерно столько же концевых вершин, сколько их порождается
на уровне D/2 без использования альфа-бета процедуры. Следовательно,
альфа-бета процедура с идеальной очередностью порождения дочерних
вершин позволяет удвоить глубину поиска при неизменном объеме требуемой
памяти. Хотя идеальная очередность в задачах поиска и недостижима
(если бы мы могли ее добиться, то нам совсем не нужен был бы процесс
поиска!), но возможная выгода, которую она сулит, указывает на важность
использования этой наилучшей из имеющихся функций упорядочения.
3.5. БИБЛИОГРАФИЧЕСКИЕ И ИСТОРИЧЕСКИЕ ЗАМЕЧАНИЯ
3.5.1. ГРАФЫ ТИПА И/ИЛИ
Декомпозиция и графы типа И/ИЛИ использовались в различных
приложениях. Хиксман обсуждал приложения к "задаче сокращения запасов"
[159]. Мартелли и Монтанари показали, как можно переформулировать
задачи динамического программирования в виде задач поиска на графах
типа И/ИЛИ и как такая формулировка применяется для оптимизации
деревьев принятия решений [226, 227]. Слэйгл использовал деревья типа
И/ИЛИ в символьном интегрировании [340]. Стокман описал применения
графов типа И/ИЛИ к анализу волновых фронтов [352]. Как мы увидим в
гл. 6, графы типа И/ИЛИ могут быть также использованы в системах
автоматического доказательства теорем.
Наш алгоритм АО*, в сущности, тот же, что и алгоритм поиска на графах
типа И/ИЛИ Мартелли и Монтанари [225, 227]. Некоторые
иллюстрированные примеры взяты нами из работы [227]. Использованные там алгоритмы
поиска на графах типа И/ИЛИ основаны на более ранних работах Нильсона
[272, 273] (см. также работу Амарела [6]). Холл доказал эквивалентность
графов типа И/ИЛИ и контекстно-свободных грамматик [134]. Леви и Си-
рович обобщили графы типа И/ИЛИ для представления ими зависитдых друг
от друга подзадач и доказали, что обобщенные таким образом графы
эквивалентны грамматикам типа ноль [192]. Чанг и Слэйгл также
рассматривали графы И/ИЛИ, хотя и не учитывали некоторые свойства, связанные с
разложимостью [49]. Берлинер предложил подобный алгоритм поиска,
использующий в каждой вершине нижнее и верхнее граничные значения
[20].
Ковальский [174] и ван дер Брюг с Минкером [364] рассмотрели
соотношения между тем, что мы называли обратными разложимыми системами
продукций (использующими графы типа И/ИЛИ), и прямыми коммутатив-
108
ными системами (использующими графы вьюода). Мичи'и Зиберт также
описали эвристические алгоритмы поиска, основанные на графах вывода
[240].
3.5.2. ИГРОВЫЕ ДЕРЕВЬЯ
Шеннон в рекомендациях по составлению программы для игры в
шахматы предложил использовать минимаксную процедуру поиска вместе со
статической оценочной функцией [326]. Эти идеи были применены Ньюэллом,
Шоу и Саймоном при создании первой шахматной программы [266]. Самуэл
разработал программу, играющую в шашки, в которой использовались
полиноминальные оценочные функции, методы альфа-бета поиска и стратегии
обучения программы для улучшения ее игры [320, 321]. Слэйгл
рассматривал аспекты сходства между деревьями типа И/ИЛИ и игровыми
деревьями [341].
Альфа-бета процедура была независимо друг от друга предложена
многими учеными на ранних этапах разработки искусственного интеллекта.
Вариант этой процедуры был впервые описан Ньюэллом, Шоу и Саймоном
[226]. Кнут и My ρ дали всесторонний анализ ее свойств и обсудили
исторические аспекты [171]. Ньюборн и Бодэ приводят дополнительные
результаты [17, 263]. Результаты по эффективности альфа-бета поиска впервые
были установлены Эдвардсом и Хартом на основе теоремы, приписываемой
Майклу Левину [86]. Затем Слэйгл и Диксон [343] рассмотрели то, что
они считали первой публикацией доказательства этой теоремы. Книга
Кнута и Мура [171] содержит наиболее полный перечень таких свойств. В
докладе Линдстрома дана новая формулировка альфа-бета процедуры для сопро-
граммного (а не рекурсивного) управления [195]. Харрис предложил
альтернативу минимаксному поиску на деревьях игры [137].
Возможности шахматных программ постоянно совершенствуются, и
многие специалисты в области искусственного интеллекта по-прежнему
уверены в том, что недалек тот день, когда ЭВМ станет чемпионом мира по
шахматам. Хорошие обзоры по шахматным программам приведены в статье
Берлинера [19] и в книгах Ньюборна и Леви [191, 262]. В недавней
программе Уилкинса [388] учтены сведения из шахматной тактики, значительно
сокращающие требуемый объем поиска (см. работу Питрата [281]) .
Упражнения
3.1. Для замены цифры на строку цифр разрешается использовать следующие
правила подстановки:
6-* 3,3 4^3,1
6-*4,2 3-*2,1
4-*2,2 2-*1Д
Рассмотрите задачу использования этих правил для преобразования цифры 6 в
строку единиц. Проиллюстрируйте работу алгоритма АО*, применив его для решения этой
задачи. Считайте, что стоимость ^-связки составляет к единиц и что функция h в
вершинах, помеченных цифрой 1, принимает значение 0, а в вершинах, намеченных цифрой
η (где η Φ 1) , - значение п.
3.2. Игра ним состоит в следующем. Двое игроков поочередно удаляют одну, две
или три монеты из кучки, первоначально содержащей пять монет. Проигрывает тот,
109
кому достанется последняя монета. Начертив игровой граф, докажите, что всегда
побеждает игрок, делающий второй ход. Подумайте над простым способом описания
выигрышной стратегии.
3.3. Проведите альфа-бета поиск на игровом дереве, показанном на рис. 3.12,
порождая вершины справа налево. Укажите вершины, где происходит отсечение, и сравните
с рис. 3.12, на котором вершины порождались слева направо.
3.4. Главы 2 и 3 были посвящены методикам поиска при пробных режимах
управления (возвращение и поиск на графе). Рассмотрите проблему поиска при
безвозвратном режиме управления, направляющем работу коммутативной системы продукций.
(Это рассмотрение можно привести, опираясь, например, на разд. 3.3.) Детально
уточните алгоритм поиска, использующий оценочную функцию с эвристической
компонентой.
3.5. Представьте конфигурацию на доске игры в крестики-нолики как девятимерный
вектор с, компоненты которого равны +1,-1 или 0 в зависимости от того, стоит ли в
соответствующей клетке доски крестик, нолик или ничего не стоит. Укажите такой
девятимерный вектор w, чтобы скалярное произведение с w являлось хорошей
оценочной функцией, с помощью которой игрок МАХ (ставящий крестики) может
оценивать нетерминальные позиции. Примените эту оценочную функцию на нескольких
проходах минимаксного поиска, проводя каждый раз такую подгонку вектора w, которая
может улучшить оценочную функцию. Можете ли вы указать вектор w, оценивающий
позиции столь точно, что отпадает необходимость в проведении поиска на поддеревьях,
исходящих из этих позиций?
ГЛАВА 4
ИСЧИСЛЕНИЕ ПРЕДИКАТОВ В ОБЛАСТИ ИСКУССТВЕННОГО
ИНТЕЛЛЕКТА
Во многих приложениях та информация, которую предстоит занести в
глобальную базу данных некоторой системы продукций, порождается
описаниями, которые трудно или неестественно представлять с помощью таких
простых структур, как массивы или множества чисел. Интеллектуальное
извлечение информации, решение задач роботом и математическое
доказательство теорем, например, требуют возможности представления,
извлечения множества утверждений и манипулирования ими.
Исчисление предикатов первого порядка представляет собой
формальный язык, в котором можно выразить большое разнообразие утверждений.
В оставшейся части книги будем применять выражения на языке
исчисления предикатов в качестве компонент глобальных баз данных систем
продукций. Прежде чем давать точное описание, каким образом этот язык
используется в системах ИИ, нам предстоит определить язык, показать, как
его использовать при представлении утверждений, объяснить, как
осуществляются выводы из множеств выражений языка, и обсудить, как выводить
утверждения в языке из других утверждений в этом языке. Все эти
фундаментальные понятия в формальной логике также очень важны в ИИ.
Опишем сам язык и методы логики, а затем покажем, какое применение
они могут найти в системах продукций ИИ.
4.1. НЕФОРМАЛЬНОЕ ВВЕДЕНИЕ В ИСЧИСЛЕНИЕ ПРЕДИКАТОВ
Язык, такой как исчисление предикатов, определяется своим
синтаксисом. Для определения синтаксиса мы должны указать алфавит используемых
в языке символов и то, как эти символы комбинируются друг с другом,
ПО
чтобы образовать допустимые в языке выражения. Допустимые выражения
в исчислении предикатов называются правильно построенными формулами
(ппф). Рассмотрим краткое неформальное описание синтаксиса исчисления
Предикатов.
4.1,1. СИНТАКСИС И СЕМАНТИКА АТОМНЫХ ФОРМУЛ
Элементарными компонентами языка исчисления предикатов являются
предикатные символы, символы переменных, функциональные символы и
символы констант, разделяемые круглыми и квадратными скобками,
запятыми, как будет показано на примерах. Предикатный символ
используется для представления отношений в некоторой области рассмотрения.
Предположим, мы хотим представить факт, что кто-то что-то написал. Мы можем
воспользоваться предикатным символом ПИСАТЬ для обозначения
отношения между пишущим лицом и тем, что пишется. Мы можем составить
простую атомную формулу, используя символ ПИСАТЬ и два терма,
обозначающих того, кто пишет, и то, что пишется. Например, чтобы представить
фразу "Вольтер написал Кандида", можно воспользоваться следующей
простой атомной формулой:
ПИСАТЬ (ВОЛЬТЕР, КАНДИД)
Здесь ВОЛЬТЕР и КАНДИД являются символами констант. В общем
случае атомные формулы состоят из предикатных символов и термов.
Символ константы — это простейший вид терма, который используется
для представления объектов или элементов некоторой области
рассмотрения. Объекты или элементы могут представлять собой физические
объекты, людей, понятия или что-то еще, что мы хотели бы назвать.
Символы переменных, такие кзк χ и у, также являются термами; их
использование позволяет быть неопределенными относительно того, на
какой элемент области дается ссылка. Формулы, в которых применяются
символы переменных наподобие ПИСАТЬ (х, у), рассматриваются дальше в
контексте квантификации.
Можно составить также термы из функциональных символов,
обозначающих функции в нашей области рассмотрения. Например, функциональный
символ отец может использоваться для обозначения отображения между
индивидуумом и его родителем. Для выражения фразы "Мать Джона
замужем за отцом Джона" можно написать атомную формулу
СУПРУЖЕСТВО [отец (ДЖОН),мать (ДЖОН)].
Обычно строка из заглавных букв используется в качестве предикатного
символа. (Примеры: ПИСАТЬ, СУПРУЖЕСТВО.) В некоторых абстрактных
примерах короткие цепочки из заглавных букв и цифр (PI, Q2) являются
предикатными символами. Строки из заглавных букв или короткие
цепочки заглавных букв и цифр применяются также в качестве символов
констант, например КАНДИД, А1 или В2. Из контекста всегда ясно, является
ли некоторая цепочка предикатным символом или же символом константы.
Строки из строчных букв применяются в качестве функциональных
символов. (Например: отец, мать.) В абстрактных примерах для этого
используются строчные буквы латинского алфавита/,g, h9 расположенные
ближе к концу алфавита.
111
Чтобы выразить английскую фразу атомной формулой, сконцентрируем
внимание на отношениях и элементах, которые описываются в этой фразе,
и представим их предикатами и термами. Часто предикаты
идентифицируются с глаголом фразы, а термы — с субъектом или объектом этого
глагола. Обычно у нас имеется несколько вариантов представления некоторого
предложения. Например, фразу "Этот дом желтый" мы можем представить
предикатом либо с одним термом: ЖЕЛТЫЙ (ДОМ-1), либо сцвумя:ЦВЕТ
(ДОМ-1, ЖЕЛТЫЙ), либо с тремя термами: ЗНАЧЕНИЕ (ЦВЕТ, ДОМ-1,
ЖЕЛТЫЙ) и т.д. Конструктор представления выбирает алфавит предиката
и термов, которыми он будет пользоваться, и определяет, что элементы
такого алфавита будут значить.
В исчислении предикатов некоторой ппф может быть придана
интерпретация приписыванием соответствия между элементами языка и
отношениями, элементами и функциями в указанной области рассуждения. Каждому
предикатному символу мы должны приписать соответствующее отношение
в этой области, каждому символу константы — элемент области, а каждому
функциональному символу — функцию в этой области. Это приписывание
определяет семантику языка исчисления предикатов. В наших применениях
мы используем исчисление предикатов специально для представления
определенных заявлений об области рассуждения. Таким образом, обычно
для ппф, которыми мы пользуемся, подразумевается конкретная
интерпретация. Как только интерпретация для некоторой атомной формулы
определена, говорим, что формула имеет значение Τ (истина) в том случае, когда
соответствующее утверждение об области обсуждения истинно, и что
формула имеет значение F (ложь), если соответствующее утверждение ложно.
Так, при использовании очевидной интерпретации формула
ПИСАТЬ (ВОЛЬТЕР, КАНДИД)
имеет значение Т, а формула
ПИСАТЬ (ВОЛЬТЕР, МАШИННЫЕ-ШАХМАТЫ)
имеет значение F. Когда некоторая атомная формула содержит переменные,
то могут быть такие приписывания значений (или означивания) для этих
переменных (элементов нашей области), для которых атомная формула
имеет значение Т, или другие приписывания значений, для которых она имеет
значение F.
4.1.2. СВЯЗКИ
Атомные формулы, подобные ПИСАТЬ (х, у), представляют собой лишь
элементарный строительный блок языка исчисления предикатов. Атомные
формулы можно комбинировать для образования более сложных ппф,
используя связки, такие как Л (и), V (или), => (импликация).
Связка Л находит очевидное использование при представлении составных
фраз, подобных "Джон любит Мери, и Джон любит Сью". Некоторые и более
простые предложения также могут быть записаны в составной форме.
Например, "Джон живет в желтом доме" может быть представлено следующей
формулой:
ЖИВЕТ (ДЖОН, ДОМ-1) Л ЦВЕТ (ДОМ-1, ЖЕЛТЫЙ) ,
112
где предикат ЖИВЕТ представляет отношение между человеком и объектом,
а предикат ЦВЕТ — отношение между объектом и цветом. Формулы,
построенные связыванием других формул с помощью Л, называются
конъюнкциями, а каждая из составляющих формул - конъюнктом. Любая
конъюнкция из ппф также является ппф.
Символ V используют для представления функции неисключающее ИЛИ.
Например, фраза "Джон играет в центре поля или около сетки" могла бы
быть представлена так: [ИГРАЕТ (ДЖОН, ЦЕНТР) V ИГРАЕТ (ДЖОН,
ОКОЛО-СЕТКИ) ]. Формулы, построенные связыванием других формул с
помощью V, называются дизъюнкциями, а каждая составляющая формула —
дизъюнктом. Любая дизъюнкция, состоящая из ппф, также является ппф.
Значение истинности конъюнкций и дизъюнкицй определяется значениями
истинностей компонент. Конъюнкция имеет значение Г, если каждый из ее
конъюнктов имеет значение Т\ в противном случае она имеет значение F.
Дизъюнкиця имеет значение Г, если по крайней мере один из ее дизъюнктов
имеет значение Т; в противном случае она имеет значение F.
Связка => используется для представления утверждений типа "если—то".
Например, фразу "Если машина принадлежит Джону, то она зеленая"
можно было бы представить так:
ВЛАДЕТЬ (ДЖОН, МАШИНА-1) ^ЦВЕТ (МАШИНА-1, ЗЕЛЕНЫЙ).
Формула, построенная соединением двух формул с помощью знака => ,
называется импликацией. Левая сторона импликации называется антецедентом,
а правая — консеквентом. Если антецедент и консеквент являются ппф, то
импликация также является ппф. Импликация имеет значение Г, если либо
консеквент имеет значение Τ (независимо от значения антецедента), либо
антецендент имеет значение F (независимо от значения консеквента); в
противном случае импликация имеет значение F. Такое определение
значения истинности импликации иногда представляется странным с точки
зрения нашей интуиции в отношении слова "предполагает". Например,
представление в исчислении предикатов для фразы: "Если луна сделана из
зеленого сыра, то лошади способны летать" — имеет значение Т.
Символ ~ (не) иногда называют связкой, хотя он используется не для
связывания двух формул, а для отрицания значения истинности некоторой
формулы, т.е. изменяет значение ппф с Τ на F, и наоборот. Например,
фразу "Вольтер не написал книгу Машинные шахматы" можно представить
так:
~ ЛИСА ТЬ (ВОЛЬ ТЕР, МАШИННЫЕ-ШАХМА ТЫ).
Формула со знаком ~, стоящий перед ней, называется отрицанием.
Отрицание ппф также является ппф. Некоторая атомная формула и ее отрицание
называются литералами.
Легко видеть, что ~F7 V F2 имеет всегда то же значение истинности, что и
Fl =>F2, так что на самом деле у нас никогда не возникнет необходимости в
использовании знака =>. Однако нашей целью здесь является предложение не
минимального, а полезного представления. Имеются случаи, когда Fl ^F2
эвристически более предпочтительно, чем ее эквивалент ~F1VF2, и
наоборот.
Если ограничим свои фразы такими, которые могут быть представлены
113
конструкциями, введенными нами до сих пор, то будем иметь дело с
некоторым подмножеством исчисления предикатов, называемым
препозиционным исчислением. На самом деле препозициональное исчисление может быть
полезным представлением для многих упрощенных областей, но в нем не
хватает средств для представления многих утверждений (таких, как "Все
слоны серые") в удобной форме. Чтобы расширить его возможности,
необходимо уметь делать утверждения с формулами, содержащими переменные.
4.1.3. КВАНТИФИКАЦИЯ
Иногда атомная формула, например Ρ (χ), имеет значение Τ (при заданной
интерпретации Р) независимо от того значения, которое приписано
переменной х. Такая атомная формула может также иметь значение Τ по крайней
мере для одного значения х. Эти свойства используются в исчислении
предикатов при установлении значения истинности формул, содержащих
конструкции, называемые кванторами. Формула, состоящая из квантора
общности (Vx) перед формулой Р(х), имеет значение Τ для некоторой
интерпретации только тогда, когда значение Р(х) для этой интерпретации есть
Τ для всех способов приписывания χ элементам области. Формула,
состоящая из квантора существования (Зх) перед формулой Р(х), имеет
значение Τ для некоторой интерпретации только тогда, когда значение Р(х)
для этой интерпретации есть Τ по крайней мере для одного способа
приписываниях некоторому элементу области рассуждения.
Например, фраза "Все слоны серые" может быть представлена так:
(\/х) [СЛОН (х) => ЦВЕТ (х, СЕРЫЙ) ].
Здесь квантифицируемая формула представляет собой импликацию, ах -
квантифицируемая переменная. Мы говорим, что χ проквантифицироваш.
Область действия квантора — это та часть последующей цепочки формул, на
которую распространяется квантор. В качестве другого примера возьмем
фразу: "Существует человек, который написал Машинные шахматы",
которую можно было бы представить следующим образом:
(Зх) ПИСАТЬ (х, МАШИННЫЕ-ШАХМАТЫ).
Любое выражение, получаемое квантифицированием ппф по некоторой
переменной, также является ппф. Если некоторая переменная в ппф про-
квантифицирована, то говорят, что она является связанной переменной, в
противном случае ее называют свободной. Мы будем интересоваться
главным образом ппф, у которых все переменные связаны. Такие ппф
называются высказываниями.
Заметим, что если в ппф встречаются кванторы, то не всегда
оказывается возможным, используя смысл кванторов, вычислить значение
истинности этой ппф. Например, рассмотрим ппф (Vx) Ρ (χ) . При данной
интерпретации для Ρ и бесконечном множестве элементов области рассуждения мы
должны убедиться, что отношение, соответствующее Р, справедливо для
каждого возможного приписывания значения χ элементу области для того,
чтобы установить, что исходная ппф имеет значение Т. Такой процесс не
имеет конца1.
1 В общем случае это так. В частных случаях, например когда элементы области
упорядочены, такой процесс может быть конечным. - Прим. ред.
114
Вариант исчисления предикатов, используемый в настоящей книге,
называется исчислением первого порядка, поскольку в нем не допускается кван-
тификация по предикатным или функциональным символам. Таким
образом, формула, подобная (\/Р) Ρ (Α), не является гшф в исчислении
предикатов первого порядка.
4.1.4. ПРИМЕРЫ И НЕКОТОРЫЕ СВОЙСТВА ПРАВИЛЬНО ПОСТРОЕННЫХ ФОРМУЛ
Используя синтаксические правила, которые мы только что неформально
обсудили, можно построить произвольно сложные ппф и определить, является ли
произвольное выражение ппф или нет. Например, следующие выражения представляют собой
ппф:
Ox) {(Vy) [(P(x,y) AQ(y,x)) ~R(x)]} ,
~(V?) (Px) [P(X) \ R(q)]} ,
~P\A, g (Α,Β,Α)],
[~\P(A)~P(B)]} ~P(B).
В приведенных выражениях для отделения друг от друга компонентных ппф мы
использовали простые, прямые и фигурные скобки. Эти разделители применены для
того, чтобы сделать формулы более легко воспринимаемыми и исключить любую
неоднозначность в отношении того, как объединяются между собой использованные ппф.
Вот некоторые примеры выражений, не являющихся,ппф:
~f(A).
/[РИ)],
Q {/(Л), \p(B)~Q(Q]} ,
A v ~=>(V~).
При заданной интерпретации значения истинности ппф (исключая некоторые из
тех, которые содержат кванторы) могут быть вычислены по правилам, которые мы
неформально описали. Когда значения истинности определяется таким образом, то мы
пользуемся методом таблиц истинности. Этот метод так называется потому, что
таблица истинности сводит вместе те правила, которые мы обсуждали. Если XI и Х2 —
любые две ппф, то значения истинности составного выражения, построенного из этих ппф,
даются таблицей истинности (табл. 4.1):
XI
τ
F
Τ
F
Х2
Τ
Τ
F
F
Таблица
XI VA7
Τ
Τ
Τ
F
истинности
XI ΑΧ2
Τ
F
F
F
Та
Χ1=ϊΧ2
Τ
Τ
F
Τ
блица 4.1
~Χ1
F
Τ
F
Τ
115
Если значения истинности двух ппф совпадают независимо от интерпретации, то
говорим, что эти ппф являются эквивалентными. Пользуясь таблицей истинности, мы
легко устанавливаем следующие эквивалентности:
~ (-Х1) эквивалентно XI,
XI V Х2 эквивалентно -XI =>Х2.
Законы де Моргана:
~ (XI А Х2) эквивалентно -XI V ~Х2,
~ (XI V Х2) эквивалентно -XI А ~Х2.
Дистрибутивные законы:
XI Л (Х2 V ХЗ) эквивалентно (XI А Х2) V (XI А Х3)>
XI V (Х2 А ХЗ) эквивалентно (XI V Х2) А (XI V ХЗ).
Коммутативные законы:
XI А Х2 эквивалентно Х2 Л XI,
XI V Х2 эквивалентно X2N XI.
Ассоциативные законы:
(XI А Х2) А ХЗ эквивалентно XI А (Х2 А ХЗ),
ДО V Х2) V ХЗ эквивалентно XI V (Х2 V ХЗ).
Контрапозитивный закон:
XI => Х2 эквивалентно ~Х2 => -XI.
Эти законы оправдывают ту форму, в которой мы записали наши примеры ппф в
проведенном обсуждении. Например, ассоциативный закон позволяет записать
конъюнкцию А7 А Х2 А ... A XN6e3 каких-либо скобок.
Исходя из смысла кванторов, можно также установить следующие эквивалентности:
~(Эх) Р(х) эквивалентно (Vx) [~P(x)],
~(\/х) Р(х) эквивалентно (Эх) [^(х)],
(Vx) [P(x) AQ(x)] эквивалентно (Vx) Ρ (χ) А (Чу) Q(y),
(Зх) [Р(х) V Q(x)] эквивалентно (Зх) Р(х) V (Зу) Q(y),
(Vx) Ρ(х) эквивалентно (\/у) Р(у),
(Зх) Р(х) эквивалентно (Зу) Ρ (у).
В двух последних соотношениях эквивалентности видно, что связанная переменная
в квантифицированном выражении представляет собой нечто вроде '*немой"
переменной. Ее можно произвольно заменять на любой другой символ переменной, который
еще не встречался в выражении.
Чтобы показать гибкость исчисления предикатов как языка для выражения
разнообразных утверждений, приведем примеры представлений в исчислении предикатов
некоторых обычных высказываний.
В каждом городе имеется собаколов, покусанный каждой собакой в городе:
(Vx) {ГОРОД (х) => (Зу) { СОБАКОЛОВ (х, у) А
A(Vz) {[СОБАКА (ζ) АЖИТЬ-В(х,2)] =>КУСАЛ (у, ζ)}}}
Для каждого множества χ существует множество у такое, что мощность у больше,
чем мощность х, т. е. G:
(Vx) {МНОЖЕСТВО (х) =* (Зу) (Зи) (Зи)
[МНОЖЕСТВО (у) А МОЩН (х, и) А МОЩН (у, v) A
Λ G (и, ν) ] } .
Все кубики, находящиеся на кубиках, которые были сдвинуты или были скреплены
с кубиками, которые сдвигались, также были сдвинуты:
116
(Vx) (Vy) {{КУБИК (χ) Л КУБИК (у) Л
Л [НА-ВЕРХУ (х, у) V СКРЕПЛЕН (х, у) ] Л
Л СДВИНУТ (у) } -* СДВИНУТ (х) } .
4.1.5. ПРАВИЛА ВЫВОДА, ТЕОРЕМЫ И ДОКАЗАТЕЛЬСТВА
В исчислении предикатов имеются правила вывода, которые можно
применять к определенным ппф и множествам ппф для построения новых ппф.
Одним важным правилом вывода является модус поненс — операция,
которая создает ппф W2 из ппф вида W1 и Wl => W2. Другое правило вывода —
специализация — создает ппф W(A) из ппф (Vx) W(x), где А — любой
символ константы. Используя вместе модус поненс и специализацию, получаем,
например, формулу W2(А) из ппф (Vx) [Wl (χ) => W2(x) ] и Wl (A) .
Таким образом, правила вывода создают правильно построенные
формулы, выведенные из данных ппф. В исчислении предикатов каждая
выведенная формула называется теоремой, а используемая последовательность
применений правил вывода составляет доказательство теоремы. Как мы
отмечали раньше, в некоторых случаях решение проблем может быть
рассмотрено как задача поиска доказательства теоремы.
4.1.6. УНИФИКАЦИЯ
При доказательстве теорем, содержащих квантифицированные формулы,
часто оказывается необходимым привести "в соответствие" определенные
подвыражения. Например, чтобы применить комбинацию модус поненс и
правила специализации при создании W2(A) из ппф (Vx) [Wl(x) => W2(x)]
и W1(A), необходимо найти подстановку "Л вместо х", которая сделает
идентичными W1(A) и Wl(x). Поиск подстановок термов на место
переменных представляет собой весьма важный процесс в задачах
искусственного интеллекта и называется унификацией. Для описания этого процесса
мы сначала должны рассмотреть вопрос подстановок.
Термы некоторого выражения могут быть переменными символами,
символами констант или функциональными выражениями, причем
последние состоят из функциональных символов и термов. Подстановочный
частный случай некоторого выражения получаем подстановкой в это выражение
термов вместо переменных. Так, для Р[х, f(y), В] имеются четыре частных
случая :
P[z,f(w),B],
P[x,f(A),B],
P[g{z),f{A),B],
P[C,f(A),B].
Первый случай называется алфавитным вариантом исходного литерала,
поскольку мы просто подставили другие переменные вместо переменных
Р[х, f(y), В]. Последний из четырех примеров называется основным
частным случаем, так как ни один из термов литерала не содержит переменных.
Любую подстановку можно представить с помощью множества
упорядоченных пар s = {tl/vl9 t2lv2, . . . , tn/vn}. Пара ίζ·/^· означает, что
переменная Vj повсюду заменяется на терм £г·. Подчеркнем, что мы
рассматриваем такую подстановку, при которой каждое вхождение переменной
заменяется на один и тот же терм. Точно также считаем, что переменная не мо-
117
жет быть заменена на терм, содержащий ту же самую переменную. Вот те
подстановки, которые мы использовали для получения четырех частных
случаев:
sl = {z/x,wly} ,
s2={A/y},
s3={g(z)/x,A/y} ,
,4={C/x,A/y} .
Для обозначения подстановочного частного случая некоторого выражения
Ε с использованием подстановки s пишем Es. Таким образом,
P[z,f{w)B]=P[x,f(y),B]*l.
Композиция двух подстановок, si и s2, обозначается sls2, что говорит о
том, что эта подстановка получается применением s2 к термам si и
последующим добавлением тех пар из s29 которые содержат переменные, не
встречающиеся среди переменных si. Таким образом,
{ё(х>У)1*} {A/x,B/y,C/w,Dfz} ={g(A,B)lz,A/x,B/y,C/w} .
Можно показать, что применение к выражению L последовательно si и
s2 — это то же самое, что применение к L подстановки sls2, т.е. {Lsl)s2 =
= L(sls2).
Можно также показать, что композиция подстановок ассоциативна:
(sls2)s3 = sl(s2s3).
В общем случае подстановки некоммутативны, т.е., вообще говоря,
равенство s1s2=s2s1hq выполняется.
Если подстановка s применяется к каждому члену некоторого
множества {Ει } выражений, то множество подстановочных примеров
обозначается {Ej} s. Мы говорим, что множество {Ej} выражений унифицируемо,
если существует подстановка s такая, что/?^ -E2s -E^s = ... В этом случае
s называют унификатором для { Ej } , так как при ее применении это
множество склеивается в один элемент. Например, подстановка s = {Α/χ, В/у]
унифицирует {P[x,f(y)>B]9P[x,f(B)B)} идает [P[A,f(B),B]}.
Хотя s = {Α/χ, В/у } является унификатором для множества {Р [х, f (γ),
В] > Ρ[χ> f (β) > В]} > в некотором смысле она не является простейшим
унификатором. Мы замечаем, что на самом деле для достижения унификации
не было необходимости в подстановке А вместо х. Наиболее общий (или
простейший) унификатор (ноу) g для множества {/?,· } обладает тем
свойством, что если s есть любой унификатор для {/?/.} , дающий {Ef } s9 то
существует некоторая подстановка s такая,что {Ej} s = {Ej } gs'. Более
того, обычный частный случай, порождаемый наиболее общим
унификатором, является единственным с точностью до алфавитных его вариантов.
Существует много алгоритмов, которые можно использовать для
унификации конечного множества унифицируемых выражений и которые
сообщают о неудаче, когда это множество не может быть унифицируемо.
Рекурсивная процедура UNIFY, приводимая неформально, полезна для уяснения
общей идеи: как проводить унификацию множества из двух выражений,
имеющих списковую структуру. (В форме списка литерал Р{х, f(A, у))
записывается в виде (Px(fAy) ).)
118
Recursive Procedure UNIFY( EI, E2)
1 if либо El либо Е2 есть атом (т. е. предикатный
символ, функциональный символ, символ
константы, символ отрицания или переменная),
то поменяйте местами аргументы Е1 и Е2 (если
необходимо), чтобы Е1 был атомом и do:
2 begin
3 if El и Е2 идентичны, return NIL
4 if El есть переменная, do:
5 begin
6 if El встречается в Е2, return FAIL
7 return { E2/E1}
8 end
9 if E2 есть переменная, return {E1/E2}
10 return FAIL
11 end
12 Fl 4— первый элемент EltTl «- остаток El
13 F2 «— первый элемент E2, T2 «- остаток Е2
14 Z7*-UNIFY(F7,F2)
15 if Zl = F4/L,return F4/L
16 G7 «— результат применения Zl к 77
17 G2 «— результат применения Ζ/ к Т2
18 Ζ2 ♦- UNIFY(G7, G2)
19 if Z2 = F4/L, return F4/L
20 return композицию Zl и Z2
119
Можно доказать, что процедура UNIFY находит наиболее общий
унификатор для множества унифицируемых выражений или сообщает о неудаче,
когда эти выражения не унифицируемы.
В качестве примеров перечислим в табл. 4.2 наиболее общие
подстановочные частные случаи (те, которые получаются применением ноу) для
нескольких множеств литералов.
Таблица 4.2
Унифицируемые множества
Наиболее общие
Множество литералов подстановочные
частные случаи
{Р(х\Р(А)} Р(А)
Обычно мы используем унификацию, чтобы показать, можно ли один
литерал привести в соответствие с другим. В обоих литералах могут быть
переменные, и вместо этих переменных могут быть подставлены термы,
что сделает литералы идентичными. Процесс сопоставления одного
выражения с эталонным выражением иногда называют сравнение с образцом. В
системах ИИ он играет ключевую роль. Однако процесс унификации является
более общим по сравнению с тем, какой обычно подразумевается под
сравнением с образцом, потому что обычно в процессах сравнение с образцом
не допускается, чтобы переменные встречались в обоих выражениях.
4.1.7. ВЫПОЛНИМОСТЬ И УДОВЛЕТВОРИМОСТЬ
Если некоторая ппф имеет значение Τ для всех возможных
интерпретаций, она называется выполненной1. (Выполненные основные ппф обычно
называются тавтологиями.) Так, согласно нашей таблице истинности ппф
Ρ (А) => [Р(А) V Ρ (В)] имеет значение Τ независимо от интерпретации,
следовательно, она выполнена. Метод таблицы истинности может всегда
быть использован для определения выполнимости любой ппф, не
содержащей переменных. Нужно просто проверить, что эта ппф имеет значение Τ
при всех возможных оценках содержащихся в ней атомных формул.
Когда встречаются кванторы, то не всегда можно вычислить, является
ли некоторая ппф выполненной. Было показано, что невозможно найти
универсальный метод установления факта выполненности квантифицирован-
ных выражений/и по этой причине говорят, что исчисление предикатов не-
разрешимо. Однако выполненность некоторых формул, содержащих
кванторы, может быть определена, так что можно говорить о разрешимых
подклассах исчисления предикатов. Более того, было показано, что если неко-
1 Справедливой или общезначимой. - Прим. ред.
120
то рая ппф на самом деле выполнена, то существует процедура, позволяющая
установить выполненность этой ппф. (Эта процедура, будучи примененной к
формулам, которые не являются выполненными, может работать
неограниченно долго.) Таким образом, говорят, что исчисление предикатов
является полуразрешимым.
Если каждая ппф в некотором множестве ппф имеет значение Τ при
одной и той же интерпретации, то говорим, что эта интерпретация
удовлетворяет множеству ппф. Некоторая ппф X логически следует из какого-то
множества S ппф, если каждая интерпретация, удовлетворяющая S,
удовлетворяет также и X. Так, легко убедиться, что ппф (Vx) (уу) [Р(х) ν Q(y)]
логически следует из множества
{(V*) (уу) [Р(х) V QО) ], (Vz) [R (ζ) V Q (A)]} .
Правильно построенная формула ^(^4) логически следует из (у/х)Р(х).
Оказывается также, что (Vx) Q(x) логически следует из множества
{(V*) [~Ρ(χ) νρ(*)],(ν*)/>(*)}.
Имеется важное соответствие между понятием логического следования
ппф из некоторого множества ппф и представлением о ппф как теореме,
выводимой из множества ппф с помощью правил вывода. Предположим,
дана система правил вывода. Будем говорить, что эти правила логичны
(sound), если любая теорема, выводимая из какого-либо множества ппф,
также логически следует из этого множества. Можно показать, например,
что модус поненс — логичное правило вывода. Будем говорить, что
система правил вывода является полной, если все ппф, которые логически
следуют из какого-либо множества, являются также теоремами, выводимыми
из этого множества. Мы всегда интересуемся логичными правилами вывода,
хотя иногда и не требуем, чтобы множество правил вывода было полным.
4.2. РЕЗОЛЮЦИЯ
4.2.1. ПРЕДЛОЖЕНИЯ
Резолюция представляет собой важное правило вывода, которое может
применяться к определенному классу ппф — предложениям. Предложение
определяется как ппф, состоящая из дизъюнкции литералов1. Процесс
резолюции в тех случаях, когда он приложим, применяется к двум
родительским предложениям и порождает выведенное предложение. Прежде чем
объяснить сам процесс резолюции, покажем, что любая ппф исчисления
предикатов может быть преобразована во множество предложений. Этот
процесс преобразования проиллюстрируем на примере ппф
(V*) {/>(*)=* {Q4y)[P(y)*-P(f{x,y))]A
*P(y))}} ■
Процесс преобразования сводится к следующим этапам:
1. Исключение символов импликации. Все вхождения символа => в ппф
исключаются подстановкой ~Х1 VХ2 вместо XI =>Х2 всюду в ппф. В нашем
примере ппф такая подстановка дает
1 По этой причине вместо слова "предложение" (в оригинале "clause") иногда
используется слово "дизъюнкт", хотя автор называет дизъюнктом любой элемент
дизъюнкции (не обязательно состоящий из литерала). - Прим. ред.
(Vx) { ~Р(х) V {(уу) [~Р(у) V P(f(x,y) )) А
/\~{\/y)[~Q(x,y)V
V/»(y)]}}·
2. Ограничения области действия символа отрицания. Мы хотим, чтобы
каждый символ отрицания, ~, применялся не более чем к одной атомной
формуле. Используя несколько раз закон Моргана и другие правила
эквивалентности, упомянутые на с. 116 преобразуем наш пример ппф к виду
(V*) {~Р(х) V {(уу) [~P(y)VP(f(x,y))] Л
Λ(3^)[ρ(χ^)Λ
Л~Р(у)]}) .
3. Разделение переменных. В пределах области действия квантора
переменная, связываемая этим квантором, представляет собой немую
переменную. Ее повсюду можно заменить любой другой (не встречающейся)
переменной в пределах области действия квантора, при этом значение
истинности этой ппф не изменится. Стандартизация переменных в пределах ппф
означает переименование немых переменных с той целью, чтобы каждый
квантор имел свою, свойственную только ему, немую переменную. Так, вместо
того, чтобы писать (Vx [Р(х) =* (Эх) Q(x) ], мы пишем
(Vx) [Р(х) =* (3y)Q(y) ]. Разделение переменных в нашем примере дает
(Vx) {~Р(х) V {(уу) [~Р(у) VP(f(x,y))]A
Λ(βιν) [Q(x,w) Л
4. Исключение кванторов существования. Рассмотрим ппф
<Уу)[ШР{х,у)],
которую можно прочесть так: "Для всех у существует некоторое χ
(возможно, зависящее от у) такое, что Р{х, у)". Поскольку квантор существования
находится в области действия некоторого квантора общности, то мы
допускаем возможность того, что тотх, который существует, может зависеть от у.
Пусть эта зависимость будет явно определена с помощью некоторой
функции g(x), отображающей каждое значение у в то х, которое "существует".
Такая функция называется сколемовской. Если х, который существует,
заменить на такую сколемовскую функцию, то можно исключить квантор
существования и написать (У у) Ρ \g (у), у] ·
Общее правило исключения квантора существования из ппф состоит
в замене каждого вхождения переменной, относящейся к квантору
существования, на сколемовскую функцию, аргументы которой представляют
собой те переменные, которые связаны кванторами общности, область
действия которых включает область действия исключаемого квантора
существования. Функциональные символы, используемые в сколемовских
функциях, должны быть новыми в том смысле, что они не должны
встречаться прежде в этой ппф. Таким образом, мы можем исключить (3ζ) из
выражения
[(Vu,) <?(«,)] =► (Ух) {<уу) {(3(«) \Р(х,у,х) ·>
~(4u)R(x,y,u,z)]}}
и получить
122
*Qfo)RQc,y.u,gQc,y))]}.
Если исключаемый квантор существования не входит в область действия
никакого из кванторов общности, то применяется сколемовская функция
без аргументов, т.е. просто константа. Так, (Зх)Р(х) становится Р(А),
где символ константы А используется для ссылки на элемент, который,
как известно, существует. Важно, чтобы А был новым символом константы
и не совпадал с другими символами, применяемыми в других формулах
для указания на известные элементы.
Для исключения всех кванторов существования из некоторой ппф
указанная процедура применяется по очереди к каждой из составляющих ее
формул. Исключение кванторов существования в нашем примере ппф (здесь
он только один) дает
(Vx) {~P(x) V {(Vy) [~Ρ(γ) VP(f(x,y))] Λ
A[0(*.*(*))A~Pfe(x))]}} ,
где g (χ) — сколемовская функция.
5. Преобразование в предваренную форму1. На этом этапе не
осталось кванторов существования и каждый квантор общности имеет свою
переменную. Теперь все кванторы общности можно переместить в начало
ппф и считать, что область действия каждого квантора включает всю
последующую часть ппф. Говорят, что результирующая ппф находится в
предваренной форме. Правильно построенная формула в предваренной форме
состоит из цепочки кванторов, называемой префиксом, и следующей за ней
бескванторной формулы, называемой матрицей. Предваренная форма для
нашей ппф имеет вид
(Vx)(Vy) {~Ρ(χ) V { [<чРО0 VP(f(x,y))] Λ
Λ[0(*.*(*))Λ
л~/ч*(*))Ш ·
6. Приведение матрицы к конъюнктивной нормальной форме. Любая
матрица может быть записана как конъюнкция конечного множества
дизъюнкций литералов. Говорят, что такая матрица находится в
конъюнктивной нормальной форме. Приведем примеры матриц в конъюнктивной
нормальной форме:
[P(x)VQ(x,y)] Λ [P(w) V~R(y)] AQ(x,y),
P(x)VQ(x,y)9
P(x)AQ(x,y),
~R(y).
Любую матрицу можно привести к конъюнктивной нормальной форме
многократным применением дистрибутивных правил, а именно заменой
выражений вида XI V (Х2 Λ ХЗ) на (XIV Х2) Λ (XI V ХЗ) .
После приведения матрицы нашего примера ппф в конъюнктивную
нормальную форму эта ппф приобретает вид
(Vx) (Vy) { [~Р(д) V~PO) VP(f(xfJ0)] Λ
λ [~ρ(χ) νρ(*.*(*))] λ [~P(x)v~P(g(x))]}.
1 Или в префиксную форму. - Прим. ред.
123
7. Исключение кванторов общности. Поскольку все переменные в
используемых нами ппф должны быть связаны, то мы можем быть уверены, что
все переменные, оставшиеся на этом этапе, относятся к квантору общности.
Кроме того, порядок кванторов общности роли не играет, так что можно
не показывать явно вхождения кванторов общности и предположить по
соглашению, что все переменные в матрице относятся к кванторам общности.
Теперь у нас остается лишь матрица в конъюнктивной нормальной форме.
8. Исключение символов Л. Теперь мы можем избежать явного
присутствия символов Л, заменяя выражения вида (XI Л Х2) на множество ппф
[Х1, Х2\ . Результатом многократного использования таких замен будет
некоторое конечное множество ппф, каждая из которых является
дизъюнкцией литералов. Любая ппф, состоящая исключительно из дизъюнкции
литералов, называется предложением. Наш пример ппф преобразуется к
следующему множеству предложений:
~Р(х) М-Р (у) VP\f{x,y)]f
~P(x)VQ[x.g{x)]9
~P{x)V~P\g(x)].
9. Переименование переменных. Символы переменных должны быть
изменены так, чтобы каждый появлялся не более чем в одном предложении.
Вспомним, что (Vx) [Р(х) Λ Q(x)] эквивалентно [(\/х)Р(х) Λ (Vy)Q(y)].
Иногда этот процесс называют разделением переменных. Теперь наши
предложения приобретают вид:
~P{xl) V~P(y) MP]f{xl9y)\9
~Р(х2) V Q[x2,g(x2)]9
~P{x3)V~P\g{x3)].
Отметим, что литералы в предложениях могут содержать переменные, но
всегда подразумевается, что они относятся к кванторам общности. Если
вместо переменных некоторого выражения подставляются термы, не
содержащие переменных, то получаем так называемый основной частный случай
литерала. Так, Q(A, fig (β))) является основным частным случаем Q(x, у).
Когда резолюция используется в качестве правила вывода в системе
доказательства теорем, то множество ппф, исходя из которого мы хотим
доказать теорему, сначала преобразуется в совокупность предложений.
Можно показать, что если ппф X логически следует из некоторого множества S
правильно построенных формул, то она также логически следует из
множества предложений, получаемых в результате преобразования ппф из S в форму
предложений. Следовательно, для наших целей предложения являются
вполне общей формой, в которой выражаются ппф.
4.2.2. РЕЗОЛЮЦИЯ ДЛЯ ОСНОВНЫХ ПРЕДЛОЖЕНИЙ
Получить общее представление о правиле вывода с использованием
резолюции лучше всего на примере того, как она применяется в случае
основных предложений. Предположим, имеются два основных предложения:
Р1 V Р2М . . .V ΡΝπ-ΡΙ V Q2 У . . . У QM. Считаем, что все Pi и Qj
различны. Обратим внимание на то, что одно из этих предложений содержит
литерал, который в точности является отрицанием одного из литералов
другого предложения. Из этих двух родительских предложений можно вы-
124
Ри~Р V Q (т.е.Р=>0
Ρ V Qn~PV Q
Ρ V Qn~PV ~Q
~PhP
~P V £(т.е.Р=*£)
H~(2V/?(T.e.(2=>i?)
(2
QV ~Qn
PV ~P
ML
~PV Λ
(т.е.Р=*Л)
вести новое предложение, называемое их резольвентной. Резольвента
вычисляется взятием дизъюнкции этих предложений с последующим
исключением дополнительной пары:Р7, ~Р1.
Некоторые интересные частные случаи резолюции приведены в табл. 4.3.
Из этой таблицы можно видеть, что резолюция позволяет объединить
несколько операций в одно простое правило вывода. Далее рассмотрим, как
можно обобщить это простое правило на случай предложений, содержащих
переменные.
Таблица 4.3
Предложения и резольвенты
Родительские предложения Резольвенты Комментарии
Модус поненс
Предложение Q V Q
"сворачивается" в Q. Эта резольвента
называется слиянием
Здесь две возможные резольвенты;
в данном случае обе являются
тавтологиями
Пустое предложение является
признаком противоречия
Цепочка
4.2.3. РЕЗОЛЮЦИЯ В ОБЩЕМ СЛУЧАЕ
Для того чтобы применить резолюцию к предложениям, содержащим
переменные, необходимо иметь возможность найти такую подстановку,
которая, будучи примененной к родительским предложениям, приведет к тому,
что они будут содержать дополнительные литералы. При обсуждении этого
случая полезно представить предложение в виде множества литералов
(дизъюнкция между литералами в множестве подразумевается). Пусть
предполагаемые родительские предложения даются множествами {Lj } и {Mj} и
пусть переменные в этих двух предложениях разделены. Предположим, что
{// } является подмножеством {L/}, а {гг^·} —подмножеством {Mj) -
такими, что для объединения множеств {/Д и {~η·} существует
наиболее общий унификатор s. Будем говорить, что два предложения (Lz-j и \Mj]
разрешаются и что новое предложение
Hl,} -{/,}}« и Км,·} -{щ}},
является их резольвентой.
Если два предложения разрешаются, то они могут иметь более одной
резольвенты, поскольку может иметься более чем один способ выбора
{li] и {тщ }. Во всяком случае, они могут иметь не более чем конечное
число резольвент. В качестве примера рассмотрим два предложения:
P[x,fW]vP[x,f(y)]vQ(y)>
~P[z,f{A))V~Q{z).
При {/; } = {P[x,f (Л)]} и [гщ] = {~P[z9f (А)]\ получаем
резольвенту
125
P[*,f(y)]v~Q(')VQ(y)·
При {/,} = {P[x, f(A)], P[x, f(y)]} и {m,} = [~P[z, f(A)]} полу-
чаем резольвенту
Q(A)V~Q(z).
Заметим, что в последнем случае два литерала в первом предложении
слились при выбранной подстановке в один, дополнительный к некоторому
частному случаю из литералов второго предложения.
Всего имеется четыре различные резольвенты для этих предложений.
Две из них получаются резолюцией на Р, а одна — резолюцией на Q.
Нетрудно показать, что резолюция является логичным правилом вьюода,
т.е. что резольвента пары предложений также логически следует из этой
пары предложений. Когда резолюция используется в системе доказательства
теорем специального вида, которая описана в следующей главе и
называется системой опровержения, то она также и полна. Любая ппф, логически
следующая из некоторого множества ппф, может быть выведена из этого
множества с использованием опровержения, основанного на резолюции. По
этой причине, а также в связи с простотой, системы резолюции являются
важным классом систем доказательства теорем. Однако их простота приводит к
определенной неэффективности, ограничивающей их применение в
искусственном интеллекте. Тем не менее понимание систем резолюции создает
базу для понимания нескольких других типов более эффективных систем
доказательства теорем.
В следующих двух главах мы изучим такие системы, начиная с системы
с применением резолюции.
Рис. 4.1. Ситуация с тремя кубиками на столе
4.3. ИСПОЛЬЗОВАНИЕ ИСЧИСЛЕНИЯ ПРЕДИКАТОВ
В ИСКУССТВЕННОМ ИНТЕЛЛЕКТЕ
Ситуации или состояния и
цели в задачах различного типа
могут быть описаны правильно
построенными формулами
исчисления предикатов. На рис. 4.1,
например, показана ситуация, в
которой на столе находится три
кубика — А, В и С. Мы можем
представить эту ситуацию в виде конъюнкции следующих формул.
НА (С, А),
НА-СТОЛЕ (А),
НА-СТОЛЕ (В),
СВОБОДНЫЙ (О,
СВОБОДНЫЙ (В),
(Vx) [СВОБОДНЫЙ (х) =* -(3>0 НА (у, х) ].
Формула СВОБОДНЫЙ (В) предназначена для обозначения того, что
кубик сверху свободен, т. е. на нем нет другого кубика. Предикат НА
используется для описания того, какие кубики находятся (непосредственно) на
других кубиках. (В этом примере отношение НА нетранзитивно; оно озна-
126
чает "находится непосредственно наверху кубика".) Формула НА -СТОЛЕ (В)
предназначена для обозначения того, что В находится где-то на столе.
Последняя формула в списке дает информацию о том, как связаны между
собой СВОБОДНЫЙ и НА.
Конъюнкция нескольких таких формул может служить в качестве
описания конкретной ситуации или "состояния мира". Мы называем его
описанием состояния. На самом деле любая конечная конъюнкция формул
описывает семейство различных состояний мира, каждый член которого
может рассматриваться как интерпретация, удовлетворяющая этим
формулам. Даже предположив, что мы даем очевидную интерпретацию "мира
кубиков" составляющим этой формулы, тем не менее будем иметь
неограниченное семейство состояний (возможно, включающих также и
дополнительные кубики), элементы которого удовлетворяют рассматриваемым
формулам. Всегда некоторые из этих интерпретаций можно исключить,
внося дополнительные формулы в описание состояния. Например,
перечисленное множество ничего не говорит о цвете кубиков и, таким образом,
описывает семейство состояний, в котором кубики могут иметь различные
цвета. Если бы мы добавили формулу ЦВЕТ (В, ЖЕЛТЫЙ), то некоторые
интерпретации были бы, очевидно, исключены. Несмотря на то, что
конечная конъюнкция формул описывает некоторое семейство состояний, мы
часто, не вдаваясь в детали, говорим о некотором состоянии, задаваемом
описанием состояния. Мы подразумеваем при этом, конечно, множество
состояний.
Мы намерены использовать формулы, подобные формулам в примере
из мира кубиков, как глобальную базу данных в некоторой системе
продукций. То, как эти формулы будут применяться, зависит от задачи и ее
представления.
Предположим, задача состоит в том, чтобы показать, что определенное
свойство имеет место в данном состоянии. Например, мы хотим установить,
что в состоянии, изображенном на рис. 4.1, на кубике С ничего нет. Этот
факт можно доказать, показав, что формула ~{^у) НА (у, С) логически
следует из описания состояния рис. 4.1. Эквивалентно мы могли бы
показать, что ~(3у) НА (у, С) есть теорема, выводимая из этого описания
состояния посредством применения логичных правил вывода.
Мы можем воспользоваться системами продукций для того, чтобы
попытаться показать, что данная формула, называемая целевой ппф, является
теоремой, выводимой из некоторого множества формул (описания
состояния). Системы продукций такого сорта мы называем системами
доказательства теорем, или системами дедукции. (В следующих двух главах
опишем различные коммутативные системы продукций для доказательства
теорем.)
В прямой системе продукций описание начального состояния заносится
в глобальную базу данных и (логичные) правила продукций применяются
до тех пор, пока не будет получено некоторое описание состояния, которое
либо включает эту целевую формулу, либо унифицируется с ней некоторым
подходящим образом. В обратной системе продукций в глобальную базу
данных заносится целевая формула, а порождаюсь* йраььла ьр л меняются
до тех пор, пока не будет создана подцель, которая унифицируется с
формулами в описании состояния. Возможны также и комбинированные системы.
127
Одним очевидным и прямым применением для систем доказательства
теорем является доказательство теорем в математике и логике. Менее
очевидное, но важное использование они находят в интеллектуальных системах
извлечения информации, где для извлечения ответа на некоторый запрос
необходимо провести дедукции в базе данных фактов. Например, исходя из
выражений вида
ГЛАВА (ОТДЕЛ-ЗАКУПОК, ДЖОН-ДЖОНС),
РАБОТАЕТ-В (ОТДЕЛ-ЗАКУПОКДЖО-СМИТ),
{[РАБОТАЕТ-В(х, у) А ГЛАВА (χ, ζ) ] => БОСС (γ, ζ) } ,
ожидается, что интеллектуальная система извлечения информации могла бы
ответить на запрос: "Кто является боссом Джо Смита?". Такой запрос может
быть сформулирован в виде теоремы, которую предстоит доказать:
(Зх) БОСС (ДЖО-СМИТ, х).
Конструктивное доказательство (определяющее х, который существует) и
дало бы ответ на этот запрос.
И даже многие из самых обычных рассуждений, которые мы не
формализуем, могут быть на самом деле проведены с помощью систем доказательства
теорем в исчислении предикатов. Общая стратегия состоит в том, чтобы
специализированные знания об области рассмотрения представить в виде
выражений исчисления предикатов, а проблему или запрос — как теорему,
которую нужно доказать. Тогда система пытается найти доказательство теоремы
исходя из заданных выражений.
Проблемы другого типа связаны с изменением описания состояния для
того, чтобы получить описание, соответствующее совершенно другому
состоянию. Предположим, что у нас имеется связанная с роботом задача, в
которой система должна найти последовательность действий робота,
изменяющих конфигурацию из кубиков. Мы можем задать цель в форме ппф,
которая описывает множество состояний, приемлемых в качестве целевых.
Обращаясь к рис. 4.1, мы, возможно, хотели бы, чтобы кубик А был на
кубике В, а В, в свою очередь, на С Такое целевое состояние (или
множество состояний) может быть выражено целевой формулой [НА (А, В) Л
Л НА (В, С)]. Заметим, что эта целевая формула, безусловно, не может
быть доказана как теорема в описании состояния на рис. 4.1. Робот должен
изменить состояние на такое, которое может быть описано некоторым
множеством формул, исходя из которых такая целевая ппф может быть
доказана.
Проблемы такого типа также могут решаться с помощью систем
продукций. Для прямой системы глобальная база данных является описанием
состояния. Каждое возможное действие робота моделируется некоторым
порождающим правилом (П-правило в прямой системе). Например, если
робот в состоянии взять некоторый кубик, то наша система продукций
должна иметь соответствующее П-правило. Действие взятия кубика изменяет
состояние мира; применение П-правила, моделирующего взятие кубика,
должно вызвать соответствующее изменение в описании состояния. Некоторая
последовательность действий для достижения цели может быть вычислена
прямой системой продукций, которая применяет эти П-правила к описаниям
состояний до тех пор, пока не получится конечное описание состояния, из
128
которого целевая ппф может быть доказана. Решающая последовательность
П-правил составляет спецификацию плана действий для достижения
целевого состояния.
Для задач изменения состояний возможно применение также и обратных
систем продукций. Они будут использовать О-правила, которые являются
"обратными" моделями для действий робота. Формула, описывающая
целевое состояние, будет применяться как глобальная база данных. О-правила
будут применяться до тех пор, пока не будет получена некоторая формула
подцели, которая может быть доказана из начального описания состояния.
Системы продукций, в которых таким образом используются П- и
О-правила для моделирования действий, изменяющих состояние, обычно
являются некоммутативными. Например, П-правило для взятия кубика в
качестве предварительного условия требует, чтобы на нем ничего не было. На
рис. 4.1 это предварительное условие удовлетворяется для кубика В, но не
будет выполняться для В после того, как на него будет помещен кубик С.
Таким образом, применение одного П-правила к определенному описанию
состояния может сделать неожиданно другие П-правила неприменимыми.
Системы продукций для решения задач, связанных с изменением
состояний, подробно изучаются в гл. 7 и 8. Они находят особое применение при
решении задач роботом и автоматическом программировании.
4.4. БИБЛИОГРАФИЧЕСКИЕ И ИСТОРИЧЕСКИЕ ЗАМЕЧАНИЯ
Книга Поспесела является хорошим элементарным введением в
исчисление предикатов и содержит множество примеров английских фраз,
представленных как ппф [287]. Выпущены два прекрасных учебника по логике,
принадлежащих Мендельсону [236] и Робину [303]. Чанг и Ли [48], Лав-
ленд [198],Робинсон [307] описали методы резолюции.
Алгоритм унификации и доказательство корректности содержатся в
статье Робинсона [306]. С тех пор появилось несколько вариантов, в
частности Ралефс с соавторами опубликовали обзор унификации и
сопоставления [296], Патерсон и Вегман — описание линейного по времени (и по
памяти) алгоритма унификации [280].
Правило резолюции, введенное Робинсоном [306], основывается на
работе Правица [290] и других. Логичность и полнота резолюции
первоначально были доказаны Робинсоном [306]; доказательство этих свойств,
следуя работе Ковальского и Хейса [180], представлено у Нильсона [273].
Этапы, которые мы очертили, для преобразования любой ппф в форму
предложений, основаны на процедуре, описанной Дэвисом и Пушнэмом [69].
Форма предложений также называется бескванторной конъюнктивной
нормальной формой. Манна и Уолдин^ер предложили понятие обобщенной
резолюции, которая применима к правильно построенным формулам в
неклассической форме [220]. Маслов [230; см. другие более ранние работы на
русском языке] дал двойственную форму резолюции при работе с "целевыми
предложениями",, являющимися дизъюнкциями конъюнкций литералов
(см. также [182]).
129
Упражнения
4.1. Предположим, мы представили фразу "Сэм является отцом Билла" с помощью
ОТЕЦ (БИЛЛ, СЭМ), а фразу "Гарри является одним из предков Билла" с помощью
ПРЕДОК (БИЛЛ, ГАРРИ). Напишите правильно построенную формулу для
представления фразы "Каждый предок Билла является либо его отцом, либо его матерью,
либо одним из их предков ".
4.2. Связка ® (исключающее ИЛИ) определяется таблицей истинности:
XI
τ
F
Τ
F
Х2
Τ
Τ
F
F
XI Θ Χ2
F
Τ
Τ
F
Какая ппф, содержащая только связки % V и Λ, эквивалентна формуле (XI ® Х2) ?
4.3. Представьте следующие фразы с помощью ппф исчисления предикатов.
(Старайтесь лучше быть экстравагантными, чем экономными в отношении числа
различных используемых предикатов и термов. Например, не прибегайте к одной
предикатной букве для представления каждого предложения.)
а) Вычислительная система интеллектуальна, если она способна выполнять задачу,
которая при выполнении ее человеком требует интеллекта.
б) Формула, в которой основной связкой является =>, эквивалентна некоторой
формуле, в которой основной связкой является V.
в) Если на входе алгоритма унификации имеется множество унифицируемых
выражений, то на выходе будет ноу; если на входе множество не унифицируемых
выражений, то на выходе будет FAIL.
г) Если программе нельзя сообщить некоторый факт, то она не может обучиться
этому факту.
д) Если система продукций коммутативна, то для любой базы данных D каждый
член множества правил, применимых к D, также применим к любой базе данных,
полученной применением некоторого применимого правила к D.
4.4. Покажите логичность правила модус поненс в исчислении предикатов.
4.5. Покажите, что (3z) (V*) [Р(х) => Q(z)] и (32) [(Зх)Р(х) =* Q(z)]
эквивалентны.
4.6. Преобразуйте следующие ппф в форму предложений:
(a) (Vx)[P(x)=*P(x)]
(b) {~{(Vx)P(x))}^(3x)[~P(x))
(c) ~С*хЦР(х)=*{(Уу){Р(у)=>Р(/(х,у))]
Λ ~Wy){Q(x,y)=>P(y)}})}
(d) 0fx)(3y)
{lP(x,y)=S>Q(y,x)\A{Q(y,x)^>S(x,y))}
^>(3x)(Vy)lP(x,y)^>S(x,y)]
4.7. Покажите на примере, что композиция подстановок не коммутативна.
4.8. Покажите логичность резолюции, т.е. покажите, что резольвента двух
предложений логически следует из этих двух предложений.
4.9. Найдите наиболее общий унификатор для множества
{P(x,z,y),P(w,u>w),P(A,u,u)} .
4.10. Объясните, почему следующие множества литералов не унифицируемы:
130
(a) {P(f(x.x),A),P(f(y.f<J>.A)), Λ)}
(b) {~Ρ(Α),Ρ(χ)\
(c) [P{f{A)9x),P(x9A)} .
4.11. Следующие ппф были даны в этой главе в качестве одной интерпретации
ситуации из "мира кубиков ":
НА (С, А)
НА-СТОЛЕ (А)
НА-СТОЛЕ (В)
СВОБОДНЫЙ (О
СВОБОДНЫЙ (В)
(\/х) [СВОБОДНЫЙ (х) =>~(3у) НА {у, х).
Придумайте две различные интерпретации (не из "мира кубиков") , которые
удовлетворяют конъюнкции этих ппф.
4.12. В наших примерах представления английских фраз с помощью ппф мы не
затрагивали вопроса времен. Можете ли выразить следующие фразы как ппф:
Шекспир пишет "Гамлета**
Шекспир писал "Гамлета"
Шекспир будет писать "Гамлета"
Шекспир напишет "Гамлета"
Шекспир написал "Гамлета"1.
ГЛАВА 5
СИСТЕМА ОПРОВЕРЖЕНИЯ НА ОСНОВЕ РЕЗОЛЮЦИИ
В этой главе и гл. 6 мы будем заниматься главным образом системами,
которые доказывают теоремы в исчислении предикатов. Наш интерес к
доказательству теорем не ограничен приложениями к математике. Мы также
рассматриваем приложения к извлечению информации, к обычным
рассуждениям и автоматическому программированию. Будут обсуждаться два
основных типа систем доказательства теорем: здесь — системы, основанные
на резолюции, а в гл. 6 — системы, использующие различные формы
импликаций в качестве порождающих правил (или продукций).
В типичной задаче на доказательство теорем имеем множество S
правильно построенных формул, исходя из которого нам нужно доказать некоторую
целевую ппф W. Системы, основанные на резолюции, предназначены для
создания доказательства путем построения противоречия или опровержения.
При таком опровержении сначала берется отрицание целевой ппф и
добавляется к множеству S. Это расширенное множество затем преобразуется в
множество предложений, после чего резолюция используется при попытке
вывести противоречие, представляемое пустым предложением, NIL.
В пользу процесса доказательства путем опровержения можно привести
простое соображение. Предположим, некоторая ппф W логически следует
из некоторого множества S правильно построенных формул, тогда по
определению каждая интерпретация, удовлетворяющая S, также удовлетворяет
и W. Никакая интерпретация, удовлетворяющая S, не может удовлетворять
1 Последние две фразы соответствуют типичным для английского языка временам
"будущее совершенное" и * 'прошлое совершенное", подчеркивающим, что действие
будет совершено (или было совершено) к определенному моменту. — Прим. ред.
131
~W и, следовательно, никакая интерпретация не может удовлетворять
объединению S и {~W }. Множество ппф, которое не может удовлетворяться
ни при какой интерпретации, называется неудовлетворимым. Таким
образом, если W логически следует из S, то множество S U {~W) является
неудовлетворимым.
Можно показать, что если резолюция многократно применяется к
некоторому неудовлетворимому множеству предложений, то, в конце концов,
будет построено пустое предложение, NIL· Так, если W логически следует
из S, то резолюция в конечном счете создаст пустое предложение из
представления S U {~W } в виде предложений. Обратно: если из представления в
виде предложений для множества S u{~W] порождается пустое
предложение, то можно показать, что W логически следует из S.
Рассмотрим простой пример такого процесса. Предположим, высказаны
следующие утверждения:
1. Кто может читать, тот грамотный (Vx) [Ч(х) => Г(х) ].
2. Дельфины не грамотны (Vx) \Д(х) => ~Г(х)].
3. Некоторые дельфины обладают интеллектом (3 х) [Д(х) АИ(х) ].
Из них мы хотим доказать следующее утверждение.
4. Некоторые из тех, кто обладает интеллектом, не могут читать
(а*)1**(*)л~?г(*)].
Множество предложений, соответствующих утверждениям с первого по
третье, таково:
1. ~4{χ)\ίΓ(χ)·9
2. ~Д(у)Ч~Г(у);
За.Д(Л);
Зб.#(Л).
Здесь переменные разделены, Λ — сколемовская константа. Отрицание
теоремы, которую необходимо доказать, преобразованное к форме
предложения, имеет вид
4/ ~#(s) V4{z).
Чтобы доказать нашу теорему опровержением с помощью резолюции,
необходимо построить резольвенты для предложений 1-3 и 4', добавить
эти резольвенты к множеству и продолжать таким же образом, пока не
будет получено пустое предложение. Одно из возможных доказательств (их
имеется более одного) создает следующую последовательность резольвент:
5. Ч(А) резольвента 36 и 4/
6. Г (А) резольвента 5 и 1.
7. ~Д(А)резольвента 6 и 2.
8. NIL резольвента 7 и За.
5.1. СИСТЕМЫ ПРОДУКЦИЙ ДЛЯ ОПРОВЕРЖЕНИЯ НА ОСНОВЕ РЕЗОЛЮЦИИ
Систему опровержения на основе резолюции можно представлять как
систему продукций. Глобальной базой данных является множество
предложений, а схемой для правил — резолюция. Частные случаи этой схемы
применяются к парам предложений из базы данных при создании некоторого
выведенного предложения. Тогда новой базой данных становится
прежнее множество предложений плюс это выведенное предложение. Условием
конца работы для этой системы продукций является результат проверки —
содержит ли база данных пустое предложение.
132
Непосредственно можно показать, что эта система продукций является
коммутативной. Из-за такой коммутативности мы можем пользоваться
некоторым безвозвратным режимом управления. Итак, после выполнения
резолюции нам никогда не нужно обращаться к процедуре возвращения
(backtracking) или рассматривать альтернативные резолюции. Следует
подчеркнуть, что использование безвозвратного режима управления не
обязательно означает, что каждая выполненная резолюция находится "на пути"
к созданию пустого предложения: обычно будет несколько резолюций,
не относящихся к делу. Но поскольку эта система коммутативна, ничто
не препятствует тому, чтобы позднее была применена относящаяся к делу
резолюция, несмотря на то, что это произойдет после нескольких ненужных
резолюций.
Предположим, мы начинаем с некоторого множества предложений,
называемых базовым. Тогда основной алгоритм системы продукций для
опровержения на основе резолюции может быть записан следующим образом:
Procedure RESOLUTION
1 CLAUSES <-S
2 until NIL не будет членом С LA USES, do:
3 begin
4 select два различных разрешимых
предложения ci и с· в CLA USES
5 вычислить резольвенту г;- · для с;- и с-
6 CLA USES 4— Множество, получаемое присое -
динением ^ · к CLA USES
7 end
5.2. СТРАТЕГИИ УПРАВЛЕНИЯ ДЛЯ МЕТОДОВ РЕЗОЛЮЦИИ
Решения о том, какие два предложения в множестве ПРЕДЛОЖЕНИЯ
(шаг 4) выбирать и какую резолюцию для этих предложений выполнять
(шаг 5), принимаются с помощью стратегии безвозвратного управления.
Для выбора предложений в методах резолюции было предложено
несколько стратегий (впоследствии дадим несколько примеров).
Чтобы следить за тем, какие резолюции были выбраны, и чтобы избежать
дублирования работы, полезно в стратегии управления использовать
структуру, называемую граф вывода. Вершины этого графа помечены
предложениями; изначально для каждого предложения из базового множества
имеется вершина. Когда два предложения cz· и су создают резольвенту г у ,
то мы образуем новую вершину, помеченную rz·.·, причем ребра связыва-
133
ют ее с вершинами с,-
и с,-.
Здесь мы отклонимся от обычной для деревьев
терминологии и будем говорить, что ci и с,· являются родителями для Гц и
что rz/· является потомком cz· и С;. (Напомним, что мы ввели
представление о графе вывода в гл. 3.)
Опровержение на основе резолюции может быть представлено некоторым
деревом опровержения ( в рамках нашего графа вывода), корневая вершина
которого помечена предложением NIL. На рис. 5.1 показан граф
опровержения для примера, рассмотренного в последнем разделе.
Стратегия управления
направляет поиск опровержения,
наращивая граф вывода до тех пор,
пока не будет создано дерево,
корневая вершина которого
помечена пустым предложением
NIL. Говорят, что стратегия
управления для некоторой системы
опровержения является полной,
если ее использование приводит
к процедуре, которая найдет
опровержение (в конце
концов), если только оно
существует. (Полноту стратегии не
следует путать с логической
полнотой правила вывода,
обсуждаемой в гл. 4.) В приложении к
искусственному интеллекту
полнота стратегии не столь важна,
как эффективность поиска
опровержений.
Рис. 5.1. Дерево опровержения на основе
резолюции
5.2.1. СТРАТ ЕГИЯ ПОИСКА В ШИРИНУ
В стратегии поиска в ширину1 сначала вычисляются все резольвенты
первого уровня, затем все резольвенты второго уровня и т.д.
[Резольвентой первого уровня является резольвента для предложений из базового
множества; резольвентой i-го уровня является такая, чей самый
глубокий родитель является резольвентой (i-l)-ro уровня.] Стратегия поиска в
ширину является полной, но весьма неэффективной.
На рис. 5.2 изображен граф опровержения, порожденный стратегией
поиска в ширину для задачи, приводимой в качестве примера в последнем
разделе. Показаны все резольвенты первого и второго уровней, а среди
резольвент третьего уровня отмечена NIL. (Обратите внимание на то, что в
опровержении, показанном на рис. 5.1, пустое предложение появляется
лишь на четвертом уровне.)
*В отечественной литературе эта стратегия обычно называется стратегией полного
перебора. - Прим. ред.
134
5
г*
к.
>
l·*
?
Γ=ΓΊ
к
ι
5
к
>
4"
ι
,
ι
J
Ι /
" ' /
Λί
к
! >
5
ι ^
?
/1 Χι
1 """"^
Ν
^
!>
i-v
Ν
\ Ι \
Ν
t:
>
κ ι \
Ν
5:
ι
\ Ι \ \ γ
-^
5C
^
ι
5
>
1 ι ι
(
>
-~-^
Ν
^
•ι \
Ν
^
ι Ι
> |
Ν
^
? |
-^
5C
к
χ
я
α,
со
ОС
I
m
2 δ
h- Ω.
I >
S о
ОЛЬ
тьег
π\ ω
ω Ο.
Ω- Η-
<Λ
α.
ПЮСТ
Η
S
<ν
Ю
S
ά*
135
5.2.2. СТРАТЕГИЯ ОПОРНОГО МНОЖЕСТВА
Опровержение с использованием опорного множества состоит в том,
что по крайней мере один из родителей в каждой резольвенте выбирается
из предложений, возникающих при отрицании целевой правильно
построенной формулы или их потомков {опорное множество). Можно показать,
что если существует какое-либо опровержение, то существует и некоторое
опровержение, основанное на опорном множестве, поэтому полная
стратегия может быть основана на опорном множестве. Такая стратегия
должна лишь обеспечивать перебор всех возможных опровержений на основе
опорного множества (скажем, методом поиска в ширину). Обычно
стратегии, основанные на опорном множестве, оказываются более эффективными
по сравнению с ничем не ограниченным поиском в ширину.
При опровержении с использованием опорного множества каждая
резолюция несет в себе черты обратного рассуждения, поскольку в ней
используется предложение, принадлежащее к целевым ппф иди же являющееся их
следствием. Поэтому каждая резольвента в опровержении с опорным
множеством могла бы соответствовать определенной поддели в некоторой
обратной системе продукций. Одним из достоинств системы опровержения
является то обстоятельство, что в ней по существу обратные или прямые
шаги рассуждения выполняются некоторым простым способом в рамках
одной и той же системы продукций. (Шаги прямого рассуждения
соответствуют резолюциям между предложениями, которые не являются
потомками предложений доказываемой теоремы.)
На рис. 5.3 показан граф опровержения, порожденный стратегией с
использованием опорного множества для нашей проблемы. В этом случае опорное
множество не приводит к появлению пустого предложения на третьем
уровне. Опровержение третьего уровня для рассматриваемой проблемы с
необходимостью включает разрешение двух предложений, не входящих в
опорное множество. При сопоставлении рис. 5.2 и 5.3 видим, что опорное
множество на каждом уровне создает меньше предложений по сравнению с
неограниченной резолюцией в ширину. Как правило, стратегия опорного
множества приводит к более медленному росту множества предложений
и тем самым позволяет ослабить обычный комбинаторный взрыв. Как
правило, такое сдерживание роста множества предложений более чем
компенсирует то, что ограничивающие стратегии типа стратегии опорного
множества часто увеличивают глубину, на которой в первый раз встречается пустое
предложение.
Дерево опровержения, показанное на рис. 5.1, также могло бы быть
порождено и стратегией опорного множества. Верхняя часть такого дерева
показана на рис. 5.3, где соответствующие ветви сделаны более жирными.
5.2.3. СТРАТЕГИЯ ПРЕДПОЧТЕНИЯ ОДНОЧЛЕНАМ
Стратегия предпочтения одночленам является такой модификацией
стратегии опорного множества, в которой вместо заполнения каждого уровня,
как при поиске в ширину, мы пытаемся выбрать однолитеральное
предложение (называемое одночленом) в качестве родительской вершины для
резолюции. Всякий раз, когда в резолюции используется одночлен,
резольвенты содержат меньшее по сравнению с другими родительскими предло-
136
о
и
о
X
(X
о
в
о
X
ε
«о
6
137
138
жениями число литералов. Этот процесс позволяет сконцентрировать поиск
в направлении создания пустого предложения и поэтому, как правило,
повышает эффективность.
Дерево опровержения на рис. 5.1 могло бы быть порождено и стратегией
предпочтения одночленам.
5.2.4. ЛИНЕЙНАЯ ПО ВХОДУ СТРАТЕГИЯ
Линейное по входу опровержение — это опровержение, в котором по
крайней мере одно родительское предложение в каждой резольвенте
принадлежит базовому множеству1. На рис. 5.4 показано, какой граф опровержения
могла бы породить данная стратегия в нашем примере. Обратите внимание,
что первый уровень на рис. 5.4 точно такой же, как и на рис. 5.2. На
последующих уровнях линейная по входу стратегия и в самом деле приводит к
снижению числа порождаемых предложений. И снова использование такой
стратегии в нашем примере не позволяет создать пустое предложение на
третьем уровне. Заметьте, что дерево опровержения на рис. 5.1 проходит в
качестве линейного по входу опровержения. Часть этого дерева показана
на рис. 5.4, где некоторые ветви сделаны более жирными.
Имеются случаи, в которых опровержение существует, но не существует
опровержения с линейной по входу стратегией, следовательно, линейные по
входу стратегии не являются полными. Чтобы убедиться в том, что такие
стратегии не всегда проходят в случае неудовлетворимых множеств,
рассмотрим пример множества предложений:
Q(u)VP(A),
~Q(w)VP(w),
~Q(x) V~P(x),
Q(y) V~P(y).
Это множество заведомо не-
удовлетворимо, что
иллюстрируется деревом опровержения на
рис. 5.5. В линейном по входу
опровержении требуется, в
частности, чтобы одно из
родительских предложений для NIL было
бы членом базового множества.
Но для порождения пустого
предложения в нашем случае
необходимо разрешить либо два одно-
литеральных предложения, либо
два предложения, которые при
резолюции сворачиваются в од-
нолитеральные предложения.
Поскольку ни один член базового
множества не удовлетворяет ни
одному из этих критериев, то
~~Q{x)\/ ~~Р{х)
Q{y)V*P{y)
Q(u)\/P(A)
NIL
Рис. 5.5. Дерево опровержения
1 Имеется в виду полное исходное множество предложений, включая предложения,
идущие от целевого утверждения. - Прим. ред.
139
для данного множества не существует линейного по входу
опровержения.
Несмотря на отсутствие свойства полноты, линейные по входу стратегии
применяются довольно часто из-за их простоты и эффективности.
5.2.5. СТРАТЕГИЯ С УЧЕТОМ ПРЕДШЕСТВУЮЩИХ ВЕРШИН
Опровержение с учетом предшествующих вершин — это такое, в котором
одно из родительских предложений для каждой резольвенты принадлежит
базовому множеству или является одним из предков для второго
родительского предложения. Таким образом, учет предшествующих вершин весьма
похож на использование линейной стратегии. Можно показать, что стратегия
управления, гарантирующая, что будут построены все доказательства с
учетом предшествующих вершин, является полной.
В качестве примера возьмем дерево опровержения на рис. 5.5, которое
могло бы быть порождено некоторой стратегией с учетом
предшествующих вершин. В данном случае предложение, отмеченное звездочкой,
используется в качестве "предка"1. Можно показать, что полнота стратегии
сохраняется, если используемые предшествующие вершины ограничены
слияниями. (Напомним из гл. 4, что слиянием называется резольвента, которая
наследует литерал от каждого родительского предложения, такой, что он
"сворачивается" в один элемент при применении ноу.) На рис. 5.5 мы
видим, что предложение, отмеченное звездочкой, является слиянием.
5.2.6. КОМБИНИРОВАНИЕ СТРАТЕГИЙ
Можно также объединять стратегии управления. Комбинация стратегий
опорного множества либо со стратегией, линейной по входу, либо
учитывающей предшествующие вершины является широко распространенной.
Рассмотрим, например, объединение стратегии опорного множества с
линейной по входу стратегией. Такую стратегию можно рассматривать как
простой пример рассуждения в обратном направлении от цели к подцели, от нее
к ее подцели и т.д. Оказывается, что первые три уровня на рис. 5.3
содержат лишь предложения, которые допускаются такой комбинированной
стратегией, так что на этих уровнях комбинация не ведет к дальнейшему
ограничению по сравнению со стратегией опорного множества, использованной
на этом рисунке. Иногда же такая комбинированная стратегия ведет к
более медленному росту множества предложений, чем это будет
происходить при использовании каждой стратегии в отдельности.
Стратегии опорного множества — линейная по входу и с учетом
предшественников — ведут к ограничению множества резолюций. Что же касается
тех резолюций, которые допускаются этими стратегиями, то в них ничего
не говорится о порядке выполнения этих резолюций. Мы уже отмечали,
что неподходящий порядок не препятствует нахождению опровержения.
Этот факт, однако, не означает, что порядок проведения резолюций не
сказывается на эффективности процесса опровержения. Напротив, использо-
1 "Предок" по отношению к пустому предложению; под этим термином
понимается фактически любая предшествующая вершина, хотя слово an ancestor обычно
предполагает "родство" более отдаленное, чем "дедушка" или "бабушка". - Прим. ред.
140
вание подходящего порядка выполнения резолюций может
воспрепятствовать порождению большого числа ненужных предложений. Стратегия
предпочтения одночленам является одним примером стратегий
упорядочения. Были разработаны также и другие стратегии упорядочения,
основанные на числе литералов в предположении и сложности термов предложения.
Порядок, в котором выполняются резолюции, является фактором,
определяющим эффективность систем опровержения. Поскольку настоящая книга
не ориентирована на применения систем опровержения на основе
резолюций, то интересующегося читателя мы отсылаем к замечаниям в конце
главы, содержащим ссылки на статьи и книги, имеющие дело со
стратегиями упорядочения для систем резолюций.
5.3. СТРАТЕГИИ УПРОЩЕНИЯ
Иногда множество предложений может быть упрощено исключением
некоторых предложений или некоторых литералов из предложений. Эти
упрощения таковы, что упрощенное множество предложений неудовлетво-
римо тогда и только тогда, когда неудовлетворимо первоначальное
множество. Следовательно, применение стратегий упрощения подобного рода
позволяет снизить скорость роста множества новых предложений.
5.3.1. ИСКЛЮЧЕНИЕ ТАВТОЛОГИЙ
Любое предложение, содержащее некоторый литерал и его отрицание
(назовем такое предложение тавтологией), может быть отброшено,
поскольку неудовлетворимое множество, содержащее тавтологию, остается неудов-
летворимым после ее удаления, и наоборот. Так, предложения типа
Р(х) VB(y) V~B(y) mP{f {A)) V~P(f(A)) могут быть отброшены.
5.3.2. ПРИСОЕДИНЕНИЕ ПРОЦЕДУР
Иногда возможно и более удобно оценивать значения истинности
некоторых литералов вместо того, чтобы включать эти литералы или их
отрицания в базовое множество. Как правило, оценивание выполняется для
основных частных случаев. Например, если предикатный символ Ε обозначает
отношение равенства чисел, то довольно просто оценить основные частные
случаи — такие,как Ε(7, 3), когда они встречаются, хотя в то же время мы,
по-видимому, не захотели бы включать в базовове множество таблицу,
содержащую большое число основных частных случаев для Е(х, у) и ^Е{х, у).
Полезно более внимательно разобраться в том, что имеется в виду под
оцениванием выражения типа Ε(7, 3). Выражения исчисления предикатов
представляют собой лингвистические конструкции, обозначающие значения
истинности, элементы, функции или отношения в некоторой области
определения. Такие выражения могут быть интерпретированы со ссылкой на
некоторую модель, которая связывает лингвистические элементы с
соответствующими элементами из области определения. Конечный результат
состоит в том, что с предложениями этого языка будут связаны значения Τ
wrnF.
При заданной модели можно воспользоваться любыми конечными
процессами для интерпретации с целью установления значений истинности выраже-
141
ний. К сожалению, в общем случае и модели, и процессы интерпретации
конечными не являются. Однако часто можно воспользоваться частичными
моделями. В нашем примере с равенством можно с предикатным символом
Ε ассоциировать программу для вычислительной машины, которая
проверяет равенство двух чисел в пределах конечной области определения
программы. Назовем эту программу EQUALS. Будем говорить, что программа
EQUALS присоединена к предикатному символу Е. Мы можем
ассоциировать лингвистические символы 7 и 3 (нумералы) с элементами данных
вычислительной машины 7 и 3 (числами) соответственно. Скажем, что 7
присоединено к 7, а 3 присоединено к 3 и что программа для вычислительной
машины и аргументы, представляемые EQUALS (7, 3), присоединены к
лингвистическому выражению Ε (7, 3). Теперь можно запустить эту программу
и получить значение F (ложь), которое, в свою очередь, даст значение F
рдяΕ (7, 3).
Мы можем также присоединять процедуры к функциональным символам.
Например, с функциональным символом plus можно связать программу
сложения. Таким образом, присоединение процедур позволяет установить
связь между кодом, выполняемым для вычислительной машины, и
некоторыми лингвистическими выражениями в нашем языке исчисления
предикатов. Оценивание присоединенных процедур можно представлять себе как
процесс интерпретации по отношению к некоторой частичной модели.
Присоединение процедур, когда удается им воспользоваться, уменьшает
объем усилий, затрачиваемых на поиск, при доказательстве теорем.
Литерал оценивается при интерпретации посредством запуска
присоединенных процедур. Как правило, не все литералы множества предложений
могут подвергаться оцениванию, но тем не менее множество предложений
может упрощаться при таких оцениваниях. Если некоторый литерал в
предложении получает оценку Г, то предложение может быть отброшено,
поскольку при этом оставшееся множество предложений остается неудовлет-
воримым. Если литерал получает оценку F, то можно исключить именно
вхождение этого литерала в предложение. Так, предложение Р(х) V Q(A) V
V Ε'(?\ 3) может быть заменено наР(д:) V Q(A), так как Ε(7, 3) получает
оценку F.
5.3.3. ИСКЛЮЧЕНИЕ ПРИ ПОДСУММИРОВАНИИ
По определению предложение [ L. } подсуммирует предложение {Мг· } ,
если существует подстановка s такая, что {Lz·} s является подмножеством
| Mj } 1. Например,
Р(х) подсуммирует Ρ (у) V Q(z),
Ρ (χ) подсуммирует Ρ (Л),
Р(х) подсуммирует Ρ (А) V Q(z),
Р(х) V Q(А) подсуммирует P(f (A)) V Q(A) VR(y).
Предложение в неудовлетворимом множестве, которое подсуммируется
другим предложением из этого множества, может быть отброшено, что не
1 Предложение {Ζ,ζ·} s составляет часть {л^· } или совпадает с этим предложением.
Словом "подсуммирует" мы отражаем тот факт, что первое предложение является более
общим видом некоторой части второго предложения. - Прим. ред.
142
повлияет на неудовлетворимость оставшейся части множества. Исключение
предложений, подсуммируемых другими предложениями, часто ведет к
существенному уменьшению числа резолюций, которые необходимо проделать
в поиске опровержения.
5.4. ИЗВЛЕЧЕНИЕ ОТВЕТА ИЗ ОПРОВЕРЖЕНИЯ, ОСНОВАННОГО
НА РЕЗОЛЮЦИИ
Многие применения систем доказательства теорем в исчислении
предикатов основаны на доказательстве с помощью формул, содержащих
переменные, относящиеся к квантору существования, и связаны с поиском
значений или частных случаев для этих переменных. Иначе говоря, мы
хотели бы узнать, следует ли правильно построенная формула (Эх) W(x)
логически из S, и если да, то мы хотели бы знать тот частный случай для х,
"который существует". Задача нахождения доказательства для (Эх) W(x),
исходя из S, является обьгдаой задачей на доказательство теорем в
исчислении предикатов, но создание удовлетворяющего теореме χ требует, чтобы
метод доказательства был "конструктивным".
Заметим, что перспектива построения удовлетворяющих частных
случаев для переменных, относящихся к кванторам существования, открывает
возможность для формулирования вопросов весьма общего вида. Например,
мы могли бы спросить: "Существует ли решение для некоторой
головоломки типа игры в 8?". Если можно найти конструктивное доказательство
того, что решение существует, то мы могли бы указать и само желаемое
решение. Мы могли бы также задаться вопросом, существуют ли
программы, выполняющие требуемые вычисления. Из конструктивного
доказательства существования некоторой программы можно было бы создать
требуемую программу. (Впрочем, мы должны помнить, что сложные вопросы в
общем случае имеют сложные доказательства, возможно, настолько
сложные, что наша автоматическая процедура поиска доказательства никогда
их не найдет.) В настоящем разделе мы описываем некоторый процесс,
с помощью которого удовлетворяющий частный случай для некоторой
переменной, относящейся к квантору существования, в правильно
построенной формуле может быть извлечен из опровержения на основе резолюции
для этой ппф.
5.4.1. ПРИМЕР
Рассмотрим следующую простую задачу: "Если Джим ходит туда же, куда ходит
Джон, и если Джон находится в школе, то где Джим?". Совершенно ясно, что в задаче
определяются два факта, а затем задается вопрос, ответ на который предположительно
может быть выведен из этих фактов. Указанные факты могут быть преобразованы в
следующее множество S правильно построенных формул:
(V*) \В(ДЖОН,х) =>Я (ДЖИМ, х)];В (ДЖОН,ШКОЛА).
На вопрос: "Где Джим?" - можно ответить, если мы сначала докажем, что ппф (3 х)
В (ДЖИМ, х) логически следует из 5, а затем найдем тот частный случай х, "который
существует". Основная идея состоит в преобразовании вопроса в целевую ппф,
содержащую квантор существования, такую, чтобы переменная, относящаяся к этому
квантору существования, представляла бы ответ на вопрос. Если на вопрос можно дать
ответ исходя из заданных фактов, то построенная таким образом целевая ппф будет
143
логически следовать из S. После получения доказательства попытаемся извлечь
служащий в качестве ответа частный случай переменной, связанной квантором
существования. В нашем примере легко доказать, что (Эх) В (ДЖИМ, х) следует из S. Можем
также показать, что с помощью относительно простого процесса можно извлечь
соответствующий ответ.
Опровержение на основе резолюции получается обычным путем. Сначала берется
отрицание ппф, которую предстоит доказать, отрицание добавляется к множеству S,
все члены полученного расширенного множества преобразуются в форму
предложений, а затем методом резолюции показывается, что это множество предложений
неудов л етворимо. Дерево опровержения для нашего примера показано на рис. 5.6.
Предложения, вытекающие из правильно построенных формул, содержащихся в 5,
называются аксиомами. Заметим, что отрицание целевой ппф (Зх) В (ДЖИМ, х) дает
(Vx) (~В(ДЖИМ, х)),
что в форме предложений представляет собой просто ~В (ДЖИМ, х).
Рис. 5.6. Дерево опровержения для рассматриваемого примера
Далее мы должны извлечь из дерева опровержения ответ на вопрос:"Где Джим?"
В данном случае это происходит в результате следующего процесса:
1. Добавить к каждому предложению, возникающему из отрицания целевой ппф,
его собственное отрицание. Таким образом ~В(ДЩИМ, х) заменяется тавтологией
-В (ДЖИМ, х) У В (ДЖИМ, х).
2. Следуя структуре дерева опровержения, выполнить те же самые резолюции, что
и раньше, пока в корневой вершине не будет построено некоторое предложение. (Мы
уточним фразу "ге же самые резолюции " позднее).
3. Использовать предложение в корневой вершине в качестве ответного
утверждения.
В нашем примере эти шаги создают дерево доказательства с предложением В (ДЖИМ,
ШКОЛА) в корневой вершине (рис. 5.7). Это предложение и является
соответствующим ответом на поставленную задачу.
Рис. 5.7. Модифицированное дерево доказательства для рассматриваемого примера
144
Видно, что ответное утверждение имеет форму, подобную форме целевой ппф. В
данном случае единственное различие состоит в том, что в ответном утверждении
(ответе) мы имеем константу на месте переменной, относящейся к квантору
существования в целевой ппф.
В следующих разделах рассмотрим процесс извлечения ответа более
тщательно, дадим оправдание его справедливости и обсудим, как им
пользоваться в случае, если целевая ппф содержит и кванторы существования, и
кванторы общности.
5.4.2. ПРОЦЕСС ИЗВЛЕЧЕНИЯ ОТВЕТА
Извлечение ответа состоит в преобразовании дерева опровержения (с NIL
в корневой вершине) в дерево доказательства с некоторым утверждением
в корневой вершине, которое может быть использовано в качестве ответа.
Поскольку при таком преобразовании каждое предложение, возникающее
в результате отрицания целевой ппф, преобразуется в тавтологию, то
преобразованное дерево доказательства является доказательством методом
резолюции, заключающимся в том, что утверждение, стоящее в корневой
вершине, логически вытекает из аксиом и тавтологий. Следовательно, оно
вытекает и просто из самих аксиом. Таким образом, само преобразованное
дерево доказательства является оправданием процесса извлечения ответа.
Хотя сам метод прост, имеется несколько тонких моментов, которые
можно пояснить на примерах.
Пример 1. Рассмотрим множество ппф:
1. (Vx)(V.y) {[Р(х,у) AP(y,z)] =>G(x,z)}
2. (Vy)(3x)P(x,y).
Их можно интерпретировать следующим образом1.
1. Для всех χ и у, если χ является родителем у, а у — родителем ζ, то jc является
дедушкой/бабушкой для ζ.
2. У каждого есть родитель.
Рассматривая эти ппф в качестве гипотез, предположим, что мы задаемся вопросом:
"Существуют ли такие лица χ и у, что χ является дедушкой yV. Целевая ппф,
соответствующая этому вопросу, имеет вид
(3x)(3y)G(x,y).
Эта целевая ппф может быть легко доказана опровержением с помощью резолюции.
Дерево опровержения изображено на рис. 5.8. Литералы, которые унифицируются при
каждой резолюции, подчеркнуты. Будем называть то подмножество литералов в
предложении, которые унифицируются в ходе некоторой резолюции, множеством
унификации.
Заметьте, что предложение P(f(w), w) содержит сколемовскую функцию /,
введенную при исключении квантора существования в аксиоме 2. (Функцию / можно
интерпретировать как функцию, указывающую имя родителя для любого лица.)
Модифицированное дерево доказательства изображено на рис. 5.9. Отрицание целевой ппф
преобразовано в тавтологию, а резолюции следуют тем резолюциям, которые выполнялись
на дереве рис. 5.8. В каждой резолюции в модифицированном дереве используются
множества унификации, которые в точности соответствуют множествам унификации
дерева опровержения. Здесь множества унификации подчеркнуты.
1 Символ Ρ обозначает отец/мать (parent), а символ G - дедушка/бабушка
(grandparent). - Прим. ред.
145
Отрицание цели
~Р(х,у) V -P{y,z) V G(x,z)
Аксиома 1
-P(u,y)V-P(\\v
Ρ(/(νν),νν)
Аксиома 2
-P(uJ(v))
^(/(νν),νν)
Аксиома 2
NIL
Рис. 5.8. Дерево опровержения для примера 1
ЛцДу))УС(ц,у)|
Рис. 5.9. Модифицированное дерево доказательства для примера 1
В корневой вершине дерева доказательства рис. 5.9 имеется предложение G{f{f{y)),
ν). Оно представляет ппф (Vi>) [G(/(/(i>)), p)], которая является ответным
утверждением. Это утверждение дает ответ на вопрос: "Сущестауют ли такие лица χ и у, что χ
146
является дедушкой yV\ В данном случае ответ содержит определительную функцию /.
Любое ν и родитель родителя ν являются примерами лиц, удовлетворяющих условиям
вопроса. И снова ответное утверждение имеет форму, подобную форме целевой ппф.
Пример 2. Проиллюстрируем способ, с помощью которого более сложные
предложения, возникающие из отрицания целевой ппф, преобразуются в тавтологии.
Рассмотрим следующее множество предложений или аксиом:
~А{х) V F(x) V G(/(x));
~F(x) V*(x);
~F(x) V С (х);
~G{x) V5(x);
~G(x) VD(x);
A(g(x)) V F{h (x)).
(В этом примере мы полагаем, что перед применением резолюции переменные в
предложениях переименовывается соответствующим обрядом, т.е. раедешскгсся.. Ддя.
простоты этот процесс явным образом не указывается.) Исходя из этих аксиом, мы хотим
~~В(х) V ~С{х)
-D{x)\f -В(χ)
-Fix)VB(x)
-/•(ν) V ~~C(x)
~G(x)VD(x)
~B{x)V ~G{x)
-Hx)VC(x)
-hix)
-G(x)V B{x)
~G{x)
~A{x)\ \A(g(x))V F{h(x))
NIL
Рис. 5.10. Дерево опровержения для примера 2
147
доказатышф (Эх) (Зу) { [В(х) Л С(х)] V [D{y) ΑΒ(γ)]\ .
Отрицание этой ппф дает два предложения, содержащие по два литерала:
~В(х) V ~С(х); ~В(х) V ~D(x).
Дерево опровержения для совокупного множества предложений изображено на
рис. 5.10. Теперь, преобразуя это дерево, мы должны превратить предложения,
полученные вследствие отрицания целевой ппф (на рис. 5.10 заключены в двойные рамки),
в тавтологию, подсоединяя к ним их отрицания. В нашем случае такие отрицания
содержат символы Л. Например, предложение ~В(х) V ~С(х) преобразуется в ~В(х) V
V ~С(х) V [В(х) Л С(х)]. Эта формула не является предложением из-за появления
конъюнкции [В(х) Л С(х)], тем не менее мы рассматриваем эту конъюнкцию как
единый литерал и формально действуем так, как будто эта формула была
предложением (ни один из элементов этой конъюнкции никогда не попадает в множество
унификации). Аналогично преобразуем ~D(x) V ~B(x) в тавтологию ~D(x) V ~B(x) V
V [D(x)AB(x)].
~~В(х) V -С(х) V (В(х) Л С{х))
-F(*)V B(x)
-F(x) V ~С(х) V (В{х) Л С(х))
~~F{x)VC{x)
~F{x)\/{B(x)AC{x))
-D(jc) V ~~В(х) V (D{x) Л В{х))
-G(a)VDCy)
~В{х)У -6(дс)У ф{х)ЛВ(х))
-С(лг)У B(x)
~G{x)y (Р(х)ЛВ{х))
~А{х) VF(.v) VG(f{x))
~А(х) V G(f{x)) V {В(х) Л С(х))
-Л(х) V (В{х) Л С(х)) V (D(J{x)) V £(/(*)))
/WO) V (#(g(0) Л C(g(x))) V Ф(/<*(-0)) Л B{j{g{x))))
[B(h{x))AC(h{x))) V (i)(/(i(.v)))Afi№v)))] V [B(g(x)) A C(g(x)))
Рис. 5.11. Модифицированное дерево доказательства для примера 2
148
Выполняя резолюции, диктуемые соответствующими множествами унификации,
получаем граф доказательства, изображенный на рис. 5.11. Здесь в корневой вершине
расположена ппф
Q/x){[B(g(x)) А С(я(х))] V [D(f(z(x))) Л В(Кк(х)))]
V [*(*(*)) Л С(А(дс))]} .
В этом примере ответное утверждение имеет форму, несколько отличную от формы
целевой ппф. Подчеркнутая часть ответного утверждения, очевидно, подобна всей
целевой ппф, причем g(x) занимает место переменной jc, относящейся к квантору
существования, в целевой ппф, a f(g{x)) занимает место переменной .у, относящейся
к квантору существования в целевой ппф. Но в нашем примере имеется также и
лишний дизъюнкт [B(h (χ)) A C(h (jc))], входящий в ответное утверждение. Этот
дизъюнкт, однако, схож с одним из дизъюнктов целевой ппф, причем занимает место
переменной, относящейся к квантору существования, в этой целевой ппф.
В общем случае, если целевая ппф находится в дизъюнктивной нормальной форме,
то наш процесс извлечения ответа породит утверждение, являющееся дизъюнкцией
двух выражений, каждое из которых подобно по форме либо всей целевой ппф, либо
одному или более дизъюнктов всей целевой формулы. По этой причине мы утверждаем,
что расположенное в корневой вершине предложение здесь может быть использовано
как "ответ" на "вопрос", представляемый целевой ппф.
5.4.3. ЦЕЛЕВЫЕ ППФ С ПЕРЕМЕННЫМИ, ОТНОСЯЩИМИСЯ К
КВАНТОРУ ОБЩНОСТИ
Некоторая трудность возникает в том случае, когда целевая ппф
содержит переменные, относящиеся к квантору общности. Они переходят в
переменные, относящиеся к квантору существования при отрицании целевой
ппф, что вызывает необходимость в ведении сколемовских функций.
Какова должна быть интерпретация этих сколемовских функций, если в
конечном счете они должны появиться в качестве термов ответного
утверждения?
Проиллюстрируем эту проблему еще на одном примере. Пусть аксиомами
в форме предложений являются:
С(х, р(х)), обозначающее: "Для всех χ χ является
ребенком ρ (χ) " (т. е. ρ — функциональное
отображение ребенка некоего лица на это лицо);
~С(х, у) V Ρ {у, х), обозначающее: "Для всех χ и у,
если χ является ребенком>>, το у является родителем х".
Теперь предположим, что мы хотим задать вопрос: для любого χ кто
является родителем χΊ Целевая ппф, соответствующая этому вопросу,
имеет вид:
{Vx){*y)P(y.x).
Преобразуя отрицание этой формулы в форму предложений, получаем
сначала
{Зх)(уу)[~Р(у,х)],
а затем
~Р(У,А),
149
где А — сколемовская функция без аргументов (константа), введенная для
того, чтобы исключить квантор существования, появляющийся при
отрицании целевой ппф. (Это отрицание целевой ппф говорит о том, что
существует некоторое лицо, которое назовем А и которое не имеет родителя.)
Модифицированное дерево доказательства с ответным утверждением в
корневой вершине показано на рис. 5.12.
-C(x,y)V Р(у.х)
~P(y.A)VP(y.A)
С\х.р(х))
Р{р(А),А)
Рис. 5.12.
Модифицированное дерево
доказательства для
ответного утверждения
Мы получили весьма странное ответное утверждение Р(р(А)9 А),
содержащее сколемовскую функцию А. Интерпретация должна быть такой,
что независимо от сколемовской функции А (по предположению она
должна была нарушить справедливость целевой ппф) мы в состоянии доказать
Р(р(А), А), т.е. любое лицо Ау которое по замыслу должно было
противоречить целевой ппф, в действительности удовлетворяет ей. Константу А
можно было бы заменить на переменную, не нарушая доказательства,
показанного на рис. 5.12. Можно показать [202], что в процессе извлечения
ответа будет правильным заменить все сколемовские функции в
предложениях, идущих от отрицания целевой ппф, новыми переменными. Эти новые
переменные никогда не будут заменяться в результате подстановок в
ходе модифицированного доказательства, а будут просто проходить по
дереву и появляться в окончательном ответном утверждении. Резолюции в
модифицированном доказательстве будут по-прежнему ограничены теми
резолюциями, которые определяются множествами унификации,
соответствующими множествам унификации в первоначальном опровержении. В ходе
некоторых резолюций переменные могут быть переименованы, так что,
возможно, некоторая переменная, использованная вместо сколемовской
функции, может быть переименованной и, таким образом, может
оказаться "предком" для нескольких новых переменных в окончательном
ответном утверждении. Проиллюстрируем некоторые моменты, которые могут
возникнуть в последнем случае, на простых примерах.
Пример 3. Предположим, S состоит из одной аксиомы (в форме предложений)
Р(В, w, w) V Р{А,и,и)
и предположим, что мы хотим доказать целевую ппф
(3x)(4z)(3y)P(x,z,y).
Дерево опровержения показано на рис. 5.13. Здесь предложение, которое
появляется при отрицании целевой ппф, содержит сколемовскую функцию g(x). На рис. 5.13
150
-P{x,g(x)y)
P(B.w.w)V PiA.u.u)
~P(x.g{x)j)
NIL
^(v,u)V Pix.r.y)
P(B.\\\w) V PjA.u.u)
P(B.w,w)\/ P(Aj.t)
-P(x.t,v)V P(xj.y)
l\A.tj)\/ P{B,z.z)
Рис. 5.13. Деревья для примера 3
изображено также модифицированное дерево доказательства, в котором переменная t
используется вместо сколемовской функции g (χ). Отсюда получаем доказательство
ответного утверждения Р(А, t, ΐ) V Р(В, ζ, ζ), которое идентично (с точностью до имен
переменных) нашей единственной аксиоме. Этот пример показывает, как переменные,
введенные при переменовании переменных в одном предложении в ходе резолюции,
могут в конечном счете появиться в ответном утверждении.
Пример 4. Предположим, мы хотим доказать ту же целевую ппф, что и в
предыдущем примере, но исходя из единственной аксиомы Ρ (ζ, и, ζ) V Ρ (А, и, и). Дерево
опровержения изображено на рис. 5.14. Здесь предложение, идущее от отрицания целевой
ппф, содержит сколемовскую функцию g (χ). На рис. 5.14 показано также модифшщ-
рованное дерево доказательства, в котором переменная н> использована вместо
сколемовской функции g (x). Здесь получаем доказательство ответного утверждения
P(z, w, ζ) V Ρ (A, w, u>), которое идентично (с точностью до имен переменных) нашей
одной аксиоме. Тщательный анализ унифицирующих подстановок в этом примере
показывает, что, хотя резолюции в модифицированном дереве ограничены
соответствующими множествами унификации, подстановки, используемые в
модифицированном дереве, могут носить более общий характер по сравнению с подстановками в
первоначальном дереве опровержения.
~P(x.g(x)y)
P(zm,z)\/ P(A.u.u)
~~P(x.gMj>)
NIL
P{z,u.z)V P(A.um)
~P(x,w,y)V P{x,w,y)\ P(z,w,z)V P(A,w,w)
P(z,w,z)V P(A,w,w)
Рис. 5.14. Деревья для примера 4
В заключение суммируем этапы процесса извлечения ответа.
1. С помощью некоторого процесса поиска находится дерево
опровержения на основе резолюции. Подмножества унификации в предложениях
отмечаются на этом дереве.
2. Вместо любых сколемовских функций, появляющихся в предложениях,
являющихся результатом отрицания целевой ппф, подставляются новые
переменные.
3. Предложения, являющиеся результатом отрицания целевой ппф,
преобразуются в тавтологии путем присоединения к ним их собственного
отрицания.
4. Модифицированное дерево доказательства образуется при
моделировании структуры первоначального дерева опровержения. Каждая резолюция в
таком модифицированном дереве использует множество унификации,
определяемое множеством унификации, использованным в соответствующей
резолюции в дереве опровержения.
152
5. Предложение, расположенное в корневой вершине модифицированного
дерева, представляет ответное утверждение, извлеченное при таком процессе.
Очевидно, ответное утверждение зависит от опровержения, из которого
оно извлекается. Для одной и той же задачи могло бы существовать
несколько различных опровержений. Из каждого опровержения можно было
бы извлечь ответ, и, хотя некоторые ответы могут оказаться
идентичными, возможно, что некоторые ответные утверждения будут носить более
общий характер по сравнению с другими. Обычно у нас нет способа узнать,
является ли ответное утверждение, извлеченное из данного доказательства,
наиболее общим. Мы могли бы, разумеется, продолжать поиск доказательств,
пока не найдем доказательства, порождающего достаточно общий ответ.
Однако ввиду неразрешимости исчисления предикатов мы не всегда будем
в состоянии узнать, нашли ли мы все возможные доказательства для
некоторой гшф Нисходя из некоторого множества S.
5.5. БИБЛИОГРАФИЧЕСКИЕ И ИСТОРИЧЕСКИЕ ЗАМЕЧАНИЯ
Разнообразные стратегии управления при построении опровержений на
основе резолюции обсуждаются Лавлендом [198], Чангом и Ли [48].
Стратегии упорядочения были предложены Бойером, Ковальским, Рейтером,
Кюхнером, Минкером, Фишманом и Максиминым, Минкером и Заноном
[38,173, 181,241,242,298].
Примерами крупномасштабных систем опровержения на основе
резолюции являются системы Гарда и соавторов [133], Маккарена и соавторов
[210], Минкера и соавторов [210], Лакхэма и соавторов [201] (последняя
система описана также в статье Аллена и Лакхэма [5]). В отличие от самых
первых систем резолюции, многие из этих систем используют при
управлении знания, обеспечивающие доказательство некоторых довольно трудных
теорем.
Наше обсуждение присоединенных процедур основано на работе Вей-
храуха по системе FOL [384]. Процесс извлечения ответов из
опровержений, основанных на резолюции, был первоначально предложен Грином
[128]. Наш анализ извлечения ответа основан на работе Лакхэма и Ниль-
сона [202], в которой обобщен метод Грина.
Упражнения
5.1. Найдите опровержение, линейное по входу для следующего неудовлетворимого
множества предложений:
-PV~QVR
~s ν τ
~rvp
s
~R
~sv и
~l/V Q
5.2. Укажите, какие из следующих предложений подсуммируются предложением
153
(a) P(f(A),f(x))V P(z,f(y))
(b) P{z,A) V ~P(A,z)
(c) P(f(f(x)%z)
(d) />(/(ζ),2)νρ(χ)
(e) P(A,A)V P(f(x),y)
5.3. Покажите посредством опровержения на основе резолюции, что каждая из
следующих формул является тавтологией:
(RVQ))
(a) (P^Q)^[(RV P)
(Ь) [(
(с) (<-
(d) 0
/>=>(?) ^/Ί^/*
„/>=>/>)=>/>
Ρ^£)^(~ρ^~
5.4. Докажите справедливость следующих ппф методом опровержения на основе
резолюции:
(a) (Эх ){[*>(*)=> Р(А)] Л[Р(х)^ Р(В)]}
(b) (Vz)[Q(z)^P(z)]
=> {(3*Χβ(*)=Φ Р(Л)] Л [β(*)=> />(Я)]}
(c) (Эх )(Э.у ){[/></(*)) Л ρ (/(Я))]
^[?(/и))л/>(;)ле(;)])
(d) (3x)(Vj)P(x,7)
=J>(VyX3x)P(jf,^)
(e) (νχ){/»(χ)Λ[ρ(^)νρ(5)]}
^(3*)[/>(*) л £(*)]
5.5. Покажите опровержением на основе резолюции, что правильно построенная
формула (Зх)Р(х) логически следует из правильно построенной формулы {Р(А1)У
V Р(А2)\. Однако сколемовская форма для (Зх)Р(х), а именно Ρ (А), не следует
логически из [Р(А1) V Ρ (А 2) ]. Объясните почему.
5.6. Покажите, что система продукций, использующая схему правила резолюции для
работы над глобальной базой данных, состоящей из предложений, является
коммутативной в смысле, определенном в гл. 1.
5.7. Найдите опровержение с учетом предшествующих вершин для предложений из
примера 2 в подразд. 5.4.2. Сравните с графом опровержения на рис. 5.10.
5.8. Имея в виду обсуждение в разд. 3.3, касающееся графов вывода (и упражнение
3.4), предложите эвристическую стратегию поиска для системы опровержения на
основе резолюции. На каких факторах будет базироваться ваша функция h ?
5.9. Это упражнение предваряет рассмотрение связи между вычислением и
дедукцией, которая более подробно будет исследована в гл. 6.
Выражение cons (χ, у) означает, что список формируется путем размещения χ в
начале списка у. Пустой список мы обозначаем символом NIL, список вида (2) - cons
(2, NIL), список вида (1,2) - cons (1, cons (2, NIL)) и т.д. Выражение LAST (χ, у)
должно означать, что у — последний элемент в списке х. Мы имеем аксиомы:
(Vw ) LA ST( cons ( w, NIL), и)
(yx)(Vy)(Vz)[LAST(y,z)^>LAST(cons(x,y\z)]
Докажите следующую теорему, исходя из этих аксиом, используя метод
опровержения на основе резолюции:
(3v) LAST (cons {2,cons (I,NIL)), ν).
154
Используйте процедуру извлечения ответа для поиска ν, τ. е. последнего элемента
списка (2,1). Кратко опишите, как этот метод можно было бы использовать для
вычисления последнего элемента более длинных списков.
ГЛАВА 6
СИСТЕМЫ ДЕДУКЦИИ НА ОСНОВЕ ПРАВИЛ
Способ, которым эксперт выражает некоторую совокупность знаний о
данной области, часто содержит важную информацию о том, как можно
использовать эти знания. Предположим, например, что математик говорит: "Если
χ и у больше нуля, то и произведение χ на у больше нуля". Прямое
изложение этого заявления на языке исчисления предикатов выглядит так:
(Vx)(Vj>) {[G(*,0)AG(y,0)] ^G(times (х,у),0)}.
Однако мы могли бы воспользоваться совершенно эквивалентной
формулировкой
(Ух)(\/у) {[G(x, 0) A ~G (times (х,у),0)] =>G(y,0)}.
Логическое содержание математического утверждения, разумеется,
остается одним и тем же, несмотря на то, что его можно было бы представить
множеством эквивалентных форм в исчислении предикатов. Но конкретная
формулировка утверждения на естественном языке часто несет
эвристическую управляющую информацию. В первом примере приведенное
утверждение, по-видимому, указывает на то, что для доказательства того, что
^помноженное на .у, больше нуля, мы должны использовать тот факт, что и х, и у
больше нуля.
Большая часть знаний, используемых в системах ИИ, непосредственно
представима импликационными выражениями. Следующие утверждения и
выражения служат дополнительными примерами:
1. Все млекопитающие являются животными.
(\/х) [МЛЕКОПИТАЮЩЕЕ (χ) ^ЖИВОТНОЕ (χ)).
2. В отделе закупок все, кому более 30, женаты:
(V*) (УУ) { [РАБОТАЕТ-В (ОТДЕЛ-ЗАКУПОК, χ) А
АВОЗРАСТ (х, у) Λ С (у, 30) ] ^ ЖЕНАТ (х)} .
3. На каждом красном цилиндре сверху стоит кубик.
(Vx) {[ЦИЛИНДР (х) А КРАСНЫЙ (х)] =*
=* (\/у) [КУБИК (у) AHA (у, х))} .
Если нам приходится преобразовывать подобные этим выражения в
форму предложений, то мы, возможно, теряем полезную управляющую
информацию, содержащуюся в исходной заданной импликационной форме.
Предложение (А V В V С), например, логически эквивалентно любой из
импликаций: (~А Α ~£) => С, (~А А ~С) =* Д (~В А ~С) =>А, ^А => (В V
V С), ~В => (А У С) или ~С => (А V В). Но каждая импликация несет свою
собственную весьма различную эвристическую управляющую информацию,
которой совсем нет в форме предложения. В этой главе мы приводим
соображения относительно того, что импликации должны использоваться в
155
своем первоначальном виде (как они были даны) наподобие П- или
Оправил системы продукций.
Применение импликационных ппф в качестве правил в системе
продукций не позволяет системе делать логический вывод непосредственно только
из одних этих ппф. Все выводы, осуществляемые системой продукций,
являются результатом применения порождающих правил к глобальной
базе данных. Следовательно, каждый вывод может опираться в данный момент
на одну ппф, являющуюся правилом. Это ограничение выгодным образом
влияет на эффективность системы. Дополнительно можно показать, что в
общем случае само преобразование ппф в предложения может привести
к потере эффективности.
Рассмотрим задачу, состоящую в попытке доказать Ρ Λ (QV R). Если бы
мы пользовались системой опровержения на основе резолюции, то взяли
бы отрицание этой ппф и преобразовали его в предложения, выполняя
следующие таги:
~[PA(QVR)],
~ρν~(ρνΛ),
~ρν(~ρΛ~Λ),
ι.~ρν~ρ.
2.~Ρν~Λ.
Предположим, что базовое множество содержит также следующие предло-
4.-UVS.
5. U.
6.-WVR.
I.W.
Одна из разумных стратегий получения опровержения могла бы быть
связана с выбором предложения, скажем, 1 и использованием его и его
потомков в резолюциях. Мы можем разрешить предложения 1 и 3, чтобы
построить ~S V ~Q9 а затем применить последовательно предложения 4 и 5,
чтобы создать ~Q. На этом этапе мы "разрешили" литерал ~Р из
предложения 1. К несчастью, мы обнаружили, что у нас нет теперь способа
разрешить ~~Q9 так что наш поиск должен перейти к работе над предложением 2.
Предыдущая работа над разрешением ~Р потрачена впустую, поскольку
нам необходимо найти путь для его разрешения вновь, чтобы образовать
предложение ~R9 которое еще ни в каком смысле не является
окончательным решением. Тот факт, что нам пришлось разрешать ~Р дважды, говорит
о неэффективности процесса, вызванной "умножением" числа
подвыражений при преобразовании в форму предложений. Если посмотрим на
исходную цель, а именно доказательство Ρ Λ (QV R), то, очевидно, компоненту Ρ
нужно доказывать только один раз. При преобразовании в предложения
такого рода трудно избежать дублирования.
Системы, рассматриваемые в этой главе, не преобразуют ппф в
предложения, а используют их в форме, близкой к первоначальному виду.
Правильно построенные формулы, представляющие знания в виде утверждений,
относящихся к нашей проблеме, разделяются на две категории: правила и
факты. Правила состоят из тех утверждений, которые даны в форме импли-
156
каций. Обычно они выражают общие знания о конкретной предметной
области и используются в качестве порождающих правил. Факты — это
утверждения, которые не выражаются в форме импликаций; они представляют
специфические знания, относящиеся к конкретному случаю. Задачей систем
продукций, обсуждаемых в настоящей главе, является доказательство
целевой ппф исходя из этих фактов и правил.
В прямых системах импликации используются в качестве П-правил для
работы над глобальной базой данных фактов до тех пор, пока не будет
достигнуто некоторое условие остановки, включающее целевую ппф. В
обратных системах эти импликации используются в качестве О-правил,
применяемых к глобальной базе данных до тех пор, пока не будет достигнуто
некоторое условие остановки, включающее данные факты. Возможна также
комбинация прямой и обратной систем. (Подробности, касающиеся
действия правил и остановки, мы рассмотрим позднее.)
Этот тип систем доказательства теорем является примером системы
непосредственного доказательства, а не системы опровержения. Система
непосредственного доказательства не обязательно является более
эффективной по сравнению с системой опровержения, но ее действие легче
воспринимается на интуитивном уровне. Системы такого типа часто называют
системами дедукции, основанными на правилах, чтобы подчеркнуть
важность использования правил при дедукции. В искусственном интеллекте
основанные на правилах системы нашли широкое применение.
6.1. ПРЯМАЯ СИСТЕМА ДЕДУКЦИИ
6.1.1. ФОРМА И/ИЛИ ДЛЯ ВЫРАЖЕНИЯ ФАКТОВ
Начнем с описания прямой системы продукций простого типа, которая
обрабатывает факты произвольной формы. Затем рассмотрим двойственный
вариант такой системы, а именно обратную систему, которая способна
доказывать целевые выражения произвольной формы. И наконец, объединим
их в одну систему.
Наша прямая система в качестве начальной глобальной базы данных
содержит некоторое представление для заданного множества фактов. Одна из
особенностей состоит в том, что мы не намерены преобразовывать эти
факты в предложения. Факты представлены как правильно построенные
формулы исчисления предикатов, преобразованные в безымпликационную
форму, которую мы называем формой И/ИЛИ. При преобразовании правильно
построенной формулы в форму И/ИЛИ символы =► (если они имеются)
исключаются посредством использования эквивалентности (Wl =» W2) с
(~W1 V W2). (Обычно символов =► бывает немного, поскольку
импликации преимущественно представляются как правила.) Далее символы
отрицания вносятся вглубь формулы (с применением законов Моргана) до тех
пор, пока область их действия не будет ограничена не более чем одним
предикатом. Результирующее выражение затем подвергается сколемовским
преобразованиям и переводится в префиксную форму; переменные в
пределах действия кванторов общности разделяются переименованием,
переменные, относящиеся к кванторам существования, заменяются сколемов-
скими функциями и кванторы общности опускаются. Подразумевается,
что все оставшиеся переменные относятся к кванторам общности.
157
Например, выражение для факта
(3ii)(V!0 [Q(v,u) A~[[R{v) VP{p)] /\S(u,v)]}
превращается в
Q(p9A) Л{[~Щ») Л~Р{р)] V~S(A,v)]} .
Переменные могут быть переименованы таким образом, чтобы одна и
та же переменная не встречалась в различных (главных) конъюнкциях
выражения для факта. Переименование переменных в нашем примере дает
выражение
Q{w,A) Л {[~R{v) Л~Р(и)] V~S(A, ρ)} .
Заметьте, что переменная ν в Q{ и,А) может быть заменена на новую
переменную w, но ни одно из вхождений переменной ν в конъюнкты
имеющейся встроенной конъюнкции [~R{y) Л ~~Р(?)] не может быть
переименовано, поскольку эта же переменная встречается в дизъюнкте ~S (А, и).
Выражение в форме И/ИЛИ состоит из подвыражений литералов, соединенных
символами Л и V. Обратите внимание, что выражение в форме И/ИЛИ не
является предложением. Оно гораздо ближе к форме первоначального
предложения. В частности, подвыражения не "размножаются".
6.1.2. ИСПОЛЬЗОВАНИЕ ГРАФОВ ТИПА И/ИЛИ ДЛЯ ПРЕДСТАВЛЕНИЯ
ВЫРАЖЕНИЙ ДЛЯ ФАКТОВ
S(A.v)
-R{v)
~~P(v)
Рис. 6.1. Представление для факта в виде дерева
типа И/ИЛИ
Выражение для факта в
форме И/ИЛИ может быть
представлено с помощью
графа типа И/ИЛИ. Например,
дерево типа И/ИЛИ на рис.
6.1 представляет выражение
для факта, которое мы
только что привели к форме
И/ИЛИ. Каждое
подвыражение выражения для факта
представляется вершиной
графа. Дизъюнктивно связанные
подвыражения Εί3 . . . , Ек
факта (Ει V . . . V Ек),
представляются нисходящими
вершинами, связанными с их
родительской вершиной &-связ-
кой. Каждое конъюнктивное
подвыражение Ех, . . . , Ек
выражения (Ει Λ ... Λ Ек),
представляется одной
нисходящей вершиной, соединенной
с родительской вершиной од-
носвязкой (1-связкой). Может показаться удивительным, что мы исполь
зуем k-связки (конъюнктивное понятие) для разделения дизъюнкций в вы
ражении для факта. Позже покажем, почему мы приняли такое решение
158
Концевые вершины представления в виде графа типа И/ИЛИ для
некоторого факта помечаются литералами, встречающимися в выражении для
факта. Вершину, помеченную всем выражением для факта, мы называем
корневой; в графе у нее нет предшествующих вершин.
Интересное свойство представления ппф в виде графа типа И/ИЛИ
состоит в том, что множество предложений, в которое эта ппф могла бы быть
преобразована, может быть прочитано как множество графов решения
(заканчивающихся на концевых вершинах) этого графа типа И/ИЛИ. Так,
предложения, соответствующие выражению Q(w, Α) Λ |[~#00 А~Р{и)] V
V~S(A,v)j, имеют вид:
Q(w,A),
~S{A,v)V~R(v),
~S(A,v) V~P(v).
Каждое предложение получается как дизъюнкция литералов в концевых
вершинах одного из графов решения на рис. 6.1. Поэтому можно было бы
думать о графе типа И/ИЛИ, как о компактной форме представления для
множества предложений. (Представление для выражения в виде графа
типа И/ИЛИ на самом деле является несколько менее общим, чем
представление в виде предложений, так как из-за отсутствия дублирования общих
подвыражений в нем предупреждаются некоторые переименования переменных,
которые были бы возможны в форме предложений. В последнем
предложении нашего примера переменную ν можно было бы заменить на
переменную и. Такое переименование не может быть выражено на графе типа И/ИЛИ,
что приводит к потере общности и иногда вызывает трудности,
рассматриваемые в этой главе.)
Как правило, мы рисуем "перевернутым" представление для факта в
виде графа типа И/ИЛИ. Позже будем также пользоваться графом типа И/ИЛИ
для представления целевых ппф. Обычно такие графы изображаются снизу
вверх.
Когда мы представляем правильно построенные формулы в виде графов
типа И/ИЛИ, то пользуемся графами типа И/ИЛИ совсем для других целей,
чем в гл. 1 и 3. Там графы типа И/ИЛИ были представлениями для
управляющей стратегии, направляющей работу систем продукций, допускающих
декомпозицию. Здесь же они применяются в качестве форм представления
для глобальной базы данных системы продукций. Различные процессы,
которые будут описаны в этой главе, включают преобразование и проверки,
осуществляемые над графом типа И/ИЛИ в целом, и поэтому вполне
уместно использовать весь граф типа И/ИЛИ как глобальную базу данных.
6.1.3. ИСПОЛЬЗОВАНИЕ ПРАВИЛ ДЛЯ ПРЕОБРАЗОВАНИЯ ГРАФОВ
ТИПА И/ИЛИ
Порождающие правила, используемые нашей прямой системой
продукций, применяются к графовым структурам типа И/ИЛИ с тем, чтобы
получить преобразованную графовую структуру. Эти правила основываются на
импликационных ппф, которые представляют общие знания или
утверждения, касающиеся проблемной области. Для простоты объяснения
ограничимся рассмотрением в качестве правил лишь таких правильно построенных
159
выражений, которые имеют вид L => W, где L —одиночный литерал; W —
произвольная ппф (по предложению в форме И/ИЛИ), а все переменные,
встречающиеся в данной импликации, считаются относящимися к
кванторам общности, охватывающим импликацию в целом. Переменные в фактах
и правилах разнесены так, чтобы одна переменная встречалась не более чем
в одном правиле и чтобы переменные в правилах были отличны от
переменных в фактах.
Ограничение однолитеральными антецедентами существенно упрощает
процесс сопоставления при применении правил к графам типа И/ИЛ И. Это
ограничение в действительности чуть менее серьезно, чем оно выглядит,
поскольку импликации, содержащие антецеденты, состоящие из дизъюнкции
литералов, могут быть переписаны как совокупность правил. Например,
импликация (L1 У L2) => W эквивалентна паре правил L1=>WhL2=>W.
Во всяком случае, указанное ограничение на вид правил, которое мы
накладываем в этой главе, по-видимому, не вызывает никаких практических
ограничений на полезность результирующих систем дедукций.
Любая импликация с однолитеральным антецедентом независимо от кван-
тификации может быть приведена к форме, в которой область
квантификании — вся импликация, посредством процесса, в котором сначала
"обращается" квантификация переменных, локальных для антецедента, а затем все
переменные, связанные с квантором существования, заменяются сколемов-
скими выражениями. Например, ппф
(У*) { [(ЭдО (V*) Р(х,у, z)] * (Vn) Q(pc, и)}
может быть преобразована в таком порядке:
1. Исключение (временное) символа импликации
(Vx){~[(3y)(Vz)P(x,y,z)]V(4u)Q(x,u)}.
2. Обращение порядка квантификации переменных в первом дизъюнкте
при внесении символа отрицания вглубь формулы
(V*) {(у у) (3*) [~Р(х,у, ζ) V (V«) Q(x, и)} .
3. Сколемовское преобразование
(У χ) {(Vj;) [~P(pc,y,f(pc,y))] V (уи) Q(x,u)} .
4. Перемещение всех кванторов общности вперед и их отбрасывание
~P{x,y,f(x.y))VQ(?c,u).
5. Восстановление импликации
P{x>y>f{x>y))*Q{x>u).
Чтобы объяснить, как такие правила применяются к графам типа И/ИЛИ,
рассмотрим сначала случай препозиционального исчисления без переменных.
Правило вида L => W может быть применено к любому графу типа И/ИЛИ,
имеющему концевую вершину п, помеченную литералом L. Результатом
является новый граф типа И/ИЛИ, в котором вершина η теперь имеет
отходящую 1-связку к некоторой дочерней вершине (также помеченной L),
являющейся корневой вершиной графовой структуры типа И/ИЛИ,
представляющей W.
В качестве примера рассмотрим правило
160
S=*(JTAY) VZ.
Мы можем применить это правило к графу типа И/ИЛИ, приведенному на
рис. 6.2, в концевой вершине, помеченной S. Результатом является
графовая структура, показанная на рис. 6.3. Две вершины, помеченные S,
соединены дугой, которую мы называем дугой соответствия.
и и
(Ρ ν<2)
и и
пи
(Г V U)
Рис. 6.2. Граф типа И/ИЛИ, не содержащий переменных
До применения какого-
либо правила граф типа
И/ИЛИ, такой, как на рис.
6.2, представлял некоторое
выражение для конкретного
факта. (Его множество
графов решения,
заканчивающихся в концевых вершинах,
представляло собой
выражение для факта в виде
предложений.) Мы хотим, чтобы
результирующий после
применения правила граф
представлял собой и
первоначальный факт, и выражение для
факта, выводимого из
первоначального и
рассматриваемого правила.
Предположим, имеется
правило L => W, где L —
литерал, a W — ппф. Из этого
правила и выражения для
факта F(L) можно вывести
выражение F (W),
выводимое из F (L) заменой всех
| (Р V Q) | | R |
^1_
Рис. 6.3. Граф типа И/ИЛИ после применения правила
161
вхождений L в F на W. Используя правило L =* W для преобразования
представления для F(JL) в виде графа типа И/ИЛИ описанным способом, мы
создаем новый граф, который можно рассматривать как граф, содержащий
представление для F (W), т. е. его множество решающих графов,
оканчивающихся в концевых вершинах, представляет множество предложений для
F(W) в форме предложений. Это множество предложений включает все
множество, которое было бы создано путем выполнения всех возможных
резолюций на L между L =* Wb форме предложений и F{L) в форме
предложений.
Рассмотрим пример на рис. 6.3. Форма предложений для правила S =>
*>[(XAY) VZ] такова: ~S VIVZh-S V Υ Μ Ζ.
Те предложения выражении [(Р V Q) Л R] V [S Λ (Τ V U)], взятом в
форме предложений, которые разрешились бы (на S) при любом из этих
двух правил, имеют вид Ρ У QV S и RV S.
Полное множество резольвент, которое может быть получено из этих
четырех предложений разрешением на S, таково:
ZVZVPV^; YVZ VPVQ; R V7VZ; R VIVZ.
Все они включены в число предложений, представленных графами решений
на рис. 6.3.
Из этого примера и предыдущих обсуждений видно, что процесс
применения правила к графу типа И/ИЛИ реализует чрезвычайно экономно тот
вывод, который иначе потребовал бы нескольких резолюций.
Мы хотим, чтобы граф типа И/ИЛИ, возникающий в результате
применения правил, продолжал представлять первоначальный факт точно так же,
как и выведенный факт. Этот факт достигается при использовании
идентично помеченной вершины по обе стороны дуги соответствия. После того,
как правило применено к некоторой вершине, последняя перестает быть
концевой вершиной графа, но по-прежнему остается помеченной
одиночным литералом и к ней можно продолжать применять правила. Назовем
вершину графа, помеченную одиночным литералом, литеральной. Множество
предложений, представляемых графом типа И/ИЛИ, — это множество,
которое соответствует множеству решающих графов, заканчивающихся в
литеральных вершинах.
До сих пор все наши рассуждения касались случая препозиционального
исчисления, в котором выражения не содержат переменных. Прежде чем
показать, как работать с выражениями, содержащими переменные, обсудим
условие остановки для случая без переменных.
6.1.4. ИСПОЛЬЗОВАНИЕ ЦЕЛЕВОЙ ППФ ДЛЯ ОСТАНОВКИ
Задачей прямой системы продукций, которая была описана, является
доказательство некоторой целевой правильно построенной формулы на
основе ппф для факта и множества правил. В этой прямой системе имеется
ограничение на тип целевого выражения, которое она способна доказать,
а именно она может доказать только такие целевые ппф, которые по форме
являются дизъюнкцией литералов. Мы представляем такую целевую ппф
множеством литералов и предполагаем, что члены множества связаны
дизъюнктивно. (Позже опишем обратную и двунаправленные системы,
162
использование которых не ограничено столь простыми целевыми
выражениями.) Целевые литералы (так же, как и правила) могут быть
использованы для наращивания графа типа И/ИЛИ. Когда один из целевых
литералов соответствует литеральной пометке для некоторой литеральной
вершины η графа, то мы связываем с вершиной η новую вершину, помеченную
этим сопоставимым целевым литералом. Этот потомок называется целевой
вершиной. Целевые вершины соединяются дугами соответствия со своими
родительскими вершинами. Система продукций успешно заканчивает работу,
если создает граф типа И/ИЛИ, содержащий граф решения, заканчивающийся
в целевых вершинах. (После окончания работы система, по существу,
вывела предложение, идентичное некоторой подчасти целевого предложения).
В приведенных графах типа И/ИЛИ мы представляем соответствие
между литеральными и целевыми вершинами точно таким же способом, как
соответствие между литеральными вершинами и вершинами,
представляющими антецеденты правила. На рис. 6.4 показан граф типа И/ИЛИ,
который удовлетворяет условию остановки, основанному на целевой ппф (С V
V G). Обратите внимание на дуги соответствия, идущие к целевым вершинам.
Граф решения типа И/ИЛИ
на рис. 6.4 может быть также ^елевь".е ?ершины
интерпретирован как
доказательство целевого выражения
(С V G) с использованием
стратегии "рассуждения,
основанного на частных случаях".
Изначально имелось
выражение для факта (А У В). Так
как мы не знаем, истинно А
или В, то можно
попытаться сначала доказать целевое
утверждение, предполагая, что
истинно А, а затем пытаться
доказать его, предполагая, что
истинно В. Если оба
доказательства оказались
успешными, то получаем
доказательство, основанное просто на
дизъюнкции (А У В), при
этом не имеет значения, что
истинно — А или В. На рис.
6.4 потомки вершины,
помеченной (А У В),
соединяются с ней двусвязкой (2-связкой). Таким образом, оба потомка должны
встретиться (что и происходит) в нашем окончательном графе решения.
Здесь мы видим интуитивное основание для использования к -связок при
разделении дизъюнктивно связанных подвыражений в фактах. Если
некоторый граф решения для вершины η включает какого-либо потомка вершины
η через некоторую к-связку, то он должен включать всех потомков,
связанных этой fc-связкой.
Правила:
А =>с Λ D
В*>Е Λ G
Факт
Рис. 6.4. Граф типа И/ИЛИ, удовлетворяющий
остановке
163
Только что описанная система продукций, основанная на применении
правил к графам типа И/ИЛИ, коммутативна, следовательно, подходит
безвозвратный режим управления. Система продолжает применять приложимые
правила до тех пор, пока не будет получен граф типа И/ИЛИ, содержащий
некоторый граф решения.
6.1.5. ВЫРАЖЕНИЯ, СОДЕРЖАЩИЕ ПЕРЕМЕННЫЕ
Теперь опишем прямые системы продукций, работающие с выражениями,
содержащими переменные. Как уже отмечалось, для переменных в фактах и
правилах неявно подразумевается наличие квантора общности.
Предполагаем, что каждая переменная, относящаяся к квантору существования, в
фактах и правилах была заменена сколемовским выражением.
Для целевых гшф, содержащих переменные, относящиеся к кванторам
общности или кванторам существования, пользуемся процессом перехода к
сколемовским выражениям, который является двойственным по отношению
к такому процессу в случае применения фактов и правил. Переменные,
относящиеся к кванторам общности, заменяются сколемовскими функциями
от переменных, относящихся к кванторам существования, в области
действия которых располагаются указанные переменные. Напомним, что в
системах опровержения, основанных на резолюции, целевые гшф
подвергаются отрицанию, превращающему все кванторы общности в кванторы
существования, и наоборот. Тогда сколемовскими функциями заменяются
переменные, относящиеся к квантору существования. Тот же эффект
достигается в системах непосредственного доказательства, если переменные,
относящиеся к кванторам общности заменяются сколемовскими функциями.
В отношении целевых ппф будем по-прежнему ограничиваться
дизъюнкцией литералов. Подвергнув целевую ппф сколемовскому преобразованию,
можем переименовать ее переменные таким образом, чтобы одна и та же
переменная встречалась не более чем в одном дизъюнкте этой целевой гшф.
(Напомним об эквивалентности ппф (3x) (Wl(x) v W2(x)] и ппф
[&x)Wl(x) V (ЭдОИ^ОО])
Теперь рассмотрим процесс применения правила вида L => W к графу
типа И/ИЛИ, где L — некоторый литерал, a W — ппф в виде И/ИЛИ, причем
все выражения могут содержать переменные. Данное правило приложимо,
если граф типа И/ИЛИ содержит литеральную вершину L', унифицируемую
с L. Предположим, что соответствующий ноу есть и. Тогда применение
правила приводит к наращиванию графа (как и в случае препозиционального
исчисления) путем образования дуги соответствия, направленной от
вершины, помеченной Z/, в нашем графе типа И/ИЛИ к новой последующей
вершине, помеченной L. Эта дочерняя вершина является корнем графа типа
И/ИЛИ, представляющего ΪΡμ. Дугу соответствия также помечаем указанием
ноу, т.е. w.
В качестве примера рассмотрим выражение для факта
{Р(х,у)\/ [Q(x,A)AR(B,y)}}.
Представление этого факта в виде графа типа И/ИЛИ*шжазано на рис. 6.5.
Теперь если мы применим к этому графу правило Ρ (А, В) => [S (А) V Х{В) ],
то получим граф типа И/ИЛИ, изображенный на рис. 6.6. Этот граф имеет два
164
графа решения, которые
заканчиваются в концевых вершинах и
включают вновь добавленную дугу
соответствия. Предложения,
соответствующие полученным графам
решения, таковы :
S(A)\/X(B)VQ(AfA)>
S(A) VX(B)VR(B,B).
При построении этих
предложений был применен наш наиболее
общий унификатор и к литералам,
появляющимся в концевых
вершинах графов решения. Эти
предложения являются теми же
предложениями, которые могли бы быть получены из факта и правила в форме
предложений при выполнении резолюции на Р.
Рис. 6.5. Представление в виде графа типа
Я/ИЛИ для факта, содержащего переменные
1 S{A)
Х{В) |
Р(А.В)
Q(x.A)
R(B,y)
Рис. 6.6. Граф типа И/ИЛИ, возникающий после применения правила, содержащего
переменные
Граф типа И/ИЛИ, изображенный на рис. 6.6, продолжает представлять
первоначальное выражение для факта, поскольку в общем случае мы
используем его для представления всех предложений, которые соответствуют
графам решения, оканчивающимся в литеральных вершинах.
После применения к графу типа И/ИЛИ нескольких правил он содержит
более одной дуги соответствия. В частности, любой граф решения
(заканчивающийся в литеральной вершине) может иметь более одной дуги
соответствия. При выделении множеств предложений, представленных некоторым
графом типа И/ИЛИ, содержащим несколько дуг соответствия, мы
учитываем только те графы решения, заканчивающиеся в литеральных вершинах,
165
которые имеют согласованные подстановки на дугах соответствия.
Предложение, представленное некоторым согласованным графом решения,
получается специальной подстановкой, называемой унифицирующей
композицией, к цдэъюнкгщи литералов, помечающих его терминальные
(литеральные) вершины.
Понятия согласованного множества подстановок и унифицирующей
композиции подстановок определяются следующим образом. Предположим,
имеется некоторое множество подстановок (и1з и2, . . . , un] . В свою
очередь каждое щ есть множество пар
ui ~ 1*1 \lvi\> · · ·» Чт(1)/и1т{1) } »
где t обозначает термы, av — переменные. Исходя из {μγ, . . . , un)
определяем два выражения:
Ui - (νιχ,- · . >vim(i) ,..·,"„!,.. *>vnm(n))'>
U2 = (*π> · · · t^im(i) > · · · >tnl, · . · >tnm{n) ·
Подстановки (wls . . . , ww) называются согласованными тогда и только
тогда, когда 1^ и U2 унифицируемы. Унифицирующей композицией и для
(и ι,..., wn) называется ноу для £Д и ί/2.
Некоторые примеры унифицирующих4 композиций [50, 332]
представлены в табл. 6.1.
Таблица 6.1
Примеры унифицированных композиций подстановок
"1
{А/х)
{χ/у)
1ЛОД)
{х/у,χ/ζ]
{*)
{g(y)/x)
lAg(xi»/x3,
f{x2)/x4)
"»
(В/х)
{У/ζ)
ЩЛ)/х)
ИД)
(}
W*Vy)
(x4/x3,g(xl)/x2}
и
Не согласованы
{*/?.*/*)
ЩЛ)/х,Л/г]
{Л/х,Л/у,Л/*}
{«)
Не согласованы
1АИ*ПУ*3.
f(g(xl))/x4,g{xl)/x2)
Нетрудно показать, что операция, соответствующая унифицирующей
композиции, ассоциативна и коммутативна. Таким образом, унифицирующая
композиция, связанная с некоторым графом решения, не зависит от
порядка, в котором при построении этого графа генерируются дуги
соответствия. (Напомним, что композиция подстановок ассоциативна, но не
коммутативна.)
166
R(A)
R(B)
[W]
Q{B)
[Alx]
P(x)
Ш
Qix)
PWVQ{x)
Рис. 6.7. Граф типа И/ИЛИ с
несогласованными подстановками
Естественно ожидать, что граф решений должен иметь некоторое
множество согласованных подстановок для дуг соответствия с тем, чтобы
соответствующие ему предложения были бы теми, которые можно было бы
вывести из первоначальных выражений для фактов и правил. Предположим,
имеются факт
Р(х) VQ(x) иправилаР(Л) => R(A); Q(B) =*R(B).
Применение этих правил привело бы к
графу типа И/ИЛИ, изображенному на
рис. 6.7. Несмотря на то, что этот граф
содержит граф решения с литеральными
вершинами, помеченными R (А) и R(B),
он имеет несогласующиеся подстановки.
Следовательно, предложение вида [R(A) V
V R(B)] не входит в число предложений,
представленных графом типа И/ИЛИ на рис.
6.7. Разумеется, это предложение не могло
бы быть выведено и посредством
резолюции из указанных ппф для факта и правил,
взятых в форме предложений.
Граф на рис. 6.7, однако, содержит
представление для такого предложения, как
[R(A) V Q(A)]. Оно получается
подстановкой (Л/х) (представляющей собой тривиальную унифицирующую
композицию для множества, содержащего единственный элемент {А/х ] ) к
выражению [Я (Л) V Q (х)]. Последнее выражение, в свою очередь,
соответствует графу решения, завершающемуся в терминальных вершинах,
помеченных R {A) uQ(x).
Если одно и то же правило применяется более одного раза, то важно,
чтобы при каждом случае использовались переименованные переменные.
В противном случае можно без необходимости наложить дополнительные
ограничения на подстановки.
Граф типа И/ИЛИ может быть надстроен и с использованием целевых
литералов. Когда целевой литерал L унифицируется с некоторым литералом
V , помечающим литеральную вершину η графа, то можно добавить дугу
соответствия (помеченную наиболее общим унификатором),
направленную от вершины η к новой дочерней целевой вершине, помеченной L. Один
и тот же целевой литерал может быть использован многократно, создавая
кратные целевые вершины, но каждый раз необходимо использовать
переименованные переменные.
Процесс надстраивания графа типа И/ИЛИ с применением правил или
целевых литералов заканчивается успешно, когда создается
согласованный граф решения, имеющий целевые вершины в качестве всех своих
терминальных вершин. Тогда наша система продукций дает доказательство
того, что целевая (под) дизъюнкция получается применением
унифицирующей композиции окончательного графа решения к дизъюнкции литералов,
помечающих целевые вершины в этом графе решения.
Проиллюстрируем работу прямой системы продукций на простом примере.
Предположим, имеются следующие факт и правила:
167
Джим лает и кусается, иначе Джим не собака:
-СОБАКА (ДЖИМ) V [ЛАЕТ (ДЖИМ) А КУСАЕТСЯ (ДЖИМ)].
Все терьеры являются собаками:
П1: -СОБАКА (х) => -ТЕРЬЕР (х).
(Здесь мы используем контрапозитивную форму для импликации.)
Тот, кто лает, является шумным:
П2.ЛАЕТ (у) ^ШУМНЫЙ (у).
Теперь предположим, что мы хотим доказать, что существует некто, кто не
является терьером или не является шумным. Целевая ппф, представляющая утверждение,
которое предстоит доказать, имеет вид
-ТЕРЬЕР(ζ ) V ШУМНЫЙ (ζ).
Напомним, что ζ — переменная, относящаяся к квантору существования.
Целевые вершины
Рис. 6.8. Граф типа И/ИЛИ для задачи о терьере
Граф типа И/ИЛИ для этой задачи показан на рис. 6.8. Целевые вершины обозначены
выражениями, заключенными в двойные рамки, а применения правил помечены
номерами этих правил. Согласующийся граф решения в рамках этого графа имеет
подстановки {ДЖИМ/х} , {дЖИМ/у} , {ДЖИМ/z} . Унифицирующей композицией из этих
подстановок является просто{ДЖИМ/х, ДЖИМ/у, ДЖИМ/z} . Применение этой
композиции к целевым литералам, использованным в графе решения, дает -ТЕРЬЕР (ДЖИМ) V
V ШУМНЫЙ (ДЖИМ), что представляет собой частный случай целевой ппф, которую
доказала наша система. Это выражение, таким образом, может быть взято в качестве
ответного утверждения.
168
Такую простую прямую систему продукций можно было бы обобщить
в нескольких направлениях. Мы еще не объяснили, как можно строить
резолюции между компонентами выражения для факта — иногда резолюции
внутри факта являются полезными (и необходимыми). Мы не описали,
как следует поступать в тех случаях, к5гда (под) выражение для факта
может потребоваться несколько раз в ходе одного доказательства с
использованием разных имен для переменных. Разумеется, существует
весьма важная проблема управления системой продукции, решение которой
обеспечивает эффективные нахождения согласующихся графов решения.
Дальнейшее обсуждение этих вопросов отложим до момента, когда они
вновь возникнут при обсуждении обратных систем.
6.2. ОБРАТНЫЕ СИСТЕМЫ ПРОДУКЦИЙ
Важным свойством логики является двойственное отношение между
утверждениями и целями в системах доказательства теорем. Мы уже
наблюдали пример такого принципа двойственности в системах опровержения
на основе резолюции. Там целевые гшф подвергались отрицанию,
преобразовывались в форму предложений и добавлялись к утверждениям, взятым
в форме предложений. Двойственность утверждений и целей позволяет
отрицание цели рассматривать так, как если бы это было утверждение. В
системах опровержения на основе резолюции применяют резолюции к
этому совокупному множеству предложений до тех пор, пока не будет
получено пустое предложение (обозначаемое символом F) .
Мы могли бы также дать описание некоторой двойственной системы
резолюции, которая работает с целевыми выражениями. При подготовке
правильно построенных формул для такой системы в первую очередь
нужно взять отрицание гшф для утверждений, преобразовать эти отрицания в
двойственную к предложениям форму (а именно взять дизъюнкцию
конъюнкции литералов) и добавить эти предложения к предложениям в
двойственной форме для целевой гшф. В такой системе будем применять
некоторую двойственную процедуру резолюции до тех пор, пока не будет
построено пустое предложение (теперь обозначаемое символом Т) .
Мы можем также вообразить смешанные системы, в которых
используются три различные формы резолюции: между утверждениями, между
целевыми выражениями и между утверждением и целью. Прямую систему,
описанную в последнем разделе, можно было бы рассматривать как одну
из таких смешанных систем, поскольку она содержит приведение в
соответствие литерала для факта в графе типа И/ИЛИ с целевым литералом.
Описываемая далее обратная система продукций также является
смешанной, в некоторых отношениях двойственной к описанной прямой системе.
Ее работа основывается на таких же представлениях и механизмах, какие
были использованы в прямой системе.
6.2.1. ЦЕЛЕВЫЕ ВЫРАЖЕНИЯ В ФОРМЕ И/ИЛИ
Наша обратная система способна работать с целевыми выражениями
произвольного вида. Сначала преобразуем целевую ппф в форму типа И/ИЛИ,
используя тот же процесс, который был применен для преобразования
выражения для факта. Мы избавляемся от символов =>, вносим символы отри-
169
цания вглубь формулы, подвергаем сколемовскому преобразованию
переменные, относящиеся к квантору общности, и опускаем кванторы
существования. Предполагаем, что переменные, остающиеся в форме типа И/ИЛИ
для целевого выражения, относятся к квантору существования.
Например, целевое выражение
(3.y)(Vx) {Р(х) =* [Q{x.y) Л~[Л(х) AS (у)]]}
преобразуется в
~P(f(y))V{Q(f(y)9y)/\[~R(f(y))V~S(y)]},
где/О) - сколемовская функция.
Процедура разделения переменных в (главных) дизъюнктах цели дает
~P(f{*))V{Q(f(y),y)A[~R(f(y))V~S(y)]} .
(Заметим, что переменную у нельзя переименовывать β пределах данного
дизъюнктивного выражения так, чтобы все дизъюнкты в нем получили
различные переменные.)
Целевые ппф в форме И/ИЛИ могут быть представлены графами типа
И/ИЛИ. Но в случае целевых выражений fe-связки в этих графах
используются для разделения конъюнктивно связанных подвыражений. Граф типа
И/ИЛИ для представления приведенного примера целевой ппф изображен
на рис. 6.9. Концевые вершины этого графа помечены литералами целевого
выражения. В целевых графах типа И/ИЛИ любая вершина, дочерняя по
отношению к корневой, называется вершиной подцели, а выражения,
помечающие такие дочерние вершины, — подцелями.
H*№))V teC/OOjO Λ [-*(/(>')) V ~S(y)]}
Рис 6.9. Представление в виде графа типа И/ИЛИ для целевой ппф
Множество предложений для представления этой целевой ппф в виде
предложений может быть "считано" с множества графов решения,
оканчивающихся в концевых вершинах:
~П/Ч*)),
0tfOO.*)A~Ji(fOO).
CtfOO.JOA-soo.
no
Целевые предложения являются конъюнкциями литералов, а
дизъюнкция этих предложений — формой предложений для нашей целевой ппф.
6.2.2. ПРИМЕНЕНИЕ ПРАВИЛ В ОБРАТНОЙ СИСТЕМЕ
В этой системе О-правила основываются на импликациях,
содержащихся в утверждениях. Они являются такими же утверждениями, какими были
П-правила в прямых системах. Для этих О-правил ограничимся
рассмотрением выражений вида W => L, где W — любая ппф (по предположению в виде
И/ИЛИ); L — литерал и областью квалификации для любой переменной
является целиком вся эта импликация. [Опять ограничение О-правилами
такой формы упрощает поиск соответствия и не вызывает никаких важных
практических трудностей. К тому же такая импликация, как W=> (L1 Λ L2),
может быть преобразована в правила W =>L1 nW => L2]
Такое О-правило применимо к графу типа И/ИЛИ, представляющему
некоторую целевую ппф, если граф содержит литеральную вершину,
помеченную V, которая унифицируется с L. Результат применения правила
состоит в том, что дуга соответствия из вершины, помеченной V ,
добавляется к новой дочерней вершине, помеченной L. Эта новая вершина
является корневой вершиной представления Wu в виде графа типа И/ИЛИ, где
и — наиболее общий унификатор для L и V , который помечает дугу
соответствия в преобразованном графе.
Наше объяснение того, что такая операция действительно имеет смысл,
носит двойственный характер по отношению к объяснению процедуры
применения П-правила к графу типа И/ИЛИ, соответствующему некоторому
факту. Правило утвердительного характера может быть подвергнуто
отрицанию и добавлено (дизъюнктивно) к целевой ппф. Эта форма после
отрицания имеет вид W Λ ~L. Выполнение всех (целевых) резолюций на L
между предложениями, выводимыми из W Λ ~L, и предложениями,
соответствующими целевой ппф, порождает множество резольвент, идентичных
предложениям среди тех предложений, которые ассоциируются с согласованными
графами решений преобразованного графа типа И/ИЛИ.
6.2.3. УСЛОВИЕ ОСТАНОВКИ
Выражения для фактов, используемых обратной системой, ограничены
выражениями в форме конъюнкции литералов. Такие выражения могут
быть представлены как некоторое множество литералов. По аналогии с
прямой системой, когда литерал, отвечающий факту, соответствует
литеральной пометке некоторой литеральной вершины графа, некоторая дочерняя
вершина факта может быть добавлена к этому графу. Эта вершина факта
связана с соответствующей ей литеральной вершиной подцели с помощью
дуги соответствия, помеченной ноу. Тот же литерал факта может быть
использован несколько раз (с различными переменными при каждом
использовании) , что приведет к созданию кратных вершин факта.
Условие успешного завершения для обратной системы состоит в том,
что граф типа И/ИЛИ должен содержать согласованный граф решений,
заканчивающийся в вершинах фактов. Опять согласованным является такой граф
решения, в котором подстановки дуги соответствия вкл/очают
унифицирующую композицию.
171
цания вглубь формулы, подвергаем сколемовскому преобразованию
переменные, относящиеся к квантору общности, и опускаем кванторы
существования. Предполагаем, что переменные, остающиеся в форме типа И/ИЛИ
для целевого выражения, относятся к квантору существования.
Например, целевое выражение
(Зу) (V*) {Р(х) *· [Q (дс, у) Λ ~ [R (χ) Λ S (у)))}
преобразуется в
~P(f(y))v{Q(f(y),y)*[~R(f(y))v~S(y)]},
где/(у) — сколемовская функция.
Процедура разделения переменных в (главных) дизъюнктах цели дает
~P(f(z))V{Q(f(y),y)A[~R(f(y))v~S(y)]} .
(Заметим, что переменную у нельзя переименовывать в пределах данного
цдзъюнктивного выражения так, чтобы все дизъюнкты в нем получили
различные переменные.)
Целевые ппф в форме И/ИЛИ могут быть представлены графами типа
И/ИЛИ. Но в случае целевых выражений fc-связки в этих графах
используются для разделения конъюнктивно связанных подвыражений. Граф типа
И/ИЛИ для представления приведенного примера целевой ппф изображен
на рис. 6.9. Концевые вершины этого графа помечены литералами целевого
выражения. В целевых графах типа И/ИЛИ любая вершина, дочерняя по
отношению к корневой, называется вершиной подцели, а выражения,
помечающие такие дочерние вершины, - подцелями.
-WU)) ν lQWy)f) Λ [~Λ(Λ.ν)) V -5(у)]]
Рис. 6.9. Представление в виде графа типа И/ИЛИ для целевой ппф
Множество предложений для представления этой целевой ппф в виде
предложений может быть "считано" с множества графов решения,
оканчивающихся в концевых вершинах:
~*ч«*)).
Q(f(y).y)*~R(f(y)).
Q(f(y),y)*~S(y).
170
Целевые предложения являются конъюнкциями литералов, а
дизъюнкция этих предложений — формой предложений для нашей целевой ппф.
6.2.2. ПРИМЕНЕНИЕ ПРАВИЛ В ОБРАТНОЙ СИСТЕМЕ
В этой системе О-правила основываются на импликациях,
содержащихся в утверждениях. Они являются такими же утверждениями, какими были
П-правила в прямых системах. Для этих О-правил ограничимся
рассмотрением выражений вида W => L, где W — любая ппф (по предположению в виде
И/ИЛИ); L — литерал и областью квалификации для любой переменной
является целиком вся эта импликация. [Опять ограничение О-правилами
такой формы упрощает поиск соответствия и не вызывает никаких важных
практических трудностей. К тому же такая импликация, как W=> (LI AL2),
может быть преобразована в правила W=>LlnW:=>L2.]
Такое О-правило применимо к графу типа И/ИЛИ, представляющему
некоторую целевую ппф, если граф содержит литеральную вершину,
помеченную L', которая унифицируется с L. Результат применения правила
состоит в том, что дуга соответствия из вершины, помеченной V ,
добавляется к новой дочерней вершине, помеченной L. Эта новая вершина
является корневой вершиной представления Wu в виде графа типа И/ИЛИ, где
и — наиболее общий унификатор для L и L', который помечает дугу
соответствия в преобразованном графе.
Наше объяснение того, что такая операция действительно имеет смысл,
носит двойственный характер по отношению к объяснению процедуры
применения П-правила к графу типа И/ИЛИ, соответствующему некоторому
факту. Правило утвердительного характера может быть подвергнуто
отрицанию и добавлено (дизъюнктивно) к целевой ппф. Эта форма после
отрицания имеет вид W Λ ~L. Выполнение всех (целевых) резолюций на L
между предложениями, выводимыми из W A ~L, и предложениями,
соответствующими целевой ппф, порождает множество резольвент, идентичных
предложениям среди тех предложений, которые ассоциируются с согласованными
графами решений преобразованного графа типа И/ИЛИ.
6.2.3. УСЛОВИЕ ОСТАНОВКИ
Выражения для фактов, используемых обратной системой, ограничены
выражениями в форме конъюнкции литералов. Такие выражения могут
быть представлены как некоторое множество литералов. По аналогии с
прямой системой, когда литерал, отвечающий факту, соответствует
литеральной пометке некоторой литеральной вершины графа, некоторая дочерняя
вершина факта может быть добавлена к этому графу. Эта вершина факта
связана с соответствующей ей литеральной вершиной подцели с помощью
дуги соответствия, помеченной ноу. Тот же литерал факта может быть
использован несколько раз (с различными переменными при каждом
использовании) , что приведет к созданию кратных вершин факта.
Условие успешного завершения для обратной системы состоит в том,
что граф типа И/ИЛИ должен содержать согласованный граф решения,
заканчивающийся в вершинах фактов. Опять согласованным является такой граф
решения, в котором подстановки дуги соответствия вкл/очают
унифицирующую композицию.
171
ΠΙ:
[Q(u)AR(v)]
Π2:Ψ{γ)
I13:S(w)
Π4:Ό(ζ)
Π5: V(A)
Ρί,χ,χ)
ч
\[xlu.<
Φ]
*R(y).
*«(«-),
~S(C),
-Q(A).
на согласованность между различными уровнями графа. Рассмотрим пример.
Предположим, что правила включают:
Далее при попытке вывести
цель Р(х, х) мы могли бы
создать граф типа И/ИЛИ,
изображенный на рис. 6.12.
Обратите внимание, что правила П4
и П5 находятся на одном
частичном графе решения,
являющемся кандидатом, и
связанные с ними подстановки [Α/χ }
и {С/х } не согласуются. Если
П5 является единственным
правилом, сопоставимым с
подцелью Q(x), то указанная
несогласованность дает нам
возможность убрать подцель U(z)
из этого графа. Разрешение
U(z) не может дать вклад ни
в какой согласованный граф
решения. Заметьте, однако, что
подцель S(x) может быть
сохранена в графе: к ней может
быть еще применена
подстановка [Α/χ]. Общее правило
состоит в том, что обнаруженное
соответствие не имеет смысла
развивать, если оно не
согласуется с подстановками во всех
R(x)
[х/у}^7^[хМ
R(y) Λ(νν)
J/75
Six)
{C!x}\\
о
\S(0
\П4
U(z)
Рис. 6.12. Другой граф типа И/ИЛИ с
несогласованными подстановками
других содержащих его частичных графах решения.
Другая стратегия управления для обратной системы дедукции,
базирующейся на правилах, связана с построением некоторой структуры,
называемой графом связи правил. В этом случае мы заранее определяем все
возможные соответствия между правилами и запоминаем результирующие
подстановки. Такая предварительная оценка выполняется до решения
какой-либо конкретной проблемы с помощью этих правил. Результат
является потенциально полезным для всех проблем, пока множество правил
остается неизменным. Такой процесс, разумеется, приемлем на практике,
только если множество правил не слишком велико.
На рис. 6.13 приведен пример графа связи правил для правил из нашего
примера "про собаку и кошку". При построении графа каждое правило
записывается в виде графа типа И/ИЛИ с последующим соединением (с
помощью дуг соответствия) литералов в антецедентах правила со всеми кон-
174
ЖИВОТНОЕ (хЗ)
ЖИВОТНОЕ (х4)
ПЗ
СОБАКА (хЗ)
П4
КОШКА (х4)
{х4/х5\
1Z
КОШКА {х5)
П5
МЯУКАЕТ (х5)
Рис. 6.13. Граф связи правил
секвентами, соответствующими правилу. После этого дуги соответствия
помечаются наиболее общими унификаторами.
Для решения конкретной задачи можно связать целевой граф типа И/ИЛИ
и вершины фактов с нашим графом связи правил, соединяя вершины
целевых литералов со всеми консеквентами, соответствующими правилу, и
вершины фактов со всеми соответствующими литералами в антецедентах этого
правила. Увеличенный граф связи можно просмотреть, чтобы найти в нем
графы решений, служащие кандидатами. Если такой кандидат найден, то
попытаемся вычислить унифицирующую композицию тех подстановок,
которые имеются в этом графе. Если такая унифицирующая композиция
существует, то значит мы нашли согласованный граф решения типа И/ИЛИ и,
следовательно, решение проблемы. В противном случае мы должны взять
в пределах этого графа связи другой граф решения, являющийся кандидатом.
Используя графы связей этого вида, мы на самом деле создаем графы
типа И/ИЛИ, исходя главным образом из заранее вычисленной структуры.
Имеется, однако, одно существенное осложнение, о котором мы еще не
говорили: может возникнуть необходимость в неоднократном использовании
одного и того же правила в графе связи правил в пределах одного графа
решения, являющегося кандидатом. Каждый раз правило должно
использоваться с различно поименованными переменными. Эти переменные должны
175
также появляться и в подстановках, переносимых в
предполагаемый граф решения.
Рассмотрим конкретный пример. Предположим,
имеются правило Р(х) => P(f(x)) и факт Р(А), и мы хотим
доказать цель P(f(f(A))). Граф связи правил для этой задачи
изображен на рис. 6.14. Здесь мы воспользовались
(непомеченной) дугой соответствия между консеквентом и
антецедентом правила, чтобы напомнить, что в этом слу-
PififiA)))
if(A)/x]
PifW)
P(J(J(A)))
^\
{f{A)lx}
PU(-r))
P(x)
PifiA))
•<!r%
[Aly]
P(J(x))
^
P{x)
P(f(y))
P(A)
P{A)
τ
P{A)
Рис. 6.14
Рис. 6.15
Рис. 6.16
Рис. 6.14. Другой граф связи правил
Рис. 6.15. Граф связей
Рис. 6.16. Граф предполагаемого решения
чае применения правила его консеквент может соответствовать антеценду
первоначального и т.д. Когда вершины целей и фактов связаны, то имеем
граф, изображенный на рис. 6.15. Просмотр этого графа связей в поиске
графа решения, являющегося кандидатом, может привести к графу,
показанному на рис. 6.16. В этом графе одно и то же правило используется
дважды (проходя по циклу в графе связи правил), и, таким образом,
переменные, появляющиеся в этом правиле, и соответствующие подстановки
должны быть переименованы. Подстановки в графе решения имеют
унифицирующую композицию { f(A)/x, А/у }.
6.2.5. ПРИМЕРЫ ОБРАТНЫХ СИСТЕМ ДЕДУКЦИИ, ОСНОВАННЫХ
НА ПРАВИЛАХ
Чтобы дать более конкретное представление об использовании
основанных на правилах систем дедукции в ИИ, опишем некоторые примеры таких
систем. Каждая из них носит лишь иллюстративный характер. Практические
варианты подобных систем, разумеется, были бы значительно крупнее и
потребовали бы многих дополнительных элементов. Интересно отметить,
однако, что имеется целый ряд важных применений, которыми можно
заниматься даже при тех ограничениях, которые мы накладывали до сих пор на
допустимые формы для правил и фактов в обратных системах.
176
6.2.5.1. Система извлечения информации. Представим себе, что множество фактов
содержит информацию о сотрудниках некоторой деловой организации, и мы хотим,
чтобы автоматическая система была в состоянии давать ответы на различные вопросы,
касающиеся сотрудников. В сильно упрощенном примере такой системы могли бы
храниться следующие факты:
ГЛАВА (О-З f ДЖОН-ДЖОНС)
Джон Джонс возглавляет отдел закупок.
РАБОТАЕТ-В (О-З, ДЖО-СМИТ)
Джо Смит работает в отделе закупок.
РАБОТАЕТ-В (О-З, САЛЛИ-ДЖОНС),
РАБОТАЕТ-В (О-З, ПИТ-СВАНСОН),
ГЛАВА (О-П, ГАРРИ-ТЕРНЕР)
Гарри Тернер возглавляет отдел продажи.
РАБОТАЕТ-В (О-П, МЕРИ-ДЖОНС),
РАБОТАЕТ-В (О-П, БИЛ-УАЙТ),
СУПРУГИ (ДЖОН-ДЖОНС, МЕРИ-ДЖОНС).
Чтобы обеспечить получение обычной информации о работающих на предприятии и
чтобы множество фактов оставалось достаточно ограниченным, можно было бы
воспользоваться следующими правилами:
П1: ГЛАВА (х,у) - РАБОТАЕТ-В (х,у).
П2: [РАБОТАЕТ-В (х, у) А ГЛАВА (χ,ζ)] => БОСС (у, ζ).
(В более точной формулировке могло бы также
утверждаться, что некоторое лицо не может быть боссом самому
себе.)
ПЗ: [РАБОТАЕТ-В (х,у) А РАБОТАЕТ-В (χ,ζ)] => ~ СУПРУГИ (yt z).
(Компания не допускает, чтобы супруги работали в одном отделе
предприятия.)
П4: СУПРУГИ (y,z)'=> СУПРУГИ (ζ, у).
(Супружество симметрично. В более точной формулировке могло
бы также утверждаться, что нельзя быть супругом самому себе.)
П5: [СУПРУГИ (х, у) А РАБОТАЕТ-В (0-3,х)] =>
=> ЗАСТРАХОВАН-В (х, КОМПАНИЯ-ИГЛ).
(Все семйные работники отдела закупок охвачены страховкой в
компании ИГЛ.)
Располагая этими фактами и правилами, простая обратная система продукций могла
бы обеспечить получение ответа на ряд вопросов. В наших примерах будем
предполагать, что выбранная стратегия управления направляет порядок создания графа типа
И/ИЛИ посредством перебора в глубину в поиске согласованного графа решения.
При выборе же литеральной вершины в некотором частичном графе решения, которая
должна соответствовать консеквенту Оправила или факта, предполагается, что
используется процедура просмотра вперед, которая выбирает литерал подцели, имеющий
наименьшее число случаев соответствия.
Запросы, на которые можно получить ответ, не прибегая к нашим правилам,
обрабатываются особенно просто. Некоторые примеры графов решения изображены на рис.
6.17. Граф решения показан таким образом, что при рассмотрении "в глубину" слева
направо порядок расположения литеральных вершин соответствует действительному
порядку, в котором режим управления обеспечивает поиск случаев соответствия для
этих литералов. Вершины, заключенные в двойные рамки, представляют собой
вершины фактов. Во втором примере, поскольку вершина СУПРУГИ (х, у) имеет наименьшее
число потенциальных случаев соответствия, она приводится в соответствие в первую
очередь. Если применить унифицирующую композицию подстановок, появляющихся
в графе решения для данного запроса, то получим ответ:
Назовите кого-то из работающих в отделе закупок.
РАБОТАЕТ-В Ю-З.х)
{ДЖО-СМИТ/х}
SZ
РАБОТАЕТ-В (О-З, ДЖО-СМИТ)
Назовите кого-то, кто имеет супружескую пару и работает
в отделе продажи.
Рис. 6.17. Некоторые простые запросы, которые сопоставимы непосредственно с фактами
РАБОТАЕТ-В (О-П, МЕРИ-ДЖОНС) Л СУПРУГИ {ДЖОН-ДЖОНС, МЕРИ-ДЖОНС).
Теперь обратимся к более сложным запросам, для ответа на которые необходимо
использовать правила. На рис. 6.18 изображен граф решения для запроса: "Кто
является боссом Джо Смита?".
{0-3/х1.ДЖОН-ДЖОНф ή
Рис. 6.18. Граф решения для задачи: "Кто является боссом Джо Смит?9
178
Единственное правило, которое может быть применено с самого начала, - это
правило П2. Из результирующих новых литеральных вершин вершина ГЛАВА (xl, zl)
имеет наименьшее возможное число случаев соответствия, поэтому с ней и
устанавливается первое соответствие. Приведение в соответствие этой вершины с ГЛАВА (О-П,
ГАРРИ-ТЕРНЕР) не может дать согласованного графа решения, так что в конечном*
счете наш процесс управления вернется назад, чтобы попробовать то соответствие,
которое показано на рис. 6.18. (Заметьте, что мы переименовали переменные в
правиле П2 так, что они отделены от переменных целевой ппф.) После получения решения
мы можем применить унифицирующую композицию, чтобы получить на запрос такой
ответ: БОСС (ДЖО-СМИТ, ДЖОН-ДЖОНС).
В качестве более сложного примера рассмотрим заявку: "Назовите кого-либо, кто
застрахован в компании ИГЛ?". Граф решения для этого запроса изображен на'рис.
6.19. Компонента подцели СУПРУГИ (x,yl) разрешена в первую очередь, а затем
правило П1 применено к РАБОТАЕТ-В (0-3, х), чтобы установить решение для другой
компоненты подцели. Применение унифицирующей композиции к запросу дает
ответ: ЗАСТРАХОВАН-В (ДЖОН-ДЖОНС, КОМПАНИЯ-ИГЛ).
ЗАСТРАХОВАН-В (х, КОМПАНИЯ-ИГЛ)
"}
iz
ЗАСТРАХОВАН-В (xl, КОМПАНИЯ-ИГЛ)
СУПРУГИ(х, у1)
РАБОТАЕТ-В (0-3,х)
lZ
(ДЖОН-ДЖОНС/х,
МЕРИ-ДЖОНС/yl]
{0-3/х2,х/у2}
ЮУПРУГИ {ДЖОН-ДЖОНС, МЕРИ-ДЖОНО\
lz
РАБОТАЕТ-В (х2, у 2)
П1
ГЛАВА (0-3, х)
lZ
[ДЖОН-ДЖОНС/х
ГЛАВА (0-3, ДЖОН-ДЖОНС)
"Назовите кого-либо, застрахованного в компа-
Рис. 6.19. Граф решения для задачи:
нии ИГЛ"
Предположим, мы хотим спросить: "Является ли Джон Джонс супругом Салли
Джонс?". Система могла бы сначала попытаться найти доказательство для СУПРУГИ
(ДЖОН-ДЖОНС, САЛЛИ-ДЖОНС). Этому факту нельзя найти никакого
соответствия, а подцель, получаемая при применении правила П4, также не помогает. Когда
доказательство нельзя найти, то разумно попытаться доказать отрицание запроса. Граф
решения для такой негативной цели изображен на рис. 6.20.
Мы можем использовать этот пример для иллюстрации того, как дополнительные
знания и возможности могут быть добавлены в систему без ее существенных
(обширных) изменений. Предположим, мы хотим уточнить правило П5, введя понятие
временного служащего. Новое правило П5' выглядит так:
П5' : [СУПРУГИ (х,у) А РАБОТАЕТ-В (0-3, χ) А
Λ -ВРЕМЕННО (χ) ] =>
=* ЗАСТРАХОВАН-В (х, КОМПАНИЯ-ИГЛ).
179
~ СУПРУГИ {ДЖОН-ДЖОНС, САЛЛИ-ДЖОНС)
(ДЖОН-ДЖОНС/yl, САЛЛИ-ДЖОНС/zl}
Рис. 6.20. Граф решения для задачи: "Джон Джонс не является супругом Салли Джонс"
Теперь мы должны добавить в наше множество фактов информацию о том, являются
ли работники временными. Мы могли бы также включить дополнительное
определяющее правило
П6: ПОСТОЯННО (х) => -ВРЕМЕННО (х).
Можно включить также дополнительные факты:
ПОСТОЯННО (ДЖОН-ДЖОНС),
ВРЕМЕННО (САЛЛИ-ДЖОНС).
Новые правила и факты оказывают незначительное влияние на то, как будет
получен ответ на предыдущие запросы. Однако когда новые правила вводятся в систему
дедукции, то важно проверить, не вступают ли они в противоречие с другими
правилами. Например, предположим, мы должны добавить правило
П7: РАНЕЕ-РАБОТАЛ-В (х,ДЖИ-ТЕК) =>
^ЗАСТРАХОВАНА (х, КОМПАНИЯ-МЕТРО).
(Всякий, кто ранее служил в ДЖИ-ТЕК>
застрахован компанией Метро.)
Мы также могли бы добавить факты относительно предыдущего места работы
служащих. С этими добавлениями появится возможность вывести конфликтные ЗАСТРА-
ХОВАН-В. Разрешение таких противоречий обычно достигается путем уточнения
антецедентов правил.
Одной из желаемых характеристик было бы введение метаправил наподобие:
"Если в базе данных явно не сказано, что работник временный, то данный работник
служит постоянно". Такое правило содержит заявление, относящееся и к базам данных,
и к служащим! Чтобы пользоваться правилами, подобными этому, системе потребуется
некоторое лингвистическое выражение, описывающее ее собственную базу данных.
Кроме того, было бы желательно иметь соответствующие связи между этими
выражениями и кодами вычислительной машины, описывающими базу данных. Однако такие
рассмотрения приведут нас к интересным осложнениям, несколько выходящим за
рамки настоящей книги, (см., однако, [384]).
180
6.2.5.2. Система рассуждений для неравенств. Теперь обратимся к некоторым
простым математическим задачам. Для иллюстрации некоторых дополнительных моментов
можно воспользоваться системой рассуждений с неравенствами. Эта система будет
в состоянии показать, например, что если О Ε > 0 и если В > А > 0, то [В (А + С) /Е] >
> В. Для упрощения рассуждений будем считать, что имеется лишь один предикат G. В
выражение G (х, у) вкладывается тот смысл, что χ больше у. (Иногда пользуемся
более понятным "инфиксным" обозначением χ > у.) В этой системе мы не имеем дело
с равенством или "меньше, чем", так что намеренно исключаем отрицание предиката G.
Настоящая система не способна выполнять арифметические операции, но способна
представлять их результаты в виде функциональных выражений. Для сложения и
умножения используем выражения plus и times. Каждое из них в качестве своего
единственного аргумента воспринимает набор, т.е. неупорядоченную группу элементов. Таким
образом, phis (3, 4, 3), например, то же самое что plus (4, 3, 3). (Самое важное то, что
последние два выражения унифицируемы, поскольку они рассматриваются как
одинаковые.) Мы допускаем, чтобы функции "divides" (деление) и "substracts" (вычитание)
имели бы два аргумента, поскольку порядок аргументов важен. Мы представляем х/у
выражением divides (χ, у), г. (х - у) выражением substracts (χ,у).
В таких обозначениях типичным выражением может быть G [divides (times (В, plus (A,
Q\ Ε), Β] , что более привычно записывается как [В(А + Q/E] > В. Причина, по
которой мы используем более сложное префиксное обозначение, состоит в том, что мы
хотим устранить источник возможной путаницы при унификации термов. После одного
примера дедукции с применением префиксного обозначения вернемся к более
привычным инфиксным обозначениям.
В нашей системе применяются правила, выражающие определенные свойства
неравенств. Начнем с правил:
П1: [G(x,0) Л G(y,0)] =Ф G (times (х,у),0)
т. е. [(* > 0) Л (у > 0)]^>(ху > 0)
П2: [G(x,0) Л G(y,z))=S> G(plus(x,y),z)
T.e.l(x>0)A(y>z))=>[{x+y)>z]
ПЗ: [G(x,w) Л G(y,z)]^> G(plus(x,y),plus(w,z)}
т. е. К* > w) А (у > ζ)] => [(χ + у) > (w + ζ)]
П4: [ G (х,0) Л G (у, ζ)] => G (times (χ,у), times (χ, ζ))
т. е. Κ* > 0) Α (у > ζ)] => (ху > χζ)
Π5: [G(\,w) Λ G(x,0)]=> G(x,times(x,w))
т. е.[(1 > w) Л (χ > 0)] => (χ > дси>)
Π6: G (χ,plus (times (w, ζ), times (у, ζ )))
=ϊ> G (χ, times (plus (w,y), ζ))
т.е.,[·* > (wz + yz)]=*[x > (w + y)z]
Π7: [G(x,times(w,y)) Λ G(/,0)]=> G (divides (x,y),w)
т. e.[(x > *У) Л (у > 0)j => [(x/y) > w)
181
Это, конечно, еще не все правила, которые могут быть полезны, и мы позже введем
несколько других правил. Наша система использует эти правила в качестве Оправил.
Можно воспользоваться различными стратегиями управления. Поскольку графы типа
И/ИЛИ, возникающие при применении этих правил, являются относительно
небольшими, то в наших примерах будем приводить все графы целиком.
Первой проблемой является доказательство [В(А + С)]/Е > В исходя из фактов:
Е>0, В>0,А>0,ОЕиС>0. Граф типа И/ИЛИ для этой задачи изображен на рис.
6.21. Граф решения выделен жирными дугами, а факты, соответствующие подцелям,
взяты в двойные рамки. Мы видим, что правило П2 использовалось дважды с
различными подстановками, причем одно из этих применений ведет к неразрешимой подцели.
Анализируя факты, на которые опирается доказательство, видим некоторую
избыточность, которую можно было бы исключить, если воспользоваться свойством тран-
Gldivides(times(B,plus(A,C))£)J)
ι
{times{B,plus{A.C))lxl.
E/yl,B/wl]
Рис. 6.21. Граф типа И/ИЛИ для задачи с неравенствами
182
зитивности для G. Иначе говоря, изОЕяЕХ) мы должны быть в состоянии вывести
при необходимости О 0 вместо того, чтобы представлять это явным образом как
некоторый факт. Такой вывод можно сделать на основе правила транзитивности
П8: [(х>у) Л 0>z)] =* (jc>z).
Сравнивая П8 с другими правилами, замечаем, что его использование практически
неограниченно; оно содержит слишком много переменных, не включенных в функции.
Таким образом, П8 может участвовать в слишком большом числе случаев соответствия
и несет в себе тенденцию к слишком частому применению. При использовании в
качестве О-правила консеквент правила П8, а именно G(jc, z), оказывается в
соответствии с любой подцелью, создаваемой нашей системой. Ясно, что мы не хотим
использовать транзитивность на каждом шаге.
К счастью, имеются способы структурирования данных так, чтобы специальные
отношения, подобные транзитивности, могли бы неявным образом быть закодированы
в такой структуре. Например, если факты, выражающие некоторое отношение
упорядоченности, хранятся как вершины в решетчатой структуре, то требуемые
последствия транзитивности (такого упорядочения) являются автоматическим результатом
простых вычислений на решетке. Эти вычисления могут рассматриваться как
привязка к предикату, обозначающему отношение упорядоченности, процедуры.
Рассмотрим более трудное доказательство. Из В > 1, 1>А,А>0, C>DhD>0
доказать
(Эм) [(Аи+Ви) >D].
Кроме того, мы бы хотели видеть пример такого м, который удовлетворяет теореме,
составленной из констант, перечисленных в фактах.
Предположим, указанные факты хранятся в решетчатой структуре и следующие
выводимые факты получаются достаточно легко: В > А, В > 0, 1 > ОиС>0. В
последующих примерах мы предполагаем, что при необходимости можно воспользоваться
любым таким фактом.
Сначала в системе делается попытка применить О-правила к главной цели.
Применимо только правило П2, но имеются две альтернативные подстановки, которые
можно использовать. Для краткости просмотрим вывод, последующий в результате выбора
одной из них. (Другой выбор довольно быстро приводит к некоторым неразрешимым
подцелям, в чем читатель, возможно, захочет убедиться самостоятельно.)
При использовании только правил П1-П7 в нашей системе будет построен граф типа
И/ИЛИ (рис. 6.22) · Обратите внимание на цель (Ви > /)), помеченную звездочкой. К
этой цели не применимы никакие правила, так что на рассматриваемой задаче система
терпит неудачу. Что можно сделать, чтобы расширить возможности системы?
Здесь мы снова имеем пример, в котором возможности системы продукций можно
расширить эволюционно, не прибегая к обширным переделкам. Мы можем добавить
в систему правило
П9: [0> 1) Λ (χ>ζ)] => (xy>z).
Это правило применимо к цели (Ви > D); в остальном его присутствие не сильно
влияет на эффективность системы. (Читатель, возможно, захочет исследовать влияние П9
на граф типа И/ИЛИ на рис. 6.21. Его наличие позволяет найти дополнительные, но в
конечном счете бесполезные соответствия с подцелью G (times (В, plus (А, С),
times (В, £)). ]
На рис. 6.23 показан граф типа И/ИЛИ, созданный в результате применения правил
ниже вершины Ви > D. Обратите внимание на наличие пары 2-связок под верхней
вершиной. Левая оказывается бесполезной, тогда как правая приводит к успеху при замене
и на С. Замечаем, что на рис. 6.22 подстановка {С/и} является одной из допустимых
подстановок под целевой вершиной и > 0. Таким образом, доказательство завершено,
и то м, которое удовлетворяет теореме, есть и =С.
183
{Au+Bu)>D
{Aulx,Buly,D/z}
[Bu/xl.Au/yl.D/zl}
(x+y)>z
(xl+yl)>zl
Π2
Π2
Au>0
{A/x2,u/y2}
Bu>D
H
Bu>0
Au>D
[u/x3,A/y3]
x2y2 > 0
хЗуЗ > 0
ΠΙ
ΠΙ
w
A >0
u>0
[А/и]
[B/u]
}p
[С/и} \\ [Dfu]
A > Ο Η И B>0 || Ij 0 0 |1 jj D > 0
Рис. 6.22. Частичный граф решения
{B/xm/v,D/z}
{Blyl,ulxLD/zl}
{Bin}
Рис. 6.23. Подцели, созданные новым правилом
{С/и}
184
Некоторые дополнения к системе рассуждений о неравенствах еще более
расширяют ее возможности. Один из фактов, имевшийся в последнем примере, - неравенство
1 > 0. Но мы не должны представлять всевозможные неравенства между числами как
факты. Необходима привязка к "больше, чем" некоторого вычисления, которое
позволило бы оценивать основные частные случаи литералов G. Должны быть также
привязки к арифметическим программам, так чтобы, например, G(10,A) могло быть
заменено на G{plus (3, 7), А). Должны быть добавлены средства, обеспечивающие упрощение
алгебраических выражений и позволяющие работать с предикатами равенства.
Некоторые механизмы для эффективной реализации улучшений, подобных этим, основаны на
приемах, обсуждаемых в конце главы.
6.3. "РЕЗОЛЮЦИЯ" ВНУТРИ ГРАФОВ ТИПА И/ИЛИ
Рассмотренная обратная система не в состоянии доказывать
общезначимые или тавтологические целевые выражения, такие как (~Р V Ρ), пока
она не докажет либо ~Р, либо Р. Точно так же прямая система не способна
распознавать противоречивые выражения для фактов, такие как (~Р А Р).
Чтобы преодолеть эти недостатки, системы должны иметь возможность
делать логические выводы "внутри" цели или факта.
Опишем, как можно было бы осуществлять выводы внутри
поставленной цели. Рассмотрим, например, следующие выражения, используемые
обратной системой:
Цель
[P(x,y)VQ(x9y)}AV(x,y).
Правила
П1: [R(v)AS(u,B)]=*P(u,i>)9
П2: [~S(Afs)AW(r)]=>Q(r,s).
Факты
R(B) AW(B) AV(A,B)AV(B,B).
После применения правил Ш иП2 получаем граф типа И/ИЛИ (рис. 6.24).
Граф имеет два дополнительных литерала, предикаты которых
унифицируются с наиболее общим унификатором вида {А/х, В/у] . На рис. 6.24 это
соответствие показано с помощью ребра, соединяющего вершины,
представляющие дополнительные литералы. Это ребро помечено указанным ноу.
Форма предложений для этих (целевых) выражений, представляемых
данным графом типа И/ИЛИ, включает предложения:
V(x,y) AR(y) AS(xyB); V(x,y) A W(x) A~S(A,y).
Если бы мы выполнили целевую резолюцию (на S) между этими двумя
предложениями (после разделения переменных), то получили бы (целевую)
резольвенту
V(Afy) AR(y) AV(t9B)AW(t).
В начале этой главы мы отмечали, что представление выражения в виде
графа типа И/ИЛИ является несколько менее общим, чем представление в
виде предложений, поскольку переменные в графе типа И/ИЛИ не могут
быть полностью "разделены". Вследствие этого ограничения достаточно
трудно в общем случае представить выражения, которые могут быть
получены при применении резолюции в целевых подвыражениях.
Одним из способов представления операции резолюции, выполняемой
между двумя целевыми предложениями, является соединение литерала
185
Рис. 6-24. Граф типа И/ИЛИ с дополнительными литеральными вершинами
в одном частичном графе решения с дополнительным литералом в другом
(как это сделано на рис. 6.24). Принимается, что эта связанная структура
представляет предложения, составленные из литеральных вершин в парах
всех графов решения (заканчивающихся в литеральных вершинах),
соединенных таким образом. Мы ассоциируем с таким спаренным графом
решения подстановку, являющуюся унифицирующей композицией
подстановок в каждом члене пары, плюс подстановку, связанную с сопоставлением
дополнительных литералов. Эта связанная со спаренным графом решения
(заканчивающимся в литеральных вершинах) подстановка применяется к
концевым литеральным вершинам для получения представляемого им
предложения.
Таким образом, структура на рис. 6.24 включает определенное
представление для предложения R (В) A W(A) AV(A,B). Это предложение не
является столь общим, как то, что мы получили раньше посредством целевой
резолюции между предложениями цели, переменные которых были
полностью разделены, и подобное ограничение общности может помешать нам
найти некоторые доказательства. (Выражение [R(В) A W(A) A V {А, В)]
не может быть доказано исходя из заданных фактов, тогда как выражение
[V {А, у) A R(γ) А V (t, В) AW(t)] может быть доказано.) Мы можем
сказать, что эта операция, т.е. сопоставление дополнительных пар литералов в
графах типа И/ИЛИ, есть ограниченная целевая резолюция (ОЦР) .
Чтобы использовать ОЦР в обратных системах продукций, мы должны
модифицировать условие остановки. Для задачи нахождения графов
решения, являющихся кандидатами, можно предположить, что литералы,
соединенные ребром соответствия ОЦР, являются терминальными вершинами.
Пара соединенных таким образом частичных графов решения составляет
186
решение-кандидат, если все другие концевые вершины являются
терминальными (т.е. если они являются либо целевыми вершинами, либо участвуют в
других сопоставлениях, связанных с ОЦР). Такой предполагаемый граф
решения является окончательным, если связанная с ним подстановка
является согласованной.
В нашем примере сопоставление остающихся нетерминальных концевых
вершин на рис. 6.24 с фактами не дает согласованного графа решения,
поскольку для решения этой проблемы требуется большая степень общности,
чем та, которая может быть получена применением ОЦР к представлению
целевого выражения в виде графа типа И/ИЛИ. Требуемая общность может
быть получена в этэм случае представлением целевого выражения в виде
предложений и разделением переменных между двумя предложениями,
что приводит к выражению
[P(xl,yl)AV (xl,yl)]V[Q(х2,у2) Λ V (х2,у2)].
Это выражение теперь может быть представлено в виде графа типа И/ИЛИ,
а правила и ОЦР могут быть применены для создания согласованного
графа решения (рис. 6.25). Унифицирующая композиция, связанная с этим
решением, содержит подстановку [В/у1, Α/xl, В/х2, В/у2 } . Применение
последней к корневой вершине графа дает ответное утверждение
[P(xl,yl) Λ V(xl.yl)} V [Q{x2,y2) Λ V(x2,y2)}
Q(x2,y2) Λ V(x2,y2)
Pixl.yl)
{xl/u,yl/v}
[A/xl.B/yl]
V{xl,yl)\ \Q(x2,y2)
P{u,v)
V(A,B)
V{x2,y2)
{x2/r,y2/s}
{B/x2,B/y2}
Q(r,s)
Π1
V{B,B)
Π2
Riyl)
S{xl,B)
S(A,y2)
W(x2)
[B/yl]
[AlxLBly2]
<*>
[B/x2]
R(B)
W(B)
Рис. 6.25. Граф решения, использующий ОЦР
187
[P(A,B)AV(A,B)]V [Q(B,B)AV(B,B)).
Чтобы избежать противоречивых ситуаций при использовании ОЦР, иногда
необходимо дублировать часть или все целевое выражение, переходя к
предложениям. Разумная стратегия для систем дедукции такого типа может
состоять в попытке сначала найти доказательство, используя исходное
целевое выражение. Если эта попытка окажется неудачной, то система может
преобразовать целевое выражение (его часть) в форму предложений,
"разделить" переменные и попытаться снова найти доказательство. В нашем
примере пришлось целевое выражение целиком перевести в форму
предложений для нахождения доказательства. В общем случае достаточно так
преобразовать только ту часть целевого выражения, которая содержит все
вхождения переменных, которые необходимо переименовать. Это те
переменные, для которых были обнаружены несогласованности при
подстановках в первой попытке доказательства. Сравнение рис. 6.24 и 6.25 показывает,
что вторая попытка доказательства может направляться структурой дерева,
полученной при первой попытке.
Иногда можно избежать развертывания в форму предложений, используя
условные подстановки. Понятие условных подстановок оказывается важным
в приложениях к синтезу программ. Условной называется подстановка,
содержащая условное выражение. Те условия, которые мы используем в
таких подстановках, базируются на дополнительной паре унифицируемых
литералов в альтернативных частичных графах решения. Например, на рис.
6.24 литералы S(x, В) и ~S(A, у) находятся в двух различных частичных
графах решения, и их предикаты унифицируются с применением наиболее
общего унификатора {А/х, В/у}. Применение этого ноу к S (х, В) дает
S (А, В), а к ~S (А, у) дает ~S (А, В) . Мы могли бы привести в соответствие
вершину, помеченную S (хУ В), с некоторой вершиной для факта, если S (А,
В) имеет значение Г. В некотором смысле условная подстановка {(если S (А,
В), то А/х)} унифицирует S (х, В) с Т. Кроме того, условная подстановка
{ (если ~S (Л, В), то В/у) } унифицирует ~S (А, у) с Т.
Использование этих двух подстановок позволяет нам найти два
согласованных графа решения (рис. 6.26). Унифицирующая композиция
подстановок в графе слева содержит подстановку {(если S(A, В), А/х, В/у) } ,
унифицирующая композиция подстановок в графе решения справа —
подстановку { (если ~S (А, В), В/у, В/х) ] . Поскольку либо S (А, В), либо ~S (A,
В) истинно, мы можем объединить эти решения в одно с унифицирующей
композицией {В/у, (если S(A, В), А/х; иначе В/х)} . Такая подстановка
могла бы обеспечить получение полезного ответного утверждения,
ассоциируемого с целевой ппф, если S(A, В) — литерал, значение которого будет
оценено пользователем, когда ему потребуется ответ.
Можно было бы дать двойственное описание для ограниченной резолюции
в графах типа И/ИЛИ, представляющих факты, но мы не будем его
приводить, поскольку обычно не предполагаем наличие противоречий в фактах,
используемых системами ИИ. (Тавтологии в целях и подцелях более
распространены.)
В следующем разделе покажем, как некоторый вариант ограниченной
целевой резолюции с использованием условных выражений может найти
применение в системах синтеза программ для вычислительной машины. Сначала
188
lB/x.B/у)
Рис. 6.26. Два графа решения с условными подстановками
опишем один альтернативный метод работы с импликационными целевыми
ппф. Обычно мы преобразуем целевую ппф вида Р1 =* Р2 в ее форму типа
И/ИЛИ, т.е. (-Р1 V Р2).Предположим для простоты, что Р1 - литерал.
Если система в дальнейшем генерирует некоторую подцель Р2, которая
содержит Р1, то она может воспользоваться ОЦР между ~Р1 и Р1.
Альтернативным подходам к цели вида Р1 => Р2 является преобразование
этой цели в подцель Р2, тогда как Р1 добавляется к множеству фактов,
которые могут быть использованы при доказательстве Р2 или его
подцелей. Тогда если система генерирует Р1 как подцель Р2, то эта подцед может
быть сопоставлена с предполагаемым фактом PL
Процесс преобразования антецедентов цели в предполагаемые факты
может повторяться многократно до тех пор, пока подцели содержат
импликации, но система должна отдельно хранить множество предполагаемых
фактов, созданных таким образом, для каждой подцели. Кроме того,
антецеденты цели должны иметь вид конъюнкции литералов, поскольку мы
по-прежнему ограничиваемся рассмотрением фактов только такого вида.
189
Логическое оправдание для такого подхода к импликационной цели
содержится в теореме дедукции в логике, которая утверждает, что если W2
логически следует из W1, то справедливо Wl => W2. Мы воспользуемся этим
методом в одном из примеров следующего раздела.
6.4. ВЫЧИСЛИТЕЛЬНЫЕ ДЕДУКЦИИ И СИНТЕЗ ПРОГРАММ
Теперь покажем, как обратные системы дедукции, основанные на
правилах, могут быть использованы для выполнения вычислений и для синтеза
некоторых типов вычислительных программ. В этих приложениях мы
пользуемся выражением на языке исчисления предикатов для обозначения
взаимоотношения между входом и выходом вычисления или программы,
которую предстоит синтезировать. Обозначим вход в программу переменной х,
а выход - у. Теперь предположим, мы хотим создать программу, для
которой между входом и выходом верно соотнощение Р. Задачу синтеза можно
сформулировать как задачу нахождения конструктивного доказательства
для выражения (Vx) (3j>) Ρ (χ, у). Если с помощью одного из наших
методов доказательства теорем мы сможем доказать, что такое у существует,
тогда можно будет записать у как некоторую комбинацию функций от х.
Эта комбинация функций и будет той программой, которую мы хотели
синтезировать. Элементарные функции, составляющие комбинацию, есть
элементы некоторого конкретного языка программирования. "Чистый"
ЛИСП является удобным языком для подхода такого рода, поскольку
все его операции могут быть определены в терминах функциональных
выражений.
Проиллюстрируем этот подход на примерах. Покажем, как можно было
бы вычислить выражение, которое отражает данное отношение выходной
величины к данному входному выражению. Затем продемонстрируем, как
для произвольных входных выражений может быть сконструирована
рекурсивная программа вычислений.
Предположим, мы просто хотим обратить порядок элементов в списке
(1, 2). Иначе говоря, мы хотим получить процедуру вычисления, которая
по списку (1,2) на входе вырабатывает список (2,1) на выходе. Покажем,
как такое вычисление может выполняться системой дедукции, основанной
на правилах. Сначала определим взаимоотношение между входом и выходом
посредством двухместного предиката REVERSED1, аргументами которого
являются термы, обозначающие списки. Предикат REVERSED
определяется, в свою очередь, через другие предикаты и элементарные выражения
языка ЛИСП.
Мы будем пользоваться принятым в языке ЛИСП способом
представления списков в виде точечных пар. В этом языке список {А, В, С, D),
например, представляется, как А. (В. (С. (D. NIL))) . Эти точки могут
рассматриваться как специальная инфиксная функция, префиксная форма которой
называется cons. Таким образом, префиксная форма А. В есть cons (А, В).
Мы отдаем предпочтение префиксной форме, потому что именно эта
форма будет использоваться в функциональных термах в нашем языке
исчисления предикатов. Применяя этот способ представления списков, покажем,
1 Означает "обратный"или перевернутый". -Прим. ред.
190
каким образом требуемое вычисление может выполняться системой,
которая пытается доказать целевое выражение
(Зу) REVERSED (cons (l, cons (2, NIL)),у).
При определении правил и фактов, используемых в нашем
доказательстве, мы употребляем трехместный предикат "APPENDED"1 .APPENDED(χ,
уf ζ) имеет значение Τ тогда, когда ζ является списком, образованным
добавлением списка χ в начале списка у. (Например, добавление списка (1,2)
к списку (3, 4) дает список (1, 2, 3, 4).)
При доказательстве целевого выражения нам потребуются следующие
факты:
Ф1: REVERSED (NIL, NIL),
Ф2: APPENDED (NIL,xl,xl).
Определенные отношения, касающиеся REVERSED и APPENDED,
выражаются правилами:
П1: APPENDED(x2,y2,z2)
=>APPENDED(cons(ul,x2),y2,cons(ul,z2))
П2: [REVERSED(x3,y3)
Л APPENDED(y3,cons(u2y NIL), vI)]
=> RE VERSED (cons (u2, x3\\I)
Первое правило ΠΙ утверждает, что список, созданный добавлением
некоторого списка, первый элемент которого есть uly а хвостовая часть - х2,
к списку у2у будет тем же самым, что и список, образованный добавлением
элемента ul перед списком, сформированным добавлением х2 к у2.
Правило П2 гласит, что результат "переворачивания" списка, образованного
добавлением элемента и2 перед списком хЗу совпадает с результатом
добавления "перевернутого" списка хЗ к списку, состоящему из одного
элемента и 2.
Покажем теперь, как обратная система продукций могла бы осуществлять
обращение списка (1,2) при заданных фактах и О-правилах. Здесь мы не
будем пытаться объяснять, как посредством некоторой стратегии
управления можно было бы эффективно решать, какое из приложимых правил
следует использовать. Большая часть знаний, необходимых при таком
управлении выбором, специфична для области автоматического
программирования и поэтому выходит за рамки настоящего рассмотрения общих
механизмов.
Сначала посмотрим, какие факты и правила сопоставимы с целью
REVERSED (cons (1, cons (2, NIL) ), у) . Мы можем применить О-правило П2 с
наиболее общим унификатором {l/w2, cons (2, NIL)jx3y у/и 1} . Применение
этого ноу к антецеденту П2 дает новые литеральные вершины, помеченные
выражениями:
REVERSED (cons (2, NIL),y3); APPENDED (у*, -ov?(\,NJI )9y).
1 Означает "добавление" или "пристраивание". - Прим. ред.
191
Мы можем применить О-правило 112 к подцели REVERSED (cons (2, NIL) ,
уЗ), образовав две новые литеральные вершины. (Чтобы избежать
путаницы с переменными, использованными в предыдущем применении,
поменяем имена переменных в П2 перед применением.)
Согласованный граф решения для этой задачи изображен на рис. 6.27.
Выходное выражение, вытекающее из доказательства, получается
комбинированием подстановок с целью нахождения терма, подставляемого вместо
у, а именно со ns (2, cons (l, NIL)). Это выражение представляет собой
список, являющийся обращением входного списка (1,2).
Интересно сравнить вычисления, связанные с поиском доказательства,
показанные на рис. 6.27, с вычислениями, возникающими при выполнении
программы обращения произвольного списка, написанной на языке ЛИСП1:
reverse(x):
ifnull(x), NIL
else, append(reverse(cdr(x)), cons(car(x ), NIL)))
appeitd(x,jO'.
if null(x),/
else, cons(car(x), append(cdr(x ),γ))
Если процесс поиска в обратной системе продукций достаточно хорошо
направляется соответствующей стратегией управления, то этапы процесса
поиска достаточно тесно согласуются с этапами, связанными с выполнением
указанной программы на языке ЛИСП при поступлении на вход списка (1,2).
Мы можем управлять процессом поиска в системе продукций, определяя,
какие из применимых правил или фактов следует использовать на каждом
этапе и в каком порядке разрешать подцели. "Язык" для определения такой
управляющей информации может быть основан на соглашении о том, в
каком порядке правила и факты проверяются на возможную сопоставимость
и в каком порядке литералы появляются в антецедентах правил. Когда
возникает необходимость в выборе факта или правила, мы при поиске
сопоставления следуем выбранному порядку. Когда возникает необходимость
выбора некоторой компоненты подцели для решения, мы ее выбираем в
соответствии с порядком, в котором литералы выписаны в антецедентах
правил. Оказывается, что порядок (ΦΙ, Φ2, ΠΙ, Π2) для сопоставлений
правил и фактов и порядок, в котором записаны антецеденты правил П1 и
/72, обеспечивают в нашем примере весьма эффективную стратегию
управления. При такой стратегии шаги, выполняемые в процессе поиска
доказательства, почти буквально отражают вычислительные шаги при выполнении
приведенной программы на языке ЛИСП.
Чтобы убедиться в такой параллели, давайте проследим несколько первых
шагов развития процесса поиска. Отправляясь от цели REVERSED (cons (l,
cons (2,NIL))y), сначала отыщем (в порядке Ф7, Ф2, ΠΙ, Π2) сопостави-
1 Строго говоря, эта программа не есть программа на языке ЛИСП ни в одном из
привычных его диалектов; автор придал программе такой вид для удобства восприятия
ее широким кругом читателей. Напомним, что вычислению функций саг(х) и cdr(x)
соответствует взятие головного элемента списка χιλ. его остатка, null(x) — предикат, кото*
рый истинен только тогда, когда χ - нулевой список, или NIL. — Прим. ред.
192
{cons{ul.x2)ly3.cons{l.NlL)lv:
cons(ul.z2)/\)
REVERSED(cons(uS,x4),v2)
is:
{NlLly4}
APPENDED(cons(u 1.x 2 ),y2.cons(u 1 .z2))
Π1
REVERSED(NlL,y4)
APPENDED(x2,cons( I.NIL ).z2)
APPENDED(\ 4.cons(2.NlL ).yJ)
REVERSED(NIL,N/L)
[NIL/x2.tons(l.NlL)/x5.
cons{l.NIL)/z2}
APPENDED{NlL.x5.x5)
[N/L/y4.cons(2.NlL)/xl.cons(2..\'lL )/\ J]
APPENDED{NIL.xl.xl)
Рис. 6.27. Граф решения для обращения списка
мый элемент. Возможно сопоставление с Ф1У поэтому проверяем,
унифицируется ли cons (\,cons (2, NIL)) с NIL. (Сравните с элементом if null (χ) в
программе.) Потерпев неудачу, проверим на сопоставимость с консеквен-
томП2. Проверка включает сопоставление (и2, хЗ) с cons (1, cons (2,NIL)) .
Это сопоставление успешно при подстановке {l/u2, cons (2,NIL)! хЗ } .
(Сравните с вычислением саг (х) и cdr (x) во второй строке программы
обращения.) Сначала работаем с первой компонентой подцели (а именно
REVERSED (cons (2, NIL), у)) антецедента правила П2. (Сравните с
рекурсивным обращением к reverse(crd (x)) в программе.)Снова проверяем на
сопоставимость с Ф1, пытаясь убедиться, что cons (2, NIL) есть NIL Опять
потерпев неудачу, перейдем к другому уровню генерации подцелей в поиске
доказательства (и к рекурсии в указанной программе). На этом уровне
добиваемся успеха при сопоставлении с Ф1 (причем ноу есть {NIL/y4}) и
начинаем работать со следующей подцелью: APPENDED (y4, cons (2,NIL),
уЗ). (В программе мы обращаемся к подпрограмме append (NIL, cons (2,
193
NIL)).) Тот же параллелизм с программой на языке ЛИСП наблюдается и в
остальной части программы поиска.
Во многих случаях можно достаточно эффективно управлять процессом
поиска так, чтобы он имитировал эффективный процесс вычисления, и по
этой причине высказывалось мнение, что вычисление направляется
дедукцией [142]. На самом деле язык программирования ПРОЛОГ основан
именно на этой идее. "Программы" языка ПРОЛОГ состоят из
последовательностей фактов и правил. Правила являются импликациями точно так же,
как наши правила, за исключением того, что в языке ПРОЛОГ считается,
что антецеденты правила должны быть конъюнкциями литералов.
Программа "вызывается" некоторым целевым выражением. Затем
просматриваются утверждения о фактах и правилах с тем, чтобы найти первый
сопоставимый элемент для первой компоненты целевого выражения. Подстановки,
найденные при таком сопоставлении, соответствуют связыванию
переменных, а управление передается к первой подцелевой компоненте этого
правила. Таким образом, "интерпретатор" для программы на языке ПРОЛОГ
соответствует обратной системе продукций, основанной на правилах, с
весьма специфической управляющей информацией о том, что делать на
следующем шаге. (Интерпретатор языка ПРОЛОГ является несколько менее
гибким, чем наша обратная система, поскольку в языке ПРОЛОГ
подстановки, использованные при сопоставлении одного литерала конъюнктивной
подцели, непосредственно применяются к другим конъюнктам.
Созданные таким образом подцели могут не иметь решения, поэтому язык
ПРОЛОГ содержит некоторый механизм возвращения, который позволяет
попробовать другие сопоставления.)
В рассмотренном нами примере имелся фиксированный входной список
(1, 2). Если бы этот список был иным, то, пользуясь системой
доказательства теорем, можно было бы построить отличное от прежнего
доказательство и другой ответ. (Предположительно, однако, наша программа на языке
ПРОЛОГ продолжала бы работать аналогично универсальной программе на
языке ЛИСП.) Вместо того, чтобы осуществлять процесс поиска, всякий
раз, когда мы "запускаем программу" (хотя, очевидно, этот поиск и
можно было бы сделать весьма эффективным), ставится вопрос: могли бы мы
автоматически синтезировать одну общую программу (наподобие, например,
указанной программы на языке ЛИСП), которая воспринимала бы любой
входной список? Для этого мы должны найти доказательство цели
(Vx) (Зу) REVERSED (x, у).
(Разумеется, мы здесь не имеем в виду буквально "для всех х'\ поскольку
нет необходимости определять эту программу для всевозможных входов.
Нам требуется определить ее лишь для списков. Мы могли бы выразить
это ограничение в самой формуле, которую предстоит доказать, но наш
иллюстрированный пример будет проще, если мы только предположим,
что областью определениях являются списки.)
Поскольку уже известно, что окончательная программа для любого
заданного входного списка носит сходный характер, то мы могли бы
высказать догадку, что программа, которую мы ищем для произвольных входных
списков, является рекурсивной. Рекурсивные функции в задаче синтеза
программ возникают при использовании для доказательства математичес-
194
кой индукции. Оказывается, что при обращении списка с применением
функции append мы имеем двойную рекурсию: одну в reverse, другую — в
append. В качестве более простого примера рассмотрим задачу создания
программы для добавления одного списка к другому (в его начало).
Нашей целью является доказательство
(Vx) (Чу) (3ζ) APPENDED (χ,у, ζ).
В этом случае у нас имеется два входных списка, χ и уу и один выходной —
ζ. Сколемовское преобразование целевой ппф дает APPENDED (А, В, ζ), где
А и В — сколемовские константы. Для доказательства такой цели нам
потребуются факт Ф2 и правило Ш из нашего предыдущего примера.
(Присутствие других, ненужных, факта и правила, однако, не мешает.) Наши
пояснения примера упростятся, если дадим другое представление Ф2 и П1 в
виде правил:
ПЗ: NULL(u)^> APPENDED(u,xl,xl)
II4:[~NULL(v)AAPPENDED(cdr(v),yO,zl)]
=> APPENDED(v,yO, cons {car (ν), ζ 1))
В этих выражениях мы вводим элементарные функции языка ЛИСП, а
именно cons, car и cdr, из которых будет конструироваться наша программа.
Эти выражения языка ЛИСП могли бы быть введены и таким правилом, как
-NULL (χ) => EQUAL (x, cons (car (χ), cdr(x) ) ).
Однако такая альтернатива повлекла бы за собой рассмотрение некоторых
дополнительных сложностей, связанных со специальными методами
использования аксиом равенства. Используя правила ПЗ и П4, мы можем обойти
эти трудности и упростить наш пример.
Как уже отмечалось, для синтеза рекурсивной программы методами
доказательства теорем необходимо применить индукцию, а именно метод
структурной индукции для списков. Для этого нам необходимо
представление о некотором списке как подсписке данного списка. Для этого
используется предикат SUBLIST (и, x). Основное свойство предиката SUBLIST, на
котором основываются наши индуктивные соображения, может быть
выражено как следующее правило:
П5: -NULL(χ) => SUBLIST(cdr (x),χ)),
т. е. что "хвост" любого непустого списках является подсписком χ.
Доказательство
(Уу1) <уу2) (3si) APPENDED (у 1,у2, zl),
используя структурную индукцию для списка, мы поведем следующим
образом:
1. Примем индуктивную гипотезу
(Vwi) (Vw2) [SUBLIST(ul, xl) =>
■> (3*2) APPENDED (ul, u2y z2)\
Иначе говоря, предполагаем, что наше целевое выражение истинно для
всех входных списков ul и и2 таких, что ul является подсписком
некоторого произвольного списка xl.
195
2. Далее при данной индуктивной гипотезе мы пытаемся доказать, что
наше целевое выражение истинно для всех входных списков xl и х2, где
xl — произвольный список из нашей индуктивной гипотезы.
Если второй шаг оказывается успешным, то наше целевое выражение
истинно для всех входных списков yl и у 2.
Эти соображения можно выразить в виде единой формулы, которую мы
назовем правилом индукции:
{(Vx7)(Vx2)
{(Vw7 )(Vw2)[ SUBLIST(ul,xl)
=> (βζ2) APPENDED (w/, u2,z2)]}
=Φ (3z3)APPENDED(xl,x2,z3)}
=Φ (Vy/ )(Vy2 )(3zl) APPENDED (yl,y2,zl)
Хотя это правило выглядит довольно сложным, мы им воспользуемся.
Если не обращать внимания на кванторы, то правило имеет вид
[{А^С1) ^С2] =*С5.
Мы будем его использовать как О-правило для доказательства СЗ. Тогда
возникает подцель доказательства
[{A^Cl) ^С2).
Мы решаем доказывать эту подцель доказательством С2, хотя у нас в
наличии (только для использования в применении к С2 и ее дочерним подцелям)
О-правило (А => С7). (Такой способ рассмотрения импликационной цели
уже обсуждался. Здесь вместо того, чтобы предполагать, что антецедент
цели есть факт, мы принимаем его за правило.) Диаграмма,
иллюстрирующая эту стратегию, показана на рис. 6.28.
СЗ
Г Ί О-правило А =>С/ может быть использовано
I С2 I на этой цели или на одной из ее дочерних
' ' вершин
Рис. 6.28. Использование правила индукции
С другой стороны, мы могли бы преобразовать антецедент нашего
правила индукции в форму типа И/ИЛИ и воспользоваться этим правилом для
соз'дания подцели [(А Л~ С1) V С2]. Такое использование правила
индукции полностью эквивалентно, но несколько менее ясно с интуитивной точки
зрения и его труднее объяснять, поскольку на этапе ОЦР между ~С1 и С2
в конечном счете потребуется доказать эту подцель.
Правило индукции после сколемовского преобразования принимает вид
{[SUBLIST(ul,Al)^>APPENDED(ulyu2yskl(ulyu2))}
=> APPENDED(Al,A2,z3)}
=>APPENDED(yl,y2,sk2(ylyy2)) .
196
Обратите внимание на сколемовские константы и функции А1, А2,ski и
sk2. Программа, которую мы ищем, на самом деле окажется одной из этих
сколемовских функций. Таким образом, разумно уже сейчас представить
их единым функциональным символом append. При таком переименовании
наше правило индукции в том виде, в котором мы им пользуемся,
принимает форму
nH:{[SUBLIST(ulyAl)
=> A PPENDED ( uly u2y append(uly u2 ))]
=>APPENDED(AlyA2,z3)}
=>APPENDED(y!,y2,append(ylyy2)) .
APPENDED(A.B.z)
[A/vM/yO.
cons(car(A).zJ )/z)
APPENDED(v.y0.cons(car(v),zl))
A PPENDED (cdr(A ).B,zl)
заметьте уместность ПИ
[A/у LBIу 2.
append(A,B)/z)
APPENDED{yl,y2,append{yl,y2))
ПИ
APPENDED {A l ,А2.гЗ)
ниже этой вершины мы можем
использовать правило ПИ
SUBLIST(ul.Al)^
APPENDED (и I, u2.append(u l.uZ))
(Продолжение на следующей странице)
197
(Начало на предыдущей странице)
APPENDED(AJ.A2.zJ)
{A//u.A2/x/.A2/zj}
О
[A l/v,A2/yO,cons(car{Al).zl ))/zj]
NULL(AI) APPENDED(v,yO,cons(car(v),z/))
{cdr(Al)/uJ.A2/u2.
append(cdr(Al),A2)/zl)
APPENDED{ul ,u2,append{ul ,u2))
ПИ'
SUBLIST(cdr(AI).Al)
[А Цх]
V
SUBLIST{cdr{x),x)
П5
-NULL{A1)
Рис. 6.29. Граф поиска для задачи APPENDED
198
Граф поиска типа И/ИЛИ для задачи доказательства APPENDED (А, В, ζ)
изображен на рис. 6.29. В нашем примере поиск начинается с применения
правил ПЗ и П4 к главной цели. Об одной из подцелей, созданных правилом
П4, можно сказать, что она подобна нашей главной цели. Создание подцели,
обладающей такого рода сходством, дает основания для используемой
стратегии управления считать уместным применение правила индукции (ДЯ)
к главной цели. (Разумеется, логически корректным будет применение
правила индукции к главной цели в любой момент. Но, поскольку
доказательство по индукции является относительно сложным, правило индукции не
следует использовать, пока это не будет оправдано эвристически. В тех
случаях, когда в попытке непосредственного доказательства строится
такого вида "частный случай" главной цели, индукция обычно становится
уместной.)
Применение ПИ к главной цели порождает полдень APPENDED (ΑΙ, А2,
ζ3) и правило
ПИ* : SUBLIST (ul, ΑΙ) =>APPENDED (ul, u2, append (ul, u2)).
Последнее правило может быть использовано только для доказательства
APPENDED (ΑΙ, Α2, ζ3) или ее подцелей.
Далее наша стратегия управления применяет те же правила, которые
ранее были применены к главной цели (ПЗ и П4), к подцели, созданной
правилом индукции. Таким образом, строятся два различных графа решения,
которые закончены, если не считать появление NULL (А 1) в одном из них и
^NULL (A1) — в другом. Этап применения ОЦР завершает решение и дает
следующую условную подстановку:
/(если null (A1) ,Α2\ζ3\
в противном случае cons (car (Al), append (cdr(Al) ,A2))/z3) ] .
Эта подстановка порождает терм для переменной z3, который
встречался в подцели главной цели. Эта подцель, которая теперь нами доказана,
есть
APPENDED (ΑΙ, Α2, (если null (А1),А2;
в противном случае cons (car (A 1) , append (cdr(Al)9A2)))).
Поскольку ΑΙ и А2 являются сколемовскими константами, идущими от
переменных, относящихся к кванторам общности в целевом выражении,
то при конструировании ответа они могут быть заменены на переменные,
относящиеся к кванторам общности. Итак, мы доказали
(Vxl) (Vx2) APPENDED (xl, x2, (если null (xl),x2;
в противном случае cons (car (xl), append (cdr (xl), x2) ) ) ) .
Теперь легко видеть, что третий аргумент в APPENDED в приведенном
выражении есть рекурсивная программа, удовлетворяющая необходимым
требованиям.
Имеется много тонкостей в использовании индукции при синтезе
программ. Полное описание процесса выходит за рамки этой книги и было бы
связано с объяснением методов построения дополнительных функций,
рекурсии внутри рекурсивных программ и использования индуктивных
гипотез, которые являются более общими или "более сильными", чем та теоре-
199
ма, которую предстоит доказать.-Специальное правило индукции, которое
мы применяли для APPENDED в нашем примере, может быть заменено на
более общие схемы структурной индукции. В них использовались бы
условия хорошо обоснованного упорядочения, более общие, чем SUBLIST [220].
6.5. КОМБИНАЦИЯ ПРЯМОЙ И ОБРАТНОЙ СИСТЕМ
И прямая, и обратная системы дедукции, основанные на правилах, имеют
ограничения. Обратная система способна обрабатывать целевые выражения
произвольного вида, но выражения для фактов должны состоять из
конъюнкций литералов. Прямая система способна обрабатывать выражения для
фактов произвольного вида, но целевые выражения должны состоять из
дизъюнкций литералов. Можно ли объединить эти системы в одну, которая
обладает достоинствами обеих, но не имеет присущих им ограничений?
Опишем систему продукций, которая основана на такой комбинации.
Глобальная база данных комбинированной системы состоит из двух
структур графов типа И/ИЛИ, одна из которых представляет цели, а другая —
факты. Сначала эти структуры типа И/ИЛИ представляют заданные
выражения для цели и факта, вид которых теперь никак не ограничен. Структуры
модифицируются соответственно О- и П-правилами. Конструктор системы
должен решать, какие правила будут работать над графом фактов, а какие —
над графом целей. Мы продолжаем называть эти правила П- и О-правилами,
хотя новая система продукций в действительности работает в одном
направлении, модифицируя ее двухчастную глобальную базу данных. Мы
продолжаем требовать, чтобы О-правило имело дело с однолитеральными консек-
вентами, а П-правило — с однолитеральными антецедентами.
Главное осложнение, превносимое этой комбинированной системой
продукции, состоит в присущем ей терминальном условии. Остановка
процедуры должна быть связана с согласованием этих двух графовых структур,
которые могут быть объединены дугами соответствия между вершинами,
помеченными унифицируемыми литералами. Мы помечаем эти дуги
соответствия отвечающими им наиболее общими унификаторами. В начальных
графах дуги соответствия между графами фактов и целей должны связывать
соответствующие концевые вершины. После расширения графов вследствие
применения О- и П-правил такие сопоставления могут встретиться в любой
литеральной вершине.
После установления между двумя графами всех возможных соответствий
у нас все еще остается вопрос о том, были ли доказаны выражение, стоящее
в корневой вершине графа целей на основе правил, и выражение в
корневой вершине графа для фактов. Наша процедура должна обрываться только
тогда, когда такое доказательство будет найдено (или когда делается
заключение, что при данных ограничениях на ресурсы такое доказательство не
может быть найдено).
Одним простым условием остановки является результат
непосредственного обобщения процедуры решения того, является ли "решенной"
корневая вершина некоторого графа типа И/ИЛИ. Условие остановки
основывается на симметричном отношении, называемом ГАШЕНИЕ, между
вершиной факта и целевой вершиной. ГАШЕНИЕ определяется рекурсивно
следующим образом:
200
Две вершины η и тнаходятся в отношении ГАШЕНИЕ
друг с другом, если одна из (и, т) является вершиной
для некоторого факта, а другая — целевой вершиной и
если η и т помечены унифицируемыми литералами или
же вершина η имеет fc-связку, отходящую к множеству
дочерних вершин {sj } такому, что отношение ГАШЕНИЕ
(sj m) справедливо для каждого члена этого множества.
Когда корневая вершина графа целей и корневая вершина графа фактов
"гасят" друг друга, то имеем предполагаемое решение (кандидат).
Графовая структура в пределах целевого графа и графа фактов, которая
показывает, что корневые вершины для цели и факта гасят друг друга, называется
предполагаемым графом гашения. Это решение является действительным,
если согласуются наиболее общие унификаторы всех соответствий в
предполагаемом графе гашение.
В качестве примера мы показываем соответствия между начальным
графом фактов и начальным графом цели на рис. 6.30. Согласованный
предполагаемый граф ГАШЕНИЕ показан более жирными дугами. Наиболее
общие унификаторы для каждого соответствия вершин факт-цель
изображены рядом с дугами соответствия, причем унифицирующая композиция
из всех этих унификаторов есть {f{A)jv,A/y ) .
Заметьте, что в нашем методе графа гашения конъюнктивно связанные
вершины рассматриваются корректно. Каждый конъюнкт должен быть
доказан перед тем, как будет доказана его родительская вершина. Подобным
образом рассматриваются дизъюнктивно связанные вершины фактов.
Чтобы использовать один член дизъюнкции в доказательстве, мы должны быть
в состоянии доказывать ту же цель, используя каждый дизъюнкт в
отдельности. Этот процесс является реализацией стратегии "рассуждение на
примерах".
По мере того, как строятся графы поиска типа И/ИЛИ при применении
О- и П-правил, с каждым применением правил связываются подстановки.
Все подстановки в графе решения, включая те ноу, которые получаются
при сопоставлении правил, и те ноу, которые получаются для
сопоставимых литералов цели и факта, должны быть согласованы.
Можно заметить, что подрезание ветвей графа типа И/ИЛИ при
обнаружении несогласованности подстановок может оказаться невозможным в
системах, использующих как О-, так П-правила, по той причине, что в них
и граф фактов, и граф целей изменяются динамично, вледствие чего на
любом этапе невозможно сказать, все ли сопоставления были проведены для
данной литеральной вершины. При одновременном использовании О- и
П-правил также может оказаться важным иметь возможность рассматривать
соответствующие частные случаи разрешимых целей как факты, так что к
ним могут применяться П-правила. (Разрешимой целью является такая,
которая погашается корневой вершиной графа фактов.)
Условие остановки, которое мы только что описали, адекватно многим
проблемам, но не годится для обнаружения того, что целевой граф,
изображенный на рис. 6.31, следует из графа фактов. Для этой проблемы
потребовалась бы операция резолюции факт-цель более общего вида, чем та, что
реализована нами в простой проверке на окончание, основанной на
свойстве ГАШЕНИЕ.
201
Начальный
г граф целей
у. Начальный
граф фактов
Рис. 6.30. Пример графа для отношения ГАШЕНИЕ
202
Альтернативный подход в
случае произвольных
выражений для фактов и
целей состоит в испольозова-
нии (однонаправленной)
системы опровержения, которая
обрабатывает только факты.
Целевое выражение сначала
отрицается, а затем
преобразуется в форму И/ИЛИ и
объединяется с выражением
для фактов. Затем П-прави-
ла, контрапозитивные
формы О-правил и операции
ограниченной резолюции
применяются к расширенному
графу фактов до тех пор,
пока не будет получено
противоречие.
Рис. 6.31. Проверка на
окончание не ведет к обнаружению
доказательства
Граф
целей
7\
и и и и
Граф
фактов
6.6. УПРАВЛЯЮЩИЕ ЗНАНИЯ В СИСТЕМАХ ДЕДУКЦИИ НА ОСНОВЕ
ПРАВИЛ
Ранее мы подразделили знания, необходимые системам ИИ, на
декларативные, процедурные и управляющие. В системах продукций, описанных
в этой главе, относительно легко выражаются декларативные и
процедурные знания. Специалисты в различных областях — таких, как медицина или
математика, возможно, не знакомые с вычислительными машинами, нашли
вполне удобным и естественным выражать свой опыт в форме предикатов
и импликационных правил.
Тем не менее имеется необходимость превносить управляющие знания в
системы дедукции. Эффективные стратегии управления для описываемых
нами систем продукций могут быть довольно сложными. От программиста
может потребоваться большое искусство для внесения этих стратегий в
управляющие программы. Поэтому имеется соблазн предоставить создание
управляющей стратегии всецело экспертам в области ИИ. Но большая часть
важных управляющих знаний является специфической для области, в
которой такая программа искусственного интеллекта работает. Часто медикам,
химикам и другим специалистам столь же важно поставлять и
управляющие, и декларативные, и процедурные знания.
Имеется несколько примеров управляющих знаний, которые могут
быть специфичными для данного применения. Разделение на О- и П-правила
203
облегчает управляющей стратегии решение задачи о направлении
использования правил. Лучшее направление, в котором следует применять правило,
иногда зависит от предметной области. Как пример важности выбора такого
направления рассмотрим правила, выражающие таксонометрическую
информацию, такую как "все кошки — животные" и "все собаки — животные":
КОШКА (х) => ЖИВОТНОЕ (х); СОБАКА (х) =* ЖИВОТНОЕ (х).
Если имеется несколько таких правил по одному для каждого типа
животного, то было бы чрезвычайно неэффективно использовать любое из них
в обратном направлении. Иными словами, не следует пытаться доказывать,
что Мурка — животное^ поставив сначала подцелью доказать, что это —
кошка, а потерпев неудачу, попробовать другие такие подцели. В таком
направлении поиска таксонометрическая иерархия слишком сильно ветвится.
Когда это возможно, направление рассуждения должно совпадать с
направлением уменьшения числа альтернатив. Описанные правила удобно
использовать в прямом направлении. Когда мы узнаем, скажем, что Мурка —
кошка, то мы можем эффективно утверждать, что она к тому же животное.
Следование по иерархии в этом направлении не ведет к комбинаторному
взрыву, поскольку поиск уточняется все более уменьшающимся числом
категорий.
Контрапозитивной формой для КОШКА (х) => ЖИВОТНОЕ (х)
является ^ЖИВОТНОЕ (х) => ^КОШКА (х). Это правило следует использовать
только в обратном направлении: чтобы доказать, что Мурка — не кошка,
достаточно эффективным является доказательство, что это не животное.
И снова поиск уточняется менее разветвленной частью таксонометрической
иерархии.
Имеются другие важные управляющие знания, зависящие от предметной
области. В правиле вида [Р1 Λ Р2 Λ . .. ί\ΡΝ\ => Q, используемом как О-пра-
вило, эксперт может захотеть указать порядок, в котором следует
атаковать подцели. Далее он, возможно, захочет для каждой из этих подцелей
явно указать множество О-правил, которые следует к ним применять, и
порядок их применения. Аналогично, когда правило вида Р=> [Q1 Λ ... Λ QN\
используется как П-правило, он, возможно, захочет указать дополнительное
множество П-правил, которые могут теперь применяться, и порядок их
применения.
Может оказаться уместным, чтобы в стратегии управления проводились
дополнительные проверки, прежде чем будет решено, применять ли
некоторое О- или П-правило. В одном из предыдущих примеров важную роль
играло свойство транзитивности предиката "больше, чем". Обычно
неэффективно применять свойство транзитивности в обратном направлении:
но могут быть случаи, когда это оказывается эффективным. Напомним,
что указанная транзитивность имела вид
[(χ>γ)Λ(γ>ζ)] =>(*>*).
Мы, возможно, захотели бы использовать это правило как О-правило,
например, если бы один из конъюнктов подцели сопоставлялся с некоторым
существующим правилом. Это условное применение будет резко
ограничивать применимость правила. Условия на применение составляют важную
часть управляющих знаний.
204
При использовании управляющих знаний такого вида необходима
формализация для их представления. По-видимому, имеется несколько подходов
к этой проблеме. Первый подход рассматривает управляющую стратегию
как проблему, которую необходимо решить с помощью другой системы
продукции искусственного интеллекта. Система ИИ объектного уровня
имела бы декларативные и процедурные знания относительно области
применения, а система метауровня — декларативные и процедурные знания,
относящиеся к управлению системой объектного уровня. В такой системе
допускалось бы удобное формулирование управляющих знаний
объектного уровня в виде правил метауровня.
Второй подход связан с внесением некоторой части управляющих знаний
в оценочные функции, используемые стратегий управления. Когда эксперт
по данному предмету указывает, скажем, что некоторая конъюнктивная
подцель А должна быть разрешена перед В, то мы должны организовать
дело так, чтобы функция, используемая для упорядочения вершин типа И
частичного графа решения типа И/ИЛИ, помещала бы А перед В. Этот
подход нашел широкое применение.
Третий подход связан с включением знания, относящегося к управлению,
непосредственно в правила. Он был реализован в нескольких языках
программирования высокого уровня в области ИИ. Мы попытаемся описать
сущность такого подхода в следующем разделе.
6.6.1. ПРОГРАММЫ, СООТВЕТСТВУЮЩИЕ П- И О-ПРАВИЛАМ
Управляющие знания определяют порядок, в котором должны
выполняться операции: сделай это перед тем, сделай это первым, сделай это, если то-то
верно, и т.д. Естественно попытаться представить знания этого типа в виде
программ. П- и О-правила могут рассматриваться как программы,
оперирующие фактами и целями. Самое непосредственное решение проблемы
управления состоит во включении управляющей компоненты непосредственно в
эти правила.
В какой же именно мере управление должно быть доверено П- и О-пра-
вилам? До сих пор мы рассматривали один крайний случай (в системах
продукций), в котором управление целиком было отдано некоторой
глобальной управляющей системе, а правила не содержади никакой
управляющей компоненты. Теперь мы рассмотрим другой крайний случай, в
котором все управление передано правилам (в результате чего отпадает
необходимость в глобальной управляющей системе) .
Мы хотим сохранить основной характер П- и О-правил. Иными словами,
П-правила должны вызываться только тогда, когда они могут
применяться к фактам, а О-правила — только тогда, когда они могут применяться
к целям. Вызывающий механизм должен действовать только тогда, когда
выводятся новые правила или факты. Механизм такого типа можно было
бы назвать вызовом, направляемым целью или фактом.
Чрезвычайно простая схема такого вызова состоит в следующем. Когда
создается новая цель (факт), собираются все правила, применимые к этой
цели (факту). Выбирается одно из правил, и ему передается целиком все
управление. Затем такая программа выполняется. В результате она может
поставить новые цели (вызывая другие О-правила) или установить новые
205
факты (вызывая другие П-правила). В любом случае управляющая
структура во всех остальных отношениях подобна обычным программам.
Программа правила работает до тех пор, пока не встретится команда RETURN.
После этого управление возвращается к той программе, от которой исходил
вызов. Пока программа правила работает, она располагает абсолютным
контролем. Если по каким-либо причинам, о которых речь пойдет ниже,
выполняемая программа терпит неудачу, то управление автоматически
передается назад в ближайшую точку выбора на более высоком уровне. Таким
образом, схема, которую мы описываем, соответствует простому режиму
управления с возвращением, в котором вся управляющая информация
сосредоточена в правилах.
Позднее мы остановимся на механизме, посредством которого для
вызова выбирается одно из многих возможных применимых правил. Мы должны
также дать описание, как в программах представлены консеквенты и
антецеденты и как осуществляется сопоставление.
Приведем некоторый упрощенный синтаксис, предназначенный для наших
программ П- и О-правил. (Он связан, хотя и не совпадает целиком, с
синтаксисом языков высокого уровня ИИ — таких, как ПЛЕННЕР, КЬЮЛИСП и
КОННАЙВЕР).
Цель или подцель вводится командой GOAL, например GOAL
{ЖИВОТНОЕ Ίχ). Эта команда эквивалентна целевому выражению ( Зх) ЖИВОТНОЕ
(х) на языке исчисления предикатов. Переменная х, снабженная
префиксом ?, является переменной, относящейся к квантору существования, когда
она входит в команды GOAL.Новый или выведенный факт добавляется в
множество фактов с помощью команды ASSERT1, например
ASSERT (КОШКА МУРКА) или ASSERT (СОБАКА Ίχ).
Последнее эквивалентно выражению (Vx) СОБАКА (х) из исчисления
предикатов. Переменная х, снабженная префиксом?, является переменной,
относящейся к квантору общности, когда она встречается в фактах или
командах ASSERT.
Каждая программа для П- и О-правил содержит включающие ее в
действие выражения, называемые образцами. Для программ П-правил образцом
является антецедент соответствующего правила, для "программ О-правил —
консеквент. Для простоты предполагаем, что образец состоит только из
одного литерала. Образцы могут содержать ?-переменные, которые могут
сопоставляться с чем угодно, когда происходит вызов программы.
Поскольку образцы для П-правил используются только при сопоставлении с
фактами, а образцы для О-правил — только при сопоставлении с целями, то
использование ?-переменных в обоих образцах согласуется с нашими
предположениями о виде квантификации в фактах и целях.
Кроме управляющей информации тело программы для правила содержит
ту часть соответствующего правила, которая не вошла в образец. Так,
программы для П-правил содержат команды ASSERT, соответствующие кон-
секвентам, а программы для О-правил — команду GOAL, соответствующую
антецедентам. Все переменные в этих командах, которые совпадают с
переменными в образце, снабжаются префиксом $ и называются $-перемен-
1 Сокращение от слова assertion - утверждение. - Прим. ред.
206
ными. Когда образец сопоставляется с фактом или целью, то ?-переменные
связываются теми термами, которым они соответствуют. Соответствующие
$ -переменные в теле программы связываются аналогично. Эти связки также
применяются локально к последующим командам вызывающей
программы, которые содержат те команды GOAL или ASSERT, которые вызвали
данное сопоставление. Таким образом, сопоставление с образцом играет роль
унификации, а связывание переменной занимает место подстановки.
Пользуясь таким синтаксисом, мы могли бы представить правило
КОШКА (х) => ЖИВОТНОЕ (х) с помощью простой программы П-правила:
ПШ (КОШКА Ίχ)
ASSERT (ЖИВОТНОЕ fix)
RETURN.
Образец (КОШКА Ίχ) идет сразу же после имени программы ПШ. В
этом случае тело программы состоит только из команды ASSERT.
Переменная fix связывается с тем же элементом, с которым сопоставляется Ίχ,
когда образец (КОШКА Ίχ) сопоставляется с некоторым фактом.
Рассмотрим правило СЛОН (х) => СЕРЫЙ (χ) , его можно записать как
О-правило:
ОП1 (СЕРЫЙ Ίχ)
GOAL (СЛОН $ χ)
ASSERT (СЕРЫЙ β χ)
RETURN.
Переменная fix связывается с тем отдельным существом, который
сопоставлялся с Ίχ в ходе сопоставления с образцом.
Механизмы применения правил к фактам и целям легко могут быть
записаны в форме программ, но мы также должны располагать возможностью
сопоставлять цели непосредственно с фактами. Решение этой задачи
достигается достаточно просто — проверкой этих фактов (помимо образцов в О-пра-
вилах) всякий раз, когда встречается команда, содержащая GOAL. Обычно
мы будем проверять эти факты в первую очередь.
Чтобы увидеть, как работают эти программы, и освоиться с их
синтаксисом, рассмотрим простой пример.
Предположим, у нас имеются программы:
ОП1 (БОСС^.х Ίζ)
GOAL (РАБОТАЕТ-В Ίχ fiy)
GOAL (ГЛАВА fix fiz)
ASSERT (БОСС fiy $z)
RETURN.
(Если у работает BX,az - главах, то ζ является боссом для .у. Обратите
внимание, что эта программа для О-правила позволяет естественным
образом определить порядок, в котором должны разрешаться конъюнктивные
цели. Переменная fix во второй поддели связывается с тем, что было
сопоставлено с Ίχ в первой поддели.)
ОП2 (СЧАСТЛИВ Ίχ)
GOAL (СУПРУГИ fix Чу)
GOAL (РАБОТАЕТ-В Ίζ fiy)
207
ASSERT {СЧАСТЛИВ fx)
RETURN.
(Счастливым является лицо, супруг (супруга) которого работает.)
ОПЗ (СЧАСТЛИВЫХ)
GOAL (РАБОТАЕТЕ 0-3 $х)
ASSERT (СЧАСТЛИВ $х)
RETURN.
(Если χ работает в отделе закупок, то χ счастлив.)
ОП4 (РАБОТАЕТ-В Ίχ Чу)
GOAL (ГЛАВА $х$у)
ASSERT (РАБОТАЕТ-В $х $у)
RETURN.
(Если у — глава х, то у работает в х.)
Предположим, факты таковы:
Ф1: ГЛАВА (0-3, ДЖОН-ДЖОНС) ;
Ф2: РАБОТАЕТ-В (0-3, ДЖО-СМИТ) ;
ФЗ: РАБОТАЕТ-В (О-П, САЛЛИ-ДЖОНС) ;
Ф4: СУПРУГИ (ДЖОН-ДЖОНС\ МЕРИ-ДЖОНС) .
Рассмотрим проблему нахождения имени работников, чей босс счастлив.
Этот запрос может быть выражен следующей программой:
BEGIN
GOAL(БОСС!и 4v)
GOAL (СЧАСТЛИВ $v)
PRINT $u "имеет счастливого босса" $v
END.
Рассмотрим типичный ход выполнения программ. Прежде всего мы
сталкиваемся с GOAL (БОСС Чи 4v). Поскольку ни один факт не
сопоставляется с этой целью, то мы смотрим на О-правила и находим 0П1.
Сопоставление с образцом просто сводится к сопоставлению переменных,
относящимся к кванторам существования. Вычислительная ситуация к настоящему
моменту показана на рис. 6.32. Звездочкой отмечена команда, которая
будет выполняться следующей, а имеющиеся связывания переменных, которые
BEGIN (связывания: ?и/?у, ? v/?z)
* GOAL {РАБОТАЕТ-В ?х $у)
GOAL (ГЛАВА $х $z )
ASSERT (БОСС $у $z)
RETURN
GOAL (СЧАСТЛИВ $v )
PRINT %u "имеет счастливого босса" $v
END
Рис. 6.32. Состояние системы при обработке запроса
208
применяются для некоторой последовательности команд, показаны сверху.
Следующей командой (после связывания переменных) будет
GOAL {РАБОТАЕТ-В ΊχΊи).
Здесь мы имеем сопоставление с Ф2, причем Ίχ связывается с 0-3, а ? и —
с ДЖО-СМИТ. Следуя последовательности, изображенной на рис. 6.32, далее
встречаем
GOAL (ГЛАВА 0-3 Ίν).
Эта команда сопоставляется с Ф1, связывая Ίν с ДЖОН-ДЖОНС. Теперь
можем утверждать БОСС (ДЖО-СМИТ, ДЖОН-ДЖОНС) и вернуться к
программе-запросу, чтобы заняться GOAL (СЧАСТЛИВ, ДЖОН-ДЖОНС). Здесь
можно было бы воспользоваться двумя различными последовательностями
программ. Команда GOAL (СЧАСТЛИВ ДЖОН-ДЖОНС) может вызвать
либо ОП2, либо ОПЗ. Мы предоставляем читателю прослеживание любого
из этих путей.
Команда, содержащая GOAL, может потерпеть неудачу, т. е. FAIL, если не
существует больше фактов или О-правил, которые сопоставляются с ее
образцом. Предположим, например, что мы сопоставили GOAL (РАБОТАЕТ-В
Ίχ ?w) с ФЗ вместо Ф2. Такое сопоставление может привести к попытке
выполнить GOAL (ГЛАВА О-П Ίν). Наше множество фактов не содержит
никакой информации о главе отдела продажи. Не применимо и ни одно из
О-правил, так что команда GOALTeprmT неудачу. В этом случае управление
возвращается в предыдущую точку выбора, а именно к сопоставлению с
образцом для GOAL (РАБОТАЕТ-В Ίχ и ?w). В добавление к передаче
управления все связывания, сделанные после этой точки выбора, отменяются.
Теперь мы можем воспользоваться успешным сопоставлением с Ф2.
Поскольку теперь правила являются программами, мы можем снабдить
их другими полезными управляющими командами. Например, можем
включить проверки для решения вопроса о том, следует ли применять некоторую
программу для П- или О-правила. Если эта проверка указывает на
непригодность программы, то мы можем выполнить специальную команду FAIL,
которая вызывает возвращение назад. Общий вид такой команды
IF (условие) FAIL.
Указанное (условие) может быть произвольной программой, имеющей
значение "истина" или "ложь". Такие команды обычно размещаются в
начале программы, чтобы сразу выделить случаи, в которых программа
должна прервать свою работу.
Важным является проверка на то, имеется ли факт, который
сопоставляется с конкретным образцом. Эта проверка осуществляется с помощью
команды IS, общий вид которой
IS < образец).
Если (образец) соответствует факту, то переменные означиваются (эти
значения локально применяются ко всем следующим командам) и
выполнение программы продолжается. В противном случае команда терпит
неудачу и происходит возвращение назад.
Ранее мы упоминали, что правило транзитивности для предиката "больше,
209
чем", т.е. G, можно было бы использовать в качестве О-правила, если один
из антецедентов оказался фактом. Мы могли бы реализовать такое
Оправило в следующей программе:
BTRANS ((7 ?x?z)
IS (G$xly)
GOAL(G$y$z)
RETURN
Теперь если G (А, В) и G (В, С) являются фактами, то можно
воспользоваться BTRANS для доказательства G(A, С). Во-первых, мы
сопоставляем BTRANS с GQAL(GA С) и отсюда пытаемся выполнить IS {G Α Ίγ). Эта
проверка оказывается успешной и ? у связывается с В; затем мы
сталкиваемся с GOAL (G В С). Эта цель сопоставляется непосредственно с одним из
указанных фактов, и доказательство завершается. Если бы проверка IS
потерпела неудачу, то мы не воспользовались бы О-правилом транзитивности и
избежали бы порождения такой подцели. Позже мы увидим другие примеры
полезности использования условий применимости.
Один из важных типов управляющей информации можно было бы
назвать "советом". В момент, когда высказывается команда GOAL, мы,
возможно, захотим дать совет относительно О-правил, которые могли бы быть
использованы при попытке решить эту цель. Такой совет может иметь форму
списка О-правил, которые следует попробовать в указанном порядке.
Подобным же образом команды ASSERT могут сопровождаться списком П-пра-
вил, которые следует попробовать в указанном порядке. Эти списки могут
изменяться посредством других программ, что делает систему весьма гибкой.
Имеются и другие преимущества программ правил кроме тех, которые
связаны со стратегиями управления. Мы можем написать весьма общие
процедуры для преобразования некоторых целей в поддели и для утверждения
новых фактов. Достижение тех же эффектов с помощью обычных
порождающих правил было бы подчас весьма непростым делом.
Предположим, например, что, занимаясь рассуждениями с неравенствами, мы
сталкиваемся с подцелью G (8,5). Далее, как уже отмечалось, мы, безусловно, не хотели бы
включать предикаты G для всех пар чисел. Эффект привязки процедуры к вычислению
типа "больше, чем" может быть достигнут с помощью следующего О-правила:
BG(G?jc?7)
IF (NOTNUM $x) FAIL
IF (NOTNUM $/) FAIL
IF(NOTG$x$^)FAIL
ASSERT (G$x $y)
RETURN
В этой программе предикат NOTNUM (не является числом) проверяет, является ли
ее аргумент нечисловым. Если NOTNUM выдает Τ (т. е. его аргумент не является
числом) , то мы с этой программой терпим неудачу. Если же обе команды NOTNUM
выдают F, то мы продолжаем выполнять это О-правило и используем программу NOTG,
чтобы проверить, больше ли первый числовой аргумент второго. Если это так, то мы
безопасно минуем очередную команду FAIL и выходим из программы.
Можно было бы привести аналогичные примеры использования присоединенной
процедуры в прямом направлении. Предположим, что в задаче анализа электрических це-
210
пей было установлено, что ток силой 0,5 А течет по резистору R3 1000 Ом. После того
как значение тока определено (но не раньше), мы, возможно, захотим использовать
ASSERT для утверждения о значении напряжения, падающего на этом резисторе. Такое
утверждение могло бы быть сделано соответствующим образом с помощью общего П-
правила:
FV (CURRENT!R1I)
IF (NOTNUM (VALUE $ R)) FAIL
IF(NOTNUM$/)FAIL
SET ? V (TIMES $ / (VALUE $ R))
ASSERT ( VOLTAGE$R$V)
RETURN
Теперь, когда выполняется команда (ASSERT CURRENT R3 0,5), то вызывается FV. Мы
оцениваем VALUE (R3), равное 1000, так что проходим первую команду NOTNUM.
Аналогично поскольку $1 связывается значением 0,5, то мы проходим вторую команду
NOTNUM и сталкиваемся с командой SET ("установить"). Она связывает ? V с 500, мы
делаем утверждение VOLTAGE (R5 500) и выходим из программы. В этом случае мы
использовали присоединенную процедуру умножения, которая реализует для
предиката VOLTAGE закон Ома.
- 6.7. БИБЛИОГРАФИЧЕСКИЕ И ИСТОРИЧЕСКИЕ ЗАМЕЧАНИЯ
Одной из причин неэффективности первых систем доказательства теорем
на основе резолюции было отсутствие в них проблемно-специфических
управляющих знаний. Такие языки искусственного интеллекта, как ПЛЕННЕР
[154,356], QA4 [312] и КОННАЙВЕР (216), являются попытками развить
формализм дедукции и решения проблем, в котором явным образом могла
бы быть представлена управляющая информация. Мур обсуждает некоторые
логические недостатки этих языков и предлагает меры избавления от них
[251]. Среди других моментов Мур отмечает: а) форма предложений
является неэффективным представлением для многих правильно построенных
выражений; б) общие импликационные ппф должны использоваться как
правила, и эти правила должны храниться отдельно от фактов; в)
направление, в котором используется правило (прямое или обратное), часто
является важным фактором в отношении эффективности.
Другие исследователи также отошли от метода резолюции после его
популярности на первом этапе. Бледсоу приводит глубокое обсуждение
"нерезолюционного" доказательства теорем [27]. Примерами систем, не
основанных на резолюции, являются системы, разработанные Бледсоу и Тай-
соном [30], Рейтером [299], Байбелом и Шрайбером [22], Невинсом [260],
Уилкинсом [387]. Многие приемы повышения эффективности,
использованные в не резол юционных системах, могут найти применение в системах,
основанных на использовании правил, описанных в настоящей главе, в которых
связь с резолюцией очевидна.
Унифицирующие композиции подстановок и их свойства обсуждаются
Вааленом [366] и Сикелем [332], каждый из которых указывает на
важность применения этих подстановок при доказательстве теорем с помощью
графов типа И/ИЛИ. Ковальский рассматривает связанный с этим процесс
поиска одновременных у нификаторов [11Ъ, 179].
Основанные на правилах прямая и обратная системы дедукции,
описанные в настоящей главе, призваны быть моделями различных систем, осно-
211
ванных на правилах, используемых в ИИ. Применение графовых структур
типа И/ИЛИ (часто называемых деревьями целей типа И/ИЛИ) в
доказательстве теорем насчитывает долгую историю, однако многие системы,
использующие такие структуры, имеют серьезные логические недочеты. Наш
вариант таких систем имеет более строгую логическую базу, чем
большинство существующих. Операция ОЦР, использованная в нашей обратной
системе, основывается на подобной операции, предложенной Муром [251].
Лавленд и Сикель [198, 199] также предлагают системы, основанные на
графах типа И/ИЛИ, и обсуждают их взаимоотношение с резолюцией.
Специалисты в определенных предметных областях, по-видимому,
способны сделать полезные выводы из правил и фактов, в которых они как
минимум не вполне уверены. Обобщения систем дедукции,
основывающихся на правилах, которые позволяют использовать правила и факты лишь
частично надежные, были сделаны Шортлиффом в системе MYCIN,
предназначенной для медицинской диагностики и выбора вида лечения [330]. Мы
могли бы описать эту систему как обратную, основанную на правилах,
дедуктивную систему, дополненную возможностью работать с неполностью
надежными правилами и фактами. Методы работы с ненадежными фактами
и правилами, основывающиеся на использовании байесовского правила и
субъективных вероятностей, описываются Дуда, Хартом и Нильсоном [80].
Идею проверки согласованности подстановок в процессе поиска впервые
высказал Сикель [332]. Использование графов связи первоначально
предложил Ковальский [177]. Различные формы графов соединений применили
Кокс [60], Клар [168], Чанг и Слейгл [50], Чанг [47]. Кокс предлагает
интересный прием для модифицирования несогласованных решений и
превращения их в согласованные [60]. Большинство этих идей первоначально
рассматривалось в качестве управляющих стратегий для систем
опровержения на основе резолюции, а не для систем дедукции на основе правил.
Использовать метасистемы с их собственными правилами для управления
системой дедукции предложило несколько исследователей, включая Дэйви-
са, де Клирас с соавторами [71] и Вейхрауха [384]. Хейес высказывает
подобную мысль [142].
Использование систем дедукции для интеллектуального извлечения
информации обсуждается в различных статьях сборника под редакцией Галла-
ира и Минкера [ИЗ]. В книге [403] Уонг и Милопулос обсуждают
соотношения между моделями данных при управлении базами данных и
представлением знаний в исчислении предикатов в области искусственного
интеллекта.
Бледсоу, Бруэл и Шостак описывают систему доказательства теорем для
неравенств [29]. Система, созданная Уолдингером и Левитом, способна
доказать определенные неравенства, возникающие в проблемах
верификации программ [371].
Наше употребление условных подстановок связано с идеей, выдвинутой
Тайсоном и Бледсоу [361]. Манна и Уолдингер применяют идею условных
подстановок в своей системе синтеза программ [220].
Грин описывает, как системы доказательства теорем могли бы быть
использованы и для вычислений, и для синтеза программ [127]. Синтез
программ посредством дедукции изучался также Уолдингером и Ли [370],
212
Манна и Уолдингером [220]. (Подходы к синтезу программ, основанные
на отличных от дедукции приемах, содержатся в обзоре Хаммера и Рута
[135]. Обсуждение "знаний" по программированию, необходимых
автоматическим системам программирования, содержится у Грина и Барстоу
[130].) Наше использование индукции для привнесения рекурсии основано
на методике, описанной у Манна и Уолдингера [220].
В защиту использования дедукции для выполнения вычислений (и
исчисления предикатов как языка программирования) выступал Ковальский
[175]. Взяв за основу эти идеи, группа в университете г. Марселя (Франция)
разработала язык ПРОЛОГ (см. [310, 378]), Уоррен и Перейра [379]
описывают ПРОЛОГ и сравнивают его с языком ЛИСП. Ван Эмден [365] дает
ясное изложение этих идей. Одна из привлекательных черт языка ПРОЛОГ
состоит в том, что он отделяет управляющую информацию от логической
информации в программировании. Эта идея, впервые выдвинутая Хейсом
[142], также получила развитие у Ковальского [178] и Прэтта [289].
(Противоположную точку зрения можно найти в статье Хьювитта [155, р. 195].)
Комбинированные прямая и обратная системы дедукции и отношение
ГАШЕНИЕ для установления факта остановки основаны на статье Нильсона
[276].
Наш раздел по программам для П- и О-правил основывается на идеях
языков программирования искусственного интеллекта ПЛЕННЕР [154,
356] и КЬЮЛИСП [319] (см. также статью Боброу и Рафаэла [31]) .
Упражнения
6.1. Представьте следующие утверждения как порождающие правила для основанной
на правилах системы доказательства геометрических теорем:
а. Соответствующие углы двух конгруэнтных треугольников конгруэнтны.
б. Соответствующие стороны двух конгруэнтных треугольников конгруэнтны.
в. Если соответствующие стороны двух треугольников конгруэнтны, то
треугольники конгруэнтны.
г. Углы при основании равнобедренного треугольника конгруэнтны.
6.2. Рассмотрим следующую информацию. Тони, Майк и Джон являются членами
Алышнклуба. Каждый член Алышнклуба, не являющийся горнолыжником, является
альпинистом. Альпинисты не любят дождя, и всякий, кто не любит снега, не является
горнолыжником. Майк не любит то, что любит Тони, и любит все то, что Тони не любит.
Тони любит дождь и снег.
Представьте это знание как множество утверждений исчисления предикатов,
подходящее для обратной системы дедукции, основанной на правилах. Покажите, как
такая система могла бы ответить на вопрос: "Имеется ли такой член Альпинклуба, кто
является альпинистом, но не является горнолыжником?".
6.3. Ситуация из мира кубиков описывается следующим множеством правильно
построенных формул:
НА-СТОЛЕ (А) СВОБОДЕН (Е)
НА-СТОЛЕ (О СВОБОДЕН (D)
НА (В, А) ТЯЖЕЛЫЙ (D)
НА (D, О ДЕРЕВЯННЫЙ (В)
ТЯЖЕЛЫЙ (В) НА (Е, В)
Сделайте набросок ситуации, которую должны описывать эти правильно построенные
формулы. Общие знания из этого мира кубиков содержат следующие утверждения:
Каждый большой голубой кубик находится на зеленом кубике.
Каждый тяжелый деревянный кубик является большим.
213
Все кубики со свободной верхней поверхностью являются голубыми.
Все деревянные кубики являются голубыми.
Представьте эти утверждения в виде множества импликаций, имеющих однолитераль-
ные консеквенты. Начертите согласованное дерево решения типа И/ИЛИ (с
использованием О-правил), которое решает такую проблему: "Какой кубик находится на зеленом
кубике?".
6.4. Рассмотрите следующий ограниченный вариант обратной системы, основанной
на правилах: только лишь концевые вершины графа типа И/ИЛИ могут
сопоставляться с консеквентами правил или литералами фактов, а наиболее общий унификатор
этого соответствия затем применяется ко всем концевым вершинам этого графа.
Объясните, почему результирующая система некоммутативна. Покажите, как такая система
могла бы решать задачу обращения списка (1, 2), используя факты и правила из разд.
6.4. Каким режимом управления вы воспользовались?
6.5. Обсудите, как обратная система, основанная на правилах, будет обрабатывать
каждую из следующих возможных ситуаций:
а. Генерируется литерал подцели, являющийся частным случаем цели более
высокого уровня (одной из ее родительских целей в графе типа И/ИЛИ) .
б. Генерируется литерал подцели такой, что цель более высокого уровня является
частным случаем этой подцели.
в. Генерируется литерал подцели, который унифицируется с отрицанием подцели
высшего уровня.
г. Генерируется литерал подцели, который идентичен другому литералу подцели в
том же самом потенциальном графе решения.
6.6. Покажите, как ОЦР может быть использована в обратной системе дедукции
для получения доказательства для такой целевой ппф:
[(Зх)(\/у)Р(х,у) - (Vj>) (Зх)Р (х,у)].
6.7. Предложите некоторый эвристический метод поиска, направляющий выбор
правила в системе дедукции, основанной на использовании правил.
6.8. Хотя мы применяли графы типа И/ИЛИ в этой главе для представления формул,
мы не выступали за использование разложимых систем продукций для доказательства
теорем. Что плохого, например, в идее декомпозиции конъюнктивной целевой формулы
и независимой обработке каждого конъюнкта? При каких обстоятельствах
декомпозиция может оказаться разумной стратегией?
6.9. Опишите, как использовать формулу, подобную РАВНЫ (/(*) , g (h (x) )) , в
качестве "правила замены" в системе дедукции, основанной на использовании правил.
Какие эвристические правила могут оказаться полезными при использовании правил
замены?
6.10. Критически проанализируйте следующее предложение:
Импликация вида {LI A L2) =>W, где L1 и L2 — литералы,
может быть использована в качестве П-правила, если сначала
она преобразуется в эквивалентную форму LI => (L2 =>W).
Это правило может быть применено, когда L1 соответствует
некоторому литералу факта и действие правила состоит в
добавлении нового П-правила L2 => W.
6.11. Системы дедукции, основанные на применении правил, не могут (легко)
использовать резолюции между фактами или между целями. Почему?
6.12. Рассмотрите следующую электрическую схему:
R1 = 2 Ом
о va
1«
:/?i
R4 = 0,5 Ом
214
Мы представляем факты, что резисторы RI и R4 включены последовательно в
виде утверждения (ПОСЛЕДОВА ТЕЛЬНЫ Rl R4), что ток через R1 равен 2 А,
утверждая (ТОК R1 2) и что R1 = 2 Ом, утверждая (СОПРОТИВЛЕНИЕ R1 2), и т. д.
Напишите программу для прямого правила, которая выражает тот факт, что если ток
/ протекает по резистору R, то тот же ток протекает по любому резистору,
включенному последовательно с R.
Напишите программу для Оправила, которая выражает тот факт, что напряжение,
падающее на некотором резисторе, равно протекающему току, умноженному на
значение сопротивления. Предполагая, что П-правило срабатывает первым (вызванное
утверждением относительно тока, протекающего через R1), проследите эффект от
следующей команды GOAL :
GOAL (VOLTAGE R4 1V).
6.13. Предложите факты и правила, касающиеся предиката MEMBER (χ, у), который
по предложению означает, что атом χ является членом списка атомов у. Используйте
эти факты и правила в системе дедукции, основанной на правилах, для доказательства
целевой ппфMEMBER (3,cons (4,cons (2, cons (3, NIL)))). Какая управляющая
информация ведет к эффективному поиску доказательства? Какой факт потребовался
бы для доказательства ~MEMBER (3, cons (4, NIL) ) ?
ГЛАВА 7
ОСНОВНЫЕ СИСТЕМЫ ПОСТРОЕНИЯ ПЛАНОВ
В гл. 5 и 6 мы видели, что широкий класс задач вывода можно решать
применением коммутативных систем продукций. Однако во многих других
случаях, представляющих интерес для искусственного интеллекта,
наиболее естественная формализация связана с некоммутативными системами.
Типичными задачами такого вида являются такие, в которых цели
достигаются в результате некоторой последовательности (или программы)
действий. Решение задач роботом и автоматическое программирование
представляют собой две области, в которых возникают такие задачи.
7.1. РЕШЕНИЕ ЗАДАЧ РОБОТОМ
Многие наши соображения о системах принятия решения явились
результатом исследований в области решения задач роботом. Поскольку такие
задачи являются Простыми и интуитивно понятиями, то мы воспользуемся
примерами из этой области для иллюстрации основных идей. В рамках
типичной формулировки "задачи для робота" у нас имеется робот,
владеющий определенным набором действий, которые он способен выполнять в
некотором легком для понимания мире. Например, говоря о "мире
кубиков", мы представляем себе несколько помеченных кубиков (наподобие
детских деревяннных), размещающихся на столе или друг на друге, и
некоторый робот, являющийся подвижной рукой, способной брать и перемещать
кубики. Изучались также и многие другие типы задач для роботов. В
некоторых задачах робот представляет собой подвижный аппарат,
выполняющий такие задачи, как перемещение объектов с места на месю в
пространстве, содержащем другие объекты.
Написание программы для робота связано с объединением многих
функций, включая восприятие окружающего мира, формулирование планов дей-
215
ствий и контроль за их выполнением. Мы сосредоточим основное внимание
на проблеме синтеза последовательности действий робота, ведущей (при ее
реализации) к достижению некоторой заранее поставленной задачи исходя
из данной начальной ситуации.
Та часть проблемы, которая связана с синтезом действий, может быть
решена с применением некоторой системы продукций. При этом глобальная
база данных предстазляет собой описание ситуации или состояния мира, в
котором находится робот, а правилами являются вычисления, отображающие
действия робота.
7.1.1. ОПИСАНИЯ СОСТОЯНИЙ И ЦЕЛИ
Описание состояний и целей, стоящих перед роботом, могут
конструироваться из правильно построенных формул исчисления предикатов, как
указывалось в гл. 4. В качестве примера рассмотрим механическую руку
робота и совокупность кубиков, изображенную на рис. 7.1. Эта ситуация может
быть представлена конъюнкцией формул, показанных на рисунке1. Формула
CLEAR (В) означает, что у кубика В свободна верхняя поверхность, т.е.
на нем нет другого кубика. Предикат ON используется для описания того,
какие кубики располагаются на других кубиках (непосредственно). Робот
в данном случае представляет собой простейшую руку, которая может
перемещаться, как это будет объяснено. Предикат HANDEMPTY имеет значение
Τ тогда, когда рука робота пуста, как это имеет место в изображенной ситуа-
Рука робота
CLEAR{B) ON (С А)
CLEAR(C) HANDEMPTY
Рис. 7.1. Расположение кубиков
О NT ABLE {A)
ONTABLE(B)
1 В гл. 7 и 8 речь идет о методах и проблемах составления программ, описывающих
последовательность действий робота в ситуациях, типичным примером которой
является картина, изображенная на рис. 7.1. В этих программах автор использует около
десяти элементарных "команд", которые, как это принято при описании программ на
некотором языке программирования, оставлены здесь в оригинальной транскрипции.
Хотя содержательный смысл каждой такой команды поясняется в авторском тексте, мы,
для облегчения восприятия и несколько предваряя события, даем их перечень.
Для описания состояния мира кубиков используются такие предикаты: CLEAR —
"не занят", ON - "находится на кубике", ONTABLE - "находится на столе".
Состояние руки робота описывается предикатами: HANDEMPTY - "рука пуста" и
HOLDING - "рука держит кубик".
Наконец, возможны следующие действия: pickup - "взять со стола", putdown -
"поставить на стол", stack - "поставить на другой кубик", unstack - "снять с другого
кубика". - Прим. ред.
216
ции. Разумеется, каждая конечная конъюнкция формул на самом деле
описывает некоторое семейство различных ситуаций мира кубиков, в котором
каждый член может рассматриваться как интерпретация, удовлетворяющая
формулам (см. гл. 4). Для краткости мы используем фразу "данная
ситуация" вместо "данное семейство ситуаций".
Описания целей могут быть также выражены формулами исчисления
предикатов. Например, если бы мы хотели, чтобы робот на рис. 7.1
построил пирамиду из кубиков, в которой кубик В был бы на кубике С, а кубик
А — на кубике В, то можно было бы так описать поставленную цель:
ON (В, С) Л ON (А, В).
Формула такого характера описывает некоторое семейство состояний мира,
каждое из которых может служить в качестве целевого.
Для облегчения понимания накладываем определенные ограничения на
вид формул, который допускаем при описании состояний мира и целей.
(Многие из этих ограничений можно было бы снять, использовав некоторые
приемы работы со сложными ппф, описанные в предыдущей главе.) В
выражениях для целей (и подцелей) допускаем лишь конъюнкции
литералов, а относительно переменных в целевых выражениях всегда предполагаем,
что они относятся к кванторам существования. В описаниях начальных и
промежуточных состояний мы допускаем лишь конъюнкции основных
литералов (т.е. литералов без переменных). Ясно, что формулы на рис. 7.1
удовлетворяют этим ограничениям.
7.1.2. МОДЕЛИРОВАНИЕ ДЕЙСТВИЙ РОБОТА
Действия робота изменяют одно состояние (или конфигурацию) мира на
другое. Мы можем смоделировать эти действия посредством П-правил,
которые изменяют одно описание состояния на другое. Один простой, но очень
полезный способ представления действий робота был использован в системе
для решения задач роботом, названной STRIPS. Этот метод может быть
противопоставлен тому, в котором мы использовали правила импликаций в
качестве правил продукций (см. гл. 6). При том подходе, когда некоторое
правило импликации применялось к глобальной базе данных, эта база
данных претерпевала изменения вследствие добавления некоторой структуры,
но из базы данных ничего не вычеркивалось. Однако при моделировании
действий робота П-правила должны допускать вычеркивание выражений,
которые могут перестать быть справедливыми. Предположим, например,
что рука робота на рис. 7.1 должна поднять кубик В. Тогда несомненно,
что выражение ONTABLE (В) больше не будет верным и должно быть
удалено при применении всякого П-правила, моделирующего действие взятия
кубика. П-правила систем типа STRIPS определяют те выражения, которые
следует отбрасывать посредством явного указания списков вычеркивания
для таких правил.
Принятая в системе STRIPS форма П-правил содержит три компоненты.
Первой является формула предварительного условия. Эта компонента
подобна антецеденту правила импликации и является выражением в
исчислении предикатов, которое должно логически следовать из фактов в описании
состояния для того, чтобы данное П-правило было приложимо к этому со-
217
стоянию. В соответствии с нашими ограничениями на форму целевых ппф
предполагаем, что такие предварительные условия для П-правил составляют
конъюнкцию литералов. Предполагается, что переменные в формулах
предусловий относятся к квантору существования. Вопрос о том, следует ли
некоторая конъюнкция литералов (формула предусловия) логически из
другой конъюнкции литералов (фактов), решается непосредственно; это так,
если среди фактов имеются литералы, которые унифицируются с каждым
литералом из предусловия и если согласуются все наиболее общие
унификаторы (т. е. если существует унифицирующая композиция для этих
унификаторов) . Если такое соответствие может быть установлено, то мы говорим,
что предусловие П-правила соответствует фактам. Мы называем
унифицирующую композицию подстановкой соответствия. Для заданных П-правил
и описания состояния может существовать много подстановок
соответствия. Каждая из них ведет к различным частным случаям П-правила,
которые могут быть использованы.
Второй компонентой П-правила является список литералов (содержащих,
возможно, свободные переменные), называемый списком вычеркиваний.
Когда некоторое П-правило применяется к описанию состояния,
подстановка соответствия применяется к литералам списка вычеркиваний. Полученные
при этом основные частные случаи вычеркиваются из описания прежнего
состояния как первый шаг на пути конструирования нового состояния. Мы
предполагаем, что все свободные переменные в списке вычеркиваний
появляются как переменные (относящиеся к кванторам существования) в
формуле предусловий. Это ограничение гарантирует, что любой частный случай
соответствия для литерала из списка вычеркиваний является основным.
Третьей компонентой является формула добавлений. Она состоит из
конъюнкции литералов (возможно, содержащих свободные переменные) и
подобна консеквенту импликативного П-правила. Когда П-правило
применяется к описанию состояния, то подстановка соответствия применяется к этой
формуле добавлений и результирующий частный случай для этого
соответствия добавляется к прежнему описанию состояния (после того, как
вычеркнуты литералы списка вычеркиваний) в качестве заключительного шага
построения нового описания состояния. Снова предполагаем, что все свободные
переменные формулы добавлений встречаются в формуле предусловий, так
что любой частный случай формулы добавлений, связанный с данным
соответствием, будет конъюнкцией основных литералов. И снова имеется
возможность ослабить некоторые из этих ограничений на компоненты
П-правила. Мы их накладываем исключительно для того, чтобы сделать изложение
предмета более простым.
В качестве примера П-правил смоделируем действие по взятию кубика
со стола. Скажем, что предусловия для выполнения такого действия состоят
в том, что кубик находится на столе, рука робота не занята и сверху на
кубике ничего нет. Результатом такого действия является то, что рука держит
этот кубик. Мы могли бы представить такое действие следующим образом:
pickup (χ)
Предусловие: ONTABLE (x) AHANDEMPTYA
Λ CLEAR (χ).
Список вычеркиваний: ONTABLE (χ), HANDEMPTY, CLEAR (x).
Формула добавлений: HOLDING (x).
218
Поскольку в силу принятых ограничений формулы предусловий и
добавлений являются конъюнкциями литералов, мы можем представить каждую
из них в виде множества или списков литералов. Иногда, как это было в
приведенном примере, формула предусловий и список вычеркиваний
содержат идентичные литералы. В нашем примере мы решили включить в
формулу добавлений только HOLDING (χ), а не включать также отрицания
литералов из списка вычеркиваний. Для наших целей будет достаточно просто
вычеркнуть эти литералы из описания состояний.
Мы видим, что pickup (χ) может быть применено к ситуации рис. 7.1,
только если вместо χ подставлено В. Новое описание состояния в нашем
случае будет
CLEAR (С) ON (С, А)
ONTABLE (A) HOLDING (В).
Системы продукций, использующие П-правила вида применяемых в
системе STRIPS, в общем случае не являются коммутативными, поскольку
эти правила могут вычеркнуть определенные литералы из описания
состояния. Такие П-правила заменяют одно множество состояний другим в
противоположность правилам, основанным на импликациях, применение
которых просто ведет к ограничению первоначального множества состояний.
Таким образом, для правил в форме, применяемой в системах типа STRIPS,
должны использоваться специальные методы. Эти методы рассматриваются
в настоящей главе и в гл. 8.
7.1.3. ПРОБЛЕМА ФРЕЙМА1
Обращаясь к знакомой аналогии, замечаем, что замена одного описания
состояния другим может быть сопоставлена со сменой кадров в
мультипликационном кинофильме. В очень простом мультфильме определенные
герои движутся от кадра к кадру на фиксированном фоне. В более
реалистичных мультфильмах (и более дорогих) фон также подвергается
многочисленным изменениям. П-правило системы STRIPS (с короткими
списками вычеркиваний и добавлений) обращается с большинством правильно
построенных формул в описании состояния, как с неизменным фоном.
Проблема определения того, какие ппф описания состояния следует
изменять, а какие нет, в области искусственного интеллекта обычно
называется проблемой фрейма. Лучший способ решения этой проблемы зависит от
типа состояний мира и действий, которые мы моделируем. Не вдаваясь в
детали, отмечаем, что если компоненты состояния мира тесно связаны между
собой или неустойчивы, то каждое действие может оказать глубокое и
глобальное воздействие на состояние мира. В таком мире попытка взять кубик
с вершины пирамиды из кубиков, например, может привести к падению
всей пирамиды, ведущему к разрушению и других пирамид, как в случае
карточных домиков. Простое П-правило системы STRIPS не было бы
адекватной моделью действия в мире такого характера.
Обычно компоненты состояния мира достаточно независимы, что
позволяет предполагать, что результаты действий носят относительно локальный
характер. Когда такое предположение является оправданным, П-правила
1 Иногда frame problem переводят как "проблема границ". - Прим. ред.
219
системы STRIPS будут эффективными и адекватными моделями для многих
типов действий.
Применение П-правила к описанию состояния может рассматриваться
как моделирование действия, представленного этим правилом.
Моделирование может изменяться в отношении уровня детализации и точности, на
котором оно отражает действия. П-правило pickup (χ), например, является
значительно более приблизительным представлением действия "взять со
стола" по сравнению с такой моделирующей программой, которая
учитывает массу и размер кубика, трение в шарнирах руки, окружающую
температуру и т. п. В следующей главе мы приведем соображения о том, что
полезно иметь модели действий на нескольких уровнях детализации. Общие
и приближенные модели полезны при вычислении, связанном с построением
высокоуровневых планов, для построения же подробных планов
необходимы более точные модели. Как правило, проблема фрейма наиболее
существенна в подробных моделях, потому что в них приходится учитывать такие
связи между компонентами состояния мира, которыми можно пренебрегать
на более высоких уровнях.
Другой аспект проблемы фрейма касается того, как работать в
аномальных условиях. Мы можем рассматривать П-правило pickup (χ) как
подходящую модель для нормального выполнения действия взятия со стола.
Но предположим, что или рука робота сломалась, или кубик оказался
слишком тяжелым, или из-за прекращения подачи электроэнергии остановились
двигатели руки, или кубик, который нужно взять со стола, оказался к нему
приклеенным. Конечно, мы могли бы включить отрицания каждого такого
аномального условия в состав предусловий П-правила, чтобы сделать это
правило соответствующим образом неприменимым. Но таких условий
слишком много (можно придумать их бесконечное число), и нормально
такое условие отклонения не будет выполняться. Все же, если одно их них
оказывается выполненным, то наша простая модель П-правила будет
неточной.
Было предложено несколько различных подходов к проблеме аномальных
условий, но пока что ни один из них не оказался удовлетворительным. Если
используется иерархия моделей действий, то, по-видимому, наиболее
подробное и точное моделирование автоматически должно учитывать все те
условия, которые (по определению) известны системе.
Оставим теперь проблему фрейма и займемся использованием
представлений (которые мы обсуждали), предназначенных для решения задач
роботом. Мы начнем с прямой системы продукций.
7.2. ПРЯМАЯ СИСТЕМА ПРОДУКЦИЙ
Простейшим типом системы, предназначенной для решения задач роботом,
является система продукций, в которой описание состояния используется
в качестве глобальной базы данных, а правила, моделирующие действия
робота, — в качестве П-правила. В такой системе П-правила из числа
применимых используются до тех пор, пока не будет построено описание
состояния, которое сопоставимо с целевым выражением. Давайте рассмотрим на
конкретном примере, как такая система могла бы действовать.
220
Обратимся к П-правилам в форме, отвечающей системе STRIPS, которые
соответствуют множеству действий робота, показанного на рис. 7.11:
1) pickup(x)
P&D: ONTABLE(x), С LEAR (χ \ HAND EMPTY
A: HOLDING {χ)
2) putdown( χ)
P&D: HOLDING(x)
A: ONTABLE(x\CLEAR(x\HANDEMPTY
3) stack(x,/)
P&D: HOLDING(x\CLEAR(y)
A: HANDEMPTY,ON(x,y\CLEAR(x)
4) unstack(x,>)
P&D: HANDEMPTY,CLEAR(x\ON(x,y)
A: HOLDING(x\CLEAR{y)
В каждом из этих правил оказалось, что формула предусловия
(выраженная в виде списка литералов) и список вычеркиваний совпадают. Первое
правило является тем же самым правилом, которое было бы
использовано в примере из предшествующего раздела. Другие являются моделями
для действия помещения кубика на стол, складывания двух кубиков в
столбик и разборки такого столбика.
Предположим, нашей целью
является состояние, показанное на
рис. 7.2. Ведя рассуждение в
прямом направлении от описания
начального состояния,
изображенного на рис. 7.1, мы видим, что
единственными применимыми П-
правилами являются pickup (В) и
unstack (С, А). На рис. 7.3
изображено полное пространство
состояний для этой задачи, а путь
решения показан жирными стрелками.
Описание начального состояния помечено символом SO, а состояние,
сопоставимое с целью, — символом G. (Отступив от стандартов с тем, чтобы
просто подчеркнуть присутствие симметрии в рассматриваемой задаче,мы не
показали вершину SO как верхнюю на рис. 7.3.) Заметим, что в этом
примере каждое П-правило имеет обратное правило.
В этом очень простом примере (всего лишь 22 состояния во всем
пространстве состояний) прямая система продукций, снабженная достаточно
простой системой управления, может быстро найти путь, ведущий к целевому
С
ЦЕЛЬ: [ON(B,C) ΛΟΝ(Α,Β)]
Рис. 7.2. Цель задачи для робота
1 Буквами Ρ (precondition) обозначены предусловие, Z)(delete list) - список
вычеркиваний, Л (add formula) - формула добавлений. - Прим. ред.
221
putdown(# )У^^грккир(В)
/
CLEARiA)
CLEARiC)
HOLDIMOiB)
ONTABLEiA)
ONTABLEiC)
Vstack(iM>V
CLEARiA) ONTABLEiA)
CLEARiB) ONTABLEiB)
CLEARiC) ONTABLEiC)
HANDEMPTY
\ /
pickup(/l rS^s. putdown(/l)
pickup(C)\ Xputdown(C)
\unstack(£./l) У
CLEARiA)
CLEARiB)
HOLDINGiC)
ONTABLEiA)
1 ONTABLEiB) 1
'VstacMC^V
stack(# 0^^/unstack<e.C) ^^4 stack(C.eV/^/unstack(Ce>
pick
stac
С
CLEARiA)
ONiB С )
CLEARiB) '
ONTABLEiA)
ONTABLEiC)
HANDEMPTY
шр(Л)
\
1
putdow
OWBC )
CLLARiB)
HOLDI\G(A)
U\TABLF(C)
kH В)
1
i
\
i unstac
()N( t //)
i)N[H О
DNTAHLCa )
И iNDtntPl)
pic
m(
sta<
\l[A
CLEARiC)
ONiB.A)
CLEARiB)
ONTABLEiA)
ONTABLEiC)
HANDEMPTY
kup(C)
4)
ι
f
putdov
ОЩВ A)
CLLARiB)
HOLDINGiC)
ONTABLEiA)
-k<( B)
B)
г
\
ι
unstac
CLEARiC )
ОЫС B)
(M[B 4)
()NT4BLF{1)
Η Λ Η Μ Μ РТУ
vn(
pic
UC
пас
CLEARiA)
ON(CB)
CLEARiC)
ONTABLEiA)
ONTABLEiB)
HANDEMPTY
C)
kupM)
1
> 1
putdov
ONiCB)
CLEARiC)
HOLDINGiA)
ONTABLbiB)
B)
к(Л С)
i
t
unstacl·
CLEAR(A)
ONi 4 С )
0N« В)
ONTABLEiB)
HANDEMPTY
SO
Vunstack(C./4) У
CLEARiB) ]
CLEARiC)
HOLDINGiA)
ONTABLEiB) 1
ONTABLEiC)
y^stack(Afi)V
4 unstack(/t B)
N>^ steck(4.C)//onstackM.C) \\
CLEAR (B)
ONiCA)
CLEARiC)
ONTABLEiA)
ONTABLEiB)
HANDEMPTY
pickup(fl)
miA)
stac
iiA C)
f
CLEARiB)
ONiA.C)
CLEARiA)
ONTABLEiB)
ONTABLEiC)
HANDEMPTY
putdown(i5)
ONiCA)
CLEARiC)
HOLDINGiB)
ONTABLEiA)
k(flC)
1
1
unstac
5
CLLARiB)
ONi В С )
OV(C A)
OMABLtiA)
HA\DLMPT\
A
pickup(fi)
MB
tac
CLEARiC)
ONiABT)
CLEARiA)
ONTABLEiB)
ONTABLEiC)
HANDEMPTY
pickup(C)
к
putdown(C)
putdown(fl)
ONiA C)
CLEARiA)
HOLDINGiB)
ONTABLEiC)
C)
kiBA)
r
[
ONiA B)
CLEARiA)
HOLDINGiC)
0NTABLEi8)
stacMC/1)
unstack(fl A)
CLEARiB)
ОЩВА)
ОЧ(А С )
0\TABLE(C )
HA\DEMPTY
f
unstack(C A)
CLEARiC )
ONiCA)
ONiA B)
0\TABLE(B)
HA\DEMPTY
Рис. 7.3. Пространство состояний задачи для робота
состоянию. В случае более сложных задач, однако, можно ожидать, что
прямой поиск, ведущий к цели, породит довольно большой граф и такой поиск
будет реальным только при использовании оценочной функции, содержащей
достаточную информацию.
7.3. СПОСОБ ПРЕДСТАВЛЕНИЯ ПЛАНОВ
Мы можем построить требуемую последовательность действий для
достижения цели в нашем примере, рассматривая П-правила, помечающие дуги
вдоль ветви, ведущей к целевому состоянию. Эта последовательность такова:
(unstack (С, А),
putdown (С), pickup (В), stack (В, С),
puckup (A), stack (А, В) } .
Мы называем такую последовательность планом достижения цели. (В нашем
случае все элементы плана относятся к "элементарным" действиям. В гл. 8
рассмотрим планы, элементы которых сами по себе могут быть целями
промежуточного уровня, требующими дальнейшего и более детального решения
задач, прежде чем они будут сведены к элементарным действиям.)
222
Во многих случаях оказывается полезным, чтобы в спецификацию плана
включалась и некоторая дополнительная информация. Мы, возможно,
захотим знать, какие отношения имеются между П-правилами и предусловиями,
которые они обеспечивают для других П-правил. Такая контекстуальная
информация может быть удобным образом представлена треугольной
таблицей, элементы которой соответствуют предусловиям и добавлениям для
П-правил, входящих в план.
Пример треугольной таблицы приведен на рис. 7.4. Над столбцами
таблицы размещаются П-правила плана. Пусть самый левый столбец считается
нулевым, тогда над у -м столбцом размещается j-e правило последовательности.
Пусть верхняя строка считается первой. Если в последовательности,
соответствующей плану, имеется N П-правил, то последняя строка является строкой
с номером N + 1. В клетке (i, j ) таблицы, j > О, ι < Ν+ 1, размещаются те
литералы, которые добавляются к описанию состояния j -м П-правилом и
сохраняются в качестве предусловий для i-ro П-правила. В клетке (г, 0),
ι < 7V+1, находятся те литералы начального описания состояния, которые
остаются в качестве предусловий для ι-го П-правила. Тогда в (iV+ 1)-ю
строку входят те литералы начального описания состояния и те литералы,
добавляемые различными П-правилами, которые являются компонентами цели
(и сохраняются для всей этой последовательности П-правил).
Треугольные таблицы легко строятся по начальному описанию состояния,
последовательности П-правил и описанию цели. Эти таблицы являются
сжатым и удобным представлением плана действий робота. Элементы строки
слева от i-ro П-правила — в точности предусловия для этого П-правила.
Элементы столбца под ι -м П-правилом — в точности литералы формулы
добавлений для этого правила, которые потребуются для последующих П-правил
или компоненты цели.
Определим i-e ядро как пересечение всех строк, расположенных ниже
i-й строки включительно, со всеми столбцами, расположенными слева от i-ro
столбца. Так, четвертое ядро отмечено на рис. 7.4 двойной линией1.
Элементами i-ro ядра являются в точности те условия, которые должны
сопоставляться с описанием состояния для того, чтобы последовательность,
составленная из i-ro и последующих за ним П-правил, была применима и достигала
бы цели. Так, первое ядро, т. е. нулевой столбец, содержит условия
начального состояния, необходимые для последующих П-правил и цели; (7V+ 1)-е
ядро, т.е. (7У+1)-я строка содержит сами целевые условия. Эти свойства
треугольных таблиц являются удобными для управления процессом
выполнения планов робота.
Поскольку планы робота в конечном счете предстоит выполнить в
реальном мире посредством некоторого механического прибора, то система их
выполнения должна учитывать возможность того, что действия плана могут
не достигать поставленной перед ними цели и механические допуски могут
привести к ошибкам в ходе выполнения плана. Незапланированные эффекты
могут либо неожиданно близко подвести нас к цели, либо отбросить в
сторону от нее. С этими трудностями можно было бы справиться, составляя
новый план (основанный на уточненном описании состояния) после каждо-
1 Имеется в виду часть таблицы, ограниченная двойной линией справа и сверху. -
ι
3
3
Ό
5:
3
20
s
κ
ΙΟ
8.
&
Ιδ~
< Uj w
5: ο ο
3
К
5"
224
го этапа резолюции, но, очевидно, такая стратегия будет обходиться весьма
дорого, поэтому мы ищем некоторую схему, которая могла бы разумным
образом управлять действиями по мере выполнения плана.
Ядра треугольных таблиц как раз и содержат информацию, необходимую
для реализации какой-то системы выполнения плана. В начале выполнения
плана мы знаем, что план в целом является применимым и соответствующим
достижению цели, поскольку литералы первого ядра находятся в
соответствии с начальным описанием состояния, которое было использовано на этапе
создания такого плана. (Здесь мы считаем, что мир носит статический
характер, т.е. в мире не происходит никаких других изменений, кроме
тех,которые вызваны самим роботом). Предположим теперь, что система выполнил а
первые ί—1 действия из последовательности, отвечающей плану. Теперь,
чтобы оставшаяся часть плана (состоящая из ί -го и последующих за ним
действий) была бы и применимой, и соответствующей достижению цели,
литералы 1-го ядра должны находиться в соответствии с текущим описанием
состояния. (Мы полагаем, что сенсорная воспринимающая система
непрерывно обновляет описание состояния мира по мере выполнения плана, так
что это описание верно отражает текущее состояние окружающего мира.)
В действительности имеется возможность не ограничиваться простой
проверкой того, соответствует ли следующее ядро описанию состояния после
совершения действия, а именно можно найти ядро с наибольшим номером,
которое соответствует описанию. Тогда, если непредвиденный эффект
приблизил нас к цели, то необходимо выполнить лишь соответствующие
остающиеся действия, а если ошибка выполнения разрушает результаты
предыдущих действий, то соответствующие действия могут быть выполнены
заново.
Чтобы найти такое сопоставимое ядро, мы проверяем каждое из них,
начиная с ядра с наибольшим номером (которое представляет собой
последнюю строку нашей таблицы), и движемся затем в обратном направлении.
Если сопоставимым оказывается целевое ядро (последняя строка таблицы),
то процесс останавливается. В противном случае предположим, что
сопоставимое ядро с наибольшим номером — это i-e ядро, тогда мы знаем, что i-e
П-правило применимо к текущему описанию состояния. В этом случае
система выполняет действие, соответствующее этому ι-му П-правилу, и
проверяет результат, снова отыскивая ядро с наибольшим номером,
соответствующее описанию состояния. В идеальном мире такая процедура приводит к
тому, что каждое действие плана просто выполняется по порядку. В
реальном мире процедура обеспечивает достаточную гибкость, чтобы пропустить
ненужные действия или преодолеть некоторые неполадки повторным
выполнением соответствующих действий. Если описаниям не соответствует ни
одно ядро, то начинается разработка нового плана.
В качестве примера работы такого процесса обратимся к нашей задаче
построения пирамиды из кубиков и плану, представленному треугольной
таблицей на рис. 7.4. Предположим, что система выполняет действия,
соответствующие первым четырем П-правилам, и что результаты этих действий
225
соответствуют запланированным. Теперь предположим, что система пыталась
выполнить действие по взятию кубика А (т.е. pickup (А)), но на этот раз
программа выполнения действия путает кубик А с В и вместо А берет со
стола кубик В. (Вновь предполагаем, что система восприятия правильным
образом обновляет описание состояния, добавляя HOLDING (В) и вычеркивая
ON (Д С), и, главное, считаем, что она не добавляет HOLDING (А).) Если
бы не было этой ошибки выполнения действия, то шестое ядро сейчас
соответствовало бы описанию состояния. В результате ошибки ядром с
наибольшим номером, соответствующим описанию, теперь является четвертое
ядро. Таким образом, действие, соответствующее stack (Д С), выполняется
заново, возвращая систему на верный путь.
Тот факт, что ядра треугольных таблиц перекрываются друг с другом,
может быть использован при организации экономного просмотра таблицы в
поиске ядра с наибольшим номером, соответствующим описанию состояния.
Начиная с нижней строки, мы просматриваем таблицу слева направо,
отыскивая первую клетку, которая содержит литерал, не соответствующий
текущему описанию состояния. Если в целой строке не нашлось такой
ячейки, то целевое ядро находится в соответствии с описанием состояния. В
противном случае если мы находим такую клетку в столбце ί, то номер ядра с
наибольшим номером, соответствующего описанию состояния, не может
быть больше г. В этом случае мы устанавливаем границу в столбце i и
переходим к следующей снизу строке, просматривая ее слева направо, однако не
переходим столбец i. Если обнаруживается клетка, содержащая литерал, не
соответствующий описанию состояния, то мы передвигаем указанную
границу и переходим к следующей строке, начиная ее просмотр слева направо, и
т. д. При граничном столбце с номером к процесс заканчивается нахождением
того, что /с-е ядро является ядром с наибольшим номером, соответствующим
описанию состояния, что происходит в случае, когда заканчивается просмотр
fc-й (снизу) строки вплоть до граничного столбца.
7.4. ОБРАТНАЯ СИСТЕМА ПРОДУКЦИЙ
7.4.1. ПОСТРОЕНИЕ О-ПРАВИЛ
Чтобы конструировать планы робота достаточно эффективно, часто
действуют в обратном направлении — от целевого выражения к начальному
описанию состояния. Такая система начинает с целевого описания (опять
некоторой конъюнкции литералов) в качестве глобальной базы данных и
применяет к этой базе данных О-правила, создавая подцелевые описания. Она
успешно заканчивает свою работу тогда, когда создает некоторое попделевое
описание, которому соответствуют факты в начальном описании состояния.
Первый шаг на пути разработки обратной системы продукций —
определение множества О-правил, которые преобразуют целевые выражения в
подцелевые. Одним из подходов является использование О-правил,
базирующихся на только что рассмотренных П-правилах; О-правило, которое
преобразует цель G в подцель G', логически основывается на П-правиле, которое,
будучи примененным к описанию состояния, соответствующего G', создает
некоторое описание состояния, соответствующее G.
Мы знаем, что применение П-правила к любому описанию состояния
порождает такое описание состояния, которое соответствует литералам из
его списка добавлений. Следовательно, если целевое выражение содержит
литерал L , который унифицируется с одним из литералов в списке добавлений
для некоторого П-правила, то мы знаем, что если мы порождаем описание
состояния, находящегося в соответствиии с некоторыми частными
случаями предусловий П-правила, то это правило может быть применено для
создания описания состояния, соответствующего L. Таким образом, подделе-
вое выражение, создаваемое обратным применением П-правила, должно,
безусловно, содержать частные случаи предусловий этого правила. Но если
целевое выражение содержит другие литералы (кроме L), то подцелевое
выражение также должно содержать другие литералы, которые после
применения нашего П-правила становтся этими другими литералами (т.е.
отличными от L ) в выражении цели.
7.4.2. РЕГРЕССИЯ
Чтобы придать формальный характер тому, что мы сейчас утверждали,
предположим, что мы имеем цель, заданную конъюнкцией литералов [L Λ
Λ G1 Λ . . . Λ GN], и что мы хотим воспользоваться некоторым П-правилом
(обратным образом) для создания какого-то подцелевого выражения.
Предположим, что некоторое П-правило с формулой предусловий Ρ и формулой
добавления А содержит литерал L' в А, который унифицируется с L
посредством наиболее общего унификатора и. Применение и к компонентам
П-правила дает частный случай П-правила. Безусловно, литералы в Ри являются
подмножеством литералов подцели, поиском которой мы занимаемся. В
полную подцель мы должны включить также выражения Gl' , . . . ,GN' ,
которые должны быть такими,чтобы при применении указанного частного
случая П-правила к любому описанию состояния, находящемуся в соответствии
с этими выражениями, создавалось описание состояния, соответствующее
G1, . . . , GN. Каждое выражение Gi' называется регрессией Gi на данном
частном случае П-правила. Процесс получения Gi' из Gi называется
регрессией.
Для П-правил, определенных в простой форме, принятой в системе
STRIPS, процедура регрессии весьма легко описывается для основных
случаев правил. {Основным частным случаем П-правила является случай, в
котором все литералы в формуле предусловий, списке вычеркиваний и
формуле добавлений являются основными.) Пусть R[Q\ Fu] будет регрессией
литерала Q на основном частном случае Fu некоторого П-правила F с
предусловием Р, списком вычеркиваний D и списком добавлений А. Тогда
если Qu есть литерал в Аи,
R[Q\ Fu] = Τ (Истина),
в противном случае, если Qu есть литерал в Du,
R[Q; Fu\ = Р(Пожъ),
в противном случае R [Q; Fu] = Qu.
На более простом языке регрессия Q на некотором П-правиле есть
тривиально Г, если Q является одним из добавляемых литералов, и есть тривиально
F, если Q является одним из вычеркиваемых литералов; в остальных
случаях это само Q.
227
Регрессия выражений на неполностью означенных П-правилах является
несколько более сложной. Мы покажем на примерах, как такие правила
обрабатываются. Предположим, что в качестве П-правила выступает
описанное ранее правило unstack, определение которого мы здесь повторяем1:
unstack(x,/)
Р& D: HAND EMPTY, CLEAR (x), ON (χ.у)
A: HOLDING(x),CLEAR{y)
Предположим далее, что мы рассматриваем частный случай правила unstack
{В, у), поскольку нашей целью, возможно, является создание литерала
HOLDING (В). Этот частный случай не является полностью означенным. Если бы
нам нужно было получить регрессию для HOLDING (В) на этом частном
случае П-правила, то мы получили бы, как и следует ожидать, значение Т.
(Литерал HOLDING (В) безусловно истинен в состоянии, возникающем в
результате применения П-правила.) Если бы на этом частном случае П-правила
нам нужно было получить регрессию HANDEMPTY, то мы получили бы F.
(Литерал HANDEMPTY не может оказаться истинным сразу же после
применения правила unstack.) Если бы нам нужно было получить регрессию
ONTABLE (С), то мы получили бы ONTABLE (С) . (Литерал ONTABLE (С)
не изменяется под действием П-правила.)
Предположим, что мы пытаемся получить регрессию для CLEAR (С) на
этом не полностью означенном частном случае нашего П-правила. Заметим,
что если бы у было равно С, то регрессией для CLEAR (С) было бы Г, в
противном случае регрессия была бы просто CLEAR (С). Мы могли бы
объединить эти результаты, сказав, что регрессия для CLEAR (С) сводится к
дизъюнкции (у = С) V CLEAR (С). (Чтобы CLEAR (С) выполнялось после
применения любого частного случая правила unstack (β, у), у должен быть
равен С или условие CLEAR (С) должно выполняться перед применением
этого П-правила.) К сожалению, такое дизъюнктивное подделевое выражение
нарушило бы наше ограничение на допустимые формы целевых выражений.
Вместо этого (когда возникает такой случай) мы создаем два
альтернативных подцелевых выражения. В нашем примере одно из подцелевых
выражений будет содержать предусловие правила unstack (В, С), а другое —
неозначенное предусловие правила unstack (В, у) , объединенное с литералом ~(у =
= С).
Подобное осложнение встречается, когда строится регрессия некоторого
выражения, сопоставимого с не полностью означенным литералом в списке
вычеркиваний. Предположим, например, что мы хотим получить регрессию
для CLEAR (С) на правиле unstack (χ, Β). Если бы χ было равно С, то
регрессия для CLEAR (С) дала бы F, в противном случае регрессией было бы
CLEAR (С). Этот результат можно было бы подытожить, сказав, что
регрессией для CLEAR (С) является
[(х=С) =>F] Λ [~(х = С) =>CLEAR (С)].
Как выражение для цели это выражение эквивалентно конъюнкции
[~(х=С) A CLEAR (С)].
1 См. примечание на с. 216. - Прим. ред.
228
Читатель может задаться вопросом: "Что произошло бы, если бы нам
нужно было найти регрессию для CLEAR (В) на unstack (В, y)V\ В нашем
примере мы получили бы Τ при у = В. Но у = В соответствует частному случаю
unstack {В, В), что на самом деле невозможно, поскольку его предусловием
является ON (В, В) (т.е. кубик В находится на кубике В). Наш простой
пример можно было бы сделать более реалистичным, если добавить
предусловие ~(х =у) к правилу unstack (χ, у).
Итак, П-правила в форме, применяемой в системе STRIPS, могут быть
следующим образом использованы в качестве О-правил. Условие
применимости О-правила состоит в том, что целевое выражение должно содержать
литерал, который унифицируется с литералами в списке добавлений
П-правила. Подцелевое выражение создается путем регрессии других (не
находящихся в соответствии) литералов из целевого выражения на частном случае
П-правила, возникающем при установлении соответствия, и объединении
результатов регрессии с частным случаем формулы предусловия этого П-
правила, отвечающим указанному соответствию.
Рассмотрим еще несколько иллюстраций процесса регрессии.
Предположим, что [ON (А, В) A ON (ДС)] — наше целевое выражение. С учетом
приводившихся ранее П-правил имеем два способа, какими правило stack (x, у)
может быть использовано в этом выражении в качестве О-правила1.
Наиболее общими унификаторами для этих двух случаев будут {А/х, В/у] и {В/х,
С/у]. Рассмотрим первый случай. Описание подцели конструируется
следующим образом:
1. Получить регрессию (не находящегося в соответствии) выражения
ON (В, С) на правиле stack (А, В), что дает ON (В, С).
2. Добавить выражения HOLDING (A), CLEAR (В), что в конечном
счете дает подцель [ON (В, С) A HOLDING (Α) A CLEAR (В)].
Другой пример служит для иллюстрации того, как порождаются подцели,
имеющие переменные, относящиеся к квантору существования.
Предположим, нашим целевым выражением является CLEAR (A) - Два П-правила
содержат CLEAR в списках добавлений. Рассмотрим правило unstack (x, у).
При использовании его в качестве О-правила наиболее общим унификатором
будет { А/у}, а порождаемым подцелевым выражением — [HANDEMTY А
A CLEAR (χ) AON (χ, Α)]. В этом выражении переменная л:
интерпретируется как относящаяся к квантору существования. Иначе- говоря, если мы
можем создать состояние, в котором имеется кубик, находящийся на кубике А,
и вершина которого пуста, то мы можем применить П-правило unstack к
этому состоянию с тем, чтобы получить некоторое состояние, сопоставимое с
целевым выражением CLEAR (A).
Заключительный пример показывает, как можно было бы получить
"невозможные" подцелевые описания. Предположим, мы пытаемся применить
обратный вариант unstack к целевому выражению [CLEAR (A) AHANDEMP-
TY]. Наиболее общий унификатор есть {А/у }. Регрессией для HANDEMPTY
на unstack (χ, А) является F. Поскольку конъюнкция, содержащая F,
является недостижимой, мы видим, что применение этого правила породило
невозможную подцель. (Не существует такого состояния, из которого примене-
1 См. определение П-правил на с. 221. - Прим. ред.
229
ние некоторого частного случая правила unstack (χ, А) порождает состояние,
сопоставимое с CLEAR (A) AHANDEMPTY.)
Невозможные целевые состояния могут быть обнаружены и другими
способами. В общем, мы могли бы использовать какую-нибудь систему
доказательства теорем для вывода факта противоречия. Если целевое выражение
противоречиво, то оно не может быть достигнуто. Проверка внутренней
согласованности целей является важным средством, с помощью которого
можно избежать напрасных затрат усилий в попытке достижения целей,
являющихся невозможными.
Иногда применение наиболее общего унификатора для установления
соответствия между литералом в списке добавлений П-правила и целевым
литералом не ведет к дальнейшему означиванию этого П-правила. Предположим,
например, что мы хотим воспользоваться правилом unstack {и, С) системы
STRIPS как О-правилом, примененным к целевому выражению [CLEAR (χ) Λ
Λ ONTABLE (χ) ]. Наиболее общий унификатор есть { С/χ ] . Теперь,
несмотря на то, что эта подстановка не ведет к дальнейшему означиванию unstack (w,
С), она используется в процессе регрессии. Когда цель ONTABLE (x)
подвергается регрессии на этом частном случае правила unstack (и, С), мы получаем
цель ONTABLE (С).
7.4.3. ПРИМЕР РЕШЕНИЯ
Покажем, как в обратной системе продукций, использующей приведенные ранее
правила системы STRIPS, можно было бы достичь цели [ON {А, В) Λ ON {В, С)] . В этом
частном случае пространство подцелей, порождаемое использованием всех применимых
Оправил, превосходит по размерам то пространство состояний, которое мы создали
применением П-правил. Многие описания подцелей, однако, являются
"невозможными", т. е. либо содержит F явным образом, либо достаточно простое устройство
доказательства теорем показывает их невозможность. Отбрасывание невозможных подцелей
значительно сокращает размеры пространства состояний.
На рис. 7.5 мы показываем результаты применения некоторого Оправила к нашему
примеру цели. (Начало каждой стрелки Оправила отходит от целевого литерала,
использованного при установлении соответствия с некоторым литералом списка
добавлений этого правила.) Заметим на рис. 7.5, что когда unstack было приведено в
соответствие с CLEAR (В), то оно не было полностью означено. Ранее обсуждалось, что если
некоторое возможное означивание показывает, что некоторый литерал в списке
добавлений для правила сопоставим с литералом в целевом выражении, то мы делаем это
означивание явным, создавая на его основе отдельную подцелевую вершину.
Все, кроме одной, концевые вершины на этом рисунке могут быть отброшены.
Концевые вершины, помеченные знаком *, представляют невозможные цели, т.е. этим
целям не могут соответствовать никакие описания состояний. В одной из вершин,
например, мы должны достичь выполнения конъюнкта [HOLDING (В) Λ ON (А, В)] (рука
держит кубик В, тогда как кубик А располагается на кубике В) , что, очевидно,
невозможно. Мы предполагаем, что наша обратная система рассуждения располагает каким-
то механизмом, позволяющим обнаруживать такие недостижимые цели.
Концевую вершину, помеченную знаком **, можно рассматривать как результат
детализации первоначальной цели (т.е. она содержит все литералы первоначальной
вершины плюс некоторые дополнительные литералы). Рассуждая эвристически, поскольку
ее, по-видимому, труднее достичь, чем первоначальную цель, мы могли бы отбросить
(или по крайней мере отложить рассмотрение) эту подцелевую вершину. К тому же
эта подцель была создана при сопоставлении цели CLEAR (В) со списком добавлений
230
stacks, В)
HOLDING(A)
CLEAR (В)
ON(B.C)
pickup(/l)
stack(#.C)
ONTABLE{A)
CLEAR{A)
HANDEMPTY
ON(B,C)
CLEAR(B)
unstack(;t,#)
HOLDING(B)
CLEAR(C)
HOLDING{A)
HASDEMPTY
CLEAR(x)
ON{x,B)
(x*A)
HOLDING{A)
ON(B,C)
HASDEMPTY
CLtAR(A)
ON{A.B)
ON(B.C)
Рис. 7.5. Часть обратного (от цели) графа поиска в задаче для робота
некоторого правила. Поскольку цель CLEAR (В) справедлива уже в начальном
состоянии, то имеются эвристические основания против попытки достичь его, когда оно
возникает в описаниях подцели. (Иногда, разумеется, целевые литералы, которые
приводятся в соответствие с литералами в начальном состоянии, могут быть вычеркнуты
предыдущими П-правилами плана и должны быть получены с помощью последующих
П-правил. Следовательно, такая эвристика не всегда надежна.)
Наша операция отбрасывания вершин оставляет ровно одну подцелевую вершину.
Непосредственные преемники этой подцели пронумерованы на рис. 7.6. Вершины 1 и 6
содержат условия на значение переменной jc. (Подобного рода условия являются
следствием процедуры регрессии, когда список вычеркиваний правила содержит литералы,
которые могли бы быть сопоставлены с литералами после регрессии.) Вершины 1 и 6
могут быть отброшены в любом случае, поскольку они содержат литерал F,
вследствие чего они становятся недостижимыми. Заметим, что вершины 2 невозможно
достичь из-за конъюнкции HOLDING (В) A ON (В, Q. Вершина 4 идентична одной из
своих предшественниц (см. рис. 7.5), и она также может быть отброшена. (Если
некоторое целевое описание просто имплицируется одним из предшествующих описаний,
а не совпадает с ним, то в общем случае мы не можем его отбросить. Некоторые
преемники, созданные из такой предшествующей вершины, могли бы быть невозможными,
поскольку литералы в этой вершине, но не литералы подцелевой вершины могли бы в
результате регрессии давать F.)
Такая процедура отбрасывания оставляет нам лишь вершины 3 и 5. Рассмотрим
пока вершину 5. Здесь в целевом описании мы имеем переменную, относящуюся к
квантору существования. Поскольку единственные возможные частные случаи для χ (в на-
231
unstack(.v.,4 )y
HANDEMPTY
CLEAR(x)
ON{x,B)
ONTABLE(A)
CLEAR(A)
F
ON(B.C)
\
pickupM)
OSTABLE(A)
CLLAR(A)
putdown(y4)
putdown( A)
В результате
регрессии
HANDEMPTY
Рис. 7.6. Продолжение графа обратного поиска
232
unstack(#.y)
HOLDING {χ
ONTABLEkB)
(χΦΑ )
CLEAR (В
(χΦΒ)
CLEAR(C)
(хФС)
ΟΝΤΑ В LEΛΑ)
CLEAR (4)
HANDEMPTY
CLEAR(C)
ON(C.A)
ONTABLEiB)
CLLAR(B)
0\'TABLEiA)
Эта подцель
сопоставима
с начальным
описанием
состояния
Идентично
вершине-предку
Рис. 7.7. Заключительная часть графа обратного поиска
шем случае В и С) ведут к невозможным целям, то будет оправданным также
отбрасывание и вершины 5.
На рис 7.7 показана часть пространства целей под вершиной 3 - единственной
сохранившейся вершины на рис. 7.6. Хотя эта часть пространства оказывается несколько
более разветвленной, но мы быстро находим решение. (Мы порождаем подделевое
описание, которое сопоставляется с начальным описанием состояния.) Если мы пройдем
назад по дугам О-правил к исходной вершине (следуя выделенным дугам), то мы
увидим, что наша проблема решается с помощью следующей последовательности П-правил:
{ unstack (С, А), putdown (Q, pickup (В), stack (В, Q, pickup (A), stack (Д В)} .
233
7.4.4. ВЗАИМОДЕЙСТВУЮЩИЕ ЦЕЛИ
Когда литералы целевого описания сохраняются в дочерних описаниях,
к последним применимы некоторые из тех же самых О-прав ил, которые
были применимы к начальной цели. Эта ситуация ведет к тому, что нам
приходится перебирать все возможные упорядочения в последовательностях
правил, пока не будет найдено приемлемое. В задачах, для которых
приемлемыми оказываются несколько упорядочений различных правил, такой
перебор будет необоснованно расточительным. Это та же самая проблема
эффективности, которая привела нас к представлению о разложимых
системах.
Один из способов избежать избыточности, связанной с кратными
решениями для одной и той же целевой компоненты в различных подцелях, состоит
в начальном выделении некоторой целевой компоненты с последующей ее
обработкой до тех пор, пока не будет достигнуто решение. После решения
одной из компонент путем поиска подходящей последовательности П-правил
мы можем вернуться к составной цели и взять другую компоненту и т. д.
Этот процесс связан с расщеплением или декомпозицией составных
(конъюнктивных) целей на однолитеральные составляющие и наводит на мысль
об использовании разложимых систем.
Если мы попытаемся воспользоваться разложимой системой для решения
нашей иллюстративной задачи о построении пирамиды из кубиков, то
составная цель будет расщеплена способом, изображенным на рис. 7.8.
Предположим, что начальным состоянием мира является состояние, показанное
на рис. 7.1. Если сначала мы будем работать с компонентой ON (В, С), то
легко обнаружим решающую последовательность вида {pickup (В) , stack (В,
С)}. Но если мы воспользуемся этой последовательностью, то состояние
мира изменится, так что решение для другой компоненты цели, ON (А, В),
окажется более трудным. Кроме того, любое решение для ON {Ay В) в этом
состоянии должно "отменить" уже достигнутую цель, ON (Bf С) .С другой
стороны, если мы работаем сначала с целью ON (А, В), то найдем, что ее можно
достигнуть, используя последовательность { unstack (С, A)t putdown (С), stack
(А, В)}. И снова состояние мира изменится так, что из него решение для
другой компоненты цели, ON (Bf С), было бы труднее получить.
По-видимому, нет способа решить эту проблему, если выбрать одну из компонент,
решить ее, а затем решить другую компоненту, не прибегая к отмене решения
для первой компоненты.
Рис. 7.8. Расщепление
составной пели
234
Мы говорим, что компоненты цели для этой проблемы взаимодействуют.
Решение для одной из целей отменяет независимо полученное решение для
другой. В общем случае, когда прямая система продукций является
некоммутативной, соответствующая обратная система является неразложимой
и не может работать с компонентами цели независимым образом.
Взаимодействия, вызванные некоммутативными эффектами применения П-правил,
не позволяют нам успешно использовать стратегию комбинирования
независимых решений, полученных для каждой компоненты.
В нашем иллюстрированном примере компоненты целей являются сильно
взаимодействующими. Но в более типичных задачах можно было бы
ожидать, что компоненты целей будут иногда вступать во взаимодействие, но
часто и не будут. Для таких задач более эффективным может оказаться
первоначальное предположение о том, что компоненты составных целей могут
быть решены независимо друг от друга, обрабатывая специальными
механизмами взаимодействия, когда они возникают, вместо того, чтобЪ1
предполагать, что все компоненты целей являются, по всей вероятности,
взаимосвязанными. В следующем разделе опишем систему решения проблем,
названную STRIPS, которая основана на этой общей стратегии.
7.5. СИСТЕМА STRIPS
STRIPS была одной из первых систем решения задач роботом. В ней
поддерживается некоторый стек целей и усилия по решению задач
концентрируются на верхней цели стека. Вначале стек целей содержит только главную
цель. Всякий раз, когда верхняя цель в стеке целей оказывается в
соответствии с текущим описанием состояния, она вычеркивается из стека и
подстановка соответствия применяется к выражениям, расположенным в стеке
под целью. В противном случае если верхняя цель в стеке целей является
составной, то система STRIPS добавляет в стек в некотором порядке
каждый из литералов компонентной цели над составной целью. Смысл состоит
в том, что система работает с каждой составляющей целью в том порядке,
в котором они размещены в стеке. Когда решены все составляющие цели,
то система пересматривает составную цель, заново перечисляя
компоненты, находящиеся на верху стека, если составная цель не приводится в
соответствие с текущим описанием состояния. Это повторное обращение к
составной цели является (довольно примитивным) средством, с помощью
которого в системе предусматривается случай возникновения
взаимодействия целей. Если решение одной составляющей цели отменяет уже
решенную компоненту, то эта "отмененная" цель пересматривается и при
необходимости решается заново.
Когда верхняя (нерешенная) цель в стеке является однолитеральной,
система ищет П-правило, которое содержит в списке добавлений литерал,
сопоставимый с нею. Затем эту однолитеральную цель на верху стека
заменяют на тот частный случай упомянутого П-правила, который возникает в
результате приведения в соответствие. Затем выше этого П-правила
заносится частный случай формулы предусловия Р, отвечающий этому соответствию.
Если Ρ носит составной характер и не сопоставляется с текущим описанием
состояния, то ее компоненты в некотором порядке заносятся на верх стека.
Когда верхний элемент стека представляет собой П-правило, то это значит,
235
ОПИСАНИЕ СОСТОЯНИЯ СТЕК ЦЕЛЕЙ
CLEAR(B) ON(C.B\AON(AC)
CLEARU >
— -j --j #^
х ас оа ki
•ч* ^ Ώ
^ 2 £ Ξ
/
/
\
\
с
ш <
ш * ^ аг
* ? Ξ >
о
к
Ζ тззС
5 с* ας χ аоаа £
sdd§§§5
I ^еЁ]
С
S-.i
ш ^ ас as
ш ***
К
§§5-551
»- ос ft: τ оз оа ^j
о J 5 ~ £ f- *
§ eej
G
ш с:
ш О ^
Ь- эг С _ <
° ίΟ£ ί
3·*3 ~
3 2$ *
К
ζ τ 5£
o§c_S5|
f: ft: ft: x ас ас k»
о ^ ^ ^ 3 3 >
ϋ vj ki .- !£ *? <
-ϊί!§15
5 Ε]
I ее]
з
I
S 2 ^
·=: $ 3
ш Ъ о ^
г t ^ ~
w "S О 3
1 ^*fc
Н ос ft: Т Q5 ас k:
У ^ 7е ° (3 3 >
О о ki ~ tr Ь <
ш ч, w ч. ч~ ч* -^
i ^
/
1 ^
5^< <
=* <^ $ оз С ~
^ £ * ~
Ш ^ 5ί ЗС ν ν>"
lI ■*· Τ X Τ Τ w
ОПИСАНИЕ СО СТО
CLEARiB
CLEARiC
Й GNTABLE
j—, GNTABLE
1*1 HANDFMI
ι На следующую страницу
\ §
4
л
*-
>
с
>5
ζ
ш
χ
»-
φ
с
υ
8·
с
ζ
φ
3
φ
α
Κ !
4 1
*
αϊ
с
°
φ
с
ο
φ
Ш
236
>s
ш
|C
Ш
^
*
ш
ίο
к
s
τ
π
κ
<->
ο
(1
ш
Χ
опис
-
χ·
5·
5·
<
5
г
(//
г
з;
г
^j
~ I
~
**
^
~ <
~ 5
τ"5ϊ
S-i^S
^ 3ς 35 35 ««J
5 £ U 2· -*
w о о г 5:
R*1
.4iil
-
ζ ё
ш ~ с:
ш
^ ^ i:
* <<
о ^_
ее ^
s
X
ВС
О ^ W
о * as
о J T
υ 5^
ш _ w
s
X
опис
-
^
5
< Ξ
- ~ - <
— i **~
3 jt s_
.* -A, O -
о ^ Й ^
а. ^ 7 ^
" =5 С
^ ^ 5·
* 5 * =?
^ -- *■- *■*■
.г-» .г-» ,- ~Г
ы*|
43
i3 £"ш5
2 2 «л*
03 4 X J05
l^se^ec
аз <o £ *.* Bl_
x M ϊ S "<ξ£ϊ
■;_. 1- ffl ■*> tr « У
5-jo*£*£
аз ю о £азаз о
αϊ ν ϋκ 2ςνο
с"5 с; О 5 "аз υ
оз.- аз о ао»- _
НО.=Ти с со ш
ш
с;
ш
-г
ш
о
ОС
S
X
ОС
о
о
о
и
ш
S
X
<
и
ι S
с
о
>
X —
а. - -
- 38 S" * * |
3 Ξ: 5 Г Ξ
^ > г ^ ^
-С |
|τΜ*|ι
Η
о
о
Я
О
в
t
а,
u
237
что формула предусловия этого правила пришла в соответствие с текущим
описанием состояния и была удалена из стека. Таким образом, это П-прави-
ло применимо. Оно применяется к текущему описанию состояния и
удаляется из верхней части стека. Теперь вместо первоначального используется
новое описание состояния, а система запоминает то П-правило, которое было
применено с тем, чтобы в дальнейшем включить его в решающую
последовательность.
Систему STRIPS мы можем рассматривать как систему продукций, в
которой глобальная база данных представляет собой комбинацию текущего
описания состояния и стека целей. Операции, совершаемые над этой базой
данных, изменяют либо описание состояния, либо стек целей, причем
процесс продолжается до тех пор, пока стек целей не опустеет. "Правилами"
такой системы продукций являются правила, которые преобразуют одну
глобальную базу данных в другую. Их не следует путать с правилами
системы STRIPS, которые соответствуют моделям действий робота.
Высокоуровневые правила изменяют глобальную базу данных, состоящую как из
описания состояния, так и из стека целей. Правила же системы STRIPS указаны
в глобальном стеке и используются для изменения описания состояния.
Работа системы STRIPS при каком-то режиме управления поиском на
графе порождает некоторый граф глобальных баз данных, причем решение
соответствует пути в этом графе, ведущему от начала к терминальной
вершине. (Терминальной является вершина, помеченная базой данных,
имеющей пустой стек целей.)
Давайте посмотрим, как система STRIPS могла бы решать довольно
простую задачу складывания кубиков в пирамиду. Предположим, целью
является [ON (С, В) и ON (A, Q ], а начальное состояние изображено на рис. 7.1.
Заметим, что цель может быть просто достигнута помещением С на В и затем
А на С. Мы используем такие же правила системы, как и раньше.
На рис. 7.9 показана часть графа, который может быть построен в ходе
решения этой иллюстративной задачи. (Для ясности мы показываем
положение кубиков вместе с каждым описанием состояния.) Так как проблема
является очень простой, то система довольно легко находит решающую
последовательность {unstack (С, А), stack (С, В), pickup (A), stack (А, С)}.
Система STRIPS встречает некоторое затруднение при решении задачи,
где целью является [ON (В, С) Λ ON (А, В)]. Начиная с той же
первоначальной конфигурации кубиков, система может создать решающую
последовательность с несколько большей длиной, чем это необходимо, а именно {
unstack (С, А), putdown (С) , pickup (A) , stack (А, В), unstack (А, В) ,putdown
(А), pickup (В), stack (В, С), pickup (A), stack (А, В)} . Правила с третьего
по шестое представляют собой ненужные действия. В данном случае это
связано с тем, что система STRIPS решает достигнуть ON (А, В) перед тем, как
достигнет ON (В, С). Взаимодействие между этими целями заставляет затем
систему отменить ON (А, В) перед тем, как оно достигнет ON (By С).
7.5.1. СТРАТЕГИИ УПРАВЛЕНИЯ ДЛЯ СИСТЕМЫ STRIPS
Управляющая компонента системы STRIPS должна принять несколько
решений. Мы кратко остановимся на некоторых из них. Во-первых, нужно
решить, каким образом упорядочить между собой составляющие сложной
238
цели, располагающиеся в стеке выше этой сложной цели. Разумный подход
состоит в том, чтобы сначала найти все те компоненты, которые приводятся
в соответствие с описанием текущего состояния. (Они как бы мысленно
помещаются на верх стека, а затем немедленно сбрасываются.) Пссле этого
остается упорядочить лишь цели, которые не приводятся в соответствие. Мы
могли бы создать новую дочернюю вершину для каждого возможного по ряд»
ка (как делали в наших примерах) или же выбрать произвольно один из них
(возможно, исходя из литерала цели, которая эвристически является
наиболее трудной) и создать дочернюю вершину, в которой только эта
составляющая цели помещается в стек. Последний подход, по-видимому, является
адекватным, поскольку после достижения этой одиночной цели мы вновь
имеем дело с составной целью и получаем возможность выбрать какую-то
другую из ее неразрешенных компонент.
Когда в стеке целей встречаются переменные (относящиеся к квантору
существования), то компонента, ответственная за управление, может
столкнуться с необходимостью определенного выбора среди нескольких
возможных означиваний. Мы можем предположить, что для каждого возможного
означивания может быть построена дочерняя вершина. Когда верхняя цель
может быть достигнута более чем одним П-правилом системы, мы снова
сталкиваемся с выбором. Каждое из уместных правил может породить
дочернюю вершину.
Стратегия управления поиском на графе должна быть в состоянии
выбрать, над какой из концевых вершин следует работать в графе решения
задачи. Здесь может быть использован любой метод, рассмотренный в гл. 2.
В частности, можно построить эвристическую оценочную функцию от этих
вершин, учитывающую, например, такие факторы, как длина стека целей,
трудность задач, находящихся в стеке, стоимость П-правил системы STRIPS
и т. п.
Интересный частный случай этой системы может быть построен, если мы
решим воспользоваться режимом с возвращением вместо поиска на графе.
Тогда можно представить себе рекурсивную функцию, называемую STRIPS,
которая при решении верхней цели в стеке может вызывать саму себя. В
этом случае явное использование стека целей будет заменено на встроенный
в язык программирования (например, ЛИСП) механизм стека,
обеспечивающий реализацию рекурсивной функции STRIPS.
Программа для рекурсивной функции STRIPS будет выглядеть примерно
следующим образом. Мы устанавливаем в качестве значения глобальной
переменной S начальное описание состояния. (Первоначально программа
вызывается с аргументом G — той целью, которую STRIPS пытается достигнуть.)
Recursive Procedure STRIPS(G)
1 until S соответствует G,do:; основной цикл процедуры
STRIPS является итеративным
2 begin
239
3 g <~ компонента G, которая не соответствует 5;
недетерминированный выбор и поэтому
это точка возврата
4 /+- некоторое Я-правило, список добавления
которого содержит литерал,сопоставимый с g;
еще одна точка возврата
5 ρ «—формула предусловия соответствующего
частного случая /
6 STRIPS(/?); рекурсивное обращение при решении
подзадачи
7 S «— результат применения к S соответствующего
частного случая /
8 end
7.5.2. АНАЛИЗ 'ЦЕЛИ-СРЕДСТВА" И СИСТЕМА GPS
В одной из первых систем решения задач, называемой GPS (General
Problem Solver), использовались методы, аналогичные примененным позднее в
системе STRIPS. В GPS по определенной методике выделяются некоторые
П-правила исходя из заданных описания состояния S и цели G. Сначала
делается попытка вычислить различие между S и G. Вычисление различий
проводится посредством функции, которая специально пишется для каждой
области применения.
Различия использовались для отбора "относящихся к делу" П-правил
путем обращения к некоторой "таблице различий", в которой эти П-правила
связаны с различиями. С данным различием ассоциировались те правила,
которые "имеют отношение к уменьшению этого различия". П-правила,
связанные с каждым различием, упорядочивались между собой в соответствии
со степенью уместности правила. Для каждой области применения должна
быть построена таблица различий. Когда принималось решение, что
некоторое П-правило может быть выбрано как относящееся к делу, то система
GPS начинала рекурсивно работать с предусловиями этого правила. Когда
они все оказывались удовлетворенными, то П-правило применялось к
текущему описанию состояния и процесс продолжался.
Таким образом, мы видим, что рекурсивная процедура GPS очень
похожа (и носит, может быть, несколько более общий характер) на
рекурсивную процедуру STRIPS. (Исторически система STRIPS создавалась под
влиянием GPS.) Программа для рекурсивной процедуры GPS могла бы
выглядеть примерно так.
Сначала устанавливаем исходное описание состояния в качестве значения
глобальной переменной S. (Программа вызывается с аргументом G, т.е.
той целью, которую GPS пытается достичь.)
240
Recursive Procedure GPS( G)
1 until S соответствует G, do:; основной цикл
процедуры GPS является итеративным
2 begin
3 d 4e— различие между S и G; точка возврата
4 /<—/7-правило, относящееся к уменьшению d;
другая точка возврата
5 ρ 4— формула предусловия соответствующего
частного случая /
6 GPS(/7); рекурсивное обращение для решения
подпроблемы
7 5* 4— результат применения к £
соответствующего частного случая/
8 end
Процесс идентификации различий и выбора П-правил для их уменьшения
называется анализом "цели-средства"'. Рекурсивная процедура STRIPS
может рассматриваться как частный случай GPS, в котором различиями между
S и G являются компоненты С, не соответствующие S, и в котором все П-
правила, в списках дополнений которых содержится литерал L,
рассматриваются как имеющие отношение к уменьшению различия L.
Хотя первоначально GPS работала рекурсивно, как только что было
описано, можно было бы легко себе представить систему GPS в режиме
управления поиском на графе, подобному режиму, описанному для системы
STRIPS.
7.5.3. ЗАДАЧА, КОТОРУЮ STRIPS HE В СОСТОЯНИИ РЕШИТЬ
Система STRIPS легко решает многие задачи, однако, как мы уже
видели, существуют задачи, для которых STRIPS может приводить к решениям,
более длинным, чем это необходимо. Кроме того, существуют некоторые
простые задачи, для которых система (в описанном виде) не в состоянии
вообще указать решение. Примером задачи, которую система STRIPS не
может решить, является задача построения программы, позволяющей поменять
местами содержание двух регистров.
Предположим, у нас имеются два регистра X и У, содержимое которых
вначале равно соответственно А и В. Мы могли бы представить эту ситуацию
описанием состояния [CONT (Χ, Λ) Λ CONT (Υ, В) ], где CONT (X, А),
например, означает, что содержимое регистра X есть А (т. е. программная пере-
241
менная X имеет величину А) . В рамках этого примера мы должны
постараться избежать путаницы, связанной с тем фактом, что программная
"переменная" наподобие X является на самом деле константным символом в нашем
языке исчисления предикатов, который относится к определенному
объекту (конкретному регистру памяти). Переменные исчисления предикатов,
подобные х и у, используются для обозначения произвольных программных
переменных (подобных X) и их "значений" (подобных А). Чтобы по
возможности избежать путаницы, мы намеренно используем термины "регистр"
и "содержимое" вместо "программная переменная" и "значение".
Нашей целью для системы STRIPS является выражение [CONT {X, В) Л
A CONT (У, А)]. Единственной операцией, которую мы допускаем,
является утверждение приписывания, в котором один регистр "приписывается" к
другому, т.е. его содержимое заменяется на содержимое другого регистра.
Мы можем представить такое приписывание в виде П-правила:
assign(w,/\/,s)
Ρ: CONT(r,s)ACONT(u,t)
D: CONT {и J)
A: COyT(u,s)
Это утверждение приписывания можно было бы прочесть следующим
образом: приписать регистр и (с текущим содержимым t) к регистру г (с
текущим содержанием s). Результатом будет то, что текущим содержимым
регистра и будет s, а содержимым г останется s. Первоначальное
содержимое регистра и, а именно t, в этом процессе теряется.
Система продукций, использующая это П-правило, является
некоммутативной, поскольку некоторое отношение CONT вычеркивается процедурой
assign. Хорошо известное начинающим программистам разрушительное
свойство утверждения присваивания требует, чтобы мы сохранили
содержимое либо X, либо Υ в третьем регистре перед тем, как приступить к
указанному обмену. Чтобы сделать формулировку проблемы для системы
STRIPS более чем "честной", мы явным образом упомянем этот
необходимый третий регистр в начале постановки задачи. Этого можно достигнуть,
если добавить факт CONT (Z, О) в начальное описание состояния. (В
следующей главе обсудим один метод, при котором дополнительные регистры
могут быть построены системой, если она решит, что такие регистры
необходимы. )
На рис. 7.10 изображена попытка решения этой задачи, предпринятая
системой STRIPS. Поскольку первоначальная задача является полностью
симметричной, то не играет роли, как мы упорядочим компоненты
начальной составной цели в вершине 1. В вершине 2 система вполне разумно решает
применить частный случай assign (X, г , t, В). Эта операция порождает
вершину 3. Теперь мы видим фатальный недостаток, присущий системе STRIPS.
Она слишком нетерпелива! Система немедленно решает, что вершина 3
может быть приведена в соответствие с текущим описанием состояния
посредством наиболее общего унификатора { Y/r , A/t } . Данный частный случай
процедуры assign ведет к потере А, в результате чего верхняя цель в вершине
4 становится неразрешимой. Более того, для имеющегося описания
состояния в вершине 3 не существует никакого другого возможного соответствия
для верхней цели вершины 3.
242
©
ОПИСАНИЕ СОСТОЯНИЯ
CONT(X.A)
СО NT {Υ.Β)
CONT(Z.O)
СТЕК ЦЕЛЕЙ
CONT(X.B) Л CONT(Y.A)
φ
ОПИСАНИЕ СОСТОЯНИЯ
CONT(XA)
COST(Y.B)
CONT(Z.O)
СТЕК ЦЕЛЕЙ
CONT(X.B)
CONT(Y.A)
CONT(X.B) A CONT( Y.A)
®
ОПИСАНИЕ СОСТОЯНИЯ
CONT(X.A)
CONT(Y.B)
CONT{Z,0)
СТЕК ЦЕЛЕЙ
CONT(rM)ACONT(Xj)
assign (X,r,t, B)
CO NT (Y.A)
CONT(X.B) A CONT(Y,A)
Θ
Здесь мы можем привести
в соответствие верхнюю цель
с помощью [Y/r,A/t]
и применить assign {Χ, Υ, А, В).
ОПИСАНИЕ СОСТОЯНИЯ
CONT{X,B)
CONT(Y.B)
CONT(Z,0)
СТЕК ЦЕЛЕЙ
CONT(YA)
CONT(X.B) A CONT(YA)
Рис. 7.10. Задача, которую система STRIPS не может решить
Единственный путь, на котором можно было бы получить решение
задачи, — временно отложить приведение в соответствие верхней цели в вершине
3 и создать дочернюю вершину с верхней целью CONT (г ,В). Тогда,
возможно, в некоторой дочерней вершине вместо г будет подставлено Z. Но
возможность задержки приведения в соответствие целевого сопоставления
значительно усложнила бы систему STRIPS. Поэтому в следующей главе мы
опишем некоторые системы решения задач, которые по своей сути являются
более мощными, чем система STRIPS.
7.6. ИСПОЛЬЗОВАНИЕ СИСТЕМ ДЕДУКЦИИ ДЛЯ ВЫРАБОТКИ ПЛАНОВ
ДЛЯ РОБОТОВ
Из примеров, приведенных в этой главе, мы видим, что проблема
составления последовательности действий имеет достаточно очевидную формули-
243
ровку с применением правил в виде, употребляемом в системе STRIPS.
Прямая система продукций, использующая эти правила,'обычно является
некоммутативной, поскольку некоторые выражения при применении правила
могут быть вычеркнуты. Мы снова обращаем внимание на то обстоятельство,
что задачам для роботов не присущи какие-либо свойства
коммутативности (или некоммутативности). Коммутативность (или ее отсутствие)
полностью определяется деталями системы продукций, используемой для
решения задач. Вполне возможной, например, является такая формулировка
задачи для робота, при которой задачи могут быть решены
коммутативными системами продукций. Одним из способов достижения такой
коммутативной формулировки является постановка задач для робота в виде теорем,
требующих доказательства, и применения одной из наших коммутативных
дедуктивных систем. Формулирование некоторой задачи для робота как
задачи вывода, возможно, является несколько более неудобным и сложным,
чем использование правил в виде, принятом в системе STRIPS. Однако
формулировки в виде задач на доказательство теорем представляют
значительный теоретический интерес, а исторически они предшествовали системе
STRIPS. Мы опишем два варианта подхода к формулировке задачи для
робота в виде задач на доказательство.
7.6.1. ФОРМУЛИРОВКА ГРИНА
Одна из первых попыток решения задач для робота была предпринята
Грином [127], который формулировал их в виде, пригодном для решения
с помощью системы доказательства теорем (коммутативной системы) на
основе резолюции. В этой формулировке одно множество утверждений
использовалось для описания начального состояния, а другое — для описания
эффектов воздействия на состояния действий, предпринимаемых роботом.
Чтобы следить за тем, какие факты являются истинными и в каком
состоянии, Грин включал в каждый предикат переменные, отвечающие
"состоянию" или "ситуации". Далее целевое условие описывалось формулой с
переменной, относящейся к квантору существования. Таким образом, система
пытается доказать, что существует некоторое состояние, в котором
некоторое условие является истинным. Затем можно было бы воспользоваться
каким-то конструктивным методом доказательства для выработки
множества действий, которые создали бы требуемое состояние. В системе Грина все
утверждения (и отрицание целевого условия) превращались в форму
предложений, предназначенных для системы доказательства на основе
резолюции, хотя точно так же можно было бы воспользоваться и другими
системами вывода.
Иллюстративный пример поможет нам показать, как же в точности
работает этот метод. К сожалению, обозначения, необходимые в этих
формулировках на доказательство, являются довольно громоздкими, и чтобы
пример оставался достаточно ясным, найти задачи со складыванием кубиков,
которые мы использовали прежде, необходимо упростить.
Предположим, что мы имеем начальную ситуацию, изображенную на
рис. 7.11. На столе имеются ровно четыре дискретных положения, Д Е, F
и С, и три кубика, А, В и С, находящихся, как показано, в определенных
позициях на столе. Обозначим начальное состояние через SO. Тогда тот факт,
244
ШШШШ/////
G D l·' F
Рис. 7.11. Начальное расположение кубиков
что кубик А находится в позиции D в состоянии SO, обозначим литералом
ON (А, Д SO). Здесь имя состояния указано в виде явного аргумента,
входящего в предикат. Полная конфигурация кубиков в начальном состоянии
дается следующим множеством формул1:
ON(A,D,SO)
ΟΝ(Β,Ε,ΞΟ)
ON(C,F,SO)
CLEAR(A.SO)
CLEAR(B,SO)
CLEAR(QSO)
CLEAR{G,SO)
Теперь нам нужен способ описания результатов влияния различных
действий робота на эти состояния. В формулировках с использованием
доказательства теорем мы их выражаем в виде логических импликаций, а не в
виде правил, принятых в системе STRIPS. Например, предположим, что у
робота имеется действие, посредством которого он может "переместить"
кубик χ из положения у в положение ζ, где у и ζ могут быть либо именами
кубиков, на которых находится кубик х, либо именами позиций на столе,
в которых может находиться кубик х. Будем полагать, что и позиция ζ
(целевая позиция), и кубик χ должны быть незанятыми, чтобы можно
было выполнить это действие. Модель такого действия выражается
формулой "trans (x,y, z)".
Когда действие выполняется в некотором состоянии, то результатом
будет новое состояние. Мы используем специальное функциональное
выражение "do (действие, состояние) " для обозначения функции, отображающей
состояние в то состояние, которое является результатом совершенного
действия. Таким образом, если trans (χ, у, ζ) выполняется в состоянии s,
то таким результатом является состояние, даваемое выражением do [trans
Тогда основной эффект от действия, моделируемого процедурой trans,
может быть сформулирован в виде2
1 В данном случае предикат CLEAR (A, S) означает, что на кубике А в состоянии S
ничего нет, а предикат CLEAR (G, S) означает, что место G не занято. - Прим. ред.
2 Предикат DIFF (χ, ζ), сокращение от английского Different - различный,
означает, что jc и ζ не совпадают. - Прим. пер.
245
[CLEAR(x,s) Λ CLEAR(z,s) Λ ΟΝ(χλ\ξ) Λ DIFF(x.z)]
^[CLEAR(x,do{trans(x,y,z\s])
Λ CL£/iR(у,do[trans(x,y,z).s])
Л ON(x,z,do[trans(x,y,z),s})] .
(Все переменные в утверждениях относятся к квантору общности.)
Эта формула утверждает, что если χ и ζ свободны и если χ находится на
у в состоянии s, χ и ζ различны между собой, то χ и у будут свободны и χ
будет находится на ζ в состоянии, являющемся результатом выполнения
действия trans (χ, у, ζ) в состоянии s. (Предикат DIFF не нуждается в
переменной, относящейся к состоянию, поскольку его значение истинности не
зависит от состояния.)
Но эта формула сама по себе не полностью описывает эффект от
совершения действия. Мы должны также указать, что на определенные отношения
это действие не оказывает влияния. В системах, подобных STRIPS, в П-пра-
вилах используется договоренность о том, что отношения, явно не
упоминаемые в правиле, остаются без изменения. Но здесь необходимо явным
образом сформулировать как "эффекты", так и "не эффекты".
К сожалению, в формулировке Грина необходимо наличие утверждений
относительно каждого отношения, на которое данное действие не оказывает
влияния. Например, следующее утверждение необходимо для того, чтобы
выразить то обстоятельство, что непередвигаемые кубики остаются в том же
положении:
[ON(u,v,s)A DIFF(u,x)\
=$ ON(u,v,do[trans(x,y,z),s\) .
А другая формула потребуется для того, чтобы показать, что кубик и
остается незанятым, если кубик и был не занят, когда кубик ν (не
совпадающий с и) был помещен на кубик w (не совпадающий с и).
Такие утверждения, которые описывают, что остается неизменным в
ходе некоторого действия, иногда называют утверждениями фрейма. В
больших системах может быть много предикатов, используемых для описания
ситуации. Формулировка Грина потребовала бы (для каждого действия)
отдельного утверждения фрейма для каждого предиката. Это
представление может быть сделано более компактным, если воспользоваться логикой
более высокого порядка, в которой можно было бы написать формулу,
подобную следующей :
(\/Р) [P(s) =>P[do (action, $)].
Но с логиками высших порядков связаны свои трудности. (Позже мы
рассмотрим другую формулировку в логике первого порядка, которая
позволит избежать многократных утверждений фрейма.)
После того, как все утверждения для действий выражены посредством
импликаций, мы готовы попытаться решить реальную задачу для робота.
Предположим, мы хотели бы достигнуть простой цели — поместить
кубик А на кубик В. Эта цель выражается следующим образом:
(3s) ON (A,B,s).
246
Теперь поставленная задача может быть решена путем поиска
конструктивного доказательства целевой формулы исходя из имеющихся
утверждений. Для этого может быть использован любой разумный метод
доказательства теорем.
Как уже указывалось, Грин использовал систему, основанную на
резолюции, в которой бралось отрицание цели, а затем все формулы
преобразовывались в форму предложений. Система пыталась установить противоречие, а
процесс извлечения ответа должен был найти целевое состояние, которое
существует. Это состояние в общем случае будет выражаться в виде
композиции функций do, указывающих на действия, связанные с построением
целевого состояния. Граф опровержения на основе резолюции для нашей задачи
показан на рис. 7.12. (Предикат DIFF оценивается, а не используется в
резолюции.) Применение процедуры извлечения ответа к графу на рис. 7.12
дает
sl= do [tzans (A,D,B),SO],
что указывает на единственное действие, которое необходимо для
достижения цели в этом случае.
Вместо резолюции можно было бы применить одну из систем дедукции,
основанной на правилах (см. гл. 6). Утверждения, описывающие начальное
состояние, можно было бы использовать в качестве фактов, а утверждения
действий и утверждения фрейма — в качестве порождающих правил.
Только что рассмотренный пример, конечно, является простым — нам не
пришлось даже воспользоваться какими-либо утверждениями фрейма. (Нам
непременно пришлось бы их использовать, если бы, например, наша цель
была бы составной вида [ON (А, В, s) AON (В, С, s)]. В этом случае мы
должны были бы доказывать, что В остается на С при размещении А на В.)
Однако даже в несколько более общих примерах объем перебора при
доказательстве теорем, необходимого для решения задач роботом с
использованием такой формулировки, может так быстро разрастаться, что метод
становится срвершенно непрактичным. Эти задачи перебора вместе с
трудностями, вызванными применением утверждений фреймов, были основным
стимулом развития системы решения задач STRIPS1.
7.6.2. ФОРМУЛИРОВКА КОВАЛЬСКОГО
Ковальский предложил иную формулировку. Она упрощает форму
утверждений фрейма. То, что обычно было бы предикатами в формулировке,
предложенной Грином, превращается в термы.
Например, вместо литерала ON (A, D, SO) для обозначения того факта,
что А находится на D в состоянии SO, мы используем литерал HOLDS [on (A,
D), SO] 2. Терм on (A, D) обозначает "концепцию" того, что А находится
на D; такие концепции используются в качестве элементов нового
исчисления. Представление того, что обычно является отношением, в виде элемента
является одним из способов использования преимуществ логики высшего
порядка в рамках формулировки первого порядка.
1 Следует заметить, что К. Грин в течение многих лет возглавлял лабораторию, в
которой была развита система STRIPS. - Прим. ред.
2 HOLDS означает "справедливо" или "выполняется". -Прим. пер.
247
-CLEAR(x.s) V ~CLEAR(z.s)V ~0.\(x.v.s) V ^DIFF(x.z)
V ON(x.z.do[trans(x,v.z).s\)
Рис. 7.12. Граф опровержения для задачи складывания кубиков
248
Тогда начальное состояние, изображенное на рис. 7.11, дается следующим
множеством выражений:
1 POSS(SO)
2 HOLDS[on(A,D),SO'}
3 HOLDS[on(B,E),SO)
4 HOLDS\on(C,F),SO]
5 HOLDS[ciear(A\SO]
6 HOLDS[clear(B),SO\
7 HOLDS[clear(C\SO]
8 HOLDS[clear(G),SO]
Литерал POSS {SO) обозначает, что состояние SO является возможным
состоянием, т.е. состоянием, которое может быть достигнуто. (Причина
использования предиката POSS станет ясной в дальнейшем.)
Теперь мы выразим часть эффектов действий (литералы из "списка
добавлений") с помощью отдельного литерала HOLDS для каждого отношения,
которое становится верным в результате этого действия. В случае нашего
действия trans (χ, у> ζ) мы имеем следующие выражения:
9 HOLDS[clear(x),do[trans{x,y,z),s))
10 HOLDS[clear{y),do{trans{x,y,z\s}\
11 HOLDS [ on ( χ, ζ), do [ trans (x,γ, z),s]]
(Снова все переменные в этих утверждениях относятся к квантору
общности.)
Другой предикат, PACT, используется для утверждения о том, что
данное действие можно выполнить в данном состоянии, т.е. что
предварительные условия действия соответствуют описанию состояния. Предикат PACT
(a, s) утверждает, что действие α может быть выполнено в состоянии s.
Для нашего действия trans мы, таким образом, имеем
12 [HOLDS\clear{x\s] Λ HOLDS[clear{z),s]
Λ HOLDS[on(x,y\s] Λ DIFF(x,z)}
=Φ PACT[trans(x,yyz),s]
Далее мы утверждаем, что если данное состояние является возможным и
если предварительные условия некоторого действия удовлетворяются в этом
состоянии, то состояние, порождаемое применением такого действия, также
является возможным:
13 [POSS(s) Л PACT(u.s)]=> POSS[do(u,s)]
Основное достоинство формулировки Ковальского состоит в том, что нам
необходимо только одно утверждение для каждого действия. В нашем
примере таким единственным утверждением фрейма является следующее:
14 {HOLDS(\\s) A DIFF[v,clear(z)\ Λ DIFF[v4on(x,y)]}
=> HOLDS[v,do[trans(x,y.z)4s]]
В этом выражении в весьма простой форме утверждается, что все термы,
отличные от clear (z) и on {x, у), по-прежнему справедливы во всех
состояниях, порождаемых выполнением действия trans (χ, у, ζ) .
249
Как обычно, цель для системы задается выражением с переменной,
относящейся к квантору существования. Если бы мы захотели достичь того,
чтобы В располагался на С, а А — на В, то нашей целью было бы выражение:
(3s){ POSS(s) Л HOLDS{on{BX\s] Л HOLDS[on(A,B),s]}
Дополнительный конъюнктPOSS (s) необходим для выражения
требования о том, чтобы состояние s было достижимо.
Утверждения 1 — 14, таким образом, выражают необходимый объем знаний
для системы решения проблем в этом примере. Если бы мы захотели
воспользоваться системами дедукции, основанными на правилах (см. гл. 6),
для решения проблем с использованием таких знаний, то мы могли бы взять
утверждения 1—11 в качестве фактов, а утверждения 12—14 — в качестве
правил. Детали работы такой системы зависели бы от того, используются ли
эти правила в качестве прямых или обратных, и от конкретной стратегии
управления, примененной в системе. Например, для того чтобы вынудить
систему, основанную на правилах, "имитировать" шаги, выполняемые
обратной системой продукций, в которой используются правила в форме
характерной для системы STRIPS, мы бы заставили систему дедукции
сначала привести в соответствии одно из утверждений 9—11 ("добавки") с
целью. (Этот шаг приведет к выбору действия, посредством которого мы
будем пытаться работать в обратном направлении.) Далее утверждения 13 и
12 использовались бы для постановки предварительных условий для этого
действия. Впоследствии утверждение фрейма 14 использовалось бы для
регрессии других условий цели на этом действии. Все предикаты DIFF
должны по возможности подвергаться оцениванию. Эта последовательность
должна затем повторяться на одном из предикатов подцели до тех пор, пока не
будет построено множество подцелей, унифицируемое с утверждениями
фактов 1—8.
Несомненно, можно было бы задать и другие стратегии управления и
позволить системе, основанной на правилах, "имитировать" шаги системы STRIPS
и других более сложных систем решения задач для робота, которые будут
рассматриваться в следующей главе. Одним из способов конкретизации
соответствующих стратегий управления было бы использование соглашений
об упорядочении фактов и правил, которые применяются в языке ПРОЛОГ,
описанном в гл. 6.
Сравнивая системы дедукции с системами, подобными STRIPS, не
следует пытаться делать вывод, что системы одного типа могут решать задачи,
которые другие решать не могут. На самом деле выбором подходящего
механизма управления пути решения задач различными системами можно
сделать по существу идентичными. Дело заключается в том, что для
эффективного решения задач для робота с помощью систем дедукции нужны
специализированные и явные стратегии управления, которые неявным образом
"встроены" в системы, подобные системе STRIPS. Поэтому системы решения
задач для робота, подобные системе STRIPS, по-видимому, следует считать
находящимися в таком же отношении к системам дедукции, в каком
языки программирвания высокого уровня находятся „в отношении к языкам
программирования низкого уровня.
250
7.7. БИБЛИОГРАФИЧЕСКИЕ И ИСТОРИЧЕСКИЕ ЗАМЕЧАНИЯ
Моделирование действий робота с помощью правил в форме, характерной
для системы STRIPS, было предложено Файксом и Нильсоном ь качестве
частичного решения проблемы фрейма [103]. Аналогичный подход
использовался в языке искусственного интеллекта, подобном языку ПЛАННЕР
[31, 73]. Проблема фрейма обсуждается Маккарти и Хейесом, Хейесом и
Рафаэлом [141, 209, 293]. Проблема работы в аномальных условиях
обсуждается Маккарти и Хейесом [206, 209]. Маккарти называет эту проблему
квалификационной и предполагает, что она может рассматриваться как
частный случай проблемы фрейма. Фальман [95] и Файкс [102] обходят
некоторые проблемы фрейма, используя различие между первичными и
вторичными отношениями. Модели действий определяются в терминах их
воздействия на первичные отношения. Вторичные отношения выводятся (по
мере необходимости) из первичных. Уолдингер [369, ч. 2] дает ясное
представление о проблемах фрейма, непреодолимых для правил системы STRIPS.
Хендрикс [150] предлагает приемы моделирования непрерывных действий.
Действия робота, использованные в примерах этой главы, основываются
на формулировках Даусона и Шиклоши [70]. Применение треугольных
таблиц для представления структур планов было предложено в статье Файкса,
Харта и Нильсона [105]. Там же обсуждаются стратегии выполнения
действий с помощью треугольных таблиц.
Использование регрессии для вычисления результатов применения О-пра-
вил основано на работе Уолдингера [369]. Система решения проблем STRIPS
описана Файксом и Нильсоном [103]. Версия этой системы,
рассматриваемая в настоящей главе, является несколько более упрощенной по сравнению
с оригинальной системой. Файкс, Харт и Нильсон [105] описывают, как
можно получать обобщения решений конкретных задач для робота с тем,
чтобы использовать их в качестве компонентов плана для решения более
трудных задач. Треугольные таблицы в этом процессе играют ключевую
роль.
Система GPS была разработана Ньювеллом, Шоу и Саймоном [267] (см.
также [266]). Эрнст и Ньювелл [93] описывают решение разнообразных
задач с помощью более поздних вариантов системы GPS. Эрнст [92]
представил формальный анализ свойств GPS.
Интересный пример применения идей решения задач "для робота",
отличных от области роботики, приводится Коэном [53], который описывает
систему для планирования речевых актов.
Использование формальных методов решения задач для робота было
предложено в отчетах Маккарти по системе "восприятия советов" [203,
205]. Работа по реализации такой системы была предпринята Б л эком [25].
Грин [127] был первым, кто построил полную формальную систему. В
статье Маккарти и Хейеса [209] содержатся предложения относительно
формальных методов решения задач. Ковальский [176, 179] дает
альтернативную формулировку, в которой удается обойти некоторые проблемы
фрейма для систем первого порядка. Саймон [336] обсуждает общую
проблему рассуждения относительно действий.
251
Упражнения
7.1. В языке ЛИСП команда rplaca (χ, у) изменяет структуру списка χ путем
замены части саг списка χ на у. Аналогично rplacd (χ, у) заменяет часть cdr от списка χ на у.
Представьте воздействие этих операций на списковую структуру правилами системы
STRIPS1.
7.2. Пусть вправо (х) обозначает клетку справа от клетки χ (когда такая клетка
существует) в игре в 8. Определите аналогично влево (χ), вверх (х) и вниз (х).
Напишите правила системы STRIPS для моделирования действий Я (пустая клетка) вверх,
Π вниз, Π влево, Π вправо.
7.3. Напишите простые фразы, которые выражали бы смысл, вложенный в литералы
на рис. 7.1. Разработайте множество бесконтекстных правил переписывания для
описания синтаксиса этих фраз.
7.4. Опишите, каким образом два правила системы STRIPS, pickup (χ) (т. е. взять) и
stack (χ, у) (т. е. поставить один кубик на другой) могут быть объединены в одно
макроправило put (x, у). Что является предусловиями, списком вычерчиваний и списком
добавлений для этого нового правила? Можете ли вы определить общее правило для
создания макроправил из компонент?
7.5. Говоря о ситуации в мнре кубиков, представленной на рис. 7.1, определим
предикат ABOVE (т.е. "выше") в терминах ON (т.е. "на") следующем образом:
ON(x,y)=>ABOVE(x,y)
ABOVE(x,y) Λ ABOVE(yyz)^ ABOVE(x,z).
Проблемы фрейма, вызываемые явным вхождением таких предикатов в описания
состояний, делает трудной задачу определения П-правил для системы STRIPS. Обсудите
трудность и предложите какие-либо решения.
7.6. Рассмотрите следующие рисунки:
\/&\
А
Щ
© □ О О Δ
Опишите каждый из них правильно построенными формулами исчисления предикатов
и постройте правило системы STRIPS, применимое и к описанию Л, и к описанию В\
будучи примененным к описанию А, оно создает описание В, а будучи примененным к
описанию С - описание одного из рисунков 1-5. Обсудите проблему построения системы,
которая могла бы создавать такие описания и правила автоматически.
7.7. Два сосуда F1 и F2 имеют соответственно емкости С1 и С2. Правильно
построенная формула CONT (х, у) обозначает, что сосуд jc содержит у объемных единиц
жидкости. Напишите правила для системы STRIPS, которое моделирует следующие
действия:
а. Перелить все содержимое сосуда F1 в сосуд F2.
б. Наполнить сосуд F2 содержимым (частью) сосуда F1. Видите ли вы какие-либо
трудности, которые могут возникнуть при попытке использовать эти правила в
обратном направлении? Дайте анализ.
1 Напомним:саг (х) представляет собой первый элемент списках, a.cdr (x)
сок, остающийся после удалений первого элемента из списка х. - Прим. ред.
252
7.8. Задача об обезьяне и бананах часто используется в литературе по
искусственному интеллекту для иллюстрации соображений, касающихся построения планов. Эта
задача может быть сформулирована следующим образом:
Обезьяна находится в комнате, содержащей ящик и связку бананов. Бананы
свисают с потолка так, что обезьяна не может до них дотянуться. Как может обезьяна
заполучить бананы?
Покажите, как эта проблема может быть представлена таким образом, чтобы система
СТРИПС была в состоянии создать план, состоящий из следующих действий: подойти
к ящику, подвинуть ящик под бананы, взобраться на ящик, схватить бананы.
7.9. Имея в виду задачу складывания кубиков в пирамиду, решенную системой
STRIPS на рис. 7.9, предложите оценочную функцию, которую можно было бы
использовать для направления процесса поиска.
7.10. Напишите правило для системы STRIPS, которое моделирует действие обмена
содержимым между двумя регистрами. (Предположите, что это действие может быть
выполнено непосредственно без явного обращения к третьему регистру.) Покажите,
как система STRIPS создала бы программу (используя это действие) для изменения
содержимого регистров Χ, Υ и Ζ сА,ВнС соответственно шС,ВиА.
7.11. Предположите, что в начальном описании на рис. 7.1 вместо выражения ΗΛΝ-
DEMPTY содержится выражение HANDEMPTYV HOLDING (D) К Обсудите то, как
можно модифицировать систему STRIPS, чтобы построить план с '^текущим условием",
разветвляющийся на HANDEMPTY. (Условные планы полезны, когда в момент планирования
значения истинности являются неизвестными и могут быть выявлены в процессе его
реализации.)
7.12. Обсудите, как программы с использованием правил (подобные тем, что
описаны в конце гл. 6) могут быть применены для решения задач складывания кубиков
в пирамиду. (Потребуется утверждение типа DELETE.) Проиллюстрируйте примером.
7.13. Найдите доказательство для целевой ппф
(3s){POSS(s) Л HOLDS[on(B,C),s] Л HOLDS[on(A,B\s]}
исходя из утверждений 1-14 формулировки Ковальского, описанной в подразд. 7.6.2.
Воспользуйтесь любой системой дедукции, описанной в гл. 5 и 6.
7.14. Животное-робот Ровер находится вне дома и хочет попасть внутрь. Ровер не в
состоянии сам открыть дверь и впустить себя в дом, но он может лаять, и этот лай
обычно приводит к тому, что дверь открывается. Другой робот, Макс, находится в доме.
Макс может открыть двери, любит покой и тишину. Макс может утихомирить Ровера,
открыв дверь. Предположим, что и Макс, и Ровер имеют в качестве систем построения
планов системы STRIPS и системы исполнения, основанные на треугольных таблицах.
Определите правила системы STRIPS и действия для Ровера и Макса и опишите
последовательность этапов планирования и выполнения, которые приводят к равновесию.
ГЛАВА 8
РАЗВИТЫЕ СИСТЕМЫ ПОСТРОЕНИЯ ПЛАНОВ
В этой главе мы продолжим рассмотрение систем построения планов для
робота. Сначала обсудим две системы, которые могут работать в случае
взаимодействия.целей более тонко, чем STRIPS. Затем рассмотрим
различные иерархические методы построения плана.
8.1. СИСТЕМА RSTRIPS
Эта система представляет собой модификацию системы STRIPS, в
которой для преодоления трудностей, связанных с взаимодействием целей, ис-
1 См. примечания к с. 216. - Прим. ред. -*з
пользуется некоторый механизм регрессии целей. Такой механизм не
позволяет системе RSTRIPS применять П-правило 171, которое вступило бы в
противоречие с некоторым уже достигнутым предусловием Р, необходимым
для другого П-правила 772, появляющегося в плане в дальнейшем.
Поскольку 772 появляется позднее 711, необходимо, чтобы у правила 772 имелось
некоторое дополнительное недостигнутое предусловие F , которое привело бы
к необходимости применения 711 первым. Вместо Я7 в системе RSTRIPS
происходит реорганизация плана путем регрессии I* на том П-правиле, которое
обеспечивает Р. Теперь достижение такого I* , которое получается при
указанной регресии, больше не противоречите.
Некоторые методы и предпосылки, используемые в системе RSTRIPS,
лучше всего показать на примере задачи, в которой цели не приходят во
взаимодействие. После их объяснения мы перейдем к детальному описанию того,
как система RSTRIPS действует в случае взаимодействия целей.
Пример 1. Воспользуемся одним из простейших примеров из мира блоков,
приведенных в последней главе. Предположим, что целью является [ON (С, В) Λ ON (A, Q ]
и что начальное состояние такое, как на рис. 7.1. Пока применяется первое П-правило
CHCTeMaRSTklPS работает точно так же, как система STRIPS. Однако в ней уже
встречается некоторая особенность в отношении использования стека целей. В частности,
когда проводится упорядочение компонент выше некоторой составной цели в стеке, то эти
компоненты вместе с их составной целью группируются в пределах некоторой
"вертикальной" скобки в стеке. Вскоре мы увидим смысл такого группирования.
Часть, соответствующая стеку целей глобальной базы данных, порождаемой
системой RSTRIPS в момент, когда первое П-правило, а именно unstack (С, А), может быть
применено, выглядит следующим образом:
\HANDEMPTY Λ CLEAR (С) Λ ON (Qγ)
unstack(C,j)
VHOLDING(C)
CLEAR(B)
LHOLDING(C) Λ CLEAR(B)
stack(C,#)
VON(C,B)
ON(AX)
[_ON(C,B)A ON (AX)
Стек целей совпадает с тем, который порожается системой STRIPS на этом этапе
решения задачи (см. рис. 7.9). Для большей ясности в примерах настоящей главы мы
сохраняем условие, достигаемое применением П-правила точно под тем П-правилом, которое
приводит к нему в стеке целей. Обратите внимание на то, что вертикальные скобки
объединяют в одну группу компоненты цели и составные цели.
При подстановке { А/у } система RSTRIPS может применить правило unstack (С, А),
поскольку предусловия этого правила (наверху в стеке) приводятся в соответствие с
описанием начального состояния. Вместо удаления такого выполненного предусловия
и соответствующего П-правила из стека целей (как делалось в ситсеме STRIPS) система
RSTRIPS оставляет эти элементы в стеке и непосредственно под условием HOLDING
(О размещает маркер, чтобы показать, что HOLDING (С) только что было достигнуто
вследствие применения такого П-правила. Когда система проверяет условия в стеке,
то положение маркера корректируется с тем, чтобы он всегда находился точно над
следующим условием в стеке, которое еще предстоит удовлетворить. После применения
правила unstack (С, А) стек целей имеет вид:
254
[ HANDEMPTY Λ CLEAR(C) Λ ON (С, А)
unstack(C,v4) |
[*HOLDING(C) Ft~]
L.HOLDING(C) Λ CLEAR(B) "/////////////"""""""
stack(C^)
[~0ЛГ(С,Я)
0ЛГ(Л,С)
LCW(C,£)A ON(AX)
Горизонтальная линия в стеке и есть такой маркер. Все П-правила выше маркера были
применены; условие, расположенное точно под маркером, а именно CLEAR (В), теперь
должно быть подвергнуто проверке. (Для ясности справа от нашего стека целей
приводится рисунок, соответствующий состоянию, порождаемому в результате применения
П-правил над маркером.)
Когда маркер пересекает вертикальную скобку (как это происходит в нашем стеке
целей), то над маркером имеются цели, которые уже были достигнуты и которые
являются компонентами составной цели, расположенной под маркером в конце скобки.
Система RSTRIPS отмечает эти компоненты и "защищает" их. Такая защита означает,
что эта система будет следить за тем, чтобы в пределах вертикальной скобки не
применялось никакое П-правило, которое вычеркивало бы или делало ложными
защищенные компоненты цели. Защищенные цели обозначены знаком "*" в нашем стеке целей.
В предыдущей главе всегда, когда в системе STRIPS удовлетворялись
предварительные условия для некоторого П-правила в стеке целей, это правило затем применялось
к описанию текущего состояния, чтобы создать новое описание состояния. В системе
RSTRIPS нет необходимости выполнять этот процесс явным образом. Вместо этого
часть стека целей, расположенная над маркером, указывает на последовательность П-
правил, примененных к данному моменту времени. Исходя из такой
последовательности П-правил система RSTRIPS всегда имеет возможность найти то описание состояния,
которое было бы результатом применения этой последовательности к начальному
состоянию. На самом деле в этой системе никогда нет необходимости вычислять описание
состояния такого типа. Самое большее, что может потребоваться, это установить,
соответствуют ли определенные подцели возникающему текущему описанию состояния.
Такое вычисление может быть проведено с помощью регрессии подцели, которая
подвергается проверке, в обратном направлении на последовательности П-правил,
примененных к настоящему моменту. Например, в случае показанного стека система RSTRIPS
должна теперь решить, соответствует ли условие CLEAR (В) тому описанию состояния,
которое достигается после применения правила unstack (С, А). Регрессия условия
CLEAR (В) на этом П-правиле порождает CLEAR (В), которое соответствует
начальному описанию состояния, а поэтому должно соответствовать и последующему
описанию. (Если бы CLEAR (В) не оказалось в соответствии с начальным состоянием, то
в системе RSTRIPS в стек целей были бы внесены П-правила для достижения такого
результата.)
На этом этапе в системе RSTRIPS удовлетворены оба предусловия для stack (С, В),
поэтому П-правило применяется (путем перемещения маркера) и ON (С, В)
защищается. (Поскольку теперь вся скобка для составной цели HOLDING (С) Λ CLEAR (В) рас-
255
полагается выше маркера, то система снимает защиту с условия HOLDING (С).) Далее
система R STRIPS пытается достичь ON (А, С). Окончательно, она создает стек целей:
[ HANDEMPTYЛ CLEAR(C) Л ON(C,A)
unstack(C^i)
Г HOLDING {С)
CLEAR(B)
IHOLDING(C) Л CLEAR(B)
stack(C,B)
Г* ON (С, В)
Ι [ HANDEMPTY Л CLEAR(A ) Л ONTABLE(A )
pickap(A)
Г HOLDING(A)
CLEAR(C)
lHOLDING(A)A CLEAR(C)
stack(^4,C)
ON(AX)
L ON(C,B)AON(A,C)
Предусловия для pickup {А) находятся в соответствии с текущим описанием
состояния, в чем можно убедиться путем их регрессии на последовательности П-правил,
примененных к текущему моменту, а именно | unstack (С, А), stack (С, В) \ . (Условие CLEAR
(А) не соответствовало начальному состоянию, но оно становится истинным в текущем
состоянии вследствие применения правила unstack (С, А). Условие HANDEMPTY
соответствовало исходному состоянию, затем было вычеркнуто после применения правила
unstack (С, А) и снова стало истинным после применения правила stack (С, В). Процесс
регрессии показывает, что эти условия в настоящее время являются выполненными.)
Прежде чем П-правило pickup (А) может быть применено, система RSTRIPS Должна
проверить, что его применение не приведет к нарушению ни одной из защищенных
подцелей. На данном этапе защищено ON (С, В). Проверка на нарушение делается с
применением регрессии ON (С, В) на pickup (А). Нарушение защищенного состояния ON (С,
В) произошло бы в том случае, если бы его регрессия дала F (т.е. только если бы
ON (С, В) вычеркивалось при применении П-правила pickup (А)). Поскольку все
состояния защищенности сохраняются, то П-правило pickup (А) может быть применено.
Маркер перемещается точно под HOLDING (А) и HOLDING (А) защищается. (ON (С,
В) сохраняет свое состояние защищенности.)
Регрессия на последовательности П-правил другого предусловия для stack (A, Q, а
именно CLEAR (О, показывает, что оно соответствует рассматриваемому описанию
текущего состояния. Таким образом, составное предусловие для правила stack (А, С)
удовлетворено. Регрессия ранее решенной компоненты основной цели - ON (С, В) - на
stack (А, С) показывает, что ее состояние защищенности не будет нарушено, так что
система RSTRIPS применяет stack (А, С) и передвигает маркер под последнее условие
на стеке. Система STRIPS может теперь прекратить свою работу, поскольку все
элементы на стеке находятся выше маркера. В этот момент П-правила в стеке целей дают
решающую последовательность вида {unstack (С, Л), stack (С, В), pickup (Л), stack
(А, С)}.
В приведенном примере все прошло гладко, поскольку не было нарушено
состояние защищенности. Однако в случае взаимодействия целей мы столкнемся с
нарушением этого состояния. Опишем, как система RSTRIPS справляется с нарушением.
ш
шжжжжш
256
Пример 2. Представим ту же исходную конфигурацию, что показана на рис. 7.1.
Однако здесь мы попытаемся разрешить более сложную составную цель [ON {Л, В) Л
Л ON (В, С)]. Все развивается, хорошо до момента, когда система RSTRIPS образует стек
целей:
" ONTABLE(A)
[HANDEMPTY Л CLEAR(C) Л ON (С, А )
unstack(C,^()
CLEAR(A)
[HOLDING(C)
putdown(C)
HANDEMPTY
L ONTABLE(A ) Л CLEAR(A ) Л HANDEMPTY
pickup(y4) |
HOLDING(A) π
HoYDINViA) A CLEAR(B) ^//ЖШ/ЖШ
stacks, Я)
■~ *ON(A,B)
^*ONTABLE(B)
[HANDEMPTY Л CLEAR(z) Л ON (ζ, Β)
unstack(z,i?)
L ONTABLE(B) Л CLEAR(B) Л HANDEMPTY
pickup(2?)
CL£4/i(C)
IHOLDING(B) Л CL£4tf(C)
stack(#,C)
CW(£,C)
L ON(A,B)AON(BX)
Рассматривая стек целей, расположенный выше маркера, можно увидеть ту
последовательность П-правил, которая была применена к описанию начального состояния:
{ unstack (С, А), putdown (О, pickup (A), stack (А, В)} . В настоящий момент подцели
ON (А, В) и ONTABLE {В) решены этой последовательностью и защищены. Заметим,
что предусловия П-правила unstack (А, В) удовлетворяются, но его применение
привело бы к нарушению защищенного состояния цели ON (А, В). Как следует поступить?
В системе RSTRIPS сначала осуществляется проверка с тем, чтобы установить,
может ли условие ON (А, В) быть достигнуто применением последовательности
П-правил, расположенных ниже маркера и выше конца соответствующей ему скобки. Лишь
в конце скобки необходимо, чтобы ON (А, В) было истинным. Положим, что одно из
П-правил в пределах скобки обладает тем свойством, что оно может еще раз достигнуть
такого условия. Если это так, то "временные" нарушения могут быть допущены. В
нашем случае ни одно из правил не может заново достигнуть ON (А, В), так что система
RSTRIPS должна предпринять определенные шаги, чтобы избежать нарушения
защищенного состояния.
257
В системе RSTRIPS обращается внимание на то, что составной целью в конце скобки,
относящейся к нарушаемой цели, является ON {Л, В) Л ON (В, Q. Необходимое для
решения одной из составляющих П-правило ON {В, Q приведет к нарушению
защищенности другой составляющей. Назовем цель ON {В, С) составляющей, нарушающей
защищенность. Система пытается избежать этого нарушения путем регрессии составляющей,
нарушающей защиту, т. е. ON (В, Q, проходя назад по последовательности П-правил
(выше маркера), которые уже были применены, пока не будет рассмотрена его
регрессия на том П-правиле, при котором достигается защищенная подцель. Поскольку
последнее П-правило, которое необходимо было применить, т.е. stack {А, В), также
является правилом, которое достигает ON (Л, В), то система RSTRIPS получает
регрессию ON (В, О на stack (А, В), что приводит к ON (В, С). В этом случае регрессия не
изменяет подцели и система пытается теперь достичь цели, полученной после регрессии,
в той точке плана, которая непосредственно предшествует применению правила stack (A,
В). Этот процесс регрессии порождает в системе стек целей:
ON TABLE {А)
[HANDEMPTY A CLEAR(C)A ON(C,A)
unstack(C,/l)
CLEAR(A)
[HOLDING{C)
HANDEMPTY /////////a
L ONTABLE(A ) Λ CLEAR(A ) Λ HANDEMPTY
pickup(/i)
r~*HOLDING(A)
*CLEAR(B)
ЖШШШШШ'
ON(BX)
HOLDING(A ) A CLEAR(B) A ON(B,C)
stack(A,B)
ON(A,B)
VQN{A,B)/\ ON(BX)
Составная цель ON {A, B) A ON (В, О в конце скобки, в которой было обнаружено
потенциальное нарушение, в стеке сохранена. Другие элементы, расположенные ниже
ON (А, В), в предыдущем стеке были частью в настоящее время отмененного плана
достижения ON (В, С). Эти элементы из стека удалены. План с целью достижения ON
(А, В) путем применения stack (А, В) остается справедливым и в стеке сохранен.
Заметьте, что мы объединили цель после регрессии ON (В, С) с составным
предусловием непосредственно над П-правилом stack {А, В). Поскольку маркер пересекает
скобку, то подцели HOLDING (A) n CLEAR (В) защищены.
В системе RSTRIPS снова начинается работа над этим стеком целей и никаких
других потенциальных нарушений защищенности не обнаруживается до тех пор, пока не
будет построен такой стек:
~ ONTABLE(A)
[HANDEMPTY A CLEAR(C) A ON(C,A)
unstack(C,>4)
CLEAR(A)
[HOLDING(C)
258
ι
putdown(C)
HANDEMPTY
ONTABLE(A) A CLEAR (A ) Λ HANDEMPTY
pickup(i4 )
*HOLDING(A)
*CLEAR(B) ,
~*ONTABLE(B) гЬ
*CLEAR{B) Ш
/ЯЯШШШЯШ?
{HOLDING:(x)
putdown(x)
#Л#/)£МРГУ
. ONTABLE(B) A CLEAR(B) A HANDEMPTY
pickup(J?)
СХ£ЛЛ(С)
IHOLDING(B) A CLEAR(C)
stack(£,C)
"ОЛГ(В,С)
HOLDING(A ) Л CLEAR(B) A ON{B,C)
stack(A,B)
ON(A,B)
[ON(A,B)AON(B,C)
Использование регрессии в системе RSTRIPS показывает, что предусловие для
putdown (А) соответствует текущему описанию состояния, но применение правила
putdown {А) привело бы к нарушению защищенности подцели HOLDING {А). Это
нарушение не носит временный характер. Чтобы избежать такого нарушения, система
RSTRIPS проводит регрессию компоненты, нарушающей защищенность ON (В, Q , еще
дальше в обратном направлении, на этот раз на П-правиле pickup (A).
После регрессии стек целей приобретает следующий вид:
~*ONTABLE(A)
[ HANDEMPTY A CLEAR(C) A ON (С, А )
unstack(C, Λ)
*CLEAR(A)
[HOLDING(C)
putdown (С) t I |
*HANDEMPTY
ON(B,C)
ONTABLE(A ) Λ CLEAR(A ) Λ HANDEMPTY
AON(B,C)
pickup (Л)
HOLDING(A)
CLEAR(B)
259
lHOLDING(A) Λ CLEAR(B)
stacks, В)
ON {Л, В)
L ON{A,B)/\ON{B,C)
Здесь план достижения условия ON (А, В) сохранен, но план достижения условия
ON (В, О, нарушающий защиту, исключен.
Начиная опять с этого результирующего стека целей, система RSTRIPS
обнаруживает другое возможное нарушение защищенности, когда образуется стек целей
следующего вида:
'*ONTABLE(A)
[HANDEMPTYЛ CLEAR(C)A ON(CyA)
unstack (С, А)
*CLEAR(A)
[HOLDING(C) r1-,
putdown(C) ΠΊ m rj] '
*HANDEMPTY /Я?М%ЯШЯЯМ&
[ONTABLE(B) Л CLEAR(B) Л HANDEMPTY
pickup (/?)
'HOLDING(B)
CLEAR(C)
IHOLDING(B) Л CLEAR(C)
stack (В, С)
OTV(£, С)
ONTABLE(A ) Л CLEAR(A ) Л HANDEMPTY
AON(ByC)
pickup (Л)
HOLDING (A)
CLEAR(B)
HOLDING (A ) Л CLEAR (В)
stack (Л, В)
ON (А, В)
ΟΝ(Α,Β)Λ ON(B,C)
Если бы применялось правило pickup (В), то была бы нарушена защищенность
HANDEMPTY. Но теперь такое нарушение носит лишь временный характер. Одно из идущих
далее П-правил, а именно stack (В, С) (в пределах относящейся к делу скобки),
приводит к повторному достижению условия HANDEMPTY, так что с этим нарушением мы
можем примириться и двигаться далее к решению.
В данном случае система RSTRIPS находит более короткую решающую
последовательность по сравнению с той, какую могла бы найти в этой задаче система STRIPS. В
решение, найденное системой RSTRIPS, входят П-правила, расположенные над маркером
в окончательном стеке целей, а именно [unstack (С, Л), putdown (О, pickup (В),
stack {В, Q, pickup (A), stack (А, В)}.
260
Пример 3. В качестве другого примера рассмотрим использование системы RSTRIPS
в задаче обмена содержимого двух регистров. П-правило имеет вид
assign(w,M,.s)
Ρ: CONT(r,s) A CONT(u,t)
D: CONT(u,t)
A: CONT(u,s)
Нашей целью является достижение [CONT (Χ, Β) Λ CONT (У, A) ] исходя из начального
состояния [CONT (Χ, Α) Λ CONT (Υ, В) Λ CONT (Ζ, О)]1.
Трудность возникает в момент, когда система RSTRIPS создает следующий стек
целей:
[CONT{ Y,В) A CONT(X,А)
assign(^, У,Λ,В)
r*CONT(X,B)
Z:0 Х:В Y:B
rcONT(rl,A)
\CONT(Yjl)
[CONT(rl,A)A CONT( Y,tl)
J assign( Y,rl,tl,A)
CONT(Y4A)
L CONT(X,B) A CONT( Y,A )
(Мы показываем справа от стека целей результат применения правила присваивания
assign (Χ Υ, А, В). Условие CONT (r 1, А) не может быть удовлетворено, поскольку
после применения assign (Χ, Υ, А, В) не существует никакого регистра, в качестве
содержимого которого выступало бы А. Здесь система RSTRIPS сталкивается с
невозможной целью, а не с потенциальным нарушением защищенности. Регрессия цели является
полезным приемом также и в этом случае. Указанная невозможная цель подвергается
регрессии на последнем из П-правил в надежде на то, что тогда ее достижение окажется
возможным.
Регрессия условия CONT {г 1,А) на правиле assign (Χ, Υ, А, В) дает выражение2
[CONT (r U A) A -EQUAL (г 1, X) ].
Результирующий стек целей имеет вид:
Z:0 X:A Y:B
fCONT(rl,A)
\^EQUAL(rl,X)
СО NT(X, A)
\C0NT(Y,B)
CONT(X,A) A CONT( Υ,Β) A CONT(rl,A )
L Λ ~EQUAL{rl,X)
assign(X,Y,A,B)
1 Здесь CONT (X, А) означает, что А содержится в регистре (ячейке) X. - Прим. ред.
2 EQUAL {Χ, Υ) означает, что регистры X н Υ совпадают (т.е. это один регистр). -
Прим. ред.
261
CONT {X, В)
CONT(Yjl)
CONT(rl,A)/\ CONT( Yjl)
assign( Y,rl,tl,A)
CONT( Y,A)
CONT(X,B) A CONT( Y,A )
Далее система RSTRIPS пытается разрешить CONT (г 1, Л). Ее нельзя просто
привести в соответствие (сопоставить) с фактом CONT {X, А), потому что подстановка \Xjrl j
сделала бы следующую цель, т. е. -EQUAL {X, X), невозможной. Единственной
альтернативой является повторное применение П-правила assign. Эта операция приводит к
следующему стеку целей :
Z:0 X:A Y:B
CONT (r, A)
CONT(rlj)
CONT(r,A) Λ CONT(rlj)
*ssign(rl,rj,A)
^l0ONT{rl,A)
^EQUAL{rl,X)
С ON Τ (X, A)
CONT(Y,B)
CONT(X,A) Λ CONT( Υ,Β) Λ CONT(rl,A )
Λ ~EQUAL(rl,X)
assign(*, Г,Л,В)
CONT {Χ, Β)
CONT(Υ\tl)
CONT(rl,A ) Λ CONT( Yjl)
assign( Y,rl,tl,A)
CONT (Y, A)
CONT(X,B) Λ CONT( Y,A )
Теперь система RSTRIPS может сопоставить CONT (г, А) с фактом CONT (X, А).
Затем она может сопоставить CONT (г 1, t) с фактом CONT (Z, 0). Эти сопоставления
открывают возможность для применения правила assign (Ζ, Χ, 0, А). Следующая
подцель в стеке, а именно -EQUAL (Ζ, А), получает оценку Т, а все другие подцели над
assign (Χ, Υ, А, В) оказываются сопоставимыми с фактами. Далее в системе RSTRIPS
подцель CONT (Υ, tl) сопоставляется с фактом CONT (Υ, В) и применяется правило
assign {Υ, Ζ, В, А). После этого маркер перемещается в основание стека и процесс
завершается результирующей последовательностью {assign (Ζ, X, 0, A), assign (Χ, Υ, Α,
Β), assign (Υ, Ζ, Β, Α)}.
Читатель может возразить, что мы дали "наводящий вопрос" в этом
примере, введя явным образом в рассмотрение третий регистр. Так же просто
было бы рассмотреть еще одно П-правило с названием, скажем genreg,
которое позволило бы при необходимости создавать новые регистры. Тогда
вместо того, чтобы приводить в соответствие подцель CONT (r7, t) с фактом
262
CONT (Ζ, 0), как было сделано в нашем примере, в системе RSTRIPS
можно было бы просто применить genreg к CONT (rl, t) для создания нового
регистра. Результатом применения genreg была подстановка имени нового
регистра вместо г 7 и, скажем, 0 вместо t.
8.2. СИСТЕМА DCOMP
Нашу следующую систему для работы со взаимодействующими целями
назовем DCOMP. Она работает в двух основных фазах. В фазе 1 система
создает временное "решение" в предположении, что взаимодействия нет.
Выражения для целей представляются в форме графов типа И/ИЛИ, а О-правила
применяются к литеральным вершинам, которые не соответствуют
начальному описанию состояния. Эта фаза завершается созданием согласованного
графа решения, концевые вершины которого оказываются в соответствии
с начальным описанием состояния. Этот граф решения служит в качестве
промежуточного решения задачи и, как правило, должен быть переработан на
фазе 2 с тем, чтобы снять взаимодействия.
Граф решения для графа типа И/ИЛИ накладывает на шаги решения
только ограничение частичного упорядочения. Если бы не было взаимодействий,
то правила из графа решения, не связанные через родительские вершины,
можно было бы применять параллельным, а не последовательным образом.
Иногда конструкция робота допускает выполнение нескольких действий
одновременно. Например, робот в состоянии двигать рукой в процессе
перемещения. В той мере, в какой возможны параллельные действия,
желательно выражать последовательности действий робота как частичное
упорядочение действий. При достижении некоторой конкретной цели чем меньше
ограничений накладывается на порядок выполнения действий, тем лучше. Граф
решения на графе типа И/ИЛИ, таким образом, выглядит как хороший
формат представления действий для достижения некоторой цели.
В фазе 2 система DCOMP исследует этот промежуточный граф решения на
взаимодействие целей. Некоторые правила, например, разрушают
предусловия, необходимые для правил в других ветвях графа. Эти взаимодействия
накладывают дополнительные ограничения на порядок применения правил.
Часто нам удается найти более ограниченное частичное упорядочение
(возможно, линейную последовательность), которое удовлетворяет всем
указанным дополнительным ограничениям. В этом случае результатом фазы 2
является некоторое решение задачи. Когда же дополнительные ограничения на
порядок вступают в противоречие, то простого решения не получается и
система DCOMP должна осуществить более радикальные изменения в плане,
найденном в фазе 1.
Эти соображения лучше всего проиллюстрировать на примерах.
Предположим, мы снова воспользуемся наиболее простыми примерами из гл. 7.
Описание исходного состояния показано на рис. 7.1, а целевое состояние
— [ON (С, В) A ON {А, С)]. В фазе 1 система применяет О-правила до тех
пор, пока все подцели не окажутся приведенными в соответствие с
начальным описанием состояния. Нет необходимости в регрессии условий на П-пра-
вилах, поскольку в этой системе предполагается отсутствие взаимодействий.
Согласованный граф решения, который может быть получен на фазе 1,
показан на рис. 8.1. (На рис. 8.1 мы не показали дуги соответствия; вопрос о
Рис. 8-1. Решение, получаемое в фазе 1
{с/у)
[С/у]
согласованных подстановках не является предметом обсуждения в этих
примерах. Подстановка, указанная вблизи концевой вершины, унифицирует
литерал, помечающий данную вершину, с некоторым литералом-фактом.) На
этом графе О-правила помечены теми П-правилами, которые их породили,
поскольку в дальнейшем мы будем упоминать различные свойства этих
П-правил. Все применения правил на графе пронумерованы (произвольно)
для облегчения обсуждения. Заметим, что мы также занумеровали
"операцию" (номером 0), в ходе которой цель [ON (А, С) Λ ON (С, В)]
расщепляется на две компоненты — ON (А, С) и ON (С, В). Можно представить себе,
что это обратное правило расщепления основано на некотором
воображаемом П-правиле "слияния", которое в окончательном варианте плана
объединяет эти две компоненты в конечную цель.
Мы видим, что решение состоит из двух последовательностей П-правил,
выполняемых параллельно, а именно {unstack (А, С), stack (С, В)} и [uns-
tack (С, Л), pickup (Л), stack (А, С) } . Вследствие взаимодействия целей мы,
264
очевидно, не можем выполнить эти последовательности параллельно.
Например, П-правило 5 вычеркивает предусловие HANDEMPTY, необходимое для
П-правила 2. Поэтому мы не можем применять правило 5 непосредственно
перед правилом 2. Что еще хуже, П-правило 5 вычеркивает предусловие
HANDEMPTY, необходимое для идущего сразу за ним П-правила 4. Граф,
представленный на рис. 8.1, имеет несколько таких дефектов, связанных с
взаимодействиями.
Процесс выделения некоторого частичного упорядочения без
взаимодействий основан на изучении каждого П-правила, упоминаемого в графе
решения (включая фиктивное правило слияния), с целью проверки, что его
предусловия приводятся в соответствие с описанием состояния в тот момент,
когда оно применяется. Обозначим через Q;· ί-й литерал предусловия для
j -го П-правила в этом графе. Для каждого такого Cjj в графе построим два
(возможно, пустых) множества. Первое множество Djj представляет собой
множество П-правил, определенных на графе, которые вычеркивают Сц и не
являются ни предшествующими правилу j на графе, ни представляющими
собой само правило /. Это множество назьюается множеством
"разрушителей" для Q ·. Любой разрушитель Сц мог бы (как П-правило) нарушить
это предусловие для П-правила j ; таким образом, порядок появления
разрушителей по отношению к П-правилу / роли не играет. Если разрушитель
является дочерним для правила j на графе, то возникают особые трудности.
(Мы не интересуемся самим правилом j или любым предшествующим ему,
которые могли бы вычеркнуть С,-у , поскольку "предназначение" С,·.· к тому
моменту уже было реализовано.)
Второе множество Aj- , построенное для Cjj, представляет собой
множество П-правил, определенных данным графом, которые добавляют Cjj и не
являются ни предшествующими правилу / на графе, ни самим правилом; . Это
множество называется множеством создателей С^ . Любой создатель С,·,·
является важным, поскольку порядок может быть выбран таким, при котором
Cjj появляется после разрушителя и перед П-правилом / , таким образом
аннулируя действие этого разрушителя. Точно так же, если некоторое правило,
скажем к, было использовано в первоначальном графе решения для
достижения условия Cji, мы могли бы применить другой создатель перед
П-правилом j вместо П-правила к> исключив, таким образом, правило к (и всех
его потомков!). Очевидно, что Пправила/ и любые его предшественники не
представляют для нас интереса, поскольку они применяются уже после
того, когда требовалось условие Cjj .
На рис. 8.2 мы показываем всех создателей и разрушителей для всех
условий на графе.
Мы имеем частичное упорядочение без взаимодействия, если для
каждого Cjj в графе выполняется любое из двух условий:
1. П-правило j встречается перед всеми элементами Djj. (В этом случае
условие Cjj не вычеркивается до момента, следующего за применением
П-правила/.)
2. Существует некоторое правило в Ац , скажем правило к, такое, что
П-правило к появляется перед П-правилом ; и ни один элемент из Djj не
попадает между П-правилами к и; .
В соответствии с этим граф решения на рис. 8.2 не является упорядоче-
265
HOLDING {С )
Создатели: 5,2
stack (С/?)/ Ш
CLEAR(H)
Создатели: 4
unstack(C/l)
Создатели: 1
Разрушители: 2,5
pickupM)
Создатели: 3 Разруши- Разруши-
Разрушители: тели: 3,5 тели:5
4,5
Создатели: 1 Создатели: 2,5
Разрушители: 2,5
unstack(C\4)
Создатели: 1 Создатели: 1 Разрушители; 2
Разрушители: 2
Разрушители: 2
Рис. 8.2. Решение фазы 1 с указанием списков создателей и разрушителей
нием без взаимодействия, потому что, например, П-правило 2 в этом
упорядочении не предшествует П-правилу 5 (и П-правило 5 вычеркивает
предусловия П-правила 2).
В фазе 2 система DCOMP старается преобразовать частичное упорядочение
в упорядочение без взаимодействия. Часто такое преобразование
оказывается возможным. Имеются два основных приема для преобразования
упорядочения. Мы можем еще более ограничить упорядочение, чтобы
удовлетворить одному из двух условий без взаимодействия, сформулированных
выше, или же отбросить некоторое П-правило (и его дочерние правила) из
данного графа, если результат его применения может быть достигнут путем
ограничения на порядок одного из других создателей.
Например, на рис. 8.2 П-правило 3 является разрушителем для условия
CLEAR (О П-правила 2. Если в силу установленного порядка П-правило 2
266
будет предшествовать П-правилу 3, то П-правило 3 больше не будет
вычеркивать это условие. Точно так же П-правило 5 является разрушителем для
условия HANDEMPTYП-правила 4. Очевидно, мы не можем сделать так,
чтобы П-правило 4 располагалось перед П-правилом 5; оно уже является
дочерним для П-правила 5 в нашем частичном упорядочении. Но мы могли бы
вставить создателя, т.е. П-правило 1, между Π-правилами 5 и 4. Или же,
если П-правило 2 стоит перед П-правилом 4 и после всех разрушителей
этого условия CLEAR (А), мы полностью исключаем П-правило 5, так как
CLEAR (А) добавляется П-правилом 2.
В системе DCOMP предпринимается попытка провести упорядочение,
достигнутое в фазе 1, без взаимодействия, внося дополнительное ограничение
или исключая П-правила. Общая проблема поиска приемлемого множества
таких манипуляций представляется весьма сложной, и здесь мы обсудим
ее лишь на неформальном уровне. Дополнительные ограничения на
упорядочение, накладываемые на исходный граф решения, сами должны быть
согласованными. В некоторых случаях система DCOMP не в состоянии найти
подходящие упорядочения. Однако в нашем примере система создает одно из
таких упорядочений с использованием следующих шагов:
1. Поместить П-правило 2 перед П-правилом 4 и исключить П-правило 5.
Заметим, что П-правило 4 теперь не может вычеркнуть какое-либо из
предусловий П-правила 2. К тому же поскольку П-правило 2 теперь
появляется перед П-правилом 3, то П-правило 3 не может вычеркнуть ни одно из
предусловий и П-правила 2.
2. Поместить П-правило 1 перед П-правилом 4. Поскольку П-правило 1
появляется после П-правила 2 и перед П-правилами 4 и 3, то оно
восстанавливает условия, необходимые для П-правил 4 и 3, вычеркиваемые
П-правилом 2.
Эти дополнительные ограничения приводят нас к упорядочению вида
{2, 1, 4, 3 } , соответствующему последовательности П-правил {unstack (С,
А), stack (С, В), pickup (A), stack (А, С)}.
В нашем случае упорядочение П-правил в плане образует строгую
последовательность. На самом деле те П-правила, которые мы использовали в
примерах, взятых из мира кубиков, таковы, что они могут применяться
только строго последовательно: у робота только одна рука, и она
используется в каждом действии. Предположим, у нас имеется робот с двумя руками,
каждая из которых способна выполнять все четыре действия,
моделируемые нашими правилами. Эти правила могут быть приспособлены к модели
двурукого робота, если в каждое из них включить дополнительный аргумент
типа "рука", принимающий значение "1" или "2". Точно так же и в
предикаты HANDEMPTY и HOLDING необходимо будет включить этот
дополнительный аргумент, соответствующий номеру руки. (Взаимодействия между
руками мы не будем принимать во внимание, например, когда одна рука
держит другую.) Для двурукого робота П-правила имеют вид:
1) pickup(x,/z)
P&D: ONTABLE(x),CLEAR(xlHANDEMPTY(h)
A: HOLDING(x,h)
267
2) putdown(x,/z)
P& D: HOLDING(x4h)
A: ONTABLE(x), CLEAR(x\ HANDEMPTY(h)
3) stack( jc, 7, Λ)
P&D: HOLDING(x,h\CLEAR{y)
A: HANDEMPTY(h\ON(x,v\CLEAR(x)
4) unstack( v, v\/0
P&D: HANDEMPTY( 'i).CLEAR(x), ON(jc,v)
A: HOLDING(x<h)<CLEAR(y)
С помощью только что указанных правил мы могли бы построить
частично упорядоченные планы, в которых руки " 1" и "2" выполняли бы действия
одновременно. Давайте попытаемся решить задачу складывания кубиков,
которую мы только что решили (т.е. исходя из начального
состояния,показанного на рис. 7.1, достигнуть цели [ON {А, С) A ON (С, В)]). (Предикат
HANDEMPTYв нашем описании состояния необходимо заменить на HAN-
DEMPTY (1) A HANDEMPTY (2).) На рис. 8.3 мы показали решение,
получаемое системой DCOMP в фазе 1, указав списки "создателей" и
"разрушителей" для каждого условия. Заметьте, что по сравнению с рис. 8.2 для
предикатов HANDEMPTY имеется меньшее число "разрушителей", поскольку у
робота теперь две руки.
В фазе 2 решения задачи система DCOMP могла бы определить, что П-пра-
вило 2 встречается перед П-правилом 4, так что П-правило 5 может быть
отброшено. Далее П-правило 2 должно появиться перед П-правилом 3 с тем,
чтобы избежать вычеркивания условия CLEAR (С) для П-правила 2. Теперь
если П-правило 1 встречается между П-правилами 2 и 3, то условие CLEAR
(С) для П-правила 3 будет восстанавливаться. Эти дополнительные
ограничения приводят нас к частично упорядоченному плану, показанному на
рис. 8.4.
Было бы удобно иметь возможность представлять любой частично
упорядоченный план в форме, подобной графам решения для графов типа
И/ИЛИ. Если бы вообще не было взаимодействия между подцелями в графе
решения, построенном в фазе 1, то сам этот граф был бы вполне
подходящим представлением для частично упорядоченного плана. Если бы
взаимодействия носили такой характер, что параллельного применения П-правил
не допускалось, то потребовался бы путь решения, подобный показанным на
рис. 7.5 — 7.7. А как обстоит дело в промежуточных между этими двумя
крайностями случаях? Один из способов представления плана рис. 8.4 мы
показываем на рис. 8.5. Отправляясь от целевого условия, мы работаем в
обратном направлении вдоль этого плана, строя соответствующие подделе-
вые состояния. Когда происходит расщепление плана, то это связано с тем,
что условие подцели в этой точке может быть разложено на составляющие.
Такое расщепление существует в точке, отмеченной знаком "*" на рис. 8.5.
Эти составляющие могут быть разрешены по отдельности, пока они снова
не объединятся в точке, отмеченной знаком "**". Обратите внимание, что
268
Создатели: 2
Создатели: 4
unstack(C4.7)
Создатели: 1
Разрушители: 2,5
pickup (Д. 2)
Разруши- Разруши
тел и: 3,5 тел и: 5
Создатели: 1 Разруши-
Разрушители: тели: 2
2
Рис. 8.3. Решение фазы 1 для некоторой задачи с использованием двух рук
stackM.C,.?)
stack(C,£,7)
pickup^,,?)
unstack(C./l,/)
Рис. 8.4. Частично упорядоченный план для задачи складывания кубиков двумя руками
269
ON{C,B) AON(A,C)
stack( Л ,С2)
H0LDING{A,2) ACLEAR{C) A ON(C,B)
ω
ONiCB)ACLEAR(C)
H0LD1SG{A,2)
stack(C,#,/)
pickup(/l,2)
HOLDING(CI) A CLEAR(B)
HANDEMPTY(2) A CLEAR(A) A ONTABLE(A)
Φ
HOLDING(Cl) A CLEAR(B) A HANDEMPTY(2)
ACLEAR{A) A ONTABLE(A)
unstack(C,A,l)
HANDEMPTY(1)A CLEAR(C) A ON(CA) A CLEAR(B)
A HANDEMPTY(J) A ONTABLE(A)
Рис. 8.5- Целевой граф для частично упорядоченного плана
регрессия на CLEAR (С) в вершине 1 дает Τ точно так же, как и регрессия
на CLEAR (С) в вершине 2. Структуры, подобные показанным на рис. 8.5,
Сакердоти назвал процедурными сетями [318].
8.3. СОВЕРШЕНСТВОВАНИЕ ПЛАНОВ
Иногда невозможно преобразовать решение, полученное з фазе 1, в
некоторое упорядочение без взаимодействия просто добавлением
дополнительных ограничений на упорядочение. Обычная ситуация в этом случае состоит
в том, что процесс, работающий в фазе 2, не может добиться ничего
большего, чем привести к частично упорядоченному плану, в котором некоторые
предварительные условия с неизбежностью вычеркиваются. Мы
предполагаем, что в фазе 2 создается план, в котором содержится как можно
меньше подобных вычеркиваний, а те, что делаются, являются такими,
элементы которых по оценкам легко могут быть заново воссозданы. После
создания некоторого такого "примерного" плана система DCOMP переходит к
фазе 3, призванной построить планы для повторного достижения вычеркну-
270
Создатели
тых условий с последующим "наложением" этих планов на план
(примерный) фазы 2 таким образом, чтобы конечный результат был лишен
взаимодействия.
Таким образом, главной задачей на фазе 3 является улучшение
существующего (и плохого) плана. Такой процесс улучшения планов требует
специального объяснения, так что мы переходим к рассмотрению общего
вопроса.
Обсуждение начнем с
рассмотрения еще одного
примера. Предположим,
мы пытаемся достичь
цели [CLEAR (Α) ΛΗΑΝ-
DEMPTY] исходя из
начального состояния,
показанного на рис. 7.1
(располагая теперь лишь
одной рукой). На рис. 8.6
мы приводим результат
фазы 1, показав на нем
создателей и
разрушителей условий. Здесь у нас,
очевидно, имеется такое
решение, которое не
может быть приведено к
виду без взаимодействия
Рис. 8.6. Решение фазы 1, требуюшее исправления
путем дополнительных ог- ги^· ° * > г * ν
раничений: имеется лишь одно П-правило, и оно вычеркивает "предусловие"
для правила слияния с номером 0. Единственное средство исправить эту
ситуацию — допустить такое вычеркивание и запланировать заново
достижение HANDEMPTY таким образом, чтобы условие CLEAR (А) оставалось
истинным.
Наша стратегия состоит в том, чтобы вставить, скажем, план Ρ между
П-правилом 1 и правилом "слияние". Требования, накладываемые наР,
таковы, что его предусловия должны в результате регрессии на П-правиле 1
давать условия, которые находятся в соответствии с начальным описанием
состояния, a CLE A R {А) после регрессии на Ρ не должно изменяться (так
что оно может достигаться П-правилом 1), Структура решения, которое мы
ищем, показана на рис. 8.7.
Если мы применим вариант в виде обратного правила для правила putdown
(χ) к HANDEMPTY, то получим подцель HOLDING (χ). Регрессия этой
подцели на правиле unstack (С, А) есть Τ с подстановкой {С/х } . Кроме того,
CLEAR (А) в результате регрессии на putdown (С) остается неизменном,
поэтому putdown (С) является подходящей "заплатой". Окончательное
решение изображено на рис. 8.8.
Когда возникают взаимодействия, которые нельзя снять, привнеся
дополнительные ограничения, то в общем случае ситуация часто^складывается
так же, как в последнем примере. В этих случаях система DCOMP пытается
наложить заплаты по мере необходимости, начиная с той, которая должна
271
CLEAR(A) Λ HANDEMPTY
Ρ— план достижения
\HANDEMPTY, условия
которого после регрессии на
unstacMC, А) приводятся в
соответствие с начальным
описанием состояния. При
регрессии на Ρ CLEAR И)
должно остаться
неизменным.
CLCARi А ) Л ΙΙΑΝΠΕΜΠ Υ
putdownK )
CL£AR(A)A HOLD/NC(C )
CLEAR{A) A < Предусловия Р)
unstacMC, Л >
unstack(C./l)
( Условия, которые находятся в соответствии
с начальным описанием состояния )
\ON(C А ) Л CLEARi С) Л HANDEMPTY
Рис. 8.7. Вид исправленного решения
Рис. 8.8. Исправленное решение
быть вставлена в план в самом начале (в месте, самом близком к начальному
состоянию). Такой процесс наложения заплат используется итеративным
образом до тех пор, пока не будут устранены взаимодействия во всем плане.
Проиллюстрируем процесс наложения заплат еще одним примером.
Обратимся к знакомой задаче складывания кубиков, которая начинается с
конфигурации, показанной на рис. 7.1, и в которой целью является [ON {А, В) Л
Л ON (В, С)]. Эта задача характеризуется высокой степенью взаимодействия.
Решение, получаемое на фазе 1 и показанное на рис. 8.9, содержит
взаимодействия, которые невозможно удалить добавлением дополнительных
ограничений на упорядочение. Порядок 3->5->4~>2->1 является хорошим
примерным решением, несмотря даже на то, что П-правило 3 вычеркивает
предусловие П-правила 4 -CLEAR (О, а также предусловие П-правила 5 -
HANDEMPTY. В процессе наложения заплат делается попытка заново достичь
вычеркнутых условий и в первую очередь ведется работа над более ранним
предусловием - HANDEMPTY,
Путь, соответствующий нашему примерному решению, показан на рис.
8.10. Мы не расщепляем начальную составную цель, поскольку ни одна из
компонент не может быть достигнута способом, не зависящим от порядка.
Заметим, что для создания дочерних вершин должна быть использована
регрессия и регрессия некоторых компонент цели есть Г, поэтому они и
исчезают. Здесь мы полагаем, что начало направленной дуги для О-правила
совмещается с условием, используемым при приведении в соответсвие с
некоторым литералом в списке добавлений этого правила. Условия, помеченные
звездочкой в нашем примерном плане, еще не достигнуты.
В первую очередь мы накладываем заплату между П-правилами 3 и 5 для
достижения предусловия HANDEMPTY. (Обратите внимание на сходство
этой ситуации с той, которая изображена на рис. 8.7.) Подходящей заплатой
является правило putdown (χ) с подстановкой { С/χ } . Его подцель
HOLDING (С) подвергается регрессии на правиле unstack (С, А) и дает Т. Кроме
272
Создатели: 1
'ш
fstack(A,B)
Создатели: 2
Создатели: 4
ш'
stack^.C)1
CLLAR(C)
Создатели: 3
HANDLMPTY
Разрушители: 1 Создатели: 1
Разрушители: 2,3
Разрушители: 4
Создатели: 4
Разрушители: 5
Рис. 8.9. Решение фазы 1 для задачи складывания кубиков при наличии взаимодействий
того, все условия вершины 2 (за исключением НАNDEMPTY, которое
достигается благодаря использованию правила putdown (С)) при регрессии на
putdown (С) остаются неизменными.
Теперь мы можем рассмотреть задачу поиска заплаты для второго
вычеркнутого условия — CLEAR (С). Заметим, однако, что в нашем примере
CLEAR (С) не изменяется в результате регрессии на П-правиле 5, т.е. pickup {В) ,
а затем оно подвергается регрессии на только что вставленном нами правиле
putdown (С) и дает Т. Следовательно, теперь нет необходимости ни в каких
модификациях плана и мы получаем обычное решение: {unstack (С, А), put-
down (С), pickup (В), stack (В, С), pickup (A) , stack (А, В)}.
273
stack( A
pickup(#)
0\'(C.A)
CLEAR(C)
Η A XD EMPTY
OXTABLE(B)
CLEAR(B)
0\TABLE(A)
Рис. 8.10. Приближенное решение
274
Процесс наложения заплат может оказаться более сложным, чем тот, что
мы видели на наших иллюстративных примерах. Если предусловия в
"залатанном" плане должны подвергаться регрессии лишь на строгой
последовательности (как в последнем примере), то этот процесс достаточно
очевиден, но как следует подвергать регрессии условия в случае частичного
упорядочения? Некоторые условия после регрессии могут приводиться к
условиям, которые сопоставляются с начальным описанием состояния
для всех случаев строгого упорядочения, согласующихся с нашим
частичным упорядочением, другие условия могут не обладать таким свойством
ни для каких таких случаев строгого упорядочения. Или же, возможно,
мы будем в состоянии наложить дополнительные ограничения на наш
частичный порядок, так что регрессия предусловий "залатанного" плана теперь
будет давать предусловия, которые удовлетворяются начальным
описанием состояния. Общая проблема латания планов с частичным упорядочением
выглядит достаточно сложной, и ей не уделяется пока что соответствующего
внимания.
В качестве последнего примера для системы DCOMP мы снова
рассмотрим проблему обмена содержимого двух регистров памяти. Из начального
состояния [CONT (X, А) Л CONT (Υ, В) Л CONT (Ζ, 0) ] мы хотим достичь
цели [CONT (Y, A) A CONT (X, В)]. На фазе 1 создается решение,
показанное на рис. 8.11. Создатели и разрушители условий показаны здесь обычным
образом. В решении фазы 1 имеются неизбежные вычеркивания. П-правило
1 вычеркивает предусловие для П-правила 2 и наоборот. Не могут же они
оба быть первыми! (Сакердоти назвал такой тип конфликта двойным
крестом [318].)
Создатели: 1
Создатели: 2
Разрушители: 2
assiun( \,rl 11,Η)
Рис. 8.11. Решение фазы 1 для задачи с двумя регистрами памяти
275
Создатели: 1
Создатели: 2
assign(X,rl,A.B)
Разрушители: 2
[Y/r2] [Z/rl,0/t2)
Рис. 8.12. Решение для задачи с двумя регистрами памяти
Вина за такой неизбежный конфликт вычеркиваний может быть
возложена на подстановки, используемые в одном из правил, скажем правиле 2.
Если бы мы не делали подстановку вместо rl V правиле 2, то П-правило 1
не вычеркнуло бы CONT (г7, В). Тогда П-правило 1 могло бы в результате
переупорядочения быть помещено перед П-правилом 2, чтобы избежать
вычеркивания предусловия CONT (X, А) для П-правила 1 в результате
действия П-правила 2. Таким образом, система DCOMP продолжает поиск
решения, устанавливая предусловия CONT (rl, В) для П-правила 2, но теперь
запрещая подстановку { У/г7 } .
Непрерывный поиск приводит к пробному решению, показанному на
рис. 8.12. Из этого решения система DCOMP может прийти к выводу, что
упорядочение 3 -* 1 -* 2 создает решение без взаимодействий.
Окончательное решение имеет вид {assign (Ζ, У, О, В), assign (Υ, Χ, Β, А), assign {X, Ζ,
А, В)}.
8.4. ИЕРАРХИЧЕСКОЕ ПЛАНИРОВАНИЕ
Все методы построения планов, которые мы обсуждали до сих пор,
работали на "одном уровне". Действуя, например, в обратном направлении, мы
276
рассматривали способы достижения условия цели, а затем—всех ее подцелей и
т. д. Во многих практических ситуациях мы можем рассматривать некоторые
условия целей и подцелей просто как некоторые детали и откладывать
попытки их решения до момента, когда главные шаги плана найдут свое место.
На самом деле целевые условия, с которыми мы сталкиваемся, и правила
их достижения могут быть организованы в виде некоторой иерархии, в
которой на самом нижнем уровне находятся наиболее детальные условия и
соответствующие им мелкие действия, а на высшем уровне — главные
условия и достигающие их правила.
Планируя дом, например, мы имеем задачи высокого уровня, такие как
подготовка строительной площадки, создание фундамента, возведение
каркаса, работы по отоплению и электрификации и т.п. Действия на низшем
уровне будут детализировать более точные шаги для достижения задач
высшего уровня. На самом низшем уровне действия могут быть связаны
с изготовлением гвоздей, нарезанием отрезков проволоки и т. д. Если план
в целом должен быть синтезирован на уровне самых детальных действий, то
путь к его созданию будет недопустимо долгим. Разрабатывая план от
уровня к уровню, мы приходим к тому, что план на каждом уровне имеет
разумную длину, что повышает вероятность его успешного построения. Такая
стратегия называется иерархическим планированием.
8.4.1. ОТКЛАДЫВАНИЕ ВЫПОЛНЕНИЯ ПРЕДУСЛОВИЙ
Один из простых методов иерархического планирования состоит в
выделении некоторой иерархии условий. Те условия, которые находятся на низших
уровнях иерархии, являются относительно несущественными деталями по
сравнению с теми условиями, которые находятся на высших уровнях и их
выполнение может быть отложено до момента, когда большая часть плана
будет построена. Общая мысль состоит в том, чтобы синтезировать план
поэтапно, имея дело сначала с условиями высшего уровня. Как только
будет построен план достижения условий высшего уровня (а также
предусловий высшего уровня и т.д.), то в план могут быть добавлены другие шаги
для достижения менее существенных условий и т.д. В этом методе не
требуется, чтобы сами правила были как-то проградуированы в соответствии
с иерархией. Мы по-прежнему можем располагать одним множеством правил.
Иерархическое планирование достигается путем конструирования по
уровням, используя любой из описанных одноуровневых методов. На каждом
уровне некоторые условия рассматриваются как детали, и откладываются
до следующего уровня. Условие, рассматриваемое как некоторая деталь на
определенном уровне, по существу, на этом уровне невидимо. Когда
детали проявляются внезапно на более низком уровне, то мы должны
располагать средствами для залатывания планов на более высоком уровне, чтобы
достичь этих условий.
8.4.2. СИСТЕМА ABSTRIPS
Процесс залатывания является относительно очевидным в случае
устройства принятия решения, подобного системе STRIPS, поэтому мы
проиллюстрируем процесс иерархического планирования сначала на системе STRIPS
277
как базовом устройстве решения задачи. Когда система STRIPS
видоизменяется таким образом, то она называется системой АВSTRIPS.
В качестве примера задачи рассмотрим снова цель (ON (С, В) Л ON (А,
С) ] и начальное состояние, изображенное на рис. 7.1. Такая цель легко
достигается с помощью одноуровневой системы STRIPS, но мы тем не менее ею
воспользуемся для иллюстрации работы системы ABSTRIPS.
П-правила, которыми мы пользуемся, совпадают с теми правилами,
которые применялись нами раньше, но для целей откладывания выполнения
предусловий нам необходимо определить некоторую иерархию условий
(включая целевые условия). Чтобы пример был правдоподобным, эта
иерархия должна отражать трудность, связанную с достижением различных
условий. Ясно, что главный предикат цели ON должен быть на верхнем уровне
иерархии, a HANDEMPTY должен, пожалуй, располагаться на самом нижнем
уровне, поскольку этого легко достигнуть. В нашем простом примере мы
используем только три иерархических уровня и размещаем три остающихся
предиката - ONTABLE, CLEAR и HOLDING - на среднем уровне.
Иерархический уровень каждого условия может быть показан с помощью
значения критичности, связанной с этим условием. Малые числа указывают
на низкий иерархический уровень или малую критичность условия, а
большие числа — на высокий иерархический уровень или большую критичность.
Ниже перечислены П-правила для системы ABSTRIPS, в которых значения
критичности приведены над соответствующими условиями:
1) pickup( χ)
2 2 1
P&D: ONTABLE(x), CLEAR(x), HANDEMPTY
A: HOLDING(x)
2) putdown(x)
2
P&D: HOLDING (χ)
A: ONTABLE(x\CLEAR(x\ HANDEMPTY
3) stack(x,/)
2 2
P&D: HOLDING(x),CLEAR(y)
A: HANDEMPTY,ON(x,y\CLEAR(x)
4) unstack(x,/)
1 2 3
P&D: HANDEMPTY, CLEAR(x), ON(x,y)
A: HOLDING(x),CLEAR(y)
Обратите внимание, что значения критичности встречаются как у
предусловий, так и у литералов списка вычеркиваний. Их нет над литералами
списка добавлений. Когда применяется некоторое П-правило, то все
литералы списка добавлений включаются в описание состояния.
278
Система ABSTRIPS начинает работу с рассмотрения только лишь
наибольших критичностей, а именно с критических значений, равных трем для
нашего примера. Все условия, для которых критические значения
оказываются ниже этого порога, невидимы, т.е. во внимание не принимаются.
Поскольку наша главная цель содержит два условия со значением критичности 3,
то система ABSTRIPS рассматривает одно из них, скажем ON (С, В), и
добавляет правило stack (С, В) к стеку целей. (Если бы системой ABSTRIPS
была выбрана другая компонента в начале работы, то впоследствии ей
пришлось бы возвращаться назад. Читатель, возможно, захочет просмотреть этот
путь самостоятельно.) К стеку целей не добавляется никаких предусловий
для правила stack, поскольку их значение критичности равно лишь 2 (ниже
порога) и на данном уровне они невидимы.
В результате система ABSTRIPS в состоянии применить П-правило stack
(С, В), что приведет к новому описанию состояния. В ней рассматривается
другая компонента цели ON (А, С) и к стеку целей добавляется правило
stack {Ay С). (Опять предусловия этого правила невидимы.) После этого в
системе ABSTRIPS правило stack (А, С) применяется к текущему описанию
состояния, что приводит к описанию состояния, находящемуся в
соответствии со всей целью. Путь решения для этого уровня работы системы ABSTRIPS
показан на рис. 8.13. Заметим, что когда литералы вычеркивания
оказываются невидимыми, то некоторые элементы, которые должны быть
вычеркнуты из описания состояния, не вычеркиваются. При этом может возникнуть
противоречивое описание состояния, но трудностей это не вызывает.
Решением первого уровня, получаемым в результате пренебрежения
некоторыми деталями, является последовательность правил {stack (С, В),
stack (А, С)1. (Точно так же справедливым решением на первом уровне,
получаемым при другом упорядочении компонент цели, будет { stack (А, С),
stack (А С)]. Это решение приведет к трудностям на более низком уровне,
что вызовет необходимость вернуться на первый уровень и создать
соответствующим образом упорядоченную последовательность.) Наше решение
первого уровня может рассматриваться, как высокоуровневый план достижения
цели. С этой точки зрения операция по складыванию кубиков в столбик
считаются самыми важными, а планирование нижнего уровня может быть
использовано для выяснения некоторых деталей.
Теперь решение первого уровня, а именно {stack (С, В), stack (А, С) } ,мы
передадим на второй уровень. На этом уровне мы рассматриваем условия со
значением критичности 2 или более, так что мы начинаем принимать во
внимание некоторые детали. Можно эффективно передать вниз решение
высшего уровня, начиная процесс на следующем уровне со стеком целей, который
включает последовательность П-правил из решения высшего уровня вместе
с одним из их видимых предусловий. Последним элементом в начале стека
является главная цель. В этом случае начало целевого стека для второго
уровня выглядит так:
HOLDING(C) Λ CLEAR(B)
*stack(C,JB)
HOLDING(A)A CLEAR(C)
*stack(/l,C)
[ON(C,B)A ON(A9C)]
279
1
Ι ОПИСАНИЕ
СОСТОЯНИЯ
CLEARiB)
CLEARiC)
ONiCA)
HANDEMPTY
ONTABLE(A)
ONTABLEiB)
ONiCB.)
СТЕК ЦЕЛЕЙ
ONiA.C)
ONiCB) A ONiA.C) \
ОПИСАНИЕ
СОСТОЯНИЯ
CLEARiB)
CLEARiC)
ONiCA)
HANDEMPTY
ONTABLEiA)
ONTABLEjB)
СТЕК ЦЕЛЕЙ
ONiCB) AONiA.C)
ОПИСАНИЕ
СОСТОЯНИЯ
CLEARiB)
CLEARiC)
ONiCA)
HANDEMPTY
ONTABLEiA)
ONTABLEiB)
\ ONiCB)
СТЕК ЦЕЛЕЙ
stackM.C)
ONiCB) A ONiA.Ql
j ОПИСАНИЕ
СОСТОЯНИЯ
CLEARiB)
CLEARiC)
ONiCA)
HANDEMPTY
ONTABLEiA)
ONTABLEiB)
СТЕК ЦЕЛЕЙ
ONiCB)
ONiA.C)
ONiCB) A ONiA.C)
I
1 ОПИСАНИЕ
СОСТОЯНИЯ
CLEAR (A)
CLEARiB)
CLEARiC)
ONiCA)
HANDEMPTY
ONTABLEiA)
ONTABLEiB)
! ONiCB)
! ONiA.C)
СТЕК ЦЕЛЕЙ
NIL
' ОПИСАНИЕ
СОСТОЯНИЯ
CLEARiB)
CLEARiC)
ONiCA)
HANDEMPTY
ONTABLEiA)
ONTABLEjB)
СТЕК ЦЕЛЕЙ
stack(C.fi)
ONiA.C)
ONiCB) AONiA.C)
Рис. 8.13. Путь решения для первого уровня системы ABSTRIPS
Поскольку система STRIPS работает со стеком целей, то нетрудно сделать
так, чтобы последующий уровень корректировал правила для обеспечения
достижения деталей. План, спускаемый вниз с более высоких уровней,
значительно ограничивает поиск на нижних уровнях, обеспечивая эффективность
вычислений и снижение степени проявления комбинаторного взрыва.
Читатель может сам убедиться, что одним из возможных решений,
порождаемых вторым уровнем, является последовательность
{ unstack (С, А), stack (С, В), pickup (A), stack (А, С)} .
Если никакого решения не может быть найдено на каком-то из уровней, то
процесс в состоянии вернуться на более высокий уровень, чтобы найти
другое решение. В нашем случае решение второго уровня является хорошим и
полным, если не считать, что при его построении мы пренебрегли условием
HANDEMPTY.
В ходе решения на третьем или самом низшем уровне мы понижаем
порог критичности до 1. Полагаем, что стек целей содержит
последовательность П-правил из второго уровня вместе (но не со всеми) с предусловиями.
В нашем примере работа на этом уровне сводится к проверке того, что ре-
шение второго уровня является правильным и с точностью до деталей
третьего уровня.
Таким образом, система ABSTRIPS является вполне оправданной для
выполнения иерархического планирования. Все, что при этом требуется, — это
градуирование важностей предикатов, которое осуществляется
приписыванием им значений критичности. В задачах более сложных, чем настоящий
пример, система ABSTRIPS является намного более эффективно для
решения задач, чем одноуровневая система STRIPS.
8.4.3. ВАРИАНТЫ
Имеются другие варианты иерархического решения задач. Во-лервых, основным
устройством решения задач на каждом уровне не обязательно должна быть система
STRIPS. Может быть использован любой метод решения задач, если только он
допускает, чтобы решение на данном уровне направлялось решением, полученным на более
высоком уровне. Например, можно воспользоваться системой RSTRIPSiuth DCOMPHa
каждом уровне, дополненном соответствующим методом "наложения заплат".
Один вариант схемы иерархического планирования содержит всего два уровня
критичности предусловий и применяет несколько отличный метод использования уровней
критичности. Поскольку этот вариант представляется важным, то мы покажем его
работу на некотором примере, используя множество П-правил:
1) pickup(jc)
Р& D: ONTABLE(x), CLEAR(x), P-HANDEMPTY
A: HOLDING (χ)
2) putdown(x)
P&D: HOLDING(x)
A: ONTABLE(x), CLEAR(x), HANDEMPTY
3) stack(x,/)
Ρ & D: P-HOLDING (χ), С LEA R (/)
A: HANDEMPTY, ON(x,y),CLEAR{x)
4) unstack(x,/)
P&D: P-HANDEMPTY, CLEAR{x\ ON{x,y)
A: HOLDING(x),CLEAR(y)
Специальная приставка Р перед предикатом указывает на то, что достижение
соответствующего предусловия всегда откладывается до следующего более низкого уровня.
Мы называем такие предусловия Р-условиями. В этой схеме мы всегда можем для
каждого П-правила определить, какие предусловия являются важными (и должны быть
достигнуты на текущем уровне планирования), а какие - деталями (которые должны
быть достигнуты на следующем, более низком уровне).
В этом примере в качестве базового устройства решения задач на каждом уровне мы
используем систему STRIPS. Давайте рассмотрим задачу, которую мы решали ранее,
а именно достижение цели [ON (С, В) A ON (А, О], исходя из начального состояния,
показанного на рис. 7.1. На рис. 8.14 отражен путь решения, полученный системой
STRIPS на первом уровне. Заметим снова, что здесь описание состояния может
содержать противоречия, поскольку детали были опущены. Решением первого уровня
является последовательность {stack (С, В), stack (А, С)}. 2gl
1
ОПИСАНИЕ
СОСТОЯНИЯ
CLEAR(C)
ON(C.A)
HANDEMPTY
ONTABLE(A)
ONTABLE(B)
ON(C.B)
СТЕК ЦЕЛЕЙ
ON(A.C)
ON(C.B) A ON(A.C)
ι ОПИСАНИЕ
СОСТОЯНИЯ
CLbAR(B)
CLbAR(C)
ON(C.A)
HANDEMPTY
ONTABLE(A)
ONTABLE(B)
СТЕК ЦЕЛЕЙ
ON(C.B) AON(A.C)
V f
ОПИСАНИЕ
СОСТОЯНИЯ
CLEAR(C)
ON(C,A)
HANDEMPTY
ONTABLE(A)
ONTABLE(B)
ON(C.B)
СТЕК ЦЕЛЕЙ
CLEAR(C)
stacks, С)
ON(C,B)AON(i.C)
\ ОПИСАНИЕ
СОСТОЯНИЯ
CLEAR(B)
CLEAR(C)
ON(C.A)
HANDEMPTY
ONTABLE(A)
ONTABLE(B)
СТЕК ЦЕЛЕЙ
ON(C.B)
ON(A.C)
ON(C.B)AON(A,C)
i ♦
ОПИСАНИЕ
состояния
ON{C.A)
HANDEMPTY
ONTABLt(A)
ONTABLE(B)
ON(C.B)
ON(A.C)
CLbAR(A)
СТЕК ЦЕЛЕЙ
NIL
ОПИСАНИЕ
СОСТОЯНИЯ
CLbAR(B)
CLhAR{C)
ON(C.A)
HANDEMPTY
ONTABLb(A)
ONTABLh(B)
СТЕК ЦЕЛЕЙ
CLEAR(B)
stack(C.fi)
ON(A.C)
ON(C.B) AON(A.C)
4 J
Рис. 8.14. Решение на первом уровне системы STRIPS с использованием Р-условий
Попытку построения решения второго уровня мы начинаем, имея стек целей,
содержащий только что полученную последовательность П-правил и их предусловий. Теперь,
однако, Р-условия должны быть включены в качестве условий и достигнуты на этом
уровне. Кроме того, когда применяются эти правила, мы вычеркиваем такие
предусловия из текущего описания состояния. Всякое новое П-правило, введенное на этом
уровне, применяется так же, как и раньше.
Начальный стек целей для решения задачи на следующем уровне дается ниже. Чтобы
отличить П-правила, унаследованные от предыдущего уровня, от тех правил, которые
могли бы быть вставлены на настоящем уровне, мы ставим перед первыми звездочку:
HOLDING(C) Λ CLEAR(B)
*stack(C,£)
HOLDING(A) Λ CLEAR(C)
*stack(^,C)
ON(C,B)A ON(AX)
Решением, полученным системой STRIPS на этом уровне, является
последовательность {unstack (С, А), stack (С, В), pickup (A), stack (А, С)}. Несмотря на то, что на
этом уровне не были рассмотрены условия, отнесенные к другим уровням, а именно
282
HANDEMPTY, данная последовательность является верным решением. Стек целей,
ориентированный на следующий более низкий уровень, не приводит к тому, что в план
вставляются дополнительные П-правила. Процесс решения задач на таком уровне
приводит лишь к проверке корректности решения плана второго уровня, когда
учитываются все детали.
8.5. БИБЛИОГРАФИЧЕСКИЕ И ИСТОРИЧЕСКИЕ ЗАМЕЧАНИЯ
Система RSTRIPS основана на системах, разработанных Уорреном [377J
и Уолдингером [369] для планирования в случае взаимодействующих целей
(Система WARPLAN Уоррена очень естественно и экономно реализуется на
языке программирвания ПРОЛОГ.) Аналогичную схему предложили Ригер
и Лондон [302].
Система DCOMP основана на идеях Сейсердоти [317, 318] и Тейта [358,
359] для построения "нелинейных" планов. Сассман [353] обсуждает
некоторые проблемы, связанные с достижением взаимодействующих целей, и
рекомендует стратегию, состоящую в разработке плана, допускающего
несколько ошибок, с последующим исправлением этого плана вместо
стратегии, состоящей в синтезировании совершенного плана.
Система ABSTRIPS, предназначенная для иерархического планирования,
была создана Сейсердоти [316]. В системе LAWALY Сиклоши и Дреуси
также используется иерархия подзадач [331]. Наш вариант системы ABSTRIPS
с использованием Р-условий основан на системе NOAH, принадлежащей
Сейсердоти [318]. В системе NOAH объединено иерархическое и нелинейное
планирование, поэтому ее можно представлять себе как систему ABSTRIPS,
использующую Р-условия. Система Тейта [359] для построения сетей
проектирования может рассматриваться как развитие системы NOAH. (См. также
систему иерархического планирования и выполнения, предложенную Ниль-
соном [274].)
Расширения возможностей систем решения задач для робота были
предложены Файксом, Хартом и Нильсоном [274]. В статье Фельдмана и Спрул-
ла обсуждаются проблемы, вызванные неопределенностью в планировании
для робота, и рекомендуется использовать в этом случае методы теории
принятия решений [101].
Упражнения
8.1. Отправляясь от начального описания состояния, приведенного на рис. 7.1,
покажите, как системой RSTRIPS достигалась бы цель [ON (В, Α) Δ ON (С, В) ].
8.2. Воспользуйтесь любой из описанных в гл. 7 и 8 систем построения плана для
решения следующей задачи складывания кубиков:
X
///////ζ///////////////
Начальное состояние
///////////Ш////
Целевое состояние
283
8.3. Покажите, как система DCOMP решала бы такую задачу из мира кубиков:
X
жттж^ /ш^т//////
Начальное состояние
Целевое состояние
Воспользуйтесь предикатами и правилами системы STRIPS из гл. 7 для представления
состояний и действий.
8.4. Начальная ситуация в мире кубиков описывается следующим образом:
ONTABLE(A)
ONTABLE(B)
ONTABLE(C)
CLEAR(A)
CLEAR(B)
CLEAR(C)
Имеется всего лишь одно П-правило1 :
puton(x,j)
Ρ: CLEAR(x),CLEAR(y)yONTABLE(x)
D: CLEAR(y),ONTABLE(x)
Α: ΟΝ(χ,γ)
Покажите, как система DCOMP могла бы достичь цели [ON (А, В) Λ ON (В, С)].
8.5. Набросайте схему иерархического варианта для системы DCOMP, которая
находится в том же отношении к DCOMP, что и система АВSTRIPS к системе STRIPS. (Мы
могли бы назвать такую систему AB-DCOMP.) Покажите на примере, как могла бы
работать такая система.
Предостережение. При создании системы AB-DCOMP возникают
определенные концептуальные трудности. Опишите те, с которыми вы столкнулись, даже если
вам не удалось их преодолеть.
8.6. Если объединить некоторые вершины в графе на рис. 7.3, то мы получим
следующую структуру:
о о
Это правило позволяет поместить кубик на кубик за одно действие. — Прим. ред.
284
Определите иерархическую систему планирования, основывающуюся на форме
этой структуры, и проиллюстрируйте ее работу на примере.
8.7. Предположим, что некоторая иерархическая система планирования
оказывается не в состоянии найти решение на одном из уровней. Какая информация о причинах
неудачи могла бы оказаться полезной при поиске альтернативного плана на более
высоком уровне? Покажите на примере.
8.8. Могли бы вы описать направления, вдоль которых рассмотренные в этой главе
идеи иерархического решения задач могли бы найти применение в системах дедукции,
основанных на использовании правил? Проверьте свои предположения, применив их к
решению на основе дедукции некоторой проблемы для робота, используя
формулировку Ковальского.
8.9. Можете ли вы найти контрпример для следующего утверждения:
любой план, который может быть построен системой STRIPS,
может быть построен также и системой АВSTRIPS?
8.10. Обсудите свойства "полноты" системы RSTRIPS и DCOMP. Иными словами,
всегда ли эти системы могут найти план, если только он существует?
ГЛАВА 9
ПРЕДСТАВЛЕНИЯ ДЛЯ СТРУКТУРИРОВАННО ОБЪЕКТОВ
Как уже обсуждалось в гл. 4, в исчислении предикатов есть много
способов для представления^ .некоторой суммы знаний. Приемлемость того или
иного представления зависит от области приложения. Выбрав конкретную
форму представления, проектировщик системы должен еще решить, какие
выражения из исчисления предикатов следует закодировать в памяти ЭВМ.
При выборе схемы реализации ключевыми являются понятия эффективной
организации запоминания, поиска и модификации. До сих пор мы не
занимались вопросами эффективности. Мы работали с каждым высказыванием
исчисления предикатов, будь то факт, правило или цель, как с
индивидуальным объектом, к которому по мере необходимости можно получать доступ,
не заботясь о действительных механизмах его реализации и о том, чего это
стоит. Однако простота доступа — вопрос столь важный, что он оказывает
основное влияние на вид представления исчисления предикатов в больших
системах искусственного интеллекта. В этой главе описывается несколько
специализированных представлений, решающих некоторые из упомянутых
проблем. Рассматриваются также вопросы представлений, которые могли
бы быть подняты и раньше, например в гл. 6, но более уместны в этой главе.
Обсуждаемые здесь представления объединяют несколько связанных
между собой выражений исчисления предикатов в структуры большего
размера (называемые иногда блоками). Эти структуры отождествляются
с важными объектами в проблемной области системы. Если системе нужна
информация об одном из этих объектов, то открывается доступ к
соответствующему блоку и отыскиваются сразу все могущие оказаться полезными
сведения об этом объекте. Для этих схем представления мы используем
термин структурированные объекты, поскольку основной упор делается
на структуру представления. В самом деле, в структуре заключены
некоторые сведения о характере представления и особенностях вычислений.
Некоторые операции, которые в иных условиях, при других представлениях
исполнялись бы с помощью явного применения правил и механизмов, опреде-
285
ляемых структурой данного представления, могут быть выполнены с
большей степенью автоматизма.
Такие схемы представления и являются предметом этой главы.
9.1. ОТ ИСЧИСЛЕНИЯ ПРЕДИКАТОВ К БЛОКАМ
Пусть нам надо представить в виде фактов исчисления предикатов
следующие предложения:
Джон дал Мери книгу.
Джон — программист.
Мери — юрист.
Адрес Джона: Мейпл-стрит, 37.
Неплохим, по-видимому, представлением являются следующие правильно
построенные формулы:
ДА ТЬ (ДЖОН, МЕРИ, КНИГА),
ЗАНЯТИЕ (ДЖОН, ПРОГРАММИСТ),
ЗАНЯТИЕ (МЕРИ, ЮРИСТ),
АДРЕС (ДЖОН, МЕЙПЛ-СТРИТ-37).
В этой небольшой базе данных для обозначения шести понятий мы
используем индивидуальные константные символы: ДЖОН, МЕРИ, КНИГА,
ПРОГРАММИСТ, ЮРИСТ и МЕЙПЛ-СТРИТ-37. Если бы база данных была расши
рена, то нам скорее всего пришлось бы упоминать большее число понятий,
однако и относительно перечисленных мы, по-видимому, ввели бы
дополнительную информацию. Для поиска может оказаться полезным собрать все
факты, относящиеся к данному понятию, в одну группу, которую мы
называем блоком. В нашем простом примере блок ДЖОН ассоциируется со
следующими фактами:
ДЖОН
ДАТЬ (ДЖОН, МЕРИ, КНИГА)
ЗАНЯТИЕ (ДЖОН, ПРОГРАММИСТ)
АДРЕС (ДЖОН, МЕЙПЛ-СТРИТ-37).
Аналогичным образом блок МЕРИ ассоциируется со следующими
фактами:
МЕРИ
ДАТЬ (ДЖОН, МЕРИ, КНИГА)
ЗАНЯТИЕ (МЕРИ, ЮРИСТ).
(Один и тот же факт можно связывать с именами, обозначающими разные
элементы проблемной области.)
Схема представления, в которой факты индексируются именами,
обозначающими элементы или объекты проблемной области, назьюается
представлением, ориентированным на объекты.
В большинстве обозначений для структурирования объектов какие-то
факты об этих объектах выражаются через бинарные (двухаргументные)
предикаты. Для записи произвольной ппф с помощью только бинарных
предикатов можно применить простую схему преобразования. Чтобы, например,
преобразовать трехаргументную формулу ДАТЬ (ДЖОН, МЕРИ, КНИГА) в
286
формулу, содержащую только бинарные предикаты, мы постулируем
существование конкретного факта передачи. Назовем это множество
ПЕРЕДА ЧИ. Для каждого аргумента исходного предиката придумаем новый
бинарный предикат, соотносящий значение этого аргумента с постулированным
в исходном предикате фактом. По этой схеме формула ДАТЬ {ДЖОН,
МЕРИ\ КНИГА) должна быть преобразована к виду
(Эх) [ЭЛЕМЕНТ (х, ПЕРЕДАЧИ) А ДАЮЩИЙ (х, ДЖОН)
ПОЛУЧАЮЩИЙ (х, МЕРИ) А ОБЪЕКТ (х, КНИГА) ].
Предикат ЭЛЕМЕНТ (ЭЛ) используется для выражения факта
принадлежности множеству. Введение сколемовских выражений для переменных,
относящихся к квантору существования, в приведенной формуле наделяет
постулированное нами событие передачи некоторым именем, скажем ΠΕΡΙ:
ЭЛ (ΠΕΡΙ, ПЕРЕДАЧИ) А ДАЮЩИЙ (ΠΕΡΙ, ДЖОН) А
Λ ПОЛУЧАЮЩИЙ (ΠΕΡΙ, МЕРИ) А ОБЪЕКТ (ΠΕΡΙ, КНИГА).
Таким образом, трехаргументный предикат преобразован в конъюнкцию
четырех бинарных.
Соотношения между ΠΕΡΙ и исходными аргументами предиката ДАТЬ
столь же успешно можно выразить с помощью не предикатов, а функций
над множеством ПЕРЕДА ЧИ. Соответственно изменив обозначения, можно
представить предложение "Джон дал Мери книгу" такой формулой:
ЭЛ (ΠΕΡΙ ПЕРЕДА ЧИ) А
АРАБ [дающий (ΠΕΡΙ),ДЖОН] А
АРАБ [получающий (ΠΕΡΙ),МЕРИ] А
АРАБ [объект (ΠΕΡΙ),КНИГА].
Подразумевается, что предикат РАБ обозначает равенство. В приведенном
выражении используются некоторые функции, определенные на множестве
ПЕРЕДАЧИ, значения которых дают имена других объектов,
составляющих ΠΕΡΙ.
Переход к представлению, в котором используются события и бинарные
отношения, содержит некоторые преимущества. Из них главное для нас —
это модулярность. Пусть, к примеру, нам надо ввести информацию о том,
когда произошел факт передачи. Прежде чем преобразовать формулу к
бинарной форме, придется ввести в предикат ДАТЬ четвертый (временной)
аргумент. Подобное изменение может потребовать серьезных перемен в
продукциях, связанных с предикатом ДАТЬ, а также в системе управления.
Напротив, если передача книги представлена понятием в проблемной
области, то информацию о ней можно легко расширить, введя новые бинарные
отношения, функции и ассоциированные правила.
В этой части книги почти все суждения представлены терминами,
обозначающими "события" или "ситуации", которые мы рассматриваем как
элементы нашей области. Нам нужно совсем немного предикатов: РАБ, чтобы
выразить идентичность двух понятий, ПМ, чтобы указать, что одно
множество является подмножеством другого, и ЭЛ чтобы сказать, что некоторое
понятие является элементом некоторого множества. В предложениях нашего
примера события состояли в том, что некие лица имеют некоторый род за-
287
нятий (РЗ) и у некоторого лица есть адрес (АДР). Эти предложения
можно представить так:
ΠΕΡΙ
Р31
Р32
ЭЛ (ПЕР1У ПЕРЕДА ЧИ)
РАВ [{дающий (ΠΕΡΙ),ДЖОН]
РАВ [получающий (ΠΕΡΙ),МЕРИ]
РАВ [объект (ΠΕΡΙ),КНИГА]
ЭЛ (Р31, РОД-ЗАНЯТИЙ)
РАВ [работающий (Р31),ДЖОЩ
РАВ [профессия (Р31),ПРОГРАММИСТ]
ЭЛ (Р32, РОД-ЗАНЯТИЙ)
РАВ [работающий (Р32),МЕРИ]
РАВ [профессия [Р32),ЮРИСТ]
АДР1
ЭЛ (АДР1, АДРЕСА)
РАВ [человек (АДР 1), ДЖОН]
РАВ [место (АДР1),МЕЙПЛ-СТРИТ-37].
В этих блоках для связи событий с другими понятиями нами
произвольно введены некоторые функции.
Заметим, что приведенные блоки обладают некоторой общей структурой.
Во-первых, для указания на то, что определенный объект, описываемый
блоком, является элементом некоторого множества, используется
предикат ЭЛ. (Если объект, представленный блоком, сам по себе является
отдельным множеством, то для указания на то, что он был подмножеством
некоторого другого множества, можно использовать предикат ПМ.)
Во-вторых, значения разных функций от объекта, представленного блоком, имеют
отношение и к другим объектам. Поэтому введем для блоков специальное
обозначение, основывающееся на этой общей структуре.
В качестве сокращенной записи формулы типа РАВ [дающий (ΠΕΡΙ,
ДЖОН)] мы используем такое выражение или пару: "дающий:ДЖОН". Все
предикаты РАВ, которые устанавливают связь между функциями от
объекта, представленного блоком, и другими объектами, выражаются
посредством таких пар, выписываемых под именем блока. Тогда для нашего
примера получаем:
ΠΕΡΙ
дающий: ДЖОН
получающий: МЕРИ
объект: КНИГА.
В тех системах искусственного интеллекта, которые используют блочную
запись, конструкции типа "дающий: ДЖОН" часто называют ячейками.
Первое выражение — дающий — называют именем ячейки, второе - ДЖОН —
значением ячейки.
Иногда значение ячейки представляет собой не константный символ
(такой,как ДЖОН), а функциональное выражение. Эта функция, в частнос-
288
ти, может относиться к имени ячейки другого блока. Рассмотрим, к
примеру, предложения: "Джон дал Мери книгу" и "Билл дал ручку тому лицу,
которому Джон дал книгу". Выразим эти предложения с помощью двух
блоков:
ΠΕΡΙ
ЭЛ (ΠΕΡΙ ПЕРЕДА ЧИ)
дающий: ДЖОН
получающий: МЕРИ
объект: КНИГА
ПЕР2
ЭЛ (ПЕР2, ПЕРЕДАЧИ)
дающий: БИЛЛ
получающий: получающий (ПЕР!)
объект: РУЧКА.
В этих примерах выражения получающий (ΠΕΡΙ) и МЕРИ служат двумя
способами называния одного и того же лица. Ниже мы рассмотрим, как
можно "вычислить" функциональное выражение типа получающий (ΠΕΡΙ),
найдя значение ячейки получающий в блоке ΠΕΡΙ.
Значениями ячеек могут быть и переменные, относящиеся к квантору
существования. Например, высказывание: "Некто дал Мери книгу",
записанное в исчислении предикатов, может содержать формулу (Зх) РАВ
[дающий (ПЕРЗ), х]. Такую переменную можно подвергнуть сколемовскому
преобразованию и получить выражение вида РАВ [дающий (ПЕРЗ), S].
О переменной, относящейся к квантору существования, как правило,
имеется некоторая информация. В нашем примере может быть известно, что
слово "некто" относится к человеку. Более удачный перевод предложения
"Некто дал Мери книгу" на язык исчисления предикатов должен содержать
формулу
(Зх) {РАВ [дающий (ПЕРЗ),х] АЭЛ (х,ЛЮДИ)] } ,
или просто
ЭЛ [дающий (ПЕРЗ), ЛЮДИ].
Чтобы иметь возможность работать с такими формулами в нашей системе
блочной записи, введем как некоторое псевдозначение ячейки специальную
форму: (элемент-множества ЛЮДИ). Такая форма служит сокращением
формулы с предикатом ЭЛ. Выражение, в котором использована такая
сокращенная форма, можно представлять как неопределенное описание
значения ячейки.
Завершая разговор о соглашениях относительно правил сокращенного
описания, укажем, что форма (элемент-множества) используется в ячейке
с именем "сам" и выражает тот факт, что объект, описываемый данным
блоком, сам по себе является элементом некоторого множества. При таких
соглашениях наше множество блоков, исходно записанное в виде группы
формул исчисления предикатов, может быть переписано так:
ΠΕΡΙ
сам: (элемент-множестваПЕРЕДАЧИ)
дающий: ДЖОН
289
получающий: МЕРИ
объект: КНИГА
Р32
АДР1
Р31
сам: {элемент-множества РОД-ЗАНЯТИЙ)
работающий: ДЖОН
профессия: ПРОГРАММИСТ
сам: {элемент-множестваРОД-ЗАНЯТИЙ)
работающий: МЕРИ
профессия: ЮРИСТ
сам: {элемент-множества АДРЕСА )
человек: ДЖОН
место: МЕЙПЛ-СТРИТ-37.
Остальные элементы нашей проблемной области можно просто описать
такими блоками:
ДЖОН
сам: {элемент-множества ЛЮДИ)
МЕРИ
сам: (элемент-множества ЛЮДИ)
КНИГА
сам: {элемент-множества ФИЗИЧ-ОБЪЕКТЫ)
ПРОГРАММИСТ
сам: {элемент-множества РАБОТЫ)
МЕЙПЛ-СТРИТ-37
сам: {элемент-множества МЕСТОЖИТЕЛЬСТВО)
ЛЮДИ
сам: {подмножество-множестваЖИВОТНЫЕ).
Эта совокупность блоков в явной форме представляет некоторую
информацию о принадлежности множествам, которая содержалась в наших
изначальных высказываниях, но в неявном виде. Заметим, что в последнем
блоке, ЛЮДИ, нами была использована форма {подмножество-множества
ЖИВОТНЫЕ) . Эта форма аналогична форме {элемент-множества); в блоке
ЛЮДИ она заменяет предикат ПМ {ЛЮДИ ЖИВОТНЫЕ).
Не составляет труда сделать обратный перевод любого из этих блоков
на общепринятый язык исчисления предикатов.
В блочной записи можно найти место и для переменных, относящихся
к квантору общности. Рассмотрим к примеру высказывание: "Джон
каждому что-то дал". В исчислении предикатов это высказывание можно
представить так:
(Vx) {3y){3z) {ЭЛ (у, ПЕРЕДАЧИ) ЛРАВ [дающий (у),
ДЖОН] Λ РАВ [объект {у), ζ] Л РАВ [получающий {у) х]] .
При сколемовском преобразовании переменные у и ζ заменяются на
функции от переменной х. В частности, факт передачи у становится теперь
290
скрлемовской функцией от χ и не является константой. Семейство фактов
передачи, представляемое этой функцией, можно описать таким
функциональным блоком:
«с*)
сам: (элемент-множества передачи)
дающий: ДЖОН
объект: s k (х)
получающий: х.
В этом блоке значением ячейки объект является сколемовская функция
sk(x). В блоках область действия переменных, стоявших под квантором
общности, распространяется на весь блок. (Предполагается, что все
формулы исчисления предикатов, записанные в блочной системе обозначений,
имеют предваренную сколемовскую форму. Иными словами, все знаки
отрицания перенесены на переменные, переменным даны различные имена,
переменные, относящиеся к квантору существования, подвергнуты сколе-
мовскому преобразованию, а все кванторы общности относятся к
выражению в целом. Тогда при обратном переводе из блочной записи в систему
обозначений исчисления предикатов все переменные под квантором
общности будут иметь максимальные области действия.)
Поскольку для рассматриваемых в этой главе способов представления
немалую роль играют идеи, связанные с множествами и принадлежностью
им, то небесполезно ввести некоторые специальные функции,
предназначенные для описания множеств. Для описания множества, составленного из
некоторых элементов, будем использовать функцию множество-из, например
множество-из {ДЖОН, МЕРИ, БИЛЛ). Для описания множеств, полученных
пересечением, объединением или дополнением до некоторых множеств, бу
дем применять соответственно функции пересечение, объединение и допол
нение-до.
Эти функции, описывающие множества, с успехом можно применять
для представления определенных высказываний, выражающих дизъюнкции
и отрицания. Рассмотрим, к примеру, высказывания: "Джон купил
автомобиль", «Это был или "Форд" или "Шевроле"» и "Он был без откидного
верха". Эти высказывания можно представить таким блоком:
ПОК1
сам: (элемент-множество ПОКУПКИ)
покупатель: ДЖОН
куплено: (элемент-множества пересечение (объединение
(ФОРДЫ, ШЕВРОЛЕ), дополнение^ (С-ОТКИДНЫМ-
ВЕРХОМ))).
Другой пример дается таким представлением высказывания "Джон дал
книгу Биллу или Мери":
ПЕР4
сам: (элемент-множества ПЕРЕДА ЧИ)
дающий: ДЖОН
получающий: (элемент-множества множество-из
(БИЛЛ, МЕРИ))
объект: КНИГА.
291
Вопрос о том, как в блочной системе обозначений представлять
импликации, мы обсудим позже. Здесь мы не стремимся развить блочную систему
обозначений до степени синтаксической системы, полноценнно заменяющей
систему исчисления предикатов. Полная синтаксическая система может быть
весьма громоздкой, на деле же разнообразные работающие системы
искусственного интеллекта используют довольно ограниченные варианты блочных
языков.
9.2. ПРЕДСТАВЛЕНИЕ В ФОРМЕ ГРАФОВ: СЕМАНТИЧЕСКИЕ СЕТИ
Введенный в предыдущем разделе вариант исчисления предикатов, в
котором применяются только бинарные предикаты, допускает представление
с использованием графов. Элементы этого формализма (константы,
символы переменных и функциональные выражения) могут быть предсталены
вершинами графа. Тогда в примере из предыдущего раздела у нас
получаются вершины ДЖОН, ΠΕΡΙ, МЕРИ, ЮРИСТ, АДР1 и т.д. Предикаты РАВ,
ЭЛ и ПМ могут быть представлены дугами графа: каждая дуга выходит из
вершины, соответствующей первому аргументу предиката, и входит в
вершину, соответствующую второму аргументу. Тогда выражение ЭЛ (ΠΕΡΙ,
ПЕРЕДАЧИ) будет представлено такой структурой:
<Ш> эл
В подобных графах вершины и дуги помечаются обозначаемыми ими
термами и предикатами.
Если предикат РАВ связывает между собой некоторый терм и некоторую
функцию от другого терма, то мы будем изображать запись этой функции
одного аргумента с помощью дуги, соединяющей два таких терма. Для
представления, например, формулы РАВ [дающий (ΠΕΡΙ), ДЖОН] мы
прибегнем к такой структуре:
(^лГ^) : ^СдЖОН)
V, У дающий Ч^ У
Набор выражений исчисления предикатов, относящихся к указанному
типу, может быть представлен некоторой графовой структурой. Такую
структуру часто называют семантической сетью. Сетевое представление
набора высказываний из рассматриваемого нами примера приведено на
рис. 9.1. Такого рода семантические сети бывают полезны для описания,
поскольку они дают простую структурную картину всей совокупности
фактов. Такими семантическими сетями можно описывать и
индексированные структуры, которые встречаются во многих конкретных системах,
использующих представления на основе исчисления предикатов. То, как
описать данное машинное представление некоторого набора фактов — с
помощью ли семантической сети, множества блоков или совокупности
линейных формул, — дело вкуса. Ведь реальная структура данных в ЭВМ
вполне может быть одинаковой во всех трех случаях! Поэтому в настоящей
главе все три типа описаний используются более или менее равноправно.
Еще один пример семантической сети приведен на рис. 9.2. В ней
представлено множество тех же фактов, которые были даны выражениями
исчисления предикатов в примере на выборку информации в гл. 6.
292
(ПЕРЕДАЧУ.
профессия
Рис. 9.1. Простая семантическая сеть
Вершины в сетях, представленных на рис. 9.1 и 9.2, помечены
константными символами. Можно ввести и вершины, соответствующие переменным,
они помечаются строчными буквами из конца латинского алфавита
(например, z,yf χ и т.д.). Здесь переменные опять разделены (выбраны
различными) и считается, что они относятся к квантору общности. Областью этих
кванторов является вся сеть фактов.
При преобразовании формул исчисления предикатов в сетевую форму
мы будем придерживаться тех же соглашений, что и при переводе их в
блочные обозначения. Считаем, что переменные, стоящие под квантором
существования, подвергнуты сколемовскому преобразованию и получающиеся
сколемовские функции представлены вершинами, которые помечены
функциональными выражениями. Так, высказывание "Джон каждому что-нибудь
дал" может быть представлено сетью, изображенной на рис. 9.3. На этом
рисунке переменная χ находится под квантором общности. Вершины,
помеченные "g(x)" и "sk(x)", являются вершинами, представляющими сколе-
293
ОТДЕЛЫ
ЭЛ
ЭЛ
0-3
служащие"
ЛЮДИ
ЛИ
ЛИ
о-п
служащие
БИЛЛ-УАЙТ
Рис. 9.2. Семантическая сеть, представляющая данные о кадрах
мовские функции. (При машинной реализации элементы, соответствующие
вершинам, помеченным функциональными выражениями, должны скорее
всего иметь какую-то структуру указателей, связывающих зависимые и не-
зазисимые вершины. Для простоты мы на рисунках не изображаем этих
указателей в семантических сетях, хотя они и имеются в Некоторых сетевых
формализмах.)
Рассмотрим теперь вопрос о графическом представлении
пропозициональных связок. Представление конъюнкции не составляет труда: конъюнкция
связанных элементарных формул представляется множественными
вершинами и дугами ЭЛ и ПМ. Для представления дизъюнкции надо иметь
возможность как-то выделять те вершины и дуги, которые входят в дизъюнкции.
При линейной записи для указания на дизъюнкцию используются круглые
294
дизъюнктивная
рамка
Рис. 9.3. Сеть с вершинами, представляющими сколемовские функции
и квадратные скобки. В
семантических сетях применяется
графический аналог скобок — рамка,
изображаемая на рисунках
замкнутой штриховой линией. В случае
дизъюнкции каждый
дизъюнктивный предикат изображается в
пределах рамки, а сама рамка
помечается знаком ДИЗ. Таким
образом, выражение [ЭЛ (А, В) V
V ПМ (В, С)] изображается так,
как показано на рис. 9.4.
Для выделения конъюнкции,
находящейся внутри дизъюнкции,
можно использовать рамку,
помеченную КОН. (Условимся не изображать подразумеваемую конъюнктивную
рамку, охватывающую всю семантическую сеть.) Подобным образом
можно изображать любые вложения одних рамок в другие. В качестве примера
на рис. 9.5 приведена семантическая сеть, соответствующая высказыванию
"Джон — программист, либо Мери — юрист".
Когда выражения исчисления предикатов приводятся к представлению
в виде семантической сети, знаки отрицания в них, как правило, вносятся
внутрь, так что область действия этих знаков ограничивается
единственным предикатом. Если это выполнено, то выражения, содержащие знаки
отрицания, можно представить в виде семантической сети, введя просто
дуги ~ЭЛ, ~ПМ к ~РАВ. В общем случае1 для ограничения областей
действия знаков отрицания можно также использовать рамки. При этом такая
рамка помечается знаком ОТР. На рис. 9.6 показано графическое
представление выражения ~ [ЭЛ (А, В) А ПМ (В, С) ]. Для упрощения обозначений
Рис. 9.4. Представление дизъюнкции
1 Когда внесение знаков отрицания внутрь формулы не выполнено. - Прим. перев.
295
Рис. 9.5. Дизъюнкция с вложенными в нее конъюнкциями
Рис. 9.6. Представление отрицания
договоримся, что предикаты, заключенные в рамку ОТР, связаны между
собой знаком конъюнкции.
На рис. 9.7 приведен пример семантической сети, содержащей
дизъюнктивную и негативную рамки. Эта семантическая сеть эквивалентна
следующей логической формуле:
ЭЛ{ПОК1, ПОКУПКИ) АРАБ [покупатель (ПОК1)9ДЖОЩ А
296
ПОКА
покупательную ^Л^куплено
диз(ж,>-
эл\
ФОРДЫ
•ХШ
ОТР
^у /С-откндныа
ВЕРХОМ
ПМ
(ШЕВРОЛЕ
ПМ
'ПМ
А
(^ТОМОБИШ)
Рис. 9Л. Семантическая сеть с логическими связками
Л РАВ [куплено (П0К1)9Х] А~ЭЛ (X, С-ОТКИДНЫМ-ВЕРХОМ) Л
Л [ЭЛ (X, ФОРДЫ) V ЭЛ (X, ШЕВРОЛЕ) ] Л
АПМ (ФОРДЫ, АВТОМОБИЛИ) ΛΠΜ (ШЕВРОЛЕ, АВТОМОБИЛИ) А
АПМ (С-ОТКИДНЫМ-ВЕРХОМ, АВТОМОБИЛИ).
Если взять отрицание от выражения, в котором переменная стоит под
квантором существования, а затем внести знак отрицания под этот
квантор, то он превратится в квантор общности. Так, высказывание "Мери не
является программистом" можно представить формулой
{(Эх) ЭЛ (х,РОД-ЗАНЯТИЙ) А
А РАВ [профессия (χ), ПРОГРАММИСТ] А
А РАВ [работающий (х)9МЕРИ]},
297
Рис. 9.8. Одно из представлений отрицания от высказывания, относящегося к квантору
существования
АДРЕСА
' ЭЛ
АНТ
КОНС^^-
О/'Н'О'ЬгГА1
^ место
/
профес-
\ сия
[ПРОГРАММИСТ
Рис. 9.9. Сеть с импликацией
298
которая эквивалентна такой формуле:
(Vx) ~ {ЭЛ (х, РОД-ЗАНЯТИЙ) А
АРАВ [профессия (х), ПРОГРАММИСТ] А
АРАБ [работающий (х),МЕРИ\).
На рис. 9.8 дано представление второй из формул в виде сети. Рамки
можно использовать и для представления импликаций в семантических
сетях. Для этого имеется пара связанных между собой рамок, помеченных
АНТ (т. е. антецедент) и КОНС (т. е. консеквент). Например,
высказывание "Всякий, кто живет по Мейпл-стрит, 37, является программистом",
можно представить сетью, изображенной на рис. 9.9. Здесь рз(х, у)
представляет собой сколемовскую функцию, обозначающую род занятий,
зависящий от χ и у. Штриховая линия соединяет рамки АНТ и КОНС и
указывает на то, что они входят в одну импликацию. Более детально вопросы
представления импликации в сетях будут обсуждены позже, когда мы
введем правила модификации баз данных.
Во всех приведенных примерах рамки использовались для того, чтобы
вычленить группу дуг типа ЭД ПМ или функциональных дуг, и поэтому
на рисунках рамки охватывают только дуги. (С точки зрения наших
обозначений в семантических сетях не имеет значения, охватывают они
вершины или нет.)
9.3. УСТАНОВЛЕНИЕ СООТВЕТСТВИЯ
При использовании структурированных объектов в качестве глобальной
базы данных для системы продукций основную роль играет операция
установления соответствия, аналогичная унификации. Ниже мы
рассматриваем этот вопрос.
Чтобы определить, что мы имеем в виду, говоря, что два
структурированных объекта соответствуют друг другу, нужно помнить, что использование
структурированных объектов представляет собой просто иной способ
представления для исчисления предикататов. Можно принять, например, такое
определение: два объекта соответствуют друг другу тогда и только тогда,
когда формула исчисления предикатов, ассоциированная с одним из них,
унифицирована с формулой исчисления предикатов, ассоциированной с
другим. Нам нужно несколько более слабое определение соответствия,
поскольку операции установления соответствия, применяемые нами, как
правило, несимметричны. Иными словами, у нас обычно имеется целевой
объект, который мы хотим поставить в соответствие с объектом,
отвечающим факту. Будем говорить, что целевой объект соответствует объекту-
факту, если формула, содержащая целевой объект, унифицируется с
некоторым подмножеством конъюнкций из формул объекта-факта. (Соответствие
устанавливается только в том случае, когда формулы целевого объекта
выводимы из формул объекта-факта.)
Используя это определение, рассмотрим некоторые примеры
установления соответсивя между блоками. Пусть дан блок, соответствующий факту
БР1
сам: {элемент-множества БРАКИ)
мужчина: ДЖОН-ДЖОНС
299
женщина: МЕРИ-ДЖОНС.
Ассоциированная с этим блоком формула исчисления предикатов такова:
ЭЛ (БР1, БРАКИ) АРАБ (мужчина (БР1), ДЖОН-ДЖОНС] А
А РАБ [женщина (БР1), МЕРИ-ДЖОНС].
Этот блок-факт будет находиться в соответствии со следующим
целевым блоком:
БР1
сам: (эл емен т-множества БРАКИ)
мужчина: ДЖОН-ДЖОНС.
Он не будет соответствовать целевому блоку:
БР1
сам (элемент-множества БРАКИ)
мужчина: ДЖОН-ДЖОНС
женщина: МЕРИ-ДЖОНС
продолжительность: 10.
В случае семантических сетей ситуация совершенно аналогична. На рис.
9.10 и 9.11 показаны сеть фактов и целевая сеть, соответствующие
рассмотренным блокам. На этих рисунках- дуги для фактов и целевые дуги
разделены штриховой линией. (Как и прежде, важно лишь положение дуг
относительно этой линии; положение вершин в нашем рассмотрении не имеет
значения.) Чтобы структура целевой сети соответствовала структуре сети
фактов, формула, ассоциированная с целевой структурой, должна унифици-
мужчина
СЕТЬ_ФАКТОВ
ЦЕЛЕВАЯ СЕТЬ
мужчина
Рис. 9.10. Целевая сеть, соответствующая сети фактов
300
женщина
[БРГ
'ДЖОНг
ДЖОНС
СЕТЬ ФАКТОВ
/женщинах
(МЕРИ-ДЖОНС)
БРАКИ
ЦЕЛЕВАЯ СЕТЬ
&
мужчина
женщина
продолжительность
ЭЛ
Рис. 9.11. Целевая сеть, не соответствующая сети фактов
роваться с формулой, являющейся некоторым подмножеством
конъюнкций формул, ассоциированных со структурой для факта. В наших примерах
надо просто отыскать дуги для фактов, соответствующие каждой целевой
дуге. На рис. 9.10 соответствие устанавливается, а на рис. 9.11 — нет.
Во всякой схеме представлений зачастую для одной и той же, в сущности,
информации имеется несколько альтернативных представлений. Поскольку
принятое нами определение соответствия структур зависит от конкретной
формы структуры, то между такими альтернативными представлениями
нельзя установить точное соответствие. Рассмотрим примеры сетей,
представленные на рис. 9.12. Там приведены два альтернативных
представления высказывания "Джон Джонс женат на Мери Джонс". В одном из них
используется событие "брак", в другом — специальная функция супруга.
(Как правило, мы избегаем применять функции типа супруга, если только
их значения не являются вполне не зависимыми от других параметров,
например от времени.) С синтаксической точки зрения две структуры на
рис. 9.12 не соответствуют друг другу, несмотря на то, что с семантической
точки зрения в них "говорится" одно и то же. Это обстоятельство
соответствует тому факту, что две формы исчисления предикатов, призванные
выразить одну и ту же идею, не унифицируются, если содержат различные
функциональные и предикатные символы. Несколько более сложный пример
эквивалентных форм приведен на рис .9.13.
В некоторых системах искусственного интеллекта, использующих
структурированные объекты, имеются развитые указатели соответствия, которые
для установления прямого соответствия между структурами, подобными
приведенным на рис. 9.12 и 9.13, используют специфику данной области
301
приложения. В таких системах
имеются так называемые
"семантические указатели соответствия", т.е.
указатели, принимающие решение
об идентичности структур с
одинаковым "смыслом".
По-видимому, границу между
вычислениями и выводами,
относящимися, с одной стороны, к
установлению соответствия, а с
другой — к манипуляции объектами,
можно провести вполне
произвольно. В программе установления
соответствия мы предпочитаем избегать
тех операций, которые требуют
сведений о конкретной специфике
области, и тех, в которые входят
вычисления комбинаторного
характера. При этом для установления
семантической эквивалентности
синтаксически различных форм мы
склонны использовать технику
дедуктивного вывода, основанную на
правилах. При такой стратегии
управляющая система по-прежнему
обязана прорабатывать все
возможные пути поиска; программа
установления соответствия может быть
программой общего назначения, которую не надо создавать заново для
каждой области приложения. Обсуждение техники дедуктивного вывода мы
отложим до того момента, когда речь пойдет об операциях над
структурированными объектами.
Главная причина синтаксических различий между сетевыми структурами
состоит в различии способов сопоставления цепей из дуг типа ЭЛ и ПМ.
Рассмотрим пример, приведенный на рис. 9.14. Целевую структуру можно
вывести из структуры фактов с помощью некоторой теоремы из теории
множеств. Поскольку такой вывод при работе со структурированными
объектами производится очень часто, он обычно встраивается в программу
установления соответствия. Одно из преимуществ структурированных объектов
состоит в том, что организация указателей в них позволяет легко
вычислять соотношения типа элемент — подмножество — множество. Таким
образом, можно сказать, что две структуры на рис. 9.14 действительно
соответствуют друг другу.
До сих пор мы рассматривали установление соответствия только между
двумя структурами с константами. Однако, как правило, одна или обе
структуры содержат переменные, вместо которых в ходе установления
соответствия могут подставляться термы. Переменные, фигурирующие в
фактических структурах, во всех содержащих их формулах входят в область
302
Рис. 9.12. Две эквивалентные структуры, не
соответствующие друг другу
Джон или Билл дал ручку Мери.
Рис. 9.13. Пример эквивалентных сетей
действия квантора общности, а переменные, входящие в целевые структуры,
во всех содержащих их формулах неявно входят в область действия
квантора существования. Рассматриваемые нами системы структурированных
объектов являются системами первого порядка, поэтому переменные в них
могут выступать только как метки, относящиеся к вершинам, блокам или
ячейкам.
Типичным примером использования структур с переменными являются
целевые структуры. Пусть к примеру мы хотим задать вопрос: "Кому
Джон дал книгу?". Этот вопрос можно представить следующим целевым
блоком:
χ
сам: (элемент-множестваПЕРЕДАЧИ)
дающий: ДЖОН
303
ЦЕЛЕВАЯ СЕТЬ
Рис. 9.14. Сети с дугами ПМ и ЭЛ
получающий: у
объект: КНИГА.
Установление соответствия этого целевого блока с блоком для факта
ΠΕΡΙ приводит к подстановке ΠΕΡΙ/χ, МЕРИ/у , которую можно
использовать для построения ответа на поставленный вопрос. На рис. 9.15
получающееся соответствие между структурой факта и целевой структурой
представлено в сетевых обозначениях. Для установления соответствия всякий
элемент целевой сети (дуга или вершина) должен быть унифицирован с
соответствующим элементом сети фактов.
При установлении соответствия между объектами, у которых
функциональные выражения являются значениями ячеек, будем полагать, что эти
функциональные выражения оцениваются, если только это оказывается
возможным. Вычисление проводится путем обращения к тому объекту,
который обозначается аргументом данной функции. Пусть, например, мы
хотим спросить: "Билл давал ручку Мери?". Этот запрос можно выразить
в виде такого целевого блока:
сам: (элемент-множества ПЕРЕДА ЧИ)
дающий: БИЛЛ
получающий: МЕРИ
объект: РУЧКА
Пусть блоки для фактов таковы:
ΠΕΡΙ
сам: {элемент-множества ПЕРЕДА ЧИ)
дающий: ДЖОН
304
ЦЕЛЕВАЯ СЕТЬ
Рис. 9.15. Соответствующие друг другу сети
получающий: МЕРИ
объект: КНИГА
ПЕР2
сам: {элемент-множества ПЕРЕДА ЧИ)
дающий: БИЛЛ
получающи й: получающий (ΠΕΡΙ)
объект: РУЧКА.
Поскольку величина получающий (ΠΕΡΙ) может быть вычислена при
обращении к ΠΕΡΙ и оказывается равной МЕРИ, то наш целевой блок
соответствует блоку ΠΕΡΙ у а на исходный запрос может быть дан ответ: "да". В
программе установления соответствия допускается проведение такого рода
вычислений, поскольку они могут быть выполнены без учета специфики
конкретной области и не связаны с вычислениями комбинаторного характера.
Возможно, было бы также желательно дать программе установления
соответствия возможность использовать некоторые общие свойства
эквивалентности блоков. Одно из таких свойств связано с использованием нами
особой дескриптивной формы, т.е. элемент-множества. Например,
предложение "Джон купил машину" можно представить либо блоком
ПОК2
сам: (элемент-множества ПОКУПКИ)
покупатель: ДЖОН
куплено: (элемент-множества МАШИНЫ),
305
либо парой блоков:
ПОК2
сам: {элемент-множества ПОКУПКИ)
покупатель: ДЖОН
куплено: ху
χ
сам: (элемент-множестваМАШИНЫ).
(Первый из приведенных блоков можно рассматривать как
сокращенную форму записи пары блоков.) Информацию об этой сокращенной
записи мы можем встроить в программу установления соответствия, так
что указанная пара блоков, например, может быть поставлена в
соответствие с таким целевым блоком:
У
сам: {элемент-множества ПОКУПКИ)
по купател ь: ДЖОН
куплено: (элемент-множества МАШИНЫ).
9.4. ДЕДУКТИВНЫЕ ОПЕРАЦИИ НАД СТРУКТУРИРОВАННЫМИ ОБЪЕКТАМИ
9.4.1. ОПИСАНИЯ МНОЖЕСТВ
В системах продукций представления с использованием
структурированных объектов можно применить и для осуществления дедукций. Как
и в случае систем дедукций в исчислении предикатов, правила продукций
будут основаны на импликациях. Прежде чем обсуждать общий способ
использования импликаций, рассмотрим распространенный частный
случай, когда некоторая импликация указывает свойства каждого элемента
данного множества.
Рассмотрим, например, такое предложение: "Все студенты
факультета вычислительных наук (ФВН) учатся на выпускном курсе". Исходя из
этого свойства и высказывания "Джон — студент ФВН", можно получить,
что "Джон учится на выпускном курсе".
В рамках исчичления предикатов эти утверждения могут быть
представлены так:
Факт: ЭЛ(ДЖОНу ВН-СТУДЕНТЫ).
Правило: ЭЛ (х, ВН-СТУДЕНТЫ) ^РАВ [курс (χ) , ВЫПУСКНОЙ].
Цель: РАВ [курс (ДЖОН), ВЫПУСКНОЙ]
В обычной системе продукций, основанной на исчислении предикатов
первого порядка, приведенное "правило" может использоваться (в любом
направлении) для доказательства целевой формулы.
На языке блоков наш факт может быть представлен так:
ДЖОН
сам: (элемент-множества ВН-СТУДЕНТЫ),
а цель так:
ДЖОН:
курс: ВЫПУСКНОЙ.
306
Теперь наша задача состоит в том, чтобы показать, как в системе,
основанной на блочной записи, представить и применить правило импликации.
При использовании блоков импликации, которые утверждают
определенные свойства каждого элемента некоторого множества, мы будем
представлять с помощью специального блока, называемого блоком описаний. Такой
блок описывает каждый член некоторого множества, заданного другим
блоком. Пусть, например, имеется блок, задающий множество студентов
отделения вычислительных наук:
ВН-СТУДЕНТЫ
сам: {подмножество-множества СТУДЕНТЫ).
Блок описания этого множества используется для описания всех
входящих в него элементов. У нас таким блоком будет видовая переменная,
относящаяся к квантору общности, областью действия которого является
все множество. Вид такой переменной, т.е. имя множества, относящегося
к области действия квантора, будем писать после этой переменной через
вертикальную черту. Таким образом, чтобы дать описание каждому
студенту, воспользуемся следующим блоком описания:
х\ ВН-СТУДЕНТЫ
специализация-: ВН
курс: ВЫПУСКНОЙ.
Не следует путать блоки описания, относящиеся к каждому из элементов
множества, с блоками, описывающими само множество, или с каким-либо
элементом данного множества! В некоторых системах искусственного
интеллекта, применяющих формальное построение блоков, имеются
структуры, называемые бпок&ма-прототипами, которые, по-видимому, играют ту
же роль, что и наши блоки описаний. В этих системах блоки-прототипы
работают так, как если бы они были особого рода константами,
представляющими некий воображаемый "типичный" элемент множества. При этом
блоки-прототипы связаны с остальными элементами множества
отношением "быть примером". Однако такие блоки-прототипы могут вызвать
путаницу, поскольку операцию замены переменной на константу ("показ на
примере") следовало бы, собственно, представлять себе не как отношение в
этом формализме, а как некоторый метапроцесс. Нам представляется более
правильным рассматривать блок описаний как специальный вид правила
импликации.
В прямом направлении блоки описаний могут использоваться для
создания новых блоков для фактов и расширения свойств уже существующих
таких блоков. Пусть к примеру у нас был такой блок для факта
ДЖОН
сам: (элемент-множества ВН-СТУДЕНТЫ).
Чтобы применить блок описаний в прямом направлении, заметим, что
л: I ВН-СТУДЕНТЫ соответствует блоку для факта ДЖОН. Видовая
переменная λ* соответствует всякому терму, являющемуся элементом
множества ВН-СТУДЕНТЫ. Процесс применения блока описаний к блоку для факта
включает в себя операцию добавления к этому блоку ячеек "специализация:
ВН" и "курс: ВЫПУСКНОЙ". После такого расширения блок для факта
ДЖОН соответствует нашему целевому блоку ДЖОН.
307
Будучи применен к целевому блоку в обратном направлении, блок
описаний выделит из него подцелевой блок
ДЖОН
сам: (элемент-множества ВН-СТУДЕНТЫ).
Поскольку этот подцелевой блок соответствует исходному блоку для
факта, то мы опять получаем некоторое доказательство.
В примере с /^//-студентами целевой блок не содержал никаких
переменных. Ввести в формулировку целей переменные, в данном случае
относящиеся к квантору существования, не составляет труда. Пусть нам надо
определить, кто из представителей множества получает высшее образование.
Целевой блок для такого запроса может иметь вид:
У
курс: ВЫПУСКНОЙ.
Проводя рассуждения в обратном направлении, можно установить
соответствие этого целевого блока блоку описаний χ I ВН-СТУДЕНТЫ и получить
подцелевой блок
сам: {элемент-множества ВН-СТУДЕНТЫ).
Этот целевой блок соответствует^ свою очередь, блоку для факта ДЖОН,
поэтому ответ на исходный запрос может быть получен подстановкой
{ДЖОН/у}.
При сетевом подходе описания могут быть представлены вершинами,
соответствующими видовым переменным. При этом считается, что такая
переменная относится в видовой сети к квантору общности. На рис. 9.16
приведено сетевое представление описания множества ВН-СТУДЕНТЫ,
аналогичное рассмотренному блочному представлению.
Рис.9.16. Сетевое описание для множества ВН-СТУДЕНТЫ
308
число-колес
Помимо представлений
некоторого множества объектов
и описаний свойств каждого
элемента этого множества мы
будем часто прибегать к
понятию абстрактного
представителя. Например,сеть,
изображенная на рис. 9.17, относится к
множеству всех автомобилей,
описывает некоторые свойства
каждого элемента этого
множества, а также включает
конкретный элемент — "машина
54". Пусть нам нужно получить
представление для фразы:
"Автомобиль был изобретен в
1892 г.". Мы без труда можем нарисовать вершину, представляющую
"ситуацию изобретения" и обладающую функциональными дугами, указывающими
на изобретателя, изобретенный объект и т.д. Однако на какую вершину
должна указывать дуга "изобретенный объект"? Это будет не машина 54 и
даже не множество всех автомобилей, изобретенных в 1892 г. Но тогда что
же было изобретено?
Ответ на этот вопрос, вполне достаточный во многих случаях, можно
дать, если прибегнуть к понятию абстрактного автомобиля, который
обозначается вершиной АБС-АВТОМОБИЛЬ. При этом такой абстрактный
представитель связан с остальной сетью так, как показано на рис. 9.18. Набор
свойств каждого элемента множества элемента автомобилей, выражаемый
описанием, на этом рисунке расширен с тем, чтобы отразить тот факт,
что абстрактный автомобиль является абстракцией каждого элемента
множества автомобилей.
Рис. 9.17. Некоторые сведения об автомобилях
Рис. 9.18. Сеть, содержащая вершину, соответствующую абстрактному представлению
309
Заметим, что функция абстракцияот не имеет обратной: она отображает
множество элементов в один. В тех системах, где с описанием работают
так, как если бы оно было отдельной константой, представляющей типичный
элемент множества, можно было бы получить функцию, обратную к абст-
ракция-от. Такой функцией была бы функция конкретный-прототип со
значением элемент-прототип. Поскольку такой прототип переносит все свои
свойства на каждый элемент множества, то каждый из них будет обладать
тем бессмысленным свойством, что он был конкретным воплощением
прототипа абстрактного представителя. Избежать этого можно, если работать
с прототипами не как с константами, а как с импликациями, стоящими под
квантором общности.
По-видимому, некоторые постоянные объекты, встречавшиеся ранее в
наших примерах, такие как ЮРИСТ или ПРОГРАММИСТ, лучше всего
рассматривать как абстрактных представителей. В дальнейшем мы столкнемся
с другими примерами абстрактных представителей.
9.4,2. НАСЛЕДОВАНИЕ СВОЙСТВ
Во многих областях приложений структурированные объекты,
обозначающие множества или отдельные элементы, образуют иерархию.
Классическим примером такой иерархии является древообразное таксономическое
деление царства животных на виды, семейства, классы и т.д. При обычных
рассуждениях таксономические единицы могут быть несколько более
"свернутыми", чем в биологической систематике, например некоторый индивид
может оказаться элементом более чем одного множества. Но все же
практически используемые иерархические системы, как правило, на верхнем
уровне сужаются до небольшого числа множества, и уж во всяком случае любые
множества образуют частичное упорядочение по отношению к свойству
"быть подмножеством".
Рассмотрим иерархию, представленную на рис. 9.19. Зная, что Клайд
является слоном, мы можем сделать некоторые выводы в прямом
направлении, используя для этого наши описания и некоторые методы теории
множеств. Можно, в частности, получить, что Клайд — серый и морщинистый,
теплокровный, любит арахис и т. д. Результаты этих операций могут
применяться для расширения структурированного объекта, обозначающего
Клайда. Из соображений эффективности в любой конкретной задаче проведения
рассуждений получение всех этих фактов о Клайде в явном виде
нецелесообразно.
Аналогичные проблемы, связанные с эффективностью, возникают, когда
описания в таксономической иерархии используются для проведения
обратных рассуждений. Пусть требуется доказать, что Клайд — серого цвета (если
этот факт в явном виде нам неизвестен) . Прибегнув в описаниям на рис. 9.19,
можно выделить несколько подцелей, в том числе доказательство того, что
Клайд—акула, кашалот или слон. Если среда этих фактов есть утверждение
о том, что Клайд — слон, то мы, видимо, можем проводить рассуждения
более эффективно, поскольку при этом мы можем избежать обработки по
крайней мере таких подцелей, как Клайд - это акула. Известно, что
человек в состоянии быстро решать подобные логические задачи, не будучи
задавлен громоздкими комбинаторными расчетами.
310
(животные
2\ЖВ0Т-
дыхание
темп.-крови
ТЕПЛАЯ
Рис- 9.19. Таксономическая иерархия множеств и их описаний
Некоторые варианты использования описаний в прямом направлении в
рамках таксономических иерархий с успехом могут быть встроены в
программу установления соответствия, причем без риска возникновения
сложных комбинаторных проблем. На простых примерах, в которых
применяется сетевой формализм, покажем, как это можно сделать.
Если способность к применению некоторых описаний в прямом
направлении ввести в программу установления соответствия, то в случае
таксономических иерархий, которые на верхнем уровне сужаются до небольшого
числа* множеств, это не вызовет почти никаких отрицательных изменений.
Рассмотрим задачу нахождения соответствующего элемента для целевой
дуги я, соединяющей две вершины для фактов N1 и N2 (рис. 9.20). Если
вершины N1 и N2 соединены дугой для факта аъ то имеем непосредствен-
311
ЦЕЛЕВАЯ СЕТЬ
Рис. 9.20. Поиск соответствия для целевой дуги
ное соответствие. Можно ограничить программу установления соответствия
с тем, чтобы она искала только такие непосредственные соответствия. Если
таковые не будут найдены, то для решения задачи можно будет применить
правила продукций, аналогичные тому описанию множеств, которое
показано на рис. 9.20.
Если в примере на рис. 9.20 программа установления соответствия не
сможет найти в сети фактов явной дуги я, соединяющей N1 и N2, то она должна
подняться из N1 по таксономической иерархии, проверяя наличие дуг а,
идущих в N2 из описаний тех множеств (и супермножеств), которым
принадлежит N1. Некоторые из возможных дуг а, которые имеет право искать
программа установления соответствия, показаны на рис. 9.20 штриховыми
стрелками. Если программа в состоянии найти такую дугу, то
соответствие благополучно установлено. Если не всем целевым дугам можно
подобрать пару, то программа установления соответствия заканчивает свою
работу, сообщив о неудаче.
Система, снабженная расширенной программой установления
соответствия подобного типа, работает так, словно объект автоматически
наследует все необходимые свойства тех множеств и супермножеств, в которые он
входит. Простота, с которой происходит наследование свойств, является
одним из преимуществ применения формального построения
структурированных объектов. В качестве иллюстрации этого процесса рассмотрим
примеры, основанные на рис. 9.19.
Пусть нам надо доказать, что Клайд — серый, если известно, что Клайд —
312
это слон (но то, что Клайд — серый, в явном виде нам неизвестно). Эта
задача изображена на рис. 9.21. Поскольку в сети фактов из вершины КЛАЙД
в вершину СЕРЫЙ не идут дуги, помеченные цвет, то мы не можем получить
непосредственного сопоставления. Поэтому поднимаемся к описанию
СЛОНЫ, где уже есть дуга цвет, идущая в вершину СЕРЫЙ. Программа
отмечает, что КЛАЙД наследует дугу цвет, и заканчивает работу, успешно
установив соответствие.
СЕТЬ ФАКТОВ
ЦЕЛЕВАЯ СЕТЬ
цвет
•
у ·
Q СЕРЫЙ J
1
··
цвет
Рис. 9.21. Сеть, предназначенная для доказательства факта "Клайд - серый"
Пусть, далее, надо доказать, что Клайд — теплокровный, если нам
известно только то, что Клайд — слон. Снова поднимаемся по таксономической
иерархии к блоку описания МЛЕКОПИТАЮЩИЕ, где без труда определяем
соответствие.
Пусть, наконец, надо доказать, что Клайд дышит кислородом, серого
цвета и теплокровный, если известно только, что Клайд — млекопитающее.
Поднимаясь по иерархии описаний, программа подыскивает дугу темп:
крови, идущую в вершину ТЕПЛАЯ, и дугу дыхание, идущую в КИСЛОРОД,
но не получает полного соответствия. Прежде чем пытаться достичь цели
доказательства с использованием правил, надо в явном виде присоединить
эти два свойства к описанию КЛАЙД.
Может возникнуть желание встроить в программу установления
соответствия другую важную операцию — операцию, в которой должна
доказываться эквивалентность наследуемой вершины, соответствующей сколемовской
313
функции, и константной вершины. Рассмотрим пример на рис. 9.22. Наша
цель здесь состоит в том, чтобы доказать, что Генри является членом
множества факультета вычислительных наук. Применение описаниях IФВН-СТУ-
ДЕНТЫ к вершине ДЖОН в прямом направлении дает структуру,
показанную на рис. 9.22 штриховой линией. Тогда, поскольку дуга "консультант"
представляет некоторую функцию, вершина ГЕНРИ должна быть
эквивалентна вершине коне (ДЖОН) , и искомое соответствие становится полным.
ЦЕЛЕВАЯ СЕТЬ
Рис. 9.22. Сеть с наследуемой вершиной, содержащей сколемовскую функцию
Чтобы подобные способы рассуждений ввести в программу, можно
воспользоваться следующей схемой. Используя рис. 9.22, попытаемся вначале
установить непосредственное соответствие, найдя дугу фактов ЭЛ,
соединяющую вершину ГЕНРИ с вершиной ВН-ПРЕПОДАВАТЕЛИ Если это не
получится, то просмотрим нашу таксономическую иерархию на уровнях выше
вершины ГЕНРИ и поищем дугу ЭЛ, которую можно было бы наследовать.
В рассматриваемом примере это опять не удается. Затем будем искать
функциональные дуги, идущие в вершину ГЕНРИ из постоянных вершин. Пусть
такая дуга #ζ·, идущая в ГЕНРИ из вершины Ni9 найдена. (Иными словами,
314
PAB [at (Nj), ГЕНРИ].) После этого над каждой из таких вершин Л^
просмотрим таксономическую иерархию и будем проверять, получает ли Л^· в
наследство дугу а^ от какой-либо вершины, соответствующей некоторой
сколемовской функции и имеющей дугу ЭЛ, идущую прямо в вершину
ВН-ПРЕПОДАВАТЕЛИ. Если факт такого наследования будет установлен,
то работа нашей расширенной программы установления соответствия
успешно завершится.
Стратегии сопоставления переменной целевой вершины с фактами из
базы данных зависят также от структуры сети. В самом простом случае
переменная целевая вершина (назовем ее х) связана с постоянными
вершинами для фактов N1, N2, . . . , Nk через дуги, помеченные αϊ, а2, . . . , ак.
Эта ситуация изображена на рис. 9.23. В константные вершины N1, . . . 9Щ
входят также и другие дуги. Пытаясь установить соответствие, мы
должны изучить вершины, из которых исходят дуги αϊ, входящие в N1, дуги
а2, входящие в N2, и т.д. (Считаем, что наша реализация сети позволяет
без труда проходить по дугам в обратном направлении.) Некоторые дуги
исходят из константных вершин, а некоторые — из описаний.
СЕТЬ ФАКТОВ
ЦЕЛЕВАЯ СЕТЬ
а!
Рис. 9.23. Сопоставление с переменной целевой вершиной
Вначале следует искать дуги, исходящие из константных вершин, посколь
ку если в рассмотрение включать и описания, то множество вершин сети
фактов, которые потенциально могут соответствавать вершине х, может
быть довольно большим. Пусть множество тех константных вершин, из
которых дуги ai идут в данную вершину, является наименьшим для
вершины iVz·. Попытаемся установить соответствие между х и вершинами из этого
множества, позволив программе установления соответствия использовать
описания при поиске соответствий для остальных дуг. На рис. 9.24
показан простой пример. Там имеется только одна константная вершина, КЛАЙД,
обладающая требуемыми свойствами. При попытке найти соответствие для
вершины КЛАЙД мы должны затем отыскать дугу ЭЛ, соединяющую вер-
315
СЕТЬ ФАКТОВ
ЦЕЛЕВАЯ СЕТЬ
темп.-крови
Рис. 9.24. Пример сети с переменной целевой вершиной
шины КЛАЙД и МЛЕКОПИТАЮЩИЕ, и дугу темп.-крови, соединяющую
КЛАЙД и ТЕПЛАЯ. Первая дуга получается из последовательности
подмножеств, а вторая — по наследству; в результате требуемое соответствие
установлено.
Если программе установления соответствия дать возможность
осуществлять просмотр, спускаясь по цепям из дуг ИМ и ЭЛ в обратном направлении,
то всегда можно найти хотя бы одну константную вершину, которую можно
использовать в качестве кандидата. Рассмотрим к примеру задачу,
изображенную на рис. 9.25. В этой сети нет "явных" константных вершин,
которые могли бы служить кандидатами на сопоставление, но если обрабатывать
эту сеть, опускаясь из вершины МЛЕКОПИТАЮЩИЕ по цепям, состоящим
из дуг ПМ и ЭЛ, то это приведет нас к константной вершине КЛАЙД.
Оставшиеся элементы соответствия нетрудно получить, используя наследование
свойств. При этом мы можем считать, что у всякой целевой вершины,
отвечающей переменной, всегда имеется дуга ЭЛ (или ПМ), указывающая на
что-нибудь в сети фактов (ведь всякая единица является элементом, по
крайней мере, множества определения).
316
п*лЕкоп1Р>>__т„
эл^^
/<\МЛЕКб^\
•
ζτΕΠ
темп.-крови
ЛАЯ^)
темп.-крови\
^^^ПМ
(^слоньГ^
эл/;
(^КЛАЙДу
\
эл
(х\ СЛОНЫ)
цвет/ >у ^s^
/ V ·
ГСЕРЫЙ J
/ СЕТЬ ФАКТОВ
Эл/ ЦЕЛЕВАЯ СЕТЬ
У цвет
Рис. 9.25. Еще один пример сети с переменной целевой вершиной
Стратегию установления соответствия можно развить так, чтобы она
могла работать с более сложной структурой целевой сети, когда эта сеть
содержит не одну переменную вершину. При этом для каждой переменной
вершины надо подобрать правильное соответствие с тем расчетом, чтобы
получилось соответствие и для всей целевой структуры. Во всяком случае если не
найдено ни одного варианта сопоставления, то надо или применять в
обратном направлении правила, использующие описания, или применять другие
правила, позволяющие изменить или целевую структуру, или структуру
для фактов. Использование таких правил рассмотрим в следующем разделе.
9.4.3. ПРИСОЕДИНЕНИЕ ПРОЦЕДУР
В некоторых приложениях ячейкам описаний можно сопоставить
программы для ЭВМ. Выполнение этих программ при соответственно подобранных
аргументах порождает значения ячеек для конкретных случаев,
свойственных одному описанию. Пусть в качестве простого примера мы хотим для
317
перемножения двух чисел применить систему, основанную на блоках. Один
из методов заключается в том, чтобы снабдить систему большим набором
таких фактов:
УМН1
сам: {элемент-множества УМНОЖЕНИЯ)
сомножитель 1:1
сомножитель 2:1
произведение: 1
УМН2
сам: {элемент-множества УМНОЖЕНИЯ)
сомножитель 1:1
сомножитель 2:2
произведение: 2
Эти блоки представляют собой способ отображения таблицы умножения.
Если нам надо узнать произведение чисел 3 и 6, мы должны запросить
систему, используя такой целевой блок:
ζ
сомножитель 1:3
сомножитель 2:6
произведение: х.
Этот целевой блок должен быть сопоставлен с некоторым имеющимся
в памяти блоком-фактом, в котором присутствует ячейка
"произведение: 18".
Можно не запоминать все необходимые факты в явной форме, а написать
программу для ЭВМ (назовем ее, например, ПЕРЕМНОЖЬ) и
"присоединить" ее к описанию УМНОЖЕНИЯ:
х\ УМНОЖЕНИЯ
сомножитель 1: {элемент-множества НАТУР-ЧИСЛА)
сомножитель 2: {элемент-множестваНАТУР-ЧИСЛА)
произведение: ПЕРЕМНОЖЬ [сомножитель 1{х),
сомножитель 2{х) ].
Блоки описания с присоединенными к ним процедурами используются
точно так же, как и обычные. Процедуры, участвующие в подстановках,
выполняются только тогда, когда это допускается означиваниями. Чтобы
продемонстрировать работу этой схемы, предположим опять, что нам
надо'найти произведение чисел 3 и 6. Вначале мы в виде блока-факта введем в
рассмотрение саму ситуацию умножения, для которой нужно получить ответ
УМН
сам: {элемент-множества УМНОЖЕНИЯ)
сомножитель 1:3
сомножитель 2:6.
Затем сформулируем целевой блок
УМН
произведение: у.
318
При попытке установить соответствие между целевым блоком УМН и
блоком для факта УМН программа использует описание умножений с тем,
чтобы дать возможность блоку-факту унаследовать ячейку произведение. В
результате получим подстановку [ПЕРЕМНОЖЬ (3, 6)/у]. Правильный
ответ может быть получен после выполнения программы ПЕРЕМНОЖЬ.
Можно составить аналогичный пример с использованием сетевого
формализма.
9.4.4. БЛОЧНЫЕ ПРАВИЛА
Некоторые импликативные высказывания непросто интерпретировать
как высказывания, несущие информацию только об элементах некоторого
множества. Для таких высказываний мы вводим понятие блочного правила,
имеющего антецедент и консеквент. Антецедент (АНТЕ) и консеквент
(КОНСЕ) представляют собой списки блоков (возможно, содержащих
переменные) . Если все блоки в АНТЕ (рассматриваемые нами как целевые)
сопоставлены с блоками-фактами, то после применения блочного правила
в прямом направлении блоки, входящие в КОНСЕ (и соответствующим
образом означенные), можно присоединить к множеству блоков для фактов.
(Если рассматривать блоки в АНТЕ как целевые, то переменные в них
будут, конечно, относиться к квантору существования.) Если некоторые из
добавляемых блоков для фактов уже имеются, то от указанной операции
присоединения требуется добавить только свойства, фигурирующие в блоках
КОНСЕ. Такой способ согласуется с использованием импликации в
описанных в гл. 6 системах дедукции, основанных на применении правил.
Если блочное правило применяется в обратном направлении к единичному
целевому блоку, то с этим блоком должен быть сопоставлен один из
блоков в КОНСЕ (рассматриваемый как блок для фактов). (Если блоки в
КОНСЕ рассматривать как факты, то переменные в них будут относиться к
квантору общности.) Если соответствие установлено, то блоки в АНТЕ
(соответствующим образом означенные) берутся как подцелевые. Несколько
более сложной оказывается операция применения блочного правила в
обратном направлении к (конъюнктивному) множеству целевых блоков; этот
процесс аналогичен рассмотренным в гл. 6 методам, использующим графы
типа И/ИЛИ и проверку согласованности подстановок. В этой главе для
простоты объяснений мы ограничимся рассмотрением тех примеров,
которые не требуют привлечения подобных дополнительных механизмов.
Ниже приводятся несложные примеры использования блочных правил.
Для удобства читателя вернемся к примеру поиска информации о
сотрудниках, рассмотренному в гл. 6. Там было применено правило
П1: ГЛАВА (х,у) =>РАБОТАЕТ-В (х,у).
Если выразить это правило в системе исчисления предикатов, то оно
принимает вид
{ЭЛ(х, ОТДЕЛЫ) АРАВ [ГЛАВА (х), у] } =*
=>РАВ \работает-в (у),*].
Если использовать синтаксис, введенный нами для блочных правил, то
это правило можно выразить так:
319
ΠΙ:
ΑΗΤΕ: χ
сам: {элемент-множества ОТДЕЛЫ)
глава: у
КОНСЕ.у
работает-в.х.
В примере о сотрудниках применялось и такое правило:
П2: [РАБОТАЕТЕ (х,у) А ГЛАВА (*,*)] =>
^БОСС (у, ζ).
В предикатной формулировке эту порцию информации можно
представить так:
{РАВ \работает-в (у),х] А РАВ (глава (x),z] } =>
=>РАВ (босс (у),ζ].
В виде блочного правила это можно записать
Л2
АНТЕ: у
работает-β χ
χ
глава:ζ
КОНСЕ:у
босс: ζ.
С помощью подобного рода блочных правил можно представлять
информацию в самых различных областях приложения. Эти правила могут, в свою
очередь, быть использованы как правила продукций для обработки блоков
для целей и фактов в системах дедукций.
Мы уже говорили о том, что одни и те же сведения часто могут быть
представлены различными способами. В сложных системах допустимо не
ограничиваться выбором только одной альтернативы, а иметь возможность
свободно переходить от одной к другой. Рассмотрим пример на рис. 9.12, где
изображены два возможных представления высказывания "Джон Джонс
женат на Салли Джонс". Эквивалентность этих форм между собой
записывается так:
РАВ [у, супруга (χ)] =(3ζ) {ЭЛ (ζ, БРАКИ) А
А РАВ [х, мужчина (ζ)] А РАВ [у, женщина (ζ)]} .
(Здесь в качестве сокращения для выражения [Wl => W2] A [W2 => W1]
мы применяем ппф от формы Wl = W2.) Если использовать импликацию
"слева направо", то в области действия двух кванторов общности получаем
переменную, относящуюся к квантору существования. Сколемовское
преобразование дает
РАВ [у, супруги (х)] => {ЭЛ[бр (х,у)9БРАКИ\ Λ
А РАВ [х, мужчина (бр (х,у))] Λ
Λ РАВ \у, женщина (бр (х, у) ) ]}.
Представим эту импликацию блочным правилом:
Л-БР
АНТЕ: χ
320
супруга: у
КОНСЕ: бр (рс,у)
сам: (элемент-множества БРАКИ)
мужчина: χ
женщина: у.
Чтобы применить это правило в прямом направлении, установим
соответствие между АНТЕ и некоторым блоком-фактом, а затем создадим новый
константный блок, соответствующий означенному блоку в КОНСЕ.
Простота блочного синтаксиса затрудняет представление импликаций,
значительно более сложных, чем те, которые мы использовали в своих
примерах. Но и при таком ограничении развитый здесь формализм
оказывается довольно полезным для широкого круга задач.
9.4.5. СЕТЕВЫЕ ПРАВИЛА
Мы уже говорили о применении рамок на рисунках для представления
импликаций в сетях. В семантических системах продукций,
основывающихся на сетях, эти импликации могут применяться как прямые и как обратные
правила. Например, импликация
{ ЭЛ (х, ОТ ДЕЛЬТ) АРАВ [глава (х) ,у]} =*
=>РАВ [работает-β (у),х]
может быть представлена сетевой структурой (рис 9.26).
Рис. 9.26. Представление
импликации
( работает-в )
^- "'КОНСЕ
Для использования сетевой импликации в качестве прямого правила надо
установить соответствие между структурой АНТЕ (рассматриваемой как
целевая) и имеющимися структурами сети фактов. После этого к сети
фактов можно присоединить структуру КОНСЕ (соответствующим образом
означенную). Для использования сетевой импликации в качестве обратного
правила надо установить соответствие между структурой КОНСЕ,
рассматриваемой как структура фактов, и целевой структурой. Тогда структура
АНТЕ (соответствующим образом означенная) станет подделевой,
порожденной применением правила. Если целевая структура вначале разбивается на
321
компонентные структуры и они по отдельности сопоставляются со
структурами из КОНСЕ, то ситуация, как и раньше, усложняется, требует
привлечения графов типов И/ИЛИ и проверки согласованности подстановок.
Более сложный пример сетевого варианта приведенной ранее импликации
показан на рис. 9.27:
БРАКИ
ЭЛ>
мужчина
\супругау
АНТЕ
у
/
бр(х,у)
Θ
"[женщина'
/
/
ч ^
КОНСЕ
Рис. 9.27. Сетевая импликация при наличии сколемовской функции
{РАБ [у, СУПРУГА (х)] =>
=> ЭЛ [бр{х,у),БРАКИ] АРАБ [х, мужчина (бр(х,у)) ] А
АРАБ [у, женщина {бр (х, у) ] i
Вершина, помеченная бр(х, у), соответствует сколемовской функции.
Каждое новое применение этого правила в прямом направлении порождает
на рис. 9.27 вершину бр{ху у) с заново установленными значениями
переменных.
9.4.6. ДОБАВЛЕНИЕ РЕКОМЕНДАЦИЙ К ОПИСАНИЯМ МНОЖЕСТВ
Чтобы минимизировать трудности, связанные с вычислениями
комбинаторного характера, применение правил должно направляться некоторой
разумной стратегией. Один из способов указания полезной управляющей
информации состоит в том, чтобы использовать рекомендации по
применению правил к описаниям. Мы упомянем две формы такой рекомендации:
"при заполнении" и "при заполненной" (ячейках информации). В первом
случае рекомендуется, какие правила надо применять в обратном
направлении, если мы пытаемся привести в соответствие переменные, относящиеся
к квантору существования, в целевых структурах. Во втором случае
рекомендуется, какие правила надо использовать в прямом направлении, чтобы
создать новые блоки фактов.
Для иллюстрации применения подобной рекомендации рассмотрим пра-
322
вила Ш и #2, использованные ранее в примере на данные о сотрудниках.
Для удобства выпишем их:
П1
АНТЕ: χ
сам: (элемент-множества ОТДЕЛЫ)
глава у
КОНСЕ:у
работает-в: χ
П2
АНТЕ: у
работает-в χ
χ
глава: ζ
КОНСЕ.у
босс: ζ.
Рекомендация по поводу того, когда применять эти правила, содержится в
следующих описаниях:
и\ СЛУЖАИЩЕ
босс: (элемент-множества СЛУЖАЩИЕ)
< при заполнении П2)
работает-в: (элемент-множества ОТДЕЛЫ)
г| ОТДЕЛЫ
глава: (элемент-множества СЛУЖАЩИЕ)
(при заполненной Ш >.
В описании и I СЛУЖАЩИЕ обозначение < при заполнении П2) указывает
на то, что правило П2 должно применяться в обратном направлении всякий
раз, когда в целевом блоке есть значение ячейки босс, являющееся
переменной (при условии, что прямого соответствия с блоком-фактом
установить нельзя). В описании г I ОТДЕЛЫ обозначение {при заполненной Ш)
указывает на то, что правило П1 должно применяться всякий раз, когда у
некоторого блока для факта ячейка сам содержит "(элемент-множества
ОТДЕЛЫ)" и ячейке глава присвоено некоторое значение. Пусть имеются
блок-факты
ДЖО-СМИТ
сам: (элемент-множества СЛУЖАЩИЕ)
работает-в: 0-3
0-3
сам: {элемент-множества ОТДЕЛЫ)
глава ДЖОН-ДЖОНС
Если предъявлен второй из этих блоков, то просмотр описания г
{ОТДЕЛЫ указывает на то, что надо применить правило П1 в прямом
направлении. Это породит такой блок-факт:
ДЖОН-ДЖОНС
работает-в: 0-3.
Пусть мы хотим узнать: "Кто является боссом Джо Смита?". Этот запрос
выражается целевым блоком
323
ДЖО-СМИТ
босс: и.
Попытка установить прямое соответствие с блоком-фактом ДЖО-СМИТ
оканчивается неудачей; однако одно из описаний, содержащее ячейку босс,
рекомендует системе применить правило П2 в обратном направлении, в
результате порождаются подцелевые блоки:
ДЖО-СМИТ
работает-в:х
χ
глава: и.
Первый из них можно сопоставить с блоком-фактом ДЖО-СМИТ и
получить подстановку [θ-3/χ] : С учетом этого значения второй подцелевой
блок можно, сопоставить с блоком-фактом 0-3 и получить подстановку
{ДЖОН-ДЖОНС/и}, в которой содержится ответ на наш исходный запрос.
9.5. НЕТОЧНЫЕ ОПИСАНИЯ И ПРОТИВОРЕЧИВАЯ ИНФОРМАЦИЯ
Многие высказывания вида "Все χ обладают свойством Р" должны
рассматриваться только как приблизительно истинные. Возможно, что
большинство χ действительно обладает свойством Р, однако, как правило, мы
будем сталкиваться и с исключениями. За примерами такого рода не надо
далеко ходить: все птицы умеют летать, кроме страусов; все насекомые
имеют по шесть ног, кроме особей на ранних стадиях развития, — вроде
гусениц; все лимоны желтые, кроме зеленых неспелых и оранжевый мутантов,
и т.д. Представляется, что многие общие синтетические суждения о мире
(в противоположность суждениям аналитическим или вытекающим из
определений) неверны до тех пор, пока они тем или иным образом не
ограничены. Более того, эти ограничения, по-видимому, столь многочисленны, что
если попытаться включить их в формализм в явном виде, то с ним нельзя
будет работать. Можно ли обойти эту трудность, сохранив вместе с тем
простоту языка исчисления предикатов?
Один из подходов, позволяющих сохранить простоту, заключается в том,
чтобы в некоторых импликативных высказываниях в области действия
квантора общности допустить неявные исключения. Так, высказывание "Все
слоны серые" вначале можно привести без списка каких-либо исключений.
Такое высказывание дает нам возможность заключить, что Клайд — серый,
если известно, что Клайд — слон. Позже, если нам станет известно, что Клайд
на самом деле белого цвета, мы должны будем отменить заключение о
присущем ему сером цвете и изменить общее суждение о слонах таким образом,
чтобы оно не распространялось на Клайда. После такого изменения уже
нельзя будет сделать ошибочное заключение относительно цвета Клайда.
Тот способ, которым программа установления соответствия использует
наследование свойств, дает нам автоматический механизм для работы с
исключениями типа "Клайд — белого цвета". Программа установления
соответствия прибегает к наследованию свойств для определения некоторого
свойства объекта по описанию его класса лишь в том случае, когда отсутствует
конкретная информация об этом свойстве объекта. Пусть к примеру надо узнать
окраску Клайда. Этот запрос надо сформулировать в виде целевого блока
324
КЛАЙД
цвет: χ.
При ответе надо сначала попытаться установить прямое соответствие
этого блока некоторому блоку-факту. Пусть у нас имеется следующий
блок-факт, описывающий Клайда:
КЛАЙД
сам: (элемент-множества СЛОНЫ)
цвет: БЕЛЫЙ
В данном случае подстановкой, ведущей к установлению соответствия,
является БЕЛЫЙ/х и ответом на наш вопрос будет БЕЛЫЙ
Если же в нашем блоке-факте говорится только, что Клайд является
слоном, то программа при ответе на наш запрос автоматически прибегнет
к описанию СЛОНЫ. Это описание может иметь примерно такой вид:
у I СЛОНЫ
цвет: СЕРЫЙ
Эту схему, которая заменяет информацию общего порядка на
противоречащую ей конкретную информацию, можно расширить до нескольких
иерархических уровней. Например, для МЛЕКОПИТАЮЩИХ у нас может быть
такое описание:
и I МЛЕКОПИТАЮЩИЕ
кожа: ГЛАДКАЯ.
Теперь, чтобы не прийти к выводу, что у слонов гладкая кожа, надо
только включить в описание СЛОНЫ такое свойство, как кожа:
МОРЩИНИСТАЯ. Клайд, однако, может оказаться и слоном с гладкой кожей, и чтобы
отменить действие описания СЛОНЫ, надо это свойство включить в блок
КЛАЙД. (В такой иерархии может быть несколько случаев подобного рода
изменений свойств.)
Чтобы схема могла функционировать, применение описаний для вывода
свойств всегда должно переходить от максимально детального уровня к
более общему. При такой встроенной в систему очередности применения
процессов приведения в соответствие и поиска информация, находящаяся на
более детальных уровнях, предохраняет систему от потенциально
противоречивых выводов при использовании описаний более высокого уровня.
Дело обстоит так, словно кванторы общности в описаниях особым образом
исключают из области своего действия все более детальные объекты,
которые противоречат данному описанию.
Однако такого вида схемы сталкиваются все же с определенными
проблемами. Пусть, например, некоторый объект в таксономической иерархии
принадлежит двум разным множествам и пусть описания этих множеств
противоречат друг другу. Эта ситуация изображена в виде сети на рис. 9.28. У
вершины КЛАЙД дуга цвет изображена неявно, однако вершина КЛАЙД
наследует два противоречащих друг другу значения цвета (считаем, что
~РАВ (СЕРЫЙ, БЕЛЫЙ)). Один из возможных путей преодоления этой
трудности состоит в том, чтобы отражать какую-то информацию о качестве
каждой дуги как ячейки описания. Если дуга цвет из описания АЛЬБИНОС
в нашем примере доминировала бы над дугой цвет из описания СЛОНЫ,
325
Рис. 9.28. Сеть с противоречивыми описаниями
то мы всегда пытались бы получить значение цвета вначале именно по
наследству от описания АЛЬБИНОС.
Тот факт, что дуга или ячейка описания обладает невысоким
приоритетом, можно констатировать, помечая ее как неточную1. Неточные описания
можно использовать только тогда, когда для получения необходимой
информации не остается других средств. Но в общем случае среди маркеров
неточности необходимо некоторое упорядочение. Если, например, оба описания
на рис. 9.28 помечены просто как неточные, то мы оказываемся в тупике:
мы могли бы доказать, что Клайд — серого цвета только в том случае, если
не могли бы доказать, что он какого-нибудь другого цвета. Однако мы
могли бы доказать, что он другого цвета, а именно белого, только в том
случае, если не могли бы доказать, что он какого-нибудь другого цвета, и т.д.
При использовании неточных описаний в ходе применения правил в
прямом направлении надо также соблюдать осторожность, поскольку мы
рискуем внести в базу данных для фактов объекты, противоречащие частным
фактам, которые уже имеются в базе данных или могут быть выведены в
дальнейшем. Чтобы противоречащие друг другу факты (и факты, которые
можно из них вывести) были заведомо либо удалены, либо тем или иным
образом нейтрализованы, надо применение описаний в прямом направлении
дополнять некоторой схемой "контроля их истинности".
1 В оригинале default, которое означает "за неимением точной информации". (Иногда
в вычислительной технике это слово переводят ''по умолчанию".) - Прим. ред.
326
9.6. БИБЛИОГРАФИЧЕСКИЕ И ИСТОРИЧЕСКИЕ ЗАМЕЧАНИЯ
Представления структурированных объектов связаны с фреймами,
введенными Минским [245] (но не с проблемой фрейма!); со сценариями,
введенными Шенком и Абельсоном [322]; с бета-струк турами > введенными
Муром и Ньюэллом [250]. Бобров и другие [33] реализовали систему,
названную GUS, в которой использовано представление, похожее на фреймы.
Роберте и Голдстейн [304] реализовали простой фреймовый язык,
названный FRL, а Голдстейн и Роберте [ 124] описали систему автоматического
составления расписаний, написанную на этом языке. Стефик [351] и Фрид-
ланд [111] описали основанное на фреймах представление, которое
использовалось в вычислительной системе, предназначенной для планирования
экспериментов в области молекулярной генетики.
Языки представления знаний KRL = 0 и KRL = 1 основаны на фреймах
и разработаны Бобровым и Виноградом [34]. (Обсуждение и критику KRL
см. также в работах [35, 36, 187].) Интересное обсуждение некоторых
преимуществ представлений, основанных на фреймах, приведено у
Винограда [393].
Хейес [143, 146] рассматривал соотношения между логикой предикатов
и основанными на фреймах представлениями. В настоящей главе
разработка вопросов, связанных со структурированными объектами с акцентом на
их связи с исчислением предикатов, близка точке зрения Хейеса. Переход
к бинарным предикатам обсуждался Делянни и Ковальским [72].
Использование семантических сетей основывается на целом ряде работ.
В области когнитивной психологии Куиллиан [291], Андерсон и Бауэр [9],
Румельхарт и Норман [313] предлагали модели памяти на основе сетей.
Система SIR, разработанная Рафаэлом [292], была основана на
использовании сетей из списков свойств; Уинстон [398] применял сети дляпредствле-
ния и получения информации о конфигурациях из блоков; Симмонс [333]
рассматривал использование сетей при работе с естественным языком.
Вудс [404] подверг обсуждению некоторые логические несоответствия в
ранних вариантах семантических сетей. Интересно отметить, что
первоначальная символика исчисления предикатов, введенная Фреге [110]
додержала двумерные диаграммы.
Было предложено несколько "языков" семантических сетей, обладающих
всей полнотой выразительной силы исчисления предикатов, например
система SNePS, принадлежащая Шапиро [327], формализм разделенных
семантических сетей, введенный Хендриком [152, 153], сетевой формализм
Шуберта [324] (см. также [325]). В статьях сборника под редакцией Финд-
лера [107] описаны другие типы семантических сетей. Формализм
семантических сетей, рассмотренный в настоящей главе, видимо, содержит в себе
основные идеи для тех перечисленных работ, в которых применяются
бинарные предикаты.
Среди типичных приложений семантических сетей — работы с
естественным языком [373], с базами данных [257] и машинное представление
геологических данных (прогнозирование рудных месторождений) [81].
Наш анализ установления соответствия между целевыми сетевыми
структурами и структурами для фактов был в значительной мере основан на
программе установления соответствия, разработанной Файксом и Хендриком
327
[106], а отчасти на идеях Мура [251]. Разнообразные механизмы
наследования свойств в блочных системах и сетевых формализмах предлагались в
качестве подходов к решению того, что некоторые называют задачей
отображения символов. Эта задача обсуждалась в двух выпусках бюллетеня
SIGART (см. [44, 96, 212, 213, 252]). Фальман рекомендовал применять
специализированные вычислительные средства в задачах, связанных с
нахождением пересечения множеств, решение которых требуется для
эффективного осуществления наследования свойств [97].
Представление и использование неточной (default) информации было
рассмотрено Бобровым и Виноградом [34], Рейтером [300]. Попытки
формализовать выводы формулы "будем считать, что X верно, до тех пор, пока
нельзя будет доказать ~Х" привели к созданию немонотонных логик. Мак-
дермотти Дойл рассматривают историю этих попыток, предлагают особый
формализм и доказывают его правильность и полноту [215]. "Уход" за
базами данных, выражающийся в удалении или модификации производных
выражений в ответ на изменения значений истинности элементарных
выражений, рассматривается Дойлом [78]. В системе Столмена и Сассмена,
предназначенной для доказательства утверждений, относящихся к электрическим
цепям, для повышения эффективности подхода с использованием процедуры
возвращения применяется схема "контроля истинности" [350].
Мартин [228], Шенк и Абельсон [322], Сринивасан [349] и Сридхаран
[348] предложили другие сложные схемы представления, имеющие
определенное отношение к схемам, рассмотренным в настоящей главе.
Упражнения
9.1. Представьте в виде семантической сети ситуацию, изображенную на рис. 7.1, а в
качестве правила продукции, предназначенного для изменения сетей, дайте
представление для правила pickup (jc) из системы STRIPS. Объясните, как проверить
приложимость правила pickup (В) и как при этом изменяется сетевое представление на рис. 7.1.
9.2. Предикат D(x, у) предназначен для того, чтобы отразить факт, что пересечение
множеств jc и у пусто. Объясните, как этот предикат можно применить для разметки
дуг семантической сети. Продемонстрируйте это на примере. Подумайте, какие еще
предикаты на дугах могут быть полезны.
9.3. Следующие высказывания представьте как описания в семантической сети:
а) Все люди смертны, б) Нет худа без добра, в) Все дороги ведут в Рим. г) Все
руководители филиалов G - ТЕК принимают участие в системе распределения прибылей,
д) Все кубики, стоящие на кубиках, которые подверглись перемещению, тоже
подверглись перемещению.
9.4. Перепишите следующие правильно построенные формулы в виде ппф с
бинарными предикатами, для чего примените предикаты ЭЛ и ПМ. Перепишите их также в
виде наборов блоков и семантических сетей:
а) [НА {С, А) АНА-СТОЛЕ (А) АНА-СТОЛЕ (В) А РУКА-ПУСТА А
А СВОБОДЕН (В) А СВОБОДЕН (С) ] ·
б) [СОБАКА {ФИДО) А -ЛАЕТ (ФИДО) А ВИЛЯЕТ-ХВОСТОМ {ФИДО) А
А МЯУКАЕТ (МИРТИ) ].
в) (Vjc) ВЕРНО [свободен (jc), делай [перенос (x,y,z),s]].
9.5. Основные идеи в методике поиска представьте в виде таксономической
иерархии. (Методы поиска можно для начала подразделить, например, на эвристические и
методы, не использующие информацию.) Каждому множеству, представленному в
вашей сети, дайте описание.
328
ГЛАВА 10
ПРОСПЕКТ
Мы видели в этой книге, что обобщенные системы продукций (особенно
такие, в которых обрабатываются выражения на языке исчисления
предикатов первого порядка) играют в области искусственного интеллекта
фундаментальную роль. Организация и управление в системах продукций
искусственного интеллекта и те способы, с помощью которых эти системы
используются для решения разнообразных проблем, подверглись нами весьма
детальному обсуждению. Чтобы у читателя не создалось впечатления, что все
эти подробности — формальные построения, математические и
эмпирические результаты — составляют уже сложившуюся инженерную дисциплину,
дающую регулярную основу для широких применений, мы попытаемся
здесь очертить перспективу всего направления искусственного интеллекта
и указать несколько областей, нуждающихся в дальнейших исследованиях.
Действительно, мы могли бы сказать, что наши сегодняшние знания,
касающиеся механизмов интеллекта, составляют малые островки в большом
океане предположений, надежд и невежества.
Точка зрения, представленная в настоящей книге, — это одно из окон,
открытых в сторону ключевых идей искусственного интеллекта.
Специалист захочет также близко познакомиться с языками программирования
ИИ — такими, как ЛИСП, и методами программирования ИИ. Мы не
пытались обсуждать эти вопросы, но в других работах концентрируется
внимание именно на них, например у Уинстона [399], Шапиро [327, 328], Чарня-
ка, Рисбека и Макдермота [51]. Серьезно настроенные студенты, изучающие
искусственный интеллект, также захотят подробно ознакомиться с
разнообразными крупномасштабными его применениями. Мы ссылались на
многие из них в разделах, посвященных библиографическим замечаниям.
В этой главе мы даем краткое описание проблемных областей, которые,
по-видимому, являются очень важными для дальнейшего прогресса в
искусственном интеллекте. В большинстве этих областей некоторая работа
уже проделана, но результаты, как правило, носят экспериментальный,
противоречивый или ограниченный характер. Эти проблемы мы разбиваем
на три основные категории. Первая из них касается новых принципов
архитектуры систем ИИ и перспектив, ожидаемых от параллельной и
распределенной обработок. Вторая категория охватывает проблемы извлечения
знаний и обучения. Наконец, существуют проблемы, связанные с
адекватностью процессов искусственного интеллекта и формальных представлений
при решении таких вопросос, как знания, цели, мнения, планы и самоанализ.
10.1. АРХИТЕКТУРА СИСТЕМ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА.
10.1.1. ОРГАНИЗАЦИЯ ПАМЯТИ
Одним из наиболее важных вопросов, стоящих перед конструктором,
пытающимся реализовать систему ИИ, является вопрос о том, как
организовать структуру базы знаний из фактов и правил, чтобы доступ к
соответствующим элементам был легким. Предложено несколько методов. В
системе доказательства теорем на основе резолюции QA3 [128] список
предложений разбивался на активный и хранимый во вторичной памяти. Предло-
329
жения переносились из вторичного списка в активный только в том случае,
когда никакая резолюция не была возможна в пределах активного списка.
Языки искусственного интеллекта, подобные ПЛЕННЕР, обычно включают
специальные методы для хранения и доступа к выражениям. Макдермотт
описывает специальные методы индексации, применяемые во многих таких
языках [214]. Дискриминационная сеть, используемая в QA4, является
примером такого подхода [312].
Вероятно, наиболее важным аспектом представлений, близких к
фреймам (системы блоков и семантические сети), являются встроенные
механизмы индексации. В самом деле, авторы языка KRL — Боброу и Виноград —
уделяют особое внимание тому, что конструктору необходимо дать
возможность организовать память в виде совокупности таких частей, которые
являются наиболее подходящими для решаемой задачи [34]. Мы ожидаем,
что работа в этих направлениях будет продолжена по мере создания
систем, которые должны использовать сотни тысяч фактов и правил.
10.1.2. ПАРАЛЛЕЛЬНЫЕ И РАСПРЕДЕЛЕННЫЕ СИСТЕМЫ
Наше обсуждение систем продукций ИИ было основано на молчаливом
предположении, что имеется единственный процессор последовательного
действия, который по очереди применяет правила к базе данных. Однако
имеется несколько направлений, по которым нашу систему продукций
можно было бы обобщить с тем, чтобы воспользоваться параллельной
обработкой. Во-первых, при параллельной организации ЭВМ некоторые
элементарные операции системы могли бы выполняться в параллель.
Например, Фальман предложил параллельную систему для выполнения
множества пересечений, необходимых для эффективных вычислений, связанных с
наследованием свойств [97].
Во-вторых, в пробных режимах управления в системах с параллельной
обработкой одновременно можно было бы применять несколько правил
вместо того, чтобы прибегать к процедурам возвращения или построения
дерева, добавляя вершины. Если число последующих элементов, которые
предстоит построить, превышает число модулей для параллельного
применения правил, то управляющая система должна попытаться распределить
имеющиеся модули как можно эффективнее.
В-третьих, в разложимых системах продукций процессоры
параллельного действия можно было бы связать с каждой компонентной базой
данных, и эти процессоры (так же, как и их потомки) могли бы работать
независимо, пока все базы данных не будут до конца обработаны. Эти три
метода использования параллелизма не изменяют основного подхода к
применению систем продукций в системах искусственного интеллекта,
представленного в настоящей книге; они просто касаются реализации этого
подхода с учетом параллельной обработки.
Другое использование параллелизма связано с обобщением
представленных здесь идей. Можно вообразить себе большое сообщество более или
менее независимых систем. (Каждая из них могла бы быть системой
продукций или системой другого типа с внутренними процессами
последовательного или параллельного типа.) Эти системы связываются между собой
для совместного решения проблем. Если каждая из систем является отно-
330
сительно простой, то конструктор может довольно точно определить
протоколы связи и процедуры управления системами и их кооперации.
Расширенные сети Петри по Зисману [407] и формальные построения,
включающие актеров, Хьювитта [156], по-видимому, являются примерами такого
типа (см. также [157, 172]). С другой стороны, если каждая из систем
сама по себе является сложной системой ИИ, то ситуация аналогична
сообществу людей или высших животных, которые должны выдвигать свои
собственные стратегии взаимосвязи и кооперации. Мы располагаем небольшим
опытом, связанным с комплексами взаимодействующих систем
искусственного интеллекта, но работы Лессера и Эрмана [190], Лессера и Коркилла
[189], Коркилла [59] представляют собой определенные шаги в этом
направлении. Работы Смита [344, 345], имеющие к этому отношение, также
использует сети из кооперирующих компонент системы решения проблем.
Крейн в несколько провокационной манере рассматривает аналогии между
параллельными вычислительными системами и сообществами людей [61].
10.2. УСВОЕНИЕ ЗНАНИЙ
Формализация знаний и реализация баз знаний являются основными
задачами при создании больших систем искусственного интеллекта. Сотни
правил и тысячи фактов, требуемые для многих из этих систем, обычно
получаются путем интервьюирования экспертов в данной области
применения. Представление экспертных знаний как фактов или правил (или как
выражений в любом другом формальном построении) обычно является
утомительным, поглощающим много времени процессом. Методы
автоматизации процесса усвоения знаний обеспечили бы основной прогресс в
технике искусственного интеллекта.
Мы кратко остановимся на трех способах, с помощью которых можно
было бы автоматизировать усвоение знаний. Во первых, можно построить
специальные редактирующие системы, которые позволили бы лицу,
обладающему экспертными знаниями о данной области применений (но который
не является сам специалистом по программированию), взаимодействовать
напрямую с базами данных систем ИИ. Во-вторых, успехи в методах
обработки естественных языков позволят людям инструктировать и обучать
вычислительные системы посредством обычного собеседования
(дополненного, возможно, использованием чертежей и другого нетекстуального
материала) . В-третьих, системы ИИ можно обучать важным знаниям
непосредственно на своем опыте в данной проблемной области.
По существу, все большие системы ИИ должны иметь систему
редактирования базы знаний какого-то типа, облегчающую процесс добавления,
вычеркивания и изменения фактов и правил по мере развития системы. Дэйвис
разработал систему, названную TEIRESIAS, которая позволяла врачам
непосредственно взаимодействовать с базой данных медицинской
диагностической системы MYCIN [65]. Фридленд сообщил о системе представления,
которая содержит экспертные знания о молекулярной генетике; ключевой
характеристикой системы является семейство редакторов,
взаимодействующих с базой знаний [111]. Дуда с соавторами дают описание системы
редактирования базы знаний для системы PROSPECTOR [83]. По мере того, как
в системах такого рода будет появляться возможность общения с их созда-
331
телями на естественном языке, процессы ввода и модификации знаний
будут становиться все эффективнее. Следует помнить, что вычислительные
системы будут не способны к действительно гибкому диалогу о
представлениях и понятиях, которые предстоит использовать в этих
представлениях, пока конструкторы не найдут возможным дать этим системам
метазнания о самих представлениях. К сожалению, мы пока что не располагаем
даже достаточно ясным наброском общей теории представления знаний.
Часто высказывается надежда, что задача усвоения знаний будет
несколько облегчена при применении автоматических механизмов обучения,
встроенных в системы ИИ. Люди и животные, по-видимому, имеют весьма
впечатляющие возможности обучаться на опыте. На самом деле первые работы в
области искусственного интеллекта основывались на стратегии
конструирования интеллектуальных машин, которые могли бы выучиться тому, как
выполнять задачи.
Имеется, конечно, несколько разновидностей обучения. Почти всякое
изменение в системе ИИ — такое, как добавление единичного нового факта,
привнесение новой компоненты в стратегию управления или глубокое
изменение архитектуры, можно было бы назвать обучением. Более того, эти
изменения могли бы быть вызваны либо непосредственно действиями
программиста (изменение конструкции), либо опосредованно через общение с
человеком или с другой системой (обучение), либо реакцией на опыт в
некоторой окружающей среде (адаптивное обучение). Эволюционные
изменения конструкции уже играют важную роль в развитии систем ИИ. Некоторая
работа была проделана по развитию методики обучения для систем ИИ.
Однако стратегии, использованные для адаптивного обучения, пока что привели
лишь к ограниченному успеху. Можно ожидать, что все эти разновидности
обучения будут важны для будущих систем ИИ. Этот предмет является
важной областью исследований.
Первые работы по адаптивному обучению концентрировались на
системах классификации образов [271] и игровых системах [320, 321], которые
были связаны с автоматическим подбором простых оценочных и
классифицирующих функций. Уинстон построил систему, способную обучиться
относительно сложным предикатам принадлежности к определенным классам:
как и во многих системах обучения, эффективность сильно зависит от
правильно подобранной последовательности опытов [397]. Митчел [246], Ди-
терих и Михальский [74] приводят хорошее обсуждение подходов как
собственного, так и принадлежащих другим авторам к проблеме обучения
понятиям и индуктивного вывода.
Определенные усилия были также направлены на сохранение
результатов вычислений (таких, как доказательства теорем и планы для роботов)
в форме, которая допускала бы их использование и в других проблемах.
Например, Файкс, Харт и Нильсон предложили метод генерирования и
сохранения треугольных таблиц, позволяющий применять их в качестве
макроопераций при создании новых планов [105].
Одним из наиболее мощных способов использования выученного или
запомненного материала является способность увидеть аналогии между
текущими и встречавшимися ранее задачами. Одна из ранних программ
Эванса была в состоянии решить такого типа задачи на геометрическую
332
аналогию, которые встречаются в обычных интеллектуальных тестах [94].
Клинг использовал метод, опирающийся на аналогию, для повышения
эффективности системы доказательства теорем [170]. Ульрих и Молл
предложили систему, в которой применяются аналогии в задаче синтеза программ
[362]. Уинстон описал теорию (сопровождаемую программой) обучения
по аналогии [400], а Макдермотт рассмотрел, как программа для
вычислительной машины могла бы обучаться аналогиям [217].
Система, предлагаемая Вере [367], способна обучаться правилам,
подобным правилам системы STRIPS, сравнивая описание состояний перед
совершением действия, которое это состояние меняют, с результатом. Букхенен
и Митчел описали процесс обучения порождающим правилам,
используемым в системе DENDRAL, предназначенной для вычисления химической
структуры [42]. Солоуэй предложил систему, которая обучается
некоторым правилам игры в бейсболл путем наблюдения (смоделированных)
действий игроков [347].
Наконец, следует упомянуть систему AM Лената [188], в которой
используется некоторый запас элементарных понятий математики и которая
способна "открывать" понятия (такие, как понятие простых чисел) .
10.3. ФОРМАЛЬНЫЕ СИСТЕМЫ ДЛЯ ПРЕДСТАВЛЕНИЯ ЗНАНИЙ
Примеры проблем, которые мы рассмотрели в этой книге, показывают,
что исчисление предикатов первого порядка может быть использовано для
представления практически всех знаний, необходимых системам ИИ.
Имеются, однако, такие виды знаний, которые обычно применяются людьми при
решении проблем и общении друг с другом, но которые представляют
определенные трудности для логики первого порядка и систем ИИ вообще.
Примерами могут быть знания ненадежные или неопределенные в различных
отношениях, обычные здравые соображения о причине и следствии, знания о
планах и процессах, предположениях, целях своих и других лиц, знание о
знаниях. Маккарти рассмотрел эти и другие эпистемологические проблемы
искусственного интеллекта [206].
Некоторые исследователи пришли к выводу, что формальные логические
построения совершенно не подходят для работы с понятиями такого вида
и должны быть разработаны совершенно другие схемы представления (см.,
например, [395]). Ссылаясь на прежние успехи формальных методов,
другие исследователи считают, что некоторого дополнения к логике первого
порядка, или достаточно сложных теорий, представленных в логике первого
порядка, или, возможно, более сложных формальных логических
построений будет в конечном счете достаточно, чтобы охватить знания и процессы,
используемые человеком.
10.3.1. РАССУЖДЕНИЯ ЗДРАВОГО СМЫСЛА
Многие из существующих идей относительно методов искусственного
интеллекта отшлифовывались на "игрушечных" задачах - таких, как
проблемы из "мира кубиков", где относительно легко формализовать
необходимые знания. Применение искусственного интеллекта в таких более
сложных областях, как медицина, геология и химия, потребовало интенсивных
333
усилий по формализации соответствующих знаний. Хейес [144] и другие
настаивали на том, что исследователи, работающие в области
искусственного интеллекта, должны попытаться формализовать фундаментальные
"знания здравого смысла, касающиеся каждодневного физического мира,
предметов, форм, пространства, движения, веществ (твердых тел и жидкостей),
времени и т.д.". Хейес начал осуществление этой задачи с эссе,
посвященного формализации свойств жидкостей [145]. Купере описал систему,
моделирующую представления здравого смысла о пространстве [183, 184].
Формализацию обыденных знаний физики следует отличать от
довольно точных математических моделей физики твердых тел, жидкости и
газов. Последние, вероятно, слишком сложны для рассуждений о физических
событиях на уровне здравого смысла. (Маккарти высказал, например,
мысль о том, что люди, по всей видимости, даже подсознательно не
производят вычислений, связанных со сложным гидродинамическим
моделированием, чтобы решить, остаться ли на месте или отодвинуться, чтобы
не обжечься кофе, выплеснувшимся из нечаянно опрокинутой чашки.)
Формализация физических событий на уровне здравого смысла является
важным моментом, поскольку во многих применениях необходимы
рассуждения о пространстве, материалах, времени и т. п. К тому же большая
часть выражений на естественном языке относится к физическому миру,
некоторые метафоры, безусловно, имеют физическую основу. На самом
деле, чтобы в полной мере воспользоваться рассуждениями по аналогии
системы искусственного интеллекта, нуждаются в хорошем, хотя и не
всегда точном, понимании простых физических процессов.
Большая часть рассуждений на уровне здравого смысла (и даже
технические рассуждения) неточны в том смысле, что выводы и те правила и факты,
на которых они основываются, лишь приблизительно верны. И тем не менее
люди способны использовать ненадежные факты и правила, приходя к
полезным выводам относительно обыденных или специализированных
предметов — таких, как медицина. Основной характеристикой такого
приближенного рассуждения является то, что заключение становится более
убедительным, если оно независимо поддерживается двумя или более независимыми
аргументами.
Мы ранее указывали на работу Шортлиффа, относящуюся к системе
MYCIN [330], и работу Дуда, Харта и Нильсона, относящуюся к системе
PROSPECTOR [80], и отмечали использование в них схожих методов
работы с ненадежными фактами и правилами. Принятый подход имеет
недостатки, в особенности когда речь идет о фактах и правилах, которые не
являются независимыми. Кроме того, неясно, можно ли эти методы
достаточно просто обобщить на факты и правила, содержащие переменные,
относящиеся к кванторам.
Коллинз подчеркивает важность метазнаний в правдоподобном
рассуждении [56]. (Мы еще обсудим предмет метазнаний.) Заде обратился к
мысли об использовании нечетких множеств при работе с задачами неточного
рассуждения [406]. Другие подходы к правдоподобному рассуждению
следуют из работ, относящихся к рассуждениям по умолчанию и немонотонной
логике, упоминаемым в конце гл. 9.
Другой важной компонентой рассуждения здравого смысла является
334
способность размышлять о действиях, процессах и планах. Поэтому нам
прежде всего необходимы способы представления этих понятий. В
библиографических замечаниях к гл. 7 и 8 мы указывали на некоторые источники,
касающиеся моделирования действий и планов. В дополнение к ним мы
могли бы упомянуть работу Мура [254], который комбинирует методы
рассуждения о действиях с методами рассуждения о знаниях (см. ниже).
Взаимодействие действий и знаний в нашей книге не обсуждалось (и на самом
деле оно недостаточно исследовано в искусственном интеллекте). Однако это
взаимодействие носит фундаментальный характер, поскольку действия,
как правило, изменяют состояние знаний действующего лица и поскольку
знания о мире необходимы для выполнения действий.
Хендрикс обсуждает использование семантических сетей для
представления процессов [151, 153, с. 76], Грож [131] и Робинсон [305]
применили структуры, подобные процедурным сетям [318], при интерпретации
высказываний на естественном языке, встречающихся в диалоге с
пользователем, участвующим в некотором производственном процессе. Шенк и Абель-
сон предложили структуры для представления процессов и планов при
использовании в областях, требующих понимания естественного языка [322].
Шмидт, Сридхаран и Гудсон рассмотрели методы распознавания планов и
целей действующих лиц исходя из их действий [323]. Все эти усилия
делают вклад в нашу способность формализовать планы, действия и процессы
и в конечном счете в построение систем, способных о них рассуждать.
10.3.2. ПРЕДСТАВЛЕНИЕ ПРЕДПОЛОЖИТЕЛЬНЫХ ОТНОШЕНИЙ
Некоторые глаголы, такие, как знать, верить, хотеть и бояться, могут
использоваться для выражения отношения между агентом и
предположением, как это иллюстрируется следующими примерами:
Сэм знает, что Питер адвокат.
Сэм не верит, что Джон доктор.
Питер хочет, чтобы шел дождь. (Или, Питер хочет, чтобы был дождь).
Джон боится, что Сэм верит, будто утренняя звезда не является Венерой.
Выделенные части этих предложений являются предположениями, а
связки знать, верить и т.д. относятся к позиции агентов в отношении этих
предположений. Поэтому знать, верить и т.д. называются предположительными
отношениями. Логический формализм для выражения предположительных
отношений должен давать возможность отображать подходящие связи между
агентами и отношениями.
Хорошо известно, что при попытках выполнить такое формальное
построение возникают различные трудности, в частности проблема реферативной
ясности. Из высказываний "Джон верит, что Санта Клаус принес ему
подарки на Рождество" и "Санта Клаус - отец Джона" мы не хотели бы, чтобы
была возможность вывести высказывание "Джон верит, что отец Джона
принес ему подарки на Рождество". Эти проблемы обсуждались логиками
на протяжении нескольких лет, и предлагались разнообразные решения (см.,
например, соответствующие эссе [196]) .
Мур рассмотрел проблемы формализации предположительных
отношений для применений в искусственном интеллекте [253, 254]. Он указал
335
на некоторые трудности, лежащие на пути прямых подходов, и показал, как
модальная логика с возможной семантикой миров может быть
использована для преодоления этих трудностей в случае отношения знать. Затем он
перешел к демонстрации того, как этот подход может быть встроен в логику
первого порядка так, чтобы обычного вида системы доказательства теорем
из области искусственного интеллекта могли быть использованы для
рассуждений о знаниях. (Как мы отметили ранее, Мур также связывает логику
знаний с логикой действий.)
Было предложено несколько других подходов. Маккарти предложил,
чтобы к области рассуждений были добавлены концепции, относящиеся
к элементам области, и показал, как в логике первого порядка с
использованием этих концепций удается избежать некоторых трудностей [207].
Креари обобщил это понятие [62]. Элыплагер рассмотрел проблему
согласованности утверждений о знаниях в формальных схемах, которые
описывают концепции как элементы области [91].
Хотя формализация для предположительных отношений в основном
были уделом логиков-теоретиков, эта проблема является фундаментальной для
будущих успехов искусственного интеллекта. Общение людей на
естественном языке, по-видимому, зависит от способности участвующих делать
выводы относительно предположений, имеющихся у партнеров, и нам следует
ожидать, что такая же способность потребуется и для систем понимания
естественного языка. Кроме того, когда две или более систем искусственного
интеллекта кооперируются при решении проблем, то у них возникает
необходимость рассуждать относительно целей, знаний и предположений
каждого. Коэн обсудил, каким образом система может заиланированно влиять
на знания другой системы посредством речевых актов [53]. В этих
направлениях еще предстоит многое сделать.
10.3.3. МЕТАЗНАНИЕ
Наличие хорошего решения проблемы рассуждения о знании других
должно быть подтверждением и способности рассуждать о своих собственных
знаниях. Мы бы хотели строить системы, которые знают или же могут
логически вывести, знают ли они некоторые факты и правила относительно
определенных объектов, не прибегая к просмотру своих больших баз знаний в
поиске этих элементов. Мы бы хотели также, чтобы системы имели знание
о том, когда и как использовать другое знание. Как отмечалось в
библиографических замечаниях к гл. 6, различные исследователи предлагали для
управления системами продукций использовать системы, содержащие
метаправила.
Коллинз считает, что метазнания могли бы быть полезными при выводе
знаний об объектах [56]. Например: "Поскольку я бы заведомо знал, что
Генри Киссинджер имеет рост три метра, и поскольку я этого о нем не знаю,
то это и не так". Метауровень знания также является легким путем для
решения многих проблем. Банда с соавторами [45] и Вейхраух [384]
проиллюстрировали этот принцип на примере решения уравнений.
336
Двумя изящными организациями систем и метасистем являются LCF [55]
и FOL, разработанная Вейхраухом в 1979 г. Вейхраух подчеркивает
способность системы FOL ссылаться на самою себя при этом не попадать в цикл.
Ссылка на себя была желаемой, но ускользающей от анализа темой в
исследованиях по искусственному интеллекту. Интересной книгой по проблемам
ссылки на себя в логике, музыке и искусстве является книга Хофштадте-
ра [160].
Вопросы, которые мы кратко обсудили в этой главе, сейчас являются
предметом интенсивных исследований в искусственном интеллекте.
Можно ожидать, что экспериментальные исследования и теоретический анализ
приведут к пересмотру и обобщению парадигм и формальных схем,
которые доказали свою полезность при систематизации прежних результатов.
В настоящей книге мы воспользовались некоторыми идеями
систематизации — такими, как обобщенные системы продукций, язык исчисления
предикатов и эвристический поиск, чтобы сделать наш рассказ проще для
восприятия и запоминания. Сейчас мы не можем сказать, сведутся ли легко новые
результаты к рассказу или они потребуют изобретения новых тем или полной
смены его содержания. Именно так наука и техника идут вперед. Каковы
бы ни были эти новые результаты, мы во всяком случае знаем, что
описание их будет столь же важным, как и их достижение, для того, чтобы мы
(да и машины) были в состоянии их понять.
СПИСОК ЛИТЕРАТУРЫ
СБОРНИКИ СТАТЕЙ
АНТ
Elithorn, A., and Jones, D. (Eds.) 1973. Artificial And Human
Thinking. San Francisco: Jossey-Bass.
AIHP
Findler, N. V., and Meltzer, B. (Eds.) 1971 .Artificial Intelligence and
Heuristic Programming. New York: American Elsevier.
AI-MIT
Winston, P. H., and Brown, R. H. (Eds.) 1979. Artificial Intelligence:
An MIT Perspective (2 vols.). Cambridge, MA: MIT Press.
AN
Findler, N. V. (Ed.) 1979. Associative Networks—The
Representation and Use of Knowledge in Computers. New York: Academic
Press.
CT
Feigenbaum, E., and Feldman, J. (Eds.) 1963. Computers and
Thought. New York: McGraw-Hill.
CVS
Hanson, A. R., and Riseman, Ε. Μ. (Eds.) 1978. Computer Vision
Systems. New York: Academic Press.
KBS
Davis, R., and Lenat, D. 1980. Knowledge-Based Systems in
Artificial Intelligence. New York: McGraw-Hill. In press.
Mil
Collins, N. L., and Michie, D. (Eds.) 1967. Machine Intelligence I.
Edinburgh: Edinburgh University Press.
MI2
Dale, E., and Michie, D. (Eds.) 1968. Machine Intelligence 2.
Edinburgh: Edinburgh University Press.
MI3
Michie, D. (Ed.) 1968. Machine Intelligence 3. Edinburgh:
Edinburgh University Press.
338
MI4
Meltzer, В., and Michie, D. (Eds.) 1969. Machine Intelligence 4.
Edinburgh: Edinburgh University Press.
MIS
Meltzer, В., and Michie, D. (Eds.) 1970. Machine Intelligence 5.
Edinburgh: Edinburgh University Press.
MI6
Meltzer, В., and Michie, D. (Eds.) 1971. Machine Intelligence 6.
Edinburgh: Edinburgh University Press.
MI7
Meltzer, В., and Michie, D. (Eds.) 1972. Machine Intelligence 7.
Edinburgh: Edinburgh University Press.
MI8
Elcock E., and Michie, D. (Eds.) 1977. Machine Intelligence 8:
Machine Representations of Knowledge. Chichester: Ellis Horwood.
MI9
Hayes, J. E., Michie, D, and Mikulich, L. I. (Eds.) 1979. Machine
Intelligence 9: Machine Expertise and the Human Interface.
Chichester: Ellis Horwood.
PCV
Winston, P. H. (Ed.) 1975. The Psychology of Computer Vision. New
York: McGraw-Hill.
PDIS
Waterman, D., and Hayes-Roth, F. (Eds.) 1978. Pattern-Directed
Inference Systems. New York: Academic Press.
RDST
Wegner, P. (Ed.) 1979. Research Directions in Software Technology.
Cambridge, MA: MIT Press.
RM
Simon, Η. Α., and Siklossy, L. (Eds.) 1972. Representation and
Meaning: Experiments with Information Processing Systems. Engle-
wood Cliffs, NJ: Prentice-Hall.
RU
Bobrow, D. G., and Collins, A. (Eds.) 1975. Representation and
Understanding. New York: Academic Press.
339
SIP
Minsky, Μ. (Ed.) 1968. Semantic Information Processing.
Cambridge, MA: MIT Press.
TAN PS
Banerji, R., and Mesarovic, M. D. (Eds.) 1970. Theoretical
Approaches to Non-Numerical Problem Solving. Berlin: Springer-
Verlag.
ТРУДЫ КОНФЕРЕНЦИЙ
IJCAI-l
Walker, D. E., and Norton, L. M. (Eds.) 1969. International Joint
Conference on Artificial Intelligence. Washington, D.C.; May.
IJCAI-2
1971. Advance Papers, Second International Joint Conference on
Artificial Intelligence. London: The British Computer Society;
September. (Xerographic or microfilm copies available from Xerox
University Microfilms. 300 North Zeeb Rd, Ann Arbor, Ml, 48106;
or from University Microfilms Ltd., St. John's Rd., Tylers Green,
Penn., Buckinghamshire HP10 8HR, England.)
IJCAI-3
1973. Advance Papers, Third International Joint Conference on
Artificial Intelligence. Stanford, CA; August. (Copies available from
Artificial Intelligence Center, SRI International, Inc., Menlo Park,
С A, 94025.)
IJCAI-4
1975. Advance Papers of the Fourth International Joint Conference
on Artificial Intelligence (2 vols.). Tbilisi, Georgia, USSR;
September. (Copies available from IJCAI-4, MIT AI Laboratory, 545
Technology Sq., Cambridge. MA, 02139.)
IJCAI-5
1977. Proceedings of the 5th International Joint Conference on
Artificial Intelligence (2 vols.). Massachusetts Institute of
Technology, Cambridge, MA; August. (Copies available from IJCAI-77,
Dept. of Computer Science, Carnegie-Mellon University,
Pittsburgh, PA, 15213.)
IJCAI-6
1979. Proceedings of the Sixth International Joint Conference on
340
Artificial Intelligence (2 vols.). Tokyo; August. (Copies available
from IJCAI-79, Computer Science Dept., Stanford University,
Stanford, CA 94305.)
PASC
1974. Proceedings of the AISB Summer Conference. (Copies
available from Dept. of Artificial Intelligence, University of Edinburgh,
Hope Park Sq., Edinburgh, EH8 9NW, Scotland.)
PC AI
1978. Proceedings of the AISB/GI Conference on Artificial
Intelligence. Hamburg; July. (Copies available from Dept. of Artificial
Intelligence, Univeiaity of Edinburgh, Hope Park Sq., Edinburgh,
EH8 9NW, Scotland.)
SCAISB-76
1976. Conference Proceedings, Summer Conference on Artificial
Intelligence and Simulation of Behavior. Department of Artificial
Intelligence, University of Edinburgh; July. (Copies available from
Dept. of Artificial Intelligence, University of Edinburgh, Hope Park
Sq., Edinburgh, EH8 9NW, Scotland.)
TIN LA PI
Nash-Webber, В., and Schank, R. (Eds.) 1975. Proceedings of
Theoretical Issues in Natural Language Processing. Cambridge,
MA; June.
TIN LA Ρ-2
Waltz, D. (Ed.) 1978. Proceedings of TIN LA Ρ-2: Theoretical Issues
in Natural Language Processing—2. University of Illinois; July.
(Copies available from the Association for Computing Machinery,
P.O. Box 12105, Church Street Station, New York, NY, 10249.)
WAD
Joy пег, W. H.. Jr. (Ed.) 1979. Proceedings of the Fourth W^tKshop on
Automated Deduction. Austin, Texas; February.
341
КНИГИ, СТАТЬИ, ОТЧЕТЫ
1 Abraham, R. G. 1977* Programmable automation of batch assembly
operations. The Industrial Robot, 4(3). 119-131. (International Fluidics
Services, Ltd.)
2 Agin, G. J. 1977. Vision systems for inspection and for manipulator
control. Proc. 1977 Joint Automatic Control Confi, vol. 1, pp. 132-138.
San Francisco, CA; June. New York: IEEE.
3 Aho, A. V., Hopcroft, J. E., and Ullman, J. D. 1974. The Design and
Analysis of Computer Algorithms. Reading, MA: Addison-Wesley.
4 Allen, J. 1978. Ana'omy of LISP. New York: McGraw-Hill.
5 Allen, J., and Luckham, D. 1970. An interactive theorem proving
program. In Μ15, pp. 321-336.
6 Amarel, S. 1967. An approach to heuristic problem-solving and
theorem proving in the propositional calculus. In J. Hart and S. Takasu
(Eds.), Systems and Computer Science. Toronto: University of Toronto
Press.
7 Amarel, S. 1968. On representations of problems of reasoning about
actions. In Μ13, pp. 131-171.
8 Ambler, A. P., et al. 1975. A versatile system for computer-controlled
assembly. Artificial Intelligence, 6(2), 129-156.
9 Anderson, J., and Bower, G. 1973. Human Associative Memory.
Washington, D.C.: Winston.
10 Athans, M., et al. 1974. Systems, Networks and Computation: Mul-
tivariable Methods. New York: McGraw-Hill.
11 Ball, W. 1931. Mathematical Recreations and Essays (10th ed.).
London: Macmillan & Co.
12 Ballantyne, A. M., and Bledsoe, W. W. 1977. Automatic proofs of
theorems in analysis using non-standard techniques. J ACM, 24(3),
353-374.
13 Banerji, R., and Mesarovic, M. D. (Eds.) 1970. Theoretical Approaches
to Non-Numerical Problem Solving. Berlin: Springer-Verlag.
342
14 Barr, Α., and Feigenbaum, Ε. Α. 1980. Handbook of Artificial
Intelligence. Stanford, CA: Stanford University Computer Science Dept.
15 Barrow, H., and Tenenbaum, J. M. 1976. MS YS: A System for
Reasoning about Scenes, Tech. Note 121, Artificial Intelligence Center, Stanford
Research Institute, Menlo Park, CA; March.
16 Barstow, D. 1979. Knowledge-Based Program Construction. New York:
North-Holland.
17 Baudet, G. M. 1978. On the branching factor of the alpha-beta pruning
algorithm. Artificial Intelligence, 10(2), 173-199.
18 Bellman, R., and Dreyfus, S. 1962. Applied Dynamic Programming.
Princeton, NJ: Princeton University Press.
!9 Berliner, H. J. 1978. A chronology of computer dies;, and its literature.
Artificial Intelligence, 10(2), 201-214.
20 Berliner, H. J. 1979. The B* tree search algorithm: A best-first proof
procedure. Artificial Intelligence, 12(1), 23-40.
21 Bernstein, M. 1.1976. Interactive Systems Research: Final Report to the
Director, Advanced Research Projects Agency. Rep. No. TM-
5243/006/00, System Development Corporation, Santa Monica, CA.
22 Bibel, W., and Schreiber, J. 1975. Proof search in a Gentzen-like system
of first-order logic. In E. Gelenbe and D. Potier (Eds.), International
Computing Symposium 1975. Amsterdam: North-Holland.
23 Biermann, A. W. 1976. Approaches to automatic programming.
Advances in Computers (vol. 15). New York: Academic Press.
24 Binford, Т. О., et al. 1978. Exploratory Study of Computer Integrated
Assembly Systems, Memo AIM-285.4, Fifth Report, Stanford Artificial
Intelligence Laboratory, Stanford University, September.
25 Black, F. 1964. A Deductive Question-Answering System. Doctoral
dissertation, Harvard, June. (Reprinted in SIP, pp. 354-402.)
26 Bledsoe, W. W. 1971. Splitting and reduction heuristics in automatic
theorem proving. Artificial Intelligence, 2(1), 55-77.
27 Bledsoe, W. W. 1977. Non-resolution theorem proving. Artificial
Intelligence, 9(1), 1-35.
343
28 Bledsoe, W.W., and Bruell, P. 1974. A man-machine theorem-proving
system. Artificial Intelligence, 5(1), 51-72.
29 Bledsoe, W. W., Bruell, P., and Shostak, R. 1978. A Proverfor General
Inequalities. Rep. No. ATP-40, The University of Texas at Austin,
Departments of Mathematics and Computer Sciences.
30 Bledsoe, W. W., and Tyson, M. 1978. The UT Interactive Theorem
Prover. Memo ATP- 17a, The University of Texas at Austin, Math. Dept.,
June.
31 Bobrow, D., and Raphael, B. 1974. New programming languages for
Artificial Intelligence research. ACM Computing Surveys, vol. 6, pp.
153-174.
32 Bobrow, D. G., and Collins, A. (Eds.) 1975. Representation and
Understanding. New York: Academic Press.
33 Bobrow, D. G., et al. 1977. GUS, A frame-driven dialog system.
Artificial Intelligence, 8(2), 155-173.
34 Bobrow, D. G., and Winograd, T. 1977a. An overview of KRL, a
knowledge representation language. Cognitive Science, 1(1), 3-46.
35 Bobrow, D. G., and Winograd, T. 1977b. Experience with KRL-0: one
cycle of a knowledge representation language. In IJCAI-5, pp. 213-222.
36 Bobrow, D. G., and Winograd, T. 1979. KRL: another perspective.
Cognitive Science, 3(1), 29-42.
37 Boden, M. A. 1977. A rtificial Intelligence and Natural Man. New York:
Basic Books.
38 Boyer, R. S. 1971. Locking: A Restriction of Resolution. Doctoral
dissertation, University of Texas at Austin, August.
39 Boyer, R. S., and Moore, J S. 1979. A Computational Logic. New York:
Academic Press.
40 Brown, J. S. 1977. Uses of Artificial Intelligence and advanced
computer technology in education. In R. J. Seidel and Μ Rubin (Eds.),
Computers and Communications: Implications for Education. New York:
Academic Press.
344
41 Buchanan, В. G., and Feigenbaum, E. A. 1978. Dendral and Meta-Den-
dral: their applications dimension. Artificial Intelligence, 11(1,2), 5-24.
42 Buchanan, B. G. and Mitchell, Т. М. 1978. Model-directed learning of
production rules. In PDIS, pp. 297-312.
43 Bundy, A. (Ed.) 1978. Artificial Intelligence: An Introductory Course.
New York: North Holland.
44 Bundy, Α., and Stone, M. 1975. A note on McDermott's
symbol-mapping problem. SIGART Newsletter, no. 53, pp. 9-10.
45 Bundy, Α., et al. 1979. Solving mechanics problems using meta-level
inference. In IJCAI-6, pp. 1017-1027.
46 Cassinis, R. 1979. Sensing system in supersigma robot. 9th International
Symposium on Industrial Robots, Washington, D.C., September.
Dearborn, Ml·. Society of Manufacturing Engineers. Pp. 437-448.
47 Chang, С L. 1979. Resolution plans in theorem proving. In IJCAI-6,
pp. 143-148.
48 Chang, С L., and Lee, R. С. Т. 1973. Symbolic Logic and Mechanical
Theorem Proving. New York: Academic Press.
49 Chang, С L., and Slagle, J. R. 1971. An admissible and optimal
algorithm for searching AND/OR graphs. Artificial Intelligence, 2(2),
117-128.
50 Chang, С L., and Slagle, J. R. 1979. Using rewriting rules for
connection graphs to prove theorems. Artificial Intelligence, 12(2).
51 Charniak, E., Riesbeck, C, and McDermott, D. 1979. Artificial
Intelligence Programming. Hillsdale, NJ: Lawrence Erlbaum Associates.
5 2 Codd, E. F. 1970. A relational model of data for large shared data banks.
С ACM, 13(6), June.
53 Cohen, P. R. 1978. On Knowing What to Say: Planning Speech Acts.
Tech. Rep. No. 118, University of Toronto, Dept. of Computer Science.
(Doctoral dissertation.)
54 Cohen, H. 1979. What is an image? In IJCAI-6, pp.4028-1057.
55 Cohn, A. 1979. High level proof in LCF. In WAD, pp. 73-80.
345
56 Collins, A. 1978. Fragments of a theory of human plausible reasoning.
In TINLA P-2, pp. 194-201.
57 Collins, N. L., and Michie, D. (Eds.) 1967. Machine Intelligence 1.
Edinburgh: Edinburgh University Press.
58 Constable, R. 1979. A discussion of program verification. In RDST, pp.
393-403.
59 Corkill, D. D. 1979. Hierarchical planning in a distributed environment.
In IJCAI-6, pp. 168-175.
60 Cox, P. T, 1977. Deduction Plans: A Graphical Proof Procedure for the
First-Order Predicate Calculus. Rep. CS-77-28, University of Waterloo,
Faculty of Mathematics Research, Waterloo, Ontario, Canada.
61 Crane, H. D. 1978. Beyond the Seventh Synapse: The Neural
Marketplace of the Mind. Research Memorandum, SRI International, Menlo
Park, CA; December.
62 Creary, L. G. 1979. Propositional attitudes: Fregean representation and
simulative reasoning. In IJCAI-6, pp. 176-181.
63 Dale, E., and Michie, D. (Eds.) 1968. Machine Intelligence 2.
Edinburgh: Edinburgh University Press.
64 Date, С J. 1977. An Introduction to Database Systems, (2nd ed.).
Reading, MA: Addison-Wesley.
65 Davis, R. 1976. Applications of Μ eta Level Knowledge to the
Construction, Maintenance and Use of Large Knowledge Bases. Doctoral
dissertation, Stanford University, Stanford Artificial Intelligence Laboraratory,
Memo 283. (Reprinted in KBS.)
66 Davis, R. 1977. Meta-level knowledge: overview and applications. In
IJCAI-5, pp. 920-927.
67 Davis, R., and King, J. 1977. An overview of production systems. In Μ18,
pp. 300-332.
68 Davis, R., and Lenat, D. 1980. Knowledge-Based Systems in Artificial
Intelligence. New York: McGraw-Hill. In press.
69 Davis, M., and Putnam, H. 1960. A computing procedure for
quantification theory. JACM, 7(3), 201-215.
346
70 Dawson, С, and Siklossy, L. 1977. The role of preprocessing in problem
solving systems. In IJCAI-5, pp. 465-471.
71 de Kleer, J., et al. 1979. Explicit control of reasoning. In ΑΙ-MIT, vol. 1,
pp. 93-116.
72 Deliyani, Α., and Kowalski, R. 1979. Logic and semantic networks.
CA CM, 22(3), 184-192.
73 Derksen, J. Α., Rulifson, J. F., and Waldinger, R. J. 1972. The QA4
language applied to robot planning. Proc. Fall Joint Computer Confi, vol.
41, Part 2, pp. 1181-1192.
74 Dietterich, T. G. and Michalski, R. S. 1979. Learning and generalization
of characteristic descriptions: evaluation criteria and comparative review
of selected methods. In IJCAI-6, pp. 223-231.
75 Dijkstra, E. W. 1959. A note on two problems in connection with
graphs. Numerische Mathematik, vol. 1, pp. 269-271.
76 Doran, J. 1967. An approach to automatic problem-solving. In Λ//7, pp.
105-123.
77 Doran, J., and Michie, D. 1966. Experiments with the graph traverser
program. Proceedings of the Royal Society of London, vol. 294 (series A),
pp. 235-259.
78 Doyle, J. 1979. A truth maintenance system. Artificial Intelligence,
12(3).
79 Duda, R. O., and Hart, P. E. 1973. Pattern Recognition and Scene
Analysis. New York: John Wiley and Sons.
80 Duda, R. O., Hart, P. E., and Nilsson, N. J. 1976. Subjective Bayesian
methods for rule-based inference systems. Proc. 1976 Nat. Computer
Confi (AFIPS Conf. Proc), vol. 45, pp. 1075-1082.
81 Duda, R. O., et al. 1978a. Semantic network representations in
rule-based inference systems. In PDIS, pp. 203-221.
82 Duda, R. O., et al. 1978b. Development of the Prospector Consultation
System for Mineral Exploration. Final Report to the Office of Resource
Analysis, U.S. Geological Survey, Reston, VA (Contract No. 14-08-
347
0001-15985) and to the Mineral Resource Alternatives Program, The
National Science Foundation, Washington, D.C. (Grant No. AER77-
04499). Artificial Intelligence Center, SRI International, Menlo Park,
CA; October.
83 Duda, R. O., et al. 1979. A Computer-based Consultant for Mineral
Exploration. Final Report, Grant AER 77-04499, SRI International,
Menlo Park, CA; September.
84 Dudeney, H. 1958. The Canterbury Puzzles. New York: Dover
Publications. (Originally published in 1907.)
85 Dudeney, H. 1967. 536 Puzzles and Curious Problems, edited by M.
Gardner. New York: Charles Scribner's Sons. (A collection from two of
Dudeney's books: Modern Puzzles, 1926, and Puzzles and Curious
Problems, 1931.)
86 Edwards, D., and Hart, T. 1963. The Alpha-Beta Heuristic (rev.). MIT
AI Memo no. 30, Oct. 28. (Originally published as the Tree Prune (TP)
Algorithm, Dec. 4, 1961.)
87 Ehrig, H., and Rosen, Β. Κ. 1977. Commutativitv of Independent
Transformations of Complex Objects. IBM Research Division Report RC
6251 (No. 26882), October.
88 Ehrig, H., and Rosen, В. К. 1980. The mathematics of record handling.
SI A M Journal of Computing. To appear.
89 Elcock E., and Michie, D. (Eds.) 1977. Machine Intelligence 8: Machine
Representations of Knowledge. Chichester: Ellis Horwood.
90 Elithorn, Α., and Jones, D. (Eds.) 1973. A rtificial A nd Human Thinking.
San Francisco: Jossey-Bass.
91 Elschlager, R. 1979. Consistency of theories of ideas. In IJCAI-6, pp.
241-243.
92 Ernst, G. W. 1969. Sufficient conditions for the success of GFS.JACM,
16(4), 517-533.
93 Ernst, G. W., and Neweil, A. 1969. GPS: A Case Study in Generality and
Problem Solving. New York: Academic Press.
94 Evans, T. G. 1968. A program for the solution of a class of geometric-
348
analogy intelligence-test questions. In SIP, pp. 271-353.
95 Fahlman, S. E. 1974. A planning system for robot construction tasks.
Artificial Intelligence, 5(1), 1-49.
96 Fahlman, S. 1975. Sv nbol-mapping and frames. SIGART Newsletter.
no. 53, pp. 7-8.
97 Fahlman, S. E. 1979. Representing and using real-world knowledge. In
ΑΙ-MIT, vol. 1, pp. 453-470.
98 Feigenbaum, E. A. 1977. The art of Artificial Intelligence: I. Themes and
case studies of knowledge engineering. In IJCAI-5, pp. 1014-1029.
99 Feigenbaum, E., Buchanan, В.-, and Lederberg, J. 1971. Generality and
problem solving: a case study using the DENDRAL program. In Л//6.
100 Feigenbaum, E., and Feldman, J. (Eds.) 1963. Computers and Thought.
New York: McGraw-Hill.
101 Feldman, J. Α., and Sproufil, R. F. 1977. Decision theory and Artificial
Intelligence II: the hungry monkey. Cognitive Science, 1(2), 158-192.
102 Fikes, R. E. 1975. Deductive retrieval mechanisms for state description
models. In IJCAI-4, pp. 99-106.
103 Fikes, R. E., and Nilsson, N. J. 1971. STRIPS: a new approach to the
application of theorem proving to problem solving. Artificial Intelligence,
2(3/4), 189-208.
104 Fikes, R. E., Hart, P. E., and Nilsson, N. J. 1972a. New directions in
robot problem solving. In Mil, pp. 405-430.
105 Fikes, R. E., Hart, P. E., and Nilsson, N. J. 1972b. Learning and
executing generalized robot plans. Artificial Intelligence, 3(4), 251-288.
106 Fikes, R. E., and Hendrix, G. G. 1977. A network-based knowledge
representation and its natural deduction system. In IJCAI-5, pp. 235-246.
107 Findler, N. V. (Ed.) 1979. Associative Networks—The Representation
and Use of Knowledge in Computers. New York: Academic Press.
108 Findler, N. V.y and Meltzer, B. (Eds.) 1971. Artificial Intelligence and
Heuristic Programming. New York: American Elsevier.
349
109 Floyd, R. W. 1967. Assigning meanings to programs. Proc. of a
Symposium in Applied Mathematics, vol. 19, pp. 19-32. (American
Mathematical Society, Providence, RI.)
110 Frege, G. 1879. Begriflsschrift, a formula language modelled upon that
of arithmetic, for pure thought. In J. van Heijenoort (Ed.), From Frege to
Godel: A Source Book In Mathematical Logic, 1879-1931. Cambridge,
MA: Harvard Univ. Press, 1967. Pp. 1-82.
111 Friedland, P. 1979. Knowledge-based Experiment Design in Molecular
Genetics. Doctoral dissertation, Stanford University, Computer Science
Dept. Report CS-79-760.
112 Friedman, D. P. 1974. The Little LIS Per. Science Research Associates,
Inc.
113 Gallaire, H., and Minker, J. (Eds.) 1978. Logic and Databases. New
York: Plenum Press.
114 Galler, В., and Perlis, A. 1970. A View of Programming Languages.
Reading, MA: Addison-Wesley.
115 Gardner, M. 1959. The Scientific American Book of Mathematical
Puzzles and Diversions. New York. Simon and Schuster.
116 Gardner, M. 1961. The Second Scientific American Book of
Mathematical Puzzles and Diversions. New York: Simon and Schuster.
117 Gardner, M. 1964,1965a,b,c. Mathematical games. Scientific American,
210(2), 122-130, February 1964: 212(3), 112-117, March 1965; 212(6),
120-124, June 1965: 213(3), 222-236, September 1965.
118 Gaschnig, J. 1979. Performance Measurement and Analysis of Certain
Search Algorithms Report CMU-CS-79-124, Carnegie-Mellon
University, Dept. of Computer Science, May
119 Gelemter, H. 1959. Realization of a geometry theorem-proving
machine. Proc. Intern Conf Inform Proc. UNESCO House, Paris, pp.
273-282. (Reprinted in CT pp. 134-152.)
120 Gelemter, H. L., et al. 1977. Empirical explorations of SYNCHEM.
Science, 197(4308), 104*1-1049.
121 Gelperin, D. 1977. On the optimahty of A*. Artificial Intelligence, 8(1),
69-76.
350
122 Genesereth, M. R. 1978; Automated Consultation for Complex
Computer Systems. Doctoral dissertation, Harvard University, September.
123 Genesereth, M. R. 1979. The role of plans in automated consultation. In
IJCAI-6, pp. 311-319.
124 Goldstein, I. P., and Roberts, R. B. 1979. Using frames in scheduling. In
ΑΙ-MIT, vol. 1, pp. 251-284.
125 Goldstine, Η. Η., and von Neumann, J. 1947. Planning and coding of
problems for an electronic computing instrument, Part 2 (vols. 1-3).
Reprinted in A. H. Taub (Ed.), John von Neumann, Collected Works (vol.
5). London: Pergamon, 1963. Pp. 80-235.
126 Golomb, S., and Baumert, L. 1965. Backtrack programming. J ACM,
12(4), 516-524.
127 Green, С. 1969а. Application of theorem proving to problem solving. In
IJCAI-1, pp. 219-239.
128 Green, С 1969b. Theorem-proving by resolution as a basis for
question-answering systems. In Μ14, pp. 183-205.
129 Green, С 1976. The design of the PSI program synthesis system.
Proceedings of Second International Conference on Software Engineering,
San Francisco, CA, pp. 4-18.
130 Green С. С, and Barstow, D. 1978. On program synthesis knowledge.
Artificial Intelligence, 10(3), 241-279.
131 Grosz, B. J. 1977. The Representation and Use of Focus in Dialogue
Understanding. Tech. Note 151, SRI International Artificial Intelligence
Center, SRI International, Menlo Park, CA; July.
132 Grosz, B. J. 1979. Utterance and objective: issues in natural language
processing. In IJCAI-6, pp. 1067-1076.
133 Guard, J., et al. 1969. Semi-automated mathematics. J ACM, 16(1),
49-62.
134 Hall, P. A. V. 1973. Equivalence between AND/OR graphs and
context-free grammars. С A CM, vol. 16, pp. 444-445.
135 Hammer, M., and Ruth, G. 1979. Automating the software development
process. In RDST, pp. 767-790.
351
136 Hanson, A. R., and Riseman, Ε. Μ. (Eds.) 1978. Computer Vision
Systems. New York: Academic Press.
137 Harris, L. R. 1974. The heuristic search under conditions of error.
Artificial Intelligence, 5(3), 217-234.
138 Hart, P. E., Nilsson, N. J., and Raphael, B. 1968. A formal basis for the
heuristic determination of minimum cost paths. IEEE Trans. Syst.
Science and Cybernetics, SSC-4(2), 100-107.
139 Hart, P. E., Nilsson, N. J., and Raphael, B. 1972. Correction to "A
formal basis for the heuristic determination of minimum cost paths."
SIGARTNewsletter, no. 37, December, pp. 28-29.
140 Hayes, J. E., Michie, D., and Mikulich, L. I. (Eds.) 1979. Machine
Intelligence 9: Machine Expertise and the Human Interface. Chichester:
Ellis Horwood.
141 Hayes, P. J. 1973a. The frame problem and related problems in
Artificial Intelligence. In AHT, pp. 45-49.
142 Hayes, P. J. 1973b. Computation and deduction. Proc. 2nd. Symposium
on Mathematical Foundations of Computer Science, Czechoslovakian
Academy of Sciences, pp. 105-118.
143 Hayes, P. J. 1977. In defence of logic. In IJCAI-5, pp. 559-565.
144 Hayes, P. J. 1978a. The Naive Physics Manifesto (working papers),
Institute of Semantic and Cognitive Studies, Geneva; May.
145 Hayes, P. J. 1978b. Naive Physics I: Ontology for Liquids (working
papers), Institute of Semantic and Cognitive Studies, Geneva; August.
146 Hayes, P. J. 1979. The logic of frames. In The Frame Reader. Berlin: De
Gruyter. In press.
147 Hayes-Roth, F., and Waterman, D. 1977. Proceedings of the workshop
on pattern-directed inference systems. A CM SIGART Newsletter, no. 63,
June, pp. 1-83. (Some of the papers of the workshop that do not appear in
PDIS are printed here.)
148 Held, M., and Karp, R. M. 1970. The traveling-salesman problem and
minimum spanning trees. Operations Research, vol. 18, pp. 1138-1162.
149 Held, M., and Karp, R. 1971. The traveling salesman problem and
minimum spanning trees—Part II. Mathematical Prog., vol. 1, pp. 6-25.
352
150 Hendrix, G. G. 1973. Modeling simultaneous actions and continuous
processes. Artificial Intelligence, 4(3,4), 145-180.
151 Hendrix, G. G. 1975a. Partitioned Networks for the Mathematical
Modeling of Natural Language Semantics. Tech. Rep. NL-28, Dept. of
Computer Science, University of Texas at Austin.
152 Hendrix, G. G. 1975b. Expanding the utility of semantic networks
through partitioning. In IJCAI-4, pp. 115-121.
153 Hendrix, G. G. 1979. Encoding knowledge in partitioned networks. In
AN, pp. 51-92.
154 Hewitt, С 1972. Description and Theoretical A nalysis (Using Schemata)
of PLANNER: A Language for Proving Theorems and Manipulating
Models in a Robot. Doctoral dissertation (June, 1971), MIT, AI Lab Rep.
AI-TR-258.
155 Hewitt, С 1975. How to use what you know. In IJCAI-4, pp. 189-198.
156 Hewitt, С 1977. Viewing control structures as patterns of passing
messages. Artificial Intelligence, 8(3), 323-364.
157 Hewitt, C, and Baker, H. 1977. Laws for communicating parallel
processes. In B. Gilchrist (Ed.), Information Processing 77, IFIP.
Amsterdam: North-Holland. Pp. 987-992.
158 HMEier, F. S., and Lieberman, G. J. 1974. Introduction to Operations
Research (2nd ed.). San Francisco: Holden Day.
159 Hsnxman, A. I. 1976. Problem reduction and the two-dimensional
trim-loss problem. In SCAISB-76, pp. 158-165.
160 Hofstadter, D. R. 1979. Godel, Escher, Bach: A n Eternal Golden Braid.
New York: Basic Books.
161 Hopcroft, J. E., and UEBman, J. D. 1969. Formal Languages and Their
Relation to Automata. Reading, MA: Addison-Wesley.
162 Horowitz, E., and S&hni, S. 1978. Fundamentals of Computer
Algorithms. Potomac, MD: Computer Science Press.
163 Hunt, Ε. Β. 1975. Artificial Intelligence. New York: Academic Press.
164 Jackson, P. C, Jr., 1974. Introduction to Artificial Intelligence. New
353
York: Petrocelli Books.
165 Joyner, W. H., Jr. (Ed.) 1979. Proceedings of the Fourth Workshop on
Automated Deduction, Austin, Texas; February.
166 Kanade, T. 1977. Model representations and control structures in image
understanding. In IJCAI-5, pp. 1074-1082.
167 Kanal, L. N. 1979. Problem-solving models and search strategies for
pattern recognition. IEEE Trans, of Pattern Analysis and Machine
Intelligence, ΡАМ1-Ц2), 193-201.
168 Klahr, P. 1978. Planning techniques for rule selection in deductive
question-answering. In PDIS, pp. 223-239.
169 Klatt, D. H. 1977. Review of the ARPA speech understanding project.
Journal Acoust. Soc. Amer., 62(6), 1345-1366.
170 KKing, R. E. 1971. A paradigm for reasoning by analogy. Artificial
Intelligence, vol. 2, pp. 147-178.
171 Knuth, D. E., and Moore, R. W. 1975. An analysis of alpha-beta
pruning. Artificial Intelligence, 6(4), 293-326.
172 Kornfeld, W. A. 1979. ETHER—a parallel problem solving system. In
IJCAI-6, pp. 490-492.
173 Kowalski, R. 1970. Search strategies for theorem-proving. In Μ15, pp.
181-201.
174 Kowalski, R. 1972. AND/OR Graphs, theorem-proving graphs, and
bidirectional search. In Λ//7, pp. 167-94.
175 Kowalski, R. 1974a. Predicate logic as a programming language.
Information Processing 74. Amsterdam: North-Holland. Pp. 569-574.
176 Kowalski, R. 1974b. Logic for Problem Solving. Memo no. 75, Dept. of
Computational Logic, University of Edinburgh, Edinburgh.
177 Kowalski, R. 1975. A proof procedure using connection graphs. J A CM,
vol. 22, pp. 572-595.
178 Kowalski, R. 1979a. Algorithm = logic 4- control. С ACM, 22(7),
424-436.
354
179 Kowalski, R. 1979b. Logic for Problem Solving. New York:
North-Holland.
180 Kowalski, R., and Hayes P. 1969. Semantic trees in automatic theorem
proving. In Μ14, pp. 87-101.
181 Kowalski, R., and Kuehner, D. 1971. Linear resolution with selection
function. Artificial Intelligence, 2(3/4), 227-260.
182 Kuehner, D. G. 1971. A note on the relation betweer resolution and
Maslov's inverse method. In MI6, pp. 73-90.
183 Kuipers, B. 1978. Modeling spatial knowledge. Cognitive Science, 2(2),
129-153.
184 Kuipers, B. 1979. On representing commonsense knowledge. In Α N, pp.
393-408.
185 Latombe, J. C. 1977. Artificial intelligence in computer aided design. In
J. J. Allen (Ed.), CAD Systems. Amsterdam: North-Holland.
186 Lauriere, J. L. 1978. A language and a program for stating and solving
combinatorial problems. Artificial Intelligence, 10(1), 29-127.
187 Lehnert, W., and Wilks, Y. 1979. A critical perspective on KRL.
Cognitive Science, 3( 1), 1 -28.
188 Lenaf, D. B. 1976. AM: An A rtificial Intelligence Approach to Discovery
in Mathematics as Heuristic Search. Rep. STAN-CS-76-570, Stanford
University, Computer Science Dept.; July. (Reprinted in KBS.)
189 Lesser, V. R. and Corkill, D. D. 1979. The application of Artificial
Intelligence techniques to cooperative distributed processing. In IJCAI-
6, pp. 537-540.
190 Lesser, V. R., and Erman, L. D. 1979. An Experiment in Distributed
Interpretation. University of Southern California Information Sciences
Institute Report No. 1SI/RR-79-76, May. (Also, Carnegie-Mellon
University Computer Science Dept. Technical Report CMU-CS-79-120,
May.)
191 Levy, D. 1976. Chess and Computers. Woodland Hills, С A: Computer
Science Press.
355
192 Levi, С and Sirovich, F. 1976. Generalized AND/OR graphs.
Artificial Intelligence, 7(3), 243-259.
193 Lin, S. 1965. Computer solutions of the traveling salesman problem.
Bell System Tech. Journal· vol. XLIV, no. 10, December 1965.
194 Lindsay, P. H., and Norman, D. A. 1972. Human Information
Processing: An Introduction to Psychology. New York: Academic Press.
195 Lindstrom, G. 1979. A Ipha-Beta Pruning on Evolving Game Trees. Tech.
Rep. UUCS 79-101, University of Utah, Dept. of Computer Science.
196 Linsky, L. (Ed.) 1971. Reference and Modality. London: Oxford
University Press.
197 London, R. L. 1979. Program verification. 4n RDST, pp. 302-315.
198 Loveland, D. W. 1978. Automated Theorem Proving: A Logical Basis.
New York: North Holland.
199 Loveland, D. W., and Stickel, Μ. Ε. 1976. A hole in goal trees: some
guidance from resolution theory. IEEE Trans, on Computers, C-25(4),
335-341.
200 Lowerre, B. T. 1976. The HA RP Υ Speech Recognition System. Doctoral
dissertation, Carnegie-Mellon University: Tech. Rep., Computer Science
Dept., Carnegie-Mellon University.
201 Luckham, D. C. 1978. A study in the application of theorem proving. In
PCAI, pp. 176-188.
202 Luckham, D. C, and Nilsson, N. J. 1971. Extracting information from
resolution proof trees. Artificial Intelligence, 2(1), 27-54
203 McCarthy, J. 1958. Programs with common sense. Mechanisation of
Thought Processes, Proc. Symp. Nat. Phys. Lab., vol. I, pp. 77-84.
London: Her Majesty's Stationary Office. (Reprinted in SIP, pp.
403-410.)
204 McCarthy, J. 1962. Towards a mathematical science of computation.
Information Processing, Proceedings of IF!Ρ Congress 1962, pp. 21-28.
Amsterdam: North-Holland.
205 McCarthy,4J. 1963. Situations. Actions and Causal Laws. Stanford
University Artificial Intelligence Project Memo no. 2. (Reprinted in SIP,
pp. 410-418.)
1<ч6
206 McCarthy, J. 1977. Epistemological problems of Artificial Intelligence.
In UCAI-5, pp. 1038-1044.
207 McCarthy, J. 1979. First order theories of individual concepts and
propositions. In MI9.
208 McCarthy, J., et al. 1969. A computer with hands, eyes, and ears. Proc.
of the American Federation of Information Processing Societies, vol. 33,
pp. 329-338. Washington, D.C.: Thompson Book Co.
209 McCarthy, J., and Hayes, P. J. 1969. Some philosophical problems
from the standpoint of Artificial Intelligence. In Μ14, pp. 463-502.
210 McCharen, J. D., Overbeek, R. Α., and Wos, L. A. 1976. Problems and
experiments for and with automated theorem-proving programs. IEEE
Trans, on Computers, C-25(8), 773-782.
211 McCorduck, P. 1979. Machines Who Think. San Francisco: W. H.
Freeman.
212 McDermott, D. V. 1975a. Symbol-mapping: a technical problem in
PLANNER-like systems. SIGARTNewsletter, no. 51, April, pp. 4-5.
213 McDermott, D. V. 1975b. A packet-based approach to the symbol-
mapping problem. SIGART Newsletter, no. 53, August, pp. 6-7.
214 McDermott, D. V. 1975c. Very Large PLANNER-Type Data Bases.
MIT Artificial Intelligence Laboratory Memo. 339, MIT; September.
215 McDermott, D. V., and Doyle, J. 1980. Non-monotonic logic I. Artificial
Intelligence, forthcoming.
216 McDermott, D. V., and Sussman, G. J. 1972. The CONNIVER
Reference Manual, MIT AI Lab. Memo 259, May. (Rev., July 1973.)
217 McDermott, J. 1979. Learning to use analogies. In IJCAI-6, pp.
568-576. '
218 Mackworth, A. K. 1977. Consistency in networks of relations. Artijwial
Intelligence, 8(1), 99-118.
219 Manna, Z„ and Waldinger, R. (Eds.) 1977. Studies in Automatic
Programming Logic. New York: North-Holland.
220 Manna, Z., and Waldinger, R. 1979. A deductive approach to program
357
synthesis. In IJCAI-6. pp. 542-551.
221 Markov, A. 1954. A Theory of Algorithms. Nat onal Academy of
Sciences, USSR.
222 Marr, D. 1976. Early processing of visual information. Phil Trans.
Royal Society (Series B), vol. 275, pp. 483-524.
223 Marr, D. 1977. Artificial intelligence—a personal view. Artificial Intel·
ligence. 9(1), 37-48.
224 Martelli, A. 1977. On the complexity of admissible search algorithms.
A rtificial Intelligence, 8(1), 1-13.
225 Martelli, Α., and Montanari, U. 1973. Additive AND/OR graphs. In
IJCAI-3, pp. 1-11.
226 Martelli, Α., and Montanari, U, 1975. From dynamic programming to
search algorithms with functional costs. In IJCAI-4, pp. 345-350.
227 Martelli, Α., and Montanari, U. 1978. Optimizing decision trees through
heuristically guided search. CACM, 21(12), 1025-1039.
228 Martin, W. A. 1978. Descriptions and the Specialization of Concepts.
Rep. MIT/LCS/TM-101, MIT Lab. for Computer Science, MIT.
229 Martin, W. Α., and Fateman, R.J. 1971. The Μ ACSYMA system. Proc.
ACM 2d Symposium on Symbolic and Algebraic Manipulation, Los
Angeles, CA, pp. 23-25.
230 Maslov, S. J. 1971. Proof-search strategies for methods of the lesolution
type. In Λ//6, pp. 77-90.
231 Medress, M. F., et al. 1977. Speech understanding systems: Report of a
steering committee. Artificial Intelligence, 9(3), 307-316.
232 Meltzer, В., and Michie, D. (Eds.) 1969. Machine Intelligence 4.
Edinburgh: Edinburgh University Press.
233 Meltzer, В., and Michie, D. (Eds.) 1970. Machine Intelligence 5.
Edinburgh: Edinburgh University Press.
234 Meltzer, В., and Michie, D. (Eds.) 1971. Machine Intelligence 6.
Edinburgh: Edinburgh University Press.
235 Meltzer, В., and Michie, D. (Eds.) 1972. Machine Intelligence 7.
Edinburgh: Edinburgh University Press.
236 Mendelson, E. 1964. Introduction to Mathematical Logic. Princeton,
NJ: D. Van Nostrand.
237 Michie, D. (Ed.) 1968. Machine Intelligence 3. Edinburgh: Edinburgh
University Press.
238 Michie, D. 1974. On Machine Intelligence. New York: John Wiley and
Sons.
239 Michie, D., and Ross, R. 1970. Experiments with the adaptive graph
traverser. In Μ15, pp. 301-318.
240 Michie, D., and Sibert, Ε. Ε. 1974. Some binary derivation systems.
JACM, 2\(2), 175-190.
241 Minker, J., Fishman, D. H., and McSkimin, J. R. 1973. The Q*
algorithm— a search strategy for a deductive question-answering system.
Artificial Intelligence, 4(3,4), 225-244.
242 Minker, J., and Zanon, G. 1979. Lust resolution: Resolution with
Arbitrary Selection Function, Res. Rep. TR-736, Univ. of Maryland,
Computer Science Center, College Park, MD.
243 Minker, J., et al. 1974. MRPPS: an interactive refutation proof
procedure system for question answering. J. Computers and Information
Sciences, vol. 3, June, pp. 105-122.
244 Minsky, M. (Ed.) 1968. Semantic Information Processing. Cambridge,
MA: The MIT Press.
245 Minsky, M. 197S. A Framework for Representing Knowledge. In PCV,
pp. 211-277.
246 Mitchell, Т. М. 1979. An analysis of generalization as a search problem.
In IJCA1-6, pp. 577-582.
247 Montanari, U. 1970. Heuristically guided search and chromosome
matching. Artificial Intelligence, 1(4), 227-245.
248 Montanari, U. 1974. Networks of constraints: fundamental properties
and applications to picture processing. Information Science, vol. 7, pp.
95-132.
359
249 Moore, E. F. 1959. The shortest path through a maze. Proceedings of an
International Symposium on the Theory of Switching, Part II.
Cambridge: Harvard University Press. Pp. 285-292.
250 Moore, J., and Newell, A. 1973. How can MERLIN understand? In L.
Gregg (Ed.), Knowledge and Cognition. Hillsdale, NJ: Lawrence Erl-
baum Assoc,
251 Moore, R. C. 1975a. Reasoning from Incomplete Knowledge in a
Procedural Deduction System. Tech. Rep. AI-TR-347, MIT Artificial
Intelligence Lab, Massachusetts Institute of Technology, Cambridge,
MA.
252 Moore, R. C. 1975b. A serial scheme for the inheritance of properties.
SIGART Newsletter, No. 53, pp. 8-9.
25 3 Moore, R. С 1977. Reasoning about knowledge and action. In IJCA1-5,
pp. 223-227.
254 Moore, R. С 1979. Reasoning About Knowledge and Action. Tech. Note
191, SRI International, Artificial Intelligence Center, Menlo Park, CA.
255 Moses, J. 1967. Symbolic Integration. MAC-TR-47, Project MAC,
Massachusetts Institute of Technology, Cambridge, MA.
256 Moses, J. 1971. Symbolic integration: the stormy decade. CACM,
14(8), 548-560.
257 MySoposilos, J., et al. 1975. TORUS—a natural language understanding
system for data management. In IJCAI-4, pp. 414-421.
258 Nash-Webber, В., and Schank, R. (Eds.) 1975. Proceedings of
Theoretical Issues in Natural Language Processing. Cambridge, MA; June.
259 Naur, P. 1966. Proofs of algorithms by general snapshots. BIT, 6(4),
310-316.
260 Nevins, A. J. 1974. A human-oriented logic for automatic theorem
proving. J ACM, vol. 21, pp. 606-621.
261 Nevins, J. L., and Whitney, D. E. 1977. Research on advanced assembly
automation. Computer (IEEE Computer Society), 10(12), 24-38.
262 Newborn, M., 1975. Computer Chess. New York: Academic Press.
360
263 Newborn, M. 1977. The efficiency of the alpha-beta search on trees with
branch-dependent terminal node scores. Artificial Intelligence, 8(2),
137-153.
264 Newell, A. 1973. Production systems: models of control structures. In
W.G. Chase, (Ed.), Visual Information Processing. New York: Academic
Press. Chapter 10, pp. 463-526.
265 Newell, Α., Shaw, J., and Simon, H. 1957. Empirical explorations of the
logic theory machine. Proc. West. Joint Computer Confix vol. 15, pp.
218-239. (Reprinted in СГ, pp. 109-133.)
266 Newell, Α., Shaw, J. C, and Simon, H. A. 1958. Chess-playing programs
and the problem of complexity. IBM Jour. R&D, vol. 2, pp. 320-355.
(Reprinted in CT, pp. 109-133.)
267 Newell, Α., Shaw, J. C, and Simon, H. A. 1960. Report on a general
problem-solving program for a computer. Information Processing: Proc.
of the Int. Conf. on Information Processing, UNESCO, Paris, pp. 256-264.
268 Newell, Α., and Simon, H. A. 1963. GPS, a program that simulates
human thought, in CT, pp. 279-293.
269 Newell, Α., and Simon, H. A. 1972. Human Problem Solving. Englewood
Gifts, NJ: Prentice-Hall.
270 Newell, Α., et al. 1973. Speech Understanding Systems: Final Report of a
Study Group. New York: American Elsevier.
271 Nilsson, N. J. 1965. Learning Machines: Foundations of Trainable
Pattern-Classifying Systems. New York: McGraw-Hili.
272 Nilsson, N. J. 1969. Searching problem-solving and game-playing trees
for minimal cost solutions. In A. J. H. Morrell (Ed.), Information
Processing 68 (vol. 2). Amsterdam: North-Holland. Pp. 1556-1562.
273 Nilsson, N. J. 1971. Problem-solving Methods in Artificial Intelligence.
New York: McGraw-Hill.
274 Nilsson, N. J. 1973. Hierarchical Robot Planning and Execution System.
SRI AI Center Technical Note 76, SRI International, Inc., Menlo Park,
CA, April.
275 Nilsson, N. J. 1974. Artificial Intelligence. In J. L. Rosenfeld (Ed.),
361
Technological and Scientific Applications; Applications in the Social
Sciences and the Humanities, Information Processing, 74: Proc. of IFIP
Congress 74, vol. 4, pp. 778-801. New York: American Elsevier.
276 Nilsson, N. J. 1979. A production system for automatic deduction. In
MI9.
277 Nitzan, D. 1979. Flexible automation program at SRI. Proc. 1979 Joint
Automatic Control Conference. New York: IEEE.
278 Norman, D. Α., and Rumelhart, D. E. (Eds.) 1975. Explorations in
Cognition. San Francisco: W. H. Freeman.
279 Okhotsimski, D. E., et al. 1979. Integrated walking robot development.
In Μ19.
280 Paterson, M. S., and Wegman, M. N. 1976. Linear Unification. IBM
Research Report 5304, IBM.
281 Pitrat, J. 1977. A chess combination program which uses plans.
Artificial Intelligence, 8(3), 275-321.
282 Pohl, I. 1970. First results on the effect of error in heuristic search. In
Μ15, pp. 219-236.
283 Pohl, 1.1971. Bi-directional search. In ΜΊ6, pp. 127-140.
284 Pohl, 1.1973. The avoidance of (relative) catastrophe, heuristic
competence, genuine dynamic weighting and computational issues in heuristic
problem solving. In IJCAI-3, pp. 12-17.
285 Pohl, 1.1977. Practical and theoretical considerations in heuristic search
algorithms. In MIS, pp. 55-72.
286 Pople, Η. Ε., Jr. 1977. The formation of composite hypotheses in
diagnostic problem solving: an exercise in synthetic reasoning. In
IJCAI-5, pp. 1030-1037.
287 Pospesel, H. 1976. Introduction to Logic: Predicate Logic. Englewood
Cliffs, NJ: Prentice-Hall.
288 Post, E. 1943. Formal reductions of the general combinatorial problem.
American Jour. Math., vol. 65, pp. 197-268.
289 Pratt, V. R. 1977. The Competence/Performance Dichotomy in Pro-
362
gramming. Memo 400, January, MIT Artificial Intelligence Laboratory,
MIT.
290 Prawitz, D. 1960. Ад improved proof procedure. Theoria, vol. 26, pp.
102-139.
291 Quillian, M. R. 1968. Semantic memory. In SIP, pp. 216-270.
292 Raphael, B. 1968. SIR: semantic information retrieval. In SIP, pp.
33-134.
293 Raphael, B. 1971. The frame problem in problem-solving systems. In
AIHP, pp. 159-169.
294 Raphael, B. 1976. The Thinking Computer: Mind Inside Matter. San
Francisco: W. H. Freeman.
295 Raphael, В., et al. 1971. Research and Applications—Artificial
Intelligence\ Stanford Research Institute Final Report on Project 8973.
Advanced Research Projects Agency, Contract NASW-2164; December.
296 Raulefs, P., et al. 1978. A short survey on the state of the art in matching
and unification problems. AI SB Quarterly, no. 32, December, pp. 17-21.
297 Reddy, D. R., et al. 1977. Speech Understanding Systems: A Summary of
Results of the Five-Year Research Effort. Dept. οϊ Computer Science,
Carnegie-Mellon University, Pittsburgh, PA.
298 Reiter, R. 1971. Two results on ordering for resolution with merging
and linear format. J ACM. vol. 18, October, pp. 630-646.
299 Reiter, R. 1976. A semantically guided deductive system for automatic
theorem proving. IEEE Trans, on Computers, C-25(4), 328-334.
300 Reiter, R. 1978. On reasoning by default. In T1NLAP-2, pp. 210-218.
301 Rich, C, and Shrobe, Η. Ε. 1979. Design of a programmer's apprentice.
In ΑΙ-MIT vol. К pp. 137-173.
302 Rieger, C, and London, P. 1977. Subgoal protection and unravelling
during plan synthesis. In UCAI-5, pp. 487-493.
303 Robbin, J. 1969. Mathematical Logic: A First Course. New York: W. A.
Benjamin.
304 Roberts, R. В., and Goldstein, I. P. 1977. The FRL Primer Memo 408,
363
MIT Artificial Intelligence Laboratory, MIT.
305 Robinson, A. E. 1978. Investigating the Process of Natural Language
Communication: A Status Report. SRI International Artificial
Intelligence Center Tech. Note 165. SRI International. Menlo Park, CA; July.
306 Robinson, J. A. 1965. A machine-oriented logic based on the resolution
principle. JACM, 12(1), 23-41.
307 Robinson, J. A. 1979. Logic: Form and Function. New York: North-
Holland.
308 Rosen, C. Α., and Nitzan, D. 1977. Use of sensors in programmable
automation. Computer (IEEE Computer Society Magazine), December,
pp. 12-23.
309 Rosen, B. K. 1973. Tree-manipulating systems and Church-Rosser
theorems. J ACM, vol. 20, pp. 160-187.
310 Roussel, P. 1975. Prolog: Manual de reference et d'utilisation. Groupe
d'lntelligence Artificielle, Marseille-Luminy; September.
311 Rubin, S. 1978. The ARGOS Image Understanding System. Doctoral
dissertation, Dept. of Computer Science, Carnegie-Mellon University,
November. (Also in Proc ARPA Image Understanding Workshop,
Carnegie-Mellon, Nov. 1978, pp. 159-162.)
312 Rulifson, J. F., Derksen, J. Α., and Waldinger, R. J. 1972. QA4: A
Procedural Calculus for Intuitive Reasoning. Stanford Research Institute
Artificial Intelligence Center Tech. Note 73, Stanford Research Institute,
Inc., November.
313 Rumelhart, D. E., and Norman, D. A. 1975. The active structural
network. In D. A. Norman and D. E. Rumelhart (Eds.), Explorations in
Cognition. San Francisco: W. H. Freeman.
314 Rustin, R. (Ed.) 1973. Natural Language Processing. New York:
Algorithmics Press.
315 Rychener, M. D. 1976. Production Systems as a Programming
Language for Artificial Intelligence Applications. Doctoral dissertation, Dept.
of Computer Science, Carnegie-Mellon University.
316 Sacenfioti, E. D. 1974. Planning in a hierarchy of abstraction spaces.
Artificial Intelligence, 5(2), 115-135.
364
317 Sacerdoti, E. D. 1975. The non-linear nature of plans. In IJCAI-4, pp.
206-214.
318 Sacerdoti, E. D. 1977. A Structure for Plans and Behavior. New York:
Elsevier.
319 Sacerdoti, E. D., et al. 1976. QLISP—A language for the interactive
development of complex systems. Proceedings of AFIPS National
Computer Conference, pp, 349-356.
320 Samuel, A. L. 1959. Some studies in machine learning using the game of
checkers. IBM Jour. R&D, vol. 3, pp. 211-229. (Reprinted in CT, pp.
71-105.)
321 Samuel, A. L. 1967. Some studies in machine learning using the game
of checkers II—recent progress. IBM Jour. R & D, 11(6), 601-617.
322 Schank, R. C, and Abelson, R. P. 1977. Scripts, Plans, Goals and
Understanding. Hillsdale, NJ: Lawrence Erlbaum Assoc.
323 Schmidt, С F., Sridharan, N. S., and Goodson, J. L. 1978. The plan
recognition problem: an intersection of psychology and Artificial
Intelligence. Artificial Intelligence, 11(1,2), pp. 45-83.
324 Schubert, L. K. 1976. Extending the expressive power of semantic
networks. Artificial Intelligence, 7(2), pp. 163-198.
325 Schubert, L. K., Goebel, R. G., and Cercone, N. J. 1979. The structure
and organization of a semantic net for comprehension and inference. In
AN, pp. 121-175.
326 Shannon, С. Е. 1950. Programming a computer for playing chess.
Philosophical Magazine (Series 7), vol. 41, pp. 256-275.
327 Shapiro, S. 1979a. The SNePS Semantic Network Processing System.
In AN, pp. 179-203.
328 Shapiro, S. 1979b. Techniques of Artificial Intelligence. New York: D.
Van Nostrand.
329 Sfcarai, Y. 1978. Recognition of real-world objects using edge cue. In
CVS, pp. 353-362.
330 SnortiifTe, Ε. Η. 1976. Computer-Based Medical Consultations:
MYCIN. New York: American Elsevier.
365
331 Siklossy, L., and Dreussi, J. 1973. An efficient robot planner which
generates its own procedures. In IJCAI-3, pp. 423-430.
332 Sickel, S. 1976. A search technique for clause interconnectivity graphs.
IEEE Trans, on Computers, C-25(8), 823-835.
333 Simmons, R. F. 1973. Semantic networks: their computation and use
for understanding English sentences. In R. Schank and K. Colby (Eds.),
Computer Models of Thought and Language. San Francisco: W. H.
Freeman. Pp. 63-113.
334 Simon, H. A. 1963. Experiments with a heuristic compiler. J ACM,
10(4), 493-506.
335 Simon, H. A. 1969. The Sciences of the Artificial Cambridge, MA: The
MIT Press.
336 Simon, H. A. 1972a. On reasoning about actions. In RM, pp. 414-430.
337 Simon, H. A. 1972b. The heuristic compiler. In RM, pp. 9-43.
338 Simon, H. 1977. Artificial Intelligence systems that understand. In
IJCAI-5, pp. 1059-1073.
339 Simon, Η. Α., and Kadane, J. B. 1975. Optimal problem-solving search:
all-or-none solutions. Artificial Intelligence, vol. 6, 235-247.
340 Slagle, J. R. 1963. A heuristic program that solves symbolic integration
problems in freshman calculus. In CT, pp. 191-203. (Also in J ACM, 1963,
vol. 10, 507-520.)
341 Slagle, J. R. 1970. Heuristic search programs. In TAN PS, pp. 246-273.
342 Slagle, J. R. 1971. Artificial Intelligence: The Heuristic Programming
Approach. New York: McGraw-Hill.
343 Slagle, J. R., and Dixon, J. K. 1969. Experiments with some programs
that search game trees. J ACM, 16(2), 189-207.
344 Smith, R. G. 1978. A Framework for Problem Solving in a Distributed
Environment. Doctoral dissertation, Stanford University, Computer
Science Dept., Report STAN-CS-78-700; December.
345 Smith, R. G. 1979. A framework for distributed problem solving. In
IJCAI-6, pp. 836-841.
366
346 Smullyan, R. Μ. 197?. What Is The Name of This Book: The Riddle of
Dracula and Other Logical Puzzles. Englewood Cliffs, NJ: Prentice-Hall.
347 Soloway, E. M. 1978. "Learning = Interpretation + Generalization": A
Case Study in Knowledge-Directed Learning. Doctoral dissertation,
University of Massachusetts at Amherst, Computer and Information
Science Dept., Technical Report 78-13; July.
348 Sridharan, N. S. 1978. AIMDS User Manual—Version 2. Rutgers
University Computer Science Tech. Report CBM-TR-89, Rutgers, June.
349 Srinivasan, C. V. 1977. The Meta Description System: A System to
Generate Intelligent Information Systems. Part I: The Model Space.
Rutgers University Computer Science Tech. Report SOSAP-TR-20A,
Rutgers.
350 Stallman, R. M., and Sussman, G. J. 1977. Forward reasoning and
dependency-directed backtracking in a system for computer-aided
circuit analysis. Artificial Intelligence, 9(2), 135-196. (Reprinted in AI-MIT,
vol. 1, pp. 31-91.)
351 Stefik, M. 1979. An examination of a frame-structured representation
system. In IJCAI-6, pp. 845-852.
352 Stockman, G. 1977. A Problem-Reduction Approach to the Linguistic
Analysis of Waveforms. Doctoral dissertation, University of Maryland,
College Park, MD.; Computer Science Technical Report TR-538.
353 Sussman, G. J. 1975. A Computer Model of Skill Acqvisition. New
York: American Elsevier.
354 Sussman, G. J. 1977. Electrical design: a problem for artificial
intelligence research. In IJCAI-5, pp. 894-900.
355 Sussman, G. J., and Stallman, R. M. 1975. Heuristic techniques in
computer aided circuit analysis. IEEE Trans, on Circuits and Systems
CAS-22( 11), November.
356 Sussman, G., Winograd, Т., and Charniak, E. 1971. Micro-Planner
Reference Manual, MIT AI Memo 203a, MIT, 1970.
357 Takeyasu, K. et al. 1977. An approach to the integrated intelligent robot
with multiple sensory feedback: construction and control functions
Proceedings 7th Intern. Symp. on Industrial Robots, Tokyo, Japan
Industrial Robot Assoc., pp. 523-530.
367
358 Tate, A. 1976. Project Planning Using a Hierarchic Non-Linear Planner.
Research Report no. 25, Department of Artificial Intelligence, University
of Edinburgh.
359 Tate, A. 1977. Generating project networks. In IJCAI-5, pp. 888-893.
360 Turing, A. M. 1950. Checking a large routine. Report of a Conference on
high speed automatic calculating machines, University of Toronto,
Canada, June 1949, Cambridge University Mathematical Laboratory,
pp. 66-69.
361 Tyson, M., and Bledsoe, W. W. 1979. Conflicting bindings and
generalized substitutions. In WAD, pp. 14-18.
362 Ulrich, J. W. and Moll, R. 1977. Program synthesis by analogy. In
Proceedings of the Symposium on A rtificial Intelligence and Programming
Languages (ACM); SIGPLAN Notices, 12(8); and SIGARTNewsletter,
no. 64, pp. 22-28.
363 vanderBrug, G. J. 1976. Problem representations and formal properties
of heuristic search. Information Sciences, vol. II, pp. 279-307.
364 vamider<Bnsg, G., and Mi raker, J. 1975. State-space, problem-reduction,
and theorem proving—some relationships. Comm. ACM, 18(2), 107-115.
365 van Emden, M. H. 1977. Programming with resolution logic. In MI8,
pp. 266-299.
366 van Vaafien, J. 1975. An extension of unification to substitutions with an
application to automatic theorem proving. In UCAI-4, pp. 77-82.
367 Vere, S. A. 1978. Inductive learning of relational productions. In PDIS,
pp. 281-295.
368 Wagner, H. 1975. Principles of Operations Research (2nd ed.). Engle-
wood Cliffs, NJ: Prentice-Hall.
369 Waidonger, R. J 1977. Achieving several goals simultaneously. In Μ18,
pp. 94-136.
370 Waidinger, R. J., and Lee, R. С. Т. 1%9. PROW: A step toward
automatic program writing. In IJCAI-L pp. 241-252.
371 Waidiinger, R. J., and LevEtt, K. N. 1974. Reasoning about programs.
Artificial Intelligence, 5(3), 235—316. (Reprinted in Z. Manna and R. J.
Waldinger (Eds.), Studies in Automatic Programming Logic. New York:
North-Holland, 1977.)
372 Walker, D. E., and Norton, L. M. (Eds.) 1969. International Joint
Conference on Artificial Intelligence. Washington, D C; May.
373 Walker, D. E. (Ed.). 1978. Understanding Spoken Language. New York:
North Holland.
374 Waltz, D. 1975. Understanding line drawings of scenes with shadows. In
PCV,pp. 19-91.
375 Waltz, D. (Ed.) 1977. Natural language interfaces. SIGART Newsletter
no. 61, February, pp. 16-64.
376 Waltz, D. (Ed.) 1978. TINLAP-2, University of Illinois, July.
377 Warren, D. H. D. 1974. WARP LAN: A System for Generating Plans.
Memo 76, Dept. of Computational Logic, University of Edinburgh
School of Artificial Intelligence, June.
378 Warren, D. H. D. 1977. Logic Programming and Compiler Writing. Res.
Rep. No. 44, Dept. of Artificial Intelligence, University of Edinburgh.
379 Warren, D. H. D., and Pereira, L. M. 1977. PROLOG—The language
and its implementation compared with LISP. Proceedings of the
Symposium on Artificial Intelligence and Programming Languages (ACM);
SIGPLAN Notices, 12(8); and SIGART Newsletter, no. 64, pp. 109-115.
380 Waterman, D., and Hayes-Roth, F. (Eds.) 1978. Pattern-Directed
Inference Systems. New York: Academic Press.
381 Wegner, P. (Ed.) 1979. Research Directions in Software Technology
Cambridge, MA: The MIT Press.
382 Weiss, S. M., Kulikowski, C. Α., AmareS, S., and Safir, A. 1978. A
model-based method for computer-aided medical decision-making.
Artificial Intelligence, 11(1,2), 145-172.
383 Weissman, C. 1967. LISP 1.5 Primer. Belmont, CA: Dickenson
Publishing Co.
384 Weyhs-aaach, R. 1980. Prolegomena to a theory of mechanized formal
369
reasoning. Artificial Intelligence, forthcoming.
385 Wickelgren, W. A. 1974. How to Solve Problems. San Francisco: W. H.
Freeman.
386 Wiederhold, G. 1977. Database Design. New York: McGraw-Hill.
387 Wilkins, D. 1974. A non-clausal theorem proving system. In PASC.
388 Wilkins, D. 1979. Using plans in chess. In IJCAI-6, pp. 960-967.
389 Will, P., and Grossman, D. 1975. An experimental system for computer
controlled mechanical assembly. IEEE Trans, on Computers, C-24(9),
879-888.
390 Winker, S. 1979. Generation and verification of finite models and
counterexamples using an automated theorem prover answering two
open questions. In WAD, pp. 7-13.
391 Winker, S. and Wos,. L. 1978. Automated generation of models and
counterexamples and its application to open questions in ternary boolean
algebra. Proc. Eighth Int. Symposium on Multiple-Valued Logic (IEEE),
Rosemont, Illinois.
392 Winograd, T. 1972. Understanding Natural Language. New York:
Academic Press.
393 Winograd, T. 1975. Frame representations and the
declarative/procedural controversy. In RU, pp. 185-210.
394 Winograd, T. 1980a. Language as a Cognitive Process. Reading, MA:
Addison-Wesley, forthcoming.
395 Winograd, T. 1980b. What does it mean to understand language?
Cognitive Science, 4. To appear.
396 Winston, P. H. 1972. The MIT robot. In Mil, pp. 431-463.
397 Winston, P. H. (Ed.) 1975. The Psychology of Computer Vision. New
York: McGraw-Hill.
398 Winston, P. H. 1975. Learning structural descriptions from examples.
In PCV, pp. 157-209.
399 Winston, P. H. 1977. Artificial Intelligence. Reading, MA: Addison-
Wesley.
370
400 Winston, P. Η. 1979. Learning by Understanding Analogies. Memo 520,
MIT Artificial Intelligence Laboratory, April. (Rev., June.)
401 Winston, P. H., and Brown, R. H. (Eds.) 1979. Artificial Intelligence: an
MIT Perspective (2 vols.). Cambridge, MA: MIT Press.
402 Wipke, W. Т., Ouchi, G. 1., and Krishnan, S. 1978. Simulation and
evaluation of chemical synthesis—SECS: an application of artificial
intelligence techniques. Artificial Intelligence, 11(1,2), 173-193.
403 Wong, H. К. Т., and Mylopoulos, J. 1977. Two views of data semantics:
a survey of data models in artificial intelligence and database
management. Information, 15(3), 344-383.
404 Woods, W. 1975. What's in a link: foundations for semantic networks.
In/Ш, pp. 35-82.
405 Woods, W., et al. 1976. Speech Understanding Systems: Final Technical
Progress Report. (5 vols.), BBN No. 3438. Cambridge, MA: Bolt, Beranek
and Newman.
406 Zadeh, L. 1979. A theory of approximate reasoning. In Μ1-9.
407 Zisman, M. D. 1978. Use of production systems for modeling
asynchronous, concurrent processes. In PDIS, pp. 53-68.
СПИСОК ЛИТЕРАТУРЫ, ПЕРЕВЕДЕННОЙ НА РУССКИЙ ЯЗЫК
100. Вычислительные машины и мышление/Под ред. Е. Фейгенбаума, Дж. Фельдмана:
Пер. с англ. - М.: Мир, 1967.
163. Хант Э. Искусственный интеллект: Пер. с англ. - М.: Мир, 1978.
273. Нильсон Н. Искусственный интеллект. Методы поиска решений: Пер. с англ. -
М.: Мир, 1973.
294. Рафаэл Б. Думающий компьютер: Пер. с англ. - М.: Мир, 1979.
342. Слейгл Дж. Искусственный интеллект. Подход на основе эвристического
программирования: Пер. с англ. - М.: Мир, 1973.
395. Виноград Т. Программа, понимающая естественный язык: Пер. сангл.- М.:Мир, 1976.
397. Психология машинного зрения /Под ред. П. Уинстона: Пер. с англ. - М.: Мир, 1978.
399. Уинстон П. Искусственный интеллект: Пер. с англ. - М.: Мир, 1980.
ДОПОЛНИТЕЛЬНЫЙ СПИСОК ЛИТЕРАТУРЫ
1*. Интегральные роботы/Под ред. Г. Е. Поздняка. - М.: Мир, 1973.
2*. Интегральные роботы/Под ред. Г. Е. Поздняка. - М.: Мир, 1975.
3*. Попов Э. В. Общение с ЭВМ на естественном языке. - М.: Наука, 1982.
4*. Алексеева Е. Ф., Стефанюк В. Л. Экспертные системы — состояние и перспективы. —
Изв. АН СССР. Техническая кибернетика, 1984, № 5, с. 153 - 167.
371
ОГЛАВЛЕНИЕ
Стр.
Предисловие редактора перевода 5
Предисловие 9
Выражение благодарности 11
Пролог 12
0.1. Некоторые приложения искусственного интеллекта 13
0.2. Содержание книги 19
0.3. Библиографические и исторические замечания 20
Глава 1. Системы продукций и искусственный интеллект 25
1.1. Системы продукций ,. 25
1.2. Специализированные системы продукций 38
1.3. Комментарии к различным типам систем продукций 48
1.4. Библиографические и исторические замечания 49
Упражнения 51
Глава 2. Стратегии поиска для систем продукций в искусственном интеллекте. . 51
2.1. Стратегии с возвращением 53
2.2. Стратегии поискана графе 58
2.3. Неинформированные процедуры поискана графе 64
2.4. Эвристические процедуры поиска на графе 65
2.5. Другие алгоритмы 80
2.6. Различные меры качества работы 82
2.7. Библиографические и исторические замечания 84
Упражнения 86
Глава 3. Стратегии поиска для разложимых систем продукций 86
3.1. Поиск на графах типа И/ИЛИ 86
3.2. АО*-эвристическая процедура поискана графах типа И/ИЛИ 89
3.3. Некоторые соотношения между разложимыми и коммутативными системами . 94
3.4. Поиск на игровых деревьях 97
3.5. Библиографические и исторические замечания 108
Упражнения 109
Глава 4. Исчисление предикатов в области искусственного интеллекта ПО
4.1. Неформальное введение в исчисление предикатов ПО
4.2. Резолюция 121
4.3. Использование исчисления предикатов в искусственном интеллекте 126
4.4. Библиографические и исторические замечания 129
Упражнения 130
Глава 5. Системы опровержения на основе резолюции 131
5.1. Системы продукций для опровержения на основе резолюции 132
5.2. Стратегии управления для методов резолюции 133
5.3. Стратегии упрощения 141
372
5.4. Извлечение ответа из опровержения, основанного на резолюции 143
5.5. Библиографические и исторические замечания 153
Упражнения 153
Глава 6. Системы дедукции на основе правил 155
6.1. Прямая система дедукции 157
6.2. Обратные системы дедукции 169
6.3. "Резолюция" внутри графов типа И/ИЛИ 185
6.4. Вычислительные дедукции и синтез программ 190
6.5. Комбинация прямой и обратных систем 200
6.6. Управляющие знания в системах дедукции на основе правил 203
6.7. Библиографические и исторические замечания 211
Упражнения 213
Глава 7. Основные системы построения планов 215
7.1. Решение задач с роботом 215
7.2. Прямая система продукций 220
7.3. Способ представления планов 222
7.4. Обратная система.продукций 226
7.5. Система STRIPS 235
7.6. Использование систем дедукции для выработки планов для роботов 243
7.7. Библиографические и исторические замечания 251
Упражнения 252
Глава 8. Развитые системы построения планов 253
8.1. Система RSTRIPS 253
8.2. Система DCOMP 263
8.3. Совершенствование планов 270
8.4. Иерархическое планирование 276
8.5. Библиографические и исторические замечания 283
Упражнения 283
Глава 9. Представления для структурированных объектов 285
9.1. От исчисления предикатов к блокам 286
9.2. Представление в форме графов: семантические сети 292
9.3. Установление соответствия 299
9.4. Дедуктивные операции над структурированными объектами 306
9.5. Неточные описания и противоречивая информация 324
9.6. Библиографические и исторические замечания 327
Упражнения 328
Глава 10. Проспект 329
10.1. Архитектура систем искусственного интеллекта 329
10.2. Усвоение знаний 331
10.3. Формальные системы для представления знаний 333
Список литературы 338
Список литературы, переведенной на русский язык 371
Дополнительный список литературы 371
нилс нильсон
ПРИНЦИПЫ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА
Редактор Е. А. Засядько
Переплет художника Г. С. Студеникина
Художественный редактор Т. В. Бусарова
Технический редактор Л. А. Горшкова
Корректор Т.В.Покатова
ИБ № 593
Подписано в печать 25.01.85 Формат 60x90/16 Бумага КН-жу/?н, ИМЯ. Гарнитура
"Пресс-роман" Печать офсетная Усл. печ. л. 23,5 Усл. кр.-отт. 23,5 Уч.-изд. л. 26,95
Тираж 7000 экз. Изд. № 20374 Зак № 672, Цена 3 р. 40 к.
Издательство "Радио и связь". 101000, Москва, Почтамт, а/я 693
Московская типография № 4 Союзполиграфпрома при Государственном комитете СССР
по делам издательств, полиграфии и книжной торговли.
129041, Москва, Б. Переяславская ул., д. 46