/










































































































































































































































































Author: Нильсон Н.
Tags: регулирование и управление машинами, процессами искусственный интеллект
Year: 1973




Text
Н.НИЛЬСОН
ИСКУССТВЕННЫЙ ИНТЕЛЛЕКТ
МЕТОДЫ ПОИСКА РЕШЕНИЙ
Перевод с английского В. Л. Стефанюка Под редакцией С. В. Фомина
ИЗДАТЕЛЬСТВО «МИР»
МОСКВА 1973
УДК 62—506,222.001.57
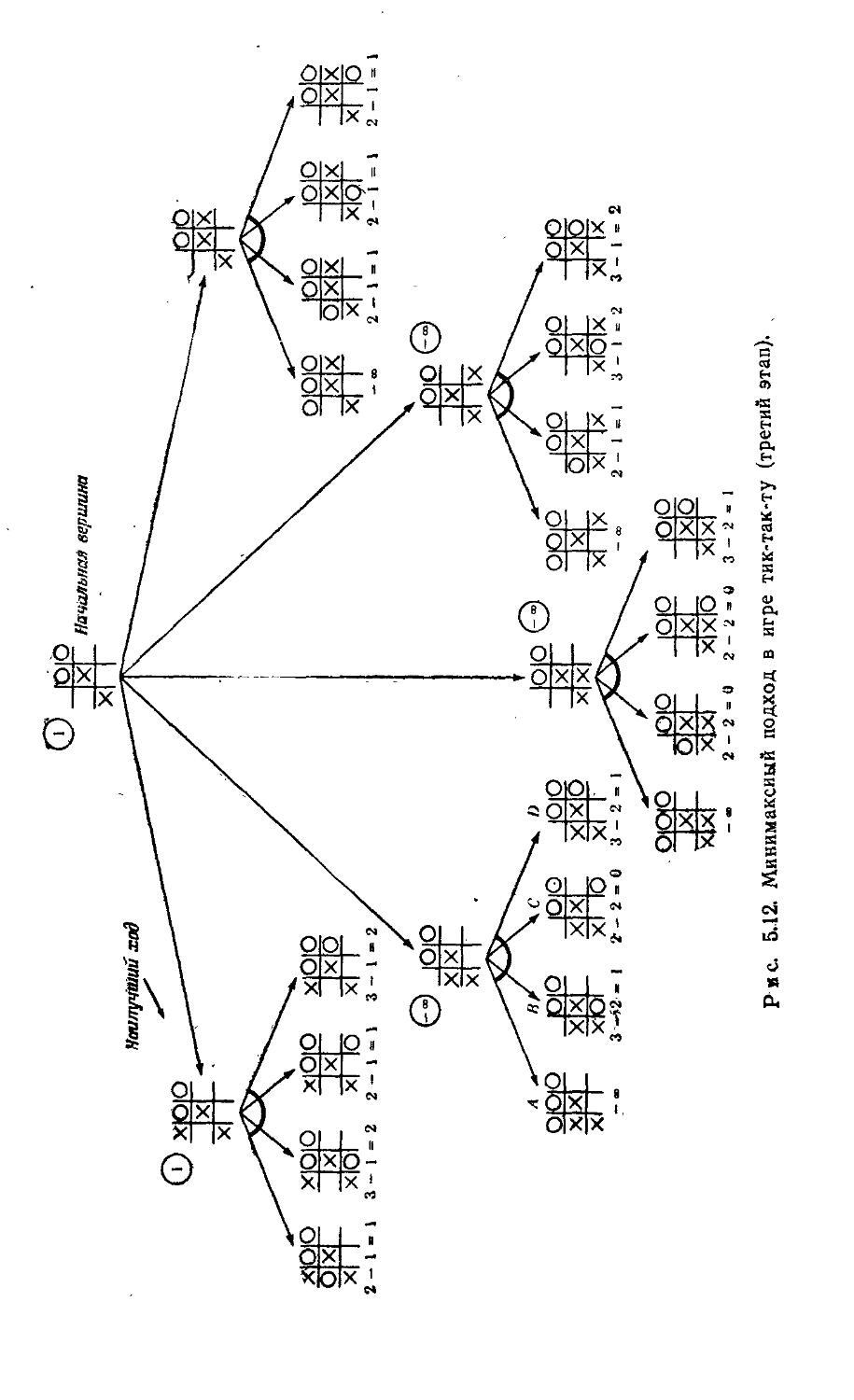
Книга Нильсона написана как учебник, посвященный методам поиска решений в пространстве состояний, — главной теме в исследованиях по искусственному интеллекту. В ней излагаются основные теоретические результаты и для их иллюстрации разбираются многочисленные примеры решения задач — игра в 15, игра тик-так-ту, задача о коммивояжере, задача о пирамидке, доказательство теорем и др.
Для чтения книги требуются небольшие познания по теории графов, комбинаторике и исчислению предикатов.
Доступность изложения и тщательно подобранные задачи различной трудности делают книгу полезной студентам и аспирантам, специализирующимся по искусственному интеллекту. Она будет интересна и специалисту как обстоятельный обзор большого числа современных работ, рассеянных по журналам, трудам конференций и отчетам.
Редакция литературы по математическим наукам
0223—016
" 041 (01)—73
Перевод на русский язык, «Мир», 1973
ПРЕДИСЛОВИЕ РЕДАКТОРА ПЕРЕВОДА
Круг вопросов, объединяемых термином «искусственный интеллект», достаточно широк и довольно неопределен. В самом общем смысле — это решение «интеллектуальных» задач с помощью автоматических методов, в первую очередь с помощью вычислительных машин. Но какую деятельность следует считать интеллектуальной, а какую нет? Это не вполне ясно. Например, мы привыкли рассматривать решение сложных вычислительных задач как деятельность, несомненно, интеллектуальную. Для специалистов же по искусственному интеллекту большой интерес, пожалуй, представит исследование игры в шашки или «крестики и нолики», чем, скажем, решение систем дифференциальных уравнений. И для этого есть довольно веские основания. Дело в том, что если для той или иной вычислительной задачи (типа решения уравнений) имеется определенный алгоритм решения, то он достаточно естественно и четко представляется последовательностью отдельных элементарных операций, которая и реализуется в виде соответствующей программы для вычислительной машины. Что же касается таких видов деятельности, как распознавание образов, различного рода игры, решение головоломок и т. д., то для них, напротив, это формальное разбиение процесса поиска решения на отдельные элементарные шаги часто оказывается весьма затруднительным, даже если само их решение и несложно.
Трудность разбиения вычислительных задач на элементарные шаги обычно бывает связана с трудностью формального описания этих задач. Например, человек может отличать кошку от собаки, совершенно не будучи в состоянии дать формальное описание соответствующей процедуры распознавания.
Многие из задач, с которыми нам прихЪдится встречаться в науке, играх, практической Деятельности, в принципе могут быть решены путем перебора некоторого, заведомо конечного числа вариантов и выбора из них варианта, в том или ином смысле наилучшего. Однако в достаточно интересных н содержательных ситуациях такой «полный перебор» неосуществим, поскольку обилие вариантов превосходит возможности любой самой совершенной вычислительной машины. Например, число различных позиций в шахматах, равно как и число возможных шахматных партий, состоящих из некоторого ограниченного числа ходов (скажем, не более 40), хотя и конечно, но столь велико, что никакой перебор здесь невозможен. Поэтому в подобных ситуациях возникает вопрос о нахождении возможно более экономных и эффективных способов сокращенного перебора, первоочередного рассмотрения наиболее перспективных путей решения задачи и т. д.
6
Предисловив редактора перевода
Итак, для проблем искусственного интеллекта существенную роль играет вопрос о формальном описании тех или иных неформально поставленных задач, методах их расчленения на отдельные элементарные шаги, а также об организации раз-' личных оптимальных в том или ином смысле процедур перебора вариантов.
Именно этим вопросам и посвящена книга Нильсона — одного из ведущих сотрудников Группы искусственного интеллекта Стэнфордского исследовательского института.
Эта книга задумана автором как учебное руководство по проблемам эвристического поиска. В первой, вводной, главе дается общее представление о рассматриваемом круге вопросов, который сам автор характеризует как эвристические методы поиска решений задач. Далее следует изложение этих методов. Методы, рассматриваемые в главах 2—5, базируются в основном на теории графов и близком к ней комбинаторном аппарате. В главах 6—8 довольно широко используются методы математической логики. Хотя все содержание книги ориентировано на автоматические (т. е. реализуемые в виде программ для вычислительных машин) методы перебора, собственно вопросы составления программ в книге не рассматриваются. Ее цель — дать логические подходы к возможно более эффективному построению таких программ.
От читателя книги Нильсона требуется очень умеренная математическая подготовка; по существу достаточно владеть элементарными теоретико-множественными понятиями и основами комбинаторики. Знакомство с математической логикой желательно, но не обязательно, поскольку необходимые сведения из этой области, равно как и используемые автором элементы теории графов, достаточно подробно изложены в самой книге.
Приводимые в книге результаты и методы автор'иллюстрирует, как правило,’ весьма элементарными модельными примерами— игрой в пятнадцать, задачей о пирамидке и т. д., однако сами эти методы применимы и ко многим проблемам, имеющим серьезный научный и практический интерес.
Доступность изложения, сравнительная элементарность аппарата, наглядность приводимых примеров позволяют читателю, желающему лишь составить себе общее представление о рассматриваемом круге вопросов, достигнуть этого с неболь-шрй Затратой времени и сил. Вместе с тем, ие пожалев труда на тщательное изучение книги и, в частности, на разбор задач, помещенных в конце каждой главы, читатель может достигнуть и значительно большего — активного владения понятиями и методами современной теории поиска решений. Такого внимательного изучения книга Нильсона несомненно заслуживает.
С. В. Фомин
'Моим родителям, .Уолтеру и Паулине Нильсон
ПРЕДИСЛОВИЕ
Цель работ по искусственному интеллекту состоит в создании машин, выполняющих такие действия, для которых обычно требуется интеллект человека. В число основных направлений этой области входят автоматические методы решения задач, «понимания» и перевода языков, доказательства теорем и распознавание зрительных образов и речи. Хотя многие из этих задач очень трудны, уже создано несколько программ для вычислительной машины, работающих на уровне, приближающемся к человеческому.
Дальнейшее продвижение в этой области зависит как от развития теории, так и от накопления практических результатов. По мере того как практики будут на основании своего опыта понимать пути построения все более сложных систем обработки информации, будет расширяться запас технических приемов работы. Мы можем ожидать, что развитие технологии цифровых вычислительных машин и совершенствование языков для этих машин (в особенности списковых языков) будет и дальше служить основой для получения необходимых новых практических сведений.
Что же касается теоретических знаний, то здесь имеются сторонники единой теории искусственного интеллекта. Моя точка зрения состоит в том, что искусственный интеллект представляет собой (или скоро бу*дет представлять собой) инженерную дисциплину, поскольку его первоначальной целью является создание конструкций. Поэтому в поисках теории искусственного интеллекта смысла не больше, чем в поисках, скажем, теории гражданского строительства. Вместо единой общей теории имеется ряд теоретических дисциплин, которые сюда относятся и которые должны изучаться теми, кто выбирает искусственный интеллект своей специальностью. К таким дисциплинам относятся математическая логика, структурная лингвистика, теория вычислений, теория информационных структур, теория управления, статистическая теория классификации, теория графов и теория эвристического поиска. Последняя из названных дисциплин— эвристический поиск — составляет основной предмет данной книги.
Решение задач посредством эвристически направляемого, метода проб и ошибок в пространстве возможных решений —
8
Предисловие
доминирующая тема в исследованиях по искусственному интеллекту. Тем не менее пока нет единого учебника, посвященного объяснению тех теоретических идей, которые лежат в основе таких поисковых процессов. Настоящая работа представляет собой попытку удовлетворить потребность в такой книге. В ней достаточно полно рассматриваются важнейшие методы эвристического поиска, используемые при автоматическом решении задач, доказательстве теореь^ в игровых ситуациях.
Эти методы поиска разъясняются на основе единой системы понятий; кроме того, приводятся некоторые теоретические результаты относительно свойств эвристического поиска. Хотя эффективное применение эвристических методов поиска в больших «практических» задачах только еще начинается, тем не менее во многих случаях они были успешно использованы в задачах несравненно более сложных, чем выбранные в книге в качестве примеров. Я упомянул некоторые из таких приложений, но я думаю, что существует еще много других.
В книгу включены три главы, связанные с доказательством теорем в исчислении предикатов, основанном на принципе построения резольвент, и его применением для решения задач. И хотя этот подход еще не нашел практического приложения, но, я думаю, что в конце концов такие приложения возникнут. Поскольку большая часть литературы по этому вопросу весьма трудна для чтения, мне казалось полезным попытаться-дать достаточно простое изложение, снабдив его большим числом примеров.
Первоначально я намеревался включить в книгу главу, где бы рассматривались методы принятия решений с использованием обучающихся машин. Однако я пришел к выводу, что этот предмет еще не разработан до такой степени, чтобы его можно было включать в учебник.
Уровень, на котором представлен материал в настоящей книге, позволяет использовать ее в качестве учебного пособия для студентов старших курсов и аспирантов. Предварительный курс лекций по математической логике был бы полезен, но совершенно необязателен для ее чтения. Читатель, знакомый с основными понятиями теории множеств и комбинаторной математики, не должен встретить трудностей при разборе приводимых в книге доказательств. В конце каждой главы даны задачи, которые можно разбить на три группы. Одни из них просто предназначаются для проверки понимания читателем материала книги, другие содержат важные идеи, которые не нашли исчерпывающего объяснения в тексте, третьи же могли бы служить темами соответствующих курсовых работ. Последняя группа задач отмечена звездочкой.
В каждой главе имеются также «Библиографические и исторические замечания», в которых перечисляются и вкратце об
Предисловие
9
суждаются наиболее важные работы по материалу соответствующей главы. Все эти работы объединены в алфавитном порядке в список литературы в конце книги.
При создании этой книги ряд организаций и отдельных лиц оказали мне неоценимую помощь. Я хотел бы особо отметить первоначальную поддержку Отдела информационных систем Управления военно-морских исследований. Дополнительная помощь исходила от Группы техники обработки информации Агентства перспективных исследовательских проектов, которое поддерживает работы по проектам искусственного интеллекта Стэнфордского исследовательского института и Стэнфордского университета (где я провел часть академического года в 1963— 1969 гг.). Группа искусственного интеллекта из Стэнфордского исследовательского института, членом которой я состою, создала все необходимые условия для выполнения этой работы.
Доктор Петер Харт из Стэнфордского исследовательского института затратил немало усилий на чтение и критический разбор нескольких вариантов рукописи. С его помощью изложение материала удалось сделать значительно более ясным. Беседы с профессорами вычислительного факультета Стэнфордского университета Эдвардом Фейгенбаумом и Артуром Сэмюэлем помогли мне в выборе структуры книги. Я также хочу поблагодарить профессора Дэвида Лакхэма из Станфорда за его попытку научить меня математической (формальной) логике. Многие из аспирантов вычислительного факультета Стэнфордского университета, в частности Дж. Кеннет Сиберз, внесли предложения, позволившие улучшить эту книгу.
Нильс Нильсон
К РУССКОМУ ИЗДАНИЮ
Это предисловие, написанное специально для русского издания, дает мне возможность высказать ряд новых соображений по поводу искусственного интеллекта вообще и этой книги в частности. Прежде всего я хотел бы остановиться на моей позиции в вопросе важности процессов поиска и различных стратегий решения задач, изучаемых в настоящей книге.
В последнее время исследования в области искусственного интеллекта в США в какой-то степени отошли от эвристического поиска. Первая причина этого состоит, по-видимому, в том, что методика эвристического поиска уже доведена до такого уровня развития, при котором дальнейшее изучение приемов поиска едва ли может коренным образом повысить их эффективность.
Другая, и более важная причина состоит в том, что, как показывает опыт, обобщенные’ процессы поиска, взятые сами по себе, как правило, недостаточны для решения по-настоящему
10
Предисловие
сложных задач. Если предстоит написать программы для вычислительной машины, позволяющие переводить с одного языка на другой, мастерски играть в шахматы, эффективно и разумно управлять деятельностью механического, робота, то в такие программы нужно вложить, помимо конкретных сведений (о языке, о шахматах и т. д.), еще и представления «здравого смысла» об окружающем мире. Поэтому исследования в области искусственного интеллекта в нескольких главных центрах США в настоящее время концентрируются на том, как представить эти знания в системах программ для вычислительной машины и как ими пользоваться.
Отметив это смещение акцентов, наш потенциальный читатель может подумать, что, пожалуй, ему следует читать вместо нее какие-то другие книги, скажем «Как вкладывать знания в программы для ЭВМ» или лучше «Как компьютеры могут усваивать знания». Мы можем только пожелать, чтобы такие книги существовали. К сожаленйю, их пока нет. (Возможно, кто-либо из читателей этого предисловия будет участвовать в их написании.) Во всяком случае, цель этой книги состоит не в объяснении наиболее модных в настоящее время вопросов из области искусственного интеллекта, а скорее в том, чтобы ввести читателя в круг идей, которые являются и существенными и достаточно установившимися.
Как отмечено в предисловии к американскому изданию, я считаю, что искусственный интеллект — это по существу инженерная дисциплина. Мы хотим строить разумные системы. Как и для всякой инженерной дисциплины, имеется несколько связанных с ней теоретических предметов, знание которых обязательно для специалиста. Я по-прежнему считаю, что эвристический поиск, обсуждаемый в этой книге, представляет главную компоненту техники искусственного интеллекта. Было бы очень трудно понять современный путь развития искусственного интеллекта, не имея основ соответствующих знаний о предметах, обсуждаемых в книге. Эти предметы не стали вдруг ненужными. Наоборот: в настоящее время принято считать, что специалист уже хорошо с ними знаком.
Совершенно ясно, что в области искусственного интеллекта существуют также и другие фундаментальные вопросы. К сказанному по этому поводу в предисловии к американскому изданию я бы добавил здесь, что будущему специалисту можно посоветовать приобрести знания в таких областях, как автоматические системы управления и информационные системы. При таких основах мыслящий исследователь будет располагать всеми возможностями для разработки новых важных идей в области искусственного интеллекта.
Март 1973 НИЛЬС НиЛЬСОН
Пало-Альто
Глава 1
ВВЕДЕНИЕ
1.1. РЕШЕНИЕ ЗАДАЧ И ИСКУССТВЕННЫЙ ИНТЕЛЛЕКТ
Многие виды деятельности человека, такие, как решение головоломок, участие в играх, занятия математикой и даже вождение автомобиля, требуют, как это принято считать, участия «интеллекта». Если бы вычислительные машины могли справляться с деятельностью такого типа, то они (вместе с их программами), вероятно, обладали бы в какой-то степени искусственным интеллектом. Многие специалисты полагают, что в конечном итоге искусственный интеллект вычислительных машин превзойдет интеллект человека, хотя теперьвсе больше и больше осознается тот факт, что процессы, требуемые для выполнения даже самых обычных для человека задач, неизбежно будут чрезвычайно сложными. В настоящей книге мы подробно исследуем некоторые процессы, связанные с решением задач, в которых участвует интеллект.
Решение задач может показаться весьма неясным предметом, 'и тем не менее на нем концентрируется большая доля исследований по искусственному интеллекту. В самом широком смысле этих слов нахождение решений включает в себя всю вычислительную науку, поскольку всякая вычислительная задача может рассматриваться как задача, решение которой надо найти. Однако для наших целей нужно более узкое определение, которое исключает такие стандартные вычислительные методы, как методы, используемые, скажем, при обращении матрицы 50-го порядка или при решении системы линейных дифференциальных уравнений.
Если мы внимательно рассмотрим методы нахождения решений, изучаемые в исследованиях по искусственному интеллекту, то обнаружим, что в большинстве из них используется понятие поиска путем проб и ошибок. Это значит, что в этих методах задачи решаются посредством поиска решения в пространстве возможных решений. Наша цель состоит в разъяснении наиболее важных методов решения задач с использованием процедур поиска.
Имеются, конечно, и другие важные направления в изучении искусственного интеллекта. Типичные представители тех из них, которым было уделено особое внимание (кроме нахождения решений), следующие:
‘ 12
Гл. 1. Введение
Обработка сенсорных данных (особенно зрительных образов и речи).
Сложные системы хранения и извлечения информации.
Обработка естественных языков.
К сожалению, никто еще не мог сказать ничего достаточно полезного относительно того, как названные элементы могли бы быть объединены вместе в' одном общем «интеллекте» (каком бы то ни было). В действительности при внимательном анализе становится ясно, что любая из предполагаемых «фундаментальных» компонент интеллектуального поведения содержит, по-видимому, в себе черты других фундаментальных компонент. Так, для сенсорного, восприятия могут потребоваться весьма изощренные способы выбора решения, для которых в свою очередь возникает необходимость в достаточно эффективной системе извлечения информации, опирающейся, возможно, на дополнительный выбор решений и т. д.
Наш опыт работы с этими сложными процессами все еще недостаточен для создания единой теории организации интеллекта. На самом деле в настоящее время нет никаких оснований полагать, что такая теория вообще могла бы существовать. Некоторые исследователи считают, что интеллектуальное поведение может быть получено на вычислительных машинах только посредством комбинирования специализированных программ, каждая из которых содержит множество подходящих к данному случаю решений (или, как их часто называют, «программистских находок»), с возможностью обращения к магазину энциклопедических сведений, содержащему хорошо систематизированные факты. Однако сейчас нам не хотелось бы занимать определенную позицию по этому вопросу. Вместо этого мы опишем те приемы решения задач, которые, по-видимому, имеют достаточно широкую область применения.
1.2. ГОЛОВОЛОМКИ И ИГРЫ КАК ПРИМЕРЫ ЗАДАЧ
Мы еще не давали точного определения, что значит решить некоторую задачу с применением методов поиска. Точно так же мы не определили, что мы понимаем под задачей. По всей видимости, еще никем не было дано такого простого определения слова «задача», которое полностью бы соответствовало тому интуитивному значению, которое мы намереваемся здесь использовать. Поэтому вместо того, чтобы пытаться дать формальное определение, мы.начнем наше обеуждение с рассмотрения типичного примера задачи.
Головоломки и игры представляют собой неисчерпаемый источник примеров, полезных для иллюстрации и испытания мето
1.2. Головоломки и игры как примеры задач
13
дов решения задач. Для вычислительных машин были написаны программы решения многих видов головоломок, достаточно трудных для человека. Были написаны также другие программы, которые побеждали опытных игроков в настольные игры, такие, как шахматы и шашки. Как говорит Минский (1968, стр. 12): «Игры и математические задачи берутся не потому, что они просты и ясны, а потому, что они при минимальных начальных структурах дают нам наибольшую сложность, так что мы можем заняться некоторыми действительно трудными ситуациями, относительно мало отвлекаясь на вопросы программирования». В игровых задачах и решениях головоломок возникли и отшлифовались многие идеи, которые оказались по-настоящему полезными для менее легкомысленных задач.
11 g 4 15 1 2 3 4
1 3 12 5 6 7 8
7 5 8 В 9 10 И 12
13 2 10 14 13 14 15
Рис. 1.1. Игра в пятнадцать (слева — начальная конфигурация, справа — целевая).
Для иллюстрации понятий, возникающих при решении за- , дач, мы часто будем пользоваться головоломкой, известной как игра в пятнадцать. В ней используется пятнадцать пронумерованных подвижных фишек, расположенных на площадке размером 4X4 клетки. Одна клетка этой площадки остается всегда пустой, так что всегда одну из соседних с ней фишек можно передвинуть на место этой пустой клетки, «передвинув», таким образом, и эту пустую клетку. Игра в пятнадцать иллюстрируется на рис. 1.1, на котором изображены две конфигурации фишек. Рассмотрим задачу перевода начальной конфигурации в заданную целевую конфигурацию. Решением этой задачи служит подходящая последовательность ходов, такая, например, как «передвинуть фишку 12 влево, фишку 15 вниз и т. д.».
Игра в пятнадцать — замечательный пример одного класса задач, для которого лучше всего приспособлены методы”, излагаемые в данной книге. В этой задаче имеется точно определенная начальная ситуация и точно определенная цель. Имеется также некоторое множество операций, или ходов, переводящих одну ситуацию в другую. Мы начнем с введения некоторых фундаментальных понятий, связанных с нахождением решений, которые могут быть использованы для нахождения решения игры в пятнадцать.
14
Гл. 1. Введение
1.3. СОСТОЯНИЯ и ОПЕРАТОРЫ
По-видимому, самый прямолинейный подход при поиске решения для игры в пятнадцать состоит в попытке перепробовать различные ходы, пока не удастся получить целевую конфигурацию. Такого рода попытка по существу связана с поиском при помощи проб и ошибок. (Мы, разумеется, предполагаем, что такой поиск может быть выполнен в принципе, скажем, на некоторой вычислительной машине, а не с привлечением реальной игры в пятнадцать). Отправляясь от начальной конфигурации, мы могли бы построить все конфигурации, возникающие в результате выполнения каждого из возможных ходов, затем построить следующее множество конфигураций после применения следующего хода и т. д., пока не будет достигнута целевая конфигурация.
Для обсуждения такого сорта методов поиска решения оказывается полезным введение понятий состояний и операторов для данной задачи. Для игры в пятнадцать состояние задачи — это просто некоторое конкретное расположение фишек. Начальная и целевая конфигурации представляют собой соответственно начальное и целевое состояния. Пространство состояний, достижимых из начального состояния,’ состоит из всех тех конфигураций фишек, которые могут быть образованы в результате допустимых правилами перемещений фишек. Многие из задач, с которыми мы будем сталкиваться, имеют чрезвычайно большие (если не бесконечные) пространства состояний1).
Оператор преобразует одно состояние в другое. Игру в пятнадцать естественнее всего интерпретировать как игру, имеющую четыре оператора, соответствующие следующим ходам: передвинуть пустую клетку (пробел) влево, вверх, вправо и вниз. В некоторых случаях оператор может оказаться неприложимым к какому-то состоянию: так, оператор «передвинуть пробел вправо» не может быть применен к целевому состоянию на рис. 1.1. На нашем языке состояний и операторов решение некоторой проблемы есть последовательность операторов, которая преобразует начальное состояние в целевое.
Пространство состояний, достижимых из данного начального состояния, полезно представлять себе в виде графа, вершины которого соответствуют этим состояниям. Вершины такого графа связаны между собой дугами, отвечающими операторам. На рис. 1.2 показана небольшая часть графа для игры в пятнадцать. На этом графе в каждой вершине помещена та конфигурация фишек, которую она представляет.
1) В игре в пятнадцать имеется 16! различных конфигураций из фишек и пустой клетки. Пологина из них (или примерно 10,5-1012) достижима из данной начальной конфигурации.
1.3. Состояния и операторы
15
Решение игры в пятнадцать можно было бы получить, используя процесс поиска (перебора) при котором прежде всего применяют операторы к начальному состоянию, с тем чтобы получить новые состояния,- к которым также применяют операторы, и т. д. до тех пор, пока не будет построено состояние, отвечающее цели. Методы организации такого поиска целевого состояния удобнее всего объяснять, пользуясь представлением в виде графа рис. 1.2.
Про метод решения задач, основанный на понятиях состояний и операторов, можно было бы сказать, что это подход к задаче с точки зрения пространства состояний. В общем случае мы будем связывать последний термин с методами, в которых опробываемые последовательности операторов строят постепенно, отправляясь от некоторого начального оператора и добавляя затем каждый раз по одному оператору до тех пор, пока не будет достигнуто целевое состояние.
Мы вернемся к дальнейшему обсуждению методов, связанных с пространством состояний, в следующих двух главах.
’) В отечественной литературе широко используется слово «перебор» в качестве значения английского «search» («поиск»). Ниже мы будем пользоваться обоими русскими терминами как эквивалентами. — Прим, перев.
16
Гл. 1. Введение
1.4. СВЕДЕНИЕ ЗАДАЧИ К ПОДЗАДАЧАМ
В некотором смысле более тонкий подход к решению задачи связан с понятием подзадач. При таком подходе производится исследование исходной задачи с целью выделения такого множества подзадач, чтобы решение некоторого определенного подмножества этих подзадач содержало в себе решение исходной задачи. Рассмотрим, например, задачу о проезде на автомобиле из Пало-Альто (шт. Калифорния) в Кембридж (шт. Массачусетс). Эта задача может быть сведена, скажем, к следующим подзадачам:
Подзадача 1. Проехать из Пало-Альто в Сан-Франциско.
Подзадача 2. Проехать из Сан-ФранцисковЧикаго, шт. Иллинойс.
Подзадача 3. Проехать из Чикаго в Олбани, шт. Нью-Йорк.
Подзадача 4. Проехать из Олбани в Кембридж.
Здесь решение всех четырех подзадач обеспечило бы некоторое решение первоначальной задачи.
Каждая из подзадач может быть решена с применением какого-либо метода. К ним могут быть применены методы, использующие пространство состояний, или же их можно проанализировать с целью выделения для каждой своих подзадач и т. д. Если продолжить процесс разбиения возникающих подзадач на еще более'мелкие, то в конце концов мы придем к некоторым элементарным задачам, решение которых может считаться тривиальным.
Про всякий метод решения задачи путем выработки и последующего решения подзадач мы будем говорить, что в нем используется подход, основанный на редукции задачи. Заметим, что, строго говоря, подход с использованием пространства состояний можно рассматривать как вырожденный случай подхода, основанного на редукции задачи, ибо каждое применение оператора сводит задачу к несколько более простой подзадаче. Правда, как правило, мы будем иметь дело со случаями, когда подзадачи, возникающие при редукции, получаются не столь тривиальным образом.
Важно отметить, что поиск методом проб и ошибок по-прежнему играет важную роль в подходе, основанном на редукции задачи. На каждом из этапов может возникнуть несколько альтернативных множеств подзадач, к которым может быть сведена данная задача. Так как некоторые из этих множеств-в конечном итоге, возможно, и не приведут к окончательному решению задачи, то, как правило, для решения первоначальной задачи необходим поиск в пространстве множеств подзадач. В главах 4 и 5 мы вернемся к обсуждению методов, основанных на редукции задач.
1.5. Использование формальной логики при решении задач 1У
1.5. ИСПОЛЬЗОВАНИЕ ФОРМАЛЬНОЙ ЛОГИКИ ПРИ РЕШЕНИИ
ЗАДАЧ
Часто для решения задачи либо требуется проведение логического анализа в определенном объеме, либо поиск решения существенно облегчается после такого анализа. Иногда такой анализ показывает, что определенные проблемы неразрешимы. В игре в пятнадцать, например, можно доказать1), что целевая конфигурация
/ 2 3 4
5 6 7 8
9 10 И 12
is 14 15
в подходах, основанных на использовании пространства состояний, так и в подходах, связанных с редукцией задач. В подходах первого типа логических выводов может потребовать тот тест, с помощью которого определяется, будет ли некоторое состояние состоянием, отвечающим поставленной цели. Кроме того, логические умозаключения могут понадобиться при определении, какой из операторов применим к данному состоя-
') Это утверждение вытекает из логического анализа данной игры, который показывает, что множество всевозможных конфигураций может быть разбито на два непересекающихся подмножества А и В, причем никакой элемент подмножества А не может быть преобразован в элемент подмножества В и обратно,
18
Гл. 1. Введение
нию. Как мы уже видели, иногда можно доказать, что некоторая задача неразрешима. В подходах, основанных на редукции задачи, доказательство такого рода позволило бы избежать тщетных попыток разрешить неразрешимые подзадачи. В дополнение к таким приложениям мы хотим также иметь возможность решать задачи, которые представляют собой задачи на доказательство. Например, возможно, мы захотим найти доказательство некоторой математической теоремы, записанной в определенной формальной системе, такой, как исчисление предикатов первого порядка.
Таким образом, полное исследование приемов'решения задач должно включать рассмотрение машинных методов поиска доказательства. Некоторые из этих методов опираются на стратегии поиска, подобные тем, которые мы будем обсуждать в связи с подходами, основанными на пространстве состояний и редукции задач. Хотя известно много способов выбора конкретного логического формализма, мы будем рассматривать разработанную в последнее время методику доказательства теорем в исчислении предикатов первого порядка, основанную на принципе резольвенций, и применения такой методики к решению задач. Этому будут посвящены гл. 6—8.
При обсуждении автоматического доказательства теорем мы покажем, что даже нематематические задачи могут быть сформулированы как теоремы, подлежащие доказательству.. Многие из головоломок, которые мы рассмотрим, так же как и многие возникающие в реальной действительности задачи, требующие для их анализа здравого смысла, могут быть в принципе сформулированы в рамках определенного логического формализма и после этого решены методом доказательства теорем. Использование формальной логики и методов доказательства теорем позволяют нам думать о действительно «универсальном» решателе задач. Новая информация в такой решатель задач могла бы вводиться просто в форме внесения в его память новых дополнительных аксиом, а не посредством переделывания его программы. Он мог бы решать задачи из достаточно широких областей, поскольку существуют логические формализмы, достаточно универсальные для того, чтобы выразить любую информацию и записать любую задачу.
1.6. ДВА СОСТАВНЫХ ЭЛЕМЕНТА ПРОЦЕССА РЕШЕНИЯ ЗАДАЧ: ПРЕДСТАВЛЕНИЕ И ПОИСК (ПЕРЕБОР)
В каждом из подходов к решению задач, о которых мы говорили, для построения решения необходим поиск какого-либо типа. Эта книга написана главным образом о том, как проводить такой поиск настолько эффективно, насколько это возможно. Но прежде чем такой процесс поиска может быть на
1.7. Библиографические и исторические замечания 19
чат, сама задача должна быть поставлена либо в рамках подхода, основанного на пространстве состояний или на редукции к подзадачам, либо же как теорема, подлежащая доказательству. Обычно при решении человеком той или иной задачи мы восхищаемся не быстрым и упорядоченным поиском в пространстве всевозможных решений, а умением найти такую ясную точку зрения на рассматриваемую задачу, которая делает решение элегантно простым.
В следующей главе мы обсудим вопрос о постановке и представлении задачи ъ такой форме, чтобы ее можно было решать методом, основанным на рассмотрении пространства состояний. Мы увидим, что существует несколько вариантов представлений для одной и той же задачи, причем некоторые представления дают намного более узкие пространства состояний, чем другие. Так как даже самые эффективные методы поиска будут непригодны, если пространство, в котором ведется поиск, слишком велико, то важно уметь представлять задачу самым экономным из возможных способов. Вопрос о выборе представления — общий для любого способа решения задач, но, к сожалению, в исследованиях по искусственному интеллекту еще не выработано универсального автоматического метода для нахождения искусных формулировок задач. Поэтому, несмотря на то что имеется два аспекта в автоматическом решении задач, а именно представление и поиск, в настоящей книге мы вынуждены ограничиться рассмотрением главным образом вопросов поиска.
1.7. БИБЛИОГРАФИЧЕСКИЕ И ИСТОРИЧЕСКИЕ ЗАМЕЧАНИЯ
«Интеллект» вычислительных машин
Вопрос о том, могут ли машины «^думать» (или будут ли они когда-либо способны на это), все еще вызывает живое обсуждение даже среди тех, кто допускает, что сам человек представляет собой некую машину. Тьюринг (L950) устранил многие из стандартных доводов против мыслящих машин. Для решения вопроса о том, может ли машина мыслить, им был предложен тест, который принято теперь называть тестом Тьюринга.
Селфридж и Келли (1962) обсуждали вопрос об объеме практических трудностей, стоящих на пути создания разумных машин, после того, как они пришли к выводу о том, что здесь неизвестно никаких теоретических запретов. Хьюберт Дрейфус (1965) заявил, что цифровые вычислительные машины принципиально неспособны на выполнение таких обязательных для интеллекта действий, как «осознание края» и «ясное группирование». Его аргументация была последовательно опровергнута Пейпертом (1968)t
20
Гл. 1. Введение
Искусственный интеллект в целом
Попытки упорядочить область искусственного интеллекта никогда не были вполне успешны. В важной обзорной статье Минский (1961а) предложил следующий перечень: поиск, распознавание образов, обучение, решение задач, логические выводы. Такая схема все еще приносит пользу, хотя ее классификационные достоинства сильно снижаются изобилием в литературе утверждений, имеющих форму: «проблема X по существу является проблемой У», где в качестве X и У можно взять любую пару компонент, о которых говорил Минский. Уже не так давно Минский (1968) написал еще одну содержательную статью об основаниях искусственного интеллекта, где делается вывод, что главной является проблема образования, поддержания и извлечения сведений из некоторой большой их совокупности.
. Различные подходы в области искусственного интеллекта
При попытке построить разумные машины мы, естественно, ставим вопрос о том, в чем же состоит секрет естественного интеллекта. Поиски ответа на этот вопрос были связаны с рядом замечательных событий, однако до сих пор никому не удалось раскрыть этой тайны. Розенблаттом (1962) были предложены модели мозга, названные персептронами. Это были сети из искусственных нейронов, в основе которых лежали нейронные модели Маккаллока — Питтса (1943). Изучение персептронов стимулировалось вначале исследователями по распознаванию образов и привело к некоторым изящным математическим результатам по вычислительной геометрии (Минский и Пей-церт, 1969). Однако сложные процессы, связанные с интеллектом, оказались вне пределов возможностей, заложенных в этих простых персептронных моделях.
Другим подходом, основанным на биологических представлениях, была весьма грандиозная попытка промоделировать саму эволюцию. Поскольку эволюционному процеСбу потребовалось два миллиарда или около того лет для .создания разумного человека, то почему бы нам не воспользоваться вычислительной машиной и не промоделировать такой эволюционный процесс при высокой скорости? Фогель и др. (1966) описывают эксперименты, в которых с использованием идей мутации ^избирательного выживания моделировался процесс построения многих поколений машин с конечным числом состояний. Хотя такой подход дает возможность свести несколько первых миллионов лет эволюции к нескольким дням вычислительного времени, создается впечатление, что важные средняя и поздняя стадии эволюции связаны со столь сложными структурами (хотя и не являющимися еще «разумными»), что их эволюция уже не может быть ускорена путем моделирования на вычислительной
1.7. Библиографические и исторические замечания
21
машине. Поэтому такая «искусственная эволюция» не привела к созданию действительно сложных машин.
Другой способ понять, что такое естественный интеллект животных, состоит в том, чтобы изучать их поведение и в особенности поведение человека при решении задач. Трейвис я(1963, 1967) обсуждает роль самонаблюдения при создании решателя задач. Ньюэлл, Шоу и Саймон (1959) описали «универсальный решатель задач», который обращается с задачей в значительной степени так же, как это делает человек. Богатым источником идей о том, как человек подходит к решению задач, является книга Пойа (1957).
Рассматривая методы решения задач, основанные на анализе поведения человека, мы обнаруживаем, что поиск путем проб и ошибок на некотором уровне играет в них ключевую роль. Кэмпбелл (1960) называет ненаправленный процесс поиска процессом «слепого изменения и избирательного выживания». Он делает вывод:
Процесс слепого изменения и избирательного выживания составляет основу успешных индуктивных построений, основу всех случаев, когда объем знаний действительно возрастает, всех случаев улучшения приспособления системы к ее окружению.
Процессы, которые обеспечивают прерывание полного процесса слепого изменения и избирательного выживания, сами по себе представляют результаты успешных индуктивных построений, содержащие полезные сведения об окружении, полученные первоначально в результате некоторого процесса слепого изменения и избирательного выживания.
Кроме того, эти подменяющие процессы сами при своей работе опираются на некотором уровне на процесс слепого изменения и избирательного выживания.
Мы согласны с Кэмпбеллом относительно первостепенной в конечном счете роли поиска. Действительно, существенным приемом при создании эффективного автоматического решателя задач -является поиск, осуществляемый на самом высшем уровне, допускаемом имеющейся информацией о самой задаче и о том, как она могла бы быть решена. Таким образом, в настоящей книге мы прежде всего интересуемся методами поиска и тем, каким образом сделать их более эффективными, используя всю имеющуюся информацию.
Методы поиска решений
В литературе имеется всего лишь несколько попыток абстрактного изучения процессов решения задач, с тем чтобы упорядочить различные методы и вывести их общие свойства.
22
Гл. 1. Введение
В настоящей книге мы делаем попытку выделить некоторые главнейшие концепции, связанные с поиском решений, и дать их связное изложение. Несколько иной путь систематизации обсуждения методов поиска решений предлагается Ньюэллом (1969). На построение настоящей книги оказала сильное влияние серия трудных, но очень ценных статей Амареля (1965, 1967, 1969). Формализация некоторых идей поиска решений, которыми мы занимаемся в нашей книге, дана в статье Сэнду-олла (1969). Весьма формальное исследование вопросов решения задач и разыгрывания игр содержится в книге Бенерджи (1969).
Подход к решению задач с использованием пространства состояний получил такое название по аналогии с ситуацией в теории управления, где также для подобных целей используются пространства состояний. Последние находят широкое применение и в теории исследования операций. Некоторые из методов поиска в пространстве состояний, которые мы будем обсуждать в дальнейшем, идентичны методам, которые в теории исследования операций получили названия методов ветвей и границ. Обзор методов ветвей и границ и их применений имеется в работе Лолера и Вуда (1966).
Наше желание различать методы, использующие понятие пространства состояний, и методы, основанные на редукции задачи, связано с тем, что в этих методах применяются различные стратегии поиска. Это различие носит тот же характер, что и отмеченное Амарелем (1967) различие между методами «продукционного типа»'и «редукционного типа». Слейджл (1963а) при описании своей программы, предназначенной для символического интегрирования, также счел полезным использовать понятие сведения задачи к подзадачам. По нашему убеждению, работу универсального решателя задач (General Problem Solver) Ньюэлла и его сотрудников (Эрнст и Ньюэлл,’ 1969) гораздо легче себе уяснить, если его описывать как решатель задач, опирающийся на сведение задачи к подзадачам.
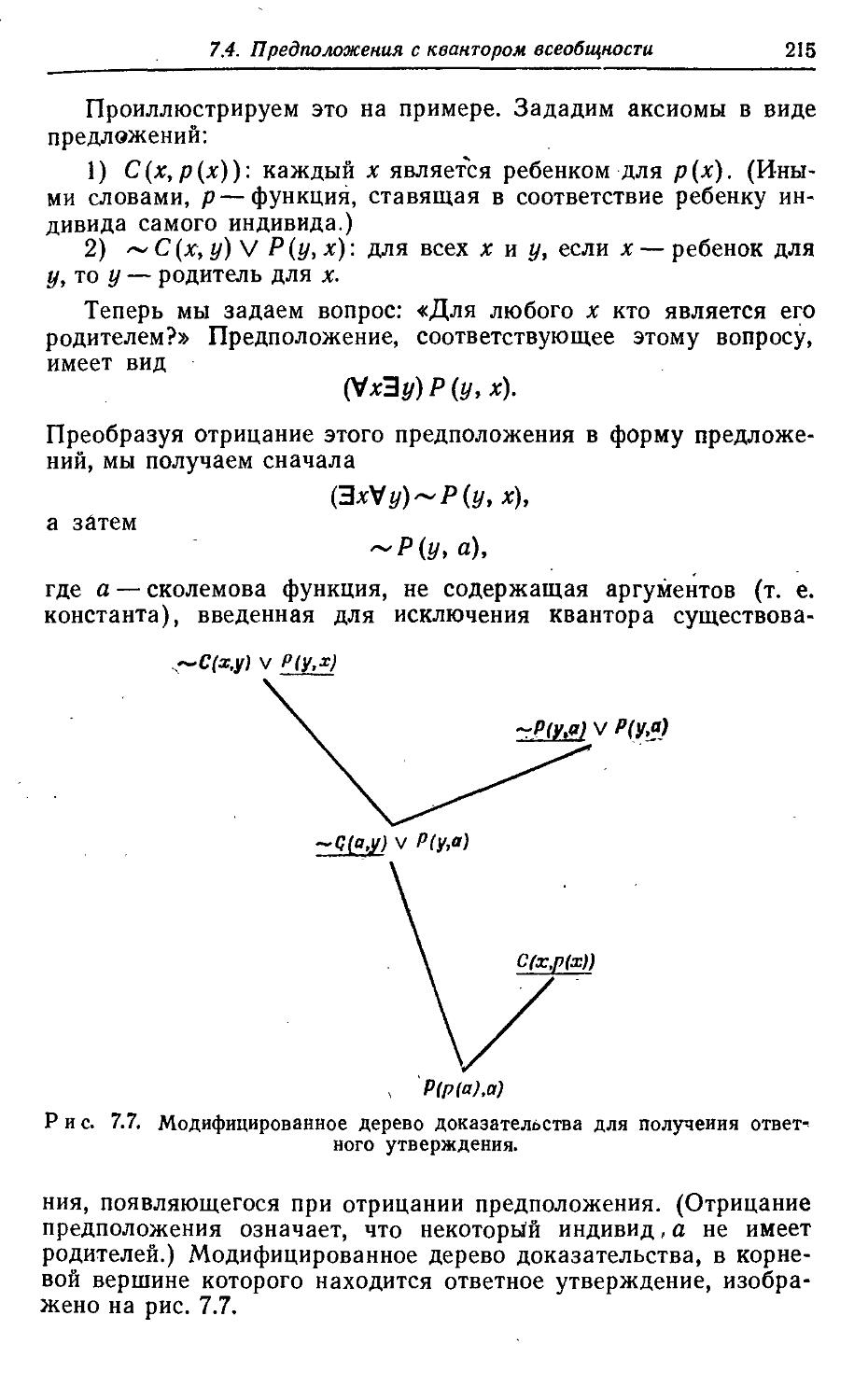
Использование формальных методов для построения логических выводов прй решении задач может быть обнаружено в заметках Маккарти (1958, 1963) о системе, «воспринимающей советы». Эта система должна была выводить решения для задач из большого количества аксиом, представляющих те знания, которые имеются у решателя. Такой системе очень легко давать «советы», просто добавляя новые аксиомы. Работа Блэка (1964) была одной из первых работ, основанных на этой идее. О. некоторых из последних работ в этой области будет идти речь в гл. 7.
Ряд блестящих идей о решении больших комбинаторных задач высказал Лин Шен (1965, 1970). Он привел несколько эффективных стратегий разбиения задачи на подзадачи.
1.7. Библиографические и исторические замечания 2<
Приложения программ решения задач
Стоит задаться вопросом о том, был' ли хоть один из методов, так хорошо работающих на головоломках и играх, когда-либо с пользой применен для «реальных» задач. Методы, использующие пространство состояний, нашли применение для решения задач исследования операций, таких, как известная задача о коммивояжере. Примером может служить метод, предложенный в диссертации Шапиро (1966) и рассмотренный затем Беллмором и Немхозером (1968). Хотя задача о коммивояжере может показаться легкомысленной, как головоломки и игры, она служит моделью важных с экономической точки зрения проблем, возникающих при составлении расписаний и планировании производства.
Другие приложения метода, использующего пространство состояний, даны в работе Уитни (1969) о дистанционном управлении манипуляторами, в работе Йелинека (1969) о последовательном декодировании и в работе Монтанари (1970) о подборе хромосом. Методы, основанные на редукции задачи, были использованы в одной системе, осуществляющей интегрирование в символической записи (Слейджл, 1963а), и в системе, анализирующей данные с масспектрографа (Фейгенбаум, Букхэнан и Ледерберг, 1971),
Важнейшая литература по искусственному интеллекту
По вопросам искусственного интеллекта имеется много обзоров и существует обширная литература. Один из первых аннотированных списков литературы принадлежит Минскому (19616). Более поздние обзоры Фейгенбаума (1963) и Соломонова (1966) содержат много дополнительных работ. Еще больше литературных ссылок, сопровождающихся рассуждениями о будущем этой области исследований, содержится в недавнем обзоре Фейгенбаума (1969).
Часто делаются ссылки на книгу «Вычислительные машины и мышление» под редакцией Фейгенбаума и Фельдмана, поскольку в ней нашло отображение много более ранних статей в этой области. Под редакцией Мичи и др. выходит серия книг, носящая название «Машинный разум». Здесь публикуются доклады, сделанные на конференциях по машинному разуму, проводимых ежегодно в Эдинбурге. Следующая важная книга — это «Обработка семантической информации» под редакцией Минского; в ней содержатся полные тексты нескольких диссертаций, связанных с обработкой языков и вопросами «понимания».
Журнал Artificial Intelligence, целиком предназначенный для работ по искусственному интеллекту, начал издаваться в 1970 г. Статьи по этой тематике время от времени публикуются также в Journal of the Association for Computing Machinery.
24
Гл. 1. Введение
В США координацию деятельности в области искусственного интеллекта осуществляет специальная исследовательская Группа по искусственному интеллекту (SIGART) Ассоциации вычислительных устройств (АСМ). Она издает информационный бюллетень, в котором время от времени появляются реферативные материалы, нигде больше не публикуемые. В Европе издается информационный бюллетень Группой искусственного интеллекта и моделирования поведения (AISB) Британского общества вычислительных машин.
Программы решений задач были отшлифованы на ряде головоломок и игр. Хорошими книгами по головоломкам являются книги Мартина Гарднера (1959, 1961), который редактирует раздел головоломок в журнале The Scientific American. Интересны также книги по головоломкам Дьюденея (1958, 1967), известного английского составителя головоломок. В книге головоломок Шуха (1968) особо выделяются стратегии поиска методом проб и ошибок и редукции задач. У игры в пятнадцать имеется длительная история, которая обсуждается Мартином Гарднером (1964, 1965а, б, в) и Боллом (1931).
Для полноты изложения мы иногда будем ссылаться в этой книге на неопубликованные работы и отчеты. Авторы этих материалов в отдельных случаях могут выслать их копии, если обратиться к ним с такой просьбой.
Задачи
1.1. Прочтите статью Ньюэлла (1969) и сопоставьте применяемую им классификацию методов решений задач с описанной в настоящей главе. Какие из методов Ньюэлла можно рассматривать как методы поиска в пространстве состояний? Что является для них состояниями и операторами?
1.2. Во многих случаях решение задач связано с 'выполнением все увеличивающегося объема вычислений с последующей проверкой, ие завершена ли задача. Если она не завершена, то производятся дополнительные" вычисления
Задачи 25
п
и т д. Примером может служить процесс нахождения суммы чисел У, х/.
1=1 представленный на стр. 24.
Можно ли представить этот процесс как метод решения задачи с использованием пространства состояний? Имеется ли в этом процессе какой-либо поиск методом проб и ошибок? (Могла бы в этом процессе возникнуть необходимость вернуться назад н пойти к цели другим путем?)
1.3. Приведите несколько примеров из повседневной человеческой деятельности, характеризующихся гем или иным поиском по методу проб и ошибок. (Примеры могут касаться вопроса о том, что одеть, что приготовить к обеду н т. д.)
1.4. Прочтите работу Ньюэлла, Шоу и Саймона (1957) о логической теории машин и опишите ее содержание как с точки зрения подхода, основанного на1 пространстве состояний, так и с точки зрения редукции задач.
Глава 2
ПРЕДСТАВЛЕНИЕ ЗАДАЧ В ПРОСТРАНСТВЕ СОСТОЯНИЙ
2.1. ОПИСАНИЯ состоянии
В предыдущей главе мы ввели понятия состояний и операторов. Здесь мы займемся детальной разработкой этих идей и дадим несколько примеров формулировки задач в терминах пространства состояний.
Чтобы построить описание задачи с использованием пространства состояний, мы должны иметь определенное представление о том, что представляют собой состояния в этой задаче. В игре в пятнадцать выбор в качестве состояний различных конфигураций из фишек был достаточно очевидным. Но процесс решения задачи, в котором решение ищется без реального перемещения настоящих фишек, может работать лишь с описанием конфигураций, а не с самими конфигурациями. Таким образом, важным этапом построения какого-либо описания задачи с использованием пространства состояний является выбор некоторой конкретной формы описания состояний этой задачи.
В сущности любая структура величин может быть использована для описания состояний. Это могут быть строки символов, векторы, двумерные массивы, деревья и списки. Часто выбираемая форма описания имеет сходство с некоторым физическим свойством решаемой задачи. Так, в игре в пятнадцать естественной формой описания состояний может быть массив 4X4. Выбирая форму описания состояний, нужно позаботиться и о том, чтобы применение оператора, преобразующего одно описание состояния в другое, оказалось бы достаточно легким.
Проиллюстрируем выбор формы описания состояний на простом примере. Рассмотрим задачу преобразования алгебраического выражения (AB-{-CD)/BC в более простое выражение А/С + DfB. Очевидно, что в качестве состояний задачи здесь должны выступать алгебраические выражения, но необходимо еще принять решение относительно формы описания состояний.
В широко используемом описании употребляются двоичные деревья. Неконцевые вершины в таком дереве описания представляют арифметические знаки (+, —, Х> Ч-), а концевые вершины представляют переменные или постоянные символы (А, В, С, D), появляющиеся в этом выражении. Таким обра
2.2. Операторы
27
зом, деревом представления для выражения (АВ Д- CD)/BC должно быть
Здесь ветвь, отходящая от вершины 4- влево, представляет числитель дроби, а ветвь, отходящая вправо, — ее знаменатель. Применение законов алгебраических преобразований (операторов в пространстве состояний) привело бы к преобразованию этого описания в другие описания. Наша задача состоит в преобразовании его в состояние, 'описываемое деревом
Другой известной формой описания служит линейная строка. Возможное описание для выражения (АВ -j- CD)/ВС в виде строки такое 4- + X АВ X CD X ВС. Здесь арифметические операторы (4-, + и X) называются префиксными операторами, поскольку они предшествуют в этой строке своим операндам. Так как нам известно, что каждый из этих операторов относится ровно к двум операндам, то в этой строке нет необходимости в пунктуации. Операндами для символа -f- в этой строке, например, должны быть две идущие непосредственно друг за другом подстроки, которые представляют собой алгебраические выражения ХАВ и У. CD. Используя описание в форме строки, можно сформулировать стоящую перед нами проблему как задачу преобразования строки 4- -f- X АВ X X CD X ВС в строку + 4- АС 4- DB.
2.2. ОПЕРАТОРЫ
Операторы переводят одно состояние в другое. Таким образом, их можно рассматривать как функции, определенные на множестве состояний и принимающие значения из этого мно-
28 Гл. 2. Представление задач в пространстве состояний'
жества1). Так как наши процессы решения задач основаны на работе с описаниями состояний, то мы будем предполагать, что операторы суть функции этих описаний, а их значения суть новые описания. Мы могли бы, конечно, определять наши операторные функции с помощью таблицы, связывающей с каждым «входным» описанием состояния некоторое «выходное» описание. Для больших задач такая таблица была бы практически непригодной, поэтому в общем случае мы будем предполагать, что операторы — это вычисления, преобразующие одни описания состояний в другие. '
Для описаний состояний в форме строки имеется очень удобный способ представления операторных вычислений. Он основан на идее правил переписывания (называемых иногда продукциями (productions)).
Множество правил переписывания определяет возможные способы преобразования одной строки в другую. Все правила переписывания имеют форму S»-*S3, означающую, что строка Si может быть преобразована в строку Sj. Пример правила- переписывания таков:
Оно означает, что если символ А появляется в качестве первого символа некоторой строки, то он может быть заменен на символ В. Знак $—произвольная подстрока (включая пустую строку). В приведенном правиле переписывания знак $ указывает, что часть строки (какова бы она ни была), идущая непосредственно за А, не изменяется, когда А заменяется на В.
Для указания нескольких различных подстрок в правилах переписывания может быть использовано несколько знаков $. Так мы получаем следующие примеры возможных правил переписывания:
1. А$А->Л (строка, начинающаяся и кончающаяся символом А, может быть заменена одиночным символом Л).
2. (одиночный символ А, стоящий между
двумя символами В, можно исключить).
3. 818283 -* 81828283 (каждая подстрока может быть повторена).
4. 81828283“* 818283 (одна из двух стоящих рядом одинаковых подстрок может быть исключена).
’) В действительности они могут быть определены не на всем множестве состояний, поскольку оператор может быть неприменим к некоторым состояниям. __
2.2. Операторы
29
Используя, например, два последних правила, строку АВСВАВС можно преобразовать в строку АВС следующим образом: - 4 4
АВСВАВС —* АВ АВСВАВС —> АВ АВС —> АВС
Правило переписывания часто может применяться к некоторой строке несколькими различными способами. Так, в приведен-
X, хг х5 1 X/ х2 Х3 Х1 Хз 7 X/ х3
х4 х5 - х4 Х? Х4 хг Хз Х4 Хг Х5
Хд X/ xs Хв X? Х6 \ Х8 Х6 Х7 Х8
X, Хг х3 2 X/ X? ха Х> Хз 8 X/ Хз
Х4 Хд - х4 х? xs Х4 хг Хз х4 Хг Х5
*8 X/ Х9 Хд Х8 Х6 Х7 X? Хз Х7 Х8
X, Хг Xj 3 X, Хз X/ Х2 Хз 9 X/ Хг
х4 Xs - — Х4 Х4 Х5 Х4 Х5 Х3
*6 X/ Х8 Хб Х7 Х8 Х6 х7 хв Хд Х7 Хд
х, хг хз 4 X, Х3 X/ Х2 Хз 10 X/ Х2 Хз
х< Хд < — > X, Х2 xs х4 Х5 « — - X# Х5 Хд
Хд X/ Х8 Хд Х7 X? Х6 Х7 % Хд Х7
X; Хг Х3 5 Х2 хз X, Х2 Хз 11 X, Хг Хз
Х4 х5 *—* X, х4 Х5 Х4 Х7 Хд - » Х4 Хг Х5
Хд Хг хв Хв Х7 Х8 хв хв Х6 Х8
X, хг Хз 6 X/ х2 Х3 Х1 Х2 хз 12 X, Хг Х3
х4 Xs *6 х4 Хз х4 х7 Х5 в» Х4 Х7 Х5
Хд X/ Х« Х7 Х8 хе Х8 Х6 Х8
Рис. 2.1. Правила переписывания для игры в восемь.
ном примере правило 4 к строке АВСВАВС вообще не может быть применено, тогда как правило 3 может применяться к ней несколькими способами. Конечно, определенному оператору отвечает некоторое конкретное применение данного правила переписывания. Поскольку одно правило переписывания может пред
30
Гл. 2. Представление задач в пространстве состояний
ставлять много различных операторов, то правила переписывания находят широкое применение при решении задач.
Представление операторов с помощью правил переписывания не должно быть обязательно ограничено ситуациями, в которых состояния описываются строками. Аналогичные идеи могут быть использованы, например, для игры в пятнадцать, в которой естественным описанием состояний служит массив 4X4. Проиллюстрируем это обобщенное понятие правил переписывания на примере игры в восемь — упрощенном варианте игры в пятнадцать. В этой игре восемь пронумерованных фишек расположены на площадке размером 3X3.
Один из способов представления допустимых ходов в этой игре состоит в задании множества правил переписывания, определенных над массивами. Эти правила определяют пути, по которым массивы 3X3 могут быть преобразованы в другие массивы того же размера. На рис. 2.1 изображено множество правил переписывания для игры в восемь. Каждое правило представляет собой в действительности два правила (как это показано двунаправленными стрелками), объединенных для экономии места в одно; в каждом случае левая запись может быть заменена правой и обратно. В каждом из правил переписывания допустимый ход определяется путем подстановки чисел 1,2, ..., 8 на место переменных Хи Х2, . .., Хя по каждую сторону от стрелки (при условии Х{ =#= Х,). Так,
2 1 6
4 8
7 Сл ' 3
может быть преобразовано в
2 1 6
4 8
7 5 3
посредством применения правила 3.
2.3. ЦЕЛЕВЫЕ СОСТОЯНИЯ
Во все наши процедуры исследования пространства состояний входит построение новых описаний состояний, исходя из старых с последующей проверкой новых описаний состояний,
2.4. Запись в виде графа
31
с тем чтобы убедиться, не описывают ли они состояние, отвечающее поставленной цели. Часто это просто проверка того, соответствует ли некоторое описание состояния данному целевому описанию состояния, но иногда должна быть произведена более сложная проверка. Например, для игры в пятнадцать целью может быть создание конфигурации из фишек, в которой в верхних двух рядах не будет фишек с номерами, превосходящими 12. Во всяком случае, то свойство, которому должно удовлетворять описание состояния, для того чтобы это состояние было целевым, должно быть охарактеризовано исчерпывающим образом.
В некоторых задачах оптимизации недостаточно найти любой путь, ведущий к цели, а необходимо найти путь, оптимизирующий некоторый критерий (например, минимизирующий число применений операторов). С такими задачами проще всего работать, сделав так, чтобы поиск не оканчивался до тех пор, пока не будет найдено некоторое оптимальное решение. Методы поиска в пространстве состояний, рассматриваемые в следующей главе, позволяют получить оптимальное решение.
Таким образом, мы видим, что для полного представления задачи в пространстве состояний необходимо задать: а) форму описания состояний и, в частности, описание начального состояния, б) множество операторов и их воздействий на описания состояний, в) свойства описания целевого состояния.
Мы уже отмечали, что пространство состояний полезно представлять себе в виде направленного, графа. Такое представление особенно полезно для исследования различных методов поиска в пространстве состояний. В следующем разделе мы приведем некоторые необходимые сведения из теории графов.
2.4. ЗАПИСЬ В ВИДЕ ГРАФА
В гл. 1 мы использовали граф с целью иллюстрации пространства состояний для игры в пятнадцать. До сих пор наше рассмотрение графов носило интуитивный характер, а в настоящем разделе будут введены некоторые полезные формальные понятия, относящиеся к графам.
„ Граф состоит из множества (не обязательно конечного) вершин. Некоторые пары вершин соединены с помощью дуг, и эти дуги направлены от одного члена этой пары к другому. Такие графы носят название направленных графов. Если некоторая дуга направлена от вершины П; к вершине п$, то говорят, что вершина nj является дочерней вершиной для вершины п», а вершина п, является родительской вершиной для Может оказаться, что некие две вершины будут дочерними друг для друга; в этом случае пара направленных дуг называется иногда ребром графа. В случае когда граф используется для пред
32
Гл. 2. Представление задач в пространстве состояний
ставления пространства состояний, с его вершинами связывают описания состояний, а с его дугами — операторы.
Последовательность вершин пц, пц, ..., в которой каждая вершина дочерняя для «j, >_i, / = 2, ..., k, называется путем длины k от вершины пц к вершине Пгк. Если существует путь, ведущий от вершины /г, к вершине П), то вершину nj называют достижимой из вершины nt или потомком вершины щ. В этом случае вершина пг- называется также предком для вершины nj. Видно, что проблема нахождения последовательности Операторов, преобразующих одно состояние в другое, эквивалентна задаче поиска пути на графе.
Часто бывает удобным приписывать дугам графа стоимости, отражающие стоимость применения соответствующего оператора. Мы будем использовать запись с(п{, п^) для обозначения стоимости дуги, направленной из вершины п, в п,. Стоимость пути между двумя верщинами определяется тогда как сумма стоимостей всех дуг, соединяющих вершины этого пути. В задачах оптимизации возникнет необходимость найти путь между двумя вершинами, имеющий минимальную стоимость.
В задачах простейшего типа нам необходимо найти путь (возможно, имеющий минимальную стоимость) между заданной вершиной $ (представляющей начальное состояние) и другой заданной вершиной t (представляющей целевое состояние). Два очевидных усложнения этой простейшей задачи следующие:
Найти путь между вершиной s и любым элементом множества вершин {Л}.
Найти путь между любым элементом множества {sj и любым элементом множества {/J.
Множество {М, называемое целевым множеством, не должно быть обязательно задано явным образом. Оно может определяться неявно через свойства, которыми обладают описания соответствующих состояний, отвечающих цели.
Граф может быть задан как явным образом, так и неявным. При явном задании его вершины и дуги (с соответствующими стоимостями) должны быть перечислены явным образом, скажем, в виде некоторой таблицы. Эта таблица может содержать перечень всех вершин графа, их дочерних вершин и стоимостей всех связанных с ними дуг. Очевидно, что явное задание оказывается практически неприемлемым для больших графов, а для графов, имеющих бесконечное число вершин, оно невозможно.
При неявном способе задания определяется некоторое конечное множество {sj вершин, являющихся начальными вершинами. Кроме того, определяется оператор Г, который, будучи примененным к любой вершине, дает все ее дочерние вершины и стоимости соответствующих дуг. (В нашей терминологии пространства состояний этот оператор «наследования» определяется
2.5. Представление посредством недетерминированных программ
33
как множество операторов, применимых к данному описанию состояния.) .Последовательное применение оператора Г к элементам множества {sj, к их дочерним элементам и так до бесконечности дает, таким образом, представление для графа, определенного неявно через Г и {sj.
При этом процесс поиска в пространстве состояний той последовательности операторов, которая решает задачу, соответствует преобразованию в явную форму достаточно большой части неявно заданного графа, такой, чтобы в нее входила вершина, отвечающая цели. Таким образом, центральным пунктом решения задачи с использованием пространства состояний является поиск на графе указанного типа. Рассмотрение приемов поиска на графе мы отложим до следующей главы.
2.5. ПРЕДСТАВЛЕНИЕ ПРОСТРАНСТВ СОСТОЯНИЙ ПОСРЕДСТВОМ НЕДЕТЕРМИНИРОВАННЫХ ПРОГРАММ1)
Процесс порождения пространства состояний может быть представлен блок-схемой, изображенной на рис. 2.2. Здесь символы х и у используются для обозначения произвольных совокупностей данных. Заметим, что оператор присваивания «положить у равным некоторому члену множества Г (у) элементов,
Рис. 2.2. Представление пространства состояний с помощью недетерминированной программы.
Исходное положение: программная переменная у (пробегающая описания состояний) полагается равной входной структуре данных х, описывающей начальное состояние.
Присваивание: новое значение программной переменной у полагается равным одному из элементов множества Г (у) дочерних значений для прежней величины у.
непосредственно следующих за у», является недетерминированным в том смысле, что при его выполнении может быть выбран любой член множества Г(у). Множество (возможно, бесконечное) всех* возможных способов выполнения программы, представленной этой блок-схемой, охватывает тогда полное про-
') Этот раздел может быть опущен при первом чтении.
2 Зак. 493
34
Гл. 2. Представление задач в пространстве состояний '
странство состояний. (При такой формулировке состояния описываются возможными величинами программной переменной у, которая может быть произвольно сложной совокупностью данных.)
Программы, в которых используются операторы присваивания (и другие), допускающие во время выполнения недетерминированные выборы, получили название недетерминированных1). Часто бывает удобно представлять пространство состояний некоторой задачи неявно, с помощью некоторой недетерминированной блок-схемы. Такая блок-схема может быть столь же простой, как канонический пример рис. 2.2, но может иметь и более сложный вид с несколькими недетерминированными и детерминированными элементами.
(Строго говоря, на нашей блок-схеме на рис. 2.2 нужно было бы дать условия для окончания и привести другие подробности, такие, как тест для проверки непустоты множества Г(у). Проверка на окончание может появиться в любой из точек, помеченных крестиком на нашей блок-схеме. В следующей главе мы дадим точное определение алгоритмов образования пространства состояний и перебора его элементов.)
В общем недетерминированные программы связаны с расширением определений оператора обычного присваивания и оператора ветвления детерминированных программ. Мы уже видели, как можно пользоваться, недетерминированными операторами присваивания. Этот тип операторов присваивания, называемый операторами типа ВЫБОР, на блок-схемах обозначается так:
I
у — ВЫБОР (F(x,y)}
Здесь совокупность данных х есть входная величина этой программы. Функция F является полной функцией, отображающей совместную область изменения х и у в некоторое непустое подмножество области изменения у. Для представления этого подмножества мы пользуемся обозначением {/•}, а ВЫБОР {F} означает выбор одного члена (любого члена) этого подмножества. Этот член затем присваивается как новое значение величине у. (Мы допускаем, что присваивание может зависеть как от значения входной переменной х, так и от имеющегося в данное время значения программной переменной у.)
') Слово «недетерминированный» в том смысле, в котором оно использовано здесь, вовсе не равносильно слову «стохастический»; недетерминированность не означает наличие каких-либо случайных механизмов.
2.5. П редставление посредством недетерминированных программ
35
Рис. 2.3. Представление
виде недетерминированной
в
игры в пятнадцать программы.
Кроме того, мы расширяем понятие оператора ветвления. В операторе V-ветвления на п направлений используется п предикатов рДх, у), ..., рп(х,‘у), принимающих либо значение Т (истина), либо F (ложь) в совместной области изменения х и у, причем по крайней мере один из предикатов должен иметь значение Т. Каждый предикат соответствует некоторой ветви. Выбирается одна ветвь (любая), для которой соответствующий ей предикат имеет значение Т. Этот тип недетерминированного ветвления называется V-ветвлением и на блок-схемах обозна>
36
Г л. 2. Представление задач в пространстве состояний
чается следующим образом:
Отметим, что обычные детерминированные присваивания и ветвления — это простые частные случаи недетерминированных операторов.
При конкретном выполнении недетерминированной программы в операторах V-ветвление и ВЫБОР делаются конкретные выборы. Тогда множество всех возможных способов выполнения определяет пространство состояний. Если для любого входного массива существует по крайней мере одно конкретное выполнение программы, имеющее окончание, то говорят, что эта программа правильно определена.
В качестве того как некоторой задаче можно придать форму недетерминированной программы, на рис. 2.3 дается одна возможная программа для игры в пятнадцать. Здесь состояние описывается значением программной переменной у, принадлежащем пространству массивов 4X4. Элементами этих массивов являются числа от 1 до 15 и символ (представляющий пустую клетку). Функции ВЛЕВО, ВВЕРХ, ВПРАВО, ВНИЗ соответствуют операторам. Они изменяют массивы посредством перемещения символа соответственно вле'во, вверх, вправо, вниз.
Оказывается, что можно определить также и другие элементы недетерминированных программ. Эти элементы полезны при обсуждении формулировок, основанных на сведении задачи к подзадачам. Они будут рассмотрены в гл. 4.
2.6. НЕКОТОРЫЕ ПРИМЕРЫ ПРЕДСТАВЛЕНИЙ ЗАДАЧ
Для большого числа задач можно дать представления, связанные с пространством состояний. Для некоторых задач такое представление удается выбрать совершенно естественно, тогда как для других любое представление, связанное с введением пространства состояний, кажется весьма искусственным. Читателю не следует предполагать, что каждая из формулировок, приведенных в настоящем разделе, — наилучшая из всех возможных. Точно так же он не должен удивляться, увидев, что может решить аддачу, опираясь на иное представление. Сейчас мы хотим лишь показать, что для некоторых различных типов задач действительно возможно представление в пространстве состояний.
2.6. Некоторые примеры представлений задач
37
Задача о коммивояжере
Задача о коммивояжере — классическая комбинаторная проблема. Коммивояжер должен построить свой маршрут так, чтобы побывать в каждом из п городов в точности по разу и возвратиться в исходный город. Желательно, чтобы этот маршрут имел минимально возможную протяженность. Было разработано несколько эффективных методов решения задачи, которые реализуемы лишь в том случае, когда число городов не превышает примерно 50. Приближенные методы дают хорошие решения (хотя не обязательно минимизирующие протяженность маршрута) уже для 200 городов. Задача о коммивояжере полезна для иллюстрации представлений, основанных на введении пространства состояний, как это видно из следующего простого частного примера.
Рис. 2.4. Карта для задачи о коммивояжере.
Коммивояже'р должен посетить каждый из пяти городов, изображенных на карте на рис. 2.4. Между каждой парой городов имеется путь, длина которого указана на этой карте. Нужно, отправляясь из города Л, найти самый короткий путь, по которому коммивояжер по одному разу проходит через каждый из городов и затем возвращается в город Д.
Чтобы дать представление в пространстве состояний, мы должны определить следующее;
Описания состояний. Будем задавать состояния списком городов, пройденных к настоящему моменту. Так, начальным состоянием будет список (Д). Мы не будем допускать, чтобы в этом списке какой-то город упоминался более одного раза, с тем лишь исключением, что после того, как в нем будут упомянуты все остальные .города, может быть снова упомянут Д.
Операторы. Операторы суть вычисления, соответствующие поступкам: (1) направиться теперь в город Д, (2) направиться
38
Гл. 2. П редставление задач в пространстве состояний
теперь в город В, ..., (5) направиться теперь в город Е. Оператор неприменим к некоторому описанию состояния, если он не преобразует его в некоторое допустимое описание. Так, оператор номер (1) (соответствующий «направиться теперь в город Д») неприменим ни к какому описанию, не содержащему названия всех городов.
Критерий достижения цели. Любое описание, начинающееся и оканчивающееся городом А и перечисляющее все другие города, есть описание состояния, удовлетворяющего поставленной цели.
На рис. 2.5 показано представление этого пространства состояний в виде графа. (Явно указаны лишь некоторые из его
Рис.
2.5. Часть графа для
задачи о Коммивояжере.
вершин.) Числа, написанные около дуг графа, указывают стоимости этих дуг’. Мы полагаем эти стоимости равными расстояниям между соответствующими городами (см. рис. 2.4). В вершинах графа стоят описания тех состояний, которые они представляют. Достоинства представления в виде графа состоят
2.6. Некоторые примеры представлений задач
39
в том, что приписывание дугам стоимостей дает нам удобный способ вычисления полной длины маршрута, а следовательно, и способ поиска кратчайшего из них. Кратчайший (34 мили) для нашего случая показан на графе жирными стрелками.
Задача о коммивояжере представляет собой пример задачи, в которой информация, содержащаяся в ее формулировке, представима в графической форме (карте расстояний). Следует быть внимательным и не смешивать какие-либо графы, используемые при формулировке задачи, с графом пространства состояний, который строится при решении задачи.
Задачи синтаксического анализа
При работе с языками часто сталкиваются с задачей синтаксического анализа. В таких задачах сначала дается некоторое формальное определение через задание грамматики, которая выделяет определенный класс строк символов. А затем возникает вопрос о том, принадлежит ли к этому классу произвольная строка. Следующий пример иллюстрирует этот тип задач.
Грамматика. Предположим, что мы определяем предложение как строку однбго из следующих видов:
за символом а следует символ b
за символом а следует некоторое предложение за некоторым предложением следует символ b за некоторым предложением следует другое предложение. Примеры предложений: aab, abaabab, aaaaab. Некоторые строки, не являющиеся предложениями: ааа, aba, abaa.
Предположим, что мы захотели определить, является ли строка abaabab предложением. Тогда формулировка этой задачи в пространстве состояний выглядит Так:
Описания состояний. Один из возможных путей формулировки этой задачи состоит в том, чтобы выбрать в качестве начального состояния рассматриваемую строку abaabab. Тогда множеством допустимых состояний будет множество строк, получающихся из нее путем применения тех правил переписывания (они даются ниже), которыми определяются операторы.
Операторы. Мы определяем операторы через следующие правила переписывания:
(подстрока ab может быть заменена символом S, обозначающим предложение)
ф ссф . Ф С’Ф
Ф1°°Ф2 Ф1°Ф2
Мы видим, что эти правила просто выражают грамматику, определяющую понятие предложения.
40
Гл. 2. Представление задач в пространстве состояний
Критерий цели. Целевое состояние описывается строкой, которая состоит из одиночного символа 3.
Последовательность состояний, представляющая собой решение этой задачи, имеет следующий вид:
abaabab Saabab SaSab SSab SSS SS S
Граф, изображающий пространство состояний для этой задачи, показан на рис. 2.6. В этой задаче оказалось так, что
с
Целевая вершина
Рис. 2.6. Граф для задачи синтаксического анализа.
в силу заданной грамматики любая строка, начинающаяся с а и оканчивающаяся на Ь, является предложением. Знание такого факта, очевидно, сильно бы упростило решение вопроса о том, будет ли некоторая произвольная строка предложением. Иногда оказывается, что заданная грамматика может быть представ
2.6. Некоторые примеры представлений задач
41
лена в эквивалентном, но более простом виде. Обнаружение таких упрощений позволяет строить меньшие пространства для перебора.
Задачи распределения
Следующая простая задача типична для класса задач, называемых иногда задачами распределения. Имеются два источника жидкости: А дает 100 галлонов в минуту, а В — 50. Источники должны снабжать два бассейна С и D, потребность каждого из которых 75 галлонов в минуту. Жидкость может
источник, 100
Рис. 2.7. Расположение источников жидкости и бассейнов (расстояния измеряются в милях).
подаваться от источника к бассейну с помощью труб с максимальной пропускной способностью 75 галлонов в минуту. Пусть источники и бассейны расположены так, как это показано на рис. 2.7, и соединения труб допускаются только в местах расположения источников и бассейнов. Спрашивается, как следует подсоединять трубы, чтобы при этом полная длина труб была наименьшей.,
Представление этой задачи в пространстве состояний выглядит следующим образом:
Описания состояний. Состояния описываются списком величин избыточного расхода жидкости, который имеется в точках А, В, С и D. Так, начальное состояние описывается списком (Л = 100, В = 50, С = 0, D = 0).
Операторы. Операторы соответствуют передаче избытка «жидкости в минуту» из одной точки в другую. В задачах, по
42
Гл. 2. П редставление задач в пространстве состояний
добных этой, в качестве подходящего избытка выступает наибольший общий делитель пропускных способностей и потребностей в жидкости в различных точках. Таким образом, у нас есть операторы:
1. Передать 25 галлон/мин из Л в В.
2. Передать 25 галлон/мин из Л в С.
12. Передать 25 галлон/мин из В в А.
Разумеется, операторы применимы лишь тогда, когда имеется достаточный избыток жидкости в той точке, от которой жидкость отбирается для передачи в другую точку. И, конечно, для осуществления каждой такой передачи нужно иметь соответствующую трубу.
Критерий цели. Целевое состояние описывается списком (Л = О, В = О, С = .75, D = 75).
Начальная вершина /
/Д = 100, В = 50, С = О, D = 0)
(А = 50, В = 50, С = 0,D = 50) (Д - 75, В = 50, С 0.D = 25)
(А = О,В = О,С = 75,0 = 75)
Целевая вершина
Рис. 2.8. Часть графа для задачи распределения.
Часть графа, получающегося таким образом пространства состояния, показана на рис. 2.8. Обозначение типа А —* D около Дуг графа показывает, что соответствующий оператор передает избыток в 25 галлон/мин от А к D. Стоимости, написанные рядом с каждой дугой, показывают, сколько миль труб нужно добавить для подачи этого избытка. Число нуль при этом озна
2.6. Некоторые примеры представлений задач
43
чает, что нет необходимости добавлять еще трубу, поскольку уже имеющаяся труба обладает достаточной дополнительной пропускной способностью. Граф на рис. 2.8 изображен не полностью— многие из его вершин не показаны. Исследовав полный граф, можно установить, что путь, ведущий от начальной вершины к целевой и обладающий наименьшей стоимостью, требует 12 миль труб.
Задачи управления
В типичной задаче управления имеется процесс, представленный системой «уетанавливаемых» переменных, которые должны управляться с помощью соответствующего управления, обеспечиваемого некоторым множеством управляющих перемен
ных.
Интересным примером служит задача о перевернутом маятнике на тележке (рис. 2.9). В этой задаче масса М прикреплена к концу стержня длины /.дру-
гой конец которого шарнирно закреплен на тележке, так что стержень может свободно вращаться в вертикальной плоскости, совпадающей с направлением движения тележки, снабженной колесами. Устанавливаемые переменные — угол наклона стержня 0, координата х тележки и производная по времени 0. Требуется, чтобы значения каждой из этих переменных поддерживались в определенных, заранее указанных границах. Управляющей переменной служит скорость тележки
Рис. 2.9. Перевернутый м:ят-
иик на тележке.
х, которая может принимать одно
из двух значений -j-o и —v. (Мы
предполагаем для простоты, что
эти значения могут сменять друг друга мгновенно.) Главная задача здесь состоит в принятии в данный момент решения о том,
следует ли перемещать тележку со скоростью v вправо или со скоростью а влево.
Описание состояний. Предположив, что переменные 0, 0 и х принимают дискретные значения с достаточно мелким шагом, можно считать состоянием вектор, составленный из этих трех переменных (пространством состояний при этом служит решетка в трехмерном пространстве 0, 0 их).
Операторы. Имеются ровно два оператора: 1. Применить управление + v.
2. Применить управление —и.
44
Гл. 2. Представление задач в пространстве состояний
Состояние, возникающее в результате применения одного из этих операторов, — это просто то состояние, которое описывается вектором (0, 0, х) по истечении А/ секунд. (Во многих типичных задачах управления действия операторов могут быть компактно представлены с помощью дифференциальных уравнений.)
Критерий достижения цели. Предположим, что целевое состояние описывается вектором (0 = 0, 0 = 0, х=»0). Тогда нам нужно найти последовательность операторов, которая будет преобразовывать любое данное состояние в целое. Конечно, такая последовательность не должна приводить ни к какому состоянию, описываемому переменными 0, 0 и х, для которого неизбежно в конце концов полное нарушение работы системы. (Оно происходит при 0 = ±90°.)
В некоторых типичных задачах управления часто можно получить (аналитическими методами) уравнения разделяющих поверхностей, которые разбивают векторное пространство состояний на непересекающиеся области, такие, что для всех векторов из данной области в данный момент должно быть применено одно и то же управление (один и тот же оператор). В этих случаях несложное вычисление может дать ответ, который иначе получался бы с помощью поиска. Читатель должен понимать, что мы но собираемся предлагать использовать поисковые процессы в случаях, когда известны прямые методы решения. Мы хотим лишь подчеркнуть, что часто можно воспользоваться эффективными методами перебора для решения тех задач, для которых прямые методы еще не найдены.
2.7. ВЫБОР «ХОРОШИХ» ПРЕДСТАВЛЕНИЙ
Выбор для данной задачи определенного представления в пространстве состояний существенно определяет те поисковые усилия, которые придется приложить для ее решения. Очевидно, что предпочтительны представления с малыми пространствами состояний (т. е. такие, графы которых имеют небольшое число вершин). Существует множество примеров задач, кажущихся трудными, но таких, что при правильной их трактовке соответствующие пространства состояний оказываются очень узкими. Подчас данное пространство состояний «сжимается в точку» после того, как обнаруживается, что некоторые операторы могут быть отброшены за ненадобностью, а другие — объединены в более мощные операторы. И даже если такие простые преобразования неосуществимы, может оказаться, что полная переформулировка задачи, изменяющая само понятие состояния, приведет к меньшему пространству.
Еще слишком слабо поняты те процессы, которые необходимы для первоначального представления задач и для усо
2.7. Выбор «хороших» представлений
45
вершенствования этих представлений. По-видимому, желаемый прогресс в представлении задачи зависит от опыта, накопленного в попытках решить задачу в рамках данного представления. Этот опыт позволяет выделить упрощающие понятия, такие, как свойства симметрии или полезные последовательности операторов, которые следует объединить в макрооператоры.
Чрезвычайно важная идея в области представлений задач связана с использованием переменных в описаниях состояний. Тогда выражения, содержащие переменные, могут быть использованы для описания целого множества состояний, а не только одного. Подстановка каких-то частных значений (констант) вместо этих переменных в указанные выражения дает конкретные описания состояний. Выражение, содержащее переменные, которое используется для описания множества состояний в указанном смысле, называется схемой для описания состояний. Мы проиллюстрируем на примере использование схем для описания состояний.
К задаче об обезьяне и бананах часто обращаются в литературе по искусственному интеллекту при демонстрации работы автоматических решателей задач, создаваемых для осуществления умозаключений, опирающихся на здравый смысл. Задачу можно сформулировать так. В комнате, где находится обезьяна, имеются ящик и связка бананов, причем бананы подвешены к потолку настолько высоко, что обезьяна не может до них дотянуться с пола. Какая последовательность действий позволит обезьяне достать эти бананы? (Предполагается, что обезьяна должна подойти к ящику, подтащить его к бананам, забраться на него и достать бананы.)
Как следует строить для этой задачи представления в пространстве состояний? В описании состояния должны непременно появиться следующие элементы: координаты обезьяны в комнате (по горизонтали и по вертикали), координаты ящика в комнате и наличие у обезьяны бананов. Эти элементы удобно представить в виде четырехэлементного списка (w, х, у, z), где
w — координаты обезьяны в горизонтальной плоскости (двумерный вектор),
х — это 1 или 0 в зависимости от того, где обезьяна находится, на ящике или нет,
у — координаты ящика в горизонтальной плоскости (двумерный вектор),
z — это 1 или 0 в зависимости от того, достала обезьяна бананы или нет.
Если бы каждое отдельное значение списка (w, х, у, z) описывало ровно одно состояние, то мы имели бы бесконечное число состояний, поскольку число различных расположений предметов в комнате бесконечно. Мы могли бы сделать про
46
Гл. 2. Представление задач в пространстве состояний
странство состояний конечным, допустив, что предметы могут находиться лишь в конечном числе точек (скажем, точек решетки), но все же число точек, достаточное для поставленной задачи, привело бы к чрезвычайно большому пространству состояний. Другой путь состоит в использовании схем. Для входящих в схему переменных имеются частные значения (например, константы), которые должны подставляться на их место при применении оператора или при проверке того, что цель достигнута.
Операторы в этой задаче соответствуют четырем возможным действиям, которые могут выполняться обезьяной:
1) подойти (и) . —обезьяна идет к точке и в плоскости
пола комнаты (и — переменная),
2) передвинуть (v) —обезьяна передвигает ящик в точку v пола комнаты (v — переменная),
3) взобраться —обезьяна забирается на ящик,
4) схватить —обезьяна хватает бананы.
В связи с наличием переменных в «подойти», «передвинуть» эти операторы на самом деле являются схемами. Условия применимости и действия этих операторов даются следующими правилами переписывания:
подойти (и)
(w, 0, у, г)--------> (и, 0, у, г),
, п \ передвинуть(v)
(w, О, W, 2)---------->(v, О, V, z),
взобраться , ,
(W, О, W, 2)-------—->(w, 1, W, 2),
. схватить
(с, 1, с, 0)------>(с, 1, с, 1),
где с — координаты точки пола, расположенной непосредственно под бананами (двумерный вектор).
Применение некоторых операторов, например «передвинуть», связано с ограничением значений переменных, представляющих координаты обезьяны и ящика, от которых теперь требуется, чтобы они были одинаковыми. Мы будем считать идентичными две схемы для описания состояний, если они отличаются лишь наименованием переменных.
В такой формулировке элементы множества целевых состояний описываются любыми списками, последний элемент которых есть единица.
Предположим, что вначале обезьяна находится в точке а пола, а ящик — в Ь. Тогда описанием начального состояния будет (а, 0, Ь, 0). Единственный оператор, который применим в этом состоянии,—это «подойти», приводящий к схеме (и, 0, Ь, 0). Теперь применимы три оператора. Если и — Ь, то обезьяна может либо забраться на ящик, либо передвинуть его. Независимо от величины и обезьяна могла бы переместиться куда-нибудь
2.7. Выбор «хороших» представлений
47
еще. Влезание на ящик приводит к состоянию с описанием (b, 1, Ь,0); перемещение ящика в v приводит к схеме (v,0,v,0), а переход в другое место, описываемое новой переменной, не изменяет описания.
Продолжая процесс применения всех операторов, мы построим пространство состояний, иллюстрируемое графом на рис. 2.10. Мы видим, что этот граф весьма невелик и на нем легко можно найти путь, решающий нашу задачу (жирные
Рис 2.10. Граф для задачи об обезьяне и бананах.
стрелки). Подставив вместо переменных их соответствующие частные значения, как это показано на рис. 2.10, мы получаем последовательность операторов: подойти (Ь), передвинуть (с), взобраться, схватить.
На этом мы закончим рассмотрение вопроса о представлениях задач в пространстве состояний. Приведенные в этой главе примеры касались нескольких сторон проблемы представлений, хотя пока еще нет удовлетворительной теории представлений и изменения представлений. В следующей главе мы перейдем к гораздо.более глубоко разработанной области приемов поиска в пространстве состояний.
48
Гл. 2. Представление задач в пространстве состояний
2.8. БИБЛИОГРАФИЧЕСКИЕ И ИСТОРИЧЕСКИЕ ЗАМЕЧАНИЯ
Составные элементы представления в пространстве состояний
Три элемента, из которых слагается представление в пространстве состояний — описания состояний, операторы и критерии цели — давно считаются основными в области автоматического решения задач. Эти понятия обсуждаются в книге Эрнста и Ньюэлла (1969), в которой рассматривается программа универсального решателя задач. Более абстрактное исследование проблемы описания состояний и операторов можно найтиуАма-реля (1967, 1969). Пример использования правил переписывания для задания операторов имеется в системе для решения задач, описанной Квинланом и Хантом (1968).
Основные элементы языка теории графов (дуги, вершины, пути и т. п.) часто используются при описании процессов решения задач. Классическими книгами по теории графов являются книги Бержа (1958) и Оре (1962). Оре (1963) написал также популярную элементарную книжку, содержащую применения теории графов к различным комбинаторным задачам.
Недетерминированные программы
Название недетерминированный алгоритм было предложено Флойдом (1967а). Флойд допускал использование в таких алгоритмах функции «выбора» для упрощения описания стратегий полного перебора. Позднее Манна (1970) описал класс программ, допускающих как недетерминированные утверждения присваивания (подобные функции выбора), так и недетерминированные операции ветвления. Он привел методику доказательства корректности (правильности) программ, содержащих эти новые элементы. В более ранней статье Манна (1969) рассмотрел проблему доказательства корректности обычных (детерминированных) программ. Файке (1970) описал полную систему решения задач, в которой задачи ставятся на некотором процедурном языке, допускающем использование недетерминированных функций выбора.
Основная литература по примерам задач
Примеры задач, которые мы использовали для иллюстрации методов работы с пространством состояний, связаны с различными областями, в каждой из которых свои традиционные специализированные методы решения. Многие из этих методов можно рассматривать как применение подхода, основанного на пространстве состояний. Читателю было бы весьма полезно попытаться в качестве упражнения перевести описания этих специа
Задачи
49
лизированных методов на обычный язык представления в пространстве состояний.
Задача о коммивояжере занимает важное место в теории исследования операций. Обзор результатов по ней можно найти у Беллмора и Немхозера (1968).
Задачи синтаксического анализа обычны при исследовании языков. Фельдман и Грис (1968) дают всесторонний обзор методов синтаксического анализа, используемых трансляционными системами для формальных вычислительных языков. Ама-рель (1965) обсуждает синтаксический анализ с позиции автоматического решения задач и предлагает процедуру, основанную на сведении задачи к подзадачам. Доступное изложение вопроса об использовании строк и символов и их продукционных систем как вычислительных моделей имеется в заключительных главах книги Минского (1967) по вычислениям.
Множество задач, таких, как распределение, потоки и очереди, может быть решено методом, связанным с пространством состояний. Они рассмотрены в книге Форда и Фалкерсона (1962).
Теория управления — это большая специальная область с разнообразными приемами решения возникающих здесь задач. Книга Де Руссо, Роя и Клоуза (1965) может служить хорошим введением в современную теорию управления.
Проблема поиска хорошего представления
Вопросы поиска хорошего представления рассматривали лишь немногие исследователи и, в частности, Амарель. Амаре-лем (1968) написана классическая работа на эту тему. В ней он последовательно показывает читателю ряд постепенно улучшающихся представлений для задачи о миссионерах и людоедах. Интересная головоломка, подчеркивающая важность выбора хорошего представления, была отмечена Маккарти (1964). Задача об обезьяне и бананах — стандартный пример задачи о построении рассуждений на основе здравого смысла. Она детально рассмотрена Амарелем (1966).
Отмечалось, что использование схем для описания состояний служит мощным приемом представления задачи. В последнем варианте универсального решателя задач допускается использование схем объектов с переменными, как это делается в системе Файкса (1970) решения задач. В статье Ньюэлла (1965) исследуются некоторые возможные подходы (и связанные с ними ограничения) к задаче получения хорошего представления.
Задачи
(Для решения задач, отмеченных звездочкой, может потребоваться несколько часов. Некоторые из этих задач могли бы служить темой курсовой работы.)
50
Гл. 2. Лредставление задач в пространстве состояний
2.1. Локомотив L н вагоны стоят на пути, показанном ниже, в порядке (слева направо), который может быть представлен строкой LABCD; Предположим, что локомотив можно произвольно отцеплять н сцеплять с отдель: ными вагонами, стрелки могут занимать произвольное положение и локомотив может тянуть и толкать тот вагон, к которому он прицеплен. Укажите множество правил переписывания для строк, которое можно было бы использовать с целью создания представлений для всех возможных расположений вагонов и локомотива на прямом отрезке пути.
Стрелка
У
2.2. Дуга между вершиной nt и вершиной п,, следующей за ней, называется невозвратной, если nt недостижима из П). Дайте два примера задач, для которых графы в пространстве состояний содержат невозвратные дуги.
2.3. Покажите, найдя соответствующий путь на графе, представляющем пространство состояний, что строка (((), ()), (), ((), ())) является предложением S в грамматике, определяемой следующими правилами переписывания:
a) S+-()
Ь) Л-e-S
с) А А, А
d)S+-(A).
В этих правилах переписывания считается, что символ, стоящий слева от стрелки, может быть подставлен вместо подстроки символов, стоящей справа от стрелки, в любом месте строки, в котором эта подстрока встретилась.
2.4. Найдите форму описания состояний, операторы и критерии достижения цели для следующей задачи о кувшинах.
Даны кувшин с водой емкостью 5 галлонов и пустой кувшин емкостью 2 галлона. Как получить ровно один галлон в кувшине емкостью в 2 галлона? Воду можно либо выливать, либо переливать из одного кувшина в другой.
Начертите часть дерева перебора, соответствующего тем шагам, которые вы предпринимаете в поиске решения.
2.5. Для следующей задачи о восьми ферзях укажите форму описания состояний, операторы и критерий достижения цели.
Разместить 8 ферзей на обычной шахматной доске так, чтобы на. каждой горизонтали, вертикали и диагонали стояло не более одного ферзя.
Начертите часть графа состояний и снабдите его вершины и дуги соответствующими описаниями.
2.6. Напишите программу для вычислительной машины, порождающую множество строк, которые могут быть получены заменой подстроки Si подстрокой S2 во всех местах данной строки S, где стоит подстрока Si.
Задачи
51
*2.7. Прочтите работу Амареля (1968) по представлениям. Обратите внимание на-то, что Амарель начинает с весьма примитивного представления, работает немного с ним, а затем постепенно еп? улучшает. Проведите подробный анализ следующей задачи, упоминаемой Маккарти (1964):
Удалите из доски, содержащей 2п X 2п клеток, по одной клетке из двух ее противолежащих углов:
Покажите, что теперь невозможно полностью покрыть эту искаженную доску фишками размером 1 X 2 так, чтобы они ие высовывались за край доски и не накрывали друг друга.
На некотором этапе исследования задачи Вы, возможно, захотите поработать с доской 2X2, затем с доской 4 X 4 и т. д., чтобы найти понятия, удобные для представления общего случая. Напишите отчет о работе иад этой задачей и в заключение укажите те наблюдения, которые, быть может, у Вас имеются относительно трудности этой задачи представления.
Глава 3
МЕТОДЫ ПОИСКА В ПРОСТРАНСТВЕ СОСТОЯНИЙ
3.1. ПРОЦЕССЫ ПОИСКА НА ГРАФЕ
При формулировке задачи в пространстве состояний решение получается в результате применения операторов к описаниям состояний до тех пор, пока не будет получено выражение, описывающее состояние, которое соответствует достижению цели. На примерах, рассмотренных в предыдущей главе, мы видели, как для иллюстрации пространств состояний могут быть использованы графы. Язык графов чрезвычайно полезен для описания эффективных стратегий перебора (поиска) в пространстве состояний. Все методы перебора в пространстве состояний, которые мы будем обсуждать, могут быть смоделированы с помощью следующего теоретико-графового процесса:
Начальная вершина соответствует описанию начального состояния.
Вершины, непосредственно следующие за данной, получаются в результате использования операторов, которые применимы к описанию состояния, ассоциированного с этой вершиной. Пусть Г —некоторый специальный оператор, который строит все вершины, непосредственно следующие за данной. Мы будем называть процесс применения оператора Г к вершине раскрытием вершины.
От каждой такой последующей вершины к породившей ее идут указатели. Эти указатели позволяют найти путь назад к начальной вершине, уже после того как обнаружена целевая вершина.
- Для вершин, следующих за данной, делается проверка, не являются ли они целевыми вершинами. (То есть проверка того, не определяют ли соответствующие описания такие состояния, которые соответствуют цели.) Если целевая вершина еще не найдена, то продолжается процесс раскрытия вершин (и установки указателей). Когда же целевая вершина найдена, эти указатели просматриваются в обратном направлении — от цели к началу, в результате чего выявляется путь решения. Тогда операторы над описаниями состояний, связанные с дугами этого пути, образуют решающую последовательность.
Этапы, указанные выше, описывают просто основные элементы процесса перебора подобно описанию, даваемому блок-
3.2. Методы полного перебора
55
схемой недетерминированной программы. При полном описании процесса перебора нужно еще задать порядок, в котором следует раскрывать вершины. Если вершины раскрываются в том же порядке, в котором они порождаются, то получается процесс, который называется полным перебором (breadth-first process). Если же сначала раскрывается всегда та вершина, которая была построена самой последней, то получается процесс перебора в глубину (depth-first process). Процессы полного перебора и перебора в глубину можно назвать также процедурами слепого перебора, поскольку расположение цели не влияет на порядок, в котором раскрываются вершины.
Возможно, однако, что у нас имеется некоторая эвристическая информация о глобальном характере графа и общем расположении цели поиска. (Слово эвристический означает «служащий открытию».) Такого рода информация часто может быть использована для того, чтобы «подтолкнуть» поиск в сторону цели, раскрывая в первую очередь наиболее перспективные вершины. В этой главе мы опишем несколько эвристических методов перебора в терминах теории графов. Но прежде мы введем ряд основных идей, связанных с перебором, рассмотрев более подробно методы слепого перебора.
Сущность этих методов станет понятнее, если мы ограничимся рассмотрением деревьев, а не произвольны'х графов. Деревом называется граф, каждая вершина которого имеет ровно одну непосредственно предшествующую ей (родительскую) вершину, за исключением выделенной вершины, называемой корнем дерева, которая вовсе не имеет предшествующих ей вершин. Таким образом, корень дерева служит начальной вершиной. Для перебора деревья проще графов прежде всего потому, что при построении новой вершины мы можем быть уверены, что она никогда раньше не строилась и никогда не будет построена вновь. Таким образом, путь от корня до данной вершины единствен. После описания методов слепого поиска для деревьев мы покажем, как их следует модифицировать в случае произвольных графов.
3.2. МЕТОДЫ ПОЛНОГО ПЕРЕБОРА
В методе полного перебора вершины раскрываются в том порядке, в котором они строятся. Простой алгоритм полного-перебора на дереве состоит из следующей последовательности шагов:
(1) Поместить начальную вершину в список, называемый ОТКРЫТ.
(2) Если список ОТКРЫТ пуст, то на выход подается сигнал о неудаче поиска, в противном -случае переходить к следующему шагу.
54
Гл. 3. Методы поиска в пространстве состояний
(3) Взять первую вершину из списка ОТКРЫТ и перенести ее в список ЗАКРЫТ; назовем эту вершину п.
(4) Раскрыть вершину п, образовав все вершины, непосредственно следующие за п. Если непосредственно следующих вершин нет, то переходить сразу же к шагу (2). Поместить имеющиеся непосредственно следующие за п вершины в конец списка ОТКРЫТ и построить указатели, ведущие от них назад к вершине п.
Рис. 3.1. Блок-схема программы алгоритма полного перебора для деревьев.
(5) Если какие-нибудь из этих непосредственно следующих за п вершин являются целевыми вершинами, то на выход выдать решение, получающееся просмотром вдоль указателей; в противном случае переходить к шагу (2).
3.2. Методы полного перебора
55-
В этом алгоритме предполагается, что начальная вершина не удовлетворяет поставленной цели, лотя нетрудно ввести этап проверки такой возможности. Блок-схема алгоритма показана на рис. 3.1. Вершины и указатели, построенные в процессе перебора, образуют поддерево всего неявно определенного дерева пространства состояний. Мы будем называть такое поддерево деревом перебора.
Легко показать, что в методе полного перебора непременно будет найден самый короткий путь к целевой вершине при условии, что такой путь вообще существует. (Если такого пути нет, то в указанном методе будет объявлено о неуспехе в случае конечных графов, а в случае бесконечных графов алгоритм никогда не кончит свою работу.)
На рис. 3.2 приведено дерево перебора, полученное в результате полного перебора, примененного к игре в восемь. (Граф пространства состояний для игры в восемь в действительности деревом не является, но этот факт несуществен, так как в рассматриваемом процессе перебора одца и та же вершина никогда не может возникнуть более, чем от одной родительской вершины.) Задача состоит в том, чтобы преобразовать конфигурацию, стоящую слева, в конфигурацию, стоящую справа:
2 в 3
1 6 4
1 5
1 2 3
8 4
1 6 5
В вершинах дерева помещены соответствующие описания состояний. Эти вершины занумерованы в том порядке, в котором они получались при раскрытии1); зачерненная ветвь представляет собой решение из пяти шагов. (Стрелки на дугах не указаны, поскольку в данном случае совершенно ясно происхождение каждой вершины.) Заметьте, что было раскрыто 26 и построено 46 вершин, прежде чем удалось найти это решение. Непосредственное рассмотрение этого графа показывает также, что не существует решения, содержащего меньшее число шагов.
Могут встретиться задачи, в которых к решению предъявляются какие-то иные требования, отличные от требования получения наикратчайшей последовательности операторов. Присваивание дугам дерева определенных цен (с последующим нахождением решающего пути, имеющего минимальную
’) Порядок последующих вершин соответствует перемещению пустой клетки сначала влево, затем вверх, вправо и вниз.
13
Рис. 3.2. Дерево, образованное
Целевая вершина
в процессе полного перебора.
3.2. Методы полного перебора
57
стоимость) соответствует многим из таких обобщенных критериев, как это было видно из нескольких примеров предыдущей главы. Более общий вариант метода полного перебора, называемый методом равных цен, позволяет во всех случаях найти некоторый путь от начальной вершины к целевой, стоимость которого минимальна. В то время как в только что описанном алгоритме распространяются линии равной длины пути от начальной вершины, в более общем алгоритме, который будет описан ниже, распространяются линии равной стоимости пути. Предполагается, что нам задана функция стоимости с(гц, n.j), дающая стоимость перехода от вершины nt к некоторой следующей за ней вершине п3.
В методе равных цен для каждой вершины п в дереве перебора нам нужно помнить стоимость пути, построенного от начальной вершины s к вершине п. Пусть g(n)—стоимость пути от вершины s к вершине п в дереве перебора. В случае деревьев перебора мы можем быть уверены, что g(ri) является к тому же стоимостью того пути, который имеет минимальную стоимость (так как этот путь единственный).
В методе равных цен вершины раскрываются в порядке возрастания стоимости g(n). Этот метод характеризуется такой последовательностью шагов: '
(1) Поместить начальную вершину s в список, называемый ОТКРЫТ. Положить g'(s) = 0.
(2) Если список ОТКРЫТ пуст, то на выход подается сигнал о неудаче поиска; в противном случае переходить к следующему шагу.
(3) Взять из списка ОТКРЫТ ту вершину, для которой величина g имеет наименьшее значение, и поместить ее в список, называемый ЗАКРЫТ. Дать этой вершине название п. (В случае совпадения значений выбирать вершину' с минимальным g произвольно, но всегда отдавая предпочтение целевой вершине.)
(4) Если п есть целевая вершина, то на выход выдать решающий путь, получаемый путем просмотра назад в соответствии с указателями; в противном случае переходить к следующему шагу.
(5) Раскрыть вершину п, построив все непосредственно следующие за ней вершины. [Если таковых не оказалось, то переходить сразу к шагу (2).] Для каждой из такой непосредственно следующей (дочерней) вершины rii вычислить стоимость положив @(ni) = g(n) 4-с(п,П{). Поместить эти вершины вместе с соответствующими им только что найденными значениями £ в список ОТКРЫТ и построить указатели, идущие назад к п.
(6) Перейти к шагу (2).
Блок-схема этого алгоритма показана на рис. 3.3. Заметьте, что проверка того, является ли некоторая вершина целевой,
.58
Гл. 3. Методы поиска в пространстве состояний
Рис. 3.3. Блок-схема программы алгоритма равных цен для деревьев.
включена в эту схему так, что' гарантируется обнаружение путей минимальной стоимости.
Мы видим, что алгоритм, работающий по методу равных цен, может быть также использован для поиска путей минимальной длины, если просто положить стоимость каждого ребра равной единице. Если имеется несколько начальных вершин, то алгоритм просто модифицируется: на шаге (1) все начальные вершины помещаются в список ОТКРЫТ. Если состояния, отвечающие поставленной цели, могут быть описаны явно, то про
3.3. Метод перебора в глубину
59
цесс перебора можно пустить в обратном направлении, приняв целевыё вершины в качестве начальных и используя обращение оператора Г.
3.3. МЕТОД ПЕРЕБОРА В ГЛУБИНУ
В методах перебора в глубину прежде всего раскрываются те вершины, которые были построены последними. Определим глубину вершины в дереве следующим образом:
Глубина корня дерева равна нулю.
Глубина любой последующей вершины равна единице плюс глубина вершины, которая непосредственно ей предшествует.
Таким образом, вершиной, имеющей наибольшую глубину в дереве перебора, в данный момент служит та, которая должна в этот момент быть раскрыта. Такой подход может привести к процессу, разворачивающемуся вдоль некоторого бесполезного пути, поэтому нужно ввести некоторую процедуру возвращения. После того как в ходе процесса строится вершина с глубиной, превышающей некоторую граничную глубину, мы раскрываем вершину наибольшей глубины, не превышающей этой границы, и т. д.
Метод перебора в глубину определяется следующей последовательностью шагов:
(1) Поместить начальную вершину в список, называемый ОТКРЫТ.
(2) Если список ОТКРЫТ пуст, то на выход дается сигнал о неудаче поиска, в противном случае перейти к шагу (3).
(3) Взять первую вершину из списка ОТКРЫТ и перенести ее в список, называемый ЗАКРЫТ. Эту вершину назваться.
(4) Если глубина вершины п равна граничной глубине, то переходить к (2), в противном случае — к (5).
(5) Раскрыть вершину п, построив все непосредственно следующие за ней вершины. Поместить их (в произвольном порядке) в начало списка ОТКРЫТ и построить указатели, идущие от них к. вершине п.
(6) Если одна из этих вершин целевая, то на выход выдать решение, просматривая для этого соответствующие указатели, в противном случае переходить к шагу (2).
На рис. 3.4 приведена блок-схема для метода перебора в глубину. Дерево, которое получается в результате применения метода перебора в глубину к той же самой игре в восемь, что и прежде, показано на рис.- 3.5. Снова нужно найти
Рис. 3.4. Блок-схема программы алгоритма поиска в глубину для деревь
Целевая вершина
Рис. 3.5. Дерево, построенное при переборе в глубину.
62
Гл. 3. Методы поиска в пространстве состояний
последовательность ходов для преобразования левой конфигурации в правую:
2 8 3
1 6 4
7 5
t 2 3
8 4
7 6 5
Вершины здесь занумерованы в том порядке, в котором они были раскрыты, причем граничная глубина выбрана равной 5 (т. е. ищутся пути, ведущие к цели, длина которых не больше пяти).
Мы видим, что в алгоритме поиска в глубину сначала идет перебор вдоль одного пути, пока не будет достигнута максимальная глубина, затем рассматриваются альтернативные пути той же или меньшей глубины, которые отличаются от него лишь последним шагом, после чего рассматриваются пути, отличающиеся последними двумя шагами, и т. д.
3.4. ИЗМЕНЕНИЯ ПРИ ПЕРЕБОРЕ НА ПРОИЗВОЛЬНЫХ ГРАФАХ
При переборе на графах, а не на деревьях, нужно внести некоторые естественные изменения в указанные алгоритмы. В простом методе полного перебора не нужно вносить никаких изменений; следует лишь проверять, не находится ли уже вновь построенная вершина в списках ОТКРЫТ или ЗАКРЫТ по той причине, что она уже строилась раньше в результате раскрытия какой-то вершины. Если это так, то ее не нужно вновь помещать в список ОТКРЫТ.
Несколько более сложные изменения должны быть сделаны в алгоритме равных цен:
(I) Если вновь построенная вершина уже имеется в списке ОТКРЫТ, то ее не следует вносить в этот список снова. Однако соответствующая ей величина стоимости g может оказаться теперь меньше (может быть найден менее дорогой путь). Мы всегда связываем с вершинами списка ОТКРЫТ наименьшие из имевшихся до сих пор значений g. Точно так же указатель от вершины всегда должен быть направлен к породившей ее вершине, расположенной на том пути, стоимость которого оказалась наименьшей среди всех путей к этой вершине, рассмотренных к настоящему моменту.
(2) Если вновь построенная вершина уже имеется в списке ЗАКРЫТ, то, казалось бы, возможно, что для нее величина & окажется меньше, чем раньше, так как направление ее указа
3.5. Обсуждение эвристической информации
63
теля должно быть выбрано заново. Но на самом деле этого не происходит. Позже мы докажем, что если в алгоритме равных цен некоторая вершина помещается'в список ЗАКРЫТ, то уже найдена наименьшая возможная величина § (и, следовательно, путь наименьшей стоимости, идущий' к этой вершине).
Прежде чем делать какие-либо изменения в алгоритме перебора в глубину, нужно решить, что понимать под глубиной вершины в графе. Согласно обычному определению, глубина вершины равна единице плюс глубина наиболее близкой родительской вершины, причем глубина начальной вершины предполагается равной нулю. Тогда поиск в глубину можно было бы получить, выбирая для раскрытия самую глубокую вершину списка ОТКРЫТ (без превышения граничной глубины). Когда порождаются вершины, уже имеющиеся либо в списке ОТКРЫТ, либо в списке ЗАКРЫТ, пересчет глубины такой вершины может оказаться необходимым.
Даже в том случае, когда перебор осуществляется на полном графе, множество вершин и указателей, построенное в процессе перебора, тем не менее образует дерево. (Указатели по-прежнему указывают только на одну порождающую вершину.) В оставшейся части этой главы мы имеем дело с общим случаем поиска на графе, и, следовательно, в алгоритмах, которые мы будем обсуждать, явным образом учитываются эти дополнительные изменения.
3.5. ОБСУЖДЕНИЕ ЭВРИСТИЧЕСКОЙ ИНФОРМАЦИИ
Методы слепого перебора, полного перебора или поиска в глубину являются исчерпывающими процедурами поиска путей к целевой вершине. В принципе эти методы обеспечивают решение задачи поиска пути1), но часто эти методы невозможно использовать, поскольку при переборе придется раскрыть слишком много вершин, прежде чем нужный путь будет найден. Так как всегда имеются практические ограничения на время вычисления и объем памяти, отведенные для перебора, то мы должны заняться поисками других методов, более эффективных, чем методы слепого перебора.
Для многих задач можно сформулировать чисто эмпирические правила, позволяющие уменьшить объем перебора. Все такие правила, используемые для ускорения поиска, зависят от специфической информации о задаче, представляемой в виде графа. Будем называть информацию такого сорта эвристической? информацией (помогающей найти решение) и называть
’) В случае перебора в глубину при дополнительном ограничении на максимально допустимую длину пути. — Прим, перев.
64
Гл. 3. Методы поиска в пространстве состояний
использующие ее процедуры поиска эвристическими методами поиска. Один из путей уменьшить перебор состоит в выборе более «информированного» оператора Г, который не строит так много не относящихся к делу вершин. Этот способ применим как в методе полного перебора, так и в методе перебора в глубину. Другой путь состоит в использовании эвристической информации для модификации шага (5) алгоритма перебора в глубину. Вместо того чтобы размещать вновь построенные вершины в произвольном порядке в начале списка ОТКРЫТ, их можно расположить в нем некоторым определенным образом, зависящим от эвристической информации. Так, при переборе в глубину в первую очередь будет раскрываться та вершина, которая представляется наилучшей.
Более гибкий (и более дорогой) путь использования эвристической информации состоит в том, чтобы, согласно некоторому критерию, на каждом шаге переупорядочивать вершины списка ОТКРЫТ. В этом случае перебор мог бы идти дальше в тех участках границы, которые представляются наиболее перспективными. Для того чтобы применять процедуру упорядочения, нам необходима мера, которая позволяла бы оценивать «перспективность» вершины. Такие меры называют оценочными функциями.
Как мы сможем убедиться, подчас удается выделить эвристическую информацию (эвристику), уменьшающую усилия, затрачиваемые на перебор (до величины, меньшей, скажем, чем при поиске методом равных цен), без потери гарантированной возможности найти путь, обладающий наименьшей стоимостью. Чаще же используемые эвристики сильно уменьшают объем работы, связанной с перебором, ценою отказа от гарантии найти путь наименьшей стоимости в некоторых или во всех задачах. Но в большинстве практических задач мы заинтересованы в минимизации некоторой комбинации из стоимости пути ,и стоимости перебора, необходимого для нахождения этого пути. -
Более того, нас обычно интересуют методы перебора, при которых минимизируется такая комбинация, усредненная по всем задачам, которые могут нам встретиться. (При вычислении этой средней стоимости мы должны использовать веса, пропорциональные частоте появления каждой задачи, так что мы допускаем большие стоимости для нечасто встречающихся задач, если они компенсируются меньшими стоимостями для часто встречающихся задач.) Если усредненная комбинационная стоимость одного метода перебора ниже соответствующей стоимости другого метода, то мы говорим, что первый метод перебора обладает большей эвристической силой, чем второй. Заметим, что по нашему определению вовсе не обязательно (хотя это обычно недопонимается), чтобы метод перебора, имеющий большую эвристическую силу, чем другой, гарантировал воз
3.6. Использование оценочных функций
65
можность нахождения путей минимальной стоимости, которую другой-метод мог бы обеспечивать.
Усредненные комбинационные стоимости в действительности никогда не вычисляются как по той причине, что трудно выбрать способ комбинирования стоимости пути и стоимости усилий, затрачиваемых на перебор, так и потому, что было бы нелегко найти вероятностное распределение на множестве задач, которые могут встретиться. Таким образом, решение вопроса о том, имеет ли один метод перебора большую эвристичёскую силу по сравнению с другим, зиждется обычно на интуиции знатока, подкрепленной реальными экспериментами с этими методами. *
3.6. ИСПОЛЬЗОВАНИЕ ОЦЕНОЧНЫХ ФУНКЦИЙ
Как мы уже отмечали, обычный способ использования эвристической информации связан с употреблением для упорядочения перебора оценочных функций. Оценочная функция должна обеспечивать возможность ранжирования вершин — кандидатов на раскрытие — с тем, чтобы выделить ту вершину, которая с наибольшей вероятностью находится на лучшем пути к цели. Оценочные функции строились на основе различных соображений. Делались попытки определить вероятность того, что вершина расположена на лучшем пути. Предлагалось также использовать расстояние или другие меры различия между произвольной вершиной и множеством целевых вершин. В салонных играх или головоломках позиции часто ставится в соответствие определенное число очков на основе тех черт, которыми она обладает и которые представляются связанными со степенью уверенности в том, что это шаг к поставленной цели.
Предположим, что задана некоторая функция f, которая могла бы быть использована для упорядочения вершин перед их раскрытием. Через f(n) обозначим значение этой функции на вершине п. Пока мы будем считать, что f— произвольная функция. Позднее же мы предположим, что она совпадает с оценкой стоимости того из путей, идущих от начальной вершины к целевой и проходящих через вершину п, стоимость которого — наименьшая (из всех таких путей).
Условимся располагать вершины, предназначенные для раскрытия, в порядке возрастания их значений функции f. Тогда можно использовать некоторый алгоритм (подобный алгоритму равных цен), в котором для очередного раскрытия выбирается та вершина списка ОТКРЫТ, для которой значение f оказывается наименьшим. Будем называть такую процедуру алгоритмом упорядоченного перебора (ordered-search algorithm).
Чтобы этот алгоритм упорядоченного перебора был применим для перебора на произвольных графах (а не только на
3 Зак. 493
66
Гл. 3. Методы поиска в пространстве состояний
деревьях), необходимо предусмотреть в нем возможность работы в случае построения вершин, которые уже имеются либо в списке ОТКРЫТ, либо в списке ЗАКРЫТ. При использовании некоторой произвольной функции f нужно учесть, что величина f для некоторой вершины из списка ЗАКРЫТ может понизиться, если к ней найден новый путь (f(n) может зависеть от пути из s к п даже для вершин списка ЗАКРЫТ). Следовательно, мы должны тогда перенести такие вершины назад в список ОТКРЫТ и позаботиться об изменении направлений соответствующих указателей.
После принятия этих необходимых мер алгоритм упорядоченного поиска может быть представлен такой последователь-: ностью шагов:
(1) Поместить начальную вершину s в список, называемый ОТКРЫТ, и вычислить f(s).
(2) Если список ОТКРЫТ пуст, то на выход дается сигнал о неудаче; вЛ противном случае переходить к следующему этапу.
(3) Взять из списка ОТКРЫТ ту вершину, для которой f имеет наименьшее значение, и поместить ее в список, называемый ЗАКРЫТ. Дать этой вершине имя п. (В случае совпадения значений f для нескольких вершин выбирать вершину с минимальным f произвольно, но всегда отдавая предпочтение целевой вершине.)
(4) Если п — целевая вершина, то на выход подать решающий путь, получаемый прослеживанием соответствующих указателей; в противном случае переходить к следующему этапу.
(5) Раскрыть вершину п, построив все непосредственно следующие за ней вершины. (Если таковых не оказалось, переходить сразу к (2).) Для каждой такой дочерней вершины Пг вычислить значение f (nt).
(6) Связать с теми из вершин n«, которых еще нет в списках ОТКРЫТ или ЗАКРЫТ, только что подсчитанные значения f(tii). Поместить эти вершины в список ОТКРЫТ,и провести от них к вершине п указатели.
(7) Связать с теми из непосредственно следующих за п вершинами, которые уже были в списках ОТКРЫТ или ЗАКРЫТ, меньшее из прежних и только что вычисленных значений f. Поместить в список ОТКРЫТ те из непосредственно следующих за п вершин, для которых новое значение f оказалось ниже, и изменить направление указателей от всех вершин, для которых значение f уменьшилось, направив их к п.
(8) Перейти к (2).
Общая структура алгоритма идентична структуре алгоритма равных цен (см.‘ рис. 3.3), поэтому мы не приводим для него блок-схему. Отметим, что множество вершин и указателей, порождаемых этим алгоритмом, образует дерево (дерево пере
3.6. Использование оценочных функций
67
бора), причем на концах этого дерева расположены вершины из списка’ ОТКРЫТ.
Работу алгоритма проще всего пояснить, рассмотрев вновь тот же самый пример игры в восемь. Мы будем пользоваться следующей простой оценочной функцией:
f(n) = £(п) + W(n),
где g(n) —длина пути в дереве перебора от начальной вершины до вершины п, a W(n) —это число фишек, которые лежат не на
Целевая вершина
Рис. 3.6. Дерево, построенное в процессе упорядоченного перебора.
своем месте в описании состояния, связанного с вершиной п.
значение f равно 0 + 4 — 4. По предположению с большей вероятностью на оптимальном пути находится та вершина, которая имеет наименьшую оценку.
На рис. 3.6 показан результат применения к игре в восемь алгоритма упорядоченного перебора и использования такой оценочной функции. Значение f для каждой вершины приведено внутри кружка. Отдельно
стоящие цифры показывают порядок, в котором раскрывались вершины. Мы видим, что найден тот же самый путь решения, который был получен другими методами перебора, но использование оценочной функции привело к существенно меньшему числу раскрытий вершин.
Выбор оценочной функции сильно влияет на результат перебора. Использование оценочной функции, не учитывающей истинной перспективности некоторых вершин, может привести к построению путей, не обладающих минимальной стоимостью. С другой стороны, использование оценочной функции, которая
68 Гл. 3. Методы поиска в пространстве состояний
придает слишком большое значение возможной перспективности всех вершин (т^кой, как в алгоритме равных цен), приведет к тому, что придется раскрыть очень много вершин. В следующих нескольких разделах будет получен ряд теоретических результатов, относящихся к некоторой специальной оценочной функции, использование которой приводит к раскрытию наименьшего числа вершин, совместимого с гарантией нахождения пути минимальной стоимости.
3.7. ОПТИМАЛЬНЫЙ АЛГОРИТМ ПЕРЕБОРА
Сейчас мы дадим описание некоторой специальной оценочной функции и покажем, что ее использование максимизирует одну меру эффективности перебора и в то же время гарантирует обнаружение пути минимальной стоимости, ведущего к цели. Определим оценочную функцию f так, чтобы значение f(n) для любой вершины п представляло собой сумму оценки стоимости пути минимальной стоимости от начальной вершины s к вершине п и оценки стоимости пути минимальной стоимости от вершины п к целевой вершине. Таким образом, f(n) представляет собой оценку стоимости пути минимальной стоимости при условии, что этот путь проходит через вершину п. По этой оценке та вершина списка ОТКРЫТ, которая имеет наименьшее значение f, считается лежащей на пути минимальной стоимости, и поэтому следующей должна быть раскрыта именно она.
Для демонстрации некоторых из свойств этой оценочной функции мы введем вначале ряд обозначений. Пусть функция Л(П{, Я;) дает действительную стоимость пути минимальной стоимости между двумя произвольными вершинами щ и щ-. (Функция k не определена для вершин, между которыми нет пути.) Если Т — множество целевых вершин, то стоимость пути минимальной стоимости от вершины щ до цели обозначим
h(nt)= min k(nh nj).
rij^T
(Функция h не определена для тех вершин п, из которых недостижима ни одна из целевых вершин.) Мы будем говорить, что любой путь от вершины п, к целевой вершине, для которого достигается /г(п4), является оптимальным путем из вершины к цели.
Нам часто будет нужно знать стоимость оптимального пути k(s, п) от данной начальной вершины s до некоторой произвольной вершины п. Наши обозначения несколько упростятся, если ввести новую функцию g, определяемую следующим образом:
g(n) = k (s, п)
для всех п, достижимых из s.
3.7. Оптимальный алгоритм перебора
69
Далее, определим функцию f так, что ее значение f(n) для любой вёршины п есть сумма действительной стоимости оптимального пути от вершины s до вершины п и стоимости оптимального пути от вершины п до какой-нибудь из целевых вершин. Таким образом, f («) = g (n) + h (n).
Иными словами, значение f(n) есть стоимость оптимального пути при условии, что он проходит через вершину п. (Заметим, что f(s) — h(s) представляет собой действительную стоимость оптимального пути от вершины s к цели без всяких ограничений.)
Мы хотим, чтобы наша оценочная функция f была оценкой функции f. Будем считать, что наша оценка дается выражением
• f («) = £(«) + 6 («).
где § — оценка для g, а К — оценка для h.
Естественно выбрать в качестве £(п) стоимость пути от s до п в дереве перебора, которая получается после суммирования стоимостей дуг, лежащих на пути, даваемом указателями, иду- Рпз
щими от п назад к s. (Этот путь / * _ $
есть путь наименьшей стоимости « , 2/ 9 ~
от s к п, найденный алгоритмом J /
к настоящему моменту.) Заме- "/</
тим, что из определения следует, / \
что g(n) ^g(n). / \
На следующем простом при- / \
мере будет видно, что эта оцен- /. \ .
ка легко вычисляется в процессе g(£________ \
работы алгоритма. Рассмотрим 7 'э”' Л-в
подграф, показанный на рис. 3.7. 9 ~
Он состоит из начальной верши- рис. 3.7. Пример вычисления ны s и трех других вершин пь п2 функции g.
и п3. На рисунке указаны стоимости дуг и их направления. Рассмотрим работу алгоритма при переборе на таком подграфе. Отправляясь от вершины s, получаем две непосредственно следующие за ней вершины пх и п2. Оценки £(П1) и g (п2) будут тогда равны соответственно 3 и 7. Предположим, что следующей, согласно алгоритму, раскрывается вершина и строятся вершины п2 и п3. На этом шаге g(n3) =3 + 2 — 5, a g(n2) снижается до 3 + 3 = 6 (поскольку теперь к этой'вершине найден менее дорогой путь). Значение остается равным трем.
Далее нам требуется оценка П(п) для h(n). Здесь мы опираемся на любую эвристическую информацию, связанную
70 Гл. 3. Методы поиска в пространстве состояний
с самой задачей. Эта информация может оказаться подобной той информации, которая была использована при решении вопроса о функции W(n) в примере игры в восемь. Мы назовем Н эвристической функцией и более подробно рассмотрим ее позже.
Предположим, что теперь мы используем оценочную функцию
f («) = £ («) + («)•
Назовем алгоритм упорядоченного перебора, в котором используется эта оценочная функция, алгоритмом А *. Заметим, что^ если /1 = 0, то алгоритм А* совпадает с описанным выше алгоритмом равных цен.
Раньше мы сделали утверждение (без доказательства), что-в алгоритме равных цен гарантируется' нахождение пути до цели, имеющего минимальную стоимость. Сейчас мы покажем, что если й — нижняя граница для h, то алгоритм А* также находит оптимальный путь к цели. (Так как /1 = 0, безусловно, служит нижней границей для h, то факт, что алгоритм равных цен позволяет находить оптимальные пути, будет следовать как частный случай этого более общего результата для Л*.)
3.8. ДОПУСТИМОСТЬ АЛГОРИТМА А*
В общем случае будем называть алгоритм перебора допустимым, если для произвольного графа он оканчивает свою работу построением оптимального пути к цели (при условии, что такой путь существует). В этом разделе мы докажем, что если Н— нижняя граница для h, то алгоритм А* допустим. Идея доказательства состоит в том, чтобы сначала убедиться, что (при нашем ограничении на Н) до завершения работы алгоритма А* в списке ОТКРЫТ и на некотором оптимальном пути -имеется некоторая вершина, значение f для которой не больше действительной стоимости f(s) оптимального пути. Используя этот результат, мы видим, что допустимость алгоритма Д* следует из того факта, что вершина из списка ОТКРЫТ, имеющая минимальное значение f, не может оказаться целевой вершиной (на которой заканчивает работу алгоритм Д*) до тех пор, пока не будет найдена целевая вершина, значение f для которой равно f(s).
Таким образом, мы прежде всего докажем лемму, утверждающую, что если эвристическая функция И является нижней границей для h, то до того, как алгоритм Д* закончит свою работу, на любом оптимальном пути будет находиться открытая ‘)
’) Любую вершину списка ОТКРЫТ мы будем называть открытой, а любую вершину списка ЗАКРЫТ — закрытой. Незакрытой вершиной является та, которая либо находится в списке ОТКРЫТ, либо еще не была построена в процессе перебора.
.3.8. Допустимость алгоритма А*
71
вершина, величина f для которой не превышает действительной стоимости f(s) оптимального пути.
Лемма 3.1. Если для всех п выполняется условие Н(п) «g; h(n), то в любой момент времени до того, как алгоритм А* закончит свою работу, на любом оптимальном пути Р от вершины s к цели существует открытая вершина п', для которой
Доказательство. Предположим, что оптимальный путь Р представляется упорядоченной последовательностью (s = = п0, пь п2,..., Пд), где Пд— целевая вершина. Пусть п' — первая открытая вершина в этой последовательности. (Должна существовать по крайней мере одна такая вершина, так как если Ид закрыта, то алгоритм А* уже закончил свою работу.) По определению f имеем
?(«') = £(«') + £("')•
Мы знаем, что алгоритм А* нашел оптимальный путь до вершины и', так как п' лежит на Р и все ее предшественницы на Р закрыты. Следовательно, g(n') = g(n') и
f («') = §(«') +/г («')•
Так как мы принимаем, что Н(п') h(n'), то мы можем запи-
сать
f (n'X g («') + h (n') = f (п').
Но значение f для любой вершины на оптимальном пути равно просто f(s), т. е. минимальной стоимости; следовательно, /(и') f(s), что и утверждает наша лемма.
Теперь мы докажем, что если Я—нижняя граница для h, то алгоритм А* допустим.
Теорема 3.1. Если для всех вершин п выполняется условие А'(и) /г(и) и если стоимости всех дуг превосходят некоторое
малое положительное число б, то алгоритм А* допустим.
Доказательство. Мы будем доказывать эту теорему, предположив противное, а именно, что не всегда работа алгоритма Л* заканчивается отысканием оптимального пути от начальной вершины s к цели. Нужно рассмотреть три случая: либо работа алгоритма А* заканчивается, но целевая вершина остается не найденной, либо работа алгоритма вообще никогда не заканчивается, либо заканчивается на некоторой целевой вершине, но при этом не достигается минимальная стоимость.
Случай 1. Работа алгоритма заканчивается, но целевая вершина не найдена. Шаг 4 алгоритма (стр. 66) показывает, что успешное окончание не может произойти до тех пор, пока не
72
Гл. 3. Методы поиска в пространстве состояний
будет найдена целевая вершина. Единственный другой случай окончания работы — окончание, свидетельствующее о неудаче (шаг 2), может произойти лишь тогда, когда список ОТКРЫТ пуст. Но по лемме 3.1, если путь от s к целевой вершине существует, то перед окончанием работы алгоритма список ОТКРЫТ не может оказаться пустым.
Случай 2. Нет окончания работы алгоритма. Пусть t — некоторая целевая вершина, достижимая из начальной вершины за конечное число шагов с соответствующей минимальной стоимостью f(s). Так как стоимость любой дуги не меньше, чем б, то для любой вершины п, расположенной на расстоянии, большем, чем М = f (s) /б шагов от s, мы имеем
f (л) >$(«)>£ (л) > M6 = f (s).
Ясно, что никогда не будет раскрыта вершина, расположенная на расстоянии большем М шагов от s, так как по лемме 3.1 на оптимальном пути найдется такая открытая вершина п', что f(n') f(s) <z f(n), и поэтому, согласно шагу 3 алгоритма, алгоритм А* выберет вершину п' вместо п. Отсюда заключаем, что невозможность окончания работы алгоритма А* может быть вызвана лишь продолжающимся переоткрытием вершин (на шаге 7) в пределах М шагов от s. Пусть х(М)—множество вершин, достижимых в пределах М шагов из s, и пусть v(Af) — 'число вершин в х(М). Далее, каждая вершина п из х(^) может быдъ переоткрыта самое большее конечное число раз, скажем p(n, М), так как имеется лишь конечное число путей от s к п, проходящих только через вершины, расположенные в пределах М шагов от вершины s. Пусть
р (М) = max р (п, М) пе=х(М)
— максимальное число раз, которое может быть переоткрыта любая вершина. Следовательно, после самое большее v(M)p(M) раскрытий вершин все вершины из х(М) должны навсегда остаться закрытыми. Так как ни одна из вершин вне множества %(М) не может быть раскрыта, то алгоритм А* обязан прекратить свою работу.
Случай 3. Окончание работы на целевой вершине без до- ’ стижения минимальной стоимости. Предположим, что работа алгоритма А* оканчивается на некоторой вершине t с f(t) = = g(t) >f(s)- Но по лемме 3.1 как раз перед окончанием ра- ' боты на оптимальном пути существует такая открытая вершина п', что /(«') ^f(s) <f(/). Таким образом, на этом шаге для раскрытия была бы выбрана вершина п.', а не t, что противоречит предположению об окончании работы алгоритма А*.
Доказательство теоремы З.Г теперь завершено. В следующем разделе мы покажем, что при задании другого разумного ограничения на функцию Н(п) алгоритм А* будет не только допу
3.9. Оптимальность алгоритма А
73
стимым, но и оптимальным в том смысле, что не существует другого сравнимого допустимого алгоритма, в котором раскрывалось бы меньшее число вершин.
3.9. ОПТИМАЛЬНОСТЬ АЛГОРИТМА А*
Точность нашей эвристической функции И зависит от объема тех эвристических знаний, которыми мы располагаем относительно задачи, моделируемой нашим графом. Ясно, что использование условия fi(n) =0 соответствует полному отсутствию какой-либо эвристической информации о задаче, хотя такая оценка и является нижней границей для h(n), и, следовательно, она приводит к допустимому алгоритму (описанному ранее алгоритму равных цен). Мы будем говорить, что алгоритм А более информирован, чем алгоритм В, если эвристическая информация, используемая в алгоритме А, позволяет вычислять такую нижнюю границу для h(n), которая всюду строго больше (для всех вершин п, не являющихся целевыми вершинами), чем та, которая вычисляется по эвристической информации, используемой в алгоритме В. Как пример рассмотрим игру в восемь, решенную на рис. 3.6. Там была использована оценочная функция f(n) = g(n) + №(п). Мы можем интерпретировать процесс упорядоченного перебора в этом примере как применение алгоритма А* с условием б(п) = W(n). Так как W(n) есть нижняя граница для числа шагов, остающихся до цели, то алгоритм А* в этом случае допустимый. Кроме того, алгоритм А* с условием Н(п) = W'(n), очевидно, более информирован, чем алгоритм равных цен, в котором принимается /г(п) =0.
Интуитивно мы ожидаем, что в более информированном алгоритме придется раскрыть меньшее число вершин, прежде чем будет найден путь минимальной стоимости. Для игры в восемь это соображение подтверждается сопоставлением рис. 3.2 и рис. 3.6. Конечно, то обстоятельство, что один алгоритм раскрывает меньшее число вершин, чем другой, еще не означает, что он более эффективен. В более информированном алгоритме могут потребоваться более дорогостоящие вычисления, которые ослабят его эффективность. Тем не менее число вершин, которые раскрываются в процессе работы алгоритма, — один из факторов, определяющий эффективность, и это как раз тот фактор, который позволяет делать простые сравнения.
Если теперь наложить еще одно слабое ограничение на функцию f, то можно показать, что алгоритм А* оптимален в следующем смысле. В алгоритме А* никогда не раскрывается больше вершин, чем в любом другом допустимом алгоритме А, таком, что А* более информирован, чем А. Формальному доказательству оптимальности алгоритма А* мы предпошлем краткое описание плана рассуждений.
74
Гл. 3. Методы поиска в пространстве состояний
Рассмотрим любой допустимый алгоритм А, такой, что Д* более информирован, чем-Л. Мы покажем, что алгоритм А раскрывает каждую вершину п, которую раскрывает алгоритм Л*. Чтобы сделать это, прежде всего мы должны доказать, что класс вершин, раскрываемых алгоритмом А*, подчиняется следующим ограничениям:
Когда в алгоритме А* раскрывается некоторая вершина п, оптимальный путь к п уже найден, т. е. g(n) = g(n).
Когда в алгоритме А* раскрывается некоторая вершина п, то оценка f(n) не больше, чем оптимальная стоимость f(s).
Пользуясь этими ограничениями, мы покажем, что если в алгоритме А не происходит раскрытия вершины п, раскрываемой в алгоритме А*, то алгоритм А должен знать, что любой путь к цели, проходящий через вершину п, не оптимален. Короче говоря, алгоритм А* не может быть более информированным, чем алгоритм А, если алгоритм А может избежать раскрытия тех вершин, которые в алгоритме А* раскрываются.
Таким образом, наша первая задача состоит в доказательстве двух сформулированных выше предварительных результатов. Очевидно, что в случае деревьев для всех вершин выполняется равенство g(n) = g(n), ибо по дереву существует только один путь от начальной вершины к любой вершине п дерева. Но в общем случае нам придется наложить еще одно ограничение на /г, для того чтобы показать, что как только в‘алгоритме А* происходит раскрытие некоторой вершины графа, то оказывается, что оптимальный путь к этой вершине уже был найден. Мы будем предполагать, что для любых двух вершин шип, для которых k(m,n) существует, выполняется условие
А (пг) — fi (n) k (m, п).
Иными словами, разность между оценками стоимостей путей от любой пары вершин m и п до цели должна быть нижней границей стоимости оптимального пути от m до п. (Заметим, что если /г == О для целевых вершин, то это ограничение включает в себя предыдущее ограничение на /г, состоящее в том, что /г — нижняя граница для h. Это можно увидеть, взяв в качестве п целевую вершину.) Это новое ограничение, например, не будет нарушаться, если эвристическая информация, используемая для вычисления /г, непротиворечиво применяется во всех' вершинах. Поэтому мы будем называть это предположение предположением о непротиворечивости. (Легко проверить, что, например, использование условия И = W(n) для игры в восемь удовлетворяет условию непротиворечивости.) Если функция Н каким-то образом изменяется в процессе перебора, то предположение о непротиворечивости может и не удовлетворяться.
3.9. Оптимальность алгоритма А*
75
Пользуясь предположением о непротиворечивости, мы можем доказать в общем случае, что когда при работе алгоритма Л* происходит раскрытие некоторой вершины, то оказывается, что оптимальный путь к этой вершине уже найден. Этот факт важен по двум причинам. Во-первых, он используется при доказательстве теоремы об оптимальности алгоритма А*, проводимом ниже. Во-вторых, в нем утверждается, что в алгоритме А* никогда не придется изменять направление указателя, идущего от закрытой вершины, так как оптимальный путь к этой вершине уже найден. Таким образом, возможность переоткры-тия вершин, предусмотренная на шаге 7 работы алгоритма упорядоченного поиска (стр. 66), оказывается излишней и может быть удалена из него, если удовлетворяется предположение о непротиворечивости.
Лемма 3.2. П редположим, что выполнено предположение о непротиворечивости, и предположим, что вершина п закрыта алгоритмом А*. Тогда g(n) = g(n).
Доказательство. Рассмотрим дерево перебора вершин, порожденных алгоритмом А* непосредственно перед закрытием вершины п, и предположим противное, т. е. предположим, что ^(n) >g(n). Далее, существует некоторый оптимальный путь Р из $ в п. Так как £(n) > g(n), то этот-путь не найден алгоритмом А*. Но по лемме 3.1 существует открытая вершина п' на пути Р с g(n') =g(n'). Если п'= п, то лемма доказана. В противном случае
g (п) — g (n') + k (п',п) = g («') + k (ri', п).
Таким образом, если мы предполагаем, что g(n) > g(n), то g («) > g (nf) + k (n', n).
Прибавляя ti(n) к обеим частям выписанного неравенства, получаем
g (п) + ft (n) > g (nf) + k (n't n) + fi (и).
Мы можем применить предположение о непротиворечивости к правой части предыдущего неравенства и получить
g(n) + fi (п) > g (п') + h (п'), или
f («) > f (п')
в противоречии с тем фактом, что в алгоритме А* для раскрытия была выбрана вершина п, когда имелась вершина п', что и доказывает лемму.
Далее нам нужно показать, что если Н — нижняя граница для /г, то значение f для вершины, закрытой алгоритмом А*,
76
Гл. 3. Методы поиска в пространстве состояний
не может быть больше стоимости оптимального пути от s к целевой вершине.
Лемма 3.3. Для любой вершины п, закрытой алгоритмом. А*, если И — нижняя граница для h, то f(n) f(s).
Доказательство. Оно легко получается из леммы 3.1. Пусть п — любая вершина, закрытая алгоритмом А*. Если п — целевая вершина, то мы тривиально имеем f(n) =f(s). Поэтому предположим, что п не есть целевая вершина. Далее, вершина п была закрыта в алгоритме А* перед окончанием его работы, так что сейчас мы знаем (по лемме 3.1), что существует некоторая открытая вершина п' на оптимальном пути от s к цели с f(n') Если п = п', то наше доказательство закончено.
В противном случае мы знаем, что для раскрытия алгоритмом А* будет выбрана вершина п, а не п', так что это должен быть случай, когда
f(«)<f (n'Xf (s).
После доказательства этих двух лемм мы можем доказать оптимальность алгоритма А*.
Теорема 3.2. Пусть А и А* — допустимые алгоритмы, такие,, что А* более информирован, чем А, и пусть предположение о непротиворечивости удовлетворяется той функцией б, которая йспользуется в алгоритме А*. Тогда для любого графа верно, что если алгоритм А* раскрывает вершину п, то ее раскрывает и алгоритм А.
Доказательство. Предположим противное. Тогда существует некоторая вершина, которая была раскрыта алгоритмом А*, но не была раскрыта алгоритмом А (поскольку вершина п была раскрыта при работе алгоритма А*, то мы знаем, что эта вершина— не целевая). Если алгоритм А никогда не приводит к раскрытию вершины п, то это должно быть по той причине, что он использовал информацию, согласно которой любой путь к целевой вершине, идущий через вершину п, имел бы стоимость, большую или равную значению f(s)—истинной стоимости оптимального пути к цели. (Если бы имелся менее дорогой путь к цели, проходящий через вершину п, то в алгоритме А он без сомнения был бы пропущен и этот алгоритм оказался бы недопустимым, что противоречит нашему предположению. Таким образом, мы должны предположить, что алгоритму А «известно» отсутствие менее дорогого пути, проходящего через п.) Действительная стоимость оптимального пути при условии, что он проходит через вершину п, равна
f («) = g («) + h (n), откуда мы получаем, что
h(n) = f(n) — g(n).
3.10. Эвристическая сила функции Н 77
Далее, согласно приведенным выше соображениям, алгоритму А «известно», что и, следовательно, ему известно,что
h (п) > f (s) — g (п).
Такая информация, доступная алгоритму А, могла бы позволить получить нижнюю граничную оценку для
/г (п) = f (s) — g (п).
С другой стороны, в алгоритме А* была использована следующая оценочная функция:
f (п) = g (п) + А (и).
Из леммы 3.3 известно, что
Таким образом, мы знаем, что ё(п) +
Следовательно, какова бы ни была функция /г, использованная в алгоритме А*, она должна удовлетворять неравенству
A (n)< f (s) — g (п).
Далее, когда по алгоритму А* раскрывается вершина п, то, согласно лемме 3.2, g(n) = g(n) и, таким образом,
fl («X f (s) — g (n).
Но теперь мы видим, что по крайней мере для вершины п в алгоритме А использована информация, дающая для h нижнюю границу, не меньшую, чем нижняя граница, использованная в алгоритме А*. Таким образом, алгоритм А* не может быть более информированным алгоритмом по сравнению с алгоритмом А, что противоречит нашему предложению. Теорема доказана.
3.10. эвристическая сила ФУНКЦИИ h
При определении эвристической силы алгоритма упорядоченного поиска выбор функции Н играет решающую роль. Использование условия Н = о гарантирует допустимость, но ведет к слепому перебору и поэтому обычно оказывается неэффективным. Выбор в качестве Н наибольшей из возможных нижних границ для h приводит к тому, что раскрывается наименьшее число вершин, при котором еще сохраняется допустимость.
Часто эвристическая сила алгоритма может быть повышена ценой отказа от допустимости при использовании в качестве Н некоторой функции, не являющейся нижней границей для h. Такая дополнительная эвристическая сила позволяет решать
78 ' Гл. 3. Методы, поиска в пространстве состояний
существенно более трудные задачи. Для игры в восемь функция /г(п) = №(п) (где W'(n) — число фишек, находящихся йена своих местах) есть нижняя граница для h(n), но эта оценка не обеспечивает очень хорошей оценки трудности данного расположения фишек (в смысле числа шагов, отделяющих от цели). Лучшую оценку дает функция /г(и)=Р(п), где Р(п) — сумма расстояний каждой фишки от «своего места» (без учета, фишек, расположенных на ее пути). Однако даже эта оценка слишком груба, так как в ней не учитывается должным образом трудность обмена местами двух соседних фишек.
Следующая оценка достаточно хороша для игры в восемь:
A(n) = P(n) + 3S(n);
здесь S(n)—число очков, учитывающее порядок расположения фишек. Для его вычисления нужно последовательно просмотреть все нецентральные фишки в данной конфигурации и за каждую фишку, за которой не идет та фишка, которая должна бы идти (в целевой конфигурации), начисляется два очка, а в противном случае берется нуль очков. За фишку, находящуюся в центре, начисляется одно очко. Отметим, что такая функция И не дает нижней границы для h.
Используя такую функцию 1г в оценочной функции f(n)=: — g(n) + И(п)> мы можем легко находить решения в намного более сложных случаях игры в восемь, чем рассмотренные ниже. •На рис. 3.8 приведено дерево, возникающее в результате применения алгоритма упорядоченного перебора с этой оценочной функцией к задаче преобразования левой из следующих конфигураций в правую:
2 1 6
4 В 8
7 5 3
I г 3
8 4
7 6 5
Как и раньше, значение f для каждой вершины помещено в кружок, а цифры без кружков указывают порядок, в котором раскрывались вершины.
Оказалось, что решающий путь имеет минимальную длину (18 шагов), хбтя, поскольку функция Н не есть нижняя граница для h, нахождение оптимального пути не было гарантировано. Заметим, что такая функция К приводит к перебору, направленному достаточно прямо к цели. Имеется лишь небольшое число ответвлений в сторону, и сосредоточены они вблизи начальной вершины.
Рис. 3.8. Дерево, построенное в процессе упорядоченного перебора.
80
Гл. 3. Методы поиска в пространстве состояний
Другим фактором, определяющим эвристическую силу алгоритма упорядоченного перебора, является объем усилий, связанных с вычислением ft. Лучшей функцией /г была бы функция, в точности совпадающая с /г, и она бы обеспечивала абсолютный минимум числа раскрытий вершин. Такая функция й могла бы, например, быть определена в результате отдельного полного перебора на каждой вершине, что, очевидно, не привело бы к уменьшению объема вычислений в целом.
Иногда намного легче вычислить некоторую функцию /г, отличную от нижней границы для й, чем такую, которая с ней совпадает. В этом случае эвристическая сила алгоритма может быть увеличена по двум причинам — как благодаря уменьшению общего числа раскрываемых вершин (ценою отказа от допустимости), так и благодаря уменьшению объема вычислений. В ряде случаев эвристическая сила данной функции Н может бьць повышена просто путем умножения ее на некоторую положительную константу, большую единицы. Если этот множитель очень велик, то мы получаем ситуацию, аналогичную условию £(«)== 0. Такой выбор, безусловно, приведет к недопустимому, но тем не менее способному удовлетворительно работать алгоритму. Опираясь на интуицию, можно было бы предположить, что выбор ^(п) = 0 приведет к повышению эффективности перебора в тех случаях, когда желательно получить любой путь к цели (не обязательно имеющий минимальную стоимость). В следующем разделе мы приведем некоторые результаты, противоречащие такого рода интуиции.
Суммируя, отметим, что имеются три важных фактора, влияющих на эвристическую силу алгоритма упорядоченного поиска:
1. Стоимость пути.
2. Число вершин, раскрытых в процессе поиска пути.
3. Объем вычислений, требуемых для подсчета ' значений функции Н.
Выбор соответствующей функции Й позволяет получить для каждой задачи требуемый компромисс между этими тремя факторами, при котором максимизируется эвристическая сила алгоритма.
3.11. ВАЖНАЯ РОЛЬ ФУНКЦИИ g
Во многих задачах нам необходимо просто найти какой-нибудь путь к целевой вершине, а стоимость результирующего пути значения не имеет. (Но, конечно, объем трудностей перебора при нахождении такого пути нас интересует.) В таких случаях можно привести интуитивные соображения как за включение функции g в оценочную функцию, так и за то, чтобы этого не делать.
3.11. Важная роль функции g
81
Интуитивное соображение против включения функции g в оценочную функцию
Если нам требуется найти какой-нибудь путь до цели, то функцию g можно не учитывать, поскольку на любом шаге перебора нам не важны стоимости уже построенных путей. Для нас существенны только те затраты на перебор, которые еще потребуются, прежде чем будет найдена целевая вершина, а они, возможно, и зависят от величин 1г для открытых вершин, но уж заведомо не зависят от значений £ для этих открытых вершин. Следовательно, в таких задачах мы должны бы пользоваться оценочной функцией f = Н.
Интуитивное соображение за включение функции g в оценочную функцию
Даже в том случае, когда не существенно, чтобы найденный путь имел минимальную стоимость, функцию g следует включить в f для того, чтобы быть уверенным, что хотя бы какой-нибудь путь будет в конечном итоге найден. Такой уверенностью необходимо заручаться всегда, когда Н не достаточно хорошая оценка для h, поскольку если всегда раскрываются вершины с минимальным Н, то может случиться так, что в нашем процессе перебора будут все время раскрываться ложные вершины, а целевая вершина достигаться не будет. Включение функции g как бы вносит определенную компоненту полного перебора и гарантирует, что нет такой части у графа, которую процесс перебора постоянно обходит.
Каждое из приведенных соображений представляется разумным, хотя нам кажется, что второе более оправдано логически. В ряде частных случаев второе соображение может быть даже подкреплено соответствующим точным анализом.
, Рассмотрим случай бесконечного графа в форме бесконечного m-арного дерева. (Бесконечное m-арное дерево — это дерево, в котором у каждой вершины имеются в точности т непосредственно следующих за ней вершин.) В этом графе имеется единственная целевая вершина, которая расположена на &-м уровне. Заметим, что цель достижима из любой вершины этого конкретного графа. Пример такого графа приведен на рис. 3.9; стоимости ребер предполагаются единичными.
Предположим, что при переборе на этом графе мы пользуемся следующей функцией /г:
/г(п) = Л(п) + Е для вершин п на кратчайшем пути,
/г(п)= Л(п) — Е для вершин п вне кратчайшего пути.
82
Гл. 3. Методы поиска в пространстве состояний
где Е — некоторая целочисленная ошибка. То есть наша функция И всегда содержит ошибку, величина которой равна некоторому целому Ег).
Кроме того, знак этой ошибки выбран так, чтобы вызвать наибольшие затруднения. Проанализировав самый худший слу-
Р и с. 3.9. Граф, изображающий бесконечное m-арное дерево.
чай, мы покажем, что при такой функции Н перебор с’ функцией f = g + Н более эффективен, чем перебор с функцией f = Н, если только Е > 1.
Мы должны сопоставить следующие два случая:
Случай 1. f = g + /z. Пусть Ns+h—число вершин, которые были раскрыты до достижения цели. Здесь мы обязаны раскрывать вершину, если она расположена в пределах Е единиц от какой-либо вершины на кратчайшем пути. (В духе рассматриваемого нами самого худшего случая мы всегда будем выбирать наихудшую из возможностей, если число вершин равно Е.) Видно тогда, что
Ng+fl = k{l +(m— 1) (число вершин в m-арном дереве
глубиной (F — 1))} = k + (пг —- 1) ] J = kmE.
’) Заметим, что функция К не дает в этом случае нижней границы для Л.
3.12. Использование других эвристик
?3
Случай 2. f = И. Пусть Nh — число вершин, которые были раскр,ыты до достижения цели. Здесь мы обязаны раскрывать вершину, если она расположена -в пределах 2Е—1 единиц от вершины на кратчайшем пути. (Обманчиво перспективные вершины в этом случае заставляют процесс перебора отойти на большее расстояние от кратчайшего пути к цели.) Итак, для Е 1 имеем
{1 +(/п— 1) (число вершин в m-арном дереве.
{Г 2Е-1 __________ ] Т)
1 +(/«—!) j—JJ — km2B-\
(Отдельно можно показать, что Nh = k для Е = 0.)
Мы видим, что Nh больше Ng+h для Е> 1, а это означает, что (для нашего графа) для эффективного перебора необходимо в оценочную функцию включить функцию g. Отношение Ng+h/Nh не зависит от k и дается просто выражением
—у для Е 1.
Хотя в реальных задачах это различие в эффективности может оказаться существенно меньше, наше исследование наихудшего случая показывает, что интуитивное соображение о необходимости включения функции £ в оценочную функцию имеет ощутимую ценность.
3.12. ИСПОЛЬЗОВАНИЕ ДРУГИХ ЭВРИСТИК
Перебор этапами
До сих пор в настоящей главе мы обсуждали вопрос о том, что использование эвристической информации может существенно уменьшить объем перебора, необходимого для пбиска приемлемого пути. Следовательно, ее использование позволяет также осуществлять перебор на гораздо больших графах. И тем не менее могут возникнуть случаи, когда имеющаяся в нашем распоряжении память оказывается исчерпанной раньше, чем будет найден удовлетворительный путь. В этих случаях может быть полезным не отказываться полностью от продолжения перебора, а «отсечь» часть ветвей дерева, построенного к этому моменту в процессе перебора, освободив тем самым пространство памяти, необходимое для углубления перебора.
Такой процесс перебора может осуществляться этапами, которые отделяются друг от друга операциями отсечения дерева, необходимыми для освобождения памяти. В конце каждого этапа удерживается некоторое подмножество открытых вершин,
84
Гл. 3. Методы поиска в пространстве состояний
например вершины с наименьшими значениями Д Наилучшие пути к этим вершинам запоминаются, а остальная часть дерева отбрасывается. Затем начинается перебор снова, уже от этих «лучших» открытых вершин. Этот процесс продолжается до тех пор, пока либо будет найдена целевая вершина, либо будут исчерпаны все ресурсы. Ясно, что даже если на каждом этапе используется алгоритм А*, то хотя весь процесс заканчивается построением некоторого пути, тем не менее у нас нет теперь гарантии, что этот путь будет оптимальным.
Ограничение числа дочерних вершин
Раньше в этой главе было отмечено, что другой путь уменьшения объема перебора состоит в том, чтобы использовать более информированный оператор Г, который не порождал бы слишком много ненужных последующих вершин. В пределе «полностью информированный» оператор Г порождал бы лишь вершины, расположенные на оптимальном пути, снимая тем самым полностью необходимость перебора.
Один из приемов, который может позволить снизить требуемый объем перебора, состоит в том, чтобы сразу же после раскрытия вершины отбросить почти все дочерние вершины, оставив лишь небольшое их число с наименьшими значениями функции f. Конечно, отброшенные вершины могут оказаться расположенными на наилучших (и даже только на наилучших) путях, так что только эксперимент может определить пригодность такого метода отсечения ветвей графа для конкретных задач.
Существуют также задачи перебора, в которых все вершины, непосредственно следующие за некоторой, могут быть перечислены и значения /г для них могут быть подсчитаны еще до построения соответствующих описаний состояний в явной форме. Более того, может оказаться полезным отложить получение описания состояния, связанного с некоторой вершиной, до той поры, когда она сама будет раскрыта. Тогда в нашем процессе никогда не будут строиться излишние дочерние вершины, которые в дальнейшем в ходе процесса так и остались бы не раскрытыми.
Поочередное построение дочерних вершин
Когда вершины, непосредственно следующие за некоторой, вычисляются с помощью операторов в пространстве состояний, то очевидно, что эти последующие вершины могут строиться по отдельности и независимо друг от друга. Кроме того, существуют случаи, когда применение всех применимых операторов было бы очень расточительно в смысле вычислительных затрат. Как указывалось выше, более информированный оператор Г
3.13. Критерии качества работы методов перебора
85
выделял бы несколько наиболее перспективных операторов и строилЛ5ы только те последующие вершины, которые возникают в результате их применения. Более гибкий подход состоит в том, чтобы сначала допускать применение самого перспективного оператора (что приведет к одной последующей вершине), оставляя в дальнейшем возможность в процессе перебора построить и другие вершины, непосредственно следующие за данной. Для того чтобы воспользоваться этой идеей вместе с оценочными функциями для упорядочения вершин, в алгоритм упорядоченного перебора следует внести соответствующие изменения.
3.13. КРИТЕРИИ КАЧЕСТВА РАБОТЫ МЕТОДОВ ПЕРЕБОРА
Эвристическая сила того или иного метода перебора в значительной степени зависит от специфических черт, характерных для данной задачи, и определение этой силы — скорее вопрос опыта,, чем вычислений. Тем не менее существуют некоторые критерии работы, которые могут быть вычислены, и хотя эти критерии не дают исчерпывающей оценки эвристической силы, они оказываются полезными при сравнении различных методов перебора.
Один из таких критериев называется целенаправленностью. Целенаправленность Р перебора позволяет узнать, в какой мере перебор идет в направлении цели, а не ведется по нежелательным направлениям. Она просто определяется как
Р== А
Т ’
где L — длина найденного пути до цели, а Т — общее число вершин, построенных в течение перебора (включая целевую вершину, но исключая начальную вершину). Например, если оператор Г, с помощью которого строятся последующие вершины, настолько точен, что строятся только вершины, лежащие на пути к цели, то для него величина Р достигает своего максимума, равного 1. Перебор в слепую характеризуется малыми величинами Р. Таким образом, целенаправленность показывает, насколько дерево, построенное при переборе, вытянуто, а не кустисто.
'Значения величин целенаправленности для некоторых примеров перебора, использованных в настоящей главе, приведены в табл. 3.1.
Величина целенаправленности перебора зависит как от трудности задачи, для которой производится этот перебор, так и от эффективности метода перебора. Для данного метода перебора целенаправленность может быть велика при коротком оптимальном решающем пути и мала, если этот путь оказывается
86
Гл. 3. Методы поиска в пространстве состояний
длинным. (Как правило, увеличение длины пути решения L приводит к тому, что Т увеличивается еще быстрее.)
Таблица 3.1
Целенаправленность н фактор эффективного ветвления для различных примеров
Игра в восемь 1 Полный перебор Игра в восемь 1 Игра в восемь 2 + P (n) + 3S (д)
Целенаправленность Р 0,108 0,385 0,419
Фактор эффективного ветвления В 1,86 1,34 1,08
Другой критерий — фактор эффективного ветвления В — гораздо меньше зависит от длины оптимального решающего пути. Его определение основано на представлении, о дереве, имеющем глубину, равную длине этого пути, и общее число вершин, равное числу вершин, построенных в процессе перебора, причем у каждой вершины этого дерева имеется в точности В дочерних вершин. Таким образом, В связано с длиной пути L и общим числом построенных вершин Т соотношениями В
В + В2+ ... +BL = T и
-g~~i'(BL— 1) = Т.
Величина В не может быть выписана как явная функция от L и Т, но на рис. 3.10 представлена диаграмма, показывающая зависимость В от Т при различных значениях L. Величина В, близкая к единице, соответствует перебору, который весьма точно направлен прямо к цели и очень мало ответвляется на другие направления. С другой стороны, кустообразный граф перебора характеризуется высоким значением В.
Значения В для наших примеров перебора были вычислены с помощью диаграммы, изображенной на рис. 3.10, и приведены вместе со значениями целенаправленности в табл. 3.1. Целенаправленность связана с В и длиной пути формулой Р = = L(B—{)/B(Bl—1). На рис. 3.11 показано изменение целенаправленности с длиной пути при различных значениях В.
В той мере, в какой В мало зависит от длины пути, эта величина может быть использована для предсказания того, сколько вершин было бы'построено при переборе той или иной длины. Например, из табл. 3.1 видно, что при / = g’ + P + 3S для игры в восемь получается величина В, равная 1,08. Попытаемся
«8
Гл. 3. Методы поиска в пространстве состояний
теперь узнать, как много вершин пришлось бы построить при использовании той же самой функции f, решая более трудную задачу в игре в восемь, требующую, скажем, 30 шагов. Из
Рис. 3.11. Зависимость Р от L для различных значений
рис. 3.10 мы видим, что тридцатишаговая задача, при условии что фактор ветвления остается неизменным, потребовала бы построения около 120 вершин. (Эта оценка, между прочим,- не противоречит экспериментальным результатам Дорана и Мичи (1966), охватывающим больше примеров задач такого типа.)
3.14. БИБЛИОГРАФИЧЕСКИЕ И ИСТОРИЧЕСКИЕ ЗАМЕЧАНИЯ
Алгоритмы поиска кратчайшего пути
Алгоритмы поиска кратчайшего пути (или пути наименьшей стоимости) между двумя вершинами графа представляют большой интерес для широкого круга дисциплин. Процедуру, названную нами методом равных цен, впервые описал Дийкстра (1959). Подобный метод полного перебора предлагался также
3.14. Библиографические и исторические замечания
89
Муром (1959). Алгоритмы динамического программирования Веллмана по существу также являются методами полного перебора. Подробное изложение динамического программирования содержится в книге Веллмана и Дрейфуса (1962). Процедура перебора на заданную глубину часто называется программированием с обратным слежением (back-track programming); она описана Голомбом и Бомертом (1965). Стюарт Дрейфус (1969) дает подробный обзор этих и других методов поиска на графах.
Эвристические приемы поиска
Вопрос использования эвристической информации для увеличения эффективности перебора рассматривался как в области искусственного интеллекта, так и в исследовании операций. Вероятно, самым известным применением эвристических оценочных функций были игровые программы, в особенности программа Сэмюэля (1959, 1967) для игры в шашки. Привлечение оценочных функций для придания направленности перебору на графе было предложено Дораном и Мичи (1966) и в дальнейшем исследовалось Дораном (1968) и Мичи и Россом (1970). Наши примеры игры в восемь основаны на примерах Дорана и Мичи. Общая теория использования оценочных функций для ведения перебора была дана в статье Харта, Нильсона и Рафаэля (1968); приведенное нами описание алгоритма упорядоченного псшска и его свойств базируется на этой статье.
В методах ветвей и границ из области исследования операций мы также находим привлечение оценочных функций для направления перебора к цели. Их описание можно найти в обзорной статье Лолера и Вуда (1966). Метод ветвей и границ,, предложенный Шапиро (1966) для задачи о коммивояжере, может быть также интерпретирован как прямое применение алгоритма А*.
Наш анализ, подтверждающий важность включения функции g (точно так же, как и функции /г) в оценочную функцию, взят из диссертации Поля (1969). (См. также Поль, 1970.) Поль (1969) рассмотрел также проблему построения перебора как из начальной, так и из целевой вершины. В особенности здесь интересно его подробное рассмотрение более сложных критериев остановки, необходимых при двунаправленном переборе.
Прерывание хода процесса перебора этапами отсечения ветвей дерева (для очищения требуемой памяти) было исследовано Дораном и Мичи (1966) и Дораном (1967).
Критерии качества работы
Доран и Мичи (1966) предложили целенаправленность как критерий эффективности данного поиска. Слейджл и Диксон 11969) предложили иную меру, которую они назвали «глубинное
•90
Гл. 3. Методы поиска в пространстве состояний
отношение». Наше «эффективное ветвление» было навеяно этими двумя введенными раньше мерами эффективности.
Задачи
3.1. Рассмотрите представление в пространстве состояний дли задачи о коммивояжере, описанной в разд. 2.6. Предложите по крайней мере две функции Н (Н й 0), являющиеси нижией границей для ft. Какая из этих функций, по вашему мнению, приведет к более эффективному перебору? Примените алгоритм А* с такими функциями к задаче о коммивояжере для 5 городов, которая показана на рис. 2.4.
3.2. На рис. 2.4 укажите, пользуясь подходом, основанным на пространстве состояний, путь максимальной протяженности, который начинается в А, проходит через каждый другой город не более одного раза и возвращается в А. Выберите представление в пространстве состояний и изобразите часть графа в пространстве состояний с вершинами и стоимостями дуг, снабженными соответствующими пометками, и укажите иа этом графе оптимальный путь от начальной вершины к целевой.
3.3. Рассмотрите возможные достоинства следующей стратегии перебора в пространстве состояний: любым удобным методом получить некоторый путь к цели и его стоимость С. Эта стоимость не обязательно минимальна, но она дает некоторую верхнюю границу для минимальной стоимости. Теперь воспользуйтесь алгоритмом А* с некоторой функцией Н, гарантирующей допустимость, 1: сразу же отбросьте те полученные открытые вершины, значения f для которых больше, чем С. Является ли эта модифицированная стратегия допустимой? Означает ли факт возможного отбрасывания некоторых из открытых вершин в этом алгоритме, что число вершин, которые будут раскрыты, может оказаться меньше? Уменьшаются ли при этом требования к памяти в целом?
3.4. Предположим, что ft — нижияя граница для ft. Докажите, что если алгоритм А* когда-либо раскроет вершину, для которой f(n) = f(s), то или вершина п была на оптимальном пути, или непосредственно перед раскрытием в списке ОТКРЫТ и на оптимальном пути была- такая вершина т, что /(«) =f(m) = f(s).
3.5. Пусть «1, п2, • • •, nk — последовательность вершии, раскрытых алгоритмом А*. Докажите, что если ft' удовлетворяет предположению о непротиворечивости (разд. 3.9), то f (nt) /(п<+1) для любого 1 i < k — 1.
*3.6. Используя наиболее развитые представления для задачи, о миссионерах и людоедах, данные Амарелем (1968), напишите программу, которая находит решение с минимальным числом ходов дли любого числа п миссионеров и людоедов и для любой вместимости лодки k.
*3.7. Напишите программу для вычислительной машины, в которой алгоритм А* используется для преобразования произвольного расположения в задаче о скользящих прямоугольниках в конфигурацию вида
г 3 ж 111' 8 9
/ 5 ?
4 £
если такое преобразование возможно в принципе.
Глава 4
ПРЕДСТАВЛЕНИЯ, ДОПУСКАЮЩИЕ СВЕДЕНИЕ ЗАДАЧ К ПОДЗАДАЧАМ
4.1. ПРИМЕР ПРЕДСТАВЛЕНИЯ, ДАЮЩЕГО СВЕДЕНИЕ ЗАДАЧИ
К ПОДЗАДАЧАМ
В этой главе мы исследуем иной подход к решению задач, основанный на сведении задачи к подзадачам. Идея такого подхода состоит «в размышлении в обратном направлении» от задачи, которую предстоит решить, с тем чтобы выделить подзадачи, подподзадачи и т. д., пока, наконец, первоначальная задача не будет сведена к набору тривиальных элементарных задач.
Для того чтобы показать, как можно решать задачу методом сведения к подзадачам, мы воспользуемся еще одной голово-ломкой. Один йз вариантов задачи о пирамидке (ханойской башне) можно сформулировать следующим образом:
Имеется три колышка 1, 2 и 3 и три различных диска А, В и С. У дисков в центре имеется отверстие, так что их можно надевать на колышки. Сначала все диски расположены на первом
Рис. 4.1. Задача о пирамидке (слева — начальное положение, справа — целевое).
колышке, больший диск С внизу, а меньший диск А — вверху. Требуется переместить все диски на третий колышек, двигая их уо очереди. Перемещать можно всегда только верхний диск, причем нельзя никакой диск помещать выше меньшего. Начальное и целевое расположения показаны на рис. 4.1.
Конечно, эта задача может быть решена методами, использующими пространство состояний. Действительно, на рис. 4.2 показано полное пространство состояний для этой задачи1). Граф имеет 27 вершин, каждая из которых представляет одно из допустимых расположений дисков на колышках. Обозначение (ijk) у каждой вершины графа описывает такое состояние,
>) Этот граф был предложен Дж. Маккарти (частное сообщение).
92 Гл. 4. Представления, допускающие сведение задач к подзадачам
когда диск С (наибольший) находится на колышке i, диск В — на колышке /, а диск А (самый маленький)—на колышке k. Если на одном и том же колышке находится более одного диска, то всегда предполагается, что самый большой находится внизу и т. д. Дуги, связывающие между собой пары вершин графа, означают, что некоторый диск может быть, переложен так, что
Р и с. 4.2. Граф для задачи о пирамидке.
конфигураций, представляемая одной из вершин пары, изменится на конфигурацию, представляемую другой вершиной. Например, дуга, идущая от (113) к (123), означает, что (113) можно изменить на (123) посредством перекладывания диска В с колышка 1 на колышек 2. Это действие отражается надписью «Переложить (В, 1,2)» у этой, дуги. (Путь, выделенный жирными линиями на этом графе, представляет собой решение задачи.)
Задачу о пирамидке можно решить также простым методом сведения задачи к подзадачам. Один из путей сведения исходной задачи о пирамидке, изображенной на рис. 4.1, к совокуп
4.1. Пример сведения задачи к подзадачам
93
ности более простых задач связан со следующей цепочкой рассуждений:
1. Для того чтобы переложить все диски на колышек 3, мы, конечно, должны переложить на этот колышек диск С, причем в момент, непосредственно предшествующий перекладыванию диска С на колышек 3, последний должен быть свободным.
2. Теперь, рассматривая исходную конфигурацию, мы видим, что диск С вообще нельзя никуда переложить, пока с этого колышка не будут сняты диски А и В. Кроме того, диски А и В лучше не размещать на колышке 3, так как тогда у нас не буд^т возможности поместить там диск С. Таким образом, прежде всего мы должны перенести диски А и В на колышек 2.
3. Затем можно сделать наш основной шаг, переложив диск С с колышка Г на 3, и перейти к решению оставшейся задачи.
Мы видим, что эти рассуждения позволяют свести исходную задачу к следующим трем задачам:
1. Задача с двумя дисками о перемещении дисков А и В на колышек 2:
2. Задача с одним диском о перемещении диска С на колышек 3:
(/22)
(322)
3. Задача с двумя дисками о перемещении дисков А и В на колышек 3:
(322) ’
. (3W) .
Элементарная Элементарная' Элементарная Элементарная Элементарная Элементарная
Рис. 4.3. Граф подзадач, сводящий задачу о пирамидке к совокупности элементарных одношаговых задач.
4.2. Описание задач
95
Каждая из этих трех полученных задач меньше, а следовательно, и должна быть легче, чем исходная задача. Действительно, задача 2 может рассматриваться как элементарная, так как ее решение состоит ровно из одного хода. Используя подобную цепочку рассуждений, задачи 1 и 3 также можно свести к элементарным, как это схематически изображено на рис. 4.3. (Точно такая же схема сведения задачи к совокупности подзадач может быть применена и в случае, когда начальная конфигурация содержит произвольное число дисков.)
Графовая структура рис. 4.3 носит название «И/ИЛИ» графа (или графа подзадач); она полезна для иллюстрации решений, получаемых методом сведения задачи к подзадачам. В этой и следующей главах мы подробно рассмотрим различные применения метода сведения задачи к подзадачам. Методы сведения задачи к подзадачам нашли применение к широкому кругу проблем, включая задачу получения выражения, которое было бы интегралом от некоторой функции, и задачу доказательства теорем планиметрии. Мы увидим также, что эти методы полностью аналогичны методам, используемым для вычисления наилучшего следующего хода в таких играх, как шашки или шахматы.
4.2. ОПИСАНИЕ ЗАДАЧ
В подходе, основанном на сведении задачи к подзадачам, используются операторы, которые преобразуют описания задач в описания подзадач. Имеется большое число форм описаний задачи. Для этой цели опять могут быть использованы списки, деревья, строки, векторь!, массивы и другие формы. В задаче о пирамидке описание подзадач может быть сделано в виде списка, содержащего два списка. Так, описание задачи [(113), (333)] означает: «Преобразовать расположение (113) в расположение (333)».
Часто удобно описывать задачу на языке элементов представления в пространстве состояний. Мы. видели, что любая задача поиска в пространстве состояний может быть представлена как совокупность трех составляющих:
1. Множество S начальных состояний.
2. Множество F операторов, отображающих описания состояний в описания состояний.
3. Множество G целевых состояний.
Тогда тройка (S, F, G) определяет задачу, и она может быть использована как описание задачи. В задаче о пирамидке мы использовали именно это обозначение, хотя, поскольку множество F операторов в пространстве состояний предполагалось одним и тем же для всех задач, в описаниях задачи оно в явном виде не присутствовало.
S6 Гл. 4. Представления, допускающие сведение задач к подзадачам
После того как задачи и подзадачи описаны в виде троек (S, F, G), естественно рассматривать эти подзадачи как задачи нахождения пути между определенными состояниями-вехами в пространстве состояний. Например, в задаче о пирамидке подзадачи [(111) ф (122)], [(122) ф (322)] и [(322) Ф (333)] определяют такие состояния-вехи (122) и (322), которые обладают тем свойством, что через них пройдет и окончательный решающий путь.
То обстоятельство, что в подходе, связанном с сведением задачи к подзадачам,, используются понятия состояний, операторов и целей при описании подзадач, само по себе еще не озна-' чает, что этот подход и подход с использованием пространства состояний по существу совпадают. На самом деле, как мы уже отмечали, последовательный перебор в пространстве состояний— это тривиальный случай сведения задачи к подзадачам; по этой причине подход, связанный со сведением задачи к совокупности подзадач, можно рассматривать как более общий метод решения, чем последовательный перебор в пространстве состояний. Можно было бы также рассматривать подход, основанный на сведении задачи к подзадачам, просто как способ перечисления отдельных этапов поиска подпутей между предполагаемыми состояниями-вехами в пространстве состояний и управления процессом компоновки подпутей в полные решения.
4.3. ОПЕРАТОРЫ СВЕДЕНИЯ ЗАДАЧИ К ПОДЗАДАЧАМ
Оператор сведения задачи к подзадачам преобразует описание задачи во множество результирующих, или дочерних, описаний задач. Это преобразование таково, что решение всех дочерних задач обеспечивает решение исходной родительской задачи. Когда множество дочерних задач состоит из одного элемента, мы имеем простейший случай замены одной задачи "другой, ей эквивалентной.
Для данного описания задачи может существовать много операторов сведения, каждьГй из которых применим. Применение каждого такого оператора порождает альтернативные множества подзадач. Некоторые из этих подзадач могут оказаться неразрешимыми, так что нам придется перепробовать несколько операторов, чтобы построить такое множество, все члены которого разрешимы. Таким образом, снова возникает задача перебора.
Один класс задач связан с доказательством *) того, что определенные утверждения истинны. Пусть S — утверждение, истин-
') В этой главе наше обсуждение доказательств будет носить совершенно неформальный характер. В последующих главах предмет доказательства и его роль в решении задач будут рассмотрены более строго.
4.4. Описания элементарных задач
97
ность которого мы хотим доказать, а Т — множество посылок, который предполагаются верными. Тогда под S | Т (читается «S при данном Т») мы будем понимать задачу доказательства утверждения S, исходя из посылок Т. Общая схема для сведения к подзадачам задач такого вида, состоит в том, чтобы ввести в исходную задачу новые посылки, а затем сформулировать дополнительные задачи на доказательство этих новых посылок. Так, при редукции задачи S|T мы добавляем, скажем, N посылок и получаем следующее множество результирующих задач:
Sir, х2,..., XN
Xt\T, х2,..., XN
Xn\T
где Xi, Х2, ..., XN — это п добавочных посылок. Часто этот оператор редукции задачи применяется так, чтобы в каждый момент времени добавлялась лишь одна посылка. Тогда S|Г сводится к множеству S[АГ, Т и Х|Т.
Символы посылок Xi, ..., XN можно было бы рассматривать как переменные, принимающие значения из некоторого множества посылок. Тогда каждое возможное значение этих переменных соответствовало бы применению отдельного оператора сведения задачи. Этим переменным могут быть сразу же приданы определенные значения в виде конкретных посылок (содержащих, возможно, новые переменные), но вместо этого их можно оставить в виде переменных, имея в виду, что конкретные значения могут быть им приданы в процессе дальнейшего сведения. Позже мы рассмотрим некоторые из предлагаемых подходов к выбору конкретных значений для посылок. Часто нам будет нужно в качестве частных значений выбрать более чем одно множество посылок, так что наше доказательство может вернуться назад и. пойти по другим альтернативным направлениям.
4.4. ОПИСАНИЯ ЭЛЕМЕНТАРНЫХ ЗАДАЧ
Конечная цель всякого рода сведений задачи к подзадачам состоит в получении таких элементарных задач, решения которых очевидны. Этими задачами могут быть как задачи, решающиеся за один шаг перебора в пространстве состояний, так и другие более сложные задачи, имеющие известные нам решения. Кроме того, что эти элементарные задачи играют очевидную роль в остановке процесса перебора, иногда они используются для ограничения процесса построения альтернативных множеств результирующих -задач в течение процесса сведения
4 Зак. 493
98 Гл. 4. Представления, допускающие сведение задач к подзадачам
задачи. Это ограничение возникает вследствие того, что одна или более из этих результирующих задач оказываются принадлежащими определенному подклассу элементарных задач.
4.5. <И/ИЛИ» ГРАФЫ
Для изображения расчленения задачи на альтернативные множества результирующих задач удобно воспользоваться графоподобной структурой. Так, предположим, что задача А может быть решена либо путем решения задач В и С, либо путем решения задач D и Е, либо путем решения задачи F. Это соотношение изображается структурой иа рис. 4.4. В вершинах структуры указаны те задачи, которые они представляют.
Рис. 4.4. Структура, показывающая различные множества подзадач для А.
Рис. 4.5. «И/ИЛИ» граф.
Задачи В и С составляют одно множество результирующих задач, задачи D и Е — другое, а задача F— третье. Вершины, соответствующие одному множеству, помечены специальным значком, связывающим подходящие к ним дуги.
В структуру обычно вводятся некоторые дополнительные вершины, так чтобы каждое множество, содержащее более одной результирующей задачи, группировалось под своей собственной родительской вершиной. При этом структура на рис. 4.4 преобразуется в структуру, изображенную на рис. 4.5. На этом рисунке добавленные вершины N и М служат отдельными родительскими вершинами для множеств {В, С} и {£>, В} соответственно. Если считать, что вершины N я М играют роль описаний задач, то мы видим, что задача А сведена к одиночным альтернативным подзадачам N, М или F. По этой причине вершины, помеченные N, М и F, называются «ИЛИ» вершинами.
4.5. «И1ИЛИ» графы
99
Задача N сводится к одному множеству подзадач В и С, причем обе они должны быть решены, чтрбы была решена задача М. По этой причине вершины, помеченные В и С, называются «И» вершинами. Вершины типа «И» выделяются отметкой, сделанной на идущих к ним дугах.
Структуры, подобные той, что изображена на рис. 4.5, называются «И/ИЛИ» графами. Если некоторая вершина «И/ИЛИ» графа имеет непосредственно следующие за ней вершины, то либо все они являются «ИЛИ» вершинами, либо все они — «И» вершины. (Если у некоторой вершины имеется ровно одна непосредственно следующая за ней вершина, то ее можно считать как «И» вершиной, так и «ИЛИ» вершиной.)
Заметим, что в частном случае, когда вершин типа «И» вообще нет, мы получаем обычный граф того типа, который появлялся при переборе в пространстве состояний. Но из-за наличия вершин типа «И» в «И/ИЛИ» графах эти структуры существенно отличаются от обычных графовых структур. Для них требуются свои собственные специализированные приемы поиска, что и служит главной причиной, по которой мы делаем различие между двумя подходами к решению задач.
При описании «И/ИЛИ» графов мы будем продолжать пользоваться такими терминами, как родительские вершины, вершины, непосредственно следующие за данной (дочерние), дуга, соединяющая две вершины, и т. д., придавая им очевидный смысл.
На языке «И/ИЛИ» графов применение одиночного оператора сведения задачи к подзадачам к некоторому описанию задачи обычно будет означать, что по очереди сначала будет построена промежуточная «ИЛИ» вершина, а затем непосредственно следующие за ней «И» вершины. (Исключение составляет случай, когда множество подзадач состоит из одного элемента. В этом случае образуется ровно одна вершина, а именно «ИЛИ» вершина.)
Таким образом, подходящей структурой, моделирующей метод расчленения задачи на подзадачи, является граф типа «И/ИЛИ». Одна из вершин этого графа, называемая начальной вершиной, соответствует описанию исходной задачи. Те вершины графа, которые соответствуют описаниям элементарных задач, называются заключительными вершинами.
Цель процесса поиска, осуществляемого иа «И/ИЛИ» графе, — показать, что начальная вершина разрешима. Общее определение разрешимости вершины в «И/ИЛИ» графе можно сформулировать рекурсивно следующим образом:
Заключительные вершины разрешимы (так как они соответствуют элементарным задачам).
Если у вершины, не являющейся заключительной, непосредственно следующие за ней вершины оказались вершинами
л*
100 Гл. 4. Представления, допускающие сведение задач к подзадачам
«ИЛИ», то она разрешима тогда и только тогда, когда разрешима по крайней мере одна из этих вершин.
Если у вершины, не являющейся заключительной, непосредственно следующие за ней вершины оказались вершинами «И», то она разрешима тогда и только тогда, когда разрешима каждая из этих вершин.
Тогда решающий граф определяется как подграф из разрешимых вершин, который показывает (в соответствии с приведенным определением), что начальная вершина разрешима.
в
Рис. 4.6. Некоторые примеры «И/ИЛИ» графов и решающих графов. Для графа (б) имеется более одного решения.
На рис. 4.6 приведены примеры «И/ИЛИ» графов. Заключительные вершины обозначены буквой t, разрешимые вершины изображены черными кружочками, а решающие графы выде* лены жирными линиями.
Если у некоторой вершины «И/ИЛИ» графа, не являющейся заключительной вершиной, вовсе нет следующих за ней вершин, то мы говорим, что такая вершина неразрешима. Появление таких неразрешимых вершин может означать, что и другие вершины графа (и даже начальная вершина) могут оказаться не
4.6. Представление с помощью недетерминированных программ’ 101
разрешимыми. Общее определение неразрешимой вершины дается рекурсивно следующим образом:
Вершины, не являющиеся заключительными и не имеющие следующих за ними вершин, неразрешимы.
Если у вершины, не являющейся заключительной, непосредственно следующие за ней вершины оказались вершинами ' «ИЛИ», то она неразрешима тогда и только тогда, когда неразрешима каждая из этих вершин.
Если у вершины, не являющейся заключительной, непосредственно следующие за ней вершины оказались вершинами «И», то она неразрешима тогда и только тогда, когда неразрешима по крайней мере одна из этих «И» вершин.
На рис. 4.6 неразрешимые вершины отмечены незачерненны-ми кружочками.
Показанные на рис. 4.6 «И/ИЛИ» графы заданы в явной форме. Точно так же, как в случае решения задач в пространстве состояний, редко .случается, чтобы граф, на котором должен осуществляться перебор, задавался в явной форме. Как правило, такой граф определен неявно посредством описания исходной задачи и операторов редукции задачи. Удобно ввести оператор Г построения непосредственно следующих (дочерних) вершин, который, будучи примененным к описанию задачи, порождает все множества следующих из него описаний задач. (Применение оператора Г означает применение всех применимых операторов сведения задачи к подзадачам.) Так, в случае рис. 4.5 применение оператора Г к алгоритму А образует всю ту структуру «И/ИЛИ» графа, которая изображена на рисунке.
Процесс решения задачи тогда состоит в том, чтобы построить достаточную часть этого «И/ИЛИ» графа, из которой было бы видно, что начальная вершина разрешима. Мы отложим до следующей главы рассмотрение эффективных методов поиска.
4.6. ПРЕДСТАВЛЕНИЕ «И/ИЛИ» ГРАФОВ С ПОМОЩЬЮ НЕДЕТЕРМИНИРОВАННЫХ ПРОГРАММ1)
Мы можем ввести некоторые дополнительные элементы недетерминированных программ, с тем чтобы эти программы можно было использовать для представления процесса построения «И/ИЛИ» графа. По аналогии с оператором присваивания ВЫБОР (в котором программная переменная принимается равной любому элементу некоторого множества) мы можем определить оператор присваивания ВСЕ. В последнем программная переменная принимается равной всем элементам некоторого
') При первом чтении этот раздел можно опустить.
102 Гл. 4. Представления, допускающие сведение задач к подзадачам
множества. (Представьте себе, что вычисление после оператора ВСЕ разветвляется на множество фиктивных параллельных про? цессов, в каждом из которых в качестве значения программной переменной берется своя величина.)
Рис. 4.7. Недетерминированная программа, определяющая «И/ИЛИ» граф.
ИСХОДНОЕ ПОЛОЖЕНИЕ: Программная переменная у (принимающая значения из области описаний задач) полагается равной входной структуре данных х, описывающей задачу.
ВЫБОР: Значение программной переменной Y (принимающей значения нз области множеств описаний задач) полагается равным некоторому элементу множества Г (у) множеств дочерних вершин для прежнего значения у. ВСЕ: Новое значение у принимается равным всем элементам множества Y.
На рис. 4.7 изображена блок-схема недетерминированной программы, определяющей «И/ИЛИ» граф. Для простоты здесь опущены условия окончания, но они состояли бы в.совершенно очевидных проверках, разрешимы вершины или неразрешимы.
В общем случае оператор ВСЕ обозначается на блок-схемах следующим образом:
I
у - ВСЕ (Г(я,у)}
I
Структура данных х служит входом «в эту программу, структура данных у — программной переменной, а функция F представляет собой функцию, отображающую прямое произведение областей изменения х и у в некоторое подмножество области изменения у. Снова для обозначения этого подмножества мы будем пользоваться символом {Е}; операция у-«-ВСЕ {Е} делает
4.6. П редставление с помощью недетерминированных программ" 103
новые значения программной переменной у равными всем членам множества {F}.
Мы также вводим обозначение Л-ветвления. Это ветвление на п направлений, в котором используется п предикатов Pi(x,у), рп(х,у). Эти предикаты имеют значение Т (истина) или F (ложь) на той области, которая является прямым произведением областей изменения х и у. (Снова х — входная структура данных, а у — программная переменная.) Значение хотя бы одного из этих предикатов должно быть Т. Каждый предикат соответствует некоторой ветви, и выбираются все те ветви, соответствующие предикаты которых имеют значения Т. (Представьте себе опять фиктивные параллельные процессоры, начинающие работать на каждой из выбранных ветвей.) На блок-схемах Л-ветвления изображаются так:
И опять, обычные детерминированные ветвления являются частными случаями Л-ветвлений. Точно так же, когда значением функции 7г(х, у) является один элемент, операторы ВЫБОР, ВСЕ и обычные детерминированные операторы совпадают.
При конкретном осуществлении недетерминированной программы делается один определенный выбор в V-ветвлениях и операторах ВЫБОР и производятся все возможные выборы в Л-вет-влениях и операторах ВСЕ. Множество всех возможных конкретных реализаций определяет некоторое «И/ИЛИ» дерево. В данной реализации содержится много путей (ветвления на А-ветвлениях и операторах ВСЕ). Ее выполнение завершается, если завершается каждый из ее путей. Если для любого входа существует по крайней мере одна завершающая реализация, то говорят, что эта программа правильно определена.
Использование всех этих недетерминированных (и детерминированных) элементов дает возможность применять для описания задач недетерминированные программы. Как пример рассмотрим задачу, о восьми ферзях. В этой задаче требуется на обычной шахматной доске расставить восемь ферзей так, чтобы ни один из них не находился под ударом других ферзей. Недетерминированная блок-схема программы для этой задачи показана на рис. 4.8. На этой блок-схеме rt и представляют собой
104 Гл. 4. Представления, допускающие сведение задач к подзадачам
координаты z-го ферзя по горизонтали и по вертикали соответ-
Р и с. 4.8. Недетерминированная
программа для задачи о восьми ферзях.
ственно. Предикат «побить ((п, Ci), (rj, cj))» имеет значение Т лишь тогда, когда i-й ферзь с координатами (г,-, Ci) может по* бить /-го ферзя с координатами (r^Cj).
4.7. Примеры сведения задачи к совокупности подзадач
105
4.7. ПРИМЕРЫ СВЕДЕНИЯ, ЗАДАЧИ К СОВОКУПНОСТИ ПОДЗАДАЧ Задача Символического интегрирования
В задаче символического интегрирования мы хотим иметь автоматический процесс, который будет воспринимать в качестве входной величины любой неопределенный интеграл, скажем J xsin3xdx, и выдавать на выходе ответ: (l/9)sin3x — — (l/3x)cos3x. Мы будем считать, что в нашем распоряжении имеется таблица таких простых интегралов, как
J«d«=-^-, J sin и du = — cos и, J audu — au logae и т. д.
Тогда любая задача символического интегрирования может быть представлена как задача преобразования данного интеграла в выражения, содержащие лишь табличные интегралы. Для простоты мы будем описывать задачу интегрирования функции 7(х) по к выражением J I(x)dx.
Описания элементарных задач даются просто табличными интегралами. Мы видим, что каждая из формул на самом деле является схемой, определяющей бесконечное множество элементарных задач. Члены этого множества получаются путем подстановки выражений вместо переменных, содержащихся в этих формулах. Для того чтобы определить, является ли данный интеграл примером некоторой элементарной формулы, нужно применить оператор сведения, который отыскивает те подстановки, после которых интеграл и формула совпадают.
Операторы сведения задачи к подзадачам могут быть основаны на правиле интегрирования по частям, на правиле интегрирования суммы функций и других правилах преобразования, таких, как правила, содержащие алгебраические и тригонометрические подстановки. Правило интегрирования по частям имеет вид
udv — u dv — Jo du.
Это правило мы можем использовать для оправдания следующего сведения задачи к подзадачам:
106 Гл. 4. Представления, допускающие сведение задач к подзадачам
Заметим, что это сведение означает всего лишь, что задача J и dv может быть решена, если мы можем решить задачи J dv и jo du. Соотношение J и dv = и J dv — J v du может быть в дальнейшем использовано для построения действительного решения. Если имеется несколько возможных способов разбиения исходного подинтегрального выражения на части, соответствующие и и dv, то каждой такой возможности ставится в соответствие отдельный оператор редукции задачи.
Согласно правилу интегрирования суммы функций, имеем
п п
ft (х) dx = J fi(x)dx. i-=l i=l
Это правило служит оправданием следующего сведения задачи к подзадачам:
Другое правило, называемое правилом вынесения постоянного множителя за знак интеграла, позволяет заменить задачу J kf(x) dx задачей Таким образом, получаем такой
сведение задачи
Jkf(x) dx
I ff(x) dx
Остальные . операторы просто осуществляют подстановку одного интегрального выражения в другое и, таким образом, порождают «ИЛИ» вершины. Эти операторы основаны на еле-» дующих процессах:
4.7. Примеры сведения задачи к совокупности подзадач 107
Алгебраические подстановки
Пример
f f l(2e-4z3 + 4)dz, z2 = (2 + Зх)2/3,
J (2 + Зх)2/3 J 9
Тригонометрические подстановки
Пример
f---? -► f 4г ctg 0 cosec 0 d0, x = 4 tg 0.
J x2 /25x2 + 16 J 16 s 5 s
Деление числителя на знаменатель
Пример
J z2+1 I (г2 — 1 + 1 + г2) dz‘
Дополнение до полного квадрата
Пример r dx Г dx
J (х2 - 4х + 13)2 J [(х - 2)2 + 9J2 *
На каждой данной стадии процесса мы располагаем многими альтернативными операторами редукции задачи, которые могли бы быть применены. Если для каждой задачи мы будем использовать все эти приложимые альтернативы, то результирующая задача перебора очень быстро станет невообразимо громоздкой. В такого типа задачах весьма существенно привлечь эвристические соображения, которые позволили бы ограничить число порождаемых вершин.
В указанной задаче интегрирования некоторые операторы редукции оказываются настолько полезными, что они (н только они) должны быть использованы во всех случаях, когда они применимы. Так, сведения задачи, соответствующие интегрированию суммы и вынесению множителя, используются всегда, когда это оказывается возможным.
Полезность других правил и операторов, таких, как тригонометрические подстановки, сильно зависит от вида подинтегрального выражения. В одной системе символического интегрирования (Слейджл, 1963а), для которой была написана программа, все подинтегральные выражения были подвергнуты классификации по тем характеристикам, которыми они обладают. Для каждого класса подинтегральных выражений выбирались различные операторы в соответствии с их эвристической применимостью.
Пример решения. На рис. 4.9 показан «И/ИЛИ» граф перебора, образованный в результате процесса, подобного
108 Гл. 4. П редставления, допускающие сведение задач к подзадачам
рассмотренному выше1)- Задача состоит в интегрировании выражения
J (1 _ ,2)5/2 dX-
Вершины графа — это описания задач, и в каждой из них указан интеграл. Заключительные вершины (соответствующие
Рис. 4.9. «И/ИЛИ» граф перебора для задачи интегрирования.
табличным интегралам) помечены двойными рамочками. Жирными дугами выделен решающий граф для этой задачи. На
*) Пример основан на одной задаче интегрирования, которая была решена программой Слейджла (1963а).
4.7. Примеры сведения задачи к совокупности подзадач 109
основании этого решающего графа и табличных интегралов устанавливаем, что
х4
(1 —х2)5/2
dx = arc sin х + -g- tg3 (arc sin x) — tg (arc sin x)3.
До настоящего момента мы, конечно, не говорили ничего о порядке, в котором производится сведение задачи к подзадачам. Этот вопрос будет освещен в следующей главе, в которой рассматриваются методы перебора при сведении задач к совокупности подзадач.
Доказательство теорем в планиметрии
пример
Доказательства теорем в планиметрии дают другой задач, которые могут быть решены путем сведения к подзадачам. Предположим, например, что нам нужно доказать следующую теорему: любая точка биссектрисы угла равноудалена от его сторон. Пусть задача сформулирована в следующем виде:
Дано: /.DBA = Z.DBC, ADA. В A, CD А. ВС, где DB — отрезок, A BCD— треугольник, ABAD — треугольник.
Требуется доказать: AD = = CD. Читатель решения титься к чертеж, задаче. (Позже мы обсудим, каким образом система решения задач также может воспользоваться «чертежом».)
Мы будем представлять такого типа задачи в виде выражения, имеющего форму S| Т, где предстоит доказать, а Т — множество посылок. Тогда наш при-
(но не наша система задач) может обра-рис. 4.10, где приведен соответствующий этой
Р н с. 4.10. Чертеж к рассматри ваемому примеру геометрической теоремы.
Дано: ZABD=^CBD, AD ± ВА, CD ± ВС.
Доказать: AD = CD.
S — то утверждение, которое
мер описывается следующим выражением:
AD = CD Z DBA = Z DBC, AD 1 BA, CD 1 BC, DB,
Д BCD, ABAD.
Элементарными задачами являются задачи доказательства утверждений, относительно которых мы хотим предположить,
110 Гл. 4. Представления, допускающие сведение задач к подзадачам
что они истинны. Например, в список элементарных задач мы могли бы включить среди других следующие задачи4):
Pl ХХ,= ХХ2\ХХ,— прямой угол, ZX2— прямой угол (прямые углы равны между собой);
Р2 XiX2 = XiX2
(отрезок равен самому себе);
РЗ XX, = XX, (угол равен самому себе);
Р4 ДадЛ Arty2y31 ХзХ, = Y3Y,, ХХ3Х,Х2= X Y3Y,Y2, lxx,x2x3= XY,Y2Y3
(сторона, угол, угол = сторона, угол, угол);
Р5 XXtXzXs — прямой | Х,Х2 ± XzX3
(два пересекающихся перпендикулярных отрезка определяют прямой угол);
Р6 ХЛ == У2Г31 ЛХ,Х2Х3 & A Y,Y2Y3 (соответственные стороны равных треугольников равны).
В достаточно сильной программе доказательства геометрических теорем, конечно, следовало бы использовать множество других более элементарных формул. Приведенных же нами формул достаточно для иллюстрации процесса доказательства нашей теоремы.
Чтобы свести задачу к подзадачам, мы введем достаточное число новых посылок с целью сделать данную задачу частным случаем некоторого истинного утверждения. Множество истинных утверждений, пригодных для этого, могло бы быть некоторым подмножеством элементарных задач. Получаемыми при этом подзадачами будут задачи доказательства новых посылок (при условии, конечно, что даны старые посылки). Чтобы сократить число различных множеств подзадач, мы потребуем, чтобы в этих дополнительных посылках упоминались только те элементы, которые уже встречались в первоначальных .посылках. Поскольку, как правило, будет существовать большое число новых посылок, удовлетворяющих этим условиям, то у нас все-таки будет очень большое число различных множеств подзадач. Каждое из них соответствует применению отдельного оператора редукции задачи.
Покажем, каким образом довольно простая система доказательства геометрических теорем могла бы доказать ту теорему, которая была сформулирована в начале раздела. В этом примере мы будем использовать в качестве элементарных задач только множество {Р1, ..., Р6}, упомянутое выше. Когда мы будем добавлять посылки с тем, чтобы сделать’ некоторое утверждение истинным, мы будем также считать, что лишь чле-
’) Как и в примере с интегрированием, выражения элементарных задач определяются формулами.
4.7. Примеры сведения задачи к совокупности подзадач'
111
ны указанного множества соответствуют истинным утверждения м.'
Сначала мы расчленим на 'подзадачи основную задачу AD = CD\T (где через Т мы для простоты обозначили множество всех посылок). Единственной элементарной задачей, которая может быть использована для этого путем добавления посылок к Т, является Р6:
Х2Х3 = Y2Y31А ВДХз ~ A YtY2Y3.
Для того чтобы эта задача нам пригодилась, нужно положить
Х2 = А, X3 = D, Y2 = C, Y3 = D,
так что нам нужна посылка вида AX,AD АУ(С£>. Так как в Т упоминаются только треугольники ABCD и АВЛД, то полагаем Xi — В и У; = В. Таким образом, мы сводим нашу первоначальную задачу к задаче
ABAD^ A BCD\T.
В результате редукции этой задачи (путем добавления посылок, согласующихся с Р4) возникает такое множество подзадач:
DB = DB\T, Z BAD= Z BCD, Z BAD=> Z BCD\T.
Продолжая аналогичным образом этот процесс, мы приходим к решающему графу типа «И/ИЛИ», изображенному на рис. 4.11. Из-за ограниченности запаса элементарных задач (хорошо соответствующих нашему примеру, но недостаточных в общем случае) в этом процессе не возникает никаких лишних множеств вершин типа «И». Читатель мог бы посмотреть, к чему привело бы добавление еще нескольких элементарных задач, таких, как
A XjX2X3 ~ А У,У2У3
X,X2 = YtY2, X ВДХ3 = Z У1У2У3, 72У3 — У2У3 (сторона-угол-сторона).
Важным средством контроля числа порождаемых вершин в «И/ИЛИ» графах служит использование моделей. Под моделью мы здесь понимаем некоторую конкретную интерпретацию общего логического утверждения. Утверждения, которые нам предстоит доказать, часто представляют собой общие утверждения, охватывающие большое число частных случаев. Любой из этих частных случаев мог бы использоваться в качестве модели общего утверждения. Если это общее утверждение в действительности можно доказать, то тем более любой частный случай, очевидно, будет истинным в соответствующей модели.
В качестве примера рассмотрим только что доказанную теорему:
AD = CD Z DBA = Z DBC, AD 1 BA, CD _L BC,
DB, A BCD, ABAD.
112 Гл. 4. Представления, допускающие сведение задач к подзадачам
Эту задачу можно представлять себе как задачу, содержащую определенное утверждение, которое может быть формально доказано посредством некоторого абстрактного процесса манипулирования с символами, использующего чисто синтаксические правила сведения задачи к совокупности подзадач. В то же время мы можем интерпретировать ее как некоторое осмысленное утверждение о реальных точках, отрезках и т. п. на плоскости. С точки зрения семантики в этом утверждении говорится,
Частный случай Р5 Частный случай Р5
Рис. 4.11. «И/ИЛИ» решающий граф для рассматриваемого доказательства теоремы.
что независимо от действительного расположения этих точек на плоскости, до тех пор пока справедливы указанные посылки, длина отрезка AD всегда будет равна длине отрезка CD. То есть мы на самом деле могли бы измерить длины этих отрезков и убедиться, что они равны. Конечно, прежде чем мы получим возможность что-то измерять, мы должны взять некоторый частный случай этих посылок и указать реальное расположение этих точек и отрезков так, как это было сделано при построении рис. 4.10. Такой частный пример и служит моделью нашего утверждения.
Конечно, если утверждение вообще доказуемо, то его интерпретация на данной модели должна быть истинной. И обратно, если будет установлено, что некоторая интерпретация в некоторой модели не является истинной, то очевидно, что- это утвер
4.7. Примеры сведения задачи к совокупности подзадач ИЗ
ждение не может быть доказано. Использование модели как «меры»' недоказуемости тех или иных возможных утверждений часто может привести к исключению из рассмотрения большого числа бесполезных порождаемых вершин графа.
Проиллюстрируем использование модели для задачи
АВ = ВС BD = AB, £ BDC — £ DCB, ВС, DC CD, AD, &DAB, A DBC.
Мы предполагаем, что программа доказательства теорем имеет доступ к чертежу на рис. 4.12. Эту задачу следовало бы решать прямым путем посредством введения посылки ВС — BD
Рис. 4.12. Чертеж для геометрической задачи. Дано: BD = АВ, Z BDC = Z DCB.
Д DAB, 7\DBC.
Доказать: АВ = ВС.
и формулировки подзадачи доказательства этой посылки. Но прежде чем будет получено решение, в простом устройстве доказательства теорем будет введена также посылка £JDAB^£\DBC и сформулирована задача ее доказательства. Очевидно, что равенство ADAB &.DBC не может быть доказано из этих посылок. Проводя несложные подсчеты на этом чертеже (рис. 4.12), решатель этой задачи мог бы легко установить, что треугольники ADAB и ADBC модели не равны друг другу, и таким путем выяснить, что подзадача AZX4B &.DBC неразрешима. После этого данную подзадачу можно было бы изъять из списка «перспективных» вершин.
Обычно программу доказательства теорем нетрудно снабдить моделью. Для геометрических теорем такой моделью мог бы быть чертеж, построенный по имеющимся посылкам и соответствующим образом представленный в виде списка координат, линий, отрезков и т. д., на основании которого могли быть
114 Гл. 4. Представления, допускающие сведение задач к подзадачам
сделаны измерения с привлечением, скажем, аналитической геометрии. При этом нужно позаботиться о том, чтобы расположение выбранных точек было наиболее общим, не допускающим появления случайных совпадений, параллельностей и т. д. Заметим, что если совпадения все же имеются или оказались неточными измерения, произведенные на чертеже, то нужно, чтобы устройство доказательства теорем, использующее этот чертеж, не могло бы даже и тогда получить доказательство для недоказуемого утверждения. (Чертежные ошибки могли бы привести к попыткам доказать недоказуемые утверждения. Однако, они, очевидно, будут безуспешными.) Ошибки могут привести также
Рис. 4.13. Пример, требующий построения вспомогательного отрезка. Дано: ВС || AD, ВС = AD. Доказать: АВ = CD.
к отбрасыванию ключевых доказуемых утверждений, в результате чего доказательство может получиться более длинным, а может и не быть найдено вовсе.
Обычно эти осложнения удается предусмотреть и в результате получить значительное возрастание эффективности поиска решения при использовании чертежа. Гелернтер и др. (1960) показали, что использование чертежа в программе -доказательства геометрических теорем уменьшает в среднем число дочерних вершин с 1000 до 5 на одну родительскую вершину.
В программе Гелернтера имелась также возможность добавлять некоторые вспомогательные линии к имеющемуся чертежу. Рассмотрим, например, следующую задачу:
AB = CD
ABCD — четырехугольник, отрезок ВС параллелен отрезку AD, BC — AD, АВ, CD.
Устройство доказательства теорем может обращаться к чертежу на рис. 4.13.
При попытке построить вершины, следующие за начальной вершиной, путем добавления посылок, наше устройство доказательства теорем не может, к сожалению, сделать попытку применить такую элементарную задачу, как АВ — CD\&ABD = /\BDC, поскольку треугольники &.ABD и &BDC не упоми
4.8. Механизмы планирования при сведении задач к подзадачам 115
наются в наших посылках. Предположим, что вообще не удается найти никаких последующих вершин. Тогда при отсутствии альтернативных подзадач, с которыми в этом случае можно работать, наше устройство вновь обратится к тем элементарным задачам, относительно которых прежде было принято считать, что они неприменимы, поскольку они содержат элементы, не упомянутые в посылках. В случае использования АВ = = CD\ AABD 04 &BDC порождается следующая «И/ИЛИ» графовая структура ниже начальной вершины:
Задачи и т. д. и /\BDC\ и т. д. берутся в качестве
элементарных (три точки определяют треугольник). Результат этой операции равносилен построению на чертеже отрезка BD, образующего на нем два треугольника. После такого построения доказательство может быть продолжено обычным образом.
4.8. МЕХАНИЗМЫ ПЛАНИРОВАНИЯ ПРИ СВЕДЕНИИ ЗАДАЧ
К ПОДЗАДАЧАМ
В настоящем разделе мы опишем один метод сведения задачи к совокупности подзадач, при котором задачи поиска в пространстве состояний сводятся последовательно к все более и более простым, которые могут быть решены тривиально. Кроме того, этот процесс сведения задач направляется одним из типов механизма планирования, играющим весьма важную роль в искусственном интеллекте.
Предположим, что задачу поиска в пространстве состояний, определяемую тройкой (S, F, G), нам нужно свести к совокупности более простых задач поиска в пространстве состояний. Если бы мы могли выделить последовательность соответствующих «основных промежуточных состояний» ‘) gi, g2, .... gN, то мы получили бы возможность свести первоначальную задачу к множеству задач, определяемых тройками (S, F, {gi}),
)' В оригинале milestones — «километровые столбы». — Прим. ред.
116 Гл. 4. Представления, допускающие сведение задач к подзадачам
({gi},F, {g2}), • ••> ({£n},F,G). Решение всех этих задач эквивалентно решению первоначальной задачи.
Если эти основные промежуточные состояния gt, gz, , gx определяются явно, то безразлично, в каком порядке решаются результирующие задачи. Иногда, однако, нам удается определить множество Gi состояний, каждое из которых могло бы служить в качестве первого основного промежуточного состояния, множество Gz состояний, каждое из которых могло бы служить в качестве второго, и т. д. Тогда задача, описываемая тройкой {S, F, GJ, должна быть решена в первую очередь, чтобы можно было найти конкретное состояние gi е Gt прежде, чем будет сформулирована следующая задача ({gi}, F, G2), и т. д. В следующем разделе мы опишем интересный прием нахождения этих множеств основных промежуточных состояний.
4.9. КЛЮЧЕВЫЕ ОПЕРАТОРЫ
Во многих задачах поиска в пространстве состояний нетрудно сообразить, как выделить по крайней мере один оператор в пространстве состояний, который будет находиться где-то в решающей цепочке операторов. То есть, хотя задача нахождения всей цепочки операторов в решении достаточно трудна, задача выделения одного из них часто оказывается легкой. С возможностью выделения одного такого оператора мы сталкиваемся тогда, когда по характеру задачи применение одного из операторов рассматривается как необходимый шаг решения задачи. (На графах в пространстве состояний применение такого оператора соответствует проведению дуги, связывающей две практически отдельные части графа.) Например, в рассмотренной задаче ю пирамидке оператор «переложить диск С на колышек 3» может быть выделен как оператор, совершенно необходимый при решении задачи (см. рис. 4.2). Мы будем называть операторы такого рода ключевыми операторами.
Когда удается найти ключевой оператор, его можно использовать для определения некоторого основного промежуточного состояния в нашем процессе сведения задачи. Предположим, что некоторый f из F — ключевой оператор для задачи, задаваемой тройкой (S, F, G). Так как мы предполагаем, что оператор f должен быть применен, то первой задачей, следующей из (S, F, G), будет задача поиска пути к некоторому состоянию, к которому f применим. Пусть Gf представляет собой множество состояний, к которым применим f. Тогда мы имеем подзадачу, описываемую тройкой (S, F, Gf). Как только такая подзадача решена и названо состояние g е Gf, мы можем сформулировать элементарную задачу ({g}, F,{f(g)}), где f(g) — состояние, достигающееся после применения оператора f к состоянию g. Эта задача элементарная, так как она решается просто
4.10. Различия
117
путем применения ключевого оператора f. У нас остается теперь задача, описываемая тройкой ({f(g)}, F, G).
Таким образом, когда может'быть найден ключевой оператор f в пространстве состояний, можно воспользоваться следующим способом редукции задачи:
(Мы упростили эту схему, не указав на ней элементарной подзадачи ({g}, F, {f(g)}).) Эти две результирующие задачи могут быть в дальнейшем решены либо путем непосредственного перебора в пространстве состояний, либо путем дальнейшего их сведения. Если наша стратегия состоит в том, чтобы прибегнуть к дальнейшему сведению задач к подзадачам, то нам нужно определить некоторый ключевой оператор для задачи (S, F, Gf) и т. д.
В большинстве задач нам не удается всегда выделить единственный ключевой оператор, про который заведомо известно, что применение его совершенно необходимо при решении задачи. Вместо этого нам удается лишь указать некоторое подмножество операторов, таких, что один из них с достаточно высокой степенью правдоподобия является таким существенным оператором. Каждый оператор из э!ого подмножества образует пару результирующих подзадач. Процесс перебора, опирающийся на эту идею, приводил бы к построению графа «И/ИЛИ» при поиске решения среди различных альтернатив.
Прежде чем у нас возникнет возможность применить этот метод, следует для любой задачи поиска в пространстве состояний указать некоторый способ построения множества операторов, которые могут быть кандидатами в ключевые. В следующем разделе мы опишем один конкретный метод, основанный на различиях (differences).
4.10. РАЗЛИЧИЯ
Один из способов нахождения операторов, которые предположительно могут быть ключевыми, состоит в вычислении различия для данной задачи (S, F, G). Попросту говоря, различие для тройки (S, F, G) это есть частичный список причин, по которым элементы множества S не удовлетворяют тем условиям, которым должны удовлетворять целевые состояния (множество 6). (Если некоторый элемент множества S находится в G, то
118 Гл. 4. Представления, допускающие сведение задач к подзадачам
наша задача решена и никакого различия нет.) Например, если множество целевых состояний G определяется некоторой группой условий, налагаемых на состояния, и если некоторый элемент s eS удовлетворяет части, но не всем этим условиям, то различием может служить частичный перечень тех условий, которым элемент s не удовлетворяет. Если эти условия могут быть расположены в порядке их важности, то в качестве различия можно было бы выбрать просто самое важное из них.
Далее, каждому возможному различию мы ставим в соответствие некоторый оператор (или множество операторов) в пространстве состояний. Это и есть операторы, которые могут быть ключевыми. Некоторый оператор ставится в соответствие различию только в том случае, когда его применение может устранить это различие. Проиллюстрируем работу этого процесса применительно к задаче об обезьяне и бананах.
Эта задача обсуждалась нами в гл. 2 в связи с использованием схем описаний состояний. Напомним, что эти схемы имели форму (w, х, у, г), где w — положение обезьяны в горизонтальной плоскости (двумерный вектор); х равен 1 или 0 в зависимости от того, находится обезьяна на ящике или нет соответственно; у — положение ящика в горизонтальной плоскости (двумерный вектор); z равен 1 или 0 в зависимости от того, получает обезьяна бананы или нет соответственно.
Имеются четыре оператора, действия и условия применимости которых даются следующими правилами переписывания:
ft (w, 0, у, z)-------► (и, 0, у, г),
f2 (w, 0, w, г)----------> (v, 0, v, z),
i ! п \ взобраться
/з (w, О, W, Z)------->(w, 1, w, z),
/4(с, 1, c,.O)-----*(c, 1, c, 1),
где c — точка пола, расположенная прямо под бананами.
Условие выполнения поставленной цели выполняется для описаний состояний лишь в том случае, когда последний элемент в этой схеме описания состояния равен 1. Начальное состояние дается списком (а, О, Ь, 0).
Если F — {fi,fz, fa, fi} — множество из четырех операторов, а G — множество целевых состояний, то наша исходная задача принимает вид
({(а, 0, Ь, 0)}, F, О).
Так как в этой задаче множество операторов остается неизменным, то символ F можно опустить и обозначить всю задачу про, сто как ({(а, 0, Ь, 0)}, G).
4.10. Различия
119
Теперь процедура сведения задачи к совокупности подзадач с использованием понятия ключевых операторов может быть описана следующим образом:
Прежде всего вычисляем различие для исходной задачи. Для списка (а, О, Ь, 0) мы получаем, что он не удовлетворяет поставленной цели, так как последний элемент в нем не равен 1. Ключевой оператор (ответственный за уменьшение этого различия — это оператор f4 «схватить».
(Мы предполагаем, что связи между возможными различиями и их ключевыми операторами заданы решателю задач с самого начала.)
Используя оператор ft для сведения иервоначальной задачи, мы приходим к следующей паре подзадач:
({(а, 0, Ь, 0)), Gh) и (tf< (S1)}, G),
где Gf, — множество описаний состояний, к которым применим оператор ft (описания состояний из области определения оператора ft), а «1 —состояние в Gf„ получаемое в результате решения подзадачи.
Так как прежде всего мы должны решить первую задачу из указанной пары, то применим к ней ту же самую процедуру. Сначала вычислим различие. Состояние, описываемое четверкой (а, 0, Ь, 0), не входит в Gf, по той причине, что
Ящик не находится в точке с.
Обезьяна не находится в точке с.
Обезьяна не на ящике.
Если теперь этот список утверждений взять в качестве различия, то мы выделяем следующие ключевые операторы:
f2 — передвинуть (с), fi — подойти (с), f3— взобраться.
Далее мы по очереди применяем каждый из этих ключевых операторов, с тем чтобы построить альтернативные пары результирующих задач. Первый из ключевых операторов используется для сведения задачи ({а, 0, Ь, 0), Gf,) к такой паре задач:
(1.1) ({(а, 0, Ь, 0)), Gf2),
(-1.2) ({f2(sn)}, Gf.),
где Sj[ е Gf2 получается в результате решения задачи 1.1.
Так как сначала необходимо решить задачу 1.1, то мы вычисляем, ее различие.
Обезьяны нет в точке Ь.
Зммеитарная Элементарная Элементарная Элементарная
Рис. 4.14. <И/ИЛИ» граф для задачи об обезьяне и бананах.
4.11. Пространства состояний высшего уровня
121’
Это различие дает нам ключевой оператор
ft — подойти (Ь).
Затем этот ключевой оператор используется для разбиения задачи ({(а, О, Ь, 0)}, Gf,) на две:
(1.11) ({а, 0, Ь, 0}, Gf,),
(1.12) ({Л(5111)},0ь)..
Первая из этих задач элементарная; для нее различие равно' нулю, поскольку (а, 0, Ь, 0) находится в области определения оператора ft. Следовательно, можно начать работать с задачей 1.12. Продолжим наше описание процесса еще на один шаг вперед. Мы видим теперь, что есть (Ь, 0, Ь, 0), так что задача 1.12 превращается в задачу
({Ь, 0, Ь, 0), Gf2).
Эта задача также элементарная, поскольку (Ь, 0, Ь, 0) находится в области определения оператора fz. Такой процесс завершения решений задач, построенных ранее, продолжается до тех пор, пока не будет решена исходная задача.
На рис. 4.14 изображен граф типа «И/ИЛИ», дающий дерево решения для этой задачи. Числа около вершин графа показывают порядок, в котором исследовались различные задачи в ходе описанного процесса перебора. Оказалось, что рассмотренный нами порядок привел к решению еще до того, как были подвергнуты изучению незанумерованные задачи, но в общем случае мог потребоваться дополнительный перебор. Анализируя граф решения на рис. 4.14, нетрудно построить последовательность операторов, решающую исходную задачу:
(подойти (Ь), передвинуть (с), взобраться, схватить).
В методе, использующем ключевые операторы, задача расщепляется на части с последующим уменьшением объема необходимых поисковых усилий. (Пространство перебора в задаче об обезьяне и бананах настолько мало, однако, что в этом случае использование ключевых операторов не дало заметного увеличения эффективности.) Для того же, чтобы воспользоваться ключевыми операторами, решателю задач должна быть сообщена процедура вычисления различий и процедура, позволяющая связывать с ними ключевые операторы. Возможность установления хороших связей между различиями и операторами сильно зависит от конкретной задачи.
4.11. ПРОСТРАНСТВА СОСТОЯНИЙ ВЫСШЕГО УРОВНЯ
Процесс сведения задачи к подзадачам, основанный на использовании ключевого оператора f и примененный к задаче (S, F, G), приводит к двум «И» подзадачам (S, F,Gf) и
122 Гл. 4. Представления, допускающие сведение задач к подзадачам
({f(g)},F,G)t где Gf — множество состояний, к которым применим оператор f, a g — элемент множества G/.
Часто оказывается необходимым решать первую из результирующих задач (S, F, Gf) еще до того, как вторая может быть сформулирована и решена. Тогда весь этот процесс решения задачи путем ее редукции удобнее представить в пространстве состояний высшего уровня. В пространстве состояний высшего уровня описанием состояния служит упорядоченный список описаний задач. (Отдельные задачи в этом списке должны быть решены в том порядке, в котором они там помещены.) Оператор построения дочерних вершин в пространстве состояний высшего уровня использует различия и ключевые операторы для создания двух подзадач, заменяющих первую задачу из этого списка, (Это делается до тех пор, пока первая из задач списка не окажется элементарной; в последнем случае она просто убирается из списка. Обычно удаление элементарной задачи из списка соответствует применению ключевого оператора. Этот факт должен быть отмечен, чтобы в дальнейшем включить такой оператор в решающую последовательность.) Состоянием цели в пространстве состояний высшего уровня служит любое описание состояния с пустым списком задач. Читатель сможет много уяснить для себя, проследив решение задачи об обезьяне и бананах с использованием такого пространства состояний высшего уровня.
4.12. ИГРЫ
Подход, связанный с расчленением задачи на совокупность подзадач, может быть использован также для поиска игровых стратегий для некоторых типов игр. Мы будем рассматривать игры двух лиц с полной информацией. В них играют два игрока, делающие свои ходы поочередно. Им полностью известно все, что было сделано и что может быть сделано в этой игре. Конкретнее, мы будем интересоваться играми, в которых один из двух игроков выигрывает (а другой проигрывает) или же результат получается ничейным. Некоторыми примерами игр такого типа служат шашки, тик-так-ту, шахматы, гоу и ним. Мы не собираемся рассматривать здесь те игры, в которых результат зависит хотя бы частично от случая: так, мы исключаем игральные кости и большинство карточных игр. (Впрочем наш анализ можно было бы обобщить, включив в рассмотрение некоторые типы игр, содержащих случайный элемент.)
В подходе, основанном на сведёнии задачи к совокупности подзадач, выигрышная стратегия ищется в процессе доказательства того, что эта игра может быть выиграна. Поэтому в описании задачи должно содержаться описание того состояния (или конфигурации) игры, про которое утверждается, что из
4.12. Игры
123
него достижение выигрыша может быть гарантировано. Например, в шахматах конфигурацией -является полное описание положений всех фигур на доске и указание, кому принадлежит следующий ход.
Пусть именами игроков будут ПЛЮС и МИНУС. Рассмотрим задачу нахождения игровой стратегии для игрока ПЛЮС, отправляясь от некоторой конфигурации Х{. Индекс I принимает значения + или —, причем Х+ представляет собой конфигурацию, в которой следующий ход принадлежит игроку ПЛЮС, а X" — конфигурацию, в которой следующий ход за игроком МИНУС. Мы хотели бы иметь возможность доказать, что игрок ПЛЮС может выиграть, исходя из конфигурации X', если же такого доказательства найти не удастся, то мы хотели бы иметь возможность доказать, что, исходя из конфигурации X', игрок ПЛЮС может по крайней мере добиться ничьей. Обозначим через ^(Х') задачу доказательства того, что ПЛЮС может выиграть, отправляясь от конфигурации X'.
Допустимые в этой игре ходы порождают схему сведения игровых задач к совокупности подзадач. Предположим, что очередь делать ход в конфигурации Х+ за игроком ПЛЮС, и предположим, что имеется N допустимых ходов, приводящих к конфигурациям XJ1, Х*22, ..., Х^. Тогда для доказательства Н?(Х+) мы должны иметь возможность доказать ту или иную из W (xj*)- С другой стороны, если очередь делать ход в конфигурации Х~ за игроком МИНУС и если имеется М допустимых ходов, приводящих ж конфигурациям У]1, У22, ..., У^*, то для доказательства Н?(Х_) мы должны уметь доказывать каждую из задач W (У^). Конечно, подобное сведение к подзадачам применимо и в том случае, когда мы пытаемся доказать лишь, что возможны ничьи.
Применение этих операторов сведения задачи порождает структуру, которая часто называется деревом игры. Элементарные задачи даются правилами окончания игры, а процесс доказательства продолжается до тех пор, пока не будет установлено, что решающее дерево оканчивается на элементарных задачах. (В большинстве игр, представляющих интерес, таких, как шахматы, 'Гоу и шашки, построить полные решающие деревья не представляется возможным. В следующей главе мы рассмотрим некоторые специализированные методы перебора на игровых деревьях, в которых строятся частичные деревья.)
Мы проиллюстрируем эти соображения на простом примере игры, называемой «игра Гранди», и применим методы сведения задачи к совокупности подзадач для поиска стратегии игрока ПЛЮС.
124 Гл. 4. Представления, допускающие сведение задач к подзадачам
Правила игры Гранди таковы. Перёд двумя играющими расположена единственная кучка предметов, например стопка монет. Первый игрок делит исходную стопку на две новые стопки, которые должны быть неравными. В дальнейшем каждый из игроков, когда приходит его очередь делать ход, делает то же самое с одной из стопок монет. Игра продолжается до тех пор,
Рис. 4.15. «И/ИЛИ» граф для игры Граиди.
пока все стопки 'не будут содержать по одной-две монеты, после чего игра заканчивается, поскольку дальнейшее ее продолжение невозможно. Проигрывает тот из игроков, который первым окажется в положении, когда игра не может продолжаться.
Начнем со стопки, содержащей семь монет, и пусть первым .делает ход игрок МИНУС. Конфигурацией в этой игре является последовательность чисел, отражающая числа монеток в различных стопках, • плюс указание на то, чей ход. Так, 7~ — начальная конфигурация.
В положении 7~ у игрока МИНУС имеются три альтернативных хода, приводящих к конфигурациям 6,1+, 5,2+ или 4,3+.
4.13. Библиографические и исторические замечания 125
Имеются всего три конфигурации, в которых игрок, имеющий право наследующий ход, проигрывает:
2, 1, 1, 1, 1, 1+, 2, 2, 1, 1, Г, 2, 2, 2, 1+.
Единственной элементарной задачей (означающей выигрыш для игрока ПЛЮС) является, таким образом, IF(2,2,1,1,1~).
Применив нашу процедуру сведения задачи к совокупности подзадач (отправляясь от задачи W(7~)), мы получаем «И/ИЛИ» граф, показанный из рис. 4.15. Жирными дугами на этом графе выделено решающее дерево, а в двойных прямоугольниках размещены элементарные задачи.
Если мы изменим игру так, чтобы первым начинал игрок ПЛЮС (отправляясь от конфигурации 7+), то окажется, что мы не можем доказать W(7+). (Второй игрок всегда может выиграть.) Пытаясь доказать W(7+), мы придем в конце концов к ситуации, когда невозможно будет построить новые вершины, и тогда можно было бы определить, что начальная вершина неразрешима. (Например, в соответствии с правилами игры у конфигурации 2, 2, 1, 1, 1+ нет следующих за ней конфигураций.)
4.13. БИБЛИОГРАФИЧЕСКИЕ И ИСТОРИЧЕСКИЕ ЗАМЕЧАНИЯ
Методы сведёния задачи к подзадачам и «И/ИЛИ» графы
В некоторых из самых первых работ по искусственному интеллекту для решения задач использовались методы сведёния задачи к совокупности подзадач (называемые также «рассуждением в обратном направлении»). Ньюэлл, Шоу и Саймон (1957) написали программу для логико-теоретической машины (ЛТ), которая доказывала теоремы исчисления предикатов, строя свою работу на рассуждении в обратном направлении от доказываемой теоремы. В этой программе было использовано дерево подзадач, для того чтобы можно было просмотреть альтернативные цепочки рассуждений.
Другой из первых программ, в которой были применены методы сведёния задачи и деревья подзадач, была программа для символьного интегрирования (SAINT) Слейджла (1963а). Слейджл первым назвал эти деревья деревьями типа «И/ИЛИ». В более поздней работе Слейджла и Бурского (1968) был использован термин «пропозициональное дерево». Ригни и Таун (1969) предложили применить граф типа графов «И/ИЛИ» для анализа структуры последовательностей операций в промышленности. Некоторые примеры представлений неявно заданных деревьев типа «И/ИЛИ» с помощью недетерминированных программ были даны Манна (1970).
126 Гл. 4. Представления, допускающие сведение задач к подзадачам
Примеры программ, использующих метод сведёния задачи к подзадачам
Наш пример символического интегрирования основан на программе Слейджла (1963а). Подробно эта программа описана в диссертации Слейджла (1961). Много более развитая система интегрирования (названная SIN) была впоследствии запрограммирован^ Мозесом (1967). Она содержала так много специальных критериев применимости различных операторов, что интегрирование по большей части производилось либо вовсе без перебора, либо после очень незначительного перебора1). Риш (1969) разработал алгоритмические процедуры для интегрирования выражений различных типов (см. задачу 4.5).
Примеры доказательства геометрических теорем были заимствованы из программы Гелернтнера и др. (1959, 1960). Некоторые элементы этой программы представляют собой важные и оригинальные нововведения.
Понятия ключевых операторов и различий и их применение при решении задач связаны главным образом с именем Ньюэлла и его сотрудников по универсальному решателю задач GPS (см. Эрнст и Ньюэлл, 1969). Можно было бы здесь упомянуть, что наше объяснение этих идей несколько отличается от того, что можно найти у Ньюэлла и др. Ньюэлл употреблял фразу «анализ цели-средства», когда говорил о процессе поиска различий и устранения этих различий с помощью подходящих операторов. Он различал также три типа целей в программе GPS: преобразование объекта, уменьшение различия и применение оператора. Из нашего описания не видна полезность такой классификации. Нас интересует программа GPS постольку, поскольку она может быть использована в системе автоматического решения задач, а многих работавших над GPS онц интересовала также и как психологическая модель мыслительного процесса. Это различие в точках зрения, без сомнения, отразилось в какой-то мере и на способах описания программы.
Особо интересуясь возможностями программы GPS для решения задач, Эрнст (1969) исследовал те условия, при которых GPS гарантирует нахождение решения. Анализ Эрнста привел к формализации понятий различия и упорядочения различий.
Игры и подход, связанный с разбиением задачи иа подзадачи
Слейджл и его сотрудники подчеркнули существенную аналогию между «И/ИЛИ» деревьями и игровыми деревьями
’) Можно было бы считать, что большая часть перебора, необходимого для проведения интегрирования, была произведена раз и навсегда самим Мозесом при разработке программы. Результатом такого перебора на стадии проектирования явились специальные правила, по которым во всех случаях применяются операторы.
Задачи
127
(Слейджл, 1970, Слейджл и Бурский, 1968). Эта аналогия в какой-то ьГере очевидна в простых играх, которые могут быть рассмотрены до конца, или в окончаниях более сложных игр, таких, как шахматы. Действительно, мы часто думаем о шахматных эндшпилях как о задачах на доказательство, а не как об играх. Наш пример игры Гранди взят из статьи О’Бирна (1961).
Задачи
4.1. (Для инженеров-электриков.) Покажите, как может быть использовано решающее «И/ИЛИ» дерево для представления вычислений импеданса показанной ниже электрической цепи. За элементарные факты возьмите возможность вычислить импеданс одиночного звена R, L или С (соответствующие значения равны R, jaL, l/jaC). Операторы построения дочерних вершин должны быть основаны иа правилах комбинирования импедансов в параллельных и последовательных соединениях.
4.2. Представьте, что Вы студент высшего учебного заведения, изучающий геометрию. Докажите следующую теорему: диагонали параллелограмма, пересекаясь, делятся пополам. Воспользуйтесь «И/ИЛИ» деревом для изображения этапов, которые Вы проходите в поиске доказательства. Проставьте в вершинах этого дерева предположения, которые были Вами рассмотрены при поиске доказательства. Были ли какие-нибудь из них отброшены после обращения к модели? Укажите решающее поддерево, дающее доказательство теоремы.
4.3. (Для программирующих на языке LISP.) Напишите на языке LISP предикат РАЗРЕШИМОЕ (ДЕРЕВО), имеющий значение Г, если корневая вершина этого дерева (графа типа «И/ИЛИ») разрешима, и значение F в противном случае. Воспользуйтесь любой удобной структурой данных для ДЕ-
4.4. Объясните, как бы Вы построили систему решения задачи, основанную на сведении задачи к подзадачам, предназначенную для разбиения любого английского слова иа составляющие его слоги. Предположите, что на каждом этапе сведения задачи к подзадачам строка символов расщепляется ровно иа две строки.
4.5. История прогресса в развитии систем для автоматического символического иитегрироваиия выдвигает интересный вопрос, касающийся определения искусственного интеллекта. Лишь немногие будут сомневаться в том, что программа SAINT Слейджла является результатом исследования в области искусственного интеллекта. В программе SIN Мозеса для символического интегрирования редко используется перебор, и по этой причине некоторые считают ее сильнее (разумнее?) программы SAINT. Риш (1969) разработал алгоритм для интегрирования многих типов выражений. Ои считает* себя математиком, а не исследователем в области искусственного интеллекта. Как по Вашему мнению, следует ли относить алгоритм Риша к области искусственного интеллекта? При ответе дайте описание критерия для определения
128 Гл. 4. Представления, допускающие сведение задач к подзадачам
того, что составляет искусственный интеллект. Если Вы исключите из искусственного интеллекта алгоритм Риша, то как Вы будете реагировать на заявление, что каждая программа из области искусственного интеллекта в конце концов будет превзойдена некоторым (более разумным?) алгоритмом ие из области искусственного интеллекта? Если же Вы относите алгоритм Риша к области искусственного интеллекта, то не включите ли Вы туда и алгоритм деления многочлена на многочлен?
4.6. Игра, называемая «последний проигрывает», состоит в следующем: два игрока поочередно берут по одной, две или три монеты из кучки, первоначально содержащей девять монет. Игрок, берущий последнюю монету, проигрывает. Нарисуйте решающее «И/ИЛИ» дерево, которое доказывает, что участник, играющий вторым, всегда может выиграть.
Глава 5
Методы поиска при сведении задач
К СОВОКУПНОСТИ ПОДЗАДАЧ
5.1. ПРОЦЕССЫ ПЕРЕБОРА (ПОИСКА) НА ГРАФАХ ТИПА «И/ИЛИ»
После выбора описаний задач и операторов сведения задач к подзадачам можно построить «И/ИЛИ» граф, предназначенный для решения исходной задачи или для демонстрации ее неразрешимости (при выбранном представлении). Построение этого графа связано с процессом перебора, который успешно завершается, когда находится решающий граф. В этой главе мы опишем основные приемы ведения эффективного поиска решающих графов.
Нахождение решающего графа основано на построении достаточно большой части «И/ИЛИ» графа, показывающей, что начальная вершина разрешима. Приведем здесь еще раз определения разрешимых и неразрешимых вершин, данные в предыдущей главе.
Разрешимые вершины
Заключительные вершины (соответствующие элементарным задачам) разрешимы.
Вершина, не являющаяся заключительной и имеющая дочерние вершины типа «ИЛИ», разрешима тогда и только тогда, когда разрешима по крайней мере одна из ее дочерних вершин.
Вершина, не являющаяся заключительной и имеющая дочерние вершины типа «И», разрешима тогда и только тогда, когда разрешимы все ее дочерние вершины.
Неразрешимые вершины
Вершины, не являющиеся заключительными и не имеющие дочерних вершин, неразрешимы.
Вершина, не являющаяся заключительной и имеющая дочерние вершины типа «ИЛИ», неразрешима тогда и только тогда, когда неразрешимы все ее дочерние вершины.
Вершина, не являющаяся заключительной и имеющая дочерние вершины типа «И», неразрешима тогда и только
б Зак, 493
130
Гл. 5. Методы поиска при сведении задач к подзадачам
тогда, когда неразрешима по крайней мере одна из ее дочерних вершин.
Мы видим, что определения разрешимых и неразрешимых вершин носят рекурсивный характер. Эти определения можно использовать в простых рекурсивных или итеративных процедурах, действующих на «И/ИЛИ» графе, для того чтобы отметить все разрешимые и неразрешимые вершины. Мы будем называть эти процедуры процедурами разметки разрешимых и неразрешимых вершин. Они применяются при контроле окончания в тех алгоритмах перебора, которые мы будем рассматривать. Перебор заканчивается успешно, если начальная вершина может быть отмечена как разрешимая. Перебор считается закончившимся безуспешно, если начальная вершина может быть отмечена как неразрешимая.
В том случае, когда начальная вершина в конечном итоге может быть отмечена как разрешимая, решающим графом будет подграф (содержащий только разрешимые вершины), показывающий в соответствии с нашим определением, что начальная вершина разрешима.
Все процессы перебора, которые мы будем рассматривать, включают следующие этапы:
(1) Начальная вершина ассоциируется с начальным описанием задачи.
(2) Строятся множества дочерних вершин для начальной вершины с помощью тех операторов сведения задач к подзадачам, которые применимы. Пусть Г — такой комбинированный оператор, применение которого дает нам все дочерние вершины для данной вершины. Мы снова назовем этот процесс применения Г к вершине раскрытием вершины. (Напомним, что если при этом строится более одного множества дочерних вершин типа «И», то каждое множество/ содержащее более одного элемента, группируется под промежуточной вершиной типа «ИЛИ».)
(3) От каждой дочерней вершины назад к ее родительским вершинам проводятся указатели. Эти указатели используются, когда делается попытка разметить разрешимые и неразрешимые вершины, а после окончания они дают решающий граф.
(4) Процесс раскрытия вершин и установки указателей продолжается до тех пор, пока начальная вершина не может быть помечена как разрешимая или как неразрешимая.
Структура из вершин и указателей, порождаемая в процессе перебора, образует «И/ИЛИ» граф, т. е. подграф всего неявно определенного, графа. Мы будем называть его графом перебора.
В этой главе мы будем заниматься различными процессами перебора на графе типа «И/ИЛИ», в которых выбран эффектив
5.1. Процессы перебора (поиска) на графах типа «И/ИЛИ»
131
ный порядок раскрытия вершин1). Эти процессы в некоторых отношениях отличаются от процессов перебора в пространстве состояний. Основные различия возникают из-за того, что теперь контроль окончания и методы упорядочения вершин должны быть намного более сложными. Вместо поиска вершин, удовлетворяющих условию цели, мы теперь ведем поиск решающего графа. Таким образом, мы должны в соответствующие моменты времени делать проверку, чтобы убедиться в том, что начальная вершина разрешима. Однако такую проверку имеет смысл делать лишь после того, как будут построены дочерние вершины, которые разрешимы (например, заключительные вершины). Для проведения такой проверки мы должны прежде всего применить процедуру разметки разрешимости вершин поискового «И/ИЛИ» графа, построенного к данному моменту. Если начальная вершина отмечена как разрешимая, то мы закончили проверку. В противном случае мы продолжаем раскрывать вершины (возможно, запоминая, какие из ранее раскрытых вершин отмечены как разрешимые, с тем чтобы уменьшить объем вычислений при следующей проверке).
Если вершина, выбранная для раскрытия, не является заключительной и не’имеет дочерних вершин, тс/она неразрешима. Тогда естественно применить процедуру разметки неразрешимости вершин с тем, чтобы проверить, не будет ли начальная вершина неразрешимой. Если начальная вершина неразрешима, то это означает, что мы потерпели неудачу. В противном случае мы продолжаем раскрывать вершины (помня снова, какие из ранее раскрытых вершин были отмечены, как неразрешимые).
Наличие разрешимых и неразрешимых вершин приводит к другой интересной особенности перебора (поиска) на графе типа «И/ИЛИ». Так как нет никаких причин искать более одного решения задачи, то можно на поисковом графе отбросить все те неразрешимые вершины, которые являются дочерними для разрешимых вершин. Точно так же можно отбросить все вершины, следующие за неразрешимыми вершинами. Перебор ниже таких отбрасываемых нами вершин был бы бессмысленным.
Методы перебора на «И/ИЛИ» графах отличаются друг от друга главным образом тем, каким образом в них упорядочиваются вершины перед раскрытием. А именно, в методах полного перебора вершины раскрываются в том порядке, в котором они строились, а в методах перебора в глубину в первую очередь раскрываются те вершины, которые были построены последними.
') Как мы видели на примере, разобранном в разд. 4.10, может оказаться, что одну из дочерних подзадач необходимо решить раньше, чем можно будет приступать к другим. Методы упорядочения настоящей главы применяются только там, где имеется возможность выбора, какую из вершин раскрывать в следующий раз.
5*
132
Г л. 5. Методы поиска при сведении задач к подзадачам
Хотя нас интересуют прежде всего методы упорядоченного перебора (в которых для упорядочения вершин при их раскрытии используют оценочные функции), но начнем мы с обсуждения методов поиска в глубину и методов полного перебора, так как они являются достаточно простыми и позволяют ввести некоторые важные представления.
Методы перебора значительно упрощаются, если их применять к деревьям (а не к произвольным графам). Мы опишем варианты этих методов, рассчитанные на перебор на деревьях, а потом отметим некоторые из проблем, связанных с обобщениями, необходимыми для перебора на графах. Дерево типа «И/ИЛИ» — это граф типа «И/ИЛИ», в котором у каждой вершины имеется ровно одна родительская вершина (исключая корневую вершину, вовсе не имеющую родительских вершин). Как и в случае обыкновенных деревьев, при построении той или иной дочерней вершины можно быть уверенным, что такая вершина в процессе нашего перебора не строилась и не будет построена вновь. Перебор на «И/ИЛИ» дереве приводит к построению поддерева, называемого деревом перебора.
5.2. МЕТОД ПОЛНОГО ПЕРЕБОРА
В методе полного перебора вершины раскрываются в том порядке, в котором они были построены. Последовательность определяющих его шагов кажется длинной, но большая часть их связана с проверками того, не должна ли данная процедура закончить свою работу. Структура этого процесса весьма проста, как видно из блок-схемы рис. 5.1. Последовательность шагов в методе перебора на «И/ИЛИ» дереве такова:
(1) Поместить начальную вершину s в список вершин с названием открыт.
(2) Взять первую вершину из списка ОТКРЫТ и поместить’ ее в список вершин с названием ЗАКРЫТ; обозначить эту вершину через п.
(3) Раскрыть вершину п, построив все ее дочерние вершины. Поместить эти дочерние вершины в конец списка ОТКРЫТ и провести от них указатели к вершине п. Если дочерних вершин не оказалось, то пометить вершину п как неразрешимую и продолжать; в противном случае перейти к (8).
(4) Применить к дереву поиска процедуру разметки неразрешимых вершин.
(5) Если начальная вершина помечена как неразрешимая, то на выход подается сигнал о неудаче. В противном случае продолжать далее.
(6) Изъять из списка ОТКРЫТ все вершины, имеющие неразрешимые предшествующие им вершины. (Этот шаг позволяет
Рис. 5.1. Блок-схема программы полного перебора на <И/ИЛИ» деревьях.
134
Гл. 5. Методы поиска при сведении задач к подзадачам
избежать ненужных затрат, связанных с попытками разрешить неразрешимые вершины.)
(7) Перейти к (2).
(8) Если все дочерние вершины являются заключительными, то пометить их как разрешимые и продолжать. В противном случае перейти к (2).
(9) Применить к дереву перебора процедуру разметки разрешимых вершин.
(10) Если начальная вершина помечена как разрешимая, та на выход выдается дерево решения, которое доказывает, что начальная вершина разрешима. В противном случае продолжать.
(11) Изъять из списка ОТКРЫТ все вершины, являющиеся разрешимыми или имеющие разрешимые предшествующие им вершины. (Этот шаг позволяет избежать ненужных затрат, связанных с поиском более одного пути решения задачи.)
(12) Перейти к (2).
Как и для обычных деревьев, глубина вершины в дереве типа «И/ИЛИ» определяется следующим образом:
Глубина начальной вершины равна 0.
Глубина любой другой вершины на 1 больше глубины ее родительской вершины (непосредственно ей предшествующей).
В дальнейшем мы докажем теорему, из которой будет, в
частности, следовать, что описанная выше процедура полного
Рис. 5.2. «И/ИЛИ» дерево, показывающее порядок, в котором раскрываются вершины при полном переборе.
перебора непременно обнаруживает то дерево решения, самая глубокая вершина которого (заключительная вершина) имеет минимальную глубину (при условии, конечно, что дерево решения вообще существует).
Пример последовательности, в которой раскрываются вершины в методе полного перебора, приведен на рис. 5.2. Числа, стоящие
рево решения выделено жирными
около вершин, указывают очередность раскрытия вершин, разрешимые вершины зачернены, а найденное деветвями. Заметим, что после
раскрытия девятой вершины и установления того, что ее дочерние вершины являются заключительными, вершины А, В и С удаляются из списка ОТКРЫТ.
5.3. Поиск в глубину
135
5.3. ПОИСК В ГЛУБИНУ
При переборе в глубину делается попытка найти в пределах определенной граничной глубины дерево решения, причем в первую очередь раскрываются только что построенные вершины. Вершины, имеющие большую глубину, чем эта граничная, никогда не будут раскрываться, поэтому незаключительные вершины с глубиной, в точности равной этой границе, отмечаются как неразрешимые. Как и при переборах в пространстве состояний, наличие граничной глубины может воспрепятствовать нахождению решения, но в ходе процесса будет найдено любое решение в пределах этого ограничения. Структура процесса аналогична структуре процесса в методе полного перебора. Она показана на блок-схеме рис. 5.3. Последовательность шагов в процедуре поиска в глубину такова:
(1) Поместить начальную вершину s в список вершин с названием ОТКРЫТ.
(2) Взять первую вершину из списка ОТКРЫТ и поместить ее в список вершин с названием ЗАКРЫТ; обозначить эту вершину через п.
(3) Если глубина вершины п равна граничной глубине, то отметить вершину п как неразрешимую и перейти к (5); в противном случае продолжать далее. z
(4) Раскрыть вершину п, построив все ее дочерние вершины. Поместить эти дочерние вершины (в произвольном порядке) в начало списка ОТКРЫТ и провести от них указатели к вершине п. Если дочерних вершин не оказалось, то пометить вершину п как неразрешимую и продолжать; в противном случае перейти к (9).
(5) Применить к дереву поиска процедуру разметки неразрешимых вершин.
(6) Если начальная вершина помечена как неразрешимая, то на выход подается сигнал о неудаче. В противном случае продолжать далее.
(7) Изъять из списка ОТКРЫТ все вершины, имеющие неразрешимые предшествующие им вершины.
(8) Перейти к (2).
(9) Если все дочерние вершины являются заключительными, то пометить их как разрешимые и продолжать. В противном случае перейти к (2).
(10) Применить к дереву перебора процедуру разметки разрешимых вершин.
(11) Если начальная вершина помечена как разрешимая, то на выход выдается дерево решения, которое доказывает, что начальная вершина разрешима. В противном случае продолжать.
Рис. 5.3. Блок-схема программы перебора в глубину на «И/ИЛИ> деревьях.
5.4. Перебор на графах типа «И/ИЛИ»
137
(12) Изъять из списка ОТКРЫТ все вершины, являющиеся разрешимыми или имеющие разрешимые предшествующие им вершины.
(13) Перейти к (2).
Пример последовательности, в которой раскрываются вершины в методе перебора в глубину, приведен н-а рис. 5.4. В этом примере граничная глубина принята равной 4. Черными кружочками показаны разрешимые вершины, белыми неразрешимые, а дерево решения выделено жирными ветвями.
5.4. ПЕРЕБОР НА ГРАФАХ ТИПА «И/ИЛИ»
Всегда, когда процесс сведения задачи к совокуп
Рис. 5.4. «И/ИЛИ» дерево, показывающее порядок, в котором раскрываются вершины при переборе в глу-бину (предельная глубина равна 4).
ности подзадач приводит к построению дочерней вершины, эквивалентной некоторому описанию задачи, уже
построенному ранее в про-
цессе перебора, результирующую структуру можно представить эффективнее не в виде дерева, а в виде «И/ИЛИ» графа, в котором вершины могут иметь более одной родительской вершины. Если у нас есть возможность распознавать случаи эквивалентности описаний задач, то задачу поиска можно в общем случае
существенно упростить, так как идентичные подзадачи достаточно решить один раз. К тому же общая .графовая структура может содержать бесполезные циклы (давая циклические цепочки рассуждений), которые мы могли бы встретить, но не быть в состоянии их обнаружить, если бы считали разными в действительности идентичные описания задач.
Некоторые примеры «И/ИЛИ» графов, вершины которых могут иметь более одной родительской вершины, показаны на рис. 5.5. Заключительные вершины отмечены буквой t, а решающие графы выделены жирными ребрами. Заметим, что у графов на рис. 5.5, а, б есть решающие подграфы, а у графа на рис. 5.5, в таких подграфов нет, поскольку на нем никак нельзя избежать зацикливания.
Казалось бы, можно предположить, что для того, чтобы не попасть в цикл, следует отказываться от построения тех дочерних вершин для данной вершины, которые были бы для этой вершины предшествующими. В действительности такое правило могло бы привести к исключению из рассмотрения некоторых
138
Гл. 5. Методы поиска при сведении задач к подзадачам
верных нециклических решений. Например, если вершины раскрываются в порядке, указанном на рис. 5.6, мы, безусловно, захотим включить вершину 2 в число дочерних вершин для в (хотя вершина 2 в то же время предшествует 6), так как в противном случае мы не получили бы решения (возможно, единственного), показанного жирными ветвями.
в
Рис. 5.5. Некоторые «И/ИЛИ» графы.
При попытке определить процедуру перебора для графа (а не дерева) типа «И/ИЛИ» возникает ряд осложнений. Во-первых, разумное определение процедуры полного перебора было бы, вероятно, связано с выбором для очередного раскрытия той вершины из списка ОТКРЫТ, которая имеет наименьшую глубину. Теперь, однако, несколько труднее, чем в случае деревьев,, дать хорошее определение глубины. Как и для обычных графов, глубина вершины в «И/ИЛИ» графе определяется следующим, образом:
Глубина начальной вершины равна 0.
Глубина любой другой вершины на 1 больше глубины самой ближайшей ее родительской вершины.
5.5. Стоимости деревьев решения
139
Второе осложнение связано с необходимостью установки указателей*, идущих от данной вершины к более чем одной родительской вершине. Все эти указатели могут оказаться необходимыми при определении решающего графа. (Например, на рис. 5.6 обязательно должны содержаться в решении указатели, идущие от вершины 2 к вершинам 1 и 6.) С другой стороны, некоторые из этих кратных указателей могут и не потребоваться в решении (например, на рис. 5.6 в решение не должен входить
указатель, идущий от вершины 3 назад к вершине 4). Поэтому в процедуре перебора на «И/ИЛИ» графе должна быть предусмотрена возможность проанализировать после окончания работы структуру указателей графа перебора, с тем чтобы отбросить несущественные указатели и сохранить те, которые необходимы в решающем графе.
Аналогично когда стр'о-ятся дочерние вершины, следует провести специальную проверку, нет ли уже каких-нибудь из этих вершин в описке ЗАКРЫТ и не были
Рис. 5.6. Пример, показывающий, что вершина 2 может быть дочерней для вершины 6 (через дугу а), хотя при этом и возникает цикл.
ли они прежде помечены
как разрешимые или как неразрешимые. Если при этом мы пришли к уже разрешимой (или неразрешимой) дочерней вершине по новому пути, то небходимо воспользоваться процедурой разметки, чтобы проверить, разрешима ли (или неразрешима ли) начальная вершина.
Разработку алгоритмов перебора на произвольных графах типа «И/ИЛИ» мы оставляем читателю в качестве упражнения. Нашей ближайшей задачей будет исследование способов эффективного упорядочения процесса раскрытия вершин с использованием оценочных функций. Снова наше рассмотрение существенно упростится, если ограничиться случаем «И/ИЛИ» деревьев.
5.5. СТОИМОСТИ ДЕРЕВЬЕВ РЕШЕНИЯ
В переборах в пространстве состояний у нас была возможность воспользоваться для упорядочения процесса раскрытия вершин эвристически выводимыми оценочными функциями. Ключевым понятием при определении этих оценочных функций
140
Гл. 5. Методы поиска при сведении задач к подзадачам
было понятие эвристической функции, оценивающей стоимость оптимального пути от некоторой вершины до цели. В «И/ИЛИ» деревьях соответствующее понятие связано с оценкой стоимости дерева решения с корнем в данной вершине. Разумеется, прежде чем решать, как давать оценку стоимости дерева решения с корнем в данной вершине, надо определить, что мы будем понимать под стоимостью «И/ИЛИ» решения.
Нетрудно определить два различных понятия, каждое из ко-
торых приписывает определенные
Р н с. 5.7. Два решающих дерева и их стоимости.
Решение Л
Суммарная стоимость =20
Максимальная стой-мость=15
стоимости дугам дерева решения : суммарную стоимость* представляющую собой сумму стоимостей всех дуг в дереве решения, и максимальную стоимость, определение которой основано на понятии пути по дереву решения. (Назовем путем по дереву с корнем в вершине п последовательность вершин (п1; п2, ..., «а) дерева, где — п, пь. — заключительная вершина, а вершина П] — дочерняя для nj-i при j — 2, ..., k.) Сумму стоимостей дуг, связывающих
Решение В
Суммарная стой-мостъ=18
Максимальная стой* мость=17
вершины некоторого пути, будем называть стоимостью пути. Максимальная стоимость —
это стоимость пути по дереву решения, имеющего максимальную стоимость.
Эти определения можно пояснить на деревьях решений, показанных на рис. 5.7, на котором числа, стоящие-около дуг, указывают стоимости последних. Здесь имеются два решения. Одно из них выделено жирными линиями (решение 4), а другое (решение В) —перечеркнутыми линиями. У решения А суммарная стоимость равна 20, максимальная равна 15, а у решения В суммарная стоимость равна 18, максимальная равна 17. Какое из этих решений предпочтительнее, зависит, конечно, от того, какую стоимость мы пытаемся минимизировать.
Часто стоимости дуг полагаются равными единице. В этом случае суммарная стоимость есть просто число вершин в дереве решения без единицы. Подобным образом максимальная стоимость дает длину самой длинной цепочки шагов в дереве решения. В любом случае достаточно хорошую оценку любой из этих стоимостей можно с пользой применить в оценочной функции и тем самым эффективно упорядочить перебор.
Дерево решения само по себе является поддеревом некоторого неявно заданного «И/ИЛИ» дерева, определяемого началь
5.6. Использование оценок стоимости для прямого перебора
141
ным описанием задачи, множеством операторов сведения задачи к подзадачам и множеством элементарных задач. Внутри всего неявно заданного «И/ИЛИ» дерева мы хотим найти дерево решения с минимальной стоимостью. Такое дерево решения будем называть оптимальным деревом. Обозначим через h(s) стоимость оптимального дерева решения с корнем в начальной вершине s. Дадим рекурсивное определение минимальной стоимости h(s) через минимальную стоимость h(n) дерева решения с корнем в любой вершине п. Будем обозначать стоимость дуги между вершиной ni и ее дочерней вершиной П] через c(tii, nJ.
1. Если п — заключительная вершина (отвечающая элементарной задаче), то
h (п) = 0.
2. Если п не является заключительной вершиной и имеет в качестве своих дочерных вершин вершины nit ..., Пй типа «ИЛИ», то
й (n) = min [с (n, n J + й (n J]. i
3. Если п не является заключительной вершиной и имеет в качестве своих дочерних вершин вершины пь ..., Пй типа «И», то для суммарных стоимостей
k
h (n) = 2 [с (n, «J + h (nJ], t=l
а для максимальных стоимостей
й (n) — max [c (n, nJ J- h (nJ]. i
Разумеется, функция й(п) не определена, если вершина п неразрешима.
5.6. ИСПОЛЬЗОВАНИЕ ОЦЕНОК стоимости для ПРЯМОГО ПЕРЕБОРА
Нас будет интересовать поиск деревьев решения, обеспечивающих минимальную стоимость (либо суммарную, либо максимальную в зависимости от ситуации). Для-этого мы воспользуемся представлением об оцененной стоимости дерева решения. Пусть И — такая функция, что для каждой вершины п, которая не является неразрешимой, Й(п) служит оценкой величины й(п), т. е. стоимости оптимального дерева решения с корнем в вершине п. Мы будем называть Й эвристической функцией и будем пользоваться ею для упорядочения процесса раскрытия вершин.
В процессе перебора, который мы опишем, строится дерево перебора. На любом этапе этого перебора внизу дерева пере
142 Гл. 5. Методы поиска при сведении задач к подзадачам
бора располагаются вершины одного из следующих трех типов:
1) вершины, признанные в процессе перебора заключительными;
2) вершины, относительно которых в процессе перебора было установлено, что они не являются заключительными и у них нет дочерних вершин;
3) вершины, для которых в процессе перебора еще не были построены дочерние вершины.
Любую из таких вершин в дереве перебора мы будем называть концевой вершиной.
Теперь мы опишем, каким образом для каждой вершины га дерева перебора должна строиться эвристическая функция Л(п).
я—концевая вер шина
Если установлено, что п является заключительной вершиной, то Н(п) = 0.
Если установлено, что п не является заключительной вершиной и у нее нет дочерних вершин, то функция Н(п) не определена.
Если у вершины п еще не были построены дочерние вершины, то за Н(п) принимается некоторая эвристическая оценка стоимости величины h(n) оптимального дерева решения с корнем в вершине п. Такая оценка могла бы быть сделана на основе эвристической информации, касающейся происхождения задачи, представляемой нашим «И/ИЛИ» деревом.
я—неконцевая вершина, имеющая дочерние вершины л.........пь
типа „ИЛИ“
Эвристическая функция fi(n) задается формулой
1г (я) = min [с (я, nz) + 1г (яг)]. ' i
л — неконцевая вершина, имеющая дочерние вершины ........Пц
типа „И“
Эвристическая функция Л{п) для суммарных стоимостей за. дается формулой
/г (я) == 2 [с (я, я,) ft (я,)],
г=1
а для максимальных стоимостей — формулой fl (я) = max [с (я, я,) -р h (я/)]
5.6. Использование оценок стоимости для прямого перебора
143
Поскольку Н(п) = 0 для заключительных вершин, наше опре-деление'дает гарантию, что при Use h в состав дерева перебора будет входить наше «И/ИЛИ» деревб целиком.
Далее, в дереве поиска на каждом этапе содержится множество поддеревьев с корнем в s, каждое из которых могло бы в зависимости от результатов дальнейшего раскрытия вершин стать верхней частью полного дерева решения. Назовем эти деревья потенциальными деревьями решений для s. Для каждой вершины, имеющей дочерние вершины типа «ИЛИ», в дереве поиска можно выбрать отдельное потенциальное дерево решения, соответствующее каждой из дочерних вершин типа «ИЛИ». Аналогично имеются также потенциальные деревья решений с корнем в вершине п, которые могли бы решать подзадачу, соответствующую этой вершине. (Конечно, если только эта вершина не помечена уже как неразрешимая.)
На каждом этапе в процессе перебора можно извлечь из дерева перебора это потенциальное дерево решения то, корень ко-, торого расположен в s и которое по оценке служит верхней частью оптимального дерева решения с корнем в s. В процедуре извлечения используются величины (г; основана процедура на следующем определении:
1. Начальная вершина входит в т0.
2. Если у вершины п, входящей в т0. в дереве перебора есть а) дочерние вершины п\,..., пк типа «ИЛИ», то та из них, для которой значение [с(п, Пг) +#(Пг)] минимально, также входит в то (в случае равных значений выбор произволен),
б) дочерние вершины типа «И», то все они входят в то.
Это потенциальное дерево решения то, по оценке служащее верхней частью оптимального дерева решения с корнем в s, является ключевым понятием в эвристическом 'процессе перебора, который нам предстоит описать. Уместная здесь процедура упорядочения связана с вопросом «Какое из потенциальных деревьев решения наиболее перспективно для раскрытия», а не с вопросом «Какая из вершин наиболее перспективна для раскрытия на следующем шаге». (Аналогично при переборе в пространстве состояний, выбирая вершину с минимальным значением f = g + Н, мы продолжаем наиболее перспективный частичный путь.) Мы будем брать то в качестве наиболее перспективного потенциального дерева решения.
Для того чтобы в ходе нашего процесса перебора можно было извлечь дерево то, мы должны следить за величинами (г в каждой вершине дерева поиска. После того как дерево то извлечено, раскрываются те его концевые вершины, которые еще не выбирались для раскрытия, и для такого выросшего дерева пересчитываются величины Н. На самом деле достаточно пересчитать величины Н только для вершин, предшествующих только
144
Гл. 5. Методы поиска при сведении задач к подзадачам
что раскрытой вершине, ибо для других вершин они не изменятся. (Величина Я для вершины зависит лишь от величин Я следующих за ней вершин.)
Прежде чем точно описать процесс перебора, основанный на этих идеях, надо располагать средствами для решения вопроса о том, какую из концевых вершин дерева т0 раскрывать на следующем шаге. Можно предложить различные методы. Возможно, хорошей идеей был бы выбор вершины, раскрытие которой с наибольшей вероятностью опровергало бы гипотезу о том, что То окажется верхней частью оптимального дерева решения. В самом деле, если То не является верхней частью оптимального дерева решения, хотя в данный момент оно и оценивается как таковое, то для эффективности процедуры перебора требуется, чтобы этот факт был обнаружен как можно быстрее. Дополнительные соображения по этому вопросу будут приведены в разд. 5.9. Пока же предположим, что у нас есть некие средства определения, какую из концевых вершин т0 раскрывать в следующую очередь.
5.7. АЛГОРИТМ УПОРЯДОЧЕННОГО ПЕРЕБОРА ДЛЯ ДЕРЕВЬЕВ ТИПА «И/ИЛИ»
Мы можем теперь дать перечень шагов, определяющий алгоритм упорядоченного перебора для деревьев «И/ИЛИ». Эти шаги лишь немного отличаются от этапов метода полного перебора:
(1) Поместить начальную вершину s в список вершин с названием ОТКРЫТ и вычислить H(s).
(2) Получить потенциальное дерево решения, которое по оценке служит верхней частью оптимального дерева решения с корнем в з, используя для этого величины Я для вершин дерева перебора.
(3) Выбрать некоторую концевую вершину дерева т0, которая имеется в списке ОТКРЫТ, и поместить ее в список вершин с названием ЗАКРЫТ. Обозначить эту вершину через п.
(4) Если п — заключительная вершина, то пометить вершину п как разрешимую и продолжать. В противном случае перейти к (9).
(5) Применить к то процедуру разметки разрешимых вершин.
(6) Если начальная вершина помечена как разрешимая, то на выход выдается То в качестве дерева решения; в противном случае продолжать.
(7) Изъять из списка ОТКРЫТ все вершины, имеющие разрешимые предшествующие им вершины.
(8) Перейти к (2).
(9) Применить к п оператор Г и построить все дочерние вершины для п. Если дочерних вершин нет, то пометить вер
5.7. Алгоритм упорядоченного перебора для деревьев типа «Й1ИЛИ» 145
шину п как неразрешимую и перейти к следующему этапу. В противной случае перейти к (14).
(10) Применить к т0 процедуру разметки неразрешимых вершин.
(11) Если начальная вершина помечена как неразрешимая, то на выход подается сигнал о неудаче. В противном случае продолжать далее.
(12) Изъять из списка ОТКРЫТ все вершины, имеющие неразрешимые предшествующие им вершины.
(13) Перейти к (2).
(14) Поместить эти дочерние вершины в список ОТКРЫТ и провести от них указатели назад к вершине п. Вычислить величины Н для этих вершин. Пересчитать величины б для вершины п и для предшествующих ей вершин.
(15) Перейти к (2).
Блок-схема этой процедуры изображена на рис. 5.8. (Заметим, что в частном случае, когда не возникает вершин типа «И», в этой процедуре перебор дерева осуществляется способом, идентичным методу упорядоченного перебора в пространстве состояний. Кроме того, если стоимости дуг равны единице, й == 0 для концевых вершин и используется определение максимальной стоимости, то эта процедура приводит к тем же результатам, что и процедура полного перебора.)
На рис. 5.9 приведена последовательность гипотетических деревьев перебора, иллюстрирующая работу нашего алгоритма упорядоченного перебора. Предположим, что раскрытие начальной вершины привело к дереву перебора, изображенному на рис. 5.9, а. Число, стоящее рядом с вершиной, указывает величину й. Для концевых вершин эти величины служат эвристическими оценками суммарных стоимостей решений соответствующих задач. Величины й для других вершин этого дерева получаются в результате применения определения Й(п) для суммарных стоимостей в предположении об единичной стоимости ребер. Исходя из этих значений Й, можно получить потенциальное дерево решения то, которое по оценке должно быть верхней частью оптимального дерева решения. Это дерево то выделено жирными ветвями.
Далее мы раскрываем некоторую концевую вершину в то-Предположим, что в результате возникает дерево перебора, изображенное на рис. 5.9, б. Из-за новых значений величин й дерево то теперь переместится в другую часть дерева перебора. Раскрытие вершины в этом дереве то приводит, скажем, к дереву перебора рис. 5.9, в. Здесь мы получили некоторые заключительные вершины, а значит, и некоторые разрешимые вершины. Они отмечены черными кружочками. Заметим, что величины ft для заключительных вершин равны нулю. После еще
Рис. 5.8. Блок-схема программы упорядоченного перебора для «И/ИЛИ» деревьев.
8
148
Гл. 5. Методы поиска при сведении задач к подзадачам
одного раскрытия мы, наконец, получаем дерево решения, выделенное на рис. 5.9, г жирными ветвями. Суммарная стоимость этого дерева равна 9, как показывают вычисления с использованием окончательных значений И.
5.8. ДОПУСТИМОСТЬ АЛГОРИТМА УПОРЯДОЧЕННОГО ПОИСКА (ПЕРЕБОРА)
Как и при переборах в пространстве состояний, алгоритм поиска на дереве «И/ИЛИ» называется допустимым, если его применение всегда приводит к решению минимальной стоимости, при условии что дерево решения существует. Мы докажем сейчас, что если оценка Й является нижней границей величины h для открытых вершин, то алгоритм упорядоченного перебора допустим. Сначала докажем следующую лемму:
Лемма 5.1. Если Н(п) ^h(n') для всех вершин из списка ОТКРЫТ, то на любом этапе процесса перебора для всех построенных вершин дерева перебора Й(п) h(n), причем для вершин, уже полученных как разрешимые, здесь достигается равенство.
Доказательство. Доказательство поведем индукцией по’ уровню дерева перебора1). Для деревьев перебора уровня О лемма тривиально выполняется, так как для таких деревьев единственной вершиной в дереве перебора будет начальная вершина з. Если з находится в списке ОТКРЫТ, то Й(з) ^й(з); если же вершина s разрешима, будучи заключительной вершиной, то Й(з) = h(s) = 0. ’
Предположим теперь, что лемма верна для деревьев перебора любого уровня, меньшего или равного некоторому произвольному числу I (/^0), и докажем, что она верна для деревьев перебора уровня /+ 1.
Возьмем некоторое дерево перебора уровня 1+1. Так как I 0, то у начальной вершины s имеются вершины, непосредственно за ней следующие, скажем вершины п\, ... nk. Эти вершины являются корнями поддеревьев уровня не выше I, так что по предположению индукции лемма верна для всех вершин этих поддеревьев. Иными словами, для всех вершин этих поддеревьев Й h (равенство достигается для разрешимых вершин). Таким образом, нам осталось доказать, что й(з) ^й(з), а равенство достигается, когда вершина s разрешима. Предположим сначала, что nlt ..., «а— вершины типа «ИЛИ». Тогда по определению Й ;
. h (s) = min [с (s, nt) + fl («<)]• i
J) Уровень дерева перебора определяется как глубина наиболее глубокой из его концевых вершин.
5.8. Допустимость алгоритма упорядоченного поиска (перебора) 149
Но по предположению индукции fi(nt) И(п<) для I — — 1, .k, так что
A (s) < min [с (s, щ) + h (nJ]. i
Правая часть этого неравенства по определению равна h(s)r и поэтому
A (s)< Л (s).
Далее, если вершина s разрешима, то алгоритм обязан был закончить свою работу, выдав дерево решения то, в котором некоторая вершина, скажем «го, является дочерней для s. Па определению т0
A ($) = с (s, nl0) + h (nt0) = min [с (s, nJ + h (nJ]. i
Но так как то — дерево решения для s, то для него вершина пю также должна быть разрешимой. По предположению индукции И(П{0) = h(riio). Следовательно,
A (s) = с (s, ni0) + h (ni0) = min [c (s, nJ + A (nJ]. i
Поскольку fi(tii) h(n.i) для i = 1, ..., k, ясно, что
A (s) = c (s, ni0) + h (nl0) < min [c (s, nJ J- h (nJ].
Так как вершина пг0 является одной из указанных вершин пг-, то
A (s) = с (s, ni0) + h (nl0) = min [c (s, nJ + h (nJ].
Поэтому по определению h(s) fi(s) = h.(s),
и лемма для случая, когда вершина s разрешима, доказана. Аналогичные рассуждения приводят к тому же результату и в случае, когда у s есть дочерние вершины типа «И» (и для суммарных, и для максимальных стоимостей). Доказательство закончено.
Заметим, что так как Й(п) ==/г(п) для всех разрешимых вершин в дереве перебора, то поиску дерева минимальной стоимости не препятствует то, что на шаге (7) нашего алгоритма мы выбрасываем из списка ОТКРЫТ все вершины, имеющие разрешимые предшествующие им вершины. Не может произойти так, чтобы отброшенные вершины составили часть дерева решения минимальной стоимости.
150
Гл. 5. Методы поиска при сведении задач к подзадачам
Теперь мы готовы сформулировать и доказать утверждение о том, что наш алгоритм упорядоченного перебора допустим в том случае, когда Й является нижней границей величины h для всех вершин из списка ОТКРЫТ.
Теорема 5.1. Если Н(п) h(n) для любой открытой вершины п и стоимости всех дуг превосходят некоторую положительную величину б, то алгоритм упорядоченного перебора допустим.
Доказательство. Стратегия доказательства этой теоремы совпадает с использованной при доказательстве теоремы 3.1. Предположим, что наш метод не приводит к построению оптимального дерева решения, но дерево решения в действительности существует. Снова мы имеем три случая: 1) алгоритм заканчивает свою работу, но дерево решения остается ненайденным; 2) алгоритм вообще не прекращает работу; 3) алгоритм заканчивает свою работу, построив дерево решения, стоимость которого неминимальна.
Случай 1. Алгоритм заканчивает работу без построения дерева решения. Окончание может произойти лишь на шагах (6) и (11) (стр. 144, 145). Если окончание произошло на шаге (6), то начальная вершина разрешима, а это может случиться, лишь если дерево решения было найдено. Если же окончание произошло на шаге (11), то,начальная вершина неразрешима. Но этот случай можно отбросить, поскольку мы предположили, что дерево решения на самом деле существует.
Случай 2. Нет окончания вообще. В этом случае в конце концов будет раскрыта вершина, имеющая глубину d> h(s)/8. По определению величины И (неважно, для суммарной стоимости или максимальной) тогда будет й(з) йб > й(з), что противоречит лемме 5.1.
Случай 3. Алгоритм заканчивает работу построением дерева решения неминимальной стоимости. В момент окончания вершина s должна оказаться разрешимой и, следовательно, по лемме 5.1 й($) = й($). Но величина Й(з) по окончании должна быть равна стоимости дерева То, т. е. найденного дерева решения, и, таким образом, это решение имеет минимальную стоимость.
5.9. ВЫБОР ВЕРШИНЫ В То ДЛЯ ОЧЕРЕДНОГО РАСКРЫТИЯ
Ясно, что свойство допустимости алгоритма упорядоченного перебора с величиной й, являющейся нижней границей функции h для открытых вершин, не зависит от того, какие из концевых вершин в списке ОТКРЫТ выбираются для раскрытия. Мы
5.9. Выбор вершины в т0 для очередного раскрытия
151
уже говорили, что, возможно, наиболее разумным было бы выбрать ту из концевых вершин в то, которая с наибольшей вероятностью5) приведет к опровержению гипотезы о том, что то служит верхней частью дерева решения,, имеющего минимальную стоимость. Если то на самом деле служит частью дерева минимальной стоимости, то безразлично, какую из открытых вершин в То раскрывать в первую очередь, ибо в этом случае они так или иначе все должны быть выбраны для раскрытия. Однако если то не составляет части дерева решения минимальной стоимости, то нет смысла вкладывать слишком много сил в ненужный перебор. Тогда следует раскрыть в первую очередь ту вершину в то, которая с наибольшей вероятностью обнаружит ошибку, допущенную при выборе то.
Если используются суммарные стоимости, то вершиной, которая с наибольшей вероятностью показала бы непригодность то, может оказаться открытая вершина в то, имеющая наибольшее значение ft. Так как она представляется концевой вершиной для решения максимальной стоимости, то, быть может, ее раскрытие в наибольшей степени повысит оцениваемую (суммарную) стоимость дерева то.
В случае же максимальных стоимостей, по-видимому, полезным -окажется метод выбора открытой вершины в то, при котором, отправляясь от вершины з, мы идем по дереву то к некоторой открытой концевой вершине, выбирая под каждой из вершин конкретную дугу следующим образом. Всякий раз, когда в то мы встречаем вершину п с несколькими дочерними вершинами (типа «И») п%, ..., то переходим к той из
неразрешимых дочерних вершин, которая максимизирует величину [с(п, щ) -|-й(пг)]. Достигнутая в результате такого процесса концевая вершина и должна быть той. вершиной, раскрытие которой с наибольшей вероятностью окажет неблагоприятное воздействие на оценку максимальной стоимости дерева то.
Во всяком случае мы не можем доказать оптимальность ни одного из этих методов выбора открытых вершин. По-видимому, для «И/ИЛИ» деревьев нет результата, аналогичного результату для пространства состояний, касающемуся раскрытия наименьшего числа вершин. Интуитивно, однако, кажется правдоподобным, что при любом способе выбора открытой вершины в то эффективность перебора выше для тех функций й, которые лучше аппроксимируют истинную величину h. Чем лучше нижняя граница для h, используемая в Й, тем направленнее будет идти перебор к дереву решения минимальной стоимости.
') Мы пользуемся словами «наибольшая вероятность», не вкладывая в них формального смысла. Мы не будем даже пытаться определить вероятности или произвести статистический анализ.
152
Гл. 5. Методы поиска при сведении задач к подзадачам
5.10. МОДИФИКАЦИИ
Как и в случае переборов в пространстве состояний, существует ряд способов модификации основного алгоритма упорядоченного перебора, делающих его более практическим в конкретных ситуациях. Прежде всего, вместо того, чтобы после каждого раскрытия вершины заново строить новое потенциальное дерево решения, можно было бы не прерываясь раскрыть одну или более вершин в то и несколько их дочерних вершин, а затем уже строить новое дерево то. Такая стратегия приводит к снижению общих затрат на построение то, но в то же время возникает риск, что некоторые из раскрытых вершин не будут расположены на наилучшем потенциальном дереве решения.
В случае «И/ИЛИ» деревьев можно выбрать также стратегию поэтапного перебора, описанную в гл. 3. При ее использовании необходимое пространство в памяти машины периодически очищается в результате отбрасывания некоторых из поисковых «И/ИЛИ» деревьев. Можно, например, определить, какое из потенциальных деревьев решения внутри дерева перебора имеет наибольшую оцениваемую стоимость. Тогда можно периодически отбрасывать некоторое число наиболее «дорогих» потенциальных деревьев решения (с риском, конечно, что отброшенное дерево окажется верхней частью истинного дерева минимальной стоимости).
Если наш метод предполагается использовать для перебора на «И/ИЛИ» графах (а не на «И/ИЛИ» деревьях), то в алгоритме следует произвести более важные изменения. При этом необходимо принять во внимание соображения, упомянутые в разд. 5.4.
5.11. МИНИМАКСНАЯ ПРОЦЕДУРА ПРИ ПЕРЕБОРЕ
НА ИГРОВЫХ ДЕРЕВЬЯХ
В гл. 4 мы видели, что игровые деревья можно представлять в виде «И/ИЛИ» деревьев. Пользуясь этим, мы пытаемся доказать, что игрок ПЛЮС может выиграть из некоторого начального положения игры. Тогда те позиции, которые возникают после хода игрока ПЛЮС, представляются «ИЛИ» вершинами, а позиции, возникающие после хода игрока МИНУС, представляются «И» вершинами. Мы примем, что ПЛЮС ходит первым и ходы ПЛЮСА и МИНУСА чередуются. Следовательно, дочерними для «И» вершин будут «ИЛИ» вершины, и обратно. В соответствии с принятым предположением мы будем считать, что начальной вершиной является «И» вершина. Заключительная вершина соответствует любой позиции, про которую известно, что она является выигрышной для игрока ПЛЮС. (Определение заключительной вершины должно быть изменено, если цель поиска состоит в доказательстве того, что ПЛЮС может добиться
5.11. Минимаксная процедура при переборе на игровых деревьях 1.г3
ничьей, исходя из заданной позиции, или что ПЛЮС в данной позиции не может проиграть.)
Для многих простых игр (а также и для окончаний более сложных игр) можно применить перебор на «И/ИЛИ» деревьях, поскольку тогда доказательство выигрыша (или ничьей) можно найти, не строя больших деревьев перебора. Тогда дерево решения, доказывающее выигрыш (или ничью), дает полную игровую стратегию для игрока ПЛЮС. Примерами простых игр, в которых перебор на «И/ИЛИ» деревьях до получения ответа представляется реально осуществимым, являются игра Гранди из предыдущей главы, тик-так-ту (крестики-нолики), различные варианты игры ним и некоторые шахматные и шашечные эндшпили. Грубую оценку размеров дерева игры для тик-так-ту, например, можно получить, заметив, что начальная вершина имеет 9 дочерних вершин, каждая из которых в свою очередь имеет по 8 дочерних вершин и т. д., что приводит к 9! = 362 880 вершинам в нижней части этого дерева. Однако многие пути обрываются на заключительных вершинах более высоких уровней, и, кроме того, значительного уменьшения размеров дерева можно достичь, если принять во внимание симметрии.
В случае более сложных игр, таких, как полная игра в шахматы или шашки, о переборе до конца на «И/ИЛИ» деревьях не может быть и речи. Число вершин в полном игровом дереве для шашек было оценено величиной 1О40, а для шахмат — 1О120. (Чтобы построить полное дерево для шашек, понадобилось бы около 1021 столетий, даже если предположить, что каждая дочерняя вершина образуется за */з наносекунды.) Процедуры упорядоченного перебора не настолько уменьшают фактор ветвления, чтобы что-то существенно изменилось. Следовательно, мы должны смириться с тем, что для сложных игр перебор до конца невозможен, т. е. следует- отказаться от мысли доказать, что можно достичь выигрыша или ничьей (исключая, возможно, эндшпили).
Вместо этого при переборе на игровых деревьях можно было бы стремиться найти просто «хороший» первый ход. Мы могли бы сделать этот ход, подождать ответа противника и вновь осуществить перебор с тем, чтобы найти «хороший» ход из новой позиции.
Перебор должен производиться так же, как обычный перебор на «И/ИЛИ» графах. Можно воспользоваться либо методом полного перебора, либо перебором в глубину, либо методами упорядоченного перебора, однако условия окончания теперь необходимо изменить. Можно указать несколько искусственных условий окончания, основанных на таких факторах, как ограничение времени перебора, ограничение объема памяти или глубины самой глубокой концевой вершины в дереве поиска. К тому же в шахматах, например, не оканчивают
154
Гл. 5. Методы поиска при сведении задач к подзадачам
перебора, если любая из концевых вершин представляет «живую» позицию, например позицию, в которой нет непосредственно выгодного размена.
После того как перебор будет закончен, мы должны извлечь из дерева перебора оценку «лучшего» первого хода. Эту оценку можно получить, применив к концевым вершинам дерева перебора статическую оценочную функцию. Оценочная функция измеряет «достоинства» позиции, отвечающей концевой вершине, и основана она на различных элементах позиции, которые, как полагают, влияют на ее достоинства. Например, в шашках такими полезными элементами являются относительная продвинутость своих шашек, контроль центра доски, контроль центра доски дамками и т. д. При анализе игровых деревьев обычно принимается соглашение, по которому в игровых позициях, где ПЛЮС имеет преимущество, оценочная функция положительна, а для позиций, где преимущество за игроком МИНУС, оценочная функция отрицательна. Значения вблизи нуля соответствуют игровым позициям, не дающим преимущества ни одному из игроков.
Хороший первый ход можно найти с помощью минимаксной процедуры. Мы предполагаем, что если бы игроку ПЛЮС пришлось выбирать между концевыми вершинами, то он выбрал бы ту из них, которая имеет наибольшую оценку. Следовательно, вершине (типа «И»), являющейся родительской для концевых вершин типа «ИЛИ», приписывается обращенная величина (backed-up value), равная максимуму оценок концевых вершин. С другой стороны, если бы между концевыми вершинами пришлось' выбирать игроку МИНУС, то он, вероятно, предпочел бы выбрать такую вершину, которая имела бы наименьшую оценку (т. е. самую отрицательную). Следовательно, вершине (типа «ИЛИ»), являющейся родительской для концевых «И» вершин, приписывается обращенная величина, равная 'минимуму оценок концевых вершин. После того как всем родительским вершинам концевых вершин приписаны обращенные величины, этот процесс «прослеживания в обратном направлении» переносится на уровень выше при условии, что ПЛЮС выбирает вершину с наибольшей обращенной величиной, а МИНУС — с наименьшей обращенной величиной.
Такое прослеживание в обратном направлении продолжается с уровня на уровень до тех пор, пока, наконец, обращенные величины не будут приписаны всем вершинам, являющимся дочерними для начальной вершины. Мы предполагаем, что если первый ход должен делать игрок ПЛЮС (т. е. дочерними для начальной вершины являются «ИЛИ» вершины), то он должен выбрать‘в качестве своего первого хода ход, соответствующий дочерней вершине с наибольшим значением этой обращенной величины.
5.11. Минимаксная процедура при переборе на игровых деревьях 155
Польза всей этой процедуры связана с тем, что величины, полученные в результате прослеживания оценок в обратном направлении, для вершин, непосредственно следующих за начальной, считаются более надежными мерами относительного достоинства соответствующих позиций, чем те величины, которые можно было бы получить прямым применением оценочной функции к этим позициям. В конце концов эти обращенные величины будут основаны на «просмотре вперед» по дереву игры, и поэтому они зависят от особенностей, возникающих ближе к концу игры.
Проиллюстрируем минимаксный метод на простом примере, использующем игру тик-так-ту. Предположим, что ПЛЮС ставит крестики (X), а МИНУС ставит нолики (О), и пусть первым ходит ПЛЮС. Мы будем производить полный перебор до тех пор, пока не будут построены все вершины на уровне 2, а затем применим статическую оценочную функцию к позициям, соответствующим этим вершинам. Пусть наша оценочная функция е(р) позиции р задается следующим образом:
Если р не является позицией выигрыша, то
е(р) = (число полных строк, столбцов или диагоналей, все еще открытых для игрока ПЛЮС) — (число полных строк, столбцов или диагоналей, все еще открытых для игрока МИНУС).
Если позиция р выигрышна для игрока ПЛЮС, то
е(р) = оо (символ оо означает очень большое положительное число).
Если позиция р выигрышна для игрока МИНУС, то
<?(£)=—оо.
|О|
Таким образом, если р есть Z*_’ тое(р)=6 — 4 = 2. При
построении дочерних позиций мы будем учитывать симметрии. Так, все позиции
мы будем считать идентичными. (В начале игры фактор ветвления в игре тик-так-ту мал из-за симметрий, а в конце игры он мал из-за небольшого числа незаполненных клеток.)
На рис. 5.10 изображено дерево, построенное при переборе до глубины 2. Под концевыми вершинами показаны их статические оценки, а величины, полученные в результате прослеживания в обратном направлении, обведены кружком. Поскольку
lOlX
Рис- 5.10. Минимаксный подход в игре тик-так-ту (первый этап).
5.12. Альфа-бета процедура
157
позици^
имеет обращенную величину с наибольшим зна
чением.она выбирается как первый ход. (Кстати, оказывается, что это лучший первый ход для игрока ПЛЮС.)
Предположим теперь, что ПЛЮС делает этот ход, и МИ-
О х
НУС отвечает позицией
. (Плохой ход для бедного игро
ка МИНУС, который, видимо, не пользуется хорошей стратегией
перебора.) Далее ПЛЮС осуществляет перебор на глубину 2
01 ч
(отправляясь от позиции х ). что приводит к дереву пе
ребора, изображенному на рис. 5.11. ПЛЮС делает наилучший ход, а МИНУС делает ход, благодаря которому он избегает .немедленного поражения; в результате получается позиция
. Затем ПЛЮС снова осуществляет перебор, что приво
дит к дереву, изображенному на рис. 5.12. Некоторые из концевых вершин этого дерева (например, вершина Д) представляют позиции, в которых МИНУС выигрывает, и поэтому они имеют оценку —сю. Проследив эти оценки в обратном направлении, мы видим, что наилучшим ходом для игрока ПЛЮС является здесь дот единственный ход, который позволяет ему избежать немедленного поражения. Теперь даже МИНУС может видеть, что ПЛЮС должен выиграть при следующем своем ходе, и потому он с достоинством уступает.
5.12. АЛЬФА-БЕТА ПРОЦЕДУРА
В только что описанной процедуре перебора процесс построения дерева перебора полностью отделен от процесса оценки позиции. Только после того, как заканчивается построение дерева, начинается оценка позиций. Оказывается, что такое разделение приводит к весьма неэффективной стратегии. Можно добиться существенного снижения необходимого объема перебора (иногда на несколько порядков), если оценивание концевых вершин и вычисление обращенных величин вести одновременно с построением дерева.
Рассмотрим дерево перебора, изображенное на рис. 5.12 (последний этап нашего перебора в игре тик-так-ту). Предположим, что концевая вершина оценивается, как только она построена. Тогда после построения и оценки вершины А нет
Рис. 5.11. Минимаксный подход в игре тик-так-ту (второй этап).
Рис.
5.12. Минимаксный подход
в игре тик-так-ту (третий этап).
160
Гл. 5. Методы поиска при сведении задач к подзадачам
никакого смысла строить (и оценивать) вершины В, С и D. В самом деле, так как в распоряжении игрока МИНУС имеется позиция А и он ничего не может ей предпочесть, то ясно, что он выберет именно А. Тогда можно приписать вершине, предшествующей А, обращенную величину —оо и продолжать перебор, сэкономив поисковые усилия, связанные с построением и оценкой вершин В, С и D. (Заметим, что эта экономия была бы даже еще значительнее, если бы перебор производился
до большей глубины, поскольку не нужно было бы строить ни одну из вершин, следующую за В, С и D.) Важно отметить, что тот факт, что вершины В, С и D не строятся, никак не может повлиять на ход, который окажется для игрока ПЛЮС наилучшим первым ходом.
В этом примере экономия затрат на перебор связана с тем, что позиция А выигрышна для игрока МИНУС. Однако экономии такого же типа можно добиться даже и тогда, когда ни одна из позиций дерева перебора не является выигрышной ни для игрока ПЛЮС, ни для игрока МИНУС.
Рассмотрим дерево для игры тик-так-ту, изображенное на рис. 5.10. Часть этого дерева воспроизведена на рис. 5.13. Предположим, что производится перебор на заданную глубину, и как только строится некоторая концевая вершина, вычисляется ее статическая оценка. Предположим также, что, как только позиции может быть приписана обращенная величина, эта величина
5.12. Альфа-бета процедура
161
сразу же вычисляется. Теперь рассмотрим ситуацию, возникающую на том этапе перебора в глубину, когда уже построены вершина А и ее дочерние вершины, но еще не построена вершина В. Для вершины А обращенная величина равна —1. Сейчас начальной вершине можно приписать предварительную обращенную величину (ПОВ), равную —1. В зависимости от обращенных величин других дочерних вершин начальной вершины окончательная обращенная величина начальной вершины может стать больше этой предварительной величины —1, но не может стать меньше.
Продолжим процесс поиска в глубину до момента, когда строятся вершина В и первая из ее дочерних вершин, т. е. С. Вершине С присваивается статическая величина —1. Вершине В можно присвоить предварительную обращенную величину (ПОВ), равную —1. В зависимости от статических величин остальных дочерних вершин вершины В окончательная обращенная величина вершины В может стать меньше—1, но не может стать больше. Заметим, что окончательная обращенная величина вершины В не может поэтому превысить ПОВ начальной вершины и, следовательно, можно прервать перебор ниже вершины В. Можно быть уверенным в том, что вершина В не окажется предпочтительнее вершины А.
Это уменьшение затрат на перебор достигается благодаря прослеживанию предварительных обращенных величин. В общем случае, как только дочерним вершинам некоторой вершины приписаны обращенные величины, следует пересмотреть ПОВ этой вершины. Следует учесть, что
1) ПОВ «И» вершин (включая начальную вершину) не может уменьшаться.
2) ПОВ «ИЛИ» вершин не может увеличиваться.
Учитывая эти замечания, сформулируем следующие правила прерывания перебора:
а) Перебор можно прервать ниже любой «ИЛИ» вершины, ПОВ которой не больше, чем ПОВ любой предшествующей ей вершины «И» (включая начальную вершину). Этой вершине «ИЛИ» затем можно присвоить ее ПОВ в качестве окончательной обращенной величины1).
б) Перебор может быть прерван ниже любой «И» вершины, ПОВ которой не меньше, чем ПОВ любой предшествующей ей «ИЛИ» вершины. Этой «И» вершине затем можно присвоить ее ПОВ в качестве окончательной обращенной величины.
>) Заметим, что эта обращенная величина может не быть «истинной» для своей вершины, но она является той границей, которая приводит к правильному вычислению предварительной обращенной величины для предшествующей вершины.
6 Зак. 493
Рис.
5.14. Пример, иллюстрирующий перебор альфа-бета
(□ — вершины типа «И», О — вершины типа «ИЛИ»).
5.13. Эффективность перебора при альфа-бета процедуре 163
В процессе поиска ПОВ вычисляются следующим образом: 1) ПОВ для «И» вершины (включая начальную вершину) полагается равной наибольшей из имеющихся в данный момент обращенных величин ее дочерних вершин.
2) ПОВ для вершины «ИЛИ» полагается равной наименьшей из имеющихся в данный момент обращенных величин ее дочерних вершин.
Обычно ПОВ для «И» вершин называют альфа-величинами, а ПОВ для «ИЛИ» вершин называют бета-величинами. Если перебор прерывается в соответствии с правилом (а), то говорят, что имеет место альфа-отсечение, а если в соответствии с правилом (б), то говорят, что имеет место бета-отсечение. Весь процесс прослеживания ПОВ и осуществления отсечений, когда это возможно, обычно называют альфа-бета процедурой. Процедура заканчивается, когда всем дочерним вершинам для начальной вершины приписаны окончательные обращенные величины. Тогда наилучшим первым ходом будет ход, приводящий к дочерней вершине с наибольшей обращенной величиной. Заметим, что такая процедура всегда приводит к тому же наилучшему первому ходу, что и простой минимаксный метод той же глубины. Единственное отличие состоит в том, что альфа-бета процедура, как правило, находит этот наилучший первый ход после перебора намного меньшего объема.
Применение альфа-бета процедуры иллюстрируется на дереве, изображенном на рис. 5.14. Это дерево перебора, построенное на глубину 6. (Для удобства «И» вершины изображены квадратиками, а вершины «ИЛИ» — кружками.) Концевые вершины имеют указанные статические значения. Предположим, что мы ведем перебор с использованием альфа-бета процедуры. (Мы опять договариваемся строить в первую очередь вершины, расположенные слева.) Поддерево, получающееся в результате альфа-бета процедуры, выделено жирными линиями. Отсеченные вершины зачеркнуты. Заметим, что пришлось оценить только 18 из. первоначальных 41 вершин. Читатель может на этом примере проконтролировать свое понимание смысла альфа-бета процедуры, попробовав повторить перебор.
5.13. ЭФФЕКТИВНОСТЬ ПЕРЕБОРА ПРИ АЛЬФА-БЕТА ПРОЦЕДУРЕ
Для того чтобы можно было произвести отсечения, по крайней мере часть дерева перебора должна быть построена до максимальной глубины, поскольку предварительные обращенные величины должны основываться на статических значениях концевых вершин. Поэтому при использовании альфа-бета процедуры обычно прибегают к той или иной разновидности перебора' в глубину. Число отсечений, возможных в процессе перебора, зависит от степени, в которой первые предварительные
С*
164
Гл. 5. Методы поиска при сведении задач к подзадачам
величины аппроксимируют окончательные обращенные величины.
Окончательная обращенная величина для начальной вершины совпадает со статическим значением одной из концевых вершин. Если эту вершину можно достичь первой при переборе в глубину, то число отсечений будет максимальным. При максимальном числе отсечений требуется строить и оценивать минимальное число концевых вершин.
Пусть дерево имеет глубину D и у каждой вершины (за исключением концевой) в точности В дочерних вершин. У такого дерева будет ровно BD концевых вершин. Предположим, что в альфа-бета процедуре дочерние вершины строятся в порядке, соответствующем их истинным обращенным величинам: для «ИЛИ» вершин строятся дочерние вершины с наибольшими значениями, а для вершин «И» — с наименьшими. (Конечно, эти обращенные величины в момент построения дочерних вершин, как правило, не известны, так что в действительности этот порядок никогда не достигается, разве что случайно.)
Оказывается, что такой порядок максимизирует число отсечений и минимизирует число построенных концевых вершин. Обозначим это минимальное число концевых вершин через ND. Можно показать, что
f 2BD/2— 1 для четного D,
Nd | 5<о+1)/2 g(D-i)/2— । для нечетного D.
Иными словами, число концевых вершин глубины D, которые будут построены при оптимальном альфа-бета переборе, примерно равно числу концевых вершин, которые были бы построены на глубине D/2 без альфа-бета процедуры. Таким образом, при тех же требованиях к памяти альфа-бета процедура с совершенным упорядочением дочерних вершин позволяет удвоить глубину перебора. Конечно, в задачах перебора невозможно добиться совершенного упорядочения (если бы это было возможно, то мы не нуждались бы ни в каком процессе перебора!), однако важно использовать наилучшую из имеющихся в нашем распрряжении функций упорядочения, поскольку это приносит большую потенциальную выгоду.
5.14. КОМБИНИРОВАННЫЕ АЛЬФА-БЕТА ПРОЦЕДУРЫ И ПРОЦЕДУРЫ УПОРЯДОЧЕНИЯ
Сразу приходят на ум две процедуры построения дочерних вершин в той последовательности, которая оценивается как наилучшая.
5.14. Комбинированные процедуры
165
Фиксированное упорядочение
Можно использовать процедуру перебора в глубину, в которой в первую очередь строится.дочерняя вершина, оцениваемая как лучший ход (для любого игрока). Мы будем говорить, что в такой процедуре используется фиксированное упорядочение. Так, если, скажем, вершина 1 оценивается как наилучшая из дочерних вершин начальной вершины (с точки зрения игрока ПЛЮС), то следующей строится она, и она же выбирается для очередного раскрытия. Тогда если, скажем, вершина 11 оценивается как наилучшая из дочерних вершин вершины 1 (с точки зрения игрока МИНУС), то она строится следующей и выбирается для раскрытия. Этот процесс продолжается до тех пор, пока не будет достигнута концевая вершина, после чего становятся возможными отсечения. Перебор в глубину (с использованием альфа-бета процедуры) продолжается обычным образом, причем построение вершин по-прежнему производится в порядке их оцениваемого достоинства.
Оценку достоинства вершины можно производить различными способами. Для ранжирования дочерних вершин можно _ взять саму статическую оценочную функцию или, быть может, какую-нибудь более простую (и менее надежную) оценочную функцию. С другой стороны, под каждой из дочерних вершин "можно произвести менее глубокий перебор, а потом упорядочить дочерние вершины, исходя из их обращенных величин, полученных в результате такого неглубокого перебора. Конечно, в каждом из этих методов следует сопоставить дополнительные затраты на перебор, связанные с упорядочением, с той экономией, которая вызывается возрастающим при этом числом отсечений ветвей в дереве перебора. Обычно для того, чтобы выбрать правильное соотношение между этими факторами, нужно произвести эксперимент.
Динамическое упорядочение
Достоинство описанной альфа-бета процедуры с фиксированным упорядочением заключается в том, что она довольно проста. Но может случиться, что в ходе перебора, идущего по определенному пути в дереве перебора, становится очевидно, что этот перебор следовало бы продолжить, отправляясь от некоторой более высокой вершины, которая теперь более эффективна. Осуществлять перебор в той части дерева, которая представляется наиболее перспективной, до тех пор пока не будет достигнута максимальная глубина, можно будет, слегка изменив алгоритм упорядоченного перебора на деревьях «И/ИЛИ». Мы будем говорить, что модифицированный алгоритм упорядоченного перебора использует в этом случае динамическое упорядочение.
166
Гл. 5. Методы поиска при сведении задач к подзадачам
Изменения весьма просты. На каждом этапе в процессе перебора в дереве перебора будут концевые вершины. Вместо того чтобы подсчитывать для этих вершин значения Н (измеряющие оцениваемую стоимость), можно для измерения достоинства соответствующих позиций игры привлечь некоторую оценочную функцию е. Тогда, по аналогии с подсчетом значений ft, для неконцевых вершин дерева перебора будут вычисляться обращенные величины, или е-значения. (Заметим, что стоимости дуг в дереве игры обычно не задаются; поэтому обращенные величины будут вычисляться точно так же, как в минимаксной процедуре.)
На основе обращенных е-значений в дереве выделяется цепочка наилучших ходов, ведущая к одной из его концевых вершин. Эта вершина и раскрывается в следующую очередь. (Наилучшим ходом под вершиной и будет выбор дочерней «ИЛИ» вершины, имеющей наибольшее обращенное е-значение; наилучшим ходом под «ИЛИ» вершиной будет выбор дочерней «И» вершины, имеющей наименьшее обращенное е-значение.) Когда в конечном итоге достигается максимальная глубина, у нас появляется возможность подсчитать предварительные обращенные величины, и тогда можно начать искать возможные отсечения. (Выполнение отсечений аналогично удалению вершин из списка ОТКРЫТ на шагах (7) и (12) алгоритма упорядоченного перебора (стр. 144, 145).)
Здесь снова можно оценить достоинства позиции, соответствующей этой концевой вершине дерева перебора, с помощью статической оценочной функции или посредством неглубокого перебора. Можно допустить также, чтобы до того, как будут производиться вычисления, связанные с получением нового дерева то, под вершиной, выбранной для раскрытия, вырастал целый кусок дерева. В ряде экспериментов (Слейджл и Диксон, 1969) на примере игры калах1) было показано, что метод альфа-бета, использующий определенный вид динамического упорядочения, более эффективен по .сравнению с альфа-бета процедурой с фиксированным упорядочением или же (естественно) по сравнению с простой минимаксной процедурой без альфа-бета.
5.15. ВОЗМОЖНОЕ УЛУЧШЕНИЕ МЕТОДОВ, ОСНОВАННЫХ НА МИНИМАКСЕ
Основная философия методов, основанных на минимаксе (включая методы, использующие альфа-бета), состоит в том, что наилучший ход игрока МИНУС определяется перебором, произведенным игроком ПЛЮС. Если предположить, что по-
) Игра калах подробно описана в журнале «Наука» и жизнь», № 12> 106—114, 1971. Там же приведено (популярное) описание нескольких программ этой игры для ЭВМ. — Прим, перев.
5.16. Библиографические и исторические замечания 167
исковые возможности игрока МИНУС те же, что и у игрока ПЛЮС; то в'действительности его^ перебор будет произведен на один уровень глубже перебора, произведенного в дереве перебора игроком ПЛЮС. Таким образом, после того как игрок МИНУС осуществит перебор, он может выбрать свой ответный ход на основе обращенных величин, более надежных, чем те, что были вычислены игроком ПЛЮС. Следовательно, наилучший ход игрока МИНУС не будет совпадать с наилучшим ходом, полученным ранее игроком ПЛЮС.
Можно исправить это положение, слегка изменив минимаксный метод построения обращенных величин. Вместо того чтобы в качестве обращенной величины брать наибольшее (или наименьшее) из значений для дочерних вершин, можно взять некоторую более сложную функцию этих значений. Например, к обращенной величине для «И» вершины предлагалось добавлять еще некоторую фиксированную величину, если наибольшее значение имеет более чем одна из дочерних вершин «ИЛИ». Аналогично эту фиксированную величину предлагалось вычитать из величин «ИЛИ» вершин, если «И» вершина имеет более чем одну «хорошую» (для игрока МИНУС) дочернюю вершину.
Эта стратегия добавления или вычитания определенной суммы позволяет выделить дополнительные достоинства позиции, из которой можно сделать несколько хороших ходов. Эксперименты, проверенные с этой стратегией (Слейджл и Диксон, 1970), показывают, что ее использование действительно приводит к лучшей игре, по крайней мере в случае игры калах.
5.16. БИБЛИОГРАФИЧЕСКИЕ И ИСТОРИЧЕСКИЕ ЗАМЕЧАНИЯ
Развитие методов перебора на «И/ИЛИ» графах
В стратегиях поиска большинства из ранних программ, в которых строились деревья подзадач, применялись лишь простые методы упорядочения. В первых вариантах универсального решателя задач применялась стратегия перебора в глубину и привлекались средства оценки трудности задач; возвращение назад производилось в тех случаях, когда дочерняя задача представлялась более сложной по сравнению с одной из предшествующих ей задач. В программе SAINT Слейджла в качестве меры трудности задачи вводится «глубина подинтегрального выражения» и обычно в первую очередь расматривается самая легкая и? задач.
В 60-х годах Слейджл и его сотрудники провели много экспериментов с различными стратегиями перебора для игровых деревьев и «И/ИЛИ» деревьев. Обзор стратегий для игровых деревьев содержится в статье Слейджла и Диксона (1969). В самой сложной из этих стратегий используется динамическое упорядочение раскрытия вершин. Программа Слейджла и
168
Гл. 5. Методы поиска при сведении задач к подзадачам
Бурского (1968), названная MULTIPLE (MULTIpurpose Program that LEarns), включает некоторую универсальную стратегию для перебора на «И/ИЛИ» графах. В этой стратегии используется понятие «вероятности того, что предположение верно», а затем определяется «функция качества», заданная на множестве открытых вершин дерева. Вершина, оказывающая наибольшее влияние на вероятность того, что первоначальное предположение верно, считается обладающей наиболее высоким «качеством». Последняя и выбирается для раскрытия.
Амарель (1967) предложил стратегию «контроля внимания» для упорядочения процесса раскрытий в «И/ИЛИ» дереве. Эта стратегия связана с попыткой найти решение минимальной стоимости. Автор этой книги (Нильсон, 1969) также предложил одну стратегию минимизации стоимости и позже понял, что она по существу совпадает со стратегией Амареля. В работе Нильсона (1969) доказывается, что эта стратегия действительно позволяет найти решения минимальной стоимости. Это доказательство, так же как и доказательство, приведенное в настоящей главе, похоже на доказательство Харта, Нильсона и Рафаэля (1968) для графов в пространстве состояний. Стратегия Амареля — Нильсона мало отличается от метода динамического упорядочения Слейджла и Диксона. Описание алгоритма упорядоченного поиска, приведенное в настоящей главе, является просто попыткой дать достаточно ясное и общее представление об этой основной стратегии.
Развитие методов перебора на игровых деревьях
Клод Шеннон (1950) рассмотрел некоторые вопросы, относящиеся к созданию программ для машины, играющей в такие сложные игры, как шахматы. Он предложил применять минимаксную поисковую процедуру вместе со статической оценочной функцией. Ньюэлл, Шоу и Саймон (1958) использовали его идеи при конструировании первых программ для игры в шахматы. Им принадлежит также блестящий обзор этой области исследований. Дополнительное обсуждение программ для игры в шахматы вместе с «пятилетним планом работ» в области автоматической шахматной игры можно найти в статье Гуда (1968), содержащей также некоторые ссылки.
В 1959 г. Сэмюэль описал программу игры в шашки, в которой использовались полиномиальные оценочные функции, минимаксные методы перебора и различные стратегии «обучения», позволяющее совершенствовать игру1)- Программа Сэмюэля
) Позднее Сэмюэль отмечал (частное сообщение), что в его программе применяется также альфа-бета процедура, но в то время он полагал, что ее использование носит слишком очевидный характер, чтобы стоило включать ее в статью.
5.16. Библиографические и исторические замечания
169
блестяще играет в шашки и выигрывает у всех, за исключением лишь очень сильных игроков. Она по-прежнему остается одним из лучших примеров применения методов искусственного интеллекта. Дальнейшая работа над этой программой описана в работе Сэмюэля (1967). Одной из особенностей самых последних вариантов программы Сэмюэля является динамическое упорядочение процедуры перебора, до некоторой степени похожее на упорядочение Слейджла и Диксона (1969).
Альфа-бета процедура обычно представляется довольно очевидным развитием минимаксного подхода и поэтому независимо «открывалась» рядом исследователей. Впервые она была описана Ньюэллом, Шоу и Саймоном (1958) и была предметом глубокого изучения, проведенного Маккарти и его учениками (Эдвардс и Харт, 1963) в Массачусетском технологическом институте. Существует несколько ясных изложений этого метода и его свойств. Хорошее его описание содержится во второй статье Сэмюэля (1967), посвященной игре в шашки, а также в статье Слейджла и Диксона (1969). Результаты, касающиеся эффективности перебора в альфа-бета процедуре, впервые были установлены Эдвардсом и Хартом (1963) на основе теоремы, которую они приписывают Михаэлу Левину. Позднее Слейджл и Диксон (1969) привели, как они полагают, первое опубликованное доказательство этой теоремы. Они рассмотрели несколько вариантов альфа-бета процедуры, в том числе (наилучший вариант) использование динамического упорядочения. Сравнение работы этих различных стратегий было проведено на примере старинной игры калах.
Наше исследование возможных усовершенствований методов, основанных на минимаксе, исходит из некоторых предложений Слейджла (19636) и Слейджла и Диксона (1970). В последней статье описываются эксперименты с «Программой перебора на деревьях M&N», в которой при вычислении обращенных величин добавляется (или вычитается) фиксированная величина.
Некоторые характерные игровые программы
Шахматы
Кистер и др. (1957) описали самую первую шахматную систему, запрограммированную на вычислительной машине (MANIAC I в Лос-Аламосе). В ней используется уменьшенная доска (6X6), и ее игра представляется довольно бедной.
Бернштейн и др. (1958) описали шахматную систему, запрограммированную на машине IBM. Она также играет довольно плохо, но на доске обычных размеров (8X8).
Ньюэлл, Шоу и Саймон (1958) дали другой пример ранней шахматной программы, разработанной в Карнеги.
170
Гл. 5. Методы поиска при сведении задач к подзадачам
Коток (1962) изложил первый вариант программы, составленной в Массачусетском технологическом институте, которая позже была взята Маккарти в Станфорд и слегка модифицирована. Она уже достигает уровня игры посредственного игрока.
Г. М. Адельсон-Вельский и др. (в нашем распоряжении нет их работы1)) написали программу в Институте теоретической и экспериментальной физики (Москва). Эта программа победила в турнире программу Котока—'Маккарти. (См. SIGART Newsletter, № 4 (июнь 1967), стр. 11.)
Гринблатт и др. (1967) описали программу, составленную в Массачусетском технологическом институте, которая теперь называется Мэк Хак. Уровень ее игры можно охарактеризовать как уровень «среднелюбительский». Она является почетным членом Массачусетского шахматного общества и получила категорию С. Некоторчяе другие примеры игр содержатся в следующих выпусках SIGART Newsletter, № 6 (октябрь 1967), стр. 8 (здес$> вычислительная машина выигрывает у X. Дрейфуса, который прежде выражал сомнение в том, что машина вообще способна выиграть у игрока-любителя); № 9 (апрель 1968), стр. 9—10, № 15 (апрель 1969), стр. 8—10; № 16 (июнь 1969), стр. 9—11. Шашки
Сэмюэль (1959, 1967) продолжает усовершенствовать программу, которая великолепно играет в шашки, но не может нанести поражение чемпиону мира.
Калах2)
Первую программу для этой игры написал Рассел (1964).
Слейджл и Диксон (1969) описали эксперименты с использованием игры калах и (1970) результаты экспериментов, в которых калах используется для испытания «процедуры M&N».
(По-видимому, в игре калах человек неспособен выиграть у машины.)
Гоу
Зобрист (1969) написал программу для игры в старинную и трудную игру гоу. С точки зрения человека, эта программа играет довольно плохо и не производит перебора по дереву. Примеры работы программы Зобриста можно найти в SIGART Newsletter, № 18 (октябрь 1969), стр. 20—22.
Задачи
5.1. При проведении индукции в лемме 5.1 мы получили доказательство для случая, когда дочерними вершинами начальной вершины являются «ИЛИ» вершины, и отметили, что подобные рассуждения можно применить и тогда,
’) См. статью Адельсона-Вельского и др., УМН, 25, вып. 2(152), (1970).—» Прим, перев.
2) См. примечание переводчика на стр. 166. — Прим, перев.
Задачи
171
когда дочерними вершинами являются «И» вершины. Дайте доказательство для этого случая, закончив, таким образом, доказательство леммы 5.1.
5.2. (Для играющих в шахматы.) Возьмите какой-нибудь шахматный эндшпиль (скажем, из шахматного раздела газеты) и решите его, построив полное игровое дерево. Нарисуйте это дерево перебора, указав все ходы, которые вы рассмотрели, и отметьте «И/ИЛИ» поддерево решения. Какие специфически шахматные эвристики вы использовали при построении дерева перебора?
*5.3. Постройте алгоритм упорядоченного перебора для «И/ИЛИ» графов (обобщив соответствующий алгоритм для деревьев, описанный в разд. 5.7).
5.4. Проведите альфа-бета перебор на игровом дереве, изображенном на рис. 5.14, строя в первую очередь самые правые вершины. Укажите, где делаются отсечения, и сравните с- рис. 5.14, на котором- в первую очередь строились самые левые вершины.
*5.5. (Для программистов на языке LISP.) Напишите на LISP функцию SEARCH (START, DEPTH), которая строит игровое дерево, применяя построитель допустимых ходов.на LISP вида LEGALS (POSITION) сначала к исходной позиции START, а затем к ее дочерним позициям и т. д. вплоть до некоторой максимальной глубины DEPTH. (Предположите, что в позиции START ходит игрок ПЛЮС, а затем ходы чередуются.) Функция SEARCH должна применять статическую оценочную функцию VAL (POSITION) к вершинам с глубиной, равной DEPTH, и производить альфа-бета перебор с тем, чтобы найти наилучший ход в позиции START. Значением SEARCH должен быть список вида (BPOSITION, VALUE), где BPOSITION — это наилучшая дочерняя (по отношению к START) позиция, a VALUE — обращенная величина для игрока ПЛЮС.
*5.6. Напишите для вычислительной машины программу игры в трехмерную игру тик-так-ту (называемую иногда Кьюбик). В эту игру играют два или более игрока на кубе 4X4X4, разделенном иа 64 ячейки. Каждый из игроков по очереди помещает один из своих значков в одну из свободных ячеек. Первый из игроков, которому удается поместить четыре своих значка в одну строку, столбец или диагональ любой из плоскостей куба или вдоль любой из главных диагоналей куба, выигрывает. В программе можно применить любую разумную стратегию перебора, но следует использовать в ней также и некоторые эвристические элементы, позволяющие ограничивать число дочерних позиций, строящихся в игровом дереве. Чтобы охватить игры п лиц, п 2, потребуется обобщить понятия игрового дерева и перебора на игровом дереве.
Глава 6
ДОКАЗАТЕЛЬСТВО ТЕОРЕМ В ИСЧИСЛЕНИИ ПРЕДИКАТОВ
6.1. ИСЧИСЛЕНИЕ ПРЕДИКАТОВ КАК ЯЗЫК ДЛЯ РЕШЕНИЯ ЗАДАЧ
Мы отмечали в гл. 1, что для решения многих задач может потребоваться логический анализ. Для автоматического логи* ческого рассуждения необходим некоторый формальный язык, на котором можно формулировать посылки и делать верные логические выводы. Все, что для этого требуется, — это возможность описать интересующую нас задачу и средства поиска со* ответствующих шагов в процессе логического вывода.
Исчисление предикатов первого порядка — это такая система в логике, в которой можно выразить большую часть того, что относится к математике, а также многое из разговорного языка. Эта система содержит правила логического вывода, позволяющие делать верные логические построения новых утверждений, исходя из некоторого заданного множества утверждений. Благодаря своей общности и логической силе исчисление предикатов может всерьез претендовать на использование его для машинного построения умозаключений.
В этой главе мы на время отойдем от нашей главной цели изучения процессов решения и дадим обзор теории исчисления предикатов и приемов дедукции в этой системе, основанных на принципе резольвенций1). В гл. 7 мы вернемся к предмету решения задач и приведем примеры, иллюстрирующие задачи. Наконец, в гл. 8 мы объясним работу некоторых наиболее эффективных способов поиска требуемых логических заключений.
Язык, подобный языку в исчислении предикатов, определяется его синтаксисом. Чтобы задать синтаксис, надо задать алфавит символов, которые будут использоваться в этом языке, и правила соединения этих символов друг с другом в выражениях, допустимых на этом языке. Один из важных классов выражений в исчислении предикатов — это класс правильно построенных формул (п. п. формул).
Мы обычно пользуемся языком для того, чтобы делать утверждения, касающиеся интересующей нас области. Отношения между языком и описываемой им областью определяются семантикой этого языка. П. п. формулы исчисления предикатов как раз являются теми выражениями, которые мы будем ис-
’) Используется также термин «резолюция», который нам представляется менее удачным русским переводом английского resolution. — Прим, перев.
6.2. Синтаксис
173
пользовать в качестве утверждений, касающихся интересующей нас области. Говорят, что п. п. формулы принимают значение Т или 'F в зависимости от того, являются эти утверждения в этой области истинными или ложными. Приемы обращения с п. п. формулами позволяют строить умозаключения, относящиеся к некоторой области, и, следовательно, могут представить интерес при создании процессов принятия решения, требующих такого умозаключения.
В следующем разделе мы зададим синтаксис одного из вариантов исчисления предикатов. Затем покажем, как на этом языке можно делать утверждения, касающиеся описываемой им области.
6.2. СИНТАКСИС
Синтаксис нашей системы исчисления предикатов включает в себя задание алфавита символов и определение различных полезных выражений, которые можно построить из этих символов.
Для того чтобы объяснить основные идеи, мы начнем с введения сравнительно • примитивной системы1). Потом добавим к этому алфавиту другие символы, позволяющие записывать некоторые из выражений короче.
Основной алфавит состоит из таких множеств символов:
1. Знаки пунктуации: , ( ).
2. Логические символы: ~ ==>. (Символ ~ читается как «не», а символ ==> как «влечет за собой».)
3. n-местные функциональные буквы: (r^l, n^O). называются константными буквами. Для простоты записи вместо ft удобно употреблять строчные буквы а, Ь, с, а вместо других — строчные буквы f, g, h.без индексов.)2)
4. n-местные предикатные буквы: р? н^О). (р°{ называются пропозициональными буквами. Мы включили их для полноты, но в последующих примерах мы ими не пользуемся. Для простоты записи вместо р" удобно употреблять прописные буквы Р, Q, Р без индексов.)
Из этих символов можно построить различные выражения. Классы выражений, представляющих для нас интерес, можно рекурсивно определить следующим образом:
*) Конкретнее, мы временно исключаем из рассмотрения кванторы и переменные.
2) У читателя может возникнуть вопрос, почему мы сразу не строили определения, употребляя буквы a, b, с, f, g, h. Причина состоит в том, что нам нужно, чтобы наши формальные определения годились для произвольно больших множеств функциональных букв, таких, как f " В конкретных примерах, однако, обычно берется небольшое число функциональных букв, и поэтому можно ограничиться более простым конечным множеством {a, b, с, f, g,h}.
174 Гл. 6. Доказательство теорем в исчислении предикатов
1. Термы.
а) Каждая константная буква есть терм.
б) Если 6, • •, tn (« > 1) — термы, то ..., 6г)—терм.
в) Никакие другие выражения не являются термами. (Заметим, что если выражение g(6, t2, .... tn) используется как терм, то оно используется вместо t2......./„) для некото-
рого I. Верхний индекс у g был бы излишним.)
2. Атомные формулы.
а) Пропозициональные буквы являются атомными формулами.
б) Если tn (и >1) —термы, то t2.........tn)-
атомная формула.
в) Никакие другие выражения не являются атомными формулами.
3. Правильно построенные формулы (п. п. формулы).
а) Атомная формула есть п. п. формула.
б) Если А — п. п. формула, то (~А)— п. п. формула.
в) Если А и В — п. п. формулы, то (А=>В)— также п. п. формула.
г) Никакие другие выражения не являются п. п. формулами (пока).
Приведем примеры п. п. формул1):
~P(a,g(a, b, а)), P(a,b)^(~Q(c)), (~(P(a)=$P(b)))^P(b), ~P(a)^Q(f(a)).
Приведем примеры выражений, не являющихся п. п. формулами:
Q(f(a), (P(&)=>Q(c))).
Добавим к нашему алфавиту логические символы А («и») и V («или»), которые позволят короче записывать более сложные п. п. формулы, содержащие ~ и =ф. Пусть Л\ и Х2 — любые две п. п. формулы. Тогда Х^/\Х2 и Л) VX2 —также правильно построенные формулы, определяемые равенствами
Х1ДХ2=~(Х1=»~Х2),
XIVX2 = (-X1)=»X2.
’) Если это не может привести к недоразумению, круглые скобки будем опускать.
6.3. Семантика
175
6.3. СЕМАНТИКА
Для того чтобы п. п. формуле придать «содержаний», ее надо интерпретировать как некоторое утверждение, касающееся рассматриваемой области. Для нас областью может служить некоторое непустое множество (возможно, бесконечное). Им может быть множество целых чисел, или множество всех конфигураций игры в восемь, или множество всех математиков и т. д. Интересующие нас утверждения будут связаны с отношениями между элементами этой области. Например, мы можем захотеть высказать утверждение: «Джон — отец Билла». Тогда областью будет множество людей, а отношением между людьми — бинарное отношение «отцовства».
Полезно также иметь функции на этой области. Если D — область, то «-местная функция ставит в соответствие каждому набору из п элементов области D некоторый элемент из этой области. Так, функция плюс отображает пары целых чисел в целые числа в соответствии с хорошо известной операцией сложения.
Именно об этих аспектах области — ее элементах, ее функциях и ее отношениях — мы и хотим говорить на нашем языке исчисления предикатов. Для того чтобы для п. п. формулы сделать утверждение определенного смысла, мы связываем с этой п. п. формулой некоторую непустую область D, а затем
с каждым константным символом в п. п. формуле — некоторый конкретный элемент из D;
с каждой функциональной буквой в п. п. формуле — некоторую конкретную функцию на D («-местные функциональные буквы соответствуют «-местным функциям);
с каждой предикатной буквой в этой п. п. формуле — некоторое конкретное отношение между элементами из D («-местные предикатные буквы соответствуют «-местным отношениям).
Конкретизация области и указанных соответствий дает интерпретацию, или модель, нашей п. п. формулы.
При заданной п. п. формуле и некоторой интерпретации каждой атомной формуле в этой п. п. формуле приписывается значение Т или F. Эти значения можно затем использовать для того, чтобы приписать значение Т или F всей п. п. формуле. Правило приписывания значения атомной формулы очень простое: если термы предикатной буквы соответствуют элементам из D, удовлетворяющим соответствующему соотношению, то значением атомной формулы будет Т, в противном случае будет F.
Рассмотрим в качестве примера атомную формулу
Р (a, f (b, с))
176
Гл. 6. Доказательство теорем в исчислении предикатов
и следующую интерпретацию:
D — множество целых чисел,
а — число 2,
b— число 4, с — число 6, f — функция сложения, Р — отношение „больше".
При такой интерпретации наша атомная формула утверждает, что «число 2 больше суммы чисел 4 и 6». Это утверждение неверно, поэтому Р(а,f(b,c)) имеет значение F. Если интерпретацию изменить так, что а станет числом 11, то Р(а, будет иметь значение Т. Очевидно, что существует много других интерпретаций, для которых эта атомная формула имеет значение Т, и много таких интерпретаций, для которых она имеет значение F, но для любой интерпретации будет либо Т, либо F и никогда то и другое одновременно.
Значение неатомной п. п. формулы можно вычислить ре-куррентно, исходя из значений составляющих ее формул. При таком вычислении используются следующие правила:
Если Xi — п. п. формула, то ~Х[ имеет значение Т, когда Xi имеет значение F, и имеет значение F, когда Xi имеет значение Т.
Если Xi и Х2— любые две п. п. формулы, то значения (Л^Х/Хг), (XtAX2) и (Xi => Х2) даются следующей таблицей истинности:
х. X, X.VX, Х,ЛХг
Т Т т Т Т
F Т Т F Т
Т F Т F F
F F F F Т
Этот метод вычисления называется методом таблиц истинности. При данной интерпретации для некоторой п. п. формулы (и, таким образом, для данных значений каждой атомной формулы, содержащейся в ней) всегда можно вычислить значение (Т или F) этой п. п. формулы с помощью таблицы истинности. Если значение некоторой п. п. формулы при данной интерпретации есть Т, то говорят, что эта интерпретация удовлетворяет указанной п. п. формуле (или выполняет указанную п. п. формулу). Неатомная п. п. формула и ее значение служат для опре
6.4. Переменные и кванторы
177
деления некоторого нового отношений между элементами из D: п. п. формула делает некоторое утверждение относительно элементов из D, истинное, когда значение этой п. п. формулы есть Т.
6.4. ПЕРЕМЕННЫЕ И КВАНТОРЫ
Рассмотрим п. п. формулу
Р (а, Ь) и интерпретацию
D — конечное множество целых чисел
1, 2, ..., 99, 100,
а — число 30,
b — число 1,
Р — отношение «.больше или равно».
При такой интерпретации п. п. формула утверждает, что «30 больше или равно 1». Это утверждение, очевидно, истинное, и наша п. п. формула при данной интерпретации имеет значение Т. Предположим, что при той же самой области мы приписываем значения 1, 2, ..., 100 константным буквам f%, ... • • • > fioo соответственно. С каждой из этих букв можно сконструировать п. п. формулу вида
р (М)-
При этом каждая из п. п. формул при данной интерпретации имеет значение Т.
Часто бывает нужно высказать определенное утверждение, относящееся к каждому элементу некоторой области. Такое утверждение можно было бы сделать в виде конъюнкции *) п. п. формул, утверждение каждой из которых касается одного из элементов. В рассмотренном выше примере п. п. формула
... лр(П».Ц)
утверждает, что «каждое целое число от 1 до 100 больше или равно 1». Так как каждая п. п. формула Pffl, f°) имеет значение Т, то мы устанавливаем с помощью таблиц истинности, что эта конъюнкция также имеет значение Т.
Использование больших конъюнкций для выражения утверждений, содержащих слова каждый или для всех, привело бы к слишком громоздким выражениям. Для их сокращенной записи введем в наш язык символ V (означающий для всех) и индивидные переменные Xi (i 1). (Иногда вместо х< мы будем употреблять буквы и, v, w, у, z.) Предполагается, что
) Конъюнкцией п. п. формул Хь Хг, Хп называется п. п. формула Xi Л Х2Д...Л х„.
178
Гл. 6. Доказательство теорем в исчислении предикатов
переменные х, принимают значения из области интерпретации. Так, в нашем примере вместо выписывания конъюнкции, содержащей п. п. формулы для каждого элемента рассматриваемой области, мы будем писать просто
(Vx)P(xJ?).
Символ V называется квантором всеобщности, а переменная, стоящая сразу же за символом V, называется переменной, относящейся к квантору всеобщности. Когда такая переменная появляется внутри области действия квантора V, про нее также говорят, что она относится к квантору всеобщности, или что она связывается этим квантором.
Теперь мы имеем новый класс п. п. формул, в которых в качестве термов могут выступать переменные, относящиеся к квантору всеобщности. В случае конечных областей значения истинности таких п. п. формул можно установить с помощью таблиц истинности. Однако такой метод нельзя применить для оценки значения истинности бесконечных конъюнкций. Тем не менее это понятие полезно, поскольку иногда значения истинности п. п. формул, содержащих кванторы, можно вычислить, минуя оценку бесконечных конъюнкций. (Например, согласно таблице истинности, простая п. п. формула
[(Vx)P(x)=^(Vx)P(x)]
в любой интерпретации имеет значение Т.)
Иногда требуется высказать утверждение, касающееся всех пар элементов из некоторой области или всех троек и т. п. Тогда используется несколько переменных и для каждой из них символ V. Так, 'правильно построенную формулу, соответствующую утверждению «для всех пар целых чисел, расположенных между 1 и 100, первое больше второго», можно запиеать в виде
(Vx)(Vz/)P(x,z/).
.Очевидно, что эта п. п. формула (двойная конъюнкция) при нашей интерпретации имеет значение F.
Подобное сокращение имеется и Для дизъюнкций1), перечисляющих каждый элемент области. Предположим, мы имеем дизъюнкцию
Q(f?)VQ(^)VQ(f3°)V ....
где /“>••• —элементы области D. Согласно таблице истинности, эта правильно построенная формула имеет значение Т,
’) Дизъюнкцией п.п. формул Х2, Хп называется п.п. формула Xi V*2V...VXn.
6.5. Общезначимость и выполнимость
179
когда верно утверждение «по крайней мере один элемент из D обладает,, свойством Q».
Вместо дизъюнкций, в которых упоминается каждый элемент области, пользуются символом 3 и соответствующей переменной. Тогда приведенная выше дизъюнкция принимает вид
(3x)Q(x).
Символ 3 (существует) называется квантором существования, а переменная, стоящая сразу же после символа 3> называется переменной, относящейся к квантору существования. Когда такая переменная появляется внутри области действия квантора з, про нее говорят, что она относится к квантору существования, а также, что она связывается этим квантором.
С помощью таблиц истинности (для конечных областей) можно показать, что всегда значение истинности п. п. формулы ~(Vx)U7 (х) совпадает со значением истинности п. п. формулы (Зх) {~ W (х)}. Аналогично ~Н(х)Ц7(х) и (Vx){~U7(x)} эквивалентны. Мы будем считать, что эти соотношения эквивалентны и в неограниченных областях.
При комбинировании кванторов всеобщности и существования действие квантора существования может оказаться «зависящим» от каких-нибудь предшествующих кванторов всеобщности. Так, утверждение «для любого целого числа существует большее целое число» можно записать в виде
(Vx)(3y)P(y,x).
Очевидно, что если эта п. п. формула должна иметь значение Т, то переменная у, которая «существует», должна зависеть от х.
В п. п. формулах, состоящих более чем из одной предикатной буквы, мы будем использовать фигурные скобки для обозначения области действия кванторов. Так, (Vx){} означает, что любая переменная х, появляющаяся в этих фигурных скобках, относится к квантору всеобщности.
6.5. ОБЩЕЗНАЧИМОСТЬ И ВЫПОЛНИМОСТЬ
Если некоторая п. п. формула имеет значение Т при всех интерпретациях, то ее называют общезначимой. Так, по таблице истинности п. п. формула Р(а)=^(Р(а) V Р(Ь)) при любой интерпретации имеет значение Т и, следовательно, она общезначима. С помощью таблиц истинности всегда можно определить, общезначима ли данная п. п. формула, не содержащая кванторов. Нужно просто проверить, имеет ли эта п. п. формула значение Т при всех возможных значениях (Т или F) содержащихся в ней атомных формул.
180
Гл. 6. Доказательство теорем в исчислении предикатов
Когда же появляются кванторы, общезначимость или ее отсутствие не всегда можно установить. Было показано, что общего. метода нахождения значений всех бесконечных формул, содержащих кванторы, не существует. По этой причине исчисление предикатов называют неразрешимым.
Можно установить общезначимость лишь некоторых типов формул, содержащих кванторы, и поэтому можно говорить о разрешимых подклассах исчисления предикатов. Более того, если некоторая п. п. формула на самом деле общезначима, то существует процедура для проверки ее общезначимости. (Та же процедура, примененная к п. п. формулам, не являющимся общезначимыми, может привести к неограниченной последовательности операций.) Поэтому исчисление предикатов можно назвать полуразрешимым.
Если при данной интерпретации каждая п. п. формула из некоторого множества п. п. формул имеет значение Т, то говорят, что данная интерпретация удовлетворяет этому множеству. Правильно построенная формула W логически следует из некоторого множества S п. п. формул, если каждая интерпретация, удовлетворяющая S, удовлетворяет также и W. Так, очевидно, что (VxVy) {Р (х) V Q (У)} логически следует из {(VxVу) {Р (х) V Q (//)} (Vz){P(z)VQ(^)}}, а Р(а) логически следует из {(Vx)P(x)}. Менее очевидно, что {(Vx)Q(x)} логически следует из {(Vx){~P(x) V VQW), (ух)Р(х)},
Именно эту концепцию логического следования мы положим в основу понятия доказательства. Доказательством того, что некоторая п. п. формула W логически вытекает из заданного множества S правильно построенных формул, назовем демонстрацию того факта, что W логически следует из S. Цель оставшихся глав — дать основы, по-видимому наиболее перспективного, механического метода поиска доказательства того, что данная п. п. формула логически следует из некоторого множества п. п. формул, и показать, как можно применить этот метод к решению задач.
Факт «неразрешимости» исчисления предикатов означает также, что при заданных произвольной п. п. формуле W и произвольном множестве п. п. формул S не существует эффективной процедуры, позволяющей всегда решить, следует ли логически W из S. Если W действительно следует из S, то существуют процедуры, которые в конце концов сообщат нам этот факт. Однако если W не следует из S, то те же процедуры, к сожалению, не всегда могут это установить.
Тем не менее умение продемонстрировать, что W логически следует из S (когда это на самом деле так), уже достаточно полезно, и мы сосредоточим на нем свое внимание. Предположим, что W логически следует из S. Тогда любая интерпретация, удовлетворяющая S, удовлетворяет также W. Но заметим,
6.6. П редложения
181
что эти интерпретации не удовлетворяют ~ W. Следовательно, никакая интерпретации не удовлетворяет объединению S и Если некоторое множество, п. п. формул не удовлетворяется ни при какой интерпретации, то оно называется неудов-летворимым (или невыполнимым). Так, если W логически следует из S, то объединение S U {~ IV} неудовлетворимо. Обратно, если ,S U {~ IV} неудовлетворимо, то W должно логически следовать из S.
Мы используем этот результат для того, чтобы придать одинаковую форму всем задачам доказательства: для доказательства логического следования W из S мы будем показывать, что объединение SU{~IV} неудовлетворимо. Для того чтобы показать, что некоторое множество п. п. формул неудовлетворимо, надо доказать, что нет такой интерпретации, при которой каждая из п. п. формул в этом множестве имеет значение Т. Хотя эта задача и кажется трудоемкой, существуют довольно эффективные процедуры ее решения. Для выполнения этих процедур требуется представить сначала п. п. формулы данного множества в специальном удобном виде — в виде предложений1).
6.6. ПРЕДЛОЖЕНИЯ
Любую п. п. формулу исчисления предикатов можно представить в виде предложения, применяя к ней последовательность простых операций. Наша ближайшая задача состоит в том, чтобы показать, как придать произвольной п. п. формуле форму предложения. Мы будем иллюстрировать этот процесс на п. п. формуле
(Vx){Р (х) =${(Уу) {Р (у) ^P(f (х, z/))} Д ~ (У у) {Q (х, у)^Р (у)}}}.
Процесс состоит из следующих этапов:
1) Исключение знаков импликации. В форме предложения в исчислении предикатов явно используются лишь связки V и ~. Знак импликации можно исключить подстановкой в исходном утверждении 4V В“ вместо „Д=>В“2). Такая подстановка в нашем примере дает
(Ух){~Р(х) V {(Ау){~Р(у) V P(f(x, у))} Д
A ~ (Vу) {~ Q (х, у) V Р (г/)}}}.
’) В оригинале clause, что иногда переводят в данной ситуации как «дизъюнкт». — Прим, перев.
2) Читателю следовало бы убедиться, что эти подстановки сохранят значение истинности первоначальной п.п. формулы. При более формальном изложении мы должны были бы показать, что „~А V В” логически следует из „А =^> В” и „А =^> В” логически следует из „~Л V б”, и поступать точно1 так же для всех других подстановок, которые будем делать.
182
Гл. 6. Доказательство теорем в исчислении предикатов
2) Уменьшение области действия знаков отрицания. Мы хотим, чтобы знак отрицания ~ применялся не более чем к одной предикатной букве. С помощью повторного применения указанных ниже подстановок можно свести область действия каждого знака ~ до отдельной предикатной буквы:
заменить ~(АД£) на
заменить ~(Л V В) на ~АД~В,
заменить ~~Л на А,
заменить ~(Ух)Л на (Эх){~Л),
заменить ~(3х) А на (Vx){~X).
Тогда наша п. п. формула примет сначала вид
(Vx) {- Р (х) V {(Vz/) {- Р (у) V Р (f (х, у))} А
A (3z/){~{~Q(x, у) V (*/)}}}}, а потом
(Vx) {~ Р (х) V {(Vz/) {-Р (у) VP(f (х, у))} А
A (3z/){Q(x, z/} А ~Р(«/)}}}.
3) Стандартизация переменных. В области действия любого квантора переменная, связываемая им, является немой переменной. Поэтому везде в области действия квантора ее можно заменить другой переменной, а это не приведет к изменению значения истинности п. п. формулы. Стандартизация переменных в п. п. формуле означает переименование немых переменных, с тем чтобы каждый квантор имел свою собственную немую переменную. Так, вместо (Vx) {Р (х) => (Зх) Q (х)} следует написать (Vx){P(x)=>(3z/) Q (#)}. Стандартизация в нашем примере дает (Vx) {~Р (х) V ((Vz/) {— Р (у) VP(f (х,у))} А
А (За») {Q (х, w) Л ~ Р (а»)}}}.
4) Исключение кванторов существования. Рассмотрим правильно построенную формулу
(Vz/3x)P(x, у),
которую можно интерпретировать, скажем, так: «Для всех у существует такой х (возможно, зависящий от у), что х больше у». Заметим, что, поскольку квантор существования О*) находится внутри области действия квантора всеобщности (V у), допускается, что х, который «существует», может зависеть от значения у. Пусть эта зависимость определяется явно с помощью некоторой функции g(y), отображающей каждое значение у вх, который «существует». Такая функция называется функцией Сколема. Если вместо х, который «существует», взять функцию Сколема, то можно исключить квантор существования: (Vz/)P(^(z/),z/).
6.6. Предложения
183
Общее правило исключения из п. п. формулы квантора существования состоит в замене всюду в' ней переменной, относящейся к квантору существования, функцией Сколема, аргументами которой служат переменные, относящиеся к тем кванторам всеобщности, области действия которых охватывают область действия исключаемого квантора существования. Функциональные буквы для функций Сколема должны быть «новыми» в том смысле, что они не должны совпадать с теми буквами, которые уже имеются в п. п. формуле.
Так, исключая (Зг) из п. п. формулы
{(Vw) Q (w)} => (Vx) {(Vу) {(Зг) {Р (х, у, 2) => (Vu) R (х, у, и, г)}}}, получаем
{(Vw)QM}^(Vx){(Vy){P(x, у, g(x, «/))=>(V«) Р(х, у, и, g(x, у))}}.
Если исключаемый квантор существования не принадлежит области действия ни одного из кванторов всеобщности, то функция Сколема не содержит аргументов, т. е. является просто константой. Так, (Зх)Р(х) превращается в Р(а), где а — константа, про которую мы знаем, что она «существует».
Чтобы исключить все переменные, относящиеся к кванторам существования, надо применить описанную выше процедуру по очереди, к каждой переменной. В нашем примере исключение кванторов существования (здесь лишь один такой квантор) дает (Vx) {~Р (х) V {(Vу) {~P(y)VP(f (х, у))} А
A {Q (х, g (х)) А ~ -Р (g (х))}}}, где g(x)— функция Сколема.
5) Приведение к предваренной нормальной форме. На этом этапе уже не осталось кванторов существования, а каждый квантор всеобщности имеет свою переменную. Теперь можно перенести все кванторы всеобщности в начало п. п. формулы и считать областью действия каждого квантора всю часть п. п. формулы, расположенную за ним. Про полученную в результате п. п. формулу говорят, что она имеет предваренную нормальную форму. Правильно построенная формула в предваренной нормальной форме состоит из цепочки кванторов, называемой префиксом, и расположенной за ней формулой, не содержащей кванторов, называемой матрицей. Предваренная нормальная форма для нашей п. п. формулы имеет вид
(Vx V у) {~Р (х) V {{-Р (У) V Р (f(x, у))} А
A{Q(x, g(x))A~P(g(x))}}}.
6) Приведение матрицы к конъюнктивной нормальной форме. Любую матрицу можно представить в виде конъюнкции конечного множества дизъюнкций предикатов и (или) их отрицаний.
184
Гл. 6. Доказательство теорем в исчислении предикатов
Говорят, что такая матрица имеет конъюнктивную нормальную форму. Дадим примеры матриц в конъюнктивной нормальной форме:
{Р (х) V Q (х, у)} A {Р (w) V ~ Р (у)} Л Q (х, у),
Р(х) V Q (х, у),
Р(х) Д Q(x, у),
Любую матрицу можно привести в конъюнктивную нормальную форму, применяя несколько раз правило:
Заменить А V {В Л С) на {Л V В) Л М V С}.
После приведения матрицы нашей п. п. формулы в конъюнктивную нормальную форму она принимает вид
<УхУу) {{ ~ Р (х) V ~ Р (*/) V Р (f (х, у))} Л
Л {~ Р (х) V Q (х, g (х))} Л {~ Р (х) V - Р (g (х))}}.
7) Исключение кванторов всеобщности. Так как все переменные п.п. формулы должны быть связанными, то все оставшиеся на этом этапе переменные относятся к кванторам всеобщности. Так как порядок расположения кванторов всеобщности несуществен, то можно эти кванторы явным образом не указывать, условившись, что все переменные в матрице относятся к кванторам всеобщности. Теперь у нас остается лишь матрица в конъюнктивной нормальной форме.
8) Исключение связок «и». Теперь можно исключить знак «и» Л, заменяя А Л В двумя п.п. формулами А, В. Результатом многократной замены будет конечное множество п. п. формул, каждая из которых представляет собой дизъюнкцию атомных формул и (или) их отрицаний. Атомную формулу или ее отрицание называют литералом, а правильно построенную формулу, состоящую лишь из дизъюнкций литералов, — предложением 1). Итак, каждая п. п. формула в нашем множестве будет предложением.
Наша п. п. формула теперь представлена в виде следующих предложений:
~Р(Х) V ~P(z/) VP (Их,*/)),
~Р(х) V Q(x, g(x)), ~P(x)V~P(g(x)).
Заметим, что в литералах предложения могут содержаться переменные, которые всегда следует считать относящимися к кванторам всеобщности. Если вместо переменных литерала
*) См. примечание на стр. 181. — Прим, перев.
6.7. Универсум Эрбрана
185
подставляются выражения, не содержащие переменных, то мы получаем так называемый константный частный случай этого литерала. Так, Q(a, —константный частный случай п. п. формулы Q(x, у).
Наш процесс, предназначенный для демонстрации того, что некоторое множество S п. п. формул неудовлетворимо (невыполнимо), начинается с превращения каждой п. п. формулы из S в предложения. В результате возникает некоторое множество S предложений. Можно показать, что если множество S неудовлетворимо, то неудовлетворимо и множество S', и обратно, из не-удовлетворимости S' вытекает неудовлетворимость S. В оставшейся части этой главы мы изложим методы, позволяющие показать, что некоторое неудовлетворимое множество предложений действительно неудовлетворимо. Эти методы носят вполне общий характер, поскольку любое множество правильно построенных формул можно представить в виде предложений.
6.7. УНИВЕРСУМ ЭРБРАНА
Рассмотрим неудовлетворимое конечное множество S предложений.
Для того чтобы убедиться в неудовлетворимости S, нужно показать, что не существует интерпретации, которая ему удовлетворяет. Задавая для S интерпретацию, следует прежде определить область D, а затем связать с каждым константным символом в S некоторый элемент из D и с каждым функциональным символом в S некоторую функцию на D и т. д. Очевидно, что для демонстрации того, что каждая получающаяся в результате интерпретация не удовлетворяет S, мы не в состоянии перечислять всевозможные области и такие связи. Но можно указать такой адекватный список имен для элементов области, что если не существует удовлетворяющей интерпретации в областях, элементы которых могут быть названы именами из нашего списка, то не существует удовлетворяющей интерпретации вообще. Одним из таких списков имен, адекватным множеству предложений S, является универсум Эрбрана для S.
Универсум Эрбрана Н (S) для множества предложений S определяется рекурсивно следующим образом:
1. Множество всех константных букв (f°), упомянутых в S, принадлежит H(S). Если {/9} пусто, то Н (S) содержит некоторую произвольную константную букву, скажем а.
2. Если термы ..., tn принадлежат H(S), то H(S) принадлежит также н /2, •••> ^п)> гДе /"—любая функциональная буква, упомянутая в S.
3. Никаких других термов в H(S) нет.
186
Гл. 6. Доказательство теорем в исчислении предикатов
Должно быть ясно, что независимо от выбора интерпретации при приписывании значений Т и F литералам из S никаких других имен для элементов области никогда не потребуется. В этом смысле H(S)—наиболее общая область; если мы покажем, что множество S неудовлетворимо в области H(S), то можно бедть уверенным, что оно неудовлетворимо в любой области.
Универсум Эрбрана, вообще говоря, бесконечен, но счетен, так что его члены всегда можно тем или иным образом упорядочить. Например, рассмотрим множество предложений S:
{/> (х) V Q (а) V ~Р (f (*)), ~ Q (b) V Р (g (х, у))}.
Здесь константные термы — {а, Ь}, а функции — Таким образом, Н (S) представляет собой (счетное) бесконечное множество
{a, b, f (a), f(b), g(a, a), g (a, b), g(b, a), g(b, b),
6.8. ЭРБРАНОВСКАЯ БАЗА
Когда мы задаем интерпретацию (на H(S)) для предложения в S, его атомным формулам приписываются значения (Т или F). Предположим, что Р есть «-местная предикатная буква в S. Означивание атомной формулы P(xi, х2, ..., хп) производится приписыванием значений Т и F независимо для всех ее константных частных случаев, получающихся в результате подстановки элементов из H(S) вместо переменных хь х2, ..., хп. Разумеется, число константных частных случаев для каждой атомной формулы в S может оказаться бесконечно большим, так что таким способом можно бесконечно долго решать задачу означивания. Но замечательно, что, прежде чем будет закончено означивание каждой атомной формулы в S, станет совершенно очевидным, что никакая интерпретация не может удовлетворить S, и это будет несмотря на то, что даже еще не всем константным частным случаям приписаны значения истинности!
Эрбрановской базой для S называется множество всех константных частных случаев для всех атомных формул в S при условии, что для наименования элементов области использован универсум Эрбрана. Элементы эрбрановской базы называются атомами. Очевидно, что задание интерпретации на Н (S) заканчивается для всех предложений из S только тогда, когда каждому атому эрбрановской базы приписано значение истинности. Эрбрановская база также является счетной, и, следовательно, ее элементы можно тем или иным образом упорядочить. Пусть упорядоченная эрбрановская база для S записана в виде последовательности {р1( pz, р3, . ..}.
6.9. Построение семантического дерева
187
6.9. ПОСТРОЕНИЕ СЕМАНТИЧЕСКОГО ДЕРЕВА
Семантическое дерево представляет собой бинарное дерево1). простирающееся вниз от корневой вершины. В соответствии со способом, который мы выбрали для приписывания значений истинности атомам Pi эрбрановской базы, мы будем спускаться по этому дереву по определенному пути. Если мы присвоим атому р{ значение Т, то окажемся непосредственно под корневой вершиной слева, а если F, то справа. Далее, независимо от того, в какой из двух вершин, расположенных непосредственно под корневой вершиной, мы оказались, если мы присвоим атому рг значение Т, то пойдем из нее по левой ветви, а если F, то по правой. Этот процесс продолжается до тех пор, пока каждому элементу эрбрановской базы не будет присвоено значение истинности. Очевидно, что в случае бесконечной эрбрановской базы любой полной интерпретации будет соответствовать бесконечный путь вниз по вершинам этого дерева. Полное дерево, содержащее все возможные пути, представляет все возможные интерпретации предложений из S; отсюда и название: семантическое дерево.
В качестве примера рассмотрим неудовлетворимое множество S предложений
P(x)VQ(y),
~Р(а),
~Q(b).
Универсумом Эрбрана будет здесь конечное множество
H(S) = {a, b}.
Эрбрановская база также конечна. Ее можно упорядочить так: {Р (a), Q (а), Р (b), Q(b)}.
Семантическое дерево для этого множества предложений конечно, оно показано на рис. 6.1. Каждое ребро, соединяющее вершину с одной из ее дочерних вершин, представляет решение, принятое относительно значения истинности одного из атомов эрбрановской базы. Условились записывать рядом с ребром, где атому присваивается значение Т, сам этот атом, а рядом с ребром, где атому присваивается значение F, — его отрицание. Каждый из путей, ведущих от корневой вершины к концевой вершине этого дерева (а именно к вершине, расположенной внизу этого дерева), дает одну из интерпретаций для множества S. Эту интерпретацию можно однозначно представить в -- г
*) Каждая вершина бинарного дерева имеет ровно две дочерние вершины, если таковые у нее вообще имеются. Можно обобщить определение семантического дерева так, чтобы допускалось более двух таких вершин.
188
Гл. 6. Доказательство теорем в исчислении предикатов
1 г
Рис. 6.1. Семантическое дерево для множества предложений {PWVQW ~Q(&).
виде множества атомов, встречающихся на этом пути. Так, интерпретация, получающаяся при прослеживании пути от корневой вершины к концевой вершине, отмеченной на рис. 6.1 цифрой 1, задается множеством
2И1 = {/>(а), ~Q(a), ~P(b), Q(6)}.
6.10. Неблагоприятные вершины 189
Такое множество называют моделью для данного множества предложений.
Говорят, что модель не удовлетворяет предложению, если существует константный частный случай этого предложения (построенный на термах универсума Эрбрана), имеющий значение F при означиваниях, определяемых этой моделью. Так, Mt не удовлетворяет ни одному из предложений ~Р(а) и Ана-
логично Л12 = {'~Р(а), ~Q(a), ~Р(6), ~Q(b)} не удовлетворяет предложению P(x)V Q(y), так как константный частный случай P(a)V Q(b) имеет значение F.
Если в S есть предложение, не удовлетворяющееся интерпретацией, или моделью, то эта модель не может удовлетворить S. Так, Mi и М2 не удовлетворяют множеству S нашего примера, более того, можно исключить по очереди каждую из 16 возможных интерпретаций и сделать’ рывод, что множество S нашего примера неудовлетворимо.
6.10. НЕБЛАГОПРИЯТНЫЕ ВЕРШИНЫ
Наиболее важным фактом, связанным с семантическими деревьями, является возможность установить, не просматривая дерево неограниченно далеко вниз, что определенные интерпретации не удовлетворяют некоторому множеству предложений. В нашем примере на рис. 6.1 мы приписали атому Р(а), расположенному слева непосредственно под корневой вершиной, значение Т. Сразу же видно, что ни одна из возможных восьми интерпретаций, в которых Р(а) имеет значение Т, не удовлетворяет S; чтобы удовлетворять S, значением атома Р(а) должно быть F. Итак, нет необходимости просматривать дальше левую часть этого дерева. Пометим черными кружочдами те вершины дерева на рис. 6.1, где впервые было установлено, что эта интерпретация не может удовлетворять S. Такие вершины будем называть неблагоприятными.
Разумеется, если множество предложений неудовлетворимо, то, даже когда эрбрановская база бесконечна, каждая возможная интерпретация в конце концов должна оборваться на какой-то неблагоприятной вершине. В самом деле, если бы хотя бы одна интерпретация не обмывалась на неблагоприятной вершине, то мы могли бы сколь угодно долго двигаться по этому пути, т. е. существовала бы интерпретация, удовлетворяющая множеству предложений, что противоречит неудовлетворимости этого множества. Семантическое дерево для множества предложений S, все пути которого обрываются на неблагоприятных вершинах, называется замкнутым для S. Таким образом, мы получили ключевой результат, на котором основаны наши методы проверки выполнения свойства неудовлетворимости. Семантическое дерево для неудовлетворимого множества предложений S
190
Гл. 6. Доказательство теорем ’в исчислении предикатов
Рис. 6.2. Замкнутое семантическое дерево для невыполнимого множества {~Р(х) VQW,
замкнуто для S и содержит конечное число вершин, расположенных над неблагоприятными вершинами 1).
') Можно показать, что это утверждение эквивалентно знаменитой тео-. реме Эрбрана (1930).
6.11. Вершины вывода
*’ 191
На рис. 6.2 изображена часть семантического дерева для не-удовлетвор'имого множества предложений
S = {-Р (х) V Q (х), Р (f (у)), ~Q(f (у))}.
Универсумом Эрбрана здесь будет множество
Н (S) ~{а, f (a), f (f (a)), f (f (f (а))), а эрбрановскую базу можно упорядочить так: {Р (a), Q (а), Р(f (a)), Q (f (а)), Р (f (f (а))), ...}._ Хотя эрбрановская база бесконечна, так что любая полная интерпретация соответствует бесконечному пути по этому семантическому дереву, мы знаем, что, в случае когда S неудовлетворимо, семантическое дерево замкнуто неблагоприятными вершинами. На рис. 6.2 показана часть семантического дерева, расположенная выше неблагоприятных вершин и включающая их. На практике редко удается установить невыполнимость множества предложений построением семантического дерева. В последнее время на основе принципа резольвенций были разработаны практически приемлемые процедуры установления неудовлетворимости. В следующих разделах мы объясним суть этого принципа, воспользовавшись уже описанными представлениями, связанными с семантическими деревьями.
6.11. ВЕРШИНЫ ВЫВОДА
Рассмотрим снова пример, приведенный на рис. 6.2. Каждая из неблагоприятных вершин этого дерева обладает тем свойством, что любое завершение части интерпретации, заданной вплоть до этой вершины, не удовлетворяет какому-то из предложений нашего множества. Ниже неблагоприятной вершины, отмеченной на рис.’6.2 цифрой 1, идут интерпретации, заведомо не удовлетворяющие предложению ~Р(х) V Q(x). Ниже неблагоприятной вершины, отмеченной цифрой 2, идут интерпретации, заведомо не удовлетворяющие предложению (/(«/))• Мы будем называть вершину 1 неблагоприятной для ~?(x)VQ(x), а вершину 2 неблагоприятной для ~Q(f(y))-Мы будем также говорить, что предложения ~P(x)V Q(x) и терпят неудачу на вершинах 1 и 2 соответственно.
Если некоторая вершина семантического дерева не является неблагоприятной, а обе ее дочерние вершины неблагоприятны, то она называется вершиной вывода. На рис. 6.2 вершина, отмеченная цифрой 3, является вершиной вывода, поскольку можно вывести новое предложение, логически следующее из предложений ~Р(х) V <2(х) и (/(#))> которые терпят неудачу на неблагоприятных вершинах, идущих сразу за ней. Кроме того, это новое предложение само терпит неудачу на вершине вывода или
192
Гл. 6. Доказательство теорем в исчислении предикатов
выше нее. (Конечно, этого нового предложения нет в S, поскольку иначе вершина 3 или какая-нибудь вершина, ей предшествующая, была бы неблагоприятной.)
Какое же предположение можно вывести из предложений ~/)(z)VQ(x) и ~Q(f (*/))? Пусть / — произвольная интерпретация, удовлетворяющая обоим предложениям ~P(x)VQ(x)h ~Q(f(y)). Так как интерпретация I удовлетворяет предложению ~P(x)V Q(x), она должна также удовлетворять любому предложению, получающемуся из него подстановкой другого выражения вместо х. В частности, I должна удовлетворять предложению V Q(f(y))- Но литерал Q(f(y)) не мо-
жет удовлетворяться этой интерпретацией, поскольку мы предположили, что интерпретацией / удовлетворяется его отрицание ~Q(f(t/))- Следовательно, если интерпретация / удовлетворяет предложению ~P(f(y)) V Q(f (у)), то только потому, что I удовлетворяет предложению ~ Р (f (у)). Тогда из данных двух предложений можно вывести предложение ~P(f(y)). Кроме того, заметим, что приписывание значений истинности дополнительным литералам Q(f(a)) и ~Q(f(a)) не изменяет означивания выведенного предложения ~ Р (}(«/))• Выведенное предложение уже потерпело неудачу на вершине вывода (вершине 3).
Выведенное предложение ~P(f (у)) называется резольвентой двух предложений ~P(x)VQ(.v) и ~ Q(f (*/)). Если у двух предложений есть резольвенты (их может быть более одной), то процесс их получения зависит от возможности делать такие подстановки термов вместо переменных, чтобы предложения, возникающие в результате подстановок, содержали дополнительные литералы. Мы обсудим детали этого процесса несколько ниже, а сейчас предположим, что мы располагаем таким процессом вывода и он обладает тем свойством, что резольвенты терпят неудачу на вершине вывода или выше нее. .
Любое замкнутое семантическое дерево для неудовлетвори-мого множества S непустых предложений должно иметь по крайней мере одну вершину вывода, так как иначе у каждой из вершин была бы по крайней мере одна дочерняя вершина, не являющаяся неблагоприятной, что противоречит предполагаемой замкнутости дерева. Пусть мы располагаем процессом вывода резольвенты С из двух предложений, терпящих неудачу ниже такой вершины вывода п, что С терпит неудачу на вершине п или выше нее. Тогда можно образовать новое (все еще) неудовлетворимое множество предложений S' — {С} U S. Семантическое дерево для S должно быть семантическим деревом для S', но только для S' вершина п (или некоторая вершина над ней) будет неблагоприятной. Ясно, что число вершин, расположенных выше неблагоприятных вершин, в дереве для S' строго меньше, чем в дереве для S. И тем не менее дерево для S' должно иметь по крайней мере одну вершину вывода, поро
6.12. Унификация
193
ждающую новую резольвенту С'. Этот процесс повторяется, и на каждом этапе число вершин, расположенных выше неблагоприятных вершин, в новом (все еще замкнутом) семантическом дереве будет меньше. После некоторого конечного числа выводов у дерева не будет вершин, расположенных выше неблагоприятных вершин, т. е. корневая вершина окажется неблагоприятной. Так как приписывания значений истинности производятся лишь ниже корня, то этот корень терпит неудачу только на пустом предложении (т. е. предложении, не содержащем литералов).
Процесс получения резольвент, терпящих неудачу на вершинах вывода или выше них, можно использовать теперь для демонстрации того, что неудовлетворимое множество предложений S действительно неудовлетворимо. Сначала надо получить все возможные резольвенты всех пар предложений в S. Так как в семантическом дереве для S должна быть по крайней мере одна вершина вывода, то одна из резольвент должна терпеть неудачу на этой вершине вывода или выше нее. Таким образом, семантическое дерево для S' = S U {все резольвенты всех пар в S} по-прежнему замкнуто и имеет меньше вершин, расположенных выше неблагоприятных вершин. Продолжение такого процесса путем нахождения всех резольвент всех пар предложений в S и т. д. должно в конечном итоге привести к появлению пустого предложения. Далее, если мы покажем, что резольвента пары предложений логически следует из этой пары, то будет доказано, что появление в результате этого процесса пустого предложения означает, что исходное множество S неудовлетворимо. (Пустое предложение тривиально неудовлетворимо; его эрбрановская база пуста, поэтому не существует удовлетворяющей его модели.)
6.12. УНИФИКАЦИЯ
Теперь мы должны обсудить процесс, называемый унификацией, являющийся основным в формальных преобразованиях, выполняемых при нахождении резольвент.
Термы литерала могут быть переменными буквами, константными буквами и выражениями, состоящими из функциональных букв и термов. (Подстановочный) частный случай литерала получается при подстановке в литералы термов вместо переменных. Например, для литерала P(x,f(y),b) частными случаями будут
Р (z, f (ay), b),
P(x,f(a), b), P (g (z), f (a), b), P(c,f(a),b).
AM
194
Гл. 6. Доказательство теорем в исчислении предикатов
Первый частный случай называется алфавитным вариантом исходного литерала, поскольку здесь вместо переменных, входящих в Р(х, f (у), Ь), подставлены лишь другие переменные. Последний из перечисленных четырех частных случаев называется константным частным случаем, или атомом, так как ни в одном из термов этого литерала нет переменных.
В общем случае любую подстановку можно представить в виде множества упорядоченных пар 0 = {(Л, oj, (/2,^2), ... .... (tn, vn) } Пара (ti, Vi) означает, что повсюду переменная Vi заменяется термом Существенно, что переменная в каждом ее вхождении заменяется одним и тем же термом, т. е. из i =/^ j следует, что о, =^= Vj, i, j = 1, . .., п. Для получения частных случаев литерала P(x,f(y),b) были использованы четыре подстановки
a = {(z, х), (w, у)},
Р = {(а, У)}, y = ((g(z), х), (а, у)}, б = {(с, х), (а, у)}.
Обозначим через Ре частный случай литерала Р, получающийся при использовании подстановки 0. Например, Р(гД(w), b) = Р(х, f (у), Ь)а- Композицией ар двух подстановок аир называется результат применения р к термам подстановки а с последующим добавлением любых пар из р, содержащих переменные, не входящие в число переменных из а. Например, (g (х, У), z)}{(а, х), (Ь, у), (с, w), (d, z)} =
= {(£ (a, b), z), (а, х), (Ь, у), (с, w).}
Можно показать, что применение к литералу Р- последовательно подстановок аир дает тот же результат, что и применение к Р подстановки ар, т. е. (Ра)р = Ра₽. Можно также показать, что композиция подстановок ассоциативна:
(ар) у = а (Py)-
Если подстановка 0 применяется к каждому элементу множества {LJ литералов, то множество соответствующих ей частных случаев обозначается через {LJe Множество {LJ литёра-лов называется унифицируемым, если существует такая подстановка 0, что = L2e = L3e = ... - В этом случае подстановку 0 называют унификатором для {LJ, поскольку ее применение сжимает множество до одного элемента. Например, подстановка 0 = {(а,х), (Ь,,у)} унифицирует множество {Р(х, f (у), Ь), p(x, f(b),b)} и дает {Р(а, f(b), b)}.
Унификатор 0 = {(а,х), (Ь,у)} для множества {Р(х, f (у), Ь), P(x,f(b),b)} в некотором смысле не является простейшим. За
6.12. Унификация
195
метим, что для унификации нет необходимости подставлять а вместо х.' Наиболее общим (или простейшим) унификатором (ноу) для {LJ будет такой унификатор X, что если 0 — какой-нибудь унификатор для {LJ, дающий {LJe, то найдется подстановка 6, для которой {AJW = {£«}е- «Общий» частный случай, соответствующий наиболее общему унификатору, единствен с точностью до алфавитных вариантов.
Существует алгоритм, называемый алгоритмом унификации, который приводит к наиболее общему унификатору для унифицируемого множества {LJ литералов и сообщает о неудаче, если это множество неунифицируемо. Схему работы алгоритма можно описать следующим образом. Алгоритм начинает работу с пустой подстановки *) и шаг за шагом строит наиболее общий унификатор, если таковой существует. Предположим, что на k-м шаге получена подстановка А*. Если все литералы множества {М} в результате применения к каждому из них подстановки становятся идентичными, то X = Х& и есть наиболее общий унификатор. В противном случае каждый из литералов в рассматривается как цепочка символов и выделяется позиция первого символа, в которой не все из литералов имеют одинаковый символ. Затем конструируется множество рассогласования, содержащее п. п. выражения из каждого литерала, который начинается с этой позиции. (П. п. выражение представляет собой либо терм, либо литерал.) Так, множеством рассогласования для
{P(a,f(a,g(z)), h(x)), P(a,f(a,u), g(w))}
t t
будет
fe (z), u}.
Далее алгоритм пытается так модифицировать подстановку Хй, чтобы сделать равным два элемента из множества рассогласования. Это можно сделать только тогда, когда множество рассогласования содержит переменную, которую можно положить равной одному из его термов. (Если множество рассогласования вообще не содержит переменных, то множество {Л;} унифицировать нельзя. Например, на первом шаге работы алгоритма множество рассогласования может оказаться самим {LJ, и тогда ясно, что ни один из элементов не будет переменной.)
Пусть Sk — переменная в множестве рассогласования и th — терм (возможно, другая переменная) в множестве рассогласования, не содержащий Sh. (Если такого Д нет, то множество {£»} неунифицируемо.) Теперь можно образовать модифицированную подстановку Xft+i = Хй{(Д, «л)} и выполнить следующий шаг работы алгоритма.
') То есть не делается никаких подстановок.—Прим, перев.
196 Гл. 6. Доказательство теорем в исчислении предикатов
Можно доказать (Робинсон, 1965а и Лакхэм, 1967), что описанный алгоритм находит наиболее общий унификатор для множества унифицируемых литералов и сообщает о неудаче, если литералы неунифицируемы. Мы не будем давать здесь доказательство этого утверждения.
В качестве примеров приведем «общие» частные случаи, соответствующие наиболее общему унификатору для ряда множеств литералов.
Множество литералов «Общие» частные случаи
{Р U), р (а)} {P(fi.x), у, g (у)), Р (f(x), z, g(x))} lp (f (X, g (a, y)), g (а, у)), P (f (x, z), z)} P(a) P(fW, X, g (x)) P(f (x, g (a, y)), g (a, y))
Принято рассматривать предложения как множества литералов. Тогда предложение, содержащее множество {А,} литералов, можно также обозначить {LJ.
Если подмножество литералов в некотором предложении {Lt} унифицируемо с помощью ноу X, то предложение {LJx, называют фактором предложения {L,}. Факторами предложения
Р (f (х)) V Р (х) V Q (a, f («)) V Q (х,f (&)) V Q (г, w)
являются, например, предложения
VP(z) VQ(a,f(u)) VQ(z,f(b)) . ' и
P(f(a)) VP (a) VQ(a,f(&)).
В первом факторе унифицированы только два последних вхождения литерала Q, а во втором все три. Заметим, что в этом предложении два вхождения литерала Р нельзя унифицировать. Вообще предложение может иметь более одного фактора, но, во всяком случае, число факторов конечно.
6.13. РЕЗОЛЬВЕНТЫ
Теперь опишем процесс, с помощью которого иногда можно вывести новое предложение из двух других (называемых исходными предложениями). Пусть исходные предложения задаются в виде {LJ и {М,} и переменные, входящие в {Af,}, не встречаются в {LJ и обратно1). Пусть {/J е{Т,} и {/nJ е {A4J — такие два подмножества в {LJ и {М,}, что для объединения {/J U {~rm} существует наиболее общий унификатор X. (Иными
') В любой паре предложений всегда можно так переименовать переменные, чтобы это предположение выполнялось.
6.13. Резольвенты
197
словами, {mjx содержит одиночный литерал, равный отрицанию одиночного литерала в {/<}х.) Тогда грворят, что два предложения {LJ и {Л4г-} разрешаются, а новое предложение
[{ЬЛ — {ZЛк и [{АГ J — {/пJ]x
является их резольвентой.
Резольвента представляет собой выведенное предложение, и процесс образования резольвенты из двух «родительских» предложений называется резольвенцией. Если два предложения разрешаются, то они могут иметь более одной резольвенты, поскольку способ выбора {/J и {mJ может оказаться не единственным. Но, во всяком случае, они имеют не более конечного числа резольвент. Сейчас мы дадим несколько примеров резоль-венции и попытаемся связать ее с более знакомыми нам правилами вывода.
Рассмотрим два предложения
{ЬЛ = Р (х, f (а)) V Р (%,f (у)) V Q (р) и
{MJ=~P(z,f(a)) V~Q(z).
Выбирая подмножества
{lt} = (P(x,f(a))} и {mJ = {~P(zJ(a))},
мы получаем резольвенту
P(z,f(y))V~Q(z) VQ(y), а если взять
{li} — (P(x,f(a)),P(x,f(y))} и {mJ = {~P(zJ(a))}, то резольвентой будет
Q(a)V~Q(z).
Всего для этих двух предложений есть четыре резольвенты: три из них получаются разрешением на Р и одна разрешением на Q.
Резольвенция является общим правилом вывода, объединяющим подстановку, modus ponens1) и различные типы силлогизмов. Рассмотрим резольвенту Q(a) двух предложений ~Р(а) V Q(a) и Р(а).
Если первое предложение записать в виде Р(а) =^>Q(a), то ясно, что в этом случае резольвенция совпадает с modus ponens.
') Modus ponens — латинское название первой формы гипотетического силлогизма, выражаемой формулой (4V (4->В))->-В (т. е. если из А следует В н А имеет место, то имеет место и В). — Прим. ред.
198
Гл. 6. Доказательство теорем в исчислении предикатов
Рассмотрим теперь резольвенту ~P(x)V Q(x) двух предложений V /?(х) и ~/?(х) V Q(x). В более привычных
обозначениях (а также на русском языке) эта цепочка рассуждений выглядит так:
Обычная логика На русском языке
(ух) {Р (х) => R (х)} (V*) {Я М => Q (х) } Следовательно: (ух) {Р (х) => Q (х)} Все, что обладает свойством Р, имеет свойство R Все, что обладает свойством R, имеет свойство Q Все, что обладает свойством Р, имеет свойство Q
Такой вывод является одним из силлогизмов.
6.14. ПРИНЦИП РЕЗОЛЬВЕНЦИИ')
Резюмируем кратко основные идеи этой главы. Мы хотим иметь возможность находить доказательство того, что некото-рая_ правильно построенная формула W в исчислении предика-тов логически следует из некоторого множества S правильно построенных формул. Мы показали, что эта задач? эквивалентна задаче доказательства того, что множество не-
удовлетворимо. Процессы выявления неудовлетворимости некоторого множества предложений называются процессами опровержения. -
Собираясь применять частный случай процесса опровержения, приложимый к п. п. формулам, имеющим форму предложений, мы привели простую последовательность операций, позволяющую представить любую п. п. формулу в виде предложений. Затем ввели понятие области, названной универсумом Эрбрана, для множества S предложений и объяснили, как использовать построенное на его основе семантическое дерево для представления всех интерпретаций предложений из S. Если множество S неудовлетворимо, то, разумеется, нельзя найти интерпретацию, при которой все п. п. формулы в S истинны. На такую неудовлетворимость множества S указывает замкнутость его семантического дерева. Мы показали, как можно использовать общее правило вывода, называемое резольвенцией, для создания новых предложений. Дальше мы покажем, что при добавлении к S этих предложений у семантического дерева.
') См. примечание йа стр. 172. — Прим, перев.
6.14. Принцип резольвенции
199
для нового множества (по-прежнему неудовлетворнмого) над неблагоприятными вершинами будет, меньше вершин, и этот процесс можно продолжать до тех пор, пока не останется только корневая вершина, соответствующая неблагоприятной вершине для пустого предложения.
Мы заключаем, что если продолжать осуществлять резольвенции на множестве неудовлетворимых предложений, то в
Рис. 6.3. Граф опровержения для невыполнимого множества {P(x)VQW, ~Q(f(z)), (f (г)) V/?(*). —/?(«,)}.
конце концов придем к пустому предложению. Этот результат позволяет пользоваться в процессе опровержения одним только правилом резольвенции без явной ссылки на семантические деревья. Пусть 5?(S)—объединение множества S с множеством всех резольвент всех пар его предложений. Пусть 5?2(S) обозначает 5?(5?(S)) и т. д. Если множество S неудовлетворимо, то мы гарантированы, что при некотором конечном п (называемом уровнем, или глубиной, опровержения) в 5?n(S) будет пустое предложение. Так как множество $!’($) при любом I конечно, если конечно S, то эта простая стратегия нахождения опровержения является конечным (хотя, быть может, долгим) процессом.
Образование множеств 5?(S), 5?2(S), ... соответствует полному перебору при поиске опровержения. В гл. 8 мы обсудим различные стратегии поиска, более эффективные, чем эта про^ стая стратегия.
Опровержения, использующие резольвенции (иногда называемые доказательствами с помощью резольвенций), можно
200 Гл. 6. Доказательство теорем в исчислении предикатов
проиллюстрировать графоподобными структурами, в которых в каждой вершине записано некоторое предложение. Предложения из S записаны в концевых вершинах этого графа. Если два предложения, находящиеся в концевых вершинах, разрешаются, то их резольвента записывается в идущей непосред-етвенно за ними вершине, которая соединяется с этими конце-
Рис. 6.4. Граф опровержения для невыполнимого множества {В(х), -BWVCW, ~C(e)VD(»), ~C(c)VE(d), ~P(x)V-^ОШ-
выми вершинами с помощью ребер. Корнем графа опровержения с помощью резольвенции (эти графы обычно изображаются с корнем, расположенным внизу рисунка) служит пустое предложение (обозначаемое символом nil).
На рис. 6.3 приведен пример графа опровержения для множества неудовлетворимых предложений. Здесь для опровержения необходимы 3 резольвенции. Другой пример приведен на рис. 6.4. (Заметим, что на рис. 6.4 предложение С(х) используется на графе дважды. Иногда эти графы изображают в виде деревьев, повторяя поддеревья, появляющиеся более одного раза.)
6.15. Непротиворечивость и полнота резольвенции
201
6.15. НЕПРОТИВОРЕЧИВОСТЬ И ПОЛНОТА РЕЗОЛЬВЕНЦИИ
В этом разделе мы покажем, что, принцип резольвенции непротиворечив и полон. Непротиворечивость означает, что если когда-нибудь мы придем к пустому предложению, то исходное множество обязано быть неудовлетворимым. Полнота означает, что если исходное множество неудовлетворимо, то в конце концов мы придем к пустому предложению.
Для того чтобы показать непротиворечивость принципа резольвенции, нужно доказать, что резольвента двух предложений логически следует из этих предложений, т. е. в прежних обозначениях, что [{Л;} — {/Jk U [{MJ — {mj]x логически следует из (Li} и {A4J. Заметим, что каждая интерпретация, удовлетворяющая {LJ и {MJ, удовлетворяет {LJX и {MJX. Но поскольку никакая интерпретация не может удовлетворять одновременно и {/Jx и {/njx, то каждая интерпретация, удовлетворяющая {LJ и {MJ, удовлетворяет также и их резольвенте. Таким образом, резольвента логически следует из тех предложений, на которых она построена.
Для того чтобы показать, что принцип резольвенции полон, достаточно показать, что он полон по отношению к вершинам вывода в семантических деревьях.
Обозначим через Тг замкнутое семантическое дерево для .невыполнимого множества предложений S, и пусть п — такая вершина вывода в Тг, что П[ и п2— неблагоприятные вершины, расположенные непосредственно под п, но ни одно предложение из S не терпит неудачу ни на п, ни выше п. Предположим, что предложение {AJ из S терпит неудачу на ги, а предложение {BJ из S терпит неудачу на п2. Тогда в данном случае полнота принципа резольвенции означает существование резольвенты для {AJ и {BJ, скажем {CJ, терпящей неудачу на вершине п или выше нее.
Нетрудно видеть, что такая резольвента существует. В самом деле, пусть L — элемент эрбрановской базы, значение истинности которого присваивается как раз под вершиной п. Пусть для определенности значение L будет истинным для tit и ложным для п2. Хотя ни {AJ, ни {BJ не терпят неудачу на вершине п, {AJ терпит неудачу на nb a {BJ— на п2. Рассмотрим сначала предложение {AJ. Так как оно терпит неудачу на nlt оно должно содержать по крайней мере одно унифицируемое подмножество, скажем {а,}, для которого ~L будет «общим» константным частным случаем. Пусть о — такой унификатор, что {a J<j = ~L. Далее, предложение {AJ— {aj терпит неудачу на вершине п (или выше нее), поскольку при переходе от п к «1 мы лишь определили значение истинности для L, a {AJ терпит неудачу на П].
Аналогично, поскольку предложение {BJ терпит неудачу на •«2, оно должно содержать унифицируемое подмножество,
202 •
Гл. 6. Доказательство теорем в исчислении предикатов
скажем {bi}, для которого L будет «общим» константным частным случаем. Пусть т — такой унификатор, что {Ь,}т = L. Предложение {Bi} — {bj также должно терпеть неудачу на вершине п (-или выше нее).
Теперь унификаторы а и т можно скомбинировать, поскольку переменные в {Xj и {&<} можно считать различными. Обозначим этот комбинированный унификатор через <о. Таким образом, так как = £ и {Ь{}а — ~L, то {Л,} и {В,} имеют резольвенту
[ИJ - {aJk и [{В«} - {Ш>
где % — наиболее общий унификатор для {a,} U {—Ь,}. Так как % — наиболее общий унификатор, то [{ЛД — {аг}]ш— частный случай предложения [{А} — {а,}]х, a [{BJ — {ML» — частный случай предложения [{В,}— {Мк Тогда, так как оба предложения IHJ—{«i)k> и [{В,} — {bjk, терпят неудачу на вершине вывода п (или выше нее), то должны терпеть неудачу и предложения [{Л<} — {aJk и [{BJ — {&г}]л- Очевидно, что их объединение — наша резольвента — также терпит неудачу.
Для иллюстрации связи между семантическими деревьями и резольвентными построениями обратимся снова к множеству предложений S, семантическое дерево которого изображено на рис. 6.2. Мы уже показали, что на вершине 1 терпит неудачу предложение ~/’(x)AQ(jt), на вершине 2 — предложение (/(«/)), а их резольвента •~B(f(«/)) терпит неудачу на вершине 3 — вершине вывода. Далее, на семантическом дереве для множества S', = {~P(f (у))} U S неблагоприятными вершинами будут вершины 3 и 4. На вершине 4 терпит неудачу предложение Построение резольвенты для P(f(y)) и ~Р(f(y))
приводит, разумеется, к пустому предложению (терпящему неудачу на корневой вершине). Итак, доказательство невыполнимости заканчивается всего лишь после двух резольвейций.
6.16. БИБЛИОГРАФИЧЕСКИЕ И ИСТОРИЧЕСКИЕ ЗАМЕЧАНИЯ
Основания логики
Наше весьма поверхностное изучение математической логики можно углубить, обратившись к некоторым стандартным учебникам. Блестящими учебниками являются книги Мендельсона (1964) и Роббина (1969)'), а для специалистов — классическая книга Чёрча (1956). В этих книгах излагается то, что можно назвать классической логикой. Принцип резольвенции (или в действительности любое обсуждение автоматического доказательства теорем) еще не попал в учебники по логике.
*) На русском языке можно порекомендовать монографию П. С. Новикова «Элементы математической логики», М., 1959. — Прим. ред.
6.16. Библиографические и исторические замечания
203
В основу настоящей главы мы положили исчисление предикатов первого порядка с резольвенциями, поскольку оно явно играет большую роль при автоматическом решении задач. Существенное упущение здесь, однако, состоит в том, что мы не рассмотрели отношения равенства. Все еще неясно, как «встроить» в автоматические доказатели теорем отношение равенства (и другие стандартные часто встречающиеся отношения). Обсуждение этих усложнений выходит за рамки настоящей книги. Одна из схем, позволяющая включить отношение равенства в устройства автоматического доказательства теорем, обсуждается Робинсоном и Восом (1969).
Далее, становится все яснее, что для создания сложных универсальных решающих устройств необходимо привлечь логики высших порядков. Обсуждение применения логики высших порядков к решению задач можно найти у Маккарти и Хэйеса (1969). В книге Роббина (1969) есть раздел, посвященный логике второго порядка, а в статьях Дж. Робинсона (1969а, 19696) рассматриваются общие проблемы процедур доказательства для логик высших порядков.
Этапы, выделенные нами при преобразовании правильно построенной формулы в совокупность предложений, основаны на процедуре Дэвиса и Путнама (1960). Такое представление в виде предложений называют также бескванторной коиъюнк-тивно нормальной формой.
Эрбрановские процедуры доказательства и резольвенция
Принцип резольвенций в автоматическом доказательстве теорем основан на процедуре доказательства Эрбрана (1930). Прямая реализация эрбрановской процедуры была бы в высшей степени неэффективной. Усовершенствования, внесенные Правицем (1960) и другими, привели в конечном итоге к принципу резольвенция Дж. Робинсона (1965а). Наш способ изложения методов доказательства, основанных на резольвенциях, опирается на работу Ковальского и Хэйеса (1969). (См. также Дж. Робинсон, 1968.) Привлечение семантических деревьев делает очевидной связь между резольвенциями и эрбрановскими методами, их можно использовать также для доказательства применимости правил, более общих по сравнению с простой ре-зольвенцией. Наше доказательство полноты принципа резоль-венции является частным случаем доказательства полноты более общего правила вывода, приведенного у Ковальского и Хэйеса (1969).
Ясно написанное, сжатое изложение принципа резольвенции с доказательством его полноты и непротиворечивости дано в статье Лакхэма (1967). Доказательство непротиворечивости и полноты можно найти еще в первой работе Дж. Робинсона (1965а). В этих двух работах приведено также доказательство
204
Гл. 6. Доказательство теорем в исчислении предикатов
«корректности» алгоритма унификации. Дж. Робинсон (1970) написал, кроме того, блестящее, исследование, посвященное «механическому доказательству теорем».
Задачи
6.1. Придать следующим п.п. формулам вид предложений:
а) (Чх){Р(х)=$ Р(х)},
b) {~{(Vx) Р (*)}) =$ (Зх) {- Р (х)},
с) -{(Vx) {Р (x)=>{(Vy) {Р (У)^Р (f (х, у))} Л - (Vy) {Q (х, у)=$ Р (у)}}}}, d) (Vx3y) {{Р (х, у) => Q (у,г)} Д {Q (у, х) =ф S (х, у)}} =ф
=Ф (3xVy) {Р (х, у) =ф S (х, у)}.
6.2. При каких условиях универсум Эрбраиа для множества предложений S конечен?
*6.3. Напишите программу для приведения п. п. формулы к виду предложений.
6.4. Пусть S — множество литералов и р— подстановка. Напишите программу для вычисления Sp.
6.5. Исчисление высказываний можно рассматривать как частный случай исчисления предикатов, когда единственными предикатными буквами являются пропозициональные символы р® (см. стр. 173). Как надо находить, реэольвенцию двух классов в исчислении высказываний? Возьмите отрицание каждой из следующих формул исчисления высказываний и используйте принцип резольвенция для доказательства неудовлетворимое™ множества предложений, получаемого из каждого такого отрицания.
а) (Р V Q) ==> (Q V Р),
b) (Р =£ Q) ((Л V Р) (Л V Q)).
с) Р =$ Р) =$ Р,
d) (—Q =>~ Р) =^> ((~Q => Р) =$ Q),
е) ((Р =ф Q) =ф Р) =ф Р.
*6.6. Определите точно (скажем, с помощью блок-схемы) алгоритм унификации, работающий в соответствии с общим описанием в разд. 6.12. Используйте этот алгоритм для поиска унификатора множества
{Р (х, z, у), Р (ш, и, w), Р (а, и, и)}.
(Замечание: будьте внимательны при точном определении композиции подстановок.) Верно ли Ваш алгоритм обнаруживает тот факт, что множество-{Р(х), Р()(х))} не унифицируемо? Используя свой алгоритм, составьте программу, выдающую наиболее общий унификатор множестиа S, если оно унифицируемо, и nil в противном случае.
6.7. Пусть Ci и С2 — два предлояцгния. Покажите, как использовать программы задач 6.4 и 6.6 для написания программы вычисления множества всех резольвент предложений С) и С2.
6.8. Возьмите отрицание каждой из следующих теорем исчисления предикатов и используйте принцип резольвенции для поиска противоречия:
a) (Vx){P(x)^ Р(х)},
b) {-{(Vx)P(x)}}^> (Зх){-Р(х)},
с) {(Vx) {Р (х) Л Q (х)} {(vx) Р (х)} Д {(У у) Q (у)},
d) {(Зх) (Уу) Р (х, у)} {(Vy) (Зх) Р (х, у)}.
Глава 7
.ПРИМЕНЕНИЯ ИСЧИСЛЕНИЯ ПРЕДИКАТОВ К РЕШЕНИЮ'ЗАДАЧ
7.1. ИСЧИСЛЕНИЕ ПРЕДИКАТОВ ПРИ РЕШЕНИИ ЗАДАЧ
В настоящей главе мы рассмотрим, как можно применить к решению задач доказательства теорем в исчислении предикатов. Иногда достаточно только знать, следует ли логически п. п. формула W из некоторого множества S п. п. формул. Если W не следует из S, то, возможно, мы захотим знать, следует ли ~ № из S. Конечно, в силу неразрешимости исчисления предикатов не всегда можно установить, следует ли W (или — W7) из S. Можно попытаться поискать ответ на каждый из этих вопросов, и, если после затраты некоторых усилий ответ не будет найден или время будет исчерпано, можно лишь заключить, что на вопрос, следует ли W (или. ~ W7) из S, нельзя дать ответ (с учетом наших возможностей). Часто, конечно, рдно из доказательств будет найдено, и вопрос окажется решенным.
В других приложениях нужно знать значение элемента х (если он существует), при котором данная правильно построенная формула W (содержащая х в качестве переменной) логически следует из некоторого множества S п. п. формул. Иными словами, мы хотели бы знать, следует ли логически п. п. формула (Bx)W(x), и если да, то каков тот частный случай переменной х, «который существует». Проблема поиска доказательства п. п. формулы (3x)W(x), исходя из S, является обычной проблемой доказательства в исчислении предикатов, но для построения удовлетворяющего частного случая требуется, чтобы метод доказательства был «конструктивным».
Заметим, что умение строить удовлетворяющие частные случаи для переменной, относящейся к квантору существования, позволяет ставить вопросы весьма общего свойства. Например, мы могли бы задаться вопросом: «Существует ли решающая последовательность для некоторого случая игры в пятнадцать?» Если можно найти конструктивное доказательство того, что решение существует, то можно указать также само решение. Мы могли бы задать даже более трудный вопрос: «Существует ли программа, которая будет производить определенные вычисления?» Из конструктивного доказательства ее существования можно было бы извлечь саму программу. (Очевидно, следует помнить, что сложные вопросы, вообще говоря, приводят к сложным доказательствам, возможно настолько сложным, что
206 Гл. 7. Применения исчисления предикатов к решению задач
наши автоматические процедуры поиска доказательства их не найдут.)
Основная цель настоящей главы — описать процесс, с помощью которого удовлетворяющий частный случай переменной, относящейся к квантору существования, в некоторой п. п. формуле можно извлечь из доказательства п. п. формулы, содержащей эту переменную. Затем на ряде примеров мы проиллюстрируем применение этого процесса и вообще исчисления предикатов к решению задач. Обсуждение процессов поиска при построении самих доказательств мы отложим до следующей главы.
Часто утверждения, относящиеся к задаче, делаются в-фор-ме фраз на разговорном языке, например английском. Поэтому естественно возникает вопрос, в каких случаях можно осуществить автоматический перевод с айглийского языка на язык п. п. формул исчисления предикатов первого порядка. Хотя такой процесс перевода должен быть одной из основных частей законченного решателя задач, мы его не будем здесь рассматривать. Написано несколько программ, позволяющих осуществлять в ограниченных рамках перевод с английского языка на язык исчисления предикатов, но способность работать с естественным языком пока находится в весьма неудовлетворительном состоянии. Можно выделить две главные трудности: (1) выбор отношений, которые следует использовать при переводе предложений с английского языка, и (2) однозначное преобразование смысла, вложенного в фразу, в п. п. формулы, использующие предикатные символы для этих отношений. Часто неоднозначность можно устранить только рассмотрением «контекста» фразы, а это сопряжено с трудными и не до конца понятыми процессами. Проблема преобразования английского языка в п. п. формулы нисколько не легче, чем, например, проблема преобразования английского языка в описания состояний, операторы и т. д. В настоящей книге мы вынуждены оставить без рассмотрения вопросы перевода (сколь ни важны они) и сосредоточить все свое внимание на процессах решения уже сформулированных задач.
7.2. ПРИМЕР
Рассмотрим следующую тривиальную задачу: «Если Майкл повсюду ходит за Джоном, а Джон находится в школе, то где Майкл?» Совершенно ясно, что в этой задаче сформулированы два «факта», а затем поставлен вопрос, который, по-видимому, можно вывести из этих двух фактов. Эти факты легко переводятся на язык п. п. формул и дают следующее множество S п. п. формул:
(Vx) {АТ (Джон, х) => АТ (Майкл, х)} и
АТ (Джон, школа),
7.2. Пример
207
где предикатному символу АТ придана очевидная интерпретация («быть в определенном месте», соответствующая предлогу «в» — Перев.).
На вопрос «Где Майкл?» можно дать ответ, если сначала доказать, что п. п. формула
(Эх) АТ (Майкл, х)
следует из S, и затем найти тот частный случай переменной х, «который существует». Ключевая идея здесь состоит в таком преобразовании вопроса в п. п. формулу, содержащую квантор существования, чтобы ответом на этот вопрос служила переменная, относящаяся к квантору существования. Если на основании данных фактов можно дать ответ на вопрос, то п. п. формула, построенная таким способом, будет логически следовать
~ АТ (Майкл,х)
~АТ(Джон,х) \j АТ(Майкл,х}
Рис. 7.1. Дерево опровержения для рассматриваемого примера.
из S. После нахождения доказательства мы пытаемся извлечь тот частный случай переменной, относящейся к квантору существования, который служит ответом. В нашем примере легко доказать, что (Эх) АТ (Майкл,х) следует из S. Легко также показать, что соответствующий ответ можно, извлечь с помощью сравнительно простой процедуры.
Доказательство получается обычным путем. Сначала отрицается п. п. формула, которую предстоит доказать. Затем это отрицание добавляется к множеству S, и все члены расширенного множества преобразуются в форму предложений. Далее с помощью принципа резольвенции показывается, что это множество предложений неудовлетворимо. Дерево опровержения для нашего примера изображено на рис. 7.1. Правильно построенная формула, которую предстоит доказать, называется предположением, а предложения, получающиеся из п. п. формул, содержащихся в S, называются аксиомами.
Заметим, что отрицание п. п. формулы (Эх)АТ (Майкл, х) дает
(Vx)[~AT (Майкл, х)], или, в форме предложения, просто ~ АТ (Майкл, х).
2С8 Гл. 7. Применения исчисления предикатов к решению задач
Теперь из этого дерева опровержения извлечем ответ на вопрос «Где Майкл?» Это осуществляется следующим образом:
(1) К каждому предложению, вытекающему из отрицания предположения, добавляется его отрицание. Тогда ~ АТ (Майкл, х) принимает вид тавтологии ') ~ АТ (Майкл, х) V АТ (Майкл, х).
(2) В соответствии со структурой дерева опровержения выполняются те же самые резольвенции* 2), что раньше, до тех пор пока я его корне не будет получено некоторое предложение.
~АТ (Майкл, х) v АТ (Майкл, х)
Рис. 7.2. Модифицированное дерево доказательства для рассматриваемого примера.
В нашем примере этот процесс порождает дерево, показанное на рис. 7.2, с предложением АТ(Майкл, школа) в его корне.
(3) Предложение в корне преобразуется в обычную форму исчисления предикатов и используется в качестве - ответного утверждения. Эту п. п. формулу затем можно снова перевести на, скажем, английский язык, как ответ на вопрос. Очевидно, что в нашем примере АТ (Майкл, школа) и является соответствующим ответом задачи.
Заметим, что форма ответного утверждения близка к форме предположения. В нашем случае единственное отличие состоит в том, что в предположении мы имеем переменную, связанную с квантором существования, а в ответном утверждении — константу (ответ).
Прежде чем приступить к обсуждению приложений этого метода, стоит подробнее изучить процесс извлечения ответа. В следующем разделе мы приведем обоснование самого про
‘) Тавтологией называется п. п. формула вида W ~ W.
2) Смысл слов «те же самые резольвенции» мы объясним позже.
7.3. Процесс извлечения ответа
209
цесса и обсудим, как применять его в случаях, когда предположение 'содержит как кванторы всеобщности, так и кванторы существования.
7.3. ПРОЦЕСС ИЗВЛЕЧЕНИЯ ОТВЕТА
Извлечение ответа связано с преобразованием графа опровержения (с nil в его корне) в граф, у которого в корне находится некоторое утверждение, могущее служить ответом. Так как при таком преобразовании каждое предложение, возникающее из отрицания предположения, превращается в тавтологию, то преобразованный граф представляет собой доказательство того, что утверждение, расположенное в его корне, логически следует из аксиом и тавтологий. Поэтому оно также следует из аксиом и только из них. Таким образом, для извлечения ответа можно использовать сам преобразованный граф доказательства. Позже станет ясно, почему утверждение, расположенное в корневой вершине модифицированного дерева опровержения, всегда можно использовать как ответ.
Хотя этот метод и прост, но у него есть несколько тонких' моментов, которые мы разъясним на примерах.
Пример 1. Рассмотрим правильно построенные формулы
1) (VxVz/) {(Р (х, у) К Р (у, г)) =$ G (х, г)},
2) (Vz/Зх) {Р (х, у)}.
Их можно интерпретировать так:
1) Для всех хну, если х является родителем у и у является родителем z, то х является прародителем z
2) Каждый индивид имеет своего родителя.
Будем считать эти формулы гипотезами и зададим такой вопрос: «Существуют ли такие индивиды х и у, что G(x,«/)?» (Иными словами, существуют ли такие х и у, что х является прародителем г/?)
Сформулируем этот вопрос в виде предположения, требующего доказательства:
(3x3 г/) G (х, у).
Это предположение легко доказать методом опровержения с помощью резольвенций, показав невыполнимость множества предложений, получаемых из аксиом и предположения. Дерево опровержения изображено на рис. 7.3. Литералы, подвергающиеся унификации при каждой из резольвенций, подчеркнуты. Подмножество литералов в предложении, подвергающееся унификации в процессе резольвенции, назовем множеством унификации.
210
Гл. 7. Применения исчисления предикатов к решению задач
(отрицание предположения)
~Р(х,у)у ~Р(у,г) у/ С(т,г)
(аксиома 1)
~Р(и,у) у ~Р(у,о)
Рис. 7.3. Дерево опровержения для примера 1.
Заметим, что предложение P(f(w),w) содержит сколемову функцию f, введенную при исключении квантора существования в аксиоме 2: (Vу^х) {Р (х, у)}. Эта функция определяется' так, чтобы (Vy) (P(f (у),у). (Функцию f можно интерпретировать как функцию, задающую имя родителя каждого индивида.)
Модифицированное дерево доказательства приведено на рис. 7.4. Отрицание предположения преобразовано в тавтологию, а резольвенции осуществляются те же самые, что и на рис. 7.3. Каждая резольвенция в модифицированном дереве опирается на множества унификации, которые в точности соответствуют множествам унификации графа опровержения. Множества унификации на рис. 7.4 подчеркнуты.
В корневой вершине дерева доказательства, изображенного на рис. 7.4, находится G(f (f (о)), о). Это предложение соответствует п. п. формуле (Vu){G(f(f(o)), о)}, представляющей собой ответное утверждение. Ответное утверждение дает полный ответ на вопрос: «Существуют ли такие х и у, что х является прародителем у?» Ответ в данном случае содержит определительную функцию f: любое v и родитель родителя этого v служат примерами индивидов, удовлетворяющих условиям вопроса. Снова ответное утверждение имеет форму, близкую к форме вопроса.
7.3. Процесс извлечения ответа
211
~G{u,u) v G(u,v)
~Р(х,у) v ~Р(у,г) V g/r.z)
~Р(и,у) v ~Р/у,Ц) v G(u,v}
~P(u,f{u)) v С(и,о)
Рис. 7.4. Модифицированное дерево доказательства для примера 1.
Пример 2. Покажем, как преобразовать в тавтологии более сложные предложения, возникающие при отрицании предположения.
Рассмотрим следующее множество предложений:
~Д(х) VB(x) V G(f(x)), ~ F (х) V В (х), ~F (х) V С (х), ~ G (х) V В (х), ~G(x)V-D(x), A(g(x))V F(h(x)).
Мы хотим доказать, исходя из этих аксиом, предположение (3x31/) {{В (х) Л С (х)} V {В (У) Л В (у)}}.
Отрицание его приводит к двум предложениям, каждое из которых содержит по два литерала:
~ В (х) V ~ С (х), ~ В (х) V ~ В (х).
Граф опровержения для нашего дополненного множества предложений приведен на рис. 7.5.
Теперь для преобразования графа мы должны превратить предложения, вытекающие из отрицания высказанного предположения (на рис. 7.5 они заключены в рамку), в тавтологии, дописав к ним их отрицания. В данном случае отрицания
212 Гл. 7. Применения исчисления предикатов к решению задач
содержат знак Л. Предложение ~ В(х)\/ ~ С(х), например, преобразуется в формулу ~B(x)V ~ С(х) V (В(х)ЛС(х)). Эта формула не будет предложением из-за имеющейся^ в ней конъюнкции (В(х) ЛС(х)). Однако мы будем обращаться с этбй конъюнкцией, как с единым литералом, и действовать формально так, как будто наша формула является предложением (ни
Рис. 7.5. Граф опровержении для примера 2.
один из элементов рассматриваемой конъюнкции не может оказаться ни в одном множестве унификации). Аналогично преобразуем предложение ~D(х) V ~В(х) в тавтологию ~£(x)V ~S(x)V (D(x)AB(x)).
Выполняя резольвенции, диктуемые соответствующими множествами унификации, мы строим граф, изображенный на рис. 7.6. В корневой вершине расположена п. п. формула
{(Vx) [В (g (х)) Л С (g (х))] V [Д (f (g (х))) Д Bff (g (х)))] V
V [В(й(х))ЛС(Л(х))1}.
Мы видим, - что здесь ответное утверждение имеет форму, несколько отличную от формы, в которой было сделано предпо
7.3. Процесс извлечения ответа
21S
ложение. Нетрудно видеть, что подчеркнутая часть ответного утверждения аналогична по форме всему предположению, но только здесь вместо переменной х, относящейся к квантору существования, стоит g(x), а вместо переменной у, относящейся к другому квантору существования, стоит f(g(x)). Но в рассматриваемом примере в ответном утверждении имеется дополни-
л С(й(я))] v л B(f(g(x)))] V [В(д(х)) л С(д(х))]
Рис. 7.6. Модифицированный граф доказательства для примера 2.
тельный дизъюнкт [В(/г(х))А С(/г(%))]. Этот дизъюнкт похож; на один из дизъюнктов, содержащихся в предположении, причем вместо переменной х, относящейся к квантору существования, здесь стоит h (х).
Вообще, если предположение делается в дизъюнктивно нормальной форме, то в процессе извлечения ответа создается утверждение, представляющее собой дизъюнкцию выражений,, каждое из которых имеет форму либо всего предположения, либо одного или нескольких дизъюнктов этого предположения. Поэтому мы и говорим, что такое утверждение можно-
214 Гл. 7. Применения исчисления предикатов к решению задач
использовать в качестве «ответа» на вопрос, представляемый исходным предположением.
Ситуацию, возникающую в общем случае, можно описать точно. Допустим, что нам нужно доказать предположение, имеющее вид
(3xi) ... (3xn) Wi (Xi..хп) V ..; V Wm (xit хп)],
где каждый член JFj представляет собой конъюнкцию литералов. Это значит, что каждый член ITj можно записать в виде
Wt — J-n Л Л • • • Л
где переменные явным образом не указаны. Отрицание предположения приводит к предложениям
V ~ £-12 V ... VLup
£-ml V V ... V l^mkm‘
После того как построен граф опровержения, каждое вхождение любого из этих предложений преобразуют в тавтологию, добавляя отрицание предложения. Иными словами, добавляют формулы вида
1 I'll Л £>12 Л ... Л Lfkf = Wi (Xt, X2t • • • > xn).
Таким образом, в корневой вершине преобразованного графа опровержения будет'получено ответное утверждение, состоящее из дизъюнкций членов Wi, в которых вместо переменных Xi, ..., хп стоят различного рода частные случаи.. Ясно, что каждый член Wi может вовсе не содержаться в ответном утверждении, а может содержаться в нем один или даже несколько раз. Таким образом, совсем не обязательно, чтобы ответное утверждение имело вид в точности как у предположения.
7.4. ПРЕДПОЛОЖЕНИЯ, СОДЕРЖАЩИЕ ПЕРЕМЕННЫЕ, ОТНОСЯЩИЕСЯ К КВАНТОРУ ВСЕОБЩНОСТИ
В случае когда предположение, которое требуется доказать, содержит переменные, относящиеся к квантору всеобщности, возникают дополнительные трудности. При отрицании такие переменные переходят в переменные, относящиеся к квантору существования, а это приводит к необходимости введения ско-лемовых функций. Что должно служить интерпретацией этих сколемовых функций, если они в конце концов появляются в качестве термов в ответном утверждений?
7.4. Предположения с квантором всеобщности
215
Проиллюстрируем это на примере. Зададим аксиомы в виде предложений:
1) С(х, р(х)) : каждый х является ребенком для р(х). (Иными словами, р — функция, ставящая в соответствие ребенку индивида самого индивида.)
2) ~ С (х, у) V Р (у, %): для всех х и у, если х — ребенок для у, то у — родитель для х.
Теперь мы задаем вопрос: «Для любого х кто является его родителем?» Предположение, соответствующее этому вопросу, имеет вид
(Vx2z/) Р (у, х).
Преобразуя отрицание этого предположения в форму предложений, мы получаем сначала
(ЗхУу)~Р(у, х), а затем ~Р(у,а),
где а — сколемова функция, не содержащая аргументов (т. е. константа), введенная для исключения квантора существова-
ние. 7.7. Модифицированное дерево доказательства для получения ответного утверждения.
ния, появляющегося при отрицании предположения. (Отрицание предположения означает, что некоторый индивид, а не имеет родителей.) Модифицированное дерево доказательства, в корневой вершине которого находится ответное утверждение, изображено на рис. 7.7.
•216
Гл. 7. Примечания исчисления предикатов к решению задач
В данном случае мы получаем довольно трудно интерпретируемое утверждение Р(р(а),а), содержащее сколемову функцию а. Интерпретация должна говорить о том, что независимо от сколемовой функции а, которая должна бы «нарушить» справедливость предположения, мы можем, как оказалось, доказать Р(р(а),а). Иными словами, любой индивид, для которого пред-• положение могло быть неверным, на самом деле удовлетворяет предположению. Доказательство, представленное на рис. 7.7, будет справедливо и.в случае, если вместо константы а взять переменную.
Можно показать (Лакхэм и Нильсон, 1971), что в процессе извлечения ответа всегда можно заменять любые сколемовы функции, возникающие при отрицании предположения, новыми переменными. В модифицированном доказательстве в эти'новые переменные не будет делаться никаких подстановок, так что они пройдут через доказательство без изменения и появятся в окончательном ответном утверждении. Резольвенциями в модифицированном доказательстве по-прежнему будут лишь резольвен-ции, определяемые множествами унификации, соответствующими множествам унификации, появляющимся в ходе первоначального опровержения. В процессе некоторых резольвенций переменные могут быть переименованы, так что, возможно, некоторая переменная, использованная на месте сколемовой функции, окажется переименованной и станет, таким образом, «родоначальником» новых переменных в окончательном ответном утверждении.
Продемонстрируем на двух простых примерах некоторые явления, связанные с этой особенностью.
Пример 3. Пусть S состоит из единственной аксиомы (в форме' предложения)
P(b, w, ®) V Р(а, и, и).
Нам нужно доказать предположение
(BxVzB«/)P(x, z, у).
Дерево опровержения изображено на рис. 7.8, а. В предложении, происходящем из отрицания нашего предположения, содержится сколемова функция g(x). На рис. 7.8,6 изображено дерево модифицированного доказательства, в котором вместо •сколемовой функции g(x) стоит переменная t. Мы получаем доказательство ответного утверждения
Р(а, t, t) V P(b, z, z),
совпадающего (с точностью до наименования переменных) с нашей аксиомой. Этот пример показывает, каким образом появляются в ответном утверждении новые переменные, введенные
7.4. Предположения с квантором всеобщности
2\7
при переименовании в процесс резольвенции переменных в одном предложении.
Пример 4. Допустим, что нам нужно доказать то же самое-предположение, что и в предыдущем примере, но теперь исходя
Рис. 7.8. Деревья доказательства для примера 3.
из аксиомы P(z, и,z) V Р(а, и, и). Дерево опровержения изображено на рис. 7.9, а. В предложении, происходящем из отрицания предположения, содержится сколемова функция g(x).
На рис. 7.9, б изображено дерево модифицированного доказательства, в котором вместо сколемовой функции g(x)
218
Гл. 7. 'Применения исчисления предикатов к решению задач
использована переменная v. Мы получаем доказательство ответного утверждения
P(z, w, z) V Р(а, w, w), совпадающего (с точностью до наименований переменных) с исходной аксиомой. Внимательный анализ унифицирующих под-
а
Рис. 7.9. Деревья доказательства для примера 4.
становок в этом примере показывает, что, хотя резольвенции в модифицированном дереве и ограничены соответствующими множествами унификации, подстановки, используемые в модифицированном дереве, могут носить более общий характер по сравнению с подстановками в первоначальном дереве опровержения.
В заключение перечислим этапы процесса извлечения ответа:
7.5. Пример автоматического написания программы 219
1. В ходе некоторого процесса поиска (перебора) строим граф опровержения на основе резольвенций и выделяем в нем множества унификации.
2. Вместо сколемовых функций, которые появляются в предложениях, происходящих из отрицания предположения, подставляем новые переменные.
3. Предложения, происходящие из отрицания предположения, превращаем в тавтологии, приписывая к ним их же отрицания.
4. Следуя структуре первоначального графа опровержения, строим граф модифицированного доказательства. В каждой ре-зольвенции модифицированного графа используем множество унификации, определяемое множеством унификации, используемым при соответствующей резольвенции в графе опровержения.
5. Предложение, находящееся в корневой вершине модифицированного графа, представляет собой ответное утверждение, извлеченное в ходе описываемого процесса.
Очевидно, что ответное утверждение зависит от того опровержения, из которого оно было извлечено. Возможно, для одной и той же задачи существует несколько различных опровержений. Из каждого такого опровержения мы могли бы извлечь ответ, и хотя некоторые из ответов могут совпасть, тем не менее некоторые утверждения, составляющие ответ, могут оказаться более общими, чем другие. Обычно у нас нет возможности установить, является, ли ответное утверждение, извлеченное из данного доказательства, наиболее общим. Мы могли бы, конечно, продолжать поиск доказательств до тех пор, пока не найдем доказательство, дающее достаточно общий ответ. Но вследствие неразрешимости исчисления предикатов не всегда можно установить, нашли ли мы все возможные доказательства для п. п. формулы № исходя из множества S. Эта трудность представляет, по-видимому, лишь теоретический интерес. В приводимых ниже примерах получаемые ответы вполне удовлетворительны.
7.5. ПРИМЕР АВТОМАТИЧЕСКОГО НАПИСАНИЯ ПРОГРАММЫ
При соответствующей формализации описанный выше процесс извлечения ответа можно применять для автоматического построения простых программ для вычислительной машины. При существующем уровне развития таких методов приемы автоматического доказательства теорем пригодны для написания лишь простейших программ. Мы проиллюстрируем этот подход на примере. Общая же проблема автоматического синтеза программы пока еще выходит за рамки возможностей всех имеющихся в настоящее время подходов.
220 Гл. 7. Применения исчисления предикатов к решению задач
Предположим, что мы хотим написать программу, в которой в качестве входной переменной берется х, а на выходе получается значение у, удовлетворяющее какому-то соотношению Д (х,у). Мы считаем, что некоторым множеством аксиом определена интерпретация предикатной буквы /?. Другие аксиомы задают элементарные функции, из которых мы будем конструировать нашу программу (создавая композиции функций). С помощью процесса извлечения ответа система доказательства теорем построит требуемую программу, если она сможет доказать, что предположение (Vx3y) R(x, у) логически следует из указанных аксиом. После того как доказательство - будет найдено, в ответном утверждении будет предположенное у как композиция элементарных функций. Эта композиция функций тогда и будет программой.
Для того чтобы писать интересные программы, мы должны располагать элементарными функциями, допускающими условные ветвления и либо итерации, либо рекурсии. Такие языки программирования, как LISP1), дают возможность писать рекурсивные программы. Для формализации действия функций, допускающих условные ветвления (таких, как функция cond в языке LISP), требуется либо возможность работать с отношением равенства, либо наличие специальных правил вывода. В настоящей книге мы не рассматриваем вопрос отношения равенства; пока еще неясно, какой именно из предлагаемых методов работы с равенством приемлем (и приемлем ли хоть один из них вообще). В некоторых случаях можно обойти эту трудность и создать рекурсивные программы с ветвлением при проверке выполненности условий окончания. Используемые в этих случаях приемы лучше всего пояснить на конкретном примере.
Допустим, что мы хотим составить программу, сортирующую входной список чисел. Выходом должен быть другой .список, содержащий те же самые числа, расположенные в порядке их убывания. Мы будем строить программу из элементарных функций car, cdr, cons и merge. Первые три из них являются элементарными функциями языка программирования LISP. Они определяются следующим образом:
саг(х) имеет в качестве своего значения первый элемент списка х;
cdr(x) имеет в качестве своего значения ту часть списка х, которая остается после удаления из него первого элемента;
cons (х, у) имеет в качестве своего значения список, получаемый в результате размещения перед списком у элемента х.
Как следствие этих определений мы получаем, что cons (саг (х), cdr (х)) = х.
’) Хорошее описание языка LISP содержится в книге Вайссмана (1967).
7.5. Пример автоматического написания программы
221
Нетрудно видеть целесообразность использования этих функций как компонент более сложных .операций над списками, таких, как программа сортировки, которую мы хотим построить. Еще одна элементарная функция, merge, выбранная нами, существенно более сложна по сравнению с первыми тремя. У функции merge (сливаться, соединяться) два аргумента: первый является элементом, а второй — отсортированным списком. Значением merge (х, у) служит новый список, содержащий элемент х и все элементы списка у, причем этот новый список уже подвергнут сортировке. Таким образом, merge (х, у) находит соответствующее место в отсортированном списке у для такого размещения там элемента х, чтобы результирующий список не нуждался в сортировке.
Теперь сформулируем «аксиомы», формализующие наши определения и нужное нам отношение вход — выход R(x, у).
Прежде всего мы определим отношение сортировки R(x,y) в терминах двух других отношений:
1. (VxV«/) {{R (х, у) ^>{S (у) Л / (х, г/)}} Л {{$ (у) Д / (х, у)}
=^>R(x, г/)}}.
Интуитивный смысл отношения S(y) состоит в том, что «список у уже подвергнут сортировке». Смысл отношения 1(х,у) — «два списка х и у содержат одни и те же элементы (но не обязательно в одинаковом порядке)». Теперь мы предлагаем (рекуррентные) определения для S и I через элементарные функции:
2. (VxV yVu){I (х, у) ==> I (cons (и, х), merge(«, i/))}.
3. /(nil, nil) (nil обозначает пустой список).
4. (VxVy) (S (у) => S (merge (х, г/))}.
5. S (nil).
На самом деле определения 2—5 несколько слабее того интуитивного определения, которое мы дали выше, но они достаточны для построения доказательства ’).
Множество предложений, соответствующих приведенным выше правильно построенным формулам 1—5, таково:
1а. ~/?(х, у) V S (у).
1Ь. ~/?(х, у) V / (х, у).
1с. ~S(i/) V~/(x, г/) V/?(х, г/).
2. ~/(х, у) V / (cons (и, х), merge (и, у)).
’) Представленная здесь аксиоматизация в сущности совпадает с аксиоматизацией, предложенной ранее Робертом Йейтсом из Стэнфордского исследовательского института.
222 Гл. 7. Применения исчисления предикатов к решению задач
3. У (nil, nil).
4. ~ S (i/) V S (merge (x, y)).
5. S(nil).
Нашей стратегией будет попытка доказать (VxBz/) /?(х, у) по индукции. Мы будем доказывать это предположение для списка длины нуль, затем предположим, что оно верно для списков длины п 0, и докажем его справедливость для списков длины n-f-l. Результатом будет рекурсивная функция, сортирующая список произвольной длины.
, ~R(nil,y) -
______v К(х,у)
~S(y) V
Рис. 7.10. Дерево опровержения для (Зу) R (nil, у).
Доказывая таким способом, мы существенно помогаем написанию программы, «встраивая» проверку условного ветвления для х = nil. Если этот тест удовлетворяется, мы переходим к программе, образованной доказательством для входных списков длины п = 0. В противном случае мы переходим к программе, образованной доказательством, использующим предположение индукции. Такая схема упрощает наш пример, поскольку освобождает от формализации условных функций и введения необходимых отношений равенства.
В случае списков длины п = 0 предположение можно сформулировать в виде (Э//)/?(пП,у). Отрицанием его будет ~/?(nil, у). Дерево опровержения изображено на рис. 7.10. После извлечения ответа из этого дерева мы получаем ответное утверждение
7?(nil, nil).
7.5. Пример автоматического написания программы
223
Таким образом, здесь мы имеем до некоторой степени тривиальный результат: «Если длина списка х равна 0, то у = nil».
~R(a,y)
v R(x,y)
~Я(соп8(сяг(а),сс1г(я)),у)
V ~Цх,у)
-/(cons(car(a),cdr(a)),yj v ~Sfy)
\z ~!(x,y)
~/fcdr(o),y) v ~S(merge(cnr(a),y))
~S(merge(cnr(a)),y) v ~K(cdr(o),y) 'S\^S(pwrgeJ^y)) v ~S(y)
~rt(cdr(e),y) v ~S(y)
(x,y)
~«(cdr(a),y) v ~Я(ж,У)
'4'\^^^^cdr(^^rt(cdrU))) nil
Рис. 7.11. Дерево опровержения для (Vx3y) R (х, у}.
Сформулируем теперь предположение индукции: «Для каждого непустого списка х значение cdr(x) можно отсортировать». Представим себе, что у нас есть функция sort, которая может произвести сортировку списка меньшего размера. Предположение индукции в форме предложения имеет вид
6. /? (cdr (х), sort (cdr (х))).
224 Гл. 7. Применения исчисления предикатов к решению задач
Разумеется, мы сейчас предполагаем, что х nil, и обращение к программе, образованной этой частью доказательства, происходит в случае, когда не выполняется тест х = nil.
Для доказательства (Vx3?/) R(x, у) нам «онадобится следующее соотношение между car, cons и cdr:
V х {cons (car (х), cdr (х)) = х).
Опять-таки, чтобы избежать трудностей, связанных с предикатами равенства, введем это соотношение в виде предложения
7. ~ A? (cons (car (х), cdr (х)), //) V R (х, у).
(Заметим, что это предложение становится тавтологией после подстановки х = cons (car(х),cdr(х)), справедливость которой вытекает из определения функций car, cons и cdr.)
Отрицанием предположения служит
8. — R (а, у).
Здесь а — сколемова функция, появляющаяся, когда в предположении содержатся переменные, относящиеся к квантору всеобщности. Граф опровержения изображен на рис. 7.11. Исключая функцию а и преобразуя граф опровержения обычным способом, получаем ответное утверждение
R (х, merge (car (х), sort (cdr (х)))).
Объединяя условное ветвление, которое мы заранее обеспечили, и элементы, созданные доказателем теорем, имеем в итоге рекурсивную программу
nil, если'х = пП, merge (car (х), sort (cdr (х))) в противном случае.
7.6. ИСПОЛЬЗОВАНИЕ ИСЧИСЛЕНИЯ ПРЕДИКАТОВ ПРИ РЕШЕНИИ ЗАДАЧ В ПРОСТРАНСТВЕ СОСТОЯНИЙ
Если состояние задачи можно определить совокупностью правильно построенных формул исчисления предикатов, то эта совокупность может составлять описание состояния, используемое для решения задачи в пространстве состояний. При такого рода описаниях операторы в пространстве состояний будут вычислениями, заменяющими одно множество правильно построенных формул другим. Множество целевых состояний можно тогда определить как множество, описываемое любой совокупностью п. п. формул, из которой следует некоторая целевая п. п. формула. Аналогично можно с помощью п. п. формулы применимости определить множество состояний, к которым применим данный оператор. В такой системе решения задач можно было
sortx =
7.6. Использование исчисления предикатов при решении задач 225
бы использовать методы доказательства теорем в исчислении предикатов для проверки выполнения условий достижения цели и условий применимости операторов.'
Представление в пространстве состояний для задачи об обезьяне и бананах, данное в гл. 3, легко модифицировать так, чтобы состояния описывались п. п. формулами. (Напомним, что в задаче об обезьяне и бананах обезьяна находится в комнате в некоторой точке айв этой же комнате в точке b находится ящик. Над точкой с пола на недосягаемой высоте находится связка бананов.)
Описание So начального состояния может состоять из четырех п. п. формул:
— ONВ ОХ
АТ (ящик, Ь)
АТ (обезьяна, а)
-НВ
Предикат ONBOX имеет значение Т только тогда, когда обезьяна находится наверху ящика; предикат НВ *) имеет значение Т только тогда, когда обезьяна получает бананы; предикат‘АТ имеет очевидную интерпретацию* 2). Целевой п. п. формулой будет просто НВ. Любое описание состояния, из которого следует НВ, соответствует целевому состоянию.
У нас, как и прежде, есть четыре оператора: «подойти (и)», «передвинуть (v)», «взобраться» и «схватить». Два первых — операторные схемы; конкретное их значение зависит от величины схемной переменной. При определении каждого оператора основными являются следующие элементы:
правильно построенная формула применимости, описывающая условия, при которых этот оператор применим;
правила преобразования множества п. п. формул, описывающих состояние, к которому применяется оператор, в новое множество п. п. формул, описывающее результирующее состояние.
Правила преобразования можно задать в виде списка п. п. формул, которые должны быть изъяты, и списка п. п. формул, которые следует добавить; при этом предполагается, что те п. п. формулы, которые не были изъяты, остаются и в новом описании состояния. На таком языке наши четыре оператора можно определить следующим образом:
) Have bananas (иметь бананы). — Прим, перев.
2) Быть в определенном месте. — Прим, перев.
О
226 Гл. 7. Применения исчисления предикатов к решению задач
подойти (и)
П. п. формула применимости: — ONBOX
Преобразования
изъять: АТ (обезьяна, $)
добавить: АТ (обезьяна, и).
Здесь символ $ стоит вместо любого терма. Правильно построенная формула АТ (обезьяна, $) должна быть изъята независимо от значения $. Так как «подойти (и)» представляет собой операторную схему, то ее применение даст схему описания состояния, содержащую переменную и. Приписывая этой переменной конкретное (константное) значение и, получаем конкретное описание состояния.
передвинуть (v)
П. п. формула применимости: Преобразования - ONBOX Л (Нх) [АТ (обезьяна,’х) Л АТ (ящик, х)]
изъять: добавить: взобраться П. п. формула применимости: Преобразования изъять: добавить: АТ (обезьяна, $) АТ (ящик, $) АТ (обезьяна, v) АТ (ящик, v) -ONBOX Л (Эх)[АТ (обезьяна, х) Л АТ (ящик, х)] -ONBOX ONBOX
схватить П. п. формула применимости: Преобразования изъять: добавить: ONBOX Л АТ (ящик, с) -НВ НВ.
При формулировке правил изъятий и добавлений, определяющих преобразование п. п. формул, осуществляемое операторами, нужно проследить за тем, чтобы изъятые п. п. формулы не следовали из неизъятых п. п. формул, ибо в противном случае эти изъятые п. п. формулы могли бы опять оказаться выведенными.
Теперь поиск целевого состояния может протекать на основе стандартного процесса применения применимых операторов.
7.6. Использование исчисления предикатов при решении задач 2Z7
к начальному состоянию So и к результирующим состояниям, до тех пор пока не будет получено рписание состояния, содержащее целевой предикат НВ. Поскольку мы пользуемся операторными схемами, мы построим сейчас граф схем описаний состояний (идентичный графу рис. 2.10).
Первым шагом нашего процесса поиска (перебора) будет выяснение того, следует ли НВ из So. Формально эту проверку можно осуществить, строя отрицание п. щ. формулы, которую нужно доказать, и используя затем методы поиска доказательства на основе резольвенции для вывода противоречия. Так как очевидно, что никакого противоречия из {So} U НВ вывести нельзя (невозможны никакие резольвенции), то мы заключаем, что результат проверки выполнения условия достижения цели отрицателен.
Следующий шаг в простейшем процессе перебора в пространстве состояний — выяснение, какой из операторов применим. Здесь опять можно использовать методы доказательства теорем на основе резольвенции. Для каждого оператора можно было бы попытаться доказать, что его п. п. формула применимости следует из So. Тогда мы быстро обнаружили бы, что оператор «схватить» неприменим. Правильно построенные формулы применимости для операторов «взобраться» и «передвинуть» совпадают. Отрицание этой общей п. п. формулы применимости (в форме предложения) имеет вид ONBOXV ~АТ (обезьяна, x)V ~ АТ (ящик, х). Попытка вывести его противоречие с So здесь также окончится неудачей, так что операторы «взобраться» и «передвинуть» также неприменимы к So.
Наконец, нам удастся доказать, что оператор подойти применим к So. Используя правило преобразования для оператора «подойти (и)», приходим к следующей схеме описания состояний:
-ONBOX
АТ (ящик, Ь)
1 АТ (обезьяна, и)
~НВ
Теперь процесс повторяется. Сначала мы выясняем, существует ли частный случай схемы Si, из которого следует целевая п. п. формула “НВ. Очевидно, что нет. Далее мы находим операторы, которые можно применить к частным случаям схемы S], Например, при проверке применимости оператора «передвинуть (v)» мы хотим узнать, существует ли частный случай схемы Si, из которого следует п. п. формула ~ONBOX А (Нх) АТ (обезьяна, х) А АТ (ящик, х). Мы видим, что подстановка в S] вместо и величины b дает частный случай, к которому оператор «передвинуть» применим. Обозначим этот частный
228 Гл. 7. Применения исчисления предикатов к решению задач
случай через S[. Обязательно нужно проследить за тем, чтобы и было заменено на b во всех случаях вхождения и в Si. (В нашем случае имеется ровно одно вхождение, но их могло бы быть и больше.)
Поскольку к SJ применим оператор «передвинуть», к S( применим также и оператор «взобраться», но оператор «схватить» неприменим ни к одному частному случаю схемы Sb К любому частному случаю схемы применим, конечно, также и оператор «подойти», но его применение не изменяет схему описания состояния.
Теперь, если применить оператор «передвинуть (v)» к S1, то получится схема описания состояния
-ONBOX
АТ (ящик, v)
2 АТ (обезьяна, v)
~НВ
Другая схема получится, если применить к Sf оператор «взобраться». Этот процесс продолжается до тех пор, пока не будет удовлетворен целевой предикат. В результате создается граф, совпадающий по форме с графом рис. 2.10. После этого нетрудно извлечь решающую последовательность операторов (с соответствующим образом выбранными конкретными значениями схемных переменных).
Учитывая различия и пользуясь ключевыми операторами, как в гл. 4, можно было бы также использовать для решения этой задачи подход, основанный на сведении задачи к совокупности подзадач. Тогда в качестве условий цели для подзадач, образованных в результате попытки применить ключевые операторы, выступили бы п. п. формулы применимости этих операторов. Пользуясь решением, представленным на рис. 4Л 4, читатель мог бы получить некоторый опыт работы с методом решения, основанным на сведении задачи к совокупности подзадач и ориентированным на исчисление предикатов.
7.7. ОДНА ФОРМАЛИЗАЦИЯ ДЛЯ РЕШЕНИЯ ЗАДАЧ В ПРОСТРАНСТВЕ СОСТОЯНИЙ
В предыдущем разделе состояния описывались с помощью множеств п. п. формул, а дочерние описания состояний получались в результате применения операторных правил изъятия и добавления п. п. формул. Так как преобразования, связанные с операторами, отображают одни множества п. п. формул в другие множества п. п. формул, то они были похожи на правила логического вывода. На самом деле они не были настоящими правилами вывода, так как дочерние п. п. формулы не
7.7. Одна формализация для решения задач
229
следовали логически из родительских п. п. формул. Преобразования, связанные с операторами, изменяли описания состояний, и совершались независимо от системы логического вывода в исчислении предикатов.
При небольшой переформулировке удается включить описание действий операторов в рамки формализма исчисления предикатов. Чтобы это сделать, добавим в каждый предикат терм состояния, указывающий состояние, к которому предикат применим, тогда в нашем предыдущем примере начальное состояние So описывалось бы с помощью множества п. п. формул
ONBOX (So), АТ (ящик, b, s0), AT (обезьяна, a, s0), ~HB(s0)}. Здесь термом состояния является s0.
В такой формулировке операторы рассматриваются как функции, отображающие одно состояние в другое. Так, значением оператора «схватить ($)» будет новое состояние, возникающее в результате применения оператора «схватить» к состоянию s. Основной эффект применения оператора «схватить» можно описать с помощью п. п. формулы
(Vs) {ONBOX (s) Л АТ (ящих, с, s)=^HB (схватить (s))}, означающий «для всех s, если обезьяна находится на ящике, а ящик расположен в точке с в состоянии s, то в состоянии, возникающем в результате применения оператора «схватить» к состоянию s, обезьяна будет иметь бананы».
При таком способе описания операторные описания — это просто дополнительные «аксиомы», которые можно объединить с п. п. формулами, описывающими начальное состояние S3. Если наша цель состоит в создании состояния s, удовлетворяющего некоторой целевой п. п. формуле U^(s), то эту задачу можно решить формально, найдя сначала доказательство для предположения (Bs)IT(s), а затем использовав процесс извлечения ответа для получения решения. Ответное утверждение будет содержать выражение для целевого состояния в форме композиции операторных функций.
Для иллюстрации этого подхода воспользуемся упрощенной формой задачи об обезьяне и бананах. Предположим, что у нас только три оператора — «схватить», «взобраться», «передвинуть»,— и условия их применимости несколько отличаются от прежних. (Эта упрощенная форма больше всего подходит для решения иллюстративных задач. Читателю предлагается поработать также с четырехоператорным вариантом задачи, который рассматривался в предыдущем разделе.) Действие этих операторов можно описать следующими п. п. формулами:
1. (VxVs){ ~ ONBOX => АТ (ящик, х, передвинуть (x,s))}, т. е. «для всех х и s, если обезьяна не находится на ящике в состоянии s, то в состоянии, возникающем в результате
230
Гл. 7. Применения исчисления предикатов к решению задач
применения оператора «передвинуть (х)». к состоянию s, ящик будет расположен в точке х.
2. (Vs){ONBOX (взобраться ($))}, т. е. для всех $ в состоянии, возникающем в результате применения оператора «взобраться» к состоянию $, обезьяна находится на ящике.
3. (V$){ONBOX(s) Л АТ (ящик, с, $)=>НВ (схватить («))}, т. е. для всех $, если обезьяна находится на ящике, а ящик расположен в точке с в состоянии s, то в состоянии, возникающем в результате применения оператора «схватить» к состоянию s, обезьяна будет иметь бананы.
В дополнение к этим аксиомам нужно выразить явно другие результаты действия этих трех операторов, например «положение ящика не изменяется, когда обезьяна на него взбирается» или «в конце этапа перемещения ящика обезьяна еще не будет находиться на ящике». Поскольку в нашем доказательстве потребуется только первый результат, запишем его формально:
4. (VxVs){AT (ящик, х, s)=^AT (ящик, х, взобраться ($))}.
Нам понадобится также адекватное описание начального состояния So:
5. ~ONBOX(s0).
Теперь поставить вопрос перед нашим формальным решателем задач — это просто сформулировать предположение
(Hs) НВ ($).
Далее надо преобразовать приведенные выше аксиомы и отрицание предположения в форму предложений и получить дерево опровержения, изображенное на рис. 7.12. Ответным утверждением, извлеченным обычным образом из этого дерева, будет утверждение
НВ (схватить (взобраться (передвинуть (с, s0)))).
Отсюда видно, что искомое состояние достигается с помощью последовательности операторов
{передвинуть (с), взобраться, схватить}.
Интересно соноставить этот формальный подход к решению задачи с методом пространства состояний (использующим исчисление предикатов для проверки выполнения условий достижения цели и применимости операторов), рассмотренным в предыдущем разделе. Формальный подход дает то преимущество, что для выполнения операторных вычислений не требуется никакого специального механизма. Вычисления выполняются автоматически с помощью механизма дедукции, воплощенного в доказателе теорем. Таким образом, не требуется никаких специальных методов перебора в пространстве состояний (или перебора при сведении задачи к подзадачам), кроме тех, которые
7.7. Одна формализация для решения задач
231
используются при поиске доказательств (их мы будем рассматривать'в следующей главе). Но эта высокая степень единообразия может оказаться также и недостатком формального метода. В формальную процедуру перебора доказателя теорем нелегко включить специальные эвристики, полезные для упорядочения процесса применения операторов при переборах в пространстве состояний.
~HB(s)
X. ~ONBOX(s) у ~АТ(ящик,с,з) V НВ(схватигпь(5))
~ONBOX(s) V-АТ (ящик, с, s)
'S^\^^^BOX(e30<ipambCK(s))
—A T (ящик, с, взобраться (s))
Рис. 7.12. Доказательство для задачи об обезьяне и бананах.
Другой недостаток формальной процедуры — необходимость явного описания с помощью специальных аксиом тех отношений, которые не изменяются под воздействием операторов. Так, в нашем примере пришлось сформулировать и использовать тот факт, что положение ящика не изменяется при действии оператора «взобраться». Доказательство того, что определенные отношения в дочерних состояниях по-прежнему удовлетворяются, утомительно и значительно увеличивает затраты усилий при поиске полного доказательства. Проблема, связанная с тем, что на одни отношения операторы воздействуют, а на другие нет, иногда называется проблемой системы отсчета. В наших
232 Гл. 7. Применения исчисления предикатов к решению задач
правилах добавлений — изъятий отражается та точка зрения, что легче назвать формулы, подвергающиеся изменению, и предположить, что все другие остаются неизменными. Слабость формального подхода, изложенного в этом разделе, состоит в том, что такого рода предварительное условие в нем не используется, и поэтому, если нам нужен факт, что некоторое отношение после применения оператора по-прежнему удовлетворяется, то мы должны этот факт явно доказать.
7.8. БИБЛИОГРАФИЧЕСКИЕ И ИСТОРИЧЕСКИЕ ЗАМЕЧАНИЯ
Системы, отвечающие на вопросы
Процесс извлечения из опровержений ответных утверждении позволяет применить формальные методы к задачам получения ответа на вопросы. Вообще говоря, система, отвечающая на вопросы, основана на весьма сложных способах извлечения информации, в которых при ответе на вопросы следует производить логические дедукции, исходя из различных фактов, хранящихся в массиве данных. При создании систем, отвечающих на вопросы, возникает также проблема осуществления перевода с естественного языка, например английского, на формальный язык, такой, как исчисление предикатов, используемый дедуктивной системой.
Первая универсальная система, отвечающая на вопросы, была предложена Рафаэлем (1964а, 19646). Рафаэль сосредоточил внимание на механизмах ассоциации и дедукции и в большой степени пренебрег вопросом перевода с естественного языка. С другой стороны, Бобров (1964а, 19646) построил систему для решения простых алгебраических задач, сформулированных на английском языке. Его система могла переводить задачи с английского языка на язык соответствующих уравнений, которые предстояло решить. Другая универсальная система, отвечающая на вопросы, названная DEDUCOM (не обладающая способностью перевода с английского языка на язык логики), предложена Слейджлом (1965). Грин и Рафаэль (1968) разработали систему, отвечающую на вопросы, в которой применялись логика первого порядка и метод резольвенции. Коулс (1968) написал программу перевода с английского языка на формально-логический язык: эта программа служила дополнением к системе Грина и Рафаэля.
Два хороших обзора работ в области систем, отвечающих на вопросы, сформулированных на естественном языке, написаны Симмонсом (1965, 1970). Бар Хиллел (1969) выделил некоторые трудности, присущие обработке естественных языков, и пришел к выводу о том, что они могут оказаться непреодолимыми.
7.8. Библиографические и исторические замечания
233
Процессы извлечения ответа
Хотя вопрос о вычислении частных случаев переменных, относящихся к кванторам существования, подвергался рассмотрению в классической теории доказательства, Грин (1969а) первым указал процедуру для систем, основанных на резольвенции. Рассмотренный в настоящей главе метод извлечения ответа обобщает подход Грина и основан на статье Лакхэма и Нильсона (1971).
Наш пример автоматического написания программы, иллюстрирующий приложения процесса извлечения ответа, представляет собой модификацию примера Грина (19696, приложение С). Вопрос написания программы для вычислительной машины связан с вопросом доказательства правильности программ. По этому последнему вопросу имеется значительное число работ, в том числе работы Маккарти (1962), Флойда (19676) и Манна (1969). Лондон (1970) дает хороший обзор работ по доказательству правильности программ. Несколько отличная (но также основанная на резольвенции) процедура автоматического написания программ описана Уолдингером и Ли (1969). Блестящую и доступную статью о связи между процедурами доказательства и автоматическим написанием программ опубликовали Манна и Уолдингер (1971).
Применения исчисления предикатов к решению задач в пространстве состояний
Идея использования множеств п. п. формул для описания состояний в решателе задач, основанном на введении пространств состояний, разрабатывается в Стэнфордском исследовательском институте. Процесс, описанный в разд. 7.6 и относящийся к задаче об обезьяне и бананах, выявился в ходе бесед между Ричардом Файксом, Бертрамом Рафаэлем, Джоном Мансоном и автором.
Мы уже отмечали, что техника решения задач в пространстве состояний с помощью формальных методов возникла в основном из заметок Маккарти (1958, 1963) о системе, «дающей советы». Работа по реализации такой системы была предпринята Блэком (1964). Корделл Грин первым разработал систему формального решения задач, опирающуюся на пространство состояний и использующую полную систему вывода (резольвенции) для логики первого порядка. Большая часть его исследований изложена в его диссертации (Грин, 19696) и двух статьях (Грин, 1969а, 1969в). В системе Грина в каждом из предикатов используется «терм состояния», который рассматривался нами в разд. 7.7,
:234 Гл. 7. Применения исчисления предикатов к решению задач
Дж. Маккарти продолжил свои исследования, касающиеся требований, предъявляемых к универсальной формальной системе решения задач. Особенно он настаивал на необходимости 'включения элементов логики более высокого (по сравнению с первым) порядка для формализации таких понятий, как ситуации, будущие операторы, действия, стратегии, результаты применения стратегий и знание. Эти идеи прекрасно изложены в статье Маккарти и Хэйеса (1969). Многие вопросы, поднимаемые Маккарти и Хэйесом, выходят за рамки вопросов, рассматриваемых в вводном курсе.
Математическое доказательство теорем
Одна из наиболее очевидных областей применения автоматических устройств для доказательства теорем (правда, не рассмотренная в настоящей главе)—доказательство математических теорем. Этим занимались Робинсон и Вос (1969), а также Гард и др. (1969). В частности, программа Гарда (в какой-то мере с помощью человека) успешно справилась с задачей поиска первого доказательства одного предположения теории модулярных структур. (
Задачи
7.1. Приведите соображения за или против следующего утверждения: «Использование формальных процедур доказательства будет приносить весьма малую пользу в любой системе решения задач, предназначенной для решения значительных, практически важных задач».
7.2. Примените процесс извлечения ответа к дереву опровержения на основе резольвенции, изображенному на рис. 7.11, с тем, чтобы получить ответное утверждение
R(x, merge (саг (х), sort (cdr (х)))).
7.3. Напишите формулы исчисления предикатов, содержащие переменные •состояния, которые задают условия применимости и результаты воздействия -операторов «подойти», «передвинуть», «взобраться» и «схватить», используемых в задаче об обезьяне и бананах из разд. 7.6. Из этих формул и предикатов, описывающих начальное состояние So. получите доказательство на основе резольвенции того, что обезьяна может схватить бананы. С помощью процесса извлечения ответа найдите выражение для целевого состояния. (Замечание:, это упражнение есть просто усложненный вариант примера из разд. 7.7.)
7.4. Робот по перевозке грузов, отправляющийся из фирмы «Универсал плэстик инкорпорейшн», должен отвезти безделушки, браслеты, бусы соответственно в магазины Гампа, Мейси и Сака. Используя простые операторы типа «перевозить (х, у)-» и «разгружать (г)» с соответствующими предварительными условиями И результатами действия, покажите, как система решения задач в пространстве состояний, опирающаяся на исчисление предикатов, могла бы найти последовательность операторов, создающую состояние, удовлетворяющее п.п. формуле
АТ (безделушки, Гамп) Л АТ (браслеты, Мейси) Д АТ (бусы, Сак).
Задачи 235
*7.5. Напишите программу для вычислительной машины, реализующую процесс извлечения ответа на основании поданного на ее вход дерева опровержения на основе резольвенций.
7.6. Сформулируйте в виде выражений исчисления предикатов факты и вопросы, содержащиеся в следующей задаче. Воспользуйтесь принципом ре-зольвеиции с извлечением ответа.
Тони, Майкл и Джон принадлежат к Альпинклубу. Каждый член Альпин-клуба является либо скалолазом, либо горнолыжником, либо тем и другим. Ни один из скалолазов ие любит дождь, и все горнолыжники любят снег. Майкл не любит все, что любит Тони, и любит все, что не любит Тони. Тонн любит снег и дождь. Есть ли в этом Альпинклубе хотя бы один член, который является скалолазом, но не является горнолыжником? Кто?
Глава 8
МЕТОДЫ ПОИСКА ДОКАЗАТЕЛЬСТВА В ИСЧИСЛЕНИИ ПРЕДИКАТОВ
81. СТРАТЕГИИ ПЕРЕБОРА
В гл. 6 мы отметили, что непосредственное применение принципа резольвенции соответствовало бы простой процедуре полного перебора при построении опровержения. Такой перебор мы начинали бы с множества предложений 5, к которому добавляли бы все резольвенты всех пар предложений в S с тем, чтобы образовать множество 91. Затем добавляли бы все резольвенты всех пар предложений в 91 с тем, чтобы образовать множества 9l(91.(S)) = 9l2(S), и т. д. Этот тип перебора, как правило, непригоден для практики, ибо множества 5?(S), 5?2(5), ... слишком быстро разрастаются. Практические процедуры доказательства определяются стратегиями перебора, применяемыми для его ускорения. Такие стратегии бывают трех типов: стратегии упрощения, стратегии очищения и стратегии упорядочения. Стратегии упорядочения точнее' двух других стратегий соответствуют методам, применяемым при переборе на графах в пространстве состояний и «И/ИЛИ» графах. В настоящей главе мы кратко обсудим все три типа стратегий.
8.2. СТРАТЕГИИ УПРОЩЕНИЯ
Иногда множество предложений удается упростить, исключив из него некоторые предложения или исключив из предложений определенные литералы. Эти упрощения таковы,'что упрощенное множество предложений выполнимо тогда и только тогда, когда выполнимо исходное множество предложений. Таким образом, применение стратегий упрощения позволяет снизить скорость роста числа новых предложений.
Исключение тавтологий
Любое предложение, содержащее литерал и его дополнение (такое предложение называется тавтологией), можно отбросить, так как любое невыполнимое множество, содержащее тавтологию, остается невыполнимым и после ее удаления, и обратно. Так, предложения типа
P(s)V В(г)У~В(у) и Р(f (a)) V-P(/(«)) можно отбросить.
S.3. Стратегии очищения 237
Исключение путем означивания предикатов
Иногда появляется возможность" означить (выяснить значение истинности) литералы, и это оказывается удобнее, чем включать соответствующие предложения в S. Такое означивание часто легко провести для константных частных случаев. Например, если предикатная буква Е обозначает отношение равенства, то означивание константных частных случаев типа £(7,3), когда они появляются, провести легко, хотя нам бы не хотелось добавлять к S полную таблицу, содержащую много константных частных случаев литералов Е(х, у) и ~£(х, у).
Если какой-нибудь литерал предложения получает значение истинности Т, то все предложения можно отбросить, не нарушая при этом свойства невыполнимости оставшегося множества. Если же какой-нибудь литерал при означивании получает значение истинности F, то из этого предложения можно исключить данное вхождение литерала. Так, предложение P(x)V VQ(a)V£(7,3) можно заменить на P(x)VQ(a), поскольку значение истинности для £(7,3) есть F.
Исключение подслучаев
Предложение {£-<} называется подслучаем предложения {Л!,}, если существует такая подстановка 0, что {£}е £= {AfJ. Например,
Р (х) — подслучай предложения P(y)VQ(z),
Р(х) — подслучай предложения Р(а),
Р(х) — подслучай предложения P(a)VQ(z),
Р(х) V Q (я) — подслучай предложения P(f (a)) V Q(«) V R(y)-
Предложение в S, являющееся подслучаем другого предложения в S, можно исключить из S, не нарушая свойства невыполнимости оставшегося множества. Отбрасывание предложений, являющихся подслучаями других, часто ведет к значительному уменьшению числа резольвенций, необходимых для нахождения доказательства.
Вообще в то время, как тавтологии можно отбрасывать сразу же, как только они появляются в процессе поиска доказательства, предложения, являющиеся подслучаями, можно отбрасывать лишь после того, как каждый «уровень» оказывается завершенным (Ковальский, 1970).
8.3. СТРАТЕГИИ ОЧИЩЕНИЯ
Стратегии очищения основаны на тех теоретических результатах в теории доказательства с помощью резольвенций, в которых утверждается, что для нахождения опровержения не
238 Гл. 8. Методы поиска доказательства в исчислении предикатов
нужны все резольвенции. Иными словами, достаточно выполнить резольвенции только для предложений, удовлетворяющих определенным требованиям. Мы будем обозначать через 5?c(S) объединение множества S и множества всех резольвент всех пар предложений из S, удовлетворяющих критерию С. Ясно, что Яс(5) =-«(S).
Про стратегию очищения, использующую критерий С, говорят, что в ней используется «резольвенции по отношению к С». Для применения такой стратегии мы сначала вычисляем 5?C(S), затем $с ($с (•$)) = (S) и т. д. до тех пор, пока при некото-
ром п в (S) не окажется пустого предложения (обозначаемого nil).
Потенциальное достоинство стратегии очищения в том, что на каждом уровне требуется меньше резольвенций. Однако уровень, на котором появляется пустое предложение, обычно возрастает, так что стратегия очищения приводит обычно к узконаправленному, но более глубокому перебору. Стратегия очищения полезна лишь в том случае, если она уменьшает все затраты усилий на перебор, включая усилия, необходимые для проверки выполнимости критерия С.
Мы рассмотрим две основные стратегии очищения, снижающие затраты усилий на перебор, а также некоторые их частные случаи.
8.4. ФОРМЫ ДОКАЗАТЕЛЬСТВА С ОТФИЛЬТРОВЫВАНИЕМ ПРЕДШЕСТВУЮЩИХ ВЕРШИН
Нашу первую стратегию очищения легко описать в терминах тех типов графов опровержения, которые она образует. Полезно сначала ввести некоторые определения.
Графом (или деревом) доказательства на основе резольвенций называется структура, в которой каждая вершина соответствует некоторому предложению. (Для простоты мы часто будем отождествлять вершину этого графа с ' - предложением.) Вершины графа, у которых нет предшествующих вершин, называются концевыми вершинами. Если граф изображает доказательство на основе резольвенций некоторого предложения (возможно nil), исходя из множества предложений S, то концевые вершины соответствуют предложениям из S. Они называются базовыми предложениями этого доказательства. Вершина графа, у которой нет следующих за ней вершин, называется корневой вершиной. Она соответствует предложению, доказанному этим графом.
Мы будем говорить, что граф доказательства имеет вид лозы, если каждая его вершина либо является базовым предложением, либо непосредственно следует из базового предложения. (Такой граф будет деревом, но не все деревья имеют вид
8.4. Формы доказательства с отфильтровыванием 2391
лозы. Это видно из примеров гл. 6, где граф рис. 6.3 имеет вид лозы, а граф, изображенный на рис. 6.4, нет.) Если граф опровержения, имеющий вид лозы, существует, то для его построения достаточно резольвент лишь тех пар предложений, из которых хотя бы одно принадлежит S. Такое ограничение на резольвенции могло бы лечь в основу прекрасной стратегии очищения, если бы только быть уверенным, что для любого невыполнимого множества предложений существует граф опровержения, имеющий вид лозы. К сожалению, стратегия очищения, основанная на графах в виде лозы, не полна; но одна очень похожая на нее стратегия полна.
Чтобы убедиться, что для невыполнимого множества граф в виде лозы существует не всегда, рассмотрим множество
Q(x)VP(a)
-QWVPW ~Q(x)V~P(x) ’ Q (x) V ~ P (x)
Из графа опровержения, представленного на рис. 8.1, видно, что это множество невыполнимо. В графе опровержения, имеющем вид лозы, одно из предложений множества S должно быть вершиной, непосредственно предшествующей корневой вершине nil. Но для образования пустого предложения нужна либо резольвента двух предложений, содержащих по одному литералу, либо два предложения, которые «факторизуются» ') к предложениям, содержащим по одному литералу. Ни один из элементов множества S не удовлетворяет этим требованиям, так что для S не может быть опровержения в виде лозы.
Из рис. 8.1 видно, что одна из резол'ьвенций производится между предложениями ~Р(а) и Р(а)У Р(х). Далее, в этом графе опровержения предложение Р(а) V Р(х) предшествует предложению ~Р(а). Граф рис. 8.1 служит примером графа с отфильтрованными предшествующими вершинами, или графа в Мт-форме.
Мы будем говорить, что граф опровержения имеет AF-фор-му, если каждая вершина графа соответствует одному из следующих предложений:
1) базовому предложению;
2) предложению, непосредственно следующему за базовым;
3) предложению, непосредственно следующему за двумя небазовыми предложениями А и В, из которых В предшествует А (отсюда термин — отфильтровывание предшествующих вершин).
Граф в виде лозы представляет собой частный случай графа в AF-форме: каждая из его вершин соответствует либо
*) См. стр. 196. — Прим, перев.
240 Гл. 8. Методы поиска доказательства в исчислении предикатов
предложению 1), либо предложению 2). Базовое предложение С в графе, имеющем AF-форму, называется концевой вершиной, если любая другая вершина дерева либо является базовым предложением, либо следует за С.
Р н с. 8.1. Граф опровержения.
Сформулируем без доказательства теорему, утверждающую, что для любого невыполнимого множества предложений всегда существует граф опровержения в AF-форме. Таким образом, стратегия очищения, основанная на поиске графов в AF-форме, полна.
Теорема 8.1. Пусть ^fr(nil)—граф опровержения для невыполнимого множества S предложений, а С — некоторое предложение из S, появляющееся в gr(nil). Тогда для S существует граф опровержения jgT'(nil) в AF-форме, для которого С служит концевой вершиной.
8.4. Формы доказательства с отфильтровыванием 241
Для многих графов частный случай опровержения в AF-форме, имеющий вид лозы, существует. Дерево, изображенное на рис. 6.4, не имеет AF-формы, однако дерево опровержения для того же самого множества предложений с D(x) V ~£(у) в качестве концевой вершины, показанное на рис. 8.2, имеет вид
~В(х)ч
\ D(b)
V . ~B(x)vC(x) ~C(a)V ~Е(у) >
V В(х)
~В(а) V ~Е(У) /
V ~С(с) v E(d) ~Е(У) /
С[с)^^С[х)
~B(cJ BJX)
nil
Рис. 8.2. Дерево опровержения в виде лозы.
лозы. Читатель может попытаться построить для этого множества предложений, но с иными концевыми вершинами, другие графы в AF-форме.
Так как в теореме 8.1 утверждается, что для любого невыполнимого множества предложений существует граф опровержения в AF-форме, то перебор можно ограничить, отыскивая лиШь опровержения такого вида. Назовем стратегией AF-формы стратегию очищения, реализующую это ограничение. В ней применяются резольвенции по отношению к критерию отфильтровывания предшествующих вершин. Этот критерий можно
242 Гл. 8. Методы поиска доказательства в исчислении предикатов
описать следующим образом. Сначала отметим, что при выборе концевой вершины для графа в AF-форме допускается некоторый произвол. Концевая вершина должна появляться в каком-нибудь графе опровержения, так что она выбирается из некоторого подмножества К <= S, содержащего предложения, появляющиеся в каком-нибудь опровержении (например, в
Рис. 8.3. Поиск опровержения с использованием AF-стратегии.
К могут содержаться предложения, возникающие при отрицании теоремы, которую предстоит доказать). Тогда критерий, которому должна удовлетворять пара предложений (А, В) для того, чтобы ее можно было подвергнуть резольвенции в отношении AF-стратегии, таков:
один элемент пары (А, В) принадлежит S, а другой есть либо предложение из К, либо предложение, следующее за предложением из К,
или
один из элементов пары (А, В) предшествует другому.
Обозначим через 5?af(S) объединение множества S и множества всех резольвент всех пар из S, допускаемых AF-страте-гией. Положим, как обычно,
^F(S) = S, ^(S)=«AF №(S)). .
Согласно теореме 8.1, если множество S неудовлетворимо, то найдется такое п, что nil е 5?Af(S).
На рис. 8.3 показан результат применения AF-стратегии к простому неудовлетворимому множеству предложений. (В этом
8.7. Модельные стратегии
243
примере К = S.) На уровнях 1 и 2 выполнялись все допустимые резольвенции до тех пор, пока не было выведено на уровне 3 пустое предложение. Образованный такой процедурой граф в AF-форме отмечен жирными линиями. Он оказался лозой.
8.5. СТРАТЕГИЯ ПОДДЕРЖИВАЮЩЕГО МНОЖЕСТВА
Стратегией поддерживающего множества называют стратегию, в которой выбирается такое непустое подмножество К исходного множества предложений S, что множество S — К удовлетворимо. Например, можно в качестве К взять множество предложений, возникающих из отрицания доказываемой теоремы. Говорят, что предложения в К имеют поддержку. При поиске опровержения допустимыми считаются резольвенции лишь тех пар предложений, в которых по крайней мере одно имеет поддержку. Каждому предложению, построенному в результате резольвенции, также придается поддержка.
Так как множество S— К удовлетворимо, существует граф опровержения, имеющий AF-форму, у которого верхней вершиной служит один из элементов множества К. Таким образом, стратегия поддерживающего множества полна, поскольку она допускает все резольвенции, допускаемые AF-стратегией (и, возможно, другие).
8.6. БОЛЕЕ ОГРАНИЧИТЕЛЬНЫЕ СТРАТЕГИИ
В действительности AF-стратегию можно еще ограничить, сохранив при этом полноту. Одно из ограничений состоит в том, что если А предшествует В, то резольвенту для А и В можно строить лишь тогда, когда она является подслучаем подстанов-кового частного случая предложения В (Лавленд, 1969). Можно наложить также и другие ограничения, связанные со специальными типами резольвенций, называемыми слияниями (Эндрюс, 1968; Йейтс, Рафаэль, Харт, 1970). Конечно, при выборе стратегии следует иметь в виду, что затраты на дополнительные вычисления, требуемые для выбора соответствующих резольвенций, могут и не перекрыться экономией, вызванной уменьшением числа резольвенций, выполненных на самом деле в процессе перебора. В настоящее время судить об этом можно лишь на основании практического опыта.
8.7. МОДЕЛЬНЫЕ СТРАТЕГИИ
Напомним, что в гл. 6 мы придали точный смысл интерпретации, задав значения истинности атомов в эрбрановской базе. Мы назвали такое задание значений истинности моделью. Так, если эрбрановская база состоит из атомов {Р(а, Ь), Р(а,а),
а»
244 Гл. 8. Методы поиска доказательства в исчислении предикатов
P(b,b), P(b,a), Q(a), Q(b)}, то одной из моделей может быть {~Р(а, b), Р(а,а), P(b,b), ~P(b,a), ~Q(a), Q(b)}. В общем случае моделью является множество (быть может, бесконечное) литералов, сконструированных исходя из эрбрановской базы таким образом, что каждый атом эрбрановской базы содержится в модели либо со знаком отрицания, либо без него (но не может быть и то и другое одновременно).
По определению модель не удовлетворяет предложению С, если С имеет константный частный случай (полученный с помощью элементов универсума Эрбрана), принимающий значение F при означивании на основе данной модели. В противном случае говорят, что модель удовлетворяет предложению С.
Обычно можно определить непосредственно, удовлетворяет ли данная модель М предложению С. Например, модель {~Р(а, Ь), Р(а,а), P(b,b), ~P(b,a), ~Q(a), Q(b)} не удовлетворяет предложению ~Q(x) V Р(у, х), так как подстановка {(/>, х), (а,у)} приводит к константному частному случаю со значением истинности F. Эта модель удовлетворяет предложению {~Q(x) V Р(у, у)}, так как ни одна из подстановок не приводит к константному частному случаю со значением истинности F.
Часто удается представить модель более компактно в виде списка литералов, у которых gee константные частные случаи (на универсуме Эрбрана) имеют значение истинности Т. При этом нужно проследить, чтобы не получилось противоречивого результата и чтобы каждому атому эрбрановской базы было присвоено значение истинности. Так, если множество есть
~ Q (х) V Р (a, f (х))
Q (х) V Р (f (х), а) ~P(x,f(x))V R(y)l’
\~R(a) . J .
то моделью может быть, например, множество
{Q(x), ~P(a,f(x)), ~P(x,f(x)), Р(/(х),а), R(x)}.
В терминах атомов эрбрановской базы эта модель представляет собой бесконечное множество
M = {R(a), R(f(a)), R(f(f(a))), Q(a),Q(f(a), Q(f(f(a))), ...
~P(a, f(a)), ~P(a, f(f(a)))........ ~P(f(a), f(f(a))), ...
.... P(/(a), a), P(f(f(a)), a), ...}.
Заметим, что первое и четвертое предложения этой моделью не удовлетворяются, а второе и третье — удовлетворяются.
Понятием модели можно воспользоваться для того, чтобы, ограничить число резольвенций, необходимых для нахождения’
8.7. Модельные стратегии
245
nil
Рис. 8.4. Граф опровержения, удовлетворяющий модельной стратегии, в которой {Q (х), Р (х)} используется для определения модели.
опровержения. Приведем без доказательства теорему, на основе которой можно построить еще одну стратегию очищения, связанную с моделями.
Теорема 8.2. Пусть S — неудовлетворимое множество предложений и М — модель, заданная на его эрбрановской базе. Тогда существует такой граф опровержения для S, что каждая его вершина либо является предложением из S, либо имеет
246 Гл. 8. Методы поиска доказательства в исчислении предикатов
в качестве одной из непосредственно предшествующих ей вершин предложение, которое не удовлетворяется моделью М.
Стратегию, основанную на теореме 8.2, называют модельной стратегией. Критерий, которому должна удовлетворять пара предложений (Д,В) для того, чтобы ее можно было подвергнуть резольвенции в отношении модельной стратегии, таков, что по крайней мере одно из предложений пары (Д, В) не удовлетворяется моделью.
Мы будем обозначать через Ям(S) объединение множества S и множества всех резольвент всех пар из S, допускаемых модельной стратегией. Положим
^(S) = S,
Согласно теореме 8.2, если множество S неудовлетворимо, то найдется такое п, что nil е 5?^(S).
На рис. 8.4 изображен граф опровержения для множества невыполнимых предложений, приведенного на рис. 8.1. Каждая резольвенция на графе удовлетворяет модельному критерию с моделью {Q(x),P(x)}. Предложения, не удовлетворяющиеся этой моделью, заключены в рамку. Степень, в которой модельная стратегия уменьшает число необходимых резольвен-ций, зависит, конечно, от модели М. Наихудшим выбором является любая модель М, которая не удовлетворяет ни одному ив предложений в S.
Полноту стратегии поддерживающего множества можно также вывести из полноты модельной стратегии. Выберем модель, удовлетворяющую каждому предложению из S — К, где К имеет поддержку. По теореме 8.2 существует такое опровержение, что для пар предложений, каждое из которых принадлежит S — К, ни одна из резольвенций не выполняется. Таким образом, модельная стратегия является усилением стратегии поддерживающего множества.
8.8. ^-ОПРОВЕРЖЕНИЯ
Назовем предложение положительным, если у всех его литералов нет знака отрицания. Ясно, что в любом невыполнимом множестве S есть по крайней мере одно положительное предложение. В противном случае модель, определяемая множеством отрицаний атомов из эрбрановской базы, удовлетворяла бы S. Опровержение, при котором каждая резольвенция осуществляется между такими двумя предложениями, что по крайней мере • одно из них положительно, назовем /^-опровержением. Полнота Pi-опровержения следует из теоремы 8.2; в самом
8.10. Стратегии упорядочения
247
деле, в качестве модели можно взять множество литералов из S с отрицаниями. Тогда предложение в рамках этой модели принимает значение истинности F тогда и только тогда, когда оно положительно.
Если непротиворечивым образом переименовать литералы, в S, то получим просто вариант Pi-опровержения. Если в нашем примере на рис. 8.4 заменить Q(x) на ~Р(х), а Р(х) на ~Т(х), то опровержение станет Pi-опровержением для переименованного множества предложений, /^-опровержение и его варианты важны, поскольку здесь легко реализовать проверку выполнения условия проведения резольвенции.
8.9. КОМБИНИРОВАННЫЕ СТРАТЕГИИ
Естественно возникает вопрос: приводит ли к полной стратегии комбинирование ограничений на резольвенции, определяемых AF-стратегией и модельной стратегией? Безусловно, такое комбинирование могло бы существенно уменьшить число требуемых резольвенций. К сожалению, эта комбинация не полна: не существует опровержения для невыполнимого множества {~R(a), R(a)V~Q(a), P(a)V R(a), P(a)V Q(a)} в AF-форме, которое удовлетворяло бы также модельному ограничению с моделью {Р(а), Q(а), R (а)}. Тем не менее, объединяя эти две стратегии эвристически, часто можно получить достаточно эффективный поиск опровержения.
8.10. СТРАТЕГИИ УПОРЯДОЧЕНИЯ
На основе резольвенций, обеспечиваемых различными стратегиями очищения, иногда можно искать опровержение, упорядочив выполняемые резольвенции. В стратегиях упорядочения не запрещаются никакие типы резольвенций, а лишь даются указания на то, какие из них надо выполнять в первую очередь. Стратегии упорядочения соответствуют рассмотренным в гл. 3 и 5 эвристическим стратегиям перебора для поиска на графах. При хорошем упорядочении не обязательно вычислять все элементы множеств $(S), 5?2(S) и т. д. Если пустое предложение появляется впервые на уровне п, то хочется думать, что перебор можно прямо направить на этот уровень, не заполняя нижние уровни.
Две довольно эффективные стратегии упорядочения — это стратегия предпочтения одночленам и стратегия наименьшего числа компонент. В стратегии предпочтения одночленам делается попытка сначала построить резольвенты между одночленами, т. е. предложениями, содержащими единственный литерал. Если это удается, то сразу же получается опровержение. Если же не могут найти пару одночленов, у которых есть
Й48 Гл. 8. Методы поиска доказательства в исчислении предикатов
резольвента, то пытаются найти резольвенту для пар одночлен— двучлен и т. д. (Как только какая-нибудь пара предложений разрешается, полученную резольвенту сразу сопоставляют с одночленами с тем, чтобы найти возможные резольвенты.) Во избежание совершения невыгодной цепочки одночленных резольвенций обычно устанавливается граничный уровень. Если предложение содержится в 5?г(5), но не содержится в то говорят, что данное предложение имеет уровень I.
Если граничный уровень равен /, то предложения из 5?г(5) не строятся. Когда граничный уровень препятствует поиску одночленных резольвенций, применяют другие схемы упорядочения’ (такие, как резольвенции двучленов и одночленов и т. д.) до тех пор, пока не будут построены новые одночлены.
Стратегия предпочтения одночленам оправдана гарантированным укорочением длины предложений, вызываемым одночленными резольвенциями. Так как цель построения резольвент состоит в образовании пустого предложения (нулевой длины), то стратегия предпочтения одночленам напрашивается сама собой. При введении граничных уровней для возможности использования и других резольвенций такая стратегия не препятствует нахождению опровержения (если оно существует в пределах заданной границы) и, как правило, сильно ускоряет процесс перебора.
Стратегия наименьшего числа компонент упорядочивает резольвенции согласно длине получаемых резольвент. Так, два предложения, дающие наиболее короткую резольвенту, разрешаются в первую очередь. Эта стратегия в некотором смысле дороже, поскольку до выполнения резольвенции надо подсчитать длины потенциальных резольвент и упорядочить их.
8.11. БИБЛИОГРАФИЧЕСКИЕ И ИСТОРИЧЕСКИЕ ЗАМЕЧАНИЯ
Обсуждения стратегий перебора
Проблема построения эвристически эффективных стратегий перебора (поиска) при условии сохранения логической полноты прекрасно изложена в статье Дж. Робинсона (1967). Г. Робинсон и др. (1964) дали ясное описание нескольких стратегий и привели много примеров.
Стратегии упрощения
Проблема исключения подслучаев в процессе поиска доказательства оказывается тоньше, чем это может показаться. В статье Ковальского (1970а) указаны некоторые несоответствия в’ исследовании данной проблемы Ковальским и Хэйесом (1969); полностью этот вопрос рассмотрен в диссертации Ковальского (19706),
8.11. Библиографические и исторические замечания
249
Стратегии очищения
Стратегия формы с отфильтрованными предшествующими вершинами (AF-формы) является простейшей из семейства связанных между собой стратегий. В теореме 8.1 утверждается, что AF-стратегия логически полна; доказательство этой теоремы приведено в работе Лакхэма (1969). Хотя мы здесь показали, что полнота стратегии поддерживающего множества следует из теоремы 8.1, на самом деле она была разработана раньше (Вос и др., 1965).
Существуют разные пути дальнейшего усовершенствования AF-стратегии. В некоторых случаях их объединяют со стратегией, предложенной Эндрюсом (1968), использующей слияния. Среди работ, в которых доказывается полнота- AF-формы со слиянием, укажем работы Киберца и Лакхэма (1971), Йейтса, Рафаэля и Харта (1970), Андерсона и Бледсоу (1970). В первой содержатся другие результаты, касающиеся свойств доказательств в AF-форме, а в двух последних применяются сравнительно новые методы доказательства полноты, представляющие самостоятельный интерес. Андерсон и Бледсоу доказали своим методом полноту и других стратегий. В статье Лавленда (1968) устанавливается полнота еще одного ограничения на AF-стратегию.
Модельные стратегии представляют собой развитие Ррде-дукций, предложенных впервые Дж. Робинсоном (19656). Слейджл (1967) доказал полноту некоторых очень общих модельных стратегий. Теорема 8.2 взята у Лакхэма (1969); она является простым частным случаем одной из теорем Слейджла. Мельцер (1966, 1968) предлагает дополнительные результаты, касающиеся дедукций Л-типа.
Стратегии упорядочения
Стратегия предпочтения одночленам была предложена и оправдана Восом и др. (1964). Она и стратегия поддерживающего множества включены как основные элементы в ряд автоматических доказателей теорем.
Читатель, вероятно, обратил внимание на то, что все стратегии перебора, обсуждаемые в настоящей главе, используют синтаксические, а не семантические правила (т. е. ограничения перебора связаны с формой предложений и возможных дедукций, а не с их смыслом). Стратегии, использующие семантику, можно построить различными способами, однако пока в этом направлении было предпринято не слишком много попыток. Возникает вопрос: нельзя ли воспользоваться оценочной функцией, заданной на парах предложений, являющихся кандидатами на разрешение? Возможно, она могла бы учитывать и
250 Гл. 8. Методы поиска доказательства в исчислении предикатов
имеющуюся семантическую информацию, и форму предложений-кандидатов. Некоторые теоретические результаты о свойствах стратегий с оценочными функциями содержатся в статье Ковальского (1970а). Его результаты о поиске на структурах «графов вывода» аналогичны результатам Харта и др. (1968) для структур графов в пространстве состояний.
Примеры реализации
Уже написано несколько программ для автоматического доказательства теорем. Например, программы Робинсона и Воса (1969), Аллена и Лакхэма (1970), Гарда и др. (1969), а также система Грина — Рафаэля — Йейтса, модифицированная Гарвеем и Клингом (1969).
Задачи
8.1. Укажите, для каких из следующих предложений предложение P(f(x),y)~является подслучаем:
а) Р (f (а), f(x)) VP(z, f (у))>
- b) Р (z, а) V' ~ Р (а, г),
с) Р (f (f (*)) z).
d) P(f(z), z) VQW,
e) P (a, a) V P (f (x), y).
8.2. Найдите опровержение в виде лозы для следующего невыполнимого множества предложений:
а) ~Р V~Q V Р,
b) ~svr,
с)
d) S, ,
е) ~Р,
f) ~syu,
g) ~U V Q-
' Можете ли вы найти другие опровержения (не обязательно в виде Лозы), Имеющие меиыпую глубину?
8.3. Найдите опровержение в AF-форме для следующего невыполнимого множества предложений:
а) ~А (х) V F (х) V G (f (х)),
b) ~F(x)VB(x),
с) ~F (х) V С (х),
d) ~G (х) V В(х),
е) ~G(x) VD(x),
f) A (g (х)) V F (й (х)),
g) ~В(х) V~C(x),
h) ~В(х) V~D(x).
Сравните с неимеющим такую форму опровержением, приведенным на рис. 7.5,
Задачи
251
8.4. Найдите контрпример к утверждению: «Стратегия предпочтения одночленам всегда позволяет найти опровержение минимальной глубины».
8.5. Рассмотрите задачу поиска опровержения с отфильтрованными предшествующими вершинами для невыполнимого множества S предложений как задачу перебора в пространстве- состояний. Пусть описание состояния содержит дерево доказательства в AF-форме и множество S.
а) Что служит начальной вершиной?
б) Что представляет собой оператор построения дочерних вершин?
в) Каков критерий достижения цели?
г) Предложите оценочную функцию f, учитывающую уровень AF-дерева, «общность» содержащихся в нем предложений, глубину размещения функций в его предложениях и другие факторы, которые вы считаете важными.
8.6. Рассмотрите утверждение: «В замкнутой ассоциативной системе с левыми и правыми решениями уравнений существует единичный элемент». Условия можно выразить следующим образом:
VxVi/3z Р (z, х, у) — для всех х и у в этой системе найдется такой элемент z нз этой системы, что г • х = у,
УхЧуЗг Р (х, z, у) — для всех х и у в этой системе найдется такой элемент z из этой системы, что х • г = у,
УхЧуЗг Р (х, у, г) — для всех х и у в этой системе найдется такой элемент 2 из этой системы, что х • у = z (замыкание);
Vuvwxyz{[P (и, о, ш) Д Р (о, х, I/)] [Р (ц, у, г)^Р (®, х, г)]} (ассоциативность).
(Замечание: A В — сокращенная запись для [(А ==> В) А (В ==> А)].)
Заключение можно записать в виде 3i/Vx Р (х, у, г) — существует правый единичный элемент.
Для этой теоремы сделайте следующее:
а) Преобразуйте условия и отрицание заключения в форму предложений.
б) С помощью этих предложений получите Л-опровержение.
в) Из этого опровержения извлеките ответное утверждение (т. е. получите выражение для правого единичного элемента).
СПИСОК ЛИТЕРАТУРЫ
АЛЛЕН, ЛАКХЭМ (ALLEN J., LUCKHAM D.)
1970 An Interactive Theorem-Proving Program, in B. Meltzer and D. Michie (eds.), «Machine Intelligence 5», 321— 336, American Elsevier Publishing Company, New York.
АМАРЕЛБ (AMAREL S.)
1965 Problem Solving Procedures for Efficient Syntactic Analysis, ACM 20th Natl. Conf. [см. также Sci. Rept. No. 1, AFOSR Contr. No. AF49(638)-1184, 1968].
1966 More on Representations of the Monkey Problem, Carnegie Institute of Technology Lecture Notes, March 1.
1967 An Approach to Heuristic Problem-Solving and Theorem Proving in the Propositional Calculus, in J. Hart and S. Takasu (eds.), «Systems and Computer Science», University of Toronto Press, Toronto.
1968 On Representations of Problems of Reasoning About Actions, in D. Michie (ed.), «Machine Intelligence 3», 131—171, American Elsevier Publishing Company, Inc., New York.
1969 On the Representation of Problems and Goal Directed Procedures for Computers, Commun. Am. Soc. Cybernetics, 1, No. 2.
АНДЕРСОН, БЛЕДСОУ (ANDERSON R., BLEDSOE W.)
1970 A Linear Format for Resolution with Merging and a New Technique for Establishing Completeness, J. ACM, 17, No. 3.
БАР ХИЛЛЕЛ (BAR HILLEL Y.)
1969 Universal Semantics and Philosophy of Language: Quandaries and Prospects, in Jaan Puhvel (ed,), «Substance and Structure of Language», University of California Press, Berkeley.
ВЕЛЛМАН, ДРЕЙФУС (BELLMAN R„ DREYFUS S.)
1962 Applied Dynamic Programming, Princeton University Press, Princeton, N. J. [Русский перевод: Прикладные задачи динамического программирования, «Наука», М., 1965.]
БЕЛЛМОР, НЕМХОЗЕР (BELLMORE М„ NEMHAUSER G.)
1968 The Traveling Salesman Problem: A Survey, Operations Res., 16, No. 3, 538—558.
БЕНЕРДЖИ (BANERJI R.)
1969 Theory of Problem Solving: An Approach to Artificial Intelligence, American Elsevier Publishing Company, Inc., New York. [Русский перевод: Теория решения задач. Подход к созданию искусственного интеллекта, «Мир», М„ 1972.]
БЕРЖ (BERGE. С.)
1958 The Theory of Graphs and Its Applications, Dunod, Paris (на франц, яз.). [Русский перевод: Теория графов и ее применения, ИЛ, М., 1962.]
Список литературы
253
БЕРНШТЕЙН и др. (BERNSTEIN A. et al.)
1958 A Chess-Playing Program for the,IBM 704 Computer, Proc. West. Joint Computer Conf., pp. 157—159.
БЛЭК (BLACK F.)
1964 A Deductive Question-Answering System, Doctoral Dissertation, Harvard. См. также M. Minsky (ed.), «Semantic Information Processing», 354—402, The M. I. T. Press, Cambridge, Mass., 1968.
БОБРОВ '(BOBROW D.)
1964a Natural Language Input for a Computer Problem-Solving System, Doctoral Dissertation, Massachusetts Institute of Technology. См. также M. Minsky (ed.), «Semantic Information Processing», The M. I. T. Press, Cambridge, Mass, 1968.
19646 A Question-Answering System for High-School Algebra Word Problems, in Proc. AFIPS Fall Joint Computer Conf., 591—614.
БОЛЛ (BALL W.)
1931 Mathematical Recreations and Essays, 10th ed., Macmillan and Co., Ltd., London. (15-puzzle, pp. 224—228; Tower-of-Hanoi, pp. 228—229.) ВАЙССМАН (WEISSMAN C.)
1967 LISP 1.5 Primer, Dickenson Publishing Company, Inc., Belmont, Calif.
ВОС, КАРСОН, РОБИНСОН (WOS L„ CARSON D„ ROBINSON G.)
1964 The Unit Preference Strategy in Theorem Proving, Proc. AFIPS 1964 Fall Joint Computer Conf., vol. 26, pp. 616—621.
ВОС, РОБИНСОН, КАРСОН (WOS L„ ROBINSON G„ CARSON D.)
1965 Efficiency and Completeness of the Set of Support Strategy in Theorem-Proving, J. ACM, 12, No. 4, 536—541.
ГАРВЕИ, КЛИНГ (GARVEY T„ KLING R.)
1969 User’s Guide to QA3.5 Question-Answering System, Stanford Research Institute Artificial Intelligence Group Technical Note 15.
ГАРД и др. (GUARD J. et al.)
1969 Semi-Automated Mathematics, J. ACM, 16, No. 1, 49—62.
ГАРДНЕР (GARDNER M.)
1959 The Scientific American Book of Mathematical Puzzles and Diversions, Simon and Schuster, New York.
1961 The Second Scientific American Book of Mathematical Puzzles and Diversions, Simon and Schuster, New York. 1961.
1964, 1965a, б, в Mathematical Games, Sci. Am., 210, No. 2, 122—130 (February 1964); 212, No. 3, 112—117 (March 1965); 212, No. 6, 120—124 (June 1965); 213, No. 3, 222—236 (September 1965).
ГЕЛЕРНТЕР (GELERNTER H.)
1969 Realization of a Geometry Theorem-Proving Machine, Proc. Intern. Conf. Inform. Proc., pp. 273—282, UNESCO House, Paris. См. также Фейген-баум Э., Фельдман Дж. (1963), стр. 145—164.
ГЕЛЕРНТЕР, ХАНСЕН, ЛАВЛЕНД (GELERNTER Н„ HANSEN J., LOVELAND D.)
1960 Empirical Explorations of the Geometry Theorem Proving Machine, Proc. West. Joint Computer Conf., vol. 17, pp. 143—147. См. также Фейген-баум Э., Фельдман Дж. (1963), стр. 165—174.
254
Список литературы
ГОЛОМБ, БОМЕРТ (GOLOMB S„ BAUMERT L.)
1965 Backtrack Programming, 1. ACM, 12, No. 4 ,516—524.
ГРИН (GREEN C.)
1969a Theorem-Proving by Resqlution as a Basis for Question-Answering Systems, in B. Meltzer and D. Michie (eds.), «Machine Intelligence 4», pp. 183—205, American Elsevier Publishing Company, Inc., New York.
19696 The Application of Theorem-Proving to Question-Answering Systems, Doctoral Dissertation, "Electrical Engineering Dept., Stanford University. См. также Stanford Artificial Intelligence Project Memo AI-96, June 1969.
1969b Application of Theorem-Proving to Problem Solving, in Donald E. Walker and Lewis M. Norton (eds.), Proc. Intern. Joint Conf. Artificial Intelligence, Washington, D. C.
ГРИН, РАФАЭЛЬ (GREEN C„ RAPHAEL B.)
1968 The Use of Theorem-Proving Techniques in Question-Answering Systems, Proc. ACM 23rd Natl. Conf., pp. 169—181, Brandon Systems Press, Princeton, N. J.
ГРИНБЛАТТ и др. (GREENBLATT R. et al.)
1967 The Greenblatt Chess Program, Proc. AFIRS Fall Joint Computer Conf., pp. 801—810, Anaheim, Calif.
ГУД (GOOD I.)
1968 A Five-Year Plan for Automatic Chess, in E. Dale and D. Michie (eds.), «Machine Intelligence 2», pp. 89—118, American Elsevier Publishing Company, Inc., New York.
ДЕ РУССО, РОИ, КЛОУЗ (DE RUSSO P., ROY P„ CLOSE C.)
1965 State Variables for Engineers, John Wiley and Sons, Inc., New York.
ДИИКСТРА (DIJKSTRA E.)
1959 A Note on Two Problems in Connection with Graphs, Numerische Math., 1, .269—271.
ДОРАН (DORAN J.)
1967 An Approach to Automatic Problem-Solving, in N. Collins and D. Michie (eds.), «Machine Intelligence 1», pp. 105—123, American Elsevier Publishing Company, Inc., New York.
1968 New Developments of the Graph Traverser, in E. Dale and D. Michie (eds.), «Machine Intelligence 2», pp. 119—135, American Elsevier Publishing Company, Inc., New York.
ДОРАН, МИЧИ (DORAN J., MICHIE D.)
1966 Experiments with the Graph Traverser Program, Proc. Roy. Soc., A, 294, 235—259.
ДРЕЙФУС C. (DREYFUS S.)
1969 An Appraisal of Some Shortest Path Algorithms, Operations Res., 17, No. 3, 395—412.
ДРЕЙФУС X. (DREYFUS H.)
1965 Alchemy and Artificial Intelligence, Rand Corporation Paper P3244 (AD 625 719).
Список литературы
255
ДЬЮДЕНЕИ (DUDENEY Н.)
1958 ' The Canterbury Puzzles, Dover Publications, Inc., New York. [Первоначально опубликовано в 1907 г.]
1967 536 Puzzles and Curious Problems, Martin Gardner (ed.), Charles
Scribner’s Sons, New York. [На основе двух книг Дьюденея: Modern Puzzles, 1926 и Puzzles and Curious Problems, 1931.]
ДЭВИС, ПУТНАМ (DAVIS M„ PUTNAM H.)
1960 A Computing Procedure for Quantification Theory, I. ACM, 7, No. 3.
ДЭЙЛ, МИЧИ (ред.) (DALE E„ MICHIE D.)
1968 Machine Intelligence 2, American Elsevier Publishing Company, Inc., New York.
ЗОБРИСТ (ZOBR1ST A.)
1969 A Model of Visual Organization for the Game of Go, Proc. AFIPS Spring Joint Computer Conf., pp. 103—112.
ЙЕЙТС, РАФАЭЛЬ, ХАРТ (YATES R., RAPHAEL B„ HART T.)
1970 Resolution Graphs, Artificial Intelligence, 1, No. 4.
ЙЕЛИНЕК (JELINEK F.)
1969 Fast Sequential Decoding Algroithm Using a Stack, IBM J. Res. Develop., 13, No. 6, 675—685.
КВИНЛАН, ХАНТ (QUINLAN J., HUNT E.)
1968 A Formal Deductive Problem-Solving System, I. ACM, 15, No. 4, 625—646.
КИБЕРЦ, ЛАКХЭМ (KIEBURTZ R„ LUCKHAM D.)
1971 Compatibility of Refinements of the Resolution Principle (в печати).
КИСТЕР и др. (KISTER J. et al.)
1957 Experiments in Chess, J. ACM, 4, No. 2, 174—177.
КОВАЛЬСКИЙ (KOWALSKI R.)
1970a Search Strategies for Theorem-Proving, in B. Meltzer an<f D. Mich’ie (eds.), «Machine Intelligence 5», pp. 181—201, American Elsevier Publishing Company, Inc., New York.
19706 Studies in the Completeness and Efficiency of Theorem-Proving by Resolution, Doctoral Thesis, University of Edinburgh.
КОВАЛЬСКИЙ, ХЭЙЕС (KOWALSKI R., HAYES P.)
1969 Semantic Trees in Automatic Theorem-Proving, in B. Meltzer and D. Michie (eds.), «Machine Intelligence 4», pp. 87—101. American Elsevier Publishing Company, Inc., New York.
КОЛЛИНЗ, МИЧИ (ред.) (COLLINS N„ MICHIE D.)
1967 Machine Intelligence 1, American Elsevier Publishing Company, Inc., New York.
КОТОК (КОТОК A.)
1962 A Chess Playing Program for the IBM 7090, неопубликовано, В. S. Thesis, Massachusetts Institute of Technology, Cambridge, Mass.
КОУЛС (COLES L. S.)
1968 An On-Line Question-Answering System with Natural Language and Pictorial Input, Proc. ACM 23rd Natl. Conf., 1968, pp. 157—167, Brandon Systems Press, Princeton, N. J.-
256
Список литературы
КЭМПБЕЛЛ (CAMPBELL D.)
1960 Blind Variation and Selective Survival as a General Strategy in Knowledge-Processes, in M. Yovits and S. Cameron (eds.), Self-Organizing Systems, pp. 205—231, Pergamon Press, New York. [Русский перевод: Самоорганизующиеся системы, «Мир», М., 1964.]
ЛАВЛЕНД (LOVELAND D.)
1968 A Linear Format for Resolution, Carnegie-Mellon University Computer Science Dept. Report, December 1968. См. также Proc. IRIA 1968 Symp. Autom. Demonstration, Lecture Notes in Mathematics No. 125, Springer-Verlag New York, Inc., New York, 1970.
ЛАКХЭМ (LUCKHAM D.)
1967 The Resolution Principle in Theorem-Proving, in N. Collins and D. Michie (eds.), «Machine Intelligence 1», pp. 47—61, American Elsevier Publishing Co., Inc.
1969 Refinement Theorems in Resolution Theory, Stanford Artificial Intelligence Project Memo AI-81, March 24, 1969. См. также Proc. IRIA 1968 Symp. Autom. Demonstration, Lecture Notes on Mathematics no. 125, Springer-Verlag New York, Inc., New York, 1970.
ЛАКХЭМ, НИЛЬСОН (LUCKHAM D„ NILSSON N.)
1971 Extracting Information from Resolution Proof Trees, Artificial Intelligence.
ЛИН ШЕН (LIN SHEN)
1965 Computer Solutions of the Traveling Salesman Problem, Bell Syst. Techn. J., XLIV, No. 10.
1970 Heuristic Techniques for Solving Large Combinatorial Problems on a Computer, in R. Banerji and M. Mesarovic (eds.), «Theoretical Approaches to Non-Numerical Problem-Solving», pp. 410—418, Springer-Verlag New York, Inc., New York.
ЛОЛЕР, ВУД (LAWLER E„ WOOD D.)
1966 Branch and Bound Methods: A Survey, Operations Res., 14, No. 4, 699—719.
ЛОНДОН (LONDON R.)
1970 Bibliography on Proving the Correctness of Computer Programs, in B. Meltzer and D. Michie (eds.), «Machine Intelligence 5», pp. 569—580, American Elsevier Publishing Company, Inc., New York.
маккаллок, питтс (McCulloch w. s„ pitts w.)
1943 A Logical Calculus of the Ideas Immanent in Neural Nets, Bull. Math. Biophys., 5, 115—137.
маккарти (McCarthy j.)
1958 Programs with Common Sense, in «Mechanization of Thought Processes», vol. I, pp. 77—84, Proc. Symp., Nat. Phys. Lab, London, Nov. 24—27, 1958. См. также M. Minsky (ed.), «Semantic Information Processing», pp. 403—410, The M. I. T. Press, Gambridge, Mass., 1968.
1962 Towards a Mathematical Science of Computation, Proc. IFIP Congr. 62, North-Holland Publishing Company, Amsterdam.
1963 Situations, Actions and Causal Laws, Stanford University Artificial Intelligence. Project Memo. No. 2. См. также M. Minsky (ed.), «Semantic Information Processing», 410—418, The M. I. T. Press, Cambridge, Mass., 1968.
1964 A Tough Nut for Proof Procedures, Stanford University Artificial Intelligence Project Memo. No. 16,
Список литературы
257
маккарти, хэйес (McCarthy j„ hayes р.)
1969 ' Some Philosophical Problems from the Standpoint of Artificial Intelligence, in B. Meltzer and D. Michie (eds.), «Machine Intelligence 4», 463—502, American Elsevier Publishing Company, Inc., New York.
МАННА (MANNA Z.)
1969 The Correctness of Programs, 1. Computer Syst. Sci., 3 (May 1969). [Русский перевод; Манна 3., Правильность программ, Кибернетический сборник, № 7, новая серия, «Мир», М., 1970.]
1970 The Correctness of Non-Deterministic Programs, Artificial Intelligence, vol. 1, No. 1.
МАННА, УОЛДИНГЕР (MANNA Z„ WALDINGER R.)
1971 Towards Automatic Program Synthesis, Commun. ACM (April 1971).
МЕЛЬЦЕР (MELTZER B.)
1966 Theorem-Proving for Computers: Some Results on Resolution and Renaming, Comp. J., 8, 341—343.
1968 Some Notes on Resolution Strategies, in D. Michie (ed.), «Machine Intelligence 3», 71—75, American Elsevier Publishing Company, Inc., New York.
МЕЛЬЦЕР, МИЧИ (ред.) (MELTZER В., MICHIE D.)
1969 Machine Intelligence 4, American Elsevier Publishing Company, Inc., New York.
1970 Machine Intelligence 5, American Elsevier Publishing Company, Inc., New York.
1971 Machine Intelligence 6, American filsevier Publishing Company,
Inc., New York.
МЕНДЕЛЬСОН (MENDELSON E.)
1964 Introduction to Mathematical Logic, D. Van Nostrand Company, Inc., Princeton, New Jersey. [Русский перевод: Введение в математическую логику, «Наука», М., 1971.]
МИНСКИЙ (MINSKY М.)
1961а Steps Toward Artificial Intelligence, Proc. IRE, 49, 8—30 (January 196Г). См. также Фейгенбаум Э„ Фельдман Дж. (1963), стр. 402—457.
19616 A Selected Descriptor-Indexed Bibliography to the Literature on Artificial Intelligence, IRE Trans. Human Factors Electron, HFE-2, pp. 39—55, March 1961. Переработанный вариант см. в Фейгенбаум Э., Фельдман Дж. (1963), стр. 475—490.
1967 Computation: Finite and Infinite Machines, Prentice-Hall, Inc., Englewood Cliffs, N. J.
1968 (ed.) Semantic Information Processing, The M. I. T. Press, Cam-
bridge, Mass.
МИНСКИЙ, ПЕИПЕРТ (MINSKY M„ PAPERT S.)
1969 Perceptrons: An Introduction to Computational Geometry, The M. I. T. Press, Cambridge, Mass. [Русский перевод: Персептроны, «Мир», М., 1971.]
МИЧИ (ред.) (MICHIE D.)
1968 Machine Intelligence 3, American Elsevier Publishing Company,
Inc., New York.
258
Список литературы
МИЧИ, РОСС (MICHIE D„ ROSS R.)
1970 Experiments with the Adaptive Graph Traverser, in B. Meltzer and D. Michie (eds.), «Machine Intelligence 5», 301—318, American Elsevier Publishing Company, Inc., New York.
МОЗЕС (MOSES J.)
1967 Symbolic Integration, thesis, Project MAC, Report MAC-TR-47, Massachusetts Institute of Technology.
МОНТАНАРИ (MONTANARI U.)
1970 Heuristically Guided Search and Chromosome Matching, Artificial Intelligence, 1, No. 4.
МУР (MOORE E.)
1959 The Shortest Path Through a Maze, Proc. Intern. Symp. Theory Switching, Part II, April 2—5, 1957; The Annals of the Computation Laboratory of Harvard University 30, Harvard .University Press, Cambridge, Mass., 1959. НИЛЬСОН (NILSSON N.)
1969 Searching Problem-Solving and Game-Playing Trees for Minimal Cost Solutions, .in A. J. H. Morrell (ed.), «Information Processing 68», vol. 2, 1556—1562, North-Holland Publishing Company, Amsterdam.
НЬЮЭЛЛ (NEWELL A.)
1965 Limitations of the Current Stock of Ideas about Problem Solving, in A. Kent and O. Taulbee (eds.), «Electronic Information Handling», Spartan Books, Washington, D. C.
1969 Heuristic Programming: Ill-Structured Problems, in J. Aronofsky (ed.), «Progress in Operations Research», vol. 3, John Wiley and Sons, Inc. НЬЮЭЛЛ, ШОУ, САЙМОН (NEWELL A., SHAW J., SIMON H.)
1957 Empirical Explorations of the Logic Theory Machine, Proc. West Joint Computer Conf., vol. 15, pp. 218—239. См. также: Фейгенбаум Э., Фельдман Дж. (1963), стр. 113—144.
1958 Chess Playing Programs and the Problem of Complexity, IBM I. Res. Develop., 2, 320—335 (October 1958). См. также Фейгенбаум Э„ Фельдман Дж. (1963), стр. 33—70.
1959 Report on. a General Problem-Solving Program, Proc. Intern. Conf. Inform. Process., pp. 256—264, UNESCO House, Paris.
О’БИРН (O’BEIRNE T. H.)
1961 Puzzles and Paradoxes, New Scientist, 245 (July 27, 1961), 246 (Aug. 3, 1961).
OPE (ORE O.)
1962 . Theory of Graphs, Am. Math. Soc. Colloq. Publ., vol. 38, Providence, Rhole Island. [Русский перевод: Теория графов, «Наука», М., 1968.]
1963 Graphs and Their Uses, Random House, New York. [Русский перевод: Графы и их применение, «Мир», М., 1965.]
ПЕЙПЕРТ (PAPERT S.)
1968 The Artificial Intelligence of Hubert L. Dreyfus. A Budget of Fallacies, M. I. T. Artificial Intelligence Memo No. 54.
ПОЙА (POLYA G.)
1957 How to Solve It, 2nd ed., Doubleday and Company, Inc., Garden City, N. Y. [Русский перевод: Как решить задачу? Учпедгиз, М., 1959.] ПОЛЬ (POHL I.)
1969 Bi-Directional and Heuristic Search in Path Problems, Doctoral Dissertation Computer Science Dept., Stanford University, Stanford, Calif. Cm, также Stanford Linear Accelerator Center Report No. 104, May 1969.
Список литературы
259
1970 First Results on the Effect of Error- in Heuristic Search, in B. Meltzer and D. Michie (eds.), «Machine Intelligence 5», 219—236, American Elsevier Publishing Company, New York.
ПРАВИЦ (PRAWITZ D.)
1960 An Improved Proof Procedure, Theoria, 26, 102—139.
РАССЕЛ (RUSSELL R.) '
• 1964 Kalah — The Game and the Program,-Stanford University Artificial Intelligence Project Memo No. 22, Sept. 3, 1964.
РАФАЭЛЬ (RAPHAEL B.)
1964a SIR: A Computer Program for Semantic Information Retrieval, Doctoral Dissertation, Massachusetts Institute of Technology. См. также M. Minsky (eds.), Semantic Information Processing, The M. I. T. Press, Cambridge, Mass., 1968. 1
19646 A Computer Program Which «Understands», Proc. AFIPS Fall Joint Computer Conf., 577—589.
РИГНИ, ТАУН (RIGNEY J. W„ TOWNE D. M.)
1969 Computer Techniques for Analyzing the Microstructure of Serial-Action Work in Industry, Human Factors, 11, No. 2, 113—122.
РИШ (RISCH R. H.)
1969 The Problem of Integration in Finite Terms, Trans. Am. Math. Soc., 139, 167—189.
РОББИН (ROBBIN J.)
1969 Mathematical Logic: A First Course, W. A. Benjamin, Inc., New York.
РОБИНСОН, ВОС (ROBINSON G. A., WOS L. T.)
1969 Paramodulation and Theorem-Proving in First-Order Theories with Equality, in B. Meltzer and D. Michie (eds.), «Machine Intelligence 4», 135—150, American Elsevier Publishing Company, Inc., New York.
РОБИНСОН, ВОС, КАРСОН (ROBINSON G. A., WOS L. T„ CARSON D. F.)
1964 Some Theorem-Proving Strategies and Their Implementation, Argonne National Laboratories Technical Memorandum No.-72.
РОБИНСОН ДЖ. (ROBINSON J. A.)
1965a A Machine-Oriented Logic Based on the Resolution Principle, J. ACM, 12, No. 1, 23—41. [Русский перевод: см. Кибернетический сборник, № 7, Новая серия, «Мир», М., 1970.]
19656 Automatic Deduction with Hyper-Resolution, Intern. J. Comp. Math., 1, 227—234, 1965.
' 1967 Heuristic and Complete Processes in the Mechanization of . Theorem-Proving, in J. T. Hart and S. Takasu (eds.), «Systems and Computer Science», 116—124, University of Toronto Press, Toronto.
1968 The Generalized Resolution Principle, in D. Michie (ed.), «Machine Intelligence 3», 77—93, American Elsevier Publishing Co., Inc., New York.
1969a New Directions in Mechanical Theorem Proving, in A. J. H. Morrell (ed.), «Information Processing 68», vol. 1, 63—67, North-Holland Publishing Company, Amsterdam.
19696 Mechanizing Higher Order Logic, in B. Meltzer and D. Michie (eds.), «Machine Intelligence 4», American Elsevier Publishing Company, Inc., New York.
1970 An Overview of Mechanical Theorem Proving, in R. Banerji and M. Mesarovic (eds.), «Theoretical Approaches to Non-Numerical Problem Solving», 2—20, Springer-Verlag New York, Inc., New York.
260
Список литературы
РОЗЕНБЛАТТ (ROSENBLATT F.)
1962 Principles of Neurodynamics, Spartan Books, New York. [Русский перевод: Принципы нейродинамики. Перцептроны и теория механизмов мозга, «Мир», М., 1965.]
СЕЛФРИДЖ, КЕЛЛИ (SELFRIDGE О., KELLY J., Jr.)
1962 Sophistication in Computers: A Disagreement, IRE Trans. Inform. Theory, IT-8, No. 2, 78-80.
СИММОНС (SIMMONS R.)
1965 Answering English Questions by Computer: A Survey, Commun. ACM, 8, 53—70 (January 1965).
1970 Natural Language Question Answering Systems: 1969, Commum ACM, 13, No. 1, 15—30.
СЛЕИДЖЛ (SLAGLE J.)
1961 A Computer Program for Solving Problems in Freshman Calculus (SAINT), Doctoral Dissertation, Massachusetts Institute of Technology, Cambridge, Mass. См. также Lincoln Laboratory Report 5G-0001, May 10, 1961.
1963a A Heuristic Program That Solves Symbolic Integration Problems in Freshman Calculus, I. ACM, 10, No. 4, 507—520. См. также Фейгенбаум Э., Фельдман Дж. (1963).
19636 Game Trees, М and N Minimaxing, and the M and N Alpha-Beta Procedure, Artifical Intelligence Group Report No. 3, UCRL-4671, University of California Lawrence Radiation Laboratory, Livermore, Calif.
1965 Experiments with a Deductive-Question Answering Program, Commun. ACM, 8, 792—798 (December 1965).
1967 Automatic Theorem-Proving with Renamable arid Semantic Resolution, J. ACM, 14, No. 4, 687—697 (October 1967).
1970 Heuristic Search Programs, in R. Banerji and M. Mesarovic (eds.), «Theoretical Approaches to Non-Numerical Problem Solving», pp. 246—273, Springer-Verlag New York, Inc., New York.
СЛЕИДЖЛ, БУРСКИЙ (SLAGLE J., BURSKY P.)
1968 Experiments with a Multipurpose, Theorem-Proving Heuristic Program, J. ACM, 15, No. 1, 85—99.
СЛЕИДЖЛ, ДИКСОН (SLAGLE J., DIXON J.)
1969 Experiments with Some Programs that Search Game Trees, J. ACM, 16, No. 2, 189—207.
1970 Experiments with the M and. N Tree Searching Program, Commun. ACM, 13, No. 3, 147.
СОЛОМОНОВ (SOLOMONOFF R.)
1966 Some Recent Work in Artificial Intelligence, Proc. IEEE, 54, No. 112, December 1966.
СЭМЮЭЛЬ (SAMUEL A.)
1959 Some Studies in Machine Learning Using the Game of Checkers, IBM J. Res. Develop., 3, No. 3, 211—229. См. также Фейгенбаум Э., Фельдман Дж. (1963), стр. 71—110.
1967 Some Studies in Machine Learning Using the Game of Checkers II. Recent Progress, IBM J. Res. and Develop., 11, No 6, 601—617.
СЭНДУОЛЛ (SANDEWALL E.)
1969 Concepts and Methods for Heuristic Search, in Donald E. Walker and Lewis M. Norton (eds.), «Proc. Intern. Joint Conf. Artificial Intelligence», Washington, D. C.
Список литературы
261
ТРЕЙВИС (TRAVIS L.)
196$ The Value of Introspection to tlje Designer of Mechanical Problem-Solvers, Behav. Sci., 8, No. 3, 227—233.
1967 Psychology and Bionics: Many Old Problems and a Few New Machines, Conf. Record 1967 Winter Conv. Aerospace Electron. Sys. (WINCON), IEEE Publication No. 10-C-42, vol. VI.
ТЬЮРИНГ (TURING A. M.)
1950 Computing Machinery and Intelligence, Mind, 59, 433—460 (October 1950). См. также Фейгенбаум Э., Фельдман Дж. (1963).
УИТНИ (WHITNEY D.)
1969 State Space Models of Remote Manipulation Tasks, in Donald E. Walker and Lewis M. Norton (eds.), «Proc. Intern. Joint Conf. Artificial Intelligence», 495—507, Washington, D. C.
УОЛДИНГЕР, ЛИ (WALDINGER R., LEE R.)
1969 PROW: A Step Toward Automatic Program-Writing, in Donald E. Walker and Lewis M. Norton (eds.), «Proc. Intern. Joint Conf. Artificial Intelligence», Washington, D. C.
ФАИКС (FIKES R.)
1970 Ref-Art: A System for Solving Problems Stated as Procedures, Artificial Intelligence, 1, No. 1.
ФЕЙГЕНБАУМ (FEIGENBAUM E.)
1963 Artificial Intelligence Research, IEEE Trans. Inform. Theory, IT-9, No. 4, 248—261.
1969 Artificial Intelligence: Themes in the Second Decade, in A. J. H. Morrell (ed.), «Information Processing 68», vol. 2, 1008—1022, North-Holland Publishing Company, Amsterdam. См. также Stanford University Artificial Intelligence Project Memo No. 67, Aug. 15, 1968.
ФЕЙГЕНБАУМ, БУКХЭНАН,. ЛЕДЕРБЕРГ (FEIGENBAUM E„ BUCHANAN B„ LEDERBERG J.)
1971 Generality and Problem Solving: A Case Study Using the DEN-DRAL Program, in B. Meltzer and D. Michie (eds.), «Machine Intelligence 6», American Elsevier Publishing Company, Inc., New York.
ФЕЙГЕНБАУМ, ФЕЛЬДМАН (ред.) (FEIGENBAUM E., FELDMAN J.)
1963 Computers and Thought, McGraw-Hill Book Company, New York. [Русский перевод: Вычислительные машины и мышление, «Мир», М., 1967.] ФЕЛЬДМАН, ГРИС (FELDMAN J., GRIES D.)
1968 Translator Writing Systems, Commun. ACM, 11, No. 2, 77—113.
ФЛОЙД (FLOYD R.)
1967a Nondeterministic Algorithms, I. ACM, 14, No. 4, 636—644.
19676 Assigning Meanings to Programs, Proc. Symp. Appl. Math. Am. Math. Soc., vol. 19, 19—32.
ФОГЕЛЬ, ОУЭНС, УОЛШ (FOGEL L„ OWENS A., WALSH M.)
1966 Artificial Intelligence Through Simulated Evolution, John Wiley and Sons, Inc., New York.
ФОРД, ФАЛКЕРСОН (FORD L„ Jr., FULKERSON D.)
1962 Flows in Networks, Princeton University Press, Princeton, • N. J. [Русский перевод: Потоки в сетях, «Мир», М., 1966.]
262
Список литературы
ХАРТ, НИЛЬСОН, РАФАЭЛЬ (HART Р„ NILSSON N„ RAPHAEL В.)
1968 A Formal Basis for the Heuristic Determination of Minimum Cost Paths, IEEE Trans. Sys. Sci. Cybernetics, SSC-4, No. 2, 100—107.
ЧЕРЧ (CHURCH A.)
1956 Introduction to Mathematical Logic, vol. 1, Princeton University Press, Princeton, N. J. [Русский перевод: Введение в математическую логику, т. I, ИЛ, М„ 1961.]
ШАПИРО (SHAPIRO D.)
1966 Algorithms for the Solution of the Optimal Cost Traveling Salesman Problem, Sc. D. Thesis, Washington University, St. Louis, Mo.
ШЕННОН (SHANNON C.)
1950 Programming a Digital Computer for Playing Chess, Philosophy Magazine, 41, 356—375 (March, 1950). См. также J. R. Newman (ed.), The World of Mathematics, vol. 4, Simon and Schuster, New York, 1954. [Русский перевод: см. Работы по теории информации и кибернетике, ИЛ, М., 1963.] ШУХ (SCHUH F.)
1968 The Master Book of Mathematical Recreations, W. J. Thieme and Cie., Zutphen, 1943 (на голланд. яз.). Английский перевод: F. Gobel, Dover Publications, Inc., New York, 1968.
ЭДВАРДС, ХАРТ (EDWARDS D„ HART T.)
1963 The a-₽ Heuristic, M. I. T. Artificial Intelligence Memo No. 30, Oct. 28, 1963. [Первоначально опубликовано как The Tree Prune (TP) Algorithm, Dec. 4, 1961.]
.ЭНДРЮС (ANDREWS P.)
1968 Resolution with Merging, I. ACM, 15, No. 3, 367—381. См. также поправки в I. ACM, 15, No. 4, 720 (October, 1968).
ЭРБРАН (HERBRAND J.)
1930 Recherches sur la theorie de la demonstration, Trav. Soc. Sci. Let-tres Varsovie, Classe III Sci. Math. Phys., No. 33.
ЭРНСТ (ERNST G.)
1969 Sufficient Conditions for the Success bf GPS, I. ACM, 16, No. 4, 517—533.
ЭРНСТ, НЬЮЭЛЛ (ERNST G., NEWELL A.)
1969 GPS: A Case Study in Generality and Problem Solving, ACM Monograph Series, Academic Press, Inc., New York.
ИМЕННОЙ УКАЗАТЕЛЬ
Адельсон-Вельский Г. М. 170
Аллен (Allen J.) 250
Амарель (Amarel S.) 22, 48, 49, 51,
90, 168
Андерсон (Anderson R.) 249
Бар Хиллел (Bar Hillel Y.) 232
Веллман (Bellman R.) 89
Беллмор (Bellmore М.) 23, 49
Бенерджи (Banerji R.) 22
Берж (Berge С.) 48
Бернштейн (Bernstein А.) 169
Бледсоу (Bledsoe W.) 249
Блэк (Black F.) 22, 233
Бобров (Bobrow D.) 232
Болл (Ball W.) 24
Бомерт (Baumert L.) 89
Букхэнан (Buchanan В.) 23
Бурский (Bursky Р.) 125, 127, 168
Вайссман (Weissman С.) 220
Вос (Wos L.) 203, 234, 249, 250
Вуд (Wood D.) 22, 89
Гарвей (Garvey Т.) 250
Гард (Guard J.) 234
Гарднер (Gardner М.)' 24
Гелернтер (Gelernter Н.) 114, 126
Голомб (Golomb S.) 89
Грин (Green С.) 232, 233, 250
Гринблатт (Greenblatt R.) 170
Грис (Gries D.) 49
Гуд (Good I.) 168
Де Руссо (De Russo Р.) 49 '
Дийкстра (Dijkstra Е.) 88
Диксон (Dixon J.) 89, 166—170
Доран (Doran J.) 88, 89
Дрейфус С. (Dreyfus S.) 89
Дрейфус X. (Dreyfus Н.) 19, 170
Дьюденей (Dudeney Н.) 24
Дэвис (Davis М.) 203
Зобрист (Zobrist А-) 170
Иейтс (Yates R.) 221, 243, 249, 250
Йелинек (Jelinek F.) 23
Квинлан (Quinlan J.) 48
Келли (Kelly J., jr.) 19
Киберц (Kieburtz R.) 249
Кистер (Kister J.) 169
Клинг (Kling R.) 250
Клоуз (Close C.) 49
Ковальский (Kowalski R.) 203, 237,
248, 250
Коток (Kotok A.) 170
Коулс (Coles L. S.) 232
Кэмпбелл (Campbell D.) 21
Лавленд (Loveland D.) 243, 249
Лакхэм (Luckham D.) 9, 196, 204,216,
233, 249, 250
Левин (Levin N.) 169
Ледерберг (Lederberg J.) 23
Ли (Lee R.) 233
Лин Шен (Lin Shen) 22
Лолер (Lawler E.) 22, 89
Лондон (London R.) 233
Маккаллок (McCulloch W. S.) 20
Маккарти (McCarthy J.) 22, 49, 51, 91, 169, 170, 203, 233, 234
Манна (Manna Z.) 48, 125, 233
Мансон (Munson J.) 233
Мельцер (Meltzer B.) 249
Мендельсон (Mendelson E.) 202
Минский (Minsky M.) 13, 20, 23, 49
Мичи (Michie D.) 23, 88, 89
Мозес (Moses J.) 126, 127
Монтанари (Montanari U.) 23
Myp (Moore E.) 89
Нильсон (Nilsson N.) 6, 89, 168, 216, 233
Немхозер (Nemhauser G.) 23, 49
Новиков П. C. 202
Ньюэлл (Newell A.) 21, 22, 24, 25, 48, 49, 125, 126, 168, 169
264
Именной указатель.
О’Бирн (O’Beirne Т. Н.) 127
Ope (Ore О.) 48
Таун (Towne D. М.) 125
Трейрис (Travis L.) 21
Тьюринг (Turing А. М.) 19*
Пейперт (Papert S.) 19, 20
Питтс (Pitts W.) 20
Пойа (Polya G.) 21
Поль (Pohl I.) 89
Правиц (Prawitz D). 203
Путнам (Putnam Н.) 203
Рассел (Russell R.) 170
Рафаэль (Raphael В.) 89, 168, 232, 233, 243, 249, 250
Ригни (Rigney J. W.) 125
Риш (Risch R. Н.) 126, 127
Роббин (Robbin J.) 202, 203
Робинсон Г. (Robinson G. А.) 203, 234, 248, 250
Робинсон Дж. (Robinson J. А.) 196, 203, 204, 248, 249
Розенблатт (Rosenblatt F.) 20
Рой (Roy Р.) 49
Росс (Ross R.) 89
Уитни (Whitney D.) 23
Уолдингер (Waldinger R.) 233
Файке (Fikes R.) 48, 49, 233
Фалкерсон (Fulkerson D.) 49
Фейгенбаум (Feigenbaum Е.) 9, 23
Фельдман (Feldman J.) 23, 49
Флойд (Floyd R.) 48, 233
Фогель (Fogel L.) 20
Форд (Ford L., jr.) 49
Хант (Hunt Е.) 48
Харт Р. (Hart Р.) 9, 89, 168, 250
Харт Т. (Hart Т.) 169, 243, 249
Хэйес (Hayes Р.) 203, 234, 248
Чёрч (Church А.) 202
Саймон (Simon Н.) 21, 25, 125, 168, 169
Селфридж (Selfridge О.) 19
Сиберз (Siberz J. К.) 9
Симмонс (Simmons R.) 232
Слейджл (Slagle J.) 22, 23, 89, 107, 108, 125—127, 166—170, 232, 249
Соломонов (Solomonoff R.) 23
Сэмюэль (§amuel А.) 9, 89, 168—170
СэндуОлл (Sandewall Е.) 22
Шапиро (Shapiro D.) 23, 89
Шеннон (Shannon С.) 168
Шоу (Shaw J.) 21, 25, 125, 168, 169
Шух (Schuh F.) 24
Эдвардс (Edwards D.) 169
Эндрюс (Andrews R.) 243, 249
Эрбран (Herbrand J.) 190, 203
Эрнст (Ernst G.) 22, 48, 126
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ
аксиома 207
алгоритм динамического программирования 89
— допустимый 70, 148
— недетерминированный 48
— унификации 195
— упорядоченного перебора 144
алфавитный вариант 194
альфа-бета процедура 157, 163
альфа-отсечение 163
атом 186, 194
атомная формула 174
бесконечное m-арное дерево 81
бета-отсечение 163
буква константная 173
— пропозициональная 173
вершина 31
— вывода 191
— достижимая 32
— дочерняя 31, 99
— заключительная 99
— закрытая 70
— «И» 99
— «ИЛИ» 98
— корневая 132, 238
— концевая 142, 238
— начальная 32, 52, 99
— неблагоприятная 189
— незакрытая 70
— неразрешимая 100, 129
— открытая 70
— разрешимая 129
— родительская 31, 99
глубина вершины 59, 63, 134, 138
— граничная 59
— опровержения 199
— подинтегрального выражения 167
глубинное отношение 89
грамматика 39-
граф 31
— доказательства на основе резол ь-венций 238
— «И/ИЛИ» 95, 98
— направленный 31
— перебора 130
дерево 53, 63
— игры 123
— «И/ИЛИ» 125
— замкнутое 189
— оптимальное 141
— перебора 55, 132
— пропозициональное 125
— решения потенциальное 143
— семантическое 187
дизъюнкция 178
доказательство 180
дуга 31, 99
— невозвратная 50
задача об обезьяне и бананах 45, 118, 225
— о восьми ферзях 50, 103
— *— коммивояжере 23, 37
-----кувшинах 50
-----миссионерах и людоедах 90
----- перевернутом маятнике 43
-----пирамидке 91
-----скользящих прямоугольниках
90
— получения ответа на вопросы 232
— распределения 41
— символического интегрирования
— синтаксического анализа 39
— управления 43
игра в восемь 30
----- пятнадцать 13
— гоу 170
— Гранди 123
— калах 166, 170
— Кьюбик 171
— «последний проигрывает» 128
— тик-так-ту 155, 158—160
— шахматы 169
— шашки 170
игры 122
индивидуальные переменные 177
интерпретация 175
исчисление предикатов 172
квантор всеобщности 178
— существования 179
266
Предметный указатель
классическая логика 202
контроль внимания 168
конфигурация начальная 13
— целевая 13
конъюнкция 177
корень дерева 53
литерал 184
логическое следование 180
лоза 238
макрооператоры 45
матрица 183
метод ветвей и границ 22
— перебора в глубину 59, 63, 131
— полного перебора 53, 62, 131, 132
— проб и ошибок 7, 16
— равных цен 57, 62
— таблиц истинности 176
множество рассогласования 195
— унификации 209
— унифицируемое 194
— целевое 32
модель 111, 175, 189, 244
невыполнимость (неудовлетвори-мость) 181
неразрешимость 180
нормальная форма конъюнктивная
184
--предваренная 183
обращенная величина 154
—.— предварительная 161
общезначимость 179
означивание 186
оператор 14
— ключевой 116
— наследования 32
— недетерминированный 33
— построения дочерних вершин 101
— префиксный 27
— присваивания 33
---ВСЕ 101
---ВЫБОР 34, 101
— сведения задачи к подзадачам 96 описание дочернее (результирующее)
96
основные промежуточные состояния 115
ответное утверждение 208
отфильтровывание предшествующих вершин 239
оценочная функция 64, 65, 139
• — — статическая 154
перебор в глубину 53
— полный 53
— слепой 53
— упорядоченный 65
— этапами 83
персептрон 20
поддержка 243
подзадача 16
подслучай 237
поиск (перебор) 15
— в глубину 135
потомок 32
правила переписывания 28, 30
— прерывания перебора 161
правильно построенная формула
(п. п. формула) 172, 174
предложение 39, 181, 184
— базовое 238
— выведенное 197
— исходное 196
— положительное 246
предположение 207
— о непротиворечивости 74
предок 32
префикс 183
принцип резольвенций 172
приписывание значения 175
проблема системы отсчета 231 программа недетерминированная 34 — Мэк Хак 170
программирование с обратным слежением 89
продукция 28
прослеживание в обратном направлении 154
пространство состояний 14
---высшего уровня 122
процесс опровержения 198
процедура минимаксная 154
— разметки разрешимых и неразрешимых вершин 130
путь 32, 140
— оптимальный 68
различия 117
разрешимость вершины 99
— пары предложений 197
раскрытие вершины 52, 130
ребро 31
редукция задачи 16
резольвента 192, 197
резольвенция 197
резолюция 172
решающая последовательность 52
решающий граф 100
решение задач 11
сведение задачи к подзадачам 91
семантика 172, 175
Предметный указатель
267
синтаксис 172, 173
слияние 243
состояние начальное 14
— целевое 14
состояния-вехи 96
стоимость 140
— дуги 32
— максимальная 140
— оцененная 141
— пути 32
— суммарная 140
стратегии комбинированные 247
стратегия модельная 246
— наименьшего числа компонент 247
— очищения 236, 237
— поддерживающего множества 243
— предпочтения одночленам 247
— упорядочения 236, 247
— упрощения 236
— AF-формы 241
схема для описания состояний 45
таблица истинности 176
тавтология 208, 236
терм 174 ‘
тест Тьюринга 19
указатели 52, 130
универсальный решатель задач 21, 22
универсум Эрбрана 185
унификатор 194
— наиболее общйй (простейший) 195 унификация 193
упорядочение динамическое 165
— совершенное 164
упорядочение фиксированное 165
уровень граничный 248
— дерева 148
— опровержения 199
фактор 196
— эффективного ветвления 86
функция качества 168
— Сколема 182
— стоимости 57
целенаправленность 85
частный случай константный 185, 194
---«общий» 196
--- подстановочный 193
эвристическая информация 63
— сила 64, 77
— функция 70, 141
эвристические методы поиска 64
эвристический поиск 7
элементарная задача 16, 91
эрбрановская база 186
V-ветвление 35, 103
AF-форма 239
саг 220
сdr 220
cons 220
е-значения 166
Pi-опровержение 246
ОГЛАВЛЕНИЕ
Предисловие редактора перевода ..................................... 5
Предисловие . ................................................ . . 7
Глава 1. Введение ..................................................11
1.1. решение задач и искусственный интеллект....................И
1.2. Головоломки и игры как примеры задач......................12
1.3. Состояния и операторы................................... 14
1.4. Сведение задачи к подзадачам..............................16
1.5. Использование формальной логики при решении задач .... 17
1.6. Два составных элемента процесса решения задач: представление и поиск (перебор) ............................................ 18
1.7. Библиографические и исторические замечания...............19
Задачи....................................................... 24
Глава 2. П редставление задач в пространстве состояний..............26
2.1. Описания состояний........................................26
2.2. Операторы ................................................27
2.3. Целевые состояния.........................................30
2.4. Запись в виде графа.......................................31
2.5. Представление пространств состояний посредством недетерминированных программ..............................................33
2.6. Некоторые примеры представлений задач.....................36
2.7. Выбор «хороших» представлений.............................44
2.8. Библиографические и исторические замечания ‘ 48
Задачи ....................................................... 49
Глава 3. Методы поиска в пространстве состояний ....................52
3.1. Процессы поиска на графе..................................52
3.2. Методы полного перебора...................................53
3.3. Метод перебора в глубину..................................59
3.4. Изменения при переборе на произвольных графах.............62
3.5. Обсуждение эвристической информации ......................63
3.6. Использование оценочных функций...........................65
3.7. Оптимальный алгоритм перебора.............................68
3.8. Допустимость алгоритма Л*.................................70
3.9. Оптимальность алгоритма 4*................................73
3.10. Эвристическая сила функции П.............................77
3.11. Важная роль функции £.....................................80
3.12. Использование других эвристик.............................83
3.13. Критерии качества работы методов перебора.................85
3.14. Библиографические и исторические замечания................88
Задачи .........................................................90
Оглавление 269
Глава 4. Представления, допускающие сведение задач к подзадачам . 91
4.1. Пример представления, дающего сведение задачи к подзадачам 91
4.2. Описание задач........................................... 95
4.3. Операторы сведения задачи к. подзадачам...................96
4.4. Описания элементарных задач...............................97
4.5. «И/ИЛИ» графы.............................................98
4.6. Представление «И/ИЛИ» графов с помощью недетерминированных программ 101
4.7. Примеры сведения задачи к совокупности подзадач .... 105
4.8. Механизмы планирования при сведении задач к подзадачам . .115
4.9. Ключевые операторы.......................................116
4.10. Различия .............................................. 117
4.11. Пространства состояний высшего уровня...................121
4.12. Игры ...................................................122
4.13. Библиографические и исторические замечания..............125
Задачи....................................................... 127
Глава 5. Методы поиска при сведении задач к совокупности подзадач . .129
. 5.1. Процессы перебора (поиска) на графах типа «И/ИЛИ» .... 129
5.2. Метод полного перебора................................. 132
5.3. Поиск в глубину..........................................135
5.4. Перебор на графах типа «И/ИЛИ»..........................1'37
5.5. Стоимости деревьев решения...............................139
5.6. Использование оценок стоимости для прямого перебора . . .141
5.7. Алгоритм упорядоченного перебора для деревьев типа «И/ИЛИ» 144
' 5.8. Допустимость алгоритма упорядоченного поиска (перебора) . . 148
5.9. Выбор вершины в т0 для очередного раскрытия ....... 150
5.10. Модификации ............................................152
5.11. Минимаксная процедура при переборе на игровых деревьях . . 152
5.12. Альфа-бета процедура....................................157
5.13. Эффективность перебора при альфа-бета процедуре.........163
5.14. Комбинированные альфа-бета процедуры и. процедуры упорядочения ........................................................ . 164
5.15. Возможное .улучшение методов, основанных иа минимаксе ... 166
5.16. Библиографические и исторические замечания..............167
Задачи ......................................................170
Глава 6. Доказательство теорем в исчислении предикатов............172
6.1. Исчисление предикатов как язык для решения задач ..... 172
6.2. Синтаксис...............................................173
6.3. Семантика ...............................................175
6.4. Переменные и кванторы....................................177
6.5. Общезначимость и выполнимость............................179
6.6. Предложения .............................................181
6.7. Универсум Эрбрана........................................185
6.8. Эрбрановская база....................................... 186
6.9. Построение семантического дерева.........................187
6.10. Неблагоприятные вершины.................................189
6.11. Вершины вывода..........................................191
6.12. Унификация .............................................193
6.13. Резольвенты ............................................196
6.14. Принцип резольвенции ......................... . ' . 198
6.15. Непротиворечивость и полнота резольвенции...............201
6.16. Библиографические и исторические замечания.............202
Задачи........................................................204
270
Оглавление
Глава 7. П рименения исчисления предикатов к решению задач .... 205
7.1. Исчисление предикатов при решении задач..................205
7.2. Пример ..................................................206
7.3. Процесс извлечения ответа............................... 209 '
7.4. Предположения, содержащие переменные, относящиеся к квантору всеобщности .............................................214
7.5. Пример автоматического написания программы...............219
7.6. Использование исчисления предикатов при решении задач в пространстве состояний...........................................224
7.7. Одна формализация для решения задач в пространстве состояний 228
7.8. Библиографические и исторические замечания ........ 232
Задачи...................................................... 234
Глава 8. Методы поиска доказательства в исчислении предикатов . . . 236
8.1. Стратегии перебора...................................... 236
8.2. Стратегии упрощения..................................... 236
8.3. Стратегии очищения...................................'. . 237
8.4. Формы доказательства с отфильтровыванием предшествующих вершин........................................................238
. 8.5. Стратегия поддерживающего множества.................... 243
8.6. Более ограничительные стратегии..........................243
8.7. Модельные стратегии......................................243
8.8. Л-опровержения ..........................................246
8.9. Комбинированные стратегии................................247
8.10. Стратегии упорядочения . ................................247
8.11. Библиографические и исторические замечания...............248
Задачи........................................................ 250
Список литературы.................................................252
Именной указатель.................................................263
Предметный указатель..............................................265
УВАЖАЕМЫЙ ЧИТАТЕЛЬ!
Ваши замечания о содержании книги, ее оформлении, качестве перевода и другие просим присылать по адресу:
129 820. Москва, И-.110 ГСП 1-й Рижский пер., д. 2, Издательство «Мир».
Н. Нильсон
ИСКУССТВЕННЫЙ ИНТЕЛЛЕКТ
Редакторы А. С, Попов и Л. Б. Штейнпресс Художник А. И. Гольдман
Художественный редактор В, И. Шаповалов Технический редактор Л. П. Бирюкова Корректор В. С. Соколов
Сдано в набор 18/1 1973 г. Подписано к печати 27/VI 1973 г. Бумага тип. № 3 60 Х90’/1б=8,50 бум. л. 17 усл. печ. л., 16,93 уч.-изд. л.
Изд, № 1/6792. Цена 1 р, 17 к. Заказ № 493
ИЗДАТЕЛЬСТВО «МИР»
Москва, 1-й Рижский пер., 2
Ордена Трудового Красного Знамени Ленинградская тйпография № 2 имени Евгении Соколовой зСоюзполнграфпрома при Государственном комитете Совета Министров СССР по делам издательств, полиграфии и книжной торговли г. Ленинград, Л-52, Измайловский проспект, 29
У НИХ ЛИШЬ ДЛЯ БОГАТЫХ ИЗОБИЛИЕ. А МЫ СТРЕМИИСЛ К ИЗОБИЛИЮ АЛО ВСЕХ