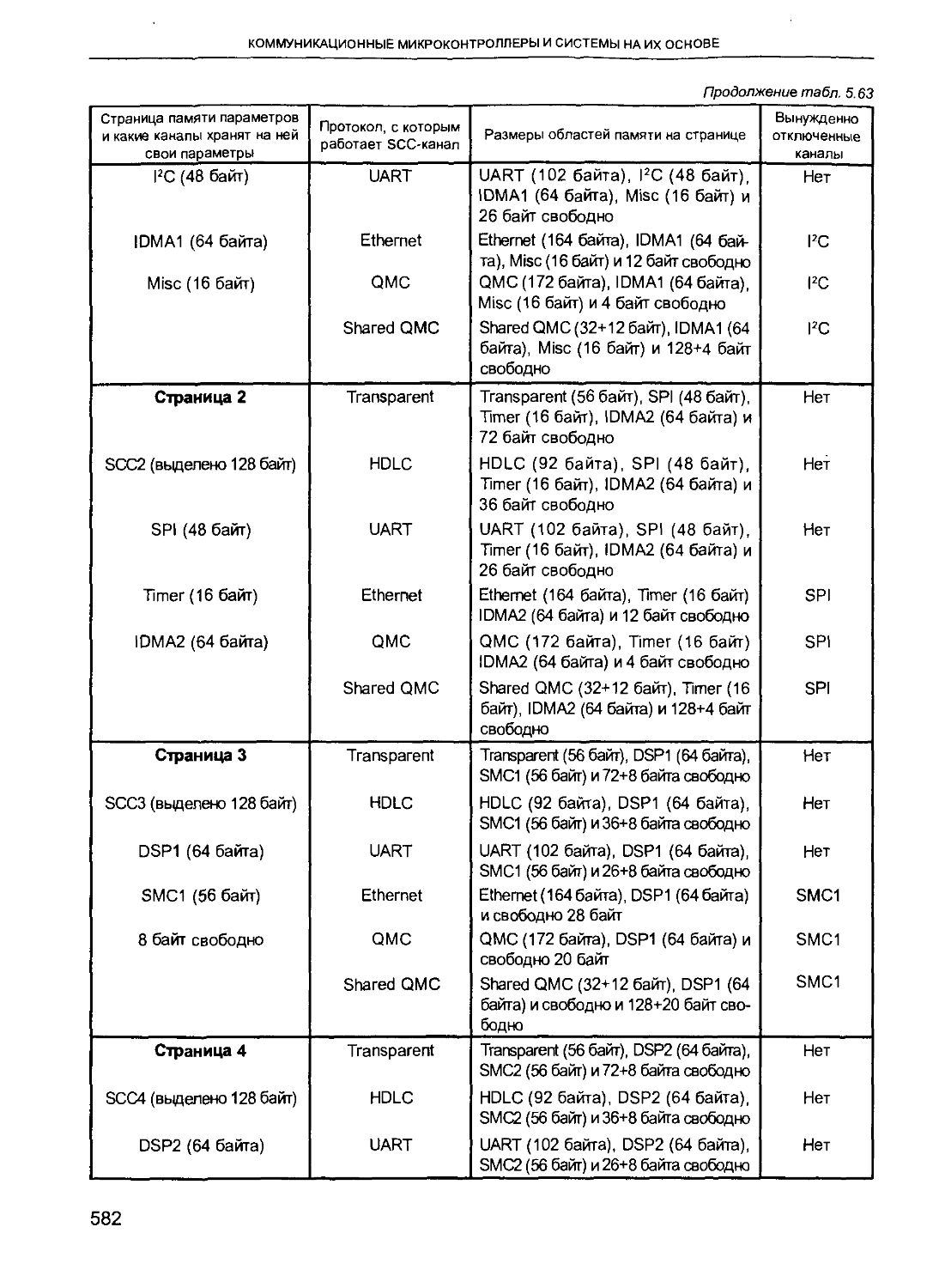
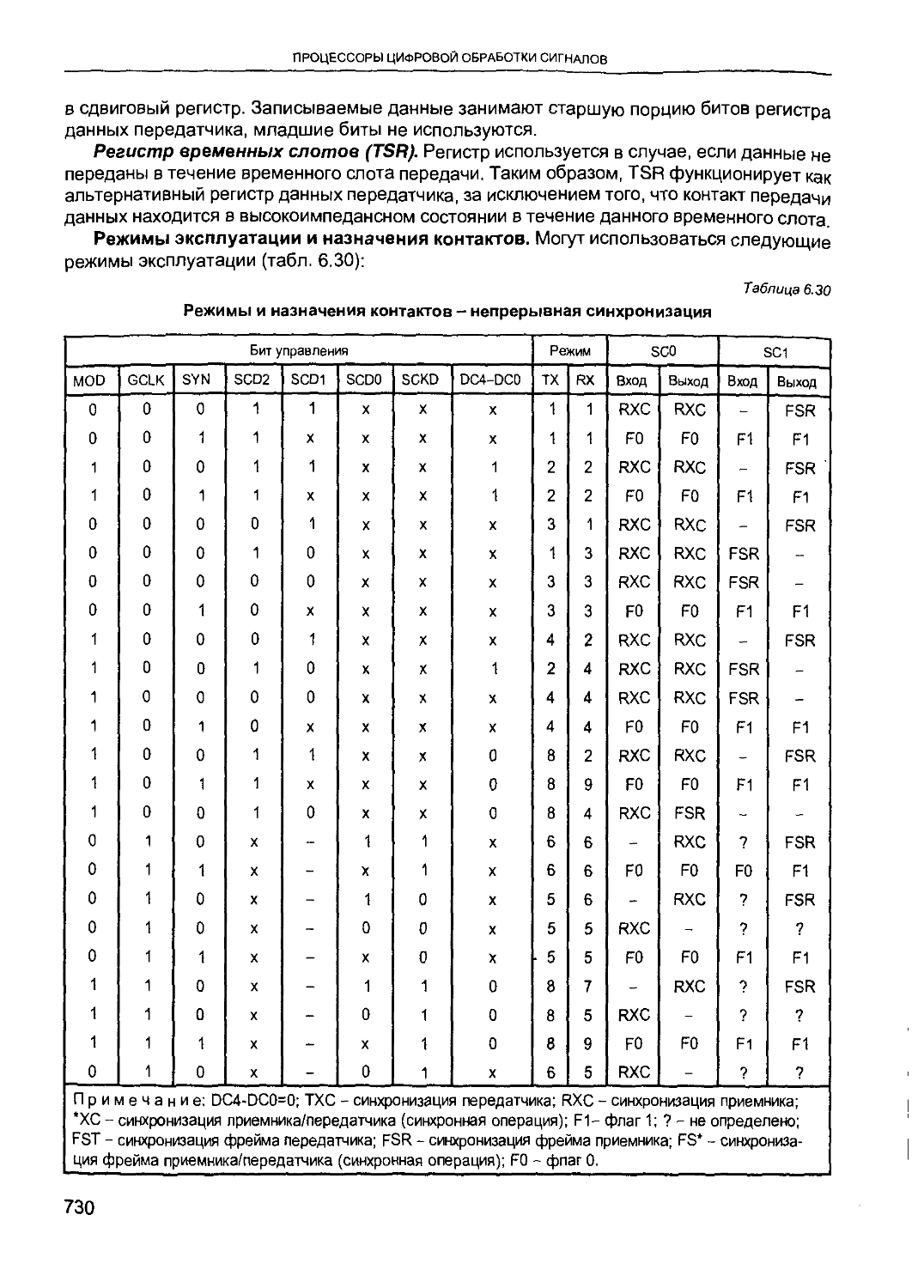
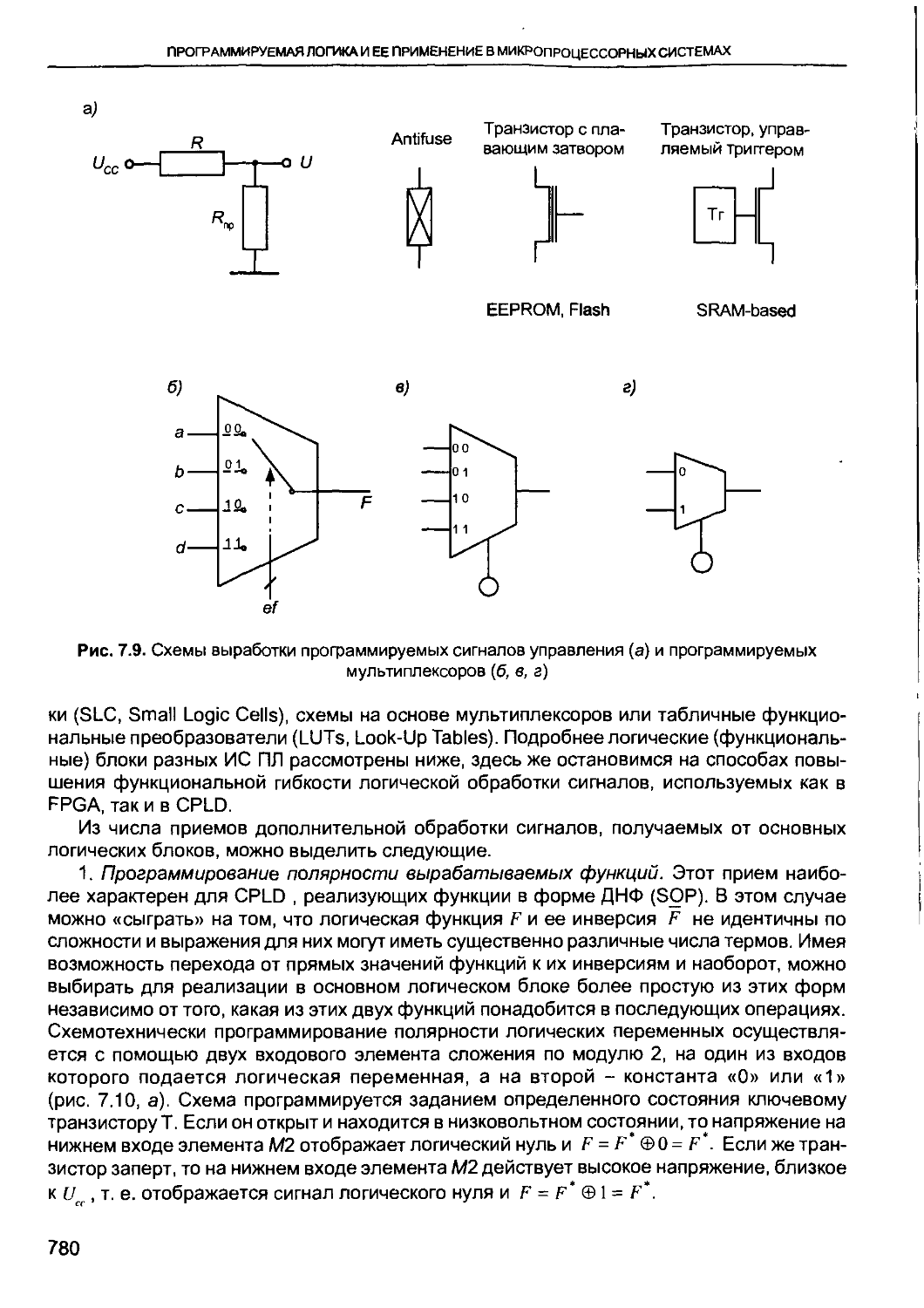
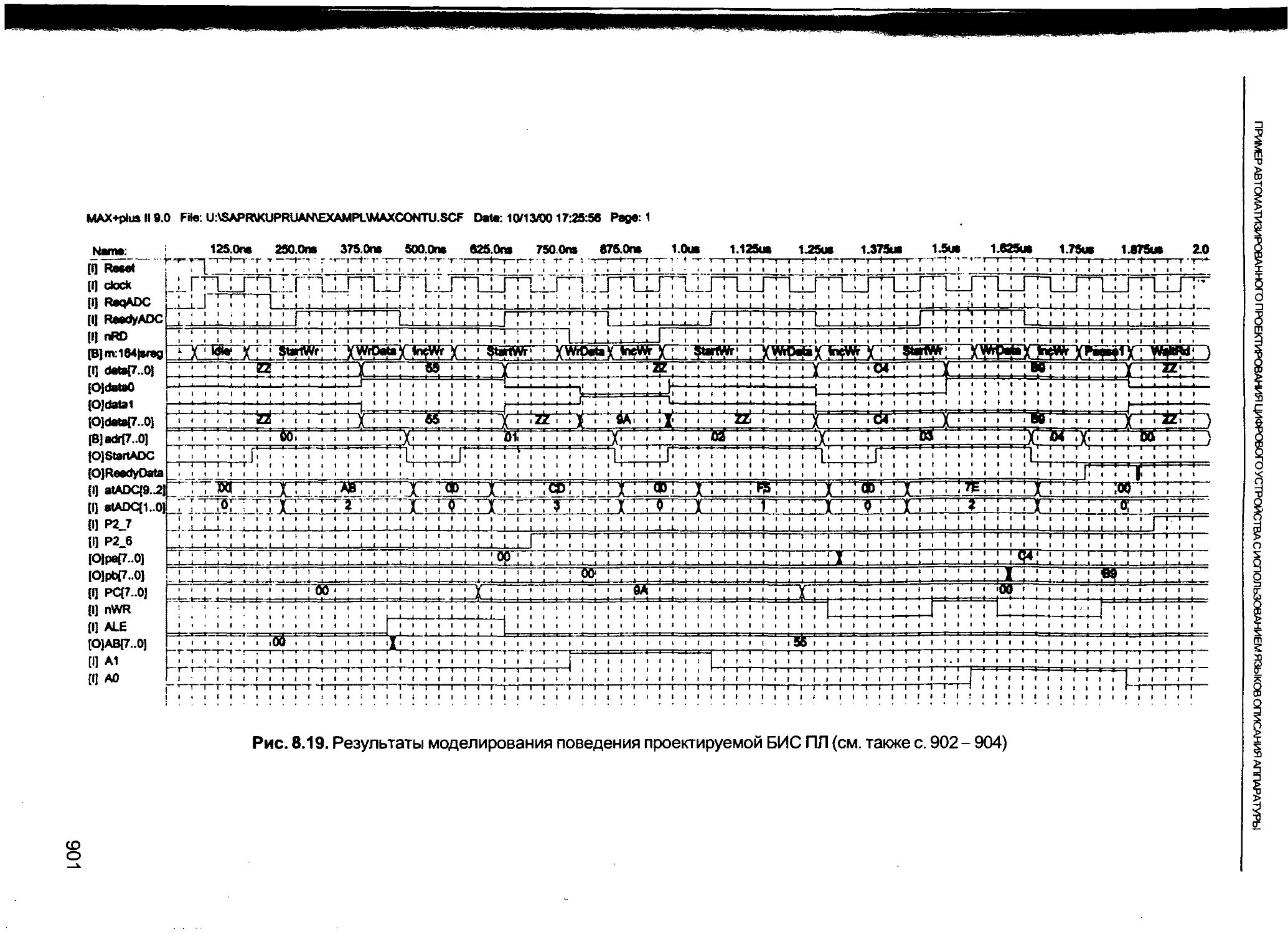
/


























































































































































































































































































































































































































































































































































































































































































































































































































































































































































Author: Пузанкова Д.В.
Tags: компьютерные технологии языки программирования трансляторы микропроцессы
ISBN: 5-7325-0516-4
Year: 2002




Text
УЧЕБНОЕ ПОСОБИЕ ДЛЯ ВУЗОВ
Под общей редакцией Д. В. Пузанкова
Допущено Министерством образования Российской Федерации в качестве учебного пособия для студентов высших учебных заведений, обучающихся по направлению подготовки бакалавров и магистров “Информатика и вычислительная техника”
БИБЛИОТЕКА
/ омского государственного университ<т & систем упрамлеяил и
радиоэл*ектрон ики ИНВ.иУе
203
ПОЛИТЕХНИКА
ИЗДАТЕЛЬСТВО
Санкт-Петербург 2002
УДК 681.3 ББК 32.973.2
М59
Федеральная программа книгоиздания России
wdo noi':
М59 Микропроцессорные системы: Учебное пособие для вузов / Е. К. Александров, Р. И. Грушвицкий, М. С. Куприянов, О. Е. Мартынов, Д. И. Панфилов, Т. В. Ремизевич, Ю. С. Татаринов, Е. П. Угрюмов, И. И. Шагурин; Под общ. ред. Д. В. Пузанкова. — СПб/. Политехника, 2002. — 935 с.: ил.
ISBN 5-7325-0516-4
Излагаются вопросы организации функционирования и программирования микропроцессорных средств. Представлены микропроцессоры общего применения ведущих мировых производителей, процессоры обработки сигналов, а также микроконтроллеры для встроенных приложений: коммуникационные, для задач управления и др. Рассматриваются программные модели процессоров и микроконтроллеров, особенности организации периферийных устройств, средства отладки и проектирования. Приводятся примеры применения и программирования. Учебное пособие ориентировано на студентов технических университетов, обучающихся по направлению «Информатика и вычислительная техника».
УДК 681.3 ББК 32.973.2
ISBN 5-7325-0516-4
© Е. К. Александров, Р. И. Грушвицкий, М. С. Куприянов, О. Е. Мартынов, Д. И. Панфилов, Т. В. Ремизевич, Ю. С. Татаринов, Е. П. Угрюмов, И. И. Шагурин, 2002
© Издательство «Политехника», 2002
ПРЕДИСЛОВИЕ
С момента выхода последних учебников и учебных пособий по микропроцессорной технике прошло значительное время. Данные книги содержали, как правило, описания конкретных микропроцессоров или микропроцессорных комплексов, включали разделы, посвященные средствам программирования, вопросам проектирования и отладки.
В настоящее время на российском рынке представлены самые разнообразные микропроцессорные средства преимущественно многочисленных зарубежных компаний: микропроцессоры (МП), используемые в первую очередь для персональных компьютеров и рабочих станций; микроконтроллеры (МК) и интегрированные процессоры (ИП), используемые для встраиваемых систем. Безусловно, в первую очередь представляют интерес МК и ИП, ориентированные на встроенные применения для таких областей как управление оборудованием, сетевые приложения, связь, портативная техника, автоматизация и т. п.
Обширная номенклатура и богатые функциональные возможности МП, МК и ИП создают специалистам хорошие условия для проектирования конкурентоспособных систем различного назначения. Однако осуществить правильный выбор типа микропроцессорного средства можно только опираясь на знания архитектуры, системных возможностей, организации и средств поддержки процесса проектирования.
Ситуация на рынке информационных ресурсов, детальное изучение фирменной литературы, а также практическая работа с микроконтроллерами и процессорами, описываемыми ниже, убеждают в том, что в классе микропроцессоров для персональных компьютеров бесспорно лидирующие позиции занимает компания Intel, а в классах интегрированных процессоров и микроконтроллеров, используемых для встраиваемых приложений, ведущее положение занимает фирма «Motorola», определяя многие стандарты и типовые решения.
Данное обстоятельство и определило структуру предлагаемой книги.
Работа над книгой распределилась следующим образом: гл. 1 написана И.И. Шагуриным и М.С. Куприяновым, гл. 2 - И.И. Шагуриным, гл. 3 - Е.К. Александровым, гл. 4 - Т.В. Ремизевич и Д.И. Панфиловым, гл. 5 - М.С. Куприяновым и О.Е. Мартыновым, гл. 6 - М.С. Куприяновым, гл. 7 - Е.П. Угрюмовым, гл. 8 - Р.И. Груш-вицким и И.И. Шагуриным, гл. 9 - Ю.С. Татариновым.
Материал по главам изложен с разной степенью детализации Это объясняется тем, что для отдельных классов микропроцессорных средств уже накоплены базовые решения, позволяющие сделать определенные обобщения, для других же классов, как, например, коммуникационных контроллеров, идеология организации и применения только формируется.
Особо нужно сказать о программном обеспечении микропроцессорных систем. Этому вопросу должна быть посвящена отдельная книга, так как слишком велико множество достаточно сложных вопросов, которые необходимо рассмотреть: языки и инструментальные средства программирования, вопросы тестирования и отладки, схемы и технологии разработки программных изделий и др. Причем для каждого класса микропроцессорных средств существуют свои особенности и отличия. В настоящей книге в отдельных главах авторы касаются вопросов программного обеспечения в той лишь степени, которая позволяет раскрыть особенности организации, функционирования или применения рассматриваемых типов процессоров или микроконтроллеров.
Конечно, принцип «с высоты птичьего полета», которым пришлось воспользоваться при подготовке книги, позволяет лишь показать общий ландшафт и область, которую занимают отдельные процессоры или микроконтроллеры. Однако в отдельных разделах «высота» рассмотрения намеренно снижена, что позволило представить читателю не только общие принципы организации, но отдельные достоинства и потребительские свойства более мелких деталей анализируемых устройств.
ПРЕДИСЛОВИЕ
Книгу нельзя рассматривать как энциклопедию: в ней нет разделов, посвященных, например, 16-разрядным микроконтроллерам общего применения, идеология организации которых во многом совпадает с организацией наиболее массового класса 8-разрядных микроконтроллеров. По аналогичной причине не излагаются вопросы организации интегрированных процессоров. Содержание книги определилось тем видением авторами общих тенденций и закономерностей развития микропроцессорной техники, которые в настоящее время имеют место с учетом достижений полупроводниковой технологии и требованиями практики проектирования информационных систем различного назначения.
Книга ориентирована на читателя разной профессиональной ориентации. Прежде всего она будет полезна студентам технических университетов, изучающих компьютерные технологии и системы. Для руководителей служб снабжения, менеджеров, инженерно-технических работников, не знакомых с МК, безусловно, полезным будет знакомство с разделами, в которых рассматривается идеология построения МК, приводятся общие сведения о МК и областях их целесообразного использования. Заинтересованный читатель далее может ознакомиться с технологией проектирования микропроцессорных систем с учетом достижений в области программируемой логики и оценить ориентировочно трудоемкость разработки системы.
Цель книги считается достигнутой, если читатель убеждается в следующем.
• Высокая эффективность проектирования достигается в тех случаях, когда каждой области применения соответствует семейство МК или ИП, максимальным образом учитывающих ее особенности,
• Работа компаний на «заказ для области использования» не приводит, как принято считать, к росту потребительской стоимости. Это достигается за счет модульной организации и технологии процессорного ядра, которые снижают затраты на производство и упрощают проектирование. Отобранные компанией в результате многолетней практики периферийные устройства с последующим их интегральным исполнением вместе с процессорным ядром обеспечивают пользователю быстрое и эффективное проектирование системы с абсолютно ясной перспективой развития.
• Преемственность в решениях (использование принципов открытых систем) дает возможность разработчику наращивать возможности своих систем, не разрушая предшествующий задел. Поистине бережное отношение компании к пользователям ее продукции воплощается в программной совместимости, наличии в разных семействах одной и той же периферии, использовании одинаковой технологии отладки и проектирования.
Семейства микропроцессорных средств создают функциональный ряд архитектур с масштабированием параметров (параметрический ряд) от 8-разрядных реализаций с CISC-архитектурой малой и средней производительностью до 32-разрядных реализаций с RISC-архитектурой сверхвысокой производительности:
• Практически все семейства МК и ИП содержат внутрикристальные средства отладки, что позволяет без дополнительного оборудования осуществить настройку аппаратного обеспечения.
• Для всех семейств созданы программно-аппаратные средства, обеспечивающие разработчиков всем необходимым для решения задач проектирования и отладки целевой системы.
• Ведущие компании - производители программного обеспечения создают системы реального времени, ориентированные на МК и ИП, что позволяет сократить сроки выполнения крупномасштабных проектов.
ВВЕДЕНИЕ
Микропроцессорная техника (МПТ) включает технические и программные средства, используемые для построения различных микропроцессорных систем, устройств и персональных микроЭВМ.
Микропроцессорная система (МПС) представляет собой функционально законченное изделие, состоящее из одного или нескольких устройств, главным образом микропроцессорных: микропроцессора и/или микроконтроллера.
Микропроцессорное устройство (МПУ) представляет собой функционально и конструктивно законченное изделие, состоящее из нескольких микросхем, в состав которых входит микропроцессор; оно предназначено для выполнения определенного набора функций: получение, обработка, передача, преобразование информации и управление.
Под микропроцессором (МП) будем понимать в дальнейшем программно-управляемое устройство, осуществляющее процесс цифровой обработки информации и управления им и построенное, как правило, на одной БИС.
Термин «микроконтроллер» (МК) вытеснил из употребления ранее использовавшийся термин «однокристальная микроЭВМ». Первый же патент на однокристальную микро-ЭВМ был выдан в 1971 году М. Кочрену и Г. Буну. Именно они предложили на одном кристалле разместить не только микропроцессор, но и память, устройства ввода-вывода. С появлением однокристальных микроЭВМ связывают начало эры компьютерной автоматизации в области управления. По-видимому, это обстоятельство и определило термин «микроконтроллер» (control - управление).
Однако впоследствии расширение сферы использования МК повлекло за собой развитие их архитектуры за счет размещения на кристалле устройств (модулей), отражающих своими функциональными возможностями специфику решаемых задач. Такие дополнительные устройства стали называться периферийными. Поэтому неслучайно в последнее время введен еще один термин - «интегрированный процессор» (ИП), который определяет новый класс функционально-емких однокристальных устройств с другим составом модулей. По количеству и составу периферийных устройств ИП уступают МК и занимают промежуточное положение между МП и МК. По этой же причине появились не только семейства МК, которые объединяют родственные МК (с одинаковой системой команд, разрядностью), но и стали выделяться подвиды МК: коммуникационные, для управления и т. д.
МП в настоящее время преимущественно используются для производства персональных ЭВМ, а МК и ИП являются основой создания различных встраиваемых систем, телекоммуникационного и портативного оборудования и т. д.
Анализ различных семейств МП, ИП и МК показывает, что наиболее жизнеспособными являются такие семейства, которые опираются в своем развитии на предшествующую эволюцию микропроцессоров, т.е. за счет «селекции» выделяются устойчивые и проверенные практикой структурные решения и закладываются в новые семейства МК. Это позволяет использовать кадры, освоившие микропроцессоры, программное обеспечение, средства поддержки этапов разработки. Фирмы «Motorola» и «Intel», являясь общепризнанными лидерами в производстве микропроцессорных средств и развивая свои семейства МК, блестяще демонстрируют на практике технологии эволюционного проектирования.
Разные МП или МК объединяют в семейства как технология «микроядра», в качестве которого выступает процессорное ядро, взаимодействующее с периферийными устройствами различной номенклатуры, так и принципы, свойственные открытым системам: совместимость (compatibility), масштабируемость (scalability), переносимость (portability) и взаимодействие приложений (introperability).
Совместимость, состоящая в выполнении приложений на всех версиях МК, обеспечивается использованием в качестве базовой системы команд и интерфейса микропроцессора с последующей унификацией путем добавления дополнительных команд и внешних выводов, повышающих эффективность использования в задачах, на которые ориентируется семейство МК. Полученное таким образом структурное образование называется процессорным ядром, на орбите которого вращаются как «отрицательно заряженные частицы» -периферийные устройства, требующие ресурсов процессорного ядра (например, память,
5
ВВЕДЕНИЕ
последовательный порт и др.), так и «положительно заряженные частицы» - периферийные устройства, аппаратно поддерживающие вычислительный процесс в МК (например, сопроцессор обработки сигналов, таймерный сопроцессор, коммуникационный сопроцессор и др.). Подобная функционально распределенная модель кристалла МК, с одной стороны, позволяет добиться более полного соответствия между особенностями предметной области и организацией кристалла, а с другой - обеспечить совместимость как в пределах различных версий определенного типа МК, так и в пределах всего семейства МК.
Масштабируемость обеспечивается выполнением приложений в пределах полного диапазона архитектур. Действительно, за счет технологии процессорного ядра обеспечивается переносимость приложений как для обычных микропроцессоров, так и для встроенных микропроцессоров (embedded microprocessors), а также для микроконтроллеров.
Переносимость для открытых систем рассматривается как возможность выполнения приложения на разных компьютерах с одной операционной системой. В нашем случае этот важный принцип состоит в том, что ядро операционной системы реального времени (OS-9, VxWorks и др.) портируется в целевые платформы на базе МК всех семейств, создавая тем самым комфортные условия для разработчика: процесс проектирования от дешевых систем с невысокой производительностью до многопроцессорных конфигураций осуществляется в рамках единой инструментальной среды.
Взаимодействие приложений - возможность общения приложений разных систем, использующих одни протоколы. Этот принцип в полной мере реализуется в системах на базе коммуникационных контроллеров фирмы «Motorola», так как на уровне кристалла реализованы типовые протоколы (HDLC, Х.25 и др.).
Таким образом, определенная выше открытая модель взаимосвязи МК (Open Microcontrollers/Microprocessors Interconnection - OMI-модель), сформированная в ходе эволюции микропроцессорных средств, находится в русле магистрального развития информационных систем и является гарантом эффективности применения микропроцессорных средств, удовлетворяющих требованиям этой модели.
Задачи системной интеграции для российских специалистов являются областью приложения их высокого интеллектуального потенциала. При этом эффективность решения этих задач во многом зависит от правильного выбора микропроцессорных средств ввиду их значительного разнообразия.
Если взять за критерий комплексный показатель «количество данных - количество вычислений», то возможны следующие его значения, определяющие классы задач и основные характеристики МК (табл. В.1).
Перечисленным четырем классам задач безусловно соответствуют определенные типы МК и ИП, наиболее полно учитывающих в своей архитектуре их специфику, а установленное соответствие, конечно, не является строгим. Так, среди 8-разрядных МК есть развитые модели (например, семейство М68НС11), которые с успехом можно использовать для решения отдельных задач из второго класса. Точно так же семейства 32-разрядных микроконтроллеров в последнее время активно вытесняют 16-разрядные микроконтроллеры, поскольку разница в цене становится несущественной, при более развитой архитектуре.
При создании системы любого назначения на базе микроконтроллеров либо интегрированных процессоров, в общем случае, необходимо выполнить следующие этапы.
1. Системный анализ задачи - выделяются процессы и функции, реализация которых будет возложена на МК или ИП.
2. Алгоритмизация процессов и функций - разрабатываются алгоритмы решения задачи.
3. Выбор МК или ИП и комплексная разработка программно аппаратных средств - осуществляется выбор технических средств соответствующей компании, инструментальных средств поддержки процесса проектирования (отладочных средств, языков программирования и т. д.), а также операционной системы реального времени, если это требуется для решения задачи. Производится программирование алгоритмов, полученных на втором этапе, изготовление системы на базе выбранного МК или ИП и комплексная отладка.
ВВЕДЕНИЕ
Таблица В. 1
Области использования МК
Значение критерия Характеристика задач Разрядность МК/ производительность
Мало данных -мало вычислений Задачи логического управления несложными объектами и процессами 8/Низкая
Мало данных-много вычислений Локальные регуляторы, системы управления электрическими двигателями, подвижными аппаратами, различными электрическими агрегатами, роботами-манипуляторами, станками, портативное оборудование и т. д. 16/Средняя
Много данных -мало вычислений Многие сетевые задачи, системы управления потоками данных, коммутаторы, концентраторы, маршрутизаторы и т.п. 32/Высокая
Много данных -много вычислений Задачи управления реального времени, обработка сигналов с интенсивным обменом, системы распознавания речи, изображений и т. п. 32/Сверхвысокая
Безусловно, для разработчика (пользователя) важно знать затраты, которые его ожидают на этом пути. Как показывает анализ практических приложений (в этом также убеждают и различные публикации), затраты распределяются по этапам следующим образом: 30 - 40; 40 - 50; 10 - 20. Затраты по каждому этапу варьируются в некотором диапазоне, но очевидно одно: первые два этапа являются определяющими.
Если МК или ИП не «окрашен» определенной областью применения (структура не содержит дополнительных модулей, которые для данной области «специализируют» ее за счет аппаратной реализации функций, выделенных на первом этапе), то разработчик реализует этапы в полной мере. Если структура МК или ИП «начинена» дополнительными модулями, то это не только упрощает программирование на третьем этапе, но и существенно сокращает трудоемкость первого и второго этапов. Кроме этого, важно иметь семейство МК или ИП, программно совместимых, но отличающихся производительностью и набором периферийных модулей, так как в процессе проектирования, во-первых, могут измениться критерии и добавиться новые функции, во-вторых, после первой версии созданной системы, даже если она удачна и жизнеспособна, как правило, создается более совершенная версия с расширенными возможностями, в которой учитываются результаты практической апробации и эксплуатации. Очевидно также, что формализация знаний на первом этапе (доведение знаний специалистов в конкретной области до алгоритмических моделей) приобретает направленный характер, если разработчик ориентируется на компанию, выпускающую многономенклатурную электронную продукцию, так как сама компания предварительно позиционирует свои микропроцессорные средства и другие электронные компоненты по определенным областям с учетом их разрядности, архитектурных особенностей, программного обеспечения, а главное, своего опыта создания электронных компонентов под конкретные задачи.
Сложность задач второго этапа также резко снижается за счет наличия в МК и ИП модулей, аппаратно реализующих алгоритмы типовых функций для тех задач, на которые он ориентируется. В этом случае разработчик, пользуясь предоставленным ему «конструктором», в котором определены типы деталей (МК и ИП, а также набор модулей), соединительные элементы (интерфейсы и средства сопряжения), а также правила соединения (средства программирования и отладки), за довольно короткий срок (в пределах одного-двух месяцев) «собирает» (решает задачи системной интеграции) в соответствии со своими требованиями на разработку изделия (систему определенного целевого назначения).
ГЛАВА 1
ОСНОВЫ МИКРОПРОЦЕССОРНОЙ ТЕХНИКИ
Микропроцессором называется программно-управляемое устройство для обработки цифровой информации и управления процессом обработки, реализованное в виде большой (БИС) или сверхбольшой (СБИС) интегральной микросхемы. Таким образом, микропроцессор играет роль процессора в цифровых системах различного назначения. Это могут быть системы обработки информации (компьютеры), системы управления объектами и процессами, информационно-измерительные системы и другие виды систем, используемых в промышленности, бытовой технике, аппаратуре связи и многих других областях применения.
1.1. КЛАССИФИКАЦИЯ МИКРОПРОЦЕССОРОВ, ОСНОВНЫЕ ВАРИАНТЫ ИХ АРХИТЕКТУРЫ И СТРУКТУРЫ
Микропроцессор является универсальным устройством для выполнения программной обработки информации, которое может использоваться в самых разнообразных сферах человеческой деятельности. Десятки компаний-производителей выпускают несколько тысяч типов микропроцессоров, имеющих разные характеристики и предназначенных для различных областей применения. Выпускаемые микропроцессоры делятся на отдельные классы в соответствии с их архитектурой, структурой и функциональным назначением. В данном разделе дается обзор основных архитектурных и структурных вариантов реализации современных микропроцессоров, используемых в различных сферах применения.
Основными направлениями развития микропроцессоров является увеличение их производительности и расширение функциональных возможностей, что достигается как повышением уровня микроэлектронной технологии, используемой для производства микропроцессоров, так и применением новых архитектурных и структурных вариантов их реализации. Развитие микроэлектронной технологии обеспечивает непрерывное уменьшение размеров полупроводниковых компонентов, размещаемых на кристалле микропроцессора. При этом уменьшаются паразитные емкости, определяющие задержку переключения логических элементов, и увеличивается число элементов, размещаемых на кристалле. В настоящее время разрешающая способность промышленной технологии изготовления микросхем обеспечивает создание компонентов с минимальными размерами 0,13-0,18 мкм. При этом обеспечивается создание микропроцессоров, работающих с тактовой частотой до 1 - 2 ГГц и содержащих на кристалле десятки миллионов транзисторов. В соответствии с эмпирическим правилом, которое сформулировал Гордон Мур, один из основателей компании Intel, степень интеграции микросхем удваивается каждые 1,5-2 года. Это правило выполнялось в течение 40 лет развития микроэлектроники, и можно прогнозировать, что оно будет выполняться и в близком будущем. Поэтому можно ожидать последующего быстрого прогресса технологии и связанного с ним повышения характеристик микропроцессоров.
Развитие технологии обеспечивает возможность создания на кристалле все большего количества активных компонентов - транзисторов, которые могут быть использованы для реализации новых архитектурных и структурных решений, обеспечивающих повышение производительности и расширение функциональных возможностей микропроцессоров. Кратко рассмотрим основные из этих решений.
Архитектурой процессора называется комплекс его аппаратных и программных средств, предоставляемых пользователю. В это общее понятие входит набор программно-доступных регистров и исполнительных (операционных) устройств, система основных команд и способов адресации, объем и структура адресуемой памяти, виды и спосо-
КЛАССИФИКАЦИЯ МИКРОПРОЦЕССОРОВ. ОСНОВНЫЕ ВАРИАНТЫ ИХ АРХИТЕКТУРЫ И СТРУКТУРЫ
бы обработки прерываний. Например, все модификации процессоров Pentium, Celeron, i486 и i386 имеют архитектуру IA-32 (Intel Architecture - 32 bit), которая характеризуется стандартным набором регистров, предоставляемых пользователю, общей системой основных команд и способов организации и адресации памяти, одинаковой реализацией защиты памяти и обслуживания прерываний.
При описании архитектуры и функционирования процессора обычно используется его представление в виде совокупности программно-доступных регистров, образующих регистровую или программную модель. В этих регистрах содержатся обрабатываемые данные (операнды) и управляющая информация. Соответственно, в регистровую модель входит группа регистров общего назначения, служащих для хранения операндов, и группа служебных регистров, обеспечивающих управление выполнением программы и режимом работы процессора, организацию обращения к памяти (защита памяти, сегментная и страничная организация и др.).
Регистры общего назначения образуют РЗУ - внутреннюю регистровую память процессора. Состав и количество служебных регистров определяется архитектурой микропроцессора. Обычно в их состав входят:
• программный счетчик PC (или CS + IP в архитектуре микропроцессоров Intel);
• регистр состояния SR (или EFLAGS);
• регистры управления режимом работы процессора CR (Control Register);
• регистры, реализующие сегментную и страничную организацию памяти;
• регистры, обеспечивающие отладку программ и тестирование процессора.
Кроме того, различные модели микропроцессоров содержат ряд других специализированных регистров.
Функционирование процессора представляется в виде реализации регистровых пересылок - процедур изменения состояния этих регистров путем чтения-записи их содержимого. В результате таких пересылок обеспечивается адресация и выбор команд и операндов, хранение и пересылка результатов, изменение последовательности команд и режимов функционирования процессора в соответствии с поступлением нового содержимого в служебные регистры, а также все другие процедуры, реализующие процесс обработки информации согласно заданным условиям.
В ряде процессоров выделяются регистры, которые используются при выполнении прикладных программ и доступны каждому пользователю, и регистры, которые управляют режимом работы всей системы и доступны только для привилегированных программ, входящих в состав операционной системы (супервизора). Соответственно, такие процессоры представляются в виде регистровой модели пользователя, в которую входят регистры, используемые при выполнении прикладных программ, или регистровой модели супервизора, которая содержит весь набор программно-доступных регистров процессора, используемых операционной системой.
Структура микропроцессора определяет состав и взаимодействие основных устройств и блоков, размещенных на его кристалле. В эту структуру входят;
• центральный процессор (процессорное ядро), состоящее из устройства управления (УУ), одного или нескольких операционных устройств (ОУ);
• внутренняя память (РЗУ, кэш-память, блоки оперативной и постоянной памяти);
• интерфейсный блок, обеспечивающий выход на системную шину и обмен данными с внешними устройствами через параллельные или последовательные порты вво-да/вывода;
• периферийные устройства (таймерные модули, аналого-цифровые преобразователи, специализированные контроллеры);
• различные вспомогательные схемы (генератор тактовых импульсов, схемы для выполнения отладки и тестирования, сторожевой таймер и ряд других).
9
ОСНОВЫ МИКРОПРОЦЕССОРНОЙ ТЕХНИКИ
Состав устройств и блоков, входящих в структуру микропроцессора, и реализуемые механизмы их взаимодействия определяются функциональным назначением и областью применения микропроцессора.
Архитектура и структура микропроцессора тесно взаимосвязаны. Реализация тех или иных архитектурных особенностей требует введения в структуру микропроцессора необходимых аппаратных средств (устройств и блоков) и обеспечения соответствующих механизмов их совместного функционирования.
В современных микропроцессорах реализуются следующие варианты архитектур.
CISC(Complex Instruction Set Computer)-apxumeKmypa реализована во многих типах микропроцессоров, выполняющих большой набор разноформатных команд с использованием многочисленных способов адресации. Эта классическая архитектура процессоров, которая начала свое развитие в 1940-х годах с появлением первых компьютеров. Типичным примером CISC-процессоров являются микропроцессоры семейства Pentium. Они выполняют более 200 команд разной степени сложности, которые имеют размер от 1 до 15 байт и обеспечивают более 10 различных способов адресации. Такое большое многообразие выполняемых команд и способов адресации позволяет программисту реализовать наиболее эффективные алгоритмы решения различных задач. Однако при этом существенно усложняется структура микропроцессора, особенно его устройства управления, что приводит к увеличению размеров и стоимости кристалла, снижению производительности. В то же время многие команды и способы адресации используются достаточно редко. Поэтому, начиная с 1980-х годов, интенсивное развитие получила архитектура процессоров с сокращенным набором команд (RISC-процессоры).
RISC(Reduced Instruction Set Сотри(ег)-архитектура отличается использованием ограниченного набора команд фиксированного формата. Современные RISC-процессоры обычно реализуют около 100 команд, имеющих фиксированный формат длиной 4 байта. Также значительно сокращается число используемых способов адресации. Обычно в RISC-процессорах все команды обработки данных выполняются только с регистровой или непосредственной адресацией. При этом для сокращения количества обращений к памяти RISC-процессоры имеют увеличенный объем внутреннего РЭУ - от 32 до нескольких сотен регистров, тогда как в CISC-процессорах число регистров общего назначения обычно составляет 8-16.
Обращение к памяти в RISC-процессорах используется только в операциях загрузки данных в РЗУ или пересылки результатов из РЗУ в память. При этом используется небольшое число наиболее простых способов адресации: косвенно-регистровая, индексная и некоторые другие. В результате существенно упрощается структура микропроцессора, сокращаются его размеры и стоимость, значительно повышается производительность.
Указанные достоинства RISC-архитектуры привели к тому, что во многих современных CISC-процессорах используется RISC-ядро, выполняющее обработку данных. При этом поступающие сложные и разноформатные команды предварительно преобразуются в последовательность простых RISC-операций, быстро выполняемых этим процессорным ядром. Таким образом, работают, например, последние модели микропроцессоров Pentium и К7, которые по внешним показателям относятся к CISC-процессорам. Использование RISC-архитектуры является характерной чертой многих современных микропроцессоров.
VLIW(Very Large Instruction Word)-apxumeKmypa появилась относительно недавно -в 1990-х годах. Ее особенностью является использование очень длинных команд (до 128 бит и более), отдельные поля которых содержат коды, обеспечивающие выполнение различных операций. Таким образом, одна команда вызывает выполнение сразу нескольких операций параллельно в различных операционных устройствах, входящих в структуру микропроцессора. При трансляции программ, написанных на языке высокого уровня,
КЛАССИФИКАЦИЯ МИКРОПРОЦЕССОРОВ, ОСНОВНЫЕ ВАРИАНТЫ ИХ АРХИТЕКТУРЫ И СТРУКТУРЫ
соответствующий компилятор производит формирование «длинных» VLIW-команд, каждая из которых обеспечивает реализацию процессором целой процедуры или группы операций. Данная архитектура реализована в некоторых типах современных микропроцессоров (РА8500 компании «Hewlett-Packard», Itanium - совместная разработка «Intel» и «Hewlett-Packard», некоторые типы DSP-цифровых процессоров сигналов) и является весьма перспективной для создания нового поколения сверхвысокопроизводительных процессоров.
Кроме набора выполняемых команд и способов адресации важной архитектурной особенностью микропроцессоров является используемый вариант реализации памяти и организация выборки команд и данных. По этим признакам различаются процессоры с Принстонской и Гарвардской архитектурой. Эти архитектурные варианты были предложены в конце 1940-х годов специалистами соответственно Принстонского и Гарвардского университетов США для разрабатываемых ими моделей компьютеров.
Принстонская архитектура, которая часто называется архитектурой Фон-Неймана, характеризуется использованием общей оперативной памяти для хранения программ, данных, а также для организации стека. Для обращения к этой памяти используется общая системная шина, по которой в процессор поступают и команды, и данные. Эта архитектура имеет ряд важных достоинств. Наличие общей памяти позволяет оперативно перераспределять ее объем для хранения отдельных массивов команд, данных и реализации стека в зависимости от решаемых задач. Таким образом, обеспечивается возможность более эффективного использования имеющегося объема оперативной памяти в каждом конкретном случае применения микропроцессора. Использование общей шины для передачи команд и данных значительно упрощает отладку, тестирование и текущий контроль функционирования системы, повышает ее надежность. Поэтому Принстонская архитектура в течение долгого времени доминировала в вычислительной технике.
Однако ей присущи и существенные недостатки. Основным из них является необходимость последовательной выборки команд и обрабатываемых данных по общей системной шине. При этом общая шина становится «узким местом» (bottleneck - «бутылочное горло»), которое ограничивает производительность цифровой системы. Постоянно возрастающие требования к производительности микропроцессорных систем вызвали в последние годы все более широкое применение Гарвардской архитектуры при создании многих типов современных микропроцессоров.
Гарвардская архитектура характеризуется физическим разделением памяти команд (программ) и памяти данных. В ее оригинальном варианте использовался также отдельный стек для хранения содержимого программного счетчика, который обеспечивал возможности выполнения вложенных подпрограмм. Каждая память соединяется с процессором отдельной шиной, что позволяет одновременно с чтением-записью данных при выполнении текущей команды производить выборку и декодирование следующей команды. Благодаря такому разделению потоков команд и данных и совмещению операций их выборки реализуется более высокая производительность, чем при использовании Принстонской архитектуры.
Недостатки Гарвардской архитектуры связаны с необходимостью проведения большего числа шин, а также с фиксированным объемом памяти, выделенной для команд и данных, назначение которой не может оперативно перераспределяться в соответствии с требованиями решаемой задачи. Поэтому приходится использовать память большего объема, коэффициент использования которой при решении разнообразных задач оказывается более низким, чем в системах с Принстонской архитектурой. Однако развитие микроэлектронной технологии позволило в значительной степени преодолеть указанные недостатки, поэтому Гарвардская архитектура широко применяется во внутренней структуре современных высокопроизводительных микропроцессоров, где используется отдельная кэш-память для хранения команд и данных. В то же время во внешней структуре большинства микропроцессорных систем реализуются принципы Принстонской архитектуры.
11
ОСНОВЫ МИКРОПРОЦЕССОРНОЙ ТЕХНИКИ
Гарвардская архитектура получила также широкое применение в микроконтроллерах -специализированных микропроцессорах для управления различными объектами, рабочая программа которых обычно хранится в отдельном ПЗУ.
Во внутренней структуре современных высокопроизводительных микропроцессоров реализуется конвейерный принцип выполнения команд. При этом процесс выполнения команды разбивается на ряд этапов. На рис. 1.1, а приведен пример разбиения команды на шесть этапов ее выполнения:
1) выборка очередной команды (ВК);
2) декодирование выбранной команды (ДК);
3) формирование адреса операнда (ФА);
4) прием операнда из памяти (ПО);
5) выполнение операции (ВО);
6) размещение результата в памяти (РР).
Реализация каждого этапа занимает один такт машинного времени и производится устройствами и блоками процессора, образующими ступени исполнительного конвейера, на каждой из которых выполняется соответствующая микрооперация. При последовательной загрузке в конвейер выбираемых команд каждая его ступень реализует определенный этап выполнения очередной команды. Таким образом, в конвейере одновременно находятся несколько команд, находящихся на разных этапах выполнения. В идеальном варианте при полной загрузке конвейера на его выход в каждом такте будет поступать результат выполнения очередной команды (рис. 1.1, а). В этом случае производительность процессора (операций/с) будет равна его тактовой частоте (тактов/с).
Однако такая эффективная работа конвейера обеспечивается только при его равномерной загрузке однотипными командами. Реально отдельные ступени конвейера могут оказаться незагруженными, находясь в состоянии ожидания или простоя. Ожиданием называется состояние исполнительной ступени, когда она не может выполнить требуемую микрооперацию, так как еще не получен необходимый операнд, являющийся результатом выполнения предыдущей команды. Простоем называется состояние ступени, когда она вынуждена пропустить очередной такт, так как поступившая команда не требует выполнения соответствующего этапа. Например, при выполнении безадресных команд не требуется производить формирование адреса и прием операнда (простой на ступенях ФА и ПО конвейера).
Тактовые импульсы
Команды 1 | ВК Дк ФА по ВО РР Результат 1
Команды 2 ВК дк ФА ПО ВО РР Результат 2
Команды 3 ВК ДК ФА по ВО РР | Результат 3
6)
Команды 1
Команды 2
Команды 3
| ВК ДК ПР ПР во ПР Результат 1
ВК дк ож ож ФА ПО ВО ПР Результат 2
ВК дк ФА ПО ОЖ ОЖ ВО ПР | Результат 3
Рис. 1.1. Реализация конвейерного исполнения команд при идеальной (а) и реальной (6) загрузке 6-ступенчатого конвейера
КЛАССИФИКАЦИЯ МИКРОПРОЦЕССОРОВ. ОСНОВНЫЕ ВАРИАНТЫ ИХ АРХИТЕКТУРЫ И СТРУКТУРЫ
На рис. 1.1,6 показан пример работы 6-ступенчатого конвейера при выполнении фрагмента реальной программы, когда отдельные ступени оказываются в состоянии ожидания (ОЖ) или простоя (ПР). Команда INC R2, которая увеличивает на 1 содержимое регистра R2, не требует выборки операндов из памяти и размещения в ней результата. Поэтому при ее выполнении реализуется состояние простоя (ПР) на ступенях конвейера, выполняющих микрооперации ФА, ПО, РР. Команда MOV (R2), R3 производит пересылку содержимого ячейки памяти, адресуемой содержимым регистра R2, в регистр R3. При ее выполнении реализуются состояния ожидания (ОЖ), пока в регистре R2 не будет получен результат предыдущей операции. Такты ожидания (ОЖ) вводятся также при выполнении команды сложения ADD R3, (R4) до получения необходимого значения операнда в регистре R3. В результате введения состояний ожиданий и простоя реальная производительность процессора при выполнении данного фрагмента программы составит 5/3 команд/такг, то есть будет в 1,7 раз меньше, чем в идеальном случае (рис. 1.1, а).
В современных высокопроизводительных микропроцессорах процедура выполнения команд может разбиваться на еще более мелкие этапы, чтобы успеть выполнить соответствующие микрооперации на каждой ступени за один такт, длительность которого при тактовой частоте более 1 ГГц составляет менее наносекунды. Поэтому в таких процессорах число ступеней конвейера достигает 10 и более. Например, в микропроцессора) Pentium 4 используется 20-ступенчатый конвейер.
Эффективность использования конвейера определяется типом поступающих команд При поступлении однородных команд обеспечивается сокращение числа состояний про стоя и ожидания в процессе их выполнения, в результате чего повышается производи тельность процессора. При использовании в программе разноформатных команд, со держащих различное количество байтов, число состояний простоя и ожидания, которые приходится вводить в процессе выполнения команд, значительно увеличивается. Поэто му принятый во многих RISC-процессорах стандартный 4-байтный формат команд обес печивает существенное сокращение числа ожиданий и простоев конвейера, что позво ляет значительно повысить производительность.
Другой причиной снижения эффективности конвейера являются команды условной ветвления. Если выполняется условие ветвления, то приходится производить перезаг рузку конвейера командами из другой ветви программы, что требует выполнения долог нительных рабочих тактов и вызывает значительное снижение производительности. Пс этому одним из основных условий эффективной работы конвейера является сокращена числа его перезагрузок при выполнении условных переходов. Эта цель достигается помощью реализации различных механизмов предсказания направления ветвления, кс торые обеспечиваются с помощью специальных устройств - блоков предсказания вете пения, вводимых в структуру процессора.
В современных микропроцессорах используются разнообразные способы предсказг ния ветвлений. Наиболее простой способ состоит в том, что процессор фиксирует ре зультат выполнения предыдущих команд ветвления по данному адресу и считает, чт следующая команда с обращением по этому адресу даст аналогичный результат, flat ный способ предсказания предполагает более высокую вероятность повторного обр< щения к определенной команде, задаваемой данным условием ветвления. Для реализг ции этого способа предсказания ветвления используется специальная память ВТВ (Вгапс Target Buffer), где хранятся адреса ранее выполненных условных переходов. При посту| пении аналогичной команды ветвления предсказывается переход к ветви, которая быг выбрана в предыдущем случае, и производится загрузка в конвейер команд из соотве ствующей ветви. При правильном предсказании не требуется перезагрузка конвейера эффективность его использования не снижается. Эффективность такого способа пре, сказания зависит от емкости ВТВ и оказывается достаточно высокой: вероятность пр
1
ОСНОВЫ МИКРОПРОЦЕССОРНОЙ ТЕХНИКИ
вильного предсказания составляет 80% и более. Повышение точности предсказания достигается при использовании более сложных способов, когда хранится и анализируется предыстория переходов - результаты нескольких предыдущих команд ветвления по данному адресу. В этом случае возможно определение чаще всего реализуемого направления ветвления, а также выявление чередующихся переходов. Реализация таких алгоритмов требует использования более сложных блоков предсказания, но при этом вероятность правильного предсказания повышается до 90-95%.
Возможность повышения производительности процессора достигается также при введении в структуру процессора нескольких параллельно включенных операционных устройств, обеспечивающих одновременное выполнение нескольких операций. Такая структура процессора называется суперскалярной. В этих процессорах реализуется параллельная работа нескольких исполнительных конвейеров, в каждый из которых поступает для выполнения одна из выбранных и декодированных команд. В идеальном случае число одновременно выполняемых команд равно числу операционных устройств, включенных в исполнительные конвейеры. Однако при выполнении реальных программ трудно обеспечить полную загрузку всех исполнительных конвейеров, поэтому на практике эффективность использования суперскалярной структуры оказывается несколько ниже. Современные суперскалярные процессоры содержат до 4 до 10 различных операционных устройств, параллельная работа которых обеспечивает выполнение за один такт в среднем от 2 до 6 команд.
Эффективная одновременная работа нескольких исполнительных конвейеров обеспечивается путем предварительной выборки-декодирования ряда команд и выделения из них группы команд, которые могут выполняться одновременно. В современных суперскалярных процессорах производится выборка нескольких десятков команд, которые декодируются, анализируются и группируются для параллельной загрузки в исполнительные конвейеры. Обычно в процессорах имеется несколько устройств для выполнения целочисленных операций, одно или несколько устройств для обработки чисел с плавающей точкой, отдельные устройства для обработки специальных форматов видео- и аудиоданных. Параллельно работают также устройства формирования адресов и выборки операндов для загружаемых команд. При этом обычно реализуется спекулятивная (предварительная) выборка операндов, чтобы для поступающих на исполнение команд уже были готовы операнды, которые записываются в специальные регистры. Чтобы обеспечить возможно полную загрузку исполнительных конвейеров, в процессе анализа и группировки декодированных команд возможно изменение порядка их следования. В результате команды выполняются не в порядке их выборки из памяти, а по мере готовности необходимых операндов и исполнительных устройств. Таким образом, позже поступившие команды могут быть выполнены до ранее выбранных. Чтобы запись в память результатов происходила в соответствии с исходной последовательностью поступления команд программы, на выходе данных включается специальная буферная память, восстанавливающая порядок выдачи результатов согласно выполняемой программе.
Одновременное параллельное выполнение команд может оказаться невозможным, если они обращаются к одному регистру. При ограниченной емкости РЗУ процессора такие случаи могут возникать достаточно часто, что снижает эффективность работы исполнительных конвейеров. Поэтому в ряде процессоров вводятся специальные регистровые блоки, дублирующие РЗУ. При поступлении команд, которые обращаются к одинаковым регистрам РЗУ, производится их переадресация к дублирующим регистровым блокам - «переименование» регистров. В результате обеспечивается возможность одновременного выполнения таких команд, что позволяет реализовать более эффективную параллельную работу исполнительных конвейеров.
В качестве примера на рис. 1.2 показана типичная суперскалярная структура процессора с Гарвардской архитектурой, которая реализована в высокопроизводительных 32-
КЛАССИФИКАЦИЯ МИКРОПРОЦЕССОРОВ. ОСНОВНЫЕ ВАРИАНТЫ ИХ АРХИТЕКТУРЫ И СТРУКТУРЫ
шины
Рис. 1.2. Типичная суперскалярная структура процессора с Гарвардской внутренней архитектурой разрядных микропроцессорах семейства PowerPC, выпускаемых компаниями Motorola и IBM. Гарвардская архитектура обеспечивается разделением потоков команд и данных во внутренней структуре процессора путем использования отдельных блоков кэш-памя-ти IC (кэш-команд) и DC (кэш-данных). Каждая кэш-память имеет отдельный блок управления MMU (Memory Managment Unit). В процессоре реализуется 6-ступенчатый конвейер выполнения команд. Устройство управления содержит три первых ступени конвейера, реализующие выборку, декодирование и распределение команд по параллельно работающим исполнительным устройствам. Команды условных ветвлений поступают на выполнение в блок предсказания ветвлений BPU (Branch Prediction Unit), который обеспечивает загрузку в конвейер следующих команд в соответствии с наиболее вероятным направлением хода программы. Исполнительные устройства сгруппированы в два блока. Блок целочисленных операций содержит два исполнительных устройства - SIU1 и SIU2 (Single Instruction Unit)-для простых операций, выполняемых за один такт, и одно устройство для выполнения сложных операций MIU (Multiple Instruction Unit), которые занимают несколько тактов. Эти устройства обслуживаются блоком из 32 регистров общего назначения GPR (General Purpose Registers). Блок FPU (Floating Point Unit) выполняет операции с плавающей точкой за несколько тактов. Он обслуживается отдельным блоком из 32 регистров FPR (Floating Point Registers), которые имеют по 64 разряда. Каждый из регистровых блоков имеет набор дублирующих регистров (буферы GPR и FPR), которые обеспечивают возможность «переименования» регистров в случае их одновременного использования несколькими командами, находящимися на стадии исполнения. Блок LSU (Load-Store Unit) производит операции загрузки регистров из памяти и записи содержимого регистров в память. После выполнения операций полученные результаты поступают в блок завершения, где они накапливаются в специальной буферной памяти, а затем записываются в кэш-данных или основную память в соответствии с исходной последовательностью команд программы (процедура обратной записи, восстанавливающая нормальную последовательность выдачи результатов). Контроллер шины BIU (Bus Interface Unit) обеспечивает обращение к системной шине, которая содержит 32-разрядную шину адреса А31-0, 64-разрядную шину данных D63-0 и многочисленные линии для передачи управляющих сигналов Схх.
ОСНОВЫ МИКРОПРОЦЕССОРНОЙ ТЕХНИКИ
Рис. 1.3. Классификация современных микропроцессоров по функциональному признаку
Хотя микропроцессор является универсальным средством для цифровой обработки информации, однако отдельные области применения требуют реализации определенных специфических вариантов их структуры и архитектуры. Поэтому по функциональному признаку выделяются два класса: микропроцессоры общего назначения и специализированные микропроцессоры (рис. 1.3). Среди специализированных микропроцессоров наиболее широкое распространение получили микроконтроллеры, предназначенные для выполнения функций управления различными объектами, и цифровые процессоры сигналов (DSP - Digital Signal Processor), которые ориентированы на реализацию процедур, обеспечивающих необходимое преобразование аналоговых сигналов, представленных в цифровой форме (в виде последовательности числовых значений).
Микропроцессоры общего назначения предназначены для решения широкого круга задач обработки разнообразной информации. Их основной областью использования являются персональные компьютеры, рабочие станции, серверы и другие цифровые системы массового применения. К этому классу относятся CISC-процессоры Pentium компании «Intel», К7 - компании «Advanced MicroDevices» (AMD), 680x0 - компании «Motorola», RISC-процессоры PowerPC, выпускаемые компаниями «Motorola» и IBM, SPARC - компании «Sun Microsystems» и ряд других изделий различных производителей.
Расширение области применения таких микропроцессоров достигается главным образом путем роста производительности, благодаря чему увеличивается круг задач, который можно решать с их использованием. Поэтому повышение производительности является магистральным направлением развития этого класса микропроцессоров. Обычно это 32-разрядные микропроцессоры (некоторые микропроцессоры этого класса имеют 64-разрядную или 128-разрядную структуру), которые изготавливаются по самой современной промышленной технологии, обеспечивающей максимальную частоту функционирования.
Ряд наиболее популярных микропроцессоров этого класса (Pentium, AMD К7 и некоторые другие) следует отнести к CISC-процессорам, так как они выполняют большой набор разноформатных команд с использованием многочисленных способов адресации. Однако в их внутренней структуре содержится RISC-процессор, который выполняет поступившие команды после их преобразования в последовательность простых RISC-операций. Ряд других микропроцессоров этого класса непосредственно реализует RISC-
КЛАССИФИКАЦИЯ МИКРОПРОЦЕССОРОВ. ОСНОВНЫЕ ВАРИАНТЫ ИХ АРХИТЕКТУРЫ И СТРУКТУРЫ
архитектуру. Поэтому можно считать, что использование RISC-архитектуры характерно для большинства этих микропроцессоров. Однако в ряде последних разработок (Itanium, РА8500) некоторых ведущих производителей успешно применяются принципы VLIW-ap-хитектуры, которая может составить конкуренцию RISC-архитектуре в соревновании за достижение наивысшей производительности.
Практически все современные микропроцессоры этого класса используют Гарвардскую внутреннюю архитектуру, где разделение потоков команд и данных реализуется с помощью отдельных блоков кэш-памяти. В большинстве случаев они имеют суперскалярную структуру с несколькими исполнительными конвейерами (до 10 в современных моделях), которые содержат до 20 ступеней.
Благодаря своей универсальности микропроцессоры общего назначения используются также в специализированных системах, где требуется высокая производительность. На их основе реализуются одноплатные компьютеры и промышленные компьютеры, которые применяются в системах управления различными объектами. Одноплатные (встраиваемые) компьютеры содержат на плате необходимые дополнительные микросхемы, обеспечивающие их специализированное применение, и предназначены для встраивания в аппаратуру различного назначения. Промышленные компьютеры размещаются в корпусах специальной конструкции, обеспечивающих их надежную работу в жестких производственных условиях. Обычно такие компьютеры работают без стандартных периферийных устройств (монитор, клавиатура, «мышь») или используют специальные варианты этих устройств, модифицированные с учетом специфических условий применения.
Микроконтроллеры являются специализированными микропроцессорами, которые ориентированы на реализацию устройств управления, встраиваемых в разнообразную -Yi. аппаратуру. Ввиду огромного количества объектов, управление которыми обеспечивает-\ ся с помощью микроконтроллеров, годовой объем их выпуска превышает 2 миллиарда экземпляров, на порядок превосходя объем выпуска микропроцессоров общего приме-нения. Весьма широкой является также номенклатура выпускаемых микроконтроллеров, ' которая содержит несколько тысяч типов.
' S Характерной особенностью структуры микроконтроллеров является размещение на одном кристалле с центральным процессором внутренней памяти и большого набора периферийных устройств. В состав периферийных устройств обычно входят несколько 8-разрядных параллельных портов ввода-вывода данных (от 1 до 8), один или два последовательных порта, таймерный блок, аналого-цифровой преобразователь. Кроме того, различные типы микроконтроллеров содержат дополнительные специализированные устройства - блок формирования сигналов с широтно-импульсной модуляцией, контроллер жидкокристаллического дисплея и ряд других. Благодаря использованию внутренней памяти и периферийных устройств реализуемые на базе микроконтроллеров системы управления содержат минимальное количество дополнительных компонентов.
В связи с широким диапазоном решаемых задач управления требования, предъявляемые к производительности процессора, объему внутренней памяти команд и данных, набору необходимых периферийных устройств, оказываются весьма разнообразными. Для удовлетворения запросов потребителей выпускается большая номенклатура микроконтроллеров, которые принято подразделять на 8-, 16- и 32-разрядные.
• 8-разрядные микроконтроллеры представляют наиболее многочисленную группу этого класса микропроцессоров, которые имеют относительно низкую производительность, которая, однако, вполне достаточна для решения широкого круга задач управления различными объектами. Это простые и дешевые микроконтроллеры, ориентированные на использование в относительно несложных устройствах массового выпуска. Основными областями их применения являются бытовая и измерительная техника, промышленная автоматика, автомобильная электроника, теле-, видео- и аудиоаппаратура, средства связи.
ОСНОВЫ МИКРОПРОЦЕССОРНОЙ ТЕХНИКИ
Для этих микроконтроллеров характерна реализация Гарвардской архитектуры, где используется отдельная память для хранения программ и данных. Для хранения программ в различных типах микроконтроллеров применяется либо масочно-программируемое ПЗУ (ROM), либо однократно-программируемое ПЗУ (PROM), либо электрически репрограммируемое ПЗУ (EPROM, EEPROM или Flash). Внутренняя память программ обычно имеет объем от нескольких единиц до десятков Кбайт. Для хранения данных используется регистровый блок, организованный в виде нескольких регистровых банков, или внутреннее ОЗУ. Объем внутренней памяти данных составляет от нескольких десятков байт до нескольких Кбайт. Ряд микроконтроллеров этой группы позволяет в случае необходимости дополнительно подключать внешнюю память команд и данных, объемом до 64—256 Кбайт.
Микроконтроллеры этой группы обычно выполняют относительно небольшой набор команд (50-100), использующих наиболее простые способы адресации. В ряде последних моделей этих микроконтроллеров реализованы принципы RISC-архитектуры, что позволяет существенно повысить их производительность. В результате такие микроконтроллеры обеспечивают выполнение большинства команд за один такт машинного времени.
• 16-разрядные микроконтроллеры во многих случаях являются усовершенствованной модификацией своих 8-разрядных прототипов. Они характеризуются не только увеличенной разрядностью обрабатываемых данных, но и расширенной системой команд и способов адресации, увеличенным набором регистров и объемом адресуемой памяти, а также рядом других дополнительных возможностей, использование которых позволяет повысить производительность и обеспечить новые области применения. Обычно эти микроконтроллеры позволяют расширить объем памяти программ и данных до нескольких Мбайт путем подключения внешних микросхем памяти. Во многих случаях реализуется их программная совместимость с более младшими 8-разрядными моделями. Основная сфера применения таких микроконтроллеров - сложная промышленная автоматика, телекоммуникационная аппаратура, медицинская и измерительная техника.
• 32-разрядные микроконтроллеры содержат высокопроизводительный процессор, соответствующий по своим возможностям младшим моделям микропроцессоров общего назначения. В ряде случаев процессор, используемый в этих микроконтроллерах, аналогичен CISC- или RISC-процессорам, которые выпускаются или выпускались ранее в качестве микропроцессоров общего назначения. Например, в 32-разрядных микроконтроллерах компании Intel используется процессор I386, в микроконтроллерах компании Motorola широко применяется процессор 680x0, в ряде других микроконтроллеров в качестве процессорного ядра служат RISC-процессоры типа PowerPC. На базе данных процессоров были реализованы различные модели персональных компьютеров. Введение этих процессоров в состав микроконтроллеров позволяет использовать в соответствующих системах управления огромный объем прикладного и системного программного обеспечения, созданный ранее для соответствующих персональных компьютеров.
Кроме 32-разрядного процессора на кристалле микроконтроллера размещается внутренняя память команд емкостью до десятков Кбайт, память данных емкостью до нескольких Кбайт, а также сложно-функциональные периферийные устройства - таймерный процессор, коммуникационный процессор, модуль последовательного обмена и ряд других. Микроконтроллеры работают с внешней памятью объемом до 16 Мбайт и выше. Они находят широкое применение в системах управления сложными объектами промышленной автоматики (двигатели, робототехнические устройства, средства комплексной автоматизации производства), в контрольно-измерительной аппаратуре и телекоммуникационном оборудовании.
Во внутренней структуре этих микроконтроллеров реализуется Принстонская или Гарвардская архитектура. Входящие в их состав процессоры могут иметь CISC- или RISC-
ОБЩАЯ СТРУКТУРА И ПРИНЦИПЫ ФУНКЦИОНИРОВАНИЯ МИКРОПРОЦЕССОРНЫХ СИСТЕМ
архитектуру, а некоторые из них содержат несколько исполнительных конвейеров, образующих суперскалярную структуру.
Цифровые процессоры сигналов (ЦПС) представляют класс специализированных микропроцессоров, ориентированных на цифровую обработку поступающих аналоговых сигналов. Специфической особенностью алгоритмов обработки аналоговых сигналов является необходимость последовательного выполнения ряда команд умножения-сложения с накоплением промежуточного результата в регистре-аккумуляторе. Поэтому архитектура ЦПС ориентирована на реализацию быстрого выполнения операций такого рода. Набор команд этих процессоров содержит специальные команды MAC (Multiplication with Accumlation), реализующие эти операции.
Значение поступившего сигнала может быть представлено в виде числа с фиксированной или с «плавающей» точкой. В соответствии с этим ЦПС делятся на процессоры, обрабатывающие числа с фиксированной или плавающей точкой. Более простые и дешевые ЦПС с фиксированной точкой обычно обрабатывают 16-разрядные операнды, представленные в виде правильной дроби. Однако ограниченная разрядность в ряде случаев не позволяет обеспечить необходимую точность преобразования. Поэтому в ЦПС с фиксированной точкой, выпускаемых компанией «Motorola», принято 24-разрядное представление операндов. Наиболее высокая точность обработки обеспечивается в случае представления данных в формате с «плавающей» точкой. В ЦПС, обрабатывающих данные с «плавающей» точкой, обычно используется 32-разрядный формат их представления.
Для повышения производительности при выполнении специфических операций обработки сигналов в большинстве ЦПС реализуется Гарвардская архитектура с использованием нескольких шин для передачи адресов, команд и данных. В ряде ЦПС нашли применение также некоторые черты VLIW-архитектуры: совмещение в одной команде нескольких операций, обеспечивающих обработку имеющихся данных и одновременную загрузку в исполнительный конвейер новых данных для последующей обработки.
1.2. ОБЩАЯ СТРУКТУРА И ПРИНЦИПЫ ФУНКЦИОНИРОВАНИЯ МИКРОПРОЦЕССОРНЫХ СИСТЕМ
Большинство микропроцессорных систем имеет магистрально-модульную структуру (рис. 1.4), в которой отдельные устройства (модули), входящие в состав системы, обмениваются информацией по общей системной шине - магистрали.
Основным модулем системы является микропроцессор, который содержит устройство управления (УУ), операционное устройство (ОУ) и регистровое запоминающее устройство (РЗУ) - внутреннюю память, реализованную в виде набора регистров. Оперативное запоминающее устройство (ОЗУ) служит для хранения выполняемой программы (или ее фрагментов) и данных, подлежащих обработке. В простейших микропроцессорных системах объем ОЗУ составляет десятки и сотни байт, а современных персональных компьютерах, серверах и рабочих станциях он достигает сотен Мбайт и более. Так как обращение к ОЗУ по системной шине требует значительных затрат времени, в большинстве современных высокопроизводительных микропроцессоров дополнительно вводится быстродействующая промежуточная память (кэш-память) ограниченного объема (от нескольких Кбайт до сотен Кбайт).
Постоянное запоминающее устройство (ПЗУ) служит для хранения констант и стандартных (неизменяемых) программ. В ПЗУ обычно записываются программы начальной инициализации (загрузки) систем, тестовые и диагностические программы и другое служебное программное обеспечение, которое не меняется в процессе эксплуатации систем. В микропроцессорных системах, управляющих определенными объектами с исполь
19
ОСНОВЫ МИКРОПРОЦЕССОРНОЙ ТЕХНИКИ
зованием фиксированных или редко изменяемых программ, для их хранения также обычно используется ПЗУ (память ROM - Read-Only Memory) или репрограммируемое ПЗУ (память EEPROM - Electrically Erased Programmable Read-Only Memory или флэш-память).
Остальные устройства являются внешними и подключаются к системе с помощью интерфейсных устройств (ИУ), реализующих определенные протоколы параллельного или последовательного обмена. Такими внешними устройствами могут быть клавиатура, монитор, внешние запоминающие устройства (ВЗУ), использующие гибкие или жесткие магнитные диски, оптические диски (CD-ROM), магнитные ленты и другие виды носителей информации, датчики и преобразователи информации (аналого-цифровые или цифроаналоговые), разнообразные исполнительные устройства (индикаторы, принтеры, электродвигатели, реле и другие). Для реализации различных режимов работы к системе могут подключаться дополнительные устройства - контроллеры прерываний, прямого доступа к памяти и другие, реализующие необходимые специальные функции управления.
Данная структура соответствует архитектуре Фон-Неймана, предложенной этим ученым в 1940-х годах для реализации первых моделей цифровых ЭВМ. Ниже будут рассмотрены и другие варианты процессорных архитектур.
Системная шина содержит несколько десятков (в сложных системах более 100) проводников, которые в соответствии с их функциональным назначением подразделяются на отдельные шины - адреса А, данных D и управления С. Шина А служит для передачи адреса, который формируется микропроцессором и позволяет выбрать необходимую ячейку памяти ОЗУ (ПЗУ) или требуемое ИУ при обращении к внешнему устройству. Шина D служит для выборки команд, поступающих из ОЗУ или ПЗУ в УУ микропроцессора, и для пересылки обрабатываемых данных (операндов) между микропроцессором и ОЗУ или ИУ (внешним устройством). По шине С передаются разнообразные управляющие сигналы, определяющие режимы работы памяти (запись или считывание), интерфейсных устройств (ввод или вывод информации) и микропроцессора (запуск, запросы внешних устройств на обслуживание, информация о текущем режиме работы и другие сигналы).
Рис. 1.4. Типовая структура микропроцессорной системы
ОБЩАЯ СТРУКТУРА И ПРИНЦИПЫ ФУНКЦИОНИРОВАНИЯ МИКРОПРОЦЕССОРНЫХ СИСТЕМ
Разрядность шины данных обычно соответствует разрядности операндов, обрабатываемых микропроцессором. Поэтому чаще всего шина D содержит 8, 16 или 32 линии для передачи соответствующих разрядов данных и команд. В ряде последних моделей микропроцессоров используется шина D с расширенной разрядностью, чтобы обеспечить одновременную передачу нескольких команд или операндов. Например, 32-разряд-ные микропроцессоры Pentium имеют 64-разрядную шину данных.
Разрядность шины адреса определяет максимальный объем адресуемой процессором внешней памяти. Например, 16-разрядная шина А обеспечивает адресацию памяти объемом до 64 Кбайт, а 32-разрядная шина-до 4 Гбайт. Процессоры Pentium II, Pentium 111, Pentium IV имеют 36-разрядную шину адреса, обеспечивающую обращение к памяти объемом до 64 Гбайт. Отметим, что в ряде микропроцессоров, например в Pentium, вместо младших разрядов адреса формируются сигналы выборки соответствующих байтов (сигналы байтной выборки BEi, где i - номер байта), которые позволяют организовать хранение байтов в отдельных банках памяти.
Во многих микропроцессорных системах передача адреса и данных сопровождается посылкой контрольных битов четности, которые обеспечивают выявление возможных ошибок, возникающих в процессе обмена. При этом обычно реализуется побайтный контроль четности, при котором каждый байт адреса или данных сопровождается дополнительным (9-м) контрольным битом, поступающим на отдельный вывод микропроцессора.
В некоторых системах для уменьшения числа необходимых линий связи и соответствующих выводов и контактов используется мультиплексирование линий адреса и данных. В таких системах для передачи адреса и данных используются одни и те же линии связи, на которые сначала выдается адрес, а затем поступают данные. Например, 16-разрядные микроконтроллеры семейства MCS-196, выпускаемые компанией Intel, имеют мультиплексированную 16-разрядную шину адреса данных AD. Обмен информацией по мультиплексированной шине AD требует введения отдельного регистра для хранения адреса в процессе пересылки данных. При этом требуется также дополнительное время для реализации обмена, что несколько снижает производительность системы.
Разрядность шины управления С определяется организацией работы системы, возможностями реализации различных режимов ее функционирования, используемыми методами контроля микропроцессора и других устройств. Поэтому набор передаваемых по шине С управляющих сигналов является индивидуальным для каждой модели микропроцессора. Имеется ряд управляющих сигналов, которые используются в большинстве микропроцессорных систем. К ним относятся сигналы начального запуска (RESET), сигналы, задающие режим работы памяти (чтение - RD, запись - WR), сигналы, необходимые для реализации прерываний и ряд других. В простых системах для передачи управляющих сигналов может использоваться всего несколько линий, а в сложных системах число этих линий составляет несколько десятков.
В процессе функционирования микропроцессорной системы реализуются следующие основные режимы ее работы:
• выполнение основной программы;
• вызов подпрограммы;
• обслуживание прерываний и исключений;
• прямой доступ к памяти.
Рассмотрим основные принципы реализации этих режимов.
Выполнение основной программы. В этом режиме процессор выбирает из ОЗУ очередную команду программы и выполняет соответствующую операцию. Команда представляет собой многоразрядное двоичное число (рис. 1.5), которое состоит из двух частей (полей) - кода опера-
Код операции (КОП) код адресации операндов (КАД)
Рис. 1.5. Формат типовой команды микропроцессора
21
ОСНОВЫ МИКРОПРОЦЕССОРНОЙ ТЕХНИКИ
ции (КОП) и кода адресации операндов (КАД). Код операции КОП задает вид операции, выполняемой данной командой, а код адресации КАД определяет выбор операндов (способ адресации), над которыми производится заданная операция. В зависимости от типа микропроцессора команда может содержать различное число разрядов (байтов). Например, команды процессоров Pentium содержат от 1 до 15 байтов, а большинство процессоров с RlSC-архитек-турой использует фиксированный 4-байтный формат для любых команд.
Для хранения адреса очередной команды служит специальный регистр процессора -программный счетчик PC (Program Counter), содержимое которого автоматически увеличивается на 1 после выборки следующего байта команды. Таким образом, обеспечивается последовательная выборка команд в процессе выполнения программы. При выборке очередной команды содержимое PC поступает на шину адреса, обеспечивая считывание из ОЗУ следующей команды выполняемой программы. При реализации безусловных или условных переходов (ветвлений) или других изменений последовательности выполнения команд выполняется загрузка в PC нового содержимого, в результате чего производится переход к другой ветви программы или подпрограмме.
В процессорах Pentium и предыдущих моделях микропроцессоров компании «Intel» (8086, 80186, 80286, 386, 486 и ряде других) реализуется сегментная организация памяти. При этом адрес выбираемой команды определяется содержимым двух регистров -указателя команды EIP, указывающего положение команды в сегменте программ, и сегментного регистра CS, который задает начальный (базовый) адрес этого сегмента. Регистры IP и CS выполняют функции программного счетчика PC, и различные виды передачи управления в программе реализуются путем изменения их содержимого.
Принятая из ОЗУ команда поступает в регистр команд, входящий в состав УУ процессора. Затем производится дешифрация команды, в процессе которой определяется вид выполняемой операции (расшифровка КОП) и формируется адрес необходимых операндов (расшифровка КАД). В соответствии с кодом поступившей команды УУ процессора генерирует последовательность микрокоманд, обеспечивающих выполнение заданной операции. Каждая микрокоманда выполняется в течение одного машинного такта - периода тактовых импульсов, задающих рабочую частоту всех внутренних узлов и блоков микропроцессора. Таким образом, тактовая частота микропроцессора определяет время выполнения отдельных микрокоманд, последовательность которых обеспечивает получение необходимого результата операции (поступившей команды).
Для выполнения каждой поступившей команды требуется определенное количество командных циклов и тактов. Командным циклом называется промежуток времени, требуемый для выполнения обращения к ОЗУ или внешнему устройству с помощью системной шины. Обычно реализация такого цикла занимает от 2 до 4 системных тактов (периодов синхросигналов шины), которые требуются для установки требуемого адреса, выдачи сигналов, определяющих вид цикла - чтение или запись, получения сигнала готовности к обмену (от памяти или внешних устройств) и собственно передачи данных или команд. При современной технологии изготовления системных плат частота синхросигналов шины обычно составляет десятки мегагерц (типичные значения 25, 33, 50, 66, 75,100, 133 МГц).
При выполнении каждой команды в первых циклах производится ее выборка из ОЗУ по адресу, который задается содержимым программного счетчика PC. Последующая дешифрация выбранной команды определяет необходимое число циклов для ее последующего выполнения. Если для выполнения команды не требуется считывание операндов из памяти (внешних устройств) или запись в память (вывод на внешние устройства) результатов операции, то такая команда выполняется за один цикл. При считываний операндов из памяти (внешних устройств) или записи результата в память (вывод на внешние устройства) требуется выполнение дополнительных циклов чтения (ввода) или записи (вывода). В зависимости от разрядности обрабатываемых операндов и разряд
ОБЩАЯ СТРУКТУРА И ПРИНЦИПЫ ФУНКЦИОНИРОВАНИЯ МИКРОПРОЦЕССОРНЫХ СИСТЕМ
ности используемой системной шины число циклов, необходимых для выполнения команд, может быть различным: от 1 (выборка команды) до 4-5 (зависит от команды, разрядности шин и операндов).
Машинным (процессорным) тактом в микропроцессорных системах является длительность периода тактовых сигналов Tt, которая задается тактовой частотой микропроцессора Ft= 1/Tt. При выполнении операций, не требующих обращений к системной шине, (эта частота определяет производительность микропроцессора. Для современных микропроцессоров частота Ft достигает 1 ГГц и более (последние модели микропроцессоров Pentium, AMD К7, Alpha и другие). Таким образом, обработка информации внутри процессора (без обращения к системной шине) производится значительно быстрее, чем обмен по шине. Если тактовая частота микропроцессора отличается от частоты обмена по системной шине, то вывод данных на шину реализуется с помощью промежуточной буферной памяти, в которой хранятся данные, посылаемые микропроцессором на системную шину. Данные выбираются из буферной памяти и поступают на системную шину с частотой, соответствующей скорости обмена по этой шине.
Текущее состояние процессора при выполнении программы определяется содержимым регистра состояния SR (State Register, в микропроцессорах Pentium данный регистр называется EFLAGS). Этот регистр содержит биты управления, задающие режим работы процессора, и биты признаков (флаги), указывающие характеристики результата выполненной операции:
N - признак знак (старший бит результата), N = 0 - при положительном результате, N = 1 -при отрицательном результате;
С - признак перенос, С = 1, если при выполнении операции образовался перенос из старшего разряда результата;
V - признак переполнения, V = 1, если при выполнении операций над числами со знаком произошло переполнение разрядной сетки процессора;
Z - признак нуля, Z = 1, если результат операции равен нулю.
Некоторые микропроцессоры фиксируют также другие виды признаков: признак четности результата, признак переноса между тетрадами младшего байта. Специальные виды признаков устанавливаются по результатам операций над числами, представленными в формате с «плавающей точкой».
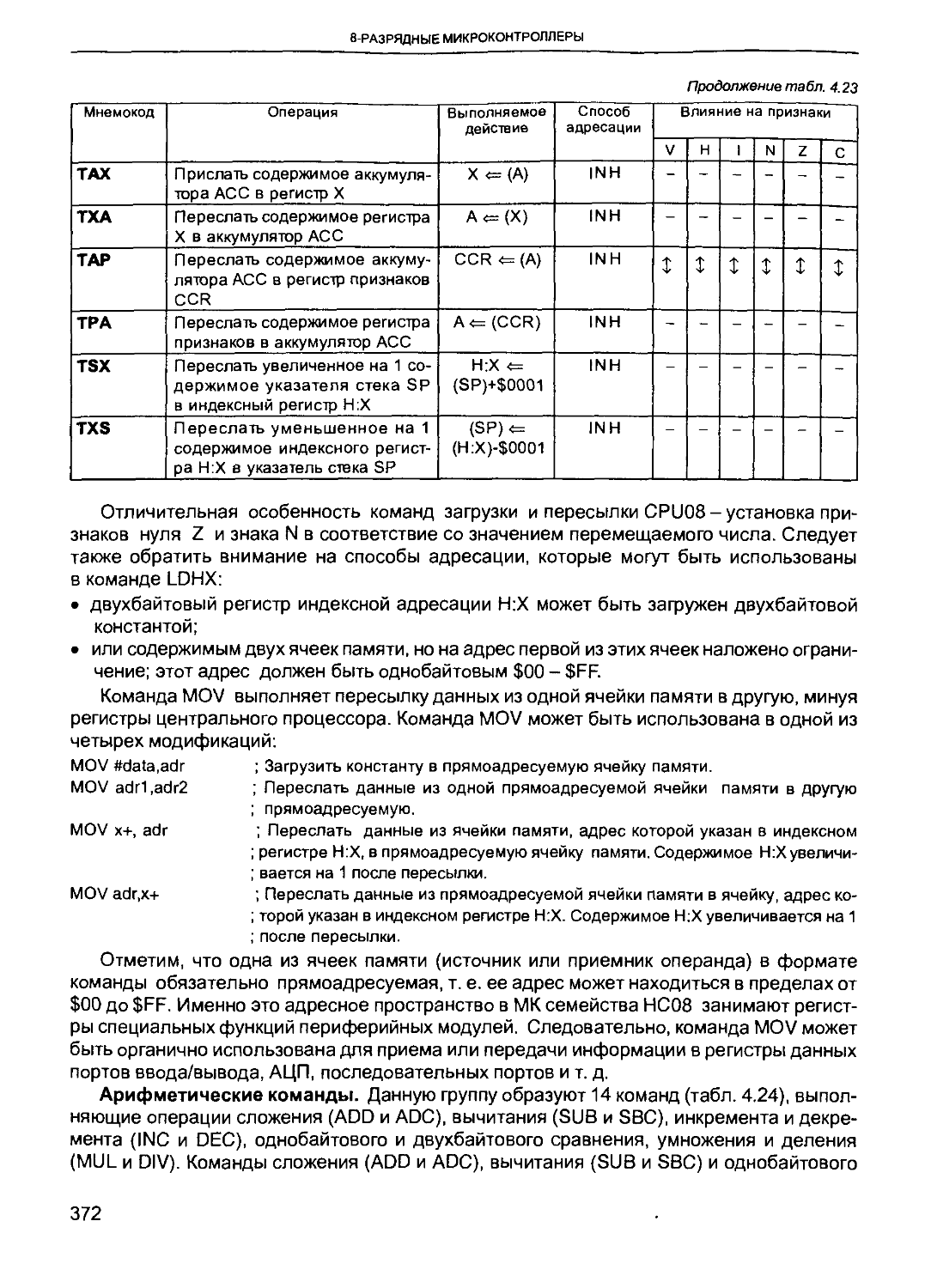
Вызов подпрограммы. Обращение к подпрограмме реализуется при поступлении в микропроцессор специальной команды CALL (в некоторых процессорах эта команда имеет мнемоническое обозначение JSR - Jump-to-SubRoutine), которая указывает адрес первой команды вызываемой подпрограммы. Этот адрес загружается в PC, обеспечивая в следующем командном цикле выборку первой команды подпрограммы. Предварительно выполняется процедура сохранения в специальном регистре или ячейке памяти текущего содержимого PC, где хранится адрес следующей команды основной программы, чтобы обеспечить возвращение к ней после выполнения подпрограммы. Возврат к основной программе реализуется при поступлении команды RETURN (мнемоническое обозначение RET), завершающей подпрограмму. По этой команде сохранявшееся содержимое PC снова загружается в программный счетчик, обеспечивая выполнение команды, которая в исходной программе следовала за командой CALL.
Особенность этой процедуры состоит в том, что большинство микропроцессоров обеспечивают возможности вложения подпрограмм, т. е. реализуют при выполнении подпрограммы вызов новой подпрограммы с последующим возвращением к предыдущей подпрограмме (рис. 1.6). При вложении нескольких подпрограмм требуется сохранение нескольких промежуточных значений содержимого PC и последовательная загрузка этих значений в PC при возврате к предыдущим подпрограммам и к основной программе.
Для реализации этой процедуры используется стек-специальная память магазинного типа, работающая по принципу «последний пришел - первый ушел» (стек типа LIFO — «Last In-First Out»). Существуют различные варианты реализации стека.
ОСНОВЫ МИКРОПРОЦЕССОРНОЙ ТЕХНИКИ
Основная программа Подпрограмма 1 Подпрограмма 2
Рис. 1,6. Последовательный вызов (вложение) подпрограмм
Регистровый стек (рис. 1.7, а) реализуется с помощью реверсивных сдвиговых регистров. Каждая команда CALL вызывает ввод в стек очередного содержимого PC. По команде RETURN направление сдвига изменяется и производится извлечение из стека последнего поступившего содержимого PC. Таким образом обеспечивается выполнение вложенных подпрограмм. Возможное число вложенных подпрограмм определяется глубиной стека, т. е. разрядностью используемых регистров сдвига. Если число вложений превышает глубину стека, первые из введенных в стекзначений PC теряются, т. е. возврат к основной программе не будет обеспечен. Поэтому при использовании регистрового стека необходим строгий контроль за числом вложений. Такая реализация стека применяется в системах, решающих задачи с ограниченным числом вложенных подпрограмм (обычно не более 10-20).
Значительно более широкие возможности вложения подпрограмм обеспечивает реализация стека в ОЗУ (рис.1.7, б). В этом случае часть ОЗУ выделяется для работы в качестве стека. Адресация к ячейкам стека производится с помощью специального регистра - указателя стека SP (Stack Pointer), который вводится в состав УУ процессора. Регистр SP содержит адрес верхней заполненной ячейки стека, в которой хранится значение PC, записанное при выполнении команды CALL. При поступлении новой команды CALL содержимое SP автоматически уменьшается на 1, адресуя следующую, еще незаполненную ячейку стека. Полученный адрес SP-1 выдается на шину А, а на шину D поступает содержимое PC, которое должно сохраняться в стеке. Таким образом, производится последовательное заполнение ячеек стека «снизу-вверх», при этом SP всегда адресует вершину стека. По команде RETURN текущее содержимое SP выдается на шину А, и по шине D производится считывание с вершины стека последнего записанного значения PC. После этого содержимое SP увеличивается на 1, адресуя предыдущее значение PC, хранящееся в стеке. Так как ОЗУ обычно имеет значительный объем, то для размещения стека можно выделить достаточно большое количество ячеек памяти, обеспечивая необходимый уровень вложения подпрограмм.
Обслуживание прерываний и исключений. При работе микропроцессорной системы часто возникают ситуации, когда требуется прервать выполнение текущей программы и перейти к подпрограмме, обеспечивающей необходимую реакцию системы на создавшиеся обстоятельства. Такие ситуации называются прерываниями или исключениями в зависимости от причин, вызывающих их возникновение.
ОБЩАЯ СТРУКТУРА И ПРИНЦИПЫ ФУНКЦИОНИРОВАНИЯ МИКРОПРОЦЕССОРНЫХ СИСТЕМ
после (RETURN)
Рис. 1.7. Варианты реализации стека: регистровый стек (а) и стек, реализуемый в ОЗУ (б)
Прерываниями (interuption) являются ситуации, возникающие при поступлении соответствующих команд (программные прерывания) или сигналов от внешних устройств (аппаратные прерывания). Исключениями (exception) являются нештатные ситуации (ошибки), возникающие при работе процессора. При выявлении таких ошибок соответствующие блоки, контролирующие работу процессора, вырабатывают внутренние сигналы запроса, обеспечивающие вызов необходимой подпрограммы обслуживания. Классификация прерываний и исключений приведена на рис. 1.8.
Во всех этих ситуациях микропроцессор завершает выполнение очередной команды и заносит в стек текущее содержимое программного счетчика PC, которое является адресом возврата к прерванной программе после реализации подпрограммы обслуживания, и содержимое релистра состояний SR. Если запрос прерывания поступает от внешнего устройства, то процессор формирует сигнал подтверждения прерывания, который информирует это устройство, что начато обслуживание данного запроса. Затем в PC загружается из памяти вектор прерывания Ve - начальный адрес соответствующей подпрограммы обслуживания. Эти вектора являются входами в подпрограммы обслуживания и хранятся в таблице векторов прерываний, которая обычно записывается в ОЗУ. Размер таблицы зависит от числа типов обслуживаемых прерываний и исключений. В простейших микропроцессорах это число составляет несколько единиц, а для микропроцессоров семейства Pentium или MC68000 обеспечивается возможность реализации до 256 различных подпрограмм обслуживания.
Рис. 1.8. Классификация прерываний и исключений
ОСНОВЫ МИКРОПРОЦЕССОРНОЙ ТЕХНИКИ
Завершается подпрограмма обслуживания специальной командой возврата из прерывания IRET, которая выбирает из стека хранившееся содержимое PC и SR и загружает его обратно в эти регистры, обеспечивая возвращение к выполнению прерванной программы.
Программные прерывания реализуются при поступлении специальных команд (INTn, INT3, INTO для микропроцессоров Pentium, TRAPn для микропроцессоров семейства MC68000 и другие). Эти команды вызывают переход к выполнению стандартных подпрограмм обслуживания, для размещения которых выделяются определенные позиции в ОЗУ. Таким образом, при вызове подпрограмм обслуживания реализуется обращение к фиксированным адресам.
Причинами аппаратных прерываний являются запросы от различных внешних (периферийных) устройств системы. Эти запросы поступают на внешние выводы микропроцессора или формируются периферийными устройствами, размещенными на одном кристалле с процессором. Аппаратные прерывания могут быть маскируемые или немаскируемые.
Запросы маскируемых прерываний обслуживаются только в том случае, если соответствующий бит управления I в регистре состояния SR, который называется маской прерываний, имеет значение 1. В процессорах Pentium это бит IF в регистре EFLAGS. С помощью специальных команд значение этого бита может быть установлено в 1 или сброшено в 0. Таким образом, можно разрешить или запретить обслуживание поступивших аппаратных прерываний при выполнении определенных программ или их фрагментов. При одновременном поступлении нескольких запросов обслуживание реализуется в соответствии с их приоритетом. В ряде микропроцессорных систем для обеспечения приоритетного обслуживания запросов от многих внешних устройств включаются специальные микросхемы -контроллеры прерываний. Некоторые типы микропроцессоров имеют внутренние контроллеры для организации приоритетных прерываний.
Немаскируемые запросы прерывания обслуживаются в первоочередном порядке и не могут быть маскированы. Обычно микропроцессор имеет один вход для подачи немаскируемых запросов, которые формируются при возникновении каких-либо аварийных ситуаций. Чаще всего этот вход используется для контроля напряжения питания. Если напряжение питания выходит за допустимые пределы, то специальный датчик вырабатывает немаскируемый запрос прерывания, поступающий в микропроцессор. При этом источник питания должен некоторое время (порядка 10 мс) сохранять необходимый уровень напряжения питания, в течение которого микропроцессор выполняет подпрограмму перезаписи на магнитный диск информации, достаточной для продолжения прерванной программы после восстановления нормального режима питания.
Для передачи сигналов запроса и подтверждения прерывания между микропроцессором и внешними устройствами или контроллером прерываний используются соответствующие линии шины управления С.
Причинами исключений могут быть различные ошибки и нештатные ситуации, возникающие при работе системы. Различные типы микропроцессоров контролируют разные варианты такого рода ситуаций. Типичными причинами исключений являются, например, использование нулевого делителя при выполнении команды деления (деление на 0); выборка неправильного кода команды; выход за границы разрешенного фрагмента памяти; поступление команд, выполнение которых запрещено при данном режиме функционирования микропроцессора и ряд других. Соответствующие причины исключений будут рассмотрены при описании конкретных типов микропроцессоров.
Прямой доступ к памяти. Режим прямого доступа к памяти DMA (Direct Memory Access) используется, если необходимо произвести пересылку значительного массива информации между ОЗУ и каким-либо внешним устройством, которое подает в систему соответствующий запрос. Реализация такой пересылки с помощью соответствующей про
СИСТЕМА КОМАНД И СПОСОБЫ АДРЕСАЦИИ ОПЕРАНДОВ
граммы обмена требует выполнения отдельной команды пересылки для передачи каждого байта или слова. При этом необходим определенный объем памяти для хранения программы и требуется значительное время для ее выполнения.
В большинстве современных микропроцессорных систем пересылка массивов информации обеспечивается с помощью специальных устройств - контроллеров DMA, которые реализуют режим прямого доступа к памяти. При поступлении запроса от внешнего устройства контроллер выдает соответствующий сигнал микропроцессору. Получив этот сигнал, микропроцессор завершает очередной цикл обмена по системной шине и отключается от нее, то есть переводит свои выводы, подключенные к шинам A, D и линиям управления ОЗУ и внешними устройствами, в отключенное (высокоимпедансное) состояние. При этом микропроцессор выдает контроллеру DMA сигнал разрешения на реализацию прямого доступа. Получив этот сигнал, контроллер принимает на себя управление системой. Он выдает на шину А адреса ячеек ОЗУ, с которыми выполняется текущий цикл обмена, формирует необходимые сигналы, определяющие режим работы ОЗУ (запись или считывание) и интерфейсного устройства, через которое производится пересылка информации (ввод или вывод).
Передача сигналов запроса и подтверждения прямого доступа к памяти между микропроцессором и контроллером DMA производится по соответствующим линиям шины управления С.
Предварительно контроллер DMA программируется для выполнения указанных функций. В него вводятся начальные адреса массивов памяти в ОЗУ, с которых начинается процесс обмена, и размеры массивов, подлежащего пересылке. Обычно контроллер DMA обслуживает запросы от нескольких внешних устройств, поэтому он программируется на реализацию определенного приоритета их обслуживания в случае одновременного поступления нескольких запросов. Программирование контроллера производится путем посылки ему необходимых управляющих сообщений. Эти сообщения обычно предварительно вводятся в контроллер от микропроцессора, когда он выполняет специальную программу инициализации контроллера DMA.
1.3. СИСТЕМА КОМАНД И СПОСОБЫ АДРЕСАЦИИ ОПЕРАНДОВ
Большинство микропроцессоров выполняют обработку следующих типов целочисленных данных:
• биты;
• байты;
• слова (16 разрядов);
• двойные слова (32 разряда).
Некоторые типы микропроцессоров обрабатывают также четверные слова (64 разряда), двоично-десятичные числа BCD (Binary Coded Decimal, представление одного десятичного разряда с помощью тетрады из 4 битов, которая называется полубайтом или нибблом), строки символов. В состав современных высокопроизводительных микропроцессоров входят также блоки, производящие обработку чисел, представленных в формате с плавающей точкой (блоки FPU - Floating Point Unit), и выполняющие обработку видео- и аудиоданных, для которых используются специальные форматы представления.
Обрабатываемые данные - операнды могут располагаться в регистрах или памяти (ОЗУ, ПЗУ или кэш-памяти). Выборка операнда - байта, слова или двойного слова производится в соответствии с заданным в команде номером (именем) регистра или адресом соответствующей ячейки памяти.
ОСНОВЫ МИКРОПРОЦЕССОРНОЙ ТЕХНИКИ
При размещении в памяти команд и данных используются два варианта расположения байтов в словах:
1) начиная с младшего байта («Little-Endian»);
2) начиная со старшего байта («Big-Endian»).
При использования размещения «Little-Endian» младший байт располагается в ячейке памяти с меньшим адресом (рис. 1.9, а). Данный вариант размещения реализуется в микропроцессорах, выпускаемых компаниями «Intel», AMD, «Hitachi» и рядом других производителей. При размещении «Big-Endian» старший байт располагается в ячейке с меньшим адресом (рис. 1.9, б). Такое расположение байтов обеспечивают микропроцессоры компании «Motorola», ряд моделей микропроцессоров, выпускаемых IBM и некоторыми другими компаниями. При обращении к памяти микропроцессор адресует ячейку с меньшим адресом, поэтому при размещении «Little-Endian» команда или операнд выбираются начиная с младшего байта, а при размещении «Big-Endian» - со старшего байта. По этой причине непосредственный перенос программного обеспечения между системами, использующими микропроцессоры с разными вариантами размещения байтов, оказывается практически невозможным. Чтобы решить эту проблему, некоторые современные микропроцессоры, например семейства PowerPC, реализуют оба возможных варианта размещения и адресации байтов - «Little-Endian» или «Big-Endian». Выбор необходимого варианта задается программно.
Различные типы микропроцессоров используют следующие основные способы адресации операндов, реализация которых обеспечивается в соответствии с кодом адреса (КАД), содержащимся в команде.
Прямая адресация. Операнд выбирается из ячейки памяти, адрес которой содержится в команде.
Регистровая адресация. Операнд выбирается из регистра РЗУ, номер (имя) которого указано в команде.
Косвенно-регистровая адресация. Операнд выбирается из ячейки памяти, адрес которой содержится в регистре РЗУ, указанном в команде.
Косвенно-регистровая адресация со смещением. Операнд выбирается из ячейки памяти, адрес которой является суммой содержимого указанного в команде регистра РЗУ и заданного в команде смещения (смещение может быть положительным или отрицательным числом).
Косвенно-регистровая адресация с индексированием и смещением. Операнд выбирается из ячейки памяти, адрес которой является суммой содержимого указанного в команде регистра, индексного регистра и заданного в команде смещения. В некоторых микропроцессорах имеются специальные индексные регистры для реализации этого способа адресации. Другие микропроцессоры используют в качестве индексного какой-либо регистр РЗУ, номер или имя которого указывается в команде. Частным случаем этого способа является индексная адресация, когда адрес образуется суммированием специального индексного регистра и заданного в команде смещения.
Рис, 1.9. Адресация байтов в слове и двойном слове при размещениях «Little-Endian» (а) и «Big-Endian» (б)
СИСТЕМА КОМАНД И СПОСОБЫ АДРЕСАЦИИ ОПЕРАНДОВ
Относительная адресация. Операнд выбирается из ячейки памяти, адрес которой является суммой текущего содержимого программного счетчика PC и заданного в команде смещения (числа со знаком). Отметим, что во многих микропроцессорах этот способ адресации используется не для адресации операнда, а для формирования адреса команды, к которой переходит программа при выполнении команд ветвления. При этом сформированный таким образом адрес загружается в PC, обеспечивая выборку требуемой следующей команды.
Непосредственная адресация. В этом случае операнд непосредственно содержится в поступившей команде, размещаясь следом за кодом операции (КОП).
Рассмотрим основные особенности данных способов адресации.
Прямая адресация обеспечивает обращение к любой ячейке ОЗУ. Однако для задания адреса операнда команда должна содержать необходимое количество байт адреса (до 4), что вызывает увеличение объема памяти программ и времени выборки команды из памяти.
Регистровая адресация является наиболее простой и быстрой. Так как объем РЗУ ограничен, то для задания номера регистра требуется всего несколько бит (обычно от 3 до 8). Так как РЗУ расположено на кристалле микропроцессора, то для выборки операнда не требуется обращение к внешней системной шине, поэтому выполнение операций при данном способе адресации требует минимального времени. Однако объем РЗУ ограничен (несколько десятков или сотен байт), поэтому необходимо периодическое обращение к ОЗУ для сохранения результатов и получения новых операндов.
Отметим, что ряд типов микропроцессоров имеет аккумуляторную организацию операционного устройства, при которой используется специальный регистр-аккумулятор, в который заносится результат операции ОУ. Содержимое этого регистра служит также операндом при выполнении очередной операции ОУ. При этом не требуется указания в команде номера (адреса) регистра-аккумулятора, так как обращение к нему обеспечивается автоматически в соответствии с внутренней структурой микропроцессора. Такой вариант регистровой адресации обеспечивает наиболее быстрое выполнение нескольких последовательных операций обработки. Однако для загрузки операнда в аккумулятор и сохранения полученных результатов приходится выполнять специальные команды пересылки, что снижает общую производительность системы.
Наиболее распространенными являются различные варианты косвенно-регистровой адресации. При этом в команде указывается только номер регистра, используемого в качестве адресного, поэтому размер команды оказывается небольшим (как при регистровой адресации). Однако выборка операнда (чтение из ОЗУ или запись в него) требует выполнения циклов передачи по системной шине, что снижает производительность системы. Различные варианты косвенно-регистровой адресации позволяют производить обработку линейных (строк) и двумерных (матриц) массивов данных, обеспечивая обращение к необходимому элементу массива по его относительному положению.
Непосредственная адресация также вызывает увеличение размера команды на число байт заданного операнда. Из-за этого возрастает объем памяти команд и время выборки команды. Однако при этом операнд поступает непосредственно в процессор, т. е. не требуется выполнение дополнительного цикла обращения к ОЗУ. Данный способ адресации широко используется для введения различных констант, используемых при обработке данных.
Различные типы микропроцессоров часто реализуют разнообразные варианты этих способов адресации. В ряде микропроцессоров используется косвенно-регистровая адресация с пост-инкрементом или пре-декрементом. При этом содержимое регистра, хранящего адрес, автоматически увеличивается на п (здесь п = 1, 2 или 4 - число байтов операнда) после его выборки (пост-инкремент) или уменьшается на п перед выборкой операнда (пре
7Q
ОСНОВЫ МИКРОПРОЦЕССОРНОЙ ТЕХНИКИ
декремент). Такая адресация удобна при обработке массивов данных, расположенных в памяти. В некоторых микропроцессорах реализуется относительная адресация с индексированием (аналогична косвенно-репистровой с индексированием и смещением). В микропроцессорах Pentium выполняется косвенно-регистровая адресация с индексированием и смещением, где возможно масштабирование - умножение содержимого индексного регистра на заданный в команде множитель.
Команды микропроцессора могут быть безадресными, одноадресными и двухадресными.
Безадресными являются команды, для выполнения которых не требуется операнд (например, команда останова HALT) или размещение операнда определяется структурой микропроцессора и задается непосредственно кодом операции. Например, в микропроцессорах, использующих регистр-аккумулятор, выполнение ряда команд над одним операндом предполагает, что он размещается в этом регистре.
Одноадресные команды содержат адрес одного операнда. Эти команды используются для выполнения операций над одним операндом, например, сдвигов, логической инверсии, изменения знака и ряда других. В микропроцессорах с аккумуляторной организацией обработки данных такие команды служат также для выполнения операций над двумя операндами, один из которых находится в аккумуляторе.
В двухадресных командах содержатся адреса двух операндов. Если при этом один из операндов выбирается из памяти, то другой операнд хранится в регистре (регистровая адресация) или содержится непосредственно в команде (непосредственная адресация). Результат операции записывается на место одного из операндов, значение которого при этом теряется.
Следует отметить, что в некоторых типах микропроцессоров реализуются также трехадресные команды, где задаются отдельные адреса размещения двух операндов и результата операции. Такие команды используют только регистровую адресацию и выполняются в микропроцессорах с RISC-архитектурой, имеющих значительный объем РЗУ, например, в PowerPC.
Микропроцессоры выполняют набор команд, которые реализуют следующие основные группы операций:
• операции пересылки;
• арифметические операции;
• логические операции;
• операции сдвига;
• операции сравнения и тестирования;
• битовые операции;
• операции управления программой;
• операции управления процессором.
При описании команд обычно используются их мнемонические обозначения (мнемокоды), которые служат для задания команды при программировании на языке ассемблера. Для различных версий ассемблера мнемокоды некоторых команд могут отличаться. Например, для команды вызова подпрограммы используется мнемокод CALL или JSR («Jump to SubRoutine»). Однако мнемокоды большинства команд для основных типов микропроцессоров совпадают или отличаются незначительно, так как они являются сокращениями соответствующих английских слов, определяющих выполняемую операцию. В данном разделе будут в основном использоваться мнемокоды команд, принятые для процессоров Pentium.
Команды пересылки. Основной командой этой группы является команда MOV, которая обеспечивает пересылку данных между двумя регистрами или между регистром и ячейкой памяти. В некоторых микропроцессорах реализуется пересылка между двумя ячейка
СИСТЕМА КОМАНД И СПОСОБЫ АДРЕСАЦИИ ОПЕРАНДОВ
ми памяти, а также групповая пересылка содержимого нескольких регистров в память или их загрузка из памяти. Например, микропроцессоры семейства 68ххх компании «Motorola» выполняют команду MOVE, обеспечивающую пересылку из одной ячейки памяти в другую, и команду MOVEM, которая производит запись в память или загрузку из памяти содержимого заданного набора регистров (до 16 регистров). Команда XCHG производит взаимный обмен содержимым двух регистров процессора или регистра и ячейки памяти.
Команды ввода IN и вывода OUT реализуют пересылку данных из регистра процессора во внешнее устройство или прием данных из внешнего устройства в регистр. В этих командах задается номер интерфейсного устройства (порта ввода-вывода), через которое производится передача данных. Отметим, что многие микропроцессоры не имеют специальных команд для обращения к внешним устройствам. В этом случае ввод и вывод данных в системе выполняется с помощью команды MOV, в которой задается адрес требуемого интерфейсного устройства. Таким образом, внешнее устройство адресуется как ячейка памяти, а в адресном пространстве выделяется определенный раздел, в котором располагаются адреса подключенных к системе интерфейсных устройств (портов).
Команды арифметических операций. Основными в этой группе являются команды сложения, вычитания, умножения и деления, которые имеют ряд вариантов. Команды сложения ADD и вычитания SUB выполняют соответствующие операции с содержимым двух регистров, регистра и ячейки памяти или с использованием непосредственного операнда. Команды ADC, SBB производят сложение и вычитание с учетом значения признака С, устанавливаемого при формировании переноса или заема в процессе выполнения предыдущей операции. С помощью этих команд реализуется последовательное сложение операндов, число разрядов которых превышает разрядность процессора. Команда NEG изменяет знак операнда, переводя его в дополнительный код.
Операции умножения и деления могут выполняться над числами со знаком (команды IMUL, IDIV) или без знака (команды MUL, DIV). Один из операндов всегда размещается в регистре, второй может находиться в регистре, ячейке памяти или быть непосредственным операндом. Результат операции располагается в регистре. При умножении (команды MUL, IMUL) получается результат удвоенной разрядности, для размещения которого используется два регистра. При делении (команды DIV, IDIV) в качестве делимого используется операнд удвоенной разрядности, размещаемый в двух регистрах, а в качестве результата в два регистра записывается частное и остаток.
Команды логических операций . Практически все микропроцессоры производят логические операции И, ИЛИ, Исключающее ИЛИ, которые выполняются над одноименными разрядами операндов с помощью команд AND, OR, XOR. Операции выполняются над содержимым двух регистров, регистра и ячейки памяти или с использованием непосредственного операнда. Команда NOT инвертирует значение каждого разряда операнда.
Команды сдвига. Микропроцессоры осуществляют арифметические, логические и циклические сдвиги адресуемых операндов на один или несколько разрядов. Сдвигаемый операнд может находиться в регистре или ячейке памяти, а число разрядов сдвига задается с помощью непосредственного операнда, содержащегося в команде, или определяется содержимым заданного регистра. В реализации сдвига обычно участвует признак переноса С в регистре состояний (SR или EFLAGS), в котором располагается последний разряд операнда, выдвигаемый из регистра или ячейки памяти.
Выполнение основных команд сдвига показано на рис. 1.10. При логических сдвигах влево (SHL) и вправо (SHR) производится заполнение освободившихся разрядов операнда нулями. Команда арифметического сдвига влево SAL реализуется аналогично команде логического сдвига SHL. При арифметическом сдвиге влево производится заполнение освободившихся разрядов значением старшего (знакового) разряда. Поэтому при таком сдвиге сохраняется знак операнда. Два варианта циклических сдвигов выполняются с включением признака С в цепь переноса (команды RCL, RCR) или с использованием признака С для хранения последнего выдвигаемого разряда операнда (команды ROL, ROR).
ОСНОВЫ МИКРОПРОЦЕССОРНОЙ ТЕХНИКИ
Рис. 1.10. Реализация команд сдвига
При выполнении арифметических, логических операций и сдвигов обычно производится установка признаков в регистре состояний в соответствии с полученным результатом.
Команды сравнения и тестирования. Сравнение операндов обычно осуществляется с помощью команды СМР, которая производит вычитание операндов с установкой значений признаков N, Z, V, С в регистре состояния в соответствии с полученным результатом. При этом результат вычитания не сохраняется и значения операндов не изменяются. Последующий анализ полученных значений признаков позволяет определить относительное значение (>,<, = ) операндов со знаком или без знака. Использование различных способов адресации позволяет производить сравнение содержимого двух регистров, регистра и ячейки памяти, непосредственно заданного операнда с содержимым регистра или ячейки памяти.
Некоторые микропроцессоры выполняют команду тестирования TST, которая является однооперандным вариантом команды сравнения. При выполнении этой команды устанавливаются признаки N, Z в соответствии со знаком и значением (равно или не равно нулю) адресуемого операнда.
Команды битовых операций. Эти команды производят установку значения признака С в регистре состояний в соответствии со значением тестируемого бита Ьп в адресуемом операнде. В некоторых микропроцессорах по результату тестирования бита производится установка признака Z. Номер тестируемого бита п задается либо содержимым указанного в команде регистра, либо непосредственным операндом.
Команды данной группы реализуют разные варианты изменения тестируемого бита. Команда ВТ сохраняет значение этого бита неизменным. Команда BTS после тестирования устанавливает значение Ьп - 1, а команда ВТС-значение Ьп = 0. Команда ВТС инвертирует значение бита Ьп после его тестирования.
СИСТЕМА КОМАНД И СПОСОБЫ АДРЕСАЦИИ ОПЕРАНДОВ
Операции управления программой. Для управления программой используется большое количество команд, среди которых можно выделить:
• команды безусловной передачи управления;
• команды условных переходов;
• команды организации программных циклов;
• команды прерывания;
• команды изменения признаков.
Безусловная передача управления производится командой JMP, которая загружает в программный счетчик PC новое содержимое, являющееся адресом следующей выполняемой команды. Этот адрес либо непосредственно указывается в команде JMP (прямая адресация), либо вычисляется как сумма текущего содержимого PC и заданного в команде смещения, которое является числом со знаком (относительная адресация). Так как PC содержит адрес очередной команды программы, то последний способ задает адрес перехода, смещенный относительно очередного адреса на заданное число байтов. При положительном смещении производится переход к последующим командам программы, при отрицательном смещении - к предыдущим.
Вызов подпрограммы также производится путем безусловной передачи управления с помощью команды CALL (или JSR). Однако в этом случае перед загрузкой в PC нового содержимого, задающего адрес первой команды подпрограммы, необходимо сохранить его текущее значение (адрес очередной команды), чтобы после выполнения подпрограммы обеспечить возвращение к основной программе (или к предыдущей подпрограмме при вложении подпрограмм). Текущее содержимое PC обычно сохраняется в стеке, который организуется в ОЗУ. После выполнения подпрограммы выполняется безусловная передача управления исходной программе с помощью команды возврата из подпрограммы RET, которая выбирает из стека и загружает в PC его старое содержимое.
Команды условных переходов (ветвлений программы) производят загрузку в PC нового содержимого, если выполняются определенные условия, которые обычно задаются в соответствии с текущим значением различных признаков в регистре состояния. Если условие не реализуется, то выполняется следующая команда программы. В табл. 1.1. приведены типовые команды условных переходов, которые реализуются в большинстве микропроцессоров (мнемокоды команд даны для процессоров Pentium).
Таблица 1.1
Типовые команды условных переходов
Мнемокод Условие Мнемокод Условие
J0 Переполнение V= 1 JNO Нет переполнения V = 0
JB Ниже (не выше и не равно) С = 1 JNB Не ниже (выше или равно) С = 0
Е Равно (нуль) ZF = 1 JNE Не равно (не нуль) Z = 0
JBE Ниже или равно (не выше) С + Z = 1 JNBE Не ниже и не равно (выше) С + Z = 0
JS Отрицательный знак № 1 JNS Положительный знак № 0
JL Меньше (не больше и не равно) N®V= 1 JNL Не меньше (больше или равно) N ®V = 0
JLE Меньше или равно (не больше) (N ФУ) + Z= 1 JNLE Не меньше и не равно (больше) (N ФЕ V) + Z = 1
33
ОСНОВЫ МИКРОПРОЦЕССОРНОЙ ТЕХНИКИ
В качестве условия часто используется относительное значение двух операндов, определяемое с помощью команды сравнения СМР. Например, равенство операндов определяется значением признака нуля Z после команды СМР: операнды равны, если Z = 1 (результат равен 0); не равны, если Z = 0 (результат не равен 0). Если сравниваются беззнаковые операнды, то соотношение их значений «выше - ниже - равно» определяют следующие условия (см. табл. 1.1):
• ниже/не выше и не равно (<), команда JB;
• не ниже/выше или равно (>=), команда JNB;
• ниже или равно/не выше (<=), команда JBE;
• не ниже и не равно/выше (>), команда JNBE.
Если сравниваются операнды со знаком, то соотношение между ними «больше - меньше - равно» определяют условия (см. табл. 1.1):
• меньше/не больше и не равно (<), команда JL;
• не меньше/больше или равно (>=), команда JNL;
• меньше или равно/не больше (<=), команда JLE;
• не меньше и не равно/больше (>), команда JNLE.
Отметим, что для предварительной установки необходимых признаков могут использоваться также команды тестирования и битовых операций.
Команды организации программных циклов осуществляют условный переход в зависимости от значения содержимого заданного регистра, который используется как счетчик циклов. Например, в процессорах Pentium для организации циклов используется команда LOOP и регистр ЕСХ. Команда LOOP уменьшает содержимое ЕСХ на 1 (декремент) и проверяет полученное значение. Если содержимое ЕСХ = 0, то выполняется переход к команде, адрес которой определяется с помощью относительной адресации (смещение задано в команде LOOP). Если ЕСХ = 0, то выполняется следующая команда программы. Команда LOOP обычно ставится в конце цикла, обеспечивая его выполнение п раз, где п задается начальным значением ЕСХ. Команды LOOPZ, LOOPNZ аналогичны команде LOOP, но используют дополнительные условия для выхода из цикла. Команда LOOPZ обеспечивает выход из цикла до выполнения заданного числа циклов п при получении ненулевого результата, т. е. при установке признака Z = 0. Если в каждом цикле реализуется нулевой результат, то выполняется п циклов, как в команде LOOP. Команда LOOPNZ прекращает выполнение циклов при получении нулевого результата, т. е. при установке ZF = 1.
Команды прерываний INT обеспечивают переход к одной из программ обслуживания исключений и прерываний (обработчику прерываний 0). При этом текущее содержимое PC и регистра состояния заносится в стек. Каждая из программ обработки соответствует определенному типу исключения или прерывания. Например, в процессорах Pentium выбор программы обработки определяется 8-разрядным операндом, задаваемым во втором байте команды INT. Вызов соответствующей программы обслуживания производится с помощью таблицы, в которой содержатся векторы исключений (прерываний) - адреса первых команд программ обслуживания. Каждый вектор задает необходимое содержимое PC, загрузка которого обеспечивает переход к выполнению первой команды программы обслуживания. Команда IRET обеспечивает возврат из подпрограммы обслуживания прерывания путем извлечения из стека и восстановления содержимого программного счетчика и регистра состояния, соответствующих прерванной процедуре.
Команды управления признаками обеспечивают запись-чтение содержимого регистра состояния, в котором хранятся признаки, а также изменение значений отдельных признаков. Например, в процессорах Pentium реализуются команды LAHF и SAHF, которые выполняют загрузку младшего байта, где содержатся признаки, из регистра состояния EFLAG в младший байт регистра ЕАХ и заполнение младшего байта EFLAGS из регистра ЕАХ. Команды CLC, STC осуществляют установку значений признака переноса CF = 0, CF - 1, а команда
СИСТЕМА КОМАНД И СПОСОБЫ АДРЕСАЦИИ ОПЕРАНДОВ
СМС вызывает инвертирование значения этого признака. Так как признаки определяют ход выполнения программы при условных переходах, то команды изменения признаков обычно используются для управления программой.
В данном разделе описывается управление программой с помощью изменения содержимого программного счетчика PC. В процессорах Pentium и ряде других моделей компании «Intel» (8086, 80186, 80286, 386,486 и других), реализуется сегментная организация памяти, при которой адрес выбираемой команды определяется содержимым двух регистров - указателя команды EIP и сегментного регистра CS. При этом различные виды передачи управления в программе реализуются путем изменения содержимого регистров EIP и CS.
Команды управления процессором. К этой группе относятся команды останова, отсутствия операции и ряд команд, определяющих режим работы процессора или его отдельных блоков. Команда HLT прекращает выполнение программы и переводит процессор в состояние останова, выход из которого происходит при поступлении сигналов прерывания или перезапуска (Reset). Команда NOP («пустая» команда), которая не вызывает выполнения каких-либо операций, служит для реализации программных задержек или заполнения пропусков, образовавшихся в программе.
Специальные команды CLI, STI запрещают и разрешают обслуживание запросов прерывания, устанавливая соответствующее значение бита управления I в регистре состояния процессора. В процессорах Pentium для этого используется бит управления (флаг) IF в регистре EFLAGS.
Многие современные микропроцессоры выполняют команду идентификации, которая позволяет пользователю или другим устройствам получить информацию о типе процессора, используемого в данной системе. В процессорах Pentuim для этого служит команда CPUID, при выполнении которой необходимые данные о процессоре поступают в регистры EAX, ЕВХ, ЕСХ, EDX и могут затем считываться пользователем или операционной системой.
В процессорах, которые имеют внутреннюю кэш-память, реализуются специальные команды, управляющие ее работой. При поступлении этих команд производится очистка (аннулирование содержимого) кэш-памяти, обеспечивается запись в ОЗУ определенных строк кэш-памяти и некоторые другие операции.
В данном разделе описаны только основные группы команд и приведены некоторые примеры типовых команд, выполняемых в наиболее распространенных моделях процессоров. В зависимости от реализуемых процессором режимов работы и заданных типов, обрабатываемых данных набор выполняемых команд может существенно расширяться.
Некоторые процессоры производят арифметические операции с двоично-десятичными числами или выполняют специальные команды коррекции результата при обработке таких чисел. В состав многих высокопроизводительных процессоров входит FPU - блок обработки чисел с «плавающей точкой». Соответственно такие процессоры выполняют большую группу команд, реализующих операции с этими числами и управляющих работой блока FPU.
В ряде современных процессоров реализована групповая обработка нескольких целых чисел или чисел с «плавающей точкой» с помощью одной команды по принципу SIMD («Single Instruction-Multiple Data!) - «Одна команда - Множество данных». Одновременное выполнение операций над несколькими операндами существенно повышает производительность процессора при работе с видео- и аудиоданными. Такие операции широко используются для обработки изображений, звуковых сигналов и в других приложениях. Для выполнения этих операций в состав процессоров введены специальные блоки, реализующие соответствующие наборы команд, которые в различных типах процессоров (Pentium, Athlon) получили название MMX («Milti-Media Extension») - Мультимедийное расширение, SSE («Streaming SIMD Extension») - Потоковое SIMD-расширение, «3D - Extension» - Трехмерное расширение.
35
ОСНОВЫ МИКРОПРОЦЕССОРНОЙ ТЕХНИКИ
Характерной особенностью процессоров компании Intel, начиная с модели 80286, является приоритетный контроль при обращении к памяти, который обеспечивается при работе процессора в режиме защищенных виртуальных адресов - «Protected Mode» (защищенный режим). Для реализации этого режима используются специальные группы команд, которые служат для организации защиты памяти в соответствии с принятым алгоритмом приоритетного обращения.
1.4. ИНТЕРФЕЙСЫ МИКРОПРОЦЕССОРНЫХ СИСТЕМ
1.4.1. ОСНОВНЫЕ ПОНЯТИЯ
Микропроцессорные системы содержат основные устройства, подразделяемые на четыре класса: процессоры, память, периферийные устройства (дисплеи, принтеры, сканеры, клавиатура, мышь и т. п.) и интерфейсы. Интерфейсы объединяют различные устройства в систему.
В вычислительной технике под интерфейсом понимается логическая или физическая структура, соединяющая устройства с разными логическими протоколами или конструкциями и служащая для передачи информации между устройствами, нередко разнородными. Интерфейс может быть определен более кратко как совокупность средств, обеспечивающих взаимодействие компонентов системы или сети.
Физический интерфейс-термин, определяющий совокупность механических и электрических средств, а также физических сред. Такая совокупность служит физической основой для создания логического интерфейса.
Логический интерфейс - термин, охватывающий все логические протоколы.
Логический протокол - совокупность правил передачи кодированной информации между устройствами, узлами или элементами системы.
Канал связи - совокупность передатчика, линии связи и приемника, обеспечивающая передачу информации в одном направлении.
Линия связи -техническое устройство (например, пара проводов, кабель, оптоволокно) или луч в физической среде, используемые для пропускания сигналов.
Гоуппа линий - набор линий, служащих для выполнения родственных функций.
Магистраль - совокупность групп линий, служащих для передачи данных и управляющих сигналов. Магистраль соединяет все станции в крейте.
Параллельная магистраль - магистраль, к которой обслуживаемые устройства присоединены параллельно и в которой передача битов происходит параллельно во времени во всех линиях.
Последовательная магистраль - состоит из одной линии с последовательной во времени передачей битов. Обслуживаемые устройства могут быть присоединены параллельно.
Передатчик - устройство, начинающее передачу запросом магистрали или посылкой запроса в канал.
Приемник- устройство, принимающее задание от передатчика и отвечающее ему.
Крейт - каркас для установки модулей, неотъемлемой частью которого являются магистраль или каналы, предназначенные для передачи данных и управляющих сигналов, а также проводники питания.
Модуль - сменный блок, использующий линии магистрали или канала в соответствии со стандартом и занимающий в крейте одну или более станций.
Станция - позиция в крейте для разъема, служащего для соединения модуля с магистралью или каналом.
ИНТЕРФЕЙСЫ МИКРОПРОЦЕССОРНЫХ СИСТЕМ
1.4.2. МАГИСТРАЛЬ VME
1. Появившись в конце 1981 г., шина VME стала наиболее популярным открытым стандартом для встраиваемых микропроцессорных систем реального времени и автоматизации рабочих мест. В настоящее время аппаратно- и программно-независимая VME-архитектура сопряжения различных устройств, принятая в качестве стандартов IEEE, ANSI, IEC, поддерживается более 400 фирмами, поизводящими аппаратуру м VMEbus.
2. Успех шины VME определяет то обстоятельство, что заложенные в ее архитектуру идеи не только не претерпели никаких изменений, но при этом и нисколько не устарели. В соответствии с требованиями стандарта IEEE-1014 шина имеет разрядность адресов и данных до 32 бит и обеспечивает возможность адресации до 4 Гбайт и скорость обмена до 40 Мбайт/с. Конструктивно платы VME соответствуют стандарту Eurocard на платы одинарной (160x100 мм) и двойной (160x234 мм) высоты. Наличие двух типоразмеров плат позволяет создавать как малые, экономичные по габаритам и стоимости, так и высокопроизводительные системы. Для подключения плат к объединительной панели используются 96-контактные соединители типа DIN602-3, имеющие высокую надежность.
Благодаря удачному сочетанию в стандарте VME многих достоинств и поддержке этого стандарта широким кругом производителей аппаратура с шиной VME находит широкое применение в самых различных отраслях - от медицины до аэрокосмических исследований.
Для VME-систем разработано и поставляется несколько операционных систем (ОС). Наиболее перспективными из них являются UNIX-совместимые ОС, а для применений реального времени - OS-9.
Сегодня VMEbus - ведущий стандарт на магистральные шины. Его будущее надежно, несмотря на появления применений, требующих большей производительности, предоставляемой шинами следующего поколения типа FUTUREbus+, SCI. i,
Распределение рынка VME по областям применения, %;
• автоматизация промышленности - 46; I
• военные/правительственные/аэроприменения - 25; 1
• разработки/наука/медицина -14;
• телекоммуникации - 4; '
• другие применения -11. *
3. Магистрально-модульная архитектура VMEbus используется для построения вычислительных систем различного диапазона производительности, от настольных компьютеров до многопроцессорных суперЭВМ, от промышленных контроллеров до систем управления тысячами аналогичных и дискретных каналов.
VMEbus находит широкое применение в:
• графических и информационных рабочих станциях;
• системах автоматизации производства, в том числе работающих в тяжелых климатических условиях и агрессивных средах;
• наземной и бортовой аппаратуре гражданского и военного назначения;
• автоматизации научных исследований;
• измерительных приборах и диагностическом оборудовании;
• системах связи и телекоммуникаций;
• медицинской технике, а также во многих других приложениях систем автоматизации.
VMEbus обеспечивает наилучшее соотношение цена - производительность для системы в целом и предоставляет практически неограниченные возможности наращивания всех ресурсов.
37
ОСНОВЫ МИКРОПРОЦЕССОРНОЙ ТЕХНИКИ
1.4.3. МАГИСТРАЛЬ VXI
В области измерительных и управляющих систем реального времени наибольшее . распространение в последние годы получил стандарт VMEbus (VersaBus Module Eurocard) и его расширение для контрольно-измерительных задач повышенной метрологической обеспеченности VXI (VMEbus eXtention for Instrumentation).
Интерфейс VXI считается в настоящее время наиболее перспективным для контрольно-измерительной техники, он имеет на западном рынке наибольшую динамику роста выпускаемой и реализуемой продукции, устойчивую тенденцию к техническому совершенствованию и расширению области применения.
Стандарт на VXIbus предложен в 1987 г. ведущими в области измерительной техники фирмами («Colorado Data Systems», «Hewlett-Packard», «Racal-Dana Instruments», «Tektronix», «Wavetek»), образовавшими VXI-Консорциум, в который вошли также фирмы: «Bruel & Kjaer», «John Fluke», «Keithley», «National Instruments» и др. В настоящее время VXI-стандарт поддерживает около 200 зарубежных фирм, которые выпускают более 500 типов модулей в этом стандарте.
Стандарт на шину VXI является открытым (не защищен патентом) и регламентирует правила объединения модульных или одноплатных измерительных приборов. Такой подход существенно снижает время и стоимость разработки новых функциональных блоков и создания на базе VXI прикладных измерительных систем.
Принципы построения интерфейса VXIbus. Интерфейс VXIbus разработан на базе двух широко используемых стандартов: VMEbus и приборного интерфейса IEEE-488, объединив в себе все преимущества магистрально-модульных и приборных измерительных систем. Такое объединение позволило создать высокопроизводительный и, в то же время, высокоточный интерфейс, обеспечивающий широкие возможности для построения контрольно-измерительных систем различного назначения. На базе стандарта VXI можно реализовать системы с частотой измерений до 2 ГГц при погрешности до 5-7 % или высокоточные системы с погрешностью менеее 0,005 % при частоте спроса до 10 кГц, при этом число каналов измерения и управления ограничивается лишь габаритными размерами и стоимостью.
При разработке стандартов на VXI-шину решены следующие технические вопросы:
• строго определены и регламентированы уровни электрических помех в модулях и на шине;
• созданы возможности для самотестирования и диагностики отдельных модулей и системы в целом;
• определены жесткие требования к конструкции крейта, к источнику питания и к системе охлаждения в целях обеспечения оптимальных условий работы модулей независимо от их количества в крейте;
• введены специальные функции управленияи и распределения ресурсами VXI-шины, позволяющие реализовать в командном блоке возможности контроллера и арбитра, а также обеспечить любое (не обязательно нулевое) стартовое состояние системы после ее включения или перезапуска.
С точки зрения эксплуатационных характеристик VXIbus отличается от других измерительных стандартов следующими основными, на наш взгляд, преимуществами.
1. В качестве измерительных модулей VXI-систем используются многоразрядные (51/2, б’/г десятичных знаков) мультиметры, позволяющие непосредственно (без дополнительных усилителей) подключать к VXI-системе датчики и сенсоры с различным уровнем сигналов (от единиц микровольт до сотен вольт). Путем программной настройки мультиметры могут производить измерение напряжения, тока, сопротивления в режиме цифрового прибора или в режиме АЦП с изменением точности измерения и соответствующим изменением времени преобразования.
ИНТЕРФЕЙСЫ МИКРОПРОЦЕССОРНЫХ СИСТЕМ
2. Коммутация измерительных каналов в VXI-системах осуществляется по специальной измерительной трехпроводной схеме, при которой используется разрыв сразу трех измерительных сигнальных линий, включая линию «земля», что компенсирует помехи общего вида. Кроме того, в измертельных мультиплексорах предусмотрена термостабилизация входных измерительных цепей, обеспечивающая температурную компенсацию изменения уровня постоянной составляющей входного сигнала.
3. В модулях VXIbus стандартизована регистровая структура (назначение и адреса внутренних регистров) памяти, что позволяет иметь для всех модулей программные драйверы управления.
4. Наряду с регистровым управлением имеется возможность программирования модулей системы на уровне сообщений (в ASCI кодах), что позволяет легко составлять исполнительные программы VXI-систем на языках высокого уровня.
5. VXI-системы имеют развитые средства коммуникации с другими интерфейсными системами, с различными типами компьютеров и приборов, в частности, имеются программно-аппаратные средства подключения VXI-крейтов к компьютерам класса IBM,
6. VXI-системы поддерживаются развитыми программными средствами, обеспечивающими минимизацию временных и материальных затрат на разборку прикладных пользовательских программ.
Реализация магистрали VXJ. Основу шины VXI-системы составляет интерфейс межмодульного обмена информацией в рамках одного крейта
Магистраль VXIbus включает в себя восемь шин:
• шину VMEbus многопроцессорных вычислительных систем;
• шину тактовой частоты и синхронизации;
• радиальную шину запуска;
• триггерную шину запуска;
• локальную шину обмена;
• аналоговую суммирующую шину;
• шину идентификации модулей;
• шину питания (+5V; +12V; ±24V; -5,2V; -2V).
Шина VMEbus объединяет все посадочные места и используется для организации быстрого обмена информацией между модулями.
Шина тактовой частоты и синхронизации является радиальной и используется для общей синхронизации всех модулей от командного блока (гнездо 0).
Радиальная шина запуска обеспечивает одинаковую для всех модулей задержку прохождения тактовых сигналов от гнезда 0 (временной сдвиг не более 2 нс).
По триггерной шине запуска реализуется синхронный, полусинхронный и асинхронный протоколы (TTL- или ECL-логики).
Локальная шина может использоваться разработчиками модулей для организации, обмена данными между соседними модулями по автономным (недоступным для других модулей) линиям.
Аналоговая суммирующая шина используется длля обмена по магистрали аналоговыми сигналами в виде согласованных значений сопротивлений и напряжений.
Шина идентификаций модулей применяется в качестве радиальной системе географической адресации и идентификации модулей со стороны гнезда 0.
Шина питания обеспечивает высокостабильное питание электронных схем TTL- и ECL-логики.
1.4.4. PCI - ЛОКАЛЬНАЯ МАГИСТРАЛЬ ПЕРСОНАЛЬНЫХ КОМПЬЮТЕРОВ
Комплекс микропроцессора и периферийных устройств. Развитие микропроцессоров привело в 1982 г. к появлению настольного персонального компьютера ПК.
39
ОСНОВЫ МИКРОПРОЦЕССОРНОЙ ТЕХНИКИ
Существовавшие в то время магистрально-модульные системы VME и Multibus 1 были слишком громоздки, а их логические протоколы ориентированы на сбор информации от датчиков и ее микропроцессорную обработку в модулях. Интерфейс для ПК пришлось разрабатывать заново, при этом в первых ПК частные технические решения были слабо стандартизованы. Широкое распространение ПК, производимых разными фирмами, привело к необходимости создания такого стандарта на магистрали, который имел бы шансы на признание множеством фирм. В конце 1980-х годов в США образовалась рабочая группа инженеров разных фирм, которая разработала и выдала первоначальную версию стандарта на синхронную магистраль Periferal Component Interconnect Local Bus - PCI bus Revision 1.0.
Ведущие фирмы по инициативе «Intel» образовали PCI Special Interest Group (PCI SIG). Эта группа и в 1998 г. поддерживает и координирует все разработки, связанные с PCI. Под эгидой PCI SIG 30 апреля 1993 г. была утверждена версия PCI 2.0 стандарта. Большинство ПК, эксплуатируемых в 1998 г., основано на этом стандарте. Однако локальная магистраль новых ПК, выпускаемых с 1996 г., выполняется по последнему стандарту PCI 2.1 от 1 июня 1995 г. Отдельный стандарт PCI BIOS Specification Revision 2.1, датированный 26.08.94, определяет протокол включения компьютерного комплекса в сеть.
Стандарт 2.1 является улучшением предыдущей версии и сохраняет основной логический протокол, нацеленный, во-первых, на обеспечение большой пропускной способности. Максимальную тактовую частоту в магистрали удалось увеличить вдвое до 66 МГц, а пропускную способность до 528 Мбайт/с при 64-разрядах и питании всего +3,3 В. Во-вторых, стандартом гарантирована возможность автоконфигурации систем (без вмешательства оператора) после подключения любого из устройств к магистрали через интерфейсную плату.
Сигналы в магистрали PCI. Синхронная магистраль PCI в 32-разрядном варианте содержит 49 информационных линий. При расширении до 64 разрядов добавляются еще 48 линий, они на рисунке не показаны. Кроме того, в расширенной магистрали могут быть добавлены 5 линий порта для проверочного сканирования присоединенных устройств в соответствии со стандартом IEEE Std 1149.1 Test Access Port and Boundary Scan Architecture.
Конфигурация и инициализация систем. В компьютерной системе PCI могут быть скомпонованы периферийные устройства различного назначения, выполненные с разнообразными характеристиками разными производителями. Для удобства пользователей стандартом предусмотрена автоконфигурация систем: чтобы скомпоновать и задействовать систему, пользователю достаточно вставить в разъемы магистралей интерфейсные платы, присоединяющие нужные периферийные устройства. В другие разъемы можно добавить платы памяти, наращивая оперативную память до нужного объема. После вставления плат пользователю не требуется вводить или запускать какие-либо программы - достаточно включить питание, и конфигурация завершится сама собой.
Информация о характеристиках подключаемых устройств, необходимая для выполнения алгоритмов конфигурации, содержится в зоне конфигурации основной памяти, а в СБИ-Сах или на платах устройств размещена в регистрах конфигурации. Для процессора-хозяина обеспечен доступ к любым регистрам сразу после подключения устройств - до введения в память системы каких-либо пользовательских программ.
В регистрах каждого устройства определен 8-разрядный код номера магистрали, к которой присоединено устройство, 5-разрядный номер самого устройства и три разряда отведены для возможных 8 функций устройства. Это не означает, что система может содержать 256 вторичных магистралей с 32 устройствами каждая, поскольку основной магистрали PCI можно подключать не более десяти «нагрузок». Просто большой выбор номеров облегчает компоновку сложных систем. В регистрах хранятся коды-идентифи-иятооы производителя изделия, типа изделия, его модификации, основного назначения
ШИНА USB
и выполняемых функций. Эта и другая информация необходима для обеспечения оптимальной конфигурации системы и наилучшего использования устройств при ее программировании.
После выполнения собственно конфигурации следует инициализация системы. Функции, запомненные в регистрах устройств, позволяют предоставить устройствам потребные системные ресурсы, например зоны в основной памяти или в памяти ввода/вывода, необходимые для бесконфликтного функционирования каждого устройства. При инициализации присваиваются приоритеты прерываний и имена прерываемых устройств.
Стандарт предоставляет разработчикам программного обеспечения информацию, достаточную для выполнения не только указанной задачи, но и для компоновки конкретных систем. Алгоритмы, описанные в стандарте, предназначены для программирования операций, связанных с зонами конфигурации устройств и систем. Эти программы выявляют наличие в системах тех или иных устройств и, обращаясь к ним, используют характеристики для конфигурации и инициализации.
Самые первые программы, начинающие работать после включения компьютера, это программы BIOS. Текущая информация об исполнении программ BIOS появляется на экране монитора в виде строк, сообщающих о наличии дисковой памяти, операционной системы, клавиатуры и других периферийных устройств. В случае отсутствия необходимых устройств или их неисправности выдается соответствующее извещение - так происходит самопроверка системы после включения (POST - Power-On Self Test). После окончания работы BIOS пользователь может вызвать свои программы.
Благодаря системе BIOS и строгому определению зон конфигурации впервые в персональных компьютерах в широких масштабах была реализована технология Plug and Play, использованная ранее в системе VXI.
1.5. ШИНА USB
1.5.1. ОСНОВНЫЕ СВЕДЕНИЯ О ШИНЕ USB
Недостаток гибкости в реконфигурировании PC - одна из основных проблем дальнейшего развития компьютерных систем. Добавление внешних скоростных периферийных устройств продолжает быть ограничением из-за небольших возможностей портов компьютера. Шина USB (Universal Serial Bus) является промышленным расширением архитектуры компьютеров PC. USB - быстрый, двунаправленный, дешевый, динамически подключаемый последовательный интерфейс, который совместим с основными требованиями различных платформ PC.
Основные отличительные особенности архитектуры шины USB:
• легкость в использовании для расширения числа периферийных устройств PC до 127;
• простота работы для конечного пользователя;
• дешевизна контроллеров, кабелей и оборудования;
• широкие возможности по подключению различных устройств со скоростями работы в пределах от нескольких Кбит/с до нескольких Мбит/с; поддержка скоростей передачи 12 Мбит/с и 1,5 Мбит/с;
• полная поддержка для передачи в реальном масштабе времени голоса, звука, и сжатого видео; при изохронных передачах обеспечивается гарантируемое требование по быстродействию и малое время оклика;
* П0ДДерживаются как изохронные, так и асинхронные типы передачи данных по одним и тем же проводам.
совместимость с различными конфигурациями PC и с существующими интерфейсами ОПеРационных систем;
41
ОСНОВЫ МИКРОПРОЦЕССОРНОЙ ТЕХНИКИ
• возможность динамически присоединять, идентифицировать и реконфигурировать периферийные устройства;
• высокая степень загрузки шины;
• широкий диапазон размеров пакета и встроенное в протокол управление потоком данных при буферной обработке;
• согласование скоростей передачи данных, размеров буферизируемого пакета и время отклика;
• встроенный в протокол механизм восстановления при ошибках и обработки неисправностей. Поддержка обнаружения и отключения отказавших устройств.
Топология USB-шины. Шина USB соединяет USB-устройства с USB-хостом (host). В любой USB-системе может быть только один хост-контроллер (Host). На физическом уровне то-пология USB представляется в виде многоуровневой звезды (рис. 1.11). Устройства USB могут подключаться непосредственно к хосту, но так как число устройств может быть велико, предусмотрено подключение через специальные концентраторы (hubs), которые расположены в центре каждой звезды. Корневой концентратор (root hub) обычно интегрирован внутрь хост-систе-мы, чтобы обеспечивать одну или большее число точек подключения. Каждый сегмент провода - двухточечное соединение между хостом и концентратором или функцией, или концентратором, соединенным с другим концентратором или функцией.
USB-xoct взаимодействует с USB-устройствами через хост-контроллер и отвечает за:
• обнаружение подключения и удаления USB-устройств;
• управление управляющим (Control) потоком между хостом и USB-устройствами;
• управление перенумерацией и конфигурирование подключенных USB-устройств;
• управление потоком данных между хостом и USB-устройствами;
• сбор статистики о состоянии и активности USB-устройств;
• обеспечение подачи питания ограниченной мощности на подключенные USB-устройства.
Существует два главных класса USB-устройств: устройства-концентраторы и устройства-функции. Устройства-концентраторы (hubs) обеспечивают дополнительное присоединение USB-узлов, а устройства-функции (functions) - подключение функциональ-
Рис. 1.11. Топология USB-шины
ШИНА USB
ных устройств. В одном USB-устройстве могут объединяться возможности устройств-функций и устройств-концентраторов, для подключения других функций (рис. 1.12).
Устройство-функция - устройство USB, которое способно передать или получить данные или управляющую информацию по шине. Функция обычно выполняется как отдельное периферийное устройство с кабелем, который подключается в порт концентратора (например, мышь, клавиатура). Каждая функция содержит информацию о конфигурации, которая описывает ее параметры и требования к ресурсам. Прежде чем устройство-функция будет использовано, оно должно быть сконфигурировано хостом. Такая конфигурация включает в себя распределение пропускной способности USB-шины и выбор специфических настроек конфигурации функции.
Конечные точки устройства. Каждое логическое устройство USB состоит из набора независимо функционирующих конечных точек - endpoints (ЕР). Конечная точка - уникально идентифицируемая часть устройства USB, которая является конечным пунктом назначения потока связи между программным обеспечением хоста и устройством USB. Каждая конечная точка создается во время разработки и имеет свой уникальный идентификатор или номер конечной точки. Конечные точки находятся в неопределенном состоянии, и к ним нельзя обратиться, пока они не будут сконфигурированы (за исключением конечной точки «О»). Комбинация уникального адреса устройства, который присваивается USB-устройству при подключении его к шине, и номера конечной точки позволяет однозначно обращаться к каждой конечной точке внутри USB-устройства.
Каждая конечная точка имеет характеристики, и их необходимо знать клиентскому ПО для определения типа соединения:
• требования к частоте доступа и времени отклика на USB-шине;
• требования по пропускной способности канала связи с этой точкой;
• уникальный номер конечной точки;
• особенности реакции при обнаружении ошибок;
• максимальный размер пакета, с которым работает конечная точка;
• тип передачи для данной конечной точки;
• направление передачи данных - для блочных (bulk) и изохронных передач.
Все USB-устройства должны иметь конечную точку с номером «О» (Endpoint 0), через которую хост инициализирует, конфигурирует и управляет устройством USB. Конечная
Устройства концентраторы/функции
Устройства-функции
Устройство-концентратор
Рис. 1.12. Пример объединения концентраторов и функций
43
ОСНОВЫ МИКРОПРОЦЕССОРНОЙ ТЕХНИКИ
точка «О» обеспечивает доступ к информации о конфигурации USB-устройства, предоставляет возможность настраивать его режимы работы и всегда конфигурируется автоматически при подключении устройства к шине USB.
Распределение пропускной способности USB-шины. Вся пропускная способность USB-шины может быть распределена среди множества различных потоков данных. Это позволяет широкому диапазону разноскоростных устройств присоединиться к USB-шине. USB-хост резервирует некоторую пропускную способность для конкретного канала только после его установления. Для USB-устройств, требующих большой пропускной способности, следует продумать вопросы буферизации, т. е. выделить большие по размеру буферы и обеспечить, чтобы аппаратная задержка буферизации не превышала нескольких миллисекунд.
Если при распределении дополнительного канала произойдет нарушение существующей пропускной способности или изменение времен отклика, USB блокирует распределение пропускной способности, и дальнейшее распределение каналов отклоняется или блокируется. Когда канал закрыт, выделенная ему пропускная способность освобождается и может быть перераспределена на другой канал.
Основные режимы работы. Как определено в спецификациях USB 1.0 и 1.1, имеются два режима передачи сигналов, которые могут использоваться на одной шине благодаря динамическому переключению скоростей. Полноскоростной режим передачи информации по USB-шине со скоростью 12 Мбит/с и низкоскоростной режим передачи сигналов в 1,5 Мбит/с, который имеет ряд функциональных ограничений и позволяет работать при меньшем уровне защиты от электромагнитных помех (EMI) и который определен, чтобы поддерживать ограниченное число низкоскоростных устройств (типа мыши), так как включение большого числа низкоскоростных устройств значительно снижает пропускную способность шины.
Определение скоростных характеристик устройства и самого факта включения его на шину производится благодаря имеющимся в устройстве pull-up-резисторам, подключенным к линиям D+ или D-. Подключение резистора к линии D+ сигнализирует подключение полноскоростного устройства, к линии D- - низкоскоростного.
Для подключения внешних устройств USB позволяет иметь кабельный сегмент длиной до 5 м. USB-кабель состоит из 4 проводов:
1) Vbus - линия для передачи питания +5 вольт при максимальном токе в 500 мА;
2) D- - первый провод витой пары для передачи данных;
3) D+ - второй провод витой пары для передачи данных;
4) GND - цифровая «земля».
Проводники Vbus и GND служат для подводки питания (+5 В) к устройствам, которые запитываются от шины. Любое подключенное устройство может или использовать свое питание (self-powered), или получать питание от хоста или хаба (bus-powered). Отметим, что системное программное обеспечение USB-хоста управляет энергосбережением в сети, посылая устройствам команды войти или выйти из режима энергосбережения.
Основные принципы передачи данных. USB передачи данных и сигналов управления происходят между программным обеспечением хоста и особой конечной точкой в USB-устройстве. Хост USB обрабатывает связь с любой конечной точкой USB-устройства независимо от любой другой конечной точки. Такие соединения между программным обеспечением хоста и конечной точкой устройства USB называются каналами. Например, USB-уст-ройство может иметь одну конечную точку, которая будет поддерживать канал для передачи данных в USB-устройство, и другую конечную точку, которая поддерживает канал для передачи данных из USB-устройства.
ШИНА USB
Стандарт USB определяет четыре типа передачи: Control, Interrupt, Bulk, Isochronous. Каждый тип передачи (табл. 1.2) определяет различные характеристики потока связи:
• свой формат кадров данных для обмена по USB;
• направление передачи;
• ограничения на размер пакета;
• ограничения на доступ к шине;
• требуемую последовательность пакетов данных.
Передача типа Управление (Control) - пакетная, непериодическая передача управляющих сигналов. Программное обеспечение хоста использует этот тип передачи в режиме запрос-ответ для инициализации, настройки конфигурации USB-устройства или получения информации о статусе USB-устройства. Control-данные доставляются без потерь, так как хост резервирует часть каждого USB-кадра для передачи control-информации.
Передача типа Bulk - непериодическая, применяется для обмена большими массивами информации для данных, которые могут использовать любую доступную пропускную способность, не используемую другими типами передач в данный момент, и могут быть задержаны, пока не будет доступна нужная пропускная способность. Надежный обмен данными обеспечивается на аппаратном уровне, с использованием обнаружения ошибок на аппаратном уровне и автоматической повторной перепосылки поврежденных данных, но только ограниченное число раз.
Таблица. 1.2
Параметры различных способов передачи
Тип передачи Размер заголовка, байт Размер поля данных (data payload), байт Минимальная пропускная способность, байт/с Максимальная пропускная способность, байт/с
Control, 12 Мбит/с 45 (9-SYNC, 9-PID, 6-EP+CRC, 6-CRC, 8-SetupData, 7-interpacked delay (EOP)) 1, 2, 4, 8, 16, 32, 64 32 000 832 000
Control, 1,5 Мбит/с 45 (9-SYNC, 9-PID, 6-EP+CRC, 6-CRC, 8-SetupData, 7-interpacked delay (EOP)) 1, 2, 4, 8 00 3000 24 000
Isochronous 9 (2-SYNC, 2-PID, 2-EP+CRC, 2-CRC, 1-interpacked delay) 1,2,4,8,16,32, 64, 128, 256, 512, 1023 150 000 1 023 000
Interrupt, 12 Мбит/с 13 (3-SYNC, 3-PID, 2-EP+CRC, 2-CRC, 3-interpacked delay) 1, 2, 4, 8, 16, 32, 64 107 000 1 216 000
Interrupt, 1,5 Мбит/с 13 (3-SYNC, 3-PID, 2-EP+CRC, 2-CRC, 3-interpacked delay) 1, 2, 4, 8 013 000 64 000
Bulk 13 (3-SYNC, 3-PID, 2-EP+CRC, 2-CRC, 3-interpacked delay) 1, 2, 4, 8, 16, 32, 64 107 000 1 216 000
46
ОСНОВЫ МИКРОПРОЦЕССОРНОЙ ТЕХНИКИ
Передача типа Прерывание (Interrupt) - передача по прерыванию - небольшая спонтанная непериодическая, низкочастотная передача небольших данных от USB-устройства, которая может быть произведена в любое время и будет передана по USB-шине со скоростью не меньшей, чем определено устройством. Данные прерывания обычно состоят из сообщений о произошедшем событии, символов или, например, координат из устройства управления, которые представляют собой один или несколько байт. Этот тип передачи похож на блочную (bulk), но передача происходит только для IN-каналов. Хотя большая скорость синхронизации ответа не требует, интерактивные данные могут иметь ограниченное время отклика, который должна поддерживать USB-шина.
Изохронные (Isochronous) или потоковые (Streaming) передачи данных в реальном времени, которые занимают заранее оговоренную пропускную способность USB-шины с заранее оговоренным временем отклика. Таким образом, это периодическая, непрерывная связь между хостом и устройством, которая обычно используется для передачи потоковой, критичной ко времени информации, такой как аудио или видеоинформация.
Таким образом, изохронные данные могут быть чувствительны к скорости и задержкам доставки, так как их поток непрерывен и требует обработки и передачи в реальном масштабе времени (например, речевая информация). Чтобы поддержать необходимую синхронизацию, изохронные данные должны передаваться по шине со скоростью их поступления. Если скорость доставки потоков этих данных не поддерживается на определенном уровне, то в потоке произойдут сбои из-за переполнения или обнуления буферов.
USB разработана так, чтобы минимизировать задержки изохронных передач данных; для этого изохронные потоки данных в USB занимают выделенную часть пропускной способности USB-шины, а это гарантирует, что данные могут доставляться с нужной скоростью. При изохронной передаче любая ошибка на физическом уровне не исправляется аппаратно путем повторений. Но эта проблема решается за счет того, что средняя частота передачи ошибочных битов в USB-шине достаточно мала. Определение ошибок происходит только на уровне согласования CRC16 контрольной суммы. Изохронная (isochronous) передача не использует механизм переключения флажков DATA0/DATA1 и всегда передается с PID DATA0.
ГЛABA 2
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
2.1. СТРУКТУРА И ФУНКЦИОНИРОВАНИЕ ПРОЦЕССОРОВ INTEL Р6
Процессоры семейства Р6, продолжая общую линию микропроцессоров Intel 80x86, имеют ряд архитектурных и структурных особенностей по сравнению с предыдущими моделями микропроцессоров фирмы «Intel». Наиболее характерными из этих особенностей являются: • гарвардская структура с разделением потоков команд и данных с помощью введения отдельных внутренних блоков кэш-памяти для хранения команд и данных, а также шин для их передачи;
• суперскалярная архитектура, обеспечивающая одновременное выполнение нескольких команд в параллельно работающих исполнительных устройствах;
• динамическое исполнение команд, реализующее изменение последовательности команд (выполнение команд с опережением - спекулятивное выполнение), использование расширенного регистрового файла (переименование регистров), эффективное предсказание ветвлений;
• двойная независимая шина, содержащая отдельную шину для обращения к кэш-памяти 2-го уровня (выполняется с тактовой частотой процессора) и системную шину для обращения к памяти и внешним устройствам (выполняется с тактовой частотой системной платы).
Процессоры семейства Р6 имеют следующие характеристики: *
• 32-разрядная внутренняя структура;
• использование системной шины с 36 разрядами адреса и 64 разрядами данных;
• раздельная внутренняя кэш-память 1-го уровня (L1) для команд и данных емкостью по 16 Кбайт;
• поддержка общей кэш-памяти команд и данных 2-го уровня (L2) емкостью до 2 Мбайт;
• конвейерное исполнение команд с реализацией 12 ступеней конвейера;
• предсказание направления программного ветвления с высокой точностью;
• ускоренное выполнение операций с плавающей точкой; ‘
• приоритетный контроль при обращении к памяти (защищенный режим);
• поддержка реализации мультипроцессорных систем;
• наличие внутренних средств, обеспечивающих самотестирование, отладку и мониторинг производительности.
Эти характеристики позволяют процессорам Р6 эффективно работать с разнообразным программным обеспечением под управлением операционных систем MS-DOS, Windows,OS/2, UNIX SVR4, Solaris 2,0, NextStep 486 и ряда других. Исполняемый код для этих процессоров полностью совместим с кодом предыдущих моделей микропроцессоров семейства Intel 80x86 (8086,8088,80186,80188,80286,80386,80486,Pentium, Pentium MMX, Pentium Pro), поэтому для них может использоваться весь объем ранее разработанного программного обеспечения.
2.1.1. СУПЕРСКАЛЯРНАЯ АРХИТЕКТУРА И ОРГАНИЗАЦИЯ КОНВЕЙЕРА КОМАНД
Общая структура процессоров семейства Р6 показана на рис. 2.1. Гарвардская внутренняя структура реализуется путем разделения потоков команд и данных, поступающих от системной шины через блок внешнего интерфейса в отдельные кэш-память команд и кэш-память данных, размещенные на кристалле процессора (кэш-память 1-го уровня, L1).
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
Системная шина
Рис, 2.1. Общая структура процессоров семейства Intel Р6
Блок внешнего интерфейса (BIU - Bus Interface Unit) реализует протоколы обмена процессора с системной шиной, к которой подключается память, контроллеры ввода/вы-вода, другие активные устройства системы, и шиной кэш-памяти 2-го уровня (L2), реализованной в виде отдельной микросхемы, размещаемой в общем корпусе (картридже) с микропроцессором. Обмен по системной шине осуществляется с помощью 64-разрядной двунаправленной шины данных, 41-разрядной шины адреса (33 адресных линии А35-3 и 8 линий выбора байтов ВЕ7-0#) и ряда линий для передачи сигналов управления.
Внутренняя кэш-память команд и данных 1 -го уровня (L1) емкостью по 16 Кбайт каждая служит для размещения наиболее часто используемых команд и данных. Доступ к ним выполняется с частотой, соответствующей тактовой частоте процессора (сотни МГц). Бла
СТРУКТУРА И ФУНКЦИОНИРОВАНИЯ ПРОЦЕССОРОВ INTEL Р6
годаря этому существенно повышается производительность процессора за счет значительного сокращения числа обращений к внешней памяти, которые выполняются с частотой, определяемой возможностями системной шины (десятки МГц). Процессоры семейства Р6 содержат также кэш-память 2-го уровня (L2) емкостью 256 Кбайт, 512 кбайт или 1 Мбайт, которая изготавливается на отдельном кристалле, но размещается в общем корпусе с процессором. Ее применение позволяет дополнительно повысить производительность.
Процессор содержит блок выборки - декодирования, который выбирает из кэш-памяти команд 32 байт командного кода (строка кэш-памяти длиной 256 бит), затем производит разделение и декодирование команд. При этом из выбранных команд выделяются простые команды, для выполнения которых достаточно одной микрооперации, и сложные команды, требующие выполнения нескольких микроопераций. К числу простых относятся, например, команды сложения, вычитания, сравнения, логических операций и ряд других, использующие регистровую адресацию операндов. Декодирование этих команд производят декодеры DC1, DC2, формирующие соответствующие микрокоманды. Декодер DC3 декодирует сложные команды (например, сложение, вычитание, сравнение, логические операции с выборкой операнда из памяти), выполнение которых требует до четырех микроопераций. Соответствующие микрокоманды формируются на выходах этого декодера. Более сложные команды (умножение, деление, операции с плавающей точкой и ряд других) требуют формирования последовательности нескольких микрокоманд. Для их реализации используется устройство микропрограммного управления с ПЗУ микропрограмм, которое обеспечивает на выходе DC3 необходимую последовательность микрокоманд. Таким образом, блок выборки - декодирования формирует шесть потоков микрокоманд, обеспечивающих параллельное выполнение трех команд программы.
Если в потоке команд оказывается команда условного перехода (ветвления программы), то включается блок предсказания ветвления, который формирует адрес следующей выбираемой команды до того, как будет определено условие выполнения перехода. Используемый механизм предсказания адреса перехода описан ниже.
После формирования потоков микрокоманд производится выделение регистров, необходимых для выполнения декодированных команд. Эта процедура реализуется блоком распределения регистров (RAT -Register Alias Table), который выделяет для каждого указанного в команде логического регистра (регистра целочисленных операндов EAX, ЕСХ и др. или регистра операндов с плавающей точкой STO - ST7) один из 40 физических регистров, входящих в блок регистров замещения (RRF - Retirement Register File). Эта процедура позволяет выполнять команды, использующие одни и те же логические регистры, одновременно или с изменением их последовательности.
Реализация наиболее эффективного выполнения потока декодированных команд обеспечивается блоком, который позволяет изменять последовательность команд (ROB - Re-Order Buffer). Этот блок реализован в виде буфера, в который поступают микрокоманды, реализующие выполнение ряда декодированных команд. Одновременно в буфере могут содержаться до 40 микрокоманд, которые затем направляются в исполнительные устройства по мере готовности операндов, поступающих из блока регистров RRF или выбираемых из памяти. При этом команды выполняются не в порядке их поступления, а по мере готовности соответствующих операндов и исполнительных устройств. В результате команды, поступившие позже, могут быть выполнены до ранее выбранных команд. Таким образом, естественный порядок следования команд нарушается, чтобы обеспечить более полную загрузку параллельно работающих исполнительных устройств и повысить производительность процессора.
Микрокоманды поступают в исполнительные устройства через блок распределения (RS -Reservation Station), который направляет их в соответствующее устройство после его освобождения. Блок распределения имеет пять выходных портов и обеспечивает в среднем выполнение трех команд одновременно.
ЛО
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
Суперскалярная архитектура реализуется путем организации исполнительного ядра процессора в виде ряда параллельно работающих блоков. Исполнительные блоки IU1, IU2 (IU - Integer Unit) производят обработку целочисленных операндов, блок FPU (Floating-Point Unit) выполняет операции над числами с плавающей точкой, блок ММХ реализует одновременную обработку нескольких упакованных символов, блок SSE, введенный в процессорах Pentium III, обеспечивает выполнение операций над потоком чисел с плавающей точкой. Один из целочисленных блоков выполняет также проверку условий ветвления для команд условных переходов и выдает сигналы перезагрузки конвейера команд в случае неправильно предсказанного ветвления.
Адреса операндов, выбираемых из памяти, вычисляются блоком MIU (Memory Interface Unite), который реализует интерфейс с кэш-памятью данных или внешней памятью. В его состав входят устройства генерации адреса AGU (Address Generated Unit), которые в соответствии с заданными в декодированных командах способами адресации одновременно формируют адреса двух операндов: один для операции чтения, второй - для операции записи. При этом MIU может формировать адреса и производить предварительное чтение операндов для команд, которые еще не поступили на выполнение. Такая процедура предварительного чтения данных для последующей их обработки в ис-полнительных блоках называется спекулятивной выборкой. Если команда, для которой проведена спекулятивная выборка операнда, не поступает на исполнение, то считанные данные теряются. Такой случай имеет место, например, для выбранных и декодированных команд, которые оказываются в нереализуемой ветви программы.
При выборке операнда из памяти производится обращение к кэш-памяти данный, которая имеет отдельные порты для чтения и записи. Таким образом обеспечивается одновременная выборка операндов для двух команд. При отсутствии адресуемого операнда в кэшпамяти данных (кэш-промах) с помощью буферного блока обращения к па-мяти MOB (Memory Order Buffer) осуществляется обращение к кэш-памяти 2-го уровня или основной памяти (по системной шине). Данный блок реализует спекулятивную выборку при чтении операнда.
Для промежуточного хранения данных, записываемых в основную память, в составе блока МОВ имеется буфер данных записи. Эта буферная память емкостью 32 байта позволяет задержать запись результата до того момента, когда системная шина завершит выполнение других циклов обмена, например, выборки команд или чтения процессором новых операндов. Запись результатов производится, когда процессор выполняет команды, не требующие обращения к системной шине. Таким образом обеспечивается дополнительное повышение производительности системы. Отметим, что буферизация не выполняется при обращении процессора к устройствам ввода/вывода с помощью команды OUT. Вывод данных в этом случае реализуется в очередном цикле шинного обмена.
Обмен с основной памятью при использовании кэш-памяти производится с помощью пакетных циклов обращения, которые позволяют за один цикл переслать содержимое целой строки кэш-памяти (32 байта). Внешняя 64-разрядная шина данных позволяет выполнить такую пересылку за 5 тактов машинного времени: первый такт служит для установки адреса строки, а в течение следующих четырех тактов идет передача данных. При этом необходимые сигналы управления обменом устанавливаются только один раз (в начале цикла), а изменение младших разрядов адреса в тактах передачи осуществляется автоматически основной памятью.
В процессорах Р6 реализован конвейер команд с 12 ступенями их выполнения. При прохождении первых семи ступеней (до блока изменения последовательности ROB) сохраняется исходный порядок следования команд, на трех исполнительных ступенях последовательность команд может быть нарушена, две заключительные ступени обеспечивают запись полученных результатов в память или регистры с восстановлением исходного ыу следования. Такое восстановление выполняется буферным блоком МОВ при
СТРУКТУРА И ФУНКЦИОНИРОВАНИЯ ПРОЦЕССОРОВ INTEL Р6
записи результатов в память или блоками изменения последовательности и распределения команд (ROB и RS) при записи результатов в регистр (блок RRF).
Последовательная работа конвейера команд нарушается при поступлении команд условных переходов, так как в случае выполнения условия перехода, которое проверяется в исполнительном устройстве, потребуется перезагрузка конвейера - очистка всех предыдущих ступеней и выборка команды из новой ветви программы. Чтобы сократить или исключить потери времени, связанные с перезагрузкой длинного 12-ступенчатого конвейера, используется блок предсказания ветвлений. Его основной частью является ассоциативная память, называемая буфером адресов ветвлений (ВТВ - Branch Target Buffer), в которой хранятся 512 адресов ранее выполненных переходов. Кроме того, ВТВ содержит четыре бита предыстории ветвления, которые указывают, выполнялся ли переход при четырех предыдущих выборках данной команды. При поступлении очередной команды условного перехода указанный в ней адрес сравнивается с содержимым ВТВ. Если этот адрес не содержится в ВТВ, т. е. ранее не производились переходы по данному адресу, то предсказывается отсутствие ветвления. В этом случае продолжается выборка и декодирование команд, следующих за командой перехода. При совпадении указанного в команде адреса перехода с каким-либо из адресов, хранящихся в ВТВ, производится анализ предыстории. В процессе анализа определяется чаще всего реализуемое направление ветвления, а также выявляются чередующиеся переходы. Если предсказывается выполнение ветвления, то выбирается и загружается в конвейер команда, размещенная по предсказанному адресу. Одновременно в блоке выборки - декодирования сохраняется декодированная следующая команда. Если после анализа условия ветвления выясняется, что предсказание было неправильным, эта декодированная команда поступает из УУ в исполнительное устройство, обеспечивая сокращение потерь времени на перезагрузку конвейера.
Используемый алгоритм предсказания ветвлений ориентирован на достаточно частое повторение обращения к процедуре, которая обеспечивается определенной ветвью программы. При этом рекомендуется более часто используемые процедуры располагать в ветвях, следующих непосредственно за командой перехода, чтобы сократить время перезагрузки конвейера при ошибочно предсказанных ветвлениях. По имеющимся оценкам, данный алгоритм обеспечивает вероятность правильного предсказания ветвлений на уровне 90%.
2.1.2. РЕЖИМЫ РАБОТЫ ПРОЦЕССОРА И ОРГАНИЗАЦИЯ ПАМЯТИ
Процессоры Р6, как и предыдущие модели микропроцессоров Intel 80286,80386,80486, Pentium имеют три основных режима функционирования:
• режим реальных адресов (реальный режим);
• режим защищенных виртуальных адресов (защищенный режим);
• режим системного управления.
В реальном режиме процессор работает как очень быстрый микропроцессор 8086, выполняющий обработку 16-разрядных операндов и адресующий 1 Мбайт оперативной памяти (20-разрядная шина адреса). При этом процессор реализует расширенный набор команд семейства Р6. Допускается также увеличение разрядности операндов и адресов До 32 с помощью префиксов, вводимых перед командами программы.
В защищенном режиме могут одновременно выполняться несколько отдельных задач (программ), которые защищены одна от другой и от операционной системы процессора. Специальный механизм обеспечивает переключение задач. В этом режиме процессор может также выполнять программы, написанные для микропроцессора 8086, если реализуется мо-
51
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
дификация защищенного режима - режим виртуального 8086. При работе в режиме виртуального 8086 процессор формирует 20-разрядный адрес, как и в реальном режиме, но может обрабатывать 32-разрядные операнды. В этом режиме обеспечивается, в случае необходимости, страничная организация памяти и защита системных программ, реализуемых процессором Р6, от пользовательских программ, выполнямых виртуальным процессором 8086 (двухуровневый механизм привилегий).
В процессорах Р6, как и в предыдущих моделях 80286,80386, 80486, «Pentium» используется четыре уровня защищенности (0, 1, 2, 3), определяющих возможность доступа к различным сегментам памяти: уровень 0- наибольшая защищенность сегмента, уровни 1 - 3 - более низкая степень защиты, которая уменьшается при возрастании номера уровня. Для каждой выполняемой программы (задачи) устанавливается один из четырех уровней привилегий, дающих право вызова сегментов: уровень 0 - максимальные привилегии, позволяющие вызывать сепиенты с любым уровнем защищенности; уровень 3 - минимальные привилегии, допускающие вызов сегментов только с минимальным уровнем защищенности 3; уровни 1, 2 имеют соответственно промежуточные привилегии. Устанавливаемые с помощью этих уровней правила обращения обеспечивают эффективную защиту сепиен-тов от несанкционированного доступа. Предусмотрены дополнительные возможности для управления доступом к устройствам ввода/вывода.
В защищенном режиме реализуется также многозадачное функционирование, когда процессор работает как несколько отдельных (виртуальных) процессоров, переключающихся под управлением операционной системы (ОС) на решение различных задач. При этом для управления процессором должна использоваться многозадачная ОС, например Windows NT, которая осуществляет распределение во времени возможностей доступа к имеющимся ресурсам системы: памяти, устройствам ввода-вывода, обеспечивая наиболее эффективное выполнение нескольких заданий.
Режим системного управления (SMM - System Management Mode) используется для реализации специальных системных функций, например, для перевода системы в режим пониженного энергопотребления. При этом процессор обращается к отдельному адресному пространству, где размещается системное ОЗУ. Переход в режим системного управления осуществляется путем подачи специального внешнего сигнала прерывания SMI# = 0, при этом процессор сохраняет в памяти контекст прерванной программы. В режиме SMM процессор функционирует как в реальном режиме с запрещенной обработкой прерываний. Выход из режима SMM производится с помощью команды, при этом восстанавливается контекст прерванной программы.
После включения питания или повторного запуска (процедура RESET) процессор начинает работу в реальном режиме. Переход процессора в защищенный режим реализуется с помощью команд LMSW или MOV CR0, которые выполняются только ядром операционной системы (программой, имеющей высший уровень привилегии 0). Эти команды устанавливают в регистре управления CR0 значение бита разрешения защиты РЕ = 1. Обратное переключение в реальный режим производится только командой MOV CR0, устанавливающей значение бита РЕ = 1. При работе процесора в защищенном режиме переход в режим виртуального 8086 выполняется путем установки в регистре флагов EFLAGS значения бита VM = 1. Установка этого значения бита или его сброс в состояние VM = 0 (выход из режима виртуального 8086) производится с помощью команды возврата из прерывания IRET, выполняемой программой с высшим уровнем привилегий 0, или в процессе переключения задач.
Процессор оперирует с физической памятью объемом до 64 Гбайт. Каждый байт памяти имеет свой физический адрес - от OOOOOOOOOOh до FFFFFFFFFh. В памяти могут храниться 8-разрядные байты, 16-разрядные слова, 32-разрядные двойные слова и 64-разрядные счетверенные слова. При выполнении блоком SSE потоковых SIMD-команд используются
СТРУКТУРА И ФУНКЦИОНИРОВАНИЯ ПРОЦЕССОРОВ INTEL Р6
128-разрядные операнды. Слова занимают два смежных байта памяти, двойные и счетверенные слова - четыре и восемь смежных байт, причем младший байт располагается в ячейке с меньшим адресом, а старший байт - в ячейке с большим адресом. Адресом слова служит адрес младшего байта.
Процессор выполняет обращение к памяти, использующей два способа организации -сегментацию и разбиение на страницы.
Сегментация памяти обеспечивается при любом режиме работы процессора. Сегментация реализуется путем разбиения адресного пространства на отдельные блоки - сегменты, доступ к которым производится в соответствии с определенными правилами. Сегментированная память представляет собой набор блоков, характеризуемых определенными атрибутами, такими как расположение, размер, тип (стек, программа, данные), характеристика защиты. В системе на основе процессора Р6 каждой задаче доступны до 8192 сегментов величиной до 4 Гбайт кахщый. Таким образом обеспечивается возможность использования до 64 Тбайт виртуальной памяти. Для обращения к ячейке сегментированной памяти используется составной (логический) адрес, который состоит из селектора, задающего базовый адрес сегмента (начало), и относительного адреса ячейки (байта, слова) в сегменте. Арифметическое сложение базового и относительного адреса дает физический (линейный) адрес байта или слова (одинарного, двойного или счетверенного). Правила определения базового адреса сегмента зависят от режима работы микропроцессора (реальный или защищенный). Формирование относительного адреса определяется заданным методом адресации.
Страничная организация памяти обеспечивается только в защищенном режиме. Для ее реализации необходимо с помощью команды LMSW или MOV CRO установить в регистре CR0 значение бита страничной адресации PG = 1. При этом сегменты делятся на отдельные страницы емкостью 4 Кбайт или 4 Мбайт, размещаемые в различных позициях адресного пространства ОЗУ. Страницы могут группироваться в разделы. Размещение разделов и страниц в ОЗУ производится диспетчером памяти, входящим в состав операционной системы. Диспетчер задает базовые адреса разделов и страниц, которые хранятся в памяти в виде адресных таблиц. При использовании страничной организации блоки трансляции адреса, входящие в состав процессора, преобразуют адрес, сформированный MIU (при выборке операнда) или блоком выборки-декодирования (при выборке команды), в реальный физический адрес байта или слова. В процессе этого преобразования, который называется страничной трансляцией адреса, блок трансляции обращается к хранящимся в ОЗУ адресным таблицам. Чтобы уменьшить число таких обращений и повысить, таким образом, производительность процессора, базовые адреса 32 страниц памяти команд и данных, к которым выполнялись последние обращения, записываются во внутренние буферы трансляции адреса (TLB). При обращении к этим страницам их базовые адреса считываются из буфера, поэтому формирование физического адреса происходит существенно быстрее.
Страничная трансляция позволяет расширить объем адресуемой памяти до 64 Гбайт, используя 36-разрядную шину адреса. Такая возможность реализуется, если установить в регистре управления CR4 значение бита РАЕ = 1. При этом в адресных таблицах задаются 36-разрядные базовые адреса разделов и страниц, а размер страниц может составлять 4 Кбайт или 2 Мбайт.
2.1.3. РЕГИСТРОВАЯ МОДЕЛЬ
Регистровая модель процессоров Р6 содержит набор регистров, большинство из которых входят в состав более ранних моделей семейства Intel 80x86/Pentium. Эти регистры составляют следующие группы.
53
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
1. Основные функциональные регистры:
регистры общего назначения ЕАХ.ЕВХ, ECX,EDX,ESP,EBP,ESI,EDI;
указатель команд EIP;
регистр флагов EFLAGS;
регистры сегментов CS,SS,DS,ES,FS,GS.
2. Регистры блока обработки чисел с плавающей точкой (регистры FPU):
регистры данных R7-0 (ST7-0);
регистр тегов TW;
регистр состояния FPSR;
регистр управления FPCR;
регистры-указатели команды и операнда FIP, FDP.
3. Регистры обработки пакетов чисел с плавающей точкой (регистры SSE): регистры пакетов данных ХММ7-0;
регистр управления состояния MXCSR.
4. Системные регистры:
регистры управления режимом CR4-0;
регистры системных адресов GDTR, LDTR, IDTR, TR;
регистры отладки DR7-0.
5. Служебные (модельно-специфические) регистры.
Регистры первых трех групп используются при выполнении прикладных программ, регистры 4-й группы - при выполнении системных программ и отладке, регистры 5-й группы - при тестировании микропроцессора и контроле эффективности выполнения программ. Системные и служебные регистры доступны только программам с высшим уровнем привилегий 0.
Номенклатура и содержимое служебных (модельно-специфических) регистров MSR (Model-Specific Registers) определяется конкретной моделью процессора. Запись и чтение их содержимого производится с помощью команд WRMSR и RDMSR. Обращение к некоторым из них может вызвать исключение, если эти регистры отсутствуют в данной модели. Регистры MSR используются в процессе отладки систем, содержат информацию о процессе выполнения программы (число декодированных команд, полученных запросов прерывания, число загрузок в кэш-память и т. п.), обеспечивают различные режимы работы кэш-памяти при обращении к определенным областям основной памяти (MTRR-регистры).
Полная номенклатура MSR содержит более 80 регистров, описание назначения которых выходит за рамки данной книги. В последующих разделах будет рассмотрено функционирование ряда регистров MSR, обеспечивающих реализацию определенных режимов работы процессора.
Основные функциональные регистры. Состав основных функциональных регистров (рис. 2.2) идентичен для всех 32-разрядных микропроцессоров семейства Intel 80x86 и Pentium.
Восемь 32-разрядных регистров общего назначения - EAX, ЕВХ, ЕСХ, EDX, ESI, EDI, EBP, ESP предназначены для хранения данных и адресов. Младшие 16 разрядов этих регистров доступны под именами АХ, ВХ, СХ, DX, SI, DI, BP, SP. При операциях с байтами можно отдельно обращаться к младшему (разряды 7-0) или старшему (разряды 15-8) байту регистров АХ, ВХ, СХ, DX: младшие байты имеют имена AL, BL, CL, DL, старшие - АН, ВН, CH, DH.
Сегментные регистры CS, SS, DS, ES, FS, GS содержат 16-разрядные значения селекторов сегментов, определяющих адресуемый сегмент памяти. В реальном режиме содержимое этих регистров непосредственно задает значение базового адреса соответствующего сегмента. В защищенном режиме содержимое этих регистров задает выбор дескриптора, который содержит значение базового адреса и другие атрибуты сегмента.
СТРУКТУРА И ФУНКЦИОНИРОВАНИЯ ПРОЦЕССОРОВ INTEL Р6
Соответствующий дескриптор выбирается из таблицы, хранящейся £дх
в ОЗУ, и размещается в программ- есх
но-недоступном (теневом) регист- Еох
ре дескриптора сегмента (рис. 2.2). евх
Селектор в регистре CS обеспечи- Es₽
вает обращение к сегменту команд, Евр
селектор в SS - к сепиенту стека, селекторы в DS, ES, FS, GS - к сегментам данных. Eip
Указатель команд EIP пред- eflags ставляет собой 32-разрядный регистр, содержимое которого используется в качестве смещения
при определении адреса следующей выполняемой команды. Смещение задается относительно базового адреса сегмента команд, задаваемого регистром CS. Младшие 16 бит EIP (биты 15-0) содержат 16-разрядный указатель команд с именем IP, который исполь-
Базовый Граница Атрибуты
адрес сегмента сегмента
Рис. 2.2. Основные функциональные регистры процессора Р6
зуется при 16-разрядной адресации. Содержимое EIP (IP) изменяется при выполнении команд передачи управления и прерываний.
Регистр флагов EFLAGS (рис. 2.3) содержит ряд битов, которые имеют различное назначение: признаки состояния CF, PF, AF, ZF, SF, OF указывают определенные характеристики результата, полученного при выполнении команды; управляющий признак DF определяет порядок адресации операндов при выполнении последовательности команд обработки строк символов; системные признаки TF, IF, IOPL, NT, RF, VM, AC, VIF, VIP, ID задают режим процессора при обслуживании исключений и прерываний, органи-
зации ввода-вывода данных, решении последовательности вызываемых задач и реализации ряда других процедур. Младшие шестнадцать бит регистра EFLAGS (биты 15-0) представляют 16-разрядный регистр флагов FLAGS, который используется при выполнении программ, написанных для микропроцессоров 8086, 80186, 80286.
Признаки состояния в регистре EFLAGS имеют следующее значение:
CF - признак переноса, принимает значение CF = 1 при возникновении переноса из старшего разряда обрабатываемых операндов;
PF-признак четности, принимает значение PF = 1, если младшие восемь разрядов результата содержат четное число единичных бит;
AF - признак полупереноса, принимает значение AF = 1, если при выполнении операции возникает перенос между младшими тетрадами (из разряда 3 в разряд 4) обрабатываемых операндов; используется при операциях с операндами, представленными в двоично-десятичном коде (BCD);
ZF - признак нуля, принимает значение ZF = 1 при получении нулевого результата операции;
15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 _______О
0 NT IOPL OF OF IF TF SF ZF 0 AF 0 PF 1 CF
—° 0 0 I 0 0 0 0 0 0 0 ID VIP VIF AC VM RF
31 30 29 28 27 26 25 24 23 22 21 20 19 18 17 16
Рис. 2.3. Формат содержимого регистра EFLAGS
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
SF-признакзнака, принимает значение старшего (знакового) разряда результата операции (S = 0-положительное число, S= 1 -отрицательное);
OF-признакпереполнения, принимает значение OF = 1 в случае переполнения разрядной сетки при обработке операндов со знаком; значение признака для п-разрядных операндов определяется логическим выражением OF = Сп + Сп - 1, где Сп - перенос, возникающий в старшем (л - 1)-м разряде (знаковом), Сп - 1 - перенос, возникающий в предыдущем (п - 2)-м разряде;
Значение управляющего признака DF устанавливается пользователем и задает порядок обработки строк символов при выполнении соответствующих команд:
DF - признак направления, при значении DF - 0 вызывает автоматический инкремент содержимого индексных регистров ESI, EDI (SI,DI) после выполнения команды обработки символа, при DF = 1 - декремент содержимого этих регистров; таким образом обеспечивается обработка символов слева направо (от младших адресов к старшим) или в обратном направлении (от старших адресов к младшим).
Системные признаки (кроме NT) устанавливаются операционной системой, которая с их помощью задает определенные режимы выполнения ряда процедур:
TF - признак трассировки, при значении TF = 1 процессор переключается в режим пошагового выполнения команд с реализацией после каждой команды соответствующего прерывания;
IF-признакразрешения прерывания, установка значения IF = 1 разрешает обслуживание запроса прерывания, поступающего на внешний вход INTR;
IOPL-уровень привилегий ввода/вывода, задает максимальную величину уровня привилегий текущей программы, при котором разрешается выполнение команд ввода/вывода;
NT-признаквложенной задачи, принимает значение NT = 1 при переключении процессора на выполнение другой задачи с помощью команды вызова CALL; используется для организации многозадачного режима;
RF- признак маскирования ошибок отладки, при установке значения RF = 1 возможные ошибки отладки игнорируются при выполнении следующей команды; используется в процессе отладки программ;
VM - признак режима виртуального 8086, установка значения VM = 1 вызывает переключение процессора в режим виртуального процессора 8086, при котором эмулируются возможности микропроцессора 8086;
АС - признак контроля выравнивания, установка значения АС = 1 и бита AM = 1 в регистре CR0 вводит контроль выравнивания операндов при обращениях к памяти; в этом случае при обращении к невыравненному операнду (выборка слова по нечетному адресу или двойного слова по адресу, не кратному четырем) реализуется исключение типа #АС;
VIF-признак разрешения обслуживания виртуального прерывания, установка значения VIF = 1 разрешает обслуживание запросов виртуальных прерываний, поступление которых фиксируется установкой признака VIP = 1;
VIP-признак запроса виртуального прерывания, значение VIP = 1 устанавливается операционной системой в защищенном режиме, если внешний запрос прерывания поступает при выполнении программ пользователя (низший уровень привилегии CPL = 3) с запрещенным обслуживанием прерываний;
ID - признак допустимости идентификации, возможность программного изменения значения ID указывает, что для данного процессора обеспечивается выполнение команды идентификации CPUID.
Особенности использования системных признаков рассматриваются в последующих разделах, где описываются соответствующие режимы работы процессора.
Регистры блока обработки чисел с плавающей точкой. В состав блока FPU процессоров Р6 входят восемь регистров данных R7-R0, регистр тегов TW, регистры «появления FPCR и состояния FPSR, указатели команды FIP и данных FDP (рис. 2.4).
СТРУКТУРА И ФУНКЦИОНИРОВАНИЯ ПРОЦЕССОРОВ INTEL Р6
Регистры данных FPU (арифметический стек) Теги
Рис. 2.4. Регистры блока FPU
Регистры данных R7-R0 содержат по 80 разрядов, разбитых натри поля: знак, порядок и мантисса, в соответствии с форматом представления чисел с плавающей точкой. Набор этих регистров организован в виде кольцевого стека, вершина которого определяется содержимым поля ТОР в регистре состояния FPSR (рис. 2.5). При выполнении различных операций над содержимым регистров данных расположение вершины стека изменяется.
Регистр тегов TW содержит 16-разрядное слово, включающее восемь двухбитных тегов tag7-tag0 (см. рис. 2.5). Каждый тег (признак) характеризует содержимое соответствующего регистра данных R7-R0, указывая, является ли регистр пустым (незаполненным) или в нем размещается конечное число, нуль или неопределенное значение (например, бесконечность). Значение тега
позволяет проверить содержимое регистра, не проводя анализ хранящихся в нем данных.
Регистр состояния FPSR хранит 16-разрядное слово состояния FPU (см. рис. 2.5), отдельные биты и поля которого имеют следующее назначение:
В - признак занятости, включен в состав слова состояния для совместимости с младшими моделями процессоров; значение В дублирует значение ES-общего признака ошибки FPU;
ТОР- поле, указывающее вершину арифметического стека (см. рис. 2.4); содержит номер регистра данных FPU, являющегося в данное время верхним в стеке;
СЗ-СО - признаки результата, значение которых характеризует результат выполнения команды FPU;
ES- общий признак ошибки, принимает значение ES = 1, если установился хотя бы один из признаков ошибки операции FPU в шести младших разрядах FPSR; одновременно выдается сигнал FERR# = 0 на соответствующий внешний вывод процессора;
SF- признак переполнения стека, принимает значение SF = 1 при нарушении нормальной работы арифметического стека; используется совместно с признаком С1: если SF = 1, то значение С1 = 1 указывает на выход за верхнюю границу (переполнение) стека, а С1 =0-на выход за нижнюю границу (антипереполнение) стека.
Младшие шесть разрядов содержимого FPSR хранят признаки ошибок, возникающих при выполнении команд FPU:
РЕ- признак нарушения точности;
UE- признак антипереполнения;
ОЕ- признак переполнения;
ZE- признак деления на нуль;
DE- признак денормализованного операнда;
/Е-признак неправильной операции.
15 14 1 3 1 2 1 1 10 9 8 7 6 5 4 3 2 1 О
tag? tag6 | tag5 tag4 tag3 tag2 tag1 tagO
В сз ТОР I сз C1 | CO ES SF PE UE OE ZE DE IE
X X x | x | RC PC X X PM UM OM ZM DM IM
Рис. 2.5. Форматы содержимого регистров TW, FPSR, FPCR
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
Таблица 2.1 Таблица 2.2
Управление округлением Точность представления результата
при операциях FPU___________ ____________ при операциях FPU_____________
RC Метод округления
00 К ближайшему числу
01 К минус бесконечности
10 К плюс бесконечности
11 К нулю
PC Т очность представления
00 Одинарная
01 (Не используется)
10 Двойная
11 Расширенная
Регистр управления РРСЩрис. 2.5) содержит в младшем байте биты PM, UM, ОМ, ZM, DM, IM, маскирующие соответствующие признаки ошибок, фиксируемых в регистре состояния FPSR. При единичном значении бита маски запрещается прерывание при возникновении соответствующей ошибки FPU. При нулевом значении бита маски установка соответствующего признака ошибки FPU вызывает прерывание процессора.
Старший байт в регистре управления FPSR определяет режим округления и точность представления результатов вычислений:
RC- поле управления округлением (табл. 2.1) определяет выбор одного из методов округления результата операций FPU;
PC- поле управления точностью (табл. 2.2) задает точность представления результатов арифметических операций FPU: одинарную (23 разряда мантиссы, 8 разрядов порядка), двойную (52 разряда мантиссы, 11 разрядов порядка) или расширенную (64 разряда мантиссы, 15 разрядов порядка).
Поле PC учитывается только при выполнении команд FADD, FSUB, FDIV, FMUL, FSQRT. Для остальных команд FPU используется расширенная точность.
Регистры -указатели команд FIPu данных. FDPслужат для идентификации команды, вызвавшей ошибку операции FPU. Содержимое этих регистров зависит от режима работы процессора. В реальном режиме при возникновении ошибки при выполнении команды FPU в эти регистры заносятся адрес и код операции данной команды, адрес использованного операнда. В защищенном режиме в них заносятся селекторы сегментов и относительные адреса команды и операнда. Эта информация используется подпрограммой обработки прерываний для выяснения причины ошибки FPU.
Системные регистры. В состав этой группы регистров (рис. 2.6) входят регистры управления CR4-CR0, регистры системных адресов GDTR, LDTR, IDTR, TR и регистры отладки DR7-DR0. Эти регистры доступны только в защищенном режиме для программ, имеющих максимальный уровень привилегий 0. Для доступа к системным регистрам используются специальные команды пересылки данных.
Регистры управления процессора имеют следующее назначение:
CR0 - содержит биты, определяющие режим работы процессора (рис. 2.7, а);
CR2- содержит 32-разрядный базовый адрес страницы, при обращении к которой зафиксирована ошибка при страничной адресации;
CR3 - содержит базовый адрес таблицы каталога страниц (20 старших битов), а также биты, управляющие загрузкой страниц в кэш-память данных (рис. 2.7, б);
CR4 - содержит биты, обеспечивающие расширение функциональных возможностей, реализуемое в процессорах Pentium и Р6 (рис. 2.7, в).
Форматы содержимого регистров CRO, CR3, CR4 приведены на рис. 2.7. Регистр CR1 в процессорах Р6 и более ранних моделях не используется (резервирован для последующих моделей).
СТРУКТУРА И ФУНКЦИОНИРОВАНИЯ ПРОЦЕССОРОВ INTEL Рв
Регистры управления
Рис. 2.6. Системные регистры процессоров Р6
Регистр управления CRO (рис. 2.7, а) содержит 11 битов, задающих режим работы различных блоков процессора:
РЕ - разрешение защиты, установка значения бита РЕ = 1 переводит процессор в защищенный режим, бит РЕ совместно с битом PG определяет режим работы процессора (см. табл .2.1);
МР-управление работой FPL), при установке значения МР = 1 и переключении задач (установка бита TS = 1) выборка команды WAIT (FWAIT) вызывает исключение типа #NM (отсутствие FPU);
ЕМ-эмуляция FPU, при установке значения ЕМ = 0 указывает на присутствие в системе блока FPU; установка значения ЕМ=О вызывает при выборке команды FPU исключение типа #NM (отсутствие FPU), которое должно обеспечить обращение к под-программе, эмулирующей работу FPU;
TS - признак переключения задачи, принимает значение TS= 1 при каждом переключении задачи и проверяется при поступлении команд FPU: если TS = 1, то реализуется исключение типа #NM (отсутствие FPU);
ЕТ-в процессорах семейств Р6 и Pentium не используется (резервирован); в процессорах Intel 386,486 установка значения ЕТ = 1 указывает на включение в систему математических сопроцессоров Intel 387DX;
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
a) CR0
15 14 13 12 1 1 10 9 8 7 6 5 4 3 2 1 0
X X X X X X X X X X NE ЕТ TS ЕМ MP PE
PG PC NW X X X X X X X X X X AM X WP
31 30 29 28 27 26 25 24 23 22 21 20 19 18 17 16
6) CR3
31_____________________________12 11______________5 4 3 2 0
| Базовый адрес таблицы разделов | х х х х х х х | PCD | PWT | х х х |
е) CR4
31_______10 9 8 7 6 5 4 3 21 0
| 00......00 I OSFXSR I РСЕ | PGE | MCE | РАЕ | PSE | DE | TSP | PVI | УМЕ |
Рис. 2.7. Форматы содержимого регистров управления CR0 (a), CR3 (б), CR4 (в)
NE - управление прерываниями FPU, при установке значения бита NE = 1 ошибки, возникающие при выполнении команд FPU, вызывают исключение типа #MF (ошибка FPU) при выборке следующей команды FPU; при установке значения NE = 0 ошибка FPU вызывает выдачу на соответствующий вывод процессора сигнала FERR# = 0, который поступает во внешний контроллер прерываний (этот способ обслуживания прерываний FPU реализуется в персональных компьютерах);
WP-защита от записи, при установке значения бита WP = 1 программам супервизора, имеющим уровень привилегий 0-2, запрещается запись на страницы пользователя, имеющие уровень привилегии 3; при значении WP = 0 такая запись разрешена;
AM - управление проверкой выравнивания, разрешает при установке значения бита AM = 1 проверку выравнивания адресов по границам слов (кратные двум) или двойных слов (кратные четырем) выборке операндов из памяти, если в регистре EFLAGS установлено значение бита АС = 1 и выполняемая программа имеет уровень привилегии 3 (программа пользователя);
NW - запрещение записи в кэш-память, совместно с битом CD определяет режим работы внутренней кэш-памяти процессора;
. CD-запрещение заполнения кэш-памяти, совместно с битом NW определяет режим работы внутренней кэш-памяти процессора;
PG - разрешение страничной трансляции адреса, при установке значения PG = 1 обеспечивает страничную адресацию памяти в защищенном режиме (табл. 2.3).
Отметим, что биты MP, ЕМ, TS влияют также на выполнение команд, реализуемых блоком ММХ. В табл. 2.4 указано, как реагирует процессор на поступление команд FPU или ММХ в зависимости от установленного значения этих битов.
Таблица 2.3
Режимы работы процессора
PG PE Режим процессора
0 0 Реальный режим
0 1 Запрещенный режим без использования страничной адресации
1 0 Запрещенная комбинация (вызывает исключение типа #СР-нар> шение защиты)
1 1 Защищенный режим с использованием страничной адресации
СТРУКТУРА И ФУНКЦИОНИРОВАНИЯ ПРОЦЕССОРОВ INTEL Р6
Таблица 2.4
Режимы работы блоков FPU и ММХ
Биты CR0 Выполняемые команды
ЕМ MP TS Команды FPU Команда WAIT (FWAIT) Команды MMX
0 0 0 Выполняется Выполняется Выполняется
0 0 1 Исключение #NM Выполняется Исключение #NM
0 1 0 Выполняется Выполняется Выполняется
0 1 1 Исключение #NM Исключение #NM Исключение #NM
1 0 0 Исключение #NM Выполняется Исключение #UD
1 0 1 Исключение #NM Выполняется Исключение #UD
1 1 0 Исключение #NM Выполняется Исключение #UD
1 1 1 Исключение #NM Исключение #NM Исключение #UD
Младшие 16 разрядов регистра CR0 для совместимости с защищенным режимом микропроцессора 80286 называют словом состояния машины MSW (Machine State Word). Команды загрузки и сохранения LMSW, SMSWflnn совместимости с микропроцессором 80286 работают только с младшими 16 разрядами регистра CR0. Для загрузки или сохранения всего содержимого регистра CR0 используются команды MOV CRO, r/m или MOV r/m, CRO, выполняемые программами с максимальным уровнем привилегии 0.
Регистр CR3 (см. рис. 2.7, б) содержит 20 старших разрядов базового адреса таблицы разделов, который используется при трансляции адреса в случае страничной организации памяти. Кроме того в этом регистре содержатся два бита, управляющих кэш-памятью при страничной адресации:
PCD-запрещает при установке значения PCD = 1 загрузку содержимого страницы в кэшпамять; при значении PCD = 0 такая загрузка разрешена;
PWT- определяет режим работы кэш-памяти при страничной адресации: при установке значения PWT = 1 реализуется режим сквозной записи (write-through), при установке PWT = 0 реализуется режим обратной записи (write-back).
Следует отметить, что биты PCD, PWT влияют на работу кэш-памяти только при страничной адресации (когда в регистре CR0 установлены значения РЕ = PG = 1). В этом случае они определяют режим работы как внутренней кэш-памяти (L1), так и внешней кэшпамяти 2-го уровня (L2).
В регистре CR4, который введен в процессорах Pentium, Р6, содержатся девять управляющих битов, обеспечивающих расширение архитектурных возможностей этих процессоров:
УМЕ- определяет способ обработки прерываний (исключений) в режиме виртуального 8086;
PVI - разрешает при установке значения VME = 1 реализацию виртуальных прерываний в защищенном режиме;
TSD- разрешает при установке значения TSD = 1 выполнение команды RDTSC (чтение содержимого таймера реального времени) только программам с максимальным уровнем приоритета 0, при TSD = 0 эта команда может выполняться программой с любым уровнем приоритета;
DE- при установке значения DE = 1 вызывает исключение #UD в случае обращения к регистрам отладки DR4, DR5, которые отсутствуют в процессорах Pentium, Р6; при DE = 0 при обращении кэти регистрам реализуется обращение к регистрам DR6, DR7;
PSE- расширяет размер адресуемых страниц до 4 Мбайт при установке значения PSE = 1, при значении PSE = 0 сохраняется размер страниц 4 Кбайт;
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
РАЕ - обеспечивает расширение разрядности физического адреса до 36 бит при установке значения РАЕ = 1;
MCE- разрешает реализацию исключения машинного контроля #МС при установке значения МС = 1;
PGE-позволяет при значении PGE = 1 определять некоторые страницы (часто используемые или используемые несколькими процессорами) как глобальные (путем установки бита глобальности G = 1 в указателе страницы или раздела); при очистке буфера страничной трансляции TLB командой MOV CR3 адреса глобальных страниц сохраняются;
РСЕ-разрешает при установке значения РСЕ = 1 выполнение команды RDPMC (чтение содержимого счетчиков, характеризующих эффективность работы процессора) программой с любым уровнем привилегий; при значении РСЕ = 1 эта команда может выполняться только программой с максимальным уровнем привилегий 0.
OSFXCR-разрешает при установке значения OSFXCR = 1 выполнение команд FXSAVE/ FXRSTOR, используемых для сохранения/восстановления состояния регистров блоков FPU, MMX, SSE при переключении задач.
Более подробно назначение этих управляющих битов описано в последующих разделах, где рассматриваются соответствующие режимы функционирования процессора.
Регистры системных адресов GDTR, IDTR, LDTR, TR (см. рис. 2.6) служат для обращения к таблицам и сегментам, с помощью которых осуществляется адресация памяти в защищенном режиме:
GDT-таблица глобальных дескрипторов;
IDT-таблица дескрипторов прерываний;
LDT - таблица локальных дескрипторов;
TSS-сегмент состояния задачи.
Регистр таблицы глобальных дескрипторов GDTR и регистр таблицы дескрипторов прерываний IDTR содержат 32-разрядные базовые адреса и 16-разрядные размеры таблиц GDT и IDT. Эти таблицы являются общими для всех задач. В регистр таблицы локальных дескрипторов LDTR и регистр задачи TR заносятся 16-разрядные селекторы, позволяющие обратиться к таблице LDT и сегменту TSS, которые определены для каждой отдельной задачи. С каждым из этих регистров связан программно недоступный регистр дескриптора сегмента.
Процессоры Р6 содержат также восемь 32-разрядных регистров отладки DR7-0.
2.1.4. ВНУТРЕННЯЯ КЭШ-ПАМЯТЬ
Кэш-память представляет собой быстродействующую буферную память ограниченного объема, которая располагается между процессором и относительно медленной основной памятью. В процессе работы отдельные блоки информации копируются из основной памяти (ОЗУ) в кэш-память. Процедура загрузки информации из ОЗУ в кэш-память называется кэшированием. Когда процессор обращается за командой или данными, то сначала проверяется их наличие в кэш-памяти. Если необходимая информация находится там, то она быстро извлекается, так как обращение к кэш-памяти производится стактовой частотой процессора. Такой случай обращения называют кэш-попаданием. Если необходимая информация в кэшпамяти отсутствует, то она выбирается из основной памяти и одновременно заносится в кэш-память. Такой случай называют кэш-промахом.
Повышение быстродействия вычислительной системы достигается в том случае, когда кэш-попадания реализуются намного чаще, чем кэш-промахи. Высокий процент кэш-попаданий обеспечивается благодаря тому, что в большинстве случаев программы
-------.. памяти, оасположенным вблизи от ранее использованных. Это свой
СТРУКТУРА И ФУНКЦИОНИРОВАНИЯ ПРОЦЕССОРОВ INTEL Р6
ство, которое называют локальностью программ, обеспечивает эффективность использования кэш-памяти.
В процессорах Р6 используется отдельная внутренняя кэш-память для хранения команд и данных, каждая из которых имеет объем 16 Кбайт. Кэш-память имеет несколько режимов работы, обеспечивающих гибкость при выполнении программ и в процессе их отладки. Отдельные области памяти могут быть определены программным обеспечением или внешней аппаратурой как не подлежащие кэшированию (загрузке в кэш-память).
Помимо внутренней кэш-памяти (уровень L1) в системах, реализуемых на базе процессоров Р6, используется дополнительная внешняя кэш-память (уровень L2), которая размещается на отдельном кристалле, но монтируется в общем корпусе с процессорным кристаллом. Для обращения к этой кэш-памяти служит отдельная шина, подключаемая к блоку внешнего интерфейса (см. рис. 2.1), которая работает с тактовой частотой процессора. Емкость кэш-памяти уровня L2 для различных моделей процессоров Р6 составляет 256 Кбайт, 512 Кбайт или 1 Мбайт.
Структура кэш-памяти, используемой в процессорах Р6, приведена на рис. 2.8. Эта память ассоциативного типа состоит из строк длиной по 32 байт. В кэш-памяти команд строки объединены в 128 наборов S0-S127 по четыре строки в каждом (LO, L1, L2, L3). В кэш-памяти данных содержится 256 наборов S0-S255 по две строки (LO, L1). Общая кэш-память команд-данных 2-го уровня содержит наборы из четырех строк.
Рис. 2.8. Структура кэш-памяти и реализация обращения к ней
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
Адресация кэш-памяти осуществляется с помощью 32 разрядов адреса, которые делятся на три поля: TAG, SET, BYTE (рис. 2.8). При обращении к кэш-памяти содержимое поля SET определяет номер выбираемого набора. Значения старших разрядов адреса (поле TAG) сравниваются с содержимым полей тегов (tag0-tag3) в строках выбранного набора. Если значение TAG совпадает с содержимым тега одной из строк, то фиксируется кэш-попадание, и производится выборка из этой строки операнда, адресуемого полем BYTE. Если совпадение не обнаружено, то фиксируется кэш-промах. В этом случае из основной памяти выбирается строка (32 байт), адресуемая разрядами А31-5 адреса, которая размещается в одной из строк выбранного набора. Заполнение кэш-памяти производится ; построчно, т. е. в случае кэш-промаха из основной памяти копируется целая строка, вклю- ' чаюшая адресованный операнд. При этом обновляется строка в наборе, номер которого ‘ определяется полем SET сформированного физического адреса. Старшие разряды адре- ! са (поле TAG) заносятся в поле tag и становятся атрибутом данной строки. I
Пересылка строк между кэш-памятью и основной памятью выполняется блоком внеш- i. него интерфейса с помощью пакетных циклов. При этом по 64-разрядной внешней шине данных за пять тактов передается 256 бит (полная строка). Использование пакетных циклов и 64-разрядной системной шины обеспечивает достаточно быстрое обновление содержимого кэш-памяти.
Нормальная работа микропроцессорной системы с кэш-памятью обеспечивается соответствующими механизмами, которые поддерживают когерентность - соответствие содержимого основной памяти и кэш-памяти. Это соответствие достигается с помощью механизмов сквозной записи (Write-Through) или обратной записи (Write-Back).
При сквозной записи выполняется одновременное изменение содержимого кэш-памяти и основной памяти. Таким образом, при любом цикле записи, даже в случаев кэш-попада-ния, производится обращение к основной памяти по системной шине. Данное обстоятельство существенно снижает производительность системы, так как циклы обращения по этой шине выполняются с тактовой частотой системной платы, которая значительно ниже тактовой частоты процессора.
При обратной записи изменение содержимого строки кэш-памяти вызывает установку признака модификации (состояние М). При обновлении содержимого кэш-памяти ее строки, находящиеся в состоянии М (имеющие установленный признак модификации), переписываются обратно в основную память. Таким образом, обращение к основной памяти в циклах записи производится только в случае кэш-промаха. При использовании кэшпамяти значительной емкости процессор может достаточно долго работать без обращения к основной памяти. Этот механизм наиболее часто используется современными процессорами, хотя многие из них могут реализовать как обратную, так и сквозную запись. В процессорах Р6 изменить механизм записи при страничной адресации можно путем соответствующей установки бита PWT в регистре CR3.
Каждая кэш-память имеет собственную служебную память, где хранятся биты, характеризующие содержимое ее строк: биты обращения ВО (если наборы содержат по 2 строки) или ВО - В2 (если наборы содержат по четыре строки), используемые при обновлении строки набора в соответствии с алгоритмом LRU (биты LRU), биты состояния SO - S1, с помощью которых обеспечивается когерентность содержимого строки в кэш-памяти и основной памяти согласно протоколу MESI (биты MESI).
Если при чтении произошел кэш-промах и кэширование данной области памяти разрешено, то производится обновление содержимого одной из строк набора, заданного полем SET адреса, в которую вводится информация из основной памяти. Новая информация замещает ранее имевшуюся в данной строке. В первую очередь замещается содержимое строки, отмеченной с помощью битов MESI как недостоверная (состояние I). Если в данном наборе нет недостоверной («пустой») строки, то производится удаление из кэш-памя-
СТРУКТУРА И ФУНКЦИОНИРОВАНИЯ ПРОЦЕССОРОВ INTEL Р6
ти содержимого строки, которая дольше всего оставалась невостребованной. Используемый алгоритм обновления называется «замещение менее используемой информации» (LRU - least recently used) и реализуется с помощью битов LRU. Один (ВО) или три (ВО - В2) бита LRU хранятся в служебной памяти для каждого из наборов строк кэш-памяти. Их содержимое определяет выбор строки, замещаемой в данном наборе при кэш-промахе.
При инициализации процессора и очистке кэш-памяти биты LRU всех наборов кэшпамяти сбрасываются в 0. В ходе работы процессора биты В0-В2 принимают следующие значения в соответствии с тем, к каким из строк набора производились последние обращения. Если в данном наборе последнее обращение выполнялось к одной из пары строк -L0 или L1, устанавливается ВО - 1, если к L3 или L4, то устанавливается ВО = 0. Биты В1 и В2 указывают, к какой из строк пары L1 - L2 и L3 - L4 осуществлялось последнее обращение. Значение В1 = 0 устанавливается при обращении к L0, значение В1 = 1 - при обращении к L1. Соответственно значение В2 = 0 или 1 устанавливается при обращении к строке L2 или L3. В соответствии с алгоритмом LRU для замены выбирается пара строк, к которым не производилось последнее обращение, а в этой паре замене подлежит строка, к которой не производилось последнее обращение. Выбранная таким образом строка считается дольше всего неиспользуемой в данном наборе, поэтому ее содержимое замещается выбираемыми из основной памяти новыми 32 байтами.
Данное описание соответствует использованию наборов из четырех строк, что имеет место в кэш-памяти команд и общей кэш-памяти 2-го уровня. Для кэш-памяти данных, содержащей две строки в наборе, каждый набор имеет всего один бит LRU, который принимает значение ВО = 0 при обращении к строке L0, и ВО = 1 при обращении к L1.
При использовании обратной записи в процессорах Р6 когерентность содержимого основной памяти и кэш-памяти обеспечивается с помощью протокола MESI, который устанавливает четыре возможных состояния строки кэш-памяти:
М (modified) - модифицированное путем записи содержимое строки, которое имеется только в кэш-памяти данного процессора;
Е (exclusive) - немодифицированное содержимое строки, которое содержится только в кэш-памяти данного процессора и основной памяти;
S (shared) - содержимое данной строки может также находиться в кэш-памяти других активных устройств (процессоров), входящих в состав системы;
I (invalid) - недействительное (аннулированное) содержимое строки.
Текущее состояние строки определяется значениями битов SO, S1, которые автоматически устанавливаются и изменяются в процессе работы процессора. При инициализации процессора или очистке (аннулировании содержимого) кэш-памяти для всех строк устанавливается состояние I, указывающее, что строки не заполнены. Дальнейшее функционирование процессора вызывает заполнение кэш-памяти. При этом для заполненной строки устанавливается состояние Е. Если в строку производится запись данных, то для нее ус-тавливается состояние М. Аннулирование содержимого всех строк (освобождение кэш-памяти) производится программно с помощью команд INVD и WBINVD. Команда INVD аннулирует содержимое внутренней кэш-памяти команд и данных, устанавливая состояние I для всех строк. Команда WBINVD перед аннулированием производит обратную запись (writeback) в основную память содержимого тех строк кэш-памяти данных, для которых установлено состояние М (в них была проведена модификация). При выполнении этих команд процессор выдает внешние сигналы для реализации аналогичных процедур в кэш-памяти 2-го уровня. Данные комаццы являются привилегированными - их выполнение в защищенном режиме разрешается только программам с максимальным уровнем привилегии 0.
Если выполняется захват шины другим процессором (активным устройством) в мультипроцессорной системе, то отключаемый от шины процессор продолжает выполнение команд и
65
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
обработку данных, содержащихся в кэш-памяти. Активный процессор может обратиться к данным, копии которых уже находятся в отключенном от шины процессоре. Поэтому необходимо принять меры для обеспечения идентичности копий данных, используемых различными процессорами. Такие меры реализуются с помощью специальных средств, выполняющих снуп-пинг (snoop) - слежение за содержимым кэш-памяти разных процессоров, входящих в систему. При этом отключенный от внешней шины процессор принимает адреса, выдаваемые на адресные линии активным процессором. Если этот адрес совпадает с адресом данных, хранящихся в одной из заполненных строк кэш-памяти данных отключенного процессора, то выполняются следующие процедуры. Если активный процессор производил запись по данному адресу, то содержимое соответствующей строки в отключенном от шины процессоре аннулируется (устанавливается состояние I). Если активный процессор производил чтение по адресу строки, имеющей состояние М, то отключенный процессор выполняет специальный цикл выдачи адресованных данных на внешнюю шину, чтобы активный процессор получил их модифицированный вариант.
Когда отключенный процессор снова становится активным, т. е. принимает на себя управление системной шиной, то для заполненных строк его кэш-памяти данных устанавливается состояние S. Оно показывает, что содержимое строки может находиться в кэшпамяти данных другого процессора, который был активным ранее. Запись данных в строку, имеющую состояние S, вызовет также их запись в основную память, после чего строка устанавливается в состояние Е.
Отметим, что описанный протокол MESI, обеспечивающий когерентность содержимого основной и кэш-памяти, действует только при обращениях к внутренней кэш-памяти данных и общей кэш-памяти 2-го уровня. Во внутренней кэш-памяти команд процедура записи (модификации) не реализуется, поэтому при обращении к ней когерентность сохраняется без использования дополнительных средств.
Управление функционированием кэш-памяти осуществляется битами CD и NW в регистре CRO (см. рис. 2.7,а), которые определяют три возможных режима работы в соответствии с табл. 2.5.
При нормальном функционировании кэш-памяти (биты CD = NW = 0) кэш-попадание вызывает чтение данных из кэша или их запись в кэш. Кэш-промах при чтении приведет к заполнению соответствующей строки кэша из основной памяти. Запись в основную память выполняется при кэш-промахе, а также в случае кэш-попадания при записи в строку, имеющую S-состояние (для обеспечения когерентности в мультипроцессорных системах).
При запрещенном заполнении кэш-памяти (бит CD = 1) ее содержимое сохраняется и может использоваться. В этом режиме кэш-память может служить в качестве быстрого статического ОЗУ, если предварительно загрузить в нее содержимое определенной области основной памяти. При кэш-попадании выполняется чтение данных из кэша или их запись в кэш. Кэш-промах при чтении или записи вызывает обращение к основной памяти для выборки операнда, но изменение содержимого кэша (заполнение строки) не производится. Если установлено значение бита NW = 0, то кэш-попадание при записи в строку, имеющую S-состояние, вызовет также запись данных в основную память для обеспечения когерентности. Если установлено значение NW = 1, то при кэш-попадании в строку, имеющую S-состояние, запись в основную память не производится, то есть когерентность не поддерживается. В этом случае строка, в которой зафиксировано кэш-попадание, сохраняет состояние S.
Чтобы полностью исключить использование кэш-памяти обоих уровней (L1 и L2), в процессоре Р6 необходимо выполнить команду WBINVD и затем установить в регистре CR0 значения битов CD = NW = 1. Обычно использование кэш-памяти запрещают в процессе отладки, чтобы по состоянию системной шины можно было контролировать каждый цикл функционирования системы.
СТРУКТУРА И ФУНКЦИОНИРОВАНИЯ ПРОЦЕССОРОВ INTEL Р6
Таблица 2.5
Режимы работы кэш-памяти
CD NW Режимы работы кэш-памяти
0 0 Нормальное функционирование кэш-памяти
0 1 Запрещенная комбинация, ее установка вызывает исключение типа #GP (нарушение защиты)
1 0 Заполнение кэш-памяти запрещено. Поддерживается когерентность с основной памятью
1 1 Заполнение кэш-памяти запрещено. Не поддерживается когерентность с основной памятью
При использовании страничной адресации памяти управление кэшированием осуществляется с помощью битов PCD, PWT в регистре CR3 и бита PGE в регистре CR4. Кроме того, используются биты G, PCD, PWT, которые содержатся в указателях разделов и страниц, хранящихся в основной памяти в виде специальных таблиц. Эти биты устанавливают различные режимы кэширования для отдельных разделов и страниц памяти.
В архитектуру процессоров Р6 введены специальные регистры MTRR (Memory Туре Range Registers), которые устанавливают режимы кэширования для определенных адресных зон памяти. Эти регистры входят в состав модельно-специфических регистров (MSR). Они определяют для 96 адресных зон фиксированного или произвольного размера следующие режимы кэширования:
UC (Uncacheable, код 0) - некэшируемая зона, все обращения для чтения и записи поступают на системную шину и выполняются в соответствии с порядком следования команд (без изменения их последовательности и без буферизации записываемых данных), спекулятивная выборка операндов не реализуется;
WC (Write Combining, код 1) - некэшируемая зона с объединением данных при записи; все обращения выполняются как для некэшируемой зоны, но допускается спекулятивная выборка при чтении операндов и буферизация данных при их записи в память;
WT (Write Through, код 4) - кэшируемая зона с использованием механизма сквозной записи; кэш-промах при записи не вызывает заполнения строки кэша, кэш-попадание при записи переводит соответствующую строку в 1-состояние (освобождение строки); допускается спекулятивная выборка при чтении и буферизация данных при записи;
WB (Write Back, код 6) - кэшируемая зона с использованием механизма обратной записи; кэш-промах при записи вызывает заполнение строки кэша, кэш-попадание при записи изменяет содержимое соответствующей строки в кэше с установкой ее в М-состояние, не вызывая обращение к основной памяти; допускается спекулятивная выборка при чтении и буферизация данных при записи;
WP (Write Protected, код 5) - кэшируемая зона для чтения, некэшируемая зона для записи; при чтении реализуется обычная процедура обращения к кэшу; при записи выполняется цикл обращения к системной шине без изменения содержимого кэша, причем во всех процессорах системы строка кэша, адресованная при записи (если таковая имеется), устанавливается в 1-состояние (освобождается); допускается спекулятивная выборка при чтении, буферизация данных при записи не выполняется.
В процессорах Р6 выделены 88 адресных зон фиксированного размера (4,16 или 64 Кбайт) и 8 зон произвольного размера:
8 зон по 64 Кбайт, занимающих диапазон адресов 0-7FFFFh (512 Кбайт);
16 зон по 16 Кбайт, занимающих диапазон адресов 80000H-8FFFFH (256 Кбайт);
64 зоны по 4 Кбайт, занимающих диапазон адресов C0000H-FFFFFH (256 Кбайт);
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
8 зон размером от 4 Кбайт до максимального размера физической памяти, которые могут размещаться в любой позиции адресного пространства.
В зависимости от назначения и реализации разделов памяти, расположенных в соответствующей адресной зоне, пользователь может задать для них тот или иной режим кэширования, записав в соответствующий регистр MTRR код требуемого режима: 0,1,4,5 или 6 (коды 2,3 и 7-255 резервированы для последующих моделей).
Регистр MTRRcap содержит информацию о структуре адресных зон, реализуемых процессором Р6 (число зон переменного размера, наличие зон фиксированного размера, реализация режима WC), которая считывается операционной системой в процессе конфигурации системы. Для процессоров Р6 содержимое этого регистра имеет значение 508Н. При попытке записи в регистр MTRRcap реализуется исключение #GP (нарушение защиты).
Содержимое регистра MTRRdefType (рис. 2.9) разрешает или запрещает использование адресных зон, устанавливает режим кэширования для остального адресного пространства, не включенного в разрешенные зоны. Отдельные биты этого регистра имеют следующее назначение:
Е- разрешает при установке значения Е = 1 использование адресных зон для определения режима кэширования, при значении Е = 0 вся физическая память работает в некэши-руемом режиме UC;
FE - разрешает при установке значения FE = 1 установку режима кэширования для зон с фиксированными размерами; при FE = 0 разрешается установка режима только для зон с произвольными размерами, если значение Е = 1; при Е = 0 значение бита FE не влияет на работу процессора;
Туре - данное поле должно содержать код режима (0,1,4,5 или 6) для адресного пространства, не включенного в зоны фиксированного или произвольного размера; при записи в это других значений кода реализуется исключение типа #GP (нарушение защиты).
Остальные биты в регистре MTRRdefType зарезервированы, и процессор реализует исключение типа #GP при попытке записи в них ненулевых значений.
Обращение к зонам с фиксированным размером производится под управлением группы 64-разрядных регистров, в которую входят:
MTRRfix64K_00000 - регистр, задающий режим для 8 зон по 64 Кбайт;
MTRRfixl 6К_80000, MTRRfix64K_A0000- два регистра, задающие режим для 16 зон по 16 Кбайт; MTRRfix4K_C0000, ..._С8000, ..._D0000, ..._D8000, ..._Е0000, ..._Е8000, ..._F0000;
MTRRfix4K_F8000 - восемь регистров, задающих режим для 64 зон по 4 Кбайт.
Имена этих регистров содержат шестнадцатиричные цифры, указывающие начальный адрес зон, режим кэширования которых данный регистр задает. Каждый байт этих регистров содержит код режима (0,1,4,5 или 6), устанавливаемого для определенной зоны (младшему байту соответствует зона с меньшими адресами).
Обращение к зонам с произвольным размером выполняется под управлением группы из 16 регистров, каждая пара которых MTRRphysBasen, MTRRphysMaskn задает размещение и размер одной из восьми зон, определяет режим ее кэширования (суффикс л = 0-7 указывает номер зоны). Эти регистры содержат поля и биты (рис. 2.10), имеющие следующее назначение:
Туре - поле, задающее режим кэширования данной зоны (код 0,1,4,5 или 6);
63__________________12 11 Ю 9_______________8 7________________0
| Резервировано (0) | Е | FE ~ 0 0 | Туре
Рис. 2.9. Формат содержимого регистра MTRRdefTуре
СТРУКТУРА И ФУНКЦИОНИРОВАНИЯ ПРОЦЕССОРОВ INTEL Р6
63 36 35 12 11 8 7 0
Резервировано Phys Base Резервировано Type
63 36 35 12 11 10 0
Резервировано Phys Mask V Резервировано
Рис. 2.10. Формат содержимого пары регистров MTRRphysBasen, MTRRphys-Maskn, определяющих режим кэширования для адресной зоны произвольного размера
PhysBase - поле, содержащее 24 старших разряда базового адреса зоны (для 12 младших разрядов принимаются нулевые значения);
PhysMask-поле, содержащее 24 разряда маски, с помощью которой задается размер зоны;
V-бит, разрешающий при значении V = 1 задание режима кэширования для адресной зоны с помощью данной пары регистров; при значении V = 0 режим этой зоны определяется содержимым регистра MTRRdefType.
Остальные биты в регистрах MTRRphysBasen, MTRRphysMaskn резервированы, и процессор реализует прерывание типа #GP при попытке записи в них ненулевых значений.
Таким образом, архитектура Р6 позволяет реализовать большой набор вариантов использования кэш-памяти и различных разделов основной памяти, что обеспечивает возможности эффективного применения процессоров для решения широкого круга задач с помощью разнообразных типов современной памяти и устройств ввода/вывода.
2.1.5. ФОРМАТЫ КОМАНД И СПОСОБЫ АДРЕСАЦИИ
Набор команд, реализуемый процессорами Р6, обеспечивает выполнение операций над операндами, которые находятся в регистре, памяти или непосредственно в команде. В набор входят безадресные, одно- и двухадресные команды. Процессор реализует следующие шесть типов двухадресных команд:
• регистр - регистр;
• память - регистр;
• непосредственные данные - регистр;
• регистр - память;
• память - память;
• непосредственные данные - память.
Операнды могут содержать 8,16 или 32 разряда. Для реализации различных типов команд определены форматы, задающие порядок размещения информации о выполняемой операции и способах выбора операндов.
Общий формат команды (рис. 2.11) содержит следующие поля: ОРС - код операции, MODR/M, SIB-байты адресации, DISP-байты смещения, IMM - непосредственно заданный операнд. Для конкретной команды отдельные поля могут иметь различное число байт или вообще отсутствовать. Поэтому команды могут содержать от 1 до 12 байт. Перед кодом операции в ряде случаев вводятся один или несколько префиксных байтов, модифицирующих выполняемую команду.
Код операции ОРС (operation code) занимает 1 или 2 байта. Во многих командах пересылок, а также в логических и арифметических командах первый байт ОРС содержит бит w, значе-
69
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
ОРС MODR/M SIB DISP IMM
(1 или 2 байт) (0 или 1 байт) (0 или 1 байт) (0,1,2 или 4 байт) (0,1,2 или 4 байт)
Рис. 2.11. Общий формат команд
ние которого определяет разрядность операндов: w=0- операция с байтами; w = 1 - операция со словами (16 или 32 разряда). Разрядность слов (16 или 32 разряда) определяется режимом работы процессора. В реальном режиме и режиме виртуального 8086 по умолчанию используются 16-разрядные слова. В защищенном режиме разрядность устанавливается значением бита D в дескрипторе сегмента команд. При выполнении отдельных команд разрядность операндов может меняться соответствующим префиксом (см. табл. 2.14).
В ряде команд первый байт ОРС содержит поля reg или sreg, определяющие выбор используемых регистров. Трехбитовое поле reg задает выбираемый регистр в соответствии с разрядностью обрабатываемых операндов (табл. 2.6). Поле sreg определяет выбор сегментных регистров (табл. 2.7). Двухбитовые коды sreg (указаны в скобках) используются для выборки регистров CS, SS, DS, ES в программах, написанных для микропроцессоров 8086, в которых регистры FS, GS отсутствовали.
Байт адресации MODR/M содержит три поля (рис. 2.12). Поля MOD и R/M задают адрес одного из операндов, который может храниться в регистре или ячейке памяти. Кодировка этих полей определяет выбираемый способ адресации.
В одноадресных командах поле REG/ОРС содержит дополнительные биты кода операции. В двухадресных командах поле REG содержит код регистра, в котором хранится второй из операндов. Тип команды (одно- или двухадресная) определяется первым битом ОРС. При этом в ОРС содержится битс1, который задает выбор регистров, используемых в качестве источника и приемника информации при выполнении ряда двухадресных арифметических и логических операциий типа регистр-регистр:
d = 0 - код источника содержится в поле REG/ОРС, код приемника - в поле R/M;
d = 1 - код источника содержится в поле R/M, код приемника - в поле REG/OPC.
Кодировка регистров указана в табл. 2.6,2.7.
Для реализации ряда способов адресации используется байт S/В. Он содержит 3-бит-ные поля INDEX и BASE, определяющие выбор регистров, используемых в качестве индексного и базового регистров, и поле SS, задающее масштабный коэффициент для модификации значения индекса (см. рис. 2.12). Правила формирования адреса при использовании байта S/S изложены ниже.
Если поле MOD байта MODR/M имеет значение 00 (при некоторых значениях R/M) или 01, 10, то для формирования адреса используется 8-, 16- или 32-разрядное смещение (табл. 2.8, 2.9). Это смещение задается соответствующими байтами в поле команды, которые располагаются после байтов адресации.
При выполнении операций с непосредственной адресацией один из операндов imm задается в последних байтах команды (поле IMM на рис. 2.11). В этом случае ОРС ряда команд содержит бит s, определяющий способ использования непосредственно задаваемых данных. Если операция выполняется над байтами (ОРС команды содержит бит w = 0), то в качестве операнда используется один байт непосредственных данных im8, содержащихся в формате команды. Если операция выполняется над 16- или 32-разрядными словами (в ОРС команды бит w = 1 или отсутствует), то возможны следующие варианты. При s = 0 непосредственные данные содержат два или четыре байта, и в качестве одного из операндов используются im16 или im32. При s = 1 непосредственные данные содержат один младший байт 16- или 32-разрядного операнда, остальные разряды которого принимают значение старшего (знакового) разряда младшего байта (расширением знаком).
СТРУКТУРА И ФУНКЦИОНИРОВАНИЯ ПРОЦЕССОРОВ INTEL Р6
Таблица 2.6
Кодировка регистров общего назначения
Поле REG Разрядность операндов
8 16 32
ООО AL АХ ЕАХ
001 CL СХ ЕСХ
010 DL DX EDX
011 BL ВХ ЕВХ
100 АН SP ESP
101 СН ВР ЕВР
110 DH SI ESI
111 ВН DI EDI
Таблица 2.7
Кодировка сегментных регистров
Поле sreg Сегментный регистр
000 (00) ES
001 (01) CS
010 (10) SS
011 (11) DS
100 FS
101 GS
При обращении к памяти байты MODR/M и SIB определяют адрес младшего байта операнда. Если операция выполняется с 16- или 32-разрядными операндами, то старшие байты выбираются из ячеек памяти, значение адреса которых на 1 или 3 больше определяемых байтами адресации.
Процессоры Р6, как и предыдущие модели семейства 80x86, реализуют сегментную организацию памяти, при которой физический адрес ячейки памяти формируется путем сложения базового адреса сегмента и относительного адреса ячейки внутри сегмента. Базовый адрес определяется содержимым 16-разрядного сегментного регистра и зависит от режима работы микропроцессора. Если микропроцессор работает в режиме обработки 16-разрядных данных (режим реальных адресов или режим виртуального 8086), то 20-разрядный базовый адрес формируется путем сдвига содержимого сегментного регистра на четыре разряда влево. Если микропроцессор работает в режиме обработки 32-разрядных данных (защищенный режим), то 32-разрядный базовый адрес содержится в дескрипторе, выбор которого из таблицы дескрипторов осуществляется с помощью селектора - содержимого соответствующего сегментного регистра.
В зависимости от типа обращения к памяти производится выбор сегментного регистра и способа определения относительного адреса (табл. 2.8). Для некоторых способов обращения возможны варианты выбора сегментных регистров, которые указаны в табл. 2.8 в скобках. Эти варианты могут быть выбраны с помощью префикса замены сегмента SEG. В качестве относительного адреса используется содержимое регистров EIP (IP), ESP (SP), ESI (SI), EDI (DI) или эффективный адрес EA, который формируется в соответствии с заданным способом адресации.
Эффективный адрес операнда ЕА является 16- или 32-разрядным и формируется в зависимости от значения полей MOD и R/M в байте адресации MODR/M и содержимого байта SIВ (для 32-разрядных адресов). В общем случае ЕА образуется путем арифме-тического сложения трех компонент:
1) содержимого базового регистра ЕВР (ВР) или ЕВХ (ВХ);
2) содержимого индексного регистра ESI (SI) или EDI (DI);
3) 8-, 16- или 32-разрядного смещения d8, d 16 или d32, заданного в одном, двух или четырех байтах поля DISP команды (см. рис. 2.11).
7 6 5 4 3 2 1 0
MOD REG/OPC R/M
SS INDEX BASE
Рис. 2.12. Форматы байтов MODR/M и SIB
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
Таблица 2. в
Выбор сегментных регистров и относительного адреса
Тип обращения к памяти Сегментный регистр Относительный адрес*
1. Выборка команды CS EIP(IP)
2. Обращение к стеку SS ESP (SP)
3. Адресация операнда DS (CS,SS,ES,FS,GS) ЕА
4. Адресация элемента строки-источника DS (CS,SS,ES,FS,GS) ESI (SI)
5. Адресация элемента строки-приемника ES EDI (DI)
6. Адресация операнда с использованием в качестве базового регистра ЕВР (ВР) или ESP (SP) * В скобках указаны регистры, содержащие о операндов SS (CS.DS.ES.FS.GS) тносительный адрес при о ЕА бработке 16-разрядных
В зависимости от значения полей MOD и R/M для формирования ЕА используются все или часть этих слагаемых в соответствии с табл. 2.9, 2.10. В этих таблицах указаны также сегментные регистры (DS: и SS:), используемые для определения базовых адресов сегмента.
Если при формировании 32-разрядного адреса значение поля R/M = 100, то команда содержит дополнительный байт адресации SIB. В таком случае правила образования ЕА определяются табл. 2.11, где (IR'F,) - масштабированный индекс; IR - содержимое индексного регистра, который.задается кодом INDEX; F - масштабный коэффициент, значение которого определяется кодом SS (табл. 2.12). В качестве индексного может использоваться любой из регистров общего назначения, кроме указателя стека Е5Р(табл. 2.13).
Разрядность обрабатываемых операндов и адресов определяется режимом работы процессора. Если программы выполняются в реальном режиме или режиме виртуального 8086, то по умолчанию используются 16-разрядные относительные адреса и операнды. При работе в защищенном режиме дескриптор сегмента исполняемой команды содержит бит D, который определяет принимаемую по умолчанию разрядность адресов и операндов: 16 при D = 0,32 при D = 1. Если команде предшествуют префиксы OS, AS, то при ее выполнении принятая по умолчанию разрядность операнда или адреса изменяется. В результате разрядность операндов и относительных адресов в защищенном режиме определяется в соответствии с табл. 2.14. Для реального режима и режима виртуального 8086 выбор разрядности определяется при значениях D = 0.
Процессор реализует ряд способов адресации операнда, набор которых обеспечивает эффективную работу с языками высокого уровня (Си, Фортран и др.).
Непосредственная адресация. В качестве операнда Imm используются один, два или четыре последних байта команды. Такой способ адресации реализуется при выполнении ряда команд пересылки (MOV, PUSH), арифметических операциях (ADD, ADC, SUB, SBB, CMP, IMUL) и логических операциях (AND, OR, XOR, TEST). Непосредственная адресация задается определенным значением кода ОРС, содержащегося в первом байте этих команд, или поля REG/ОРС байта MODR/M. Разрядность используемых непосредственных данных (8,16 или 32 разряда) зависит от режима работы процессора и может изменяться соответствующим префиксом.
Регистровая адресация. Операнд выбирается из регистра, определяемого полем R/M в байте MODR/M. Код, содержащийся в этом поле, задает выбираемый регистр в соответствии с табл. 2.6. Данный способ реализуется при задании в байте MODR/M значения поля ЛЛПГ) =11.
СТРУКТУРА И ФУНКЦИОНИРОВАНИЯ ПРОЦЕССОРОВ INTEL Р6
Таблица 2.9
Формирование 16-разрядного ЕА
Поле R/M Поле MOD
00 01 10
ООО DS:[BX+SI] DS:[BX+SI+d8] DS:[BX+SI+d16]
001 DS:[BX+DI] DS:[BX+DI+d8] DS:[BX+DI+d16]
010 SS:[BP+SI] SS:[BP+SI+d8] SS:[BP+SI+d16]
011 SS:[BP+DI] SS:[BP+DI+d8] SS:[BP+DI+d16]
100 DS:[SI] DS:[SI+d8] DS:[SI+d16]
101 DS:[DI] DS:[DI+d8] DS:[DI+d16]
110 DS:[d16] SS:[BP+d8] SS:[BP+d16]
111 DS:[BX] DS:[BX+d8] DS:[BX+d16]
Таблица 2.10
Формирование 32- разрядного ЕА (байт SIB отсутствует)
Поле R/M Поле MOD
00 01 10
000 DS:[EAX] DS:[EAX+d8] DS:[EAX+d32]
001 DS:[ECX] DS:[ECX+d8] DS:[ECX+d32]
010 DS:[EDX] DS:[EDX+d8] DS:[EDX+d32]
011 DS:[EBX] DS:[EBX+d8] DS:[EBX+d32]
100 (см. табл. 1.10) (см. табл. 1.10) (см. табл. 1.10)
101 DS:[d32] SS:[EBP+d8] SS:[EBP+d32]
110 DS:[ESI] DS:[ESI+d8] DS:[ESI+d32]
111 DS:[EDI] DS:[EDI+d8] DS:[EDI+d32]
Таблица 2.11
Формирование 32- разрядного ЕА (байт SIB присутствует)
Поле BASE Поле MOD
00 01 10
000 DS:[EAX+(IR*F)] DS:[EAX+(IR*F)+d8] DS:[EAX+(IR*F)+d32]
001 DS:[ECX+(IR*F)] DS:[ECX+(IR*F)+d8] DS:[ECX+(IR*F)+d32]
010 DS:[EDX+(IR*F)] DS:[EDX+(IR*F)+d8] DS:[EDX+(IR*F)+d32]
011 DS:[EBX+(IR*F)J DS:[EBX+(IR*F)+d8] DS:[EBX+(IR*F)+d32]
100 SS:[ESP+(IR*F)J SS:[ESP+(IR*F)+d8] SS:[ESP+(IR*F)+d32]
101 DS:[d32+(IR*F)] SS:[EBP+(IR*F)+d8] SS:[EBP+(IR*F)+d32]
110 DS:[ESI+(IR*F)] DS:[ESI+(IR*F)+d8] DS:[ESI+(IR*F)+d32]
111 DS:[EDI+(IR*F)] DS:[EDI+(IR*F)+d8] DS:[EDI+(IR*F)+d32]
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
Таблица 2.12
Кодировка значений масштабного коэффициента F
Поле SS Масштабный множитель F
00 1
01 2
10 4
11 8
Косвенно-регистровая адресация. Относительный адрес ЕА содержится в индексном (SI, DI, ESI, EDI) или базовом (ВХ, ЕВХ) реестрах или регистрах общего назначения (EAX, ЕСХ, EDX). Данный способ реализуется при значении поля MOD -00 (см. табл. 2.9,2.10).
Прямая адресация. Относительный адрес операнда ЕА содержится в команде в виде смещения d 16 или d32. Этот способ адресации реализуется при значениях полей R/M = 110 и MOD = 00, R/M= 110 (см. табл. 2.9)илиЛ/М = 101 (см. табл. 2.10).
Базовая адресация. Относительный адрес ЕА формируется путем сложения содержимого базового регистра (ВХ, ВР) и смещения d8 или d16. Базовая адресация реализуется при MOD = 01 или 10 и значениях R/M = 110 или 111 (см. табл. 2.9).
Индексная адресация. Относительный адрес ЕА формируется путем сложения содержимого индексного регистра (SI, DI) и смещения d8 или d16. Для реализации этого способа задаются значения MOD = 01 или 10 и R/M = 100 или 101 (см. табл. 2.8). При формировании 32-разрядных адресов в качестве базового или индексного может использоваться любой из регистров: ЕАХ, ЕСХ, EDX, ЕВХ, EBP, ESI, EDI (см. табл. 2.9).
Базово-индексная адресация. Относительный адрес ЕА образуется путем сложения содержимого базового (ВХ, ВР) и сегментного регистров (SI, DI). Такой способ адресации операнда реализуется при значениях поля R/M = 000,001,010,011, если задано MOD = 00 (см. табл. 2.10).
Базово-индексная адресация со смещением. Это вариант базово-индексной адресации, при котором к относительному адресу ЕА дополнительно прибавляется смещение d8 или d 16. Данный способ адресации осуществляется при значениях поля MOD = 01 или 10 (см. табл. 2.8).
Дополнительные способы адресации реализуются при использовании 32-разрядных адресов, если задано значение R/M = 100 и команда содержит байт SIB. При этом поля INDEX и BASE определяют коды регистров, содержимое которых определяет индекс и базу для формирования адреса операнда (см. табл. 2.13).
Таблица 2.13
Кодировка индексных и базовых регистров в байте SIB
Поле INDEX Индексный регистр Поле BASE Базовый регистр
000 ЕАХ 000 ЕАХ
001 ЕСХ 001 ЕСХ
010 EDX 010 EDX
011 ЕВХ 011 ЕВХ
100 - 100 ESP
101 ЕВР 101 EBP(d32)
110 ESI 110 ESI
111 EDI 111 EDI
СИСТЕМА КОМАНД: ОПЕРАЦИИ НАД ЦЕЛЫМИ ЧИСЛАМИ
Таблица 2.14
Разрядность операндов и относительных адресов в защищенном режиме (+ наличие префикса, - отсутствие префикса) |
Значение бита D 0 0 0 0 1 1 1 1
Префикс OS (66Н) - - + + - - + +
Префикс AS (67Н) - + - + - + - +
Разрядность операнда 16 16 32 32 32 32 16 16
Разрядность относительного адреса 16 32 16 32 32 16 32 16
При коде INDEX - 100 значение индекса принимается равным 0. В этом случае при MOD = 00 реализуется косвенно-регистровая или прямая (при BASE = 101) адресация, а при MOD = 01 или 10 - базовая адресация. Регистр ЕВР выбирается в качестве базового при значениях MOD - 01 или 10; при MOD = 00 в качестве базы используется 32-разрядное смещение (d32), задаваемое в четырех следующих байтах команды. В качестве индексного может использоваться любой из 32-разрядных регистров общего назначения, кроме ESP (см. табл. 2.6). Содержимое этого регистра умножается на масштабный коэффициент F (см. табл. 2.12), т. е. сдвигается влево на число разрядов (0, 1, 3 или 4), задаваемое содержимым поля SS в байте SIB.
Таким образом, при введении байта SIB реализуются три дополнительных варианта индексной и базово-индексной адресации (см. табл. 2.11).
Индексная адресация с масштабированием. Относительный адрес образуется сложением масштабированного индекса (содержимого индексного регистра, умноженного на коффициент F) и смещения d32. Этот способ осуществляется при MOD = 00 и значении поля BASE = 101.
Базово-индексная адресация с масштабированием. Относительный адрес образуется сложением масштабированного индекса и базы, в качестве которой используется содержимое одного из регистров: ЕАХ, ЕВХ, ЕСХ, EDX, ESP, ESI или EDI. Выбор базового регистра задается значением поля BASE при MOD = 00 (см. табл. 2.13).
Базово-индексная адресация со смещением и масштабированием. Относительный адрес формируется сложением масштабированного индекса, базы и смещения d8 или d32. Поле BASE задает выбор базового регистра (см. табл. 2.13), а поле MOD = 01 или 10 определяет разрядность смещения (см. табл. 2.11).
При описанных способах задается относительный адрес операнда в сегменте данных DS или стека SS (см. табл. 2.11).Для адресации операндов в других сегментах перед командой необходимо ввести префиксный байт SEG.
Относительная адресация. Используется при выполнении ряда команд управления (условные и безусловные переходы, вызовы подпрограмм, управление циклами), чтобы адресовать ячейку памяти, содержащую следующую команду. При этом способе адрес формируется как сумма содержимого регистра EIP, соответствующего текущей команде, и смещения d8, d16 или d32, определяющего положение следующей команды относительно текущей.
2.2. СИСТЕМА КОМАНД: ОПЕРАЦИИ НАД ЦЕЛЫМИ ЧИСЛАМИ
К этому классу относятся команды выполнения пересылок, арифметических и логических операций, сдвигов и других преобразований данных, в том числе операции над битами и строками символов. Ниже дается перечень команд этого класса, разбитых на несколько функциональных групп.
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
Пересылка данных и адресов
Пересылка данных без преобразования:
MOV - Пересылка операнда
CMOVcc - Условная пересылка операнда
SETcc-Условная установка байта
PUSH - Запись операнда в стек
PUSHA(D) - Запись в стек содержимого всех регистров
POP - Чтение операнда из стека
POPA(D) - Чтение из стека содержимого всех регистров
XCHG - Обмен между регистрами или памятью и регистром
XLAT - Преобразование кодов BSWAP -Перестановка байтов
Пересылка данных с преобразованием:
MOVSX - Пересылка байта или слова с расширением знака MOVZX- Пересылка байта или слова с расширением нулями
Ввод/вывод данных:
IN - Ввод операнда из порта в аккумулятор
OUT - Вывод операнда из аккумулятора в порт
Загрузка эффективного адреса и селекторов:
LEA - Загрузка эффективного адреса ЕА в регистр LDS - Загрузка указателя адреса для сегмента DS LES - Загрузка указателя адреса для сегмента ES LFS - Загрузка указателя адреса для сегмента FS LGS - Загрузка указателя адреса для сегмента GS LSS - Загрузка указателя адреса для сегмента SS
Арифметические операции
Сложение:
ADD - Сложение операндов
ADC - Сложение операндов с признаком CF (перенос)
XADD - Обмен операндами и сложение
INC - Инкремент операнда
AAA-ASCII-коррекция результата сложения
DAA - Десятичная коррекция результата сложения
Вычитание:
SUB - Вычитание операндов
SBB - Вычитание операндов и признака CF (заем)
DEC - Декремент операнда
NEG - Изменение знака операнда (с переводом в дополнительный код) AAS - ASCII-коррекция результата вычитания
DAS-Десятичная коррекция результата вычитания
Сравнение:
СМР - Сравнение операндов
CMPXCHG - Сравнение и обмен операндами
CMPXCHG8B - Сравнение и обмен счетверенными словами (8 байтов)
Умножение:
MUL - Беззнаковое умножение
IMUL - Знаковое (целочисленное) умножение
* “ ‘ ' я ог'" "'—™ ихо ло-шпктятя чмножения
СИСТЕМА КОМАНД: ОПЕРАЦИИ НАД ЦЕЛЫМИ ЧИСЛАМИ
Деление:
DIV - Беззнаковое деление
IDIV - Знаковое (целочисленное) деление
AAD - ASCII-коррекция результата деления
Изменение разрядности путем расширения знака:
CBW - Преобразование байта (AL) в слово (АХ)
CWDE - Преобразование слова (АХ) в двойное слово (ЕАХ)
CWD- Преобразование слова (АХ) в двойное слово (DX, АХ)
CDQ - Преобразование двойного слова (ЕАХ) в учетверенное слово (EDX, ЕАХ)
Логические операции
NOT - Инверсия операнда (логическое НЕ)
AND - Конъюнкция операндов (логическое И)
OR-Дизъюнкция операндов (логическое ИЛИ)
XOR - Неравнозначность операндов (исключающее ИЛИ)
TEST - Логическое сравнение операндов (установка признаков ZF, SF, PF)
Сдвиги
SHL/SAL-Сдвиг влево
SHR-Логический сдвиг вправо
SAR - Арифметический сдвиг вправо
SHLD - Двухопера ндный сдвиг влево
SHRD - Двухоперандный сдвиг вправо
ROL - Циклический сдвиг влево
ROR - Циклический сдвиг вправо
RCL - Циклический сдвиг влево через перенос (CF)
RCR - Циклический сдвиг вправо через перенос (CF)
Операции с битами и байтами
ВТ - Проверка бита
BTS - Проверка и установка бита
BTR - Проверка и сброс бита
ВТС - Проверка и инверсия бита
BSF - Прямое сканирование битов
BSR - Обратное сканирование битов
See-Условная установка байта
Операции со строками символов
LODS - Загрузка символа в аккумулятор
STOS - Запись символа из аккумулятора
INS - Ввод символа
OUTS - Вывод символа
MOVS - Пересылка символа
CMPS - Сравнение символов
SCAS - Сканирование строки символов
В последующих разделах дается описание этих команд. При этом используется синтаксис команд, принятый для языка Ассемблер:
ОРС <dst>, <src>,
где в качестве ОРС указывается мнемокод команды; dst (destination - приемник) - адрес первого операнда, на место которого помещается результат операции; sre (source - источник) - адрес второго операнда. Таким образом, порядок следования адресов в поле операндов команды определяет размещение результата. При описании команд приняты следующие обозначения:
г(8,1б,32)-8-, 16- или 32-разрядный регистр общего назначения;
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
т(8,16,32)-8-, 16- или 32-разрядная ячейка памяти (адресуется байтами MODR/M, SIB); sreg - сегментный регистр CS, SS, DS, ES, FS или GS;
А - регистр-аккумулятор ЕАХ, АХ или AL (в зависимости от разрядности операндов).
Большинство команд данного класса выполняет операции над 8-, 16- или 32-разрядными операндами. Заданная разрядность определяется, как указано в п. 1.4, режимом работы процессора (16 - для реального режима и режима виртуального 8086; 16 или 32 - для защищенного режима в зависимости от значения бита D в дескрипторе) и может меняться с помощью префиксных байтов.
2.2.1. КОМАНДЫ ПЕРЕСЫЛКИ
Команды этой группы приведены в табл. 2.15. Значения признаков в регистре EFLAGS при выполнении команд пересылок не изменяются.
Таблица 2.15
Команды пересылок
Синтаксис команды Операция
MOV r/m(8,16,32), r(8,16,32) r(8,16,32), r/m(8,16,32) r(8,16,32) —> r/m(8,16,32) r/m (8,16,32) -> r(8,16,32)
CMOVcc r/m(8,16,32), r(8,16,32) r(8,16,32), r/m(8,16,32) r(8,16,32) -> г/т(8,16,32),если (cc)=1 r/m(8,16,32) -> r(8,16,32), если (cc)=1
MOV EAX (AX,AL),d(16,32) d(16,32), EAX(AX.AL) (d16 или d32) -> EAX(AX.AL) EAX (AX, AL)-> (d 16 или d32)
MOV r/m(8,16,32), im(8,16,32) lm(8,16,32) -> r/m(8,16,32)
MOV sreg, r/m16 r/m 16 -> sreg sreg -> r/m 16
MOV CRi, r32 r32, CRi r32 -> CRi CRi -> r32
MOV DRi, r32 r32, DRi r32-> DRi DRi -> r32
XCHG r(8,16,32), r/m(8,16,32) EAX(AX), r/m(16,32) r(8,16,32)o r/m(8,16,32) EAX(AX) о r/m(16,32)
PUSH r/m (16,32) im(16,32) SP - (2или 4) -> SP, r/m(16,32) о (SP) SP - (2или 4) о SP, im(16,32) -» (SP)
POP r/m (16,32) sreg SP (SP) -> sreg, SP+ (2или 4) -> S
PUSHA AX,CX, DX,BX,SP,BP,SI, DI) о стек
POPA стек -> DI,SI,BP,SP,BX,DX,CX,AX
PUSHAD ЕАХ,ЕСХ,EDX,ЕВХ,ESP,EBP,ESI,EDI - -> стек
POPAD стек -> EDI,ESI,EBP,ESP,ЕВХ,EDX,ЕСХ,EAX
IN EAX(AX.AL), im8 EAX(AX.AL), DX port(im8)-> EAX(AX.AL) port(DX) о EAX(AX.AL)
OUT Im8, EAX(AX.AL) DX, EAX(AX.AL) EAX (AX,AL) -> port(im8) EAX(AX.AL)—> port(DX)
СИСТЕМА КОМАНД: ОПЕРАЦИИ НАД ЦЕЛЫМИ ЧИСЛАМИ
Продолжение табл. 2.15
Синтаксис команды Операция
MOVSX r(16,32), r/m8 r32, r/m16 r/m8 - r/m 16 -» r(16,32), расширение знаком -> г32, расширение знаком
MOVZX r(16,32), r/m8 r/m8 - -> г(16,32), расширение нулями
r32, r/m16 r/m 16 -» г32, расширение нулями
BSWAP r32 r(7-0) ->г(31-24), г(15-8) ->г(23-16),
r(23-16) -> r(15-8), r(31-24) -> r(7-0)
XLATB XLAT m8 (EBX + AL) -> AL
LEA r(16,32), m(16,32) EA-> г(16,32)
LDS r16, m16:16 m16 - •» DS, т16 —> г16
r32, m16:32 m16 - DS, т32 -> г32
LES r16, m16:16 m16 - -> ES, т16 —> г16
r32, m16:32 m16 - ES, т32 -> г32
LFS r16, m16:16 m16 - -> FS, т16 -» г16
r32, m16:32 m16 - FS, т32 -> г32
LGS r16, m16:16 m16 - -> GS, т16 -> г16
r32, m16:32 m16 - -> GS, т32 -> г32
LSS r16, m16:16 m16 - -> SS, т16 -> г16
r32, m16:32 m16 - •» SS, т32 -> г32
Команда пересылки MOV имеет ряд модификаций, основная из которых MOV r/m.m, MOV m,r/m - выполняет передачу данных (регистр-регистр) или (регистр-память) между регистрами общего назначения и ячейками памяти. Модификация MOV A,m, MOV m,A, которая реализует загрузку или сохранение в памяти содержимого аккумулятора, имеет сокращенный формат (отсутствуют байты адресации MODR/M, SIB). При этом в команде задается относительный 16- или 32-разрядный адрес операнда сП 6 или d32 в адресуемом сегменте данных, т. е. используется только прямая адресация памяти. Модификация MOV r/m,im производит запись в регистр или ячейку памяти непосредственно заданного операнда. Пересылки с участием управляющих регистров CR4-CR0 или регистров отладки DR7-DR0 (команды MOV CRi.r, MOV r,CRi, MOV DRi.r, MOV r.DRi) выполняются только в защищенном режиме программами, имеющими высший уровень привилегии 0. Они не реализуются в режиме виртуального 8086. В качестве регистра г должен использоваться один из 32-разрядных регистров общего назначения.
В процессорах семейства Р6 введены команды условной пересылки CMOVcc. Эти команды производят передачу данных только в случае выполнения определенного условия (сс), которое задается различными значениями признаков, установленных в регистре EFLAGS. Вид проверяемого условия указывается с помощью суффикса сс, вводимого в мнемокод команды: например, CMOVZ - пересылка, если значение признака ZF = 1. Виды условий и соответствующие суффиксы сс в командах CMOVcc аналогичны используемым в командах условных переходов Jcc, которые рассмотрены в п. 2.3.1 (см. табл. 2.22).
Две модификации команды XCHG обеспечивают обмен содержимым (регистр-регистр или регистр-память). В обмене могут участвовать только регистры общего назначения.
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
Модификация XCHG А,г, реализующая обмен (аккумулятор-регистр), имеет сокращенный формат команды (без байтов адресации MODR/M, SIB),
Команды PUSH, POP производят запись в стек или извлечение из стека 16- или 32-раз-рядных операндов. В стек может быть загружено содержимое регистра, ячейки памяти или непосредственный операнд im. При извлечении из стека данные могут поступать в регистр общего назначения, ячейку памяти или указанный в команде сегментный регистр sreg. Адресация стека производится с помощью регистра ESP (или SP), который содержит относительный адрес последней заполненной ячейки памяти в сегменте стека SS. При выполнении команды PUSH содержимое ESP (или SP) уменьшается на 4 (или на 2), адресуя выше расположенную (незаполненную) ячейку стека, которая становится его новой вершиной. Эта ячейка затем заполняется поступающими данными. При выполнении команды POP производится выборка данных из ячейки стека, адресуемой содержимым регистра ESP (или SP). После выборки содержимое этого регистра увеличивается на 4 (или 2), адресуя ниже расположенную заполненную ячейку стека, которая становится его новой вершиной.
Команды PUSHA, PUSHAD и РОРА, POPAD выполняют запись в стек и извлечение из нега всех восьми регистров общего назначения. При этом последовательно заполняются или освобождаются восемь 16- или 32-разрядных ячеек стека. Соответственно содержимое регистра ESP (или SP) уменьшается или увеличивается на 32 (9 или 16). Команды PUSHA, РОРА оперируют с 16-разрядными регистрами АХ, СХ, DX, ВХ, SP, ВР, SI, DI, команды PUSHAD, РОРАО-с32-разрядными регистрами ЕАХ, ЕСХ, EDX, ЕВХ, ESP, EBP, ESI, EDI.
При выполнении команд ввода-вывода IN, OUT производится пересылка данных между аккумулятором ЕАХ (АХ или AL) и адресуемым портом. Адрес порта может задаваться непосредственно операндом 1гп8 (фиксированный порт) или содержимым регистра DX (изменяемый порт). При работе процессора с 8-разрядными портами возможно обращение к 256 портам, адреса которых фиксированы в программе, или к 65536 портам, адреса которых могут изменяться путем перезагрузки содержимого регистра DX. При работе с 16-разрядными портами число адресуемых портов уменьшается вдвое, а их нумерация (адресация) должна производиться четными числами: 0, 2, 4...254 - для фиксированных портов; 0,2,4...65532, 65534-для изменяемых портов. Соответственно для 32-разрядных портов их число сокращается еще вдвое, а нумерация производится числами, кратными четырем: 0,4,8,...248, 252,...65528, 655332. Таким образом, номера портов должны быть выравнены по границам передаваемых данных согласно их разрядности: 1,2 или 4 байта. В этом случае пересылка осуществляется за один цикл. Если заданный в команде номер 16- или 32-разрядного порта имеет невыравненное значение, например 03h, то для передачи данных требуется дополнительный цикл. Отметим, что номера портов от 00F8h до OOFFh зарезервированы фирмой «Intel» для внутреннего использования. Во избежание возможных сбоев в работе системы применение этих номеров программистами должно быть исключено.
Выполнение команд IN, OUT в защищенном режиме зависит от значений уровня привилегии текущей программы CPL и уровня привилегии ввода-вывода IOPL, задаваемого соответствующим полем регистра EFLAGS. При CPL < IOPL команда выполняется. При CPL > IOPL эта возможность обращения к адресованному порту проверяется по битовой карте ввода-вывода (БКВВ), содержащейся в сегменте состояния выполняемой задачи TSS. Если БКВВ разрешает обращение к данному порту, то команда IN, OUT выполняется, если не разрешает, то реализуется прерывание типа #GP «нарушение защиты». При работе процессора в режиме виртуального 8086 проверка допустимости обращения к заданному порту производится с помощью БКВВ при любых значениях CPL, IOPL.
Команды MOVSX, MOVZX осуществляют пересылку в регистр общего назначения содержимого novroro регистра или ячейки памяти с одновременным расширением разрядности операнда.
СИСТЕМА КОМАНД: ОПЕРАЦИИ НАД ЦЕЛЫМИ ЧИСЛАМИ
При этом производится либо преобразование байта в слово (реальный режим и режим виртуального 8086) или двойное слово (защищенный режим), либо слово преобразуется в двойное слово (защищенный режим). При выполнении команды MOVSX расширение производится путем заполнения старшего байта или слова значением знака (старшего разряда), при выполнении команды MOVZX - заполнением нулями.
Команда BSWAP осуществляет перестановку байтов в заданном 32-разрядном регистре. При этом попарно меняются местами старший и младший байты (байт 3 и байт 0) и промежуточные байты (байт 1 и байт 2), т. е. порядок следования байтов меняется справа налево. Численные значения байтов сохраняются.
Команды XLAT, XLATB заменяют содержимое младшего байта аккумулятора AL на байт, хранящийся в 256-байтовой таблице, начальный (базовый) адрес которой содержится в регистре ЕВХ (или ВХ в реальном режиме или режиме виртуального 8086). При этом содержимое AL (беззнаковое число) используется как относительный адрес (индекс) выбираемого в таблице байта. Выполнение команд XLAT, XLATB иллюстрируется на рис. 2.13. Эти команды служат для табличного преобразования одного кода в другой. Отметим, что команда XLATB всегда реализует обращение к таблице, размещенной в сегменте данных DS. Команда XLAT позволяет обращаться к таблицам в различных сегментах данных путем задания соответствующего адреса операнда. Например, обращение к таблице в сегменте ES реализуется с помощью команды XLAT ES:[EBX],
При выполнении команд LEA, LDS, LES, LFS, LGS, LSS операнд-источник <src> всегда размещается в памяти, операнд-приемник <dst> - в регистре общего назначения.
Команда LEA производит вычисление эффективного адреса ЕА операнда-источника и загружает его в указанный регистр.
Команды LDS, LES, LFS, LGS, LSS производят извлечение из памяти и запись в регистры процессора указателя адреса, который состоит из 16-разрядного селектора, поступающего в соответствующий сегментный регистр DS, ES, FS, GS, SS, и 16- или 32-разрядного относительного адреса операнда, поступающего в заданный регистр общего назначения. Разрядность адреса определяется режимом работы процессора: 16 - в реальном режиме и режиме виртуального 8086,32 - в защищенном режиме. Соответственно из памяти выбираются 4 или 6 байт, начиная с адреса, указанного в поле операндов команды. С помощью этих команд реализуется переключение программы с одного сегмента данных на другой. Например, команда LSS при заданном регистре-приемнике ESP позволяет перейти к новому сегменту стека.
Рис. 2.13. Выполнение команды преобразования кодов XLAT
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
2.2.2. КОМАНДЫ АРИФМЕТИЧЕСКИХ ОПЕРАЦИЙ
Команды данной группы приведены в табл. 2.16. При выполнении команд производится установка признаков OF, SF, ZF, AF, DF, CF в регистре EFLAGS в соответствии с табл. 2.17.
Таблица 2.16
Команды арифметических операций
Синтаксис команды Операция
ADD r/m(8,16,32), r(8,16,32) r(8,16,32), /m(8,16,32) r/m(8,16,32), im(8,16,32) r/m(16,32), im8 EAX(AX.AL), im(16,8) r/m(8,16,32) + r(8,16,32) —> r/m(8,16,32) r(8,16,32) + r/m(8,16,32) -> r(8,16,32) r/m(8,16,32) + im(8,16,32) -и r/m(8,16,32) r/m(16,32) + 1гп8(знак) -и r/m(8,16,32) EAX(AX.AL) + im32(16,8) -> EAX(AX,AL)
ADC r/m(8,16,32), r(8,16,32) EAX(AX.AL), im(16,8) r/m(8,16,32) + r(8,16,32) + CF -> r/m(8,16,32) + CF r(8,16,32) + r/m(8,16,32) + CF -и r(8,16,32) + CF r/m(8,16,32) + im(8,16,32) + CF -и r/m(8,16,32) + CF r/(16,32) + 1гп8(знак) + CF -и r/m(8,16,32) + CF EAX(AX.AL) + im32(l6,8) + CF EAX(AX.AL) + CF
SUB r/m(8,16,32), r(8,16,32) r(8,16,32), r/m(8,16,32) r/m(8,16,32), im(8,16,32) r/m(16,32), im8 EAX(AX.AL), im(16,8) r/m(8,16,32) - r(8,16,32) -и r/m(8,16,32) r(8,16,32) - r/m(8,16,32) -> r(8,16,32) r/m(8,16,32) - im(8,16,32) -и r/m(8,16,32) r/m(16,32) - 1гп8(знак) -> r/m(8,16,32) EAX(AX.AL) - im32(16,8) -и EAX(AX.AL)
SBB г/т(8,16,32), r(8,16,32) r(8,16,32), r/m(8,16,32) r/m(8,16,32), im(8,16,32) r/m(16,32), im8 EAX(AX.AL), im(16,8) r/m(8,16,32) - r(8,16,32) - CF r/m(8,16,32) r(8,16,32) - r/m(8,16,32) - CF -и r(8,16,32) r/m(8,16,32) - im(8,16,32) - CF -> r/m(8,16,32) r/m(16,32) - 1гп8(знак) - CF -> r/m(8,16,32) EAX(AX.AL) - im32(16,8) - CF -и EAX(AX.AL)
CMP r/m(8,16,32), r(8,16,32) r(8,16,32), r/m(8,16,32) r/m(8,16,32), im(8,16,32) r/m(16,32), im8 EAX(AX.AL), im(16,8) r/m(8,16,32) - r(8,16,32), установка OF,SF,ZF,AF,PF,CF r(8,16,32) - r/m(8,16,32), установка OF,SF,ZF,AF,PF,CF r/m(8,16,32)-im(8,16,32), установка OF,SF,ZF,AF,PF,CF r/m(16,32) - 1гп8(знак), установка OF,SF,ZF,AF,PF,CF EAX(AX,AL)-im32( 16,8), установка F,SF,ZF,AF, PF,CF
MUL AL, r/m8 AL * r/m8 AX AX* r/m16 * EAX EAX * r/m32 EDX : EAX
IMUL r/m(8,16,32) r(16,32), r/m(16,32) r(16,32), im(16,32) r(16,32), im8 r(16,32), r/m(16,32),im8 r(16,32),r/m(16,32),im(16,32) AL(AX,EAX) * r/m(8,16,32) AX(EAX,EDX: EAX) r(16,32) * r/m(16,32)-> r(16,32) r(16,32) * im(16,32) —> r(16,32) r(16,32) * 1гп8(знак) -> r(16,32) r( 16,32) * r/m(16,32) * 1гп8(знак) r(16,32) r( 16,32) * r/m(16,32) * im( 16,32) r(16,32)
DIV AL, r/m8 AX, r/m16 EAX, r/m32 AX / r/m8 —> AL, остаток —> AH DX : AX / r/m16 -и AX, остаток -> DX EDX : EAX / r/m32 -> ЕАХ, остаток -и EDX
СИСТЕМА КОМАНД: ОПЕРАЦИИ НАД ЦЕЛЫМИ ЧИСЛАМИ
Продолжение табл. 2.16 ,
Синтаксис команды Операция
IDIV AL, г/т8 AX / r/m8 -> AL, остаток AH
АХ, г/т16 DX : AX / r/m 16 -> AX, остаток Dx
ЕАХ, г/т32 EDX : EAX / r/m32 ЕАХ, остаток EDX
CBW Знаковое расширение AL —> AX
С WOE Знаковое расширение AX EAX
CWD Знаковое расширение AX DX : AX
CDQ Знаковое расширение ЕАХ EDX : ЕАХ
AAA Десятичная коррекция после сложения (команда ADD) двух неупакованных двоично-десятичных чисел
AAS Десятичная коррекция после вычитания (команда SUB) двух неупакованных двоично-десятичных чисел
ААМ Десятичная коррекция после умножения (команда MUL) двух неупакованных двоично-десятичных чисел
AAD Десятичная коррекция после деления (команда DIV) двух неупакованных двоично-десятичных чисел
DAA Десятичная коррекция после сложения (команды ADD, INC) двух упакованных двоично-десятичных чисел
DAS Десятичная коррекция после вычитания (команды SUB, DEC) двух упакованных двоично-десятичных чисел
INC r/m(8,16,32) г/гп(8,16,32) + 1 -> г/гп(8,16,32)
r(16,32) г(16,32) + 1 -> г(16,32)
DEC r/m(8,16,32) г/т(8,16,32) - 1 -> г/гп(8,16,32)
r(16,32) r(16,32) - 1 —> r(16,32)
NEG r/m(8,16,32) - r/m(8,16,32) -> r/m(8,16,32)
XADD r/m(8,16,32), r(8,16,32) r/m(8,16,32) r(8,16,32) r/m(8,16,32) + r(8,16,32) ->r/m(8,16,32)
CMPXCHG r/m(8,16,32),r(8,16,32) r(8,16,32) -> r/m(8,16,32), ZF=1, если (AL,AX,EAX)=r(8,16,32) r/m(8,16,32) -> (AL, AX,EAX), ZF=0, если (AL,AX,EAX) / r(8,16,32)
CMPXCHG8B r/m(64) ECX:EBX -> r/m64, ZF=1, если EDX:EAX = r(m64), расширение нулями EDX:EAX -> r/m64, ZF=O, если EDX:EAX / r(m64), расширение нулями
Команды сложения, вычитания (ADD, SUB) и сложения, вычитания с переносом/заемом (ADC, SBB), учитывающие значение признака CF, имеют несколько модификаций для различных вариантов адресации операндов. Отметим, что при операциях, использующих 16- или 32-разрядный операнд, хранящийся в регистре или памяти, и непосредственно заданный 8-раз-рядный операнд im8, производится его знаковое расширение до разрядности слова или двойного слова.
При выполнении команды сравнения СМР производится вычитание содержимого адресуемых регистров и ячеек памяти без их изменения и устанавливаются значения признаков в регистре EFLAGS, определяющих результат сравнения. При равенстве операндов устанавливается значение ZF - 1, при неравенстве-ZF = 0. Если при сравнении операндов
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
без знака уменьшаемое выше (больше) вычитаемого, то устанавливается значение CF = О, если уменьшаемое ниже (меньше) вычитаемого, то CF = 1. Если при сравнении операндов со знаком уменьшаемое больше вычитаемого, то устанавливаются значения SF = OF = 0 или SF = OF = 1; если меньше, то SF = О, OF = 1 или SF = 1, OF = 0.
Для умножения 8-, 16- или 32-разрядных операндов используются одноадресная команда MUL и команда IMUL, имеющая одно-, двух- или трехадресную форму. Команда MUL служит для умножения беззнаковых операндов, команда IMUL -для умножения операндов со знаком.
В одноадресных командах MUL и IMUL один из сомножителей и произведение размещаются в аккумуляторе: AL, АХ или ЕАХ в соответствии с разрядностью операндов. Так как разрядность произведения может вдвое превышать разрядность операндов, то для его размещения производится расширение аккумулятора AL -> АХ, АХ -> DX:AX, ЕАХ -> EDX:EAX. При этом 16-разрядное произведение 8-разрядных операндов заносится в AL (младшие разряды), АН (старшие разряды), 32-разрядное произведение - в АХ (младшие разряды), DX (старшие разряды), 64-разрядное произведение - в ЕАХ (младшие разряды), EDX (старшие разряды).
При двух- и трехадресной формах команды IMUL операндами служат 16- или 32-разрядные числа. Один операнд выбирается из регистра, в качестве второго операнда при двухадресной форме служит либо содержимое регистра или адресуемой ячейки памяти, либо непосредственный операнд im. При трехадресной форме содержимое регистра или ячейки памяти является вторым сомножителем, а непосредственный операнд - третьим. Если в качестве непосредственного операнда используется 8-разрядное число im8, то оно преобразуется до заданной разрядности (16 или 32) путем расширения знака. Произведение размещается в 16- или 32-разрядном регистре, указанном в поле операнда. Так как при этом старшие 16-го или 32-го разряда произведения теряются, то после умножения следует проверять значение признака переполнения OF.
Таблица 2.17
Установка признаков при выполнении команд арифметических, логических операций и сдвигов
Команды Признаки
OF SF ZF AF DF CF
ADD,ADC,SUB,SBB,CMP,NEG,XADD,CMPXCHG + + + + + +
INC, DEC + + + + + -
MUL, IMUL + н н н н +
DIV, IDIV н н н н н н
DAA, DAS н + + + + +
AAA, AAS н н н + н +
AAM, AAD н + + н + н
CMPXCHG8B - - + - - -
AND, OR, XOR, TEST 0 + + н + 0
SAL, SAR, SHL, SHR (1 разряд) + + + н + +
SAL, SAR, SHL, SHR (n разрядов), SHLD, SHRD н + + н + +
ROL, ROR, RCL, RCR (1 разряд) + - - - - +
ROL, ROR, RCL, RCR (n разрядов) н - - - - +
Примечание. + - установка признака по результагу операции; - - сохранение
ранее установленного признака; н - неопределенное значение признака; 0 - уста-
новка нулевого значения признака.
СИСТЕМА КОМАНД: ОПЕРАЦИИ НАД ЦЕЛЫМИ ЧИСЛАМИ
При выполнении команд MUL, IMUL признаки OF, CF устанавливаются в единицу, если разрядность результата превышает разрядность регистров, используемых для его размещения. Команды MUL, IMUL различаются условиями установки этих признаков. При выполнении беззнакового умножения командой MUL устанавливаются значения OF = CF = 1, если старшая половина произведения не равна нулю, OF = CF = 0, если все разряды старшей половины равны нулю. При выполнении знакового умножения командой IMUL устанавливаются значения OF = CF - 1, если старшая половина произведения не является расширением знака младшей половины, OF = CF = 0, если во всех разрядах старшей половины повторяются значения старшего бита (знака) младшей половины.
Команды деления DIV и IDIV имеют только одноадресную форму, причем разрядность делимого, которое размещается в аккумуляторе с расширением, должна вдвое превышать разрядность делителя (8,16 или 32 разряда). Реализуемое при этом размещение делимого, результата и остатка указано втабл. 2.16. Знак остатка при выполнении команды IDIV устанавливается равным знаку делимого. Дробное частное округляется до целого значения отбрасыванием его дробной части. Если делитель равен нулю или разрядность частного превышает разрядность аккумулятора (AL, АХ или ЕАХ), то выполняется прерывание типа #DE (ошибка деления).
Команды CBW/CWDE и CWD/CDQ осуществляют преобразование хранящегося в аккумуляторе байта (AL), слова (АХ) или двойного слова (ЕАХ) соответственно в одинарное, двойное или четверное слово (16,32 или 64 разряда) путем расширения знакового разряда. При выполнении команд CBW, CWDE расширенный операнд остается в аккумуляторе: AL в АХ или АХ в ЕАХ. При выполнении команд CWD, CDQ расширение АХ, ЕАХ производится в регистры DX или EDX, куда заносится старшая половина (расширенный знак) результата. Команды CBW, CWD реализуются, когда процессор работает в режимах реальных адресов или виртуального 8086 (обработка 16-разрядных слов). Команды CWDE, CDQ выполняются в защищенном режиме (обработка 32-разрядных слов). Эти операции обычно производятся перед выполнением команды IDIV для образования из 8-, 16- или 32-разрядных операндов делимого удвоенной разрядности.
Команды AAA, AAS, ААМ, AAD обеспечивают получение правильного результата арифметических операций над неупакованными двоично-десятичными числами (от 0 до 9), значение которых представляется одним байтом. Такое представление чисел используется в коде ASCII (КОИ-7), который в младшей тетраде содержит двоичный код соответствующего десятичного числа (0 - 9), а в старшей тетраде - код 0011. Для получения правильного результата перед обработкой таких чисел в старшей тетраде устанавливается код 0000. Результат арифметических операций над двоично-десятичными числами размещается в ре- гистре АХ. После сложения, вычитания, умножения выполняются команды коррекции AAA, AAS, ААМ, после чего в младшей тетраде регистра AL образуется двоичный код младшего десятичного разряда результата, а в младшей тетраде регистра АН - двоичный код старшего разряда результата. Например, после умножения чисел 9 и 7, которые в неупакованной двоично-десятичной форме задаются кодами 0000 1001 и 0000 0111, в регистре AL будет содержаться произведение 001111111 = 63, которое после коррекции с помощью команды ААМ будет представлено в регистре АХ в следующем виде: (АН) = 00000110, (AL) = 00000111 (соответственно 6 и 3 в двоично-десятичном коде). Команда AAD, в отличие от AAA, AAS, ААМ, выполняется перед командой DIV. При этом двоично-десятичное число, старший десятичный разряд которого расположен в регистре АН, а младший - в регистре AL, преобразуется таким образом, чтобы после команды DIV содержимое AL, АН представляло младший и старший десятичные разряды частного в неупакованной двоично-десятичной форме.
Команды DAA и DAS осуществляют коррекцию результата сложения и вычитания чисел в упакованной двоично-десятичной форме. При этом старшая и младшая тетрады байта
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
содержат двоичные коды старшего и младшего разряда двухразрядного десятичного числа. Например, число 63 в данной форме будет представлено в регистре AL кодом 011 ОО011. После сложения упакованных двоично-десятичных чисел 63=0110 0011 и 18 = 00011000 в регистре AL будет получен код 01111011, который после выполнения команды DAA преобразуется в двоично-десятичную форму 10000001 = 81. При выполнении команд DAA и DAS учитывается значение признака переноса между тетрадами AF. После их выполнения устанавливается AF = 0. Следует отметить, что при использовании двоично-десятичного представления чисел соответствующие команды коррекции должны выполняться и после команд INC, DEC.
Команда NEG изменяет знак операнда, преобразуя его в дополнительный код. Комплексная команда XADD осуществляет обмен содержимым между регистром и регистром или ячейкой памяти, после чего выполняет их сложение, результат которого размещается в регистре или ячейке памяти.
Данная группа команд включает также комплексные команды сравнения/пересылки CMPXCHG, CMPXCHG8B. Команда CMPXCHG производит сравнение содержимого аккумулятора (AL, АХ или ЕАХ) и заданного в команде регистра или ячейки памяти г/т. В случае их равенства устанавливается значение признака ZF = 1, и содержимое регистра или ячейки памяти пересылается в 8-, 16- или 32-разрядный регистр, указанный в команде. В случае неравенства устанавливается значение ZF = 0, и содержимое регистра или ячейки памяти r/m пересылается в аккумулятор AL, АХ или ЕАХ (в зависимости от заданной разрядности). Команда CMPXCHG8B оперирует с 8-байтными (счетверенными) словами. Она сравнивает значение счетверенных слов, хранящихся в паре регистров EDX.ECX и адресованной ячейке памяти. При их равенстве устанавливается значение ZF = 1, и по указанному адресу в ячейку памяти пересылается содержимое пары регистров ECX:EDX. При неравенстве устанавливается значение ZF = 0, и содержимое адресованной ячейки памяти пересылается в пару регистров EDX:ECX. Отметим, что при выполнении команды CMPXCHG производится установка всех признаков в соответствии с результатом сравнения, а при выполнении команды CMPXCHG8B устанавливается только признак ZF (см. табл. 2.17).
2.2.3. КОМАНДЫ ЛОГИЧЕСКИХ ОПЕРАЦИЙ И СДВИГОВ
Команды этой группы приведены в табл. 2.18. Установка признаков по результатам и> выполнения указана в табл. 2.17.
Таблица 2.18
Команды логических операций и сдвигов
Синтаксис команды Операция
AND г/ш(8,16,32), г(8,1б,32) г(8,16,32), г/т(8,16,32) r/m(8,16,32), im(8,16,32) г/т(16,32), irn8 EAX(AX.AL), im32(16,8) r/m(8,16,32) AND r(8,16,32) -> r/m(8,16,32) r(8,16,32) AND r/m(8,16,32) -> r(8,16,32) r/m(8,16,32) AND im(8,16,32) r/m(8,16,32) r/m(16,32) AND 1т8(знак) r/m(16,32) EAX(AX.AL) AND im32(16,8) EAX(AX.AL)
OR г/т(8,16,32), г(8,16,32) г(8,16,32), г/т(8,1б,32) г/т(8,16,32), im(8,16,32) г/т(16,32), im8 EAX(AX.AL), im32(16,8) r/m(8,16,32) OR r(8,16,32) -> r/m(8,16,32) r(8,16,32) OR r/m(8,16,32) —»r(8,16,32) r/m(8,16,32) OR im(8,16,32) -> r/m(8,16,32) г/т(1б,32) OR 1т8(знак) —> r/m(16,32) EAX(AX.AL) OR im32(16,8) -> EAX(AX.AL)
СИСТЕМА КОМАНД: ОПЕРАЦИИ НАД ЦЕЛЫМИ ЧИСЛАМИ
Продолжение табл. 2.18
Синтаксис команды Операция
XOR r/m(8,16,32), r(8,16,32) r(8,16,32), r/m(8,16,32) r/m(8,16,32), im(8,16,32) r/m(16,32), im8 EAX(AX.AL), im32(16,8) r/m(8,16,32) XOR r(8,16,32) r/m(8,16,32) r(8,16,32) XOR r/m(8,16,32) r(8,16,32) r/m(8,16,32) XOR im(8,16,32) -> r/m(8,16,32) r/m(16,32) XOR ип8(знак) —> r/m(16,32) EAX(AX.AL) XOR im32(16,8) -> EAX(AX.AL)
NOT r/m(8,16,32) Инверсия r/m(8,16,32)
TEST r/m(8,16,32), r(8,16,32) r/rn(8,16,32),irn(8,16,32) EAX(AX,AL), im32(16,8) r/m(8,16,32) AND r(8,16,32), установка SF, ZF, PF r/m(8,16,32) AND im(8,16,32), установка SF, ZF, PF EAX(AX.AL) AND im32(16,8), установка SRZF.PF
SAL r/m(8,16,32), im8 Арифметический сдвиг r/m(8,16,32) влево на п разрядов, n=im8 Арифметический сдвиг г/гп(8,16,32) влево на п разрядов, n=(CL)
SAR r/m(8,16,32), im8 r/m(8,16,32), CL Арифметический сдвиг г/гп(8,16,32) вправо на п разрядов, n=im8 Арифметический сдвиг г/гп(8,16,32) вправо на п разрядов, n=(CL)
SHL r/m(8,16,32), im8 r/m(8,16,32), CL Логический сдвиг г/гп(8,16,32) влево на п разрядов, n=im8 Логический сдвиг г/гп(8,16,32) влево на л разрядов, n=(CL)
SHR r/m(8,16,32), im8 r/m(8,16,32), CL Логический сдвиг г/гп(8,16,32) вправо на п разрядов, n=im8 Логический сдвиг г/гп(8,16,32) вправо на п разрядов, n=(CL)
ROL r/m(8,16,32), im8 r/m(8,16,32), CL Циклический сдвиг r/m(8,16,32) влево на п разрядов, n=im8 Циклический сдвиг г/гп(8,16,32) влево на п разрядов, n=(CL)
ROR r/m(8,16,32), im8 r/m(8,16,32), CL Циклический сдвиг r/m(8,16,32) вправо на п разрядов, п=1гп8 Циклический сдвиг r/m(8,16,32) вправо на п разрядов, n=(CL)
RCL r/m(8,16,32), im8 r/m(8,16,32), CL Циклический сдвиг г/гп(8,16,32) влево через CF на п разрядов, п=йп8 Циклический сдвиг г/гп(8,16,32) влево через CF на п разрядов, n=(CL)
RCR r/m(8,16,32), im8 r/m(8,16,32), CL Циклический сдвиг г/гп(8,16,32) вправо через CF на п разрядов, n=im8 Циклический сдвиг г/гп(8,16,32) вправо через CF на п разрядов, n=(CL)
CHLD r/m(16,32),r(16,32),im8 r/m(16,32),r(16,32), CL Сдвиг г/гп( 16,32) влево на п разрядов с запоминанием разрядов справа из г(16,32), n=im8 Сдвиг г/гп( 16,32) влево на п разрядов с запоминанием разрядов справа из г(16,32), n=(CL)
CHRD r/m(16,32),r(16,32),im8 r/m(16,32),r(16,32), CL Сдвиг г/гп(16,32) вправо на п разрядов с запоминанием разрядов слева из г(16,32), n=im8 Сдвиг r/m(16,32) вправо на п разрядов с запоминанием разрядов слева из г(16,32), n=(CL)
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
Логические операции конъюнкции (И), дизъюнкции (ИЛИ), неравнозначности (исключающее ИЛИ) выполняются командами AND, OR, XOR побитно над значениями каждого из разрядов операндов. В этих командах реализуются такие же варианты адресации операндов, как и в арифметических командах ADD, SUB, При использовании в качестве операндов 16- или 32-разрядного содержимого регистра или ячейки памяти и 8-разрядного непосредственного операнда im8 последний расширяется знаком до 16 или 32 разрядов. Команда NOT производит инвертирование значения каждого бита в адресуемом регистре или ячейке памяти. При этом значения признаков не изменяются.
Команда проверки TEST реализует побитную конъюнкцию операндов без изменения их значений и устанавливает соответствующие признаки в регистре EFLAGS (аналогично арифметической команде СМР).
Процессор выполняет несколько команд, реализующих сдвипи размещенного в регистре или памяти 8-, 16- или 32-разрядного операнда г/m на заданное число разрядов п. Значение п определяется содержимым регистра CL (переменная разрядность) или числом, заданным в виде непосредственного операнда im8 (фиксированная разрядность). Величина п задается пятью младшими разрядами содержимого CL или операнда im8 и может принимать значения от 0 до 31. Реализация различных команд сдвигов показана на рис. 2.14.
r/m (16,32)
SHRD
r/m (16,32)
Операнд
Рис. 2.14. Выполнение команд сдвигов
СИСТЕМА КОМАНД: ОПЕРАЦИИ НАД ЦЕЛЫМИ ЧИСЛАМИ
Команда SHL/SAL осуществляет сдвиг адресуемого операнда, размещенного в регистре или памяти, влево на заданное число разрядов; освобождающиеся младшие разряды заполняются нулями. Команды SHR, SAR сдвигают адресуемый операнд вправо. При выполнении команды SHR освобождающиеся старшие разряды заполняются нулями. Команда SAR сохраняет знак операнда; для этого освобождающиеся слева разряды заполняются значениями старшего (знакового) разряда. Выполнение команд циклических сдвигов ROL, ROR, RCR, RCL иллюстрируется на рис. 2.14.
Команды SHLD, SHRD используют два операнда, первый из которых r/m может храниться в регистре или памяти, второй r-в регистре. При выполнении команды SHLD первый операнд сдвигается влево на заданное число разрядов, а в его освободившиеся младшие разряды вводится соответствующее число старших разрядов второго операнда. При выполнении команды SHRD первый операнд сдвигается вправо, а в освобождающиеся старшие разряды последовательно вводятся младшие разряды второго операнда. Копия второго операнда г сохраняется в соответствующем регистре в исходном состоянии (без сдвига).
Во всех видах сдвигов признак CF принимает значение последнего выдвигаемого бита (в командах SHLD, SHRD - последнего бита, выдвигаемого из первого операнда). При одноразрядных сдвигах (п = 1) устанавливается значение признака переполнения OF = 1, если изменилось значение знака (старший разряд). При многоразрядных сдвигах (п > 1) значение признака OF оказывается неопределенным. При выполнении команды SAR значение знакового разряда не меняется, поэтому всегда устанавливается значение OF = 0.
2.2.4. КОМАНДЫ БИТОВЫХ И БАЙТОВЫХ ОПЕРАЦИЙ
Команды данной группы приведены в табл. 2.19.
Команды битовых операций ВТ, BTS, BTR, ВТС выбирают из регистра или ячейки памяти значение определенного бита и копируют его в признак CF. Номер бита п задается пятью или четырьмя младшими разрядами содержимого регистра г или непосредственного операнда im8 (в зависимости от разрядности обрабатываемого слова r/m32 или г/т 16). При выполнении команды ВТ значение выбранного бита в исходном 16- или 32-разрядном слове остается неизменным; при выполнении BTS значение этого бита устанавливается в 1; при выполнении BTR - сбрасывается в нуль; при выполнении ВТС - инвертируется.
Команды условной установки байтов SETcc производят установку содержимого байта в регистре или ячейке памяти г/гп8, указанных в команде.
Таблица 2.19
Команды битовых и байтовых операций
Синтаксис команды Операция
ВТ r/m(16,32), r(16,32) r/m(16,32), im8 bn —> bn —> CF, n=(r4-0) CF, n=(im4-0)
BTS r/m(16,32), r(16,32) bn —> CF, n=(r4-0), 1 -> bn
r/m(16,32), im8 bn —> CF, n=(im4-0), 1 bn
BTR r/m(16,32), r(16,32) bn —> CF, n=(r4-0), 0 —> bn
bn —> CF, n=(im4-0), 0 -» bn
ВТС r/m(16,32), r(16,32) bn —> CF, n=(r4-0), bn -> bn
r/m(l6,32), im8 bn -> CF, n=(im4-0), bn —> bn
BSF r(16,32), r/m(16,32) n1 -> r(16,32); если r/m=0, to ZF=1
BSR r(16,32), r/m(16,32) n1 —> r(16,32); если r/m=0, to ZF=1
SETcc r/m8 OFFH —> r/m8, если cc=1,
OOH —> r/m8, если cc=0
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
Команды сканирования битов BSF, BSR производят анализ битов операнда г/т, содержащегося в адресуемом регистре или ячейке памяти, и заносят значение п1 - номер первого встреченного бита, имеющего значение единица, в регистр-приемник г, заданный в команде. При выполнении команды BSF сканирование начинается с младшего разряда операнда, при выполнении BSR-со старшего разряда. Если операнд равен нулю (единичные биты отсутствуют), то устанавливается признак2Е = 1. При этом содержимое регистра-приемника будет неопределенным. Если единичный бит найден, то устанавливается ZF = 0.
Команды условной установки байта SETcc устанавливают определенное значение байта, который содержится в регистре или ячейке памяти r/m, указанных в команде. Условие установки байта определяется суффиксом сс, который добавляется к мнемокоду команды. В соответствии с этим суффиксом команда проверяет выполнение определенного условия (сс), которое задается различными значениями признаков, установленных в регистре EFLAGS. Виды проверяемых условий и соответствующие суффиксы сс указаны в табл. 2.22. Они аналогичны условиям, используемым в командах условных пересылок CMOVcc и условных переходов Jcc. Если условие выполняется (сс = 1), то все разряды адресованного байта устанавливаются в единицу (записывается OFFh), если не выполняется - все разряды байта сбрасываются в нуль (запись 00h).
2.2.5. КОМАНДЫ ОПЕРАЦИЙ СО СТРОКАМИ СИМВОЛОВ
Команды данной группы приведены в табл. 2.20. При выполнении этих команд символом является 8-, 16- или 32-разрядный операнд, являющийся элементом строки, которая представляет последовательность символов, расположенных в смежных ячейках памяти. При программировании на языке Ассемблера мнемокоды команд дополняются суффиксом В (байт), W (слово) или D (двойное слово), указывающим разрядность обрабатываемых операндов (символов).
Различаются два типа строк символов. Строка-источник обычно (по умолчанию) располагается в сегменте DS. Размещение этой строки в других сегментах (см. табл. 2.8) обеспечивается путем введения соответствующего префикса SEG перед командой обработки строк символов. Относительный адрес символа в строке задается содержимым регистра SI. Полный указатель адреса для символа строки-источника имеет вид DS:[SI], если не используется префикс замены сегмента SEG. Строка-приемник всегда размещается в сегменте ES (см. табл. 2.8). Относительный адрес символа в этой строке задается содержимым регистра DI, поэтому полный указатель адреса для символа строки-приемника имеет вид ES:[SI]. После выполнения очередной команды со строкой содержимое SI и DI изменяется на +1 или - 1, +2 или - 2, +4 или - 4 в зависимости от разрядности символа (8, 16 или 32). Направление изменения адресов определяется значением признака DF в регистре EFLAGS. Если значение DF = 0, осуществляется увеличение адреса (автоинкремент) на 1,2 или 4; если DF = 1, осуществляется его уменьшение (автодекремент).
Если перед командами отсутствует префикс повторения, то соответствующие операции выполняются только для одного символа в строке, адресуемого содержимым регистров SI, DI. Префиксы повторения REP, REPE(REPZ) и RERNE(REPNZ) обеспечивают последовательное выполнение команд над символами строки. При этом количество повторений определяется содержимым регистра ЕСХ или выполнением определенного условия. Так как регистр ЕСХ имеет 32 разряда, то максимальная длина обрабатываемых строк составляет 232 символа. Префикс REP используется для последовательного выполнения команд LCDS, STOS, INS, OUTS, MOVS, префиксы REPE (синоним REPZ), REPNE (синоним REPNZ) используются с командами CMPS и SCAS.
СИСТЕМА КОМАНД: ОПЕРАЦИИ НАД ЦЕЛЫМИ ЧИСЛАМИ
Таблица 2.20
Команды операций со строками символов
Синтаксис команды Операция о
LODS (B,W,D) В, W или D (строка-источник) -> AL, AX или EAX
STOS (B,W,D) AL, AX или ЕАХ -> B, W или D (строка-приемник)
MOVS (B,W,D) В, W или D (строка-источник) -> В, W или D (строка-приемник)
INS (B.W.D) port (DX) -> В, W или D (строка-приемник)
OVT (B,W,D) В, W или D (строка-источник) -> port (DX) V
REP Префикс повторения, n=(ECX) и
SCAS (B,W,D) В, W или D (строка-источник) - В, W или D (строка-приемник)
установка признаков OF,SF,AF,ZF,PF,CF
CMPS (B,W,D) AL, АХ или ЕАХ - В, W или D (строка-приемник)
установка признаков OF,SF,AF,ZF,PF,CF
REPE (REPZ) Префикс повторения до установки ZF=1
REPNE (REPNZ) Префикс повторения до установки ZF=10
Команда LODS осуществляет загрузку символа из строки-источника в аккумулятор (AL, АХ или ЕАХ). Команда STOS заносит содержимое аккумулятора в качестве символа в строку-приемник. Команда MOVS пересылает символ из строки-источника в строку-приемник. При наличии префикса REP эти команды повторяются п раз, где п = (ЕСХ). В результате после выполнения команды REP LODS в аккумулятор будет помещен п-й символ строки-источника, а после REP STOS содержимое аккумулятора будет введено п раз в качестве п символов строки-приемника. Команда REP MOVS осуществляет пересылку п символов из строки-источника в строку-приемник.
Команды ввода-вывода символов INS и OUTS выполняют ввод символа в строку-приемник или вывод символа из строки-источника. Номер адресуемого порта задается содержимым регистра DX. Команды с префиксом REP INS и REP OUTS осуществляют ввод последовательности из п символов в строку-приемник или их вывод из строки-источника. Выполнение этих команд в защищенном режиме производится, как и команд IN, OUT, в зависимости от значения уровней привилегий CPL и IOPL.
При выполнении команды сравнения CMPS происходит вычитание символа строки-приемника из символа строки-источника с установкой соответствующих признаков. Команда сканирования SCAS производит аналогичное вычитание символа строки-приемника из содержимого аккумулятора. Установка признаков для команд CMPS, SCAS выполняется так же, как для команды СМР (см. табл. 2.17). Результат вычитания в командах CMPS, SCAS не сохраняется, поэтому эти команды используются для сравнения значений символов двух строк между собой или сравнения символа строки-приемника и эталонного символа, размещенного в аккумуляторе.
Наличие префикса ЙЕРЕ(или REPNZ) останавливает повторение операций при обнаружении одинаковых символов в строках (команда CMPS) или в строке-источнике и аккумуляторе (команда SCAS). Если одинаковые символы отсутствуют, то выполнение команды продолжается до конца строки. Префикс REPNE (или REPNZ) останавливает выполнение команд CMPS и SCAS при обнаружении неодинаковых символов. Если все символы одинаковы, то команды выполняются п = (ЕСХ) раз. Команда CMPS используется для поиска одинаковых (с префиксом REPE) или различных (префикс REPNE) символов в строках. Команда SCAS с префиксом REPE(REPNZ) или REPNE (REPNZ) служит для поиска в строке-источнике символа, совпадающего или не совпадающего с заданным в аккумуляторе эталоном.
01
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
Чтобы сократить время реакции на внешние прерывания, процессор при выполнении команд этой группы может принимать и обслуживать запросы прерывания INTR после обработки каждого символа строки.
2.3. СИСТЕМА КОМАНД: ОПЕРАЦИИ УПРАВЛЕНИЯ
К этому классу относятся команды, которые обеспечивают управление программой -условные и безусловные переходы, обращение к подпрограммам прерывания, организацию цикла и др., поддержку языков высокого уровня, организацию защиты памяти и управления процессором. Ниже дается полный перечень этих команд, разбитых на функциональные группы.
Управление программой
Безусловная передача управления:
JMP - Безусловный переход
CALL- Вызов подпрограммы
RET - Возврат из подпрограммы
Условные переходы без учета знака:
JA/JNBE - Переход, если выше (не ниже, не равно)
JAE/JNB/JNC - Переход, если CF = 0: выше или равно (не ниже)
JB/JNAE/JC - Переход, если CF = 1: ниже (не выше или равно)
JBE/JNA- Переход, если ниже или равно (не выше)
JE/JZ - Переход, если равно (нуль): ZF - 1
JNE/JNZ-Переход, если не равно (не нуль): ZF = 0
JP/JPE - Переход, если четность: PF = 1
JNP/JPO - Переход, если нечетность: PF = 0
Условные переходы с учетом знака:
JG/JNLE - Переход, если больше (не меньше, не равно)
JGE/JNL-Переход, если больше или равно (не меньше)
JL/JNGE - Переход, если меньше (не больше, не равно)
JLE/JNG - Переход, если меньше или равно (не больше)
JS - Переход, если отрицательно: SF = 1
JNS - Переход, если положительно: SF = 0
JO-Переход, если переполнение: OF - 1
JNO - Переход, если нет переполнения: OF = 0
Вызов системных программ:
SYSENTER - Быстрый переход к системной программе
SYSEXIT - Быстрый возврат из системной программы
Прерывания
INT-Прерывание
INTO - Прерывание по переполнению (OF = 1)
INT3 - Прерывание в контрольной точке
UD2 - Прерывание недействительного кода операции
IRET - Возврат из подпрограммы обслуживания прерывания
CLI-Запрещение прерываний
STI - Разрешение прерываний
СИСТЕМА КОМАНД: ОПЕРАЦИИ УПРАВЛЕНИЯ
Организация циклов
LOOP - Реализация циклов, пока ЕСХ = О
LOOPE/LOOPZ - Реализация циклов, пока ЕСХ = 0 или ZF = 1
LOOPNE/LOOPNZ - Реализация циклов, пока ЕСХ - 0 или ZF = О
JCXZ (JECXZ) - Реализация циклов, пока СХ = О (ЕСХ - 0)
Операции над признаками
LAHF - Загрузка признаков в регистр АН
SAHF - Запись содержимого АН в регистр признаков
PUSHF - Запись содержимого регистра признаков в стек
POPF - Загрузка содержимого регистра признаков из стека
CLC - Сброс признака переноса: CF = 0
STC-Установка признака переноса: CF = 1
СМС - Инвертирование признака переноса CF
CLD - Сброс признака направления: DF = 0
CTD-Установка признака направления: DF = 1
Поддержка языка высокого уровня
BOUND - Проверка границ массива
ENTER - Обращение к процедуре
LEAVE - Выход из процедуры
Организация защиты памяти
SGDT - Запись содержимого регистра таблицы глобальных дескрипторов SLDT - Запись содержимого регистра таблицы локальных дескрипторов SIDT - Запись содержимого регистра таблицы дескрипторов прерываний STR- Запись содержимого регистра задачи
LGD - Загрузка регистра таблицы глобальных дескрипторов
LLDT -Загрузка регистра таблицы локальных дескрипторов
LIDT- Загрузка регистра таблицы дескрипторов прерываний
LTR- Загрузка регистра задачи
CLTS - Сброс признака переключения задачи: TS = 0
ARPL - Коррекция запрошенного уровня привилегий
LAR - Загрузка прав доступа
LSL- Загрузка границы сегмента
VERR- Проверка доступности сегмента при чтении
VERRW - Проверка доступности сегмента при записи
Управление процессором
LMSW - Загрузка слова состояния машины (MSW)
SMSW - Запись в память слова состояния машины (MSW)
NOP - Отсутствие операции
HLT-Останов
CPUID - Идентификация модели процессора
RSM - Возврат из режима системного управления
INVD-Аннулирование содержимого кэш-памяти
WBINVD - Обратная запись и аннулирование кэш-памяти
INVLPG-Аннулирование входа в таблицу страниц
RDMSR-Чтение содержимого модельно-специфических регистров MSR WRMSR- Запись содержимого модельно-специфических регистров MSR RDPMC - Чтение счетчика-монитора производительности
RDTSC -Чтение содержимого регистра-счетчика времени
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
Префиксные байты, которые вводятся перед очередной командой, изменяют процедуру ее выполнения. Поэтому префиксные байты можно рассматривать как дополнительные команды управления, которые определяют процесс выполнения последующей операции:
префикс SEG - замена сегмента
префикс AS - изменение разрядности адреса
префикс OS - изменение разрядности операнда
префикс LOCK-блокировка магистрали
префиксы REP, REPE(NE) - повторение операций со строками символов
2.3.1. КОМАНДЫ УПРАВЛЕНИЯ ПРОГРАММОЙ
К этой группе относится большое число команд, которые для удобства описания разобьем на несколько подгрупп.
Команды безусловной передачи управления (табл. 2.21) осуществляют безусловный переход (JMP), вызов подпрограммы (CALL) и возврат из подпрограммы (RET).
Если передача управления происходит внутри сегмента (NEAR - ближняя передача), то содержимое регистра CS не меняется и реализуется переход к команде, расположенной в текущем сегменте кодов. Команды JMP и CALL с относительной адресацией производят увеличение содержимого регистра IP или EIP на указанную в команде величину ге18,16 или 32, которая воспринимается как число со знаком. При вычислении нового относительного адреса команды (IP, EIP)+(rel8,16,32) возникающий перенос игнорируется, поэтому полученный адрес остается в пределах текущего сегмента кодов. Команды JMP и CALL с косвенной адресацией загружают в IP или EIP содержимое регистра или ячейки памяти г/т(16,32), адресуемых байтом MODR/M. Команда CALL перед этим заносит в стек текущее значение IP или EIP, которое является относительным адресом следующей команды программы. При поступлении команды RET производится восстановление из стека содержимого IP, EIP, необходимого для вычисления адреса возврата.
При передаче управления между сегментами (FAR - дальняя передача) меняется не только содержимое регистра EIP или IP, но и базовый адрес сегмента, определяемый содержимым регистра сегмента кодов CS. При выполнении команд JMP и CALL с непосредственной адресацией в качестве операнда ptr16:16 или ptr16:32 в команде задается 16-разрядное число ptr16 - новое содержимое регистра CS, и ptr16 или ptr32 - новое содержимое регистра IP или EIP. При косвенной адресации с помощью байта MODR/M адресуются ячейки памяти т(16:16, 16:32), в которых последовательно располагается новое содержимое IP или EIP и 16-разрядный селектор, загружаемый в регистр CS. Отметим, что в этом случае не производится адресация к регистрам, т е. в байте MODR/M должно быть установлено значение поля mod = 11.
Для возврата из подпрограммы используется команда RET, которая восстанавливает из стека содержимое регистров EIP или IP и CS (при выполнении межсегментных переходов). Если команда RET содержит непосредственный операнд im 16, то после извлечения из стека содержимого регистров EIP (IP) и CS (при межсегментном переходе) содержимое указателя стека ESP (или SP) увеличивается на величину im16. Таким образом, из стека исключается число ячеек памяти, равное im16. Эта команда производит очистку сегмента стека от использованных в программе параметров, если они не требуются для продолжения выполнения основной программы.
Команды условных переходов Jcc выполняют переходы только в пределах текущего сегмента кодов с использованием относительной адресации. При выполнении заданного условия производится переход к команде, относительный адрес которой в сегменте кодов равен (1Р+ге18,16) или (EIP+rel8,32), гдеге!8,16 или 32 представляете-, 16-или32-разрядное смеще
СИСТЕМА КОМАНД: ОПЕРАЦИИ УПРАВЛЕНИЯ
ние со знаком. Таким образом, допускаются переходы к ячейкам памяти, размещенным в текущем сегменте кодов перед командой Jcc или после нее. Возникающие при вычислении этих относительных адресов переносы не учитываются. Имеется две модификации команд Jcc: короткие и длинные переходы. Первая модификация использует 8-разрядное смещение (ге18), вторая модификация использует 16- или 32-разрядное смещение (rel 16 или ге!32) в зависимости от разрядности адреса, устанавливаемой режимом работы микропроцессора или соответствующим префиксом перед командой Jcc.
В подгруппу входят 16 команд, различающихся условием выполнения перехода сс (табл. 2.22). Соответствующие мнемокоды условий добавляются к букве J (JUMP), образуя мнемокод команды, например: J+O -JO- мнемокод команды условного перехода по переполнению. Условие определяется значением отдельных признаков или их комбинацией.
В качестве условия часто используется относительное значение двух операндов, определяемое с помощью команды сравнения СМР. Равенство операндов определяется значением признака нуля ZF после команды СМР: равно Е/Z (результат равен 0); не равно NE/NZ (результат не равен 0). Если сравниваются беззнаковые операнды, то соотношение их значений (выше - ниже - равно) определяют условия:
• ниже (не выше и не равно) (<) B/NAE;
• не ниже (выше или равно) (>=) NB/AE;
• ниже или равно (не выше) (<=) BE/NA;
• не ниже и не равно (выше) (>) NBE/A.
Отметим, что команды JB/JNAE и JNB/JAE эквивалентны командам переходов по наличию переноса JC или отсутствию переноса JNC. „
Таблица 2.21 ъ
Команды передачи управления и прерывания ».
Синтаксис команды Операция
JMP NEAR rel(8,16,32) EIP(IP) + rel —> EIP(IP)
r/m(16,32) E IP(IP) + r/m -> EIP(IP)
JMP FAR ptr(16:16, 16:32) ptr16 -> CS, ptr(16,32) -> IP, EIP
т(16:1б, 16:32) m16 -> CS, m(16,32) -> IP, EIP
CALL NEAR rel(16,32) EIP(IP) -> стек, EIP(IP) + rel -> EIP(IP)
r/m(16,32) EIP(IP) -> стек, EIP(IP) + r/m -> EIP(IP)
CALL FAR ptr(16:16, 16:32) CS,EIP(IP) -> стек, ptr(16,32) -> IP, EIP
m(16:16, 16:32) CS.EIP(IP) -> стек, m16 -> CS, m(16,32) -> IP, EIP
RET NEAR (im16) стек-> EIP(IP); (SP + im16-> SP)
RET FAR (im16) стек -> EIP(IP), CS; (SP + im16-> SP)
Jcc rel(8,16,32) EIP(IP) + rel -> EIP(IP), если (cc) = 1
JECXZ (JCXZ) re!8 ECX-1 -> ECX; EIP + rel8 -> EIP, если ЕСХ = 0
LOOP rel8 ECX-1 -> ECX; EIP + rel8 -> EIP, если ECX / 0
LOOPE(Z) rel8 ECX-1 -> ECX; EIP + rel8 EIP, если ECX # 0 или ZF=1
LOOPNE(NZ) rel8 ECX-1 -> ECX; EIP + rel8 -> EIP, если ECX # 0 или ZF=0
1NT im8 EFLAGS,CS,EIP -> стек, Ve -> CS, EIP
1NT3 EFLAGS,CS,EIP -> стек, Ve(#3) -> CS, EIP
INTO EFLAGS,CS,EIP -> стек, Ve(#4) -> CS, EIR если
UD2 OF=1 EFLAGS,CS,EIP -> стек, Ve(#7) -> CS, EIP
IRET стек -> EIP, CS, EFLAGS
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
Таблица 2.22
Виды условий при выполнении условных операций
Мнемокод Условие (cc=1) Мнемокод Условие (сс=1)
0 Переполнение OF=1 NO Нет переполнения OF=0
В (NAF) Ниже (не выше и не равно) CF=1 NB (АЕ) Не ниже (выше или равно) CF=0
E(Z) Равно (нуль) ZF=1 NE (NZ) Не равно (не нуль) ZF=0
BE (NA) Ниже или равно (не выше) CF v ZF = 1 NBE (А) Не ниже и не равно (выше) CF v ZF = 0
S Отрицательный знак SF=1 NS Положительный знак SF=0
P(PE) Четность PF=1 NP (РО) Нечетность PF=0
L (NGE) Меньше (не больше и не равно) SF ФOF = 1 NL (GE) Не меньше (больше или равно) SF © OF = 0
LE(NG) Меньше или равно (не больше) (SF © OF) v ZF = 1 LNE (G) Не меньше и не равно (больше) (SF © OF) vZF= 1
Если сравниваются операнды со знаком, то соотношение между ними (больше - меньше - равно) определяют условия:
• меньше (не больше и не равно) (<) < L/NGE;
• не меньше (больше или равно) (>=) NL/GE;
• меньше или равно (не больше) (<=) LE/NG;
• не меньше и не равно (больше) (>) NLE/G.
Команды организации циклов осуществляют условный переход в зависимости от значения содержимого регистра ЕСХ (или СХ), которое автоматически уменьшается на единицу (декремент) при поступлении команд этой подгруппы: JECXZ, (JCXZ), LOOP, LOOPE/LOOPZ, LOOPNE/LOOPNZ. Таким образом, регистр ЕСХ используется в качестве счетчика циклов.
Команды LOOPE/LOOPZ, LOOPNE/LOOPNZ аналогичны команде LOOP, но используют дополнительные условия для повторения цикла. Команда LOOPE/LOOPZ обеспечивает выход из цикла при получении ненулевого результата, т. е. при установке ZF - 0, до выполнения заданного числа циклов п = (ЕСХ). Если в каждом цикле реализуется нулевой результат, то выполняется п = (ЕСХ) циклов, как в команде LOOP. Команда LOOPNE/LOOPNZ прекращает выполнение циклов при получении нулевого результата, т. е. при установке ZF = 1.
В зависимости от режима работы процессора и наличия префиксов изменения разрядности адреса при выполнении команд организации циклов вместо регистров EIP, ЕСХ могут использоваться IP, СХ. При этом вместо мнемокода команды JECXZ используется JCXZ.
Команды прерываний обеспечивают переход к одной из 256 программ обслуживания исключений и прерываний. При этом текущее содержимое регистров IP (EIP), CS и FLAGS (EFLAGS) заносится в стек. Каждая из программ обработки соответствует определенному типу исключения или прерывания, номер которого определяется 8-разрядным непосредственным операндом im8, задаваемым во втором байте команды INT. Вызов соответствующей программы обслуживания производится с помощью таблицы, в которой содержатся векторы исключений (прерываний) Ve - адреса первых команд программ обслуживания. Номер вектора Ne = im8 указывает его положение в таблице векторов. Каждый вектор задает необходимое содержимое CS и EIP (IP), загрузка которого в эти регистры обеспечивает переход к выполнению первой команды программы обслуживания. Обращение к таблице векторов Ve производится процессором в зависимости от режима его работы. В защищенном режиме при
СИСТЕМА КОМАНД: ОПЕРАЦИИ УПРАВЛЕНИЯ
Таблица 2.23
Команды управления признаками
Синтаксис команды Операция
CLI 0 -5 IF
ST1 1 -Э IF
CLC 0 -ч CF
STC 1 -> CF
СМС CF -> CF
CLD 0 -ч DF
STD 1 -ч DF
LAHF EFLAGS(7-0) -> АН
SAHF АН -> EFLAGS(7-0)
PUSHF EFLAGS -> Стек
POPF Стек -> EFLAGS
переходе к программе обслуживания прерываний в стеке сохраняется также заданное число 16- или 32-разрядных параметров из вершины стека, которые при выполнении команд прерываний переносятся в стек программы обслуживания прерываний для использования или сохранения.
Первые 32 вектора прерываний зарезервированы для обслуживания исключительных ситуаций (ошибки, отказы и т. п.), возникающих при выполнении программы. Для трех из этих ситуаций предусмотрены отдельные однобайтные команды 1NT3, INTO и UD2.
Команда INT3 имеет вектор с номером Ne = 3 (исключение типа #ВР - останов в контрольной точке) и используется для установки контрольных точек в процессе отладки программы. Программа, вызываемая этой командой, обеспечивает останов процессора и выдачу пользователю необходимой информации о его текущем состоянии. Команда INTO проверяет значение признака OF и вызывает соответствующую программу обслуживания, если OF - 1, т. е. результат предыдущей операции (число со знаком) вышел за пределы разрядной сетки. Эта команда обращается к вектору прерываний с номером Ne=4 (исключение типа #OF - переполнение разрядной сетки). Команда UD2, введенная в процессорах семейства Р6, реализует прерывание с номером Ne -1 (#UD - недействительный код операции). Эта команда используется для вызова программы обслуживания прерывания типа #UD в процессе выполнения текущей программы.
Команда IRET обеспечивает возврат из подпрограммы обслуживания прерывания путем извлечения из стека и возвращения в регистры содержимых EIP или IP, CS, EFLAGS или FLAGS, соответствующих прерванной процедуре.
Дополнительные команды вызова системных процедур SYSENTER, SYSEXIT введены в процессорах Pentium II и последующих моделях данного семейства. Эти команды используют специальные модельно-специфические регистры (MSR), которые имеют имена SYSENTER_CS_MSR (адрес 174h), SYSENTER_ESP_MSR (адрес 175h), SYSENTER_EIP_MSR (адрес 176h). В эти регистры с помощью команд WRMSR записываются адреса ячеек памяти, содержимое которых обеспечивает переход к определенной системной программе, имеющей максимальный уровень привилегии DPL = 0. При поступлении команды SYSENTER из этих ячеек памяти производится загрузка нового содержимого: в регистр CS - из ячейки, адресуемой регистром SYSENTER_CS_MSR, в регистр EIP - ячейки, адресуемой SYSENTER_EIP_MSR, в регистр SS - из ячейки, адрес которой равен (SYSENTER_CS_MSR) + 8, в регистр ESP - из ячейки, адресуемой SYSENTER_ESP_MSR. Таким образом, обеспечивается переход к новым сегментам команд и стека. При этом не
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
сохраняется адрес возврата к выполняемой команде и содержимое каких-либо регистров. Если эта информация необходима для выполнения последующих процедур, то программист должен предварительно позаботиться о ее сохранении. Для возврата из системной программы с максимальным уровнем приоритета CPL - 0 к программе пользователя (DPL = 3) служит команда SYSEXIT, которая производит загрузку нового содержимого: в регистр CS из ячейки памяти с адресом (SYSENTER_CS_MSR) + 16, в регистр SS-из ячейки с адресом (SYSENTER_CS_MSR) + 24, в регистр SS - из регистра EDX, в регистр ESP - из регистра ЕСХ. В эти регистры и ячейки памяти предварительно должно быть записано содержимое, обеспечивающее переход к необходимой программе пользователя.
Команды управления признаками (табл. 2.23) обеспечивают запись-чтение содержимого регистра признаков и их изменение. Команды LAHF и SAHF выполняют загрузку младшего байта из регистра EFLAG в регистр АН и заполнение младшего байта в EFLAGS из регистра АН. Команды POPF, PUSHF производят загрузку в стек или выборку из стека содержимого FLAGS при обработке 16-разрядных операндов или EFLAGS при обработке 32-разрядных операндов. Команды CLC, STC осуществляют установку значений признака переноса CF = О, CF = 1, а команда СМС вызывает инвертирование значения этого признака. Команды CLD, STD устанавливают значения признака направления DF = О, DF = 1. Команды CLI, ST/ выполняют соответственно установку значений признака разрешения прерываний IF=0 (запрещение прерываний), IF=1 (разрешение прерываний). В защищенном режиме изменение значения IF с помощью этих команд производится при выполнении условия CPL < IOPL, как и для команд IN, OUT, INS, OUTS. При нарушении этого условия реализуется исключение типа #GP («нарушение защиты»).
Необходимо отметить, что команды IRET, POPF в защищенном режиме могут изменить значение признака IF в регистре EFLAGS только при выполнении такого же условия: CPL < IOPL. Содержимое поля IOPL в регистре EFLAGS эти команды могут изменять только при наиболее высоком уровне привилегий текущей программы: CPL = 0.
2.3.2. КОМАНДЫ ПОДДЕРЖКИ ЯЗЫКОВ ВЫСОКОГО УРОВНЯ
Команды этой группы (табл. 2.24) обеспечивают реализацию ряда процедур, широко используемых при программировании на языках высокого уровня.
Команда BOUND проверяет, находится ли содержимое регистра, адресуемое полем reg байта MODR/M, в заданных пределах. Если содержимое регистра меньше нижнего или больше верхнего предела, то процессор переходит к выполнению программы обработки прерывания типа 5 - «превышение границы». Содержимое регистра рассматривается как число со знаком. Значения верхнего и нижнего пределов размещаются в двух последовательно расположенных 16- или 32-разрядных ячейках памяти, адресуемых с помощью байта MODR/M: в первой ячейке задается нижняя граница диапазона, во второй ячейке - верхняя граница. При этом не допускается использование регистровой адресации, т. е. в байте MODR/M должно быть указано значение поля mod =11. Если команда будет иметь поле mod = 11, то выполняется прерывание с номером Ne = 6-«неправильный код операции». Данная команда служит для проверки нахождения индекса в заданных границах.
Команда ENTER создает стековый кадр заданного размера для размещения параметров процедуры. Перед этим кадром в стек помещается список указателей на стековые кадры, созданные ранее выполняемыми вложенными процедурами. Таким образом обеспечивается возможность из текущей процедуры обращаться к параметрам других процедур. Обычно команда ENTER является первой командой выполнения определенной процедуры.
Размер стекового кадра, создаваемого командой ENTER, определяется содержимым первого операнда im8. Второй операнд I8 может иметь значения от 0 до 31 и указывает уровень
СИСТЕМА КОМАНД: ОПЕРАЦИИ УПРАВЛЕНИЯ
Таблица 2.24
Команды поддержки языков высокого уровня и управления защитой памяти
Синтаксис команды Операция
BOUND r(16,32) т(16:16,32:32) EFLAGS,CS,EIP -> стек, Ve(#S) -> CS, EIP, еспи (r16,32) выходит за границы диапазона
ENTER im16,18 EBP -> стек; если п=(18) 4 0, то т(ЕВР) -> стек, ЕВР - 4 —> ЕВР, выполняется п раз; ESP -» EBP, ESP - im8 -> ESP
LEAVE EBP —> ESP, стек -> EBP
LGDT m16:32 m16:32 -> GDTR
SGDT m16:32 GDTR—> m16:32
LIDT m16:32 m16:32 -> IDTR
SIDT m16:32 IDTR—>m16:32
LLDT r/m16 r/m16 -> LDTR
SLDT r/m(16,32) LDTR —> r/m(16,32)
LTR r/m16 r/m16—> LTR
STR r/m 16 TR—>r/m16
CLTS 0 —> TS (бит 3 регистра CRD)
LAR r(16,32), r/m(16,32) Биты доступа сегмента (селектор r/m16,32) -»r(16,32)
LSL r(16,32), r/m(16,32) Размер сегмента (селектор r/m16,32) -> г( 16,32)
ARPL r/m16, r16 1 -» ZF, RPL<src> -» RPL<dst>, если RPL<dst> < RPL<src>
VERR r/m16 1 -» ZF, если чтение сегмента разрешено
VERW r/m16 1 -> ZF, если запись в сегмент разрешена
LMSW r/m 16 r/m16 —> MSW (биты 15-0 регистра CRD)
SMSW r/m MSW -» r/m16
вложенности текущей процедуры. Этот уровень определяет количество указателей (относительных адресов) предыдущих стековых кадров, помещаемых в стек перед образуемым стековым кадром. При поступлении команды ENTER содержимое регистра ЕВР (или ВР) посылается в стек, а последнее значение указателя стека ESP (или SP) заносится в ЕВР (или ВР), после чего содержимое ESP (или SP) уменьшается на величину im8, образуя стековый кадр заданного размера. Однако, если второй непосредственный байт 18 > 0, то после содержимого ЕВР (или ВР) в стек заносится п - (18) слов (32- или 16-разрядных) из последовательно расположенных 32- или 16-разрядных ячеек памяти, адрес которых задается содержимым регистра ЕВР (или ВР), последовательно уменьшаемым на 4 (или 2).
При выполнении команды выхода из процедуры LEAVE содержимое регистра ЕВР (или ВР) заносится в регистр ESP (или SP), восстанавливая значение указателя стека, которое было до входа в процедуру с помощью предыдущей команды ENTER. Затем из стека извлекается старое значение ЕВР (или ВР). Таким образом, производится подготовка к возврату в предыдущую процедуру. Обычно команда LEAVE является последней в программе реализации вызванной процедуры, и следующая за ней команда RET обеспечивает возврат к выполнению предыдущей процедуры.
2.3.3. КОМАНДЫ ОРГАНИЗАЦИИ ЗАЩИТЫ ПАМЯТИ
В эту группу объединены (см. табл. 2.24) команды, выполняющие пересылку содержимого регистров таблиц глобальных и локальных дескрипторов (GDTR и LDTR), дескрипторов прерываний (IDTR), младших 16 разрядов регистра управления CR0, содержащих слово состо-
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
яния машины MSW (machine status word); команды, управляющие переключением задач; команды, изменяющие уровень привилегий, права доступа и границы сегментов; команды, проверяющие допустимость записи и считывания для адресованных сегментов.
Команда LGDT загружает из памяти в регистр GDTR 32-разрядный линейный адрес начала и 16-разрядную границу (размер) таблицы глобальных дескрипторов. В команде задается адрес младшего из загружаемых в регистр байтов. Команда SGDT посылает содержимое регистра GDTR в память, размещая его в ячейках памяти, начиная с указанного в команде адреса. Команды LIDT и SIDT выполняют аналогичные процедуры с содержимым регистра таблицы прерываний IDTR, определяющим 32-разрядный начальный адрес и 16-разрядную границу таблицы дескрипторов прерываний.
Команда LLDT загружает в регистр LDTR 16-разрядный селектор, определяющий выбор дескриптора локальной таблицы LDT из таблицы GDT. Загрузка производится из регистра или ячейки памяти, заданных в команде (адресуемых байтом MODRM). Команда SLDT посылает содержимое регистра LDTR в регистр или ячейку памяти, указанные в команде. Команда LTR загружает в регистр задачи TR из памяти или регистра 16-разрядный селектор, с помощью которого в таблице GDT выбирается дескриптор, определяющий сегмент состояния выполняемой задачи TSS. Команда STR посылает селектор из регистра TR в регистр или ячейку памяти, указанные в команде.
Команда CLTS сбрасывает в нуль бит TS в регистре управления CR0 (см. рис. 2.7, а), который служит признаком переключения задачи. Этот бит устанавливается в состояние TS = 1 при каждом переключении задачи.
Команды LAR и LSL загружают в регистр г16 или г32, указанный в команде, определенные фрагменты дескрипторов. Дескриптор выбирается с помощью селектора, содержащегося в памяти или регистре, которые адресуются вторым операндом r/m(16,32) команды. По команде LAR из выбранного дескриптора выделяется и загружается в регистр байт 5 дескриптора, называемый байтом доступа. Этот байт содержит информацию о наличии сегмента, его типе, уровне его привилегий DPL. Байт доступа загружается в разряды 8-15 адресованного регистра, остальные разряды которого принимают нулевое значение. Команда LSL загружает в регистр г(16,32) значение границы сегмента, которая определяется двадцатью разрядами L19-0 содержимого выбранного дескриптора. Если в дескрипторе бит дробности G - 0, то граница определяется в байтах, и в регистр загружается 20-разрядное число, указывающее число байтов в сегменте. Если в дескрипторе бит G - 1, то соответствующие двадцать разрядов дескриптора определяют число страниц в сегменте. В этом случае процессор преобразует число страниц в число байтов (1 страница = 4096 байт) и загружает полученное 32-разрядное число в заданный регистр.
После загрузки командами LAR или LSL байта доступа или границы сегмента в адресованный регистр устанавливается признак нуля ZF = 1 в регистре EFLAGS. Если же выбранный этими командами дескриптор недоступен из-за нарушения уровня привилегий или границы таблиц GDT, LDT, то устанавливается значение признака ZF = 0.
Команда ARPL выполняет сравнение значений двух младших разрядов (1-0) операндов, первый из которых хранится в памяти или регистре, второй в регистре. В качестве операндов используются селекторы, разряды (1-0) которых содержат запрашиваемый уровень привилегий RPL, имеющий значение от 00 (высший уровень) до 11 (низший уровень). Вторым операндом обычно служит селектор текущей программы, который предварительно перегружается из регистра CS в регистр, адресуемый командой ARPL. При этом младшие разряды регистра будут содержать уровень привилегий текущей программы CPL. Если RPL первого операнда-селектора меньше CPL, то значение RPL в этом операнде устанавливается равным CPL, т. е. уровень его привилегий снижается. При этом устанавливается признак нуля ZF -1, указывающий на возможную попытку нарушения защиты. Если (RPL) >= (CPL), то значение RPL сохраняется и признак нуля сбрасывается: ZF = 0.
СИСТЕМА КОМАНД: ОПЕРАЦИИ УПРАВЛЕНИЯ
Команды VERR и VERW проверяют доступность выбранного сегмента при текущем уровне привилегий и допустимость чтения или записи в этом сегменте. Команда адресует память или регистр, где хранится селектор проверяемого сегмента. С помощью этого селектора выбирается дескриптор сегмента, байт доступа которого содержит бит R или W, определяющий право чтения или записи. Для сегментов программ (CS) это бит разрешения считывания R, для сегментов данных (DS, ES, FS, GS) - бит разрешения записи W. Таким образом, команда VERR используется для проверки доступности сегментов кодов, команда VERW - для проверки доступности сегментов данных. Если выбранный сегмент при текущем уровне привилегий недоступен, или чтение/запись в них запрещены, то признак нуля сбрасывается: ZF = 0. При этом не возникает прерывания по нарушению защиты. Если проверяемый сегмент доступен, то устанавливается значение признака ZF =1.
Команды LLDT, SLDT, LTR, STR, LAR, LSL, VERR, VERW выполняются только в защищенном режиме. Попытка их выполнения в реальном режиме вызовет прерывание типа 6 (неразрешенный код команды).
Команды LGDT, LLDT, LIDT, LTR, CLTS при работе в защищенном режиме выполняются только при наиболее высоком уровне привилегий текущей программы: CPL = 0. Выполнение этих команд при других уровнях привилегий программ вызывает прерывание с номером Ne = 13 (#GP - нарушение защиты).
2.3.4. КОМАНДЫ УПРАВЛЕНИЯ ПРОЦЕССОРОМ '"
Команда LMSW загружает из памяти или регистра слово состояния машины MSW в младшие 16 разрядов регистра управления CR0. Так как младший бит MSW управляет включением защиты, то данная команда используется для перехода в защищенный режим. Команда SMSW пересылает содержимое 16 младших разрядов CR0 в регистр или ячейку памяти, заданные в команде.
Команда NOP («пустая» команда), не вызывающая выполнения каких-либо операций, служит для реализации программных задержек или заполнения пропусков, образовавшихся в программе. Команда HLT прекращает выполнение программы и переводит процессор в состояние останова, выход из которого происходит при поступлении сигналов прерывания или перезапуска (Reset).
Отметим, что команды HLT и LMSW выполняются только при наиболее высоком уровне привилегий программы: CPL = 0. При всех других значениях CPL эти команды вызывают прерывание с номером Ne = 13 (#GP - нарушение защиты).
Команда CPUID позволяет получить информацию о типе процессора, используемом в данной системе. Эта информация вводится после выполнения данной команды в регистры ЕАХ, ЕВХ, ЕСХ, EDX и может быть считана пользователем или операционной системой. Содержание этой информации зависит от содержимого ЕАХ, которое предварительно записывается в этот регистр.
Если предварительное содержимое ЕАХ = 0, то после выполнения команды CPUID в этом регистре будет установлено значение ЕАХ - 2 (идентификатор семейства Р6). В регистрах EBX:ECX:EDX будет записано «Genuinelntel» («Настоящий Интел») в коде ASCII (один символ в каждом байте), что указывает на производство данного процессора 999 на заводах компании «Intel».
Если предварительное содержимое ЕАХ = 1, то в регистрах ЕАХ, EDX будет содержаться информация о типе и модели процессора, о реализуемых процессором режимах и функциональных возможностях (регистры ЕВХ,ЕСХ при этом не используются). Формат содержимого регистров ЕАХ, EDX после выполнения команды CPUID представлен для этого случая на рис. 2.15.
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
а)
31______________________1413 12 11___________8 7__________4 3_________О
| Резервировано (R) [ Туре [ Family | Model | Stepping ID
б)
15 14 13 12 1 1 10 9 8 7 6 5 4 3 2 1 О
CMOV | MCA | PGE | MTRR | SEP R APIC CX8 MCE PAE | MSR | TSC | PSE DE VME FPU
Резервировано (R) XMM FXSR MMX R R R R PN PSE36 PAT
31 2625 24 23 22 19 18 17 16
Рис. 2.15. Форматы содержимого регистров ЕАХ (а) и EDX (6) после выполнения команды CPUID (предварительное содержимое ЕАХ = 1)
Регистр ЕАХ (рис. 2.15, а) содержит поля, указывающие тип (Туре), семейство (Family) и модель (Model) процессора, которые для процессоров семейства Р6 имеют следующие значения: Туре = 00, Family = 0110, Model = 0001. Регистр EDX (рис. 2.15, б) содержит биты, единичное значение которых определяет следующие характеристики процессора:
FPU - указывает на наличие блока обработки чисел с плавающей точкой FPU;
VME - процессор реализует режим виртуального 8086, используя биты VME, PVI в регистре CR0 и биты VIF, VIP в регистре EFLASGS;
DE - процессор поддерживает отладку с установкой контрольных точек, используя бит DE в регистре CR0 и регистры отладки DR4, DR5;
PSE - процессор обеспечивает возможность использования страниц объемом 4 Мбайт при установке значения бита PSE = 1 в регистре CR0;
TSC - процессор содержит счетчик времени TSC, чтение содержимого которого производится командой RDTSC;
MSR - процессор содержит модельно-специфические регистры MSR, чтение и запись содержимого которых производится командами RDMSR, WRMSR;
РАЕ - реализуется 36-разрядная адресация памяти, если в регистре CR4 установлено значение бита РАЕ - 1;
MCE - процессор реализует прерывание машинного контроля #МС, если в регистре CR4 установлено значение бита MCE = 1;
СХ8 - процессор выполняет команду CMPXCHG8B;
APIC - процессор содержит усовершенствованный программируемый контроллер прерываний APIC (Advanced Programmable Interrupt Controller);
SEP - процессор реализует быстрое обращение к системным процедурам с помощью команд SYSENTER, SYSEXIT;
MTTR - процессор обеспечивает использование модельно-специфических регистров MTTR, реализующих обращение к разделам памяти с различными характеристиками;
PGE - процессор использует бит глобальности G при страничной адресации, если в регистре CR4 установлено значение бита РСЕ = 1;
MCA - процессор обеспечивает использование MSR-регистра MCG_CAP, используемого при контроле ошибок;
CMOV - процессор выполняет команды условной пересылки CMOVcc, а также (если значение бита FPU = 1) команд FCMOVcc и FCOMI;
РАТ - процессор поддерживает таблицу атрибутов страниц, позволяя операционной системе задавать определенные атрибуты для каждой страницы;
PSE36 - процессор обеспечивает работу со страницами размером 4 Мбайт при 36-разрядной шине адреса;
PN - процессор имеет 96-разрядный идентификационный номер, к которому обеспечен внешний доступ (чтение);
СИСТЕМА КОМАНД: ОПЕРАЦИИ УПРАВЛЕНИЯ
ММХ- процессор выполняет набор ММХ-команд;
FXSR - процессор выполняет команды FXSAVE, FXRSTOR, используемые для записи в память и последующего восстановления содержимого регистров FPU, MMX, SSE;
ХММ - процессор выполняет набор SSE-команд (SIMD-команды с плавающей точкой.
Если предварительное содержимое регистра ЕАХ = 2, то после выполнения команды CPUID в регистрах ЕАХ, ЕВХ, ЕСХ, EDX будет размещаться информация о характеристиках используемой процессором кэш-памяти 1-гои2-го уровней, а также о характеристиках буферной памяти TLB, используемой для страничной трансляции адреса. Например, для процессора Pentium Pro содержимое этих регистров будет следующим: ЕАХ = 03020101 h, ЕВХ = 00h, ЕСХ = 00h, EDX - 06040A42h. Каждый байт содержимого регистров является дескриптором, указывающим характеристики определенного вида внутренней памяти. В регистре ЕАХ байт 0 указывает число команд CPUID, которое надо выполнить, чтобы получить полную информацию о внутренней памяти процессора (для семейства Р6 - одна команда, byteO = 01 h), байт 1 определяет характеристики TLB, транслирующего адреса команд при использовании страниц по 4 Кбайт (кэш-память, организованная в виде 8 наборов по 4 строки, дескриптор bytel = 01 h), байт 2-характеристики TLB команд при использовании страниц по 4 Мбайт (кэш-память, организованная в виде 1 набора из 2 строк, дескриптор byte2 = 02h), байт 3 - характеристики TLB, транслирующего адреса данных при использовании страниц по 4 Кбайт (кэш-память, организованная в виде 16 наборов по 4 строки, дескриптор byte3 = 03h). Дескрипторы в регистре EDX имеют следующее назначение: байт 0 указывает характеристики общей кэш-памяти 2-го уровня (кэш-память команд и данных емкостью 256 Кбайт, наборы по 4 строки длиной 32 байт, дескриптор byte0=42h), байт 1 - характеристики кэш-памяти данных 1-го уровня (8 Кбайт, наборы по 2 строки длиной 32 байт, дескриптор bytel =0Ah), байт 2 - характеристики TLB данных при использовании страниц по 4 Мбайт (кэш-память, организованная в виде 2 наборов по 4 строки, дескриптор byte2 = 04h), байт 3 - характеристики кэш-памяти команд 1 -го уровня (8 Кбайт, наборы по 4 строки длиной 32 байт, дескриптор byte3 = 06h). Регистры ЕВХ, ЕСХ при идентификации семейства Р6 не используются (содержат нулевые дескрипторы).
Команды INVD, WBINVD, INVLPG служат для управления кэш-памятью. Они являются привилегированными, т. е. выполняются только программами с максимальным уровнем приоритета CPL - 0.
Команды INVD, WBINVD аннулируют содержимое всех ячеек (строк) внутренней кэшпамяти данных и кэш-памяти 2-го уровня, запрещая запись/считывание ее содержимого. При обращениях к памяти после этих команд осуществляется заполнение строк кэш-памяти новым содержимым из основной памяти. Отличие этих команд состоит в том, что при выполнении команды WBINVD производится обратная запись из внутренней кэш-памяти в основную память содержимого тех ячеек (строк), в которые производилась запись информации (модификация).
Команда INVLPG аннулирует (делает недействительным) содержимое строки в буфере трансляции страничных адресов TLB, где содержится базовый адрес страницы, на которой располагается адресуемая ячейка памяти (ml 6 или т32). В этом случае при последующем обращении к данной странице выполняется процедура трансляции адреса с помощью хранящихся в основной памяти таблиц, в которых записаны базовые адреса разделов и страниц.
Команда RSM возвращает процессор из режима системного управления SMM к выполнению программы, которая была прервана поступлением внешнего запроса SMI#. При этом восстанавливается содержимое регистра процессора, которое было сохранено в памяти при поступлении этого запроса.
Команды RDMSR, WRMSR позволяют загрузить содержимое одного из 64-разрядных модельно-специфических регистров MSR в пару регистров EDX:EAX или записать содержимое этой пары регистров в MSR. Выбор регистра MSR определяется его кодом, который
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
предварительно заносится в регистр ЕСХ. Эти команды выполняются в реальном режиме или защищенном режиме при максимальном уровне привилегии программы CPL = 0. В других случаях попытка их выполнения вызовет исключение типа #GP («нарушение защиты»).
Команда RDPMC производит загрузку в пару регистров EDX:EAX содержимого одного из двух 64-разрядных счетчиков, используемых для мониторинга производительности процессора. Эти счетчики входят в состав модельно-специфических регистров процессора. Номер считываемого счетчика - 0 или 1 - задается содержимым регистра ЕСХ. Если в регистре управления CR4 установлено значение бита РСЕ = 1, то выполнение этой команды производится при любом уровне привилегии текущей программы. Если значение РСЕ - 0, то команда RDPMC выполняется только программой с уровнем привилегии CPL - 0, а при других значениях CPL будет реализовано исключение типа #GP («нарушение защиты»).
Команда RDTSC загружает в пару регистров EDX:EAX содержимое счетчика текущего времени TSC (Time-Stamp Counter), который также является одним из модельно-специфических регистров MSR. Счетчик TSC переключается в каждом такте работы процессора и сбрасывается в ноль при его перезапуске (reset). Выполнение этой команды производится при любом уровне привилегии текущей программы, если в регистре управления CR4 установлено значение бита TSD = 0. При TSD = 1 команда выполняется только программой с уровнем привилегии CPL = 0, в противном случае реализуется исключение #GP.
2.3.5. ПРЕФИКСНЫЕ БАЙТЫ
Префиксы (табл. 2.25), имеющие разрядность один байт, оказывают влияние на выполнение команды, которой они предшествуют. Таким образом, они являются дополнительными программными средствами, управляющими работой процессора.
Префикс SEG определяет выбор сегмента CS, DS, ES, FS, GS или SS для адресации операнда в выполняемой команде. При отсутствии этого префикса сегмент выбирается по умолчанию согласно табл. 2.8. Префикс действует, если команда выбирает операнд из памяти; в противном случае он не учитывается.
Префиксы AS, OS позволяют при выполнении последующей команды изменять разрядность адреса и операнда в соответствии с табл. 2.14.
Префикс блокировки LOCK, который используется для организации работы мультипроцессорных систем, вызывает установку на выходе LOCK# процессора низкого потенциала, запрещающего другим устройствам системы (процессорам) обращаться к системной шине в течение времени выполнения последующей команды. Префикс LOCK может предшествовать только командам ADD, XADD, ADC, SUB, SBB, AND, OR, XOR, DEC, INC, NEG, NOT, ВТ, BTC, BTR, BTS, CMPXCHG и XCHG. Использование префикса LOCK перед другими командами вызовет прерывание с номером Ne = 6 (#UD - неразрешенный код операции).
Префиксы повторения REP, REPE/REPZ и REPNE/REPNZ применяются только с командами операций над строками. Префикс REP используется с командами INS, OUTS, MOVS и STOS и вызывает их повторение до тех пор, пока содержимое регистра ЕСХ (или СХ)>0. С командами CMPS и SCAS используются префиксы REPE или REPNE. Префикс REPE (возможная форма REPZ) обеспечивает повторение команды до тех пор, пока значение признака ZF = 0, т. е. поступают одинаковые символы. При поступлении различных операндов устанавливается значение ZF = 1, и выполнение команды прекращается. Если все операнды в строках одинаковы, то команда выполняется до получения ЕСХ(СХ) = 0, т. е. до конца строки. Префикс REPNE (возможная форма REPNZ) вызывает повторение команды, пока значение признака ZF = 0 (сравниваемые символы не одинаковы). Выполнение команды прекращается либо при поступлении одинаковых символов, когда устанавливается ZF = 1, либо при получении ЕСХ(СХ) = 0 (конец строки), если в строке отсутствуют одинаковые признаки.
СИСТЕМА КОМАНД: ОПЕРАЦИИ НАД ЧИСЛАМИ С ПЛАВАЮЩЕЙ ТОЧКОЙ
Таблица 2.25
Команды управления процессором и префиксные байты
Синтаксис команды Операция
LMSW r/m16 SMSW r/m16 r/ml6 -> MSW (биты 15-0 регистра CRO) MSW -> r/m16
NOP HLT CPUID Отсутствие операции Останов процессора Информация о процессоре -> ЕАХ,ЕВХ,ЕСХ,EDX
INVD Аннулирование содержимого внутренней кэш-памяти данных и кэш-памяти 2-го уровня (L2)
WBINVD Аннулирование содержимого внутренней кэш-памяти данных и кэш-памяти 2-го уровня (L2) с обратной записью в основную память модифицированных строк
INVLPG m(16,32) Аннулирование входа в страницу, содержащую адресную ячейку памяти
RSM Выход из режима SSM, восстановление состояния процессора
RO MSR WRMSR MSR -> EDX:EAX EDX:ЕАХ-> MSR
RDPMC RDTSC PMC -> EDX:EAX TSC -> EDX:EAX
SEG (CS,DS,ES,FS,GS,SS) AS OS LOCK REP, REPE/REPZ, REPNE/REPNZ Префикс выбора сегмента Префикс разрядности адреса Префикс разрядности операнда Префикс блокировки сегментной шины Префикс повторения операции над строками символов
2.4. СИСТЕМА КОМАНД: ОПЕРАЦИИ НАД ЧИСЛАМИ 4
С ПЛАВАЮЩЕЙ ТОЧКОЙ
К данному классу относятся команды, которые осуществляют операции над вещественными, целыми и двоично-десятичными числами, представленными в формате с плавающей точкой. Такое представление позволяет значительно расширить диапазон обрабатываемых чисел. Ниже дается перечень команд надданными с плавающей точкой, разбитых на функциональные группы. Мнемокод каждой команды начинается с префикса F (float -плавающий). Для команд, оперирующих с целыми числами, за буквой F идет буква I, сдво-ично-десятичными числами-буква В.
Пересылка данных
FLD - Загрузка вещественного числа
FILD - Загрузка целого числа
FBLD - Загрузка двоично-десятичного числа
FST-Запись в память вещественного числа
FIST -Запись в память целого числа
FSTP - Запись в память вещественного числа с выталкиванием из стека
FISTP - Запись в память целого числа с выталкиванием из стека
FBSTP - Запись в память двоично-десятичного числа с выталкиванием из стека
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
FCMOVcc - Условная пересылка данных между регистрами FPU
FXCH - Обмен данными между регистрами стека
FLDZ - Загрузка нуля + 0.0
FLD1 - Загрузка единицы + 1.0
FLDPI - Загрузка р (пи)
FLDL2T - Загрузка log210 (основание log = 2)
FLDL2E - Загрузка log2 е (основание log = 2)
FLDLG2 - Загрузка Ig 2 (основание log =10)
FLDLN2 - Загрузка In 2 (основание log = е)
Арифметические операции
FADD - Сложение вещественных чисел
FADDP - Сложение вещественных чисел с выталкиванием из стека
FIADD - Сложение целых чисел
FSUB - Вычитание вещественных чисел
FSUBP - Вычитание вещественных чисел с выталкиванием из стека
FSUBR - Обратное вычитание вещественных чисел
FSUBRP - Обратное вычитание вещественных чисел с выталкиванием из стека
FISUB - Вычитание целых чисел
FISUBR - Обратное вычитание целых чисел
FMUL-Умножение вещественных чисел
FMULP - Умножение вещественных чисел с выталкиванием из стека FIMUL-Умножение целых чисел
FDIV - Деление вещественных чисел
FDIVP - Деление вещественных чисел с выталкиванием из стека
FDIVR - Обратное деление вещественных чисел
FDIVRP - Обратное деление вещественных чисел с выталкиванием из стека
FIDIV - Деление целых чисел
FIDIVR- Обратное деление целых чисел
FPREM - Нахождение частичного остатка от деления
FPREM1 - Нахождение частичного остатка в стандарте IEEE 754
FSQRT - Вычисление квадратного корня
FABS - Получение абсолютного значения
FCHS - Изменение знака числа
Операции сравнения
FCOM - Сравнение вещественных чисел
FCOMP - Сравнение вещественных чисел с выталкиванием из стека '
FCOMPP-Сравнение вещественных чисел с двойным выталкиванием из стека 1 FCOMI - Сравнение вещественных чисел
FCOMIP - Сравнение вещественных чисел
FICOM - Сравнение целых чисел
FICOMP - Сравнение целых чисел с выталкиванием из стека
FUCOM - Сравнение неупорядоченных чисел
FUCOMP - Сравнение неупорядоченных чисел с выталкиванием из стека
FUCOMPP - Сравнение неупорядоченных чисел с двойным выталкиванием из стека FUCOMI - Сравнение неупорядоченных чисел с установкой признаков в регистре EFLAGS FUCOMIP - Сравнение неупорядоченных чисел с установкой признаков в регистре EFLAGS и выталкиванием из стека
FTST - Сравнение с нулем
FXAM - Анализ вещественного числа
СИСТЕМА КОМАНД: ОПЕРАЦИИ НАД ЧИСЛАМИ С ПЛАВАЮЩЕЙ ТОЧКОЙ
Специальные операции
FSCALE - Масштабирование (изменение порядка числа)
FXTRACT - Выделение мантиссы и порядка
FRNDINT - Округление до целого значения
FSIN - Вычисление синуса
FCOS - Вычисление косинуса
FSINCOS - Вычисление синуса и косинуса
FPTAN - Вычисление тангенса
FPATAN - Вычисление арктангенса
F2XM1 - Вычисление функции Y = 2х-1
FYL2X - Вычисление функции Y = log2X
FYL2XP1 - Вычисление функции Y = 1од2(Х+1)
Операции управления
FINIT/FNINIT-Инициализация FPU
FSTSW/FNSTSW - Передача слова состояния из регистра FPSR в память
FSTCW/FNSTCW - Передача управляющего слова из регистра FPCR в память
FLDCW - Загрузка из памяти управляющего слова в регистр FPCR ।
FCLEX/FNCLEX - Сброс флагов в регистре состояния FPSR
FSTENV/FNSTENV - Запись в память содержимого вспомогательных регистров
FLDENV-Загрузка содержимого вспомогательных регистров
FSAVE/FNSAVE - Запись в память содержимого вспомогательных регистров и арифметического стека
FRSTOR - Загрузка из памяти содержимого вспомогательных регистров и арифметического стека
Fl NCSTP - Инкремент содержимого указателя стека
FDECSTP - Декремент содержимого указателя стека
FFREE-Освобождение регистра ST(i) ‘ 1
FNOP-Отсутствиеопераций FPU >
FWAIT/WAIT-Ожидание готовности блока FPU
Блок FPU, входящий в состав процессоров Р6, обеспечивает реализацию современных стандартов обработки чисел с плавающей точкой IEEE 754 и IEEE 854. х
2.4.1. ФОРМАТЫ ПРЕДСТАВЛЕНИЯ ЧИСЕЛ
Процессор оперирует с данными, представленными в одном из семи форматов:
16-, 32- или 64-разрядные целые двоичные числа;
80-разрядные целые двоично-десятичные числа;
32-, 64- или 80-разрядные вещественные числа.
Целые двоичные числа (рис. 2.16, a-е) представляются в дополнительном коде. В качестве знакового разряда S используется старший бит числа. При этом 16-разрядные операнды рассматриваются как целые числа (формат ЦС) в диапазоне ± 32768; 32-разрядные операнды - как короткие целые числа (формат КЦ) в диапазоне ±10 9; 64-разрядные операнды-как длинные целые числа (формат ДЦ) в диапазоне ±1018.
Максимальное значение отрицательного целого числа 100...00 (1 в старшем бите и 0 во всех остальных) в форматах ЦС, КЦ, ДЦ используется для обозначения неопределенности. Это значение устанавливается в качестве результата выполнения недопустимой операции, например извлечение квадратного корня (команда FSQRT) из отрицательного числа. В таких исключительных случаях может выполняться прерывание.
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
в)
63 62 О
S Целое число
79 78 72 71 О
S 0 0 d17 d0
д)
31 30 23 22 0
S Порядок (Е) Мантисса
е)
63 62 52 51 0
S Порядок (Е) Мантисса
ж)
79 78_____________64 63 _____0
S Порядок (Е) Мантисса
Рис. 2.16. Форматы представления чисел, обрабатываемых блоком FPU
Двоично-десятичные целые числа в формате ДД (рис. 2.16, г) представляются в упакованной форме и содержат 18 тетрад, каждая из которых соответствует одному десятичному разряду. Для представления знака S используется старший разряд старшего байта (бит 79), в остальных разрядах этого байта устанавливается нулевое значение. Таким образом, формат ДД обеспечивает представление целых чисел в диапазоне ±1018. Неопределенность в этом формате представляется числом 1111 1111 1111 1111 хх...хх, в котором два старших байта содержат единицу во всех разрядах, а все остальные разряды (восемь младших байтов) имеют произвольное значение х.
Вещественные числа в каждом из трех форматов их представления ОТ, ДТ, Р (рис. 2.16, д~ж) содержат три поля: поле знака S (старший бит числа), поле порядка и поле мантиссы. Вещественные числа одинарной точности (формат ОТ, 32-разрядные операнды) имеют 23-разрядную мантиссу и 8-разрядный порядок; числа двойной точности (формат ДТ, 64-разрядные операнды) имеют 52-разрядную мантиссу и 21-разрядный порядок; числа расширенной точности (формат РТ, 80-разрядные операнды) имеют 64-разрядную мантиссу и 15-разрядный порядок. Двоичное число без знака Е, содержащееся в поле порядка, указывает смещенный порядок. Истинный порядок числа будет равен (Е-Р), где Р - смещение, величина которого зависит от формата: Р = 127 для ОТ, Р = 1023 для ДТ, Р = 16383 для РТ. Мантисса записывается в нормализованном виде (за исключением особых случаев): 1 ,ххх...х. При этом стоящая перед точкой единица в форматах ОТ, ДТ не указывается в поле мантиссы. В формате РТ эта единица содержится в старшем разряде мантиссы: тбЗ = 1.
СИСТЕМА КОМАНД: ОПЕРАЦИИ НАД ЧИСЛАМИ С ПЛАВАЮЩЕЙ ТОЧКОЙ
Таким образом, значения вещественных чисел X определяются выражениями:
Х = (-1) S х (1. гп22 m21...m0) х2 Е-127-для формата ОТ;
X = (-1) S х (1. гп52 гп51 ...тО) х 2 Е-1023 - для формата ДТ;
X = (-1) S х (т63.т62.тО) х 2 Е-16383 - для формата РТ;
где S-знак мантиссы;...гп1т0- разряды мантиссы.
Использование смещенного порядка Е позволяет упростить операцию сравнения вещественных чисел. При этом в большинстве случаев достаточно сравнить значения Е. Диапазон представляемых вещественных чисел составляет:
±10 +38-для формата ОТ,
±10 +308 - для формата ДТ,
+10 ±4932-дляформата РТ.
Таблица 2.26
Форматы и диапазоны представления вещественных чисел
Наименование числа Форматы ОТ/ДТ Формат РТ
Знак S Порядок 8/11 бит Мантисса 23/52 бита Значение КВ/ВВ Знак S Порядок 15 бит Мантисса 64 бита Значение
Положительная бесконечность 0 11...11 00... 00 + 0 11.„11 00...00 +
Положительное нормализованное число max min 0 0 11.„10 00...01 11.„11 00... 00 +3,37x1О38/ + 1,67x1030’ 0 0 11.„11 111.„11 +1,18хЮ*932
+ 1,17x10'38/ +2,23x10'308 00...01 100...00 +3,37х104932
Положительное денорма-лизованное число max min 0 0 00...00 00...00 11.„11 00...01 +0,58x10'38/ + 1,12x10™- 0 0 00...00 00...00 011.„11 000...01 + 1,68x104932
Нуль 0 1 00...00 00...00 00...00 00...00 +0 -0 0 1 00...00 00...00 000...00 000...00 +0 -0
Отрицательное денорма-лизованное число max min 1 1 00...00 00...00 00...01 11.„11 1 1 00...00 00...00 000...01 011...11
-0,58x1038/ + 1,12x10'308 -1,68x104932
Отрицательное нормализованное число max min 1 1 00...01 11.„10 00... 00 11.„11 -1,17x10’38/ -2,23x10’308 1 1 00...01 100...00 -3,37x104932
-3,37x1038/ -1,67x10308 11.„10 111.„11 -1,18x104932
Отрицательная бесконечность 1 11.„11 00...0 - 1 11.„11 100...00 -
Не-числа SNAN QNAN XX 11.„11 11.„11 ОХ... XX 1X...XX XX 11.„11 11.„11 10X...XX 11Х...ХХ
Неопределенность 1 11.„11 10...00 1 11.„11 110...00
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
Следует отметить, что диапазон чисел, представляемых в форматах ОТ, ДТ, вполне достаточен для решения практически любых задач. Поэтому данные, поступающие на обработку в FPU, обычно представлены в этих форматах. Однако в процессе обработки чисел FPU использует формат РТ, позволяющий избежать потери точности результата при многократном выполнении операций над вещественными числами.
Различные форматы представления вещественных чисел даны в табл. 2.26. Числа с нулевым значением мантиссы и максимальным порядком отведены для представления бесконечных значений. При этом различаются значения +L и - L, которые связаны соотношением+L> - L (афинная арифметика). Для нуля также введены два значения:+0 и - 0. При выполнении операций знак нуля устанавливается согласно правилам формирования знаков при соответствующих операциях, например: +X/+L = +0, +Х/ - L = - 0 и т. д.
В табл. 2.26 указаны максимальные (±Мах) и минимальные (±Min) десятичные значения представляемых вещественных чисел. При получении результатов, превышающих максимальное положительное число (+Мах), или меньших минимального отрицательного числа (- Min) в регистре FPSR устанавливается флаг переполнения ОЕ -1. В этом случае либо реализуется прерывание, либо результатом операции является бесконечность (+L или - L). Если полученный результат меньше минимального положительного нормализованного числа (+Min) или больше максимального отрицательного нормализованного числа (- Мах), то в регистре FPSR устанавливается флаг антипереполнения UE = 1. В таком случае FPU может перейти к обработке денормализованных чисел. При этом диапазон представления чисел расширяется в сторону нуля, и точность вычислений увеличивается. На рис. 2.17 показано размещение представляемых вещественных чисел на числовой оси и условия формирования признаков ОЕ, UE.
Специальные коды введены для представления нечисловых операндов NAN (Not-A-Number, не-числа). Эти коды (см. табл. 2.26) имеют единичные значения всех разрядов порядка и произвольные значения знака и мантиссы (за исключением нулевого значения мантиссы, используемого для представления бесконечности). Различаются два типа не-чисел: SNAN, имеющие нулевое значение старшего (после точки) разряда мантиссы; QNAN, имеющие единичное значение старшего разряда.
He-числа, выбираемые из памяти в качестве операндов FPU, определяются как SNAN. Если не-число является результатом выполняемой операции FPU (например, извлечение квадратного корня из отрицательного числа, команда SQRT), то оно будет иметь тип QNAN. Отметим, что неопределенность является частным случаем не-числа QNAN.
В табл. 2.26 представлены все форматы чисел, поддерживаемые процессором. Однако существует множество чисел, не вошедших в эти форматы. В формате РТ к ним относятся: ненормализованные числа, имеющие ненулевое значение порядка и мантиссу с нулевым значением старшего разряда; псевдоненормализованные числа, имеющие нулевой порядок и мантиссу с единичным значением старшего разряда; nceefloNAN и псевдобесконечность, имеющие единичные значения всех разрядов порядка и мантиссу с нулевым значением старшего разряда. Такие варианты представления чисел называются неподдерживаемыми (unsupported) формами, так как их появление вызывает прерывание работы процессора.
- Min
- Мах
+ Мах
+ Min
UE
ОЕ( -~)
UE
Рис. 2.17. Размещение представляемых вещественных чисел на числовой оси
ОЕ( +~)
СИСТЕМА КОМАНД: ОПЕРАЦИИ НАД ЧИСЛАМИ С ПЛАВАЮЩЕЙ ТОЧКОЙ
При описании команд FPU выбираемые из памяти вещественные числа обозначаются символами т32геа1 (число в формате ОТ), m64real (число в формате ДТ), m80real (число в формате РТ). Для обозначения целых чисел используются символы m16int (число в формате ЦС), m32int (число в формате КЦ), m32int (число в формате ДЦ). Двоично-десятичные числа обозначаются символом m80bcd.
2.4.2. ВЫПОЛНЕНИЕ ОПЕРАЦИЙ
Описанные в предыдущем разделе форматы применяются для представления целых, двоично-десятичных и вещественных чисел в памяти. При обработке чисел в FPU используется только расширенный формат РТ. При вводе в FPU числа, представленные в форматах ЦС, КЦ, ДЦ, ДД, ОТ, ДТ, преобразуются в формат РТ. При записи результата из FPU в память производится, в случае необходимости, обратное преобразование.
Команды FPU имеют общий формат, показанный на рис. 2.11. При выполнении операций в качестве одного из операндов всегда используется содержимое ST(0) - регистра данных FPU, являющегося вершиной стека. Физический номер этого регистра определяется полем ТОР в регистре состояния FPSR (см. рис. 2.4), содержимое которого изменяется при выполнении ряда команд. Таким образом осуществляется заполнение или освобождение регистров арифметического стека. Второй операнд при выполнении двухоперандных команд FPU выбирается из памяти или из i-ro регистра данных ST(i), входящего в состав арифметического стека.
Форматы команд FPU показаны на рис. 2.18. Каждая из этих команд начинается 5-бито-вым полем ESC = 11011, поля ОРС определяют выбор одной из возможных операций FPU. При обращениях к памяти возможно использование всех способов адресации. При этом после байта MODR/M могут следовать байт SIB, обеспечивающей масштабирование адреса, байты d8, d16 или d32, задающие необходимое смещение DISP (см. рис. 2.18, а). При регистровой адресации (MOD = 11) поле R/М задает адрес i арифметического регистра ST(i), из которого выбирается операнд (см. рис. 2.18, б). В качестве i используется не физический номер регистра, а его номер относительно вершины стека.
При выполнении операций FPU контролирует точность представления чисел и производит в случае необходимости округление результата. Эти процедуры осуществляются в соответствии со значениями полей PC, RC в регистре управления FPCR.
Значение поля PC (см. табл. 2.2) определяет точность результатов арифметических операций над вещественными числами: сложения, вычитания, умножения деления, извлечения квадратного корня (команды FADD, FSUB, FSUBR, FMUL, FDIV, FDIVR, FSQRT). На результаты других операций FPU значение поля PC не влияет. При PC = 11 результат представляется с обычной для FPU расширенной точностью (64 значащих разряда мантиссы), которая обеспечивается используемым форматом РТ. При PC = 00 или 10, реализуется одинарная (23 значащих разряда мантиссы) или двойная (52 значащих разряда мантиссы) точность представления чисел. В этом случае при получении результатов с более высокой точностью производится их округление. Значение PC = 01 не используется (резервировано).
а)
| 11011 | ОРС | МОР | ОРС | R/M | SIB | DISP |
б)
I 11011 | ОРС | 11 | ОРС [ ST(i) |
Рис. 2.18. Форматы команд FPU: с адресацией памяти (а), с регистровой адресацией (б)
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
Значение поля RC определяет способ округления результата операций FPU до заданной точности (см. табл. 2.1). При RC = 00 реализуется обычный способ округления. При RC = 01 или 10 выполняется округление в сторону меньших или больших чисел. При RC = 11 осуществляется обнуление лишних разрядов мантиссы. Поле RC влияет на результаты арифметических операций (кромеопераций, определяемых командами FPREM, FPREMI, FXTRACT, FABS, FCHS), операций вычисления трансцендентных функций и операций передачи, выполняемых по командам FST, FSTP, FIST.
При выполнении операций FPU контролируется шесть видов ошибок:
1) #1-недействительная операция;
2) #D - поступление денормализованного операнда;
3) #Z-деление на нуль; '
4) #0 - переполнение;
5) #U-антипереполнение;
6) #Р - неточный результат. ‘
При обнаружении ошибки устанавливается единичное значение соответствующего признака IE, DE, ZE, ОЕ, UE, РЕ в регистре состояний FPSR. В регистре управления FPCR содержатся маски этих ошибок IМ, DM, ZM, ОМ, UM, РМ: при нулевом значении маски соответствующая ошибка вызовет прерывание программы (исключение), при единичном значении маски процессор продолжает выполнение программы.
Признак неточного результата РЕ = 1 устанавливается, если результат операции не может быть точно представлен в заданном командой формате. Если установлена маска РМ = 1, то процессор продолжает программу без прерывания. В этом случае производится округление результата в соответствии со значением поля RC в регистре FPCR (см. рис. 2.6).
Признак антипереполнения UE = 1 устанавливается, если результат слишком мал для представления нормализованным числом, т. е. меньше значений +Min для положительных или больше значений - Мах для отрицательных нормализованных чисел (см. табл. 2.26). Если установлена маска UM - 1, то процессор продолжает программу без прерывания, а результат представляется денормализованным числом.
Признак деления на нуль ZE = 1 устанавливается, когда делимое является конечным числом, отличным от нуля, а делитель равен нулю. Если установлена маска ZM = 1, то выполнение программы продолжается без прерывания, в качестве результата деления выдается код бесконечности. Знак результата определяется в зависимости от знаков операндов в соответствии с правилами деления.
Признак денормализованного операнда DE = 1 устанавливается, если денормализован хотя бы один из операндов. Если установлена маска DM =1, то процессор оперирует с денормализованным операндом, каке нормализованным.
Признак недействительной операции 1Е=1 устанавливается при извлечении содержимого из пустого регистра или загрузки в заполненный регистр, выполнении действий с не-числа-ми SNaN, QNaN, извлечении квадратного корня из отрицательного числа, делении L/L и ряде других операций, указанных в табл. 2.27. Если установлена маска IM = 1, то выполнение программы продолжается без прерывания, а результат недействительной операции определяется согласно табл. 2.27.
При выполнении операций FPU контролируется переполнение или антипереполнение арифметического стека. Переполнение фиксируется, если команда пытается произвести загрузку в заполненный регистр стека. При этом в регистре FPSR устанавливаются признак SF = 1 и бит условия С1 = 1. Антипереполнение фиксируется, если команда пытается считать операнд из пустого регистра стека. В этом случае устанавливаются значения SF = 1 и С1 = 0. Значение SF = 1 указывает на выполнение недействительной операции и вызывает установку признака 1Е=1. Если флаг IE маскирован (IM = 1), то результатом операций, вызвавших переполнение или антипереполнение стека, будет загрузка или считывание не-числа QNAN.
СИСТЕМА КОМАНД: ОПЕРАЦИИ НАД ЧИСЛАМИ С ПЛАВАЮЩЕЙ ТОЧКОЙ
Таблица 2.27
Недействительные операции FPU и их результаты при маскировании (IM = 1)
Недействительная операция Результат при |М = 1
Любая арифметическая операция над SNaN или операндами с неподдерживаемыми форматами Сложение с разными знаками или вычитание с одинаковым знаком Умножение 0 х»=,о=х 0 или деление о=/°°, 0 / 0 Сравнение или тестирование, если один или оба операнда NAN Операция вычисление остатка (команды FPREM, FPREM1), когда делитель равен 0 или делимое равно »= Тригонометрические операции вычисления sin, cos, частичного tg (команды(РСО8, FPTAN, FSIN, FSINCOS), когда операнд равен <*> Операция извлечения корня, вычисления функции log2x над отрицательными операндами вычисления, 1од2(х+1) над операндом х<-1 (команды FSQRT, FYL2X, FYL2XP1) Операция пересылки в память целых и двоичнодесятичных чисел и регистра данных FPU, если регистр пуст, содержит NaN или бесконечность либо его содержимое превышает диапазон представления адресуемой памяти (команды FIST, FISTP, FBSTP) Операция обмена содержимого регистров данных, если один из них или оба пусты (команда FXCH) QNaN Неопределенность (QNaN) Неопределенность (QNaN) Устанавливает код условия «не сравнимы» Неопределенность (QNaN) с установкой бита условия 02=1 Неопределенность (QNaN) с установкой бита условия 02=1 Неопределенность (QNaN) Целочисленная неопределенность, код 100...00 Установка неопределенности (QNaN) для пустых регистров и последующий обмен
Если хотя бы один из признаков IE, DE, ZE, ОЕ, UE, РЕ установлен в состояние «1» и не маскирован, то общий признак ошибки устанавливается в состояние ES = 1 и формируется сигнал ошибки FERR# = 0 на внешнем выводе процессора. Если в регистре управления CR0 установлено значение бита NE = 1, то в этом случае непосредственно перед следующей командой FPU реализуется исключение типа #MF («ошибка FPU»).
При значении NE - 0 процедура обработки прерывания вызывается командой INTn, формируемой внешним контроллером прерываний. Получив сигнал FERR#=0, этот контроллер должен подать сигнал IGNNE# = 1 на соответствующий вход процессора. Данный сигнал вызывает остановку процессора непосредственно перед следующей командой FPU или WAIT. Эта остановка продолжается до поступления от контроллера прерываний команды INTn. Если на входе IGNNE# поддерживается состояние «О», то процессор продолжает выполнение программы, игнорируя ошибки FPU.
Процедуры обслуживания исключений, вызываемых FPU, могут использовать для выявления причины ошибок содержимое регистров FIP и FDP - указателей команд и данных, которое выводится из процессора с помощью команд управления FSTENV, FSAVE. В регистр FIP заносится адрес текущей команды FPU и 11 разрядов ее кода (два первых байта без кода ESC), если эта команда не входит в группу команд управления. Если команда выбирает операнд из памяти, то в регистр FDP заносится адрес операнда, в противном случае разряды
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
регистра устанавливаются в неопределенное состояние. Когда выполнение команды вызывает немаскированное прерывание вследствие возникновения какой-либо из вышеуказанных ошибок, регистры FIP и FDP содержат информацию об этой команде и операнде, которая может быть использована для анализа причин ошибки. Так как команды управления не изменяют содержимое FIP и FDP, то процедура обработки ошибок FPU с помощью этих команд может выбирать содержимое FIP, FDP для проведения такого анализа.
Необходимо отметить влияние битов ЕМ, TS, МР регистра управления CR0 на выполнение команд FPU и WAIT/FWAIT. При TS - 1 или ЕМ = 1 поступление команд FPU вызовет исключение типа #NM («FPU недоступен»). Команда WAIT/FWAIT вызывает это исключение только при TS = МР - 1.
2.4.3. КОМАНДЫ ПЕРЕСЫЛКИ ДАННЫХ
Команды этой группы реализуют операции загрузки, записи в память, обмена и загрузки констант (табл. 2.28).
Команды загрузки FLD, FILD, FBLD служат для передачи данных (вещественных чисел - real, целых чисел - int, двоично-десятичных чисел - bed) в ST(0) - верхний регистр арифметического стека FPU. Перед загрузкой производится декремент содержимого поля ТОР в регистре состояния FPSR, т. е. вершина стека перемещается на один регистр вверх. При этом проверяется значение тега для регистра, ставшего новой вершиной стека. Если для него значение tag - 11, т. е. этот регистр пустой, то производится его загрузка из адресуемой ячейки памяти или регистра ST(i), номер которого i указан в байте MODR/M команды. После загрузки в поле tag устанавливается код, соответствующий значению поступившего числа. Отметим, что регистр ST(i) после выполнения команды увеличивает свой номер на единицу, как и все остальные регистры арифметического стека. Если значение tag = 11, т. е. регистр не пустой, то устанавливается флаг IЕ=1 в регистре FPSR, указывающий на выполнение недействительной операции. Если этот флаг не маскирован, т. е. в регистре FPCR бит маски IM = 0, то загрузка не производится, и реализуется исключение типа #MF («ошибка FPU»). Загружаемые числа, принимаемые в форматах ОТ, ДТ (команда FLD), ЦС, КС, ДЦ (команда FILD), DD (команда FBLD), заносятся в арифметический стек в формате РТ.
Команды записи в память FST, FIST используются для передачи содержимого ST(0) в память с преобразованием данных из внутреннего формата РТ в ОТ, ДТ или ЦС, КЦ. При этом значение поля ТОР в регистре FPSR не меняется, т. е. состояние стека сохраняется. Команда FST позволяет также переписать содержимое ST(0) в любой другой регистр стека ST(i).
Команды записи с выталкиванием из стека FSTP, FISTP, FBSTP после передачи содержимого осуществляют инкремент значения ТОР в регистре FPSR. Таким образом, вершина арифметического стека перемещается на один регистр вниз. Для регистра ST(0), служившего старой вершиной стека, устанавливается значение tag = 11 (пусто), т. е. он освобождается. Отметим, что регистр ST(i) после команды FSTP также уменьшает свой номер I на единицу, как и остальные регистры стека. Если в этой команде задать ST(i) = ST(0), то выполняется сокращение заполненного стека без сохранения содержимого вершины. В соответствии с кодом команды выбираемые из стека числа преобразуются из формата РТ в форматы ОТ, ДТ (команда FSTP), ЦС, КЦ, ДЦ (команда FISTP), ДЦ (команда FBSTP). При этом производится округление чисел в соответствии со значением поля RC в регистре FPSR. Исключение составляет команда FBSTP, которая независимо от значения RC осуществляет округление путем прибавления числа 0,5 и отбрасывания дробной части.
СИСТЕМА КОМАНД: ОПЕРАЦИИ НАД ЧИСЛАМИ С ПЛАВАЮЩЕЙ ТОЧКОЙ
Таблица 2.28
Команды пересылки данных FPU
Синтаксис команды Операция
FLD m(32,64,80) real m(32,64,80) ST(0)
ST(i) ST(i) -+ ST(0)
FILD m(16,32,64)int m(16,32,64) -> ST(0)
FBLD m80bcd m80 - + ST(0)
FST m(16,32)real ST(0) -> m(32,64)
ST(i) ST(0) -» ST(i)
FSTP m(32,64,80)real ST(0) -> m(32,64,80), освобождение ST(0)
ST(i) ST(0) -> ST(i), освобождение ST(0)
FIST m(16,32)int ST(0) -> m(16,32)
FISTP m(16,32,64)int ST(0) -> m(16,32,64), освобождение ST(0)
FBSTP m80bcd ST(0) -> m80, освобождение ST(0)
FCMOVcc ST(0), ST(i) ST(j) -> ST(0), если (cc) = 1
FXCH ST(0) ++ ST(1)
FXCH ST(i) ST(0) ++ ST(i)
FLDZ 0 -> ST(0)
FLDL 1 -> ST(0)
FLDPI p ST(0)
FLDL2T log210 -» ST(0)
FLDL2E log2e -» ST(0)
FLDLG2 ig2 -> ST(0)
FLDLN2 In2-» ST(0)
Если при выполнении команд записи в память регистр ST(0) оказывается пустым, содержит NAN, L и число, выходящее за пределы представления в заданном формате, то устанавливается флаг недействительной операции IE = 1 и реализуется прерывание, если значение маски IM = 0. Если установлена маска IM - 1, то прерывание не выполняется. Для команд FIST, FISTP, FBSTP в этом случае в память заносится код неопределенности, представленный в заданном формате: ЦС, КЦ, ДЦ или ДД (см. табл. 2.26).
Команды FCMOVcc выполняют условную пересылку содержимого регистра ST(i) на вершину стека - в регистр ST(0). В качестве условий пересылки (сс) используются значения ряда признаков в регистре EFLAGS (табл. 2.29). При этом мнемокод условия добавляется в качестве суффикса к мнемокоду команды: например, FCMOVB - команда пересылки при значении признака переноса CF = 1.
Команда FXCH производит обмен содержимым регистров ST(0) и ST(i) арифметического стека. Соответственно изменяются и значения тегов для этих регистров. Если в команде FXCH не указан операнд ST(i), то обмен производится между регистрами ST(0) и ST(1), расположенными в верхней части стека. Значение поля ТОР сохраняется неизменным. Если регистры ST(0), ST(i) пустые, то в них помещается код QNAN (не-число), а затем выполняется обмен.
Команды загрузки констант FLDZ, FLD1, FLDPI, FLDL2T, FLDL2T, FLDLG2, FLDLN2 вводят в регистр-вершину стека значения чисел + 0.0; +1.0; р (пи); log210,1од2е, 1п2, которые хранятся в ПЗУ констант FPU. Эти константы представляются в формате РТ и имеют точность 19 десятичных цифр.
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
Таблица 2.29
Виды и мнемокоды условий при выполнении команд FCMOVcc
Мнемокод (сс) Условие
В CF=1
NB CF=0
Е ZF=1
NE ZF=0
и PF=1
NU PF=0
BE CF+ZF=1
NBE CF+ZF=0
2.4.4. КОМАНДЫ АРИФМЕТИЧЕСКИХ ОПЕРАЦИЙ
Команды этой группы обеспечивают выполнение арифметических операций сложения, вычитания, умножения, деления и ряда других (табл. 2.30).
Один из операндов всегда размещается в верхнем регистре арифметического стека ST(0), второй операнд выбирается из памяти или регистра стека ST(i), номер которого задается байтом MODRM. Формат выбираемого из памяти операнда ОТ, ДТ, ДВ, ЦС, КЦ определяется кодом операции. Результат операции размещается в регистрах арифметического стека ST(0) или ST(i).
Таблица 2.30
Команды арифметических операций
Синтаксис команды Операция
FADD m(32,64)real ST(0),ST(i) ST(i),ST(0) m(32,64)+ST(0) -» ST(0) ST(0)+ST(i) -» ST(0) ST(0)+ST(i) -» ST(i)
FADDP ST(i),ST(0) ST(0)+ST(1) -» ST(1), освобождение ST(0) ST(0)+ST(i) -» ST(i), освобождение ST(0)
FIADD m(16,32)int m(16,32)+ST(0) ->ST(0)
FSUB m(32,64)real ST(0),ST(i) ST(i),ST(0) ST(0) - m(32,64) -> ST(0) ST(0) -ST(i) -> ST(0) ST(i) - ST(0) -> ST(i)
FSUBP ST(i),ST(0) ST(1)-ST(0) -> ST(1), освобождение ST(0) ST(i)-ST(0) -> ST(i), освобождение ST(0)
FISUB m(16,32)int ST(0)-m(16,32)-»ST(0)
FISUBP ST(1)—ST(0) -» ST(1), освобождение ST(0)
FMUL m(32,64)real ST(0),ST(i) ST(i),ST(0) ST(0) * m(32,64) -» ST(0) ST(0)*ST(i) -» ST(0) ST(0)*ST(i) -> ST(i)
FMULP ST(i),ST(0) ST(0)*ST(1) -» ST(1), освобождение ST(0) ST(0)*ST(i) -> ST(i), освобождение ST(0)
FIMUL m(16,32)int ST(0)‘m(16,32)-»ST(0)
СИСТЕМА КОМАНД: ОПЕРАЦИИ НАД ЧИСЛАМИ С ПЛАВАЮЩЕЙ ТОЧКОЙ
Продолжение табл. 2.30
Синтаксис команды Операция
FDIV m(32,64)real ST(i),ST(0) ST(0) / m(32,64) -» ST(0) ST(0)/ST(i) -> ST(0) ST(0)/ST(i) -> ST(i)
FDIVP ST(i),ST(0) ST(1)/ST(0) —> ST(1), освобождение ST(0) ST(i)/ST(0) -> ST(i), освобождение ST(0)
FIDIV m(16,32)int ST(0)/m(16,32) —> ST(0)
FDIVR m(32,64)real ST(0),ST(i) ST(i),ST(0) m(32,64)/ST(0) -> ST(0) ST(i)/ST(0) -» ST(0) ST(0)/ST(i) -> ST(i)
FDIVRP ST(i),ST(0) ST(0)/ST(1) -> ST(1), освобождение ST(0) ST(0)/ST(i) -> ST(i), освобождение ST(0)
FIDIVR m(16,32)int m(16,32)/ST(0) -> ST(0)
FPREM FPREM1 ST(0)/ST(1), остаток -> ST(0) ST(0)/ST(1), остаток (формат IEEE) -> ST(0)
FSQRT 7.ST(0)
FABS |ST(O) I -> ST(0)
FCHS -ST(0) -» ST(0)
После выполнения операций FADDP, FSUBP, FMULP, FDIVP вершина стека освобождается, т. е. для регистра ST(0) устанавливается значение tag = 11. Содержимое поля ТОР в регистре FPSR увеличивается на единицу, т. е. производится сдвиг вершины стека на один регистр вниз. Соответственно, значение номера i для регистра ST(i) уменьшается на единицу. Например, если операнд выбирается из регистра ST(3), то после выполнения операции и размещения результата в этот регистр его номер относительно новой вершины стека принимает значение ST(2).
Команды обратных операций FSUBR, FSUBRP, FDIVR, FDIVRP обеспечивают изменение порядка следования операндов при вычитании и делении.
При выполнении операций над вещественными числами операндами могут служить ± О и + L. В этих случаях формирование результатов арифметических операций производится в соответствии с табл. 2.31, где используются следующие обозначения:
Н, IE = 1 - устанавливается флаг недействительной операции IE = 1, результатом является код неопределенности, если значение маски IM = 1;
(±) - знак результата S устанавливается с помощью операции «Исключающее ИЛИ» над знаками операндов S1, S2, т. е. S = S1 (+) S2;
+0 при UE = 1 - результат +0 или -0 устанавливается при получении антипереполнения (UE = 1), если значение маски UM = 1;
*0 - знак устанавливается в зависимости от способа округления, заданного полем RC: +0 при RC = 00,10,11; -0 при RC = 01.
При выполнении операций, вызывающих установку флагов IE = 1, UE = 1 или ZE = 1, реализуется прерывание, если флаги не маскированы. Если же соответствующие маски имеют значение IМ = 1, UM = 1, или ZM = 1, то процессор продолжает выполнение программы, а результатами операций служат коды неопределенности (Н) при IE = 1, +0 при UE-1, +L при ZE = 1, согласно табл. 2.31.
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
Не-числа SNAN, QNAN также могут быть операндами при выполнении команд над вещественными числами. В этом случае результат арифметической операции определяется согласно табл. 2.32, где QNAN (SNAN) обозначает не-число QNAN, полученное из SNAN путем установки единицы в старшем разряде мантиссы. Остальные разряды мантиссы при преобразовании SNAN в QNAN сохраняют свое значение.
Команда FPREM производит деление числа, расположенного в ST(0), на число в ST(1), остаток накапливается в регистре ST(0). Деление осуществляется путем последовательного вычитания, которое выполняется п раз-до тех пор, пока не будет получено ST(0) < ST(1).
При этом в регистре FPSR бит С2 принимает значение 0. Число вычитаний п определяется как частное ST(0)/ST(1), которое округляется до целого путем отбрасывания дробной части. Знак остатка устанавливается таким же, как знак делимого. Максимальное число выполняемых вычитаний ограничено п <- 64. Если 64 вычитаний недостаточно для получения ST(0)<ST(1), то в регистре FPSR устанавливается значение бита С2 = 1, а в регистре ST(0) сохраняется частичный остаток. Точный остаток получается при повторных выполнениях команды FPREM до получения С2 = 0. После выполнения этой команды биты СО, С1, СЗ регистра FPSR содержат три младших разряда частного.
Команда FPREM 1 также осуществляет вычисление частичного остатка. Отличие от команды FPREM состоит в том, что число вычитаний при выполнении команды FPREM1 определяется в соответствии со стандартом IEEE 754, как частное ST(0)/ST(1), которое округляется до ближайшего целого. Получаемый остаток в этом случае будет не больше половины делителя.
Таблица 2.31
Результаты арифметических операций при использовании операндов ±0 и ±L
Операция Результат Операция Результат
FADD, FADDP
(+0) + (ч-О) +0 (4 ос ) 4 (4ос ) + ос
(-0) + (-0) -0 (. ос ) + (- ос ) - ОС
(ч0) 4 (-0); (-0) 4 (40) *0 (+ ос ) + (- ос ) Н, 1Е=1
(-Х) 4 (+Х); (+Х) 4 (-Х) *0 (±Х) + (± ~ ) ± ОС
FSUB.FSUBP.FSUBR.FSUBRP (40) - (-0) 40 (+°с ) - (- ос ) +ос
(-0) - (40) -0 (- ОС ) - (Чое ) - ОС
(40) - (40); (-0) - (-0) *0 (4ОС ) - (Чос ) Н, 1Е=1
(' «с ) - (- ос ) Н, 1Е=1
(4Х) - (+Х); (-Х) - (-Х) *0 (± “ ) - (±Х) ± ж
(±Х) - (± ос ) ± ж
FMULP, FMULP
(4-0) * (4-0) (4-)0 (± ос ) * (± ОС ) (Ч.)ос
(4-0) * (+-Х) (4.)0 (± ОС ) * (±Х) (Ч-)ос
(4Х) * (4Y); (-Х) х (-Y) +0 при UE=1 (± ОС ) * (±0) Н, 1Е=1
(+X)*(-Y);(-X)x(4Y) -0 при UE=1
FDIV,FDIVP,FDIVR,FDIVRP (4-0) / (4-0) Н, 1Е=1 (±ос)/(±ос) Н, 1Е=1
(4-Х) / (4-0) (4-)« , ZE=1 (4ОС )/(±Х) (Ч.)ос
(4-0) 1 (4-Х) (+-)0 (±Х) / (± ос ) (4-)0
(-Х) / (-Y); (4Х) 1 (+Y) +0 при UE=1 (± ОС ) / (±0) (Ч)ос
(-Х) / (+Y); (4Х) / (-Y) -0 при UE=1
СИСТЕМА КОМАНД- ОПЕРАЦИИ НАД ЧИСЛАМИ С ПЛАВАЮЩЕЙ ТОЧКОЙ
Таблица 2.32
Результаты арифметических операций над не-числами SNAN, QNAN
Операнды Результат
SNAN и QNAN SNAN и SNAN QNAN и QNAN SNAN и число QNAN и число QNAN QNAN (SNAN с большей мантиссой) QNAN с большей мантиссой QNAN (SNAN) QNAN
Команда FSQRT вычисляет квадратный корень из содержимого ST(0) и размещает его в этом же регистре.
Команды FABS и FCHS изменяют знак числа в регистре ST(0), чтобы получить абсолютное значение этого числа (команда FABS) или число с противоположным знаком (команда FCHS).
2.4.5. КОМАНДЫ СРАВНЕНИЯ
К этой группе относятся команды (табл. 2.33), выполняющие сравнение двух операндов с плавающей точкой и установкой соответствующих битов в регистре состояния FPSR или регистре EFIAGS, а также команды тестирования (сравнение операнда с нулем) и анализа содержимого регистра ST(0).
Команды FCOM, FCOMP, FCOMPP производят сравнение вещественных чисел. При выполнении команды FCOMP после сравнения производится освобождение вершины стека - регистра ST(0), т. е. значение поля ТОР увеличивается на единицу, а бывший регистр ST(0) становится пустым. После сравнения содержимого двух верхних регистров стека ST(0) и ST(1) по команде FCOMPP освобождаются оба этих регистра. Команды FICOM, FICOMP выполняют аналогичные операции с целыми числами в формате ЦС (ml 6int) и КЦ (m32int). По результатам сравнения устанавливаются соответствующие значения битов СО, С1, СЗ в регистре FPSR согласно табл. 2.34. При этом проверяются типы сравниваемых операндов. Операнды считаются не сравнимыми, если один из них или оба являются не-числами или представлены в неподдерживаемом (unsupported) формате. В этом случае фиксируется ошибка FPU типа #1 (недействительная операция) и реализуется исключение типа #MF («Ошибка FPU»), если в регистре FPCR бит маски IM = 0.
Команды FUCOM, FUCOMP, FUCOMPP выполняют такие же операции, как FCOM, FCOMP, FCOMPP, но не реализуют исключение при поступлении не-чисел типа QNAN, позволяя текущей программе обрабатывать неупорядоченные (unordered) операнды.
Команды FCOMI, FCOMIP, FUCOMIP, FUCOMIP производят сравнение операндов, размещенных в регистрах ST(0), ST(1). При этом результаты сравнения представляются определенными значениями признаков ZF, PF, CF в регистре EFLAGS в соответствии с табл. 2.35. После выполнения сравнения команды FCOMIP, FUCOMIP освобождают регистр ST(0). Команды FCOMI, FCOMIP реализуют исключение типа #MF при сравнении операндов, являющихся не-числами, команды FUCOMI, FUCOMIP не вызывают исключения, позволяя сравнивать, таким образом, неупорядоченные (unordered) операнды.
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
Таблица 2.33
Команды сравнения
Синтаксис команды Операция
FCOM ST(i) m(32,64) real Сравнение ST(0) cST(1) Сравнение ST(0) c ST(i) Сравнение ST(0) c m(32,64)
FCOMP ST(i) m(32,64) real Сравнение ST(0) c ST(1), освобождение ST(0) Сравнение ST(0) c ST(i), освобождение ST(0) Сравнение ST(0) c m(32,64), освобождение ST(0)
FCOMPP Сравнение ST(0) c ST(1), освобождение ST(0), ST(1)
FICOM m(16,32) int FICOMP m(16,32) int Сравнение ST(0) cm(16,32) Сравнение ST(0) c m(16,32), освобождение ST(0)
FCOM I ST(0), ST(i) FCOMIP ST(0), ST(i) Сравнение ST(0) c ST(i), установка ZF,PF,CF Сравнение ST(0) c ST(i), установка ZF,PF,CF, освобождение ST(0)
FUCOMI ST(0), ST(i) FUCOMIP ST(0), ST(i) Сравнение ST(0) c ST(i), установка ZF,PF,CF Сравнение ST(0) c ST(i), установка ZF,PF,CF, освобождение ST(0)
FUCOM ST(i) Сравнение ST(0) cST(1) Сравнение ST(0) c ST(i)
FUCOMP ST(i) Сравнение ST(0) c ST(1), освобождение ST(0) Сравнение ST(0) c ST(i), освобождение ST(0)
FUCOMIP Сравнение ST(0) c ST(1), освобождение ST(0), ST(1)
FTST Сравнение ST(0) с нулем
FXAM Проверка содержимого ST(0)
Таблица 2.34
Коды результата операций сравнения в регистре FPSR
Результат C3 C2 co
ST(0) > X 0 0 0
ST(0) < X 0 0 1
ST(0) = X 1 0 0
He сравнимы 1 1 1
Таблица 2.35
Коды результата операций сравнения в регистре EFLAGS
Результат ZF PF CF
ST(0) > ST(i) 0 0 0
ST(0) < ST(i) 0 0 1
ST(0) = ST(i) 1 0 0
He сравнимы 1 1 1
СИСТЕМА КОМАНД: ОПЕРАЦИИ НАД ЧИСЛАМИ С ПЛАВАЮЩЕЙ ТОЧКОЙ
Таблица 2.36
Результаты анализа содержимого регистра ST(0)
Содержимое СЗ С2 со
Неподдерживаемый формат 0 0 0
Не-число 0 0 1
Нормализованное число 0 1 0
Бесконечность 0 1 1
Нуль 1 0 0
Пусто 1 0 1
Денормализованное число 1 1 0
Команды FUCOM, FUCOMP, FUCOMPP производят сравнение мантисс операндов. При этом допускается сравнение не-чисел (они имеют единичные значения всех разрядов порядка). Если один или оба операнда являются не-числами, то устанавливается значение бита С2 = 1, а биты СЗ и СО определяют соотношение между мантиссами в соответствии с табл. 2.34, где х = ST(1). Команда FUCOMP освобождает вершину стека - регистр ST(0), команда FUCOMPP-два верхних регистра стека-ST(0) и ST(1).
Команда FTST выполняет сравнение содержимого регистра ST(0) с нулем, устанавливая биты СЗ, С2, СО в регистре FPSR в соответствии с табл. 2.34, где х = 0.
Команда FXAM производит анализ содержимого ST(0) и устанавливает соответствующие значения битов СО-СЗ в регистре FPSR. При этом бит С1 принимает значения знака, а разряды СО, С2, СЗ определяют содержимое ST(0) в соответствии с табл. 2.36.
2.4.6. КОМАНДЫ СПЕЦИАЛЬНЫХ ОПЕРАЦИЙ
К этой группе относятся команды, реализующие некоторые арифметические процедуры, и вычисление тригонометрических и трансцендентных функций. Коды и форматы команд приведены в табл. 2.37.
Команда масштабирования FSCALE прибавляет к порядку числа, хранящегося в ST(0), содержимое регистра ST(1), которое рассматривается как целое число со знаком. Если в регистре ST(1) содержится нецелое число, то его дробная часть отбрасывается.
Команда FXTRACT разлагает содержимое ST(0) на два компонента: порядок и мантиссу со знаком, которые размещаются в двух верхних регистрах арифметического стека. При этом значение поля ТОР в регистре FPSR уменьшается на единицу, и в новую вершину стека ST(0) заносится мантисса, а в регистр ST(1) [бывший ST(0)] - порядок, представленный в виде вещественного числа (формат РТ). В поле Е регистра ST(0) заносится число 3FFFh, соответствующее нулевому значению порядка. Если после команды FXTRACT выполнить команду FSCALE, то будет восстановлено исходное число.
Команда FRNDINT выполняет округление числа, хранящегося в ST(0), до целого значения в соответствии со способом, определяемым полем RC в регистре FPCR.
При выполнении тригонометрических функций sin, cos с помощью команд FSIN, FCOS, FSINCOS содержимое ST(0) воспринимается как число радианов. Значения функций, полученные с помощью команд FSIN, FCOS, заносятся в регистр ST(0). При выполнении команд FSINCOS производится уменьшение на единицу поля ТОР, и полученные значения функций sin и cos заносятся в два верхних регистра ST(0) и ST(1) [бывший ST(0)].
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
Таблица 2.37
Команды специальных операций FPU
Синтаксис команды Операция
FSCALE FXTRACT FRNDINT Порядок ST(0) + целое ST(1) -> порядок ST(0) Округление ST(0) Мантисса ST(0) ST(0), порядок ST(0) -> ST(1)
FSIN FCOS FSINCOS sin ST(0) -> ST(0) cos ST(0) -> ST(0) sin ST(0) -+ ST(0), cos ST(0) —> ST(1)
FPTAN FPATAN tg ST(0) -» ST(1), 1.0 -> ST(0) arctg (ST(1)/ST(0)) -> ST(0)
F2XM1 FYL2X FYL2XP1 2ST(0)-1 -» ST(0) ST(1)*log2ST(0) -> ST(0) ST(1)*log2(ST(0)+1.0) -> ST(0)
Команда FPTAN производит вычисление функции tg от числа, содержащегося в регистре ST(0). Полученный результат сохраняется в этом же регистре, после чего значение поля ТОР в регистре FPSR уменьшается на единицу, и в новую вершину стека ST(0) записывается число 1,0 в формате РТ. Таким образом, значение функции tg оказывается в регистре ST(1).
При выполнении команд FSIN, FCOS, FSINCOS, FPTAN исходный операнд в регистре ST(0) должен находиться в диапазоне - 2 63... +2 63. Если операнд выходит за указанные границы, то в регистре FPSR устанавливается значение бита С2 = 1, а результатом операции будет неопределенное значение (код неопределенности в формате РТ). Какое-либо исключение при этом не реализуется.
Команда FPATAN вычисляет значение функции arctg (х/у), где х содержится в регистре ST(1), у в ST(0). После вычисления производится выталкивание из стека (значение поля ТОР в регистре FPSR увеличивается на единицу), а результат вычисления размещается в новой вершине стека ST(0) [бывшем регистре ST( 1)].
Команда F2XM1 вычисляет значение функции 2 х - 1, где х-содержимое регистра ST(0). Результат операции размещается в том же регистре ЭТ(0).При этом величина х должна находиться в диапазоне - 1 ... +1, иначе результатом операции будет неопределенность (см. табл. 2.26).
При вычислении логарифмических функций y*log 2 х, у*1од 2 (х+1) с помощью команд FYL2X, FYL2XP1 операнд х размещается в ST(0), операнд у - в ST(1). При выполнении команд производится извлечение операндов из стека, а результат заносится в вершину стека. Значение поля ТОР в регистре FPSR после выполнения этих команд возрастает на единицу, т. е. результат будет содержаться в новой вершине стека ST(0) - бывшем регистре ST(1). На значения операнда х накладываются определенные ограничения. При выполнении команды FYL2X должно быть значение х > 0, иначе реализуется исключение недействительной операции #1. При выполнении команды FYL2XP1 операнд х должен находиться в диапазоне
- (1 - I 2/2) < х < + (1 - I 2/2),
иначе результатом операции будет неопределенность (см. табл. 2.26).
СИСТЕМА КОМАНД: ОПЕРАЦИИ НАД ЧИСЛАМИ С ПЛАВАЮЩЕЙ ТОЧКОЙ
2.4.7. КОМАНДЫ УПРАВЛЕНИЯ FPU
В эту группу включены системные команды, определяющие режим функционирования FPU (табл. 2.38). Отметим, что многие системные команды: FINIT/FNINIT, FSTSW/FNSTSW, FSTCW/FNSTCW, FCLEX/FNCLEX, FSTENV/FNSTENV, FSAVE/FNSAVE - имеют две модификации: с обычным для команд FPU префиксом F или префиксом FN.
При выборке команды с префиксом F проверяются значения признаков в регистре FPSR и реализуется обработка соответствующих исключений FPU, если в этом регистре установлены единичные значения признаков, не маскируемые содержимым регистра FPCR. После обработки исключений выполняется поступившая команда. Если команда имеет префикс FN, то она выполняется без проверки и обработки исключений.
Таблица 2.38
Команды управления FPU
Синтаксис команды Операция
FINIT 037Fh -> FPGR, 0 -> FPSR, FFFFh -> TW, 0 -> FIP, 0 -> FDP, проверка исключений FPU
FNINIT 037Fh -> FPCR, 0 -> FPSR, FFFFh -> TW, 0 -> FIP, 0 -> FDP, без проверки исключений FPU
FSTSW АХ FPSR -> AX, проверка исключений FPU
m2 byte FPSR -> m2byte, проверка исключений FPU
FNSTW АХ FPSR -> AX, без проверки исключений FPU
m2byte FPSR -> m2byte, без проверки исключений FPU
FLDCW m2byte m2byte -» FPCR
FSTCW m2byte FPSR -> m2byte, проверка исключений FPU
FNSTCW m2byte FPCR -> m2byte, без проверки исключений FPU
FCLEX 0 -> PE,VE,OE,ZE,DE,IE,ES,SF,B, проверка исключений FPU
FNCLEX 0 -> PE,VE,OE,ZE,DE,IE,ES,SF,B, без проверки исключений FPU
FSTENV m14/28byte FPCR,FPSR,TW,FIP,FDP -> m14/28byte,проверка исключений FPU
FNSTENV m14/28byte FPCR,FPSR,TW,FIP,FDP m14/28byte,6e3 проверки исключений FPU
FDENV m14/28byte m14/28/byte -» FDP,FIP,TW,FPSR,FPCR
FSAVE m94/108byte FPCR,FPSR,TW,FIP,FDP,ST(0)-ST(7) -> m94/108byte,проверка исключений FPU
FNSAVE m94/108byte FPCR,FPSR,TW,FIP,FDP,ST(0)-ST(7) -> m94/108byte,6e3 проверки исключений FPU
FRSTOR 17194/108byte m94/108byte -> ST(7)-ST(0),FDP,FIP,TW,FPSR,FPCR
FINCSTP TOP+1 ->TOP
FDECSTR TOP- 1 -> TOP
FFREI ST(i) 11В —> tag i
FNOP Отсутствие операции
WATT/FWATT Проверка и обслуживание исключений FPU
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
Команды инициализации FINIT/FNI NT устанавливают регистры FPU в начальное состояние. При этом для всех арифметических регистров FPU значения тегов в регистре TW принимают значение tag = 11 (регистры пустые); все биты регистра FPSR принимают нулевые значения. В регистре управления FPCR устанавливаются значения полей RC = 00 (округление к ближайшему), PC = 11 (расширенная точность, формат РТ), биты маски РМ, UM, ОМ, ZM, DM, IM = 1 (прерывания замаскированы), бит 12 принимает значение «0», остальные биты принимают произвольное значение (не определены). Аналогичное состояние регистров FPU устанавливается при поступлении внешнего сигнала сброса RESET.
Команды FSTSW/ FNSTSW осуществляют запись содержимого регистра FPSR в регистр АХ или 16-разрядную ячейку памяти m2byte, адресованную в команде процессора. Если после команд FSTSW АХ или FNSTSW АХ выполнить команду FSAHF, то биты условий СО, С2, СЗ регистра FPSR замещают определенные флаги в регистре EFLAGS: СО оказывается на месте CF, С2 - на месте PF, СЗ - на месте ZF. Используя затем команды условных переходов, можно управлять ходом выполнения программы в зависимости от значений битов условий FPU, поступивших в регистр EFLAGS.
Команда FLDCW загружает в регистр управления FPCR содержимое адресуемой ячейки памяти, команды FSTCW/FNSTCW пересылают содержимое этого регистра в память. Данные команды используются для изменения режима работы FPU: маскирования определенных флагов, перемены способа округления и точности представления результата.
Команды FCLEX/FNCLEX сбрасывают в состояние «0» признаки ES, SF, РЕ, UE, ОЕ, ZE, DE, IE в регистре FPSR, а так же бит В. Значение поля ТОР и кодов условий СО-СЗ в этом регистре сохраняются неизменными.
Команды FSTENV/FNSTENV, FLDENV, FSAVE, FRSTOR используются для пересылки содержимого регистров FPU в память и обратно. Обычно эти процедуры используются при переключении задач, и адресуемым сегментом служит SS (сегмент стека). При выполнении команд FSTENV/FNSTENV производится запись в память содержимого регистров FPSR, FPCR, TW, FIP, FDP. Команда FLDENV загружает содержимое этих регистров из памяти, начиная с указанной в команде ячейки памяти. Размещение содержимого регистров FPU в памяти для этих команд показано на рис. 2.19 и 2.20, где Ах - адрес младшего байта содержимого регистра FPCR, который задается операндом m14byte или m28byte. Когда процессор работает в реальном режиме или в режиме виртуального 8086, регистры FIP, FDP содержат 20-разрядный физический адрес команды и операнда. При работе в защищенном режиме в этих регистрах хранятся относительный адрес (содержимое EIP и эффективный адрес ЕА) и селекторы (содержимое соответствующих сегментных регистров). Объем памяти, используемой при выполнении команд FSTENV, FLDENV, составляет 14 байт при 16-разрядной адресации и 28 байт при 32-разрядной (часть байтов не используется).
Команды FSAVE/FNSAVE дополнительно пересылают в память содержимое всех восьми 80-разрядных арифметических регистров, которое располагается после содержимого регистра FDP (рис. 2.19, 2.20), начиная с содержимого вершины стека ST(0). Используемый объем памяти при этом возрастает на 80 байт по сравнению с командами FSTENV/ FNSTENV. Команда FRSTOR восстанавливает содержимое всех регистров FPU, загружая его из памяти.
После выполнения команд FSTENV/FNSTENV, FSAVE/FNSAVE, содержимое регистров FPU принимает такое же значение, как после команд FINIT/FNINIT.
Команды FINCSTP и FDECSTP увеличивают и уменьшают на единицу значение поля ТОР в регистре FPSR, меняя, таким образом, физический номер регистра ST(0)- вершины стека (см. рис. 2.16). При этом содержимое регистров данных и значения полей tag в регистре TW не изменяются.
Команда FFREE освобождает адресуемый регистр ST(i), устанавливая для него в регистре TW значение поля tag I = 11 (пустой).
СИСТЕМА КОМАНД ОПЕРАЦИИ НАД ЧИСЛАМИ С ПЛАВАЮЩЕЙ ТОЧКОЙ
а) 15 0 б) 15 0
FPCR Ах FPCR Ах
FPSR Ах + 2 FPSR Ах + 2 >х’Г,
TW Ах + 4 TW Ах + 4
FIP EIP Ах + 6 FIP Адрес команды А15-0 Ах + 6
CS (селектор) Ах + 8 А19-16 | 0 | Код операции Ах + 8
FDP ЕА Ах + 10 FDP Адрес операнда А15-0 Ах + 10
DS или другие (селектор) Ах + 12 А19-16 000000000000 Ах + 12 0 /
ST (0), 10 байтов Ах + 14 ST (0), 10 байтов Ах + 14
ST (7), 10 байтов Ах + 84 ST (7), 10 байтов Ах + 84
Рис. 2.19. Размещение содержимого регистров FPU в памяти при 16-разрадной адресации: для защищенного режима (а), для реального режима и режима виртуального 8086 (б)
а) 31 16 15 0
Резервировано FPCR Ах
Резервировано FPSR Ах + 4
Резервировано TW Ах + 8
FIP EIP Ах + 12
00000 | Код операции CS (селектор) Ах + 16
FDP ЕА Ах+ 20
Резервировано DS или другие (селектор) Ах+ 24
ST (0), 10 байтов Ах+ 28
ST (7), 10 байтов Ах+ 98
б) 31 16 15 0 А
Резервировано FPCR Ах
Резервировано FPSR Ах + 4
Резервировано TW Ах + 8
FIP Резервировано Адрес команды А15-0 Ах + 12
0000 | Адрес команды А31-16 0 I Код операции Ах + 16
FDP Резервировано Адрес команды А15-0 Ах+ 20
0000 | Адрес команды А31-16 0100 0000 0000 Ах+ 24
ST (0), 10 байтов Ах+ 28
ST (7), 10 байтов Ах + 98
Рис. 2.20. Размещение содержимого регистров FPU в памяти при 32-разряд-ной адресации: для защищенного режима (а), для реального режима и режима виртуального 8086 (б)
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
Команда FNOP не выполняет каких-либо операций. Поступление команды WAIT(FWAIT) также не реализует каких-либо операций. Однако эта команда проверяет значения признаков в регистре FPSR и реализует обработку соответствующих исключений FPU, если установлены единичные значения немаскированных признаков, аналогично тому, как это выполняют системные команды с префиксом F.
2.5. СИСТЕМА КОМАНД: ОПЕРАЦИИ ММХ
В процессорах Pentium был впервые введен блок, предназначенный для обработки данных по принципу SIMD (Single Instruction Multiple Data: Одна Команда - Много Данных). Реализация этого принципа позволяет при помощи одной команды обработать несколько единиц однотипной информации. Такая технология обработки данных получила название MMX (Multi-Media Extension) - «мультимедийное расширение», так как она позволяет существенно повысить скорость выполнения операций преобразования изображений и звуковых сигналов. Процессоры, поддерживающие технологию ММХ, имеют расширенный набор команд, обрабатывающих данные, представленные в форматах упакованных чисел. В процессоре Pentium III метод обработки данных по принципу SIMD получил дальнейшее развитие. Расширенные возможности процессора Pentium III объединены под термином Streaming SIMD Extension (SSE) - «потоковое SIMD-расширение». В этих процессорах реализована технология SSE, обеспечивающая обработку потока данных, представленных в формате с плавающей точкой, по принципу SIMD. Кроме того, в процессорах Pentium III введены дополнительные команды, расширяющие возможности MMX-технологии. Современные модели процессоров семейства Р6 поддерживают технологии ММХ и SSE. Чтобы определить, реализует ли данный процессор технологию ММХ и расширение SSE, следует воспользоваться командой CPUID.
Ниже дается перечень MMX-команд, разбитых по функциональным группам. Команды, помеченные символом *, выполняются только процессорами, реализующими SSE-расширение.
Команды пересылки данных
MOVD - Пересылка 32-разрядных данных
MOVQ - Пересылка 64-разрядных данных
PEXTRW- Пересылка слова из MMX-регистра в регистр общего назначения PINSRW- Пересылка слова из регистра общего назначения в ММХ-регистр PMOVMSKB'- Пересылка знаковых битов из MMX-регистра в регистр общего назначения EMMS - Пересылка числа FFFFh в регистр тегов TW (освобождение ММХ-регистров)
Команды преобразования
PACKSS[WB,DW] - Упаковка со знаковым насыщением
PACKUSWB - Упаковка с беззнаковым насыщением
PUNPCKH[BW,WD,DQ] - Распаковка из старших половин PUNPCKL[BW,WD,DQ] - Распаковка из младших половин PSHUFW- Переупорядочивание слов
Арифметические команды
PADD[B,W,D] - Сложение с циклическим переносом
PSUB[B,W,D] - Вычитание с циклическим переносом
PADDS[B,W] - Знаковое сложение с насыщением
PSUBS[B,W] - Знаковое вычитание с насыщением
PADDUS[B,W] - Беззнаковое сложение с насыщением
PSUBUS[B,W] - Беззнаковое вычитание с насыщением
СИСТЕМА КОМАНД: ОПЕРАЦИИ ММХ
PMULHW - Знаковое умножение с сохранением старшей половины результата PMULLW - Знаковое умножение с сохранением младшей половины результата PMULHUW- Беззнаковое умножение с сохранением старшей половины результата PMADDWD - Знаковое умножение с накоплением PSADBW- Сложение абсолютных разностей байтов PAVG[B,W]'- Нахождение среднего значения
Команды нахождения максимума и минимума
PMAXSW- Нахождение большего значения (знаковые слова)
PMAXUB'- Нахождение большего значения (беззнаковые байты)
PMINSW- Нахождение меньшего значения (знаковые слова) а,,
PMINUB'- Нахождение меньшего значения (беззнаковые байты)
Команды сравнения гс
PCMPEQ[B,W,D] - Сравнение на равенство
PCMPGT[B,W,D] - Сравнение на большее значение
Команды логических операций
PAND - Логическое И
PANDN - Логическое НЕ-И
POR - Логическое ИЛИ
PXOR - Исключающее ИЛИ
Команды сдвига
PSLL[W,D,Q] - Логический сдвиг влево
PSRL[W,D,Q] - Логический сдвиг вправо
PSRA[W,D] - Арифметический сдвиг вправо
При выполнении MMX-команд процессор использует для хранения операндов восемь арифметических регистров R7-0 блока FPU (см. рис. 2.4), реализующего обработку чисел с плавающей точкой. В этом случае арифметические регистры получают обозначения ММ7-0. Так как MMX-команды обрабатывают 64-разрядные операнды, то ММХ-реги-стры имеют разрядность 64 бит, используя только 64 младших разряда в 80-разрядных регистрах FPU (см. рис. 2.22).
2.5.1. ФОРМАТЫ ПРЕДСТАВЛЕНИЯ ДАННЫХ И ВЫПОЛНЕНИЕ ОПЕРАЦИЙ
Почти все мнемокоды MMX-команд начинаются с префикса Р (Packed), которые указывает, что технология ММХ имеет дело с упакованными данными. За префиксом следует полное или сокращенное название выполняемой операции, например, OR, СМР, SUB. После названия операции может стоять несколько суффиксов, имеющих следующее значение:
US (Unsigned Saturation) - беззнаковое насыщение;
S (Signed saturation) - знаковое насыщение;
В, W, D, Q (Byte, Word, Doubleword, Quadword)- формат используемых упакованных данных.
Если при выполнении MMX-команды используется арифметика с насыщением, особенности которой описаны ниже в данном разделе, то в мнемокоде сначала указывается суффикс US или S, определяющий вид насыщения (беззнаковое или знаковое). Мнемокоды команд, не использующих принцип насыщения, не содержат этот суффикс. Далее в мнемокоде указывается суффикс, определяющий формат обрабатываемых данных. Команды, использующие различные форматы для представления исходных данных и результата, содержат
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
ОРС MODR/M SIB DISP IMM
OFh OpCode MOD REG (mmxreg) R/M (mmxreg) SS INDEX BASE d8/d16/d32 im8
Рис. 2.21. Формат ММХ-команд
два суффикса, определяющие формат: первый задает формат результата, а второй - формат исходных данных. Например, в команде PACKUSWB название операции задается мнемокодом РАСК (упаковка), первый суффикс US указывает на то, что применяется беззнаковое насыщение, следующий суффикс (^определяет формат результата в виде упакованных байтов, а последний суффикс В - формат исходных данных в виде упакованных слов.
MMX-команды поддерживают все способы адресации, реализуемые с использованием байтов MODR/M и SIB. Формат MMX-команды показан на рис. 2.21. Любая ММХ команда начинается с байта OFh, затем идет второй байт кода операции OpCode. Для указания используемых в команде MMX-регистров в байте MODR/M в полях REG и R/M (при MOD = 11, регистровая адресация) указываются номера используемых MMX-регистров mmxreg. Присутствие байтов SIB, смещения DISP и непосредственного операнда IMM зависит от выбранного способа адресации. Следует отметить, что MMX-регистры не могут служить для формирования адреса.
Для команд пересылки операнд-приемник и операнд-источник могут располагаться в памяти, регистре общего назначения или MMX-регистре. Для остальных команд операнд-приемник всегда находится в MMX-регистре, а операнд источник может находиться в памяти, MMX-регистре или являться непосредственным операндом.
Если MMX-команда использует операнды, размещенные в памяти, то перед ней могут присутствовать префиксы замены сегмента SEG и разрядности адреса AS. Префиксы разрядности операнда OS и повторения REP, REPE/REPNE, предшествующие ММХ-команде, игнорируются процессором. Наличие перед MMX-командой префикса блокировки шины LOCK вызовет исключение типа #UD («недействительный код операции»).
При ошибках обращения к памяти MMX-команды генерируют исключения #SS, #GP, #PF или #АС, как и остальные команды. Попытка выполнить MMX-команду, когда в регистре управления CR0 установлено значение бита ЕМ = 1, приводит к исключению типа #UD. Эмуляция ММХ-команд невозможна. Попытка выполнить MMX-команду, когда в регистре управления CR0 бит TS = 1, приводит к исключению типа #NM («устройство недоступно»). Если при обработке исключения FPU встретится MMX-команда, то это приведет к исключению типа #MF и/или FERR#.
MMX-команды могут выполняться в любом режиме работы процессора: реальном, защищенном и виртуального 8086.
MMX-регистры (рис. 2.22) имеют разрядность 64 бита и отображены на поля мантиссы арифметических регистров блока FPU (см. рис. 2.4). При записи нового значения в ММХ-регистр это значение автоматически появляется в поле мантиссы (биты 63-0) соответствующего регистра FPU. При этом в поле порядка (биты 78-64) и знаковый бит (бит 79) записываются единицы. После выполнения любой MMX-команды в поле ТОР регистра FPSR (см. рис. 2.5), указывающем вершину арифметического стека, записывается значение ООО. Любая MMX-команда (кроме EMMS) заносит во все поля регистра тегов TW значение 00. Для блока FPU это означает, что во всех регистрах находятся допустимые ненулевые числа (все регистры заняты). Команда EMMS устанавливает значения всех полей регистра тегов в 11 (для блока FPU это означает, что все арифметические регистры пусты). Значение регистра TW, содержащего теги, не оказывает никакого влияния на выполнение ММХ-команд. При выполнении ММХ-команд содержимое регистров FPU устанавливается в соответствии с табл. 2.39.
2.5. СИСТЕМА КОМАНД: ОПЕРАЦИИ ММХ
Рис. 2.22. Отображение MMX-регистров на регистры блока FPU
Отображение MMX-регистров на регистры блока FPU фиксировано и не зависит от значения поля ТОР регистра состояния FPSR. В обозначении ММп число п указывает на физический номер регистра ММп -> Rn. Напомним, что при выполнении операций FPU в обозначении регистра ST(n) число п указывает относительный номер регистра, а его физический номер определяется значением поля ТОР. Поэтому при значении ТОР = ООО регистр ММО отображается на ST(0), ММ1 - на ST(1) ит. д.; при ТОР = 010 ММО отображается на ST(6), ММ1-наЗТ(7), ММ2-на ЭТ(0)ит.д.
Так как блоки ММХ и FPU используют физически одни и те же регистры, то для сохранения и восстановления содержимого MMX-регистров используются команды FSAVE и FRSTOR.
На рис. 2.23 приведены форматы упакованных данных, обрабатываемых ММХ-комаццами:
• упакованные байты В7-0 (8 элементов по 8 бит, рис. 2.23,а);
• упакованные слова W3-0 (4 элемента по 16 бит, рис. 2.23,6);
• упакованные двойные слова D1-0 (2 элемента по 32 бита, рис. 2.23,в);
• упакованное счетверенное слово Q (1 элемент, 64 бита, рис. 2.23,г).
а)
63 56 56 48 47 40 39 32 31 24 23 16 15 8 7 0
| В7 | В6 | В5 | В4 | ВЗ | В2 | B1 | ВО |
б)
63__________48 47_________32 31__________16 15__________0
| W3 | W2 | W1 | W0 |
в)
63________________________32 31_________________________0
I D1 | D0 |
г)
63__________________________________________0
I- Q I
Рис. 2.23. Форматы упакованные данных: а)-байты, б)-слова, е) - двойные слова, г) - счетверенное слово
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
Таблица 2.39
Влияние MMX-команд на содержимое регистров FPU
Тип команды Регистр TW Поле ТОР Поле порядка и знаковый бит ММп (79-64) Поле мантиссы ММп (63-0)
Чтение из регистра ММп Все поля 00 000 Не изменяется Не изменяется
Запись в регистр ММп Все поля 00 000 Заполняется единицами Перезаписывается
EMMS Все поля 11 000 Не изменяется Не изменяется
Элементами обрабатываемых данных являются соответственно байты, 16-разрядные слова, 32-разрядные двойные слова или 64-разрядные счетверенные слова. При обработке упакованных данных с помощью MMX-команд одновременно (параллельно) выполняется одна и та же операция над всеми элементами заданного формата, каждый из которых представляет отдельное число (данные). Например, при помощи одной команды можно сложить элементы, хранящиеся в одном MMX-регистре с элементами в другом MMX-регистре, получив восемь отдельных результатов (сумм) в виде упакованных байтов. Одновременно можно обработать либо восемь байт, либо четыре слова, либо два двойных слова, либо одно счетверенное слово. Таким образом, реализуется принцип 8/МО-обработки: одновременное выполнение одной команды над многими данными (до восьми 8-разрядных элементов). В памяти упакованные данные располагаются так, как зто принято в Intel-архитектуре, т. е. младший байт размещается первым - по младшему адресу (рис. 2.24).
63 56 56 48 47 40 39 32 31 24 23 16 15 8 7 О
| В7 I В6 I В5 I B4 I ВЗ I В2 | В1 | ВО |~
Адрес 2008h Адрес 2000h
Рис. 2.24. Расположение упакованных байтов в памяти по адресу 2000h
Рад MMX-команд используют арифметику с насыщением (saturation arithmetic). Если произошло переполнение, то в арифметике с насыщением результатом операции будет ближайшее к полученному значению число, которое умещается в формате, определенном для результата. Таким образом, результат как бы «насыщается» до максимально возможного значения. Например, результатом сложения двух байтов без знака B8h (184) и E1h (225), при использовании арифметики с насыщением, будет байт FFh (255) (рис. 2.25,а). Если сложить байты со знаком 90h (- 112) и E1h (- 31), то результатом сложения с насыщением будет байт 80h (-128) (рис. 2.25,6).
Арифметика с насыщением различает знаковые и беззнаковые операнды - от этого зависят пределы насыщения (табл. 2.40). Если результат операции не выходит за пределы насыщения, то арифметика с насыщением даеттотже результат, что и обычная арифметика.
а) Числа без знака б) Числа co знаком
|10 1110 0 0 | B8h | 1 0 0 1 0 0 0 0 | 90h
11 1 1 0 0 0 0 1 | E1h | 1 1 1 0 0 0 0 1 I E1h
= =
(11111111 | FFh | 1 0 0 0 0 0 0 0 I 99h
Рис. 2.25. Выполнение операций сложения при использовании арифметики с насыщением
СИСТЕМА КОМАНД: ОПЕРАЦИИ ММХ
Таблица 2.40
Пределы насыщения
Нижний предел Верхний предел
Со знаком
Байт 80h =-128 7Fh =127
Слово 8000h = -32768 7FFFh = 32767
Двойное слово 80000000h =-2147483648 7FFFFFFFh = 2147483647
Без знака
Байт 00h = 0 FFh = 255
Слово OOOOh = 0 FFFFh = 65535
Двойное слово OOOOOOOOh = 0 FFFFFFFFh = 4294967295
Ряд ММХ-команд выполняет операции обычной арифметики с циклическим переносом (wraparound arithmetic). Мнемокоды таких команд не имеют суффикса S или US.
MMX-команды не изменяют содержимое регистра EFLAGS. При этом переполнение разрядной сетки, возникающее при операциях с упакованными данными, нигде не фиксируется и не вызывает обработки исключения.
2.5.2. КОМАНДЫ ПЕРЕСЫЛКИ И ПРЕОБРАЗОВАНИЯ ДАННЫХ
Команды этой группы приведены в табл. 2.41. Команды MOVD, MOVQ, PEXTRW, PINSRW и PMOVMSKB осуществляют пересылку данных, а команды PACKSS[WB,DW], PACKUSWB, PUNPCKH[BW,WD,DQ], PUNPCKL[BW,WD,DQ] и PSHUFW-преобразование данных: упаковку, распаковку и переупорядочивание элементов. Используемые операнды задаются в синтаксисе Ассемблера номером MMX-регистра mm, именем регистра общего назначения г32 или адресом ячейки памяти m 16, m32 или т64, хранящей, соответственно 16-, 32- или 64-разрядные данные. При определении выполняемой операции в табл. 2.41 указывается формат пересылаемых упакованных данных (В, W, D или Q), а в случае необходимости также и номер соответствующего элемента: например, mm(W) - слово из ММХ-регистра с номером mm, mm(BO) -элемент (байт) ВО из ММХ-регистра с номером mm.
Таблица 2.41
Команды пересылки и преобразования данных
Синтаксис команды Операция
MOVQ mm,mm/m64 MOVQ mm/m64,mm mm/m64(Q) -> mm(Q) mm(Q) -> mm/m64(Q)
MOVD mm,r/m32 MOVD r/m32,mm r/m32 -> mm(DO) 0 —> mm(D1) mm(DO) -> r/m32
PEXTRW r32,mm,imm8 mm[W(im8[1..O])] -> r32(15..O) 0 -»г32(31..16)
PINSRW mm,r32/m16,imm8 r32(15..0)/m16 -> mm[W(im8[1..O])]
PMOVMSKB r32,mm mm[b7(Bi)] -> r32(i), i = 0..7 0 —>r32(31.,8)
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
Продолжение табл. 2.41
Синтаксис команды Операция
PACKSSWB rnm,mm/m64 Преобразование c насыщением из слов со знаком в байты со знаком mm(WO) -> mm(BO) mm(W1) -> mm(B1) mm(W2) -> mm(B2) mm(W3) -> mm(B3) mm/m64(W0) -> mm(B4) mm/m64(W1) -> mm(B5) mm/m64(W2) -> mm(B6) mm/m64(W3) -> mm(B7)
PACKSSDW mm,mm/m64 Преобразование с насыщением из двойных слов со знаком в слова со знако Mmm(DO) -> mm(WO) mm(D1) ->mm(W1) mm/m64(D0) -> mm(W2) mm/m64(D1) -> mm(W3)
PACKUSWB mm,mm/m64 Преобразование с насыщением из слов co знаком в байты без знака mm(WO) -> mm(BO) mm(W1) -> mm(B1) mm(W2) -> mm(B2) mm(W3) -> mm(B3) mm/m64(W0) -> mm(B4) mm/m64(W1) -> mm(B5) mm/m64(W2) -> mm(B6) mm/m64(W3) -> mm(B7)
PUNPCKHBW mm,mm/m64 mm(B4) -> mm(BO) mm/m64(B4) -> mm(B1) mm(B5) -> mm(B2) mm/m64(B5) -> mm(B3) mm(B6) -> mm(B4) mm/m64(B6) -> mm(B5) mm(B7) -> mm(B6) mm/m64(B7) -> mm(B7)
PUNPCKHWD mm,mm/m64 mm(W2) -> mm(WO) mm/m64(W2) -> mm(W1) mm(W3) -> mm(W2) mm/m64(W3) -> mm(W3)
PUNPCKHDQ mm,mm/m64 mm(D1) -> mm(DO) mm/m64(D1) -> mm(DO)
PUNPCKLBW mm,mm/m64 mm/m64(B3) -> mm(B7) mm(B3) -> mm(B6) mm/m64(B2) -> mm(B5) mm(B2) -> mm(B4) mm/m64(B1) -> mm(B3) mm(B1) -> mm(B2) mm/m64(B0) -> mm(B1) mm(BO) -> mm(BO)
СИСТЕМА КОМАНД: ОПЕРАЦИИ ММХ
Продолжение табл. 2.41
Синтаксис команды Операция
PUNPCKLWD mm,mm/m64 PUNPCKLDQ mm,mm/m64 mm/m64(W1) -> mm(W3) mm(W1) -> mm(W2) mm/m64(W0) -> mm(W1) mm(WO) -> mm(WO) mm/m64(D0) -> mm(D1) mm(DO) -> mm(DO)
PS HUF W mm,mm/m64,imm8 mm/m64[W(im8[1..O])] —»mm(WO) mm/m64[W(im8[3..2])] mm(W1) mm/m64[W(im8[5..4])] mm(W2) mm/m64[W(im8[7.,6])] -> mm(W3)
Команда MOVQ производит пересылку 64-разрядного операнда - счетверенного слова mm(Q) - между двумя MMX-регистрами или между MMX-регистром и памятью. Эта команда не выполняет перенос данных между MMX-регистром и регистром общего назначения. Команда MOVD производит пересылку 32-разрядного операнда - двойного слова mm(DO) -между MMX-регистром (младший элемент) и памятью или регистром общего назначения. Если операндом-приемником является MMX-регистр, то в его старшую половину загружается нулевое значение. Данная команда не может использоваться для передачи данных между двумя ММХ-регистрами.
Команды PEXTRW и PINSRW производят пересылки 16-разрядных элементов - слов mm(Wi) - между MMX-регистром и регистром общего назначения или памятью. Команда PEXTRW пересылает любой элемент (слово) из MMX-регистра в младшие разряды Ь15-0 регистра общего назначения г32. В старшие разряды Ь31-16 этого регистра загружается нулевое значение. Команда PINSRW выполняет обратную операцию, пересылая слово из младших разрядов Ь15-0 регистра общего назначения или 16-разрядной ячейки памяти с адресом гп16 на место заданного элемента mm(Wi) в MMX-регистр. Остальные три элемента (слова) в MMX-регистре остаются без изменения. Номер i пересылаемого или замещаемого элемента в MMX-регистре задается двумя младшими битами непосредственного операнда im8.
Команда PMOVMSKB формирует байт (8-битовую маску) из старших (знаковых) разрядов Ь7 каждого байта Bi, хранящегося в MMX-регистре mm. Эта маска размещается в младших разрядах регистра общего назначения г32, а его старшие разряды заполняются нулями (рис. 2.26).
Команды PACKSS[WB,DW] и PACKUSWB выполняют операцию, которая называется упаковкой данных. Исходные элементы преобразуются в элементы, имеющие в два раза меньший размер, чем исходные (разрядность элементов уменьшается вдвое). При данном преобразовании используется принцип насыщения. Если значение исходного элемента больше верх-
PMOVMSKB r32, mm
63 56 56 48 47 40 39 32 31 24 23 16 15 8 7 0
Рис. 2.26. Выполнение команды PMOVMSKB*
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
него предела или меньше нижнего предела, установленных для формата результата операции (см. табл. 2.40), то в качестве результирующего элемента в MMX-регистр заносится значение соответствующего предела. Выполнение этих комаед иллюстрируется на рис. 2.27.
Команда PACKSSWB (рис. 2.27, а) упаковывает знаковые слова в знаковые байты. Если значение какого-либо исходного слова больше 007Fh (+127), то значение соответствующего байта результата будет 7Fh; если значение слова меньше FF80h (- 128), то значение байта результата 80h (- 128). Аналогичную операцию реализует команда PACKUSWB, которая упаковывает знаковые слова в беззнаковые байты. Отличие от предыдущей операции состоит только в определении пределов для беззнаковых байтов результата согласно табл. 2.40: если значение исходного слова больше OOFFh (255), то значение соответствующего байта результата FFh (255), если значение слова меньше OOOOh (0), то значение байта результата 00h (0).
Команда PACKSSDW (рис. 2.27, б) упаковывает знаковые двойные слова в знаковые слова. Если значение исходного двойного слова больше 00007FFFh (+32767), то значение соответствующего слова результата будет 7FFFh; если значение исходного слова меньше FFFF8000h (- 32768), то значение слова результата 8000h (- 32768).
Команды PUNPCKH[BW,WD,DQ] и PUNPCKL[BW,WD,DQ] производит операцию, которая называется распаковкой данных. Эти команды объединяют старшие (команды PUNPCKH) или младшие (команды PUNPCKL) половины исходных операндов, хранящихся в регистре mm и регистре или ячейке памяти mm/m64, в один результирующий операнд, который размещается в регистре mm. При этом элементы исходных операндов перемешиваются, располагаясь через один (рис. 2.28). Дополнительный суффикс в мнемокодах этих команд определяет, какие половины исходных операндов объединяются: старшие (мнемокоды с суффиксом Н) или младшие (мнемокоды с суффиксом L). Суффиксы BW (распаковка байтов), WD (распаковка слов), DQ (распаковка двойных слов) задают форматы представления результата и исходных операндов. Реализация операции распаковки иллюстрируется на рис. 2.28 на примере выполнения команд PUNPCKHBW, PUNPCKLWD и PUNPCKLDQ.
а) PACKSSWB mm, mm/m64 или PACKUSWB mm, mm/m64
mm/m64
63 ______32 31
| W3 | W2 | \
0
WO I
mm
63
| W3 I W2
mm
32 31 ______0
| W1 | WO |
0
32 31
| B7 | B6 | B5 | B4 | B3 | B2 | B1 | B0~]
63 *
Рис. 2.27. Выполнение команд PACKSSWB, PACKUSWB (a), PACKSSDW (6)
СИСТЕМА КОМАНД: ОПЕРАЦИИ ММХ
a) PUNPCKLWO mm, mm/m32
mm/m64 mm
mm/m32 mm
Команда PSHUFW производит переупорядочивание слов, перемещая элементы (слова) операнда-источника из регистра или ячейки памяти mm/m64 в соответствующие позиции элементов операнда-приемника в регистре mm. Непосредственный операнд im8 указывает, какой из элементов операнда-источника помещается в определенной позиции операнда-приемника: биты Ь1-0 этого операнда задают номер элемента в операнде-источнике, который помещается на место слова W0 операнда-приемника, биты ЬЗ-2 - номер элемента, помещаемого на месте слова W1, биты Ь5—4 - номер элемента, помещаемого на месте слова W2, биты Ь7-6 - номер элемента, помещаемого на месте слова W3. Выполнение данной команды иллюстрируется на рис. 2.29.
Команда EMMS выполняет пересылку числа FFFFh в регистр тегов TW. При этом теги Для всех регистров FPU и соответствующих им MMX-регистров принимают значение 11, что соответствует их пустому состоянию. Таким образом, данная команда производит освобождение всех регистров FPU и соответственно MMX-регистров. Данная команда используется после завершения процедуры обработки упакованных данных, чтобы освободить регистры для последующего выполнения операций блоком FPU. Если эта команда не будет выполнена, то регистры остаются заполненными упакованными данными (при ММХ-операциях теги принимают значение 00, что соответствует заполнению регистров), и обращение к ним вызовет исключение типа #MF («ошибка FPU»).
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
PSHUFW mm, mm/m64, 92h
Рис. 2.29. Выполнение команды PSHUFW при значении операнда im8 = 11010010
2.5.3. КОМАНДЫ АРИФМЕТИЧЕСКИХ ОПЕРАЦИЙ
Эта группа (табп. 2.42) содержит как команды, использующие принцип циклического переноса, таки команды, использующие принцип насыщения. Мнемокоды команд, при выполнении которых реализуется принцип циклического переноса, содержат только суффиксы В, W или D, определяющие тип обрабатываемых данных. При переполнении перенос не фиксируется, сохраняется только элемент формата. Мнемокоды команд, реализующих принцип насыщения, кроме суффиксов, определяющих тип данных, содержат суффикс S или US, указывающий вид насыщения - знаковое или беззнаковое.
Таблица 2.42
Команды арифметических операций
Синтаксис команды Операция
PADDB mm,mm/m64 PADDW mm,mm/m64 PADDD mm,mm/m64 mm(B) + mm/m64(B) ->mm(B) циклический перенос mm(W) + mm/m64(W) -> mm(W) циклический перенос mm(D) + mm/m64(D) -> mm(D) циклический перенос
PADDSB mm,mm/m64 PADDSW mm,mm/m64 mm(B) + mm/m64(B) -> mm(B) насыщение co знаком mm(W) + mm/m64(W) -> mm(W) насыщение co знаком
PADDUSB mm,mm/m64 PADDUSW mm,mm/m64 mm(B) + mm/m64(B) -> mm(B) насыщение без знака mm(W) + mm/m64(W) -> mm(W) насыщение без знака
PSUBB mm,mm/m64 PSUBW mm,mm/m64 PSUBD mm,mm/m64 mm(B) - mm/m64(B) -> mm(B) циклический перенос mm(W) - mm/m64(W) -> mm(W) циклический перенос mm(D) - mm/m64(D) -> mm(D) циклический перенос
PSUBSB mm,mm/m64 PSUBSW mm,mm/m64 mm(B) - mm/m64(B) -> mm(B) насыщение co знаком mm(W) - mm/m64(W) -> mm(W) насыщение co знаком
PSUBUSB mm,mm/m64 PSUBUSW mm,mm/m64 mm(B) - mm/m64(B) ->mm(B) насыщение без знака mm(W) - mm/m64(W) -> mm(W) насыщение без знака
PMADDWD mm,mm/m64 mm(W) * mm/m64(W) —> temp(D) temp(D3) + temp(D2) -> mm(D1) temp(D2) + temp(DO) -> mm(DO)
СИСТЕМА КОМАНД: ОПЕРАЦИИ ММХ
Продолжение таблицы 2.42
Синтаксис команды Операция
PMULHW mm,mm/m64 Умножение слов co знаком с сохранением старшего слова результата mm(W) * mm/m64(W) -> mm(W)
PMULLW mm,mm/m64 Умножение слов со знаком с сохранением младшего слова результата mm(W) * mm/m64(W) -> mm(W)
PMULHUW mm,mm/m64 Умножение слов без знака с сохранением старшего слова результата mm(W) * mm/m64(W) -> mm(W)
PAVGB mm,mm/m64 PAVGW mm,mm/m64 (mm(B) + mm/m64(B) + 1] / 2 —> mm(B) без знака [mm(W) + mm/m64(W) + 1] / 2 -> mm(W) без знака
PSADBW mm,mm/m64 Abs[mm(B0) - mm/m64(B0)] + Abs[mm(B1) - mm/m64(B1)] + ... + Abs[mm(B7) - mm/m64(B7)j -> mm(WO) 0 -> mm(W3-W1)
Команды PADD[B,W,D] и PSUB[B,W,D], PADDS[B,W] и PSUBS[B,W], PADDUS[B,W] и PSUBUS[B,W] производят сложение и вычитание элементов данных, представленных в соответствующем формате. При выполнении этих операций один из операндов всегда размещается в MMX-регистре mm, другой операнд - в регистре или ячейке памяти mm/m64, результат располагается в регистре mm. Команды PADD[B,W,D], PSUB[B,W,D] выполняют сложение и вычитание элементов без знака, используя принцип циклического переноса (обычная арифметика). Команды PADDS[B,W], PSUBS[B,W] и PADDUS[B,W], PSUBUS[B,W] выполняют сложение и вычитание элементов со знаком (суффикс S) и без знака (суффикс US), используя принцип насыщения.
Команды PMULHW и PMULLW осуществляют умножение слов со знаком, хранящихся в MMX-регистре mm и регистре или ячейке памяти mm/m64. После выполнения операции в соответствующих элементах (словах) регистра mm размещается старшее (команда PMULHW с суффиксом Н) или младшее (команда PMULLW с суффиксом L) слово полученного 32-разрядного произведения. Команда PMULHUW выполняет действия, аналогичные команде PMULHW, над словами без знака.
Команда PMADDWD реализует операцию умножения с накоплением. Обрабатываемые элементы представляются в виде чисел со знаком. Выполнение этой команды иллюстрируется на рис. 2.30. Слова W3-0 операнда, хранящегося в MMX-регистре mm, умножаются
PMADDWB mm, mm/m64 63 О
Рис. 2.30. Выполнение команды PMADDWD
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
PSADBW mm, mm/mM
на слова W3-0 операнда, хранящегося в регистре или ячейке памяти mm/m64. Таким образом, получается промежуточный результат в виде четырех двойных слов D3-0. Затем два старших двойных слова этого результата - D3 и D2 - суммируются. Их сумма записывается в MMX-регистр mm в качестве старшего двойного слова D1 конечного результата. Два младших двойных слова промежуточного результата - 01 и DO - также суммируются, и их сумма записывается в регистр mm в качестве младшего двойного слова DO конечного результата.
При сложении двойных слов промежуточного результата (D3 и D2, или D1 и DO) может образоваться перенос, если все четыре слова, участвующие в операции умножения при получении промежуточного результата, равны 8000h (- 32768). В этом случае двойное слов D1 или DO в окончательном результате данной операции будет иметь значение 800000006 (- 2147483648).
Команда PAVG[B,W] производит вычисление средних значений беззнаковых элементов (байтов или слов) в исходных операндах, которые хранятся в регистре mm и регистре или ячейке памяти mm/m64. Эти элементы сначала складываются, а затем их сумма вместе с битом переноса сдвигается на один разряд влево, что эквивалентно делению на 2. При этом старший бит элемента заполняется битом переноса, который получился в результате сложения. Таким образом, в каждом элементе результата, записываемого в регистр mm, оказывается среднее значение элементов исходных операндов.
Команда PSADBW выполняет сложение абсолютных разностей байтов без знака (рис. 2.31). Беззнаковые байты, хранящиеся в регистре или ячейке памяти mm/m64, вычитаются из беззнаковых байтов в регистре mm, а затем абсолютные значения полученных разностей суммируются. Результат их сложения записывается в качестве младшего слова W0 в регистр mm. В старшие три слова W3-1 этого регистра записываются нули.
2.5.4. КОМАНДЫ ЛОГИЧЕСКИХ ОПЕРАЦИЙ И СДВИГОВ
Команды этой группы приведены в таблице 2.43.
Команды PAND, PANDN, POR, PXOR выполняют логические операции И, НЕ-И (Запрет), ИЛИ, Исключающее ИЛИ соответственно. Логические операции выполняются над значениями каждого из разрядов исходных операндов, которые размещаются в регистре mm и регистре или ячейке памяти mm/m64. Результат операции записывается в регистр mm.
В командах сдвига сдвигаемый операнд всегда размещается в MMX-регистре mm. Число разрядов сдвига указывается во втором операнде (операнде-источнике), который может храниться в MMX-регистре mm, ячейке памяти т64 или задаваться непосредственно операндом im8. Сдвиг выполняется отдельно для каждого элемента исходного операнда. При этом выдвигаемые биты не сохраняются.
СИСТЕМА КОМАНД: ОПЕРАЦИИ ММХ
Таблица 2.43
Команды логических операций и сдвигов
Синтаксис команды Операция
PAND mm,mm/m64 mm a mm/m64 -> mm
PANDN mm,mm/m64 mm a mm/m64 —» mm
POR mm,mm/m64 mm v mm/m64 -> mm
PXOR mm,mm/m64 mm ® mm/m64 — mm
PSLLW mm,mm/m64 PSLLW mm,imm8 PSLLD mm,mm/m64 PSLLD mm,imm8 PSLLQ mm,mm/m64 PSLLQ mm,imm8 Логический сдвиг влево mm(W) « mm/m64 —> mm(W) mm(W) « imm8 -> mm(W) mm(D) « mm/m64 -> mm(D) mm(D) « imm8 -> mm(D) mm(Q) « mm/m64 -> mm(Q) mm(Q) « imm8 -> mm(Q)
PSRAW mm,mm/m64 PSRAW mm,imm8 Арифметический сдвиг вправо mm(W) >> mm/m64 -> mm(W) mm(W) >> imm8 -> mm(W)
PSRAD mm,mm/m64 PSRAD mm,imm8 Арифметический сдвиг вправо mm(D) >> mm/m64 -> mm(D) mm(D) >> imm8 —> mm(D)
PSRLW mm,mm/m64 PSRLW mm,imm8 PSRLD mm,mm/m64 PSRLD mm,imm8 PSRLQ mm,mm/m64 PSRLQ mm,imm8 Логический сдвиг вправо mm(W) >> mm/m64 -> mm(W) mm(W) >> imm8 -> mm(W) mm(D) >> mm/m64 -> mm(D) mm(D) >> imm8 -> mm(D) mm(Q) » mm/m64 -> mm(Q) mm(Q) >> imm8 -> mm(Q)
эт те • я
Команды PSLL[W, D, Q] производят логический сдвиг каждого элемента (слова, двойного или счетверенного слова) влево. При этом освобождающиеся младшие биты каждого элемента заполняются нулями. Команда PSRL[W, D, Q] осуществляет логический сдвиг соответствующих элементов вправо, заполняя освобождающиеся старшие биты каждого элемента нулями. Отметим, что если заданное число разрядов сдвига превышает 15 (при сдвиге слов), 31 (при сдвиге двойных слов) или 63 (при сдвиге счетверенного слова), то результатом операции являются нулевые значения всех элементов.
Команда PSRA[W,D] выполняет арифметический сдвиг вправо каждого элемента (слова или двойного слова), хранящегося в заданном MMX-регистре mm. При таком сдвиге освобождающиеся старшие биты каждого элемента заполняются значением знакового бита.
2.5.5. КОМАНДЫ СРАВНЕНИЯ И НАХОЖДЕНИЯ МАКСИМУМА/МИНИМУМА
Команды этой группы приведены в табл. 2.44. Выполнение этих команд отличается от обычных команд сравнения, которые работают с регистрами общего назначения. Обычные команды сравнения СМР не изменяют значения исходных операндов, а результатом сравнения является установка соответствующих признаков в регистре EFLAGS. ММХ-ко-манды сравнения представляют результат операции в виде значения операнда, помещаемого в регистр mm, и не устанавливают каких-либо признаков.
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
Таблица 2.44
Команды операций сравнения и нахождения максимума/минимума
Синтаксис команды Операция
PCMPEQB mm,mm/m64 PCMPEQW mm,mm/m64 PCMPEQD mm,mm/m64 FFh -> mm(Bi), если mm(Bi) = mm/m64(Bi)0 Oh -> mm(Bi), если mm(Bi) * mm/m64(Bi) FFFFh -> mm(Wi), если mm(Wi) = mm/m64(Wi)0 OOOh -> mm(Wi), если mm(Wi) # mm/m64(Wi) FFFFFFFFh -> mm(Di), если mm(Di) = mm/m64(Di) OOOOOOOOh -> mm(Di), если mm(Di) t mm/m64(Di)
PCMPGTB mm,mm/m64 PCMPGTW mm,mm/m64 FFh -> mm(Bi), если mm(Bi) > mm/m64(Bi) OOh -> mm(Bi), если mm(Bi) < m/m64(Bi) FFFFh -> mm(Wi), если mm(Wi) > mm/m64(Wi) OOOOh —> mm(Wi), если mm(Wi) < mm/m64(Wi)
PCMPGTD mm,mm/m64 FFFFFFFFh -> mm(Di), если mm(Di) > mm/m64(Di) OOOOOOOOh -> mm(Di), если mm(Di) < mm/m64(Di)
PMAXSW mm,mm/m64 PMAXUB mm,mm/m64 Max[mm(W), mm/m64(W)] -> mm(W) co знаком Max[mm(B), mm/m64(B)] -> mm(B) без знака
PMINSW mm,mm/m64 PMINUB mm,mm/fti64 Min[mm(W), mm/m64(W)j -> mm(W) co знаком Min[mm(B), mm/m64(B)] -> mm(B) без знака
Команды PCMPEQ[B, W, D] и PCMPGT[B, W, О] производят сравнение элементов (байтов, слов или двойных слов), которые представляются как числа со знаком. Если значения элемента в исходных операндах, которые располагаются в регистре mm и регистре или ячейке памяти mm/m64, равны, то при выполнении команды PCMPEQ (сравнение элементов на равенство), все биты в соответствующем элементе результата, размещаемого в регистре mm, принимают значение «1». В противном случае (неравенство элементов) все биты в элементе результата принимают значение «О». Команда PCMPGT (сравнение на большее значение) проверяет, имеет ли элемент операнда в регистре mm большее значение, чем аналогичный элемент в регистре или ячейке памяти mm/m64. Если это условие выполняется, то все биты соответствующего элемента результата в регистре mm принимают значение «1», в противном случае-значение «О».
Команды PMAXSW и PMAXUB реализуют выделение в исходных операндах элементов с большим значением, из которых формируется результат операции. Эти команды выполняют сравнение элементов исходных операндов, размещенных в регистре mm и регистре или ячейке памяти mm/m64, выделяют элементы с большим значением и размещают их в качестве соответствующих элементов результата в регистр mm. Команды PMINSW и PMINUB также производят сравнение элементов в исходных операндах, но выделяют элементы с меньшим значением, которые размещаются в регистре mm в качестве результата операции. Команды PMAXSW, PMINSW обрабатывают слова со знаком, команды PMAXUB, PMINUB - байты без знака.
2.6. СИСТЕМА КОМАНД: ОПЕРАЦИИ SSE
В процессорах Pentium III технология ММХ получила дальнейшее развитие. В структуру этих процессоров введен исполнительный блок SSE (см. рис. 2.1), который обрабатывает по принципу SIMD (Single Instruction - Multiple Data: Одна Команда - Много Данных) данные, представленные в формате с плавающей точкой. Блок SSE содержит набор специализиро
СИСТЕМА КОМАНД: ОПЕРАЦИИ SSE
ванных регистров и обеспечивает выполнение набора дополнительных команд. Это расширение архитектуры процессоров семейства Р6 получило название Streaming SIMD Extension - SSE (потоковое SIMD-расширение). Блок SSE входит в структуру ряда типов процессоров семейства Р6. Чтобы определить, поддерживает ли данный процессор SSE-расширение, следует воспользоваться командой CPUID.
Ниже дается перечень SSE-команд, разбитых по функциональным группам.
Команды пересылки данных
MOVAPS - Пересылка выровненных 128-разрядных данных ’
MOVHLPS - Пересылка 64-разрядных данных из старшей половины одного SSE-регистра в младшую половину другого SSE-регистра
MOVHPS - Пересылка в память 64-разрядных данных из старшей половины SSE-регистра
MOVLHPS - Пересылка 64-разрядных данных из младшей половины одного SSE-регистра в старшую половину другого SSE-регистра
MOVLPS - Пересылка в память 64-разрядных данных из младшей половины SSE-регистра MOVMSKPS - Пересылка знаковых битов пакета с одинарной точностью в регистр общего назначения
MOVSS - Пересылка 32-разрядных данных
MOVUPS - Пересылка 128-разрядных данных
Команды преобразования данных
SHUFPS - Изменение порядка размещения элементов в пакете одинарной точности UNPCKHPS - Распаковка из старших половин пакетов UNPCKLPS - Распаковка из младших половин пакетов
Арифметические команды
ADDPS - Сложение пакетов одинарной точности
ADDSS - Сложение двух чисел одинарной точности
DIVPS - Деление пакетов одинарной точности
DIVSS - Деление двух чисел одинарной точности
MULPS -Умножение пакетов одинарной точности
MULSS -Умножение двух чисел одинарной точности
RCPPS - Вычисление обратной величины элементов в пакете одинарной точности RCPSS - Вычисление обратной величины числа одинарной точности
RSQRTPS - Вычисление обратной величины квадратного корня из элементов пакета одинарной точности
RSQRTSS - Вычисление обратной величины квадратного корня из числа одинарной точности SQRTPS - Вычисление квадратного корня из элементов пакета одинарной точности SQRTSS - Вычисление квадратного корня из числа одинарной точности SUBPS - Вычитание пакетов одинарной точности SUBSS - Вычитание двух чисел одинарной точности
Команды нахождения максимума и минимума
MAXPS - Нахождение максимума пакетов одинарной точности
MAXSS - Нахождение максимума двух чисел одинарной точности
MINPS - Нахождение минимума пакетов одинарной точности
MINSS - Нахождение минимума двух чисел одинарной точности
Команды сравнения
CMPPS - Сравнение пакетов одинарной точности
CMPSS - Сравнение двух чисел одинарной точности
COMISS - Сравнение двух чисел одинарной точности с установкой признаков в регистре EFLAGS
UCOMISS - Сравнение двух чисел одинарной точности с установкой признаков в регистре EFLAGS
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
Команды логических операций
ANDNPS -Логическое НЕ-И над 128-разрядными операндами
ANDPS-Логическое И над 128-разрядными операндами
ORPS-Логическое ИЛИ над 128-разрядными операндами
XORPS - ИСКЛЮЧАЮЩЕЕ ИЛИ над 128-разрядными операндами
Команды преобразования формата чисел
CVTPI2PS - Преобразование двойных слов со знаком в числа одинарной точности
CVTPS2PI - Преобразование чисел одинарной точности в двойные слова со знаком (округление)
CVTSI2SS - Преобразование двойного слова со знаком в число одинарной точности
CVTSS2SI - Преобразование числа одинарной точности в двойное слово со знаком (округление)
CVTTPS2PI - Преобразование чисел одинарной точности в двойные слова со знаком (отбрасывание дробной части)
CVTTSS2SI - Преобразование числа одинарной точности в двойное слово со знаком (отбрасывание дробной части)
Команды управления
FXRSTOR - Загрузка содержимого регистров FPU/ММХ и SSE
FXSAVE-Сохранение содержимого регистров FPU/ММХ и SSE
LDMXCSR - Загрузка содержимого регистра MXCSR
STMXCSR - Сохранение содержимого регистра MXCSR
Команды передачи данных с управлением кэшированием
MASKMOVQ - Выборочная запись в память байтов из ММХ-регистра
MOVNTPS - Запись в память содержимого SSE-регистра
MOVNTQ - Запись в память содержимого ММХ-регистра
PREFETCHTO - Предварительная выборка в кэш-память уровня L1 и L2
PREFETCHT1 - Предварительная выборка в кэш-память уровня L2 PREFETCHT2 - Предварительная выборка в кэш-память уровня L2 PREFETCHNTA-Предварительная выборка в кэш-память уровня L1 SFENCE-Упорядочивание записи в памяти
2.6.1. ФОРМАТЫ ПРЕДСТАВЛЕНИЯ ДАННЫХ И ВЫПОЛНЕНИЕ ОПЕРАЦИЙ
Команды SSE обрабатывают данные в формате с плавающей точкой одинарной точности (ОТ, рис. 2.16, д). Блок SSE содержит восемь 128-разрядных регистров ХММ0-ХММ7 (рис. 2.32). В каждом SSE-регистре может храниться четыре упакованных числа в формате с плавающей точкой одинарной точности (рис. 2.33). Такой тип данных называется пакетом одинарной точности. Элементами F3-F0 пакета являются 32-разрядные числа ОТ, которые содержат знаковый бит S, 8-разрядный смещенный порядок Е и 23-разрядную мантиссу М. При выполнении SSE-команд производится обработка каждого из элементов аналогично тому, как это выполняется блоком ММХ с упакованными числами. Большинство SSE-команд способны обрабатывать как весь пакет (такие команды имеют суффикс PS - Packed Single), так и один младший элемент пакета (такие команды имеют суффикс SS - Scalar Single).
В памяти пакет одинарной точности располагается так, как это принято в lntel-архитекту-ре, т. е. младший байт размещается по меньшему адресу (рис. 2.33). Когда один из 128-раз-рядных операндов (пакет) находится в памяти, то он должен быть выравнен по 128-разряд-ной границе, иначе при выполнении SSE-команды произойдет исключение типа #GP «нарушение общей защиты». Только выполнение команды MOVUPS не вызывает исключения в данном случае. Операнды меньших размеров (64 или 32 разряда) могут быть невыравнены.
СИСТЕМА КОМАНД: ОПЕРАЦИИ SSE
127 О
ХММ7 ХММ6 __________________ХММ5_________________ _______________________________________ХММ4_ хммз ХМ М2 ХММ1 хммо
31_____________________________________о
MXCSR
Рис. 2.32. Регистры блока SSE
При выполнении SSE-команд могут возникать такие же типы ошибок (исключительных случаев) #l, #D, #Z, #0, #U, #Р, как и при работе блока FPU. В этом случае в регистре управления-состояния MXCSR блока SSE соответствующий признак IE, DE, ZE, ОЕ, UE или РЕ принимает значение «1». При установке этого значения признака ошибки реализуется исключение типа #ХМ «ошибка SSE», если в регистре управления CR4 установлено значение бита OSXMMEXCPT = 1 (см. рис. 2.16, в). Для обслуживания исключения процессор вызывает необходимую подпрограмму. Если в регистре CR4 значение бита OSXMMEXCPT = 0, то при установке какого-либо из признаков ошибки реализуется исключение #UD «недействительный код операции». В табл. 2.45 приведена информация о том, какие ошибки могут возникать при выполнении SSE-команд (команды, не указанные в данной таблице, не вызывают появления таких ошибок). Необходимо отметить, что блок SSE не фиксирует, обработка какого из элементов пакета вызвало появление ошибки. Эту задачу должна выполнять подпрограмма обслуживания исключения.
Реализация исключения может быть замаскирована установкой в единичное значение соответствующего бита маски IM, DM, ZM, ОМ, UM или РМ в регистре MXCSR (рис. 2.34). В этом случае при возникновении ошибки (установке какого-либо из признаков IE, DE, ZE, ОЕ, UE, РЕ в «1») процессор продолжает выполнение программы без реализации исключения, а результат операции принимает такое же значение, как при маскировании аналогичных исключений для операций FPU.
Формат содержимого SSE-регистра управления-состояния MXCSR показан на рис. 2.34. Отметим, что большинство битов этого регистра имеют такое же назначение, как соответствующие биты в регистрах FPCR, FPSR блока FPU (см. рис. 2.5). Поле RC в регистре MXCSR определяет правила округления результата в соответствии с табл. 2.1. Бит FZ в этом регистре управляет реакцией блока SSE на антипереполнение. Согласно стандарту IEEE, если произошло антипереполнение (признак UE = 1), а соответствующее исключение замаскировано (бит UM = 1), то процессор выдает в качестве результата денормализованное число. Установка бита FZ -1 позволяет отойти от стандарта IEEE. При FZ = 1 результатом антипереполнения будет нуль соответствующего знака (устанавливаются признаки ошибок UE = РЕ = 1). Если установлено значение бита маски UM = 0 (ошибка #U не маскирована), то независимо от значения бита FZ при установке признака антипереполнения UE = 1 реализуется исключение #ХМ.
127 126 119 118 96 95 94 87 86 64 63 62 55 54 32 31 30 23 22 О
|s[ Е I М | s I Е [ М I S I Е [ М |S| Е | М~~|
I F3(B15-B12) F2(B11-B8) F1(B7-B4) F0(B3-B0) I
201 Oh 2000h
Рис. 2.33. Упакованные числа в формате с плавающей точкой одинарной точности (пакет одинарной точности)
ГЛАВА 2. ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
Таблица 2.45
Типы ошибок, возникающих при выполнении SSE-команд
Команда #1 #D #z #о #и #р
ADDPS + + + + +
ADDSS + + + + +
CMPPS + +
CMPSS + +
COMISS + +
CVTPI2PS +
CVTPS2PI + +
CVTSI2SS +
CVTSS2SI + +
CVTTPS2PI + +
CVTTSS2SI + +
DIVPS + + + + + +
DIVSS + + + + + +
MAXPS + +
MAXSS + +
MINPS + +
MINSS + +
MULPS + + + + +
MULSS + + + + +
SQRTPS + + +
SQRTSS + + +
STMXCSR
SUBPS + + + + +
SUBSS + + + + +
UCOMISS + +
Если в регистре управления CR0 установлено значение бита ЕМ = 1, то попытка выполнить SSE-команду приведет к исключению #UD. Если в регистре управления CR4 значение бита OSFXSR = 0 (это означает, что операционная система не поддерживает сохранение и восстановление содержимого SSE-регистров при переключении задач), то попытка выполнить SSE-команду приведет к исключению #UD. Если в регистре CR0 значение бита TS = 1, то попытка выполнить SSE-команду приведет к исключению #NM.
Формат SSE-команд аналогичен формату ММХ-команд. SSE-команды поддерживают все возможные способы адресации с использованием байтов MODR/M и SIB. Префиксы влияют на выполнение этих команд таким же образом, как на выполнение ММХ-команд (см. табл. 2.39). Для команд, которые имеют две формы (пакетную и скалярную), присутствие префикса REP указывает на скалярную форму команды. Если префикс REP отсутствует, то команда выполняет пакетную обработку данных.
15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
RC РМ им I ом ZM I DM I IM I Резер. 1 РЕ ] UE | ОЕ | ZE | DE | IE
Резервировано
31 0
Рис. 2.34. Формат содержимого регистра управления-состояния MXCSR
СИСТЕМА КОМАНД: ОПЕРАЦИИ SSE
2.6.2. КОМАНДЫ ПЕРЕСЫЛКИ И ПРЕОБРАЗОВАНИЯ ДАННЫХ
Команды этой группы приведены в табл. 2.46.
Команды MOVAPS и MOVUPS производят пересылку 128-разрядных данных между SSE-регистрами xmm или SSE-регистром и ячейкой памяти с адресом т128. Эти команды не могут переносить данные из памяти в память. Команда MOVAPS осуществляет пересылку выравненных данных: если один из операндов находится в памяти, то его адрес должен быть выравнен по 16-байтной границе, иначе реализуется исключение типа #GP («нарушение защиты»). Для пересылки невыравненных данных следует использовать команду MOVUPS, которая не вызывает исключения в этом случае.
Таблица 2.46
Команды пересылки и преобразования данных
Синтаксис команды Операция
MOVAPS xmrn,xmm/m128 MOVAPS xmm/m128,xmm xmm/m128 -> xmm xmm ->xmm/m128 (выравненные данные)
MOVUPS xmm,xmm/m128 MOVUPS xmm/m128,xmm xmm/m128 -> xmm xmm ->xmm/ml28 (невыравненные данные)
MOVHLPS xmm1,xmm2 xmm2(F2,F3) -» xmm1(F0,F1)
MOVHPS xmm,m64 MOVHPS m64,xmm m64 -> xmm(F2,F3) xmm(F2,F3) -> m64
MOVLHPS xmm1,xmm2 xmm2(F0,F1) -> xmm1(F2,F3)
MOVLPS xmm,m64 MOVLPS m64,xmm m64 ->xmm(F0,F1) xmm(F0,F1) -> m64
MOVMSKPS r32,xmm xmm[b7(F0)] -> r32(b0) xmm[b7(F1)] -> г32(Ы) xmm[b7(F2)] -» r32(b2) xmm[b7(F3)] -> r32(b3) 0 г32(Ь31..Ь4)
MOVSS xmm,m32 MOVSS xmm1,xmm2 MOVSS m32,xmm m32 xmm(FO) 0 -> xmm(F1-F3) xmm2(F0) ->xmrn1(F0) xmm(FO) -> m32
UNPCKHPS xmm,xmm/m128 xmm(F2) -> xmm(FO) xmm/m128(F2) —> xmm(F1) xmm(F3) -> xmm(F2) xmm/m128(F3) -» xmm(F3)
UNPCKLPS xmm,xmm/m128 xmm(FO) -»xmm(FO) xmm/m128(F0) -> xmm(F1) xmm(F1) -»xmm(F2) xmm/m128(F1) -> xmm(F3)
процессоры общего назначения и системы на их основе
Продолжение табл. 2.46
Синтаксис команды Операция
SHUFPS xmm,xmm/m128,imm8 xmm/m128[F(im8[1..O])] xmrn(FO) xmm/m128[F(im8[3..2])] ->xmm(F1) xmm/m128[F(im8[5..4])] -> xmm(F2) xmm/m128[F(im8[7..6])] xmm(F3)
Команды MOVHLPS и MOVLHPS пересылают 64-разрядные данные из старшей половины (элементы F3-F2) SSE-регистра xmm2 в младшую половину (элементы F1-F0) SSE-регистра xmm1 или из младшей половины в старшую половину. При пересылке содержимое остальных половин в регистре приемнике не изменяется. Операнды могут храниться только в SSE-регистрах.
Команды MOVHPS и MOVLPS выполняют пересылку 64-разрядных данных между SSE-регистром xmm и ячейкой памяти с адресом т64. Эти команды не могут использоваться для переноса данных из памяти в память или из SSE-регистра в SSE-регистр. Когда приемником операнда является SSE-регистр, то данные из памяти загружаются в старшую (команда MOVHPS) или младшую (команда MOVLPS) его половину, а содержимое другой половины не изменяется. Если приемником операнда является ячейка памяти, то в нее записываются данные из старшей/младшей (команды MOVHPS/MOVLPS) половины SSE-регистра.
Команда MOVMSKPS формирует 4-битовую маску из старших (знаковых) битов S каждого элемента F3-F0, хранящегося в SSE-регистре xmm. Затем эта маска расширяется нулем до 32 бит и записывается в регистр общего назначения г32 (рис. 2.35).
Команда MOVSS производит пересылку 32-разрядных данных между SSE-регистрами xmm или SSE-регистром и ячейкой памяти с адресом т32. В случае, когда источником и приемником операндов являются SSE-регистры, младшее двойное слово (элементы F1-FO) из регистра-источника копируется в младшее двойное слово регистра-приемника, а его старшие разряды (элементы F3-F2) не изменяются. Если приемником является ячейка памяти, то в нее записывается младшее двойное слово из SSE-регистра. Если же операнд из ячейки памяти т32 пересылается в SSE-регистр, то двойное слово из памяти расширяется нулем до 128 разрядов и загружается в регистр xmm.
Команда SHUFPS изменяет порядок размещения (производит перестановку) элементов F3-F0 в SSE-регистрах аналогично тому, как это реализует MMX-команда PSHUFW. При этом элементы операнда из SSE-регистра или ячейки памяти xmm/m128 перемещаются в определенные позиции элементов результата, которые записываются в регистр-приемник xmm. Непосредственный операнд im8 определяет расположение элементов результата: биты b 1 —0 этого операнда задают номер i элемента Fi исходного операнда, который размещается в качестве элемента F0 результата, биты ЬЗ-2 - номер элемента, размещаемого на месте элемента F1, биты 65-4 - номер элемента, размещаемого на месте F2, биты Ь7-6 - номер элемента, размещаемого на месте F3. Выполнение данной операции иллюстрируется на рис. 2.36.
Команды UNPCKHPS и UNPCKLPS производят распаковку данных аналогично тому, как это выполняют MMX-команды PUNPCH, PUNPCKL. Данные команды объединяют в один операнд старшие половины (элементы F3-F2, команда UNPCKHPS) или младшие половины (элементы F1-FO, команда UNPCKLPS) операндов, хранящихся в SSE-регистре xmm и регистре или ячейке памяти xmm/m128. Результат записывается в регистр xmm, причем элементы исходных операндов чередуются, размещаясь в этом регистре. Выполнение этих операций показано на рис. 2.37
СИСТЕМА КОМАНД: ОПЕРАЦИИ SSE
MOVMSKPS r32, xmm
Рис. 2.35. Выполнение команды MOVMSKPS
SHUFPS xmm, xmm/m128, 82h
Рис. 2.36. Выполнение команды SHUFPS
a) UNPCKHPS xmm, xmm/m128
xmm/m 128 xmm
xmm
6) UNPCKLPS xmm, xmm/m128
xmm
Рис. 2.37. Выполнение команд UNPCKHPS (а) и UNPCKLPS (6)
147
ПРОЦЕССОРЫ общего назначения и системы на их основе
2.6.3. КОМАНДЫ АРИФМЕТИЧЕСКИХ ОПЕРАЦИЙ
пЫ этой группы (табл. 2.47) имеют две формы: пакетную (суффикс PS) и скаляр-/н«ьикс SS). Пакетная форма команды обрабатывает пакеты одинарной точности: ную (СУЧ3™ ента F3-F0 одинарной точности, упакованные в 128 разрядов. Скалярная форма четыре эле^ботаеТТОЛЬКО с одНИМ элементом одинарной точности F0 (младшие 32 разря-команды р g-j-pa), остальные 96 разрядов (старшие элементы F3F1) содержимого этого да SSE-pe^ изменЯЮТСЯ ДпЯ всех команд данной группы результат операции размещается р™ра истре xmm, а исходные операнды - в SSE-регистре xmm или ячейке памяти в SSE-ре 28 (пакетная форма), либо m32 (скалярная форма).
с адресом Таблица 2.47
Команды арифметических операций
Синтаксис команды Операция
ADDPS xmm,xmm /т128 xmm + xmm /m128 xmm (пакет)
ADDSS xmm,xmm /m32 xmm + xmm /m32 -> xmm (скаляр)
"sUBPS xmm,xmm /m128 xmm - xmm /m128 - xmm (пакет)
SUBSS xmm,xmm /m32 xmm - xmm /m32 — xmm (скаляр)
"fJlULPS xmm,xmm /m128 xmm * xmm /m128 - -> xmm (пакет)
MULSS xmm,xmm /m32 xmm * xmm /m32 - > xmm (скаляр)
DIVPS xmm,xmm /m128 xmm 1 xmm /m128 - > xmm (пакет)
DIVSS xmm,xmm /m32 xmm / xmm /m32 — xmm (скаляр)
SQRTPS xmm,xmm /ml 28 sqrt(xmm /m128) -» xmm (пакет)
SQRTSS xmm,xmm /m32 sqrt(xmm /m32) -> xmm (скаляр)
-RCPPS xmm,xmm /m128 1 1 xmm /m128 -> xmm (пакет)
RCPSS xmm,xmm /m32 1 / xmm /m32 -> xmm скаляр)
RSQRTPS xmm,xmm /m128 1 / sqrt(xmm /m128) —> xmrr (пакет)
RSQRTSS xmm,xmm /m32 1 / sqrt(xmm /m32) -> xmm (скаляр)
К маНДь1 ADD[PS,SS], SUB[PS,SS], DIV[PS,SS], MUL[PS,SS] производят соответственен сложения, вычитания, деления и умножения. Если при выполнении операций Н° Рм-либо элементами происходит переполнение, то устанавливаются значения при-с каким^бки оЕ = РЕ = 1 и реализуется исключение типа #ХМ (при значении бита маски ОМ“Ш Если с00тветствУюЩее исключение замаскировано (установлено значение ПМ = 1) то результатом операции является число, округленное в соответствии с полем RC в г стре MXCSR (см. табл. 2.1). В случае антипереполнения устанавливаются значения Р кОвUE ~ = 1 • При значении бита маски UM=0 реализуется исключение #ХМ, а при
призна UM = 1 результатом становится округленное число. Команда DIV[PS,SS] вызывает 4 ацовку признака ошибки ZE = 1, если операнд-делитель равен нулю. В этом случае e^aveTcn исключение #ХМ, если соответствующий бит маски ZM = 0. Если данная ошиб-Р алИ Еревана (значение бита ZM = 1), то результатом операции будет код бесконечности о етствУющеГ0 знака (7F800000h или FF800000h, см. табл. 2.16).
С° г? и выполнении данных команд элементами исходных операндов могут быть не-числа ON N цЛи SNaN. Результаты операций в этих случаях приведены в табл. 2.48. В случаях, U Э сгановлено значение бита маски IM - 1 (исключение типа #1 маскировано), элементом когда у будет не-число QNaN, являющееся элементом одного из операндов, или полу-ре3Уп₽> из не-числа SNaN, являющегося элементом операнда, путем изменения значения ^енн (^2 (первого разряда мантиссы) с «0» на «1»(SNaN -> QNaN)*. В случаях, когда значе
СИСТЕМА КОМАНД: ОПЕРАЦИИ SSE
ние бита маски IM = О (исключение #1 не маскировано), реализуется переход к подпрограмме обслуживания данного исключения, если элементами операндов являются не-числа SNaN. Если же элементами являются не-числа QNaN, то они представляются в качестве результата операции, а исключение не реализуется.
В табл. 2.48 указан также результат выполнения ряда арифметических операций, когда элементами операндов являются «О» или «бесконечность». В этих случаях элементом результата становится код FFCOOOOOh («неопределенность», см. табл.2.16), если установлено значение бита маски IM - 1 (исключение #1 маскировано). Если же значение IM = 0, то реализуется исключение #1.
Таблица 2.48
Результаты выполнения команд ADD[PS,SS], SUB[PS,SS], DIV[PS,SS], MUL[PS,SS], когда элементами операндов являются не-числа (NaN)
Элементы операндов Результат при IM=1 Результат при IM=O
SNaN1, SNaN2 SNaN1 QNaN1 Исключение типа #l
SNaN1, QNaN2 SNaN1 -» QNaN1 Исключение типа #1
QNaN1, SNaN2 QNaN1 Исключение типа #1
QNaN1, QNaN2 QNaN1 QNaN1 (нет исключения)
SNaN, число SNaN -> QNaN1 Исключение типа #1
число, SNaN SNaN -> QNaN1 Исключение типа #1
QNaN, число QNaN QNaN (нет исключения)
число, QNaN QNaN QNaN (нет исключения)
00 - 00 OO * 0, ©o/oo 0/0 QNaN (FFCOOOOOh) Исключение типа #1
Команда SQRT[PS,SS] вычисляет значение квадратного корня из элементов исходного операнда (f = 77 )• Результаты этой операции в случаях, если элементом операнда является He-число или отрицательное число, указаны в табл. 2.49. Отметим, что данные результаты аналогичны приведенным в табл. 2.48 для исключительных случаев, возникающих при выполнении других арифметических операций.
Таблица 2.49
Результаты выполнения команды SQRT[PS,SS] с не-числами и отрицательными числами
Элемент операнда Результат при |М=1 Результат при IM=O
QNaN QNaN QNaN (нет исключения)
SNaN SNaN -> QNaN Исключение типа #1
Отрицательное число QNaN (FFCOOOOO) Исключение типа #1
Все рассмотренные выше команды данной группы устанавливают значение признака DE = 1 и реализуют исключение #ХМ, если один из элементов исходных операндов представлен в денормализованном виде.
Команда RCP[PS,SS] вычисляет обратную величину операнда (/ = !/*), а команда RSQRT[PS,SS] - обратную величину квадратного корня из операнда (/= i/VT ) Правила округления, определяемые значением поля RC в регистре MXCSR, не оказывают влияния на выполнение этих команд. Денормализованные операнды воспринимаются как нули соответствующего знака. Результат антипереполнения всегда округляется до нуля. Максимальная величина ошибки при выполнении этих команд составляет 1,5х212. Команды RSQRT[PS,SS] и RCP[PS,SS] не реализуют какие-либо исключения, поэтому контроль ошибок при их выполнении должен выполняться программными средствами.
1AQ
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
2.6.4. КОМАНДЫ ЛОГИЧЕСКИХ ОПЕРАЦИЙ
Команды этой группы ANDPS, ANDNPS, ORPS и XORPS выполняют соответственно логические операции И, НЕ-И, ИЛИ, ИСКЛЮЧАЮЩЕЕ ИЛИ над 128-разрядными операндами (табл. 2.50). Операции выполняются над значениями каждого из разрядов содержимого регистра xmm и регистра или ячейки памяти xmm/m128, результат размещается в регистре xmm. Данные команды не вызывают каких-либо исключений.
Таблица 2.50
Команды логических операций
Синтаксис команды Операция
ANDPS xmm,xmm/m128 xmm л xmm/m128 - -> xmm
ANDNPS xmm,xmm/m128 xmm a xmm/m128 - xmm
ORPS xmm,xmm/m128 xmm j xmm/m128 - -> xmm
XORPS xmm,xmm/m128 xmm © xmm/m128 - у xmm
2.6.5. КОМАНДЫ СРАВНЕНИЯ И НАХОЖДЕНИЯ МАКСИМУМА / МИНИМУМА
Как и арифметические команды, большинство команд сравнения (табл.2.51) имеют две формы: скалярную (суффикс SS) и пакетную (суффикс PS).
Таблица 2.51
Команды сравнения
Синтаксис команды Операция
CMPEQPS xmm,xmm /m128 CMPEQSS xmm,xmm /m32 FFFFFFFFh-* xmm(Fi), xmm(Fi) = xmm /m128(Fi) OOOOOOOOh -* xmm(Fi), xmm(Fi) / xmm /m128(Fi) FFFFFFFFh -> xmm(FO), xmm(FO) = xmm /m32(F0) OOOOOOOOh -* xmm(FO), xmm(FO) / xmm /m32(F0)
CMPLTPS xmm,xmm /m128 CMPLTSS xmm,xmm /m32 FFFFFFFFh -* xmm(Fi), xmm(Fi) < xmm /m128(Fi) OOOOOOOOh -* xmm(Fi), xmm(Fi) > xmm /m128(Fi) FFFFFFFFh -* xmm(FO), xmm(FO) < xmm /m32(F0) OOOOOOOOh -> xmm(FO), xmm(FO) > xmm /m32(F0)
CMPLEPS xmm,xmm /m128 CMPLESS xmm,xmm /m32 FFFFFFFFh -> xmm(Fi), xmm(Fi) < xmm /m128(Fi) OOOOOOOOh-* xmm(Fi), xmm(Fi) > xmm /m128(Fi) FFFFFFFFh xmm(FO), xmm(FO) < xmm /m32(F0) OOOOOOOOh -* xmm(FO), xmm(FO) > xmm /m32(F0)
CMPUNORDPS xmm,xmm /m128 CMPUNORDSS xmm,xmm /m32 FFFFFFFFh -> xmm(Fi), xmm(Fi) ? xmm /m128(Fi) OOOOOOOOh -» xmm(Fi), xmm(Fi) ? xmm /m128(Fi) FFFFFFFFh -* xmm(FO), xmm(FO) ? xmm /m32(F0) OOOOOOOOh -* xmm(FO), xmm(FO) ? xmm /m32(F0)
CMPNEQPS xmm,xmm /m128 CMPNEQSS xmm,xmm /m32 FFFFFFFFh -* xmm(Fi), xmm(Fi) / xmm /m128(Fi) OOOOOOOOh -» xmm(Fi), xmm(Fi) = xmm /m128(Fi) FFFFFFFFh -> xmm(FO), xmm(FO) / xmm /m32(F0) OOOOOOOOh -* xmm(FO), xmm(FO) = xmm /m32(F0)
CMPNLTPS xmm,xmm /m128 CMPNLTSS xmm,xmm /m32 FFFFFFFFh -> xmm(Fi), xmm(Fi) > xmm /ml 28(Fi) OOOOOOOOh -* xmm(Fi), xmm(Fi) < xmm /m128(Fi) FFFFFFFFh xmm(FO), xmm(FO) > xmm /m32(F0) OOOOOOOOh -> xmm(FO), xmm(FO) < xmm /m32(F0)
СИСТЕМА КОМАНД: ОПЕРАЦИИ SSE
Продолжение табл. 2.51
Синтаксис команды Операция
CMPNLEPS xmm,xmm /m128 CMPNLESS xmm,xmm /m32 FFFFFFFFh -> xmm(Fi), xmm(Fi) > xmm /m128(Fi) OOOOOOOOh -> xmm(Fi), xmm(Fi) < xmm /m128(Fi) FFFFFFFFh -> xmm(FO), xmm(FO) > xmm /m32(F0) OOOOOOOOh -> xmm(FO), xmm(FO) < xmm /m32(F0)
CMPORDPS xmm,xmm /m128 CMPORDSS xmm,xmm /m32 FFFFFFFFh -> xmm(Fi), xmm(Fi) ? xmm /m128(Fi) OOOOOOOOh -> xmm(Fi), xmm(Fi) ? xmm /m128(Fi) FFFFFFFFh-> xmm(FO), xmm(FO) ? xmm/m32(F0) OOOOOOOOh -> xmm(FO), xmm(FO) ? xmm /m32(F0)
COMISS xmm,xmm /m32 UCOMISS xmm,xmm /m32 EFLAGS ? xmm - xmm /m32 EFLAGS ? xmm - xmm /m32
MAXPS xmm,xmm /128 MAXSS xmm,xmm /m32 Max(xmm, xmm/m128)->xmm (пакет) Max(xmm, xmm /m32) -> xmm (скаляр)
MINPS xmm, xmm/128 MINSS xmm,xmm /m32 Min(xmm, xmm /m128) -> xmm (пакет) Min(xmm, xmm/m32) -> xmm (скаляр)
Команды CMP[PS, SS] имеют следующую особенность: вид сравнения («равно», «меньше» и т. д.) определяется не кодом операции, а непосредственным операндом im8. Биты Ь2-0 этого операнда задают вид сравнения, остальные биты Ь7-3 зарезервированы для будущего использования. При программировании на языке Ассемблера для этих команд сравнения существует две формы записи (табл. 2.52): фактическая - с указанием соответствующего значения операнда im8 = 0-7, и эквивалентная символическая, где вид сравнения указывается соответствующим предикатом EQ, LT, LE, UNORD, NEQ, NLT, NLE, ORD в мнемокоде команды (табл. 2.53). В табл. 2.51 принята эквивалентная форма записи команд. Если при сравнении элементов операндов, хранящихся в регистре xmm и регистре или ячейке памяти xmm/m128, xmm/m32, выполняется заданное условие, то соответствующий элемент результата принимает значение FFFFFFFFh («1» во всех разрядах), если не выполняется - значение OOOOOOOOh («0» во всех разрядах).
Таблица 2.52
Две формы записи команд сравнения CMP[PS,SS]
Эквивалентная форма Фактическая форма Тип сравнения
CMPEQ[PS,SS] xmm1,xmm2 CMP[PS,SS] xmm1,xmm2,0 Равно
CMPLT[PS,SS] xmm1,xmm2 CMP[PS,SS] xmm1,xmm2,1 Меньше
CMPLE[PS,SS] xmm1,xmm2 CMP[PS,SS] xmm1,xmm2,2 Меньше или равно
CMPUNORD[PS,SS] xmm1,xmm2 CMP[PS,SS] xmm1,xmm2,3 Неупорядочены
CMPNEQ[PS,SS] xmm1,xmm2 CMP[PS,SS] xmm1,xmm2,4 Не равно
CMPNLT[PS,SS] xmm1,xmm2 CMP[PS,SS] xmm1,xmm2,5 Не меньше
CMPNLE[PS,SS] xmm1,xmm2 CMP[PS,SS] xmm1,xmm2,6 Не меньше или равно
CMPORD[PS,SS] xmm1,xmm2 CMP[PS,SS] xmm1,xmm2,7 Упорядочены
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
Команды сравнения по-разному реагируют на поступление операндов - не-чисел. Если элементом сравниваемых операндов является NaN, то для одних команд результатом сравнения может быть число FFFFFFFFh, а для других OOOOOOOOh (табл. 2.53). Команды CMPUNORD[PS, SS] и CMPORD[PS, SS] специально предназначены для сравнения не-чисел. Результатом выполнения команды CMPUNORD[PS, SS] будет FFFFFFFFh, если хотя бы один из элементов является He-числом (NaN), и OOOOOOOOh, если оба операнда являются достоверными числами. Результатом выполнения команды CMPORDfPS, SS] будет, наоборот, FFFFFFFFh - при сравнении достоверных чисел и OOOOOOOOh - при сравнении не-чисел. Различные команды сравнения могут вызывать или не вызывать исключение типа #1 при NAN операндах (табл. 2.53).
Таблица 2.53
Результаты выполнения команд сравнения при поступлении операндов NaN
Предикат im8 Результат, если NaN операнд Исключения #1 при NaN операнде
EQ 0 OOOOOOOOh Нет
LT 1 OOOOOOOOh Да
LE 2 OOOOOOOOh Да
UNORD 3 FFFFFFFFh Нет
NEQ 4 FFFFFFFFh Нет
NLT 5 FFFFFFFFh Да
NLE 6 FFFFFFFFh Да
О RD 7 OOOOOOOOh Нет
Команды COMISS и UCOMISS производят сравнение двух чисел одинарной точности с установкой признаков в регистре EFLAGS. При этом признаки OF,SF,AF принимают значение «О», а признаки ZF,PF,CF устанавливаются в зависимости от результатов сравнения (табл. 2.54). Команда COMISS реализует исключение типа #1, если элемент хотя бы одного из операндов является не-числом (SNaN или QNaN), а команда UCOMISS - если элемент одного из операндов является SNaN. Состояние регистра EFLAGS при реализации данного исключения не изменяется. В случае, если соответствующий бит маски имеет значение IM = 1 (исключение маскировано), то исключение не реализуется, а признаки ZF, PF, CF устанавливаются в «1».
Таблица 2.54
Установка признаков командами COMISS и UCOMISS
Условие ZF PF CF
Не-числа 1 1 1
xmm > xmm /т32 0 0 0
xmm < xmm /т32 0 0 1
xmm = xmm /т32 1 0 0
Команды MAX[PS,SS] и MIN[PS,SS] выделяют из исходных операндов элементы с наибольшими или наименьшими значениями. Элементы операндов попарно сравниваются между собой, и в качестве соответствующего элемента результата в регистр xmm заносится элементе наибольшим (команда МАХ) или наименьшим (команда MIN) значением. Если хотя бы один из сравниваемых элементов является не-числом, и значение бита маски IM = 1, то соответствующим элементом результата становится элемент из операнда-источника xmm/m128 или xmm/m32 независимо оттого, является ли он достоверным числом или NaN.
СИСТЕМА КОМАНД: ОПЕРАЦИИ SSE
2.6.6. КОМАНДЫ ПРЕОБРАЗОВАНИЯ ФОРМАТА ЧИСЕЛ
Команды этой группы производят преобразование операндов из формата с плавающей точкой одинарной точности (ОТ) в 32-разрядные целые числа (двойное слово) и обратно (табл. 2.55). Мнемокоды команд начинаются буквами CVT, а в качестве суффикса дается символическое обозначение преобразования, которое выполняет команда:
Р12РЭ-два двойных целых числа со знаком в два числа ОТ;
SI2SS - одно двойное целое число со знаком в одно число ОТ;
PS2PI - два числа ОТ в два двойных целых числа со знаком;
SS2SI - одно число ОТ в одно двойное целое число со знаком.
Таблица 2.55
Команды преобразования из формата с плавающей точкой в целочисленный формат и наоборот
Синтаксис команды Операция
CVTPI2PS xmm,mm/m64 CVTSI2SS xmm,r/m32 CVTPS2PI mm,xmm/m64 CVTTPS2PI mm,xmm/m64 CVTSS2SI r32,xmm/m32 CVTTSS2SI r32,xmm/m32 mm/m64(D1, DO) -> xmm(F1 ,F0) r/m32 -> xmm(FO) xmm/m64(F0,F1) -> mm(D0,D1) (округление) xmm/m64(F0,F1) -> mm(D0,D1) (отброс дробной части) xmm/m32(F0) -> r32 (округление) xmm/m32(F0) -> г32 (отброс дробной части)
Команды CVTPI2PS, CVTSI2SS выполняют преобразование 32-разрядных целых чисел в формат чисел с плавающей точкой ОТ. Команда CVTPI2PS преобразует два двойных слова со знаком D1, DO, хранящихся в MMX-регистре mm или ячейке памяти mm64, в два числа ОТ, которые записываются в качестве младших элементов F1, F0 в SSE-регистр mmx. Два старших элемента F3, F2 в SSE-регистре при этом не изменяются. Команда CVTSI2SS преобразует одно двойное слово со знаком DO, которое содержится в регистре общего назначения г (регистры с именами ЕАХ,.... EDI) или ячейке памяти т32, в одно число одинарной точности. Это число заносится в качестве младшего элемента F0 в SSE-регистр mmx. Три старших элемента F3-F1, хранящихся в этом регистре, не изменяются. При выполнении данных команд в случае необходимости осуществляется округление результата в соответствии со значением поля RC в регистре MXCSR.
Команды CVTPS2PI и CVTTPS2PI осуществляют преобразование двух чисел ОТ, являющихся младшими элементами F1, F0 в SSE-регистре mmx или хранящихся в ячейке памяти т64, в два целых двойных слова со знаком D1, DO, которые записываются в ММХ-ре-гистр mm. Команда CVTPS2PI выполняет округление в соответствии со значением поля RC регистре MXCSR, а команда CVTTPS2PI отбрасывает дробную часть. Если результат преобразования не может уместиться в двойное слово со знаком, то в качестве соответствующего элемента результата заносится число 80000000h.
Команды CVTSS2SI и CVTTSS2SI преобразуют одно число ОТ, хранящееся в SSE-регистре mm или ячейке памяти т32, в двойное слово со знаком, которое поступает в регистр общего назначения г. Команда CVTSS2SI выполняет округление, как это задается значением поля RC в регистре MXCSR, а команда CVTTSS2SI отбрасывает дробную часть. Если результат не может уместиться в двойное слово со знаком, то в регистре г устанавливается значение 80000000h.
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
Если элементом исходного операнда является не-число (SNaN или QnaN), то выполнение команд CVTPS2PI, CVTSS2SI, CVTTPS2PI, CVTTSS2SI вызывает исключение типа #1. Если при этом установлено значение бита маски IM = 1 (исключение маскировано), то результатом операции будет целое число 80000000h.
Все команды данной группы реализуют исключение типа #Р, если преобразование не может быть выполнено точно.
2.6.7. КОМАНДЫ УПРАВЛЕНИЯ
Команды данной группы приведены в табл. 2.56.
Команды FXRSTOR и FXSAVE производят сохранение и восстановление содержимого регистров FPU/ММХ и SSE. При выполнении этих команд операндом является блок данных размером 512 байт, начальный адрес его размещения в памяти m512byte задается в команде. В отличие от команды FSAVE команда FXSAVE не изменяет содержимое этих регистров после его сохранения. Для очистки регистров после команды FXSAVE необходимо выполнить команду FINIT. Содержимое регистров, сохраненное в памяти с помощью команды FSAVE, не может быть восстановлено с помощью команды FXRSTOR, и наоборот, содержимое регистров, сохраненное с помощью команды FXSAVE, не может быть восстановлено с помощью команды FRSTOR. Размещение в памяти содержимого регистров, выполняемое по команде FXSAVE, показано на рис. 2.38. Если при восстановлении (загрузке из памяти) по команде FXRSTOR зарезервированные биты в регистре MXCSR примут значение «1», то это приведет к исключению #GP (нарушение общей защиты).
15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
Резерв. | CS EIP СОР TW FPSR | FPCR 0
Резервировано MXCSR Резерв. DS ЕА 16
Резервировано ST0/MM0 32
Резервировано ST1/MM1 48
Резервировано ST2/MM2 64
Резервировано ST3/MM3 80
Резервировано ST4/MM4 96
Резервировано ST5/MM5 112
Резервировано ST6/MM6 128
Резервировано ST7/MM7 144
хммо 160
ХММ1 176
ХММ2 192
хммз 208
ХММ4 224
ХММ5 240
ХММ6 256
ХММ7 272
Резервировано 288
Резервировано 496
Рис. 2.38. Размещение в памяти содержимого регистров при выполнении команды FXSAVE
СИСТЕМА КОМАНД: ОПЕРАЦИИ SSE
Таблица 2.56
Команды управления
Синтаксис команды Операция
FXRSTOR m512byte FXSAVE m512byte LDMXCSR m32 STMXCSR т32 Загрузка из памяти содержимого FPU/ММХ и SSE-регистров Сохранение в памяти содержимого FPU/ММХ и SSE-регистров m32 -> MXCSR MXCSR -> т32
Команда STMXCSR сохраняет содержимое регистра MXCSR в ячейке памяти с адресом т32. На месте зарезервированных бит в память записываются нули. Команда LDMXCSR загружает (восстанавливает) содержимое регистра MXCSR из адресуемой ячейки памяти.
2.6.8. КОМАНДЫ ПЕРЕСЫЛКИ ДАННЫХ С УПРАВЛЕНИЕМ КЭШИРОВАНИЕМ
Эта группа команд приведена в табл. 2.57. На их выполнение не влияет значение бита ЕМ в регистре управления CR0 и значение бита OSFXSR в регистре управления CR4.
Команда MASKMOVQ производит выборочную запись байтов из ММХ-регистра mm1 в память по адресу DS:[ЕDI], т. е. в ячейку памяти, адресуемую содержимым регистра EDI, в сегменте данных DS. Второй операнд команды, выбираемый из ММХ-регистра mm2, содержит маску, которая определяет, какие байты из регистра mm1 будут записаны в память. Если старший бит какого-либо байта в регистре mm2 содержит «1», то соответствующий байт из регистра mm1 посылается в память. Если старший бит байта в регистре mm2 содержит «О», то запись в память соответствующего байта из mm1 не производится.
Команды MOVNTPS и MOVNTQ реализуют соответственно запись в адресуемую ячейку памяти гл 128 или т64 содержимого SSE-регистра ХММ или ММХ-регистра mm. При выполнении этих команд данные пересылаются непосредственно в основную (системную) память, их запись в кэш-память (кэширование) не производится.
Команды PREFETCHTO, PREFETCHT1, PREFETCHT2, PREFETCHNTA производят предварительную выборку строки данных из системной памяти в кэш-память. Выбирается строка (32 байта), содержащая байт с адресом гп8, который указан в команде. Выбранная строка поступает в кэш-память определенного уровня в соответствии с мнемокодом команды. Данные команды рассчитаны на реализацию в процессорах, имеющих кэш-память различного уровня, включая самый нижний - «нулевой» уровень (L0). Кэш-память этого уровня отсутствует в ныне выпускаемых моделях процессоров Pentium III, которые содержат только кэш-память 1-го и 2-го уровней (L1 и L2). Полностью возможности использования этих команд будут реализованы в последующих моделях процессоров семейства Р6. Процессоры Pentium III при поступлении команд PREFETCHT1 и PREFETCHT2 выполняют одинаковые действия, обеспечивая загрузку строки в кэш-память 2-го уровня (L2).
Команды PREFETCH дают возможность произвести предварительную загрузку данных в кэш-память до их непосредственного использования. Эффективное применение этих команд позволяет избежать нежелательных остановок конвейера, связанных с ожиданием загрузки данных.
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
Таблица 2.57
Команды пересылки данных с управлением кэшированием
Синтаксис команды Операция
MASKMOVQ mm1,mm2 mm1(Bi) ds:[edi+l], если mm2[b7(Bi)] = 1; i = 0..7
MOVNTPS m128,xmm xmm -> m128
MOVNTQ m64,mm mm -> m64
PREFETCHTO m8 Предвыборка данных в кэш-память всех уровней(В L1 и L2 для процессора Pentium III)
PREFETCHT1 m8 Предвыборка данных в кэш-память всех уровней кроме нулевого^ L2 для процессора Pentium III)
PREFETCHT2 m8 Предвыборка данных в кэш-память всех уровней кроме нулевого и первого(В L2 для процессора Pentium III)
PREFETCHNTA m8 Предвыборка данных в «ближайший» к процессору кэш (В L1 для процессора Pentium III)
SFENCE Упорядочивание обращений к памяти
Команда SFENCE упорядочивает обращения к памяти в процессе записи. Отметим, что процессоры семейства Р6 производят изменение последовательности выполнения команд, заданной исходной программой, чтобы обеспечить повышение производительности за счет сокращения числа тактов простоя и ожидания при работе конвейера. При этом запись в память результатов операций также может выполняться с нарушением заданной программой последовательности. Данное обстоятельство вызывает определенные трудности при работе систем, в которых допускается одновременное обращение к основной памяти нескольких устройств. Команда SFENCE позволяет избежать этих трудностей, обеспечивая выполнение записи результатов операций в память в соответствии с порядком следования команд в исходной программе.
2.7. РАБОТА ПРОЦЕССОРА В ЗАЩИЩЕННОМ И РЕАЛЬНОМ РЕЖИМАХ
Процессоры семейства Р6, как и другие микропроцессоры 80x86, имеют два основных рабочих режима: защищенный и реальный.
Наиболее полно возможности процессора реализуются при работе в защищенном режиме. При этом обеспечивается физическая адресация памяти объемом до 2 32 = 4 Гбайт и доступ к виртуальной памяти объемом до 2 46 = 64 Гбайт. Помимо сегментации памяти в защищенном режиме может быть реализована страничная организация. Этот режим позволяет использовать дополнительные команды, введенные для поддержки многозадачных операционных систем. Кроме того, обеспечивается защита пользовательских программ друг от друга и от операционной системы, предотвращающая возможное взаимное вмешательство в их работу.
При работе в реальном режиме возможности микропроцессора существенно ограничиваются: сокращается до 1 Мбайт объем адресуемой памяти, исключаются основные механизмы защиты, не реализуется страничная организация памяти и многозадачное функционирование систем. Этот режим обычно используется либо как промежуточный для перехода в защищенный режим после инициализации микропроцессорной системы, либо для более быстрого выполнения программ, написанных для микропроцессоров 8086,80186. По сравнению с ними процессоры Р6 в реальном режиме имеют более широкий набор выполняемых команд и обеспечивают обработку 32-разрядных операндов.
РАБОТА ПРОЦЕССОРА В ЗАЩИЩЕННОМ И РЕАЛЬНОМ РЕЖИМАХ
Быстрое выполнение программ, написанных для микропроцессоров 8086, вместе собес-печением защиты памяти, страничной организации и многозадачности достигается при работе процессора в режиме виртуального 8086, который является вариантом защищенного режима.
В настоящей главе подробно рассматривается функционирование процессоров Р6 в защищенном режиме (сегментация, страничная организация памяти, многозадачность), особенности реализации реального режима и режима виртуального 8086.
2.7.1. СЕГМЕНТАЦИЯ ПАМЯТИ В ЗАЩИЩЕННОМ РЕЖИМЕ
При работе процессора в защищенном режиме каждый из сегментов команд, данных, стека характеризуется соответствующими параметрами, которые определяют локализацию данного сегмента в общем пространстве адресуемой памяти и правила обращения к нему. Параметры сегмента представляются в виде 8-байтной структуры данных, называемой дескриптором. При адресации памяти процессор использует дескриптор для того, чтобы определить разрешено ли обращение к данному сегменту, вычислить адрес ячейки памяти и проверить, находится ли этот адрес в пределах выбранного сегмента.
Дескрипторы сегментов хранятся в памяти в виде массивов данных, которые сформированы в виде таблиц. Таблицы могут иметь размеры от 8 байт до 64 Кбайт, т. е. содержать до 8192 дескрипторов. Имеется три типа таблиц дескрипторов:
GDT - глобальная таблица дескрипторов;
LDT - локальная таблица дескрипторов;
IDT - таблица дескрипторов прерываний.
Таблица GDT содержит дескрипторы, которые могут использоваться системой при выполнении различных задач. Таблицы LDT содержат дескрипторы сегментов, используемых при решении данной задачи. Количество создаваемых таблиц LDT определяется операционной системой и зависит от числа выполняемых задач. Общее количество таблиц LDT может достигать 8192. В принципе, каждая задача может иметь отдельную LDT, которая включает дескрипторы сегментов, используемых при ее решении. В случае совместного использования сегментов таблицы LDT могут полностью или частично перекрывать друг друга. Таблица IDT обеспечивает выполнение процедур обслуживания исключений (прерываний), которые будут рассмотрены в гл. 8. В данной главе описывается адресация памяти в защищенном режиме, которая обеспечивается с помощью таблиц GDT и LDT.
Обращение к необходимому дескриптору в таблице осуществляется с помощью селектора, загружаемого в соответствующий сегментный регистр: CS, DS, SS, ES, FS или GS. Селектор представляет собой 16-разрядный указатель, который имеет три поля (рис. 2.39).
Поле RPL (биты 0-1) определяет уровень привилегий запроса (request privilege level). Это двухразрядный код, указывающий допустимый уровень защиты сегмента, который может быть выбран с помощью данного селектора.
Поле TI (бит 2) служит индикатором таблицы. Его значение указывает выбираемую таблицу: GDT при TI = 0, LDT при TI = 1.
Поле INDEX (биты 3-15) служит индексом для выбора одного из 8192 дескрипторов, содержащихся в таблице.
15 3210
| INDEX | TI | PRL |
Рис. 2.39. Формат селектора
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
««Регистр LDTR (см. рис. 2.6) содержит 16-разрядный селектор, определяющий размещение в GDT дескриптора используемой таблицы LDT. Поле INDEX в этом указателе содержит смещение, которое используется для формирования адреса дескриптора таблицы LDT, выбираемого из GDT. Дескриптор LDT содержит 32-разрядный базовый адрес используемой LDT, ее 16-разрядную границу и атрибуты, определяющие права доступа к таблице. При загрузке в LDTR селектора таблицы LDT соответствующий дескриптор выбирается из GDT и хранится во внутреннем программно недоступном регистре процессора - «теневом» регистре LDTR (рис. 2.40).
Загрузка регистров GDTR, LDTR из памяти, а также сохранение в памяти их содержимого реализуется с помощью команд LGDT, LLDT и SGDT, SLDT. Загрузка селекторов в регистры сегментов данных DS, ES, FS, GS, SS производится командами LDS, LES, LFS, LGS, LSS. Регистр CS является программно недоступным, поэтому прямая загрузка в него (или выгрузка) селекторов для выбора сегментов программ невозможна. Начальное содержимое CS устанавливается при инициализации системы и затем изменяется программно при выполнении команд межсегментных вызовов и переходов CALL, JUMP и при переключении задач.
Если селектор, загруженный в сегментный регистр CS, SS, DS, ES, FS или GS, обращается к таблице GDT (бит TI = 0) или LDT (бит TI = 1), то его индекс, сдвинутый на три разряда влево
Селектор сегмента Дескриптор сегмента
(CS ... GS) («Теневой регистр» CS ... GS)
15 3210
LDTR «Теневой регистр» LDTR
Рис. 2.40. Выборка дескрипторов из таблиц GDT и LDT
РАБОТА ПРОЦЕССОРА В ЗАЩИЩЕННОМ И РЕАЛЬНОМ РЕЖИМАХ
(т. е. умноженный на 8 - число байтов в дескрипторе), служит в качестве относительного адреса (смещения) для формирования адреса дескриптора в данной таблице (рис. 2.40). Это смещение сравнивается с границей таблицы, хранящейся в GDTR или «теневом» регистре LDTR. Если смещение превышает границу, т. е. выходит за пределы таблицы GDT, то вырабатывается прерывание типа #GP («нарушение защиты»). Если нарушения границы нет, то смещение прибавляется к содержащемуся в GDTR базовому адресу, в результате чего образуется адрес младшего байта выбираемого дескриптора. При обращении к таблице LDT проверяются также права доступа к данной таблице, которые устанавливаются также, как для выбираемых сегментов.
Селектор с нулевым значением полей INDEX и TI (разряды 2-15, рис. 2.39) называется нуль-индикатором. Он обеспечивает обращение к первому дескриптору в таблице GDT (нуль-дескриптор). Загрузка такого селектора в регистр CS или SS для выборки сегмента команд или стека вызывает исключение типа #GP («нарушение общей защиты»). Так как при инициализации системы обычно производится установка нулевых начальных значений дескрипторов и селекторов, то данное исключение предотвращает возможность запуска рабочих программ до загрузки операционной системой необходимых сегментов и дескрипторов.
Таким образом, в защищенном режиме программно задается логический адрес ячеек памяти, хранящих команды или данные, который состоит из селектора и относительного адреса. С помощью селектора и таблиц GDT, LDT процессор производит выборку соответствующего дескриптора. Затем формируется линейный адрес ячейки памяти путем сложения базового адреса, содержащегося в дескрипторе, и относительного адреса, образуемого в соответствии с используемым способом адресации (рис. 2.41). Линейный адрес определяет местоположение ячейки в линейном адресном пространстве, которое может быть разбито на отдельные страницы при введении страничной организации памяти.
Логический адрес
I I
15 0 31/15 0
Рис. 2.41. Формирование линейного адреса
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
Если при работе процессора не используется страничная организация памяти (бит 32 в регистре управления CRO сброшен: PG = 0), то полученный линейный адрес является физическим адресом для выбора требуемой ячейки памяти.
При выполнении программ, написанных для процессоров 80386,80486, Pentium, Р6, базовый и относительный адреса содержат по 32 разряда. При работе в режиме виртуального 8086 в качестве базового адреса используется селектор, сдвинутый влево на 4 разряда. Таким образом, базовый адрес имеет 20 разрядов. В этом режиме используется 16-разряд-ный относительный адрес, а формируемый линейный адрес содержит 20 разрядов.
Иногда при работе микропроцессорной системы сегментации памяти не требуется. В этом случае необходимо загрузить все регистры сегментов селекторами дескрипторов, имеющих нулевые базовые адреса и задающие размеры сегментов по 4 Гбайт. В результате каждый из сегментов использует полное адресное пространство, т. е. сегментация подавляется. При этом может быть реализована страничная организация памяти.
В таблицах GDT, LDT могут размещаться следующие виды дескрипторов:
• дескрипторы сегментов команд;
• дескрипторы сегментов данных;
• системные дескрипторы.
В общем виде формат дескриптора представлен на рис. 2.42, где 32-разрядный базовый адрес сегмента (база ВА31-0) и 20-разрядная граница сегмента (L19-0) размещены по частям в различных байтах дескриптора.
Граница сегмента L указывает максимальное допустимое значение относительного адреса, которое может использоваться при обращении к сегменту. Величина (L+1) определяет размер сегмента в байтах или страницах. Обращение к ячейке памяти, находящейся за границей данного сегмента, вызывает исключение типа #GP.
Помимо базового адреса и границы сегмента дескрипторы задают ряд других важных его атрибутов, состав которых зависит от вида сегмента. Отдельные биты байта 6 дескриптора определяют следующие атрибуты сегмента.
Бит дробности G указывает, в каких единицах задан размер сегмента: в байтах при G = 0 или страницах объемом по 4 Кбайт при G = 1. Таким образом, сегмент может иметь размер до 220 = 1 Мбайт при G = 0 или до 232 = 4 Гбайта при G = 1.
Бит разрядности по умолчанию D/В для сегментов команд определяет разрядность формируемого относительного адреса и выбираемого операнда: 16 разрядов при D/В = 0, 32 разряда при D/В = 1. Если производится обращение к сегменту стека (при выполнении команд типа PUSH, POP, CALL), то при D/В = 0 используется регистр SP и 16-разрядные, а при D/В = 1 - регистр ESP и 32-разрядные данные. Для расширяемых вниз сегментов данных (сегменты со стековой адресацией) бит D/В определяет их верхнюю границу: М = FFFFh при D/В = 0 или М = FFFFFFFFh при D/В = 1. Для системных дескрипторов этот бит должен иметь нулевое значение.
Байт 8 Байт 7 Байт 6 Байт 5
31 24 23 22 21 20 19 16 15 14 13 12 11 8 7 0
Базовый адрес ВА31-24 G D/B 0 AVL Граница L19-16 р DPL S TYPE Базовый адрес BA23-16
Базовый адрес ВА15-С Граница сегмента L15-0
31 16 15 0
Байты 2,3 Байты 0,1
Рис. 2.42. Общий формат дескриптора
РАБОТА ПРОЦЕССОРА В ЗАЩИЩЕННОМ И РЕАЛЬНОМ РЕЖИМАХ
Бит 5 в байте 6 всегда должен иметь нулевое значение, а бит 4 (AVL) может принимать значение, устанавливаемое пользователем или операционной системой.
Байт 5 дескриптора определяет права доступа к выбираемому сегменту. В зависимости от вида сегмента байт доступа имеет различные форматы (рис. 2.43), хотя назначение ряда полей (битов) остается одинаковым. Одинаковое назначение имеют следующие биты и поля.
Бит присутствия Р определяет наличие соответствующего сегмента в памяти. Если Р = 0 (сегмент отсутствует), то данный дескриптор не используется для формирования адресов, т. е. соответствующие байты дескриптора не загружаются в регистры, хранящие базовый адрес и размер сегмента. Поэтому содержимое этих байтов может быть установлено произвольно. Если в регистр сегмента поступает селектор дескриптора, имеющего Р = 0, то процессор переходит к обработке соответствующего исключения #NP («отсутствие сегмента»).
Поле DPL (биты 6-5) указывает уровень защиты сегмента (уровень привилегий дескриптора). В зависимости от соотношения значений DPL и RPL, задаваемого в младших битах селектора (см. рис. 2.39), разрешается или запрещается обращение к данному сегменту. Таким образом, обеспечивается требуемый уровень защиты сегмента.
Системный бит S определяет вид выбираемого сегмента. При S = 1 дескриптор обеспечивает обращение к сегментам программ (кодов) или данных (включая стек). Системные дескрипторы, имеющие значение S = 0, служат для обращения к таблицам LDT, сегментам состояния задачи TSS или шлюзам для входа в другие задачи или программы, включая программы обслуживания исключений и прерываний.
Форматы байта доступа для дескрипторов сегментов программ и данных (рис. 2.43, а, б) отличаются значениями бита 3, который имеет значение «1» для сегментов программ и «О» для сегментов данных.
Бит обращения А устанавливается в единицу при обращении к сегменту, т. е. при загрузке соответствующего селектора в сегментный регистр. Этот бит периодически проверяется операционной системой, реализующей виртуальную память, которая таким образом выявляет невостребованные сегменты, имеющие А = 0. Сегменты, долгое время остающиеся невостребованными, выводятся из оперативной памяти на магнитный диск, освобождая место для других сегментов.
Назначение битов 1 и 2 байта доступа зависит от типа сегмента.
Бит разрешения считывания R вводится для сегмента программ и разрешает при R=1 производить считывание его содержимого. При R = 0 допускается только выборка содержимого этого сегмента для выполнения через регистр CS. Попытка считывания сегмента в этом случае вызовет исключение типа #GP. Отметим, что прерывание этого типа возникает также при попытке записи в сегмент программ независимо от значения бита R. Таким образом, запись в сегмент программ запрещена. Если возникает необходимость внести изменение в этот сегмент, то можно создать сегмент данных с разрешением записи (W = 1), занимающий то же адресное пространство, что и модифицируемый сегмент программ. После внесения изменений в созданный сегмент данных можно обратиться к нему как к сегменту программ, загрузив селектор этого сегмента в регистр CS.
7 6 5 4 3 2 1 0
а) | Р | PPL | S = 1 | 1 | С | R | А |
7 6_____5 4 3 21 0
б) | Р | PPL | S = 1 | 0 | Е | W | А |
7 6 5 4 3 0
в) | Р | PPL | S = 0 | TYPE |
Рис. 2.43. Формат байта доступа для дескрипторов сегментов программ (а), данных (б) и системных дескрипторов (в)
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
Бит подчиненности С определяет дополнительные правила обращения, которые обеспечивают защиту сегментов программ: при С = 0 обращение к данному сегменту разрешается только программам, имеющим уровень привилегии CPL (значение поля RPL в регистре CS) такой же, как значение поля DPL в дескрипторе сегмента; при С = 1 допускается обращение к данному сегменту программ, имеющих CPL >= DPL.
Бит разрешения записи W вводится для сегментов данных. Разрешает (при W = 1) или запрещает (при W = 0) изменение содержимого этих сегментов. При W = 0 разрешается только считывание данных, а при попытке записи реализуется исключение типа #GP.
Бит направления расширения Е определяет размещение сегмента данных относительно заданной границы сегмента. При Е = 0 (расширение вверх) данные в сегменте размещаются от базового адреса ВА, задающего нижний предел сегмента до верхнего предела, определяемого суммой базового адреса и границы сегмента: (BA+L). Таким образом, сегмент размещается вниз от границы - в направлении уменьшения адресов до базового.
При Е = 1 (расширение вниз) данные располагаются, начиная с адреса (BA+L+1), определяющего нижний предел сегмента. Остальные ячейки размещаются в направлении возрастания адресов (вниз от границы) до верхнего предела, задаваемого адресом (ВА+М). Верхний предел сегмента в этом случае равен базовому адресу, увеличенному на М = FFFFh (размер сегмента до 64 Кбайт) или на М = FFFFFFFFh (размер сегмента до 4 Гбайт) в зависимости от значения бита разрядности D/В в байте 6 дескриптора (см. рис. 2.42). Размер сегмента будет равен (М-L), и его максимальное значение достигается, когда заданная граница L = 0. Отметим, что для сегментов с расширением вниз значения битов дробности и разрядности должны быть равными: G - D/B.
Таким образом, при расширении вверх (бит Е = 0) относительный адрес выбираемой ячейки должен быть меньше или равен границе сегмента, при расширении вниз (бит Е = 1) относительный адрес должен быть больше границы сегмента.
Формат байта доступа для системных дескрипторов (S = 0) приведен на рис. 2.43, в. Поле TYPE определяет тип системного дескриптора в соответствии с табл. 2.58. Можно выделить три основных класса системных дескрипторов.
Таблица 2.58
Типы системных дескрипторов
TYPE Тип системного дескриптора
0000 Резервировано
0001 TSS, 16-разр. (доступен)
0010 LTD
0011 TSS, 16-разр. (занят)
0100 Шлюз вызова подпрограммы, 16-разр.
0101 Шлюз вызова задачи
0110 Шлюз вызова прерываний, 16-разр.
0111 Шлюз вызова ловушки, 16-разр.
1000 Резервировано
1001 TSS, 32-разр. (доступен)
1010 Резервировано
1011 TSS, 32-разр. (занят)
1100 Шлюз вызова подпрограммы, 32-разр.
1101 Резервировано
1110 Шлюз вызова прерываний, 32-разр.
1111 Шлюз вызова ловушки, 32-разр.
!> ГТ!
•'У
' н
X
РАБОТА ПРОЦЕССОРА В ЗАЩИЩЕННОМ И РЕАЛЬНОМ РЕЖИМАХ
Дескрипторы таблиц LDTобеспечивают обращение к локальной таблице дескрипторов для выбора сегментов, используемых при выполнении текущей программы.
Дескрипторы сегментов TSS используются при переключении задач в многозадачном режиме. При этом бит 3 поля TYPE байта доступа указывает, решается ли вызываемая задача с использованием 16- или 32-разрядных адресов и данных. Бит В в байте доступа сегмента TSS называется битом занятости и указывает, является ли вызываемый сегмент занятым (соответствующая задача находится в процессе выполнения) или доступным (задача еще не поступила на выполнение). Переключение на занятую задачу вызывает исключение типа #GP («нарушение защиты»). Отметим, что дескрипторы LDT и TSS всегда должны иметь значение бита разрядности D/В = 0 (см. рис. 2.42).
Дескрипторы шлюзов используются для реализации специальных правил доступа при обращении к программам и задачам, а также при обработке прерываний и ловушек.
Дескрипторы сегментов, использующих 16-разрядные адреса и операнды при размере сегментов до 1 Мбайт (значения битов G = D/В = 0), имеют нулевые значения байтов 5 и 6 дескриптора (см. рис. 2.42). Такие дескрипторы использовались в 16-разрядных микропро-цесорах 80286. Остальные биты и поля дескрипторов для процессоров 80286 полностью соответствуют форматам, приведенным на рис. 2.42, 2.43. Поэтому процессоры семейства Р6, как и более ранние модели, обеспечивают полную программную совместимость с 16-разрядным микропроцессором 80286, выполняя сегменты команд (программы), написанные для 80286, без какой-либо модификации. Отличие состоит только в разрядности базового адреса, которая для 80286 равна 24 битам (ВА23-0 в байтах 2,3,4 дескриптора), и границе сегмента, которая не должна превышать 64 Кбайт (L15-0 в байтах 0,1 дескриптора). Дробность и разрядность для этих сегментов устанавливается байтами G, D/B дескриптора, которые имеют нулевое значение.
Если системные дескрипторы имеют нулевые значения старших байтов 6,7 дескриптора (дескрипторы, аналогичные используемым для процессора 80286), то старший бит в поле TYPE байта доступа (см. рис. 2.43, в) всегда должен иметь нулевое значение. При этом допускается использование только тех типов системных дескрипторов, которые указаны в восьми верхних строках табл. 2.58.
2.7.2. СТРАНИЧНАЯ ОРГАНИЗАЦИЯ ПАМЯТИ
Страничная организация памяти реализуется процессором только в защищенном режиме, если в регистре управления CR3 установлено значение бита PG = 1. Размер страниц может составлять 4 Кбайт или 4 Мбайт при использовании 32-разрядных адресов и 4 Кбайт или 2 Мбайт при использовании расширенных 36-разрядных адресов. В отличие от сегментов, которые могут иметь различные размеры (от 1 байта до 4 Гбайт), размеры страниц строго фиксированы.
Если размер страниц составляет 4 Кбайт, то сегмент разбивается на отдельные разделы, число которых может достигать 210 = 1024. Каждый раздел может содержать до 210 = 1024 страниц по 4 Кбайт. Если размер страниц составляет 4 Мбайт или 2 Мбайт, то сегмент разбивается только на отдельные страницы, число которых может составлять 1024 или 2048.
Начальные (базовые) адреса страниц и разделов содержатся в специальных таблицах (каталогах), которые хранятся в основной памяти. Кроме базовых адресов в этих таблицах содержатся также атрибуты соответствующих разделов и страниц, определяющие правила доступа к ним и указывающие текущее состояние их содержимого. Совокупность этих параметров, характеризующих страницы и разделы (каталоги), представляется в виде 32-или 64-разрядных указателей страниц, разделов и каталогов (см. рис. 2.45,2.47).
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
Страницы, содержащие определенный сегмент программ или данных, могут быть рассеяны по разным частям памяти, а их размещение определяется содержанием каталога разделов и таблиц страниц. Таким образом обеспечивается более эффективное использование (заполнение) памяти по сравнению с сегментной. Однако при этом требуется дополнительное время и специальные аппаратные средства для преобразования (трансляции) адресов.
Линейный 32-разрядный адрес, получаемый в результате преобразования логического адреса, является исходной информацией для формирования физического адреса с помощью каталога разделов и таблиц страниц. Процедура формирования физического адреса при страничной организации зависит от размера используемых страниц и разрядности адреса, которые определяются значениями ряда битов, содержащихся в регистре управления CR4 и указателях разделов и страниц:
PSE в регистре CR4 (см. рис. 2.7) - разрешает при значении PSE = 1 использование страниц расширенного размера (4 или 2 Мбайт), при PSE = 0 используются только страницы стандартного размера (4 Кбайт);
РАЕ в регистре CR4 (см. рис. 2.7) - задает разрядность формируемого физического адреса: стандартная (32 разряда) при РАЕ = 0 или расширенная (36 разрядов) при РАЕ = 1;
PS в указателе раздела или страницы (см. рис. 2.45,2.47) - указывает размер используемых страниц аналогично биту PSE.
Совместное действие этих битов при установленном значении бита PG = 1 определяет разрядность формируемого физического адреса и размер используемых страниц (табл. 2.59).
Линейный адрес при страничной организации рассматривается как совокупность трех полей (рис. 2.44). Поле Directory (разряды А31-22 линейного адреса) указывает относительный адрес таблицы страниц, выбираемой в каталоге раздела. Поле Table (разряды А21-12 линейного адреса) задает относительный адрес требуемой страницы раздела. Поле Offset (разряды А11-0 линейного адреса) содержит относительный адрес выбираемого на странице байта.
Формирование 32-разрядного физического адреса выбираемого байта при использовании страничной адресации с размером страниц 4 Кбайт осуществляется путем последовательного обращения к каталогу разделов и таблице страниц (рис. 2.44, а). Каталог разделов занимает одну страницу памяти, где для каждого из 1024 возможных разделов содержатся 32-разрядные указатели входа в таблицу страниц этого раздела. Каждая из таблиц страниц также занимает одну страницу, где для каждой из 1024 страниц раздела даются 32-разрядные указатели входа в нее.
Выбор раздела определяется содержимым поля Directory линейного адреса, которое указывает относительный адрес А11-2 указателя таблицы страниц, хранящегося в каталоге разделов. Содержимое регистра управления CR3 задает базовый адрес (значение 20 старших разрядов А31 -12) каталога разделов, ячейки памяти, содержащей указатель входа в таблицу страниц раздела. Этот указатель задает базовый адрес (разряды А31-12) таблицы страниц выбранного раздела. Поле Table линейного адреса содержит разряды А11-А2 адреса ячейки (относительный адрес в таблице страниц), в которой хранится указатель страницы. Указатель задает базовый адрес (разряды А31-12) страницы, на которой размещается выбираемый байт, относительный адрес которого (разряды А11-0) содержится в поле Offset линейного адреса. Таким образом, при страничной организации памяти 32-разрядный (физический) адрес формируется как сумма базового адреса, задаваемого указателем страницы, и относительного адреса, содержащегося в поле Offset.
Если в регистре управления CR4 установлено значение бита PSE = 1, то обеспечивается работа со страницами расширенного размера 4 Мбайт. При этом линейный адрес содержит два поля: Directory и Offset, и для формирования 32-разрядного физического адреса используется только одна таблица - каталог страниц (рис. 2.44, б). Процедура формирования адреса в этом случае аналогична рассмотренной выше для страниц размером 4 Кбайт.
РАБОТА ПРОЦЕССОРА В ЗАЩИЩЕННОМ И РЕАЛЬНОМ РЕЖИМАХ
Таблица 2.59
Размер страниц и разрядность физического адреса при страничной адресации памяти
PG РАЕ PSE PS Размер страницы Физический адрес
0 X X X - 32 разряда
1 0 0 X 4 Кбайт 32 разряда
1 0 1 0 4 Кбайт 32 разряда
1 0 1 1 4 Мбайт 32 разряда
1 1 X 0 4 Кбайт 36 разрядов
1 1 X 1 2 Мбайт 36 разрядов
Формат содержимого указателей таблиц и страниц при использовании 32-разрядных адресов приведен на рис. 2.45. Помимо базового адреса таблицы и страницы указатели содержат дополнительную информацию, определяющую порядок их использования. Эта информация задается значениями следующих битов.
Бит присутствия Р разрешает при установленном значении Р = 1 использование соответствующего раздела или страницы. Если же Р = 0 (раздел или страница отсутствует), то попытка обращения к ним вызовет исключение типа #PF («отсутствие доступа к странице»). Отметим, что при Р = 0 остальные биты указателя могут служить для представления какой-либо информации, используемой операционной системой.
Бит чтения-записи R/W, бит пользователя- супервизора U/S определяют права доступа к соответствующим разделу или странице для программ пользователя, имеющих минимальные привилегии (уровень PL = 3). Если осуществляется запрос с уровнем привилегий RPL = 3 (программы пользователя), то при значении U/S = 0 ему запрещается доступ к соответствующему разделу или странице. Если U/S = 1, то при значении R/W = О разрешается только чтение раздела или страницы, а при R/W = 1 и чтение, и запись. При запросах с большими привилегиями (системные программные уровни 0,1,2) допускается запись и чтение разделов и страниц при любых значениях U/S, R/W.
Биты PWT и PCD указателя используются для управления работой кэш-памяти при страничной адресации.
Бит обратной записи страниц PWT определяет метод обновления содержимого кэшпамяти. При PWT = 1 для текущей страницы обновление реализуется методом сквозной записи, при PWT = 0 - методом обратной записи.
Бит запрещения кэширования страницы PCD запрещает при PCD = 1 загрузку содержимого данной страницы во внутреннюю кэш-память. При PCD = 0 такая загрузка разрешена.
Бит PWT и PCD определяют значения сигналов на внешних выходах PWT, PCD процессора. Бит PCD вместе с входным сигналом KEN управляет работой внутренней кэш-памяти.
Бит доступа А автоматически устанавливается процессором в состояние А = 1 при обращении к данному разделу или странице для записи или чтения информации.
Бит модификации D в указателе страницы устанавливается в состояние D = 1 при записи на данную страницу. В указателях таблиц данный бит не используется (устанавливается в «0»),
Биты А и D используются операционной системой, поддерживающей виртуальную память, для определения в оперативной памяти разделов и страниц, содержание которых подлежит замене из внешней памяти. Проверку и сброс этих битов выполняет операционная система.
Бит размера страниц PS при установленном значении бита PSE = 1 указывает размер используемых страниц: 4 Кбайт при PS = 0, 4 Мбайт при PS = 1 (если PSE = 0, то используются страницы по 4 Кбайт при любом значении PS).
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
а) Линейный адрес
Базовый Базовый Базовый
адрес адрес адрес
А31-12 А31-12 А31-12
6) 31 22 21 О
Базовый Базовый
адрес адрес
А 31-12 А31-22
Рис. 2.44. Формирование 32-разрядного физического адреса при страничной орга-
низации памяти для страниц стандартного (а) и расширенного (б) размеров
РАБОТА ПРОЦЕССОРА В ЗАЩИЩЕННОМ И РЕАЛЬНОМ РЕЖИМАХ
31 12 11 987654 3 2 10
Рис. 2.45. Формат указателей таблицы (а), страницы (б) для страниц 4Кбайт и указателя страницы для страниц 4Мбайт (в) при 32-разрядном адресе
Бит глобальности G программно устанавливается в состояние «1», чтобы отметить разделы или страницы, часто используемые при решении данной задачи. Базовые адреса этих разделов или страниц, загруженные во внутреннюю буферную память TLB, сохраняются при ее очистке. Подробнее работа TLB рассмотрена ниже.
Биты 9-11 указателей (AVL на рис. 2.45) зарезервированы для операционной системы (ОС), которая может использовать их для своих потребностей. Например, в этих битах может размещаться информация о времени последнего обращения к данному разделу или странице. Эта информация используется ОС для определения разделов и страниц, подлежащих замене из внешней памяти.
Если процессор работает в режиме формирования расширенных 36-разрядных адресов (в регистре CR4 установлено значение бита РАЕ = 1), то процедура формирования физического адреса несколько усложняется (см. рис. 2.46). В этом случае вводится дополнительная таблица каталогов, с помощью которой адресуется каталог разделов (при использовании стандартных страниц 4 Кбайт, рис. 2.46, а) или каталог страниц (при использовании расширенных страниц 2 Мбайт, рис. 2.46, б). Для обращения к таблице каталогов в линейном адресе выделяется 2-разрядное поле Directory Pointer. В основном процедура трансляции производится также, какописано выше для формирования 32-разрядных адресов. Отличия состоят в том, что выполняется дополнительный этап трансляции с обращением к таблице каталогов.
Форматы указателей каталогов, разделов и страниц, используемых при расширенной адресации, показаны на рис. 2.47. Указатели содержат 64 бита (часть из них резервирована), назначение которых аналогично соответствующим битам указателей при стандартной 32-разрядной адресации (см. рис. 2.45). Указатели имеют поля, в которых хранятся старшие разряды 36-разрядных базовых адресов каталогов, разделов и страниц. С помощью страничной трансляции (рис. 2.46) формируется 36-разрядный физический адрес команды или операнда.
Отметим, что расширенная разрядность адреса реализуется только при использовании страничной адресации, когда установлены значения битов PG = РАЕ = 1.
Как указано выше, страничная организация памяти требует дополнительных затрат вре-ме ни для преобразования (трансляции) линейного адреса в физический. Эти затраты будут весьма значительными, если в каждом цикле производить обращение к оперативной памяти для выбора указателей таблиц и страниц. Существенное сокращение времени преобразования адресов достигается путем использования специализированной внутренней кэш-памяти, которая называется буфером ассоциативной трансляции TLB (translation look-aside buffer). Эти буферы хранят физические адреса нескольких ранее
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
Линейный адрес
Базовый адрес А31-5
б)
Линейный адрес
31 30 29 21 20 0
Базовый адрес А31-5
Базовый адрес А35-12
Базовый адрес АЗ5-12
Рис. 2.46. Формирование 36-разрядного физического адреса при страничной
организации памяти для страниц стандартного (а) и расширенного (6) размеров
РАБОТА ПРОЦЕССОРА В ЗАЩИЩЕННОМ И РЕАЛЬНОМ РЕЖИМАХ
а)
а)
63 36 31 12 11 9 8 7 6 5 4 3 2 1 0
Резервировано Базовый адрес страницы AVL G О D А PCD PWT V/S Р
г)
63 36 31 22 21 12 11 9 8 7 6 5 4 3 2 1 0
Резервировано Базовый адрес страницы Резерв. AVL G 1 D А PCD PWT V/S Р
Рис. 2.47. Формат указателей каталога (а), указателя раздела и страницы для страниц 4Кбайт (б, в) и указателя страницы для страниц 4Мбайт (г) при 36-разрядном адресе
выбранных страниц. При повторном обращении к этим страницам процедура трансляции не выполняется, а выбирается из TLB ранее полученный базовый адрес страницы. Процессоры семейства Р6 содержат два отдельных буфера TLB - для трансляции адресов команд и данных (см. рис. 2.1).
Буфер TLB для трансляции адресов команд состоит из двух блоков, которые обеспечивают формирование физических адресов при использовании страниц объемом 4 Кбайт и 4 Мбайт. Буфер для страниц 4 Кбайт содержит 8 наборов по 4 строки, в которых хранятся физические адреса 32 ранее выбранных страниц. Буфер для страниц 4 Мбайт хранит базовые адреса двух страниц, к которым производились последние обращения при выборке команд.
Буфер TLB для трансляции адресов операндов содержит два блока, в которых хранятся физические адреса 64 ранее выбранных страниц размером 4 Кбайт (16 наборов по 4 строки) и 8 адресов страниц размером 4 Мбайт (2 набора по 4 строки).
Таким образом, в TLB команд имеются готовые физические адреса для 32 страниц объемом 4 Кбайт или 2 страниц объемом 4 Мбайт. В TLB данных содержатся физические адреса 64 страниц объемом 4 Кбайт и 8 адресов страниц объемом 4 Мбайт. При обращении к этим страницам (кэш-попадание) процедура трансляции не выполняется, что позволяет существенно сократить время выполнения команд при использовании страничной организации памяти. Как показывает имеющийся опыт применения процессоров семейства Р6 в различных системах, при данной структуре TLB вероятность выборки адреса команд и данных из буфера (без выполнения страничной трансляции адреса с обращением к катологам разделов и таблицам страниц) составляет около 98%. При этом формирование физического адреса не требует дополнительных машинных циклов.
Если базовый адрес нужной страницы отсутствует в TLB, то такой случай является кэш-промахом. При этом процессор выполняет описанную выше процедуру формирования физического адреса с помощью каталога разделов и таблицы страниц, затрачивая на это значительное время. Полученный базовый адрес страницы заносится в строку одного из блоков TLB.
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
С помощью команды INVLPG производится очистка (аннулирование содержимого) строк TLB. При этом очищается строка, содержащая базовый адрес страницы, на которой размещается адресованная командой ячейка памяти. Одновременная очистка всех строк TLB производится при записи в регистр CR3 нового значения базового адреса каталога разделов, а также при переключении задач.
Можно предохранить от аннулирования в TLB базовые адреса страниц, задав для них в указателе страницы (см. рис. 2.45, б, в, 2.47, в, г) значение бита глобальности G = 1. Если в регистре CR4 (см. рис. 2.7) установлен бит разрешения глобальности PGE = 1, то базовые адреса этих страниц в TLB не будут аннулироваться при переключении задач или перезагрузке содержимого CR3. Таким образом, можно избежать потерь времени на трансляцию базового адреса для страниц, используемых в процессе выполнения различных задач (например, для страниц, содержащих ядро операционной системы).
2.7.3. ЗАЩИТА ПАМЯТИ
Процессоры Р6 имеют специальные средства, обеспечивающие в защищенном режиме защиту от случайного (непредусмотренного решаемой задачей) обращения к сегментам и страницам, хранящимся в памяти. Система защиты предусматривает различные виды контроля, которые реализуются процессором:
• контроль доступа к сегментам и страницам, который обеспечивается описанной ниже системой привилегий;
• контроль использования сегментов и страниц, который вводит ряд ограничений на возможные виды обращения к ним: запрещение записи в сегменты данных (страницы), разрешенные только для чтения, запрещение чтения сегментов программ (страниц), разрешенных только для выполнения, запрещение обращения к незагруженным (отсутствующим) сегментам и страницам и ряд других;
• ограничение набора выполняемых команд в зависимости от уровня привилегий выполняемой программы (выделение привилегированных команд).
Для защиты информации, хранящейся в сегментах памяти, используется система привилегий, которая регулирует доступ к тому или иному сегменту в зависимости от уровня его защищенности и от степени важности (привилегированности) запроса. В процессорах Р6, также как в более раних моделях 80286, 80386, 80486, Pentium, установлены четыре уровня привилегий PL (privilege level), которые задаются номерами от 0 до 3. Наиболее привилегированным является уровень с меньшим номером. Степень защищенности сегмента также имеет четыре уровня, которые схематически представляются в виде вложенных колец защиты (рис. 2.48).
Соответствующие уровни защищенности иллюстрируются на примере сегментов программ. Наименее защищенными (привилегированными) являются прикладные программы пользователя, для которых выделяется уровень с номером PL = 3. Уровни с номерами PL = 0,1,2 отводятся для системных программ (супервизора), которые можно разделить на три уровня в зависимости от требований к их защищенности. Наиболее защищенная часть - ядро операционной системы (ОС) имеет уровень PL = 0. В ядро входит часть ОС, обеспечивающая инициализацию работы, управление доступом к памяти, защиту и ряд других жизненно важных функций, нарушение которых полностью выводит систему из строя. Основная часть программ ОС (утилиты) должна иметь уровень PL = 1. К уровню PL = 2 обычно относят ряд служебных программ ОС, например, драйверы внешних устройств, системы управления базами данных, специализированные подсистемы программирования и другие.
РАБОТА ПРОЦЕССОРА В ЗАЩИЩЕННОМ И РЕАЛЬНОМ РЕЖИМАХ
Для программ с различными уровнями привилегий организованы отдельные стеки. Таким образом, в системе, использующей все четыре уровня привилегий, функционируют четыре различных стека, каждый из которых обслуживает только программы соответствующего уровня. При передаче управления программе другого уровня производится переключение стеков.
В соответствии с уровнями привилегий и защищенности установлены следующие правила доступа для сегментов программ и данных:
• данные из сегмента, имеющего уровень защиты PL, могут быть выбраны программой, имеющей такой же или более высокий уровень привилегий;
• сегмент программ (процедура), имеющий уровень защиты PL, может быть вызван программой, имеющей такой же или более низкий уровень привилегий; различные варианты вызова сегментов программ описаны ниже.
Уровни защиты и привилегий определяются двумя битами, значение которых указывает номер кольца защиты или уровня. В зависимости от места размещения эти биты имеют различное назначение.
Уровень привилегий дескриптора DPL задается битами 5, 6 в байте доступа дескриптора (см. рис. 2.43). Указывает уровень защищенности сегмента, т. е. номер кольца защиты, к которому он относится.
Уровень привилегий запроса RPL задается битами 0,1 селектора, загруженного в сегментный регистр при обращении к соответствующему сегменту. Этот уровень устанавливается выполняемой программой, которая с помощью данного селектора обращается к памяти системы.
Текущий уровень привилегий CPL задается битами 0, 1 селектора, размещенного в регистре сегмента программ CS. Определяет уровень привилегий выполняемого в настоящий момент сегмента программы.
Напомним, что меньшее значение DPL, RPL, CPL соответствует более высокому уровню привилегий (защиты). Наиболее защищенный сегмент имеет значение DPL = 0, наименее защищенный - DPL = 3. Для наименее привилегированных программ пользователя CPL = 3, наиболее привилегированные программы ядра ОС имеют CPL = 0.
Процессор имеет специальную команду ARPL, используемую для коррекции значения RPL селектора. Данная команда выполняет сравнение двух младших битов селекторов, предварительно загруженных в адресуемые командой регистры или ячейку памяти. Результатом команды является селектор, в котором эти биты имеют максимальное из значений, заданных в исходных селекторах.
Программы пользователя Служебные программы
Утилиты ОС
Ядро ОС
Рис. 2.48. Уровни привилегий и защиты
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
Обращение к сегментам программ и данных в защищенном режиме производится с учетом описанной выше системы привилегий. При этом правила обращения зависят от типа сегмента.
Обращение к сегментам данных производится с помощью селекторов, загружаемых в регистры DS, ES, FS, GS. При обращении анализируются значения RPL селектора и CPL текущей программы. Эффективный уровень привилегий для запроса данных в этом случае определяется как максимальное из значений RPL и CPL. Обращение к запрашиваемому сегменту данных разрешается, если его уровень защиты DPL >- max(RPL, CPL). Нарушение этого правила при обращении вызывает исключение типа #GP («нарушение общей защиты»).
Таким образом, задавая определенное значение RPL в селекторе, можно управлять доступом текущей программы к сегментам данных, имеющим различный уровень защиты. Например, при RPL = 0 доступ к данным будет определяться значением CPL текущей программы. Если задать RPL = 3, то при любом CPL программа может обратиться только к наименее защищенным сегментам данных, относящимся к кольцу 3.
Обращение к сегменту стека выполняется путем загрузки селектора в регистр SS. Этот селектор должен выбирать дескриптор сегмента с разрешенной записью, т. е. бит 1 в байте доступа должен иметь значение W - 1 (см. рис. 2.43, б). Значения RPL и DPL должны быть равны CPL. Нарушение этих правил (обращение к сегменту, для которого W = 0; использование селекторов и дескрипторов, имеющих значения RPL и DPL, не равные CPL) приводит к исключению типа #GP. При обращении к дескриптору, имеющему значение бита присутствия Р = 0 (отсутствующий сегмент) возникает исключение типа #SS («ошибка обращения к стеку»).
Обращение к сегментам программ (передача управления) реализуется при выполнении команд межсегментного перехода JMP, вызова подпрограммы CALL и возврата из подпрограммы RET, прерывания INT и возврата из прерывания IRET. Правила обращения к сегментам программ зависят от значения бита подчиненности С в байте доступа дескриптора (см. рис. 2.43, а).
Обращение к подчиненным сегментам, для которых установлено значение С = 1, допускается только из программ, имеющих такой же или более низкий уровень привилегий. Таким образом, в программах с текущим уровнем привилегий CPL могут выполняться межсегментные команды JMP, CALL с передачей управления подчиненному сегменту, имеющему DPL= < CPL. При такой передаче значение CPL сохраняется, т. е. сохраняется уровень привилегий исходной (вызывающей) программы.
Обычно бит подчиненности С = 1 устанавливается для сегментов, которые могут использоваться программами с различными уровнями привилегий, например для системных библиотек. При этом подчиненные сегменты должны размещаться в кольце защиты с номером, соответствующим максимальному уровню привилегий (минимальному значению CPL) вызывающих программ.
Обращение к неподчиненным сегментам, имеющим значение С = 0, с помощью команд JMP и CALL допускается только в случае, если уровень привилегий текущей программы равен уровню защиты сегмента: CPL = DPL.
Обращение через шлюз используется для вызова неподчиненных сегментов программ с более высоким уровнем привилегий, чем текущая программа. Для реализации таких вызовов служат специально установленные точки входа в программы, которые называются шлюзами (или вентилями) вызова. Менее привилегированная процедура может вызвать более привилегированную, обращаясь к ней через дескриптор шлюза вызова, определяющий доступную точку входа. Этот способ обращения позволяет программам пользователя обращаться за обслуживанием к операционной системе. При этом допускаются обращения только к определенным процедурам, которые санкционируются путем введения в систему
РАБОТА ПРОЦЕССОРА В ЗАЩИЩЕННОМ И РЕАЛЬНОМ РЕЖИМАХ
соответствующего шлюза. Тем самым исключается возможность несанкционированного обращения менее привилегированных процедур к более привилегированным, что позволяет защитить их от возможных искажений.
Отметим, что в процессорах Pentium вызов через шлюз может осуществляться командами CALL и JMP, тогда как в процессорах 486 и более ранних моделях такой вызов производился только командой CALL.
Для вызова более привилегированной программы команда CALL или JMP должна обратиться к хранящемуся в LDT дескриптору шлюза вызова, формат которого показан на рис. 2.49, а.
В байтах 2,3 дескриптора шлюза содержится селектор вызываемого сегмента программы, а байты 0, 1, 6, 7 задают относительный адрес команды, являющейся точкой входа в эту программу. Байт доступа 5 содержит бит присутствия Р и поле уровня привилегий дескриптора шлюза gDPL, которые имеют такое же назначение, как и в дескрипторах сегментов. Поле TYPE в байте доступа шлюза (табл. 2.59) содержит код 0100, если вызываемая программа написана для 16-разрядного процессора 80286, или код 1100, если программа написана для 32-разряд-ных процессоров 386,486, Pentium, Р6. Пятибитовое поле WC в байте 4 указывает количество параметров, которые переносятся из стека, обслуживающего программы с текущим уровнем привилегий CPL, в стек, используемый программами с уровнем привилегий вызываемой программы. Параметры представляют собой 32-разрядные слова (16-разрядныедля процессоров 80286), число которых может составлять от 0 до 31.
При вызове программ через шлюз должны выполняться следующие правила.
• Значения RPL селектора, вызывающего шлюз, и CPL текущей программы должны быть меньше или равны значению gDPL в байте доступа шлюза. Таким образом, дескриптор шлюза должен иметь такой же или меньший уровень привилегий, чем запрос и текущая программа: gDPL >= (RPL,CPL).
• Значение gDPL шлюза вызова должно быть больше или равно уровню DPL вызываемого сегмента программ: gDPL >= DPL.
• Вызываемый сегмент программ должен иметь такой же или более высокий уровень привилегий DPL, чем текущая программа: DPL<= CPL.
• Последнее из перечисленных правил реализуется при выполнении команды CALL с обращением клюбым видам сегментов программ (подчиненным и неподчиненным) и команды JUMP, вызывающей подчиненный сегмент. Если команда JUMP осуществляет переход к неподчиненному сегменту программ, то необходимо выполнение правила DPL = СРЕ.При вызове программ через шлюз должны выполняться следующие правила.
• Значения RPL селектора, вызывающего шлюз, и CPL текущей программы должны быть меньше или равны значению gDPL в байте доступа шлюза. Таким образом, дескриптор шлюза должен иметь такой же или меньший уровень привилегий, чем запрос и текущая программа: gDPL>= (RPL,CPL).
• Значение gDPL шлюза вызова должно быть больше или равно уровню DPL вызываемого сегмента программ: gDPL >= DPL.
Байт 7,6 Байт 5 Байт 4
I----------------------------------II------------------------------------II-------1
31 16 15 14 13 12 11 8 7 5 4 0
Относительный адрес А31 -16 Р gDPL 1 TYPE 000 WC
Селектор сегмента Относительный адрес А15 -0
। 31_______________________16 „ 15___________________________________0 ,
Байт 3,2 Байт 1,0
Рис. 2.49. Формат дескриптора шлюза
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
• Вызываемый сегмент программ должен иметь такой же или более высокий уровень привилегий DPL, чем текущая программа: DPL <= CPL.
• Последнее из перечисленных правил реализуется при выполнении команды CALL с обращением к любым видам сегментов программ (подчиненным и неподчиненным) и команды JUMP, вызывающей подчиненный сегмент. Если команда JUMP осуществляет переход к неподчиненному сегменту программ, то необходимо выполнение правила DPL = CPL.
Примеры реализации этих правил при различных комбинациях значений RPL, CPL, gDPL, DPL иллюстрируются на рис. 2.50.
Если эти правила выполняются, то после вызова дескриптора шлюза в сегментный регистр CS загружается селектор - байты 3,2 этого дескриптора. Этот селектор выбирает из LDT дескриптор вызываемого сегмента программы. При этом младшие два бита (поле RPL) селектора игнорируются, а вместо них в регистр CS в качестве CPL заносится значение DPL из дескриптора вызываемого сегмента. В регистр EIP из дескриптора шлюза загружается относительный адрес входа в программу-байты 0,1,6,7 (для программ процессора 80286 в IP загружаются байты 0,1).
Если вызванная программа имеет другой (более высокий) уровень привилегий, чем текущая, то при выполнении команд JMP, CALL с использованием шлюза вызова производится переключение стека. Выполняется обращение к стеку, организованному для программ с уровнем привилегий, соответствующим уровню вызванной программы. В этот стек последовательно вводятся старые значения SS и ESP; параметры, переносимые из старого стека; старые значения CS и EIP. Число переносимых параметров определяется полем WC (см. рис. 2.49), причем выбираются последние из загруженных в старый стек параметров. Последующие ячейки стека используются для хранения новых параметров. Переключение стека производится автоматически путем загрузки в регистры SS и ESP из сегмента состояния задачи TSS нового содержимого, которое определяет начальный адрес стека для программ данного уровня привилегий.
Необходимо отметить, что переключение стека реализуется только при обращении к неподчиненным сегментам программ (имеющих в дескрипторе значение бита С = 0). Если через шлюз осуществляется вызов подчиненного сегмента программ (значение бита С -1), то переключение стека не производится.
По команде RET производится восстановление из стека старого содержимого регистров CS, EIP (IP) и SS, ESP (SP). Таким образом, одновременное возвратом к исходной программе происходит и возвращение к старому стеку. Команда RET проверяет значение CPL и два младших разряда извлекаемого из стека старого содержимого CS, определяющие уровень привилегий программы, к которой осуществляется возврат. Команда выполняется только в том случае, когда значение этих битов больше или равно CPL, т. е. возврат осуществляется к программе с таким же или меньшим уровнем привилегий.
Нарушение командами JMP, CALL, RET указанных правил обращения к сегментам программ вызывает исключение типа #GP («нарушение защиты»).
Чтобы избежать частых нарушений хода выполнения программы из-за несоблюдения правил доступа к сегментам, в набор команд процессора введены специальные команды, используемые для проверки различных условий доступа. Команда LAR осуществляет загрузку в регистр байта доступа сегмента, выбираемого с помощью селектора, который содержится в адресуемой ячейке памяти или регистре. После этой операции процессор может произвести побитный анализ содержимого байта доступа, определяя возможности обращения к данному сегменту. Команда LSL загружает в регистр значение границы сегмента, который выбирается таким же образом, как командой LAR. Используя полученное значение этой границы, процессор может организовать контроль формирования адреса, чтобы избежать прерывания программы при выходе за пределы адресуемого сегмента. Команды VERR, VERW проверяют
РАБОТА ПРОЦЕССОРА В ЗАЩИЩЕННОМ И РЕАЛЬНОМ РЕЖИМАХ
Рис. 2.50. Варианты реализации передачи управления с использованием шлюза вызова
возможности записи в сегмент данных и чтения из сегмента программ, устанавливаемые соответствующими битами дескрипторов. Если запись или чтение разрешены, то устанавливается значение признака ZF = 1 в регистре EFLAGS. Предварительный анализ значения этого признака позволяет избежать запрещенных видов обращения к данному сегменту, вызывающих прерывание текущей программы. Адресация необходимого сегмента при выполнении команд VERR, VERW производится таким же образом, как и командой LAR.
Реализация ввода-вывода с помощью команд IN, OUT, INS, OUTS в защищенном режиме производится с учетом CPL выполняемой программы. Величина CPL сравнивается со значением поля IOPL в регистре EFLAG. Ввод/вывод производится только при выполнении условия CPL >= IOPL. Нарушение этого условия вызывает исключение типа #GP, если доступ к адресованному командой порту не разрешен специальной битовой картой ввода-вывода, задаваемой при решении отдельных задач.
2.7.4. ПОДДЕРЖКА МНОГОЗАДАЧНОГО РЕЖИМА
Многозадачностью называется такой способ организации работы системы, при котором в ее памяти одновременно содержатся программы и данные для выполнения нескольких процессов обработки информации (задач). При этом должна обеспечиваться взаимная защита программ и данных, относящихся к различным задачам, а также возможность перехода от выполнения одной задачи кдругой (переключение задач). Процессоры семейства Р6 имеют эффективные средства поддержки многозадачного режима, реализующие защиту и быстрое переключение задач. В качестве таких средств используется специальная структура данных, организованная в виде сегмента, который называется сегментом состояния задачи TSS. Аппаратными средствами для поддержки многозадачности служит
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
16-разрядный регистр задачи TR, в который заносится селектор дескриптора TSS, и связанный с TR программно недоступный 64-разрядный регистр, в который из GDT загружается 8-байтовый дескриптор TSS.
Сегмент состояния задачи TSS, структура которого показана на рис. 2.51, состоит из двух частей. Обязательная часть TSS объемом 104 байта содержит всю информацию, необходимую процессору для решения данной задачи. Дополнительная часть может содержать какую-либо информацию об этой задаче, используемую операционной системой (имя задачи, комментарии и т. д.), и битовые карты, одна из которых определяет номера прерываний, для которых реализуется виртуализация, другая указывает адреса устройств ввода-вывода, к которым разрешено обращение при выполнении данной задачи. Рассмотрим содержание обязательной части сегмента TSS.
Первые два байта в сегменте TSS используются для хранения селектора TSS предыдущей задачи, при выполнении которой произошел вызов данной задачи. В эти байты заносится содержимое регистра TR для предыдущей задачи, чтобы обеспечить возврат к ее выполнению. Поэтому данный селектор называется селектором возврата. Отдельные поля TSS хранят содержимое сегментных регистров ES, CS, SS, DS, FS, GS, регистров общего назначения ЕАХ, ЕСХ, EDX, ЕВХ, ESP, EBP, ESI, EDI, регистра флагов EFLAGS и указателя команд EIP. При переключении задач содержимое указанных полей из вызванного TSS загружается в соответствующие регистры процессора. При следующем переключении
31 16 15 0
Резервировано (0...0) Селектор возврата Ах
ESP0 Ах + 4
Резервировано (0...0) SS0 Ах + 8
ESP1 Ах + С
Резервировано (0...0) SS1 Ах + 10
ESP2 Ах+ 14
Резервировано (0...0) SS2 Ах + 18
CR3 Ах + 1С
EIP Ах+ 20
EFLAGS Ах+ 24
ЕАХ Ах+ 28
ЕСХ Ах + 2С
EDX Ах+ 30
ЕВХ Ах + 34
ESP Ах+ 38
ЕВР Ах + ЗС
ESI Ах+ 40
EDI Ах + 44
Резервировано (0...0) ES Ах+ 48
Резервировано (0...0) CS Ах + 4С
Резервировано (0...0) SS Ах+ 50
Резервировано (0...0) DS Ах + 54
резервировано (0...0) FS Ах+ 58
Резервировано (0...0) GS Ах + 5С
Резервировано (0...0) LDT Ах + 60
Относительный адрес БКВВ Резервировано (0...0) Ах + 64
Дополнительная информация для ОС
Битовая карта обслуживания прерываний
Битовая карта ввода-вывода (БКВВ)
I 11111111
Рис. 2.51. Структура сегмента TSS
РАБОТА ПРОЦЕССОРА В ЗАЩИЩЕННОМ И РЕАЛЬНОМ РЕЖИМАХ
текущее содержимое регистров заносится в TSS данной задачи, после чего производится загрузка регистров из TSS новой задачи, Таким образом, содержимое TSS обновляется при каждом переключении задачи, фиксируя текущее состояние.
Содержимое ряда полей в обязательной части TSS не изменяется при решении задачи. Так, не изменяется содержимое поля, определяющего значение селектора LDT для данной задачи, и содержимое регистра управления CR3, которое используется при страничной организации памяти. Не изменяется также содержимое полей SSO, ESPO, SS1, ESP1, SS2, ESP2, которые определяют начальный адрес стека при переключении к задачам с более высоким уровнем привилегий PL = 0,1,2. Такое выделение отдельных стеков для задач с различными уровнями привилегий обеспечивает их более надежную защиту. Содержимое указанных полей TSS загружается в соответствующие регистры в процессе выполнения конкретной задачи.
Бит ловушки Т в сегменте TSS вызывает при Т = 1 исключение типа #DB («исключение отладки») при переключении на данную задачу. Это исключение используется при отладке программного обеспечения.
Два последних байта в обязательной части TSS определяют относительный адрес начала битовой карты ввода/вывода (БКВВ) в TSS. Каждый бит БКВВ соответствует однобайтовому порту ввода/вывода. Так как процессор обеспечивает обслуживание до 65536 портов, то полная БКВВ, определяющая возможность их обслуживания, будет представлять строку длиной 64 Кбит, занимающую 8 Кбайт памяти. Поэтому относительный адрес БКВВ должен быть меньше или равен DFFFh. При записи в бите БКВВ нуля разрешается обращение к порту ввода-вывода, адрес (номер) которого соответствует порядковому номеру данного бита в карте ввода-вывода. Если значение некоторого бита БКВВ равно единице, то при поступлении команд обращения к соответствующему порту процессор реализует исключение типа #GP («нарушение защиты»).
Таким образом, использование БКВВ вводит для команд ввода-вывода дополнительный вид защиты (помимо выполнения условия CPL<IOPL), который устанавливается для каждого порта индивидуально. Эту защиту можно обеспечить как для всех, так и для части портов. Если конец БКВВ выходит за границу сегмента, определенную его размером, который задается дескриптором TSS, то доступность соответствующих портов с высокими номерами не зависит от БКВВ. При этом БКВВ контролирует доступ только к портам с меньшими номерами, для кото-рых биты БКВВ вошли в заданную дескриптором границу сегмента. Если значение размера сегмента, заданное дескриптором TSS, меньше указанного в TSS относительного адреса БКВВ, то эта карта не влияет на доступность портов и ее можно полностью исключить.
Перед БКВВ располагаются 32 байта (256 бит) таблицы, определяющей способ обслуживания программных прерываний, реализуемых при поступлении команды INTn в режиме виртуального процессора 8086. Каждому из 256 значений п в команде INTп соответствует битс таким же номером в данной таблице. Если этот бит имеет значение «1», то при поступлении соответствующей команды INTn вызывается подпрограмма обслуживания в защищенном режиме, обращение к которой производится с помощью таблицы прерываний IDT. Если бит в этой таблице имеет значение «0», то выполняется обращение к подпрограмме обслуживания, которая должна содержаться в составе выполняемой программы, написанной для процессора 8086 (вектор соответствующей подпрограммы обслуживания должен размещаться в таблице, расположенной в начале адресуемой памяти, адреса OOOOh -03FFh).
За последним байтом БКВВ в TSS должен следовать заключительный байт, содержащий единицу во всех разрядах (FFh). Адрес этого байта должен соответствовать границе сегмента, определенной дескриптором TSS.
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
Объем дополнительной части TSS зависит от размеров применяемой БКВВ и количества служебной информации, используемой операционной системой. Этот объем определяется характером решаемой задачи. Во многих случаях дополнительная часть TSS вообще отсутствует.
Обращение к TSS осуществляется путем загрузки в регистр TR селектора, который адресует размещенный в GDT дескриптор TSS соответствующей задачи (рис. 2.52). Содержимое регистра TR можно загружать или заносить в память командами LTR, STR. Однако обычно команда LTR используется только при инициализации системы для установки начального содержимого TR. В процессе дальнейшей работы этот регистр загружается процессором при выполнении команд JMP, CALL, IRET, переключающих задачу.
Дескриптор TSS должен храниться только в таблице GDT. Поэтому обращение к дескриптору TSS с помощью селектора, имеющего бит TI = 1 (индикатор таблицы LDT), вызовет исключение типа #TS («ошибка обращения к TSS»). При загрузке селектора дескриптора TSS в какой-либо из регистров сегментов (CS, DS, SS, ES, FS, GS) возникает исключение того же типа.
Содержимое сегмента TSS не может быть непосредственным образом считано или изменено. При необходимости считывания или изменения TSS необходимо сформировать дескриптор сегмента данных, имеющий те же атрибуты (базовый адрес, размер и другие), что и TSS. После этого содержимое TSS может быть считано или модифицировано путем обращения к сегменту TSS как сегменту данных с помощью сформированного дескриптора.
Формат дескриптора TSS приведен на рис. 2.52. Назначение битов присутствия Р и дробности G такое же, как в дескрипторах сегментов. Поле TYPE (см. рис. 2.43, е) в байте доступа определяет тип задачи (см. табл. 2.59): код 01В1 указывает, что данная задача запрограммирована для решения на 16-разрядном процессоре 80286, код 11В1 - что задача предназначена для 32-разрядных процессоров 386, 486, Pentium, Р6. Бит занятости В в этом байте устанавливается в состояние В = 1 при переключении на данную задачу. Указанная в дескрипторе граница сегмента TSS должна иметь значение не менее чем 67h, что соответствуют минимальному объему его обязательной части 104 байт. В противном случае при обращении к TSS реализуется исключение типа #TS. Неиспользуемый бит AVL в байте 6 дескриптора может быть использован операционной системой и установлен ею в любое состояние.
При выполнении задач, запрограммированных для решения 16-разрядным процессором 80286, структура сегмента TSS изменяется (рис. 2.53). Объем обязательной части сегмента в этом случае составляет 44 байта, и его граница должна иметь значение не менее чем 2Ch.
Переключение задач осуществляется с помощью команд межсегментного перехода JUMP, вызова CALL и возврата IRET. Если селектор (sei 16) команды JUMP или CALL выбирает из
Байт 3, 2 Байт 1, 0
Рис. 2.52. Формат дескриптора TSS
РАБОТА ПРОЦЕССОРА В ЗАЩИЩЕННОМ И РЕАЛЬНОМ РЕЖИМАХ
Байт 7,6 Байт 5 Байт 4
I II II I
31 16 15 14 13 12 11 8 7 О
Резервировано Р DPL 0 0101 Резервировано
Селектор сегмента TSS Резервировано
, 31 16 и 15 0|
Байт 3, 2 Байт 1, О
Рис. 2.53. Структура сегмента TSS для процессора 80286
таблицы GDT дескриптор, который содержит в поле TYPE байта доступа код 0001 (обращение к TSS для процессора 80286) или 1001 (обращение к TSS для процессоров 386,486, Pentium, Р6), то выполняется переключение задач. При этом селектор sei 16 заносится в регистр TR, а в связанный с ним программно-недоступный регистр загружается дескриптор TSS. В соответствии с содержимым обязательной части TSS производится загрузка регистров процессора, после чего он начинает выполнение поступившей задачи. Следует отметить, что межсегментные команды JUMP и CALL содержат байты eip32, определяющие новое содержимое регистра EIP. Однако, если селектор выбирает дескрип-тор TSS, то эти байты игнорируются, а регистр EIP загружается содержимым соответствующего поля TSS. При переключении задачи устанавливается значение TS = 1 в регистре управления CR0, хранящем слово состояния машины MSW. Сброс этого бита в состояние TS = 0 может производиться командой CLTS или путем загрузки нового содержимого в CR0 командами LMSW или MOV.
Переключение задач производится, если бит занятости В в байте доступа дескриптора TSS вызываемой задачи имеет значение «0» (задача свободна). При В = 1 выполняется исключение типа #GP (нарушение защиты). Установка значения В = 1 (задача занята) в дескрипторе TSS производится командами JUMP или CALL, переключающими процессор на выполнение данной задачи. Обращение к задаче, находящейся в процессе решения, которая имеет значение бита В = 1, запрещено (вызовет исключение #GP). Если решение данной задачи было прервано переключением на другую задачу, то возврат к ее выполнению может быть реализован только командой IRET.
При переключении задач с помощью команд JUMP или CALL должны выполняться правила доступа, установленные для обращения к сегментам данных: DPL >= CPL, RPL, где значение DPL задается соответствующим полем в дескрипторе сегмента TSS (см. рис. 2.52). Таким образом, допускается переключение на решение задач, чья степень защиты меньше или равна уровню привилегий текущей программы и запроса.
При использовании команды CALL возможно обращение к задачам с более высокой степенью защиты, чем уровень привилегий текущей программы, с помощью шлюза задачи. Использование шлюзов задачи аналогично шлюзам вызова. Дескриптор шлюза задачи, формат которого показан на рис. 2.54, может размещаться в любой из дескрипторных таблиц: GDT, LDT или IDT. Содержащийся в этом дескрипторе селектор сегмента TSS обращается к дескриптору TSS, располагаемому в таблице GDT.
Обращение к шлюзу разрешается, если для текущей программы значение CPL, RPL <= gDPL, указанному в дескрипторе шлюза задачи. Селектор TSS из дескриптора шлюза должен иметь значение бита TI = 1. Селектор загружается в регистр TR и выбирает из GDT дескриптор TSS, при этом значение уровня DPL, указанное в выбранном дескрипторе, не учитывается. При нарушении указанных правил обращения возникает исключение типа #TS («ошибка обращения к TSS»).
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
15 О
Селектор возврата Ах4
SP0 Ах + 2
SS0 Ах +4
SP1 Ах + 6
SS1 Ах + 8
SP2 Ах +А
SS2 Ах + С
IP Ах + Е
FLAGS Ах + 10
АХ Ах + 12
GX Ах + 14
DX Ах + 16
ВХ Ах+18
SP Ах+ 1А
BP Ах+ 1С
SI Ах + 1B
DI Ах+ 20
ES Ах+ 22
GS Ах+ 24
SS Ах+ 26
DS Ах+ 28
Селектор LDT Ах + 2А
Дополнительная информация для ОС
Рис. 2.54. Формат дескриптора шлюза задачи
При использовании шлюзов задачи с меньшим уровнем привилегий могут вызывать более привилегированные (защищенные) задачи, поэтому в данном случае встает задача обеспечения сохранности содержимого стеков. Эта проблема решается путем использования трех отдельных начальных адресов стеков, которые задаются тремя парами полей TSS: SS0 и ESPO, SS1 и ESP1, SS2 и ESP2. Если дескриптор вызываемого TSS имеет поле DPL = 0, то при вызове задачи через шлюз в регистры SS и ESP процессора загружаются значения SS и ESP0. При DPL = 1 загружается SSI и ESPI, при DPL = 2 загружается SS2 и ESP2. Если DPL = CPL = 3, то создание отдельного стека не требуется, и вызванная задача продолжает заполнение и использование стека, созданного в процессе выполнения старой (вызывающей) задачи. Таким образом, для задач каждого уровня привилегий создается отдельный стек, что исключает возможность нарушения его содержимого задачами с более низким уровнем привилегий.
При переключении задач с помощью команды CALL содержимое TR заносится в два младших байта сегмента TSS в качестве селектора, обеспечивающего возврат к выполнявшейся задаче. В этом случае в регистре EFLAGS устанавливается значение бита вложенной задачи NT = 1 .Такимобразом, при последовательном использовании команды CALL можно реализовать многократное вложение задач.
Возврат из текущей задачи к выполнению предыдущей осуществляется с помощью команды IRET, которая анализирует значение NT. При NT = 1 осуществляется обратное переключение на задачу, задаваемую селектором возврата в сегменте TSS текущей задачи. В этом случае изТЗБ возвращаемой задачи загружается сохранившееся содержимое основных регистров. При NT = 0 команда IRET осуществляет обычную процедуру возврата из подпрограммы с восстановлением из стека содержимого регистров CS, EIP, EFLAGS.
Команда JUMP при переключении задач не сохраняет в TSS селектор возврата и устанавливает значение NT = 0. Кроме того, команды JUMP и CALL по-разному влияют на значение бита занятости. Команда JUMP при переключении устанавливает в дескрипторе старой
РАБОТА ПРОЦЕССОРА В ЗАЩИЩЕННОМ И РЕАЛЬНОМ РЕЖИМАХ
задачи значение бита занятости В = 0, а в дескрипторе новой задачи - В = 1. Команда CALL также устанавливает В = 1 для новой задачи, но сохраняет В = 1 и для предыдущей задачи. Таким образом, каждая задача в цепи вызовов с помощью команды CALL оказывается занятой, что запрещает применение рекурсивных процедур и реентерабельных программ.
2.7.5. РЕАЛИЗАЦИЯ РЕЖИМА ВИРТУАЛЬНОГО 8086 (V86) , -
Процессоры Р6, как и более младшие модели 386, 486, Pentium, могут выполнять в защищенном режиме все программы, написанные для микропроцессора 8086, обеспечивая при этом ряд средств защиты и возможность страничной организации памяти. Такой вариант защищенного режима называется режимом виртуального процессора 8086 (сокращенно V86) и реализуется при установке в регистре EFLAGS значения признака VM = 1. Таким образом, в режиме V86 микропроцессор работает как виртуальный процессор, состоящий из аппаратных средств процессора Р6, прикладного программного обеспечения, написанного для 8086, и системного программного обеспечения (монитор V86).
Все программы, выполняемые в режиме V86, имеют низший уровень привилегий: CPL = 3. Этим режим V86 отличается от реального режима, при котором всем программам предоставляется высший уровень привилегий: CPL = 0. При формировании линейного адреса в режиме V86 не используются дескрипторы, поэтому правила доступа к сегментам в соответствии с уровнем привилегий в этом режиме не выполняются. В режиме V86 используются следующие способы защиты.
• В режиме V86 не осуществляется защита сегментов. Если используется страничная организация памяти, то ее защита при нарушении правил доступа к странице реализуется путем исключения типа #PF («ошибка обращения к странице»).
• Поступление команд, которые выполняются в защищенном режиме только при уровне CPL = 0, в режиме V86 вызывает исключение типа #GP («нарушение защиты»). Это команды LIDT, LGDT, LMSW, CLTS, HLT, а также MOV для регистров управления, тестирования и отладки.
• Поступление команд, выполняемых только в защищенном режиме, вызывает в режиме V86 исключение типа #UD («неразрешенный код команды»). Это команды LLDT, SLDT, LTR, STR, LAR, LSL, ARPL.VERR, VERW.
• Команды PUSHF, POPF, CLI, STI, INT и IRET в режиме V86 чувствительны к значению поля IOPL в EFLAGS. Они выполняются только при IOPL = 3, в противном случае реализуется исключение типа #GP. Отметим, что команды INTO, INT3, ROUND в режиме V86 (и вообще в защищенном режиме) выполняются независимо от значения поля IOPL.
• Выполнение команд ввода/вывода IN, OUT, INS, OUTS в режиме V86 не зависит от значения поля IOPL (отличие от защищенного режима). Однако при вызове в режиме V86 задачи, имеющей БКВВ в сегменте TSS, данные команды учитывают значение битов разрешения для соответствующих портов. При обращении к порту, для которого в БКВВ бит разрешения установлен в «1», реализуется исключение типа #GP.
С учетом указанных выше особенностей процессор в режиме V86 выполняет весь набор команд, включая битовые операции, операции над числами с плавающей точкой и ряд других, не реализуемых микропроцессором 8086. Допускается использование всех регистров процессора Р6, включая сегментные регистры FS, GS.
По умолчанию в режиме V86 используются 16-разрядные регистры и исполнительные адреса. С помощью префиксов размера можно производить обработку 32-разрядных операндов и формировать 32-разрядные адреса. Однако значение полученного физического адреса в режиме V86 не должно превышать 65535, в противном случае возникает исключение типа #GP.
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
При работе в режиме V86 процессор формирует 20-разрядный линейный адрес таким же способом, как в реальном режиме. Если при этом бит страничной адресации в регистре управления CR3 имеет значение PG = 1, то используется страничная организация памяти. В этом случае адресуемая в режиме V86 память объемом 1 Мбайт делится на 256 страниц по 4 Кбайта. Младшие 12 разрядов линейного адреса выбирают адресуемый байт в кадре страницы, а старшие 8 разрядов определяют с помощью таблицы страниц базовый адрес страницы. Каталог разделов в режиме V86 не используется, и базовый адрес таблицы страниц задается содержимым регистра CR3. Отдельные страницы могут быть размещены в любом месте адресного пространства, имеющего объем 4 Гбайта. Каждая задача в режиме V86 может использовать свои варианты размещения страниц, так как при переключении задач загружается заново содержимое регистра управления CR3, определяющее базовый адрес таблицы страниц. При использовании страничной организации памяти в режиме V86 реализуются соответствующие способы защиты страниц.
Способ обработки исключений (прерываний) в режиме V86 определяется значением бита VME в регистре управления CR4 (см. рис. 2.7, в). При значении VME = 0 обработка исключений производится в защищенном режиме, если в регистре EFLAGS поле IOPL = 3. Если IOPL < 3, то реализуется исключение типа #GP. При значении VME= 1 способ обработки программных прерываний, реализуемых при поступлении команды INTn, зависит от значения соответствующего бита в таблице, располагаемой в сегменте TSS решаемой задачи. Если этот бит равен «О», и в регистре EFLAGS значение поля IOPL = 3, то прерывание обслуживается как в процессоре 8086:
• в стек последовательно загружается содержимое регистра EFLAGS, в котором устанавливаются значения бита NT - 0 и поля IOPL - 0, регистров CS, IP (младшие 16 разрядов содержимого EIP);
• в регистре EFLAGS устанавливаются значения битов IF = TF = 0;
• из таблицы прерываний, расположенной в начале адресуемой памяти (начиная с адреса OOOOOOOOOOh), загружается вектор соответствующего прерывания -новое содержимое CS и IP.
Если бит в таблице обслуживания прерываний TSS равен «1», то обработка прерывания производится в защищенном режиме.
Если при VME = 1 значение поля IOPL < 3, то при обслуживании исключений используется механизм виртуальных прерываний.
Вход процессора в режим виртуального 8086 можно осуществить в защищенном режиме двумя способами.
1. Переключение на выполнение задач, которая имеет в TSS поле EFLAGS с установленным битом VM = 1. При этом новая задача будет выполнять команды процессоров 8086 и Р6 и формировать базовые адреса, как 8086. Отметим, что переключение на задачу микропроцессора 80286 не может вызвать переход в режим V86, так как при этом из TSS загружается только 16 младших разрядов поля EFLAGS, в которые не входит бит VM.
2. Поступление команды IRET в ходе выполнения программы, которая имеет высший уровень привилегий CPL = 0, если в загружаемом при этом из стека содержимом регистра EFLAGS установлено значение бита VM=1. При других уровнях привилегий команда IRET не будет изменять значения VM, т. е. переход в режим V86 не реализуется.
Выход процессора из режима V86 может произойти только при обработке прерываний или исключений. При этом возможны два варианта.
1. В результате прерывания происходит переход на процедуру с высшим уровнем привилегий, т. е. устанавливается CPL = 0. При этом текущее состояние регистра EFLAGS заносится в стек, а бит VM сбрасывается в нуль. Таким образом, вызванная процедура будет выполняться в защищенном режиме. Если вызванная процедура имеет более низкий уровень привилегий (CPL > 0), то происходит исключение типа #GP.
РАБОТА ПРОЦЕССОРА В ЗАЩИЩЕННОМ И РЕАЛЬНОМ РЕЖИМАХ
2. Прерывание вызывает переключение задачи. При этом в TSS старой задачи, выполнявшейся в режиме V86, заносится текущее содержание регистров, в том числе EFLAGS с установленным битом VM = 1. Таким образом, имеется возможность вернуться к выполнению этой задачи в режиме V86. Если загружаемый при переключении задач новый TSS является сегментом 32-разрядного процессора (386,486, Pentium или Р6) со значением бита VM=0 в поле EFLAGS, то признак VM в режиме EFLAGS сбрасывается в нуль, и процессор будет выполнять новую задачу в защищенном режиме.
Отметим, что команда POPF не изменяет значение флага VM, даже если она выполняется в защищенном режиме с наивысшим уровнем привилегий (CPL = 0). Эта команда не обеспечивает переход процессора в режим V86.
Таким образом, процессоры семейства Р6 в режиме V86 могут не только выполнять с более высокой производительностью программы, написанные для 8086, но и реализовывать новые прикладные программы, эффективно использующие расширенные возможности этого семейства. Следует отметить, что процессоры Р6 требуют для выполнения команд значительно меньше машинных тактов, чем 8086. Поэтому при реализации программных задержек на этих процессорах могут возникнуть значительные расхождения во времени по сравнению с реализацией на 8086.
2.7.6. ФУНКЦИОНИРОВАНИЕ ПРОЦЕССОРА В РЕАЛЬНОМ РЕЖИМЕ
В реальном режиме процессор выполняет программы, написанные для микропроцессоров 8086 (или 8088) и для реального режима микропроцессоров 80286, 80386. С точки зрения программиста, процессор Р6 в реальном режиме представляет собой более быстрый процессор 8086 с расширеным набором команд и регистров. При работе в реальном режиме все процедуры выполняются с наиболее высоким уровнем привилегий (CPL - 0) в отличие от процедур в режиме V86, для которых устанавливаются низший уровень привилегий (CPL - 3).
В реальном режиме процессор выполняет весь набор команд, за исключением команд управления ARPL, LAR, LSL, STR, LTR, SLDT, LLDT, VERR, VERW. При поступлении этих команд, которые оперируют с дескрипторами сегментов, реализуется исключение типа #UD («неправильный код операции»).
При работе в данном режиме процессор не обращается для формирования адресов к дескрипторам сегментов, а использует для образования базового адреса сегмента значение селектора, расположенного в соответствующем регистре CS, SS, DS, ES, FS или GS. Формирование физического адреса в реальном режиме иллюстрирует рис. 2.55.
Базовый адрес сегмента имеет 20 разрядов и образуется путем сдвига 16-разрядного селектора (содержимого регистра CS, SS, DS, ES, FS или GS) влево на 4 разряда. Размеры сегментов фиксированы и составляют 64 Кбайт. Допускается взаимное наложение сегментов. Линейный адрес, образованный в результате суммирования базового адреса и селектора, служит физическим адресом для выбора байта, так как в реальном режиме страничная организация не реализуется. Если полученный физический адрес выходит за границу адресуемой в реальном режиме памяти (1 Мбайт), то выполняется исключение типа #GP.
По умолчанию в реальном режиме используются 16-разрядные операнды и адреса. При использовании префиксов можно обрабатывать 32-разрядные операнды и формировать 32-разрядные адреса. Однако, если эти адреса выходят за пределы границ сегмента (64 Кбайт) или адресуемой памяти (1 Мбайт), то реализуется исключение типа #GP.
При осуществлении ряда типов исключений в реальном режиме имеются отличия от защищенного режима. Исключения типа #TS, #NP, #PF, #АС не реализуются в реальном режиме. Исключение #GP в реальном режиме осуществляется при выходе за границу сегмента.
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
Рис. 2.55. Формирование физического адреса в реальном режиме
Отметим, что в памяти системы должны быть зарезервированы две области, необходимые для обеспечения реального режима. Первые 1024 ячейки памяти (адреса от OOOOh до 03FFh) резервируются в реальном режиме для размещения векторов прерываний. Последние 16 ячеек памяти (адреса от FFFFFFFOh до FFFFFFFFh) резервируются для программы инициализации системы. После включения процессора программа инициализации автоматически вводит его в реальный режим. Аналогичная процедура выполняется и после поступления сигнала сброса. Перейти из реального в защищенный режим можно с помощью команд MOV или LMSW, загружающих в регистр CR0 слово состояния с установленным битом защиты РЕ = 1. Перед этим в реальном режиме должна быть проведена загрузка необходимых регистров (GDTR, LDTR, и др.) и таблиц (GDT, LDT и др.), используемых в защищенном режиме.
Обратное переключение из защищенного в реальный режим выполняется только командой MOV, загружающей в регистр CR0 слово, которое имеет значение бита РЕ = 0 (команда LMSW не может устанавливать значение РЕ = 0). Предварительно необходимо провести некоторые подготовительные процедуры, обеспечивающие сохранение правильного функционирования процессора при переходе к реальному режиму: отключить механизм страничной трансляции, перейдя к использованию линейных адресов, равных физическим; установить для всех сегментов размер 64 Кбайт и ряд других. После выполнения команды MOV, устанавливающей в регистре CR0 бит РЕ = 0, следует перейти к программе, выполняемой в реальном режиме, с помощью команды межсегментного перехода JMP, которая очищает очередь команд. Затем в сегментные регистры загружается новое содержимое, обеспечивающее формирование физических адресов в реальном режиме (см. рис. 2.55).
2.8. РЕАЛИЗАЦИЯ ПРЕРЫВАНИЙ И ИСКЛЮЧЕНИЙ. ОБЕСПЕЧЕНИЕ ТЕСТИРОВАНИЯ И ОТЛАДКИ
При работе микропроцессорной системы часто возникают ситуации, когда требуется прервать выполнение текущей программы и перейти к подпрограмме, обеспечивающей необходимую реакцию системы на создавшиеся обстоятельства. Такие ситуации называются прерываниями или исключениями в зависимости от причин, вызывающих их возник
РЕАЛИЗАЦИЯ ПРЕРЫВАНИЙ И ИСКЛЮЧЕНИЙ. ОБЕСПЕЧЕНИЕ ТЕСТИРОВАНИЯ И ОТЛАДКИ
новение. Специальные виды таких прерываний реализуются при отладке программ, для чего в состав процессора введены необходимые функциональные блоки, работа которых контролируется с помощью регистров отладки DR7-0.
Особенно большое значение для современных процессоров и систем, реализуемых на их основе, имеют тестирование и самотестирование. Процессоры семейства Р6 содержат ряд средств, которые обеспечивают выполнение данных процедур.
2.8.1. ВИДЫ ПРЕРЫВАНИЙ И ИСКЛЮЧЕНИЙ, РЕАЛИЗАЦИЯ ИХ ОБСЛУЖИВАНИЯ
Прерываниями (interruption) являются штатные ситуации, возникающие при поступлении соответствующих команд (программные прерывания) или внешних сигналов (аппаратные прерывания). Исключениями (exeption) являются нештатные ситуации (ошибки), возникающие при работе процессора. При выявлении таких ошибок соответствующие блоки, контролирующие работу процессора, вырабатывают внутренние сигналы запроса, обеспечивающие вызов необходимой подпрограммы обслуживания. Классификация прерываний и исключений иллюстрируется на рис. 2.56.
Процессор способен обеспечить обслуживание 256 различных типов исключений и прерываний. Соответствующая обработка информации при возникновении таких ситуаций выполняется с помощью специальных подпрограмм обслуживания, начальные адреса (вектора) которых хранятся в таблице, размещаемой в памяти системы.
Запросы на выполнение аппаратных прерываний поступают от внешних устройств на входы LINTO/INTR, LINT1/NMI процессора. В мультипроцессорной системе, когда включен внутренний контроллер локальных прерываний APIC, сигналы LINT1 -0 на этих входах определяют номер запроса, поступающего от других устройств (процессоров) системы. В однопроцессорной системе, когда функционирование контроллера APIC запрещено, эти входы служат соответственно для подачи маскируемых INTR и немаскируемых NMI запросов прерывания от различных внешних устройств.
На вход INTR поступают маскируемые запросы прерываний, обслуживание которых может быть запрещено (замаскировано) путем установки значения признака IF = 1 в регистре состояний EFLAGS. Обычно такой запрос поступает от внешнего устройства через специальный контроллер прерываний, который собирает запросы от различных внешних устройств и передает их для обработки процессору, указав для них также номер п, определяю-
Рис. 2.56. Классификация прерываний и исключений
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
щий вид прерывания (INTR п). На вход NMI поступает запрос на немаскируемое прерывание, процедура обслуживания которого имеет фиксированный номер п - 2 (табл. 2.60). Значение признака IF в регистре EFLAGS не влияет на обслуживание процессором немаскируемого запроса прерывания NMI. При работе процессора в мультипроцессорной системе, когда функционирует контроллер локальных прерываний APIC, запросы аппаратных прерываний (маскируемые и немаскируемые) поступают по специальной APIC-шине.
Программные прерывания реализуются при поступлении команд: INT п, INT3, INTO, BOUND. Эти команды вызывают переход к выполнению подпрограмм обслуживания, вектора которых выбираются согласно табл. 2.60.
Таблица 2.60
Виды реализуемых прерываний
Номер (тип) Мнемоническое обозначение Описание Способ обслуживания Код ошибки Класс
0 #DE Ошибка деления Ошибка Нет В
1 #DB Отладка Ошибка/Ловушка Нет А
2 Сигнал NMI Прерывание Нет А
3 #ВР Команда INT3 (программный останов) Ловушка Нет А
4 #OF Переполнение (команда INTO) Ловушка Нет А
5 #BR Выход за границы (команда BOUND) Ошибка Нет А
6 #UD Недействительный код операции Ошибка Нет А
7 #NM FPU недоступен Ошибка Нет А
8 #DF Двойная ошибка Отказ Да (нуль)
9 Резервировано Нет
10 #TS Недействительный сегмент TSS Ошибка Да В
11 #NP Отсутствие сегмента Ошибка Да В
12 #SS Ошибка при обращении к стеку Ошибка Да В
13 #GP Нарушение общей защиты Ошибка Да В
14 #PF Страничное нарушение Ошибка Да С
15 Резервировано Нет
16 #MF Исключение FPU Ошибка Нет А
17 #AC Ошибка выравнивания Ошибка Да (нуль) А
18 #MC Машинный контроль Отказ Нет А
19 #XM Исключение SSE Ошибка Нет А
20-31 Резервировано
32-255 Прерывания пользователя Прерывание А
РЕАЛИЗАЦИЯ ПРЕРЫВАНИЙ И ИСКЛЮЧЕНИЙ. ОБЕСПЕЧЕНИЕ ТЕСТИРОВАНИЯ И ОТЛАДКИ
Для исключений зарезервированы первые 32 вектора в таблице прерываний, из которых в процессорах семейства Р6 используются только 17 (см. табл. 2.60). Каждый тип исключения имеет мнемоническое обозначение. Исключения делятся на ошибки (faults), ловушки (traps) и отказы (aborts). Ошибки выявляются и обслуживаются до выполнения команды, которая является причиной их возникновения. Примером ошибки может служить ситуация, возникающая при обращении очередной команды к странице или сегменту, отсутствующим в адресуемой оперативной памяти (обращение к сегменту или странице, для которых значение бита присутствия Р = 0). При ошибке в качестве адреса возврата к прерванной программе сохраняется адрес команды, выполнение которой вызвало данное исключение. Ловушка - это исключение, которое выявляется после выполнения команды. Примером ловушки может служить команда INTO, которая реализует исключение с номером п = 4 в случае, если в регистре EFLAGS значение признака переполнения OF = 1. При обслуживании ловушки в качестве адреса возврата сохраняется адрес команды, следующей за командой, вызвавшей данное исключение. Ошибки и ловушки предусматривают продолжение нормального выполнения программы после завершения их обслуживания.
Отказы сообщают о возникновении серьезных нарушений в работе системы. Примером таких нарушений может быть неисправность аппаратуры или возникновение исключения при обслуживании ранее поступившего запроса. Отказ не предусматривает продолжение выполнения прерванной программы, поэтому при его возникновении обычно производится повторный запуск (Restart) процессора.
Если одновременно произошло несколько событий, требующих обслуживания с помощью механизма прерываний, то процессор обрабатывает такие события последовательно, в соответствии с их приоритетами, которые указаны в табл. 2.61 (1 - высший приоритет, 8- низший). Отметим, что в этом приоритетном списке указан также ряд входных управляющих сигналов. При поступлении этих сигналов одновременно с другими событиями, вызывающими переход на обслуживание прерываний или исключений, процессор реагирует в соответствии с их приоритетами, приведенными в табл. 2.61.
Обработка прерываний в реальном режиме. Для перехода к обслуживанию поступившего запроса прерывания или исключения процессор обращается к таблице векторов прерываний, которая должна располагаться в начальной области памяти, начиная с адреса 0...0h. Элементами таблицы являются вектора прерываний - указатели входа в подпрограммы обслуживания различных типов прерываний. Вектор прерывания в реальном режиме содержит четыре байта, а размер всей таблицы составляет 1024 байт, если процессор обеспечивает обслуживание всех 256 возможных видов прерывания (табл. 2.60). Формат вектора прерываний для реального режима показан на рис. 2.57.
При возникновении прерывания процессор производит следующие действия:
• заносит текущее значение регистров CS и IP в стек;
• заносит текущее значение регистра FLAGS в стек;
• устанавливает значение признака IF = 0 в регистре EFLAGS (запрещение прерываний);
• устанавливает значения признаков TF = RC = АС = 0 в регистре EFLAGS;
• загружает в регистры CS, IP новое содержимое, заданное в выбранном векторе таблицы прерываний.
31 16 15 0
Селектор (CS) Смещение (IP)
Рис. 2.57. Формат вектора прерываний в реальном режиме
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
Таблица 2.61
Приоритеты событий, вызывающих прерывания
Приоритет Описание
1 (наивысший) Аппаратный RESET и машинный контроль: • внешний сигнал RESET#=0 (повторный запуск), • отказ типа #МС (машинный контроль).
2 Ловушка при переключении задач: • бит Т=1 в сегменте TSS.
3 Внешние сигналы: • FLUSH#=0 (очистка кэш-памяти), • STOPCLK#=0 (перевод в энергосберегающий режим), • SMI#=0 (вход в системный режим), • INIT=1 (инициализация процессора).
4 Ловушки на предыдущей команде: • останов в контрольной точке, • исключение отладки (признак TF=1 в регистре EFLAGS), точка останова при выборке данных из памяти или вводе-выводе.
5 Внешние сигналы прерывания: • немаскируемое прерывание NMI-1, • маскируемое прерывание INTR=1.
6 Ошибки при выборке следующей команды: • точка останова при выборке команды, • превышение границы сегмента команд, • ошибка обращения к странице при выборке команды.
7 Ошибки при декодировании следующей команды: • длина команды больше 15 байт, • ошибка типа #UD (недействительный код операции), • ошибка типа #NM (FPU недоступен).
8 Ошибки при выполнении команды: • #MF (исключение FPU), • #OF (переполнение) , • #BR (выход за границы массива), • #TS (недействительный TSS), • #NP (отсутствие сегмента), • #SS (ошибка обращения к стеку), • #GP (нарушение общей защиты), • #PF (ошибка обращения к странице при выборке данных), • #АС (ошибка выравнивания).
В реальном режиме процессор не заносит в стек кед ошибки и использует только младшие 16 разрядов регистра EIP (регистр IP) и EFLAGS (регистр FLAGS). Возврат из подпрограммы обслуживания прерывания выполняется с помощью команды IRET, которая восстанавливает сохраненное в стеке содержимое регистров FLAGS, CS и IP, обеспечивая возвращение к выполнению прерванной программы.
Обработка прерываний в защищенном режиме. Вызов подпрограмм обслуживания прерываний осуществляется через дескрипторную таблицу прерываний IDT (Interrupt Descriptor Table), которая может располагаться в любом месте адресного пространства. Базовый линейный адрес этой таблицы хранится в регистре IDTR (рис. 2.58).
РЕАЛИЗАЦИЯ ПРЕРЫВАНИЙ И ИСКЛЮЧЕНИЙ. ОБЕСПЕЧЕНИЕ ТЕСТИРОВАНИЯ И ОТЛАДКИ
47 16 15 0 q>'i
Базовый адрес IDT ГраницаIDT
Рис. 2.58. Формат содержимого регистра IDTR
Загрузка содержимого регистра IDTR осуществляется с помощью команды LIDT, а его сохранение в памяти - с помощью команды SIDT. Команда LIDT является привилегированной и может выполняться только программой, имеющей высший уровень привилегий CPL = 0. Команда SIDT может быть выполнена при любом уровне привилегий программы.
Элементами таблицы IDT являются системные дескрипторы прерываний, имеющие размер по 8 байт. Поэтому максимальный размер таблицы IDT составляет 2 Кбайт при использовании всех 256 видов прерываний (исключений). В таблице могут содержаться три вида системных дескрипторов: шлюз прерывания, шлюз ловушки и шлюз задачи.
Форматы содержимого шлюзов прерывания и ловушки приведены на рис. 2.59, а, б. Они содержат селектор вызываемого при обслуживании сегмента, который поступает в регистр CS, и относительный адрес первой команды подпрограммы обслуживания, который загружается в регистр EIP. В дескрипторе также содержится бит Р, указывающий на присутствие (при значении Р = 1) в памяти сегмента, в котором находится соответствующая подпрограмма обслуживания, и двухбитовое поле gDPL, определяющее уровень привилегий шлюза. Бит D в байте доступа определяет режим работы процессора при обслуживании прерываний: если значение D = 0, то процессор функционирует как 16-разрядный процессор 80286, если D = 1, то обеспечивается 32-разрядный режим функционирования, характерный для процессоров 386,486, Pentium, Р6.
Передача управления через шлюз прерывания или шлюз ловушки может сопровождаться изменением уровня привилегий. Процессор проверяет значение gDPL в дескрипторе шлюза при выполнении программных прерываний, вызываемых командами INT п, INT3, INTO. Переход к выполнению подпрограммы обслуживания в этих случаях производится, если уровень привилегий текущей программы меньше или равен значению gDPL шлюза: CPL <= gDPL. Таким образом, величина gDPL ограничивает уровень привилегий программ, которые могут вызывать данную процедуру обслуживания. При выполнении других видов прерываний и исключений процессор игнорирует gDPL шлюза.
Уровень привилегий сегмента команд, в котором размещается подпрограмма обслуживания, должен быть меньше или равен уровню привилегий текущей программы: DPL <= CPL. Нарушение этого правила приводит к исключению типа #GP. Поэтому рекомендуется под-а)
31____________________________16 15 14 13 12________8 7 5 4_______0
| Смещение 31.„16 | Р | PPL | 0D110 | ООО | Резерв. | 4
31____________________________16 15_________________________________0
| Селектор сегмента | Смещение 15-0 | 0
Шлюз прерывания б)
31____________________________16 15 14 13 12________8 7 5 4_______0
| Смещение 31.„16 | Р | PPL | 0D111 | ООО (Резерв. | 4
31____________________________16 15_________________________________0
| Селектор сегмента | Смещение 15-0 | 0
Шлюз ловушки
Рис. 2.59. Формат содержимого дескрипторов - шлюзов прерывения (а) и ловушки (б)
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
программы обслуживания прерываний и исключений располагать в сегментах с уровнем привилегий DPL = 0, чтобы избежать ситуации, когда при поступлении запроса прерывания или исключения уровень текущей программы CPL окажется меньше, чем DPL сегмента команд обработчика прерывания.
При возникновении прерывания процессор сохраняет в стеке (рис. 2.60):
• содержимое регистра SS прерванной процедуры (если имеет место изменение уровня привилегий);
• содержимое регистра ESP прерванной процедуры (если имеет место изменение уровня привилегий);
• содержимое регистра EFLAGS;
• содержимое регистра CS;
• содержимое регистра EIP;
• код ошибки (если он формируется для данного исключения).
После сохранения в стеке содержимого регистра EFLAGS процессор устанавливает в этом регистре значения признаков TF=VM=NT=0. Единственное различие между использованием шлюза ловушки и шлюза прерывания состоит в том, как процессор поступает с признаком IF. Если вызов подпрограммы обслуживания производится через шлюз прерывания, то процессор после сохранения в стеке содержимого регистра EFLAGS устанавливает значение признака IF = 0, запрещая маскируемые прерывания. Если переход к подпрограмме обслуживания осуществляется через шлюз ловушки, то значение признака IF не изменяется.
Без изменения уровня привилегий
Рис. 2.60. Использование стека при прерываниях в защищенном режиме
РЕАЛИЗАЦИЯ ПРЕРЫВАНИЙ И ИСКЛЮЧЕНИЙ. ОБЕСПЕЧЕНИЕ ТЕСТИРОВАНИЯ И ОТЛАДКИ
31_____ ____________16 15___________________3 2 1 0
' ^jfjjSjwpiaBaHO ~ Индекс селектора TI IDT EXT Jl’! "
Рис. 2.61. Формат кода ошибки
Возврат из подпрограммы обслуживания прерывания осуществляется с помощью команды IRET. При восстановлении из стека содержимого регистра EFLAGS действуют следующие правила:
• поле IOPL восстанавливается только если CPL = 0;
• флаг IF изменяется только если CPL J IOPL.
Формат дескриптора шлюза задачи при реализации прерываний и исключений имеет вид, представленный на рис. 2.54. Когда прерывание обрабатывается через шлюз задачи, то процессор выполняет обычную процедуру переключения задач.
При реализации некоторых исключений (табл. 2.60) процессор заносит в стек код ошибки, формат которого приведен на рис. 2.61.
Индекс селектора (биты 15-3) - указывает на дескриптор, использование которого вызвало исключение. Биты ЮТ, TI указывают на таблицу, в которой находится неверный дескриптор. Бит ЮТ = 1, если дескриптор находится в таблице IDT. При значении бита IDT = 0 размещение дескриптора определяется битом TI: если TI = 0, то дескриптор находится в таблице GDT, если TI -1 - в таблице LDT. Бит EXT = 1, если исключение вызвано не выполняемой программой, а внешним сигналом прерывания.
2.8.2. ПРИЧИНЫ ВОЗНИКНОВЕНИЯ ИСКЛЮЧЕНИЙ
В предыдущих главах рассмотрены основные случаи, при которых реализуются различные виды исключений (табл. 2.60). Поэтому в данном разделе ограничимся кратким обзором причин их возникновения.
Исключение 0 -деление на нуль (#DE). Возникает при выполнении команд DIV, IDIV, если делитель равен нулю или если результат не может разместиться в операнд-приемник (превышает разрядность приемника).
Исключение 1 - исключение для отладки (#ОВ). Возникает в пошаговом режиме (при значении признака TF = 1 в регистре EFLAGS) после выполнения каждой команды; при переключении на задачу, в сегменте TSS которой установлен бит Т=1; при достижении аппаратных точек останова, устанавливаемых с помощью регистров DR0-DR3. В зависимости от типа аппаратной точки останова исключение #DB может обслуживаться как ошибка или как ловушка.
Прерывание 2 - немаскируемое прерывание. Возникает при поступлении внешнего сигнала NMI=1 на вход NMI процессора или приеме соответствующего сообщения по шине APIC. Это прерывание может быть вызвано как программное с помощью команды INT п, где п = 2.
Исключение 3 - исключение программной точки останова (#ВР). Имеет место при выполнении однобайтной команды INT3. Команда INT3 обычно вводится в текст отлаживаемой программы для ее останова и контроля текущих результатов выполнения.
Исключение 4 - переполнение (#OF). Это исключение вызывается с помощью команды INTO. Команда INTO проверяет признак OF в регистре EFLAGS и реализует исключение #OF, если значение этого признака OF = 1.
Исключение 5 - превышение границы массива (#BR). Имеет место при выполнении команды BOUND, если содержимое проверяемого регистра выходит за указанные пределы.
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
Исключение 6 - недействительный код операции (#1)0). Возникает при попытке выполнить команду, в коде которой обнаружено какое-либо из следующих нарушений:
• указан неиспользуемый (резервированный) код операции;
• используется неправильный способ адресации операнда;
• указан код ММХ- или SSE-комацд при установленном в регистре CRO значении бита ЕМ = 1;
• выбраны коды команд LLDT, SLDT, LTR, STR, LSL, ARPL, VERR, VERW при работе процессора в реальном режиме или режиме виртуального 8086;
• префикс LOCK используется с командой, при выполнении которой не должен производиться захват шины;
• выбран код команды UD2, которая служит для вызова подпрограммы обслуживания данного исключения.
Исключение 7- процессор FPU недоступен (#NM). Реализуется в следующих случаях:
• при попытке выполнить команду FPU, когда в регистре CR0 установлено значение бита ЕМ = 1;
• при попытке выполнить FPU-, ММХ- или SSE-команду, когда в регистре CR0 установлено значение бита TS = 1;
• попытка выполнить команду WAIT или FWAIT, когда в регистре CR0 установлено значение битов МР = TS = 1.
Исключение 8 - двойная ошибка (#DF). Реализуется в случае, когда при вызове подпрограммы обслуживания одного исключения выявляется другое. Если процессор не может обработать такие исключения последовательно, то генерируется исключение #DF. При этом в стек заносится код ошибки с нулевым значением всех битов. Чтобы определить исключения, которые могут обрабатываться последовательно, они разбиты на три класса: А, В и С (см. табл. 2.60). В табл. 2.62 указано, какие классы исключений могут обрабатываться последовательно, а какие вызовут исключение #DF. Если при вызове исключения #DF обнаруживается другое исключение, то процессор переходит в отключенное состояние (shutdown).
Исключение 10 - недействительный сегмент TSS (#TS). Это исключение может иметь место при переключении задач. В табл. 2.63 указаны случаи, когда сегмент TSS считается недостоверным. При вызове исключения #TS процессор включает в стек код ошибки. Если в коде ошибки установлен бит EXT - 1, то это означает, что переключение на неверную задачу произошло не программным путем, а от внешнего прерывания через шлюз задачи. Исключение #TS должно обрабатываться только через шлюз задачи!
Исключение 11 - отсутствие сегмента (#NP). Реализуется при обращении к дескриптору, который имеет значение бита присутствия Р = 0. Такая ситуация возникает в следующих случаях:
• попытка загрузить сегментные регистры CS, DS, ES, GS или FS селекторами дескрипторов, у которых бит Р = 0 (загрузка регистра SS приводит к исключению #SS); этот случаи может иметь место при переключении задач;
• попытка загрузить регистр LDTR с помощью команды LLDT селектором дескриптора, у которого бит Р = 0;
• попытка загрузить регистр TR с помощь команды LTR селектором дескриптора TSS, у которого бит Р - 0;
• попытка использовать дескриптор шлюза или дескриптор TSS, для которых бит присутствия Р = 0.
Код ошибки содержит индекс селектора, приведшего к возникновению #NP. Если в коде ошибки установлен бит ЕХТ = 1, то это означает, что в результате внешнего прерывания произошло обращение к отсутствующему объекту (например, шлюз прерывания ссылается на отсутствующий сегмент). Если в коде ошибки значение бита IDT = 1, то это означает, что индекс кода ошибки ссылается на дескрипторную таблицу IDT (например, команда INT п выбирает шлюз, у которого бит присутствия Р = 0).
РЕАЛИЗАЦИЯ ПРЕРЫВАНИЙ И ИСКЛЮЧЕНИЙ. ОБЕСПЕЧЕНИЕ ТЕСТИРОВАНИЯ И ОТЛАДКИ
Таблица 2.62
Возможности последовательной обработки исключений различных классов
Первое прерывание Второе прерывание
А В С
А Последовательно Последовательно Последовательно
В Последовательно #DF Последовательно
С Последовательно #DF #DF
Исключение 12 - ошибка при обращении к стеку (#SS). Возникает при неправильном обращении к стеку, которое имеет место в следующих ситуациях:
• нарушение границы сегмента стека, на который ссылается регистр SS; команды, которые могут вызвать нарушение границы стека: POP, PUSH, CALL, RET, IRET, ENTER и LEAVE, а также команды, у которых один из операндов находится в сегменте стека (например, MOV СХ, [ВР+8] или MOV EDX, SS:[EAX+6]);
• попытка загрузить сегментный регистр SS селектором дескриптора, у которого бит присутствия Р = 0; это нарушение может возникнуть: при переключении задач, при переходе с одного уровня привилегий на другой с помощью команды CALL, при возврате с другого уровня привилегий, при выполнении команды LSS, при загрузке регистра SS с помощью команд MOV или POP.
Исключение 13 - нарушение общей защиты (#GP). Возникает во всех случаях нарушения защиты, которые не вызывают исключений #NP, #SS, #PF или #TS. К таким случаям относятся:
• нарушение границы сегмента при обращении к сегментам, на которые ссылаются регистры CS, DS, ES, GS и FS;
• нарушение границы дескрипторной таблицы (кроме случаев переключения задач и переключения стека);
• передача управления невыполняемому сегменту;
• запись в сегмент кода или в сегмент данных, для которого разрешено только чтение;
• чтение из сегмента кода, для которого разрешено только выполнение;
• попытка загрузить сегментный регистр SS селектором сегмента, для которого разрешено только чтение (кроме случая переключения задач);
• загрузка сегментных регистров SS, DS, ES, FS или GS селекторами системных дескрипторов;
• загрузка сегментных регистров DS, ES, FS или GS селекторами сегментов кода, допускающих только выполнение;
• загрузка сегментного регистра SS нуль-селектором или селектором сегмента кода;
• загрузка сегментного регистра CS нуль-селектором или селектором сегмента данных;
• обращение к памяти с использованием сегментных регистров DS, ES, FS или GS, когда они содержат нуль-селекторы;
• переключение на занятую задачу;
• переключение на незанятую задачу при выполнении команды IRET;
• использование селектора, который ссылается на дескриптор TSS в LDT (дескрипторы TSS могут находиться только в GDT);
• нарушение правил защиты сегментов;
• превышение длины команды в 15 байт (такая ситуация может возникнуть при использовании излишних префиксов);
• загрузка в регистр управления CR0 содержимого, в котором бит PG = 1 (страничное преобразование разрешено) при значении бита РЕ = 0 (защищенный режим запрещен).
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
Таблица 2.63
Условия недостоверности сегмента TSS
Условие Индекс кода ошибки
Предел сегмента TSS меньше 67h для 32-разряд-ного TSS или меньше 2Ch для 16-разрядного TSS Индекс селектора TSS
Неверный селектор LDT или LDT не присутствует Индекс селектора LDT
Селектор сегмента стека SS выходит за границу дескрипторной таблицы Индекс селектора SS
Сегмент стека не записываемый Индекс селектора SS
DPL сегмента стека не равно CPL Индекс селектора SS
RPL селектора сегмента стека SS не равно CPL Индекс селектора SS
Селектор сегмента кода CS выходит за границу дескрипторной таблицы Индекс селектора CS
Сегмент кода неисполняемый Индекс селектора CS
DPL неподчиненного сегмента кода не равно CPL Индекс селектора CS
DPL подчиненного сегмента кода больше, чем CPL Индекс селектора CS
Селектор сегмента данных DS, ES, FS или GS выходит за границу дескрипторной таблицы Индекс селектора данных
Сегмент данных не допускает чтение Индекс селектора данных
• загрузка в регистр управления CR0 содержимого, в котором бит NW = 1 и бит CD = 0;
• использование элемента таблицы IDT, который не является шлюзом прерывания, шлюзом ловушки или шлюзом задачи;
• попытка в режиме виртуального 8086 передать управление обработчику прерывания через шлюз ловушки или шлюз прерывания, когда сегмент кода программы-обработчика имеет DPL > 0;
• попытка записать «1» в зарезервированные биты регистры управления CR4;
• попытка выполнить привилегированную команду, когда CPL № 0;
• попытка записать «1» в зарезервированные биты MSR регистров;
• использование шлюза, который содержит нуль-селектор;
• выполнение команды INTп, когда CPL > gDPL выбираемого шлюза;
• использование в дескрипторе шлюза селектора, который не ссылается на сегмент команд;
• использование в команде LLDT операнда, который не является селектором LDT или имеет значение бита TI = 1;
• использование в команде LTR операнда, который является локальным селектором или ссылается на занятую задачу;
• попытка использовать нуль-селектор для межсегментных переходов;
• выборка процессором, работающим в режиме расширенной адресации (установлено значение бита РАЕ = 1 в регистре CR4), указателя каталога страниц, в зарезервированных полях которого имеются «1».
Исключение 14-ошибка обращения к странице (#PF). Имеет место при страничном преобразовании адресов в следующих случаях:
• бит присутствия Р = 0 в указателе таблицы или страницы;
• нарушение правил защиты страниц.
РЕАЛИЗАЦИЯ ПРЕРЫВАНИЙ И ИСКЛЮЧЕНИЙ. ОБЕСПЕЧЕНИЕ ТЕСТИРОВАНИЯ И ОТЛАДКИ
31 4 3 2 1 0
Рис. 2.62. Формат кода ошибки для исключения #PF
Формат кода ошибки для этого исключения (рис. 2.62) содержит биты, которые имеют следующее назначение:
Р = 0, если исключение вызвано отсутствием страницы, Р = 1, если исключение вызвано нарушением правил защиты для страниц;
W/R = 0, если исключение произошло при чтении страницы, W/R = 1, если - при записи на страницу;
U/S = 0, если исключение произошло при работе процессора в режиме супервизора, U/S -1, если исключение произошло при работе в режиме пользователя;
RSVD = 0, если исключение #PF произошло из-за того, что процессор обнаружил «1» в зарезервированных полях указателя таблицы или указателя страницы; RSVD - 1 при других причинах исключения.
В регистр CR2 процессор заносит линейный адрес, приведший к исключению #PF.
Исключение 16-исключение FPU (#MF). Реализуется при различных видах ошибок при обработке чисел с плавающей точкой.
Исключение 17 - ошибка выравнивания (#АС). Возникает при нарушении правил выравнивания операндов, которые процессор проверяет, если в регистре EFLAGS установлено значение признака АС = 1, и в регистре CR0 бит AM = 1. Исключение реализуется в случае нарушения следующих правил формирования адреса операнда:
• адрес должен быть кратным 2 при выборке слова, селектора или 32-разрядного дальнего (far) указателя;
• адрес должен быть кратным 4 при выборке двойного слова, числа с плавающей точкой одинарной точности, 48-разрядного дальнего (far) указателя, 32-разрядного ближнего (near) указателя или битовой строки;
• адрес должен быть кратным 8 при выборке числа с плавающей точкой двойной точности или числа с плавающей точкой расширенной точности.
Процессор всегда заносит в стек нулевой код ошибки при вызове исключения #АС.
Исключение 18 - машинный контроль (#МС). Обеспечивает контроль работы процессора с помощью специализированных (модельно-специфических) регистров MSR.
Исключение 19 - исключение SSE (#ХМ). Реализуется при различных видах ошибок, возникающих при выполнении SSE-команд.
2.8.3. СРЕДСТВА ОБЕСПЕЧЕНИЯ ОТЛАДКИ
Процессоры семейства Р6 реализуют широкий набор вариантов отладки:
• программный останов,
• пошаговый режим,
• отладку с использованием регистров отладки,
• отладку с использованием специализированных MSR-регистров,
• режим зондовой отладки.
Программный останов. Этот способ отладки реализуется с помощью однобайтной команды INT3, которая вводится программистом в критические точки программы, где необходимо выполнить контроль текущего состояния. Команда INT3 устанавливает безуслов-
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
ную программную точку останова, при выполнении которой процессор реализует исключение #ВР. Команда INT3 выполняется при любых значениях уровня привилегий программы CPL и содержимого поля IOPL. Исключение #ВР всегда вызывается через таблицу IDT. При работе процессора в режиме виртуального 8086 на выполнение команды INT3 не оказывает влияния значение битов в карте перенаправления прерываний (при установленном значении бита VME = 1 в регистре CR4). При вызове подпрограммы обслуживания через шлюз уровень приоритета этого шлюза gDPL должен быть больше или равен CPL.
Пошаговый режим. Пошаговый режим имеет место, когда установлено значение признака TF=1 в регистре EFLAGS. В этом случае процессор после выполнения каждой команды (ловушка) реализует исключение типа #DB, вызывая соответствующую подпрограмму обслуживания. Перед вызовом этой подпрограммы процессор устанавливает значение признака TF = 0, чтобы обеспечить выполнение обработки без пошаговых остановов. Команда IRET, завершающая подпрограмму обработки, восстанавливает из стека содержимое регистра EFLAGS (где значение TF = 1), передавая управление следующей команде программы, после которой снова реализуется прерывание #DB.
Останов с помощью регистров отладки DR0-DR7. Регистры отладки имеют следующее назначение:
DR3-0 - содержат линейные адреса четырех контрольных точек останова;
DR6 - регистр состояния, указывающий причину останова в контрольной точке;
DR7 - регистр управления, задающий условия останова в контрольных точках.
Доступ к регистрам отладки разрешен только программам с уровнем привилегий CPL = 0. Попытка обратиться к этим регистрам на другом уровне привилегий (CPL > 0) приводит к исключению #GP.
Регистры DR4, DR5 в выпускаемых моделях процессоров не используются. Если в регистре управления CR4 установлено значение бита DE = 1 (расширение отладки), то обращение к регистрам DR4, Drs приводит к исключению #UD. Если бит DE = 0, то при вызове DR4, DR5 производится обращение к регистрам DR6, DR7.
Формат содержимого регистров управления DR7 и состояния DR6 отладки показан на рис. 2.63.
Регистр управления отладкой DR7 определяет условия останова для каждой из четырех контрольных точек, линейные адреса которых находятся в регистрах DR0-DR3. Отдельные биты и поля в регистре DR7 имеют следующее назначение:
LENi - размер точки останова. Двухбитные поля LEN/указывают, какие биты линейного адреса участвуют в определении адреса срабатывания /-Й точки останова, определяя, таким образом, размер области памяти, в пределах которой выполняется останов.
При реализации останова по обращению к данным поле LEN/ может принимать следующие значения:
• 00-1 байт (используются биты А31-0 линейного адреса в регистре DRi);
• 01-2 байта (используются биты А31-1 линейного адреса);
• 10-не определено;
• 11-4 байта (используются биты А31-2 линейного адреса).
Если соответствующее поле R/W/ в регистре DR7 равно 00 (реализация останова по выборке команды), то поде LENi должно быть равно 00.
31 30 29 28 27 26 25 24 23 22 .21 20 19 18 17 16 15 14 13 12 10 9 8 7 6 5 4 3 2 1 0 | LEN3 | R/W3 | LEN2 | R/W2 | LEN1 I ~R/W1 ( LENO ] R/WQ t 0Q I GD [ 001 ] GE I G3 | L3 ] G2 | L2 | G1 | L1~ | GO | L0 | DR7
31 _______________1615 14 13 12______________________________________________4 3 2 1 0
k Рвзервировдно "" , . |'bt"|'bs~[ bd | O11111111 >>• | вз | B2 | bi | во"*] DR6
Рис. 2.63. Формат содержимого регистров отладки DR7 (a), DR6 (б)
РЕАЛИЗАЦИЯ ПРЕРЫВАНИЙ И ИСКЛЮЧЕНИЙ. ОБЕСПЕЧЕНИЕ ТЕСТИРОВАНИЯ И ОТЛАДКИ
R/Wi- тип доступа. Двухбитные поля R/W/ определяют тип обращения к памяти, при котором происходит срабатывание ьй точки останова. Поле R/Wi может принимать следующие значения:
• 00 - выборка команды;
• 01 - запись данных;
• 10 - чтение или запись порта ввода/вывода (при значении бита DE = 1 в регистре управления CR4, при DE = 0 значение R/Wi=10 не определено);
• 11 - запись или чтение данных.
Точки останова по выборке команд обрабатываются как ошибки, а точки останова по обращению к данным - как ловушки. Срабатывание точки останова при выборке команды происходит только тогда, когда линейный адрес точки останова указывает на первый байт команды (включая префиксы). Срабатывание точки останова при обращении к данным или портам ввода/вывода имеет место, когда заданный адрес операнда полностью или частично попадает в область срабатывания точки останова (область определяется регистром DR/ и полем LENi в регистре DR7).
GD - идентификация обращений к регистрам отладки. Когда установлено значение бита GD = 1, то обращение к регистрам отладки приводит к исключению #DB. В этом случае перед реализацией исключения #DB в регистре состояния DR6 устанавливается значение бита BD = 1, а бит GD сбрасывается в «0», что дает возможность обработчику исключения #DB обращаться к регистрам отладки.
GE, LE - не используемые (резервированные) биты, которые рекомендуется устанавливать в «1».
Gi - разрешение глобальных точек останова. Установка этого бита разрешает срабатывание соответствующей контрольной точки во всех задачах. Если выполняется условие срабатывания i-й контрольной точки (определенное регистром DRi и полями LENi, R/Wi в регистре DR7) и установлено значение бита Gi = 1, то реализуется исключение #DB. Бит Gi не изменяется при переключении задач.
Li - разрешение локальных точек останова. Установка этого бита разрешает срабатывание соответствующей контрольной точки в текущей задаче. Если выполняется условие срабатывания /-Й контрольной точки и значение бита L/ = 1, то реализуется исключение #DB. Бит Li автоматически сбрасывается в «0» при переключении задач.
Так как точки останова по выборке команды обрабатываются как ошибки, то после возврата из подпрограммы обработки процессор снова попытается выполнить команду, на которую установлена точка останова, и снова будет реализовано исключение #DB. Для предотвращения такого зацикливания на одной точке останова в архитектуре процессора предусмотрен признак RF в регистре EFLAGS. Когда установлено значение RF = 1, то процессор игнорирует точки останова по выборке команды. Значение флага RF не оказывает влияния на срабатывание точек останова по выборке данных или точек останова по операциям ввода/вывода. Процессор автоматически устанавливает флаг RF = 1 перед вызовом любого исключения-отказа, кроме #DB, которое было вызвано точкой останова по выборке команды. Программа-обработчик исключения #DB может либо запретить точку останова, либо установить значение признака RF = 1 в содержимом регистра EFLAGS, хранящемся в стеке. При возврате из обработчика команда IRETD восстановит значение признака RF из хранящегося в стеке содержимого регистра EFLAGS. Команды POPF, POPFD и IRET не изменяют значение RF. После возврата повторной генерации исключения #DB не произойдет, так как значение признака RF = 1. Процессор автоматически устанавливает значение RF = 0 после выполнения любой команды, кроме команды IRETD и команд JMP, CALL, INT п, которые вызывают переключение задач. Процессор не устанавливает признак RF перед вызовом исключений-ловушек, аппаратных или программных прерываний.
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
Регистр состояния DR6 содержит информацию, которая указывает причину последнего исключения отладки #DB. Отдельные биты содержимого DR6 имеют следующее назначение:
ВТ-ошибка при переключении задач. Принимает значение ВТ = 1, если исключение #DB имело место из-за переключения на задачу, имеющую бит Т = 1 в сегменте TSS. Исключение #DB происходит после выполнения первой команды в новой задаче. Если исключение #DB обрабатывается через шлюз задачи, то бит Т в сегменте TSS обработчика должен иметь значение «1».
BS - реализация пошагового режима отладки. Принимает значение BS = 1, если исключение #DB имело место из-за установленного значения признака TF = 1 в регистре EFLAGS. Исключение пошагового режима самое приоритетное среди исключений отладки. Вместе с битом BS может быть установлен любой другой бит в регистре DR6.
BD - отказ при обращении к регистрам отладки при установленном бите GD в регистре DR7. Значение BD = 1 устанавливается, если исключение #DB происходит из-за попытки обратиться к регистрам отладки, когда установлен бит GD в регистре управления отладкой DR7. Перед передачей управления обработчику исключения #DB бит GD в регистре управления отладкой DR7 сбрасывается в «О». Это дает возможность обработчику исключения #DB обращаться к регистрам отладки.
В/ - останов в i-й контрольной точке. Четыре бита индикации останова соответствуют четырем регистрам DR0-DR3. Значение В/ -1 устанавливается при выполнении условий, определенных регистром DR/' и полями LEN/, R/W/ в регистре DR7. Биты В/ устанавливаются в «1» даже в том случае, когда соответствующая точка останова не разрешена с помощью битов L/7G/ в регистре DR7. Если одновременно выполняются условия для нескольких точек останова и хотя бы одна из этих точек останова разрешена, то реализуется исключение #DB. При этом значения битов В/ = 1 будут установлены для всех точек останова.
Биты регистра DR6 устанавливаются в «1» аппаратно при реализации соответствующих исключений. Сброс этих битов в нулевое значение выполняется программно, путем загрузки нового содержимого в регистр DR6. Эта процедура осуществляется программой обработки исключения #DB, которая перед возвратом к исходной программе должна очистить регистр DR6, установив значение «О» для всех битов.
Поддержка отладки с помощью MSR-регистров. Процессоры семейства Р6 содержат пять MSR регистров, которые предоставляют дополнительные возможности отладки: DebugCtIMSR (адрес 1D9h), LastBranchTolP (адрес 1DCh), LastBranchFromlP (адрес 1DBh), LastExceptionTolP (адрес 1DEh) и LastExceptionFromlP (адрес 1DDh).
На рис. 2.64 приведен формат содержимого регистра DebugCtIMSR, с помощью которого производится управление режимом отладки. Его отдельные биты имеют следующее назначение:
BTF-бит разрешения пошаговых ветвлений. Когда значение BTF = 1, процессор интерпретирует значение признака TF = 1 в регистре EFLAGS как «пошаговые ветвления», а не «пошаговые команды». Это означает, что исключение #DB будет генерироваться только при обнаружении ветвления, прерывания или исключения. Бит BTF автоматически устанавливается в «О» перед передачей управления обработчику исключения #DB.
31 76543210
Резервировано TR PB3 РВ2 | РВ1 | РВО BTF LBR
Рис. 2.64. Формат содержимого регистра DebugCtIMSR
РЕАЛИЗАЦИЯ ПРЕРЫВАНИЙ И ИСКЛЮЧЕНИЙ. ОБЕСПЕЧЕНИЕ ТЕСТИРОВАНИЯ И ОТЛАДКИ
PBi - биты разрешения выдачи внешних сигналов при останове в контрольных точках. Когда бит Pbi = 1, то на соответствующем выходе процессора устанавливается сигнал BPi# = 0 при останове в контрольной точке, определенной регистром DRi. Когда значение битов PBi = 0, то выводы BPi# используются для вывода данных о мониторинге производительности процессора.
TR - бит разрешения выдачи сообщений о трассировке ветвлений. Если установлено значение TR=1, то процессор при выполнении ветвления, прерывания или исключения выдает на системную шину адрес исходной команды и команды, которой передается управление. Трассировка ветвлений приводит к снижению производительности процессора, так как о каждом ветвлении выполняется сообщение по системной шине.
LBR - бит разрешения записи информации о ветвлениях. При установке значения LBR = 1 процессор фиксирует все передачи управления. Когда происходит ветвление, процессор заносит в регистр LastBranchFromlP адрес команды ветвления, а в регистр LastBranchTolP - адрес самого перехода. Если реализуется прерывание или исключение (кроме исключения #DB), процессор копирует значение регистров LastBranchFromlP и LastBranchTolP в регистры LastExceptionFromlP и LastExceptionTolP соответственно. Затем адрес прерванной команды заносится в регистр LastBranchFromlP, а адрес вызываемого обработчика - в регистр LastBranchTolP. Бит LBR автоматически устанавливается в «О» перед передачей управления обработчику исключения #DB.
Таким образом, использование отладочных MSR-регистров обеспечивает дополнительные возможности контроля выполнения программы в процессе ее отладки.
Режим зондовой отладки. Этот способ отладки реализуется с помощью тестового пор-, та ТАР, который служит для тестирования процессора и подключенных к нему устройств системы. Специальный режим «зондовой» отладки (Probe Mode) позволяет использовать порт ТАР для ввода команд и данных, чтения и записи содержимого всех внутренних регистров процессора. С помощью этого режима можно обеспечить выполнение отлаживаемой программы, контролируя и корректируя содержимое регистров.
2.8.4. РЕАЛИЗАЦИЯ ТЕСТИРОВАНИЯ И КОНТРОЛЯ ФУНКЦИОНИРОВАНИЯ
Характерной особенностью современных процессоров является размещение на кристалле специальных средств, облегчающих процедуру их тестирования и контроля. Для процессоров семейства Р6 реализуются следующие варианты тестирования и контроля:
• самотестирование в процессе начальной установки (RESET) состояния процессора;
• тестирование при работе в составе целевой системы в соответствии с международным стандартом JTAG (IEEE 1149.1);
• контроль функционирования с помощью исключения типа #МС («машинный контроль»).
Самотестирование при начальной установке процессора после поступления сигнала RESET реализуется, если в процессе выполнения этой процедуры на вход INIT# подается «О». В этом случае выполняется достаточно сложная программа проверки функционирования основных блоков процессоров Р6, которая занимает около 5,5 млн тактов. Если подтверждается правильность их функционирования, то в регистре ЕАХ устанавливается значение OOOOOOOOh. Любое другое содержимое регистра ЕАХ указывает на обнаружение ошибок в ходе самотестирования.
Согласно международному стандарту JTAG (IEEE 1149.1), для выполнения тестирования цифровое устройство должно иметь специальный последовательный порт ТАР (test access port), через который производится ввод тестовых комбинаций (входных сигналов)
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
и вывод данных об ответной реакции (состоянии выходов) устройства. При тестировании используются следующие выводы ТАР:
• ТСК- вход синхросигналов, используемых в режиме тестирования;
• TMS - вход управляющего сигнала, определяющего режим работы ТАР;
• TDI - вход для последовательного ввода тестовых команд и сигналов;
• TDO - выход для последовательного вывода данных о состоянии входов и выходов тестируемого устройства;
• ТКЭТ#-входдля подачи сигнала сброса (установки в начальное состояние) в процессе тестирования.
Тестирование выполняется методом сканирования границ (boundary scan), при котором все входы и выходы процессора подключаются к отдельным разрядам общего сдвигового регистра тестовых данных, вход которого соединен с выводом TDI, выход - с выводом TDO. Таким образом, обеспечивается возможность подачи на входы процессора необходимых тестовых сигналов, которые последовательно вводятся через вход TDI, и считывания получаемых при этом выходных сигналов, которые последовательно выводятся через выход TDO. Различные процедуры тестирования осуществляются при поступлении определенных тестовых команд, которые предварительно последовательно вводятся через вывод TDI.
Такой способ тестирования позволяет проверять функционирование различных устройств, входящих в систему, путем соответствующего соединения их входов и выходов (рис. 2.65). При этом реализуется общий кольцевой регистр сдвига, объединяющий входы и выходы различных устройств системы. Путем последовательного ввода в этот регистр реализуется подача входных воздействий на все устройства системы, а путем последовательного вывода данных из регистра производится считывание состояния выходов этих устройств, которое определяет реакцию на поступившие воздействия.
В состав порта ТАР входят два основных сдвиговых регистра: регистр команд IR и регистр тестовых данных BSR. В зависимости от значения сигнала TMS производится выбор одного из этих регистров, в результате чего обеспечивается последовательный ввод (через TDI) и вывод (через TDO) тестовых команд или данных. Ввод и вывод выполняются при поступлении синхросигналов ТСК.
При вводе в регистр команд соответствующего кода процессор выполняет одну из тестовых команд. В их состав входят команды, определяемые стандартом JTAG, и дополнительные команды, введенные для тестирования определенных моделей процессоров.
Вывод результатов тестирования
Вывод тестовых данных
Сигналы зондовой отладки
Тестовые синхросигналы Выбор текстового режима
Тестовый сброс
Рис, 2.65. Использование портов ТАР при тестировании цифровых систем
РЕАЛИЗАЦИЯ ПРЕРЫВАНИЙ И ИСКЛЮЧЕНИЙ. ОБЕСПЕЧЕНИЕ ТЕСТИРОВАНИЯ И ОТЛАДКИ
В число выполняемых команд стандарта JTAG входят SAMPLE/PRELOAD, EXTEST, BYPASS, IDCODE. После поступления команды SAMPLE/PRELOAD осуществляется последовательная загрузка регистра тестовых данных BSR при поступлении синхросигналов ТСК. В результате обеспечивается подача необходимых тестовых сигналов на входы процессора и предварительная установка состояния его выходов. После окончания загрузки регистра BSR устанавливается соответствующее состояние выходов процессора, которое фиксируется в определенных разрядах этого регистра. При последующей подаче синхросигналов ТСК производится последовательный вывод содержимого регистра данных, соответствующие разряды которого фиксируют реакцию процессора на поступление тестовых сигналов. Анализ выведенных данных позволяет определить правильность функционирования процессора. Если после загрузки регистра BSR в процессор вводится команда EXTEST, то на внешние выводы процессора выдаются сигналы, значения которых установлены предыдущей командой SAMPLE/PRELOAD. Эти сигналы могут использоваться для тестирования других устройств, подключенных к процессору в данной системе. Команда BYPASS обеспечивает непосредственную передачу сигналов со входа TDI на выход TDO. Таким образом, можно вводить тестовые команды и данные в другие устройства системы, минуя процессор. При поступлении команды IDCODE на выход TDO последовательно выдается код, идентифицирующий тип процессора и реализованную версию JTAG. Этот код заносится в процессе изготовления процессора в 32-разрядный регистр идентификации DID, входящий в состав порта ТАР. Команда RUNBIST, специфическая для каждой модели процессора, запускает тестовую последовательность сигналов, аналогичную той, которая выполняется при установке начального состояния. После ее завершения производится считывание содержимого однобитового регистра RUNBIST, входящего в состав порта ТАР. Его нулевое значение указывает на успешное завершение самотестирования процессора.
Регистр тестовых данных BSR содержит различное число разрядов (150-200) в зависимости от модели процессора. Каждому выводу процессора соответствуют определенные разряды регистра BSR. Однонаправленные выводы подключены к одному из разрядов, а двунаправленные - к двум разрядам, один из которых задает значение входного сигнала, второй принимает значение выходного сигнала. Для двунаправленных выводов используются также дополнительные разряды регистра, содержимое которых определяет использование этих выводов в качестве входов или выходов. Последовательный ввод данных в регистр BSR, выполняемый при поступлении синхросигналов ТСК, позволяет установить необходимое исходное состояние всех выходов, последовательный вывод данных обеспечивает возможность контроля их текущего состояния.
Расширение возможностей порта ТАР обеспечивается в режиме «зондовой» отладки (Probe Mode). Для реализации этого режима в состав порта ТАР введены дополнительные регистры команд PIR (Probe Instruction Register) и данных PDR (Probe Data Register), с помощью которых последовательно вводятся команды и данные, выводятся полученные результаты и информация о текущем состоянии процессора. При этом для управления портом используются дополнительные выводы PREQ# и PRDY#. В зондовом режиме процессор выполняет команды, последовательно вводимые в регистр PIR. При этом не производится контроль привилегий, т. е. выполняются все поступающие команды. Обслуживание прерываний и исключений не реализуется. Обеспечивается возможность записи и считывания содержимого всех регистров процессора, что позволяет контролировать и корректировать их текущее состояние.
Вход и выход в зондовый режим обеспечивается с помощью специальных команд, вводимых в регистр IP порта ТАР, или подачей сигнала запроса на вход RREQ#. При поступлении внешнего сигнала RREQ# = 0 процессор входит в этот режим, устанавливая на выходе
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
PRDY# сигнал готовности PRDY# = 0. Выход из зондового режима происходит при подаче сигнала RREQ# = 1. Возможен также вход в зондовый режим при реализации исключения отладки #ВР. В этом случае не производится вызов подпрограммы обслуживания, а выдается сигнал готовности PRDY# = 0, который инициирует последовательный ввод команд обработки исключения в регистр PIR через порт ТАР. Такой способ входа в зондовый режим разрешается после подачи специальной команды ICEBP, вводимой в регистр IP порта ТАР.
Процессоры семейства Р6 обладают возможностями обнаружения ряда аппаратных ошибок, возникающих при функционировании систем. Эти возможности реализуются с помощью средств машинного контроля (machine-check architecture), которые выявляют следующие виды ошибок:
• ошибка обращения к системной шине, которая фиксируется внешней схемой контроля шины, подающей сигнал BINIT# = 0 на соответствующий вход процессора;
• ошибка ЕСС (Error Checking and Correcting) при обращении к памяти, которая выявляется внешним устройством контроля памятью; код этой ошибки подается на входы DEP7-0# процессора;
• ошибка контроля четности при передаче адреса или данных;
• ошибка в кэш-памяти или буферах страничной трансляции TLB.
При выявлении этих ошибок реализуется исключение #МС «машинный контроль», если в регистре CR4 установлено значение бита MCE = 1. Программа обработки данного исключения может получить информацию о происшедшей ошибке из специальных MSR-регистров, состав и содержимое которых зависят от модели процессора. Полный набор этих 64-разрядных регистров содержит глобальные регистры MCG CAP, MCG CTL, определяющие возможные режимы контроля, и MCG STATUS, указывающий текущее состояние процессора после начала обработки исключения #МС, а также пять банков регистров сообщений об ошибках. Каждый из банков предназначен для контроля ошибок, происходящих в определенных устройствах системы. В состав i-го банка входят регистры: MCi CTL, определяющий вид контролируемых ошибок, MCi STATUS, MCi MISC, указывающие вид обнаруженных ошибок, MCi ADDR, содержащий адрес, при обращении к которому была зафиксирована ошибка.
Следует отметить, что в процессорах семейства Р6 практически используется только небольшая часть этих регистров. Основная часть их содержимого зарезервирована для использования в последующих моделях процессоров, где предполагается значительное расширение возможностей контроля функционирования различных устройств системы.
2.9. RISC-МИКРОПРОЦЕССОРЫ И RISC-МИКРОКОНТРОЛЛЕРЫ СЕМЕЙСТВ POWERPC (МРС60Х, МРС50Х)
RISC-архитектура достаточно широко используется в различных изделиях, выпускаемых компанией «Motorola». Поэтому целесообразно определить ее основные особенности. Первые RISC-микропроцессоры, разработанные в Стенфордском и Калифорнийском университетах США в начале 1980-х гг., выполняли относительно небольшой набор команд - 50-100 вместо 100-200, выполняемых обычными - CISC- (complex instruction set computer- компьютер co сложным набором команд) процессорами. Именно эта особенность и определила название данного класса микропроцессоров - RISC (reduced insruction set computer - компьютер с сокращенным набором команд). Однако в последующих разработках RISC-микропроцессоров набор команд значительно расширен, вклю-. тмяипы обоаботки чисел с плавающей точкой. t
RISC-МИКРОПРОЦЕССОРЫ И RISC-МИКРОКОНТРОЛЛЕРЫ СЕМЕЙСТВ POWERPC И COLDFIRE
В настоящее время определились следующие характерные особенности RISC-микропроцессоров:
• расширенный объем регистровой памяти: от 32 до нескольких сотен регистров общего назначения, входящих в состав микропроцессора;
• использование в командах обработки данных только регистровой адресации (обращение к памяти используется в командах загрузки и сохранения содержимого регистров, а также в командах управления программой);
• отказ от аппаратной реализации сложных способов адресации (с пост-инкрементом или пре-декрементом, косвенная адресация и др.);
• фиксированный формат команд (обычно четыре байта) вместо переменного формата (от 1 до 12 и более байт), характерного для CISC-микропроцессоров;
• исключение из набора команд, реализующих редко используемые операции, а также команд, не вписывающихся в принятый формат.
Преимущественное использование регистровой адресации значительно повышает производительность микропроцессоров. Фиксированный формат команд, отказ от сложных и редко используемых команд и способов адресации существенно упрощает устройство управления, сокращает объем микропрограммной памяти, что позволяет уменьшить размер кристалла RISC-процессоров, снизить их стоимость и повысить тактовую частоту. Введение фиксированного формата команд обеспечивает также более эффективную работу конвейера, уменьшает число тактов простоя и ожидания, что дает дополнительный рост производительности.
Перечисленные достоинства RISC-микропроцессоров определили значительный интерес к этим изделиям. В настоящее время данный вид СБИС выпускают практически все ведущие производители микропроцессорной техники - «Motorola», «Intel», «Hewlett -Packard», IBM и другие, а также ряд компаний, специализирующихся в этой области: «Sun Microsystems», MIPS.
Компания «Motorola» более 10 лет назад начала выпуск RISC-микропроцессоров семейства М860, которые используются главным образом для управления сложнофункциональными объектами - лазерными принтерами, дистанционными манипуляторами и др. В последние годы широкую популярность получили RISC-процессоры и RISC-контроллеры семейства PowerPC, созданные на базе разработок консорциума компаний «Motorola», IBM, «Apple Computers», а также разработанные компанией «Motorola» RISC-процессоры семейства ColdFire, которые в значительной степени интегрируют достоинства RISC-и CISC-архитектур. В данной главе описывается архитектура и особенности функционирования основных моделей микропроцессоров и микроконтроллеров семейств PowerPC и ColdFire.
2.9.1. RISC-МИКРОПРОЦЕССОРЫ СЕМЕЙСТВА МРС60Х (POWERPC)
Начало созданию этого семейства было положено в октябре 1991 гг., когда компании IBM, «Motorola» и «Apple Computers» объявили об организации консорциума для совместной разработки и внедрения RISC-микропроцессоров новой архитектуры. Их прототипом был выбран процессор Power, используемый в широко распространенной рабочей станции RS/6000, которая выпускалась компанией IBM. Для решения этой задачи были сделаны крупные инвестиции (около 1 млрддолл.) и построен новый центр проектирования в г. Остин (Техас), открытый в мае 1992 г. Штат центра составили 300 ведущих специалистов из компаний IBM и « Motorola», в результате работы которых уже в октябре 1992 г. были получены первые образцы 32-разрядных RISC-микропроцесоров типа PowerPC 601, а с апреля 1993 г. начался их
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
серийный выпуск. В ноябре 1993 г. началось производство следующей модели - PowerPC 603, предназначенной для использования в портативных компьютерах. В апреле 1994 г. было объявлено о выпуске более высокопроизводительной модели PowerPC 604, а в октябре 1994 г. - о создании модели PowerPC 620, которая положила начало ветви 64-раз-рядных микропроцессоров этого семейства. В 1995 г. появились модификации моделей PowerPC 603,604 с тактовой частотой 133 и 166 МГц, а в 1996 г. —с частотой 200 МГц. Эти модели микропроцессоров, выпускаемые фирмой «Motorola», входят в семейство МРСбОх. Все микропроцессоры семейства имеют суперскалярную структуру, которая содержит от 4 до 6 параллельно работающих исполнительных устройств, обеспечивающих одновременное выполнение нескольких команд.
Таким образом, менее чем за четыре года было разработано и выпущено семейство из четырех высокопроизводительных микропроцессоров, на базе которых уже реализованы десятки типов компьютеров, серверов и других цифровых систем различного назначения. Эти микропроцессоры послужили основой для создания новых семейств микроконтроллеров МРС5ххх и коммуникационных контроллеров МРС860.
В данном параграфе рассматривается архитектура и функционирование наиболее производительной 32-разрядной модели МРС604, а также дается обзор основных характеристик других моделей этого семейства, которое получило название МРСбхх.
Структура и функционирование микропроцессора МРС604. В микропроцессорах PowerPC, как и в семействе М68ххх, реализован принцип выделения отдельных ресурсов для решения задач пользователя и супервизора. В соответствии с этим принципом архитектура PowerPC содержит регистры, входящие в модели пользователя или супервизора, а также имеет ряд привилегированных команд, выполняемых только в режиме супервизора.
В регистровую модель пользователя (рис. 2.66), которая является общей для всего семейства PowerPC, входят:
• тридцать два 32-разрядных регистра общего назначения GPR31-0 для хранения целочисленных операндов;
• тридцать два 64-разрядных регистра FPR31-0 для хранения операндов с плавающей точкой;
• 32-разрядные регистры условий (признаков) CR и состояния при обработке чисел с плавающей точкой FPSR;
• 32-разрядные регистры XER, LR, CTR, используемые при обработке исключений.
Рис. 2.66. Регистровая модель пользователя для микропроцессоров PowerPC
RISC-МИКРОПРОЦЕССОРЫ И RISC-МИКРОКОНТРОЛЛЕРЫ СЕМЕЙСТВ POWERPC И COLDFIRE
В отличие от CISC-процессоров эта регистровая модель не содержит программного счетчика PC и указателя стека SP. Отсутствие PC связано с тем, что микропроцессоры PowerPC не выполняют команд записи или чтения программного счетчика. Эти микропроцессоры не выполняют также операций со стеком (в случае необходимости стек реализуется программно), поэтому они не содержат SP.
Регистр условий CR (рис. 2.67, а) состоит из восьми 4-битовых полей CR7-0. Младшее поле CR0 содержит признаки, формируемые в результате целочисленных операций:
LT = 1 — при отрицательном результате;
GT = 1 - при положительном ненулевом результате;
EQ = 1 - при нулевом результате;
SO-принимает значение аналогичного бита в регистре XER.
Поле CR1 содержит признаки FX, FEX, VX, ОХ, устанавливаемые при операциях над числами с плавающей точкой, которые принимают значения аналогичных битов в регистре FPSCR. Содержимое остальных полей CR7-2 устанавливается по результату операций сравнения целых или вещественных (с плавающей точкой) чисел. При сравнении целых чисел формируются признаки LT (меньше), GT (больше), EQ (равно), SO, назначение которых указано выше. При сравнении вещественных чисел устанавливаются аналогичные признаки FL (меньше), FG (больше), FE (равно), а также признак FU, который принимает значение FU = 1, если хотя бы один из сравниваемых операндов является не-числом (NAN). Наличие различных полей для признаков позволяет сохранять несколько результатов сравнения, которые используются по мере необходимости.
Следует отметить, что в микропроцессорах семейства PowerPC принята нумерация разрядов, начиная со старшего. При этом биты АО, DO содержат старшие разряды, а биты А31, D31 - младшие разряды 32-разрядного слова адреса или данных. Соответственно и содержимое регистров микропроцессора представляется в формате, начальный бит которого имеет номер 0 (см. рис. 2.67, 2.69, 2.70, 2.71).
Регистр FPSCR определяет состояние и режим работы блока обработки чисел с плавающей точкой.
Регистр XER (рис. 2.67, б) содержит признаки переноса СА, переполнения OV, устанавливаемые в результате выполнения арифметических целочисленных операций, и признак общего переполнения SO, который сохраняет установленное при переполнении значение SO = 1 до выполнения команд загрузки в регистр нового содержимого. Значение SO переносится в соответствующие биты регистра CR после каждой операции. Таким образом, признак SO = 1 указывает на возникновение переполнения в ранее выполненных командах программы. Поле SS определяет число байтов (длину строк символов), пересылаемых соответствующими командами.
a) CR
012 3 4 5 6 7________________________________ 28
| LT | GT | EQ | SO | FX | FEX | УХ | ОХ | | LT/FL | GT/FG | EQ/FE | SQ/FU | | |
CRO CR1 CRi
б) XER
0 12 3______________________________________________24 25 31
| SO | OV | SA | Резервировано | SS ]
Рис. 2.67. Форматы содержимого регистров CR и XER
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
Регистровая модель пользователя
Регистры 31_____________О
| MSR |
Конфигурации 31 0 31 О
| PVR (SPR1008) I I HIDO (SPR287) |
Регистры управления памятью
31 О
IBATOU (SPR528)
IBATOL (SPR529)
IBAT1U (SPR530)
IBAT1L (SPR531)
IBAT2U (SPR532)
IBAT2L (SPR533)
IBAT3U (SPR534)
IBAT3L (SPR535)
31_____________О
| PAR (SPR19) |
31 О
| DAR(SPR18) |
31______________О
SRRO (SPR26)
SRR1 (SPR27)
31______________О
DBATOU (SPR536) DBATOL (SPR537) DBAT1U (SPR538) DBAT1L (SPR539) DBAT2U (SPR540) DBAT2L (SPR541) DBAT3U (SPR542) DBAT3L (SPR543)
Регистры обработки исключений
31 О
SPRGO (SPR272)
SPRG1 (SPR273)
SPRG2 (SPR274)
SPRG3 (SPR275)
Вспомогательные регистры
31______________О
TBL (SPR284)
TBU (SPR285)
31 О
| EAR (SPR282) |
31______________О
| IABR (SPR1010) |
31 О
| DEC (SPR22)
31 0 31 О
| PIR(SPR1023) I I DABR (SPR1013) |
Регистры контроля эффективности
Рис. 2.68. Регистровая модель супервизора микропроцессора МРС604
Регистр связи LR служит для хранения адреса команды, к которой осуществляется условный или безусловный переход. При вызове подпрограммы в этот же регистр заносится адрес команды возврата. В регистр-счетчик CTR заносится число циклов, которое используется для организации программных циклов. При этом содержимое CTR уменьшается на единицу после завершения очередного цикла. Имеются также специальные команды условного ветвления bcctr, использующие содержимое CTR в качестве адреса перехода.
Следует отметить, что в микропроцессорах PowerPC имеются команды обращения к служебным регистрам-mfspr (чтение), mtspr (запись). Поэтому для служебных регистров, кроме имени XER, LR, CTR и др., принята цифровая нумерация SPR1, SPR8, SPR9 и т. д. (рис. 2.66, 2.68), где номер служит для идентификации регистров при обращении к ним с помощью этих команд.
Регистровая модель супервизора (рис. 2.68) включает в себя регистровую модель пользователя, а также содержит несколько групп служебных регистров, часть из которых являются общими для всего семейства PowerPC, а часть - специфичными для модели PowerPC 604.
В группе регистров конфигурации основным является регистр управления MSR, определяющий режим функционирования процессора. Биты его содержимого имеют следующее назначение (рис. 2.69):
RISC-МИКРОПРОЦЕССОРЫ И RISC-МИКРОКОНТРОЛЛЕРЫ СЕМЕЙСТВ POWERPC И COLDFIRE
POW - переводит при значении POW = 1 процессор в режим отключения с пониженным потреблением мощности;
ILE - определяет порядок адресации байтов в слове при обработке исключений: начиная со старшего байта (big-endian) при ILE = 0, начиная с младшего байта (little-endian) при ILE = 1;
ЕЕ - разрешает при ЕЕ = 1 обслуживание внешних запросов прерывания и периодических прерываний от регистра декремента DEC;
PR - задает режим работы процессора: при PR - 0 - режим супервизора, при PR = 1 -пользователя;
FP - разрешает при FP = 1 выполнение операций над числами с плавающей точкой;
ME, SE, BE - разрешают обслуживание внешнего запроса прерывания MCP# (при ME = 1), выполнение пошаговой трассировки (при SE - 1) и трассировки после команд переходов (при BE -1);
FEO, FE1 - запрещают при FEO = FE1 =0 обслуживание исключений при обработке чисел с плавающей точкой, при других значениях FEO, FE1 обеспечивают различные варианты обслуживания;
ЕР - определяет базовый адрес размещения векторов исключений: $00000000 при ЕР - 0, $FFF00000при ЕР = 1;
IT, DT - разрешают трансляцию адресов команд (при IT = 1) и данных (при DT = 1) с помощью устройств управления памятью IMMU, DMMU;
РМ - задает режим процессора, при котором осуществляется контроль эффективности его работы;
RE - обеспечивает при RE = 1 возврат к выполнению прерванной программы после установки начального состояния (RESET) или обслуживания прерывания по внешнему запросу МСР#;
LE - определяет порядок адресации байтов в слове: начиная со старшего байта (big-endian) при LE - 0 или начиная с младшего разряда (little-endian); при переходе к обслуживанию исключений LE принимает значение ELE.
Регистр HID0 содержит биты Hi, определяющие функционирование отдельных устройств микропроцессора. Биты НО-3 в этом регистре разрешают обслуживание исключения типа «контроль процессора» при поступлении внешнего сигнала МСР#, при нарушении четности в циклах обращения к внутренней кэш-памяти или внешней памяти. Бит Н15 запрещает при значении Н15 = 1 выполнение начальной установки при поступлении внешнего сигнала RESET. Биты Н16-21 определяют режим функционирования внутренних кэшей команд и данных. При значении бита Н24 = 0 обеспечивается последовательное выполнение поступающих команд, т. е. не реализуется параллельная работа исполнительных устройств в суперскалярной структуре. Бит Н29 управляет работой блока предсказания ветвлений, задавая статический (при Н29 = 0) или динамический (при Н29 = 1) способ предсказания дальнейшего хода программы.
Регистр PVR содержит коды, указывающие тип микропроцессора и его модификацию, которые записываются в процессе изготовления микросхемы и затем могут только считываться.
0 12 13 14 15
Резервировано I puw | - I ele
- | PR | FP I ME I FEO I SE I BE I FE1 | - | EP | IT | DT | | PM RE | LE
16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
Рис. 2.69. Формат содержимого регистра управления процессора MSR
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
Отдельная группа регистров используется в процессе обслуживания исключений. В эту группу входят регистры: DAR, хранящий адрес операнда, выборка которого вызвала исключение; DSISR, содержащий код команды, вызвавшей исключение; SRRO, SRR1, в которые заносятся адрес следующей команды и текущее содержимое регистра MSR для возврата к основной программе после обслуживания исключения. Микропроцессор имеет также четыре регистра SPRGO—4, которые обычно служат для хранения адресов, используемых подпрограммой обработки исключения.
К группе вспомогательных регистров относятся регистры: декремента DEC, базового времени ТВ, адресов останова в контрольной точке IABR, DABR, идентификации PIR, а также регистр EAR, используемый для обращения к внешним устройствам с помощью специальных команд eciwx, ecowx.
Регистр DEC работает как вычитающий счетчик с частотой, равной 1/4 от тактовой частоты Ft. Когда его содержимое становится равным нулю, формируется запрос исключения. Таким образом, можно использовать регистр DEC для реализации периодических прерываний.
Регистр PIR содержит 4-разрядный код идентификации PID, определяющий номер микропроцессора в мультипроцессорных системах.
Таймер базового времени ТВ представляет собой 64-разрядный счетчик, переключающийся с частотой Ft. Его содержимое может записываться и считываться путем обращения к 32-разрядным регистрам TBU (младшие 32 разряда) и TBL (старшие 32 разряда). Отметим, что этот регистр доступен также в режиме пользователя, но только для чтения его содержимого.
Регистр IABR содержит адрес команды, а регистр DABR - адрес операнда, при обращении к которым реализуется исключение останова в контрольной точке.
Кроме того, в состав модели супервизора входят пять регистров (MMCRO, РМС1, РМС2, SDA, SIA), которые используются для контроля эффективности работы микропроцессора. В зависимости от значения битов РМ, PR в MSR и содержимого регистра управления MMCR0 в регистры РМС1, РМС2 при работе процессора заносятся такие показатели, как число выполненных циклов, число команд, завершившихся в данном цикле, общее количество выполненных ветвлений, число неправильно предсказанных ветвлений, число кэш - промахов и др. Общее число таких контролируемых параметров составляет 46. Эти данные позволяют программисту оценить эффективность программного обеспечения и оптимизировать его в процессе отладки.
При возникновении исключений их вектора (начальные адреса подпрограмм обслуживания) выбираются из таблицы, базовый адрес которой определяется значением бита ЕР в регистре MSR (рис. 2.68, а). Виды исключений и относительные адреса соответствующих векторов приведены в табл. 2.64. Отдельные виды исключений маскируются путем установки в нуль битов ЕЕ, SE, BE, ME в регистре MSR. При реализации большинства исключений в регистр SRR0 заносится адрес следующей команды программы, обеспечивающий возврат к ее выполнению после обслуживания исключения, а в регистр SRR1 - текущее содержимое MSR. После выполнения подпрограммы обслуживания команда возврата из исключения rfi производит восстановление содержимого программного счетчика и регистра состояния MSR из SRRO, SRR1.
При исключениях типа «системный сброс», «контроль процессора» в регистре SRRO сохраняется ранее записанное содержимое. Поэтому после их обслуживания можно обеспечить переход к заданной команде, адрес которой предварительно заносится в SRRO. В регистре SRR1 при исключении «контроль процессора» отдельные биты указывают на поступление сигналов TEA# = О, MCP# = 0, нарушение четности при обращениях к кэшам команд или данных, при выборке команд или данных из внешней памяти. Анализ содержимого SRR1
RISC-МИКРОПРОЦЕССОРЫ И RISC-МИКРОКОНТРОЛЛЕРЫ СЕМЕЙСТВ POWERPC И COLDFIRE
позволяет в этом случае определить причину исключения. Если исключение «контроль процессора» замаскировано (в регистре MSR бит ME = 0), то микропроцессор останавливает свою работу, выдавая внешний сигнал контрольной остановки CKSTP - OUT# = 0. При исключениях типа «ошибка выбора данных», «нарушение выравнивания» в регистр DAR заносится код выполнявшейся команды, а в регистр DSISR - адрес операнда, выборка которого вызвала исключение.
Микропроцессор МРС604 имеет суперскалярную структуру (рис. 2.70), которая содержит шесть параллельно работающих исполнительных устройств: блок обработки ветвлений BPU, два устройства для выполнения простых (одноцикловых) целочисленных операций SIU1, SIU2, одно устройство для выполнения сложных (многоцикловых) целочисленных операций MIU, устройство обработки чисел с плавающей точкой FPU и блок выборки операндов из памяти LSU. При этом обеспечивается одновременное выполнение четырех команд. Все операции обработки данных выполняются с регистровой адресацией. Выборка данных из памяти производится только командами пересылки, которые выполняются блоком LSU и осуществляют загрузку данных в регистры GPR, FPR или запись содержимого этих регистров в память.
Таблица 2.64
Виды и относительные адреса векторов исключений
Адрес вектора Av Вид исключения
$00100 «Системный сброс» - установка в начальное состояние при поступлении внешних сигналов сброса SRESET# = 0 HRESET = 0
$00200 «Контроль процессора»- поступление сигналов ошибки пересылки TEA# = 0 или контроля процессора MCP# = 0 (различные, если в MSR биг ME = 1)
$00300 «Ошибка выбора данных» - ошибка при трансляции адреса данных; нарушение защиты при выборе данных; формирование адреса, совпадающего с содержимым регистра DABR
$00400 «Ошибка выбора команды» - ошибка при трансляции адреса команды; нарушение защиты при выборе команды
$00500 «Внешнее прерывание» - поступление внешнего сигнала INT# = U (разрешено, если в MSR биг ЕЕ = 1)
$00600 «Нарушение выравнивания» - обращение к памяти по адресу, не кратному четырем
$00700 «Программное исключение» - неправильный код команды; нарушение защиты; программное прерывание по командам tw, twi; прерывания при обработке чисел с плавающей точкой
$00900 «Периодическое прерывание» - изменение содержимого регистра декремента DEC с 00...0 на 11 ...1 (разрешено, если в MSR биг ЕЕ = 1)
$00С00 «Системный вызов» - вызов подпрограммы обслуживания при поступлении команды системного вызова sc
$00D00 «Исключение трассировки» - пошаговый режим с остановкой после каждой команды (если в MSR битБЕ = 1) или после команд ветвлений (если в MSR биг BE = 1)
$00F00 «Исключение контроля эффективности» - переполнение регистра РМС1 или РМС2
$01300 «Прерывание в контрольной точке»- выборка команды, адрес которой совпадает с содержимым регистра IABR
$01400 «Системное прерывание» - поступление сигнала SMI# = 0 (если в MSR биг ЕЕ = 1)
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
шины
Рис. 2.70. Структура микропроцессора МРС604
При параллельной работе исполнительных устройств возможно их одновременное обращение к одним регистрам. Чтобы избежать ошибок, возникающих при этом, в случае записи в регистр нового содержимого до того, как другим устройством будет считано предыдущее, введены буферные регистры -12 для GPR, 8 для FPR. Эти регистры служат для промежуточного хранения операндов, дублируя регистры GPR, FPR, используемые при выполнении текущих операций. После завершения этих операций производится перезапись полученных результатов в GPR, FPR (обратная запись).
Конвейер выполнения команд имеет шесть основных каскадов: выборка команды (1) и ее дешифрация (2), распределение команд по исполнительным устройствам (3), выполнение команд (4), запись результатов в буфер (5) и обратная запись результатов в регистры SPR или FPR. Устройство управления одновременно выбирает из кэша и декодирует четыре команды, которые распределяются в соответствующие исполнительные устройства. Большинство команд выполняется за один такт. Эти команды реализуются с помощью SIU1, SIU2, которые осуществляют сложение - вычитание, сравнение, сдвиги, логические операции. Выполнение ряда команд требует нескольких тактов. Например, целочисленное умножение осуществляется за 3—4 такта, деление за 20 тактов. Эти операции производятся MIU. Большинство операций с плавающей точкой (кроме деления), выполняется за три такта, поэтому во внутренней структуре FPU реализовано три исполнительных каскада. Блок завершения обеспечивает получение правильной последовательности результатов выполняемых операций. Он содержит буферную память типа очереди, в которую по мере поступления записываются результаты, получаемые от исполнительных устройств. Обратная запись результатов из буфера в регистры GPR, FPR производится в соответствии с порядком поступления команд, выбираемых устройством управления, т. е. восстанавливается необходимая последовательность результатов.
Блок обработки ветвлений BPU предсказывает направление ветвления программы при поступлении соответствующих команд. В микропроцессорах семейства МРСбхх реализуется два механизма предсказания: статическое предсказание, которое дается программистом и содержится в тексте выполняемой программы, и динамическое предсказание, которое выполняется BPU по результатам предыдущих ветвлений. Блок BPU использует для предсказания кэш-адресов ветвлений ВТАС и таблицу истории ветвлений ВНТ. Кэш ВТАС
RISC-МИКРОПРОЦЕССОРЫ И RISC-МИКРОКОНТРОЛЛЕРЫ СЕМЕЙСТВ POWERPC И COLDFIRE
хранит 64 адреса ветвлений, выполнявшихся предыдущими командами. Если поступившая команда ветвления содержит адрес, совпадающий с одним из имеющихся в ВТАС, то процессор предсказывает ветвление по этому адресу и выбирает команды из соответствующей ветви в конвейер (ветвление выполняется). Если адрес ветвления не содержится в ВТАС, то выбирается следующая команда программы (ветвление отсутствует).
При поступлении команд условных ветвлений BPU анализирует таблицу ВНТ, которая представляет собой кэш-память, где содержатся 512 адресов предыдущих условных ветвлений. Для каждого адреса в таблице имеются два бита, определяющие вероятность ветвления по данному адресу: 00 - практически не выполняется ,01- выполняется редко, 10 -выполняется часто, 11 - выполняется очень часто. Значения этих битов меняются после каждой операции ветвления: если производится ветвление поданному адресу, то вероятность увеличивается на единицу (максимальное значение 11), если данный адрес не использован, то вероятность уменьшается на единицу (минимальное значение 00). Новые адреса вводятся в ВНТ вместо адресов с нулевой вероятностью. Ветвление по имеющемуся в таблице адресу предсказывается, если его вероятность больше 01. Правильность предсказания проверяется после определения соответствующих признаков в регистре условий CR. Если условия не выполняются (неправильное предсказание), то процессор освобождает конвейер от команд из неправильно выбранной ветви, и загружает новые команды из другой ветви. Таким образом, при неправильных предсказаниях требуется перезагрузка конвейера, что снижает производительность процессора.
Так как одновременно могут выполняться несколько команд, изменяющих значения признаков в регистре CR, то в BPU имеются восемь буферных регистров, дублирующих содержимое CR. Эти регистры используются различными исполнительными устройствами, а после завершения соответствующих операций их содержимое переносится в основной регистр условий CR (обратная запись), обеспечивая правильный порядок выполнения условных команд.
Микропроцессор МРС604 осуществляет раздельную выборку команд и данных с помощью двух устройств управления памятью IMMU, DMMU, которые могут выполнять сегментную, страничную и блочную адресацию. Внутренние кэши команд IC и данных DC имеют емкость по 16 Кбайт.
Контроллер шины BIU обеспечивает интерфейс микропроцессора с внешними устройствами. Системная шина передает 32-разрядный адрес АО-31 и 64-разрядные данные DH0-31 (старшее слово), DL0-31 (младшее слово). Для каждого байта адреса и данных передаются и принимаются биты четности, с помощью которых осуществляется контроль ошибок обращения к шине. Увеличенная разрядность шины данных позволяет быстрее производить загрузку строк кэш-памяти, которые содержат по 32 байта. При кэш-промахе производится пакетная передача данных, которая обеспечивает пересылку содержимого строки за 4 последовательных цикла. Контроллер BIU реализует выдачу и прием необходимых сигналов для управления обменом, выполнения прерываний, захвата шин, снупинга (обращения внешнего устройства к внутреннему кэшу данных) и установки начального состояния (RESET). Формируются также сигналы для управления внешней кэш-памятью 2-го уровня.
Микропроцессор содержит специализированный, последовательный порт для выполнения тестирования по стандарту JTAG (IEEE 1149.1). Тестирование осуществляется с помощью специального тест-порта ТАР также, как в микропроцессоре МС68060 и ряде моделей семейства М683хх.
Для питания микропроцессора используется напряжение Уп = 3,3В. При тактовой частоте Ft = 100 МГц потребление мощности не превышает 10 Вт. Пониженное энергопотребление (400 мВт) обеспечивается при останове микропроцессора, который осуществляется программно путем установки в регистре MSR значения бита POW = 1. В этом случае прекращается выполнение команд, продолжают работать только базовый таймер ТВ, ре
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
гистр декремента DEC и блок обслуживания запросов прерывания. Микропроцессор уста-навливает выходной сигнал HALTED = 1, информируя о своем останове внешние устройства. Выход из этого состояния происходит при поступлении внешних сигналов прерывания INT#, МСР#, SMI# или начальной установки RESET#, а также при запросе периодического прерывания от регистра DEC.
Способы адресации и система команд. Микропроцессоры семейства PowerPC используют следующие способы адресации:
• регистровую;
• косвенно-регистровую со смещением;
• косвенно-регистровую с индексированием;
• относительную;
• абсолютную;
• непосредственную.
Все команды арифметических и логических операций, сравнения и сдвигов (табл. 2.65-2.67) выполняются только с регистровой и непосредственной адресацией. Благодаря этому обеспечивается высокая производительность, так как при обработке данных не требуется выполнять циклов обращения к шине для выбора операндов. Трехадресный формат команд позволяет исключить лишние пересылки данных между регистрами. При этом в качестве rD, гА, гВ указываются номера регистров GPR31-0, определяющие регистр размещения результата (rD) и регистры операндов (гА, гВ). Непосредственный операнд со знаком Sim или без знака Ulm задается 32-разрядным словом, следующим за кодом команды.
Таблица 2.65
Команды арифметических операций
Синтаксис Ассемблера Операция
add! (addis) add (add., addo, addo.) addic (addic.) adde (adde., addeo, addeo.) adde (adde., addeo, addeo.) addme (addme., addmeo, addmeo.) addze (addze., addzeo, addzeo.) rD, rA, Sim rD, rA, rB rD, rA, Sim rD, rA, rB rD, rA, rB rD, rA rD, rA гА|О + Sim -> rD ( сдвиг Sim) rA + rB rD rA + Sim —> rD, установка CA rA + rB —> rD, установка CA rA + rB + CA -> rD, установка CA rA - 1 + CA ~> rD, установка CA rA + CA —> rD, установка CA
subf (subf., subfo, subfo.) subfic subfc (subfe., subfeo, subfeo.) subfe (subfe., subfeo, subfeo.) subfme (subfme., subfmeo, subfmeo.) subfze (subfze., subfzeo, subfzeo.) rD, rA, rB rD, rA, Sim rD, rA, rB rD, rA, rB rD, rA rD, rA -rA + rB -> rD -rA + Sim —> rD, установка CA -rA + rB —> rD, установка CA -rA + rB + CA -> rD, установка CA -rA - 1 + CA —> rD, установка CA -rA + CA -> rD, установка CA
multimullw (mullw., mullwo.mullwo.) mulhw (mulhw.) mulhwu (mulhwu.) rD, rA, Sim rD, rA, rB rD, rA, rB rD, rA, rB rA * Sim —> rD, знаковое 16x16 rA * rB -> rD, знаковое 16x16 rA * rB -> rD, знаковое 32x32 rA * rB —> rD, беззнаковое 32x32
divw (divw., divwo, divwo.Jdivwu (divwu., divwuo, divwuo.) rD, rA, rB rD, rA, rB rA/гВ -> rD, знаковое 32:32 гА/rB —> rD, беззнаковое 32:32
neg (neg., nego, nego.) rD, rA -rA -> rD
extsb (extsb.) extsh (extsh.) rD, rS rD, rS rS (мл. байт) -> rD ~ Расширение rS (мл. п/слова) —> rD_j знаком
RISC-МИКРОПРОЦЕССОРЫ И RISC-МИКРОКОНТРОЛЛЕРЫ СЕМЕЙСТВ POWERPC И COLDFIRE
Команды загрузки и сохранения содержимого регистров (табл. 2.68) используют при обращении к памяти косвенно-регистровую адресацию со смещением или индексированием. Эффективный адрес операнда ЕА определяется выражениями:
ЕА = (гА! О) + d32 - при адресации со смещением;
ЕА = (гА! О) + (гВ) - при адресации с индексированием,
где гА, гВ - номера регистров общего назначения GPR31-1, d32-32 - разрядное смещение. Регистр GPR0 не используется при этих способах адресации: если в качестве номера гА указан нуль, то формируется адрес ЕА = d32 при адресации со смещением, ЕА = (гВ) при адресации с индексированием. Так реализуется прямая (абсолютная) адресация с обращением по заданному в команде адресу d32 и косвенно-регистровая адресация по адресу, заданному содержимым регистра гВ.
Команды ветвления (табл. 2.69) используют прямую или относительную адресацию. При этом адресом перехода служит указанный в команде адрес t-adr или сумма (PC + t-adr).
Все команды микропроцессора имеют 32-разрядный формат кода операции. При использовании непосредственной адресации после кода команды следует 32-разрядный операнд. В командах, использующих косвенно-регистровую адресацию со смещением, после кода операции следует 32-разрядное смещение, а в командах ветвления - 32-разрядный адрес t-adr. Таким образом, все команды содержат4 или 8 байтов.
Команды арифметических операций (табл. 2.65) имеют ряд модификаций, отличающихся формированием признаков по результатам операций. Если после мнемокода операции идет символ «.», то по результатам операции устанавливаются соответствующие значения битов SO, EQ, GT, LT в поле CR0 регистра CR (рис. 2.67, а). Если мнемокод команды имеет суффикс «о», то по результату ее выполнения устанавливаются биты OV, SO в регистре XER (рис. 2.67, б), при этом бит SO дублируется в поле CR0. Команды сложения addic, addc, adde, addme, addze и вычитания subfc, subtle, subfe, subfme, subfze вызывают установку признака переноса СА в регистре XER по результату операции. Команда addi при значении гА = 0 производит загрузку непосредственного операнда со знаком Sim в регистр rD, а при гА =/ О выполняет сложение этого операнда с содержимым регистра гВ. Команда непосредственного сложения со сдвигом addis производит при гА =/ 0 сложение содержимого гА с непосредственным операндом Sim, сдвинутым на четыре разряда влево, а при гА = 0 загружает сдвинутый операнд Sim в регистр rD.
Таблица 2.66
Команды логических операций
Синтаксис Ассемблера Операция
andi. (andis.) ori. (oris.) xori. (xoris.) rA, rS, Ulm rA, rS, Uimr A, rS, Ulm rS a Ulm —> rA ( сдвиг Ulm) rS v Ulm -> rA ( сдвиг Uim) rS ffi Ulm -> rA ( сдвиг Uim)
and (and.) or (or.) xor (xor.) and (nand.) nor (nor.) andc (andc.) orc (orc.) egv (egv.) rA, rS, rB rA, rS, rB rA, rS, rB rA, rS, rB rA, rS, rB rA, rS, rB rA, rS, rB rA, rS, rB rS л rB —> rA rS v rB -> rA rS ffi rB -> rA rS a rB —> rA rS v rB -> rA rS a rB —> rA rS v rB -> rA rS ffi rB —> rA
entizw (cnitzw.) rA, rS Число старших 0 в rS -> rA
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
Команды умножения и деления могут оперировать с операндами без знака и со знаком. При знаковом умножении 16-разрядных операндов (команды multi, mullw) в регистре rD размещается 32-разрядный результат. При умножении 32-разрядных чисел со знаком (команда mulhw) или без знака (команда mulhwu) в регистр rD поступают старшие 32 разряда результата, а в следующий регистр с номером (гВ + 1) - младшие 32 разряда. При делении 32-разрядных чисел со знаком (команда divw) или без знака (команда divwu) в регистр rD заносится 32-разрядное частное.
Команда neg меняет знак операнда. Команда extsb преобразует младший байт содержимого регистра rS путем расширения знака в 32-разрядное слово, размещаемое в rD. Команда extsh выполняет аналогичное расширение для 16 младших разрядов (младшее полуслово) содержимого регистра rS.
Команды логических операций (табл. 2.66) производятся над операндами без знака, содержащимися в регистрах (rS, гВ) или заданными непосредственно в команде (Ulm). Микропроцессор реализует восемь логических операций - И, ИЛИ, Исключающее ИЛИ, НЕ - И, НЕ - ИЛИ, Запрет, Импликация, Эквивалентность. При выполнении команд, имеющих после мнемокода символ «.», производится установка соответствующих признаков в поле CR0 регистра условий CR. Команды логических операций со сдвигом andis., oris., xoris. перед выполнением операций И, ИЛИ, Исключающее ИЛИ производят сдвиг непосредственного операнда влево на 16 разрядов. В данную группу входит также команда cntizw, определяющая число последовательно расположенных нулей в регистре rS, начиная со старшего разряда. Это число заносится в регистр гА.
Команды сравнения (табл. 2.67) осуществляют вычитание двух операндов, содержащихся в регистрах (гА, гВ) или заданных непосредственно (Sim, Ulm), которые могут быть числами со знаком (знаковое сравнение) или без знака (беззнаковое сравнение). По результатам вычитания осуществляется установка признаков в поле CRi регистра условий CR. Номер поля i = 7...2 задается операндом crfD в команде Ассемблера. Если этот операнд не задан или равен 0, то признаки устанавливаются в поле CR0. Операнд L в этих командах для микропроцессора МРС604 задается равным 0.
Команды сдвигов (табл. 2.67) реализуют многоразрядные логические (slw, srw), арифметические (sraw, srawi) и циклические (riwinm, rlwnm, rlwimi) сдвиги содержимого регистра rS с размещением результата в гА. Число разрядов сдвига задается непосредственно операндом Ns или содержимым шести младших разрядов регистра гВ. При логических сдвигах влево (команда slw) или вправо (команда srw) освободившиеся разряды заполняются нулями. При арифметическом сдвиге вправо (команды sraw, srawi) в освободившихся слева разрядах дублируется знак исходного операнда.
Таблица 2.67
Команды операций сравнения и сдвигов
Синтаксис Ассемблера Операция
cmpi стр cmpli cmpi CrfD, L, rA, Sim CrfD, L, rA, rB CrfD, L, rA, Uim CrfD, L, rA, rB - rA + Sim (знаковое) - rA + rB (знаковое) - rA + Sim (беззнаковое) - rA + rB (беззнаковое)
swl (swl.) srw (srw.) srawi (srwi.) sraw (sraw.) rA, rS, rB rA, rS, rB rA, rS, Ns rA, rS, rB [rS <- s(rB)] -> rS, заполнение нулями [rS -» s(rB)] -> rA, заполнение нулями [rS -> s(Ns)] -> rA, заполнение знаком [rS -> s(rB)] -> rA, заполнение знаком
riwinm (riwinm.) rlwnm (rlwnm.) rlwimi (rlwimi.) rA, rS, Ns, Mb, Me rA, rS, Ns, Mb, Me rA, rS, Ns, Mb, Me [rS «- r(Ns)J лМ -нА [rS <- r(rB)] л M ч rA ([rS«— r(Ns)] л M ) v (rA a M) -> rA
RISC-МИКРОПРОЦЕССОРЫ И RISC-МИКРОКОНТРОЛЛЕРЫ СЕМЕЙСТВ POWERPC И COLDFIRE
Циклические сдвиги производятся только влево, причем результат сдвига логически умножается на маску М. Маска формируется в соответствии с задаваемыми в команде номерами начального Mb и конечного Me битов. Биты маски с номерами от Me до Mb имеют значение «1», поэтому соответствующие биты результата сохраняются. Остальные биты маски имеют значение «О», и соответствующие биты результата принимают такое же значение. Полученный после маскирования результат размещается в регистре гА. При выполнении команд rlwinm, rlwnm предыдущее содержимое гА не сохраняется. Команда rlwimi сохраняет в регистре гА значения битов, соответствующих замаскированным битам результата (для которых биты маски равны нулю).
Команды сдвигов могут вызывать установку признаков в поле CR0 регистра CR в соответствии с результатом операции. Для этого после мнемокода команды следует поставить символ «.».
Команды загрузки и сохранения (табл. 2.68) производят загрузку в регистр GPR с номером rD байта, слова или полуслова (16-разрядное слово) из памяти (команды, начинающиеся с буквы «I» - load), либо записывают в память байт, слово или полуслово из регистра rS (команды, начинающиеся с букв «st» - store). Для обращения к памяти используется косвенно-регистровая адресация со смещением или индексированием. При адресации с индексированием в команде указываются адресный (гА) и индексный (гВ) регистры (мнемокод этих команд заканчивается буквой «х»), при адресации со смещением - адресный регистр (гА) и смещение d32. При загрузке байта (команды Ibz, Ibzx) старшие разряды регистра rD заполняются нулями (расширение нулями). При загрузке полуслова старшие разряды заполняются либо нулями (команды Ihhz, Ihzx), либо значением старшего (знакового) бита Ь15 загружаемого слова (команды lha, lhax, расширение знаком).
Таблица 2.68
Команды загрузки и сохранения содержимого регистров GPR
Синтаксис Ассемблера Операция
Ibz (Ibzu) Ibzx (Ibzux) Ihz (lhzu)l hzx (Ihzux) lha (lhau) lhax (lhaux) Iwz (Iwzu) Iwzx (Iwzux) rD, d(rA) rD, rA, rB rD, d(rA) rD, rA, rB rD, d(rA) rD, rA, rB rD, d(rA) rD, rA, rB (EA) -> rD, байт (EA -> rA) (EA) -> rD, байт (EA -> rA) (EA) -> rD, полуслово (EA —> rA) (EA) -> rD, полуслово (EA —> rA) (EA) -> rD, полуслово (EA -> rA) (EA) -> rD, полуслово (EA -> rA) (EA) -> rD, слово (EA -> rA) (EA) -> rD, слово (EA -> rA)
stb (stbu) stbx (stbux) sth (sthu) sthx (sthux) stw (stwu) stwx (stwux) rS, d(rA) rD, rA, rB rS, d(rA) rD, rA, rB rS, d(rA) rD, rA, rB rS -> (EA), байт (EA rA) rS -> (EA), байт (EA -> rA) rS —> (EA), полуслово (EA -> rA) rS -> (EA), полуслово (EA -> rA) rS —> (EA), слово (EA -> rA) rS -> (EA), слово (EA -> rA)
Ihbrx (Iwbrx) sthbrx (stwbrx) rD, rA, rB rS, rA, rB (EA) -> rD, перестановка байтов rS -> (EA), перестановка байтов
Imw stmw rD, d(rA) rS, d(rA) (EA) -> rD...GPR31, групповая пересылка rS...GPR31 -> (EA), групповая пересылка
Iswi (Iswx) stswi (stswx) rD, rA, Nb(rS) rS, rA, Nb(rB) (EA) -> rD , пересылка строки rS —> (EA) , пересылка строки
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
Команды загрузки-сохранения имеют модификации с суффиксом и (указаны в скобках). При наличии данного суффикса в регистр гА после пересылки загружается эффективный адрес ЕА, использованный в данной команде. Эти модификации позволяют, например, реализовать постинкрементную адресацию байтов, полуслов или слов, если задать в соответствующих командах значения смещения d32 = 1,2 или 4. В командах загрузки с суффиксом и нельзя использовать номера rD = гА, при этом реализуется исключение с адресом вектора Av = $00700 (неправильный код команды, табл. 2.64).
Команды Ihbrz, Iwbrz осуществляют перестановку байтов при загрузке в регистр rD полуслова (Ihbrz) или слова (Iwbrz). Команды sthbrx, stwbrx выполняют аналогичную перестановку байтов при записи из регистра rS в память полуслова (sthbrx) или слова (stwbrx).
Команды групповой пересылки Imw, stmw производят загрузку или запись в память содержимого группы регистров, начиная с заданного в команде номера rD или rS до последнего регистра с номером GPR31. Загружаемые или записываемые данные располагаются в ячейках памяти, начиная с адреса ЕА, определяемого косвенно-регистровой адресацией со смещением. Регистр гА не должен входить в группу адресуемых регистров, иначе реализуется исключение с адресом Av = $00700 (неправильный код команды).
Команды пересылки строк символов Iswi, Iswx, stswi, stswx осуществляют загрузку в регистры или запись в память п символов (байтов). Число пересылаемых байтов задается данным в команде операндом Nb (команды Iswi, stswi), или значением 8 старших битов (поле SS, рис. 2.67, а) в регистре XER (команды Iswx, stswx). Начальный адрес пересылаемых байтов ЕА - (гА) - для команд Iswi, stswi (косвенно-регистровая адресация) и ЕА = (гА!О) + (гВ) - для команд Iswx, stswx (адресация с индексированием). Данные в регистрах размещаются или выбираются, начиная с младшего байта регистра rD или rS.
Команды вызывают исключение с адресом Av = $00700 (неправильный код команды), если гА или гВ входит в число регистров, в которые загружается или из которых выбирается строка символов.
Управление программой производится командами безусловных и условных ветвлений (их мнемокоды начинаются с буквы «Ь» - branch), программных прерываний tw, twi, системного вызова sc и возврата из прерывания rfi (табл. 2.69). При ветвлениях адрес команды перехода определяется с помощью прямой (команды ba, Ыа, bca, bcla) или относительной (команды b, bl, be, bcl) адресации. Заданное в команде число t-adr служит при этом абсолютным адресом или смещением, определяющим значение адреса перехода. Если мнемокод команды ветвления имеет суффикс I (команды Ы, Ыа, bcl, bcla), то при ее выполнении текущее содержимое программного счетчика PC заносится в регистр связи LR, обеспечивая возможность возвращения к следующей команде программы. Таким образом, эти команды могут служить для вызова подпрограмм.
Команды be, bca, bcl, bcla реализуют условные ветвления или вызовы подпрограмм. Условием ветвления является совпадение содержимого поля CRi в регистре условий CR с четырьмя младшими битами заданного в команде операнда ВО. Номер используемого для сравнения поля i задается операндом BI. При совпадении заданного значения ВО и содержимого поля CRi производится переход к команде, адрес которой определяется абсолютной (команды bca, bcla) или относительной (команды be, bcl) адресацией. При их несовпадении выполняется следующая команда программы. Команды bcl, bcla, сохраняющие в регистре LR адрес следующей команды, служат для реализации условных вызовов подпрограммы.
Команды bclr, belli реализуют условный возврат из подпрограмм, если заданное значение ВО совпадает с содержимым поля CRi. При этом в программный счетчик PC загружается содержимое регистра связи LR. Команда bcrlri сохраняет в регистре LR текущее содержимое PC, обеспечивая возможность возвращения к подпрограмме.
RISC-МИКРОПРОЦЕССОРЫ И RISC-МИКРОКОНТРОЛЛЕРЫ СЕМЕЙСТВ POWERPC И COLDFIRE
Таблица 2,69
Команды управления программой
Синтаксис Ассемблера Операция
b t - adr PC + (t - adr) -> PC
Ьа t - adr (t - adr) -> PC
Ы t - adr PC -> LR, PC + (t - adr) -> PC
Ыа t - adr PC -> LR, (t - adr) -> PC
Ьс BO, Bl, t - adr PC + (t - adr) -> PC, если BO = CRi
Ьса BO, Bl, t - adr (t - adr) -> PC, если BO = CRi
bcl BO, Bl, t - adr PC -4 LR, PC + (t - adr) -> PC, если BO = CRi
bcla BO, Bl, t - adr PC -> LR, (t - adr) -> PC, если BO = CRi
bclr BO, Bl LR -> PC, если BO = CRi
bclrl BO, Bl PC -> LR, если BO = CRi
bcctr BO, Bl CTR -> PC, если BO = Cri
bcctrl BO, Bl PC -> LR, CTR -> PC, если BO = CRi
twi TO, rA, Sim -rA + Sim, если TO, to PC, MSR SRRO, SRR1, Ve -> PC
tw TO, rA, rB -гА + rB, если TO, to PC, MSR —> SRRO, SRR1, Ve —> PC
SC *rfi PC, MSR SRRO, SRR1, Ve -> PC SRRO, SRR1 -> PC, MSR
При выполнении команд bcctr, bcctrl в программный счетчик PC загружается содержимое регистра CTR, если выполняется условие ВО - CRi. Команда bcctrl обеспечивает сохранение текущего содержимого PC в регистре связи LR.
При условных ветвлениях программист может указать на повышенную вероятность ветвления, задав значение «1», для пятого бита операнда ВО. В этом случае блок обработки ветвления BPU обеспечит выборку в конвейер следующих команд в соответствии сданным предсказанием. Такой способ предсказания ветвлений называется статическим. При нулевом значении пятого бита в операнде ВО блок BPU осуществляет динамическое предсказание ветвлений с помощью кэша адресов ВТАС и таблицы истории ветвлений ВНТ.
Команды программных прерываний tw, twi производят условное обращение к подпрограмме обслуживания, вектор которой Ve размещен по адресу Av = $00700 (см. табл. 2.64). Текущее содержимое PC и MSR сохраняется в регистрах SRRO, SRR1. Условием обращения является совпадение признаков в поле CR0, устанавливаемых при сравнении содержимого регистра гА с непосредственным операндом Sim (команда twi) или с содержимым регистра гВ (команда tw), с битами заданного в команде 4-разрядного операнда ТО. Прерывание реализуется, если хотя бы один из установленных в «1» признаков в CR0 совпадает с соответствующим битом ВО. Содержимое гА, гВ и операнд Sim представляются при сравнении числами со знаком.
Команда sc осуществляет вызов системного прерывания с подпрограммой обслуживания, вектор которой Ve размещен по адресу Av = $00000 (см. табл. 2.64). Команда rfi реализует возврат из прерывания, при котором из регистров SRRO, SRR1 восстанавливается содержимое программного счетчика PC и регистра управления MSR, обеспечивая возвращение к выполнению прерванной программы. Команда rfi может выполняться только в режиме супервизора, так как она изменяет содержимое регистра MSR.
При выполнении команд условных переходов используется содержимое различных полей регистра условий CR. Различные операции с содержимым этого регистра реализуются с помощью специальных команд (табл. 2.70). Команда mtcrf производит загрузку в CR содержимого
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
регистра rS, которое логически умножается на 32-битовую маску, заданную в команде. Эта команда устанавливает требуемые значения содержимого CR или его немаскированных полей. Пересылка содержимого CR в регистр rD производится командой mfcr. Команда тсгхг копирует четыре младших бита из регистра исключений XER (признаки SO, OV, СА, рис. 2.67, а) в поле CRi регистра CR, где номер поля i задается операндом crfD. После копирования признаки SO, OV, САв регистре XER принимают значение «О». Команда mcrf копирует содержимое поля CRi в поле CRj, где значения i, j задаются операндами crfS, crfD.
Ряд команд выполняет логические операции над отдельными битами bi, bj содержимого регистра CR (табл. 2.70). Номера i, j этих битов задаются операндами crbA, сгЬВ, результат операции размещается в бите bk, номер которого к определяется операндом crbD. Данные команды обеспечивают выполнение операций И (crand), ИЛИ (сгог), Исключающее ИЛИ (сгхог), НЕ/И (crnand), HE/ИЛИ (сгпог), Эквивалентность (creqv), Запрет (crandc), Импликация (сгогс).
В группу служебных команд (табл. 2.71) входят команды пересылки содержимого служебных регистров. Команды mtmsr, mfmsr, пересылки содержимого регистра управления MSR выполняются только в режиме супервизора. Команды mtspr, mfspr осуществляют пересылку содержимого служебных регистров SPRi, номер которых i задается операндом SPR. Большинство служебных регистров входит в модель супервизора (см. рис. 2.68), поэтому обращение к ним допускается только в режиме супервизора. Исключение составляют регистры XER (SPR1), LR (SPR8), CTR (SPR9), входящие в модель пользователя (см. рис. 2.66). Обращение к этим регистрам осуществляется командами mtspr, mfspr, выполняемыми в режиме пользователя, при значениях операнда SPR =1,8 или 9. Команда mftb производит считывание в регистр rD старшего (TBU) или младшего (TBL) слова из базового таймера.
Команды Iwarx, stwcx. обычно используются совместно. При этом задаются одинаковые значения гА, гВ и rD = rS. Команда Iwarx загружает операнд из памяти в регистр rD, а команда stwcx. возвращает его обратно по тому же адресу ЕА = (гА!0) + (гВ), устанавливая в поле CR0 соответствующие признаки EQ, GT, LT. Если же перед командой stwcx. произошла новая загрузка rD или запись по адресу ЕА, то эта команда не вызовет каких-либо операций. Данная пара команд обычно используется операционной системой для проверки значений программных «семафоров», аналогично команде TAS в микропроцессорах семейства М68ххх. При поступлении этих команд на внешних выводах микропроцессора, определяющих тип выполняемого цикла, устанавливается определенная комбинация сигналов, которая должна запретить другим устройствам обращение к общей шине до завершения их выполнения.
Таблица 2.70
Команды изменения содержимого регистра условий CR
Синтаксис Ассемблера Операция
mtcrf Mcr, rS rS a Mcr -> CR
mfcr rD CR-^rD
mcrxr crfD XER (3-0) CRi
mcrf crfD, crfS Cri -> CRj
crand CrbD, crbA, crbB bi a bj —> bk
cror CrbD, crbA, crbB bi v bj —> bk
СГХОГ CrbD, crbA, crbB bi ffi bj -> bk
crnand CrbD, crbA, crbB bi a bj —> bk
СГПОГ CrbD, crbA, crbB bi v bj -> bk
cregv CrbD, crbA, crbB bi ffi bj bk
crandc CrbD, crbA, crbB bi a bj —> bk
СГОГС CrbD, crbA, crbB bi v bj -> bk
RISC-МИКРОПРОЦЕССОРЫ И RISC-МИКРОКОНТРОЛЛЕРЫ СЕМЕЙСТВ POWERPC И COLDFIRE
Таблица 2.71
Служебные команды микропроцессора МРС604
Синтаксис Ассемблера Операция
‘mtmsr ‘mfmsr ‘mtspr ‘mfspr mftb rS rD SPRi, rS rD, SPRi rD. TBCL, U rS MCR MCR rD rS SPRi SPRi rD TB(L,U) -> rD
Iwarx stwcx. rD, rA, rB rS, rA, rB (EA) -> rD rS (EA)
sync *isync *eieio Задержка конвейера Очистка конвейера Задержка обращений к памяти
eciwx ecowx rD, rA, rB rS, rA, rB (RID, ЕА) -> rD rS (RID, ЕА)
Команды sync, isync, eieio используются для синхронизации выполнения программ несколькими совместно работающими микропроцессорами. Команда sync вызывает завершение выполнения всех предшествующих команд, а затем разрешает выполнение последующих команд, т. е. осуществляет задержку конвейера до освобождения всех исполнительных устройств. Команда isync обеспечивает завершение выполнения предшествующих команд, после чего освобождает конвейер от поступивших в него последующих команд и выбирает из памяти новую пару команд. Таким образом, эта команда производит очистку конвейера. Команда eieio вызывает завершение выполнения предыдущих команд, требующих обращения к внешней памяти данных. Последующие обращения к памяти данных производятся только после выполнения этой команды, т. е. реализуется задержка обращений, которая может быть использована другими устройствами. При выполнении данной команды на внешних выводах, определяющих тип цикла обращения к шине, устанавливается определенная комбинация сигналов, которая используется, чтобы упорядочить обращения различных устройств к общей оперативной памяти. Команды isync, eieio выполняются микропроцессором только в режиме супервизора.
Команды eciwx, ecowx обеспечивают обращение микропроцессора к выделенным ресурсам системы - специализированным внешним устройствам или разделам памяти, для которых устанавливаются 4-разрядные коды идентификации RID. При обращении к этим ресурсам соответствующий код RID загружается в старшие разряды Ь31-28 регистра EAR (см. рис. 2.68). Младший разряд ЬО этого регистра содержит бит Е, определяющий вид обращения: при Е = О разрешается выполнение команды ecowx, посылающей слово из регистра rS в устройство, идентифицированное кодом RID, при Е = 1 -команды eciwx, принимающей слово от идентифицированного устройства в регистр rD. Код RID выдается микропроцессором на специальные внешние выводы, а на адресную шину поступает адрес ЕА - (гАЮ) + (гВ). При этом на выводах, определяющих тип цикла, устанавливается определенная комбинация сигналов, указывающая на выполнение команды ecwix или ecwox. Данные команды используются микропроцессором при обращении к выделенным внешним устройствам для приема или передачи управляющей информации.
Напомним, что команды rfi, mtmsr, mfmsr, mtspr, mfspr, isync, eoeoi (отмечены символом «*» в табл. 5.69, 5.71) выполняются микропроцессором только в режиме супервизора. Попытка их выполнения в режиме пользователя вызовет исключение с адресом вектора Av = $00700 (неправильный код команды).
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
Кроме описанных команд микропроцессор выполняет команды обработки чисел с плавающей точкой и команды управления кэшами и внешней памятью.
Обработка чисел с плавающей точкой. Операции над числами с плавающей точкой выполняются с использованием 64-разрядных регистров FPR31 -О и регистра управления и состояния FPSCR, входящих в регистровую модель пользователя (см. рис. 2.66). Обрабатываемые числа представляются в формате одинарной (ОТ, 32 разряда) или двойной (ДТ, 64 разряда) точности в соответствии со стандартом IEEE 754. Данные форматы обеспечивают также представление бесконечности и не-чисел (NAN) двух типов - SNAN и QNAN.
Регистр FPSCR управляет обслуживанием исключений при обработке чисел с плавающей точкой, а также определяет вид используемого округления. Отдельные биты содержимого FPSR (рис. 2.71) имеют следующее функциональное назначение:
FX - признак общего исключения FPU, принимает значение FX = 1, если в регистре FPSCR установлен в «1» какой-либо из признаков исключения VX, OX, UX, ZX, XX;
FEX - признак разрешенного общего исключения FPU, принимает значение FEX = 1, если хотя бы один из установленных признаков исключения разрешен для обслуживания битами VE, ОЕ, UE, ZE, ХЕ;
VX - общий признак исключения при выполнении неправильной операции FPU; принимает значение VX = 1, если в FPSCR установлен в «1» какой-либо из признаков неправильной операции (эти признаки отмечены начальными символами VX);
ОХ - признак переполнения принимает значение ОХ = 1, если результат превышает максимальную допустимую величину max;
UX - признак антипереполнения принимает значение UX = 1, если результат меньше минимальной допустимой величины min;
ZX - признак деления на нуль принимает значение ZX = 1 при нулевом делителе;
XX - признак неточного результата принимает значение XX = 1, если произошла потеря точности при округлении (XX копирует признак FI);
VXSNAN, VXISI, VXIDI, VXZDZ, VXIMZ, VXVC.VXSOFT, VXSQRT, VXCVI - признаки неправильной операции FPU при использовании в качестве операнда не-числа (VXSNAN = 1), при вычитании или делении бесконечностей (VXISI = 1 или VXIDI = 1), при делении нуля на нуль (VXZDZ = 1) или умножении нуля на бесконечность (VXIMZ =1), при программном вызове исключения неправильного кода команды (установка VXSOFT = 1 с помощью команд mcrfs, mtfsf, mtfsfi, mtfsbl), попытке извлечения квадратного корня из отрицательного числа (VXSQRT = 1) или неопределенном результате сравнения (VXCVI = 1);
FR - признак округления принимает значение FR = 1, если при выполнении команды производится округление результата;
FI - признак потери точности принимает значение FI = 1, если округление вызывает потерю точности (признак FI копируется в XX);
FPRF или FPCC- поле, определяющее результат выполняемых FPU арифметических операций, округления или сравнения (табл.2.72);
VE, ОЕ, UE, ZE, ХЕ-биты разрешения обслуживания исключений при выполнении неправильной операции (VE = 1), переполнении (ОЕ = 1), антипереполнении (UE = 1), делении на нуль (ZE = 1), получении неточного результата (ХЕ = 1);
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
FX FEX VX OX UX ZX XX VX SNAN VX ISI VX IDI VX ZDZ VX IMZ VXVC FR F1 —»
FPRF (FPCC) - VX SOFT VX SOFT VX CVI VE DE UE ZE XE Nl RN
16 19 20 21 22 23 24 25 26 27 28 29 30 31
Рис. 2.71. Формат содержимого регистра FPSR
RISC-МИКРОПРОЦЕССОРЫ И RISC-МИКРОКОНТРОЛЛЕРЫ СЕМЕЙСТВ POWERPC И COLDFIRE
Таблица 2.72
Содержимое полей FPRF, FPCC в регистре FPSCR
RN - определяет вид выполняемого округления: к ближайшему числу (RN = 00), к нулю (RN = 01), к + - (RN = 10) или к - ~(RN = 11).
При выполнении команд FPU, вызывающих изменение содержимого регистра условий CR (такие команды имеют символ «.» после мнемокода, см. табл. 2.73 - 2.75), содержимое четырех младших разрядов регистра FPSCR (признаки FX, FEX, VX, ОХ) копируется в поле CR1 регистра CR (рис. 2.67, а).
Признаки FX, OX, UX, ZX, XX, VXSNAN, VXISI, VXIDI, VXZDZ, VXIMZ, VXVC, VXSOFT, VXSQRT, VXCVI сохраняют установленное значение «1», пока оно не будет изменено с помощью команд mcrfs, mtfsfi, mtfsf, mtfsbO. Таким образом, эти признаки хранят информацию о причинах возникших замаскированных исключений, которая в дальнейшем может быть использована подпрограммой обслуживания.
Значения битов 15-19 в регистре FPSCR (поле FPRF или FPCC) зависят от типа выполняемой команды. При арифметических операциях (табл. 2.73) и операциях округления (табл. 2.74) значения битов FPRF устанавливаются согласно табл. 2.72 в соответствии с полученным результатом. При выполнении команд сравнения fcmpu, fcmpo биты 16-19 (поле FPCC) принимают такие же значения (табл. 2.71), как признаки FL (меньше), FG (больше), FE (равно), FU (не сравнимо) в поле CRi регистра условий CR, номер которого задается операндом crfd команды (табл. 2.74).
Команды арифметических операций сложения (fadd), вычитания (fsub), умножения (fmul), деления (fdiv), вычисления квадратного корня (fsqrt), обратной величины (fres) и обратной величины от квадратного корня (fsqrte) выполняются с операндами, располагаемыми в регистрах FPR, номера которых frA, frB, frC, frD задаются в команде (табл. 2.73). Блок FPU реализует также комбинированные операции умножение-сложение (fmadd), умножение-вычитание (fmsub) и аналогичные операции с изменением знака результата (fnmadd, fnmsub). Операции производятся над вещественными числами одинарной точ-
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
Таблица 2.73
Команды арифметических операций FPU
Синтаксис Ассемблера Операция
fadd (fadd., fadds, fadds.) fsub (fsub., fsubs, fsubs.) fmul (fmul., fmuls, fmuls.) fdiv (fdiv., fdivs, fdivs.) fsqrf (fsqrt., fsqrts, fsqrts.) fres (fres.) frsqrte (frsqrte.) fsel frD, frA, frB frD, frA, frB frD, frA, frB frD, frA, frB frD, frB frD, frB frD, frB frD, frA, frC, frB frA + frB -4 frD frA - frB -> frD frA * frB -> frD frA / frB frD frB -> frD 1/frB —> frD frC -> frD, если (frA) = 0 frB —► frD, если (frA) <> 0, NAN
fmadd (fmadd., fmadds, fmadds.) fmsub (fmsub., fmsubs, fmsubs.) fnmadd (fnmadd., fnmadds, fnmadds.) fnmsub (fnmsub., fnmsubs, fnmsubs.) frD, frA, frC, frB frD, frA, frC, frB frD, frA, frC, frB frD, frA, frC, frB frA * frC + frB -> frD frA * frC - frB -> frD -(frA * frC + frB) frD -(frA * frC - frB) -4 frD
ности ОТ, если мнемокод команды имеет в конце суффикс «э», или двойной точности ДТ, если суффикс отсутствует.
Команды fres, frsqrte выполняются только с числами двойной точности. Команда fsel производит сравнение содержимого регистра frA с нулем: если оно больше или равно нулю, то в регистр frD загружается содержимое frC, если меньше нуля или не-число, то содержимое frB.
При операциях сравнения (команды fcmpu, fcmpo) производится сравнение содержимого указанных в команде регистров frA, frB и установка соответствующих признаков в поле CRi регистра условий CR (см. рис. 2.67, а), номер которого i определяется операндом crfD (табл. 2.74). Два варианта операции сравнения, выполняемые FPU, отличаются установкой значений признаков исключений в регистре FPSCR. Команда fcmpu устанавливает значение признака VXSNAN = 1, если какой-либо из сравниваемых операндов является не-числом SNAN. Команда fcmpo в этом случае тоже устанавливает значение VXSNAN -1, а если исключения при неправильном результате операции не разрешены (в регистре FPSCR бит VE = 0), то устанавливается также признак VXVC. Если же операндом является не-число QNAN, то устанавливается только признак VXVC = 1.
Команда frsp преобразует число двойной точности (64 разряда) из регистра frA в число одинарной точности (32 разряда), посылаемое в регистр frD. В случае необходимости выполняется округление числа в соответствии со значением поля RN в регистре FPSCR. Команды fctiw, fctiwz преобразуют число двойной точности из регистра frA в целое 32-разрядное число со знаком, загружаемое в регистр frD. При этом команда fctiw проводит округление в соответствии с полем RN в регистре FPSCR, а команда fctiwz выполняет округление к нулю.
Таблица 2.74
Команды сравнения и округления
Синтаксис Ассемблера Операция
fcmpu (fcmpo) cfrD, frA, frB frA - frB, установка FPCC
frsp (frsp.) fctiw (fctiw.) fctiwz (fctiwz.) frD, frB frD, frB frD, frB frB(DT) -> frD(OT), округление RN frB -> frD(qenoe), округление RN frB -> frD(qenoe), округление к 0
ООО
RISC-МИКРОПРОЦЕССОРЫ И RISC-МИКРОКОНТРОЛЛЕРЫ СЕМЕЙСТВ POWERPC И COLDFIRE
Таблица 2.75
Команды пересылки данных между регистрами FPR и изменения содержимого регистра условий CR
Синтаксис Ассемблера Операция
fmr (fmr.) fmg (fmg.) fabs (fabs.) fnabs (fnabs.) frD, frA frD, frA frD, frA frD, frB frA frD -frA frD IfrA 1 frD - IfrA 1 -> frD
mffs (mffs.) mcrfs mtfsfi (mtfsfi.) mtfsf (mtfsf.) mtfsbO (mtfsbO.) mtfsbl (mtfsbl.) frD crfD, crfS crfD, Im FM, frA crbD crbD (FPSCR) frD (FPSCR)i Cri Im -> (FPSCR)i (frA)h л FM -> FPSCR 0 —> bi (FPSCR) 1 -> bi (FPSCR)
Команды fmr, fneg, fabs, fnabs (табл. 2.75) производят пересылку содержимого регистра FPR с номером frA в регистр с номером frD. При этом команда fneg изменяет знак операнда, команда fabs пересылает его абсолютное значение, команда fnabs устанавливает отрицательный знак операнда.
Отдельная группа команд служит для пересылки и изменения содержимого регистра FPSCR. Команда mffs пересылает содержимое FPSCR в регистр FPR с номером frD. Команда mcrfs пересылает 4-битовое поле, номер которого задается операндом crfS, из регистра FPSCR в поле CRi регистра условий CR, где значение i = crfD. Команда mtfsfi загружает 4-битовый непосредственный операнд Im в поле регистра FPSCR, номер которого равен crfD. Команда mtfsf заносит в регистр FPSCR старшее 32-разрядное слово (frA)h из регистра с номером frA (разряды 63-32 содержимого регистра FPR), логически умноженные на заданную в команде 32-битную маску FM. Установка в «О» и «1» отдельных битов bi в регистре FPSCR производится командами mtfsbO, mtfsbl, в которых задается номер бита i = crbD.
Большинство рассмотренных команд может изменять содержимое поля CR1 в регистре условий CR (см. рис. 2.67, а), перенося в него значения признаков FX, FEX, VX, ОХ, устанавливаемых в регистре FPSCR. Для этого необходимо после мнемокода команды поставить символ «.» (см. табл. 2.73-2.75).
Команды загрузки и сохранения (табл. 2.76) производят загрузку в регистр FPR с номером frD вещественного числа одинарной (ОТ) или двойной (ДТ) точности из памяти (команды, начинающиеся с буквы «I» - load), либо записывают в память число ОТ или ДТ из регистра frS (команды, начинающиеся с букв «st» - store). Для обращения к памяти используется эффективный адрес ЕА, формируемый с помощью косвенно-регистровой адресации со смещением или индексированием (мнемокод команд с индексированием заканчивается буквой «х»). Команда stfiwx выполняет запись в память по адресу ЕА младшего 32-разрядного слова (frS)l из регистра FPR с номером frS (разряды 31-0 содержимого регистра).
Команды загрузки-сохранения имеют модификации с суффиксом и (указаны в скобках). При наличии этого суффикса в регистр GPR с номером гА после пересылки загружается эффективный адрес ЕА, использованный в данной команде. Эти модификации позволяют реализовать постинкрементную адресацию операндов.
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
Таблица 2.76
Команды загрузки и сохранения содержимого регистров FPR
Синтаксис Ассемблера Операция
Ifs (Ifsu) frD, d(rA) (EA) -> frD, ОТ
flsx (Ifsux) frD, rA, rB (EA) -> frD, ОТ
Ifd (Ifdu) frD, d(rA) (EA) -> frD, ДТ
Ifdx (Ifdux) frD, rA, rB (EA) -> frD, ДТ
stfs (stfsu) frS, d(rA) frS -> (EA), ОТ
stfsx (stfsux) frS, rA, rB frS -> (EA), ОТ
stfd (stfdn) frS, d(rA) frS -> (EA), ДТ
stfdx (stfdux) frS, rA, rB frS -> (EA), ДТ
stfiwx frS, rA, rB (frS)1 -> (EA)
Внутренняя кэш-память и устройства управления памятью. Микропроцессор МРС604 имеет отдельные устройства управления памятью IMMU, DMMU и внутренние кэши для команд IC и данных DC (см. рис. 2.70). Емкость каждого кэша составляет 16 Кбайт. Устройства управления IMMU, DMMU обеспечивают блочную, сегментную и страничную организацию памяти, а также обращение к внешним устройствам с использованием специального протокола DS.
Принцип работы кэшей команд и данных аналогичен описанному для микропроцессоров семейства М680хх. Однако их организация и функционирование в МРС604 имеет некоторые особенности. Оба кэша организованы в виде группы из 128 наборов, каждый из которых содержит по четыре 32-байтной строки. В качестве тега в МРС604 используются 20 старших разрядов адреса. Старшие 7 разрядов адреса определяют номер набора строк, в котором должны размещаться выбираемые данные или команда. Младшие 5 разрядов адресуют расположенные в строке байт, полуслово или слово. При кэш-промахе в выбранном наборе производится замещение пустой (недостоверной) строки или строки, к которой дольше всего не производилось обращение (метод замещения LRU - least-recently used). Каждая строка в кэше содержит 20-разрядный тег, восемь 32-разрядных слов (данные или команды) и биты, идентифицирующие текущее состояние строки: V или I - для кэша команд, М, Е, Били I -для кэша данных.
Для строк кэша команд IC возможны два состояния: V (valid) - достоверное или I (invalid) -недостоверное содержимое строки. Недостоверное (незаполненное) состояние строк этого кэша устанавливается при сбросе процессора в начальное состояние (reset) путем загрузки соответствующего содержимого в регистр конфигурации HID0 или с помощью команды icbi (табл. 2.77), аннулирующей содержимое строки. При заполнении строки устанавливается достоверное состояние ее содержимого.
Для кэша данных DC введено четыре возможных состояния строки, идентификация которых обеспечивает возможность совместного использования нескольких кэшей в мультипроцессорной системе:
М (modified) - содержимое строки модифицировано путем записи по соответствующему адресу, и новое содержимое не переписано в ОЗУ;
Е (exclusive) - содержимое строки хранится только в этом кэше и ОЗУ;
S (shared) - содержимое строки хранится в данном кэше, ОЗУ и каком-либо другом устройстве (кэше);
I (invalid) - недостоверное (аннулированное) содержимое строки.
Для идентификации состояния строки служат соответствующие биты состояния. Для каждого состояния установлен определенный протокол обращения к содержимому строки.
RISC-МИКРОПРОЦЕССОРЫ И RISC-МИКРОКОНТРОЛЛЕРЫ СЕМЕЙСТВ POWERPC И COLDFIRE
Таблица 2.77
Команды управления внутренней кэш-памятью
Синтаксис Ассемблера Операция
dcbz dcbst dcbf *dcbi icbi debt (st) *) DC - кэш данных; rA, rB rA, rB rA, rB rA, rB rA, rB rA, rB IC - кэш команд. 0 -> (строка DC) (строка DC) -> ОЗУ Аннулирование строки DC Аннулирование строк всех DC Аннулирование строки IC Строка из ОЗУ DC
При этом реализуется снупинг - возможность обращения к содержимому кэша данных со стороны другого устройства (процессора в мультипроцессорной системе). Установленный протокол обращения (MESI - протокол) с применением снупинга обеспечивает соответствие данных, хранящихся в различных кэшах мультипроцессорной системы, что позволяет избежать ошибок из-за использования каким-либо из процессоров старых данных, которые были модифицированы другим процессором.
Обращение к кэшу команд IC производится устройством управления микропроцессора (см. рис. 2.70), которое одновременно выбирает из строки четыре команды (16 байт). Обращение к кэшу данных выполняется блоком LSU, который одновременно выбирает два слова (8 байт). Оба кэша подключены к общей шине через блок интерфейса ВIU, который обеспечивает пересылку двух слов (8 байт) в одном цикле. Пересылка содержимого кэшей в ОЗУ или в обратном направлении выполняется с помощью пакетного обмена, при котором реализуется четыре последовательных цикла для передачи содержимого строки (32 байт).
Отдельные биты содержимого регистра конфигурации HID0 определяют режим использования кэшей. Установкой значения «0» или «1» этих битов можно обеспечить включение или отключение каждого кэша, его блокировку, при которой кэш не используется, но его содержимое сохраняется, освобождение кэша путем аннулирования содержимого его строк (перевод в недостоверное состояние).
Обычно кэши работают в режиме обратной записи, который снижает нагрузку на общую шину, обеспечивая повышение производительности системы. Однако при обращении к отдельным блокам или страницам памяти возможна реализация сквозной записи.
Изменение содержимого отдельных строк кэша IC или DC осуществляется с помощью специальных команд (см. табл. 2.77). Эти команды производят расчет адреса ЕА = (гА!0) + (гВ), а затем выбирают строку кэша, в которой размещаются команды или данные с таким адресом. При выполнении операций со строками кэша данных учитывается состояние их содержимого: М, Е, S или I.
Команда dcbz записывает «О» во все байты выбранной строки, после чего для нее устанавливается состояние М. Если перед этим строка имела состояние S, то при выполнении команды производится обращение (снупинг) к кэшам других устройств, содержащих данную строку, и содержимое аналогичных строк аннулируется (для них устанавливается состояние I). Команда dcbst выполняет запись в память содержимого выбранной строки кэша данных, если она имеет состояние М. При других состояниях строки или при отсутствии в кэше строки, содержащей данные с полученным адресом, эта команда не производит каких-либо операций. Команда dcbf аннулирует содержимое выбранной строки кэша данных, устанавливая для нее состояние I. Если перед этим строка имела состояние М, то предварительно ее содержимое переписывается в ОЗУ. При выполнении команды dcbi аннулируется содержимое строк с аналогичным содержимым в кэшах данных всех устройств системы.
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
Так как при этом могут быть потеряны модифицированные данные, хранящиеся в кэшах других процессоров, то команда dcbi выполняется только в режиме супервизора (привилегированная команда, помечена символом «*» в табл. 2.77). Команда icbi производит аннулирование содержимого строки кэша команд. При выполнении команды debt (возможен вариант мнемокода debtst) из ОЗУ в кэш данных загружается строка, для которой устанавливается состояние Е или S (если эта строка уже присутствует в кэшах других устройств системы).
Полная очистка (аннулирование содержимого всех строк) кэшей команд или данных реализуется путем записи соответствующего содержимого в регистр HID0, которая производится с помощью команды mtspr, выполняемой в режиме супервизора (см. табл. 2.71).
Устройства управления памятью IMMU, DMMU осуществляют трансляцию адреса при выборке команд и данных, обеспечивая возможность блочной, сегментной и страничной организации памяти. Кроме того, DMMU позволяет реализовать специальный протокол DS для многобайтного обмена данными с внешними устройствами. Работа IMMU, DMMU обеспечивается с помощью 8 пар регистров IBAT, DBAT, 16 сегментных регистров SR0-SR15 и регистра SDR1, обращение к которым выполняется только в режиме супервизора. Форматы содержимого этих регистров приведены на рис. 2.72.
Если в регистре управления MSR биты IT, DT имеют значение «О», то трансляция адреса не выполняется (IMMU, DMMU отключены), и сформированный процессором эффективный адрес поступает на выводы АО-31 в качестве физического адреса ячейки памяти или внешнего устройства. Включение IMMU, DMMU производится путем записи в регистр MSR содержимого, в котором соответствующий бит IT, DT имеет значение «1». В этом случае сформированный адрес команды или данных воспринимается как логический адрес LA0—31, который с помощью IMMU или DMMU транслируется в физический адрес РАО-31, поступающий на внешние адресные выводы. Рассмотрим реализуемые IMMU, DMMU варианты адресной трансляции.
О 14 15 18 19 29 30 31
| BLPI | Резервировано | BSM | Vs | Vu |
IBAT(0-3)U, DBAT(0-3)U 0 14 15 24 25 26 27 28 29 30 31
| PBN | Резервировано I W | I | M I G I I - I РР I
IBAT(0-3)L, DBAT(0-3)L 0 12 7 8 31
| T = 0 | N | Резервировано | VSID I
SRi(T = 0, страничная адресация) 0 12 3 11 12 31
| Т = 1 I Ks I Ku I BUID I Служебные данные I
SRi(T = 1, обращение к внешним устройствам) 0 15 16 22 23 31
| HTABORG | Резервировано I HTABMASK I
SDR1
Рис. 2.72. Формат содержимого регистров управления памятью
RISC-МИКРОПРОЦЕССОРЫ И RISC-МИКРОКОНТРОЛЛЕРЫ СЕМЕЙСТВ POWERPC И COLDFIRE
Таблица 2.78 Значения маски BSM и соответствующие объемы блока памяти
BSM Объем блока
ООО 0000 0000 128 Кбайт
000 0000 0001 256 Кбайт
000 0000 0011 512 Кбайт
000 0000 0111 1 Мбайт
000 0000 1111 2 Мбайт
000 0001 1111 4 Мбайт
000 0011 1111 8 Мбайт
000 0111 1111 16 Мбайт
000 1111 1111 32 Мбайт
001 1111 1111 64 Мбайт
011 1111 1111 128 Мбайт
111 1111 1111 256 Мбайт
1. Блочная трансляция обеспечивает обращение к блокам внешней памяти заданного объема - от 128 Кбайт до 256 Мбайт. Возможна организация четырех блоков для хранения команд и четырех-для хранения данных. Параметры каждого блока задаются дескриптором, который содержится в паре регистров IBATiU - IBATiL для команд, DBATiU - DBATIL для данных, где i = 0...3 - номер блока (рис. 2.72, а, б). Поле BSM в дескрипторе определяет объем блока памяти (табл. 2.78) и служит маской при сравнении разрядов LA4—14 логического адреса и соответствующих разрядов логического индекса данного блока BLPI. Поле PBN содержит старшие разряды получаемого при трансляции физического адреса.
Процесс трансляции иллюстрируется рис. 2.73. Если устройство IMMU или DMMU включено, то старшие разряды сформированного логического адреса LA0-14 команды или данных сравниваются со значениями индекса BLPI в дескрипторах блоков, хранящихся в регистрах IBAT0U-IBAT3U (для команд) или DBAT0U - DBAT3U (для данных). При этом BSM служит маской для разрядов 4-15 адреса LA и индекса BLPI: разряды, для которых биты BSM имеют значение «1», не участвуют в сравнении. Таким образом, сравниваются старшие разряды, определяющие базовый адрес блока заданного объема. Младшие разряды LA, указывающие относительное положение байта (смещение), транслируются в младшие разряды физического адреса РА без изменений.
0 34 10 11 14 15 31
Логический адрес LA0 -31
Сравнение (, 0000000 1111 BSM МАСКА 1 BSM 31
BLPI хххх
PBN хххх
» 0000000 1111
Физический адрес РАО-31
।----------------------------1 I______________________________________I
Биты 0-10 из PBN Биты 11 -31 логического адреса
Рис. 2.73. Трансляция адреса при блочной организации памяти
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
Если обнаруживается совпадение старших немаскированных разрядов LA с соответствующими разрядами BLPI в одном из дескрипторов, то выбираемая команда или данные размещаются в i-м блоке. В этом случае базовый физический адрес блока задается немаскированными старшими разрядами поля PBN в дескрипторе. Полученный в результате трансляции физический адрес РАО-31 содержит базовый адрес блока РА0-(14 - п), полученный из PBN, и смещение РА(15-п)-31 = 1_А(15-п)-31, где л-число«1» в маске BSM. В примере, данном на рис. 2.71, обеспечивается обращение к блоку объемом 2 Мбайт, для которого базовый физический адрес РАО-10 задается битами 0-10 поля PBN, а смещение РА11-31 указывается разрядами LA11-31 логического адреса.
Остальные биты в дескрипторах блоков обеспечивают защиту памяти и определяют работу кэша при обращении к блоку:
Vs, Vu - разрешают обращение к блоку в режиме супервизора (при Vs =1) или в режиме пользователя (при Vu = 1);
W - обеспечивает при W = 1 режим сквозной записи для соответствующего кэша, если его использование разрешено (бит I = 0);
I - запрещает при I = 1 использование кэша при обращении к блоку;
М - обеспечивает при М = 1 соответствие данных, размещаемых в разных кэшах, путем реализации при обменах MESI-протокола;
G - запрещает при G = 1 чтение изданного блока (устанавливается только в регистрах DBATiL);
РР - определяет условия доступа кданному блоку (табл. 2.79), обеспечивая совместно с битами Vs, Vu защиту блока памяти.
При нарушениях правил обращения реализуется исключение с адресом вектора Av = $00300 при выборке данных или Av = $00400 при выборке команд (см. табл. 2.64).
Если немаскированные старшие разряды логического адреса команды или данных не совпадают с разрядами индекса BLPI в каком-либо из четырех дескрипторов, то выполняется сегментная трансляция адреса.
2. Сегментная трансляция обеспечивает обращение к сегментам памяти емкостью 256 Мбайт, которые разбиваются на страницы объемом по 4 Кбайт, размещаемые в ОЗУ, или представляют массивы данных, расположенные во внешних устройствах. Для обращения к сегментам используются 16 сегментных регистров SR0-SR15, которые содержат дескрипторы сегментов (см. рис. 2.72, в, г). Если при значении бита IT = 1 или DT = 1 в регистре MSR не реализуется блочная трансляция (старшие немаскированные разряды логического адреса не совпадают с полями BLPI в дескрипторах блоков), то производится сегментная трансляция. В этом случае разряды LA0-3 задают номер i регистра SRI, из которого выбирается дескриптор соответствующего сегмента. В зависимости от значения бита Т в выбранном дескрипторе реализуется страничная адресация памяти (при Т = 0) или адресация внешних устройств (при Т - 1).
Таблица 2.79
Правила доступа к блокам и страницам памяти («+» - доступ разрешен, «-» - доступ запрещен)
РР Режим пользователя (PR = 1) Режим супервизора (PR = 0)
Чтение Запись Чтение Запись
00 - - + +
01 + — + +
10 + + + +
11 + - + -
risc-микропроцессоры и risc-микроконтроллеры семейств powerpc и coldfire
При страничной адресации памяти биты дескриптора сегмента (рис. 2.72, в) имеют следующее назначение:
Т = 0 - определяет вид трансляции;
N - запрещает при N = 1 выборку команд из данного сегмента;
поле VSID - содержит 24-разрядный виртуальный индекс сегмента.
Процесс страничной адресации иллюстрируется на рис. 2.74. Устройство управления памятью IMMU или DMMU формирует при этом 52-разрядный виртуальный адрес VA0-51, составленный из виртуального адреса сегмента VSID, индекса страницы (разряды LA4-19 логического адреса) и относительного адреса байта на странице (разряды LA20-31 логического адреса). Старшие разряды VA0-39 этого адреса, представляющие виртуальный номер страницы VPN, поступают в блок страничной трансляции (БСТ), определяющий физический номер страницы RPN, который служит разрядами РАО-19 физического адреса. Младшие разряды физического адреса совпадают с адресом байта на странице РА2О-31 = = LA20-31. Для определения RPN используются дескрипторы страниц PD, которые хранятся в специальной таблице TPD, хранящейся в ОЗУ. Базовый адрес этой таблицы задается содержимым регистра SDR1 (рис. 2.72, д): поле HTABORG содержит старшие разряды адреса, в поле HTABMASK дается маска адреса.
Дескрипторы в таблице TPD объединены в группы по восемь 64-битовых дескрипторов PD. Каждый дескриптор содержит: 30-битовый виртуальный индекс страницы, который сравнивается со значением битов (VSID:API) виртуального номера VPN; 20-битовый физический номер страницы RPN; биты W, I, М, G, имеющие такое же назначение, каканалопичные биты в дескрипторах блоков; биты РР, реализующие защиту страницы (см. табл. 2.79) совместно
Физический адрес РАО-31
Рис. 2.74. Трансляция адреса при страничной организации памяти
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
с битом N в дескрипторе сегмента; а также биты R, С, характеризующие предыдущие обращения к этой странице («историю» страницы). 5htR = 1, если к данной странице производилось обращение, бит С - 1, если выполнялась запись на эту страницу. Биты R, С используются операционной системой для организации виртуальной памяти, которая требует оперативного обмена содержимым страниц между ОЗУ и внешней памятью большого объема.
Дескрипторы страниц, к которым выполнялось обращение, хранятся в специальной кэш-памяти TLB, входящей в состав IMMU и DMMU. Каждый TLB содержит 128 дескрипторов PD, которые размещены в 64 наборах, имеющих по две строки. Работа TLB организована по такому же принципу, как и работа кэшей IC, DC. В каждую из строк TLB заносится один дескриптор страницы PD, при этом для данной строки устанавливается бит достоверности V = 1. Для пустых (незаполненных) строк значение бита V = 0. Освобождение (аннулирование содержимого) строки выполняется с помощью команды tlbie, останавливающей для выбранной строки TLB значение V = 0. В качестве тега строки используются старшие разряды виртуального номера VPN, содержащиеся в дескрипторе. При совпадении тега одной из строк выбранного в TLB набора и соответствующих разрядов сформированного номера VPN (кэш-попадание) из размещенного в строке дескриптора извлекается значение RPN, используемое в качестве разрядов РАО-19 физического адреса. Таким образом, при кэш-попадании в TLB для страничной трансляции адреса не требуется обращения к таблице TPD в ОЗУ.
Дескрипторы страниц, к которым выполнялось обращение, хранятся в специальной кэш-памяти TLB, входящей в состав IMMU и DMMU. Каждый TLB содержит 128 дескрипторов PD, которые размещены в 64 наборах, имеющих по две строки. Работа TLB организована по такому же принципу, как и работа кэшей IC, DC. В каждую из строк TLB заносится один дескриптор страницы PD, при этом для данной строки устанавливается бит достоверности V = 1. Для пустых (незаполненных) строк значение бита V = 0. Освобождение (аннулирование содержимого) строки выполняется с помощью команды tlbie, останавливающей для выбранной строки TLB значение V = 0. В качестве тега строки используются старшие разряды виртуального номера VPN, содержащиеся в дескрипторе. При совпадении тега одной из строк выбранного в TLB набора и соответствующих разрядов сформированного номера VPN (кэш-попадание) из размещенного в строке дескриптора извлекается значение RPN, используемое в качестве разрядов РАО-19 физического адреса. Таким образом, при кэш-попадании bTLB для страничной трансляции адреса не требуется обращения к таблице TPD в ОЗУ.
Если же дескриптора страницы, адресуемой VPN, не оказывается в TLB (кэш-промах), то БСТ производит обращение к TPD. При этом из ОЗУ выбирается сразу группа PD, а затем БСТ сравнивает значения полей (VSID:API) в каждом из 8 выбранных дескрипторов с соответствующими разрядами полученного виртуального номера VPN. В случае совпадения значение RPN, хранящееся в данном дескрипторе, служит разрядами РАО-19 формируемого физического адреса, а сам дескриптор заносится в TLB. Он занимает в соответствующем наборе TLB пустую строку, устанавливая для нее бит достоверности V = 1, а при отсутствии пустой строки заменяет в этом наборе дескриптор, который дольше не использовался. Если в выбранной группе PD дескриптор адресуемой страницы отсутствует, то из TPD выбирается еще одна группа дескрипторов. Если и в ней не оказывается требуемого дескриптора, то реализуется исключение с адресом вектора Av = $00300 при выборке данных или Av = $00400 при выборке команды (см. табл. 2.64). При организации виртуальной памяти подпрограмма обслуживания должна в этом случае обеспечить загрузку в ОЗУ необходимой страницы из внешней памяти, поместив в TPD соответствующий дескриптор.
При выполнении страничной трансляции учитываются значения битов N, W, I, М, G дескрипторов. При нарушении правил обращения к сегментам и страницам реализуется исключение «ошибка выбора данных» (Av = $00300) или «ошибка выбора команды» (Av =$00400).
RISC-МИКРОПРОЦЕССОРЫ И RISC-МИКРОКОНТРОЛЛЕРЫ СЕМЕЙСТВ POWERPC И COLDFIRE
При адресации внешних устройств (ВУ) с помощью сегментной трансляции (реализация протокола DS) биты дескриптора сегмента в регистре SRi имеют следующее назначение (рис. 2.72, г):
Т = 1 - определяет вид трансляции;
Ks, Кр - адресные ключи, которые выдаются на шину адреса при адресации внешних устройств для идентификации режима процессора;
BUID - 9-битовый код идентификации внешнего устройства, к которому производится обращение.
Этот вид трансляции адреса реализуется только при передаче данных с помощью команд загрузки-сохранения содержимого регистров GPR (см. табл. 2.68) или FPR (см. табл. 2.76).
Если при сегментной трансляции адреса данных из регистра SRi выбирается дескриптор, имеющий значение бита Т = 1, то реализуется специальный протокол DS (direct-store) прямого обмена данными с ВУ. В этом случае процессор выполняет сдвоенные циклы обмена, каждый из которых занимает три такта. В первой части цикла на шину адреса выдается адресный пакет РО, во второй части цикла - пакет Р1. Каждый пакет сопровождается выдачей на внешние выводы микропроцессора 8-разрядного кода ХАТС, определяющего тип и параметры выполняемого цикла. Код ХАТС поступает на выходы, которые при обычных циклах обмена указывают тип выполняемого цикла и разрядность данных.
Адресный пакет РО (рис. 2.75, а), выдаваемый DMMU в начале каждого цикла обмена, содержит ключевой бит Ks или Кр, код BUID, идентифицирующий адресуемое ВУ, и служебную информацию, которая может быть записана в разрядах 12-27 используемого сегментного регистра SRi. Таким образом, биты РА2-27 формируемого физического адреса соответствуют битам выбранного регистра SRi (рис. 2.72, г), причем значение РА2 = Ks, если микропроцессор работает в режиме супервизора, или РА2 = Кр, если в режиме пользователя. В разрядах РА28-31 указывается код идентификации (номер) процессора, выбираемый из регистра PIR (рис. 2.68). Пакет РО определяет источник и приемник данных -процессор с номером PID и ВУ с номером BUID.
Во второй половине цикла DMMU выдает адресный пакет Р1 (рис. 2.75, б), содержащий разряды 0-3 регистра SRi и разряды ЕА4-31 Этот пакет позволяет выбрать различные адресаты (регистры) в составе ВУ, к которым выполняется обращение (запись или считывание) в данном цикле.
В соответствии с протоколом DS обмен начинается циклом инициализации и завершается циклом подтверждения. Между этими циклами выполняется необходимое число циклов пересылки данных.
ХАТС
а) О_________7
| Тип |
ХАТС
б) 0_________7
| Число байт |
ХАТС
в) 0_________7
| Тип цикла |
РАО-31 0 1 2 3 11 12 27 28 31
| 00 | KS, Р| BUID | SRi (12-27) | PIP ~|
РАО-31
0_______________3 4__________________________________31
| SRi (0-3) | ЕА4-31 |
РАО-31 0 1 2 3 11 12 27 28 31
| 00 | ЕВ | BUID | | PIP ~|
Рис. 2.75. Форматы адресных пакетов Р0 (а), Р1 (б), Рг (в) при реализации протокола прямого обмена DS
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
Для пересылки содержимого сегментного регистра SRi в какой-либо из регистров общего назначения rD и обратно используются команды mfsr, mfsrin и mtsr, mtsrin (табл. 2.80). Номер сегментного регистра i задается операндом SR (команды mfsr, mtsr) или разрядами 0-3 регистра гА (команды mfsrin, mtsrin). Команда tlbie аннулирует содержание выбранной строки в кэше дескрипторов страниц TLB, устанавливая для нее значение бита бита V = 0. При этом содержимое регистра гА, указанного в качестве операнда, используется в качестве логического адреса LA0-31, для которого определяется виртуальный номер страницы VPN. Если дескриптор этой страницы присутствует в какой-либо из строк TLB команд или данных, то содержимое данной строки аннулируется. Команда tlbsync выполняется после команд tlbie, если требуется произвести аннулирование соответствующих строк в TLB других (ведомых) микропроцессоров. Эта команда осуществляет снупинг, обращаясь к внутреннему содержимому других TLB, чтобы обеспечить соответствие выполняемых программ и используемых данных при совместной работе микропроцессоров в составе мультипроцессорной системы.
Таблица 2.80 , .
Команды пересылки содержимого сегментных регистров SR0-SR15 и изменения содержимого TLB
Синтаксис Ассемблера Операция
‘mfsr rD, SR Sri -> rD
‘mfsrin rD, rA Sri -> rD, i = rA(0-3)
‘mtsr SR, rS rS - ч Sri
‘mtsrin rS, rA rS - -> Sri, i = rA(0-3)
‘tlbie rA Аннулирование строки TLB
‘tlbsyne Синхронизация TLB
Номенклатура и применение микропроцессоров МРСбхх. Как отмечалось выше, консорциум компаний, реализующих семейство PowerPC, разработал и выпускает ряд моделей микропроцессоров этого семейства. Основные характеристики этих моделей приведены в табл. 2.81.
Все микропроцессоры семейства имеют одинаковую архитектуру PowerPC, которая включает регистровую модель пользователя (см. рис. 2.67), набор реализуемых команд и способов адресации, состав исключений и процедуру их обслуживания. Только в модели МРС620 введено несколько дополнительных команд для выполнения операций с 64-раз-рядными числами. Функции большинства регистров в модели супервизора (см. рис. 2.68) также одинаковы для всего семейства. Все модели имеют суперскалярную структуру (см. рис. 2.70), которая содержит 3 или 4 исполнительных устройства: два (SIU, MIU) или три (SIU1, SIU2, MIU) для обработки целочисленных операндов и одно (FPU) -для обработки операндов с плавающей точкой.
В состав семейства МРСбхх входят четыре основных модели: 601,603,604 и 620, которые имеют ряд модификаций, отличающихся в основном объемом внутренней кэш-памяти и уровнем технологии изготовления, определяющей размеры кристалла и расположенных на нем компонентов микропроцессора. Все микропроцессоры семейств изготавливаются с помощью КМОП-технологии с минимальными размерами компонентов (МОП-транзисторов): от 0,65 мкм для первых моделей 601,603 до 0,35 мкм для моделей 603Е, 604Е, 620, выпущенных в 1995-96 it. Уменьшение размеров компонентов позволило повысить тактовую частоту до Ft=200 МГц и увеличить за счет этого производительность микропроцессоров.
Для относительной оценки производительности в табл. 2.81 приведены результаты испытаний, полученных при использовании стандартных тестовых программ обработки целых чисел (SPECint 95) и чисел с плавающей точкой (SPECfp 95). В скобках указано значение тактовой частоты Ft, при котором проводились испытания. Как показывают приведен
232
RISC-МИКРОПРОЦЕССОРЫ И RISC-МИКРОКОНТРОЛЛЕРЫ СЕМЕЙСТВ POWERPC И COLDFIRE
ные данные, за 5 лет, прошедших с начала выпуска микропроцессоров этого семейства, их производительность возросла в 3 - 4 раза.
Тиловое значение напряжения питания микропроцессоров составляет 3,3 В. При этом в ряде моделей для питания основной части (ядра) процессора используется напряжение 2,5 В. Благодаря пониженному напряжению питания сохраняется допустимый уровень потребления мощности. Так как для КМОП-микросхем потребляемая мощность возрастает пропорционально тактовой частоте, в табл. 2.81 для каждого микропроцессора дано значение Ft (в скобках), при котором потребляется указанная мощность.
Таблица 2.81
Основные характеристики микропроцессоров семейства МРСбхх
Основные характеристики Модели микропроцессора
601 603 603Е 603Р 604 604Е 620
Разрядность адреса 32 32 32 32 32 32 40
Разрядность данных 32 32 32 32 32 32 64
Разрядность шины 32 32 32 32 64 64 128
Емкость кэшей: команд 32К 8К 16К 16К 16К 32К 32К
данных *) 8К 16К 16К 16К 32К 32К
Число исполнительных устройств 3 3 3 3 4 4 4
Тактовая частота, МГц 80-100 80 100-133 150-200 100-150 150-200 180-200
Напряжение питания, В 3,6 3,3 3,3 3,3-2,5 3,3 3,3-2,5 3,3-2,5
Потребляемая мощ- 9,0 2,0 4,3 3,0 12,5 10,0 -
ность, Вт (100) (80) (133) (166) (133) (166) -
Число транзисторов, млн. 2,8 1,6 - - 3,6 - 7,6
Число внешних выводов 304, 240, 240, 240, 304, 256 256
256 256 256 256 256
Производительность (80) (80) (133) (166) (133) (166) -
SPECint95 2,2 1,9 3,9 4,0 5,23 6,35 —
SPECfp95 1,7 1,4 3,1 5,3 4,86 5,46 -
Сразу после начала выпуска микропроцессоры семейства МРСбхх нашли широкое применение в разнообразных цифровых системах. На базе первой модели МРС601 были реализованы персональные компьютеры PowerMacintosh компании «Apple Computers» и PowerStack компании «Motorola», рабочие станции RS/6000 компании IBM и ряд других изделий. Появление новых микропроцессоров этого семейства еще более расширило сферу его применения. В настоящее время определился следующий ряд областей, где использование микропроцессоров МРСбхх наиболее эффективно.
Модель МРС603 и ее модификации, имеющие наиболее низкое энергопотребление, широко используются в персональных компьютерах класса «notebook» и различной сложнофункциональной портативной аппаратуре. Так как модификация МРС603Р обеспечивает достаточно высокую производительность, то на ее базе реализуются также портативные рабочие станции. Модель МРС604 и ее модификации используется в основном в персональных компьютерах, заменяя в этой области более раннюю модель МРС601. Широкое применение данная модель находит также в серверах, особенно ее быстродействующая модификация МРС604Е. Модель МРС620 ориентирована на применение в высокопроизводительных рабочих станциях и мощных серверах.
233
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
Помимо перечисленных выше областей применения RISC-микропроцессоры с архитектурой PowerPC используются в разнообразных устройствах управления системами и объектами, где требуется высокая производительность и широкие функциональные возможности в сочетании с пониженным энергопотреблением и относительно невысокой стоимостью. На базе RISC-процессоров с этой архитектурой разработаны RISC-микроконтроллеры и коммуникационные контроллеры для использования в системах управления и связи. Особенности их структуры и функционирования рассмотрены в следующих разделах данной главы.
Следует отметить, что наряду с микропроцессорами и микроконтроллерами семейств МРСбОх, МРСбОх фирма «Motorola» выпускает также магистральные адаптеры МРС105, МРС106, которые обеспечивают интерфейс между общей шиной систем с архитектурой PowerPC и 32-разрядной шиной PCI, широко используемой в современных персональных компьютерах. С помощью этих адаптеров можно организовать совместную работу систем, реализуемых на базе МРСбОх или МРСбОх, с персональными компьютерами.
2.9.2. RISC-МИКРОКОНТРОЛЛЕРЫ СЕМЕЙСТВА МРС5ХХ ( POWERPC)
Разработка этого семейства микроконтроллеров началась недавно, поэтому в настоящее время выпускается только одна модель МРС505. На примере этой модели рассмотрим особенности структуры и функционирования RISC-микроконтроллеров, реализованных на базе процессора PowerPC.
Структура и особенности функционирования МРС505. Микроконтроллер МРС505 (рис. 2.76) содержит 32-разрядный RISC-процессор (RCPU), внутреннее ОЗУ данных емкостью 4 Кбайт, кэш-память команд (IC) емкостью 4 Кбайт, системное интерфейсное устройство (SIU) с несколькими параллельными портами ввода/вывода и блок управления периферийными устройствами (PCU) с портом Q. Отдельные шины используются для передачи команд (IB) и данных (LB). В последующих моделях семейства предполагается размещение на кристалле различных периферийных устройств (таймерных блоков, последовательных портов и др.), как это делается в модульных микроконтроллерах семейства МббЗхх. Для их подключения будет применяться межмодульная шина IMB, аналогичная используемой в семействе МббЗхх, которая связывается с шиной данных LB через блок PCU. В модели МРС505, где такие периферийные устройства отсутствуют, блок PCU выполняет функции контроллера прерываний, сторожевого устройства (watchdog) для контроля выполнения программы и схемы управления портом Q.
RCPU имеет характерную для PowerPC архитектуру, которая включает описанные выше регистровую модель пользователя (см. рис. 2.67), набор реализуемых команд и способов адресации, состав исключений и процедуру их обслуживания.
Регистровая модель супервизора RCPU содержит ряд регистров, которые выполняют такие же функции, как в модели МРС604 (см. рис. 2.68). Это регистр управления MSR, регистр PVR, указывающий тип микроконтроллера, регистры SRRO, SRR1, DAR, DSISR, SPRG0-SPRG3, используемые при обслуживании исключений, таймер базового времени ТВ и регистр декремента DEC. Кроме того, в регистровую модель супервизора RCPU входят регистры, обеспечивающие управление кэшем команд, реализацию отладки микропроцессорных систем и ряд других функций
Микроконтроллер МРС505 реализует такой же набор исключений, как и микропроцессор МРС604 (см. табл. 2.64). Векторы исключений располагаются в таблице, базовый адрес которой равен $00000000, если в регистре MSR значение бита ЕР = 0, или $FFFOOOOO, если ЕР = 1. Таким образом, предусмотрены две возможных позиции для размещения таблицы векторов исключений в адресном пространстве.
234
RISC-МИКРОПРОЦЕССОРЫ И RISC-МИКРОКОНТРОЛЛЕРЫ СЕМЕЙСТВ POWERPC И COLDFIRE
и тестирования
Рис. 2.76. Структура RISC-микроконтроллера МРС505
Внутренняя структура RCPU представляет собой упрощенный вариант суперскалярной структуры процессора в модели МРС604. RCPU содержит устройство управления, два устройства обработки для целочисленных операндов (SIU, MIU) и одно для чисел с плавающей точкой (FPU), устройство загрузки-сохранения (LSU), подключенное к внутренней шине LB, и регистровые блоки GPR0-31, FPR0-31. В данном процессоре реализуется 4-каскадный конвейер выполнения команд, набор которых практически совпадает с набором команд МРС604. Используемые регистры условий CR (см. рис. 2.67, а), исключений XER (см. рис. 2.67, б), состояния FPU - FPSCR (см. рис. 2.70) имеют такое же назначение битов, как в микропроцессорах семейства МРСбхх, описанных выше.
Микроконтроллер не реализует сегментной, страничной или каких-либо других способов организации памяти, поэтому в его составе нет устройств управления памятью MMU, выполняющих трансляцию адреса. Формируемый микроконтроллером адрес служит физическим адресом, который используется для обращения к кэшу команд, внутреннему ОЗУ или внешней памяти.
235
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
Входящий в состав микроконтроллера кэш команд IC содержит 128 наборов по 2 строки, в каждой из которых хранятся четыре слова (16 байт). В качестве тега используются разряды А0-20 адреса команды. Кэш имеет также три регистра ICCST, ICADR, ICDAT, которые входят в модель супервизора как регистры специального назначения с номерами SPR560, SPR561, SPR562. Регистр управления кэша ICCST содержит бит IEN, указывающий на включенное или отключенное состояние кэша, поле CMD, в которое может быть записан код команды обращения к кэшу, биты CCER1-3, которые показывают наличие ошибок при обращении к кэшу. Записью соответствующего кода в поле CMD можно включить или отключить кэш, аннулировать его содержимое (очистить кэш), заблокировать или разблокировать строку или весь кэш (запретить или разрешить использовать их содержимое ), загрузить строку кэша. Перед выполнением загрузки или блокировки строки в регистр адреса ICADR заносится адрес команды, которую следует загрузить или заблокировать в кэше. Из регистра ICDAT можно считать команду, хранящуюся в кэше, если предварительно записать ее адрес в регистр ICADR. Таким образом, используя регистры ICCST, ICADR, ICDAT, можно управлять работой кэша и контролировать его содержимое, что особенно важно в процессе отладки программного обеспечения.
Внутреннее ОЗУ емкостью 4 Кбайт может быть расположено в одной из четырех возможных позиций адресного пространства с начальным адресом $00000000, $000FF000, $ FFF00000 или $FFFFFOOO. Выбор позиции задается содержимым поля LMB в регистре конфигурации памяти МЕММАР, который входит в состав системного интерфейсного устройства SIU. Режим работы внутреннего ОЗУ задается содержимым регистра управления SRAMMCR, отдельные биты которого разрешают или запрещают использование ОЗУ, определяют его использование для хранения команд-данных или только данных, допускают запись-считывание или только считывание, разрешают обращение к ОЗУ в режиме супервизора-пользователя или только супервизора, задают длительность цикла обращения -1 или 2 такта.
При обращении к памяти или внешним устройствам могут выдаваться сигналы разрешения выборки CSI#. Эти сигналы формируются блоком выборки кристаллов (БВК), который работает как аналогичный блок в модуле SIM микроконтроллеров семейства М683хх. Микроконтроллер МРС505 обеспечивает формирование 12 сигналов разрешения выборки CS0-11, которые поступают на выводы портов А, В.
Блок конфигурации и контроля (БКК) содержит регистр SIUMCR, определяющий режим функционирования SIU, и ряд других регистров и блоков, контролирующих работу различных устройств МРС505. Входящий в состав БКК монитор шины реализует исключение ошибки обращения к шине (адрес вектора Av = $00200), если в течение заданного времени не будет получен сигнал подтверждения обмена ТА# = 0. Время, в течение которого должен быть получен сигнал подтверждения, программируется в пределах от 16 / Ft до 256 / Ft. Таймер периодических прерываний содержит 16-разрядный счетчик, который переключается с частотой Ft / 4. Запрос прерывания вырабатывается, когда содержимое счетчика становится равным нулю. Этот запрос вместе с запросами от других устройств поступает в контроллер прерываний, расположенный в блоке PCU, который управляет их обслуживанием.
В случае необходимости БКК реализует захват шины. Эта процедура выполняется с помощью внешних сигналов BR# - запрос на захват шины, BG# - разрешение захвата, ’ BB# - захват шины. При этом сигналы BR#, BG#, BB# поступают на выводы порта М в числе других сигналов управления СМх.
Генератор тактовых импульсов (ГТИ) формирует тактовые импульсы заданной частоты Ft. Для функционирования ГТИ необходимо подключение внешнего частотно-задаю-щего элемента (обычно кварца), однако получаемая частота Ft может быть в 4 - 11 раз выше резонансной частоты кварца илив2,4, 8,16, ...1024 раза ниже. Требуемое значение Ft программируется путем загрузки соответствующего кода в SCCR - регистр уп-
236
RISC-МИКРОПРОЦЕССОРЫ И RISC-МИКРОКОНТРОЛЛЕРЫ СЕМЕЙСТВ POWERPC И COLDFIRE
равнения ГТИ. Например, при подключении кварца с резонансной частотой 4 МГц можно получить значения тактовой частоты Rot 15,6 КГц до 44 МГц. Для синхронизации работы внешних устройств ГТИ выдает на свои выходы CLKOUT и ECROUT импульсы с частотой R и R / 4 соответственно.
Установка определенных значений поля LPM в регистре SCCR переводит микроконтроллер в один из режимов пониженного энергопотребления: LPM1 - прекращение обращений к шине, LPM2 -частичный останов, LPM3 - полный останов. В режиме LPM1 прекращается выдача синхросигналов CLKOUT, ECROUT, но процессор продолжает выполнение программы, пока не поступит команда, требующая обращения к внешней шине, после чего процессор останавливается. В режиме LPM2 процессор не функционирует, но работают ГТИ, регистр базового времени ТВ, таймер периодических прерываний в БКК, блок обслуживания внешних запросов прерывания, при поступлении которых микроконтроллер возвращается в нормальный рабочий режим. В режиме полного останова LPM3 прекращается работа всех устройств и блоков микроконтроллера, в том числе ГТИ. Выход из режима LPM3 происходит только путем установки начального состояния (reset).
В нормальном рабочем режиме микроконтроллер МРС505 потребляет мощность 530мВт на частоте Ft = 25 МГц. В режиме LPM2 потребление мощности снижается до десятков мегавольт, а в режиме LPM3 составляет единицы мегавольт.
Блок тестирования и отладки (БТО) обеспечивает тестирование микроконтроллера в соответствии со стандартом JTAG (IEEE 1149.1), как это выполняется в микропроцессоре МС68060 и микроконтроллерах семейства М683хх. Сигналы для тестирования TDI, TDO, TMS, ТСК, TRST# поступают на выводы Тхх. Кроме того, БТО реализует режим отладки, который является расширенным вариантом аналогичного режима в микроконтроллерах семейства М683хх. Кроме режима отладки BDM, выполняемого семейством М68ххх, БТО в МРС505 поддерживает отладку в процессе выполнения рабочей программы в реальном времени (без остановов), с остановами в контрольных точках и с применением схемного эмулятора. При этом внешние сигналы микропроцессора указывают состояние очереди команд.
Для отладки программ в реальном времени вводятся 8 точек наблюдения (watchpoint), 4 из которых служат для контроля выборки команд, а 4 - для контроля выборки данных из внешней памяти с помощью LSU. Установка точек наблюдения производится путем загрузки 8 специальных регистров - компараторов СМРА- СМРН, входящих в состав БТО. При контроле выборки команд проводится сравнение их адреса с содержимым компараторов CMPA-CMPD, при контроле выборки данных-сравнение их адреса с содержимым компараторов СМРЕ, CMPF или сравнение выбираемых данных с содержимым компараторов CMPG, СМРН. Точки наблюдения устанавливаются, если адреса или данные равны или не равны, больше или меньше, чем содержимое соответствующих компараторов. При контроле выборки данных можно с помощью регистров СМРЕ, CMPF или CMPG, СМРН задать границы контролируемых значений адресов или данных. В этом случае точка наблюдения устанавливается при попадании или непопадании адреса или данных в заданный диапазон.
Установка точек наблюдения не прерывает исполнения программы, но изменяет состояния контрольных выходов WP0-5 (выводы PL2-7 порта L), из которых четыре (WP0-3) контролируют выборку команд, а два (WP4-5) - выборку данных, а также вызывает декремент содержимого одного из контрольных счетчиков - CNTA при контроле команд, CNTB при контроле данных. Когда содержимое счетчиков становится равным нулю, реализуется прерывание в контрольной точке. Обращение к этим компараторам и счетчикам производится как к служебным регистрам SPRx в регистровой модели супервизора процессора RCPU. Микроконтроллер выполняет также прерывание в контрольной точке при обращении к адресу, значение которого совпадает с содержимым регистра BAR (служебный регистр SPR159).
Специальный режим отладки BDM реализуется, если в процессе начальной установки подать на соответствующий вход микроконтроллера сигнал DSCK - 1. В этом режиме
237
ПРОЦЕССОРЫ ОБЩЕГО НАЗНАЧЕНИЯ И СИСТЕМЫ НА ИХ ОСНОВЕ
микроконтроллер выполняет команды отладки, которые последовательно вводятся в БТО через вход DSI при поступлении внешних синхросигналов на вход DSCK. Вводимые 35-битные команды содержат 3-битный код операции отладки, а в остальных 32 битах задается код команды, выполняемой процессором, или данные. Данные заносятся в специальный регистр данных отладки DPDR (служебный регистр SPR630 в модели супервизора), откуда они считываются процессором при последующем вводе команды mfsr. Последовательный вывод данных из микроконтроллера производится через выход DSO при поступлении синхросигналов DSCK. Данные выводятся из регистра DPDR, куда они должны быть предварительно загружены командой mtsr. Помимо ввода команд и пересылки данных команды отладки позволяют выполнять запись или считывание массивов данных из ОЗУ, разрешать или отменять остановы в контрольных точках. Используемые при отладке сигналы DSI, DSO, DSCK и другие, поступают на выводы порта К (сигналы DKx). Выход из режима отладки BDM производится при вводе команды rfi.
В состав SIU входят также семь 8-разрядных параллельных портов для ввода/вывода данных (в портах L, М используются по 6 выводов PL2-7, РМ2-7, в порте J-7 выводов PJ1-7). Каждый из портов содержит регистр данных PORTx и регистр управления PxPAR, где х = А, В, I, J, К, L или М - имя соответствующего порта. Каждый бит bi в регистре управления определяет функции соответствующего вывода порта: если bi = 0, то i-й вывод служит для передачи i-ro разряда данных, если bi = 1, то вывод используется для передачи разрядов адреса, данных или сигналов выборки CS# (порты А, В), различных управляющих сигналов Clx, CJx, СМх (порты I, J, М), сигналов отладки DKx, DLx (порты К, L) и ряда других. Двунаправленные порты I, J, К, L, М имеют также регистры DDRx, каждый бит bi в которых определяет направление передачи данных для i-ro вывода: при bi = 0 вывод служит входом, при bi = 1 - выходом. Регистры портов имеют фиксированные адреса в адресном пространстве.
Каждый порт Рх может использоваться для передачи данных, если загрузить 0 в его регистр управления. При этом содержимое регистра DDRx задает направление передачи. В таком случае вывод данных осуществляется путем их записи в регистр PORTx, а ввод - путем чтения содержимого этого регистра (из регистров PORTA, PORTB будет считываться ранее записанное содержимое).
Блок управления периферийными устройствами PCU. Блок управления периферийными устройствами PCU содержит сторожевое устройство (watchdog), контроллер прерываний и порт О, выводы которого могут использоваться в качестве входов запросов прерывания. Кроме того, в состав PCU входит интерфейсное устройство, обеспечивающее связь периферийных устройств, подключаемых к межмодульной шине IMB, с устройством загрузки-сохранения данных LSU в RISC-процессоре, которое подключено к внутренней шине LB. Однако эти функции PCU не используются в МРС505, так как он не содержит периферийных устройств.
Сторожевое устройство осуществляет контроль правильности работы микроконтроллера, проверяя периодичность загрузки в специальный регистр SWSR последовательности двух 16-разрядных чисел $556С-$АА39. Период загрузки Tw = Nw I Ft задается 24-раз-рядным числом Nw, которое записывается в регистр управления сторожевого устройства. Если за время Tw в регистр SWSR не будет проведена загрузка очередного числа последовательности, то реализуется программное исключение с адресом вектора Av = $00700.
Контроллер прерываний содержит 32-разрядный регистр IRQPEND, биты которого фиксируют запросы прерывания от внешних устройств, поступающие на входы IRQ0-6 порта Q, и от таймера периодических прерываний. Запросы IRQ3-6 фиксируются в битах Ь6, Ь8, Ь1, а запросы IRQ0-2 и таймера - в битах, номера которых задаются содержимым специального регистра PITQIL. В следующих моделях семейства МРС50х в регистре IRQPEND будут также фиксироваться запросы прерывания от внутренних периферийных
238
RISC-МИКРОПРОЦЕССОРЫ И RISC-МИКРОКОНТРОЛЛЕРЫ СЕМЕЙСТВ POWERPC И COLDFIRE
устройств. Обслуживание зафиксированных запросов разрешается, если соответствующие биты в 32-разрядном регистре IRQENABLE контроллера установлены в «1». В этом случае запрос прерывания поступает на вход RCPU, и реализуется внешнее исключение с адресом вектора Av - 00500 (см. табл. 2.66). Вызванная подпрограмма должна проанализировать содержимое регистра IRQPEND и реализовать соответствующую процедуру обслуживания в зависимости от приоритета поступивших запросов.
Регистр управления PQPAR определяет режим функционирования порта Q. Путем записи в этот регистр соответствующего содержимого каждый вывод порта Q может быть запрограммирован на работу в качестве входа или выхода данных, либо в качестве входа запроса прерывания. При этом прерывание может вызываться установкой уровня «1» на этом входе, подачей положительного или отрицательного перепада потенциала. Можно запрограммировать регистр PQPAR на передачу запросов прерывания непосредственно в RCPU, минуя контроллер прерываний. Путем записи-чтения регистра PQEDGDAT, входящего в состав порта Q, производится вывод или ввод данных, а также контроль поступивших запросов прерывания.
Таким образом, микроконтроллер МРС505, интегрирующий на одном кристалле высокопроизводительный процессор с возможностями обработки чисел с плавающей точкой, значительный объем внутренней памяти (8 Кбайт) и необходимые интерфейсные устройства, является мощным средством для реализации сложнофункциональных устройств управления.
ГЛАВАЗ
ИСПОЛЬЗОВАНИЕ КЭШ-ПАМЯТИ И ОРГАНИЗАЦИЯ ОСНОВНОЙ ПАМЯТИ
Одной из особенностей построения ВС на базе МП является использование кэш-памяти. Этот механизм прозрачен для пользователя. Он позволяет существенно повысить быстродействие за счет снижения времени получения информации из основной памяти.
В этой главе будут рассмотрены общие принципы организации кэш-памяти, а также особенности конкретной реализации при построении МП-систем.
3.1. ОБЩИЕ ПРИНЦИПЫ ОРГАНИЗАЦИИ КЭШ-ПАМЯТИ
Кэш-память располагается между основной памятью (ОП) и центральным процессором для снижения затрат времени на обращение ЦП к ОП.
Идея кэш-памяти основана на прогнозировании наиболее вероятных обращений ЦП к ОП. Наиболее «вероятные» данные и команды копируются в быструю, работающую в темпе ЦП, кэш-память до начала их непосредственного использования ЦП, так что обращение к данным и командам, используемым ЦП в текущий момент времени, может происходить быстро, без обращения к ОП.
В основу такого подхода положен принцип локальности программы или, как еще говорят, гнездовой характер обращений, имея в виду, что адреса последовательных обращений к ОП образуют, как правило, компактную группу.
Развивая идею «кэширования» обращений к ОП, необходимо сделать следующие уточнения. При обращении к ОП в кэш-память копируются не отдельные данные, а блоки информации, включающие те данные, которые с большой степенью вероятности будут использованы в ЦП на последующих шагах работы. Если, например, данное-одна из команд потока последовательных команд, то при выборке этой команды в кэш-памяти копируются одна или несколько последующих команд потока. В связи с этим последующие команды выбираются ЦП уже не из ОП, а из быстрой кэш-памяти.
Блок данных из ОП, копируемый в кэш-памяти, называется кэш-блоком.1 Размер блока (измеренный в числе байтов) различен в разных МП-системах.
Основная память
Кэш-память
Процессор
Блочная выборка в кэш-память - блок содержит две команды
Рис. 3.1. Использование кэш-памяти для просмотра вперед
' В дальнейшем ' блок
240
ОБЩИЕ ПРИНЦИПЫ ОРГАНИЗАЦИИ КЭШ-ПАМЯТИ
Итак, все данные хранятся в ОП и в системе с кэш-памятью копируются в нее. Когда ЦП нужно считать или записать некоторое данное в ОП, он сначала проверяет его наличие в кэш-памяти. Если данное скопировано в кэш-память (эту ситуацию называют кэш-попада-нием), ЦП может быстро получить или передать это данное. В противном случае (кэш-про-мах), блок, содержащий данное обращение, извлекается или записывается через обращение к ОП и одновременно блок переписывается в кэш-память, поддерживая тенденцию к кэш-попаданиям на последующих шагах программы.
Пример копирования в кэш-память последовательности команд приведен на рис. 3.1.
Отметим, что совершенно аналогично в кэш-память копируются и операнды команд. Для чтения или записи данных в порядке, обратном порядку адресов ОП, кэш-память настраивается на работу для просмотра назад.
Различные способы организации кэш-памяти направлены на увеличение доли кэш-по-паданий в общем потоке обращений к памяти от ЦП. Следует отметить, что эффективность кэш-системы зависит и от размера блока и от алгоритма программ.
3.1.1. ПОНЯТИЯ ТЕГА, ИНДЕКСА И БЛОКА
При использовании кэш-памяти, память ЭВМ условно представляется в виде прямоугольника, разделенного на строки и столбцы.
Число строк и столбцов принимается кратным степени 2. На пересечении строк и столбцов находятся блоки, состоящие из нескольких байтов, обычно 2,4,8,16 или 32 в разных МП-системах. Адрес блока в строке называется значением индекса (или просто индексом) блока, а строка, которой он принадлежит, - значением тега (или просто тегом).
I разрядов
m разрядов
п разрядов
Рис. 3.2. Разделение пространства ОП на блоки (Т- значение тега блока; I -значение индекса блока; К - адрес байта внутри блока)
241
ИСПОЛЬЗОВАНИЕ КЭШ-ПАМЯТИ И ОРГАНИЗАЦИЯ ОСНОВНОЙ ПАМЯТИ
Итак, индекс и тег однозначно задают место блока в памяти ЭВМ, Все блоки одного столбца имеют одинаковый индекс, но разные теги, и наоборот - у всех блоков одной строки одинаковый тег, но разные индексы (рис. 3.2).
Поскольку число строк, столбцов и размер блока кратны степени 2, двоичный адрес памяти представляется совокупностью полей.
3.1.2. МЕХАНИЗМ КЭШ-ПАМЯТИ С ПРЯМЫМ ОТОБРАЖЕНИЕМ ДАННЫХ
Во всех механизмах кэш-памяти она представляет собой две сверхоперативные памяти (СОП): память отображения данных и память тегов. В случае кэш-памяти прямого отображения данных память отображения имеет объем одной строки памяти. Размер ее ячейки достаточен для размещения одного блока.
Память значений тегов имеет тот же объем, что и память данных, а размер ее ячейки достаточен для представления в ней значения тега.
Из рис. 3.3 следует, что если блок ОП с адресом TI0 скопирован в кэш-памяти прямого отображения, то в ячейке I СОП данных находится скопированный блок.
СОП прямого отображения блоков
СОП значений тегов блоков в СОП отображения данных
Рис. 3.3. Кэш-память прямого отображения данных
С учетом сказанного общий алгоритм использования кэш-памяти прямого отображения следующий. При обращении ЦП к памяти по адресу TIK вначале проверяется по Т и I присутствие блока, содержащего байт с этим адресом в кэш-памяти. Если копия блока в кэшпамяти, то искомое данное с адресом TIK быстро читается или записывается в кэш-память (кэш-попадание). В случае кэш-промаха происходит обращение к ОП с параллельной записью блока в ячейку I СОП данных и тега Т в ячейку СОП тегов. При этом предполагается, что велика вероятность последующих кэш-попаданий.
3.1.3. МЕХАНИЗМ КЭШ-ПАМЯТИ
С АССОЦИАТИВНЫМ ОТОБРАЖЕНИЕМ ДАННЫХ
Наряду с описанной в предыдущем разделе кэш-памятью прямого отображения данных в МП системах применяется и кэш-память ассоциативного отображения данных. Такая кэш-память, как и в предыдущем случае, состоит из двух СОП: СОП данных и СОП тегов. Но обе эти памяти содержат по нескольку «строк». Число строк кэш-памяти может быть разным в разных ЭВМ, но обычно кратно степени 2. Известны кэш-памяти на 2,4,8 строк. Однако число строк отображения данных и число строк тегов обязательно равны, так что каждой строке данных однозначно соответствует определенная строка тегов.
242
ОБЩИЕ ПРИНЦИПЫ ОРГАНИЗАЦИИ КЭШ-ПАМЯТИ
СОП отображения данных
СОП тегов
1_,0,0
Кэш-блок
Кэш-блок
Кэш-блок
Ассоциативный поиск по Т в столбце I
Рис. 3.4. Кэш-память с ассоциативным отображением данных
Первая строка СОП данных однозначно соответствует первой строке СОП тегов, вторая-второй.
На рис. 3.4 приведен пример КЭШ-памяти с ассоциативным отображением данных. В примере скопированы блоки ОП с адресами L, 0, 0; Т2, И, 0;...; Р, 12, 0;...; Т1, 2т-1,0; Р00; ...; Т1, И, 0; Т2,12, 0;...; L, 2т-1,0.
Обращение к ОП по адресу Т, I, К происходит следующим образом. Проверяется, нет ли блока TI в кэш-памяти. По ассоциативному признаку Т адреса обращения осуществляется ассоциативный поиск в СОП тегов в столбце с индексом I из адреса обращения.
Если значение Т совпадает с одним из значений, записанных в памяти тегов, то фиксируется кэш-попадание и обращение реализуется через обращение к СОП данных кэш-памяти по значению I адреса обращения из соответствующей строки. В нашем примере-из первой или второй строки в зависимости от того, в какой строке совпали теги.
Копирование блока в кэш-память осуществляется путем записи блока и тега, ему соответствующего, в любую свободную строку; если таковой нет, то в соответствии с принятым алгоритмом обновления на место прежней копии записывается новый блок. Для управления перезаписью блоков используются различные алгоритмы, основанные на учете статистики кэш-попаданий за некоторый интервал наблюдения. При этом обычно в ячейку СОП тегов вводятся дополнительные разряды, учитывающие частоту кэш-попаданий. Чем меньше кэш-попаданий, тем скорее последует перезапись блока.
3.1.4. ОБНОВЛЕНИЕ ИНФОРМАЦИИ В КЭШ-ПАМЯТИ
При работе с кэш-памятью одновременно могут существовать две копии одних и тех же данных: одна в кэш-памяти, другая - в основной памяти. Если изменяется только одна из этих копий, то по одному и тому же адресу будут существовать два набора информации, которые отличаются друг от друга. Для того чтобы согласовать содержимое кэш-памяти и основной памяти, используется три метода: сквозная запись, буферизованная сквозная запись и обратная запись.
243
ИСПОЛЬЗОВАНИЕ КЭШ-ПАМЯТИ И ОРГАНИЗАЦИЯ ОСНОВНОЙ ПАМЯТИ
Сквозная запись. При использовании этого метода кэш-контроллер одновременно с записью в кэш-память обновляет и содержимое ОП, которая таким образом отражает текущее содержимое кэш-памяти. Быстрое обновление позволяет перезаписывать любой блок в кэшпамяти в любое время без потерь данных. Система со сквозной записью проста, но время, требуемое для записи в ОП, снижает производительность и увеличивает количество обращений по магистрали.
Буферизованная сквозная запись. В этой схеме любая запись в ОП буферизуется, т. е. информация задерживается в кэш-памяти перед записью в ОП (схемы кэш-памяти управляют доступом к ОП асинхронно по отношению к работе процессора). Затем процессор начинает новый цикл до завершения цикла записи в ОП. Если за записью следует чтение, то это кэш-попадание, так как чтение может быть выполнено в то время, когда кэш-контроллер занят обновлением основной памяти. Буферизация позволяет избежать снижения производительности, характерного для системы со сквозной записью.
Существенным недостатком этого метода является то, что обычно буферизуется только одиночная запись, поэтому две последовательные записи в ОП требуют цикла ожидания процессора. Кроме того, запись с пропущенным последующим чтением также требует ожидания процессора (состояние ожидания используется для синхронизации работы процессора с медленной памятью). Работу по этой схеме иллюстрирует рис. 3.5.
В этот момент времени МП закончил запись «Новых данных 1». Кэш-контроллер поместил в буфер данные для записи и обновления кэш-памяти. Процессор считал «Старые данные 2». Возникло кэш-попадание. В то время, когда «Старые данные 2» находятся на пути к МП. «Новые данные 1» будут переписаны вОП вместо «Старых данных 1».
Обратная запись. В схеме обновления с обратной записью используется специальный бит «Изменения» в поле тега. Этот бит устанавливается, если в блок были записаны новые данные, и он является более «поздним», чем его оригинал в ОП.
Рис. 3.5. Пример буферизованной сквозной записи
244
ОБЩИЕ ПРИНЦИПЫ ОРГАНИЗАЦИИ КЭШ-ПАМЯТИ
Перед тем, как перезаписать блок в кэш-памяти, контроллер переписывает состояние этого бита. Если он установлен, то контроллер переписывает данный блок в ОП перед загрузкой новых данных в кэш-память.
Обратная запись быстрее сквозной, так как обычно число случаев, когда блок изменяется и должен быть переписан в ОП, меньше числа случаев, когда эти блоки только считываются.
Метод обратной записи имеет несколько недостатков. Во-первых, все измененные блоки должны быть переписаны в ОП перед тем, как другое устройство сможет получить к ним доступ. Во-вторых, в случае катастрофического отказа (например, отключения питания), когда содержимое кэш-памяти теряется, а основной - сохраняется, нельзя определить, какие места в ОП содержат устаревшие данные. В-третьих, кэш-контроллер для обратной записи содержит больше (и более сложных) логических микросхем, чем контроллер для сквозной записи. Например, когда система с обратной записью осуществляет запись измененного блока в память, она формирует адрес записи из тега и выполняет цикл обратной записи точно так, как и вновь запрашиваемый доступ.
3.1.5. СОГЛАСОВАННОСТЬ КЭШ-ПАМЯТИ
Особая ситуация при работе с кэш-памятью возникает в том случае, когда она используется в системе с доступом к памяти более чем из одного устройства. Например, пусть два устройства копируют раздел памяти, и устройство 1 обновляет ее первым. Когда устройство 2 производит запись в память, оно «разрушает» любые изменения, сделанные устройством 1. Такое событие называют нарушением согласованности кэш-памяти. Существуют три подхода к обеспечению согласованности кэш-памяти.
а)
Рис. 3.6. Использование аппаратуры кэш-памяти (а - все записи проходят через единственную кэш-память; б - каждая запись обновляет ОП и все кэш-памяти, разделяющие эту область памяти)
245
ИСПОЛЬЗОВАНИЕ КЭШ-ПАМЯТИ И ОРГАНИЗАЦИЯ ОСНОВНОЙ ПАМЯТИ
Очистка кэш-памяти. В этом варианте измененные данные записываются в ОП, а кэшпамять очищается. Если все кэш-памяти системы очищаются перед операцией записи устройствами в память совместного пользования, то возможность появления устаревших данных в любой кэш-памяти исключается. Преимуществом этого метода является простая аппаратная реализация, а главный недостаток заключается в том, что следующий за очисткой доступ в память будет по определению кэш-промахом и так до тех пор, пока кэш-память не заполнится новыми данными.
Аппаратная прозрачность. Аппаратное решение проблемы устаревших данных дает уверенность, что все обращения к ОП (т. е. к той ее части, которая отображается в кэш-память) проводятся через кэш-память. Это может быть сделано либо путем копирования всех кэш-записей как в ОП, так и во все другие кэш-памяти, либо пересылкой всех кэш-записей через единственную кэш-память. На рис. 3.6 показаны различные аппаратные подходы.
Некэшируемая память. Другой метод решения проблемы согласованности кэш-памяти - это использование общей памяти как некэшируемой. В системе, основанной на этом методе, все обращения к общей памяти являются кэш-промахами, поскольку эта память никогда не копируется в кэш. Некэшируемая память может быть идентифицирована путем использования старших битов адреса или с помощью логики выбора микросхем памяти.
При конструировании систем, как правило, применяется некоторая комбинация этих трех методов для уверенности в достоверности данных. Например, одна система может использовать некэшируемую память для «медленных» задач ввода/вывода, таких как вывод на печать, и аппаратную прозрачность для критичных по времени операций ввода/ вывода, подобных разбиению на страницы.
3.2. КЭШ-ПАМЯТЬ КОМАНД И ДАННЫХ
Включение в ЧИП МП кэш-памятей команд, данных и адресной трансляции обеспечивает:
• низкую стоимость ЧИПа для подсистемы ЦП;
• большую ширину обмена процессор - кэш-память: 16 байт для данных, 8 байт для команд;
• быстроту обращений, не требующую сколько-нибудь значительного повышения быстродействия системы. Быстрая схемотехника кэш-обращений скрыта в ЧИПе. Внешняя магистраль может работать более медленно, без значительного снижения производительности системы.
3.2.1. КЭШ-ПАМЯТЬ АДРЕСНОЙ ТРАНСЛЯЦИИ
Современные МП поддерживают или только 4-Кбайтные размеры страниц или как 4-Кбайтные так и 8-Мбайтные размеры страниц, и для каждого размера страниц используются отдельные кэш-буферы (TLB) (TLB-буфер ассоциативной трансляции или, в дальнейшем, буфер страничной трансляции). Буфер страничной трансляции TLB в МП INTEL для 4-Кбайтных страниц имеет 64 записи (рис. 3.7), а TLB-буфер для 8-Мбайтных страниц (рис. 3.8.) содержит 16 записей. Оба буфера используют 4 ассоциативных входа. Буферы работают, если разрешена страничная трансляция. При первом обращении к странице информация, связанная с трансляцией адреса, записывается в соответствующий TLB буфер наряду с другими атрибутами страницы, такими как права доступа и копируемость в кэшпамять. При каждой адресной трансляции осуществляется обращение по линейному адресу одновременно в оба TLB-буфера. Лишь в том случае, если необходимой информации
246
КЭШ-ПАМЯТЬ КОМАНД И ДАННЫХ
31
о
Виртуальный адрес
1615 1211
Физический адрес
Рис. 3.7. Организация буфераTLB для 4-Кбайтных страниц (D - «грязь»; CD -кэш-копирование разрешено; WT-сквозная запись; U/S-режим пользователь/супервизор; R/W-разрешение записи; V - корректность)
нет ни в одном из КЭШ-буферов, происходит обращение к таблицам страниц в основной памяти. При обновлении записей используется алгоритм псевдонормального распределения выбора того, какой из четырех входов (блоков) должен замещаться.
Если линейный адрес команды обнаруживается в кэш-памяти команд, трансляция виртуального адреса не производится, права доступа программы не проверяются. Однако, если линейный адрес команды не обнаружен в кэш-памяти команд, трансляция адреса осуществляется и проверяются все права доступа. Линейные адреса данных всегда транслируются и всегда проверяются на права доступа.
МП обычно предусматривают одновременное обращение и к кэш-памяти команд и кэшпамяти данных, но TLB буферы могут обеспечить в данный момент времени только одну трансляцию адреса. Если оба обращения нужны в одно и то же время, трансляция адреса данного имеет приоритет в доступе к TLB-буферам перед трансляцией адреса команды.
Любая ошибка обращения к данному или команде тотчас же останавливает трансляцию адреса и TLB буфер не обновляется. Если чтение директории вызывает ошибку обращения, таблица страниц вообще не читается.
Если блок страничной трансляции вырабатывает ошибку, например, разряд D для первой записи на чистую страницу, соответствующая запись удаляется из TLB-буфера.
247
ИСПОЛЬЗОВАНИЕ КЭШ-ПАМЯТИ И ОРГАНИЗАЦИЯ ОСНОВНОЙ ПАМЯТИ
Виртуальный адрес
31 24 23 22 21 О
ТЕГ РЯД БАЙТ (смещение)
R
W R
W R
W R
ТЕГ виртуального адреса ТЕГ виртуального адреса ТЕГ виртуального адреса ТЕГ виртуального адреса
С D
W
С D
С D
W
W
31-22-разряды физического адреса страничного кадра 31-22 - разряды физического адреса страничного кадра
31-22 - разряды физического адреса страничного кадра
31-22 - разряды физического адреса страничного кадра
31 V 22 21 И О
Страничный кадр БАЙТ (смещение)
Физический адрес
Рис. 3.8. Организация буфера TLB для 8-Мбайтных страниц (D - «грязь»; CD - кэш-копирование разрешено; WT- сквозная запись; U/S- режим пользователь/супервизор; R/W-разрешение записи; V - корректность)
3.2.2. ВНУТРЕННИЕ КЭШ-ПАМЯТИ КОМАНД И ДАННЫХ
В современных МП реализованы отдельные кэш-памяти для данных и команд. Использование раздельных кэш-памятей для данных и команд обеспечивает одновременные кэш-просмотры. До двух команд и до одного данного в формате до 128 разрядов можно одновременно просмотреть в кэш-памятях. Каждая кэш-память поддерживает до 16Кбайт. Строка может быть скопирована из основной памяти в кэш-память за четыре обмена.
Кэш-памяти полностью прозрачны для прикладного ПО. Управление адресами в обоих кэшпамятях обеспечивает кэш-согласование для мультипроцессорных систем.
Каждая кэш-память имеет два ряда тегов: виртуальные теги для внутренних обращений из МП и физические теги, используемые для обращений к основной памяти (внешних обращений через магистраль). На рис. 3.9 показано, как разряды виртуального и соответствующего ему физического адреса управляют обращениями к кэш-памяти. Наличие виртуального и физического тегов позволяет поставить один единственный физический адрес, полученный при трансляции, через TLB-буфер в соответствие двум или более виртуальным адресам.
248
КЭШ-ПАМЯТЬ КОМАНД И ДАННЫХ
Генерируемые из кристалла адреса
Рис. 3.9. Выдача адресов для кэш-просмотров
Кэш-промахи при записи в память не копируются в кэш-памяти, а данные, связанные с ними, помещаются в буфер записи и затем, когда внешняя магистраль доступна, отправляются в основную память.
Кэш-память данных. Рис. 3.10. иллюстрирует организацию кэш-памяти данных. Кэшпамять данных использует два разряда статуса для каждого физического тега и один разряд статуса - разряд корректности - для виртуального тега.
Кэш-попадание по виртуальному тегу возможно лишь, когда разряд корректности виртуального тега установлен, а состояние физического тега-это М, Е или S.
Рис. 3.10. Организация кэш-памяти данных (М - модифицированная; Е - исключительная; S- разделяемая; I - некорректная; V-корректность)
ИСПОЛЬЗОВАНИЕ КЭШ-ПАМЯТИ И ОРГАНИЗАЦИЯ ОСНОВНОЙ ПАМЯТИ
Соответствие виртуального и физического тегов поддерживается алгоритмом кэш-поис-ка. Даже хотя физическая строка может использовать совмещение имен (имеется в виду ситуация, когда кэш-строка может быть доступна при обращении по разным виртуальным тегам), процессор никогда не вводит строку в кэш-память данных дважды. Если виртуальный адрес не обнаруживается среди виртуальных тегов в кэш-памяти данных, инициируется цикл магистрали (за исключением того, что чтение не осуществляется, если конвейер магистрали заполнен) и в тоже самое время ищется физический тег для физического адреса (который к этому времени был возвращен из блока страничной обработки). При чтениях, если обнаруживается физический адрес (кэш-попадание по физическому адресу), данное из магистрали игнорируется, а используется данное в ЧИПе, и поле виртуального тега замещается новым виртуальным тегом. При записях, если обнаруживается виртуальный адрес (кэш-по-падание по виртуальному адресу обращения), запись вводится на магистраль и обновляется память. Если физический адрес обнаруживается (кэш-попадание по физическому адресу), обновляется строка в кэш-памяти, а виртуальный тег замещается новым виртуальным тегом. Однако разряды состояния кэш-памяти (М, Е или S) из тега физического адреса при переписи виртуального тега остаются неизменными.
Стратегии обновления кэш-памяти данных. Для минимизации трафика магистрали обычно используется стратегия обратной записи (write-back). Стратегия обратной записи (также называемая обратным копированием и отложенной записью) уменьшает трафик внешней магистрали путем значительного ограничения многих ненужных записей в память. Записи в какую либо строку кэш-памяти не немедленно перезаписываются в основную память, а накапливаются в кэш-памяти. Измененная кэш-строка переписывается в основную память лишь тогда, когда ее место в кэш-памяти нужно другому данному, когда модифицированное данное нужно другому процессору или когда выполняется процедура сброса кэш-памяти.
При стратегии обратной записи запись при кэш-попаданиях реализуется кэш-памятью за два цикла (один проверяет виртуальные теги на кэш-попадание, другой обновляет кэш-стро-ку). Однако кэш-конвейер позволяет накапливать кэш-попадания для работы за один цикл.
При стратегии сквозной записи запись, запрашивающая строку в кэш-памяти, вызывает обновление как кэш-памяти, так и основной памяти. Дешифратор адреса, например, может выбрать стратегию сквозной записи для записей в видео RAM, когда необходимо, чтобы запись высвечивалась на экране дисплея. ПО путем установки разряда WT таблицы страниц может выбрать стратегию сквозной записи для специфических областей основной памяти, таких, например, которые используются под очереди межпроцессорных сообщений.
строки
Рис. 3.11. Организация кэш-памяти команд (V-корректность)
250
КЭШ-ПАМЯТЬ КОМАНД И ДАННЫХ
Стратегия (write-once) - однократная запись - представляет собой сочетание сквозной и обратной записей. Сквозная запись применяется для первой записи кэш-строки, в то же время последующие записи в ту же строку идут по стратегии обратной записи. Однократная запись выгодна в мультипроцессорных системах для обеспечения кэш-согласования при минимально возможном трафике магистрали. Первая запись извещает другой процессор о факте изменения строки. Стратегия однократной записи используется также, если к МП подключена кэш-память второго уровня для согласования обоих уровней кэш-памятей.
Внешняя система может динамически изменять стратегию обновления (обратная запись, сквозная запись, однократная запись) внутренней кэш-памяти данных МП для каждой кэш-строки.
Кэш-память команд. На рис. 3.11 представлена организация кэш-памяти команд. В кэш-памяти команд разряд корректности V является общим для виртуального и физического тега. Поддержание ситуации, когда одна физическая строка может отвечать разным виртуальным адресам для команд состоит не в том, чтобы просто изменять виртуальный тег для некоторой строки, а скорее в выборе строки, если имеет место кэш-промах по значению виртуального тега. Если физический адрес уже существует в кэш-памяти команд, соответствующая ему строка и теги перезаписываются. Таким образом, даже несмотря на то, что к некоторой физической строке можно обращаться по разным виртуальным адресам, процессор никогда не вводит строку дважды в кэш-память команд.
3.2.3. АЛГОРИТМ КЭШ-ЗАМЕЩЕНИЙ
Кэш-памяти данных, команд и адресной трансляции (TLB) используют аналогичные алгоритмы для выбора того, какой из четырех кэш-модулей (четырех входов) будет перезаписан, когда выборка строки сопровождается кэш-промахом.
Во-первых, замещается первая некорректная строка в ряду из четырех в порядке 0,1, 2, 3. Когда нет больше некорректных строк в данном ряду, работает алгоритм псевдослучайного выбора замещаемой корректной строки. Алгоритм управляется размещенными внутри ЧИПа МП-счетчиками. По сигналу RESET эти счетчики обнуляются, так что «случайность» детерминирована и два ЦП на базе МП данного типа, исполняющие одну и ту же программу на идентичных материнских платах, будут иметь абсолютно одинаковую последовательность кэш-попаданий, кэш-промахов и кэш-замещений.
3.24. СОСТОЯНИЯ КЭШ-ПАМЯТИ ДАННЫХ
Каждая строка кэш-памяти данных может находиться в состояниях, заданных табл. 3.1.
Таблица 3.1
MESI-состояния кэш-строк
Состояние кэш-строки М - модифицированная Е - исключительная S - разделяемая I - некорректная
Эта кэш-строка корректна? Да Да Да Нет
Копия в памяти Не соответствует данным ... корректна ... не корректна -
Существуют копии в других кэш? Нет Нет Могут быть Могут быть
Запись в эту строку ... не ищет на магистраль ... не ищет на магистраль ... ццет на магистраль и обновляет кэш-память ...цдет на магистраль
251
ИСПОЛЬЗОВАНИЕ КЭШ-ПАМЯТИ И ОРГАНИЗАЦИЯ ОСНОВНОЙ ПАМЯТИ
Отметим, что кэш-команда реализует лишь «SI» часть MESI-протокола, так как команды из кэш-памяти команд нельзя записывать обратно в память.
Состояние кэш-строки может изменяться как в результате внутренних (из ЧИПа), так и внешних (от магистрали) воздействий, связанных с этой строкой. В табл. 3.2 представлены переходы состояний в кэш-памяти данных в результате внутренних воздействий со стороны МП.
Таблица 3.2
Переходы состояний кэш-памяти, инициируемые схемотехникой МП
Состояние Следующее состояние после чтения Следующее состояние после записи
1 EcnnWB/WT #= 1; Е; иначе S заполнение строки Сквозная запись I
S S Сквозная запись если WB/WT # = 1, Е; иначе S
Е Е М
М М М
Примечание: «Запись» не включает обратной записи при замещении. Они могут только вызвать переход из М в 1.
Протокол кэш-согласования. МП обычно реализуют кэш-согласование посредством MESI-протокола (Modified-измененный, Exclusive-исключительный, Shared-разделенный, Invalid -некорректный).
Поддержка внешнего кэш-согласования обеспечивается с помощью циклов запросов. Циклы запросов инициируются другими процессорами в мультипроцессорной системе для проверки, нет ли кэш-копии адреса во внутренней кэш-памяти МП. В табл. 3-3 представлены переходы состояния строки, инициированные циклами запросов.
Таблица 3.3
Переходы состояний кэш-строк, инициируемые внешними запросами
Состояние INV = 0 INV = 1
I S I S I I
Е S I
М S; обратная запись строки I; обратная запись строки
Стратегия однократной записи (write once). Стратегия однократной записи может быть осуществлена, используя входной контакт WB/WT#. Сигнал на этом контакте опрашивается как в цикле записи, так и чтения. Кэш-промах при чтении вызывает, после заполнения строки, перевод строки, в состояние S или Е. Если контакты WB/WT# имеют низкий уровень сигнала и в то же время контакт NA# активен или первый сигнал на контакте BRDY# активен, строка входит в состояние S, усиливая следующее КЭШ-попадание при записи в эту строку передачей на магистраль. Если контакты WB/WT# имеют высокий уровень сигнала, строка переходит в состояние Е. В циклах сквозной записи состояние строки изменяется с S на Е при высоком уровне сигнала на контакте WB/WT #, так что последующие записи не будут сквозными. Таким образом, если этот сигнал приводить к низкому уровню при циклах чтения и высокому при циклах записи, то реализуется стратегия однократной записи. Самый простой путь осуществления однократной записи - это подключить этот контакт к выходному контакту W/R# процессора.
252
КЭШ-ПАМЯТЬ КОМАНД И ДАННЫХ
Если разряд WT в записи таблицы страниц установлен, то МП игнорирует сигнал на контакте WB/WT# для циклов, которые связаны кэш-попаданиями в эту страницу, и всегда выполняет сквозную запись. Другими словами, аппаратура не может изменить выбор стратегии сквозной записи, осуществленный ПО.
Блокированные обращения. Блокированные обращения - это те загрузки или сохранения данного, которые возникают после команды «lock», включая первую загрузку или сохранение после соответствующей команды «unlock».
Переходы состояния для блокированных обращений отличаются от приведенных в табл. 3.2 в плане гарантий таким образом, что блокированные обращения видны всем процессорам в системе. Любая блокированная загрузка или сохранение производит как просмотр кэш, так и вырабатывает цикл внешней магистрали независимо от того, есть кэш-попадание или нет.
1. При блокированном чтении:
а) если требуемое данное не обнаруживается в кэш-памяти, используется данное с магистрали; оно помещается в кэш, если оно копируемое в кэш-память, а также возбужден контакт KEN#;
б) если требуемое данное находится в неизмененном состоянии (S или Е), используется данное с магистрали;
в) если данное находится в кэш-памяти в измененном состоянии (М), используется данное из кэш-памяти, а данное магистрали игнорируется, пока нет запроса обратной записи перед возбуждением контакта BRDY# циклом магистрали; если, однако, возникающий в процессе чтения запрос обратной записи переводит строку в S- или 1-состояние используется данное магистрали.
2. При блокированном сохранении данное вводится в кэш-память сигнала на контакте BRDY# из магистрали. Отметим, что строка, записанная при блокированном сохранении, остается в состоянии М несмотря на сквозную запись на магистраль, так как длина данного сквозной записи меньше размера строки из 32 байт.
Блокированные обращения являются полностью «выходящими» в том смысле, что:
• до ввода первого блокированного обращения все загрузки и сохранения, которые предшествуют команде «lock» вводятся на магистраль (если они кэш-промахи); блокированное обращение может быть введено до последнего сигнала на контакте BRDY# предшествующего цикла, если активирован контакт NA# в ответ на предшествующий цикл;
• никакие данные по командам загрузки или сохранения после последнего блокированного обращения не поступают в кэш или на магистраль до последнего сигнала на контакте BRDY# для всех блокированных обращений.
Для достижения максимальной производительности выборки команд в ходе выполнения блокированной последовательности являются «не выходящими». Когда сигнал на контакте NA# вызывает конвейеризацию, выборки команд могут быть осуществлены, в то время как блокированные обращения к данным остаются на магистрали.
3.2.5. СОГЛАСОВАННОСТЬ ВНУТРЕННИХ КЭШ-ПАМЯТЕЙ
Просмотры как кэш-памяти команд, так и кэш-памяти данных могут быть обусловлены генерируемыми извне запросами циклов и результат кэш-просмотра представляется сигналами на выходных контактах HIT# и HITM#. Эти циклы помогают осуществить согласованность с кэш-памятями других процессоров. Однако ПО должно принять на себя заботу
253
ИСПОЛЬЗОВАНИЕ КЭШ-ПАМЯТИ И ОРГАНИЗАЦИЯ ОСНОВНОЙ ПАМЯТИ
не создавать несогласованностей какие наблюдаются между внутренними кэш-памятями (включая и буферы страничной трансляции -TLB):
• изменение адресного пространства, в то время как сохраняются теги виртуальных адресов предшествующего пространства в кэш-памяти команд или данных;
• изменение команде памяти (или в кэш-памяти данных) без их изменения в кэш-памяти команд;
• изменение информации в таблице страниц в памяти (или в кэш-памяти данных) без изменения той же самой информации в буферах TLB.
Некоторые обстоятельства, такие как обращение к вводу/выводу, самоизменяющаяся машинная программа, обновления таблицы страниц или разделяемые данные в мультипроцессорной системе необходимо обойти, установить некорректность или сбросить кэш-памяти. МП фирмы «Intel» обеспечивает это так.
Обход кэш-памятей команд и данных:
1. Сигнал на контакте KEN# запрещает копирование данного и команды из обращения к данному, если этот сигнал сброшен в ходе выполнения кэш-промаха.
2. Если разряд CD из соответствующей таблицы страниц в единице, копирование в кэшпамять из этой страницы замаскировано. Значение разряда CD повторяется на выходном контакте PCD# для использования внешнего кэш-копирования.
3. Если разряд WT из записи таблицы страниц установлен, кэш-копирование не маскируется, а записи пропускаются сквозь кэш-память. Значение разряда WT дублируется значением на выходном контакте PWT# и может быть использовано внешними кэш-памятями. (Заметим, что значение WT не воздействует на стратегию кэш-памяти команд, поскольку кэш-память команд является не записываемой. Однако, если команда из страницы, имеющей разряд WT установленным в записи РТЕ, помещается в кэш-память данных, стратегия сквозной записи применяется точно так же, как для страницы данных).
4. Записи с некорректностью кэш-копий - установленный разряд ITI в регистре dirbase фиксирует, что каждая строка кэш-памятей адресной трансляции и команд некорректна. В кэш-памяти данных он фиксирует некорректности виртуальных тегов, но не физических.
5. Сброс (очистка) кэш-памяти данных - кэш-память данных очищается программой ПО, которая использует команду «flush». Команда «flush» очень быстро реализует обратные записи в памяти. Тот же эффект (обратная запись измененной строки) можно получить по команде загрузки, но это будет сделано в два раза медленнее - загрузка должна сначала сделать 4 передачи по магистрали, чтобы получить новое данное, затем сделать обратную запись измененной строки. Команда «flush» реализует обратные записи, не требуя чтения данного из основной памяти, замещающего измененную строку.
Согласованность пространства адресов. В мультизадачных системах с виртуальной адресацией ОС может управлять памятью так, что несколько процессов используют одну и ту же физическую память при доступах по разным виртуальным адресам. Когда ОС переключает процессы, она изменяет поле DTB регистра базы таблицы страничных директорий для указания другой страничной директории, задающей новое адресное пространство. При этом все кэш-памяти должны стать некорректными: поскольку из TLB-буферов должны читаться новые страничные директории, а не кэш-памяти данных и команд, потому что, виртуальные адреса из нового адресного пространства, очевидно, не совпадают со скопированными в кэш-память виртуальными адресами из старого пространства.
Некорректность кэш-памятей фиксируется путем установки разряда ITI при записи содержимого в регистр базы таблицы страничных директорий. Некорректность кэш-команд относится как к физическим, так и виртуальным тегам, поскольку кэш-память команд имеет один разряд корректности, общий для физического и для виртуального тегов. Для кэшпамяти данных установка разряда ITI фиксирует некорректность только виртуальных тегов. Тем не менее, некоторые измененные строки будут возможно перезаписаны в память,
254
КЭШ-ПАМЯТЬ КОМАНД И ДАННЫХ
когда их место потребуется для строк из нового адресного пространства иди когда внешние устройства, подключенные к магистрали, запросят измененные данные через циклы запросов. _
Как уже сказано, некорректность кэш-памятеи фиксируется установкой разряда ITI при занесении содержимого в регистр базы таблицы страничных директорий. Тем не менее отметим, что программа ОС, которая очищает кэш-памяти, должна находиться в памяти в ходе очистки. Обычно эта программа имеет один и тот же виртуальный адрес дЛЯ всех процессов. _
Разрешение или маскирование (запрещение) адресной трансляции (с помощью разряда APG) подобно изменению поля DTB, так как в этом случае также изменяется распределение памяти. Перед изменением состояния разряда APG виртуальные теги в кэш-памятях команд и данных должны быть помечены как некорректные.
Согласованность кэш-памяти команд. Когда ПО модифицирует некоторую страницу, содержащую команды [например, отладчик помещает некоторую команду с командой «trap» (ловушка] для указания точки останова) кэш-память команд может оказаться несогласованной по следующим причинам:
• из-за того, что кэш-память данных использует стратегию обратной записи, изменения в страницах скопированных в кэш-память и содержащих команды обновляют память с задержкой;
• изменения в командах не приводят к автоматическому обновлению кэш-памяти команд;
• кэш-промахи при обращениях к кэш-памяти команд не проверяются в кэш-памяти данных.
ПО должно удостовериться, что измененные строки, содержащие команды, записаны в основную память до попытки прочитать их в кэш-памяти команд. Для этого пригодны два способа:
1) очистка кэш-памяти данных с применением команды «flush»; заметим, что для того чтобы сделать кэш-память команд согласованной с кэш-памятью данных, кэшпамять данных должна быть очищена перед фиксацией некорректности кэш-памяти команд;
2) пометить все страницы команд как страницы со сквозной записью установкой разряда WT в записях страниц, так чтобы изменения в командах приводили к немедленной перезаписи в память; этот вариант, пожалуй, самый лучший.
В любом случае после того как страница программы будет изменена, чтобы обновленные команды читались из основной памяти, должна быть зафиксирована некорректность кэш-памяти команд (путем установки разряда ITI в содержимом регистра базы таблицы страничных директорий).
Согласованность таблиц страниц. Данные в TLB-буферах становятся некорректными, когда ОС изменяет таблицы страниц или страничных директорий по следующим причинам: • так как кэш-память данных использует стратегию обратной записи, обновления кэш-копий таблиц страниц не приводят к незамедлительному обновлению памяти;
• изменения таблиц страниц не сопровождаются автоматическим обновлением TLB-бу-феров;
• в процессе трансляции МП «Intel» обращаются за страничными директориями и таблицами страниц, размещенными только во внешней памяти; он не использует кэш-данных (данные не передаются из кэш-памяти данных в TLB-буферы в ходе циклов замещения TLB-буферов).
ПО должно удостовериться в том, что измененные строки, содержащие записи таблицы страниц, записаны в основную память, прежде чем блок страничной трансляции попытается прочитать их. Для этого можно применять два способа:
1) хранить таблицы страниц и директорий в некопируемой в кэш-память области основной памяти или использовать режим сквозной записи страниц,
255
ИСПОЛЬЗОВАНИЕ КЭШ-ПАМЯТИ И ОРГАНИЗАЦИЯ ОСНОВНОЙ ПАМЯТИ
2) чистить кэш-данных по команде «flush»; процессор самостоятельно фиксирует некорректность записей в TLB в случае выработки ловушки нужной для установки разрядов А и D; в других случаях после изменений таблицы страниц или страничных директорий некорректность TLB-буферов должно зафиксировать ПО (путем установки разряда ITI в содержимом регистра базы таблицы страничных директорий, так что обновленные записи будут считываться из основной памяти).
Если программа изменяет только разряды Р, U, W, А или D из записи РТЕ (коль скоро адрес страничного кадра не изменяется и сама запись РТЕ не находится в кэш-памяти данных), нет необходимости очищать кэш-память данных. МП не использует TLB-буферы для обратных записей строк, он пишет их по адресу физического тега.
Таким образом, обработчик ловушки может обработать ловушку доступа к данному для нулевого разряда D только устанавливая D в единицу. При установке разрядов Р или А нет необходимости фиксировать некорректность кэш-памятей или очищать какие-либо кэш-памяти, так как процессор не загружает записи в TLB, у которых разряд Р = 0 или А = 0.
Резюме:
В современных МП ВС МП может быть использован как без, так и с внешней (вторичной или как ее еще называют общей) кэш-памятью команд и данных.
Такая память размещается на материнской плате и состоит из двух компонент - кэш-контроллера и кэш-памяти. Эти компоненты позволяют иметь в ВС общую высокоскоростную кэш-память команд и данных емкостью в сотни Кбайт.
Большой размер внешней кэш-памяти может, естественно, дать увеличение доли «кэш-попаданий», когда размер или число структур данных и программ превышает размер внутренних, реализованных в ЧИПе МП кэш-памятей. В мультипроцессорных системах внешняя кэш-память используется как локальная память и может уменьшить трафик магистрали ВС. Кроме того, внешняя кэш-память «скрывает» процессор от остальных систем, что может иметь двоякое значение:
1) процессор может быть заменен (возможен upgraded) без изменения памяти и других подсистем МП ВС;
2) без особого снижения общих характеристик системы могут быть использованы более медленные и менее емкие устройства памяти и устройства ввода/вывода.
Кэш-память названа так потому, что она прозрачна, скрыта от программиста, через нее прокачиваются команды и данные по магистралям ОП - МП. Подобный механизм применен и при организации «скрытой» части регистров, хранящих дескрипторы сегментов, используемых в данный момент, если МП ВС реализует сегментно-страничную организацию основной памяти.
3.3. ФУНКЦИОНИРОВАНИЕ ПАМЯТИ
Современные МП ВС используют сегментно-страничную организацию памяти, преобразуют логические адреса (т. е. адреса, которые видят программисты) в физические адреса (реальные адреса физической памяти) за два шага:
1) трансляция сегмента, при которой логический адрес, состоящий из селектора сегмента и смещения (относительного адреса внутри сегмента), преобразуется в линейный адрес1;
1 Ряд микропроцессорных систем использует только страничную организацию памяти. В них трансляция виртуального адреса происходит за один шаг.
256
ФУНКЦИОНИРОВАНИЕ ПАМЯТИ
Логический адрес
15 0 31 0
Рис. 3.12. Общая идея трансляции адресов
2) страничная трансляция, при которой полученный на первом шаге линейный адрес преобразуется в физический адрес. Этот шаг необязательный, он используется по усмотрению проектировщиков программного обеспечения (ПО).
Транспяция происходит незаметно для прикладного программиста. На рис. 3.12 представлены два шага трансляции на высоком уровне абстракции. Этот рисунок и дальнейшее содержание этой главы представляют упрощенный взгляд на механизм адресации. На самом деле механизм адресации включает также механизмы защиты памяти. Аспекты защиты рассмотрены в п. 3.4.
3.3.1. ТРАНСЛЯЦИЯ СЕГМЕНТОВ
На рис. 3.13 показано более детально то, как процессор преобразует логический адрес в линейный.
При выполнении этого шага трансляции процессор использует следующие структуры данных:
• дескрипторы;
• таблицы дескрипторов;
• селекторы;
• регистры сегментов.
257
ИСПОЛЬЗОВАНИЕ КЭШ-ПАМЯТИ И ОРГАНИЗАЦИЯ ОСНОВНОЙ ПАМЯТИ
Логический адрес
15 0 31 О
Рис. 3.13. Преобразование логического адреса в линейный
Дескрипторы. Дескриптор сегмента обеспечивает процессор данными, которые необходимы для преобразования логического адреса в линейный. Дескрипторы создаются компиляторами, редакторами связей, загрузчиками или другими системными программами, но не прикладными программами.
На рис. 3.14 приведены два общих формата дескрипторов МП фирмы «Intel».
Дескрипторы всех типов имеют один из этих форматов. Дескрипторы сегментов содержат следующие поля;
База: задает расположение сегмента в 4-Гбайтном линейном адресном пространстве. Процессор объединяет три фрагмента поля База из формата дескриптора для образования единого адреса.
Дескрипторы, используемые для кодовых сегментов прикладных программ и сегментов данных
31 23 15 70
База 31-24 G X 0 AVL Предел 19-16 Р DPL 1 Тип А База 23-16
База сегмента 15-0 Предел сегмента 15 -0
Дескрипторы, используемые для специальных системных сегментов 31 23 15 7 0
База 31-24 G X 0 AVL Предел 19-16 Р DPL 0 Тип А База 23-16
База сегмента 15-0 Предел сегмента 15-0
Рис. 3.14. Общий формат дескриптора сегмента (A-доступность; AVL-пригоден для использования прикладными программами; DPL-уровень привилегий дескриптора; G-дробность; Р-присутствие сегмента)
258
ФУНКЦИОНИРОВАНИЕ ПАМЯТИ
31 15 70
Пригодны 0 | DPL S Тип Пригодны
Пригодны
Рис. 3.15. Формат неприсутствующего дескриптора
Предел: задает размер сегмента. В результате объединения процессором двух частей поля предела дескриптора получается 20-разрядное значение. Процессор интерпретирует поле предела двояко, в зависимости от состояния разряда дробности G:
• в байтах, для задания границы до 1 Мбайта;
• в 4-Кбайтных единицах для задания предела до 4 Гбайт. При загрузке предел сдвигается влево на 12 разрядов, и младшие 12 разрядов устанавливаются в «1».
Разряд дробности (G): указывает единицы, в которых интерпретируется предел. Когда разряд нулевой (G = 0), предел интерпретируется в байтах, когда установлен (G = 1) - предел интерпретируется в единицах по 4 Кбайта.
Тип: устанавливает различия между разными видами дескрипторов.
DPL (уровень привилегий дескриптора): используется механизмом защиты.
Разряд присутствия сегмента (Р): если этот разряд нулевой, дескриптор не пригоден для преобразования адресов; процессор вырабатывает исключение в то время, когда селектор для этого дескриптора загружается в сегментный регистр. На рис. 3.15. приведен формат дескриптора для случая нулевого значения разряда присутствия. Операционная система может использовать поля, помеченные как «пригодны». Операционная система, которая использует идею сегментированной виртуальной памяти, устанавливает разряд Р в «0» в одном из двух случаев:
• когда линейное адресное пространство, занимаемое сегментом, не преобразуется механизмом страничной организации;
• когда сегмента нет в основной памяти.
Разряд доступа (А): процессор устанавливает этот разряд тогда, когда осуществляется обращение к сегменту, т. е. когда селектор для этого дескриптора загружается в сегментный регистр или когда селектор этого дескриптора используется командой проверки селектора. Операционная система, которая использует виртуальную память на уровне сегментов, может, периодически проверяя и очищая этот разряд, контролировать частоту использования сегмента. Создание и сопровождение дескрипторов входит в компетенцию системного ПО и обычно осуществляется по запросам компиляторов, загрузчиков, компоновщиков и систем управления процессами.
Таблицы дескрипторов. Дескрипторы сегментов хранятся в таблицах двух видов:
1) глобальной таблице дескрипторов (GDT);
2) локальной таблице дескрипторов (LDT).
Таблица дескрипторов - это просто массив из 8 байтовых записей, которые содержат дескрипторы, как показано на рис. 3.16. Таблица дескрипторов имеет переменную длину и может содержать до 8192 (213) дескрипторов. Однако первая запись GDT (ИНДЕКС = 0) не используется для размещения дескриптора.
Процессор размещает GDT и текущую LDT в памяти посредством регистров GDTR и LDTR. Эти регистры хранят базовые адреса таблиц в линейном адресном пространстве, а также пределы сегментов таблиц. Команды LGDT и SGDT обеспечивают доступ к регистру GDTR, команды же LLDT и SLDT-доступ к LDTR.
259
ИСПОЛЬЗОВАНИЕ КЭШ-ПАМЯТИ И ОРГАНИЗАЦИЯ ОСНОВНОЙ ПАМЯТИ
Селекторы. Область селектора из логического адреса задает дескриптор, специфицируя таблицу дескрипторов и индексируя дескриптор внутри этой таблицы. Селекторы могут быть «видны» прикладным программам как поле внутри изменяющихся указателей команд, но значения селекторов обычно вырабатываются редакторами связей и загрузчиками. На рис. 3.17. представлен формат селектора.
Индекс, задает один из 8192 дескрипторов в таблице дескрипторов. Процессор просто умножает значение индекса на 8 (длина дескриптора) и прибавляет этот результат к базовому адресу таблицы дескрипторов для доступа к соответствующему дескриптору сегмента в таблице.
Глобальная таблица дескрипторов (GDT)
Локальная таблица дескрипторов (LDT)
Рис. 3.16. Таблица дескрипторов
Индикатор таблицы (TI): определяет, на какую таблицу дескрипторов ссылается ей» лектор: нуль указывает GDT, единица -текущую LDT. °
Запрашиваемый уровень привилегий: используется механизмом защиты. !
Так как первая запись GDT не используется процессором, селектор с индексом «О» и нулевым указателем таблицы (т. е. селектор, который определяет первую запись GDT), может быть использован как нуль-селектор. При загрузке сегментного регистра (кроме CS или SS) нуль-селектором процессор не вырабатывает исключения. Это свойство полезно при инициализации неиспользованных сегментных регистров как средство обнаружения случайных ссылок. Если сегментный регистр используется для обращения к памяти, будет выработано исключение.
Регистры сегментов. МП сохраняет информацию из дескрипторов в сегментных регистрах, поэтому нет необходимости обращаться к таблице дескрипторов при каждом обращении к памяти.
Каждый регистр сегмента имеет «видимую» и «скрытую» часть, как показано на рис. 3.18. Видимыми частями этих регистров манипулируют программы, как если бы эти регистры были просто 16-разрядными регистрами. Скрытые части контролируются процессором. Операции, которые загружают регистры, реализуются обычными командами программы.
Так как большинство команд обращаются к данным в сегментах, селекторы которых уже загружены в сегментные регистры, процессор может прибавить относительный адрес из команды к базовому адресу из скрытого регистра, не прибегая к процедуре обращения к памяти, которая описана выше (т. е. без обращения к резидентной таблице дескрипторов).
15 3 2 1 0
Индекс TI RPL
Рис. 3.17. Формат селектора (TI - индикатор таблицы; RPL - запрашиваемый уровень привилегий)
260
ФУНКЦИОНИРОВАНИЕ ПАМЯТИ
16-разрядный «видимый» селектор «Скрытый» дескриптор
CS
SS
DS
ES
FS
GS
Рис. 3.18. Регистры сегментов
3.3.2. АДРЕСАЦИЯ ФИЗИЧЕСКОЙ ПАМЯТИ
Адресуемыми единицами физической памяти являются отдельные байты. Физическое Адресное пространство, разбитое на страничные кадры, содержит 232байт. Команды и данные могут размещаться в любом месте этого адресного пространства.
Обычно многобайтовые данные размещаются в физической памяти в формате «младший крайний», т. е. младший байт формата - это байт с наименьшим адресом памяти (данное размещено в порядке адресов памяти и задано адресом своего младшего байта). ПО в режиме «супервизор» может динамически выбирать вариант упорядочения байтов. Вариант упорядочения определяется состоянием специального разряда в одном из управляющих регистров МП. МП обеспечивает также режим «старшего крайнего», при котором самый старший байт элемента данных является байтом с самым младшим адресом.
Программы всегда строятся с адресацией по принципу «младший крайний». Адреса последовательных команд возрастают в памяти. Это подразумевает, что команды при обращениях к командам как к данным в режиме «старший крайний», появляются в порядке, отличном от естественного. Фирма «Intel» рекомендует, чтобы дисассемблеры , выполняющие систему конвертирования команд в режиме «старший крайний», читали их как данные в порядке, обратном порядку «младший крайний», а представляли их в приведенном здесь формате «младший крайний».
Таблицы страничных директорий и таблицы страниц также доступны в порядке адресов памяти (режим «младший крайний»).
Практически во всех МП необходимо следующее выравнивание адресов на адреса целочисленных границ (любое несоответствие вызывает ловушку обращения к данным):
• 128-разрядные значения должны быть размещены в памяти по адресу, соответствующему целочисленной границе для 16-байтового формата (т. е. четыре младших разряда адреса должны быть нулевыми);
• 64-разрядные данные должны размещаться в памяти по адресу, соответствующему целочисленной границе для 8-байтового формата (т. е. по адресу, кратному 8, три младших разряда адреса должны быть нулевыми);
• 32-разрядные данные размещаются по адресу целочисленной границы для 4-байтового формата (т. е. по адресу, кратному 4, два младших разряда адреса нулевые);
• 16-разрядные данные выравниваются по целочисленной границе для 2-байтового формата (т. е. их адреса должны быть кратны 2, младший разряд адреса нулевой).
' Программы, получающие на вход программу в машинном коде или в виде загрузочных и объектных модулей и выдающие на выходе эквивалентные программы на языке Ассемблера.
261
ИСПОЛЬЗОВАНИЕ КЭШ-ПАМЯТИ И ОРГАНИЗАЦИЯ ОСНОВНОЙ ПАМЯТИ
3.3.3. ТРАНСЛЯЦИЯ СТРАНИЦ
Если страничная трансляция разрешена, то процессор перед обращением к памяти преобразует линейные адреса данных и команд в физические адреса. Механизм преобразования адресов в разных МП фирмы «Intel» обладает всеми особенностями, присущими системам со странично-организованной памятью с защитой уровня страниц.
Трансляция адресов может быть и отключена. В исходном состоянии процессора (системный сброс по RESET) трансляция адресов отключена. Она включается при установке разряда PG управляющего регистра CRO в ходе выполнения команды загрузки содержимого в регистр базового адреса таблицы страничных директорий.Обычно операционная система делает это в ходе инициализации ПО. Адресная трансляция вновь отключается при загрузке в регистр базового адреса таблицы страничных директорий значения, в котором разряд PG сброшен. Иными словами, разряд PG должен быть установлен, если ОС предусматривает страничную защиту или странично-организованную память.
Страничный кадр. Страничный кадр - это единица объединения байтов с последовательными адресами в физической памяти. Страница объединяет данные, которые занимают страничный кадр, когда данные находятся в основной памяти или данные из некоторого раздела внешней памяти, если не хватает места в основной памяти.
Архитектура современных МП поддерживает один или два размера страниц и соответственно страничных кадров: 4-Кбайтный или 4-Кбайтный и 4-Мбайтный одновременно. 4-Кбайтные страничные кадры начинаются с адресов основной памяти, отвечающих 4-Кбайтным целочисленным границам и имеют фиксированный размер. 4-Мбайтные страничные кадры располагаются в основной памяти по целочисленным границам для 4-Мбай-тного формата и также фиксированы по размеру.
Линейный адрес. Линейный адрес косвенно ссылается на физический адрес путем спецификации страницы и смещения внутри этой страницы. На рис. 3.19 представлены форматы линейных адресов.
Форматы линейных адресов для 4-Кбайтных страниц и 4-Мбайтных страниц естественно отличаются друг от друга.
На рис. 3.20 показано преобразование линейного адреса с помощью таблиц страниц. МП использует поле DIR (Директория) как индекс страничной директории в таблице страничных директорий. Для 4-Кбайтных страниц он использует поле PAGE (Страница) в качестве индекса в таблице страниц соответствующей страничной директории и поле OFFSET (Смещение) как адрес байта внутри страничного кадра, заданного этой таблицей страниц. Для 4-Мбайтных страниц, запись страничной директории определяет адрес страничного кадра.
Таблицы страниц. Таблица страниц-это просто массив 32-разрядных указателей страниц. Таблица страниц сама по себе страница в 4-Кбайта или в 1К 32-разрядных записей. На верхнем уровне находится таблица страничных директорий. Таблица страничных
Рис. 3.19. Форматы линейных адресов (а - для 4-Кбайтной страницы; б - для 4-Мбайтной страницы)
262
ФУНКЦИОНИРОВАНИЕ ПАМЯТИ''
Рис. 3.20. Трансляция адреса (DTB - база таблицы страничной директории)
директорий содержит до 1К записей, которые адресуют или таблицы страниц второго уровня или 4-Мбайтные страничные кадры. Могут использоваться или только 4-Кбайт-ные или только 4-Мбайтные страницы, или некоторая комбинация тех и других. Одна таблица страничных директорий может перекрыть все 4-Гбайтное физическое адресное пространство (1К записей страничных директорий х 4 Мбайта страницы или 1К записей страничных директорий х 1К записей таблицы страниц соответствующей страничной директории х 4 Кбайта страницы).
Физический адрес текущей таблицы страничных директорий находится в поле DTB управляющего регистра МП. ПО управления памятью может предусмотреть одну таблицу страничных директорий на все процессы, одну таблицу страничных директорий на каждый процесс или некоторую комбинацию этих двух подходов.
Записи таблиц страниц. На рис.3.21 представлены форматы записей таблиц страниц (PTEs - Page table entries).
Адрес страничного кадра. Поле адреса страничного кадра специфицирует физический начальный адрес страничного кадра. В записи страничной директории адрес страничного
263
ИСПОЛЬЗОВАНИЕ КЭШ-ПАМЯТИ И ОРГАНИЗАЦИЯ ОСНОВНОЙ ПАМЯТИ
Присутствие
Право записи
Попьзователь/супервизор
Разряд доступа
Размер страницы ( 0 для 4 Кб) Доступны для использования системным программистом
Запись страничных директорий для 4-Кбайтной страницы
31 12 9 7 5 2 1 О
Разряды 31 -12: адрес таблицы страниц страничной директории AVAIL 0 0 0 А 0 0 и / S R / W р
Притсутствие
Право записи
Попьзователь/супервизор
Сквозная запись
Кэш-копирование выключено
Разряд доступа
Разряд грязи
Размер страницы (1 для 4 Мб) Доступны для использования системным программистом
31 22 21
Запись страничных директорий для 4-Мбайтной страницы
Присутствие
Право записи попьзователь/супервизор Сквозная запись
Кэш-копирование отключено Разряд доступа
Разряд грязи
Доступны для использования системным программистом
О
Запись таблицы страниц только для 4-Кбайтных страниц
зарезервирован фирмой Intel
Рис. 3.21. Форматы записей таблиц страниц
264
ФУНКЦИОНИРОВАНИЕ ПАМЯТИ
кадра является или адресом таблицы страниц второго уровня или адресом 4-Мбайтного страничного кадра, который содержит требуемый операнд памяти. В таблице страниц второго уровня, адрес страничного кадра - это адрес 4-Кбайтного страничного кадра, содержащего требуемый операнд памяти.
Разряд присутствия. Разряд присутствия Р (Present) указывает на то, может ли запись таблицы страниц использоваться при страничной трансляции. Значение Р = 1 свидетельствует о возможности использования записи. Если Р = 0 в записях таблиц страниц любого уровня, запись не корректна для адресной трансляции и остаток записи может использоваться ПО. Ни один из оставшихся разрядов записи не проверяется аппаратурой.
Если Р = 0 в записях таблиц страниц любого уровня и делается попытка использовать запись для адресной трансляции, процессор вырабатывает сигнал ошибки при обращении к данным или ошибки при обращении к команде. В системах страничной виртуальной памяти обработчик ловушки может перенести запрашиваемую страницу в физическую память.
Заметим, что для самой таблицы страничных директорий не существует разряд Р. Таблица страничных директорий может и отсутствовать, пока связанный с ней процесс находится в состоянии ожидания, но ОС перед запуском процесса должна удостовериться, что таблица страничных директорий, специфицированная содержимым регистра базового адреса таблицы страничных директорий и связанная с процессом, присутствует в физической памяти.
Разряды «Право записи» и «Пользователь/супервизор». Разряды «право записи» R/W и «пользователь» U/S предназначены для защиты уровня страниц, которую МП реализует в процессе трансляции адреса. Концепция привилегий реализуется для страниц путем отнесения каждой страницы к одному из двух уровней:
1) уровень супервизора (U/S=0) - для программ ОС и других систем ПО и связанных с ними данных;
2) уровень пользователя (U/S=1) - для прикладных программ и данных.
Разряд U в регистре psr указывает на то, в каком режиме («пользователь» или «супервизор») работает процессор. МП изменяет содержимое разряда U регистра psr следующим образом:
1) сбрасывает разряд U регистра psr, чтобы инициировать уровень «супервизора», при возникновении ловушки в том числе, если ловушка вызвана командой ловушки trap («ловушка»); предыдущее значение U копируется в разряд PU (Prior user);
2) переписывает содержимое разряда PU регистра psr в разряд U этого регистра, если выполняется косвенная передача управления и один из разрядов ловушек установлен; если PU содержал единицу, МП переходит на уровень «пользователя».
С помощью разряда U из регистра psr и разрядов U/S и R/W из записей таблиц страниц МП осуществляет следующие правила защиты:
• с уровня «пользователь» попытка чтения или записи страницы уровня «супервизор» приводит к ловушке;
• с уровня «пользователь» попытка записи в страницу, для которой разряд R/W не установлен, приводит к ловушке;
• с уровня «пользователь» запись в основную память содержимого некоторых управляющих регистров по команде сохранения игнорируется;
• на уровне «пользователь», привилегированные команды не работают.
При работе МП на уровне «супервизор» все страницы доступны для чтения. Возможность записи в какую-либо страницу зависит от режима защиты по записи, индицируемого разрядом WP регистра epsr:
WP = 0 - запись возможна во все страницы
WP = 1 - запись в страницу, разряд W которой не установлен, вызывает ловушку.
265
ИСПОЛЬЗОВАНИЕ КЭШ-ПАМЯТИ И ОРГАНИЗАЦИЯ ОСНОВНОЙ ПАМЯТИ
Если МП работает на уровне «пользователь», только страницы, принадлежащие уровню «пользователь» и с правом записи (R/W = 1) - действительно доступны для записи. С уровня «пользователь» страницы, принадлежащие уровню «супервизор», недоступны ни для записи, ни для чтения.
Разряд сквозной записи (WT -Write-Through). МП реализуют алгоритмы обратной записи и сквозной записи для кэш-памятей команд и данных, размещенных в кристалле МП. Если разряд WT установлен, то используется алгоритм сквозной записи для данных из соответствующей страницы. Если разряд WT = 0, то для данных из этой страницы используется алгоритм обычной обратной записи.
Для 4-Мбайтных страниц используется разряд WT из записи страничной директории. Для 4-Кбайтных страниц используется только разряд WT из записи таблицы страниц второго уровня.
Значение разряда WT управляет уровнем потенциала на выходном контакте МП PWT. Это позволяет использовать для кэш-памяти второго уровня тот же алгоритм обновления основной памяти, что и для кэш-первого уровня.
Разряд «кэш-память запрещена» (отключена). Если разряд CD (cache disable - кэшпамять отключена) установлен, то данные из страницы не размещаются в кэш-памятях команд или данных (безотносительно к значению разряда WT). При нулевом содержимом разряда CD процессор помещает данные во внутренние кэш-памяти.
Для 4-Мбайтных страниц используется разряд CD из записи страничной директории. Для 4-Кбайтных страниц используется только разряд из записи таблицы страниц второго уровня.
Значение разряда CD управляет уровнем на внешнем контакте PCD, так что возможность копирования во внутренних и внешней КЭШ-памятях одинакова.
Разряды «Доступа» и «Грязи». Разряды «Доступа» A (accessed) и «Грязи» D (dirty) обеспечивают операционную систему данными об обращениях к странице в таблицах страниц обоих уровней.
МП устанавливает разряд А до записи или чтения при обращении к странице. Для 4-Кбайтных страниц МП устанавливает разряды А в записях таблиц страниц обоих уровней.
Процессор проверяет разряд «грязи» D перед записью и при некоторых условиях вырабатывает ловушки. Обработчик ловушки затем может проанализировать соответствующие значения разрядов «грязи». Для 4-Мбайтных страниц используется разряд D из записи страничной директории, а для 4-Кбайтных страниц - разряд D только из записи таблицы страниц второго уровня.
ОС, поддерживающая страничную память, может воспользоваться разрядами D и А для выбора страниц, подлежащих удалению из физической памяти, когда запросы на память превышают возможности физической памяти. Разряды D и А обычно сбрасываются в «О» по инициативе ОС. Процессор устанавливает разряд А при обращении к странице при операции записи или чтения. Если при обращении к данным происходит ошибка и выполняется разрешенная запись, обработчик ловушки устанавливает разряд D, затем повторно выполняет команду.
ОС несет ответственность за координацию обновлений этих разрядов центральным процессором или другими процессорами, которые могут разделять эти страницы.
Алгоритм адресной трансляции. Процесс трансляции линейного адреса в физический проходит по следующему алгоритму. Положим, что «Директория» (DIR), «Страница» (PAGE) и «Смещение» (OFFSET) являются полями линейного адреса; пусть PFA1 и PFA2 являются соответственно адресными полями страничных кадров из записей таблиц страниц первого и второго уровней (PDE и РТЕ); DTB - базовый адрес таблицы страничных директорий, содержащийся в регистре базового адреса таблицы страничных директорий (в МП «Intel»-управляющий регистр CR3).
1. Читается запись страничной директории (PDE) по физическому адресу, сформированному по полям DTB:DIR:OO.
266
ФУНКЦИОНИРОВАНИЕ ПАМЯТИ
2. Если в PDE разряд Р равен нулю, генерируется ошибка обращения к данному или команде.
3. Если в PDE разряд R/W равен нулю, выполняется запись, и, если или разряд U в регистре psr установлен или разряд WP установлен, то генерируется ошибка обращения к данному.
4. Если в PDE разряд U/S в нуле и установлен разряд U в регистре psr, генерируется ошибка доступа к данному или команде.
5. Если в PDE разряд доступа А нулевой и имеет место кэш-промах при обращении к буферу ассоциативной трансляции TLB в блокированной последовательности, генерируется ошибка доступа к данному или команде. (Данная ловушка позволяет ПО установить разряд А в «1» и осуществить рестарт последовательности. Это помогает аппаратуре внешней магистрали недвусмысленно установить тот факт, что адрес соответствует закрытому семафору).
6. Если в PDE разряд 7 находится в единице (4-Мбайтная страница) и выполняется операция записи, и в PDE разряд «грязи» D = 0, генерируется ошибка доступа к данному.
7. Если в PDE разряд А = 1, перейти к шагу 11, в противном случае возбуждается сигнал на контакте LOCK#.
8. Выполняется чтение PDE подобно тому, как это делалось на шаге 1, и проверяются разряды Р, W, U аналогично шагам со 2-го по 4-й.
9. Записывается PDE с разрядом доступа А, равным единице.
10. Снимается сигнал блокировки на контакте LOCK#.
11. Если в PDE разряд 7 в единице (4-Мбайтная страница), формируется физический адрес из полей PFA1 :OFFSET и осуществляется выход из алгоритма страничной трансляции. В этом случае поле PFA1 является 10-разрядным, а поле OFFSET -22-разрядным.
12. Остальные шаги выполняются для 4-Кбайтных страниц. Если в PDE разряд доступа А был перед началом трансляции нулевым, возбуждается сигнал блокировки на контакте LOCK#.
13. Выбирается запись страничной директории РТЕ по физическому адресу, сформированному по полям: PFA1 :PAGE:OO.
14. Выполняются проверки разрядов А, Р, W, итак же как это делалось в шагах со 2-го по 5-й только по записи РТЕ таблицы страниц второго уровня. Если в РТЕ разряд А в нуле и имел место кэш-промах в блокированной последовательности, вырабатывается ошибка доступа к данному или команде. Сигнал на контакте LOCK# остается активным.
15. При операции записи и нулевом значении разряда D в РТЕ генерируется ошибка доступа к данному.
16. Если разряд доступа А в PDE до того как началась трансляция уже установлен и разряд А в РТЕ уже также установлен, осуществляется переход к шагу 20.
17. Если контакт LOCK# уже не активен, он возбуждается и повторно выбирается запись РТЕ.
18. Делаются проверки разрядов U, W, Р и установка разряда А в РТЕ подобно тому как, это делается в шагах 8-9. Делается блокированное обновление записи РТЕ, чтобы разблокировать магистраль, даже если разряд доступа А в РТЕ уже в единице.
19. Сбрасывается сигнал на контакте LOCK#.
20. Формируется физический адрес из полей PFA2:0FFSET. В этом случае поле PFA2 -20-разрядное, а поле OFFSET - 12-разрядное.
Во время трансляции МП обращается только к основной памяти для доступа к страничным директориям и таблицам страниц. Обращений к кэш-памяти данных нет. Поэтому любая программа, которая изменяет страничные директории или таблицы страниц второго уровня, должна поддерживать их вне кэш-памяти. Таблицы должны храниться или в не поддерживаемой кэш-памятью основной памяти, или в страницах со сквозной записью, или должны быть стерты в кэш-памяти.
267
ИСПОЛЬЗОВАНИЕ КЭШ-ПАМЯТИ И ОРГАНИЗАЦИЯ ОСНОВНОЙ ПАМЯТИ
МП предполагает, что страничные директории и таблицы страниц представлены в основной памяти в формате «младший крайний» (в порядке возрастания адресов памяти с заданием адреса формата адресом младшего байта). ОС должна перевести эти таблицы в формат «младший крайний» или путем установки в «О» разряда BE (Big endian) при манипуляциях с таблицами или путем дополнения двойкой 32-разрядного адреса при загрузке или сохранении записей).
Ошибки адресной трансляции. Ошибка адресной трансляции может возникнуть вследствие или ошибки доступа к команде, или ошибки доступа к данному.
Команда, вызвавшая ошибку, может быть повторно выполнена при возврате из обработчика ловушки.
3.3.4. КОМБИНИРОВАНИЕ СЕГМЕНТНОЙ И СТРАНИЧНОЙ ТРАНСЛЯЦИИ
Рис. 3.22 объединяет рис. 3.13 и 3.20, чтобы суммировать оба шага трансляции логического адреса в физический для случая использования страничной трансляции. Соответствующий выбор вариантов и параметров для обоих шагов может осуществляться системой управления памятью операционной системы и включать различные способы организации памяти.
Логический адрес
15 0 31 0
Регистр базы таблицы страничных
директорий
Рис. 3.22. Механизм адресации для 4-Кбайтных страниц
268
ФУНКЦИОНИРОВАНИЕ ПАМЯТИ
Плоская (линейная) архитектура. В тех случаях, когда МП используется для выполнения программ, спроектированных для архитектур памяти, не создающих сегменты, может оказаться целесообразным выключение режима сегментации. Современные МП обычно не предусматривают отключение сегментации, но тот же эффект может быть достигнут первоначальной загрузкой сегментных регистров селекторами дескрипторов, которые охватывают все 32-разрядное линейное адресное пространство.
Однажды загруженные, регистры сегментов не нужно перезагружать. 32-разрядные смещения, используемые командами, будут адекватно адресовать все линейное адресное пространство.
Страницы, занимаемые несколькими сегментами. С другой стороны, сегменты могут быть меньше страницы. Рассмотрим, к примеру, такую структуру данных, как семафор. Так как защита и разделение обеспечиваются сегментацией, может оказаться полезным создать отдельные сегменты для каждого семафора. Но так как системе может понадобиться много семафоров, то выделение отдельной страницы для каждого не эффективно. Поэтому можно объединить в группу много сегментов данного назначения внутри одной страницы.
Невыравненные границы страниц и сегментов. Архитектура современных МП не требует соответствия границ сегментов и страниц. Совершенно нормально, когда одна и та же страница содержит конец одного и начало другого сегмента. Сегмент может также содержать конец одной страницы и начало другой.
Выравненные границы сегментов и страниц. Система управления памятью может упроститься, если она поддерживает некоторое соответствие границ сегментов и страниц. Например, если сегменты содержат целое число страниц, алгоритмы размещения сегмента и страницы становятся одинаковыми. В алгоритме не нужно определять частично использованные страницы.
Таблица страниц как сегмент. Подход к управлению пространством памяти, обеспечивающий даже еще большую простоту алгоритма управления, состоит в установлении соответствия один к одному между дескрипторами сегментов и записями страничных директорий. Это иллюстрирует рис. 3.23. Каждый дескриптор имеет базовый адрес, в котором младшие 22 разряда нулевые, другими словами, базовый адрес устанавливается по пер-
Таблица страничных Страничные
LDT дескрипторов Таблица страниц кадры
Рис. 3.23. Дескриптор на таблицу страниц
269
ИСПОЛЬЗОВАНИЕ КЭШ-ПАМЯТИ И ОРГАНИЗАЦИЯ ОСНОВНОЙ ПАМЯТИ
вой записи в таблице страниц. Сегмент может иметь любой предел от 1 до 4 Мбайт. В зависимости от предела сегмент размещается в страничных кадрах с 1 до 1 К. Задача, таким образом, ограничивается 1 К сегментов (достаточным для любого прикладного применения), каждый из сегментов содержит до 4 Мбайт. Дескриптор, запись соответствующей страничной директории и соответствующая таблица страниц могут быть размещены в памяти и удалены одновременно.
3.4. ЗАЩИТА ПАМЯТИ
3.4.1. ЗАЧЕМ НУЖНА ЗАЩИТА? ,
Цель механизмов защиты - обеспечить обнаружение и распознавание ошибок в программах. Обычно МП поддерживает прикладные системы, которые могут содержать сотни и тысячи программных модулей. Для таких систем важна возможность обнаруживать ошибки, причем как можно быстрее, и сводить к минимуму ущерб от таких ошибок. Для быстрой отладки прикладных программ и для более надежного их выполнения современные МП имеют механизмы проверки обращений к памяти и выполнения инструкций (команд) на соответствие критериям защиты. Эти механизмы могут быть проигнорированы в реальных проектах систем.
3.4.2. ОБЗОР МЕХАНИЗМОВ ЗАЩИТЫ
Защита в современных МП ВС имеет 5 аспектов:
1) проверка типа;
2) проверка границы (предела);
3) ограничение адресуемой области;
4) ограничение точек входа в процедуру;
5) ограничение набора команд.
Аппаратура защиты МП является неотъемлемой частью аппаратуры управления памятью. Защита применяется как при сегментной, так и при страничной трансляции. Каждое обращение к памяти проверяется аппаратурой на предмет удовлетворения критерию защиты. Все эти проверки делаются до начала цикла обращения к памяти. Любое противоречие предотвращает начало цикла и вырабатывает исключение. В данной главе говорится только о том, какие нарушения приводят к исключениям.
Концепция «привилегий» является центральной для нескольких аспектов защиты (аспекты 3, 4, 5 вышеприведенного перечня). Эта концепция используется как при защите сегментов, так и при защите страниц.
3.4.3. УРОВЕНЬ ЗАЩИТЫ СЕГМЕНТОВ
Все пять аспектов защиты используются при сегментной трансляции:
1) проверка типа;
2) проверка границы;
3) ограничение адресуемой области;
4) ограничение точек входа в процедуру;
5) ограничение набора команд.
Сегмент с позиций защиты - это единица защиты, а дескрипторы сегментов хранят параметры защиты. Проверка защиты выполняется ЦП автоматически в момент загрузки
270
ЗАЩИТА ПАМЯТИ
селектора дескриптора сегмента в сегментный регистр и при каждом обращении к сегменту. Сегментные регистры хранят параметры защиты текущих сегментов (сегменты текущего, выполняемого процесса).
Сохраняемые параметры защиты в дескрипторах. На рис. 324 показаны поля дескрипторов сегментов, имеющие отношение к защите сегментов.
Параметры защиты помещаются в дескриптор операционной системой в момент создания дескриптора. Обычно программисты-прикладники не имеют дело с параметрами защиты.
Когда программа загружает селектор в сегментный регистр, процессор загружает не только базовый адрес сегмента, но и информацию, связанную с защитой. Каждый сегментный регистр имеет «скрытую»1 часть, в которой сохраняются: база сегмента, предел сегмента, тип и уровень привилегий; поэтому последовательные проверки защиты при обращении к одному и тому же сегменту не связаны с затратой дополнительных тактов.
Проверка типа. Поле «тип дескриптора» имеет две функции:
1) устанавливает различие между разными форматами дескрипторов;
2) специфицирует функциональное назначение сегмента.
Кроме дескрипторов сегментов данных и кодовых сегментов, обычно используемых прикладными программами, есть еще дескрипторы специальных сегментов, используемые операционной системой и дескрипторы вентилей (шлюзов). Табл. 3.4 содержит все значения поля «тип» для системных сегментов и вентилей.
Дескриптор сегмента данных
31 23 15 70
База 3124 G В 0 AVL Предел 19-16 Р DPL Тип 1 0EWA База 23-16
База сегмента 15-0 Предел сегмента 15-0
Дескрипторы исполняемого сегмента
31 23 15 70
База 31-24 G В 0 AVL Предел 19-16 Р DPL Тип 1 1 CRA База 23-16
База сегмента 15-0 Предел сегмента 15-0
Дескрипторы системного сегмента
31 23 15 7 0
База 31-24 G X 0 AVL Предел 19-16 Р DPL 0 Тип База 23-16
База сегмента 15-0 Предел сегмента 15-0
Рис. 3.24. Поля защиты дескриптора сегментов (А - бит обращения; AVL - бит, доступный для использования программистом; В - «большой» бит; С - бит согласования; D - разряд по умолчанию; DPL - уровень привилегий дескриптора; Е - бит прямой и обратной записи; G - бит дробности; Р - бит присутствия; R - бит доступности для чтения; W - бит доступности для записи)
1 Ее называют также невидимой или кэш-частью сегментного регистра.
271
1
ИСПОЛЬЗОВАНИЕ КЭШ-ПАМЯТИ И ОРГАНИЗАЦИЯ ОСНОВНОЙ ПАМЯТИ
Таблица 3.4
Значения поля «тип» для системных сегментов и вентилей
Шестнадцатеричный код Тип сегмента или вентиля
0 Зарезервирован
1 16 разр. TSS доступен
2 Таблица LDT
3 16 разр. TSS занят
4 16 разр. Вентиль вызова
5 Вентиль задачи
6 16 разр. Вентиль прерывания
7 16 разр. Вентиль ловушки
8 Зарезервирован
9 16 разр. TSS доступен
А Зарезервирован
В 32 разр. TSS занят
С 32 разр. Вентиль вызова
D Зарезервирован
Е 32 разр. Вентиль прерывания
F 32 разр. Вентиль ловушки
Заметим, что не все дескрипторы описывают сегменты; дескрипторы вентилей вызова имеют другую цель.
Поля типа дескрипторов сегментов данных и кодовых сегментов включают разряды, которые в дальнейшем определяют степень защиты сегмента (см. рис. 3.24.).
Разряд разрешения записи (W) в дескрипторе сегмента данных указывает, могут ли команды осуществлять запись в этот сегмент.
Разряд разрешения чтения (R) в дескрипторе кодового1 сегмента указывает, разрешено ли командам читать из сегмента (например, для доступа к константам, которые хранятся в командах). Кодовый сегмент, разрешенный для чтения, может быть прочитан двумя способами:
1) через регистр CS, путем использования префикса переопределения CS;
2) путем загрузки селектора дескриптора кодового сегмента в регистр сегментов данных (DS, ES, FS или GS).
Проверка типа может быть использована для обнаружения ошибок программы, при которых делается попытка использовать сегменты так, как это не предусмотрено программистом . Процессор проверяет информацию типа по двум алгоритмам:
1) когда селектор дескриптора загружается в сегментный регистр; определенные сегментные регистры могут содержать только определенные типы дескрипторов, например: CS-регистр может загружаться только селектором кодового сегмента; селекторы кодовых сегментов, для которых не разрешено чтение, не могут быть загружены в регистры сегментов данных; только селекторы сегментов данных с разрешением записи в сегмент могут быть загружены в регистр SS;
1 Синонимы: исполняемый (выполняемый) сегмент, программный сегмент.
272
ЗАЩИТА ПАМЯТИ
2) когда команда содержит обращение (неявное или явное) к сегментному регистру; определенные сегменты могут быть использованы командами лишь в определенных, наперед заданных случаях, например: никакая команда не может записывать информацию в кодовый сегмент; никакая команда не может записывать информацию в сегмент данных, если разряд разрешения записи не установлен; никакая команда не может прочитать кодовый сегмент, если не установлен разряд разрешения чтения.
Проверка предела1 (границы). Поле границы дескриптора сегмента используется процессором для того, чтобы предотвратить адресацию за пределы сегмента.
Процессор по-разному интерпретирует границу в зависимости от состояния разряда дробности (G), а для сегментов данных процессор по-разному интерпретирует границу в зависимости также от состояния разряда Е (разряд прямой или обратной записи) и разряда В («большого»2 разряда - см. табл. 3.5).
Когда G = 0, истинная граница имеет значение поля 20-разрядной границы, которая указана в дескрипторе. В этом случае граница может простираться от 0 до OFFFFFH (220- 1 или 1 Мбайт).
Таблица 3.5
Интерпретация границы в зависимости от разрядов
Случай 1 2 3 4
Направление расширения Е=0(вверх) Е=0(вверх) Е=1(вниз) Е=1(вниз)
G-бит 0 1 0 1
В-бит X X 0 1
Нижняя граница равна: 0 LIMIT+1 Shi (LIMIT, 12,1)+1 * * * *
Верхняя граница равна: LIMIT Shi (LIMIT, 12,1) 64К-14 Г-1 * * * *
Максимальный размер сегмента равен: 64К 64К-14 Г-4К 4Г * * * *
Минимальный размер сегмента равен: 0 4к * * * *
Примечание. Shl(x. 12.1) - сдвиг влево на 12 разрядов со вставкой справа 12 единичных разрядов; х - любое состояние разряда
1 Поле предела называют также полем границы.
2 Байты сегмента размещены в ОП в порядке возрастания адресов памяти или в обратном порядке. Такое размещение также называют соответственно по принципу «младший» и «старший крайний».
273
ИСПОЛЬЗОВАНИЕ КЭШ-ПАМЯТИ И ОРГАНИЗАЦИЯ ОСНОВНОЙ ПАМЯТИ
Когда G = 1, процессор присоединяет 12 младших единичных разрядов к значению границы поля из дескриптора. В этом случае истинная граница находится в диапазоне от OFFFH (212 или 4 Кбайта) до 0FFFFFFFFH(232- 1 или 4 Гбайта).
Для всех типов сегментов, за исключением сегментов данных в обратной записи, значение границы на единицу меньше, чем размер сегмента, выраженный в байтах. Процессор вырабатывает исключение по общей защите в любом из четырех случаев:
1) попытка обращения к байту памяти по адресу > границы;
2) попытка обращения к слову памяти по адресу > (граница-1);
3) попытка обращения к двойному слову памяти по адресу > (граница-3);
4) попытка обращения к учетверенному слову по адресу памяти >(граница-7).
Для сегментов данных в обратной записи граница имеет ту же самую функцию, но интерпретируется иначе. В этом случае диапазон ошибочных адресов находится в пределах от границы +1 до: или 64К или 232- 1 (4 Гбайт) в зависимости от состояния разряда В.
Сегмент в обратной записи имеет максимальный размер, когда граница равна нулю.
Свойство обратной записи делает возможным увеличить размер стека при копировании его в любой сегмент памяти большего размера без необходимости одновременной корректировки указателей стека.
Поле границы дескриптора для дескрипторов таблиц используется процессором, чтобы сделать невозможным обращение из программы к таблице за ее пределы. Так как каждый дескриптор имеет 8-байтовую длину, значение границы равно N*8 - 1 для таблицы, которая может содержать до N дескрипторов.
Проверка границы позволяет улавливать такие программные ошибки, как превышение длин записей или ошибочные точки входа. Эти ошибки обнаруживаются в момент их возникновения, поэтому легко найти их причину. Без проверки границы такие ошибки могут испортить другие модули. Наличие их невозможно обнаружить позднее, когда испорченные модули ведут себя некорректно и когда установление причины ошибки затруднено.
Уровни привилегий. Концепция привилегий реализуется посредством задания ключа, принимающего значения от 0 до 3, объектам, распознаваемым процессором. Это значение называется уровнем привилегий. Значение «О» представляет самые большие привилегии, а значение «3» - самые малые. К числу объектов с распознаваемым процессором уровнем привилегий относятся:
• дескрипторы - они содержат поле, называемое уровнем привилегий дескриптора (DPL);
• селекторы - они содержат поле, называемое запрашиваемым уровнем привилегий (RPL), RPL предназначен для задания уровня привилегий процедуры, которая вызывает (загружает) селектор;
• скрытый в процессоре регистр сегмента хранит текущий уровень привилегий (CPL), обычно CPL равен DPL сегмента, который процессор выполняет в данный момент.
Процессор автоматически реализует право процедуры на доступ к другому сегменту путем сравнения CPL с одним или большим числом (из перечисленных выше) других указателей уровня привилегий. Оценивание происходит во время загрузки селектора дескриптора в сегментный регистр. Критерий, используемый для оценки обращений к данным, отличается от критериев оценки передач управления кодовому сегменту, поэтому эти два типа обращений рассматриваются в дальнейшем отдельно.
На рис. 3.25 показано, как уровни привилегий могут интерпретироваться кольцами защиты. Центральное кольцо содержит сегменты части ПО, наиболее критичной с позиций защиты, обычно ядра операционной системы. Другие кольца используются под сегменты, менее критичные с точки зрения защиты.
Можно и не использовать все четыре уровня привилегий. Существующие системы ПО спроектированы как одно- или двухуровневые. Такие системы просто игнорируют другие уровни.
Одноуровневая система должна использовать уровень «О». Двухуровневая система должна использовать уровни «О» и «3».
274
ЗАЩИТА ПАМЯТИ
Ограничение доступа к данным.Прежде чем программа сможет обратиться к операндам, она должна загрузить селектор соответствующего сегмента данных в сегментный регистр данных (DS, ES, FS, GS, SS). Процессор автоматически оценивает обращение к сегменту данных путем сравнения уровней привилегий. Эта оценка обращения происходит в момент загрузки селектора для дескриптора сегмента назначения в сегментный регистр данных. Как следует из рис. 3.26, в проверке привилегий участвуют три значения уровня привилегий:
1) CPL (текущий уровень привилегий);
2) RPL (уровень привилегий источника обращений к сегменту) из селектора, используемый для спецификации сегмента назначения;
3) DPL дескриптора сегмента назначения.
Команды могут загрузить сегментный регистр данных (и затем использовать целевой сегмент), лишь если DPL целевого сегмента численно больше или равен максимальному из значений CPL и RPL селектора. Другими словами, процедура может иметь доступ к данным того же самого или менее привилегированного уровня.
Разрешенная для адресации область задачи изменяется, когда изменяется CPL. Если CPL - нулевое, сегменты данных всех уровней привилегий доступны. Когда CPL = 1, доступны только данные с уровнями привилегий от 1 до 3. Когда CPL равно 3, доступны только сегменты данных с уровнем привилегий 3. Это свойство может быть использовано, например, чтобы предотвратить возможность чтения или изменения таблиц операционной системы прикладной программой.
275
ИСПОЛЬЗОВАНИЕ КЭШ-ПАМЯТИ И ОРГАНИЗАЦИЯ ОСНОВНОЙ ПАМЯТИ
Скрытый дескриптор (КЭШ-дескриптор)
16-разрядный видимый селектор
Рис. 3.26. Проверка привилегий доступа к данным (CPL - текущий уровень привилегий; RPL - запрашиваемый уровень привилегий; DPL - уровень привилегий дескриптора)
Доступность данных в кодовых сегментах. Менее общий характер, чем использование сегментов данных, носит работа с данными, сохраняемыми в кодовых сегментах. Кодовые сегменты могут на совершенно законном основании содержать константы, нельзя только что-либо писать в кодовый сегмент. Возможны следующие варианты доступа к данным в кодовом сегменте:
1) загрузить регистр сегмента данных селектором несогласованного, с разрешением чтения кодового сегмента;
2) загрузить регистр сегмента данных селектором кодового сегмента, который является согласованным и разрешенным для чтения;
3) использовать префикс переопределения CS, чтобы прочитать разрешенный для чтения кодовый сегмент, селектор которого уже загружен в CS регистр.
В 1 -м случае используются те же самые правила доступа, как и для доступа к сегментам данных. Во 2-м случае доступ корректен, так как уровень привилегий согласованных сегментов является, по существу, тем же самым, что и CPL независимо от DPL. В 3-м случае обращение правильное, так как DPL кодового сегмента в CS является при переопределении равным CPL.
Ограничения передач управления. Передачи управления осуществляются МП по командам JMP, CALL, INT и RET, а также при прерываниях и исключениях. В этой главе обсуждаются передачи управления по командам JMP, CALL, и RET.
Так называемые «близкие» передачи управления по командам JMP, CALL, и RET предполагают передачи управления в пределах исполняемого (текущего) кодового сегмента, и поэтому проверяются только на границу сегмента. Процессор реализует только те передачи управления, которые не превышают границу исполняемого сегмента. Предел сегмента находится в скрытом CS-регистре, а потому проверка защиты для «близких» передач управления не требует дополнительных тактовых циклов.
Операнды так называемых «дальних» передач управления, осуществляемых по командам JMP и CALL, находятся в других сегментах. Возможны два варианта передач управления другому сегменту по командам JMP и CALL:
1) операнд команды - это дескриптор другого кодового сегмента;
2) операнд команды - это дескриптор вентиля вызова.
276
ЗАЩИТА ПАМЯТИ
Векторизация передач управления через вентили вызова будет рассматриваться позднее.
Рис. 3.27 показывает, что при проверке привилегий для передач управления, которые не используют вентиль вызова, контролируются два различных уровня привилегий:
1) CPL (текущий уровень привилегий);
2) DPL дескриптора вызываемого сегмента.
Обычно CPL равен DPL сегмента, который в данный момент выполняет процессор, CPL может, однако, быть больше (по величине), чем DPL, если в дескрипторе выполняемого сегмента установлен бит согласования (С = 1).
Процессор разрешает обращения непосредственно к другому сегменту, если удовлетворяется одно из двух правил привилегий:
1) DPL целевого сегмента равен CPL;
2) разряд согласования дескриптора целевого кодового сегмента установлен (С = 1), a DPL целевого сегмента меньше или равен CPL.
Кодовый сегмент, разряд согласования дескриптора которого установлен, называется согласованным сегментом.
Механизм согласования позволяет обращаться к процедурам из сегментов с разным уровнем привилегий и при этом выполнять их на уровне привилегий вызывающего сегмента. Примерами таких процедур являются различные библиотеки процедур и некоторые процедуры обработки исключений. Когда управление передается согласованному сегменту, CPL не изменяется, но это происходит лишь в случае неравенства CPL и DPL текущего кодового сегмента. Большинство кодовых сегментов не согласованы.
Основные правила привилегий, описанные выше, означают, что для несогласованных сегментов управление может быть передано без использования вентиля вызова лишь кодовым сегментам на том же уровне привилегий. Нужно, однако, передавать управление и сегментам с (численно) меньшим уровнем привилегий, это обеспечивается передачей управления по команде CALL через дескрипторы вентилей вызова. Команды JMP никогда не передают управление несогласованному сегменту, DPL которых не равен CPL.
16-разрядный Скрытый дескриптор
Рис. 3.27. Проверка привилегий для непосредственных передач управления другому сегменту (CPL - текущий уровень привилегий; DPL - уровень привилегий дескриптора; С - бит согласования)
277
ИСПОЛЬЗОВАНИЕ КЭШ-ПАМЯТИ И ОРГАНИЗАЦИЯ ОСНОВНОЙ ПАМЯТИ
31 23 15 7 О
Сдвиг точки входа кодового сегмента 31-16 р DPL Тип 10100 ООО Счетчик DWORD
Селектор Сдвиг точки входа кодового сегмента 15-0
Рис. 3.28. Формат вентиля вызова
Дескрипторы вентилей «охраняют» точки входа в процедуру. Для обеспечения защиты передач управления между исполняемыми сегментами с разными уровнями привилегий МП фирмы «Intel» используют дескрипторы вентилей (шлюзов). Существует четыре вида вентилей:
1) вызова;
2) ловушек;
3) прерываний;
4) задач.
В этой главе рассматриваются вентили вызова. Вентили задач используются для переключения задач. Вентили ловушек и вентили прерываний используются в механизмах прерываний и исключений. Рис. 3.28. иллюстрирует формат вентиля вызова.
Вентиль вызова может быть размещен в GDT или в LTD.
Вентиль вызова имеет две главные функции:
1) задать точку входа процедуры;
2) специфицировать уровень привилегий точки входа.
Код операции Смещение Селектор
CALL (не используется) Индекс RPL
Таблица дескрипторов
Дескриптор кодового сегмента назначения
Дескриптор вентиля
Смещение DPL Счетчик
Селектор Смещение
База DPL База
База
Кодовый сегмент назначения
Процедура
Рис. 3.29. Косвенная передача управления через вентиль вызова
278
ЗАЩИТА ПАМЯТИ
Дескрипторы вентиля вызова используются командами CALL и JMP подобно дескрипторам кодовых сегментов. В тех случаях, когда аппаратура распознает, что селектор назначения ссылается на дескриптор вентиля, выполнение команды расширяется для определения содержимого вентиля вызова.
Поля «Селектор» и «Сдвиг» вентиля обеспечивают формирование точки входа в процедуру. В целом же вентиль гарантирует, что все обращения к другому сегменту пройдут через правильную точку входа, даже, возможно, в середину процедуры (или даже в середину команды). Поле операнда команды передачи управления для «дальней» передачи задает не сегмент и не смещение целевой команды, а задает вентиль. На рис. 3.29 показан этот способ адресации.
На рис. 3.30. показано, что для проверки правильности передач управления через вентиль вызова используются 4 уровня привилегий:
1) CPL (текущий уровень привилегий);
2) RPL (запрашиваемый уровень привилегий) селектора, используемого для указания вентиля вызова;
3) DPL дескриптора вентиля;
4) DPL дескриптора кодового сегмента назначения.
Поле DPL дескриптора вентиля определяет, какие уровни привилегий может использовать вентиль. Кодовый сегмент может содержать несколько процедур, которые предполагается использовать на разных уровнях привилегий, например, ОС может содержать некоторые утилиты, которые могут использоваться прикладными программами, в то время как другие утилиты могут использоваться только системными программами.
16-разрядный видимый селектор
Скрытый дескриптор
Рис. 3.30. Проверка привилегий при использовании вентиля вызова
279
ИСПОЛЬЗОВАНИЕ КЭШ-ПАМЯТИ И ОРГАНИЗАЦИЯ ОСНОВНОЙ ПАМЯТИ
Вентили позволяют передавать управление численно меньшим уровням привилегий или тому же самому уровню привилегий (хотя они и не нужны для передач тому же уровню привилегий). Использовать вентили вызова для передач управлёния (численно) меньшим уровням привилегий могут только команды CALL. JMP-команды предназначены для передач управления исполняемому сегменту с тем же самым уровнем привилегий для согласованного сегмента.
Для команд JMP в случае несогласованного сегмента должны быть выполнены два следующих правила привилегий (в противном случае механизм защиты вырабатывает исключение общей защиты):
1) MAX (CPL, RPL) < DPL вентиля;
2) DPL сегмента назначения = CPL.
Для команды CALL (или для команды ЗМРдля согласованного сегмента) должны быть выполнены следующие правила привилегий:
1) MAX (CPL, RPL) < DPL вентиля;
2) DPL сегмента назначения < CPL.
Некоторые команды, зарезервированные для операционной системы. Команды, которые могут воздействовать на механизм защиты или влиять на выполнение системных программ, используются только в программах с особой степенью доверия. МП реализует два типа таких команд:
1) привилегированные команды, которые нужны для систем управления вычислительным процессом;
2) чувствительные команды (Sensitive Instructions), которые используются для ввода/вывода и для действий, связанных с вводом/выводом.
Привилегированные команды. Команды, воздействующие на системные структуры данных, могут выполняться только при CPL, равном нулю. Если процессор обращается к одной из этих команд, когда CPL больше нуля, вырабатываются сигналы общей защиты. Примерами таких команд являются следующие:
HLT - остановить процессор;
LGDT -загрузить регистр GDT (GDTR);
LLDT - загрузить регистр LDT (LDTR);
LMSW - загрузить Слово Состояние Машины (Machine Status Word);
LTR - загрузить регистр задачи (TR);
MOVE to/from CRn - перенести в управляющий/из управляющего регистра п (CRn);
MOVE to/from DRn - перенести в отладочный/из отладочного регистра п (DRn);
MOVE to/from TRn - перенести в регистр/из регистра задачи n (TRn).
Чувствительные команды. Команды, имеющие дело с вводом/выводом, нуждаются в особом статусе, но необходимо, чтобы они могли выполняться и в процедурах с уровнями привилегий большими нуля. Механизмы ограничений команд ввода/вывода подробно раскрыты в главе организация ввода/вывода современных МП ВС.
Команды проверки указателей. Команды проверки указателей - это важная составляющая локализации программных ошибок. Проверка указателей необходима для обеспечения независимости между уровнями привилегий. Проверка указателей содержит следующие шаги (этапы):
1) проверка того, имеет ли назначение, специфицированное указателем право доступа к сегменту;
2) проверка того, соответствует ли тип сегмента заданному использованию;
3) проверка указателя на соответствие границе сегмента.
280
ЗАЩИТА ПАМЯТИ
Проверки 2 и 3 процессор делает автоматически во время выполнения команды, а вот 1-ю проверку должно осуществлять системное ПО. Для этой цели предназначена непривилегированная команда ARPL. ПО может провести предварительно проверки 2 и 3 на потенциальные ошибки (не дожидаясь исключения). Это позволяют сделать непривилегированные команды LAR, LSL, VERR и VERW.
LAR (Load Access Rights) - загрузить права доступа - используется для проверки ссылок указателей на сегменты с соответствующим уровнем привилегий и типом. LAR имеет один операнд - селектор дескриптора, права доступа к которому проверяются. Дескриптор должен быть доступен на уровне привилегий, который равен максимальному из CPL и RPL селектора. Если дескриптор доступен, то по команде LAR в указанном в команде 32-разрядном регистре назначения формируется замаскированный вид двух двойных слов дескриптора. Это - 00FXFF00H (X - означает, что соответствующие 4 разряда сохраненного значения неопределенны). Одновременно команда LAR устанавливает флаг нуля. Загруженные командой LAR разряды прав доступа могут быть протестированы. Если RPL или CPL больше чем DPL или если селектор содержит ссылку за предел таблицы, значение прав доступа не загружается, а флаг нуля сбрасывается. Согласованные кодовые сегменты могут быть доступны с любого уровня привилегий.
LSL (Load Segment Limit) - загрузить границу сегмента - позволяет ПО проверить предел дескриптора. Если дескриптор, специфицированный данным селектором (в памяти или регистре), доступен по CPL, LSL загружает специфицированный в команде 32-разрядный регистр 32 битовым линейным адресом границы, которая вычисляется по фрагментам полей предела и разряда дробности этого дескриптора. Это можно сделать лишь для сегментов данных, кодовых сегментов; сегментов состояния задачи и локальных таблиц дескрипторов; дескрипторы вентилей недоступны. Интерпретация предела является функцией типа сегмента. Например, для сегментов в обратной записи в памяти трактовка предела отличается от трактовки предела кодового сегмента. Как для LAR, так и для LSL, флаг нуля (ZF) устанавливается, если загрузка произошла, в противном случае ZF сбрасывается.
В МП есть команды VERR и VERW, определяющие, указывает ли селектор на сегмент, который соответственно может читаться или в который может осуществляться запись на текущем уровне привилегий? Команды вызывают ошибку по защите, если результат отрицательный.
VERR (Verify for Reading) - проверка на читаемость - проверяет сегмент на возможность чтения и загружает ZF единицей, если сегмент доступен для чтения с текущего уровня привилегий. VERR проверяет, что:
• селектор ссылается на дескриптор в границах GDT или LDT;
• селектор задает дескриптор кодового сегмента или сегмента данных;
• сегмент доступен по чтению и имеет соответствующий уровень привилегий.
Проверка привилегий для сегментов данных и несогласованных кодовых сегментов проводится так: DPL должно быть численно больше или равно какСРЕ, таки RPL селектора. Согласованные сегменты на уровень привилегий не проверяются.
VERW (Verify for Writing) - проверка доступности по записи - обеспечивает те же самые возможности, что и VERR для проверки доступности по чтению.
Подобно команде VERR, VERW устанавливает фла^Р, если результат проверки возможности записи является положительным. Команда проверяет: находится ли дескриптор в границах таблицы дескрипторов, является ли дескриптором сегмента, является ли дескриптором сегмента с возможностью записи и имеет ли DPL численно больший или равный как CPL, так и RPL селектора. Кодовые сегменты независимо от того, согласованные они или нет, не допускают записи.
281
ИСПОЛЬЗОВАНИЕ КЭШ-ПАМЯТИ И ОРГАНИЗАЦИЯ ОСНОВНОЙ ПАМЯТИ
3.4.4. УРОВЕНЬ ЗАЩИТЫ СТРАНИЦ
На страницы распространяются два типа защиты:
1) ограничение адресуемой области;
2) проверка типа страницы.
Записи таблиц страниц содержат параметры защиты. На рис. 3.31. высвечены поля PDE (записи страничных директорий) и РТЕ (записи таблиц страниц), которые используются для управления обращениями к страницам.
Ограничение адресуемой области. Концепция привилегий для страниц реализуется путем отнесения каждой страницы к одному из двух уровней:
1) уровню супервизора (U/S = 0) - для операционной системы и другого системного ПО и соответствующих данных;
2) уровню пользователя (U/S = 1) -для прикладных программ и данных.
Текущий уровень (U или S) связан с CPL. Если CPL равен 0,1 или 2, процессор находится на уровне супервизора. Если CPL = 3 - на уровне пользователя.
Когда процессор работает на уровне супервизора, все страницы доступны и по записи и по чтению. Когда процессор работает на уровне пользователя, доступны только страницы уровня пользователя, помеченные R/W = 1 (доступны для записи и чтения); страницы, принадлежащие уровню супервизора, недоступны ни для чтения, ни для записи с уровня пользователя.
Проверка типа страниц. Рассматриваются два типа страниц:
1) с доступом только по чтению (R/W = 0);
2) с доступом и по чтению и по записи (R/W = 1).
Когда процессор работает на уровне супервизора, все страницы доступны и по записи и по чтению. Когда процессор работает на уровне пользователя, доступны только страницы уровня пользователя, помеченные R/W = 1 (доступны для записи и чтения). Страницы, принадлежащие уровню супервизора, не доступны ни для чтения, ни для записи с уровня пользователя.
Комбинирование защиты с помощью таблиц страниц обоих уровней. Для любой страницы атрибуты защиты из записи страничной директории могут отличаться от атрибутов защиты записи таблицы страниц.
МП вычисляет так называемые эффективные атрибуты защиты для страницы путем проверки атрибутов защиты и в таблице страниц, и в таблице директорий. В табл. 3.6 показаны эффективные атрибуты защиты, обеспечиваемые возможными комбинациями атрибутов защиты записей обоих таблиц страниц.
31 12 11 0
AVAIL 00 D А 00 U/S R/W F
Рис. 3.31. Поля защиты записей таблиц страниц (R/W-чтение/запись; U/S - пользова-тель/супервизор)
282
ЗАЩИТА ПАМЯТИ
Таблица 3.6
Комбинирование атрибутов защиты
Запись страничной директории (PDE) Запись таблицы страниц (РТЕ) Комбинированная защита
U/S R/W U/S R/W U/S R/W
0 0 0 0 S X
0 0 0 1 S X
0 0 1 0 S X
0 0 1 1 S X
0 1 0 0 S X
0 1 0 1 S X
0 1 1 0 S X
0 1 1 1 S X
1 0 0 0 S X
1 0 0 1 S X
1 0 1 0 и R
1 0 1 1 и R
1 1 0 0 S X
1 1 0 1 S X
1 1 1 0 и R
1 1 1 1 и W
Примеча н и е: S - супервизор (PL0-PL2); U - пользователь (PL3); R - только чте-
ние; W - чтение и запись; X - означает, что когда комбинированный U/S атрибут равен;
U/S, R/W - атрибут не проверяется
3.4.5. КОМБИНИРОВАНИЕ ЗАЩИТЫ СЕГМЕНТОВ И СТРАНИЦ
Когда страничная трансляция включена, МП, во-первых, оценивает защиту сегмента, во-вторых, защиту страницы. Если он устанавливает нарушение защиты на любом из уровней, запрашиваемая операция не выполняется, а вместо этого вырабатывается исключение по защите.
Например, можно создать большой сегмент данных, состоящий из нескольких разделов, которые доступны только для чтения, в то время как другие разделы доступны и для чтения и для записи. В этом случае записи страничных директорий (или записи таблицы страниц) для разделов сегмента, которые доступны только для чтения, будут иметь разряды U/S и R/W установленными в ХО, указывая на отсутствие прав защиты для всех страниц, описанных этой записью страничных директорий (или записью для страниц).
Этот механизм может быть использован, например, в UNIX - подобной ОС для спецификации большого сегмента данных, часть которого только читается (для разделяемых данных или ROM констант).
Это дает возможность в UNIX - подобных системах задавать «плоское» адресное пространство как один большой сегмент, используя «плоские» указатели внутри этого адресного пространства, есть возможность даже защитить разделяемые данные, разделяя файлы, отображаемые на виртуальное пространство и области супервизора.
ГЛABA 4
8-РАЗРЯДНЫЕ МИКРОКОНТРОЛЛЕРЫ
4.1. СТРУКТУРА СОВРЕМЕННЫХ 8-РАЗРЯДНЫХ МИКРОКОНТРОЛЛЕРОВ
4.1.1. МОДУЛЬНЫЙ ПРИНЦИП ПОСТРОЕНИЯ
Микроконтроллеры (МК) представляют собой законченную микропроцессорную систему обработки информации, которая реализована в виде одной большой интегральной микросхемы. МК объединяет в пределах одного полупроводникового кристалла основные функциональные блоки МП управляющей системы: центральный процессор (ЦПУ), постоянное запоминающее устройство (ПЗУ), оперативное запоминающее устройство (ОЗУ), периферийные устройства для ввода и вывода информации (УВВ).
Широкое разнообразие моделей МК, возможность разработки и производства новых моделей в короткие сроки обеспечивает модульный принцип построения МК. При модульном принципе построения все МК одного семейства содержат в себе базовый функциональный блок, который одинаков для всех МК семейства, и изменяемый функциональный блок, который отличает МК разных моделей в пределах одного семейства (рис. 4.1).
Базовый функциональный блок включает:
• центральный процессор;
• внутренние магистрали адреса, данных и управления;
• схему формирования многофазной импульсной последовательности для тактирования центрального процессора и межмодульных магистралей;
• устройство управления режимами работы МК, такими как активный режим, в котором МК выполняет прикладную программу, режимы пониженного энергопотребления, в один из которых МК переходит, если по условиям работы выполнение программы может быть приостановлено, состояния начального запуска (сброса) и прерывания.
Базовый функциональный блок принято называть процессорным ядром МК. Процессорное ядро обозначают именем семейства МК, основой которого оно является. Например, ядро НС08 - процессорное ядро семейства Motorola МС68НС08, ядро MCS-51 - ядро семейства МК Intel 8хС51, ядро PIC16 - процессорное ядро Microchip PIC 16.
Микроконтроллер
Рис. 4.1. Модульная структура МК
284
СТРУКТУРА СОВРЕМЕННЫХ 8-РАЗРЯДНЫХ МИКРОКОНТРОЛЛЕРОВ
Изменяемый функциональный блок включает модули различных типов памяти, модули периферийных устройств, модули генераторов синхронизации и некоторые дополнительные модули специальных режимов работы МК. Представленный на уровне схемы электрической принципиальной, каждый модуль имеет выводы для подключения его к магистралям процессорного ядра. Это позволяет на уровне функционального проектирования новой модели МК «подсоединять» те или иные модули к магистралям процессорного ядра, создавая, таким образом, разнообразные по структуре МК в пределах одного семейства. На уровне топологического проектирования ИС МК, объединенные в составе МК, модули размещают на одном полупроводниковом кристалле. Отсюда появилось выражение «интегрированные на кристалл» периферийные модули. Совокупность модулей, которые разработаны для определенного процессорного ядра, принято называть библиотекой периферийных модулей. Библиотека каждого современного семейства МК включает модули пяти функциональных групп:
1) модули памяти;
2) модули периферийных устройств;
3) модули встроенных генераторов синхронизации;
4) модули контроля за напряжением питания и ходом выполнения программы;
5) модули внутрисхемной отладки и программирования.
Термин «модуль памяти» в применении к МК стал использоваться на этапе перехода к новым технологиям резидентной памяти программ и данных. Энергонезависимая память типа FLASH и EEPROM имеет не только режимы хранения и чтения информации, которая была в нее записана до начала эксплуатации изделия на этапе программирования, но и режимы стирания и программирования под управлением прикладной программы. Вследствие этого энергонезависимая память типа FLASH и EEPROM требует управления режимами работы, для чего снабжена дополнительными схемами управления. Массив ячеек памяти, доступных для чтения, стирания и записи информации, дополнительные аналоговые и цифровые схемы управления, а также регистры специальных функций для задания режимов работы объединены в функциональный блок, который и носит название модуля памяти. В настоящее время термин «модуль памяти» используется в равной мере для всех типов резидентной памяти: ОЗУ и ПЗУ.
В направлениях развития 8-разрядной элементной базы МК отчетливо прослеживается тенденция к закрытой архитектуре, при которой линии внутренних магистралей адреса и данных отсутствуют на выводах корпуса МК. И, как следствие, не представляется возможность использования внешних по отношению к МК БИС запоминающих устройств. В этом случае разработчик изделия на МК при выборе элементной базы должен позаботиться о том, чтобы предполагаемый алгоритм управления, реализованный в виде прикладной программы, сумел разместиться в резидентной (внутренней) памяти МК. В противном случае придется сменить элементную базу и перейти к МК с большим объемом внутреннего ПЗУ. Для подобных случаев разработчики элементной базы МК обычно предлагают ряд модификаций МК с одним и тем же набором периферийных модулей и различающимся объемом резидентной памяти программ и данных.
Группа модулей периферийных устройств включает следующие основные типы:
• параллельные порты ввода/вывода;
• таймеры-счетчики, таймеры периодических прерываний, процессоры событий;
• контроллеры последовательного интерфейса связи нескольких типов (UART, SCI, SPI, l2C, CAN, USB);
• аналого-цифровые преобразователи (АЦП);
• цифроаналоговые преобразователи (ЦАП);
• контроллеры ЖК индикаторов и светодиодной матрицы.
285
8-РАЗРЯДНЫЕ микроконтроллеры
Возможны также некоторые другие типы модулей, например, модуль прямого доступа к памяти, модуль управления ключами силовых инверторов напряжения, модуль генератора DTMF для тонального набора номера в телефонии и т. п.
Существенное изменение претерпели в настоящее время генераторы синхронизации 8-разрядных МК. Произошло функциональное разделение собственно генератора синхронизации, который выделился в отдельный модуль, и схемы формирования многофазной последовательности импульсов для тактирования центрального процессора и межмодульных магистралей, которая является неотъемлемой частью процессорного ядра. Появилась возможность выбора внешнего времязадающего элемента: кварцевый или керамический резонатор, RC-цепь. Поскольку схемотехника выполнения усилителей с положительной обратной связью определяется типом времязадающего элемента, то для одного и того же МК появились разные модификации модулей встроенного генератора синхронизации. Повышение производительности процессорного ядра МК связано с повышением частоты тактирования центрального процессора и межмодульных магистралей. Однако применение высокочастотных кварцевых резонаторов в качестве времязадающего элемента повышает уровень электромагнитного излучения, т. е. возрастает интенсивность генерации помех. Поэтому все чаще генераторы синхронизации имеют в своем составе умножитель чатоты с программно настраиваемым коэффициентом. Умножитель частоты часто выполняется по схеме синтезатора с контуром фазовой автоподстройки (англо-язычная аббревиатура PLL- Phase Loop Lock). Цепи синтезатора частоты и регистры специальных функций для управления режимами его работы объединены в один из модулей генератора синхронизации.
Относительно новыми для 8-разрядных МК являются две последние группы модулей. Модули контроля за напряжением питания и ходом выполнения программы осуществляют диагностику некоторых подсистем МК и позволяют восстановить работоспособность устройства на основе МК при нарушениях программного характера, сбоях в системе синхронизации, снижении напряжения питания.
Модули внутрисхемной отладки и программирования являются аппаратной основой режимов отладки и программирования в системе, которые позволяют отлаживать прикладную программу и заносить коды программы в энергонезависимую память МК прямо на плате конечного изделия, без использования дополнительных аппаратных средств отладки и программирования.
4.1.2. ПОПУЛЯРНЫЕ СЕМЕЙСТВА 8-РАЗРЯДНЫХ МК
Число различных модификаций 8-разрядных МК, представленных на мировом рынке, столь велико, что лишь одно их перечисление может занять несколько десятков страниц. Поэтому кратко охарактеризуем лишь те семейства МК, которые получили широкое распространение в России на протяжении последних десяти лет.
В первую очередь следует остановиться на МК с ядром MCS-51. Начало мощному клану с ядром MCS-51 положила фирма «Intel», выпустив в 1980 г. МК 8051 АН. Его аналог получил в России распространение под именем 1816ВЕ51. Для своего времени МК 8051 АН был очень сложным изделием - на кристалле размещалось 128 тыс. транзисторов. Этот микроконтроллер содержал процессорное ядро MCS-51, резидентные ПЗУ объемом 4 Кбайта, ОЗУ в 128 байт, 4 порта ввода/вывода, 2 таймера и асинхронный порт. Быстродействие центрального процессора MCS-51 в МК 8051АН по нынешним меркам было невелико. Частота внутренней шины составляла 1 МГц. Однако само ядро MCS-51 оказалось настолько удачным, что на два десятилетия стало стандартом «де-факто» в области 8-разрядных МК.
286
СТРУКТУРА СОВРЕМЕННЫХ 8-РАЗРЯДНЫХ МИКРОКОНТРОЛЛЕРОВ
Фирма «Intel» непрерывно совершенствовала МК с архитектурой MCS-51:
• частота внутренней шины в последних моделях возросла до 3 МГц;
• появились модели с объемом памяти программ 8, 16 и 32 Кбайта;
• в составе МК появились новые периферийные модули (АЦП, программируемый счетный массив, сторожевой таймер).
Одновременно ряд других фирм разработали МК, программно совместимые с MCS-51, обладающие современными типами памяти программ и данных (Flash и EEPROM), имеющие расширенный набор периферийных модулей, работающие в расширенном диапазоне напряжения питания. Фирма «Intel» постепенно свернула производство 8-раз-рядных МК. В результате основными производителями в мире 51-го семейства оказались фирмы «Philips», «Infineon», «Atmel», «Dallas Semiconductor», «Temic». В 1999 г. фирма «Analog Devices» представила совершенно новый МК Adu812 на основе 51-го ядра. Отличия в технических характеристиках встроенных модулей ЦАП и АЦП этого изделия столь велики, что семейство Adu8xx было названо семейством интеллектуальных преобразователей или микроконверторами.
Одновременно с первым МК семейства MCS-51 появился первый МК популярного до настоящего времени семейства НС05 фирмы «Motorola». В рамках этого семейства фирма «Motorola» провозгласила и успешно реализует стратегию «заказных» МК. Многие модели этого семейства своим рождением обязаны крупным потребителям, которые заказывали конфигурацию МК под конкретную продукцию. Сейчас семейство НС05 насчитывает около 180 различных МК, начиная с простейшего 68HC05KJ1 в корпусе DIP16 и заканчивая 128-выводным бескорпусным 68HC05L10 со встроенным контроллером управления 960 сегментами ЖКИ. На протяжении всего своего еще не оконченного периода жизни семейство НС05 является сильным и успешным оппонентом семейству MCS-51. Выполненное на основе принстонской архитектуры в противовес MCS-51 с гарвардской архитектурой, это семейство демонстрирует, во-первых, многообразие возможных технических решений даже для очень несложных задач управления, во-вторых, успех стратегии полного удовлетворения технических требований пользователя без избыточности в архитектуре и производительности. Долгое пребывание семейства НС05 на столь динамичном рынке МК определяется отнюдь не сверхбыстродействием (частота внутренней шины для большинства моделей равна 2 МГц) или уникальным набором команд. Причина успеха кроется в очень точной ориентации на различные сектора рынка массового потребления. Широчайшее разнообразие периферийных модулей при неизменном, очень простом ядре НС05 позволяет разработчику для каждой задачи найти МК практически без избыточных ресурсов архитектуры, что обусловливает низкую стоимость изделия.
В дополнение к дешевым «заказным» МК семейства НС05 фирма «Motorola» еще в 1980-х гг. предложила семейство универсальных и более производительных МК семейства НС11. Это семейство насчитывает около 40 моделей. Процессорное ядро семейства НС11 отличается от НС05 возможностью выполнения операций над 16-разрядными операндами, наличием дополнительных методов адресации, повышенной частотой внутренней шины (до 4 МГц). МК семейства НС11 выгодно отличает наличие трех типов памяти на кристалле: однократно программируемого ПЗУ программ, статического ОЗУ данных и электрически программируемого и электрически стираемого ПЗУ данных.
В конце 1990-х годов фирма «Motorola» представила новое 8-разрядное семейство НС08, которое должно постепенно заменить МК семейства НС05 и стать новым «промышленным стандартом» 8-разрядных МК фирмы. Отличительные особенности и направления развития семейства НС08 перечислены ниже:
• Высокопроизводительное 8-разрядное АЛУ. Увеличение производительности достигается повышением частоты обмена внутренней шины до 8,0 МГц, совмещением цикла
287
8-РАЗРЯДНЫЕ микроконтроллеры
исполнения и цикла выборки следующей команды, введением специальных команд просмотра таблиц и организации циклов, расширением числа способов адресации операндов. Указанные меры позволили повысить производительность центрального процессора НС08 в 6 раз по сравнению с процессором семейства НС05.
• Программная совместимость «снизу вверх» как на уровне исходного текста, так и на уровне объектных кодов с процессорным ядром семейства НС05.
• Переход к FLASH-технологии для ПЗУ программ пользователя. Для большинства типов МК проектируется создание двух моделей с возможностью замены «корпус в корпус». Эти МК полностью идентичны по функциональному составу и различаются только технологией занесения информации в ПЗУ программ (maskROM или FLASH).
• Библиотека периферийных модулей имеет расширенный набор контроллеров последовательного обмена. Кроме стандартных для МК фирмы «Motorola» портов асинхронного (SCI) и синхронного (SPI) обмена, разработаны контроллеры для работы в промышленных сетях с протоколом CAN и для перспективной шины вычислительной техники USB.
• Существенно улучшены возможности отладки МК. Встроенный монитор и специальный порт позволяют производить отладку прикладных программ управления непосредственно на плате конечного изделия без использования дорогостоящих схемных эмуляторов.
• МК с памятью программ типа FLASH позволяют реализовать режим программирования в системе, при котором прикладная программа заносится в память МК, который стационарно расположен на плате изделия. Коды программы передаются по последовательному интерфейсу от персонального компьютера.
• Специальные схемотехнические решения повышают надежность работы МК в условиях электромагнитных помех и неблагоприятной внешней среды.
Архитектура МК семейства НС08 рассмотрена в п. 4.3.
В конце 1980-х годов фирма «Microchip» выпустила МК Р1С16С5х, которые основали ныне широко распространенное семейство PIC16. Благодаря высокой производительности, малому потреблению и низкой стоимости это семейство с RISC-архитектурой составило серьезную конкуренцию производимым в то время 8-разрядным МК с CISC-архитектурой. В основу концепции PIC была положена RISC-архитектура с системой простых однословных команд. Система команд базового семейства Р1С16С5х содержит только 33 команды. Все команды, кроме команд перехода, выполняются за один машинный цикл с перекрытием по времени выборок команд из памяти и их исполнения. Производительность Р1С16С5х при частоте тактирования в 20 МГц составляет 5 MIPS. В настоящее время фирма «Microchip» выпускает пять семейств МК с RISC-архитектурой:
1) Р1С15С5х включает недорогие контроллеры с минимальным набором периферии;
2) Р1С12Сххх включает МК в миниатюрном 8-выводном корпусе со встроенным тактовым генератором; однако «миниатюрность» не мешает некоторым моделям этого семейства иметь встроенный модуль 8-разрядного АЦП;
3) Р1С16х/7х/8х/9х объединяет МК с развитой периферией; в число периферийных модулей входят таймеры-счетчики с опциями захвата/сравнения, широтно-импульсные модуляторы, аналоговые компараторы, АЦП, контроллеры различных последовательных интерфейсов;
4) Р1С17С4х/5хх включает высокопроизводительные МК с расширенной системой команд и обширной периферией; МК этого семейства имеют встроенный аппаратный умножитель 8x8, выполняющий операцию умножения за один машинный цикл;
5) Р1С18Сххх - новое семейство с оптимизированным под использование Си-компилятора RISC-ядром и частотой внутренней шины до 10 МГц.
В1997 г. фирма «Atmel» представила первые МК семейства AVR. Семейство AVR AT90S объединяет мощный гарвардский RISC-процессор с раздельным доступом к памяти программ и данных, 32 регистра общего назначения и развитую систему команд. Последние
288
СТРУКТУРА СОВРЕМЕННЫХ 8-РАЗРЯДНЫХ МИКРОКОНТРОЛЛЕРОВ
версии семейства AVR имеют в составе АЛУ аппаратный умножитель. Базовый набор команд AVR содержит 120 инструкций. Большинство команд выполняется за один машинный цикл, производительность ряда моделей составляет 20 MIPS. Периферия AVR МК включает параллельные порты, таймеры-счетчики, различные последовательные интерфейсы, АЦП, аналоговые компараторы. МК AVR подразделяются на три серии:
1) tiny AVR - МК в 8-выводном корпусе низкой стоимости;
2) classic AVR - основная линия МК с производительностью до 16 MIPS, Flash память программ объемом до 8 Кбайт и статическим ОЗУ данных 128...512 байт;
3) mega AVR - МК для сложных приложений, требующих большого объема памяти (Flash ПЗУ до 128 Кбайт), ОЗУ до 4 Кбайт, производительностью до 6 MIPS.
Приведенная краткая аннотация семейств 8-разрядных МК является далеко не полной, 8-разрядные МК выпускают также фирмы «ST-Microelectronics» (семейства ST6, ST7 и ST9), «National Semiconductor» (семейство СОР8), «Zilog», NEC, «Mitsubishi», «Hitachi», «Toshiba», «Scenix» и др. Продукция этих фирм постепенно появляется на российском рынке, но пока не получила широкого распространения.
4.1.3. ПРОЦЕССОРНОЕ ЯДРО МК
Процессорное ядро представляет собой неразрывное единство трех составляющих его технического решения:
1) архитектуры центрального процессора с присущими ей набором регистров для хранения промежуточных данных, организацией памяти и способами адресации операн-. дов в пространстве памяти, системой команд, определяющей набор возможных действий над операндами, организацией процесса выборки и исполнения команд;
2) схемотехники воплощения архитектуры, которая определяет последовательность перемещения данных по внутренним магистралям МК между регистрами, арифметическо-логическим устройством и ячейками памяти в процессе выполнения каждой команды;
3) технологии производства полупроводниковой БИС МК, которая позволяет разместить схему той или иной сложности на полупроводниковом кристалле, определяет допустимую частоту переключений в схеме и энергию потребления.
Эти три составляющие неразрывно связаны друг с другом и, в конечном счете, определяют важнейший параметр процессорного ядра МК - его производительность.
Ядро современных 8-разрядных МК реализуют как на основе CISC-архитектуры - это МК семейств НС05, НС11, НС08 фирмы «Motorola», семейства MCS-51 фирм «Intel», «Atmel», «Philips», МКсемейства С500 фирмы «Infineon», -так и на основе RISC-архитектуры - семейства PIC16, PIC17, Р1С18фирмы «Microchip», семейство AVR фирмы «Atmel», семейство SX фирмы «Scenix».
В приложении к 8-разрядным МК микропроцессор с CSIC-архитектурой имеет однобайтовый, двухбайтовый и трехбайтовый (редко четырехбайтовый) формат команд. Выборка команды из памяти осуществляется побайтно в течение нескольких машинных циклов. Время выполнения каждой команды с учетом времени выборки в большинстве случаев составляет от 1 до 10 циклов. Длительность машинного цикла равна периоду частоты тактирования внутренних магистралей микроконтроллера f Максимально допустимое значение частоты fBUS является одной из важнейших характеристик процессорного ядра, так как чем больше fBUS, тем выше его производительность. Следует особо обратить внимание, что для МК с CISC архитектурой частота тактирования внутренних магистралей МК fBUS всегда в несколько раз меньше предельно допустимой частоты кварцевого резонатора, который используется в качестве времязадающего элемента встроенного генератора.
289
а-РАЗРЯДНЫЕ микроконтроллеры
Микроконтроллер с RISC-архитектурой имеет формат команды фиксированной длины: например, 12, 14 или даже 16 бит для МК с 8-разрядным форматом обрабатываемого слова. Выборка из памяти и исполнение подавляющего большинства команд осуществляются за один машинный цикл МК, т. е. один период fgus - одна команда. Однако и для МК с RISC-архитектурой частота f8usHe всегда совпадает с частотой подключаемого кварцевого резонатора.
Производительность микропроцессоров и МК в том числе принято оценивать числом элементарных операций, которые могут быть выполнены в течение одной секунды. Единица измерения производительности - миллион операций в секунду (MIPS). Для расчета численного значения производительности в MIPS принято использовать время выполнения команды пересылки «регистр-регистр». Эта команда присутствует в перечне инструкций Ассемблера любого микропроцессора и имеет минимальное время выполнения.
Производительность (MIPS) = 1/1ктандЬ1 (мкс).
На практике в качестве косвенного параметра для оценки производительности МК используют предельную частоту тактирования, т. е. частоту времязадающего элемента генератора синхронизации fXCLK. Именно эта частота обычно указана в справочных данных 8-разрядного МК. Однако использовать ее для прямого расчета производительности в большинстве случаев нельзя. Дело в том, что длительность машинного цикла центрального процессора определяется частотой обмена по внутренним магистралям адреса и данных fBus. Соотношение fXCLK и f8(7S индивидуально для каждого процессорного ядра МК. Так для «Intel» MSC-51 - 12, для «Microchip» PIC16 fxcu</fBUS = 4, для AVR «Amtel» fXCLI/fBUS = 1. В МК «Motorola» НС08 тактирование осуществляется с использованием умножителя частоты и fBUS > fXCLK Поэтому при сравнении производительности различных МК следует сопоставлять максимальную частоту тактирования межмодульных магистралей fBUS, а не приведенную в паспортных данных fXCLK. Численные значения fBUS для популярных семейств 8-разрядных МК приведены в табл. 4.1.
По определению МК с RISC-архитектурой должны иметь более высокую производительность по сравнению с CSIC МК при одной и той же частоте внутренней магистрали fBUS, так как первые выполняют каждую команду за один машинный цикл, а последние -за несколько. Для МК с RISC-архитектурой время выполнения любой операции составляет MfBUS, следовательно, их производительность (в MIPS) равна fBUS(e МГц). Например, производительность МК PIC16 составляет 5 MIPS, МК AVR - 20 MIPS. В МК с CISC-архитектурой число циклов выполнения операции «регистр-регистр» составляет от 1 до 3, что снижает производительность.
Однако такая оценка производительности является общей. Она не учитывает особенности алгоритмов управления, используемых в каждой конкретной области применения. Так, при реализации быстродействующих регуляторов основное внимание следует уделять времени выполнения операций умножения и деления, которые требуются при реализации уравнений различных передаточных функций. А при реализации кнопочной станции кабины лифта следует оценивать время выполнения только логических функций, которые используются при опросе клавиатуры и при генерации протокола последовательного интерфейса связи с контроллером управления движения, который оптимизирует перемещение между этажами сразу нескольких кабин лифта. В задачах оптимального управления по таблицам, которые характерны для устройств силовой электроники, на первый план выходит возможность быстрого перебора больших таблиц данных. Поэтому в критических ситуациях, связанных с требованиями высокого быстродействия, следует оценивать производительность на основе тех операций, которые преимущественно используются в алгоритме управления и имеют ограничение по времени выполнения.
В задачах управления объектом в реальном времени существует еще один очень важный фактор производительности, который никак не отображается числом операций
290
СТРУКТУРА СОВРЕМЕННЫХ 8-РАЗРЯДНЫХ МИКРОКОНТРОЛЛЕРОВ
Таблица 4.1
Частота тактирования межмодульных магистралей 8-разрядных МК
Семейство МК Архитектура ядра /max J BUS (МГц) fXCLK faus /max JXCLK (МГц)
МК с ядром MSC-51
Intel MSC-51 CISC 2 12 24
Atmel 89С55 CISC 2,75 12 33
Infineon C500 CISC 3,3 12 40
Pfilips 89C51/52 CISC 2,75 12 33
Pfilips 8051XA CISC 20' - 30
Dallas High Speed CISC 8,25 4 33
МК с другими типами процессорного ядра
Motorola НС05 CISC 2" 2 4
Motorola HC08 CISC 8 4 или < Г" 32
Motorola НС 11 CISC 4 4 16
Microchip PIC16 RISC 5 4 20
Microchip PIC17 RISC 8,25 4 33
Microchip PIC18 RISC 10 4 40
Atmel AVR RISC 20 1 20
Scenix RISC 50 1 50
' Указана эквивапентная частота, повышение быстродействия связано с коренной переработкой ядра MSC-51. " Дпя версий с повышенным быстродействием - 4 МГц. " В МК НС08 реализованы два режима тактирования: от генератора кварцевого резонатора, тогда fxax = 4, или от умножителя частоты, тогда fmJS > fXCLK
в секунду. Это время перехода на подпрограмму прерывания по запросу внешнего устройства или периферийного модуля. В процессе перехода на подпрограмму прерывания каждый МК должен:
• распознать запрос на прерывание;
• дождаться завершения выполнения текущей команды;
• сохранить программный счетчик PC и некоторые регистры центрального процессора в стеке, загрузить вектор прерывания;
• выполнить некоторые вспомогательные команды;
• и лишь затем приступить к выполнению алгоритма обслуживания устройства, которое вызвало это прерывание;
Суммарное время перехода на подпрограмму прерывания определяется архитектурой процессорного ядра МК и частотой его тактирования.
4.1.4. РЕЗИДЕНТНАЯ ПАМЯТЬ МК
Закрытая архитектура современных 8-разрядных МК стала реализуемой лишь при условии интеграции на кристалл МК модулей памяти двух типов; энергонезависимого запоминающего устройства для хранения кодов прикладных программ (ПЗУ) и оператив
291
8-РАЗРЯДНЫЕ МИКРОКОНТРОЛЛЕРЫ
ного запоминающего устройства для хранения промежуточных результатов вычислений (ОЗУ). С момента появления МК технология энергонезависимых запоминающих устройств претерпела множество изменений, которые позволили не только повысить информационную емкость, быстродействие, надежность хранения информации, но и привели к появлению принципиально новых технологий программирования резидентной памяти МК. С точки зрения пользователей МК следует различать пять типов энергонезависимой резидентной памяти.
1. ПЗУ масочного типа - Mask-ROM. Содержимое ячеек ПЗУ этого типа записывается на заводе-изготовителе МК с помощью масок и не может быть заменено или «допрог-раммировано» в области ранее не использованного сегмента памяти. Поэтому МК с таким типом памяти программ следует использовать в изделии только после достаточно длительной опытной эксплуатации этого изделия. Первые образцы масочных ПЗУ появились в начале 1960-х гг., но даже сегодня ПЗУ масочного типа - самое дешевое и эффективное решение при больших объемах выпускаемой аппаратуры. Использование МК с масочным ПЗУ экономически становится рентабельным при партии в несколько десятков тысяч штук. Кроме благоприятных экономических аспектов решения с ПЗУ масочного типа имеют и другое преимущество. Они обеспечивают высокую надежность хранения информации по причине программирования в заводских условиях с последующим контролем качества. Недостатки ПЗУ масочного типа очевидны: любое изменение прикладной программы потребует новой серии ИС МК, что может оказаться весьма дорогостоящим и времяемким решением.
2. ПЗУ, однократно программируемые пользователем - OTPROM (One-Time Programmable ROM). В незапрограммированном состоянии каждая ячейка памяти модуля однократно программируемого ПЗУ при считывании возвращает код SFF. Программированию подлежат только те разряды, которые после программирования должны содержать «0». Если в процессе программирования некоторые разряды какой-либо ячейки памяти были установлены в «0», то восстановить в этих разрядах единичное значение уже невозможно. Поэтому рассматриваемый тип памяти и носит название «однократно программируемые ПЗУ». Однако те разряды, которые в процессе предшествующего сеанса программирования не изменялись, т. е. имеют единичные значения, могут быть подвергнуты программированию в последующем и «доустановлены» в «0». Число возможных сеансов программирования модуля однократно программируемого ПЗУ в составе МК не имеет ограничений. Технология программирования состоит в многократном приложении импульсов повышенного напряжения к элементарным ячейкам адресуемого байта памяти (т. е. к битам), подлежащим программированию. Уровень напряжения программирования, число импульсов и их временные параметры должны в точности соответствовать техническим условиям. В противном случае ячейки памяти могут восстановить единичное значение по прошествии некоторого времени (иногда нескольких лет) или при изменении условий работы. МК с однократно программируемым ПЗУ рекомендуется использовать в изделиях, выпускаемых небольшими партиями.
3. ПЗУ, программируемые пользователем с ультрафиолетовым стиранием-EPROM (Erasable Programmable ROM). ПЗУ данного типа допускают многократное программирование. Технология программирования близка к технологии однократно программируемых ПЗУ. Перед каждым сеансом программирования для восстановления единичного значения ранее запрограммированных ячеек памяти весь модуль ПЗУ должен быть подвергнут операции стирания при помощи ультрафиолетового облучения. Для этого корпус МК выполнен со специальным стеклянным окном, внутри которого расположена пластина ИС МК. Но если некоторые разряды ячеек памяти должны быть «допрограммированы» с «1» на «0» при неизменном состоянии ранее запрограммированных разрядов, то операция стирания может быть пропущена. Число сеансов стирания/программирования ПЗУ
292
СТРУКТУРА СОВРЕМЕННЫХ 8-РАЗРЯДНЫХ МИКРОКОНТРОЛЛЕРОВ
данного типа ограничено и составляет 25 -100 раз при условии соблюдения технологии программирования (напряжение, число и длительность импульсов программирования) и технологии стирания (волновой диапазон источника ультрафиолетового излучения). МК с ПЗУ данного типа имеют высокую стоимость, поэтому их рекомендуется использовать только в опытных образцах изделий.
4. ПЗУ, программируемые пользователем с электрическим стиранием - EEPROM или E2PROM (Electrically Erasable Programmable ROM). Электрически программируемые и электрически стираемые ПЗУ совместили в себе положительные качества рассмотренных выше типов памяти. Во-первых, ПЗУ типа EEPROM программируются пользователем, во-вторых, эти ПЗУ могут быть многократно подвергнуты операции стирания, и, следовательно, многократно программируются пользователем, в-третьих, эти ПЗУ дешевле ПЗУ с ультрафиолетовым стиранием. Максимальное число циклов сти-рания/программирования ПЗУ типа EEPROM в составе МК обычно равно 10000. Для сравнения тот же тип памяти в автономном корпусе допускает 106 циклов стира-ния/программирования. Технология программирования памяти типа EEPROM позволяет реализовать побайтное стирание и побайтное программирование, для чего к выбранной ячейке памяти должно быть приложено относительно высокое напряжение 10 -20 В. Однако допускается также одновременное стирание некоторого количества ячеек памяти с последовательными адресами, т. е. стирание блока памяти. Несмотря на очевидные преимущества, редкие модели современных МК используют ПЗУ типа EEPROM для хранения программ. Виной тому два обстоятельства. Во-первых, ПЗУ типа EEPROM имеют ограниченную емкость и могут использоваться в качестве резидентной памяти программ только в маловыводных МК с небольшим объемом памяти. Во-вторых, почти одновременно с EEPROM ПЗУ появились ПЗУ типа FLASH, которые обеспечивают близкие пользовательские характеристики, но при этом имеют более низкую стоимость.
5. ПЗУ с электрическим стиранием типа FLASH - FLASH ROM. Электрически программируемые и электрически стираемые ПЗУ типа FLASH были предназначены для заполнения «ниши» между дешевыми однократно программируемыми ПЗУ большой емкости и дорогими EEPROM ПЗУ малой емкости. ПЗУ типа FLASH сохранили преимущества, присущие EEPROM: возможность многократного стирания и программирования посредством приложения повышенного напряжения. Однако для увеличения объема памяти транзистор адресации каждой элементарной ячейки был удален, что не дает возможности программировать каждый бит памяти отдельно. Память типа FLASH стирается и программируется страницами или блоками. Страница, как правило, составляет 8, 16 или 32 байта памяти, блоки могут объединять некоторое число страниц, вплоть до полного объема резидентного ПЗУ МК (до 60 Кбайт). Упрощение декодирующих схем, произошедшее из-за уменьшения числа транзисторов, и, как следствие, снижение стоимости и размеров привело к тому, что МК с FLASH памятью программ в настоящее время становятся конкурентоспособными не только по отношению к МК с однократно программируемым ПЗУ, но и с масочным ПЗУ также.
Первый тип памяти (mask ROM) предполагает программирование МК только в заводских условиях. Второй и третий типы памяти (OTPROM и EPROM) могут программироваться непосредственно пользователем, но в режиме программирования требуют подключения источника повышенного напряжения к одному из выводов МК. Для их программирования используются специальные программаторы, в которых требуемая последовательность импульсов программирования с амплитудой 10 -25 В создается внешними по отношению к МК средствами. Технология программирования памяти первых трех типов не предполагает изменения содержимого некоторых ячеек энергонезависимой памяти в процессе работы устройства под управлением прикладной программы.
293
8-РЛЗРЯДНЫЕ микроконтроллеры
Память типа EEPROM и FLASH также требует в процессе стирания/программирова-ния приложения повышенного напряжения. В ранних образцах МК (например, Microchip Р1С16С5хх) это напряжение должно было быть подано на один из выводов МК в режиме программирования. В новейших версиях МК (Motorola НС08, Microchip PIC16, Atmel AVR) модули FLASH и EEPROM ПЗУ содержат встроенные схемы усиления, которые называют генераторами накачки. Допускается включение и отключение генератора накачки под управлением программы посредством установки битов в регистрах специальных функций модулей памяти. Следовательно, появилась принципиальная возможность осуществить программирование или стирание ячеек памяти FLASH и EEPROM ПЗУ в процессе управления объектом, без останова выполнения прикладной программы и перевода МК в режим программирования. Вспомним разницу между EEPROM и FLASH ПЗУ в составе МК. EEPROM ПЗУ практически никогда не используется для хранения программ, но оно имеет режим побайтного программирования. Предоставленная техническая возможность программирования под управлением прикладной программы становится реализуемой, так как носителем программы в МК является другой модуль памяти. Следовательно, в процессе программирования повышенное напряжение не прикладывается к носителю программы алгоритма программирования, и эта программа может быть выполнена в обычном режиме. Данное обстоятельство сделало EEPROM память идеальным энергонезависимым запоминающим устройством для хранения изменяемых в процессе эксплуатации изделия настроек пользователя. В качестве примера достаточно вспомнить современный телевизор или музыкальный центр: настройки каналов сохраняются при отключении питания. Одной из тенденций совершенствования резидентной памяти 8-разрядных МК стала интеграция на кристалл МК сразу двух модулей энергонезависимой памяти: ОТР или FLASH - для хранения программ и EEPROM - для хранения перепрограммируемых констант.
Сложнее обстоит дело с возможностью программирования FLASH ПЗУ под управлением прикладной программы. Даже если модуль FLASH ПЗУ содержит встроенный генератор накачки, то попытка перевода модуля в режим программирования посредством установки битов режима приведет к невозможности дальнейшего считывания программы, которая в это FLASH ПЗУ записана. И МК «зависнет». Поэтому та часть программы, которая реализует программирование FLASH ПЗУ, должна быть обязательно расположена в памяти другого типа. Наиболее часто в качестве такой памяти выбирают ОЗУ МК. Поскольку, если в МК имеется EEPROM ПЗУ, то бессмысленно «допрограммировать» FLASH в процессе работы изделия, в противном случае другой памяти, кроме ОЗУ, в МК просто нет. Если МК допускает возможность выполнения программы, расположенной в ОЗУ, и имеет встроенный генератор накачки модуля FLASH ПЗУ, то такой МК становится «программируемым в системе» (англоязычный термин «In system programmable» -ISP). Для того чтобы возможность программирования в системе стала реализуемой, необходимо предусмотреть пути, по которым в ОЗУ МК будет передана программа алгоритма программирования FLASH ПЗУ, а затем порциями будут передаваться коды прикладной программы, которая должна быть занесена во FLASH ПЗУ. Не следует забывать, что объем сегмента программирования значительно превышает объем резидентного ОЗУ МК. В качестве такого «пути» разработчики МК назначают один из последовательных портов МК. Обслуживание порта реализует специальная программа монитора связи, которая расположена в резидентном масочном ПЗУ МК. Эта программа активизируется посредством установки определенных линий ввода/вывода МК в указанное в спецификации состояние при сбросе МК или простым обращением к ней. Способ активизации указан в техническом описании МК. По последовательному интерфейсу связи персональный компьютер загружает в ОЗУ МК сначала коды программы «программирования», а затем порциями коды прикладной программы для программирования. Возможны так
294
СТРУКТУРА СОВРЕМЕННЫХ 8-РАЗРЯДНЫХ МИКРОКОНТРОЛЛЕРОВ
же решения, при которых программа «программирования» сразу записана в память масочного типа и не требует загрузки в ОЗУ МК.
Рассмотренный режим «программирования в системе» в настоящее время все шире используется для занесения прикладной программы в МК, расположенный на плате конечного изделия. Специальный программатор в этом случае не нужен. Кроме того, надежность программирования гарантируется внутренними режимами МК и не зависит от схемных решений программатора. Однако режим «программирования в системе» отличается от режима «допрограммирования» нескольких байтов FLASH памяти под управлением прикладной программы в процессе работы системы. Теоретически возможно решение, при котором программа «программирования», хранящаяся во FLASH ПЗУ, сначала будет перенесена в ОЗУ под управлением прикладной программы, а затем выполнена из ОЗУ. Но при таком решении на время программирования потребуется запретить все прерывания МК, поскольку их обслуживание невозможно по причине недоступности векторов прерывания. Поэтому реализация описанного режима возможна далеко не всегда. В качестве одного из путей предлагается разбить модуль FLASH ПЗУ на два - с независимыми генераторами накачки и регистрами управления. Такое решение предложено в МК HC908AZ60 фирмы «Motorola». Тогда один из модулей может быть поставлен в режим программирования, в то время как программа «программирования» будет выполняться из другого модуля. Впрочем, следует надеяться, что в недалеком будущем проблема программирования FLASH памяти программой из FLASH памяти будет решена. А пока наиболее совершенные модели МК со свойством «программирования в системе» часто имеют в своем составе четыре типа памяти: FLASH ПЗУ программ, mask-ROM монитора связи, EEPROM ПЗУ для хранения изменяемых констант и ОЗУ промежуточных данных.
Технология резидентной FLASH памяти МК непрерывно совершенствуется. Одни из лучших показателей достигнуты в МК семейства НС08 фирмы «Motorola»:
• гарантированное число циклов стирания/программирования составляет 10s;
• гарантированный период хранения записанной информации равен 10 годам, т. е. составляет жизненный цикл изделия;
• модули FLASH памяти работают и программируются при напряжении питания МК от 1,8 до 2,7 В;
• эквивалентное время программирования 1 байта памяти снижено до 60 мкс, что позволяет выполнить программирование МК с 32 Кб памяти в течение 2 с.
Перспективные технологии FLASH памяти предполагают увеличение скорости программирования до 1 Мбит/с.
Кроме ПЗУ в состав МК входит также и статическое оперативное запоминающее устройство (ОЗУ). Определение «статическое» выделено не случайно: современные 8-разрядные МК допускают снижение частоты тактирования до сколь угодно малых значений с целью снижения энергии потребления. Содержимое ячеек ОЗУ при этом сохраняется в отличие от динамической памяти. В качестве еще одной особенности следует отметить, что многие МК в техническом описании имеют параметр «напряжение хранения информации» - USTANDBY. При снижении напряжения питания ниже минимально допустимого уровня UDDMIN, но выше напряжения хранения USTANDBY программа управления микроконтроллером выполняться не будет, но информация в ОЗУ сохранится. Тогда при восстановлении напряжения питания можно будет выполнить сброс МК и продолжить выполнение программы без потери данных. Уровень напряжения хранения составляет = 1 В. Это позволяет в случае необходимости перевести МК на питание от автономного источника (батарейки или аккумулятора) и сохранить тем самым данные ОЗУ. Большого расхода энергии потребления в этом случае не будет, так как система тактирования МК может быть отключена. В последнее время появились МК, которые в корпусе имеют автономный источник питания, гарантирующий сохранение данных в ОЗУ на протяжении 10 лет (МК DS5000 фирмы «Dallas Semiconductor»).
295
8-РАЗРЯДНЫЕ МИКРОКОНТРОЛЛЕРЫ
4.1.5. ПОРТЫ ВВОДА/ВЫВОДА
Каждый МК имеет некоторое количество линий ввода/вывода, которые объединены в 8-разрядные параллельные порты ввода/вывода РТх («х»-имя порта, используемое в техническом описании). Порты обозначают либо цифрами (РТО, РТ1, РТ2 и т.д.), либо буквами латинского алфавита (РТА, РТВ, РТС и т. д.). В карте памяти МК каждый порт ввода/вывода представлен регистром данных порта DPTx. В режиме ввода логические уровни сигналов на линиях порта РТх отображаются нулями и единицами в соответствующих разрядах регистра DPTx. В режиме вывода данные, записанные под управлением программы в регистр DPTx, передаются на выводы МК, которые отмечены в качестве линий порта РТх. Обращение к регистру данных DPTx осуществляется теми же командами, что и обращение к ячейкам резидентной оперативной памяти. Кроме того, во многих МК отдельные разряды портов могут быть опрошены командами битового процессора.
С функциональной точки зрения различают следующие типы параллельных портов.
1. Однонаправленные порты, предназначенные в соответствие со спецификацией МК только для ввода или только для вывода информации.
2. Двунаправленные порты, направление передачи которых (ввод или вывод) определяется в процессе инициализации системы.
3. Порты с альтернативной функцией. Отдельные линии этих портов связаны со встроенными в МК периферийными устройствами, такими как таймер, АЦП, контроллеры последовательных приемо-передатчиков. Если соответствующий периферийный модуль МК не используется, то его выводы можно задействовать как обычные линии ввода/вывода. Напротив, если модуль активизирован, то принадлежащие ему линии ввода/вывода автоматически конфигурируются в соответствии с функциональным назначением в модуле и не могут быть использованы в качестве линий ввода/вывода. Как однонаправленные, так и двунаправленные линии портов могут иметь альтернативную функцию.
Рассмотрим схемотехнические особенности буферов линий ввода/вывода МК. В специальной литературе выходные каскады линий ввода/вывода часто называют драйверами (не путать с аналогичным обозначением программных средств). Двунаправленные порты большинства современных МК выполнены с возможностью независимого задания направления передачи каждой линии, т. е. объединение групп линий в порты позволяет организовать обращение к ним как к ячейкам памяти, что удобно при организации обмена в параллельном формате. Но в случае необходимости каждая линия может быть сконфигурирована индивидуально и обслужена командами битового процессора независимо от других линий того же порта ввода/вывода. Учитывая это обстоятельство, схемотехника портов ввода/вывода рассматривается на уровне одной линии.
Различают следующие типы драйверов ввода/вывода:
1) двунаправленные линии, которые настраиваются на ввод или на вывод программированием бита в регистре направления передачи DDPTx; при работе в режиме ввода линия имеет высокое входное сопротивление,
2) двунаправленные линии, которые не требуют предварительной инициализации; такие линии имеют некоторые особенности при считывании; в режиме ввода эти линии также имеют высокое входное сопротивление;
3) квазидвунаправленные линии; не требуют предварительной инициализации; в режиме ввода драйвер автоматически подключает «подтягивающий» к напряжению питания резистор;
4) двунаправленные линии с возможностью программного подключения «подтягивающих» резисторов.
Примером драйверов 1-го типа могут служить линии ввода/вывода МК НС08 Motorola (рис. 4.2). Каждой линии порта поставлен в соответствие одноименный разряд регистра
296
СТРУКТУРА СОВРЕМЕННЫХ 8-РАЗРЯДНЫХ МИКРОКОНТРОЛЛЕРОВ
Регистр управления
Альтернативная функция, вход
Рис. 4.2. Драйвер двунаправленной линии ввода/вывода МК семейства с
НС08 фирмы «Motorola»
направления передачи DDPTx. Нулевое значение разряда конфигурирует линию на ввод, единичное - на вывод. После сброса МК все линии настроены на ввод. Из рис. 4.2 видно, что в режиме ввода состояние непосредственно в момент считывания логический уровень сигнала линии передается на внутреннюю магистраль данных, минуя регистр данных порта DPTx. В процессе чтения линии ее состояние не запоминается в регистре DPTX и, следовательно, каждое новое обращение к порту ввода может возвращать новое значение. В режиме ввода транзисторы VT1 и VT2 закрыты, буфер находится в высокоомном состоянии (Z-состояние). Значение, которое будет возвращать операция чтения неподключенного входа, в общем случае не определено. Однако на практике его «доопределяют» за счет различия эквивалентных сопротивлений плеча с VT1 и с VT2. Так, в МК семейства НС08 Motorola чтение неподключенного входа возвращает «О». Если в качестве источника сигнала для рассматриваемого высокоомного входа используется логический элемент с открытым коллекторным выходом, то входной сигнал не будет зависеть от состояния выходного транзистора элемента. Он всегда будет равен «О». Для задания единичного логического уровня входного сигнала следует подключить внешний резистор, который обычно обозначают RPULLUP. При работе линии в режиме вывода транзисторы VT1 и VT2 драйвера управляются сигналом с выхода триггера регистра данных DPTx.
Примером драйверов двунаправленных портов, которые не требуют инициализации, могут служить драйверы порта РО МК 8051 АН фирмы «Intel» (рис. 4.3). Особенность этих драйверов заключается в том, что при считывании возвращаемое значение равно логическому произведению сигнала на линии и содержимого одноименного триггера регист-
297
8-РАЗРЯДНЫЕ МИКРОКОНТРОЛЛЕРЫ
Рис. 4.3. Драйвер двунаправленной линии ввода/вывода МК семейства MCS-51 фирмы «Intel»
ра данных порта DPTx. По этой причине те разряды порта, которые будут считываться, должны быть предварительно установлены в «1» командой записи в порт и лишь затем прочитаны. Порты с рассматриваемой схемотехникой не имеют регистра направления передачи и, следовательно, не должны инициализироваться. При работе в режиме ввода линия имеет высокое входное сопротивление, но при чтении неподключенного входа возвращается «1».
Квазидвунаправленные драйверы реализованы в портах Р1, Р2, и РЗ МК8051АН фирмы «Intel». Они отличаются от предыдущего драйвера тем, что вместо транзистора VT2 установлен внутренний «подтягивающий» резистор RPULLUP(pnc. 4.4). Поэтому входное сопротивление линии ввода не столь велико, как в двух предыдущих случаях, т. е. входной буфер линии не эквивалентен входу логического элемента. Поэтому драйвер с рассматриваемой схемотехникой и получил названиетквазидвунаправленного. Линии с этим типом драйвера не требуют инициализации, но для работы в режиме ввода так же как и в предыдущем случае, необходимо предварительно записать в соответствующий разряд регистра данных «1».
Драйверы линий с изменяемой схемотехникой могут быть выполнены двумя способами (рис. 4.5, 4.6). Однако преследуемая цель одна - сократить число навесных элементов платы МП контроллера.
В первом случае (рис. 4.5) драйвер каждой линии содержит «подтягивающим к 1» резистор (RpULLUP), который обеспечивает уровень логической единицы на входе при разомкнутом контакте. Во втором случае (рис. 4.6) драйвер дополнен «подтягивающим к О» резистором (Rpulldoun), который способен служить нагрузочным резистором датчика, выходной каскад которого выполнен по схеме эмиттерного повторителя. Рассматривае-
298
СТРУКТУРА СОВРЕМЕННЫХ 8-РАЗРЯДНЫХ МИКРОКОНТРОЛЛЕРОВ
Альтернативная функция, вход
Рис. 4.4. Драйвер квазидвунаправленной линии ввода/ вывода МК семейства MCS-51 фирмы «Intel».
мые драйверы часто используются в МК фирмы «Motorola». Логика управления встроенными «подтягивающими» резисторами одинакова для обоих типов драйверов:
• подключение «подтягивающих» резисторов допускается аппаратными средствами драйвера только при конфигурировании линии порта на ввод;
• специальный бит регистра конфигурации МК разрешает программное подключение «подтягивающих» резисторов на всех линиях ввода одновременно, но не выполняет это подключение;
• коммутацией «подтягивающего» резистора каждой линии управляет одноименный бит регистра входного сопротивления PTUEx; значение этого бита может многократно изменяться в ходе выполнения прикладной программы, тем самым осуществляется динамическое управление входным сопротивлением линии порта ввода и током потребления этой линии.
Рассматривая особенности драйверов линий ввода/вывода, нельзя не остановиться на понятии нагрузочной способности линии. Различают линии с нормальной и повышенной нагрузочной способностью. Если речь идет о нормальной нагрузочной способности, то следует ориентироваться на следующие цифры: 1°ых = 1,6+2,0 мА, 1ЙЫХ = 0,4+2,0 мА. Типовые значения повышенной нагрузочной способности: /°ых = l'mx = = 25 мА. Предельное значение повышенной нагрузочной способности на сегодняшний день составляет: /,ых =60 мА для Microchip PIC17. Следует заметить, что число выводов с повышенной нагрузочной способностью обычно ограничено. Кроме того, в справочных данных указан максимальный суммарный ток всех линий ввода/вывода, который ограничен теплоотводом корпуса МК.
299
8-РДЗРЯДНЫЕ микроконтроллеры
Vdd
Логика управления двунаправленной линии ввода/ вывода
Рис. 4.5. Драйвер линии ввода/вывода МК семейства НС08 фирмы «Motorola» с программно подключаемым резистором Rpullup
Vdd
Логика управления двунаправленной линии ввода/ вывода
Рис. 4.6. Драйвер линии ввода/вывода МК семейства НС08 фирмы «Motorola» с программно подключав-мым резистором RpuLLDOVVN
4.1.6. ТАЙМЕРЫ И ПРОЦЕССОРЫ СОБЫТИЙ
Опыт построения МП-систем позволяет выделить типовые задачи, которые должен уметь решать МК для эффективного управления в реальном времени:
• отсчет равных интервалов времени заданной длительности, повтор алгоритма управления по истечении каждого такого временного интервала; обычно эту функцию называют формированием меток реального времени.
• контроль за изменением состояния линии ввода МК;
• измерение длительности сигнала заданного логического уровня на линии ввода МК;
• подсчет числа импульсов внешнего сигнала на заданном временном интервале;
• формирование на линии вывода МК сигнала заданного логического уровня с программируемой задержкой по отношению к изменению сигнала на линии ввода;
• формирование на линии вывода МК импульсного сигнала с программируемой частотой и программируемым коэффициентом заполнения.
Каждая из перечисленных задач в отдельности может быть выполнена только программными средствами, без использования специальных аппаратных решений. Так, для формирования интервала времени следует загрузить в регистр центрального процессора число, а затем выполнять команду декрементирования этого регистра до тех пор, пока содержимое регистра не станет равным нулю. Похожие решения можно предложить и для остальных перечисленных задач. Однако все эти решения будут обладать общим недостатком: невозможностью выполнения вычислений одновременно с отсчетом временного интервала. Поэтому для выполнения функций, связанных с управлением в реальном времени, в состав МК включают специальные аппаратные средства, которые называют таймером.
В процессе развития модули таймеров в составе 8-разрядных МК непрерывно совершенствовались. Рассмотрим принцип действия одного из первых модулей, который входит в состав МК 8051 АН фирмы «Intel».
300
СТРУКТУРА СОВРЕМЕННЫХ 8-РАЗРЯДНЫХ МИКРОКОНТРОЛЛЕРОВ
Таймер представляет собой 16-разрядный счетчик со схемой управления (рис. 4.7). В карте памяти МК счетчик отображается двумя регистрами: TH - старший байт счетчика, TL - младший байт. Регистры доступны для чтения и для записи. Направление счета счетчика - только прямое, т. е. при поступлении тактовых импульсов десятичный эквивалент двоичного кода счетчика изменяется в сторону увеличения. В зависимости от программных настроек счетчик может использовать один из двух источников тактирования:
1) импульсную последовательность с выхода управляемого делителя частоты f ;
2) внешнюю импульсную последовательность, поступающую на один из входов МК.
В первом случае говорят, что счетчик работает в режиме таймера, во втором -в режиме счетчика событий. При переполнении счетчика устанавливается триггер переполнения TF, который генерирует запрос на прерывание, если прерывания от таймера разрешены. После переполнения работа счетчика продолжается. Последовательность изменения кодов следующая: $FF, $00, $01 и т. д. Пуск и останов счетчика могут выполняться только под управлением программы посредством установки/сброса соответствующего бита. Программа также может установить старший TH и младший TL байты счетчика в произвольное состояние или прочитать текущий код счетчика. Однако эти операции не следует выполнять в процессе счета, так как длительность операции чтения или записи может превысить длительность периода частоты тактирования счетчика. Тогда за время чтения одного из байтов второй успеет измениться. В результате будет прочитана недостоверная информация. По этой же причине может оказаться ошибочной операция записи. Например, пользователь записывает в регистры счетчика код $0005: сначала старший байт $00, а затем младший - $05. Если текущее состояние
Рис. 4.7. Структура модуля таймера-счетчика
301
8-РАЗРЯДНЫЕ МИКРОКОНТРОЛЛЕРЫ
счетчика пользователю неизвестно, то может оказаться, что на момент завершения операции записи старшего байта младший равен $FF.
Тогда в процессе записи младшего байта старший, ранее записанный, успеет измениться, и конечный код счетчика будет равен $0105.
Если рассмотренный таймер используется для измерения временного интервала tM3M (рис. 4.8), то необходимо выполнить следующую последовательность действий:
1) прервать выполнение текущей программы при изменении сигнала на линии РТх1 с «0» на «1»; в подпрограмме прерывания установить регистры счетчика таймера в $0000 и разрешить счет;
2) при изменении сигнала на линии РТх1 с «1» на «0» еще раз прервать выполнение программы МК; в подпрограмме прерывания остановить счет; код в регистрах TH и TL будет равен длительности интервала 1ИЗМ, выраженной числом периодов частоты тактирования счетчика таймера.
Однако такой способ измерения годится для сигналов, длительность которых составляет единицы мс и более. Моменты разрешения счета таймера t, и его остановки t2 не совпадают с моментами изменения сигнала на входе РТх1, так как пуск и останов выполняются в подпрограмме прерывания. Ошибка счета равна t, -t2. Каждое из значений t, и t2 определяется временем перехода МК к выполнению подпрограммы прерывания и временем выполнения некоторого количества инструкций, предшествующих команде разрешения или останова счета таймера. Вторая величина является систематической ошибкой и может быть учтена при выполнении дальнейших расчетов, в то время как первая - время перехода на подпрограмму прерывания - величина случайная, которая зависит от особенностей выполнения программного обеспечения МП системы. Так, если рассматриваемых каналов измерения несколько, и изменение сигналов на входах PTxi произошло одновременно, то в первом из обслуженных по прерыванию каналов ошибка будет минимальной, а в последнем - максимальной. Эта максимальная ошибка может составить несколько десятков микросекунд, поэтому рассмотренный метод не может быть использован для изменения временных интервалов микросекундного диапазона. В противном случае точность измерения будет недостаточной. Наряду с задачей измерения временного интервала может возникнуть необходимость одновременного формирования времяимпульсных сигналов по нескольким каналам. Тогда желательно, чтобы МК имел в своем составе несколько таймеров. Увеличение числа модулей таймеров, интегрированных на кристалл МК, является объективной тенденцией совершенствования структуры современных МК.
Рис. 4.8. Измерение временного интервала с использованием «классического» таймера
302
СТРУКТУРА СОВРЕМЕННЫХ 8-РАЗРЯДНЫХ МИКРОКОНТРОЛЛЕРОВ
Рассмотренный «классический» модуль таймера наиболее часто используется в МК с архитектурой MSC-51. Однако даже в составе основателя семейства МК 8051 АН он претерпел некоторые усовершенствования:
• дополнительная логика счетного входа позволяет тактовым импульсам поступать на вход счетчика, если уровень сигнала на одной из линий ввода равен 1; это повышает точность измерения временного интервала, так как интервалы t, и t2 теперь не являются составляющими погрешности измерения;
• реализован режим перезагрузки счетчика произвольным кодом в момент переполнения; это позволяет формировать метки реального времени с периодом, отличным от периода полного коэффициента счета, равного 216.
Более подробно режимы работы таймера МК 8051 АН рассмотрены в п. 4.2.6.
Главный недостаток модуля «классического» таймера - невозможность одновременного обслуживания (измерения или формирования импульсного сигнала) сразу в нескольких каналах. Совершенствование структуры подсистемы реального времени 8-разрядных МК ведется по двум направлениям:
1) простое увеличение числа модулей таймеров; этот путь характерен для части МК компаний «Pfilips» и «Atmel» со структурой MSC-51, для МК компаний «Mitsubishi» и «Hitachi».
2) модификация структуры модуля таймера, при которой увеличение числа каналов достигается не увеличением числа счетчиков, а введением дополнительных аппаратных средств входного захвата и выходного сравнения; Такой путь характерен для 8-разрядных МК «Motorola», «Microchip», «Pfilips», «Infineon», более поздних моделей семейства MCS-51 Intel.
Типовая структура усовершенствованного модуля таймера представлена на рис. 4.9 и 4.11. Счетчик таймера дополнен аппаратными средствами входного захвата и выходного сравнения. Эти средства принято называть каналом входного захвата IC (Input Capture) и выходного сравнения ОС (Output Compare).
Принцип действия канала входного захвата поясняет рис. 4.9. Схема детектора события «наблюдает» за уровнем напряжения на одном их входов МК. Обычно это одна из линий порта ввода/вывода. При изменении уровня логического сигнала на входе детектора с «0» на «1» или наоборот вырабатывается строб записи, и текущее состояние счетчика таймера записывается в 16-разрядный регистр данных TIC канала захвата. Описанное действие в микропроцессорной технике называют событием захвата. Предусмотрены три типа изменения сигнала на входе детектора, которые воспринимаются как событие захвата:
1) изменение логического уровня с 0 на 1 (нарастающий фронт сигнала);
2) изменение логического уровня с 1 на 0 (падающий фронт сигнала);
3) любое изменение логического уровня сигнала.
Выбор типа события захвата устанавливается в процессе инициализации модуля таймера и может многократно изменяться по ходу выполнения программы. Каждое событие захвата отмечается установкой в «1» триггера TFIC. Состояние триггера может быть считано программно, а если прерывания по событию захвата разрешены, то генерируется запрос на прерывание.
Временные диаграммы рис. 4.10 поясняют процесс изменения временного интервала с использованием режима входного захвата. Первоначально детектор события инициализируется на контроль за нарастающим фронтом сигнала на линии РТх1. При изменении уровня сигнала с «0» на «1» код счетчика К, копируется в регистр канала захвата TIC. Триггер TFIC устанавливается в «1», одновременно формируется запрос на прерывание: таймер «сообщает» МК о том, что измеряемый интервал начался. С задержкой времени t, по отношению к моменту появления запроса на прерывание МК считывает код
303
8-РАЗРЯДНЫЕ МИКРОКОНТРОЛЛЕРЫ
Регистр выходного
Счетчик таймера сравнения TIC
Рис. 4.9. Принцип действия канала входного захвата твймера
К, из регистра TIC, сбрасывает триггер TFIC и инициализирует детектор события на контроль за падающим фронтом сигнала РТх1. При изменении уровня сигнала с «1» на «О» детектор снова фиксирует событие захвата, и код счетчика К2 копируется в регистр TIC. Снова выставляется запрос на прерывание, с задержкой t2 этот код считывается в память МК. Разность кодов К2 - К, и есть длительность измеряемого временного интервала, выраженная в числе периодов частоты тактирования счетчика таймера. Максимальная ошибка измерения равна двум периодам частоты тактирования, так как погрешность детектора событий не может превышать единицы квантования таймера. Время перехода к подпрограммам прерывания tt или t2 не оказывает влияния на точность измерения, так как копирование текущего состояния счетчика осуществляется аппаратными, а не программными средствами. Однако время перехода на подпрограмму прерывания (t,) на
304
СТРУКТУРА СОВРЕМЕННЫХ 8-РАЗРЯДНЫХ МИКРОКОНТРОЛЛЕРОВ
кладывает ограничение на длительность измеряемого интервала tM3M, так как обсуждаемый метод реализуем при условии, что второе событие захвата произойдет позже, чем код К, будет считан в память МК.
Структура аппаратных средств канала выходного сравнения представлена на рис. 4.11. Многоразрядный цифровой компаратор непрерывно сравнивает изменяющийся во времени код счетчика таймера с кодом, который записан в 16-разрядном регистре ТОС канала сравнения. В момент равенства кодов на одном из выводов МК (РТх2 на рис. 4.11) устанавливается заданный уровень логического сигнала. Рассмотренное действие называют событием выходного сравнения. Предусмотрены три типа изменения сигнала на выходе РТх2 в момент события выходного сравнения:
1) инвертирование сигнала на выходе;
2) установка низкого логического уровня;
3) установка высокого уровня.
При наступлении события захвата устанавливается в «1» триггер TFOC. Аналогично предыдущему случаю состояние триггера может быть считано программно, а если прерывания по событию выходного сравнения разрешены, то генерируется запрос на прерывание.
Временные диаграммы рис. 4.12 иллюстрируют способ формирования временного интервала предварительно рассчитанной длительности tx с использованием аппаратных средств канала выходного захвата. Первое событие сравнения в момент t, формирует нарастающий фронт сигнала РТх2. Одновременно генерируется запрос на прерывание МК, и в подпрограмме прерывания происходит загрузка нового кода сравнения К2. Время, необходимое для записи нового значения в регистр канала сравнения ТОС, ограничивает минимальную длительность формируемого временного интервала. В момент t, наступает второе событие сравнения, и выход РТх2 устанавливается в «О». Таким образом, длительность сформированного временного интервала tx определяется только разностью кодов и не зависит от особенностей программного обеспечения МК.
В рассмотренных примерах каждому событию модуля таймера (изменению уровня логического сигнала на входе или выходе МК) ставится в соответствие код счетчика, т. е.
счетчик используется для создания непрерывно изменяющихся меток текущего времени. В отличие от «классического» таймера, где счетчик используется непосредственно
для формирования кода измеряемого временного интервала, в усовершенствованном таймере счетчик лишь создает образ времени, подобно часам. А все действия по формированию или измерению временных интервалов производят аппаратные средства сравне-ния/захвата. Поэтому счетчик в составе модуля усовершенствованного таймера называют счетчиком временной базы, или просто «временной базой». Эта же тер
Рис. 4.10. Измерение временного интервала средствами канала входного захвата
минология сохранится и далее в модулях процессоров событий.
305
8-РАЗРЯДНЫЕ микроконтроллеры
Рис. 4.11. Принцип действия канала выходного сравнения таймера
Рис. 4.12. Формирование импульса длительностью tx средствами канала выходного сравнения
306
СТРУКТУРА СОВРЕМЕННЫХ 8-РАЗРЯДНЫХ МИКРОКОНТРОЛЛЕРОВ
Если говорить о модификациях модуля усовершенствованного таймера в 8-разрядных МК различных фирм, то необходимо отметить следующие особенности.
• Число каналов входного сравнения и выходного захвата (IC и ОС), которые реализованы в модуле усовершенствованного таймера МК, может быть различно. Так, в МК семейства НС05 Motorola типовыми решениями являются модули 2IC+2OC или 1IC+1OC, и модуль таймера в составе МК всегда только один. МК семейства НС11 Motorola имеют в своем составе модуль таймера с конфигурацией 4IC+5OC. МК PIC16 Microchip содержат до трех модулей таймеров, но обязательно со структурой 1IC или ЮС (обозначается IC/OC).
• В ряде модулей каналы могут быть произвольно настроены на функцию входного захвата (IC) или выходного сравнения (ОС) посредством инициализации.
• Счетчик модуля усовершенствованного таймера может не иметь функции программного останова, т. е. он будет считать всегда. Поскольку в этом случае состояние счетчика нельзя синхронизировать с каким-либо моментом работы МП системы, то такой счетчик характеризуют как свободно считающий (free counter).
• Часто счетчик таймера не имеет опции тактирования внешним сигналом, т. е. не может работать в режиме счетчика событий.
Аппаратные средства усовершенствованного таймера позволяют решить многие задачи управления в реальном времени. Однако процесс совершенствования алгоритмов управления предъявляет все новые требования к структуре МК. И, как следствие, все более отчетливо проявляются ограничения модулей усовершенствованного таймера:
• недостаточное число каналов сравнения и захвата, принадлежащих одному счетчику временной базы; в результате невозможно сформировать синхронизированные между собой многоканальные импульсные последовательности;
• однозначно определенная конфигурация каналов (или захват или сравнение) часто не удовлетворяет пользователя;
• с использованием средств выходного сравнения возможно формирование сигнала по способу широтно-импульсной модуляции (ШИМ), однако несущая частота ШИМ сигнала тем меньше, чем больше вычислений требуется выполнять при реализации алгоритма управления и чем больше число ШИМ каналов требуется реализовать.
Следующий этап в развитии модулей подсистемы реального времени - модули процессоров событий. Впервые модули процессоров событий были предложены фирмой «Intel» в составе МК 8xC51FA/FB/FC/GB, позже аналогичный модуль появился в МК с ядром MSC-51 фирмы «Pfilips». Модуль, который входит в состав перечисленных МК, носит название программируемого счетного массива РСА (Programmable Counter Array). В МК других фирм аналогичные по функциональному назначению модули обозначают САРСОМ («Infineon»), TIM08 (семейство НС08 Motorola).
Структурная схема процессора событий приведена на рис. 4.13. Модуль процессора событий содержит в себе 16-разрядный счетчик временной базы и некоторое количество универсальных каналов захвата/сравнения. Счетчик может тактироваться импульсной посдедовательностью с выхода программируемого делителя частоты стробирования межмодульных магистралей fBUS или внешним генератором. Счетчик имеет опции пуска/ останова и сброса в «О». В некоторых моделях процессора событий счетчик временной базы доступен для чтения «на лету». Режим чтения «на лету» предусматривает автоматическое копирование содержимого старшего и младшего байтов счетчика в специальные буферные регистры в момент выполнения операции чтения указанного в спецификации байта счетчика (старшего или младшего). Тогда при чтении второго байта счетчика возвращается код из соответствующего буферного регистра. Тем самым исключается ошибка считывания по причине изменения состояния счетчика временной базы за время чте-
307
8-РАЗРЯДНЫЕ МИКРОКОНТРОЛЛЕРЫ
ВХОД/ВЫХОД
Рис. 4.13. Структурная схема процессора событий
ния. Наиболее совершенные модели процессора событий 8-разрядных МК допускают изменение коэффициента счета счетчика временной базы или, что то же самое, изменение периода его работы. Для этого в составе модуля имеется двухбайтовый программно доступный регистр периода и многоразрядный цифровой компаратор (не путать с каналом захвата). При совпадении текущего кода счетчика временной базы с кодом периода триггеры счетчика временной базы автоматически сбрасываются в «О».
Универсальные каналы захвата/сравнения в процессоре событий полностью идентичны друг другу и в зависимости от программных настроек могут работать в одном из трех режимов:
1) режим входного захвата;
2) режим выходного сравнения;
3) режим широтно-импульсной модуляции (ШИМ).
Первые два режима по принципу действия ничем не отличаются от аналогичных режимов модуля усовершенствованного таймера. Программно-логическая модель каждого канала включает двухбайтовый регистр данных канала и триггер события. В зависимости от выбранного режима регистр данных канала используется аппаратными средствами для записи кода временной базы в момент наступления входного захвата или для хранения кода выходного сравнения. Триггер устанавливается при наступлении любого из этих событий. При работе канала в режиме выходного сравнения могут возникать нарушения алгоритма работы, приводящие к неправильному формированию сигнала на выходе PTxi модуля. Причиной таких сбоев является изменение под управлением программы величины кода сравнения в процессе работы канала. Наиболее совершенные модели процессора событий предусматривают для таких случаев специальный режим буферированного сравнения, при котором: 16-разрядный регистр кода сравнения дублируется; в каждый момент времени ко входу компаратора оказывается подключенным один из регистров данных, а для записи оказывается доступным другой; в момент наступлении события выходного сравнения регистры автоматически меняются местами. Более подробно режим буферированного выходного сравнения, а также режим буферированной ШИМ рассмотрен в п. 4.3.7.
308
СТРУКТУРА СОВРЕМЕННЫХ 8-РАЗРЯДНЫХ МИКРОКОНТРОЛЛЕРОВ
Рис. 4.14. Временные диаграммы работы канала в режиме ШИМ
В режиме широтно-импульсной модуляции (рис. 4.14) на выводе PTxi МК формируется последовательность импульсов с периодом, равным периоду работы счетчика временной базы. Длительность импульса (в некоторых моделях длительность паузы) прямо пропорциональна коду в регистре данных канала. Режим ШИМ чрезвычайно удобен сточки зрения программного обслуживания. Если изменение коэффициента заполнения у не требуется, то достаточно один раз занести код у в регистр данных и проинициали-зировать режим ШИМ, и импульсная последовательность будет воспроизводиться с требуемыми параметрами без дальнейшего вмешательства со стороны программы.
Режим ШИМ в различных моделях процессоров событий имеет существенные отличия. В модулях программируемого счетного массива РСА код коэффициента заполнения имеет однобайтовый формат, следовательно, дискретность регулирования коэффициента заполнения составляет 1/256 периода ШИМ-сигнала. Причем, 16-разрядный регистр данных универсального канала РСА в режиме ШИМ «распадается» на два однобайтовых регистра. Доступным для записи является только один из регистров. В начале каждого периода ШИМ-сигнала содержимое этого регистра копируется во второй регистр, который используется аппаратными средствами для формирования длительности импульса в текущем периоде. Такое буферирование позволяет избежать нарушений при формировании импульсной последовательности в случаях, когда до наступления момента равенства кодов регистра и счетчика происходит изменение кода коэффициента у. и новое значение у меньше текущего кода счетчика. Тогда сравнение кодов в текущем периоде ШИМ сигнала не наступит, и импульс будет пропущен. Кроме недостатка по низкой дискретности регулирования коэффициента заполнения модуль РСА имеет ограниченный набор несущих частот сигнала ШИМ. Это происходит потому, что коэффициент счетчика временной базы не может быть изменен, а регулирование частоты достигается только изменением коэффициента деления предварительного делителя частоты. Параметры модулей процессоров событий некоторых 8-разрядных МК приведены в табл. 4.2.
В модулях TIM08 МК семейства НС08 фирмы «Motorola» рассмотренные недостатки устранены. Код коэффициента заполнения имеет двухбайтовый формат и, следовательно, дискретность регулирования составляет 1/216 периода ШИМ-сигнала. Одновременно период широтно-модулированной импульсной последовательности может регулироваться в широких пределах, поскольку счетчик временной базы допускает изменение коэффициента счета. Подробно модуль процессора событий TIM08 рассмотрен в п. 4.3.7.
309
8-РАЗРЯДНЫЕ МИКРОКОНТРОЛЛЕРЫ
Таблица 4.2
Модули процессоров событий некоторых 8-разрядных МК
ТипМК Число разрядов счетчика временной базы Число универсальных каналов Максимальная частота тактирования счетчика таймера Дискретность ШИМ-модулятора Частота ШИМ-модулятора (при дискретности регулирования 8 бит)
MC68HC908AZ60 Motorola 16 6 8 16 31,2
MC68HC908MR32 Motorola 16 4 8 16 31,2
С504 Infineon 16 3 20 16 79
89C51Rx Philips 16 5' 8,25 8 32,2
PIC16C72 Microchip 16 1" 20 10 78,1
PIC17C7xx Microchip 16 4" 25 10 97,7
’ МК 89C51RX имеют модуль программируемого счетного массива РСА, аналогичный снятым с производства МК Intel 8хС51 FA/FB/FC.
' Реально функции IC/OC и PWM обеспечивает три разных таймера, но в целом получается уни-версальный модуль типа процессора событий.
Модули «классических» таймеров и таймеров со схемами захвата/сравнения - достаточно сложные устройства. Их функциональная гибкость в простейших системах управления часто оказывается избыточной. Поэтому в некоторых маловыводных МК, выполненных в корпусах с 16 и 20 выводами, с целью снижения стоимости ИС реализуются упрощенные таймеры. Таймеры содержат постоянно считающий 8-разрядный счетчик с триггером переполнения и программируемый делитель частоты. Такие таймеры могут формировать лишь метки реального времени с периодом следования, который определяется набором коэффициентов деления программируемого делителя частоты. Упрощенные модули таймера имеются в составе МК MC68HC705KJ1 фирмы «Motorola» и Р1С16С5хх фирмы «Microchip». Однако среди последних разработок наблюдается тенденция к функциональному усложнению модуля таймера даже в очень простых МК. Так, модуль процессора событий с небольшим числом каналов имеется в составе всех маловыводных МК семейства НС08 фирмы «Motorola» (серии JL/JK, КХ/КТ).
Тенденция увеличения числа таймеров-счетчиков, интегрированных на кристалл МК, нашла свое продолжение и для модулей процессоров событий. Так, во многих современных 8-разрядных МК совершенствование подсистемы реального времени идет не просто по пути увеличения числа каналов процессора событий. Растет число модулей процессоров событий, предоставляя разработчику возможность использования нескольких «временных баз», что позволяет обрабатывать и формировать сигналы разного временного масштаба. Кроме того, в состав МК вводятся упрощенные модули таймеров, способные «разгрузить» процессор событий от выполнения простейших функций.
4.1.7. АНАЛОГО-ЦИФРОВЫЕ И ЦИФРОАНАЛОГОВЫЕ ПРЕОБРАЗОВАТЕЛИ
Отличительная особенность многих современных 8-разрядных МК - интегрированный на кристалл МК модуль многоканального аналого-цифрового преобразователя (АЦП). Модуль АЦП предназначен для ввода в МК аналоговых сигналов с датчиков физических величин и преобразования этих сигналов в двоичный код с целью последующей программной обработки. Структурная схема типового модуля АЦП представлена на рис. 4.15.
310
СТРУКТУРА СОВРЕМЕННЫХ 8-РАЗРЯДНЫХ МИКРОКОНТРОЛЛЕРОВ
Рис. 4.15. Типовая структура модуля АЦП
Многоканальный аналоговый коммутатор служит для подключения одного из источников аналоговых сигналов (РТхО - РТх7) ко входу АЦП. Выбор источника сигнала для измерения осуществляется посредством записи номера канала коммутатора в соответствующие разряды регистра управления АЦП. Заметим, что в модулях АЦП 8-разрядных МК предусмотрена только программная установка номера канала, режим автоматического последовательного сканирования каналов с записью результата измерения каждого канала в индивидуальную ячейку памяти не реализуется.
Диапазон измеряемых значений напряжения аналоговых входов определяется напряжением опоры Urjlr Разрешающая способность АЦП составляет 17^/2", где л- число двоичных разрядов в слове результата. Максимальное значение опорного напряжения, как правило, равно напряжению питания МК. Два вывода модуля АЦП используются для задания опорного напряжения: L/REFH - верхний предел, U^, C/REFL - нижний предел. Разность потенциалов на входах L/REFH и UREFL и составляет U^. Если измеряемое напряжение Уюм> UREFH, то результат преобразования будет равен $FF, код $00 соответствует напряжениям (7ИЗМ < 0/REFL. Для достижения максимальной точности измерения следует выбрать максимально относительно малые погрешности.
Собственно аналого-цифровой преобразователь выполнен по способу последовательного приближения. Принцип действия АЦП иллюстрируют функциональная схема и временные диаграммы (рис. 4.16 и 4.17).
311
8-РАЗРЯДНЫЕ МИКРОКОНТРОЛЛЕРЫ
Рис. 4.16. Структура АЦП последовательного приближения
АЦП включает регистр последовательного приближения, цифроаналоговый преобразователь, компаратор, генератор импульсов синхронизации, схему управления, регистр результата ADCDATA и триггер готовности данных. Начало преобразования задает сигнал «Пуск», который устанавливает регистр последовательного приближения в состояние 10000000. При этом на выходе ЦАП формируется напряжение, равное половине опорного. Компаратор сравнивает измеряемое напряжение с напряжением ЦАП. Если 17изм > U^, то в регистре последовательного приближения формируется следующий код сравнения, равный 11000000. Если Ц,зм < L/ц^, то старший разряд регистра последовательного приближения устанавливается в «0», следующий код сравнения равен 01000000. Таким образом, на первом такте измеряемое напряжение сравнивается с эталонным значением Uon/2. Аналогичные действия выполняются в каждом из тактов преобразования, однако значение напряжения сравнения зависит от результатов сравнения в предыдущих тактах. В примере рис. 4.2 на втором такте напряжение сравнения равно UJ2 + UJ4, на третьем такте - Uon/2 + UJ8, поскольку на втором такте было установлено, что 17изм < Uon/2 + UJA. Интервал преобразования состоит из п тактов: один такт для получения каждого двоичного разряда слова результата. Точность аналого-цифрового преобразования определяется разрешающей способностью блока ЦАП. В разных моделях МК он может быть выполнен на основе матрицы из 256 резисторов равных номиналов, матрицы весовых резисторов R/2R, достаточно часто встречается решение на основе емкостного делителя. Однако во всех моделях МК разрешающая способность ЦАП составляет 8 двоичных разрядов. Соответственно формат представления результата измерения АЦП - однобайтовый. Исключение составляют лишь модули АЦП микроконтроллеров для управления преобразователями частоты электропривода, разрешающая способность которых равна 10 двоичным разрядам. Два младших разряда результата получают с помощью дополнительного емкостного делителя, не связанного с регистром последовательного приближения. Длительность такта преобразования задает генератор синхронизации: один цикл равен двум периодам
312
СТРУКТУРА СОВРЕМЕННЫХ 8-РАЗРЯДНЫХ МИКРОКОНТРОЛЛЕРОВ
Рис. 4.17. Принцип действия АЦП последовательного приближения
частоты генератора tADC. Время преобразования можно рассчитать по формуле 1изм = = (2n+1)tADC, последний цикл необходим для переноса результата в регистр данных АЦП. Частота генератора синхронизации, как правило, не может быть выбрана произвольно.
Ее ограничение определяется двумя обстоятельствами:
1) конденсаторы емкостного делителя неидеальны и имеют определенное сопротивление утечки; поэтому длительность такта измерения должна быть, с одной стороны, достаточна для заряда конденсаторов до уровня напряжения, определяемого разрядами регистра последовательного приближения, а с другой стороны, не слишком большой, чтобы погрешность утечки не была значительной;
2) в некоторых моделях источник питания аналоговой части модуля АЦП выполнен на основе импульсного преобразователя; для его работы требуется тактирование, частота тактирования определена с достаточно узким допуском ±10 %.
Источником синхронизации модуля АЦП может служить встроенный RC-генератор или импульсная последовательность тактирования межмодульных магистралей МК. В первом случае частота синхронизации АЦП обязательно окажется оптимальной, той, которая рекомендуется в техническом описании. Во втором случае выбранная в результате других соображений fBUS может оказаться неподходящей для модуля АЦП. На этот случай в составе некоторых модулей предусмотрен программируемый делитель частоты fsus.
Большинство моделей АЦП имеет только режим программного запуска: установка одного из битов регистра режима запускает очередное измерение. Наиболее универсальные модули АЦП имеют также режим автоматического запуска, при котором после завершения одного цикла преобразования немедленно начинается следующий. Однако данные измерения каждого цикла должны быть считаны программным способом (см. модуль ADC08 НС08 фирмы «Motorola»).
В заключение приведем технические характеристики модулей АЦП некоторых популярных 8-разрядных МК (табл. 4.3).
313
8-РАЗРЯДНЫЕ МИКРОКОНТРОЛЛЕРЫ
Таблица 4.3
Технические характеристики модулей АЦП
ТипМК Разрешающая способность (бит) Время преобразования (мкс) Число каналов
МС68НС705В16 Motorola 8 32 8
MC68HC908JL3 Motorola 8 17 12
MC68HC908MR32 Motorola 10 8,5 10
С504 Infineon 8 5 10
PIC16C72 Microchip 8 16 8
PIC17C7xx Microchip 12 24 10
Цифроаналоговые преобразователи в составе МК являются большой редкостью. Модули параллельных ЦАП можно встретить лишь в МК «Mitsubishi» и «Hitachi».
Функция цифроаналогового преобразователя реализуется средствами модуля программируемого таймера. На одном из выводов МК формируется высокочастотная импульсная последовательность с регулируемой длительностью импульса. Полученный сигнал сглаживается фильтром нижних частот на операционном усилителе (рис. 4.18). Разрешающая способность такого ЦАП определяется дискретностью регулирования коэффициента заполнения у в режиме ШИМ. Как было отмечено в п. 4.1.6, немногие модели 8-разрядных МК способны реализовать у с дискретностью более 8 разрядов (табл. 4.3). Этим вызвана необходимость применения внешних ИС ЦАП. Кроме того, частота ШИМ сигнала определяет время преобразования ЦАП, этим объясняется особая привлекательность МК с частотой ШИМ в десятки килогерц.
Рис. 4.18. ЦАП на основе ШИМ-генератора (а - функциональная схема; б - временные диаграммы работ)
314
СТРУКТУРА СОВРЕМЕННЫХ 8-РАЗРЯДНЫХМИКРОКОНТРОЛЛЕРОВ
4.1.8. КОНТРОЛЛЕРЫ ПОСЛЕДОВАТЕЛЬНОГО ВВОДА/ВЫВОДА
Наличие в составе 8-разрядного МК модуля контроллера последовательного ввода/ вывода стало настолько обычным явлением, что лишь самые простые, маловыводные МК в корпусах DIP16 и DIP20 не имеют портов последовательного обмена. При анализе структуры более сложных 8-разрядных МК отчетливо прослеживается тенденция наличия с их составе двух контроллеров последовательного обмена, а в некоторых новейших моделях - даже трех (серия AZ семейства НС08 фирмы «Motorola»). Задачи, которые решаются средствами модуля контроллера последовательного ввода/вывода, могут быть условно разделены на три группы:
1) связь встраиваемой МП-системы с системой управления верхнего уровня: промышленным компьютером, программируемым контроллером, офисным компьютером; наиболее часто для этих целей используются интерфейсы RS-232C и RS-485; в настоящее время все более широкую популярность приобретает интерфейс USB;
2) связь с внешними по отношению к МК периферийными ИС встраиваемой МП-системы, а также с датчиками физических величин с последовательным выходом; для этих целей используются интерфейсы SPI, FC, а также нестандартные протоколы обмена;
3) интерфейс связи с локальной сетью в мультимикропроцессорных системах; в системах с числом МК до пяти обычно используют сети на основе интерфейсов l2C, RS-232C, RS-485 с собственными сетевыми протоколами верхнего уровня; в более сложных системах все более популярным становится протокол CAN.
С точки зрения инженера-схемотехника, упомянутые типы интерфейсов последовательной связи отличаются: режимом передачи данных (синхронный или асинхронный), форматом кадра (число бит в посылке при передаче байта полезной информации) и временными диаграммами сигналов на линиях (уровни сигналов и положение фронтов при переключениях). Число линий, по которым происходит передача в последовательном коде, обычно равно двум (l2C, RS-232C, RS-485, CAN) или трем (SPI, некоторые нестандартные синхронные протоколы). Последнее позволяет спроектировать модули контроллеров последовательного обмена таким образом, чтобы с их помощью на аппаратном уровне можно было бы реализовать несколько типов последовательных интерфейсов. При этом режим передачи (синхронный или асинхронный) и формат кадра поддерживаются на уровне логических сигналов, а реальные физические уровни сигналов, характерные для каждого типа интерфейса, получают с помощью специальных ИС, которые носят название приемопередатчиков, конверторов, трансиверов.
В состав 8-разрядных МК различных фирм производителей входят следующие модули контроллеров последовательных интерфейсов:
• модуль универсального последовательного интерфейса USI (Universal Serial Interface); входит в состав МК семейства AVR фирмы «Atmel»; может поддерживать протоколы асинхронного обмена для интерфейсов RS-232, RS-422 и RS-485, а также синхронные протоколы интерфейсов SPI и 12С;
• модуль универсального асинхронного интерфейса UART (Universal Asynchronous Receiver and Transmitter); поддерживает протоколы асинхронного обмена интерфейсов RS-232, RS-422 и RS-485;
• модуль универсального асинхронного интерфейса SCI (Serial Communication Interface); характерен для МК фирмы «Motorola»; входит в состав 8-разрядных МК семейств НС05, НС11 и НС08; является функциональным аналогом модулей типа UART, т. е. поддерживает протоколы асинхронного обмена для интерфейсов RS-232, RS-422 и RS-485;
• модуль синхронного последовательного интерфейса SPI (Serial Peripheral Interface); поддерживает протокол синхронного обмена в стандарте SPI; интерфейс SPI был предложен фирмой «Motorola», поэтому контроллер SPI входит в состав большого числа
315
8-РАЗРЯДНЫЕ МИКРОКОНТРОЛЛЕРЫ
моделей МК семейств НС05, НС11 и НС08. В МК других производителей протокол SPI обычно реализуется в качестве альтернативного одним из модулей контроллеров последовательных интерфейсов;
• модуль синхронного последовательного интерфейса FC (Inter Integrated Circuit); входит в состав 8-разрядных МК фирмы «Pfilips» и «Microchip»; следует заметить, что для МК «Microchip» характерна реализация аппаратными средствами одного и того же модуля протоколов SPI и 12С;
• модуль контроллера CAN (Control Aria Network); присутствует в 8-разрядных МК семейства НС08 фирмы «Motorola», МК семейства С500 фирмы «Infineon», семейства 89 фирмы «Pfilips»; поддерживает стандартные протоколы обмена CAN сетей;
• модуль контроллера USB (Universal Serial Bus); поддерживает новый стандарт периферийного интерфейса вычислительной техники USB.
Протоколы интерфейсов локальных сетей на основе МК - 12С и CAN - отличает более сложная логика работы. То же можно сказать и о новом стандарте периферийного интерфейса USB. Поэтому контроллеры CAN и USB интерфейса всегда выполняются в виде самостоятельного модуля, аппаратные средства которого ориентированы на поддержку соответствующих протоколов обмена. Интерфейс 12С с возможностью работы как в ведущем, так и ведомом режиме, также обычно поддерживается специальным модулем (модуль последовательного порта в МК 89С52 фирмы «Philips»). Но если реализуется только ведомый режим !2С, то в МК PIC16 «Microchip» он успешно сочетается с SPI: настройка одного и того же модуля на один из протоколов осуществляется путем инициализации.
Следует заметить, что одноименные модули контроллеров последовательных интерфейсов даже одной фирмы-производителя имеют отличия в реализации для разных семейств МК. Так, аппаратные средства контроллера SCI в составе МК семейства НС08 диагностируют большее количество ошибок на линии, чем одноименные контроллеры в составе семейства НС05. И естественно, отличаются одноименные модули в МК различных фирм. Однако эти отличия преимущественно сводятся к различию регистров специальных функций, которые обслуживают модуль. Меньше затрагивают алгоритмы функционирования одноименных модулей. И, по определению, все аналогичные модули обязательно реализуют на аппаратном уровне логику протокола обмена выбранного интерфейса. Поэтому при рассмотрении данной темы целесообразно остановиться именно на протоколах обмена. По режиму обмена информацией интерфейсы подразделяют на симплексные, полудуплексные, дуплексные, мультиплексные. В интерфейсах с симплексным режимом обмена информацией возможна лишь однонаправленная передача информации от одного абонента к другому. Соответственно и буферы приемника и передатчика информации выполнены однонаправленными. В интерфейсах с полудуплексным режимом обмена в произвольный момент времени может производиться либо только прием, либо только передача данных между двумя абонентами, буферы приемопередатчика каждого из абонентов связи выполнены двунаправленными. В интерфейсах с дуплексным режимом обмена в любой произвольный момент времени может производиться одновременный прием и передача данных между двумя абонентами. Линии приема и передачи информации физически разделены, соответственно контроллер обмена каждого абонента имеет два вывода (приемника и передатчика), и буферы этих выводов однонаправленные. В интерфейсах с мультиплексным режимом обмена в каждый момент времени может осуществляться прием или передача данных между парой любых абонентов сети.
Среди большого множества различных типов встроенных контроллеров последовательного обмена, которые входят в состав тех или иных 8-разрядных МК, сложился стандарт «де-факто» - модуль UART (Universal Asynchronous Receiver and Transmitter).
316
СТРУКТУРА СОВРЕМЕННЫХ 8-РАЗРЯДНЫХ МИКРОКОНТРОЛЛЕРОВ
В переводе с английского UART - универсальный асинхронный приемопередатчик. Однако многие из модулей UART кроме асинхронного режима обмена способны также реализовать простейший режим синхронной передачи данных. Поэтому более правильным с точки зрения терминологии было бы именовать эти модули USART (Universal Synchronous/Asynchronous Receiver and Transmitter) - универсальный синхронно/асинх-ронный приемопередатчик. Такой термин тоже существует, но пользуются им редко.
Не все производители МК используют термин UART для обозначения типа модуля контроллера последовательного обмена. Так, в МК фирмы «Motorola» модуль асинхронной приемопередачи, который поддерживает те же режимы асинхронного обмена, что и UART, принято называть SCI (Serial Communication Interface). Следует отметить, что модуль типа SCI обычно реализует только режим асинхронного обмена, однако МК фирмы «Motorola» традиционно имеют в своем составе два модуля последовательного обмена: модуль SCI с возможностью реализации только протоколов асинхронной приемопередачи для интерфейсов RS-232C, RS-422A, RS-485 и модуль контроллера синхронного интерфейса в стандарте SPI.
Модуль типа UART в максимальной конфигурации обычно реализует два типа протокола обмена в асинхронном режиме (кадр длиною в 10 бит или в 11 бит) и два типа протокола в синхронном режиме (трехпроводный полнодуплексный обмен или двухпроводный полудуплексный обмен). Упрощенная структура модуля типа UART приведена на рис. 4.19.
Модуль состоит из двух независимых подсистем: передатчика (Transmitter) и приемника (Receiver), поэтому возможен режим одновременной передачи и приема информации в последовательном коде. Основу каждой подсистемы составляют сдвиговый регистр и параллельный регистр буфера данных. Обращение к буферу данных приемника и передатчика осуществляется по одному и тому же адресу, но при выполнении операции записи данные будут помещены в буфер передатчика TDBUF, операции чтения -данные будут считаны из буфера приемника RDBUF.
Передача данных от МК к другому устройству инициируется посредством записи байта данных в регистр TDBUF. Если работа передатчика разрешена (бит ТЕ в регистре
RDBUF
Рис. 4.19. Структурная схема модуля контроллера последовательного интерфейса типа UART
317
8-РАЗРЯДНЫЕ МИКРОКОНТРОЛЛЕРЫ
управления модулем равен 1), то аппаратные средства модуля загружают содержимое TDBUF в сдвиговый регистр и под управлением генератора скорости обмена биты из сдвигового регистра, начиная с младшего DO, последовательно передаются на вывод TxD МК. По завершении передачи байта данных устанавливается битТ1, который информирует МК о том, что буфер передатчика пуст и в него могут быть загружены новые данные для передачи. Бит TI генерирует запрос на прерывание, если прерывания от передатчика в МК разрешены. Бит TI может также быть считан программно.
Если работа приемника разрешена (бит RE в регистре управления модулем равен 1), то после распознавания стартового бита аппаратные средства приемника преобразуют данные, которые поступают на вход RxD в последовательном коде, в параллельный код. После завершения приема последнего бита в сдвиговом регистре приемника находится принятый байт данных, который автоматически переносится в регистр RDBUF. Одновременно устанавливается в «1» флаг завершения приема RI. Бит RI может быть считан под управлением программы, а если прерывания от приемника разрешены, то генерируется запрос на прерывание. В процессе выполнения подпрограммы прерывания принятый байт данных считывается из регистра данных приемника RDBUF в память МК. Сразу после копирования байта данных из сдвигового регистра в RDBUF приемник может начать формирование следующего байта данных, отдельные биты которого продолжают поступать на вход RxD. Однако необходимо, чтобы центральный процессор МК успел считать данные из буферного регистра RDBUF до завершения формирования в сдвиговом регистре следующего принятого байта. Если этого не произошло, то возникшая аварийная ситуация в модулях UART разрешается различными путями. В модулях SCI фирмы «Motorola» запись следующего принятого байта в буферный регистр данных не производится и устанавливается флаг ошибки OR (Overrun). Этот флаг наравне с триггером RI может генерировать запрос на прерывание от приемника. В модулях МК Intel MSC-51 и ему полностью аналогичных такая защита отсутствует: следующий принятый байт затирает предыдущий в регистре RDBUF.
Для повышения достоверности приема каждого разряда аппаратные средства модуля UART считывают уровень сигнала на входе RxD три раза в течение интервала присутствия бита. Значение бита, которое будет занесено в младший разряд сдвигового регистра приемника, определяется мажоритарным способом: по принципу два из трех. Модули SCI сообщают пользователю о наличии шума на линии приема: если не все три значения при приеме любого из битов кадра совпали, то устанавливается флаг NF (Noise Error). В модулях UART МК Intel MSC-51 такая защита не предусмотрена.
Подсистемы приемника и передатчика модуля UART не являются полностью автономными. Скорость обмена и формат кадра асинхронной приемопередачи назначаются в процессе инициализации модуля одинаковыми для приемника и для передатчика. Модули UART различных МК предоставляют неодинаковые возможности по регулированию скорости обмена. В МК Intel MSC-51 допускается плавное регулирование с дискретностью, равной периоду частоты тактирования таймера. Для задания скорости обмена используется один из каналов модуля таймера. Напротив, модуль SCI МК Motorola не использует ресурсы модуля таймера для этих целей. Такой подход, с одной стороны, имеет преимущество по экономии использования ресурсов МК, однако, с другой стороны, не позволяет задать произвольное соотношение между частотой обмена и собственной частотой кварцевого резонатора генератора синхронизации МК. Последнее накладывает ограничения на выбор частоты кварцевого резонатора, если скорость обмена в разрабатываемом устройстве должна соответствовать стандартному ряду.
Все модули типа UART предусматривают два типа кадров асинхронного обмена. На рис. 4.20 представлена временная диаграмма 10-битового кадра: 8 бит данных передаются вслед за стартовым битом, начиная с младшего D0, завершает передачу стопо-
318
СТРУКТУРА СОВРЕМЕННЫХ 8-РАЗРЯДНЫХ МИКРОКОНТРОЛЛЕРОВ
Рис. 4.20. Формат 10-битового кадра обмена в асинхронном режиме
вый бит. Логические уровни для передачи стартового бита (низкий) и стопового бита (высокий) формируются аппаратными средствами передатчика. Приемник распознает начало передачи нового кадра по изменению уровня сигнала на входе RxD с высокого, который может длиться сколь угодно долго, на низкий. Передаваемая в кадре полезная информация длиною в один байт может кодироваться абсолютно произвольно. Но может быть использовано и стандартное решение, при котором информация кодируется семью битами D6 - D0, старший бит D7 используется для контроля правильности приема. С этой целью передающий МК кодирует бит паритета D7 из условия четного (контроль на четность) или нечетного (контроль на нечетность) числа единиц в передаваемом слове, а принимающий МК производит проверку принятого кода в соответствии с выбранным способом кодирования. Если число единиц в байте данных соответствует выбранному способу кодирования, т. е. четное (нечетное), то передача считается успешной.
Следует заметить, что не все модули UART 8-разрядных МК имеют опции автоматического формирования бита паритета и не контролируют принятое слово на четность или нечетность аппаратными средствами. Поэтому при необходимости эти операции должны быть реализованы программными средствами. Рассмотренный 10-битовый формат кадра наиболее часто используется при организации связи встраиваемой МП системы с системой управления верхнего уровня.
Временная диаграмма 11-битового кадра асинхронного обмена представлена на рис. 4.21: 9 бит данных обрамляются одним стартовым и одним стоповым битом. При формировании 9-разрядного слова для передачи сначала старший разряд D8 помещается в бит Т8 одного из регистров управления модулем, а затем младшие разряды D7 - D0 записываются в обычном порядке в регистр TDBUF. При приеме 9-разрядного слова младшие биты D7 - D0 размещаются в регистре RDBUF, старший бит D8 передается в разряд R8 одного из регистров управления. Рассматриваемый формат представления кадра обычно используется для организации протокола обмена верхнего уровня в локальных сетях на основе нескольких МК. С этой же целью в модулях UART реализован специальный режим ожидания с механизмом пробуждения (Wake-up).
На рис. 4.22 приведена структура такой локальной сети. Один из МК в этой сети является ведущим, все остальные - ведомыми. В каждый момент времени обмен возможен между ведущим и одним из ведомых, обмен между двумя ведомыми не реализуется. Инициатором обмена всегда является только ведущий. Обмен производится пакетами, каждый из которых включает не менее трех 11-битовых кадров. Первый кадр определяет адрес ведомого МК, с которым будет производиться обмен. Бит D8 этого кадра должен быть равен «1». Следующие кадры используются для обмена данными с выбранным ведомым.
Рис. 4.21. Формат 11-битового кадра обмена в асинхронном режиме
319
8-РАЗРЯДНЫЕ МИКРОКОНТРОЛЛЕРЫ
Ведущий
необходимо установить бит SBK (Send
Рис. 4.22. Структура локальной сети микроконтроллера
Бит D8 этих кадров должен быть установлен в «О». Последний кадр пакета обмена должен содержать 11 нулевых битов. Так как подобная последовательность не может быть сформирована в результате записи в регистр буфера передатчика TDBUF нулевого слова (необходимо также обнулить столовый бит), то для ее воспроизведения предусмотрена специальная опция формирования сигнала «Break». В модулях SCI для ее реализации ) в одном из регистров управления.
Обмен между ведущим и ведомым происходит в следующем порядке.
• В исходном состоянии приемники всех ведомых МК находятся в состоянии ожидания. В этом состоянии прием байта данных осуществляется, но принятое слово переписывается в буферный регистр RDBUF с одновременной установкой в «1» флага завершения приема RI только в том случае, если бит D8 этого слова равен «1». Остальные слова с признаком D8 = 0 игнорируются.
• Ведущий МК посылает всем ведомым одновременно первый кадр пакета обмена. Разряды D7 - DO этого кадра содержат адрес ведомого, бит D8 равен «1».
• Все ведомые МК принимают это 9-разрядное слово, и, поскольку разряд D8 кадра равен «1», приемник модуля UART каждого МК выходит из состояния ожидания. Формируется запрос на прерывание. Подпрограмма обработки этого прерывания сравнивает принятый адрес с собственным адресом в локальной сети. Если адреса совпадают, т. е. ведущий будет производить обмен именно с этим ведомым, то МК ожидает передачи от ведомого следующего кадра. Если адреса не совпадают, то МК посредством специального бита управления переводит приемник модуля UART снова в режим ожидания. Тогда все следующие кадры пакета обмена этим МК восприняты не будут, поскольку они содержат нулевой разряд D8.
• Ведущий МК передает ведомому необходимое число байтов, сопровождая каждый из них признаком данных D8 = 0. При необходимости ведущий принимает данные от ведомого. О завершении обмена ведущий информирует ведомый посылкой сигнала «Break».
• Ведомый в ответ на сигнал «Break» переводит приемник модуля UART в состояние ожидания. Локальная сеть приведена в исходное состояние и готова к передаче нового пакета.
Кроме рассмотренных режимов асинхронного обмена, многие из модулей UART поддерживают режим синхронной приемопередачи. Так, в МК MSC-51 контроллер последовательного интерфейса реализует полудуплексный обмен в синхронном режиме, при котором импульсы синхронизации выдаются на линию TxD, данные передаются или принимаются по линии RxD (см. 4.2.7). Важно отметить, что при синхронном обмене модуль UART МК MSC-51 может работать только в ведущем режиме, т. е. именно этот модуль формирует импульсы синхронизации независимо от направления обмена. Модуль SCI МК МС68НС705В16 (модуль типа UART) реализует симплексный синхронный обмен, при котором возможно только одно направление передачи данных: из МК к периферийной ИС.
Большинство МК фирмы «Motorola» имеют в своем составе контроллер последовательного интерфейса SPI (Serial Peripheral Interface). Стандарт SPI предложен фирмой «Motorola». Он предназначен для связи МК с периферийными устройствами МП системы. Наиболее часто эти устройства расположены на одной плате с МК, реже - это вынесенные пульты
320
СТРУКТУРА СОВРЕМЕННЫХ 8-РАЗРЯДНЫХ МИКРОКОНТРОЛЛЕРОВ
Ведущий
MOSI MISO SCK
Ведомый 1 Ведомый 2
Рис. 4.23. Сопряжение МК с переферийными ИС посредством интерфейса SPI
управления, индикаторные панели и т. п. В качестве периферийных устройств могут использоваться как простейшие сдвиговые регистры, так и сложные периферийные ИС
со встроенными контроллерами управления, такие как ЦАП, сигма-дельта АЦП с цифровой фильтрацией, последовательные запоминающие устройства типа FLASH или EEPROM, энергонезависимые ОЗУ и т. д. В редких случаях интерфейс SPI используется для обмена данными между несколькими МК системы.
На рис. 4.23 представлена структурная схема сопряжения МК и двух периферийных ИС с использованием интерфейса SPL В рассматриваемом примере МК является ведущим устройством, он инициирует обмен при передаче информации между МК и одной из периферийных ИС. Каждая из периферийных ИС является устройством ведомым. SPI- шина представлена тремя общими линиями связи (MISO, MOSI, SCK) и двумя линиями выбора ведомого устройства (SS1, SS2), которые индивидуальны для каждой периферийной ИС:
MOSI - линия передачи данных от ведущего к ведомому (Master Output Slave Input);
MISO - линия передачи данных от ведомого к ведущему (Master Input Slave Output);
SCK - линия сигнала стробирования данных;
SS1 и SS2 - линии сигналов выбора ведомого устройства.
Как видно из рис. 4.23, образованная на основе интерфейса SPI мини-сеть относится к классу магистрально-радиальных. Линии передачи данных и линия синхронизации являются примером шинной организации, а линии выбора ведомого устройства - элемент системы радиального типа. Перед началом обмена (рис. 4.24) ведущее устройство отмечает одно ведомое устройство, с которым будет производиться обмен. Для этого на линии выбора устройства SSI устанавливается низкий активный уровень сигнала. Затем ведущее устройство последовательно выставляет на линию MOSI восемь бит информации, сопровождая каждый бит сигналом синхронизации SCK. Ведомое устройство де-
SCK
П П- п л п_п п п
пппппппп
SS
Сеанс обмена
t
)4
Рис. 4.24. Временные диаграммы обмена в стандарте SPI
321
8-РАЗРЯДНЫЕ микроконтроллеры
шифрирует переданный байт информации и определяет, в каком направлении будет производиться дальнейший обмен. Если ведомое устройство должно принимать информацию, то ведущее устройство, не снимая сигнала выбора ведомого SSi, продолжит передачу по линии MOSI. Если ведомое устройство должно передавать информацию, то оно активизирует линию MISO и в ответ на каждый импульс синхронизации от ведущего будет выставлять один бит информации. Длина посылки обмена в общем случае не ограничена, но для правильной работы модуля SPI должна составлять целое число байтов. Завершение обмена также инициируется ведущим посредством установки в неактивное состояние сигнала выбора ведомого SSi.
Для подключения к SPI-шине встроенный контроллер SPI имеет четыре вывода: MOSI, MISO, SCK, SS. Модули контроллеров SPI фирмы «Motorola» могут работать как в ведущем, так и в ведомом режимах. Скорость приема и передачи определяется частотой тактирования межмодульных магистралей МК fBUS: в ведущем режиме скорость обмена не может превышать fsus/2, в ведомом режиме максимальная скорость обмена равна f Поэтому для МК семейства НС05 максимальная скорость обмена в ведущем режиме составляет 1 Мбит/с, в ведомом - 2 Мбит/с. Аналогичные показатели для МК семейства НС08 соответственно 4 и 8 Мбит/с.
При работе встроенного контроллера в ведущем режиме к выводу MOSI подключается выходная линия данных, а к MISO - входная. При работе в ведомом режиме выводы меняются ролями. Вывод SCK является выходом, если контроллер SPI работает в ведущем режиме, и входом, если - в ведомом. В системах с несколькими ведущими устройствами все выводы SCK соединяются вместе. То же делается с выводами MOSI и MISO. На время отсутствия связи буферы выводов встроенного контроллера SPI переводятся в высокоимпедансное состояние. Последнее позволяет избежать конфликтов на шине SPI. В противном случае несколько выводов MISO ведомых устройств одновременно были бы активными, что не позволило бы ведущему устройству произвести прием достоверной информации.
Вывод SS встроенного контроллера SPI используется в зависимости от того, в каком режиме работает данное устройство. При работе в ведомом режиме при подаче высокого уровня сигнала на вход SS устройство игнорирует сигналы SCK и удерживает вывод MISO в высокоимпедансном состоянии. Если же в ведомом режиме работы на входе SS установлен низкий логический уровень, то буферы линий MOSI и SCK разворачиваются на ввод, линия MISO - на вывод. При работе в ведущем режиме вывод SS может быть использован как обычная линия вывода. В системах со сложной логикой работы этот вывод может использоваться как вход сигнала обнаружения ошибки для индикации состояния шины в случаях, если более чем одно устройство пытается стать ведущим.
Схема управления контроллера SPI интерфейса позволяет выбрать один из двух протоколов обмена и полярность импульсов синхронизации SCK. При работе в ведущем режиме возможно также программно выбрать частоту импульсов синхронизации.
Два бита регистра управления любого контроллера SPI интерфейса определяют временную диаграмму обмена по шине SPI:
1) бит СРНА назначает протокол обмена;
2) бит CPOL определяет полярность сигнала синхронизации SCK.
В соответствии с комбинацией битов CPHA:CPOL принято различать четыре режима работы интерфейса SPI. Комбинации CPHA:CPOL = 00 соответствует режим 0, комбинации CPHA:CPOL = 11- режим 3. Встроенный контроллер SPI МК позволяет программно настраивать режим SPI в процессе инициализации, в то время как периферийные ИС реализуют один или два режима SPI, которые определяются их техническим описанием. Наиболее часто это режимы 0 и 3.
322
СТРУКТУРА СОВРЕМЕННЫХ 8-РАЗРЯДНЫХ МИКРОКОНТРОЛЛЕРОВ
SCK (CPOL « 0)
SCK(CP0L- U
MOSI от ведущего к ведомому
MISO от ведомого к ведущему
25 от ведущего к ведомому
Моменты фиксации снэрадного бита
MISO/MOSJ "% Байт 1 jf Байт 2 X БайтЭ
55 ведомого СРНА-0
55 ведомого С₽НА = 1
л
л
Рис. 4.25. Временные диаграммы обмена SPI интерфейса в режимах 0 и 1
На рис. 4.25 представлены временные диаграммы сигналов для протокола передачи СРНА = 0. Для сигнала SCK приводятся две диаграммы, различающиеся полярностью сигнала.
Первая соответствует режиму 0, вторая - режиму 1. Диаграммы относятся как к ведущему, так и к ведомому устройству, поскольку выводы MISO и MOSI ведущего соединены с аналогичными выводами ведомого. Сигнал SS подается только на ведомое устройство. Поэтому вывод SS у ведущего остается незадействованным и его диаграмма не представлена, но имеется в виду, что она соответствует неактивному состоянию. Встроенные контроллеры SPI выполнены таким образом, что длина посылки составляет один байт, что и отражено на временных диаграммах.
Начало обмена рассматриваемого протокола определяется установкой сигнала выбора ведомого SS в активное состояние SS - 0. При направлении передачи от ведущего к ведомому первый перепад сигнала синхронизации SCK используется ведомым устройством для запоминания очередного бита во внутреннем сдвиговом регистре контроллера SPI. Ведущий выставляет очередной бит посылки на линии MOSI по каждому четному фронту сигнала SCK. При передаче данных от ведомого к ведущему старший бит передаваемого байта должен быть выставлен ведомым на линию MISO сразу после изменения уровня сигнала SS - 0. По первому фронту SCK уровень сигнала на линии MISO будет запомнен в младшем разряде сдвигового регистра ведущего устройства. По этой причине сигнал на линии выбора ведущего должен быть возвращен в неактивное состояние SS = 1 после передачи каждого байта в любом направлении. Тогда передача каждого нового байта будет сопровождаться предварительной установкой SS в «0».
323
8-РАЗРЯДНЫЕ микроконтроллеры
Рис. 4.26. Временные диаграммы обмена SPI интерфейса в режимах 2 и 3
Начало обмена для протокола опции СРНА= 1 (рис. 4.26) определяет первое изменение уровня сигнала на линии SCK после установки сигнала выбора ведомого SS в активное состояние SS = 0. При передаче данных от ведущего к ведомому и в обратном направлении все нечетные перепады SCK вызывают выдвижение очередного бита посылки из сдвигового регистра передатчика на линию. Каждый четный перепад используется для записи этого бита в сдвиговый регистр приемника. Сигнал выбора ведомого может оставаться в активном состоянии SS - 0 в течение передачи нескольких байт информации. Это несколько упрощает логику программного драйвера SPI.
Рассмотренные протоколы обмена не имеют различий по скорости и надежности передачи информации. Выбор протокола диктуется периферийным устройством. В некоторых случаях полярность и фаза сигнала SCK изменяются между передачами для того, чтобы обеспечить связь с устройствами, имеющими различный протокол. Пример контроллера SPI рассмотрен в п. 4.3.9.
Интерфейс 12С является двухпроводным последовательным интерфейсом, разработанным фирмой «Philips Corporation».
Основными свойствами интерфейса 12С являются следующие:
• двунаправленная передача данных между главными и подчиненными устройствами;
• многоабонентская шина (центрального главного узла в сети может не быть);
• арбитраж между одновременно передающими устройствами без разрушения целостности передаваемых данных;
• последовательная тактовая синхронизация позволяет приборам с различными скоростями передачи битов осуществлять связь через одну последовательную шину;
• последовательная тактовая синхронизация может использоваться в качестве механизма квитирования установления связи, чтобы приостанавливать и возобновлять последовательную передачу.
Магистраль интерфейса 12С использует две линии для передачи информации между приборами:
1) SDA - двунаправленную линию данных;
2) SCL - линию сигнала стробирования данных.
Типовая конфигурация 12С-шины показана на рис. 4.27. :
324
СТРУКТУРА СОВРЕМЕННЫХ 8-РАЗРЯДНЫХ МИКРОКОНТРОЛЛЕРОВ
Рис. 4.27. Конфигурация 12С-шины
В протоколе интерфейса 12С каждое устройство имеет адрес. Когда ведущее устройство желает инициировать передачу данных, оно передает адрес устройства, с которым будет производить обмен. Все устройства на шине следят за выставляемым на шину адресом и сравнивают его с собственным адресом. Вместе с адресом передается бит направления передачи R/W, который определяет, будет ли ведущий читать из ведомого или будет писать в него. При R/W = 0 реализуется режим записи в ведомое устройство. При R/W = 1 реализуется режим чтения из ведомого устройства. Интерфейс 12С поддерживает два формата передачи адреса. Простейший - 7-битный формат с битом R/W в младшем разряде передаваемого байта (рис. 4.28). Более сложным является 10-битный формат.
В зависимости от направления передачи возможны два типа обмена данными для 12С-шины.
1. Передача данных от главного передатчика к подчиненному приемнику. Первый байт, передаваемый передатчиком, является адресом подчиненного приемника. Затем следует несколько байтов данных. Подчиненный приемник возвращает бит подтверждения после каждого принятого байта.
2. Передача данных от подчиненного передатчика к главному приемнику. Первый байт (адрес подчиненного передатчика) передается главным устройством. Затем подчиненный передатчик возвращает бит подтверждения. Следующие несколько байтов данных передаются подчиненным устройством главному. Главное устройство возвращает бит подтверждения после каждого принятого байта, кроме последнего. В конце последнего принятого байта возвращается «нет подтверждения».
Когда нет передачи данных, реализуется режим ожидания: линии тактирования SCL и Данных SDA приведены подтягивающими резисторами к высокому уровню логического сигнала.
Старший бит
Младший бит
S
Аб Аз Ат Аз Аг | Ат | Ао
R/W ASK]
Адрес ведомого
Посылается ведомым
Рис. 4.28. Формат 7-битного адреса (S - START; R/W - бит «чтение/запись»; ASK - подтверждение)
325
8-РАЗРЯДНЫЕ микроконтроллеры
Ведущее (главное) устройство генерирует все последовательные синхроимпульсы и условия START и STOP, определяющие начало и конец передачи данных. Условие START определяется как переход SDA из высокого уровня в низкий при высоком уровне SCL, а условие STOP - как переход SDA из низкого уровня в высокий при высоком уровне SCL (рис. 4.29). Ввиду такого способа определения условий START и STOP при передаче данных линия SDA может изменять свое состояние только при низком уровне SCL.
Модуль контроллера интерфейса 12С, который удовлетворяет спецификации 12С-шины и поддерживает два вышеперечисленных типа передачи данных, может работать в следующих четырех режимах.
1. Режим главного передатчика. Последовательный вывод данных через выход SDA передатчика, в то время как на выходе SCL передатчика формируются последовательные синхроимпульсы. Первый переданный байт содержит адрес подчиненного приемного устройства (7 бит) и бит направления данных R/W - 0. В этом случае говорят, что передается «W». Таким образом, первый переданный байт представляет собой адрес подчиненного приемника плюс «W». Последовательные данные передаются по 8 бит. После отправки каждого байта главный передатчик ожидает от подчиненного устройства бит подтверждения ASK. Условия START и STOP формируются ведущим (главным) устройством для указания начала и конца сеанса последовательного обмена посылкой, состоящей в общем случае из нескольких байтов.
2. Режим главного приемника. Первый переданный приемником байт содержит адрес подчиненного передающего устройства (7 бит) и бит направления данных R/W = 1. В этом случае говорят, что передается «R». Таким образом, первый переданный приемником байт представляет собой адрес подчиненного передатчика плюс «R». Последовательные данные передаются по линии SDA от ведомого (подчиненного) устройства к ведущему (главному), в то время как импульсы синхронизации на линии SCL формирует ведущий. Последовательные данные передаются по 8 бит. После того, как ведущий (главный) принял очередной байт, он выставляет на линию сигнал подтверждения приема ASK. Сигналы START и STOP формируются ведущим.
3. Режим подчиненного приемника. Последовательные данные и синхроимпульсы передаются по линиям SDA и SCL на одноименные входы подчиненного приемника. После того, как принят каждый байт, приемник анализирует наличие на линии бита подтверждения ASK, который формирует передатчик. Условия START и STOP формируются передатчиком. Распознавание адреса выполняется аппаратными средствами модуля приемника после приема адреса подчиненного устройства и бита направления.
4. Режим подчиненного передатчика. Первый байт принимается и обрабатывается подчиненным передатчиком также, как и в режиме подчиненного приемника. Однако бит направления в принятом байте будет указывать, что направление обмена должно быть изменено на обратное. Далее последовательные данные передаются по линии SDA с одноименного выхода подчиненного (ведомого) передатчика, в то время как синхроимпульсы принимаются им по входу SCL от главного приемника. После передачи каждого байта подчиненный передатчик анализирует наличие на линии бита подтверждения ASK. Условия START и STOP формирует главный приемник.
В подчиненном режиме аппаратные средства контроллера 12С-интерфейса осуществляют поиск своего собственного подчиненного адреса или адреса общего вызова. Если детектируется один из этих адресов, запрашивается прерывание. Когда микроконтроллер желает, чтобы шина стала главной, аппаратные средства ожидают, пока шина освободится. Возможное функционирование в качестве подчиненного при этом не прерывается. Если арбитраж шины потерян в главном режиме, то соответствующий контроллер 12С переключается в подчиненный режим немедленно и может детектировать свой собственный подчиненный адрес.
326
СТРУКТУРА СОВРЕМЕННЫХ 8-РАЗРЯДНЫХ МИКРОКОНТРОЛЛЕРОВ
Рис. 4.29. Пример обмена данными в 12С
Разработанный в середине 1980-х фирмой «Bosch» для систем управления узлами автомобиля, протокол CAN (Controller Area Network - сеть контроллеров) является последовательным протоколом высокоскоростной и высоконадежной передачи данных в широковещательном (broadcast) режиме в мультимастерной среде. Удачное сочетание низкой стоимости подключения, простоты и надежности с доступностью элементной базы и инструментальных средств разработки - одни из основных достоинств CAN-техноло-гии. Положения стандарта, закрепленные в используемой на сегодня спецификации 2.0А/В фирмы «Bosch» и международном стандарте ISO 11898, соответствуют двум начальным уровням (физическому и канальному) 7-уровневой модели взаимодействия открытых систем ISO/OSI. Ряд оригинальных технических решений, реализованных при разработке протокола, наилучшим образом позволили сориентировать его на решение задач контроля и управления.
Структура CAN-сети представлена на рис. 4.30. Шинная топология, являющаяся основой CAN, требует наличия механизма адресации узлов, однако в CAN нет адресов как таковых: сообщение принимается всеми узлами. Любое передаваемое сообщение имеет определяющий его содержание уникальный идентификатор (ID), на основании которого каждый узел фильтрует «свои» сообщения и «решает», реагировать или нет на сообщение, транслируемое в данный момент. Неоспоримыми преимуществами
отсутствия адресации являются теоретически
неограниченное число узлов и простота их добавления и отключения.
Физическая среда передачи данных в CAN может быть самой разной - витая пара, плоский кабель, оптоволокно, а так же радио- и ИК-каналы и даже линии электропередач. Основным ограничением протяженности шины является лишь предельно допустимая суммарная задержка распространения сигнала для заданной скорости передачи (в кабеле, трансиверах, входных цепях контроллеров и т. д.). В соответствии с рекомендациями IS011898 при использовании стандартных трансиверов и быстродействующих оптопар (для гальванической развязки) макси-
Рис. 4.30. Структура CAN-сети
327
а-РАЗРЯДНЫЕ микроконтроллеры
мальная протяженность сети при скорости передачи 1 Мбит/с ограничена девятью метрами. Предельная рекомендуемая протяженность сети в соответствии с тем же стандартом достигается при снижении скорости передачи до 50 кбит/с. А в документах промыщ. ленной CAN-группы CiA (CAN in Automation) приведены следующие полученные практическим путем соотношения «скорость - протяженность» для проводной сети без гальванической развязки: 1 Мбит/с - 30 м; 500 кбит/с -100 м; 125 кбит/с - 500 м; 20 кбит/с -2500 м; 10 кбит/с - 5000 м.
Сообщения, передаваемые по CAN-шине, именуются фреймами. Форматы фреймов передаваемых данных приведены на рис. 4.31. В зависимости от инициатора передачи и ее цели существуют четыре типа фреймов:
1) Data Frame - фрейм данных;
2) Remote Frame - фрейм запроса данных;
3) Error Frame - фрейм ошибки;
4) Overload Frame - фрейм перегрузки.
Собственно для передачи данных используется Data Frame, в поле данных которого (Data Field) могут находиться от 0 до 8 байтов данных.
Поле арбитража (Arbitration Field) фрейма включает в себя идентификатор (ID), однозначно определяющий содержание и приоритет сообщения. Стандартным форматом сообщений (CAN Specification 2.0А) предусмотрен 11-битный идентификатор, позволяющий различать до 20348 типов сообщений (на практике обычно до 2032), а расширенный (CAN Specification 2.0В) - 29-битный (стандартный 11-битный с 18-битным расширением) с теоретически возможным числом типов сообщений более 536 млн. Фреймы, соответствующие стандартному и расширенному форматам сообщений, приведены на рис. 4.31.
Бит RTR (Remote Transmission Request - запрос передачи данных) для фрейма должен иметь доминантный уровень. В расширенном формате фрейма бит SRR (Substitute Remote Request) с рецессивным уровнем заменяет следующий (в стандартном формате) за 11-разрядным идентификатором бит RTR. Бит распознавания формата фрейма IDE (ID Extension) имеет доминантный уровень для стандартного формата фрейма и рецессивный - для расширенного. Биты гО и г1 - резервные.
В поле управления (Control Field) содержится 4-разрядный код, задающий длину поля данных (0-8 байт) - DLC - Data Lenght Code. Поле контрольной суммы CRC Field включает в себя контрольную сумму сообщения (15 бит) и бит-разделитель. В поле подтверждения АСК (Acknowledgement) передающий узел всегда выставляет рецессивный уровень. В случае, если передача прошла успешно, приемный узел сигнализирует об этом установкой в этом поле доминантного уровня.
Начинается фрейм доминантным битом SOF (Start of Frame), служащим также для синхронизации битового потока, а заканчивается семью битами рецессивного уровня поля EOF (End of Frame) и 3-битным того же уровня промежутком между фреймами. Для не-
стандартный формат Е_ Поле _______
арбитража
11 бит ID | RTR
Поле управления IDE | Ю
- Поле данных
DLC | ~
Расширенный формат ---------------------- Поле арбитража ----
11 бит ID I SRR I IDE
Поле управления
18 бит ID | RTR | г1 | r0 | DLC
Поле
данных
Рис. 4.31. Формат сообщения CAN-протокола
328
СТРУКТУРА СОВРЕМЕННЫХ 8-РАЗРЯДНЫХ МИКРОКОНТРОЛЛЕРОВ
ключения потери синхронизации при передаче длинной последовательности одинаковых битов в пределах полей начала фрейма, арбитража, управления, данных и контрольной суммы используется битстаффинг - вставка дополнительного бита противоположного значения после подряд идущих пяти одинаковых. При приеме производится обратная (дебитстаффинг) операция.
Для запроса данных от удаленного узла служит фрейм запроса данных Remote Frame, также имеющий стандартный и расширенный форматы. Отличия фрейма запроса данных от фрейма данных - в отсутствии поля данных и рецессивном уровне бита RTR. При получении фрейма запроса данных запрашиваемый узел отвечает передачей фрейма данных.
Сигнализация об ошибках происходит посредством передачи фрейма Error Frame. Он инициируется любым узлом (в CAN правильность передачи контролируется каждым узлом), обнаружившим ошибку.
Шесть доминантных бит флага ошибки (активный флаг ошибки) перекрывают остаток ошибочно переданного фрейма и создают глобальную ошибку в сети - ошибку битстаф-финга, которая воспринимается остальными узлами, если им не удалось обнаружить первоначальную (локальную) ошибку. Далее они выставляют свои флаги ошибки. Ввиду этого обстоятельства последовательность доминантных бит (суперпозиция флагов ошибки) может иметь длину от 6 до 12 бит. Ненадежным или частично поврежденным узлам (см. ниже) при обнаружении ошибки разрешено посылать лишь пассивный флаг ошибки - последовательность шести рецессивных бит.
Для задержки передачи данных или посылки фрейма запроса данных (при неготовности приемника или наличии доминантных бит в промежутке между фреймами) служит фрейм перегрузки Overload Frame. В отличие от фрейма ошибки он не влияет на счетчик ошибок и не вызывает повторную передачу сообщения.
Несколько необычно решается проблема коллизий (столкновений в сети), присущая шинной топологии. В этом случае снова используется идентификатор сообщения в сочетании со схемой подключения к шине типа «монтажное ИЛИ», где узел, выставляющий на шину «О» - доминантный уровень, подавляет «1» - рецессивный уровень, выставленный другим узлом. Победителем в арбитраже является узел, имеющий идентификатор с наименьшим численным значением и, как следствие, наивысший приоритет. Только победивший узел продолжает передачу данных, остальные пытаются сделать это позже. На рис. 4.68 наглядно отражена процедура арбитража при попытке передачи сообщений одновременно четырьмя узлами сети.
Подобный режим доступа к шине известен как CSMA/CD+AMP (Carrier Sense Multiple Access with Collision Detection and Arbitration on Message Priority) - множественный доступ с контролем несущей, обнаружением коллизий и арбитражем на основе приоритета сообщений. Этот режим не позволяет поспорившим узлам устраивать столкновение на шине, а сразу выявляет победителя. CAN-протокол, изначально разработанный специально для систем управления жизненно важными узлами автомобилей, критичных к уровню безопасности и степени достоверности передаваемых данных, обладает эффективными средствами обнаружения ошибок.
В отличие от других сетевых протоколов, в CAN не используются подтверждающие сообщения, а при обнаружении одной или более ошибок хотя бы одним узлом (в CAN все узлы принимают все сообщения и участвуют в проверке сообщения на наличие ошибок -вычисляют контрольную сумму и т. п.) текущая передача прерывается (при условии, что ошибку обнаружил как минимум один узел со статусом Error Active) генерацией фрейма ошибки с флагом ошибки. Передатчик, сообщение которого было прервано, повторяет передачу.
329
8-РАЗРЯДНЫЕ МИКРОКОНТРОЛЛЕРЫ
4.2. СЕМЕЙСТВО МК MCS-51 ФИРМЫ «INTEL»
4.2.1. АРХИТЕКТУРА МК 8051 АН
На рис. 4.32 приведена внутренняя структура МК 8051 АН фирмы «Intel», с которого началось семейство MCS-51 (отечественный аналог 1816ВЕ51).
Контроллер включает следующие модули:
• центральный процессор CPU MCS-51; разрядность обрабатываемого слова составляет один байт;
• внутреннюю память программ объемом 4096 однобайтовых ячеек памяти (4 Кбайта);
• внутреннюю память данных объемом 128 однобайтовых ячеек;
• четыре 8-разрядных параллельных порта ввода/вывода;
• два 16-разрядных программируемых таймера;
• последовательный порт;
• схему формирования сигналов внешней мультиплексированной магистрали адрес/ данные и внешней магистрали управления.
Память программ (4К х в)
-4—>-P0.0/AD0
•4—►P0.1/AD1
—►P0.2/AD2
<<—►P0.3/AD3 4—►P0.4/AD4 ««—►P0.5/AD5
4—► P0.6/AD6
4—►P0.7/AD7
<4—►Рг.О/Ав 4—►ргл/АЭ <4—►рг.г/АЮ
-4—►рг.з/АИ 4—*-Р2.4/А12 4—►Р2.5/А13 «4—► Р2.6/А14 4—*-Р2.7/А15
4—►РЗ.О/RxD 4—►P3.1/TxD «4—►P3.2/INT0
-4—►P3.3/INT1 4—►Р3.4/Т0 <4—»-Р3.5/Т1
<—► P3.6/WR
4—►P3.7/RD
(ф Гб
, f!
Ч
lift
"А
е до
Рис. 4.32. Структура МК8051АН фирмы «Intel»
U лит
____Voo
GND
3»' УТ а-S'.l, lift хн dH
330
СЕМЕЙСТВО МКMCS-51 ФИРМЫ «INTEL»
Обмен информацией между модулями осуществляется по 8-разрядной внутренней магистрали.
МК семейства MCS-51 используют гарвардскую архитектуру: память программ (ПЗУ) и память данных (ОЗУ) имеют раздельное адресное пространство. И, как следствие, для обращения к ячейкам памяти разного типа должны быть использованы разные типы команд. Максимальный размер адресного пространства для каждого типа памяти составляет 64 Кбайта. Однако непосредственно на кристалле МК 8051 АН располагаются только 4 Кбайта ПЗУ и 128 байт ОЗУ. МК семейства MCS-51 имеют открытую архитектуру, т.е. позволяют подключать внешнюю память. Поэтому при необходимости, как память программ, так и память данных могут быть увеличены посредством подключения дополнительных микросхем памяти.
Варианты организации памяти в МП системе на основе МК8051АН поясняет рис. 4.33. МК может быть использован в однокристальном режиме (сигнал на линии ЕА равен 1). Тогда внешняя память в системе отсутствует, память программ располагается по адресам 0000h...0FFFh, память данных - с 00h по 7Fh. Регистры специальных функций периферийных модулей имеют объединенное с внутренним ОЗУ адресное пространство. Они расположены по адресам 80h...0FFh. Даже если МК 8051 АН работает в однокристальном режиме, к нему может быть подключена внешняя память программ. Она должна располагаться в диапазоне адресов 1000h-0FFFFh, т. е. дополнять внутреннее ПЗУ МК. Если МК работает в расширенном режиме (сигнал на линии ЕА равен 0), то он будет адресовать только внешнюю память программ - с OOOOh по OFFFFh, несмотря на то, что внутреннее (резидентное) ПЗУ на кристалле имеется.
В каждом из рассмотренных режимов МК 8051 АН может использовать два массива памяти данных: внутреннее ОЗУ, расположенное по адресам 00h...7Fh, и подключаемое внешнее ОЗУ, или ПЗУ, которое может располагаться, начиная с адреса OOOOh вплоть до OFFFFh. Не следует бояться возможного перекрытия адресного пространства внутренней и внешней памяти данных. Доступ к ним осуществляется разными командами.
Память программ
Внутренняя память данных
OOOOh
FFFFh
Внешняя память данных
Рис. 4.33. Организация памяти в микропроцессорной системе на основе МК 8051АН
331
8-РАЗРЯДНЫЕ МИКРОКОНТРОЛЛЕРЫ
Адрес
7Fh
30h 2Fh 2Eh 2Dh 2Ch 2Bh 2Ah 29h 28h 27h 26h 25h 24h 23h 22h 21 h 20h
1Fh
18h 17h
10h OFh
08h 07h
OOh
Ячейки резидентного ОЗУ
7F 7Е 7D 7С 7В 7А 79 78
77 76 75 74 73 72 71 70
6F 6Е 6D 6С 6В 6А 69 6S
67 66 65 64 63 62 61 60
5F 5Е 5D 5С 5В 5А 59 58
57 56 55 54 53 52 51 50
4F 4Е 4D 4С 4В 4А 49 48
47 46 45 44 43 42 41 40
3F ЗЕ 3D зс ЗВ ЗА 39 38
37 36 35 34 33 32 31 30
2F 2Е 2D 2С 2В 2А 29 28
27 26 25 24 23 22 21 20
1F 1Е 1D 1С 1В 1А 19 18
17 16 15 14 13 12 11 10
OF ОЕ 0D ос ов 0А 09 08
07 06 05 04 03 02 01 00
БанкЗ(Я7 -R0)
Банк 2 (R 7 -R0)
Банк 1 (R7 - R0)
Банк 0 (R7 -R0)
Адрес OFFh
OFOh
OEOh
ODOh
0B8h
OBOh
0A8h
0A7h
99h 98h
90h 8Dh 8Ch 8Bh 8Ah 89h 88h 87h 83h
82h 81h
80h
F7 I F6 I F5 I F4 I F3 I F2 | F1 | FO E7 | E6 | E5 | E4 | E3 |E2|E1|E0 D7 | D6 | D5 | D4 | D3 | D2 | D1 fDO
- | - | - | ВС I BB I BA I B9 I bT
B7 | B6 | B5 | В4 | B3 | B2 | B1 ТвО
AF | - | - | AC | AB | AA | A9 | A81
A7 | A6 | A5 | A4 | АЗ | A2 | A1 | AO-
9F | 9E I 9D | 9C | 9B | 9A | 99 T~98~
97 | 96 | 95 | 94 | 93 | 92 | 91 |~9O~
8F | 8E | 8D | 8C | 8B | 8A | 89 T~88
87 | 86 | 85 | 84 | 83 | 82 | 81 1~8O
Имя
регистра
В
A
PSW
IP
P3
IE
P2 SBUF SCON
P1 TH1 THO TH TLO TMOD TCON PCON DPH DPL SP
PO
Рис. 4.34. Структура внутренней памяти данных
В архитектуре MCS-51 адресное пространство внутренней памяти данных объединяет все программно доступные ресурсы МК, в том числе регистры центрального процессора. Пространство внутренней памяти данных делится на пространство адресов внутреннего ОЗУ и пространство адресов регистров специальных функций (рис. 4.34).
В области ОЗУ выделяют три сегмента.
1. Младшие 32 адреса занимают четыре регистровых банка, каждый из которых содержит по 8 регистров общего назначения RO - R7. При обращении к ячейкам памяти этого сегмента могут быть использованы как абсолютные адреса OOh - 1 Fh, так и символьные имена регистров RO - R7. Для выбора одного регистра из четырех, имеющих одно имя, используется механизм задания текущего банка регистров. Номер банка, на 8 ячеек которого в данный момент времени распространяются имена RO - R7, определяется значением битов RS1:RS0 регистра признаков PSW.
2. Ячейки памяти с адресами 20h - 2Fh допускают побитное обращение. Прямоадресуемые биты имеют адреса OOh - 7Fh. Таким образом, обращение к данным, расположенным в ячейках памяти с адресами 20h - 2Fh, может быть осуществлено как в байтовом, так и в битовом формате.
332
СЕМЕЙСТВО МК MCS-51 ФИРМЫ «INTEL:
3. Ячейки памяти с адресами 30h - 7Fh допускают обращение только посредством абсолютных адресов, данные доступны только в байтовом формате.
Область памяти с адресами 80h - OFFh занимают регистры специальных функций: регистры данных портов ввода/вывода РО, Р1, Р2, РЗ, регистры задания режимов работы других периферийных модулей. Обратите внимание, что в этом же адресном пространстве расположены регистры центрального процессора: аккумулятор АСС, регистр В, регистр состояния PSW, старший DPH- и младший DPL-байты двухбайтового регистра DPTR, указатель стека SP. Большая часть регистров специальных функций, а также АСС, В и PSW допускают побитное обращение. Прямоадресуемые биты имеют адреса с 80h по OFFh. Формат регистров специальных функций будет рассмотрен в разделах, посвященных соответствующим периферийным модулям. Из рис. 4.34 видно, что не все адресное пространство области 80h - OFFh использовано, имеются свободные адреса. В версиях МК с ядром MCS-51, но с большим по сравнению с моделью 8051 АН набором периферийных модулей эти адреса используются для размещения дополнительных регистров специальных функций. Перечень регистров специальных функций МК 8051 АН приведен в табл. 4.4.
Таблица 4.4
Регистры специальных функций МК 8051АН
Имя регистра Назначение Адрес
Р0 Регистр данных порта 0 80h
Р1 Регистр данных порта 1 90h
Р2 Регистр данных порта 2 AOh
РЗ Регистр данных порта 3 BOh
IE Регистр разрешения прерываний A8h
IP Регистр приоритетов прерываний B8h
ТС ON Регистр управления таймерами и внешними прерываниями 88h
TMOD Регистр режима работы таймеров/счетчиков 89h
THO Старший байт счетчика Таймера 0 8Ch
TLO Младший байт счетчика Таймера 0 8Ah
TH1 Старший байт счетчика Таймера 1 8Dh
TL1 Младший байт счетчика Таймера 1 8Bh
SCON Регистр управления последовательным портом 98h
SBUF Регистр данных последовательного порта 99h
PCON Регистр управления энергопотреблением 87h
4.2.2. ПРОЦЕССОРНОЕ ЯДРО МК СЕМЕЙСТВА MCS-51
Центральный процессор МК семейства MCS-51 (далее CPU MCS-51) выполняет действия над 8-разрядными операндами. Программная модель CPU MCS-51 (рис. 4.35) содержит шесть регистров. Все регистры, кроме счетчика команд PC, являются частью объединенного адресного пространства ОЗУ данных. Следовательно, для обращения к ним могут быть использованы как символьные имена этих регистров - АСС, В, PSW, SP, DPH, DPL, так и их абсолютные адреса - OEOh, OFOh, ODOh, 81 h, 82h, 83h соответственно.
Аккумулятор ACC - 8-разрядный регистр, в котором хранятся операнды, результаты арифметических и логических операций. Сброс устанавливает все разряды АСС в «0».
333
8-РАЗРЯДНЫЕ МИКРОКОНТРОЛЛЕРЫ
Регистр признаков PSW
| С | AC I FO I RS11 RSOI ОУ I | Р |
Сброс: 00000000
Рис. 4.35. Программно-логическая модель центрального процессора CPU MCS-51
Регистр В - дополнительный 8-разрядный регистр. Используется в операциях умножения и деления. В других командах может интерпретироваться как регистр общего назначения, его абсолютный адрес указывается во втором байте команды. Сброс устанавливает все разряды В в «0».
Регистр-указатель данных DPTR - 16-разрядный регистр (DPH - старший байт, DPL - младший байт). Основное назначение регистра DPTR - участие в формировании адреса при чтении данных (не команд) из области памяти программ, а также при обмене с внешним ОЗУ данных. Система команд предусматривает возможность обращения к отдельным байтам (DPH или DPL) регистра DPTR, что позволяет использовать эти регистры для хранения промежуточных результатов вычислений или как источник одного из операндов, указывая во втором байте команды абсолютный адрес DPH или DPL. Сброс устанавливает все разряды DPTR в 0.
Программный счетчик РС-16-разрядный регистр, содержит адрес текущей команды либо адрес операнда, используемого в текущей команде. После сброса МК программный счетчик автоматически устанавливается в «0». Поэтому в МК с процессорным ядром MCS-51 любая программа пользователя должна начинаться с адреса 0000h.
Указатель стека SP- 8-разрядный регистр, содержит адрес верхушки стека. Архитектура процессорного ядра MCS-51 предполагает размещение области стековой памяти только в области внутреннего ОЗУ данных. Поэтому глубина стека ограничена объемом резидентного ОЗУ. Вызов подпрограммы использует 2 ячейки стека, прерывание -4 ячейки. При сбросе МК указатель стека устанавливается в состояние 07h, назначая область стека в первый банк регистров (регистр R7 нулевого банка имеет адрес 07h, при загрузке в стек содержимое указателя SP увеличивается на 1).
334
СЕМЕЙСТВО МК MCS-51 ФИРМЫ «INTEL»
Регистр признаков PSW- 8-разрядный регистр, содержит 7 флагов условий: переноса С, дополнительного переноса АС, переполнения OV, четности Р, два флага RS1 :RS0 для выбора текущего банка регистров, свободно программируемый пользователем флаг F0. Обратите внимание: в регистре признаков отсутствуют флаги нулевого результата Z и отрицательного результата N. Однако, если флаг N в архитектуре MCS-51 действительно отсутствует, то признак нулевого состояния аккумулятора (и только аккумулятора!) формируется, но не запоминается и в регистре признаков не отображается. Поэтому при составлении прикладной программы пользователя команды условного перехода по признаку Z (JZ и JNZ) должны быть выполнены сразу после команды действия над операндами, этот признак формирующей. Краткое описание логики установки «незнакомых» флагов:
P-флаг четности. Устанавливается в «1», если число единиц в аккумуляторе нечетное. При четном числе единиц в АСС сбрасывается. Все попытки принудительно установить флаг Р в состояние, которое не соответствует текущему состоянию аккумулятора АСС, будут безуспешными.
RS1:RS0-6umbi выбора банка регистров. Во избежание нежелательного изменения других битов регистра признаков рекомендуется производить модификацию номера банка с использованием команд битового процессора. Распределение регистров общего назначения приведено в табл. 4.5.
Таблица 4.5
Распределение регистров Rn по банкам » *
RS1 RS0 Номер банка Границы адресов IV <
0 0 0 00h...07h
0 1 1 08h...0Fh
1 0 2 10h...17h
1 1 3 18h...1Fh .'•Vi
F0 - флаг пользователя. Назначается пользователем по желанию. Изменение состояния F0 и ветвление по значению флага выполняются командами битового процессора.
Процессорное ядро MCS-51 может оперировать с тремя основными типами операндов: булевыми (1 бит), байтовыми (8 бит) и двухбайтовыми (16 бит). В операциях обмена тетрадами используется дополнительное представление информации полубайтами (4 бита). В МК с ядром MCS-51 используются следующие способы адресации:
• неявная (INH - Inherent);
• регистровая (REG - Register);
• непосредственная (IMM - Immediate); И,
• прямая (DIR - Direct);
• косвенная (IDIR - Indirect);
• относительная (REL - Relative).
К инструкциям с неявной адресацией относятся команды, которые не требуют для своего выполнения каких-либо операндов: RTI, NOP. Неявную адресацию имеют инструкции, которые содержат адрес операнда в коде команды, например, команда установки бита переноса SETB С или команды инкремента аккумулятора INC А и регистров INC Rn. Все команды с неявной адресацией имеют длину в 1 байт и состоят только из кода операции. Обратите внимание: мнемоника команды содержит имя регистра в поле операнда (А, Rn). Но при кодировании команды это имя будет помещено в байт кода операции.
335
8-РАЗРЯДНЫЕ МИКРОКОНТРОЛЛЕРЫ
Код операции команды с непосредственной адресацией размещается в первом байте. Сразу же за кодом операции следует 1 байт данных. Эти данные не могут быть изменены в ходе выполнения программы, так как они расположены непосредственно в памяти программ, т. е. в ПЗУ. Большинство команд с непосредственной адресацией имеют длину в 2 байта. Условное обозначение операнда в мнемонике команды - #d8:
Примеры.
ADD A,#d8 ADD А,#3
ORL A,#0Ah
; Запись команды сложения ADD с непосредственной адресацией в общем виде. ; Сложить содержимое аккумулятора АСС с числом 3,
; результат записать в АСС.
; Выполнить операцию поразрядного ИЛИ над содержимым АСС и
; шестнадцатеричным числом OAh. Результат записать в АСС.
Всего одна команда с непосредственной адресацией MOV DPTR,#d16 имеет трехбайтовый формат, поскольку выполняет загрузку данных в двухбайтовый регистр DPTR. MOV DPTR,#3400h ; Загрузить в регистр-указатель число 3400h
В командах с регистровой адресацией один из операндов находится в одном из регистров общего назначения Rn = RO - R7 банка, номер которого определяется разрядами RS1:RS0 регистра признаков PSW. Если команда производит действие над одним операндом, то формат команды однобайтовый. Номер регистра Rn определяется тремя младшими битами байта кода операции.
Примеры.
MOV A,Rn MOV A,R5
Двухадресные команды, которые используют регистровую адресацию вместе с непосредственной или прямой адресацией, имеют двухбайтовый формат команды.
Примеры.
MOV ad,Rn
; Запись команды загрузки аккумулятора АСС из регистра Rn в общем виде. ; Загрузить аккумулятор АСС операндом из регистра R5.
; Запись команды загрузки ячейки памяти с адресом ad из регистра Rn в общем ; виде.
; Загрузить ячейку памяти с адресом ЗОИ операндом из регистра R5.
; Загрузить в регистр R7 число 6.
MOV 30h,R5 MOV R7,#06
Команды с прямой адресацией имеют длину 2 байта. Первый байт предназначен для кода команды, второй байт содержит адрес ячейки резидентной памяти данных, где хранится операнд. Так как МК с ядром MCS-51 имеют адресное пространство внутренней памяти данных 00h - OFFh, то в использовании двухбайтового формата адреса нет необходимости. Условное обозначение адреса в мнемонике команды - ad.
Примеры.
ADD A,ad ADD A,31h
MOV add,ads
; Запись команды ADD с прямой адресацией в общем виде.
; Сложить содержимое аккумулятора АСС с содержимым ячейки ; резидентной памяти с адресом 31 h. Результат поместить в АСС. ; Переслать содержимое ячейки памяти с адресом ads в ячейку ; памяти с адресом add. Например: MOV 10h,21 h.
Команды с косвенной адресацией имеют длину 1 байт. В этом байте расположен код операции. Адрес операнда находится в регистре Ro или R1 текущего банка, если обмен или операция производится с внутренним ОЗУ данных. Обратите внимание, в качестве источника адреса операнда могут использоваться только регистры Ro и R1 (общее обозначение Ri), но не могут использоваться регистры R2- R7.
Примеры.
ADD A, @R0
; Сложить содержимое аккумулятора АСС с содержимым ячейки памяти, ; адрес которой находится в регистре R0.
336
СЕМЕЙСТВО МК MCS-51 ФИРМЫ «INTEL»
DEC @R1 ; Уменьшить на 1 содержимое ячейки памяти, адрес которой находится
; в регистре R1.
Косвенная адресация используется также для обращения к внешней памяти данных. Однако адрес ячейки внешней памяти должен быть двухбайтовым (см. рис. 4.3). Поэтому при использовании в качестве регистра-указателя R0 или R1 старший байт адреса должен быть предварительно загружен в порт Р2. При обращении к внешней памяти данных в качестве регистра-указателя может быть также использован двухбайтовый регистр DPTR. Тогда предварительное формирование старшего байта адреса в Р2 не требуется.
Примеры.
MOVXA, @R0 ; Переслать в ACC содержимое ячейки внешней памяти данных,
; старший байт адреса которой находится в Р2, младший байт -; в регистре R0 текущего регистрового банка. *
MOVX A,@DPTR ; Переслать в АСС содержимое ячейки внешней памяти данных,
; старший и младший байты адреса которой находятся в двух-; байтовом регистре DPTR.
Косвенная адресация используется также для чтения данных из памяти программ, в том числе для выборки элемента с порядковым номером из таблицы.
Примеры.
MOVC A, @A+DPTR ; Переслать в АСС содержимое ячейки памяти программ, адрес
; которой вычисляется сложением двухбайтового значения ; регистра-указателя DPTR с однобайтовым беззнаковым ; операндом из аккумулятора. Эту же операцию можно t .
; интерпретировать, как чтение элемента с номером i, который
;задан в аккумуляторе, из таблицы с начальным адресом, который Л,
; хранится в DPTR. >
MOVC А,@А+РС ; Переслать в АСС содержимое ячейки из области памяти
; программ, адрес которой равен текущему значению счетчика ; команд PC плюс значение операнда в аккумуляторе.
Относительная адресация используется только в командах условных переходов, которые используются для организации ветвления программ. Команды условных переходов имеют двухбайтовый формат или трехбайтовый формат. В командах типа «перейти по флагу» первый байт содержит код операции, а второй - смещение адреса следующей команды относительно адреса текущей команды в целочисленном формате со знаком. Диапазон возможных кодов смещения: от -128 до +127. В командах типа «выполнить действие и перейти по его результату» первый байт содержит код операции, второй байт -операнд для выполнения действия, третий байт - смещение адреса.
Если условие, заданное типом используемой команды условного перехода, выполняется, то адрес следующей команды центральный процессор вычисляет путем сложения текущего адреса с кодом смещения. Если условие не выполняется, то МК переходит к выполнению следующей команды.
При написании программ нет необходимости вычислять абсолютные коды смещения для команд условного перехода. Достаточно указать лишь метку, численное значение кода смещения вычислит программа Ассемблер.
Примеры.
JZ rel ; Перейти по метке rel, если значение аккумулятора АСС равно 0.
DJNZ ad,rel ; Вычесть 1 из содержимого ячейки памяти с адресом ad и перейти
; по метке, если в ячейке не 0.
337
8-РАЗРЯДНЫЕ МИКРОКОНТРОЛЛЕРЫ
4.2.3. СИСТЕМА КОМАНД МК СЕМЕЙСТВА MCS-51
Система команд MCS-51 включает 111 инструкций. Команды процессорного ядра MCS-51 имеют однобайтовый, двухбайтовый и трехбайтовый формат. Большинство команд (94) имеют формат один или два байта и выполняются за один или два машинных цикла. При тактовой частоте 12 МГц длительность машинного цикла составляет 1 мкс. Множество команд делится на 5 традиционных групп, каждая из которых рассмотрена ниже. Распределение команд по группам приведено в табл. 4.6.
Таблица4.6
Распределение команд ассемблера MCS-51 по типовым группам
Группа команд Число инструкций в группе
Команды передачи данных 28
Арифметические команды 24
Логические команды и команды сдвигов 25
Команды битового процессора 12
Команды управления ходом вычислительного процесса 22
Главная отличительная особенность системы команд ядра MCS-51 - наличие большого числа двухадресных команд передачи данных. Операнды под управлением одной команды могут перемещаться не только между одним из регистров центрального процессора и ячейкой памяти, но и между двумя ячейками памяти, которые адресуются различными способами. Множество сочетаний возможных способов адресации операндов в двухадресных командах обусловливает наличие 13 различных форматов команд (рис. 4.36). Первый байт команды всегда содержит код операции (КОП). Второй и третий байты содержат либо адреса операндов, либо сам операнд.
1 КОП |
2 КОП | I #4 I
3 КОП | I ad |
1 ,
4 КОП j 1 bit |
5 КОП i 1 rel |
6 аЮа9а8 | КОП | I a7 aO | i-i
0
7 КОП j 1 ad | I #d |
8 КОП | 1 ad | 1 rel |
9 КОП | | ads | | add |
10 КОП | 1 1 1 rel |
11 КОП | 1 bit | 1 rel |
12 КОП I | ad16h | | ad 161 |
13 коп j | #d16h | | #d16l |
Рис. 4.36. Форматы команд МК MCS-51
338
СЕМЕЙСТВО МК MCS-51 ФИРМЫ «INTEL»
Команды передачи данных. Команды этой группы осуществляют перемещение данных между ячейками памяти и регистрами центрального процессора, а также между двумя ячейками памяти, минуя регистры центрального процессора (табл. 4.7). Все команды данной группы не модифицируют флаги результата, за исключением команд загрузки регистра признаков PSW и аккумулятора (изменяется признак четности Р).
Таблица 4.7
Команды передачи данных
Мнемокод Операция Выполняемое действие Способ адресации Влияние на признаки
с AC OV
MOV А, ' MOV A, Rn MOV A, #d8 MOV A, ad MOV A, @Ri Загрузить в ACC константу или содержимое ячейки памяти А <= (М) А <= (Rn) А <= (d8) А <= (ad) А <= ((Ri)) REG IMM DIR IDIR - - -
MOV *,A MOV Rn, A MOV ad, A MOV @Ri, A Переслать содержимое АСС в ячейку памяти (М) <= А (Rn) <= А (ad) <= А ((Ri)) «= А REG DIR IDIR - - -
MOV *,* MOV Rn, #d8 MOV Rn, ad MOV ad, Rn MOV ad, #d8 MOV ad, @Ri MOV @Ri, #d8 MOV @Ri, ad MOV add, ads Переслать данные из одной ячейки памяти в другую (MLsnnato^ (М)«»™> (Rn) <= (d8) (Rn) <= (ad) (ad) <= (Rn) (ad) <= (d8) (ad) <= ((Ri)) ((Ri)) <= (d8) ((Ri)) «= (ad) (ad) <= (ad) REG/IMM REG/DIR DIR/REG DIR/IMM DIR/IDIR IDIR/IMM IDIR/DIR DIR/DIR - -
MOV MOV DPTR, #d16 Загрузить двухбайтовый регистр DPTR константой DPTR<=d16 IMM - - -
MOVC MOVC A, @A+DPTR MOVC A, @A+PC Переслать данные из памяти программм в АСС A <= (M) A<= (A)+(DPTR)) PC <= (PC)+1 А ь= ((A)+(PC)) IDIR IDIR - - -
MOVX A,* MOVX A, @Ri MOVX A, @DPTR Переслать данные из внецней памяти данных в АСС A<=(M) A «= ((Ri)) A <= (DPTR) IDIR IDIR - - -
MOVX *, A MOVX @Ri, A MOVX @DPTR, A Переслать данные из АСС во внецнюю память данных (M)<= A IDIR IDIR - - -
PUSH PUSH ad Загрузить в стек (SP) <= (SP)+1 (SP) <= (ad) INH - - -
POP POP ad Извлечь из стека (ad) <= (SP) (SP) <= (SP)-1 INH - - -
339
8-РАЗРЯДНЫЕ МИКРОКОНТРОЛЛЕРЫ
Продолжение табл. 4.7
Мнемокод Операция Выполняемое действие Способ адресации Влияние на признаки
с АС OV
хсн ХСН A, Rn ХСН A, ad ХСН A, @Ri Обмен аккумулятора с ячейкой памяти (А) <-> (М) (А) <-> (Rn) (А)«(ad) (А) «((Ri)) REG DIR IDIR - - -
XCHD XCHD A, @Ri Обмен младшей тетрады АСС с младшей тетрадой ячейки памяти (А),3 « ((Ri))0_3 IDIR - -
В зависимости от способа адресации и места расположения операнда можно выделить девять типов операндов, между которыми возможен обмен. Граф возможных операций передачи данных показан на рис. 4.37. Аккумулятор АСС представлен на этом графе отдельной вершиной, поскольку многие команды используют неявную адресацию аккумулятора (символ А присутствует в мнемонике команды, в то время как поле адреса аккумулятора отсутствует). Команды передачи данных допускают также прямую адресацию аккумулятора. Для этого его абсолютный адрес OEOh должен быть указан во втором или третьем байтах команды. Косвенная адресация по указателям @R0 и @R1 распространяется только на адресное пространство 00h...7Fh внутреннего ОЗУ. Регистры специальных функций и регистры центрального процессора (диапазон адресов 8Fh - OFFh) не могут быть адресованы косвенно.
Следует обратить внимание, что команды обращения к ячейкам внешней памяти (MOVX) и команды чтения из памяти программ (MOVC) отличаются от команд обмена с внутренним ОЗУ. Такое положение дел полностью соответствует теории: для обращения к ячейкам с одинаковыми адресами, но в разных массивах памяти должны быть сгенерированы разные сигналы управления. Следовательно, должны использоваться
разные команды.
Рис. 4.37. Пути передачи данных в МК MCS-51
340
СЕМЕЙСТВО МК MCS-51 ФИРМЫ «INTEL:
Арифметические команды. Данную группу образуют 24 команды (табл. 4.8), которые выполняют операции сложения (ADD и ADDC), вычитания (SUBB), инкремента и декремента (INC и DEC), умножения (MUL), деления (DIV) и десятичной коррекции (DAA). Команды сложения, вычитания, инкремента и декремента могут быть использованы с четырьмя различными способами адресации внутренней памяти. Команда инкремента выполняется также над двухбайтовым регистром DPTR. Арифметические действия с операндами из внешней памяти данных и памяти программ не производятся.
Команда умножения MUL выполняет операцию целочисленного беззнакового умножения. Сомножители расположены в регистрах АСС и В, двухбайтовое произведение в В.АСС. Время выполнения операции составляет 4 машинных цикла. Команда деления DIV выполняет целочисленное беззнаковое деление однобайтового делимого (АСС) на однобайтовый делитель (В). Целое частное расположено в АСС, остаток - в В. Время выполнения операции - 4 цикла.
Таблица 4.8
Арифметические команды
Мнемокод Операция Выполняемое действие Способ адресации Влияние на признаки
с AC OV
ADD ADD A, Rn ADD A, #d8 ADD A, ad ADD A, @Ri Сложить содержимое аккумулятора АСС с байтом данных памяти М (или константой). Результат поместить в АСС А <= (А)+(М) А <= (A)+(Rn) А «= (A)+(d8) А «= (A)+(ad) А <= (A)+((Ri)) REG IMM DIR IDIR $ I I
ADDC ADDC A, Rn ADDC A, #d8 ADDC A, ad ADDC A, @Ri Сложить содержимое аккумулятора АСС с байтом данных памяти М (или константой) и значением бита переноса С. Результат поместить в АСС А <= (А)+(М)+(С) А «= (A)+(Rn)+(C) А «= (A)+(d8)+(C) А ф= (A)+(ad)+(C) А <= (A)+((Ri))+(C) REG IMM DIR IDIR $ I I
SUBB SUBB A, Rn SUBB A, #d8 SUBB A, ad SUBB A, @Ri Вычесть байт данных памяти М (или константу) и значение признака С (заем) из содержимого аккумулятора АСС. Результат поместить в АСС А <= (А)-(М)-(С) А <= (A)-(Rn)-(C) А «= (A)-(d8)-(C) А <= (A)-(ad)-(C) А <= (A)-((Ri))-(C) REG IMM DIR IDIR I $ I
MUL AB Умножить содержимое АСС на содержимое регистра В. Произведение представлено в двухбайтовом формате. Старший байт произведения содержится в регистре В, младший байт - в АСС В:А<=(В) х (А) INH $ $ I
DIV AB Разделить однобайтовое делимое (АСС) на однобайтовый делитель (В). Целое частоное помещается в АСС, остаток отделения - в В А<= (А)/(В) В <= Remainder INH $ $ I
341
8-РАЗРЯДНЫЕ МИКРОКОНТРОЛЛЕРЫ
Продолжение табл. 4.8
Мнемокод Операция Выполняемое действие Способ адресации Влияние на признаки
с AC ov
INC INC А INC Rn INC ad INC @Ri INC DPTR Увеличить на единицу содержимое аккумулятора АСС или ячейки памяти М М 4= (М)+$01 А <= (А)+$01 Rn <= (Rn)+$01 ad (ad)+$01 (Rj) <= ((Ri))+$01 DPTR <= (DPTR)+$01 INH REG DIR IDIR INH I I I
DEC DEC A DEC Rn DEC ad DEC @Ri Уменьшить на единицу содержимое аккумулятора АСС или ячейки памяти М M (M)-$01 A (A)-$01 Rn «= (Rn)-$01 ad <= (ad)—$01 (Ri) 4= ((Ri))—$01 INH REG DIR IDIR I $ I
DAA Десятичная коррекция аккумулятора (A)10 INH I I I
Логические команды и операции сдвига. Данную группу образует 25 команд. Выполняются операции логического И, ИЛИ, Исключающего ИЛИ, операции очистки и инверсии аккумулятора, различные операции сдвига. Логические команды модифицируют только флаг7, команды сдвига - флаги С и Z. Типы инструкций данной группы приведены в табл. 4.9 и 4.10.
Логические команды
Таблица 4.9
Мнемокод Операция Выполняемое действие Способ адресации Влияние на признаки
с AC ov
ANL ANL A, Rn ANL A, #d8 ANL A, ad ANL A, @Ri ANL ad, A ANL ad, d8 Поразрядное логическое & над содержимым аккумулятора АСС и байтом данных М. Результат поместить в АСС. Две последние команды результат помещают в прямоадресуемую ячейку памяти А <= (А) & (М) А <= (А) & (Rn) А 4= (А) & (d8) А <= (А) & (ad) А <= (А) & ((RI)) ad «= (ad) & (А) ad (ad) & (d8) REG IMM DIR IDIR DIR DIR/IMM - - -
ORL ORL A, Rn ORL A, #d8 ORL A, ad ORL A, @Ri ORL ad, A ORL ad, d8 Поразрядное логическое ИЛИ над содержимым аккумулятора АСС и байтом данных М. Результат поместить в АСС. Две последние команды результат помещают в прямоадресуемую ячейку памяти A 4= (A) | (M) A 4= (A) I (Rn) A <= (A) I (d8) A <= (A) I (ad) A <= (A) I ((Ri)) ad <= (ad) I (A) ad <= (ad) I (d8) REG IMM DIR IDIR DIR DIR/IMM - - -
XRL XRL A, Rn XRL A, #d8 XRL A, ad XRL A, @Ri XRL ad, A XRL ad, d8 Поразрядное исключающае ИЛИ над содержимым аккумулятора АСС и байтом данных М. Результат поместить в АСС. Две последние команды результат помещают в прямоадресуемую ячейку памяти A 4= (А) Ф (M) A <= (А) Ф (Rn) A 4= (А) Ф (d8) A 4= (А) Ф (ad) A <= (А) Ф ((Ri)) ad 4= (ad) Ф (A) ad 4= (ad) Ф (d8) REG IMM DIR IDIR DIR DIR/IMM - - -
342
СЕМЕЙСТВО МК MCS-51 ФИРМЫ «INTEL»
Продолжение табл. 4.9
Мнемокод Операция Выполняемое действие Способ адресации Влияние на признаки
с АС OV
CPLA Инверсия содержимого аккумулятора АСС А <= (А) INH - - -
CLR А Очистить (установить в «0») аккумулятор АСС А <=$00 INH - - -
SWAP А Поменять местами тетрады (полубайты) аккумулятора АСС А <= (А[3:0]:А[7:4]) INH - - -
Команды битового процессора. Данную группу образуют 12 команд (табл. 4.11). Совокупность этих команд называют битовым процессором. Наличие команд битового процессора позволяет существенно сократить управляющие программы по объему кода и времени выполнения. Обратите внимание, что прямоадресуемые биты находятся только в части ячеек внутреннего ОЗУ и в регистрах специальных функций. Аккумулятор АСС, регистр В и регистор признков PSW также имеют побитный доступ (см. рис. 4.34).
Команды условного перехода по значениям отдельных битов JB и JNB могут быть отнесены как к группе команд битового процессора, так и к группе команд управления. Поэтому последние приведены в следующем разделе.
Команды передачи управления. Группа команд передачи управления является самой многочисленной группой. Она содержит 40 инструкций, которые делятся на две
подгруппы: _(
1) команды условных и безусловных переходов (табл. 4.12);
2) команды вызова подпрограмм и обслуживания прерываний (табл. 4.13). "I
Таблица 4.10
Команды сдвигов
Мнемокод Операция Выполняемое действие Способ адресации Влияние на признаки
с АС OV
RLA Сдвиг аккумулятора влево циклический (Ал<1) «= (А„) для п = 0+6 (Л,) «= (А,) INH - -
RR А Сдвиг аккумулятора вправо циклический (А„) <= (Ал.,) для п = 0+6 (А,)*=(^) INH - -
RLC А Сдвиг аккумулятора влево через перенос (А ,) <= (А„) для п = 0+6 (Л,) *= (С) (С) <= (А,) INH - -
RRC А Сдвиг аккумулятора вправо через перенос (А) <= (А„41) для п = 0+6 (А.) *= (С) (С) <= INH - -
343
8-РАЗРЯДНЫЕ МИКРОКОНТРОЛЛЕРЫ
Таблица 4.11
Команды битового процессора
Мнемокод Операция Выполняемое действие Способ адресации Влияние на признаки
с АС OV
SETB ЬП Установить бит в «1 «.Данные могут располагаться в ячейке внутреннего ОЗУ или регистре специальных функций. В команде используется только прямая адресация. Диапазон адресов битов $00-$FF в «= 1 DIR - - -
CLR ЬП Установить битв «0» (очистить). Диапазон адресов битов $00-$FF в <=0 DIR - - -
CPL ЬП Инвертировать бит. Диапазон адресов битов $00-$FF ь <= ь DIR
SETB С Установить в «1» бит переноса С с 4= 1 INH 1 - -
CLRC Установить в «0» бит переноса С с «=0 INH 0 - -
CPLC Инвертировать бит переноса с <=с INH I - -
ANL С,bit Логическое И бита и переноса с <= с & ь DIR I - -
ANL С,/bit Логическое И инверсии бита и переноса с с= с & ь DIR I - -
ORL С,bit Логическое ИЛИ бита и переноса с с= с| ь DIR I - -
ORL С,/bit Логическое ИЛИ инверсии бита и переноса с с= Cl ь DIR I - -
MOV С,ЬИ Пересылка бита в перенос с 4= Ь DIR $ - -
MOV ЬИ,С Пересылка переноса в бит ь s=C DIR - - -
Центральный процессор MCS-51 может использовать три команды условного перехода: традиционную трехбайтовую команду (длинный переход - LongJMP) и две двухбайтовые команды - AJMP и SJMP. При написании программ на языке Ассемблера допускается употребление мнемоники JMP. Транслятор с языка Ассемблера выберет вариант с меньшим временем реализации.
Группа команд ветвления позволяет выполнить переходы по значениям бита переноса С и флага нулевого результата в аккумуляторе Z, а также по значению прямоадресуемого бита. Особое внимание следует обратить на команды CJNZ и DJNZ. Первая (CJNZ) позволяет сравнить два операнда и перейти по метке в случае неравенства. Вторая (DJNZ) предназначена для организации циклов: содержимое счетчика циклов уменьшается на единицу и осуществляется переход по метке, если результат не равен нулю.
344
СЕМЕЙСТВО МК MCS-51 ФИРМЫ «INTEL:
Таблица 4.12
Команды условных и безусловных переходов
Мнемокод Операция Выполняемое действие Способ адресации Влияние на признаки
с АС OV
Команды безусловного перехода
LJMP LJMP ad16 Безусловный переход в полном объеме памяти программ (64 Кбайт) PC ad16 DIR - - -
AJMP AJMP ad11 Безусловный переход внутри страницы 2 Кбайт PC (PC) + 2 (PC,,0)<=ad11 DIR - - -
SJMP SJMP rel Безусловный переход внутри страницы 256 байт PC (PC) + 2 PC «= (PC) + rel REL - - -
JMP JMP @A+DPTR Косвенный относительный переход (PC) <= (A) + (DPTR) REL - - -
NOP Пустая операция. Счетчик команд PC увеличивается на единицу. Другие регистры не изменяются None INH - - -
Команды ветвления
JC JC rel Перейти по метке, если бит переноса С установлен. Иначе перейти к следующей команде PC <= (PC)+2+rel&(C) REL - - -
JNC JNC rel Перейти по метке, если бит переноса С сброшен. Иначе перейти к следующей команде PC c= (PC)+2+rel&(C) REL - - -
JZ JZ rel Перейти по метке, если АСС=0. Иначе перейти к следующей команде PC «= (PC)+2+rel&(Z) REL - - -
JNZ JNZ rel Перейти по метке, если АС £ 0. Иначе перейти к следующей команде PC «= (PC)+2+rel&(Z) REL - - -
CJNE CJNE A,#d8,rel CJNE A,ad,rel CJNE Rn,#d8,rel CJNE @Ri,#d8,rel Сравнить содержимое аккумулятора АСС с содержимым ячейки памяти М (или константой) и перейти по метке, если не равны PC <=(PC)+3+rel если условие выполнено, иначе РС<=(РС) + 3 INH/IMM/REL INH/DIR/REL REG/IMM/REL IDIR/IMM/REL - -
345
8-РАЗРЯДНЫЕ МИКРОКОНТРОЛЛЕРЫ
Продолжение табл. 4.12
Мнемокод Операция Выполняемое действие Способ адресации Влияние на признаки
с АС OV
Команды ветвления
DJNZ DJNZ Rn.rel DJNZ ad.rel Вычесть единицу из содержимого ячейки памяти М и перейти по метке, если результат не равен нулю РС «= (PC)+3+rel если не равно 0, иначе РС <=(РС) + 3 REG/REL DIR/REL - - -
JB JB bit.rel Перейти по метке, если бит установлен. Иначе перейти к следующей команде. Диапазон адресов битов $00- $FF РС <= (PC)+3+rel&(b) DIR/REI - - -
JNB JNB bit.rel Перейти по метке, если бит сброшен. Иначе перейти к следующей команде. Диапазон адресов битов $00 - $FF РС «= (PC)+3+rel&(b) DIR/REI - - -
JBC JBC bit.rel Перейти по метке с последующим сбросом бита, если бит установлен. Иначе перейти к следующей команде. Диапазон доресов битов $00 - $FF РС с= (PC)+3+rel&(b) С <= 0 DIR/REI - -
Подобно командам безусловного перехода, центральный процессор MCS-51 имеет две команды вызова подпрограмм: трехбайтовую LCALL и двухбайтовую ACALL. При составлении исходного текста прикладной программы можно использовать аббревиатуру CALL. Транслятор с языка Ассемблера подставит необходимый код в зависимости от расположения вызываемой программы в кодовом сегменте.
Особое внимание следует обратить на команду выхода из подпрограммы прерывания RTI. На первый взгляд, ее действие ничем не отличается от команды RET. Однако в дополнение к последней команда RTI восстанавливает программно недоступный триггер разрешения прерывания, который автоматически сбрасывается при входе в подпрограмму прерывания.
Таблица 4.13
Команды вызова подпрограмм и обслуживания прерываний
Мнемокод Операция Выполняемое действие Способ адресации Влияние на признаки
с АС OV
Команды безусловного перехода
LCALL LCALL ad 16 Длинный вызов подпрограммы. Адрес начала подпрограммы может находиться в полном объеме памяти программ (64 Кбайт) РС = РС + 3 SP = SP +1 (SP) «= PCL SP = SP + 1 (SP)<=PCH PC <=ad16 DIR - -
346
СЕМЕЙСТВО МК MCS-51 ФИРМЫ «INTEL,
Продолжение табл. 4.13
Мнемокод Операция Выполняемое действие Способ адресации Влияние на признаки
с АС OV
Команды безусловного перехода
ACALL ACALL ad11 Абсолютный вызов подпрограммы в пределах страницы 2 Кбайт PC = РС + 2 SP = SP + 1 (SP) «= PCL SP = SP + 1 (SP)t=PCH PC0.10«=ad11 DIR - - -
RET Возврат из подпрограммы. Адрес возврата загружается из стека в счетчик команд PCH t=(SP) SP = SP - 1, PCL «= (SP) SP = SP - 1 INH - - -
RETI Возврат из прерывания. Восстанавливается содержимое счетчика команд PCH «= (SP) SP =SP - 1, PCL^(SP) SP = SP - 1 Восстанавливается триггер разрешения прерывания INH
4.2.4. СИСТЕМА ПРЕРЫВАНИЙ
Система прерываний МК 8051 АН включает пять источников - два внешних и три внутренних. Внешние запросы поступают на входы INT0/P3.2 и INT1/P3.3, внутренние запросы формируются модулями таймеров Таймер 0 и Таймер 1, а также контроллером последовательного интерфейса. В процессе формирования запроса на прерывание каждый источник запроса выставляет в «1» специальный флаг. Этот флаг вызовет генерацию запроса на прерывание, если прерывания от данного источника разрешены. В подпрограмме обслуживания прерывания флаг-источник запроса-должен быть сброшен. Если же прерывания отданного источника запрещены, то логика установки флага запроса не изменяется, но обслуживаться данный флаг должен только программно, без использования аппаратных средств подсистемы прерывания.
Для формирования внешнего запроса на прерывание необходимо установить активный уровень сигнала на одном из входов: INT0/P3.2 или INT1/P3.3 (см. рис. 4.32). Распознавание микроконтроллером активного уровня сопровождается установкой триггеров запроса внешних прерываний IE0 и IE1 в регистре управления таймера TCON (см. табл. 4.19). Прерывания по входу INT0/P3.2 разрешает флаг ЕХО регистра разрешения прерываний IE, по входу INT 1/РЗ.З - флаг ЕХ1 того же регистра (см. табл. 4.15). Каждый из входов - INT0/P3.2 или INT1/P3.3 - может быть программно настроен на один из двух режимов распознавания сигнала запроса:
1) Активным является низкий уровень сигнала. Он должен удерживаться на входе до начала обслуживания микроконтроллером данного запроса. Далее сигнал должен стать пассивным до завершения процедуры обслуживания. В противном случае триггер запроса на прерывание будет установлен повторно. Описанная логика установки триггера внешнего прерывания получила название статического режима распознавания запроса.
347
8-РАЗРЯДНЫЕ МИКРОКОНТРОЛЛЕРЫ
2) Активным является перепад сигнала с «1» на «О». Для распознавания запроса высокий и низкий уровни сигнала должны быть длительностью не менее одного машинного цикла каждый. По истечении одного машинного цикла после перепада сигнала внешнего запроса с «1» на «О» устанавливается в «1» один из флагов ЕХО или ЕХ1. После этого уровень сигнала внешнего запроса может быть произвольным. Даже если он остался низким после завершения процедуры обслуживания прерывания, то повторной установки флагов ЕХО или ЕХ1 не произойдет. Следующий запрос будет воспринят МК только если сигнал на входе INTO или INT1 установится в «1», а затем опять в «О». Описанная логика установки триггера запроса на прерывание носит название динамического режима распознавания запроса.
Выбор режима распознавания внешнего запроса определяют биты IT0 и IT1 регистра TCON (см. табл. 4.19). Если выбран статический режим распознавания внешнего запроса, то установленные триггеры ЕХО и ЕХ1 должны быть сброшены в подпрограмме обслуживания соответствующего прерывания. Для этой цели наиболее удобно использовать команды битового процессора: CLR ЕХО и CLR ЕХ1. Если выбран динамический режим распознавания внешнего запроса, то триггеры ЕХО и ЕХ1 сбрасываются автоматически при переходе на соответствующую подпрограмму прерывания.
Модули таймеров таймер 0 и таймер 1 используют для формирования запросов на прерывания триггеры переполнения TF0 и TF1 регистра TCON (см. табл. 4.19). При переходе к выполнению соответствующей подпрограммы прерывания эти флаги сбрасываются автоматически. Поэтому нет необходимости предусматривать специальные команды для сброса флагов TF0 и TF1. Прерывания по переполнению таймера 0 разрешает флаг ЕТО регистра разрешения прерывания IE, по переполнению таймера 1 - флаг ЕТ1 того же регистра (см. табл. 4.15).
Модуль последовательного порта выставляет два флага, которые могут генерировать запросы на прерывание. Это триггеры TI и RI регистра SCON. Первый формируется по окончании передачи байта данных, второй - по окончании приема очередного байта. Флаги генерируют один общий запрос на прерывание. В подпрограмме обслуживания прерывания следует проанализировать, какой из триггеров вызвал формирование запроса на прерывание, и сбросить его. Если к моменту перехода на подпрограмму прерывания установленными оказались сразу оба флага TI и RI, то удобно производить обслуживание последовательного порта, прерываясь дважды. В первой подпрограмме прерывания распознается один из флагов, например TI. Выполняются действия по загрузке нового байта в регистр данных последовательного передатчика и сбрасывается флаг TI. Первая подпрограмма прерывания завершается командой RETI. Так как флаг RI остался в «1», то генерируется новый запрос на прерывание от последовательного порта и в соответствующей подпрограмме прерывания обслуживается блок приемника данного модуля. Перед завершением подпрограммы прерывания сбрасывается флаг RI. Прерывания по запросу последовательного порта разрешает флаг ES регистра IE.
Все рассмотренные прерывания могут быть вызваны или отменены программой, поскольку перечисленные флаги запросов программно доступны и могут быть установле-ны/сброшены программой так же, как и аппаратными средствами МК.
Сформированные посредством установки триггеров запросы на прерывание поступают в центральный процессор. Эти запросы могут быть приняты к обработке, если триггер ЕА регистра IE установлен в «1», или обработка запросов будет задержана до тех пор, пока триггер ЕА будет находиться в «О». Триггер ЕА устанавливается и сбрасывается только программно. Таким образом, команда SETB ЕА эквивалентна команде «разрешить прерывания», а команда CLR ЕА - команде «запретить прерывания». Если прерывания центрального процессора разрешены, то МК завершает выполнение текущей ко
348
СЕМЕЙСТВО МК MCS-51 ФИРМЫ «INTEL»
манды, сравнивает уровни приоритетов в случае одновременного поступления нескольких запросов и формирует внутренними аппаратными средствами код команды LCALL. Двухбайтовый адрес команды LCALL соответствует вектору прерывания с наивысшим приоритетом. МК с ядром MCS-51 имеют фиксированные векторы прерывания. Абсолютные значения векторов прерывания для каждого из источников, соответствующие им триггеры запросов и флаги битов разрешения прерывания приведены в табл. 4.14.
Таблица 4.14
Таблица векторов прерывания и сброса МК 8051 АН
Источник события прерывания или сброса Вектор сброса ИЛИ прерывания Триггер запроса на прерывание Общий бит разрешения прерывания Индивидуальный бит разрешения прерывания Приоритет
Вектор сброса OOOOh Сигнал сброса формируется аппаратно МК переходит в режим сброса немедленно после подачи сигнала на вход RST. Выполнение любой программы немедленно прекращается
Вектор прерывания по внешнему запросу INTO 0003h IE0 регистра TCON ЕА ЕХО регистра IЕ Высший Л Низший
Вектор прерывания по переполнению счетчика таймера 0 OOOBh TF0 регистра TCON ЕА ЕТО регистра IE
Вектор прерывания по внешнему запросу INT1 0013h IE1 регистра TCON ЕА ЕХ1 регистра IЕ
Вектор прерывания по переполнению счетчика таймера 1 001Bh TF1 регистра TCON ЕА ЕТ1 регистра IE
Вектор прерывания по запросу последовательного порта 0023h TI, RI регистра SCON ЕА ES регистра IЕ
Запрос на прерывание не обслуживается центральным процессором и откладывается на более позднее время в следующих случаях:
• текущий цикл не является последним циклом команды;
• выполняется процедура обслуживания прерывания с более высоким приоритетом;
• выполняется команда RETI, команды обращения к регистрам специальных функций подсистемы прерывания IE и IP.
Если флаг прерывания был установлен, но не получил обслуживания, а к моменту снятия блокировки прерываний был сброшен, то запрос на прерывание теряется.
При появлении запросов от нескольких источников очередность их обслуживания определяется механизмом приоритетов. В МК с ядром MCS-51 реализована двухступенчатая система приоритетов. Все запросы подразделяются на две группы: с высоким или с низким уровнем приоритета. Принадлежность к той или иной группе определяется значением битов регистра приоритетов IP (табл. 4.16). Если бит регистра IP равен 1, то
349
8-РАЗРЯДНЫЕ микроконтроллеры
соответствующий источник запроса относится к группе с высоким приоритетом, если 0-то с низким. Действие механизма приоритетных прерываний в MCS-51 заключается в выборе одного из источников при одновременном появлении нескольких запросов а также в принятии решения о прерывании подпрограммы обслуживания другого прерывания при поступлении нового запроса. При одновременном появлении нескольких запросов сначала обслуживаются запросы группы с высоким приоритетом, а затем группы с низким приоритетом. Внутри каждой группы распределение приоритетов фиксировано в соответствие с табл. 4.14. Механизм приоритетных прерываний использует два программно-недоступных триггера уровня обслуживаемого прерывания. Переход к подпрограмме обслуживания запроса сопровождается установкой триггера того уровня приоритета, к которому относится запрос. При установленном триггере низшей группы запрос высшей группы вызовет прерывание подпрограммы обслуживания прерывания. Команда RETI в конце процедуры обслуживания сбрасывает триггер своего уровня. В этом отличие команды возврата из прерывания RETI от команды возврата из подпрограммы RET.
Процесс выполнения команды LCALL сопровождается загрузкой в стек содержимого счетчика команд PC (адрес следующей команды). Сохранение в стеке других регистров МК может быть выполнено в подпрограмме прерывания с использованием команды PUSH. В конце подпрограммы прерывания эти регистры должны быть восстановлены из стека командами POP. Однако следует иметь в виду, что программное сохранение в стеке регистров значительно увеличивает время реакции на прерывание. Минимальное время перехода к подпрограмме прерывания составляет 3 машинных цикла. Последней командой каждой подпрограммы прерывания должна быть команда RETI, которая восстанавливает из стека адрес следующей команды прерванной программы и очищает флаг блокировки прерываний своего уровня.
Непосредственно к подсистеме прерывания относятся два регистра специальных функций:
IE - регистр разрешения прерываний;
IP - регистр приоритетов прерываний.
Форматы этих регистров приведены в табл. 4.15 и 4.16. Кроме этого, в обслуживании прерываний используются биты регистров управления таймерами TCON и портом последовательного ввода/вывода SCON.
Таблица 4.15
Формат регистра IE
IE | Регистр разрешения прерываний
7 Адрес 0A8h 6 5 4 3 2 1 0
еа I | | ES | ЕТ1 | EX1 | ЕТО | EXO
Состояние при сбросе: OOh
Имя бита Назначение бита
ЕА Глобальная маска прерывания. Сбрасывается программно для запрета всех прерываний, независимо от значения IE4 - IE0
ES Бит разрешения прерывания по запросу от последовательного порта. Устанавливается/ сбрасывается программно для разрешения/запрета прерывания по флагам TI и RI
ЕТ1 Бит разрешения прерывания по запросу таймера 1. Устанавливается/сбрасывается программно для разрешения/запрета прерывания по флагу TF1
EX1 Бит разрешения внешнего прерывания по запросу на входе INT1. Устанавливается/ сбрасывается программно для разрешения/запрета прерывания по флагу IЕ1
ЕТО Бит разрешения прерывания по запросу таймера 0. Устанавливается/сбрасывается программно для разрешения/запрета прерывания по флагу TF0
EX0 Бит разрешения внешнего прерывания по запросу на входе INTO. Устанавливается/ сбрасывается программно для разрешения/запрета прерывания по флагу IE0
350
СЕМЕЙСТВО МК MCS-51 ФИРМЫ «INTEL»
Таблица 4.16
Формат регистра IP
IP | Регистр приоритетов прерываний
7 Адрес OBBh 6 5 4 3 2 1 0
~ - I | - | PS | РТ1 | РХ1 | РТО | РХО
Состояние при сбросе: 00h
Имя бита Назначение бита
PS Бит приоритета последовательного порта. Устанавливается/сбрасывается программно для присвоения данному прерыванию высшего/низшего приоритета
РТ1 Бит приоритета таймера 1. Устанавливается/сбрасывается программно для присвоения данному прерыванию высшего/низшего приоритета
РХ1 Бит приоритета внешнего прерывания 1 (по входу INT1). Устанавливается/сбрасывается программно для присвоения данному прерыванию высшего/низшего приоритета
РТО Бит приоритета таймера 0. Устанавливается/сбрасывается программно для присвоения данному прерыванию высшего/низшего приоритета
РХО Бит приоритета внешнего прерывания 0 (по входу INTO). Устанавливается/сбрасывается программно для присвоения данному прерыванию высшего/низшего приоритета
4.2.5. ПОРТЫ ВВОДА/ВЫВОДА МК 8051 АН
Линии ввода/вывода МК 8051 АН сгруппированы в четыре 8-разрядных параллельных порта Р0, Р1, Р2 и РЗ. Эти порты могут использоваться как для обмена данными с внешними устройствами в параллельном коде, так и для выполнения альтернативных функций. Спецификация линий ввода/вывода МК 8051АН приведена в табл.4.17.
Таблица 4.17
Спецификация линий портов
Имя порта Альтернативная функция Схемотехника линий Адрес регистра данных портов
Р0 Мультиплексированная магистраль адрес/ данные (при использовании внешней памяти данных или программ) Двунаправленные 80h
Р1 - Квазидвунаправленные 90h
Р2 Магистраль адреса - старший байт (при использовании внешней памяти данных или программ) Квазидвунаправленные AOh
РЗ Каждая из линий специфицирована индивидуально: РЗ.О - вход приемника последовательного порта RXD Р3.1 - выход передатчика последовательного порта TXD Р3.2 - вход внешнего запроса INTO РЗ.З - вход внешнего запроса INT1 Р3.4 - внешний вход таймера ТО Р3.5 - внешний вход таймера Т1 Р3.6 - сигнал магистрали управления WR Р3.7 - сигнал магистрали управления RD Последние два сигнала используются при адресации внешней памяти данных Квазидвунаправленные BOh
351
8-РАЗРЯДНЫЕ микроконтроллеры
При использовании по своему прямому назначению каждая линия любого порта может быть задействована для ввода или для вывода информации независимо от направления передачи других линий этого же порта. Каждый порт отображается в карте памяти МК регистром специальных функций с тем же именем (РО, Р1, Р2, РЗ). Для обращения к портам ввода/вывода следует использовать те же команды, что и для регистров специальных функций с побитным доступом, например:
MOV А,Р1 ; Считать состояние линий порта Р1 и переслать данные в АСС.
MOV P3,#67h ; Выдать на линии порта РЗ код 67h.
SETB Р0.2 ; Установить в 1 линию 2 порта РО.
Обратите внимание: обращаться к регистрам данных портов РО - РЗ следует с использованием прямой адресации. Как и для других регистров специальных функций, обращение с использованием косвенной адресации по указателям @R0 и @R1 не приведет к успеху. Все регистры данных портов допускают прямую побитную адресацию. Отдельные линии портов ввода/вывода могут быть установлены и сброшены с использованием команд битового процессора.
На рис. 4.3 и 4.4 приведены функциональные схемы аппаратных средств для одной линии портов РО и РЗ. Порты Р1 и Р2 имеют такую же схемотехнику, что и порт РЗ. Все линии портов имеют защелки на основе D-триггеров, которые объединены в группы по восемь и составляют регистры данных портов РО - РЗ. Драйвер каждой линии имеет в своем составе также формирователь выходного уровня и входной буфер. Из рис. 4.3 следует, что на внутреннюю магистраль данных может быть прочитано как состояние линии ввода, так и содержимое одноименного разряда защелки. Часть МК во время выполнения читают именно защелку. Такие команды относятся к группе команд «чтение-модификация-запись». Режим «чтение-модификация-запись» автоматически реализуется, когда порт одновременно является операндом и местом назначения результата, например:
ANL Р1,А ORL Р2,А XRL РЗ,А JBC Р2.3,Label ; Логическое И над содержимым порта Р1 и АСС. Результат - в порт. ; Логическое ИЛИ над Р2 и АСС. Результат - в порт Р2. ; Исключающее ИЛИ над РЗ и АСС. Результат - в порт РЗ. ; Переход, если в адресуемом бите Р2.3 единица и последующий сброс ; этого бита.
INC РО DEC Р1 DJNZ Р2, Label SETB Р1.2 CLR P1.3 ; Инкремент порта РО. ; Декремент порта Р1. ; Декремент порта Р2 и переход, если его содержимое не равно 0. ; Установить бит Р1.2. ;Сбросить бит Р1.3.
Последние две команды также относятся к рассматриваемой группе, хотя это и не очевидно.
Порты ввода/вывода МК 8051АН не имеют специальных регистров направления передачи данных. Для перевода линии в режим ввода следует записать в ее защелку «1». При этом нижний транзистор драйвера линии перейдет в закрытое состояние и не будет влиять на уровень сигнала входной линии. При этом у портов Р1, Р2, и РЗ линия поддтягивается внутренним резистором RPULLUP к уровню «1», но может быть переведена в «О» внешним источником сигнала (рис. 4.4). Благодаря такой схемотехнике линии портов Р1, Р2, и РЗ получили название «квазидвунаправленных». Драйверы линий порта РО, кроме нижнего, имеют также и верхний транзистор. Поэтому линии порта РО являются действительно двунаправленными.
Для выполнения альтернативных функций линиями порта РЗ следует в соответствующий разряд регистра порта записать «1». Во время обращения к внешней памяти
352
СЕМЕЙСТВО МК MCS-51 ФИРМЫ «INTEL»
во все разряды порта РО автоматически записываются «1», значения защелок порта Р2 не изменяются. Нагрузочная способность линий портов МК 8051 АН невелика: выходные линии портов Р1, Р2, РЗ могут работать на одну TTL-схему, линии порта РО - на две.
4.2.6. ТАЙМЕРЫ
Микроконтроллер 8051 АН имеет два 16-разрядных таймера-счетчика, которые именуют таймер 0 и таймер 1. Каждый из них может работать как в режиме программируемого таймера, так и в режиме счетчика событий (см. п. 4.1.6). При работе в режиме таймера на вход счетчика поступает импульсная последовательность с частотой f т. е. период тактирования счетчика равен длительности машинного цикла. При работе в режиме счетчика событий на вход счетчика таймера поступает импульсная последовательность со входов Т0/Р3.5 и Т1/Р3.6 соответственно. Максимальная частота этой внешней последовательности импульсов составляет fBUS/2. Каждый из модулей таймер 0 или таймер 1 - имеет четыре режима работы.
В режиме 0 модуль таймера представляет собой 8-разрядный счетчик ТНх, на вход которого поступает импульсная последовательность с выхода программно недоступного делителя на 32 (х - номер модуля таймера, ТНО для таймера 0, ТН1 для таймера 1). Последний выполнен на основе младшего байта счетчика TLx (рис. 4.38). При переполнении счетчик ТНх изменяет состояние с OFFh на OOh и продолжает счет. Одновременно устанавливается триггер переполнения TFx. Коэффициент счета счетчика в режиме 0 составляет 256. Изменение коэффициента счета требует записи начального кода под управлением прикладной программы каждый раз после наступления события переполнения.
В режиме 1 таймер представляет собой 16-разрядный счетчик. Регистр ТНх - старший байт этого счетчика, TLx - младший байт (рис. 4.39). При переполнении состояние счетчика изменяется с FFFFh нв OOOOh, устанавливается триггер переполнения TFx, 16-разрядный счетчик продолжает счет поступающих импульсов. Коэффициент счета счетчика в режиме 1 составляет 216. Как и в режиме 0, изменение этого коэффициента требует «программного вмешательства» на каждом периоде работы счетчика.
В режиме 2 работа таймера организована таким образом, что переполнение 8-раз-рядного счетчика TLx приводит не только к установке флага TFx, но и автоматически перезагружает в TLx содержимое старшего байта счетчика таймера ТНх, которое было задано предварительно (рис. 4.40). Перезагрузка оставляет содержимое ТНх неизмен-
INT / Р3.2(3)
Рис. 4.38. Структура таймера-счетчика в режиме 0
353
8-РАЗРЯДНЫЕ микроконтроллеры
Рис. 4.39. Структура таймера-счетчика в режиме 1
ным. В этом режиме появляется возможность задания пользователем коэффициента счета счетчика в диапазоне от 1 до 256. При этом в процессе работы счетчик не будет требовать программного обслуживания, если коэффициент счета не изменяется.
В режиме 3 может работать только таймер 0, таймер 1 блокирован, как если бы бит разрешения работы таймера 1 TR1 был сброшен. Таймер 0 распадается на два независимых 8-разрядных счетчика, причем TLO управляется битами управления таймера О, а ТНО - битами управления таймера 1 (рис. 4.41).
Режимы работы таймеров задают два регистра специальных функций:
TMOD - регистр режима работы таймеров-счетчиков;
TCON - регистр управления таймерами и внешними прерываниями.
Формат этих регистров приведен в табл. 4.18 и 4.19. Кроме того, таймер 0 и таймер 1 имеют по два программно доступных 8-разрядных регистра: ТНО и TLO для таймера О, ТН1 и TL1 для таймера 1.
Таблица 4.18
Формат регистра TMOD
Регистр режима работы таймеров-счетчиков, 1 мои «х» — номер таймера
Адрес 89h 7 6 5 4 3 2 1 0
GATE1 I С/Т1 I М1.1 I М0.1 I GATED | С/ТО | М1.0 | МО.О
Состояние при сбросе: 00h
Имя бита Назначение бита
GATEx (GATE1, GATED) Управление блокировкой счета: 1 - таймер-счетчик «х» разрешен до тех пор, пока на входе INTx высокий уровень и бит TRx установлен 0 - таймер-счетчик «х» разрешен, если бит TRx установлен
СГГх (СЛТ, С/ТО) Бит выбора режима таймера или счетчика событий: 1 - режим счетчика внешних событий. Счетчик тактируется от внешних сигналов на входе Тх 0 - режим таймера. Счетчик тактируется от внутренннего генератора синхронизации
М1.х:М0.х Биты выбора режима работы таймера-счетчика «х»: М1 МО Режим 0 0 0 1 0 1 0 1 2 1 1 3
354
СЕМЕЙСТВО МК MCS-51 ФИРМЫ «INTEL»
INT/P3.2(3)
Рис. 4.40. Структура таймера-счетчика в режиме 2
Рис. 4.41. Структура таймера-счетчика в режиме 3
т
Таблица 4.19
Формат регистра TCON
TCON Регистр управления таймерами и внешними прерываниями, «х» —номер таймера
Адрес 88h 7 6 5 4 3 2 1 0
TF1 | TR1 | TFO | TRO | IE1 | IT1 | IE0 | IT0
Состояние при сбросе: OOh
Имя бита Назначение бита
TFx (TF1, TF0) Флаг переполнения таймера-счетчика «х» Устанавливается при переполнении таймера/счетчика. Сбрасывается аппаратно при переходе на подпрограмму прерывания по запросу от TFx
TRx (TR1, TRO) Бит разрешения таймера-счетчика «х» Устанавливается/сбрасывается программой для пуска/останова
lEx (IE1, IE0) Флаг запроса прерывания по входу INTx (INT1 или INTO)
ITx (IT1, ITO) Бит выбора типа активного сигнала на входе INTx: 1 - активным является переход из «1» в «0» 0 - активным является низкий уровень сигнала
355
8-РАЗРЯДНЫЕ микроконтроллеры
4.2.7. АСИНХРОННЫЙ ПОРТ
Режим 0. В этом режиме информация и передается и принимается через внешний вывод входа приемника RXD. Принимаются или передаются 8 бит данных. Через внешний вывод передатчика TXD выдаются импульсы синхронизации, которые сопровождают каждый принимаемый или передаваемый бит. Частота синхросигналов равна f т. е. скорость обмена в синхронном режиме равна частоте внутренней шины МК. Временные диаграммы обмена в синхронном режиме приведены на рис. 4.42.
Режим 1. В этом режиме передаются через TXD или принимаются из RXD 10 бит информации: старт-бит, 8 бит информации, стоп-бит (см. рис. 4.20). Скорость приема/ передачи - величина переменная и задается таймером.
Режим 2. В этом режиме передаются через TXD или принимаются из RXD 11 бит информации: старт-бит, 8 бит данных, программируемый девятый бит и стоп-бит (см. рис. 4.21). При передаче девятый бит может принимать произвольное значение 0 или 1, но чаще этот бит используется для повышения достоверности обмена путем контроля по четности. Для этого при передаче информации в него помещается значение признака Р из регистра PSW. После приема информации другим МК признак четности для 8 бит данных вычисляется снова и сравнивается с принятым в девятом бите признаком Р. Если они совпадают, то считается, что обмен произошел без нарушения исходных данных. Частота приема/передачи выбирается программно: либо 1/32, либо 1/64 частоты кварцевого резонатора fXCLK, который используется в качестве времязадающего элемента генератора синхросигналов МК.
Режим 3. Совпадает с режимом 2 во всех деталях, за исключением частоты приема/ передачи. Последняя является величиной переменной и задается таймером.
Два регистра специальных функций используются для работы с последовательным портом в МК MCS-51:
SCON - регистр управления последовательного порта (табл. 4.20);
SBUF - регистр данных последовательного порта.
Таблица 4.20
Формат регистра SCON
SCON | Регистр управления последовательного порта
7 Адрес 98h 6 5 4 3 2 1 0
SMO I SM1 I SM2 I REN | TBS | RB8 | TI { RI
Состояние при сбросе: OOh
Имя бита Назначение бита
SM0:SM1 Биты выбора режима работы последовательного порта: SMO SM1 Режим 0 0 0 1 0 1 0 1 2 1 1 3
SM2 Бит управления режимом приема. Устанавливается программно для запрета приема сообщения, в котором девятый бит имеет значение «0»
REN Бит разрешения приема. Устанавливается/сбрасывается программно для разрешения/ запрета приема последовательных данных
TB8 Передавемый бит D8. Устанавливается/сбрасывается программно для задания девятого передаваемого бита в режимах 2 и 3
RB8 Принимаемый бит D8. Устанавливается/сбрасывается аппаратно для фиксации девятого принимаемого бита в режимах 2 и 3
TI Флаг прерывания от передатчика. Устанавливается аппаратно по окончании передачи каждого байта данных. Сбрасывается программно после обслуживания прерывания
RI Флаг прерывания от приемника. Устанавливается аппаратно по окончании приема байта данных. Сбрасывается программно после обслуживания прерывания
356
СЕМЕЙСТВО МК MCS-51 ФИРМЫ «INTEL»
RxD
(входные или выходные данные)
TxD
(синхронизация)
Рис. 4.42. Временные диаграммы последовательного обмена в синхронном режиме
4.2.8. ОРГАНИЗАЦИЯ ДОСТУПА К ВНЕШНЕЙ ПАМЯТИ
В микропроцессорных системах, построенных на основе МК MCS-51, возможно использование двух типов внешней памяти (см. п. 4.2.1): постоянной памяти программ и постоянной или оперативной памяти данных. Доступ к внешней памяти программ осуществляется с использованием специального управляющего сигнала стробирования PSEN. Доступ к внешней памяти данных обеспечивают сигналы RD/P3.7 и WR/P3.6 внешней магистрали управления МК (см. рис. 4.32).
При обращении к внешней памяти программ МК формирует двухбайтовый адрес. Доступ к внешней памяти данных возможен как с использованием двухбайтового адреса (MOV А, @ DPTR), так и с однобайтовым адресом (MOVX A,©Ri). В цикле обращения к памяти старший байт двухбайтового адреса фиксируется в регистре-защелке порта Р2. При этом ранее записанное в порт Р2 значение восстанавливается в следующем цикле. Если используется однобайтовый адрес внешней памяти, то содержимое порта Р2 не претерпевает изменений.
Внешняя Внешняя
магистраль магистраль
Рис. 4.43. Схема сопряжения МК 8051АН с внешними БИС памяти
данных .........* A ROM
RAM
CS___
RD/WR
357
8-РАЗРЯДНЫЕ микроконтроллеры
Функциональная схема сопряжения МК 8051АН с внешними БИС ПЗУ программ и ОЗУ данных приведена на рис. 4.43. Через порт 0 в режиме мультиплексирования во времени выдается сначала младший байт адреса, а затем осуществляется передача данных. Сигнал ALE должен быть использован для записи младшего байта адреса во внешний регистр-защелку. Выходы регистра-защелки и линии порта Р2 составляют внешнюю 16-разряднуу магистраль адреса для БИС памяти. В качестве сигнала стробирования чтения памяти программ используется сигнал PSEN. При обращении к внешней памяти данных в качестве стробирующих используются сигналы RD и WR.
4.2.9. РАЗВИТИЕ МК С ЯДРОМ MCS-51
Совершенствование МК на основе процессорного ядра MCS-51 происходило в следующих направлениях:
• увеличение частоты тактирования fXCLK, посредством перехода к другой, более совершенной технологии изготовления БИС;
• увеличение объема резидентной памяти программ и памяти данных; переход к FLASH технологии памяти программ;
• совершенствование структуры МК посредством введения в его состав новых типов периферийных модулей;
• кардинальная переработка архитектуры процессорного ядра с сохранением системы команд MCS-51; полученные решения полностью совместимы с MCS-51 на уровне исходного текста программ.
Начало столь бурной модернизации положила сама фирма «Intel», выпустив МК 80С52 с увеличенным объемом памяти программ (8 Кбайт), памяти данных (256 байт), третьим таймером на кристалле с функциями захвата/сравнения и расширенной подсистемой прерываний. Ныне аббревиатура 8052 используется для обозначения одного из стандартов в рамках архитектуры MCS-51.
Следующим шагом в развитии MCS-51 был предложенный фирмой «Intel» модуль процессора событий РСА (Program Counter Array), который входил в состав МК 8xC51FA/ FB/FC/GB. Модуль РСА включает 16-разрядный счетчик временной базы и пять полностью идентичных каналов захвата/сравнения. Каждый из каналов может быть настроен на один из четырех режимов:
1) входного захвата по положительному/отрицательному/любому фронту входного сигнала;
2) выходного сравнения с формированием запроса на прерывание;
3) входного сравнения с формированием как «1» так и «0» на соответствующем выходе; эта функция в МК фирмы «Intel» получила название высокоскоростного выхода;
4) широтно-импульсного модулятора с дискретностью 8 разрядов и 4 фиксированными частотами сигнала.
Модуль РСА в настоящее время воспроизводится в МК фирмы «Pfilips», близкий аналог модуля присутствует в МК семейства С500 фирмы «Infineon».
Новую жизнь в популярные модификации МК с ядром MCS-51 вдохнули фирмы «Pfilips» и «Atmel», переведя резидентное ПЗУ на FLASH технологию. Более того, МК от «Atmel» стали программируемыми в системе. Дополнительный порт SPI в составе МК этой фирмы обеспечил такую возможность.
Фирма «Pfilips», выпуская самый большой ряд МК на основе стандартного ядра MCS-51, предложила новое семейство 51 ХА с расширенной архитектурой. Основные отличия нового процессорного ядра:
• 16-разрядное АЛУ на базе регистровой архитектуры;
358
СЕМЕЙСТВО МК MCS-51 ФИРМЫ «INTEL:
• восемь 16-разрядных регистров для выполнения арифметических и логических операций;
• расширенный набор инструкций;
• аппаратная поддержка мультизадачное™.
Новое процессорное ядро не совместимо по кодам инструкций со своим предшественником. Но каждой инструкции MCS-51 поставлена в соответствие инструкция нового ядра 51ХА. Специальный транслятор исходного текста конвертирует программы, написанные на языке Ассемблера MCS-51, в исходный текст для нового ядра 51ХА. Именно поэтому ядро 51 ХА относят к семейству MCS-51. По результатам тестов архитектура ХА обеспечивает увеличение производительности до 100 раз по сравнению с традиционной архитектурой MCS-51.
Фирма «Infineon» также поддерживает две линии МК, принадлежащих к семейству MCS-51. Наряду с выпуском полностью идентичных некоторым моделям стандартов 8051 и 8052 Intel, фирма разработала свое собственное ядро С500, полностью совместимое с MCS-51 на уровне кодов. И уже на базе этого ядра создала целый ряд МК со встроенными модулями CAN интерфейсов, а также специализированные МК для управления силовыми преобразователями частоты.
Еще одну оригинальную модернизацию ядра MCS-51 предложила фирма «Dallas Semiconductor». Изменение схемотехники базового ядра было проведено таким образом, что типовой цикл выборки команд сократился до 4 машинных тактов против исходных 12 тактов. В результате производительность МК при той же тактовой частоте возросла от 1,5 до 3 раз в зависимости от типа алгоритма. Эту новую линию МК назвали High Speed MCS-51 - высокоскоростные МК семейства 8051.
И, наконец, сама фирма «Intel» предложила новое процессорное ядро MCS-251, совместимое на уровне кодов с программами для 8051. Основные характеристики центрального процессора с архитектурой MCS-251:
• расширенный набор команд, включающий 16-бит арифметические и логические инструкции;
• регистровая архитектура, допускающая обращение к переменным в байтовом, двухбайтовом и четырехбайтовом форматах;
• конвейер команд;
• линейная адресация до 16 Мбайт памяти программ;
• выполнение самой быстрой инструкции в шесть раз быстрее MCS-51.
МК семейства MCS-251 содержат на кристалле три таймера, программируемый счетный массив РСА, улучшенный асинхронный порт, сторожевой таймер. Технические характеристики выборочного ряда МК клона MCS-51 приведены в табл. 4.21.
Таблица 4.21
Технические характеристики выборочного ряда МК клона MCS-51
ТипМК Максимальная частота, МГц Память программ, байт Память данных, байт Линии ввода/ вывода Таймер Последовательный интерфейс АЦП входы/раз-решения
Микроконтроллеры фирмы «Intel», семейство MCS-51
8хС51ВН 24 4К ROM/EPROM 128 32 2 UART Нет
8хС52 24 8К ROM/EPROM 256 32 3 UART Нет
8хС58 33 32К ROM/EPROM 256 32 3 UART Нет
359
8-РАЗРЯДНЫЕ МИКРОКОНТРОЛЛЕРЫ
Продолжение табл. 4.21
Тип МК Максимальная частота, МГц Память программ, байт Память данных, байт Линии ввода/ вывода Таймер Последовательный интерфейс АЦП входы/раз-решения
Микроконтроллеры фирмы «Intel», семейство MCS-51
8xC51FA 8xC51FB 8XC51FC 24 8К/16К/32К ROM/EPROM 512 32 3+PCA+WDT UART Нет
8xC51FA 16 8К/16К/32К ROM/EPROM 256 48 3+РСА+РСА WDT UART 8-каналов 8-бит
Микроконтроллеры фирмы «Atmel»
АТ89С51 24 4К FLASH 128 32 2 UART Нет
АТ89С52 24 8К FLASH 256 32 3 UART Нет
АТ89С55 33 20К FLASH 256 32 3 UART Нет
Микроконтроллеры фирмы «Philips», семейство 8951
89С52 33 8К FLASH 256 32 3 UART Нет
89C51RC* 33 32К FLASH 512 32 3+PCA+WDT UART Нет
89СЕ558 16 32К FLASH 1024 48 3+PCA+WDT ШИМ 2x8 UART 8-каналов 8-бит
Микроконтроллеры фирмы «Philips», семейство 51 ХА
Р51ХАСЗх 25 32K ROM/EPROM 1024 32 3+WDT UART CAN Нет
P51XAS3X 25 32K ROM/EPROM 1024 80 3+PCA+WDT ШИМ 6x8 2 UART l2C 8-каналов 10-бит
Микроконтроллеры фирмы «Infineon», семейство С500
C501G 40 8K ROM/EPROM 256 32 3 UART Нет
C504G 40 16K ROM/EPROM 512 32 4+WDT модуль ШИМ Для управления двигателями UART 8-каналов 10-бит
С515С 10 64K ROM/EPROM 2304 57 3WDT ШИМ 4x8 UART CAN *) 8 DPTR
Микроконтроллеры фирмы «Dallas Semiconductor», семейство High Speed
DC80C310 33 Нет 256 32 3 UART Нет
DS87C530 33 16K ROM/EPROM 1280 32 3+WDT UART *) 2 DPTR
360
СЕМЕЙСТВО МК НС08 ФИРМЫ «MOTOROLA»
Продолжение табл. 4.21
Тип МК Максимальная частота, МГц Память программ, байт Память данных, байт Линии ввода/ вывода Таймер Последовательный интерфейс АЦП входы/раз-решения
Микроконтроллеры фирмы «Intel», семейство MCS-251
8хС251 SA 16 8К ROM/EPROM 1К 32 3+PCA+WDT UART Нет
TSC8xC251 А1 16 24К ROM/EPROM 1К 32 2+WDT UART 4-канала 8-6ит
TSC8xC251 G1 16 16К ROM/EPROM 1К 32 3+WDT UART PC, SPI Нет
4.3. СЕМЕЙСТВО МК НС08 ФИРМЫ «MOTOROLA»
4.3.1. АРХИТЕКТУРА МК MC68HC908GP32
На рис. 4.44 приведена внутренняя структура МК MC68HC908GP32 фирмы «Motorola». Микроконтроллер выпущен в конце 1999 г. и является базовой моделью нового семейства 8-разрядных МК с FLASH памятью программ (цифра 9 в аббревиатуре НС(9)08 указывает на наличие FLASH памяти в кристалле МК).
МК включает следующие модули:
• центральный процессор CPU08; разрядность обрабатываемого слова составляет один байт;
• внутреннюю FLASH память программ объемом 32 Кбайта;
• внутреннюю память данных объемом 512 байт;
• 33 двунаправленных линии ввода/вывода, объединенных в пять портов;
• два модуля процессора событий; каждый с 16-разрядной временной базой и двумя каналами захвата/сравнения/ШИМ;
• модуль базового таймера для формирования меток реального времени;
• модуль последовательного асинхронного интерфейса SCI;
• модуль последовательного синхронного интерфейса SPI;
• модуль 8-канального 8-разрядного АЦП;
• сторожевой таймер;
• дополнительные системные модули, обеспечивающие работу процессорного ядра.
Обмен информацией между модулями осуществляется по внутренней 8-разрядной магистрали данных и 16-разрядной магистрали адреса. Максимальная частота тактирования межмодульных магистралей fBUS составляет 8 МГц, соответственно длительность машинного цикла, равная 1 /fst,s, составляет 125 нс. МК может работать только в однокристальном режиме, адресация внешней памяти не предусмотрена.
Процессорное ядро семейства НС08, также как MCS-51, относится к процессорам с CISC-архитектурой. CPU08 является высокопроизводительным 8-разрядным устройством обработки данных. Поддерживает 11 способов адресации, имеет команды умножения и деления. Операция сложения или вычитания однобайтовой константы выполняется за 2 цикла (250 нс). Операция умножения двух однобайтовых операндов в формате без знака занимает 5 циклов (625 нс), операция целочисленного деления двухбайтового делимого на однобайтовый делитель - 7 циклов (875 нс).
361
8-РАЗРЯДНЫЕ МИКРОКОНТРОЛЛЕРЫ
<-► РА7/КВ17
РА6/КВ16
«*-► РА5/КВ15
<-► РА4/КВ14
<-*• PA3/KB13
*-► РА2/КВ12
► РА1/КВ11
*-► РАО/КВ10
PTB1/AD1 PTB0/AD0
PTB6/AD6
PTB5/AD5
PTB4/AD4
PTB3/AD3
РТС7 РТС6 РТС5 РТС4 РТСЗ РТС2 РТС1 РТСО
PTD7/T2CH1 РТ06ГГ2СНО РТО5ГГ2СН1 РТО4ГГ2СН0 PTD3/SPSCK PTD2/MOSI PTD1/MISO
PTD0/SS
<—►РТЕ'1/RxD
<—*-PTE0/TxD
Рис. 4.44. Структура МК MC68HC908GP32 фирмы «Motorola»
МК семейства НС08 имеют объединенное адресное пространство памяти программ, данных и регистров специальных функций периферийных модулей (рис. 4.45) и, как следствие, полную идентичность команд обращения к памяти программ, памяти данных и регистрам специальных функций.
Такая организация имеет ряд преимуществ:
• позволяет интегрировать на кристалл МК практически любое число периферийных модулей;
• позволяет на этапе отладки выполнять программу, которая размещается в ОЗУ МК;
• существенно упрощает процесс программирования.
Внутренняя магистраль адреса позволяет адресовать 64К памяти. В карту памяти (рис. 4.45) включены регистры специальных функций: регистры параллельных портов
362
СЕМЕЙСТВО МК НС08 ФИРМЫ «MOTOROLA»
Регистры портов ввода/вывода расположены в общей карте памяти и не требуют для обращения специальных команд
Обращение к ячейкам ОЗУ и ПЗУ не требует применения разных типов команд
Сегменты памяти программ и памяти данных допускают произвольное распределение адресного пространства в пределах объема ПЗУ выбранного типа микроконтроллера
Адресное пространство программы встроенного монитора лежит вне области ПЗУ пользователя
Произвольный выбор векторов сброса и прерываний сокращает время обслуживания внешних устройств и создает удобство программисту
OOOOh
003Fh
004Fh
023Fh
0800h
OFDFFh 0FE20h
OFFDCh
OFFFFh
Рис. 4.45. Распределение адресного пространства МК MC68HC908GP32
ввода/вывода, регистры данных и регистры управления периферийных модулей. Адреса регистров специальных функций и ОЗУ располагаются в верхней части карты памяти, начиная с адреса 00h. Это связано с особенностью системы команд, которая позволяет производить операции над отдельными битами ячеек памяти, адрес которых лежит в пределах 00h - OFFh. Кроме того, система команд CPU08 предусматривает специальные команды для пересылки массива именно в регистры данных периферийных модулей. Каждая такая команда производит пересылку байта, а затем автоматически инкрементирует текущие адреса байта данных в исходном массиве. Отличительной особенностью МК фирмы «Motorola» и семейства НС08 в том числе являются программируемые пользователем векторы прерывания и сброса, которые располагаются в нижней части карты памяти в области ПЗУ.
Модуль FLASH памяти программ МК MC68HC908GP32 имеет в своем составе повышающий преобразователь напряжения, который позволяет выполнять операции стирания и программирования FLASH ПЗУ под управлением программы, размещенной в ОЗУ, без подключения внешнего источника напряжения программирования.
МК MC68HC908GP32 в отличие от ранее рассмотренных представителей семейства MCS-51 (см. п. 4.2) имеет в своем составе большое число системных модулей. К группе системных модулей относятся:
• модуль системной интеграции;
• модуль генератора тактовой частоты; м
• модуль сброса при нарастании напряжения питания; с,- .
• модуль распознавания пониженного напряжения питания; :
• модуль памяти отладочного монитора;
• модуль прерываний по контрольным точкам.
Модуль системной интеграции выполняет следующие функции:
• формирует на основе импульсной последовательности генератора тактовой частоты систему импульсных последовательностей для организации работы центрального процессора, межмодульных магистралей и периферийных модулей;
363
8-РАЗРЯДНЫЕ микроконтроллеры
• осуществляет арбитраж внутренних и внешних источников прерываний, производит загрузку векторов прерывания из ячеек памяти в счетчик адреса центрального процессора, управляет процессом перехода к подпрограмме прерывания и возвратом из нее-• управляет ресурсами МК в различных режимах работы (активном, пониженного энергопотребления, отладочном), обеспечивает взаимный переход между режимами;
• управляет ресурсами МК в состоянии начального запуска (сброса); содержит в себе аппаратные блоки для реализации сброса по несуществующему адресу и несуществующему коду команды.
Остальные системные модули не принимают непосредственного участия в процессе преобразования цифровых данных. Но они обеспечивают надежную работу аппаратных средств МК и тем самым повышают устойчивость системы преобразования данных к неблагоприятным внешним воздействиям.
МК MC68HC908GP32 имеет достаточно сложную для 8-разрядных МК систему синхронизации. Модуль формирования тактовой частоты CGM08 позволяет обеспечить тактирование центрального процессора CPU08 и периферийных модулей от двух источников: генератора кварцевого резонатора и синтезатора частоты (PLL). Причем возможно динамическое изменение источника тактирования в процессе выполнения прикладной программы. Если синхронизация МК осуществляется от генератора кварцевого резонатора, то его частота должна быть в 4 раза больше частоты тактирования внутренних магистралей. Синтезатор частоты в составе модуля CGM08 позволяет снизить частоту подключаемого кварцевого резонатора до 32,768 кГц при сохранении максимального быстродействия центрального процессора. По способу действия синтезатор частоты является системой импульсно-фазовой автоподстройки частоты, т. е. умножителем частоты генератора кварцевого резонатора. Использование низкочастотного кварцевого резонатора в качестве времязадающего элемента системы тактирования МК позволяет уменьшить уровень электромагнитного излучения, т. е. интенсивность генерации помех.
Модуль сброса по нарастанию напряжения питания совместно с модулем распознавания пониженного напряжения питания выполняет функцию мониторинга напряжения питания БИС МК. Для надежного вступления МК в работу при включении питания необходимо сформировать сигнал сброса определенной длительности, что и выполняет первый из упомянутых модулей. Второй модуль детектирует снижение напряжения питания, при котором работа МК не является устойчивой. В этом случае генерируется внутренний сигнал сброса. Он удерживается до тех пор, пока напряжение питания МК не станет номинальным. Тогда сигнал сброса будет снят, и МК восстановит процесс выполнения прикладной программы.
Аппаратные средства модуля системной интеграции включают систему контроля считывания неправильного кода команды или формирования адреса несуществующей ячейки памяти. Такие неисправности МК могут возникнуть в результате влияния электромагнитных помех. Указанные средства распознают подобные ситуации и восстанавливают работоспособность прикладной программы посредством генерации сигнала сброса. Однако эта функция не является основной для модуля системной интеграции.
Модуль памяти монитора отладки совместно с модулем прерываний по контрольным точкам позволяет организовать режим внутрисистемного программирования и внутрисхемной отладки с минимальными внешними по отношению к МК аппаратными «добавками» (см. п. 4.4). Процесс программирования и отладки прикладной программы становится более экономичным, что снижает стоимость встраиваемой системы на основе МК.
364
СЕМЕЙСТВО МК НС08 ФИРМЫ «MOTOROLA»
4.3.2. ПРОЦЕССОРНОЕ ЯДРО СЕМЕЙСТВА НС08
Центральный процессор МК семейства НС08 (далее CPU08) выполняет действия над 8-разрядными операндами.Программная модель CPU08 (рис. 4.46) содержит пять регистров, которые не являются частью объединенного адресного пространства, и, следовательно, для обращения к ним должны быть использованы специальные команды.
Аккумулятор (АСС) - 8-разрядный регистр, в котором хранятся операнды, результаты арифметических и логических операций. Сброс не изменяет состояние АСС.
Индексный регистр (Н:Х)~ 16-разрядный регистр (Н-старший байт, Х-младший байт). Основное назначение индексного регистра - участие в формировании адреса операнда в режимах индексной адресации. Индексный регистр может также использоваться для хранения промежуточных результатов вычислений или как источник одного из операндов в операциях умножения и деления. Система команд CPU08 предусматривает загрузку данных в индексный регистр и выполнение операций над ними как в двухбайтовом, так и в однобайтовом форматах. В последнем случае обращение производится только к младшему байту регистра X. После сброса МК старший байт индексного регистра Н принудительно устанавливается в «О», что обеспечивает адекватное выполнение программ, ранее написанных для семейства НС05. Сброс не изменяет состояние младшего байта индексного регистра X.
Программный счетчик (PC)- 16-разрядный регистр, содержит адрес текущей команды либо адрес операнда, используемого в текущей команде. После сброса МК программный счетчик автоматически загружается вектором начального запуска, который записан в ячейках памяти резидентного ПЗУ с адресами $FFFE (старший байт) и $FFFF (младший байт). Вектор начального запуска является адресом начала прикладной программы управления.
Указатель стека (SP) - 16-разрядный регистр, содержит адрес верхушки стека. В отличие от CPU05, глубина стека МК семейства НС08 ограничена только объемом резидентного ОЗУ. Вызов подпрограммы использует 2 ячейки стека, прерывание-5 ячеек. Следует отметить, что стремление разработчиков обеспечить полную программную совместимость с CPU05 привело к тому, что при переходе на подпрограмму прерывания CPU08 автоматически сохраняет в стеке программный счетчик PC, аккумулятор АСС, младший байт индексного регистра X и регистр признаков CCR, но не сохраняет старший байт индексного регистра Н. При сбросе МК указатель стека устанавливается в состояние $00FF, назначая область стека в нулевую страницу ОЗУ МК.
Регистр признаков (CCR)- 8-разрядный регистр, содержит 6 флагов условий: переноса (С), нулевого результата (Z), отрицательного результата (N), переполнения (V), дополнительного переноса (Н), бит глобальной маски прерывания (I). Особенностью флага нулевого результата Z и флага знака N является установка их после операций пересылки (см. систему команд). Отличительная особенность ядра CPU08 и всех 8-разрядных процессорных ядер фирмы «Motorola» - расположение маски прерывания в составе регистра признаков.
Установка маски прерывания в «1» запрещает все прерывания, кроме программного по команде SWI. Если запрос на прерывание появится, когда маска I = 0, то центральный процессор сохранит в стеке содержимое программного счетчика PC, аккумулятора АСС, младшего байта индексного регистра X и регистра признаков, установит бит I в «1» и перейдет на выполнение подпрограммы прерывания. Если запрос на прерывание появится, когда флаг I = 1, то запрос на прерывание будет запомнен. МК начнет обрабатывать запрос на прерывание сразу, как только бит I будет очищен. Инструкция RTI (возврат из прерывания) сбрасывает бит I в «О» автоматически. CPU08 имеет две специальные команды: CLI - очистить бит маски, SEI - установить бит маски.
365
8-РАЗРЯДНЫЕ микроконтроллеры
Регистр признаков CCR_________
I V м I 1 I Н । 1 I N I Z |С~|
Сброс: х 1 1 х 1 х х х
Рис. 4.46. Программно-логическая модель центрального процессора МК НС08
В состоянии сброса бит I устанавливается в «1», что запрещает аппаратные прерывания. Разрешение аппаратных прерываний (установка I в «О») может быть выполнено только программно командой CLL
Для выборки операндов из памяти МК семейства НС08 используют следующие способы адресации:
• неявную (INH - Inherent);
• непосредственную (IMM - Immediate);
• прямую (DIR - Direct);
• прямую расширенную (EXT - Extended);
• индексную (IX - Indexed);
• индексную со смещением в один байт (1X1 - Indexed, 8 bit offset);
• индексную со смещением в два байта (IX2 - Indexed, 16 bit offset);
• индексную с постинкрементированием (IX+ - Indexed with post incrementer);
• индексную co смещением в один байт с постинкрементированием (1X1+ - Indexed, 8 bit offset with post incrementer);
• индексную по указателю стека co смещением в один байт (SP1 - Stack pointer, 8 bit offset);
• индексную по указателю стека со смещением в два байта (SP2 - Stack pointer, 16 bit offset);
• относительную (REL - Relative).
Неявная адресация. К инструкциям с неявной адресацией относятся команды, которые не требуют для своего выполнения каких-либо операндов, например команда STOP или команда возврата из прерывания RTI.
Неявную адресацию имеют инструкции, которые содержат адрес операнда в коде команды, например, команда установки бита переноса SEC или команда инкремента аккумулятора INCA. Все команды с неявной адресацией имеют длину в 1 байт и состоят только из кода операции.
366
СЕМЕЙСТВО МК НС08 ФИРМЫ «MOTOROLA»
Непосредственная адресация. Код операции команды с непосредственной адресацией размещается в первом байте. Сразу же за кодом операции следует 1 байт данных. Эти данные не могут быть изменены в ходе выполнения программы, так как они расположены непосредственно в памяти программ, т.е. в ПЗУ. Большинство команд с непосредственной адресацией имеют длину в 2 байта. Условное обозначение операнда в мнемонике команды - #орг:
Примеры.
ADD #орг ;3апись команды ADD с непосредственной адресацией в общем виде.
ADD #3 ; Сложить содержимое аккумулятора АСС с числом 3,
; результат записать в АСС.
ORA #$0А ; Выполнить операцию поразрядного ИЛИ над содержимым АСС и
; шестнадцатеричным числом $0А. Результат записать в АСС.
Прямая адресация. Команды с прямой адресацией имеют длину 2 байта. Первый байт предназначен для кода команды, второй байт содержит адрес ячейки памяти, где хранится операнд. Так как МК семейства НС08 имеют адресное пространство, превышающее диапазон $00 — $FF, то во втором байте команды задается только младший байт адреса, а старший автоматически устанавливается $00. Условное обозначение адреса в мнемонике команды - орг:
Примеры.
ADD орг ; Запись команды ADD с прямой адресацией в общем виде.
ADD $31 ; Сложить содержимое аккумулятора АСС с содержимым ячейки памяти
; с адресом $0031. Результат поместить в АСС.
ORA $0А ; Выполнить операцию поразрядного ИЛИ над АСС и содержимым ячейки
; памяти с адресом $0031. Результат поместить в АСС.
Прямая расширенная адресация. Команды с прямой расширенной адресацией имеют длину 3 байта. Первый байт предназначен для кода команды, второй и третий байты содержат адрес ячейки памяти, где хранится операнд. Команды с прямой расширенной адресацией позволяют работать со всем адресным пространством МК. Мнемоническое обозначения команд с прямой и прямой расширенной адресацией совпадают. При трансляции программ не следует заботиться о том, что инструкции с прямой и прямой расширенной адресацией имеют одинаковую мнемонику. Программа Ассемблер самостоятельно подставит код необходимой операции, проанализировав численное значение адреса орг.
Примеры.
ADD орг ; Запись команды ADD с прямой расширенной адресацией в общем виде.
ADD $01Е1 ; Сложить содержимое аккумулятора АСС с содержимым ячейки памяти
; с адресом $01Е1. Результат поместить в АСС.
LDX $01Е1 ; Загрузить в младший байт индексного регистра X содержимое ячейки памяти ; с адресом 01Е1 h.
Индексная адресация. Команды с индексной адресацией имеют длину 1 байт, в котором расположен код операции. Адрес операнда находится в двухбайтовом индексном регистре Н:Х.
Примеры.
ADD ,Х ; Запись команды ADD с индексной адресацией в общем виде.
ADD ,Х ; Сложить содержимое аккумулятора АСС с содержимым ячейки памяти,
; адрес которой находится в индексном регистре Н:Х.
LDA ,Х ; Загрузить в аккумулятор АСС содержимое ячейки памяти, адрес которой
; находится в индексном регистре Н:Х.
367
8-РАЗРЯДНЫЕ микроконтроллеры
Индексная адресация со смещением 1 байт. Команды с данным типом адресации имеют длину 2 байта. Первый байт содержит код операции, а второй - беззнаковую константу, которая носит название «смещение». В определении адреса операнда участвует индексный регистр Н:Х, который содержит код базового адреса. Центральный процессор вычисляет адрес операнда путем сложения содержимого индексного регистра Н:Х с кодом второго байта команды. После сложения адрес операнда представляется в двухбайтовом формате.
Примеры. ADD орг,Х ; Запись команды ADD с индексной адресацией со смещением в один байт ; в общем виде.
ADD $80,X ; Сложить содержимое аккумулятора АСС с содержимым ячейки памяти, ; адрес которой равен (Н:Х)+128.
LDA$1,X ; Загрузить в аккумулятор АСС содержимое ячейки памяти, адрес которой ; равен (Н:Х)+1.
Индекенс имеют длину двухбайтову) байтовый ин, путем сложе! жен и я адрес значения ком не следует б< Ассемблер с: ленное значе Примеры. ADD орг,Х 1я адресация со смещением 2 байта. Команды с данным типом адресации ' 3 байта. Первый байт содержит код операции, а второй и третий байты -о беззнаковую константу. В определении адреса операнда участвует двух-дексный регистр Н:Х. Центральный процессор вычисляет адрес операнда ния двухбайтового кода смещения с содержимым регистра Н:Х. После сло-операнда представляется в двухбайтовом формате. Мнемонические обо-1анд с индексной адресацией со смещениями 1 и 2 байта совпадают. Однако эспокоиться об этом при написании программы. При трансляции программа амостоятельно подставит код необходимой операции, проанализировав чис-гние адреса орг. ; Запись команды ADD с индексной адресацией со смещением в два байта ; в общем виде.
ADD $0100,Х ; Сложить содержимое аккумулятора АСС с содержимым ячейки памяти, ; адрес которой равен (Н:Х)+512.
LDA $01FF,X ; Загрузить в аккумулятор АСС содержимое ячейки памяти, адрес которой ; равен (Н:Х)+1023.
Индекснг крементиров рандов этих( ния команды Примеры. MOV Х+,орг 1я адресация с постинкрементированием. Индексная адресация с постин-анием используется только в командах MOV и CBEQ. Адрес одного из опе-соманд находится в двухбайтовом индексном регистре Н:Х. После выполне-содержимое индексного регистра Н:Х увеличивается на 1. ; Запись команды MOV с индексной адресацией ; с постинкрементированием в общем виде.
MOV Х+,$68 ; Записать данные из ячейки памяти с адресом $68 в ячейку памяти, адрес ; которой находится в индексном регистре Н:Х. Увеличить на 1 адрес ; в регистре Н:Х.
CBEQ Х+,ге1 ; Запись команды CBEQ с индексной адресацией ; с постинкрементированием в общем виде.
CBEQ X+,m1 ; Сравнить аккумулятор АСС и содержимое ячейки памяти, адрес которой ; находится в индексном регистре Н:Х. Перейти по метке ml в случае ; равенства. Увеличить на 1 адрес в регистре Н:Х.
Индекснг Индексная а ется только 1я адресация со смещением в один байт и постинкрементированием, дресация со смещением в один байт и постинкрементированием использу-в команде CBEQ. В определении адреса одного из операндов команды
368
СЕМЕЙСТВО МК НС08 ФИРМЫ «MOTOROLA»
участвует индексный регистр Н:Х, который содержит код базового адреса. Центральный процессор вычисляет адрес операнда путем сложения содержимого индексного регистра Н:Х с байтом кода смещения, который указан во втором байте команды. После сложения адрес операнда представляется в двухбайтовом формате. После выполнения команды содержимое индексного регистра Н:Х увеличивается на 1.
Примеры.
CBEQ opr,X+,rel
CBEQ $80,X+,m1
; Запись команды CBEQ с индексной адресацией со смещением в один ; байт и постинкрементированием в общем виде.
; Сравнить аккумулятор АСС и содержимое ячейки
; памяти, адрес которой равен (Н:Х)+128. Перейти по метке ml в случае
; равенства. Увеличить на 1 адрес в регистре Н:Х.
Индексная адресация по указателю стека со смещением в 1 байт. Команды с данным типом адресации имеют длину 3 байта. Первый и второй байты содержат код операции, а третий байт - беззнаковую константу смещения. В определении адреса операнда участвует указатель стека SP, который содержит код базового адреса. Центральный процессор вычисляет адрес операнда путем сложения содержимого указателя стека SP с кодом смещения. После сложения адрес операнда представляется в двухбайтовом формате.
Примеры.
ADD opr.SP
; Запись команды ADD c адресацией по указателю стека co смещением в один ; байт в общем виде.
; Сложить содержимое аккумулятора АСС с содержимым ячейки памяти,
; адрес которой равен (SP)+128. ,
; Загрузить в аккумулятор АСС содержимое ячейки памяти, адрес которой
; равен (SP)+1.
адресация по указателю стека со смещением в 2 байта. Команды
ADD $80,SP
LDA$1,SP
Индексная
сданным типом адресации имеют длину 4 байта. Первый и второй байты содержат код операции, а третий и четвертый байты - двухбайтовую беззнаковую константу. В определении адреса операнда участвует указатель стека SP. Центральный процессор вычисляет адрес операнда путем сложения двухбайтового кода смещения с содержимым указателя стека SP. После сложения адрес операнда представляется в двухбайтовом формате. Мнемонические обозначения команд с индексной адресацией со смещениями 1 и 2 байта совпадают. Однако не следует беспокоиться об этом при написании программы. В процессе трансляции программа Ассемблер самостоятельно подставит код необходимой операции, проанализировав численное значение адреса орг.
Примеры.
ADD opr.SP
ADD $0100,SP
LDA $01 FF,SP
; Запись команды ADD с адресацией по указателю стека со смещением ; в один байт в общем виде.
; Сложить содержимое аккумулятора АСС с содержимым ячейки памяти, ; адрес которой равен (SP)+512.
; Загрузить в аккумулятор АСС содержимое ячейки памяти, адрес которой ; равен (SP)+1023.
Относительная адресация. Относительная адресация применяется только в командах условных переходов, которые используются для организации ветвления программ. Команды условных переходов имеют двухбайтовый формат. Первый байт содержит код операции, а второй - смещение адреса следующей команды относительно адреса текущей команды в целочисленном формате со знаком. Диапазон возможных кодов смещения: от -128 до +127.
369
8-РАЗРЯДНЫЕ микроконтроллеры
Если условие, заданное типом используемой команды условного перехода, выполняется, то адрес следующей команды центральный процессор вычисляет путем сложения текущего адреса с кодом смещения. Если условие не выполняется, то МК переходит к выполнению следующей команды.
При написании программ нет необходимости вычислять абсолютные коды смещения для команд условного перехода. Достаточно указать лишь метку, численное значение кода смещения вычислит программа Ассемблер.
Примеры.
JZ 1аЫе1 ; Перейти по метке 1аЫе1, если результат операции равен 0.
4.3.3. СИСТЕМА КОМАНД МК СЕМЕЙСТВА НС08
Система команд CPU08 включает 90 инструкций.
Длина кода команды в байтах определяется типом инструкции и способом адресации. Команды CPU08 могут иметь однобайтовый, двухбайтовый, трехбайтовый и четырехбайтовый формат. Однобайтовыми командами в соответствии с теорией являются команды с неявной адресацией (INH) и с индексной адресацией без смещения (IX: LDA, х). В двухбайтовом формате представлены команды с непосредственной (IMM: LDA #орг), прямой (DIR: LDA орг) и индексной с однобайтовым смещением (1X1: LDA орг,х) адресацией. Трехбайтовый формат имеют команды с прямой расширенной адресацией (EXT: LDA орг), индексной со смещением в два байта адресацией (IX2: LDA орг,х) и адресацией по указателю стека со смещением в один байт (SP1: LDA opr,SP). Четырехбайтовыми командами являются только команды с адресацией по указателю стека со смещением в два байта (SP2: LDA opr.SP).
Множество команд делится на 6 традиционных групп, каждая из которых рассмотрена ниже. Распределение команд по группам приведено в табл. 4.22.
Таблица 4.22
Распределение команд Ассемблера CPU08 по типовым группам
Группа команд Число инструкций в группе
Команды загрузки и пересылки 13
Арифметические команды 14
Логические команды и команды сдвигов 15
Команды битового процессора 6
Команды управления ходом вычислительного процесса 40
Команды перехода к режимам пониженного потребления 2
Команды загрузки и пересылки данных. Команды этой группы осуществляют перемещение данных между ячейками памяти и регистрами центрального процессора (табл. 4.23).
370
СЕМЕЙСТВО МК НС08 ФИРМЫ «MOTOROLA»
Таблица 4.23
Команды загрузки и пересылки данных
Мнемокод Операция Выполняемое действие Способ адресации Влияние на признаки
V н I N Z с
LDA LDA #орг LDAopr LDA opr LDA opr,x LDA opr,x LDA ,x LDA opr.SP LDA opr,SP Загрузить в ACC константу или содержимое ячейки памяти А <= (М) IMM DIR ЕХТ IX SP1 SP2 0 ф ф
LDX LDX #opr LDX opr LDX opr LDX opr,x LDX opr,x LDX ,x LDX opr.SP LDX opr.SP Загрузить в регистр X константу или содержимое ячейки памяти X <= (М) IMM DIR ЕХТ IX SP1 SP2 0 ф ф
LDHX LDHX #opr LDHX opr Загрузить в индексный регистр Н:Х двухбайтовую константу или содержимое двух ячейек памяти Н:Х <=(М: М+$0001) IMM DIR 0 - - ф ф -
STA STA opr STA opr STA opr.X STA opr.X STA.X STA opr.SP STA opr.SP Запомнить содержимое аккумулятора АСС в ячейке памяти М <=(А) DIR ЕХТ IX SP1 SP2 0 ф ф
STX STX opr STX opr STX opr.X STX opr.X STX ,X STX opr.SP STX opr.SP Запомнить содержимое регистра X в ячейке памяти М <= (X) DIR ЕХТ IX SP1 SP2 0 ф ф
STHX STHX opr Запомнить содержимое индексного регистра Н:Х в двух ячейках памяти (М:М+$0001) <=(Н:Х) DIR 0 - - ф ф -
MOV MOV opr,opr MOV opr.X + MOV #opr,opr MOV X+,opr Прислать данные из одной ячейки памяти в другую (М2)<= (М2) DIR/DIR DIR/IX + IMM/DI-R IX+/DIR 0 - - ф ф -
371
8-РАЗРЯДНЫЕ микроконтроллеры
Продолжение табл. 4.23
Мнемокод Операция Выполняемое действие Способ адресации Влияние на признаки
V н I N Z с
ТАХ Прислать содержимое аккумулятора АСС в регистр X Х<=(А) INH - - - - - -
ТХА Переслать содержимое регистра X в аккумулятор АСС Аь:(Х) INH - - - - - -
ТАР Переслать содержимое аккумулятора АСС в регистр признаков CCR CCR <= (А) INH $ $ $ $ $ $
ТРА Переслать содержимое регистра признаков в аккумулятор АСС А<= (CCR) INH - - - - - -
TSX Переслать увеличенное на 1 содержимое указателя стека SP в индексный регистр Н:Х Н:Х <= (SP)+$0001 INH — - - - - -
TXS Переслать уменьшенное на 1 содержимое индексного регистра Н:Х в указатель стека SP (SP)<= (Н:Х)-$0001 INH — — - - - -
Отличительная особенность команд загрузки и пересылки CPU08 - установка признаков нуля Z и знака N в соответствие со значением перемещаемого числа. Следует также обратить внимание на способы адресации, которые могут быть использованы в команде LDHX:
• двухбайтовый регистр индексной адресации Н:Х может быть загружен двухбайтовой константой;
• или содержимым двух ячеек памяти, но на адрес первой из этих ячеек наложено ограничение; этот адрес должен быть однобайтовым $00 - $FF.
Команда MOV выполняет пересылку данных из одной ячейки памяти в другую, минуя регистры центрального процессора. Команда MOV может быть использована в одной из четырех модификаций:
MOV #data,adr ; Загрузить константу в прямоадресуемую ячейку памяти.
MOV adr1,adr2 ; Переслать данные из одной прямоадресуемой ячейки памяти в другую ; прямоадресуемую.
MOV х+, adr ; Переслать данные из ячейки памяти, адрес которой указан в индексном
; регистре Н:Х, в прямоадресуемую ячейку памяти. Содержимое Н:Хувеличи-; вается на 1 после пересылки.
MOV adr,x+ ; Переслать данные из прямоадресуемой ячейки памяти в ячейку, адрес ко-
; торой указан в индексном регистре Н:Х. Содержимое Н:Х увеличивается на 1 ; после пересылки.
Отметим, что одна из ячеек памяти (источник или приемник операнда) в формате команды обязательно прямоадресуемая, т. е. ее адрес может находиться в пределах от $00 до $FF. Именно это адресное пространство в МК семейства НС08 занимают регистры специальных функций периферийных модулей. Следовательно, команда MOV может быть органично использована для приема или передачи информации в регистры данных портов ввода/вывода, АЦП, последовательных портов и т. д.
Арифметические команды. Данную группу образуют 14 команд (табл. 4.24), выполняющие операции сложения (ADD и ADC), вычитания (SUB и SBC), инкремента и декремента (INC и DEC), однобайтового и двухбайтового сравнения, умножения и деления (MUL и DIV). Команды сложения (ADD и ADC), вычитания (SUB и SBC) и однобайтового
372
СЕМЕЙСТВО МК НС08 ФИРМЫ «MOTOROLA»
сравнения (СМР и СРХ) могут быть использованы с восемью различными способами адресации. Однако сравнение двухбайтового индексного регистра Н:Х может быть выполнено только с двухбайтовой константой, которая задана во втором и третьем байтах команды, или с содержимым двух ячеек памяти, адрес первой из которых равен $00 - $FF, Команда умножения MUL выполняет операцию целочисленного беззнакового умножения. Сомножители расположены в регистрах АСС и X, двухбайтовое произведение - в Н:АСС. Время выполнения операции составляет 5 машинных циклов. Команда деления DIV выполняет целочисленное беззнаковое деление двухбайтового делимого (Н:АСС) на однобайтовый делитель (X). Целое частное расположено в АСС, остаток - в Н. Делитель X сохрани-. ется без изменения. Время выполнения операции - 7 машинных циклов. |
Следует обратить внимание на формат представления операнда в командах AIX и AIS. ’ Однобайтовый операнд должен быть представлен в дополнительном коде со знаком: J а AIX #$FF ; Вычесть 1 из содержимого двухбайтового индексного регистра Н:Х. ,. j
AIX #$80 ; Вычесть 128 из содержимого двухбайтового индексного регистра Н:Х. !
AIS #$01 ; Увеличить на 1 указатель стека SP. (
AIS #$FF ; Вычесть 1 из указателя стека SP.
Несмотря на то, что инструкции инкремента и декремента над содержимым двухбайтовых регистров центрального процессора в системе команд CPU08 отсутствуют, эти операции могут быть выполнены с использованием команд AIX и AIS.
Фрагмент программы вычисления однобайтовой контрольной суммы таблицы из однобайтовых чисел:
TABLE: equ $7000 org $6Е00 LDHX #511 CLRA ADDLOOP: ADD TABLE,X AIX #$FF CPHX #0 ; Определить начальный адрес таблицы. ; Определить начальный адрес программы. ; Задать число элементов таблицы. ; Очистить регистр контрольной суммы. ; Получить частичную контрольную сумму. ; Уменьшить число элементов на 1. ; Проверка: все элементы перебраны? Команда AIX не ; устанавливает признаки, поэтому следует применить ; команду СРНХ.
BPL ADDLOOP ; Продолжить, если не все элементы перебраны
Логические команды и операции сдвига. Данную группу образуют 15 команд, которые выполняют операции логического И, ИЛИ, Исключающего ИЛИ, различные операции сдвига, операции взятия обратного и дополнительного кода. Следует обратить внимание на специальные команды установки признаков без изменения содержимого тестируемых регистров и ячеек памяти (TST и BIT). Все логические команды модифицируют флаги в регистре признаков. Типы инструкций данной группы приведены в табл. 4.25. и 4.26.
Таблица 4.24
Арифметические команды
Мнемокод Операция Выполняемое действие Способ адресации Влияние на признаки
V н I N Z с
ADD ADD #opr ADD opr ADD opr ADD opr.X ADD opr,X ADD ,X ADD opr.SP ADD opr.SP Сложить содержимое аккумулятора АСС с байтом данных памяти М (или константой). Результат поместить в АСС А <= (А)+(М) IMM DIR EXT IX2 1X1 IX SP1 SP2 $ $ $ $ $
373
8-РАЗРЯДНЫЕ МИКРОКОНТРОЛЛЕРЫ
Продолжение табл. 4.24
Мнемокод Операция Выполняемое действие Способ адресации Влияние на признаки
V н I N Z с
ADC ADC #орг ADC орг ADC орг ADC орг.Х ADC орг,Х ADC ,Х ADC opr.SP ADC opr.SP Сложить содержимое аккумулятора АСС с байтом данных пемяти М (или константой) и значением бита переноса С. Результат поместить в АСС A (А)+(М)+(С) IMM DIR EXT 1X2 1X1 IX SP1 SP2 ф ф - ф ф ф
SUB SUB #opr SUB opr SUB opr SUB opr.X SUB opr.X SUB ,X SUB opr.SP SUB opr.SP Вычесть байт данных памяти М (или константу) из содержимого аккумулятора АСС. Результат поместить в АСС А <= (А)-(М) IMM DIR EXT IX2 1X1 IX SP1 SP2 ф - - ф ф ф
SBC SBC #opr SBC opr SBC opr SBC opr.X SBC opr.X SBC ,x SBC opr.SP SBC opr.SP Вычесть байт денных памяти М (или константу) и бит переноса из содержимого аккумулятора АСС. Результат поместить в АСС А«=(АНМНС) IMM DIR EXT IX2 1X1 IX SP1 SP2 ф - - ф ф ф
MUL Умножить содержимое АСС на содержимое регистра X. Произведение представлено в двух байтовом формате. Старший байт произведения содержится в регисте X, младший байт-в АСС Х:А «= (X) X (А) INH - 0 - - - 0
DIV Разделить двухбайтовое делимое на однобайтовый делитель. Старший байт делимого находится в регистре Н, младший байт- в АСС. Однобайто-вов делимое находится в регистре X. Целое частное пом е-щается в АСС, остаток отделения в - регистр Н А «= (Н:А) / (X) Н <= Remainder INH — — — — ф ф
CMP CMP #opr CMP opr CMP opr CMP opr.X CMP opr.X CMP ,X CMP opr.SP CMP opr.SP Сравнить содержимое аккумулятора АСС с байтом памяти М (или константой). По результату сравнения установить признаки. Содержимое АСС и ячейки памяти М после операции не изменяется (А) - (М) IMM DIR EXT IX2 1X1 IX SP1 SP2 ф - - ф ф ф
374
СЕМЕЙСТВО МК НС08 ФИРМЫ «MOTOROLA»
Продолжение табл. 4.24
Мнемокод Операция Выполняемое действие Способ адресации Влияние на признаки
V н I N Z с
СРХ СРХ #орг СРХ орг СРХ орг СРХ ,Х СРХ орг.Х СРХ орг.Х СРХ opr.SP СРХ opr.SP Сравнить содержимое регистра X с байтом памяти М (или константой). По результату сравнения установить признаки. Содержимое регистра X и ячейки памяти М после операции не изменяется (Х)-(М) IMM DIR ЕХТ IX2 1X1 IX SP1 SP2 ф - ф ф ф
СРНХ СРНХ #орг СРНХ орг Сравнить содержимое индексного регистра Н:Х с двухбайтовой константой или содержимым двух ячеек памяти М:М+1. По результату сравнения уста новитъ признаки. Содержимое Н:Х и ячеек памяти после операции не изменяется (Н:Х)-(М:М+$0001) IMM DIR ф - - ф ф ф
INC INC opr INCA INCX INC opr.X INC ,X INC opr.SP Увеличить на 1 содержимое аккумулятора АСС, регистра X, ячейки памяти М М <= (М) + $01 А <= (А) + $01 X <= (X) + $01 М <= (М) + $01 М <= (М) + $01 М <= (М)+ $01 DIR INH INH 1X1 IX SP1 ф - - ф ф ф
DEC DEC opr DECA DECX DEC opr.X DEC ,X DEC opr.SP Уменьшить на 1 содержимое аккумулятора АСС, регистра X, ячейки памяти М М <= (М) + $01 А <= (А) + $01 X <= (X) + $01 М <= (М) + $01 М <= (М) + $01 М <= (М) + $01 DIR INH INH 1X1 IX SP1 ф - - ф ф ф
DAA Десятичная коррекция аккумулятора (А),0 INH и - - ф ф ф
AIX AIX #opr Сложить содержимое индексного регистра Н:Х с однобайтовой константой, представленной в дополнительном коде со знаком. Результат поместить в Н:Х Н:Х «=(Н:Х) + (16«М) IMM - - - - - -
AIS AIS #opr Сложить содержимое указателя стека SP и однобайтовой константой, представленой в дополнительном коде со знаком. Результат поместить в SP SP <= (SP) + (16«М) IMM - - - - - -
8-Р АЗРЯДНЫЕ МИКРОКОНТРОЛЛЕРЫ
Таблица 4.25
Логические команды
Мнемокод Операция Выполняемое действие Способ адресации Влияние на признаки
V н 1 N Z с
AND AND #opr AND opr AND opr AND opr,X AND opr,X AND ,X AND opr.SP AND opr.SP Поразрядное логическое H над содержимым аккумулятора АСС и байтом данных М. Результат поместить в АСС А <= (А) & (М) IMM DIR ЕХТ 1X2 1X1 IX SP1 SP2 0 Ф ф —
ORA ORA #opr ORA opr ORA opr ORA opr.X ORA opr.X ORA ,X ORA opr.SP ORA opr.SP Поразрядное логическое «ИЛИ» над содержимым аккумулятора АСС и байтом данных М. Результат поместить в АСС А <= (А) | (М) IMM DIR ЕХТ IX2 1X1 IX SP1 SP2 0 Ф ф
EOR EOR #opr EOR opr EOR opr EOR opr.X EOR opr.X EOR ,X EOR opr.SP EOR opr.SP Поразрядное исключающее «ИЛИ» над содержимым аккумулятора АСС и байтом данных. Результат поместить в АСС А <= (А ® М) IMM DIR ЕХТ IX2 1X1 IX SP1 SP2 0 Ф ф
COM COM opr COMA COMX COM opr.X COM ,X COM opr.SP Инверсия содержимого аккумулятора АСС, или регистра X, ипи ячейки памяти М <= (M)=$FF-(M) А <= (A)=$FF-(M) X <= (X)=$FF-(M) М <= (B)=$FF-(M) М <= (M)=$FF-(M) М <= (B)=$FF-(M) DIR INH INH 1X1 IX SP1 0 - - Ф ф 1
NEG NEG opr NEGA NEGX NEG opr.X NEG ,X NEG opr.SP Получение дополнительного кода содержимого аккумулятора АСС, или региста X, или ячейки памяти М М <= -(М)=$00-(М) А <= -(А)=$00-(М) X <=- (Х)=$00-(М) М <= -(М)=$00-(М) М <= -(М)=$00-(М) М <= -(М)=$00-(М) DIR INH INH 1X1 IX SP1 - - Ф ф ф
NSA Поменять местами тетрады (полубайты) аккумулятора АСС А <= (А[3:0]:А[7:4]) INH -
376
СЕМЕЙСТВО МК НС08 ФИРМЫ «MOTOROLA»
Продолжение табл. 4.25
Мнемокод Операция Выполняемое действие Способ адресации Влияние на признаки
V н I N Z С
CLR CLR орг CLRA CLRX CLRH CLR орг.Х CLR ,Х CLR opr.SP Очистить (установить в «0») аккумулятор АСС, или регистр X, или регистр Н, или ячейку памяти М М <=$00 А <=$00 X <= $00 М <= $00 М<=$00 М <= $00 DIR INH INH 1X1 IX SP1 0 - - 0 1 ф
вгг BIT #орг BIT орг BIT орг BIT орг.Х BIT орг.Х BIT ,Х BIT opr.SP BIT opr.SP Выполняет операцию поразрядного логического И над содержимым аккумулятора АСС и байтом памяти М. Результат операции никуда не записывается. По результату операции устанавливаются признаки N и Z А& М IMM DIR ЕХТ IX2 1X1 IX SP1 SP2 0 I Ф
TST TST opr TSTA TSTX TST opr.X TST ,X TST opr.SP Устанавливает признаки NnZ по содержимому аккумулятора АСС, или регистра X, или ячейки памяти М. Содержимое последних не изменяется (А) - $00 (X)- $00 (М) - $00 DIR INH INH 1X1 IX SP1 0 - — Ф Ф -
Таблица 4.26
Команды сдвигов
Мнемокод Операция Выполняемое действие Способ адресации Влияние на признаки
V н I N Z с
ASL ASL орг ASLA ASLX ASL орг.Х ASL ,Х ASL opr.SP Сдвиг влево содержимого аккумулятора АСС, или регистра X, или байта памяти М. В битЬО загружается «0», битЬ7 загружается в бит переноса С ICH-I I I I I I I I Н-о Ь7 Ь0 DIR INH INH 1X1 IX SP1 ф Ф ф ф
ASR ASR орг ASRA ASRX ASR орг.Х ASR орг.Х ASR opr.SP Сдвиг вправо содержимого аккумулятора АСС, или регистра X, или байта памяти М. БитЬ7 не изменяется, битЬО загружается в битпереноса С I Г1ТГП-»1с1 Ь7 Ь0 DIR INH INH 1X1 IX SP1 ф Ф ф ф
377
8-РАЗРЯДНЫЕ МИКРОКОНТРОЛЛЕРЫ
Продолжение табл. 4.26
Мнемокод Операция Выполняемое действие Способ адресации Влияние на признаки
V н I N Z с
LSL LSL орг LSLA LSLX LSL орг.Х LSL ,Х LSL opr.SP Сдвиг влево содержимого аккумулятора АСС, или регистрах, или байта памяти М. В битЬО загружается «0», битЬ7 загружается в бит переноса С (аналог ASL) ICkH I 1 I I 1 1 1 н> ы ьо DIR INH INH 1X1 IX SP1 $ $ $ $
LSR LSR орг LSRA LSRX LSR орг.Х LSR ,Х LSR opr.SP Сдвиг вправо содержимого аккумулятора АСС, или регистра X, или байта памяти М. В бит Ь7 загружается «0», битЬО загружается в бит переноса С ()-»| 1 1 1 1 1 1 1 I-HC1 Ъ7 ЬО DIR INH INH 1X1 IX SP1 $ t $ I
ROL ROL opr ROLA ROLX ROL opr.X ROL ,X ROL opr.SP Циклический сдвиг влево содержимого аккумулятора АСС, или регистра X, или байта памяти М через бит переноса С LEKI Г 1 1 1 1 1' 1 н-1 Ь7 ьо DIR INH INH 1X1 IX SP1 $ $ I I
ROR ROR opr RORA RORX ROR opr.X ROR ,X ROR opr.SP Циклический сдвиг вправо содержимого аккумулятора АСС, или регистра X, или байта памяти М через бит переноса С 1*1 1 1 1 1 1 1 1 НсР Ь7 ЬО DIR INH INH 1X1 IX SP1 $ I $ $
Команды битового процессора. Данную группу образуют 6 команд (табл. 4.27). Совокупность этих команд называют битовым процессором. Наличие команд битового процессора позволяет существенно сократить управляющие программы по объему кода и времени выполнения. Обратите внимание, что команды BSET и BCLR действуют только на ячейки памяти с однобайтовыми адресами $00 - $FF и не действуют на регистры центрального процессора. Следует правильно указывать операнды в командах BSET и BCL:
BSET 3,$35
BSET 0,$FF
BCLR 3,$35
Команды условного перехода по значениям отдельных битов BRSET и BRCLR могут быть отнесены как к группе команд битового процессора, так и к группе команд управления.
Команды передачи управления. Группа команд передачи управления является самой многочисленной группой. Она содержит 40 инструкций, которые делятся на две подгруппы: команды условных и безусловных переходов (табл. 4.28), команды вызова подпрограмм и обслуживания прерываний (табл. 4.29).
Установить в 1 бит D3 в ячейке памяти с адресом $35.
Установить в 1 бит DO в ячейке памяти с адресом $FF.
.Сбросить (установить в 0) бит D3 в ячейке памяти с адресом $35.
378
СЕМЕЙСТВО МК НС08 ФИРМЫ «MOTOROLA»
Таблица 4.27
Команды битового процессора
Мнемокод Операция Выполняемое действие Способ адресации Влияние на признаки
V н I N z c
BSET BSET п, орг Установить в «1» бит с номером п в байте данных. Данные могут располагаться в ячейке ОЗУ или регистре специальных функций. В команде используется только прямая адресация. Диапазон адресов байтов данных $00-$FF Мп <= 1 DIR(bO) DIR(b1) DIR(b2) DIR(b3) DIR(b4) DIR(b5) DIR(b6) DIR(b7)
BCLR BCLR п, орг Установить в «0» (очистить) битс номером п в байте данных. Данные могут располагаться в ячейке ОЗУ или регистре специальных функций. В команде используется только прямая адресация. Диапазон адресов байтов данных $OO-$FF Мп «= 0 DIR(bO) DIR(b1) DIR(b2) DIR(b3) DIR(b4) DIR(b5) DIR(b6) DIR(b7)
SEC Установить в «1» бит переноса С С <= 1 INH - - - - - 1
CLC Установить в «0» бит переноса С С <= 0 INH - - - - - 0
SEI Установить в «1» глобальную маску прерываний I. Запретить прерывания 1<= 1 INH - - 1 - - -
CLI Установить в «0» глобальную маску прерываний I. Разрешать прерывания !<= 1 INH - - 0 - - --
Центральный процессор CPU08 может использовать три команды условного перехода: традиционную трехбайтовую команду JMP и две двухбайтовых команды BRA и BRN. Команда JMP отличается расширенным набором способов задания адреса перехода. Этот адрес может быть в том числе определен одним из способов индексной адресации, что позволяет разместить изменяемый в ходе выполнения программы адрес в одной из ячеек ОЗУ. Двухбайтовая команда BRA реализует безусловный переход в пределах смещения от -128 до +127 относительно текущего адреса. Эта команда позволяет более экономно расходовать память. Команда BRN аналогична команде NOP, но имеет двухбайтовый формат. Значение смещения, которое указано во втором байте команды, смысла не имеет. Эта команда полезна для режимов отладки программного обеспечения в абсолютном коде. Она позволяет заменить инструкцию ветвления на инструкцию NOP без изменения байта смещения rel в формате команды условного перехода.
Группа команд ветвления чрезвычайно широка. Кроме переходов по традиционным условиям С, Z, N, Н, реализованы переходы по комбинациям флагов С и Z для сравнения операндов в прямом коде без знака, а также по комбинациям флагов С, Z.nV/vin сравнения операндов в дополнительном коде со знаком.
Особое внимание следует обратить на команды CBEQ и DBNZ:
CBEQ opr,rel ; Сравнить аккумулятор АСС с содержимым прямоадресуемой
; ячейки памяти и перейти по метке, если они равны.
CBEQ x+,rel ; Сравнить аккумулятор АСС с содержимым ячейки памяти, ; адрес которой содержится в индексном регистре и перейти ; по метке, если они равны. Содержимое индексного регистра Н:Х ; увеличивается на 1 после выполнения сравнения.
379
8-РАЗРЯДНЫЕ МИКРОКОНТРОЛЛЕРЫ
DBNZ x.rei ; Уменьшить на 1 содержимое ячейки памяти, адрес которой
; указан в индексном регистре Н;Х, и перейти по метке, если ; результат не равен 0.
DBNZA rel ; Уменьшить на 1 содержимое аккумулятора АСС и перейти по
; метке, если результат не равен 0.
Команды CBEQ и DBNZ имеют достаточно широкий набор способов адресации (см. табл. 4.28).
Таблица 4.28
Команды условных и безусловных переходов
Мнемокод Операция Выполняемое действие Способ адресации Влияние на признаки
v н Z C
Команды безусловного перехода
JMP JMP орг JMP орг JMP орг.Х JMP орг.Х JMP ,Х Безусловный переход по адресу, указанному в ячейке памяти (ОЗУ или ПЗУ). Адрес ячейки задан используемым в команде способом адресации PC <= Jump Address DIR EXT IX2 1X1 IX
BRA BRA rel Безусловный переход по адресу, код смещения которого указан во втором байте команды PC <= (PC)+$0002+rel REL - - - - - -
BRN BRN rel Перейти к следующей команде. Эквивалентна двум инструкциям NOP. Полезна в режиме отладки в абсолютном коде для замены инструкций условного перехода без изменения абсолютных адресов PC <= (PC)+$0002 REL
NOP Пустая операция. Счетчик команд PC увеличивается на 1. Другие регистры не изменяются None INH - - - - - -
Команды ветвления
BCS BCS rel Перейти по метке, если бит переноса С установлен. Иначе перейти к следующей команде PC <= (PC)+$0002+rel? (C) = 1 REL - — - — — —
вес ВСС rel Перейти по метке, если бит переноса С сброшен. Иначе перейти к следующей команде PC <= (PC)+$0002+rel? (C) = 0 REL - - - - - -
BEQ В EQ rel Перейти по метке, если r= т. Иначе перейти к следующей команде PC <= (PC)+$0002+rel? (Z) = 1 REL - - - - - -
BNE BNE rel Перейти по метке, если г/ т. Иначе перейти к следующей команде PC <= (PC)+$0002+rel? (Z) = 0 REL - - - - -
380
СЕМЕЙСТВО МК НС08 ФИРМЫ «MOTOROLA»
Продолжение табл. 4.28
Мнемокод Операция Выполняемое действие Способ адресации Влияние на признаки
V н I N z c
BHCS BHCS rel Перейти по метке, если бит дополнительного переноса Н установлен. Иначе перейти к следующей команде РС <= (PC)+$0002+rel? REL — — - - - -
внес внес rel Перейти по метке, если бит дополнительного переноса Н сброшен. Иначе перейти к следующей команде РС <= (PC)+$0002+rel? (Н) = 0 REL — — - - - -
CBEQ CBEQ opr,rel CBEQA #opr,rel CBEQX #opr,rel CBEQ opr, X+, rel CBEQ X+,rel CBEQ opr.SP, rel Сравнить содержимое аккумулятора АСС с содержимым ячейки памяти М (или константой) и перейти по метке, если равны РС<=(РС)+$0003+ rel? (А) - (М) = $00 PCt=(PC)+$0003+ rel? (А) - (М) = $00 РСНРС)+$0003+ rel? (X) - (М) = $00 PCt=(PC)+$0003+ rel? (А) - (М) = $00 РС<=(РС)+$0003+ rel? (А) - (М) = $00 РС<=(РС)+$0003+ rel? (А) - (М) = $00 DIR IMM IMM 1X1 + IX+ SP1
DBNZ DBNZ opr,rel DBNZA rel DBNZX rel DBNZ opr, X, rel DBNZ X,rel DBNZ opr.SP, rel Вычесть единицу из содержимого ячейки памяти М, или аккумулятора АСС, или регистра X и перейти по метке, если результат не равен 0 А<=(А)-$0001 or М<=(М)-$01 or Х<=(Х)-$0001 РС<=(РС)+$0003+ rel if (result) / 0 for DBNZ direct, 1X1 PC<=(PC)+$0002+ rel if (result) / 0 for DBNZA, DBNZX, or 1X1 PC<=(PC)+$0004+ rel if (result) / 0 for DBNZ SP1 DIR INH INH 1X1 IX SP1
BIH BIH rel Перейти по метке, если на входе IRQ высокий логический уровень. Иначе перейти к следующей команде PC <= (PC)+$0002+rel? (IRQ) = 1 REL - - - - - —
BIL BIL rel Перейти по метке, если на входе IRQ низкий логический уровень. Иначе перейти к следующей команде PC €= (PC)+$0002+rel? (IRQ) = 0 REL - - - - — —
BMS BMS rel Перейти по метке, если бит маски I установлен. Иначе перейти к следующей комацде.Условие: I = 1 PC <= (PC)+$0002+rel? REL - - - - — —
381
8-РАЗРЯДНЫЕ МИКРОКОНТРОЛЛЕРЫ
Продолжение табл. 4.28
Мнемокод Операция Выполняемое действие Способ адресаци и Влияние на признаки
V н I N z c
ВМС ВМС rel Перейти по метке, если бит маски 1 сброшен. Иначе перейти к следующей команде. Условие: 1 = 0 РС €= (PC)+$0002+rel? REL — -
BRSET BRSET п, opr, rel Перейти по указанному адресу, если битп в байте данных установлен. Иначе перейти к следующей команде. Для указания байта данных используется только прямая адресация. Диапазон адресов $00 - $FF РС €= (PC)+$0002+rel? (Мп) = 1 (Н) = 0 DIR(bO) DIR(b1) DIR(b2) DIR(b3) DIR(b4) DIR(b5) DIR(b6) DIR(b7) I
BRCLR BRCLR п, opr, rel Перейти по указанному адресу, если бит п в байте данных равен 0. Иначе перейти к следующей команде. Для указания байта данных используется только прямая адресация. Диапазон адресов $00- $FF РС €= (PC)+$0002+rel? (Мп) = 0 DIR(bO) DIR(b1) DIR(b2) DIR(b3) DIR(b4) DIR(b5) DIR(b6) DIR(b7) I
Команды ветвления при сравнении чисел без знака
BHI BHI rel Перейти по метке, если г > т. Иначе перейти к следующей команде РС €= (PC)+$0002+rel ? (С) I (Z) REL - - - - - -
BHS BHS rel Перейти по метке, если г > m. Иначе перейти к следующей команде РС €= (PC)+$0002+rel ? (С) = 0 REL - - - - - -
BLO BLO rel Перейти по метке, если г < т. Иначе перейти к следующей команде РС €= (PC)+$0002+rel ? (С) = 1 REL - - - - - -
BLS BLS rel Перейти по метке, если г< m. Иначе перейти к следующей команде РС €= (PC)+$0002+rel ? (С) I (Z) = 1 REL - - - -
Команды ветвления при сравнении чисел со знаком
BPL BPL rel Перейти по метке, если бит знака установлен в «0», т. е число положительное. Иначе перейти к следующей команде РС €= (PC)+$0002+rel ? (N) = 0 REL - — - — - —
BMI BMI rel Перейти по метке, если бит знака установлен в «1», т. е число отрицательное. Иначе перейти к следующей команде PC €= (PC)+$0002+rel ? (N) = 1 REL - - — - - —
BGE В GE rel Перейти по метке, если r>m. Иначе перейти к следующей команде PC <= (PC)+$0002+rel ? (N ffi V) = 0 REL - - - - - —
382
СЕМЕЙСТВО МК НС08 ФИРМЫ «MOTOROLA»
Продолжение табл. 4.28
Мнемокод Операция Выполняемое действие Способ адресации Влияние на признаки
V н I N Z с
BGT BGT rel Перейти по метке, если г > т. Иначе перейти к следующей команде РС €= (РС)+$0002+ге1 ? (Z) | (N ffi V) = 0 REL - - - - - -
BLE BLE rel Перейти по метке, если г < т. Иначе перейти к следующей команде РС<= (РС)+$0002+ге1 ? (Z) | (N © V) = 1 REL — - - — - -
BLT BLT rel Перейти по метке, если г < т. Иначе перейти к следующей команде РС <= (PC)+$0002+rel ? (N ffi V) = 1 REL — - - - - -
Таблица 4.29
Команды работы со стеком вызова подпрограмм и обслуживания прерываний
Мнемокод Операция Выполняемое действие Способ адресации Влияние на признаки
V н I N z c
JSR JSR орг JSR орг JSR орг,Х JSR орг,Х JSR ,Х Вызов подпрограммы. Адрес подпрограммы хранится в ячейке памяти (ОЗУ или ПЗУ). Адрес ячейки задан используемым в команде способом адресации PC = РС + п, где п = 1,2,3 в зависимости от способа адресации. (SP) <= PCL SP = SP- 1 (SP) PCH SP = SP - 1 PC <= адрес подпрограммы DIR EXT IX2 1X1 IX
BSR BSR rel Вызов подпрограммы, записанной по адресу, код смещения которого указан во втором байте команды PC = PC + 002 (SP) <= PCL SP = SP - 1 (SP) PCH SP = SP - 1 PC= PC + Rel, где Rel - код смещения REL
SWI Программное прерывание. PC = РС + 01 (SP) €= PCL SP = SP - 1 (SP)<=PCH SP = SP-1 (SP) €= X SP = SP - 1 (SP) <= A SP = SP - 1 (SP) €= CCR SP = SP - 1 1 = 1, установка глобальной маски прерывания РСН<= ($FFFC) PCH <= ($FFFD) Счетчик команд загружается вектором программного прерывания из ячеек памяти $FFFC и $FFFD PC = PC + 01 (SP) €= PCL SP = SP - 1 (SP) PCH SP = SP - 1 (SP) <= X SP= SP - 1 (SP) <= A SP= SP - 1 (SP) €= CCR SP = SP - 1 1 = 1, установка глобальной маски прерывания PCH €= ($FFFC) PCH ($FFFD) INH 1
383
8-РАЗРЯДНЫЕ МИКРОКОНТРОЛЛЕРЫ
Продолжение табл. 4.29
Мнемокод Операция Выполняемое действие Способ адресации Влияние на признаки
V н । N Z с
RTS Возврат из подпрограммы. Адрес возврата загружается из стека в счетчик команд SP = SP + 1 PCH <= (SP) SP = SP + 1 PCL €= (SP) INH — — — - -
RTI Возврат из прерывания.Восстанавливается содержимое регистров CPU и счетчика команд SP = SP + 1 CCR <= (SP) SP = SP + 1 А <= (SP) SP = SP + 1 X <= (SP) SP = SP + 1 PCH <= (SP) SP = SP + 1 PCL €= (SP) INH г г г г г
RSP Установить регистр указатель стека в состояние $FF SP €= $FF INH -
PSHA Загрузить аккумулятор АСС в стек Push (A); SP<= (SP) - $0001 INH -
PSHH Загрузить старший байт индексного регистра Н в стек Push (H); SP€= (SP) - $0001 INH -
PSHX Загрузить младший байт индексного регистра X в стек Push (X); SP<= (SP)-$0001 INH -
PULA Восстановить аккумулятор АСС из стека SP<= (SP+$0001); Pull (A) INH -
PULH Восстановить старший байт индексного регистра Н из стека SP€= (SP+$0001); Pull (H) INH -
PULX Восстановить младший байт индексного регистра X из стека SP€= (SP+$0001); Pull (X) INH -
Среди команд вызова подпрограмм и обслуживания прерываний следует выделить команду программного немаскируемого прерывания SWL Механизм программного прерывания позволяет обратиться к какой-либо подпрограмме прерывания по ходу выполнения прикладной программы и воспользоваться подпрограммой прерывания как обычной подпрограммой. Наличие в системе команд инструкции программного прерывания SWI предоставляет такую возможность. Эта команда автоматически загружает в стек регистры CCR, АСС, X и увеличенное на единицу содержимое счетчика команд РС, а затем осуществляет переход по адресу, который указан в ячейках памяти $FFFC и $FFFD сегмента векторов прерывания. Этот адрес может быть начальным адресом подпрограммы прерывания или же находиться внутри нее. При выходе из подпрограммы прерывания команда RTI восстановит содержимое регистров центрального процессора, и МК продолжит выполнение прикладной программы с команды, которая была следующей за командой SWI. Таким образом, программисту предоставляется возможность обращения в произвольный момент времени к фрагменту подпрограммы прерывания, который начинается с произвольно выбранной инструкции внутри подпрограммы прерывания, но заканчивается обязательно командой RTI.
384
СЕМЕЙСТВО МК НС08 ФИРМЫ «MOTOROLA»
Команды управления режимами энергопотребления. Команды WAIT и STOP переводят МК в один из режимов пониженного энергопотребления (табл. 4.30).
Таблица 4.30
Команды перехода к режимам пониженного энергопотребления
Мнемокод Операция Выполняемое действие Способ адресации Влияние на признаки
V н I N Z с
WAIT Переводит МК в режим ожидания (Wait mode) I бит <= 0 INH - - - - - -
STOP Переводит МК в режим оста нова (Stop mode) I бит <= 0; Stop Oscillator INH - - - - - -
4.3.4. СРАВНИТЕЛЬНЫЙ АНАЛИЗ СИСТЕМЫ КОМАНД MCS-51 И НС08
В предыдущих разделах вы познакомились с двумя представителями CISC-архитектуры в классе 8-разрядных МК. Процессорное ядро MCS-51 выполнено по гарвардской архитектуре с раздельным адресным пространством памяти программ и памяти данных. Напротив, процессорное ядро НС08 использует принстонскую архитектуру с объединенным адресным пространством. Соответственно отличаются и системы команд. Однако не все отличия обусловлены способами доступа к тем или иным ячейкам памяти. Значительную часть определяет техническое творчество разработчиков ядра и традиции фирмы. Последнее не является лишь данью истории:
• во-первых, многие решения проверены десятилетиями, и именно это обстоятельство обеспечивает высокую надежность БИС;
• во-вторых, использование новых моделей МК в значительной степени определяется возможностью использования имеющихся наработок программного обеспечения. Поэтому при разработке нового процессорного ядра фактор программной совместимости стоит на одном из первых мест.
Однако, к счастью, последнее не всегда берет верх в технической политике. Иначе принципиально новые решения были бы невозможными.
Итак, сравним два процессорных ядра.
• Несмотря на кажущиеся принципиальные отличия, и в архитектуре MCS-51, и в НС08 нулевая страница оперативной памяти данных (00h - OFFh) занимает особое место. Для обращения именно к этой странице предназначены двухадресные команды, которые имеют короткий формат и малое время выполнения. Сравните:
MCS-51 НС08
MOV @ri,ad MOV adr,x+
MOV add,ads MOV adr1,adr2
• MCS-51 использует 6 методов адресации, с учетом различных указателей при косвенной адресации и двухадресных команд общее число режимов адресации составляет 11. CPU08 использует 11 методов адресации, общее число режимов адресации с учетом двухадресных команд равно 16. Среди последних нет регистровой адресации, которая характерна для MCS-51, но присутствуют различные варианты индексной адресации, в том числе по указателю стека с автоинкрементированием, что позволяет создать экономичные по длине кода компиляторы с языка Си. Именно поэтому ядро НС08 характеризуют как оптимизированное под использование языков высокого уровня.
385
8-РАЗРЯДНЫЕ МИКРОКОНТРОЛЛЕРЫ
• MCS-51 имеет значительно большее число команд для обмена с ячейками памяти нулевой страницы, в то время как число команд обращения к памяти программ и расширенной памяти данных сведено до минимума. Напротив, в НС08 число дополнительных команд обмена с нулевой страницей памяти равно четырем, но сразу 8 режимов адресации используется в каждой команде группы пересылки для адресации ячеек памяти полного адресного пространства.
• Набор арифметических и логических действий АЛУ того и другого ядра практически одинаковы. Но в НС08 набор методов адресации второго операнда (первый располагается в АСС) значительно шире. Причем диапазон адресов ячеек памяти второго операнда в MCS-51 составляет 00h - OFFh, в то время как в НС08 при выполнении арифметических и логических действий доступно все адресное пространство в 64 К.
• Процессорное ядро НС08 значительно превосходит MCS-51 по числу команд условных переходов: 40 инструкций НС08 против 22 у MCS-51. Несомненным достоинством CPU08 является присутствие в перечне его команд инструкций ветвления по условиям >, >, <, < по результатам сравнения операторов в формате как со знаком, так и без него.
• Прямо противоположна идеология подсистем прерывания. В MCS-51 при переходе на процедуру обслуживания прерывания в стеке сохраняется лишь адрес возврата в основную программу. Остальные регистры должны сохраняться программно. А в НС08 в процессе перехода к подпрограмме прерывания автоматически дополнительно сохраняются аккумулятор, регистр признаков и регистр X. Такое решение увеличивает время перехода к подпрограмме прерывания, но исключает ошибки при программировании. С другой стороны, ядро MCS-51 имеет фиксированные векторы прерывания, что требует занесения по адресам этих векторов дополнительных команд безусловного перехода. В то время как в НС08 векторы прерывания произвольно определяются пользователем, поэтому дополнительных команд безусловного перехода не требуется.
Какое ядро предпочтительней? Однозначного ответа на этот вопрос не может дать никто. Ведь то, что требуется от процессорного ядра, это удовлетворять по быстродействию и объему адресуемой памяти для решаемой задачи и быть удобным в программировании. При этом следует учитывать, что в процессе выбора элементной базы МК для проекта будут оцениваться множество факторов, прямо не связанных с архитектурой процессорного ядра. Это набор и технические характеристики периферийных модулей, напряжение питания, мощность потребления, тип корпуса, возможности программирования и отладки, стоимостные показатели, и, наконец, доступность образцов кристаллов МК. Именно поэтому тесты на производительность МК проводятся, но по ним никогда не делается абсолютного заключения. Остается простор для творчества.
4.3.5. ИСТОЧНИКИ И МЕХАНИЗМ ОБРАБОТКИ ПРЕРЫВАНИЙ
Прерывания изменяют текущую последовательность выполнения команд с целью обслуживания внешнего или внутреннего события, вызывавшего прерывание. Прерывание в отличие от сброса не останавливает выполнение текущей инструкции. При поступлении запроса на прерывание МК завершает выполнение текущей команды, а затем реализует механизм перехода к подпрограмме прерывания:
• регистры центрального процессора автоматически сохраняются в стеке в следующем порядке: регистр признаков CCR, аккумулятор АСС, младший байт индексного регистра X, старший байт счетчика адреса РСН, младший байт счетчика адреса PCL; по завершении прерывания инструкция возврата из прерывания RTI восстанавливает в обратном порядке все регистры центрального процессора для возобновления выполнения фоновой программы;
386
СЕМЕЙСТВО МК НС08 ФИРМЫ «MOTOROLA»
• бит глобальной маски прерывания I в регистре признаков CCR устанавливается в «1», запрещая обслуживание любых других запросов на прерывание до тех пор, пока не будет завершена текущая подпрограмма прерывания;
• счетчик адреса РС загружается адресом начала подпрограммы прерывания, который называют вектором прерывания.
В МК семейства НС08 реализован традиционный для всех МК фирмы «Motorola» механизм загрузки векторов прерывания. В адресном пространстве памяти программ МК выделена специальная область, которая носит название сегмента векторов прерывания. Каждому источнику запросов на прерывание в этой области отведено по два байта памяти с фиксированными адресами. Пользователь на этапе программирования МК заносит в эти ячейки памяти адрес начала подпрограммы прерывания. При переходе к выполнению подпрограммы прерывания этот адрес автоматически загружается в счетчик адреса центрального процессора. В рассматриваемом сегменте памяти размещается также вектор сброса.
Ниже приведен пример структуры прикладной программы с двумя подпрограммами прерывания по запросам на входе Jrq и от процессора событий TIM1. Абсолютные адреса сегмента векторов прерывания соответствуют карте памяти МК MC68HC908GP32.
vector! rq: equ $FFFA
vectortiml: equ $FFF2
vectorreset: equ $FFFE
;Основная программа
START: Idhx #$1 FF ; Инициализация указателя стека с целью переместить
txs ; область стековой памяти из нулевой в первую страницу
; ОЗУ МК.
Тело подпрограммы инициализации
cli ; Разрешить прерывания: установить в 0 глобальную ; маску прерываний.
Тело основной программы управления
; Подпрограмма прерывания по INTJRQ: pshh внешнему запросу. ; Сохранить в стеке старший байт индексного регистра Н:Х. ; Сохранение остальных регистров центрального процессора ; (регистра признаков CCR; аккумулятора АСС и младшего ; байта индексного регистра X) произошло автоматически при ; переходе к выполнению подпрограммы прерывания.
Тело подпрограммы прерывания
pulh rti ; Восстановить из стека старший байт индексного регистра ; Н:Х. ; Возврат из прерывания. Эта команда восстанавливает
; из стека регистры X, АСС и CCR автоматически без ; использования специальных команд.
387
в-НАЗРЯДНЫЕ МИКРОКОНТРОЛЛЕРЫ
; Подпрограмма прерывания по переполнению счетчика временной базы процессора ; событий TIM1
INT_TIMA1: pshh ; Сохранить в стеке старший байт индексного регистра Н.
Тело подпрограммы
прерывания
pulh ; Завершение подпрограммы прерывания,
rti ;
; Определить вектора прерывания и начального запуска org vectorjrq dw INTJRQ org vector_tima dw INT_TIM1 org vector_reset dw START
Аппаратные средства прерывания МК семейства НС08 имеют следующие особенности:
• выполнение команды возврата из прерывания RTI автоматически разрешает прерывания;
• выполнение команды возврата из прерывания RTI не блокирует прерывания на период выполнения следующей команды; вход в новую подпрограмму возможен сразу после выполнения команды RTI.
Дело в том, что при входе в подпрограмму прерывания бит глобальной маски прерывания I обязательно равен 0. Иначе прерывания были бы запрещены и говорить о подпрограмме прерывания не имело бы смысла. Содержимое регистра признаков, в котором располагается маска I, сохраняется в стеке при входе в подпрограмму прерывания. Следовательно, при восстановлении регистра признаков из стека по команде RTI бит глобальной маски прерывания установится в «0», и прерывания будут разрешены.
Все источники прерываний МК семейства НС08 можно разделить на три группы:
1) немаскируемое программное прерывание по команде SWI;
2) маскируемые внешние прерывания по входу IRQ и по некоторому числу линий портов ввода/вывода, которые принадлежат модулю сканирования клавиатуры KBI08;
3) маскируемые прерывания от периферийных модулей.
Механизм программного прерывания позволяет обратиться к какой-либо подпрограмме прерывания по ходу выполнения прикладной программы и воспользоваться подпрограммой прерывания как обычной подпрограммой. Наличие в системе команд инструкции программного прерывания SWI предоставляет такую возможность. Эта команда автоматически загружает в стек регистры CCR, АСС, X и увеличенное на единицу содержимое счетчика команд РС, а затем осуществляет переход по адресу, который указан в ячейках памяти $FFFC и $FFFD сегмента векторов прерывания. Этот адрес может быть начальным адресом подпрограммы прерывания или же находиться внутри нее. При выходе из1-подпрограммы прерывания команда RTI восстановит содержимое регистров централь- * ного процессора и МК продолжит выполнение прикладной программы с команды, кото-рая была следующей за командой SWI. Таким образом, программисту предоставляется возможность обращения в произвольный момент времени к фрагменту подпрограммы прерывания, который начинается с произвольно выбранной инструкции внутри подпрограммы прерывания, но заканчивается обязательно командой RTI.
Число линий МК MC68HC908GP32 для приема внешних запросов на прерывания_ва-рьируется от одной линии (вход IRQ) до 9 линий. Обслуживание запросов по входу irq
388
СЕМЕЙСТВО МК НС08 ФИРМЫ «MOTOROLA,
осуществляет модуль внешних прерываний IRQ08. Активный уровень сигнала запроса на входе irq - низкий логический, длительность сигнала запроса должна составлять не менее tILIH=50 нс. Дополнительные входы внешних запросов могут быть получены путем соответствующей инициализации модуля сканирования клавиатуры KBI08, который позволяет настроить некоторое число линий ввода/вывода МК для приема внешних запросов на прерывание.
Все прерывания, кроме программного по команде SWI, могут быть разрешены или запрещены сбросом или установкой глобальной маски прерывания I в регистре признаков CCR:
cli ; команда сбрасывает в «О» бит I, т. е. разрешает прерывания.
sei ; команда устанавливает бит I в «1», т. е. запрещает прерывания.
Кроме того, каждому источнику прерывания, за исключением программного, поставлена в соответствие индивидуальная маска прерываний, которая расположена в одном из регистров специальных функций соответствующего периферийного модуля.
Подсистема прерываний МК семейства НС08 имеет жесткое распределение приоритетов, которое не может быть скорректировано программными настройками. Источники прерываний, уровни их приоритетов, абсолютные адреса векторов прерываний для МК MC68HC908GP32 приведены в табл. 4.31.
Таблица 4.31
Таблица векторов прерывания МК MC68HC908GP32
Источник события прерывания или сброса Адрес ячейки памяти вектора Бит регистра ISRi Флаг - источник запроса Условия маскирования Приоритет
Вектор прерывания по запросу модуля базового таймера ТВМ08 $FFDC $FFDD IF16 TBIF Глобальная маска I в регистре CCR. Маска AIEN в регистре ADSCR. Низший Высший
Вектор прерывания по запросу модуля аналого-цифрового преобразователя ADC08 $FFDE $FFDF IF15 COCO Глобальная маска I в регистре CCR. Маска AIEN в регистре ADSCR.
Вектор прерывания по запросу модуля сканирования клавиатуры KBI08 $FFE0 $FFE1 IF14 IMASKK Глобальная маска I в регистре CCR. Маска IMASKK в регистре KBSCR.
Вектор прерывания по запросу передатчика модуля последовательного асинхронного интерфейса SCI $FFE2 $FFE3 IF13 TC SCTE Глобальная маска I в регистре CCR. Маски SCTIE и TCIE в регистре SCC2.
Вектор прерывания по запросу приемника модуля последовательного асинхронного интерфейса SCI $FFE4 $FFE5 IF12 SCRFIDLE Глобальная маска I в регистре CCR. Маски SCRIE и ILIE в регистре SCC2.
389
8-РАЗРЯДНЫЕ МИКРОКОНТРОЛЛЕРЫ
Продолжение табл. 4.31
Источник события прерывания или сброса Адрес ячейки памяти вектора Бит регистра ISRi Флаг - источник запроса Условия маскирования Приоритет
Вектор прерывания по событию ошибки обмена в модуле последовательного асинхронного интерфейса SCI $FFF6 $FFF7 IF11 ORNFFEPE Глобальная маска I в регистре CCR. Маски ORIE, NEIE, FEIE, PEIE в регистре SCC3. Низший Высший
Вектор прерывания по запросу передатчика модуля последовательного синхронного интерфейса SPI $FFE8 $FFE9 IF10 SPTE Глобальная маска I в регистре CCR. Маска SPTIE в регистре SPCR.
Вектор прерывания по запросу приемника модуля последовательного синхронного интерфейса SPI $FFEA $FFEB IF9 SPRFOVRF-MODF Глобальная маска I в регистре CCR. Маски SPRIE в регистре SPCR и ERRIE в регистре SPSCR.
Вектор прерывания по переполнению счетчика временной базы модуля процессора событий TIM2 SFFEC $FFED IF8 TOF Глобальная маска I в регистре CCR. Маска TOIE в регистре T2SC.
Вектор прерывания по событию канала 1 модуля процессора событий TIM2 $FFEE $FFEF IF7 CH1F Глобальная маска I в регистре CCR. Маска CH1IE в регистре T2SC1 .
Вектор прерывания по событию канала 0 модуля процессора событий TIM2 $FFF0 $FFF1 IF6 CHOF Глобальная маска I в регистре CCR. Маска CHOIЕ в регистре T2SC0.
Вектор прерывания по переполнению счетчика временной базы модуля процессора событий TIM1 $FFF2 $FFF3 IF5 TOF Глобальная маска I в регистре CCR. Маска TOIE в регистре T1SC.
Вектор прерывания по событию канала 1 модуля процессора событий TIM1 $FFF4 $FFF5 IF4 CH1F Глобальная маска I в регистре CCR. Маска CH1IE в регистре T1SC1.
Вектор прерывания по событию канала 0 модуля процессора событий TIM1 $FFF6 $FFF7 IF3 CHOF Глобальная маска I в регистре CCR. Маска CH0IE в регистре T1SC0.
Вектор прерывания по запросу модуля формирования тактовой частоты CGM08 $FFF8 $FFF9 IF2 PLLF Глобальная маска I в регистре CCR. Маска PLLIE в регистре PCTL.
390
СЕМЕЙСТВО МК НС08 ФИРМЫ «MOTOROLA»
Продолжение табл. 4.31
Источник события прерывания или сброса Адрес ячейки памяти вектора Бит регистра ISRi Флаг - источник запроса Условия маскирования Приоритет
Вектор прерывания по входу IRQ $FFFA $FFFB IF1 IM AS К1 Глобальная маска I в регистре CCR. Маска IMASK1 в регистре INTSCR. Низший
Вектор программного прерывания по команде SWI $FFFC $FFFD - — Немаскируемое
Вектор сброса $FFFE $FFFF - - Немаскируемое Высший
4.3.6. ПОРТЫ ВВОДА/ВЫВОДА ।
МК MC68HC908GP32 обладает 33 линиями ввода/вывода данных. Эти линии объединены в 8-разрядные параллельные порты, которые именуют в соответствии с буквами латинского алфавита: Port A, Port В, Port С, Port D, Port Н.
Все линии ввода/вывода МК MC68HC908GP32 - двунаправленные, т. е. могут использоваться разработчиком как для ввода данных в МК, так и для вывода логических сигналов. Направление передачи линий ввода/вывода настраивается программно путем записи управляющих слов в регистры специальных функций. Возможно изменение направления передачи в ходе выполнения программы посредством перепрограммирования этих регистров. Сигнал сброса устанавливает все линии в режим ввода. Направление передачи каждой линии может быть выбрано разработчиком произвольно, независимо от других линий, принадлежащих к одному и тому же порту ввода/вывода.
Большинство линий ввода/вывода обладают так называемой альтернативной функцией. Эти линии связаны со встроенными в МК периферийными устройствами, они обеспечивают связь периферийных модулей с «внешним миром». Так, линии порта Port В используются для подключения к встроенному АЦП измеряемых напряжений, линии других портов служат линиями ввода/вывода последовательных приемопередатчиков. Если соответствующий периферийный модуль МК не используется, то его выводы можно задействовать как обычные линии ввода/вывода. Распределение линий ввода/вывода по портам, спецификация линий альтернативных функций для МК MC68HC908GP32 приведены в табл. 4.32.
По способу схемного решения выходного драйвера различают два типа линий ввода/ вывода:
1) линии с обычной схемотехникой двунаправленной линии ввода/вывода;
2) двунаправленные линии с программно-подключаемыми в режиме ввода подтягивающими резисторами RpuLLUp (см. рис. 4.5).
Если порт имеет «обычную» схемотехнику, то для его обслуживания предусмотрены два типа регистров:
1) РТх - регистр данных порта х, где х - имя порта ввода/вывода;
2) DDRx - регистр направления передачи порта х.
Если порт имеет схемотехнику с программно-подключаемым «подтягивающим» резистором, то для обслуживания порта предусмотрены три регистра:
391
8-РАЗРЯДНЫЕ МИКРОКОНТРОЛЛЕРЫ
1) РТх - регистр данных порта х;
2) DDRx - регистр направления передачи порта х;
3) PTxPUE - регистр входного сопротивления порта х.
Так, порт Port А микроконтроллера MC68HC908GP32 обслуживается регистрами РТА, DDRA и PTAPUE. В табл. 4.33, 4.34, и 4.35 приведен формат регистров специальных функций РТх, DDRx и PTxPUE. Заметим, что формат регистров РТх и DDRx для портов с различной схемотехникой полностью совпадает.
Таблица 4.32
Спецификация линий ввода/вывода МК MC68HC908GP32
Имя порта Число линий Схемотехника линий Альтернативная функция
Port А 8 Двунаправленные, с возможностью программного подключения резистора RpuLLUp 8 линий являются входами модуля сканирования клавиатуры (8 KBI)
Port В 8 Двунаправленные 8 линий являются аналоговыми входами встроенного АЦП
Port С 7 Двунаправленные, с возможностью программного подключения резистора RPULLUP Не имеют альтернативной функции
Port D 8 Двунаправленные, с возможностью программного подключения резистора RPULLUP 4 линии обслуживают модуль SPI, 2 линии - модуль TIM1 2 линии - модуль TIM2
Port Е 2 Двунаправленные 2 линии обслуживают модуль SCI
Таблица 4.33
Формат регистра РТх
РТх | Регистр данных порта х
7 6 5 4 3 2 1 0
РТх7 | РТхб | РТхб | РТх4 | РТхЗ | РТх2 | РТх1 | РТхО
Сброс не влияет на состояние регистра
Имя бита Назначение бита
РТх7-РТхО Биты данных порта х Эти биты доступны как для чтения, так и для записи. Если порт сконфигурирован в режим ввода, то при чтении регистра РТх возвращается значение логических сигналов на одноименных входах МК. Если порт сконфигурирован в режим вывода, то при записи данные заносятся в соответствующие биты регистра РТх. Операция чтения возвращает последние записанные данные.
Таблица 4.34
Формат регистра DDRx
DDRx | Регистр направления передачи порта х
7 6 5 4 3 2 1 0
DDRx7 | DDRx6 | DDRx5 | DDRx4 ( DDRx3 | DDRx2 DDRx! | DDRxO
Состояние при сбросе: OOh
Имя бита Назначение бита
DDRx7-DDRxO Биты направления передачи порта х 1 -конфигурирует линию на вывод; 0 - конфигурирует линию на ввод; При сбросе все биты регистра устанавливаются в «0», т. е. программируются на ввод. все линии
392
СЕМЕЙСТВО МК НС08 ФИРМЫ «MOTOROLA!
Формат регистра PTxPUE
Таблица 4.35
PTxPUE I Регистр входного сопротивления порта х
7 6 5 4 3 2 1 0
PTXPUE7 | PTxPUE6 | PTxPUE5 | PTxPUE4 | PTxPUE3 | PTxPUE2 | PTxPUEl | PTxPUEO
Состояние при сбросе: 00h
Имя бита Назначение бита
PTxPUE7-PTxPUE0 Биты разрешения подключения входного «подтягивающего» резистора для линий порта х Эти биты доступны только для записи 1 - «подтягивающий резистор» подключен; 0 - «подтяпывающий резистор» отключен.
Детальный формат всех регистров специальных функций портов ввода/вывода приведен ниже (рис. 4.47).
Адрес Имя регистра Формат регистров
$0000 РТА РТА7 РТА6 РТА5 РТА4 РТАЗ РТА2 РТА1 PTA0 |
$0001 РТВ РТВ7 РТВ6 РТВ5 РТВ4 РТВЗ РТВ2 РТВ1 PTB0 |
$0002 РТС о РТС6 РТС5 РТС4 РТСЗ РТС2 РТС1 PTC0 |
$0003 PTD PTD7 PTD6 PTD5 PTD4 PTD3 PTD2 PTD1 PTD0 |
$0008 РТЕ о о 0 0 0 о РТЕ1 РТЕО |
$0004 DDRA DDRA7 DDRA6 DDRA5 DDRA4 DDRA3 DDRA2 DDRA1 DDRA0
$0005 DDRB DDRB7 DDRB6 DDRB5 DDRB4 DDRB3 DDRB2 DDRB1 DDRB0 |
$0006 DDRC о DDRC6 DDRC5 DDRC4 DDRC3 DDRC2 DDRC1 DDRC0
$0007 DDRD DDRD7 DDRD6 DDRD5 DDRD4 DDRD3 DDRD2 DDRD1 DDRD0
$000С DDRE о 0 0 0 о о DDRE1 DDRE0
$000D PTAPUE PTAPUE? РТА-PUE6 РТА-PUE5 РТА-PUE4 РТА-PUE3 РТА-PUE2 РТА- PUE1 РТА-PUE0
$000Е PTCPUE 0 РТС-PUE6 РТС-PUE5 РТС- PUE4 РТС-PUE3 РТС-PUE2 РТС- PUE1 РТС- PUE0
$000F PTDPUE PTDPUE? PTD-PUE6 PTD-PUE5 PTD-PUE4 PTD-PUE3 PTD-PUE2 PTDPUE! PTD- PUE0
Рис. 4.47. Регистры для обслуживания портов ввода/вывода МК MC68HC908GP32
393
8-РАЗРЯДНЫЕ МИКРОКОНТРОЛЛЕРЫ
4.3.7. ПРОЦЕССОР СОБЫТИЙ TIM08
Модуль TIM08, хотя и носит дословное название «модуль таймерного интерфейса», по сути, является одним из лучших процессоров событий в 8-разрядных МК.
Модуль TIM08 состоит из 16-разрядного таймера-счетчика и некоторого количества связанных с ним полностью идентичных каналов захвата/сравнения. Каждый из каналов в процессе инициализации может быть настроен на один из пяти режимов работы:
1) входного захвата;
2) небуферированного выходного сравнения; i
3) буферированного выходного сравнения; j
4) небуферированной широтно-импульсной модуляции (ШИМ);
5) буферированной ШИМ.
Каждый канал захвата/сравнения связан с одним из выводов МК. Функция входного или выходного сигнала модуля процессора событий является альтернативной функцией линий порта Port D. МК MC68HC908GP32 имеет в своем составе два модуля процессора событий - TIM1 и TIM2. Каждый из модулей имеет по два канала захвата/сравнения.
Структурная схема модуля двухканального процессора событий представлена на рис. 4.48. Шестнадцатиразрядный таймер-счетчик служит временной базой для модулей захвата/сравнения. Он подсчитывает импульсы тактовой частоты, поступающие на его вход. Все интервалы времени, которые генерируются или измеряются МК, измеряются числом периодов этой тактовой частоты.
В общем случае (модули TIM08 других МК семейства НС08) таймер-счетчик имеет два источника тактирования:
1) внутренний генератор, выполненный на основе программируемого делителя частоты шины МК fBUS;
2) внешний генератор, подключаемый к выводу TxCLK МК.
Выбор между внутренним и внешним генераторами, а также выбор коэффициента деления программируемого делителя частоты шины КТ|Мх определяется комбинацией битов PS2 - PS0 регистра управления таймера-счетчика TxSC. Коэффициент деления КТ1Мх может принимать семь различных значений: 1, 2, 4, 8, 16, 32, 64. Максимальная частота сигнала внешнего генератора, подключаемого ко входу TxCLK, составляет 4 МГц при условии, что МК работает на предельной частоте внутренней шины fBUS= 8 МГц. Процессоры событий TIM1 и TIM2 в составе МК MC68HC908GP32 не имеют выводов T1CLK и T2CLK в перечне выводов корпуса и, следовательно, могут использовать для тактирования только встроенный генератор.
Таймер-счетчик временной базы допускает программную установку периода работы. Если не предпринимать специальных действий при инициализации процессора событий, то коэффициент счета счетчика временной базы будет равен 2'6, т. е. счетчик проходит полный цикл от начального состояния кода $0000 до конечного состояния кода $FFFF. Если таймер-счетчик находится в состоянии $FFFF, то при поступлении на его вход очередного тактового импульса наступает переполнение таймера-счетчика. Счетчик переходит в состояние $0000, одновременно устанавливается флаг переполнения TOF. Переполнение счетчика не оказывает влияния на его работу: при поступлении следующих тактовых импульсов код в счетчике продолжает нарастать. Коэффициент счета таймера-счетчика может быть изменен посредством записи кода желаемого Ксч в двухбайтовый регистр периода TxMOD (TxMODH и TxMODL - старший и младший байты этого регистра, х - номер таймерного модуля, для TIM1 х = 1, для TIM2 х = 2). Вход сброса счетчика подключен к выходу цифрового компаратора (см. рис. 4.48), на один из входов которого поступает код текущего состояния таймера-счетчика, а на другой - код Ксч, за
394
СЕМЕЙСТВО МК НС08 ФИРМЫ «MOTOROLA»
писанный в регистре TxMOD. Если эти коды равны, то при поступлении следующего тактового импульса счетчик сбрасывается в «О», и флаг переполнения TOF устанавливается в «1». Диапазон допустимых значений Ксч составляет от 1 до (2,6-1). Таким образом, дискретность регулирования периода таймера-счетчика, который в режиме ШИМ образует период ШИМ-сигнала, составляет 16 бит.
Предусмотрена возможность пуска и останова таймера-счетчика под управлением программы (бит TSTOP в регистре управления таймером-счетчиком TxSC). Кроме того, счетчик и программируемый делитель частоты могут быть одновременно сброшены посредством установки в «1» бита TRST в регистре TxSC. При этом все триггеры таймера-счетчика установятся в «О», а программируемый делитель частоты будет настроен на режим единичного коэффициента деления частоты внутренней шины МК. Заметьте, что бит TRST не останавливает работу таймера-счетчика, с приходом очередного тактового импульса состояние счетчика станет равным $0001. Сброс таймера-счетчика рекомендуется проводить в следующем порядке:
• остановите таймер-счетчик (бит TSOP = 1);
• выполните операцию сброса таймера-счетчика (бит TRST = 1);
• переинициализируйте биты PS2-PS0 регистра TxSC, которые определяют источник и частоту тактирования;
• разрешите счет таймера-счетчика.
Код таймера-счетчика в процессе счета может быть считан прикладной программой при обращении к регистрам текущего кода TxCNTH и TxCNTL. При обращении к регистру старшего байта код таймера-счетчика автоматически копируется в указанную регистровую пару. Поэтому, несмотря на то, что операции чтения старшего и младшего байтов разнесены во времени, вы прочитаете состояние таймера-счетчика в момент обращения к регистру старшего байта TxCNTH. Такое решение предотвращает получение ложной информации в случае, если частота тактирования таймера-счетчика высока, и по этой причине в моменты обращения к регистрам TxCNTH и TxCNTL состояния счетчика различаются. Однако нельзя допускать ситуацию, при которой после прочтения старшего байта младший прочитан на будет. Повторное чтение старшего байта не сопровождается защелкиванием текущего кода таймера-счетчика в регистрах TxCNTH и TxCNTL.
При переполнении таймера-счетчика устанавливается флаг переполнения TOF в регистре управления TxSC (табл. 4.36) и генерируется запрос на прерывание, если бит разрешения прерывания TOIE установлен в «1», т. е. прерывания по переполнению таймера-счетчика разрешены.
Таблица 4.36
Формат регистра TxSC
TxSC | Регистр управления таймером-счетчиком «х»
7 6 5 4 3 2 1 0
TOF | TOIE | TSTOP | TRST | 0 | PS2 | PS1 | PS0
Состояние при сбросе: 20h
Имя бита Назначение бита
TOF Флаг переполнения таймера-счетчика Бит переполнения устанавливается в «1», если текущий код таймера достиг максимального значения, которое записано в регистрах периода, и при поступлении следующего импульса сбросился в «0». Для сброса флага переполнения необходимо выполнить следующую последовательность действий: • прочитать регистр TxSC при уже установленном флаге TOF;- • записать «0» в бит TOF.
395
8-РАЗРЯДНЫЕ МИКРОКОНТРОЛЛЕРЫ
Продолжение табл. 4.36
TxSC | Регистр управления таймером-счетчиком «х»
7 6 5 4 3 2 1 0
TOF | TOIE | TSTOP | TRST | 0 | PS2 | PS1 | PSO
Состояние при сбросе: 20h
Имя бита Назначение бита
TOIE Бит разрешения прерывания по переполнению таймера 1 - прерывания по переполнению таймера разрешены; 0 - прерывания по переполнению таймера запрещены. Этот бит разрешает генерацию запроса на прерывание, если бит TOF установлен. Бит доступен как для записи, так и для чтения.
TSTOP Бит разрешения работы таймера-счетчика 1 - таймер-счетчик остановлен, текущий код таймера не изменяется; 0 - работа таймера-счетчика разрешена, код счетчика изменяется во времени. Этот бит доступен как для записи, так и для чтения. При сбросе МК счетчик таймера останавливается.
TRST Бит сброса таймера-счетчика Установка этого бита в «1» вызывает сброс таймера-счетчика и сброс битов управления делителем частоты PS2-PS0. Текущий код становится равным $0000, а делитель частоты переводится в состояние КД=1. Бит TRST предназначен только для записи. Попытка записать 0 в этот бит не изменит состояние бита и не будет иметь никаких других последствий. Бит сбрасывается автоматически по окончании сброса таймера-счетчика.
PS2-PS0 Биты выбора коэффициента деления Эти биты определяют источник тактирования таймера-счетчика, а также частоту тактирования в случае, если в качестве тактирующего генератора выбран программируемый делитель частоты. PS2 PS1 PS0 Частота тактирования 0 0 0 fBus^ 0 0 1 fBUS/2 0 1 0 fBUS/4 0 1 1 fBUS/& 1 0 0 fBUS/16 1 0 1 fBlJs132 1 1 0 fBUS/&4 1 1 1 внешний генератор, подключенный ко входу TxCLK " Эти биты доступны для чтения и для записи
Эта опция возможна, только если МК имеет вывод TxCLK. Если режим внешнего тактового генератора в модуле процессора событий не предусмотрен, то комбинация 111 является запрещенной.
Для управления таймером-счетчиком модуля TIM08 предусмотрены пять регистров специальных функций:
TxSC - регистр управления таймером-счетчиком «х», где «х» - имя модуля процессора событий МК (для TIM1 х=1, для TIM2 х=2 );
TxMODH - регистр периода таймера-счетчика (старший байт );
TxMODL- регистр периода таймера-счетчика (младший байт);
TxCNTH - регистр текущего значения таймера-счетчика (старший байт);
TxCNTL - регистр текущего значения таймера-счетчика (младший байт).
396
СЕМЕЙСТВО МК НС08 ФИРМЫ «MOTOROLA»
Рис. 4.48. Структурная схема процессора событий TIM08 МК MC68HC908GP32 ! 1
Каждый канал захвата/сравнения в составе процессора событий связан с одним выводом МК (см. рис. 4.48). Вывод обозначают TxCHi, где i - порядковый номер канала захвата/ сравнения в составе процессора событий х. Например, Т1СНО - вывод канала 0 процессора событий TIM1. В режиме захвата аппаратные средства канала захвата/сравнения фиксируют моменты времени, когда логический сигнал на входе TxCHi изменяет свое состояние. В режимах выходного сравнения и широтно-импульсной модуляции (ШИМ) канал захвата/сравнения формирует импульсный сигнал с заданными временными параметрами на выходе TxCHi. Направление передачи сигнала по линии TxCHi (вход или выход) определяется инициализацией каналов захвата/сравнения на тот или иной режим. Несмотря на то, что работа линии TxCHi в составе процессора событий является альтернативной функцией линии одного из портов ввода/вывода МК, состояние регистра направления передачи порта DDRx в этом случае значения не имеет.
Программно-логическая модель каждого канала захвата/сравнения включает три регистра: 16-разрядный регистр данных канала i (TxCHiH и TxCHiL - старший и младший байты этого регистра) и регистр управления каналом i - TxSCi. Функция регистра данных определяется режимом работы канала захвата/сравнения, регистр управления TxSCi служит для выбора этого режима и для обслуживания прерываний по запросам модуля захвата/сравнения.
В режиме входного захвата аппаратные средства модуля следят за уровнем сигнала на входе TxCHi микроконтроллера (рис. 4.49).
При изменении уровня логического сигнала с «О» на «1» или наоборот вырабатывается строб записи, и текущее состояние таймера-счетчика временной базы копируется
397
8-РАЗРЯДНЫЕ микроконтроллеры
в 16-разрядный регистр данных TxCHi канала захвата/сравнения. Событие захвата отмечается установкой в «1» флага CHiF в регистре управления каналом с номером i. Этот флаг может быть считан программно, а если прерывания по событию канала i разрешены (флагСНПЕ в регистре управления установлен), то модуль процессора событий выставляет запрос на прерывание. Предусмотрены три типа изменения сигнала на входе TxCHi МК, которые воспринимаются модулем захвата/сравнения, как событие захвата:
1) передний (нарастающий) фронт сигнала;
2) задний (падающий) фронт сигнала;
3) любое изменение логического уровня сигнала.
Выбор типа события захвата для модуля определяется битами ELSiB:ELSiA регистра управления каналом TxSCi.
В режиме выходного сравнения аппаратные средства модуля непрерывно сравнивают изменяющийся во времени код таймера-счетчика с кодом, который записан в 16-разрядный регистр данных TxCHi модуля захвата/сравнения i (рис. 4.50).
В момент равенства кодов аппаратные средства модуля устанавливают на выходе микроконтроллера TxCHi заданный уровень логического сигнала либо изменяют этот уровень на противоположный. При наступлении события выходного сравнения в регистре управления канала TxSCi устанавливается в «1» флаг CHiF, тот же, что и при наступлении события захвата. Аналогично предыдущему случаю этот флаг вызывает формирование запроса на прерывание, если прерывания от модуля i разрешены. Предусмотрены три типа изменения сигнала на выходе TxCHi МК в момент события выходного сравнения:
1) инвертирование сигнала на выходе;
2) установка низкого логического уровня;
3) установка высокого уровня.
Выбор типа изменения выходного сигнала для модуля определяется битамй ELSiB:ELSiA регистра управления каналом TxSCi. :
Рис. 4.49. Временные диаграммы работы канала процессора событий в режиме захвата
I.» J
Г
£'
Л
-i
10
398
СЕМЕЙСТВО МК НС08 ФИРМЫ «MOTOROLA»
Рис. 4.50. Временные диаграммы работы канала процессора событий в режиме небуферированного выходного сравнения
При работе в режиме выходного сравнения могут возникать нарушения алгоритма работы канала захвата/сравнения, приводящие к неправильному формированию сигнала на выходе TxCHi модуля. Причиной таких сбоев является изменение величины кода сравнения в процессе работы канала, а также конечное время выполнения программы перезагрузки кода сравнения в регистр данных канала TxCHi. Например, событие выходного сравнения еще не произошло, когда код в регистре данных TxCHi был изменен на меньшее значение (рис. 4.51). Причем это значение таково, что текущий код таймера-счетчика превышает его. В результате в текущем периоде работы таймера-счетчика события выходного сравнения уже не произойдет, так как равенство кодов наступит только в следующем периоде работы таймера-счетчика. Подобная ситуация исключается при использовании режима буферированного выходного сравнения.
В режиме буферированного выходного сравнения каналы захвата/сравнения объединяются в пары: канал 0 с каналом 1 (канал 2 с каналом 3, канал 4 с каналом 5 - в других МК семейства НС08). Канал с нечетным номером работает в режиме выходного сравнения. Канал с четным номером переводится в нерабочее состояние, и его нельзя использовать ни в каком из режимов работы. Вывод TxCHi МК, принадлежащий каналу с четным номером, автоматически конфигурируется в режим обычной линии ввода/вывода. Далее для определенности рассмотрим логику работы на примере пары 0 и 1. Сразу, после инициализации в качестве источника кода сравнения модуль 0 использует регистры данных ТхСНО, принадлежащие модулю 0. После того, как событие сравнения произошло, в качестве источника кода сравнения могут использоваться как регистры данных канала 0, так и регистры данных канала 1. Выбор регистра данных осуществляется модулем автоматически: используется та пара регистров данных, в которую запись была произведена последней. По этой причине не следует новое значение кода сравнения записывать в текущий активный регистр данных канала. Эта операция в соответствии с принципом действия режима буферированного сравнения фактически переведет канал в режим небуферированного выходного сравнения. Никаких сбоев формирования сигнала на выходе TxCHi в режиме буферированного выходного сравнения не возникнет, если:
• производить запись нового кода сравнения в регистр неактивного канала;
• выполнять эту операцию в подпрограмме прерывания по событию выходного сравнения обслуживаемого канала.
399
8-РАЗРЯДНЫЕ МИКРОКОНТРОЛЛЕРЫ
Реальная форма сигнала на выходе TxCHi
Рис. 4.51. Временные диаграммы работы канала процессора событий в режиме небуферированного выходного сравнения. Ошибка формирования по причине изменения кода сравнения
Назначение режима буферированного выходного сравнения производится установкой бита MSiB в регистре управления каналом с номером i=0. Регистр управления канала 1 в этом случае не оказывает влияния на работу канала 0 в режиме буферированного выходного сравнения. Однако для однозначного определения состояния неиспользуемой в режиме буферированного выходного сравнения линии ТхСН1 канала 1 биты ELSiBrELSiA регистра управления канала 1 должны быть установлены в «00».
Особенности инициализации каналов захвата/сравнения поясняет табл. 4.37.
Режим небуферированного выходного сравнения может быть использован для получения на выходе модуля TxCHi широтно-модулированного импульсного сигнала. С этой целью следует запрограммировать логику изменения сигнала на выходе TxCHi следующим образом (рис. 4.52):
• при наступлении события выходного сравнения на выходе TxCHi устанавливается низкий логический уровень;
• при переполнении таймера-счетчика уровень сигнала на выводе инвертируется.
Вы получите ШИМ сигнал, у которого длительность импульса будет изменяться по закону:
Т = К/f , имп такт’
где К - код регистра данных канала, /акт - частота тактирования таймера-счетчика.
Период широтно-модулированных импульсов определяется периодом таймера-счетчика:
T=KJf_.
При тактированиии таймера-счетчика от внутреннего генератора период таймера-счет-s чика составляет: I
где RTlMx - коэффициент деления программируемого делителя частоты, - коэффициент счета таймера-счетчика.
400
СЕМЕЙСТВО МК НС08 ФИРМЫ «MOTOROLA»
Таблица4.37
Инициализация режимов каналов захвата/сравнения
Биты регистра управления Режим управления Опция режима работы
"MSiB:MSiA ELSiB:ELSiA
х0 00 TCHi работает в режиме порта ввода/вывода Начальное состояние порта - «1»
х1 00 Начальное состояние порта - «0»
00 01 Режим захвата Активный уровень - перепад из «0» в «1»
00 10 Активный уровень - перепад из «1» в «0»
00 11 Активный уровень - любое изменение уровня сигнала
01 01 Небуферированное сравнение/Ш ИМ Изменяет уровень на противоположный
01 10 Устанавливает на выходе «0» при сравнении
01 11 Устанавливает на выходе «1» при сравнении
1х 01 Буферированное сравнение/Ш ИМ Изменяет уровень на противоположный
1х 10 Устанавливает на выходе «0» при сравнении
1х 11 Устанавливает на выходе «1» при сравнении
Коэффициент заполнения у по определению равен отношению длительности импульса к длительности периода ШИМ сигнала:
Y = T„JT= (КуК /fBUS)/(K^K lfBUS) = К1К„.
ТИМх ТИМх
Код таймера-счетчика
Код в регистре данных TxCHi определяет коэффициент заполнения в режиме ШИМ
Моменты наступления события выходного сравнения
Моменты переполнения таймера-счетчика
Выбрана опция установки TxCHi в «О» при наступлении события сравнения
ШИМ-сигнал на выходе TxCHi
Рис. 4.52. Временные диаграммы работы канала процессора событий в режиме небуферированной ШИМ
Выбрана опция установки TxCHi в противоположное состояние при переполнении таймера-счетчика
401
8-РАЗРЯДНЫЕ МИКРОКОНТРОЛЛЕРЫ
Из приведенного соотношения следует, что дискретизация коэффициента заполнения у определяется выбранным коэффициентом счета /<Сч таймера-счетчика. Следовательно, модуль процессора событий TIM08 может реализовать ШИМ с дискретизацией коэффициента заполнения вплоть до 16 бит. При необходимости полярность импульсов ШИМ-сигнала может быть изменена. Для этого необходимо при инициализации выбрать следующие опции:
• при наступлении события выходного сравнения на выходе устанавливается высокий логический уровень;
• при переполнении таймера-счетчика уровень сигнала на выходе инвертируется.
Рассмотренный режим небуферированной ШИМ подвержен сбоям в работе так же, как и режим небуферированного выходного сравнения (рис. 4.52). Так, если вы станете менять код заполнения в течение периода, то при смене большего кода на меньший возможен пропуск момента сравнения и, как следствие, получение единичного коэффициента заполнения. Поэтому режим небуферированной ШИМ следует использовать в тех случаях, когда код коэффициента заполнения требуется изменять крайне редко. В остальных случаях следует использовать режим буферированной ШИМ.
Для получения буферированной ШИМ используют режим буферированного выходного сравнения, при котором каналы объединяются по парам, и для генерации ШИМ сигнала на одном выводе используются регистры сразу двух каналов захвата/сравнения. Вследствие этого число линий с ШИМ-сигналами для любого процессора событий TIM08 сокращается вдвое. Особенности инициализации модулей захвата/сравнения в режиме буферированной ШИМ определяются правилами инициализации канала на режим буферированного выходного сравнения.
Формат регистра управления канала захвата/сравнения приведен в табл. 4.38.
Регистры данных канала TxCHiH и TxCHiL являются 8-разрядными регистрами, которые доступны для чтения и для записи. Полный перечень регистров двух процессоров событий МК MC68HC908GP32 приведен в табл. 4.39.
Таблица 4.38
Формат регистра TxSCi
TxSCi | Регистр управления каналом i захвата/сравнения
7 6 5 4 3 2 1 0
CHiF | CHilE | MSiB | MSiA | ELSiB | ELSiA | TOVi | CHiMAX
Состояние при сбросе: 00h
Имя бита Назначение бита
CHiF Флаг наступления события в канале захвата/сравнения i Бит наступления события устанавливается в «1», если: • канал установлен в режим захвата внешнего события, и соответствующее изменение уровня сигнала на наблюдаемом входе произошло; • канал установлен в режим выходного сравнения, и момент равенства текущего кода таймера-счетчика коду в регистре данных канала наступил. При попытке сброса в «0» программными средствами флаг CHiF в «0» не устанавливается. Для сброса флага наступления события необходимо выполнить следующую последовательность действий: • прочитать регистр TxSCi при уже установленном флаге CHiF; • записать «0» в бит CHiF. Если следующее событие переполнения произойдет до того момента, когда в бит CHiF запишут «0», то флаг CHiF не сбросится. Таким образом блокируется пропуск возможного запроса на прерывание, в подпрограмме обслуживания которого осуществляется пере- запись значений других регистров модуля. Попытка записать «1» в бит CHiF не изменит состояние бита.
402
СЕМЕЙСТВО МК НС08 ФИРМЫ «MOTOROLA,
Продолжение табл. 4.38
TxSCi | Регистр управления каналом i захвата/сравнения
7 6 5 4 3 2 1 0
CHiF | CHilE ] MSiB | MSiA | ELSiB | ELSiA | TOVi| CHiMAX
Состояние при сбросе: 00h
Имя бита Назначение бита
CHilE Бит разрешения прерывания по событию канала i 1 - прерывания по событию канала разрешены; 0 - прерывания от канала запрещены. Этот бит разрешает генерацию запроса на прерывание, если бит CHilF установлен. Бит доступен как для записи, так и для чтения. При сбросе МК прерывания по запросу канала запрещаются.
MSiB Бит разрешения буферированного режима сравнения/ШИМ 1 - режим буферированного сравнения/ШИМ разрешен; 0 - модуль работает в режиме небуферированного сравнения/ШИМ. Этот бит может быть установлен в «1» только в модулях с нечетными номерами i, которые являются «ведущими» в паре каналов, реализующих буферированный режим. Установка бита в «1» автоматически запрещает работу канала с четным номером i+1, и вывод ТСН i+1, связанный с каналом i+1 становится обычной линией ввода/вывода. При сбросе МК устанавливается небуферированный режим работы.
MSiA Бит выбора режима канала i Если значение битов ELSiB и ELSiA не равно «00», то бит MSiA определяет режим работы канала: 1 - канал работает в режиме сравнения/ШИМ; 0 - канал работает в режиме входного сравнения. Если значение битов ELSiB и ELSiA равно «00», то бит MSiA определяет начальный логический уровень на выходе TCHi: 1 - начальный логический уровень равен «0»; 0 - начальный логический уровень равен «1». Бит доступен для записи и для чтения. При сбросе МК бит устанавливается в «0».
ELSiB-ELSiA Биты активного перепада в режиме захвата Если канал i установлен в режим захвата, то эти биты определяют активный перепад сигнала на входе TCHi, при котором устанавливается бит ChiF: 01 - активный уровень - перепад из «0» в «1»; 10 - активный уровень - перепад из «1» в «0»; 11 - активный уровень - любое изменение уровня сигнала. Если канал i установлен в режим выходного сравнения, то эти биты определяют алгоритм изменения сигнала при наступлении события равенства кодов: 01 - инвертирует сигнал на выходе; 10 - устанавливает на выходе «0» при сравнении; 11 -устанавливает на выходе «1» при сравнении. Биты доступны для записи и для чтения. При сбросе МК устанавливается в «00».
TOVi Бит разрешения переключения выхода при переполнении таймера-счетчика/ШИМ Бит TOVi определяет способ изменения сиггнала на выходе TCHi при переполнении счетчика таймера, когда модуль работает в режиме сравнения/ШИМ: 1 - выход изменяет состояние на противоположное; 0 - выход не изменяет состояния. Бит доступен для записи и чтения. Сброс МК устанавливает бит в «0».
403
8-РАЗРЯДНЫЕ МИКРОКОНТРОЛЛЕРЫ
Продолжение табл. 4.38
TxSCi | Регистр управления каналом i захвата/сравнения
7 6 5 4 3 2 1 0
CHiF Г CHilE 1 MSiB | MSiA I ELSiB | ELSiA | TOVi | CHiMAX ’
Состояние при сбросе: 00h
Имя бита Назначение бита
CHiMAX Бит максимального коэффициента заполнения в режиме ШИМ Этот бит оказывает влияние на работу модуля захвата/сравнения только в режиме ШИМ: 1 - коэффициент заполнения g = 1; 0 - коэффициент заполнения определяется кодом регистра данных канала. Бит доступен для записи и для чтения. При сбросе МК бит устанавливается в «0».
Таблица 4.39
Регистры специальных функций модулей процессора событий МК MC68HC908GP32
Модуль TIM 1 Модуль TIM2
Имя регистра Адрес Имя регистра Адрес
Таймер-счетчик временной базы 1 Таймер-счетчик временной базы 2
Регистр управления таймером-счетчиком 1 T1SC $0020 Регистр управления таймером-счетчиком 2 T2SC $002В
Регистр текущего значения таймера-счетчика 1 (старший байт) T1CNTH $0021 Регистр текущего значения таймера-счетчика 2 (старший байт) T2CNTH $002С
Регистр текущего значения таймера-счетчика 1 (младший байт) T1CNTL $0022 Регистр текущего значения таймера-счетчика 2 (младший байт) T2CNTL $002D
Регистр периода таймера-счетчика 1 (старший байт) T1MODH $0023 Регистр периода таймера-счетчика 2 (старший байт) T2MODH $002Е
Регистр периода таймера-счетчика 1 (младший байт) Т1MODL $0024 Регистр периода таймера-счетчика 2 (младший байт) T2MODL $002F
Канал захвата/сравнения 0 Канал захвата/сравнения 0
Регистр управления каналом 0 T1SC0 $0025 Регистр управления каналом 0 T2SC0 $0030
Регистр данных канала 0 (старший байт) Т1СН0Н $0026 Регистр данных канала 0 (старший байт) Т2СН0Н $0031
Регистр данных канала 0 (младший байт) T1CH0L $0027 Регистр данных канала 0 (младший байт) T2CH0L $0032
Канал захвата/сравнения 1 Канал захвата/сравнения 1
Регистр управления каналом 1 T1SC1 $0028 Регистр управления каналом 1 T2SC1 $0033
Регистр данных канала 1 (старший байт) Т1СН1Н $0029 Регистр данных канала 1 (старший байт) Т2СН1Н $0034
Регистр данных канала 1 (младший байт) T1CH1L $002А Регистр данных канала 1 (младший байт) T2CH1L $0035
404
СЕМЕЙСТВО МК НС08 ФИРМЫ «MOTOROLA»
4.3.8. МОДУЛЬ ПОСЛЕДОВАТЕЛЬНОГО СИНХРОННОГО ИНТЕРФЕЙСА SPI08
Модуль последовательного периферийного интерфейса SPI08 предназначен для высокоскоростного обмена между МК и периферийными микросхемами, такими как АЦП и ЦАП, FLASH-память большой информационной емкости, часы реального времени. Модуль SPI08 обладает следующими характеристиками:
• поддерживает два режима работы: ведущего (master) и ведомого (slave) приемопередатчиков;
• позволяет программно настраивать частоту обмена, причем в формировании сетки частот модули таймеров TIM08 и PIT08 не задействованы:
f _ feus
J spi ’
KSPI
где KSPj — 2, 8, 32, 128; максимальная частота обмена в режиме ведущего составляет 4,0 МГц, в режиме ведомого - 8,0 МГц;
• генерирует запросы на прерывание с раздельными векторами по завершению приема очередного байта или по окончании передачи байта;
• генерирует два флага нарушения режима работы: при переполнении приемника и при принудительной смене режима работы (ведущий/ведомый) в процессе незавершенного обмена;
• позволяет программно конфигурировать линии приема и передачи данных (MISO и MOSI) как линии с открытым коллекторным выходом; объединение MISO и MOSI по схеме «монтажное ИЛИ» делает модуль совместимым с протоколом интерфейса 12С.
Контроллер SPI08 обслуживает стандартную шину SPI, для чего имеет четыре линии: MOSI - линия передачи данных от ведущего к ведомому (Master Output Slave Input); MISO - линия передачи данных от ведомого к ведущему (Master Input Slave Output); SPSCK - линия сигнала синхронизации данных;
SS - линия выбора ведомого.
Направление передачи каждой линии определяется выбором режима работы контроллера SPI08. Если назначен режим ведущего (бит MSTR регистра управления SPCR равен 1), то линии MOSI и SCK работают в режиме вывода, а линия MISO в режиме ввода. Если назначен режим ведомого (MSTR = 0), то линии MOSI, SCK и SS работают в режиме ввода, a MISO - в режиме вывода. В режиме ведущего линия §S может быть использована, как обычная линия ввода/вывода.
Обслуживание модуля SPI08 является альтернативной функцией для линий PTD (см. рис. 4. 44). Если бит разрешения работы контроллера модуля установлен SPE = 1, то независимо от значения соответствующих битов регистра направления передачи порта ввода/вывода его линии назначаются для работы в составе контроллера SPI08.
Функциональная схема контроллера SPI08 приведена на рис. 4.53. Основные элементы контроллера - 8-разрядный сдвиговый регистр (Shift Register) и два буферных регистра данных, программно доступных по одному и тому же адресу. При выполнении операции записи в регистр данных SPDR данные будут запомнены в буферном регистре передатчика. Буфер данных передатчика недоступен для чтения. Операция чтения регистра SPDR возвращает данные из буферного регистра приемника. Буфер данных приемника недоступен для записи.
Если контроллер настроен для работы в режиме ведущего, то обмен данными в любом из направлений (прием или передача) инициируется операцией записи байта в регистр данных. Этот байт сначала автоматически копируется в сдвиговый регистр, а затем
405
8-РАЗРЯДНЫЕ МИКРОКОНТРОЛЛЕРЫ
Рис. 4.53. Функциональная схема контроллера SPI08
сдвигается в течение 8 тактов генератора синхронизации обмена на линию MOSI. Одновременно на линию SCK выдаются импульсы синхронизации. Каждый из импульсов синхронизации SCK, поступающих от ведущего на одноименный вход ведомого, вызывает операцию сдвига данных на один разряд в сдвиговом регистре принимающего устройства. В результате очередной бит, переданный ведущим по линии MOSI, запоминается в регистре-приемнике, но одновременно на линию MISO выдвигается очередной старший бит этого регистра. Бит с линии MISO фиксируется в сдвиговом регистре ведущего. При завершении передачи 8 бит данных от ведущего к ведомому в сдвиговом регистре ведущего окажется принятый байт данных от ведомого. Если пользователь желает реализовать передачу байта данных от ведущего к ведомому, то для осуществления обмена в программе ведущего в регистр данных контроллера SPI08 записывается передаваемый байт, а при завершении передачи бесполезные данные из регистра данных порта SPI08 просто не считываются. Если же пользователь желает реализовать прием байта данных, то для осуществления обмена в программе ведущего в регистр данных контроллера SPI08 записывается любой «ненужный» байт, а при завершении передачи принятый полезный байт данных считывается из регистра данных порта SPI08. Завершение передачи каждого байта данных отмечается установкой в «1» бита SPIF регистра состояния SPSR. Этот бит генерирует запрос на прерывание, если прерывания от модуля SPI
406
СЕМЕЙСТВО МК НС08 ФИРМЫ «MOTOROLA»
разрешены (бит SPIE = 1). При обмене с высокими скоростями в режиме ведущего бит завершения передачи байта SPIF следует контролировать программно. Для этого после записи очередного байта в регистр данных следует прочитать регистр состояния SPSR, дождаться, пока бит SPIF не установится, а затем произвести считывание принятых данных или запись следующего передаваемого байта в регистр данных (в зависимости от направления передачи). Бит SPIF сбрасывается в «О» автоматически при выполнении последовательности из двух операций:
• чтение регистра состояния SPSR при установленном бите SPIF;
. чтение или запись в регистр данных SCDR.
Если контроллер SPI08 работает в режиме ведомого, то момент начала передачи определяет ведущий. Поэтому следует организовать прерывания по запросу от триггера SPIF, в подпрограмме обработки которого принятый байт будет прочитан из регистра данных и проанализирован, а при необходимости предоставления ведущему каких-либо данных очередной байт будет записан в регистр данных для последующей передачи при поступлении импульсов синхронизации SCK от ведущего.
Контроллер SPI08 поддерживает 4 возможных режима SPI. Для задания детализированной временной диаграммы обмена следует использовать биты СРНА и CPOL регистра управления SPCR. Скорость обмена в режиме ведущего определяется программно настраиваемым коэффициентом делителя fBUS (биты SPR1 :SPR0 регистра управления). Максимальная скорость обмена составляет fBUS!2, минимальная - fsus/128. В режиме ведомого биты SPR1 :SPR0 не оказывают влияния на работу контроллера. Скорость обмена определяется ведущим, она может достигать fBUS.
Программно-логическая модель модуля SPI08 включает три регистра специальных функций:
1) SPCR - регистр управления модуля SPI08; ’
2) SPSCR - регистр состояния модуля SPI08;
3) SPDR - регистр данных модуля SPI08.
Форматы регистров SPCR и SPSCR приведены в табл. 4.40 и 4.41. Регистр данных SPDR доступен по адресу 0012h.
Таблица 4.40
Формат регистра SPCR
SPCR | Регистр управления модуля SPI08
7 6 5 4 3 2 1 0
SPRIE | х | SPMSTR | CPOL | СРНА | SPWOM | SPE | SPTIE
Состояние при сбросе: 28h Адрес 00106
Имя бита Назначение бита
SPRIE Бит разрешения прерывания по запросу приемника модуля SPI Бит разрешает генерацию запроса на прерывание при установленном бите SPRF: 1 -прерывания по запросу приемника разрешены; 0 - прерывания по запросу приемника запрещены. Биты доступен для чтения и для записи. При сбросе прерывания от приемника запрещаются.
SPMSTR Бит режима работы контроллера SPI 1 - контроллер SPI работает в режиме ведущего (Master); 0 - контроллер SPI работает в режиме ведомого (Slave). Бит доступен для чтения и для записи. При сбросе назначается режим ведомого.
407
8-РАЗРЯДНЫЕ МИКРОКОНТРОЛЛЕРЫ
Продолжение табл. 4.40
SPCR | Регистр управления модуля SPI08
7 6 5" 4 ^3 2 1 0
SPRIE | х | SPMSTR | CPOL | СРНА | SPWOM | SPE | SPTIE~~
Состояние при сбросе: 28h Адрес 001 Oh
Имя бита Назначение бита
CPOL Бит выбора полярности сигнала синхронизации SCK Этот бит определяет состояние линии SCK (вывод SPSCK) между сеансами передачи данных. Бит CPOL вместе с битом СРНА задает один из четырех возможных режимов SPI интерфейса: 1 - SCK = 1 - между сеансами передачи данных; 0 - SCK = 0 - между сеансами передачи данных. Бит доступен для чтения и для записи. После сброса МК CPOL = 0.
СРНА Бит выбора фазы сигнала синхронизации SCK Этот бит определяет протокол обмена по SPI-шине. Если СРНА = 0, то начало обмена инициируется установкой сигнала выбора ведомого SS в активное состояние (режимы 0 и 1). Первый перепад сигнала синхронизации SCK используется принимающим устройством для запоминания очередного бита в сдвиговом регистре. Передающее устройство выставляет очередной бит посылки на линии MOSI по каждому четному фронту сигнала SCK. Сигнал на линии выбора ведущего SS должен быть возвращен в неактивное состояние после передачи каждого байта в любом направлении (рис. 4.25). Если СРНА = 1, то начало обмена определяет первое изменение уровня сигнала на линии SCK после установки сигнала выбора ведомого SS в активное состояние (режимы 2 и 3). Все нечетные перепады SCK вызывают выдвижение очередного бита посылки из сдвигового регистра передатчика на линию. Каждый четный перепад используется для записи этого бита в сдвиговый регистр приемника. Сигнал выбора ведомого может оставаться в активном состоянии SS = 0 в течение передачи нескольких байт информации (рис. 4.26). Бит доступен для чтения и для записи. После сброса МК СРНА = 1.
SPWOM Бит выбора режима открытого коллектора Этот бит определяет состояние выходных буферов линий MOSI, MISO, SPSCK: 1 - буферы переведены в режим открытого коллекторного выхода; 0 - буферы работают в режиме двунаправленной передачи с возможностью установки в высокоимпедансное состояние. Перевод линий MOSI и MISO в режим открытого коллектора позволяет соединить их по схеме «монтажное ИЛИ», что делает интерфейс SPI совместимым с интерфейсом 12С. Бит доступен для чтения и для записи. После сброса SPWOM = 0.
SPE Бит разрешения работы модуля SPI 1 - контроллер SPI включен; 0 - контроллер SPI выключен. Бит доступен для чтения и для записи. При сбросе МК контроллер SPI отключается.
SPTIE Бит разрешения прерывания по запросу передатчика модуля SPI Бит разрешает генерацию запроса на прерывание при установленном бите SPTE: 1 - прерывания по запросу передатчика разрешены; 0 - прерывания по запросу передатчика запрещены. Биты доступен для чтения и для записи. При сбросе прерывания от передатчика запрещаются.
408
СЕМЕЙСТВО МК НС08 ФИРМЫ «MOTOROLA,
Таблица 4.41
Формат регистра SPSCR
SPSCR | Регистр управления модуля SPI08
7 6 5 4 3 2 1 0
SPRF | ERRIE | OVRF | MODF | SPTE | MODFEN | SPR1 | SPR0
Состояние при сбросе: 08h Адрес 0011 h
Имя бита Назначение бита
SPRF Бит завершения приема байта данных Устанавливается в момент, когда принятые данные автоматически переписываются в буферный регистр данных приемника. Бит SPRF генерирует запрос на прерывание, если бит SPRIE установлен. Сбрасывается в «0» автоматически при выполнении последовательности из двух операций: • чтение регистра состояния SPSCR при установленном бите SPRF; • чтение из регистра данных SPDR принятого байта данных. Бит доступен только для чтения. При сбросе МК бит устанавливается в «0».
ERRIE Бит разрешения прерывания по флагам ошибки OVRF и MODF Этот бит разрешает генерацию запроса на прерывание при установке в «1» флага нарушения режима MODF и флага ошибки приема OVRF: 1 -- прерывания по флагам OVRF и MODF разрешены; 0 - прерывания по флагам OVRF и MODF IDLE запрещены. Бит доступен для чтения и для записи. При сбросе прерывания по флагам ошибки запрещаются.
OVRF Бит ошибки приема Устанавливается при попытке записи аппаратными средствами приемника очередного принятого байта из сдвигового регистра в буферный регистр данных в то время, как предыдущие данные из буферного регистра еще не считаны (бит SPRF установлен). При таком стечении обстоятельств содержимое буферного регистра приемника сохраняется, а второй принятый байт теряется. Бит OVRF сбрасывается в «0» автоматически при выполнении последовательности из двух операций: • чтение регистра состояния SPSCR при установленном бите OVRF; • чтение из регистра данных SPDR первого принятого байта данных. Бит доступен только для чтения. При сбросе МК бит устанавливается в «0».
MODF Бит нарушения режима контроллера SPI Устанавливается, если на линию 55_ведущего подали сигнал низкого логического уровня или если на линию SS ведомого подали сигнал высокого логического уровня в процессе незавершенного обмена. Сбрасывается в «0» автоматически при выполнении последовательности из двух операций: • чтение регистра состояния SPSCR при установленном бите MODF; • запись в регистр данных SPDR.Бит доступен толь ко для чтения. При сбросе МК бит устанавливается в «0».
SPTE Бит готовности буфера передатчика к приему новых данных Устанавливается в момент, когда предварительно загруженные в регистр буфера передатчика данные автоматически переписываются в сдвиговый регистр передатчика. Однако процесс передачи нового байта из сдвигового регистра начнется только после того, как бит SPTE будет сброшен. Бит SPTE информирует МК о том, что буфер передатчика пуст, и в него может быть записан новый байт. Бит SPTE генерирует запрос на прерывание, если бит SPTIE установлен. Бит SPTE сбрасывается в «0» автоматически при выполнении операции записи в регистр данных SPDR Бит доступен только для чтения. При сбросе МК бит устанавливается в «1».
409
«-РАЗРЯДНЫЕ МИКРОКОНТРОЛЛЕРЫ
Продолжение табл. 4.41
SPSCR | Регистр управления модуля SPI08 ~~]
7 6 5 4 3 2 1 о
SPRF | ERRIE | OVRF | MODF | SPTE | MODFEN | SPR1 | SPRO
Состояние при сбросе: 08h Адрес 0011h
Имя бита Назначение бита
MODFEN Бит разрешения работы логики нарушения режима MODF 1 - работа и установка бита MODF разрешены; 0 - работа и установка бита MODF запрещены. Если бит MODFEN сброшен и контроллер SPI работает в режиме ведущего, то линия SS может быть использована как обычная линия ввода/вывода. Бит доступен для чтения и для записи. При сбросе МК устанавливается в «0».
ELSiB-ELSiA Биты выбора скорости передачи Биты SPR1 - SPRO определяют скорость обмена при работе контроллера в режиме ведущего. В режиме ведомого скорость ограничена величиной f SPR1 SPRO Частота следования Значения частоты импульсов SCK следования при f = 8 МГЦ 0 0 fBUS /2 4 МГц 0 1 fBUS /4 2 МГц 1 0 fBUS /32 250 кГц 1 1 fsus/128 62,5 кГц После сброса МК значения битов равны 0, т. е. выбрана максимальная скорость обмена.
4.3.9. МОДУЛЬ ПОСЛЕДОВАТЕЛЬНОГО АСИНХРОННОГО ИНТЕРФЕЙСА SCI08
Контроллер последовательного асинхронного интерфейса SCI предназначен для обмена с устройствами управления верхнего уровня. Модуль SCI08 обладает следующими характеристиками:
• поддерживает полнодуплексный режим обмена данными:
• реализует стандартный протокол асинхронного обмена с длиной кадра в 10 или 11 бит;
• подсистема передатчика реализует режим вставки бита паритета, подсистема приемника автоматически контролирует соблюдение логики паритета в принятом байте данных;
• позволяет программно настраивать частоту обмена, причем в формировании сетки частот модуль таймера TIM08 не задействован; частота обмена программируется в соответствии с формулой
Г = feus
Jscl 64 NP -NS
где NP = 1,3,4,13; NS = 2", n = 07; максимальная скорость обмена составляет 131 Кбит/с;
• имеет независимые биты разрешения работы приемника и передатчика;
• генерирует запросы на прерывание с раздельными векторами по окончании передачи байта, завершению приема очередного байта и при диагностировании ошибок приема байта;
• генерирует 4 флага нарушения режима работы: при переполнении приемника, при возникновении шума на линии в процессе приема, при нарушении формата принимаемого кадра, при нарушении логики паритета; каждое из перечисленных событий фор
410
СЕМЕЙСТВО МК НС08 ФИРМЫ «MOTOROLA»
мирует запрос на прерывание; реализуется раздельное маскирование всех указанных событий нарушения режима работы;
« имеет встроенные аппаратные средства для организации работы в локальной сети;
• позволяет реализовать «замкнутый» режим работы, при котором передаваемые данные без внешних коммутаций поступают на вход приемника;
. имеет опцию изменения полярности передаваемых данных.
Контроллер SCI08 обслуживается двумя выводами: TxD - линия передачи данных; RxD - линия приема данных. Обслуживание модуля SCI08 является альтернативной функцией линий порта РТЕ (см. рис. 4.44). Если бит разрешения работы модуля ENSCI в регистре SCC1 установлен, то независимо от значения соответствующих битов регистра направления передачи порта ввода/вывода его линии назначаются для работы в составе контроллера SCI08.
Принцип действия модуля SCI08 аналогичен рассмотренному принципу действия модуля типа UART. По сравнению с рассмотренным ранее последовательным портом МК MCS-51 модуль SCI08 отличает значительно более сложная функциональная схема, которая реализует логику паритета, а также диагностирует пять типов ошибок приема, позволяя существенно повысить надежность обмена данными. Соответственно увеличилось и число регистров специальных функций, которые обслуживают модуль. Однако протоколы обмена и базовые алгоритмы функционирования модуля остались неизменными. Аппаратные средства модуля SCI08 делят на две подсистемы: приемника и передатчика. Основу каждой подсистема составляют сдвиговый регистр и буферный регистр данных (см. рис. 4.19).
Различают два состояния подсистемы передатчика:
1) активное состояние или состояние передачи данных, которое характеризуется периодическим появлением на линии TxD сигнала низкого логического уровня; даже если все биты данных передаваемого кадра равны 1, то линия TxD будет находиться в «О» в течение интервала передачи стартового бита; в состоянии передачи данных в буферном регистре или в сдвиговом регистре обязательно присутствуют еще не переданные данные;
2) состояние ожидания (IDLE), которое характеризуется наличием сигнала высокого логического уровня на линии TxD в течение не менее 10 или 11 тактов работы передатчика (для 10- и 11-битового кадра соответственно); передатчик переходит в состояние ожидания, если в буферном регистре данных и в сдвиговом регистре новые данные для передачи отсутствуют.
Передача данных от МК к другому устройству инициируется посредством записи байта данных в буферный регистр передатчика по адресу регистра данных SCDR. Аппаратные средства передатчика загружают содержимое буферного регистра данных в сдвиговый регистр. Одновременно устанавливается флаг SCTE (флаг очистки регистра буфера данных в регистре SCS1), который информирует МК о том, что буферный регистр передатчика пуст, и в него могут быть загружены новые данные. Если следующий байт данных для передачи будет загружен в буферный регистр SCDR до завершения передачи предыдущего байта, то нарушения в работе передатчика не произойдет. Второй байт данных будет сохраняться в буферном регистре до тех пор, пока передача предыдущего байта не будет завершена. Следует иметь в виду, что копирование содержимого буферного регистра в сдвиговый регистр под управлением аппаратных средств не сопровождается автоматическим началом передачи этого байта данных. Процесс передачи нового байта из сдвигового регистра на линию TxD начнется только после того, как бит SCTE будет сброшен. Для достижения последнего необходимо выполнить две операции:
1) прочитать регистр состояния SCS1 при установленном бите SCTE;
2) записать в регистр буфера передатчика по адресу SCDR новый байт данных.
411
8-РАЗРЯДНЫЕ МИКРОКОНТРОЛЛЕРЫ
Тогда под управлением генератора скорости передачи GT биты предыдущего байта данных начнут последовательно передаваться из сдвигового регистра на вывод TxD.
После завершения передачи пакета обмена, когда в сдвиговом и буферном регистрах не осталось данных для передачи, устанавливается в «1» бит ТС. Флаги очистки буфера данных SCTE и окончания передачи ТС имеют независимое маскирование (биты SCTIE и TCIE регистра SCC2 соответственно). Если прерывания по этим запросам разрешены, то любой из триггеров генерирует запрос на прерывание. Рассматриваемые запросы объединяются по «ИЛИ» и обслуживаются по единому вектору прерывания от передатчика модуля SCI08 (см. табл. 4.31).
Формат кадра передаваемых данных определяется значением бита М в регистре управления SCC1. Если М = 0, то обмен осуществляется с использованием 10-битового кадра . Сдвиговый регистр передатчика автоматически настраивается на 10-разрядный формат, в младшем и старшем разрядах сдвигового регистра устанавливаются логические уровни стартового и стопового битов (см. рис. 4.20). Если М = 1, то используется 11-битовый кадр обмена (см. рис. 4.21). Сдвиговый регистр настраивается на 11-разрядный формат. Недостающий бит данных D8 заполняется значением Т8 из регистра управления SCC3, которое должно быть определено программой до записи в буферный регистр восьми младших бит передаваемого слова. Значение бита М определяет формат кадра обмена как для приемника, так и для передатчика. Поэтому обмен в дуплексном режиме возможен только с одинаковым форматом кадра.
Скорость передачи данных, так же как и скорость приема, определяется собственным генератором модуля SCI08. Этот генератор состоит из двух делителей частоты тактирования межмодульных магистралей fBUS: предварительного с коэффициентом деления NP и основного с коэффициентом деления NS. Скорость обмена данными следует определить во формуле:
f _ feus SCI 64 NP -NS '
где NP - коэффициент деления предварительного делителя, NP = 1,3, 4,13; NS - коэффициент деления основного делителя, NS= 1,2, 4, 8, 16, 32, 64, 128.
Значения коэффициентов NP и NS определяются установкой соответствующих разрядов в регистре скорости передачи SCBR.
Передатчик модуля SCI08 реализует режим генерации сигнала «конец сеанса обмена» (сигнал «Break»), который состоит из 10 или 11 нулей, и в мультимикропроцессорных системах обозначает конец сеанса обмена между двумя устройствами. Для генерации сигнала «конец сеанса обмена» необходимо установить бит SBK в регистре управления SCC2.
Основные элементы приемника - сдвиговый регистр, 8-разрядный буферный регистр данных, схема мажоритарной логики для формирования значения очередного принимаемого бита, схема детектирования условия вывода приемника из режима ожидания, логический блок управления. Различают два состояния подсистемы приемника:
1) активное состояние, которое характеризуется периодическим формированием байта данных из последовательности битов на входе RxD, копированием принятого байта в буферный регистр данных приемника с одновременной установкой в «1» бита завершения приема данных SCRF;
2) состояние ожидания, в котором также реализуется преобразование последовательного кода на входе RxD в параллельный код в сдвиговом регистре, но копирование принятого байта в буферный регистр данных приемника и установка бита завершения приема SCRF выполняется только тогда, когда значение принятого слова удовлетворяет одному из условий выхода из режима ожидания.
412
СЕМЕЙСТВО МК НС08 ФИРМЫ «MOTOROLA»
Формат кадра принимаемых данных определяется значением бита М в регистре управ-ления SCC1. При М = 0 обмен осуществляется 10-битовыми кадрами, при М = 1 используется 11-битовый кадр обмена. В последнем случае сдвиговый регистр настраивается на -(1-разрядный формат. Бит данных D8, который не помещается в разрядную сетку буферного регистра данных приемника, записывается в разряд R8 регистра управления SCC3.
Блок логики управления подсистемы приемника детектирует наличие на входе RxD последовательности из не менее чем одного стопового бита, а затем стартового бита, и начинает формирование слова данных посредством выполнения под управлением генератора скорости передачи GR сдвиговых операций. Значение старшего бита на каждом такте работы сдвигового регистра определяет схема мажоритарной логики. Эта схема производит три выборки уровня сигнала на входе RxD в течение одного такта работы, значение старшего бита определяется по правилу «два из трех». Момент окончания формирования слова в сдвиговом регистре отмечается установкой в «1» триггера завершения приема SCRF в регистре SCS1. Одновременно принятые данные записываются в буферный регистр данных приемника, который доступен для чтения по адресу SCDR. Бит SCRF по существу является флагом готовности данных приемника, он информирует МК о том, что произошел прием очередного слова данных, и его следует переместить в память МК. Бит SCRF может быть считан программно, а если прерывания от приемника разрешены (бит SCRIE регистра управления SCC2 равен «1»), то генерируется запрос на прерывание от приемника модуля SCI08. Сброс бита готовности данных приемника осуществляется в процессе выполнения двух операций:
• чтения регистра состояния SCS1 при установленном бите SCRF;
• чтения регистр данных приемника SCDR.
Нетрудно заметить, что именно эта последовательность операций должна быть выполнена при считывании очередного принятого по линии RxD байта в память МК.
Если бит SCRF находится в «1», т. е. байт данных принят и находится в буферном регистре приемника, то подобная ситуация не препятствует процессу приема в сдвиговый регистр приемника следующего байта данных. Необходимо только, чтобы до завершения приема последующего байта данных предыдущий байт был считан из буферного регистра приемника. Если этого не произошло, то аппаратные средства блокируют запись нового байта в буферный регистр приемника, поэтому новый принятый байт будет потерян. Одновременно устанавливается бит нарушения работы OR в регистре SCS1 (Overrun - попытка перезаписи). Установленный в «1» бит OR может вызывать генерацию запроса на прерывание, если прерывания именно по этому событию разрешены (бит ORIE в регистре SCC3 равен «1»).
Аппаратные средства приемника сообщают пользователю о наличии шума на линии RxD при приеме каждого байта данных: бит NF регистра SCS1 устанавливается в «1», если при определении значения хотя бы одного из битов кадра обмена, включая стартовый и столовый биты, не все три выборки сигнала были равны. Установленный в «1» бит NF может вызывать генерацию запроса на прерывание, если прерывания именно по этому событию разрешены (бит NEIE в регистре SCC3 равен «1»). Если следующий принятый байт не содержит признака шума на линии, то бит NF не сбрасывается автоматически. Условия сброса бита NF указаны в табл. 4.46.
Аппаратные средства приемника также распознают нарушение формата кадра обмена: бит FE регистра SCS1 устанавливается в «1», если на линии RxD присутствует сигнал низкого логического уровня в то время, когда должен присутствовать столовый бит с высоким логическим уровнем. Подобная ситуация может возникнуть, если скорости обмена приемника и передатчика не совпадают, или если принимается специальный сигнал «конец сеанса обмена». Бит FE может вызывать генерацию запроса на прерывание, если прерывания именно по этому событию разрешены (бит FEIE в регистре SCC3 равен «1»).
413
8-РАЗРЯДНЫЕ микроконтроллеры
В процессе приема каждого байта информации в формате 11-битового кадра аппаратные средства приемника автоматически производят контроль бита паритета. Управление функцией паритета осуществляется с использованием битов PEN и PTY регистра SCC1. Если функция контроля паритета разрешена, то бит РЕ в регистре SCS1 устанавливается в «1», если в принятом байте данных вычисленный бит паритета не совпадает со значением принятого бита паритета. Установленный бит РЕ может генерировать запрос на прерывание, если прерывания по событию несовпадения паритетов разрешены (бит PEIE в регистре SCC3 равен «1»),
Запросы на прерывание, сформированные признаками ошибки приема (триггеры OR, NF, FE, РЕ) объединены по «ИЛИ» и обслуживаются по одному вектору прерывания (см. табл. 4.31).
Неактивное состояние линии RxD, которое характеризуется наличием на линии Ю или 11 (в зависимости от формата кадра) последовательных единиц, отмечается установкой бита IDLE регистра состояния SCS1. Неактивное состояние линии RxD свидетельствует о том, что передатчик другого устройства, которое выставляет данные на линию RxD, находится в состоянии ожидания IDLE. Бит IDLE может быть считан программно, но может также генерировать запрос на прерывание, если эти прерывания разрешены (бит ILIE в регистре управления SCC2 равен «1»), Вектор обслуживания запроса по флагу IDLE совпадает с вектором обслуживания приемника модуля SCI08.
Бит RWU в регистре управления SCC2 переводит приемник модуля SCI08 в режим ожидания. Этот режим позволяет организовать протокол обмена локальной управляющей сети МК. В режиме ожидания приемник продолжает преобразование последовательного кода на входе RxD в параллельный код в сдвиговом регистре. Однако формирование признаков SCRF, IDLE, OR, NF, FE, PE приемник не производит, и принятые данные в буферный регистр не копируются. Определено два способа перевода приемника из режима ожидания в активный режим работы:
• поступление последовательности битов с установленным в «1» маркером адреса; в качестве маркера адреса используют старший значащий бит; поэтому, для 10-битового кадра бит D7 должен быть равен «1», чтобы приемник вышел из состояния ожидания, для 11-битового кадра - бит D8.;
• нахождение линии RxD в неактивном состоянии IDLE.
Выбор способа «пробуждения» приемника определяется предварительной установкой бита WAKE в регистре управления SCC1. При диагностировании на входе RxD одной из двух указанных последовательностей приемник выходит из состояния ожидания, устанавливает бит готовности данных SCRF и копирует принятые данные в буферный регистр SCDR. Бит RWU автоматически сбрасывается, логика формирования бита IDLE не работает. Она начнет функционировать только при поступлении следующего байта в активном режиме работы приемника. На практике при организации локальных сетей чаще используется первый способ «пробуждения». Тогда младшие 7 или 8 бит данных первого принятого в процессе «пробуждения» слова содержат в себе адрес МК, с которым будет производиться обмен. Программа обслуживания прерывания по запросу от приемника сравнивает принятый адрес с собственным и, если адреса не совпадают, снова переводит приемник в режим ожидания. В случае равенства адресов приемник остается в активном режиме работы и участвует в сеансе обмена.
Программно-логическая модель модуля SCI08 включает семь регистров специальных функций: SCDR - регистр данных порта SCI08; SCC1 - регистр управления контроллером SCI08; SCC2 - регистр управления контроллером SCI08; SCC3 - регистр управления контроллером SCI08; SCS1 - регистр состояния контроллера SCI08; SCS2 - регистр состояния контроллера SCI08; SCBR - регистр скорости обмена контроллера SCI08.
Форматы этих регистров представлены в табл. 4.42 - 4.48.
414
СЕМЕЙСТВО МК НС08 ФИРМЫ «MOTOROLA»
Таблица 4.42
Формат регистра SCDR
SCDR | Регистр данных порта SCI08
7 Адрес 0018h 6 5 4 3 2 1 0
D7 I D6 | D5 | D4 | D3 | D2 | D1 | D0
Сброс не влияет на состояние регистра
Имя бита Назначение бита
D7-D0 Биты регистра данных порта SCI Регистр SCDR доступен как для чтения, так и для записи. Однако при выполнении операции записи данные будут запомнены в буферном регистре данных передатчика. Буфер данных передатчика недоступен для чтения. Операция чтения регистра SCDR возвращает данные из буферного регистра данных приемника. Буфер данных приемника недоступен для записи. Сброс не влияет на состояние регистра.
Таблица 4.43
Формат регистра SCC1
SCC1 I Регистр управления контроллером SPI08
7 6 5 4 3 2 1 0
LOOPS | ENSCI | TXINV | М | WAKE | ILTY | PEN | PTY
Состояние при сбросе: OOh Адрес 0013h
Имя бита Назначение бита
LOOPS Бит разрешения «замкнутого» режима работы контроллера SCI08 Установка в «1» бита LOOPS вызывает перекоммутацию входа приемника линии RxD, который внутренними средствами подсоединяется к выходу передатчика TxD, но отсоединяется от вывода RxD МК. В этом режиме возможен контроль передаваемой информации. Также режим может быть использован для тестирования работы программного обеспечения без использования устройства управления верхнего уровня: 1 - «замкнутый» режим работы разрешен; 0 - «замкнутый» режим работы запрещен. Бит доступен только для чтения. При сбросе МК режим LOOP отменяется.
ENSCI Бит разрешения работы контроллера SCI08 Бит ENSCI разрешает работу генератора скорости обмена, а также подсистемы передатчика и приемника, если индивидуальные биты разрешения их работы (ТЕ и RE в регистре SCC2 установлены). Сброс бита ENSCI устанавливает в «1» флаги SCTE и ТС в регистре SCS1 и запрещает прерывания от передатчика: 1 - работа контроллера SCI08 разрешена; 0 - работа контроллера SCI08 запрещена. Бит доступен для чтения и для записи. После сброса МК контроллер SCI08 находится в неактивном режиме.
TXINV Бит разрешения формирования инверсных уровней сигналов на выходе передатчика TxD 1 - работа в инверсном режиме разрешена; 0 - работа в инверсном режиме запрещена, реализуется общепринятый режим работы передатчика. Бит доступен для чтения и для записи. После сброса МК передатчик контроллера SCI08 работает в общепринятом режиме .
| 415
I
8-РАЗРЯДНЫЕ МИКРОКОНТРОЛЛЕРЫ
Продолжение табл. 4.43
SCC1 | Регистр управления контроллером SPI08
7 6 5 4 3 2 1 0
LOOPS | ENSCI | TXINV | М | WAKE I ILTY | PEN | PTY
Состояние при сбросе: 00h Адрес 0013h
Имя бита Назначение бита
М Бит выбора формата кадра асинхронного обмена 1 - 11-битовый формат кадра: 1 стартовый бит, 9 бит слова данных, 1 столовый бит; 0 - 10-битовый формат кадра: 1 стартовый бит, 8 бит слова данных, 1 столовый бит. Бит доступен для чтения и для записи. После сброса МК назначается 10-би-товый формат кадра.
WAKE Бит выбора способа выхода приемника из режима ожидания 1 - установка маркера адреса (бит D7=1 при М=0 или бит D8=1 при М=1) переводит приемник в активный режим работы. 0 - состояние IDLE другого передатчика (11 последовательных единиц на линии RxD при М = 0 или 12 последовательных единиц при М = 1) переводит приемник в активный режим работы. Бит доступен для чтения и для записи. При сбросе МК бит устанавливается в «0».
ILTY Бит выбора режима распознавания неактивного состояния линии RxD Этот бит определяет момент начала отсчета для определения неактивного состояния линии RxD: 1 - отсчет начинается после идентификации стоп-бита; 0 - отсчет начинается после идентификации старт-бита. После сброса МК бит устанавливается в «0».
PEN Бит разрешения работы логики паритета 1 - формирование бита паритета передатчиком и его анализ приемником реализуются; 0 - функция паритета отключена. Бит доступен для чтения и для записи. После сброса МК контроллер SCI08 не использует логику паритета.
PTY Бит выбора четного или нечетного паритета 1 - бит паритета формируется из условия нечетного числа «1» в слове; 0 - бит паритета формируется из условия четного числа «1» в слове. После сброса МК бит устанавливается в «0».
Таблица 4.44
Формат регистра SCC2
SCC2 | Регистр управления контроллером SCI08
7 Адрес 0014h 6 5 4 3 2 1 0
SCTIE ] TCIE | SCRIE | ILIE ] ТЕ | RE | RWU | SBK
Состояние при сбросе: 00h
Имя бита Назначение бита
SCTIE Бит разрешения прерывания от передатчика контроллера SCI08 Этот бит разрешает генерацию запроса на прерывание при установке в «1» флага готовности буфера данных передатчика к приему от программы нового байта (бит SCTE): 1 - прерывания от передатчика по флагу SCDE разрешены; 0 - прерывания от передатчика по флагу SCDE запрещены. Бит доступен для чтения и для записи. При сбросе МК все прерывания от передатчика контроллера SCI запрещаются.
416
СЕМЕЙСТВО МК НС08 ФИРМЫ «MOTOROLA»
Продолжение табл. 4.44
SCC2 | Регистр управления контроллером SCI08
7 Адрес 0014h 6 5 4 3 2 1 0
SCTIE | TCIE | SCRIE | ILIE | lb | Rb | RWU | SBK
Состояние при сбросе: 00h
Имя бита Назначение Оита
TCIE Бит разрешения прерывания от передатчика контроллера SCI08 Этот бит разрешает генерацию запроса на прерывание при установке в «1» флага завершения работы передатчика ТС: 1 - прерывания от передатчика по флагу ТС разрешены; 0 - прерывания от передатчика по флагу ТС запрещены. Бит доступен для чтения и для записи. При сбросе МК все прерывания от передатчика контроллера SCI запрещаются.
SCRIE Бит разрешения прерывания от приемника контроллера SCI08 Этот бит разрешает генерацию запроса на прерывание при установке в «1» флага завершения приема очередного байта SCRF: 1 - прерывания от приемника по флагу SCRF разрешены; 0 - прерывания от приемника по флагу SCRF запрещены. Бит доступен для чтения и для записи. При сбросе МК все прерывания от приемника контроллера SCI запрещаются.
ILIE Бит разрешения прерывания от приемника по флагу IDLE Этот бит разрешает генерацию запроса на прерывание при установке в «1» флага неактивного состояния линии RxD. 1 - прерывания при установленном флаге IDLE разрешены; 0 - прерывания по флагу IDLE запрещены. Бит доступен для чтения и для записи. При сбросе прерывания от приемника контроллера SCI запрещаются.
ТЕ Бит разрешения работы передатчика контроллера SCI08 После установки бита ТЕ передатчик формирует на линии TxD слово из 10 или 11 последовательных единиц, и только затем осуществляет посылку данных из регистра буфера передатчика. Если бит ТЕ будет сброшен в процессе передачи, то передача текущего байта будет завершена: 1 - передача разрешена; 0 - передача запрещена. Бит доступен для чтения и для записи. После сброса МК передача запрещена.
RE Бит разрешения работы приемника контроллера SCI08 1 - прием разрешен; 0 - прием запрещен. При сбросе бита RE все биты регистра состояния SCS1, связанные с работой приемника (SCRF, IDLE, OR, NF, FE, PE), становятся неактивными. Однако после сброса бита RE ранее установленные флаги запросов на прерывание автоматически не сбрасываются. Бит RE доступен для чтения и для записи. После сброса МК прием запрещен.
RWU Бит управления режимом ожидания приемника контроллера SCI08 Установка бита RWU под управлением программы в «1» переводит приемник контроллера SCI в режим ожидания. Пока приемник находится в этом режиме, ни один из флагов, которые связаны с работой приемника (SCRF, IDLE, OR, NF, FE, PE), не может быть установлен. Однако те флаги, которые уже были установлены к моменту перевода при- емника в режим ожидания, не сбрасываются в момент записи «1» в бит RWU. Способ перевода приемника в активный режим работы определяет бит WAKE в регистре SCC1. Бит доступен для чтения и для записи. После сброса МК бит RWU = 0.
417
8-РАЗРЯДНЫЕ МИКРОКОНТРОЛЛЕРЫ
Продолжение табл. 4.44
SCC2 I Регистр управления контроллером SCI08
Адрес 0014h 7 6 5 4 3 2 1 0
SCTIE | TCIE | SCRIE | ILIE | ТЕ | RE | RWU | SBK
Состояние при сбросе: OOh
Имя бита Назначение бита
SBK Бит управления сообщением «конец сеанса обмена» Если бит SBK установить под управлением программы в «1», а затем в «0» то передатчик контроллера SCI генерирует в линию TxD последовательность из 10 (бит М = 0) или 11 (бит М = 1) нулевых битов и одного единичного бита. Если бит SBK установить в «1» и не сбрасывать, то передатчик будет генерировать сигнал «конец сеанса обмена» до тех пор, пока бит SBK не будет сброшен. Бит доступен для чтения и для записи После сброса МК бит SBK = 0.
Таблица 4.45
Формат регистра SCC3
SCCR3 | Регистр управления контроллером SCI08
7 Адрес 0015h 6 5 4 3 2 1 0
RS | Тй | bMARE | ЬМАТЁ | OWE MEtE | FEiE | ЙЁ1Ё
Состояние при сбросе: ххООООООВ
Имя бита Назначение бита
R8 Бит D8 принимаемого 9-разрядного слова 11-битового кадра асинхронного приемопередатчика Значение логического «0» или «1» заносится в этот бит одновременно с записью младших восьми бит принятого 9-разрядного слова из сдвигового регистра в буфер данных приемника. Бит доступен только для чтения. При сбросе МК состояние бита не определено.
Т8 Бит D8 передаваемого 9-разрядного слова 11-битового кадра асинхронного приемопередатчика Предварительно установленное значение бита Т8 автоматически загружается в сдвиговый регистр передатчика одновременно с младшими восемью битами из регистра буфера данных. Бит доступен для чтения и для записи. При сбросе МК состояние бита не определено.
DMARE/DMATE Биты разрешения режима прямого доступа к памяти для приемника (DMARE) и передатчика Модуль прямого доступа к памяти DMA08 в составе рассматриваемых МК отсутствует. Поэтому эти биты должны быть обязательно установлены в «0». При сбросе биты устанавливаются в «0».
ORIE Бит разрешения прерывания от приемника по флагу OR Этот бит разрешает генерацию запроса на прерывание при установке в «1» флага ошибки приема OR: 1 - прерывания при установленном флаге OR разрешены; 0 - прерывания по флагу OR запрещены. Бит доступен для чтения и для записи. При сбросе прерывания от приемника контроллера SCI запрещаются.
418
СЕМЕЙСТВО МК НС08 ФИРМЫ «MOTOROLA»
Продолжение табл. 4.45
SCCR3 Регистр управления контроллером SCI08
7 6 5 Адрес 0015h 4 3 2 1 0
R8 | Т8 IDMARE | DMATE | ORIE | NEIE | FEIE| РЁ1Ё
Состояние при сбросе: ххООООООВ
Имя бита Назначение бита
NEIE Бит разрешения прерывания от приемника по флагу NF Этот бит разрешает генерацию запроса на прерывание при установке в «1» флага NF наличия шума на линии: 1 - прерывания по флагу NF разрешены; 0 - прерывания по флагу NF запрещены. Бит доступен для чтения и для записи. При сбросе прерывания от приемника контроллера SCI запрещаются.
FEIE Бит разрешения прерывания от приемника по флагу FE Этот бит разрешает генерацию запроса на прерывание при установке в «1» флага нару- шения формата кадра FE: 1 - прерывания по флагу FE разрешены; 0 - прерывания по флагу FE запрещены. Бит доступен для чтения и для записи. При сбросе прерывания от приемника контроллера SCI запрещаются.
PEIE Бит разрешения прерывания от приемника по флагу РЕ Этот бит разрешает генерацию запроса на прерывание при установке в «1» флага ошибки функции паритета в принятом кадре РЕ: 1 - прерывания по флагу РЕ разрешены; 0 - прерывания по флагу РЕ запрещены. Бит доступен для чтения и для записи. При сбросе прерывания от приемника контроллера SCI запрещаются.
Таблица 4.46
Формат регистра SCS1
SCSI 1 Регистр состояния контроллера SCI08
7 Адрес 0016h 6 5 4 3 2 1 0
SCTE I ТС I SCRF ( IDLE | OR I NF | FE I РЕ
Состояние при сбросе: OCOh
Имя бита Назначение бита
SCTE Бит готовности буфера передатчика к приему новых данных Устанавливается в момент, когда предварительно загруженные в регистр буфера передатчика данные автоматически переписываются в сдвиговый регистр передатчика. Однако процесс передачи нового байта из сдвигового регистра на линию TxD начнется только после того, как бит SCTE будет сброшен. Бит SCTE информирует МК о том, что буфер передатчика пуст, и в него может быть записан новый байт. Этот бит вызывает генерацию запроса на прерывание, если бит SCTIE в регистре SCC2 установлен. Бит SCTE сбрасывается в 0 автоматически при выполнении последовательности из двух операций: • чтение регистра состояния SCS1 при установленном бите SCTE; • запись в регистр буфера передатчика SCDR нового байта данных. Бит доступен только для чтения. При сбросе МК бит устанавливается в «0».
419
8-РАЗРЯДНЫЕ микроконтроллеры
Продолжение табл. 4.46
SCS1 | Регистр состояния контроллера SCI08
7 Адрес 0016h 6 5 4 3 2 1 0
SCTE I ГС | SCRF [ IDLE | OR | NF | FE | РЕ
Состояние при сбросе: OCOh
Имя бита Назначение бита
ТС Бит завершения передачи данных Устанавливается, если данные для передачи в сдвиговом и буферном регистре данных передатчика отсутствуют, а также, если не реализуется режим передачи сообщения «конец сеанса обмена». Бит ТС информирует МК об отсутствии процесса передачи данных в текущий момент времени. В это время на линии TxD установлен высокий логический уровень сигнала (состояние IDLE). Бит ТС вызывает генерацию запроса на прерывание, если бит TCIE в регистре SCC2 установлен. Бит ТС сбрасывается в «0» автоматически при выполнении последовательности из двух операций: • чтение регистра состояния SCS1 при установленном бите ТС; • запись в регистр буфера передатчика SCDR нового байта данных. Бит доступен только для чтения. При сбросе МК бит устанавливается в «0».
SCRF Бит завершения приема байта данных Устанавливается в момент, когда принятые по линии RxD данные автоматически переписываются в буферный регистр данных приемника. Бит SCRF вызывает генерацию запроса на прерывание, если бит SCRIE в регистре SCC2 установлен. Бит SCRF сбрасывается в «0» автоматически при выполнении последовательности из двух операций: • чтение регистра состояния SCS1 при установленном бите SCRF; • чтение из регистра данных SCDR принятого байта данных. Бит доступен только для чтения. При сбросе МК бит устанавливается в «0».
IDLE Бит неактивного состояния линии RxD Устанавливается в 1, если на линии RxD диагностируются 10 или 11 (в зависимости от формата кадра) последовательных единиц. Бит IDLE вызывает генерацию запроса на прерывание, если бит ILIE в регистре SCC2 установлен. Бит IDLE сбрасывается в 0 автоматически при выполнении последовательности из двух операций: • чтение регистра состояния SCS1 при установленном бите IDLE; • чтение регистра данных SCDR. Бит доступен только для чтения. При сбросе МК бит устанавливается в «0».
OR Бит ошибки приема Устанавливается при попытке записи аппаратными средствами приемника очередного принятого байта из сдвигового регистра в буферный регистр данных в то время, как предыдущие данные из буферного регистра еще не считаны (бит SCRF установлен). При таком стечении обстоятельств содержимое буферного регистра приемника сохраняется, а второй принятый байт теряется. Бит OR вызывает генерацию запроса на прерывание, если бит ORIE в регистре SCC3 установлен. Бит OR сбрасывается в «0» автоматически при выполнении последовательности из двух операций: • чтение регистра состояния SCS1 при установленном бите OR; • чтение из регистра данных SCDR первого принятого байта данных. Бит доступен только для чтения. При сбросе МК бит устанавливается в «0».
420
СЕМЕЙСТВО МК НС08 ФИРМЫ «MOTOROLA»
Продолжение табл. 4.46
SCS1 ( Регистр состояния контроллера SCI08
7 Адрес 0016h 6 5 4 3 2 1 0
SCTE | ГС | SCRF | IDLE I OR | NF | FE | РЁ
Состояние при сбросе: OCOh
Имя бита Назначение бита
NF Бит наличия шума на линии приемника RxD Устанавливается в случае, если при выборке очередного бита информационного кадра, включая стартовый и столовый биты, не все три детектированные значения бита оказались равными. Бит NF устанавливается одновременно с битом завершения приема того байта, при передаче которого обнаружен шум. Бит NF вызывает генерацию запроса на прерывание, если бит NFIE в регистре SCC3 установлен. Бит NF сбрасывается в «0» автоматически при выполнении последовательности из двух операций: • чтение регистра состояния SCS1 при установленном бите NF; • чтение регистра данных SCDR. Бит доступен только для чтения. При сбросе МК бит устанавливается в «0».
FE Бит нарушения формата кадра Устанавливается, если поступающая на вход RxD последовательность битов не соответствует меткам синхронизации, формируемым внутренним счетчиком приемника. Аппаратные средства приемника распознают состояние нарушения синхронизации по признаку наличия на линии нулевого логического уровня в то время, когда должен присутствовать столовый бит с высоким логическим уровнем сигнала. Бит FE вызывает генерацию запроса на прерывание, если бит FEIE в регистре SCC3 установлен. Бит FE сбрасывается в «0» автоматически при выполнении последовательности из двух операций: • чтение регистра состояния SCS1 при установленном бите FE; • чтение регистра данных SCDR. Бит доступен только для чтения. При сбросе МК бит устанавливается в «0».
РЕ Бит нарушения паритета кадра Устанавливается, если функция паритета при обмене разрешена, и в принятом кадре значение бита паритета не удовлетворяет принятой логике формирования паритета: при назначенном нечетном паритете число единиц в слове четное, и наоборот Бит РЕ вызывает генерацию запроса на прерывание, если бит PEIE в регистре SCC3 установлен. Бит РЕ сбрасывается в «0» автоматически при выполнении последовательности из двух операций: • чтение регистра состояния SCS1 при установленном бите РЕ; • чтение регистра данных SCDR. Бит доступен только для чтения. При сбросе МК бит устанавливается в «0».
Таблица 4.47
Формат регистра SCS2
SCS2 | Регистр состояния контроллера SCI08
Адрес 0017h 7 6 5 4 3 2 1 0
х|х|х|х|х|х| BRK | RPF
Состояние при сбросе: 00h
Имя бита Назначение бита
RPF Бит незавершенного приема Устанавливается, если приемник распознал старт-бит, но еще не завершил прием байта данных. Бит доступен только для чтения. При сбросе МК бит устанавливается в «0».
421
8-РАЗРЯДНЫЕ МИКРОКОНТРОЛЛЕРЫ
Продолжение табл. 4.47
SCS2 | Регистр состояния контроллером SCI08
7 Адрес 0017h 6 5 4 3 2 1 0
х 1 х | х | х I х | х | BRK | RPF
Состояние при сбросе: 00h
Имя бита Назначение бита
BRK Бит сигнала «Вгеакяна линии RxD Устанавливается в «1», если на линии RxD диагностируется сигнал «конец сеанса обмена». Одновременно устанавливаются биты FE и SCRF в регистре SCS1. Диагностируются 10 или 11 (в зависимости от формата кадра) последовательных единиц. Бит IDLE вызывает генерацию запроса на прерывание, если бит ILIE в регистре SCC2 установлен. Бит IDLE сбрасывается в «0» автоматически при выполнении последовательности из двух операций: • чтение регистра состояния SCS1 при установленном бите BRF; • чтение регистра данных SCDR. Бит доступен только для чтения. При сбросе МК бит устанавливается в «0».
Таблица 4.48
Формат регистра SCBR
SCBR | Регистр скорости обмена контроллера SCI08
Адрес 0019h 7 6 5 4 3 2 1 0
х | х | SCP1 | SCP0 | х | SCR2 | SCR1 | SCR0
Состояние при сбросе: 00h
Имя бита Назначение бита
SCP1-SCP0 Биты выбора коэффициента деления NP SCP1 SCP0 Коэффициент деления NP 0 0 1 0 1 3 1 0 4 1 1 13 После сброса МК значения битов равны «00».
SCR2-SCR0 Биты выбора скорости обмена SCT2 SCT1 SCT0 Коэффициент деления NR 0 0 0 1 0 0 1 2 0 10 4 0 11 8 10 0 16 10 1 32 110 64 111 128 После сброса МК значения битов равны «000».
422
СЕМЕЙСТВО МК НС08 ФИРМЫ «MOTOROLA»
4.3.10. РАЗВИТИЕ СЕМЕЙСТВА НС08
Семейство 8-разрядных МК НС08 активно развивается в следующих направлениях.
• На базе уже отработанного процессорного ядра появляются различные модели МК, которые интегрируют на кристалле ПЗУ от 1,5 до 60 Кбайт, и широкий набор периферийных модулей. Поскольку объем прикладной программы управления в большинстве случаев соотносится с необходимым набором периферийных модулей, то в составе семейства НС08 присутствуют как очень простые МК в корпусах с 16 и 20 выводами с малым объемом резидентного ПЗУ и небольшим набором периферийных модулей, так и сложные МК с большим объемом ПЗУ программ и широким набором периферийных модулей. Таким образом, на основе одного процессорного ядра пользователю предоставляется широкий ряд моделей, на основе которого могут быть решены любые прикладные задачи для 8-разрядных МК.
• Постоянно пополняется библиотека периферийных модулей семейства. Появляются новые модули встроенного АЦП с увеличенным числом разрядов и меньшим временем преобразования, контроллеров последовательных интерфейсов USB и CAN, новые более совершенные модули FLASH ПЗУ.
• Повышается производительность центрального процессора путем увеличения частоты тактирования.
В конце 2000 г. семейство НС08 насчитывало 17 моделей МК (табл. 4.49). В настоящее время продолжают появляться новые модели. Для удобства пользователя МК семейства НС08 объединены в серии. Каждая серия имеет буквенное обозначение: HC08AZ, HC08GP и др. (МК семейства НС08, серия AZ, серия GP). МК, принадлежащие к одной серии, имеют одинаковый набор периферийных модулей, но различаются объемом и типом встроенной памяти, числом каналов в том или ином периферийном модуле, нагрузочной способностью выводов портов, параметрами модуля формирования тактовой частоты, напряжением источника питания, типом корпуса ИС. Серии МК в составе семейства НС08 только нарождаются. В настоящее время оформились шесть семейств: HC08AZ, HC08AS, HC08GP, HC08MR, HC08JK/JL и НС08КХ.
Наибольшее развитие в настоящее время получила серия AZ. Это обусловлено наличием в составе семейства контроллера локальной промышленной сети с протоколом CAN, которая приобретает все большее распространение в системах промышленной автоматики и автомобильной электроники. МК серии AZ представляют собой верхний уровень семейства НС08: предельно реализуемая для CPU08 резидентная память и широкий набор периферии.
К «среднему классу» следует отнести семейство GP с его представителем HC908GP32, рассмотренным выше, и HC908GP20.
Нижний уровень семейства НС08 представлен пока тремя маловыводными моделями - HC(9)08JL3, HC(9)08JK3 и HC(9)08JK1, которые выполнены в корпусах с 28 и 20 выводами. Эти МК имеют две линии вывода с повышенной нагрузочной способностью (25 МА), 7/4 линий предназначены для непосредственного подключения светодиодов. Спектр применения МК HC(9)08JL3/JK3/JK1 - устройства локального управления, не требующие сопряжения с управляющим устройством верхнего уровня. МК HC(9)08JL3/JK3Z JK1 выпускаются как с масочным ПЗУ (HC08JL3/JK3/JK1), так и с модулем FLASH ПЗУ (HC908JL3/JK3/JK1).
Кроме МК общего применения, в состав семейства НС08 включены специализированные микроконтроллеры: HC908MR32, HC908MR24, HC908MR16 и HC908MR8-для управления преобразователями частоты электропривода и другими типами уст
423
8-РАЗРЯДНЫЕ МИКРОКОНТРОЛЛЕРЫ
ройств силовой электроники, НС08Ь1М56-для управления панелями ЖКИ индикаторов; НС(9)08КН12 и HC(9)08JB8 - для управления компьютерной периферией на основе шины USB.
Таблица 4.49
Технические характеристики некоторых типов МК с ядром НС08
Тип МК Максимальная частота, МГц Память программ, байт Память данных, байт Линии ввода/ вывода Таймер Последовательный интерфейс АЦП входы/разрешения
MC68HC08AZ0 8,0 Внешняя 1К RAM 512 EEPROM 49 2x16 бит 4 канала 2 канала IC, ОС, PWM, СОР SCI SPI msCAN 8 каналов 8 бит
MC68HC08AZ32 8,0 32К mask-ROM 1К RAM 512 EEPROM 49 2x16 бит 4 канала 2 канала IC, ОС, PWM, СОР SCI SPI msCAN 8 каналов 8 бит
MC68HC908AZ60 8,0 60К FLASH 2К RAM 1К EEPROM 49 2x16 бит 4 канала 2 канала IC, ОС, PWM, СОР SCI SPI msCAN 15 каналов 8 бит
Серия GP
MC68HC908GP32 8,0 32К FLASH 512 RAM 33 2x16 бит 2 канала 2 канала IC, ОС, PWM, СОР SCI SP 8 каналов 8 бит
MC68HC908GP20 8,0 20К FLASH 512 RAM 33 2x16 бит 2 канала 2 канала IC, ОС, PWM, СОР SCI SP 8 каналов 8 бит
Серия JL/JK
MC68HC(9)08JL3 8,0 4K mask-ROM или FLASH 128 RAM 23 2х25мА 7 LED 16 бит 2 канала IC, ОС, PWM, СОР Нет 12 каналов 8 бит
MC68HC(9)08JK3 8,0 4K mask-ROM или FLASH 128 RAM 15 2х25мА 4 LED 16 бит 2 канала IC, ОС, PWM, СОР Нет 10 каналов 8 бит
424
СЕМЕЙСТВО МК НС08 ФИРМЫ «MOTOROLA»
Продолжение табл. 4.49
Тип МК Максимальная частота, МГц Память программ, байт Память данных, байт Линии ввода/ выаода Таймер Последовательный интерфейс АЦП входы/раз-решения
MC68HC(9)08JK1 8,0 1536 mask-ROM или FLASH 128 RAM 15 2х25мА 4 LED 16 бит 2 канала IC, ОС, PWM, СОР Нет 10 каналов 8 бит
Серия MR Имеют в своем составе специальный модуль PWM08 для управления силовыми полупроводниковыми ключами
MC68HC908MR32 8,0 32К FLASH 768 RAM 44 2x16 бит 4 канала 2 канала 1С, ОС, PWM, СОР SCI SPI 10 каналов 10 бит
MC68HC908MR24 8,0 20К FLASH 512 RAM 44 2x16 бит 4 канала 2 канала IC, ОС, PWM, СОР SCI SPI 10 каналов 10 бит
MC68HC908MR8 8,0 8К FLASH 768 RAM 44 2x16 бит 4 канала 2 канала IC, ОС, PWM, СОР SCI SPI 10 каналов 10 бит
Другие серии
МС68НС(9)08 КН12 8,0 12К mask-ROM или FLASH 384 RAM 42 2x16 бит 4 канала 2 канала IC, ОС, PWM, СОР USB Нет
МС68НС(9)08 КХ8 8,0 8K mask-ROM или FLASH 192 RAM 14 2x16 бит 1 канал 1 канал (С, ОС, PWM, СОР SCI 4 канала 8 бит
XC68HC08LN56 8,0 56K mask-ROM 1280 RAM 42 16 бит 4 канала IC, ОС, PWM, СОР 4 канала 8 бит 4 канала 8 бит Контроллер ЖКИ 40x32
425
8-РАЗРЯДНЫЕ МИКРОКОНТРОЛЛЕРЫ
4.4. RISC-МИКРОКОНТРОЛЛЕРЫ СЕМЕЙСТВА PIC16 ФИРМЫ «MICROCHIP»
4.4.1. АРХИТЕКТУРА МК PIC16C54
На рис. 4.54 приведена структура МК PIC16C54. Серия Р1С16С5х («х» - номер модели, для рассматриваемого МК PIC16C54 х = 4) объединяет самые простые МК семейства PIC16. Каждый МК серии Р1С16С5х интегрирует на кристалле высокопроизводительное процессорное ядро и минимальный набор периферийных модулей. Так, МК PIC16C54 размещается в корпусе всего с 18 выводами. Его изучение позволит вам познакомиться с самым распространенным RISC-ядром в секторе 8-разрядных МК, не осложняя описание множеством регистров специальных функций периферийных модулей.
МК PIC16C54 включает следующие функциональные блоки:
• центральный RISC-процессор PIC16; разрядность обрабатываемого слова - 8 бит, число команд - 33;
• память программ: 512 12-разрядных ячеек памяти однократно программируемого ПЗУ;
• память данных: ОЗУ емкостью 25 однобайтовых ячеек памяти;
• таймер;
• два порта ввода/вывода с общим числом линий, равным 12;
• сторожевой таймер.
RA3:RA0 RB7:RB0
Рис. 4.54. Структура МК PIC16C54 фирмы «Microchip»
426
V
СЕМЕЙСТВО МК НС08 ФИРМЫ «MOTOROLA»
I
i
I
МК семейства PIC 16 используют гарвардскую архитектуру, основанную на концепции раздельных магистралей и областей памяти для команд и для данных. Разделение магистралей позволяет увеличить разрядность команды по сравнению с разрядностью данных. В МК Р1С16С5х формат команды составляет 12 бит, в то время как разрядность слова памяти данных равна одному байту. Все без исключения команды МК PIC16 являются однословными, т. е. длина кода любой команды равна 12 бит. Двухступенчатый конвейер обеспечивает одновременную выборку и исполнение команд. Все команды, кроме команд передачи управления, выполняются за один машинный цикл. Длительность цикла составляет 200 нс при частоте тактирования fXCLK - 20 МГц (fBUS = fXCLK/4).
Адресное пространство памяти программ МК Р1С16С5х делится на страницы (банки) по 512 ячеек в каждой (рис. 4.55). Прямая адресация памяти программ возможна только в пределах одной страницы. Доступ к памяти свыше 512 ячеек осуществляется после переключения под управлением программы указателя страницы. В качестве указателя используются биты РА1:РА0 регистра признаков центрального процессора, который в МК PIC16 носит название STATUS. Рассматриваемая модель МК PIC16C54 имеет всего 512 ячеек памяти программ, т. е. использует только нулевую страницу адресного пространства. Соответственно и разрядность счетчика адреса РС для данного МК равна 9. В других моделях серии Р1С16С5х используется до 4 страниц памяти программ, тогда разрядность счетчика адреса РС составляет 11 бит. Причем младшие 9 бит работают в режиме двоичного счетчика, адресуя 512 ячеек памяти в пределах каждой страницы. А старшие два разряда устанавливаются только по значению битов РА1:РА0 регистра STATUS.
Адресное пространство оперативного запоминающего устройства объединяет регистры специальных функций и регистры общего назначения. Карта памяти данных МК Р1С16С5х представлена на рис. 4.56.
Память данных разбита на 4 банка. В нулевом банке 32 ячейки памяти, в остальных трех банках -по 16 ячеек. Номер используемого банка задают разряды FSR.6 и FSR.5 регистра косвенной адресации FSR (00 - банк 0, 01 - банк 1, 10 - банк 2,11- банк 3). Обратите внимание, что младшие 16 адресов в банках 1, 2 и 3 недоступны. При обращении по адресам, принадлежащим недоступным областям, эти адреса будут отображаться на соответствующий адрес банка 0: например, по адресам 21 h, 41 h, 61 h будет считываться одна и та же ячейка памяти с адресом 01 h.
Из регистра STATUS
| РС10
2
| Счетчик адреса РС
РС9 | PCS | PC7...PC0 |<--------------
00
8,
X
Адреса
000
Страница 0 OFF
100
1FF
200
Страница 1
300
3FF
400
Страница 2 4FF
500
Страница 3
5FF
600
700
7FF
Стек уровня 1
Стек уровня 2
PIC16C54
PIC16C56
PIC16C57/C58
Рис. 4.55. Распределение адресного пространства ПЗУ программ для МК Р1С16С5х
427
8-РАЗРЯДНЫЕ МИКРОКОНТРОЛЛЕРЫ
Рассматриваемый МК PIC16C54 имеет всего один банк оперативной памяти. Адресное пространство из 32 ячеек памяти делится следующим образом: диапазон адресов с 00h по 06h принадлежит адресам регистров специальных функций, адреса с 07h по 1 Fh используют 25 ячеек памяти общего назначения. В описании системы команд и те и другие именуются регистрами общего назначения в противовес рабочему регистру центрального процессора W, который по функциональному назначению близок к аккумулятору. Для обращения к регистрам специальных функций и просто к ячейкам памяти используются одни и те же способы адресации: прямая адресация и косвенная с использованием регистра косвенной адресации FSR. Кроме того, каждый бит любой ячейки памяти данных доступен с использованием одной из 4 команд битового процессора. Перечень регистров специальных функций МК Р1С16С5х с указанием назначения битов для некоторых из них приведен в табл. 4.50.
Адрес регистра 00
01
02
03
04
05
06
07
08
09
0А
0В
ОС
0D
0Е
0F
• - Регистр физически не существует
* * - Банк 0 доступен во всех микроконтроллерах семейства Р1С16С5х, банки 1,2,3 доступны только для PIC16C57/58
Рис. 4.56. Распределение адресного пространства памяти данных и регистров специальных функций для МК Р1С16С5х
428
СЕМЕЙСТВО МК НС08 ФИРМЫ «MOTOROLA»
Часть регистров специальных функций МК не входит в адресное пространство ОЗУ данных. Это регистры направления передачи портов ввода/вывода TRIS, регистр конфигурации МК OPTION и некоторые другие. Для обращения к этим регистрам используются специальные команды.
Рассматриваемый МК PIC16C54 имеет 12 двунаправленных линий ввода/вывода, которые объединены в два порта: 4-разрядный порт PORTA и 8-разрядный порт PORTB. Регистры данных портов располагаются в адресном пространстве памяти данных (табл. 4.50). Каждая линия может быть настроена на ввод или вывод посредством записи слова управления («0» - вывод, «1» - ввод) в соответствующий регистр направления передачи порта TRISA или TRISB.
Модуль таймера в составе МК PIC16C54 имеет следующие особенности:
• 8-разрядный таймер-счетчик допускает внутреннее и внешнее тактирование;
• регистр таймера TMR0 доступен для чтения и для записи;
• 8-разрядный программируемый предварительный делитель.
Режим таймера или счетчика внешних событий, а также коэффициент предварительного делителя выбираются битами регистра OPTION.
Таблица 4.50
Регистры специальных функций МК Р1С16С5х
Имя регистра Назначение Адрес
INDF Не физический регистр. Используется для перехода к косвенному методу адресации 00h
TMR0 Регистр 8-разрядного счетчика/таймера 01h
PCL Младшие 8 разрядов счетчика адреса РС (РС7 - РС0) 02h
STATUS Регистр признаков центрального процессора 03h
РА2 РА1 РАО ТО PD 2 DC С
FSR Регистр косвенной адресации 04h
PORTA Регистр данных порта А 05h
х._ х х . х _ РАЗ РА2 РА1 РАО
PORTB Регистр данных порта В 06h
РВ7 РВ6 РВ5 РВ4 РВЗ РВ2 РВ1 РВО
TRISA’ Регистр направления передачи порта PORTA -
TRI SB’ Регистр направления передачи порта PORTB -
OPTION’ Регистр управления таймером -
’ Эти регистры не принадлежат к адресному пространству ОЗУ
4 .4.2. ПРОЦЕССОРНОЕ ЯДРО PIC16
Центральный процессор CPU PIC 16 включает (рис. 4.54):
• 8-разрядное АЛУ с регистром признаков STATUS;
• рабочий регистр W;
• регистр косвенной адресации FSR;
• 9-разрядный счетчик команд РС;
• 12-разрядный регистр кода команды и дешифратор команд.
8-Р АЗРЯДНЫЕ МИКРОКОНТРОЛЛЕРЫ
Программно доступными регистрами центрального процессора являются младший байт счетчика команд PCL, регистр признаков STATUS, регистр косвенной адресации FSR и рабочий регистр W. Причем первые три расположены в адресном пространстве регистров специальных функций (табл. 4.50), следовательно, для обращения к ним может быть использована любая команда обращения к регистрам общего назначения. Рабочий регистр W не имеет собственного адреса в карте памяти, поэтому он не может быть прямо адресован. Для его загрузки и пересылки используются специальные команды:
MOVLW к ; Загрузить константу к в рабочий регистр W
MOVWF f ; Загрузить содержимое рабочего регистра W в регистр общего ; назначения f.
Рабочий регистр W по функциональному назначению близок к аккумулятору. При выполнении любой операции в АЛУ используется регистр W. В командах, имеющих два операнда, одним из операндов обязательно является рабочий регистр W. При выполнении действий над одним операндом, например операции инкремента и декремента, рабочий регистр W может не быть источником операнда, но всегда имеется возможность поместить результат операции в рабочий регистр W.
АЛУ выполняет минимально необходимый набор операций: сложение, вычитание, логические операции, сдвиг, операции над битами. В командах с двумя операндами (сложение, вычитание, логические операции) один из операндов расположен в рабочем регистре W, другой операнд может быть содержимым любой ячейки ОЗУ, в том числе и регистра специальных функций. Результат операции может иметь один из двух регистров назначения: рабочий регистр W, если суффикс d в аббревиатуре команды равен 0, или источник второго операнда регистр общего назначения f, если суффикс d равен 1. В командах с одним операндом (инкремент, декремент, сдвиги вправо и влево) источником операнда является любой регистр встроенного ОЗУ, результат операции размещается так же, как и в предыдущем случае.
По результатам арифметических и логических операций устанавливаются три признака: переноса С, нулевого результата Z и дополнительного переноса DC (см. табл. 4.50). Остальные разряды регистра признаков STATUS используются для адресации памяти программ (биты РА2 - РАО), а также для управления сторожевым таймером и режимом низкого энергопотребления (биты ~?Б и то ). Регистр признаков STATUS доступен для любой команды так же, как и любой другой регистр. Однако следует иметь в виду, что биты ~pd и то устанавливаются только аппаратно и не могут быть изменены посредством какой-либо команды._Например, команда CLRF STATUS обнулит все биты регистра признаков, кроме ~рё> и то , а затем установит триггер Z.
Все без исключения команды МК Р1С16С5х имеют длину 12 бит, т. е. любая команда размещается в одной ячейке памяти программ. Формат команд МКР1С16С5х представлен на рис. 4.57.
Для выборки операндов из внутренней памяти данных в CPU PIC16 используются два способа адресации: прямая (DIR) и косвенная (INDIR). Прямоадресуемыми являются все ячейки внутренней памяти данных, т. е. регистры специальных функций, расположенные в карте памяти данных, и регистры общего назначения (см. рис. 4.56). В мнемонике команд с прямой адресацией все эти регистры обозначаются общей аббревиатурой f. Например:
ADDWF f,d ; Мнемоника команды:
; Сложить содержимое рабочего регистра W с содержимым
; регистра общего назначения f. Результат поместить в W при
; d=0 или в f при d=1 (0< f < 31).
ADDWF 1 Eh,1 ; Сложить содержимое рабочего регистра W с содержимым
; ячейки памяти 1 Eh, результат поместить в ячейку памяти 1Eh.
430
СЕМЕЙСТВО МК НС08 ФИРМЫ «MOTOROLA»
ADDWF FSR,0 ; Сложить содержимое рабочего регистра W с содержимым ; регистра косвенной адресации FSR, результат поместить в ; рабочий регистр W.
Прямая адресация используется также всеми командами работы с битами.
В качестве указателя адреса при косвенной адресации используется регистр FSR. Пять младших битов этого регистра адресуют ячейку памяти в пределах банка (адреса ячеек 0 - 1Fh). Разряды FSR6:FSR5 используются для выбора текущего банка. В МК PIC16C54 всего один банк памяти данных. Но в других моделях МК серии Р1С16С5х используется ОЗУ большей емкости. При написании программ для этих моделей следует помнить, что содержимое разрядов FSR6:FSR5 регистра косвенной адресации определяет адрес ячейки памяти не только при использовании косвенной адресации, но и при прямой адресации, так как непосредственно в коде команды с прямой адресацией указывается лишь 5-разрядный адрес ячейки.
При просмотре таблиц с перечнем команд МК Р1С16С5х Вы не увидите специальных мнемоник команд, использующих косвенную адресацию. Дело в том, что любая команда, которая использует прямую адресацию, может также использовать и косвенную. Для обозначения перехода от прямой адресации к косвенной при записи мнемоники команды используется имя регистра INDF. Этот регистр реально не существует, но при его указании в поле прямого адреса операнда центральный процессор использует содержимое регистра FSR в качестве адреса операнда. Например:
ADDWF INDF,О ; Сложить содержимое рабочего регистра W с содержимым
; ячейки памяти, адрес которой находится в регистре косвенной ; адресации FSR, результат поместить в рабочий регистр W.
ADDWF 0,1 ; Сложить содержимое рабочего регистра W с содержимым
; ячейки памяти, адрес которой находится в регистре косвенной
; адресации FSR (0 - абсолютный адрес несуществующего ; регистра INDF), результат поместить в ту же ячейку памяти.
Чтение косвенным образом самого регистра INDF даст результат 00h (т. е. FSR = 0). Косвенная запись в регистр INDF не приведет к изменению состояния регистра FSR, хотя биты состояния могут быть изменены.
Регистры OPTION и TRIS не имеют собственных адресов в карте памяти, поэтому для работы с ними используются специальные команды с неявной адресацией (команды «OPTION» и «TRIS f»).
Для работы с константами, которые по определению могут быть расположены только в области ПЗУ, используется непосредственная адресация (IMM). Центральный процессор PIC16 может оперировать с константами двух форматов, для которых в мнемонике команды используется общая аббревиатура константы к. В командах загрузки и логических операций используются 8-разрядные константы (рис. 4.57). Это и понятно: разрядность константы должна совпадать с разрядностью второго операнда и регистра результата. Кроме того, 8-разрядный адрес вызываемой подпрограммы указывается в коде команды CALL. И лишь одна команда безусловного перехода GOTO к использует 9-разрядную константу, которая содержит абсолютный адрес следующей команды.
Формат счетчика адреса РС в МК серии Р1С16С5х может быть 9-разрядным, как в рассматриваемом PIC16C54, или 10- или даже 11-разрядным. Для каждой модели МК серии Р1С16С5х формат счетчика адреса определяется объемом резидентного ПЗУ, которое хранит прикладную программу. Младший байт счетчика команд PCL интерпретируется как регистр специальных функций. Поэтому PCL имеет собственный адрес в карте адресного пространства внутреннего ОЗУ и, следовательно, программно доступен. Если счетчик команд является операндом в какой-либо команде (например, MOVWF РС, ADDWF PC или BSF PC,5) то результат операции в 8-разрядном формате загружается
431
8-РАЗРЯДНЫЕ МИКРОКОНТРОЛЛЕРЫ
| Команды работы с байтами
11 6 5 4_________________О
| Код операции | d | f
d = 0 - для назначения W
d = 1 - для назначения f
f = 5-разрядный адрес регистра
| Команды работы с битами
11_____________8 7 5 4______________О
| Код операции | d(BIT#) | f
Ь = 3-разрядный номер бита f = 5-разрядный адрес регистра
I Команды управления и операции с константами (кроме GOTO)
11 8 7 О
| Код операции | к (константа)
к = 8-разрядное значение
| Команда GOTO
11___________________9 8_________________О
| Код операции | к (константа)
к = 9-разрядное значение
Рис. 4.57. Форматы команд МК серии Р1С16С5х
в младший байт счетчика команд PCL. Восьмой бит сбрасывается в «О», а остальные загружаются из регистра состояния STATUS (см. табл. 4.50). Поэтому вычисляемые переходы и таблицы могут располагаться только в диапазоне первых 256 адресов каждой страницы памяти программ.
Если счетчик адреса 9-разрядный, т. е. объем ПЗУ составляет 512 ячеек, то формат команды «GOTO к» допускает переход в любую ячейку памяти программ (рис. 4.58).
В то же время формат команды «CALL к» предписывает использование только 8-разрядного формата адреса (рис. 4.58). Следовательно, все подпрограммы должны быть расположены только в диапазоне адресов 00h - OFFh.
Если счетчик адреса имеет разрядность 10 или 11 бит, то команда «GOTO к» может передать управление только в пределах текущей страницы памяти программ (рис. 4.59). Команда «CALL к» производит вызов подпрограммы, начальный адрес которой должен быть расположен в первых 256 ячейках памяти текущей страницы ПЗУ.
При достижении границы страницы счетчик команд автоматически переходит на начало следующей страницы. Однако биты выбора страницы в регистре признаков STATUS не изменяются автоматически. Поэтому последующие команды GOTO, CALL, MOVWF PC возвратят управление к предыдущей странице, если биты РА1:РА0 не будут изменены программно. После сброса МК в регистре STATUS биты выбора страницы указывают на страницу 0, в то время как счетчик команд указывает на последнюю ячейку памяти последней страницы (для PIC16C54 состояние РС после сброса равно 1 FFh). Поэтому, если по стартовому адресу будет расположена команда “GOTO к", управление будет передано на нулевую страницу.
МК серии Р1С16С5х имеют двухуровневый аппаратный стек. Разрядность ячеек памяти стека совпадает с разрядностью счетчика команд РС. Команда CALL загружает в вершину стека (стек уровня 1) предварительно увеличенный на единицу счетчик команд. Одновременно предыдущее значение вершины стека копируется в стек уровня 2.
432
СЕМЕЙСТВО МКНС08 ФИРМЫ «MOTOROLA»
Команда CALL и команды, модифицирующие РС
Команда GOTO
Регистр состояния STATUS
Рис. 4.58. Выполнение команд, модифицирующих 9-разрядный счетчик команд РС для МК PIC16C54
Команда CALL и команды, модифицирующие РС
Рис. 4.59. Выполнение команд, модифицирующих 10- или 11-разрядный счетчик команд РС для МК PIC16C54
Предыдущее значение стека уровня 2 теряется. Таким образом, глубина вложения подпрограмм в МК серии Р1С16С5х равна 2.
Подсистема прерывания в рассматриваемых МК серии Р1С16С5х (но не во всех МК семейства PIC16) отсутствует. Следовательно, нет в системе команд инструкций работы со стеком.
4.4.3. СИСТЕМА КОМАНД МК СЕМЕЙСТВА PIC16
Система команд МК серии PIC16С5х содержит всего 33 инструкции. Множество инструкций делится на 6 традиционных групп. Распределение команд по группам отражено в табл. 4.51.
Таблица 4.51
Распределение команд Ассемблера CPU PIC16 по типовым группам
Группа команд Число инструкций в группе
Команды загрузки и пересылки 6
Арифметические команды 4
Логические команды и команды сдвигов 11
Команды битового процессора 4
Команды управления ходом вычислительного процесса 6
Команды управления режимами МК 2
433
8-РАЗРЯДНЫЕ МИКРОКОНТРОЛЛЕРЫ
Описание инструкций приведено в табл. 4.52 - 4.57.
Таблица 4.'
Команды загрузки и пересылки
Мнемокод Операция Выполняемое действие Способ адресации Влияние на признаки
Z DC c
MOVLW к Загрузить константу k в рабочий регистр W W<=(k) IMM - - -
MOVLW f Загрузить содержимое рабочего регистра W в регистр общего назначения f (0 < f < 31) f<=(W) DIR - - -
MOVF f,d При d=0 загрузить содержимое регистра общего назначения f в рабочий регистр W. При d=1 перегрузить f в f. Имеет смысл использовать эту команду для проверки f на 0 (0 < f < 31) W<=(f) f4=(f) DIR DIR
OPTION Загрузить содержимое регистра W в регистр OPTION QPTION <= (W) INH - - -
TRIS f Загрузить содержимое регистра W в регистр TR IS (5 < f < 7). При f=5 адресуется TRISA, при f=6 адресуется TRISB TRIS <= (W) INH — — —
SWAPF f,d Содержимое младшей и старшей тетрады регистра общего назначения f меняются местами и результа т загружается в рабочий регистр W при d=0 или в f при d=1 (0_< f < 31) DIR
Таблица 4.53
Арифметические команды
Мнемокод Операция Выполняемое действие Способ адресации Влияние на признаки
z DC c
ADDWF f,d Сложить содержимое рабочего регистра W с содержимым регистра общего назначения f. Результат поместить BWnpnd=0 илив(приб=1 (0<f <31) W <= (W) + (f) f <= (W) + (f) DIR i i i
SUBWF f,d Вычесть содержимое рабочего регистра W из содержимого регистра общего назначения f. Результат поместить в Wnpnd=0nnHBfnpnd=1 (0_<f<31) W <= (f) - (W) f4=(f)-(W) DIR J
INCF f,d Инкремент регистра общего назначения f. Результат поместить в W при d=0 или в f при d=1 (0 <J<_31) W <= (f) + 1 f *= (f)+1 DIR t - -
DECF f,d Декремент регистра общего назначения f. Результат поместить в W при d=0 или в f при d=1 (0 <J <J31) W <= (f) - 1 f <= (f) -1 INH — —
434
СЕМЕЙСТВО МК НС08 ФИРМЫ «MOTOROLA»
Таблица 4.54
Логические команды и команды сдвигов
Мнемокод Операция Выполняемое действие Способ адресации Влияние на признаки
z DC c
ANDLW к Логическое «И» содержимого рабочего регистра W и константы к W <= (W) & к IMM t - -
IORLW к Логическое «ИЛИ» содержимого рабочего регистра W и константы к W <= (W) I к IMM I - -
XORLW к Логическое исключающее «ИЛИ» содержимого рабочего регистра W и константы к W <= (W) © к IMM t - -
ANDWF f,d Логическое «И» содержимого рабочего регистра W и регистра общего назначения f (0 < f <_31) W <= (W) & (f) f <= (W) & (f) IMM I - -
IORWF f,d Логическое «ИЛИ» содержимого рабочего регистра W и регистра общего назначения f (0 <J<_31) w <= (W) I (f) f<=(W)|(f) IMM i - -
XORWF f,d Логическое исключающее «ИЛИ» содер жимого рабочего регистра W и регистра общего назначения f (0 <f < 31) W <= (W) © к W<=(W)ffik IMM t — —
CLRW Очистить (установить в «0») содержимое ребочего регистра W W<=0 INH i - -
CLRF f Очистить (установить в «0») содержимое регистра общего назначения f (Q<1<31) f <=0 i - -
COMF f,d Инверсия содержимого регистра общего назначения f (0_<f<31) W<=f f<=f DIR - -
RLF f,d Сдвиг влево через перенос содержимого регистра общего назначения f. Результат сохранить в W при d=0 или в f при d=1 (0 < f < 31) для n = 0...6 W) 4= (C) (C) <= (f7) DIR — I —
RRF f,d Сдвиг вправо через перенос содержимого регистра общего назначения f. Результат сохранить в W при d=0 или в (при d=1 (0_< f_< 31) (W <=((„.,) для п = 0...6 (f7/Wz) <= (C) (C) <= (f„) IMM - I
Таблица 4.55
Команды битового процессора
Мнемокод Операция Выполняемое действие Способ адресации Влияние на признаки
Z DC с
BCF f,d Установить в 1 бит с номером d в регистре общего назначения f (0<f<31); (0<d<7) fd *= 1 DIR - - -
BSF f,d Установить в 0 бит с номером d в регистре общего назначения f (0<f <31), (0 < d < 7) fd <= 0 DIR - - -
435
8-РАЗРЯДНЫЕ МИКРОКОНТРОЛЛЕРЫ
Продолжение табл. 4.55
Мнемокод Операция Выполняемое действие Способ адресации Влияние на признаки
Z DC c
BTFSS f,d Пропустить команду, если бит d в регистре общего назначения f равен «1» (0 < f < 31), (0 < d < 7) (PC) <= (РС) +2 если fd - 1 (PC) <= (PC) +1 если fd = 0 DIR — — -
BTFSC f,d Пропустить команду, если бит d в регистре общего назначения f равен «0» (0 < f < 31), (0 < d < 7) (PC) 4= (PC) +2 если fd - 0 (PC) 4= (PC) +1 если fd = 1 DIR — — —
Таблица 4.56
Команды управления ходом вычислительного процесса
Мнемокод Операция Выполняемое действие Способ адресации Влияние на признаки
Z DC c
GOTOk Перейти по адресу k (0 < k < 511). Младшие 9 бит адреса загружаются в программный счетчик из кода команды. Старшие 2 бита адреса загружаются в РС из регистра STATUS (03h) РС8_0^к РС10.9<= STATUS^ DIR
CALL k Вызов подпрограммы с адресом к (0< к <255). Младшие 8 бит адреса загружаются в РС из кода команды. Старшие 2 бита адреса загружаются в РС из регистра STATUS (03h), бит РС8 устанавливается в «0» РСм<=к РСа<=0 РС,М*= STATUS^ DIR
RETLWk Возврат из подпрограммы с загрузкой константы к в рабочий регистр W PC <= (TOS) W<= к IMM - - -
NOP Пустая операция. Счетчик команд РС увеличивается на единицу PC 4= (PC) + 1 INH - - -
INCFSZ f.d Увеличить на единицу содержимое регистра f. Результат сохранить в W при d=0 или в f при d=1. Пропустить команду, если результат операции равен «0» (0 < f < 31) W <= (f) + 1 f <= (f) +1 PC <= (PC) + 2 если результат=0 PC <= (PC) + 1 если результата DIR
DECFSZ f,d Вычесть единицу из содержимого регистра f. Результат сохранить в W при d=0 или в f при d=1. Пропустить команду, если результат операции равен «0» (0 < f < 31) W <= (f) - 1 f<=(f)-1 PC <= (PC) + 2 если результат=0 PC <= (PC) + 1 если результата DIR
436
ПРИНЦИПЫ ПОСТРОЕНИЯ ОТЛАДОЧНЫХ СРЕДСТВ ДЛЯ 8-РАЗРЯДНЫХ МК
Таблица 4.57
Команды управления режимами МК
Мнемокод Операция Выполняемое действие Способ адресации Влияние на признаки
Z DC с
CLRWDT Сброс сторожевого таймера - INH - - -
SLEEP Переход в режим малого потребления - INH - - -
4.5. ПРИНЦИПЫ ПОСТРОЕНИЯ ОТЛАДОЧНЫХ СРЕДСТВ ДЛЯ 8-РАЗРЯДНЫХ МК
На основе 8-разрядных МК выполняются, как правило, одноплатные (т. е. расположенные на одной монтажной плате) встраиваемые микропроцессорные системы. Каждая такая система при проектировании должна пройти не только этапы разработки алгоритма работы, выбора элементной базы, проектирования аппаратных средств и прикладной программы управления, но и этапы совместной отладки аппаратной и программной составляющих, как в условиях автономной работы, так и совместно с объектом управления в реальном масштабе времени.
Технология процесса отладки в значительной степени определяет время поиска неисправностей на аппаратном, программном и алгоритмическом уровнях, т. е. время получения работоспособного опытного экземпляра разрабатываемого изделия. Поэтому технология отладки должна быть выбрана еще на этапе проектирования аппаратной и программной части микропроцессорного контроллера с учетом особенностей конечного изделия. Более того, особенности процесса отладки должны быть учтены при разработке аппаратных и программных решений.
В настоящее время для 8-разрядных МК выпускаются следующие типы отладочных средств:
Программные симуляторы. Представляют собой программно-логическую модель МК на персональном компьютере. Позволяют загрузить файл кода разработанной программы управления в память МК и исполнить любой фрагмент этой программы, наблюдая за изменением состояния любого программно доступного ресурса МК. Современные симуляторы обладают полноэкранным графическим интерфейсом пользователя, предоставляя разработчику программного обеспечения возможность одновременного контроля в процессе выполнения программы за изменением содержимого регистров и ячеек памяти. Симулятор имитируют работу не только процессорного ядра, но и всех периферийных модулей. Причем при отладке программы по шагам остановка в контрольной точке эквивалентна останову системы тактирования МК. Вследствие этого одновременно с остановкой программы «приостанавливают» работу и все периферийные модули. При дальнейшем прогоне программы работа периферийных модулей возобновляется с того состояния, в котором они были «приостановлены». Именно такой режим работы наиболее удобен для наблюдения за процессом реализации микроконтроллером управляющей программы. Но именно этот режим обычно не достижим в аппаратных средствах отладки (схемных эмуляторах и отладочных платах). Дело в том, что для наблюдения за состоянием ресурсов реального МК необходимо передавать это состояние в персональный компьютер с целью отображения на экране дисплея. Такую передачу осуществляет специальная программа монитора отладки, которую продолжает исполнять реальный
437
8-РАЗРЯДНЫЕ МИКРОКОНТРОЛЛЕРЫ
МК после останова в контрольной точке тестируемой программы. Выполнение любой программы возможно только при работающей системе тактирования. Следовательно, после останова тестируемой программы в контрольной точке все периферийные модули МК продолжают работать. В результате совокупное состояние периферии МК перестает соответствовать предполагаемому состоянию в ходе непрерывного выполнения тестируемой программы.
С точки зрения современной терминологии, программный симулятор можно охарактеризовать как «виртуальный МК». Алгоритмы такого «виртуального МК» полностью совпадают с алгоритмами работы реальной микросхемы, но при этом имеются широкие дополнительные возможности по вмешательству в процесс исполнения тестируемой программы управления. Именно поэтому симуляторы следует использовать на начальном этапе отладки программного обеспечения. Кроме того, поскольку реального МК на этапе программной симуляции просто не существует, то и ограничений в использовании ресурсов МК, связанных с обслуживанием процесса отладки, тоже нет. Таким образом, все ресурсы (правда, виртуальные), которые могут быть использованы в проекте, предоставлены в распоряжение пользователя.
Основной недостаток программного симулятора - невозможность подключения реальных физических источников входной информации и невозможность формирования реальных выходных сигналов для управления объектом. Поэтому с помощью программного симулятора можно проверить лишь правильность исполнения микроконтроллером программы управления, но нельзя проверить работоспособность аппаратной части проектируемого одноплатного контроллера и, как следствие, достижение управляемым объектом требуемых технических характеристик.
Целесообразность этапа моделирования на программном симуляторе определяется также тем фактом, что его можно проводить на самой ранней стадии работы над проектом, когда аппаратная часть находится еще в стадии проектирования.
Внутрисхемные симуляторы. Позволяют провести отладку программного обеспечения и аппаратной части разрабатываемого контроллера. При этом электрические характеристики выходных и входных сигналов МК полностью идентичны реальным характеристикам, но программа управления работает в замедленном масштабе времени.
Набор внутрисхемного симулятора включает простую плату аппаратных средств и комплект программного обеспечения для персонального компьютера. Обмен данными между персональным компьютером и платой внутрисхемного симулятора осуществляется в большинстве случаев посредством интерфейса RS-232. Основным элементом платы внутрисхемного симулятора является реальный физический МК. Однако конкретная модель этого замещающего МК не обязательно совпадает с моделью целевого МК (т. е. того МК, на основе которого ведется разработка устройства управления). Периферийные модули замещающего МК идентичны модулям целевого МК, а число линий портов ввода/вывода замещающего МК может превышать аналогичное число целевого МК. Эти «лишние» линии используются для обмена с персональным компьютером. Выводы замещающего МК, полностью совпадающие по функциональному назначению с выводами целевого МК, выведены на разъем с цоколевкой последнего. Персональный компьютер имитирует программно-логическую модель целевого МК, включая алгоритмы работы периферийных модулей. Отлаживаемая прикладная программа также, как и в программном симуляторе, выполняется внутренними средствами персонального компьютера. Связь с замещающим МК осуществляется только в случае необходимости ввода или вывода данных. Под управлением программы монитора, которая записана в ПЗУ замещающего МК, сформированные в персональном компьютере выходные воздействия поступают на соответствующие выводы замещающего МК, а затем на одноименные контакты разъема целевого МК. Или состояния входов целевого МК считываются со входов замещающего
438
ПРИНЦИПЫ ПОСТРОЕНИЯ ОТЛАДОЧНЫХ СРЕДСТВ ДЛЯ 8-РАЗРЯДНЫХ МК
МК и передаются в персональный компьютер. При подключении разрабатываемого изделия к разъему целевого МК создается полная иллюзия работы под управлением целевого МК, но в замедленном по отношению к реальному масштабе времени. Отсюда и название - «симулятор».
Главное преимущество внутрисхемных симуляторов: возможность совместной отладки аппаратной и программной частей изделия, а также возможность совместной с объектом управления отладки при сохранении доступа разработчика ко всем внутренним ресурсам МК. Главный недостаток - замедленный масштаб времени при исполнении алгоритма управления. Поэтому отладку с использованием внутрисхемных симуляторов следует применять в тех случаях, когда время реализации алгоритма управления заведомо превышает требования объекта управления. Например, если МК в составе домашнего термометра начнет выполнять программу в замедленном темпе, изменится лишь время вывода значения измеренной температуры на экран индикатора, человек при этом вряд ли заметит эти изменения на глаз. Задачи, которые не требуют предельного быстродействия, обычно реализуются на основе сравнительно простой элементной базы 8-разрядных МК. Поэтому внутрисхемные симуляторы выпускаются для МК в корпусах с 16, 20, 28 и максимум с 40 выводами. Для более сложных МК с большим набором периферийных модулей следует использовать средства отладки, работающие в реальном масштабе времени.
Отладочные платы, оценочные модули. Позволяют провести отладку программного обеспечения и аппаратной части разрабатываемого микропроцессорного контроллера в реальном масштабе времени. Исполнение отлаживаемой программы управле- , ния осуществляет реальный МК, полностью идентичный целевому микроконтроллеру. Исполнение программы между точками останова происходит в реальном масштабе времени. Поэтому как электрические, так и временные характеристики входных и выходных сигналов МК полностью идентичны характеристикам целевого МК на плате конечного изделия.
Средство отладки, именуемое отладочной платой или оценочным модулем (англоязычная терминология - evaluation board), представляет собой комплекс из одноплатного контроллера и программного обеспечения для персонального компьютера. Микропроцессорный контроллер выполнен на основе БИС МК, который принадлежит к тому же семейству, что и целевой МК. Желательно, чтобы целевой МК был как можно ближе к модели МК отладочной платы. Как правило, рассматриваемый класс средств отладки выполняется на основе МК с открытой архитектурой, т. е. на основе МК, которые имеют внешние магистрали адреса и данных и допускают подсоединение внешней памяти. Аппаратные средства отладочной платы включают БИС МК, БИС памяти программ двух типов (ПЗУ и ОЗУ), минимальный набор типовых периферийных средств (простейшая клавиатура, несколько светодиодов) и последовательный интерфейс для связи с персональным компьютером. В ПЗУ размещаются программа обмена с персональным компьютером и программа монитора отладки. При включении питания отладочной платы запускается программа монитора отладки, которая реализует функции:
• загрузки программного кода по последовательному интерфейсу из персонального компьютера в ОЗУ отладочной платы;
• загрузку регистров центрального процессора требуемыми значениями под управлением оператора персонального компьютера;
• запуск программы из ОЗУ на исполнение в автоматическом режиме или с остановом по контрольным точкам;
• передачу в персональный компьютер состояния регистров и ячеек памяти МК после останова в контрольной точке.
439
8-РАЗРЯДНЫЕ МИКРОКОНТРОЛЛЕРЫ
Под управлением монитора отладки в память отладочной платы из персонального компьютера загружается исполняемый код прикладной программы. Затем эта программа управления выполняется в любом желаемом режиме: по шагам, с остановом по контрольным точкам, в автоматическом режиме. В моменты останова прикладной программы управление передается монитору отладки, который пересылает в персональный компьютер состояние внутренних программно доступных регистров МК и ячеек памяти для отображения их состояния на экране дисплея.
Несомненным преимуществом такого решения является тот факт, что фрагменты прикладной программы или эта программа целиком могут быть выполнены в реальном масштабе времени. Поэтому под управлением отладочной платы может непосредственно работать управляемый объект. Недостатком отладочных плат является тот факт, что часть ресурсов МК должна быть задействована для выполнения программы монитора отладки и не может быть использована разработчиком при моделировании прикладной программы. Так, для реализации отладочного режима обязательно будут использованы встроенный модуль контроллера асинхронного последовательного интерфейса, некоторое количество ячеек ОЗУ данных, наиболее вероятно использование одного таймера.
Ряд МК (например, семейство НС11 фирмы «Motorola») выпускается со встроенной программой загрузки программного кода по последовательному интерфейсу. Эта программа запускается сразу после включения напряжения питания БИС МК, если на некоторые входы параллельных портов подана оговоренная в техническом описании комбинация нулей и единиц. В англоязычной терминологии эта программа носит название «boot loader». Тогда эта программа используется в отладочном модуле для загрузки из персонального компьютера во внешнее ОЗУ программы монитора отладки. Такое решение упрощает задачу разработчика отладочных средств, поскольку БИС внешнего ПЗУ на плате отладочного модуля теперь может отсутствовать, а часть необходимого программного обеспечения для организации отладки уже имеется в готовом виде. Однако основной недостаток рассматриваемого способа отладки не устраняется: по-прежнему часть ресурсов МК «отнимается» у разрабатываемой программы управления для реализации программы отладочного монитора.
Схемные эмуляторы. Позволяют провести отладку программного обеспечения и аппаратной части разрабатываемого микропроцессорного контроллера в реальном масштабе времени. Исполнение отлаживаемой программы управления осуществляет замещающий МК, полностью идентичный целевому микроконтроллеру. Исполнение программы между точками останова происходит в реальном масштабе времени. Поэтому как электрические, так и временные характеристики входных и выходных сигналов МК полностью идентичны характеристикам целевого МК. Связь с персональным компьютером, управление режимами отладки возложены на другой МК, который входит в состав аппаратных средств платы схемного эмулятора. Поэтому при отладке разрабатываемой программы разработчик не имеет ограничений в использовании внутренних ресурсов замещающего МК. Выводы замещающего МК выведены на разъем, который посредством гибкого высокочастотного кабеля со специальной переходной головкой соединяется с розеткой целевого МК на плате разрабатываемого изделия. Такая организация позволяет производить отладку разработанных аппаратных средств совместно с объектом управления при реализации сложных алгоритмов управления в реальном времени.
Схемный эмулятор является почти идеальным средством отладки. Но и он обладает недостатками:
• во-первых, конструкция с гибким высокочастотным кабелем не позволяет встраивать его в конструктив конечного изделия;
440
ПРИНЦИПЫ ПОСТРОЕНИЯ ОТЛАДОЧНЫХ СРЕДСТВ ДЛЯ 8-РАЗРЯДНЫХ МК
• во-вторых, высокочастотный кабель не может работать в условиях сильных электромагнитных помех, поэтому невозможна отладка систем управления силовыми полупроводниковыми преобразователями;
• в третьих, схемные эмуляторы дороги и не всегда оправданы в применении с экономической точки зрения.
Внутрисистемное программирование и отладка. Большинство современных 8-раз-рядных МК имеют закрытую архитектуру, т. е. на их основе невозможно выполнить отладочную плату или плату развития по описанному выше принципу. Но отладочные средства, которые могут работать в реальном времени и по возможности лишены недостатков схемного эмулятора, крайне необходимы. Задача построения таких средств решается с использованием специальных режимов работы МК и при наличии в составе МК многократно перепрограммируемой памяти программ типа FLASH или EEPROM.
Примером могут служить МК семейства НС08 фирмы «Motorola». Все МК этого семейства кроме пользовательского режима работы, в котором выполняется прикладная программа управления, имеют вспомогательный отладочный режим работы (Monitor mode). Этот режим позволяет организовать «диалог» МК с персональным компьютером верхнего уровня с целью отладки программ управления и выполнения операций стира-ния/программирования областей резидентной памяти типа FLASH или EEPROM.
При переходе МК в отладочный режим работы аппаратные средства автоматически подменяют векторы сброса и программного прерывания. В результате после сброса по внешнему сигналу на входе RST счетчик адреса МК загружается начальным адресом программы монитора отладки. Эта программа располагается в специальной области памяти, которая не является частью адресного пространства памяти программ МК (см. рис. 4.45). Прошивка монитора отладки осуществляется на этапе производства. Пользователь может либо активизировать эту программу посредством перевода МК в отладочный режим работы, либо не использовать эту программу вообще.
Программа монитора отладки содержит в себе подпрограмму драйвера обмена по однопроводной двунаправленной линии и подпрограмму выполнения шести команд отладки, которые поступают в МК по этому однопроводному интерфейсу. С использованием команд отладки может быть создано специальное программное обеспечение, которое позволит выполнить следующие действия:
• если прикладная программа управления уже загружена в МК каким-либо образом, то запустить эту программу на выполнение с заданного адреса и, используя встроенный в МК модуль прерываний по контрольным точкам BRAKE08, остановить ее в желаемой точке;
• загрузить в ОЗУ МК фрагмент разрабатываемой прикладной программы и запустить ее на выполнение: с остановкой по контрольной точке или без нее, по желанию пользователя;
• передать в компьютер верхнего уровня состояние регистров центрального процессора и ячеек памяти после остановки в контрольной точке;
• загрузить в ОЗУ МК по однопроводному интерфейсу программу стирания/программи-рования FLASH или EEPROM ПЗУ и, передавая коды прикладной программы или таблиц данных порциями, осуществить программирование резидентной памяти МК объемом вплоть до 64 Кбайт.
Все перечисленные действия, за исключением последнего, являются типовыми режимами работы средства отладки МП системы. Таким образом, наличие в МК семейства НС08 отладочного режима работы позволяет перевести задачу создания простых средств отладки в плоскость создания программного обеспечения для процесса отладки. Такое
441
8-РАЗРЯДНЫЕ МИКРОКОНТРОЛЛЕРЫ
программное обеспечение должно быть разработано как для МК, так и для персонального компьютера. Однако это программное обеспечение полностью инвариантно к прикладной задаче управления.
Минимальные ограничения, которые накладывает отладочный режим на аппаратные и программные ресурсы МК, с одной стороны, и универсальность резидентного программного обеспечения для отладки и программирования, с другой стороны, являются весомыми предпосылками для проектирования аппаратной части встраиваемой МП-си-стемы с несколько избыточной схемотехникой. Такая схемотехника обеспечит работу МК в рабочем режиме в процессе эксплуатации изделия и в отладочном режиме - в процессе отладки изделия. Если в разработке используется МК с FLASH-памятью программ, то такой МК можно будет программировать прямо на плате конечного изделия без использования специальных средств программирования. МК, которые обеспечивают такую возможность, принято называть программируемыми в системе (англоязычный термин - «In system programmable»).
Возможность многократного программирования FLASH-памяти программ позволяет при работе в отладочном режиме записать вариант отлаживаемой программы в резидентную память МК, а затем под управлением встроенного монитора запустить ее с остановкой в желаемых точках. Таким образом получается, что устройство отладки реального времени уже существует в самом МК, т. е. прикладная программа может отлаживаться прямо на плате конечного изделия, без дополнительных аппаратных средств отладки, с применением только специального программного обеспечения для персонального компьютера.
Рассматриваемый принцип организации отладки в настоящее время является самым перспективным для 8-разрядных МК. Поэтому большинство новых моделей МК уже имеют в своем составе аппаратные средства внутрисхемной отладки.
ГЛАВА 5
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
5.1. ОБЩИЕ ПОНЯТИЯ
5.1.1. СЕМИУРОВНЕВАЯ МОДЕЛЬ УПРАВЛЕНИЯ В СЕТЯХ
К сновным требованиям, которым должна удовлетворять организация вычислительных сетей:
• открытость, т. е. возможность подключения дополнительного оборудования и каналов связи без изменения технических и программных средств существующих компонентов;
• гибкость, т. е. сохранение работоспособности при изменении структуры в результате выхода из строя какого-либо оборудования, допустимость изменения типов аппаратуры или каналов связи, а также возможность подключения к общей сети станций разного типа;
• эффективность, т. е. обеспечение требуемого качества обслуживания пользователей при минимальных затратах.
Указанные требования реализуются за счет модульного принципа организации управления процессами в сети. Для обеспечения гибкости, открытости и эффективности сети управление в сетях реализуется по многоуровневой схеме. За каждым уровнем закреплены программные и аппаратные модули, которые реализуют определенные функции обработки и передачи данных.
Главные принципы разделения модулей на уровни перечислены ниже:
• Каждый уровень реализует определенные сетевые задачи обработки и передачи данных и обеспечивает определенный набор услуг для уровня, расположенного в структуре над ним. Совокупность правил взаимодействия объектов одноименных уровней называется протоколом.
• Уровень N взаимодействует только с уровнями N - 1 и N + 1.
• Функции соседних уровней не перекрываются и не совпадают.
• Многоуровневая организация управления процессами в сети приводит к необходимости модифицировать на каждом уровне передаваемые сообщения применительно только к функциям, реализуемым на этом уровне. При передаче данных между уровнями каждый из уровней добавляет некоторую служебную информацию (заголовок и концевик для данных, которые поступили от верхнего уровня управления), адресованную другим одноименным уровням управления в сети и не рассматриваемую уровнями с другими названиями. На каждом этапе число передаваемых данных возрастает. И каждый более низкий уровень рассматривает всю информацию, поступившую от более высокого уровня, как данные. Чем больше создается уровней управления, тем гибче управление, но тем больше аппаратные затраты и время обработки. Гибкость организации и простота реализации достигаются за счет того, что обмен данными допускается только между объектами одного уровня.
• Большинство сетевых устройств имеют в своем составе реализацию от одного до N уровней управления.
• Границы между уровнями располагаются таким образом, чтобы взаимовлияние смежных уровней было минимальным и изменения внутри одного уровня не требовали перестройки других, т. е. работа уровня N не зависит от функционирования верхних и нижних уровней управления.
443
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
С появлением необходимости объединения разнотипных ЭВМ возникла острая потребность в разработке некоторой идеологической концепции, которая позволила бы установить универсальные правила взаимодействия разнотипных машин. Таким образом, для того чтобы машина смогла войти в сеть, ее аппаратное и программное обеспечение должно удовлетворять некоторому набору универсальных соглашений, точное выполнение которых гарантирует возможность взаимодействия различных машин.
По линии Международной организации по стандартизации ISO (International Standart Organization) принята в 1977 г. и рекомендована 7-уровневая модель OSI (Open System Interconnection).
Модули расположены по уровням 1-7. Первый нижний уровень взаимодействует с передающей средой, а седьмой верхний - отвечает за общение с пользователем. OSI содержит следующие уровни (рис. 5.1):
1) физический уровень;
2) канальный уровень;
3) сетевой уровень;
4) транспортный уровень;
5) сеансовый уровень;
6) представительский уровень;
7) пользовательский (прикладной) уровень.
Физический уровень осуществляет управление физическим каналом связи (подключение, поддержание и разрыв физического соединения), параметрами физического канала связи и формированием электрических сигналов, представляющих передаваемые данные. Уровень контролирует передачу потока битов, в виде которого передаются данные, через среду передачи. Обеспечивает восстановление канала при отказах электрической цепи. Уровень определяет; I
• параметры физической среды передачи;
• механизм кодирования битов; , h
Рис. 5.1. Семь уровней эталонной модели взаимосвязи открытых систем
444
ОБЩИЕ ПОНЯТИЯ
• механизм передачи данных и способ синхронизации битов в канале;
• физическую топологию сети (шина, кольцо, звезда, сетка);
• тип соединения: точка с точкой (point to point) или многоточечное (multipoint);
• параметры аналоговых и цифровых сигналов (уровни напряжений, фронты сигналов, амплитуды сигналов, фазы, частоты);
• тип кабеля и способ передачи по нему (baseband - один канал в кабеле, broadband -несколько передающих каналов в одном кабеле);
• тип мультиплексирования в канале связи: частотное, временное, статистическое временное;
• тип передачи (асинхронная или синхронная, дуплексная или полудуплексная).
Канальный уровень обеспечивает управление каналом связи и передачу данных по физическому уровню, формирует кадры данных, следит за порядком подключения станций к сети.
Уровень определяет:
• логическую топологию сети;
• тип доступа (конкуренция, передача маркера, опрос и т. д.);
• передачу кадров по физическому пути;
• организацию битов в логические группы (или кадры - frames);
• синхронизацию передачи (указывает начало и конец кадра);
• синхронизацию кадра (определяет расположение и размер полей в кадре);
• обнаружение ошибок передачи кадров (потеря кадра, ошибка в заголовке, в контрольной сумме) и повторяет передачу кадра с ошибкой;
• разбивку длинного сообщения по кадрам, нумерацию кадров и контроль корректности обмена нумерованными кадрами;
• гарантирует, что ни один кадр не пропадет;
• адресует кадры к нужной машине, производит идентификацию (адресацию) станций в рамках одной сети;
• максимизирует пропускную способность сети.
Сетевой уровень управляет передачей данных через сеть, осуществляет выбор маршрута передачи и его реализацию. Уровень обеспечивает установление, поддержание и разъединение логических (виртуальных) сетевых соединений между двумя пользователями, не информируя их о том, по каким физическим линиям идет их обмен. Сетевой уровень в отличие от канального описывает методы передачи информации между независимыми сетями через коммутаторы, адресацию сетевого уровня и алгоритмы маршрутизации. Уровень обеспечивает:
• определение типа соединения (коммутация цепей - circuit switching, коммутация сообщений - message switching, коммутация пакетов - packet switching);
• адресацию в рамках нескольких объединенных сетей;
• управление маршрутизацией пакетов по логическим каналам между машинами, но без оптимизации нагрузок по маршрутам;
• разбиение сообщений на пакеты для уменьшения времени их доставки и уменьшения требований к буферам. Каждый пакет имеет адрес назначения и порядковый номер; существуют пакеты с данными и управляющие пакеты (запрос на соединение или разъединение, готовность приема, подтверждение соединения); в процессе передачи последовательность пакетов может быть нарушена, и уровень обеспечивает, что они будут доставлены пользователю в том порядке, в каком они были посланы;
• применение алгоритмов исследования маршрутов в сети; •
• обход поврежденных узлов по альтернативным маршрутам (маршрутизацию);
446
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
• управление потоками сообщений с целью избежания заторов трафика и нехватки буферов для приема и сборки пакетов;
• восстановление при неполадках в виртуальной цепи.
Транспортный уровень обеспечивает оптимизацию использования ресурсов сети и передачи пакетов в сети, выбирая наиболее выгодные маршруты и учитывая все заявки и ресурсы, имеющиеся в системе. Уровень использует динамическую маршрутизацию, при этом различные пакеты одного сеанса могут следовать разными маршрутами для уменьшения заторов и выравнивания интенсивности трафика. При необходимости могут использоваться параллельные маршруты для передач одного и того же пакета.
Уровень гарантирует:
• отсутствие пропаданий (потерь) пакетов и дублирование при обработке одинаковых пакетов;
• оптимизацию маршрута передачи;
• доставку сообщений в порядке их отправления, отправку извещения о невозможности передачи или выполняет повторную передачу при возникновении ошибок;
• контроль ошибок в средствах доступа к сети;
• предотвращение перегрузок ресурсов передач машинами, блокирующими других пользователей.
Все уровни 1 - 4 предоставляют транспортную услугу, т. е. обеспечивают передачу сообщений между станциями, не обрабатывая их.
Сеансовый уровень стандартизирует процессы установления, поддержки и завершения сеанса обмена. В момент установления сеанса определяется правило ведения диалога и производится администрация сеанса. Таким образом, уровень занимается организацией и синхронизацией диалога.
Диалог может быть следующих типов: однонаправленный (один передает, а другие только принимают), полудуплексный (устройство может передавать и принимать, но в текущий момент времени передача идет в одном направлении по одному каналу) и полнодуплексный (одновременная передача в обоих направлениях по двум каналам связи).
Уровень выполняет:
• обмен информацией о протоколах диалога, который будет использован в работе;
• администрирование сеанса: проверку login-имени и паролей; установление связи с узлом, получение его согласия на сеанс; определение необходимого сервиса соединения; проверку наличия на узле необходимых для взаимодействия ресурсов; контроль и восстановление протокольных ошибок и ошибок выполнения функций; продолжение сеанса без потерь в случае сбоя или его завершение; определение условий окончания сеанса.
Представительский уровень обеспечивает представление данных пользователя в унифицированной форме, понятной для сетевого программного обеспечения. Уровень может осуществлять следующие виды трансляций для обеспечения работы компьютеров разного типа в сети:
• битов (если компьютеры в сети имеют разное - 7- или 8-битовое представление данных);
• байтов (если компьютеры в сети имеют разный порядок выдачи байтов в канал связи:
т. е. первым может выдаваться или старший, или младший бит, кроме того, на стороне абонента могут по разным правилам определяться младший и старший значащие биты в слове);
• символов (если компьютеры в сети имеют разное представление символов, отличное от ASCII);
• файлов (если компьютеры в сети работают с разными локальными ОС, в которых различаются форматы представления файлов MS DOS-UNIX).
446
ОБЩИЕ ПОНЯТИЯ
Основные задачи уровня:
• пользовательские данные делятся на группы сообщений, по отношению к которым будут применяться те или иные методы восстановления;
• пользовательские данные редактируются, перекодируются, шифруются, уплотняются и реорганизовываются в сеансовые сообщения;
• определяются форматы представления данных, используемых для связи пользовательского и сетевого ПО;
• выполняет контроль и восстановление при ошибках в прикладном ПО.
Прикладной уровень (уровень пользователя) обеспечивает доступ ПО пользователя к сетевому ПО. Поддержка команд пользователя или прикладных программ в «сетевой архитектуре». Уровень обеспечивает поддержку различных служб сервиса в сети:
• File service (обмен, хранение, создание резервных копий файлов);
• Print service (доступ к одному ресурсу от многих пользователей, управление очередями, разделение ресурсов и назначение приоритетов доступа к ним);
• Message service (электронные средства общения, контроль совместной работы в рабочих группах);
• Directory service (позволяет сетевым приложениям общаться с другими приложениями, не «задумываясь», где они находятся, на каком устройстве, и о маршрутизации к этому устройству);
• Application service (координируют деятельность ПО, запуская ее на соответствующем оборудовании, управляют специализированными серверами, повышают вычислительную мощность сети);
• Database service (управление базами данных, распределение БД, защита информации, координация территориально распределенных БД, управление способом доступа и временем доступа для клиентов, репликация содержимого БД).
Организация сетей также базируется на принципах многоуровневого управления. Создан специальный стандарт IEEE 802 (Institute of Electrical and Electronics Engineers), ориентированный на локальные сети, отличие заключается в том, что канальный уровень OSI разбивается на два подуровня:
• управление доступом к среде (Medium Access Controls, МАС) обеспечивает доступ станции к среде передачи, не мешая при этом другим станциям и учитывая особенности физического канала.
• управление логической связью (Logical Link Control, LLC) обеспечивает надежность передачи данных по сети, определяет порядок и способы проверок достоверности информации.
В узловых сетях каналы соединяют два узла, причем каналы не имеют на своем протяжении контактов с иными узлами. Так выглядят соединения «точка-точка». К узлу могут быть подключены несколько каналов. Узлы могут соединять и системы с разнородными протоколами. Типы узлов поясняет рис. 5.2.
Шлюз предназначен для соединения сетей, созданных по разным стандартам. Передача информации из одной сети в другую выполняется при помощи прикладных программ.
Маршрутизатор удобен, когда уровни 7, 6, 5 и 4 ЭМВОС одинаковые, для этих уровней маршрутизатор «прозрачен» благодаря тому, что на нижних трех уровнях происходит преобразование протоколов. Если к тому же и нижние уровни одинаковые, то маршрутизатор является узлом коммутации пакетов, выполняемой в соответствии с адресами назначения, записанными в заголовках пакетов.
Мост служит для соединения каналов различного типа, например моноканала с циклическим кольцом. При передаче через мосты преобразуется структура адресов пакетов
447
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
и, возможно, размеры кадров, для этого мост содержит память и хотя бы простейший процессор.
Коммутатор не имеет буферных памятей, физический процесс соединения реализуется электронной схемой.
Семиуровневая модель позволила улучшить понимание этапов подготовки пакетов, внутри которых передаются данные пользователя, а это позволило фирмам создать аппаратуру, обеспечивающую разные уровни системы и стыковку изделий разных фирм. Нередко в одном изделии объединены функции нескольких уровней. Наибольшую пользу модель принесла в области телекоммуникаций. Новейшие стандарты на вычислительные системы создаются так, чтобы один базовый стандарт охватывал возможно большее число уровней для достижения максимальной экономичности изделий и скомпонованных из них систем.
5.1.2. ФУНКЦИИ, РЕАЛИЗУЕМЫЕ КОММУНИКАЦИОННЫМ КОНТРОЛЛЕРОМ
Коммуникационные контроллеры позволяют подключать периферийное оборудование или компьютер к глобальным и локальным сетям. В основе коммуникационных контроллеров лежат коммуникационные каналы, которые настраиваются для работы на один из протоколов канального уровня, RISC-процессор, который управляет работой коммуникационных каналов, и физический интерфейс, который обеспечивает доступ к внешним трансиверам. Таким образом, коммуникационный контроллер реализует в полном объеме функции канального уровня управления и частично функции физического и сетевого уровней. На сетевом уровне в основном реализуется только одна функция - управление маршрутизацией пакетов по логическим каналам между машинами, но без оптимизации нагрузок по маршрутам. На физическом уровне контроллер выполняет подготовку данных к обмену и их кодирование, а адаптацию данных к конкретному кабелю и к конкретным электрическим сигналам выполняет внешний трансивер. Поскольку функции, которые связаны с непосредственным каналом связи (кабелем), реализуются внешней микросхемой трансивера, это позволяет обеспечить более гибкое и универсальное использование коммуникационных контроллеров.
448
ОБЩИЕ ПОНЯТИЯ
Отличительной особенностью коммуникационных МК является наличие в их составе специализированного скоростного коммуникационного сопроцессора с RISC-ядром, управляющего обменом данными по нескольким независимым каналам, поддерживающего практически все распространенные протоколы обмена и позволяющего гибко и эффективно распределять и обрабатывать последовательные потоки данных с временным разделением каналов (например, ИКМ и ISDN PRI). Среди многочисленных применений КМК можно выделить цифровые телефонные станции, абонентское и групповое оборудование ISDN, базовые станции сотовой связи, модемы, терминалы, мосты, маршрутизаторы, а также распределенные промышленные контроллеры и многие другие устройства.
Все КМК имеют похожую структуру, включающую центральный процессор (CPU), осуществляющий общее управление; коммуникационный процессорный модуль (СРМ), обрабатывающий последовательные данные, и модуль системной интеграции (SIM), упрощающий подключение памяти и внешних устройств. Обмен данными требует минимального участия CPU, функции которого сводятся, как правило, к обработке флагов окончания передачи и переустановке указателей - все остальные задачи по обработке протокола и управлению обменом автоматически выполняет интеллектуальный коммуникационный сопроцессор.
Функции, которые реализует физический интерфейс коммуникационных контроллеров:
• контроль за передачей потока битов;
• механизм кодирования битов;
• механизм передачи данных и способ синхронизации битов в канале;
• тип соединения: точка с точкой (point to point) или многоточечное (multipoint);
• тип мультиплексирования в канале связи: частотное, временное, статистическое временное; • тип передачи (асинхронная или синхронная, дуплексная или полудуплексная).
Функции, которые реализуют внешние трансиверы:
• подключение, поддержание и разрыв физического соединения; 'о
• определение параметров физического канала связи; -
• формирование электрических сигналов;
• восстановление канала при отказах электрической цепи;
• определение параметров физической среды передачи: физическая топология сети (шина, кольцо, звезда, сетка); параметры аналоговых и цифровых сигналов (уровни напряжений, фронты сигналов, амплитуды сигналов, фазы, частоты);
• тип кабеля и способ передачи по нему (baseband - один канал в кабеле, broad-band -несколько передающих каналов в одном кабеле).
В результате коммуникационный контроллер объединяет в себе большинство аппаратных функции семиуровневой модели управления. Это позволяет коммуникационным контроллерам находить широкое применение в различных сетевых устройствах, начиная от простейших сетевых карт, которые можно запрограммировать на любой из сетевых протоколов канального уровня, и до мостов и маршрутизаторов, которые можно использовать для объединения различных глобальных сетей.
5.1.3. СЕМЕЙСТВО КОММУНИКАЦИОННЫХ МИКРОКОНТРОЛЛЕРОВ МРС860
Наиболее высокую производительность и скорость передачи данных обеспечивают коммуникационные контроллеры семейства МРС8хх, использующие в качестве центрального процессора RISC-процессоры с архитектурой PowerPC (табл. 5.1). Базовой моделью этого семейства является контроллер МРС860 (PowerQUICC), который имеет произ-
449
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
Таблица 5.1
Параметры контроллеров семейства МРС860
Контроллер Ядро Производительность на частоте Рабочие частоты Размер кэш-памяти, байт
МРС860 PowerPC 33 MIPS/25 МГц, 52 MIPS / 40 МГц, 66 MIPS/50 МГц, 88 MIPS / 66 МГц 0-40 4 К - инструкций 4 К - данных
МРС860Р MPC860DP PowerPC 106 MIPS / 80 МГц 0-80 16 К - инструкций 8 К - данных
МРС860Т MPC860DT PowerPC 66 MIPS / 50 МГц 87 MIPS / 66 МГц 0-50 4 К - инструкций 4 К - данных
MPC860SAR PowerPC 66 MIPS/50 МГц 0-50 4 К - инструкций 4 К - данных
МРС823 PowerPC 99 MIPS/75 МГц 0-75 2 К - инструкций 1 К - данных
МРС855Т PowerPC 105 MIPS/80 МГц 0-80 4 К - инструкций 4 К - данных
водительность 53 MIPS при тактовой частоте 40 МГц и обеспечивает скорость обмена свыше 40 Мбит/с.
Контроллер семейства МРС860 состоит из нескольких основных модулей (рис. 5.3), объединенных внутренней 32-битной магистралью: высокопроизводительное встроенное ядро PowerPC, блок интеграции системы SIU (System Integration Unit), коммуникационный модуль СРМ (Communication Processor Module), а в некоторых модификациях - и модуль поддержки Fast Ethernet Module (FEM). Большинство внутренних модулей периферийного оборудования способны работать в режиме пониженного энергопотребления.
Контроллеры могут работать при питании 3,3 В и обеспечивать совместимость по уровням с ТТЛ логическими сигналами (+5 В). Контроллеры выпускаются в 357-контакт-ном корпусе Ball Grid Array (BGA) и только контроллер МРС823 выпускается в 256-контактном корпусе BGA.
Базовая модель коммуникационного RISC-контроллера МРС860 (рис. 5.4) имеет ряд модификаций. Модель MPC860EN обеспечивает возможность одновременного обслуживания четырех каналов связи с сетью Ethernet. Ряд моделей имеет сокращенное число каналов связи: MPC860DC содержит лишь два интерфейса SCC, a MPC860DE обслуживает только два канала связи Ethernet. Наиболее широкими возможностями обладает модель МРС860МН, которая, помимо связи с сетью Ethernet, обеспечивает обслуживание до 64 каналов связи типа HDLC, что позволяет реализовать широко используемый протокол цифровой сети ISDN PRI.
Контроллер МРС860Р (МРС860 Plus) - совместимая по контактам версия контроллера МРС860, в которой увеличен размер кэша инструкций с 4 до 16 Кбайт, размер кэша данных с 4 до 8 Кбайт. Размер двухпортовой памяти увеличен с 5 до 8 Кбайт, что позволило повысить производительность и гибкость использования коммуникационного процессора (рис. 5.5). Также контроллер МРС860Р может работать на тактовых частотах от 80 МГц и выше. Совокупность всех его вычислительных и коммуникационных свойств
450
ОБЩИЕ ПОНЯТИЯ
Рис. 5.3. Структура контроллера МРС860
делает его наиболее привлекательным для применения в сетях телекоммуникаций при построении маршрутизаторов. Объединив достоинства контроллеров MPC860SR и MPC860DT, контроллер МРС860Р поддерживает ATM-протокол, включая интерфейс UTOPIA, протокол Fast Ethernet стандарта 10/100BaseT, и QMC-протокол для реализации многоканальной обработки HDLC-кадров на одном SCC-канале.
Контроллеры MPC860T/MPC860DT. МРС860Т (DT) - это один из представителей семейства контроллеров МРС860 PowerQUICC, в котором к уже имеющимся возможностям МРС860 добавлена поддержка МАС-уровня (уровень доступа к среде 7-уровневой модели OSI) 10/100 Мбит/с Ethernet-протокола. Данный контроллер разработан для применения в сетевых приложениях и ориентирован на работу в сетях Fast Ethernet (рис. 5.6). Совокупность всех его вычислительных и коммуникационных свойств делает его наиболее привлекательным для применения в сетях телекоммуникаций при построении маршрутизаторов (рис. 5.7).
451
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
Рис. 5.4. Пример использования контроллера МРС860
Рис. 5.5. Структурная схема контроллера МРС860Р
452
ОБЩИЕ ПОНЯТИЯ
Рис. 5.6. Структурная схема контроллера МРС860Т
Рис. 5.7. Пример использования контроллера МРС860Т
453
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
Контроллер MPC860SAR - представляет собой расширенную версию базового контроллера МРС МРС860, внутренняя структура которого оптимизирована для работы с ATM-сетями (Asynchronous Transfer Mode) (рис. 5.8);
• удалена встроенная поддержка DSP-функций и вместо нее помещен АТМ-микрокод;
• часть внутренней двухпортовой памяти отводится для хранения таблиц соединений (Connection Table); размер этих таблиц определяется пользователем;
• внутренний таймер 4 используется как АРС-таймер контроля темпа передачи АТМ-ячеек;
• поддерживается до 4 ATM-каналов по линиям E1/T1/DS1 или ADSL при работе всех 4 SCC-контроллеров в последовательном режиме работы;
• если используется UTOPIA-интерфейс, то контроллер SCC4 не функционирует, так как его память параметров будет использована UTOPIA-интерфейсом; внешние выводы ЭСС4-контроллера частично используются для передачи данных UTOPIA-интерфейсом и для сигналов управления; большинство внешних сигналов UTOPIA-интерфейса мультиплексируются через контакты параллельного порта D, поэтому другие SCC-koh-троллеры будут ограничены в использовании своих сигналов через контакты порта D; таким образом, в режиме UTOPIA-интерфейса контроллер может поддерживать работу с 3 ATM-каналами (через последовательный режим контроллеров SCC1 - SCC3) и 1 UTOPIA-интерфейс.
• контроллер поддерживает до 32 виртуальных каналов, используя внутреннее адресное пространство двухпортовой памяти и до 64 К каналов во внешней памяти; в режиме расширенного канала число соединений, поддерживаемое ATM-контроллером, увеличивается с 32 до 65 535 каналов для приема и передачи; в этом режиме таблицы соединений RCT и ТОТ, размер которых больше 31 ячейки, размещаются во внешней памяти; при этом каналы с номерами от 0 до 31 доступны в нормальной двухпортовой памяти, а при работе с каналами, у которых номера больше 32, требуется ПДП-доступ к таблицам соединений во внешней памяти; скорость передачи в этом случае уменьшается в зависимости от выбранного соотношения числа каналов, описанных во внутренней памяти, и каналов, описание которых хранится во внешней памяти.
Средняя скорость передачи АТМ-ячеек для контроллера MPC860SAR при системной частоте 50 МГц составляет в последовательном режиме 20 Мбит/с и 60 Мбит/с при работе в режиме UTOPIA порта.
860SAR использует UTOPIA-интерфейс (рис. 5.9) как 8-разрядную двунаправленную шину данных UTPB[7-0], использующую обмен на уровне АТМ-ячеек и функционирующую на частотах до 25 МГц. UTOPIA-контроллер также управляет всеми интерфейсными сигналами. Для тактирования PHY-блока ATM-контроллер вырабатывает тактовый сигнал UTPCLK генератора UTOPIA-интерфейса. При возникновении возможности передачи (появился активный входной сигнал разрешения передачи TxCav) или получения ячейки (появился активный входной сигнал разрешения приема RxCav) интерфейс выдает запрос к процессору для начала обработки операций приема или передачи. Во время передачи UTOPIA-контроллер вырабатывает управляющие сигналы разрешения передачи ТхЕпЬ или приема RxEnb и следит за сигналом начала передачи ячейки (TxSOC), а также анализирует сигнал RxSOC в течение передачи ячейки.
860SAR поддерживает работу до 4 различных PHY-устройств в режиме UTOPIA Multi-PHY. Для управления MPHY-адресацией входные сигналы запроса шины PHY PHREQ (контакты РВ16 и РВ17, где РВ16 - MSB) и выходные сигналы выбора шины PHY PHSEL (контакты РВ20 и РВ21, где РВ20 - MSB) должны быть запрограммированы пользователем как сигналы параллельного порта ввода/вывода общего назначения.
454
ОБЩИЕ ПОНЯТИЯ
Рис. 5.8. Структурная схема контроллера MPC860SAR
PHY
MPC860SAR
Рис. 5.9. UTOPIA-интерфейс MPC860SAR
455
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
Контроллер позволяет работать с 53- и 64-байтными ATM-ячейками, а также может работать с постоянной скоростью передачи CBR (Constant Bit Rate), неопределенной скоростью передачи UBR (Unspecified Bit Rate) и подстраиваться под текущую скорость передачи канала ABR (Available Bit Rate). При использовании CBR-соединения сеть все время должна поддерживать ресурсы и скорость, выделенные при установлении соединения, а это не всегда эффективно. В случае ABR-соединения сеть может динамически изменять полосу пропускания, выделенную соединению, и тем самым адаптироваться к возникающей перегрузке. Механизм управления потоком ABR основан на ячейках управления ресурсами (RM-ячейки).
Типовой размер ATM-ячейки составляет 53 байта (4 байта заголовка ячейки (header), 1 байт НЕС контрольная сумма заголовка и 48 байт данных (payload)). Контроллер 860SAR поддерживает работу с 64-байтными расширенными ячейками, где дополнительные байты используются для передачи в заголовке ячейки служебной информации между АТМ-ком-мутаторами. Расширенные ячейки имеют формат: 0/4/8/12 байт расширенного заголовка, 4 байта стандартного заголовка и 48 байт данных. Поле НЕС удалено из формата ячейки, так как контроль информации при передачи данных между коммутаторами не требуется. Контроллер может работать с расширенными ячейками только при работе с UTOPIA-интерфейсом. Во время передачи расширенная информация заголовка берется из специальных полей буферного дескриптора BD и передается перед стандартным заголовком и полем данных. При приеме расширенной ячейки дополнительная информация из последней ячейки текущего соединения копируется в специальные поля буферного дескриптора.
Для включения контроллера MPC860SAR в работу с сетью ATM пользователь должен настроить канал SCC4 на работу в одном из двух режимов: UTOPIA-интерфейса или последовательного интерфейса. В обоих режимах ATM-контроллер поддерживает функции уровня адаптации AAL (работает с протоколами AAL0 и AAL5), функции подуровня сборки и реассемблирования SAR (Segmentation and Reassemly), а также реализует функции уровня ATM. При работе в режиме UTOPIA-интерфейса уровень ATM соединяется с подуровнем физического управления PHY напрямую через UTOPIA-интерфейс. При работе в режиме последовательного интерфейса ATM-контроллер также использует функции подуровня ТС (Transmission Convergence) и подключается к подуровню физического интерфейса PHY через схемы SCC-канала. Дополнительно при работе с любым интерфейсом контроллер выполняет функции сборки и разборки (функции подуровня SAR) пользовательских данных на пакеты (cells) ATM длиной по 48 байт.
Напомним, что в сетях ATM физический уровень PHY разбит на два подуровня: преобразования передачи (TC-Transmission Covergence) и адаптации к среде передачи (Physical Medium Dependent, PMD). Подуровень PMD отвечает за корректную передачу и получение битового потока в соответствующей среде передачи. Подуровень ТС отвечает за адаптацию к системе передачи, т. е. за прием ячеек с уровня ATM и упаковку их в соответствующий формат для передачи по уровню PMD. На уровне ТС производится выделение ячеек из битового потока, поступающего от PMD, вставка и подавление пустых ячеек в потоке данных с целью обеспечения приемлемой скорости передачи, генерация и проверка контрольной суммы НЕС для заголовка ячейки. Вычисление НЕС-суммы в дальнейшем будет использовано для синхронизации ячеек.
Уровень адаптации AAL (ATM Adaptation Layer) обеспечивает преобразование информации с верхних уровней управления ATM-сети в фиксированные ATM-ячейки и состоит из двух подуровней: подуровень сегментации и сборки SAR (Segmentation and Reassembly) и подуровень сходимости CS (Convergence Sublayer). Уровень адаптации позволяет установить требуемое качество сервиса для передаваемых данных (классы используемого трафика передачи, используемый тип скорости передачи). Каждому классу сервиса 456
ОБЩИЕ ПОНЯТИЯ
соответствует свой протокол - от AAL0 до AAL5. Основная задача уровня SAR - это преобразование данных верхних уровней управления в 48-байтные ATM-ячейки и наоборот. При работе с АА1_5-кадрами ATM-контроллер выполняет обработку всех служебных полей кадра, формирует/удаляет заголовок ATM-ячейки, обрабатывает поле контрольной суммы и сохраняет в буферах памяти только содержимое поля данных кадра (48 байт). При работе с AALO-кадрами (обычно длиной 52 байта = 48 байт данные и 4 байта заголовка) контроллер выполняет прозрачный прием и передачу ячеек без их обработки прямо из памяти контроллера (это так называемый протокол пользовательских ячеек AAL0, который позволяет ячейкам других AAL-протоколов быть переданными через данный коммуникационный контроллер), не анализируя содержимого ячейки и не добавляя (заполняя) служебных полей ячейки, полностью собранная пользователем ячейка берется из памяти при передаче и все поля принятой ячейки сохраняются в памяти. Подуровень CS выполняет функцию идентификации сообщений, синхронизацию с верхними уровнями управления, синхронизацию для различных классов сервиса, контроль и обработку ошибок.
При приеме ячеек контроллер вычисляет контрольную сумму НЕС заголовка принятой ячейки и сравнивает ее с контрольной суммой, указанной в поле НЕС заголовка принятой ячейки. Когда начинается прием ячеек, с целью оптимизации синхронизации ячеек через НЕС-образец ATM-контроллер блокирует (locked) рассмотрение поля данных ячейки, пока не будет проведено корректное выделение ячейки из потока. Если в 6-7 соседних принятых ячейках вычисленная и принятая контрольные суммы совпадают, то считается, что контроллер правильно произвел выделение ячейки из потока битов, т. е. провел процесс синхронизации ячеек (Cell Delineation).
В любом режиме работы контроллер темпа АРС (ATM расе controller) выполняет контроль темпа передачи. Работа блока АРС (рис. 5.10) контролируется коммуникационным процессором через таблицы соединений для передачи ТСТ и для приема RCT и АРС-таблицу, которые хранятся в двухпортовой памяти.
В таблицах соединений ТС (Connection table) хранится информация о конфигурации канала (размере его буферов приема и передачи, указателях на их расположение в памяти) и его текущих параметрах (указателях, флагах, временном значении переменных, текущем состоянии канала, размере последнего обработанного кадра). Внутренняя ТС-таблица, которая располагается в двухпортовой памяти, может содержать информацию о 32 каналах приема (RCT-таблица) и 32 каналах передачи (ТСТ-таблица). Если требуется обработка более 32 каналов, то используется внешняя ТС-таблица, которая располагается во внешней памяти. Каждая единица ТС-таблицы содержит 64 байта, а общее число единиц в ТС-таблице равно числу обслуживаемых каналов плюс один.
Рис. 5.10. Работа АРС при передаче в режиме UTOPIA-интерфейса
де
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
АРС-таблица расположена во внутренней двухпортовой памяти. Пользователь программирует число ячеек таблицы в соответствии с требуемыми параметрами трафика. АРС может быть сконфигурирован для управления таблицами с двумя уровнями приоритета. Первая таблица предназначена для обработки ячеек с высоким приоритетом, а вторая - для обработки ячеек с низким приоритетом. Вначале АРС будет планировать для передачи каналы из таблицы с приоритетом 1, назначая до NCITS каналов в указанный переменной APCT_PTR временной слот. Если ячейки из первой таблицы уже переданы, а временной слот еще не закончен (т. е. существует более чем NCITS каналов в этом временном слоте), АРС начинает обработку каналов из таблицы с приоритетом 2.
АРС-таблица содержит массив номеров каналов. При работе с таблицей используются два типа указателей: APCPTRx и APC_SPTRx (рис. 5.11.). Каждая ячейка таблицы представляет собой временной слот, через который будут переданы NCITS АТМ-ячеек. Размер АРС-таблицы зависит от минимальной скорости передачи для одиночного соединения и числа ячеек, которые передаются во временном слоте.
Каждый раз при выполнении АРС-алгоритма, который активизируется по истечении тайм-аута АРС-таймера (обычно это таймер 4 блока системной интеграции), блок АРС считывает из АРС-таблицы содержимое ячейки, адрес которой задан в APC_PTRx (см. рис. 5.11), и определяет, какой канал требуется запланировать для передачи АТМ-ячеек. Затем указатель APC_PTRx перемещается на следующую ячейку таблицы. Таким образом, тайм-аут таймера (АРС timer) задает период очередного планирования передач через временные слоты и определяет максимальную скорость передачи передатчика, так как период АРС timer рассматривается как длина временного слота (АРС time slot). В процессе работы АРС-блок читает параметр APC_period для каждого канала из ТСТ-таблицы и, используя внутренний алгоритм, определяет следующий канал, который должен быть передан. Затем АРС помещает номер выбранного канала из ячеек ТСТ-таблицы в очередь передачи(ТгапзтИ Queue), чтобы передатчик мог начать передачу и планирует для этого канала определенное количество временных слотов в соответствии с параметром АРС расе из ячейки канала в ТСТ-таблице. Значение NCITS (Number of Channels to be transmitted In a Time Slot) в памяти параметров АРС определяет число АТМ-ячеек, которые будут переданы в указанном временном слоте.
Передатчик передает одну ячейку для каждого канала, номер которого появится в очереди на передачу. Таким образом, передатчик выполняет передачу ячеек от многих каналов из одной очереди на передачу, т. е. осуществляет мультиплексирование. Передатчик выполняет функции AAL и SAR во внешней памяти для выбранного канала и передает ячейку в физический PHY-интерфейс. PHY-интерфейс выполняет функции уровней transmission convergence (ТС) и physical media dependent (PMD).
458
ОБЩИЕ ПОНЯТИЯ
Если для выбранного канала для передачи больше не подготовлено буферов, то процесс передачи прекращается и ячейки контроллером не передаются. В этом случае PHY-блок будет отвечать за передачу idle-ячеек во временной слот, который назначен АРС-блоком для данного канала до тех пор, пока не будут подготовлены новые буферы данных для передачи или пока не будет получена команда деактивации канала.
Пользователь может производить настройку параметров АРС-таблицы под параметры требуемого трафика.
Например, если АРС-таймер (таймер 4) запрограммирован для выработки запроса каждые 42,4 мс (размер временного слота равен 42,4 мс) и блок АРС запрограммирован для выдачи до 2 (NCITS) каналов за один запрос на передачу, передатчик будет брать в среднем по 2 номера каналов из очереди для каждого временного слота. Таким образом, АРС будет планировать передачу ячеек со скоростью ((2 х 53 байта х 8 бит)/42,4 мс)[бит/ с], или 20 Мбит/с. При этом PHY-интерфейс будет выполнять адаптацию ячеек (вставку idle cell) в случае, если реальная скорость передачи ячеек будет меньше, чем скорость передачи по PHY-каналу.
Максимальная скорость передачи для выбранного канала достигается, когда он запланирован для передачи в каждой ячейке АРС-таблицы (т. е., когда параметр АРС расе равен единице). Минимальная скорость передачи для выбранного канала достигается, когда он запланирован для передачи только в одной ячейке АРС-таблицы (т. е., когда параметр АРС расе равен APC_table_size-1).
Максимальная скорость передачи max_rate для одиночного соединения равна [Р/ NCITS], где Р - планируемая скорость передачи ячеек (обычно берется равной скорости передачи PHY-блока). Минимальная скорость передачи min_rate для одиночного соединения равна [Р/((М-1) х NCITS)], где М - минимальный допустимый размер АРС-таблицы для данной конфигурации. Таким образом, размер АРС-таблицы равен [1 + max_rate/ (min_rate х NCITS)] и определяется минимальной скоростью передачи и числом ячеек, передаваемых во временном слоте. Например, если требуется средняя скорость передачи данных 51,84 Мбит/с и минимальная скорость передачи равна 32 Кбит/с, то размер АРС-таблицы равен ((51,84 Мбит/32 Кбит)+1), или 1621 ячейки.
Скорость передачи конкретного ATM-канала определяется параметром АРС расе в ячейке ТСТ-таблицы, которая соответствует выбранному каналу. Значение АРС расе рассчитывается как [P/(NCIST хтребуемая_скорость_передачи_канала)]. Например, при скорости передачи АТМ-канала 51,84 Мбит/с и NCITS = 4, если требуется скорость передачи канала 100 Кбит/с, то значение АРС_расе = 51,84 Мбит/с /(4 х 100 Кбит/с) = 129,6.
Таким образом, блок АРС поддерживает заданные параметры трафика для каждого канала и распределяет суммарный трафик среди требуемых каналов. Он может обеспечивать CBR- и UBR-сервисы для трафика. При контроле АРС-периода для CBR-трафика пользователь должен установить новые значения до передачи контроллеру команды активации (Activation), и CBR-передача ведется только из высокоприоритетной таблицы передачи. Таким образом, значение APC_period для CBR-трафика на период работы соединения является константой. При контроле UBR-трафика период АРС также является константой, но передача будет вестись из низкоприоритетной АРС-таблицы.
При контроле ABR-трафика период АРС (APC_period) может быть динамически изменен пользователем в ходе работы для регулирования требуемой скорости передачи данных. В этом режиме APC_period динамически изменяется ATM-контроллерами при получении ячейки RM (Resource Management) и определяет требуемую ACR (Available Cell Rate) скорость передачи ячеек. Механизм RM-ячеек работает следующим образом. После передачи N ячеек пользовательской информации исходный контроллер вставляет в поток RM-ячейку, в которой указывает свою текущую скорость передачи. ATM-коммутатор принимает эту ячейку и анализирует состояние каналов связи. При необходимости он посылает
459
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
обратно АТМ-контроллеру RM-ячейку, в которой указывает, что надо сохранить (увеличить или уменьшить) скорость передачи. Число N обычно находится в пределах от 2 до 256 ячеек и определяется на этапе установки соединения.
Контроллер MPC860SAR может быть использован для реализации различных сетевых устройств: маршрутизаторов, АТМ-контроллеров, ADSL-модемов, АТМ-коммутато-ров и других устройств (рис.5.12).
Контроллеры МРС821 и МРС823. В состав семейства МРС860 входят также модели МРС821, МРС823, которые по основным характеристикам аналогичны МРС860, отличаясь от нее объемом кэш-памяти и возможностями интерфейса. Модель МРС821 имеет кэши команд и данных емкостью по 4 Кбайт и модуль коммуникационного процессора СРМ с двумя SCC-контроллерами. Модель МРС823 содержит кэш команд емкостью 2 Кбайт, кэш данных емкостью 1 Кбайт и модуль СРМ с двумя SCC-контроллерами. Кроме того, в составе МРС821, МРС823 имеется контроллер жидкокристаллического дисплея, а в МРС823 еще и графический контроллер, что делает эти модели особенно привлекательными для применения в портативных системах и устройствах, встраиваемых в аппаратуру различного назначения и поддерживающих режим пониженного энергопотребления.
В контроллере МРС823 встроенный коммуникационный RICS-процессор используется и для коммуникационных задач, и для решения задач обработки изображений. DSP-составляющая имеет дополнительные встроенные функции для JPEG-сжатия и декомпрессии изображений. При системной частоте в 75 МГц коммуникационный процессор может обеспечивать производительность 75 MIPS параллельно с работой основного процессора. Дополнительно МРС823 имеет 7 каналов ввода/вывода: два SCC-контроллера, два SMC-канала, по одному порту SPI и 12С и один канал USB (Universal Serial Bus). Максимальная скорость передачи данных - 35 Мбит/с.
Контроллер МРС855Т. Это одна из последних разработок фирмы «Motorola» в семействе PowerQUICC, которая ориентирована на сетевое применение. Контроллер выпускается в версиях 50,66 и 80 МГц. МРС855Т-это удешевленная версия контроллера МРС860 PowerQUICC, которая имеет всего один контроллер 10/100 Fast Ethernet и один SCC-контроллер, который поддерживает протоколы ATM, HDLC, ISDN, многоканальный HDLC и 10BaseT Ethernet, а также два SMC-контроллера, один SPl-порт и один 12С-порт. Гиб-
Рис. 5.12. Пример использования контроллера MPC860SAR или МРС860Р (контроллеры SCC2 и SCC3 могут работать с протоколами ATM, или HDLC, ипи РРР, или FUNI)
460
ОБЩИЕ ПОНЯТИЯ
кость архитектуры делает контроллер МРС855Т идеальным для реализации маршрутизаторов, устройств ADSL и модемов, а также интеллектуальных коммутаторов.
Контроллер МРС8260. PowerQUICC II открывает следующее поколение коммуникационных микропроцессоров, спроектированное специально для сетевых задач и телекоммуникаций.
МРС8260 PowerQUICC II - это дальнейшее развитие (следующая версия) коммуникационного процессора МРС860 PowerQUICC, обеспечивающее высокую производительность и гибкость во всех областях применения. Как и МРС860, МРС8260 состоит из двух основных компонентов: встроенного ядра PowerPC и коммуникационного процессора Communications Processor Module (СРМ). Двухпроцессорная архитектура позволяет снизить потребление энергии по сравнению с однопроцессорной структурой, так как основной процессор осво-божден от части периферийных задач, которые выполняет коммуникационный модуль.
Коммуникационный модуль одновременно поддерживает три быстрых SCC-канала FCC (Fast Serial Communications Controllers), два многоканальных контроллера МСС
Рис. 5.13. Структура контроллера МРС8260
461
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
(Multichannel Controllers), четыре обыкновенных SCC-канала (Serial Communications Controllers), два контроллера управления SMC (Serial Management Controllers), один последовательный порт SPI (Serial Peripheral Interface) и один интерфейс 12С.
Встроенное процессорное ядро представляет собой высокопроизводительный ЕСбОЗе(ТМ) микропроцессор, работающий на частотах 100-200 МГц, обеспечивающий производительность 140,0 MIPS на частоте 100 МГц и 280,0 MIPS на частоте 200 МГц. Поддерживается режим работы с выключенным процессорным ядром, при этом можно в полном объеме использовать все периферийные модули контроллера при работе с внешним более мощным процессором. Возможен режим работы с внешним кэшем, типа Motorola L2 cache МРС2605.
Контроллер поддерживает режим работы с пониженным энергопотреблением. При частоте 133 МГц микросхема потребляет 2,5 Вт. Микросхема выпускается в 480-контактном корпусе TBGA.
В состав входят кэш данных и кэш инструкций (по 16 Кбайт), блок управления памятью. Из состава процессора исключен блок обработки данных с плавающей запятой. Внутри контроллера используются две шины: 64-битная шина ядра PowerPC и 32-битная шина PCI или локальная шина (рис. 5.13).
Блок системной интеграции System Integration Unit (SIU) содержит контроллер памяти, контроллер шины PCI с частотой работы до 66 МГц, аппаратный монитор ошибок шины и программный сторожевой таймер. Для внешней отладки системы в состав включена поддержка IEEE 1149.1 JTAG-порта.
Высокопроизводительный коммуникационный контроллер СРМ может работать на частотах до 133 или 166 МГц. Таким образом, процессорное ядро PowerPC и СРМ могут работать с разными частотами. Контроллер может работать с максимальной скоростью в 710 Мбит/с при частоте 133 МГц. Объем двухпортовой памяти расширен до 24 Кбайт. Скоростные каналы FCC позволяют реализовать работу с 45 Мбит/с HDLC-протоколом, 10/100 Мбит/с Ethernet-протоколом, 155 Мбит/с ATM SAR-протоколом. Многоканальные контроллеры МСС могут каждый поддерживать 128 полнодуплексных 64 Кбит/с линий HDLC. Контроллеры SCC поддерживают все протоколы, которые были реализованы в контроллере МРС860. В результате с помощью контроллера МРС8260 можно реализовать поддержку.
• восьми TDM-интерфейсов (Т1/Е1) или двух TDM-портов, которые работают с ТЗ/ЕЗ;
• трех МП-интерфейсов;
• двух master/slave портов UTOPIA (уровень 2), которые оба поддерживают интерфейс multi-PHY; один порт может работать с 8/16-битными данными.
5.2. ОРГАНИЗАЦИЯ КОММУНИКАЦИОННЫХ ПРОЦЕССОРНЫХ МОДУЛЕЙ В КМК
5.2.1. СТРУКТУРА КОММУНИКАЦИОННОГО ПРОЦЕССОРНОГО МОДУЛЯ
Коммуникационный процессорный модуль СРМ (Communication Processor Module) автоматически, с минимальным вмешательством CPU центрального процессора выполняет прием и передачу потоков информации в соответствии с выбранным коммуникационным протоколом. При приеме СРМ автономно выполняет следующие действия:
1) поиск и выделение кадра данных во входном потоке информации или выделение из потока данных определенного временного канала с помощью TDM временного мультиплексора;
462
ОРГАНИЗАЦИЯ КОММУНИКАЦИОННЫХ ПРОЦЕССОРНЫХ МОДУЛЕЙ В КМК
2) обработку принятого кадра в соответствии с правилами выбранного сетевого протокола: проверку контрольных сумм, сравнение адресов, выделение и анализ формата служебных символов, отбрасывает служебную информацию;
3) полученные данные без дополнительной служебной информации помещаются в буфер FIFO;
4) RISC-процессор управляет передачей этих данных по каналам SDMA в ячейки памяти по адресу, определенному в буферном дескрипторе (BD) данного канала ввода/ вывода;
5) RISC-процессор устанавливает биты в слове состояния буфера дескриптора и соответствующие биты в регистре прерываний этого канала, сигнализируя центральному процессору о том, что данные в памяти готовы или о возникшей при приеме данных ошибке.
Далее центральный процессор выполняет обработку данных в соответствии с программами пользователя.
При передаче данных СРМ осуществляет обратное преобразование информации. Он получает данные из ячеек памяти по каналам SDMA, добавляет служебную информацию и передает их по сети. При этом центральный процессор через регистры состояния буферного дескриптора и регистры прерываний канала уведомляется о том, как закончилась передача.
Таким образом, СРМ выполняет функции канального уровня управления семиуровневой модели OSI, освобождая центральный процессор для обработки протоколов более высокого уровня. Следует отметить, что СРМ не реализует функции физического уровня модели OSI, он только подготавливает данные, кодирует их для передачи определенным способом (например, манчестерское кодирование, частотная модуляция, NRZ-кодирование и другие виды кодирования) и передает на внешние выводы контроллера. Для преобразования цифровых сигналов в электрические на выходах контроллера необходимы дополнительные микросхемы, которые в большом ассортименте также выпускаются фирмой «Motorola».
СРМ состоит из следующих основных частей (рис. 5.14):
• RISC-процессора, управляющего работой каналов ввода/вывода и обрабатывающего информацию в соответствии с заданными коммуникационными протоколами;
• регистра команд RISC-процессора;
• 2, 3 или 4 независимых полнодуплексных последовательных коммуникационных каналов SCC (Serial Communication Controllers), выполняющих основные функции передачи данных;
• двух каналов управления обменом SMC (Serial Management Controllers), которые используются как вспомогательные каналы для передачи служебной информации при работе с протоколами ISDN или как самостоятельные каналы передачи данных;
• 6-18 каналов прямого доступа в память (Serial Direct Memory Access Channels, SDMA Channels) для обмена информацией между буферами каналов ввода/вывода и внешней памятью;
• генератора частоты обмена (Baud Rate Generator, BRG), который формирует тактовые частоты для работы последовательных каналов связи; источником частоты для генератора может быть или внутренняя системная тактовая частота, или тактовые сигналы на внешних контактах;
• последовательного SPI-интерфейса для подключения периферийных устройств по последовательному каналу связи;
• двухпортовой памяти (dual-port RAM), используемой для хранения информации о буферных дескрипторах, параметров каналов и параметров выбранного протокола, а также загружаемого микрокода;
463
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
• физического интерфейса SI (Serial Channels Physical Interface), обеспечивающего выдачу информации каналов ввода/вывода на внешние контакты в двух режимах: мультиплексированном (TSA) и немультиплексированном (NMSI);
• 12С-канала ввода/вывода (Interprocessor Integrated Controller).
Дополнительно в состав СРМ в МРС860 включены новые модули, работой которых руководит RISC-контроллер (см. рис. 5.14):
• параллельные порты ввода/вывода;
• параллельный интерфейсный порт (Parallel Interface Port, PIP), через который реализуется стандартный протокол обмена типа Centronics;
• контроллер прерываний СРМ;
• 4 таймера общего назначения;
• 2 канала прямого доступа в память IDMA;
• в состав RISC-процессора включен дополнительный внутренний таймер, с помощью которого можно реализовать работу 16 шестнадцатиразрядных таймеров, которые обеспечивают периодическое прерывание центрального процессора для обработки определенных подпрограмм обслуживания прерываний;
• DSP-составляющая к RISC-контроллеру.
RISK-контроллер. СРМ функционирует под управлением собственного ядра, выполненного в виде RISC-процессора. Основная задача RISC-ядра - обеспечение функционирования каналов SCC, SMC, SPI без постоянного вмешательства основного центрального процессора CPU. Основные способы взаимодействия центрального процессора и RISC-ядра:
464
ОРГАНИЗАЦИЯ КОММУНИКАЦИОННЫХ ПРОЦЕССОРНЫХ МОДУЛЕЙ В КМК
• пользователь из своей программы может передать СРМ команду управления каналом связи (табл. 5.3-5.4);
• СРМ после выполнения приема/передачи кадра или в случае возникновения ошибки при передаче извещает CPU прерыванием;
• ядра могут обмениваться информацией о текущем состоянии каналов ввода/вывода через регистр статуса буферов дескрипторов и протокол-ориентированную область внутренней двухпортовой памяти.
Работа RISC-процессора прозрачна для пользователя. RISC-ядро выполняет задачи нижних уровней управления и контроля над DMA-передачами, освобождая центральный процессор для решения задач более высоких уровней управления. Все передачи между RISC-ядром и модулем коммуникационного процессора производятся по внутренней периферийной шине и не оказывают влияния на работу центрального процессора. RISC-процессор управляет работой коммуникационных каналов ввода/вывода, реализуя выбранные пользователем протоколы, координирует работу каналов SDMA при передаче информации между FIFO SCC и памятью, следит за правильностью заполнения буферных дескрипторов и их слов состояния. При реализации коммуникационных протоколов в зависимости от выбранного типа протокола RISC-контроллер осуществляет вставку служебной информации (преамбула, флаги, символы синхронизации) при передаче и ее удаление при приеме, контролирует правильность появления и корректность формата служебных символов и символов синхронизации, формирует при передаче и проверяет при приеме контрольную сумму целого кадра или частей пакета.
В контроллере МРС860 RISC-ядро имеет полностью 32-разрядную архитектуру, настроено и оптимизировано специально для решения коммуникационных задач. Благодаря введению DSP-составляющей RISC-процессор поддерживает встроенные команды МАС-арифметики (операции умножения и сложения над 16-битными операндами и 40-битным результатом), обработки контрольной суммы и вычисления специальных режимов адресации и выполняет МАС-команду за один период тактовой частоты. Особенности архитектуры RISC-ядра, использование 4-Кбитных кэш-памяти команд и данных позволили увеличить производительность ядра до 53 MIPS при 40 МГц.
Работу RISC-контроллера определяет микропрограмма, расположенная во внутреннем масочном ПЗУ микрокода. Пользователь не может изменить содержимое ПЗУ микрокода. Но предусмотрена возможность загрузки микрокода новых протоколов (например, SS#7, Profibus), для этого во внутренней двухпортовой памяти выделена специальная область для загрузки микрокода.
CPU может передавать команды управления работой каналов для RISC-контроллера через регистр команд CR (рис. 5.15). Обычно эти команды используются, если необходимо провести инициализацию канала или изменить его режим работы. CPU записывает код выполняемой команды в биты OPCODE, определяет канал, для которого должна быть выполнена команда в битах CHNUM (табл. 5.2), и устанавливает флаг FLG. Выполнив команду, RISC-процессор сбрасывает флаг FLG, сообщая центральному процессору, что он готов выполнить новую команду. Бит программного сброса RST = 1, установленный CPU, сбрасывает в исходное состояние регистры и параметры всех коммуникационных каналов приблизительно за 60 периодов тактовой частоты.
15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0 |
RST - OPCODE CHNUM - FLG
Рис. 5.15. Формат регистра команд CR RISC-контроллера
465
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
Таблица 5.2
Номера каналов ввода-вывода в МРС860
Биты CHNUM Тип канала Биты CHNUM Тип канала
0000 SCC1 1000 SCC3
0001 FC/IDMA1 1001 SMC1/DSP (Rx)
0100 SCC2 1100 SCC4
0101 SPI/IDMA2/RISC Timer 1101 SMC2/DSP (Тх)
Команды управления каналом связи рассмотрены в табл. 5.3 - 5.4. В состав СРМ контроллера МРС860 введены дополнительные каналы и модули, и поэтому набор команд управления расширен для обеспечения более гибкого управления каналами связи (см. табл. 5.4).
Типовой набор команд, которые чаще всего применяются для управления работой SCC-каналов в контроллере МРС860, включает 7 команд: STOP TRANSMIT, GRACEFUL STOP TRANSMIT, RESTART TRANSMIT, INIT TX PARAMETERS, ENTER HUNT MODE CLOSE RX BD и INIT RX PARAMETERS.
Таблица 5.3
Основные команды управления работой каналов ввода/вывода
Команда / Код команды.Описание
STOP TRANSMIT / 0100
Применяется для всех SCC-каналов и для SMC-каналов, работающих с протоколами UART, Transparent. Команда обычно передается при выключении передатчика и приводит к остановке передачи на канале. Происходит прерывание передачи текущего кадра данных, и в канал выдается только содержимое FIFO передачи: для протоколов UART, BISYNC и DDCMP - по 3 байта данных, для протоколов HDLC и Transparent - по 4 слова данных, для канала SMC с протоколом Transparent -2 символа. После передачи этих данных из FIFO контроллеры SCC-каналов передают служебные символы в соответствии с правилами коммуникационного протокола, на который они настроены. UART-контроллер передает определенное счетчиком BRKCR число символов BREAK (все биты в символе равны 0), а затем передает символы IDLE (все биты в символе равны 1). HDLC-контроллер передает символ флага (01111110) или символ ABORT (01111111). BISYNC-контроллер передает комбинации служебных символов SYNC-SYNC или DLE-SYNC. Следует отметить, что данная команда не поддерживается в Ethernet-контроллере.
RESTART TRANSMIT /0110
Применяется для всех SCC-каналов и для SMC-каналов, работающих с протоколами UART, Transparent. По этой команде возобновляется передача из текущего буфера BD. Обычно выполнение этой команды требуется после получения каналом команды STOP TRANSMIT или после возникновения ошибки потери сигнала при приеме. Рекомендуется передавать каналам эту команду перед установлением бита разрешения их работы.
ENTER HUNT MODE / 0011
Применяется для всех SCC-каналов и SMC-каналов, работающих с протоколом Transparent. По этой команде производится прерывание приема текущего пакета и закрытие текущего буфера BD. UART-контроллер производит поиск и открытие нового буфера и ожидает приема или пакета с установленным битом адреса при работе в многоточечном соединении или символа холостого хода IDLE при работе в двухточечном соединении. HDLC-контроллер сбрасывает содержимое FIFO приема и ожидает получения по сети символа флага (01111110), затем он открывает новый буфер BD и сбрасывает счетчик проверки контрольной суммы кадра. BISYNC- и DDCMP-контроллеры ожидают получения символов синхронизации SYN1-SYN2, затем закрывают текущий буфер и сбрасывают счетчик проверки контрольных сумм кадра и отдельных блоков. Эту команду рекомендуется передавать каналам перед установкой бита разрешения их работы.
466
ОРГАНИЗАЦИЯ КОММУНИКАЦИОННЫХ ПРОЦЕССОРНЫХ МОДУЛЕЙ В КМК
Продолжение табл. 5.3
Команда / Код команды. Описание__________________________________________________
INIT RX and ТХ PARAMETERS / 0000
Применяется для всех SCC-каналов, SMC-каналов, канала SPI и канал 12С. По этой команде производится инициализация всех параметров приемника и передатчика в исходное состояние, которое они имеют после выполнения команды сброса. Обычно эта команда передается при выключенных приемнике и передатчике, ко гда необходимо произвести перекоммутацию выходов приемника и передатчика.____________________________________________________________
INIT RX PARAMETERS / 0001 INIT ТХ PARAMETERS / 0010
Применяются для всех SCC-каналов, для SMC-каналов, работающих с протоколами UART и Transparent, для канала SPI и канала РС. По этим командам производится инициализация всех параметров приемника или передатчика выбранного канала в исходное состояние, которое они имеют после выполнения команды сброса. Обычно эти команды передаются при выключенном приемнике или передатчике.
RESET RECEIVER BCS CALCULATION /1010
Применяется для всех SCC-каналов, работающих с протоколом BISYNC. По этой команде производится немедленный сброс счетчиков проверки BCS контрольной суммы блоков пакета. Обычно команда должна поступать после приема контрольного символа начала блока, например символов SOT или SOH._____________________________________________________________________
GRACEFUL STOP TRANSMIT / 0101
Применяется для всех SCC-каналов и каналов ЮМА. По этой команде после передачи текущего кадра из буфера FIFO производится остановка передачи по выбранному каналу и генерируется специальный запрос прерывания INT_GRA, с использованием регистра событий данного канала. Следующий буфер BD, если он готов, становится текущим, и после получения команды RESTART TRANSMIT данные из него будут передаваться по каналу. Обычно эта команда используется, если необходимо передать более приоритетный кадр данных или нужно поменять параметры канала.
CLOSE RXBD/0111
Применяется для всех SCC-каналов, для SMC-каналов, работающих с протоколами UART и Transparent, для канала SPI и канала РС. По этой команде закрывается текущий буфер приема BD и открывается новый. После закрытия старый буфер приема становится доступным для пользователя. Команда применяется для получения доступа к буферу, не заполненному целиком. Действие команды не оказывает влияния на принимаемые данные. Команда не используется, если контрол-лер настроен на работу с протоколом HDLC или Ethernet.__________________________
TRANSMIT ABORT REQUEST / 1010
Применяется только для SMC-каналов, работающих в режиме поддержки GCI-интерфейса. По этой команде производится передача запроса на прерывание через A-бит канала управления в кадре GCI.____________________________________________________________________
TIMEOUT / 1001
Применяется только для SMC-каналов, работающих в режиме поддержки GCI-интерфейса. По этой команде, если приемник не отвечает, или получена ошибка в бите А канала управления, посы-лается запрос на прерывание в бите Е канала управления.
В контроллере МРС860 пользователь может настраивать режим работы RISC-ядра при программировании регистра конфигурации RISC-контроллера RCCR (рис. 5.16).
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
TIME - TIMER DR1M DR0M DRQP EIE SCD ERAM
Рис. 5.16. Формат регистра конфигураций RISC-контроллера RCCR для МРС860
467
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
В СРМ RISC-контроллер содержит таблицу 16 программных таймеров, при помощи которых пользователь может управлять частями своего программного обеспечения. Параметры настройки всех 16 таймеров сведены в общую таблицу. Период сканирования таблицы задается внутренним таймером RISC-контроллера. Величина периода опроса зависит от системной частоты и значений в битах TIMEP регистра конфигурации RCCR. Значение периода опроса вычисляется так: (системная частота)/[(Т1МЕР+1)х1024]. Бит TIME = 1 разрешает работу внутреннего таймера и сканирования таблицы таймеров. Если бит TIME = 0, то сканирование таблицы таймеров (RISC timer table) не производится.
Бит SCD определяет режим работы RISC-контроллера. Если этот бит равен 0, то устанавливается нормальный режим работы, а если -1, то альтернативный режим конфигурации планировщика.
В контроллере МРС860 RISC-контроллер дополнительно управляет работой IDMA-каналов, и в регистр конфигурации введены дополнительные биты. Биты DR1М, DR0M и DRQP (табл. 5.5) программируются только при работе с IDMA-каналами. Внешние сигналы-запросы на контактах DREQ1 и DREQ0 используются при активации канала IDMA1 и канала IDMA0. Биты DR1М и DR0M определяют, как будут восприниматься эти сигналы. Если данные биты равны 0, то соответствующий запрос регистрируется по перепаду сигнала, а если бит равен 1, то - по уровню сигнала.
Если установлен бит EIE = 1, то появление сигнала DREQO-запроса вызовет прерывание работы RISC-контроллера. Этот бит используется пользователем только во время процесса загрузки внешнего микрокода нового протокола в двухпортовую память.
Микрокод в МРС860 может быть загружен в двухпортовую память в трех режимах, выбор режима производится при программировании бита ERAM (табл. 5.6).
Таблица 5.4
Дополнительные команды управления работой каналов ввода/вывода
Команда 1 Код команды. Описание
INIT IDMA / 0101
Применяется для IDMA-каналов и производит инициализацию всех параметров приемника или передатчика выбранного IDMA-канала в исходное состояние, которое они имеют после выполнения команды сброса. Указатель текущего буфера BD устанавливается на первый BD в таблице дескрипторов.
SET TIMER / 1000
По этой команде производится активация/ деактивация/ реконфигурация одного из 16 таймеров в таблице таймеров RISC-процессора.________________________________________________
SET GROUP ADDRESS /1000
По этой команде производится установка бита логического группового адреса для каналов, работающих с протоколом Ethernet.
STOP IDMA /1011
Оказывает воздействие только на IDMA-каналы. По этой команде RISC-контроллер прерывает текущую IDMA-передачу, при приеме от внешнего источника внутренний буфер IDMA-канала пересылается в память, текущий BD закрывается и бит завершения передачи DONE устанавливается в регистре статуса IDMA-канала IDSR. Для очередного обращения открывается следующий BD в таблице._____
START DSP CHAIN / 1100
По этой команде производится перевод в активное состояние соответствующей таблицы дескрипторов (FD) выполняемых функций. Дескрипторы функций FD определяют функцию, используемую DSP-составляющей, и хранят параметры этой функции._________________________________
INITDSP CHAIN / 1101
По этой команде производится перевод в неактивное состояние таблицы дескрипторов выполняемых функций. В ячейку указателя (переменная FDBASE) на текущий дескриптор функции (FD) записывает-ся стартовый адрес таблицы дескрипторов функций.
468
ОРГАНИЗАЦИЯ КОММУНИКАЦИОННЫХ ПРОЦЕССОРНЫХ МОДУЛЕЙ В КМК
Таблица 5.5
Назначение битов DRQP
Таблица 5.6
Назначение битов ERAM
Биты DRQP Приоритет I DMA-запроса
00 I DMA-запрос имеет приоритет выше, чем SCC-каналы
01 I DMA-запрос имеет приоритет ниже, чем SCC-каналы
10 IDMA-запрос имеет самый низкий приоритет
11 Комбинация битов не используется
Биты ERAM Способ загрузки микрокода
00 Пользователь не работает с загружаемым микрокодом
01 Микрокод выполняется из первых 512 байт области двухпортовой памяти
10 Микрокод выполняется из первых 1024 байт области двухпортовой памяти
11 Микрокод выполняется из первых 2048 байт области двухпортовой памяти
SDMA-каналы. По два независимых SDMA-канала выделено для обслуживания приема и передачи данных в каждом канале ввода/вывода. Общее число SDMA-каналов равно удвоенному числу внешних каналов ввода/вывода контроллера. В контроллере МРС860 для обслуживания всех каналов ввода/вывода отведено два физических SDMA-канала, на базе которых реализовано 16 виртуальных SDMA-каналов. Восемь SDMA-каналов обслуживают четыре SCC-контроллера и восемь SDMA-каналов работают с интерфейсом SPI, портом 12С и двумя SMC-контроллерами.
Данные через SDMA-каналы могут передаваться для хранения как во внешнюю память, так и во внутреннюю двухпортовую память. Доступ к внешней памяти требует предварительного арбитража шины UBUS, доступ к двухпортовой памяти не требует арбитража шины микроконтроллера.
Управление работой SDMA-каналов осуществляется микропрограммой, выполняемой RISC-процессором. Пользователь не может контролировать или изменять процесс управления SDMA-каналами. При необходимости доступа к внешней памяти RISC-контроллер формирует внутренний запрос к арбитру шины микроконтроллера, получает подтверждение и становится владельцем шины на один стандартный цикл обмена по шине. Во время стандартного цикла обмена могут выставляться внешние сигналы CS Если шиной владел внешний арбитр, то SDMA-канал выставляет сигнал BCLR с требованием освободить шину. Стандартный цикл шины предусматривает передачу до 32 бит данных, после чего необходимо освободить шину, даже если больше нет других устройств, требующих шину для передачи. Такой способ обслуживания арбитража шины гарантирует пропорциональное гарантированное время доступа SCC-каналов и обеспечивает постоянное время задержки при обработке полученных по сети данных и не переполнение их FIFO. Если размер шины установлен меньшим, чем размер передаваемых данных (например, шина размером 16 бит, а размер данных - 32 бита), то SDMA-контроллер становится владельцем шины на два цикла передачи и освобождает шину только по завершении всей передачи, даже если во время передачи пришел более приоритетный запрос на владение шиной от другого модуля.
В МРС860 пользователь может сам назначить приоритеты доступа к шине всех устройств, использующих внешнюю шину для передач (IDMA-контроллер, SDMA-каналы, DRAM-контроллер или внешний master), с помощью программирования регистра конфигурации SDCR (SDMA), изображенного на рис. 5.17. Все SDMA-каналы имеют общий регистр конфигурации SDCR. Изменение параметров в этом регистре рекомендуется производить при выключенном коммуникационном контроллере.
В контроллере МРС860 кэш инструкций (l-кэш), кэш данных (D-кэш), блок системной интеграции SIU и SDMA-каналы могут требовать арбитража внутренней шины данных,
469
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
О _____16 17 18 19_______________ 29 30 ____31
Резервировано FRZ Резервировано | RAID
Рис. 5.17. Формат регистра SDCR в контроллере МРС860
таким образом, пользователю требуется установить относительные приоритеты запросов на арбитраж между указанными источниками. Реально пользователь имеет право установить только относительный приоритет SDMA-каналов, а приоритеты остальных модулей строго фиксированы.
Все SDMA-каналы имеют одно значение ID приоритета, которое устанавливается пользователем в регистре SDCR и которое позволяет SDMA-каналам соперничать за право передачи по внутренней шине данных с другими источниками внутренних и внешних запросов на арбитраж. Биты RAID устанавливают уровень приоритета запросов SDMA-каналов по доступу к внутренней шине среди других внутренних источников запросов (табл. 5.7). Арбитраж запросов от внутренних источников выполняет RISC-контроллер. Обычно устанавливается значение 5 (код 01).
Биты FRZ определяют реакцию SDMA-каналов на выставление сигналов контроля: 00 - SDMA-канал игнорирует сигнал FREEZE, 01 - SDMA-канал сбрасывает сигнал ВйГ и останавливает (замораживает) передачу, пока выставлен сигнал FREEZE или пока не произойдет сброс системы.
Каналы SDMA имеют один собственный регистр статуса SDSR (рис. 5.18), в котором отмечается состояние каналов SDMA в текущий момент времени или регистрируется событие, произошедшее в SDMA-канале. Сброс бита события в регистре статуса SDSR производится записью в разряд, соответствующий выбранному событию, кода «1».
Если возникла ошибка при передаче данных SDMA-канала, то генерируется прерывание и устанавливается бит SBER в SDSR-регистре. Адрес, при обращении по которому возникла ошибка, будет сохранен в регистре SDAR. Пользователь может сравнивать этот адрес с адресами в ячейках внутренних указателей на обрабатываемые RX- и ТХ-данные (internal data pointer) в протокол-независимой области памяти параметров SCC-канала, чтобы определить, при каком цикле обращения и в каком месте была обнаружена ошибка.
Биты DSP1 и DSP2 служат для регистрации события прерывания при работе с таблицами DSP функций DSP1 и DSP2.
Бит RINT используется только во время промышленного тестирования контроллера и пользователю не рекомендуется его изменять.
Регистр маски SDMA-канала (SDMR) имеет такой же формат расположения битов, как и регистр статуса SDSR, и служит для маскирования запросов на прерывание при возникновении различных событий в канале прямого доступа к памяти. Если некоторый бит в регистре маски равен 1, то выбранное прерывание разрешено.
Таблица 5.7
Назначение битов RAID
Значение битов RAID Уровень приоритета доступа SDMA-канала к внутренней шине
00 6
01 5
10 2
11 1
470
ОРГАНИЗАЦИЯ КОММУНИКАЦИОННЫХ ПРОЦЕССОРНЫХ МОДУЛЕЙ В КМК
О_________ 1 2 3 4 5________6__________7
SBER RINT Резервировано DSP2 DSP1
Рис. 5.18. Формат регистра статуса SDSR в контроллере МРС860
Двухпортовая память (DUAL-PORT RAM). Обмен информацией между центральным процессором (CPU) и коммуникационным процессором (СРМ) может осуществляться через двухпортовую память. Двухпортовая память включена между внутренней шиной центрального процессора и периферийной шиной RISC-процессора. Доступ к двухпортовой памяти может производить или RISC-контроллер через один порт или один из владельцев внутренней шины через другой порт. В контроллере МРС860 владельцем внутренней шины может быть одно из двух устройств: или центральный процессор, или каналы SDMA. При доступе любого из владельцев внутренней шины источников к двухпортовой памяти обращение выполняется, как к стандартной памяти с использованием линии адреса и данных внутренней шины контроллера. При этом цикл доступа к памяти составляет два периода тактовой частоты (два такта шины), а доступ от RISC-контроллера требует одного такта шины. При одновременном доступе к двухпортовой памяти центрального процессора и RISC-контроллера доступ RISC-контроллера задерживается на один такт.
Приоритеты обработки запросов по доступу к двухпортовой памяти от блоков коммуникационного процессора распределены следующим образом:
1) выполнение команды RESET или при системном сбросе (наивысший приоритет);
2) обращение от RISC-ядра;
3) обработка ошибки при передаче в режиме SDMA;
4) обращение от DRAM-контроллера;
5) выполнение команды от CPU, включая команды управления DSP-составляющей;
6) эмуляция IDMA-канала (если приоритет IDMA-запроса выше, чем у запроса от SCC-канала); настраивается при программировании регистра конфигурации RISC-контроллера в МРС860;
7) прием данных от SCC1-канала;
8) передача данных по SCC1-каналу;
9) прием данных от ЭСС2-канала;
10) передача данных по ЭСС2-каналу;
11) эмуляция IDMA-канала (если приоритет IDMA-запроса ниже, чем у запроса от SCC-канала); настраивается при программировании регистра конфигурации RISC-контроллера в МРС860;
12) прием данных от ЭССЗ-канала;
13) передача данных по ЭССЗ-каналу;
14) прием данных от ЗСС4-канала;
15) передача данных по 5СС4-каналу;
16) прием данных от SMCI-канала;
17) передача данных по SMC1-каналу;
18) прием данных от ЗМС2-канала;
19) передача данных по ЗМС2-каналу;
20) прием данных от канала SPI;
21) передача данных по каналу SPI;
22) прием данных от 12С-канала;
23) передача данных по 12С-каналу;
24) прием данных от PIP-порта;
471
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
25) передача данных через Р1Р-порт;
26) обработка запросов к таблице RISC-таймеров;
27) эмуляция IDMA-канала (если IDMA-запрос имеет самый низший приоритет); настраивается при программировании регистра конфигурации RISC-контроллера.
Двухпортовая память состоит из двух основных частей: памяти параметров каналов (parameter RAM) и памяти системных переменных (system RAM). Двухпортовая память решает следующие основные задачи.
• Хранение параметров каналов передачи данных в разделе параметров (parameter RAM).
• Хранение буферных дескрипторов (BD), которые определяют, куда будут передаваться принимаемые данные и откуда будут читаться данные для передачи. Обычно дескрипторы хранятся в разделе памяти параметров (parameter RAM), но для их хранения в МРС860 могут быть отведены незанятые области системного ОЗУ (system RAM). Число буферных дескрипторов в контроллере МРС860 ограничено лишь максимальным числом BD (512 BD).
• Хранение данных, полученных из последовательных каналов. Обычно эти данные по каналам SDMA пересылаются во внешнюю память.
• Хранение загружаемого RAM микрокода нового коммуникационного протокола. Микрокод обычно загружается в разделы системного ОЗУ.
• Системное ОЗУ, как правило, хранит загружаемый микрокод новых протоколов и внутренние системные параметры, но может использоваться для хранения буферных дескрипторов и данных пользователя.
• Временное хранение данных пользователей.
В контроллере МРС860 двухпортовая память занимает 8 Кбайт внутренней памяти (табл. 5.8), но реально заняты только 5 Кбайт, которые разбиты на две части: 4096 байт системного ОЗУ и 1024 байта памяти параметров (parameter RAM). Стартовый адрес (DPRAM BASE) двухпортовой памяти во внутренней памяти контроллера рассчитывается как IMMR+0x2000, где содержимое регистра IMMR задает стартовый адрес внутренней памяти в 4-Гбайтном адресном пространстве контроллера. Размер внутренней памяти -16 Кбайт.
Таблица 5.8
Распределение адресного пространства двухпортовой памяти в МРС860
Адрес Размер, байт Раздел Назначение
IMMR+0x2000 512 Системное ОЗУ Блок 1. Хранит данные, BD, микрокод
IMMR+0x2200 512 Системное ОЗУ Блок 2. Хранит данные, BD, микрокод
IMMR+0x2400 1024 Системное ОЗУ Блок 3. Хранит данные, BD, микрокод
IMMR+0x2800 3,5 Кбайт Системное ОЗУ Блок 4. Хранит данные и BD
IMMR+0x2E00 512 Системное ОЗУ Блок 5. Хранит данные, BD и рабочие значения микрокода
IMMR+ОхЗООО Системное ОЗУ Резервировано
IMMR+ОхЗСОО 256 Память параметров Страница 1. Хранит параметры канала SCC1 (смещение 0x00), канала I2C (смещение + 0x80), MISC-параметры (смещение + + ОхВО) и канала IDMA1 (смещение + ОхСО)
472
ОРГАНИЗАЦИЯ КОММУНИКАЦИОННЫХ ПРОЦЕССОРНЫХ МОДУЛЕЙ В КМК
Продолжение табл. 5.8
Адрес Размер, байт Раздел Назначение
|MMR+0x3D00 256 Память параметров Страница 2. Хранит параметры канала SCC2 (смещение 0x00), канала SPI (смещение + 0x80), параметры таймеров (смещение + 0хВ0), канала IDMA2 (смещение + + ОхСО)
IMMR+ОхЗЕОО 256 Память параметров Страница 3. Хранит параметры канала SCC3 (смещение 0x00), канала SMC1 (смещение +0x80) и канала DSP1 (смещение + + ОхСО)
IMMR+0x3F00 до |MMR+0x4000 256 Память параметров Страница 4. Хранит параметры канала SCC4 (смещение 0x00), канала SMC2 (смещение +0x80), канала DSP2 (смещение + + ОхСО)
В МРС860 существуют три режима загрузки микрокода:
1) микрокод загружается в первые 512 байт адресного пространства памяти и в последние 256 байт блока 5 системного ОЗУ; таким образом, размер микрокода составляет 768 байт;
2) микрокод загружается в первые два блока по 512 байт и в последние 256 байт блока 5 системного ОЗУ; размер микрокода составляет 1280 байт;
3) микрокод загружается в первые четыре блока по 512 байт и в 512 байт блока 5 системного ОЗУ; размер микрокода равен 2560 байт.
Распределение внутренней памяти в контроллерах МС68302, МС68360, МРС860 описано в табл. 5.9.
RISC-контроллер записывает 16/8-битный контрольный номер, хранящийся в его ПЗУ микрокода, в специальную ячейку REV_NUM в области parameter RAM двухпортовой памяти (MISC-параметры). В контроллере МРС860 данная ячейка имеет адрес IMMR+ОхЗСВО и расположена на первой странице памяти параметров.
Таблица 5.9
Сводная таблица распределения внутренней памяти в контроллерах
Тип памяти Размер для контроллеров, байт
МС68302 МС68360 МРС860
Внутренняя память 4 К 8 К 16 К
Двухпортовая память 1152 2,5 К 5 К
Внутренняя память регистров 2 К 4 К 8 К
System RAM 576 1792 4 К
User microcode RAM + 768/1280 768/1280/2560
Router RAM - 256 (2x32x2) 512 (2x64X2)
Parameter RAM 576 768 1 К
Количество буферных дескрипторов (BD) 48 (по 8x2 для SCC-каналов и по 1x2 для SCP и SMC) 224 512
473
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
Продолжение табл. 5.9
Тип памяти Размер для контроллеров, байт
МС68302 МС68360 МРС860
Протокол-независимая информация о SCC-канале 128 (включая BD) 48 48
Протокол-ориентированная информация о SCC-канале 64 42 52
Синхронизация. BRG-генератор. В СРМ для каждого канала, работающего в режиме NMSI, источниками тактовых сигналов может быть или один из четырех BRG-генера-торов, или один из восьми входов внешнего генератора. В СРМ нет жесткого закрепления генераторов BRG за конкретным каналом, и один генератор может обслуживать сразу несколько SCC- или SMC-каналов. Такой способ реализации системы синхронизации повышает эффективность использования внешних выводов микросхемы. Во-первых, для любого SCC и SMC можно выбирать любой источник синхронизации с любого контакта микросхемы. Например, можно для всех каналов назначить внешние источники тактовых сигналов, поступающие только через контакты порта В, при этом входы источников тактовых сигналов на контактах порта А можно использовать для других целей. Во-вторых, можно назначить для нескольких каналов один источник тактирования, или сделать так, чтобы у одного канала для приема и для передачи использовалась бы одна частота тактирования, а это тоже освобождает внешние контакты незанятых генераторов и источников внешнего тактирования для других целей.
В СРМ каждый канал ввода/вывода имеет свой специальный регистр синхронизации SICR (рис. 5.19), который определяет, работает ли этот канал в режиме мультиплексирования, и с какой частотой он синхронизируется.
Биты SC1, SC2, SC3, SC4 при значении, равном 1, определяют, что выбранный канал подключен к временному мультиплексору TSA, и его внешние выводы NMSI-сигналов можно использовать для других целей. Если эти биты равны 0, то соответствующий канал работает в немультиплексируемом режиме NMSI.
Биты R4CS, R3CS, R2CS, R1CS, T4CS, T3CS, T2CS, T1CS определяют источник синхронизации приемной и передающей частей соответствующего канала (табл. 5.10). Эти биты игнорируются, если канал работает в мультиплексном режиме и подключен к TSA. Код, записанный в биты R4CS, R3CS, R2CS, R1CS, определяет источник тактирования выбранного канала при приеме данных, а код, записанный в биты T4CS, T3CS, T2CS, T1CS, определяет источник тактирования соответствующего канала при передаче. Для каждого канала выбранная частота поступает или на тактовый вход приемника RCLKx, или на тактовый вход передатчика TCLKx, или на оба входа одновременно.
Биты GR1 - GR4 определяют, поддерживает ли данный канал механизм подтверждений (grant) при работе с протоколами ISDN, как определено в битах GM1 - GM4 настройками этого канала («0» - не поддерживают, «1» - поддерживают).
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
GR4 SC4 R4CS T4CS GR3 SC3 R3CS T3CS
16 17 18 19 20 21 22 . 23 24 25 26 27 28 29 30 31
GR2 SC2 R2CS T2CS GR1 SC1 R1CS T1CS
Рис. 5.19. Формат регистра синхронизации SICR в СРМ-модуле
474
ОРГАНИЗАЦИЯ КОММУНИКАЦИОННЫХ ПРОЦЕССОРНЫХ МОДУЛЕЙ В КМК
Таблица 5.10
Выбор источника синхронизации
Значения битов xxCS Источник тактирования
000 Канал тактируется от BRG1-генератора
001 Канал тактируется от BRG2-reHeparopa
010 Канал тактируется от BRG3-reHepaTopa
011 Канал тактируется от BRG4-reHeparopa
100 Каналы SCC1 и SCC2 тактируются сигналом с контакта CLK1, а каналы SCC3 и SCC4 - сигналом с контакта CLK5
101 Каналы SCC1 и SCC2 тактируются сигналом с контакта CLK2, а каналы SCC3 и SCC4 - сигналом с контакта CLK6
110 Каналы SCC1 и SCC2 тактируются сигналом с контакта CLK3, а каналы SCC3 и SCC4 - сигналом с контакта CLK7
111 Каналы SCC1 и SCC2 тактируются сигналом с контакта CLK4, а каналы SCC3 и SCC4 - сигналом с контакта CLK8
Существует два ограничения по тактированию каналов в СРМ:
1) только 8 источников тактирования из 12 могут быть выбраны для каждого канала; этот источник задается при программировании регистра синхронизации SICR;
2) SMC-каналы, когда они работают в немультиплексированном режиме, должны иметь одинаковую частоту для тактирования приемника и передатчика; источник тактовых сигналов задается при программировании регистра конфигурации физического интерфейса SIMODE.
Все генераторы тактовой частоты BRG в СРМ полностью независимы. Настройка генератора на определенный режим работы осуществляется при программировании его регистра конфигурации BRGC в СРМ (рис. 5.20). Каждый генератор имеет свой собственный регистр настройки и одинаковую структуру (рис. 5.21).
Биты ЕХТСх определяют источник тактовых сигналов для BRG-генератора. Это может быть или выход внутреннего генератора микросхемы (биты ЕХТС1 ,ЕХТС0 = 00), или сигнал с внешнего входа микросхемы CLK2 (биты ЕХТС1.0 = 01) или входа CLK6 (биты ЕХТС1,0 = 10). Сигнал от внутреннего генератора обычно равен системной частоте (после предварительного деления ее внутренним генератором, такое деление системной частоты выполняется для систем с низким энергопотреблением, где не нужны высокие скорости передачи).
Далее полученная частота может предварительно делиться на 16 в СРМ (если бит DIV16 = 1), или на 1 (если бит DIV16 равен 0). Пользователь дополнительно может управлять делением частоты генератора с помощью программирования предварительного делителя Prescale. СРМ имеет 12-разрядный счетчик предварительного деления. Коэффициент деления частоты программируется битами CD11 - CD0 и может иметь значения от 1 до 4096, где «1» соответствует нулям во всех разрядах CDi. На выходе счетчика
14 15
RST EN
16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
ЕХТС[1:0] АТВ CD[11:0] DIV16
Рис. 5.20. Формат регистра конфигураций BRG-генератора
475
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
Бит EXTC Бит DIV16
Бит АВТ
Рис. 5.21. Структура BGR-генератора в контроллере МРС860
предварительного деления Prescale получается рабочая частота, которая поступает на внешний контакт и на внутренние цепи для тактирования каналов SCC и SMC. Но существуют ограничения на максимальную частоту тактирования каналов: для СРМ максимальная частота тактирования равна 1/2 частоты внутреннего генератора микросхемы (SyncCLK/2). Например, при системной частоте 25 МГц максимальная частота на выходе BRGO может быть только 12,5 МГц.
Бит EN = 1 обеспечивает включение соответствующего генератора в работу. При значении EN = 0 генератор выключен и его внешние контакты могут быть использованы для других целей как разряды параллельных портов ввода/вывода. Выключение генератора из работы обычно применяется в режимах пониженного энергопотребления.
Пример расчета максимальной скорости работы каналов. Для синхронных передач, когда период тактовой частоты равен битовому интервалу передачи данных:
Скорость Входная частота (SyncCLK или CLK2, или CLK6)
канала (делитель CD+1) х (делитель 1 или 16 при DIV16)
Для асинхронных передач используется увеличение частоты тактирования в 8, 16, 32 раза для реализации процедуры oversampling. При oversampling производится опрос трех значений бита на одном битовом интервале и за верное значение берется значение по максимальному совпадению из трех. Увеличение частоты в 16 раз обычно используется при работе с UART-протоколом. Таким образом, максимальная частота генератора, используемая для тактирования UART-контроллера, равна 1/2xSyncCLK/16, что составляет для СРМ 781,3 Кбит/с при частоте 25 МГц:
Входная частота (SyncCLK или CLK2, или CLK6)
Скорость__________________________________________________________________
канала (делитель CD+1) х (делитель 1 или 16 при DIV16 )х (8 или 16 или 32))
476
ОРГАНИЗАЦИЯ КОММУНИКАЦИОННЫХ ПРОЦЕССОРНЫХ МОДУЛЕЙ в кмк
Управление встроенными RISC-таймерами. RISC-контроллер может управлять работой 16 внутренних таймеров. Функционирование этих таймеров не зависит от таймеров общего назначения и генераторов BRG, а определяется тактовыми сигналами от внутреннего таймера в составе RISC-контроллера и программируется в регистре RCCR. Наиболее эффективно применение этих таймеров в системах, где необходимо освободить центральный процессор от функции контроля и управления таймерами общего назначения. При использовании 16 внутренних таймеров все функции управления их работой возложены на RISC-контроллер.
В двухпортовой памяти в разделе parameter RAM на странице 2 выделена специальная область, в которой хранятся параметры настройки таймеров.
Параметры, определяющие работу каждого из 16 таймеров, сгруппированы в таблицу (RISC TIMER TABLE), которая располагается в двухпортовой памяти. Переменная TM_BASE (в ячейке с адресом TimerBase+ОО) задает местоположение таблицы таймеров во внутренней двухпортовой памяти. В этой ячейке указывается смещение таблицы таймеров относительно начального адреса двухпортовой памяти во внутренней памяти контроллера. Каждая ячейка таблицы таймеров предназначена для управления одним таймером и имеет размер 4 байта. Первые два байта хранят значение, которое было записано при инициализации таблицы таймеров во время выполнения RISC-контроллером команды SET TIMER. При работе таймеров начальные значения будут уменьшаться до 0. В следующих двух байтах хранится текущее значение таймера.
Таким образом, если пользователь работает со всеми 16 таймерами, то размер таблицы составит 64 байта. RISC-контроллер будет обрабатывать таймер с номером N при просмотре таблицы, если в регистре R_TMV (в ячейке с адресом TimerBase+06) бит с соответствующим номером установлен в «1».
Все операции с таблицей таймеров выполняются по тактам внутреннего таймера. Частота работы внутреннего таймера настраивается при программировании битов TIME и TIMER в регистре конфигурации RISC-процессора. Обработка таблицы таймеров имеет самый низкий приоритет среди всех операций RISC-контроллера, поэтому если RISC-контроллер занят выполнением других задач, то обработка таймеров в текущем такте внутреннего таймера может не производиться, поскольку процессор просто не успевает выполнить эти действия. При своей работе пользователь может, прочитав содержимое ячейки TM_PTR (с адресом TimerBase+02), всегда узнать адрес ячейки таймера из таблицы, которая будет обрабатываться следующей.
Для обнаружения данной ситуации в памяти параметров введена переменная TM_CNT (в ячейке с адресом TimerBase+OC). RISC-процессор увеличивает эту переменную при каждом обращении к таблице таймеров для обработки, если, конечно, разрешена работа внутреннего таймера. Таким образом, пользователь в своем программном обеспечении всегда может сравнить, сколько тактов от внутреннего таймера получил RISC-контроллер и сколько из них он обработал, обращаясь к таблице таймеров.
Управление работой таймера. Для управления работой таймера центральный процессор может передать RISC-контроллеру команду SET TIMER. По этой команде производится включение, выключение и настройка параметров одного из 16 таймеров в таблице. Код этой команды 0x0851 записывается в регистр команд RISC-процессора. Но перед тем как переслать эту команду, пользователь должен записать определенные значения в ячейку TM_CMD (с адресом TimerBase+08) (рис. 5.22). Переменная TM_CMD - это регистр команд таймеров, в котором определяются параметры настройки таймеров, выполняемые при обработке команды SET TIMER.
Поле TIMER NUMBER определяет номер таймера от 0 до 15, для которого производится настройка параметров. Поле TIMER PERIOD определяет 16-битное значение тайм-
477
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
V R PWM — TIMER NUMBER
16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
TIMER PERIOD
Рис. 5.22. Формат регистра команд RISC-таймеров TMCMD
аута для выбранного таймера. Максимальное значение 65 536 соответствует коду 0x0000 в этом поле.
Если пользователь желает работать с определенным таймером, он должен перед подачей команды SET TIMER установить бит V := 1 в ячейке TD_CMD. Если же таймер не будет использован, то бит V := 0. Значения бита V (Valid) при выполнении команды SET TIMER будут переписаны в соответствующий бит ячейки R_TMV, анализируемой RISC-контроллером при обслуживании таблицы таймеров.
Таймеры могут работать в трех режимах:
1) выработки одиночного импульса (One-Shot);
2) перезапуска (Restart);
3) генерации импульсов PWM (Pulse Width Modulation).
Если необходимо, чтобы таймер работал в режиме ONE-SHOT, надо установить в регистре TM_CMD бит R := 0 (RESTART). Если бит R := 1, то таймер будет работать в режиме автоматического рестарта. При выполнении команды SET TIMER значение бита R будет перезаписано для таймера номер N в соответствующий бит ячейки R_TMR (с адресом TimerBase+04). Ячейка R_TMR - это регистр режима таймеров, она недоступна для записи пользователю и анализируется RISC-контроллером при обработке таблицы таймеров.
При работе таймера в PWM-режиме (бит PWM = 1) каждая пара таймеров может быть настроена для генерации PWM-импульсов через контакты порта В. Можно организовать до восьми дополнительных генераторов тактовых сигналов для внешних устройств. Первый таймер в паре (четный номер) используется для контроля длительности уровня «1» в импульсе. При настройке параметров этого таймера в регистре TM_CMD биты PWM := 1 и V := 1, а в поле TIMER PERIOD загружается период уровня «1» в импульсе. Второй таймер в паре (нечетный номер) используется для контроля длительности периода тактовых сигналов и работает в режиме автоматической перезагрузки, когда истечет время цикла. При его настройке значения битов R := 1 и V := 1, а в поле TIMER PERIOD загружается значение периода импульсов.
Алгоритм обработки таблицы таймеров. RISC-контроллер сканирует таблицу таймеров один раз за период внутреннего таймера и проверяет для каждого таймера в регистре R_TMV, включен этот таймер или нет. Для каждого работающего таймера RISC-контроллер уменьшает его счетчик в ячейке таблицы таймеров и контролирует, закончился ли интервал тайм-аута для этого таймера. Если тайм-аут не закончился, то RISC-процессор переходит к обработке следующего таймера в таблице. Если тайм-аут закончен, то в регистре событий таблицы таймеров RTER (рис. 5.23) устанавливается бит, который соответствует номеру обрабатываемого таймера, далее проверяется бит этого таймера в регистре режима R_TMR. Если этот бит равен 1, то производится рестарт (сброс в начальное состояние) счетчика данного таймера. Если данный бит равен 0, т. е. включен режим ONE-SHOT, то в регистре готовности таймера R_TMV сбрасывается бит работоспособности таймера. Таким образом, в режиме RESTART производится перезагрузка таймера и его дальнейшая нормальная работа, а в режиме ONE-SHOT по окончании интервала счета таймер останавливается.
478
ОРГАНИЗАЦИЯ КОММУНИКАЦИОННЫХ ПРОЦЕССОРНЫХ МОДУЛЕЙ в кмк
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
ТМ15 ТМ14 ТМ13 ТМ12 ТМ11 ТМЮ ТМ9 ТМ8 ТМ7 ТМ6 ТМ5 ТМ4 ТМЗ ТМ2 ТМ1 ТМО
Рис. 5.23. Формат регистра событий RTER и регистра маски RTMR
Когда RISC-контроллер заканчивает обработку всех таймеров в таблице, он увеличивает значение в ячейке TM_CNT и останавливает работу с таблицей до следующего периода внутреннего таймера.
Если была получена команда SET TIMER, то RISC-контроллер только загружает но вые параметры для одного из 16 таймеров из ячейки TM_CMD во внутренние рабочие регистры параметров таймеров, но не производит сканирование и обработку таблицы.
Отметим, что окончание тайм-аута одного из таймеров может вызывать прерывание системы при установке бита в регистре RTER, только, если данный бит не замаскирован в регистре маски таблицы таймеров RTMR (рис. 5.23), и если в контроллере прерываний СРМ разрешено прерывание от таблицы таймеров. Бит, равный 0 в RTMR, маскирует прерывание от соответствующего таймера в регистре событий RTER. Сброс запроса на прерывание в регистре RTER можно произвести записью в этот бит «1».
Практическое применение RISC-таймеров. С помощью таблицы таймеров пользователь может определить уровень загрузки RISC-контроллера. Если уровень загрузки составляет более 96%, это значит, что пользователь нерационально распределил ресурсы коммуникационного контроллера, и его программное обеспечение разработано не оптимально. При высокой загрузке повышается вероятность потери сетевых данных из-за переполнения буферов FIFO и низкой скорости передач данных по каналам SDMA.
Для проведения анализа уровня загрузки необходимо выполнить следующие действия.
• Запрограммировать период внутреннего таймера как 1024x16 = 16384 периодов системной частоты.
• Запретить прерывания от таблицы таймеров.
• С помощью команды SET TIMER проинициализировать параметры всех 16 таймеров для работы с периодом тайм-аута, равным 65 536 периодам внутреннего таймера.
• Запрограммировать один из четырех таймеров общего назначения на работу с увеличением при каждом импульсе внутреннего таймера, и период их тайм-аута необходимо установить равным 65 536.
• Запустить работу системы на несколько часов. Затем сравнить показания счетчиков RISC-таймера номер 15 и таймера общего назначения.
• При сравнении результатов следует учитывать, что таймеры общего назначения считают на увеличение, а RISC-таймеры - на уменьшение. Если в результате разница составит более чем два тика, то это значит, что RISC-контроллер на каком-то интервале работы внутреннего таймера не смог обратиться к таблице таймеров для ее обработки, и уровень его загрузки превысил 96%.
При анализе результатов следует учитывать, что обработка таблицы таймеров увеличивает загрузку RISC-контроллера приблизительно на 4%.
DSP-составляющая, ее использование. Для выполнения различных DSP-приложений и повышения вычислительной мощности процессора в состав RISC-контроллера семейства МРС860 введена DSP-составляющая, которая состоит из блока MAC (Multiply And Accumulate), встроенной команды МАС, и дополнена введением специальных режимов адресации для более эффективного выполнения DSP-алгоритмов. RISC-контроллер работает параллельно с основным процессором и освобождает его от выполнения некоторых функций, тем самым повышает его производительность и снижет потребление энергии.
479
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
0 1 15
S Вещественное число Real
S Вещественная часть комплексного числа
S Мнимая часть комплексного числа
Рис. 5.24. Форматы хранения вещественных и комплексных чисел в памяти
Блок МАС имеет организацию 16x16 бит и выполняет операции над содержимым двух 32-битных регистров. Для хранения результата выделены два 40-битных аккумулятора с фиксацией признаков переполнения. Одна МАС-операция выполняется за 1 - 2 такта ожидания (latency) и 1 такт блокировки (blockage). Одна инструкция может предусматривать выполнение 1, 2 или 4 МАС-операций. Одновременно в контроллере могут выполняться несколько инструкций. Блок DSP поддерживает операции с комплексными числами (complex), для хранения которых отведена 32-битная ячейка памяти (рис. 5.24). Для хранения вещественного (real) числа предназначена 16-битная ячейка памяти. Бит S (Sign) служит для хранения знака числа.
В результате DSP-библиотека встроенных функций включает 11 блоков (табл. 5.11), необходимых для построения и обработки модемных протоколов V.32bis и V.34. Микрокод выполняемых DSP-функций хранится во внутреннем ПЗУ микрокода.
Все параметры функций, указатели на буферы данных и результатов организованы в памяти контроллеров в виде дескрипторов функций (FD), структура которых похожа на буферные дескрипторы (BD) SCC-каналов SCC, тоже организованные в виде таблицы и хранимые во внешней памяти.
Используются две таблицы (chain) дескрипторов FD: 1) для обработки данных при приеме, 2) для обработки данных при передаче. Специальная команда START DSP CHAIN заставляет RISC-контроллер начать обработку дескрипторов из таблицы FD.
Таблица 5.11
Встроенные DSP-функции и типы их аргументов
Функция Назначение функции OPCODE Тип аргумента
X (input) C (coefficient) Y (output)
FIR1 Decimation, RX Interpolation 00001 Real Real Real
FIR2 Tx Filter, RX Filter 00010 Complex Real Complex
FIR3 EC Computation, Equalizer 00011 Complex Complex Real/Complex
FIR5 Fractionally Spaced Equalizer 00101 Complex Complex Real/Complex
FIR6 Basic FIR Filter 00110 Real Complex Complex
HR Biquad FIR filter 00111 Real Real Real
MOD TX Modulation 01000 Complex Complex Real/Complex
DEMOD RX Demodulation 01001 Real Complex Complex
LMS1 EC Update, Equalizer Update (T/2, T/3) 01010 Complex Real/Complex Real/Complex
LMS2 Equalizer Update (2T/3) 01011 Complex Real/Complex Real/Complex
WADD Interpolation 01100 Real Real Real
480
ОРГАНИЗАЦИЯ КОММУНИКАЦИОННЫХ ПРОЦЕССОРНЫХ МОДУЛЕЙ В КМК
0 1 2 3 4 5 6 7
SBER RINT — — — — DSP2 DSP1
Рис 5.25. Формат регистра SDSR
По завершении обработки каждого дескриптора пользователь может установить выставление запроса маскируемого прерывания. Если в слове состояния дескриптора FD установлен бит I (Interrupt) = 1, то запрос на прерывание будет зарегистрирован в битах DSP1 (для таблицы приема) и DSP2 (для таблицы передачи) в регистре SDSR (регистр статуса каналов SDMA) (рис. 5.25). Сброс бита запроса на прерывание может быть произведен записью в этот разряд «1». При желании пользователь может замаскировать прерывание от битов DSP1 и DSP2, установив соответствующие биты в регистре маски канала SDMA.
С каждой таблицей дескрипторов FD связана своя область памяти параметров в двухпортовой памяти на странице 3 - таблица DSP1 (адрес DPRAM_BASE+0x1EC0) и странице 4 - таблица DSP2 (адрес DPRAM_BASE+0x1 FC0). В этих таблицах в ячейках FDBASE (с адресом DSP base+ОО) хранятся указатели на таблицы дескрипторов FD: RxCHAIN BASE и TxCHAIN BASE, которые расположены во внешней памяти.
Перед началом работы пользователю требуется задать в таблице только один параметр -FDBASE, который определяет месторасположение таблицы дескрипторов FD в памяти. Далее для инициализации таблицы дескрипторов FD контроллеру необходимо передать команду INIT DSP CHAIN. По этой команде в ячейку текущего указателя на таблицу FD_ptr (с адресом DSP base+04) записывается стартовый адрес таблицы FD из ячейки FDBASE.
Также в двухпортовой памяти хранятся текущие значения числа итераций I (ячейка с адресом DSP base+12), числа повторов ТАР (ячейка с адресом DSP base+14), указателя на таблицу коэффициентов CBASE (ячейка с адресом DSP base+16), размера буфера исходных данных (ячейка с адресом DSP base+18), указателя на ячейку таблицы входных данных XPTR (ячейка с адресом DSP base+1A), размера буфера результатов (ячейка с адресом DSP base+Ю), указателя на ячейку таблицы выходных результатов YPTR (ячейка с адресом DSP base+1E), размера буфера исходных данных М (ячейка с адресом DSP base+20), указателя на обрабатываемую ячейку таблицы входных данных (ячейка с адресом DSP base+22), размера буфера результатов N (ячейка с адресом DSP base+24), указателя на обрабатываемую ячейку таблицы выходных результатов (ячейка с адресом DSP base+26), размера таблицы коэффициентов К (ячейка с адресом DSP base+28), указателя на обрабатываемую ячейку таблицы коэффициентов (ячейка с адресом DSP base+2A). Термин «текущий», применяемый при описании ячеек, означает, что их исходные значения заносятся из дескриптора выбранной функции и их содержимое используется при работе только с текущим дескриптором FD и может изменяться при начале работы со следующим дескриптором.
Каждый дескриптор FD состоит из восьми 16-битных ячеек (рис. 5.26). Первое слово -это регистр состояний. Слова со второго по восьмое определяют параметры функций, тип (номер) которой задан в битах OPCODE слова состояния.
Назначение бит слова состояния для большинства функций одинаково. Если бит S (Stop) равен 1, то RISC-процессор остановит вычисления (обработку) дескрипторов этой функции после обработки текущего дескриптора FD. Если бит S = 0, то процессор перейдет к обработке следующего дескриптора из таблицы.
Бит W (Wrap) определяет последний дескриптор FD в таблице. Если бит W = 1, то после обработки данногадескриптора процессор перейдет к проверке готовности первого дескриптора в таблице. Если бит W = 0, то после обработки дескриптора процессор перейдет к проверке следующего дескриптора в таблице.
481
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
S - W I X IALL INDEX PC - - OPCODE Offse1+0
I Для FIR, Для LMS HR, MOD, DEMOD, WADD - зарезервировано -число итераций Offset+2
к к TPTR Для FIR, LMS - число сумм (ТАР -1) Для MOD, DEMOD - размер таблицы модуляции или демодуляции Для IIR - указатель на временный указатель задержки линии Для WADD- весовой коэффициент при X1 Offset+4
CBASE МРТР Для FIR, HR, LMS - указатель на начало таблицы коэффициентов в памяти Для MOD, DEMOD - указатель на начало таблицы коэффициентов модуляции (демодуляции) Для WADD - весовой коэффициент при Х2 Offset+6 q L*
М Размер буфера входных данных X. Минимальное значение 4 (FIR6, IIR) или 8 (FIR1, FIR2, FIR3, FIR5, MOD, DEMOD, LMS) Offset+8
XYPTR Указатель на месторасположение в памяти структуры, которая содержит указатели на буферы входных X и выходных Y данных Offset+A . ,
N EPRT Размер буфера выходных данных Y. Минимальное значение 4 (FIR1, FIR5 при X = 0, HR, MOD) или 8 (FIR2, FIR3, FIR5 при Х = 1, FIR6, DEMOD) Для LMS - указатель на ячейку, содержащую значение масштабирующего коэффициента Offset+C
- Зарезервировано Offset+E
Рис. 5.26. Формат дескриптора функций FD
Если бит I = 1 (Interrupt), то после завершения обработки текущего дескриптора будет выработан запрос на прерывание, но только если это прерывание не замаскировано пользователем. Если бит I = 0, то запрос на прерывание не вырабатывается.
Бит IALL (используется только в FD FIR функций) определяет правило изменения указателя входного аргумента после выполнения очередной итерации. Если бит IALL = 1, то указатель входного аргумента X (или, другими словами, адрес ячейки, содержащей параметр X) увеличивается по модулю (М + 1) на число, заданное в битах INDEX после каждой итерации. Если бит I ALL = 0, то указатель входного аргумента X увеличивается по модулю (М + 1) на число INDEX, заданное в битах, только после последней итерации.
Биты INDEX задают приращение указателя ячейки X переменной. Если INDEX = 00, то указатель не изменяется. Если INDEX = 01, то указатель изменяется на 1. Если INDEX = 10, то указатель изменяется на 2. Если INDEX = 11, то указатель изменяется на 4. Бит отсутствует в слове состояния FD функций MOD, DEMOD и WADD.
Бит РС (используется только в FD FIR функций) определяет правило изменения значения указателя на ячейку таблицы коэффициентов. Если бит РС = 0, то указатель не меняет свое значение при переходе к новому этапу итерации. Если бит РС = 1, то после каждой итерации в ячейку указателя заносится содержимое ячейки СВАБЕ памяти параметров, т. е. указатель устанавливается на начало таблицы коэффициентов.
Бит X определяет тип выходных переменных. Если бит X - 0, то в память записывается только вещественная часть результата. Если бит X = 1, то в выходной буфер будут записаны и вещественная и мнимая часть результата. Бит отсутствует в слове состояния FD функций HR, WADD, FIR1, FIR2 и FIR6.
Реализуемые DSP-функции. Функции FIR1-FIR6. Все функции выполняют вычисления базового фильтра с конечной импульсной характеристикой (Finite Impulse Response, FIR), но только с разным типом входных/выходных переменных и коэффициентов (рис. 5.27). Возможны два типа аргументов: вещественный (real) и комплексный (complex). Функция FIR1 применяется в алгоритмах децимации (decimation) и интерполяции входного сигна-
482
ОРГАНИЗАЦИЯ КОММУНИКАЦИОННЫХ ПРОЦЕССОРНЫХ МОДУЛЕЙ В КМК
ла, функция FIR2 - при расчете входных и выходных КИХ-фильтров, функция FIR3 с вещественным результатом - при вычислении коррекции ошибок, а с комплексным результатом - в корректоре (equalizer); FIR5 - в дробно-интервальном корректоре (fractionally spaced equalizer), a FIR6 - при расчетах КИХ-фильтров общего назначения.
Функция IIR. Функция IIR выполняет расчет параметров фильтра с бесконечной импульсной характеристикой (Infinite Impulse Response, IIR) и вычисление параметров фильтров интерполяции (рис. 5.28). При расчете базового BIQUAD IIR-фильтра используются 6 вещественных коэффициентов С, вещественные входные данные X, и результат представляет собой вещественное число Y(n). На рис. 5.28 буквами Т отмечены блоки задержки.
Функции MOD и DEMOD. Функции MOD (рис. 5.29) и DEMOD (рис. 5.30) выполняют операции модуляции и демодуляции входного сигнала Х(п) с помощью таблиц модуляции и демодуляции, которые содержат пары значений Sin сопТ и Cos сопТ. Константа AGC при демодуляции может принимать значения от -1 < AGC < +1. Модуляционная и демо-дуляционная таблицы содержат (К + 1) байт данных и представляют собой наборы пар 16-битных ячеек, у которых в первой ячейке хранится вещественное значение Sin, а во второй - вещественное значение Cos.
Функции LMS. Функции LMS реализуют алгоритм минимизации среднеквадратичной ошибки (Least Mean Square, LMS) и применяются для обновления коэффициентов С, базового FIR-фильтра. Изменение значения коэффициента производится по общей формуле. Функция LMS1 используется для улучшения вычислений коррекции ошибки (ЕС update). Отличие в функциях LMS1 и LMS2 заключается в том, что входной аргумент функции LMS2 дополнительно еще увеличивается в 2 раза, как это требуется при обновлении значений коэффициентов дробно-интервального корректора (fractionally spaced
%(«)-----нЯ)-------► Г(Л)
а
coscon7’,sinco«7’
REAlfy(n)}= REAl{x(n)}*cosa>nT- IMAG$X(nft*sma>nT
lMAG^Y(n)}= REAl{x(n)}*smo>nT+ IMAG^X(n^*cosa>nT
Рис. 5.29. Реализация функции MOD
x(n)------нЯ)-------► w
X
co&a>nT, sinajnT, AGC
REAL.{Y(n)}=( I + AGC)* X(n)* cos conT
IMAGE{Y(n)}=( I + AGO* X(n)*( -sinwnT)
Рис. 5.30. Реализация функции DEMOD
483
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
equalizer). Входные данные X и коэффициент С должны быть комплексными числами а масштабирующий коэффициент Е может быть или комплексным, или вещественным числом:
С"+1=С" + ЕхХ , где 1 = 0, к - 1.
Функция WADD. Функция WADD (Weighted Vector ADDition) выполняет операцию взвешенного сложения векторов. Исходными данными являются два вещественных вектора Х1 и Х2 и два вещественных коэффициента а и р. Выходной вектор У формируется как линейная комбинация входных векторов в соответствии с коэффициентами аир:
Y(n) = axXJn) + рхХ/и/
При значения коэффициентов 0 £ а £ 1 и р = 1-а функция выполняет линейную интерполяцию. Если 0 о а и Р = 0, то выполняется масштабирование У (л) = аХ(п). Если а = 1 и р = -1, то выполняется вычитание векторов Y(n) = Х1(п) -Х2(п).
5.2.2. КОНТРОЛЛЕРЫ КОММУНИКАЦИОННЫХ КАНАЛОВ SCO
Структура и основные режимы работы. Контроллер МРС860 (рис. 5.31) имеет четыре полностью независимых SCC-канала, реализующих различные сетевые протоколы канального уровня. Совместное использование всех каналов позволяет реализовать широкий спектр сетевых устройств на одном контроллере (мосты, маршрутизаторы, шлюзы, коммутатор) при поддержке большого спектра протоколов локальных и глобальных сетей, а также сетей ISDN.
Функции SCC не включают физический интерфейс и не реализуют в полном объеме функции физического уровня модели OSI, но SCC подготавливает, форматирует и кодирует данные для физического интерфейса. SCC поддерживает шесть способов кодирования данных: NRZ, NR2I, FMO, FM1, Manchester, Differential Manchester. Кодированием данных в структуре SCC-контроллера занимается специальный блок DPLL (Digital Phase-Locked Loop). Если при работе не требуется специальная модификация данных и входных сигналов при приеме и передаче через SCC-канал, то рекомендуется выбирать кодирование NRZ.
^bus
Рис. 5.31. Структура SCC-контроллера в МРС860
484
ОРГАНИЗАЦИЯ КОММУНИКАЦИОННЫХ ПРОЦЕССОРНЫХ МОДУЛЕЙ в кмк
Выбор поддерживаемых SCC-каналом протоколов не зависит от режима функционирования физического интерфейса SI. Каждый SCC-канал может работать совместно с протоколами физического интерфейса IDL, GCI, PCM, NMSI, а также может быть сконфигурирован для поддержки тестовых режимов «эхо» (echo) и «петля» (loopback). В режиме «эхо» канал сразу же передает принятую информацию, а в режиме «петля» - сразу же принимает только что переданную им информацию.
Каждый SCC-канал имеет собственные внешние контакты (TXD, RXD, TCLK, RCLK, CTS , RTS , CD ) и использует их, если он работает в NMSI-режиме. При работе в немуль-типлексируемом режиме стандартные модемные сигналы rts , cts , CD находятся лсд автоматическим управлением SCC, а дополнительные модемные сигналы DSR и DTR могут быть реализованы пользователем через выводы параллельных портов.
В контроллере МРС860 выбор режима работы SCC-контроллера выполняется при программировании регистров SICR и GSMR. Настройка режимов работы SMC-контрол-леров выполняется в регистре SIMODE.
Для каждого SCC-канала настройка параметров выбранного сетевого протокола производится с помощью параметров инициализации, хранящихся во внутренней памяти параметров (parameter RAM) двухпортовой памяти (dual-port RAM).
Выбор поддерживаемого протокола производится в битах MODE регистра GSMR. Каждый SCC-канал поддерживает следующие протоколы канального уровня:
• High-Level/Synchronous Data Link Control (HDLC/SDLC);
• Universal Asynchronous Receiver Transmitter (UART);
• Binary Synchronous Communication (BISYNC);
• режим прозрачной передачи (Transparent Mode);
• IEEE 802.3 (Ethernet);
• Local Talk (основанный на протоколе HDLC);
• Infrared protocol;
• Synchronous UART (1x clock mode);
• Асинхронный HDLC (AHDLC). s
В контроллере MPC860 дополнительно поддерживаются протоколы, загружаемые в память в виде микрокода:
• Digital Data Communications Message Protocol (DDCMP);
• Signaling System #7 (SS#7);
• Profibus; ,
• V.14; \
• X.21. ’
Различные модификации базового контроллера МРС860 также поддерживают дополнительные современные сетевые протоколы (табл. 5.12).
Обычно каждый SCC-канал работает в полнодуплексном режиме, поддерживая выбранные протоколы и для приемника, и для передатчика, но в настройках SCC-канала имеется опция, которая позволяет каналу работать в одну сторону с протоколом прозрачной передачи (transparent), а в другую - со стандартным выбранным протоколом.
Внутренние сигналы тактирования приемника (RCLK) и передатчика (TCLK) каждого SCC-канала в СРМ могут поступать или от внутреннего источника (один из четырех BRG-генераторов или один из четырех внешних сигналов CLK), или от внешнего источника через контакты TCLKx и RCLKx с предварительной обработкой этих сигналов в блоке DPLL. У любого SCC-канала приемник и передатчик полностью независимы и могут иметь раздельные источники тактирования. Максимальная частота тактирования SCC-каналов составляет в СРМ 1/г системной частоты. Например, при системной частоте 50 МГц максимальная частота тактирования каналов ввода/вывода составляет не более 25 МГц.
485
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
Таблица 5.12
Параметры контроллеров семейства МРС860
Контроллер Размер двухпортовой памяти, байт Число SCC-каналов Поддержка протоколов
QMC ATM Fast Ethernet Ethernet
МРС860 5К 4 - - - +
МРС860Р 8 К 4 + + + +
MPC860DP 8 К 2 + + + +
МРС860Т 5 К 4 + - + 10/100
MPC860DT 5 К 2 + - + 10/100
MPC860SAR 5 К 4 + + - +
MPC860DC 5 К 2 - - - SCC1
MPC860DE 5К 2 - - - +
MPC860DH 5 К 2 + - - +
MPC860EN 5 К 4 - - - +
МРС860МН 5 К 4 + - - +
МРС823 8 К 2 - - — —
МРС855Т 8 К 1 + + + 10/100
При работе в полнодуплексном режиме одновременно всех четырех каналов с одним из протоколов HDLC, HDLC bus или Transparent гарантированная скорость передачи каждого канала составляет 2 Мбит/с (табл. 5.13). Если с указанными протоколами работает только один SCC-канал (остальные выключены), то в полнодуплексном режиме скорость передачи может достигать 8 Мбит/с.
Таблица 5.13
Скорости передачи коммуникационных каналов, Мбит/с
Одновременно работающие каналы в МРС860 Скорость передачи
1 HDLC 8
2 HDLC 4
3 HDLC 2,6
4 HDLC 2,05
1 Transparent 8
3 Transparent 2,6
4 Transparent 2,05
1 UART 1,56
3 UART 0,943
4 UART 0,625
4 BISYNC 0,46
1 HDLC + Ethernet 10Mb/s 7,6
3 HDLC + Ethernet 10Mb/s 2,05
Full duplex Ethernet 2
2 Transparent через SMC 1,6
2 UART через SMC 0,1
SPI - 8-битный порт 0,5
1 Centronics port 0,625
486
ОРГАНИЗАЦИЯ КОММУНИКАЦИОННЫХ ПРОЦЕССОРНЫХ МОДУЛЕЙ В КМК
о 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
- IPR -
16 17 18 19 20 21 22 23_____24_____25 26 27 28 29 30 31
TCRC REVD TRX ТТХ СОР | CTSP CDS CTSS TFL RFW TXSY SYNL RTSM RSYN
Рис. 5.32. Формат регистра режима GSMR H
Настройка общих режимов SCC-каналов в МРС860. GSMR - это регистр настройки режимов SCC-контроллера, которые являются общими для всех SCC-каналов и не зависят от используемого коммуникационного протокола. Поскольку это 64-разрядный регистр, то обращение к нему выполняется как к двум регистрам GSMR_H (старшая часть регистра GSMR) (рис. 5.32), который содержит разряды с 63 по 32, и GSMR_L (младшая часть регистра GSMR), который содержит разряды с 31-го по 0-й (рис. 5.33).
Включение схем приемника и передатчика выбранного канала производится при записи «1» в биты ENR и ENT. Рекомендуется разделить на два этапа процесс установки битов настройки режимов работы и включение схем канала. Вначале первой командой Ассемблера выполняется установка битов режимов работы, затем делается пауза, необходимая для настройки и переключения внутренних цепей на новый режим работы, а затем, следующей командой, устанавливается бит ENT := 1 для включения передатчика канала и бит ENR .= 1 - для включения приемника. Если эти биты будут сброшены в «0» во время работы SCC-канала, то прием/передача текущего символа прерывается и буфер FIFO приемника очищается. Настройка SCC-канала на работу с определенным протоколом канального уровня выполняется в битах MODE (табл. 5.14).
Таблица 5.14
Выбор коммуникационного протокола
Значение битов MODE Коммуникационный протокол
0000 HDLC
0001 Зарезервировано
0010 Apple Talk (Local Talk)
0011 Зарезервировано для загружаемого протокола SS#7
0100 UART
0101 Зарезервировано для загружаемого протокола Profibus
0110 Зарезервировано для загружаемого протокола ASYNC HDLC
0111 Зарезервировано для загружаемого протокола V.14
1000 BISYNC
1001 Зарезервировано для загружаемого протокола DDCMP
1010 Зарезервировано для QMC-версий
1011 Зарезервировано
1100 Ethernet
1101, 1110, 1111 Зарезервировано
I
487
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47
SIR EDGE TCI TSNC RINV TINV TPL TPF TEND TDCR
48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63
RDCR RENC TENC DIAG ENR ENT MODE
Рис. 5.33. Формат регистра режима GSMRL
В битах DIAG (табл. 5.15) производится настройка рабочего режима функционирования SCC-канала.
Таблица 5.15
Настройка режимов работы SCC-контроллеров
Значение битов DIAG Режим работы контроллера
00 Канал работает в нормальном режиме. Данные принимаются по RXD-пинии и передаются по TXD-пинии. Сигналы CD и CTS находятся под автоматическим контролем и используются для разрешения приема данных (сигнал CD) и для разрешения передачи данных (сигнал CTS).
01 Канал работает в режиме локальной петли (local loopback). В этом режиме выход передатчика внутренне соединен со входом приемника. Передатчик и приемник работают в нормальном режиме, тактирование передатчика и приемника должно выполняться с одинаковой частотой. Значение сигнала на линии RXD игнорируется. Этот режим используется для тестирования аппаратуры приемника и передатчика. Данные передаются на линию TXD или по желанию пользователя внешний контакт TXD не будет использоваться совсем и при программировании порта А на этом контакте будет уровень логической «1». Сигнал RTS при программировании регистра конфигурации SIMODE может быть запрограммирован или работать нормально (RTS = 0 во время передачи данных), или оставаться не активным в течение всей передачи. Другие модемные сигналы игнорируются.
10 Канал работает в режиме автоматического эхо-сигнала (echo). В этом режиме канал автоматически, бит за битом, передает данные, которые только что получил. Для тактирования передатчика используется тактовая частота приемника. Приемник работает в нормальном режиме и принимает данные, когда сигнал CD = 0. Передатчик просто передает принятые данные, при этом значение сигнала CTS игнорируется.
11 Канал одновременно работает в режиме и автоматического эхо-сигнала, и внутренней петли. Сигналы на пиниях CD и CTS игнорируются. Приемник и передатчик тактируются с одной частотой тактового сигнала.
Настройка режимов работы при «прозрачном способе обмена». В нормальном режиме работы (Биты ТТХ = TRX = 0) приемник и передатчик работают с одинаковым протоколом, выбранным в битах MODE, при настройке SCC-контроллера. Но в МРС860 для повышения гибкости работы каналов ввода/вывода введена дополнительная опция, при которой протоколы работы приемника и передатчика могут различаться. Дополнительно поддерживаемый протокол - это протокол полностью прозрачной передачи. Биты ТТХ и TRX позволяют реализовать режим работы с двумя протоколами на одном SCC-канале. Если бит ТТХ = 1, то передатчик работает в режиме прозрачной передачи, независимо от протокола работы приемника. Если бит TRX = 1, то приемник работает в режиме про
488
ОРГАНИЗАЦИЯ КОММУНИКАЦИОННЫХ ПРОЦЕССОРНЫХ МОДУЛЕЙ В КМК
зрачного приема независимо от протокола работы передатчика. Для работы в полнодуплексном режиме прозрачной передачи необходимо установить оба бита ТТХ := TRX := 1. Исключение составляет SCC-канал, который настроен на работу с протоколом Ethernet, и у такого контроллера биты ТТХ и TRX всегда должны быть равны.
Если канал работает в прозрачном режиме передачи, то биты REVD, TCRC и RSYN используются для настройки его рабочих параметров. Если бит REVD = 0, то соблюдается нормальный порядок передачи битов в байте - LSB-бит передается первым. Если бит REVD = 1, то используется инверсный порядок передачи битов в байте - первым передается MSB-бит.
Бит RSYN используется только для каналов, работающих в режиме прозрачной передачи, и служит для определения времени синхронизации приемника. Если бит равен О, то приемник работает в нормальном режиме и обнаруживает приход данных по активному сигналу CD = 0, который выставляется передатчиком одновременно с передачей первого бита данных. Если же бит RSYN = 1, а также бит CDS = 1, то активный сигнал CD = 0 появится только при приеме второго бита кадра данных. Этот режим используется, например, в сети HDLC bus, когда первый бит кадра служит для обнаружения коллизии и реальные данные начинаются только со второго бита кадра.
Если в слове состояния TxBD текущего буфера данных установлен режим передачи данных с подсчетом контрольной суммы, то биты TCRC (табл. 5.16) определяют тип проверочного полинома. ,
Таблица 5.16
Выбор типа контрольной суммы
Значение битов TCRC Тип полинома контрольной суммы
00 16-битный полином Хл16+Хл12+Хл5+1. Обычно используется в HDLC-контроллере.
01 16-битный полином ХЛ16+ХЛ15+ХЛ2+1. Обычно используется в BYSINC-контроллере.
10 32-битный полином Хл32+Хл26+Хл23+Хл22+Хл16+Хл12+Хл11 + +Хл10+Хл8+Хл7+Хл5+ХМ+Хл2+Хл1 + 1. Обычно используется в Ethernet- или HDLC-контроллерах.
11 Зарезервировано.
Временной контроль сигналов управления. Управление сигналами CD , CTS и RTS .Когда SCC-канал запрограммирован на работу в нормальном режиме (биты DIAG = 00), сигналы сЕГ и cts находятся под автоматическим контролем SCC-koh-троллера.
Биты CDP, CDS, CTSP, CTSS определяют, как SCC-контроллер воспринимает и работает с сигналами cd и cts . Если бит CDP = 0, то сигнал на линии сЕГ должен контролироваться в течение приема всего кадра данных. Если во время приема кадра сигнал cd будет сброшен в пассивное состояние cd = 1, то регистрируется ошибка потери CD-сигнала и прием кадра прерывается. Если бит CDP = 1, то сигнал на линии cd появляется в виде импульса, который синхронизирует начало кадра, и дальнейшие изменения сигнала на линии cd не влияют на прием текущего кадра данных.
Если бит CDS = 0, то сигнал на линии cts должен контролироваться в течение передачи всего кадра данных. Если во время передачи кадра сигнал cts будет сброшен в пассивное состояние cts = 1, то регистрируется ошибка потери CTS-сигнала и передача кадра прерывается. Если бит CDS = 1, то сигнал на линии cts появляется в виде импульса, который синхронизирует начало передачи кадра, и дальнейшие изменения сигнала на линии cts не влияют на передачу текущего кадра данных.
489
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
Бит CTSP определяет взаимную синхронизацию внешних сигналов на линиях cd~ и RXD. Если бит CTSP равен 0, то два этих сигнала поступают асинхронно. SCC-контрол-лер внутренне синхронизирует их, а затем принимает данные с линии RXD. Если бит CTSP = 1, то сигнал cd синхронизирован с появлением данных на линии RXD, а это позволяет контроллеру проводить их быструю обработку. В этом случае состояние сигнала cd изменяется во время нулевого «О» полупериода тактового сигнала, и сигнал остается активным ссГ = 0 в течение приема всего кадра данных. Часто синхронизированный режим работы используется для соединения двух коммуникационных контроллеров в прозрачном режиме передачи, у которых выход rts” одного из них соединен со входом cd- другого.
Бит CTSS определяет взаимную синхронизацию внешних сигналов на линиях cts” и TXD. Если бит CTSS равен 0, то два этих сигнала поступают асинхронно. SCC-контроллер внутренне синхронизирует их, а затем данные выставляются на линию TXD после нескольких периодов задержки. Если бит CTSS = 1, то сигнал cts синхронизирован с передачей данных по линии TXD. В этом случае состояние сигнала cts изменяется во время нулевого «О» полупериода тактового сигнала. Как только сигнал cts стал активным cts = 0, данные начинают немедленно передаваться по линии TXD. Часто синхронизированный режим работы используется для соединения двух коммуникационных контроллеров в прозрачномрежиме передачи, у которых выход rts одного контроллера соединен со входом cts другого контроллера.
Бит RTSM используется для контроля режимов работы внешнего сигнала при передаче данных. Если бит RTSM = 0, то сигнал rts активен только при передачекадра данных, а в промежутке между кадрами передаются IDLE/Flag-символы и сигнал rts становится пассивным. Если бит RTSM = 1, то сигнал rts всегда активен после включения выбранного SCC-контроллера в работу, и в промежутке между кадрами данных передаются символы IDLE или Flag, как определено в выбранном коммуникационном протоколе.
Временной контроль сигналов управления для синхронных протоколов. При работе в нормальном режиме для синхронных протоколов сигнал rts становится активным, когда данные для передачи загружены в буфер FIFO и наступает отрицательный перепад тактового сигнала TCLK. Если при этом сигнал cts” = 0 или вывод cts используется как контакт параллельного порта, то данные начнут сразу же передаваться в сеть. Если вывод cts запрограммирован на использование как контакт параллельного порта ввода/вывода, то для SCC-контроллера он будет всегда восприниматься как активный сигнал. Задержка между выставлением активного сигнала rts = 0 и выставлением на линию TXD первого бита данных (рис. 5.34) составляет или нуль периодов тактового сигнала - если бит CTSS = 1 в регистре GSMR, или один период тактового сигнала - если бит CTSS = 0. Сигнал rts сбрасывается, т. е. становится пассивным rts = 1, через один период тактового сигнала после начала передачи последнего бита данных, т. е. сразу после окончания передачи кадра данных. Если при выставлении активного сигнала rts = 0, сигнал cts остается пассивным cts = 1, то задержка начала передачи данных зависит от момента появления активного сигнала cts = 0. Изменение состояния сигнала cts всегда контролируется по отрицательному перепаду тактового сигнала передатчика TCLK. После появления активного сигнала cts первый бит данных будет выставлен на линию TXD сразу же по тому же перепаду тактового сигнала TCLK, по которому был обнаружен активный сигнал cts = 0, если бит CTSS = 1 в регистре GSMR, или с задержкой от 0,5 до 1 периода тактового сигнала (т. е. по следующему отрицательному перепаду тактового сигнала после обнаружения активного сигнала cts ), если бит CTSS = 0.
Если бит CTSP = 0, то сигнал cts должен оставаться активным в течение всей передачи кадра данных, иначе будет зарегистрирована ошибка «потери CTS-сигнала». Если
490
ОРГАНИЗАЦИЯ КОММУНИКАЦИОННЫХ ПРОЦЕССОРНЫХ МОДУЛЕЙ В КМК
Рис. 5.34. Задержка выдачи данных относительно сигнала RTS для синхронных протоколов (сигнал CTS = 0)
при передаче данных сигнал cts станет пассивным, то это вызовет установку сигнала rts' тоже в пассивное состояние, немедленное прерывание передачи данных и начало передачи IDLE-символов. Но если при этом бит CTSS = 0, то перед регистрацией ошибки «потери сигнала CTS» и прерыванием передачи SCC-контроллер должен по положительному перепаду тактового сигнала (рис. 5.35) опросить состояние сигнала на линии cts . Если бит CTSS = 1, то все изменения сигнала cts могут производиться, только когда тактовый сигнал TCLK = 0 (рис. 5.36).
Задержка приема данных определяется состоянием сигнала на входе cd . Если бит CDS = 0, то состояние cd -сигнала опрашивается по каждому положительному перепаду тактового сигнала RCLK, и, если обнаружен активный сигнал cd = 0, то прием данных начинается по следующему отрицательному перепаду тактового сигнала. Если бит CDS = 1, то изменение пассивного состояния сигнала cd на активное по любому фронту тактового сигнала вызывает немедленное начало приема данных.
Если бит CDP = 0, то сигнал cd должен оставаться в активном состоянии до конца приема кадра данных, иначе будет зарегистрирована ошибка «потери CD-сигнала» и прием данных будет немедленно прерван. Но если при этом бит CDS =0 , то перед регистрацией ошибки «потери сигнала CD» и прерыванием приема SCC-контроллер должен по положительному перепаду тактового сигнала опросить состояние сигнала на линии cd* . Если бит CDS = 1, то все изменения сигнала cd* могут производиться, только когда тактовый сигнал RCLK = 0.
— ллллпллшшллплллялляляшт
RTS
cts I I _ i I \ \ Установка в «1»
ч
TXD Первый Кадр бит данных К
Данные готовы к передаче Обнаружен CTS=1
Обнаружен CTS=0
Рис. 5.35. Задержка выдачи данных относительно сигнала CTS для >
синхронных протоколов (бит CTSS = 0) и пример потери сигнала СТ$
'МП
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
TCLK
RTS
CTS
TXD
Рис. 5.36. Задержка выдачи данных относительно сигнала CTS для синхронных протоколов (бит CTSS = 1) и пример потери сигнала CTS
Временной контроль сигналов управления для асинхронных протоколов. При работе в нормальном режиме для асинхронных протоколов сигнал rts становится активным, когда данные для передачи загружены в буфер FIFO и наступает отрицательный перепад тактового сигнала TCLK. Выводы cts , сгГ могут использоваться для контроля передачи так же, как и в синхронных протоколах. Дополнительно UART-контроллер имеет специальную опцию настройки для контроля передачи с помощью cts -сигнала.
Если сигнал rts становится активным, когда сигнал cts' = 0, то передача начинается через два битовых интервала. Если же сигнал rts- = 0, но сигнал стеГ-1 и бит CTSS = О, то передача начнется через три битовых интервала. Если же сигнал rts = 0, но сигнал cts - 1 и бит CTSS = 1, то передача начнется через два битовых интервала.
Управление буферами FIFO приемника и передатчика. Бит TFL определяет длину буфера FIFO передатчика. Если бит TFL = 0, то используется стандартный размер буфера - 32 байта для SCC1 -контроллера и по 16 байт для других SCC-контроллеров. Режим TFL = 1 используется для символьно-ориентированных протоколов, например, UART или BISYNC, и устанавливает размер буфера FIFO в 1 байт. Этот минимальный размер буфера используется для ускорения процесса обработки информации.
Бит RFW определяет ширину ячеек буфера FIFO приемника. Если бит RFW = 0, то размер ячейки буфера равен 32 битам. Данные принимаются бит за битом, пока не будет принято 32 бита информации, только затем они могут быть переданы в память по каналам SDMA. Эта конфигурация необходима для протоколов, основанных на HDLC-типе кадра и протокола Ethernet, а также рекомендована для высокоскоростных протоколов «прозрачной передачи». В этом режиме размер ячейки FIFO для SCCI-канала равен 32 битам и 16 битам для других каналов SCC.
Режим работы с битом RFW = 1 предназначен для низкоскоростных протоколов «прозрачной передачи» и для символьно-ориентированных протоколов. Размер ячейки буфера устанавливается равным 8 битам, буфер FIFO SCC1 канала имеет размер 8 байт, а у других SCC-каналов размер буфера - 4 байта. Таким образом, принимаемые данные передаются в буферы данных в памяти по 8 бит, не дожидаясь приема всех 32 битов. Этот режим может быть использован для протоколов HDLC, HDLC bus, Apple Talk и Ethernet.
Настройка синхронизации. Бит TXSY определяет взаимную синхронизацию между приемником и передатчиком. Обычно установка этого бита требуется при работе с внешним оборудованием, которое поддерживает стандарт Х.21. При работе с обычным се
492
ОРГАНИЗАЦИЯ КОММУНИКАЦИОННЫХ ПРОЦЕССОРНЫХ МОДУЛЕЙ В КМК
тевым оборудованием бит TXSY = 0 и приемник с передатчиком работают независимо. Если выбран режим с битом TXSY = 1, то передача начнется только через 8 периодов тактовой частоты после начала приема данных. Дополнительно, в режиме прозрачной передачи, если установлен бит RSYN = 1, то приемник предварительно должен быть синхронизирован с частотой входного потока битов и до начала передачи должен быть выставлен активный сигнал cts = 0.
Бит SYNL используется при настройке режимов работы BISYNC- и Transparent-контроллеров и служит для задания длины синхросимволов (табл. 5.17). Формат синхросимволов SYNC1 и SYNC2 для синхронных протоколов обычно задается в регистре синхронизации DSR. При передаче перед посылкой кадра передатчик добавляет к кадру данных заданное число символов синхронизации. Формат дополнительных синхросимволов может быть определен в специальных ячейках протокол-ориентированной части памяти параметров SCC-канала.
Таблица 5.17
Размер символов синхронизации
Значение битов SYNL Размер символа синхронизации
00 Синхросимволы не используются, и прием кадра синхронизируется внешним сигналом СБ = 0
01 4-битный синхросимвол
10 8-битный синхросимвол
11 16-битный синхросимвол
Назначение битов в регистре синхронизации (рис. 5.37) различно для разных коммуникационных протоколов (табл. 5.18). После системного сброса этот регистр настроен на работу с HDLC-протоколом. Если регистр DSR содержит символы синхронизации, то содержимое регистра всегда передается по правилу «LSB бит - первым».
Бит TCI при значении, равном 1, задает внутреннее инвертирование тактового сигнала передатчика перед его использованием схемами SCC-контроллера. В нормальном режиме работы данные выставляются на линию TXD по отрицательному перепаду тактового сигнала, а считываются с линии RXD - по положительному перепаду тактового сигнала. Установка режима внутреннего инвертирования позволяет выдавать данные на полпериода раньше, т. е. по положительному перепаду тактового сигнала. В данном случае внешним приемником эти же данные будут приняты на один период тактового сигнала позже, т. е. по следующему положительному перепаду этого же тактового сигнала. Использование этого режима работы рекомендовано для контроллеров HDLC, Transparent и Ethemet-протоколов при высоких частотах передачи (больше чем 8 МГц), так как этот режим обеспечивает дополнительное время предустановки и настройки рабочей частоты для внешнего приемника.
Таблица 5.18
Тип синхросимволов
Протокол Назначение регистра DSR
UART Используется для задания коэффициента дробных стоп-битов
BISYNC, Transparent Задает формат синхросимволов SYNC1, SYNC2
HDLC Задает формат двух открывающих флагов кадра (код 0х7Е7Е)
N8
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
15 14 13 12 1 1 10 9 8 7 6 5 4 3 2 1 0
SYN2 I SYN1
Рис. 5.37. Формат регистра синхронизации DSR
Настройка режимов блока DPLL. Каждый SCC-канал содержит блок DPLL (Digital Phase-Locked Loop), который выполняет кодирование/декодирование данных от SCC-канала. Ниже приведены основные режимы кодирования/декодирования (рис. 5.38).
• NRZ: «1 •> - кодируется высоким уровнем сигнала на битовом интервале; «О» - кодируется низким уровнем сигнала на битовом интервале.
• NRZI MARK: «1» - кодируется отсутствием перепадов и смен состояния сигналов на битовом интервале; «О» - кодируется перепадом сигнала (сменой состояния сигнала на противоположное) в начале битового интервала.
• NRZI SPACE: «1» - смена состояния сигнала на противоположное в начале битового интервала; «О» - нет смен и перепадов сигнала на битовом интервале.
• FM0: «1» - кодируется перепадом сигнала в начале битового интервала; «О» - кодируется перепадом сигнала в начале и в центре битового интервала.
• FM1: «1» - кодируется перепадом сигнала в начале и в центре битового интервала; «О» - кодируется перепадом сигнала в начале битового интервала.
• Manchester: «1» - кодируется отрицательным перепадом сигнала в середине битового интервала; «О» - кодируется положительным перепадом сигнала в середине битового интервала. При этом допускаются перепады сигналов на границах битового интервала, чтобы обеспечить правильную полярность перехода в середине.
• Differential Manchester: «1» - кодируется сменой сигнала в середине битового интервала. Направление перепада должно быть противоположным направлению перепада на предыдущем битовом интервале; «О» - кодируется сменой сигнала в середине битового интервала. Направление перепада должно быть аналогичным направлению перепада на предыдущем битовом интервале.
Настройка блока DPLL на определенный режим работы производится при программировании регистра режима SCC-канала GSMR (табл. 5.19). Биты RENC определяют способ декодирования данных при приеме, а биты TENC - способ кодирования данных при передаче. Способ кодирования NRZ обычно используется SCC-каналами, если блок DPLL не работает.
DATA
NRZ
NRZI MARK
NRZI SPACE
FMO
FM1
MANCHESTER
DIFFERENTIAL MANCHESTER
Рис. 5.38. Способы кодирования сигналов в DPLL-блоке
494
ОРГАНИЗАЦИЯ КОММУНИКАЦИОННЫХ ПРОЦЕССОРНЫХ МОДУЛЕЙ В КМК
Таблица 5.19
Выбор способа кодирования данных
Значение битов RENC или TENC Способ кодирования/декодирования
ООО NRZ
001 NRZI MARK
010 FM0
011 Зарезервировано
100 Manchester
101 Зарезервировано
110 Differential Manchester
111 Зарезервировано
Блок DPLL может быть настроен на дополнительное инвертирование выходных данных при передаче, если 6htTINV = 1, и на инвертирование входных данных при приеме, если бит RINV = 1, Инвертирование сигналов используется для получения дополнительных способов кодирования. Например, для получения способа кодирования FM1, если выбран способ кодирования FM0, или для получения способа кодирования NRZI SPACE, если выбрано кодирование NRZI MARK.
Обычно преобразование сигналов в DPLL-блоке используется, если канал работает ссамосинхронизирующимися кодами, в которых тактовая частота передается внутри сигналов данных, т. е. она заложена в специально кодированные данные. Но если пользователь желает работать с данными, которые тактируются отдельной внешней частотой, то режим DPLL может быть выключен. DPLL-кодирование также не применяется, если SCC-контроллер настроен на режим работы с протоколом Ethernet.
При приеме DPLL-блок выделяет тактовую частоту из сигналов данных и передает ее и сами данные на обработку SCC-каналу. При передаче DPLL-блок кодирует данные от SCC-каналов, используя самосинхронизирующее кодирование, и передает их по сети. Для определения величины битового интервала блок DPLL использует или внешнюю тактовую частоту, или частоту от внутреннего BRG-генератора. Рекомендуется, чтобы тактовая частота была в 8, 16 или 32 раза больше, чем частота передачи данных по каналам связи. Биты TDCR и RDCR в регистре GSMR задают коэффициент отношения частоты передава-емых/принимаемых данных и частоты тактирования блока DPLL (табл. 5.20). Если блок DPLL не используется, то все протоколы, кроме UART, работают с коэффициентом 1х. При работе с протоколом UART в асинхронном режиме значения этих битов всегда определяют коэффициенты 8х, 16х или 32х. Выбор значений этих битов зависит от способа кодирования, и обычно приемник и передатчик используют одинаковый коэффициент увеличения TDCR = = RDCR. При использовании коэффициента 8х достигается максимальная скорость обработки данных в контроллере, а коэффициент 32х обеспечивает высокое разрешение и высокую надежность приема/передачи данных.
Таблица 5.20
Коэффициент внутреннего увеличения частоты
Значение битов TDCR или RDCR Коэффициент внутреннего увеличения частоты
00 1х (используется только для NRZ- и NRZI-кодирования)
01 8х
10 16х (рабочий режим работы для протоколов UART и Apple Talk)
11 32х
495
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
При начале работы блок DPLL находится в режиме поиска и ожидает перепада сигнала на линиях данных. Первый перепад вызывает сброс внутренних счетчиков DPLL и начало рабочего режима работы. Далее блок DPLL запускает счетчики и ищет очередной перепад сигнала на линиях данных. Если следующий перепад сигнала обнаружен, то блок DPLL, зная используемый способ кодирования и анализируя значение счетчиков определяет частоту передаваемых данных.
Биты EDGE определяют, по какому фронту тактового сигнала блок DPLL будет анализировать линии данных. Если биты EDGE = 00, то состояние линии данных RXD будет анализироваться и по положительному перепаду тактового сигнала, и по отрицательному. При приеме закодированного сигнала блок DPLL должен настроиться на определение значения входных данных в определенных точках, чтобы проверить правильность кодирования данных и определить величину битового интервала. Если EDGE = 01, то только положительный фронт тактового сигнала используется для опроса значения на линии RxD, а если EDGE = 10 - только отрицательный фронт. Если EDGE = 10, то настройка DPLL-блока не производится.
В регистре GSMR в бите TSNC пользователь может определить максимально допустимый интервал без перепадов сигналов (табл. 5.21). Если счетчик DPLL достиг указанного значения, а перепада сигнала на линии RXD нет, то сигнал несущей тактовой частоты становится пассивным. Если на линии RXD есть передача, то сигнал несущей частоты активен.
Таблица 5.21
Задержки потери несущей частоты
Значение бита TSNC Интервал задержки в битовых интервалах
Режим 1х Режимы 8х, 16х, 32х
00 Без ограничения Без ограничения
01 14 6,5
10 04 1,5
11 03 1
Значение бита TSNC = 01 обычно применяется, если SCC-контроллер работает с протоколом Apple Talk. Эти биты могут быть использованы в протоколе, чтобы избежать возникновения прерываний при изменении состояния сигнала cd , которое может происходить в течение передачи последовательности синхронизации кадра, которая предшествует открывающему флагу кадра.
Для того чтобы блок DPLL мог заранее настроиться на частоту приема данных, перед кадром данных обычно посылаются специальные символы или преамбулы (preamble), или символы флага, или SYNC-символы синхронизации. Другие же протоколы требуют посылки специальных символов, состоящих из чередующихся битов «1» и «0». При передаче данных каждый SCC-канал может быть настроен на передачу преамбулы. Длину преамбулы определяют значения битов TPL (табл. 5.22) в регистре GSMR, а формат преамбулы определяют значение битов ТРР (табл. 5.23). Значения битов ТРР и TPL игнорируются, если SCC-канал работает с протоколом UART.
В табл. 5.24 приведены требования к формату и длине преамбулы для различных методов кодирования, соблюдение которых необходимо, чтобы блок DPLL смог распознать несущую частоту.
496
ОРГАНИЗАЦИЯ КОММУНИКАЦИОННЫХ ПРОЦЕССОРНЫХ МОДУЛЕЙ В КМК
Таблица5.22
Длина преамбулы
Биты TPL Длина преамбулы пр передача кадра, бит
ООО Преамбула не используется
001 8
010 16
011 32
100 48 (используется для протокола Ethernet)
101 64
110 128
111 Зарезервировано
Таблица 5.23
Длина преамбулы
Биты ТРР Формат преамбулы
00 Все биты равны 0
01 Повтор комбинации 10 (используется для Ethernet-протокола)
10 Повтор комбинации 01
11 Все биты равны 1 (используется для протокола Local Talk)
Таблица5.24
Требования к формату преамбулы для различных протоколов ><.
Метод кодирования Формат преамбулы Требуемая максимальная длина, бит
NRZI Mark 11111111 8
NRZI Space 11111111 8
FM0 11111111 8
FM1 00000000 8
Manchester 10101010 8
Differential Manchester 11111111 8
Бит TEND определяет состояние сигналов на выходах передатчика при пассивном состоянии линии TxD при работе в NMSI-режиме. Если бит TEND = 0, то кодировке подвергаются только данные кадра, включая все флаги и синхропоследовательности. Когда передачи нет, линия TxD = 1 (высокий уровень). Если бит TEND = 1, то все данные, которые выдаются на линию TxD, кодируются выбранным способом. При пассивном состоянии линии передаются закодированные единичные биты IDLE.
Максимальная частота передачи данных, которую может обеспечить блок DPLL при работе в режиме 8х и внешнем кварце в 25 МГц, равна 25 МГц/8 = 3,125 МГц. Таким образом, частота, которая поступает с внешнего входа CLKx или от внутреннего BRG-генератора при работе с 25 МГц контроллером, может быть более 25 МГц, если DPLL работает в режиме 8х, 16х или 32х. Ограничение частоты тактирования SCC-каналов величиной SynCLK/2 не применяется к увеличению частоты блоком DPLL, так как часто
497
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
та для тактирования SCC-каналов формируется внутри, после того как блок DPLL сформирует частоту приемника. Поэтому даже самая быстрая DPLL частота (8х) просто удовлетворяет требованию 1:2.
Настройка режима кодирования в SIR-протоколе. Особый способ кодирования применяется в протоколе Serial Infta-RED (SIR). Канальный уровень этого протокола основан на стандарте передачи асинхронного протокола ASYNC HDLC. Для передачи данных по сети используется формат UART-кадра: 1 старт-бит, 8 бит данных, 1 стоп-бит, битов контроля по четности нет (рис. 5.39). При кодировке данных нулевой бит «О» кодируется импульсом шириной 3/16 битового интервала по середине битового интервала, бит IRP в регистре режима GSMR определяет полярность этого импульса. Единичный бит «1» кодируется битовым интервалом без изменения сигнала. Если бит IRP равен 0, то «О» кодируется импульсом высокой полярности (high), если же IRP = 1, то импульсом отрицательной полярности (low). Способ кодирования SIR-протокола поддерживается только на канале SCC2. Для активации этого способа кодирования требуется в битах RDCR и TDCR регистра режима GSMR задать коэффициент увеличения частоты 16х, а бит SIR установить в «1».
Устранение помех и ложных срабатываний. Помехи, которые воздействуют на тактовые сигналы и приводят к неправильному срабатыванию схем приемника и передатчика, являются проблемой систем телекоммуникаций. Системы, которые используют для тактирования своих схем внешние источники тактовых сигналов, особенно подвержены этим ошибкам, которые могут возникать из-за сторонних шумов, из-за подключения/разъе-динения аппаратуры и кабелей или из-за неправильного волнового согласования линий. Каналы SCC-контроллеров в МРС860 содержат специальную схему, которая позволяет обнаруживать «глюк» (glitch) на линиях тактового сигнала, который может вызвать переход SCC-контроллера в неправильное ошибочное состояние. Эта схема позволяет вовремя известить систему о проблемах на физическом уровне управления. Схема обнаруживает два типа «глюка». Первый тип (или всплеск) регистрируется, если перепад сигнала между уровнями «О» и «1» состояния происходит быстрее, чем за минимальный допустимый интервал смены состояния тактового сигнала. Второй тип регистрируется, когда смена состояния тактового сигнала происходит с нормальной скоростью, но присутствует большой чрезмерный сторонний шум.
Внутренние схемы блока DPLL пропускают входную частоту через фильтр шумов, чтобы убрать паразитные всплески и оставить один чистый сигнал. Для включения этой схе-
498
ОРГАНИЗАЦИЯ КОММУНИКАЦИОННЫХ ПРОЦЕССОРНЫХ МОДУЛЕЙ В КМК
мы в работу в регистре GSMR введен дополнительный бит GDE. Если этот бит равен 1, то схема обнаружения «глюка» работает нормально и в случае возникновения ошибки будет установлен соответствующий бит в регистре событий SCC-канала. Если этот бит равен О, то схема обнаружения ошибок выключена и данный режим следует использовать, если каналы тактируются от внутренних источников тактовых сигналов или если тактовая частота от внешних источников превышает максимальную частоту работы схемы обнаружения, что составляет 6,25 МГц при частоте кварца 25 МГц.
Механизм прерываний. Управление обработкой прерывания от SCC-каналов производится контроллером прерывания, который входит в состав СРМ, с помощью регистров запросов CIPR, регистра маски CIMR и регистра обслуживаемого прерывания CISR.
Если некоторый SCC-канал желает прервать работу центрального процессора, то он должен установить i бит в регистре запросов на прерывание CIPR (табл. 5.25), который соответствует прерыванию от этого канала. При желании пользователь может замаскировать прерывание от выбранного SCC-канала, сбросив в «О» i бит в регистре маски CIMR. Если же центральный процессор в текущий момент времени занят обработкой прерывания от выбранного SCC-канала, то в регистре обслуживаемых прерываний CISR будет установлен в «1» i бит, соответствующий этому SCC-каналу. Во всех регистрах обслуживания прерывания i бит соответствует одному и тому же SCC-контроллеру.
Таблица 5.25
Прерывание от каналов
Канал ввода/вывода Номера битов, закрепленных за каналом в регистрах контроллера прерываний MPC860
SCC1 30
SCC2 29
SCC3 28
SCC4 27
Ошибки SDMA 22
Таблица RISC-таймеров 17
!2С 16
SPI 05
SMC1 04
SMC2 (PIP) 03
Взаимные приоритеты запросов на прерывание между четырьмя SCC-каналами в СРМ программируются в регистре конфигураций контроллера прерываний CICR (рис. 5.40). Следует отметить, что регистр CICR производит настройку приоритетов только SCC-каналов и не влияет на приоритеты других каналов ввода/вывода. Имеется четыре позиции приоритетов (a, b, с, d), самая приоритетная - позиция а.
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 3
Зарезервировано SCdP SCcP SCbP SCaP
16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
IRL[0:2] НР[0:4] IEN Зарезервировано SPS
Рис. 5.40. Формат регистра конфигураций контроллера прерываний CICR в МРС860
499
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
Биты SCCaP, SCbP, SCcP и SCdP определяют, какой SCC-канал занимает выбранную позицию в таблице приоритетов (табл. 5.26).
Таблица5.26
Приоритеты каналов
Биты SCxP Канал
00 SCC1
01 SCC2
10 SCC3
11 SCC4
Бит SPS определяет абсолютные приоритеты запросов от SCC-каналов среди запросов от других модулей контроллера (табл. 5.27). Если бит SPS = 0, то все запросы от SCC-каналов сгруппированы вместе и имеют высокий приоритет относительно других запросов. Если бит SPS = 1, то запросы от SCC-каналов распределены по таблице приоритетов среди других запросов.
Таблица 5.27
Уровни приоритетов модулей коммуникационного процессора в МРС860
Канал ввода/вывода Вектор прерывания Уровень приоритета
Бит SPS = 0 Бит SPS = 1
SCCa 11110 (1E) 11110 (1Е) Высокий
SCCb 11101 (1D) 10011 (13)
SCCc 11100 (1C) 01101 (0D)
SCCd 11011 (1B) 01000 (08)
Ошибки SDMA 10110 (16) 10110 (16)
RISC-таймеры 10001 (11) 10001 (11)
l2C 10000 (10) 10000 (10)
SPI 00101(05) 00101 (05)
SMC1 00100 (04) 00100 (04)
SMC2/PIP 00011 (03) 00011 (03) Низкий
Остальные биты в регистре CICR определяют работу самого контроллера прерывания. Бит IEN при значении IEN = 1 разрешает работу контроллера прерывания, а при значении IEN = 0 - запрещает.
Биты IPL определяют уровень приоритета запросов на прерывание от контроллера прерывания к центральному процессору. Уровень 0 соответствует самому высокому приоритету, а уровень 7-самому низкому. Обычно для нормальной работы механизма прерывания устанавливают уровень приоритетности запросов от контроллера прерывания равным IPL = 4.
Биты HP определяют, запрос на прерывание от какого модуля будет иметь самый высокий приоритет при обработке его контроллером прерывания. Значения этих битов могут динамически меняться вовремя работы. Обычно самым приоритетным устанавливают запрос с вектором прерывания, равным 11111 (1F), от линии 15 порта С.
Регистры событий. При работе в канале связи каждого канала ввода/вывода происходит достаточно много различных событий, каждое из которых может требовать прерывания и вмешательства центрального процессора для анализа сложившейся ситуации.
500
ОРГАНИЗАЦИЯ КОММУНИКАЦИОННЫХ ПРОЦЕССОРНЫХ МОДУЛЕЙ В КМК
15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
— — — GLr GLt — AB IDL GRA BRKe BRKs — CCR BSY TX RX UART
— — — GLr GLt DCC FLG IDL GRA — — TXE RXF BSY TXB RXB HDLC
— — — GLr GLt — — IDL — BRKe BRKs TXE RXF BSY TXB RXB ASYNC HDLC
— — — GLr GLt DCC — — GRA — — TXE RCH BSY TX RX BISYNC
— — — GLr GLt DCC — — GRA — — TXE RCH BSY TX RX Transparent
— — — — — — — — GRA — — TXE RXF BSY TXB RXB Ethernet
Рис. 5.41. Форматы регистров событий в МРС860 для коммуникационных протоколов, с которыми работают SCC-контроллеры
Так, в контроллере МРС860 регистрируется до 13 событий, которые могут требовать выставления запросов на прерывание (рис. 5.41,5.42). Набор событий в канале связи зависит от типа протокола, с которым работает SCC-контроллер. Для регистрации этих событий каждый SCC-канал имеет собственный регистр событий SCCE. При регистрации некоторого события в SCC-канале происходит установка бита, соответствующего этому событию, в регистре SCCE.
Установка хотя бы одного бита события в этом регистре приводит к немедленной установке бита прерывания отданного SCC-канала в регистре регистрации прерываний CIPR. Прерывание от SCC-канала не регистрируется, если содержимое регистра SCCE равно 0. Следует помнить, что прерывание от SCC-канала в регистре CIPR будет обнаружено контроллером прерываний, только если оно разрешено в регистре маски CIMR.
Обработка регистров событий всех каналов производится независимо друг от друга. При обработке прерывания от SCC-канала следует сразу же сбрасывать соответствующий бит события в регистре SCCE, чтобы контроллер прерывания мог зарегистрировать и обработать запросы на прерывания от других событий. Сброс бита события в ре-гист-ре SCCE производится записью в этот бит «1».
Прерывание от любого события может быть замаскировано в регистре маски SCCM. Расположение битов событий в регистрах SCCE и SCCM аналогично. При включении питания и при системном сбросе регистр регистрации событий SCCE равен 0 и все прерывания от событий, происходящих в SCC-канале, замаскированы.
Изменение состояния на линии приема RXD, т. е. идет прием данных или идет прием IDLE-последовательностей холостого хода, регистрируется в бите IDL. Но для того, чтобы узнать новое состояние сигналов на линии RXD, пользователь должен прочитать содержимое регистра статуса SCCS.
Событие приема по линии RXD BREAK символа будет зарегистрировано в бите BRK регистра событий SCCE. Событие начала приема по линии RXD BREAK последовательности (при этом начало каждого нового BREAK-символа в последовательности отдельно не регистрирует) будет зарегистрировано в бите BRKs регистра событий SCCE. Событие
7 6 5 4 3 2 1 0
— BRKe — BRK — BSY TX RX SMC UART-контроллер
— — — TXE — BSY TX RX SMC Transparent-контроллер
— — MIME TXE — BSY TXB RXB SPI-контроллер
— — — TXE — BSY TXB RXB 12С-контроллер
Рис. 5.42. Форматы регистров событий в МРС860 для коммуникационных протоколов, с которыми работают другие каналы ввода/вывода
501
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
обнаружения на линии RXD конца BREAK-последовательности (получении первого «единичного» бита) будет зарегистрировано в бите.
Если во время передачи данных в SCC-канале возникла ошибка или потери cts -сигнала, или незаполнения буфера (underrun), то это событие регистрируется в бите ТХЕ := 1. Transparent-контроллер регистрирует только возникновение ошибки underrun. Для SPI-контроллера ошибка underrun регистрируется только в slave-режиме работы.
UART-контроллер проверяет, является ли каждый принимаемый символ контрольным служебным символом, сравнивая формат символа с заданными форматами служебных символов. Если некоторый символ распознан как контрольный, и в ячейке таблицы служебных символов для него установлен бит R = 1, то символ не сохраняется в буфере памяти, а только записывается в регистр временного хранения RCCR, и это событие регистрируется в бите CCR.
В BISYNC-контроллере прием по каналу связи одного из заранее определенных служебных символов, который записывается в буфер данных в памяти, регистрируется в регистре событий установкой бита RCH. В Transparent-контроллере в этом бите регистрируется событие приема одного символа данных.
Если корректный символ данных был принят во внутренний регистр SCC-канала, но RISC-контроллер не обнаружил свободного буфера BD для передачи в него данных, то регистрируется состояние занятости и устанавливается бит события BSY := 1. При приеме символа в UART-контроллере свободный буфер должен быть подготовлен не позднее середины приема стоп-бита, иначе принятый символ будет отброшен из-за возникшего состояния занятости. Приемник при этом переходит в режим поиска следующего кадра данных (режим «охоты»).
Если при приеме данных текущий буфер заполнился, то устанавливается бит RX = 1 в регистре SCCE и текущий буфер закрывается. Регистрация этого события происходит в UART-контроллере и в UART SMC-контроллере не раньше середины приема первого стоп-бита последнего символа в буфере. В Transparent-контроллере событие регистрируется не раньше чем через 10 периодов тактового сигнала после приема последнего бита последнего байта данных из текущего буфера.
Событие завершения приема полного кадра данных регистрируется установкой бита RXF. В контроллерах HDLC и ASYNC HDLC этот бит устанавливается не раньше, чем через два периода тактового сигнала после окончания приема последнего бита, закрывающего флага кадра.
Событие приема одного из буферов данных (но не полного кадра или не полного законченного сообщения в DDCMP-контроллере) регистрируется установкой бита RXB в регистре событий, обычно это имеет место, если в слове состояния дескриптора текущего буфера приема установлен бит I = 1 (Interrupt), т. е. пользователь настроил контроллер на прерывание после приема этого буфера данных. В контроллерах SPI и 12С это событие регистрируется, когда последний символ записан в буфер приемника, и этот буфер закрыт.
Событие передачи буфера данных регистрируется в бите ТХ. Если в слове состояния текущего буфера UART-контроллера был установлен бит CR = 1, то бит ТХ будет установлен в «1», когда передатчик начнет передачу последнего символа из буфера FIFO. Если же бит CR=0 или с UART-протоколом работает канал SMC, то бит ТХ будет установлен, когда последний символ из буфера данных будет передан в буфер FIFO передатчика SCC-канала. В BISYNC-контроллере этот бит устанавливается, когда началась передача последнего бита данных или поля BCS. В контроллере SMC, работающем с протоколом Transparent, если переданный буфер не был последним буфером кадра, то установка бита ТХ производится при записи в буфер FIFO передатчика последнего байта из
502
ОРГАНИЗАЦИЯ КОММУНИКАЦИОННЫХ ПРОЦЕССОРНЫХ МОДУЛЕЙ В КМК
буфера данных, и пользователь должен будет ждать два периода передачи символа, чтобы быть уверенным, что передача прошла успешно. Если же это был последний буфер текущего кадра, то бит устанавливается не раньше, чем начнется передача последнего символа кадра, и пользователь должен будет ждать один период передачи символа, чтобы быть уверенным, что передача прошла успешно.
Если текущий буфер данных был передан по каналу связи и если в слове состояния переданного буфера был установлен бит прерывания l(lnterrupt), то устанавливается бит ТХВ. Если это был не последний буфер кадра или контроллер настроен на работу с интерфейсом SPI, то установка бита ТХВ производится при записи в буфер FIFO передатчика последнего байта из буфера данных. Если же это был последний буфер текущего кадра, то бит устанавливается не раньше, чем начнется передача предпоследнего бита последнего байта кадра. В контроллерах HDLC и ASYNC HDLC это будет байт закрывающего флага, в Transparent-контроллере - последний байт данных. В контроллере BISYNC бит события ТХВ устанавливается после передачи последнего бита кадра. В контроллерах SPI и 12С бит события ТХВ устанавливается после передачи последнего символа кадра в буфер FIFO передатчика, и пользователь должен будет ждать два периода передачи символа, чтобы быть уверенным, что передача прошла успешно.
Бит GLr устанавливается, когда внутренняя схема DPLL блока обнаруживает «глюк» на линии тактового сигнала приемника.
Бит GLt устанавливается, когда внутренняя схема DPLL блока обнаруживает «глюк» на линии тактового сигнала передатчика.
Бит АВ устанавливается, когда блок автоподстройки частоты обнаруживает отличие в частоте передачи и в частоте работы приемника, и процессор должен произвести запись новых значений в регистры настройки BRG-генератора.
Бит GRA устанавливается, когда передатчик, завершив передачу текущего буфера, закончил выполнение команды GRACEFULL STOP TRANSMIT. Если передатчик в текущий момент времени не вел передачу, то бит GRA устанавливается немедленно.
Изменение состояния (контроллер начинает или заканчивает прием символов флага) на линии приема RXD контроллера HDLC регистрируется в бите FLG. Но для того чтобы узнать новое состояние сигналов на линии RXD, пользователь должен прочитать содержимое регистра статуса SCCS.
Изменение состояния несущей частоты, генерируемой DPLL-блоком, регистрируется в бите DCC. Но для того чтобы узнать новое состояние сигналов на линии RXD, пользователь должен прочитать содержимое регистра статуса SCCS.
Если SPI-контроллер, работая в режиме master, обнаружил активный сигнал SPISEL от другого master-устройства, то регистрируется ошибка режима multimaster и устанавливается бит MIME := 1.
Программирование SCC-контроллера. Буферные дескрипторы. Данные для каждого канала хранятся в буферах данных. Для управления обменом данными с памятью используются параметры, хранящиеся в буферных дескрипторах в области parameter RAM в двухпортовой памяти (dual-port RAM). Месторасположение BD в памяти для каждого канала и распределение их между каналами определяется пользователем. Например, для передатчика канала SCC1 можно выделить 200 BD, а для приемника - только 24 BD.
Все буферные дескрипторы для приема и передачи имеют единый стандартный формат в 4 слова (рис. 5.43), который одинаков для всех используемых коммуникационных протоколов. Первое слово - регистр статуса и контроля, формат которого зависит от конкретного выбранного протокола. Второе слово определяет длину данных или размер текущего буфера данных. Максимальный размер составляет (64 К-1) байт. Третье и четвертое слова содержат 32-битный указатель на расположение первой ячейки буфера данных в памяти.
503
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
15 14 13 12 1 1 10 9 8 7 6 5 4 3 2 1 0
Слово состояния буфера данных Offset+O
Размер буфера данных в байтах Offset+2
Адрес буфера данных в памяти Offset+4
Off set+6
Рис. 5.43. Формат буферного дескриптора BD
Для упорядочения доступа к буферам в СРМ все BD сгруппированы в таблицу, в которой хранятся ссылки на расположение в памяти отдельных буферов (рис. 5.44). Пользователь может запрограммировать стартовый адрес таблицы указателей BD во внутренней памяти контроллера и количество BD в таблице для передачи или для приема для каждого канала. Для ограничения числа BD в таблице в слове состояния последнего BD пользователь устанавливает бит конца таблицы W := 1. Обнаружив этот бит, RISC-контроллер переходит на работу с первым дескриптором в таблице.
При приеме и передаче данные из буферов памяти через SDMA-каналы передаются во внутренние FIFO-буферы канала. Каждый SCC-канал имеет по два SDMA-канала, один из них используется при передаче данных в память, другой - при чтении данных из памяти. Обычно каналы хранят таблицу BD во внутренней двухпортовой памяти, а сами буферы данных - во внешней памяти. Но существует возможность хранить небольшие по размеру буферы данных, например, буферы каналов SPI и PIP, в неиспользуемых областях внутренней двухпортовой памяти. При любом варианте размещения буферов данных доступа к ним будет осуществляться по внутренней шине контроллера.
При доступе к внешней памяти всегда используются специальные функциональные коды FC1-FC3, которые определяют тип адресного пространства. Функциональные коды для каждого канала определены в ячейках RFCR (при приеме) и TFCR (при передаче), которые расположены в протокол-независимой области parameter RAM выбранного канала. Пользователь может изменять значения в этих регистрах, только когда уверен, что канал не обращается к внешней памяти в текущий момент времени.
Для некоторых протоколов поддерживается мультибуферная структура (кадр может занимать несколько буферов). При этом обычно в слове состояния BD бит F (First) указывает первый буфер кадра данных и бит L (Last) - последний буфер кадра. Если кадр занимает несколько буферов, то не обязательно предварительно готовить в памяти все буферы перед началом приема/передачи кадра. Можно подготовить/освободить несколько буферов для начала работы с кадром, а в ходе работы параллельно подготавливать следующие буферы и их дескрипторы. Однако при такой конфигурации буферов возможно возникновение ошибок незаполнения (underrun), если центральный процессор не успеет подготовить для передатчика следующие буферы данных текущего сетевого кадра, или ошибок переполнения (overrun или busy error), если центральный процессор не успеет освободить новые буферы при приеме следующих частей кадра или нового кадра.
Выборка из таблицы BD выполняется по круговой системе. После включения канала в работу RISC-контроллер опрашивает первый BD в таблице. Если буфер, соответствующий этому дескриптору, готов, то он обрабатывается. При обработке текущего буфера RISC-контроллер периодически опрашивает готовность следующего буфера. Алгоритм опроса зависит от конфигурации канала. Если после обработки текущего буфера N следующий буфер N+1 не готов к обработке (не заполнен для передачи или не освобожден для приема), то возникает ошибка переполнения (overrun) при приеме и ошибка незаполнения (underrun) при передаче. В этой ситуации RISC-контроллер будет ждать го-
504
ОРГАНИЗАЦИЯ КОММУНИКАЦИОННЫХ ПРОЦЕССОРНЫХ МОДУЛЕЙ В КМК
DUAL-PORT RAM
TX BUFFER DESCRIPTORS
RX BUFFER DESCRIPTORS
SCC TX BD TABLE POINTER
SCC RX BD TABLE POINTER
FRAME STATUS DATA LENGTH DATA POINTER
SCC RX BD
TABLE
SCC TX BD TABLE
EXTERNAL OR
INTERNAL RAM
TX DATA BUFFER
RX DATA BUFFER
FRAME STATUS DATA LENGTH
DATA POINTER p
Рис. 5.44. Организация памяти при работе с SCC-каналами
товности N+1 буфера и не перейдет к проверке готовности N+2 буфера, даже если он уже готов к обработке. Если следующий буфер готов к обработке, то RISC-контроллер приступает или к его передаче, или к его заполнению при приеме. При переходе к новому буферу контроллер проверяет в слове состояния текущего буфера бит последнего BD в таблице W (Wrap). Если этот бит установлен, то после текущего буфера будет проверяться готовность первого BD в таблице. Если этот бит равен 0, то будет обрабатываться следующий по порядку BD в таблице.
Каждый SCC-контроллер содержит собственный FIFO для передачи данных и FIFO для приема данных. Наличие дополнительной памяти в виде FIFO позволяет согласовывать по скорости работы внутренние каналы передачи данных по шинам контроллера и скорости передачи данных по сети, а также позволяет избежать потерь данных из-за переполнения буферов каналов. У МРС860 в СРМ-модуле объем FIFO не зависит от используемого протокола и составляет по 16 байт для приема и передачи у каналов SCC2-SCC4 и по 32 байта для приема и для передачи у канала SCC1. Размер буферов FIFO каналов SMC, а также портов SPI и РС составляет по два символа для приема и передачи. В контроллере МРС860 порт PIP имеет FIFO приема и передачи размером по одному символу каждый.
При передаче данных бит готовности буфера для передачи R := 1 (Ready) устанавливается центральным процессором. Данные из этого буфера RISC-контроллер передает в буфер FIFO канала передачи. По окончании передачи всех данных из буфера RISC-контроллер сбрасывает бит R := 0. Таким образом, дважды содержимое одного буфера в нормальном режиме работы не передается. Но у СРМ существует одно исключение. В слове состояния BD пользователь может установить бит повторной передачи СМ := 1 (Continuous Mode), при этом если RISC-контроллер снова через цикл опроса обратится к этому буферу, то его содержимое будет повторно передаваться, даже если бит готовности R = 0.
В режиме приема центральный процессор освобождает буфер для приема новых данных и в слове состояния BD этих буферов устанавливает бит пустого буфера Е := 1 (Empty). При приеме данных RISC-контроллер находит пустой буфер и записывает в него данные из буфера FIFO канала приемника. Заполненный буфер закрывается, а RISC-контроллер устанавливает бит занятого буфера Е := 0 и переходит к заполнению очередного буфера. Если текущий буфер заполнен, а следующий еще не освобожден центральным процессором, то генерируется ошибка занятости (busy error).
505
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
15 14 13 12 1 1 10 9 8 7 6 5 4 3 2 1 О
TOD Зарезервировано
Рис. 5.45. Формат регистра TODR
Таким образом, при приеме данных буфер считается занятым, пока центральный процессор не обработает его данные и не установит бит незанятости буфера Е := 1. В нормальном режиме RISC-контроллер не будет записывать новые данные в этот буфер, пока он не будет отмечен как пустой. Но в СРМ пользователь может установить в слове состояния этого буфера бит повторной записи СМ := 1 (Continuous Mode), и RISC-контроллер при повторном обращении к этому буферу будет записывать новые данные поверх старых, даже если буфер отмечен как занятый Е = 0.
Когда буфер весь заполнен при приеме или весь передан при передаче и в его слове состояния установлен бит прерывания 1 = 1, RISC-контроллер посылает прерывание центральному процессору, чтобы он мог обрабатывать данные этого буфера при приеме или заполнять буфер новыми данными при передаче. Прерывание может быть также передано CPU, если при работе с буфером произошла одна из возможных ошибок. Более точная причина ошибки будет установлена в регистре событий (events) SCC-канала и указана в слове состояния текущего буфера.
Существует исключение в правилах обработки буфера при передаче в СРМ. При нормальном алгоритме опроса готовности буфера к передаче RISC-контроллер анализирует бит готовности буфера R каждые 8-32 периода тактового сигнала. Но пользователь может заставить RISC-контроллер начать обработку буфера немедленно, не ожидая, когда наступит время нового опроса готовности бита R у данного буфера. Для чего пользователь должен установить бит R := 1 в слове состояния BD этого буфера и установить бит TOD := 1 в регистре TODR канала SCC (рис. 5.45). Установка бита TOD := 1 повышает приоритет текущего буфера и заставляет RISC-контроллер начать немедленно его обработку. При нормальном алгоритме опроса готовности буфера бит TOD = 0.
Механизм программирования бита TOD позволяет повысить интенсивность передачи данных и часто применяется в протоколах, которые имеют временные ограничения на максимальный интервал между кадрами. Однако использование такого механизма может оказать негативное влияние на передачу данных, которые уже находятся в буфере FIFO передатчика. Поэтому рекомендуется применять программирование регистра TODR канала SCC, только когда буфер данных уже подготовлен и нет передачи на канале в текущий момент времени. Установка бита TOD = 1 в новом буфере не даст желаемого результата, если в текущий момент времени ведется передача из другого буфера, поскольку вначале будет закончена передача из старого буфера, а затем будет опрашиваться бит готовности нового буфера.
Форматы слова состояния буферного дескриптора. Форматы слова состояния буферного дескриптора приемника для различных коммуникационных протоколов приведены в табл. 5.28, 5.29.
При приеме биты с 15-го по 12-й и бит 9 заполняются пользователем перед началом работы с контроллером. Они содержат информацию об общих правилах обработки буфера при приеме. Биты с 11-го по 0-й часто называют битами статуса принятого или переданного кадра. Биты 11 и 10 обычно заполняются при приеме и определяют тип записанной в буфер информации. В биты с 8-го по 2-й записываются коды ошибок, возникших при приеме в кадре данных, и зависящие от типа коммуникационного протокола. В биты 1 и 0 записывается код ошибки, возникшей при приеме в канале связи или аппаратуре.
506
ОРГАНИЗАЦИЯ КОММУНИКАЦИОННЫХ ПРОЦЕССОРНЫХ МОДУЛЕЙ В КМК
Таблица 5.28
Формат слова состояния буферного дескриптора приемника для различных протоколов
Номера битов Протокол
15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
Е - W I с А см ID AM - BR FR PR - OV CD UART-протокол
Е - W I - - см ID - - BR FR PR - OV CD UART-протокол SMC-канала
Е - W I L F см - DE - LG NO AB CR OV CD HDLC-протокол
Е - W I с В см - DE - - DL PR CR OV CD BISYNC-протокол
Е - W I L - см - DE - - NO - CR OV CD Transparent-протокол
Е - W I - - см - - - - - - - OV - Transparent-протокол SMC-канала
Е - W I L F - м - - LG NO SH CR OV CL Ethernet-протокол
Е - W I L - см - - - - - - - OV ME SPI-нтерфейс
Е - W I L F см - ив - LG NO AB CR - - ОМС-протокол
При передаче биты с 15-го по 1-й заполняются пользователем перед началом работы с контроллером. Они содержат информацию об общих правилах обработки буфера при передаче и правилах передачи данных, которые зависят от типа коммуникационного протокола, а также определяют тип передаваемой в буфере информации В биты 1 и 0 записывается код ошибки, возникшей при передаче в канале связи или аппаратуре.
Ниже перечислены биты общего назначения, которые определяют правила обработки и состояние текущего буфера BD.
• Бит пустого буфера Е (Empty) устанавливает в «1» центральный процессор после того, как обработает данные из этого буфера, и буфер можно использовать для приема новых данных. Бит Е = 0 записывает в слово состояния RISC-контроллер после заполнения буфера данными из сети.
• Бит заполненного буфера R (Ready) устанавливает центральный процессор после того, как закончит подготовку в буфере данных для передачи по сети. Этот бит постоянно анализируется RISC-контроллером для начала передачи новых данных и сбрасывается (R = 0) после передачи всех данных из этого буфера.
• Бит последнего буфера W (Wrap), равный 1, сообщает RISC-контроллеру, что текущий буфер - это последний буфер, выделенный этому каналу ввода/вывода, и после его обработки необходимо переходить для работы к первому элементу BD в таблице буферных дескрипторов.
• Бит прерывания I (Interrupt), равный 1, вызывает установку в регистре событий данного канала ввода/вывода бита запроса на прерывание RX или RXB при полном заполнении буфера при приеме данных и бита запроса на прерывание ТХ или ТХВ при передаче всех данных из буфера в сеть.
• Бит продолжения работы CM (Continues Mode), равный 1, определяет, что содержимое этого буфера может быть передано в сеть, даже если не установлен бит готовности буфера R = 0, или что в этот буфер можно записывать данные при приеме, даже если не установлен бит пустого буфера Е = 0.
507
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
Таблица 5.23
Формат слова состояния буферного дескриптора передатчика для различных протоколов
Номера битов Протокол
15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
R - W I CR A CM P NS - - - - - - CT UART-протокол
R - W I - - CM P - UART-протокол SMC- канала
R - W I L TC CM - - - - - - - UN CT HDLC-протокол
R - W I L ТВ CM BCR TD TR в - - - UN CT BISYNC-протокол
R - W I L TC CM - - - - - - - UN CT Transparent-протокол
R - W I L - CM - - - - - - - UN - Transparent-протокол SMC-канала
R PAD W I L TC DEF HB LC RL RC UN CSL Ethernet-протокол
R - W 1 L - CM - - - - - - - UN ME SPI-интерфейс
R - W 1 L TC CM - UB - - - PAD QMC-протокол
Следующая перечисленная группа битов регистрирует возникновение аппаратных ошибок при работе с любым из коммуникационных протоколов и заполняется после завершения обработки текущего буфера.
• Бит СТ (CTS Lost), равный 1, регистрирует ошибку, связанную с потерей сигнала cts= 0 при передаче данных из текущего буфера.
• Бит CD (Carrier Detect Lost), равный 1, регистрирует ошибку, связанную с потерей сигнала cd" = 0 при приеме данных в этот буфер.
• Бит переполнения буфера OV (Overrun), равный 1, регистрирует ошибку, связанную с переполнением буфера FIFO приемника канала ввода/вывода из-за несогласования скорости работы сети и скорости работы каналов SDMA, по которым данные из FIFO пересылаются в память.
• Бит незаполнения буфера UN (Underrun), равный 1, регистрирует ошибку, которая возникает при передаче кадра данных, занимающего несколько буферов, когда передатчик передал всю информацию из буфера FIFO, а новые данные для передачи еще не поступили по каналам SDMA.
Следующий набор битов определяет содержимое буферов.
• Бит контрольного символа С (Control), равный 1, указывает, что последний принятый в буфер символ является контрольным символом.
• Если бит В (BCS received) равен 1, то последний принятый байт в буфере данных содержит контрольную сумму блока (BCS) или части кадра данных.
• Бит адреса A (Address), равный 1, при передаче указывает, что все данные из буфера должны быть переданы как адреса, а при приеме указывает, что первый принятый символ в буфере - это адрес.
• Бит совпадения адреса AM (Address Match) указывает, содержимому какого адресного регистра: UADD1 (если бит AM = 1) или UADD2 (если бит AM = 0) равен адрес в принятом пакете.
• Биты первого F (First) и последнего L (Last) буферов используются в протоколах, где кадр данных может занимать несколько буферов, для указания первого (если бит
508
ОРГАНИЗАЦИЯ КОММУНИКАЦИОННЫХ ПРОЦЕССОРНЫХ МОДУЛЕЙ в кмк
F = 1) и последнего буфера кадра (если бит L = 1). Указание первого и последнего буферов в кадре необходимо для организации прерываний при начале и конце обработки всего кадра данных.
• Если бит В (BCS Enable) равен 1, то при работе с протоколом BISYNC содержимое буфера участвует в вычислении контрольной суммы BCS. Если бит В = 0, то содержимое буфера исключается из подсчета контрольной суммы.
Далее перечислена группа битов, предназначенных для указания ошибок, обнаруженных при приеме кадра данных.
• Если бит BR (Break received) равен 1, то при приеме данных в текущий буфер была получена BREAK-последовательность.
• Если бит FR (Frame Error) равен 1, то при приеме кадра данных была обнаружена ошибка в формате кадра. Например, UART-контроллер принял кадр без стоп-битов.
• Если бит PR (Parity Error) равен 1, то при приеме кадра данных была обнаружена ошибка проверки четности/нечетности.
• Если бит ID (IDLE received) равен 1, то текущий буфер был закрыт при получении максимально возможного запрограммированного числа IDLE-символов «холостого хода».
• Если бит DE (DPLL error) равен 1, то при приеме данных в буфер блоком DPLL была обнаружена ошибка в кодировании данных. Например, при заданном способе кодирования данных перепад сигнала произошел не в центре битового интервала, а на его крае. Обнаружение этой ошибки дополнительно позволяет избежать потери данных из-за сбоя в синхронизации приемника и передатчика.
• Если бит LG (Lenght Violation) равен 1, то принят кадр данных, длина которого превышает максимально допустимую запрограммированную для данного канала ввода/вывода длину принимаемых кадров. При этом в буфер будет записана только часть кадра, размер которой равен установленному пределу.
• Если бит АВ (Abort received) равен 1, то при приеме кадра в буфер была получена ABORT-последовательность минимум из семи последовательных единиц.
• Если бит NO (Nonoctet Aligned Frame) равен 1, то принят кадр данных, длина которого не кратна 8 битам.
• Если бит CR (CRC Error) равен 1, то получен кадр с ошибкой при проверке поля контрольной суммы кадра CRC или поля контрольной суммы части кадра (блока) BCR.
• Если бит SH (Short Frame) равен 1, то принят кадр, длина которого меньше минимальной длины кадра, установленной для данного канала ввода/вывода.
• Если бит CL (Collision) равен 1, то текущий буфер был закрыт из-за обнаружения коллизии при приеме данных.
• Если бит ME (Multimaster Error) равен 1, то текущий буфер был закрыт, поскольку контроллер SPI, работая в текущий момент времени как master-станция, обнаружил сигнал SPISEL от другой станции, действующей в таком же режиме.
• Если бит DL (DLE character error) равен 1, то BISYNC-контроллер, работая в прозрачном режиме, принял служебный символ DLE, но следующий символ не был ни одним из установленных контрольных символов.
Опишем набор битов, предназначенных для управления передачей данных из текущего буфера.
• Если бит Р (Preamble) равен 1, то перед передачей в канал связи содержимого буфера в канал передается символ преамбулы, которая служит разделителем между передачей двух буферов и обеспечивает синхронизацию приемника и передатчика.
• Если бит NS (No Stop Bit) равен 1, то UART-контроллер передает данные из этого буфера, не добавляя к ним единичные стоп-биты.
509
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
• Если бит CR (CTS Report) равен 1, то при передаче двух соседних буферов данных между ними будет передана комбинация из трех битов idle и сброшен сигнал cts . Потеря этого сигнала будет нормально зафиксирована в бите СТ слова состояния этого буфера BD. Если бит CR = 0, то передача двух соседних буферов ведется без пауз и сигнал cts может не сбрасываться, таким образом, бит СТ может быть не установлен, как положено по окончании передачи данного буфера.
• Если бит ТС (Tx CRC) равен 1 и если в BD установлен бит L=1, то после передачи последнего байта данных кадра контроллер передает в канал контрольную сумму кадра. Если бит ТС = 0, то контрольная сумма не передается. При этом контроллер HDLC может после передачи всех данных передавать закрывающий флаг. Отсутствие в кадре данных поля контрольной суммы может использоваться для тестирования работы приемника.
• Если бит ТВ (Tx BCS) равен 1 и если в BD установлен бит L=1, то после передачи последнего байта данных кадра BISYNC-контроллер передает в канал контрольную сумму блока. Если бит ТВ = 0, то контрольная сумма не передается. При этом контроллер может после передачи всех данных передавать символы синхронизации или символы idle.
• Если бит BCR (BCS Reset) равен 1, то перед передачей текущего буфера сбрасывается счетчик контроля BCS суммы блока. Обычно это выполняется при передаче нового блока данных текущего кадра из нового буфера. Если бит равен 0, то сброс счетчиков не производится.
• Если битТО (Transmit DLE) равен 1, то перед передачей этого буфера данных BISYNC-контроллер передает в канал служебный символ DLE.
• Если бит TR (Transparent Mode) равен 1, то BISYNC-контроллер после передачи текущего буфера переходит в режим прозрачной передачи. При возникновении ошибки незаполнения буфера underrun контроллер посылает в канал пары символов DLE-SYNC для поддержания синхронизации в канале связи. Если бит TR = 0, то после передачи текущего буфера контроллер переходит в нормальный режим работы и при возникновении ошибки underrun передает в канал символы синхронизации SYNC.
• Если бит PAD (Short Frame Padding) равен 1 и в слове состояния буфера установлен бит L = 1, то Ethernet-контроллер после передачи всех данных текущего кадра дополняет короткие кадры заполнителем PAD, пока длина кадра не станет равной минимальной установленной длине кадра для данного контроллера. Если бит PAD = 0 и бит L = 1, то добавление заполнителя не производится.
Следующие перечисленные биты устанавливаются Ethernet-контроллером после передачи текущего буфера данных.
• Бит DEF (Defer Indication) устанавливается, если при передаче текущего кадра была обнаружена коллизия.
• Бит НВ (Heartbeat) устанавливается, если коллизия не произошла в течение 20 периодов тактового сигнала передатчика после завершения текущей передачи.
• Бит LC (Late Collision) устанавливается, если коллизия произошла после передачи определенного в контроллере (56 или 64) числа байтов. Передача прерывается. Минимальная длина кадра в Ethernet-протоколе равна 64 байтам, поэтому после успешной, без коллизий, передачи такого кадра возможно возникновение поздней коллизии, которая характерна для протяженных сетей и связана со временем распространения сигналов по кабелю и их задержки в повторителях.
• Бит RL (Retransmission Limit) устанавливается, если контроллер превысил установленное число попыток повторного выхода в сеть после очередного обнаружения коллизии. Обычно число попыток равно 16.
510
ОРГАНИЗАЦИЯ КОММУНИКАЦИОННЫХ ПРОЦЕССОРНЫХ МОДУЛЕЙ В КМК
• Четыре бита RC (Retry Count) хранят число повторных попыток выхода в сеть при возникновении коллизии, которые были сделаны до проведения успешной передачи кадра.
• Бит CSL (Carrier Sence Lost) устанавливается, если при передаче кадра была обнаружена потеря несущей частоты, т. е. нарушена кодировка данных, например, при манчестерском кодировании.
При работе с многоканальным QMC-протоколом вместе с основными стандартными битами в слове состояния буферных дескрипторов используются дополнительные биты.
• Специальный бит UB (User Bit) используется при работе с QMC-протоколом. Пользователь самостоятельно определяет назначение этого бита, который может служить, например, флагом обмена между протоколами верхних уровней управления, пока буфер данных обрабатывается в процессоре. Коммуникационный процессор не работает с этим битом.
• При передаче биты PAD определяют число символов IDLE (OxFF) или FLAG (0х7Е), которые передаются после закрывающего флага. Тип символа определяется значением бита IDLM в регистре режима CHAMR контроллера QMC. Прерывание ТХВ будет выработано только после передачи заданного числа этих символов. Если биты PAD = О, то прерывание будет выработано сразу после передачи закрывающего флага. Число символов PAD зависит от размера ячейки буфера FIFO и числа занимаемых временных слотов, например, число PAD = (размер ячейки FIFO/число временных слотов). Таким образом, после кадра данных передается (PAD+1) число символов флага.
Протокол-независимая часть памяти параметров. Каждый SCC-канал имеет свою собственную память параметров (parameter RAM), которая состоит из двух частей. В первой части (протокол-независимая часть) хранятся параметры настройки SCC-канала, общие для всех каналов. Во второй (протокол-ориентированной) хранятся параметры настройки SCC-канала на работу с определенным протоколом. Содержимое области parameter RAM может быть прочитано пользователем и CPU в любое время. Параметры, которые должны быть проинициализированы пользователем, необходимо записать до момента включения SCC-канала в работу.
Для каждого SCC-канала во внутренней двухпортовой памяти выделена своя область адресного пространства. Начальные адреса памяти, отведенной для каждого канала, фиксированы и известны пользователю. В контроллере МРС860 (табл. 5.30) смещение (offset) канала parameter RAM от базового адреса SCC base address составляет 0 байт.
Внутри область parameter RAM разделена на две части: протокол-независимую (смещение SCC base+OxOO) и протокол-ориентированную независимую (смещение SCC base+ОхЗО). Формат протокол-независимой памяти приведен в табл. 5.31.
Таблица 5.30
Протокол-независимая память параметров для контроллера МРС860
Адрес Название Размер, бит Описание
SCC base+00 RBASE 16 Базовый адрес таблицы RX BD
SCC base+02 TBASE 16 Базовый адрес таблицы ТХ BD
SCC base+04 RFCR 08 Функциональные коды Rx
SCC base+05 TFCR 08 Функциональные коды Тх
SCC base+06 MRBLR 16 Максимальная длина Rx-буфера
SCC base+08 RSTATE 32 Rx-состояние
SCC base+OC - 32 Указатель на ячейку памяти в буфере приема Rx
SCC base+10 RBPTR 16 Указатель на ячейку памяти дескриптора RX BD
SCC base+12 - 16 Счетчик принятых в буфер Rx байт данных
511
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
Продолжение табл. 5.30
Адрес Название Размер, бит Описание
SCC base+14 - 32 Временная переменная Rx
SCC base+18 TSTATE 32 Тх-состояние
SCC base+1C - 32 Указатель на ячейку памяти в буфере приема Тх
SCC base+20 TBPTR 16 Указатель на ячейку памяти дескриптора Тх BD
SCC base+22 - 16 Счетчик переданных из буфера Тх байт данных
SCC base+24 - 32 Временная переменная Тх
SCC base+28 RCRC 32 Текущее значение CRC-суммы при приеме кадра
SCC base+2C TCRC 32 Текущее значение CRC-суммы при передаче кадра
Примечание. Переменные в ячейках RBASE, TBASE, RFCR, TFCR и MRBL инициализируются пользователем до начала работы с SCC-контроллером. К остальным ячейкам контроллер обращает -ся при работе, и пользователю не рекомендуется изменять их содержимое.
Переменные RBASE и TBASE содержат базовый адрес начала таблицы буферов дескрипторов для приема (RxBD) и для передачи (TxBD). В СРМ таблицы BD могут располагаться в любом месте в двухпортовой памяти и иметь размер, который определяет сам пользователь (только установка бита W = 1 в слове состояния BD закрывает таблицу BD). Переменные RBASE и TBASE должны содержать значения, кратные 8.
Каждый SCC-канал имеет переменную MRBLR, определяющую максимальное число байт, которые канал может записать в буфер приема перед переходом на следующий пустой буфер. Канал может записать в буфер меньшее число байт, например, при закрытии буфера из-за ошибки приема, но никогда не сможет записать больше данных, чем указано в MRBLR. Поэтому пользователь должен подготавливать буферы приема размером не меньше, чем величина, указанная в байтах ячейки MRBLR. Изменения, которые пользователь вносит в переменную MRBLR во время работы канала, вступают в силу только тогда, когда SCC-канал переходит к обработке нового буфера BD, т. е. на работу текущего BD изменения не оказывают влияния.
Размер буфера при передаче может быть любым. Общее число байт в буфере для передачи указывается в поле длины буфера во втором слове BD.
Переменные RBPTR и TBPTR указывают адреса текущих обрабатываемых буферов BD во внутренней памяти. После системного сброса или достижения конца таблицы в эти переменные записываются значения RBASE и TBASE соответственно, а далее переход к следующему буферу означает смещения +0x08 (например, RBPTR: = RBPTR + 0x08).
Регистры функциональных кодов RFCR и TFCR имеют одинаковый формат (рис. 5.46) и определяют функциональные коды для приемников и передатчиков SCC. В битах АТЗ-АТ1 содержится код, который будет выставлен на внешних контактах функциональных кодов, чтобы идентифицировать тип доступа к памяти, когда SDMA-канал контроллера обратится к буферам данных, расположенным в памяти. Если в этих битах записан код 1, то канал SDMA обращается к памяти в режиме прямого доступа. .
0 1 2 3 4 5 6 7
Все 0 ВО АТ1 АТ2 AT3
Рис 5.46. Формат ячеек RFCR и TFCR в памяти параметров контроллера МРС860
512
ОРГАНИЗАЦИЯ КОММУНИКАЦИОННЫХ ПРОЦЕССОРНЫХ МОДУЛЕЙ В КМК
Таблица 5.31
Порядок передачи байтов в словах при обмене по сети
Биты Порядок передачи
ВО = 00 ВО = 01 ВО = 10 или ВО = 11 Этот режим поддерживается только для работы с 16(32)-разрядной памятью и реализует при обмене по сети порядок байтов в словах, характерный для оборудования фирм DEC и «Intel». Порядок передачи байтов у этих фирм противоположен порядку байтов, используемому фирмой «Motorola». Таким образом, этот режим работы используется, если в сети работает оборудование различных фирм-производителей. Режим передачи, реализованный в PowerPC-станциях. Данные в этом режиме передаются в сеть в последовательном коде, LSB байт слова передается первым. Этот режим поддерживается большинством коммуникационных контроллеров фирмы «Motorola». Данные передаются в сеть в последовательном коде, и MSB-байт ячейки памяти передается первым.
Биты ВО регистров RFCR и TFCR (табл. 5.31) определяют порядок передачи байтов в словах при обмене по сети. Если пользователь изменил значение этих битов при передаче текущего кадра, то это изменение окажет влияние только при передаче следующего кадра данных в протоколах Ethernet, HDLC и Transparent или следующего буфера данных для других протоколов.
Остальные параметры используются только RISC-контроллером и могут потребоваться пользователю лишь при отладке. Ячейки RX-указатель, ТХ-указатель заполняются для SDMA-канала и указывают адрес следующей ячейки данных в буфере данных, которая должна быть записана/прочитана в режиме SDMA. Счетчики Rx и Тх - это вычитающие счетчики, значение которых уменьшается на единицу при передаче каждого байта по каналу SDMA. Счетчик Rx инициализируется значением MLBR, а счетчикТх-значением из поля длины BD передачи.
Инициализация SCC-каналов. После включения питания все регистры настроек SCC-контроллера находятся в исходном состоянии (состоянии после системного сброса) и для того, чтобы настроить SCC-канал для приема/передачи информации, пользователь должен записать в эти регистры коды настроек. Основные этапы программирования регистров настроек каналов ввода/вывода приведены ниже.
1. Настроить регистры параллельных портов ввода/вывода, чтобы SCC мог использовать внешние контакты (выводы портов) для передачи/приема информации.
В регистре PxPAR указывается, какие линии порта ввода/вывода будут использованы для работы SCC-канала. В регистре PxDIR указывается назначение выбранной линии ввода (input) или вывода (output). В регистре PxODR указывается тип выходного каскада выбранной линии, например, выхода с открытым коллектором, с открытым истоком, с Z-состоянием.
Дополнительно для параллельного порта С в его регистрах PCPAR, PCDIR, PCODR производится настройка выводов cts и со” для работы или как линии портов с возможностью регистрации сигналов по прерыванию, или как дополнительных модемных сигналов для SCC-канала.
2. Если SCC-канал будет работать в режиме временного мультиплексирования с TSA, то необходимо произвести настройку регистров последовательного интерфейса SI. В регистре SIGMR производится выбор рабочего канала TDMa или TDMb и режимов его работы при операциях маршрутизации.
513
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
3. В регистре SIMODE производится настройка рабочего или тестового режима работы каждого TDM-канала, определяется, по каким фронтам и каких сигналов будут производиться действия с данными, а также производится настройка режимов работы SMC-контроллеров и выбор их источников тактирования.
4. Если канал TDM будет работать с памятью маршрутизации, то проводится настройка режимов работы ячеек памяти в SIRAM и настройка регистра команд SICMR.
5. Если SCC-контроллер будет работать в режиме NMSI, то проводится выбор источников тактирования приемника и передатчика в регистре SICR.
6. В регистре конфигурации GSMR следует произвести настройки режимов работы блока кодирования и декодирования сигналов DPLL, выбрать 16/32-разрядную сумму, настроить режимы работы с внешними сигналами сгГ, rts , cts , определить размер FIFO-буфера для временного хранения данных, выбрать режим кодирования данных и формат преамбулы. В этом регистре производится также выбор режима работы или тестового режима работы SCC-канала, но биты включения приемника и передатчика ENT и ENR пока не устанавливаются в активное состояние.
7. Для выбранного коммуникационного протокола необходимо провести настройку его режимов работы в регистре режима PSMR.
8. Если необходимо, для выбранного протокола в регистре синхронизации DSR пользователь может определить формат SYNC-символов синхронизации.
9. Произвести инициализацию параметров в протокол-независимой памяти параметров SCC-контроллера и в протокол-ориентированной памяти параметров в соответствии с особенностями выбранного протокола канального уровня.
10. Очистить все биты регистрации событий в регистре событий SCC-канала SCCE, для того чтобы после включения канала в работу регистрировать события, которые будут происходить при приеме/передаче кадров данных.
11. При необходимости замаскировать в регистре маски SCC-канала SCCM регистрацию прерываний при возникновении некоторых событий.
12. В регистре CICR требуется установить приоритет запросов на прерывание от SCC-канала. При необходимости запросы на прерывание от других источников можно отключить, уменьшив их приоритет до 0.
13. Разрешить прерывание от SCC-каналов в регистре маски CIMR-контроллера прерываний.
14. При необходимости в регистре регистрации прерывания CIPR можно сбросить зарегистрированные в текущий момент времени прерывания от других источников.
15. Установить биты ENT = ENR := 1 в регистре GSMR, разрешив работу передатчика и приемника выбранного SCC-канала.
16. При работе с SCC-каналами пользователь может в любой момент времени произвести модификацию параметров канала, например, настроить его на работу с другой частотой или с другим коммуникационным протоколом. Для этого канал должен быть выключен из работы, а затем снова включен. При этом текущие буферы данных, с которыми работает канал, закрываются, и после возобновления работы канал будет работать с другими буферами.
Последовательность инициализации параметров приемника SCC-канала следующая.
1. Сбросить бит работоспособности (разрешения работы) приемника ENR := 0 в регистре GSMR. Прием будет немедленно прерван и приемник установлен в нормальное состояние.
2. Произвести модификацию памяти параметров и регистров SCC-канала. При желании пользователь может просто сбросить все параметры в исходное состояние, передав контроллеру команду INIT RX PARAMETERS.
514
ОРГАНИЗАЦИЯ КОММУНИКАЦИОННЫХ ПРОЦЕССОРНЫХ МОДУЛЕЙ В КМК
3. Если необходимо, подготовить приемник канала к началу работы и поиску нового кадра данных, который будет записываться в новый буфер. Эти действия выполняются при передаче контроллеру команды ENTER HUNT MODE. После возобновления приема данные будут записываться в буфер BD, адрес которого указан в ячейке RBPTR памяти параметров SCC-канала, но только если этот буфер помечен как пустой (бит Е = 1). Команда ENTER HUNT MODE обязательно передается, если на предыдущем этапе пользователь самостоятельно настраивал новые параметры SCC-контроллера и не использовал команду INIT RX PARAMETERS.
4. Установить бит разрешения приема ENR := 1 в регистре GSMR, разрешив контроллеру начать прием информации из канала связи.
Последовательность инициализации параметров передатчика SCC-канала следующая.
1. Если контроллер в текущий момент времени выполняет передачу кадра данных, то предварительно требуется передать ему команду STOP TRANSMIT для прерывания процесса передачи.
2. Сбросить бит работоспособности (разрешения работы) передатчика ENT := 0 в регистре GSMR_L. Передатчик будет установлен в начальное состояние.
3. Произвести модификацию памяти параметров и регистров SCC-канала. При желании пользователь может просто сбросить все параметры в исходное состояние, передав контроллеру команду INIT ТХ PARAMETERS. Если команда INIT ТХ PARAMETERS не используется, то необходимо передать команду RESTART TRANSMIT.
4. Установить бит разрешения передачи ENT := 1 в регистре GSMR_L, разрешив контроллеру начать передачу в сеть информации из буфера данных, адрес которого указан в ячейке TBPTR.
Если пользователь решил изменить протокол, с которым работает в текущий момент времени SCC-контроллер, то он должен выполнить следующие шаги.
1. Сбросить биты разрешения работы приемника и передатчика SCC-канала ENT = = ENR := 0.
2. Передать каналу команду инициализации всех параметров приемника и передатчика в исходное состояние INIT ТХ and RX PARAMETERS. Произвести настройку регистра GSMR и памяти параметров на работу с другим протоколом.
3. Установить биты ENR = ENT := 1, разрешив SCC-контроллеру работать с новым протоколом.
В коммуникационных контроллерах реализовано полезное решение. Когда биты ENR и ENT некоторого SCC-контроллера равны нулю, то этот контроллер переходит в режим потребления минимальной мощности.
5.2.3. КОНТРОЛЛЕРЫ УПРАВЛЕНИЯ SMC
Каждый коммуникационный контроллер содержит два SMC-контроллера (Serial Management Controllers). SMC-контроллер в МРС860 - это полнодуплексный порт, поддерживающий протоколы UART, Transparent, GCI. Настройка режимов работы SMC-контроллера производится в регистре SMCMR (рис. 5.47). Биты 10, 9, 8 задают параметры, которые определяют работу выбранного коммуникационного протокола.
15 14 13 12 11 10 9 8 7 6 5_____4 3_____2 10
- CLEN * * * - - SM DM TEN REN
Рис. 5.47. Формат регистра режима SMCMR SMC-контроллера
515
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
Включение передатчика SMC-контроллера в работу производится при установке бита TEN, а включение приемника выполняется при записи «1» в бит REN. В SMC-контроллерах реализован режим пониженного энергопотребления, в который он переходит, когда биты разрешения работы TEN и REN некоторого SMC-контроллера равны 0.
Длина передаваемых символов, с которыми работает SMC-контроллер, задается в битах CLEN.
Выбор протокола, с которым будет работать SMC-канал, производится в битах SM (табл. 5.32).
SMC-контроллер поддерживает упрощенную версию UART-протокола, который может быть использован для целей управления и отладки работы контроллера, позволяя освободить от этих задач основные SCC-каналы. Каждый SMC-контроллер поддерживает UART-протокол только в режиме NMSI, используя для его реализации свои собственные внешние контакты. Функционирование контроллера в этом режиме аналогично работе UART-контроллера для SCC-каналов. Тактирование работы SMC UART-koh-троллера выполняется от одного из четырех внутренних BRG-генераторов или от внешнего источника. Но поддерживается только коэффициент внутреннего увеличения частоты, равный 16х.
Таблица 5.32
Режимы работы SMC-контроллера
Биты SM Режим работы канала
00 GCI- или SCIT-интерфейс
01 Зарезервировано
10 UART-протокол
11 Режим «прозрачной передачи» (протокол Transparent)
Протокол Transparent может быть реализован, используя или NMSI-режим работы последовательного интерфейса или мультиплексируемый режим работы TSA совместно с другими каналами ввода/вывода. Функционирование контроллера в этом режиме аналогично работе Transparent-контроллера для SCC-каналов. При подключении SMC Transparent-контроллера к TDM-каналам (например, к линиям Т1) тактирование работы контроллера выполняется от одного из четырех внутренних BRG-генераторов или от внешнего источника (в этом случае поддерживается только коэффициент внутреннего увеличения частоты 1 х). SMC Transparent-контроллер может также использовать для синхронизации приемника и передатчика внешние сигналы через специальные внешние контакты.
Каждый SMC-контроллер поддерживает в полном объеме работу с С/l- и Monitor-каналами GCI-интерфейса для сетей ISDN. Для работы в этом режиме контроллер должен быть подключен к TDM-каналу последовательного интерфейса. При работе в SCIT-режи-ме SMC-контроллеры могут управлять работой каналов С/l и Monitor для временных каналов Channel 0 и Channel 1. В контроллере МС68302 канал SMC дополнительно поддерживает работу и с IDL-интерфейсом, но в МРС860 встроенная поддержка этого интерфейса не предусмотрена, и при желании пользователь при настройке работы памяти маршрутизации TDM-канала может программным путем выбрать режим работы с IDL-интерфейсом. В этом случае SMC-контроллер может работать только с Transparent-протоколом.
Для тестирования работы своих схем приемника и передатчика SMC-контроллер может быть настроен для работы в режимах «внутренней петли» или «автоматического эха» (табл. 5.33). В этих тестовых режимах функционирование SMC- и SCC-контролле-ров аналогично.
516
ОРГАНИЗАЦИЯ КОММУНИКАЦИОННЫХ ПРОЦЕССОРНЫХ МОДУЛЕЙ В КМК
Таблица 5.33
Диагностические режимы работы SMC-контроллера
Биты DM Диагностический режим работы
00 Нормальная работа
01 Режим «внутренней петли»
10 «Эхо»-режим
11 Зарезервировано
При работе SMC-контроллера в режиме NMSI внешний стробирующий сигнал начала обмена поступает и анализируется на контакте SMSYN , внешние тактовые сигналы поступают на вход SMCLK, данные читаются с линии SMRXD и передаются на ли-нию SMTXD. Но для работы SMC UART контроллера внешний стробирующий сигнал SMSYN не используется. При работе в мультиплексируемом режиме данные передаются на контакт L1TXD в выбранном временном слоте и читаются из временного слота с контакта L1RXD. Частота тактовых сигналов для работы приемника и передатчика должна быть одинаковой, и она поступает с контакта L1CLK, строб начала TDM-кадра поступает с контакта L1SYNC.
Память параметров SMC-контроллера. Когда контроллер работает с протоколами UART и Transparent, структура распределения и организация его памяти параметров и буферных дескрипторов аналогичны способам распределения памяти для SCC-контрол-леров. Данные для передачи и данные, которые приняты из сети, хранятся в буфере памяти. В буферах хранится только содержимое поля данных. Старт-бит, стоп-бит и бит контроля при передаче вставляются автоматически и при приеме удаляются самим SMC-каналом и в памяти не хранятся. Все буферные дескрипторы для приема и передачи организованы в виде таблицы, опрос которой ведется по круговой системе. Буферы могут быть расположены или во внутренней, или во внешней памяти. При необходимости буферы могут быть расположены в неиспользуемых областях памяти параметров других SCC- или SMC-каналов. Но, если SMC-контроллер работает с протоколом GCI, для передачи и приема данных заранее выделены буферы фиксированного размера по 16 бит каждый, которые располагаются в протокол-независимой части памяти параметров SMC-контроллера.
Память параметров SMC-каналов располагается во внутренней памяти параметров коммуникационного контроллера для МРС860 на страницах 3 и 4. Память параметров SMC-канала состоит из двух частей: протокол-независимой части, в которой определены общие параметры работы SMC-контроллера, и протокол-ориентированной части, в которой содержатся параметры, определяющие работу выбранных коммуникационных протоколов. Назначение переменных в протокол-независимой памяти параметров SMC-контроллера и структура распределения протокол-независимой памяти совпадает с назначением аналогичных ячеек в протокол-независимой памяти параметров SCC-контроллера.
При работе с SMC-каналами пользователь может в любой момент времени произвести модификацию параметров канала, например, настроить его на работу с другим коммуникационным протоколом. Для этого канал должен быть выключен из работы, а затем снова включен. Большинство параметров настройки контроллера рекомендуется произ-: водить только при выключенных приемнике (бит REN = 0) и передатчике (бит TEN = 0). . При этом текущие буферы данных, с которыми работает канал, закрываются, и после возобновления работы канал будет работать с другими буферами. Рекомендованная последовательность инициализации приемника SMC-канала следующая.
1. Сбросить бит работоспособности (разрешения работы) приемника REN := 0 в регистре SMCMR. Прием будет немедленно прерван, и приемник будет установлен в нормальное состояние.
517
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
2. Произвести модификацию памяти параметров и регистров SMC-канала. При желании пользователь может просто сбросить все параметры в исходное состояние не изменяя режимов работы, передав контроллеру команду INIT RX PARAMETERS. Если команда INIT RX PARAMETERS не используется, то необходимо передать команду CLOSE RX BD или ENTER HUNT MODE.
3. Установить бит разрешения приема REN := 1 в регистре SMCMR, разрешив контроллеру начать прием информации из канала связи.
Рекомендованная последовательность инициализации передатчика SMC-канала приводится ниже.
1. Если контроллер в текущий момент времени выполняет передачу кадра данных, то предварительно требуется передать ему команду STOP TRANSMIT для прерывания процесса передачи.
2. Сбросить бит работоспособности (разрешения работы) передатчика TEN := О в регистре SMCMR. Передатчик будет установлен в начальное состояние.
3. Произвести модификацию памяти параметров и регистров SMC-канала. При желании пользователь может просто сбросить все параметры в исходное состояние, передав контроллеру команду INIT ТХ PARAMETERS. Если команда INIT ТХ PARAMETERS не используется, то необходимо передать команду RESTART TRANSMIT.
4. Установить бит разрешения передачи TEN := 1 в регистре SMCMR, разрешив контроллеру начать передачу в сеть информации из буфера данных, адрес которого указан в ячейке TBPTR.
Работа SMC-контроллера с протоколом UART. Работа SMC-контроллера с UART-протоколом производится аналогично работе с этим протоколом основных коммуникационных SCC-каналов. Но SMC-контроллер поддерживает упрощенную версию UART-протокола, которая имеет следующие отличия:
• контроллер работает с символами, длина которых может быть от 5 до 14 бит (в SCC-контроллерах длина данных может быть от 5 до 8 бит); для хранения данных в памяти используются 16-битные слова;
• контроллер не поддерживает работу с дробными стоп-битами; число стоп-битов задается в разрядах SL; если SL = 0, то один стоп-бит, если SL = 1, то два стоп-бита;
• контроллер не может работать в multidrop-конфигурациях, поэтому из формата кадра исключен бит адреса;
• не поддерживается режим изохронной передачи с коэффициентом внутреннего увеличения частоты 1х;
• при обмене не анализируются сигналы на контактах аГ и rts- ;
• приемник и передатчик могут тактироваться с разной частотой;
• не поддерживается режим распознавания специальных контрольных символов при приеме;
• не поддерживается режим передачи более приоритетного кадра, использующий механизм регистра TODR;
• в регистре статуса не регистрируется IDLE-состояние на линии приемника;
• при передаче данных SMC-контроллер не регистрирует никаких ошибок состояния канала связи и процесса передачи.
Общая длина кадра данных задается в битах CLEN (рис. 5.48) и равна (CLEN+1). Если в этих битах задан код меньше четырех, то будет зарегистрирована ошибка.
15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 О
— CLEN SL PEN PM — — SM DM TEN REN
Рис. 5.48. Формат регистра режима SMCMR для SMC UART-контроллера
518
ОРГАНИЗАЦИЯ КОММУНИКАЦИОННЫХ ПРОЦЕССОРНЫХ МОДУЛЕЙ В КМК
В битах PEN и РМ задается правило использования бита контроля. Если бит PEN = О, то бит контроля исключен из формата кадра. Если PEN = 1 и РМ = 0, то используется контроль по нечетности. Если PEN = 1 и РМ = 1, то используется контроль по четности.
Прием данных SMC UART-контроллером. Если SMC-канал настроен на работу с протоколом UART, то параметры конкретного протокола хранятся в протокол-ориентирован-ной области parameter RAM (табл. 5.34).
После включения приемника в работу контроллер переходит в режим поиска нового кадра данных. После приема первого кадра во временный регистр сдвига контроллер проверяет бит незанятости первого буферного дескриптора в таблице RxBD. Если этот бит Е = 1, то контроллер сохраняет принятый символ в буфере. Если буфер данных заполнен или переполнился счетчик принятых IDLE-символов, SMC-контроллер сбрасывает бит Е:=0 в слове состояния буфера и, если в слове состояния установлен бит I = 1, то генерируется прерывание. Далее контроллер проверяет готовность к приему данных следующего буфера в таблице и, если он пустой, продолжает прием в новый буфер. Если в слове состояния буфера установлен бит СМ = 1, то бит Е при заполнении буфера не очищается, и при следующем обращении контроллера к этому буферу новые данные будут записываться поверх старых.
В UART-протоколе, если в сети нет передачи, то по ней передаются IDLE-символы, которые состоят из определенного числа «1» битов. Размер IDLE-символа зависит от размера кадра данных, на работу с которым настроен канал, и равен: 1 старт-бит + 5-14 битов данных + 1 бит контроля (если он используется) + 1-2 стоп-бита. Приемник канала постоянно подсчитывает число полученных. Таким образом, счетчик IDLC подсчитывает число IDLE-символов, полученных между приемом двух кадров данных, в счетчике IDLC. Если начинается прием нового кадра данных, то содержимое счетчика IDLC сбрасывается. IDLC -это вычитающий счетчик, и при сбросе в него записывается содержимое ячейки MAXJD.
Пользователь может определить максимально допустимое число IDLE-символов между кадрами данных. Это число записывается в ячейку MAXJDL. Если счетчик IDLC досчитал до 0, то возникает ошибка приема «IDLE sequence». Текущий буфер закрывается, в нем устанавливается бит ошибки ID := 1 (закрыто из-за IDLE-переполнения) и генерируется ^-прерывание в регистре событий, если оно разрешено. Если не был открыт буфер для приема, то прерывание не генерируется.
Если при приеме кадра данных обнаружена ошибка контроля по четности/нечетности (parity error), то канал записывает принятый байт в буфер, закрывает буфер, устанавливает бит ошибки PR .- 1 в слове состояния BD и генерирует RX-прерывание через регистр событий (если оно разрешено). Но далее прием продолжается в нормальном режиме.
Таблица 5.34
Протокол-ориентированная память параметров SMC UART-контроллера
Адрес Название Размер, бит Описание
SMC base+28 MAXJDL 16 Максимальное число IDLE-символов
SMC base+2A IDLC 16 Счетчик IDLE-символов
SMC base+2C BRKLN 16 Длина принятой BREAK-последовательности
SMC base+2E BRKEC 16 Счетчик полученных BREAK-символов
SMC base+30 BRKCR 16 Счетчик передаваемых BREAK-символов
SMC base+32 R_MASK 16 Временная переменная
Примечание. Переменные в ячейках MAXJDL, BRKEC и BRKCR должны быть проинициали-зированы пользователем до начала работы с SMC UART-контроллером.
519
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
При приеме UART-контроллер выделяет кадр данных из битового потока по старт-биту в начале и стоп-битам в конце кадра. Если в кадре не обнаружены «1» стоп-биты, то возникает ошибка формата (frame error). Канал записывает принятый символ в буфер, закрывает буфер, устанавливает в его слове состояния бит FR := 1 и генерирует прерывание RX через регистр событий (если оно разрешено). Если произошла ошибка формата, контроль по четности не производится.
При приеме данные записываются в FIFO выбранного канала, далее они под управлением RISC-контроллера по SDMA-каналам пересылаются в память. Размер буфера FIFO приемника равен двум символам (регистр сдвига и регистр данных). Если скорость работы SDMA-каналов и сети не согласована, возможно возникновение ошибки переполнения (overrun), когда ячейки FIFO все заняты, а из сети получены новые данные. В этом случае новые данные пишутся поверх старых, символ записывается в буфер, буфер закрывается и устанавливается бит переполнения OV := 1 в слове состояния BD, и генерируется прерывание RX через регистр событий (если оно разрешено). Далее прием продолжается в нормальном режиме.
При приеме UART-контроллер может использовать вход cd для автоматического контроля наличия передачи в сети. Если сигнал cd равен 1 при приеме символа,, то возникает ошибка (CD lost) потери CD-сигнала. Прием символа прекращается, буфер закрывается, устанавливается бит CD := 1 в слове состояния BD и генерируется прерывание RX через регистр событий (если оно разрешено).
При приеме SMC UART-контроллер может контролировать прием символов BREAK. BREAK - это символ, состоящий из «О» битов и не содержащий стоп-биты. Если контроллер получил последовательность BREAK-символов, то он увеличивает счетчик BRKEC и закрывает текущий буфер приема, устанавливает в его слове состояния бит BR := 1, генерирует прерывание BRK через регистр событий, если оно разрешено. Если контроллер получил последовательность BREAK-символов в середине обработки текущего буфера, то он увеличивает счетчик BRKEC и закрывает текущий буфер приема, устанавливает в его слове состояния бит BR := 1 и генерирует RX-прерывание через регистр событий, если оно разрешено. Контроллер также контролирует длину BREAK-последовательности и записывает измеренное значение в ячейку BRKLN памяти параметров.
Пользователь может управлять работой приемника при помощи команд ENTER HUNT MODE, CLOSE RX BD, INIT RX PARAMETERS.
Передача символов SMC UART-контроллером. При передаче UART-конгроллер получает из буфера FIFO только сам символ, который будет передан в поле данных. Остальные поля кадра заполняются внутри SCC-контроллера. Во-первых, контроллер анализирует, какой тип контроля будет применен, и вычисляет контрольную сумму, которая записывается в бит контроля в кадре данных. Во-вторых, в формат кадра вводится необходимое число стоп-битов.
После включения передатчика в работу (бит TEN = 1 на рис. 5.48) контроллер начинает передавать в сеть символы IDLE. Далее контроллер опрашивает готовность первого буфера BD к передаче. Если буфер готов (бит R = 1 в его слове состояния), то данные по SDMA-каналу загружаются в буфер FIFO канала и начинают передаваться в сеть. Если первый буфер не готов, т. е. бит R = 0, то контроллер передает I DLE-символ и обращается к буферу повторно через 7-16 периодов тактового сигнала передатчика. Где задержка обращения к таблице буферов, определяется длиной кадра данных, на работу с которой запрограммирован контроллер.
Когда все данные из буфера загружены в буфер FIFO, SMC-контроллер устанавливает в слове состояния текущего буфера биты статуса переданного кадра и сбрасывает бит готовности R := 0. Если в слове состояния был установлен бит СМ = 1, то бит R не сбрасывается и содержимое буфера будет повторно передаваться в сеть при следую
520
ОРГАНИЗАЦИЯ КОММУНИКАЦИОННЫХ ПРОЦЕССОРНЫХ МОДУЛЕЙ В КМК
щем обращении контроллера к этому буферу при новом цикле опроса таблицы буферов передачи, и так будет продолжаться, пока пользователь не сбросит бит R. Если в слове состояния был установлен бит прерывания I = 1, то генерируется прерывание к центральному процессору. Далее контроллер проверяет готовность следующего буфера передачи в таблице TxBD. Если этот буфер готов, то данные из него начинают без перерыва передаваться в сеть сразу же за данными предыдущего буфера. Если же следующий буфер не готов (бит R = 0), то контроллер начинает передавать IDLE-символы, пока данные не будут подготовлены.
Если передается первый символ из нового буфера данных, то в слове состояния буферного дескриптора анализируется бит Р. Если этот бит равен 1 (Р = 1), то перед передачей содержимого буфера передается символ преамбулы (все биты 1) и на другом конце канала обнаруживают IDLE-состояние линии связи перед получением данных. Преамбула передается, даже если длина буфера в BD установлена равной нулю. Преамбула представляет собой символ такой же длины, что и передаваемые данные, только все биты в символе равны 1. Если бит Р = 0, то при передаче данных содержимое двух соседних буферов может передаваться без задержек между буферами.
Если UART-контроллер получил от CPU ядра команду STOP TRANSMIT, то он передает в сеть содержимое буфера FIFO передачи, затем передает определенное число символов BREAK, далее он переходит к передаче IDLE-символов, пока не получит команду RESTART TRANSMIT. BREAK-символ представляет собой символ установленной длины, у которого все биты равны 0 и отсутствуют стоп-биты. Количество BREAK-символов, которые UART-контроллер передаст в сеть, указывается пользователем в регистре BRKCR. После передачи заданного числа BREAK-символов контроллер обязательно передаст в сеть хотя бы один символ IDLE перед началом передачи следующего кадра данных. Это необходимо, чтобы приемник смог нормально распознать старт-бит нового кадра.
Контроллер SMC Transparent. SMC-канал, работающий с протоколом Transparent, поддерживает более простые режимы работы и меньшие скорости обмена, чем SCC-канал, работающий с аналогичным протоколом «прозрачной передачи».
В отличие от SCC-каналов, которые могут работать в прозрачном режиме только с 8-или 32-битными символами (это определяется при программировании бита RWF в регистре GSMR), SMC-канал в режиме прозрачной передачи поддерживает символы длиной от 4 до 16 бит. Биты CLEN в регистре SMCMR (рис. 5.49) задают длину символа, которая равна (CLEN+1) байт и должна быть больше четырех.
Если длина символа больше 8 бит, то бит BS в регистре SMCMR определяет, какой байт данных будет передаваться в сеть первым. В нормальном режиме работы, если длина символа меньше 8 бит, то бит BS = 0. Если же длина символа больше 8, и бит BS = 1, то первым будет передаваться байт, расположенный в ячейке памяти с младшим адресом.
В отличие от SCC-каналов SMC-канал не поддерживает подсчет и проверку контрольной суммы CRC при обмене кадрами.
При передаче, так же как в SCC-каналах, в канале SMC поддерживается режим инвертирования порядка следования битов в символе. Если бит REVD = 0, то используется нормальный порядок битов и LSB-бит передается первым. Если бит REVD = 1, то первым передается MSB-бит.
15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
— CLEN — — REVD — — SM DM TEN REN
Рис. 5.49. Формат регистра режима SMCMR для SMC-контроллера при работе в Transparent-режиме
521
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
Как и у SCC-каналов, передатчик и приемник канала SMC в прозрачном режиме для начала работы должны быть синхронизированы. Синхронизация может выполняться двумя способами. Но при любом способе синхронизация производится от внешнего сигнала, а внутренняя синхронизация от SYNC-символов не используется.
Синхронизация SMC-контроллера. Первый способ применяется, когда SMC-контроллер подключен к TDM-каналам через блок TSA последовательного интерфейса. При этом синхронизация кадра выполняется выбранным временным слотом. После обнаружения сигнала синхронизации TDM-кадра строб-сигнала TxSYNC при передаче или строб-сиг-нала RxSYNC при приеме данные будут передаваться/читаться только в те временные слоты, которые закреплены за данным SMC-каналом при программировании памяти маршрутизации SIRAM последовательного интерфейса. Если SMC-контроллер работает с TDM-каналом в режиме полнодуплексного обмена и его приемник и передатчик функционируют независимо со своими стробирующими сигналами TxSYNC и RxSYNC и со своими тактовыми сигналами RxCLK и TxCLK, то синхронизация приемника и передатчика SMC-канала производится отдельно и независимо. Если приемник при чтении данных из TDM временного канала получит команду ENTER HUNT MODE, то синхронизация приемника будет потеряна, текущий буфер закрывается, и канал будет ждать новой синхронизации сигналом RxSYNC.
SMC-канал в режиме прозрачной передачи поддерживает многобуферную структуру хранения кадра данных в памяти. Если текущий буфер данных уже передан во временной канал, то следующий буфер может быть передан в любом временном канале, выделенном для данного SMC-контроллера и новый кадр данных может начаться в том же временном канале, где закончился предыдущий кадр. Если данные из следующего буфера еще не готовы, то во временной канал выдаются символы IDLE, пока не будет подготовлен следующий кадр данных. Таким образом, при передаче данных в первый временной канал TDM-кадра к моменту прихода сигнала строба начала кадра должен быть готов хотя бы один TxBD-буфер данных, и при его передаче не должна возникнуть ошибка незаполнения (underrun), иначе SMC-контроллер будет выключен.
Второй способ синхронизации применяется, когда канал работает со своими собственными выводами в режиме NMSI. Для синхронизации используется отрицательный фронт внешнего сигнала SMSYNx. При этом сигналы RTS > CTS. CD не используются. После включения передатчика (бит TEN = 1) или приемника (бит REN = 1) в работу по первому положительному перепаду тактового сигнала SMCLK контроллер анализирует значение сигнала на внешнем контакте SMSYN. Если сигнал SMSYN = 0, то синхронизация считается установленной. Таким образом, в NMSI-режиме работы последовательного интерфейса приемник и передатчик тактируются от одного тактового сигнала SMCLK и синхронизируются одним сигналом SMSYNC. Ресинхронизация производится только при выключении SMC-контроллера.
Приемник начинает считывать данные по тому же положительному перепаду тактового сигнала, по которому обнаруживается активный сигнал SMSYNC = 0 и устанавливается синхронизация. Приемник не производит повторной синхронизации, даже если в дальнейшем сигнал SMSYNC изменит свое состояние, пока пользователь не выключит приемник из работы, т. е. не сбросит бит REN := 0.
Передатчик начинает выдавать первый символ данных, состоящих из одних единиц, асинхронно от тактового сигнала SMCLK, как только обнаружит отрицательный перепад сигнала на линии SMSYN. Далее, если данные для передачи готовы, то их передача начнется по следующему отрицательному перепаду тактового сигнала SMCLK после окончания передачи первого служебного символа. Если данные для передачи будут подготовлены позднее, то их передача начнется после передачи нескольких символов, состоящих только из единиц. Передатчик не производит повторную синхронизацию, даже если
522
ОРГАНИЗАЦИЯ КОММУНИКАЦИОННЫХ ПРОЦЕССОРНЫХ МОДУЛЕЙ В КМК
в дальнейшем сигнал SMSYNC изменит свое состояние, пока пользователь не выключит передатчик из работы, т. е. не сбросит TEN := 0, или пока не будет получена команда ENTER HUNT MODE.
Передача данных. После включения SMC-передатчика в работу (установлен бит TEN = 1) он начинает выдавать в канал IDLE-символы и опрашивает готовность первого буфера данных в таблице TxBD. Когда буфер будет подготовлен, данные по каналам SDMA переписываются в FIFO-буфер и после синхронизации передатчика передаются в сеть. После передачи всех данных из текущего буфера проверяется бит L в его слове состояния. Если это был последний буфер кадра (бит L = 1), то контроллер сбрасывает бит готовности R := 0 в слове состояния буфера и устанавливает биты статуса переданного кадра данных. После этого контроллер начинает передавать в сеть символы IDLE. Если это был не последний буфер данных текущего кадра (бит L = 0), то в слове состояния сбрасывается только бит готовности R := 0, и контроллер начинает передавать данные из следующего буфера передачи в таблице TxBD.
Если при передаче данные из текущего буфера еще не переписаны в буфер FIFO передатчика, то регистрируется ошибка незаполнения underrun, SMC-контроллер прекращает передачу данных из буфера, буфер закрывается, устанавливается бит ошибки UN := 1 в слове состояния текущего буфера и бит ТХЕ := 1 в регистре событий SMC-канала, вызывая прерывание работы центрального процессора. Далее контроллер начинает передавать в сеть символы IDLE. Ошибка незаполнения underrun не регистрируется в интервалах между передачами отдельных кадров данных. При обнаружении этой ошибки SMC-канал возобновит передачу после получения команды RESTART TRANSMIT.
Если в слове состояния переданного буфера установлен бит прерывания I = 1, то по окончании передачи всех данных из этого буфера центральный процессор будет уведомлен об этом маскируемым прерыванием.
Если в слове состояния буфера передачи установлены биты СМ = 1 и R = 1, то этот буфер будет автоматически повторно передаваться в сеть при каждом новом обращении к нему RISC-контроллера, до тех пор пока пользователь не сбросит бит R := 0.
Прием данных. После включения в работу (установлен бит REN = 1) приемник SMC-контроллера проверяет установление синхронизации. Когда синхронизация приемника выполнена, он проверяет незанятость первого буфера приема в таблице RxBD и начинает записывать в него данные. Когда буфер приема будет полностью заполнен, SMC-контроллер сбросит бит незанятости Е := 0 в его слове состояния и, если установлен бит 1 = 1, сгенерирует маскируемое прерывание к процессору. Если длина принимаемого кадра больше, чем размер текущего буфера приема, то контроллер проверяет незанятость следующего буфера приема в таблице RxBD. Если новый буфер свободен (бит Е = 1), то прием данных продолжается в этот буфер. Если в слове состояния установлены биты Е = СМ = 1, то новые принятые данные будут записываться в этот буфер поверх старых при новом обращении к нему SMC-контроллера.
Если при приеме данных обнаруживается ошибка переполнения буфера FIFO приемника, т. е. RISC-контроллер не успевает освобождать ячейки для приема новых данных, то SMC-контроллер будет вынужден писать новые принятые данные поверх старых, которые будут потеряны. При возникновении этой ошибки SMC-контроллер прекращает прием данных, закрывает текущий буфер приема, устанавливает в слове состояния буфера бит ошибки OV := 1 и бит RX := 1 в регистре событий, уведомляя прерыванием центральный процессор о возникшей ошибке. Прием следующих кадров данных будет продолжен в новый буфер приема из таблицы RxBD.
Работа SMC в режиме GCI-контроллера. В МРС860 каждый SMC-контроллер может управлять и С/l- и Monitor-каналами GCI-кадра в сетях ISDN, а при работе в режиме SCIT-конфигурации каждый из SMC-контроллеров может управлять работой любого 0 или 1 SCIT-канала.
523
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
При функционировании в режиме GCI-контроллера SMC-канал может быть настроен для работы с соответствующим С/1- и Monitor-каналом при программировании памяти маршрутизации SIRAM. Каждый SMC-канал поддерживает полнодуплексные операции с данными выбранного временного канала и может работать в тестовых режимах внутренней петли и автоматического эха.
Карта распределения памяти параметров GCI-контроллера значительно отличается от карт распределения памяти нормальных коммуникационных протоколов (табл. 5.35). В режиме SMC GCI протокол-независимая часть памяти параметров содержит буферные дескрипторы приема и передачи для С/1- и Monitor-каналов и, реже, содержит таблицу указателей на место расположения дескрипторов в других областях памяти. Прото-кол-ориентированная часть памяти параметров для SMC GCI просто отсутствует.
Таблица 5.35
Память параметров SMC GCI-контроллера
Адрес Название Размер, бит Описание
SMC base+00 M_RXBD 16 Буфер приема Monitor-канала
SMC base+02 M_TXBD 16 Буфер передачи Monitor-канала
SMC base+04 CI_RXBD 16 Буфер приема С/1-канала
SMC base+06 CI_TXBD 16 Буфер приема С/1-канала
SMC base+08 RSTATE 32 Переменная внутреннего состояния
SMC base+OC M_RxD 16 Текущие принятые данные Monitor-канала
SMC base+OE M_TxD 16 Текущие переданные данные Monitor-канала
SMC base+10 CI_RxD 16 Текущие принятые данные С/1-канала
SMC base+12 CI_TxD 16 Текущие переданные данные С/1-канала
Каждый SMC-контроллер имеет свой собственный регистр настройки режима SMCMR (рис. 5.50), в котором производится настройка параметров работы SMC GCI-контроллера.
Биты CLEN определяют в битах размеры каналов С/1 и Monitor для SCIT-каналов 0 и 1. Длина каналов вычисляется как CLEN = длина канала C/I + бит А + бит Е + длина канала Monitor - 1.
Биты REN и TEN разрешают функционирование приемника и передатчика SMC-контроллера. Биты SM и DM определяют режимы работы SMC-контроллера и являются общими для всех режимов работы SMC-контроллера.
Бит C# определяет, с каким из SCIT-каналов будет работать выбранный SMC-контроллер. Если бит равен 0, то используется SCIT-канал 0. Если бит равен 1, то используется SCIT-канал 1.
Бит ME определяет, поддерживает ли выбранный SMC-контроллер работу и управление Monitor-каналом. Если бит ME = 0, то М-канал не используется. Если бит ME = 1, то SMC-контроллер работает с Monitor-каналом по правилам протокола Monitor Channel.
Для управления работой SMC-контроллера в режиме GCI пользователь может применять команды: INIT ТХ and RX PARAMETERS - для инициализации ячеек памяти параметров в начальное состояние, TRANSMIT ABORT REQUEST и TIMEOUT - для управления процессом обмена данными при работе с М-каналом в режиме Monitor Channel Protocol. При получении команды TRANSMIT ABORT REQUEST контроллер передаст в сеть запрос на прерывание, используя бит А в формате GCI-кадра. Команда TIMEOUT передается контроллеру, если получен запрос на прерывание в А-канале или истек тайм-аут ожидания ответа от сетевого устройства, к которому была передана команда. При получении этой команды контроллер передаст в сеть запрос на прерывание, используя бит Е в формате GCI-кадра.
524
ОРГАНИЗАЦИЯ КОММУНИКАЦИОННЫХ ПРОЦЕССОРНЫХ МОДУЛЕЙ В КМК
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
CLEN I ME I — I C# — — SM DM TEN REN
Рис. 5.50. Формат регистра режима SMCMR SMC GCI-интерфейса в МРС860
Передача данных по С/1-каналу. Канал С/l с номером 0 в SCIT-режиме используется для передачи управляющей информации между сетевыми устройствами 1-го уровня управления (физический уровень). Сетевые устройства 2-го (канального) уровня управления посылают по нулевому С/1-каналу команды и получают ответы-индикацию от устройств 1-го уровня. Например, коммуникационный контроллер, работающий в режиме ТЕ (terminal equipment), посылает команды активации/деактивации к S/T-трансиверу и получает ответы, сообщающие о переходе в новый режим работы. С/1-канал 1 в режиме SCIT используется для обмена текущей информации о состоянии между сетевыми устройствами 2-го уровня управления или несетевыми периферийными устройствами, например между АЦП или CODEC.
Передача начинается после загрузки данных в буфер передачи C/l-канала (рис. 5.51), который расположен в ячейке CI_TXBD памяти параметров. Далее SMC-контроллер начинает последовательно выдавать данные через C/l-канал к устройству 1-го уровня управления (физический уровень управления).
Бит R (Ready) устанавливается в «1» центральным процессором по окончании подготовки данных для передачи и записи их в биты C/l DATA. Сброс этого бита R := 0 RISC-контроллером после завершения передачи показывает, что центральный процессор может записывать в буфер новые данные для передачи.
Если SMC-контроллер работает в SCIT-режиме с 0-м каналом, то по C/l-каналу передаются 4-разрядные данные, и в битах C/l DATA для хранения этих данных используются только разряды с 10-го по 13-й, а в 8-й и 9-й разряды заносится код 0. Если SMC-контроллер работает в SCIT-режиме с 1-м каналом, то по C/l-каналу передаются 6-разрядные данные, а биты C/l DATA используются для подготовки этих данных к передаче.
О 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
R — C/l DATA — —
Рис. 5.51. Формат буфера передачи C/l-канала в МРС860
Когда буфер передачи C/l-канала становится пустым, будет установлен бит СТХВ в регистре событий SMC GCI-контроллера. При установке любого бита в регистре событий SMCE (рис. 5.52) будет выработан запрос на прерывание, если только прерывание от этого события не замаскировано в соответствующем бите регистра маски SMCM, формат которого совпадает с форматом регистра событий. Запрос на прерывание вырабатывается к контроллеру прерывания, и пользователь должен предварительно разрешить прерывание от SMC-контроллера, чтобы нормально зарегистрировать запрос при наступлении некоторого события в SMC-канале. Сброс запроса на прерывание в регистре событий производится записью в этот разряд кода «1». После системного сброса все разряды регистра событий сброшены в «О».
7_______6________5_______4 3_______2 1 О
Зарезервировано СТХВ CRXB МТХВ MRXB
Рис. 5.52. Формат регистра событий SMCE и регистра маски SMCM в МРС860
525
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
0 1 2 3 4 5 6 7 8 9 10 1 1 12 13 14 15
Е — — — — — | _ | — | СЛ DATA | — —
Рис. 5.53. Формат буфера приема C/l-канала в МРС860
Прием данных по С/1-каналу. При приеме данных по С/1-каналу 0 в режиме SCIT SMC-контроллер постоянно контролирует информацию, которую он получает по С/1-ка-налу. Если одинаковый код получен по C/l-каналам двух соседних GCI-кадров, то он считается корректным. Дублирование передачи данных введено для повышения надежности передачи информации. Принятую информацию SMC-контроллер сравнивает с предыдущей полученной информацией, и, если они различны, то контроллер реагирует на новую команду или ответ. Такая проверка необходима, поскольку некоторые сетевые устройства при отсутствии новых данных для передачи могут повторно передавать последние данные для поддержания канала в рабочем состоянии. При работе в режиме SCIT с С/1-каналом 1 метод дублирования данных при передаче не используется. Прием данных из C/l-канала выполняется в буфер приема (рис. 5.53), который расположен в ячейке CI_RXBD. После приема данных генерируется маскируемое прерывание к центральному процессору и устанавливается бит CRXB в регистре событий SMC-контроллера.
Сброс бита Е (Empty) в «О» RISC-контроллером сообщает центральному процессору, что получены новые данные. Центральный процессор после обработки этих данных устанавливает этот бит в «1», разрешая прием в буфер новых данных. Если бит Е = О и получены новые данные, то они будут потеряны.
Если SMC-контроллер работает в SCIT-режиме с 0-м каналом, то по C/l-каналу передаются 4-разрядные данные, в битах C/l DATA для хранения этих данных используются только разряды с 10-го по 13-й, а в 8-й и 9-й разряды заносится код «0». Если SMC-контроллер работает в SCIT-режиме с 1-м каналом, то по C/l-каналу передаются 6-раз-рядные данные и биты C/l DATA используются для хранения этих данных при приеме.
Передача данных по Monitor-каналу. Канал Monitor (М-канал) 0 предназначен для обмена данными между устройствами 1-го уровня управления, например, для обмена содержимым внутренних регистров. М-канал 1 используется для настройки режимов работы (программирования) и для чтения регистров состояния устройств передачи цифровых данных и голоса типа CODEC.
Передача начинается после загрузки данных в буфер передачи М-канала (рис. 5.54), который расположен в ячейке M_TXBD памяти параметров.
Бит R (Ready) устанавливается в «1» центральным процессором по окончании подготовки данных для передачи и после записи их в биты DATA. Сброс этого бита R := 0 RISC-контроллером после завершения передачи показывает, что центральный процессор может записывать в буфер новые данные для передачи. Если SMC-контроллер работает в режиме протокола Monitor Channel, то бит R сбрасывается после получения подтверждения на переданные данные. Далее SMC-контроллер начинает последовательно выдавать данные в сеть через М-канал. Как только буфер М-канала становится пустым, будет установлен бит МТХВ в регистре событий SMC-контроллера.
О 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
R L AR — — — — DATA
Рис. 5.54. Формат буфера передачи М-канала для МРС860
526
ОРГАНИЗАЦИЯ КОММУНИКАЦИОННЫХ ПРОЦЕССОРНЫХ МОДУЛЕЙ в кмк
Биты каналов А и Е используются для управления передачей по М-каналу. Если SMC-контроллер должен передавать данные, поскольку начался закрепленный за ним временной канал, но бит R = 0, то контроллер будет передавать предыдущие данные, и так будет продолжаться, пока не закончится подготовка новых данных.
Бит L (Last) устанавливается в «1» центральным процессором при записи в буфер передачи последнего байта сообщения (End of Message). SMC-контроллер, проанализировав этот бит, вначале дважды передает (дублирует) последний байт данных по М-каналу, а затем дважды в соседних кадрах передает неактивное значение бита в Е-канале. Получив два раза в соседних кадрах неактивный бит в Е-канале, приемник воспринимает эту ситуацию как прием индикации о конце сообщения.
Когда приемник получит запрос на прерывание по A-каналу и центральный процессор обнаружит эту ситуацию, то последний установит бит AR := 1 (Abort Request), и SMC-передатчик передаст команду End of Message в виде двух соседних GCI-кадров с неактивным значением бита в Е-канале.
Пользователь может принудительно вызвать передачу запроса на прерывание no Е-каналу, если передаст SMC-контроллеру команду TRANSMIT ABORT REQUEST.
В биты 3-7 пользователь должен записывать коды «О» при заполнении буфера новыми данными.
Прием данных по Monitor-каналу. При приеме полученные данные и биты статуса размещаются в буфере приема в ячейке M_RXBD памяти параметров (рис. 5.55).
Биты каналов А и Е используются для управления обменом по М-каналу. Когда принятые данные будут сохранены в буфере приема, центральный процессор уведомляется об этом маскируемым прерыванием. Бит Е (Empty) в ячейке буфера приема сбрасывается в «О» RISC-контроллером, чтобы сообщить центральному процессору, что получены новые данные. Центральный процессор после обработки этих данных устанавливает этот бит в «1», разрешая прием в буфер новых данных. Если бит Е = 0 и получены новые данные, то SMC-контроллер будет ждать установки бита Е = 1 и временно не будет подтверждать прием данных из М-канала. Для подтверждения приема данных от отправителя используется А-канал.
Бит L (Last) устанавливается в «1» SMC-контроллером при приеме по Е-каналу сообщения (End of Message), которое распознается при приеме два раза в соседних кадрах неактивного бит в Е-канале. В этом случае данные, которые были приняты по М-каналу, игнорируются.
Если передатчик SMC-контроллера еще не успел подтвердить по A-каналу прием предыдущего полученного байта данных, а приемник уже принял следующий новый байт данных из М-канала, то регистрируется состояние ошибки и устанавливается бит ER = 1 в ячейке буфера приема M_RXBD.
Для повышения надежности передачи информации передача каждого нового байта данных по М-каналу производится два раза в двух соседних GCI-кадрах. При приеме информации обе копии сравниваются и при их совпадении байт записывается в биты DATA буфера приема и посылается подтверждение о приеме байта по A-каналу. Если же при приеме обнаружено несовпадение двух байтов в соседних кадрах, то они отбрасываются и регистрируется ошибка сравнения с установкой бита ошибки MS = 1.
При заполнении буфера М-канала данными будет установлен бит MRXB в регистре событий SMC-канала.
0 1 2 3 4 5 6 7 8 9 10 1 1 12 13 14 15
Е L RE MS — — — — DATA
Рис. 5.55. Формат буфера приема М-канала
527
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
5.2.4. КОНТРОЛЛЕРЫ ДОПОЛНИТЕЛЬНЫХ КОММУНИКАЦИОННЫХ КАНАЛОВ
Контроллер 12С. Контроллер 12С введен в состав СРМ-модуля коммуникационного контроллера МРС860 и позволяет ему обмениваться данными с другими ЕС-устройствами, такими как микроконтроллеры, EEPROM, устройства реального времени, аналого-цифровые преобразователи.
12С - это синхронный, двунаправленный интерфейс (линия данных SDA и линия тактовых сигналов SCL), который может работать в режимах master-slave и multimaster. Выбор режима выполняется в регистре команд I2COM (рис. 5.56). Если бит M/S = 0, то контроллер работает как slave-устройство, если M/S = 1, то - как master.
О 1_________2_______3______4_______5_______6____7 I
STR Зарезервировано. Инициализируется пользователем записью «0». M/S
Рис. 5.56. Формат регистра команд I2COM
Оба вывода SCL и SDA являются двунаправленными и подсоединяются через резистор к положительному напряжению. Таким образом, поскольку контроллер имеет выводы типа «открытый исток» (open drain), то они могут быть объединены в единую шину для работы в конфигурации multimaster. Когда на 12С-шине нет передачи, то линии SCL и SDA находятся в пассивном «1» состоянии.
Настройка режимов работы ЕС-контроллера производится в регистре режима I2MOD (рис. 5.57). h
'•к
О_______1_______2_______3______4_______5________6______7
— — REVD GCD FLT PDIV EN
Рис. 5.57. Формат регистра режима 12MOD
Включение контроллера в работу производится установкой бита EN := 1. В выключенном режиме (бит EN = 0) контроллер работает в режиме пониженного энергопотребления.
Тактирование приемника и передатчика 12С-контроллера выполняется одной частотой. Если устройство работает в режиме slave, то тактовые сигналы поступают от внешнего источника по линии SCL. Источником тактового сигнала для master-устройства является собственный внутренний генератор BRG. Тактовый сигнал BRGCL-Кдля работы BRG-генератора поступает от системного синтезатора частоты и может быть предварительно изменен. Биты PDIV определяют коэффициент предварительного деления входной частоты (табл. 5.36).
BRG-генератор 12С-контроллера может также изменять входную частоту генератора. Коэффициент деления частоты задается пользователем в режиме I2BRG и рассчитывается как 2х (I2BRG+3). На выходе BRG-генератора тактовый сигнал представляет собой меандр. При системной частоте 25 МГц максимальная скорость передачи данных может достигать 520 КГц (BRGCLK/(4x2x(0+3)= BRGCLK/48).
Таблица 5.36
Коэффициент внутреннего увеличения частоты
Биты PDIV Коэффициент деления частоты Биты PDIV Коэффициент деления частоты
00 BRGCLK/32 10 BRGCLK/8
01 BRGCLK/16 11 BRGCLK/4
528
ОРГАНИЗАЦИЯ КОММУНИКАЦИОННЫХ ПРОЦЕССОРНЫХ МОДУЛЕЙ В КМК
Поскольку 12С-интерфейс используется для связи устройств на одной плате, в одном приборе, то на линии тактового сигнала может оказывать влияние посторонний шум. Установка бита FLT := 1 позволяет пропустить тактовый сигнал через цифровой фильтр, чтобы убрать возможные наводки из-за шумов.
Бит REVD задает порядок передачи битов при обмене символами. Если бит REVD = О, то первым передается SLB. Если REVD = 1, то первым передается MSB, этот режим является рабочим для контроллеров фирмы «Motorola».
Бит GCD в регистре I2MOD определяет, как должен вести себя приемник при получении общего запроса от master-станции. Если бит GCD = 1, то никакие действия не производятся. Если бит GCD = 0, то приемник посылает подтверждение на адрес общего вызова (general call address).
В контроллере МРС860 параметры 12С-контроллера хранятся на 1-й странице памяти параметров (parameter RAM) со смещением + 0х1С80 от начала двухпортовой памяти. Структура и состав памяти параметров 12С-контроллера совпадают со структурой таблицы протокол-независимых параметров (см. табл. 5.30). Отличие заключается только в том, что отсутствуют две последние ячейки таблицы со смещениями I2C base+28 и I2C base+2C.
Данные для 12С-канала хранятся в буферах памяти, которые организованы в таблицу TxBD (передачи) и RxBD (приема). Принцип организации таблицы аналогичен таблицам буферов для SCC-каналов ввода/вывода. Стартовый адрес таблиц в памяти контроллера хранится в ячейках RBASE и TBASE памяти параметров 12С-контроллера. Пользователь может ограничить число буферов в таблице, установив бит W := 1 в слове состояния последнего необходимого буферного дескриптора. При подготовке обмена данными центральный процессор готовит данные для передачи в буферах памяти, заполняет соответствующие буферные дескрипторы и устанавливает в их слове состояния бит готовности к передаче R := 1, а также заранее подготавливает буферы для приема данных.
Режимы работы PC-контроллера. В режиме master 12С-контроллер управляет обменом данными со slave-устройствами. Для этого он передает slave-устройству специальное сообщение, которое определяет режим работы (чтение или запись). Если это операция чтения, то после передачи первого сообщения направление передачи по линии SDA меняется, и передавать будет slave-устройство.
Для начала обмена сообщениями master-устройство должно подготовить данные для передачи в буферах TxBD, установив бит готовности R := 1 в слове состояния буферного дескриптора, а также подготовить буферы приема RxBD. Затем центральный процессор должен установить бит STR := 1 в регистре команд I2COM. Данные будут передаваться после того, как они будут загружены в буфер FIFO передатчика по SDMA-каналам из памяти, и после того, как 12С-шина будет свободна. Размер буфера FIFO приемника и передатчика установлен равным двум символам. При передаче MSB передается первым.
При начале передачи 12С-контроллер выставляет start-условия (адрес slave-устройства) на линии SDA и тактовые импульсы , число которых соответствует числу передаваемых битов, на линию SCL. Для каждого переданного бита на линию SDA контроллер производит его повторное чтение (контроль), чтобы обнаружить состояние коллизии (collision) с другим master-устройством. Поскольку выводы контроллера объединены по схеме «монтажное ИЛИ» в единую шину, то коллизии обнаруживаются, если была выставлена «1», а обнаружен «0». При этом передача прерывается и канал переводится в режим slave и генерируется маскируемое прерывание к центральному процессору.
После передачи каждого байта данных устройство master контролирует индикацию подтверждения от slave-станции. Если подтверждение не пришло, передача прерывается и условие «остановки» генерируется master-станцией. Регистрация stop- и start-условий всегда приводит к закрытию текущего буфера приемника.
529
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
Для передачи данных slave-устройству master-станция подготавливает в буфере п+1 байт данных, где первый байт содержит адрес slave-устройства и бит, определяющий режим чтение/запись. Остальные п байт - это данные, которые передаются slave-устройству. Если R/W = 1, то будет производиться чтение с устройства slave.
Если 12С-контроллер работает в режиме slave, то его адрес задается пользователем в регистре I2ADD (рис. 5.58) и имеет 7 разрядов, таким образом, в сети может быть до 128 slave-устройств. Если slave-устройство распознало свой адрес, то данные принимаются во внутренние буферы RxBD, на них передаются подтверждения, и так продолжается, пока по линии SDA не придет от master-станции новое start/stop-усповие. Если совпадения адреса не произошло, slave-устройство ожидает следующего start-условия. Slave-контроллер подтверждает прием каждого байта, пока не обнаружит ошибку переполнения overrun своего буфера FIFO.
Если данные для передачи от master-устройства занимают несколько буферов TxBD, то они будут передаваться байт за байтом, пока не будет достигнут последний буфер (бит L = 1 в его слове состояния), при этом бит STR = 1 повторно для каждого нового байта не устанавливается. Бит STR будет автоматически сбрасываться после передачи первого бита байта данных.
Если контроллер работает в режиме slave, то для начала обмена данными он ожидает команды и тактового сигнала SCL от master-устройства. Все принятые от master-станции сообщения тут же посылаются обратно, таким образом, обеспечивается подтверждение их приема.
Перед началом обмена центральный процессор slave-станции должен подготовить буферы данных для передачи (TxBD) и для приема данных (RxBD), затем установить бит STR := 1 в регистре команд I2COM. Установка бита STR в slave-устройстве не начинает передачу, а только подготавливает схемы контроллера и данные для передачи. Передача начнется только после прихода команды от master-станции.
Если при начале передачи start-условия slave-станция в первом передаваемом байте распознала свой адрес (биты с 7-го по 1-й), то проверяется бит 0 - это бит команды R/W. Если R/W = 0, то происходит прием данных от master-станции, и эти данные принимаются в RxBD-буферы, пока не будут получены новые start- или stop-условия. Если R/W = 1, то данные из буфера FIFO передатчика slave-станции будут переданы master-станции. Если данные готовы, то они будут переданы по следующему импульсу тактового сигнала после передачи подтверждения на предыдущее сообщение. Если данные не готовы, то передача прерывается и генерируется маскируемое прерывание ТхЕ, которое уведомляет центральный процессор, что надо подготовить данные для передачи.
После передачи каждого байта передатчик проверяет бит подтверждения от master-станции. Если подтверждение не получено, то передача прерывается и генерируется прерывание центрального процессора. Прерывание также может генерироваться после передачи полного буфера, если возникла ошибка или произошло незаполнение underrun буфера FIFO передатчика. Если произошла ошибка незаполнения (underrun), то передатчик slave-станции будет передавать «1» биты, пока не получит stop-условие от master-станции.
Пользователь может управлять работой 12С-контроллера, передавая RISC-контроллеру команды INITTX PARAMETERS, CLOSE RX, INIT RX PARAMETERS, INITTX and RX PARAMETERS.
0_______1________2________3 4________5_______6_______7
SAD[O] SAD[1] SAD[2] SAD[3] SAD[4] SAD[5] SAD[6] 0
Рис. 5.58. Формат регистра адреса I2ADD
530
ОРГАНИЗАЦИЯ КОММУНИКАЦИОННЫХ ПРОЦЕССОРНЫХ МОДУЛЕЙ В КМК
15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
— Loop Cl СР DIV16 Е M/S EN LEN РМ[3:0]
Рис. 5.59. Формат регистра режима SPIMODE SPI-интерфейса
Последовательный коммуникационный порт. Последовательный порт в контроллере МРС860 реализован в виде SPI (Serial Peripheral Interface). SPI - полнодуплексный, синхронный, символьно-ориентированный канал связи, использующий 4-проводной интерфейс (линия приема SPIMISO, линия передачи SPIMOSI, линия тактовых сигналов SPICLK и линия выбора slave-устройства SPISEL), предназначен для обмена данными между коммуникационными контроллерами, ISDN- и другими сетевыми устройствами. Конфигурирование режимов работы интерфейса выполняется в регистре режима SPIMODE (рис. 5.59).
Устройство, поддерживающее SPI-интерфейс, может работать в режиме master (бит M/S = 1) или slave (бит M/S = 0). Также поддерживается конфигурация multimaster для объединения нескольких SPI-устройств на общую шину, используя их выводы в режиме открытого стока (open-drain).
В режиме master SPI-контроллер передает данные для других slave-станций, которые обязаны немедленно вернуть принятый кадр (режим back-to-back). Это используется для обеспечения надежности передачи и подтверждения корректности передачи кадра.
Тактирование приемника и передатчика канала выполняется одной тактовой частотой. Если выбранное устройство работает в режиме master, то тактовый сигнал поступает от собственного независимого BRG-генератора. В режиме master устройство вырабатывает внешние сигналы выбора (разрешения работы) SPISEL для slave-устройства и сигнал SPICLK, который выставляется только во время передачи данных, для тактирования других slave-устройств. Если устройство работает в режиме slave, то тактовые сигналы поступают от внешнего источника.
Если контроллер работает в режиме master, то пользователь может управлять входной частотой для BGR-генератора. Генератор BRG для своей работы использует входную тактовую частоту от внутреннего синтезатора частоты микросхемы (SynCLK). Если бит DIV16 равен 1, то входная частота генератора BRGCLK перед поступлением на вход схемы генератора делится на 16 (BRGCLK = SynCLK/16). Если бит DIV16 = 0, то предварительного деления частоты нет.
Сам генератор может также делить входную частоту на коэффициент, который определен в битах РМ, перед тем как передать ее для тактирования схемам приемника и передатчика каналов связи. Входная частота BRGCLK делится на 4х([РМ0-РМЗ])+1), таким образом, коэффициент внутреннего деления частоты может быть от 4 до 64. Сигнал на выходе генератора представляет собой меандр.
Максимальная скорость передачи отдельных символов в режиме master равна SynCLK/ 4, а в режиме slave - SynCLK/2. При передаче нескольких символов подряд интервал между ними не должен превышать значения SynCLK/50.
Особенности работы интерфейса. SPI-интерфейс выполняет полнодуплексные операции, т. е. прием данных и передача данных выполняются одновременно. При передаче наиболее значимый бит (MSB) передается первым, если бит REV = 1, и наоборот, первым передается LSB-бит, если бит REV = 0.
Размер передаваемых символов может колебаться от 4 до 16 бит. Биты LEN в регистре режима задают рабочую длину символа от 1 бита (код 0000) до 16 бит (код 1111), но, если пользователь выберет длину меньше 4 бит, будет зарегистрирована ошибка.
531
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
Как и все другие каналы ввода/вывода, SPI-интерфейс в выключенном состоянии потребляет минимум энергии, внутренний генератор не работает, и все регистры интерфейса находятся в исходном состоянии. Включение SPI-интерфейса в работу производится записью «1» в бит EN регистра SPIMODE, как показано на рис. 5.59. После установки этого бита изменять значения других битов в регистре режима пользователю запрещено.
Порт может работать или в нормальном режиме (если бит LOOP = 0) или в тестовом петлевом режиме (бит LOOP = 1). В петлевом режиме приемник и передатчик работают нормально, но выходы передатчика внутренне соединены со входом приемника, а данные на входных контактах приемника игнорируются.
Назначение выводов SPIMOSI и SPIMISO может меняться в зависимости от режима работы контроллера (табл. 5.37). Это сделано для упрощения объединения контроллеров в режиме multimaster.
Таблица 5.37
Режимы использования контактов
Контакт Назначение выводов
Режим-master Режим slave
SPIMISO Вход (прием) Выход (передача)
SPIMOSI Выход (передача) Вход (прием)
При помощи сигнала SPISEL master-станция активизирует работу slave-станции. Когда контроллер работает в режиме multimaster, вход SPISEL используется для обнаружения ошибки, когда несколько master-станций хотят работать одновременно. При этом, если контроллер работает как master-станция и обнаруживает на своем входе активный сигнал выбора slave-станции SPISEL от другого устройства master, то регистрируется ошибка.
Когда контроллер работает с несколькими slave-устройствами, следует использовать выводы параллельных портов ввода/вывода для формирования сигналов выбора slave-устройств.
Для инвертирования полярности тактового сигнала для SPI-порта используется бит CI. Если бит CI = 0, то данные выставляются на линию TXD по положительному перепаду тактового сигнала, а считываются с линии RXD - по отрицательному (рис. 5.60). Когда SPI-порт не передает данные, пассивное состояние линии тактового сигнала равно 0. Если же бит CI = 1, то данные передаются по отрицательному перепаду тактового сигнала, а считываются по положительному. Когда SPI-порт не передает данные, пассивное состояние линии тактового сигнала равно 1.
SPICLK (CI-0)
SPICLK (CI-1)
SPITXD (output)
SPIRXD (input)
SPITXD (output)
SPIRXD (input)
Рис. 5.60. Временные диаграммы работы SPI-интерфейса в различных режимах
532
ОРГАНИЗАЦИЯ КОММУНИКАЦИОННЫХ ПРОЦЕССОРНЫХ МОДУЛЕЙ в кмк
Бит СР определяет рабочую фазу тактового сигнала при передаче данных. Если бит СР = 0, то тактовый сигнал выставляется на линию SPICLK только в середине битового интервала передачи первого бита данных. Если бит СР = 1, то тактовый сигнал выставляется в начале битового интервала передачи первого бита данных.
Пользователь может управлять работой SPI-интерфейса при помощи команд INIT ТХ PARAMETERS, CLOSE RX BD и INIT RX PARAMETERS.
Прием и передача данных. В контроллере МРС860 параметры SPI-контроллера хранятся на 2-й странице памяти параметров (parameter RAM) со смещением + 0x1 D80 от начала двухпортовой памяти. Структура и состав памяти параметров SPI-контроллера совпадают со структурой таблицы протокол-независимых параметров (см. табл. 5.30). Отличие заключается только в том, что отсутствуют две последние ячейки таблицы со смещениями SPI base+28 и SPI base+2C.
Данные для SPI-канала хранятся в буферах памяти, которые организованы в таблицу TxBD (передачи) и RxBD (приема). Принцип организации таблицы аналогичен таблицам буферов для SCC-каналов ввода/вывода. Стартовый адрес таблиц в памяти контроллера хранится в ячейках RBASE и TBASE памяти параметров SPI-контроллера. Число буферов в таблице пользователь может ограничить, установив бит W := 1 в слове состояния последнего необходимого буферного дескриптора. Значения, хранящиеся в ячейках RBASE и TBASE, должны быть кратны 8.
Буферы данных могут быть расположены или во внешней памяти или во внутренней двухпортовой памяти, например, в области параметров неиспользуемых SCC-каналов.
При подготовке обмена данными центральный процессор готовит данные для передачи в буферах памяти, заполняет соответствующие буферные дескрипторы и устанавливает в их слове состояния бит готовности к передаче R := 1, а также заранее подготавливает буферы для приема данных.
Для начала передачи данных необходимо установить бит STR в регистре команд SPICOM (рис. 5.61). Остальные биты регистра SPICOM должны быть сброшены в «0». Если SPI-интерфейс работает в режиме master, то при установке бита STR := 1 контроллер начинает передавать и принимать данные. Данные начнут передаваться только тогда, когда они будут загружены по SDMA-каналам в буфер FIFO передатчика. Когда контроллер работает в режиме slave, то передача начнется только после прихода сигнала выбора SPISEL и внешнего тактового сигнала. Бит STR сбрасывается в «0» автоматически через один период системной тактовой частоты после начала передачи.
Размер буферов FIFO для приема и передачи ограничен двумя символами.
Master-станция начинает выдавать тактовые импульсы для каждого символа на контакт SPICLK и одновременно передавать данные на контакт SPIMOSI и принимать данные с контакта SPIMISO. Контроллер заканчивает прием и передачу, когда будут переданы все данные из буфера передачи или если при передаче возникла ошибка, а затем сбрасывает биты готовности буфера передачи R := 0 и бит пустого буфера приема Е := 0 и уведомляет центральный процессор об окончании передачи маскируемым прерыванием.
Если данные для передачи занимают несколько буферов в памяти, то они будут передаваться из нового буфера без задержек по окончании передачи из текущего буфера без ожидания повторной установки бита STR. Если в текущем буфере установлен бит последнего буфера кадра L = 1, то передача после передачи этого буфера будет остановлена. И текущий буфер приема данных будет закрыт, даже если он не заполнен.
7____________6_____________5____________4_____________3____________2_____________1____________О
STR Зарезервировано
Рис. 5.61. Формат регистра команд SPICOM
533
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
При работе в режиме slave SPI-интерфейс принимает данные от SPI master-станций и немедленно передает их обратно. Для начала передачи slave-устройством центральный процессор должен подготовить данные в буферах памяти, заполнить слово состояния буферного дескриптора и установить для буферов TxBD бит готовности к передаче R := 1. Кроме этого, процессор должен подготовить для обмена и буферы приема RxBD. Когда данные будут подготовлены, процессору необходимо установить бит STR := 1 в регистре SPICOM, чтобы SPI-интерфейс мог подготовиться к возможному обмену данными. Обмен начнется, когда придет активный сигнал выбора SPISEL = 0 и поступят тактовые сигналы на вход SPICLK. Данные будут передаваться на контакт SPIMISO и приниматься с контакта SPIMOSI. Маскируемое прерывание может быть выставлено при завершении работы с текущим буфером или если в ходе обмена зарегистрирована ошибка. SPI-контроллер продолжает принимать данные в буферы приема RxBD, пока все подготовленные буферы не будут заполнены или не будет снят активный сигнал SPISEL.
Если сигнал SPISEL стал пассивным, но все данные из буфера передачи еще не переданы, то передача все равно будет прервана, а текущий буфер TxBD останется открытым. После прихода активного сигнала SPISEL и тактового сигнала SPICLK передача будет продолжена с точки остановки. Если же все данные переданы, а сигнал SPISEL остается активным, то контроллер будет продолжать передачу единичных битов «1».
При работе интерфейса в режиме multimaster одноименные выводы SPIMOSI, SPIMISO, SPICLK всех SPI-устройств соединяются вместе, а линии SPISEL присоединяются к каждому устройству по отдельности. При таком соединении в каждый момент времени только один SPI-контроллер может быть master-станцией, а все остальные - только устройствами slave. Если SPI-контроллер в текущий момент времени сконфигурирован как master-станция, и приходит активный сигнал SPISEL = 0 от другого master-устройства, то регистрируется ошибка совместной работы multimaster-станций, устанавливается бит MIME в регистре событий и генерируется маскируемое прерывание центрального процессора. Работа SPI-устройств останавливается, и для повторного использования контроллеров пользователь должен сбросить бит включения EN в регистре SPIMODE.
Контроллер доступа к шине USB. Основные сведения о USB-контроллере в МРС823. USB-контроллер в МРС823 состоит из четырех основных блоков: приемника, передатчика и двух автоматов для реализации протоколов обмена (protocol state machines). Оба автомата предназначены для управления работой блоков приемника и передатчика, один из них используется, когда контроллер работает в режиме function, а другой - когда контроллер работает в режиме host. Таким образом, USB-контроллер в МРС823 может работать или в режиме function, или в режиме host, или в обоих режимах сразу (это используется при loop-back диагностировании аппаратуры).
Для тактирования USB-контроллера в МРС823 должна быть использована частота (USB reference clock), которая в четыре раза превышает тактовую частоту передаваемых данных, т. е. при работе с шиной 12 Мбит/с тактовая частота должна составлять 48 МГц, а при работе с шиной 1,5 Мбит/с - 6 МГц.
В режиме function контроллер автоматически выполняет обработку контрольной суммы CRC16/CRC5, NRZI-кодирование/декодирование данных с операцией вставки/удале-ния бит-стаффинга (bit stuffing). В подчиненном режиме контроллер может работать со скоростями 12 или 1,5 Мбит/с и обеспечивает автоматическую повторную передачу в случае возникновения ошибок.
В режиме host контроллер автоматически выполняет обработку только контрольной суммы CRC16, NRZI-кодирование/декодирование данных с операцией вставки/удаления бит-стаффинга (bit stuffing). В режиме master контроллер может работать только со скоростью 12 Мбит/с и обеспечивает поддержку диагностического режима работы «внутренняя петля» (local loopback). Таким образом, при функционировании МРС823 в режиме host-контроллера существуют ряд нижеперечисленных ограничений.
534
ОРГАНИЗАЦИЯ КОММУНИКАЦИОННЫХ ПРОЦЕССОРНЫХ МОДУЛЕЙ в кмк
• Не поддерживается обмен со скоростью 1,5 Мбит/с, так как передатчик не может вырабатывать биты преамбулы при низкоскоростном обмене.
• USB-контроллер в МРС823 не может выполнять функции корневого хаба (root hub).
• Некоторые функции удалены с аппаратного уровня и должны быть реализованы на программном уровне: генерация контрольной суммы CRC5 для кадров маркера (token); обнаружение ошибок и повторная передача кадра при ошибке; генерация и передача каждую 1 мс маркеров SOF tokens.
Обратите внимание, что в отличие от других коммуникационных каналов, в USB-koh-троллере изменена схема распределения буферов FIFO. USB-передатчик обслуживает четыре независимых 16-байтных буфера FIFO, т. е. за каждой конечной точкой (endpoint) закреплен свой буфер передачи. А USB-приемник имеет один общий 16-байтный буфер FIFO приема.
Настройка основных режимов работы USB-контроллера производится при программировании регистра режима USMOD (рис. 5.62), который расположен в памяти по адресу (IMMR&0xFFFF000)+0xA00.
Бит EN разрешает работу USB-контроллера. Если бит EN = 1, то контроллер работает в нормальном режиме, а если бит EN = 0, то контроллер находится в состоянии сброса, а его схемы - в режиме пониженного энергопотребления.
Бит LSS определяет скорость работы USB-контроллера. Если бит LSS = 0, то скорость передачи составляет 12 Мбит/с, а если LSS = 1, то 1,5 Мбит/с.
Бит HOST определяет режим работы USB-устройства. При значении бита HOST = О устройство работает как функция, а при значении HOST = 1 - как хост (host).
При установленном бите RESUME = 1 устройство-функция будет передавать по шине специальные сигналы при выходе из состояния «сон» (suspend mode).
Установка бита TEST = 1 переводит контроллер в тестовый режим внутренней петли. В тестовом режиме включается режим низкоскоростной передачи 1,5 Мбит/с, и, если установлен бит HOST = 1, то конечная точка Endpoint 0 работает как хост, a Endpoint 1-Endpoint 3 - как функции.
Контроллер поддерживает работу с четырьмя конечными точками (endpoints), каждая из которых может работать в одном из четырех режимов передачи (control, interrupt, bulk, isochronous). Обратите внимание, что точка Endpoint 0 должна быть сконфигурирована для control-обмена. Выбор режима работы каждой из конечных точек настраивается при программирова-нии регистров конфигурации USEPx конечной точки (рис. 5.63), которые расположены в памяти по адресу (IMMR&0xFFFF000)+0xA04 - USEP0,
(IMMR&0xFFFF000)+0xA06 - USEP1, (IMMR& 0xFFFF000)+0xA08 - USEP2,
(IMMR&0xFFFF000)+0xA0A - USEP3. Все регистры конфигурации имеют одинаковый формат.
Номер конечной точки, с которой связан тот или иной регистр USEPx, определяется в поле EPN (Endpoint Number). Биты ТМ (Transfer Mode) определяют, какой режим обмена использует конечная точка (00 - Control, 01 - Interrupt, 10 - Bulk, 11 - Isochronous).
Для того чтобы увеличить скорость передачи, пользователь может изменить бит MF (MultiFrame). Если бит MF = 0, то в буфере FIFO передатчика всегда могут быть данные только одного кадра. Если же бит MF = 1, то в буфер FIFO передатчика во время передачи данных текущего кадра может начаться загрузка данных следующего кадра.
О 1 2_______3_____4_____ 5 6 7
LSS RESUME Зарезервировано. Все 0 TEST HOST EN
Рис. 5.62. Регистр режима USB-контроллера USMOD
836
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
0 1 2 3 4 5 6 7 8 9 10 1 1 12 13 14 15
EPN 0 0 ТМ 0 0 MF RTE THS RHS
Рис. 5.63. Формат регистра конфигурации конечных точек USEPx
Если таймер ожидания ответа на переданный пакет истек, а ответ-подтверждение не поступил, то USB-контроллер, если установлен бит RTE = 1, произведет повторную передачу текущего кадра данных.
Обратите внимание, что при работе в изохронном (isochronous) режиме передачи биты MF и RTE должны быть равны нулю.
Если USB-контроллер работает в режиме slave, то биты THS и RHS определяют, какой тип пакета-подтверждения будет выдаваться в ответ на прием маркера OUT или IN (табл. 5.38). Но следует обратить внимание, что посылка подтверждений NAK и STALL не разрешена для конечной точки Control.
Таблица 5.38
Типы пакетов подтверждений
Биты RHS или THS Тип пакета подтверждения
00 АСК (Acknowledge) - положительное подтверждение
01 Игнорировать прием маркера IN или OUT
10 NAC (Negative Acknowledge) - отрицательное подтверждение
11 В ответ посылается STALL-пакет
Подключение USB-контроллера в МРС823. Поскольку коммуникационные контроллеры «Motorola» не реализуют в полном объеме функции физического уровня управления модели OSI, то для доступа к линиям D+ и D- USB-шины требуются дополнительные внешние трансиверы или драйверы линий. Для подключения к трансиверам используются следующие шесть сигналов контроллера МРС823 (рис. 5.64):
USBOE - сигнал разрешения работы трансивера (активный уровень - низкий), когда USB-
контроллер передает данные по шине;
USBRXD - принимаемые данные;
USBRXP, USBRXN - служат для определения скорости обмена (USBRXP=1, USBRXN = 0 - скорость 12 Мбит/с, USBRXP = О, USBRXN = 1-1,5 Мбит/с) и состояния асимметричного (singled ended) «О» (если USBRXP = USBRXN = 0);
USBTXP, USBTXN - определяют передаваемые данные (USBTXP = USBTXN = = 0 - передается singled ended «О», если USBTXP = 0 и USBTXN = 1, то передается логический «О», а если USBTXP = 1 и USBTXN = 0, то - логическая «1».
Рис. 5.64. Схема подключения USB-контрол-лера в МРС823 к внешнему трансиверу
536
ОРГАНИЗАЦИЯ КОММУНИКАЦИОННЫХ ПРОЦЕССОРНЫХ МОДУЛЕЙ В КМК
Некоторые трансиверы имеют дополнительные линии определения текущей скорости передачи или перехода в режим пониженного энергопотребления (sleep, suspend), в этом случае управление данными сигналами можно выполнять программно через контакты параллельного порта ввода/вывода.
Процесс приема и передачи в сети USB. USB - полностью контролируемая хостом шина. В системе USB может быть только один хост. Любая транзакция в ней осуществляется передачей до трех пакетов. Хост в соответствии с определенной временной диаграммой посылает USB-устройству пакет-маркер (token), описывающий тип и направление транзакции, адрес USB-устройства и номер конечной точки. Устройства USB проверяют, кому адресовано сообщение, декодируя соответствующие поля адреса. Направление передачи данных определено в маркерном пакете.
Устройства USB только отвечают на запросы хоста и не могут передавать информацию друг другу. Фактически может быть только один случай, когда устройство может инициировать передачу без активности хоста. После перевода хостом устройства в режим пониженного энергопотребления устройство может сигнализировать о своем пробуждении.
Затем источник транзакции посылает пакет данных (data packet) или сообщает, что данных для передачи нет. Получив пакет данных, адресат пакет квитирования (handshake packet), который сообщает, была ли передача успешной.
После системного сброса USB-контроллер имеет адрес 0x00 и хост должен определить новый адрес USB-устройства.
Для этого после разрешения работы USB-контроллер прослушивает шину и ожидает получение корректного кадра маркера (token). Некорректные маркеры игнорируются. Маркер считается некорректным, если его длина не равна 3 байтам, или в случае неправильной CRC (контрольной суммы), или если поле идентификаторов PID содержит некорректные данные. Маркеры могут быть четырех типов:
1) Setup token - при получении этого маркера начинается процедура конфигурирования устройств или обмен информацией о статусе;
2) IN tokenm - при получении данного маркера начинается передача подготовленных данных от USB-устройства к host-устройству;
3) OUT token - при получении этого маркера USB-устройство начинает прием данных;
4) SOF token.
Процесс реконфигурирования USB-устройства начинается при приеме маркера SETUP token, поступающего на конечную точку, которая определена как Control Endpoint. Маркер SETUP обычно содержит код команды, которую должно выполнить USB-устройство. Если тип SETUP-пакета требует приема последующих данных, то USB-контроллер выполняет прием данных так же, как и после приема маркера OUT. Если тип SETUP-пакета требует передачи некоторых данных хосту, то USB-контроллер выполняет передачу данных так же, как и после приема маркера IN.
При получении SETUP-маркера контроллер анализирует тип команды, которая содержится в маркере. Если это команда Set Address, и контроллер работает в режиме Slave, то контроллер принимает следующий пакет, который содержит назначенный хостом новый адрес USB-устройства и переписывает значение адреса в поля SAD регистра USADR (рис. 5.65), который располагается в памяти по адресу (IMMR & OxFFFFOOOO) + 0хА01.
0 1 2 3 4 5 6 7 ‘JI
0 SAD
Рис. 5.65. Формат регистра адреса Slave USB-устройства ,.ji-
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
Подключение USB-устройств в сеть. Все устройства USB присоединяются к USB-шине через порт специализированного устройства - USB-концентратора. Концентраторы анализируют состояние порта и определяют, присоединено или удалено устройство. Если обнаружено новое подключенное устройство, то концентратор уведомляет об этом хост. Далее хост посылает запрос концентратору, чтобы определить причину уведомления. Концентратор отвечает, указывая номер используемого порта, к которому присоединено USB-устройство. Хост через порт создает канал связи с USB-устройством, используя заданный по умолчанию адрес (Default Address = 0), который действовал при первом соединении или после сброса, и конечную точку с номером «0». Хост посылает запрос Get_Descriptor/Device на адрес «0» контрольной точки «0».
Устройство обязательно отвечает на запрос, посылая байты идентификатора обратно хосту, говорящие, какое устройство подключено.
Хост определяет, является ли недавно присоединенное устройство USB концентратором или функцией, и посылает устройству запрос Set_Address, передавая в этом пакете новый назначенный уникальный адрес устройства, позволяющий отличить это устройство от других подключенных к шине. Если присоединенное устройство - концентратор и есть USB-устройства, подключенные к его портам, то вышеупомянутая процедура сопровождается для каждого из присоединенных USB-устройств. Если присоединенное устройство - функция, то уведомление о подключении будет послано в программное обеспечение хоста.
Затем хост посылает еще запросы, запрашивая остальную информацию об устройстве. Из этих ответов хост узнает, как много каналов устройство имеет, его требования по питанию, необходимую пропускную способность канала и какой драйвер следует загрузить.
Отключение USB-устройств. Когда USB-устройство отключается от порта, концентратор автоматически отключает порт и сообщает на хост об удалении устройства. Если удаленное USB-устройство-функция, уведомления об удалении посылаются программному обеспечению хоста. Затем хост удаляет информацию относительно данного USB-устройства из всех своих структур данных. Если же удаленное USB-устройство - концентратор, процесс удаления должен быть выполнен для всех USB-устройств, которые были предварительно присоединены к концентратору.
Прием пакетов. После того как USB-контроллер получит маркер OUT token, он должен начать прием данных. Контроллер проверяет в таблице дескрипторов, которые связаны с данной конечной точкой, следующий буферный дескриптор и, если он свободен, начинает прием в буфер данных, адрес которого указан в дескрипторе. После заполнения текущего буфера контроллер закрывает буфер, сбрасывает бит незанятости Е := 0 (Empty) в слове состояния его дескриптора и, если в слове состояния дескриптора установлен бит прерывания I = 1 (Interrupt), формирует запрос на прерывание.
Если длина принимаемого кадра данных превышает размер буфера, выделенного в памяти, то контроллер продолжает запись принимаемых данных в буфер, адрес которого указан в следующем дескрипторе, но только если у этого дескриптора установлен бит незанятости Е = 1. Если же следующий дескриптор окажется занятым, то будет зарегистрирована ошибка. После завершения приема всех данных из пакета в слове состояния буферного дескриптора последнего занятого буфера памяти устанавливается бит L = 1 (Last) и буфер закрывается.
Если принимаемый пакет содержит поле «идентификатор пакета» (DATA0/DATA1 packet ID (PID)), то в буфер будет записано только содержимое пакета, а содержимое поля PID будет занесено в соответствующие поля PID слова состояния дескриптора.
Протокол USB-шины предусматривает принцип «запрос-ответ» при реализации обмена по сети. Если при приеме пакета обнаружена ошибка, то пакет с подтверждениями не
538
ОРГАНИЗАЦИЯ КОММУНИКАЦИОННЫХ ПРОЦЕССОРНЫХ МОДУЛЕЙ в кмк
посылается и в слове состояния буферного дескриптора последнего буфера сданными из пакета устанавливаются соответствующие биты ошибок. Если же пакет принят без ошибок и проверка CRC контрольной суммы завершилась успешно, то содержимое пакета сохраняется в буфере памяти и в ответ на получение OUT-маркера может быть послано подтверждение. Тип пакета подтверждения определяется в битах RHS в регистре конфигурации конечной точки USEPx.
Протокол предусматривает обработку ошибок на аппаратном и программном уровнях. Аппаратная обработка включает в себя анализ целостности сообщения и повторение неудачных передач. Хост-контроллер повторит передачу ошибочного кадра данных три раза, а затем проинформирует клиентское программное обеспечение об ошибке.
Большинство ошибок, которые регистрирует USB-контроллер в МРС823 при своей работе, фиксируются установкой соответствующих битов ошибок в слове состояния буферных дескрипторов. Ниже перечислены ошибки, регистрируемые при приеме.
• Переполнение буфера FIFO приемника (Overrun). Данная ошибка регистрируется, если USB-контроллер не успел переписать данные из общего для всех конечных точек (endpoints) буфера FIFO приемника в буферы памяти, а по шине уже получены новые данные, которые были записаны в FIFO-буфер поверх старых. При возникновении этой ошибки контроллер закрывает буфер, устанавливает бит ошибки OV := 1 в слове состояния дескриптора и устанавливает бит прерывания RXB в регистре событий USB-контроллера. Если новый пакет данных был принят без ошибок, то после завершения его приема USB-контроллер передает по шине отрицательное подтверждение NAK.
• Занятость (Busy). Данный тип ошибки регистрируется, если по шине принят корректный кадр данных, но RISC-контроллер не обнаружил свободных буферов для приема данных. При этом в регистре событий USB-контроллера устанавливается бит прерывания BSY.
• Нарушение формата кадра (Non Octet Aligned). Данный тип ошибки регистрируется, если принят кадр, длина которого не кратна 8 битам. При возникновении этой ошибки контроллер сохраняет принятый кадр данных в буферах памяти, закрывает буфер, устанавливает бит ошибки NO := 1 в слове состояния дескриптора и устанавливает бит прерывания RXB в регистре событий USB-контроллера.
• Ошибка проверки контрольной суммы (CRC Error). При обнаружении этой ошибки контроллер закрывает буфер приема, устанавливает бит ошибки CR := 1 в слове состояния дескриптора и устанавливает бит прерывания RXB в регистре событий USB-контроллера.
• Ошибка проверки алгоритма вставки/удаления бит-стаффинга. Если обнаруживается данная ошибка, то принятый кадр сохраняется в буфере памяти, заполняется его слово состояния и последним в нем устанавливается бит AB(Frame Aborted) := 1.
Передача данных. При передаче данных пользователь должен предварительно загрузить данные в буфер FIFO выбранной конечной точки. Для этого пользователь должен подготовить данные для передачи в буферах памяти, заполнить слово состояния соответствующего буферного дескриптора и установить бит STR := 1 в регистре команд USB-контроллера. Далее USB-контроллер перепишет данные в соответствующий FIFO-буфер конечной точки (endpoint) и будет ожидать появления маркера IN, при получении которого он начнет передачу данных в сеть.
Если при получении IN-маркера данные в буфере FIFO не готовы или в регистре конфигурации выбранной Endpoint USEPx установлено значение битов THS = 10, то в ответ на маркер IN посылается пакет с отрицательным подтверждением NAK. Значение битов THS определяет тип пакета подтверждения, который может быть передан в ответ на получение маркера IN.
539
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
Когда все данные текущего буферного дескриптора переданы и в слове состояния установлен бит последнего дескриптора пакета L = 1 (Last), то контроллер добавляет к пакету поле контрольной суммы и завершает передачу пакета.
В ответ на передачу пакета данных USB-контроллер ожидает от хоста получения пакета подтверждения. Если в течение определенного времени подтверждение не получено, то в слове состояния последнего дескриптора переданного пакета устанавливается бит ТО := 1 (Time Out).
Обратите внимание, что пользователь должен самостоятельно заполнять поля DATA0/ DATA1 PID в передаваемом пакете.
Основные ошибки, регистрируемые при передаче, перечислены ниже.
• Незаполнение буфера FIFO передатчика (underrun). При возникновении этой ошибки контроллер специально нарушает процедуру вставки бит-стаффинга, прекращает передачу из буфера, закрывает буфер, устанавливает бит ошибки UN := 1 в слове состояния дескриптора и устанавливает бит прерывания ТХЕ в регистре событий USB-koh-троллера.
• Истек тайм-аут ожидания ответа (Timeout). Если установлен бит RTE = 1 в регистре конфигурации, то при возникновении этой ошибки USB-контроллер делает попытку повторной передачи пакета, на который не пришло подтверждение. Если же бит RTE = О или вторая попытка повторной передачи тоже завершилась неудачей, то контроллер закрывает буфер передачи, устанавливает бит ошибки ТО := 1 в слове состояния дескриптора и устанавливает бит прерывания ТХЕ в регистре событий USB-контроллера.
• Данные для передачи не готовы (TxData not Ready). Данная ошибка возникает, когда контроллер получил IN-маркер, а буфер FIFO передачи соответствующей конечной точки пуст, или если конечная точка запрограммирована на посылку подтверждений NAK или STALL. При обработке данной ошибки контроллер устанавливает бит прерывания ТХЕ в регистре событий USB-контроллера.
Прием служебных маркеров. При приеме маркера SOF (Start of Frame) USB-контроллер регистрирует маскируемое прерывание SOF и увеличивает значение в ячейке FRAME_N в памяти параметров (рис. 5.66), подсчитывая количество принятых маркеров SOF. Если SOF-маркер был принят без ошибок, то в ячейке FRAME_N будет установлен бит V := 1.
Прием маркера PRE USB-контроллер выполняет (т. е. не игнорирует этот пакет) только при работе в режиме host (но генерировать PRE-маркеры в режиме host контроллер не может). Появление этого маркера сообщает о начале низкоскоростной передачи данных.
Настройка USB-контроллера в МРС823. Память параметров USB-контроллера. Память параметров USB-контроллера состоит из двух частей: память основных параметров USB-контроллера (табл. 5.39) и память параметров каждой из конечных точек (табл. 5.40). Память основных параметров обычно располагается в области протокол-независимых параметров 5СС2-контроллера по адресу, который вычисляется как USBBase = (IMMR & 0xFFFF0000)+0x3C00.
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
V Зарезервировано Frame Number
Рис. 5.66. Формат ячеек FRAME_N
540
ОРГАНИЗАЦИЯ КОММУНИКАЦИОННЫХ ПРОЦЕССОРНЫХ МОДУЛЕЙ В КМК
Таблица 5.39
Память основных параметров USB-контроллера
Адрес Название Размер, бит Описание
USBBASE+00 EPOPTR 16 Указатель на начало памяти параметров Endpoint 0
USBBASE+02 EP1PTR 16 Указатель на начало памяти параметров Endpoint 1
USBBASE+04 EP2PTR 16 Указатель на начало памяти параметров Endpoint 2
USBBASE+06 EP3PTR 16 Указатель на начало памяти параметров Endpoint 3
USBBASE+08 RSTATE 32 Внутреннее Rx-состояние
USBBASE+OC RPTR 32 Временный внутренний указатель на текущую обрабатываемую ячейку RX буфера приемника
USBBASE+10 FRAME_N 16 Номер кадра
USBBASE+12 RBCNT 16 Внутренний счетчик принятых в буфер Rx байт данных
USBBASE+14 RTEMP 32 Временная RX-переменная
Примечание. Переменные в ячейках EPOPTR, EP1PTR, EP2PTR, EP3PTR и FRAME_N инициализируются пользователем до начала работы с USB-контроллером. Остальные ячейки используются контроллером при его работе и поэтому их содержимое изменять не рекомендуется.
В ячейках EPxPTR (рис. 5.67) указываются адреса начала памяти каждой из используемых конечных точек (требуется, чтобы адреса были кратны 32).
В USB-контроллере назначение переменных в ячейках памяти параметров отдельной контрольной точки (табл. 5.40) полностью совпадает с назначением одноименных переменных в SCC- и SMC-контроллерах.
Таблица 5.40
Память параметров отдельной конечной точки
Адрес Название Размер, биг Описание
Base+00 RBASE 16 Базовый адрес таблицы Rx BD
Base+02 TBASE 16 Базовый адрес таблицы Тх BD
Base+04 RFCR 08 Функциональные коды Rx
Base+05 TFCR 08 Функциональные коды Тх
Base+06 MRBLR 16 Максимальная длина Rx-буфера
Base+08 RBPTR 16 Указатель на следующий дескриптор Rx BD
Base+OA TBPTR 16 Указатель на следующий дескриптор Тх BD
Base+OC TSTATE 32 Внутреннее Тх-состояние
Base+10 TPTR 32 Временный внутренний указатель на текущую обрабатываемую ячейку Тх буфера передатчика
Base+14 TCRC 16 Текущее значение CRC суммы при передаче кадра
Base+16 TBCNT 16 Внутренний счетчик переданных Тх байт данных
Base+1C 32 Зарезервировано
Примечани e. Переменные в ячейках RBASE, TBASE, RFCR, TFCR, RBPTR, TBPTR, MRBLR и TSTATE = 0 инициализируются пользователем до начала работы с USB-конгроллером. Остальные ячейки используются контроллером при его работе и поэтому их содержимое изменять не рекомендуется.
541
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
О 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
Endpoint Pointer 0 [ О ООО
Рис. 5.67. Формат ячеек EPxPTR
Дополнительно в ячейке TBCNT содержится внутренний вычитающий счетчик, в который при переходе к новому дескриптору передачи заносится длина буфера из соответствующего поля дескриптора и значение которого уменьшается на единицу при передаче очередного байта через SDMA-канал.
Однотипная же ячейка RBCNT имеется только в памяти параметров всего USB-контроллера и отсутствует среди параметров отдельных конечных точек, так как все конечные точки выполняют прием через общий FIFO буфер приема, и содержит внутренний вычитающий счетчик, в который при переходе к новому дескриптору приема заносится содержимое ячейки MRBLR и значение которого уменьшается на единицу при передаче очередного байта через SDMA-канал.
Управление USB-контроллером. Пользователь может управлять работой USB-контроллера, программируя его регистр команд CPCR (рис. 5.68), который расположен в ячейке памяти по адресу (IMMR & 0xFFFF0000)+0x9C0. Код команды управления записывается в биты USBCMD регистра команд (табл. 5.41). Указанная команда будет применена к конечной точке, номер которой указан в битах ENDPOINT (OO-EndpointO, 01-Endpointl, 10-Endpoint2, 11-Endpoint3). Для того чтобы USB-контроллер начал выполнять команду, необходимо установить бит FLG = 1. После выполнения команды контроллер автоматически сбросит этот бит.
0 1 2 3 4 5 6 7 8 9 10 1 1 12 13 14 15
RST USBCMD 1 1 1 1 1 0 0 0 0 ENDPOINT — FLG
Рис. 5.68. Формат регистра команд USB-контроллера CPCR
Бит RST = 1 следует устанавливать, если требуется сбросить параметры всех коммуникационных каналов, регистры RISC-контроллера и RISC-таймера коммуникационного контроллера в исходное состояние. Процедура сброса выполняется RISC-контроллером в течение 60 тактов шины. Через два такта шины бит RST будет автоматически сброшен в «0».
Таблица 5.41
Коды команд управления USB-контроллером
Код команды Тил команды Описание команды
001 STOP тх ENDPOINT Останавливается передача данных на указанной конечной точке (endpoint). Буфер FIFO конечной точки заполняется полностью. Передача может быть возобновлена только после получения команды RESTART ТХ ENDPOINT.
010 RESTART ТХ ENDPOINT Возобновление передачи на указанной конечной точке. Обычно команда используется для возобновления передачи после выполнения команды STOP ТХ ENDPOINT или после возникновения ошибок передачи (незаполнение underrun или переполнение таймера ожидания ответа timeout).
000, 011, 100, 101, 110, 111 - Зарезервировано.
542
ОРГАНИЗАЦИЯ КОММУНИКАЦИОННЫХ ПРОЦЕССОРНЫХ МОДУЛЕЙ В КМК
О__________1__________ 2 ___________3_________4___________5___________6 7
STR FLUSH 0 0 0 0 ЕР
Рис. 5.69. Регистр USB-команд
При работе пользователь также имеет возможность управлять работой USB-контроллера, программируя регистр USB-команд (рис. 5.69), который расположен в ячейке памяти по адресу (IMMR & 0xFFFF0000)+0xA02. Если установить бит STR := 1, то контроллер начнет подготовку данных к передаче и заполнение данными буфера FIFO передатчика конечной точки, номер которой указывается в битах ЕР. Реально передача этих данных в сеть начнется только после приема маркера IN.
При передаче данных пользователь может также, если необходимо, заменить содержимое буфера FIFO передатчика. Для этого следует передать контроллеру команду STOP ТХ ENDPOINT и установить бит FLUSH .= 1. Для возобновления передачи надо использовать команду RESTART ТХ ENDPOINT.
Буферные дескрипторы USB-контроллера. USB-контроллер использует такую же структуру буферных дескрипторов, что и большинство коммуникационных каналов, состоящую из четырех ячеек по 16 бит (первая ячейка - слово состояния дескриптора (рис. 5.70, 5.71), вторая - длина буфера данных в памяти, адрес которого указан в 3-й и 4-й ячейках дескриптора).
Большинство битов слов состояния имеют такое же функциональное назначение, что и для других коммуникационных каналов.
Бит Е (Empty) - бит незанятого буфера («0» - буфер занят, «1» - не занят). Бит R (Ready) - бит готовности буфера к передаче («0» - не готов, «1» - готов или уже передается). Бит W (Wrap) - бит последнего дескриптора в таблице дескрипторов («0» - не последний дескриптор, «1» - последний). Бит I (Interrupt) - бит прерывания при завершении обработки данного буфера («0» - прерывание не регистрируется, «1» - регистрируется в регистре событий в бите RXB при приеме и ТХВ или ТХЕ при передаче). Биты F (First) и L (Last) первого и последнего буфера, в которых расположен первый (последний) бит текущего кадра данных («0» - это не первый и не последний буфер, «1» - это первый (последний) буфер кадра).
0 1 2 3 4 5 6 7 8 9 10 1 1 12 13 14 15
Е — W I L F — — PID — NO АВ CR OV —
Рис. 5.70. Слово состояния буферного дескриптора приема USB-контроллера
Если установлен бит ТС = 1 (Transmit CRC), то после завершения передачи содержимого последнего буфера кадра (установлен бит L = 1) сразу же будет передана контрольная сумма кадра. Если бит ТС = 0, то будет передан признак EOP (End of Packet).
После завершения передачи содержимого последнего буфера кадра (бит L = 1), если установлен бит CNF = 1, то контроллер будет ожидать получение подтверждения о доставке пакета. Если же бит CNF = 0, то, не ожидая ответа, будет загружать в буфер FIFO передатчика данные следующего пакета.
R — W I L ТС CNF — PID — NAK STAL TO UN —
Рис. 5.71. Слово состояния буферного дескриптора передачи USB-контроллера
543
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
В бите NO (Non Octet) регистрируется ошибка приема кадра, длина которого не кратна байту. В бите АВ (Frame Aborted) регистрируется ошибка нарушения алгоритма работы с бит-стаффингом. Ошибка при проверке контрольной суммы регистрируется в бите CR (CRC Error). Ошибка переполнения буфера FIFO приемника регистрируется в бите OV (Overrun), а переполнение буфера FIFO передатчика - в бите UN (Underrun).
В биты PID (Packed ID) при приеме контроллер заносит тип принятого пакета. Биты PID заполняются только для первого дескриптора принимаемого кадра данных (бит F = 1). При передаче данных эти биты анализируются только для первого буфера (бит F = 1) передаваемого кадра и определяют тип передаваемого пакета. Если PID = 00, то буфер содержит пакет DATA0. Если же бит PID = 01, то буфер содержит пакет DATA1.
Если принятый пакет не содержит ошибок, но в настройках контрольной точки определенным образом определен тип пакета подтверждения, то будут установлены биты NAK (в ответ посылается пакет отрицательного подтверждения) или STALL (в ответ посылается пакет подтверждения STALL). Эти биты устанавливаются после завершения передачи соответствующего буфера данных.
Если после передачи конечная точка не дождалась подтверждения, то будет установлен бит ТО := 1 (Time Out).
Регистр событий. Регистр событий USBER (рис. 5.72) расположен в ячейке памяти по адресу (IMMR&0xFFFF0000)+0xA10. Сброс битов событий в регистре событий производится записью единицы в соответствующий бит. Прерывание от любого события в USB-контроллере будет зарегистрировано, только если установлен в «1» бит регистра маски USBMR, соответствующий этому событию. Регистр маски расположен в ячейке памяти по адресу (IMMR&0xFFFF0000)+0xA14 и имеет формат, аналогичный регистру событий.
Если USB-контроллер находится в состоянии «сброс», то будет установлен в «1» бит RESET регистра событий.
Бит IDLE регистра событий показывает, что изменилось состояние линий связи.
Биты ТХЕх регистра событий устанавливаются в «1», если произошла ошибка при передаче пакета данных: или не пришло подтверждение о получении пакета, или произошла ошибка незаполнения Underrun.
При приеме пакета SOF (Start of Frame) устанавливается бит SOF := 1 регистра событий и увеличивается на единицу счетчик в ячейке FRAME_N памяти параметров.
Если USB-контроллер начал прием нового кадра данных, значит RISC-контроллер не нашел свободных буферных дескрипторов, а принимаемый кадр будет игнорирован и будет установлен бит BSY регистра событий.
Установка бита ТХВ регистра событий свидетельствует о том, что из текущего (но не последнего в кадре) буфера был передан в буфер FIFO передатчика последний символ, или если это последний буфер кадра, то бит будет установлен, только когда последний символ кадра будет передан в линию связи.
Установка бита RXB регистра событий свидетельствует о том, что при приеме данных текущий буфер заполнен и его дескриптор закрыт.
012345 6 7 8 9 10 11 12 13 14 15
Зарезервировано. Все «0». Reset IDLE ТХЕЗ ТХЕ2 ТХЕ1 TXE0 SOF BSY ТХВ RXB
Рис. 5.72. Формат регистра событий USB-контроллера USBER и регистра маски USBMR
544
ПОДДЕРЖКА ПРОТОКОЛОВ В КОММУНИКАЦИОННЫХ КОНТРОЛЛЕРАХ
5.3. ПОДДЕРЖКА ПРОТОКОЛОВ В КОММУНИКАЦИОННЫХ КОНТРОЛЛЕРАХ
5.3.1. ДОСТУП К ЛИНИЯМ Т1/СЕРТ. ПОДДЕРЖКА BASIC ISDN
Последовательный интерфейс. Физический интерфейс SI (Serial Interface) может работать в двух режимах: TSA и NMSI. Режим TSA (Time Slot Assigner) или мультиплексированный режим объединяет передачу данных от нескольких каналов ввода/вывода в режиме временного мультиплексирования на общие выводы. В контроллере МРС860 (рис. 5.73) блок TSA имеет собственные внешние контакты для двух каналов временного мультиплексирования: TDMa и TDMb (Time Division Multiplexed). При совместной работе нескольких каналов в коммуникационных контроллерах возможна любая комбинация режимов работы TSA и NMSI для каждого из каналов.
В режиме TSA синхронизация работы каналов осуществляется через внешние контакты (TCLOCK и RCLOCK в СРМ или TCLK и RCLK в СР) от внешнего источника. Каждый TDM-канал имеет независимые приемник и передатчик, которые используют каждый свою внешнюю синхронизацию через контакты RCLOCK и TCLOCK, и свои внешние стробирующие сигналы RSYNC и TSYNC, которые уведомляют о начале нового кадра данных. Работа каждого TDM-канала может быть запрограммирована на срабатывание или по положительному или по отрицательному фронту тактового сигнала.
Максимальная частота синхронизации TSA-каналов - это системная частота, деленная на 2,5 (SyncCLK/2,5). Напомним, что модуль конфигурации системы SIM60 может производить предварительное деление системной частоты. Системная частота зависит от частоты внешнего источника тактирования контроллера (обычно это кварц) и равна 1/2 частоты внешнего кварца. Например, если частота кварца 25 МГц, то SyncCLK равна 12,5 МГц.
Блок Time Slot Assigner (TSA) обеспечивает на каждом TDM-канале объединение данных от двух-четырех любых SCC-контроллеров и двух SMC-контроллеров в два мультиплексированных интерфейса с временным разделением TDM (рис. 5.74), использующих форматы:
• Motorola Interchip Digital Link (IDL);
• General Circuit Interface (GCI), известный как IOM-2;
• Pulse Code Modulation (PCM) Highway Interface; .
• Т1/СЕРТ-ЛИНИЙ;
• User-defined interace.
Рис. 5.73. Структура последовательного интерфейса в контроллере МРС860
545
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
TDMa
MULTIPLEXED-интерфейс
NMSI-интерфейс
Рис. 5.74. Мультиплексирование каналов в контроллере МРС860
В ^мультиплексируемом режиме NMSI (Nonmultiplexed Serial Interface) каждый канал - SCC или SMC имеет собственные внешние контакты (через контакты параллельных портов А, В и С) и может работать независимо от других каналов.
Каждый SCC-канал в режиме NMSI поддерживает следующие модемные сигналы: TXD, RXD, TCLK, RCLK, rts , cts , cd . Поддержку дополнительных сигналов DSR и DTD пользователь может запрограммировать через порты ввода/вывода. В СРМ каналы SMC также имеют четыре внешних контакта: SMTXD, SMRXD, CLK и SMSYNC. Если контроллер канала ввода/вывода работает в мультиплексируемом режиме, то его NMSI-выводы могут быть использованы для других целей как линии параллельных портов.
В режиме NMSI в СРМ каждый канал может тактироваться или от восьми внешних источников тактовых сигналов, или от четырех встроенных генераторов скорости передачи BRG. В режиме NMSI максимальная частота синхронизации каналов - это системная частота, деленная на два (SyncCLK/2).
Настройка режимов работы последовательного интерфейса. Главным регистром, который определяет работу физического интерфейса SI в мультиплексируемом TSA- и немультиплексируемом NMSI-режимах, является регистр режима SIMODE (рис. 5.75).
Биты SMC1 и SMC2 определяют режим работы соответствующих каналов управления SMC1 и SMC2 (0 - режим NMSI, 1 - режим TSA). Каналы SMC могут иметь независимые источники тактирования, но всегда приемник и передатчик одного канала используют одну частоту синхронизации, и, если каналы SMC работают в немультиплексируемом режиме NMSI, то биты SMC1CS и SMC2CS определяют источник тактирования для данного канала управления (табл. 5.42).
546
ПОДДЕРЖКА ПРОТОКОЛОВ В КОММУНИКАЦИОННЫХ КОНТРОЛЛЕРАХ
0 1 2 3 4 5 6 7 8 9 10 1 1 12 13 14 15
SMC2 SMC2CS SDMb RFSDb DSCb CDTb STZb CEb FEb GMb TFSDb
16 17 18 19 21 22 23 24 25 26 27 28 29 30 31
SMC1 SMC1CS SDMa RFSDa DSCa CDTa STZa CEa FEa GMa TFSDa
Рис. 5.75. Формат регистра настройки режимов работы последовательного интерфейса SIMODE в контроллере МРС860
Во всех коммуникационных контроллерах интерфейс SI поддерживает режимы контроля аппаратуры приемника и передатчика. Биты SDMa и SDMb определяют, какой режим контроля выбран для канала TDMa и канала TDMb (табл. 5.43).
В режиме автоматического эха канал сразу же передает принятый от физического интерфейса бит данных. Значения сигналов на контакте L1GRx игнорируются. В режиме внутренней петли происходит внутреннее соединение выводов LITXDx и LIRXDx. Данные передаются по линии LITXDx и сразу же читаются. Сигнал L1RQx выставляется нормально, а значения сигналов на входах L1 RXDx и L1GRx игнорируются. Режим циклического контроля работает аналогично режиму внутренней петли, только он предназначен для контроля работы аппаратуры приемника и передатчика без воздействия на внешние выводы микросхемы. Поэтому внешние выводы LITXDx и L1RGx остаются в неактивном состоянии.
В модуле СРМ предусмотрена возможность работы с повышенной частотой синхронизации, так как некоторые TDM-каналы при работе в режиме GCI-интерфейса требуют, чтобы на каждый битовый интервал приходилось по два периода тактового сигнала. Биты DSCa и DSCb, если они равны единице, определяют для своего канала TDMx режим работы с удвоенной частотой.
Таблица 5.42
Выбор источника тактирования канала
Биты SMC1CS (или SMC2CS) Источник тактирования каналов SMC1 или SMC2
ООО Канал тактируется от генератора BRG1.
001 Канал тактируется от генератора BRG2.
010 Канал тактируется от генератора BRG3.
011 Канал тактируется от генератора BRG4.
100 Если это канал SMC1, то он тактируется от внешнего генератора через вход CLK1. Если это канал SMC2, то он тактируется от внешнего генератора через вход CLK5.
101 Если это канал SMC1, то он тактируется от внешнего генератора через вход CLK2. Если это канал SMC2, то он тактируется от внешнего генератора через вход CLK6.
110 Если это канал SMC1, то он тактируется от внешнего генератора через вход CLK3. Если это канал SMC2, то он тактируется от внешнего генератора через вход CLK7.
111 Если это канал SMC1, то он тактируется от внешнего генератора через вход CLK4. Если это канал SMC2, то он тактируется от внешнего генератора через вход CLK8.
547 '
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
Таблица 5.43
Режимы работы TDM-каналов
Биты SDMx Режим контроля
00 Нормальный режим работы без дополнительного контроля
01 Режим «автоматическое эхо»
10 Режим «внутренняя петля»
11 Режим «циклический контроль»
Каждый кадр данных при работе в режиме TSA стробируется внешним сигналом SYNC. Обычно наличие этого сигнала в TDMx-канале проверяется по положительному перепаду тактового сигнала CLK, если биты FEa и FEb равны единице для каналов TDMa и TDMb соответственно, и по отрицательному перепаду тактового сигнала, если эти биты равны нулю. Анализ наличия стробирующего сигнала по отрицательному перепаду тактового сигнала используется, если выбранный TDMx-канал работает с IDL-или GCI-интерфейсами.
Биты RFSDa, RFSDb, TFSDa и TFSDb определяют количество тактов задержки при передаче/приеме на выбранном канале TDMa или TDMb (табл. 5.44).
Таблица 5.44
Задержки при обмене через TDM-канал
Биты RFSDx Режим работы
00 Задержек нет. Данные принимаются или передаются по тому же тактовому сигналу CLK, по которому проверялось наличие сигнала строба SYNC.
01 Задержка равна одному периоду. Данные передаются и принимаются по следующему импульсу тактового сигнала.
10 Операции с данными производятся с задержкой два периода тактового сигнала.
11 Операции с данными производятся с задержкой три периода тактового сигнала.
Значения битов СЕа и СЕЬ определяют, по какому перепаду тактового сигнала CLK производятся операции с данными на каналах TDMa и TDMb соответственно. Если бит равен нулю, то на выбранном TDMx-канале данные передаются по положительному перепаду тактового сигнала и считываются по отрицательному перепаду. Такой режим обработки данных используется при работе с IDL- и GCI-интерфейсами. Если бит равен единице, то на выбранном TDMx-канале данные выставляются по отрицательному перепаду тактового сигнала, а считываются - по положительному. На рис. 5.76 представлен пример настройки работы последовательного интерфейса.
TDM-канал при работе может поддерживать механизм запросов на передачу no D-каналу (grant механизм). Биты GMa и GMb определяют, для какого физического интерфейса GCI (значение бита равно нулю) или IDL (значение бита равно единице) будет включен этот механизм. Дополнительно пользователь должен настроить каждый SCC-канал на поддержку механизма запросов, установив биты GR1-GR4 в регистре SICR.
Если биты STZa и/или STZb имеют значение «1», то для GCI-активации данного TDM-канала будет использована установка в «О» сигналов на линиях LITXDa и/или LITXDb при передаче тактовых сигналов CLK.
548
ПОДДЕРЖКА ПРОТОКОЛОВ В КОММУНИКАЦИОННЫХ КОНТРОЛЛЕРАХ
L1CLK
(бит СЕ = 0)
LISYNC
(битРЕ = 1)
DATA
Выставлены данные. Один такт задержки (биты RFSD = 01)
Данные выставлены без задержки (биты RFSD = 00)
Обнаружен сигнал LISYNC
Обнаружен сигнал LISYNC
Рис. 5.76. Пример настройки последовательного интерфейса. Первый кадр данных выставляется с одним тактом задержки (бит RFSD = 01), второй -без задержки (бит RFSD = 00). Данные передаются по положительному перепаду тактового сигнала L1CLK (бит СЕ = 0). Анализ сигнала L1SYNC производится по положительному перепаду тактового сигнала (бит FE = 1)
Реализация функций маршрутизации. TSA разрешает одновременную работу двух полнодуплексных TDM-каналов. Каждый TDM-канал может работать с временными каналами, длина которых задается как в битах, так и в байтах. Максимальная длина обрабатываемого кадра для МРС860 составляет 8192 бита. Максимальное число обрабатываемых временных каналов в в МРС860 - 64. Каналы могут обмениваться данными между своими временными слотами, и TSA может решать задачи маршрутизации временных каналов с помощью программирования внутренней памяти маршрутизации SI RAM. Примеры использования TDM-каналов приведены на рис. 5.77 - 5.80.
TDM SYNC
Л__________________
Рис. 5.77. Один внешний ситал tdmclk строба кадра SYNC и одна внешняя син-
хронизация используются и для прием- TDM Тх ника Rx, и для передатчика Тх одного TDM-канала. Модификация временных
каналов не производится TDM Rx
SCC1 SMC2
SCC1 SMC2
TDM SYNC
Рис. 5.78. Один внешний сигнал строба кадра SYNC и одна внешняя син- TDM CLK хронизация используются и для приемника Rx, и для передатчика Тх одного TDMTx TDM-канала. Производится изменение
временного слота для данных от кана-
лов SCC2 и SMC1 TDMRx
л____________________
ibiiimeiiidiilbii
SMC1 SCC2
SCC2 SMC1
549
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
TDM SYNC
Рис. 5.79. Производится модифика-
ция временных каналов. Изменяется раз- том clk
мер каналов. Данные от SCC1 занима-
ют несколько временных слотов при при- TDM Тх
еме и выдаются в другие временные
слоты при передаче с изменением раз-
меров этих временных слотов TDM
л__________________________
11ЛПШ1ШЛ11ПШШ1ЛШ1^^
SCC1 SMC2 SCC1
SMC2 SCC1 SCC1
TDM Rx SYNC
TDM Rx CLK
TDMRx
Рис. 5.80. Полностью независи-
мые приемная (Rx) и передающая TDM Тх SYNC (Тх) части, каждая использует свою частоту синхронизации и свой сигнал стробирования кадра. Также произ- TDM Тх CLK водится модификация временных
слотов TDM Тх
При работе с временными каналами TSA дополнительно поддерживает выработку четырех внешних стробирующих сигналов - L1STA1, L1STA2, L1STB1 и L1STB2. Функционирование этих стробов не зависит от работы SCC- и SMC-каналов, и они могут быть использованы для управления обменом данными с другими устройствами, которые не поддерживают работу в режиме временного мультиплексирования.
Использование памяти маршрутизации SI RAM. Программирование функций маршрутизации или функций обмена данными между временными слотами производится с использованием специальной памяти маршрутизации SI RAM, которая введена в состав СРМ. Память маршрутизации состоит из двух частей, каждая размером 64x16 бит в МРС860. Одна часть памяти используется для управления маршрутизацией принимаемой информации, другая - для управления пересылкой передаваемой информации.
Суммарный объем SI RAM в МРС860 - 256 байт. Память маршрутизации расположена во внутренней памяти регистров контроллера и может программироваться центральным процессором. Следует обратить внимание, что SI RAM расположена не в двухпортовой памяти и предназначена только для управления потоками данных между временными слотами TDM-каналов и буферами контроллеров SCC- и SMC-каналов и не используется для хранения данных. С помощью памяти маршрутизации пользователь может определять, информация какого SCC- или SMC-канала будет передана/принята на какой TDM-канал, в какой временной слот и каким внешним стробирующим сигналом она будет синхронизирована. Размер каждой части SI RAM зависит от конфигурации TDM-каналов и может иметь, например, для МРС860 контроллера максимальный размер 256 байт или минимальный размер 32 байта.
SI RAM состоит из ячеек (entries), которые определяют режимы работы и параметры каждого временного слота. Содержимое i-ячейки (рис. 5.81) определяет, как будет обрабатываться i-временной слот кадра. Число ячеек равно числу поддерживаемых временных слотов в кадре данных. Бит LST = 1, установленный в некоторой ячейке, сообщает,
550
ПОДДЕРЖКА ПРОТОКОЛОВ В КОММУНИКАЦИОННЫХ КОНТРОЛЛЕРАХ
О 1 2 3 4 5 6 7 8 9 10 1 1 12 13 14 15
Loop SWTR SSEL1-SSELS | — | CSEL STZb BYT LST
Рис. 5.81. Формат ячейки памяти маршрутизации
что кадр данных закончен, и это ячейка соответствовала последнему временному каналу этого кадра. Это значит, что теперь Sl-интерфейс заканчивает обработку текущего кадра и будет ждать появления нового внешнего SYNC-сигнала, стробирующего начало нового кадра, чтобы начать обработку нового кадра. Если бит LST = 0, то текущий временной канал - не последний в кадре, и Sl-интерфейс читает содержимое очередной ячейки, чтобы определить правила обработки следующего временного слота.
Биты CSEL определяют, откуда будет взята информация для выбранного временного слота (табл. 5.45).
Таблица 5.45
Соответствие между SCC-каналом и временным слотом
Бит CSEL Какой канал работает с временным слотом Бит CSEL Какой канал работает с временным слотом
000 Зарезервировано 100 Канал SCC4
001 Канал SCC1 101 Канал SMC1
010 Канал SCC2 110 Канал SMC2
011 Канал SCC3 111 Зарезервировано
Размер временного слота определяют биты CNT и BYT. Если BYT = 0, то размер равен (CNT+1) бит. Если BYT = 1, то размер равен (CNT+1) байт.
Биты SSEL1-SSEL4 определяют, какой из внешних стробирующих сигналов-L1STA1, L1STA2, L1STB1, L1STB2 может быть выставлен в течение временного слота. Возможно использовать для стробирования одного временного канала одновременно несколько стробирующих сигналов. Если один стробирующий сигнал выбран для двух последовательных временных каналов, то он будет удерживаться без сброса на границе временных каналов.
Бит SWTR используется для особых случаев, когда пользователь желает принимать данные с Тх-входа и передавать данные на Rx-выход. Этот режим может быть применен для функций контроля работы приемника и передатчика каждого TDM-канала. Установка этого бита оказывает влияние только на часть SI RAM, которая относится к приемнику, и на состояние сигналов на контактах L1RXD и L1TXD.
При значении бита LOOP = 1 включается тестовый режим для выбранного временного слота. В этом режиме полученные с контакта RXD данные будут бит за битом передаваться на контакт TXD.
Выбор режима работы TDM-каналов производится при программировании регистра режима SI SIGMR, формат которого приведен на рис. 5.82.
Биты RDM[1], RDM[0] задают один из четырех режимов работы, описанных в табл. 5.46.
0 1 2 3____4 5 6 7
Зарезервировано ENB ENA RDM
Рис. 5.82. Формат регистра режима SIGMR памяти маршрутизации
551
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
Таблица 5.46
Режимы работы блока TSA
Биты RDM Режим работы
00 Режим 1. Один TDM-канал с постоянными временными каналами
01 Режим 2. Один TDM-канал с переменными временными каналами
10 Режим 3. Два TDM-канала с постоянными временными каналами
11 Режим 4. Два TDM-канала с переменными временными каналами
Биты ENb и ENa определяют, работает ли маршрутизация на каналах TDMb и TDMa. Если бит ENx равен единице, то память SI RAM доступна при работе данного канала.
При режиме работы TDM-каналов с переменными временными каналами назначение источников маршрутизации и параметров канала может быть изменено во время работы. Для этого SI RAM дополнительно делится на основную, с которой работает TSA в данный момент времени, и теневую, в которую пользователь вносит свои изменения в таблицу маршрутизации. Когда все изменения внесены, пользователь устанавливает соответствующие биты - CSRRa, CSRTa, CSRRb, CSRTb в регистре команд SICMR (рис. 5.83). Биты CSRRa и CSRRb, равные единице, задают смену назначения частей памяти для приемников каналов TDMa и TDMb соответственно, а биты CSRTa и CSRTb, равные единице, - для передатчиков каналов TDM. В результате происходит преобразование теневой памяти (shadow RAM) в основную. Преобразование предусматривает смену внутреннего назначения частей памяти, теневая становится основной, а основная - теневой. По окончании преобразования сбрасывается соответствующий бит CSRxx.
Характеристики временных каналов приведены в табл. 5.47.
Таблица 5.47
Характеристики временных каналов
Характеристика Контроллеры
МС68360 МРС860
Максимальное число каналов 32 64
Максимальная длина кадра, байт 32*16 64*16
Максимальное число каналов при приеме и передаче в режиме 1 32 64
Максимальное число каналов при приеме и передаче в режиме 2 16 32
Максимальное число каналов при приеме и передаче в режиме 3 16 32
Максимальное число каналов при приеме и передаче в режиме 4 8 16
Режим 1. SI RAM разделена на две части - по 64 ячейки у МРС860. Работает только канал TDMa. Теневая память не используется (табл. 5.48). Все ячейки расположены в основной памяти. Максимальное число обрабатываемых временных каналов в кадре - 64.
О_____1______2______3 4_____5_____6______7
CSRRa CSRTa CSRRb CSRTb Зарезервировано
Рис. 5.83. Формат регистра команд SICMR памяти маршрутизации
552
ПОДДЕРЖКА ПРОТОКОЛОВ В КОММУНИКАЦИОННЫХ КОНТРОЛЛЕРАХ
Таблица 5.48
Деление ячеек памяти маршрутизации между основной и теневой памятью
Адрес ячеек Основная память Теневая память
Режим 1: Приемника RXa канала TDMa Передатчика Тха канала TDMa 0-127 128-255 -
Режим 2: Приемника RXa канала TDMa Передатчика Тха канала TDMa 00-63 128-191 64-127 192-255
Режим 3: Приемника RXa канала TDMa Передатчика Тха канала TDMa Приемника RXb канала TDMb Передатчика ТхЬ канала TDMb 00-63 128-191 64-127 192-255 -
Режим 4: Приемника RXa канала TDMa Передатчика Тха канала TDMa Приемника RXb канала TDMb Передатчика ТхЬ канала TDMb 00-31 128-159 64-96 192-223 32-63 160-191 097-127 224-255
Режим 2. SI RAM разделена на четыре части - по 32 ячейки у МРС860. Максимальное число обрабатываемых временных каналов в кадре - 32. Работает только канал TDMa. Распределение памяти проиллюстрировано в табл. 5.48.
Режим 3. SI RAM разделена на четыре части - по 32 ячейки у МРС860. Максимальное число обрабатываемых временных каналов в кадре - 32. Работают оба TDM-канала. Теневая память не используется (табл. 5.48). Все ячейки расположены в основной памяти.
Режим 4. SI RAM разделена на восемь частей - по 16 ячейки у МРС860. Максимальное число обрабатываемых временных каналов в кадре - 16. Работают оба TDM-канала (табл. 5.48).
Пользователь может в любой момент времени прочитать содержимое регистра статуса SI (SISTR), формат которого показан на рис. 5.84, и определить, какая часть SI RAM считается основной в текущий момент времени.
О_____1______2______3 4_____5_____6_____7
CSORa CSOTa CSORb CSOTb Зарезервировано
Рис. 5.84. Формат регистра статуса SISTR памяти маршрутизации
Значение бита CRORa определяет адреса ячеек основной памяти, которые выделены для работы с приемником RXa канала TDMa (табл. 5.49). Значение бита CROTa определяет адреса ячеек основной памяти, которые выделены для работы с передатчиком ТХа канала TDMa (табл. 5.49).
Таблица 5.49
Основная память приемника и передатчика TDMa-канала
Адрес ячеек Для приемника Для передатчика
Бит CRORa = 0 Бит CRORa = 1 Бит CROTa = 0 Бит CROTa - 1
При работе с одним TDM-каналом 0-63 64-127 128-191 192-255
При работе с двумя TDM-каналами 0-31 32-63 128-159 160-191
553
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
Значения битов CRORb и CROTb определяют адреса ячеек основной памяти, которые выделены для работы с приемником RXb и передатчиком ТХЬ канала TDMb (табл. 5.50). Значения этих битов имеют смысл, только если TSA настроен на работу с двумя TDM-каналами.
Таблица 5.50
Основная память приемника и передатчика TDMb-канала
Адрес ячеек Для приемника Для передатчика
Бит CRORa = 0 Бит CRORa = 1 Бит CROTa = 0 Бит CROTa = 1
При работе с двумя TDM-каналами 64-95 96-127 192-223 224-255
IDL-интерфейс. IDL интерфейс - полнодуплексный ISDN-интерфейс, предназначенный для подключения сетевых устройств к коммуникационному контроллеру. Для выхода на S/T-интерфейс требуется дополнительно на выводах контроллера подключать специальный S/T-трансивер, например, Motorola МС145474.
Контроллер МРС860 поддерживает все каналы IDL-протокола в режимах работы basic ISDN и primary ISDN. В режиме basic ISDN данные передаются по трем временным каналам (В1 и В2 - 8-битные информационные каналы, D - 2-битный канал управления) в виде 20-битного кадра со скоростью 160 Кбит/с.
Коммуникационные контроллеры могут работать только как пассивные (slave) ISDN-устройства, поэтому тактовая частота и сигнал строба начала кадра должны поступать от внешнего активного (master) устройства. Все контроллеры поддерживают полнодуплексный режим обмена и имеют независимые линии приема и передачи данных, но одни и те же сигналы тактовой частоты и строба кадра используются и для приемника, и для передатчика. СРМ может обрабатывать IDL-протокол одновременно на двух TDM-каналах, причем каждый канал может иметь свои сигналы синхронизации и стробирования. Назначение сигналов IDL-интерфейса приведено в табл. 5.51.
Таблица 5.51
Назначение сигналов IDL-интерфейса
Сигнал интерфейса Назначение сигнала
LIRCLKx Внешняя тактовая частота
L1RSYNCX Внешний строб начала IDL-кадра
LIRXDx Принимаемые данные
LITXDx Передаваемые данные
L1RQx Запрос на передачу по D-каналу
L1GRx Разрешение передачи (СРМ принимает этот сигнал на входе L1TSYNC)
СРМ поддерживает две разновидности IDL-кадров: 8-битный и 10-битный. Разница заключается только в порядке передачи битов внутри кадра. Общая длина IDL-кадра постоянна и равна 20 битам. Функциональное назначение полей в обоих типах кадра совпадает. Ранние версии Motorola IDL-интерфейса, например в СР контроллера МС68302 (рис. 5.85), поддерживали дополнительно два однобитовых канала: (auxiliary) A-канал и (maintenance) М-канал, которые использовались для передачи информации о дополнительном управлении и контроле обмена между сетевыми устройствами. При желании пользователь может запрограммировать в СРМ TDM-каналы на передачу через эти битовые служебные каналы «прозрачной» информации от любого SCC или SMC-контроллера.
554
ПОДДЕРЖКА ПРОТОКОЛОВ В КОММУНИКАЦИОННЫХ КОНТРОЛЛЕРАХ
SMC2
SMC1
Рис. 5.85. IDL-кадр в контроллере МС68302
Поскольку IDL-интерфейс поддерживает рекомендации ССПТ I.460, то каждый бит 20-битного IDL-кадра может быть запрограммирован пользователем в TDM как отдельный битовый временной канал со скоростью передачи данных 8 Кбит/с, предназначенный для работы со своим SCC- или SMC-контроллером. Работа с таким битовым каналом может сопровождаться выработкой специальных стробирующих сигналов (при приеме или передаче этого бита) для внешних устройств, которые не поддерживают ISDN-интерфейс. Таким образом, 20-битный IDL-кадр в контроллере МРС860 (рис. 5.86) может рассматриваться как объединение от 1 до 20 различных каналов, каждый из которых может обрабатываться своим SCC- или SMC-контроллером. Настройку на конкретный режим работы пользователь выполняет при программировании ячеек памяти маршрутизации SI RAM.
При передаче данных по D-каналу для определения коллизий коммуникационный контроллер использует метод запросов-подтверждений. Контроллер выставляет запрос L1RQx к устройству физического уровня модели OSI, например к S/T-трансиверу. Если D-канал свободен, то устройство выставляет ответный активный сигнал подтверждения L1 GRx. Контроллер проверяет наличие сигнала L1 GRx в течение действия импульса строба LIRSYNCx. Если обнаружен активный сигнал подтверждения, то контроллер выставляет на D-канал первый бит кадра данных. Если во время передачи по D-каналу сигнал L1GRx будет сброшен в пассивное состояние, то контроллер остановит передачу и начнет повторную передачу, когда сигнал L1GRx станет активным.
СРМ-контроллер также поддерживает режим работы с primary IDL-протоколом. В этом режиме IDL-кадр может состоять из четырех восьмибитных временных каналов данных.
LITxD
LI RxD
LITxD
LIRxD
LISYNC
LICLK
10-битный IDL
8-битный IDL
Рис. 5.86. 10- и 8-битные IDL-кадры в контроллерах МРС860
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
При программировании памяти маршрутизации SI RAM пользователь может запрограммировать прием более чем одного временного канала на один высокоскоростной SCC-контроллер, а также может обеспечить выработку внешних стробирующих сигналов при передаче/приеме каждого временного канала. На практике возможна реализация 32 виртуальных каналов (четыре канала в IDL-кадре по 8 бит), каждый из которых имеет размер 1 бит, представляет собой независимый В-канал и адресован своему SCC-контроллеру. Такое применение 32 виртуальных каналов реализовано в контроллере МРС860МН.
Рассмотрим пример программирования таблицы маршрутизации для реализации basic IDL-интерфейса с 10-битным форматом кадра, состоящим из трех каналов. Канал В1 обслуживается контроллером SCC2, канал В2 - контроллером SMC1, канал D - контроллером SCC1. В табл. 5.52 приведено заполнение ячеек SI RAM, которое необходимо повторить и для секции памяти приема и для секции памяти передачи. Во все оставшиеся ячейки записывается код 0x0001. При этом в каждой из ячеек будет установлен бит последней ячейки LST, и эти ячейки будут выключены из работы.
Таблица 5.52
Память маршрутизации приемника
Номер ячейки Ячейка памяти SI RAM
Коммутация SWTR Строб SSEL Канал CSEL Размер С NT Байт/бит BYT Последняя LST Назначение
0 0 0000 010 0000 1 0 1 байт от канала SCC2
1 0 0000 001 0000 0 0 1 бит от канала SCC1
2 0 0000 000 0000 0 0 1 битовый слот не используется
3 0 0000 100 0000 1 0 1 байт от канала SMC1
4 0 0001 001 0000 0 1 1 бит от канала SCC1 и выставляется строб 1
PCM-интерфейс. В режиме импульсной модуляции PCM (Pulse Code Modulation) несколько SCC-каналов объединяются в режиме временного мультиплексирования. Стандарт РСМ поддерживает такие хорошо известные интерфейсы, как Т1 и СЕРТ.
Внешняя частота синхронизации поступает на вход L1CLK для тактирования как приемника, так и передатчика. Если необходимо использовать разные частоты синхронизации приемника и передатчика, то рекомендуется запрограммировать немультиплексиру-емый NMSI-режим работы канала вместо РСМ-режима.
Для выделения временных каналов в СРМ используются два стробирующих сигнала -L1SYNC0 и L1SYNC1. Комбинация этих сигналов определяет выбор одного из трех РСМ-каналов (табл. 5.53).
Таблица 5.53
Назначение РСМ-каналов
Значение сигналов L1SYNC1 и L1SYNC0 Выбранный канал
00 Каналы не выбраны
01 Выбран первый РСМ-канал
10 Выбран второй РСМ-канал
11 Выбран третий РСМ-канал
556
ПОДДЕРЖКА ПРОТОКОЛОВ В КОММУНИКАЦИОННЫХ КОНТРОЛЛЕРАХ
12345 678 9 10
LITXD L1RXD
8 бит 8 бит 8 бит 8 бит 8 бит 8 бит 8 бит 8 бит 8 бит 8 бит
LISYO
Рис. 5.87. РСМ-каналы
Эти стробирующие сигналы могут удерживаться или в течение передачи всех данных канала или стробировать появление первого бита данных канала. В случае стробирования первого бита стробирующий сигнал представляет собой импульс шириной один битовый интервал, по отрицательному фронту которого выставляется первый бит данных. На линиях в интерфейсе Т1/СЕРТ используется удержание стробирующих сигналов в течение передачи всех данных PCM-канала. На рис. 5.87 приведен пример различных способов стробирования РСМ-каналов.
После выбора SCC-канала, работающего с данным PCM-каналом, данные от него будут передаваться по линии L1TXD и приниматься с линии L1RXD, но только пока идет передача тактирующих импульсов по линии L1CLK. Если на линии L1CLK нет передачи тактовых импульсов, то линия L1TXD находится в Z-состоянии, а сигналы на линии L1RXD игнорируются.
Можно настроить режим, когда каждый PCM-канал управляется отдельным SCC-контроллером или когда все РСМ-каналы запрограммированы для работы с одним SCC-контроллером, который будет в одиночку обрабатывать высокоскоростной поток данных. В этом режиме рекомендуется остальные каналы ввода/вывода перевести в выключенное состояние, так как при увеличении числа одновременно работающих каналов уменьшается максимальная скорость передачи информации. При увеличении числа работающих каналов усложняется процесс арбитража доступа к шине для передач от SDMA-каналов и увеличивается время ожидания доступа к шине для передачи данных между FIFO и памятью. Максимальная скорость передачи канала контроллера достигается, когда работает только один канал ввода/вывода.
При работе с PCM-интерфейсом можно дополнительно использовать выработку сигналов RTSi для каждого PCM-канала. Эти сигналы выставляются, когда SCC-контроллер желает передать данные по PCM-каналу и удерживаются в течение передачи всех данных от этого контроллера, даже если эта передача требует занятия нескольких временных слотов. На рис. 5.87 приведен пример использования нескольких РСМ-каналов, причем второй канал занимает два временных слота.
GCI-интерфейс. Основные режимы работы GCI-интерфейса. GCI (General Circuit Interface) - 4-проводной интерфейс для подключения устройств к ISDN-сети. Интерфейс может работать в режиме передачи данных и в режиме контроля (maintenance) функционирования сетевых устройств. Контроллер может работать как NT(Network Terminal)- или TE(Terminal ЕцЫртеп1)-устройство в сети ISDN. При работе в NT-режиме станция может быть или master- или slave-устройством. При работе в ТЕ-режиме станция может быть только slave-устройством.
Интерфейс использует четыре сигнала: прием, передача, единый тактовый сигнал для приема и передачи и сигнал строба начала обмена данными. Передний фронт строб-
557
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
сигнала говорит о начале кадра и сбрасывает счетчики контроля длины кадра. В режиме slave тактовый сигнал и строб являются внешними сигналами по отношению к контроллеру.
Тактовая частота должна быть в два раза больше частоты передачи данных. Данные выставляются по положительному перепаду тактового сигнала и читаются через 1-1,5 периода после начала битового интервала.
Интерфейс позволяет работать в сетях с конфигурациями point-to-point и multipoint. Входные данные поступают от S/T-передатчика. Выходные данные передаются на внешний контакт с открытым коллектором и с внешним pull-up-сопротивлением, такой способ подключения реализован для объединения в шину «монтажное ИЛИ» с выходами других GC 1-устройств. Данные передаются S/T-передатчику в определенные временные слоты, в другое время линия находится в Z-состоянии.
В СРМ каждый TDM-канал поддерживает независимые GCI-интерфейсы с независимыми приемной и передающей частями. В табл. 5.54 приведен набор сигналов GCI-ин-терфейса, которые используют коммуникационные контроллеры для обмена информацией с внешними S/T-трансиверами.
Таблица 5.54
Назначение сигналов GCI-интерфейса
Сигнал Назначение сигнала
LIRCLKx Внешняя тактовая частота для синхронизации приемника и передатчика. Входная частота должна быть в два раза больше частоты передачи данных согласно требованиям GCI-интерфейса.
LIRSYNCx Внешний строб начала GCI-кадра.
LIRXDx Принимаемые данные. Вход приемника данных.
L1TXDX Передаваемые данные. Вывод типа «открытый исток» (open-drain) для передачи данных может использоваться при объединении выводов нескольких контроллеров в общую шину.
L1CLKOX Дополнительный выходной сигнал, который можно использовать для тактирования внешних устройств, которые не могут быть напрямую соединены с GCI-устройства-ми. Частота сигнала на выходе LICLKOx в два раза ниже частоты сигнала на входе LIRCLKx.
GCI-интерфейс может быть настроен на работу в двух режимах: нормальном рабочем GCI-режиме и в режиме SCIT (Special Circuit Interface for Terminal). Режим SCIT настраивается при программировании регистра SIMODE.
Структура GCI-кадра. Каждый GCI-канал представляет собой 4-байтовую структуру, использующую режим временного мультиплексирования (рис. 5.88). Сигнал начала кадра выставляется с частотой 8 КГц, т. е. один раз в 125 мкс. Два независимых В-канала с пропускной способностью 64 Кбит/с используются для передачи цифровых данных и голоса. М-канал используется для настройки и управления передачей. C/l-канал делится на 2-битовый D-канал, 4 бита C/l-канала (Control/lndication) и 2 бита для А- и Е-каналов, которые предназначены для контроля за передачей информации по М-каналу.
При работе в режиме SCIT СРМ поддерживает механизм определения коллизий при передаче по D-каналу. Управление доступом к D-каналу в устройствах S/T-интерфейса реализуется с помощью канала команд C/l (Command/lndicator). Внешние сетевые устройства, работающие на физическом уровне модели OSI (например, трансивер), определяют активность D-канала и уведомляют об этом СРМ обычно через бит 4 второго канала С/l. Этот бит СН4 выполняет функции сигнала SG (stop/go). Если этот бит равен О,
558
ПОДДЕРЖКА ПРОТОКОЛОВ В КОММУНИКАЦИОННЫХ КОНТРОЛЛЕРАХ
125 мкс
LISYNC
Рис. 5.88. Структура GCI-кадра для различных режимов работы
то канал занят или произошла коллизия. В этом случае СРМ прекращает передачу и > возобновляет ее только после сброса этого бита. Обычно повторная передача прерванной информации выполняется автоматически для двух первых буферов данных кадра.
Каналы 0 и 2 предназначены для обмена данными между устройствами.
Обычно GCI-кадр содержит комбинацию 32 битовых временных каналов, передавае-' мых со скоростью 8 КГц, что составляет суммарную скорость передачи кадра в 256 Кбит/с.
Но в устройствах NT1 и NT2 до 8 GCI-каналов могут быть объединены в один кадр с пропускной способностью от 256 до 3088 Кбит/с. При этом для всего объединенного кадра используется строб-сигнал с частотой 8 КГц, как и для GCI-кадра с одним каналом. Таким образом, во временной интервал 125 мкс, заданный строб-сигналом, можно вло-* жить от 1 до 8 отдельных GCI-каналов, которые образуют единый кадр. Каждый отдельный GCI-канал в таком кадре имеет номер от 0 до 7, соответствующий временному слоту, в который он вставлен. Скорость передачи данных внутри каждого GCI-канала составляет 256 Кбит/с. В режиме SCIT кадр данных объединяет три GCI-канала. В этом случае скорость передачи данных в кадре составляет 2048 Кбит/с.
При доступе к каналу GCI-SCIT-кадра (Special Circuit Interface for Terminal) до 8 HDLC-контроллеров могут быть объединены для передачи по D- и C/l-каналам. Механизм дос-! тупа к каналу позволяет исключить потерю данных. Перед началом передачи GCI-koh-троллер проверяет состояние СН4 - 4 бита третьего GCI-канала (канал номер 2). Этот бит показывает состояние С/l- и D-каналов. Если бит равен 1, то канал свободен, если .. бит равен 0, то канал занят. Если канал свободен, то HDLC-контроллер начинает передавать на биты СН1-СНЗ третьего канала GCI свои разряды адреса AD2-AD0 и тут же их , читает. Если при чтении обнаружено несовпадение адресов, то процедура доступа к каналу прекращается. Если выставленный адрес совпал с прочитанным, то контроллер получает доступ к каналу и передает бит СН4 = 0. HDLC-контроллер с наименьшим адресом имеет самый высокий приоритет доступа к каналу. Структура GCI-SCIT-кадра приведена в табл. 5.55.
Рассмотрим пример программирования таблицы маршрутизации для реализации basic 2B+D GCI-интерфейса для 96-битного кадра, состоящего из объединения трех каналов GCI по 32 бита каждый. Канал В1 обслуживается контроллером SCC2, канал В2 - контроллером SCC4, канал D - контроллером SCC1. Контроллер SMC1 передает . управление по C/l-каналу. Включена поддержка механизма обнаружения коллизий при доступе к D-каналу, которая реализуется в 4 бите C/l-канала на втором SCIT GCI-кана
559 '
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
ле. В табл. 5.56 приведено заполнение ячеек SI RAM, которое необходимо повторить и для секции памяти приема и для секции памяти передачи. Во все оставшиеся ячейки записывается код 0x0001. При этом в каждой из ячеек будет установлен бит последней ячейки LST, и эти ячейки будут выключены из работы.
Таблица 5.55
Структура кадра GCI-SCIT
Тип канала Назначение
Канал 0 Стандартный 32-битный GCI-кадр. Bl-канал (8 бит) + В2-канал (8 бит) + М-канал (8 бит)+ D-канал (2 бита) + С/1-канал (4 бита) +А-канал +Е-канал.
Канал 1 В1-канал (8 битов) + В2-канал (8 битов) + М-канал (8 битов)+ С/1-канал (6 битов)+ +А-канал +Е-канал. Всего 32 бита. По 6 битам C/l-канала передаются различные запросы от ТЕ-устройств к микропроцессору. До 6 slave-устройств могут сделать запрос одновременно. Устройство slave выставляет вектор прерывания (запросы) и принимает сигналы разрешения bus grant. Master-устройство выставляет вектор прерывания (сипналы разрешения) и принимает сигналы запросов от slave. Master постоянно сравнивает старую информацию из C/l-канала с новой, которая должна быть повторена в двух соседних кадрах. Если действительно получена новая информация, то он на нее реагирует.
Канал 2 24 бита не используются. Среди оставшихся 8 бит канала - с 0-го по 7-й (0 бит передается первым) используются только 4 бита СН1-СН4.
Таблица 5.56
Память маршрутизации
Номер ячейки Ячейка памяти SI RAM
Коммутация SWTR Строб SSEL Канал CSEL Размер CNT Байт/бит BYT Последняя LST Назначение
0-й GCI-канал:
0 0 0000 010 0000 1 0 1 байт от SCC2 (В1-канал)
1 0 0000 100 0000 1 0 1 байт от SCC4 (В2-канал)
2 0 0000 101 0000 1 0 1 байт от SMC1 (Monitor-канал)
3 0 0000 001 0001 0 0 2 бита от SCC1 (D-канал)
4 0 0000 101 0101 0 0 6 бит от SMC1 (С/1-канал)
1-й и 2-й GCI-каналы
в SCIT-режиме:
5 0 0000 000 0110 1 0 7 байт не используется
6 0 0000 000 0001 0 0 6 бит не используется
7 0 0000 111 0000 0 1 1 бит D-grant (C/l-канал второго GCI-канала)
М- и А/Е-каналы. Канал Monitor (М-канал) - независимый канал, который служит для передачи команд и управляющей информации между схемами 1-го уровня управления в сетевых устройствах. Через М-канал происходит обмен содержимым и конфигурирование внутренних регистров GCI-устройств, например, S/T-передатчика. А- и Е-каналы предназначены для контроля передачи информации по М-каналу (flow control) с использованием режима подтверждений. Для А- и Е-битов активное состояние - «0», а пассивное
560
ПОДДЕРЖКА ПРОТОКОЛОВ В КОММУНИКАЦИОННЫХ КОНТРОЛЛЕРАХ
состояние канала - Z-состояние. MSB-байт передается по М-каналу первым. Если по каналу нет передачи, то во время данного временного слота выводы контроллера находятся в Z-состоянии.
Все сообщения М-канала имеют длину 2 байта. При записи информации в регистры GCI-устройства в первом байте передается адрес регистра. Для некоторых микросхем бит АО = 0 определяет цикл записи содержимого второго байта в регистр с указанным адресом. Если АО = 1, то это означает цикл чтения с возвратом, и значение второго байта игнорируется и GCI-устройство должно послать сообщение-ответ, в котором передает содержимое регистра с указанным адресом.
Каждый байт посылается (дублируется), по крайней мере, в двух соседних кадрах для обеспечения надежности передачи, при этом приемник проверяет совпадение и целостность информации. Биты А и Е в GCI-канале используются для контроля и подтверждений передачи между GC 1-устройствами по М-каналу. Когда по М-каналу нет передачи, биты А и Е находятся в неактивном состоянии (Z-состоянии). Бит Е устанавливается передатчиком, чтобы указать, что он передает байт. Бит А используется приемником для подтверждения приема байта. Второй байт команды передается только после получения подтверждения на первый байт.
Передача по М-каналу начнется только после получения неактивного бита А = Z в течение двух последовательных GCI-кадров. Передача начинается с установки GCI-устройством бита Е в активное состояние (Е = 0) и посылкой этого бита в том же кадре, в котором передается первый байт данных. Передача этого байта повторяется, по крайней мере, в двух соседних GCI-кадрах, пока не будет получено подтверждение. После получения двух одинаковых байтов приемник подтверждает прием байта, установив бит А в активное состояние и удерживая его активным, по крайней мере, в течение следующего кадра. Если совпадение не обнаружено, то устанавливается активный бит А только для одного кадра.
Поскольку пока ожидается подтверждение на первый байт, посылающее устройство устанавливает бит Е в неактивное Z-состояние и передает первый кадр второго байта. Затем второй байт повторяется, но уже с активным битом Е = 0, до тех пор пока не будет получено подтверждение.
Успешная передача следующего байта подтверждается принимающим устройством установкой и передачей неактивного значения А = Z во время приема первой копии следующего байта данных и передачей активного значения А = 0, когда будет получена вторая копия байта. При совпадении двух байтов приемник в течение двух соседних кадров вначале устанавливает бит А в неактивное состояние (предустановка подтверждения), а затем снова в активное состояние (подтверждение). Если совпадения не произошло, то бит А остается неактивным в течение двух соседних кадров, тем самым показывая запрос на прерывание. Передатчик после получения запроса на прерывание будет повторно передавать все последние сообщения, пока не получит правильного подтверждения.
Бит Е может быть неактивным только для одного кадра. Конец сообщения отмечается установкой бита Е = Z при передаче обеих копий последнего байта сообщения. Если бит Е неактивен более двух кадров, то это означает конец сообщения.
Передача кода IDLE (OxFF) по М-каналу отмечается тем, что биты А и Е будут неактивны (в Z-состоянии) в течение двух последовательных GCI-кадров.
Сообщения М-канала. Используются три типа сообщений. Первая группа сообщений и команд - для чтения и записи внутренних регистров GCI-устройства. Это команды, которые записывают данные во внутренние регистры, принимаются и выполняются, но сообщение-ответ не передается. GCI-устройство подтверждает все принятые по М-каналу команды (табл. 5.57). Если принята некорректная команда, то она не выполняется, но подтверждение посылается.
561
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
Таблица 5.57
Типы сообщений М-канала для S/T-трансивера МС145574
MSB Байт 1 LSB MSB Байт 2 LSB Команда
7 6 5 4 3 2 1 0 7 6 5 4 3 2 1 0
Команды М-канала
0 0 0 0 Адрес регистра Байтданных Запись байта
0 0 0 1 Адрес регистра X X X X X X X X Чтение байта
0 0 1 0 0 Адрес Данные X X X X Запись куска байта
0 0 1 1 0 Адрес X X X X X X X X Чтение куска байта
1 0 0 0 0 0 0 0 X X X X X X X X ID-команда
Сообщения-ответы на команды
0 0 0 1 Адрес регистра Байтданных Чтение байта
0 0 1 1 1 Адрес Данные X X X X Чтение куска байта
0 1 0 0 0 0 0 0 X X X X X X X X ID-отеет
Сообщения-изменения статуса
0 0 1 1 0 0 1 1 Данные X X X X Чтение регистра NR3
Вторая группа - ответы от GCI-устройства, которые передаются после получения по М-каналу команды чтения или записи. Сообщения-ответы передаются по М-каналу в ответ на команду чтения регистра.
Третья группа сообщений - сообщения индикации состояния. Эти сообщения отражают изменение статуса регистров устройства. Сообщения изменения статуса автоматически передаются в GCI Monitor-канал GCI-устройством, когда изменение статуса обнаруживается внутри устройства. Эти сообщения - аналог сигнала Interrupt. Сообщения Status Indication должны вызывать чтение регистра состояния прерываний (interrupt status).
Управление передачей по C/l-каналу. Канал C/l (Command/lndication) служит для передачи процедур управления 1-го уровня, таких как активация и деактивация линии, петлевой контроль и другие контрольные функции. C/l-коды имеют длину 4 бита и должны быть получены приемником в двух последовательных кадрах, прежде чем команда будет выполнена. Биты команды нумеруются от 4-го до 1-го, и старший (MSB) 4-й бит передается в канал первым.
Для любого канала 4-битное слово команды передается последовательно в GCI-ка-нал кадра, пока не будет заменено другой командой C/l-канала. Поэтому при приеме новой команды приемник сравнивает ее код с кодом предыдущей команды и приступает к выполнению полученной команды, только если ее код отличается от кода предыдущей команды. Для каждой микросхемы может быть определен свой набор регистров и команд для C/l-управления (табл. 5.58).
Таблица 5.58
Названия основных команд C/l-канала
С/1-команда Аббревиатура С/1-комацца Аббревиатура
Activation Indication Al Activation Request, End of Message AREOM
Activation Indication Priority 1 Al 8 Deactivation Confirmation DC
562
ПОДДЕРЖКА ПРОТОКОЛОВ В КОММУНИКАЦИОННЫХ КОНТРОЛЛЕРАХ
Продолжение табл. 5.58
С/1-команда Аббревиатура С/1-комакда Аббревиатура
Activation Indication Priority 2 AI10 Deactivation Indication DI
Activation Indication Local Test Loop AIL Deactivation Request DR
Activation Request AR Reset RES
Activation Request Priority 1 AR8 Resynchronization (Loss of Framing) RSY
Activation Request Priority 2 AR10 Timing Request TIM
Activation Request Local Test ARL Activation Timer Expired - Force T1/T3EXP
Loop Deactivation
Процедуры активации и деактивации S/Т трансивера. В состоянии деактивации тактовые сигналы CLK между контроллером и внешним сетевым устройством не передаются, а линии данных находятся в состоянии логической «1». Сетевые устройства активируют работу сетевого контроллера, начиная передавать на его входы тактовые сигналы CLK, и с помощью команд индикации на канале 0 C/l-канала. СРМ выставляет немаскируемое прерывание, извещая центральный процессор о том, что в буфере SMC-контроллера находится код «индикации».
При активации линий центральный процессор выставляет на линии передачи данных LITXDx код «О» (при программировании используется бит STZx = 1 в регистре конфигурации последовательного интерфейса SIMODE) и передает сетевому устройству код команды «Timing TIM» (код «О») по 0-му каналу С/l временного канала до тех пор, пока не будет сброшен бит STZx. Этот бит сбрасывает центральный процессор, когда необходимо разрешить передачу данных. Код «0» на нулевом канале С/l сообщает внешнему сетевому устройству о процессе активации коммуникационного контроллера.
Обычно C/l-канал используется для контроля процедур активации/деактивации. Стандартные процедуры активации/деактивации выполняются при помощи команд AR, DR и AI. Команда DI обычно передается по сети перед выключением питания. Класс сообщения выделяется C/l-командами AR8 и AR10. Команда AREOM может быть использована для завершения передачи сообщения на D-канале.
Если нет активных S/T-трансиверов, то тактовый сигнал TCLK между S/T-трансиве-ром и контроллером не вырабатывается. Первый передатчик, который будет активирован, начнет выдавать TCLK-сигнал. В контроллере QUICC для формирования тактового сигнала может быть использован внутренний BRG-генератор с соответствующими коэффициентами деления, чтобы получить частоту 2,048 МГц.
Кадр S/Т содержит 48 бит. При передаче от NT к ТЕ-станциям один из битов, А-бит, используется для контроля. Бит А = 1, когда S/T loop работает в активном рабочем режиме и бит А = 0 в другое время.
Активация режима S/TLoop от NT-станции. NT-станция активирует режим S/T Loop, передавая кТЕ-станции в кадре команду AR. ТЕ станция, получив кадр, синхронизируется этим сигналом, начинает выдавать своему контроллеру TCLK сигнал и передает подтверждение о начале активации в виде кадра с командой AI. Далее, получив от ТЕ-стан-ции этот кадр, NT-станция отвечает кадром с командой AI, тем самым активизируя цикл обмена (loop).
Активация режима S/T Loop от ТЕ-станции. ТЕ-станция запускает свой тактовый генератор TCLK сигнала и активирует этот режим, передавая кадр с командой AR8/AR10 к NT-станции. NT-станция, получив кадр, начинает выдавать своему контроллеру TCLK-сигнал и передает в ответ подтверждение в виде кадра с командой AR и битом А = 0.
563
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
ТЕ-станция, приняв ответный кадр от NT и убедившись, что это кадр с командой AR, прекращает передачу предыдущего кадра, дублирует содержимое принятого кадра в кадр с командой AI и возвращает его NT-станции, тем самым активизируя цикл (loop). NT-станция подтверждает активацию канала, передав ТЕ-станции кадр с командой AI8/AI10 и битом А = 1.
Деактивация. Стандарты CCITT I.430 и ANSI Т1.605 определяют, что только NT-станция может провести процедуру деактивации режима S/T loop посылкой кадра с командой DR к ТЕ-станциям, которые подтверждают получение кадра и начало деактивации, передавая в ответ кадр с командой DI и выключая свой генератор TCLK-сигнала. Получив подтверждение, NT-станция завершает процедуру деактивации, передав ТЕ-станции команду DC.
5.3.2. ВИРТУАЛЬНЫЕ КАНАЛЫ И ПОДДЕРЖКА PRIMARY ISDN
Общие сведения о контроллере QMC (QUICC Multichannel Controller). QMC-про-токол обеспечивает поддержку до 64 логических каналов внутри одного SCC-канала, используя TDM-интерфейс временного мультиплексирования. QMC-протокол реализуется за счет оптимального использования аппаратуры и не является загружаемым микрокодом. Любой из TDM-каналов в последовательном интерфейсе определенных версий контроллеров может быть назначен для работы с QMC-протоколом. Стандартный МРС860 может работать с TDM-каналом, но поддерживает только один логический канал для каждого SCC-контроллера. QMC-протокол реализован в следующих версиях контроллеров: МРС860МН (расширение MPC860EN), MPC860DH (расширение MPC860DE).
Поддержка 64-канального QMC-канала возможна только в версиях контроллеров с частотой не меньше 50 МГц, так как в версиях контроллеров с меньшими системными частотами не обеспечить требуемой скорости обработки сетевых данных. Реализация 64-канального QMC-контроллера в 50 МГц версии МРС860МН производится с использованием двух SCC-каналов, каждый из которых работает с 32-канальным QMC-протоколом. Контроллер МРС860МН имеет достаточный объем внутренней двухпортовой памяти для реализации двух QMC-каналов без значительных ухудшений в показателях работы коммуникационного модуля.Каждый QMC-канал обеспечивает передачу данных со скоростью 64 Кбит/с, как и в обычном временном слоте линии Т1/Е1, что обеспечивает суммарную пропускную способность 64хг,64 Кбит/с = 4 Мбит/с.
Версия PRI ISDN широко используется в мире как высокоскоростной и эффективный по стоимости интерфейс. В Северной Америке стандарт предусматривает реализацию физического соединения по линиям Т1 с использованием 24 каналов по 64 Кбит/с каждый. В Европе соединения реализуются по линиям Е1 (СЕРТ) с использованием 32 каналов по 64 Кбит/с каждый. Поток данных внутри каналов может быть разделен на подканалы. Для каждого канала назначен при обмене свой временной слот внутри кадра. Начало кадра отмечается стробирующим сигналом с частотой 8 КГц (125 мкс). Пропускная способность линии рассчитывается так: 8 КГц х длину кадра данных в битах. Например, для линии Е1 со скоростью передачи данных 2048 Кбит/с = 8 КГцх256 бит, для линии Т1 со скоростью передачи данных 1544 Кбит/с=8 КГцх193 бита. Общая длина кадра данных должна быть поделена между 24 каналами для линии Т1 и между 32 каналами для линии Е1. Для повышения надежности передачи информации и с целью подстройки синхронизации отдельные специальные временные каналы могут быть выделены для целей управления и контроля.
Для поддержки интерфейсов Е1/Т1 QMC-протокол может мультиплексировать до 64 различных групп каналов на одном TDM-интерфейсе. Так как Е1-интерфейс работает с 32 564
ПОДДЕРЖКА ПРОТОКОЛОВ В КОММУНИКАЦИОННЫХ КОНТРОЛЛЕРАХ
временными каналами (64 Кбит/с), а Т1 - с 24 каналами (64 Кбит/с), а QMC-контроллер может поддерживать на каждом SCC-канале до 64 логических каналов, то в контроллерах возможно организовать обработку сразу двух отдельных Е1/Т1-линий, каждая на своем SCC-контроллере. Логический канал может быть независимо запрограммирован на работу или с HDLC-кадрами, или в режиме прозрачной (transparent) передачи. Это дает возможность разделять TDM-потоки между несколькими SCC-контроллерами. Благодаря RISC-контроллеру SCC-каналы работают в нормальном режиме, не замечая и не принимая участие в реализации некоторых функций QMC-протокола. SCC только выполняют последовательно-параллельное преобразование данных канала и реализуют алгоритмы работы выбранных протоколов, а СРМ-модуль, используя встроенный микрокод и дополнительную аппаратуру, позволяет передавать кадры всех протоколов по любому из 64 каналов. Любой SCC-канал может работать в QMC-режиме независимо от режимов работы других SCC-контроллеров. Так как SCC1-контроллер имеет больший размер буферов FIFO по сравнению с другими SCC-каналами, то он и рекомендован для работы с QMC-протоколом. Один TDM может быть настроен для работы с несколькими SCC-каналами, которые работают с QMC-протоколом, при этом каждый SCC-контроллер работает со своим временным слотом. Если два TDM-канала подключены к одному SCC-контроллеру, то возникают ограничения, связанные с использованием одинаковых тактовых и стробирующих сигналов, и при программировании памяти маршрутизации следует контролировать коллизии, когда в один и тот же момент времени придется работать с несколькими каналами одновременно или при приеме, или при передаче данных.
Особенности работы MC860MH/DH.
• Поддерживается до 64 независимых логических каналов для каждого SCC-контроллера.
• Каждый логический канал может работать с любым из 64 временных слотов TDM-канала. А так как каждый контроллер из семейств МРС860 имеет два полностью независимых TDM-канала, то это делает их особо привлекательными при построении мостовых схем.
• При объединении RX- и ТХ-частей памяти маршрутизации каждый логический канал может работать с любым из 128 временных слотов TDM-канала.
• Возможна одновременная поддержка двух 32-канальных Е1-соединений при системной частоте в 50 МГц.
• При работе с буферами памяти используется до 128 DMA-каналов.
• Полностью независимое распределение временных каналов для приемника и передатчика.
• Поддерживается или HDLC или Transparent-протокол для каждого логического канала.
• Прерывание может быть назначено после обработки буфера заданного размера или при переполнении буфера.
• Каждый логический канал может работать в режиме внутренней петли.
• Число обрабатываемых временных каналов зависит только от числа ячеек в памяти маршрутизации. Пользователь может сам программироватьв памяти маршрутизации, какие временные каналы и какого размера будут использоваться в TDM-кадре.
• Начало кадра регистрируется при приходе стробирующего сигнала. Дополнительные внешние сигналы - стробы могут выставляться для работы с сетевыми устройствами, которые не поддерживают работу с TDM-каналами, например для обмена данными с контроллером МС68302.
Особенности последовательного интерфейса.
• Поддерживает работу с 24-канальным T1/DS1 и 32-канальным Е1/СЕРТ РСМ-интерфейсами, basic ISDN и primary ISDN.
• Поддерживается работа с 2048, 1544, 1536 Кбит/с РСМ-интерфейсами.
565
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
• Любой временной слот может быть разделен на логические каналы.
• Полностью независимые приемная и передающая части.
• Несколько, не обязательно соседних, временных слотов могут быть объединены в логический канал.
• Поддерживает НО, Н11, Н12 ISDN-каналы.
При работе с TDM-каналами доступны следующие функции последовательного интерфейса: синхронизация кадров, тестовый режим локальной петли, тестовый режим автоматического эха. При работе в NMSI-режиме эти функции не доступны. При работе в NMSI-режиме синхронизация кадров достигается за счет использования импульсов внешних сигналов сеГ , cts .
Режим локальной петли (при программировании ячейки памяти маршрутизации бит LOOP := 1) может быть включен для любого как временного, так и логического канала. Требуется только, чтобы частоты тактовых сигналов приемника и передатчика были равны и использовался общий импульс строба начала кадра. При этом данные, принятые из N логического канала, будут без промежуточной буферизации выдаваться в N логический канал на выходе передатчика.
Режим автоматического эха для QMC-протокола можно включить только для всего TDM-кадра. Режим автоматического эха для отдельного временного канала можно реа-
лизовать только программным путем.
QMC-маршрутизация. QMC-протокол обеспечивает реализацию обработки нескольких логических каналов на одном SCC-контроллере. Выбор и программирование работы
SCC-контроллера с некоторым временным каналом TDM-кадра осуществляется обыч-
ным способом, как описано ранее. Индивидуальное разделение временного канала по
логическим каналам производится внутри QMC-контроллера с помощью специальных внутренних таблиц маршрутизации.
На рис. 5.89, 5.90 показаны схемы реализации Ethernet-BRI ISDN моста на базе MPC860EN (не поддерживает QMC-протокол) и на базе МРС860МН (поддерживает QMC-протокол). BRI ISDN-протокол требует обработки трех каналов (2B+D). В первом случае для обработки трех каналов пришлось задействовать три SCC-контроллера (SCC2, SCC3, SCC4), объединив их в мультиплексируемом режиме работы, а во втором - только один SCC2. Освободившиеся SCC-контроллеры можно использовать для реализации дополнительных линий связи или просто выключить, чтобы снизить потребление энергии и
повысить производительность системы. Дополнительно контроллер SCC1 используется для подключения к сети Ethernet, а SMC-контроллер, работающий с протоколом UART, -
для передачи данных на терминал компьютера контроля. Оба контроллера - и SCC1 и SMC2 настроены на NMSl-режим работы. Порт SPI используется для настройки режимов
работы микросхемы ISDN-передатчика. Если во втором варианте схемы заменить контроллер на МРС860МН и S/T-передатчик МС145574 - на микросхему DS2180A, то получим схему моста Ethemet-PRI ISDN, обслуживающую 32-канальный ISDN (ЗОВ +1D) на одном 5СС2-контроллере.
Рис. 5.89. Пример реализации моста Ethernet-BRI ISDN на основе контроллера MPC860EN
566
ПОДДЕРЖКА ПРОТОКОЛОВ В КОММУНИКАЦИОННЫХ КОНТРОЛЛЕРАХ
Рис. 5.90. Пример реализации моста Ethernet-BRI ISDN на основе контроллера МРС860МН
Обратите внимание, что если один временной канал TDM-кадра занят QMC SCC-контроллером для работы с логическими каналами, то остальные временные каналы без ограничений могут быть использованы для нормальной работы другими SCC- и SMC-контроллерами.
При работе с QMC-протоколом могут регистрироваться следующие типы ошибок.
• Ошибка в битах данных обычно регистрируется контроллером, который работает с конкретным протоколом в соответствии с правилами работы этого протокола. Обычно это может быть ошибка CRC контрольной суммы, ошибка длины кадра протокола, ошибка кадра, длина которого не кратна 8 битам. Эти типы ошибок регистрируются коммуникационными контроллерами и отмечаются в битах ошибок буферов дескрипторов приемника или передатчика.
• Ошибка тактовых импульсов. При программировании памяти маршрутизации пользователь задает общую длину TDM-кадра в битах, таким образом, известно число тактовых импульсов между двумя строб-импульсами. Внутренние схемы контроллера подсчитывают число тактов между стробами и регистрируют ошибку, если оно не совпадает с ожидаемым.
• Ошибка импульсов синхронизации связана с моментом прихода внешнего строб-им-пульса. Если пользователь неправильно запрограммировал память маршрутизации, то момент окончания обработки TDM-кадра может не совпасть с реальным концом кадра, приходящим от внешнего источника и отмечаемым внешним сигналом.
Организация памяти QMC-протокола. SCC-контроллер, для которого выбран QMC-протокол, в целом функционирует аналогично SCC-контроллерам, которые работают с обычными коммуникационными протоколами. При обмене данными используется структура буферов данных и буферных дескрипторов, память параметров служит для реализации контрольных функций в соответствии с выбранным протоколом. Карта распределения внутренней двухпортовой памяти в контроллере МРС860МН та же, что и в базовой модификации контроллера.
Для каждого SCC-канала в памяти параметров выделена специальная область (страница), где хранятся общие и протокол-ориентированные параметры настройки выбранного SCC-контроллера. При работе с QMC-протоколом на этих страницах будут храниться параметры настройки и указатели для всех логических каналов, с которыми будет
567
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
работать SCC-контроллер. Но так как для хранения параметров логических каналов необходимо OxAF байт памяти, то другие контроллеры, параметры которых располагались на той же странице памяти параметров, временно не будут доступны. Например, в МРС860МН при работе SCC1-контроллера с QMC-протоколом 12С-контроллер не будет доступен.
Память параметров QMC-контроллера так же состоит из двух частей: в первой части описываются параметры, общие для всех логических каналов, во второй части - параметры работы каждого логического канала в отдельности (канал-ориентированная память).
Большую часть памяти параметров (табл. 5.59) занимают TSA-таблицы для приемника и для передатчика. В нормальном режиме работы используются две таблицы - TSATRx и TSATTx по 32 ячейки каждая, которые располагаются в памяти по адресам от SCC base+0x20 и до SCC base+OxAO, и переменные Rx_S_PRT и Tx_S_PTR указывают на расположение этих таблиц в памяти параметров (более точно, они задают смещение начала таблицы относительно адреса DPRBASE). Но при поддержке 64 логических каналов используется одна объединенная таблица из 64 ячеек, которая содержит общие параметры и приемника и передатчика и которая располагается в памяти по тем же адресам. В этом варианте приемник и передатчик работают с одинаковым закреплением между временными каналами и логическими каналами. Если же такой вариант распределения памяти не может быть применен, так как приемник и передатчик должны иметь разные параметры настроек, тогда для хранения общих Rx- и Тх-параметров может быть использована память параметров других SCC-каналов, и переменные Rx_S_PRT и Tx_S_PTR будут указывать на расположение частей этой таблицы в других областях памяти параметров.
Переменная Tx_S_PTR задает адрес начала таблицы TSATTx. В нормальном режиме работы с двумя TSA-таблицами значение TX_S_PTR = SCCbase+ОхбО, но если используется объединенная таблица для приема и передачи, то значение TX_S_PTR = SCCbase+0x20. Эта таблица может быть размещена только внутри области общих параметров SCC.
Переменная Rx_S_PTR задает адрес начала таблицы TSATRx. В нормальном режиме работы значение RX_S_PTR=SCCbase+0x20. Эта таблица может быть размещена только внутри области общих параметров SCC-канала.
Переменная MCBASE задает адрес начала таблицы буферных дескрипторов во внешней памяти, а переменные RBASE и TBASE из канал-ориентированной части памяти параметров определяют 16-битный сдвиг (offset) буфера дескриптора конкретного логического канала относительно адреса начала таблицы дескрипторов. Каждый логический канал имеет свои ячейки RBASE и TBASE в своей памяти параметров. Например, адрес дескриптора приема пятого логического канала будет равен MCBASE+RBASE_5.
Таблица буферов дескрипторов QMC-протокола располагается внутри 64-Кбайтной области внешней памяти. Размер таблицы определяется числом обрабатываемых логических каналов. Каждый SCC-контроллер имеет максимум 64 К/4 = 16384 буферов дескрипторов. Каждый дескриптор имеет стандартный 4-байтный формат, как и при работе с другими коммуникационными протоколами. Если при работе используются 32 логических канала, то каждый канал имеет по 16384/(32x2) = 256 буферов для приема и 256 буферов для передачи. Для каждого логического канала пользователь может программно задавать стартовый адрес таблицы дескрипторов и ее длину. Формат буферных дескрипторов аналогичен формату дескрипторов для других коммуникационных протоколов. Каждый буферный дескриптор имеет 32-битный адрес, который указывает расположение во внешней памяти буфера данных, связанного с этим дескриптором. Рекомендуется буферные дескрипторы других не QMC-протоколов располагать во внутренней памяти для уменьшения загрузки внешней шины.
568
ПОДДЕРЖКА ПРОТОКОЛОВ В КОММУНИКАЦИОННЫХ КОНТРОЛЛЕРАХ
Таблица 5.59
Память общих параметров всех логических каналов
Адрес Название Размер, бит Описание
SCC base+00 MCBASE 32 Базовый адрес 64-Кбайтной таблицы BD во внешней памяти
SCC base+04 QMCSTATE 16 Внутреннее состояние QMC-контроллера
SCC base+06 MRBLR 16 Максимальная длина Rx-буфера приемника
SCC base+08 Tx_S_PTR 16 Стартовый адрес TSA-таблицы передатчика
SCC base+OA RxPTR 16 Указатель на ячейку временного слота, с которым работаете текущий момент времени приемник
SCC base+OC GRFTHR 16 Число принятых HDLC-кадров, после которого будет выставлен запрос на прерывание
SCC base+OE GRFCNT 16 Счетчик принятых кадров данных
SCC base+10 IN TBASE 32 Стартовый адрес таблицы запросов на прерывание
SCC base+14 INTPTR 32 Указатель на следующую ячейку очереди запросов на прерывание
SCC base+18 Rx_S_PTR 16 Стартовый адрес TSA-таблицы приемника
SCC base+1A TxPTR 16 Указатель на ячейку временного слота, с которым работает в текущий момент времени передатчик
SCC base+1C C_MASK32 32 СРС32-константа 0xDEBB20E3 для вычисления 32-битной CRC-CCITT при работе с HDLC-протоколом
SCC base+20 TSATRx 32 ячейки по 16 TSA Rx-таблица
SCC base+60 TSATTx 32 ячейки по 16 TSA Тх-таблица
SCC base+AO C_MASK16 16 СRC 16-константа 0xF0B8 для вычисления 16-битной CRC-CCITT при работе с HDLC-протоколом
SCC base+A4 TEMPRBA 32 Временное значение адреса буфера приема
SCC base+A8 TEMPCRC 32 Временное значение контрольной суммы
Примечан и e. Все переменные в ячейках, кроме TEMP_RBA и TEMP CRC, инициализируются
пользователем до начала работы с SCC-контроллером. Переменная QMCSTATE инициализируется кодом 0x8000 до начала работы с QMC-протоколом и используется при отладке. К остальным ячейкам обращается контроллер, и пользователю не рекомендуется изменять их содержимое.
Переменная MRBLR задает размер буфера приемника в байтах. После заполнения текущего буфера до значения MRBLR приемник переходит к заполнению следующего буфера. Для хранения каждого буфера в памяти выделяется MRBLR+4 байт. При работе этот параметр используется только в режиме HDLC-протокола. Если QMC-контроллер работает с 32-разрядными словами, то значение MRBLR должно быть кратным 4 байтам.
Переменная RxPTR инициализируется значением SCCbase+0x20, т. е. стартовым адресом таблицы TSARx. Переменная TxPTR инициализируется значением SCCbase+0x60, т. е. стартовым адресом таблицы TSATx. При работе RlCS-контроллер увеличивает значение этих переменных после завершения обработки текущего временного слота.
Переменная GRFCNT - вычитающий счетчик, который подсчитывает число кадров данных, которые необходимо принять до выработки запроса на прерывание. При достижении счетчиком значения «О» вырабатывается RXF-запрос на прерывание и в ячейку загружается значение из переменной GRFTHR.
Запросы на прерывание расположены в памяти в виде очереди, которая обрабатывается по кругу. Ячейки этой очереди содержат информацию о запросе на прерывание,
569
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
О 1_____________2 3 4 5 6 7 8 9 10 1 1 12 13 14 15
V W Mask[0:1] | Channel Pointer | Mask[2:7]
Рис. 5.91. Формат ячейки TSA-таблицы
который может быть выставлен QMC-контроллером к центральному процессору. Переменная INTBASE определяет стартовый адрес таблицы запросов в памяти, а переменная INTPTR-адрес следующей ячейки очереди, куда RISC-контроллер запишет информацию о прерывании при возникновении соответствующего события. Перед началом работы в ячейку загружают значение INTPTR := INTBASE.
Каждая TSA-таблица содержит 32 ячейки по 16 бит каждая (рис. 5.91) и определяет правила обработки каждого из 32 логических каналов при приеме (TSA Rx-таблица) и при передаче (TSA Тх-таблица). Ячейки таблицы определяют, из какого временного слота будет читать информация в текущий логический канал при приеме или в какой временной слот будет выдаваться информация от текущего логического канала при передаче.
Бит V (Valid) определяет, используется данный временной слот или нет. Если бит V = 0, то 8-битный временной слот не используется и его данные игнорируются при приеме, а при передаче во временной слот будет выдаваться код логической «1». Если бит V = 1, то 8 бит данных из временного слота после удаления служебных битов (например, типа бит-стаффинг) записываются в текущий буфер при приеме и выдаются в этот временной слот при передаче.
Бит W (Wrap) позволяет программисту ограничивать число используемых временных слотов в TDM-кадре данных. Если бит W = 1, то это последняя ячейка в таблице. Далее после получения нового импульса синхронизации (строба) RISC-контроллер перейдет к обработке ячейки временного слота «О».
Channel pointer - 6-битный указатель, определяющий логический канал, с которым будет связан данный временной слот. На самом деле реальный указатель имеет длину 12 бит и представляет собой адрес канал-ориентированной памяти параметров (адрес RBASE или TBASE). Шесть старших значащих бит берутся из поля TSATRx channel pointer (или TSATTx channel pointer), а младшие 6 бит всегда обнуляются. Таким образом, 12-битный адрес указывает на 64-байтную область канал-ориентированной памяти параметров. Канал-ориентированная память всегда общая для приемника и передатчика, таким образом, для 32-канального интерфейса требуется 32x64 = 2 Кбайт памяти внутри двухпортовой RAM, а для 64-канального интерфейса - 64x64 = 4 Кбайт.
Обычно канал-ориентированная память каждого канала занимает 8 байт, и поэтому в большинстве случаев указатель channel pointer временного канала «О» содержит адрес начала двухпортовой памяти (DPBASE), начиная с которого располагаются параметры «О» логического канала. Указатель channel pointer временного канала «1» обычно содержит адрес DPBASE+4, начиная с которого располагаются параметры «1» логического канала. Если необходимо объединить несколько временных слотов для работы с одним логическим каналом, то в полях channel pointer ячеек TSA-таблицы, которые закреплены за выбранными временными слотами, указывается одно и то же значение адреса памяти параметров логического канала.
Биты MASK[0:7] определяют, какие из восьми битов данных временного слота будут использоваться при работе. Если бит маски равен 0, то соответствующий ему бит временного канала игнорируется при обработке. Во время передачи данных на месте замаскированного бита временного канала передается «1».
Работа нескольких SCC-контроллеров с одним TDM-каналом. Рассмотрим пример, когда один TDM-кадр обслуживается двумя SCC-контроллерами (допустим SCC2 и SCC3), которые оба настроены на работу с QMC-протоколом. Причем оба SCC-контролле-570
ПОДДЕРЖКА ПРОТОКОЛОВ В КОММУНИКАЦИОННЫХ КОНТРОЛЛЕРАХ
ра обслуживают одну и ту же последовательность логических каналов. Другими словами, обработка TDM-кадра разделена между двумя SCC-контроллерами с целью увеличить скорость и распараллелить обработку данных. Допустим, контроллер SCC2 обрабатывает нечетные временные слоты, а контроллер SCC3 - четные. При этом возникают проблемы программирования доступа нескольких SCC-каналов к общей TSA-памяти параметров одного TDM-кадра. Поэтому существует два варианта настройки режимов работы SCC-контроллеров с TSA-памятью.
При первом варианте (допустим, обрабатывается 32-канальный TDM-кадр) каждый SCC-канал настроен на работу с QMC-протоколом, каждый канал имеет ячейки указателей Rx_S_PTR_2 и Rx_S_PTR_3, но эти указатели адресуются только к одной TSA-таблице контроллера SCC2. Таким образом, TSA-таблица располагается в памяти параметров контроллера SCC2, а область памяти TSA-таблицы контроллера SCC3 не используется. Указатель Rx_S_PTR_2 первоначально содержит адрес SCC2_base+0x20. Шестнадцать логических каналов, которые обрабатываются SCC2, расположены в первых 16 ячейках таблицы. В ячейке канала 30 установлен бит W = 1, показывающий, что обработка логических каналов контроллером SCC2 закончена. Указатель Rx_S_PTR_3 первоначально содержит адрес SCC2_base+0x40. Шестнадцать логических каналов, которые обрабатываются SCC3, расположены в ячейках таблицы, начиная с 17-го по 32-й. В ячейке канала 31 установлен бит W = 1, показывающий, что обработка логических каналов контроллером SCC3 закончена. Каждая ячейка в таблице имеет указатель на область параметров обрабатываемого логического канала. Но здесь необходимо проверять, чтобы случайно контроллеры SCC2 и SCC3 не обрабатывали один и тот же логический канал. Таблица TSATTx тоже находится в области памяти параметров контроллера SCC2, TSA-таблица в области SCC3 не используется, и эта память может быть отведена для других целей.
При втором варианте (допустим, обрабатывается 64-канальный TDM-кадр) для хранения TSA-таблиц приемника и передатчика требуется 256 байт памяти (64ячейки х 2 байта х 2 таблицы), но в памяти параметров одного SCC-канала свободно только 128 байт. Поэтому можно применить следующий способ размещения. Таблица приемников контроллеров SCC2 и SCC3 располагается в области памяти параметров канала SCC2, а таблица передатчиков - в области памяти параметров канала SCC3. Разделение таблицы на две части между SCC-каналами будет такое же, как и в первом варианте. Такое распределение памяти контроллеров более эффективно.
На основе приведенных примеров можно запрограммировать режим работы, когда все временные слоты будут обрабатываться разными SCC-контроллерами и TSA-память будет распределена между страницами памяти параметров отдельных контроллеров, а это позволяет эффективно расходовать память и вычислительные мощности каждого SCC-канала. Но при этом пользователь должен быть уверен, что не возникнут коллизии, когда из-за ошибок при программировании несколько SCC-контроллеров будут обрабатывать один временной слот.
Канал-ориентированная память параметров. Канал-ориентированная память параметров (Channel-Specific parameter RAM) занимает нижнюю (младшую) часть двухпортовой памяти. Каждый логический канал может быть связан с временным каналом TDM-кадра с помощью указателей канала в ячейках TSA-памяти. Пользователь может сам < определять количество необходимых логических каналов. Для каждого логического канала в памяти выделяется область размером 64 байта, формат которой зависит от коммуникационного протокола, по правилам которого передается информация по логическому каналу. Свободные области логических каналов могут быть отведены для хранения буферных дескрипторов других SCC-контроллеров. При работе с QMC-протоколом логические каналы могут работать или в режиме HDLC-протокола или в режиме transparent «прозрачной передачи».
571
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
Работа с HDLC-протоколом. Распределение памяти при работе с этим протоколом приведено в табл. 5.60.
Переменные TBASE и RBASE задают смещение стартового адреса таблицы буферных дескрипторов конкретного логического канала относительно базового адреса 64-Кбай-тной таблицы буферных дескрипторов всех логических каналов, который задан в ячейке MCBASE памяти общих параметров.
Переменные TBPTR и RBPTR задают смещение адреса текущего буферного дескриптора обрабатываемого логического канала относительно базового адреса 64-Кбайт-ной таблицы буферных дескрипторов всех логических каналов, который задан в ячейке MCBASE памяти общих параметров. Например, реальный адрес текущего буферного дескриптора передатчика вычисляется как MCBASE+TBPTR.
Таблица 5.60
Канал-ориентированная память параметров при работе с HDLC-протоколом
Адрес Название Размер, бит Описание
DPBASE+00 TBASE 16 Базовый адрес таблицы Тх BD
DPBASE+02 CHAMR 16 Регистр режима при работе с HDLC-протоколом
DPBASE+04 TSTATE 32 Внутреннее Тх-состояние
DPBASE+08 32 Указатель на ячейку памяти в Тх-буфере канала
DPBASE+0C TBPTR 16 Указатель на ячейку памяти дескриптора Тх BD
DPBASE+0E 16 Счетчик переданных из буфера Тх байт данных
DPBASE+10 TUPACK 32 Временная переменная Тх
DPBASE+14 ZISTATE 32 Состояние автомата zero-insertion
DPBASE+18 TCRC 32 Текущее значение CRC-суммы при передаче кадра
DPBASE+1C INTMSK 16 Маска флагов прерываний каналов
DPBASE+1E BDflag 16 Временная переменная
DPBASE+20 RBASE 16 Базовый адрес таблицы Rx BD
DPBASE+22 MFLR 16 Максимальная длина кадра данных
DPBASE+24 RSTATE 32 Внутреннее Rx-состояние
DPBASE+28 32 Указатель на ячейку памяти в Rx-буфере канала
DPBASE+2C RBPTR 16 Указатель на ячейку памяти дескриптора Rx BD
DPBASE+2E 16 Счетчик принятых в буфер Rx байт данных
DPBASE+30 RPACK 32 Временная переменная Тх
DPBASE+34 ZDSTATE 32 Состояние автомата zero-deletion
DPBASE+38 RCRC 32 Текущее значение CRC-суммы при приеме кадра
DPBASE+3C MAX_cnt 16 Вычитающий счетчик максимальной длины
DPBASE+3E TMPMB 16 Временная переменная
Примечание. Переменные в ячейках TBASE, RBASE, CHAMR, TSTATE, RSTATE, TBPTR, RBPTR, ZISTATE := 0x00000100, ZDSTATE := 0x00000080 при работе c HDLC протоколом, INTMSK и MFLR инициализируются пользователем до начала работы с SCC-контроллером. Программисту не рекомендуется изменять содержимое остальных ячеек, так как они используются контроллером.
572
ПОДДЕРЖКА ПРОТОКОЛОВ В КОММУНИКАЦИОННЫХ КОНТРОЛЛЕРАХ
Каждый SCC-канап имеет переменную MFLR, определяющую максимальное число байт (максимум 64 Кбайт), которые могут передаваться в кадре. При приеме кадра, длина которого больше MFLR, кадр будет отброшен, установлен бит ошибки LG = 1 в слове состояния текущего буферного дескриптора, буфер будет закрыт и будет выставлен запрос на прерывание от событий RXF и RXB в регистре событий, если они не замаскированы.
Бит MODE в регистре режима CHAMR (рис. 5.92) определяет протокол, с которым работает выбранный логический канал. Если MODE = 0, то канал работает с протоколом Transparent, если MODE=1 - с HDLC-протоколом.
Бит IDLM определяет режим передачи символов IDLE (если бит IDLM = 1) в промежутках между передачей кадров данных. Если IDLM = 0, то между кадрами данных IDLE-символы не передаются. В промежутке между кадрами передатчик передает NOF+1 символов флага, а затем передает следующий кадр данных. Если кадр еще не готов, то продолжается передача символов флага.
Бит ENT = 1 разрешает работу передатчика, и во временной канал будут передаваться данные согласно выбранному протоколу. Если бит ENT = 0, то передатчик выключен, и если канал подключен к временному слоту, то в этот временной канал будут передаваться «1». Следует отметить, что отсутствует бит разрешения работы приемника с QMC-протоколом, но для разрешения работы приемника необходимо инициализировать переменные ZDSTATE и RSTATE в памяти параметров.
Если бит POL = 0, то коммуникационный процессор не контролирует значение бита готовности R (Ready) в слове состояния дескриптора буфера при передаче. Если бит POL = 1, то при передаче контролируется значение бита готовности буфера.
0 1 2 3 4 5 6 7 8 9 10 1 1 12 13 14 15
MODE 0 IDLM ENT — — — POL CRC 0 — — NOF
Рис. 5.92. Формат регистра режима CHAMR для QMC HDLC-контроллера
При работе с HDLC-протоколом бит CRC определяет тип контрольной суммы. Если бит CRC = 0, то используется 16-битная CCITT-CRC контрольная сумма для данного канала. Если бит CRC = 1, то используется 32-битная CCITT-CRC контрольная сумма.
Содержимое ячейки TSTATE определяет внутреннее состояние передатчика, а содержимое ячейки RSTATE - внутреннее состояние приемника. Старший байт ячейки (рис. 5.93) содержит функциональные коды и бит Motorola/lntel. В битах АТЗ-АТ1 содержится код, который будет выставлен на внешних контактах функциональных кодов, чтобы идентифицировать тип доступа к памяти. Бит МОТ определяет порядок передачи байтов в длинных словах при обмене по сети. Если бит МОТ = 0, то используется порядок передачи little-endian, характерный для фирмы «Intel». Если бит МОТ = 1, то используется порядок передачи big-endian, характерный для фирмы «Motorola». У МРС860МН ячейка TSTATE перед использованием канала должна быть проинициализирована кодом 0x30000000. Ячейка RSTATE перед началом работы с канала, при возникновении ошибки или после получения команды STOP RX должна быть проинициализирована кодом 0x31000000 для МРС860МН. Эти ячейки используются также при отладке системы. Если бит 8 32-разрядной ячейки xSTATE равен 1, то в текущий момент времени кадр переда-
0 12 3 4 5 6 7
0 0 1 MOT AT[1:3]
Рис. 5.93. Формат регистра TSTATE и RSTATE в памяти параметров QMC HDLC-протокола
573
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
0 12 3 4 5 6 7 8 9 10 11 12 13 14 15
V | W NID IDL — Номер канала MRF UN | RXF | BSY ТХВ RXB
Рис. 5.94. Регистр событий канала в очереди прерываний для QMC HDLC-контроллера
0 12 3 4 5 6 7 8 9 10 1 1 12 13 14 15
О О NID IDL О О 0 0 0
0 MRF UN RXF BSY ТХВ RXB
Рис. 5.95. Регистр маски INTMSK для QMC HDLC-контроллера
ется (или принимается). Если бит 9 равен 1, то текущий буфер BD открыт, и из него читаются данные (или в него записываются данные). Если бит 12 в ячейке TSTATE равен 1, то канал был проинициализирован и работает. Если бит 11 в ячейке RSTATE равен 1, то прием остановлен. В младших 16 битах регистра RSTATE хранится слово состояния текущего BD.
Все события, которые могут возникать при работе каналов, регистрируются в циклической очереди прерываний, в регистре событий (рис. 5.94). Для всех логических каналов существует один регистр маски. В регистре INTMSK (рис. 5.95) пользователь может при желании замаскировать прерывание от некоторых событий, если сбросит в «0» бит, соответствующий выбранному событию.
Работа с Transparent-протоколом. В табл. 5.61 приведено распределение канал-ориентированной памяти параметров при работе с протоколом Transparent.
Переменные TBASE и RBASE, TBPTR и RBPTR, ZISTATE и ZDSTATE, TSTATE и RSTATE имеют назначение, аналогичное одноименным переменным для QMC HDLC-протокола.
Бит MODE в регистре CHAMR (рис. 5.96) определяет протокол, с которым работает выбранный логический канал. Если MODE = 0, то канал работает с протоколом Transparent, если MODE = 1 - с HDLC-протоколом.
Бит RD определяет порядок передачи битов в байте. Если бит RD = 0, то в канал передается/принимается первым LSB-бит. Если бит RD = 1, то первым передается или принимается MSB-бит.
Бит ENT = 1 разрешает работу передатчика, и во временной канал будут передаваться данные согласно выбранному протоколу. Если бит ENT=0, то передатчик выключен, и если канал подключен к временному слоту, то в этот временной канал будут передаваться «1». Следует отметить, что отсутствует бит разрешения работы приемника с QMC-протоколом, но для разрешения работы приемника необходимо инициализировать переменные ZDSTATE и RSTATE в памяти параметров.
Если бит POL = 0, то коммуникационный процессор не контролирует значение бита готовности R (Ready) в слове состояния дескриптора буфера при передаче. Если бит POL = 1, то при передаче контролируется значение бита готовности буфера.
Все события, которые могут возникать при работе каналов, регистрируются в циклической очереди прерываний, в регистре событий (рис. 5.97). Для всех логических каналов существует один регистр маски. В регистре INTMSK (рис. 5.98) пользователь может при желании замаскировать прерывание от некоторых событий, если сбросит в «0» бит, соответствующий выбранному событию.
___0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
MODE RD 1 ENT — SYNC — POL 0 0 — — 0 0 0 0
Рис. 5.96. Формат регистра режима CHAMR для QMC-Transparent-контроллера
574
ПОДДЕРЖКА ПРОТОКОЛОВ В КОММУНИКАЦИОННЫХ КОНТРОЛЛЕРАХ
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
V W — — — Номер канала — UN — BSY TXB RXB
Рис. 5.97. Регистр событий канала в очереди прерываний для QMC-Transparent-контроллера
Бит SYNC в регистре режима CHAMR предназначен для выбора режима контроля за синхронизацией при работе с протоколом QMC Transparent. Если бит SYNC равен 0, то первый байт данных передается или принимается из первого доступного для данного логического канала временного слота. Если бит SYNC = 1, то используется алгоритм синхронизации одиночного временного слота, заданный в ячейке TRNSYNC памяти параметров. Если сообщение передается в нескольких временных слотах, то необходимо знать, когда передается первый байт сообщения. Регистр TRNSYNC состоит из двух частей. Старший байт контролирует первый временной слот при приеме, а младший байт -синхронизацию при передаче.
Таблица 5.61
Канал-ориентированная память параметров при работе с протоколом Transparent
Адрес Название Размер, бит Описание
DPBASE+00 TBASE 16 Базовый адрес таблицы Тх BD
DPBASE+02 CHAMR 16 Регистр режима для протокола Transparent
DPBASE+04 TSTATE 32 Внутреннее Тх-состояние
DPBASE+08 32 Указатель на ячейку памяти в Тх-буфере канала
DPBASE+OC TBPTR 16 Указатель на ячейку памяти дескриптора Тх BD
DPBASE+OE 16 Счетчик переданных из буфера Тх байт данных
DPBASE+10 TUPACK 32 Временная переменная Тх
DPBASE+14 ZISTATE 32 Состояние автомата zero-insertion
DPBASE+18 32 Резервировано
DPBASE+1C INTMSK 16 Маска флагов прерываний каналов
DPBASE+1E Bdflag 16 Временная переменная
DPBASE+20 RBASE 16 Базовый адрес таблицы Rx BD
DPBASE+22 TMRBLR 16 Максимальная длина буфера приема
DPBASE+24 RSTATE 32 Внутреннее Rx-состояние
DPBASE+28 32 Указатель на ячейку памяти в Rx-буфере канала
DPBASE+2C RBPTR 16 Указатель на ячейку памяти дескриптора Rx BD
DPBASE+2E 16 Счетчик принятых в буфер Rx байт данных
DPBASE+30 RPACK 32 Временная переменная Тх
DPBASE+34 ZDSTATE 32 Состояние автомата zero-deletion
DPBASE+38 32 Зарезервировано
DPBASE+3C TRNSYNC 16 Регистр контроля синхронизации
DPBASE+3E 16 Зарезервировано
П p и м e ч a н и e. Переменные в ячейках TBASE, RBASE, CHAMR, TSTATE, RSTATE, TBPTR,
RBPTR, ZISTATE := 0x00000100, ZDSTATE = 0x18000080 при работе с Transparent-протоколом,
INTMSK, TMRBLR и TRNSYNC инициализируются пользователем до начала работы с SCC-koht-
роллером. Содержимое остальных ячеек изменять не рекомендуется, так как они используются
контроллером.
575
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
О 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
0 0 0 0 0 0 0 0 0 0 0 UN | 0 BSY TXB RXB
Рис. 5.98. Регистр маски INTMSK для QMC-Transparent-контроллера
Команды QMC-контроллера. Для управления работой QMC-контроллера пользователь может применять стандартные команды управления работой RISC-контроллера. Команды записываются в регистр команд CR (рис. 5.99).
Основной набор команд представляет собой стандартные команды управления работой коммуникационного модуля (табл. 5.62). Обратите внимание, что отсутствуют команды запуска (start) приема и передачи, эти функции выполняются через регистр общих режимов GSMR.
Таблица 5.62
Основные команды управления работой QMS-каналов ввода/вывода
Команда и ее код QMC OPCODE. Описание команды. Действия контроллера при получении команды
STOP TRANSMIT 001 Команда обычно передается при выключении передатчика и приводит к остановке передачи на выбранном канале и сбросу бита POL в регистре CHAMR. При получении этой команды во время передачи кадра контроллер выдает в канал ABORT символ (0х7Е) и далее продолжает передавать или символы флага или символ(-ы), как это определено в бите IDLM. Указатель текущего буфера TBPTR не изменяется. Если команда получена в интервале между кадрами, то контроллер начинает передавать или символы флага или IDLE-символы. Для возобновления передачи необходимо установить бит POL := 1. После получения команды для деактивации канала необходимо сбросить бит V = 0 в TSA-таблице и бит ENT := 0 в регистре режима.
STOP RECEIVE ООО Команда обычно передается при выключении приемника и приводит к остановке приема на выбранном канале. Указатель текущего буфера RTBPTR не изменяется. Для возобновления приема необходимо проинициализировать переменные в ячейкахZDSTATE и RSTATE,. установив бит POL := 1. После получения команды для деактивации канала необходимо сбросить бит V = 0 в TSA-таблице и бит ENT := 0 в регистре режима.
О 1 2 3 4 5 6 7 8 9 10 11 12____13 14 15
RST QMC OPCODE 1 1 1 0 0 CHNUM — FLG
Рис. 5.99. Формат регистра команд RISC-контроллера CR для QMC
Механизм обработки прерываний. При обработке прерываний используются регистр событий SCC-канала (рис. 5.100), который работает с QMC-протоколом, и циклическая таблица прерываний, к которой обращаются логические каналы при своей работе. Напоминаем, что сброс битов в регистре событий производится записью в соответствующий бит кода «1». При желании пользователь может замаскировать прерывание от отдельных событий, установив в «1» соответствующий бит в регистре маски SCCM.
Формат ячеек в таблице прерываний зависит от типа протокола, с которым работает канал, и был описан выше (см. рис. 5.94, 5.97). Переменная INTBASE указывает на расположение первой ячейки таблицы прерываний во внешней памяти контроллера. Переменная INTPTR указывает на текущую пустую ячейку в таблице, доступную для RISC-контроллера. Бит W = 1 (Wrap) в составе каждой ячейки отмечает последнюю ячейку таблицы прерываний. Таблица прерываний обрабатывается циклически - после обработки последней ячейки RISC-контроллер перейдет к обработке первой ячейки таблицы и произойдет переназначение указателя INTPTR := INTBASE.
576
ПОДДЕРЖКА ПРОТОКОЛОВ В КОММУНИКАЦИОННЫХ КОНТРОЛЛЕРАХ
0 1 2 3 4 5 6 ________7
— — — — IQOV GINT GUN GOV
Рис. 5.100. Регистр событий SCCE и регистра маски SCCM-контроллера при работе с QMC-протоколом
Когда один из QMC-каналов генерирует запрос на прерывание, то RISC-контроллер проверяет, маскировано это прерывание в регистре INTMSK или нет. Если прерывание не маскировано, то контроллер заполняет следующую свободную ячейку таблицы. Эта ячейка (рис. 5.101) содержит номер логического канала в поле «номер канала» и тип । события, вызвавшего прерывание. Затем устанавливается бит V = 1 (Valid), который указывает, что данная ячейка используется и содержит флаги прерываний. Также увеличивается счетчик в ячейке INTPTR. После записи прерывания в таблицу QMC-контроллер • устанавливает бит соответствующего прерывания в регистре событий SCCE SCC-koh-? троллера. Если это прерывание RXF (прерывание, регистрирующееся после приема каж-' дого кадра), то уменьшается счетчик GRFCNT, который контролирует, после приема сколь-
ких кадров будет выработано прерывание. Если этот счетчик не равен 0, то обработка прерывания прекращается. Если счетчик GRFCNT равен 0 или зарегистрировано другое прерывание, то в регистре событий используется дополнительный бит GINT, установка которого в «1» регистрирует, что в очереди на прерывание заполнена новая ячейка. После сброса бита GINT центральный процессор начинает обрабатывать очередь на прерывание. После чтения содержимого очередной ячейки таблицы процессор сбрасывает бит V := 0 и переходит к обработке следующей ячейки таблицы, и так продолжается, пока в таблице есть ячейки с установленным битом V = 1.
Если RISC-контроллер делает попытку записать данные о запросе на прерывание в ячейку, которая еще не обработана, т. е. у этой ячейки установлен бит V = 1, то регистрируется ошибка переполнения таблицы прерываний и в регистре событий устанавливается бит IQOV := 1. При возникновении этой ошибки данная ячейка таблицы немедленно программно сбрасывается и последнее прерывание теряется.
Бит NID (not idle) в ячейке таблицы устанавливается в «1», когда приемник получает данные, формат которых отличается от формата IDLE-символа. При работе с Transparent-протоколом NID-прерывание не регистрируется.
I Бит IDL используется при работе с HDLC-протоколом для регистрации приема IDLE-сим-
I вола (OxFFFE). При работе с протоколом Transparent прерывание IDL не регистрируется.
Бит MRF устанавливается в «1» при работе с HDLC-протоколом, когда приемник принимает кадр, длина которого превышает максимальную длину, заданную в ячейке MFLR памяти параметров. При возникновении этой ошибки лишние байты кадра отбрасываются и не сохраняются в буфере памяти, в буферный дескриптор записывается длина полного кадра между двумя флагами и далее прием продолжается в обычном режиме. При работе с протоколом Transparent прерывание MRF не регистрируется.
При работе QMC-протокола регистрируются два типа глобальных ошибок, общих для всех каналов: ошибка незаполнения передатчика GUN (Global transmitting underrun), когда передача многобуферного кадра прекращается из-за неподготовленности очередных данных, и ошибка переполнения приемника GOV (Global receiver overrun), когда приемник не успевает принимать поступающие из сети данные. При возникновении ошибки GUN-контроллер передает во временной слот не менее 16 единиц, генерирует запрос на
0 1 2 3 4 5 6 7 8 9 10 1 1 12 13 14 15
V W NID IDL — Номер канала MRF UN RXF BSY TXB RXB
Рис. 5.101. Общий формат регистра событий канала в очереди прерываний для QMC-контроллера
577
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
прерывание и устанавливает бит GUN в регистре событий SCCE SCC-канала, останавливает передачу данных во всех логических каналах и начинает передавать в канал или символы IDLE или символы FLAG в зависимости от типа используемого протокола. При возникновении ошибки GOV контроллер обновляет значение в ячейке RSTATE (бит 20 указывает, что прием остановлен), генерирует запрос на прерывание и устанавливает бит GOV в регистре событий SCCE SCC-канала, останавливает прием данных во все буферы всех каналов и ожидает, что центральный процессор сбросит в исходное состояние вначале ячейку ZDSTATE, а затем ячейку RSTATE.
Другой тип ошибок связан со скоростью передачи данных по SDMA-каналам внутри контроллера. Ошибка bus latency регистрируется, когда SDMA-контроллер не успевает освобождать FIFO приемника, и новые данные записываются в буфер поверх старых, что ведет к потере данных.
Такие же ошибки незаполнения (бит UN в ячейке таблицы прерываний) и переполнения могут быть зарегистрированы для каждого логического канала в отдельности с использованием ячейки таблицы прерываний. При возникновении ошибки незаполнения контроллер передает во временной слот не менее 16 единиц, генерирует запрос на прерывание и устанавливает бит UN в ячейке прерывания канала, останавливает передачу данных и начинает передавать в канал или символы IDLE или символы FLAG в зависимости от настройки регистра режима.
Бит RXF устанавливается в «1», если получен завершенный HDLC-кадр, он сохранен в памяти и обновлена информация в буферном дескрипторе. Далее декрементируется счетчик GRFCNT для генерации запроса на прерывание. Если во время приема кадра получена последовательность ABORT, состоящая минимум из семи единиц, буфер закрывается и устанавливаются биты RXB = RXF := 1 в регистре прерываний и бит АВ := 1 в слове состояния буферного дескриптора. При работе с протоколом Transparent прерывание RXF не регистрируется.
Если принят корректный кадр данных, но нет буферов для его сохранения, то регистрируется событие переполнения приемника, формируется условие занятости (busy condition) и устанавливается бит BSY := 1. После этого приемник выключается и прекращает прием данных.
Если текущий буфер данных успешно передан, то регистрируется событие и устанавливается бит ТХВ := 1. Но этот бит устанавливается, а прерывание генерируется только после того, как в FIFO-буфер передатчика будет записано заданное количество символов PAD или будет записан один закрывающий флаг, если в слове состояния дескриптора бит PAD = 0. Таким образом, время начала ТХВ-прерывания зависит от времени передачи закрывающего флага на линию TXD.
При получении по сети полного буфера данных устанавливается бит события RXB := 1. Инициализация QMC-контроллера.
1. Проинициализировать регистр настройки последовательного интерфейса SIMODE. Установить нормальный режим работы (биты SDMx:=00), выключить механизм grant (бит GMx := 0) и сбросить бит STZx0. Остальные биты - SMCx, SMCxGS, RFSDx, DSCx, CRTx, CEx, FEx и TFSDx - устанавливаются в соответствии с системными установками для выбранного основного коммуникационного протокола. Обычно устанавливают CRTa - RFSDa = TFSDa := 1, включая общую синхронизацию для приемника и передатчика с задержкой в 1 бит при обработке кадра.
2. Проинициализировать регистр синхронизации последовательного интерфейса SICR. Сбросить бит GRx := 0, выключив механизм подтверждений (grant), и установить бит SCx = 1, подключив канал к SCCx мультиплексору TSA. Так как SCC-канал будет работать в мультиплексируемом режиме, также требуется установить биты RxCSx и TxCSx, выбрав источник тактирования для приемника и передатчика канала.
578
ПОДДЕРЖКА ПРОТОКОЛОВ В КОММУНИКАЦИОННЫХ КОНТРОЛЛЕРАХ
3. Сконфигурировать выводы параллельного порта А для работы с сигналами интерфейсов TDMa или TDMb: LITXDx (передача данных), LIRXDx (прием данных), LITCLKx (тактовый сигнал передатчика), LIRCLKx (тактовый сигнал приемника). Например, проинициализировать регистры порта A: PAPAR := 0xA5F0 и PADIR := OxOOFO.
4. Сконфигурировать выводы параллельного порта В для работы с выходным сигналом тактового генератора LICLKOx интерфейсов TDMa или TDMb, а также с выходными стробирующими сигналами L1ST1—L1ST4. Например, проинициализировать регистры порта В: PBPAR := OxFCOO и PBDIR := ОхОСОО.
5. Сконфигурировать выводы параллельного порта С для работы с сигналами интерфейсов TDMa или TDMb: LITSYNCx и LIRSYNCx (внешние стробы начала кадров при передаче и приеме), L1ST1-L1ST4 (выходные строб-сигналы для тактирования периферийных устройств). Например, проинициализировать регистры порта С: PCPAR := := OxOFOF и PCDIR := OxOOOF.
6. Записать исходные значения в ячейки памяти маршрутизации SI RAM, определив, какие временные слоты и какими SCC-каналами будут обрабатываться. Например, если каждый байтовый временной канал будет обрабатываться SCC1-контроллером, то ячейки приемника программируются: SIRAM[0] := 0x0042... SIRAM[n-1] := 0x0042, SIRAM[n] := := 0x0043 (в последней ячейке дополнительно устанавливается бит Last = 1), а ячейки передатчика: SIRAM[32] := 0x0042... SIRAM[32+n-1] := 0x0042, SIRAM[32+n] := 0x0043.
7. В регистре общих режимов памяти маршрутизации SIGMR установить бит Епх := 1, выбрав, какой канал - TDMa или TDMb - будет использоваться для обмена, а также установить биты RDM, выбрав режим работы памяти маршрутизации. Например, SIGMR
:= 0х0Е. Таким образом, выбран режим работы обоих - TDMa- и TDMb-каналов, каждый работает с 32 (64)-ячейками для приема и передачи и без теневой памяти.
8. Если во время работы необходимо перенастраивать память маршрутизации, то требуется использовать теневую память. Настройка режимов работы основной и теневой памяти производится в регистре команд Sl-интерфейса SICMR. Если SICMR = 0x00, то работает основная память, а если SICMR = 0xF0, то работает теневая память на обоих TDM-каналах.
9. Произвести настройку регистра общих режимов выбранных SCC-каналов GSMR_H. Выключить Transparent-режим обмена (биты TRX = ТТХ = TCRC = RSYN := 0), включить режим распознавания импульса сигналов cd и cts (биты CDP = СТСР = CDS = CTSS := 1), выключить режим инвертирования данных (бит REVD := 0), при необходимости определить полярность сигнала InfraRed (бит IRP) и включить схему распознавания паразитных перепадов на линиях тактового сигнала (бит GDE), установить нормальную длину буфера FIFO передатчика (бит TFL := 0), установить размер ячейки буфера FIFO приемника в 32 бита (бит RFW := 0), выключить взаимную синхронизацию приемника и передатчика (бит TXSY := 0), синхронизация будет производиться от внешнего сигнала (бит SYNL := 00), между кадрами данных в канал будут передаваться IDLE-символы (бит RTSM := 0). Обычно устанавливается GSMR_H := 0x00000780.
10. Произвести настройку регистра общих режимов выбранных SCC-каналов GSMR_L. При необходимости установить способ кодирования сигнала для InfraRed протокола (бит SIR), сигналы будут анализироваться по обоим фронтам тактового сигнала (бит EDGE := 00), тактовый сигнал передатчика не инвертируется (бит TCI := 0), несущая частота всегда присутствует в канале (бит TSNC := 00), блок DPLL не инвертирует данные (биты RINV = = TINV := 0) и выполняет NRZ-кодирование (биты RENC = TENC := 000), внутреннее увеличение частоты тактового сигнала не производится (биты TDCR = RDCR := 000), пассивное состояние линии «1» (бит TEND := 0), преамбула не используется (биты TPL = = ТРР .= 000), приемник и передатчик пока выключены (биты ENT = ENR := 0), выбран режим работы с QMC-протоколом (биты MODE := 1010), диагностический режим работы
579
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
устанавливается в соответствии с требованиями пользователя (бит DIAG). Обычно устанавливается GSMR_L := ОхОООООООА.
11. Для работы с QMC-протоколом проинициализировать основные общие параметры каналов: указатель на таблицу буферных дескрипторов MCBASE, указатель на таблицу прерываний INTBASE, при работе с HDLC-протоколом установить максимальный размер приемного буфера MRBLR (рекомендованное значение должно быть больше 30 байт и кратно 4 байтам), установить значение «прерывания после приема» GRFTHR кадров (обычно GRFTHR := 1), установить значение счетчика принятых кадров GRFCNT (обычно GRFCNT := GRFTHR), для работы с 32-разрядной контрольной суммой записать значение константы C_MASK32 := 0xDEBB20E3, а при работе с 16-разрядной контрольной суммой - C_MASK16 := 0xF0B8.
12. Скопировать значение ячейки INTBASE в ячейку указателя на пустой элемент таблицы прерываний INTPTR := INTBASE.
13. Проинициализировать TSA-таблицы TSATTx и TSATRx. Во всех рабочих ячейках установить бит V := 1, а также сбросить бит W := 0 во всех ячейках, кроме последней. Для работы со всеми восемью битами канала установить биты маски, равные OxFF. Установить требуемое значение указателя на таблицу канал-ориентированной памяти параметров (channel pointer).
14. Проинициализировать значения указателей Tx_S_PTR и Rx_S_PTR, а также значения указателей на ячейку текущего временного слота TxPTR и RxPTR. Обычно в указатели Tx_S_PTR = TxPTR записывается стартовый адрес TSA-таблицы передатчика, а в указатели Rx_S_PTR = RxPTR - стартовый адрес TSA-таблицы приемника. Если используется общая TSA-таблица, то во все ячейки указателей заносится значение MCBASE+0x20.
15. Установить значение переменной внутреннего состояния QMCSTATE := 0x8000.
16. Проинициализировать ячейки протокол-ориентированной памяти параметров каждого логического канала для работы с выбранным коммуникационным протоколом (HDLC или Transparent). Для каждого используемого логического канала записать в их ячейки TBASE и RBASE стартовые адреса таблиц буферов дескрипторов каналов при передаче и приеме (напоминаем, что при работе стартовые адреса таблиц дескрипторов рассчитываются как MCBASE+TBASE или MCBASE+RBASE). Проинициализировать значения указателей на таблицу дескрипторов RBPTR := RBASE и TBPTR := TBASE. Установить значение внутренних переменных состояния передатчика TSTATE := 0x30000000 для МРС860МН и приемника RSTATE := 0x31000000 для МРС860МН. Установить начальные значения в ячейки ZISTATE := 0x00000100, ZDSTATE := 0x80 для HDLC-протокола и ZDSTATE := 0x18000080 для Transparent-протокола. Разрешить прерывание от требуемых событий, записав соответствующее значение в ячейку INTMSK, например, разрешить все прерывания INTMSK := ОхА. При работе с HDLC-протоколом установить максимальный размер кадра данных MFLR, а для Transparent-протокола установить максимальный размер приемного буфера TMRBLR (рекомендованное значение должно быть больше 30 байт и кратно 4 байтам). При работе с Transparent-протоколом также следует определить значение в регистре контроля синхронизации TRNSYNC.
17. Подготовить буферы и буферные дескрипторы приемника для каждого используемого логического канала. Буферные дескрипторы должны располагаться в памяти по адресу RBASE. В их слове состояния рекомендуется установить бит готовности Е := 1, установить бит прерывания I := 1, а в последнем дескрипторе таблицы требуется установить бит W 1.
18. Подготовить буферы и буферные дескрипторы передатчика для каждого используемого логического канала. Буферные дескрипторы должны располагаться в памяти по адресу TBASE. В их слове состояния рекомендуется установить бит готовности R := 1, установить бит прерывания I := 1, а в последнем дескрипторе таблицы требуется установить бит W := 1.
580
ПОДДЕРЖКА ПРОТОКОЛОВ В КОММУНИКАЦИОННЫХ КОНТРОЛЛЕРАХ
19. Проинициализировать таблицу прерываний. Если прерывания будут использоваться, то для каждой ячейки таблицы рекомендуется сбросить биты V := W := 0, и только у последней ячейки таблицы бит W := 1.
20. Для каждого логического канала проинициализировать регистр режима CHAMR, выполнив настройку на работу или с HDLC-протоколом или с протоколом Transparent. Бит включения передатчика пока сброшен (ENT := 0), его необходимо установить только тогда, когда канал будет готов к передаче. Например, настроим канал для работы с HDLC-протоколом CHAMR := 0x9187.
21. Проинициализировать регистр событий SCCE для выбранного SCCx-канала. Сброс битов в регистре производится записью в соответствующие разряды кода «1» SCCE := OxF.
22. Проинициализировать регистр маски SCCM для выбранного SCCx-канала. Чтобы разрешить прерывание от всех событий, рекомендуется записать в регистр код OxF. Для выбранного SCCx-канала в регистре контроллера прерывания CIMR в соответствующий бит требуется записать «1», чтобы разрешить регистрацию запросов на прерывание от этого канала.
23. В регистре режимов GSMR_L SCCx-канала разрешить работу приемника и передатчика, установив биты ENT := ENR := 1.
Особенности распределение памяти параметров для QMC-протокола. В контроллере МС860МН для поддержки 64-каналов требуется 4 Кбайт внутренней памяти (64 х 64 байта = 4096 байт). Если QMC-протокол использует для хранения буферных дескрипторов внешнюю память, то никаких конфликтов между одновременно работающими протоколами нет, и буферные дескрипторы других протоколов могут располагаться во внутренней памяти. Если используются все 64 канала, то для параметров других протоколов остальных каналов ввода/вывода в памяти параметров осталось только 4 страницы по 256 байт каждая. Первая страница содержит параметры канала SCC1, l2C, IDMA1 и параметр miscellaneous. Вторая - параметры канала SCC2, SPI, RISC-таймеров и SPI-канала. Третья страница содержит параметры каналов SCC3, SMC1 и параметры DSP1-операций. Четвертая - параметры каналов SCC4, SMC2 и параметры О5Р2-операций. Из-за конфликта в распределении памяти невозможно одновременное использование некоторых коммуникационных протоколов, каналов или функций.
Если QMC-канал обрабатывается несколькими SCC-каналами (Shared QMC), то каждому SCC-контроллеру требуется 170 байт для хранения глобальных параметров и таблицы маршрутизации, а также для хранения TSA-таблиц приема и передачи (128 байт). Но SCC-каналы могут использовать общие TSA-таблицы, и тогда для одного SCC-канала требуется 172 байта (44 байта для регистров и 128 байт для общей TSA-таблицы), а другим SCC-каналам потребуется только 44 байта для хранения регистров (табл. 5.63).
Таблица 5.63
Конфигурация памяти параметров при работе с различными протоколами в контроллере МРС860МН
Страница памяти параметров и какие каналы хранят на ней свои параметры Протокол, с которым работает SCC-канал Размеры областей памяти на странице Вынужденно отключенные каналы
Страница 1 Transparent Transparent (56 байт), 12С (48 байт), IDMA1 (64 байта), Misc (16 байт) и 72 байт свободно Нет
SCC1 (выделено 128 байт) HDLC HDLC (92 байта), 12С (48 байт), IDMA1 (64 байта), Misc (16 байт) и 36 байт свободно Нет
581
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
Продолжение табл. 5.63
Страница памяти параметров и какие каналы хранят на ней свои параметры Протокол, с которым работает SCC-канал Размеры областей памяти на странице Вынужденно отключенные каналы
12С (48 байт) UART UART (102 байта), PC (48 байт), IDMA1 (64 байта), Misc (16 байт) и 26 байт свободно Нет
IDMA1 (64 байта) Ethernet Ethernet (164 байта), IDMA1 (64 байта), Misc (16 байт) и 12 байт свободно РС
Misc (16 байт) QMC QMC (172 байта), IDMA1 (64 байта), Misc (16 байт) и 4 байт свободно РС
Shared QMC Shared QMС (32+12 байт), IDMA1 (64 байта), Misc (16 байт) и 128+4 байт свободно РС
Страница 2 Transparent Transparent (56 байт), SPI (48 байт), Timer (16 байт), IDMA2 (64 байта) и 72 байт свободно Нет
SCC2 (выделено 128 байт) HDLC HDLC (92 байта), SPI (48 байт), Timer (16 байт), IDMA2 (64 байта) и 36 байт свободно Нет
SPI (48 байт) UART UART (102 байта), SPI (48 байт), Timer (16 байт), IDMA2 (64 байта) и 26 байт свободно Нет
Timer (16 байт) Ethernet Ethernet (164 байта), Timer (16 байт) IDMA2 (64 байта) и 12 байт свободно SPI
IDMA2 (64 байта) QMC QMC (172 байта), Timer (16 байт) IDMA2 (64 байта) и 4 байт свободно SPI
Shared QMC Shared QMC (32+12 байт), Timer (16 байт), IDMA2 (64 байта) и 128+4 байт свободно SPI
Страница 3 Transparent Transparent (56 байт), DSP1 (64 байта), SMC1 (56 байт) и 72+8 байта свободно Нет
SCC3 (выделено 128 байт) HDLC HDLC (92 байта), DSP1 (64 байта), SMC1 (56 байт) и 36+8 байта свободно Нет
DSP1 (64 байта) UART UART (102 байта), DSP1 (64 байта), SMC1 (56 байт) и 26+8 байта свободно Нет
SMC1 (56 байт) Ethernet Ethernet (164байта), DSP1 (64 байта) и свободно 28 байт SMC1
8 байт свободно QMC QMC (172 байта), DSP1 (64 байта) и свободно 20 байт SMC1
Shared QMC Shared QMC (32+12 байт), DSP1 (64 байта) и свободно и 128+20 байт свободно SMC1
Страница 4 Transparent Transparent (56 байт), DSP2 (64 байта), SMC2 (56 байт) и 72+8 байта свободно Нет
SCC4 (выделено 128 байт) HDLC HDLC (92 байта), DSP2 (64 байта), SMC2 (56 байт) и 36+8 байга свободно Нет
DSP2 (64 байта) UART UART (102 байта), DSP2 (64 байта), SMC2 (56 байт) и 26+8 байта свободно Нет
582
ПОДДЕРЖКА ПРОТОКОЛОВ В КОММУНИКАЦИОННЫХ КОНТРОЛЛЕРАХ
Продолжение табл. 5.63
Страница памяти параметров и какие каналы хранят на ней свои параметры Протокол, с которым работает SCC-канал Размеры областей памяти на странице Вынужденно отключенные каналы
SMC2 (56 байт) Ethernet Ethernet (164 байта), DSP2 (64 байта) и свободно 28 байт SMC2
8 байт свободно QMC QMC (172 байта), DSP2 (64 байта) и свободно 20 байт SMC2
Shared QMC Shared QMC (32+12 байт), DSP2 (64 байта) и свободно и 128+20 байт свободно SMC2
Применение контроллеров. В табл. 5.64 приведены наиболее распространенные варианты конфигурации контроллеров МРС860МН.
Таблица 5.64
Конфигурации контроллеров МРС860МН
Поддерживаемые протоколы Рабочая частота, МГц
25 40 50
SCC1: 24-канальный QMC. Скорость передачи 1,544 Мбит/с (линия Т1). + + +
SCC1: 32-канальный QMC. + + +
Скорость передачи 2,048 Мбит/с (линия Е1/СЕРТ). SCC1: 10 Мбит/с Ethernet. SCC2: 12 * 64 Кбит/с QMC. SCC3: 12 * 64 Кбит/с QMC. Скорость передачи по TDM 1,544 Мбит/с. + + +
SCC1: 10 Мбит/с Ethernet. SCC2: 12 * 64 Кбит/с QMC. Скорость передачи по TDM 1,544 Мбит/с. + + +
SCC1: 32 * 64 Кбит/с QMC. SCC2: 64 Кбит/с HDLC. SCC3: 64 Кбит/с HDLC. SCC4: 64 Кбит/с HDLC. + + +
SCC1: 10 Мбит/с Ethernet. SCC2: 16 * 64 Кбит/с QMC.
SCC3: 16 * 64 Кбит/с QMC. SCC4: 64 Кбит/с HDLC. Скорость передачи по TDM 2,048 Мбит/с.
SCC1: 10 Мбит/с Ethernet. SCC2: 12 * 64 Кбит/с QMC.
SCC3: 12 * 64 Кбит/с QMC. SCC4: 64 Кбит/с HDLC. Скорость передачи по TDM 1,544 Мбит/с.
SCC1: 24-канальный QMC. SCC2: 24-канальный QMC. - + +
Скорость передачи по двум TDM 2*1,544б/с (две Т1-линии). SCC1: 10 Мбит/с Ethernet. SCC2: 24-канальный QMC. SCC3: 24-канальный QMC. Скорость передачи по двум TDM 2*1,544 Мбит/с (две Т1-линии). - - +
SCC1: 32-канальный QMC. SCC2: 32-канальный QMC. Скорость передачи по двум TDM 2*2,048 Мбит/с (Е1/СЕРТ-линия). - + +
В табл. 5.65 приведены максимальные скорости передачи контроллеров при использовании различных коммуникационных протоколов в режиме полнодуплексной передачи.
По материалам вышеприведенных таблиц легко рассчитать коэффициент загрузки коммуникационного процессора или сколько процентов полосы пропускания контролле
583
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
ра будет занято коммуникационными протоколами. Коэффициент загрузки рассчитывается как сумма для всех каналов отношений скорости работы канала к максимальной скорости работы канала. Если коэффициент оказывается больше единицы, то такая конфигурация работы системы невозможна. Рассмотрим примеры.
Таблица 5.65
Скорости работы каналов при использовании различных протоколов
Протокол Соотношение скорости, Мбит/с к тактовой частоте, МГц Максимальная скорость передачи, Мбит/с
25 МГц 33 МГц 40 МГц 50 МГц
Transparent 1 : 3,12500 8 10,56 12,8 16
HDLC 1 : 3,12500 8 10,56 12,8 16
UART 1 : 10,4000 2,4 3,168 3,84 4,8
Ethernet 1 : 1,13600 22 29 35 44
SMC transparent 1 : 16,6700 1,5 1,98 2,4 3
SMC UART 1 : 113,636 0,22 0,29 0,352 0,44
QMC 1 : 11,9000 2,1 2,8 3,36 4,2
BISYNC 1 : 16,6700 1,5 1,98 2,4 3
Пример 1. Рассчитаем коэффициент загрузки для контроллера с частотой 25 МГц, в котором канал SCC1 работает в режиме полудуплекса с 10-Мбит/с Ethernet-протоколом, SCC2 работает с 2-Мбит/с HDLC-протоколом, SCC3 работает с 64-Кбит/с HDLC-протоколом, SCC4 работает с 9,6-Кбит/с UART-протоколом, SMC1 работает с 38-Кбит/с UART-протоколом. Коэффициент равен (10/22) + (2/8) + + (0,064/2,4) + (0,0096/2,4) + (0,038/0,22) = 0,96 < 1. Таким образом, коммуникационный процессор будет загружен на 96%.
Пример 2. Рассчитаем коэффициент загрузки для контроллера с частотой 25 МГц, в котором реализованы двадцать четыре 64-Кбит/с QMC-канала и два 128-Кбит/с HDLC-канала. Коэффициент равен (24x0,064/2,1) + (2x0,128/8) = 0,76 < 1. Таким образом, коммуникационный процессор будет загружен на 76%.
Пример 3. Рассчитаем коэффициент загрузки для контроллера с частотой 25 МГц, в котором реализованы тридцать два 64-Кбит/с QMC-канала и один 2-Мбит/с HDLC-канал. Коэффициент равен (32x0,064/2,1) + (2/8) = 1,22 > 1. Таким образом, коммуникационный процессор будет загружен на 122% и работать не будет.
5.3.3. РАБОТА В АСИНХРОННЫХ КАНАЛАХ СВЯЗИ
Асинхронный HDLC-протокол. Асинхронный HDLC - это протокол, использующий для передачи HDLC-кадров по каналу связи технологию UART-кадров. Данный протокол используется как физический уровень для протоколов PPP (point-to-point). Так же как и в других протоколах, СРМ, работая с асинхронным HDLC-протоколом (AHDLC-контрол-лер), выполняет формирование кадров и передачу их по сети с минимальным вмешательством центрального процессора. Работа AHDLC-контроллера похожа на работу классического HDLC-контроллера.
ASYNC HDLC-контроллер передает HDLC-кадры в пакетах UART-протокола. UART-пакет служит средством передачи данных HDLC-кадра по асинхронной сети. При формировании кадра данных для непосредственной передачи по сети контроллер использует следующий формат: 1 старт-бит, 8 бит данных, 1 стоп-бит, битов контроля четности нет.
584
ПОДДЕРЖКА ПРОТОКОЛОВ В КОММУНИКАЦИОННЫХ КОНТРОЛЛЕРАХ
О 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
FLC 0 1 1 0 0 0 0 0 0 0 0 0 0 0 0
Рис. 5.102. Формат регистра режима PSMR ASYNC HDLC-протокола
Для обеспечения указанного выше формата UART-кадра в регистре режима AHDLC-npo-токола PSMR (рис. 5.102) биты CHLN1 и CHLN0 должны быть установлены в «1». Для других протоколов эти биты определяют число битов в передаваемом символе данных.
Бит FLC в регистре PSMR определяет тип контроля при передаче данных. Если бит FLC = 0, то идет обыкновенная передача. Если бит FLC = 1, то производится асинхронный контроль передачи. При этом, если сигнал cts станет равным единице, то передача останавливается после завершения передачи текущего символа. Если сигнал cts = 1 после середины передачи текущего символа, то передача может остановиться после передачиследующего символа. Пока cts = 1, могут передаваться символы IDLE. Когда сигнал cts восстановится ( cts = 0), передача продолжится с того места, где она оста-новиласыТаким образом, при передаче регистрируется всего одна ошибка - это потеря сигнала cts . При этом передача прерывается, буфер закрывается, устанавливается признак ошибки СТ = 1 в слове состояния буфера BD и устанавливается бит ТХЕ прерывания в регистре событий SCCE. После получения команды RESTART TRANSMIT передача возобновляется из следующего TxBD.
Отличия между протоколами HDLC и ASYNC HDLC перечислены ниже.
• Для AHDLC-контроллера нет ограничения на максимальную длину принимаемого кадра, так как принимаются все символы между открывающим и закрывающим флагами. Таким образом, не существует механизма ограничения числа байтов принимаемых в буфер данных, и все данные будут записаны в память даже из кадра с длиной, превышающей максимальную.
• Если во время приема кадра произошла одна из ошибок приема, то принятый кадр игнорируется и не записывается в память. Таким образом, счетчик принятых байтов регистрирует только кадры, записанные в память.
• Команда GRACEFUL STOP TRANSMIT не используется.
• Счетчики ошибок контрольной суммы CRCEC и ошибок принятия ABORT-последова-тельностей в ASYNC HDLC-контроллере не используются.
Особенности программирования регистра GSMR для ASYNC HDLC-контроллера перечислены ниже.
• Бит RFW := 1. Для AHDLC-контроллера устанавливается размер буферов FIFO, равный 8 байтам для канала SCC1 и 4 байтам для других SCC-каналов. Размер ячейки буфера равен 8 битам.
• В битах TDCR и RDCR должен быть задан коэффициент внутреннего увеличения тактовой частоты приемника и передатчика. Для AHDLC-контроллера допустимые значения коэффициента 8х, 16х и 32х. Но если используется протокол IrLAP, то должен быть выбран коэффициент 16х (биты TDCR = RDCR := 10).
При работе с ASYNC HDLC-протоколом в регистр синхронизации DSR должен быть записан код 0х7Е7Е.
Передача символов. При включении в работу передатчика AHDLC-контроллер проверяет бит готовности R первого буфера BD-дескриптора. Если бит R = 1, то контроллер читает данные из памяти по SDMA-каналам в буфер FIFO канала передачи и начинает передавать их в канал. Перед началом передачи данных из нового кадра контроллер добавляет к кадру открывающий флаг. Набор символов, которые могут быть переданы по AHDLC-каналу, ограничен рекомендациями RFC 1549.
585
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
Открывающий флаг BOF Адрес Контроль Данные Контрольная сумма FCS Закрывающий флаг EOF
8 бит
8 бит
8 бит Мх8 бит
16 бит
8 бит
Рис 5.103. Формат кадра ASYNC HDLC-протокола
Формат поля, флаг задается пользователем в ячейке BOF памяти параметров. Реко-мендованные значения: для протокола РРР - 0х7Е, для протокола IRLAP (infra-red link access protocol) - OxCO.
Когда контроллер обнаружит последний буфер BD кадра данных (буфер в слове состояния которого будет установлен бит L = 1), то он подсчитывает контрольную сумму кадра CRC и передает ее в канал, а затем передает закрывающий флаг. Формат закрывающего флага задается пользователем в ячейке EOF памяти параметров. Рекомендованное значение для протокола РРР - 0х7Е, для протокола IRLAP - 0хС1.
Далее, если сброшен бит продолжения СМ = 0 в слове состояния последнего буфера BD, то AHDLC-контроллер устанавливает в слове состояния последнего буфера кадра биты статуса передачи кадра и сбрасывает бит готовности буфера к передаче R := О.
Если в слове состояния BD был установлен бит I = 1, то контроллер генерирует ТхВ-прерывание через регистр событий. Таким образом, прерывание может регистрироваться после передачи буфера, группы буферов или после окончания передачи всего кадра.
Если в слове состояния буферного дескриптора установлен бит продолжения СМ = 1, то после передачи данных из этого буфера будут установлены биты статуса передачи, но бит готовности кадра к передаче сбрасываться не будет, т. е. R = 1. После передачи буфера с СМ = 1 контроллер переходит к передаче следующего буфера BD. Если он еще не готов, т. е. бит R = 0, то контроллер будет ожидать его готовности. Формат кадра ASYNC HDLC-протокола представлен на рис. 5.103.
Открывающий и закрывающий флаги вставляются при передаче данных и удаляются контроллером при приеме. Контроллер принимает кадры только с одним разделяющим флагом между кадрами. Если между кадрами передается несколько символов флага, то контроллер будет их игнорировать. В ячейке NOF памяти параметров хранится число N, которое определяет, сколько N+1 открывающих флагов будет передано перед кадром.
Поле адреса может быть заполнено, только если оно получено при передаче из буфера данных, у которого в слове состояния буферного дескриптора установлен бит А = 1. RISC-контроллер не занимается в своей микропрограмме вопросами вставки, распознавания и контроля адресов. Все эти функции должны быть возложены на центральный процессор.
То же самое относится и к полю контроля. RISC-контроллер не выполняет функции обработки этого поля. Он только заполняет его при передаче данных из буфера, если в слове состояния буферного дескриптора указано, что буфер содержит контрольный символ (бит С = 1). Всей обработкой данных из этого поля должен заниматься центральный процессор.
При передаче контрольная сумма кадра FCS (Frame Control Sequence) автоматически добавляется к кадру данных перед закрывающим флагом. Контрольная сумма вычисляется над содержимым первоначального кадра до добавления в него символов «прозрачности», старт- и стоп-битов или символов флагов. Для формирования контрольной суммы контроллер использует 16-битный образующий полином циклического кода. В ячейке C_MASK памяти параметров хранится константа этого полинома 0x0000F0B8, а в ячейке C_PRES - начальное значение счетчика контрольной суммы OxOOOOFFFF.
При передаче данных AHDLC-контроллер постоянно контролирует, что за байты данных он передает в сеть. Если для байта данных выполняется одно из перечисленных ниже 586
ПОДДЕРЖКА ПРОТОКОЛОВ В КОММУНИКАЦИОННЫХ КОНТРОЛЛЕРАХ
условий, то включается алгоритм обеспечения «прозрачности» данных и вместо одного исходного байта передается двухбайтовая последовательность. Первый байт - это специальный символ control-escape, формат которого задан в ячейке ESC памяти параметров (для протоколов РРР и IrLAP рекомендуется значение 0x7D). Второй байт - это исходный байт, над которым выполнена операция «исключающее ИЛИ» XOR с константой 0x20.
Условия включения алгоритма кодировки «прозрачности» при передаче байта данных:
1) если этот байт - флаг (формат 0х7Е для протокола РРР и 0хС0/0С1 - для IrLAP);
2) если этот байт - контрольный символ control-escape - 0x7D;
3) если этот байт имеет значение между 0x00 и 0x1 F и соответствующий бит установки в таблице Тх контрольных символов. Эта кодировка выполняется только для протокола РРР.
В ячейке TXCTL_TBL памяти параметров хранится таблица контрольных символов при передаче, а в ячейке RXCTL_TBL - таблица контрольных символов при приеме данных. Эти таблицы используются только для протокола РРР. Если используется протокол IrLAP, эти ячейки должны быть инициализированы в «0». Каждая из этих ячеек представляет собой таблицу из 32 бит. Бит номер 0 соответствует символу 0x00, бит номер 1 -0x01, бит номер 2 - 0x02 и т. д. Бит номер 31 соответствует символу 0x1 F. Если в этих таблицах в бите I установлена «1», то символ, соответствующий этому биту, рассматривается как контрольный.
Распределение памяти параметров ASYNC HDLC-протокола приведено в табл. 5.66.
Таблица 5.66
Память параметров ASYNC HDLC-протокола
Адрес Название Размер, бит Описание
SCC base +34 C_MASK 32 Константа полинома CRC
SCC base+38 C_PRES 32 Начальные значения CRC
SCC base+3C BOF 16 Открывающий флаг
SCC base+3E EOF 16 Закрывающий флаг
SCC base+40 ESC 16 Контрольный ESC-символ
SCC base+42 - 16 Зарезервировано
SCC base+44 - 16 Зарезервировано
SCC base+46 ZERO 16 Инициализация «0»
SCC base+48 - 16 Зарезервировано
SCC base+4A RFTHR 16 Число принятых кадров до прерывания
SCC base+4C - 16 Зарезервировано
SCC base+4E - 16 Зарезервировано
SCC base+50 TXCTL_TBL 32 Таблица контрольных символов Тх
SCC base+54 RXCTL_TBL 32 Таблица контрольных символов Rx
SCC base+58 NOF 16 Число открывающих флагов
SCC base+5A - 16 Зарезервировано
Примечание. Все переменные в таблице ZERO должна быть проинициализирована «0». контроллером для временного хранения данных инициализируются пользователем. Ячейка Зарезервированные ячейки используются
587!
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
Пользователь может остановить передачу данных из буферов, передав AHDLC-koh-троллеру команду STOP TRANSMIT. Эта команда используется, если необходимо изменить порядок передачи данных из буферов или если обнаружена ошибка передачи в канале. После получения данной команды AHDLC-контроллер начинает передавать в сеть ASYNC HDLC ABORT-последовательность, которая состоит из ESCAPE-символа (0x7D) и закрывающего флага. После передачи такой ABORT-последовательности контроллер передает в сеть символы IDLE, пока не получит команду возобновления передачи RESTART TRANSMIT. Форматы ABORT-последовательности для протоколов РРР и IrLAP приведены в табл. 5.67.
Таблица 5.67 ,
Формат ABORT-последовательности
Протокол Формат
РРР 0x7D, 0х7Е
IrLAP 0x7D, 0хС1
При получении команды STOP TRANSMIT контроллер не переходит к передаче из следующего TxBD и текущим остается буфер, передачу которого прервали. Также останавливается передача и данных, которые уже находились в FIFO. В этом отличие ASYNC HDLC-протокола от других протоколов, в которых содержимое FIFO передается в сеть перед остановкой. Пользователь всегда может прочитать в ячейке TBPTR протокол-независимой части памяти параметров SCC-канала 0 номер, передача из которого прервалась.
Команда INIT ТХ PARAMETERS используется для инициализации параметров в памяти параметров передатчика контроллера.
Прием данных. После включения в работу (бит ENR = 1 в регистре GSMR) приемник ожидает появления кадра данных на линии RXD, анализируя присутствие на линии символа открывающего флага кадра. Обнаружив начало нового HDLC-кадра данных, контроллер обращается к следующему буферному дескриптору в таблице и проверяет его готовность к приему, т. е. проверяет бит незанятости буфера Е = 1 в слове состояния дескриптора. Если буфер не занят, то контроллер начинает записывать в него данные. Когда буфер будет заполнен, контроллер сбросит бит Е := 0. Если длина текущего кадра данных превышает размер буфера (максимальный размер буфера указан в ячейке переменной MRBLR), то производится опрос готовности к приему данных следующего буфера в таблице, и, если он свободен, прием текущего кадра будет продолжен в новый буфер.
Во время приема кадра ASYNC HDLC-контроллер автоматически контролирует принимаемый символ, декодируя его в соответствии с заданным алгоритмом.
1) Если код принятого символа находится между 0x00 и 0x1 F и в таблице ячейки RXCTL_TBL памяти параметров для этого символа в соответствующем бите установлена «1», то принятый символ считается служебным и отбрасывается. Если соответствующий символу бит равен 0, то символ принимается в нормальном режиме и записывается в память.
2) Если принят символ control-escape 0x7D, то этот символ отбрасывается, а над следующим принятым символом выполняется операция «исключающее ИЛИ» с константой 0x20, прежде чем этот символ будет участвовать в подсчете контрольной суммы и будет записан в память.
3) Если принята пара символов 0x7D, 0x7D, то первый символ будет отброшен, а второй - декодирован с помощью операции XOR с константой 0x20, а затем записан в память как код 0x5D.
588
ПОДДЕРЖКА ПРОТОКОЛОВ В КОММУНИКАЦИОННЫХ КОНТРОЛЛЕРАХ
4) Если принят символ закрывающего флага (0х7Е для протокола РРР или 0хС1 для протокола IrLAP), то прием кадра данных будет закончен.
5) При приеме все символы IDLE автоматически удаляются.
После завершения приема кадра данных и удаления из него всех служебных «transparents-символов, всех старт- и стоп-битов и всех символов флагов контроллер сравнивает подсчитанную с помощью 16-битного CRC CCITT-полинома контрольную сумму со значением, которое было получено в поле контрольной суммы принятого кадра. Далее контроллер записывает полученную контрольную сумму в буфер и закрывает буфер. В ячейку длины последнего буферного дескриптора контроллер заносит длину реально принятого кадра, устанавливает бит последнего буфера кадра L := 1 в слове состояния последнего буфера, заполняет биты статуса принятого кадра и сбрасывает бит незанятости буфера Е := 0, если только бит СМ = 0. Затем контроллер устанавливает бит RXF в регистре событий, уведомляя через маскируемое прерывание центральный процессор, что данные приняты и находятся в памяти. После завершения всех этих действий контроллер начинает поиск нового кадра данных.
Пользователь может управлять работой приемника ASYNC HDLC-контроллера, передавая ему команды: ENTER HUNT MODE, CLOSE RX BD, INIT RX PARAMETERS. После получения команды «поиск нового кадра» контроллер перейдет в нормальный режим работы при обнаружении в канале одного или более символов открывающего флага кадра.
При приеме AHDLC-контроллер регистрирует следующие типы ошибок (см. ниже).
• Ошибка переполнения overrun. Для временного хранения принятой информации каждый AHDLC-контроллер имеет внутренние буферы FIFO размером 8 байт для канала SCC1 и по 4 байта для других SCC-каналов. Данные из FIFO по SDMA-каналам под управлением RISC-контроллера начинают передаваться в соответствующие буферы памяти как только будут получены первые 8 бит кадра. Если RISC-контроллер не успевает очищать ячейки FIFO для приема новой информации из сети и в момент прихода новой порции данных все ячейки FIFO окажутся занятыми, то возникает ошибка переполнения буферов overrun. При этом контроллер будет вынужден записать новые данные поверх старых, что приведет к потере информации. Далее текущий буфер закрывается, в его слове состояния устанавливается бит ошибки переполнения OV := 1 и через регистр событий генерируется, если оно разрешено, RXF-прерывание к центральному процессору. После этого контроллер начинает поиск следующего кадра в канале связи.
• Ошибка потери CD-сигнала. Во время приема кадра данных контроллер постоянно проверяет наличие сигнала на линии сгГ. Если во время приема этот сигнал будет потерян cd = 1, то контроллер прекращает прием, закрывает текущий буфер, устанавливает в слове состояния текущего BD бит потери сигнала CD. CD := 1 и генерирует, если разрешено, прерывание RXF через регистр событий. Эта ошибка имеет самый высокий приоритет, и после ееобнаружения другие ошибки не проверяются, а приемник после установки сигнала cd = 0 переходит в режим «охоты» (поиска нового кадра).
• Прием ABORT-последовательности. Эта ошибка регистрируется ASYNC HDLC-контроллером, когда он получит пару символов 0x7D, 0х7Е. При возникновении этой ошибки открытый буфер приема закрывается, в его слове состояния устанавливается бит ошибки АВ := 1 и генерируется, если разрешено, прерывание RXF через регистр событий. При этом для прерванного кадра CRC-контроль не выполняется. Если ABORT-последовательность была получена, когда не было приема и не было открытых буферов, в этом случае следующий в таблице буфер приема открывается и тут же закрывается с установленным битом ошибки АВ = 1 в его слове состояния.
• Ошибка контрольной суммы. Если при подсчете контрольной суммы была выявлена ошибка, то контроллер записывает принятую контрольную сумму в буфер, затем
589
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
закрывает буфер и устанавливает бит ошибки проверки CRC суммы CR := 1 в слове состояния буферного дескриптора и бит RXF := 1 в регистре событий, вызывая маскируемое прерывание центрального процессора. Далее контроллер переходит в режим поиска нового кадра данных.
• Ошибка приема BREAK-последовательности. Эту ошибку обнаруживает UART-приемник при приеме break-символа, состоящего из одних нулевых битов. При обнаружении этой ошибки открытый буфер приема закрывается, в его слове состояния устанавливается бит ошибки BRK := 1 и генерирует, если разрешено, прерывание RXF через регистр событий. При этом для прерванного кадра CRC контроль не выполняется. Событие начала приема BREAK-последовательности регистрируется в бите BRKs регистра событий, а окончание BREAK-последовательности при получении первого единичного бита регистрируется в бите BRKe регистра событий.
Ошибки шума, характерные для UART-протокола в асинхронном режиме, не регистрируются. Появление ошибок такого типа должно обнаруживаться при проверке контрольной суммы.
UART-контроллер. Основные режимы работы UART-контроллера. Протокол UART (Universal Asynchronous Receiver Transmitter) используется для организации низкоскоростного канала связи между двумя станциями в сети. Термин асинхронный означает, что между станциями передаются только данные и не передаются тактовые сигналы. Протокол UART-это символьно-ориентированный протокол, т. е. минимальная единица передаваемой информации - это символ, и при передаче могут встречаться только символы строго определенного формата. Если принят символ, который не входит в установленный протоколом набор символов, то принятый пакет игнорируется и генерируется сообщение об ошибке. Ряд символов из установленного набора используются для управления передачей и не являются информационными. Наиболее часто асинхронный канал связи применяется для соединения терминалов и компьютеров или для подключения отладочного оборудования.
Генераторы тактовых сигналов приемника и передатчика работают независимо и асинхронно, но с близкими частотами синхронизации. Для связи двух станций достаточно всего двух линий (одна - для передачи данных TxD, другая - для приема данных RxD). Признаком начала кадра является появление старт-бита на линии данных. Приемник измеряет длину старт-бита, измеряет частоту передачи данных и внутри приемника увеличивает ее в 8, 16, 32 раза. Затем приемник опрашивает 8, 16, 32 раза значение бита на битовом интервале. Обычно используется увеличение частоты в 16 раз и опрос значения бита производится тоже 16 раз. Выбрав из проведенных 16 опросов три опроса в центре битового интервала (обычно это опросы 7, 8, 9), приемник анализирует их значение и за значение бита на битовом интервале выбирается значение по максимальному совпадению результатов этих трех опросов. Этот процесс определения значения бита при асинхронной передаче носит название oversampling.
Когда в UART сети нет передачи информации, передатчик посылает в канал последовательность битов «1», которая называется IDLE-последовательность. Так как старт-бит в кадре всегда равен 0, то приемник может всегда легко выделить начало кадра в канале связи. UART-протокол также использует последовательность из всех «О», которая называется BREAK-последовательностью и служит для прерывания передач в канале.
В современных сетях применяется и вариант синхронного UART-протокола. В этом протоколе полностью поддерживается формат кадра асинхронного UART-протокола, только при приеме не используется механизм oversampling и частота увеличивается в один раз, т.е. на каждый битовый интервал приходится один период тактовой частоты и один опрос значения бита. При работе в синхронном режиме тактовый сигнал может быть получен или от внутреннего генератора или от внешнего источника через внешние контакты (рис. 5.104).
590
ПОДДЕРЖКА ПРОТОКОЛОВ В КОММУНИКАЦИОННЫХ КОНТРОЛЛЕРАХ
UART TXD
5, 6, 7, 8 битов данных (LSB-бит передается первым) Бит адреса Бит контроля От 9/16 до 2 стоп-битов
JlЛЛШlЛЛШlЛЛЛШlЛf^^
8х, 16х, 32х
Рис. 5.104. Формат кадра UART-протокола (тактовая частота показана не масштабированной)
Любой SCC может быть запрограммирован на работу в UART-протоколе. В СРМ дополнительно SMC-каналы могут работать с упрощенной версией UART-протокола. Программирование каналов осуществляется в регистре GSMR в СРМ.
При работе UART-контроллер поддерживает режим multidrop для работы в сетях master/slave (рис. 5.105). Для обеспечения работы в сетях с многоточечной (multipoint) конфигурацией в состав кадра данных введен дополнительный «адресный» бит.
При работе с UART-протоколом, но в режиме NMSI, каждый SCC-канал получает доступ к семи внешним контактам: передаваемые данные TXD, принимаемые данные RXD, синхронизация приема RCLK, синхронизация передачи TCLK, запрос передачи RTS , разрешение приема cts и индикатор передачи cd . Другие модемные сигналы - DSR (готовность данных) и готовность терминала DTR - могут быть реализованы через контакты параллельных портов ввода/вывода. Таким образом, каналы, работающие с UART-протоколом, могут обмениваться данными с любыми внешними устройствами, поддерживающими стык RS-232.
Формат кадра. В любом режиме работы формат кадра UART-протокола состоит из следующих элементов:
• старт-бита «0»;
• битов данных (LSB-бит передается первым);
• необязательного адресного бита;
• необязательного бита контроля по четности/нечетности;
• одного или двух стоп-битов «1».
Пользователь может сам определить формат кадра, программируя регистр настройки UART-режима PSMR (рис. 5.106) в контроллере МРС860.
Рис. 5.105. Два способа включения UART-контроллера в конфигурации multidrop
591
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОППЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
FLC SL CL им FRZ RZS SYN DRT — PEN | RPM TPM
Рис. 5.106. Формат регистра режима PSMR для UART-контроллера
Биты CL определяют длину передаваемых данных (табл. 5.68).
Таблица 5.68
Длина передаваемых данных
Бит CL Размер поля данных, бит
00 5
01 6 • Ц '1
10 7
11 8
Биты SL определяют длину стоп-битов: 0 - один стоп-бит, 1 -два стоп-бита. Для того чтобы правильно распознать конец кадра, приемник должен получить хотя бы один стоп-бит. Стоп-бит-это логическая «1». Для асинхронного UART передатчик может быть запрограммирован на использование дробных стоп-битов. Дробным может быть только последний стоп-бит, т. е. если используются два стоп-бита, то первый передается в полном формате, а второй - в дробном. Символы IDLE всегда передаются с полными стоп-бита-ми. При программировании дробных стоп-битов (табл. 5.69) используются биты FSB в регистре синхронизации SCC-канала DSR. Эти биты доступны пользователю и могут быть модифицированы в любое время.
Таблица 5.69
Использование дробных стоп-битов
Значение DSR[14-11] Коэффициент увеличения частоты тактирования
16х 32х 8х
0000 - 17/32 -
0001 - 18/32 -
0010 - 19/32 -
0011 - 20/32 -
0100 - 21/32 -
0101 - 22/32 -
0110 - 23/32 -
0111 - 24/32 -
1000 09/16 25/32 -
1001 10/16 26/32 -
1010 11/16 27/32 -
1011 12/16 28/32 -
1100 13/16 29/32 5/8
1101 14/16 30/32 6/8
1110 15/16 31/32 7/8
1111 16/16 32/32 8/8
592
ПОДДЕРЖКА ПРОТОКОЛОВ В КОММУНИКАЦИОННЫХ КОНТРОЛЛЕРАХ
Приемник UART может всегда принимать дробные стоп-биты. Следующий кадр может начинаться в любое время по истечении трех периодов увеличенной тактовой частоты после получения стоп-бита предыдущего кадра.
Для контроля правильности передачи данных по сети в состав кадра введен бит контроля. Пользователь может выбирать тип контроля по четности или по нечетности. Если выбран контроль по четности, то при передаче подсчитывается число «1» в поле данных, и если это число нечетное, то бит контроля устанавливается в «1», если число единиц в поле данных четное - бит контроля в кадре равен 0. Если выбран контроль по нечетности и число «1» в поле данных нечетное, то бит контроля равен 0, иначе - 1.
Бит контроля может быть удален из кадра, если пользователь установил бит PEN := 0 в регистре настройки. Если бит PEN := 1, то производится контроль и бит контроля включен в кадр данных. Тип контроля задают значения битов RPM при приеме и ТРМ при передаче (табл. 5.70).
Таблица 5.70
Тип контроля в сети
Биты RTM или ТРМ Тип контроля
00 Контроль по нечетности
01 Бит контроля всегда равен 0
10 Контроль по четности
11 Бит контроля всегда равен 1
Подсчет контрольной суммы всегда производится и на приемной и на передающей стороне канала.
Для работы UART-контроллера в многоточечном соединении в состав кадра введен бит адреса. Если бит адреса в кадре равен 1, то в поле данных передается адрес узла, который требует соответствующей обработки. Если станция работает в двухточечном соединении, то бит адреса может быть исключен из кадра данных. Настройку UART-контроллера на определенный режим работы (табл. 5.71) производят биты UM в регистре настройки.
Таблица 5.71
Режимы работы UART-контроллера
Значение битов UM Режим работы
00 Станция работает в нормальном двухточечном режиме. В этом режиме пользователь может временно выключить приемник из работы, но при приеме символа IDLE (все «1») приемник автоматически включается в работу.
01 Станция работает в многоточечном соединении в неавтоматическом режиме. В этом режиме в состав кадра введен бит адреса, но канал не занимается его обработкой. При приеме кадра с битом адреса, равным 1, приемник повторно переводится в рабочий режим, принимает кадр и помещает его в новый буфер данных. Проверку адреса выполняет центральный процессор,который также решает, принимать или игнорировать следующие дальше кадры данных.
10 Режим не используется в контроллерах МС68360 и МРС860. В МС68302 UART-канал настраивается на работу с асинхронным DDCMP-протоколом.
11 Станция работает в многоточечном соединении в автоматическом режиме. В этом режиме СР принимает кадр с адресом, сравнивает его с разрешенными адресами в ячейках UADDR1 и UADDR2 памяти параметров канала и сам принимает решение, принимать ли дальнейшие данные, если они адресованы ему, или игнорировать их, если проверка адресов завершилась неудачно.
593
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
При работе с UART-контроллером пользователю предоставлена возможность временно остановить передачу и возобновить ее с точки останова через некоторое время. Остановкой передачи управляет бит FRZ. Если бит FRZ = 0, то передатчик работает в нормальном режиме. Если бит FRZ = 1, то передатчик передает все данные из FIFO канала и останавливает передачу. После сброса бита FRZ = 0 передача будет продолжена со следующего символа. Значение бита FRZ не влияет на работу приемника.
При работе с UART-протоколом пользователь может также управлять работой сигналов управления CTS и RTS и сигналами тактовой частоты.
При значении бита FLC - 1 производится контроль сигнала «разрешение передачи» cts ПРИ передаче символов. Если во время передачи символа сигнал CTS = 1, то передатчик передает^гекущий символ до конца и останавливает передачу. Генерируется ошибка «потеря CTS -сигнала», признак этой ошибки отмечается в бите CTS в слове состояния BD. Передача возобновляется после установки сигнала CTS = 0. Если сигнал CTS = 1, то возможна передача только IDLE-символов. Если бит FLC = 0, то UART-контроллер не анализирует состояние сигнала CTS при передаче.
При значении бита DRT = 1 пользователь может запретить совместную одновременную работу приемника и передатчика. Этот режим часто применяется в многоточечной конфигурации, когда пользователь не желает принимать данные, которые он сам передает. Для этого он на время работы своего передатчика запрещает работу приемника. При значении DRT = 0 обеспечивается совместная работа приемника и передатчика.
Пользователь может при работе настраивать работу UART-контроллера или в асинхронном режиме, если бит SYN = 0, или в синхронном режиме, если бит SYN = 1. При работе в асинхронном режиме коэффициент внутреннего увеличения тактовой частоты в 8х, 16х или 32х раза устанавливается при программировании соответствующих битов в регистре GSMR модуля СРМ.
Если канал работает с синхронным UART-протоколом и требуется увеличение скорости передачи (например, при работе с V.14 устройствами), то при программировании бита RZS = 1 может быть включен режим прием кадра данных без стоп-битов. На практике это реализуется как передача нулевого стоп-бита. Для ускорения работы канала нулевой стоп-бит может рассматриваться и как старт-бит следующего кадра данных. Получив кадр данных с нулевым стоп-битом, приемник продолжает свою работу, регистрирует ошибку кадра (так как кадр принят без стоп-бита), но генерирует прерывание по ошибке, только когда примет два BREAK-символа без стоп-битов.
Работа UART-контроллера. При передаче данные выставляются на TXDx-контакт, при приеме данные читаются с RXDx-контакта. При передаче LSB-биты в поле данных передаются первыми.
Данные для передачи и данные, которые приняты из сети, хранятся в буфере памяти. В буферах хранится только содержимое поля данных. Старт-бит, стоп-бит, бит контроля и бит адреса добавляются при передаче и удаляются при приеме самим SCC-каналом и в памяти не хранятся. При работе в многоточечном соединении допускается хранение в памяти адреса, принятого в кадре данных. Данные одного кадра могут занимать несколько буферов. Если при приеме или передаче символа произошли ошибки, то будет установлен соответствующий бит ошибки в слове состояния BD.
Размер FIFO SCC-канала при работе с UART-протоколом равен 32 байтам для приема и 32 байтам для передачи, если используется канал SCC1, и по 16 байт, если используются другие SCC-каналы. Размер ячейки буфера FIFO устанавливается равным 8 битам при программировании регистра GSMR. В СРМ пользователь может ускорить передачу данных из FIFO-буфера передачи, сократив число ячеек FIFO до одной, установив соответствующее значение в бите TFL в регистре GSMR.
594
ПОДДЕРЖКА ПРОТОКОЛОВ В КОММУНИКАЦИОННЫХ КОНТРОЛЛЕРАХ
Если SCC-канал настроен на работу с UART-протоколом, то параметры конкретного протокола хранятся в протокол-ориентированной области parameter RAM (табл. 5.72).
Таблица 5.72
Память параметров UART-контроллера в микроконтроллере МРС860
Адрес Название Размер, бит Описание
SCC base+30 - 32 Зарезервировано
SCC base+34 - 32 Зарезервировано
SCC base+38 MAXJDL 16 Максимальное число IDLE-символов
SCC base+3A IDLC 16 Счетчик IDLE-символов
SCC base+3C BRKCR 16 Регистр передаваемого BREAK-символа
SCC base+3E PAREC 16 Счетчик ошибок четности
SCC base+40 FRMEC 16 Счетчик ошибок формата кадра
SCC base+42 NOSEC 16 Счетчик ошибок шума
SCC base+44 BRKEC 16 Счетчик полученных BREAK-символов
SCC base+46 BRKLN 16 Длина принятой BREAK-последовательности
SCC base+48 UADDR1 16 Первый адрес
SCC base+4A UADDR2 16 Второй адрес
SCC base+4C RTEMP 16 Временная память приемника
SCC base+4E TOSEQ 16 Передаваемый служебный символ
SCC base+50 CHAR1 16 Контрольный символ 1
SCC base+52 CHAR2 16 Контрольный символ 2
SCC base+54 CHAR3 16 Контрольный символ 3
SCC base+56 CHAR4 16 Контрольный символ 4
SCC base+58 CHAR5 16 Контрольный символ 5
SCC base+5A CHAR6 16 Контрольный символ 6
SCC base+5C CHAR7 16 Контрольный символ 7
SCC base+5E CHAR8 16 Контрольный символ 8
SCC base+60 RCCM 16 Маска контрольных символов
SCC base+62 RCCR 16 Регистр принятого контрольного символа
SCC base+64 RLBC 16 Регистр принятого BREAK-символа
Примечание. Все переменные в табл. 5.72, кроме ячеек IDLC, BRKLN, RTEMP, RCCR и RLBC, инициализируются пользователем до начала работы с UART-контроллером.
Прием данных UART-контроллером. В UART-протоколе в отсутствие передачи по сети передаются IDLE-символы, которые состоят из 9—13 единиц «1». Размер IDLE-noc-ледовательности зависит от размера кадра данных, на работу с которым настроен канал. Размер IDLE-символа равен: 1 старт-бит + 5, 6, 7, 8 битов данных + 1 бит контроля (если он используется) + 1,2 стоп-бита. Приемник канала постоянно подсчитывает число полученных IDLE-символов в счетчике IDLE-символов IDLC. Если начинается прием нового кадра данных, то содержимое счетчика IDLC сбрасывается. Таким образом, IDLC-счетчик подсчитывает число IDLE-символов, полученных между приемом двух кадров данных. Пользователь может в ячейке MAXJDL определить максимально допустимое число IDLE-символов между кадрами данных .IDLC - это вычитающий счетчик, и при
595
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
сбросе в него записывается содержимое ячейки MAX_IDL, если счетчик IDLC досчитал до 0, то возникает ошибка приема «IDLE sequence». Текущий буфер закрывается, в нем устанавливается бит ID := 1 (закрыто из-за IDLE-переполнения) и генерируется RX-прерывание в регистре событий, если оно разрешено. Если не был открыт буфер для приема, то прерывание не генерируется.
Для работы в сетях, где присутствуют более двух станций, в состав кадра UART-протокола введен бит адреса. Если бит адреса равен единице, то в кадре данных передается адрес получателя всех следующих кадров данных до кадра, в котором снова будет установлен бит адреса равный единице. UART-контроллер при обработке кадра с адресом может работать в двух режимах.
1. Неавтоматический режим. В этом режиме канал принимает пакет с адресом как обычные данные, закрывает текущий буфер и записывает адрес в новый буфер. В слове состояния этого буфера устанавливается бит, показывающий, что буфер содержит адрес. Дальнейшую обработку адреса должен выполнять центральный процессор.
2. Автоматический режим. В этом режиме канал сам анализирует принятый адрес. Он сравнивает принятый адрес с двумя возможными, которые записаны в ячейки UADRR1 и UADRR2. В ячейках хранятся 8-битные разрешенные адреса для данного канала. Если хотя бы один адрес совпал, то данные из следующих кадров данных будут приниматься в буфер канала. При этом в первом буфере, в который будут записываться данные, в слове состояния устанавливается бит А := 1, показывающий, что это первый буфер с данными из последовательности, и бит AM, показывающий, какой адрес совпал. Если AM = 0 - совпал адрес ADRR2, если AM = 1 - то совпал адрес ADRR1.
Если при приеме кадра данных обнаружена ошибка контроля по четности/нечетности (parity error), то канал записывает принятый байт в буфер, закрывает буфер, устанавливает бит ошибки PR := 1 в слове состояния BD и генерирует RX-прерывание через регистр событий (если оно разрешено). Также увеличивается на единицу счетчик ошибок четности в счетчике PAREC. В автоматическом многоточечном режиме работы канал переходит в режим «охоты».
При приеме в асинхронном режиме UART-контроллер три раза опрашивает значение бита на битовом интервале (oversampling). Если эти значения не равны, то возникает ошибка шума (noise error). При этом канал увеличивает на единицу счетчик ошибок шума в ячейке NOSEC, записывает принятый символ в буфер и продолжает нормальную работу.
При приеме UART-контроллер выделяет кадр данных из битового потока по старт-биту в начале и стоп-битам в конце кадра. Если в кадре не обнаружены «1» стоп-битов, то возникает ошибка формата (frame error). Канал записывает принятый символ в буфер, закрывает буфер и устанавливает в его слове состояния бит FR := 1, увеличивает на единицу счетчик ошибок формата FRMEC и генерирует прерывание RX через регистр событий (если оно разрешено). Если произошла ошибка формата, контроль по четности не производится. В автоматическом многоточечном режиме работы канал переходит в режим «охоты».
Если UART-контроллер работает в синхронном режиме с нулевыми стоп-битами (бит RZS = 1 в регистре PSMR настройки UART-режима), ошибка формата обнаруживается, но пользователь может не реагировать на нее.
При приеме данные записываются в FIFO выбранного канала, далее они под управлением RISC-контроллера по SDMA-каналам пересылаются в память. Если скорость работы SDMA-каналов и сети не согласована, возможно возникновение ошибки переполнения (overrun), когда ячейки FIFO все заняты, а из сети получены новые данные. В этом случае: новые данные запишутся поверх старых символов в FIFO-буфер, буфер приема в памяти закроется, установится бит переполнения OV := 1 в слове состояния BD и будет сгенерировано прерывание RX через регистр событий (если оно разрешено). В автоматическом многоточечном режиме работы канал переходит в режим «охоты».
596
ПОДДЕРЖКА ПРОТОКОЛОВ В КОММУНИКАЦИОННЫХ КОНТРОЛЛЕРАХ
При приеме UART-контроллер может использовать вход CD для автоматического контроля наличия передачи в сети. Если сигнал cd равен единице при приеме символа, то возникает ошибка (CD lost) «потери CD-сигнала». Прием символа прекращается, буфер закрывается, устанавливается бит CD := 1 в слове состояния BD и генерируется прерывание RX через регистр событий (если оно разрешено). В автоматическом многоточечном режиме работы канал переходит в режим «охоты».
В режим «охоты» перевести канал может и пользователь, если передаст через RISC-контроллер каналу команду ENTER HUNT MODE. Если при этом канал принимал сообщение, то оно будет потеряно. Находясь в режиме «охоты», приемник принимает BREAK-символы, увеличивает счетчик BRKEC, генерирует BRK-прерывание через регистр событий. Переход в рабочий режим возможен, если придет IDLE-символ или кадр с установленным битом адреса в многоточечной сети. Таким образом, в режиме «охоты» канал прекращает текущий прием кадра, закрывает старый буфер, подготавливает новый буфер и ждет нового кадра.
Если при приеме символов в режиме UART-протокола коммуникационный процессор получит команду CLOSE Rx BD, то он останавливает прием в текущий буфер, закрывает текущий BD, генерирует маскируемое прерывание и начинает прием в новый буфер.
Прием служебных символов. В ходе своей работы приемник может быть запрограммирован на выявление во входном битовом потоке кадров, которые содержат служебные символы. Служебным называется символ, при приеме которого может генерироваться прерывание. При обработке этого прерывания пользователь может анализировать процесс приема символов в сети. Формат служебных символов задает сам пользователь в регистрах CHAR1-CHAR8. Регистры управления служебными символами имеют следующий формат (рис. 5.107).
Каждый служебный символ имеет размер 8 бит. Принимая новый кадр данных, приемник начинает последовательно сравнивать его содержимое со служебными символами в таблице. Пользователь может управлять размером таблицы служебных символов с помощью бита Е (конец таблицы). Если у символа CHARi бит Е = 1, то это последний символ в таблице, и приемник прекращает проверку служебных символов. Если необходимо иметь таблицу из восьми символов, то у всех ячеек Е = 0.
Если служебный символ принят и совпал с шаблоном из таблицы, то он может быть сохранен в буфере, если бит R = 0 в ячейке шаблона, или может быть сохранен во временном регистре RCCR, если бит R = 1. Если бит R = 0, то после передачи символа в буфер буфер закрывается, новый буфер открывается для приема следующих данных и генерируется прерывание, если бит I = 1 в слове состояния BD. Если бит R = 1, то операции с текущим буфером не производится, но прерывание генерируется.
CHAR1
CHAR2
CHAR3
CHAR4
CHAR5
CHAR6
CHAR7
CHAR8 RCCM
О 1 2 3 4 5 6 7 8 9 10 1 1 12 1 3 14 1 5
Е R — — — — — — Служебный символ 1
Е R — — — — — — Служебный символ 2
Е R — — — — — — Служебный символ 3
Е R — — — — — — Служебный символ 4
Е R — — — — — Служебный символ 5
Е R — — — — — Служебный символ 6
Е R — — — — — — Служебный символ 7
Е R — — — — — — Служебный символ 8
1 1 — — — — — — Регистр маски служебных символов
Рис. 5.107. Формат ячеек служебных символов
>
п а !•»
> )
595?
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
Пользователь может запретить проверку сравнения некоторых служебных символов с помощью регистра маски RCCM (рис. 5.107). В младших восьми битах этого регистра хранятся признаки проверки символов. Если i-разряд равен нулю, то проверка на сравнение принятого символа и служебного символа CHARi не производится. Если i-разряд равен единице, то символ CHARi принимает участие в сравнении. В старших разрядах (15-й и 14-й биты) ячейки RCCM хранятся, для того чтобы избежать ошибок при обработке битов Е и R в таблице служебных символов.
Если служебный символ был сохранен в буфере, то в слове состояния BD устанавливается бит С := 1, который сообщает пользователю, что последний байт в буфере - это служебный символ.
Кроме служебных символов UART-контроллер может контролировать прием символов BREAK. Символ BREAK - это от 9 до 13 «0» без стоп-битов. Если контроллер получил последовательность BREAK-символов, то он увеличивает счетчик BRKEC и закрывает текущий буфер приема, устанавливает в его слове состояния бит BR := 1 и генерирует Rx-прерывание через регистр событий, если оно разрешено. В СРМ-процессоре контроллер также контролирует длину BREAK-последовательности.
При приеме первого BREAK-символа контроллер устанавливает бит начала последовательности BRKs в регистре событий. Далее он подсчитывает длину последовательности в символах. При получении первого бита, равного единице, контроллер записывает длину BREAK-последовательности в регистр BRKLN и устанавливает бит конца последовательности BRKe в регистре событий. Напомним, что изменение значения любого бита в регистре событий может вызвать прерывание центрального процессора, если оно разрешено.
Если UART-контроллер работает в синхронном режиме (бит SYN = 1 в регистре режима UART-контроллера) и установлен бит нулевых стоп-битов RZS = 1, то BREAK-после-довательность регистрируется только после приема двух BREAK-символов. Каждый последний принятый BREAK-символ будет сохраняться в регистре RLBC. Пользователь может подсчитать длину (число «0») в последнем BREAK-символе, начиная с 15-го бита в регистре RLBC и в сторону 0-го бита до бита, значение которого равно единице. Например, если в регистре RLBC записан двоичный код 0001хххххххх, то это значит, что было принято три нулевых бита.
Передача символов. При передаче UART-контроллер получает из буфера FIFO только сам символ, который будет передан в поле данных. Остальные поля кадра заполняются внутри SCC-контроллера. Во-первых, контроллер анализирует, какой тип контроля будет применен, и вычисляет контрольную сумму, которая записывается в бит контроля в кадре данных. Во-вторых, надо или нет вводить бит адреса в формат кадра. В-третьих, в формат кадра вводится необходимое число стоп-битов, при этом контролируется использование дробных стоп-битов.
Если передается первый символ из нового буфера данных, то в слове состояния буферного дескриптора анализируются биты А, Р, NS, CR. Бит NS = 1 определяет, что все данные из буфера должны передаваться без стоп-битов. Если бит NS = 0, то все данные передаются со стоп-битами. Если установлен бит А = 1, то все данные из буфера передаются как адреса с установленным в «1» битом адреса в формате кадра, но только если контроллер настроен на работу в режиме многоточечного соединения. Если установлен бит CR = 1, то между передачами содержимого двух соседних буферов данных в канал выводятся три бита IDLE «1». Сигнал CTS , который должен быть активен при передаче данных, во время передачи IDLE-битов становится пассивным, генерируется прерывание «потеря CTS сигнала» и выставляется бит СТ = 1 (потеря CTS) в слове состояния текущего буфера. Если бит CR = 0, то следующий буфер передается сразу за текущим без задержек, если он был готов к передаче. При этом бит потери CTS - бит СТ в слове состояния BD не
598
ПОДДЕРЖКА ПРОТОКОЛОВ В КОММУНИКАЦИОННЫХ КОНТРОЛЛЕРАХ
устанавливается. Если в слове состояния BD установлен бит Р = 1, то перед передачей содержимого буфера передается символ преамбулы (все биты «1»), и на другом конце канала обнаруживают IDLE-состояние линии связи перед получением данных. Преамбула передается, даже если длина буфера в BD установлена равной нулю. Преамбула представляет собой символ такой же длины, что и передаваемые данные, только все биты в символе равны единице.
Если UART-контроллер получил от CPU-ядра команду STOP TRANSMIT, то он передает в сеть содержимое FIFO передачи, затем передает определенное число символов BREAK, далее он переходит к передаче IDLE-символов, пока не получит команду RESTART TRANSMIT. Формат BREAK-символа представляет собой символ установленной длины, у которого все биты равны нулю и без стоп-битов. Количество BREAK-символов, которые UART-контроллер передаст в сеть, указывается пользователем в регистре BRKCR.
Пользователь может управлять процессом передачи данных (flow control), вставляя в поток передаваемой информации служебные символы. Для этого в области параметров протокола выделена специальная ячейка TOSEQ. В эту ячейку записывается символ управления передачей, который имеет наивысший приоритет перед передачей других символов. Перед тем как прочитать очередной символ из буфера данных, UART-koh-троллер проверяет готовность этого служебного символа. Если символ готов, то он помещается в FIFO передачи, а затем в канал будет передан символ управления передачей, например символы XON или XOFF.
Когда центральный процессор подготовил символ для передачи, устанавливается бит REA (READY) := 1 (рис. 5.108). Коммуникационный контроллер сбрасывает этот бит REA := 0 только после окончания передачи служебного символа, формат которого указан в поле CHARACTER. После передачи служебного символа, если установлен бит I (Interrupt) = 1, то CPU уведомляется прерыванием через бит Тх-регистра событий UART -контроллера.
Длина служебного символа CHARACTER совпадает с запрограммированной длиной других символов, с которыми работает контроллер. Значение поля CHARACTER может быть изменено пользователем, только когда сброшен бит готовности REA = 0.
При передаче служебного символа контролируется состояние сигнала разрешения передачи cts = 0. Если при передаче служебного символа был потерян сигнал, т. е. cts" = 1, то устанавливается бит СТ := 1 в ячейке CHAR8 или TOSEQ, а также устанавливается бит CTS := 1 в регистре событий UART-контроллера. Если передача служебного символа прервала передачу символов из буфера данных и при этом был потерян сигнал cts , то и в слове состояния BD текущего буфера будет установлен бит потери сигнала cts бит СТ := 1.
Когда UART-контроллер работает в многоточечной конфигурации, пользователь должен установить бит А := 1 в ячейке служебного символа.
О 1 2 3 4 5 6 7 8 9 10 1 1 12 1 3 14 1 5
— — REA I СТ 0 0 А Символ для передачи (CHARACTER)
Рис. 5.108. Формат регистра TOSEQ
)
Transparent-контроллер. Transparent-контроллер позволяет SCC-каналу прини^цть и передавать сетевые данные без их модификации. Выделяют несколько задач, для которых характерно использование режима «прозрачной передачи».
• Для передачи по сети в последовательном коде «особенных» данных, например, голоса, если не выделено специального протокола для этих целей.
599
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
• Для передачи данных в последовательном коде между микросхемами на плате или приборе. Для этого требуется выполнять последовательно-параллельное и параллельно-последовательное преобразование.
• Пользователь может организовать передачу кадров любого протокола в поле данных кадра «прозрачного» уровня без промежуточного их декодирования. Например, для организации связи между высокоскоростной и низкоскоростной сетями, которые обе работают с временным мультиплексированием. В этом случае SCC-контроллер будет выполнять функцию согласования скоростей двух сетей.
• Наиболее часто SCC-контроллеры с Transparent-режимом работы используются для построения коммуникаторов и концентраторов. В этих случаях контроллер будет выполнять функции мультиплексирования данных от нескольких низкоскоростных каналов в один высокоскоростной.
• Часто режим прозрачной передачи применяют для передачи данных из памяти одного компьютера в память другого компьютера, используя при этом преобразование данных в последовательный код при передаче по последовательному каналу связи.
Настройка SCC-канала для работы в Transparent-режиме обмена в контроллере МРС860 производится в регистре общих режимов GSMR. Установка битов ТТХ = 1 для передатчика и TRX = 1 для приемника включает полнодуплексный режим «прозрачной передачи» независимо от значений битов MODE, которые осуществляют выбор коммуникационного потока для SCC-канала. Если же установлен только один из битов, то лишь одна часть SCC-канала будет работать в прозрачном режиме, а другая часть будет работать с коммуникационным протоколом, который выбран в битах MODE.
Transparent-контроллер имеет полностью независимые приемную и передающую части. Тактирование работы контроллера может производиться от внутреннего BRG-гене-ратора, или через внешние контакты, или через блок DPLL.
При передаче может быть выбран любой порядок битов в байте (или LSB-бит первый, или MSB-бит первый) и факультативно добавленные при передаче и контролированные при приеме поля контрольной суммы CRC. Для проверки передаваемых данных может быть использована или 16- или 32-разрядная CRC-контрольная сумма. В ячейке CRC_P (табл. 5.73) хранится начальное значение счетчика CRC OxOOOOFFFF - для CRC16 и OxFFFFFFFF - для CRC32. Для счетчика CRC_C памяти параметров хранится константа, определяющая тип образующего полинома циклического кода 0x0000F0B8 - для CRC16 и 0xDEBB20F3 - для CRC32. Выбор типа CRC контрольной суммы производится в бите TCRC регистра режима GSMR.
Таблица 5.73
Память параметров Transparent-протокола в микроконтроллере МРС860
Адрес Название Размер, бит Назначение
SCC base+30 CRC_P 32 Начальное значение CRC-счетчика
SCC base+34 CRC_C 32 Константа CRC для приемника
Синхронизация Transparent-контроллера. Синхронизация приемника и передатчика может выполняться двумя способами:
1) при помощи синхросигналов в канале связи;
2) при помощи внешних сигналов синхронизации.
Режим синхронизации устанавливается в битах SYNL в регистре GSMR (табл. 5.74).
600
ПОДДЕРЖКА ПРОТОКОЛОВ В КОММУНИКАЦИОННЫХ КОНТРОЛЛЕРАХ
Таблица 5.74
Размер синхросимволов
Бит SYNL Тип синхронизации
00 Внешними сигналами
01 4-битные синхросимволы
10 8-битные синхросимволы
11 16-битные синхросимволы
Формат 4/8/16-битных синхросигналов задается в регистре синхронизации DSR. Например, если для синхронизации приемника выбран режим SYNL = 01, то прием кадра начинается после приема четырех бит синхросигнала.
Внешние сигналы cts и cd могут быть использованы для синхронизации передатчика и приемника. Бит CTSP в регистре GSMR определяет вид сигнала CTS и способ синхронизации передатчика, а бит CDP - вид сигнала CD и способ синхронизации приемника. Если биты CTSP и CDP равны единице, то соответствующие сигналы выставляются в виде импульсов, которые отмечают момент начала обмена. В дальнейшем при обмене изменение состояния этих сигналов игнорируется. Этот режим удобен, когда пользователь желает передавать все данные без прерывания при передаче отдельных кадров. Если же биты CTSP или CDP равны нулю, то эти сигналы выставляются (становятся активными) только во время передачи кадра данных, во время промежутка между отдельными кадрами эти сигналы пассивны. Этот режим рекомендуется использовать, когда необходимо через прерывание отслеживать моменты передачи отдельных кадров в потоке данных.
Сигналы CTS и CD могут быть или асинхронными к передаваемым данным, и тогда контроллер будет производить внутреннюю синхронизацию, или синхронизированными с кадрами данных, что используется для ускорения обработки данных. Биты CDS и CTSS при значении «0» определяют асинхронный режим работы, а значение «1» определяет синхронизированный режим работы данных и сигналов cd и CTS соответственно (рис. 5.109).
Синхронизированный режим работы часто используется для соединения нескольких коммуникационных контроллеров (рис. 5.110), когда выход RTS одного контроллера соединяется со входом CD другого. При такой конфигурации сигнал CTS не используется, а начало передачи данных отмечается активным сигналом RTS= 0.
Таким образом, синхронизация передатчика может быть выполнена или при помощи внешнего сигнала CTS , или приемником после того, как он сам синхронизируется.
Если в регистре GSMR установлен бит TXSY = 1, то работа приемника и передатчика синхронизирована. Если дополнительно установлен бит RSYN = 1, то передатчик будет синхронизирован только после получения активного сигнала CTS = 0 и после того, как будет синхронизирован приемник. Если сигнал CTS = 0, то передача начнется через восемь периодов тактовой частоты передатчика после того, как приемник начнет получать данные.
Рис. 5.109. Синхронизация передачи кадра данных
601
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
QUICC МС68302
TXD р RXD
RTS р CD
BRGO ь CLK
RXD TXD
CD 4 RTS
CLK ч BRG
Рис. 5.110. Пример соединения двух контроллеров, работающих с Transparent-протоколом
Передача сообщений. После включения в работу (бит ENT - 1 в регистре GSMR) передатчик начинает передавать в сеть символы IDLE и опрашивает готовность к передаче данных из первого буфера таблицы TxBD. Если данные готовы (бит R = 1 в слове состояния буфера), то они по каналам SDMA загружаются в буфер FIFO передатчика, и контроллер ожидает синхронизации для начала передач.
После того как передатчик будет синхронизирован, он начнет передачу данных из FIFO-буфера.
После передачи каждого буфера данных контроллер проверяет бит последнего буфера кадра (L = 1) в слове состояния буфера. Если бит L = 1, то контроллер записывает в слово состояния буфера биты статуса переданного кадра, сбрасывает бит R := 0 и начинает передавать символы IDLE, пока следующие данные не будут подготовлены. Если же бит L = 0, то контроллер сбрасывает бит готовности буфера к передаче R := 0 и переходит к передаче следующего буфера данных текущего кадра без разрывов на линиях связи при передаче соседних буферов. Если очередной буфер данных еще не готов (его бит R = 0), то регистрируется ошибка underrun и устанавливается бит ТХЕ в регистре событий Transparent-контроллера.
Если в слове состояния буфера был установлен бит I = 1, то генерируется прерывание к центральному процессору по окончании передачи этого буфера.
При передаче может быть передано любое количество байт данных. Если в регистре GSMR бит REVD = 1, то Transparent-контроллер дополнительно будет менять порядок бит в байте. По умолчанию LSB-бит передается первым.
Пользователь может управлять размером буфера FIFO передатчика, программируя значение бита TFL в регистре GSMR. Если бит TFL = 0, то размер буфера равен 32 байт для SCCI-канала и 16 байт для других SCC-каналов. Если же бит TFL = 1, то размер буфера FIFO передатчика равен 1 байт. Этот режим используется для низкоскоростных каналов связи, так как при высоких скоростях возрастает вероятность возникновения ошибки underrun, когда центральный процессор не будет успевать заполнять FIFO-буфер по SDMA-каналам.
Пользователь может управлять работой передатчика с помощью команд STOP TRANSMIT, GRACEFUL STOP TRANSMIT, RESTART TRANSMIT, INITTX PARAMETERS.
При передаче регистрируется два типа ошибок.
1. Незаполнение (underrun), когда RISC-контроллер не успевает заполнять ячейки буфера FIFO при передаче кадра данных. При возникновении этой ошибки контроллер прекращает передачу, закрывает буфер и устанавливает бит ошибки UN := 1 в слове состояния буфера и бит ТХЕ := 1 в регистре событий, вызывая прерывание процессора. Эта ошибка регистрируется только между передачей соседних кадров. Если ошибка произошла при передаче последнего буфера кадра (бит L = 1 в слове состояния), то устанавливается только бит ТХЕ := 1 в регистре событий канала.
602
ПОДДЕРЖКА ПРОТОКОЛОВ В КОММУНИКАЦИОННЫХ КОНТРОЛЛЕРАХ
2. Ошибка потери сигнала cts Если во время передачи данных будет сброшен активный сигнал, и cts = 1, то регистрируется ошибка, контроллер прекращает передачу, закрывает буфер, устанавливает бит ошибки СТ := 1 в слове состояния буфера и бит ТХЕ := 1 в регистре событий, вызывая прерывание процессора.
Прием сообщений. Для начала приема данных приемник SCC-канала должен пройти процедуру синхронизации. Синхронизация достигается или при приходе внешнего сигнала, или при приходе SYNC-последовательностей. По окончании синхронизации приемник начинает прием символов.
Когда текущий буфер приема полностью заполняется, SCC-контроллер сбрасывает бит пустого буфера Е := 0 в слове состояния и генерирует прерывание, если установлен бит 1 = 1. Далее контроллер переходит к заполнению следующего буфера. Если этот буфер еще не подготовлен центральным процессором, то регистрируется ошибка занятости и устанавливается бит BSY := 1 в регистре события Transparent-контроллера.
Если в регистре GSMR установлен бит REVD=1, то контроллер при записи данных в буфер меняет порядок битов в байтах.
Пользователь может управлять размером буфера FIFO приемника, программируя значение бита RFW в регистре GSMR. Если бит RFW = 0, то канал SCC1 имеет буфер FIFO 32 байта и 16 байт для других SCC-каналов. Размер каждой ячейки буфера - 32 бита. Этот режим используется для высокоскоростных сетей. Для низкоскоростных сетей используется установка бита RFW = 1. Канал SCC1 имеет буфер FIFO размером 8 байт и 4-байтный FIFO для других SCC-каналов, а размер каждой ячейки 8 бит. Но использование режима с битом RFW = 1 может привести к возникновению ошибки overrun (переполнения), если скорость работы сети выше скорости обработки данных в коммуникационном контроллере.
Приемник всегда проверяет и производит подсчет контрольной суммы CRC в принимаемом кадре. Тип контрольной суммы задается в бите TCRC регистра GSMR. Если контроль CRC не требуется, то результат проверки игнорируется.
Для управления работой приемника предназначены команды ENTER HUNT MODE, CLOSE RX BD, INIT RX PARAMETERS. Приемник переходит в режим поиска нового кадра (hunt mode) или когда получит команду ENTER HUNT MODE, или будет обнаружена ошибка при приеме.
При приеме обнаруживаются два вида ошибок.
1. Переполнение (overrun), когда RISC-контроллер не успевает освобождать ячейки буфера FIFO для приема новых данных, и они вынуждены записываться поверх старых данных, что приводит к потере информации. При возникновении этой ошибки текущий буфер закрывается, устанавливается бит OV := 1 в слове состояния буфера и бит RX := 1 в регистре событий Transparent-контроллера. ___
2. Ошибка потери сигнала СР. Если во время приема кадра данных сигнал CD устанавливается пассивным cd := 1, то контроллер прекращает прием данных, закрывает буфер, устанавливает бит ошибки CD := 1 в слове состояния буфера и бит RX := 1 в регистре событий, вызывая прерывание центрального процессора.
При возникновении этих ошибок канал немедленно переходит в режим поиска новых кадров (hunt mode).
5.3.4. ДОСТУП К СЕТЯМ С ПАКЕТНОЙ ПЕРЕДАЧЕЙ (С ПРОТОКОЛАМИ Х.25)
Описание HDLC-протокола. Протокол канального уровня HDLC (Higher-level Data Link Control) принят международной организацией по стандартизации ISO. Различные промышленные фирмы пользуются своими производными этого протокола, среди кото-
603
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
рых наиболее известен протокол SDLC (Synchronous Data Link Control) фирмы IBM. При создании этих протоколов преследовались следующие цели:
• поле передаваемых данных должно содержать любое количество битов и любую их комбинацию, т. е. протоколы не являются байт-ориентированными;
• необходимо предусмотреть средства защиты от ошибок при передаче;
• функционирование должно быть устойчивым к сбоям и отказам; при отказах и сбоях протокол не должен допускать потерь пакетов, доставок одних и тех же пакетов дважды или доставок искаженных пакетов;
• протокол должен работать в конфигурациях point-to-point, multipoint, кольцевых структурах;
• протокол должен допускать работу в сети полнодуплексных и полудуплексных терминалов;
• при полнодуплексном режиме полоса пропускание должна использоваться максимально, а в многоточечных конфигурациях должен быть предусмотрен режим одновременной передачи и приема информации от разных станций;
• протокол должен эффективно работать при большом времени распространения сигнала по сети и при высоких скоростях передачи;
• при работе должны обнаруживаться состояния неработоспособности или некорректной работы станций в сети.
Типы станций в сети. Для организации управления передачами в сети в несбалансированном режиме обмера одна станция в сеансе связи обозначается как первичная, другая как вторичная. Первичная станция - станция , которая организует обмен в сети, контролирует его и организует восстановление после сбоев. Вторичная станция - ведомая станция, ее действия полностью контролируются первичной станцией. От первичной станции ко вторичной идут кадры с командами, обратно кадры с ответами. При нормальной работе в качестве реакции на команду ожидается ответ. В сетях с multipoint-соединениями работа происходит в режиме опроса, и станция, которая опрашивает другие, является первичной.
Некоторые станции могут сочетать функции первичных и вторичных станций. В этом случае они называются комбинированными. Если при передаче между комбинированными станциями обе станции выполняют один и тот же набор управляющих функций, то такой способ работы называется сбалансированным.
В сбалансированных режимах каждая станция может выполнять функции первичной или вторичной станции (комбинированная станция). Комбинированная станция может посылать и принимать как команды, так и ответы. Если комбинированная станция начала обмен, то она и контролирует его ход. Станции несут равную ответственность за нейтрализацию ошибок.
Каждое сообщение начинается и заканчивается флагом 01111110. Для обеспечения прозрачности данных внутри пакета применяется процедура вставки бита. Нулевой бит вставляется после каждых пяти единичных битов в потоке данных так, чтобы комбинация, соответствующая флагу, не могла встречаться среди битов данных. Вставка и исключение нулевых битов применяются для всех полей кадра между ограничивающими флагами и носят название «bit staffing». Если при приеме между флагами окажется меньше 32 бит, то кадр считается неправильным и принимающая станция его отбрасывает.
В промежутке между передачей кадров канал находится в активном состоянии, при котором в него непрерывно посылаются флаговые байты. Если за флаговым байтом не следует флаговый байт, то принимающая станция считает, что началась передача кадра.
Передающая станция может прервать передачу кадра передачей, по крайней мере, семи смежных единиц без вставки нулей (1111111). При этом канал, когда в нем обнаруживается 15 и более смежных единиц, переходит в пассивное состояние. В этом случае для возобновления передачи передающая станция должна повторно опросить готовность принимающей, перед тем как посылать ей данные. Передающая станция может прервать передачу кадра и без перевода канала в пассивный режим, передав восемь смеж
604
ПОДДЕРЖКА ПРОТОКОЛОВ В КОММУНИКАЦИОННЫХ КОНТРОЛЛЕРАХ
ных единиц, а затем флаговый байт (1111111101111110). Это приведет к отмене приема только текущего кадра, после чего можно передавать следующий кадр.
Основные типы кадров. HDLC-пакет (или кадр) состоит из 3-байтного заголовка и 3-байтного концевика, между которыми может располагаться любое число битов данных. Кадры могут быть двух типов: информационные и управляющие. В управляющих кадрах между заголовком и концевиком может не быть ни одного бита. Байты заголовка содержат следующую информацию:
Байт 1: байт флага, открывающий кадр данных. Формат флага 01111110.
Байт 2:8 битовый адрес станции, которой посылается кадр. Для проверки работоспособности станций и канала связи выделен специальный адрес 00000000 - «не станция». Для передачи сообщения всем станциям, подключенным к сети, выделен специальный глобальный адрес 11111111. При этом любой кадр-ответ на команду с глобальным адресом должен содержать индивидуальный адрес станции, которая его передала. Поле адреса можно расширить путем присоединения дополнительного байта. Обычно поле адреса содержит 8 бит и 256 комбинаций адресов. Но существует договоренность, что если первый передаваемый бит адреса (младший значащий бит) равен нулю, то и следующий байт тоже относится к полю адреса. Аналогично, если первый передаваемый бит адреса второго байта равен нулю, то и третий байт относится к полю адреса, и так далее. Если первый передаваемый бит адреса равен единице, то дополнительных адресных байтов нет и разрешено использовать 128 адресов.
Байт 3: 8 битовое поле, содержащее информацию, управляющую процессом передачи. Существует два формата кадра: основной и расширенный. Разница заключается в разной разрядности поля управления кадром (8 бит и 16 бит) из-за изменения в размере полей порядковых номеров кадра и ответа Ns, Nr, которые составляют 3 и 7 бит соответственно.
Байты концевика содержат следующую информацию:
Байты 1 и 2: 16-битный код контрольной суммы кадра для проверки ошибок.
Байт 3: байт флага, закрывающий кадр данных.
В протоколе HDLC используются три типа кадров (рис. 5.111):
• l-кадр: информационный кадр для передачи данных пользователей;
• S-кадр: супервизорный кадр, в котором передаются команды управления процессом передачи ( подтверждение приема, переспрос, остановка, запрос на передачу).
• U-кадр: ненумерованный кадр, который используется для дополнительных функций управления сеансом передачи и смены режима передачи; ненумерованный кадр не содержит порядкового номера.
При нормальном режиме работы сети необходимы только l-кадры и S-кадры. Эти кадры внутри поля управления кадром содержат порядковые номера передаваемого кадра.
Управляющий байт в кадре выполняет функции управления процессом передачи информации.
7 6 5 4 3 2 1 0
Порядковый номер приема Nr P/F Порядковый номер передачи Ns 0
Порядковый номер приема Nr P/F Супервизорные команды/ответы 0 1
Ненумерованные команды и ответы P/F Ненумерованные команды/ответы 1 1
Рис. 5.111. Три типа кадров
605
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
Первым в канал при передаче передается 0-й бит. Биты 1 и 0 определяют тип кадра. Бит Р/F имеет два значения: это бит опроса (polling), если кадр передается первичной станцией, и это бит конца, если кадр передается вторичной станцией. Бит опроса устанавливается в Р = 1 в командах, если требуется ответ. Последний кадр в кадрах ответа содержит бит конца, равный F = 1, и на него требуется подтверждение. Таким образом, функция бита Р/F одна и та же в обоих случаях. Этот бит показывает, что станция ожидает ответ и не будет передавать новый кадр до его получения.
Первичная станция , послав кадр с установленным битом опроса, ожидает ответ в течение заданного времени. Не получив его, станция снова пошлет кадр, запрашивающий ответ. Повторная передача осуществляется заданное количество раз. При этом используются два тайм-аута: 1) при отсутствии ответа от вторичной станции, 2) при получении неправильного ответа. Ни длительность тайм-аутов, ни число попыток повторных передач не регламентированы в HDLC, и эти числа меняются в зависимости от конкретной реализации.
Обмен между станциями контролируется с помощью порядковых номеров. Счет в 3-битовых номерах идет по модулю 8 от 0 до 7, после чего снова идет 0. В расширенном режиме управляющее поле может быть увеличено до 16 бит, так, чтобы счетчики порядковых номеров стали 7-битовыми и счет мог идти по модулю 128. Каждый информационный кадр идентифицируется порядковым номером Ns в поле управления кадром. Прием информации подтверждается посылкой подтверждения, в котором содержится порядковый номер Nr следующего информационного кадра, который ожидает принимающая станция. При этом предполагается, что все кадры до Nr были приняты правильно. Таким образом, l-кадр содержит два номера: Ns - собственный порядковый номер и Nr - номер, которым подтверждается принятие Nr-1-го кадра.
Подтверждение может посылаться или в виде информационных 1-кадров, или в виде S-кадра, в котором также присутствует номер последнего правильно принятого кадра Nr—1.
Основные режимы работы. Протокол HDLC определяет следующие основные рабочие режимы:
• нормального ответа NRM (normal response mode);
• асинхронного ответа ARM (asynchronous response mode);
• асинхронного сбалансированного ответа ABM (asynchronous balanse response).
Режим NRM. Соединение устанавливается по команде первичной станции. Только одна станция ведет передачу в данный момент времени, остальные только слушают. Вторичная станция может начать действия только по команде от первичной. Это процедура опроса (polling) первичной станции вторичной. При опросе используется бит P/F (poll/final) из поля управления кадром. Первичная станция инициализирует обмен, посылая или кадр-опроса (S-кадр с установленным битом опроса, опрашивающий есть ли у вторичной станции данные для передачи), или информационные l-кадры для передачи данных от первичной ко вторичной, указав в поле адреса адрес вторичной и установив в последнем кадре бит опроса Р = 1. После этого первичная станция ждет ответа. Вторичная станция, получив право на ответ, передает ответ в виде или S-кадров ( если нет данных для передачи), или информационных l-кадров, установив в последнем кадре бит конца передачи F = 1. В любом случае, если вторичная станция получила от первичной станции l-кадры, она должна подтвердить их прием. Первичная станция, получив ответ от вторичной в виде l-кадров, посылает подтверждение в виде S-кадра или новых 1-кадров. Этот процесс передачи кадров продолжается, пока у первичной или у вторичной станции есть данные для передачи. В этом режиме все управление лежит на первичной станции, она должна:
• послать кадр-запрос;
• следить за тайм-аутом передачи;
• организовать повторные передачи, если нет подтверждения.
606
ПОДДЕРЖКА ПРОТОКОЛОВ В КОММУНИКАЦИОННЫХ КОНТРОЛЛЕРАХ
Режим ARM. В этом режиме вторичная станция, не получив подтверждение от первичной, по собственной инициативе начинает передачу. Это режим используется при работе в кольце, когда разрешение приходит от другой вторичной станции ( или в шине с опросом по цепочке). При этом вторичная станция может передавать данные и кадры-управления и руководить обменом. Весь контроль за передачей в этом режиме лежит на вторичной станции, т.е. она отвечает за тайм-ауты и за повторные передачи, если нет подтверждений правильности приема.
Режим АВМ. В этом режиме любая станция может начать передачу. Каждая станция в этом режиме может выполнять функции первичной или вторичной станций. Любая станция может посылать и принимать как кадры-команды, так и кадры-ответы. Этот режим введен для повышения пропускной способности сети и снижения задержек в сети.
Вспомогательные режимы работы. Вспомогательные режимы разработаны для состояний, когда вторичная станция отключена от звена связи. В этих режимах станция не может получать и передавать 1-кадры и S-кадры. Такой режим предотвращает работу станции в необычных условиях, которые могут привести к соперничеству между станциями, работающими в режимах асинхронного ARM- и асинхронного сбалансированного АВМ-от-вета, несоответствию порядковых номеров передаваемых и принимаемых данных.
Вспомогательные режимы:
• нормального разъединения NDM (Normal Disconnect Mode);
• асинхронного разъединения ADM (Asynchronous Disconnected Mode);
• запуска (инициации) IM (Initialization Mode).
Режимы разъединения применяются при необходимости предотвратить неожиданный выход станции в сеть, когда происходит другой обмен. Вторичная станция должна переходить в режим разъединения при следующих обстоятельствах:
• временном отключении или начальном включении питания; i
• ручном управлении установкой логических цепей станции в исходное состояние; j
• ручном переводе станции в режим подсоединения. '
Режим нормального разъединения NDM. В этом режиме вторичная станция отсоединена от звена связи и не может принимать и предавать I- и S-кадры. Но ей разрешено отвечать на команду, полученную в U-кадре с битом опроса Р = 1 передачей одного кадра ответа, указывающего статус станции. Станция также должна выполнять команды:
• команду с требованием об идентификации; кадр ответа содержит признаки идентификации станции;
• команду установления режима работы; если станция может включить новый режим работы, то она передает ответ подтверждение в виде U-кадра и изменяет режим работы;
• команду начала теста; если станция может провести тест, то она передает ответ в виде U-кадра, содержащего ответ-тест.
Асинхронный режим разъединения ADM. Режим ADM аналогичен режиму NDM стой разницей, что вторичная станция может послать ответ по собственной инициативе, без опроса со стороны первичной станции. В этом режиме станция посылает ответ в асинхронном режиме при полудуплексном обмене, когда обнаружит нерабочее состояние канала связи, а при полнодуплексном обмене - в любое удобное для станции время.
Режим запуска (инициации) IM. Режим используется для передачи программы управления на удаленную вторичную станцию, ее коррекции в случае необходимости, а также для обмена параметрами между удаленными станциями. Станция может находиться в этом режиме, перед тем как перейти в рабочий режим. Переключение в рабочий режим выполняется по специальным командам в виде U-кадров. Вторичная станция может сама запросить переход в этот режим, если обнаружит ошибки своего функционирования, для получения корректной программы управления от первичной станции. Если команда на
607
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
переход в режим инициации поступила от первичной станции , то вторичная станция переходит в этот режим только после передачи ответа-подтверждения. При нахождении станций в этом режиме обмен служебной информацией ведется ненумерованными информационными кадрами (U-кадры). Режим инициации заканчивается, когда вторичная станция принимает одну из команд установления другого режима работы и подтверждает переход в этот режим ответом-подтверждением.
Расширенные рабочие режимы. Расширенные режимы используют два управляющих байта в заголовке кадра, увеличив разрядность счетчиков принятых и переданных кадров с 3 бит до 7 бит.
• NRME (Normal Response Mode Extended) - расширенный режим нормального ответа (расширенная версия режима NRM).
• ARME (Asynchronous Response Mode Extended) - расширенный режим асинхронного ответа (расширенная версия режима ARM).
• АВМЕ (Asynchronous Balanced Mode Extended) - расширенный асинхронный сбалансированный режим (расширенная версия режима АВМ).
Супервизорные кадры. S-кадры осуществляют управление процессом передачи данных в информационных кадрах. Обычно они не имеют поля данных и их размер 6 байт. Два бита в супервизорном кадре определяют его тип. Таким образом, S-кадры могут быть четырех типов (табл. 5.75).
Таблица 5.75
Типы S-кадров
Значение битов 3, 4 в поле типа кадра Мнемоника команды Описание команды
00 RR (Receive Ready) К приему готов. Станция готова к приему Nr-кадра, кадры до Nr приняты правильно.
01 REJ (Reject) Переспрос. Запрос передачи или повторной передачи l-кадра номер Nr и следующих за ним. Кадры до Nr приняты правильно.
10 RNR (Receive Not Ready) К приему не готов. Станция занята и не может принимать l-кадры. По окончании занятости она ждет кадр Nr, кадры до Nr приняты правильно.
11 SREJ (Selective reject) Селективный переспрос. Требуется повторная передача одного Nr-кадра. Кадры до Nr приняты правильно.
Ненумерованные кадры. С помощью ненумерованных кадров осуществляются следующие функции:
• реализуется механизм передачи информации, не используя контроль по порядковым номерам;
• передаются команды, которые осуществляют запуск станции, изменение режима передачи, отключение станции;
• производится отказ от выполнения неправильных команд или обработка особых ситуаций, например, если размер кадра больше чем размер буфера на станции.
В ненумерованных кадрах нет полей с номерами кадров, поэтому для идентификации типа U-кадра используются 5 бит. Таким образом может быть 32 типа ненумерованных кадров, однако не все типы задействованы (табл. 5.76).
608
ПОДДЕРЖКА ПРОТОКОЛОВ В КОММУНИКАЦИОННЫХ КОНТРОЛЛЕРАХ
Таблица 5.76
Команды U-кадров
Номер бига в поле типа кадра Мнемоника Описание команды
7 6 5 4 3 2
0 0 1 р 1 1 SABM Установка основного асинхронного сбалансированного режима
1 0 0 р 0 0 SNRM Установка основного режима нормального ответа
0 0 0 р 1 1 SARM Установка основного асинхронного режима
0 1 1 р 1 1 SABME Установка расширенного асинхронного сбалансированного режима
1 1 0 р 1 1 SNRME Установка расширенного режима нормального ответа
0 1 0 р 1 1 SARME Установка расширенного асинхронного режима
0 1 0 р 0 0 DISC Разъединение виртуального канала связи
0 0 0 р 0 1 SIM Установка режима инициализации
1 0 0 р 1 1 RSET Сброс в исходное состояние
0 0 1 р 0 0 UP Ненумерованный запрос передачи
0 0 0 F 1 1 DM Режим разъединения
0 0 0F F 0 1 RIM Запрос инициализации
0 1 1 F 0 0 UA Ненумерованное подтверждение
0 1 0 F 0 0 RD Запрос на разъединение
1 0 0 F 0 1 FRMR Некорректный кадр
1 0 1 P/F 1 1 XID Идентификатор станции
1 1 1 P/F 0 0 TEST Проверка
0 0 0 P/F 0 0 Ul Ненумерованная информация
Кадры команды
DISC (Disconnect) - используется для завершения ранее установленного режима работы или режима инициации и перехода в режим разъединение.
SIM (Set Initialization Mode) - используется для перевода удаленной станции в режим инициации с целью изменения на ней текущих параметров или для введения новых параметров или программ.
RSET (Reset) - применяется только в тех случаях, если станция работает в режиме АВМ, для сброса в исходное состояние счетчика номера принятого пакета с целью возобновления сеанса упорядоченной передачи пакетов нового сообщения.
UP (Unnumbered Poll). Получив такую команду, удаленная станция должна выставить ответ, содержащий информацию о ее состоянии. В качестве ответа могут быть переданы и еще не переданные информационные кадры.
Кадры ответа
DM (Disconnect Mode) - ответ удаленной станции, что она находится в режиме разъединения.
RIM-(Request Initialization Mode) - ответ, который используется для оповещения удаленной станции о необходимости перехода в режим инициации для изменения текущих параметров или введения новых параметров для вторичной или комбинированной станции, которая послала этот запрос.
609
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
UA (Unnumbered Acknowledgement) - ответ используется вторичной или комбинированной станцией для подтверждения выполнения команд, переданных в U-кадре.
RD (Request Disconnection) - ответ используется для сообщения станции, что на вторичной или комбинированной станции желателен переход в режим разъединения.
В составе U-кадра, в котором передаются ответы RIM, UA, RD, не допускается использование информационной области данных.
FRMR (Frame Reject) - ответ используется вторичной или комбинированной станцией для передачи на удаленную станцию сообщения о том, что принят некорректный кадр данных, который не может быть исправлен повторной передачей. В информационной области кадра дается обоснование переданного ответа. События, связанные с некорректной ситуацией: 1) принят кадр с командой, которая не используется в данном протоколе; 2) принят кадр, длина которого превышает максимально допустимую длину, определенную в данной реализации сети для обработки на вторичной станции; 3) принят кадр, который содержит информационную область, которая недопустима для данного типа кадра; 4) принят кадр с нарушенным порядком нумерации кадров Ns или Nr; 5) причина, по которой кадр отнесен к некорректным, не оговаривается.
Команда и ответ
Команды и ответы XID, TEST, U1 используются для передачи по сети информации о состоянии станции.
XID (Exchange Identification) - используется для опознания станции, обмена параметрами и другой служебной информацией. Кадр может содержать информационную область, при этом первый байт этой области определяет формат всей ее остальной части. TEST используется для тестирования канала связи. Вторичная станция, получив эту команду, должна передать ответ, скопировав в него информационную часть кадра. Если станция не может провести копирование данных, то она посылает ответ без информационного поля. Команда «тест» не должна менять содержимого переменных на станциях в сети.
U1 (Unnumbered Information) - служит для передачи информации от источника по каналу связи до удаленного пользователя без гарантии упорядоченной доставки ее получателю.
Алгоритмы работы сети. Процесс установления соединения
1. Первичная станция. Для установления соединения станция передает в канал непрерывную последовательность флагов, т. е. переводит канал в активное состояние. Затем посылает команду установления соединения (например, SABM или SABME) и включает таймер Т1.
2. Вторичная станция. Если команда «установить режим работы» принята без ошибок, посылает кадр подтверждение UA и соединение считается установленным или , если не может установить соединение, посылает кадр DM и соединение считается не установленным. При установления соединения счетчики принятых и переданных кадров Nr и Ns сбрасываются.
3. Первичная станция. Получив ответ без ошибок, выключает таймер Т1, сбрасывает счетчики принятых и переданных кадров и полагает, что соединение установлено. Если принят ответ DM, то таймер выключается и соединение считается не установленным. Если ответ-подтверждение принят с ошибкой или истек тайм-аут на таймере Т1, то выполняется повтор процесса установления соединения. Число повторных попыток ограничено, если все попытки израсходованы, то станция переходит в режим «разъединения».
Во время процесса установки соединения все кадры, кроме кадров установки соединения (в примере SABM или SABME), - DISC, UA, DM, станциями, участвующими в попытке связаться, игнорируются.
610
ПОДДЕРЖКА ПРОТОКОЛОВ В КОММУНИКАЦИОННЫХ КОНТРОЛЛЕРАХ
Процесс разъединения
1. Первичная станция. Посылает команду DISC с установленным битом опроса Р = 1 и включает таймер Т1.
2. Вторичная станция. Приняв правильный кадр DISC, посылает ответ подтверждение в кадре UA и переходит в режим разъединения. Если станция уже находилась в режиме разъединения , то она посылает кадр-подтверждение DM с установленным битом конца F = 1 , оставаясь в режиме разъединения.
3. Первичная станция. Приняв кадр «ответ-подтверждение», выключает таймер Т1 и переходит в режим разъединения. Если в процессе ожидания истек таймер Т1, то производится повтор процесса разъединения. Число повторных попыток ограничено, если все попытки разъединить соединение израсходованы, об этом сообщается более высокому уровню управления сети, чтобы он начал процедуру восстановления канала связи на своем уровне.
Во время передачи команды DISC станция игнорирует все команды, за исключением команд и ответов установления соединения (в примере SABM и SABME), UA, DISC, DM.
Находясь в режиме разъединения, станция реагирует только на команды установления соединения и команду DISC. Приняв любой другой кадр-команду с битом опроса Р = 1, станция передает ответ DM в кадре с битом конца F = 1.
Процесс передачи сообщения
1. Первичная станция. При передаче информационного l-кадра указывает в поле Ns его порядковый номер: Ns = Vs. Запускает таймер ожидания ответа Т1 и увеличивает значение счетчика переданных кадров Vs := Vs+1.
2. Вторичная станция. При получении кадра из сети запускает таймер выдачи ответа Т2, который измеряет максимальное время от получения пакета до выдачи ответа. Получив адресованный ей информационный l-кадр, станция сравнивает значение в поле Ns-кадра со значением счетчика ожидаемых кадров Vr. Если значения совпали, то кадр передается в буфер, а значение счетчика увеличивается Vr := Vr+1. Если буфер переполнен, то пакет сбрасывается, станция переходит в режим «занято» и посылает первичной станции уведомление в виде S-кадра типа RNR со значением поля Nr - Vr. Станция-передатчик, получив такой кадр, останавливает передачу новых l-кадров и повторную передачу неподтвержденных 1-кадров, пока не получит S-кадр типа RR или REJ, либо же не истечет интервал ожидания ответа, контролируемый таймером Т1.
Получив без ошибок кадр от первичной станции, вторичная станция должна передать подтверждение приема кадра. Если у станции есть данные для передачи, то подтверждение посылается в l-кадре, установив значение поля Nr := Vr. Если данных для передачи нет, то посылается управляющий S-кадр типа RR со значением поля Nr = Vr.
Если же вторичная станция приняла без ошибок кадр с порядковым номером Ns о Vr, то станция переходит в режим «прием неупорядоченного l-кадра», не учитывает информацию из принятого кадра и посылает S-кадр переспроса типа REJ с номером Nr = Vr. После передачи этого кадра станция игнорирует все l-кадры, пока не будет принят без ошибок I-кадр с номером Ns = Vr.
Если у станции истекает интервал, ограниченный таймером Т2, то первичной станции уведомление не пересылается, так как значения таймеров Т1 и Т2 подобраны так, что если станция-приемник не выдаст подтверждение до окончания счета Т2, то кадр не успеет дойти по станции-передатчика до окончания счета Т1.
3. Первичная станция. Ожидает пока не придет или подтверждение в виде информационного l-кадра, или S-кадр (типа RNR или REJ). После получения этих кадров станция останавливает таймер ожидания ответа Т1 и переходит к передаче следующего кадра данных. Получив подтверждение приема Nr-1-го кадра в пакете REJ, станция прерывает передачу новых 1-кадров и повторно передает 1-кадры с номерами от Nr до Ns. Если
611
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
станция передавала S-кадры или U-кадры, то она заканчивает их передачу и только потом начинает повторную передачу 1-кадров. Если истек интервал ожидания ответа, то станция передает управляющий S-кадр типа RR, RNR или REJ с установленным битом опроса Р = 1 и снова запускает таймер Т1. Эти действия производятся для определения изменения статуса станции приемника.
4. Вторичная станция. В ответ на прием S-кадра определения статуса с установленным битом опроса F - 1 станция передает S-кадр типа RNR , установив бит F := 1, указывая, что она продолжает оставаться в состоянии «занято», или S-кадр типа RR, или REJ с битом F = 1, если состояние «занято» снято. Состояние «занято» заканчивается, если станция снова может принимать информационные 1-кадры.
5. Первичная станция. Если истек таймер ожидания ответа Т1, а ответ о статусе станции не пришел, то снова посылается кадр запроса о статусе. Число повторных попыток посылки это кадра ограничено конкретной реализацией протокола.
Использование режима повторной передачи. Режим повторной передачи может быть начат первичной станцией и без использования специального REJ-пакета с помощью механизма P/F-битов. Согласно требованиям протокола, на каждый кадр, передаваемый с битом Р = 1, должен прийти кадр ответа с битом F = 1. Передача новых кадров с битом Р = 1 не начинается, пока не будет получен ответный кадр с битом F = 1. Таким образом, если на переданный кадр с установленным битом Р = 1 не пришел ответ и истек интервал ожидания ответа, контролируемый таймером Т1, то первичная станция, не ожидая получения REJ-кадра, может произвести повторную передачу.
Если текущая версия протокола поддерживает S-кадры типа SREJ, то вторичная станция может запросить повторную передачу только одного искаженного кадра, запомнив при этом все принятые неупорядоченные l-кадры. Кадр SREJ передается станцией получателем, если она не получила l-кадр с номером Ns-1 = Vr, при этом в кадре указывается номер кадра Nr = Vr, который станции передатчику необходимо повторно передать. Это кадр также служит подтверждением приема 1-кадров с номерами Ns < Nr.
Передав SREJ кадр, станция-приемник не может больше передавать новые SREJ-кадры, связанные с новыми ошибками, пока не придет правильный повторный 1-кадр с номером, указанным в первом SREJ-кадре. Так как передача нового SREJ-кадра может привести к подтверждению приема 1-кадра, запрос на повторную передачу которого передан в первом SREJ-кадре и который может быть еще не получен станцией приемником. Для повышения эффективности передачи SREJ-кадров было принято соглашение, что все SREJ-кадры запрашивают повторную передачу 1-кадра с номером Nr, но только кадры с установленными битами P/F = 1 подтверждают прием информационных кадров с номерами Ns < Nr, а SREJ-кадры с битами P/F = 0 не используются для подтверждений приема информационных кадров.
HDLC-контроллер. Основные режимы работы. HDLC - один из наиболее известных протоколов канального уровня управления 7-уровневой модели OSI. Решения, применяемые в протоколе для контроля за процессом передачи, оказались настолько удачными, что многие другие протоколы (SDLC, SS#7, LAPD, LAPB) базируются на основе HDLC-протокола и используют его алгоритмы обработки кадров данных. Формат HDLC-кадра показан на рис. 5.112.
Открывающий флаг Адрес Контроль Данные Контрольная сумма CRC Закрывающий флаг
вбит 16 бит вбит Мхвбит 16 бит вбит
Рис. 5.112. Формат кадра HDLC-протокола
612
ПОДДЕРЖКА ПРОТОКОЛОВ В КОММУНИКАЦИОННЫХ КОНТРОЛЛЕРАХ
Для синхронизации приемника и передатчика, а также для выделения кадра данных из потока битов на физическом уровне OSI применяется механизм ограничения кадра открывающим флагом в начале и закрывающим флагом в конце. Флаги имеют уникальный формат 01111110 (0х7Е), который не может встречаться внутри области, ограниченной флагами. Для этого при передаче данных применяется процедура bit-stuffing, которая производит при передаче вставку нулевого бита после каждых пяти следующих подряд единичных битов и удаление этого нулевого бита при приеме кадра.
Введение в формат кадра поля адреса позволяет протоколу работать с групповыми адресами и в многоточечных соединениях. Размер адресного поля зависит от конкретной реализации протокола. Обычно HDLC-протокол использует или 8- или 16-битное поле адреса.
Поле контроля (8- или 16-битное) предназначено для указания типа передаваемого кадра (информационный l-кадр, управляющий S-кадр, служебный U-кадр) и для нумерации пакетов при выполнении контроля за передачей и контроля правильности последовательности принимаемых пакетов.
В поле данных передается информация 3-го (сетевого) уровня модели OSI. Размер поля данных ограничивается только типом конкретной реализации протокола. Если пакет, содержащий данные сетевого уровня управления, невозможно передать внутри одного кадра данных HDLC-протокола, то длинные кадры при передаче разбиваются на части и каждая часть пакета нумеруется по модулю 8 или 128. Номер пакета передается в поле контроля.
Для контроля за правильностью передаваемой информации используются или 16-разрядные, или 32-разрядные циклические коды. Результат контроля записывается в 16-битное поле контрольной суммы CRC. При передаче байта данных первым передается младший значащий бит LSB, но при передаче байта CRC поля первым передается старший значащий бит MSB. Такой порядок передачи позволяет начинать проверку контрольной суммы поступающей информации сразу же после приема первого бита данных.
Настройка SCC-контроллера на работу с HDLC-протоколом выполняется в регистре GSMR при программировании битов MODE. Настройка режимов работы HDLC-контрол-лера выполняется в регистре PSMR (рис. 5.113). HDLC-контроллер может работать с любым ISDN-интерфейсом (IDL, GCI или РСМ) и выдавать информацию в В-канал или в D-канал, или может работать с внешними контактами соответствующего SCC-контроллера при работе в NMSI-режиме. Обычно из-за большого количества хорошо продуманных управляющих функций HDLC-протокол используют для управления передачей коммуникационного контроллера и передач данных по D-каналу ISDN-интерфейса.
Для работы в кольцевых структурах в контроллере МРС860 реализован дополнительный режим работы контроллера HDLC bus. Биты BUS в регистре конфигурации PSMR (рис. 5.113) определяют режим работы HDLC-контроллера (0 - нормальный HDLC-koh-троллер, 1 - контроллер HDLC bus).
Для управления передачей HDLC-контроллера, работающего в режиме HDLC bus, в регистре режима введен бит BRM. Если BRM = 0, то сигнал RTS работает нормально, j он выставляется rts= 0 при начале передачи первого бита и сбрасывается rts= 1 по окончании передачи, или если обнаружена коллизия во время передачи. Режим с установленным битом BRM = 1 используется при передаче в протяженных сетях. В этом режиме вначале выставляются данные, а затем, с задержкой на 1 бит, вырабатывается
0 1 2 3 4 5 6 7 8 9 10 1 1 12 13 14 15
NOF CRC RTE - FSE DTR BUS BRM MFF -
Рис. 5.113. Формат регистра режима PSMR HDLC-контроллера в МРС860
613
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
активный сигнал о начале передачи rts = 0, который используется для резервирования канала передачи и буферов в контроллере приемнике. Такой способ обмена часто применяется в сетях, где первый бит кадра данных служит для обнаружения коллизий, и реальные данные начинаются только со второго бита.
HDLC-контроллер имеет полностью независимую приемную и передающую части. Только если контроллер работает в мультиплексируемом режиме, его приемник и передатчик должны иметь одинаковую тактовую частоту, поступающую от внешнего источника. При работе в NMSI-режиме приемник и передатчик могут иметь различные тактовые частоты, которые могут поступать или от внутреннего генератора BRG, или от внешнего источника. HDLC-контроллер поддерживает и синхронный, и асинхронный режимы работы SCC-каналов.
Приемник и передатчик каждого HDLC-контроллера имеют полностью независимые таблицы буферных дескрипторов BD для работы с буферами данных. Контроллер поддерживает мультибуферную структуру, когда длинный кадр данных может быть расположен в нескольких буферах данных. Для указания первого буфера кадра в слове состояния BD используется бит F = 1 (First), а для указания последнего буфера кадра - бит L = 1 (Last). При работе с мультибуферной структурой пользователь может подготавливать следующие буферы данных постепенно, по мере обработки уже подготовленных буферов. Только в этом случае возможно возникновение ошибки переполнения (overrun) при приеме данных и ошибки незаполнения (underrun) при передаче, если центральный процессор не успеет вовремя подготовить новые буферы данных к тому моменту, когда будет завершена обработка старых.
Пользователь может управлять работой передатчика HDLC-контроллера с помощью команд STOP TRANSMIT, GRACEFUL STOP TRANSMIT, RESTART TRANSMIT, INIT TX PARAMETERS и работой приемника с помощью команд ENTER HUNT MODE, INIT RX PARAMETERS.
В СРМ добавлена возможность выключить работу приемника при передаче данных передатчиком этого же канала контроллера. Данный режим выбирается при программировании значения бита DRT := 1. При этом приемник будет находиться в выключенном состоянии, пока выставлен сигнал передачи RTS= 0. Такой режим работы полезен, когда линии данных приемника и передатчика объединены в одну шину (режим multidrop), и пользователь не желает принимать данные, которые он сам передает в текущий момент времени.
Распределение памяти параметров в микроконтроллере МРС860 приведено в табл. 5.77.
Таблица 5.77
Память параметров HDLC-протокола в микроконтроллере МРС860
Адрес Название Размер, бит Описание
SCC base+30 - 32 Зарезервировано
SCC base+34 C_MASK 32 Константа CRC
SCC base+38 C_PRES 32 Начальные значения CRC
SCC base+3C DISFC 16 Счетчик непринятых кадров
SCC base+3E CRCEC 16 Счетчик ошибок контрольной суммы CRC
SCC base+40 ABTSC 16 Счетчик принятых ABORT-последовательностей
SCC base+42 NMARC 16 Счетчик несовпадений адресов при приеме
SCC base+44 RETRC 16 Счетчик переданных кадров
SCC base+46 MFLR 16 Максимальная длина кадра
SCC base+48 MAX_cnt 16 Текущая длина кадра
SCC base+4A RFTHR 16 Число принятых кадров до прерывания
614
ПОДДЕРЖКА ПРОТОКОЛОВ В КОММУНИКАЦИОННЫХ КОНТРОЛЛЕРАХ
Продолжение табл. 5.77
Адрес Название Размер, бит Описание
SCC base+4C RFCNT 16 Счетчик принятых кадров
SCC base+4E HMASK 16 Регистр маски адресов
SCC base+50 HADDR1 16 Адрес, заданный пользователем
SCC base+52 HADDR2 16 Адрес, заданный пользователем
SCC base+54 HADDR3 16 Адрес, заданный пользователем
SCC base+56 HADDR4 16 Адрес, заданный пользователем
SCC base+58 ТМР 16 Ячейка временного хранения
SCC base+5A ТМР_МВ 16 Ячейка временного хранения
Примечание. Все переменные в таблице, кроме ячеек MAX_cnt, RFCNT, ТМР и ТМР МВ,
инициализируются пользователем до начала работы с HDLC-контроллером.
Прием данных. При приеме данных HDLC-контроллер в МРС860 может без вмешательства центрального процессора принимать до 196 кадров, удалять открывающие и закрывающие флаги, распознавать, кому адресован пакет, проверять контрольную сумму и контролировать максимальную длину пакета.
После включения в работу приемник ожидает получение открывающего флага кадра. Когда флаг получен, далее контроллер проверяет содержимое поля адреса, чтобы определить, ему адресован пакет или нет. Для операций с адресами в памяти параметров HDLC-контроллера выделены четыре регистра адреса HADDR1-HADDR4 и один регистр маски адреса HMASK. Контроллер проверяет адрес, полученный в пакете, на совпадение с одним из четырех допустимых адресов, при этом учитывается содержимое регистра маски. Если некоторый бит регистра маски равен единице, то при сравнении адресов в этих битах в регистрах HADDR и в поле адреса принятого пакета должно быть совпадение. Если бит в регистре маски равен нулю, то при сравнении адресов совпадение этих битов необязательно. Например, если необходимо контролировать все 16 разрядов адреса в пакете, то регистр маски HMASK = OxFFFF, если же достаточно контролировать только восемь младших разрядов адреса, то HMASK = OxOOFF. Маскирование отдельных разрядов адреса при сравнении часто используется при работе с групповыми адресами. Если пользователь желает установить для работы с контроллером только один сетевой адрес, то во все регистры HADDRi необходимо записать одно и то же значение единственного адреса. HDLC-контроллер допускает работу с широковещательными адресами, для этого в одной из ячеек HADDRi достаточно записать широковещательный (broadcast) адрес OxFFFF.
Если пакет принят без ошибки, но совпадения адресов в регистрах и в поле адреса пакета не произошло, то пакет игнорируется и увеличивается счетчик непринятых пакетов в ячейке NMARC памяти параметров HDLC-контроллера.
Если совпадение адреса в принятом пакете с одним из допустимых адресов произошло, то содержимое пакета, начиная с поля адреса, записывается в память. Для этого HDLC-контроллер проверяет готовность следующего буфера BD для записи в него данных. Если бит незанятости в слове состояния BD Е = 1, то контроллер производит запись информации в этот буфер по каналам SDMA. После заполнения текущего буфера контроллер сбрасывает бит Е := 0 и, если установлен бит прерывания в слове состояния текущего BD I = 1, вырабатывает прерывание к центральному процессору, чтобы он мог начать обработку данных из этого буфера. Если же прием текущего кадра еще не закончен, то контроллер проверяет, свободен ли следующий буфер BD в таблице дескрипторов, чтобы продолжить запись информации в данный буфер. Этот процесс повторяется, пока не будет принят весь кадр данных.
615
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
Во время приема данных HDLC-контроллер контролирует длину принимаемого кадра (размер полей кадра в байтах между ограничивающими флагами). Пользователь может в ячейке MFLR памяти параметров задать максимально допустимую длину кадра данных для этой сети. Если длина текущего кадра достигла этого предела, прием кадра в буфер прекращается и в слове состояния последнего BD устанавливается бит приема длинного кадра LG := 1. Далее контроллер, не принимая данные из кадра, дожидается окончания кадра, устанавливает в слове состояния последнего BD соответствующие биты статуса принятого кадра и записывает длину реально принятого кадра в последний буфер кадра. В ячейке MAX_CNT памяти параметров вычитающий счетчик ведет подсчет текущей длины принятого кадра. При начале приеме нового кадра в эту ячейку загружается значение максимальной допустимой длины кадра MAX_CNT := MFLR. Для полученной и записанной в буфер части длинного кадра также вычисляется контрольная сумма, которая записывается в последний буфер кадра.
По окончании приема кадра нормальной длины заново вычисляется контрольная сумма кадра по всем полям внутри ограничивающих флагов, которая сравнивается с содержимым поля контрольной суммы. Если произошла ошибка сравнения контрольных сумм, то принятая контрольная сумма записывается в последний буфер кадра, затем буфер закрывается, в слове состояния последнего BD устанавливается бит ошибки проверки контрольной суммы CR := 1 и вырабатывается, если разрешено, RXF-прерывание к центральному процессору через регистр событий канала. При этом увеличивается счетчик CRC ошибок в ячейке CRCEC памяти параметров, и приемник переходит в режим «охоты» (режим поиска нового кадра).
Если проверка контрольной суммы закончилась успешно, то контроллер устанавливает в слове состояния последнего BD биты состояния кадра, закрывает буфер и сбрасывает бит свободное™ этого буфера Е := 0. Далее контроллер генерирует, если разрешено, прерывание к центральному процессору, уведомляя его, что кадр получен и находится в памяти, и переходит в режим приема нового кадра.
При работе с HDLC-контроллером пользователь может запрограммировать выработку сигналов прерывания по окончании обработки каждого нового буфера BD или после обработки нескольких буферов, или целого кадра данных. В СРМ пользователь может разрешить HDLC-контроллеру прерывать центральный процессор не после приема каждого кадра данных, а только после приема определенного в ячейке RFTHR-памяти параметров числа кадров. Подсчет текущего числа принятых кадров производится в ячейке RECNT. Установив этот режим работы и настроив таймеры на соответствующий режим работы, пользователь может измерять рабочие параметры канала связи, например его пропускную способность. Но для того чтобы успешно использовать этот режим работы, следует заранее подготовить необходимое число буферов для приема заданного числа кадров без вмешательства центрального процессора.
Для временного хранения принятой информации каждый HDLC-контроллер имеет внутренние буферы FIFO. Данные из FIFO по SDMA-каналам под управлением RISC-контроллера начинают передаваться в соответствующие буферы памяти, как только будут получены первые 8-32 байта кадра. Если RISC-контроллер не успевает очищать ячейки FIFO для приема новой информации из сети и в момент прихода новой порции данных все ячейки FIFO окажутся занятыми, то возникает ошибка переполнения буферов overrun. При этом контроллер будет вынужден записать новые данные поверх старых, что приведет к потере информации. Далее текущий буфер закрывается, в его слове состояния устанавливается бит ошибки переполнения OV := 1 и через регистр событий генерируется, если оно разрешено, прерывание к центральному процессору. В некоторых случаях, если размер FIFO минимален и RISC-контроллер работает с максимальной загрузкой, это прерывание может возникнуть при приеме и анализе поля адреса в любом
616
ПОДДЕРЖКА ПРОТОКОЛОВ В КОММУНИКАЦИОННЫХ КОНТРОЛЛЕРАХ
пакете, даже если этот пакет адресован другому контроллеру. В случае возникновения ошибки переполнения контроллер после вышеуказанных действий переходит в режим «охоты» (поиска нового кадра).
Если кадр данных, адресованный данному контроллеру, был принят без ошибок, но RISC-контроллер не нашел свободных буферов для сохранения данных, то информация из кадра сбрасывается и увеличивается счетчик непринятых кадров в ячейке DISFC памяти параметров.
Во время приема кадра данных контроллер постоянно проверяет наличие сигнала на линии CD . Если во время приема этот сигнал будет потерян (CD = 1), то контроллер прекращает прием, закрывает текущий буфер, устанавливает в слове состояния текущего BD бит потери сигнала CD (CD := 1) и генерирует, если разрешено, прерывание RXF через регистр событий. Эта ошибка имеет самый высокий приоритет, и после ее обнаружения другие ошибки не проверяются, а приемник переходит в режим поиска нового кадра (hunt-режим).
Длина всех полей в HDLC-кадре всегда кратна 8 битам. Если принят кадр с длиной, не кратной 8, то он сохраняется в буфере, затем буфер закрывается, устанавливается бит ошибки NO := 1 в слове состояния BD и генерируется, если разрешено, RXF-прерывание центрального процессора через регистр событий контроллера. Результат проверки контрольной суммы этого кадра игнорируется.
Если во время приема кадра контроллер получил из канала подряд семь и более единичных бит, то регистрируется ошибка принятия ABORT-последовательности. Текущий буфер закрывается, в слове состояния BD устанавливается бит ошибки АВ := 1 и генерируется, если разрешено, прерывание RXF через регистр событий. Контроллер увеличивает счетчик принятых ABORT-последовательностей в ячейке ABTSC памяти параметров, и приемник переходит в режим «охоты». Принятый кадр игнорируется, проверка его контрольной суммы CRC и кратности 8 битам не производятся.
Передача данных. Для синхронизации станций в канале при включении в работу передатчик HDLC-контроллера начинает передавать символы флага (формат 01111110). Если установлен бит FSE = 1 и бит RTSM в регистре GSMR равен единице, то между кадрами передается [NOF+1] флагов. Если же бит RTSM = 0, то между кадрами передаются IDLE-символы.
Далее контроллер начинает опрашивать готовность первого буфера BD. Если буфер готов, то данные по SDMA-каналу загружаются в буфер FIFO канала. Передав заданное пользователем число символов флага между кадрами, контроллер начинает передавать данные из FIFO в сеть. Минимальное число символов, передаваемых между соседними кадрами, задается в битах NOF3 - NOFO. Если в этих битах записан код 0000, то открывающий флаг одного кадра следует сразу без интервала за закрывающим флагом предыдущего кадра.
Когда переданы все буферы текущего кадра, и контроллер обнаружил в слове состояния последнего буфера BD установленный бит L = 1 (Last), то он передает в канал контрольную сумму кадра и закрывающий флаг. Если биты CRC = 00, то контрольная сумма вычисляется с помощью 16-разрядного циклического кода. Если биты CRC = 10, то контрольная сумма вычисляется по 32-разрядному циклическому коду. Вид образующего полинома задается пользователем в ячейках C_MASK памяти параметров, где «1» в i-бите соответствует включению в полином слагаемого X в степени i. Для полинома Х’6+Х12+Х5+1 в этой ячейке хранится код 0x000F0B8, а для полинома Х32+ Х26+Х23+Х22+ Х16+Х12 + + Х1’+Х10+Х8+Х7+Х5+Х4+Х2+Х’+1 - код 0xDEBB20E3. При инициализации параметров HDLC-контроллера в ячейку C_PRES памяти параметров записывается начальное значение счетчика CRC. Для 16-разрядного полинома это код OxOOOOFFFF, а для 32-разрядного -OxFFFFFFFF. Пользователю не рекомендуется при работе изменять содержимое ячеек,
617
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
связанных с настройкой работы счетчика CRC, так как это может привести к неправильному применению теории циклического кодирования.
Формирование контрольной суммы начинается сразу же при начале передачи первого бита кадра данных. Временные промежуточные значения контрольной суммы хранятся в ячейках TCRC памяти параметров при передаче и в ячейке RCRC - при приеме данных.
32-битная контрольная сумма часто используется, если необходимо пересылать пакеты между сетями HDLC и Ethernet. При согласовании форматов пакетов в узле коммутации целесообразно использовать одинаковый формат 32-разрядной CRC, чтобы упростить и ускорить преобразование форматов, а не тратить дополнительное время на перекодировку 16-разрядной контрольной суммы в 32-разрядную.
Если все данные из текущего буфера переданы в сеть, то RISC-контроллер сбрасывает бит готовности буфера R := 0 в слове состояния BD, чтобы центральный процессор мог в этом буфере подготовить новые данные для передачи. Если текущий буфер был еще и последним буфером кадра, то контроллер дополнительно устанавливает биты состояния кадра при передаче в слове состояния последнего буфера BD. Далее контроллер переходит к передаче данных из следующего буфера, если, конечно, в нем установлен бит готовности к передаче R = 1.
Если в слове состояния переданного буфера был установлен бит I = 1 (Interrupt), то после окончания передачи буфера будет генерироваться прерывание. Пользователь может гибко устанавливать требования прерывания после передачи каждого буфера, после передачи определенных буферов или после передачи всех буферов кадра.
Пользователь может в любой момент времени остановить передачу и переопределить содержимое буферов, передав контроллеру команду STOP TRANSMIT. Часто эта команда используется, когда надо передать более приоритетные кадры данных из других буферов, прервав передачу текущих данных, или в случае возникновения ошибки при передаче текущей информации. Для передачи более приоритетных кадров без прерывания передачи текущего кадра в СРМ предназначена команда GRACEFUL STOP TRANSMIT. Получив команду остановки передачи STOP TRANSMIT, HDLC-контроллер начинает передавать в канал или символы IDLE, или символы флага и ожидает получения команды RESTART TRANSMIT для возобновления передачи.
Если во время передачи обнаруживается ошибка, то HDLC-контроллер прерывает текущую передачу, закрывает буфер, устанавливает бит соответствующей ошибки в слове состояния BD и генерирует, если разрешено, ТХЕ-прерывание через регистр событий SCC-канала. Получив команду возобновления передачи RESTART TRANSMIT, контроллер продолжает дальнейшую передачу.
При передаче регистрируются два типа ошибок. Ошибка незаполнения буфера undernun возникает, если при передаче мультибуферных кадров данных центральный процессор не успел подготовить для передачи новые буферы, содержащие данные текущего кадра, а данные из последнего подготовленного буфера уже переданы в сеть. Признаком этой ошибки будет установка бита UN := 1 в слове состояния текущего ВР.
При передаче НОЕС-контроллер_постоянно контролирует наличие сигнала CTS = 0. Если этот сигнал будет сброшен (CTS = 1), то генерируется ошибка потери CTS-сигнала (ошибка коллизии). Признаком этой ошибки будет установка бита СТ := 1 в слове состояния текущего BD. Бит RTE в регистре конфигурации определяет действия контроллера при восстановлении сигнала CTS = 0 после состояния коллизии. Если сигнал CTS был потерян при передаче двух первых буферов кадра и бит RTE = 1, то HDLC-контроллер просто начинает повторную передачу прерванного кадра данных и увеличивает на единицу счетчик повторных передач в ячейке RETRC памяти параметров контроллера. Если бит RTE = 0, то повторная передача не производится, и контроллер переходит к передаче следующего кадра. Для того чтобы механизм обнаружения коллизий и повторных пе-618
ПОДДЕРЖКА ПРОТОКОЛОВ В КОММУНИКАЦИОННЫХ КОНТРОЛЛЕРАХ
редач был успешно применен, размер первых двух буферов данных должен быть не менее 36 байт для канала SCC1 и 20 байтов - для других SCC-каналов в контроллере МРС860. ____
Сброс сигнала CTS = 1 при передаче может служить признаком конца передачи текущего кадра. Но при передаче может сложиться ситуация, когда в буфере FIFO находятся данные от нескольких HDLC-кадров и тогда анализ состояния CTS-сигнала может быть проведен некорректно. Для исключения возможных ошибок в состав регистра режима СРМ введен бит MFF. Если этот бит равен нулю, то в буфере FIFO могут быть данные только одного кадра, и появление сигнала стз = 1 свидетельствует о завершении передачи текущего кадра. Если бит MFF = 1, то в буфере могут находиться данные от нескольких кадров, и для обнаружения конца передачи кадра производить анализ сигнала CTS бесполезно. Такой режим работы может быть удобен для случая, когда передаются небольшие кадры back-to-back (кадры, требующие немедленного возврата), или пользователь жестко фиксировал число флагов, передаваемых между кадрами. В этих случаях конец передачи кадра может быть проанализирован или вычислен на основе имеющейся информации.
Контроллер HDLC bus. Контроллер HDLC bus - это расширение HDLC-протокола, позволяющее применять его в сетях с конфигураций point-to-point и point-to-multipoint. Протокол HDLC bus используется на канальном уровне управления как вариант HDLC-протокола, часто называемый LAPD, для работы в point-to-multipoint конфигурациях, так как контроллер HDLC может работать только в конфигурациях point-to-point. На физическом уровне управления протокол позволяет восьми терминалам получить доступ к S/T bus для передачи кадров. Контроль доступа к каналу связи производится через D-канал.
Контроллер HDLC bus позволяет создавать сеть небольшого размера, при этом выходы TxD станции должны быть сконфигурированы как выходы open-drain, чтобы было возможно объединять их в общую шину. Контроллер HDLC bus может работать с внешними контактами или в режиме NMSI, или в режиме TDM bus.
Устройства S/T-интерфейса проверяют незанятость канала передачи, просматривая состояние «эхо»-бита на линии. В «эхо»-бите отражаются все биты, которые недавно передавались по D-каналу. В зависимости от класса терминала устройства могут ожидать получение от 7 до 10 единичных битов на «эхо»-бите канала, перед тем как начать передачу LAPD-кадра. Наличие 7-10 последовательных «1» в канале свидетельствует о том, что в канале нет передачи данных и идет передача IDLE-последовательностей. Контроллер HDLC bus поддерживает формат кадра HDLC, а значит максимальное число последовательных «1» в кадре не может превышать шести, так как после каждых пяти последовательных «1» в кадре происходит вставка «0» (операция bit-stuffing).
После начала передачи станция постоянно контролирует, что она передала, читая «эхо»-бит. В контроллере HDLC bus механизм «эхо»-бита реализован через внешние контакты. Вывод TxD соединен с контактом cts . Контроллер передает данные на контакт TxD и контролирует их с контакта CTS . Передача продолжается, пока бит, который станция передала, совпадает с битом, который станция прочитала («эхо»-бит). Если эти биты не совпадают, возникает состояние коллизии между терминалами. При этом станции, которые передавали нулевой бит, прекращают передачу, а станции, которые передавали единичный бит, продолжают передачу. Для того чтобы уменьшить вероятность возникновения коллизии и захвата шины одной станцией, после завершения передачи станции понижают свой приоритет, чтобы разрешить другим станциям доступ к шине.
Основные отличия протокола HDLC bus:
• протокол HDLC bus поддерживает все другие протоколы, которые базируются на HDLC-кадре; таким образом, в сети могут одновременно работать несколько станций, которые используют различные варианты HDLC-протокола;
619
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
• станции HDLC bus могут объединяться в сеть с HDLC-станциями для совместной работы;
• перед началом передачи контроллер HDLC bus ожидает получение или 8, или 10 единичных битов, чтобы убедиться, что канал передачи свободен;
• HDLC bus позволяет строить более короткие по размерам сети; это ограничение связано с типом выхода контакта TxD, так как выход open-drain требует дополнительного сопротивления, подключенного к источнику питания, и ориентирован на небольшие сети;
• карта памяти параметров контроллера HDLC bus полностью совпадает с картой памяти обычного HDLC-контроллера; таким образом, основные режимы функционирования контроллеров HDLC и HDLC bus совпадают.
На рис. 5.114 приведена схема подключения HDLC bus-контроллеров в сети с конфигурацией multimaster. При этой конфигурации все станции могут передавать/принимать данные от любой станции и все передачи идут в режиме полудуплекса.
В режиме одиночного мастера (single-master) master-станция может передавать данные любой slave-станции без коллизии, так как все управление передачей возложено на master-станцию. Slave-станции могут взаимодействовать только через master-станцию. Если slave-станция желает передать данные другой slave-станции, то она пересылает их master-станции, которая принимает их в свой буфер, а затем передает их другой slave-станции. Достоинство этой конфигурации заключается в том, что может быть реализована полнодуплексная передача. Конфигурация single master (рис. 5.115) наиболее предг почтительна для сетей с конфигурацией соединений point-to-multipoint.
620
ПОДДЕРЖКА ПРОТОКОЛОВ В КОММУНИКАЦИОННЫХ КОНТРОЛЛЕРАХ
Доступ к HDLC bus. Для доступа к шине контроллер HDLC bus подсчитывает число единичных битов, полученных по линии контакта CTS . Если на этом контакте обнаружен «О», то счетчик единиц сбрасывается. Наличие «О» на линии данных может свидетельствовать о том, что кто-то уже начал передачу, послав открывающий флаг кадра формата 01111110. Если два и более передатчиков пытаются получить доступ к шине, то возникает состояние коллизии. В этом случае только один передатчик продолжит передачу, а остальные ее прервут. В дальнейшем контроллер HDLC bus обеспечит автоматическую повторную передачу для передатчиков, работа которых была прервана во время коллизии.
Если с линии CTS получено восемь последовательных единичных бит, то передатчик считает канал свободным и начинает свою передачу. При передаче данные на контакт TxD выставляются по отрицательному перепаду сигнала TCLK, а сигнал CTS читается по следующему положительному перепаду тактового сигнала. Если значение бита, переданного на линию TxD, совпадает со значением бита, полученного по линии CTS , то передача бита прошла успешно. Поскольку контроллер HDLC bus использует схему «монтажное ИЛИ» для соединения выходов TxD, то передача «0» всегда имеет больший приоритет, чем передача «1», поэтому коллизия обнаруживается, только если TxD = 1, a CTS = 0 и в этом случае контроллер прекращает текущую передачу. Если в формат HDLC-кадра включен адрес отправителя, то коллизия будет обнаружена не позднее конца передачи адреса источника.
Для того чтобы избежать захвата канала передачи одной станцией, введен приоритетный механизм. Станция, которая только что закончила передачу, ожидает не 8, а 10 последовательных «1» из канала перед тем, как начать новую передачу. Это задержка в два дополнительных бита дает другим станциям возможность выйти в сеть для передачи. Если станция обнаружила в сети 10 последовательных «1», то она повторно выходит в сеть для передачи новой информации, снижая обратно свое время ожидания до 8 единичных битов, так как никакая другая станция за этот интервал времени не начала свою передачу.
Протяженность сети HDLC bus зависит от метода подключения станции в сети. Так как выходы TXD объединены в «монтажное ИЛИ», и на них данные выставляются по отрицательному переходу сигнала TCLK, а сигнал CTS считывается по положительному переходу тактового сигнала, то протяженность сети зависит от длительности нулевого полупериода тактового сигнала, поскольку за это время сигнал с линии TXD должен успеть дойти до самой удаленной станции в сети, иначе при анализе сигнала на линии CTS может произойти ошибка, и возникшая коллизия не будет обнаружена. Для увеличения протяженности сети рекомендуется использовать несимметричный тактовый сигнал, у которого длительность «1» короче длительности «0» полупериода.
Для того чтобы обеспечить доступ локальной сети HDLC bus к сетям, которые не являются сетью HDLC bus, в контроллере реализован режим работы «задержки RTS-сигнала». Обычно сигнал RTS= 0 выставляется при начале передачи первого бита открывающего флага, и этот сигнал не используется для построения сети HDLS bus. Но в контроллере МРС860 введен дополнительный режим работы «задержки RTS-сигнала» на 1 бит, если установлен бит BRM = 1 в регистре PSMR. В этом режиме данные на линию передаются как обычно, но сигнал rts= 0 выставляется с задержкой на один период тактовой частоты. Наличие сигнала RTS= 0 можно использовать для открытия буфера (рис. 5.116). Введение режима задержки rts-сигнала позволяет не пропускать во внешнюю сеть первый бит кадра, который используется для обнаружения коллизий и не является битом данных. В этой схеме контроллеры HDLC bus не взаимодействуют друг с другом, но могут передавать информацию во внешнюю сеть. При этом выходы TXD всех контроллеров должны быть объединены и настроены на режим open-drain. А все RTS-выводы должны быть настроены на режим работы с задержкой.
621
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
Рис. 5.116. Построение сети с использованием режима задержки RTS-сигнала
Если включен режим задержки RTS, то этот сигнал появляется активным (rtS= 0) с задержкой на 1 бит относительно момента выставления битов данных. Таким образом, за этот такт задержки контроллеры HDLC bus определяют, есть коллизия или нет. Если коллизия возникла, то сигнал RTS = 1 и выхода на внешнюю сеть нет. Если коллизии нет, то данные передаются во внешнюю сеть, так как сигнал RTS= 0 откроет буфер.
Если необходимо организовать доступ из локальной сети HDLS bus к сети, которая работает с TDM-каналами передачи, то можно применить схему, похожую на схему рис. 5.117. Отличие заключается в том, что нет необходимости использовать сигнал RTS. Просто в каждом контроллере HDLC bus производится настройка его TSA-блока в последовательном интерфейсе SI на работу с определенным временным слотом. К каждому временному слоту может быть подключено произвольное число контроллеров HDLC bus. Локальные контроллеры HDLC bus не смогут общаться друг с другом, но смогут передавать информацию на внешний TDM-канал. Данные будут передаваться по контакту L1TXD и приниматься по линии L1RXD. Коллизия будет обнаруживаться через линию CTS , но этот сигнал следует анализировать только во время наступления выбранного временного слота (см. рис 5.117).
622
ПОДДЕРЖКА ПРОТОКОЛОВ В КОММУНИКАЦИОННЫХ КОНТРОЛЛЕРАХ
5.3.5. ДОСТУП К СЕТЯМ ETHERNET
Ethernet-контроллер. Протокол Ethernet/IEEE 802.3 широко распространен в современных локальных сетях. Протокол предлагает множественный доступ станций к сети с обнаружением сигнала несущей частоты (метод CSMA/CD). Ethernet-версии - это расширение базовых версий контроллера МРС860, в которых к имеющимся коммуникационным протоколам добавлена поддержка Ethernet-протокола и реализованы функции МАС-уровня в соответствии с требованиями стандарта IEEE 802.3. Настройка SCC-канала на работу с Ethernet-протоколом (10 Мбит/с) производится в битах MODE (MODE = 1100) регистра GSMR. Рекомендуется для работы с Ethernet-протоколом использовать SCC1-контроллер, так как он имеет буферы FIFO, размер которых больше в два раза аналогичных буферов FIFO других SCC-каналов.
Для подключения Ethernet-контроллера к сети Ethernet требуется дополнительный внешний передатчик. Фирма «Motorola» выпускает специализированный модуль МС68160 EEST (Enhanced Ethernet Serial Transceiver) для подключения к реальной сети. QUICC-контроллер подготавливает кадры данных, а EEST-передатчик выполняет манчестерское кодирование/декодирование сигналов, автоматическое определение типа разъема и типа сетевого кабеля (AUI или 10Base-T) и выполняет преобразование логических сигналов в электрические импульсы, которые используются при передаче сигналов по выбранному кабелю. Следует обратить внимание, что встроенный блок DPLL не используется для манчестерского кодирования/декодирования сигналов, так как не обеспечивает требуемой скорости передачи данных в 10 Мбит/с. Поэтому при работе с Ethernet-протоколом DPLL-блок должен быть выключен, а все функции кодирования и декодирования данных возлагаются на внешний передатчик EEST. Подключение контроллера к микросхеме EEST показано на рис. 5.118.
Перечислим правила подключения PowerQUICC-контроллера к микросхеме EEST.
1. Тактовая частота приемника RCLK и передатчика TCLK поступает на QUICC через внешние контакты CLK1, CLK2, CLK3, CLK4 от выводов RCLK и TCLK микросхемы EEST.
2. Для передачи данных вывод TXD контроллера соединяется со входом ТХ передатчика, а для приема данных вход RXD контроллерасоединен с выходом RX передатчика.
3. При работе с Ethernet-протоколом вывод RTS контроллера становится выводом сигнала разрешения передачи TENA (Transmit Enable), который поступает на вход TENA передатчика. Активное состояние сигнала - «1»._
4. При работе с Ethernet-протоколом вход CD контроллера становится входом сигнала разрешения приема RENA (Receive Enable), который поступает с выхода RENA передатчика. Активное состояние сигнала - «1».
Рис. 5.118. Подключение контроллера к микросхеме EEST
623
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
5. При работе с Ethernet-протоколом вход CTS контроллера становится входом сигнала обнаружения коллизий CLSN (Collision), который поступает с выхода CLSN передатчика. Активное состояние сигнала - «1».
Сигнал обнаружения несущей частоты формируется как комбинация сигналов RENA или CLSN. Дополнительно передатчик EEST имеет вход LOOP, на который пользователь может программно подать сигнал с выхода параллельного порта ввода/вывода для циклического тестирования работы передатчика.
Коммуникационный контроллер сохраняет в буферах памяти каждый принятый байт кадра данных после получения начального ограничителя, используя каналы SDMA. При передаче пользователь должен подготовить в памяти данные, адрес приемника и передатчика и данные поля «тип кадра». При передаче этих данных в сеть QUICC-контроллер автоматически добавит поле контрольной суммы и заполнит поле данных, если его длина меньше 46 байт, специальными символами-заполнителями до заданного минимума.
Для тестирования работы аппаратуры приемника, передатчика и буферов FIFO Ethernet-контроллера пользователь может включить петлевой (loopback) тестовый режим. Этот режим включается при установке бита LPB := 1 в регистре режима PSMR Ethernet-контроллера. Если используется режим внешнего loopback, то биты DIAG в регистре общих режимов работы должны быть настроены для работы в нормальном режиме. Если установлен режим внутреннего loopback, то биты DIAG в регистре GSMR должны быть настроены для работы в петлевом режиме (loopback). В режиме внутренней петли схемы SCC-контроллера отключаются от схем последовательного интерфейса, выход передатчика внутри подключается ко входу приемника SCC-контроллера, тактирование приемника и передатчика производится от одного источника. В режиме внешней петли Ethernet-контроллер одновременно передает и принимает данные от микросхемы EEST.
В контроллере МРС860 пользователь имеет дополнительную возможность для настройки работы Ethernet-контроллера в полнодуплексном режиме обмена. Для этого требуется установить бит FDE := 1 в регистре режима PSMR (см. рис. 5.119).
Формат Ethernet-кадра. Кадр начинается с 7-байтного поля преамбулы, которое состоит из повторяющихся «1» и «О» и которое необходимо для подстройки генераторов станции приемника на частоту передатчика. Формат поля преамбулы фиксирован и известен всем станциям в сети, поэтому данное поле может быть использовано для регистрации начала нового кадра данных и обнаружения состояния коллизии, которое возникает, когда две или более станций пытаются одновременно выйти в сеть. Контроллер обеспечивает автоматическую вставку преамбулы при передаче кадра и ее удаление при приеме кадра. Далее следует поле «начального ограничителя», которое извещает приемник о начале нового кадра данных. Формат кадра представлен на рис. 5.120.
__0 1 2 3 4 __5 6 7 8 9 10 11 12 13 14 15
FDE FC RSH IAM CRC PRO BRO SBT LPB SIP LOW NIB
Рис. 5.119. Формат регистра режима PSMR Ethernet-контроллера
Preamble Start Frame Delimiter Destination Address Source Address Type/Length DATA Frame Check Sequence
7 байт 1 байт 6 байт 6 байт 2 байта 46-1500 байт 4 байта
Рис. 5.120. Формат кадра Ethemet-лротокола
624
ПОДДЕРЖКА ПРОТОКОЛОВ В КОММУНИКАЦИОННЫХ КОНТРОЛЛЕРАХ
Два 48-битных поля адресов предназначены для указания адреса станции отправителя и адреса станции получателя информации. Адрес станции отправителя (48 бит) пользователь может задать в ячейках памяти параметров PADDR1_H, PADDR1_M, PADDR1_L (табл. 5.78). Двухбайтное поле «тип/длина» предназначено для задания длины поля данных или, в некоторых версиях протокола Ethernet, для задания типа кадра.
Таблица 5.78
Память параметров Ethernet-контроллера в микроконтроллере МРС860
Адрес Название Размер, бит Описание
SCC base+30 CPRES 32 Начальные значения CRC
SCC base+34 C MASK 32 Константа CRC
SCC base+38 CRCEC 32 Счетчик ошибок контрольной суммы CRC
SCC base+3C ALEC 32 Счетчик принятых невыравненных кадров
SCC base+40 DISFC 32 Счетчик непринятых кадров
SCC base+44 PADS 16 Формат символа заполнителя
SCC base+46 RET_LIM 16 Максимальное число повторных попыток выхода в сеть
SCC base+48 RETcnt 16 Текущее число повторных попыток выхода в сеть
SCC base+4A MFLR 16 Максимальная длина кадра
SCC base+4C MINFLR 16 Минимальная длина кадра
SCC base+4E MAXD1 16 Максимальная длина DMA1 передачи при приеме
SCC base+50 MAXD1 16 Максимальная длина DMA2 передачи при приеме
SCC base+52 MAXD 16 Максимальная длина DMA посылки при передаче
SCC base+54 DMA_cnt 16 Текущее значение счетчика DMA2 передачи
SCC base+56 MAX_b 16 Максимальное значение счетчика байт в BD
SCC base+58 GADDR1 16 Фильтр группового адреса
SCC base+5A GADDR2 16 Фильтр группового адреса
SCC base+5C GADDR3 16 Фильтр группового адреса
SCC base+5E GADDR4 16 Фильтр группового адреса
SCC base+60 TBUFO.dataO 32 Save Area 0. Временное хранение текущего кадра
SCC base+64 TBUFO.datal 32 Save Area 1. Временное хранение текущего кадра
SCC base+68 TBUFO.rbaO 32 Временное хранение текущего кадра
SCC base+6C TBUFO.crcO 32 Временное хранение текущего кадра
SCC base+70 TBUFO.bcnt 16 Временное хранение текущего кадра
SCC base+72 PADDR_H 16 MSB
SCC base+74 PADDR_M 16 Физический адрес станции
SCC base+76 PADDR_L 16 LSB
SCC base+78 P_PER 16 Индекс активности после коллизии
SCC base+7A RFBD_ptr 16 Указатель первого BD приема
SCC base+7C TFBDptr 16 Указатель первого BD передачи
SCC base+7E TLBD_ptr 16 Указатель последнего BD передачи
SCC base+80 TBUFl.dataO 32 Save Area 0. Временное хранение текущего кадра
SCC base+84 TBUF1.data1 32 Save Area 1. Временное хранение текущего кадра
SCC base+88 TBUFI.rbaO 32 Временное хранение текущего кадра
SCC base+8C TBUFl.crcO 32 Временное хранение текущего кадра
SCC base+90 TBUFl.bcnt 16 Временное хранение текущего кадра
SCC base+92 TXLEN 16 Счетчик текущей длины передаваемого кадра
SCC base+94 IADDR1 16 Фильтр индивидуальных адресов
625
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
Продолжение табл. 5.7в
Адрес Название Размер, бит Описание
SCC base+96 IADDR2 16 Фильтр индивидуальных адресов
SCC base+98 IADDR3 16 Фильтр индивидуальных адресов
SCC base+9A IADDR4 16 Фильтр индивидуальных адресов
SCC base+9C BOFF_CNT 16 Счетчик кадров backoff
SCC base+9E TADDR_L 16 LSB
SCC base+AO TADDR_M 16 Временное значение адреса при настройке
SCC base+A2 TADDR_H 16 MSB
П p и м e ч a и e. Все переменные в таблице, кроме ячеек RET^cnt, MAXD, DMA ent MAX h"
TBUFO.dataO, TBUFO.datal, TBUFO.rbaO, TBUFO.crc, TBUFO.bcnt, RBFDptr, TBFD_ptr, TBLD ptr TBUFLdataO, TBUF1.data1, TBUFI.rbaO, TBUFl.crc, TBUFLbcnt, TXjen и BOFF CNT, инициалйзи-
руются пользователем до начала работы с Ethernet-контроллером.
Поле данных может иметь размер от 46 до 1500 байт. В ячейке MINFLR пользователь должен задать минимальный размер кадра (>64 байт), а в ячейке MFLR - максимальный размер кадра (<1518 байт). Если длина кадра меньше установленного минимума, то при передаче поле данных кадра будет дополнено специальными символами-заполнителями, формат которых указывается в ячейке PADS памяти параметров, но только если в слове состояния буферного дескриптора установлен бит PAD = 1. Если же бит PAD = 0, то символы PAD не добавляются к короткому кадру.
Для контроля правильности передачи данных в состав кадра данных введено поле контрольной суммы, в которое записывается 32-разрядная контрольная сумма кадра данных. Для настройки режима работы с 32-битной CCITT-CRC контрольной суммой с образующим полиномом Хл32+Хл26+Хл23+Хл22+Хл16+ХЛ12+Хл 11+ХЛ10+Хл8+Хл7+Хл5+ +Хл4+Хл2+Хл1+1 в биты CRC регистра режима РБМРтребуется записать код 10. В ячейке C_MASK пользователь перед началом работы с Ethernet-контроллером должен задать константу образующего полинома 0xDEBB20E3, а в ячейке C_PRES - начальное значение счетчика контрольной суммы OxFFFFFFFF.
Передача данных. После включения передатчика канала в работу Ethernet-контрол-лер начинает периодически раз в 128 тактов опрашивать готовность первого буфера в таблице буферов для передачи ТxBD. Если пользователь подготовил данные для передачи и не желает ждать 128 тактов, то он может установить бит TOD := 1 в регистре TODR, чтобы вызвать принудительное начало опроса буферов для передачи данных.
Если данные для передачи подготовлены, то контроллер начинает загружать кадр по SDMA-каналам из буфера данных в буфер FIFO, выставляет сигнал TENA к микросхеме EEST и начинает передавать преамбулу, начальный ограничитель и далее сам кадр данных. При передаче Ethernet-контроллер передает LSB-бит первым. Перед началом передачи контроллер проверяет наличие сигнала несущей частоты в канале; после того как в канале будет обнаружен пассивный сигнал несущей частоты, контроллер проверяет, чтобы этот сигнал был пассивным в течение 6,4 мкс. Далее передача будет начата после ожидания 3,2 мкс. Таким образом, сигнал несущей должен быть пассивным в течение 9,6 мкс, перед началом передачи кадра. Поэтому минимальный межкадровый интервал (interpacket gap) для передачи кадров back-to-back установлен равным 9,6 мкс, и при возникновении коллизии повторная передача начинается через 9,6 мкс после того, как сигнал несущей в канале станет пассивным, при условии что он оставался пассивным в течение 6,4 мкс.
После окончания передачи кадра данных, когда в слове состояния последнего буфера кадра обнаружен бит L = 1 (Last) и установлен бит ТС = 1, контроллер начинает пере-626
ПОДДЕРЖКА ПРОТОКОЛОВ В КОММУНИКАЦИОННЫХ КОНТРОЛЛЕРАХ
давать контрольную сумму кадра и по окончании передачи сбрасывает сигнал TENA в пассивное состояние. Сброс этого сигнала заставляет микросхему EEST начать передачу специального некорректного символа, закодированного манчестерским кодом, уведомляющего о конце Ethernet-кадра.
Далее контроллер заполняет биты статуса переданного кадра в слове состояния последнего буфера и сбрасывает бит готовности буфера к передаче (бит R := 0). Если же текущий буфер кадра передан, но бит L = 0, то для данного буфера только сбрасывается бит R := 0, и контроллер переходит к обработке следующего буфера в таблице TxBD. Если в слове состояния переданного буфера установлен бит прерывания I = 1, то будет выработан запрос на прерывание.
Если во время передачи кадра данных обнаруживается коллизия, то контроллер выполняет специальную процедуру остановки, возвращается к первому буферу кадра и через некоторый интервал времени делает попытку повторной передачи. Для каждого переданного кадра данных в слове состояния последнего буфера кадра устанавливаются биты RC, значения которых определяют, сколько повторных попыток потребовалось, чтобы успешно закончить передачу текущего кадра. Общее число повторных попыток передачи задается в ячейке RET_LIM (стандартное значение 15). При начале передачи контроллер сохраняет первые 5-8 байт передаваемого кадра во внутренней памяти в ячейках TBUFx xxx, поэтому при повторной передаче не требуется дополнительная загрузка этих данных из буферов данных. Единственное ограничение состоит в том, что первый буфер кадра должен иметь длину не менее 9 байт. Текущее значение числа повторных передач подсчитывается в ячейке RET_CNT, и если число повторов превысило значение RET_LIM, то генерируется ТХЕ-запрос на прерывание в регистре событий, устанавливается бит ошибки RL := 1 в слове состояния буферного дескриптора, передача данных из буфера останавливается и буфер закрывается. Продолжение передачи возможно после получения контроллером команды RESTART TRANSMIT.
Ячейка Р_Рег памяти параметров предназначена для определения «степени активности» станции после обнаружения состояния коллизии. В нормальном режиме в эту ячейку заносится код 0x0000 и выполняется стандартный алгоритм расчета следующего момента выхода станции в сеть для повторной передачи. Если же в эту ячейку записан код от 1 до 9, то данный код будет добавлен к счетчику тайм-аута ожидания, и станция выйдет в сеть через большее время. Таким образом, значение «9» предназначено для менее активных станций. Пользователю также предоставляется возможность управлять временем выхода станции в сеть для повторной передачи через бит STB (Stop Backoff Timer) в регистре режима Ethernet-контроллера. Если бит STB = 0, то счетчик времени работает в обычном режиме. Если же бит STB = 1, то счетчик будет останавливаться всякий раз, когда в канале будет активным сигнал несущей частоты.
Если во время передачи обнаруживается ошибка незаполнения буфера underrun, которая возникает, если при передаче мультибуферных кадров данный центральный процессор не успел подготовить для передачи новые буферы, содержащие данные текущего кадра, а данные из последнего подготовленного буфера уже переданы в сеть, то Ethernet-контроллер прерывает текущую передачу, передает 32 «1» бита, которые позволят определить другим станциям CRC ошибку, закрывает буфер, устанавливает бит ошибки UN := 1 в слове состояния BD и генерирует, если разрешено, ТХЕ-прерывание через регистр событий SCC-канала. После получения команды возобновления передачи RESTART TRANSMIT контроллер продолжает дальнейшую передачу.
При передаче Ethernet-контроллер постоянно контролирует наличие сигнала несущей частоты. Если этот сигнал будет сброшен, но состояние коллизии не будет зафиксировано, то генерируется ошибка потери несущей частоты. Признаком этой ошибки будет установка бита CSL = 1 в слове состояния текущего BD. Передача кадра будет продолжена в нормальном режиме.
627
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
Для тестирования своей работоспособности некоторые передатчики могут регистрировать ошибку Heartbeat. Если установлен бит НВС = 1 в регистре режима PSMR, то передатчик через 20 битовых интервалов (2 мкс) после завершения передачи кадра данных зарегистрирует внутреннее возникновение коллизии, которая не связана с реальной коллизией в сети и предназначена для проверки работы передатчика. Если бит НВС = 1, но через 2 мкс состояние heartbeat не зарегистрировано, то это значит, что контроллер работает некорректно, поэтому регистрируется ошибка, текущий буфер данных закрывается, в слове состояния буфера устанавливается бит ошибки НВ := 1 и генерируется запрос на прерывание ТХЕ через регистр событий канала, конечно, если это прерывание не замаскировано.
Пользователь может управлять передачей при помощи команд STOP TRANSMIT, RESTART TRANSMIT, INIT TX PARAMETERS. Специальная команда GRACEFUL STOP TRANSMIT позволяет изменить порядок передачи содержимого буферов или кадров или при возникновении ошибки. При получении этой команды Ethernet-контроллер немедленно останавливается, если не было передачи, или если была передача кадра, то продолжает передачу текущего кадра либо до ее успешного завершения, либо до возникновения ошибки коллизии.
Прием данных. При приеме кадров Ethernet-контроллер работает независимо и автономно от центрального процессора и выполняет распознавание адреса станции, проверку контрольной суммы кадра, контроль длины кадра на предельное максимальное и минимальное значение, контролирует максимальное значение размера данных, передаваемых по DMA-каналам.
После включения приемника в работу, если нет коллизий в канале и выставлен активный сигнал RENA, контроллер переходит в режим «охоты» или поиска кадра данных во входном потоке, ожидая получения символа SYN1, формат которого задан в регистре синхронизации DSR. Для Ethernet-контроллера в этот регистр записываются стандартные значения SYN1 = 0x55 и SYN2 = 0x05. Биты NIB в регистре режима PSMR определяют, через сколько битов после установки активного сигнала RENA контроллер будет искать стартовый ограничитель во входном потоке. Обычно устанавливается значение задержки, равное 22 битам. Начальный ограничитель имеет размер 1 байт фиксированного формата 0xD5. Значения задержек при приеме кадра приведены в табл. 5.79.
Формат начального ограничителя и преамбулы включает повторяющиеся комбинации 1 и 0. Если при начале приема кадра между 14-м и 21-м битами обнаруживается комбинация 11 или 00, то текущий кадр отвергается. Если комбинация 11 или 00 встречается после приема 21-го бита, но до начала приема начального ограничителя, то кадр тоже отбрасывается. Если принятый набор битов совпадает с содержимым регистра синхронизации, то режим «охоты» выключается и начинается прием кадра данных. При приеме кадра первым принимается LSB-бит.
Первыми принимаются и распознаются 48 бит адреса получателя. Приемник может распознавать индивидуальный физический адрес станции, групповой (multicast) адрес и широковещательный (broadcast) адрес. Пока контроллер не проведет сравнение адреса, полученного в пакете, со своим адресом, заданным в ячейках памяти параметров, никакие данные не записываются в буферы данных.
Таблица 5.79
Значения задержек при приеме кадра
Бит NIB Задержка, бит Бит NIB Задержка, бит
ООО 13 100 21
001 14 101 22
010 15 110 23
011 16 111 24
628
ПОДДЕРЖКА ПРОТОКОЛОВ В КОММУНИКАЦИОННЫХ КОНТРОЛЛЕРАХ
При приеме нового кадра вначале проверяется бит l/G (Individual/Group) в поле адреса приемника. Если это индивидуальный адрес (бит I/G = 0), то, проверяя физический адрес, контроллер сравнивает его с единственным адресом, указанным в 48-битной ячейке PADDR1 памяти параметров, если бит IAM = 0 в регистре PSMR. Если же бит IAM = 1, то специальная хэш-таблица индивидуальных адресов в ячейках IADDR1-IADDR4 используется для сравнения и распознавания группового адреса.
Если это групповой адрес (бит I/G = 1), то вначале контроллер проверяет, является ли адрес широковещательным. Широковещательный адрес представляет собой код, состоящий только из единицы. Если прием широковещательных адресов разрешен (бит BRO = 0 в регистре PSMR), то кадр принимается. Если же бит BRO = 1, то все кадры с широковещательными адресами отбрасываются, даже если установлен бит PRO = 1.
Если сравнение адреса прошло успешно, то начинается прием кадра, независимо от значения сигнала на контакте RRJCT (Reject). Если это групповой, но не широковещательный адрес, то производится сравнение адреса с использованием хэш-таблицы групповых адресов в ячейках GADDR1-GADDR4.
Если проверка адреса прошла неудачно и в регистре режима PSMR установлен бит PRO = 0, т. е. проверка адреса должна была выполняться для всех кадров, то кадр отбрасывается. Если же бит PRO = 1, то кадры принимаются без проверки адреса, если сигнал на контакте RRJCT пассивный, и отбрасываются, если сигнал RRJCT активный. При этом в слове состояния последнего буфера приема кадра устанавливается бит признака М (Miss). Если бит М = 1, то кадр был принят без контроля адреса, а если бит М = 0, то кадр был принят после проверки совпадения поля адреса получателя и адреса станции.
Если внешняя CAM-память используется при сравнении адресов, то следует установить режим без проверки совпадения адресов (promiscuous), установив бит PRO = 1, и тогда кадр может быть отброшен, если от CAM-памяти будет выставлен активный сигнал RRJCT во время приема кадра. Если CAM-память используется для хранения адресов, которые должны быть отброшены, а не приняты, то сигнал на контакте RRJCT для САМ-памяти должен быть инвертирован.
Если сравнение адресов закончилось успешно, то контроллер проверяет бит незанятости Е в слове состояния следующего буфера в таблице RxBD, и если буфер свободен (бит Е = 1), то прием данных производится в этот буфер. Если при приеме кадра обнаружена коллизия, то текущий буфер может быть использован для приема нового кадра. Когда буфер заполнен, то контроллер сбрасывает бит Е := 0 и, если в слове состояния установлен бит прерывания 1 = 1, генерирует запрос на прерывание.
Если длина принимаемого кадра превышает размер буфера приема, то контроллер проверяет незанятость следующего буфера в таблице RxBD и, если буфер не занят, продолжает прием кадра в новый буфер. Максимальная длина приемного буфера задается пользователем в ячейке MRBLR протокол-независимой памяти параметров SCC-контроллера. При работе с Ethernet-протоколом рекомендуется в эту ячейку записывать значение не меньше 64 байт.
По окончании приема кадра, когда сигнал несущей станет пассивным, подсчитывается контрольная сумма принятого кадра и кадр сохраняется в буфере.
При приеме кадра Ethernet-контроллер постоянно проверяет длину кадра на максимальное и минимальное значение. Максимальная длина кадра данных (или число байт между начальным ограничителем и концом кадра) задается в ячейке MFLR памяти параметров и по стандарту 802,3 она равна 1518 байт. Если получен кадр, длина которого превышает значение MFLR, то излишек кадра отбрасывается, а 1518 байт кадра записываются в буфер. В слове состояния последнего буфера устанавливается бит LG := 1 (LonG). При этом длина кадра, записанная в ячейку длины последнего буферного дескриптора, является длиной реально принятого кадра. Специальный вычитающий счетчик
629
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
в ячейке DMA_CNT контролирует, сколько байт кадра передано в буфер памяти. Минимальная длина кадра данных задается в ячейке MINFLR памяти параметров, и по стандарту 802,3 она равна 64 байтам. Если получен кадр, длина которого меньше значения MINFLR и бит RCH = 0 в регистре режима PSMR, то этот кадр отбрасывается и в слове состояния последнего буферного дескриптора текущего кадра устанавливается бит SH := 1 (SHort), если же бит RCH = 1, то кадр будет принят.
Пользователь может управлять процессом записи байтов кадра в буферы памяти по системной шине. Для этого предназначены ячейки MAXD1, MAXD2. Ячейка MAXD1 используется, если сравнение адресов прошло успешно, а ячейка MAXD2 - в режиме без проверки совпадения адресов (promiscuous mode). Пользователь имеет возможность остановить запись данных в память при передаче установленного в этих ячейках числа байт, и остаток кадра будет отброшен. Затем контроллер дождется окончания приема всего кадра, или пока не будет принято MFLR байт кадра, и заполнит в слове состояния буфера биты статуса принятого кадра и длину реально принятого кадра. Если такая остановка не требуется, то при инициализации в эти ячейки заносится значение 1518 байт. Эти ячейки могут быть использованы для контроля состояния сети, например, для приема только заголовков пакета, содержащих адресное поле, для проверки работающих в сети станций.
После завершения приема кадра, и если бит SIP в регистре PSMR установлен в «1», то байт информации (этот байт называется tag-байт) с контактов 23-16 параллельного порта В будет добавлен в последний буфер кадра. Если эти контакты настроены как выходы, то байт данных читается из регистра PBDAT. Если кадр данных отбрасывается, то и tag-байт тоже отбрасывается. Далее контроллер устанавливает в слове состояния буфера бит последнего буфера L := 1, заполняет биты состояния принятого кадра и сбрасывает бит незанятости Е := 0. Затем контроллер генерирует маскируемое прерывание, которое сообщает процессору, что кадр данных принят и находится в памяти, и переходит к ожиданию приема следующего кадра данных.
Для временного хранения принятой информации каждый Ethernet-контроллер имеет внутренние буферы FIFO. Данные из FIFO по SDMA-каналам под управлением RISC-контроллера начинают передаваться в соответствующие буферы памяти. Если RISC-контроллер не успевает очищать ячейки FIFO для приема новой информации из сети, и в момент прихода новой порции данных все ячейки FIFO окажутся занятыми, то возникает ошибка переполнения буферов overrun. При этом контроллер будет вынужден записать новые данные поверх старых, что приведет к потере информации. Далее текущий буфер закрывается, в его слове состояния устанавливается бит ошибки переполнения OV := 1 и через регистр событий генерируется, если оно разрешено, RXF-прерывание к центральному процессору и увеличивается счетчик потерянных кадров в ячейке DISFC памяти параметров. После вышеуказанных действий контроллер переходит в режим «охоты» и ожидает новый кадр данных.
Если при приеме правильного кадра данных нет свободных буферов в памяти для сохранения информации, то кадр будет потерян. Признаком этой ошибки является установка бита ошибки занятости BSY := 1 в регистре событий Ethernet-контроллера и увеличение счетчика потерянных кадров в ячейке DISFC памяти параметров.
Если Ethernet-контроллер принял кадр данных с длиной, не кратной 8 битам, то вначале он проверяет контрольную сумму кадра, и если будет обнаружена ошибка проверки CRC суммы, то регистрируется ошибка принятия невыравненного кадра, устанавливается бит ошибки NO := 1 в слове состояния BD и увеличивается счетчик принятых, некратных 8, кадров в ячейке ALEC памяти параметров. Если же ошибка проверки CRC не регистрируется, то продолжается обычный прием кадров.
Если при приеме кадра данных контроллер обнаруживает ошибку проверки CRC контрольной суммы, то текущий буфер закрывается, устанавливается бит ошибки CRC := 1 630
ПОДДЕРЖКА ПРОТОКОЛОВ В КОММУНИКАЦИОННЫХ КОНТРОЛЛЕРАХ
в его слове состояния, устанавливается бит RXF-прерывания в регистре событий и увеличивается счетчик CRC ошибок в ячейке CRCEC памяти параметров. После приема кадра с ошибкой проверки CRC суммы приемник переходит в режим поиска нового кадра.
Пользователь может также управлять процессом приема кадра при помощи команд ENTER HUNT MODE и INIT RX PARAMETERS. Команда CLOSE RxBD при работе c Ethemet-контроллером не применяется.
Проверка адресов с помощью САМ-памяти. CAM-память (контекстно-адресуемая или ассоциативная память) предназначена для сравнения адресов станции и адреса получателя в пакете. Ethernet-контроллер может подключаться к внешней контекстно-адресуемой САМ-памяти двумя способами: через последовательный интерфейс и/или через системную шину. Для включения того или иного режима пользователь должен просто разрешить работу с определенными внешними контактами и аппаратно подключить внешние схемы блока памяти. Если при работе пользователь отключит выбранные контакты контроллера, то текущий кадр может быть потерян.
При работе с внешней CAM-памятью можно также использовать внутреннюю логику выработки сигналов CS блока системной интеграции.
При работе с последовательным интерфейсом после распознавания начального ограничителя контроллер выставляет сигнал начала приема RSTRT = 0 (receive start). Этот сигнал выставляется только на один битовый интервал во время приема второго бита адреса назначения. ______
Логические схемы САМ-памяти используют комбинацию сигналов rstrt , RXD, RCLK для записи в память полей кадра и для генерации сигнала «записи» к микросхеме САМ-памяти для начала сравнения адреса. Сигнал RENA от микросхемы EEST может быть использован для прекращения сравнения адресов, если при приеме кадра обнаружено состояние коллизии.
После окончания сравнения адреса кадра и, если текущий кадр должен быть отбро-шен, логика САМ-памяти вырабатывает активный сигнал «отмена приема» RRJC = О (receive reject). Получив этот сигнал, контроллер прекращает прием кадра в системную память, и текущий буфер будет подготовлен для приема нового кадра данных. Поэтому сигнал RRJC должен быть выставлен до момента завершения приема кадра. Если сравнение адресов прошло успешно, то сигнал RRJC не выставляется.
Дополнительно логика САМ-памяти может выставлять дополнительную служебную информацию на линии РВ23-РВ16 параллельного порта В. Этот tag-байт выставляется на линии РВ23-РВ16 не раньше, чем закончится прием кадра без коллизий, и будет сброшен сигнал RENA. Если в регистре режима PSMR Ethernet-контроллера установлен бит SIP = 1, то этот дополнительный байт данных (tag-байт) контроллер сохранит в последнем буфере памяти принятого кадра данных. Tag-байт удерживается на линиях порта В, пока коммуникационный контроллер сигналом на линиях SDACK2 -SDACK1 не подтвердит, что tag-байт записан в память. Длина tag-байта не включается в общую длину принятого кадра, которую контроллер записывает в поле длины последнего буферного дескриптора RxBD.
В режиме параллельного интерфейса во время записи кадра данных в память, т. е. каждый цикл шины данных коммуникационный контроллер выставляет сигналы подтверждения SDMA-доступа SDACK2 -SDACK1 . Отметим, что эти сигналы не используются при работе контроллера канала с другими коммуникационными протоколами. CAM-логика использует эти сигналы для разрешения записи данных в CAM-память одновременно с записью их в системную память контроллера. Преимущество этого способа состоит в том, что запись в CAM-память данных производится по системной шине в параллельном виде.
Сигналы SDACK2 -SDACK1 выставляются в течение всех циклов шины при записи кадра данных в буфер памяти. Одна комбинация сигналов SDACK2 — SDACK1 определя-
631
L
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
ет, что по шине передаются первые 32 бита кадра (SDACK2 =1 , SDACK1 = 0), другая комбинация определяет, что передаются данные из середины кадра (SDACK2 = 0, SDACK1 - 1), и третья комбинация определяет, что в память записываются последние 32 бита кадра (SDACK2 = 0, SDACK1 = 0), но только если к данным кадра добавлен tag-байт. Tag-байт должен быть включен в три байта последней 32-битной пересылки по шинам контроллера.
Если контроллер использует 32-битную шину данных, то 32 бита данных кадра записываются в память за один цикл шины. Если используется 16- или 8-битная шина, то для записи 32 бит данных требуется два или четыре цикла шины. В этом случае сигналы SDACK2 -SDACK1 выставляются в течение всех циклов шины, которые требуются для передачи всех 32 бит данных.
Алгоритм проверки адреса при работе с таблицей адресов. Специальная команда SET GROUP ADDRESS используется для установки в «1» одного из 64 бит четырех индивидуальных/групповых регистров фильтров GADDR1-GADDR4 или IADDR1-IADDR4. Для того чтобы индивидуальный или групповой адрес был занесен в хэш-таблицу, пользователь перед передачей контроллеру этой команды должен записать требуемый адрес в ячейку TADDR (TADDR_H, TADDR_M, TADDR_L) памяти параметров. При выполнении команды SET GROUP ADDRESS RISC-контроллер проверяет в ячейке TADDR значение бита I/G и определяет, в какую хэш-таблицу - индивидуальную или групповую - будет занесен адрес. Далее 48-битный адрес преобразуется в один из 64 бит. Для этого он пропускается через 32-разрядную контрольную сумму CRC32. В результате получается 6-битная контрольная сумма, двоичный код которой представляет число от 1 до 64. Два старших бита контрольной суммы определяют номер одного из четырех регистров xADDR1-xADDR4, а оставшиеся четыре бита - номер бита в регистре, который будет установлен в «1».
Если требуется удалить адрес из хэш-таблицы, то Ethernet-контроллер должен быть выключен и хэш-таблица должна быть очищена. Пользователь может записать код «все 0» в регистры IADDR1-IADDR4 и GADDR1-GADDR4 для сброса хэш-таблиц и всех адресов после системного сброса и при включении Ethernet-контроллера. После этого следует восстановить адреса, которые надо сохранить, так как на один бит в хэш-таблице может быть назначено несколько адресов.
При приеме кадра содержимое поле адреса приемника по этому же алгоритму пропускается через CRC32 контрольную сумму. И если бит с вычисленным номером в ячейке хеш-таблицы равен единице, то кадр данных принимается. Если же бит равен нулю, то кадр отбрасывается. Эффективность хэш-таблиц возрастает с увеличением числа используемых адресов.
Обработка коллизий. Если при передаче кадра контроллер регистрирует состояние коллизии, то он в течение 32 битовых интервалов продолжает передачу «1» битов (JAM pattern). Если коллизия обнаруживается во время передачи преамбулы, то контроллер завершает передачу преамбулы, а затем передает 32 «1».
Если коллизия обнаруживается в течение 64 битовых интервалов после начала передачи кадра, то передача кадра останавливается, передатчик ожидает случайное количество заданных временных интервалов и делает попытку повторного выхода в сеть. Этот интервал называется Slot time и равен 512-битовым интервалам или 52 мкс.
Если коллизия обнаруживается после передачи или 64 битовых интервалов (если бит LCW = 0 в регистре режима) или после 56 битовых интервалов (если бит LCW = 1), то повторная передача кадра не производится, буфер закрывается, устанавливается бит ошибки LC := 1 в слове состояния буферного дескриптора и генерируется запрос на прерывание ТХЕ через регистр событий. Этот случай носит название «поздняя коллизия» (Late Collision).
Если коллизия обнаружена при приеме кадра, то прием останавливается. Бит ошибки LC := 1 в слове состояния буфера устанавливается, только если длина принятой части 632
ПОДДЕРЖКА ПРОТОКОЛОВ В КОММУНИКАЦИОННЫХ КОНТРОЛЛЕРАХ
кадра не менее значения параметра MINFLR, или если разрешен прием коротких кадров (бит RSH - 1 в регистре режима), или если зарегистрирована поздняя коллизия.
При работе в петлевом режиме для тестирования работы обнаружения коллизий приемника и передатчика пользователь может запрограммировать принудительную выработку состояния коллизии после передачи каждого кадра данных. Для включения этого режима необходимо установить бит FC := 1 в регистре режима Ethernet-контроллера. Если же бит FC - 0, то схемы контроллера работают в обычном режиме.
Fast Ethernet-контроллер. Fast Ethernet-контроллер является дальнейшим расширением Ethernet-контроллера и реализует сетевой протокол стандарта IEEE 802.3u. Так же как и просто Ethernet, контроллер Fast Ethernet поддерживает метод доступа «множественный доступ с прослушиванием несущей и обнаружением коллизий» CSMA/CD (Carrier-Sense Multiple Access/Collision Detect) и использует кадр данных стандартного формата. Ethernet Fast Ethernet-протокол реализуется через Mll-интерфейс (mediaindependent interface). Формат кадра протокола Fast Ethernet представлен на рис. 5.121.
Применение во всех версиях Ethernet-сетей одного типа кадра данных значительно облегчает совместную работу оборудования 10/100 Мбит/с и упрощает соединение разноскоростных Ethernet-сегментов. Кадр начинается со стандартной 7-байтовой преамбулы, которая представляет собой чередование «1» и «0», затем идет 1-байтовое поле начального ограничителя кадра (Start Frame Delimiter, SFD). При передаче преамбула и поле SFD автоматически вставляются, а при приеме автоматически удаляются самим контроллером.
Поля адреса получателя и отправителя занимают 48 бит. 10/100 МАС-подуровень (Media Access Control) реализует функции обработки адресов в принимаемых пакетах (широковещательного, одиночного, группового), обеспечивает полную поддержку интерфейса МН, позволяя регистрировать прерывания после обработки полного кадра и каждого отдельного буфера кадра. Анализ поля адреса принимаемых кадров выполняется контроллером тремя способами. Способ Promiscuous - принимаются все кадры, независимо от их адреса, а для фильтрации адресов используется внешняя контекстная САМ-память. Способ Logical - прием кадров выполняется на основе анализа групповых и широковещательных адресов. Способ Physical - анализируется уникальный 48-битный адрес станции. Анализ совпадения адресов станции и в поле принятого кадра обычно производится с использованием механизма хэш-таблицы.
Двухбайтовое поле «Длина/Тип» для локальных сетей, без выхода на другие сети, обычно используется для указания типа кадра.
Поле данных должно быть кратно 8 битам, а его длина может составлять от 48 до 1500 байт. Время передачи самого короткого кадра данных (64 байта) называется slot time. При передаче происходит автоматическое дополнение поля данных служебными символами, если его длина меньше 48 байт.
Для контроля правильности передачи используется 4-байтовое поле контрольной суммы, которое строится по правилу 32-bit CCITT-CRC циклического полинома. Подавление контрольной суммы при передаче и контроль ее при приеме выполняются автоматически.
Отличия между Fast Ethernet и Ethernet-протоколами в основном заключаются в изменении временных параметров, которые произошли вследствие увеличения скорости передачи с 10 до 100 Мбит/с (табл. 5.80).
Preamble Start Frame Delimiter Destination Address Source Address Type/Length DATA Frame Check Sequence
7 байт 1 байт 6 байт 6 байт 2 байта 46-1500 байт 4 байта
Рис. 5.121. Формат кадра Fast Ethernet-протокола
633
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
Таблица 5.80
Параметры протоколов Fast Ethernet и Ethernet
Параметр Ethernet Fast Ethernet
Скорость передачи, бит/с 10 100
Скорость передачи, мкс/байт 0,8 0,08
Время передачи преамбулы и поля SFD, мкс 6,4 0,64
Интервал между кадрами (interframe gap), мкс 9,6 0,96
Slot time, мкс 51,2 5,12
Контроллер МРС860Т. Контроллер МРС860Т является дальнейшим расширением семейства МРС860, в дополнение к возможностям контроллера МРС860МН в него добавлен 10/100 Ethernet-контроллер. Таким образом, МРС860Т состоит из трех основных блоков обработки: ядра PowerPC, которое предназначено для выполнения задач общего класса, встроенного в коммуникационный СРМ-модуль RISC-процессора, который выполняет реализацию стандартных коммуникационных протоколов (тех же, что и в МРС860МН), и 10/100 Fast Ethernet-контроллера, который предназначен для реализации 10/100 Мбит/с Ethernet-протокола. Поскольку блок Fast Ethernet реализован как отдельный модуль, имеет свои буферы FIFO и использует для передач данных по внутренней шине режим bursting DMA, то высокоскоростной обмен через сети Ethernet реализуется независимо от СРМ-модуля. Все другие функции СРМ-модуля сохранены в полном объеме. Так, МРС860Т-контроллер поддерживает протокол QMC с 64 временными каналами в режимах HDLC или Transparent.
В отличие от основных SCC-каналов FEC-контроллер не поддерживает набор команд управления от коммуникационного процессора и функционирует полностью автономно.
Контроллер может работать с полудуплексным 100 Мбит/с каналом или полнодуплексным каналом 10 Мбит/с в версиях с тактовыми частотами больше 25 МГц и полнодуплексным 100 Мбит/с каналом в версиях с тактовыми частотами больше 40 МГц. Fast Ethernet-контроллер (Fast Ethernet Controller, FEC) поддерживает три способа подключения к различным внешним трансиверам, выбор режима работы интерфейса производится битом MII_MODE в регистре R_CNTRL:
• 100 Мбит/с 802.3 Media-Independent Interface (МИ);
• 10 Мбит/с 802.3 МП;
• 10 Мбит/с 7-wire interface (7-проводной последовательный интерфейс для обычного 10 Мбит/с Ethernet).
Пример подключения контроллера МРС860Т показан на рис. 5.122.
МС68160
МРС860Т
Рис. 5.122. Пример подключения контроллера МРС860Т к 10 Мбит/с внешнему трансиверу
634
ПОДДЕРЖКА ПРОТОКОЛОВ В КОММУНИКАЦИОННЫХ КОНТРОЛЛЕРАХ
Если контроллер МРС860Т работает в режиме Fast Ethernet-протокола, то для реализации интерфейса МН (Media Independent |ЩегТасе)функциональное назначение некоторых внешних контактов будет изменено. Большинство сигналов Mll-интерфейса реализуется через контакты 13-разрядного параллельного порта D. Каждый разряд порта D может быть настроен или на работу как независимый разряд параллельного порта ввода/вывода (соответствующий бит в регистре PDPAR = 0), или как функциональный вывод коммуникационного контроллера (соответствующий бит в регистре PDPAR = 1). Биты в регистре PDDIR определяют направление передачи через выбранную линию порта D (PDDIR - 0 - вход, PDDIR = 1 - выход). Для включения режима Mll-интерфейса требуется записать код 0x1 FFF в регистр PDPAR, код 0x1 С58 в регистр PDDIR.
Подключение Fast Ethernet-контроллера к внешнему устройству PHY интерфейса производится с использованием следующих 18 сигналов Mll-интерфейса (табл. 5.81).
Таблица 5.81
Дополнения в структуре внешних контактов контроллера
Старое назначение при PDPAR=0 Новое назначение при PDPAR = 1 Описание нового сигнала дпя режима FEC-контроллера
PDDIR = 0 (вход) PDDIR = 1 (выход)
PD[15-13, 10] MII_RXD[3-0] -, -, -, TXD3 Reseive Data. Четыре бита принимаемых данных, которые поступают от блока PHY к МАС-блоку при наличии активного сигнала RX_DV.
PD[12] L1RSYNCB MII_MDC Выходной тактовый сигнал (MU Management Data Clock) для обмена служебными данными, который поступает на блок PHY и уведомляет, что данные будут переданы по линии MDIO.
PD[11] RXD3 MII_TX_ER Transmit Error. Ошибка передачи. Появление этого сигнала во время передачи (когда установлен активный сигнал TX_EN) заставляет PHY-блок прекратить передачу и выдать в сеть «мусор» (несколько некорректных символов).
PD[5-3, 9] REJECT2 REJECT3 REJECT4 RXD4 MII_TXD[3-0] Transmit Data. Четыре бита передаваемых данных, которые поступают от блока МАС к блоку PHY при наличии активного сигнала TXEN.
PD[8] MII_RX_Clk TXD4 Reseive Clock. Внешняя тактовая частота для схем приемника RX_EN, RXD, RX_ER
PD[7] MII_RX_ER RTS3 Reseive error. Ошибка приема. Появление двух активных сигналов RX_ER и RX_DV заставляет PHY-блок регистрировать ошибку при приеме текущего кадра.
PD[6] MII_RX_DV RTS4 Reseive Data Valid. Разпешение приема данных. Блок PHY выставляет этот сигнал, когда на МИ выставлены корректные данные.
Примечание. 1.В режиме 100 Мбит/с для увеличения скорости обмена данные между МАС-и PHY-блоками передаются в параллельном коде по 4 бита по линиям MII_RXD[0-3] и MII_TXD[0-3]. В режиме же 10 Мбит/с используется только одна линия для обмена данными (MII_RXD[0] и MII_TXD[0]). 2. Сигналы управления MDC и MDIO являются общими для всех подключенных Fast Ethernet-контроллеров, поэтому предполагается, что каждый PHY-блок будет иметь свой адрес.
635
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
Ниже перечислены новые контакты, которые используются при работе МП-интерфейса:
MII_TX_EN - Transmit Enable. Разрешение передачи. Сигнал выставляется, когда на МП выставлены корректные данные, т. е. при начале передачи преамбулы контроллером, и сбрасывается по перепаду TX_CLK для последнего бита кадра.
MII_TX_Clk (Старое назначение контакта - IRQ7) - Transmit Clock. Внешняя тактоаая частота для схем передат-чика TX_EN, TXD, TX_ER.
MII_CRS - Carrier Receive Sense. Если входной сигнал CRS активен, то в сети присутствует какой-то обмен данными.
MII_COL - Collision Detect. Если в сети обнаружена коллизия, то выставляется этот сигнал, который остается активным в течение все- го времени обработки коллизии. Этот сигнал не определен для полнодуплексного обмена.
MII MDIO - Management Data I/O. Двунаправленная линия. Используется для обмена служебной информацией между блоками PHY и МАС. Обмен обычно синхронизируется сигналом на линии MDC.
Настройка FEC-контроллера производится с помощью программирования регистров памяти параметров и буферных дескрипторов. Доступ к регистрам, которые расположены во внутренней двухпортовой памяти (табл. 5.82), и к буферным дескрипторам производится в режиме big-endian.
Таблица'5.82
Память параметров Fast Ethernet-контроллера в микроконтроллере МРС860Т
Адрес Название Размер, бит Описание
Е00 ADDRJ.OW 32 Младшие 32 бита адреса станции
Е04 ADDR_HIGH 32 Старшие 32 бита адреса станции
Е08 HASHTABLEHIGH 32 Старшие 32 бита хэш-таблицы
ЕОС HASH_TABLE_LOW 32 Младшие 32 бита хэш-таблицы
ЕЮ R_DES_START 32 Адрес начала таблицы дескрипторов приема RECV
Е14 X_DES_START 32 Адрес начала таблицы дескрипторов передачи ХМ IT
Е18 R_BUFF_SIZE 32 Размер буфера приема
Е40 ECNTRL 32 Регистр контроля FEC-контроллера ,
Е44 IEVENT 32 Регистр прерываний FEC-контроллера (’.
Е48 IMASK 32 Регистр маски прерывания FEC-контроллера
Е4С IVEC 32 Уровень прерывания и вектор статуса fJC
Е50 R_DES_ACTIVE 32 Флаг обновления таблиц буферов приема
Е54 X_DES_ACTIVE 32 Флаг обновления таблиц буферов передачи
Е80 Mll-DATA 32 Регистр данных МН-интерфейса
Е84 MII_SPEED 32 Регистр скорости МН-интерфейса
ЕСС RBOUND 32 Адрес конца памяти буфера FIFO приема
EDO R_FSTART 32 Адрес начала буфера FIFO приема
EEC X_FSTART 32 Адрес начала буфера FIFO передачи
F34 FUN_CODE 32 Функциональные коды для SDMA
F44 R-CNTRL 32 Регистр контроля приемника
F48 R_HASH 32 Хэш-регистр приемника
F84 XCNTRL 32 Регистр контроля передатчика
Примечание, регистры ECNTRL, IEVENT, IMASK, MIISPEED, PDPAR, PDDIR могут быть сброшены в «0» или пользователем или при системном сбросе. Регистры блока DMA, блока передатчика, R_DES_ACTIVE, X_DES_ACTIVE могут быть сброшены в «0» только при выключенном FEC-контроллере, т.е. когда бит ETHER EN = 0.
636
ПОДДЕРЖКА ПРОТОКОЛОВ В КОММУНИКАЦИОННЫХ КОНТРОЛЛЕРАХ
О____________________________15 16 ___________________29________30 ______31
Резервировано. Все «О». Все «0». ETHER EN RESET
Рис. 5.123. Формат регистра ECNTRL в контроллере МРС860Т
Регистр контроля ECNTRL (рис. 5.123) предназначен для включения/выключения FEC-контроллера пользователем. При установке бита ETHER_NET = 1 FEC-контроллер начинает работать. При сбросе этого бита контроллер немедленно прекращает прием кадра, а передача будет остановлена только после передачи неправильной CRC контрольной суммы в конце текущего кадра. При выключении контроллера указатели FIFO, буферные дескрипторы и схемы DMA сбрасываются.
При установке бита RESET := 1 производится сброс FEC-контроллера, аналогичный аппаратному сбросу или сбросу по команде процессора, все операции приема и передачи немедленно прекращаются.
В регистре R_HASH (рис. 5.124) пользователь может установить максимальную длину используемых кадров в байтах. Напомним, что при приеме/передаче кадра с длиной более указанной будет выработаны прерывания BABR/BABT. Стандарт 802.3 рекомендует устанавливать параметр MAX_FRAME_LENGTH равным 0х5ЕЕ, что соответствует 1518 байтам.
0 ____ _________ __________ __________ 20 21 ______ 31
Все «0». MAX FRAME LENGTH
Рис. 5.124. Формат регистра R_HASH
При возникновении определенных событий в канале связи происходит их регистрация в регистре прерываний l_EVENT (рис. 5.125). Сброс бита события производится записью в выбранный разряд кода «1». Регистрация прерывания, связанного с любым из событий, может быть замаскирована пользователем при программировании регистра маски IMASK. Форматы регистров прерываний и маски совпадают. Прерывание разрешено, если соответствующий бит в регистре маски установлен в «1».
Бит HBERR (Heartbeat Error) регистрируется, когда в слове состояния буферного дескриптора передачи был установлен бит ошибки НВС = 1, т. е. была обнаружена ошибка проверки аппаратуры.
Если был принят кадр длиной более 1518 байт, будет зарегистрирована ошибка Babbling Receive Error, которая фиксируется установкой бита ошибки BABR := 1.
Если из-за ошибок пользователя при программировании контроллер передал кадр длиной более 1518 байт, то будет зарегистрирована ошибка Babbling Тransmit Error, которая фиксируется установкой бита ошибки ВАВТ := 1.
После завершения передачи полного кадра и заполнения слова состояния последнего буферного дескриптора регистрируется прерывание и устанавливается бит TFINT := 1 (Transmit Frame Interrupt). После передачи каждого отдельного буфера текущего кадра регистрируется прерывание и устанавливается бит ТХВ := 1 (Transmit Buffer Interrupt).
0123456789 10 31
HBERR BABR ВАВТ GRA TFINT ТХВ RFINT RXB Mil EBERR Зарезервировано. Все «0».
Рис. 5.125. Формат регистра прерываний LEVENT и регистра маски l_MASK
637
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
О_____1 2 3_________ ____________________________27 28 29 30 31
ILEVEL Все «0». IVEC | 0 0
Рис. 5.126. Формат регистра IVEC
После завершения приема полного кадра и заполнения слова состояния последнего буферного дескриптора регистрируется прерывание и устанавливается бит RFINT := 1 (Receive Frame Interrupt). После приема каждого отдельного буфера текущего кадра регистрируется прерывание и устанавливается бит RXB := 1 (Receive Buffer Interrupt), но только если в слове состояния этого дескриптора установлен бит разрешения прерывания при приеме данных I - 1 (Interrupt).
После завершения Mll-интерфейсом очередной порции обмена данными регистрируется прерывание МН Interrupt и устанавливается бит МН := 1.
Если при обмене FEC-контроллером по системной шине произошла ошибка, то регистрируется прерывание Ethernet Bus Error и устанавливается бит EBERR = 1.
В регистре IVEC (Interrupt Vector Register, рис. 5.126) хранится информация об уровне прерывания 0-7 (биты ILEVEL), который будет связан с FEC-контроллером, и вектор прерывания (биты IVEC). Установка битов IVEC назначает для блоков FEC-контроллера наивысший уровень приоритета прерываний (IVEC = 00 - не рассматривать FEC-прерывания, 01 -для некритичных ко времени прерываний, 10-для передатчика, 11 -для приемника).
Внутренний буфер FIFO модуля Fast Ethernet, который имеет размер 448 байт (размер одной ячейки 32 бита), может динамически распределяться между приемником и передатчиком, например 32x56 RX и 32x56 ТХ. Увеличенный размер буфера позволяет контроллеру иметь переменное время доступа к внутренней шине для передачи данных в память. В случае коллизии в сети повторная передача кадра начинается автоматически из внутренних FIFO-буферов контроллера и не требует повторного чтения данных из памяти по системной шине. Для хранения буферов принятых данных и данных для передачи всегда требуется внешняя память. Буферы данных во внешней памяти организованы по кольцевой структуре (аналогично всем другим коммуникационным контроллерам фирмы «Motorola»), и их общее количество зависит только от размера памяти и требований к быстродействию канала связи.
Восьмибитный, только для чтения, регистр R_BOUND (рис. 5.127) определяет верхний адрес блока буфера FIFO приема в памяти. Содержимое регистров R_BOUND, R_FSTART, и X_START используется RISC-процессором, чтобы рассчитать доступное пространство между областями памяти для приема и передачи. В поле R_BOUND указан самый большой доступный для FIFO адрес в памяти.
О 20 21 22 29 30 31
Зарезервировано. Все «0». 1 R_BOUND 0 0
Рис. 5.127. Формат регистра R_BOUND
Восьмибитный регистр R_FSTART (рис. 5.128) программируется пользователем и определяет адрес начала блока FIFO приема в памяти контроллера. Блок FIFO приема занимает область от R_FSTART до R_BOUND.
0 20 21 22 ____ 29 30 31
Зарезервировано. Все «0». 1 RESTART 0 0
Рис. 5.128. Формат регистра R_FSTART
638
ПОДДЕРЖКА ПРОТОКОЛОВ В КОММУНИКАЦИОННЫХ КОНТРОЛЛЕРАХ
О______________________ 20 21 22__________________29 30 31
Зарезервировано. Все «0». 1 X_FSTART 0 0
Рис. 5.129. Формат регистра X FSTART
Восьмибитный регистр X_FSTART (рис. 5.129) программируется пользователем и определяет адрес начала блока FIFO передачи в памяти контроллера. Блок FIFO передачи занимает область от X_FSTART до R_FSTART-4. Значение по умолчанию (значение, которое будет записано в регистр при сбросе) запрограммировано в микрокоде, и пользователю нет необходимости самостоятельно программировать этот регистр.
Обработка коллизий. При передаче станция постоянно контролирует состояние коллизии, которое возникает, если еще одна станция начала вести передачу и произошло наложение кадров данных. При обнаружении коллизии станция начинает передавать в сеть сигнал «мусор» (jam signal), состоящий из одних «единиц», и прекращает передачу своего кадра данных. Далее станция замолкает на интервал (backoff), а затем автоматически делает попытку повторного доступа к сети. В контроллере поддерживаются два алгоритма вычисления интервала backoff. Число повторных попыток доступа к сети из-за коллизии ограничено 15, далее будет генерироваться ошибка.
При обнаружении коллизии FEC-контроллер продолжает передавать в сеть в течение 32 битовых интервалов специальные символы «мусор» (JAM pattern), в результате в сеть передается 32 «единицы». Если коллизия обнаружена во время передачи преамбулы, то контроллер заканчивает передачу преамбулы, а затем начинает передавать JAM-символы.
Если коллизия обнаружена во время передачи первых 64 байт (это размер окна коллизии и длина минимального пакета), то контроллер запускает процедуру повторной передачи. Для этого он замолкает на N х 512 битовых интервалов (512 бит = 64 байта, a N -случайное число). Поскольку N - случайное число, то две станции, вышедшие одновременно в сеть и создавшие коллизию, повторят процедуру выхода в сеть через разное время. Теоретически окно коллизии определяет время, необходимое для доставки сигнала по сети до всех станций, т. е. если одна станция выйдет в сеть, то все другие станции увидят, что канал занят в течение 512 битовых интервалов.
Если же коллизия произошла после передачи 64 байт пакета (поздняя коллизия, обычно регистрируется в протяженных сетях и сетях с несколькими повторителями), то повторная передача не производится, и после передачи последнего буфера данных кадра в его слове состояния устанавливается бит ошибки передачи LC := 1 (Late Collision).
Передача кадров FEC-контроллером. Пользователь может также настраивать режимы работы и блока передатчика FEC-контроллера при программировании регистра X_CNTRL (рис. 5.130). Пользователь может изменять значение бит в регистре только при выключенном контроллере (бит ETHER_EN = 0).
Бит FDEN (Full Duplex Enable) определяет включение режима полнодуплексной передачи для передатчика. Если бит равен 1, то передача начнется независимо от наличия сигналов «наличие несущей частоты в канале» и «коллизия».
При установленном бите НВС = 1 (Heartbeat) будет включен режим тестирования аппаратуры. В этом режиме в течение некоторого интервала (heartbeat window) после завершения корректной передачи кадра аппаратура дает сигнал о коллизии, которой на
0_____________________________________ 28 29 30 31
Все «0». FDEN НВС GTS
Рис. 5.130. Формат регистра X_CNTRL
639
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
самом деле в сети нет, и смотрит, как схемы контроллера отработают процедуру регистрации и обработки этой ситуации. Если коллизия не обнаружена (на контакте MII_COL не появился активный сигнал), то будет установлен бит НВ в регистре статуса и выработано соответствующее прерывание.
С помощью программирования бита GTS (Graceful Transmit Stop) пользователь может управлять порядком передачи кадров данных в сеть. Если установить этот бит в «1» то после окончания передачи текущего кадра или если при его передаче обнаружена коллизия, передатчик остановится. Продолжение передачи возможно только после сброса бита GTS = 0.
Когда у станции есть данные для передачи, она проверяет, свободен канал или нет. Если канал свободен, то станция сразу же начинает вести передачу. Если канал занят, то станция после его освобождения ожидает дополнительно некоторый интервал времени, равный интервалу между кадрами данных (interframe gap), а затем начинает передавать свои данные.
Минимальный интервал между пакетами по стандарту Ethernet составляет 96 битовых интервалов. Этот тайм-аут запускается передатчиком, после того как в канале исчезнет несущая частота от предыдущей передачи. Для новой передачи достаточно, чтобы несущая частота отсутствовала в канале не менее 60 битовых интервалов. Если несущая появится в течение 36 битовых интервалов, она будет игнорироваться передатчиком, но будет зафиксирована коллизия.
Регистр X_DES_ACTIVE (рис. 5.131) используется для индикации состояния обработки таблицы дескрипторов передачи. Этот регистр сбрасывается при системном сбросе и при сбросе бита готовности FEC-контроллера ETHER_EN = 0. После того как программное обеспечение пользователя обработало очередной буферный дескриптор, т. е. записало в него данные для передачи и установило бит R := 1 (Ready) в его слове состояния, необходимо записать в данный регистр любое значение. Бит X_DES_ACTIVE будет установлен в «1», когда в этот регистр было записано какое-либо значение. Если биты X_DES_ACTIVE = 1 и ETHER_EN = 1, то контроллер будет искать в таблице дескрипторов передачи заполненный буфер, чтобы передать его по сети. Этот бит сбрасывается контроллером, когда в таблице буферов приема нет готовых к передаче буферов.
Окно коллизий для всех протоколов Ethernet составляет 512 бит, поэтому передача начнется только тогда, когда FEC-контроллер загрузит в буфер FIFO передатчика не менее 512 байт данных. Затем контроллер анализирует незанятость канала связи. Для этого он проверяет наличие несущей частоты (carrier sense) в канале. Передача начнется, когда несущая частота будет оставаться неактивной в течение 60 битовых интервалов. Дополнительно контроллер ожидает еще 36 битовых интервалов, и только после этого, если канал никто не займет, блок МАС выставляет сигнал TX_EN, и контроллер начинает передавать в сеть преамбулу, начальный ограничитель кадра и затем сам кадр данных. При передаче первым в сеть поступает LSB-бит байта.
Первые 64 байта данных контроллер сохраняет в своей внутренней памяти, поэтому если при передаче кадра обнаруживается коллизия, то FEC-контроллер начинает процедуру повторного доступа в сеть независимо от других схем и каналов сетевого контроллера и не требуя дополнительной подкачки данных в буферы FIFO из внешней памяти системы.
О 6 7 8 31
Все «0». X_DES_ACTIVE Все 0.
Рис. 5.131. Формат регистра X_DES_ACTIVE
640
ПОДДЕРЖКА ПРОТОКОЛОВ В КОММУНИКАЦИОННЫХ КОНТРОЛЛЕРАХ
Стартовый адрес таблицы буферных дескрипторов передачи, которые расположены во внешней памяти, должен быть предварительно записан пользователем в регистре X_DES_START памяти параметров. Младшие 31-й и 30-й биты регистра должны быть равны нулю, так как адрес должен быть кратен четырем.
Если при завершении передачи очередного буфера данных контроллер обнаружит в слове состояния буферного дескриптора установленный бит L = 1 (Last) и установленный бит ТС -1 (Тх CRC), то контроллер добавит к переданному кадру данных поле контрольной суммы FCS (32-битовое поле CRC) и сбросит сигнал TX_EN в пассивное состояние. После завершения передачи поля контрольной суммы контроллер заполняет в слове состояния дескриптора переданного кадра данных биты статуса переданного кадра и сбрасывает бит R := 0 (Ready). Если переданный буфер был не последним в кадре (бит L = 0), то контроллер сбрасывает только бит R:=0 в слове состояния переданного буфера.
Если длина передаваемого кадра меньше минимально допустимой длины Ethemet-кадра (64 байта), то кадр данных дополняется до необходимой длины специальными символами-заполнителями (padds). Если же длина передаваемого кадра больше максимально допустимой длины Ethernet-кадра (1518 байт), то длинный кадр данных будет передан целиком, но будет выработано прерывание ВАВТ.
При необходимости пользователь, программируя регистр l_MASK, может определять, нужны ли ему прерывания после передачи отдельных буферов данных или кадра данных целиком.
Пользователь может вмешиваться в процесс передачи Ethernet-кадров. Если установить бит GTS := 1 (Graceful Тransmit Stop) в регистре X_CNTRL, то FEC-контроллер завершит передачу текущего кадра данных (или прервет его передачу из-за коллизии) и остановится. После остановки передатчика будет выработано GRA-прерывание и установлен бит GRA 1 в регистре прерываний l_EVENT. Передача следующих кадров будет продолжена только после сброса бита CTS := 0.
Основные ошибки, возникающие при работе передатчика Ethernet-контроллера, регистрируются в слове состояния буферных дескрипторов и в регистре прерываний l_EVENT. • Переполнение передатчика (Transmitter Underrun, UN). При возникновении этой ошибки FEC-контроллер передает в сеть 32 символа «единицы», которые создадут ситуацию ошибки при проверке CRC суммы у приемника, и приемник удалит принятый кадр. Передача текущего кадра прерывается, в слове состояния всех не переданных буферов устанавливается бит ошибки UN := 1, и они закрываются. Далее контроллер переходит к передаче следующего кадра.
• Потеря несущей при передаче кадра (Carrier Sense Lost, CSL). Если при передаче кадра не обнаружено коллизий, но исчезла несущая частота в канале, то кадр передается до конца, повторных передач не будет, но в слове состояния последнего буферного дескриптора кадра устанавливается бит ошибки CSL := 1.
• Превышен предел повторных попыток передач (Retransmission Limits, RL). При возникновении коллизии FEC-контроллер делает попытку автоматического повторного доступа к сети. Число таких попыток ограничено. При превышении установленного числа попыток передача текущего кадра прерывается, все не переданные буферы закрываются, в слове состояния последнего не переданного буфера устанавливается бит ошибки RL := 1. Далее контроллер переходит к передаче следующего кадра.
• Поздняя коллизия (Late Collision, LC). Передача текущего кадра прерывается, все не переданные буферы закрываются, в слове состояния последнего не переданного буфера устанавливается бит ошибки LC:=1. Далее контроллер переходит к передаче следующего кадра.
• Ошибка из-за самотестирования аппаратуры (Heartbeat, НВС). Через 20 битовых интервалов после успешного завершения передачи кадра передатчик для проверки системы 641
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
регистрирует коллизию (которой на самом деле нет). Этот режим проверки включается установкой бита НВС := 1 в регистре X_CNTRL. При возникновении этой ошибки FEC закрывает буферы текущего передаваемого кадра (на самом деле, если 20 интервалов назад был успешно передан кадр, то в данный момент передатчик должен ожидать 96 интервалов до начала передачи следующего кадра, и открытых буферов не должно быть), в слове состояния текущего буферного дескриптора устанавливается бит ошибки НВ := 1 и генерируется прерывание HBEER, если оно разрешено.
Прием кадра FEC-контроллером. Пользователь может настраивать режимы работы блока приемника FEC-контроллера при программировании регистра R_CNTRL (рис. 5.132).
0_________________________ 27 28 29__ 30 31 '
Все «0». PROM MII_MODE DRT LOOP
Рис. 5.132. Формат регистра R_CNTRL
Если установлен бит PROM = 1 (Promiscuous), то сетевой контроллер будет принимать все кадры, не проверяя совпадения адреса станции и адреса в поле «получатель».
Бит MII_MODE определяет используемый режим внешнего интерфейса как для приемника, так и для передатчика (0 - «7-проводной» режим, используется только для режима 10 Мбит/с; 1 - режим Mil-интерфейса).
FEC-контроллер поддерживает тестовые режимы внутренней и внешней петли. Эти режимы программируются битами LOOP и DRT в регистре R_CNTRL (LOOP = 1, DRT = 0 -внутренняя петля, LOOP = 0 и DRT = 0 - внешняя петля). В режимах петли FEC-контрол-лер работает в полнодуплексном режиме.
Бит DRT (Disable Receive on Transmit) определяет включение режима полнодуплексной передачи. Если бит DRT = 0, то приемник и передатчик работают независимо (полнодуплексный режим). Если же бит DRT = 1, то во время передачи кадров приемник временно отключается (полудуплексный режим).
Бит LOOP используется для тестирования аппаратуры. Если бит равен единице, то будет включен режим внутренней петли и выход передатчика внутри будет замкнут на вход приемника. Сигналы на внешние контакты передатчика не поступают. Обратите внимание, что в режиме внутренней петли бит DRT должен быть равен нулю.
Регистр R_DES_ACTIVE используется для индикации состояния обработки таблицы дескрипторов приема. Регистр R_DES_ACTIVE (рис. 5.133) сбрасывается при системном сбросе и при сбросе бита готовности FEC-контроллера ETHER_EN = 0. После того как программное обеспечение пользователя обработало очередной буферный дескриптор, т. е. считало из него данные и установило бит Е := 1 (Empty) в его слове состояния, необходимо записать в этот регистр любое значение. Бит R_DES_ACTIVE будет установлен в «1», когда в этот регистр было записано какое-либо значение. Если биты R_DES_ACTIVE = 1 и ETHER_EN = 1, то контроллер будет искать в таблице дескрипторов приема незанятый буфер, чтобы принять в него данные из сети. Этот бит сбрасывается контроллером, когда в таблице буферов приема нет готовых свободных буферов.
Первым в байте принимаемых последовательных данных принимается LSB-бит. Когда выставлен активный сигнал RX_DV, приемник вначале проверяет корректность РА/ SFD-заголовка. Если заголовок правильный, то он будет удален, а последующие данные
О__________________6________7_______8_______________________31
Все «0». R_DES_ACTIVE Все «0».
Рис. 5.133. Формат регистра R_DES_ACTIVE
642
ПОДДЕРЖКА ПРОТОКОЛОВ В КОММУНИКАЦИОННЫХ КОНТРОЛЛЕРАХ
будут обрабатываться приемником. Если же заголовок некорректный, то следующий за ним кадр данных будет игнорирован.
При приеме кадры, которые не удовлетворяют по формату требованиям стандарта 802.3, автоматически удаляются, но при этом регистрируются соответствующие ошибки, например прием слишком длинного кадра.
При работе в последовательном режиме (данные поступают по линии RX_D0) после появления активного сигнала RX_DV приемник первые 16 битовых интервалов игнорирует поступающие данные. Следующие 16 битовых интервалов приемник анализирует принимаемые данные на 1/0, подстраиваясь под частоту передаваемого сигнала. Поскольку формат преамбулы и начального ограничителя кадра состоит из повторяющихся комбинаций «1» и «0», то при появлении комбинаций «11» или «00» на участке от 17-го до 21-го битовых интервалов будет зафиксирована ошибка, и кадр будет игнорирован. После 21-го битового интервала приемник контролирует наличие в канале связи комбинации «11» (конец приема поля начального ограничителя РА/SFD и начало полей кадра). Если после 21-го битового интервала до приема комбинации «11» обнаружена комбинация «00», то кадр будет отброшен.
При работе в режиме МП приемник побайтно контролирует совпадение формата преамбулы и начального ограничителя. Но если в байте обнаруживается комбинация «00», то кадр будет отброшен.
После завершения приема первых 8 байт преамбулы и начального ограничителя следующие принятые данные начинают записываться в буфер FIFO и приемник начинает процедуру распознавания адреса принятого кадра. Если при приеме произошла коллизия, то проверка адреса прекращается и принятые данные отбрасываются. Если успешно принято 64 байта кадра (64 байта - это размер окна коллизий для сетей Ethernet) и адрес получателя в пакете совпал с адресом станции приемника, то FEC-контроллер начинает перезаписывать принятые кадры в буферы во внешней памяти, адреса которых указаны в дескрипторах RxBD. Таким образом, контроллер автоматически отслеживает и обрабатывает все коллизии в сети без вмешательства пользователя (единственное, что следует отслеживать пользователю, - это поздние коллизии).
Стартовый адрес таблицы буферных дескрипторов приема, которые расположены во внешней памяти, должен быть предварительно записан пользователем в регистре R_DES_START памяти параметров (см. табл. 5.82). Младшие 31-й и 30-й биты регистра должны быть равны нулю, так как адрес должен быть кратен четырем.
После заполнения очередного буфера данных в памяти FEC-контроллер сбрасывает бит Е := 0 (Empty) и генерирует RXB-прерывание (если, конечно, установлен бит разрешения прерывания RBIEN в регистре l_MASK). Если длина принимаемого кадра превышает длину буфера данных, то контроллер выбирает следующий буфер из таблицы дескрипторов, и если он пустой, то продолжает записывать в него последующие данные.
Максимальная длина буфера приема указывается пользователем в регистре R_BUFF_SIZE (рис. 5.134) в памяти параметров FEC-контроллера и должна быть кратна 16 байтам и не меньше 128 байт (R_BUFF_SIZE = 0x000005F0). Поскольку максимальная длина кадра не должна превышать 1518 байт, то в регистре R_BUFF_SIZE используются только биты 21-27. Обычно максимальную длину буфера приема устанавливают равной максимальной длине кадра.
О____________ 20 21____________________________27 28 ____31
Резервировано. Все «0». R_BUF_SIZE Резервировано. Все «0».
Рис. 5.134. Формат регистра R_BUFF_SIZE в контроллере МРС860Т
643
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
При приеме кадра контроллер контролирует длину принятого кадра на максимальное и минимальное значения. Кадры длиной меньше 64 байт автоматически отбрасываются. Кадры длиной больше 1518 байт сохраняются полностью, но генерируется прерывание BABR и устанавливается бит LG := 1 в слове состояния буферного дескриптора последнего буфера кадра (на практике длинный кадр все-таки усекается, если его длина больше 2047 байт, так как это связано с ограничением разрядности внутренних контрольных счетчиков). После завершения приема кадра (несущая частота в канале становится пассивной) производится проверка контрольной суммы принятого кадра, и она тоже записывается в буфер. Длина реально принятого кадра также записывается в буфер данных в памяти.
После завершения приема всего кадра FEC-контроллер устанавливает бит L := 1 (Last) в слове состояния последнего буферного дескриптора. Также устанавливаются биты статуса принятого кадра и сбрасывается бит Е := 0 (Empty). Затем FEC-контроллер генерирует прерывание (если, конечно, установлен бит разрешения прерывания RFINT в регистре l_EVENT и бит разрешения прерывания RFIEN в регистре l_MASK).
Ошибки, возникающие при работе приемника Ethemet-контроллера, регистрируются в слове состояния буферных дескрипторов и в регистре прерываний l_EVENT и перечислены ниже.
• Переполнение приемника (Overrun, OV). Ошибка регистрируется при переполнении внутреннего буфера FIFO приемника. Текущий буфер приема закрывается, и в его слове состояния устанавливается бит ошибки OV := 1.
• Кадр, не кратный 8 битам (Non-Octet, NO). Кадр с длиной, не кратной 8 битам, обычно обнаруживается по нарушению CRC контрольной суммы. В слове состояния последнего буферного дескриптора принятого кадра устанавливается бит ошибки NO := 1. Обратите внимание, что если кадр имеет длину, не кратную 8 битам, но проверка контрольной суммы не выявила ошибку, то ошибка NO не регистрируется.
• Ошибка проверки контрольной суммы (CRC Error, CR). При обнаружении ошибки при проверке контрольной суммы принятого кадра FEC-контроллер закрывает все буферы данного кадра и устанавливает в слове состояния последнего буферного дескриптора приема бит ошибки CR := 1. При необходимости пользователь может игнорировать результаты проверки контрольной суммы.
• Нарушение длины кадра (Frame Length Violation, LG). Если длина принятого кадра превышает 1518 байт, то генерируется прерывание BABR и в слове состояния последнего буферного дескриптора принятого кадра устанавливается бит ошибки LG := 1.
Алгоритмы распознавания адреса. FEC-контроллер в каждом принятом пакете производит анализ поля «адрес получателями фильтрует пакеты по индивидуальному (unicast), групповому (multicast) и широковещательному (broadcast) адресам. Отличие между индивидуальным и групповым адресом заключается в значении бита l/G (individual/ group 0/1) в соответствующей позиции поля «адрес получателя».
Если принят пакет с индивидуальным адресом, то контроллер сравнивает его значение с 48-битным значением, которое пользователь определил в ячейках ADDR_LOW и ADDRJHIGH памяти параметров FEC-контроллера. В регистр ADDR_LOW пользователь должен предварительно записать младшие 32 бита 48-битного адреса станции, в регистр ADDR_HIGH - старшие 3 байта адреса. Байт 0 (биты 0-7 регистра ADDR_LOW) передается по сети первым.
Если принят пакет с групповым адресом (бит I/G = 1), то контроллер проверяет, не является ли этот адрес широковещательным. Если это широковещательный адрес, то пакет принимается без всяких условий. Если же это просто групповой адрес, то для его проверки будет использована 64-битная хэш-таблица, содержимое которой заполняется пользователем в ячейках HASH_TABLE_LOW и HASH_TABLE_HIGH памяти параметров. 644
ПОДДЕРЖКА ПРОТОКОЛОВ В КОММУНИКАЦИОННЫХ КОНТРОЛЛЕРАХ
Если же пользователь установил режим прозрачного приема пакетов (бит PROM = 1 в регистре R_CNTRL), то все пакеты принимаются независимо от их адреса, но в слове состояния буферного дескриптора принятого пакета в бите MISS отмечается, произошло ли совпадение адреса в принятом пакете с адресом станции. Если бит MISS = 1, то пакет принят без совпадения адресов.
При работе с хэш-таблицей 48-битный адрес приемника из пакета преобразуется в код, который определяет адрес некоторой ячейки в хэш-таблице. Для этого 48-битный адрес пропускается через 32-битный CRC-генератор (используется полином Хл32+ Хл26+ + Хл23+ Хл22+ Хл16+ Хл12+ ХЛ11+ +Хл10+ Хл8+ Хл7+ Хл5+ Хл4+ Хл2+ Х+1). 31-й бит результата определяет выбор ячейки таблицы HASH_TABLE_LOW (бит 31 = 0) или HASH_TABLE_HIGH (бит 31 = 1). Биты с 30-го по 26-й определяют номер бита внутри выбранной ячейки. Если этот бит равен 1, то кадр принимается. Если бит равен 0 - игнорируется. Бит О HASH_TABLE_LOW содержит бит индекса 31, а бит 31 регистра HASH_TABLE_LOW соответствует индексному биту 0.
Настройка SDMA-каналов. В контроллере МРС80Т при доступе к внутренним источникам реализованы два уровня арбитража среди коммуникационных модулей. Первый уровень - это доступ к SDMA-каналам, а второй - доступ к PowerPC-ядру. При одновременном доступе к SDMA-каналам от СРМ-модуля и модуля WOBaseT, первым получит доступ коммуникационный СРМ-процессор и все его коммуникационные каналы (SCC, SMC и др.). Далее, при доступе от SDMA-каналов к ядру, уже не рассматривается отдельно, кто запрашивает доступ: СРМ или модуль 10OBaseT, и приоритет доступа SDMA к шине PowerPC определяется битами RAID и FAID в регистре SDCR (табл. 5.83). Все SDMA-каналы имеют одно значение ID приоритета, которое устанавливается пользователем в регистре конфигурации SDMA-канала (SDCR, рис. 5.135) и которое позволяет SDMA-каналам соперничать за право передачи по внутренней шине данных с другими источниками внутренних и внешних запросов на арбитраж.
Таблица5.83
Назначение битов RAID и FAID
Бит Уровень приоритета доступа к внутренней шине Бит Уровень приоритета доступа к внутренней шине
00 6 (высший) 10 2
01 5 11 1 (низший)
Биты FRZ определяют реакцию SDMA-каналов на выставление сигналов контроля: 00 - SDMA-канал игнорирует FREEZE-сигнал, 10 - SDMA-канал сбрасывает сигнал BR и останавливает (замораживает) передачу, пока выставлен сигнал FREEZE или пока не произойдет сброс системы.
Биты RAID устанавливают уровень приоритета запросов SDMA-каналов по доступу к внутренней шине среди других внутренних источников запросов. Арбитраж запросов от внутренних источников выполняет RISC-контроллер. Обычно устанавливается значение «5» (код 01).
Биты FAID определяют значение ID приоритета арбитража для FEC-контроллера. Обычно устанавливается значение «0».
О___________16 17 18 19__________24 25_______________28 29 30 31
Резервировано FRZ Резервировано FAM Резервировано FAID RAID
Рис. 5.135. Формат регистра SDCR в контроллере МРС860Т
645
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
О 1 2 3 4 5 6 7 8_________ __________________________31
0 DATA-ВО DESC_BO FC[1-3] Все «0».
Рис. 5.136. Формат регистра функциональных кодов
Программируя биты FAM (FEC Aggressive Mode), пользователь может устанавливать для FEC-контроллера наивысший приоритет доступа к внутренней шине. Если бит FAM = 1, то агрессивный режим доступа разрешен, и биты FAID и RAID должны быть равны нулю (наивысший приоритет). Если же бит FAM = 0, то агрессивный режим выключен и приоритет доступа определяется битами FAID.
В регистре FUN_CODE (рис. 5.136) содержится информация, которая используется при обменах между системным DMA-контроллером и SDMA-контроллером коммуникационных каналов. В битах FC1-FC3 хранятся функциональные коды, которые используются при обменах по системной шине во всех контроллерах «Motorola» и которые будут выдаваться при обмене на одноименные контакты.
В битах DATA_BO[0-1] определяется порядок передачи байт (byte-ordering), который будет использовать SDMA-интерфейс при DMA-обмене (00 - резервировано; 01 - PowerPC Little-endian byte-ordering (64-разрядное слово передается побайтно, начиная с адреса байта 0Ь111 идо адреса ОЬООО); 1Х- Big-endian byte-ordering (64-разрядное слово передается частями по 16 бит, начиная с ячейки с адресом ОЬОО и доОЫ 1)).
В битах DESC_BO[0-1] определяется порядок передачи байт (byte-ordering), который будет использовать SDMA-интерфейс при DMA-обмене для открытия и закрытия буферных дескрипторов (00 - резервировано; 01 - PowerPC Little-endian, 1Х - Big-endian).
Настройка режимов работы МП-интерфейса FEC-контроллера. Для взаимодействия с внешним PHY-устройством, которое совместимо с Mil-интерфейсом, используются специальные регистры MII_DATA и MII_SPEED. Запись информации в регистр MII_DATA вызывает передачу кадра управления от одного устройства к другому, но только если в регистр MII_SPEED занесено число, отличное от нуля. Логика управления начинает передавать преамбулу, а затем сразу же содержимое регистра MII_DATA при выдаче данных во внешнее устройство и принимать данные в регистр при чтении данных. Поэтому рекомендуется записывать данные в регистр MII_DATA при MII_SPEED = 0.
В ходе обмена данными регистр MIIJDATA представляет собой последовательный сдвиговый регистр, поэтому чтение его содержимого до завершения процесса обмена не рекомендуется. При завершении передачи или приема данных будет выработано прерывание MII_DATAIO_COMPL. Если во время обмена записать в регистр MII_DATA новое число, то его содержимое изменится, и станут возможными сбои в алгоритмах работы PHY-устройств.
При выдаче данных из регистра MII_DATA (рис. 5.137) в сеть в битах MII_DATAIO_STATE в регистре MII_STATUS отображается текущее состояние процесса обмена кадрами управления.
Содержимое регистра данных MII_DATA представляет собой кадр управления МП-интерфейса. В битах ST (Start of Frame Delimiter) указывается начальный ограничитель кадра управления (для корректного кадра указывается формат заполнителя ST := 01). В битах OP (Operation Code) указывается направление передачи данных (ОР = 10 чтение, ОР = 01 запись). Биты РА содержат адрес внешнего PHY-устройства, с которым
О 1 2 3 4 8 9 13 14 15 16 31
ST OP РА RA ТА DATA
Рис. 5.137. Формат регистра данных Mil-интерфейса MII_DATA
646
ПОДДЕРЖКА ПРОТОКОЛОВ В КОММУНИКАЦИОННЫХ КОНТРОЛЛЕРАХ
О______________________ 23________________24________ 25____________________30 31
Зарезервировано. Все «О». I DIS PREAMBLE MII SPEED О
Рис. 5.138. Формат регистра MII_SPEED
производится обмен данными. Контроллер МРС860Т может поддерживать до 32 внешних подключенных PHY-устройств. Биты RA определяют один из 32 регистров внутри PHY-устройства, с содержимым которого будут производиться действия. Биты ТА (Turn Around) задают режим инвертирования информации, для нормальной работы требуется записать в эти биты ТА := 10. Поле DATA содержит сами данные, которые необходимо записать или прочитать в/из указанного регистра. Все рекомендованные значения полей ST, OP и ТА соответствуют требованиям стандарта 802.3.
Регистр MII_SPEED (рис. 5.138) используется для контроля тактовой частоты, которая поступает на вывод MDC (МН Clock). Появление тактовой частоты на этом выводе позволяет начать передачу/прием преамбулы и остального кадра данных.
Стандарт МН позволяет «опускать» передачу преамбулы, если PHY-устройство этого не требует. Если установлен бит DIS_PREAMBLE = 1, то при обмене будет выдаваться преамбула из 32 «единиц». Если бит равен нулю, то преамбула не выдается.
Содержимое поля MH_SPEED определяет частоту тактового сигнала на контакте MDC. MDC-частота вычисляется как [(системная частота)/(МП_ЭРЕЕОх2)]. Если в поле MII_SPEED - 0, то на контакте MDC будет «логический нуль». Программируемая частота должна быть не более 2,5 МГц, как определено Mll-спецификацией IEEE.
Формат буферного дескриптора FEC-контроллера. Для обеспечения более гибкого управления буферы данных FEC-контроллера и связанные с ними буферные дескрипторы расположены во внешней памяти. Буферные дескрипторы FEC-контроллера так же, как и буферные дескрипторы других коммуникационных каналов, организованы в таблицу и имеют аналогичный формат, который состоит из четырех слов. Последний дескриптор в таблице имеет в слове состояния установленный бит W = 1 (Wrap).
Готовность буфера передачи и приема к обмену контролируется по состоянию бита готовности R = 1 (Ready) и бита незанятости Е = 1 (Empty) в слове состояния дескриптора. Дополнительно программное обеспечение устанавливает биты X_DES_ACTIVE и R_DES_ACTIVE в одноименных регистрах, чтобы уведомить FEC-контроллер, что данные для передачи в буферах подготовлены или буферы для приема освобождены. После окончания работы с буфером аппаратное обеспечение сбрасывает биты R и Е, чтобы пользователь мог начать обработку их содержимого.
Буферный дескриптор приема. Формат слова состояния дескриптора приема приведен на рис. 5.139.
Бит пустого буфера Е (Empty) устанавливается в «1» пользователем после того, как он обработал данные из этого буфера, и буфер можно использовать для приема новых данных. Бит Е = 0 записывает слово состояния FEC-контроллера после заполнения буфера данными из сети.
Биты RO1 и RO2 (Receive Software Ownership) предназначены только для программного обеспечения пользователя и не взаимодействуют с аппаратурой.
Бит последнего буфера W (Wrap), равный единице, сообщает FEC-контроллеру, что текущий буфер - это последний буфер в таблице и после его обработки необходимо переходить для работы к первому буферу BD в таблице буферных дескрипторов. «
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
Е RO1 W RO2 L 0 0 м вс NC LG NO SH CR OV TR
Рис. 5.139. Формат слова состояния дескриптора приема
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
Бит последнего буфера L (Last) используется в протоколах, где кадр данных может занимать несколько буферов, для указания последнего буфера кадра (если бит L = 1). Указание последнего буфера в кадре обычно применяется для организации прерываний в конце обработки всего кадра данных.
Бит М (Miss) устанавливается в «1» FEC-контроллером, если кадр данных был принят без проверки совпадения адреса (режим promiscuous). Если бит М = 0, то кадр принят, так как адресован именно этой станции.
Бит ВС устанавливается в «1», если принятый кадр данных имеет широковещательный адрес получателя (broadcast).
Бит МС устанавливается в «1», если принятый кадр данных имеет групповой (но не широковещательный) адрес получателя (multicast).
Если бит LG (Lenght Violation) равен «1», то принят кадр данных, длина которого превышает максимально допустимую, запрограммированную для FEC-контроллера длину принимаемых кадров. При этом в буфер будет записана только часть кадра, размер которой не превышает 2047 байт.
Бит TR устанавливается, если длина принятого кадра больше 2047 байт, и кадр был обрезан при приеме.
Если бит NO (Nonoctet Aligned Frame) равен «1», то принят кадр данных, длина которого не кратна 8 битам, и обнаружена ошибка проверки контрольной суммы CRC.
Если бит SH (Short Frame) равен «1», то принят кадр данных, длина которого меньше минимально допустимой для FEC-контроллера длины принимаемых кадров.
Бит CR (CRC Error) устанавливается, если обнаружена ошибка при проверке контрольной суммы, но длина кадра кратна 8 битам.
Бит переполнения буфера OV (Overrun), равный «1», регистрирует ошибку, связанную с переполнением буфера FIFO приемника. Если установлен бит OV -1, другие ошибки приема не регистрируются.
Буферный дескриптор передачи. Формат слова состояния дескриптора передачи приведен на рис. 5.140.
Бит заполненного буфера R (Ready) устанавливается пользователем после того, как он закончит подготовку в буфере данных для передачи по сети. Этот бит постоянно анализируется FEC-контроллером для начала передачи новых данных и сбрасывается (R := 0) после передачи всех данных из этого буфера.
Биты ТО1 и ТО2 (Transmit Software Ownership) предназначены только для программного обеспечения пользователя и не взаимодействуют с аппаратурой.
Бит последнего буфера W (Wrap), равный «1», сообщает FEC-контроллеру, что текущий буфер - это последний буфер в таблице и после его обработки необходимо переходить для работы к первому буферу BD в таблице буферных дескрипторов.
Бит последнего буфера L (Last) используется в протоколах, где кадр данных может занимать несколько буферов, для указания последнего буфера кадра (если бит L = 1).
Если в слове состояния последнего буфера кадра (бит L = 1) установлен битТС=1 (Тх CRC), то при передаче вычисляется контрольная сумма содержимого кадра и она передается после последнего байта кадра. Если бит ТС = 0, то передача заканчивается сразу после передачи последнего байта кадра.
Если в слове состояния последнего буфера кадра (бит L = 1) установлен бит DEF = 1 (Defer Indication), то контроллер должен задержаться перед передачей кадра. Этот бит не устанавливается, если при передаче обнаружена коллизия.
О 1 2 3 4 5 6 7 8 9 10 1 1 12 13 14 15
R | TO1 W TO2 L тс DEF НВ LC RL RC UN CSL
Рис. 5.140. Формат слова состояния дескриптора передачи
648
ПОДДЕРЖКА ПРОТОКОЛОВ В КОММУНИКАЦИОННЫХ КОНТРОЛЛЕРАХ
Если в слове состояния последнего буфера кадра (бит L = 1) установлен бит НВ - 1 (Heartbeat Error), то при процедуре тестирования аппаратура не выставила активный сигнал на линию «коллизия», т. е. произошел сбой в работе аппаратуры. Этот бит устанавливается, только если в регистре состояния X_CNTRL установлен бит НВС = 1.
Если в слове состояния последнего буфера кадра (бит L - 1) установлен бит LC = 1 (Lata Collision), то обнаружена ошибка «поздняя коллизия», которая регистрируется после корректной передачи более чем 56 байт кадра (размер окна коллизий), и контроллер прервал передачу.
Если в слове состояния последнего буфера кадра (бит L = 1) установлен бит RL = 1 (Retransmission Limit), то контроллер превысил установленный предел числа повторных попыток выхода в сеть из-за коллизий. Текущее число повторных попыток выхода в сеть регистрируется в битах RC (Retry Count).
Если в слове состояния последнего буфера кадра (бит L - 1) установлен бит незапол-нения буфера UN (Underrun), равный «1», то регистрируется ошибка, которая возникает при передаче кадра данных, занимающего несколько буферов, когда передатчик передал всю информацию из буфера FIFO, а новые данные для передачи еще не поступили по каналам SDMA. Передача кадра останавливается, и к нему добавляется некорректная контрольная сумма.
Если в слове состояния последнего буфера кадра (бит L - 1) установлен бит CSL (Carrier Sence Lost), то при передаче кадра была обнаружена потеря несущей частоты, т. е. нарушена кодировка данных (например, манчестерское кодирование), но коллизия не обнаружена.
5.3.6. ПРОТОКОЛЫ, ПОДДЕРЖИВАЕМЫЕ НА УРОВНЕ ЗАГРУЖАЕМОГО МИКРОКОДА
Apple Talk-контроллер. Стек протоколов Apple Talk разработан фирмой «Apple Computer» для объединения в сеть компьютеров Macintosh. Протоколы Apple Talk могут использовать для передачи данных по физическому и канальному уровням управления многие протоколы других фирм-производителей, например протокол Ethernet. Но в стеке протоколов Apple тоже есть протокол канального уровня Local Talk, который основан на создании HDLC-канала и который обеспечивает на физическом уровне управления скорость передачи 230,4 Кбит/с.
Контроллер Apple Talk реализуется в МРС860 при помощи настроек HDLC-контроллера и за счет изменения установки отдельных бит в регистрах настройки, он обеспечивает работу SCC-канала с протоколом Local Talk, а также необходимую синхронизацию кадра, порядок битов, преамбулу и закрывающую ABORT-последовательность для HDLC-кадра. Таким образом, в основе кадра Apple Talk лежит HDLC-кадр с его управляющими полями и процедурами. Сам Apple Talk-контроллер только добавляет поля, необходимые для передачи этого кадра по сети APPLE. Благодаря этой особенности HDLC-контроллер при работе с FMO-способом кодирования данных может быть легко настроен на работу с кадрами Local Talk Bus. Карта памяти параметров HDLC-контроллера и контроллера Apple Talk совпадают, так как оба эти контроллера используют одинаковые алгоритмы обработки и контроля на канальном уровне управления. Формат кадра протокола Apple Talk представлен на рис. 5.141.
Первый символ синхронизации имеет размер не менее 3 бит (обычно используется 6 бит), среди которых должен быть, по крайней мере, один бит «1», следующий за двумя или более нулевыми битами IDLE. Передача IDLE-символов позволяет сетевым устрой-
649
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
SYNC HDLC FLAG DEST address SOURCE address CONTROL DATA CRC CLOSING FLAG ABORT sequence
6 бит 2 байта 1 байт 1 байт 1 байт 0-600 байт 2 байта 1 байт 15 бит «1»
Стандартный HDLC-кадр
Рис. 5.141. Формат кадра протокола Apple Talk
ствам обнаружить в канале несущую частоту и настроить свои приемники на работу с этой частотой передачи данных.
Таким образом, при передаче кадра данных контроллер Apple Talk автоматически встав-ляет/добавляет начальную синхропоследовательность из 6 бит (preamble) и конечную закрывающую последовательность из 16 единичных бит (postamble). При приеме получение 6-битной последовательности не вызывает дополнительного CD-прерывания.
Для обнаружения следующего далее полудуплексного HDLC-кадра передается не менее двух открывающих HDLC-флагов. Размер полей адреса и контроля соответствует требованиям HDLC-протокола. В поле данных может быть передано до 600 байт информации. Двухбайтное поле контрольной суммы используется для хранения 16-битного проверочного кода, вычисленного с использованием циклических полиномов. HDLC-кадр закрывается 8-битным закрывающим флагом. Формат полей флага 01111110 совпадает с форматом флага в протоколе HDLC. Кадр Local Talk закрывается специальным флагом, состоящим из 12-18 (обычно 16) «единичных» бит. Такой набор единичных бит будет воспринят HDLC-приемником как ABORT-последовательность. После передачи кадра передатчик выключается.
При передаче контроллер получает из буфера данные полей адресов, контроля и данных и добавляет поле контрольной суммы, два флага HDLC-кадра и две последовательности кадра Apple Talk.
При приеме контроллер выделяет из полученного кадра поля адреса, контроля, данных и CRC. Содержимое этих полей передается в буфер приема. Формат других полей контролируется, но в памяти не хранится.
Хотя поле контроля имеет одинаковый размер в кадрах Local Talk и HDLC, назначение его различно. В поле контроля HDLC-протокола передается информация, управляющая процессом передачи и контроля последовательности пакетов. В Local Talk-протоколе содержимое этого поля определяет тип кадра и тип передаваемой в поле данных информации. Если в поле содержится код от 0x01 до 0x7F, то это информационный кадр, а если код от 0x80 до OxFF, то это управляющий кадр. В протоколе Local Talk определены 4 типа управляющих кадров:
1) кадр запроса ENQ (enquiry);
2) кадр подтверждения запроса АСК (ENQ acknowledgment);
3) запрос для передачи данных RTS (request to send data frame);
4) разрешение передачи данных CTS (clear to send data frame). »
Процесс передачи группы кадров называется диалогом и обычно управляется программным обеспечением пользователя. Обычно диалог состоит из трех основных кадров. Если станция желает передать данные, она посылает кадр запроса на передачу RTS, указав в поле адреса свой адрес и адрес получателя. Если станция-получатель готова, то она посылает кадр разрешения передачи CTS к станции отправителя запроса. Далее передается кадр данных. Эти три кадра определяют один из возможных типов диалога. Другие станции, не участвующие в диалоге, вынуждены ждать, пока диалог будет закончен. Кадры внутри диалога передаются с максимальным межкадровым интервалом 200 мс (IFG-interframe gap). Минимальное значение IFG = 50 мс. Интервал между 650
ПОДДЕРЖКА ПРОТОКОЛОВ В КОММУНИКАЦИОННЫХ КОНТРОЛЛЕРАХ
диалогами IDG (interdialog gap) должен быть не менее 400 мс. Все эти временные интервалы контролируются программным обеспечением.
Коллизия может возникнуть в сети только при передаче кадра RTS и ENQ-кадров. Если обнаружена коллизия, то текущая передача кадров станциями не прекращается и доводится до конца.
Кадр ENQ передается по сети только при начальном включении питания на станции и при инициализации сети. Обычно в этом кадре передается управляющая информация более высоких уровней управления OSI.
Кадр ENQ передается по сети только при начальном включении питания на станции и при инициализации сети. Обычно в этом кадре передается управляющая информация более высоких уровней управления OSI.
Для кодирования данных используется способ FM0. При этом «1» кодируется перепадом сигнала в начале битового интервала, а «0» - двумя перепадами сигнала: первый в начале, второй - в середине битового интервала. Под перепадом следует понимать смену состояния или уровня сигнала на противоположное. Способ FM0 позволяет передавать тактовую частоту прямо в закодированных данных и не использовать дополнительные линии для передачи тактовых сигналов. Специальная SYNC-последовательность «начало кадра Local Talk» позволяет приемнику распознать частоту передачи и подстроить свой тактовый генератор.
Передача выполняется в полудуплексном режиме, и приемник на время передачи
находится в выключенном режиме.
Для того чтобы контроллер Apple Talk получил непосредственный доступ к физическому уровню управления сети, необходимо на его выходах подключить микросхему RS-422 передатчика (transceiver). Для обмена сигналами с RS-422 передатчика используются всего три сигнала SCC-канала: TxD, RxD и rts , который используется для стробирования передачи данных. Сигнал rts равен нулю во время передачи всего кадра данных контроллера Apple Talk и используется для управления RS-422 передатчиком. Пример построения сети Apple Talk показан на рис. 5.142.
Для синхронизации работы приемника и передатчика тактовая частота в 3,686 МГц может быть получена или от внешнего источника, или от внутреннего BRG-генератора.
При выполнении операции oversampling контроллер протокола Apple Talk производит внутреннее увеличение частоты в 16х раз.
Кроме вышеперечисленных особенностей, функционирование контроллера Apple Talk полностью совпадает с работой HDLC-koh-троллера, поэтому настройки регистров режима совершенно аналогичны. Только при настройке регистров GSMR и PSMR следует учитывать специфические режимы работы контроллера Apple Talk.
Рис. 5.142. Пример построения сети Apple Talk
651
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
Настройки регистра GSMR и PSMR для работы с AppleTalk:
1. Бит GSMR[MODE] := 0010 - произведена настройка для работы с протоколом Apple Talk
2. Биты GSMR[ENR] := 1 и GSMR[ENT] := 1 - разрешена работа приемника и передатчика.
3. Биты GSMR[DIAG] := 00 - контроллер SCC-канала настроен на нормальный режим работы с использованием внешних сигналов cd и cts .
4. Биты GSMR[RDCR] := 10 и GSMR[TDCR] := 10-для приемника и передатчика установлено внутреннее увеличение частоты в 16х раз.
5. Биты GSMR[RENC] := 010 и GSMRfTENC] := 010 - для приемника и передатчика установлен способ кодирования/декодирования данных FM0.
6. Бит GSMRfTEND] := 0 - данные на линии TxD при передаче кодируются FM0-способом. В пассивном состоянии на линию TxD выдается постоянный уровень «1» без кодирования.
7. Биты GSMR[TRR] := 11 - формат преамбулы - все биты равны «1».
8. Биты GSMR[TPL] равны 000, если между кадрами не нужна синхронизирующая preamble-последовательность, или равны 001, если следующий кадр AppleTalk передается с 6-битной синхропоследовательностью.
9. Биты GSMRfTINV] = GSMR[RINV] := 0 - при кодировке данных способом FM0 дополнительное инвертирование не используется.
10. Биты GSMR[TSNC] := 10 - следующий перепад сигнала на линии RxD должен произойти через 1,5 битовых интервала увеличенной в 16х тактовой частоты. Этот бит определяет, сколько битовых интервалов внутреннего сигнала будет показывать свободный канал после начала передачи по RxD-линии. В контроллере Apple Talk эта задержка используется, чтобы не вызвать CD-прерывания при приеме первой 6-битной синхропоследовательности.
11. Биты GSMR[EDGE] := 00 - линии данных будут анализироваться блоком DPLL и по положительному перепаду тактового сигнала, и по отрицательному.
___12. Бит GSMR [RTSM] := 0 - при передаче кадров сигнал rts будет сбрасываться (RTS= 1) в интервале между кадрами и устанавливаться (RTS= 0) при передаче кадра. В перерыве между кадрами передаются IDLE-символы, как определено битом TEND. Если бит RTSM = 1, то сигнал rts равен нулю всегда после включения SCC-канала в работу, даже когда в интервале между кадрами передаются символы флага или IDLE.
Настройка всех остальных бит производится как в HDLC-контроллере и согласно режимам, выбранным пользователем.
Настройка регистра режима PSMR производится также, как для HDLC-протокола:
1. Биты PSMR[NOF] := 0001 - между кадрами передаются два флага: один - открывающий, второй - дополнительный.
2. Бит PSMR[CRC] =00-для контроля используется 16-битный CRC-CCITT полином.
3. Бит PSMR[DRT] := 1 - при передаче данных приемник временно выключается, пока сигнал rts = 0.
Другие биты регистра PSMR либо сбрасываются в «0», либо принимают значения по умолчанию.
BISYNC-контроллер. BISYNC-байт-ориентированный (или символьно-ориентированный) протокол, впервые был разработан фирмой IBM в 1960-х годах для работы в различных сетях. Недостатком символьно-ориентированных процедур являются жесткая привязка к используемому первичному коду, выделение части комбинаций битов или символов для целей управления, необходимость распознавания во входном потоке управляющих и информационных символов, а также то, что защите от ошибок, как правило, подлежит только информационная часть кадра или поле данных, а не весь кадр целиком.
652
ПОДДЕРЖКА ПРОТОКОЛОВ В КОММУНИКАЦИОННЫХ КОНТРОЛЛЕРАХ
SYN1 SYN2 SOH HEADER STX TEXT ЕТХ ВСС
Non Transparent with header
SYN1 SYN2 STX TEXT ЕТХ ВСС
Non Transparent without header
SYN1 SYN2 DLE STX TRANSPARENT TEXT DLE ETX BCC
Transparent
Рис. 5.143. Типы кадров BISYNC-протокола
BISYNC-контроллер может функционировать в двух режимах работы (нормальной передачи - «режим nontransparent» и прозрачной передачи «режим transparent») и поддерживает работу с немультиплексируемым интерфейсом NMSI и мультиплексируемыми интерфейсами IDL, GCI, РСМ.
Протокол поддерживает три типа кадров: Transparent-для «прозрачной» передачи данных, Тransparent with header - для передачи команд управления и служебной информации и Non Тransparent without header - для непрозрачной передачи данных (рис. 5.143). Каждый кадр начинается с двух 8-битных синхросимволов SYN1 и SYN2, которые обеспечивают взаимную синхронизацию приемника и передатчика, и заканчивается 16-битным полем контрольной суммы блока ВСС. Приемник автоматически выделяет символы синхронизации из входного потока и удаляет их.
Если контроллер работает с 8-битными символами, то для вычисления контрольной суммы ВСС применяется 16-разрядный циклический код CRC16. Если же контроллер использует 7-битные символы, то применяется комбинация вертикальной контрольной суммы (VRC parity) и горизонтальной контрольной суммы (LRC).
Служебный символ SOH (Start of Heading) определяет начало заголовка сообщения. В заголовок сообщения обычно включают информацию, требующуюся для выполнения функций адресации, управления потоком данных и маршрутизации.
Текст в поле данных выделяется служебными символами «старт текста» (STX) и «конец текста» (ЕТХ). В режиме прозрачной передачи поле данных является бит-ориенти-рованным, т. е. допускаются любые комбинации битов. Для выделения прозрачной части кадра введен специальный 8-битный символ DLE (Data Link Escape), который сигнализирует, что дальше до следующего символа DLE следует текст, а не контрольные символы из таблицы служебных символов. Если символ DLE должен быть передан в тексте как данные, то ему должен предшествовать дополнительный DLE-символ. Этот дополнительный DLE-символ вставляется при передаче и автоматически удаляется при приеме (процедура byte-stuffing). Формат символа DLE задается пользователем в ячейке BDLE памяти параметров BISYNC-контроллера (рис. 5.144).
В BISYNC-контроллере ошибка незаполнения (underrun) буфера FIFO передатчика не является фатальной, контроллер регистрирует ее, но не прерывает своей работы и передатчик передает в канал при нормальном режиме обмена синхронизирующие последовательности SYNC или DLE-SYNC при прозрачном режиме обмена, пока не будут подготовлены новые данные для передачи. А приемник выполняет автоматическое удаление этих синхропоследовательностей из входного потока. Единственное ограничение заключается в том, что ошибка underrun не должна возникать между передачей DLE-символа и следующего за ним символа.
0123456789 10 11 12 13 14 15
V 0 0 0 0 0 0 0 SYNC или DLE
Рис. 5.144. Формат ячеек служебных символов BSYNC и BDLE
653
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
012345 6 7 8 9 10 11 12 1 3 14 1 5
NOS CRC RBCS RTR RVD DRT _db RPM ТРМ
Рис. 5.145. Формат регистра режима PSMR для BISYNC-контроллера
Если при приеме данных в прозрачном режиме работы приемник получил DLE-символ и установлен бит V = 1 в ячейке BDLE памяти параметров, то контроллер удаляет этот символ и не учитывает его при подсчете контрольной суммы блока BSC. Если следующим принят символ SYNC, то контроллер его тоже отбрасывает и не учитывает при подсчете контрольной суммы. Если же второй принятый символ - DLE, то он записывается в буфер приема и учитывается при подсчете BSC. Если следующий принятый символ и не DLE, и не SYNC, то контроллер проверяет его на совпадение в таблице служебных символов. Если этот символ не является и контрольным, то буфер приема закрывается и регистрируется ошибка «некорректного символа, следующего за DLE-символом». Признаком этой ошибки является установка бита DLE := 1 в слове состояния буфера приема. Если же бит V = 0, то контроллер воспринимает этот символ как корректный и записывает его в буфер приема.
Формат символа SYNC задается пользователем в регистре BSYNC памяти параметров (см. рис. 5.144). Если во время нормальной непрозрачной (nontransparent) передачи данных обнаруживается ошибка незаполнения буфера FIFO передатчика underrun, то контроллер начинает передавать в канал связи SYNC-символы, пока не будут подготовлены следующие данные для передачи.
Если контроллер работает в нормальном режиме (не режим «охоты» hunt) и в ячейке BSYNC установлен бит V = 1, то при приеме SYNC-символы будут отбрасываться. Если бит V = 0, то принятый SYNC-символ воспринимается как обычные данные и записывается в память.
Выбор протокола BISYNC производится в битах MODE в регистре GSMR_L, а конфигурирование режимов работы BISYNC-контроллера выполняется в регистре PSMR (рис. 5.145).
Если система сконфигурирована так, что выводы RXD и TXD объединены в одну шину, и передача идет в режиме полудуплексного обмена, то пользователь, установив бит DRT := 1 в регистре PSMR, может на время работы передатчика выключать работу приемника, чтобы не принимать собственную передаваемую информацию.
Бит RVD определяет порядок передачи битов внутри байтов данных в канал. Если бит равен нулю, то первым передается LSB-бит, это нормальный режим. Если бит равен единице, то первым в канал передается MSB-бит, это инверсный режим.
Распределение памяти параметров BISYNC-контроллера в микроконтроллере МРС860 приведено в табл. 5.84.
Таблица 5.84
Память параметров BISYNC-контроллера в микроконтроллере МРС860
Адрес Название Размер, бит Описание
SCC base+30 - 32 Зарезервировано
SCC base+34 CRCC 32 Временное значение CRC-константы
SCC base+38 PRCRC 16 Начальное значение счетчика CRC/LRC приемника
SCC base+3A PTCRC 16 Начальное значение счетчика CRC/LRC передатчика
SCC base+3C PAREC 16 Счетчик ошибок четности при приеме
SCC base+3E BSYNC 16 Формат SYNC-символа
SCC base+40 BDLE 16 Формат DLE-символа
SCC base+42 CHAR1 16 Контрольный символ 1
654
ПОДДЕРЖКА ПРОТОКОЛОВ В КОММУНИКАЦИОННЫХ КОНТРОЛЛЕРАХ
Продолжение табл. 5.84
Адрес Название Размер, бит Описание
SCC base+44 CHAR2 16 Контрольный символ 2
SCC base+46 CHAR3 16 Контрольный символ 3
SCC base+48 CHAR4 16 Контрольный символ 4
SCC base+4A CHAR5 16 Контрольный символ 5
SCC base+4C CHAR6 16 Контрольный символ 6
SCC base+4E CHAR7 16 Контрольный символ 7
SCC base+50 CHAR8 16 Контрольный символ 8
SCC base+52 RCCM 16 Маска принятых контрольных символов
Примечание. Все ячейки памяти параметров должны быть проинициализированы пользователем до включения канала в работу. Ячейки PRCRC и PTCRC должны быть проинициализированы начальными значениями в зависимости от типа BCS, выбор которой проведен в бите CRC регистра PSMR. Если выбрана контрольная сумма LRC, то ячейки инициализируются кодом «все 0» при контроле по четности и кодом «все 1» при контроле по нечетности.
Передача данных. Когда центральный процессор устанавливает бит ENT := 1, BISYNC-контроллер включается в работу, и его передатчик начинает передавать в канал символы синхронизации. Бит RTSM в регистре GSMR_H определяет тип синхросимволов. Если бит RTSM=1, то контроллер передает синхросимволы SYN1 и SYN2, формат которых определен в регистре синхросимволов DSR. Если бит RTSM = 0, то передатчик передает в канал связи для синхронизации IDLE-символы («все 1»),
Далее контроллер опрашивает первый буфер в таблице дескрипторов передачи и, если он готов, начинает передачу сообщения. Перед началом передачи в канал всегда предварительно передается не менее одной пары синхросимволов SYN1 и SYN2 для синхронизации приемника. Биты NOS в регистре PSMR определяют минимальное число пар синхросимволов, которые передаются между сообщениями или перед новым сообщением. Число пар символов SYN1-SYN2 равно ([NOS3-NOSO]+1).
Когда буфер данных полностью передан, контроллер сбрасывает бит R := 0 и проверяет бит L в его слове состояния. Если бит L = 1 и бит ТВ = 1, то контроллер добавляет к кадру данных поле контрольной суммы блока CRC16 или LRC и завершает передачу всего кадра. По окончании передачи кадра в слове состояния последнего буфера устанавливаются биты статуса переданного сообщения. Перед началом передачи следующего сообщения в канал выдается заданное число символов синхронизации. Если бит L = 0, т. е. сообщение занимает несколько буферов, то контроллер переходит к передаче следующего буфера данных.
Если следующий буфер данных еще не готов, то регистрируется ошибка незаполнения underrun, и BISYNC-контроллер начинает передавать в канал символы синхронизации SYN1-SYN2 или IDLE-символы. Если же контроллер работает в прозрачном режиме работы, он начинает передавать пары символов DLE-SYNC.
После передачи текущего буфера данных, если в его слове состояния установлен бит 1 = 1, контроллер выставляет запрос на маскируемое прерывание к центральному процессору, уведомляя его о завершении передачи очередной порции данных.
Биты CRC в регистре PSMR определяют тип контрольной суммы, которая может вычисляться по двум алгоритмам. Если биты CRC = 01, то 8-битные данные кодируются с использованием 16-разрядного циклического кода с полиномом Хл16+Хл15+Хл12+1. Если биты CRC = 11, то 7-битные данные кодируются при помощи комбинации горизонтальной контрольной суммы LRC и вертикальной контрольной суммы VRC (контроль четности). Сумма LRC вычисляется как операция «исключающего ИЛИ» XOR всех 7-
655
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
битных символов. Контроль VRC используется для заполнения восьмого незанятого бита (бит контроля или parity-бит) и представляет собой контроль по четности/нечетнос-ти, как определено в битах ТРМ в регистре PSMR (табл. 5.85).
Таблица5.85
Тип контроля в сети
Бит ТРМ Тип контроля
00 На нечетность
01 Бит контроля устанавливается в «0»
10 На четность
11 Бит контроля устанавливается в «1»
Вычисление контрольной суммы производится побуферно. Если в слове состояния текущего буфера бит В - 1, то содержимое буфера участвует в подсчете контрольной суммы. Если же бит В - 0, то содержимое буфера игнорируется при подсчете контрольной суммы. Если же в слове состояния текущего буфера установлен бит BR = 1, то BISYNC-контроллер перед передачей текущего буфера сбросит счетчик контрольной суммы BCS. Обычно этот сброс производится при передаче специфичных буферов, например, содержащих символы начала блока STB или начала текста STX. Если бит BR = 0, то сброс счетчика BCS не производится.
Если BISYNC-контроллер работает в прозрачном режиме передачи, то перед каждым DLE-символом в кадре вставляется дополнительный DLE-символ, но при подсчете контрольной суммы учитывается только первый DLE-символ.
Пользователь может управлять работой передатчика BISYNC-контроллера при помощи команд RESTART TRANSMIT, STOP TRANSMIT, GRACEFUL STOP TRANSMIT, INIT TX PARAMETERS.
___При передаче кадра данных контролируются ошибки незаполнения и потери сигнала CTS . Ошибка незаполнения underrun возникает, когда RISC-процессор не успевает подготовить новые данные в ячейке буфера FIFO передатчика. При возникновении этой ошибки контроллер прекращает передачу текущего буфера, закрывает буфер, устанавливает бит ошибки UN := 1 в его слове состояния и бит ТХЕ :- 1 в регистре событий канала, вызывая маскируемое прерывание центрального процессора. Передатчик возобновит свою работу после получения команды RESTART TRANSMIT. Ошибка underrun не регистрируется в интервале между передачей отдельных кадров и при передаче пары символов DLE-XXX в прозрачном режиме работы.
В контроллере МРС860 размер буфера FIFO передатчика должен быть установлен равным 32 байтам для канала SCC1 и 16 байтам - для других SCC-каналов (бит TFL = О в регистре GSMR_H). ____
Ошибка потери сигнала CTS возникает, если при передаче сигнал CTS станет пассивным (CTS = 1). При возникновении этой ошибки канал прерывает передачу, закрывает буфер передачи, устанавливает бит ошибки СТ := 1 в слове состояния буферного дескриптора и бит ТХЕ := 1 в регистре событий канала, вызывая прерывание центрального процессора. Передача будет возобновлена после получения команды RESTART TRANSMIT.
Прием данных. При приеме данных BISYNC-контроллер без вмешательства центрального процессора выполняет обработку кадра данных: подсчет и сравнение контрольной суммы блока BCS (CRC16 или LRC, VRC), удаление символов SYNC в нормальном режиме передачи, удаление пар символов DLE-SYNC и первого DLE-символа в паре DLE-DLE при работе в прозрачном режиме передачи, сравнение принятого символа со служебными символами в таблице контрольных символов.
656
ПОДДЕРЖКА ПРОТОКОЛОВ В КОММУНИКАЦИОННЫХ КОНТРОЛЛЕРАХ
После включения приемника в работу (бит ENR = 1) канал переходит в режим поиска нового кадра (hunt mode). Начало нового кадра обнаруживается при приеме символов SYN1-SYN2, формат которых задан в регистре синхросимволов DSR. Прием этих символов выполняет синхронизацию кадра данных, далее контроллер начинает прием и обработку самого кадра.
Возврат в режим hunt будет возможен или когда контроллер получит от центрального процессора команду ENTER HUNT MODE, или если при приеме будет обнаружена ошибка, или если будет принят определенный контрольный символ.
Бит RTR определяет режим работы приемника. Если бит RTR = 0, то приемник работает в нормальном режиме с распознаванием и удалением SYNC-символов и анализом служебных символов. Если бит RTR = 1, то приемник работает в режиме прозрачного обмена (в этом режиме всегда вычисляется контрольная сумма CRC16).
При приеме каждого байта данных контроллер подсчитывает контрольную сумму принятых данных и обновляет значение бита CR в слове состояния буферного дескриптора. При этом контроллер при приеме очередного байта данных делает паузу в восьми периодах тактового сигнала приемника RCLK перед включением этого байта в расчет контрольной суммы BCS. В течение приема следующего байта пользователь может установить бит RBCS = 0 в регистре PSMR, и тогда предыдущий принятый байт будет исключен из расчета контрольной суммы BCS. Если же бит RBCS = 1, то принятый байт будет включен в подсчет контрольной суммы.
Если выбран подсчет LRC контрольной суммы, то бит RPM определяет тип контроля по четности/нечетности (табл. 5.86) для приемника.
Таблица 5.86
Тип контроля в сети
Бит RPM Тип контроля
00 На нечетность
01 Бит контроля должен быть равен «0»
10 На четность
11 Бит контроля должен быть равен «1»
Когда буфер приема будет полностью заполнен, контроллер сбрасывает бит пустого буфера Е := 0, и если установлен бит I = 1, то генерирует маскируемое прерывание к центральному процессору. Если размер принимаемых данных больше, чем установленная длина буфера приема, то контроллер проверяет бит незанятости следующего буфера в таблице RxBD, и если этот бит равен Е = 1, то продолжает прием данных в новый буфер.
Когда принимается поле BCS, BISYNC-контроллер сравнивает подсчитанное значение контрольной суммы блока с содержимым этого поля и записывает его в буфер. Поскольку это было последнее поле кадра, контроллер устанавливает в слове состояния буфера бит последнего буфера кадра L = 1, записывает биты статуса принятого кадра и сбрасывает бит Е := 0. Затем контроллер генерирует маскируемое прерывание к центральному процессору, уведомляя его, что блок данных принят и находится в памяти.
Пользователь может управлять работой приемника BISYNC-контроллера при помощи команд INIT RX PARAMETERS, ENTER HUNT MODE, CLOSE RX BD, RESET BCS CALCULATION. Команда RESET BCS CALCULATION обычно передается контроллеру после того, как получен и проанализирован контрольный символ начала блока, например символы STX или SOH, чтобы для последующих данных нового блока данных провести независимый подсчет контрольной суммы.
При приеме кадра данных контролируются ошибки переполнения, ошибки проверки бита контроля, ошибки проверки контрольной суммы и ошибки потери сигнала CD .
657
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
Ошибка переполнения overrun возникает, когда RISC-процессор не успевает освобождать ячейки буфера FIFO приемника, и BISYNC-контроллер вынужден записывать новые данные поверх старых, в результате старые данные теряются. При возникновении этой ошибки канал прекращает прием данных, закрывает буфер приема, устанавливает бит ошибки OV := 1 в слове состояния буферного дескриптора и бит RX := 1 в регистре событий, вызывая запрос на прерывание.
В контроллере МРС860 размер ячейки буфера FIFO приемника должен быть установлен равным 8 битам (бит RFW = 1 в регистре GSMR_H). При этом размер буфера FIFO будет установлен равным 8 байтам для канала SCC1 и 4 байтам для других SCC-каналов. ___
Ошибка потери сигнала CD возникает, если при приеме данных этот сигнал становится пассивным (CD = 1). При возникновении этой ошибки канал прекращает прием данных, закрывает буфер, устанавливает бит ошибки CD:=1 в слове состояния буферного дескриптора и бит RX := 1 в регистре событий BISYNC-контроллера, вызывая запрос на прерывание. Эта ошибка имеет самый высокий приоритет среди других ошибок приема, и при ее возникновении другие ошибки не проверяются.
При приеме сообщений BISYNC-контроллер постоянно проверяет полученные данные по четности/нечетности. Если возникает ошибка четности (parity), то канал записывает последний принятый символ в буфер, прекращает дальнейший прием данных, закрывает буфер приема, устанавливает бит ошибки PR := 1 в его слове состояния и бит RX := 1 в регистре событий, а также увеличивает на единицу счетчик ошибок четности/нечетности в ячейке PAREC памяти параметров BISYNC-контроллера.
При возникновении всех вышеперечисленных ошибок приема контроллер немедленно переходит в режим поиска новых кадров (hunt mode).
Во время приема каждого символа BISYNC-контроллер постоянно, с задержкой в восемь периодов тактовой частоты приема RCLK обновляет значение бита CR в слове состояния текущего буфера приема. Контроллер, получив служебный символ окончания блока данных, завершает вычисление контрольной суммы CRC и сравнивает ее со значением в поле CRC, которое следует сразу за символом окончания блока. Если обнаружено несовпадение подсчитанной и полученной контрольных сумм, то контроллер записывает полученную CRC-сумму в буфер приема, закрывает буфер, устанавливает бит ошибки CR := 1 в слове состояния буферного дескриптора и бит RX := 1 в регистре событий канала, вызывая маскируемое прерывание центрального процессора.
Прием служебных символов. Существует два способа управлять приемом данных в BISYNC-контроллере. При первом способе используются однобайтовые буферы для приема, и прерывание назначено после приема каждого буфера, таким образом, прерывание уведомляет центральный процессор о приеме каждого символа. Это достаточно простой и гибкий метод управления приемом, но он имеет существенный недостаток, так как требуется постоянная обработка прерываний и работа основного процессора будет замедляться.
Второй способ более эффективен, так как используется при приеме данных в многобуферную структуру. Программное обеспечение пользователя, анализируя первые биты буфера приема, определяет, какой тип кадра или блока принимается контроллером, и производит дополнительные настройки режима приема. Приход контрольного символа может информировать контроллер, что закончен прием текущего блока данных и ожидается следующий блок данных. Например, символ ЕТВ информирует о приеме блока данных, а символ ЕТХ - о приеме блока текста, и что контроллер ожидает приема блока контрольной суммы BCS. Прием символа ENQ информирует, что принят блок данных, но без поля BCS. Дальнейший прием данных будет производиться без вмешательства центрального процессора. Для реализации этого метода бит разрешения прерывания от события RCH
658
ПОДДЕРЖКА ПРОТОКОЛОВ В КОММУНИКАЦИОННЫХ КОНТРОЛЛЕРАХ
в регистре маски BISYNC-контроллера должен быть предварительно установлен, разрешая прерывание при приеме каждого байта данных. Это позволит программному обеспечению пользователя анализировать тип принимаемого блока данных. После этой проверки, если был принят символ DLE-STX, приемник необходимо перевести в режим «прозрачного» приема данных, установив для этого бит RTR := 1 в регистре режима BISYNC-контроллера. Этот бит необходимо сбросить после приема пары символов DLE-ETX. Если же был принят символ начала блока SOH, то каналу необходимо передать команду сброса в исходное состояние счетчиков контрольной суммы RESET BCS CALCULATION. После выполнения этих действий прерывание от бита RCH должно быть замаскировано.
Далее BISYNC-контроллер будет принимать данные без вмешательства основного процессора, пока не примет контрольный символ, означающий конец принимаемого блока. После приема символа конца текста ЕТХ-контроллер будет ожидать прием поля контрольной суммы BCS, а затем буфер приема будет закрыт.
Символ ENQ используется для прерывания передачи текущего блока данных. Для приемника получение этого символа означает конец блока, после которого не ожидается CRC-блок контрольной суммы.
После приема контрольного символа конца блока данных бит RCH в регистре маски BISYNC-контроллера должен быть снова установлен, чтобы начать прием нового блока данных.
Таким образом, специальные служебные символы могут быть использованы для управления процессом передачи по сети. Обычно это рекомендуется, если размер буфера приема данных больше 1 байта, так как при настройке работы с однобайтовым буфером прием каждого байта данных легко контролируется, и служебные символы не нужны. При приеме все контрольные символы записываются в буферы памяти.
BISYNC-контроллер позволяет определить до восьми служебных символов в ячейках CHAR1-CHAR8 (рис. 5.146) памяти параметров. В полях CHAR1-CHAR8 определен формат служебного символа. Бит Е = 1 (end of table) позволяет ограничивать число служебных символов в таблице. Бит В определяет действия контроллера при приеме служебного символа. Если бит В = 0, то символ записывается в память и буфер закрывается. Если бит В = 1, то принятый символ записывается в буфер и контроллер ожидает приема, или 1 байта контрольной суммы LRC, или 2 байт контрольной суммы CRC. После приема поля контрольной суммы текущий буфер закрывается. Рекомендуется служебные символы конца блоков ЕТХ (End of Text) и ЕТВ (End of Transmission Block) использовать с битом В = 1. После закрытия буфера генерируется маскируемое прерывание к центральному процессору.
Бит Н определяет режим работы BISYNC-контроллера после закрытия текущего буфера. Если бит Н = 0, то контроллер остается в рабочем режиме и поддерживает синхронизацию символа. Если бит Н = 1, то контроллер после закрытия буфера переходит в режим поиска нового кадра (hunt mode). Если установлены оба бита - В = Н = 1, то контроллер перейдет в режим поиска нового кадра сразу по окончании приема поля контрольной суммы BCS.
В контроллере МРС860 пользователь может управлять проверкой контрольных символов при приеме с помощью регистра маски RCCM (рис. 5.147) в памяти параметров BISYNC-контроллера. В младших восьми разрядах этого регистра можно маскировать
О 1 2 3 4 5 6 7 8 9 10 1 1 12 1 3 14 15
Е В н - - - - - CHARACTER!
Рис. 5.146. Формат ячеек служебных символов CHAR1-CHAR8
659
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
0123456789 10 11 12 13 14 15
1 1 1 - - - - - Значение маски служебных символов
Рис. 5.147. Формат ячейки RCCM
проведение анализа (сравнение) выбранного служебного символа. Бит i, равный единице, разрешает проверку/сравнение принятого символа с контрольным символом CHARi в таблице служебных символов. Бит i, равный нулю, запрещает проведение проверки. Биты с 0-го по 2-й должны быть всегда установлены, иначе может возникнуть ошибка при начале анализа служебных символов.
Приведем пример программирования таблицы контрольных символов для реализации второго способа управления приемом данных (табл. 5.87).
Таблица 5.87
приводятся данные, позволяющие сопоставить по основным параметрам символьноориентированную процедуру BISYNC и бит-ориентированную процедуру HDLC.
Таблица 5.88
Сравнение протоколов канального уровня
Признак сравнения BISYNC HDLC
Передача знаков управле-ния/ответа и текста Зависимость от знаков первичного кода Прозрачность текста Защита от ошибок Зависимость от режима работы и конфигурации соединения Длина текста (в байтах) Адресация Нумерация последовательностей ведется по модулю Вцд передачи Осуществляется отдельными последовательностями Имеется (символьно-ориентированная) Достигается использованием специальных знаков управления Применяется только для последовательностей, содержащих текст/заголовок Присутствует Переменная Осуществляется с применением выделенных последовательностей 2 Полудуплексная В одном кадре Отсутствует (байт-ориентиро-вэнная) Присуще процедуре Используется для всех типов кадров Отсутствует Переменная Поле адреса в каждом кадре 8/128 Полнодуплексная
660
ПОДДЕРЖКА ПРОТОКОЛОВ В КОММУНИКАЦИОННЫХ КОНТРОЛЛЕРАХ
Продолжение табл. 5.88
Признак сравнения BISYNC HDLC
Опрос Сигналы подтверждения приема текста Осуществляется с применением выделенной последовательности Передаются специальными последовательностями управления Может проводиться с исполь зованием каждого кадра Могут быть объединены с передаваемыми данными
Основным отличием процедуры HDLC от процедуры BISYNC является использование в ней единой структуры формата кадров, передаваемых по сети. При этом внутри кадра области адреса, управления, информации последовательности проверки кадра располагаются на строго определенных местах, что позволило выработать единый подход к формированию кадра при передаче и его обработке при приеме.
Наличие областей адреса и управления в каждом кадре, передаваемом по сети, позволило достичь требуемой степени гибкости бит-ориентированной процедуры в отношении ее приспособляемости к конкретному способу организации и конфигурации сети. В данном случае избирательная передача в адрес какой-либо станции ведется уже не на основе удержания соединения в режиме передачи избранному абоненту, что равносильно коммутации каналов, а на основе соответствующей адресации каждого кадра тому абоненту, которому предназначена содержащаяся в нем информация. В процедуре BISYNC используются управляющие последовательности, передаваемые по каналу в режиме управления, тогда как в процедуре HDLC выбор вторичной станции, к которой обращается первичная станция, осуществляется передачей в области адреса соответствующего адреса вторичной станции. При этом область управления кадра используется не только для передачи команд и ответов, но и номеров передаваемых и подтверждаемых кадров, применяющихся для организации надежного упорядоченного обмена данными, а также организации управления. Функция опроса осуществляется с применением бита Р/F, передаваемого в области управления каждого кадра. При этом первичная станция устанавливает бит Р := 1 (опрос - Poll), если требуется инициировать передачу данных или сигналов подтверждения от вторичной станции, которой адресуется кадр с битом Р = 1. Вторичная станция оповещает первичную о завершении передачи установкой («1») в последнем передаваемом кадре бита F (окончание опроса - Final). Этот способ реализации функции выбора и опроса позволяет организовать достаточно эффективное управление передачей данных в сети с различными конфигурациями и разными способами передачи данных.
При использовании процедуры HDLC отпадает необходимость в дополнительных командах для перевода станций, подсоединенных к каналу, в состояние управления, что требуется в процедуре BISYNC каждый раз при переключении направления передачи.
Так как в процедуре HDLC имеется возможность передачи в одном кадре информации верхнего уровня сети и сигналов подтверждения, то рассматриваемой процедуре присуще организация одновременно двунаправленной передачи данных. Это в большинстве случаев позволяет сократить по сравнению с процедурой BISYNC простои соединения из-за необходимости переключения канала для организации работы в противоположном направлении.
Высокая степень надежности при передаче данных по каналу связи с использованием процедуры HDLC достигается за счет, во-первых, контрольной суммы кадра, которая формируется для каждого передаваемого по сети кадра, а во-вторых, организации повторной передачи тех кадров, которые по какой-либо причине не были получены принимающей станцией, с целью упорядоченной выдачи содержащейся в ней информации получателю. Последнее в процедуре HDLC достигается нумерацией передаваемых кад
661
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
ров, содержащих данные источника (верхнего уровня), по модулю «8», т. е. передачей номера передаваемого кадра, а также сигналов подтверждения, передаваемых в противоположном направлении с номером ожидаемого кадра. При организации одновременной двунаправленной передаче данных передача номеров в каждом направлении осуществляется независимо.
Протокол DDCMP. Символьно-ориентированный DDCMP-протокол (Digital Data Communication Message Protocol) разработан фирмой DEC для применения в сетях и системах телекоммуникации. Протокол DDCMP предназначен для синхронной работы по полнодуплексным и полудуплексным соединениям, устанавливаемым по сетям «точка-точка» и многоточечным соединениям. Протокол может быть также использован для передачи данных в асинхронном старт-стопном режиме. В настоящее время этот протокол мало используется в современных сетях и поэтому как основной протокол он реализован только в контроллерах семейства МС68302, а в контроллере семейств МРС860 этот протокол предлагается фирмой «Motorola» в виде загружаемого микрокода, который пользователь при необходимости может загрузить в память контроллера.
Протокол DDCMP является переходным от символьно-ориентированных к бит-ориен-тированным протоколам. Недостатками символьно-ориентированных процедур являются: жесткая привязка к используемому первичному коду, выделение части комбинаций битов или символов для целей управления, необходимость распознавания во входном потоке управляющих и информационных символов. Для устранения указанных недостатков заголовок пакета в DDCMP-протоколе выполнен символьно-ориентированным, а поле данных - бит-ориентированным, т. е. внутри поля данных разрешены любые комбинации битов. Основной целью создания DDCMP-протокола являлась разработка процедуры обмена, которая сочетает применение методов помехоустойчивого кодирования частей кадра с алгоритмами переспроса и подтверждений при обмене кадрами, и предназначена для безошибочной передачи данных в сетях с помехами.
Для передачи информации протокол использует три типа пакетов. Каждый тип пакета начинается с двух байтовых синхросимволов SYN1 и SYN2, формат которых задается в регистре синхронизации DSR и в специальном регистре DSYN1, и заканчивается 16-битной контрольной суммой. В зависимости от типа пакета и для повышения надежности передачи информации каждый логически законченный блок кадра (заголовок или блок данных) может иметь свою контрольную сумму. Например, заголовок кадра (от поля SOH/ ENQ/DLE до поля ADDR) и поле данных имеют различные поля контрольных сумм -CRC1 и CRC2. Типы пакетов показаны на рис. 5.148.
В перерывах между кадрами передаются или символы синхронизации SYN1-SYN2 или IDLE-символы. Тип пакета определяется 8-битным служебным символом, который передается сразу за синхросимволами. С помощью этих символов осуществляется автоматическая синхронизация сообщений. Всего выделяют три типа пакета:
1) информационное сообщение (data message) служит для передачи данных и отмечается символом SOH (формат 0x81);
SYN1 SYN2 SOH COUNT F RESP NUM ADDR CRC1 DATA CRC2
Data
Message
SYN1 SYN2 ENQ MESSAGE TYPE ADDR CRC3
Control
Message
SYN1 SYN2 DLE COUNT F FILL FILL ADDR CRC1 DATA CRC2
Transparent Message
Рис. 5.148. Типы кадров DDCMP-протокола
662
ПОДДЕРЖКА ПРОТОКОЛОВ В КОММУНИКАЦИОННЫХ КОНТРОЛЛЕРАХ
2) управляющее сообщение (control message) служит для передачи управляющей и контрольной информации и отмечается символом ENQ (формат 0x05);
3) вспомогательное сообщение (transparent message) служит для передачи служебной информации и команд управления и отмечается символом DLE (формат 0x90).
Поле данных является байт-ориентированным. Полная длина поля данных в байтах указана в поле COUNT. Суммарная длина полей COUNT+F(Flag) равна 2 байтам.
Поле F (Flag) имеет размер 2 бита и содержит флаги соединения, которые используются для управления монопольным использованием соединения и синхронизацией сообщения. Назначение бит:
• bit 0 - флаг быстрой синхронизации (QSYNC флаг), используемый, чтобы сообщить приемнику, что после этого сообщения должна следовать повторная синхронизация; быстрый синхронизирующий флаг уменьшает длину синхронизирующих последовательностей на синхронных каналах;
• bit 1 - флаг выбора (флаг SELECT); используется для управления монопольным использованием передачи на многоточечных и полудуплексных каналах; изменяет направление передачи в полудуплексных каналах; в multipoint-режиме разрешает передавать или требует остановить передачу у выбранного узла.
Заголовка любого пакета в DDCMP имеет фиксированную длину, поэтому в состав некоторых пакетов введен байт заполнитель FILL со значением «0».
Для повышения надежности передачи информации используется механизм нумерации пакетов, аналогичный механизму, который применяется в HDLC-контроллере. Для нумерации передаваемых пакетов используется 8-битное поле NUM, а для нумерации подтверждаемых пакетов - 8-битное поле RESP.
Поле Message type определяет тип управляющего сообщения и обычно состоит из четырех полей (табл. 5.89).
Таблица 5.89
Типы управляющих сообщений DDCMP
Поле 1 Поле 2 Поле 3 Поле 4 Тип сообщения
ACKTYPE ACKSUB + F RESP FILL АСК-сообщение
NAKTYPE REASON + F RESP FILL NAK-сообщение
REPTYPE REPSUB + F FILL NUM REP-сообщение
STRTTYPE STRTSUB + F FILL FILL STR-сообщение
STCKTYPE STCKSUB + F FILL FILL STACK-сообщение
АСК-сообщение (Acknowledge Message) используется, чтобы подтвердить правильное получение пронумерованных информационных сообщений с номерами до RESP. ACKTYPE - тип сообщения АСК со значением «1», ACKSUB - подтип АСК со значением «0», F - флаги соединения, FILL - байт заполнитель со значением «0».
NAK-сообщение (Negative Acknowledge Message) используется, чтобы передать информацию об ошибке от приемника данных передатчику данных. Причина ошибки указывается в поле подтипа REASON. Сообщение NAK выполняет две функции: подтверждение предварительно полученных сообщений с номерами до RESP и об ошибке в RESP+1 сообщении и передача передатчику информации об ошибке. NAKTYPE - тип сообщения NAK со значением «2», REASON - причина ошибки, F - флаги соединения, FILL - байт заполнитель со значением «0».
663
КОММУНИКАЦИОННЫЕ МИКРОКОНТРОЛЛЕРЫ И СИСТЕМЫ НА ИХ ОСНОВЕ
REP-сообщение (Reply to Message Number) используется, чтобы запросить о состоянии определенного полученного сообщения с номером NUM от приемника данных. Оно обычно высылается, когда master-станция передала информационные сообщения и не получила ответ за некоторое фиксированное время. Ответом на REP-пакет является или АСК- или NAK-ответ в зависимости от того, получила ли slave-станция (приемник) или не получила все сообщения, предварительно посланные master-станцией (передатчиком). REPTYPE - тип сообщения REP со значением «3», REPSUB - подтип REP со значением «О», F-флаги соединения, FILL - байт заполнитель со значением «О».
Стартовое сообщение (STRT - Start Message) не используется, чтобы установить соединение и синхронизацию или при его реинициализации. Функционирует совместно с сообщением подтверждения начала STACK. При передаче этого сообщения сбрасываются счетчики нумерации сообщения в передатчике и в адресованном приемнике. STRTTYPE - тип сообщения STRT со значением «6», STRTSUB - подтип STRT со значением «О», F - флаги соединения (оба флага равны «1»), FILL - байт заполнитель со значением «О».
Сообщение, подтверждающее установление соединения (STACK - Start Acknowledge Message) является ответом на STRT-сообщение, когда станция-получатель завершила инициализацию и сбросила счетчики нумерации сообщения. STCKTYPE - тип сообщения STACK со значением «7», STCKSUB - подтип STACK со значением «О», F - флаги соединения (оба флага равны «1»), FILL - байт заполнитель со значением «О».
DDCMP протокол функционирует в двух основных режимах:
1) on-line (интерактивный), или нормальный режим выполнения;
2) off-line (автономный), или режим сопровождения.
Предыдущие сообщения описывают режим on-line. Off-line (автономный), или режим сопровождения, может использоваться для тестирования/диагностики станций и простых рабочих процедур типа начальной загрузки или загрузки по линии связи, для передачи этих «прозрачных» данных используются служебные сообщения (Transparent Message).
ГЛАВА 6
ПРОЦЕССОРЫ ЦИФРОВОЙ ОБРАБОТКИ СИГНАЛОВ
6.1. ПРИНЦИПЫ ОРГАНИЗАЦИИ ПРОЦЕССОРОВ ОБРАБОТКИ СИГНАЛОВ
6.1.1. ПРИНЦИПЫ ОБРАБОТКИ СИГНАЛОВ В ЦИФРОВЫХ СИСТЕМАХ !
Архитектура DSP определяется несколькими базовыми операциями, которые используются в алгоритмах ЦОС.
Для выделения таких операций проведем функциональный анализ основных направлений ЦОС, к которым относятся цифровая фильтрация и спектральный анализ.
Цифровая фильтрация. В области цифровой фильтрации разработчик систем ЦОС имеет дело с реализацией КИХ- и БИХ-фильтров (с конечной и бесконечной импульсными характеристиками соответственно).
Оба класса фильтров относятся к классу линейных систем с постоянными параметрами (ЛСПП), в которых входная хп и выходная уп последовательности связаны отношениями типа свертки. Если обозначить через hk отклик системы на единичный импульс (импульсную характеристику ЛСПП), то получим свертку вида
У„ =Ъ\хп_к, п = 0, 1, 2....
к =0
где хп, уп - отсчеты входного и выходного сигналов; хп к - входной отсчет, задержанный на к интервалов дискретизации.
В КИХ-фильтре отсчет выходного сигнала определяется только значениями входного сигнала, а в БИХ-фильтре - значениями входного и выходного сигналов. Это хорошо видно из линейных разностных уравнений с постоянными коэффициентами, которыми описывается данный класс дискретных систем. В общем виде разностное уравнение, описывающее БИХ-фильтр, имеет вид
N - 1 м - 1
Уп = Ъькхп-к - ^АУп-к , к =0 к =1
где N, М- постоянные целые числа; Ьк, ак- постоянные коэффициенты, описывающие конкретную систему; хп, уп - отсчеты входного и выходного сигналов.
КИХ-фильтр задается уравнением
N - I
Уп = ^Ъкхп-к
1 = 0 или иначе
У„=Ьох„+ЬЛ_}+Ь2хп_2 + ... +b„xn_N + i.
Таким образом, для построения систем цифровой фильтрации требуется эффективная реализация соотношения типа дискретной свертки, которая раскладывается на операции умножения и накапливающего суммирования, а также операции задержки.
Спектральный анализ. В области спектрального (или гармонического анализа) используются прямое и обратное дискретное преобразование Фурье (ДПФ), а также рациональный способ реализации дискретного преобразования Фурье - быстрое преобразование Фурье (БПФ).
Спектральный анализ основан на известных методах представления данной функции при помощи других функций, которые называются базовыми и свойства которых считаются известными.
665
ПРОЦЕССОРЫ ЦИФРОВОЙ ОБРАБОТКИ СИГНАЛОВ
Если входная последовательность хр периодична, то ее можно представить рядом Фурье
= YXpke^\ к =
где xf - амплитуда гармоники; ejcat" = coswkn + jsmwkn- комплексная переменная; шк = 2лк / N - частота спектральной составляющей (гармоники).
Учитывая, что периодична, ряд Фурье записывается в виде
rP _ ' Y Р» Ц2я!Ы'>к п 1 уР„ Ц2яШ')кп
Хп X Xк Р ИЛИ -Гл X Хк Р
к=0 /V к=0
Данное выражение, описывающее Фурье-образ функции, называется обратным преобразованием.
Для вычисления коэффициентов ряда используется следующее выражение для ДПФ
%Р _ ХР1 ~)к.2я1Ы)пк
л=0 •
или в более компактной форме
Xf = £'х>л\где
п=0
Анализ данного выражения показывает, что основными операциями при вычислении выражения являются операции комплексного умножения и суммирования. Трудоемкость прямого вычисления данного выражения велика и возрастает с ростом N.
Для упрощения вычисления ДПФ исходную Л/-точечную последовательность разбивают на две более короткие, для которых отдельно вычисляется БПФ, а результаты далее комбинируются для получения окончательного БПФ всей последовательности. Причем деление последовательности может быть многократным.
Если последовательность разбивается на две: одна с четными, а другая с нечетными номерами, то БПФ реализуется с прореживанием по времени (входная последовательность прореживается на каждом этапе разбиения). Если в первой последовательности берутся первые N/2 отсчеты (0,.... N/2), а во второй - вторые N/2отсчетов, N/2 + 1,.... N), то БПФ реализуется с прореживанием по частоте.
Оценить сложность алгоритмов БПФ, а также их особенности можно из анализа вычислительной схемы, в основе которой лежит операция над двумя точками последовательности.
Элементарная операция (операция «бабочка»), которая определяет двухточечное преобразование, сводится к вычислению выражений: '
х = А + BW*;
y = A-BW*,
где А, В- входные значения; W.- - коэффициент.
Для получения выходной последовательности в естественном порядке необходимо определенным образом переставить входную последовательность. Перестановка входных элементов состоит в образовании двоичных номеров выходной последовательности путем добавления единицы к старшему разряду с распространением переноса в сторону младших разрядов (вправо). Такая адресация получила название бит-реверсивной.
Вычисление коэффициента wfi = cos[(2tz7/V) к] - ;sin[(2fl7/V)K] можно осуществлять следующим образом:
666
ПРИНЦИПЫ ОРГАНИЗАЦИИ ПРОЦЕССОРОВ ОБРАБОТКИ СИГНАЛОВ
• используя подпрограммы или таблицы синуса и косинуса;
• прямым табличным способом (выборкой готовых значений из таблицы);
• используя рекуррентную формулу
W* = (W*~') При = 1;
• таблично-алгоритмическим способом, так как на последующих этапах коэффициенты повторяются.
При использовании алгоритма БПФ с прореживанием по частоте требуется перестановка элементов выходной последовательности, а базовая операция «бабочка» сводится к вычислению выражений:
х = А + В,
y = (A-B)W*,
Для получения амплитуд и фаз составляющих спектра (гармоник) необходимо также вычислить следующие выражения:
+ ^Ira . Xrc t
----------; arctg ——, . !
N x„„ j
где XRc, вещественная и мнимая части комплексных коэффициентов.
В гомоморфной обработке сигналов дополнительно требуется вычисление функций log 2 X И 2'.
6.1.2. ОБОБЩЕННАЯ АРХИТЕКТУРА DSP
На рис. 6.1 приведен операционный базис алгоритмов ЦОС. Поставив в соответствие каждой операции блок, можно получить обобщенную архитектуру DSP (рис. 6.2). Очевидно, что реализация выделенных операций может быть различной. Предельное быстродействие достигается при максимальной аппаратной поддержке операций, что приводит к значительным аппаратным затратам.
Это обстоятельство, а также желание обеспечить преемственность в решениях и программную совместимость приводят, в конечном счете, к аппаратной реализации не в целом той или иной операции, а отдельных ее составляющих. Причем в разных семействах (16-, 24-, 32-разрядных) архитектура отражает специфику задач ЦОС, на которые она ориентирована.
Основными операциями являются: задержка, АЦП и ЦАП (функции кодека), умножение с накоплением - операция MAC (multiply and accumulate), умножение, сложение, вычисление значений функций sin, cos, arctg, log2 л, 2х, табличное вычисление коэффициентов W*. К особенностям следует также отнести необходимость использования бит-реверсивной адресации.
Обобщенная архитектура процессора DSP образуется тремя составляющими: процессорным ядром, подсистемами ввода/вывода и хранения. Структура процессорного ядра отражает выделенный операционный базис и учитывает особенности алгоритмов ЦОС. Блок генерации адреса обеспечивает необходимые способы адресации, в том числе бит-реверсивную. Синтезатор тактовой частоты (PLL) дает возможность регулировать производительность и потребляемую мощность. Блок выполнения операций реализует операции с фиксированной точкой и операции с плавающей точкой для приложений, где
667
ПРОЦЕССОРЫ ЦИФРОВОЙ ОБРАБОТКИ СИГНАЛОВ
К
иг
Рис. 6.1. Операционный базис процессоров DSP
требуются высокая точность и производительность. Очевидно, что поддержка операций с плавающей точкой может и отсутствовать (используется обычно в 32-разрядных DSP).
В процессорное ядро введен блок отладки и контроля, который содержит средства внутрисхемной эмуляции (ОпСЕ), средства тестирования и отладки (JTAG), сторожевой таймер (WDT). Данный набор средств сегодня практически является стандартным.
Подсистема ввода/вывода включает кодек (АЦП и ЦАП), параллельные и последовательные порты ввода/вывода, host-интерфейс для связи с персональным компьютером или другой ЭВМ, аудио-интерфейс, широтно-импульсный модулятор, таймеры и другие устройства.
Организация подсистемы хранения также во многом отражает специфику алгоритмов ЦОС. Так, в частности, выделение двух блоков памяти X и Y позволяет одновременно считывать операнды для свертки, а выделение памяти программ позволяет распараллелить выполнение этапов командного цикла (чтение команды и формирование адреса -
668
ПРОЦЕССОРЫ СЕМЕЙСТВА DSP56000
Блок управления:
Блок выполнения операций:
Блок генерации адреса
Блок управления программой
Синтезатор тактовой частоты
Контроллер прерываний
с фиксированной точкой
bl, Qk X и - к, Ул к
г
Блок
задержки
J~
| МЛС, ллу |
с плавающей точкой
Сопроцессоры: фильтр-сопроцессор, витерби-сопроцессор, сопроцессор циклического кода
Процессорное ядро
Блок отладки и контроля:
OnCE, JTAG,
WDT
Подсистема ввода / вывода
Подсистема хранения
Внутренняя память
Периферийные устройства: кодек, порты ввода/вывода, host -интерфейс, таймеры и т.п.
Память
Память
данных
данных
Память значений sin, arctg и т.д.
Память значений
Память
Память
загрузки
программ
Рис. 6.2. Обобщенная архитектура DSP
чтение операндов - выполнение - запись результата). Такая модель используется в архитектурах гарвардского типа.
Необходимые сложные операции (sin, arctg, и др.) целесообразно выполнять табличным способом.
В случае использования А- и ц-нелинейных зависимостей, для представления отсчета требуется в данном случае 8 бит: 1 бит - знак, 3 бита - номер участка А- или ц-закона, 4 бита - номер шага на выбранном участке. Данные нелинейные характеристики позволяют устранить избыточность данных за счет компандирования (COMpressor/ exPANDER), которое заключается в сужении динамического диапазона при аналого-цифровом преобразовании и расширение при цифроаналоговом преобразовании. Очевидно, что скорость выполнения алгоритма БПФ существенно возрастет, если хранить таблицы значений W„. Наличие памяти загрузки позволяет упростить процесс занесения кода программы в процессор. Конкретную реализацию обобщенной архитектуры рассмотрим на примере семейства DSP 56000, которое по организации процессорного ядра и составу переферии является базовым.
6.2. ПРОЦЕССОРЫ СЕМЕЙСТВА DSP56000
6.2.1. ОБЗОР АРХИТЕКТУРЫ И ШИННОЙ ОРГАНИЗАЦИИ DSP56000
Общая характеристика
Высокая производительность процессоров DSP позволяет использовать их в области коммуникаций, высокоскоростного управления, обработке данных, компьютерных приложениях и аудиоприложениях. Приложения цифровой обработки сигналов эффектив
669
ПРОЦЕССОРЫ ЦИФРОВОЙ ОБРАБОТКИ СИГНАЛОВ
ны в любой области электроники, поскольку любое приложение для аналоговой электронной схемы может быть разработано с использованием DSP.
Ниже приведены типичные задачи цифровой обработки сигналов, для решения которых успешно используется DSP:
• телекоммуникации (голосовая почта, телеконференции, секретные телефоны);
• коммуникации;
• радиокоммуникации;
• компьютерное оборудование (матричные процессоры, рабочие станции, графические акселераторы);
• обработка изображений;
• графика;
• инструментарий (спектральный анализ, волновая генерация); I
• обработка речи;
• обработка аудиосигналов; —,
• высокоскоростное управление; >
• медицинская электроника; {
• цифровое видео;
• радары и сонары (навигация, океанография, поиск);
• сейсмография.
Как было показано ранее, МАС - основная операция, используемая в процессорах DSP. Структура DSP содержит необходимые блоки, обеспечивающие эффективную реализацию операции МАС. Два операнда непосредственно участвуют в операции умножения, и результат суммируется. Этот процесс происходит внутри DSP56000 с использованием двух отдельных модулей памяти за один цикл. Благодаря наличию двух модулей памяти и независимого суммирующего умножителя, можно объединить две пересылки, умножение и сложение в одну операцию.
Основу процессора составляют три параллельно работающих устройства: арифметико-логическое устройство (ALU), устройство генерации адреса (AGU) и программируемый контроллер (РС).
DSP имеет периферийные устройства на кристалле в стиле микроконтроллеров, программируемую память, память данных и порты расширения памяти. Программная модель и система инструкций ориентированы на разработку эффективных и компактных программ.
Основные характеристики DSP перечислены ниже:
• Скорость - до 30 и более миллионов операций в секунду.
• Точность - 24-разрядные данные, обеспечивающие обработку в динамическом диапа- , зоне 144 децибел, промежуточные результаты хранятся в 56-разрядном аккумуляторе, что обеспечивает диапазон в 336 децибел.
• Параллелизм - каждое из операционных устройств на кристалле, память, периферий- > ные операции независимы и работают параллельно благодаря развитой системе шин.
• Интеграция - в дополнение к трем независимым операционным устройствам DSP имеет шесть видов памяти на кристалле, три периферийных устройства (последовательный коммуникационный интерфейс (SCI), синхронный последовательный интерфейс (SSI), host-интерфейс, генератор тактовой частоты и семь шин (три адресных и четыре шины данных); при этом система является компактной и достаточно дешевой, а также обладает низким энергопотреблением.
• Невидимый конвейер - трехступенчатый конвейер инструкций прозрачен для программиста.
670
ПРОЦЕССОРЫ СЕМЕЙСТВА DSP56000
• Система инструкций - 62 инструкции, мнемоники которых совпадают с инструкциями микроконтроллеров и упрощают трансляцию программ для DSP. Дополнительные инструкции DSP служат для управления параллельными операционными устройствами.
• Совместимость программного кода для всех представителей семейства.
• Низкое энергопотребление - за счет использования КМОП-технологии, а также следующих дополнительных возможностей управления энергопотреблением: инструкция WAIT; инструкция STOP, останавливающая внутренний генератор тактовой частоты; уменьшение потребления энергии за счет уменьшения частоты.
Архитектура DSP, как это следует из приведенных выше характеристик, разработана специально для приложений цифровой обработки сигналов.
Структура DSP56002, который является базовым для семейства, представлена на рис. 6.3. Модули, входящие в состав других процессоров семейства, рассматриваются в отдельных параграфах настоящей главы.
Основные компоненты DSP:
• шины данных;
• шины адреса;
• арифметико-логическое устройство данных;
• устройство генерации адреса;
• память данных X;
• память данных Y;
• контроллер программ;
• память программ;
• устройства ввода/вывода: расширение памяти (порт А); порты ввода/вывода (В и С); host-интерфейс; последовательные интерфейсы; таймеры.
Рис. 6.3. Структура DSP56002
671
ПРОЦЕССОРЫ ЦИФРОВОЙ ОБРАБОТКИ СИГНАЛОВ
Структура шин
Шины данных. DSP организован на регистрах центрального процессора, составляющих три независимых операционных устройства. Передача данных на кристалле осуществляется по четырем двунаправленным 24-разрядным шинам: шине данных X (XDB), шине данных Y (YDB), шине данных программ (PDB), глобальной шине данных (GDB). Шины данных X и Y могут объединяться в 48-разрядную шину для передачи инструкций. Шины XDB и YDB сделаны локальными для увеличения скорости и уменьшения потребления мощности. Все другие передачи данных происходят по шине GDB. Структура шин поддерживает передачу данных типов «регистр - регистр», «регистр - память», «память -регистр». Размер передаваемых данных изменяется от 24- до 56-битных слов в одном командном цикле. Переходы между шинами осуществляются с помощью специального
переключателя.
Шины адреса. Адреса внутренней памяти данных X и Y передаются по двум однонаправленным 16-битным шинам - адресной шине X (ХАВ) и адресной шине Y (YAB). Адреса памяти программ передаются по двунаправленной шине адресов программ (РАВ).
Пространство внешней памяти адресуется с помощью однонаправленной 16-битной шины с тремя состояниями выходов, которую можно переключить на ХАВ, YAB или РАВ. В одном командном цикле может быть произведен только один доступ к внешней памяти.
Переход между шинами осуществляется с помощью переключателя внутренних шин. Он представляет собой программируемую матрицу ключей, позволяющую соединять две любые внутренние шины без задержек.
Устройство манипуляций с битами физически расположено в блоке переключателя шин, так как переключатель обеспечивает доступ к любому адресному пространству. Устройство манипуляций с битами выполняет соответствующие операции в памяти, адресных регистрах, регистрах управления и регистрах данных через шины XDB, YDB и GDB.
Рис. 6.4. АЛУ данных
Арифметико-логическое устройство данных
АЛУ данных (рис. 6.4) разработано для улучшения возможности обработки сигналов широкого динамического диапазона. Специальные схемы обеспечивают простой контроль ошибок округления и переполнения обрабатываемых данных. АЛУ содержит четыре 24-битных входных регистра, два 48-битных аккумулятора, два 8-битных регистра расширения аккумулятора, аккумулятор сдвига, две шины данных и параллельное неконвейеризованное устройство умножения с аккумулированием (МАС). Операции АЛУ используют арифметику дополнения до двух. В регистры АЛУ могут быть записаны 24- или 48-разрядные операнды. АЛУ позволяет выполнять в одном командном цикле инструкции умножения, сложения, вычитания, итерационного
672
ПРОЦЕССОРЫ СЕМЕЙСТВА DSPS6000
деления, нормализации, сдвигов, логических операций. Регистры АЛУ данных могут быть прочитаны или записаны 24-битными или 48-битными операндами по шинам XDB, YDB. Операнды источника могут иметь длину 24,48 и 56 бит и всегда находятся в регистрах АЛУ данных. Результат любой операции в АЛУ данных сохраняется в аккумуляторе.
24-битные данные обеспечивают динамический диапазон в 144 дБ. Такого диапазона достаточно для большинства приложений, в которых используются параметры разрядностью не больше 24 бит. 56-битный аккумулятор АЛУ данных обеспечивает 336 дБ внутреннего динамического диапазона.
За один цикл в АЛУ выполняются следующие операции: умножение, округление, сложение, вычитание, деление, нормализация, сдвиги и логические операции.
АЛУ данных имеет следующие компоненты:
• четыре 24-битных входных регистра;
• параллельный умножитель - аккумулятор (МАС);
• два 48-битных регистра аккумулятора;
• два 8-битных регистра расширения аккумулятора;
• аккумулятор сдвига;
• два устройства одвига/ограничения по шине данных.
Входные регистры АЛУ данных (Х1, ХО, Y1, Y0). Это 24-битные регистры данных общего назначения. Они могут использоваться как независимые 24-битные регистры или как два 48-битных регистра X и Y, образованные объединением Х1 :Х0 и Y1 :Y0 соответственно. Х1 - старшее слово X, Y1 - старшее слово Y. Регистры служат входными буферами между XDB или YDB и устройством МАС. Они используются как операнды источника АЛУ данных. Содержимое регистров может быть выдано на соответствующую шину данных для процедур обработки прерываний.
Аккумуляторы АЛУ данных. Шесть регистров АЛУ данных (А2, А1, АО, В2, В1 и ВО) формируют два 56-битных аккумулятора общего назначения. Каждый из аккумуляторов содержит по три объединенных регистра (А2:А1 :А0 и В2:В1 :В0). 24-битная MSP хранится в А1 или В1,24-битная LSP - в АО или ВО. 8-битное расширение - в А2 или В2.
8-битные регистры расширения предназначены для защиты от переполнения. В DSP56000/DSP56001 диапазон значений операндов составляет от -1 до +0,9999998. Если сумма двух чисел меньше -1 или больше +0,9999998, то возникает потеря значимости или переполнение. 8-битный регистр расширения формирует результат в случае 255 переполнений или 255 потерь значимости.
При использовании регистра расширения аккумулятора бит переполнения в регистре кодов условий всегда установлен в единицу.
Расширение знака обеспечивается автоматически при записи в 56-битный аккумулятор А или В 48-битного или 24-битного операнда. Если записывается 24-битный операнд, LSP автоматически заполняется нулями для представления операнда в 56-битной форме.
Если аккумуляторы А и В прочитаны, можно с помощью опций масштабировать их содержимое на один бит влево или вправо для блока арифметики с плавающей точкой.
МАС и логическое устройство. МАС и логическое устройство входят в главное арифметическое устройство DSP и выполняют все вычисления с операндами данных. В случае арифметической инструкции устройство обрабатывает до трех операндов и выдает 56-битный результат в следующем формате: расширение: старшая значащая часть: младшая значащая часть (EXT: MSP:LSP).
Операция МАС выполняется независимо и параллельно с операциями на шинах данных, что облегчает буферизацию входных и выходных данных АЛУ.
Арифметическое устройство содержит умножитель и два аккумулятора. На вход умножителя могут поступать данные только из регистров X и Y. Умножитель выполняет умножение
673
ПРОЦЕССОРЫ ЦИФРОВОЙ ОБРАБОТКИ СИГНАЛОВ
ХО, XI.YO ХО, X1.Y0
Рис. 6.5. Устройство МАС
24 х 24 с дополнением до двух. 48-битный результат выравнивается и суммируется с 56-битным содержимым аккумулятора А или В. 56-битная сумма сохраняется в аккумуляторе (рис. 6.5). 8-битное расширение аккумулятора фиксирует переполнение до 256 и позволяет складывать или вычитать содержимое 56-битных аккумуляторов. Операция МАС (умножение/ сложение) - неконвейеризо-ванная одноцикловая операция. Если инструкция предусматривает умножение без сложения, то устройство МАС очищает аккумулятор и складывает его содержимое с произведением. Таким образом, результат всех ариф-
метических инструкций представляется в формате EXT:MSP:LSP (А2:А1 :А0 или В2:В1 :В0). Если результат сохраняется в 24-битном операнде, LSP просто отсекается или округляется до MSP.
Округление до ближайшего целого применяется при сложении произведения с содержимым аккумулятора в специальной команде DSP - MACR. Бит, до которого идет округление в аккумуляторе, определяется битом режима масштабирования в регистре статуса.
Логическое устройство выполняет логические операции AND, OR, EOR, NOT над регистрами АЛУ. Это устройство имеет разрядность 24 бита и оперирует старшей значащей частью операнда в аккумуляторе.
Устройство сдвига аккумулятора. Асинхронное параллельное устройство сдвига с 56-битным входом и 56-битным выходом подключено непосредственно к выходам МАС. Выполняет операции: нет сдвига; сдвиг на один бит влево: ASL, LSL, ROL; сдвиг на один бит вправо: ASR, ASL, ROR; обнуление.
Устройство сдвига/ограничения. Обеспечивает специальную обработку данных при выдаче из регистров аккумулятора на шины данных. Для каждой шины данных имеется отдельное устройство сдвига/ограничения.
Ограничение (насыщенная арифметика). Аккумулятор АЛУ данных в DSP56000/ DSP56001 имеет 8 бит расширения. При выдаче данных из регистров аккумулятора А или В на шины данных необходимо производить ограничение битов расширения.
Устройство ограничения нормализует результат вычислений без изменения содержимого регистров аккумулятора А и В.
Если содержимое аккумулятора источника может быть представлено без переполнения, то устройство ограничения отключено, и операнд не модифицируется.
В противном случае устройство ограничения заменяет данные максимальной величиной и устанавливает знак данных соответственно операнду источника: $7FFFFF - для 24-битного или $7FFFFF FFFFFF - для 48-битного положительного числа, $800000 - для 24-битного, $800000 000000 - для 48-битного отрицательного числа. Этот процесс называется насыщенной арифметикой (табл. 6.1).
674
ПРОЦЕССОРЫ СЕМЕЙСТВА DSP56000
Таблица 6.1
Ограничения данных
Приемник Операнд источника Знак аккумулятора Ограничивающее значение Тип доступа
XDB YDB
X Х:А + 7FFFFF - Один 24-битный
Х:В - 800000 -
Y Y:A + - 7FFFFF Один 24-битный
Y:B - - 800000
ХиУ Х:А Y:A + 7FFFFF 7FFFFF Два 24-битных
Х:А Y:B - 800000 800000
Х.В Y.A + 7FFFFF 7FFFFF
Х:В Y:B — 800000 800000
L:AB + 7FFFFF 7FFFFF
L:BA - 800000 800000
L(X:Y) L:A + 7FFFFF 7FFFFF Один 48-битный
L:B - 800000 800000
Представление данных и округление. DSP56000/DSP56001 используют дробное представление данных для всех операций АЛУ. На рис. 6.6 показан механизм этого представления. Десятичная точка всегда расположена слева.
МАС использует округление содержимого аккумулятора с одинарной точностью. Данный метод округления называется округлением до ближайшего целого или конвергентным округлением.
АЛУ данных
Слово операнда
XI, ХО
Y1,YO Al, АО Bl,ВО
Длинное слово операнда
Х1:Х0=Х
Y1:YO=Y А1:А0=А10 В 1:В0=В 10
Аккумулятор А или В _28
А2, В2 А1,В1
АО, ВО
Знак расширения Операнд Нули
Рис. 6.6. Расширение битов и выравнивание операндов
Программная модель АЛУ данных. Программная модель АЛУ данных приведена на рис. 6.7 («*» - читаются как нули и не записываются).
675
ПРОЦЕССОРЫ ЦИФРОВОЙ ОБРАБОТКИ СИГНАЛОВ
Входные регистры АЛУ данных
47______X_________0 47______Y_________О
I XI | ХО | I Y1 | Y0 |
23 0 23 0 23 0 23 0
Аккумуляторные регистры АЛУ данных
55 А 0 ________________55 ____________В________0
| ♦ |А2 I Al | АО | | * | В2| В1 | ВО |
23 8 7 0 23 0 23 0 23 8 7 0 23 0 23 0
Рис. 6.7. Программная модель АЛУ данных
Пространство памяти DSP56002. Пространство памяти DSP56002 представлено на рис. 6.8.
Регистр OMR расширен битами YD (3 бит), МС (4 бит) SD (6 бит). Биты DE и YD задают режимы памяти (табл. 6.2).
Таблица 6.2
Режимы работы памяти
DE YD Память данных
0 0 Внутренние ПЗУ запрещены и их адреса являются частью внешней памяти.
0 1 Внутреннее ПЗУ данных X запрещено и является частью внешней памяти. Внутренние ОЗУ и ПЗУ данных Y запрещены и являются частью внешней памяти.
1 0 ПЗУ данных X и Y разрешены.
1 1 Внутренние ОЗУ и ПЗУ данных Y запрещены и являются частью внешней памяти. Внутреннее ПЗУ данных X разрешено.
Однокристальный режим. В однокристальном режиме разрешены все внутренние памяти данных и программ. Программный сброс вызывает переход по адресу $0000 и выполнение соответствующей процедуры.
Карты памяти для режима 0 и режима 2 идентичны, но в режиме 2 вектор сброса находится по адресу $Е000.
Режим загрузки из EEPROM. Загрузочные режимы предназначены для загрузки программ из байтового ПЗУ во внутреннюю память программ в течение сброса по питанию. После включения питания генератор состояний ожидания добавляет 15 состояний ожидания ко всем обращениям к внешней памяти, что позволяет использовать медленную память.
Программа загрузки использует байты в трех последовательно расположенных ячейках внешнего ПЗУ для образования слова внутренней памяти программ. В загрузочном режиме разрешены загрузочное ПЗУ на кристалле и выполнение программы загрузки.
Нормальный расширенный режим. В этом режиме разрешено внутреннее ОЗУ программ и вектор аппаратного сброса по адресу $Е000.
Режим разработки. В этом режиме внутреннее ОЗУ программ запрещено, а вектор аппаратного сброса находится по адресу $0000. Все ссылки на пространство памяти программ переадресуются прямо во внешнюю память.
Режим загрузки по Host. В этом режиме разрешены загрузочное ПЗУ и выполнение программы загрузки. Режим аналогичен режиму 1, за исключением того, что программа загружается из внешней памяти программ по host-интерфейсу.
Режим загрузки по SCI. В этом режиме разрешены загрузочное ПЗУ и выполнение программы загрузки. Внутреннее и/или внешнее ОЗУ программ загружается по интерфейсу SCI. Количество слов программы и стартовый адрес должны быть определены.
676
ПРОЦЕССОРЫ СЕМЕЙСТВА DSP56000
Режим О
SFFFF $01FF Внешняя
Внутреннее ОЗУ
S003F Прерывания
$0 Сброс
Режим 2
SFFFF
$Е000
$01FF
Сброс
Внешняя
Внутреннее ОЗУ
Внутреннее ОЗУ Внутренний сброс
$003F
$0
Внутреннее ОЗУ Внешний сброс
Прерывания
Режим 3
SFFFF
----------5
Внешняя
Память программ
$00 3F
$0
Прерывания
Сброс
Нет внутреннего ОЗУ Внешний сброс
DE=1 YD=0 DE YD =0 =0
$FFFF $FFC0 Периферия па кристалле Внешняя периферия SFFFF SFFC0 Периферия ла кристалле Внешняя периферия
SFFBF Внешняя Внешняя SFFBF
$01 FF S0I7F память данных X • память • данных Y Внешняя память данных X Внешняя память
Внутреннее ПЗУ Х+А Внутреннее ПЗУ х+м и Внутреннее ПЗУ Y данных Y Память данных
$0FF $0 Внутреннее ОЗУХ Внутреннее ОЗУ Y $OFF $0 Внутреннее ОЗУХ Внутреннее ОЗУ Y
ПЗУ данных разрешено ПЗУ данных запрещено
DE= 1 YD= 1 DE YD =0 = 1
SFFFF SFFCO Периферия на кристалле Внешняя периферия $FFFF $FFC0 Периферия на кристалле Внешняя периферия
$ FFB F Внешняя $FFB F
память
$01 FF $017 F данных X Внешняя Внешняя память Внешняя память
Внутреннее ПЗУ Х + А Внутреннее ПЗУ х + ми память данных Y данных X данных Y
$0FF $0 Внутреннее ОЗУХ SOFF $0 Внутреннее ОЗУХ
Рис. 6.8. Пространство памяти DSP56002
677
ПРОЦЕССОРЫ ЦИФРОВОЙ ОБРАБОТКИ СИГНАЛОВ
Программа загрузки по SCI ожидает приема трех байтов, определяющих количество слов программы, трех байтов, определяющих адрес, с которого будут загружаться слова программы, и трех байтов для загрузки каждого слова программы.
Режимы DSP56002 и управляющие сигналы приведены в табл. 6.3.
Таблица 6.3
Операционные режимы работы DSP56002
Опер, режим МС МВ МА Описание
0 0 0 0 Однокристальный режим - ОЗУ программ разрешено
1 0 0 1 Режим загрузки с EPROM, выход в режим 0
2 0 1 0 Нормальный расширенный режим - ОЗУ программ разрешено
3 0 1 1 Режим разработки - ОЗУ программ запрещено
4 1 0 0 Резерв
5 1 0 1 Загрузка по Host, выход в режим 0
6 1 1 0 Загрузка по SCI (внешняя синхронизация), выход в режим 0
7 1 1 1 Резерв
Данные принимаются в SCI, начиная с младших битов. После окончания приема слов программы начинается выполнение загруженной программы. SCI запрограммирован на работу в асинхронном режиме сдлиной данных-8 бит, 1 стоп-бит, проверка на четность отсутствует.
Устройство генерации адресов (AGU) и режимы адресации
Структура AGU. AGU выполняет вычисление эффективных адресов данных в памяти. Это устройство использует три типа адресной арифметики: линейную модификацию адреса, модульную модификацию адреса, адресацию с реверсивным переносом и работает параллельно с остальными устройствами на кристалле, что сокращает время на генерацию адресов. Структура AGU показана на рис. 6.9. Все регистры AGU являются 24-разрядными, в которых 16 младших разрядов являются значащими. Старшие 8 разрядов недоступны для записи и при чтении заполняются нулями.
Блок регистров адреса (R0-R3 И R4-R7). Каждый из двух подблоков регистров адреса содержит четыре 16-битных регистра, которые содержат адреса для обращения к памяти. Каждый регистр может быть прочитан или записан с использованием глобальной шины данных. При выдаче содержимого регистров на шину данных 16-битные регистры записываются в два младших значащих байта шины данных, а старший значащий байт заполняется нулями.
При записи в регистры старший значащий байт шины данных отсекается. Каждый адресный регистр может использоваться как вход АЛУ адресов для модификации регистров. Регистр из АЛУ нижних адресов и регистр из АЛУ верхних адресов доступны в одной инструкции.
АЛУ нижних
------► |«4-----АЛУ верхних ХА YA РАВ
NO МО
N1 Ml
N2 М2
N3 М3
R0 R4
R1 R5
R2 R6
R3 R7
16
| Тронной мультиплексор
М4 N4
М5 N5
Мб N6
М7 N7
Рис. 6.9. Структура AGU
Глобальная шина
678
ПРОЦЕССОРЫ СЕМЕЙСТВА DSP5S000
Если параллельно осуществляется пересылка данных из памяти X и из памяти Y, адресные регистры разделяются на два блока: RO - R3, R4 - R7. Содержимое регистров адреса может модифицироваться соответственно режиму адресации. Тип модификации определяется содержимым регистров модификации (Мп). Регистры смещения (Nn) используются для режима адресации «модификация со смещением».
Большинство режимов адресации модифицируют регистры адреса в цикле «чтение -модификация - запись».
Блок регистров смещения (N0-N3 И N4-N7). Каждый из двух подблоков регистров смещения содержит четыре 16-битных регистра, которые содержат величину смещения, используемую для модификации адресных указателей или данных. Каждый регистр может быть прочитан или записан с использованием глобальной шины данных. При выдаче содержимого регистров на шину данных 16-битные регистры записываются в два младших значащих байта шины данных, а старший значащий байт заполняется нулями. При записи в регистры старший значащий байт шины данных отсекается.
Блок регистров модификации (МО-МЗ И М4-М7). Каждый из двух подблоков регистров модификации содержит четыре 16-битных регистра, которые определяют тип адресной арифметики для вычисления модификаций регистров адреса или данных. Каждый регистр может быть прочитан или записан с использованием глобальной шины данных. При выдаче содержимого регистров на шину данных 16-битные регистры записываются в два младших значащих байта шины данных, а старший значащий байт заполняется нулями. При записи в регистры старший значащий байт шины данных отсекается. Каждый регистр модификации устанавливается в $FFFF после сброса, что определяет линейную арифметику при вычислении модификаций адреса.
АЛУ адресов. Два идентичных АЛУ адресов содержат 16-битный полный адрес, который может быть инкрементирован, декрементирован или к которому может быть добавлено содержимое регистра смещения. Второе полное слагаемое (называемое модулем) определяется результатом суммирования первого полного слагаемого с величиной модуля, хранящейся в регистре модификации. Третье полное слагаемое определяется инкрементированием, декрементированием содержимого адресного регистра или его суммированием с величиной смещения и переносом. Смещение и реверсивный перенос подаются параллельно на разные входы. Тестовая логика определяет, какой из трех результатов подается на выход в качестве полного адреса.
Каждое АЛУ адресов может модифицировать один регистр адреса в течение одного командного цикла. Содержимое регистра модификации определяет тип арифметики для модификации адреса. Величина модификатора декодируется в АЛУ адресов.
Адресация. DSP56000/DSP56001 обеспечивают три различных типа адресации: прямая регистровая, косвенная регистровая и специальная (табл. 6.4). При прямой регистровой адресации и специальных режимах использование AGU не является обязательным (эти режимы описаны в Приложении).
Косвенная регистровая адресация. Если регистр адреса используется для указания ячейки памяти, адресация называется косвенной регистровой, т.е. содержимое регистра указывает не на сам операнд, а на адрес операнда.
Поле «перемещение по шине данных» в инструкции указывает пространство памяти, на которое идет ссылка. Содержимое регистров AGU определяет эффективный адрес и его модификацию.
Без модификации. Адрес операнда содержится в регистре адреса Rn. Содержимое регистра не изменяется при выполнении инструкции.
Постинкремент. Адрес операнда содержится в регистре адреса Rn. После использования содержимое регистра инкрементируется. Этот режим адресации используется для работы с памятью X, Y и для модификации содержимого регистра адреса без пересылки соответствующих данных.
679
ПРОЦЕССОРЫ ЦИФРОВОЙ ОБРАБОТКИ СИГНАЛОВ
Таблица 6.4
Косвенная регистровая адресация
Режим адресации Использование модификатора Ссылка на операнд Синтаксис
S с D А Р X Y L XY
Без модификации Постинкремент с 1 Постдекремент с 1 Постинкремент со смещением Nn Постдекремент со смещением Nn Индексация со смещением Nn Предекремент с 1 Нет Да Да Да Да Да Да X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X X (Rn) (Rn)+ (Rn)-(Rn)+(Nn) (Rn)-(Nn) (Rn+Nn) -(Rn)
Примечание: S = ссылка на системный стек; С = ссылка на регистр программного контроллера; D = ссылка на регистр АЛУ данных; А = ссылка на регистр АЛУ адресов; Р = ссылка на память программ; X = ссылка на память данных; XY = ссылка на память данных Y; L = ссылка на память L; ХУ=ссылка на память XY.
Постдекремент. Адрес операнда содержится в регистре адреса Rn. После использования содержимое регистра декрементируется. Этот режим адресации используется для работы с памятью X, Y и для модификации содержимого регистра адреса без пересылки соответствующих данных.
Постинкремент со смещением Nn. Адрес операнда содержится в регистре адреса Rn. После использования содержимое регистра суммируется с содержимым регистра смещения Nn и сохраняется в регистре адреса. Содержимое регистра смещения не изменяется. Этот режим адресации используется для работы с памятью X, Y и для модификации содержимого регистра адреса без пересылки соответствующих данных.
Постдекремент со смещением Nn. Адрес операнда содержится в регистре адреса Rn. После использования из содержимого регистра адреса вычитается содержимое регистра смещения Nn и результат сохраняется в регистре адреса. Содержимое регистра смещения не изменяется. Этот режим адресации используется для работы с памятью X, Y и для модификации содержимого регистра адреса без пересылки соответствующих данных.
Индексный со смещением Nn. Адрес операнда - сумма содержимого регистра адреса Rn и содержимого регистра смещения Nn. Содержимое регистра адреса и регистра смещения не изменяется. Этот режим адресации не может использоваться для работы с памятью X, Y.
Предекремент. Адрес операнда - содержимое регистра адреса Rn, декрементированное на единицу перед выборкой операнда. Содержимое регистра адреса декрементируется и сохраняется. Этот режим адресации используется для работы с памятью X, Y, но не может использоваться для модификации содержимого регистра адреса без пересылки соответствующих данных.
Типы модификации адреса. АЛУ адресов поддерживает линейную, модульную арифметику и арифметику с реверсивным переносом для всех режимов косвенной адресно-регистровой адресации. Эти типы арифметики упрощают создание структур данных в памяти для очередей, линии задержки, циклических буферов, стеков. Содержимое регистров модификации определяет тип арифметики для вычисления адреса; для модульной арифметики содержимое регистра модификации также определяет модуль. Каждому регистру адреса соответствует свой регистр модификации.
680
ПРОЦЕССОРЫ СЕМЕЙСТВА DSP56000
Таблица 6.5
Линейная модификация адресов
Величина модификатора Мп Арифметика режима адресации
0 1 2 32766 32767 65535 Реверсивный перенос (реверсия бита) Модуль 2 Модуль 3 Модуль (Мп+1) Модуль 32767 Модуль 37768 Резерв Линейная
Линейный модификатор (Мп = $FFFF). Используется нормальная 16-битная линейная арифметика (табл. 6.5). При вычислении адреса используется 16-битное смещение Nn, инкремент и декремент. Диапазон величин Nn для чисел со знаком - от -32,768 до +32,767, для беззнаковых чисел - от 0 до +65,535.
Модульный модификатор (Мп = Модуль - 1). Модификация адреса использует модуль М значением от +2 до +32,767 (см. табл. 6.5).
Содержимое регистра адреса ограничивается адресным интервалом размера М, определяющего верхнюю и нижнюю границы адресов. Величина m = М - 1 сохраняется в регистре модификации (рис. 6.10). Нижняя граница (базовый адрес) должна содержать нули в К младших значащих битах, где 2К> М и, следовательно, должна быть умножена на 2К. Верхняя граница = нижняя граница плюс модуль минус 1.
Начиная с М <2К, при однажды выбранном М создается последовательная серия блоков памяти (каждый длиной 2К), в которой размещается циклический буфер. Если М < 2К, то расстояние между двумя последовательными циклическими буферами должно быть (2К) - М. Например, для создания циклического буфера с 21 уровнями (М = 21) нижняя адресная граница должна иметь пять младших битов, равных 0 (2К > 21, поэтому К > 5). В регистр Мп загружается значение 20. Нижняя граница может выбираться из величин 0, 32, 64, 96,128,160 и т. д. Верхняя граница буфера равна нижней границе плюс 21. Таким образом, остается 11 неиспользованных ячеек памяти между верхним адресом и следу-
ющим нижним адресом.
Для указателя адреса не требуется установка на начало нижней границы или на ко-
нец верхней границы адреса - он может быть инициализирован по любому адресу, входящему в диапазон, определяемый модулем. Также не нужно запоминать верхнюю или
нижнюю границу адресов - сохраняется только область модуля в Мп (границы определя-
ются содержимым Rn). Использование косвенного режима адресации (Rn)+ при инкременте адресного регистра после верхней границы буфера вызывает возврат обратно через базовый адрес (нижняя граница). Аналогично, использование косвенного режима адресации (Rn)- при декременте адресного регистра после нижней границы буфера вызывает возврат через базовый адрес + М - 1.
Указатель адреса
Верхняя граница
I
М = модуль
Нижняя граница
Рис. 6.10. Циклический буфер
681
ПРОЦЕССОРЫ ЦИФРОВОЙ ОБРАБОТКИ СИГНАЛОВ
Рис. 6.11. Линейная адресация с модульной модификацией
В случае использования смещения Nn при вычислении адреса 16-битное абсолютное значение |Nn| должно быть равно или меньше М. Если Nn > М, результат зависим отданных и непредсказуем, за исключением специального случая: Nn = Р х 2К, где Р - положительное целое число. Для этого случая, когда используется режим адресации (Rn) + Nn, указатель Rn будет перемещаться линейно, к тому же самому относитель
ному адресу в новом буфере, который находится на Р блоков памяти впереди (рис. 6.11). Аналогично для (Rn) - Nn указатель будет перемещаться на Р блоков памяти назад. Эта техника используется при последовательной обработке нескольких таблиц или N-раз-мерных массивов. Диапазон значений Nn: от -32768 до +32767. Устройство модульной арифметики автоматически перемещает указатель адреса на требуемую позицию. Этот тип модификации адреса используется для создания циклических буферов FIFO, линий
задержки и простых буферов длиной до 32786 слов. Специальный случай (Rn) ± Nn по модулю М с Nn = Р х 2К используется для обработки одинаковых алгоритмов в памяти, т. е. для параллельных вычислений КИХ-фильтров. Пример модульной адресации показан на рис. 6.12. Начиная с позиции 64, создается циклический буфер с 21 уровнями. Нижняя граница = L х (2К), где 2К> 21, таким образом, К = 5 и нижняя граница адресов
должна быть умножена на 32. Нижняя граница выбирается из значений 0, 32, 64, 96,128, 160 и т. д. В данном примере L = 2 и нижняя граница адресов равна 64.
Верхняя граница буфера равна 84 (нижняя граница + 20 (М - 1)). Регистр смещения выбирается равным 15 (Nn < М). Указатель адреса не нужно устанавливать на начало нижней границы адресов. В данном примере указатель устанавливается на позицию 75. Если R2 постинкрементируется со смещением при выполнении инструкции MOVE, указатель, который установился бы на позицию 90 для линейной адресации, вернется на позицию 69. Если указатель инкрементируется после верхней границы буфера [базовый адрес плюс (М - 1)], он возвращается на базовый адрес. Если указатель адреса декрементируется после нижней границы буфера, он возвращается на базовый адрес плюс (М - 1). Если Rn находится вне корректного диапазона буфера и выполняется операция,
требующая модификации Rn, содержимое Rn модифицируется в соответствии с правилами модульной арифметики. Например, инструкция MOVE B0,X:(R0) + NO (где RO = 6, МО = = 5, NO = 0) не требует явной модификации регистра. Однако, если R0 выше верхней границы, вычисляется новое содержимое R0 = = RO + NO - МО -1 и R0 устанавливается в «0».
Модификатор реверсивного переноса. Реверсивный перенос выбирается, если регистр модификации установлен в «0». Модификация адреса осуществляется аппаратно -переносом в обратном направлении: из старших битов в младшие биты. Реверсивный перенос эквивалентен реверсии битов содержимого Rn и величины смещения Nn, сложению и реверсии битов результата. Если используется режим адресации +Nn и содержимое Nn
682
ПРОЦЕССОРЫ СЕМЕЙСТВА 0SP560C0
равно 2<к-1), этот адресный модификатор эквивалентен реверсии К младших битов Rn (LSB), инкременту Rn и еще одной реверсии К младших битов Rn. Диапазон возможных значений Nn составляет от 0 до +32, что позволяет адресовать 65536 точек для ДПФ. Для корректного применения бит-реверсивной адресации для 2К точек ДПФ, необходимо использовать приведенную ниже процедуру:
1) установить Мп в 0;
2) установить Nn равным 2<к*1);
3) установить Rn между нижней и верхней границами буфера памяти. Нижняя граница равна L х 2К , где L - целое число; эта граница дает 16-битный двоичный номер «хх...хх00...00», где хх...хх = L и 00...00 - эквивалент К нулей; верхняя граница равна L х 2К+ +(2К - 1); эта граница дает 16-битный двоичный номер «хх...хх11...11», где хх...хх - L и 11 ...11 - эквивалент К единиц;
4) использовать режим адресации (Rn) + Nn.
В качестве примера рассмотрим 1024-точечный ДПФ с вещественными данными, хранящимися в X памяти и мнимыми данными, хранящимися в Y памяти (1024 = 210; К = 10). Регистр модификации Мп установлен в «0». Регистр смещения Nn содержит величину 512 (2К 1). Регистр Rn содержит 3072 (L х 2К = 3 х 210). Верхняя граница равна 4095 (нижняя граница + (2К - 1) = 3072 + 1023).
Постинкремент со смещением N генерирует последовательность адресов (0,512,256, 768,128, 640,...), которая добавляется к нижней границе. Эта последовательность представляет собой порядок поступления точек частоты в интервале от 0 до 2л (входных отсчетов для БПФ с прореживанием по времени). В табл. 6.6 приведено содержимое Rn при использовании модификации (Rn) + Nn.
Таблица 6.6
Бит-реверсивная адресация
Rn Смещение относительно нижней границы
3072 0
3584 512
3328 256
3840 768
3200 128
3712 640
Модификатор реверсивного переноса работает только в том случае, если базовый адрес буфера данных умножается на 2К, т. е. принимает такие значения, как 1024, 2048, 3072 и т. д. Можно использовать другие режимы адресации, но они могут привести
к неудовлетворительному результату.
В данном примере L = 3, К -10. Первый используемый адрес - нижняя граница (3072), вычисление следующего показано на рис. 6.13.
Заключение. Бит-реверсивнаяадресация используется для 2к-точечного ДПФ. Модульная адресация используется для создания циклических буферов очередей, линий задержки и простых буферов до 32768 слов длиной. Линейная адресация используется для общих случаев.
Рис. 6.13. Вычисления при бит-реверсивной адресации
Реверсия
Инкремент:
Реверсия
Rn = 00001 I 0000000000 = 3072
0000000000
Rn = 000011 0000000000
+ 1
OOOOH 0000000001
Rn = 000011 0000000001
1000000000
Rn = 000011 1000000000 = 3584
683
ПРОЦЕССОРЫ ЦИФРОВОЙ ОБРАБОТКИ СИГНАЛОВ
Линейная модификация
МО = 255 = 11111111 для линейной адресации cRO Начальные значсиия:М0 = 5, R0 = 75 = 01001011 Постинкрсмент со смещснисмМ): R0 = 80 = 01010000 Постинкрсмент со смсщсниемМО: R0 = 85 = 01010101 Постинкремсит со смещением^: R0 = 90 = 01011010
Модульная
МО = 19 = 00010011 для адрссациис R0 по модулю 20 Начальные значения: N0 = 5, R0 = 75 = 01001011
Постинкремент со смещением^: R0 = 80 = 01010000 Постинкрсмеит со смещением^): R0 = 65 = 01000001 Постинкремент со смсщенисмМО: R0 = 70 = 01000110
Бит-певепсивная
МО = 0 = 00000000 для бит-рсвсрсивиой адресации cRO Начальные значения: N0 - 8, R0 = 64 = 01000000 Постинкрсмент со смещением^: R0 = 72 = 01001000 Постинкрсмент со cmcluchhcmNO: R0 = 68 = 01000100 Постинкрсмент со cmcwckkcmNO: R0 = 76 = 01001100
Рис. 6.14. Примеры использования модификаторов адреса
На рис. 6.14 приведены примеры использования трех модификаторов адреса, использующих для упрощения анализа 8-битные регистры. В примере используется режим адресации «постинкремент со смещением». Линейный модификатор адреса адресует каждую пятую позицию, поскольку регистр смещения содержит $5.
Использование бит-реверсивной адресации в режиме «постинкремент со смещением» Nn вызывает реверсию четырех младших битов, инкремент и еще одну реверсию четырех битов. Модульный модификатор адреса имеет заданную нижнюю границу, верхняя граница определяется суммой модуля и нижней границы. Эти границы создают циклический буфер таким образом, что если содержимое адресного регистра выходит за границы буфера, происходит циклический возврат в пределы буфера.
Программный контроллер
Программный контроллер обеспечивает предварительную выборку инструкций, декодирование инструкций, управление аппаратными циклами и обработку исключений. Контроллер содержит 15-уровневый 32-разрядный системный стек и шесть непосредственно адресуемых регистров (рис. 6.15): программный счетчик PC (Program Counter), регистр адреса цикла LA (Loop Address), счетчик петли LC(Loop Counter), регистр статуса SR (Status Registr), регистр режима операций OMR (Operating Mode Register) и указатель стека SP (Stack Pointer). Регистры контроллера приведены на рис. 6.15. Системный стек представляет собой отдельный блок внутренней памяти, используемый для хранения регистра статуса и программного счетчика при вызовах подпрограмм и длительных прерываниях. В стеке также хранятся LA и LC для организации программных циклов.
684
ПРОЦЕССОРЫ СЕМЕЙСТВА DSP56000
Каждая ячейка стека включает два 16-разряд-ных регистра: старшую часть (SSH) и младшую часть (SSL) стека.
Все эти регистры могут быть прочитаны или записаны для упрощения отладки системы. Хотя ни один из регистров программного контроллера не является 24-битным, все они читаются и записываются через 24-битную шину PDB. При чтении регистров младшая часть битов (LSB) является значащей, а старшая значащая часть битов (MSB) заполняется нулями. При записи регистров младшая часть битов (LSB) является значащей, а старшая значащая часть битов просто отбрасывается, поскольку имеет смысл только младшая значащая часть битов (биты 15-0). Программный контроллер содержит конвейер с тремя ступенями и управляет пятью состо-
РАВ PDB
Глобальная шииа данных
Рис. 6.15. Регистры контроллера
яниями процессора: нормальным, обработкой исключений, сбросом, ожиданием и оста-
новом.
Структура программного контроллера. Программный контроллер состоит из тре> аппаратных блоков: контроллера декодирования программ (PDC), генератора адресов программ (PAG) и контроллера прерываний (PIC).
Контроллер декодирования программ. PDC включает в себя программную логику дл? декодирования, генератор адреса регистра, механизм выполнения циклов, механизм выполнения повторений, генератор кодов условий, механизм выполнения прерываний регистр-защелку инструкций и его копию. PDC декодирует 24-битную инструкцию, загруженную в регистр-защелку, и вырабатывает все сигналы, необходимые для управления конвейером. Копия регистра-защелки инструкций оптимизирует выполнение инструкций повторения и перехода.
Генератор адресов программ. PAG содержит: PC, SP, SS (системный стек), ОМР (регистр операционного режима), SR, LC и LA. Циклы, являющиеся основной конструкцией алгоритмов цифровой обработки сигналов, поддерживаются аппаратно.
При выполнении инструкции DO в регистр счетчика цикла загружается количество повторений цикла, а в регистр адреса цикла - адрес последней инструкции цикла, И устанавливается флаг цикла в регистре статуса. Перед выполнением инструкции DO содержимое регистров LA, LC и SR сохраняется в стеке. Под управлением механизма выполнения циклов адрес первой инструкции цикла помещается в стек. Пока флаг цикла 0 регистре статуса не сброшен, механизм выполнения циклов сравнивает содержимое Рб с содержимым LA для определения последней инструкции цикла. Когда последняя инструкция выбрана, содержимое LC сравнивается с единицей. Если равенство не выполняется, содержимое LC декрементируется и из SS читается адрес первой инструкции цикла. Если равенство выполняется, то значения LA, LC и флага цикла в SR восстанавливаются из стека, а выборка инструкций продолжается с адреса LA + 1.
Пересылка массива данных может быть выполнена с использованием механизм^ повторений. Инструкция REP загружает в LC количество повторений следующей за ней инструкции. Так как команда, которая будет повторяться, выбрана только один раз, эт<1 увеличивает производительность за счет уменьшения обращений к внешней шине. Однако инструкция REP не может быть прервана, поскольку выбирается только один раз.
68&
ПРОЦЕССОРЫ ЦИФРОВОЙ ОБРАБОТКИ СИГНАЛОВ
Контроллер прерываний. PIC принимает все запросы прерываний, осуществляет арбитраж в каждом цикле и генерирует адрес вектора прерывания. Прерывания могут вызывать четыре внешних и 16 внутренних источников прерываний.
Используется структура гибкого приоритета прерываний. Каждое прерывание получает свой уровень приоритета (IPL) - от 0 до 3. Уровень 0 - самый низкий, а уровни 1 и 2 маскируются. Уровень 3 является высшим и не маскируется. Биты маски прерываний в регистре статуса (SR) показывают текущий уровень приоритета прерываний в процессоре. Прерывания, имеющие уровень приоритета меньше текущего, не учитываются при арбитраже. Уровень приоритета 3 всегда вызывает прерывание процессора. Уровни приоритета прерываний для каждого периферийного устройства на кристалле (HI, SSI, SCI) и для каждого внешнего источника прерываний (-JRQA, —.IRQB) могут задаваться программным путем от 0 до 2. Уровни приоритета устанавливаются при записи в регистр уровней приоритета, представленный на рис. 6.16.
В DSP56002 регистр уровней приоритета прерываний расширен: добавлены биты 16 -TIL1 и 17 - TIL0, которые задают уровень приоритета прерываний от таймера. Источники прерываний и их уровни приоритета указаны в табл. 6.7. Каждый источник прерываний имеет свой вектор для вызова процедуры обработки прерывания, расположенной в младших 64 словах памяти программ. При переходе к обработке исключений текущая инструкция выполняется, если только выбранное слово не является первым словом двухсловной инструкции, иначе выполнение инструкции прерывается.
Далее выполняется две выборки адреса, во время которых РС не изменяется. PIC генерирует выборку адреса инструкции прерывания, указывающего на первое слово двухсловной инструкции подпрограммы быстрой обработки прерывания. Затем производится выборка двух слов инструкции по вектору прерывания.
Если одно из этих слов - переход к подпрограмме, то быстрая обработка прерывания переводится в длительную. Процедура длительной обработки прерывания помещает текущий контекст процессора в стек. Подпрограммы и прерывания могут быть вложенными. Стек может быть расширен в память за счет использования программного доступа к регистрам SSH и SSL. Контакты внешних прерываний —.IRQA и -.IRQB могут быть настроены на прерывания по переднему или заднему фронту. Немаскируемое прерывание NMI осуществляется по уровню и выполняется по первому появлению на контакте —.1RQB 10В после последнего обслуживания NMI или сброса. NMI имеет уровень приоритета 3 и не маскируется. NMI не используется как вход прерывания общего назначения, поскольку зарезервировано для аппаратных разработок.
Вектор аппаратного сброса может указывать на внутреннюю или внешнюю (Р:$Е000) память программ. Немаскируемое прерывание, трассировка и программное прерывание используются при отладке.
Программное прерывание используется для организации точек останова. При трас-
is 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
| SCL1 | SCLO | SSL1 | SSLO | Н PL1 | HPL0 | 0 | 0 | 0 | 0 | IBL2 | IBL1 | IBLO | IAL2 | IAL1 | IAL0 |
'----------"---------"-------------' '---------------"-------1-------'
I Режим ->1RQA
..——---------- Режим-IRQB
______________Уровень приоритета HOST '•
L. —— . , Уровень приоритета SSI
...... Уровень приоритета SCI
Рис. 6.16. Формат регистра уровней приоритета
686
ПРОЦЕССОРЫ СЕМЕЙСТВА DSP56000
Программное прерывание используется для организации точек останова. При трассировке инструкции выполняются в пошаговом режиме.
Все периферийные устройства на кристалле используют одинаковый механизм запроса прерываний. Каждое устройство имеет одну линию запроса прерывания в PIC и две входные линии: линию чтения вектора и линию ответа.
Устройство, имеющее более одного источника прерывания, проводит собственный арбитраж прерывания в соответствии с его внутренним уровнем приоритета. PIC выбирает одно из периферийных устройств и посылает ему адрес вектора прерывания.
Таблица 6.7
Уровни приоритета
Стартовый адрес IPL Источник
Р:$0000/Р:$Е000 3 Аппаратный внешний сброс
Р:$0002 3 Ошибка стека
Р:$0004 3 Трассировка
Р:$0006 3 Программное прерывание SWI
Р:$0008 0-2 Внешнее прерывание LUIRQA
Р:$000А 0-2 Внешнее прерывание LUIRQB
Р:$000С 0-2 SSI - Приемник данных
Р:$000Е 0-2 SSI - Приемник данных в состоянии исключения
Р:$0010 0-2 SSI - Передатчик данных
Р:$0012 0-2 SSI - Передатчик данных в состоянии исключения
Р:$0014 0-2 SCI - Приемник данных
Р:$0016 0-2 SCI - Приемник данных в состоянии исключения
Р:$0018 0-2 SCI - Передатчик данных
Р:$001А 0-2 SCI - Простой линии
Р:$001С 0-2 SCI - Таймер
Р:$001Е 3 NMI - Зарезервировано для разработок
Р:$0020 0-2 Host - Приемник данных
Р:$0022 0-2 Host - Передатчик данных
Р:$0024 0-2 Host - Команда
Р:$0026 0-2 Доступно для команд Host
Р:$0028 0-2 Доступно для команд Host
Р:$002А 0-2 Доступно для команд Host
Р:$002С 0-2 Доступно для команд Host
Р:$002Е 0-2 Доступно для команд Host
Р:$0030 0-2 Доступно для команд Host
Р:$0032 0-2 Доступно для команд Host
Р:$0034 0-2 Доступно для команд Host
Р:$0036 0-2 Доступно для команд Host
Р:$0038 0-2 Доступно для команд Host
Р:$003А 0-2 Доступно для команд Host
Р:$003С 0-2 Доступно для команд Host
Р:$003Е 0-2 Неправильная инструкция
Й7
ПРОЦЕССОРЫ ЦИФРОВОЙ ОБРАБОТКИ СИГНАЛОВ
11 MACRXO,Y1,A X:(R0)+X0 Y:(R4)+,Y1
12 CLR A X0,X:(R0)+ A,Y:(R4)-
13 MAC XO,Y1,A X:(R0)+,X0 Y:(R4)+,Y1
Выборка 11 12 13 14 15
Декодирование И 12 13 14
Исполнение 11 12 13
Рис. 6.17. Пример выполнения фрагмента программы на конвейере
Конвейер инструкций. Программный контроллер содержит трехуровневый конвейер, выполняющий выборку, декодирование и исполнение инструкций. Устройства выборки, декодирования и исполнения расположены последовательно. Пример работы конвейера приведен на рис. 6.17.
Синхронизация. DSP56000/DSP56001 использует четырехфазную синхронизацию выполнения инструкций. Синхронизация обеспечивается внутренним генератором, соединенным с внешним кристаллом контактами XTAL и EXTAL, или внешним генератором по линии EXTAL.
Программная модель. Программная модель контроллера представлена на рис. 6.18. Она содержит наряду с программным счетчиком, регистром статуса и системным стеком дополнительные регистры счетчика цикла и адреса цикла, предназначенные для аппаратной поддержки инструкции DO.
Рис. 6.18. Программная модель программного контроллера (* - запрещены для изменения, читаются как нуль)
688
ПРОЦЕССОРЫ СЕМЕЙСТВА DSP56000
Программный счетчик (РС). 16-битный регистр, содержащий адрес следующей ячейки в памяти программ. РС может указывать на инструкции, операнды данных или адреса операндов. Ссылки на этот регистр подразумеваются в большинстве инструкций. РС запоминается в стеке при выполнении программного цикла, подпрограммы или прерывания.
Регистр статуса (SR). 16-битный регистр статуса SR состоит из регистра режима MR, занимающего 8 старших битов и регистра кодов условий CCR, занимающего 8 младших битов. Регистр статуса сохраняется в стеке при выполнении программного цикла, подпрограммы или прерывания. Формат регистра показан на рис. 6.19.
Регистр управления (MR). MR - специальный управляющий регистр, определяющий текущее состояние процессора для супервизора. На биты регистра режима MR воздействуют сброс процессора, выполнение цикла, возврат из прерывания, программное прерывание и инструкции, оперирующие непосредственно с содержимым регистра. После аппаратного сброса в регистре устанавливается маска прерывания, биты масштабирования, флаг цикла, бит трассировки сбрасываются в «О».
Регистр кодов условий (CCR). Регистр кодов условий определяет текущее состояние процессора для пользователя. На регистр кодов условий воздействуют арифметические и логические операции, операции пересылки и инструкции, оперирующие непосредственно с содержимым регистра. После сброса все биты CCR устанавливаются в «О».
Перенос (С-бит 0).
Флаг переноса устанавливается в «1» при наличии переноса из старшей значащей части числа в результате сложения. Перенос или заем генерируется из бита 55 результата. Перенос также возникает при манипуляциях с битами, сдвигах и циклических сдвигах.
Переполнение (V-бит 1).
Флаг переполнения устанавливается при арифметическом переполнении 56-битного результата. Это означает, что результат не может быть представлен в аккумуляторе.
Нуль (Z - бит 2).
Бит устанавливается в «1», если результат равен нулю.
Минус (N - бит 3).
Бит устанавливается в «1», если результат имеет отрицательный знак. j Денормализация (U- бит 4).
Бит устанавливается, если два старших бита идентичны. Механизм вычисления де-нормализации представлен в табл. 6.8. j
Таблица 6.8
Механизм вычисления денормализации
S1 so Режим масштабирования Денормализация
0 0 Нет 1)=ЧБит 47 © Бит 46)
0 1 Нижний и=->(Бит 48 © Бит 47)
1 0 Верхний и=->(Бит 46 © Бит 45)
689
ПРОЦЕССОРЫ ЦИФРОВОЙ ОБРАБОТКИ СИГНАЛОВ
Расширение (Е- бит 5).
Бит расширения сброшен в «О», если все биты целой части 56-битного результата -нули или единицы, иначе бит установлен. Целая часть определяется режимом масштабирования и битом Е (табл. 6.9). Если бит расширения равен нулю, то младшая часть числа содержит все значащие биты, а старшая часть числа является расширением знака. В этом случае регистр расширения аккумулятора игнорируется. Если бит расширения равен единице, то регистр расширения аккумулятора используется.
Таблица 6.9
Определение целой части результата
S1 so Режим масштабирования Целая часть
0 0 Нет Биты 55, 54, ... 48, 47
0 1 Нижний Биты 55, 54, ... 49, 48
1 0 Верхний Биты 55, 54, ... 47, 46
Ограничение (L- бит 6). L.
Бит установлен, если установлен бит переполнения. Также устанавливается при выполнении операций ограничения устройством сдвига/ограничения данных. Бит сбрасывается только при сбросе процессора или специальной командой. г
Маска прерывания (11,10 - биты 8 и 9).
Показывает текущий уровень приоритета прерываний в процессоре. Уровень приоритета изменяется программным путем. Биты маски прерываний устанавливаются в «1» при аппаратном сбросе процессора и не изменяются при программном сбросе.
Режим масштабирования (S1,S0 - биты 10 и 11).
Биты определяют режим масштабирования для устройства сдвига/ограничения данных АЛУ и позиции округления для МАС (табл. 6.10). Действие режима масштабирования проявляется при чтении данных из аккумуляторных регистров А и В на шины данных и при округлении в МАС. При сбросе процессора и начале длительной обработки прерывания эти биты равны нулю.
Режим трассировки (Т- бит 13).
Бит устанавливается в начале выполнения каждой инструкции в пошаговом режиме. Если бит равен нулю, трассировка запрещена и выполнение инструкций идет нормальным образом. При сбросе процессора бит равен нулю.
Таблица 6.10
Режимы масштабирования
S1 S0 Бит округления Режим масштабирования
0 0 23 Нет
0 1 24 Нижний (первый бит арифметически сдвигается вправо)
1 0 22 Верхний (первый бит арифметически сдвигается влево)
1 1 - Резерв
Флаг цикла (LF-бит 15).
Бит устанавливается при выполнении программного цикла и разрешает определение окончания цикла. По завершении цикла бит устанавливается в «0».
Регистр операционного режима (OMR). OMR - 24-битный регистр (рис. 6.20), в котором определены 5 битов для DSP56000/DSP56001 и 7 битов для DSP56002. Устанавливает текущий операционный режим процессора (табл. 6.11,6.12, 6.13).
690
ПРОЦЕССОРЫ СЕМЕЙСТВА DSP56000
23__________________8 7 6 5 4 3 2 1 0
I * | ЕА TSD I * I МС I YD I DE I MB | мГ~|
Рис. 6.20. Формат регистра операционного режима DSP56002
На биты регистра воздействует только сброс процессора и непосредственные операции с содержимым регистра. После сброса биты МА и МВ могут быть загружены извне через контакты А и В.
Таблица 6.11
Операционные режимы и карта памяти DSP56000
Операционный режим МВ МА Карта памяти программ DSP56000
Внутреннее ПЗУ Внешнее ПЗУ Сброс
0 0 0 $0000 - $0EFF $0200 - FFF Внутреннее - $0000
1 0 1 Режим не используется в DSP56000
2 1 0 $0000 - $0EFF $0FFF - $FFFF Внешнее - $Е000
3 1 1 - $0000 - $FFFF Внешнее - $0000
Таблица 6.12
Операционные режимы и карта памяти DSP56001
Операционный режим МВ МА Карта памяти программ DSP56000
Внутреннее ОЗУ Внешнее ОЗУ Сброс
0 0 0 $0000 - $01FF $0200 - $FFFF Внутреннее - $0000
1 0 1 Специальный загрузочный режим
2 1 0 $0000 - $01FF $0200 - $FFFF Внешнее - $Е000
3 1 1 - $0000 - $FFFF Внешнее - $0000
Таблица 6.13
Управление памятью битом DE
DE Карта памяти
Y-память Х-память
0 Внутреннее ОЗУ: $0000 - $00FF Внешнее: $0100 - $FFFF Внутреннее ОЗУ: $0000 - $00FF Внешнее: $0100 - $FFBF Периферия: $FFC0 - $FFFF
1 Внутреннее ОЗУ: $0000 - $00FF Внутреннее ПЗУ: $0100 - $01FF Внешнее: $0200 - $FFFF Внутреннее ОЗУ: $0000 - $00FF Внутреннее ПЗУ: $0100 - $01FF Внешнее: $0200 - $FFBF Периферия: $FFC0 - $FFFF
Операционный режим кристалла (МА,МВ - биты 0 и 1). Показывают режим расширения шин в процессоре (табл. 6.14). После сброса эти значения загружаются извне через внешние контакты выбора операционного режима -.MODA и ->MODB, либо могут быть изменены программным путем. Операционные режимы кристалла DSP56002 представлены в табл. 6.15.
691
ПРОЦЕССОРЫ ЦИФРОВОЙ ОБРАБОТКИ СИГНАЛОВ
Таблица 6.14
Операционные режимы кристалла DSP56000/DSP56001
МВ МА Операционный режим
0 0 Однокристальный режим
0 1 Специальный загрузочный режим
1 0 Нормальный расширенный режим
1 1 Режим разработки
Таблица 6.15
Операционные режимы кристалла DSP56002
Опер, режим МС МВ МА Операционный режим
0 0 0 0 Однокристальный режим, ОЗУ программ разрешено
1 0 0 1 Режим загрузки из EEPROM, выход в режим 0
2 0 1 0 Нормальный расширенный режим, ОЗУ программ разрешено.
3 0 1 1 Режим разработки, ОЗУ программ запрещено
4 1 0 0 Резерв
5 1 0 1 Загрузка по Host, выход в режим 0
6 1 1 0 Загрузка по SCI (внешняя синхронизация), выход в режим 0
7 1 1 1 Резерв
Разрешение ПЗУ данных (DE - бит 2).
Установка бита разрешает использование двух ПЗУ данных размером 256 х 24, находящихся по адресам $0100 -$01FF в пространствах памяти X и Y.
Запрещение внутренней памяти Y (YD - бит 3).
Установка бита запрещает доступ к внутренней памяти данных Y. Если бит равен нулю, внутренняя память данных Y доступна в соответствии с состоянием управляющего бита DE. Аппаратный сброс очищает бит YD.
Операционный режим кристалла (МО - бит 4).
Бит МС наряду с битами МА и МВ определяет карту памяти и операционный режим кристалла. После сброса процессор загружает этот бит через внешний контакт MODC. После выхода процессора из состояния сброса бит МС может быть изменен программным путем.
Задержка останова (SD - бит 6).
При выходе из состояния останова (по инструкции STOP) если этот бит равен нулю, генерируется задержка в 64К циклов синхронизации (131072 Т состояний). Если бит установлен в «1», задержка составляет 16 Т состояний. Длительная задержка используется для стабилизации синхронизации.
Доступ к внешней памяти (ЕА- бит 7).
Бит определяет функции двух линий порта А, указанные в табл. 6.16.
Таблица 6.16
Функции линий порта А
ЕА Линия -1BR (Вход) Линия -.BG (Выход)
0 Запрос шины (-BR) Предоставление шины (-BG)
1 Ожидание (-.WT) Стробирование шины (-.BS)
692
ПРОЦЕССОРЫ СЕМЕЙСТВА DSP56000
Регистр адреса цикла и регистр счетчика цик-
ла (LA и LC). Содержимое регистра адреса цикла LA ,—-—,—-—,—-—,—-—,—!—,—?—. указывает на местонахождение слова последней инет- | uf | SE | рз | Р2 | pi | ро | рукции программного цикла. LC -специальный 16-бит-
ный счетчик, определяющий число повторений цикла. Рис- 6-21. Формат регистра SP
При выполнении инструкции DO содержимое реги-
стра LA помещается в SSH, а регистра LC - в SSL, откуда оно извлекается только после окончания цикла по инструкции ENDDO.
При выборке инструкции по адресу, содержащемуся в LA, проверяется содержимое LC Если содержимое LC не равно единице, оно декрементируется и следующая инструкция выбирается по адресу, находящемуся в верхней ячейке стека. В противном случае РС инкрементируется, флаг цикла сбрасывается, регистры LA и LC восстанавливаются из стека и продолжается нормальное выполнение программы.
Регистр LC программно доступен, и выполнение цикла может быть прекращено программным путем. Регистр LC также используется в инструкции REP.
Системный стек (SS). SS - отдельная внутренняя память размером 15 х 32 бита, разделенная на два блока: SSL и SSH. SSH сохраняет содержимое программного счетчика, SSL - регистра статуса при вызовах подпрограмм и длительных прерываниях. В стеке сохраняются также значения LA и LC при выполнении программных циклов. Стек обеспечивает выполнение 15 длинных прерываний, семи циклов DO, 15 вызовов подпрограмм. Если стек переполняется, возникает немаскируемое прерывание - ошибка стека. Значение РС теряется, что приводит к ошибке программы, выполняющейся, когда возникло прерывание по переполнению стека.
Указатель стека (SP). 6-битный указатель стека определяет последнюю занятую ячейку стека и состояние стека (потеря содержимого, пустой, полный, переполнение). Формат регистра SP указан на рис. 6.21.
Указатель стека (Р0,Р1,Р2-биты 0-3). Показывает последнюю используемую ячейку стека. После аппаратного сброса все биты равны нулю, что означает - стек пуст.
Флаг ошибки стека (SE-бит 4). Показывает возникновение ошибки стека. Если стек заполнен, указатель стека равен 001111, и любая операция, вызывающая запись в стек, приведет к возникновению ошибки стека, т. е. SP будет равен 010000. Аналогично, если SP равен 0, любая операция чтения из стека приведет к возникновению ошибки стека. Флаг ошибки стека остается равным единице, пока пользователь не сбросит его в «0».
Флаг потери содержимого (UF-бит 5). Устанавливается при потере содержимого стека. Сбрасывается в «0» пользователем.
Остальные биты стека зарезервированы для будущих разработок.
Состояния процессора
DSP всегда находится в одном из пяти состояний: нормальное, обработка исключения, сброс, ожидание и останов.
Нормальное состояние процессора связано с выполнением инструкций. Описание выполнения инструкций приведено в описании системы инструкций. Инструкции выполняются с использованием трехуровневого конвейера.
Состояние обработки исключения связано с прерываниями, которые генерируются как внутренними устройствами DSP, так и поступают от внешних источников.
Состояние сброса возникает при появлении сигнала активного уровня на контакте RESET. В этом состоянии происходит сброс внутренних периферийных устройств; регистры модификации устанавливаются в $FFFF; регистр уровней приоритета прерываний очищается; регистр BCR устанавливается в $FFFF, что добавляет 15 состояний ожидания ко всем обращениям к внешней памяти; указатель стека очищается; биты режима
693
ПРОЦЕССОРЫ ЦИФРОВОЙ ОБРАБОТКИ СИГНАЛОВ
масштабирования, режима трассировки, флаг цикла и биты условий в SR сбрасываются, биты маски прерываний в SR устанавливаются в «1»; бит разрешения ПЗУ данных, бит задержки и бит стробирования памяти сбрасываются. DSP не выходит из состояния сброса, пока на контакте RESET сохраняется сигнал активного уровня. После выхода из состояния сброса биты операционного режима в OMR загружаются извне по линиям MODA, MODB и выполнение программы начинается с адреса $Е000 в памяти программ в нормальном расширенном режиме или с адреса $0000 в остальных операционных режимах.
Состояние ожидания - это состояние пониженного энергопотребления, в которое процессор переходит при выполнении инструкции WAIT. В состоянии ожидания запрещена внутренняя синхронизация всех устройств на кристалле, за исключением внутренней периферии (генератор частоты работает). Все внутренние процессы остановлены до тех пор, пока не поступит немаскируемое прерывание или не будет произведен сброс.
Состояние останова - это состояние самого низкого энергопотребления, в которое процессор переходит при выполнении инструкции STOP. В этом состоянии генератор частоты отключен. При переходе в состояние останова кристалл сбрасывает все прерывания от периферийных устройств и внешние прерывания. Уровни приоритетов прерываний остаются такими же, как перед выполнением инструкции STOP. Процессор остановлен до тех пор, пока не появится сигнал низкого логического уровня на контакте -JRQA или на контакте -iRESET. Эти события включают генератор, и после стабилизации частоты включается синхронизация всех устройств на кристалле. Период стабилизации частоты определяется битом SD в OMR.
6.2.2. ПОРТА
Порт А может использоваться для расширения памяти или обычного ввода/вывода. Шина данных порта А имеет разрядность 24 бита, шина адреса разрядностью 16 бит обеспечивает доступ к памяти за один машинный цикл (рис. 6.22).
Интерфейс порта А
Во время выполнения инструкции могут быть доступны следующие блоки памяти DSP: Х-память данных, Y-память данных, память программ или несколько блоков сразу.
Каждый из этих блоков памяти может быть внутренним или внешним. Шины данных и адреса порта А обеспечивают доступ к внешней памяти.
На рис. 6.22 показаны сигналы порта А. Все сигналы разделены на три функциональные группы: адресные, данных и управления.
Сигналы шины управления также подразделяются на три группы: управление чтением и записью, выбор адресного пространства, управление доступом к шине. Сигналы управления чтением и записью могут быть декодированы как сигналы чтения и сигналы записи или сигнал записи может использоваться в качестве сигнала чтения/записи, сигнал чтения - в качестве выхода разрешения доступа к памяти. Сигналы выбора памяти программ, памяти данных и типа памяти данных могут рассматриваться как дополнительные адресные линии, позволяющие расширять пространство адресуемой памяти от 64К до 192К слов.
На рис. 6.23 показано использование сигнала выбора памяти данных для доступа к двум блокам памяти данных и использование сигнала X/-.Y для переключения между ними.
Одиночный блок памяти может использовать сигналы —iPS, —.DS, X/-.Y в качестве дополнительных адресных линий для сегментации памяти на три пространства. В табл. 6.17 приведены варианты использования этих сигналов.
Простой вариант подключения периферийных устройств семейства МС6800 заключается в использовании линии X/-.Y для указания R/-.W.
694
ПРОЦЕССОРЫ СЕМЕЙСТВА DSP56000
16-битные внутренние адресные шины
Внешние адресные шины А0-А15
16-битные внутренние шины данных
Внешние шниы данных D0-D23
Логика управления внешними шинами
Сигналы управления шины
'» -лRD разрешение чтения
-> -nWR разрешение записи
-iPS выбор памяти программ
► -1DS выбор памяти данных ----► X/-.Y выборХ/Y
--------1BR/-1WT запрос/ожидание шины
______-iBG/-nBS предоставление шины/ стробирование шины
Рис. 6.22. Структура порта А
Выбор кристалла периферии должен осуществляться с помощью линий адреса и строба данных так, чтобы регистры периферийных устройств находились в пространствах X и Y по одним и тем же адресам. На рис. 6.24 приведена структурная схема системы ЦОС с внешней памятью на основе DSP56000 и показаны сигналы управления блоками памяти данных и программ.
Для операции чтения применяется чтение памяти X: j
MOVE X:PERIPHERAL,XO ; Х/Y имеет высокий уровень. , j
Для операции записи применяется запись в память Y:
MOVE XO,Y:PERIPHERAL ; Х/Y имеет низкий уровень.
аай W9
ПРОЦЕССОРЫ ЦИФРОВОЙ ОБРАБОТКИ СИГНАЛОВ
Таблица 6.17
Управление памятью DSP
^PS -.DS X/-.Y Ссылка на внешнюю память
1 1 1 Не активна
1 0 1 Х-память данных на шине данных
1 0 0 Y-память данных на шине данных
0 1 1 Память программ на шине данных (не исключение)
0 1 0 Исключение: выборка вектора и вектора + 1 (только режим разработки)
0 0 X Резерв
1 1 0 Резерв
Отдельные сигналы стробирования чтения и записи, используемые в DSP, являются взаимоисключающими и позволяют осуществлять доступ к двум буферам данных одновременно без конфликта.
Использование внешней логики позволяет подключать более быстрые ОЗУ или внешние буферы данных без конфликтов на шине данных.
На рис. 6.25 приведен пример расширенной системы с устройствами разного быстродействия.
Регистр управления шиной (BCR). Регистр определяет синхронизацию расширения шины с использованием сигналов -.RD и -AA/R и выходных линий данных. Этот регистр имеет адрес $FFFE в памяти X. Каждое из пространств памяти имеет свой соб-
Vcc +5V Vss OV
Данные
Адрес
Данные
Адрес
Шина адреса
A0-A15
Шина данных
D0-D23
Управление шиной
-.RD
-,WR
-.PS
-.DS
X/-.Y ,BR/—WT nBG/-BS
Память данных X 24 битах N слов
Память данных X 24 битах N слов
R/-.W -,CS СЕ
.ОЕ R/—iW —>CS
Рис. 6.23. Внешнее пространство данных
696
ПРО1 ССОРЫ СЕМЕЙСТВА DSP56000
ственный 4-битовый BCR, который программирует до 15 состояний ожидания (каждое состояние занимает половину цикла инструкции при доступе к памяти - 50 нс на частоте 20 МГц). После сброса процессора все разряды регистра равны единице (15 состояний ожидания). Содержимое BCR должно соответствовать используемой памяти, иначе процессор вставит 15 состояний ожидания между выборками из памяти и DSP будет работать медленнее.
На рис. 6.26 показаны все четыре поля регистра BCR для работы с внешней памятью. Все периферийные устройства на кристалле входят в карту памяти, регистры управления ими расположены в диапазоне адресов X:$FFC0 - X:$FFFF.
Таймер DSP56002
Таймер использует внутреннюю или внешнюю синхронизацию и может прерывать работу процессора через заданное пользователем число тактов или выдавать сигнал внешним устройствам после подсчета внутренних событий.
С внешней средой таймер соединен двунаправленной линией ТЮ. Если TIO используется как вход, модуль таймера функционирует как счетчик внешних событий по этой линии, иначе модуль функционирует как таймер и на линию ТЮ выдается пульсация таймера. Линия ТЮ может использоваться также как линия ввода/вывода общего назначения.
Таймерный модуль, структура которого приведена на рис. 6.27, включает в себя 24-битный регистр статуса/управления таймером, 24-битный регистр таймера/счетчика, логику выбора синхронизации и генерации прерывания.
697
ПРОЦЕССОРЫ ЦИФРОВОЙ ОБРАБОТКИ СИГНАЛОВ
Рис. 6.25. Система ЦОС с внешними устройствами
15 12 11 8 7 4 1 О
Рис. 6.26. Управление внешней памятью
698
ПРОЦЕССОРЫ СЕМЕЙСТВА DSP56000
Рис. 6.27. Структура таймера
Программная модель таймерного модуля. Программная модель таймера представлена на рис. 6.28.
Регистр таймера/счетчика (TCR). 24-битный регистр TCR содержит величину, загружаемую в счетчик, если таймер разрешен (ТЕ = 1), или если было декрементировано нулевое значение счетчика и произошло новое событие. Если в TCR загружено число п, то счетчик перезагружается через (п + 1) событий. Если таймер запрещен (ТЕ = 0) и программа пользователя производит запись в TCR, величина, находящаяся там до момента записи, сохраняется и снова загружается в счетчик когда устанавливается разрешение таймера (ТЕ = 1). В режимах 4 и 5 TCR может быть загружен текущим значением счетчика по фронту сигнала ТЮ.
Регистр статуса/управления таймером (TCSR). 24-битный регистр управляет таймером и производит верификацию его состояний. Регистр может быть доступен по инструкциям пересылки или манипуляций с битами.
Разрешение таймера (ТЕ - бит 0).
Бит разрешает или запрещает использование таймера. Установка бита в «1» разрешает использование таймера, счетчик загружается величиной, хранящейся в TCR, и начинает декрементирование при каждом событии. После сброса бит равен нулю.
Разрешение прерываний от таймера (TIE- бит 1).
Установка бита в «1» разрешает прерывания от таймера после установки счетчика в «0» и возникновении нового события. После сброса бит равен нулю.
Регистр статуса /управления таймером (TCSR):
Адрес X: $ F F D Е
Чтепие/запись
Таймер/счетчик (TCR):
Адрес X.-SFFDF Чтение/запись
II 10 9 8 7 6 5 4 3 2 10
* DO DI dir TS GPIO TC2 TCI TCO INV TIE ТЕ
Рис. 6.28. Программная модель таймера (* - зарезервировано)
699
ПРОЦЕССОРЫ ЦИФРОВОЙ ОБРАБОТКИ СИГНАЛОВ
Инвертор (INV-бит 2).
Бит устанавливает полярность внешнего сигнала на входной линии TIO и полярность импульсов на выходной линии TIO.
Если ТЮ запрограммирован как вход и INV - 0, переход сигнала из «О» в «1» на линии TIO вызывает декрементирование счетчика. Если INV = 1, декрементирование осуществляется при переходе сигнала из «1» в «О».
Если ТЮ запрограммирован как выход и INV = 1, импульсы таймера инвертируются перед выдачей на линию ТЮ. Если INV = 0, импульсы таймера не изменяются.
В режиме 4 бит INV определяет, по какому уровню (низкому или высокому) происходит измерение входных импульсов.
В режиме 5 бит INV определяет, по какому фронту измеряется период сигнала.
В режиме обычного ввода/вывода бит определяет, инвертируются ли данные, читае-мые/записываемые на линию TIO (INV = 1), или нет (INV = 0).
После сброса бит равен нулю.
Биты управления таймером (ТС0-ТС2 - биты 3-5).
Биты управляют источником синхронизации, назначением линии ТЮ и выбором режима таймера (табл. 6.18).
Таблица 6.18
Варианты использования таймера
ТС2 ТС1 тсо ТЮ Синхронизация Режим
0 0 0 GPIO Внутренняя Таймер (режим 0)
0 0 1 Выход Внутренняя Импульсный (режим 1)
0 1 0 Выход Внутренняя Переключение (режим 2)
0 1 1 - - Резерв
1 0 0 Вход Внутренняя Измерение длительности (режим 3)
1 0 1 Вход Внутренняя Измерение периода (режим 4)
1 1 0 Вход Внешняя Счетчик (режим 6)
1 1 1 Вход Внешняя Счетчик событий (режим 7)
Стандартный ввод/вывод (GPIO-бит 6).
Если этот бит установлен и биты ТС2 - ТОО равны нулю, линия ТЮ используется как линия обычного ввода/вывода, направление передачи по которой определяет бит DIR. После сброса бит равен нулю.
Статус таймера (TS - бит 7).
Если бит равен единице, это означает, что произошло декрементирование нулевого значения счетчика. Бит сбрасывается при чтении регистра статуса/управления. Также бит сбрасывается при обработке прерывания от таймера. После сброса бит равен нулю.
Направление (DIR- бит 8).
Бит определяет направление передачи данных по линии ТЮ, если линия используется для обычного ввода/вывода. Если DIR = 1, то ТЮ - выход, иначе - вход.
Вход данных (DI- бит 9.
Если ТЮ используется как линия ввода, содержимое DI соответствует сигналу на линии ТЮ. После сброса бит равен нулю.
Выход данных (DO-бит 10).
Если ТЮ используется как линия вывода, содержимое DO выдается на линию ТЮ. После сброса бит равен нулю.
700
ПРОЦЕССОРЫ СЕМЕЙСТВА DSP56000
Режимы таймера. Ниже перечислены возможные режимы работы таймера.
Режим 0 (стандартный режим таймера, внутренняя синхронизация, нет выхода таймера). Если таймер разрешен (ТЕ = 1), счетчик загружается значением, содержащимся в TCR. Счетчик декрементируется на каждом такте внутренней частоты DSP, деленной на два (CLK/2). Если декрементирование осуществляется из нулевого значения счетчика, бит TS устанавливается в «1» и генерируется прерывание от таймера. Счетчик снова загружается значением TCR и процесс продолжается, пока таймер не запрещен (ТЕ = 0).
Режим 1 (стандартный режим таймера, внутренняя синхронизация, разрешены выходные импульсы). Если таймер разрешен (ТЕ = 1), счетчик загружается значением, содержащимся в TCR. Счетчик декрементируется на каждом такте внутренней частоты DSP, деленной на два (CLK/2). Если декрементирование осуществляется из нулевого состояния, бит TS устанавливается в «1» и генерируется прерывание от таймера. На линию ТЮ поступают импульсы шириной в два цикла синхронизации, полярность которых определяется значением бита INV. После обработки прерывания счетчик снова загружается значением TCR и процесс продолжается, пока таймер не запрещен (ТЕ = 0).
Режим 3 (стандартный режим таймера, внутренняя синхронизация, разрешены выходные переключения). Если таймер разрешен (ТЕ = 1), счетчик загружается значением, содержащимся в TCR. Счетчик декрементируется на каждом такте внутренней частоты DSP, деленной на два (CLK/2). Если декрементирование осуществляется из нулевого состояния, бит TS устанавливается в «1» и генерируется прерывание от таймера. По каждому декрементированию из нулевого значения выход ТЮ переключается. Полярность выхода определяется значением бита INV. После обработки прерывания счетчик снова загружается значением TCR и процесс продолжается, пока таймер не запрещен (ТЕ = 0).
Режим 4 (режим измерения длительности импульса). В этом режиме события на линии ТЮ являются сигналом для начала синхронизации. Если таймер разрешен (ТЕ = 1), счетчик работает с тактовой частотой DSP, деленной на два .При возникновении первого события на линии ТЮ счетчик загружается нулем и начинается инкрементирование. По первому фронту сигнала противоположной полярности на линии ТЮ счетчик останавливается, бит TS устанавливается в «1» и, если TIE = 1, генерируется прерывание. Содержимое счетчика загружается в TCR и может быть прочитано пользователем. Процесс повторяется, пока таймер не запрещен. Бит INV определяет, по какому уровню сигнала на линии ТЮ начинается счет.
Режим 5 (режим измерения периода). Счетчик работает с тактовой частотой DSP, деленной на два. Если таймер разрешен, по первому фронту сигнала на линии ТЮ счетчик загружается значением, содержащимся в TCR, и начинается инкрементирование. По каждому фронту сигнала одной и той же полярности на линии ТЮ бит TS устанавливается в «1» и генерируется прерывание, если прерывания от таймера разрешены. Значение счетчика загружается в TCR и может быть прочитано пользователем. Бит INV определяет, по какому фронту измеряется период сигнала: по переходу из «0» в «1» (INV = 0) или по переходу из «1» в «0» (INV = 1).
Режим 6 (стандартный режим счетчика, внешняя синхронизация). Если таймер разрешен, счетчик загружается дополнительным кодом значения, содержащегося в TCR. Счетчик инкрементируется при возникновении событий на линии ТЮ. После каждого инкрементирования значение счетчика загружается в TCR. Если происходит декрементирование из нулевого состояния, бит TS устанавливается в «1» и генерируется прерывание от таймера. Процесс продолжается, пока таймер не запрещен.
Режим 7 (стандартный режим таймера, внешняя синхронизация). Если таймер разрешен, счетчик загружается значением, содержащимся в TCR. Счетчик декрементируется при возникновении события на линии ТЮ. Если происходит декрементирование из
701
ПРОЦЕССОРЫ ЦИФРОВОЙ ОБРАБОТКИ СИГНАЛОВ
нулевого состояния, бит TS устанавливается в «1» и генерируется прерывание от таймера. Процесс продолжается, пока таймер не запрещен. Бит INV определяет, по какому фронту сигнала на линии TIO декрементируется счетчик: по переходу из «О» в «1»(INV = 0) или по переходу из «1» в «0» (INV = 1).
При выполнении инструкции WAIT таймер не останавливается.
6.2.3. ПОРТ В
Стандартный ввод/вывод
Порт В может использоваться как 15 линий ввода/вывода общего назначения, каждая из которых конфигурируется индивидуально как вход или выход или как 8-битный двунаправленный host-интерфейс. Линии порта В представлены на рис. 6.29. Сконфигурированный как порт ввода/вывода общего назначения, порт В может использоваться для управления устройствами. В качестве host-интерфейса порт В обеспечивает соединение с другим процессором.
Функции по умолчанию
Внешний переключатель адресов ► ◄ ► ◄ ► ◄ ► ◄ ► ◄ ► Порт А В/В (47) АО-А 15 ► D0-D23 ► —1PS k —DS ► X/-.Y ► -tRD > -,WR 4 BR/-.WT ► -BG/-BS ► РВ0-РВ7 <—РВ8 ► РВ9 ◄—► РВЮ —► РВИ ◄ ► РВ12 "< ► РВ13 ► РВ14 ◄ —► рсо <—► РС1 < ► РС2 < —► РСЗ ◄ ► РС4 ► РС5 ◄ ► РС6 ◄ ► РС7 ◄ ► РС8
Внешний переключатель данных
Управление шиной
Host/ПДП параллелшый интерфейс Порт В В/В (15)
Интерфейс SCI Интерфейс SSI Порт С В/В (9)
Альтернативные функции
► Н0-Н7
◄ ~ НАО
◄-- Н А I
◄--НА2
◄--HR/-.W
◄---—HEN
-----► —HREQ
◄---.HACK
◄----- RXD
-----► TXD
---► SCL К
◄ ► SCO
◄ ► SCI
< ► SC2
◄ ► SCK
◄ SRD
-----► STD
Рис. 6.29. Структура порта В
702
ПРОЦЕССОРЫ СЕМЕЙСТВА DSP56000
При использовании в качестве линий стандартного ввода/вывода порт В может быть представлен в виде трех регистров, которые управляют 15 контактами ввода/вывода. Это регистр управления порта В (РВС, адрес X:$FFED), регистр направления данных порта В (PBDDR, адрес X:$FFE2) и регистр данных порта В (PBD, адрес X:FFE4). Регистры PBDDR и PBD имеют разрядность 24 бита, из которых используются только младшие 15 битов. Соответственно установка в «1» бита в регистре PBDDR означает, что данная линия порта В используется для вывода, в противном случае - для ввода. Установка в «1» бита 0 в регистре РВС означает, что порт В используется в качестве host-интерфейса, иначе порт В используется для стандартного ввода/вывода.
Адреса регистров периферийных устройств приведены на рис. 6.30.
Host-интерфейс (HI)
Структура HI. HI - 8-битный полнодуплексный, с двойной буферизацией параллельный порт, который может быть соединен непосредственно с шиной данных host-npo-цессора.
23____16_____15_____8 7_______О
X:$FFFF I I
X:$FFFE
X:$FFFD
X:$FFFC
X:$FFFB
X:$FFFA
X:$FFF9
X:$FFF8
X:$FFF7
X:$FFF6
X:$FFF5
X:$FFF4
X:$FFF3
X:$FFF2
X:$FFF1
X:$FFFO
X:$FFEF
X:$FFEE
X:$FFEB
X:$FFEA
X:$FFE9
X:$FFE8 III
X:$FFE7
X:$FFE6
X:$FFE5 I
X:$FFE4
X:$FFE3 I
X:$FFE2
X:$FFE1 I
X:$FFE0 I
X:$FFDF
X:$FFC0 ——
Регистр приоритета прерываний (IPR)
Регистр управления порта A (BCR)
Резерв
Резерв
Резерв
Резерв
Резерв
Резерв
Резерв
SCI HI - регистр данных (SRX/STX)
SCI MID - регистр данных (SRX/STX)
SCI LOW - регистр данных (SRX/STX)
SCI - регистр адреса передачи данных (STXA)
Регистр управления SCI (SCCR)
Регистр статуса управления SCI (SSR)
Регистр управления интерфейса SCI (SCR)
Регистр приема/передачи данных SSI (RX/TX
Регистр слота статуса/времени SSI (SSISR/TSR)
Регистр управления В SSI (CRB)
Регистр управления A SSI (CRA)
Регистр приема/ передачи HOST (HRX/HTX)
Резерв
Регистр статуса HOST (HRX/HTX)
Регистр управления HOST (HSR)
Резерв
Резерв
Регистр данных порта С (PCD)
Регистр данных порта В (PBD)
Регистр направления данных порта С (PCDDR)
Регистр направления данных порта В (PBDDR)
Регистр управления порта С (РСС)
Регистр управления порта В (РВС)
Резерв
Резерв
Рис. 6.30. Карта памяти периферийных устройств на кристалле
703
ПРОЦЕССОРЫ ЦИФРОВОЙ ОБРАБОТКИ СИГНАЛОВ
Рис. 6.31. Структура HI
Host-процессор может быть микроконтроллером, микропроцессором, другим DSP или аппаратным ПДП, поскольку этот интерфейс работает со статической памятью. HI - асинхронный интерфейс и содержит два банка регистров: один банк, доступный host-процес-сору, и второй банк, доступный процессору DSP (рис. 6.31).
HI имеет следующие параметры:
скорость: 8 Мбайт/с - передача пакетов; 1,71 миллион слов/с - скорость передачи данных при обработке прерываний (мах).
сигналы (15): Н0-Н7 - шина данных; НА0-НА2 - выбор адреса; HR/-.W - управление чтением/записью; -.HEN - разрешение передачи; -.HREQ - запрос; -.HACK - ответ.
Host-интерфейс со стороны процессора DSP. Процессор DSP рассматривает HI как периферийное устройство, занимающее три 24-битных слова в пространстве памяти данных. DSP может использовать HI как обычную периферию, входящую в карту памяти. Отдельные регистры приемника и передатчика данных имеют двойную буферизацию, что существенно повышает скорость передачи данных.
Регистры интерфейса доступны с помощью стандартных инструкций и режимов адресации. При программном и аппаратном сбросе HI запрещен, и порт В используется для стандартного ввода/вывода.
704
ПРГ>[ (FC-ПОРЫ СЕМЕЙСТВА DSP56000
Программная модель со стороны порцессора DSP. Программная модель со стороны программиста DSP показана на рис. 6.32.
Регистр управления HI (HCR). 8-битный регистр управления используется в DSP для управления прерываниями HI и флагами. Регистр недоступен host-процессору. HCR занимает младший байт внутренней шины данных, старшие байты шины данных запол-, няются нулями. Отдельные биты регистра могут быть установлены в «1» или сброшены в «О». Резервные биты читаются нулями.
Разрешение прерываний приемника (HRIE - бит 0).
Бит используется для разрешения прерываний DSP, если приемник данных заполнен. Программный и аппаратный сбросы устанавливают этот бит в «О».
Разрешение прерываний передатчика (HTIE - бит 1).
Бит используется для разрешения прерываний DSP, если передатчик данных пуст. Программный и аппаратный сбросы устанавливают этот бит в «О».
Разрешение командных прерываний (HCIE - бит 2).
Бит используется для разрешения векторных прерываний DSP, если в регистре статуса установлен бит задержки команд. Стартовый адрес процедуры обработки этого прерывания определен host-вектором (HV). Программный и аппаратный сбросы устанавливают этот бит в «О».
Флаг 2 (HF2-6um 3).
Бит используется в качестве флага для связи DSP - Host. Бит может быть очищен или установлен со стороны DSP и виден со стороны host-процессора. Программный и аппаратный сбросы устанавливают этот бит в «О».
Флаг 3 (HF3 - бит 4).
Бит используется в качестве флага для связи DSP - Host. Бит может быть очищен или установлен со стороны DSP и виден со стороны host-процессора. Программный и аппаратный сбросы устанавливают этот бит в «О».
Регистр статуса host(HSR). 8-битный регистр статуса используется для запроса статуса и флагов HI. Регистр занимает младший байт внутренней шины данных, старшие байты шины данных заполняются нулями.
Приемник данных заполнен (HRDF- бит 0).
Бит показывает, что регистр приемника данных заполнен данными из host-процессо-ра. Бит очищается при чтении данных со стороны DSP, а также при инициализации со стороны DSP. Программный и аппаратный сбросы, а также инструкция STOP устанавливают этот бит в «О».
Регистр управления HCR (чтение/запись) X:$FFF8
7_____________________________________О
| 0 | 0 | 0 | HF3 | HF2 | HCIE | HTIE | HRIE |
Регистр статуса HSR (чтение/запись) X:$FFF9
7 ______ О
| DMA | 0 | 0 | HF1 | HFO | НСР | HTDE | HRDF~| '
Регистр приемника данных HRX (только чтение) X.SFFEB 1
23___________16 15_____________8 7_______________0 ..
| Старший байт | Средний байт | Младший байт | t
Регистр передатчика данных НТХ (только запись) X:$FFEB "*
23___________16 15_____________8 7_______________О
| Старший байт | Средний байт | Младший байт |
Рис. 6.32. Программная модель HI
705
ПРОЦЕССОРЫ ЦИФРОВОЙ ОБРАБОТКИ СИГНАЛОВ
Передатчик данных пуст (HTDE - бит 1).
Бит показывает, что регистр передатчика данных пуст, т. е. данные переданы в host-процессор. Бит очищается при записи данных со стороны DSP. Бит устанавливается при инициализации со стороны host-интерфейса. Программный и аппаратный сбросы, а также инструкция STOP устанавливают этот бит в «1».
Задержка команд (НСР - бит 2).
Бит показывает, что установлен бит НС в регистре вектора команд (CVR) и командные прерывания HI задерживаются. НС и НСР очищаются при обработке аппаратных исключений DSP. Host может очистить НС и НСР. Программный и аппаратный сбросы, а также инструкция STOP устанавливают этот бит в «О».
Флаг О (HFO- бит 3).
Бит показывает состояние флага 0 в ICR Host-процессора. Бит может быть изменен host-процессором. Программный и аппаратный сбросы, а также инструкция STOP устанавливают этот бит в «О».
Флаг 1 (HF1 - бит 4).
Бит показывает состояние флага 1 в ICR Host-процессора. Бит может быть изменен host-процессором. Программный и аппаратный сбросы, а также инструкция STOP устанавливают этот бит в «О».
Статус ПДП (DMA - бит 7).
Бит показывает, что в host-процессоре разрешен режим ПДП и бит НМ1 или бит НМО равен единице. Если бит ПДП равен нулю, это означает запрещение режима ПДП. Если бит установлен в «1», режим ПДП разрешен и один из битов host-режима установлен в «1». Программный и аппаратный сбросы, а также инструкция STOP устанавливают этот бит в «О».
Регистр приемника данных (HRX). Используется для передачи данных между DSP и host-процессором. HRX - 24-битный регистр только для чтения со стороны DSP. В этот регистр загружаются данные из регистра передатчика host-процессора, если регистр приемника DSP пуст, а регистр передатчика host-процессора полон. Операция передачи устанав» ливает TXDE и HRDF. Регистр содержит корректные данные только в том случае, если установлен бит HRDF. Чтение регистра сбрасывает HRDF. Сброс не влияет на этот регистр.
Регистр передатчика данных (НТХ). Используется для передачи данных между DSP и host-процессором. 24-битный регистр - только для записи со стороны DSP. Запись в регистр очищает HTDE. Регистр передает 24-битные данные в регистр приемника host-процессора, если приемник данных пуст и бит HTDE = 0. Операция передачи устанавливает TXDE и HRDF. Данные не могут быть записаны в регистр, пока бит HTDE не станет равен единице, чтобы не изменять предыдущие данные, хранящиеся в регистре. Сброс не влияет на этот регистр.
Прерывания. HI может вызывать процедуры обработки прерываний как со стороны DSP, так и со стороны host-процессора. В первом случае прерывания являются внутренними и не требуют использования внешних линий. Если соответствующая маска установлена в HCR, прерывание вызывает установку соответствующих битов в HSR, которые генерируют запрос прерывания в процессор DSP. Ответ на прерывание вызывает переход host-процессора к выполнению соответствующей процедуры обработки прерывания. Возможны три типа прерываний: по заполнению регистра приемника данных, по опустошению регистра передатчика данных и по host-команде. Процедура обработки прерываний должна осуществить чтение или запись в регистр HI, чтобы сбросить флаг прерывания.
Host-интерфейс со стороны Host-процессора. HI оперирует host-процессором как восемью словами статической памяти разрядностью 8 бит. Host-процессор может работать с интерфейсом асинхронно с использованием техники опроса или с использованием прерываний. Отдельные регистры приемника и передатчика данных имеют двойную
706
ПРОЦЕССОРЫ СЕМЕЙСТВА DSP56000
буферизацию, что существенно повышает скорость передачи данных. HI содержит простейший контроллер ПДП, генерирующий адреса (НА0-НА2) для регистров TX/RX.
Программная модель со стороны Host-процессора. Программная модель со стороны host-процессора показана на рис. 6.33.
Регистр управления прерываниями (ICR). 8-битный регистр используется host-процессором для управления прерываниями и флагами. Регистр не доступен DSP. Чтение и запись в регистр осуществляются стандартными инструкциями.
Разрешение прерывания приемника (RREQ- бит 0).
Бит используется для управления -J-IREQ при передаче данных (табл. 6.19).
В режиме прерывания (ПДП отключен), RREQ используется для разрешения запроса прерывания через внешний вывод (-.HREQ), если регистр приемника данных заполнен и бит RXDF в регистре статуса установлен. Если бит RREQ равен нулю, прерывания по заполнению приемника запрещены.
В режиме ПДП RREQ должен быть установлен или сброшен программным путем для выбора направления перемещения данных при ПДП. Установка бита определяет направление ПДП и разрешает использование вывода -,HREQ для запроса перемещения данных. Аппаратный, программный сброс, а также команда STOP сбрасывают этот бит.
Разрешение прерывания передатчика (TREQ — бит 1).
Бит используется для управления выводом -,HREQ при передаче данных. В режиме прерывания (ПДП отключен), TREQ используется для разрешения запроса прерывания через внешний вывод (-,HREQ), если регистр передатчика данных пуст и бит TXDE в регистре статуса установлен. Если бит TREQ равен нулю, прерывания по опустошению передатчика запрещены.
Регистр управления прерываниями ICR 7 (чтение/запись) $0 q
I INIT I НМ1 I HMD I HF1 I HFO | 0 | TREQ | RREQ |
0 0 Режим прерываний (ПДП отключен)
0 1 24-битный режим ПДП
1 0 16-битный режим ПДП
1 1 8-битный режим ПДП
Регистр командного вектора CVR (чтение/запись) $1 7 4_________________________0
| НС | 0 | 0 | Host-вектор |
Регистр статуса прерываний ICR (только чтение) $2 7.....................................0 . ,4
| HREQ | DMA | 0 | HF3| HF2| TRDY| TXDE | RXDF |
Регистр вектора прерывания IVR (чтение/запись) $3 '
7_________________4_________________________0
| Номер вектора прерывания ($0F) |
Регистр приемника данных RX (только чтение)
31 $4 24 23 $5 16 15 $6 8 7 $7 0
0000000 0| Старший байт | Средний байт | Младший байт | . у,
Регистр передатчика данных ТХ (только запись)
31 $4 24 23 $5 16 15 $6 8 7 $7 0 5
Не используется | Старший байт | Средний байт | Младший байт | !
Рис. 6.33. Программная модель HI со стороны host-процессора
707
ПРОЦЕССОРЫ ЦИФРОВОЙ ОБРАБОТКИ СИГНАЛОВ
Таблица 6.19
Управление прерываниями и ПДП
TREQ RREQ Вывод -.HREQ
Режим прерывания
0 0 Нет прерываний (опрос)
0 1 Запрос RXDF (прерывание)
1 0 Запрос TXDE (прерывание)
1 1 Запросы RXDF и TXDE (прерывания)
Режим ПДП
0 0 Нет ПДП
0 1 Запрос otDSP к Host (RX)
1 0 Запрос от Host к DSP (ТХ)
1 1 Не определено
В режиме ПДП TREQ должен быть установлен или сброшен программным путем для выбора направления перемещения данных при ПДП. Установка бита определяет направление ПДП и разрешает использование вывода -.HREQ для запроса перемещения данных. Аппаратный, программный сброс, а также команда STOP сбрасывают этот бит.
Флаг О (HF0 - бит 3).
Бит используется как флаг общего назначения для связи Host и DSP. Бит может быть установлен или сброшен только со стороны host-процессора. Соответственно бит является видимым со стороны DSP. Аппаратный, программный сбросы, а также команда STOP сбрасывают этот бит.
Флаг 1 (HF1 - бит 4).
Бит используется как флаг общего назначения для связи Host и DSP. Бит может быть установлен или сброшен только со стороны host-процессора. Соответственно бит является видимым со стороны DSP. Аппаратный, программный сбросы, а также команда STOP сбрасывают этот бит.
Управление режимом Host (НМ1 и НМО - биты 5 и 6).
Биты определяют режим передачи host-интерфейса (табл. 6.20).
В режиме прерываний биты TREQ и RREQ используются для управления прерываниями host-процессора через внешний выходной контакт -.HREQ. Входной контакт -.HACK используется в семействе MC68000 для ответа на запрос прерывания. Если один из битов - НМ1 и НМО - установлен, режим ПДП разрешен; контакт -.HREQ используется для запроса перемещения данных в режиме ПДП. При этом биты TREQ и RREQ определяют направление ПДП. Входной контакт -.HACK используется для ответа на запрос ПДП. При направлении перемещения данных из DSP в Host содержимое выбранного регистра разрешено читать с шины данных HI, если на контакте -.HACK есть ответ. При направлении перемещения данных из Host в DSP содержимое выбранного регистра записывается на шину данных HI, если на контакте -.HACK есть ответ.
Размер слова ПДП также определяется битами НМ1 и НМО. Регистр HI, выбранный для передачи, определяется 2-битным адресным счетчиком, который загружается значениями НМ1 и НМО. В адресном счетчике используются два бита: НА1 и HAO. НА2 устанавливается в «1» при каждой операции ПДП. Адресный счетчик инициализируется битом INIT. После каждой операции ПДП на шине данных host-счетчик инкрементируется. После достижения граничного значения (RXL или TXL) счетчик снова загружается значениями НМ1 и НМО. Это позволяет 8-, 16- и 24-битные данные перемещать круговым способом и устраняет потребность в контроллере ПДП при работе с контактами НА2, НА1 и НАО. Аппаратный, программный сбросы, а также команда STOP сбрасывают этот бит.
708
ПРОЦЕССОРЫ СЕМЕЙСТВА DSP560GO
Таблица 6.20
Режимы HI
НМ1 НМО Режим
0 0 Режим прерываний (ПДП отключен)
0 1 Режим ПДП (24 бита)
1 0 Режим ПДП (16 бит)
1 1 Режим ПДП (8 бит)
Инициализация (INIT-бит 7).
Бит используется в host-процессоре для инициализации аппаратной части HI. Инициализация заключается в конфигурировании битов управления приемом и передачей и загрузке НМ1 и НМО во внутренний адресный счетчик ПДП. Загрузка НМ1 и НМО в счетчик ПДП вызывает начало передачи данных. Существует два метода инициализации: 1) разрешение автоматической установки счетчика ПДП после передачи слова; 2) установка бита INIT, который устанавливает счетчик ПДП. Использование бита INIT не является необходимым для инициализации HI и зависит от программных разработок. Выполняемый тип инициализации при установке бита INIT зависит от состояния битов TREQ и RREQ в HI (табл. 6.21) Команда INIT, локальная для HI, разработана для удобства конфигурации HI в режиме передачи данных. Эта команда описана в табл. 6.26. Аппаратный, программный сбросы, а также команда STOP сбрасывают этот бит. Выполнение INIT всегда загружает счетчик ПДП и очищает каналы TREQ и RREQ, но не влияет на биты НМ1 и НМО. Внутренний счетчик ПДП инкрементируется при каждой операции ПДП (каждом импульсе -.HACK), пока не будет указывать на последние регистры данных (RXL или TXL). По завершении цикла ПДП счетчик загружается значениями НМ1 и НМО. При изменении размера слова ПДП (НМ1 и НМО) счетчик не модифицируется автоматически, поэтому необходимо использовать функцию INIT для корректной установки счетчика. Счетчик ПДП не может инициализироваться в середине цикла ПДП, поэтому контроллер ПДП ожидает завершения цикла передачи перед выполнением инициализации.
Таблица 6.21
Конфигурирование HI
TREQ RREQ Вывод -.HREQ Направление передачи
Режим прерывания (НМ1=0, НМ0=0). Выполнение INIT
0 0 INIT = 0; адресный счетчик = 00 Нет
0 1 INIT = 0; RXDF = 0; HTDE = 1; адресный счетчик = 00 Из DSP в Host
1 0 INIT = 0; TXDE = 1; HRDF = 0; адресный счетчик = 00 Из Host в DSP
1 1 INIT = 0; RXDF = 0; HTDE = 1; TXDE = 1; HRDF = 0; Host в/из DSP
адресный счетчик = 00
Режим ПДП (НМ1 или НМ0=1). Выполнение INIT
0 0 INIT = 0; адресный счетчик = НМ 1, НМО Нет
0 1 IN 1Т= 0; RXDF=0; HTDE=1; адресный счетчик = НМ1, НМО Из DSP в Host
1 0 INIT= 0; TXDE=1; HRDF=0; адресный счетчик = НМ1, НМО Из Host в DSP
1 1 Не определено Не определено
Регистр командного вектора (CVR). Регистр используется host-процессором в случае выполнения векторных прерываний DSP.
Host-вектор (HV - биты 0-4).
Пять битов вектора выбирают адрес команды исключения. Если команда исключения распознана логикой управления прерываниями DSP, стартовый адрес исключения равен
709
ПРОЦЕССОРЫ ЦИФРОВОЙ ОБРАБОТКИ СИГНАЛОВ
2 х HV. Если это необходимо, host может записать НС и HV в обычном цикле записи. Host-процессор может выбрать одно из 32 возможных стартовых адресов исключений в DSP при записи стартового адреса процедуры обработки исключения, деленного на два, в HV. Таким образом, host-процессор может использовать любое из существующих исключений, а также любой из резервных или неиспользованных адресов. Для программного и аппаратного сбросов, а также сброса по STOP HV = $12.
Бит Host-команды (НС - бит 7).
Бит используется host-процессором при выполнении исключений по host-команде. Обычно НС = 1 для запроса исключения по host-команде из DSP. Если исключение по host-команде отвечает DSP, бит НС очищается аппаратно. Host-процессор может прочитать состояние НС для определения выбора host-команды. Host-процессор может очистить НС, отменяя тем самым запрос исключения по host-команде в любое время перед тем, как оно будет выбрано DSP. Если это необходимо, host может записать НС и HV в обычном цикле записи. Аппаратный, программный сброс, а также команда STOP сбрасывают этот бит.
Регистр статуса прерывания (ISR). 8-битный регистр только для чтения используется host-процессором для получения статуса и флагов HI. Host-процессор может производить запись по этому адресу без влияния на внутреннее состояние HI, что полезно при обращении пользователя к регистрам HI. Регистр не доступен в DSP.
Регистр приемника данных заполнен (RXDF- бит 0).
Бит показывает, что байты регистра приемника (RXH, RXM, RXL) содержат данные из DSP и могут быть прочитаны host-процессором. Бит устанавливается, если содержимое НТХ передано в регистр приемника. Бит очищается при чтении младшего байта данных (RXL) host-процессором. Также бит может быть очищен процедурой инициализации. RXDF может использоваться для выбора -.HREQ, если бит RREQ установлен в «1». Аппаратный, программный сбросы, и команда STOP сбрасывают этот бит.
Регистр передатчика данных пуст (TXDE - бит 1).
Бит показывает, что байты регистра передатчика (ТХН, ТХМ, TXL) пусты и могут снова быть записаны host-процессором. Бит устанавливается, если содержимое регистра передатчика передано в HRX. Бит очищается при записи младшего байта данных (TXL) host-процессором, а также процедурой инициализации. TXDE может использоваться для выбора -iHREQ, если бит TREQ установлен в «1». Аппаратный, программный сбросы, а также команда STOP сбрасывают этот бит.
Передатчик готов (TRDY- бит 2).
Бит показывает, что регистры ТХН, ТХМ, TXL и HRX пусты. TRDY = TXDE • ->HRDF. Если бит установлен в «1», данные, записанные host-процессором в ТХН, ТНМ и TXL, будут перемещены непосредственно в DSP. Аппаратный, программный сбросы, а также команда STOP сбрасывают этот бит.
Флаг 2 (HF2 - бит 3).
Бит показывает состояние флага 2 в HCR со стороны DSP. Аппаратный и программ-* ный сбросы очищают этот бит.
Флаг 3 (HF3 - бит 4). ;
Бит показывает состояние флага 3 в HCR со стороны DSP. Аппаратный и программный сбросы очищают этот бит.
Статус ПДП (DMA - бит 6).
Бит показывает, разрешен ли в host-процессоре режим ПДП. Если бит равен нулю, режим ПДП запрещен. Если бит равен единице, режим ПДП разрешен и процессор не использует активные каналы ПДП (RXH, RXM, RXL или ТХН, ТХМ, TXL в зависимости от направления ПДП) во избежание конфликтов при передаче данных. Аппаратный, программный сбросы, а также команда STOP сбрасывают этот бит.
Запрос (HREQ- бит 7).
Бит показывает состояние внешнего выходного контакта -iHREQ. Если бит равен нулю,
710
ПРОЦЕССОРЫ СЕМЕЙСТВА DSP56000
то -.HREQ не является активным и запросов прерываний или ПДП нет. Если бит равен единице, то -1HREQ является активным и происходит прерывание host-процессора или операция ПДП. Аппаратный, программный сбросы, и команда STOP сбрасывают этот бит.
Регистр вектора прерывания (IVR). Это 8-битный регистр чтения/записи, содержащий обычно номер вектора исключения, используемый в векторных прерываниях процессоров семейства MC68000. Содержимое регистра выдается на шину данных (НОНУ), если контакты -.HREQ и -.HACK активны, а режим ПДП запрещен. Аппаратный, программный сброс инициализируют этот регистр значением $0F.
Байты регистра приемника (RXH, RXM, RXL). Байты регистра приемника представлены как три 8-битных регистра только для чтения. Эти регистры принимают данные из соответствующих байтов регистра НТХ и выбираются тремя внешними входами адреса (НА2, НА1 и НАО) при чтении или при выполнении операций ПДП. Корректные данные находятся в регистре приемника только в том случае, если установлен бит RXDF. Host-процессор может программировать бит RREQ для выбора контакта -.HREQ при установке RXDF. Чтение младшего байта регистра приемника очищает бит RXDF. Сброс не влияет на регистр приемника.
Байты регистра передатчика (ТХН, ТХМ, TXL). Байты регистра передатчика представлены как три 8-битных регистра только для записи. Данные из этих регистров пересылаются в соответствующие байты регистра HRX, а сами регистры выбираются тремя внешними входами адреса (НА2, НА1 и НАО) при записи. Данные могут быть записаны в регистр передатчика только в том случае, если бит TXDE = 1. Host-процессор может программировать бит TREQ для выбора контакта -.HREQ при установке TXDE. Запись в младший байт регистра передатчика очищает бит TXDE. Сброс не влияет на регистр передатчика.
Контакты Host-интерфейса. Существуют следующие виды контактов HI.
Шина данных (Н0-Н7). Двунаправленная шина данных, используемая для перемещения данных между host-процессором и DSP.
Адрес (НА0-НА2). Контакты обеспечивают адресную выборку регистра HI. Эти входы стабильны, если -.HEN активен.
Чтение/запись (HR/—, W). Этот контакт выбирает направление перемещения данных при доступе к host-процессору. Если HR/-.W = 1 и -.HEN активен, данные перемещаются в host-процессор. Если HR/-,W=0 и -.HEN активен, данные перемещаются из host-npo-цессора в DSP. HR/-.W стабилен, если -.HEN активен.
Разрешение Host (-. HEN). Этот вход разрешает перемещение данных по шине данных host. Если -.HEN неактивен, линии шины данных находятся в третьем состоянии.
Запрос (-. HREQ). Выходной сигнал, используемый для процедуры запроса host-npo-цессором, контроллером ПДП или простейшим внешним контроллером. Контакт может быть соединен с контактом запроса прерывания host-процессора, запросом передачи контроллера ПДП или входом управления внешнего устройства.
Ответ (-. HACK). Этот вход имеет две функции: 1) обеспечивает сигнал ответа при операциях ПДП; 2) обеспечивает сигнал ответа при прерывании для совместимости с процессорами семейства MC68000. В первом случае сигнал может использоваться для стробирования данных при операциях ПДП. Во втором случае сигнал используется для разрешения выдачи на шину данных вектора прерывания, если HREQ активен.
Примеры использования HI. На рис. 6.34 показана система на основе DSP и распространенного промышленного микроконтроллера МС68НС11, который имеет мультиплексированные шины адреса и данных (требуется защелкивание адреса). Поскольку контакт -.HACK в данном примере не используется, он подключен к цепи питания. Все неиспользованные входные контакты должны быть отключены во избежание возникновения ошибочных сигналов.
711
ПРОЦЕССОРЫ ЦИФРОВОЙ ОБРАБОТКИ СИГНАЛОВ
Рис. 6.34. Система на базе DSP и М68НС11
Рис. 6.35. Система на базе DSP и М68000
712
ПРОЦЕССОРЫ СЕМЕЙСТВА OSP56000
. л . , Синх. Последовательные
Флаг О Флаг 1 Такт . -фрейма данные
Рис. 6.36. Система на базе нескольких DSP
Комплексирование DSP и процессора MC68000, который является основой не только процессоров общего применения семейства 68К и интегрированных процессоров, но и развитого семейства 32-разрядных микроконтроллеров М68300, показано на рис. 6.35. Процессор М68000 может использовать инструкцию MOVEP со словом и длинным словом для передачи последовательности данных. Если используются MC68020 или MC68030, в любой инструкции может использоваться динамически изменяемый размер шины.
Использование одного host-интерфейса для объединения нескольких DSP показано на рис. 6.36. Данная система из четырех DSP может выполнять до 41 млн инструкций в секунду и может быть расширена для обеспечения большей производительности.
6.2.4. ПОРТ С
Стандартный ввод/вывод
Порт С имеет девять линий и три функциональных назначения (рис. 6.37). Три из девяти линий могут использоваться для стандартного ввода/вывода или для последовательного коммуникационного интерфейса SCI, другие шесть линий могут использоваться для стан-
713
ПРОЦЕССОРЫ ЦИФРОВОЙ ОБРАБОТКИ СИГНАЛОВ
23 9876543210
0 STD SRD SCK SC2 SC1 SCO SCLK TXD RXD
--------------7< ------------------у------
SSI SCI
Рис. 6.37. Назначение линий порта С
дартного ввода/вывода или для синхронного последовательного интерфейса SSI. Таким образом, порт С может использоваться для управления устройствами, если он сконфигурирован как порт стандартного ввода/вывода, и для соединения с другими DSP, процессорами, АЦП и ЦАП, если он сконфигурирован как последовательные интерфейсы.
При использовании в качестве линий стандартного ввода/вывода порт С может быть представлен в виде трех регистров, которые управляют девятью контактами ввода/вывода. Это регистр управления порта С (РСС, адрес X:$FFE1), регистр направления данных порта С (PCDDR, адрес X:$FFE3) и регистр данных порта С (PCD, адрес X:FFE5).
Регистры PCDDR и PCD имеют разрядность 24 бита, из которых используются только младшие девять битов. Соответственно, установка в «1» бита в регистре PCDDR означает, что данная линия порта С используется для вывода, в противном случае - для ввода.
Выбор между стандартным вводом/выводом и последовательными интерфейсами осуществляется с помощью регистра РСС, в котором установка соответствующего бита в «1» означает использование последовательного интерфейса, а сброс в «О» - стандартный ввод/вывод.
Последовательный коммуникационный интерфейс (SCI)
SCI обеспечивает полнодуплексную последовательную связь с другими DSP, микропроцессорами или периферийными устройствами типа модемов. Сигналы интерфейса могут иметь ТТЛ-уровень или стандарт RS232C, RS422 и т. д. Этот интерфейс использует три линии: передачи данных (TXD), приема данных (RXD) и синхронизации (SCLK).
Прием данных (RXD- бит 0).
Этот вход принимает байт последовательных данных и передает их в регистр сдвига. Асинхронный ввод данных осуществляется по положительному фронту сигнала синхронизации 1 х SCLK, если SCKP = 0.
Передача данных (TXD-бит 1).
На этот выход передаются последовательные данные из регистра сдвига. Данные меняются по отрицательному фронту сигнала синхронизации SCLK, если SCKP = 0.
Синхронизация (SCLK— бит 2).
Двунаправленная линия обеспечивает синхронизацию при приеме или передаче данных в асинхронном режиме, а также при передаче данных в синхронном режиме.
23 16 15 14 13 12 11 10 Регистр управления 9 8 7 (SCR) 6 5 4 3 2 1 0
I o | SCKP I 0 I TIMIE I TIE IRIEI ILIE | ТЕ | RE | WOMS | RWU | WAKE | SBK I SSFTD | WDS2 | WDS1 | WDS0 |
23 Регистр статуса 8 7 (SSR) 6 5 4 3 2 1 0
| 0 | R8 I I PE I OR I IDLE | RDRF | TORE | TRNE |
23 16 15 14 13 12 Регистр управления синхронизацией 11 10 9 8 7 6 (SCCR) 5 4 3 2 1 0
I ° | TCM I RCM I SCP I coo | CD11 | CD10 | CDS | CD8 | CD7 | CDS | CDS | CD4 | CD3 | CD2 I CD1 I. CDS |
Рис. 6.38. Программная модель SCI
714
ПРОЦЕССОРЫ СЕМЕЙСТВА DSP56000
Программная модель SCI. Программная модель SCI приведена на рис. 6.38. Программная модель может быть представлена в виде регистров трех типов: 1) управления (SCR); 2) статуса (SSR); 3) управления синхронизацией (SCCR).
Регистр управления (SCR). 16-битный регистр чтения/записи, управляющий операциями последовательного интерфейса. 15 из 16 битов имеют функциональное назначение.
Выбор слова (WDSO, WDS1, WDS2-6umbi 0-2).
Три бита выбирают формат данных для передачи и приема (табл. 6.22).
Таблица 6.22
Выбор формата данных
WDS2 WDS1 WDS0 Формат слова
0 0 0 8-битные синхронные данные (режим сдвигового регистра)
0 0 1 Резерв
0 1 0 10-битные асинхронные данные (старт-бит, 8 бит данных, стоп-бит)
0 1 1 Резерв
1 0 0 11-битные асинхронные данные (старт-бит, 8 бит данных, бит четности, стоп-бит)
1 0 1 11-битные асинхронные данные (старт-бит, 8 бит данных, бит нечетности, стоп-бит)
1 1 0 11-битные мультиточечные данные (старт-бит, 8 бит данных, бит типа данных, стоп-бит)
1 1 1 Резерв
Асинхронные режимы совместимы с большинством последовательных устройств типа DUART. Эти режимы поддерживают стандарт RS-232. Мультиточечный режим совместим с МС68681 DUART, интерфейсом SCI М68НС11 и последовательным интерфейсом Intel 8051. Синхронный режим, по существу, представляет собой сдвиговый регистр для расширения ввода/вывода. Синхронизация данных выполняется с использованием синхронизации приема и передачи, которая совместима с режимом 0 последовательного интерфейса Intel 8051. При аппаратном сбросе биты очищаются.
Направление сдвига (SSFTD - бит 3).
Регистр сдвига данных может быть запрограммирован на сдвиг битов, начиная с младших (SSFTD - 0) или - со старших битов (SSFTD = 1). Местоположение битов четности и типа данных не изменяется - они находятся рядом со стоп-битом. Программный и аппаратный сбросы очищают этот бит.
Посылка маркера паузы (SBK - бит 4).
Маркер паузы представляет собой нулевой фрейм данных. Если бит установлен и затем очищен, передатчик завершает передачу данных, посылает нулевой фрейм и возвращается к холостому режиму или посылке данных. Программный и аппаратный сбросы очищают этот бит.
Выбор режима пробуждения (WAKE- бит 5).
Если бит равен нулю, выбирается режим пробуждения по холостой линии. В данном режиме приемник повторно разрешен по приему, по крайней мере, 10 или 11 единичных последовательностей. Программное обеспечение передатчика должно обеспечить холостую строку между последовательными сообщениями. Холостая строка не должна возникать между корректными сообщениями, поскольку каждый фрейм содержит старт-бит, равный нулю.
Если WAKE = 1, выбирается режим пробуждения по биту адреса. В этом режиме приемник разрешен, если последний бит принимаемых данных (8 или 9) равен единице.
715
ПРОЦЕССОРЫ ЦИФРОВОЙ ОБРАБОТКИ СИГНАЛОВ
9-й бит данных (R8) - бит адреса в 11-битном мультиточечном режиме, 8-й бит - бит адреса в 10-битном асинхронном и 11-битном асинхронном режиме с четностью. Таким образом, характер принимаемых данных определяет адрес, обрабатываемый всеми приостановленными процессорами: каждый процессор сравнивает его с собственным адресом и либо принимает данные, либо игнорирует их. Программный и аппаратный сбросы очищают этот бит.
Разрешение пробуждения приемника (RWU - бит 6).
Если бит равен единице и SCI находится в асинхронном режиме, разрешена функция пробуждения (SCI находится в состоянии ожидания, пока не появится причина пробуждения). В состоянии ожидания все флаги приемника, за исключением IDLE и прерывания, запрещены. При пробуждении приемника бит RWU сбрасывается аппаратно. Бит может быть сброшен программистом. RWU может использоваться программистом, чтобы игнорировать сообщения от других устройств в мультиточечном сетевом режиме. Может быть выбрано пробуждение по холостой линии или по адресному биту. Если WAKE = 0 и RWU = 1, приемник не отвечает на данные, пока не определена холостая линия. Если WAKE = 1 и RWU = 1, приемник не отвечает на данные, пока не выявлен 9-й бит данных, равный единице.
При пробуждении приемника бит RWL) сбрасывается и принимается 1-й байт данных. Если прерывания разрешены, процессор прерывает свою работу и процедура обработки прерываний читает заголовок сообщения, чтобы определить, относится ли сообщение к данному DSP. Если сообщение предназначено для данного DSP, то оно принимается и RWL) устанавливается в «1» для ожидания следующего сообщения.
Если сообщение предназначено не для данного DSP, DSP немедленно устанавливает RWU в «1», что означает игнорирование этого сообщения и ожидание следующего. Программный и аппаратный сбросы очищают этот бит. RWU не используется в синхронном режиме.
Выбор режима объединения по ИЛИ (WOMS - бит 7).
Если бит равен единице, SCI TXD драйвер программируется как открытый выход и может быть объединен вместе с другими контактами TXD, что соответствует конфигурации мультиточечного режима. В этом случае на шине требуется внешний резистор нагрузки. Если бит равен нулю, контакт TXD используется как активная внутренняя нагрузка. Программный и аппаратный сбросы очищают этот бит.
Разрешение приемника (RE - бит 8).
Если бит равен единице, приемник разрешен, иначе приемник запрещен и запрещены передачи данных в регистр SRX из сдвигового регистра приемника. Прерывания или RDRF не запрещаются. Программный и аппаратный сбросы очищают этот бит.
Разрешение передатчика (ТЕ - бит 9).
Если бит равен единице, передатчик разрешен, иначе передатчик завершает передачу данных в сдвиговый регистр передатчика и последовательный выход переводится в холостой режим. Данные в регистре STX не передаются. STX может быть записан и TDRE очищен, но данные не передаются в сдвиговый регистр. Бит ТЕ не запрещает TDRE и прерывания. Программный и аппаратный сбросы очищают этот бит.
Установка ТЕ вызывает передачу преамбулы из 10 или 11 единичных последовательностей (определенных WDS). Эта процедура дает программисту еще один метод перевода линии в холостой режим перед приемом нового сообщения. Рекомендуются следующие действия:
1) записать последний байт первого сообщения в STX;
2) ожидать условия TDRE = 1, что означает передачу последнего байта в сдвиговый регистр передатчика;
716
ПРОЦЕССОРЫ СЕМЕЙСТВА DSP56000
3) очистить ТЕ и снова установить ТЕ в «1»; эта последовательность вызывает немедленную посылку преамбулы;
4) записать 1-й байт второго сообщения в STX.
Если 1-й байт второго сообщения не будет передан в STX до того, как окончится преамбула, линия передачи данных просто перейдет в холостой режим, пока STX не будет полностью записан.
Разрешение прерывания по холостой линии (ILIE - бит 10).
Если бит равен единице, возникает прерывание по установке бита IDLE в «1». Если бит ILIE - 0, прерывания по холостой линии запрещены. Программный и аппаратный сбросы очищают этот бит. В качестве запроса прерывания выступает флаг прерывания по холостой линии (SRIINT), который не доступен пользователю. Если принят корректный старт-бит, прерывание генерируется при IDLE - 1 и ILIE = 1. Ответ из контроллера прерываний очищает запрос прерывания. Прерывание по холостой линии не может возникнуть, пока не принят последний бит данных. Бит IDLE всегда показывает реальный статуса линии приема.
Разрешение прерывания приемника (RIE-бит 11).
Бит используется для разрешения прерывания приемника. Если бит равен нулю, прерывания запрещены и необходимо опрашивать бит RDRF в регистре статуса для определения заполнения приемника. Если бит RIE = 1 и RDRF = 1, SCI посылает запрос прерывания в контроллер прерываний. Программный и аппаратный сбросы очищают этот бит.
Разрешение прерывания передатчика (TIE- бит 12).
Бит разрешает прерывания передатчика. Если бит равен нулю, прерывания запрещены и необходимо опрашивать бит TDRE в регистре статуса для определения, пуст ли передатчик. Если бит TIE = 1 и TDRE = 1, SCI посылает запрос прерывания в контроллер прерываний. Программный и аппаратный сбросы очищают этот бит.
Разрешение прерывания таймера (TMIE-бит 13).
Бит используется для разрешения прерывания от таймера SCL Если бит равен единице, генерируется запрос прерывания к контроллеру прерываний. Прерывание таймера очищает запрос прерывания к контроллеру. Эта позволяет программисту использовать генератор SCI в качестве генератора периодических прерываний, если SCI не используется, если в SCI используется внешняя синхронизация или если необходимы периодические прерывания SCI. Внутренняя частота SCI делится на 16 для генерации прерываний от таймера. Программный и аппаратный сбросы очищают этот бит.
Полярность частоты (SCKP- бит 15).
Полярность частоты на линии SCLK можно инвертировать с помощью этого бита. Если бит равен нулю, полярность положительная, в противном случае - отрицательная. В синхронном режиме положительная полярность означает прием корректных данных по низкому уровню сигнала синхронизации, отрицательная полярность означает прием корректных данных по высокому уровню сигнала синхронизации. В асинхронном режиме положительная полярность означает прием корректных данных по отрицательному фронту сигнала синхронизации, отрицательная полярность означает прием корректных данных по положительному фронту сигнала синхронизации. Программный и аппаратный сбросы очищают этот бит.
Регистр статуса (SSR). Это 8-битный регистр только для чтения, используемый для определения состояния SCI. При чтении регистр занимает младший байт на шине данных, старшие байты заполняются нулями.
Передатчик пуст (TRNE - бит 0).
Установка флага TRNE означает, что сдвиговый регистр передатчика и регистр данных пусты, т. е, в передатчике нет данных. При установке этого бита данные записывают
717
ПРОЦЕССОРЫ ЦИФРОВОЙ ОБРАБОТКИ СИГНАЛОВ
ся в один из трех блоков STX, или STXA передается в сдвиговый регистр передатчика и передаются первые данные. TRNE сбрасывается, когда TDRE очищается при записи данных в регистр STX или STXA, при передаче преамбулы по холостой линии, при останове передачи. Назначение этого бита - указывать, что передатчик пуст. Следовательно, данные, записанные в STX или STXA, будут передаваться следующими (в сдвиговом регистре передатчика нет слова для передачи). Эта процедура используется для инициализации передачи сообщения. TRNE устанавливается в «1» при программном, аппаратном сбросах и сбросе по STOP.
Регистр данных передатчика пуст (TDRE - бит 1).
Бит равен единице, если регистр данных передатчика пуст. Если бит установлен, новые данные могут записываться в один из регистров передатчика или регистр адреса данных (STXA). TDRE очищается при программном, аппаратном сбросах и сбросе по STOP.
В синхронном режиме при внутренней синхронизации между записью STX и установкой бита TDRE формируется задержка до 5,5 циклов, показывающая, что данные передаются из STX в сдвиговый регистр передатчика. Между записью данных в STX и передачей их в сдвиговый регистр задержка составляет от двух до четырех циклов. Кроме того, TDRE устанавливается в середине передачи 2-го бита. В случае использования внешней синхронизации и если синхронизация прекращается, передатчик останавливается. TDRE не может быть установлен во время передачи 2-го бита после начала внешней синхронизации. Прекращение синхронизации после 1-го бита приводит к неопределенной задержке TDRE.
В асинхронном режиме флаг TDRE устанавливается в «1» после сдвига первого слова. TDRE устанавливается в течение 2 циклов после старт-бита.
Регистр данных приемника заполнен (RDRF- бит 2).
Бит устанавливается при появлении в регистре данных приемника корректных данных из сдвигового регистра приемника. Бит очищается при программном, аппаратном сбросах и сбросе по STOP.
Флаг холостой линии (IDLE-бит 3).
Бит устанавливается, если приняты 10 или 11 единичных последовательностей. Переход IDLE из «О» в «1» вызывает прерывание по ILIE. Бит сбрасывается при определении старт-бита, при программном или аппаратном сбросах и сбросе по STOP.
Флаг ошибки по выходу за границы (OR - бит 4).
Флаг устанавливается, если байт готов для передачи из сдвигового регистра приемника в регистр данных приемника (SRX), который полон. Флаг показывает, что данные из регистра данных могут быть потеряны. Бит OR сбрасывает биты FE и РЕ, поскольку его приоритет выше. Бит очищается при чтении регистра статуса следом за чтением SRX, при программном, аппаратном сбросах и сбросе по STOP.
Ошибка четности (РЕ- бит 5).
В 11-битном асинхронном режиме бит устанавливается, если обнаружен некорректный бит четности в принимаемых данных. Если бит РЕ установлен, это не запрещает дальнейшую передачу данных в SRX. Бит очищается при программном, аппаратном сбросах и сбросе по STOP. В 10-битном асинхронном, 11-битном мультитчечном и 8-битном синхронном режимах бит РЕ очищается всегда, поскольку бит четности в этих режимах не используется.
Флаг ошибки фрейма (FE-бит 6).
Бит устанавливается в асинхронном режиме, если не обнаружено стоп-бита в принимаемых данных. FE и RDRF устанавливаются при пересылке принятого слова в SRX. Таким образом, FE запрещает дальнейшую передачу данных в SRX, пока не сброшен. Бит очищается при программном, аппаратном сбросах и сбросе по STOP. В 8-битном синхронном режиме бит FE всегда сброшен.
718
ПРОЦЕССОРЫ СЕМЕЙСТВА DSP56000
Бит принимаемого адреса (R8- бит 7).
В 11 -битном асинхронном мультиточечном режиме бит R8 используется для указания характера принимаемых данных - адрес это или данные. Бит очищается при программном, аппаратном сбросах и сбросе по STOP.
Регистр управления синхронизацией (SCCR). Это 16-битный регистр чтения/за-писи, управляющий выбором режима синхронизации и скоростью передачи интерфейса SCI. При аппаратном сбросе регистр очищается. Генератор скорости передачи приведен на рис. 6.39.
Делитель частоты (CD11-CD0- биты 11 -0).
Биты используются для переустановки 12-битного счетчика, который декрементируется с частотой, равной половине частоты генератора на кристалле. Счетчик не доступен пользователю. При достижении нулевого значения счетчик перезагружается значением, содержащимся в данных битах. Биты очищаются при программном и аппаратном сбросах.
Делитель выходной частоты (COD - бит 12).
Выходной делитель частоты управляется этим битом. В синхронном режиме частота делится на два; в асинхронном режиме, если COD = 0 и ТСМ = О, RCM = 0, частота делится на 16; если COD = 1 и ТСМ = О, RCM = 0, частота выдается на линию SCLK без изменений. Бит очищается при программном, аппаратном сбросах и сбросе по STOP.
Масштабирование синхронизации (SCP-бит 13).
Бит выбирает деление на единицу (SCP - 0) или деление на восемь (SCP - 1) делителя частоты. Выход устройства масштабирования выдает поделенную на два частоту для формирования синхронизации SCI. Бит очищается при программном, аппаратном сбросах и сбросе по STOP.
Режим синхронизации приемника (RCM- бит 14).
Бит выбирает внутреннюю или внешнюю синхронизацию приемника. Бит очищается при программном, аппаратном сбросах и сбросе по STOP.
KSCLK
Рис. 6.39. Генератор скорости передачи
719
ПРОЦЕССОРЫ ЦИФРОВОЙ ОБРАБОТКИ СИГНАЛОВ
Таблица 6.23
Режимы синхронизации
тем RCM Синхронизация ТХ Синхронизация RX SCLK Режим
0 0 Внутренняя Внутренняя Выход Синхронно/асинхронный
0 1 Внутренняя Внешняя Вход Только асинхронный
1 0 Внешняя Внутренняя Вход Только асинхронный
1 1 Внешняя Внешняя Вход Синхронно/асинхронный
Режим синхронизации передатчика (ТСМ-бит 15).
Бит выбирает (табл. 6.23) внутреннюю или внешнюю синхронизацию передатчика. Бит очищается при программном, аппаратном сбросах и сбросе по STOP.
Регистры данных SCI. Регистры данных SCI подразделяются на две группы: приемника и передатчика. Группа регистров приемника включает регистр данных приемника и сдвиговый регистр данных приемника. Соответственно передатчик также имеет два регистра: регистр данных передатчика и сдвиговый регистр передатчика.
Регистры приемника (SCI). Слова данных, принимаемые по линии RXD, сдвигаются с помощью сдвигового регистра приемника. По завершении приема порция данных передается в регистр SRX, имеющий разрядность в один байт. Этот процесс преобразования данных из последовательной формы в параллельную имеет двойную буферизацию, которая обеспечивает гибкость программирования и увеличение производительности, поскольку программист имеет возможность сохранять предыдущее слово данных во время приема следующего. Регистр SRX занимает три ячейки памяти: X:$FFF4, X:$FFF5, X:$FFF6. При чтении X:$FFF4 содержимое SRX располагается в младшем байте шины данных, старший и средний байты шины данных заполняются нулями. Аналогично при чтении среднего байта регистра данных SRX заполняются нулями старший и младший байты шины данных, а при чтении старшего байта регистра данных SRX заполняются нулями средний и младший байты шины данных.
Регистры передатчика (SCI). Регистр данных передатчика представляет собой 8-разрядный регистр, расположенный по четырем адресам: X:$FFF3, X:$FFF4, X:$FFF5, X:$FFF6. В асинхронном режиме используются X:$FFF4, X:$FFF5, X:$FFF6 и регистр называется STX. При записи X:$FFF4 в STX передается младший байт шины данных, при записи X:$FFF5-средний байт, при записи X:$FFF6 - старший байт шины. Такая структура облегчает для программиста распаковку 24-битного слова данных. Слово по адресу X:$FFF3 используется в 11-битном асинхронном мультиточечном режиме, когда в качестве данных передается адрес (9-й бит фрейма установлен в «1»). При использовании X:$FFF3 регистр называется STXA и данные из младшего байта шины данных сохраняются в STXA. Бит адреса очищается после каждой записи в X:$FFF4, X:$FFF5 или в X:$FFF6. Пересылка данных из регистра STX или STXA в сдвиговый регистр передатчика осуществляется автоматически, но не раньше, чем предыдущее слово данных преобразовано (если сдвиговый регистр пуст). Подобно приемнику передатчик также имеет двойную буферизацию. Пересылка данных в сдвиговый регистр из регистра данных и появление на линии TXD происходит за промежуток времени от двух до четырех последовательных циклов синхронизации (один цикл требуется для передачи одного бита данных). Поскольку сдвиговый регистр не доступен программисту, а передача данных занимает некоторое количество циклов синхронизации, необходимо производить запись в регистр данных, опрашивая флаг TDRE во избежание потери данных вследствие записи поверх еще не отправленного слова данных.
720
ПРОЦЕССОРЫ СЕМЕЙСТВА DSP56000
Рис. 6.41. Пример мультимастерной системы
Рис. 6.40. Пример синхронного режима
Приоритет команд передачи. Возможны несколько команд передачи: преамбула (переключение ТЕ), пауза (переключение или установка SBK) и данные для передачи (TDRE = 0). При наличии двух или более этих команд высший приоритет имеет преамбула, а низший - данные.
Исключения SCI. SCI может вызывать пять различных исключений:
1) прием данных - регистр данных полон, но ошибки приема не возникает; это прерывание разрешается битом RIE в регистре управления;
2) прием данных со статусом исключения - регистр данных полон и возникла ошибка приемника (четности, фрейма или записи поверх имеющихся данных); регистр статуса должен быть прочитан для сброса флага ошибки; это прерывание разрешается битом RIE в регистре управления;
3) передача данных - регистр данных передатчика пуст; это прерывание разрешается битом TIE в регистре управления;
4) холостая линия - линия приема находится в холостом состоянии (10 или 11 единичных битов); флаг прерывания сбрасывается автоматически при вызове процедуры обработки прерывания; это прерывание разрешается битом ILIE в регистре управления;
5) таймер - переполнение счетчика.
Флаг прерывания сбрасывается автоматически при вызове процедуры обработки прерывания. Это прерывание разрешается битом TMIE в регистре управления.
Примеры использования SCI. SCI может использоваться для связи между процессорами в мультипроцессорной конфигурации. Синхронный режим с DSP в качестве ведомого иллюстрирует рис. 6.40. Микроконтроллер 8051 обеспечивает синхронизацию данных в SCI и внешней среде. Это возможно, поскольку синхронизация сдвигового регистра совместима с микроконтроллерами 8051/8096. Мультимастерная система (рис. 6.41) использует одиночную линию приема/передачи, мультиточечный формат слова и объединение по ИЛИ (требующее регистра нагрузки). Пример системы master/slave (рис. 6.42) использует полнодуплексную передачу. Контакт синхронизации не требуется, поэтому он используется как контакт параллельного ввода/вывода.
Рис. 6.42. Пример системы master/slave
721
ПРОЦЕССОРЫ ЦИФРОВОЙ ОБРАБОТКИ СИГНАЛОВ
Синхронный последовательный интерфейс SSI.
Синхронный последовательный интерфейс является полнодуплексным последовательным портом для последовательной связи с устройствами типа преобразователей, DSP, микропроцессорами и различной периферией, которая разработана компанией «Motorola». Интерфейс называется синхронным, поскольку все последовательные передачи синхронизированы.
SSI имеет следующие характеристики:
• 6,75 млн бит/с на 27 МГц (частота генератора/4);
• двойная буферизация;
• программируемость;
• отдельные секции приема и передачи;
• биты управления и статуса;
• поддержка последовательных устройств, включая:
кодеки: МС145500; МС145501; МС145502; МС145503; МС145505; МС145402 (13-раз-рядный кодек); МС145554 (семейство кодеков);
последовательную периферию (АЦП, ЦАП) - промышленные стандарты АЦП, ЦАП; DSP56ADC16 (16-разрядный АЦП);
сетевые средства DSP56000;
периферию SPI и процессоры;
сдвиговые регистры.
Контакты данных и управления SSI. SSI имеет три контакта ввода/вывода, которые используются для передачи данных (STD), приема данных (SRD) и синхронизации (SCK). Причем линия синхронизации может использоваться в приемнике и передатчике для синхронной передачи данных или в передатчике только для асинхронной передачи данных. Три других контакта также используются в зависимости от выбранного режима - контакты SCO, SC1, SC2. В табл. 6.24 показаны варианты использования контактов SSI и режимы передачи.
Контакт передачи данных (STD). Контакт используется для передачи данных из сдвигового регистра передатчика. Данные меняются по положительному фронту такта сигнала синхронизации. STD переводится в высокоимпедансное состояние по отрицательному фронту такта сигнала синхронизации последнего бита в слове данных (т. е. во время второй половины периода последнего бита) при использовании внешней синхронизации. При внутренней синхронизации STD переводится в высокоимпедансное состояние после того, как последний бит данных передан, в течение целого периода. Если данные следуют непосредственно друг за другом, интервал высокого импеданса может отсутствовать.
Контакт приема последовательных данных (SRD). SRD принимает данные и передает их в сдвиговый регистр. Может использоваться как линия ввода/вывода. Данные меняются по отрицательному фронту сигнала синхронизации.
Синхронизация (SCK). SC К-двунаправленная линия, обеспечивающая синхронизацию передачи данных в интерфейсе SSI. SCK используется для синхронизации приемника и передатчика в синхронном режиме и передатчика в асинхронном режиме (табл. 6.25).
Контакт управления (SCO). Назначение этого контакта - определение синхронного или асинхронного режима (табл. 6.26). В асинхронном режиме этот контакт используется как контакт синхронизации приемника. В синхронном режиме контакт используется в качестве флага. Типичным применением данного флага является селекция адреса в системах с большим количеством устройств. Направление передачи на этом контакте определяется битом SCD0 в CRB. Если контакт конфигурируется как выход, то это флаг последовательного выхода 0, управляемый битом OF0 в CRB, или выход синхронизации сдвигового регистра приемника. Если контакт конфигурируется как вход, то это флаг последовательного входа 0, управляемый битом IF0 в SSISR, или выход синхронизации сдвигового регистра приемника.
722
ПРОЦЕССОРЫ СЕМЕЙСТВА DSPS6000
Таблица 6.24
Использование контактов SCO, SC1, SC2, SCK
Контакты SSI (биты управления) Асинхронный (SYN = 0) Синхронный (SYN = 1)
Непрерывная синхронизация (GCK = 0) Шлюзовая синхронизация (GCK = 1) Непрерывная синхронизация (GCK = 0) Шлюзовая синхронизация (GCK= 1)
SCO=0 (вход) SC0=1 (выход) (SCD0) RXC - Внешний RXC - Внутренний RXC - Внешний RXC - Внутренний Вход F0 Выход F0 Вход F0 Выход F0
SC1=0 (вход) SC1 = 1 (выход) (SCD1) FSR - Внешний FSR - Внутренний Не используется FSR - Внутренний Вход F1 Выход F1 Вход F1 Выход F1
SC2=0 (вход) SC2=1 (выход) (SCD2) FST - Внешний FST - Внутренний Не используется FST - Внутренний FS* - Внешний FS* - Внутренний Не используется FS* - Внутренний
SCK=0 (вход) SCK=1 (выход) (SCKD) ТХС - Внешний ТХС - Внутренний ТХС - Внешний ТХС - Внутренний *ХС - Внешний *ХС -Внутренний *ХС - Внешний *ХС - Внутренний
Примечание. ТХС - синхронизация передатчика; RXC - синхронизация приемника; *ХС - синхронизация приемника/передатчика (синхронные операции); FST -синхронизация фрейма передатчика; FSR - синхронизация фрейма приемника; FS* - синхронизация фрейма приемника/передатчика (синхронные операции); F0- флаг 0; F1- флаг 1.
Таблица 6.25
Синхронизация в SSI
SSYN SCKD SCD0 R-источник RX-выход Т-источник ТХ-выход
Асинхронный
0 0 0 EXT, SCO - EXT, SCK -
0 0 1 INT SCO EXT, SCK -
0 1 0 EXT, SCO - INT SCK
0 1 1 INT SCO INT SCK
Синхронный
1 0 0 EXT, SCK - EXT, SCK -
1 0 1 EXT, SCK - EXT, SCK -
1 1 0 INT SCK INT SCK
1 1 1 INT SCK INT SCK
Прим е ч а н /I е. EXT - имя внешнего контакта; INT- внутренний бит
синхронизации.
Контакт управления (SC1). Назначение этого контакта - определение синхронного или асинхронного режима (табл. 6.27). В асинхронном режиме этот контакт используется как контакт синхронизации фрейма приемника. В синхронном режиме с непрерывной синхронизацией контакт используется в качестве флага SC1 и выполняет функции, аналогичные функциям флага SCO. SCO и SC1 - независимые флаги, однако они могут использоваться совместно для селекции устройств.
723
ПРОЦЕССОРЫ ЦИФРОВОЙ ОБРАБОТКИ СИГНАЛОВ
Таблица 6.26
Назначение контакта SCO
SYN GCK SCD0 Назначение SCO
Синхронный Непрерывный Вход Выход Флаг 0 (вход) Флаг 0 (выход)
Шлюзовой Вход Выход Флаг 0 (вход) Флаг 0 (выход)
Асинхронный Непрерывный Вход Выход RX-синхронизация - внешняя RX-синхронизация - внутренняя
Шлюзовой Вход Выход RX-синхронизация - внешняя RX-синхронизация - внутренняя
Таблица 6.27
Назначение контакта SC1
SYN GCK SCD1 Назначение SC1
Синхронный Непрерывный Вход Выход Флаг 1 (вход) Флаг 1 (выход)
Шлюзовой Вход Выход Флаг 1 (вход) Флаг 1 (выход)
Асинхронный Непрерывный Вход Выход RX-синхронизация - внешняя RX-синхронизация - внутренняя
Шлюзовой Вход Выход RX-синхронизация - внутренняя
Направление передачи контакте определяется битом SCD1 в CRB. Если контакт определяется как выход, то это флаг последовательного выхода «О», управляемый битом OF1 в CRB, или сигнал синхронизации фрейма приемника, иначе - флаг последовательного входа, управляемый битом IF1 в SSISR, или вход синхронизации фрейма приемника из внешнего источника в режиме непрерывной синхронизации. При шлюзовой синхронизации сигнал внешней синхронизации фрейма не используется.
Контакт управления SC2. Используется в синхронизации фреймов (табл. 6.28).
Таблица 6.28
Назначение контакта SC2
SYN GCK SCD2 Операция
Синхронный Непрерывный Вход Выход RX- и ТХ-синхронизация фреймов RX- и ТХ-синхронизация фреймов
Шлюзовой Вход Выход RX- и ТХ-синхронизация фреймов
Асинхронный Непрерывный Вход Выход ТХ-синхронизация фреймов - внешняя ТХ-синхронизация фреймов - внутренняя
Шлюзовой Вход Выход ТХ-синхронизация фреймов - внутренняя
724
ПРОЦЕССОРЫ СЕМЕЙСТВА DSP56000
SC2 - сигнал синхронизации фреймов для передатчика и приемника в синхронном режиме и для передатчика в асинхронном режиме. Направление передачи на этом контакте определяется битом SCD2 в CRB. Если SC2 определяется как выход, то это внутренний сигнал синхронизации фреймов, иначе - внешний сигнал синхронизации фреймов для передатчика (приемника в синхронных операциях). В режиме шлюзовой синхронизации сигнал внешней синхронизации фрейма не используется.
Программная модель интерфейса SSI. SSI включает в себя два управляющих регистра, один регистр статуса, регистр передатчика, регистр приемника и регистр временных слотов. Эти регистры представлены на рис. 6.43. Регистры SSI не имеют в своем названии первой буквы «S», как регистры SCI.
Регистр управления A (CRA). CRA - 16-битный регистр управления операциями SSL Регистр управляет генератором частоты SSI и синхронизацией фреймов, длиной слова и количеством слов в фрейме последовательных данных.
Выбор модуля масштаба (РМ7-РМ0 - биты 0-7).
Биты РМ7-РМ0 определяют коэффициент деления делителя частоты генератора SSI. Может быть выбран коэффициент от 1 до 256. Выход синхронизации битов может располагаться на линии синхронизации передатчика SCK и/или синхронизации приемника SCO. Также выход синхронизации битов может быть внутренним для использования синхронизации сдвиговых регистров приемника и передатчика. Необходимо выбирать частоту генератора и коэффициент деления так, чтобы была совместимость с промышленными стандартами кодеков 2,048 МГц, 1,544 МГц, 1,536 МГц. Аппаратный и программный сбросы очищают биты РМ7-РМ0.
Управление делителем частоты фреймов (DCJ-DCO-биты 8-12).
Биты DC4-DC0 определяют коэффициент деления частоты фреймов. В сетевом режиме этот коэффициент может интерпретироваться как «число слов в фрейме минус один». В нормальном режиме этот коэффициент определяет скорость передачи слов. Коэффициент может задаваться в диапазоне от 1 до 32 в нормальном режиме и в диапазоне от 2 до 32 в сетевом режиме. Аппаратный и программный сбросы очищают биты DC4 - DC0.
Управление длиной слова (WLO, WL1 - биты 13 и 14).
Биты WLO, WL1 используются для выбора длины слова передаваемых данных в SSL Возможные варианты длины слова приведены в табл. 6.29. Эти биты управляют количеством активных переходов в шлюзовом режиме синхронизации и управляют делителем длины слова, который является частью генератора сигнала скорости передачи фреймов в непрерывном режим синхронизации. Также биты управляют длиной импульса синхронизации фреймов, если FSL0 и FSL1 выбирают синхронизацию по битам WL. Аппаратный и программный сброс очищают биты WLO, WL1.
Регистр управления A (CRA) (чтение/запись) X:$FFEC
15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
PSR WL1 WLO DC4 DC3 DC2 DC1 I DCO PM7 PM6 PM5 PM4 PM3 PM2 PM1 PMO
Регистр управления В (CRB) (чтение/запись) X:$FFED
15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
RIE TIE ТЕ | MOD GCK SYN| FSL1 FSLO SHFD SCKD SCD2 SCD1 SCDO OF1 oFF]
7 6 5 4 3 2 1 0
Регистр временных слотов (TSR) (запись) X:$FFEl * * * * * * *
Регистр статуса (SSISR) (запись) X:$FFEE RDF TDE ROE TUE RFS TFS IF1 IFO
Рис. 6.43. Программная модель интерфейса SSI
725
ПРОЦЕССОРЫ ЦИФРОВОЙ ОБРАБОТКИ СИГНАЛОВ
Таблица 6.29
Управление длиной слова
WL1 WL0 Число битов в слове
0 0 8
0 1 12
1 0 16
1 1 24
Диапазон масштабирования (PSR-бит 15).
PSR управляет устройством масштабирования с фиксированным делением на восемь. Бит используется для расширения диапазона устройства для случаев, когда желательна более медленная частота синхронизации. Если PSR равен нулю, фиксированное масштабирование не используется. Максимальная внутренняя частота синхронизации равна частоте генератора, деленной на четыре; минимальная равна частоте генератора, деленной на 8192. Аппаратный и программный сбросы очищают бит PSR.
Регистр управления В (CRB). Это 16-битный регистр управления операциями SSI. Регистр управляет многофункциональными контактами SC2, SC1 и SCO, которые используются как входы и выходы синхронизации, контакты синхронизации фреймов или флаги. Биты управления выходными флагами и направлением передачи также находятся в CRB. В регистре CRB находятся также биты управления прерываниями. При чтении CRB занимает на шине данных два младших байта, старший байт заполняется нулями. Операционный режим также выбирается с помощью этого регистра. Программный и аппаратный сбросы очищают все биты регистра CRB.
Выходной флаг О (OFO - бит 0).
Если используется синхронный режим SSI и бит SCD0 = 1, то контакт SCO работает как выход, и данные на контакте OFO записываются в SCO в начале фрейма в нормальном режиме или в начале следующего временного слота в сетевом режиме. Аппаратный и программный сбросы очищают бит OFO.
Выходной флаг О (OF1 - бит 1).
Если используется синхронный режим SSI и бит SCD1 = 1, то контакт SC1 работает как выход и данные на контакте OFO записываются в SCO в начале фрейма в нормальном режиме или в начале следующего временного слота в сетевом режиме.'Аппаратный и программный сбросы очищают бит OF1.
Бит направления О (SCD0 - бит 2).
Бит управляет направлением линии ввода/вывода SCO. Если SCD0 = О, SCO - вход; если SCD0 = 1, SCO - выход. Аппаратный и программный сбросы очищают бит SCD0.
Бит направления О (SCD1 - бит 3).
Бит управляет направлением линии ввода/вывода SC1. Если SCD1 = О, SC1 - вход; если SCD1 = 1, SC1 - выход. Аппаратный и программный сбросы очищают бит SCD1.
Бит направления О (SCD2 - бит 4).
Бит управляет направлением линии ввода/вывода SC2. Если SCD2 = О, SC2 - вход; если SCD2 = 1, SC2 - выход. Аппаратный и программный сбросы очищают бит SCD2.
Направление источника синхронизации (SCKD - бит 5).
Бит выбирает источник сигнала синхронизации для сдвигового регистра передатчика в асинхронном режиме и для обоих сдвиговых регистров в синхронном режиме. Если SCKD = 1, то используется внутренняя синхронизация и внутренний генератор соединен с контактом SCK, в противном случае - синхронизация внешняя и к контакту SCK может быть подсоединен внешний источник. Аппаратный и программный сбросы очищают бит SCKD.
726
процессоры семейства dsrsbooo
Направление сдвига (SHFD - бит 6).
Бит определяет направление сдвига данных из сдвигового регистра, начиная со старших битов, если SHFD = 0, или, начиная с младших битов, если SHFD = 1. Аппаратный и программный сбросы очищают бит SHFD.
Длина синхронизации фрейма (FSLO, FSL1 - биты 7 и д).
Эти биты выбирают тип синхронизации фрейма. Если FSL1 = 0 и FSLO = 0, синхронизация фрейма длиной в одно слово выбирается для ТХ и RX, длина слова данных определяется битами WL1 и WL0. Если FSL1 = 1 и FSLO = 0, 1-битный период синхронизации фрейма выбирается для ТХ и RX. Если FSLO = 1, синхронизация фреймов для ТХ и RX имеет различную длину (1-битный период для ТХ и период WL для RX). Аппаратный и программный сбросы очищают биты FSL1 и FSLO.
Синхронный/асинхронный режим (SYN- бит 9).
Бит управляет функциями приема и передачи. Если SYN = 0, выбран асинхронный режим, отдельная синхронизация и отдельные сигналы синхронизации фреймов используются в секциях приема и передачи. Если SYN = 1, выбран синхронный режим и общая синхронизация для секций приема и передачи, включая общие сигналы синхронизации фреймов. Аппаратный и программный сброс очищают бит SYN.
Управление шлюзовой синхронизацией (GCK- бит 10).
Бит используется для выбора непрерывной синхронизации и синхронизации только в те моменты, когда данные посланы в сдвиговый регистр передатчика. Если бит равен нулю, синхронизация непрерывная, в противном случае - выборочная. Аппаратный и программный сбросы очищают бит GCK.
Выбор режима (MOD - бит 11).
Бит выбирает операционный режим SSL Если бит равен нулю, выбран нормальный режим, если бит равен единице, выбран сетевой режим. В нормальном режиме делитель частоты фрейма определяет скорость передачи данных: одно слово передается в течение временного слота фрейма. В сетевом режиме слово передается в каждом временном слоте. Аппаратный и программный сбросы очищают бит MOD.
Разрешение передачи (ТЕ-бит 12).
Бит разрешает передачу данных из ТХ в сдвиговый регистр передатчика. Если бит равен единице и определена синхронизация фрейма, разрешается передача порции данных в этот фрейм. Если бит равен нулю, передатчик запрещен по завершении передачи текущих данных в сдвиговый регистр передатчика. Последовательный выход переводится в третье состояние, и любые данные, находящиеся в ТХ, не передаются (т. е. данные могут быть записаны в ТХ, ТЕ очищается, однако данные не передаются в сдвиговый регистр). В нормальном режиме - разрешающая последовательность: данные записываются в ТХ или TSR перед установкой ТЕ; запрещающая последовательность: сброс ТЕ и TIE после того, как TDE станет равным единице. В сетевом режиме операция сброса и установки ТЕ запрещает передатчик по завершении передачи текущего слова данных до начала следующего фрейма. В этот период времени контакт STD переводится в третье состояние. Аппаратный и программный сбросы очищают бит ТЕ.
Разрешение приема (RE- бит 13).
Если бит равен единице, разрешен прием порции данных. Если бит равен нулю, запрещены передачи данных в RX. Если данные принимаются, пока бит равен нулю, остаток слова сдвигается и передается в регистр данных приемника.
RE должен быть установлен в «1» в нормальном режиме и в режиме по требованию для приема данных. В сетевом режиме операция сброса и установки RE запрещает приемник после приема текущего слова данных, пока не начнется следующий фрейм данных. Аппаратный и программный сбросы очищают бит RE.
Разрешение прерывания передатчика (TIE- бит 14).
Функционирование DSP может быть прервано, если TIE и бит TDE в регистре статуса
727
ПРОЦЕССОРЫ ЦИФРОВОЙ ОБРАБОТКИ СИГНАЛОВ
установлены в «1». Если TIE равен нулю, прерывание запрещено. Бит TDE показывает, что регистр данных передатчика пуст, даже если передатчик запрещен битом ТЕ. Запись данных в ТХ или TSR очищает запрос этого прерывания. Аппаратный и программный сбросы очищают бит TIE. Используется два типа прерываний:
1)если TIE = 1, TDE = 1, TUE = 1;
2) если TIE = 1, TDE = 1, TUE = 0.
Разрешение прерывания приемника (RIE- бит 15). *
Если RIE равен единице, функционирование DSP может быть прервано, если установлен бит RDF в регистре статуса. Если RIE = 0, прерывание запрещено. Бит RDF показывает условие заполнения регистра данных приемника. Чтение регистра данных приемника очищает RDF и соответствующий запрос прерывания. Аппаратный и программный сбросы очищают бит RIE. Используется два типа прерываний при приеме данных :
1) прием данных с исключением (прерывание генерируется при условии: RIE = 1, RDF = 1, ROE = 1);
2) прием данных без исключения (прерывание генерируется при условии: RIE = 1, RDF = 1, ROE = 0.
Регистр статуса (SSISR). Это 8-битный регистр статуса, предназначенный только для чтения, используется для опроса статуса и флагов SSI. При чтении регистр занимает младший байт шины данных, старшие байты шины данных заполняются нулями.
Входной флаг 0 (IFO-бит 0).
SSI защелкивает данные, появившиеся на контакте SCO в течение приема 1-го бита после обнаружения сигнала синхронизации фрейма. Флаг 0 модифицируется, если данные из сдвигового регистра приемника переданы в регистр данных приемника. Бит IF0 разрешен, если SCD0 - 0 и SYN = 1, т. е. SCO работает как вход и выбран синхронный режим. В противном случае IF0 не разрешен и читается нулем. Аппаратный и программный сбросы, а также сброс по STOP очищают бит IF0.
Входной флаг 1 (IF1 - бит 1).
SSI защелкивает данные, появившиеся на контакте SCO в течение приема 1-го бита после обнаружения сигнала синхронизации фрейма. Флаг 1 модифицируется, если данные из сдвигового регистра приемника переданы в регистр данных приемника. Бит IF1 разрешен, если SCD1 = 0 и SYN = 1, т. е. SC1 работает как вход и выбран синхронный режим. В противном случае IF1 не разрешен и читается нулем. Аппаратный и программный сбросы, а также сброс по STOP очищают бит IF1.
Флаг сигнала синхронизации передаваемого фрейма (TFS - бит 2).
Если TFS = 1, это означает, что появился сигнал синхронизации фрейма в текущем временном слоте. TFS устанавливается по старту первого временного слота во фрейме данных и сбрасывается всеми остальными временными слотами. Данные записываются в регистр данных передатчика в течение временного слота, если TFS = 1, и передаются (в сетевом режиме) в течение второго временного слота фрейма. TFS используется в сетевом режиме для идентификации старта фрейма. Аппаратный и программный сбросы, а также сброс по STOP очищают бит TFS.
Флаг сигнала синхронизации принимаемого фрейма (RFS - бит 3).
Если RFS = 1, это означает, что появился сигнал синхронизации фрейма во время появления слова в регистре данных приемника (слово данных из первого временного слота фрейма). Если RFS = 0 и слово принято (только в сетевом режиме), это означает, что во время появления данного слова сигнала синхронизации фрейма не было. Аппаратный и программный сбросы, а также сброс по STOP очищают бит RFS.
Флаг ошибки повторной передачи (TUE - бит 4).
TUE - 1, если сдвиговый регистр передатчика пуст (нет новых данных для передачи) и появился временной слот передачи. При возникновении данной ошибки предыдущие дан
728
ПРОЦЕССОРЫ СЕМЕЙСТВА DSP56000
ные, которые находятся в ТХ, передаются еще раз. В нормальном режиме есть только один временной слот передачи на фрейм. В сетевом режиме может быть до 32 временных слотов передачи на фрейм. TUE не вызывает прерываний, но вызывает смену вектора прерывания передатчика. Если прерывание передатчика возникает, когда TUE = 1, то возникает запрос прерывания со статусом исключения. Если прерывание передатчика возникает, когда TUE = 0, то формируется запрос прерывания без возникновения ошибки. Аппаратный и программный сбросы, а также сброс по STOP очищают бит TUE. Этот бит сбрасывается также при чтении регистра статуса.
Флаг ошибки повторной записи (ROE-бит 5).
ROE = 1, если сдвиговый регистр приемника заполнен и готов к передаче в регистр данных приемника (RX), а также заполнен регистр данных. Содержимое сдвигового регистра не передается в регистр данных.
ROE не вызывает прерываний, однако ROE вызывает смену вектора прерывания, используемого для прерываний приемника. Если прерывание приемника возникает, когда ROE = 1, то формируется запрос прерывания со статусом исключения. Если прерывание приемника возникает, когда ROE = 0, то формируется запрос прерывания без возникновения ошибки. Аппаратный и программный сброс, а также сброс по STOP очищают бит ROE. Этот бит сбрасывается также при чтении регистра статуса.
Регистр данных передатчика пуст (TDE - бит 6).
Этот флаг устанавливается в «1», если данные из регистра данных передатчика переданы в сдвиговый регистр передатчика. Бит устанавливается также для запрещения временного слота в сетевом режиме (если данные передаются после того, как произошла запись в TSR). Аппаратный и программный сбросы, а также сброс по STOP устанавливают бит TDE. Таким образом, TDE показывает, что данные записаны в ТХ или в регистр временных слотов TSR. TDE сбрасывается при записи в регистр данных передатчика или записи в TSR для запрещения передачи в следующем временном слоте. Если TIE = 1, возникает запрос на прерывание.
Регистр данных приемника заполнен (RDF- бит 7).
Этот флаг устанавливается в «1», если содержимое сдвигового регистра приемника передано в регистр данных приемника. RDF сбрасывается при чтении регистра данных приемника или по аппаратному, программному сбросам, а также сбросу по STOP. Если RIE = 1, возникает запрос на прерывание.
Регистр сдвига приемника. 24-битный сдвиговый регистр принимает данные с контакта последовательного приема данных. Данные сдвигаются по такту сигнала синхронизации, если активен соответствующий сигнал синхронизации фрейма. Данные принимаются, начиная со старшего бита MSB, если SHFD = 0, и с младшего бита LSB, если SHFD = 1. Данные передаются в регистр данных приемника, если принято количество битов, определенное битом управления длиной слова в CRA.
Регистр данных приемника (RX). 24-битный регистр используется только для чтения. Принимает данные из сдвигового регистра приемника, если тот заполнен. Данные для чтения занимают старшую порцию битов регистра данных приемника. Неиспользованные биты читаются нулями.
Регистр сдвига передатчика. 24-битный сдвиговый регистр содержит данные для передачи. Данные сдвигаются по такту сигнала синхронизации, если активен соответствующий сигнал синхронизации фрейма. Количество битов, сдвигаемое для передачи, определяется битом управления длиной слова в CRA. Данные для передачи занимают старшую порцию битов сдвигового регистра, неиспользуемые биты игнорируются. Данные передаются, начиная со старшего бита, если SHFD = 0, и с младшего бита, если SHFD = 1.
Регистр данных передатчика (ТХ). 24-битный регистр используется только для записи. Данные для передачи записываются в этот регистр и автоматически передаются
729
ПРОЦЕССОРЫ ЦИФРОВОЙ ОБРАБОТКИ СИГНАЛОВ
в сдвиговый регистр. Записываемые данные занимают старшую порцию битов регистра данных передатчика, младшие биты не используются.
Регистр временных слотов (TSR). Регистр используется в случае, если данные не переданы в течение временного слота передачи. Таким образом, TSR функционирует как альтернативный регистр данных передатчика, за исключением того, что контакт передачи данных находится в высокоимпедансном состоянии в течение данного временного слота.
Режимы эксплуатации и назначения контактов. Могут использоваться следующие режимы эксплуатации (табл. 6.30):
Таблица 6.30
Режимы и назначения контактов - непрерывная синхронизация
Бит управления Режим SCO SC1
MOD GCLK SYN SCD2 SCD1 SCD0 SCKD DC4-DC0 ТХ RX Вход Выход Вход Выход
0 0 0 1 1 X X X 1 1 RXC RXC - FSR
0 0 1 1 X X X X 1 1 F0 F0 F1 F1
1 0 0 1 1 X X 1 2 2 RXC RXC - FSR '
1 0 1 1 X X X 1 2 2 F0 F0 F1 F1
0 0 0 0 1 X X X 3 1 RXC RXC - FSR
0 0 0 1 0 X X X 1 3 RXC RXC FSR -
0 0 0 0 0 X X X 3 3 RXC RXC FSR -
0 0 1 0 X X X X 3 3 F0 F0 F1 F1
1 0 0 0 1 X X X 4 2 RXC RXC - FSR
1 0 0 1 0 X X 1 2 4 RXC RXC FSR -
1 0 0 0 0 X X X 4 4 RXC RXC FSR -
1 0 1 0 X X X X 4 4 F0 F0 F1 F1
1 0 0 1 1 X X 0 8 2 RXC RXC - FSR
1 0 1 1 X X X 0 8 9 F0 F0 F1 F1
1 0 0 1 0 X X 0 8 4 RXC FSR -
0 1 0 X - 1 1 X 6 6 - RXC ? FSR
0 1 1 X - X 1 X 6 6 F0 F0 F0 F1
0 1 0 X - 1 0 X 5 6 - RXC ? FSR
0 1 0 X - 0 0 X 5 5 RXC - ? ?
0 1 1 X - X 0 X 5 5 F0 F0 F1 F1
1 1 0 X - 1 1 0 8 7 - RXC ? FSR
1 1 0 X - 0 1 0 8 5 RXC - ? ?
1 1 1 X - X 1 0 8 9 F0 F0 F1 F1
0 1 0 X - 0 1 X 6 5 RXC - ? ?
Примечание: DC4-DC0=0; ТХС - синхронизация передатчика; RXC - синхронизация приемника; *ХС - синхронизация приемника/передатчика (синхронная операция); F1- флаг 1; ? - не определено; FST - синхронизация фрейма передатчика; FSR - синхронизация фрейма приемника; FS* - синхронизация фрейма приемника/передатчика (синхронная операция); F0 - флаг 0.
730
ПРОЦЕССОРЫ СЕМЕЙСТВА DSP56000
1) непрерывная синхронизация:
режим 1 - нормальный с внутренней синхронизацией фрейма;
режим 2 - сетевой с внутренней синхронизацией фрейма;
режим 3 - нормальный с внешней синхронизацией фрейма;
режим 4 - сетевой с внешней синхронизацией фрейма.
2) шлюзовая синхронизация (табл. 6.31):
режим 5 - внешняя синхронизация;
режим 6 - нормальный с внутренней синхронизацией;
режим 7 - сетевой с внутренней синхронизацией.
Таблица 6.31
Режимы и назначение контактов - шлюзовая синхронизация
Бит управления Режим SC2 SCK
MOD GCLK SYN SCD2 SCD1 SCD0 SCKD DC4-DC0 тх RX Вход Выход Вход Выход
0 0 0 1 1 X X X 1 1 - FST ТХС ТХС
0 0 1 1 X X X X 1 1 - FS* *ХС *хс
1 0 0 1 1 X X 1 2 2 - FST ТХС ТХС
1 0 1 1 X X X 1 2 2 - FS* *ХС *хс
0 0 0 0 1 X X X 3 1 FST - ТХС ТХС
0 0 0 1 0 X X X 1 3 - FST ТХС ТХС
0 0 0 0 0 X X X 3 3 FST - ТХС ТХС
0 0 1 0 X X X X 3 3 FS* - *хс *хс
1 0 0 0 1 X X X 4 2 FST - ТХС ТХС
1 0 0 1 0 X X 1 2 4 - FST ТХС ТХС
1 0 0 0 0 X X X 4 4 FST - ТХС ТХС
1 0 1 0 X X X X 4 4 FS* - *хс *хс
1 0 0 1 1 X X 0 8 2 - FST ТХС ТХС
1 0 1 1 X X X 0 8 9 - FS* *хс *хс
1 0 0 1 0 X X 0 8 4 - FST ТХС ТХС
0 1 0 X X 1 1 X 6 6 7 FST - ТХС
0 1 1 X X X 1 X 6 6 7 FS* - *хс
0 1 0 X X 1 0 X 5 6 7 7 ТХС -
0 1 0 X X 0 0 X 5 5 7 7 ТХС -
0 1 1 X X X 0 X 5 5 7 ? •хс -
1 1 0 X X 1 1 0 8 7 7 FST - ТХС
1 1 0 X X 0 1 0 8 5 7 FST - ТХС
1 1 1 X X X 1 0 8 9 7 FS* - *хс
0 1 0 X X 0 1 X 6 5 7 FST - ТХС
Примечание: DC4-DC0=O; ТХС - синхронизация передатчика; RXC - синхронизация приемника; *ХС - синхронизация приемника/передатчика (синхронная операция); FST - синхронизация фрейма передатчика; FSR - синхронизация фрейма приемника; FS* - синхронизация фрейма приемника/передатчика (синхронная операция); F0 - флаг 0; F1 - флаг 1; ? - не определено.
731
ПРОЦЕССОРЫ ЦИФРОВОЙ ОБРАБОТКИ СИГНАЛОВ
3) специальный случай:
режим 8 - режим по требованию (только передатчик);
режим 9 - приемник следует за синхронизацией передатчика.
Исключения SSI. SSI может генерировать четыре различных исключения.
1. Прием данных - возникает, если разрешено прерывание приемника, регистр данных приемника полон и нет ошибки приема. Чтение RX сбрасывает запрос на прерывание.
2. Прием данных со статусом исключения - возникает, если разрешено прерывание приемника, регистр данных приемника полон и есть ошибка приема. Чтение SSISR и последующее чтение RX сбрасывает запрос на прерывание.
3. Передача данных - возникает, если разрешено прерывание передатчика, регистр данных передатчика пуст и нет ошибки передачи. Запись в ТХ или TSR сбрасывает запрос на прерывание.
4. Передача данных со статусом исключения - возникает, если разрешено прерывание передатчика, регистр данных передатчика пуст и есть ошибка передачи. Чтение SSISR и последующая запись в ТХ или TSR сбрасывает запрос на прерывание.
Операционные режимы SSI. SSI имеет три основных операционных режима и несколько форматов данных и операций. Эти режимы выбираются с помощью битов регистра управления. В табл. 6.32 приведены режимы и типовые примеры использования этих режимов.
Выбор нормального/сетевого режима. Выбор между нормальным и сетевым режимом осуществляется сбросом или установкой бита MOD в CRB. В нормальном режиме SSI функционирует с одним словом данных на фрейм. В сетевом режиме может быть от двух до 32 слов данных на фрейм. В этом случае передача периодическая. Нормальный режим используется обычно для передачи данных в одиночные устройства. Сетевой режим используется в сетях с разделением времени (TDM).
Таблица 6.32
Операционные режимы SSI
Формат Синхронизация Секция ТХ, RX Использование
Нормальный Непрерывная Асинхронная Асинхронный кодек
Нормальный Непрерывная Синхронная Синхронные кодеки
Нормальный Шлюзовая Асинхронная DSP-DSP, последовательная периферия (АЦП, ЦАП)
Нормальный Шлюзовая Синхронная Устройства типа SPI, DSP-MK
Сетевой Непрерывная Асинхронная Сети TDM
Сетевой Непрерывная Синхронная Сетевые кодеки TDM, сетевые DSP, TDM
По требованию Шлюзовая Асинхронная Параллельно-последовательные и последовательно-параллельные преобразования
По требованию Шлюзовая Синхронная DSP-периферия SPI
Выбор непрерывной/шлюзовой синхронизации. Синхронизация ТХ и RX может быть задана как непрерывная или шлюзовая с помощью бита GCK в CRB.
Непрерывная синхронизация используется при связи с кодеками, шлюзовая (только во время передачи данных) - для совместимости с SPL Выходной сигнал синхронизации фрейма можно использовать как сигнал старта преобразования АЦП или ЦАП.
Синхронный/асинхронный операционный режим. Секции передачи и приема SSI могут работать синхронно и асинхронно - т. е. передатчик и приемник могут использовать общие сигналы синхронизации (синхронный операционный режим - рис. 6.44) или они могут иметь отдельные сигналы синхронизации (асинхронный операционный режим).
732
ПРОЦЕССОРЫ СЕМЕЙСТВА DSP56000
Старт фрейма
Один фрейм
Скорость передачи слов (=3) 3 слова в фрейме
Последовательная синхронизация
Рис. 6.44. Синхронный операционный режим
Бит SYN в CRB выбирает синхронные или асинхронные операции. Если SYN = 1, сигналы синхронизации ТХ, RX и фреймов независимы; если SYN = 0, сигналы синхронизации ТХ, RX и фреймов идут из одного источника (внутреннего или внешнего).
Синхронизация данных и фреймов может быть внутренней или из внешних источников. В случае внутренней синхронизации генератор SSI использует для формирования сигнала синхронизации внутренний системный генератор DSP.
Выбор синхронизации фрейма. Передатчик и приемник могут работать полностью независимо друг от друга. Передатчик может использовать формат сигнала синхронизации длиной в один бит или одно слово, а приемник может иметь такой же или противоположный формат. Выбор сигнала синхронизации фрейма осуществляется с помощью битов FSL1 и FSLO в регистре CRB:
• если FSL1 = 0, сигнал синхронизации фрейма RX выбирается длиной в период передачи данных; этот сигнал совместим с кодеками, периферией SPI, АЦП, ЦАП, сдвиговыми регистрами и телекоммуникациями РСМ;
• если FSL1 = 1, сигнал синхронизации фрейма RX становится активным за один бит синхронизации непосредственно перед периодом передачи данных; этот сигнал совместим с компонентами Intel, кодеками и телекоммуникациями РСМ;
• если FSLO = О, ТХ и RX имеют сигнал синхронизации фрейма одинаковой длины, выбираемой FSL1; если FSLO = 1, ТХ и RX имеют сигналы синхронизации фрейма разной длины, выбираемые FSL1.
Приемник SSI ожидает появления сигнала синхронизации фрейма только по завершении предыдущего фрейма данных. Если сигнал синхронизации приходит до того, как фрейм завершен, текущий сигнал синхронизации фрейма не распознается и приемник запрещен до следующего сигнала синхронизации фрейма. Фреймы не должны следовать друг за другом без пауз - между ними должны быть промежутки арбитража. Передатчик в этих промежутках времени находится в третьем состоянии.
Примеры использования режимов. Нормальный операционный режим SSI характеризуется одним временным слотом на последовательный фрейм и передачей данных по каждому сигналу синхронизации фрейма. На рис. 6.45 показан пример использования SSI для связи кодека МС15500 и DSP56000/ DSP56001. В данном случае требуется раздельная логика. Синхронизация, вырабатываемая внутри DSP, обеспечивает синхронизацию передачи и приема для кодека (рис. 6.46). Передача данных начинается по сигналу синхронизации фрейма. По окончании передачи данных генерируется прерывание DSP и модифицируется SSISR.
733
ПРОЦЕССОРЫ ЦИФРОВОЙ ОБРАБОТКИ СИГНАЛОВ
Аналоговый вход Фильтрующий кодек МС1550х TXl TDD RDD TDC RDC DSP56000 SRD STD SCK SC2
Аналоговый выход
RXO TDE RCE MSI
Последовательная синхронизация
Рис. 6.45. Пример использования SSI для связи кодека и DSP
Синхронизация фрейма
Передача данных
Данные DSI’
Прием данных
Данные кодека
Рис. 6.46. Пример нормального режима
Сетевой режим является типичным режимом для сетевых коммуникаций с другими DSP (рис. 6.47) или кодеками ТСМ и совместим с форматом данных/операций Bell и CCITT PCM. DSP может выступать в качестве ведущего, управляющего собственной сетью, или ведомого, соединенного с существующей сетью ТСМ, и занимать один и более временных слотов.
Ключевой характеристикой сетевого режима является то, что каждый временной слот идентифицируется прерыванием или опросом бита статуса.
Сигнал синхронизации фрейма показывает начало нового фрейма данных. Каждый фрейм данных подразделяется на временные слоты; передача или получение могут происходить в каждом временном слоте. Делители скорости фрейма (DC4-DC0) управляют количеством слотов на фрейм от двух до 32. Назначение временных слотов находится под программным управлением.
Передача ведущего
Рис. 6.47. Пример сетевого режима
734
ПРОЦЕССОРЫ СЕМЕЙСТВА DSP56000
DSP56000 DSP1 STD SCK SRD SCO » DSP56000 DSP2 SRD SCO STD SCK Рис. 6.48. Пример режима «по требованию»
Рис. 6.49. Последовательное соединение DSP
Синхронизация
Рис. 6.50. Параллельное соединение DSP
735
ПРОЦЕССОРЫ ЦИФРОВОЙ ОБРАБОТКИ СИГНАЛОВ
Устройства могут передавать множество временных слотов, принимать множество временных слотов и динамически управлять назначением временных слотов.
Режим «по требованию». Коэффициент деления «1» в сетевом режиме задает режим «по требованию», поскольку в этом режиме данные передаются сразу после появления (рис, 6.48). Передача данных в этом режиме непериодическая и временные слоты не определены. В этом режиме возможны ошибки повторной передачи и поэтому они должны быть запрещены.
В режиме передачи «по требованию» два последовательных цикла синхронизации автоматически вставляются между каждыми передачами данных. Эта процедура гарантирует, что сигнал синхронизации фрейма будет иметь низкий уровень при передаче каждого слова данных или синхронизация будет прервана между двумя словами в шлюзовом режиме.
Режим «по требованию» представляет собой режим простого сдвигового регистра при SSFTD = 1 и SCKP = 1. Приемник должен быть настроен на внешний сигнал синхронизации (при непрерывной синхронизации) или на прием бита синхронизации. Для полнодуплексной передачи в режиме «по требованию» асинхронный режим не используется. Режим «по требованию» совместим с распространенным интерфейсом SPI, который широко используется также и в микроконтроллерах.
Примеры использования SSI. Последовательное соединение DSP, показанное на рис. 6.49, использует логику кристалла для сетевого соединения. Все последовательные данные синхронизируются источником данных (все тактовые линии объединены). Подобное каскадирование DSP применяется в сетевых топологиях типа «кольцо» или «звезда».
Параллельная топология, показанная на рис. 6.50, используется для интерполяции фильтров. Последовательные данные принимаются одновременно всеми DSP, работающими параллельно, а результат мультиплексируется в одиночную линию последовательных данных.
Возможны также и другие варианты соединения DSP для повышения производительности системы ЦОС.
6.2.5. ВНУТРИКРИСТАЛЬНЫЙ ЭМУЛЯТОР ОпСЕ
Структура ОпСЕ. Внутрикристальное устройство эмуляции DSP56K (ОпСЕ) обеспечивает простой, недорогой и быстрый инструмент независимого доступа к внутренним регистрам процессора и периферии. ОпСЕ сообщает программисту статус регистров, ячеек памяти, шин и пяти инструкций, выполненных последними. На рис. 6.51 приведены основные компоненты устройства эмуляции ОпСЕ, шины подключения к процессору, а также его внешние контакты.
Внешние контакты ОпСЕ. Ниже перечислены внешние контакты ОпСЕ.
Последовательный вход отладки/статус кристалла 0 (DSI/OSO). По этому контакту в контроллер ОпСЕ поступают последовательные данные или команды, если он сконфигурирован как вход.
Данные, принимаемые по контакту DSI, распознаются только в том случае, если DSP находится в режиме отладки. Данные защелкиваются по отрицательному фронту сигнала последовательной синхронизации DSCK. Данные всегда сдвигаются из последовательного порта эмулятора, начиная со старшего бита.
Если контакт сконфигурирован как выход, он работает в сочетании с контактом OS1 для выдачи информации о статусе кристалла (табл. 6.33). Как выход контакт работает, если процессор не находится в режиме отладки. После аппаратного сброса контакт сконфигурирован как выход.
736
ПРОЦЕССОРЫ СЕМЕЙСТВА DSP56000
PDB P1L GDB
Рис. 6.51. Структура OnCE
Последовательная синхронизация отладки/статус кристалла 1 (DSCK/OS1). Контакт, если он сконфигурирован как вход, обеспечивает последовательную синхронизацию для сдвига данных в последовательный порт ОпСЕ или из него. Частота синхронизации не должна быть больше, чем 1/8 частоты синхронизации процессора. Если контакт сконфигурирован как выход, он работает в сочетании с контактом OSO для выдачи информации о статусе кристалла. Как выход контакт работает, если процессор не находится в режиме отладки. После аппаратного сброса контакт сконфигурирован как выход.
Последовательный выход отладки (DSO). Через этот контакт из ОпСЕ читаются последовательные данные, определяемые последней командой, принятой от внешнего контроллера команд. Данные всегда сдвигаются из последовательного порта эмулятора, начиная со старшего бита. Данные защелкиваются по положительному фронту сигнала синхронизации за пределами последовательного порта ОпСЕ. Контакт DSO обеспечивает также ответные импульсы для внешнего контроллера команд.
При входе в режим отладки сигнал на контакте DSO имеет низкий уровень, который показывает, что ОпСЕ ожидает команды. После приема команды чтения низкий уровень на контакте DSO показывает, что запрашиваемые данные доступны и последовательный порт ОпСЕ готов для к передаче данных. После приема команды записи низкий уровень на контакте DSO показывает, что последовательный порт ОпСЕ готов к записи данных; после того, как данные записаны, выдается другой ответный импульс. После аппаратного сброса и во время простоя процессора сигнал на контакте DSO имеет высокий уровень.
Таблица 6.33 '
Информация о статусе кристалла
OS1 OSO Статус
0 0 Нормальное состояние
0 1 Состояние останова или ожидания
1 0 Кристалл ждет шину
1 1 Кристалл ждет окончания состояния ожидания памяти (выбран -,WT или BCR)
737
ПРОЦЕССОРЫ ЦИФРОВОЙ ОБРАБОТКИ СИГНАЛОВ
7 6 5 4 3 2 1 О
R/W GO EX RS4 RS3 RS2 RS1 RSO
Рис. 6.52. Формат команды
Вход запроса отладки DR). Вход запроса отладки позволяет пользователю входить в режим операций отладки из внешнего контроллера команд. При появлении активного сигнала на этом контакте DSP56K заканчивает выполнение текущей инструкции, сохраняет информацию о конвейере инструкций, переходит в режим отладки и ожидает команд по линии DSL В режиме отладки контакт используется для сброса контроллера ОпСЕ при потере синхронизации между контроллером ОпСЕ и внешним устройством. Сигнал на контакте -.DR должен быть переведен в неактивное состояние после получения ответа на линии DSO и перед посылкой первой команды. Появление активного сигнала -.DR выводит кристалл из состояния останова или ожидания.
Регистр команды ОпСЕ (OCR). Это 8-битный регистр сдвига, принимающий последовательные данные по контакту DSI. Он сохраняет 8-битные команды и используется как вход декодера ОпСЕ. Формат команды показан на рис. 6.52.
Биты выбора регистра (RS4-RS0) биты 4-0. Биты определяют регистр, предназначенный в качестве источника /приемника для чтения /записи (табл. 6.34).
Таблица 6.34
Адресация регистров ОпСЕ
RS4-RS0 Регистр
00000 Регистр статуса и управления ОпСЕ (OSCR)
00001 Счетчик точек останова памяти (ОМВС)
00010 Резерв
00011 Счетчик трассировки (ОТС)
00100 Резерв
00101 Резерв
00110 Регистр верхней границы памяти (OMULR)
00111 Регистр нижней границы памяти (OMLLR)
01000 GDB-регистр (OGDBR)
01001 PDB-регистр (OPDBR)
01010 РАВ-регистр для выборки (OPABFR
01011 PIL-регистр (OPILR)
01100 Очистка счетчика точек останова памяти (ОМВС)
01101 Резерв
01110 Очистка счетчика трассировки (ОТС)
01111 Резерв
10000 Резерв
10001 Инкрементирующий счетчик и FIFO шины адресов программ
10010 Резерв
10011 РАВ-регистр для декодирования (OPABDR)
101хх Резерв
11хх0 Резерв
11х0х Резерв
110хх Резерв
11111 Нет выбранного регистра
738
ПРОЦЕССОРЫ СЕМЕЙСТВА DSP56000
Команда Exit (EX) бит 5. Если этот бит установлен, процессор выходит из режима отладки и продолжает выполнять операции в нормальном режиме. Команда выхода выполняется только в том случае, если выдана команда Go и производится запись в OPDBR или чтение/запись при невыбранном регистре. В противном случае команда Exit игнорируется.
Команда Go (бит 6). Если бит равен единице, кристалл выполняет инструкцию, которая находится в регистре PIL. Для выполнения инструкции процессор выходит из режиме отладки, соответствующим образом показывая это на контактах OSO, OS1. Процессор возвращается в режим отладки непосредственно после выполнения инструкции, если бит ЕХ = 0. Если бит ЕХ = 1, процессор остается в нормальном режиме. Команда Go выполняется только в том случае, если производится запись в OPDBR или чтение/запись при невыбранном регистре. В противном случае команда Go игнорируется.
Команда чтения/записи (R/W) бит 7. Бит определяет направление передачи данных. Если бит равен нулю, выполняется запись данных в регистр, определенный битами RS4-RS0. Если бит равен единице, выполняется чтение данных из регистра, определенного битами RS4-RS0.
Счетчик битов ОпСЕ (ОВС). Это 5-битный счетчик, связанный со сдвигом битов данных. Счетчик инкрементируется по отрицательному фронту DSCK. Счетчик сбрасывается при аппаратном сбросе и при переходе DSP56K в режим отладки. ОВС выдает на декодер два сигнала: один показывает, что первые 8 бит сдвинуты, второй показывает, что сдвинуты 24 бита.
Декодер ОпСЕ (ODEC). ODEC управляет работой эмулятора ОпСЕ. Он принимает 8-битную команду из OCR, два сигнала из ОВС и два сигнала, показывающие, что процессор остановлен. Декодер генерирует стробы, необходимые для чтения и записи выбранных регистров.
Регистр статуса и управления (OSCR). 24-разрядный регистр OSCR используется для задания режима трассировки операций и индикации причины наступления режима отладки. Управляющие биты доступны для чтения/записи, биты состояния - для чтения. Биты регистра устанавливаются в «0» при аппаратном сбросе. Структура регистра представлена на рис. 6.53.
Управление памятью точек останова (ВСО, ВС1, ВС2 ,ВСЗ - биты 0-3). Биты разрешают использование памяти точек останова. Останов происходит, если адрес памяти находится в диапазоне значений в регистрах верхней и нижней границ памяти. Биты очищаются при аппаратном сбросе (табл. 6.35).
Разрешение режима трассировки (ТМЕ- бит 4). Если бит равен единице, разрешен режим трассировки операций. По аппаратному сбросу бит сбрасывается в «0».
Местонахождение программной отладки (SWO- бит 8). Бит статуса равен единице, если процессор переходит в режим отладки в результате выполнения инструкции DEBUG или DEBUGcc и если условие перехода истинно. Сбрасывается в «0» по аппаратному сбросу или при выходе из режима отладки при установленных битах GO и ЕХ.
Местонахождение памяти точек останова (МВО - бит 9). Бит статуса равен 1, если происходит точка останова. Бит сбрасывается в «0» по аппаратному сбросу или при выходе из режима отладки при установленных битах GO и ЕХ.
15 11 10 9876543210
* то МВО SWO * * * ТМЕ вез ВС2 ВС1 ВСО
Рис. 6.53. Структура регистра статуса и управления
739
ПРОЦЕССОРЫ ЦИФРОВОЙ ОБРАБОТКИ СИГНАЛОВ
Таблица 6.35
Типы точек останова
вез BC2 ВС1 всо Описание
0 0 0 0 Точки останова запрещены
0 0 0 1 Точка останова по любой выборке, включая прерванные инструкции
0 0 1 0 Точка останова по чтению Р (любая выборка или пересылка)
0 0 1 1 Точка останова по любому доступу к Р (любая выборка, Р пересылается R/W)
0 1 0 0 Точка останова только по выполняемой выборке
0 1 0 1 Точка останова по записи в пространство Р
0 1 1 0 Точка останова по чтению из пространства Р (без выборки)
0 1 1 1 Точка останова по чтению или записи в пространство Р (без выборки)
1 0 0 0 Резерв
1 0 0 1 Точка останова по записи в пространство X
1 0 1 0 Точка останова по чтению из пространства X
1 0 1 1 Точка останова по чтению или записи в пространство X
1 1 0 0 Резерв
1 1 0 1 Точка останова по записи в пространство Y
1 1 1 0 Точка останова по чтению из пространства Y
1 1 1 1 Точка останова по чтению или записи в пространство Y
Местонахождение трассировки (ТО - бит 10). Бит статуса равен единице, если процессор переходит в режим отладки, счетчик трассировки равен нулю и установлен режим трассировки. Бит сбрасывается в «О» по аппаратному сбросу или при выходе из режима отладки при установленных битах GO и ЕХ.
Логика точек останова ОпСЕ. Точки останова могут быть установлены в памяти программ или в памяти данных. Логика точек останова содержит защелку адреса, регистры хранения верхней и нижней границы адресов, компараторы и счетчик точек останова (рис. 6.54). Адресные компараторы помогают определять момент останова программы или запись данных в недозволенные области.
Они также используются для останова программы по определенному значению регистров или ячейки памяти. Использование адресных компараторов позволяет пользователю устанавливать точки останова в ОЗУ или ПЗУ в любом операционном режиме. Доступ к памяти управляется содержимым OSCR. Компаратор нижнего адреса генерирует сигнал «истинно», если адрес на шине больше или равен содержимому регистра нижней границы адресов. Компаратор верхнего адреса генерирует сигнал «истинно», если адрес на шине меньше или равен содержимому регистра верхней границы адресов. Если компаратор нижнего адреса и компаратор верхнего адреса выдают сигнал «истинно», адрес входит в заданный диапазон и счетчик точек останова декрементируется, если его содержимое больше нуля. Если оно равно нулю, счетчик не декрементируется и возникает точка останова.
Защелка адреса памяти (OMAL). Это 16-битный регистр, защелкивающий содержимое РАВ, ХАВ или YAB в каждом цикле в соответствии с битами ВСЗ-ВСО в OSCR.
Регистр верхней границы памяти (OMULR). Это 16-битный регистр, хранящий верхнюю границу памяти точек останова. Регистр может быть прочитан или записан с помощью последовательного интерфейса ОпСЕ. Перед выполнением точек останова регистр должен быть загружен из внешнего контроллера команд.
740
ПРОЦЕССОРЫ СЕМЕЙСТВА DSP56000
DSCK
Рис. 6.54. Логика задания точек останова
Регистр нижней границы памяти (OMLLR. Это 16-битный регистр, хранящий нижнюю границу памяти точек останова. Регистр может быть прочитан или записан с помощью последовательного интерфейса ОпСЕ. Перед выполнением точек останова регистр должен быть загружен из внешнего контроллера команд.
Компаратор верхнего адреса памяти (ОМНС). Компаратор верхнего адреса сравнивает текущий адрес памяти (в OMAL) с содержимым OMULR. Если OMULR выше или равен OMAL, компаратор вырабатывает сигнал, показывающий, что адрес меньше или равен верхней границе.
Компаратор нижнего адреса памяти (OMLC). Компаратор нижнего адреса сравнивает текущий адрес памяти (в OMAL) с содержимым OMLLR. Если OMLLR ниже или равен OMAL, компаратор вырабатывает сигнал, показывающий, что адрес больше или равен нижней границе.
Счетчик точек останова (ОМВС). 24-битный счетчик загружается величиной, равной числу циклов доступа к памяти минус единица, которые должны предшествовать выполнению точек останова. Доступ к памяти определяется битами ВСЗ-ВСО в регистре OSCR и регистрами верхней и нижней границ адресов. Во время выполнения каждого доступа счетчик точек останова декрементируется. Когда значение счетчика достигает нуля, кристалл переходит в режим отладки. Счетчик может быть прочитан или записан с помощью последовательного интерфейса ОпСЕ. При изменении адресов верхней или нижней границы счетчик должен быть перезаписан. Это гарантирует сброс логики точек останова и то, что предыдущие события никоим образом не отразятся на новых событиях. Счетчик сбрасывается по аппаратному сбросу.
741
ПРОЦЕССОРЫ ЦИФРОВОЙ ОБРАБОТКИ СИГНАЛОВ
Логика трассировки ОпСЕ. Логика трассировки ОпСЕ позволяет пользователю выполнять инструкции за один или несколько шагов перед возвращением кристалла в режим отладки и ожиданием команд по последовательному порту отладки. Счетчик трассировки позволяет выполнить более чем одну инструкцию в реальном времени перед возвращением кристалла в режим отладки. Это устройство помогает разработчику программного обеспечения отлаживать участки кода, которые имеют разветвления, а также бесконечные циклы. Счетчик трассировки разрешает пользователю также считать число инструкций, выполняемых в сегменте кода.
Для инициализации режима трассировки счетчик загружается определенной величиной, в РС устанавливается адрес инструкции, выполняемой в реальном времени, бит ТМЕ в OSCR устанавливается в «1»; процессор выходит из режима отладки при выполнении соответствующей команды от внешнего контроллера команд. При выходе из режима отладки счетчик декрементируется после выполнения каждой инструкции. Прерывания обслуживаются, и все инструкции вызывают декремент счетчика трассировки. Когда значение счетчика трассировки становится равным нулю, процессор возвращается в режим отладки, бит ТО в OSCR устанавливается в «1», контакт DSO показывает, что процессор вошел в режим отладки и требует обслуживания.
Счетчик трассировки - 24-битный счетчик, который может быть прочитан, записан или сброшен по последовательному интерфейсу ОпСЕ. Если требуется выполнить N инструкций перед возвращением в режим отладки, в счетчик должно быть загружено значение N-1. По аппаратному сбросу счетчик сбрасывается в «О».
Методы входа в режим отладки. В режиме отладки появляется импульс низкого уровня на линии DSO, информирующий внешний контроллер команд о том, что DSP находится в режиме отладки и ожидает команды.
Внешний запрос отладки по -<RESET. DSP входит в режим отладки при наличии сигналов активного уровня на линиях -.RESET и -DR. После приема ответа кристалла внешний контроллер команд должен сбросить сигнал -.DR перед посылкой первой команды. DSP не выполняет никакой инструкции перед входом в режим отладки.
Внешний запрос отладки при обычном функционировании. Появление сигнала активного уровня на линии -.DR во время обычного функционирования процессора вызывает завершение выполнения текущей инструкции и переход в режим отладки. После приема ответа кристалла внешний контроллер команд должен сбросить сигнал -.DR перед посылкой первой команды. В данном случае кристалл полностью выполняет текущую команду и останавливает выборку следующей команды.
Внешний запрос отладки при выполнении инструкции STOP. Появление сигнала активного уровня на линии —>DR, когда кристалл находится в приостановленном состоянии (по инструкции STOP), и сохранение этого сигнала до появления ответного импульса на DSO вызывает выход кристалла из приостановленного состояния и вход в режим отладки. После приема ответа кристалла внешний контроллер команд должен сбросить сигнал -.DR перед посылкой первой команды. В данном случае кристалл завершает выполнение инструкции STOP и останавливается после защелкивания следующей инструкции.
Внешний запрос отладки при выполнении инструкции WAIT. Появление сигнала активного уровня на линии —.DR, когда кристалл находится в состоянии ожидания (по инструкции WAIT), и сохранение этого сигнала до появления ответного импульса на DSO вызывает выход кристалла из приостановленного состояния и вход в режим отладки. После приема ответа кристалла внешний контроллер команд должен сбросить сигнал ->DR перед посылкой первой команды. В данном случае кристалл завершает выполнение инструкции WAIT и останавливается после защелкивания следующей инструкции.
742
ПРОЦЕССОРЫ СЕМЕЙСТВА DSP56000
Программный запрос отладки при обычном функционировании. При выполнении инструкций DEBUG или DEBUGcc, если условие истинно, кристалл переходит в режим отладки после того, как следующая инструкция будет защелкнута.
Разрешение режима трассировки. Если разрешен механизм трассировки и счетчик трассировки имеет значение больше нуля, счетчик трассировки декрементируется после выполнения каждой инструкции. При равенстве значения счетчика нулю кристалл возвращается в режим отладки. Декремент счетчика вызывают только выполняемые инструкции (прерванные не вызывают декремент счетчика трассировки).
Разрешение точек останова. Если разрешен механизм точек останова и счетчик точек останова равен нулю, кристалл переходит в режим отладки после завершения выполнения инструкции, вызвавшей точку останова. В случае останова по программной выборке точка останова вызывается сразу после выполнения выбранной инструкции. В случае останова по адресу памяти данных (доступ к памяти X, Y или Р по инструкции MOVE) точка останова вызывается после завершения инструкции, следующей за инструкцией, которая обращалась к заданному адресу.
Последовательный протокол. Этот протокол используется для эффективной связи между внешним контроллером команд и кристаллом DSP56K. Перед началом отладки внешний контроллер команд должен ждать ответа по линии DSO, показывающего, что кристалл находится в режиме отладки. Внешний контроллер команд связывается с кристаллом посредством 8-битных команд, которые могут сопровождаться 24-битными данными. Данные и команды передаются или принимаются, начиная со старшего бита. После посылки команды внешний контроллер команд должен ждать ответа кристалла о выполнении принятой команды, а только потом посылать следующую. При работе с 16-битными регистрами ОпСЕ используются старшие 16 бит в 24-битном поле данных, а младшие 8 бит заполняются нулями.
• ®
6.2.6. ШИРОТНО-ИМПУЛЬСНЫЙ МОДУЛЯТОР (PWM) 1 *
Состав PWM.
Широтно-импульсный модулятор (Pulse Width Modulator - PWM) использует два типа блоков:
1) блок PWMA, который является 16-битным знаковым широтно-импульсным модулятором данных;
2) блок PWMB, который является 16-битным положительным дробным широтно-импульсным модулятором данных;
PWM состоит из трех блоков PWMA, двух блоков PWMB, а также связанных с ними выводов и блоков предварительного масштабирования тактового сигнала.
Характеристики PWMA:
• программируемая ширина - от 9-битных до 16-битных знаковых дополненных до двух дробных данных;
• внутренний или внешний тактовые сигналы; '
• внутренняя или внешняя несущие частоты;
• максимальный уровень тактовой частоты равен 1/2 тактового сигнала ядра DSP;
• четыре вектора прерываний.
Характеристики PWMB:
• программируемая ширина - от 9-битных до 16-битных знаковых дополненных до двух дробных данных;
• внутренний или внешний тактовые сигналы;
743
ПРОЦЕССОРЫ ЦИФРОВОЙ ОБРАБОТКИ СИГНАЛОВ
• внутренняя или внешняя несущие частоты;
• максимальный уровень тактовой частоты равен 1/2 тактового сигнала ядра DSP;
• три вектора прерываний.
Внутренняя архитектура PWM.
PWM состоит из трех блоков PWMA и двух блоков PWMB. В семействе 560ХХ каждый блок рассматривается как периферийное устройство, занимающее одно 16-битное слово в пространстве памяти данных X и четыре дополнительных 16-битных слова (два из которых - совместно всеми блоками PWMA, а два других используются совместно всеми блоками PWMB). В семействе 560ХХ широтно-импульсный модулятор используется как обычное периферийное устройство со стандартной технологией опроса или программирования прерываний.
Импульсы от блоков PWMn генерируются следующим образом (рис. 6.55):
1) внутренний или внешний источник управляет периодом выхода PWMn, т. е. от фронта до фронта сигнала;
2) в регистр счета (PWACRn и PWBCRn) загружается номер, который определит ширину импульса, т. е. расстояние от фронта сигнала до его спада;
3) выбор источника тактового сигнала и числа, загружаемого в блок предварительного масштабирования, для определения ширины импульса.
Структура PWMA. На рис. 6.56 показана внутренняя структура PWMA.
Регистры счета PWMA (PWMAO, PWMA1, PWMA2). Каждый из блоков - PWMA0, PWMA1, PWMA2 состоит из следующих элементов: .’<
• 16-битного регистра счета (PWACRn);
• 16-битного буферного регистра (PWABUFn); й
• 15-битного счетчика (PWACNn);
• компаратора;
• логики управления, которая отвечает за генерацию выходных импульсов на выводах PWM, прерываний и битов статуса.
Если в регистр счета PWMAn (PWMACRn) загружается данное из ядра процессора, поступающее через общую шину данных, то при появлении фронта сигнала несущей частоты:
• данные будут передаваться в буферный регистр PWABUFn;
• 15-битный счетчик PWACNn начнет счет на увеличение;
• будет активизирован сигнал PWAPn или сигнал PWANn (в зависимости от знака данных - PWABUFn(23)).
Когда компаратор определяет равенство значений PWABUFn и PWBCN, выходной сигнал (PWAPn или PWANn) переводится в неактивное состояние. На рис. 6.57 показан двигатель, управляемый выводами PWAP1 и PWBN1.
Регистр счета
Несущая частота
Выход широтно-импульсного модулятора
Выход предварительного масштабирования
Рис. 6.55. Диаграмма управления широтно-импульсным модулятором
744
ПРОЦЕССОРЫ СЕМЕЙСТВА DSP56000
□ Внешний вывод
Рис. 6.56. Структурная схема PWMA
Рис. 6.57. Пример управления двигателем постоянного тока на основе PWMA
745
ПРОЦЕССОРЫ ЦИФРОВОЙ ОБРАБОТКИ СИГНАЛОВ
Если в PWACN1 загружается положительное значение, выводом PWAP1 можно управлять с помощью переключателей S, и S4 и создавая положительный ток I,. Когда число в PWACN1 приближается к нулю, то и электродвижущая сила стремится к нулю. Если в PWACN1 загружается отрицательное значение, выводом PWAN1 можно управлять с помощью переключателей S2 и S3, создавая отрицательный ток lL. Таким образом, можно получить противоположное направление движения двигателя.
Тактовый сигнал и логика управления PWMA. Тактовый сигнал используется для инкремента счетчиков PWMAO, PWMA1, PWMA2.
Тактовый сигнал может быть:
• внешним, получаемым через вывод PWACLK; в этом случае внешний тактовый сигнал является внешне синхронизируемым по внешнему тактовому сигналу и входу блока предварительного масштабирования; эта частота должна быть ниже, чем внутренний тактовый сигнал ядра 56К, деленный на 2 (CLK/2);
• внутренним, получаемым от тактового сигнала ядра 560ХХ после предварительного масштабирования; максимальный уровень тактовой частоты для счетчиков равен половине тактовой частоты ядра 56К (CLK/2).
Если сигнал несущей частоты программируется как внутренний, то внутренний сигнал, который эквивалентен «фронту сигнала несущей частоты», возникает в следующих случаях;
• счетчик осуществляет циклический переход (т. е. PWACNn выполняет инкрементирование от $7FFF до 0);
• разрешается работа модуля PWMAn (WAEn = 1) после того, как бит был предварительно сброшен (WAEn = 0).
Если используется меньше чем 16 бит в дробных данных, то счетчик выполняет циклический переход в соответствии с шириной данных (т. е. если ширина данных равна 15 (т. е. 14 бит плюс знаковый бит), то счетчик выполняет циклический переход после того, как достигает значения 3FFF). «Ширина» счетчика может быть запрограммирована в диапазоне от 9 до 16 бит (т. е. счетчик может выполнить циклический переход, когда достигнет значения от $FF до $7FFF в соответствии со значением в битах WAW(2:0) в PWACSR0).
Структура PWMB. На рис. 6.58 показана внутренняя архитектура PWMB.
Регистры счета PWMB (PWMBO, PWMB1). Каждый из блоков - PWMBO, PWMB1 состоит из следующих элементов:
• 16-битного регистра счета (PWBCRn);
• 16-битного буферного регистра (PWBBUFn);
• компаратора;
• логики управления, которая отвечает за генерацию выходных импульсов на выводах PWM, прерываний и битов статуса.
Если в регистр счета PWMBn (PWMBCRn) из процессора через общую шину данных загружается положительное дробное число, то при появлении фронта сигнала:
• данные будут передаваться в буферный регистр PWBBUFn;
• 15-битный счетчик PWBCNn начнет счет на увеличение;
• будет активизирован сигнал PWBn.
Когда компаратор определяет равенство значений PWBBUFn и PWBCN, выходной сигнал (PWBn) переводится в неактивное состояние (рис. 6.58).
Тактовый сигнал и логика упарвления PWMB. Тактовый сигнал, используемый для инкремента счетчиков PWMBO, PWMB1 (рис. 6.58) может быть:
• внешним, получаемым через вывод PWBCLK; в этом случае внешний тактовый сигнал является внешне синхронизируемым по внешнему тактовому сигналу и входу блока
746
ПРОЦЕССОРЫ СЕМЕЙСТВА DSP56000
24 Общая шина данных
□ Внешний вывод
Рис. 6.58. Структурная схема PWMB
!
1 .л
' I
> i
I i
предварительного масштабирования; эта частота должна быть ниже, чем внутренний тактовый сигнал ядра 56К, деленный на 2 (CLK/2);
• внутренним, получаемым от тактового сигнала ядра 56К после предварительного масштабирования; максимальный уровень тактовой частоты для счетчиков равен половине тактовой частоты ядра 56К (CLK/2).
Если сигнал несущей частоты программируется как внутренний, то сигнал, который эквивалентен «фронту сигнала несущей частоты», возникает в следующих случаях:
• когда счетчик осуществляет циклический переход (т. е. PWBCNn выполняет инкрементирование от $7FFF до 0);
• когда разрешается работа модуля PWMBn (WBEn = 1) после того, как бит был предварительно сброшен (WBEn = 0), пока работа второго модуля PWMBk запрещена; если работа второго модуля PWMBk разрешена, то следующий сигнал «фронт сигнала несущей частоты» произойдет когда счетчик выполнит циклический переход (т. е. когда PEBCN осуществляет инкремент от $7FFF до 0 - см. рис. 6.69).
Если используется меньше чем 16 бит в дробных данных, то счетчик выполняет циклический переход в соответствии с шириной данных. Таким образом, если ширина данных равна 15 (т. е. 14 бит плюс знаковый бит), то счетчик выполняет циклический переход после того, как достигает значения 3FFF. Разрядность счетчика может быть запрограммирована в диапазоне от 9 до 16 бит (т. е. счетчик может выполнить циклический переход, когда достигнет значения от $FF до $7FFF в соответствии со значением в битах WBW(2:0) регистра PWBCSR0). Знаковый бит 16-битных слов дробных данных в регистрах счета PWMB игнорируется, a PWMB осуществляет операции с этими данными как с положительными.
747
ПРОЦЕССОРЫ ЦИФРОВОЙ ОБРАБОТКИ СИГНАЛОВ
Программная модель PWM
Регистры счета PWMAN (PWACRO, PWACR1, PWACR2). Регистры счета PWACRn (п = 0...2) являются 16-битными регистрами, доступными для чтения и записи. Данные, записанные в такой регистр, автоматически передаются в связанный с регистром буфер PWABUFn после первого перехода сигнала несущей частоты PWACn или (когда используется внутренняя несущая частота) после выполнения циклического перехода счетчика PWACNn.
Регистр управления/статуса PWMAN (PWACSRO). PWACSR0 является 16-битным регистром, доступным для чтения и записи, и управляющим уровнями предварительного масштабирования тактового сигнала PWM, их источниками и шириной данных PWM. Биты статуса PWACSRO позволяют программисту DSP осуществлять опрос статуса PWMA.
Биты предварительного масштабирования PWMAn (WAP0-WAP2 - биты 0-2). Доступные для чтения и записи биты WAP0-WAP2 определяют значение делителя предварительного масштабирования PWMA. Эти биты определяют значение любого коэффициента в диапазоне от 2° до 27. Тактовый сигнал формируется с помощью тактового сигнала ядра 56К (CLK/2) или с помощью вывода PWACLK и делится на значение, соответствующее коэффициенту масштабирования. В табл. 6.36 показано программирование битов WAP0-WAP2. Эти биты сбрасываются (масштаб 1:1) после аппаратного -.RESET или программного сброса.
Таблица 6.36
Биты масштабирования WAP0-WAP2
WAP0-WAP2 Коэффициент предварительного масштабирования
$0 20
$1 21
$2 22
$3 23
$4 24
$5 25
$6 26
$7 27
Бит источника тактового сигнала PWMAn (WACK- бит 3). Доступный для чтения и записи бит WACK определяет источник тактового сигнала для 7-битного предварительного масштабирования тактового сигнала. Когда бит устанавливается, масштабируемый тактовый сигнал берется от внешнего тактового сигнала через вывод PWACLK. Бит сбрасывается после аппаратного или программного сброса.
Биты ширины данных PWMAn (WAW0-WAW2 - биты 4-6). Доступные для чтения и записи биты WAW0-WAW2 определяют ширину данных PWMA. Эти биты позволяют определить ширину данных от 9 до 16 бит. Представление данных остается выровненным слева,невзирая на дробное представление значение в битах WAW0-WAW2. В табл. 6.37 показано использование битов WAW0-WAW2. Эти биты сбрасываются (16-битная ширина данных) после аппаратного сброса -.RESET или после программного сброса (команда RESET).
Резервные биты PWMAn (PWACSRO - биты 7-9). Биты PWACSRO зарезервированы и не используются. Они могут считываться и их следует записывать как нули для дальнейшей совместимости.
Биты статуса PWMAn (WAS0-WAS2 - биты 10-12). Доступный только для чтения бит WASn (п = 0+2) устанавливается, когда данные из регистра счета PWMAn (PWACRn) передаются в буферный регистр PWMAn (PWABUFn). Бит WASn очищается, когда в ре-748
ПРОЦЕССОРЫ СЕМЕЙСТВА DSP56000
Таблица 6.37
Биты ширины данных WAW0-WAW2
WAW0-WAW2 Ширина данных
$0 $1 $2 $3 $4 $5 $6 $7 16 15 14 13 12 11 10 9
гистр счета PWMAn (PWACRn) заносятся новые данные. Биты устанавливаются после аппаратного сброса -.RESET или после программного сброса (команда RESET). Пользовательская программа может протестировать биты для того, чтобы проверить загрузку регистра счета новыми данными.
Биты ошибки PWMAn (WAR0-WAR2 - биты 13-15). Доступный только для чтения бит WASn (n = 0...2) устанавливается, когда выполняется условие ошибки PWMAn, т. е. когда фронт сигнала несущей частоты появляется перед тем, как компаратор PWMAn определит равенство регистров PWACRn и PWACNn. Бит статуса WARn сбрасывается, когда работа PWMAn запрещается (WAEn сбрасывается). Бит статуса WARn сбрасывается после аппаратного или программного сброса.
Регистр управления/статуса PWMA (PWACSR1). PWACSR1 является 16-битным регистром, доступным для чтения и записи и используемым для задания направления работы PWMA. Биты управления PWACSR1 разрешают/запрещают в блоках PWMA0, PWMA1, PWMA2:
• регистры;
• прерывания;
• источник сигнала несущей частоты;
• полярность вывода PWMA (выхода).
Биты разрешения работы PWMAn (WAEn - биты 0-2). Доступный для чтения и записи бит WAEn (п = 0+2) разрешает/запрещает работу PWMAn. Когда WAEn устанавливается, работа PWMAn разрешается. Когда WAEn сбрасывается, работа PWMAn запрещается и PWMAn переводится в собственное состояние сброса. Бит сбрасывается после аппаратного сброса -.RESET или после программного сброса (команда RESET).
Биты разрешения прерываний (WAIn - биты 3-5). Доступный для чтения и записи бит WAIn (п = 0+2) разрешает/запрещает прерывания PWMAn. Когда WAIn устанавливается, прерывание PWMAn генерируется после того, как данные передаются из регистра счета PWMAn (PWACRn) в буферный регистр PWMAn (PWABUFn), т.е. появления нового перехода сигнала несущей частоты. Когда WAIn сбрасывается, прерывание PWMAn запрещается. Бит сбрасывается после аппаратного или программного сбросов.
Биты выбора несущей частоты PWMAn (WACn - биты 6-8). Доступный для чтения и записи бит WACn (п = 0+2) осуществляет выбор между внутренней и внешней несущей частотой для PWMAn. Когда бит установлен, несущая частота является внутренней. Сигнал внутренней несущей частоты активизируется на каждом циклическом переходе счетчика PWACNn. Циклический переход может быть выполнен при различных значениях счета в соответствии с шириной данных, запрограммированной в битах WAW0-WAW2 PWACSR0. Отметим, что поскольку управление внутренней несущей частотой может
749
ПРОЦЕССОРЫ ЦИФРОВОЙ обработки сигналов
осуществляться программно, то период сигнала PWM может контролироваться или меняться независимо от ширины импульса, управляемой через регистр счета (от фронта до спада). Когда WACn сбрасывается, несущая частота PWMAn формируется через вывод PWACn. Бит сбрасывается после аппаратного сброса -.RESET или после программного сброса (команда RESET).
Биты полярности выходов PWACSR1 (WALn - биты 9-11). Доступный для чтения и записи бит WALn (п = 0...2) осуществляет выбор полярности выводов PWAPn PWANn. Когда бит сбрасывается, эти выводы являются активными по низкому сигналу выходами. Если бит устанавливается, выводы являются активными выходами по высокому сигналу. Бит сбрасывается после аппаратного или программного сбросов.
Резервные биты PWACSR1 (биты 12-14). Биты 12-14 PWACSR1 зарезервированы и не используются. Они читаются и их следует записывать как нули для дальнейшей совместимости.
Бит разрешения прерываний ошибки PWACSR1 (WAEIn - бит 15). Доступный для чтения и записи бит WAEIn (n = 0...2) разрешает/запрещает прерывания ошибки PWMAn. Когда WAEIn устанавливается, и возникает условие ошибки, генерируется прерывание ошибки PWMA. Когда WAEIn сбрасывается, прерывание ошибки PWMAn запрещается. Когда происходит прерывание ошибки, пользовательская программа должна протестировать все биты ошибок PWMAn (WARO, WAR1, WAR2) и биты ошибок PWMBn (WBR0, WBR1) для того, чтобы выявить, какой именно блок (PWMAn или PWMBn) сгенерировал ошибку. Бит сбрасывается после аппаратного сброса -.RESET или после программного сброса (команда RESET).
Регистры счета PWMB (PWBCRO, RWBCR1). Регистры счета PWBCRn (п = 0,1) являются 16-битными регистрами, доступными для чтения и записи. Данные, записанные в такой регистр, автоматически передаются в связанный с регистром буфер PWABUFn после первого перехода сигнала несущей частоты PWACn или (когда используется внутренняя несущая частота) после выполнения циклического перехода счетчика PWBCN.
Регистр управления/статуса PWMB (PWBCSRO). PWBCSR0 является 16-битным регистром, доступным для чтения и записи, и управляющим уровнями предварительного масштабирования тактового сигнала PWMB, их источниками и шириной данных PWMB. Биты статуса PWBCSRO позволяют программисту DSP осуществлять опрос статуса PWMB.
Биты предварительного масштабирования PWMB (WBP0-WBP2 - биты 0-2). Доступные для чтения и записи биты WBP0-WBP2 определяют значение делителя предварительного масштабирования PWMB. Эти биты определяют значение коэффициента в диапазоне от 2° до 27. Тактовый сигнал формируется с помощью тактового сигнала ядра 56К (CLK/2) или с помощью вывода PWACLK и делится на значение, соответствующее коэффициенту. Выбор коэффициента масштабирования с помощью битов WBP0-WBP2 осуществляется аналогично табл. 6.36. Эти биты сбрасываются (масштаб 1:1) после аппаратного сброса -.RESET или после программного сброса (команда RESET).
Бит источника тактового сигнала PWBCSRO (WBCK-бит 3). Доступный для чтения и записи бит WBCK определяет источник тактового сигнала для 7-битного предварительного масштабирования тактового сигнала. Когда этот бит устанавливается, масштабируемый тактовый сигнал берется от внешнего тактового сигнала через вывод PWBCLK. Этот бит (внешний тактовый сигнал) сбрасывается после аппаратного сброса -.RESET или после программного сброса (команда RESET).
Биты ширины данных PWBCSRO (WB WO-WBW2 - биты 4-6). Доступные для чтения и записи биты WBW0-WBW2 определяют ширину данных PWMA. Эти биты позволяют определить ширину данных от 9 до 16 бит. Данные представлены выровненными слева, поскольку нежелательно дробное представление значение в битах WBW0-WBW2.
750
ПРОЦЕССОРЫ СЕМЕЙСТВА DSP56000
Использование битов WBW0-WBW2 аналогично использованию битов WAW0-WAW2 (см. табл. 6.37). Эти биты сбрасываются (16-битная ширина данных) после аппаратного сброса -.RESET или после программного сброса (команда RESET).
Резервные биты PWBCSRO (биты 7-11). Биты 7-11 PWBCSR0 зарезервированы и не используются. Они читаются и их следует записывать как нули для дальнейшей совместимости.
Биты статуса PWBCSRO (WBS0-WBS2 - биты 12-13). Доступный только для чтения бит WBSn (п = 0,1) устанавливается, когда данные из регистра счета PWMBn (PWBCRn) передаются в буферный регистр PWMBn (PWBBUFn). Бит WBSn очищается, когда в регистр счета PWMBn (PWBCRn) заносятся новые данные. Эти биты устанавливаются после аппаратного сброса -.RESET или после программного сброса (команда RESET).
Пользовательская программа может протестировать этот бит для того, чтобы проверить загрузку регистра счета PWBCRn новыми данными.
Биты ошибок PWBCSRO (WBRn - биты 14-15). Доступный только для чтения бит WBSn (п - 0,1) устанавливается, когда выполняется условие ошибки PWMBn, т. е. когда фронт сигнала несущей частоты появляется перед тем, как компаратор PWMBn определит равенство регистров PWBCRn и PWBCNn. Бит статуса WBRn сбрасывается, когда работа PWMBn запрещается (WBEn сбрасывается).
Бит статуса WBRn сбрасывается после аппаратного сброса -.RESET или после программного сброса (команда RESET).
Регистр управления/статуса PWMB (PWBCSR1). Это 16-битный регистр, доступный для чтения и записи и используемый для задания направления работы PWMB. Биты управления PWBCSR1 разрешают/запрещают в PWMB:
• регистры;
• прерывания;
• источник сигнала несущей частоты.
Биты разрешения работы PWBCSR1 (WBEn - биты 0-1). Доступный для чтения и записи бит WBEn (п = 0,1) разрешает/запрещает работу PWMBn. Когда WBEn устанавливается, работа PWMBn разрешается. Когда WBEn сбрасывается, работа PWMBn запрещается и PWMBn переводится в собственное состояние сброса. Бит сбрасывается после аппаратного сброса -.RESET или после программного сброса (команда RESET).
Биты разрешения прерываний PWBCSR1 (WBIn - биты 2-3). Доступный для чтения и записи бит WBIn (п = 0,1) разрешает/запрещает прерывания PWMBn. Когда WBIn устанавливается, прерывание PWMBn генерируется после того, как данные передаются из регистра счета PWMBn (PWBCRn) в буферный регистр PWMBn (PWBBUFn), т. е. появления нового перехода сигнала несущей частоты. Когда WBIn сбрасывается, прерывание PWMBn запрещается. Бит сбрасывается после аппаратного сброса -.RESET или после программного сброса (команда RESET).
Резервные биты PWBCSR1 (биты 4-12). Биты 4-12 PWBCSR1 зарезервированы и не используются. Они читаются и их следует записывать как нули для дальнейшей совместимости.
Бит выбора несущей частоты PWBCSR1 (WBC-бит 13). Доступный для чтения и записи бит WBC осуществляет выбор между внутренней и внешней несущей частотой для PWMB. Когда бит установлен, несущая частота является внутренней. Сигнал внутренней несущей частоты активизируется на каждом циклическом переходе счетчика PWBCN. Циклический переход может быть выполнен при различных значениях счета в соответствии с шириной данных, запрограммированной в битах WBW0-WBW2 PWBCSRO. Отметим, что, поскольку управление внутренней несущей частотой может осуществляться программно, то период сигнала PWM может контролироваться или меняться независимо от ширины импульса, управляемой через регистр счета (от фронта
751
ПРОЦЕССОРЫ ЦИФРОВОЙ ОБРАБОТКИ СИГНАЛОВ
до спада). Когда WBC сбрасывается, несущая частота PWMB формируется через вывод PWBC. Бит сбрасывается после аппаратного или программного сброса.
Бит выхода с открытым коллектором PWBCSR1 (WBO - бит 14). Доступный для чтения и записи бит управления WBO конфигурирует выводы выходов PWMB (-.PWB0, -iPWB1) как выходы с открытым коллектором или как выходы TTL-уровня. Когда бит сбрасывается, выходы конфигурируются в режим с открытым коллектором. Когда бит устанавливается, выходы конфигурируются в режим TTL-уровня. Бит сбрасывается после аппаратного или программного сброса.
Бит разрешения прерывания ошибки PWBCSR1 (WBEI-бит 15). Доступный для чтения и записи бит WBEI разрешает/запрещает прерывания ошибки PWMB. Когда WBEI устанавливается и возникает условие ошибки, генерируется прерывание ошибки PWMB. Когда WAEIn сбрасывается, прерывание ошибки PWMAn запрещается. Когда происходит прерывание ошибки, пользовательская программа должна протестировать все биты ошибки PWMAn (WARO, WAR1, WAR2) и биты ошибки PWMBn (WBRO, WBR1) для того, чтобы выявить, какой именно блок (PWMAn или PWMBn) сгенерировал ошибку. Бит сбрасывается после аппаратного сброса -.RESET или после программного сброса (команда RESET).
6.2.7. ПОСЛЕДОВАТЕЛЬНЫЙ АУДИОИНТЕРФЕЙС (SAI)
Общая характеристика
DSP осуществляет объединение источников и приемников данных через последовательный аудиоинтерфейс (Serial Audio Interface - SAI). SAI является синхронным и специально предназначен для передачи аудиоданных. Он обеспечивает взаимодействие полнодуплексного последовательного порта с различными аудиоустройствами, в том числе такими как АЦП, ЦАП, устройствами компакт-дисков и т. д. SAI реализует широкий диапазон форматов последовательных данных, используемых в настоящее время в аудиопромышленности:
• формат l2S (Philips);
• формат CDP (Sony);
• формат МЕС (Matsushita); 7
• промышленные А/Ц-и Ц/А-стандарты.
SAI состоит из независимых секций приемника, передатчика и разделяемого (совместно используемого) генератора скорости передачи данных. Каждая из секций приемника и передатчика может работать в режиме ведомого или ведущего. В режиме ведущего в соответствии с программой работы генератора скорости передачи данных производится внутреннее управление последовательным тактовым сигналом и выбором линий данных. В режиме ведомого от внешнего источника передаются три вида сигналов. Передатчик состоит из трех регистров передаваемых данных, трех полностью синхронизируемых регистров сдвига на выходе и трех линий выхода последовательных данных, управляемых одним контроллером передатчика. Это обеспечивает возможность осуществления одновременной передачи для одного, двух или трех стерео-, аудиоустройств. Приемник состоит из двух регистров принимаемых данных, двух полностью синхронизируемых регистров сдвига на входе и двух линий входа последовательных данных, управляемых одним контроллером приемника. Это обеспечивает одновременный прием из одного или двух аудиоустройств.
Основные признаки SAI:
• программируемый генератор последовательного тактового сигнала с высоким разрешением, равным fck= /^/2/(для /> 1);
752
ПРОЦЕССОРЫ СЕМЕЙСТВА DSP56000
• максимальный уровень внешнего последовательного тактового сигнала равен 1/3 тактового сигнала ядра DSP;
• режимы ведущего и ведомого;
• три линии синхронизируемой передачи данных;
• две линии синхронизируемого приема данных;
• двойная буферизация;
• программная поддержка пользователей в различных аудиоформатах;
• три вектора прерываний приемника: прием с левого канала, прием с правого канала, прием с исключительной ситуацией;
• три вектора прерываний передатчика: передача с левого канала, передача с правого канала, передача с исключительной ситуацией.
Структурная организация SAI Функционально SAI включает три блока:
1) генератор скорости передачи данных;
2) секцию приемника;
3) секцию передатчика.
Секции приемника и передатчика полностью независимы и могут работать как вмес-
те, так и отдельно.
Генератор скорости передачи данных. Генератор скорости передачи данных вырабатывает внутренний последовательный тактовый сигнал для SAI, если одна или обе секции (приемника и передатчика) сконфигурированы в режиме ведущего. Работа гене
ратора запрещается, если эти секции сконфигурированы как ведомые.
Рис. 6.59 иллюстрирует соединения для внутреннего последовательного тактового сигнала. Тактовые сигналы приемника и передатчика могут быть как внешними, так и
внутренними в зависимости от значений управляющих битов: ведущий - приемник (RMST); ведущий - передатчик (TMST).
Секция приемника. Секция приемника содержит два приемника и состоит из 16-битного регистра управления/статуса, двух 24-битных сдвиговых регистров и двух 24-бит-ных регистров данных. Приемники имеют один механизм управления, поэтому тактовый сигнал, линия выборки слова данных и все управляющие сигналы, сгенерированные в
секции приемника, одновременно влияют на оба приемника. Секция приемника может
быть сконфигурирована или в режим ведущего (при этом тактовый сигнал и линии выборки слова данных берутся от внутреннего генератора скорости передачи данных) или в режим ведомого (тогда эти сигналы поступают от внешнего источника).
Когда работа обоих приемников запрещена, контроллер приемника прекращает свою работу, биты статуса RDLF и RRDF в регистре управления/статуса приемника RCS сбрасываются, внешние выводы секции приемника переводятся в третье состояние.
Рис. 6.59. Структурная схема генератора скорости передачи данных SAI
Тактовый сигнал
TMST=0 передатчика
PSR РМ0-РМ7
753
ПРОЦЕССОРЫ ЦИФРОВОЙ ОБРАБОТКИ СИГНАЛОВ
Структурная схема секции приемника представлена на рис. 6.60.
24-битные сдвиговые регистры получают входные данные с выводов входа последовательных данных (SDIO, SDI1 или SDIx). Данные поступают в соответствии с тактовым сигналом последовательного приема SCKR.
Если RDIR сбрасывается, то должен быть получен первым старший байт слова MSB, в противном случае первым будет получен младший байт - LSB. Данные передаются в регистры данных приемника SAI после того, как поступили 16, 24 или 32 бита, как определено битами RWL1 и RWL0 управления длиной слова. Для эмуляции 32-битного сдвигового регистра, если длина слова определена как 32 бита, используется специальный механизм управления. Такой механизм работает за счет запрещения сдвига данных на восемь разрядов в начале/конце передачи данных в соответствии с содержимым бита RDWT в регистре RCS. Эти сдвиговые регистры не могут быть непосредственно доступны DSP.
Секция передатчика. Структурная схема секции передатчика представлена на рис. 6.61. Секция передатчика содержит три передатчика и состоит из 16-битного регистра управления/статуса, трех 24-битных сдвиговых регистров и трех 24-битных регистров данных. Передатчики имеют один механизм управления, поэтому тактовый сигнал, линия выборки слова данных и все управляющие сигналы, сгенерированные в секции передатчика, одновременно влияют на все три передатчика.
Секция передатчика может быть сконфигурирована или в режим ведущего (при этом тактовый сигнал и линии выборки слова данных берутся от внутреннего генератора скорости передачи данных) или в режим ведомого (тогда эти сигналы поступают от внешнего источника). Каждый из трех передатчиков может работать независимо от остальных. Когда работа передатчика запрещена, связанный с ним вывод выхода последовательных данных (SDO) находится в состоянии высокого уровня. Когда работа всех передатчиков запрещена, контроллер приемника прекращает свою работу, биты статуса TRDE и TLDE сбрасываются, внешние выводы секции передатчика, WST - выбор слова, SCKT -тактовый сигнал последовательной передачи переводятся в третье состояние. Секция передатчика состоит из полностью синхронизированных трех регистров данных и трех
754
ПРОЦЕССОРЫ СЕМЕЙСТВА DSP56000
сдвиговых регистров, способных работать одновременно. 24-битные сдвиговые регистры выдают данные с выводов выхода последовательных данных (SDO). Данные выдвигаются в соответствии с тактовым сигналом последовательной передачи SCKT. Если TDIR сбрасывается, то первым выдается старший байт слова MSB, в противном случае - младший байт LSB.
Число передаваемых данных - 16, 24 или 32 бита, как определено битами управления длиной слова TWL1 и TWL0. Для эмуляции 32-битного сдвигового регистра, если длина слова определена как 32 бита, используется специальный механизм управления. Такой механизм работает за счет запрещения сдвига данных на восемь разрядов в нача-ле/конце передачи данных в соответствии с содержимым бита TDWE в регистре TCS. Описанные сдвиговые регистры не могут быть непосредственно доступны DSP.
Программная модель SAI
Регистры последовательного аудиоинтерфейса, которые доступны программисту, показаны на рис. 6.62.
Расположение векторов прерываний для SAI показано в табл. 6.38. Прерывания генерируются в соответствии с заданными приоритетами, как показано в табл. 6.39.
Векторы прерываний SAI могут быть размещены в одной или двух различных областях памяти. Расположение вектора прерывания передатчика контролируется с помощью бита TXIL в регистре управления/статуса передатчика (TCS). Аналогично этому расположение вектора прерывания передатчика контролируется с помощью бита RXIL в регистре управления/статуса приемника (RCS).
755
ПРОЦЕССОРЫ ЦИФРОВОЙ ОБРАБОТКИ СИГНАЛОВ
Таблица 6.38
Расположение векторов прерываний для SAI
Прерывание TXIL=0 TXIL=1 RXIL=O RXIL=1
Передача по левому каналу Р:$0010 Р:$0040 - -
Передача по правому каналу Р:$0012 Р:$0042 - -
Исключительная ситуация передачи Р:$0014 Р:$0044 - -
Прием по левому каналу - - Р:$0016 Р:$0046
Прием по правому каналу - - Р:$0018 Р:$0048
Исключительная ситуация приема - - Р:$001А Р:$004А
Таблица 6.39
Приоритеты прерываний SAI
Приоритет Прерывание
Высший Низший Приемник SAI Передатчик SAI Прием по левому каналу SAI Передача по левому каналу SAI Прием по правому каналу SAI Передача по правому каналу SAI
Регистр управления скоростью передачи (BRC). Частота тактового сигнала последовательной передачи данных определяется управляющими битами в регистре управления скоростью передачи (BRC. Содержимое этого регистра показано на рис. 6.62. Максимально допустимая частота внутренне сгенерированного сигнала равна fosc!4, максимально допустимая частота внешне сгенерированного сигнала - foscl3. Биты BRC следует модифицировать только тогда, когда работа генератора скорости передачи данных запрещена (т. е. когда секции приемника и передатчика данных определены как ведомые или когда они находятся в своих состояниях сброса).
Когда с помощью DSP осуществляется чтение, содержимое этого регистра появляется в двух младших байтах 24-битного слова, остальные биты читаются как нули. Содержимое регистра сбрасывается при аппаратном или программном сбросе.
Выбор величины модуля делителя при предварительном масштабировании (РМ[7:0]~ биты 7-0). Биты РМ[7:0] определяют значение делителя в генераторе скорости передачи SAI. При этом может быть выбрано значение делителя от 1 до 256 (РМ[7:0] = $00-$FE). Биты РМ[7:0] сбрасываются во время аппаратного или программного сброса.
Диапазон предварительного масштабирования (PRS - бит 8). Бит PRS управляет предварительным масштабированием деления на восемь, которое выполняется перед обработкой в блоке делителя. Этот бит используется для того, чтобы расширить диапазон предварительного масштабирования для тех случаев, когда желательно использование более медленного тактового сигнала. Когда этот бит устанавливается, то предварительное масштабирование пропускается. Когда бит сбрасывается, выполняется деление на восемь. Бит PRS сбрасывается во время аппаратного или программного сброса.
Резервные биты BRC (биты 15-9). Эти биты не используются и читаются как нули, записывать в них следует нули для обеспечения дальнейшей совместимости.
756
ПРОЦЕССОРЫ СЕМЕЙСТВА DSP56000
Регистр управления скоростью передачи (BRC) X:$FFEO
23 16 15 14 13 12 11 10 Э 8 7 6 5 4 3 2 1 0
^ | | | | I I | | PSR | рм7 | рм6 | РМ5 I РМ4 I рмз I рмг| PM1 I РМ0~
Регистр управления/статуса приемника (RCS) X:$FFE1
23 г/ 16f 15 14 t 13 , 12 11 10 9 8 7 6 5 4 3210
” I RRDf| RLDF I ] RXIL | RXIE | RDWT | RREL | RCKR ^RbRS | RDIR | RWL1 [ RWLO | RMST | | R1En| ROEN
Регистр управления/статуса передатчика (TCS) X:$FFE4
23 16 15 14 13 12 11 10 9 8 7 8 5_____4____3 2 1____Q
„ | TRDF | TLDF | | TXIL | TXIE | TDWT | TREE | TCKR | TLRS | TDIR | TWL1 | TWLO | TMST | | T1EN | TOEN
23 0
Резервные биты | | Регистр данных приемника 0. Только для чтения. X:$FFE2 23 0 j j Регистр данных приемника 1, Только для чтения. X:$FFE3 23 0 | | Регистр данных передатчика 0. Только для записи. X:$FFE5 23 Q | | Регистр данных передатчика 0. Только для записи. X:$FFE6 23 0 I I Регистр данных передатчика о. Только для записи. X:$FFE7
Рис. 6.62. Регистры SAI
Регистр управления/статуса приемника (RCS). Регистр RCS является 16-битным регистром управления/статуса, доступным для чтению и записи и используемым для управления при выполнении операции в секции приемника (рис. 6.62). Управляющие биты регистра определяют последовательный формат передачи данных, а биты статуса этого регистра используются программистом DSP для опроса статуса приемника. Также в регистре RCS находятся биты разрешения приема и прерываний. Когда DSP осуществляет чтение, содержимое этого регистра появляется в двух младших байтах 24-битного слова, остальные биты читаются как нули. Содержимое регистра сбрасывается во время аппаратного или программного сброса. Если оба бита R0EN и R1EN сбрасываются, то работа секции приемника запрещается и она переводится в состояние сброса. Такой индивидуальный сброс происходит в первом цикле команды после сброса указанных битов. Во время нахождения в состоянии останова или индивидуального сброса биты статуса регистра также сбрасываются. Останов или сброс не оказывают влияния на управляющие биты регистра RCS. Следует изменять содержимое управляющих битов регистра, пока секция приемника находится в состоянии сброса (или запрещения работы), иначе результаты операции будут неверны.
Бит разрешения работы приемника (R0EN - бит 0). Доступный для записи и для чтения управляющий бит разрешения работы приемника 0 разрешает выполнение операции приемника О SAL Когда этот бит установлен, работа приемника 0 разрешена. И наоборот, когда этот бит сброшен, работа приемника запрещена. Если оба бита R0EN и R1EN сбрасываются, то работа секции приемника запрещается, что эквивалентно состоянию индивидуального сброса. Содержимое бита R0EN сбрасывается во время аппаратного или программного сбросов.
Бит разрешения работы приемника (R0EN - бит 1). Доступный для записи и для чтения управляющий бит разрешения работы приемника 1 разрешает выполнение операции приемника 1 SAL Когда этот бит установлен, работа приемника 1 разрешена. И наоборот, когда этот бит сброшен, работа приемника запрещена. Если оба бита R0EN и R1EN сбрасываются, то работа секции приемника запрещается, что эквивалентно со
757
ПРОЦЕССОРЫ ЦИФРОВОЙ ОБРАБОТКИ СИГНАЛОВ
стоянию индивидуального сброса. Содержимое бита R1EN сбрасывается во время аппаратного или программного сбросов.
Резервные биты (RCS-биты 13 и 2). Эти биты не используются. Они читаются как нули; в эти биты также следует записывать нули для обеспечения дальнейшей совместимости.
Бит ведущего приемника (RMST- бит 3). Доступный для записи и для чтения управляющий бит ведущего приемника позволяет переключать работу секции приемника из режима ведущего в режим ведомого и наоборот. Когда этот бит установлен, секция приемника SAI устанавливается в режим ведущего. В режиме ведущего управление приемника происходит с помощью выводов SCKR и WSR. В режиме ведомого управление этими выводами осуществляется от внешнего источника. Содержимое бита RMST сбрасывается во время аппаратного или программного сброса.
Биты управления длиной слова приемника (RWL[1:0] - биты 4 и 5). Доступный для записи и чтения бит управления длиной слова используется для выбора длины слова, получаемой SAL Длина слова данных определяется числом циклов тактового сигнала последовательной передачи между двумя краями сигнала выбора слова. Слово длиной 16, 24 или 32 бита может быть выбрано в соответствии с табл. 6.40. Регистры данных приемника всегда заполняются 24-битными данными, когда поступает новое слово данных. Если выбрана 16-битная длина слова, то полученное 16-битное слово данных будет размещено в 16 старших битах регистра данных приемника независимо от бита направления сдвига данных приемника (RDIR); восемь младших битов регистра данных приемника очищаются. Если выбрана 32-битная длина слова, то восемь бит отбрасываются в соответствии со значением управляющего бита округления слова данных приемника (RDWT). Биты RWL[1:0] также используются для генерации отображения выбранного слова, когда секция приемника сконфигурирована в режим ведущего (RMST - 1). Содержимое битов RWL[1:0] сбрасывается во время аппаратного или программного сброса.
Таблица 6.40
Управление длиной слова приемника
RWL1 RWL0 Число битов/слово
0 0 16
0 1 24
1 0 32
1 1 Зарезервировано
Бит направления сдвига данных приемника (RDIR-бит 6). Доступный для записи и чтения бит RDIR позволяет выбрать направление сдвига. Когда бит сбрасывается, то данные вдвигаются со стороны старшего бита. Когда бит установлен, данные вдвигаются со стороны младшего бита (рис. 6.63). Содержимое бита сбрасывается во время аппаратного или программного сброса.
SCKR
RDIR = <1
SD1
RDIR - 1 LSB MSB
Рис. 6.63. Программирование направления сдвига данных приемника
758
ПРОЦЕССОРЫ СЕМЕЙСТВА DSP56000
WSR
Слово справа
Слово слева
Слово справа
RLRS = 1 —
Рис. 6.64. Программирование выбора правого/левого слова приемника
Бит выбора правого/левого слова приемника (RLRS-бит 7). Доступный для записи и чтения бит RLRS позволяет выбрать полярность сигнала выбора слова приемника (WSR), который определяет левое и правое слово во входном потоке. Когда бит сбрасывается, низкий сигнал WSR идентифицирует левое слово данных. Когда бит устанавливается, низкий сигнал WSR идентифицирует правое слово данных (рис. 6.64). Содержимое бита сбрасывается во время аппаратного или программного сброса.
Бит полярности тактового сигнала приемника (RCKP - бит 8). Доступный для записи и чтения бит RCKP позволяет выбрать полярность тактового сигнала последовательного приема данных. Когда бит очищается, полярность тактового сигнала отрицательна. Когда бит устанавливается, полярность тактового сигнала положительна. Отрицательная полярность означает, что линии приема выбранного слова (WSR) и входа последовательных данных (SDIx) работают синхронно по отрицательному краю (спаду) тактового сигнала и рассматриваются как действительные во время положительного перехода тактового сигнала. Положительная полярность означает, что WSR и SDIx работают синхронно по положительному краю (фронту) тактового сигнала и рассматриваются как действительные во время отрицательного перехода тактового сигнала (рис. 6.65). Содержимое бита сбрасывается во время аппаратного или программного сброса.
Бит относительной синхронизации приемника (RREL - бит 9). Доступный для записи и чтения бит RREL позволяет выбрать синхронизацию сигнала приемника выбранного слова (WSR) относительно линии входа последовательных данных (SDIx). Когда бит сбрасывается, переход на линии WSR, отражающий начало слова данных, происходит одновременно с 1-м битом слова данных. Когда этот бит устанавливается, переход на линии WSR происходит на один такт раньше (вместе с последним битом предыдущего слова данных), что соответствует формату l2S (рис. 6.66).
Содержимое бита сбрасывается при аппаратном или программном сбросе.
Бит округления слов данных приемника (RDWT- бит 10). Доступный для записи и чтения бит RDWT позволяет выбрать 24-битную часть полученного 32-битного слова, которая будет передаваться из сдвигового регистра в регистр данных. Когда бит сбрасывается, в регистр данных передаются первые 24 бита. Когда бит устанавливается, в регистр данных передаются последние 24 бита. Бит RDWT игнорируется, если биты RWL[1:0]
Рис. 6.65. Программирование полярности тактового сигнала приемника
759
ПРОЦЕССОРЫ ЦИФРОВОЙ ОБРАБОТКИ СИГНАЛОВ
RREL = О
WSR
Слово слева
Слово справа
RREL = 1 -
WSR
Слово слева
Слово справа
Рис. 6.66. Относительная синхронизация приемника
устанавливаются в положение, соответствующее длине, не равной 32 битам (рис. 6.67). Содержимое бита сбрасывается во время аппаратного или программного сброса.
Бит разрешения прерывания приемника (RXIE - бит 11). Когда доступный для записи и чтения управляющий бит RXIE устанавливается, разрешаются прерывания приемника для слов данных справа и слева, а работа DSP прерывается, если установлен один или оба бита - RLDF и RRDF. Когда RXIE сбрасывается, прерывания приемника запрещаются, однако биты RLDF и RRDF продолжают отображать условие заполнения регистра данных приемника. Отметим, что сброс бита RXIE будет маскировать отложенное прерывание приемника только после задержки величиной в один цикл команды. Если бит RXIE сбрасывается в подпрограмме обслуживания длительного прерывания, то рекомендуется, чтобы хотя бы одна команда была вставлена между командами, которые очищают RXIE, а в конце процедуры обработки прерывания была бы вставлена команда RTI. Существуют три различных типа прерываний для приемника, которые имеют отдельные вектора прерываний:
1) прерывание приема полевому каналу; генерируется когда RXIE = 1, RDLF = 1, RRDF = 0;
2) прерывание приема по правому каналу; генерируется когда RXIE = 1, RDLF = 0, RRDF = 1;
3) прерывание приема с исключительной ситуацией (перезапуск); генерируется когда RXIE = 1, RDLF = 1, RRDF = 1; это означает, что предыдущие данные в регистре данных приемника были потеряны или произошел перезапуск.
1 32 1 32
WSR Слово слева Слово справа
ЯИИмН»
Рис. 6.67. Программирование округления слов данных приемника
760
ПРОЦЕССОРЫ СЕМЕЙСТВА DSP56000
Для того чтобы очистить RDLF и RRDF во время обслуживания прерываний по правому или левому каналу, должно быть прочитано содержимое регистра данных приема того приемника, работа которого разрешена. Очистка RDLF или RRDF приведет к сбросу соответствующего запроса на прерывание. Если возникает ситуация «прерывания приема с исключительной ситуацией» (RDLF = RRDF = 1), то оба бита - RDLF и RRDF очищаются с помощью чтения содержимого регистра RCS, которое следует за чтением содержимого регистра данных приема тех приемников, работа которых разрешена.
Бит размещения прерываний приема (RXIL - бит 12). Доступный для записи и чтения бит управления RXIL определяет размещение векторов прерываний приемников. Когда RXIL = 0, прерывания по левому и правому каналам приемника, а также прерывание приема с исключительной ситуацией размещаются по программным адресам $16, $18, $1А соответственно. Когда RXIL = 1, прерывания по левому и правому каналам приемника, а также прерывание приема с исключительной ситуацией размещаются по программным адресам $46, $48, $4А соответственно. Бит RXIL сбрасывается во время аппаратного или программного сброса (см. табл. 6.38).
Бит полноты данных слева при приеме (RLDF- бит 14). Бит RLDF доступен только для чтения и вместе с битом RRDF (см. ниже) отражает статус регистров данных приема, работа которых разрешена. Бит RLDF устанавливается, когда слово данных слева (что отражается на выводе WSR и в бите RLRS регистра RCS) передается в регистры данных приема после того, как они были получены с помощью сдвига через регистр сдвига разрешенного приемника. Поскольку аудиоданные располагаются в словах двух типов (слева и справа) и читаются наоборот, то обычная операция приема происходит, когда установлен или бит RLDF или бит RRDF. Условие перезапуска приема показывает, что установлены оба бита. Бит RLDF сбрасывается, когда DSP осуществляет чтение содержимого регистра данных приема того приемника, работа которого разрешена; при этом RLDF Ф RRDF = 1. В случае возникновения условия перезапуска (RLDF • RRDF = 1), бит RLDF сбрасывается при первом чтении содержимого RCS, следующем за чтением регистра данных приема разрешенного приемника. Бит RLDF также сбрасывается при аппаратном или программном сбросе, когда DSP находится в состоянии останова и когда все приемники запрещены (R0EN и R1EN сброшены). Если бит RXIE установлен, то, когда будет установлен бит RLDF, возникнет запрос прерывания. Вектор запроса прерывания будет зависеть от условия перезапуска приема.
Бит полноты данных справа при приеме (RRDF- бит 15). Бит RRDF доступен только для чтения и вместе с битом RLDF отражает статус регистров данных приема, работа которых разрешена. Бит RRDF устанавливается, когда слово данных справа (что отражается на выводе WSR и в бите RLRS регистра RCS) передается в регистры данных приема после того, как они были получены с помощью сдвига через регистр сдвига разрешенного приемника. Поскольку аудиоданные располагаются в словах двух типов (слева и справа) и читаются наоборот, то обычная операция приема происходит, когда установлен бит RLDF или бит RRDF. Условие перезапуска приема показывает, что установлены оба бита. Бит RRDF сбрасывается, когда DSP осуществляет чтение содержимого регистра данных приема того приемника, работа которого разрешена; при этом RLDF Ф RRDF = 1. В случае возникновения условия перезапуска (RLDF • RRDF = 1) бит RLDF сбрасывается при первом чтении содержимого RCS, следующем за чтением регистра данных приема разрешенного приемника. Бит RRDF также сбрасывается при аппаратном или программном сбросе, когда DSP находится в состоянии останова и когда все приемника запрещены (R0EN и R1EN сброшены). Если бит RXIE установлен, то при установке бита RRDF возникнет запрос прерывания. Вектор запроса прерывания будет зависеть от условия перезапуска приема.
Регистры данных приема SAI (RXO, RX1). Регистры данных приема (RXO, RX1) являются 24-битными регистрами, доступными только для чтения. Они обеспечивают дос
761
ПРОЦЕССОРЫ ЦИФРОВОЙ ОБРАБОТКИ СИГНАЛОВ
туп данных из регистров сдвига при приеме информации, когда все биты поступающих данных уже получены. Регистры данных приема содержат два канала данных - левый и правый. В первую очередь, после разрешения работы соответствующего приемника должны появиться данные для левого канала.
Регистр управления/статуса передатчика (TCS). Регистр TCS является 16-битным регистром управления/статуса, доступным для чтения и записи и используемым для управления при выполнении операции в секции передатчика (см. рис. 6.62). Управляющие биты регистра определяют последовательный формат передачи данных, а биты статуса этого регистра используются программистом DSP для опроса статуса приемника. В регистре TCS также находятся биты разрешения раздельной передачи и прерываний. Когда DSP осуществляет чтение, содержимое этого регистра появляется в двух младших байтах 24-битного слова; биты старшего байта читаются как нули. Содержимое регистра сбрасывается во время аппаратного или программного сброса. Если биты TOEN, T1EN и T2EN сбрасываются, то работа секции приемника запрещается и секция переводится в состояние сброса после задержки в один цикл команды. Во время нахождения в состоянии останова или индивидуального сброса биты статуса регистра также сбрасываются. Останов или сброс не оказывают влияния на управляющие биты регистра TCS.
Биты разрешения работы передатчика 0,1,2 (TOEN, T1EN, T2EN - биты 0,1,2). Доступный для записи и чтения управляющий бит разрешения работы передатчика 0/1/ 2 разрешает выполнение операции передатчика 0/1/2 SAI соответственно. Когда этот бит установлен, работа передатчика разрешена. И наоборот, когда этот бит сброшен, работа передатчика запрещена, а на линии SDO0/SDO1/SDO2 находится сигнал высокого уровня. Если биты TOEN, T1EN и T2EN сбрасываются, то работа секции передатчика запрещается, что эквивалентно состоянию индивидуального сброса. Содержимое бита TOEN/ T1EN/T2EN сбрасывается во время аппаратного или программного сброса.
Бит ведущего передатчика (TMST- бит 3). Доступный для записи и чтения управляющий бит ведущего передатчика позволяет переключать работу секции передатчика из режима ведущего в режим ведомого и наоборот. Когда этот бит установлен, секция передатчика SAI устанавливается в режим ведущего. В режиме ведущего управление передатчика происходит с помощью выводов SCKT и WST. В режиме ведомого управление этими выводами осуществляется от внешнего источника. Содержимое бита TMST сбрасывается во время аппаратного или программного сброса.
Бит управления длиной слова передатчика (TWL[1:0] - биты 4 и 5). Доступные для записи и чтения биты управления длиной слова используется для выбора длины слова, передаваемой SAI. Длина слова данных определяется числом циклов тактового сигнала последовательной передачи между двумя краями сигнала выбора слова. Слово длиной 16, 24 или 32 бита может быть выбрано в соответствии с табл. 6.41. Если выбрана 16-битная длина слова, то 16 старших значащих битов регистра данных передачи будет передано в выбранном направлении сдвига (TDIR см. ниже). Если выбрана 32-битная длина слова, то 24 бита слова регистра данных передачи дополняются до 32 бит в соответствии со значением управляющего бита (TDWE).
Таблица 6.41
Управление длиной слова передатчика
TWL1 TWL0 Число битов/слово
0 0 16
0 1 24
1 0 32
1 1 Зарезервировано
762
ПРОЦЕССОРЫ СЕМЕЙСТВА DSP56000
Рис. 6.66. Программирование направления сдвига данных передатчика
Биты TWL[1:0] также используются для генерации отображения выбранного слова, когда секция передатчика сконфигурирована в режим ведущего (TMST = 1). Содержимое битов TWL[1:0] сбрасывается при аппаратном или программном сбросе.
Бит направления сдвига данных передачи (TDIR- бит 6). Доступный для записи и чтения бит TDIR позволяет выбрать направление сдвига передаваемых данных. Когда бит сбрасывается, то данные выдвигаются со стороны старшего значащего бита. Когда бит установлен, данные выдвигаются со стороны младшего значащего бита (рис. 6.68). Содержимое бита сбрасывается во время аппаратного или программного сбросе.
Бит выбора правого/левого слова передачи (TLRS - бит 7). Доступный для записи и чтения бит TLRS позволяет выбрать полярность сигнала выбора слова передатчика (WST), который определяет левое и правое слово в выходном потоке. Когда бит сбрасывается, низкий сигнал WST идентифицирует левое слово данных. Когда бит устанавливается, низкий сигнал WST идентифицирует правое слово данных (рис. 6.69). Содержимое бита сбрасывается при аппаратном или программном сбросе.
Бит полярности тактового сигнала передатчика (ТСКР - бит 8). Доступный для записи и чтения бит ТСКР позволяет выбрать полярность тактового сигнала последовательного приема данных. Когда бит очищается, полярность тактового сигнала отрицательна. Когда бит устанавливается, полярность тактового сигнала положительна. Отрицательная полярность означает, что линии приема выбранного слова (WST) и входа последовательных данных (SDOx) работают синхронно по отрицательному краю (спаду) тактового сигнала и рассматриваются как действительные во время положительного перехода тактового сигнала. Положительная полярность означает, что WST и SDOx работают синхронно по положительному фронту тактового сигнала и рассматриваются как действительные во время отрицательного перехода тактового сигнала (рис. 6.70). Содержимое бита сбрасывается во время аппаратного или программного сброса.
Бит относительной синхронизации передатчика (TREL - бит 9). Доступный для записи и чтения бит TREL позволяет выбрать относительную синхронизацию сигнала WST относительно линии выхода последовательных данных (SDOx). Когда бит сбрасы-
tlrs = о —
WSR
WSR
Слово слева
Слово справа
Слово слева
Слово справа
TLRS = 1 —
Рис. 6.69. Программирование выбора правого/левого слова передатчика
763'
ПРОЦЕССОРЫ ЦИФРОВОЙ ОБРАБОТКИ СИГНАЛОВ
Рис. 6.70. Программирование полярности тактового сигнала передатчика
вается, переход на линии WST, отражающий начало слова данных, происходит одновременно с 1-м битом слова данных. Когда этот бит устанавливается, переход на линии WST происходит на один такт раньше (вместе с последним битом предыдущего слова данных), что соответствует формату l2S (рис. 6.71). Содержимое бита сбрасывается во время аппаратного или программного сброса.
Бит округления слов данных при передаче (TDWE) - бит 10). Доступный для записи и для чтения бит TDWE позволяет выбрать метод расширения во время передачи 24-битного слова данных до 32 битов. Когда бит сбрасывается после передачи 24-битного слова данных из регистра передачи данных, восемь раз передается последний бит. Когда бит устанавливается, восемь раз передается 1-й бит, а затем из регистра данных передачи передается 24-битовое слово. Бит TDWE игнорируется, если биты TWL[1:0] устанавливаются в положение, соответствующее длине, не равной 32 битам (рис. 6.72). Содержимое бита сбрасывается во время аппаратного или программного сброса.
Бит разрешения прерывания передатчика (TXIE- бит 11). Когда доступный для записи и чтения управляющий бит TXIE устанавливается, разрешаются прерывания передатчика для слов данных справа и слева, а работа DSP прерывается, если установлен один или оба бита TLDE и TRDE. Когда TXIE сбрасывается, прерывания передатчика запрещаются, однако биты TLDE и TRDE продолжают отображать условие пустоты регистра данных приемника. Отметим, что сброс бита RXIE будет маскировать отложенное прерывание приемника только после задержки величиной в один цикл команды. Если бит TXIE сбрасывается в подпрограмме обслуживания длительного прерывания, то рекомендуется, чтобы хотя бы одна команда была вставлена между командами, которые очищают TXIE, а в конце процедуры обработки прерывания была вставлена команда RTI.
TREL = О
WSR
SDO
TREL s 1
WSR
Рис. 6.71. Относительная синхронизация передатчика
764
ПРОЦЕССОРЫ СЕМЕЙСТВА DSP56000
I 32 I 32
WST Слово слева Слово справа
шшпними^ипппппппйпщи^н 1М11‘‘|‘||‘‘|>‘‘,,11111111ИИ11111111111111111Ш1111
Рис. 6.72. Программирование округления слов данных передатчика
Существуют три различных типа прерываний для передатчика, которые имеют отдельные векторы прерываний.
1. Прерывание передачи по левому каналу; генерируется при TXIE = 1, TDLE = 1, TRDE = 0. Регистры данных передачи следует загрузить данными слева.
2. Прерывание передачи по левому каналу; генерируется при TXIE = 1, TDLE = 0, TRDE = 1. Регистры данных передачи следует загрузить данными справа.
3. Прерывание передачи с исключительной ситуацией; генерируется при ТХ1Е=1, TDLE = 1, TRDE = 1. Это означает, что предыдущие данные в регистре данных приемника были потеряны или произошел перезапуск, т. е. передаются старые данные.
Для того чтобы очистить TDLE и TRDE во время обслуживания прерываний по правому или левому каналу, должно быть прочитано содержимое регистра данных передачи того приемника, работа которого разрешена. Очистка TDLE или TRDE приведет к сбросу соответствующего запроса на прерывание. Если возникает ситуация «прерывания приема с исключительной ситуацией» (TDLE = TRDE = 1), то оба бита TDLE и TRDE очищаются с помощью чтения содержимого регистра TCS, которое следует за чтением содержимого регистра данных приема тех приемников, работа которых разрешена.
Бит размещения прерываний передачи (TXIL - бит 12). Доступный для записи и чтения бит управления TXIL определяет размещение векторов прерываний приемников. Когда TXIL = 0, прерывания по левому и правому каналам приемника, а также прерывание приема с исключительной ситуацией размещаются по программным адресам $10, $12, $14 соответственно. Когда TXIL = 1, прерывания по левому и правому каналам приемника, а также прерывание приема с исключительной ситуацией размещаются по программным адресам $40, $42, $44 соответственно. Бит TXIL сбрасывается во время аппаратного или программного сброса (см. табл. 6.38).
Резервный бит (TCS - бит 13). Этот бит не используется и читается как нуль, его следует также записывать нулевым для обеспечения дальнейшей совместимости.
Бит пустоты данных слева при передаче (TLDE - бит 14). Бит TLDE доступен только для чтения и вместе сбитом TRDE отражает статус регистров данных передачи, работа которых разрешена. Бит TLDE устанавливается, когда слово данных справа (что отражается в бите TLRS регистра TCS) одновременно передается из регистров данных передачи в регистры сдвига передачи разрешенного передатчика. Это означает, что регистры данных передачи в данный момент свободны для загрузки слов данных слева. Поскольку аудиоданные располагаются в словах двух типов (слева и справа) и читаются наоборот, то обычная операция передачи происходит, когда установлен только один бит статуса (TLDE или TRDE). Условие дополнительного запуска передачи показывает, что установлены оба бита. Бит TLDE сбрасывается, когда DSP осуществляет запись содержимого регистра данных передачи того передатчика, работа которого разрешена, при этом
765
ПРОЦЕССОРЫ ЦИФРОВОЙ ОБРАБОТКИ СИГНАЛОВ
TLDE ® TRDE = 1. В случае возникновения условия дополнительного запуска TLDE • TRDE = 1, предыдущие данные будут переданы повторно (те данные, которые находятся в регистре данных передачи). В этом случае бит TLDE сбрасывается при первом чтении содержимого TCS, следующем за записью регистра данных передачи разрешенного передатчика. Если бит TXIE установлен, то, когда будет установлен бит TLDE, возникнет запрос прерывания. Вектор запроса прерывания будет зависеть от условия дополнительного запуска передачи. Бит TLDE также сбрасывается при аппаратном или программном сбросе, когда DSP находится в состоянии останова и когда все передатчики запрещены (TOEN, T1EN, T2EN сброшены).
Бит пустоты данных справа при передаче (TLDE - бит 15). Бит TLDE доступен только для чтения и вместе с битом TRDE отражает статус регистров данных передачи, работа которых разрешена. Бит TLDE устанавливается, когда слово данных слева (что отражается в бите TLRS регистра TCS) одновременно передается из регистра данных передачи в регистры сдвига передачи разрешенного передатчика. Это означает, что регистры данных передачи в данный момент свободны для загрузки слов данных слева. Поскольку аудиоданные располагаются в словах двух типов (слева и справа) и читаются наоборот, то обычная операция передачи происходит, когда установлен только один бит статуса (TLDE или TRDE). Условие дополнительного запуска передачи показывает, что установлены оба бита. Бит TLDE сбрасывается, когда DSP осуществляет запись содержимого регистра данных передачи того передатчика, работа которого разрешена, при этом TLDE ® TRDE = 1. В случае возникновения условия дополнительного запуска (TLDE • TRDE = 1) предыдущие данные будут переданы повторно (те данные, которые находятся в регистре данных передачи). В этом случае бит TLDE сбрасывается при первом чтении содержимого TCS, следующем за записью регистра данных передачи разрешенного передатчика. Если бит TXIE установлен, то, когда будет установлен бит TLDE, возникнет запрос прерывания. Вектор запроса прерывания будет зависеть от условия дополнительного запуска передачи. Бит TLDE также сбрасывается при аппаратном или программном сбросе, когда DSP находится в состоянии останова и когда все передатчики запрещены (TOEN, T1EN, T2EN сброшены).
Регистры данных передачи SAI (ТХО, RX1, ТХ2). Регистры данных передачи (ТХО, ТХ1, ТХ2) являются 24-битными регистрами. Данные, которые следует передать, записываются в эти регистры и одновременно передаются в соответствующие регистры сдвига после того, как выдвинут последний бит. Регистры данных приема следует записывать попеременно по правому и левому каналам. После разрешения работы соответствующего передатчика в первую очередь должны появиться данные для левого канала.
Особенности программирования SAI
Работа SAI во время останова. Работа SAI не может быть продолжена, когда DSP находится в состоянии останова, поскольку DSP не активизирует тактовый сигнал. Входящие последовательные данные будут проигнорированы. Пока DSP находится в состоянии останова, секции SAI будут оставаться в состоянии индивидуального сброса, а биты статуса регистров RCS и TCS будут сброшены. Управляющие биты в этом процессе не задействованы. Рекомендуется запретить работу SAI перед вхождением в состояние останова.
Инициализация сеанса передачи. Рекомендуемым методом инициализации сеанса передачи является запись в регистры данных передачи действительных данных и затем разрешение выполнения операции передачи. Данные при этом будут передаваться после разрешения работы передатчиков (при работе в режиме ведущего) или после события выбора слова для слова передачи слева на выводе WST (при работе в режиме ведомого). Отметим, что, хотя флаги статуса TRDE и TLDE всегда сбрасываются, пока секция передатчика находится в состоянии индивидуального сброса, регистры данных передачи в этом состоянии могут записываться. Данные останутся в регистрах данных передачи, пока секция передатчика будет находиться в состоянии индивидуального сброса, и будут передаваться в сдвиговые регистры передачи только после разрешения ра
766
ПРОЦЕССОРЫ СЕМЕЙСТВА DSP56000
боты соответствующего передатчика и когда произойдет передача слова слева непосредственно для режима ведущего или в соответствии с WST для режима ведомого.
Использование прерывания для обслуживания секций приемника и передатчика. Допускается использовать одну процедуру обработки прерываний для обслуживания двух секций (приемника и передатчика), если эти секции полностью синхронизированы. Для того чтобы обеспечить полную синхронизацию, обе секции должны работать с одним протоколом и одним источником тактового сигнала. Следует разрешить выполнение прерываний приема (RXIE = 1). При возникновении условия прерывания приема та же самая процедура обслуживания прерывания может использоваться для чтения данных из секции приемника и записи в секцию передатчика. При работе в режиме ведущего рекомендуется выполнение следующей процедуры инициализации:
1) запись слова данных слева в регистры данных передачи;
2) разрешение работы приемников SAI, если RXIE = 1 (в регистре RCS);
3) разрешение работы приемников SAI, если TXIE = 0 (в регистре TCS); разрешение работы передатчиков обеспечит передачу слова данных слева из регистров данных передачи в сдвиговые регистры;
4) опрос бита статуса TRDE в регистре TCS для того, чтобы определить, когда в регистры данных передачи можно загрузить слово данных справа; запись слова данных справа в регистры данных передачи, если бит TRDE установлен;
5) момент прерывания приема следует использовать для обслуживания и приемников и передатчиков; когда генерируется прерывание приема по левому каналу, в процедуре обслуживания прерывания следует осуществить запись слов данных слева в передатчики и прочитать полученные слова данных слева из приемников (повторить эту процедуру для приемников/передатчиков правого канала).
Машинное состояние SAI. Когда SAI работает в режиме ведущего, а битовый тактовый сигнал и входы выбора слова неожиданно меняются, то результат может быть непредсказуемым. В частности, это может произойти, когда SCKR (SCKT) запущен, a WSR/ WST-передачи выполняются раньше или позже, чем ожидается (в соответствии с полным циклом битового тактового сигнала). Реакция SAI на подобное условие определяется через машинное состояние SAI.
После выполнения передачи слова данных (или вплоть до осуществления индивидуального останова) SAI ищет отдельные передачи WSR/WST для того, чтобы отслеживать правую/левую ориентацию следующего ожидаемого слова. Например, после выполнения передачи слова данных справа или вплоть до осуществления индивидуального останова SAI ищет передачи WSR/WST, которые определяют начало передачи слова данных слева. Аналогично этому после выполнения передачи слова данных слева SAI ищет передачи WSR/WST, которые определяют начало передачи слова данных справа. Если определено, что передача верна, то SAI начинает вдвигать данные (прием) или выдвигать данные (передача) по одному сдвигу за один цикл битового тактового сигнала. Передача слова данных завершается, когда число поступающих в SCKR (SCKT) битовых тактовых сигналов во время определения корректности передачи WSR/WST достигает заранее запрограммированного значения длины слова данных. Во время передачи слова данных (т. е. перед завершением) все переходы в WSRA/VST игнорируются. После завершения передачи слова данных SAI останавливает сдвиг данных в любом направлении до появления следующей корректной передачи. Таким образом, когда передача WSR/ WST появляется раньше чем ожидалось, она игнорируется, и следующая пара слов данных (правое и левое) теряется. Подобно этому, когда передача WSRA/VST появляется позже, чем ожидалось, в период времени между завершением предыдущего слова и появлением опоздавшей передачи WSR/WST, получаемые биты данных игнорируется; данные в этом случае не передаются.
Кроме того, запрещение приема или передачи ненужных слов данных может осуществляться с помощью задержки запуска SCKR(SCKT) и задержки WSR/WST на определенное число циклов битового тактового сигнала.
ГЛABА7
ПРОГРАММИРУЕМАЯ ЛОГИКА И ЕЕ ПРИМЕНЕНИЕ В МИКРОПРОЦЕССОРНЫХ СИСТЕМАХ
7.1. ОБЩИЕ СВЕДЕНИЯ, КЛАССИФИКАЦИЯ
7 1 1 УРОВЕНЬ ИНТЕГРАЦИИ ИНТЕГРАЛЬНЫХ СХЕМ (ИС) И ЕГО ВЛИЯНИЕ НА КАЧЕСТВО ЦИФРОВОЙ АППАРАТУРЫ И ЕЕ ПРОЕКТИРОВАНИЕ.
БИС/СБИС ПРОГРАММИРУЕМОЙ ЛОГИКИ-СРЕДСТВО ИСКЛЮЧЕНИЯ ИНТЕГРАЛЬНЫХ СХЕМ МАЛОГО И СРЕДНЕГО УРОВНЕЙ ИНТЕГРАЦИИ ИЗ СОСТАВА МИКРОПРОЦЕССОРНЫХ СИСТЕМ
Интегральные схемы (ИС), составляющие основу элементной базы средств обработки информации, характеризуются широким диапазоном сложности (уровня интеграции). Уровень интеграции оценивается условным числом эквивалентных вентилей (чаще всего вентилей типа 2И-НЕ), которые могли бы быть размещены на данном кристалле. Выпускаемые промышленностью цифровые схемы имеют уровень интеграции от нескольких единиц для малых интегральных схем (МИС) до нескольких миллионов для сверхбольших интегральных схем (СБИС).
Генеральная тенденция развития цифровых интегральных схем - постоянный рост уровня интеграции. Непрерывное за все время существования ИС совершенствование технологии их производства позволяет постоянно снижать минимальные размеры схемных элементов и потребляемую ими мощность и увеличивать площадь кристалла, благодаря чему растет достижимый уровень интеграции. Эти же факторы существенно улучшают технико-экономические параметры не только самих ИС (быстродействие, надежность, стоимость, отнесенную к единице логической мощности, и др.), но и параметры реализованной на ИС аппаратуры.
К основным модулям микропроцессорной системы относятся процессоры, память, внешние устройства и интерфейсные схемы. Микросхемы процессоров и памяти с точки зрения производителей ИС являются стандартной продукцией. Промышленность выпускает широкий спектр обоих типов микросхем, отличающихся большим разнообразием параметров. Из имеющегося множества типономиналов процессоров и запоминающих устройств проектировщик (системотехник) выбирает наиболее подходящий для своего проекта вариант. Важно, что изготовитель микросхем процессоров и памяти не выполняет индивидуальные заказы потребителей, а работает на широкий рынок. Это обеспечивает стандартным микросхемам большие объемы производства - необходимое условие реализуемости ИС высокого уровня интеграции. Действительно, стоимость проектирования Спр сложных ИС чрезвычайно велика, но входит в стоимость микросхемы в виде составляющей Слр/Л/, где Л/- тиражность производства данной ИС. Только при достаточно больших значениях N будут оправдываться большие затраты средств на проектирование БИС/СБИС.
Кроме стандартных частей микропроцессорная система содержит и некоторые индивидуальные схемотехнические части для сопряжения модулей и управления ими. Такие индивидуальные части системы ранее приходилось строить с помощью ИС малого и среднего уровней интеграции, применение которых ведет к резкому увеличению числа корпусов и внешнего монтажа в схемах МПС, а это сопровождается столь же резким снижением их быстродействия и надежности, росту габаритных размеров и потребляемой мощности.
Таким образом, для создания высококачественной сложной цифровой аппаратуры следует использовать ИС высокого уровня интеграции.
768
ОБЩИЕ СВЕДЕНИЯ, КЛАССИФИКАЦИЯ
Появление в нестандартных блоках системы малых и средних ИС всегда объяснялось только экономическими причинами - чрезмерно высокой стоимостью заказных БИС/СБИС при малых объемах их выпуска. С точки зрения технологии, естественно, реализация специализированных БИС/СБИС была вполне осуществима. Препятствия к применению БИС/СБИС в специализированных частях микропроцессорных систем стали постепенно устраняться по мере развития программируемых ИС.
Как будет показано далее, применение БИС/СБИС с программируемой логикой улучшает и ряд других важных параметров проектов - время подготовки продукции к выходу на рынок (Time to Market), безошибочность проектирования и др.
7.1.2. КЛАССИФИКАЦИЯ ИС ПРОГРАММИРУЕМОЙ ЛОГИКИ
Микросхемы программируемой логики классифицируются по нескольким признакам (рис. 7.1). По уровню интеграции их можно разделить на простые, сложные и схемы типа «системы на кристалле» (SOC, System On Chip), как показано на рис. 7.1. Можно сказать также, что простые ИС программируемой логики относятся к первому их поколению, тогда как сложные и SOC принадлежат к следующим.
Простые ИС с программируемой логикой (ИС ПЛ), обозначаемые в совокупности как PLD (Programmable Logic Devices), делятся на микросхемы программируемой матричной логики ПМЛ (PAL, Programmable Array Logic) и микросхемы программируемых логических матриц ПЛМ (PLA, Programmable Logic Array). Усложненные варианты PAL некоторые производители называют схемами GAL (Generic Array Logic). Простые ИС ПЛ рассчитаны на реализацию систем переключательных функций и использовались для замены нескольких корпусов или даже десятков корпусов стандартных ИС на один корпус PLD. По мере их усложнения решаемые ими задачи также усложнялись, в частности, появилась ориентация на реализацию конечных автоматов (в схемы PLD стали вводить элементы памяти).
Продолжением линии развития ПМЛ стали сложные БИС/СБИС типа CPLD (Complex PLD), в которых, как и в PLD, используются схемы непосредственной реализации дизъюнктивных нормальных форм переключательных функций (функций типа SOP, Sum Of Products), но в одной CPLD имеется несколько ПМЛ (PAL, GAL), объединенных системой коммутации.
Сложные ИС ПЛ типа FPGA (Field Programmable Gate Arrays) содержат матрицу логических блоков того или иного типа, расположенных по строкам и столбцам, между которыми размещены средства коммутации, позволяющие с помощью программирования получать необходимые взаимные соединения логических блоков. Сами блоки могут быть выполнены различным образом. Стремление объединить достоинства, присущие CPLD и FPGA, привело к созданию БИС/СБИС комбинированной архитектуры, для которых еще не выработано общепринятое название.
Рост уровня интеграции дал возможность размещать на кристалле схемы, сложность которых соответствует целым системам (мегавентильные схемы). Такие схемы именуются SOC и могут быть разделены на два типа - однородные схемы, в которых функциональное назначение отдельных областей кристалла обеспечивается программированием одних и тех же по типу ресурсов (схемы типа generic), и блочные структуры, в которых отдельные области кристалла специализированы уже при их изготовлении. Про такие кристаллы говорят, что они содержат специализированные аппаратные ядра (Hardcores).
Важным классификационным признаком ИС ПЛ является тип памяти конфигурации, т. е. тип программируемых элементов, задаваемое состояние которых как раз и создает требуемое устройство как конкретный вариант межсоединений имеющихся на кристалле схемотехнических ресурсов. Программируемые элементы представляют собой двухпо-
769
ПРОГРАММИРУЕМАЯ ЛОГИКА И ЕЕ ПРИМЕНЕНИЕ В МИКРОПРОЦЕССОРНЫХ СИСТЕМАХ
Рис. 7.1. Классификация ИС программируемой логики
люсники, играющие роль ключей, которым при программировании задаются состояния «замкнуто» или «разомкнуто». Число программируемых элементов в ИС ПЛ зависит от их сложности и в схемах наибольшего уровня интеграции измеряется миллионами.
770
ОБЩИЕ СВЕДЕНИЯ, КЛАССИФИКАЦИЯ
В ИС ПЛ используются или использовались ранее следующие типы программируемых элементов:
• плавкие перемычки Fuse (в схемах самых первых образцов);
• пробиваемые диэлектрические перемычки Antifuse (краткий русский термин отсутствует);
• однократно заряжаемые «плавающие затворы» МОП-транзисторов (EPROM-OTP);
• перезаряжаемые «плавающие затворы» с введением заряда электрическими воздействиями на транзистор и его стиранием с помощью облучения кристалла ультрафиолетовыми лучами (EPROM);
• перезаряжаемые «плавающие затворы» с электрическими записью и стиранием зарядов (EEPROM, Flash);
• ключевые МОП-транзисторы, управляемые триггерами памяти конфигурации (SRAMbased).
Репрограммируемые элементы EPROM, EEPROM, Flash, SRAM-based различаются по свойствам. Элементы EPROM с ультрафиолетовым стиранием допускают ограниченное число перезаписей заряда, так как процесс облучения постепенно изменяет свойства кристалла.
Элементы с электрическим стиранием имеют существенно большее число допустимых перезаписей заряда (приблизительно в тысячу раз), а элементы с триггерной памятью конфигурации могут репрограммироваться неограниченно.
Одним из признаков классификации служит наличие или отсутствие связи между задержками распространения сигналов и конкретными путями их передачи по межсоединениям кристалла. Этот фактор важен, так как независимость задержки от конкретного пути передачи сигнала означает предсказуемость задержек, что существенно облегчает построение на кристалле работоспособных схем, особенно схем высокого быстродействия.
7.1.3. КОНСТРУКТИВНО-ТЕХНОЛОГИЧЕСКИЕ ТИПЫ СОВРЕМЕННЫХ ПРОГРАММИРУЕМЫХ ЭЛЕМЕНТОВ
Программируемые перемычки типа «antifuse» (рис. 7.2, а, б) в исходном состоянии (до программирования) имеют чрезвычайно большие сопротивления (токи утечки порядка фемтоампер). Программирующий импульс напряжения пробивает трехслойный диэлектрик с чередованием слоев «оксид - нитрид - оксид» и создает проводящий поли-кремниевый канал между поликремниевым электродом и диффузионной областью п+, причем в зависимости от тока через перемычку в режиме ее программирования можно
Рис. 7.2. Схематическое представление программируемой перемычки типа «antifuse»: до программирования (а) и после него (6)
ПРОГРАММИРУЕМАЯ ЛОГИКА И ЕЕ ПРИМЕНЕНИЕ В МИКРОПРОЦЕССОРНЫХ СИСТЕМАХ
получить проводящий участок с сопротивлениями от 100 Ом и выше при очень малой паразитной емкости.
Элементы EEPROM и Flash реализуются на ЛИЗМОП-транзисторах (название транзистора отражает процесс лавинной инжекции заряда в плавающий затвор). На рис. 7.3 показан ЛИЗМОП-транзистор с двумя затворами - плавающим и обычным.
Плавающий затвор не имеет внешнего вывода и как бы погружен в диэлектрик (оксид, т. е. двуокись кремния). В этом затворе может создаваться или ликвидироваться заряд электронов. При подаче на обычный затвор повышенного значения программирующего напряжения через тонкий слой оксида электроны туннелируют в плавающий затвор, в котором создается заряд отрицательного знака. После снятия программирующего напряжения и возврата напряжения на затворе к уровню рабочих напряжений электроны оказываются в ловушке, где могут сохраняться в течение десятков лет. При этом транзистор будет заперт, так как отрицательный заряд плавающего затвора создает электрическое поле, противодействующее полю положительно заряженного затвора. При отсутствии заряда в плавающем затворе рабочее положительное напряжение на внешнем затворе обеспечивает отпирание транзистора (создает между стоком и истоком проводящий канал). На рис. 7.3,а показан режим программирования ЛИЗМОП-транзистора, а на рис. 7.3,6 - режим стирания заряда. Стрелками показаны пути туннелирования электронов через тонкий слой оксида.
Память конфигурации типа EEPROM на основе ЛИЗМОП для обновления содержимого не требует извлечения микросхемы из устройства и допускает большое число циклов стирания данных (от десятков тысяч до миллиона). Стирание старой информации и запись новой занимают время порядка миллисекунд.
Программирование заряда в плавающем затворе используется и в технике EPROM, причем в этом случае возможно применение ЛИЗМОП-транзисторов с одним плавающим затвором при стирании заряда путем облучения кристалла ультрафиолетовыми лучами через специальное окошко в корпусе микросхемы. Стирание информации в памяти конфигурации типа EPROM является длительным процессом, занимающим десятки минут, и производится на специальном программаторе. Число циклов стирания существенно ограничено (сотни, тысячи). В последнее время схемотехника EEPROM быстро совершенствуется и все больше вытесняет схемотехнику EPROM, широко распространенную в предыдущих программируемых схемах.
Вариантом схемотехники EEPROM является так называемая Flash-память. Принцип работы элементов этой памяти не отличается от принципа работы описанных ЛИЗМОП-
Рис. 7.3. Схематическое представление ЛИЗМОП-транзистора с двойным затвором
772
ОБЩИЕ СВЕДЕНИЯ, КЛАССИФИКАЦИЯ
Линия выборки
Триггер
Линия
Т2
а
Рис. 7.4. Ключевой транзистор, управляемый триггером памяти конфигурации транзисторов, но новый технологический уровень их реализации и полученные вследствие этого улучшенные технико-экономические характеристики, как и блочное стирание данных, выделили Flash-память в отдельный класс, который считается вершиной достижений в
области памяти с электрическим стиранием записи/чтения ь
данных, хранимых в виде зарядов плавающих затворов.
В схемах со статической памятью конфигурации роль программируемого соединения играет транзисторный ключ. Такой ключ, управляемый триггером памяти конфигурации, показан на рис. 7.4. Ключевой транзистор Т2 замыкает или размыкает участок ab в зависимости от состояния триггера, подключенного к затвору транзистора .При программировании сигналом с линии выборки включается транзистор Т1 и с линии записи/чтения подается сигнал установки или сброса триггера. В рабочем режиме транзистор Т1 заперт, а триггер сохраняет заданное ему состояние. Соответственно характеру памяти конфигурации (статическая триггерная) схемы такого типа называют SRAM-based.
Загрузка тех или иных данных в память конфигурации программирует микросхему. Процесс программирования может производиться неограниченное число раз и с высокой скоростью. При выключении питания конфигурация разрушается, поэтому после каждого включения питания требуется новая загрузка данных в память конфигурации. Такая загрузка может производиться из какой-либо энергонезависимой памяти за время порядка миллисекунд (в зависимости от объема файла конфигурации за единицы, десятки, сотни миллисекунд или даже больше). Триггеры памяти конфигурации распределены по всей площади кристалла и размещаются вблизи тех схем, которые они конфигурируют.
В современных микросхемах программируемой логики триггерная память конфигурации занимает важнейшее место.
Завершая обсуждение общих вопросов, связанных с особенностями микросхем программируемой логики, следует подчеркнуть, что они выпускаются промышленностью как полностью готовые. При использовании таких схем потребитель не обращается к изготовителю для проведения каких-либо завершающих разработку операций и выполняет программирование микросхем самостоятельно. Это дает основание отнести ИС ПЛ к стандартной продукции электронной промышленности, что ведет к известным положительным последствиям - массовости производства и снижению стоимости микросхем.
7.1.4. ОБЛАСТИ ПРИМЕНЕНИЯ МИКРОСХЕМ С ПРОГРАММИРУЕМОЙ ЛОГИКОЙ
Вначале развитие FPGA рассматривалось как перенос концепции БМК в область создания малотиражной аппаратуры, а развитие CPLD - как средство замены нескольких PLD на одну микросхему, однако позднее свойство репрограммируемости чрезвычайно расширило сферу применения БИС/СБИС ПЛ. Эффективность БИС/СБИС ПЛ стимулирует быстрый рост соответствующих отраслей промышленности и объемов их производства, научных исследований по развитию их архитектур, схемотехники, алгоритмов решения практических задач.
Согласно мнению, высказанному в одной из публикаций в известном журнале «Electronic Design», микросхемы с программируемой логикой произведут в ближайшие годы такую же революцию в микроэлектронике, как микропроцессоры в 1970-х.
773
ПРОГРАММИРУЕМАЯ ЛОГИКА И ЕЕ ПРИМЕНЕНИЕ В МИКРОПРОЦЕССОРНЫХ СИСТЕМАХ
Возможности применения микросхем с программируемой логикой в системах обработки информации самых разных видов настолько обширны, что их рассмотрение в рамках одного подпараграфа не представляется возможным. Поэтому ограничимся лишь несколькими примерами.
Построение реконфигурируемых систем. В аппаратуре различного назначения нередко встречаются ситуации, в которых те или иные блоки работают поочередно. Например, в системе передач сообщений с помощью помехоустойчивых кодов средства кодирования используются в процессе выдачи данных в канал связи, а средства декодирования - при их приеме. Поэтому не обязательно иметь два устройства (кодер и декодер), а можно иметь одну ИС ПЛ с двумя различными конфигурациями, хранимыми в энергонезависимой памяти и используемыми поочередно. Таким образом, одна и та же аппаратура может решать несколько задач после соответствующей перестройки. Техникоэкономические выгоды такого варианта очевидны.
В настоящее время развивается концепция систем с динамической реконфигурацией (Run - Time Reconfiguration), применимая в системах с выполнением действий по шагам, последовательным во времени, когда в данное время требуется только одна определенная конфигурация ИС ПЛ. Этот режим работы сходен с рассмотренным выше, но в устройствах с динамическим реконфигурированием может потребоваться быстрая смена настроек. Обычное реконфигурирование с введением в микросхему последовательного потока битов или байтов занимает довольно большое время. Для динамически реконфигурируемых систем задача решается иначе. В системе уже хранится набор заранее загруженных настроек, быстро сменяющих друг друга соответственно требованиям реализуемого алгоритма.
Проблема построения систем на основе СБИС ПЛ с динамической реконфигурацией активно исследуется.
Использование БИС/СБИС ПЛ как окончательной продукции при изготовлении малых партий изделий. В этом случае проявляются такие их достоинства как простота проектирования, скорость разработки и получение технических параметров, соответствующих возможностям микросхем высокого уровня интеграции. При этом продукция остается достаточно дешевой.
Использование микросхем программируемой логики для отладки прототипов при проектировании устройств и систем. Системные компании широко используют репрограммируемые БИС/СБИС на стадиях отработки проектов. В проекты, реализованные на таких БИС/СБИС, легко вносить изменения, так как новый вариант получается путем простой коррекции кода конфигурации. Отладка репрограммируемого прототипа обеспечивает устранение ошибок в проекте, после отладки можно пользоваться ее результатами независимо от способа изготовления конечной продукции. При большом объеме выпуска реализацию проекта можно перенести на БИС/СБИС типа БМК, а при очень большом - и на схемы заказного изготовления.
Следует отметить, что отладка прототипов проекта на репрограммируемых микросхемах не отменяет, а дополняет традиционные методы отладки устройств и систем. При такой отладке издавна пользовались изготовлением макетного прототипа и программными моделями. Изготовление макетного прототипа - сложная и дорогостоящая задача, но зато с его помощью можно вести тестирование и отладку с реальными сигналами и на высоких скоростях, наблюдая фактические возможности устройства или системы. Программное моделирование лишено этих достоинств, но проще и дешевле. Модели легко изменяются, и в них просто обеспечивается хорошая наблюдаемость процессов в объекте исследования.
Применение репрограммируемых микросхем в задачах логической эмуляции дает сочетание достоинств обоих классических подходов. Система из таких микросхем легко
774
ПЕРВЫЕ ПОКОЛЕНИЯ МИКРОСХЕМ С ПРОГРАММИРУЕМОЙ СТРУКТУРОЙ
создается и изменяется, но в то же время может работать с реальными сигналами и частотами их изменения. Однако по затратам труда и времени создание системы из микросхем репрограммируемой логики все же сложнее, чем создание программной модели. Поэтому программные модели не исключаются с появлением репрограммируемых микросхем. С другой стороны, следует также учитывать, что полные свойства окончательно изготовленной продукции эмуляция на репрограммируемых микросхемах при переходе в последующем на иные методы производства отобразить не может, так как временные характеристики зависят от конкретной трассировки схемы, которой еще нет на этапе отладки с помощью репрограммируемых микросхем. Таким образом, эмуляция проектов на репрограммируемых микросхемах не отменяет прежние методы разработки и тестирования схем, а лишь эффективно их дополняет.
7.2. ПЕРВЫЕ ПОКОЛЕНИЯ МИКРОСХЕМ С ПРОГРАММИРУЕМОЙ СТРУКТУРОЙ
7.2.1. ПРОГРАММИРУЕМЫЕ ЛОГИЧЕСКИЕ МАТРИЦЫ И ПРОГРАММИРУЕМАЯ МАТРИЧНАЯ ЛОГИКА
Первыми представителями микросхем с программируемыми структурами явились ПЛМ (программируемые логические матрицы), ПМЛ (программируемая матричная логика) и БМК (базовые матричные кристаллы). «Предками» БИС/СБИС программируемой логики следующих поколений в первую очередь можно считать ПМЛ и БМК.
Основу типичных ПМЛ, называемых в английской терминологии PAL (Programmable Array Logic) или GAL (Generic Array Logic), составляют программируемая матрица элементов И и набор элементов ИЛИ, ко входам которых подключены выходы матрицы И. Условное изображение основной части ПМЛ (рис. 7.5.) показано для варианта с m входами, п выходами и р термами. Матрица элементов И состоит из р конъюнкгоров, на входы каждого из которых поданы все m входных переменных как в прямой, так и в инверсной форме.
Сокращенное условное обозначение схем типа рис. 7.5 показано на рис. 7.6. В этом обозначении многовыходные элементы И изображаются с одной входной линией, пересекающей множество линий входных переменных. Линии, подключаемые к конъюнкго-рам, отмечены точками. Терм tt, например, содержит переменные %! и хт (остальные переменные на рисунке не показаны), а терм t2 содержит переменные х, и хт (остальные переменные также не показаны). Терм 0, так как содержит логическое произведение х1х1, равное нулю. Такой терм не влияет на вырабатываемую функцию Fr
Обобщенная структура ПМЛ приведена на рис. 7.7, где помимо рассмотренных выше основных блоков МИ и набора дизъюнкгоров показаны также входной и выходной буферы БВх и БВых. Входной буфер преобразует однофазные входные сигналы в парафазные, необходимые для матрицы И, а выходной буфер формирует сигналы, необходимые для передачи во внешнюю среду. Во многих ПМЛ выходной буфер в зависимости от его программирования может формировать прямые или инвертированные величины воспроизводимых функций.
Используя обратные связи с выхода ПМЛ на входы матрицы И, можно воспроизводить скобочные (факторизованные) формы логических функций, что увеличивает функциональные возможности ПМЛ. Рассмотрим простой пример. Пусть требуется получить функции суммы S и переноса С для одноразрядного сумматора, входами которого являются слагаемые а и b и входной перенос с. Искомые функции в дизъюнктивной нормальной форме выражаются следующим образом:
5 = abc v abc v abc v abc и C = ab\/ac\/bc.
775
ПРОГРАММИРУЕМАЯ ЛОГИКА И ЕЕ ПРИМЕНЕНИЕ В МИКРОПРОЦЕССОРНЫХ СИСТЕМАХ
I
Рис. 7.5. Схема основных элементов ПМЛ
Рис. 7.6. Сокращенное условное обозначение основных элементов ПМЛ
776
ПЕРВЫЕ ПОКОЛЕНИЯ МИКРОСХЕМ С ПРОГРАММИРУЕМОЙ СТРУКТУРОЙ
Рис. 7.7. Обощенная структура ПМЛ
При воспроизведении этих функций требуется выработка семи термов (четырех для функции S и трех для функции С). Вынося за скобки величину с для первой пары слагаемых и с для второй, получим
S = (ab v ab)c v (ab v abjc = (ab v ab)c v (ab v abjc = fcvfc, где f =ab v ab
Функцию переноса можно записать в виде
С = abv (ab v ab)c =abv fc
Реализация полученных факторизованных соотношений требует выработки всего пяти термов. Схема реализации (рис. 7.8) предусматривает выработку вначале функции f и затем ее использование в качестве одного из аргументов функций S и С. Задержка выработки результата возрастает.
В рассмотренной схеме один из выходов матрицы ИЛИ не требует внешнего вывода (является скрытым). Такие конфигурации (наличие обратных связей и скрытых выходов) широко встречаются в микросхемах программируемой логики. Они характерны для ряда типовых узлов цифровой техники, например, счетчиков.
Схемотехническая реализация программируемых соединений первого поколения осуществлялась с помощью плавких перемычек (типа fuse) или цепочек из двух встречно включенных диодов. У таких цепочек начальная проводимость близка к нулю, а при пробое одного из диодов со сплавлением его электродов цепочка приобретает одностороннюю проводимость. Позднее появились более совершенные программируемые соединения.
а Ь а b Мили Ч>
фС
фС
фС
Рис. 7.8. Схема реализации на ПМЛ факторизованных функций с помощью обратных связей
777
ПРОГРАММИРУЕМАЯ ЛОГИКА И ЕЕ ПРИМЕНЕНИЕ В МИКРОПРОЦЕССОРНЫХ СИСТЕМАХ
В схемотехнике, использующей МОП-транзисторы, базовыми элементами служат, как правило, элементы ИЛИ-HE, на которых строятся как программируемая матрица, так и элементы, формирующие выходные функции из сигналов, получаемых от программируемой матрицы.
Функциональные возможности биполярных и МОП-структурных ПМЛ принципиально сходны. Это можно показать с помощью правил де Моргана. Действительно, терм в МОП-структурной ПМЛ вида a v ь v < равноценен терму abc , т. е. относительно инвертирован-ных переменных этим термом воспроизводится конъюнкция. Функция a v ь v с отличается от функции ИЛИ только инверсией. Следовательно, на основе элементов ИЛИ-HE реализуются ПМЛ с функциональными характеристиками, совпадающими с функциональными характеристиками биполярных ПМЛ на элементах И, ИЛИ, если иметь в виду инвертированные входные и выходные величины.
С течением времени функциональные возможности ПМЛ обогащались. Тракты обработки выходных сигналов матрицы элементов И усложнились и место простых дизъюнкто-ров заняли так называемые макроэлементы (макроячейки), в которых появились не только дополнительные логические элементы, но и триггеры с разнообразными вариантами функционирования.
7.2.2. БАЗОВЫЕ МАТРИЧНЫЕ КРИСТАЛЛЫ
Представителями БИС/СБИС первого поколения для микросхем с программируемыми структурами были и базовые матричные кристаллы (БМК), называемые также вентильными матрицами (ВМ). Второй из этих терминов менее распространен, хотя и удобен тем, что совпадает с английским обозначением таких БИС/СБИС - Gate Array (GA).
Основой БМК является его внутренняя область, в которой регулярно (по строкам и столбцам) расположены базовые ячейки или их компактные группы, между которыми оставлены горизонтальные и вертикальные зоны (каналы) для реализации межсоединений. Базовые ячейки - совокупности нескоммутированных схемных элементов, на основе которых при том или ином варианте схемных межсоединений реализуются определенные схемы (функциональные ячейки). В периферийных областях БМК размещены периферийные ячейки, выполняющие операции ввода/вывода сигналов.
БМК получили название полузаказных БИС/СБИС, хорошо отражающее их главную особенность. В отличие от полностью заказных БИС/СБИС, которые проектируются по индивидуальному заказу, БМК примерно на 3/4 стандартны. Независимо от конкретного потребителя делается матрица базовых ячеек и периферийные ячейки. Специализация кристалла, т. е. получение на его основе требуемой схемы (такие схемы называют МАБИС или БИСМ), производится с помощью заключительных операций создания металлизированных межсоединений. Таким образом, для превращения полуфабриката БМК в МАБИС требуется разработка лишь малого числа дорогостоящих фотошаблонов. Сам же БМК сравнительно недорог, так как выпускается как массовая продукция широкого потребления. Сроки и стоимость проектирования МАБИС в 3—4 раза меньше, чем аналогичные показатели для полностью заказных БИС/СБИС. Понятно также, что сокращение в 3—4 раза очень больших сумм все же оставляет стоимость проектирования МАБИС довольно высокой, так что их использование экономически целесообразно при достаточно большой тиражности производства. Область целесообразного применения МАБИС зависит от конкретных условий, нередко она начинается с объемов выпуска в 5-10 тыс. экземпляров.
Проектирование МАБИС облегчается тем, что разработчики БМК предоставляют проектировщику обширную библиотеку функциональных ячеек, т. е. вариантов готовых решений, соответствующих той или иной схеме (логическим элементам, триггерам, более сложным узлам).
778
ТИПИЧНЫЕ ФРАГМЕНТЫ СХЕМОТЕХНИКИ ИС ПЛ. ОБЩИЕ СВОЙСТВА ИС ПЛ
Платой за сокращение сроков и стоимости проектирования является неоптималь-ность МАБИС, быстродействие и компактность которой уступают тем, которые можно было бы получить при полностью заказном проектировании реализуемой схемы. Это вполне объяснимо, так как отсутствие ориентации БМК на конкретный проект означает неполное использование его элементов в составе данной МАБИС, неминимальность длин связей между схемными элементами и т. д.
7.3. ТИПИЧНЫЕ ФРАГМЕНТЫ СХЕМОТЕХНИКИ ИС ПЛ. ОБЩИЕ СВОЙСТВА ИС ПЛ
7.3.1. ТИПИЧНЫЕ СХЕМОТЕХНИЧЕСКИЕ РЕШЕНИЯ
Разработкой и производством микросхем программируемой логики занимаются десятки фирм, каждая из которых выпускает обычно одновременно несколько семейств микросхем. Семейства, в свою очередь, представлены совокупностью микросхем, отличающихся своими архитектурными и схемотехническими особенностями. Так образуется чрезвычайно большое число вариантов микросхем, и на первый взгляд сориентироваться в их многообразии достаточно сложно. Вместе с тем при внимательном рассмотрении обнаруживается, что для построения разных вариантов микросхем программируемой логики используется та или иная комбинация типичных элементов и блоков, число которых относительно невелико. Такие элементы и блоки рассмотрены ниже.
Простейшими элементами, обеспечивающими конфигурирование микросхем на заданное функционирование, являются рассмотренные ранее программируемые элементы связей (перемычки типа «antifuse», ЛИЗМОП-транзисторы с плавающим затвором, ключевые транзисторы, управляемые триггерами памяти конфигурации). Такие элементы могут просто замыкать или размыкать участки цепей, в которые они включены, либо входить в схемы резисторных делителей напряжения с программируемым коэффициентом деления для задания сигналов логического нуля или логической единицы. На рис. 7.9, а показан делитель напряжения, состоящий из резистора с постоянным сопротивлением R и программируемого сопротивления Rn, выходное напряжение делителя U = U<t R„/(R + R„)- В зависимости от программирования сопротивление Rnp имеет значения R„ « R или R* » R. В первом случае напряжение U мало (близко к нулю) и с делителя снимается сигнал логического нуля, во втором случае значение U близко к Ucc и соответствует логической единице.
Для конфигурирования межсоединений, а также построения логических блоков используются программируемые мультиплексоры. В первом из названных режимов (рис. 7.9, б) мультиплексор можно условно отобразить в виде переключателя, который под управлением адресующих входов (в данном случае это двухразрядное двоичное число ef) передает на выход Аодну из входных величин -а,Ь,с или d. На линии каждого входа отмечена комбинация адресующих величин, подключающая данный вход к выходу мультиплексора. В условном обозначении программируемого мультиплексора в режиме коммутации сигналов (рис. 7.9, в) факт программируемости обозначается кружком на адресующем входе. При программировании устанавливается определенный код ef и соответственно ему связь между выходом схемы и одним из входов. Для часто применяемых программируемых мультиплексоров размерности 2-1 условное обозначение имеет вид, изображенный на рис. 7.9, г. Комбинации адресующих величин против линий входов могут и не показываться, если в этом нет необходимости.
В п. 7.1.2 указано, что логические блоки CPLD выполняются как двухуровневые схемы И-ИЛИ, на входы которых подаются парафазные входные переменные. Логические блоки FPGA более разнообразны и могут представлять собою простые логические ячей-
779
ПРОГРАММИРУЕМАЯ ЛОГИКА И ЕЕ ПРИМЕНЕНИЕ В МИКРОПРОЦЕССОРНЫХ СИСТЕМАХ
Antifuse
Транзистор с плавающим затвором
Транзистор, управляемый триггером
EEPROM, Flash SRAM-based
Рис. 7.9. Схемы выработки программируемых сигналов управления (а) и программируемых мультиплексоров (б, в, г)
ки (SLC, Small Logic Cells), схемы на основе мультиплексоров или табличные функциональные преобразователи (LUTs, Look-Up Tables). Подробнее логические (функциональные) блоки разных ИС ПЛ рассмотрены ниже, здесь же остановимся на способах повышения функциональной гибкости логической обработки сигналов, используемых как в FPGA, так и в CPLD.
Из числа приемов дополнительной обработки сигналов, получаемых от основных логических блоков, можно выделить следующие.
1. Программирование полярности вырабатываемых функций. Этот прием наиболее характерен для CPLD , реализующих функции в форме ДНФ (SOP). В этом случае можно «сыграть» на том, что логическая функция F и ее инверсия F не идентичны по сложности и выражения для них могут иметь существенно различные числа термов. Имея возможность перехода от прямых значений функций к их инверсиям и наоборот, можно выбирать для реализации в основном логическом блоке более простую из этих форм независимо от того, какая из этих двух функций понадобится в последующих операциях. Схемотехнически программирование полярности логических переменных осуществляется с помощью двух входового элемента сложения по модулю 2, на один из входов которого подается логическая переменная, а на второй - константа «О» или «1» (рис. 7.10, а). Схема программируется заданием определенного состояния ключевому транзистору Т. Если он открыт и находится в низковольтном состоянии, то напряжение на нижнем входе элемента М2 отображает логический нуль и F = F* ®Q= F*. Если же транзистор заперт, то на нижнем входе элемента М2 действует высокое напряжение, близкое к Ucr, т. е. отображается сигнал логического нуля и F = F* © 1 = F*.
780
ТИПИЧНЫЕ ФРАГМЕНТЫ СХЕМОТЕХНИКИ ИС ПЛ, ОБЩИЕ СВОЙСТВА ИС ПЛ
Рис. 7.10. Схемы программирования полярности логических функций (а), организации двунаправленных выводов (6) и программирования типа выхода ячейки (в)
2. Организация двунаправленных выводов. В зависимости от конкретного проекта для ИС ПЛ одной и той же сложности могут потребоваться различные соотношения чисел входов и выходов. Поэтому специализация выводов и жесткое разделение их на входы и выходы сужает функциональные возможности микросхемы. Вследствие этого широкое применение находят микросхемы с двунаправленными выводами, которые путем программирования можно сделать либо входами, либо выходами. Микросхема, имеющая т специализированных входов, л специализированных выходов и р двунаправленных выводов, может программироваться на число входов от тцо т + р и на число выходов от п ррп + р при условии, что в сумме число выводов не превысит т + п + р. Схемотехнически это реализуется с помощью буферов, имеющих третье состояние (рис 7.10, б). Если сигналом ОЕ1 (Output Enable 1) буфер 1 разрешен, то вывод является выходом и переменная Fпоступает на внешний контакт (КП - контактная площадка). Если буфер 1 находится в третьем состоянии «отключено», а буфер 2 разрешен сигналом ОЕ2, то вывод служит входом. При этом входной сигнал преобразуется буфером 2 в парафазный. При активном буфере 1 через буфер 2 можно подавать в схему сигнал обратной связи, что также существенно увеличивает функциональные возможности микросхемы.
Если сигнал управления буфером 1 вырабатывается как терм, формируемый в матрице И, то возможны такие варианты программирования функций вывода:
• вывод является входом, если терм ОЕ1 запрограммирован на константу 0;
• вывод является простым выходом, если терм ОЕ1 запрограммирован на константу 1, а сигнал ОЕ2 запрещает буфер 2;
• выходной сигнал подается как сигнал обратной связи, если разрешена работа обоих буферов, причем выходной сигнал может вырабатываться постоянно при неизменном разрешающем сигнале ОЕ1 или появляться только в момент возникновения определенной комбинации входных переменных матрицы И соответственно программированию терма ОЕ1.
3. Введение триггеров. Еще один прием обогащения функциональных возможностей микросхем программируемой логики - введение триггеров в их макроячейки (это понятие объясняется ниже) или непосредственно в логические блоки, причем чаще все
781
ПРОГРАММИРУЕМАЯ ЛОГИКАМ ЕЕ ПРИМЕНЕНИЕ В МИКРОПРОЦЕССОРНЫХ СИСТЕМАХ
го логическое функционирование триггеров программируется. Обычно триггеры строятся на основе триггера типа D и дополнительных логических элементов. Триггеры типа D легко обеспечивают режим триггера типа Т (рис. 7.10, в) с помощью подключенных к ним элемента М2 и программируемого мультиплексора 1.
Если мультиплексор запрограммирован на передачу сигнала от верхнего входа D, то триггер работает как триггер типа D , принимая по разрешению тактового сигнала ТИ значение F. Если мультиплексор 1 запрограммирован на передачу сигнала от нижнего входа, то под воздействием тактового сигнала при F= 0 триггер принимает свое собственное состояние Q, т. е. находится в режиме хранения, а при F= 1 - инверсию своего состояния, т. е. переключается. Отсюда видно, что триггер функционирует как синхронный Т-триггер, ко входу Т которого подключен сигнал F.
В ряде микросхем программируемой логики возможно программирование триггеров на режимы не только D и Т, но и JK, RS (с помощью дополнительной внешней логики).
Для обогащения функциональных возможностей микросхем часто программируется тип выхода как комбинационный (combinatorial) или регистровый (registered). Для этого также используются программируемые мультиплексоры. Из рис. 7.10, в видно, что при программировании мультиплексора 2 на передачу сигнала от входа С реализуется комбинационный вариант выхода, когда величина F в обход триггера передается прямо на выход, а при передаче через мультиплексор сигнала от входа R реализуется регистровый вариант выхода (выходной сигнал снимается с триггера).
Перечисленные приемы повышения функциональной гибкости микросхем программируемой логики являются наиболее общими и характерны для многих из них. Ряд приемов более специфичен, такие приемы будут рассмотрены при описании конкретных разновидностей микросхем или их блоков.
7.3.2. СВОЙСТВА ИС ПЛ, ВАЖНЫЕ ДЛЯ ИХ ПРИМЕНЕНИЯ В СОСТАВЕ СИСТЕМ
Ряд свойств микросхем программируемой логики не связан непосредственно с их логическим функционированием, но имеет важное значение при их использовании в системе. К таким (системным) свойствам относятся следующие.
Уровни питающих напряжений. Имеются веские причины для перехода ко все меньшим напряжениям как для питания микросхем в рабочих режимах, так и для программирования таких элементов, как ЛИЗМОП-транзисторы в схемах с памятью конфигурации типов EPROM и EEPROM. Если сравнительно недавно типовым значением питающего напряжения было 5 В, то сейчас все больше используются схемы с напряжениями питания 3,3; 2,5; 1,8 и даже 1,6 В. Кроме того, исключаются требования повышенных напряжений для программирования, и все процессы в схемах обеспечиваются с помощью внутренних средств от единого источника внешнего питания.
Наличие режимов различного энергопотребления. При работе того или иного блока для поддержания его быстродействия требуются определенные затраты энергии (для быстрых переключений требуется быстрый перезаряд неизбежно существующих паразитных емкостей, т. е. нужны большие токи, обеспечивающие требуемые длительности переходных процессов). При отсутствии переключений в той или иной схеме можно резко снизить ее энергопотребление, так как для сохранения неизменного логического состояния достаточны микротоки. Кроме двух указанных режимов можно создавать и ряд промежуточных, что широко используется в микросхемах программируемой логики. Активные режимы могут программироваться в разных вариантах (максимального быстродействия и номинального быстродействия с меньшей потребляемой мощностью). Пассивные режи
782
FPGA - ПРОГРАММИРУЕМЫЕ ПОЛЬЗОВАТЕЛЕМ ВЕНТЕЛЬНЫЕ МАТРИЦЫ
мы также часто имеют несколько подрежимов (покоя, когда схема не переключается, но готова к быстрому вхождению в рабочий режим, глубокого понижения мощности, когда потребление энергии чрезвычайно мало, но переход в активный режим занимает относительно большое время, и т. д.).
Интересно отметить, что с помощью несложных логических элементов схемы могут автоматически переходить из одного режима в другой, выявляя факт изменения информационных сигналов и реагируя на него увеличением рабочих токов.
В число программируемых величин может входить так называемый Turbo bit, задающий один из двух режимов, различающихся по соотношению скорость/мощность.
Наличие или отсутствие в микросхеме средств поддержки интерфейса JTAG. Первоначальные версии этого интерфейса обеспечивали тестирование систем методом периферийного (граничного) сканирования, более поздние расширенные версии, ориентированные на микросхемы программируемой логики, позволяют через интерфейс JTAG конфигурировать схемы с триггерной памятью, для чего требуется лишь загрузка в память конфигурации загрузочного файла.
Свойство программируемости в системе. Схемы, обладающие этим свойством, называются In-System Programmable (ISP). Свойство ISP могут иметь микросхемы с триггерной памятью конфигурации (заметим, что термин «программируемость» появился в этом абзаце в связи с его наличием в английском термине ISP, по существу же он означаетто же самое, что и термин «конфигурируемость»). Поскольку триггерная память теряет свое содержимое при выключении питания, схемы типа SRAM-based программируются при каждом включении питания. Свойство ISP означает, что реконфигурацию можно производить без изъятия микросхемы из системы, перезагружая файл конфигурации, что возможно и во время функционирования системы. Такая возможность позволяет строить системы с многофункциональным использованием одних и тех же программируемых микросхем в качестве разных блоков системы, если эти блоки не используются одновременно, а также и другие варианты адаптивных систем.
Наличие средств защиты от считывания данных конфигурации. Такие средства имеют разную степень защиты. В простейшем случае предусматривается бит защиты или несколько таких битов.
Программирование крутизны фронтов. Известно, что одной из острых проблем при реализации цифровых устройств и систем является борьба с помехами, в том числе создаваемыми самими схемами этих устройств и систем. С целью снижения уровня возникающих импульсных помех для мощных буферов, прежде всего тех, которые формируют выходные сигналы кристалла, вводится программирование крутизны фронтов. Бит SLC (Slew Rate Control) задает режимы крутых или пологих фронтов. Рекомендуется везде, где допустимо, устанавливать режим пологих фронтов, создающий гораздо меньшие помехи. В критичных для быстродействия цепях с целью повышения производительности системы используются режимы крутых фронтов (т. е. быстрых переключений).
7.4. FPGA - ПРОГРАММИРУЕМЫЕ ПОЛЬЗОВАТЕЛЕМ ВЕНТИЛЬНЫЕ МАТРИЦЫ >
7.4.1. АРХИТЕКТУРА И БЛОКИ FPGA
Программируемые пользователем вентильные матрицы (FPGA или ППВМ) топологически сходны с канальными БМК. Их основой служит матрица регулярно расположенных по строкам и столбцам идентичных конфигурируемых логических блоков. Между строками и столбцами логических блоков проходят трассировочные каналы, содержащие ре
783
ПРОГРАММИРУЕМАЯ ЛОГИКА И ЕЕ ПРИМЕНЕНИЕ В МИКРОПРОЦЕССОРНЫХ СИСТЕМАХ
сурсы межсоединений. При программировании логические блоки настраиваются на требуемые операции преобразования данных, а трассировочные ресурсы - на обеспечение нужных взаимных соединений логических блоков. В результате во внутренней области FPGA реализуется функциональная схема проектируемого устройства. В периферийной области кристалла, по его краям, размещены блоки ввода/вывода, обеспечивающие интерфейс FPGA с другими микросхемами, причем в современных FPGA схемы ввода/ вывода способны выполнять требования множества стандартов на сигналы передачи данных, число которых может доходить до 20.
Свойства и возможности FPGA зависят прежде всего от ключевых архитектурных факторов - типа логических блоков и системы межсоединений.
Важной характеристикой логических блоков (ЛБ) является зернистость (granularity). Зернистость характеризует уровень разбиения схемы блока на коммутируемые при программировании части. Примерами наиболее мелкозернистых логических блоков могут служить цепочки транзисторов с р- и л-каналами, с помощью которых можно собирать логические схемы непосредственно из пар транзисторов по обычной методике реализации КМОП-логики. Мелкозернистость придает гибкость использованию схемных элементов кристалла, но усложняет систему межсоединений. Более крупнозернистые блоки используются в большинстве FPGA и имеют довольно разнообразный характер.
Типичными представителями логических блоков FPGA являются:
• логические модули на основе мультиплексоров;
• логические модули на основе программируемой памяти (блоки типа ШТ - Look-Up Tables).
Известно, что мультиплексоры могут работать в режиме универсальных логических модулей, если на их адресные входы подавать аргументы переключательной функции, а на информационные - настроечные сигналы. При настройке константами 0 и 1 мультиплексор размерности 2" - 1 воспроизводит функции п переменных, что иллюстрируется на рис. 7.11, а примером для функции двух переменных. Действительно, комбинация х1 х0 = 00 определяет передачу на выход мультиплексора сигнала D0 с нулевого информационного входа. Если на этом входе задано в качестве настроечного сигнала значение функции при нулевом аргументе F(0), то на выходе получим искомый результат. Комбинация xtx0 = 01 передает на выход сигнал D1, и если D1 = F(1), то получим необходимый результат и для этого набора аргументов и т. д. Таким образом можно получать с помощью мультиплексора любую функцию л аргументов.
В некоторых FPGA применяют логические блоки, состоящие из нескольких малоразмерных мультиплексоров (2 - 1,4 - 1), получая при этом программируемые логические блоки с широкими логическими возможностями.
Рис. 7.11. Схема мультиплексора в режиме логического блока (а) и схема табличного логического блока (б)
784
FPGA- ПРОГРАММИРУЕМЫЕ ПОЛЬЗОВАТЕЛЕМ ВЕНТЕЛЬНЫЕ МАТРИЦЫ
Самые распространенные логические блоки FPGA - табличные (LUTs). Эти блоки называют часто табличными функциональными преобразователями. В них используются программируемые запоминающие устройства. При этом набор аргументов служит адресом, по которому записывается соответствующее значение функции, если память имеет одноразрядную организацию, или значения m функций, если разрядность хранимых слов равна т. Число аргументов воспроизводимых функций равно разрядности адреса памяти. Табличные функциональные преобразователи (рис. 7.11, б) воспроизводят любые функции данного числа аргументов.
Для систем межсоединений FPGA характерны сегментированные линии, составленные из отдельных отрезков, соединяемых друг с другом программируемыми элементами. Программируемые соединительные элементы могут быть размещены в так называемых переключательных блоках, конфигурируемых так, чтобы составить из сегментов необходимые цепи. Программируемые соединительные элементы (ключи) вносят в линии передач сигналов задержки, так как имеют паразитные параметры (сопротивление R и емкость С). Задержки, обусловленные постоянными времени ключей RC, доминируют над другими, так что число ключей в линии передачи сигнала практически определяет и задержку в линии связи.
Выбор длин сегментов - непростая задача, поскольку короткие сегменты затрудняют передачи сигналов на большие расстояния (появится большое число ключей в линии), а длинные сегменты неудобны для реализации коротких передач. Обычно применение однотипных сегментов не может дать удовлетворительных результатов, и система межсоединений организуется как иерархическая. Так, например, в широко известных FPGA фирмы «Xilinx» ресурсы межсоединений содержат основные связи (General Purpose Interconnects) с сегментами единичной длины, основные связи с сегментами двойной длины, так называемые прямые связи для соединения логических блоков с ближайшими соседями (Direct Connects) и длинные линии (Long Lines), пересекающие кристалл по всей его длине и ширине для передач сигналов на большие расстояния и с малыми задержками.
На рис. 7.12, а представлена структура FPGA с простейшей системой межсоединений, содержащей только основные связи с единичной длиной сегментов. Через ЛБ обозначены
Рис. 7.12. Структура FPGA с межсоединениями общего назначения (а), схема переключательного блока (б) и узла пересечения линий с программируемыми соединениями в этом блоке (в)
785
ПРОГРАММИРУЕМАЯ ЛОГИКА И ЕЕ ПРИМЕНЕНИЕ В МИКРОПРОЦЕССОРНЫХ СИСТЕМАХ
Рис. 7.13. Полные ресурсы межсоединений в микросхемах семейства ХС4000Е
конфигурируемые логические блоки (для краткости принято обозначение ЛБ, в котором конфигурируемость не обозначена, также обозначаются конфигурируемые логические блоки и в дальнейшем). В структуру входят также переключательные блоки ПБ и соединительные блоки СБ. Соединительные блоки обеспечивают связи ПБ с трактами передач сигналов, проходящими через переключательные блоки.
В сущности, это совокупность пересечений линий ввода/вывода логических блоков с линиями, проходящими через переключательные блоки, с элементами программируемых соединений в точках пересечений. Схема ПБ раскрыта на рис. 7.12, б. Сигналы, поступающие по какой-либо линии в ПБ, могут быть направлены далее по трем направлениям, что обеспечивается наличием в ПБ показанных зачерненными квадратами схем, представленных на рис. 7.12, в. Иными словами, сигналы могут передаваться по горизонтальным или вертикальным линиям и переходить с одних на другие.
Ресурсы межсоединений в FPGA в полном виде показаны на рис. 7.13 на примере микросхемы ХС4000Е фирмы «Xilinx» . Здесь наряду с основными связями единичной длины (восемь линий в каждом из направлений) имеются основные связи с линиями двойной длины (четыре линии в каждом из направлений), шесть вертикальных и шесть горизонтальных длинных линий и четыре линии глобального, т. е. общего для всей микросхемы тактирования.
В сегментированных линиях межсоединений задержки сигналов зависят от путей их распространения, так как пути неидентичны и в них может оказаться разное число ключей.
786
FPGA - ПРОГРАММИРУЕМЫЕ ПОЛЬЗОВАТЕЛЕМ ВЕНТЕЛЬНЫЕ МАТРИЦЫ
7.4.2. ПОПУЛЯРНЫЕ FPGA ФИРМЫ «XILINX»
Логический блок семейства FPGA ХС4000Е фирмы «Xilinx» (рис. 7.14) иллюстрирует характерные особенности подобных блоков. Фирма «Xilinx» является ведущей в области разработки FPGA, ее продукция занимает 30-40% мирового рынка микросхем программируемой логики, ею был созда- перспективный класс FPGA с триггерной памятью конфигурации.
Заметим предварительно, что на рис. 7.14 программируемость не отражена в обозначениях мультиплексоров, так как все они являются программируемыми.
Логические преобразования выполняются тремя табличными преобразователями: G, F и Н. Преобразователи G и F представляют собою программируемые запоминающие устройства с организацией 16 х 1 и могут воспроизводить любые функции четырех переменных. Через нижние входы мультиплексоров 1 и 2 выходы преобразователей G и F могут быть поданы на преобразователь Н (память с организацией 8x1) для образования «функции от функций» с целью получения функций, зависящих от более чем четырех аргументов. Преобразователь Н может также использоваться как третий независимый генератор функций со входами НО, Н1 и Н2, если через мультиплексоры 1 и 2 передаются сигналы их верхних входов. Имеется возможность добавления в число аргументов преобразователя Н входного сигнала DIN. Таким образом, два из входов преобразователя Н могут быть альтернативно заданы как внешние входы или выходы преобразователей G и F, третий же вход Н1 всегда является внешним.
Рис. 7.14. Схема логического блока микросхем семейства ХС4000Е
787
ПРОГРАММИРУЕМАЯ ЛОГИКА И ЕЕ ПРИМЕНЕНИЕ В МИКРОПРОЦЕССОРНЫХ СИСТЕМАХ
Как видно из схемы, на выход Y в зависимости от программирования мультиплексора 4 могут подаваться значения функций G или Н, а на выход X в зависимости от программирования мультиплексора 6 - значения функций F или Н.
С помощью имеющихся функциональных преобразователей можно получать различные результаты: три отдельные функции независимых переменных (две от четырех аргументов и одну от трех при запоминании одного из выходов триггером), любую функцию пяти переменных, некоторые функции большего числа переменных (вплоть до девяти).
В зависимости от программирования мультиплексоров 3 и 5 триггеры принимают данные от функциональных преобразователей или внешнего входа DIN.
Сигнал тактирования триггеров К поступает от общего входа через мультиплексоры 7 и 8, программирование которых позволяет индивидуально выбирать полярность фронта, тактирующего триггер. Сигнал разрешения тактирования ЕС (Enable Clock) также поступает от общего входа. Благодаря наличию мультиплексоров 9 и 10 можно либо пользоваться сигналом ЕС, либо постоянно разрешить тактирование сигналом логической единицы.
Триггеры имеют асинхронные входы установки SD (Set Direct) и сброса RD (Reset Direct), один из которых через программируемый селектор S/R может быть подключен к сигналу SR, который, в свою очередь, может программироваться для подключения к любому из внешних выводов С1-С4. Возможно подключение к разным линиям С1-С4 и для выходов других мультиплексоров верхней строки (на рисунке не пронумерованы).
Блок ввода/вывода микросхем ХС4000Е (рис. 7.15) имеет два канала - для ввода сигналов и для вывода. В каждом канале возможна как прямая передача сигнала, так и с запоминанием его в триггере в зависимости от программирования мультиплексоров
Рис. 7.15. Схема блока ввода/вывода микросхем семейства ХС4000Е
788
CPLD - СЛОЖНЫЕ ПРОГРАММИРУЕМЫЕ ЛОГИЧЕСКИЕ УСТРОЙСТВА
7 и 4. При переводе буфера 1 в третье состояние выходной контакт не должен оставаться разомкнутым, так как в этом случае на нем может накапливаться неконтролируемый заряд в силу чрезвычайно высокого входного сопротивления МОП-транзистора. Подключение к выходу одного из резисторов R либо «подтягивает» потенциал выхода к высокому уровню напряжения, либо привязывает его к нулевой точке. Вследствие своей высо-коомности подключенные к выходу сопротивления R не оказывают заметного влияния на режимы работы при использовании выхода для передачи сигналов. Выбор между двумя вариантами задания потенциала разомкнутому выходу программируется элементами памяти конфигурации в схеме U/D (Up/Down). Выходной буфер 1 имеет регулировку крутизны фронта SLR (Slew Rate). Можно выбрать одно из двух значений скорости изменения выходного сигнала, для чего в схеме имеется элемент памяти SLR. Везде, где это приемлемо, желательны пологие фронты для снижения уровня помех, возникающих при переключениях буферов.
Если вывод работает в режиме входа (буфер 1 в третьем состоянии, буфер 2 активен), то внешний сигнал может подаваться в схему либо напрямую, либо через триггер, либо в обоих вариантах одновременно. В последнем случае блок ввода/вывода может демультиплексировать внешние сигналы (например, для шин адресов/данных сохранить принятый адрес в триггере и передавать данные по прямому входу). Синхросигналы триггеров различны для входного (CLKI) и выходного (CLKO) триггеров. Их полярности, как и полярность выходного сигнала О (Output), могут программироваться соответствующими мул ьтиплексорами.
Сигнал на входе триггера 2 можно специально задерживать на несколько наносекунд программированием мультиплексора 8. Это сделано для такого подбора временного положения сигнала относительно тактирующего импульса, который обеспечивает компенсацию задержек в цепях распределения синхросигналов.
7.5. CPLD - СЛОЖНЫЕ ПРОГРАММИРУЕМЫЕ ЛОГИЧЕСКИЕ УСТРОЙСТВА
7.5.1. АРХИТЕКТУРА И БЛОКИ CPLD
CPLD - совокупность нескольких PAL-подобных блоков, объединенных системой межсоединений. Упрощенная архитектура «классической» CPLD показана на рис. 7.16. PAL-подобные блоки выполняют логические преобразования сигналов, а матрица соединений обеспечивает межсоединения блоков. Каждый блок имеет свои входы/выхо-ды для приема и выдачи сигналов и специализированные входы для глобальных сигналов управления различными элементами схемы.
Простейшие PAL-блоки (иначе говоря, функциональные блоки ФБ) имеют структуру, рассмотренную в п. 7.1, и содержат программируемую матрицу элементов И и группу не программируемых элементов ИЛИ. Матрица вырабатывает конъюнктивные термы (логические произведения предусмотренных программированием входных переменных и их инверсий) для последующего получения из них дизъюнктивных нормальных форм (ДНФ) требуемых функций. Эта структура реализует так называемую двухуровневую логику.
Более развитые функциональные блоки помимо программируемых матриц И и жестких схем ИЛИ имеют и ряд дополнений, обогащающих функциональные возможности блоков путем перехода от простого логического суммирования термов элементами ИЛИ к более сложным операциям как над термами, так и над первоначально получаемыми функциями. При этом архитектурно ФБ трактуются как содержащие матрицу И , элементы ИЛИ и выходные макроячейки (макроэлементы). Иногда говорят о сочетании в CPLD матрицы И и макроячеек, подразумевая включение элементов ИЛИ в состав макроячеек.
789
ПРОГРАММИРУЕМАЯ ЛОГИКА И ЕЕ ПРИМЕНЕНИЕ В МИКРОПРОЦЕССОРНЫХ СИСТЕМАХ
Рис. 7.16. Упрощенная архитектура «классической» CPLD
Рис. 7.17. Система межсоединений CPLD с единой матрицей ПМС
790
CPLD - СЛОЖНЫЕ ПРОГРАММИРУЕМЫЕ ЛОГИЧЕСКИЕ УСТРОЙСТВА
Архитектурно CPLD состоят из программируемой матрицы соединений ПМС (PIA, Programmable Interconnect Array), множества функциональных PAL-блоков и блоков ввода/вывода (lOBs, Input/Output Blocks), расположенных на периферии кристалла (рис. 7.16). В отличие от типичных для FPGA систем сегментированных связей в CPLD связи одномерно непрерывны, причем все связи идентичны, и это дает хорошую предсказуемость задержек в связях (рис. 7.17). Программируемая матрица соединений позволяет соединять выход любого функционального блока с любыми входами других. Входы блоков связаны с горизонтальными линиями, пересекающими все вертикальные линии матрицы, отведенные для выходов функциональных блоков. Таким образом, любой вход блока может быть подключен к любому выходу программированием точек связи между вертикальными и горизонтальными линиями матрицы. В подобных случаях говорят, что система межсоединений обеспечивает полную коммутируемость блоков (100 %-ную разводку сигналов между функциональными блоками). Обеспечить полную коммутируемость блоков в сложных микросхемах программируемой логики удается не всегда. Для CPLD без полной коммутации в процессе проектирования может появляться задача такого преобразования проекта, которое дает уменьшение числа связей между функциональными блоками.
Рост сложности CPLD затрудняет реализацию полной коммутируемости блоков в рассмотренной структуре и вызывает к жизни структуры с двумя уровнями матриц соединений - глобальным и локальным. Локальные матрицы обслуживают группы функциональных PAL-блоков (сегменты), а глобальные обеспечивают межсегментный обмен сигналами. Такую архитектуру имеют, например, CPLD семейства МАСН5 фирмы AMD (рис. 7.18).
Рис. 7.18. Структура CPLD с двумя уровнями матриц соединений
ПРОГРАММИРУЕМАЯ ЛОГИКА И ЕЕ ПРИМЕНЕНИЕ В МИКРОПРОЦЕССОРНЫХ СИСТЕМАХ
7.5.2. ПОПУЛЯРНЫЕ CPLD ФИРМЫ «ALTERA»
Фирма «Altera» наряду с фирмой «Xilinx» принадлежит к крупнейшим разработчикам ИС ПЛ и занимает 30-40 % мирового рынка этой продукции. Преобладающей линией деятельности фирмы «Altera» является разработка именно CPLD, к которым далее добавились микросхемы комбинированной архитектуры и типа «система на кристалле».
Классическим представителем CPLD является семейство МАХ7000 (МАХ - аббревиатура от Multiple Array Matrix), выпускаемое фирмой «Altera». Микросхемы этого семейства имеют память конфигурации типа EEPROM, т. е. программируются введением зарядов в плавающие затворы ЛИЗМОП-транзисторов. При снятии питания конфигурация сохраняется. Стирание содержимого памяти конфигурации производится электрически-
Рис. 7.19. Фрагмент микросхемы CPLD семейства МАХ7000
792
CPLD - СЛОЖНЫЕ ПРОГРАММИРУЕМЫЕ ЛОГИЧЕСКИЕ УСТРОЙСТВА
На рис. 7.19 показан фрагмент микросхемы семейства МАХ7000. Показан один ярус, содержащий логические блоки ЛБ и блоки ввода/вывода БВВ. У разных представителей семейства схемы составляются из разного числа ярусов: у младшего представителя всего один ярус, у старшего - восемь, соответственно этому у младшего представителя два ЛБ, у старшего -16. Логические блоки имеют по 16 макроячеек (МЯ), получающих термы от локальных программируемых матриц И (ЛПМИ). Программируемая матрица соединений ПМС обеспечивает межсоединения логических блоков таким образом, что на любой вход ЛБ может быть подан сигнал от любого выхода ЛБ или контакта ввода/вывода.
ПМС организована так, что на пути сигнала нет программируемых ключей и сигналы передаются через конъюнкторы, открытые по второму входу единичным сигналом, там, где это предусмотрено при конфигурировании микросхемы. Такое решение ускоряет передачу сигналов по линиям связи (рис. 7.20).На вход ЛБ может быть подан сигнал с любой непрерывной по длине вертикальной линии ПМС.
Все Л Б связаны со своими блоками ввода/вывода, имеющими от 6 до 12 контактов (КП - контактная площадка). Так как в блоке 16 макроячеек, не все они могут иметь внешний вывод. Часть макроячеек может быть использована только для выработки сигналов обратной связи, передаваемых в ПМС. Это решение обосновано тем, что при построении ряда узлов многие логические функции нужны только для использования внутри схемы.
ПМС получает от каждого ЛБ 16 сигналов обратной связи, от блоков ввода/вывода - от 6 до 12 сигналов и четыре специализированных сигнала. К специализированным сигналам относятся глобальные (т. е. единые для всех одноименных блоков схемы) сигналы тактирования (GCLK1, GCLK2) и сброса (GCLR), а также сигналы разрешения выходов ОЕ. Из ПМС поступает по 36 сигналов для каждого ЛБ и еще шесть сигналов, которые прямо или инверсно передаются через мультиплексор MUX3 для глобальной шины разрешения выходов БВВ.
Схема макроячейки показана на рис. 7.21. Из матрицы элементов И в матрицу распределения термов МРТ поступает пять основных термов (на рисунке слева). МРТ дает возможность использовать эти термы для сборки по ИЛИ с последующей подачей результата на элемент сложения по модулю 2 для образования комбинационной функции, а также для управления триггером по входам сброса (CLRn) и установки (PRn). Терм t может быть использован для тактирования триггера или разрешения тактирования в зависимости от программирования мультиплексора MUX2.
Триггер имеет гибкую систему управления записью данных. Он может тактироваться от глобального сигнала GCLK, причем такое тактирование может сопровождаться индивидуальным управлением от сигнала разрешения ENA. Возможно тактирование и от локального сигнала I
Линии ПМС
Рис. 7.20. Цепь передачи сигнала из программируемой матрицы межсоединений в логические блоки
793
ПРОГРАММИРУЕМАЯ ЛОГИКА И ЕЕ ПРИМЕНЕНИЕ В МИКРОПРОЦЕССОРНЫХ СИСТЕМАХ
От ПМС
Общий ЛР
Рис. 7.21. Схема макроячейки CPLD семейства МАХ7000
Рис. 7.22. Схема параллельного логического расширителя
794
CPLD - СЛОЖНЫЕ ПРОГРАММИРУЕМЫЕ ЛОГИЧЕСКИЕ УСТРОЙСТВА
Разнообразные варианты тактирования предоставляют удобство построения автоматов с памятью разных типов (синхронных, апериодических, асинхронных).
Установка и сброс триггера возможны от асинхронных сигналов PRn и CLRn, кроме того, возможен сброс от глобального сигнала GCLR при соответствующем программировании мультплексора MUX3.
В зависимости от программирования мультиплексора MUX1 на вход триггера поступает значение функции, выработанное логическими схемами макроячейки, или же триггер загружается от внешнего вывода по цепи быстрого ввода.
Мультиплексор MUX4 позволяет подавать на выход макроячейки (к блоку ввода/вывода) либо непосредственно комбинационную функцию, либо хранимую в триггере (регистровый выход).
Если для реализации требуемой функции макроячейке не хватает термов, можно воспользоваться ресурсами логических расширителей ЛР. Первый тип ЛР, называемый общим (разделяемым), образуется за счет терма пятой линии, который вводится в матрицу И и становится доступным для всех макроячеек. Так как в логическом блоке 16 макроячеек, общий ЛР может иметь до 16 линий (рис. 7.21).
Параллельный ЛР образуется с помощью коммутации термов, передаваемых от предшествующих макроячеек в последующие как по цепочке (рис. 7.22).Допускается образование цепочек длиною до 8 звеньев.
Блок ввода/вывода (рис. 7.23) позволяет гибко управлять состоянием выходного буфера. ПМС формирует для этой цели шесть глобальных сигналов разрешения выхода ОЕ, каждый из выводов благодаря программированию мультиплексора MUX может подключаться к любому из шести сигналов. У некоторых микросхем семейства МАХ7000 предусмотрена возможность запрограммировать выход с открытым стоком. Кроме того, программируется и скорость изменения выходных напряжений буферов (крутизна фронтов) в вариантах быстрая/медленная; полезность этой возможности обсуждалась ранее.
Рис. 7.23. Схема блока ввода/вывода микросхем семейства МАХ7000
795
ПРОГРАММИРУЕМАЯ ЛОГИКА И ЕЕ ПРИМЕНЕНИЕ В МИКРОПРОЦЕССОРНЫХ СИСТЕМАХ
7.6. СБИС ПЛ КОМБИНИРОВАННОЙ АРХИТЕКТУРЫ
7.6.1. ОБЩИЕ СВЕДЕНИЯ
Непрерывное усложнение современных цифровых систем, высокий уровень и разнообразие предъявляемых к ним требований затрудняют получение необходимых свойств ИС ПЛ в рамках той или иной «классической» архитектуры. Микросхемы высшей сложности строятся по все более оригинальным архитектурам, не только сочетающим в себе черты FPGA и CPLD, но и обладающим новыми особенностями.
Комбинированные архитектуры, объединяющие в той или иной мере достоинства обеих предшествующих линий развития ИС ПЛ, появились впервые в микросхемах семейств FLEX8000, FLEX10K фирмы «Altera», семейства ХС9500 фирмы «Xilinx» и ATF1500 фирмы «Atmel».
Заметим, кстати, что приводимые сведения не являются строгим историческим свидетельством в отношении развития ИС ПЛ, они прежде всего отражают тенденции и процессы, наблюдаемые в деятельности тех ведущих фирм - мировых лидеров, которые взяты в качестве характерных образцов происходящих событий.
Микросхемы FPGA и CPLD с точки зрения функциональных возможностей могут решать одни и те же задачи, но по своим характеристикам имеют и различия. В CPLD логические функции выражаются в ДНФ, что для сложных функций может оказаться достаточно громоздким, но в то же время они обеспечивают малые и хорошо предсказуемые задержки сигналов в цепях их передачи. В микросхемах FPGA средства выработки логических функций более гибки, но задержки сигналов в системе межсоединений не столь малы и предсказуемы, как в CPLD. Таким образом, для реализации на CPLD более подходят устройства «небольшие, но быстродействующие», а для реализации на FPGA -«большие, но менее быстродействующие».
7.6.2. СБИС ПЛ КОМБИНИРОВАННОЙ АРХИТЕКТУРЫ FLEX10K
По архитектуре микросхемы семейства FLEX занимают промежуточное положение между классическими вариантами CPLD и FPGA. Сохранив ряд качеств CPLD, разработанных ранее фирмой «АИега», микросхемы семейства FLEX в то же время имеют логические элементы табличного типа (LUT), расположенные в виде матрицы, и трассировочные каналы, проходящие горизонтально и вертикально между столбцами и строками матрицы логических элементов, что характерно для FPGA. В то же время трассы в каналах не сегментированы, а непрерывны, что типично для CPLD и дает хорошо предсказуемые и малые задержки сигналов.
На фрагменте микросхемы семейства FLEX10K (рис. 7.24) показаны логические блоки LAB (Logic Array Blocks), содержащие по восемь логических элементов LE (Logic Elements) табличного типа, и локальная программируемая матрица межсоединений (локальная ПМС), обеспечивающая коммутацию сигналов в блоке. Коммутация сигналов на втором уровне обеспечивается глобальной программируемой матрицей соединений ГМПС, организованной в виде совокупности строк и столбцов, к концам которых подсоединены элементы ввода/вывода ЭВВ. Линии связи в ГПМС непрерывны и проходят по всей длине соответствующего направления (горизонтально или вертикально). Это отличает их от сегментированных линий связи в типичных FPGA и придает свойства CPLD в отношении предсказуемости задержек при передаче сигналов.
Важным новшеством в архитектуре семейства FLEX10K стало наличие блоков EABs (Embedded Array Blocks), представляющих собою реконфигурируемые модули памяти 796
СБИС ПЛ КОМБИНИРОВАННОЙ АРХИТЕКТУРЫ
Рис. 7.24. Фрагмент микросхемы семейства FLEX10K
(РМП). Эти блоки создают ресурсы встроенной памяти сверх тех распределенных ресурсов, которые имеют логические элементы табличного типа. Память может быть организована в вариантах 2048 х 1,1024 х 2, 512 х 4 и 256 х 8 и ориентирована также на реализацию буферов FIFO. В микросхемах FLEX10KE память блоков EABs ориентирована и на организацию двухпортовых ОЗУ, в которых может одновременно осуществляться запись по одному адресу и чтение по другому. Несколько блоков ЕАВ могут быть объединены для создания более емких блоков памяти.
Блоки встроенной памяти обладают характеристиками быстродействующих ОЗУ. При необходимости они могут применяться и для воспроизведения табличным способом сложных логических функций (арифметических операций, функций цифровой обработки сигналов и т. п.).
В микросхемах семейства FLEX10K средства логического преобразования данных имеют два уровня. Наименьшей структурной единицей является логический элемент (ЛЭ, LE).Компактная группа из восьми логических элементов образует логический блок (ЛБ, LAB - Logic Array Block). Логический блок выступает как самостоятельная структурная единица следующего иерархического уровня. Строкам и столбцам логических блоков соответствуют строки и столбцы глобальной матрицы соединений.
Логический элемент микросхем семейства FLEX10K (рис. 7.25) имеет в своем составе четырехвходовый табличный функциональный преобразователь типа LUT (т. е. программируемую память с организацией 16 х 1), схемы переноса и каскадирования, программируемый триггер и несколько программируемых мультиплексоров. Функциональный преобразователь ФП-4 может быть сконфигурирован для воспроизведения двух функций трех переменных, для чего память с организацией 16x1 разбивается на два блока с организацией 8x1. Такое разбиение позволяет, например, воспроизводить функции суммы и переноса для одноразрядного сумматора. Цепи переноса у микросхем семейства FLEX10K имеют высокое быстродействие (задержка 1 нс на каскад), что улучшает быстродействие схем с последовательными переносами, отличающихся простотой реализации.
797
ПРОГРАММИРУЕМАЯ ЛОГИКА И ЕЕ ПРИМЕНЕНИЕ В МИКРОПРОЦЕССОРНЫХ СИСТЕМАХ
Вход переноса Вход каскадирования
Выход переноса Выход каскадирования
Рис. 7.25. Логический элемент микросхем семейства FLEX10K
Синхронный триггер может функционировать не только как триггер типа D (режим, соответствующий непосредственному использованию имеющейся схемы), но и как триггер типа Т или даже типов JK и RS, работа которых эмулируется с привлечением логических ресурсов, не входящих в схему триггера. Входные сигналы асинхронных сброса и установки вырабатываются схемой управления, в которую поступают два локальных управляющих сигнала ЛУС1, ЛУС2, сигнал общего сброса микросхемы и входная переменная D3. В схеме управления установкой/сбросом (СУ уст/сбр) имеются программируемые мультиплексоры, благодаря которым можно задать один из шести режимов воздействия на триггер. Все режимы асинхронные - это сброс, установка или загрузки в разных вариантах.
Триггер может быть использован не только совместно с комбинационной частью логического элемента, но и независимо от нее, как отдельный элемент, если на его вход через мультиплексор 1 поступает сигнал со входа D4.
Выходные сигналы ЛЭ через мультиплексоры 3, 4 могут подаваться в глобальную и локальную программируемые матрицы соединений в комбинационном или регистровом варианте.
Тактирование триггера возможно от любого из двух локальных управляющих сигналов ЛУСЗ и ЛУС4.
Функции, число аргументов у которых превышает четыре, получаются как композиции из функций четырех аргументов одним из двух способов. Первый способ (рис. 7.26, а) предполагает применение схем каскадирования, которые можно настраивать на любую функцию двух переменных, кроме функций суммы по модулю 2 и функции равнозначности. Схемами каскадирования отдельные функции четырех переменных объединяются в функцию большего числа аргументов.
Второй способ использует схему с обратными связями (рис. 7.26, б). Вначале вырабатываются функции, зависящие не более чем от четырех аргументов, а затем они играют роль аргументов для логического элемента, вырабатывающего окончательный вариант. Результатом является получение «функции от функций».
798
СБИС ПРОГРАММИРУЕМОЙ ЛОГИКИ ТИПА «СИСТЕМА НА КРИСТАЛЛЕ»
Рис. 7.26. Схемы реализации функций многих переменных
Возможности обоих вариантов определяются возможностями декомпозиции воспроизводимых функций.
Встроенные конфигурируемые блоки памяти ЕАВ с общей емкостью от 6 до 20 Кбит у разных представителей семейства расположены в центре каждой строки матрицы логических блоков. В каждом блоке имеется 2К программируемых битов памяти. Блок может быть как запоминающим устройством, так и функциональным преобразователем табличного типа для получения сложных функций.
Не рассматривая подробно глобальную систему коммутации и работу элементов ввода/вывода, заметим, что в них много сходства с работой схем аналогичного назначения, рассмотренных ранее.
7.7. СБИС ПРОГРАММИРУЕМОЙ ЛОГИКИ ТИПА «СИСТЕМА НА КРИСТАЛЛЕ»
7.7.1. ОБЩИЕ СВЕДЕНИЯ
Кристаллы современных СБИС ПЛ максимальной сложности содержат миллионы эквивалентных вентилей, а их рабочие частоты достигли сотен мегагерц. На таких кристаллах можно разместить целую систему со всеми ее характерными частями - процессором, памятью, интерфейсными схемами, обеспечив при этом высокую ее производительность. Подобные кристаллы относят к классу «система на кристалле» (в английской терминологии SOC, System On Chip или SOPC, System On Programmable Chip).
Стратегическая значимость решения задачи создания законченных систем на одном кристалле очевидна и вытекает из известных закономерностей зависимости качества цифровой аппаратуры от уровня интеграции ее элементной базы.
799
ПРОГРАММИРУЕМАЯ ЛОГИКА И ЕЕ ПРИМЕНЕНИЕ В МИКРОПРОЦЕССОРНЫХ СИСТЕМАХ
Реализация заказных систем на одном кристалле практически недоступна для подавляющего большинства пользователей по экономическим соображениям. СБИС программируемой логики позволяют ставить задачу создания систем на одном кристалле как задачу сегодняшнего дня. Соответствующие средства уже появились в составе продукции ряда фирм.
СБИС типа «система на кристалле» можно разделить на две разновидности. Первая разновидность реализуется схемами просто настолько «большими», что на них можно сконфигурировать целую систему, причем ее части (процессор, память, интерфейсные схемы и другие блоки) реализуются как мегафункции библиотеки кристалла или проектируются разработчиком и реализуются, в сущности, идентичными аппаратными средствами кристалла благодаря их программируемости. Такие СБИС ПЛ в английской терминологии иногда обозначают термином «generic».
Вторая разновидность - СБИС ПЛ блочного типа, в которых на кристалле выделяют специализированные области, предназначенные для выполнения определенных функций - аппаратные ядра (hardcores). Поскольку системы самого разного назначения в качестве составных частей имеют типовые модули, вопрос о целесообразности применения блочных структур СБИС ПЛ возник вполне закономерно.
Введение специализированных аппаратных ядер, имея ряд позитивных следствий, может в то же время сузить круг потребителей СБИС ПЛ, поскольку в сравнении со схемами типа «generic» схемы с аппаратными ядрами имеют меньшую универсальность.
Реализация сложных функций специализированными аппаратными ядрами по площади кристалла и достижимому быстродействию значительно эффективнее в сравнении с реализациями на конфигурируемых логических блоках общего назначения. Например, для умножителя 8x8, построенного по модифицированному алгоритму Бута методом заказного проектирования, потребовалась площадь кристалла в пять раз меньшая, чем для такого же умножителя, реализованного на реконфигурируемых логических блоках FPGA. Заметно выше было и быстродействие умножителя, реализованного в виде специализированной схемы.
Таким образом, введение специализированных аппаратных ядер в СБИС ПЛ - процесс, противоречивый по результатам. Он улучшает параметры схем, воспроизводящих сложные функции, но может и сузить рынок сбыта СБИС ПЛ, что, как известно, ведет к росту цен и потере в той или иной мере конкурентоспособности продукции. В связи с этим к выбору применяемых аппаратных ядер следует относиться с большой осторожностью. Наиболее бесспорным решением является применение аппаратных ядер памяти, так как блоки памяти нужны почти для всех систем, причем для многих в большом объеме. Для эффективного использования таких ядер целесообразно применять не слишком крупные блоки, обеспечивать возможность иметь асинхронный и синхронный режимы работы, организовывать буферы FIFO и двухпортовую память. В среднем блок памяти с заказным проектированием емкостью 256-512 бит может быть реализован на площади, приблизительно равной 1/10 от той, которая затрачивается на подобный блок, составленный из распределенных на кристалле ячеек памяти конфигурации. Времена доступа также уменьшаются (в 1,5—4 раза).
Области памяти - первые по времени освоения и самые важные аппаратные ядра блочных СБИС ПЛ типа «система на кристалле».
Других хорошо обоснованных аппаратных ядер не так уж много. Среди них можно назвать схемы быстродействующих умножителей и схемы интерфейса JTAG, которые выполняют важные функции, нужные очень многим потребителям. По-видимому, самыми сложными из практически разработанных ядер являются контроллеры шины PCI, также необходимые в очень многих проектах и требующие максимального быстродействия.
800
СБИС ПРОГРАММИРУЕМОЙ ЛОГИКИ ТИПА «СИСТЕМА НА КРИСТАЛЛЕ»
7.7.2. СБИС ПЛ С КОНФИГУРИРУЕМОСТЬЮ ВСЕХ ОБЛАСТЕЙ КРИСТАЛЛА
К СБИС ПЛ с конфигурируемостью всех областей кристалла (типа «generic») принадлежат СБИС АРЕХ20К, АРЕХ20КЕ фирмы «Altera», Virtex и VirtexE фирмы «Xilinx», Ultra39K фирмы «Cypress Semiconductor», QL фирмы «QuickLogic», ProASIC500K фирмы «Actel», PSD фирмы WSI и др.
СБИС ПЛ АРЕХ20К/КЕ имеют уровень интеграции до более чем 2,5 млн системных вентилей и архитектуру комбинированного типа, называемую Multicore. В них комбинируются табличные методы реализации функций и реализации их в ДНФ, имеются встроенные блоки памяти и гибкая система межсоединений. Сочетая достоинства FPGA и CPLD, семейства с комбинированной архитектурой и высоким уровнем интеграции, в том числе и АРЕХ20К/КЕ, пригодны для решения как задач с интенсивными вычислениями, так и для реализации сложных логических контроллеров и других быстродействующих автоматов. На момент своего появления микросхемы АРЕХ20К/КЕ, которые были объявлены фирмой как первые промышленные СБИС ПЛ с интеграцией уровня SOPC, отличались и наибольшим объемом встроенной памяти (ядра ЗУ), составлявшим от 26 до 264 Кбит для разных представителей семейства при общих ресурсах памяти от 54 до 540 Кбит. Сложность микросхем характеризовалась числом системных вентилей от 162 К до 2,4 М. В первой половине 2000 г. появилось новое семейство фирмы «Altera» -АСЕХ, являющееся более дешевой версией семейства АРЕХ20К/КЕ с числом системных вентилей от 10 до 100 К и рабочей частотой 160 МГц. Ценой микросхем семейства АСЕХ считают 1 долл, за 5К вентилей.
Ядро ЗУ в микросхемах семейства АРЕХ20К/КЕ состоит из блоков ESB (Embedded System Blocks) по 2 Кбита в каждом, число блоков составляет от 26 у младших представителей семейства до 264 у старших. Блоки могут работать независимо с вариантами организации 128 х 16, 256 х 8, 512 х4, 1024 х 2, 2048 х 1 или соединяться с другими для образования более емкой памяти. Вместе со схемами близлежащих логических блоков ESB могут образовывать блоки SRAM, буферы FIFO, двухпортовую память, а в некоторых микросхемах возможна и организация ассоциативной памяти САМ (Content Addressable Memory). Память типа САМ используется в системах коммуникаций, и ее наличие открывает много новых применений для микросхем.
Архитектура микросхем семейств АРЕХ20К/КЕ (рис. 7.27) характеризуется наличием трех типов структур: 1) табличных функциональных преобразователей типа LUT, заимствованных от семейства FLEX10K и FLEX6000; 2) блоков типа SOP (Sum Of Products) для воспроизведения ДНФ логических функций, заимствованных от микросхем семейства МАХ7000; 3) блоков встроенной памяти от микросхем FLEX10KE.
Архитектура Multicore включает в себя новый уровень иерархии, называемый MegaLAB. Каждый MegaLAB составлен из 16 логических блоков LABs, каждый из которых, в свою очередь, содержит по 10 логических элементов LE, и встроенной структуры ESB. На уровне MegaLAB реализованы локальные межсоединения без использования глобальных ресурсов коммутации. Между структурами MegaLAB и контактами ввода/вывода сигналы распространяются по непрерывным связям FastTrack, вносящим малые и предсказуемые задержки.
Блоки ввода/вывода БВВ (lOEs) позволяют работать со многими стандартами сигналов интерфейса: LVTTL; LVCMOS; 1.8-VI/O; 2,5-VI/O; 3,3-VI/O;3,3-VPCI; 3.3AGP; LVDS; GTL+; СТТ; SSTL-3 I,II; STTL-2 I,II.
В состав современных СБИС ПЛ высокого уровня интеграции, как правило, включаются блоки, управляющие фазовыми соотношениями между синхросигналами в разных точках схемы. Одним из названий подобных блоков является PLL (Phase Locked Loop). В микросхемах семейства АРЕХ20К/КЕ такие блоки усовершенствованы отно-
801
ПРОГРАММИРУЕМАЯ ЛОГИКА И ЕЕ ПРИМЕНЕНИЕ В МИКРОПРОЦЕССОРНЫХ СИСТЕМАХ
Рис. 7.27. Архитектура микросхем семейства АРЕХ20К/КЕ
сительно своих предшественников и выполняют функции ClockLock, ClockBoost и ClockShift. Первая из этих функций снижает задержки контролируемых синхросигналов относительно опорных, вторая состоит в делении или умножении частот синхросигналов, а третья программирует фазовые сдвиги между контролируемыми синхросигналами. Наличие перечисленных возможностей позволяет существенно повысить тактовые частоты реализуемых устройств без нарушения их работоспособности по сравнению с вариантами без блоков PLL.
Каждый внешний вывод микросхем связан с блоком ввода/вывода (БВВ или IOE). Блоки ввода/вывода расположены в концах строк и столбцов шин быстрых связей (FastTracks), которые проходят по всей длине или ширине схемы. Каждый БВВ содержит двунаправленный буфер и триггер (регистр), который может быть входным, выходным или входить в состав двунаправленной линии. БВВ обеспечивает поддержку интерфейса JTAG с возможностями периферийного сканирования для тестирования и конфигурирования микросхемы, имеет управляемую крутизну фронтов, формируемых буферами сигналов, и управление третьими состояниями буферов. Имеется опция Турбо-бита, т. е. его программирование на быстрый или экономичный режим работы схемы.
Микросхемы семейства APEX выпускаются в вариантах с напряжением питания 2,5 В (вариант 20К) и 1,8 В (вариант 20КЕ). При этом напряжения питания для периферийных элементов, обеспечивающих передачу сигналов во внешние цепи, могут составлять 1,8; 2,5 или 3,3 В.
Семейства СБИС ПЛ Virtex и VirtexE фирмы «Xilinx» - FPGA с триггерной памятью конфигурации (SRAM-based), заявленные фирмой как «истинные программируемые системы на кристалле». Семейство Virtex с напряжением питания 2,5 В выпущено в конце 1998 г., семейство VirtexE с напряжением питания 1,8 В и более высоким уровнем интеграции - несколько позднее. Оба семейства имеют мегавентильный уровень интеграции, блоки встроенной памяти большой емкости и работают на системной частоте до 200 МГц. Основные технологические параметры: минимальный технологический размер 802
СБИС ПРОГРАММИРУЕМОЙ ЛОГИКИ ТИПА «СИСТЕМА НА КРИСТАЛЛЕ»
Рис. 7.28. Архитектура микросхем семейств Virtex и VirtexE
0,22 мкм, пять слоев металлизации. Число пользовательских выводов у корпусов микросхем для разных представителей семейства составляет от 180 до 804. Эффективная система межсоединений согласно данным фирмы, обеспечивает достижимый процент использования вентилей до 90 даже в сложных проектах. Линии ввода/вывода программиру
ются на 15 стандартов интерфейсных сигналов. Реализуется интерфейс для шины PCI, работающей на частотах 33 или 66 Мгц.
Общий план кристаллов микросхем Virtex и VirtexE показан на рис. 7.28. Сердцевина схемы - матрица блоков, основу которых составляют конфигурируемые логические блоки КЛБ (CLB, Configurable Logic Blocks) и переключательные блоки ПБ (GRM, Global Routing Matrix). В совокупности КЛБ и ПБ составляют так называемый VersaBlock. Переключательный блок содержит набор программируемых ключей на пересечениях горизонтальных и вертикальных линий каналов трассировки, таким образом, VersaBlock имеет как средства логической обработки данных, так и средства локальной трассировки, обеспечивающие коммутацию КЛБ (рис. 7.29). Как видно из рисунка, VersaBlock обеспечивает связи трех типов: 1) межсоединения в составе КЛБ и между КЛБ и ПБ; 2) внутренние обратные связи для КЛБ, позволяющие подавать выходные сигналы КЛБ к табличным функциональным преобразователям этого же КЛБ с малыми задержками; 3) прямые связи, соединяющие горизонтально-смежные КЛБ без использования ПБ, что ускоряет передачу сигналов.
К соседнему ПБ
с соседними КЛБ
Рис. 7.29. Схема блока VersaBlock семейств Virtex и VirtexE
ПРОГРАММИРУЕМАЯ ЛОГИКА И ЕЕ ПРИМЕНЕНИЕ В МИКРОПРОЦЕССОРНЫХ СИСТЕМАХ
Иерархическая система межсоединений семейств Virtex и VirtexE сохранила многие черты, традиционные для фирмы «Xilinx», но имеет и своеобразные особенности, в частности, систему коммутации, названную VersaRing, дающую дополнительные возможности межсоединений в периферийной области кристалла. Благодаря этой системе облегчается взаимозаменяемость выводов микросхемы и их размещения по тем или иным цепям конфигурируемой схемы. Такие возможности могут обеспечивать сохранение прежних печатных плат при модификациях внутренней структуры СБИС.
На периферии кристалла располагаются блоки ввода/вывода (lOBs), а в углах - схемы DDL (Digital Delay Loops), назначение и функционирование которых аналогичны рассмотренным для блоков PLL семейства АРЕХ20К/КЕ несмотря на иное название блоков.
Блоки ввода/вывода имеют и тракт ввода, и тракт вывода сигнала, так что подключенные к ним контактные площадки могут быть использованы как входы или выходы в зависимости от программирования блока (рис. 7.30). Через тракт ввода входные сигналы передаются во внутренние цепи микросхемы либо непосредственно, либо с запоминанием триггером, тип которого можно выбрать из числа возможных вариантов (управляемый фронтом, защелка). В цепь информационного входа триггера включен программируемый элемент задержки, который при необходимости позволяет исключить нарушение условий предустановки или выдержки сигналов, соблюдение которых обеспечивает работоспособность схемы.
Тракт вывода содержит буфер с третьим состоянием, выводящий сигналы на контактную площадку КП. Выходные сигналы могут быть поданы на вход буфера непосредственно от комбинационных цепей выработки логических функций или через триггер, тип которого также может быть выбран из числа имеющихся вариантов. Управление третьим состоянием может осуществляться как от комбинационных логических схем, так и через триггер, который обеспечивает синхронизацию сигналов разрешения или запрещения буфера.
Рис. 7.30. Схема блоков ввода/вывода семейств Virtex и VirtexE
804
СБИС ПРОГРАММИРУЕМОЙ ЛОГИКИ ТИПА «СИСТЕМА НА КРИСТАЛЛЕ»
Блоки ввода/вывода могут обеспечивать интерфейс шины PCI с частотой до 66 Мгц.
Блоки ввода/вывода семейств Virtex и VirtexE способны воспринимать и вырабатывать сигналы, отвечающие широкому спектру стандартов на интерфейс: LVTL; LVCMOS2; PCI3.3V; PCI5.0V; GTL; GTL+; HSTL 1,11,111; SSTL3 1,11; SSTL21,11; СТТ; AGP. Для конфигурации буферов, соответствующей тому или иному стандарту, в некоторых случаях требуются определенные значения двух внешних напряжений: VCCO и VREF. Входной буфер воспринимает пороговое напряжение VREF. Уровень сигнала логической единицы для большинства стандартов интерфейса зависит от напряжения VCCO. Оба напряжения задаются на контактах микросхемы и обслуживают группу блоков ввода/вывода, называемую банком. Для всех БВВ данного банка напряжения идентичны, поэтому существуют ограничения на стандарты интерфейса у близко расположенных контактов. Внутри банка могут быть и разные стандарты интерфейса, если они требуют одних и тех же напряжений VCCO и VREF. В качестве входных для напряжений VREF могут быть запрограммированы определенные пользователем внешние выводы. В микросхемах Virtex и VirtexE организовано по восемь банков (по два на каждую сторону кристалла).
Основой конфигурируемого логического блока КЛБ семейств Virtex и VirtexE (рис. 7.31) являются четыре логические ячейки ЛЯ (LCs, Logic Cells). В каждой логической ячейке имеется четырех входовый функциональный преобразователь табличного типа LUT, логические схемы переноса и управления и триггер (регистр) типа D. КЛБ делится на две идентичные секции (Slice 1 и Slice 2), схема одной из секций раскрыта на рисунке. Величины G1-G4 и F1-F4-это аргументы функций Y иХ, вырабатываемых преобразователями LUT. Выходные сигналы от преобразователей могут передаваться прямо на выход КЛБ или на вход триггера типа D. Имеющиеся в логических ячейках специальные логические схемы позволяют комбинировать выходы нескольких функциональных преобразователей для получения любых функций пяти и шести аргументов и некоторых функций большего числа аргументов, а также мультиплексоров размерностью до 8 - 1.
Рис. 7.31. Схема конфигурируемого логического блока микросхем семейств Virtex и VirtexE
805
ПРОГРАММИРУЕМАЯ ЛОГИКА И ЕЕ ПРИМЕНЕНИЕ В МИКРОПРОЦЕССОРНЫХ СИСТЕМАХ
Ресурсы памяти функциональных преобразователей секции можно использовать как синхронную статическую память SRAM с организацией 16x2 или 32 х 1 или как двухпортовую синхронную SRAM с организацией 16x1 или для образования 16-разрядного регистра сдвига.
Специальные логические схемы выработки сигналов переноса упрощают и ускоряют воспроизведение арифметических функций. Ресурсы одной ЛЯ позволяют реализовать в ней схему разряда полного сумматора. Предусмотрены и специальные логические элементы для построения из ЛЯ множительных устройств.
Триггер типа D программируется в вариантах управления фронтом или защелки. Информационный вход триггера подключается к выходам функциональных преобразователей или же прямо ко входам секций (входы BY, ВХ). Помимо сигналов Clock и Clock Enable каждая секция имеет синхронные сигналы сброса и установки триггеров.
В каждом КЛБ имеются два буфера с третьим состоянием, способные работать на внешние шины.
При работе микросхем большинство сигналов передается через основную систему межсоединений (General Purpose Routing). Линии связей этой системы расположены в горизонтальном и вертикальном каналах трассировки между строками и столбцами КЛБ. Ресурсы этой системы следующие.
• Переключательный блок у каждого КЛБ, обеспечивающий ему доступ к трассам основной системы межсоединений.
• По 24 линии передач сигналов от ПБ к соседним ПБ в каждом из четырех направлений.
• 96 буферированных линий передач сигналов между ПБ от одного к другому через шесть блоков в каждом из четырех направлений. Сигналы поступают на эти линии только в их концах и доступны в концах линий или в их серединах (на расстоянии трех блоков от источника). Треть этих линий двунаправленные, остальные однонаправленные.
• 12 длинных линий, буферированных, двунаправленных, передающих сигналы по всей схеме (по всей высоте или ширине кристалла) с малыми задержками.
Кроме системы основных соединений микросхемы имеют ресурсы VersaRing, о которых уже говорилось, а также глобальные и специальные ресурсы. Глобальные ресурсы используются для распределения синхросигналов и других сигналов, поступающих на большое число приемников, а специальные - для распространения сигналов переноса и т. п.
Микросхемы семейств Virtex и VirtexE воспринимают все команды, специфицированные в стандарте IEEE 1149.1 интерфейса JTAG.
7.7.3. СБИС ПЛ КЛАССА «СИСТЕМА НА КРИСТАЛЛЕ» С БЛОЧНОЙ АРХИТЕКТУРОЙ
В СБИС ПЛ класса «система на кристалле» с блочной архитектурой выделяются специализированные области (аппаратные ядра), проектируемые методами заказных схем. Достоинства и недостатки применения блочных архитектур обсуждались ранее, в п. 7.7.1. По субъективному мнению авторов, использование микросхем с блочной архитектурой является весьма перспективным направлением.
Первые объявленные СБИС, в которых процессор, память и FPGA размещены на одном кристалле - семейство FPSLIC (Field Programmable System Level Integration Chips) фирмы «Atmel», одной из крупных фирм-разработчиков цифровых микросхем, в том числе микросхем программируемой логики. До появления семейства FPSLIC, выход которого на рынок датируется серединой 2000 г., фирмой «Atmel» были разработаны хорошо известные процессоры AVR и FPGA семейства АТ40К. В микросхемах семейства FPSLIC 806
СБИС ПРОГРАММИРУЕМОЙ ЛОГИКИ ТИПА «СИСТЕМА НА КРИСТАЛЛЕ»
как раз и совмещены процессорное ядро AVR, FPGA типа АТ40К и блоки статической памяти SRAM. Такая «комплектация» соответствует возможностям построения системы на кристалле. При закреплении функций процессора и памяти за соответствующими ядрами на программируемую логику возлагаются все остальные функции, необходимые для построения системы (например, функции управления памятью и/или внешними устройствами, создание проблемно-ориентированных сопроцессоров, реализация интерфейсных функций тех или иных шин и т. д.). В СБИС FPSLIC FPGA рассматривается как «большое внешнее устройство» с разнообразными заказными или общеупотребительными функциями, к которому процессор обращается для выдачи ему команд и исходных данных и получения результатов.
На рис. 7.32 представлена обобщенная структура микросхем семейства FPSLIC. Микросхемы имеют напряжение питания 3,3 В, изготовляются технологическими процессами с топологической нормой 0,35 мкм, имеют несколько режимов пониженного энергопотребления.
AVR - 8-разрядное процессорное ядро производительностью более 30 MIPS (при тактовой частоте 40 Мгц) с RISC-архитектурой, имеющее систему команд, содержащую около 120 инструкций. Особенностями микроконтроллера с ядром AVR в первую очередь являются выполнение команд, извлекаемых непосредственно из статической памяти SRAM, что значительно ускоряет работу микроконтроллера, и наличие в АЛУ умножителя MPL для аппаратной реализации операции умножения, широко используемой в процессах цифровой обработки сигналов (ЦОС). Архитектура AVR оптимизирована для разработки приложений на языке С, ядро имеет регистровый файл из 32 регистров.
Рис. 7.32. Обобщенная структура микросхем семейства FPSLIC
807
ПРОГРАММИРУЕМАЯ ЛОГИКАИ ЕЕ ПРИМЕНЕНИЕ В МИКРОПРОЦЕССОРНЫХ СИСТЕМАХ
С ядром AVR связан ряд устройств, характерных для микроконтроллеров: два универсальных асинхронных программируемых связных адаптера (UARTs), два 8-разрядных и один 16-разрядный таймер-счетчик, два программируемых порта ввода/вывода. Дополнительно введен специальный аппаратный интерфейс 12С для обеспечения связи с внешней энергонезависимой памятью типа EEPROM, используемой для конфигурирования микросхем FPSLIC.
Блок статической памяти общей емкостью 36 Кбайт - двухпортовая память с временем доступа 15 нс содержит фиксированные области памяти программ (с организацией ЮК х 16) и памяти данных (с организацией 4К х 8) и, кроме того, область, которую при конфигурации схемы можно по желанию разработчика полностью или частями добавить к памяти программ или к памяти данных. Предписание по использованию не фиксированной области памяти содержится в специальном регистре конфигурации в контроллере памяти микросхемы (Memory Controller).
В блоке FPGA используются стандартные структуры микросхем АТ40К, работающие на системной частоте 100 Мгц, сложностью от 10 до 40К используемых эквивалентных вентилей с емкостью встроенной памяти от 2048 до 18 432 бит. В основных чертах эти структуры типичны для FPGA, хотя и имеют некоторые оригинальные особенности (рис. 7.33). Основа блока - симметричная матрица идентичных логических ячеек, в каждую из которых входят несколько программируемых мультиплексоров, триггер типа D, буфер с тремя состояниями и два табличных функциональных преобразователя (LUT). Функциональные преобразователи воспроизводят функции трех переменных (одних и тех же для обоих преобразователей) и могут быть объединены для выработки любых функций четырех переменных. Для логических ячеек предусмотрены несколько стандартных режимов (конфигураций), а именно следующие:
• реализации функций одноразрядного сумматора (арифметический режим);
• выполнения операции умножения (режим DSP/Multiplier);
• реализации разряда счетчика;
• выполнения функций мультиплексоров с буферами на три состояния (режим Тristate/MUX).
Рис. 7.33. Структура FPGA, используемой в микросхемах семейства FPSLIC
808
СБИС ПРОГРАММИРУЕМОЙ ЛОГИКИ ТИПА «СИСТЕМА НА КРИСТАЛЛЕ:
Перечисленные режимы, как видно, ориентированы на проекты с интенсивными вычислениями, такие как реализация цифровых фильтров, быстрых преобразований Фурье, конвольверов, криптографических алгоритмов и многих других мультимедийных задач. На основе блока FPGA реализуются и общеупотребительные интерфейсные функции (UARTs, PCI и др.).
Топологически логическая ячейка трактуется как восьмиугольник и с восемью ближайшими соседями она имеет прямые связи (Direct Connects), проходящие по матрице ячеек в ортогональных и диагональных направлениях. Благодаря прямым связям, в частности, строятся ультрабыстродействующие матричные множительные устройства.
Массив FPGA имеет шесть внешних и две внутренних линии тактирования. Для внутренних линий тактирования источником сигналов служит ядро AVR, причем одна из этих линий принадлежит системной линии тактирования микроконтроллера, а вторая может быть запрограммирована на соединение с одним из нескольких источников тактовых сигналов, генерируемых внутри AVR (таймеров и др.).
Ядро АТ40К имеет свою статическую память, называемую FreeRam. Время доступа к данным этой памяти составляет 10 нс. Благодаря наличию FreeRAM функции памяти в создаваемых на основе FPGA устройствах реализуются без затрат логических ресурсов FPGA. Возможны различные варианты организации памяти FreeRAM: синхронный или асинхронный, одно- или двухпортовый для RAM, FIFO и др. Варианты организации создаются инструментальными средствами макрогенерации функций.
Система межсоединений элементов FPGA иерархична и включает в себя локальные шины и экспресс-шины. С восемью ближайшими соседями, как уже отмечалось, логические ячейки имеют прямые связи. Сегменты локальных шин покрывают расстояния в четыре ячейки, экспресс-шин - в восемь. Шины соединяются через повторители (Repeaters), подключаемые к двум соседним сегментам. Повторители регенерируют сигналы и выполняют также некоторые функции их коммутации. В системе межсоединений используются программируемые пасс-вентили (Pass gates), с помощью которых формируются шины с тремя состояниями.
Интерфейс FPGA с ядром AVR предусматривает для FPGA 16 входных линий декодированного адреса от AVR, 16 выходных линий запросов прерываний с различными приоритетами для AVR. Таким образом, каждому устройству, реализованному в FPGA и имеющему адрес в адресном пространстве ввода/вывода AVR, придается возможность иметь собственный запрос прерывания.
Кроме того, AVR определяет направление передачи данных, посылая для FPGA сигналы стробов чтения и записи. Эти сигналы управляют двунаправленной шиной данных, образуемой из линий Express Lines системы межсоединений FPGA. Таким образом, ядро микроконтроллера взаимодействует с устройствами, созданными в FPGA, принципиально подобно тому, как обычно процессор взаимодействует с внешними устройствами.
Для функций заказной периферии, реализуемой в FPGA, существует макробиблиотека, что существенно упрощает проектирование. Автоматическая генерация макросов, которую способна выполнять FPGA АТ40К, минимизирует также риски проектирования, так как дает возможность пользоваться уже хорошо проверенными схемными решениями.
Другой аспект взаимодействия AVR и FPGA состоит в том, что они имеют общий доступ к двухпортовой памяти SRAM с временем доступа 15 нс (рис. 7.34). Между FPGA и AVR размещены 36 Кбайт этой памяти, которая в первую очередь используется микроконтроллером, подсоединенным к одному из портов, для хранения команд и данных. Порт, подсоединенный к FPGA, используется во время загрузки конфигурации, чтобы загрузить память программ и память данных микроконтроллера. FPGA может обращаться к SRAM одновременное AVR. Разделяемая память позволяет реализовать различные варианты буферного обмена между FPGA и AVR (буферы FIFO, LIFO или др.).
809
ПРОГРАММИРУЕМАЯ ЛОГИКА И ЕЕ ПРИМЕНЕНИЕ В МИКРОПРОЦЕССОРНЫХ СИСТЕМАХ
Рис. 7.34. Использование внутренней памяти ядрами FPGA и AVR микросхем семейства FPSLIC
У порта SRAM, подключенного к FPGA, нет сигнала разрешения чтения, т. е. чтение данных для FPGA всегда разрешено. Для предотвращения конфликтов при обращениях FPGA и AVR в одно и то же время к одному и тому же адресу требуется позаботиться о логике арбитража (чаще всего специальный управляющий регистр микроконтроллера при необходимости ограничивает доступ к памяти со стороны FPGA).
Важная особенность микросхем семейства FPLIC - способность реализовать концепцию кэш-логики (Cache Logic), впервые введенную фирмой «Atmel». Понятие кэш-логики отражает достижения в области развития адаптивных систем. Кэш-логика позволяет производить полное или частичное реконфигурирование системы «на лету», без потери имевшихся данных и нарушения работы неизменяемой части устройств. Сохраняются данные, которые были получены к моменту перестройки той или иной части системы. Та часть аппаратуры, в которой в данный момент происходит обработка информации, представлена схемой соответствующей конфигурации в FPGA, а пассивная часть системы представлена данными, сохраняемыми в недорогих устройствах памяти. В результате экономно выполняются логические преобразования. Когда активизируются новые операции, новая конфигурация записывается «поверх старой».
Та или иная решаемая задача может быть разложена на множество операций низшего иерархического уровня, таких как сдвиг, счет, сложение, умножение, мультиплексирование и т. д. Ясно, что каждая из подобных функций может быть использована многократно в разных ситуациях, причем в каждый момент времени активна только малая часть функций. Исключая избыточность и контролируя условия появления каждой операции, можно так организовать систему, что сложные функции будут воспроизводиться с помощью небольшого числа несложных и, следовательно, дешевых схем программируемой логики. В одном из примеров требуемая задача решалась обычным способом с помощью 10 000 вентилей, а применение кэш-логики позволило применить микросхему программируемой логики сложностью всего 2000 эквивалентных вентилей, причем остальные 8000 вентилей удалось исключить, используя «кэширование», т. е. запоминание неизменной в данное время информации в более дешевой системной памяти.
Концептуально выделяют предопределенную (predermined) и динамическую кэш-логику. Первая подразумевает использование предопределенных функций и макросов, хранимых во внешней энергонезависимой памяти (EPROM, EEPROM, диск, CD-ROM). Эти функции уже проработаны, размещены и трассированы и имеют ранее сгенерированные битовые потоки (Bit streams) конфигурирования. Выполнением их управляют средства самой кэш-логики или внешние средства (программы процессора). При загрузке новых функций данные в регистрах не теряются даже в модифицируемой части системы.
Второй тип кэш-логики подразумевает определение требуемых функций, размещение и трассировку схем их реализации и генерацию битовых потоков настройки програм
810
КОНФИГУРИРОВАНИЕ БИС/СБИС ПРОГРАММИРУЕМОЙ ЛОГИКИ
мируемой логики в реальном масштабе времени. Такая кэш-логика ассоциируется с разработкой адаптивных систем и в настоящее время существует лишь как концепция, еще не имеющая законченной физической реализации.
Применение кэш-логики снижает сложность программируемой части аппаратуры и, в конечном счете, удешевляет аппаратуру и улучшает такие ее характеристики, как надежность (вследствие уменьшения числа физически существующих схемных компонентов), потребляемую мощность и др. Область перспективного применения кэш-логики достаточно широка: это портативная аппаратура с ее высокими требованиями к снижению потребляемой мощности и габаритных размеров, системы с интенсивными вычислениями (компьютерная графика, распознавание образов и речи и многое другое).
Микросхемы семейства FPSLIC имеют механизм конфигурирования FPGA под управлением AVR, который может загружать кэшевую память FPGA, имея прямой доступ к шине данных SRAM-конфигурации. При обычной загрузке конфигурации кэшевый доступ в память конфигурации блокируется. При кэшевом доступе AVR использует три регистра для формирования адреса и один регистр для данных. Типовое назначение этого режима для AVR - принять последовательные данные через UART и направить их в качестве данных конфигурации в FPGA, вызывая таким образом загрузку или разрешая системную реконфигурацию, при которой структура FPGA алгоритмически видоизменяется.
Разработчики таких сложных СБИС, как FPSLIC, подчеркивают, что подобные микросхемы с их впечатляющими возможностями не следует рассматривать как просто микроконтроллеры с программируемой проектировщиком периферией, поскольку для этой относительно ограниченной цели могут найтись более простые решения (например, с применением микросхем программируемой пользователем периферии фирмы WSI). С точки зрения технико-экономических показателей, эффект достигается в первую очередь при достаточно полном использовании новых функциональных возможностей, присущих такой качественно новой продукции как микросхемы семейства FPSLIC и им подобные [уже объявлено о выпуске блочных СБИС типа «система на кристалле» фирмой «Тriscend» (Triscend Е5, Configurable System-on-Chip) ожидаются подобные разработки и от фирмы «Altera» и других].
7.8. КОНФИГУРИРОВАНИЕ БИС/СБИС ПРОГРАММИРУЕМОЙ ЛОГИКИ
Способ конфигурирования БИС/СБИС ПЛ, т. е. настройки их на определенный алгоритм функционирования, зависит от типа программируемых элементов. Для микросхем с энергонезависимой памятью конфигурации (EPROM, EEPROM, Flash) запись в память является специальным с точки зрения электрических процессов режимом. Конфигурирование таких СБИС может производиться вне создаваемой системы с помощью программаторов или же в составе системы (т. е. при сохранении монтажа микросхемы на плате), но также с использованием специальных устройств, выпускаемых фирмами-производителями, и, как правило, посредством расширенного интерфейса JTAG. При этом для процессов записи информации требуются повышенные напряжения программирования Unp (для микросхем семейств МАХ7000 и МАХ9000 фирмы «Altera», например, это 12 В при рабочем напряжении питания 5 В). Для старых микросхем требовались несколько источников питания, более новые стали снабжаться внутренними преобразователями рабочего напряжения в повышенное напряжение программирования.
Для БИС/СБИС ПЛ со статической памятью конфигурации ее загрузка не требует каких-либо специальных электрических режимов и процесс конфигурирования состоит в передаче в микросхему информации, необходимой для получения требуемых соедине
811
ПРОГРАММИРУЕМАЯ ЛОГИКА И ЕЕ ПРИМЕНЕНИЕ В МИКРОПРОЦЕССОРНЫХ СИСТЕМАХ
ний в логических блоках, блоках ввода/вывода и подключения их к трассам межсоединений (локальным и глобальным матрицам межсоединений, системам основных и прямых связей, длинным линиям и т. д.). Операция конфигурирования выполняется после каждого выключения питания, причем обычно сам факт очередного включения питания автоматически инициирует процесс конфигурирования, который может повторяться неограниченное число раз. Отсутствие специальных электрических режимов для записи информации в память конфигурации обеспечивает возможность ее проведения в работающей схеме, причем возможна и частичная реконфигурация, относящаяся лишь к части системы.
Конфигурирование БИС/СБИС ПЛ со статической (триггерной) памятью конфигурации, о которой подробнее говорится ниже, представляет собою запись во внутренние регистры (триггеры) данных, задающих структуру блоков системы и их межсоединений. Каждый бит настроечных данных задает состояние соответствующему триггеру, управляющему программируемым ключом в схеме логического блока, программируемого мультиплексора, программируемого межсоединения и т. п.
БИС/СБИС ПЛ обычно имеет несколько возможных режимов конфигурирования (например, у FPGA ХС4000 фирмы «Xilinx» их шесть, у СБИС семейства Virtex той же фирмы четыре, у микросхем семейства Spartan - два). У способов конфигурирования микросхем разных фирм и разных типов много общего. Для конкретности рассмотрим способы конфигурирования СБИС ПЛ типа SOC семейства Virtex.
Для конфигурирования этой микросхемы используются как специализированные выводы, так и выводы, которые после завершения конфигурирования могут играть роль выводов общего назначения. К специализированным относятся выводы М2, М1, МО, на которых задается код того или иного режима, вывод для синхросигналов процесса конфигурирования, выводы PROGRAM, DONE и выводы периферийного сканирования TDI, TDO, TMS, ТСК. Вывод синхросигнала может быть выходом, когда этот сигнал генерируется микросхемой, или входом, когда поступает извне.
Возможные способы конфигурирования:
• пассивный последовательный (Slave-serial mode);
• активный последовательный (Master-serial mode);
• байт-поспедовательный (SelectMAP mode);
• периферийного сканирования.
В пассивном последовательном режиме микросхема получает данные конфигурирования в виде потока битов из последовательной памяти PROM или другого источника. Синхронизация осуществляется от внешнего источника, каждый положительный фронт синхросигнала вводит бит данных от входа DIN. Несколько микросхем могут быть соединены в цепочку для конфигурирования в едином процессе от общего потока битов. В этом случае после завершения конфигурирования очередной микросхемы данные конфигурации для следующих микросхем появляются на выводе DOUT микросхемы, завершившей конфигурирование.
В активном последовательном режиме выходной синхросигнал микросхемы подается на последовательное ЗУ, с которого на вход DIN микросхемы поступает последовательный поток битов конфигурации. Микросхема воспринимает каждый бит под управле-нием положительного фронта синхросигнала. После загрузки очередной микросхемы цепочки данные для следующей снимаются с выхода DOUT той микросхемы, которая ' закончила конфигурирование. Для синхронизации процесса можно выбирать частоту из широкого диапазона значений. По умолчанию используется наименьшая частота 2,5 МГц. ' Максимальная частота - 60 МГц. Устанавливаемые частоты, естественно, должны соответствовать возможностям используемых PROM и включенных в цепочку микросхем. При включении питания устанавливается частота 2,5 МГц. Если не поступит команда на изменение этого значения (опция ConfigRate в программе генерации битового потока конфигурации), процесс продолжится до конца на частоте 2,5 Мгц.
812
МЕТОДИКА ОЦЕНКИ ПАРАМЕТРОВ ИС ПЛ
В байт-последовательном режиме время конфигурирования минимально. Используется байт-последовательный поток данных, которые записываются в микросхему с учетом флажка ее готовности BUSY. Байтовый поток задается от внешнего источника, как и сигналы тактирования, разрешения работы CS и WRITE. В этом режиме данные могут и читаться. Если сигнал WRITE пассивен, то данные конфигурации читаются из микросхемы (этот процесс есть часть процесса Readback). В режиме SelectMAP также можно конфигурировать одновременно несколько микросхем, но в этом случае они включаются параллельно по входам синхронизации, данных, WRITE и BUSY. Загружаются микросхемы поочередно, путем соответствующего управления сигналами разрешения их работы CS.
В режиме периферийного сканирования конфигурирование осуществляется исключительно через выводы порта тестирования ТАР (Test Access Port) интерфейса JTAG. Используется специальная команда CFGJN, позволяющая входным данным от вывода TDI преобразовываться в пакеты данных для внутренней шины конфигурации микросхемы.
Процесс конфигурирования для микросхем Virtex содержит три этапа: очистка памяти конфигурации, загрузка в нее данных и активизация логических схем, участвующих в процессе.
Конфигурирование начинается автоматически после включения питания, но может быть и задержано пользователем с помощью сигнала PROGRAM, снятие которого запрещает конфигурирование. Завершение очистки памяти выявляется с помощью сигнала INIT, а завершение всего процесса - с помощью сигнала DONE.
Данные для загрузки памяти конфигурации формируются системой автоматизированного проектирования.
Реконфигурация в системе - одно из важнейших достоинств СБИС ПЛ, позволяющее легко изменять логику их работы. Потребности в изменениях возникают как для устранения не выявленных при первоначальном тестировании ошибок, так и для модернизации (Upgade) систем. Возможности программирования в системе растут, если при проектировании часть функциональных возможностей СБИС ПЛ оставлять свободной, имея запас по скорости, функциональным возможностям и ресурсам межсоединенй. При реконфигурации в системе должно сохраняться назначение внешних выводов, иначе потребуется изменить монтаж печатных плат.
Среди СБИС ПЛ имеются и такие, в которых реализованы одновременно триггерная и энергонезависимая память конфигурации. В этом случае конфигурирование СБИС ПЛ можно производить без внешних источников данных путем автоматической загрузки триггерной памяти из энергонезависимой.
7.9. МЕТОДИКА ОЦЕНКИ ПАРАМЕТРОВ ИС ПЛ
7.9.1. ВВОДНЫЕ ЗАМЕЧАНИЯ
Для системотехника, выбирающего ту или иную ИС ПЛ с целью применения в конкретных условиях, имеют значение многие параметры микросхемы.
К важнейшим техническим параметрам относятся следующие:
• уровень интеграции, характеризующий логические ресурсы микросхемы (предполагаем, что имеющимся блокам и элементам кристалла соответствуют и его трассировочные ресурсы);
• быстродействие, характеризуемое задержками сигналов в элементах и связях реализуемой схемы, а также предсказуемостью таких задержек;
• кратность программирования, определяемая типом программируемых элементов;
813
ПРОГРАММИРУЕМАЯ ЛОГИКА И ЕЕ ПРИМЕНЕНИЕ В МИКРОПРОЦЕССОРНЫХ СИСТЕМАХ
• архитектура, в частности, наличие или отсутствие в микросхеме специализированных областей памяти и других аппаратных ядер;
• коммерческое, индустриальное или военное исполнение (т. е. уровень допустимых воздействий со стороны внешней среды) и т. д.
Кроме указанных факторов важен и ряд других: наличие или отсутствие интерфейса JTAG и возможностей программирования в системе (ISP), совместимость со стандартными интерфейсами, количество и параметры режимов пониженной мощности, наличие или отсутствие средств засекречивания конфигурации реализованного проекта и др.
Важной экономической характеристикой ИС ПЛ является стоимость. Стремление снизить стоимость микросхем ПЛ постоянно подталкивает фирмы-производители к разработке новых модификаций, которая особенно интенсивно ведется в последнее время (семейство относительно простых CPLD фирмы «Altera» МАХ3000 и микросхем типа «система на кристалле» АСЕ той же фирмы, семейство FPGA ХС5200 фирмы «Xilinx» и др.).
Чрезвычайно важна обеспеченность проектирования на основе микросхем ПЛ средствами САПР. Разработкой соответствующих САПР заняты как фирмы-производители кристаллов, так и фирмы, специализирующиеся на создании САПР универсального типа, рассчитанных на проектирование систем на микросхемах многих производителей.
Способы оценки некоторых параметров микросхем ПЛ неоднозначны и требуют пояснений.
7.9.2. ОБ ОЦЕНКЕ СЛОЖНОСТИ МИКРОСХЕМ ПРОГРАММИРУЕМОЙ ЛОГИКИ
Уровень интеграции (Density) оценивается с использованием понятия «число эквивалентных вентилей». Указывается число таких вентилей (обычно вентилей 2И-НЕ) на кристалле. Однако объективная оценка сложности не так проста, как может показаться на первый взгляд, поскольку схемы ИС ПЛ отнюдь не состоят из простых вентилей и нельзя просто подсчитать их число в той или иной микросхеме. До некоторых пор даваемые изготовителями оценки сложности микросхем ПЛ получались по разным методикам, что вносило путаницу в задачи сравнительной оценки разных ИС ПЛ. Затем консорциум компаний под названием PREP (Programmable Electronics Performance Corporation) предложил подход к оценке сложности ИС ПЛ с помощью набора эталонных схем. Для измерения сложности кристалла каждая схема набора реализуется в нем в максимально возможном числе раз, что дает оценку числом размещающихся на кристалле эталонных схем. В качестве эталонных схем были выбраны более 10 типовых функциональных узлов (регистры, дешифраторы, счетчики и т. п.). Для эталонных схем известно число эквивалентных вентилей, необходимых для их реализации, что позволяет получить и оценку уровня интеграции ИС ПЛ в целом также числом эквивалентных вентилей. При этом методика PREP четко оговаривает условия измерений, использует усреднение данных по разным эталонным узлам и приводит к более или менее объективным оценкам сложности ИС ПЛ.
Тестовый набор PREP явился базой и для созданных другими авторами методик оценки сложности и быстродействия ИС ПЛ. Например, идея эталонных наборов схем использована в методике оценки сложности ИС ПЛ фирмы «Altera».
Сложность ИС ПЛ первых поколений характеризовалась обычно общим числом эквивалентных вентилей или числом пользовательских (usable) эквивалентных вентилей, так как не все элементы схемы кристалла могут быть использованы системотехником для реализации его проекта. В дальнейшем положение осложнилось в связи с появлением на кристалле специализированных областей памяти и других структурных неоднородностей. Возникли понятия числа логических вентилей для оценки сложности микросхемы без учета памяти и числа системных вентилей для оценки, учитывающей и об
814
МЕТОДИКА ОЦЕНКИ ПАРАМЕТРОВ ИС ПЛ
ласть памяти, сложность которой также пересчитана в число эквивалентных вентилей. Число эквивалентных вентилей, характеризующих логические ресурсы кристалла, часто задается диапазоном значений, так как конкретные числа существенно зависят от типа реализуемого проекта.
Из сказанного следует, что при рассмотрении параметра сложности ИС ПЛ нужно внимательно следить за тем смыслом, который вкладывается в данном конкретном случае в приводимый показатель «число эквивалентных вентилей».
7.9.3. ОБ ОЦЕНКЕ БЫСТРОДЕЙСТВИЯ МИКРОСХЕМ ПРОГРАММИРУЕМОЙ ЛОГИКИ
Быстродействие ИС ПЛ характеризуется либо задержками распространения сигналов по указанным путям, либо максимально возможными частотами их работы. Путями распространения сигналов, для которых задаются задержки, могут быть пути от любого входа до любого выхода (pin-to-pin, comer-to-corner,clock-to-pin), в качестве максимально возможных частот могут быть указаны частота работы счетного триггера fCNT или частота работы (тактирования) системы в целом, так называемая системная частота. Обычно системная частота приблизительно вдвое ниже, чем частота переключения счетного триггера.
Оценка быстродействия дается также с использованием параметра, называемого градацией быстродействия. Этот параметр входит в состав кода обозначения микросхемы в виде цифры, перед которой ставится дефис (-3,-4,-5 и т. д.). Цифра либо совпадает с округленным значением задержки распространения сигнала от входа к выходу схемы, либо отображает эту задержку условно (увеличивается с увеличением задержки, но численно с нею не совпадает).
Указание градаций быстродействия полезно для характеристики микросхем, принадлежащих к одному и тому же типу (семейству), но считается недостаточно точным для сравнения микросхем разной архитектуры. Для сравнения разнотипных ИС ПЛ полезнее оценивать тактовые частоты устойчивой работы типовых функциональных узлов, реализованных на этих микросхемах.
I
7.9.4. ПАРАМЕТРЫ ПОПУЛЯРНЫХ СЕМЕЙСТВ МИКРОСХЕМ ' ПРОГРАММИРУЕМОЙ ЛОГИКИ
Параметры ИС ПЛ быстро изменяются, новые их поколения изготовляются по все более совершенным технологиям и обновленным архитектурам. Поэтому конкретные численные данные быстро устаревают. Тем не менее для понимания уровня возможностей современных микросхем программируемой логики полезно иметь представление об их логических и скоростных возможностях. Ниже приводятся параметры семейств микросхем, выпускаемых фирмами «Altera» и «Xilinx», на долю которых приходится 70-80 % общего объема производства ИС ПЛ в мире. Нельзя отрицать ценность ряда разработок других фирм, однако рассматривать все разработки нецелесообразно и не входит в задачи учебника.
В составе продукции фирмы «Altera» имеются следующие семейства.
• Classic - относительно простые БИС ПЛ, использование которых позволяет заменить одним кристаллом устройства, содержащие один-два десятка микросхем среднего уровня интеграции при рабочих частотах до 100 Мгц.
• МАХ7000 - микросхемы этого семейства позволяют разместить на одном кристалле устройства, содержащие около 100 микросхем среднего уровня интеграции при рабочих частотах приблизительно до 180 Мгц. Технология программируемых элементов EEPROM. Подробные сведения о семействе МАХ7000 приведены в табл. 7.1.
815
ПРОГРАММИРУЕМАЯ ЛОГИКА И ЕЕ ПРИМЕНЕНИЕ В МИКРОПРОЦЕССОРНЫХ СИСТЕМАХ
• МАХ9000 - микросхемы семейства позволяют заменить одним кристаллом устройство, соответствующее десяткам плат с микросхемами среднего уровня интеграции при рабочих частотах до 125 Мгц. Технология программируемых элементов EEPROM. Параметры микросхем семейства приведены в табл. 7.1
• Все остальные семейства микросхем имеют технологию типа SRAM-based.
• FLEX8000 - эти микросхемы позволяют заменять устройства на десятках плат с ИС среднего уровня интеграции при частоте работы приблизительно до 290 Мгц.
• FLEX10K - микросхемы семейства заменяют устройства с сотнями плат, содержащих ИС среднего уровня интеграции при частоте работы до 450 Мгц. Параметры микросхем семейства приведены в табл. 7.2.
• АРЕХ20К/КЕ и ее версия пониженной стоимости АСЕ - микросхемы типа «система на кристалле», сведения о которых приведены в табл. 7.3.
В составе продукции фирмы «Xilinx» имеются следующие семейства микросхем с технологией типа SRAM-based (за исключением микросхем семейства ХС9500).
• ХС3000 и ХС5200 - относительно простые СБИС ПЛ невысокой стоимости с системными частотами 50-85 Мгц.
• ХС4000 - микросхемы значительно большей сложности и быстродействия с системными частотами около 80 МГц. Параметры микросхем этого семейства приведены в табл. 7.4.
• ХС9500 - микросхемы типа CPLD с программируемыми элементами типа FLASH невысокой стоимости и высокого быстродействия с системной частотой до 200 Мгц.
• Spartan и Spartan 2 - микросхемы, предоставляющие хорошие возможности создания устройств сложностью до 40 тысяч эквивалентных вентилей с системной частотой до 80 Мгц.
• Virtex и VirtexE - микросхемы типа «система на кристалле» с системными частотами до 200 МГц. Параметры микросхем семейства приведены в табл. 7.5.
Таблица 7. Г
Основные параметры СБИС семейства МАХ фирмы «Altera»
Семейство Число макроячеек Число вентилей, тыс. Число контактов входов/выходов Градации скорости Напряжение питания, В
МАХ 7000
ЕРМ7032 S 32 0,6 36 -5, -6, -7, -10 5,0
ЕРМ7032 АЕ 32 0,6 36 -4, -7, -10 3,3
ЕРМ7032 В 32 0,6 36 -3, -5, -7 2,5
ЕРМ7064 S 64 1,25 36-68 -5, -6, -7, -10 5,0
ЕРМ7064 АЕ 64 1,25 36-68 -4, -7, -10 3,3
ЕРМ7064 В 64 1,25 36-68 -3, -5, -7 2,5
ЕРМ7128 S 128 2,5 68-100 -6, -7, -10, -15 5,0
ЕРМ7128 А 128 2,5 68-100 -6, -7, -10, -12 3,3
ЕРМ7160 S 160 3,2 64-104 -7, -10, -15 5,0
ЕРМ7192 S 192 3,75 124 -7, -10, -15 5,0
ЕРМ7256 S 256 5 164 -7, -10, -15 5,0
ЕРМ7256 А 256 5 84-164 -7, -10, -12 3,3
ЕРМ7256 АЕ 256 5 84-164 -5, -7, -10 3,3
ЕРМ7256 В 256 5 84-164 -5, -7, -10 2,5
ЕРМ7512 АЕ 512 10 120-212 -5, -7, -10, -12 3,3
ЕРМ7512 В 512 10 84-212 -5, -6, -7, -10 2,5
816
МЕТОДИКА ОЦЕНКИ ПАРАМЕТРОВ ИС ПЛ
Продолжение табл. 7.1
Семейство Число макроячеек Число вентилей, тыс. Число контактов входов/выходов Градации скорости Напряжение питания, В
МАХ 9000
ЕРМ9320 320 6 60-168 -10, -15, -20 5,0
ЕРМ9400 400 8 59-159 -10, -15, -20 5,0
ЕРМ9480 480 10 146-185 -10, -15, -20 5,0
ЕРМ9560 560 12 153-216 -10, -15, -20 5,0
МАХ 3000
ЕРМ3032 А 32 0,6 84-164 -4, -7, -10 3,3
ЕРМ3064 А 64 1,25 84-164 -4, -7, -10 3,3
ЕРМ3128 А 128 2,5 120-212 -5, -7, -10 3,3
ЕРМ3256 А 256 5 84-212 -6, -7, -10 3,3
Примечание. Несколько значений цифр в графе «Число контактов входов/выходов»
соответствуют реализациям микросхем в разных корпусах.
Таблица 7.2
Основные параметры СБИС семейства Flex ЮК фирмы «Altera»
Микросхема Число вентилей, тыс. Емкость ОЗУ, Кбит Число контактов входов/выходов Градации скорости Число логических элементов Напряжение питания, В
EPF10K10 10 6 59-134 -3,-4 576 5,0
EPF10K20 20 12 147-189 -3,-4 1152 5,0
EPF10K30 30 12 107-246 -3,-4 1728 5,0
EPF10K40 40 16 147-189 -3,-4 2304 5,0
EPF10K50 50 20 189...310 -3,-4 2880 5,0
EPF10K70 70 18 189-358 -3,-4 3744 5,0
EPF10K100 100 24 406 -3,-4 4992 5,0
EPF10K130V 130 32 470 -2,-3,-4 6656 3,3
EPF10K130 Е 130 64 186-424 -1,-2,-Э 6656 2,5
EPF10K200 Е 200 96 470 -1,-2,-3 9984 2,5
EPF10K200 S 200 96 186-424 -1,-2,-3 9984 2,5
EPF10K250А 250 40 470 -1,-2,-Э 12160 3,3
Таблица 7.3
Основные параметры СБИС семейства APEX и АСЕХ фирмы «Altera» _____________
Микросхема Число вентилей, тыс. Емкость ОЗУ, Кбит Число контактов входов/выходов Градации скорости Число логических элементов Напряжение питания, В
АРБХ20К
EF20K30E 30 24 92-108 1200 192 1,8
ЕР20К60Е 60 32 92-104 2560 256 1,8
ЕР20К100 100 53 101-252 4160 416 2,5
ЕР20К100Е 100 53 92-246 4160 416 1,8
ЕР20К160Е 160 81 87-324 6400 640 1,8
ЕР20К200 200 106 144-376 8320 832 2,5
817
ПРОГРАММИРУЕМАЯ ЛОГИКА И ЕЕ ПРИМЕНЕНИЕ В МИКРОПРОЦЕССОРНЫХ СИСТЕМАХ
Продолжение табл. 7.3
Микросхема Число вентилей, тыс. Емкость ОЗУ, Кбит Число контактов входов/выходов Г радации скорости Число логических элементов Напряжение питания, В
ЕВ20К200Е 200 106 136-376 8320 832 1,8
ЕР20К300Е 300 148 152-408 11520 1152 1,8
ЕР20К400 400 212 502 16640 1664 2,5
ЕР20К400Е 400 212 488 16640 1664 1,8
ЕР20К600Е 600 311 488-588 24320 2432 1,8
ЕР20К1000Е 1000 327 488-708 38400 2560 1,8
ЕР20К1500Е 1500 442 488-808 51840 3456 1,8
ACEXIK
EPIK10 10 11 66-130 576 - 2,5
EPIK30 30 24 102-171 1728 - 2,5
EPIK50 50 40 102-249 2880 - 2,5
EPIK100 100 49 147-333 4992 - 2,5
Таблица 7.4
Основные параметры FPGA семейства ХС4000, Spartan и Spartan-Il фирмы «Xilinx»
Микросхема Число логических ячеек Максимальное число вентилей (без ЗУ), тыс. Максимальная емкость памяти (без логики), бит Типичный диапазон числа вентилей (логика + ЗУ), тыс. * Число КЛБ в матрице Число триггеров Число пользовательских входов/выходов, макс.
XC4000E/EX/XL ХС4003Е 238 3 3200 2-5 100= 10 X 10 360 80
XC4005E/XL 466 5 6272 3-9 196= 14 х 14 616 112
ХС4006Е 608 - 6 8192 4-12 256= 16х16 768 128
ХС4008Е 770 8 10368 6-15 324= 18х18 936 144
XC4010E/XL 950 10 12800 7-20 400 = 20 х 20 1120 160
XC4013E/XL 1368 13 18432 10-30 576 = 24 х 24 1536 192
XC4020E/XL 1862 20 25088 13-40 784 = 28 х 28 2016 224
ХС4025Е 2452 25 32768 15-45 1024=32 х 32 2560 256
XC4028EX/XL 2432 28 32768 18-50 1024= 32 х 32 2560 256
XC4036EX7XL 3078 36 41472 22-65 1296=36 х 36 3168 288
XC4044XL 3800 44 51200 27-80 1600=40x 40 3840 320
XC4052XL 4598 52 61952 33-100 1936=44 х 44 4576 352
XC4062XL 5472 62 73728 40-130 2304 = 48 х 48 5376 384
XC4085XL 7448 85 100352 55-180 3136=56х 56 7168 448
Spartan XCS05(XL) 238 5 - 2-5 100= 10 х 10 360 77
XCS10(XL) 466 10 - 3-10 196= 14 х 14 616 112
XCS20(XL) 350 20 - 7-20 400 = 20 х 20 1120 160
XCS30(XL) 1368 30 - 10-30 576 = 24 х 24 1536 192
XCS40(XL) 1862 40 - 13-40 784 = 28 х 28 2016 205
818
МЕТОДИКА ОЦЕНКИ ПАРАМЕТРОВ ИС ПЛ
Продолжение табл. 7.4
Микросхема Число логических ячеек Максимальное число вентилей (без ЗУ), тыс. Максимальная емкость памяти (без логики), бит Типичный диапазон числа вентилей (логика + ЗУ), тыс.* Число КЛБ в матрице Число триггеров Число пользовательских входов/выхо-дов.макс.
Spartan-Il XC2S15 XC2S30 XC2S50 XC2S100 XC2S150 XC2S200 432 972 1728 2700 3888 5252 - 16384 24576 32768 40960 49152 57344 6-15 13-30 23-50 37-100 52-150 71-200 96=8 х12 216=12 х18 384=16 х 24 600=20 х 30 864=24 х 36 1176=28 x42 - 86 132 176 196 260 284
Примечание. Семейства ХС4000 и Spartan способны работать на системной частоте свыше 80 МГц, Spartan-Il - свыше 200 МГц. Низковольтные версии семейства ХС4000 ( с буквами L в маркировке) работают при напряжениях питания 3,0—3,6 В, микросхемы семейства Spartan - при напряжении питания 3,3 В; Spartan-Il - 2,5 В. * При использовании ресурсов схем для реализации как логики, так и памяти, предполагается, что в качестве запоминающих устройств работают 20-30 % конфигурируемых логических блоков
Таблица 7.5
Основные параметры СБИС семейства Virtex и VirtexE фирмы «Xilinx»
Микросхема Число КЛБ в матрице Число логических ячеек Максимальное число системных вентилей Емкость встроенного ОЗУ, бит Емкость распределенного ОЗУ, бит Число пользовательских вхо-дов/выходов, макс.
XCV50 16x24 1,728 57,906 32,768 24,576 180
XCV100 20x30 2,700 108,904 40,960 38,400 180
XCV150 24x36 3,888 164,674 49,152 55,296 260
XCV200 28x42 5,292 236,666 57,344 75,264 284
XCV300 32x48 6,912 322,970 65,536 98,304 316
XCV400 40x60 10,800 468,252 81,920 153,600 404
XCV600 48x72 15,552 661,111 98,304 221,184 512
XCV800 56x84 21,168 888,439 114,688 301,056 512
XCV1000 64x96 27,648 1,124,022 131,072 393,216 512
XCV1000E 64x96 27,648 1,569,178 393,216 393,216 660
XCV1600E 72x108 34,992 2,188,742 589,324 497,664 724
XCV2000E 80x120 43,200 2,541,952 655,360 614,400 804
XCV2600E 92x138 57,132 3,263,755 749,568 812,554 804
XCV3200E 164x156 73,008 4,074,387 851,968 1,038,336 804
Примечание. Для семейства XCVXXXE показаны лишь микросхемы наивысшей сложности, имеющие напряжение питания 1,8 В. Кроме них имеются шесть микросхем с напряжением питания 2,5 В, сложность которых ниже.
819
ПРОГРАММИРУЕМАЯ ЛОГИКА И ЕЕ ПРИМЕНЕНИЕ В МИКРОПРОЦЕССОРНЫХ СИСТЕМАХ
7.10. АНАЛОГОВЫЕ ПРОГРАММИРУЕМЫЕ МИКРОСХЕМЫ
7.10.1 ОБЩИЕ СВЕДЕНИЯ
Более половины всех электронных проектов связаны с применением аналоговой или аналого-цифровой схемотехники. Поэтому естественно, что в области разработки БИС/ СБИС с программируемой структурой этому направлению также уделяется необходимое внимание.
Аналоговые и аналого-цифровые фрагменты уже давно встраиваются в БИС/СБИС микроконтроллеров, технология БМК также нашла применение в этой области. В последние годы интерес фирм-разработчиков вызывают аналоговые и аналого-цифровые БИС/ СБИС с программируемой структурой. Наличие микросхем, структура которых конфигурируется из аналоговых блоков с программируемыми параметрами, позволяет создавать устройства для решения многих задач обработки аналоговых сигналов. Такие задачи характерны для систем управления техническими объектами различного назначения, получающими информацию от датчиков физических величин той или иной природы (температуры, давления и т. п.) в виде электрических сигналов. В подобных системах нужны как аналого-цифровые преобразователи (АЦП) для оцифровки выходных сигналов датчиков, так и средства коммутации аналоговых сигналов, их предварительной фильтрации, суммирования или вычитания, нормализации, интегрирования и т. д. Подобные задачи решаются средствами, для которых иногда используется термин «Front-End Design». На основе микросхем с программируемыми структурами возможно быстрое проектирование подсистем аналоговой и аналого-цифровой обработки сигналов, их отладка, создание промышленных образцов и быстрый выход на рынок.
Впервые о создании БИС с массивом программируемых пользователем аналоговых элементов объявила фирма «Motorola» (1997 г.). Эти БИС были анонсированы под названием МРАА020 (Motorola Field Programmable Analog Arrays), но не доведены до промышленного выпуска. Тем не менее анализ организации и возможностей этих БИС представляет интерес, поскольку проявляется преемственность в вопросах реализации между этими БИС и последующими разработками. В 1999 г. фирма «Lattice Semiconductor» выпустила семейство внутрисхемно программируемых (In-System Programmable) аналоговых схем типа ispPACIO и ispPAC20.
В микросхемах фирмы «Motorola» для построения операционных звеньев используется схемотехника с переключаемыми конденсаторами, в микросхемах фирмы «Lattice. Semiconductor» - традиционные решения с применением точных масштабирующих резисторов.
В цифровой технике сигналы принимают лишь два значения, одно из которых соответствует логической единице, другое - логическому нулю. Проблема точного задания этих сигналов отсутствует-требуется лишь надежно отличать один из этих сигналов от другого. Совершенно иным является положение в аналоговой технике, где сигнал должен передавать точное значение величины с погрешностью в десятые или сотые доли процента, т. е. требуется «дозирование» сигналов с разрешающей способностью в тысячи или даже более уровней. Традиционно (до конца 1970-х-начала 1980-х гг.) роль дозирующих параметров играли в первую очередь сопротивления точных резисторов. Так, например, в известной схеме масштабирующего усилителя, т. е. устройства умножения сигнала, заданного напряжением постоянного тока, на константу (рис. 7.35, а) используются два точных резистора, от соотношения сопротивлений которых зависит функциональная характеристика схемы, в идеализированном виде имеющая вид 1/2= (- Я2/Д1)С/1. Интегратор (рис. 7.35, б) имеет идеализированную функциональную характеристику вида U2 = (- WRC^INT U1(t)dt,
820
АНАЛОГОВЫЕ ПРОГРАММИРУЕМЫЕ МИКРОСХЕМЫ
в которой роль масштабирующего коэффициента играет произведение сопротивления точного резистора на емкость конденсатора цепи обратной связи.
В схемотехнике с дискретными схемными элементами проблема реализации точных резисторов нашла удовлетворительное решение. Для технологии интегральных схем эта проблема намного сложнее, но существует альтернативное схемное решение, благодаря которому резисторы имитируются цепями, содержащими коммутируемые (переключаемые) конденсаторы (рис. 7.35, в). В такие цепи входят конденсатор С и ключевые транзисторы Т1 и Т2, управляемые тактирующими напряжениями UT1 и UT2. Транзисторы Т1 и Т2 под воздействием тактирующих напряжений замыкаются поочередно, и конденсатор С попеременно заряжается через замкнутый ключевой транзистор до напряжения U1 или U2. В момент замыкания ключевого транзистора заряд конденсатора изменяется на величину q = q1 =q2 = C(U1 - 172/Изменение заряда осуществляется короткими импульсами тока, протекающими через конденсатор при замыкании соответствующего ключевого транзистора.
Среднее значение тока в цепи между точками 1 и 2 составляет величину i = q/T = - (U1-U2)CfT, где Т - период тактирующих импульсов.
Из полученного выражения видно, что в определенном смысле, для средних значений сигналов цепь ведет себя как резистор с сопротивлением R=T/C.
На основе схем с переключаемыми конденсаторами можно строить разнообразные операционные звенья, аналогичные известным из традиционной аналоговой схемотехники, путем замены резисторов эквивалентными им цепями. Сопротивления эквивалентных цепочек управляются значениями тактовой частоты f- МТ. В схемотехнике с переключаемыми конденсаторами строятся схемы, масштабные коэффициенты функциональных характеристик которых зависят от отношения емкостей, которое может задаваться с высокой точностью. Параметры емкостей мало критичны к изменению температуры и старению. Резко (в сотни раз) снижается площадь, занимаемая цепями с переключаемыми конденсаторами в сравнении с цепями, содержащими точные резисторы.
Схема интегратора с переключаемыми конденсаторами, основного элемента для многих операционных звеньев, показана на рис. 7.35, г. Ее функциональная характеристика в терминах теории импульсных цепей с использованием Z-преобразования имеет вид H(Z) = (- CMC2)(Z~'/1 - Z~'), где H(Z) - функция передачи интегратора, Z - оператор дискретного преобразования Лапласа.
Рис. 7.35. Схемы масштабирующих усилителей и интеграторов, реализованные в традиционной схемотехнике (а, б) и в схемотехнике с переключаемыми конденсаторами (в, г)
821
ПРОГРАММИРУЕМАЯ ЛОГИКА И ЕЕ ПРИМЕНЕНИЕ В МИКРОПРОЦЕССОРНЫХ СИСТЕМАХ
7.10.2. ПРАКТИЧЕСКИЕ РАЗРАБОТКИ
БИС МРАА020 фирмы «Motorola» (рис. 7.36) - набор конфигурируемых аналоговых блоков CAB (Configurable Analog Blocks), соединяемых между собой и подключаемых к элементам ввода/вывода ключевыми КМОП-элементами. Конфигурации САВ и состояния переключателей определяются содержимым памяти типа SRAM.
БИС реализованы в корпусе с 160 контактами и содержат 20 САВ в матрице 4x5. Каждый САВ (рис. 7.37) содержит один операционный усилитель ОУ, пять регулируемых конденсаторов, компаратор, набор переключателей и управляющую логику.
Для разработок проектов с использованием БИС типа МРАА фирма «Motorola» создала специальные средства: библиотеку макрофункций, САПР для проектирования конфигурации БИС, кабели для загрузки данных конфигурации из компьютеров и прототип-ные платы (Evaluation Boards) для верификации проектных решений.
Каждая макрофункция библиотеки соответствует решению определенной задачи и позволяет задать функциональную характеристику проектируемого блока не путем вычисления требуемых параметров схемы, а путем задания функциональных характеристик узла (частоты генератора, коэффициента усиления усилителя, полосы пропускания для фильтра и т. д.).
В качестве САПР разработан программный пакет EasyAnalogDesign-Software, ориентированный на работу в PC-совместимых компьютерах в ОС Windows 95/NT. Работа проектировщика с проектом организована в форме интерактивного общения. Проектировщик задает типы макрофункций, расположенных в выбранных местах матрицы, и требуемые свойства узлов. Далее пакет позволяет организовать соединения между схемными элементами и их связи с выходными блоками, контролируя и блокируя при этом недопустимые типы соединений. После завершения формирования проекта пакет позволяет загрузить данные конфигурации БИС соединением при помощи специального загрузочного кабеля выхода последовательного порта компьютера с БИС МРАА020.
Рис. 7.36. Структура БИС МРАА020 фирмы «Motorola»
822
АНАЛОГОВЫЕ ПРОГРАММИРУЕМЫЕ МИКРОСХЕМЫ
Рис. 7.37. Структура конфигурируемого блока микросхемы МРАА020
Прототипная плата Evaluation Board помимо БИС РАА020 содержит цепи, поддерживающие функционирование БИС, и различные органы пользовательского управления, что обеспечивает легкость и скорость верификации созданных проектов.
К реализуемым на одном САВ функциональным узлам относятся усилительные каскады с заданным коэффициентом усиления, сумматоры, вычитатели, сглаживающие каскады, цепи выборки и хранения аналоговых сигналов, фильтры первого порядка. Более сложные функциональные узлы, такие как биквадратные и полосовые фильтры, детекторы уровней и др. могут быть образованы с помощью соединения нескольких САВ в требуемую структуру.
Микросхемы семейства ispPAC фирмы «Lattice Semiconductor» имеют ряд отличий от микросхем фирмы «Motorola». В них не используется техника переключаемых конденсаторов, они архитектурно проще (имеют меньше конфигурируемых ресурсов), имеют меньшие габаритные размеры и число контактов ввода/вывода. Память конфигурации реализована по технологии EEPROM и может загружаться через специально выделенные контакты JTAG интерфейса. Конфигурация может быть закрыта от несанкционированного доступа битом секретности. Отличием является и включение в состав конфигурируемых ресурсов не только аналоговых, но и цифроаналоговых средств (схема ispPAC20 имеет встроенный 8-разрядный цифроаналоговый преобразователь). Заметим при этом, что цифроаналоговые и аналого-цифровые блоки имеют, как правило, жесткую внутреннюю структуру, не позволяющую произвольно их перестраивать. Например, ясно, что из двух 8-разрядных ЦАП или АЦП непосредственным образом не составить 16-разрядные ЦАП и АЦП, поскольку точностные требования к параметрам таких блоков резко различаются. Также не имеет смысла разбивать 16-разрядные ЦАП и АЦП на 8-разрядные, поскольку при реализации 8-разрядных преобразователей не нужны такие жесткие точностные требования, как это необходимо для 16-разрядных.
Структура ИС ispPAC20 (рис. 7.38) имеет в основе два программируемых усилительных блока (РАСЫоск) с дифференциальными входными усилителями, имеющими и дифференциальный выход, что позволяет изменять знак и численное значение коэффициента усиления в пределах от 1 до 10 целочисленными приращениями. Конденсаторы цепей обратных связей могут программироваться на величины от 1 до 63 пФ (всего 128 возможных значений) и позволяют строить на основе усилительных ступеней активные фильтры. Возможны конфигурации интеграторов. Как видно из рисунка, один РАС-блок имеет на входе двухвходовый коммутатор, а другой - внешнее управление инвертированием. Помимо РАС-блоков в БИС включены два аналоговых компаратора, коммутационные линии, 8-разрядный ЦАП, память конфигурации и средства ее загрузки (JTAG контроллер).
Схема ispPACW отличается от уже рассмотренной наличием только четырех программируемых РАС-блоков.
823
ПРОГРАММИРУЕМАЯ ЛОГИКА И ЕЕ ПРИМЕНЕНИЕ В МИКРОПРОЦЕССОРНЫХ СИСТЕМАХ
CP1OUT
_CP2OUT
_DACOUT
_OUT1
OUT2
Память конфигурации
Управление конфигурацией JTAG
Коммутационная матрица
Рис. 7.38. Структура микросхемы ispPAC20 фирмы «Lattice Semiconductor»
Точностные возможности макроячеек микросхем ispPAC достаточно далеки от предельных для аналоговой техники, но могут считаться удовлетворительными для немалого числа практически реализуемых устройств. Общее представление об этих точностных возможностях дают следующие цифры. Приведенный ко входу температурный дрейф макроячейки составляет 50 мкВ/град., диапазон изменения выходного напряжения на отдельном выходе микросхемы 3-4 В при сопротивлении нагрузки между дифференциальными выходами 300 Ом. Для выходных напряжений АЦП достижимо полное использование напряжения питания 5 В, при этом значение единицы младшего разряда 1,25 мВ. Эксплуатационный диапазон температур микросхемы - от -40 до +85 °C. Если алгоритм работы конкретного устройства допускает наличие пауз в процессе его функционирования, то можно проводить периодическую автокалибровку характеристик блоков, длительность которой 100 мс. Автокалибровка гарантирует дифференциальное напряжение смещения нуля в 1 мВ.
Типовые значения коэффициента гармоникдля дифференциального выхода при единичном усилении -88 дб на 10 кГц и -67 дб на 100 кГц, а при коэффициенте усиления 10 соответственно -72 дб и -61 дб.
Максимальная погрешность установки коэффициента усиления макроячейки составляет 4 %.
Погрешность установки частоты полюса в схеме активного фильтра не более 5 %. Время установления выходного напряжения ЦАП с погрешностью в 0,1 % - не более 6 мкс, дифференциальная нелинейность ЦАП - не более значения единицы младшего разряда. Типовое время переключения компаратора при напряжении перепада 10 мВ составляет 750 нс.
Типовой входной ток макроячейки - 3 пА, максимальные токи потребления микросхем - приблизительно 20 мА.
Число циклов стирания-перепрограммирования - не менее 10 000.
Программное обеспечение фирмы «Lattice Semiconductor» под названием РАС-Designer ориентировано на использование в PC-совместимых компьютерах с ОС Windows. САПР позволяет вводить информацию о проекте, моделировать функционирование схем, компилировать проекты и загружать результаты компиляции в память конфигурации БИС.
ГЛ ABА8
ПРОЕКТИРОВАНИЕ МПС
8.1. МЕТОДИКА И СРЕДСТВА ПРОЕКТИРОВАНИЯ
8.1.1. ОБЩЕЕ ОПИСАНИЕ ПРОЦЕССА ПРОЕКТИРОВАНИЯ
Проектирование — разработка технической документации, позволяющей изготовить устройство с заданным функционированием, с заданными свойствами и в заданных условиях.
В основе стратегии проектирования лежит функциональная декомпозиция. Для системы в целом и ее блоков используется концепция «черного ящика». Для «черного ящика» разрабатывается функциональная спецификация, включающая внешнее описание блока (входы и выходы) и внутреннее описание - функцию или алгоритм работы: F = Ф(Х, t), где X-вектор входных величин, Г-вектор выходных величин, t- время. При декомпозиции функция Ф разбивается на более простые функции Ф1-Фк, между которыми должны быть установлены определенные связи, соответствующие принятому алгоритму реализации функции Ф. Переход от функции к структуре - синтез.
Синтез неоднозначен. Выбор наилучшего варианта осуществляется по результатам анализа, когда проверяется правильность работы и некоторые показатели, характеризующие устройство.
Декомпозиция функций блоков выполняется до тех пор, пока не получатся типовые функции, каждая из которых может быть реализована элементами выбранного уровня иерархии.
Процесс проектирования - многоуровневый, многошаговый и итерационный, с возвратами назад и пересмотром ранее принятых решений.
Последовательная декомпозиция проекта на отдельные фрагменты (с определением функций каждого фрагмента и его интерфейса) не зависит от иерархического уровня проектирования и характерна для разработки широкого класса цифровых устройств, начиная от устройства целиком и кончая проектированием отдельных БИС/СБИС. Такая методология проектирования отображает процесс проектирования «сверху - вниз»: от технического задания до электрических схем, файлов прошивки ПЗУ и конфигурации программируемых приборов, а также конструкции устройства в целом.
Другая последовательность, соответствующая методологии «снизу - вверх», предусматривает объединение простейших модулей в более сложную структуру до тех пор, пока, в конце концов, не будет создан конечный проект. Исходные модули - это решения, созданные проектировщиком на более ранних этапах работы или в ходе работ над другими проектами или доступные проектировщику и входящие в состав имеющихся библиотек САПР.
Современным условиям проектирования, когда создаются сложные проекты с привлечением большого числа разработчиков, больше соответствует применение стратегии «сверху-вниз».
Следует отметить, что приведенное выше наглядное описание процесса проектирования относится к каждому уровню проектирования. При этом декомпозиция заканчивается при получении типовых функций, соответствующих выбранному уровню иерархии. Так, на верхнем уровне (при многоплатной реализации) декомпозиция заканчивается при представлении проекта в виде отдельных плат, на следующем уровне - в виде отдельной платы (типового элемента замены), еще ниже декомпозиция осуществляется до реализации функций при помощи той или иной микросхемы. А при ориентации на программируемые (разрабатываемые) пользователем микросхемы процедура декомпозиции осуществляется уже для этой микросхемы в соответствии с составом функциональных библиотек программируемых БИС/СБИС.
825
ПРОЕКТИРОВАНИЕ МПС
С учетом возможностей современных систем автоматизации проектирования (САПР) проектирование может считаться законченным после верификации проекта в целом, когда завершена отладка готового изделия.
Различие теоретической базы и понятийного аппарата, используемых на разных стадиях проектирования, приводит к тому, что традиционным является разбиение процесса проектирования, как цифровых устройств, так и БИС/СБИС на следующие этапы:
• системного проектирования;
• структурно-алгоритмического проектирования;
• функционально-логического проектирования;
• конструкторско-технологического проектирования.
На этапе системного проектирования определяется архитектура будущей системы, состав компонентов и основные характеристики системы при таком её построении. При структурно-алгоритмическом проектировании определяются алгоритмы функционирования аппаратных и программных компонентов системы. На этапе функционально-логического проектирования разрабатываются функциональные и принципиальные электрические схемы, программы, подготавливаются тестовые и контрольные данные. На конструкторском этапе производится привязка элементов проекта к конструктивным элементам. Широкое использование САПР на всех этапах проектирования приводит к тому, что современные подходы к разбиению процесса проектирования связывают с различием как технических средств (инструментария), привлекаемых для создания проекта, так и технических средств, используемых в качестве компонентов проекта и технологических особенностей реализации конечного продукта. Хотя общая методология процесса проектирования не зависит от варианта разбиения процесса проектирования на отдельные уровни, содержание, а также методы и средства проектирования для различных уровней оказываются очень специфичными и существенно зависят как от типа применяемой элементной базы, таки от способа реализации (изготовления) конечного продукта.
8.1.2. КЛАССИФИКАЦИЯ МЕТОДИК ПРОЕКТИРОВАНИЯ ЭЛЕКТРОННЫХ СХЕМ
Первым фактором, влияющим на специфику проектирования, является тип обрабатываемой информации и связанные с ним методы и способы ее обработки. Проект или его отдельные фрагменты могут включать аналоговые, аналого-цифровые и/или цифро-аналоговые элементы, строиться на основе дискретных (цифровых) компонентов или опираться на встроенные микропроцессорные средства. Отсюда следует многообразие вариантов проектирования, эти варианты в современных технологиях часто называют потоком проектирования (Design Flow). Проектирование при этом может быть цифровым, аналого-цифровым, смешанным цифровым и программным, а также проектированием с ориентацией на синтезируемые цифровые или аналоговые схемы. Возможны и другие комбинации этих вариантов.
Следующим определяющим фактором является выбор технической базы для реализации проекта, а также технологического способа реализации самого проекта. Как правило, одно и то же электронное изделие может быть реализовано различными способами. Здесь должен быть дан ответ на вопрос - будет ли проект построен на стандартных микросхемах или будут использоваться те или иные специализированные ИС и/или комбинация различных типов ИС.
Описание особенностей организации было приведено выше, а классификация ИС по этому признаку приведена на рис. 8.1. Способ изготовления ИС не определяет типы обрабатываемой информации.
826
МЕТОДИКА И СРЕДСТВА ПРОЕКТИРОВАНИЯ
Рис. 8.1. Классификация ИС по признаку способа изготовления
К стандартным микросхемам отнесены схемы малой и средней степени интеграции -МИС и СИС. Эти микросхемы производятся массовыми тиражами и реализуют стандартные элементы и узлы, функционирование которых никак не определяется конкретными потребителями. К стандартным схемам высокого уровня интеграции (БИС и СБИС) относятся цифровые схемы: микропроцессоры, микроконтроллеры и запоминающие устройства (ЗУ), разнообразные периферийные схемы для МП и МК, включая и аналого-цифровые схемы: аналого-цифровые преобразователи (АЦП), цифроаналоговые преобразователи (ЦАП). Общее свойство этих схем то, что они остаются неизменными после изготовления независимо от устройств и систем, в которых они используются.
К специализированным ИС (СпИС) относятся все, структура которых в отличие от структур стандартных ИС массового производства каким-либо способом приспосабливается к конкретным требованиям того или иного проекта. В английской терминологии СпИС именуются ASICs (Application Specific Integrated Circuits). Среди СпИС различают классы полузаказных и заказных. Разновидностями заказных микросхем являются полностью заказные и спроектированные методом «на стандартных ячейках».
Полностью заказные схемы целиком проектируются по требованиям конкретного заказчика. Проектировщик имеет полную свободу действий, определяя схему по своему усмотрению вплоть до уровня схемных компонентов (отдельных транзисторов и т. п.). Для изготовления схемы требуется разработка всего комплекта фотошаблонов, верификация и отладка всех схемных фрагментов. Такие схемы очень дороги и имеют длительные циклы проектирования.
827
ПРОЕКТИРОВАНИЕ МПС
Схемы на стандартных ячейках отличаются от полностью заказных тем, что их фрагменты берутся из заранее разработанной библиотеки схемных решений. Такие фрагменты уже хорошо отработаны, стоимость и длительность проектирования при этом снижаются. Для производства схем тоже требуется изготовление полного комплекта фотошаблонов, но разработка их облегчена. Потери по сравнению с полностью заказными ИС состоят в том, что проектировщик имеет меньше свободы в построении схемы, т. е. результаты ее оптимизации по таким критериям как площадь кристалла, быстродействие и т. д. менее эффективны. Наивысших технических параметров добиваются от полностью заказных схем, однако метод стандартных ячеек популярен, так как при небольших потерях в технических характеристиках с его помощью можно заметно упростить проектирование схемы. Полностью заказные схемы разрабатываются за время, превышающее время разработки методом стандартных ячеек приблизительно в два раза.
Промежуточное положение занимают схемы, проектируемые по технологии «стандартная продукция для фиксированных приложений» (Application Specific Standard Products -ASSP). Основой технологии является использование в качестве строительных блоков заранее разработанной библиотеки схемных решений системного уровня, таких как микро-контроллеры/ОБР-ядра, память, блоки стандартных интерфейсов и блоки специфической системной логики. Для экономической целесообразности реализации подобных проектов для фирмы «Atmel», например, требуется тиражность продукции порядка 100 тыс. кристаллов в заказе.
К полузаказным схемам относятся базовые матричные кристаллы БМК (в английской терминологии MPGA- Mask Programmable Gate Arrays). В этом случае имеется стандартный полуфабрикат, который доводится до готового изделия с помощью индивидуальных межсоединений. Реализация требует изготовления лишь малого числа фотошаблонов. Стоимость и длительность проектирования в данном случае по сравнению с полностью заказными схемами сокращаются в 3-4 раза. Однако результат проектирования еще дальше от оптимального, поскольку в матричных БИС (МАБИС) менее рационально используется площадь кристалла (на кристалле остаются неиспользованные элементы и т. п.), не минимальны длины связей и не максимально быстродействие.
Сходство методов проектирования на БМК и стандартных ячейках состоит в использовании библиотек функциональных элементов. Различие в том, что для схем, проектируемых по методу стандартных ячеек, библиотечный набор элементов имеет более выраженную топологическую свободу. Например, стандартизируется только высота ячеек, а их длины могут быть различными. При проектировании вначале из набора библиотечных элементов подбираются необходимые функциональные блоки, а затем решаются задачи их размещения и трассировки.
Методика, а соответственно и САПР для проектирования по методу стандартных ячеек более сложны, чем для проектирования на основе БМК, которому свойственны более жесткие топологические ограничения. Ограничения вводятся и для метода стандартных ячеек (постоянство высоты ячеек, предопределенность геометрических размеров и положения шин питания, тактирования и др.), но по мере применения более мощных САПР ограничения ослабляются.
Длительность изготовления БИС/СБИС методом стандартных ячеек превышает этот же показатель для МАБИС на основе БМК в 1,3-1,8 раз.
Особое место в классификации занимают БИС/СБИС с программируемой структурой. С одной стороны, они относятся к СпИС, так как в конечном счете приспосабливаются к требованиям конкретного проекта. В то же время этот процесс (конфигурация схемы) не затрагивает изготовителя, для которого схемы являются стандартным продуктом со всеми вытекающими из этого выгодами.
828
МЕТОДИКА И СРЕДСТВА ПРОЕКТИРОВАНИЯ
8.1.3. ОБЛАСТИ ПРИМЕНЕНИЯ СПИС РАЗЛИЧНЫХ ТИПОВ
Все типы СпИС имеют свои области применения. Каждому типу свойственно определенное соотношение таких параметров как сложность (достижимый уровень интеграции), быстродействие, стоимость. На выбор типа СпИС для реализации проекта влияет совокупность свойств. Основные соображения можно пояснить с позиций экономики, обратившись к формуле стоимости ИС, которая производится с использованием освоенного технологического процесса:
С = С +С /N, ис ичг пр где С - стоимость изготовления ИС (стоимость кристалла и других материалов, стоимость технологических операций по изготовлению ИС, контрольных испытаний); затраты на изготовление относятся к каждой ИС, т. е. повторяются столько раз, сколько ИС будет произведено; С, - стоимость проектирования ИС, т. е. однократные затраты для данного типа ИС; N- объем производства (тиражность), т. е. число ИС, которое будет произведено.
Стоимость проектирования БИС/СБИС велика и может достигать сотен миллионов долларов. Для дорогостоящих вариантов проектирования БИС/СБИС производство становится рентабельным только при большом объеме их продаж.
Затраты С„, и Стг находятся во взаимосвязи. Рост затрат на проектирование, как правило, ведет к снижению С ,г, поскольку, чем совершеннее проект, тем рациональнее используется площадь кристалла и другие его ресурсы. Отсюда видно, что выигрыш по экономичности могут получать те или иные типы СпИС в зависимости от тиражно-сти их производства N и сложности.
Применительно к микросхемам программируемой логики справедливы следующие положения. Простые устройства со сложностью в сотни эквивалентных вентилей целесообразно реализовывать на PLD (PAL, GAL, PLA). При росте сложности проекта естественен переход к FPGA и CPLD, если тиражность ИС сравнительно невелика. Росттиражно-сти (приблизительно свыше десятков тысяч) ведет к преимуществам реализаций на БМК, так как стоимость изготовления небольшого числа шаблонов для создания межсоединений разложится на большое число микросхем, а стоимость изготовления каждой ИС уменьшится благодаря исключению из схемы схем программируемых связей и средств их программирования.
При еще большей тиражности выгодным оказывается метод стандартных ячеек, позволяющий дополнительно улучшить параметры схемы, плотнее разместить ее элементы на кристалле, т. е. уменьшить Стг и улучшить быстродействие. При этом слагаемое Cnp/N в формуле стоимости ИС не окажется слишком большим благодаря большой величине N, хотя необходимость проектировать весь комплект шаблонов для технологических процессов приводит к большим затратам С .
Полностью заказное проектирование для СпИС не характерно. Оно стоит настолько дорого, что применяется практически только для создания стандартных БИС/СБИС массового производства. Например, проектирование первого 32-разрядного микропроцессора обошлось в свое время в 140 млн долл., а ЗУ емкостью в 1 Мбит- в 395 млн долл.
Диаграмма областей целесообразного применения разных типов СпИС в зависимости от их сложности и тиражности приведена на рис. 8.2.
Интересно отметить, что ведущая компьютерная фирма IBM использует методологию проектирования смешанного типа БМК/СЯ (Gate-Array/Standard Cell Intermix), размещая в одной СБИС области, выполненные по методу стандартных ячеек СЯ и по методу БМК. Более плотные и быстродействующие схемы типа СЯ используются в критических трактах обработки сигналов, остальная площадь занимается транзисторами БМК.
829
ПРОЕКТИРОВАНИЕ МПС
ства. шт
Рис. 8.2. Диаграмма областей целесообразного применения различных типов специализированных БИС/СБИС
8.1.4. МЕСТО БИС С ПРОГРАММИРУЕМЫМИ СВОЙСТВАМИ В ПРОЦЕССЕ СОЗДАНИЯ СОВРЕМЕННОЙ АППАРАТУРЫ
Проектирование стандартных ИС массового производства, как и проектирование заказными методами вообще - удел крупных специализированных фирм. На долю системотехников приходятся главным образом другие разработки: цифровые устройства малой сложности на МИС и СИС, микропроцессорные системы для целей управления техническими объектами и технологическими процессами, малотиражная аппаратура либо прототипы систем на основе ИС программируемой логики.
Проектирование на основе МИС, СИС — наиболее традиционный процесс, в котором используются как эвристические подходы, так и формализованные методики. Проектировщик задает структуру устройства на базе своих знаний, идей и освоения опыта предшественников, а при определении функций отдельных блоков пользуется и формальными методами. Требуется знание типовых функциональных узлов, их свойств и параметров. В современных условиях (тенденции снижения стоимости схем с программируемой структурой) следует ожидать замещения систем, построенных на МИС/СИС, на БИС программируемой логики.
Микропроцессорная система создается в результате разработки комплекса программно-аппаратных средств. Разработка аппаратной части сводится к компоновке системы из типовых модулей: центрального процессорного элемента, различных видов памяти, адаптеров, контроллеров и внешних устройств. Способы подключения модулей к шинам микропроцессорной системы, описания основных модулей, сведения о типах и методике их выбора, программировании и применении приводятся в главах, посвященных описаниям конкретных семейств. Ключевой проблемой при проектировании микропроцессорных систем была и остается проблема разработки программного обеспечения. Некоторые сведения о средствах и методике отладки ПО приведены в данной главе.
Помимо проектирования микропроцессорных систем различного уровня и функционального назначения в основе большого числа инженерных разработок различной аппаратуры, по-видимому, лежит использование схем с программируемой структурой для создания
830
МЕТОДИКА И СРЕДСТВА ПРОЕКТИРОВАНИЯ
требуемых устройств и/или их отладки. При этом программируемые ИС могут использоваться как в виде автономных устройств, так и в составе микропроцессорных систем. Более того, в соответствии с ростом возможностей создания систем на одном кристалле сами микропроцессорные системы могут оказаться одним из элементов, входящих в состав БИС с программируемой структурой. В подобной ситуации уже трудно определить, являются ли подобные СБИС программируемой логикой со встроенным МП или это МП-система со встроенной программируемой периферией. Также трудно провести четкую грань между проектированием собственно МП, проектированием его периферии и тем более проектированием связей между МП-ядром и периферией. Поэтому, по мнению авторов, вопросам проектирования схем с программируемой структурой следует уделять особое внимание.
8.1.5. СТРУКТУРА АЛГОРИТМА ПРОЕКТИРОВАНИЯ
Проектирование на основе программируемых ИС (даже не очень высокой сложности) выполняется только с помощью систем автоматизированного проектирования САПР (САПР для проектирования и комплексной отладки программного обеспечения МП-систем обычно называют интегрированной средой разработки, или оболочкой). Для общности рассмотрения, кроме случаев, связанных с традиционным использованием терминов типа интегрированная среда и узко ориентированных на разработку ПО МП-систем, будем использовать общий термин САПР для любых систем автоматизированного проектирования. Для большей общности дальнейшего рассмотрения будем предполагать необходимость проектирования устройства, включающего в свой состав как БИС МП, так и БИС с программируемой структурой (как для реализации цифровых, так и для реализации аналоговых фрагментов устройства). Укрупненная структура алгоритма проектирования для подобных устройств показана на рис. 8.3.
Проектирование на концептуальном уровне возлагается на проектировщика и слабо связано с автоматизацией. Исходные данные для проектирования на этом этапе содержат требования к основным технико-экономическим показателям: производительности, энергопотреблению, стоимости, надежности, конструктивным и другим параметрам. Кроме того, для управляющих систем должны быть определены реализуемые алгоритмы управления, для универсальных систем - классы выполняемых задач.
На этом уровне, исходя из требуемого функционирования устройства, проектировщик осуществляет разбиение проекта на части, определяет множества входных и выходных сигналов (какустройства в целом, таки его составных частей), их характер и взаимосвязь, а также решает отдельные вопросы реализации составных частей. Основным результатом этого этапа является разбиение алгоритмов работы системы на две составляющие для реализации программным и аппаратным обеспечением выбранного типа МП-ядра, а также выделение задач, требующих для своего выполнения разработки нетипового оборудования, как цифрового, так и аналогового. Прежде всего должен быть решен основной вопрос этого этапа - вопрос о технической реализации микропроцессорного ядра (будет ли он автономен или встроен в БИС ПЛ; если встроен, то каким образом). МП-ядро может быть реализовано как библиотечный элемент или как БИС, относящаяся к типу SOPC.
Результаты концептуального этапа позволяют перейти к следующим этапам проектирования. Порядок работы по параллельным ветвям процедуры проектирования произволен и может во времени выполняться как параллельно или последовательно, так и в произвольных комбинациях. Более того, даже этап конструкторско-технологического проектирования может начинаться (благодаря перепрограммируемое™ результатов любой ветви проектирования) до получения окончательных результатов проектирования отдельных фраг-
831
ПРОЕКТИРОВАНИЕ МПС
Рис. 8.3. Укрупненная структура алгоритма автоматизированного проектирования вычислительных устройств с использованием микросхем с программируемой структурой
ментов устройства. Следует отметить схожесть процедур проектирования по всем па- ' раллельным ветвям. Как разработка программного обеспечения для МП- (МК) ядра, так и разработка дискретной и аналоговой частей проекта могут рассматриваться как последо- 1 вательность трех этапов.
1. Ввод исходной для проектирования информации (спецификация работ этапа).
2. Компиляция проекта.
3. Верификация (тестирование) полученных результатов. Конкретное содержание этапов для аппаратной и программной частей проекта (а тем более цифровой и аналоговой частей) естественно различное. Компиляция аппаратной части проекта приводит к синтезу устройства (или устройств) в базисе выбранных элементов (со стандартной и/или программируемой структурой), а компиляция программной части проекта приводит к синтезу кодового представления программ. Полученные результаты требуют тщательной проверки, поэтому за этапом синтеза следует этап верификации, проводимого моделированием
832
МЕТОДИКА И СРЕДСТВА ПРОЕКТИРОВАНИЯ
и/или реальными экспериментами. Моделирование, как правило, имеет несколько уровней с разной степенью отображения свойств реального объекта. Оно может быть функциональным, проверяющим правильность логической структуры устройства или программы, временным, учитывающим задержки сигналов в схемах устройства без учета окончательной топологии трассировки или время исполнения отдельных программных фрагментов и т. д. В результате верификации могут выявиться ошибки, требующие исправления, что придает процессу проектирования итеративный характер с возвратами к прежним этапам и введением в проект нужных коррекций.
Более того, по мере отработки решений по отдельным ветвям проектирования отрабатываются и вопросы связи между этими ветвями (например, между программной и аппаратной частями проекта), хотя комплексный анализ и отладка могут быть выполнены только после завершения отдельных ветвей процедуры проектирования. Естественно, такое последовательное проектирование является условным. В реальных условиях выполняется последовательно-параллельное проектирование с многократными итерационными возвратами к началу проектных процедур.
Завершение этапов проектирования по отдельным ветвям создает исходные данные для завершающего конструкторско-технологического этапа проектирования, результатом которого явится создание реальной системы. Физическая реализация проекта в свою очередь создает основу для комплексной отладки решений, полученных на отдельных ветвях проектирования.
Однако для экспериментальной проверки совсем не обязательно ждать реализации будущей системы целиком. Возможна практическая проверка либо всего устройства, либо его отдельных фрагментов с использованием предлагаемых различными фирмами специальных отладочных средств. Названия таких средств в целом отражают их целевую направленность. Спектр отладочных средств включает средства, предназначенные для предварительного знакомства с БИС рассматриваемого класса (обычно называемых Starter Kit), средства для отладки прикладных проектных решений (обычно называемые Evaluation Board или Development Board) и, наконец, средства, используемые на начальных этапах выпуска готовой продукции и замещающие оборудование, которое еще находится на этапах конструкторско-технологической разработки (обычно называемых Prototype Plate). Несмотря на некоторые отличия по имеющимся ресурсам и предлагаемым возможностям, любая плата позволяет производить либо изменение программного обеспечения МП, либо конфигурирование микросхем с программируемой структурой и выполнять желаемые эксперименты. При успешном завершении экспериментальных работ файлы с программным обеспечением или конфигурационные файлы могут использоваться либо для изготовления требуемых программируемых БИС, либо для записи в соответствующие виды ПЗУ. Файлы отчетов о результатах компиляции обычно содержат информацию о конкретных данных по монтированию проекта в реальную систему или БИС. Поэтому уже после этапа компиляции проектов возможен переход к технологической реализации проекта, например, проектированию топологии печатных плат, являющихся, как правило, конечной продукцией проектирования.
Ввиду легкости перепрограммирования как программной части проекта, так и аппаратной части, этап экспериментальных работ с проектом может быть отложен до завершения конструкторской разработки печатной платы. Даже значительные изменения схемы обычно не влекут за собой столь катастрофических последствий, как в случаях использования жесткой стандартной логики. Наличие у фирм - разработчиков БИС с программируемыми свойствами различной логической мощности с совпадением общего числа выходных контактов, их функционального назначения и расположения делает модификацию проектов вопросом скорее экономическим (более мощные БИС стоят дороже), чем техническим.
833
ПРОЕКТИРОВАНИЕ МПС
Поэтому экспериментальные работы целесообразно производить на различных отладочных прототипных системах исключительно для ускорения общего процесса проектирования, поскольку в этом случае для разрабатываемых БИС удается совместить во времени этапы конструкторской разработки и экспериментальных работ.
Итерационные возвраты к повторным процедурам компиляции в ходе конструкторско-технологического этапа проектирования возникают в том случае, если целесообразно изменить месторасположение входных и/или выходных контактов БИС ПЛ, исходя из соображений более эффективной разводки соединений БИС на печатной плате как между собой, так и их подключения к выходным разъемам печатной платы. Подобная возможность следует из способности современных БИС ПЛ обеспечивать различные варианты монтирования одного и того же проекта в одну и ту же БИС.
8.1.6. СОПРЯЖЕННОЕ ПРОЕКТИРОВАНИЕ И СОПРЯЖЕННАЯ ВЕРИФИКАЦИЯ
До настоящего времени в проектировании аппаратно-программных систем доминирует подход, основанный на разделении задачи на аппаратно-реализуемую и программно-реализуемую части на ранних этапах проектирования, и эти части проектируются относительно независимо вплоть до окончательного объединения системы. Тесное взаимодействие аппаратных и программных средств как в системах типа «процессор общего назначения -программируемый аппаратный периферийный модуль», так и в системах SOPC потребовало разработки новых подходов к процессу проектирования, что нашло свое отражение в концепции «сопряженного проектирования аппаратно-программных систем» - (Hardware-Software Codesign).
Основа методологии сопряженного проектирования (сопроектирования) - параллельная взаимосвязанная проработка программных и аппаратных средств, что обеспечивает создание наиболее эффективных конфигураций при сокращении времени разработки.
Концепция сопроектирования предполагает решение следующих вопросов.
• Анализ задачи и ее разделение на фрагменты, безусловно назначаемые к исполнению программно, безусловно исполняемые в аппаратуре, и фрагменты, которые могут быть назначены как в аппаратную, так и в программную части таким образом, чтобы максимизировать показатель качества системы в целом в зависимости от имеющихся ресурсов. Процедуру такого предварительного распределения весьма сложно формализовать. Рекомендуется назначать в программную часть сравнительно редко выполняемые фрагменты и фрагменты, требующие больших аппаратных ресурсов, например, содержащие операции арифметики с плавающей запятой. К безусловно аппаратным относят обычно операции непосредственного управления периферией.
• Создание библиотеки возможных исполнителей алгоритмов, типичных для предполагаемой области применения. Каждый объект такой библиотеки представляет некоторую задачу и включает несколько вариантов программной реализации, например, в форме С-кодов, а также несколько вариантов реализующих структур, обычно представляемых как описания на языках схемотехнического проектирования, например VHDL. Эти варианты сопровождаются количественными характеристиками возможных исполнителей, таких как время исполнения, затраты памяти, используемые ресурсы микросхем программируемой логики.
• Выбор оптимального сочетания исполнителей частей задачи исходя из определенной целевой функции, ограничений и характеристик задачи. Обычно за критерий оптимиза
834
МЕТОДИКА И СРЕДСТВА ПРОЕКТИРОВАНИЯ
ции принимается время исполнения задачи. Имеющиеся ресурсы (память, свободные макроячейки FPGA и т. п.) выступают как ограничения. Задача поиска оптимума является дискретной оптимизационной задачей. Прямые, «точные» методы оптимизации, такие как метод ветвей и границ, требуют весьма большого времени решения. Известен ряд приближенных эвристических методов сокращения перебора, которые позволяют решать задачу выбора исполнителей с приемлемой точностью при сравнительно небольших затратах.
• Разработка соответствующего интерфейса между процессором общего назначения и специализированным модулем, равно как и между блоками, включаемыми в аппаратную часть системы. При этом следует обращать внимание на такие проблемы, как согласованность форматов данных, буферизация, взаимное оповещение и взаимное блокирование процессов.
Функции, назначенные для аппаратной реализации, должны объединяться и компилироваться в файл конфигурации, который используется при настройке программируемых логических схем. Если дополнительный модуль реализован на оперативно репрограммируемых БИС (FPGA), то конфигурационный файл загружается в них при запуске соответствующей задачи. В программной части соответствующие модули заменяются процедурами преобразования данных в форму, «понятную» для аппаратных блоков. Эти процедуры вычисляют вспомогательные переменные и выполняют обмен с сопроцессорным блоком в соответствии с принятым протоколом.
Ресурсы, предоставляемые БИС ПЛ вообще, а в особенности классом SOPC, будучи поддержанными возможностями, предназначенными для их проектирования современными САПР, существенно расширили рамки совместного проектирования, позволяя говорить о совместной верификации и отладке аппаратных и программных средств (Co-verification).
Основным достоинством такой совмещенной процедуры является сокращение требуемого времени. При традиционном раздельном процессе проектирования аппаратных и программных средств неизбежно возникающие итерационные возвраты в проектной последовательности требовали для своей реализации нескольких недель, использование же современных подходов и современных технических средств позволяет выполнять подобные возвраты значительно быстрее (на это требуется всего нескольких часов).
Следует отметить некоторые специфические особенности процедуры отладки проектов, реализующих сложные системы, конструктивно расположенные в одном кристалле. Специфика состоит в сложности отладки готовых систем, поскольку увеличение логической мощности проекта сопровождается уменьшением числа контрольных точек системы (вывод некоторых промежуточных точек проекта на выходные контакты бывает даже недопустим, так как может приводить к потере производительности проекта). Поэтому современной тенденцией является интеграция отладочных средств в состав целевой системы. Затраты на отладочные средства могут составлять единицы процентов общих ресурсов БИС, а если при этом используется технология использования расширенных вариантов интерфейса JTAG, то подобный подход даже не требует увеличения числа контактов БИС. Более того, репрограммируемость структуры БИС ПЛ создает предпосылки для разработки специальных (возможно, в корне отличающихся от исходных) тестовых конфигураций БИС, ориентированных на контроль и/или настройку оборудования, расположенного вокруг БИС ПЛ. Другими словами, идеология и возможности БИС с программируемой структурой приводят к определенным изменениям не только в процедуре изготовления конечной продукции, но и в процедуре как комплексной отладки готовой системы, так контроля и отладки этой продукции даже после завершения процесса проектирования.
835
ПРОЕКТИРОВАНИЕ МПС
8.2. ПРОЕКТИРОВАНИЕ ТИПОВОЙ КОНФИГУРАЦИИ МП-СИСТЕМЫ
8.2.1. ТИПОВЫЕ КОНФИГУРАЦИИ МП СИСТЕМ
Методики проектирования/отладки микропроцессорных и микроконтроллерных систем имеют определенную специфику. В соответствии с названием микроконтроллерные системы ориентированы на выполнение задач управления определенными устройствами или их комплексами. Микропроцессорные системы можно условно разделить на два основных класса: универсальные, которые используются для решения широкого круга задач обработки информации, и управляющие, которые специализируются на решении задач управления процессами и объектами. Типичными примерами универсальных микропроцессорных систем являются персональные компьютеры и рабочие станции, которые применяются в самых различных сферах деятельности.
Управляющие микропроцессорные системы имеют много общего с микроконтроллерами. Они также содержат различные устройства, расширяющие возможности процессора для реализации сложных алгоритмов управления. При этом периферийные устройства, многие из которых располагаются на кристалле микроконтроллера, в микропроцессорных системах реализуются с помощью дополнительных микросхем, что повышает их стоимость и снижает надежность. Разработка интегрированных микропроцессоров, имеющих в своем составе ряд периферийных устройств, и сложнофункциональных микроконтроллеров, содержащих высокопроизводительное 32-разрядное процессорное ядро, приводит к размыванию границы применения управляющих микропроцессорных и микроконтроллерных систем, постепенному стиранию функциональных и структурных различий между ними.
Основной особенностью микроконтроллеров является наличие в их составе ПЗУ (ППЗУ, РППЗУ, ЭСППЗУ, флэш-памяти), в которое записывается резидентная рабочая программа системы. Разработка, отладка и запись в ПЗУ этой программы является важнейшей стадией проектирования микроконтроллерных систем. Записанная в ПЗУ рабочая программа становится составной частью системы, последующее изменение или коррекция которой обычно нежелательны или невозможны. При использовании внутреннего ПЗУ возможности внешнего контроля работы микроконтроллера в процессе отладки очень ограничены. Поэтому комплексная отладка программного и аппаратного обеспечения микроконтроллерных систем является достаточно сложной процедурой, требующей использования специализированных методов и средств контроля. Данный этап проектирования является также наиболее ответственным, так как невыявленная ошибка может привести к весьма дорогостоящим последствиям. Особенностью микропроцессорных систем для ряда областей применения является необходимость строгого соблюдения определенных норм времени на выполнение программы или ее отдельных модулей.
В микропроцессорных системах выполняемые модули рабочей программы загружаются в ОЗУ. Благодаря этому имеется возможность оперативной коррекции рабочей программы в случае необходимости. В процессе отладки проектировщик имеет доступ к общей шине, что облегчает текущий контроль за работой системы. Однако наличие в большинстве современных микропроцессоров внутренней кэш-памяти ограничивает возможности внешнего контроля за ходом выполнения программы. Особенно возрастают сложности отладки при использовании микропроцессоров с суперскалярной структурой, в которых несколько команд выполняются одновременно и естественная очередность их выполнения может не соблюдаться. Хотя при проектировании микропроцессорных систем выполняются практически те же этапы, что и для микроконтроллерных систем, однако используемая процедура разработки и средства отладки во многих случаях существенно различаются. Рассмотрим основные этапы проектирования/отладки этих систем и особенности их реализации.
836
ПРОЕКТИРОВАНИЕ ТИПОВОЙ КОНФИГУРАЦИИ МП-СИСТЕМЫ
8.2.2. ОСНОВНЫЕ ЭТАПЫ ПРОЦЕДУРЫ ПРОЕКТИРОВАНИЯ
Общая процедура проектирования-отладки микропроцессорных и микроконтроллерных систем включает этапы, показанные на рис. 8.4. Исходные данные для проектирования содержат требования к основным технико-экономическим показателям: производительности, энергопотреблению, стоимости, надежности, конструктивным и другим параметрам. Кроме того, для управляющих систем должны быть определены реализуемые алгоритмы управления, для универсальных систем - классы выполняемых задач.
Разработка архитектуры системы подразумевает определение оптимального состава аппаратных и программных средств для решения поставленных задач. При этом разработчик решает, какие функции системы будут реализованы аппаратными средствами (АС), а какие - программным обеспечением (ПО). Определяется номенклатура АС: выбираются тип микропроцессора или микроконтроллера, объем и тип памяти, номенклатура периферийных устройств, протоколы обмена информацией и состав требуемых сигналов управления системой. Определяется также состав ПО: наличие операционной системы, ее тип и характеристики, номенклатура необходимых программных модулей, характер их взаимодействия, используемый язык программирования. Результатом выполнения этого этапа являются частные технические задания на проектирование АС и ПО.
Рис. 8.4. Основные этапы проектирования/отладки микропроцессорных и микроконтроллерных систем
837
ПРОЕКТИРОВАНИЕ МПС
Этап разработки АС может быть выполнен традиционными методами, с помощью которых проектируется и моделируется электрическая схема, разрабатывается печатная плата или комплект плат, после чего выполняются монтаж и отладка системы. Однако во многих случаях можно обеспечить сокращение сроков и повышение качества разработки АС путем использования «полуфабрикатов» или готовых изделий, выпускаемых рядом производителей.
Существует достаточно большая номенклатура таких изделий, которые носят названия оценочных или целевых плат (evaluation board, target board), оценочных наборов или систем (evaluation kit, evaluation system), одноплатных компьютеров или контроллеров (SBC -single-board computer, single-board controller). В их состав входит базовый микропроцессор или микроконтроллер, память (ОЗУ, флэш-память, служебное ПЗУ), ряд периферийных и вспомогательных схем. Обычно такие платы имеют разъем для подключения к персональному компьютеру, с помощью которого производится комплексная отладка системы.
Если состав средств, имеющихся на плате развития, достаточен для реализации проектируемой системы, то ее разработка сводится к созданию ПО и выполнению комплексной отладки системы. Если имеющихся средств недостаточно, то они проектируются и размещаются на дополнительной плате, подключаемой к разъему на плате развития непосредственно или с помощью кабеля. Так реализуется прототип проектируемой системы, на котором можно выполнить комплексную отладку программных и аппаратных средств, а в ряде случаев и провести проверку их функционирования в рабочих условиях. После этого нетрудно разработать рабочий вариант системы, объединив на одной плате используемые модули прототипной системы. Прототипная система может использоваться в качестве рабочей (целевой), если ее параметры и конструктивное оформление удовлетворяют требованиям технического задания. В этом случае достигается сокращение сроков и стоимости проектирования системы.
Особенно следует отметить перспективность использования при разработке АС мезонинной технологии, которая унифицирует размеры и интерфейс базовой платы-носителя и размещаемых над ней небольших плат- мезонинов (типичный размер 45x99 мм). Одна плата-носитель несет от 2 до 12 мезонинов. Каждый мезонин соединяется с носителем двумя разъемами.
На этапе автономной отладки АС основными орудиями разработчика являются традиционные измерительные приборы -осциллографы, мультиметры, пробники и другие, а также логические анализаторы, которые обладают широкими возможностями контроля состояния различных узлов системы в заданные моменты времени. Весьма эффективным является использование на этом этапе средств тестирования по стандарту JTAG, которые имеются в составе многих современных моделей микропроцессоров и микроконтроллеров. С помощью размещенного на кристалле тест-порта ТАР и специальных выводов TDI, TDO, ТСК, TMS, TRST# обеспечивается возможность подачи необходимых входных воздействий и считывания выходной реакции, запуск-останов процессора, изменение режима его работы. Вводом специальной команды можно установить выводы микропроцессора или микроконтроллера в отключенное состояние, чтобы отдельно протестировать другие устройства системы.
8.3. СРЕДСТВА И МЕТОДЫ ПРОЕКТИРОВАНИЯ И АВТОНОМНОЙ ОТЛАДКИ АППАРАТНЫХ СРЕДСТВ МП-СИСТЕМЫ
8.3.1. ВЫБОР СЕМЕЙСТВА МП И СТАНДАРТНОЙ ПЕРИФЕРИИ
Разработка архитектуры системы подразумевает определение оптимального состава аппаратных и программных средств для решения поставленных задач. При этом разработчик решает, какие функции системы будут реализованы аппаратными средствами, а какие -программным обеспечением. Определяется номенклатура АС - выбираются тип микропроцессора или микроконтроллера, объем и тип памяти, номенклатура периферийных уст
838
СРЕДСТВА И МЕТОДЫ ПРОЕКТИРОВАНИЯ И АВТОНОМНОЙ ОТЛАДКИ АППАРАТНЫХ СРЕДСТВ МП-СИСТЕМЫ
ройств, протоколы обмена информацией и состав требуемых сигналов управления системой. Определяется также состав ПО - наличие операционной системы, ее тип и характеристики, номенклатура необходимых программных модулей, характер их взаимодействия, используемый язык программирования. Результатом выполнения этого этапа являются частные технические задания на проектирование АС и ПО.
Широкая номенклатура микропроцессоров и микроконтроллеров, выпускаемых различными фирмами, позволяет удовлетворить запросы подавляющего большинства потребителей. Однако выбор типа микропроцессора или микроконтроллера является только первым шагом на пути создания системы, соответствующей требованиям заказчика. Реализация такой системы является сложным и трудоемким процессом, выполнение которого на современном уровне невозможно без использования комплекса специализированных программных и аппаратных средств, помогающих разработчику на различных этапах проектирования, программирования и отладки. Поэтому при оценке и выборе типа микропроцессора или микроконтроллера для конкретного применения необходимо учитывать не только его технико-экономические характеристики, но и уровень развития программно-аппаратных средств, предлагаемых для использования в процессе проектирования-отладки систем на его основе.
Этап разработки АС может быть выполнен традиционными методами, с помощью которых проектируется и моделируется электрическая схема, разрабатывается печатная плата или комплект плат, после чего выполняются монтаж и отладка системы. Однако во многих слу-чаях можно обеспечить сокращение сроков и повышение качества разработки АС путем использования «полуфабрикатов» или готовых изделий, выпускаемых рядом производителей.
8.3.2. ТЕСТОВЫЕ ПРОЦЕДУРЫ
Если МП-система строится на основе использования типовых и стандартных элементов, то моделирование работы аппаратуры для проверки правильности её работы (ввиду невозможности влияния на содержимое этих элементов), как правило, не выполняется. Однако использование в учебных целях для уточнения представлений разработчика о функционировании таких элементов в отдельности или в каких-либо сочетаниях, естественно, допустимо, хотя обычно это совмещается с разработкой программного обеспечения, опирающегося на возможности проектируемых аппаратных средств. С другой стороны, обучение может производиться на достаточно дешевых аппаратных средствах типа Starter Kit.
8.3.3. АППАРАТНЫЕ СРЕДСТВА ОТЛАДКИ
На этапе автономной отладки АС основными орудиями разработчика являются традиционные измерительные приборы - осциллографы, мультиметры, пробники и другие, а также логические анализаторы, которые обладают широкими возможностями контроля состояния различных узлов системы в заданные моменты времени. Весьма эффективным является использование на этом этапе средств тестирования по стандарту JTAG, которые имеются в составе многих современных моделей микропроцессоров и микроконтроллеров. С помощью размещенного на кристалле тест-порта ТАР и специальных выводов TDI, TDO, ТСК, TMS, TRST# обеспечивается возможность подачи необходимых входных воздействий и считывания выходной реакции, запуск/останов процессора, изменение режима его работы. Вводом специальной команды можно установить выводы микропроцессора или микроконтроллера в отключенное состояние, чтобы отдельно протестировать другие устройства системы.
ПРОЕКТИРОВАНИЕ МПС
8.4. СРЕДСТВА И МЕТОДЫ РАЗРАБОТКИ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ
8.4.1. СРЕДСТВА ИНДИВИДУАЛЬНЫХ И ИНТЕГРИРОВАННЫХ ПАКЕТОВ
При разработке ПО для универсальных микропроцессорных систем используется достаточно широкий набор языков высокого уровня, для которых имеются соответствующие компиляторы. Чаще всего используются языки С, C++, FORTRAN, Pascal, Forth. Для решения ряда задач применяются языки поддержки искусственного интеллекта Ada, Modula-2 и некоторые другие. При программировании управляющих систем чаще всего используются машинно-ориентированный язык Ассемблера или языки С / C++. Язык Ассемблера применяется в случаях, когда имеются жесткие ограничения на объем требуемой памяти или на время выполнения программных модулей. Такие случаи являются достаточно типичными при решении задач управления, поэтому Ассемблеры являются одним из основных средств создания ПО для микроконтроллерных систем. В тех случаях, когда указанные ограничения не очень жесткие, для создания ПО используются языки высокого уровня (обычно С / C++).
Автономная отладка ПО выполняется с помощью симулятора - программной модели используемого микропроцессора или микроконтроллера. На этом этапе разработчики используют широкий набор средств программирования - компиляторы, ассемблеры, дисассемблеры, отладчики, редакторы связей и другие, без которых практически невозможно создание работоспособного ПО в течение ограниченных сроков выполнения проекта.
Как отмечалось выше, комплексная отладка АС и ПО является наиболее сложным и ответственным этапом создания системы. На этом этапе разработчик использует весь набор программных и аппаратных средств, применяющихся для автономной отладки АС и ПО, а также ряд специальных средств комплексной отладки. К числу таких средств относятся схемные эмуляторы - специализированные устройства, включаемые вместо микропроцессора или микроконтроллера прототипной системы и обеспечивающие возможность контроля ее работы с помощью персонального компьютера, связанного со схемным эмулятором. Схемные эмуляторы являются наиболее эффективным средством комплексной отладки систем.
Одним из наиболее эффективных средств комплексной отладки микроконтроллерных систем являются эмуляторы ПЗУ. Это устройство включается вместо ПЗУ прототипной системы и работает под управлением подключенного к нему персонального компьютера. Так обеспечивается текущий контроль за выполнением программы и ее оперативная коррекция, что значительно упрощает процесс отладки.
Для микроконтроллерных систем заключительной процедурой комплексной отладки является запись в ПЗУ объектных модулей отлаженной программы и завершающее испытание ее работоспособности. Запись программы в ПЗУ осуществляется с помощью специальных программаторов.
Для универсальных микропроцессорных систем после комплексной отладки производится оценка их производительности путем прогона специального набора тестовых программ (benchmarks).
После выполнения указанных этапов отлаженная прототипная система может быть испытана в рабочих условиях с подключением полного набора реальных периферийных устройств и объектов управления. В процессе опытной эксплуатации выявляются ошибки, не обнаруженные на этапе отладки, определяется реакция системы на возможные непредвиденные ситуации.
Как показывает данное описание процесса разработки, при создании современных микропроцессорных и микроконтроллерных систем используется комплекс программноаппаратных средств, которые помогают качественно и в ограниченные сроки выполнить их проектирование и отладку.
840
СРЕДСТВА И МЕТОДЫ РАЗРАБОТКИ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ
8.4.2. ПРОГРАММНЫЕ СРЕДСТВА ПОДДЕРЖКИ ПРОЕКТИРОВАНИЯ/ ОТЛАДКИ СИСТЕМ
В процессе разработки и отладки программного обеспечения микропроцессорных систем используются следующие программные средства:
• ассемблеры, компиляторы;
• симуляторы (программно-логические модели);
• отладчики, редакторы связей (компоновщики, загрузчики).
В современных комплексах проектирования/отладки систем эти средства обычно работают совместно, в составе интегрированной среды (оболочки) программирования.
Особенно сложные задачи приходится решать при программировании управляющих систем, работающих в реальном масштабе времени. В этом случае разработчик должен использовать какую-либо из имеющихся операционных систем реального времени (ОСРВ) или создавать собственные программы-мониторы реального времени с помощью указанных выше средств программирования. В составе многих ОСРВ имеются средства поддержки программирования, которые могут использоваться при проектировании/отладке системы.
Таким образом, при создании программного обеспечения микропроцессорных и микроконтроллерных систем разработчик имеет следующие возможности:
• использовать набор отдельных средств поддержки программирования (ассемблер или компилятор, симулятор, отладчик), которые предлагаются рядом фирм-производителей;
• выполнять программирование и отладку с помощью интегрированной среды разработки (development environment);
• разрабатывать программное обеспечение с помощью средств поддержки, имеющихся в составе ОСРВ, которая используется в проектируемой системе.
В настоящее время программирование и отладка чаще всего выполняются с помощью интегрированной среды развития или средств ОСРВ. Программирование производится обычно с помощью кросс-средств, инсталлированных на инструментальном компьютере с мощной операционной системой. В качестве инструментальных компьютеров используются персональные компьютеры (чаще всего IBM-РС старших моделей, реже PS-2 и Macintosh) или рабочие станции (SPARC фирмы «SUN Microsystems», DECStation, DEC-Alpha фирмы «Digital Equipment», HP-9000 фирмы «Hewlett-Packard», IBM RS/6000), иногда компьютеры типа VAX (фирмы «Digital Equipment»). Операционными системами этих компьютеров служат различные версии Windows и UNIX (Solaris, AIX, ULTRIX и другие).
Язык Ассемблера очень часто применяется при программировании микропроцессорных и микроконтроллерных систем, так, его использование обеспечивает существенное уменьшение объема памяти программ и времени выполнения программных модулей (до 20 - 50 %). Упрощенные (демонстрационные) версии Ассемблеров для всех семейств микропроцессоров и микроконтроллеров Motorola предоставляются бесплатно рядом фирм и распространяются по сети Интернет. Эти версии обычно имеют ограничения на объем транслируемых программ (до нескольких сотен или тысяч строк), а также не обеспечивают ряд сервисных возможностей. Ассемблеры с широким набором функциональных возможностей, включая макросы (макроассемблеры), поставляются рядом разработчиков, втом числе фирмой «Motorola».
В качестве языков высокого уровня чаще всего используются С, C++. Некоторыми фирмами поставляются также компиляторы для языков FORTRAN, Modula-2, Ada, Pascal. Все эти компиляторы обеспечивают также программирование на языке Ассемблера. Большинство из них содержат компоновщики для связи программных модулей, библиотеки функций. Многие компиляторы по указанию разработчика могут оптимизировать процесс трансляции исходного текста с целью получения объектного кода с минимальным объемом или минимальным временем выполнения программы. Такие компиляторы называются оптимизирующими.
841
ПРОЕКТИРОВАНИЕ МПС
8.5. СРЕДСТВА И МЕТОДЫ ОТЛАДКИ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ
8.5.1. ПРОГРАММНЫЕ СИСТЕМЫ МОДЕЛИРОВАНИЯ
Симуляторы (программно-логические модели) микропроцессоров и микроконтроллеров, используемые при отладке программ, редко поставляются в виде отдельных средств поддержки программирования. Обычно они входят в состав отладчиков.
Отладчики являются основным инструментом разработчика программного обеспечения, без которого практически невозможно получить работоспособные объектные модули рабочей программы. Отладчик реализует различные режимы выполнения транслированной программы - пошаговый или с остановами в контрольных точках, позволяет производить просмотр и коррекцию содержимого регистров и ячеек памяти, обеспечивает в точке останова контроль выполнения предыдущих шагов программы (просмотр трассы), дисассемблирование команд. Отладчик воспринимает программу на уровне исходного кода или в символическом виде, с использованием введенных разработчиком имен и меток. Символические отладчики являются наиболее удобным средством отладки, так как они представляют и воспринимают информацию в наиболее наглядной и удобной для программиста форме.
Помимо симулятора, отладчики содержат обычно компоновщик-загрузчик объектного кода, библиотеки стандартных функций (вычисление специальных и тригонометрических функций, обработка чисел с плавающей точкой и другие). Для визуализации состояния системы на экране монитора современные отладчики используют многооконный графический интерфейс. Многие отладчики могут работать не только с симуляторами, но и реализуют интерфейс со схемными эмуляторами, т. е. с реальными микропроцессорами или микроконтроллерами в процессе комплексной отладки системы.
8.5.2. ПРОТОТИПНЫЕ ПЛАТЫ ,
Этот класс средств проектирования микропроцессорных и микроконтроллерных систем является наиболее многочисленным. Условно их можно разделить на следующие типы:
• системные комплекты (evaluation kit) - набор размещенных на плате аппаратных средств, достаточных для реализации несложных систем;
• отладочные платы и системы (evaluation board, system) - размещенные на плате про-граммно-аппаратные комплексы, обеспечивающие моделирование и отладку систем различного назначения на базе определенных моделей микропроцессоров или микроконтроллеров;
• целевые платы (target board) - программно-аппаратные комплексы, ориентированные на использование после отладки в качестве прототипной системы;
• одноплатные компьютеры и контроллеры (single-board computer, controller) - конструктивные комплексы, предназначенные для использования в качестве базовых модулей при реализации целевых систем промышленного применения.
Эти средства могут использоваться для следующих целей:
• изучение функционирования определенных моделей микропроцессоров и микроконтроллеров, получение навыков их практического применения;
• тестирование и отладка программного обеспечения систем на реальных образцах микропроцессоров (микроконтроллеров);
• комплексная отладка макета системы, используемого затем в качестве образца для реализации прототипной системы;
• сборка и отладка прототипной или целевой системы, в состав которой входят платы развития в качестве базовых модулей.
842
СРЕДСТВА И МЕТОДЫ ОТЛАДКИ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ
Практически все типы плат разаития содержат в своем составе порты для подключения управляющего персонального компьютера. Чаще всего для этой цели используется последовательный обмен по стандарту RS-232. Ряд типов отладочных и целевых плат имеют также отдельное поле для макетирования пользователем дополнительных устройств с помощью проводного монтажа.
Ввиду большого разнообразия областей и способов применения номенклатура выпускаемых плат развития очень широка и четкие границы между их типами отсутствуют. Во многих случаях отладочные платы могут использоваться в качестве целевых, а одноплатные компьютеры часто служат средствами отладки прототипных систем. В данном разделе приводится краткое описание отдельных типичных представителей этого класса средств проектирования/отладки.
Отладочные платы серии M68HC05EVM, производимые фирмой «Motorola», служат для проектирования/отладки систем на базе семейства М68НС05. Ввиду большой номенклатуры этого семейства выпускается несколько типов таких плат для различных серий микроконтроллеров. Платы комплектуются соответствующими типами микроконтроллеров, эму-ляционной памятью емкостью 8 или 16 Кбайт, содержат резидентный отладчик, позволяющий выполнять отладку программ без использования управляющего компьютера. Порты микроконтроллера выведены на внешние разъемы платы, что дает возможность подключать к ней различные периферийные устройства. На плате расположен также программатор, который позволяет переписывать отлаженную программу в ПЗУ микроконтроллера, используемого в прототипной системе. Два отдельных последовательных порта типа RS-232 обеспечивают подключение к ней управляющего компьютера и монитора.
В режиме автономной отладки плата M68HC05EVM работает совместно с внешним монитором под управлением резидентного отладчика. При этом управление осуществляется с клавиатуры монитора, информация о состоянии системы выводится на экран его дисплея, отладка программы реализуется с помощью однострочного ассемблера - дисассемблера. При работе под управлением персонального компьютера может быть использован полный комплект программных средств проектирования/отладки. Имеющийся набор разнообразных плат развития помогает разработчику спроектировать и отладить макет или опытный образец системы, а в ряде случаев позволяет собрать рабочую систему из готовых модулей. При проектировании сложнофункциональных систем целесообразно использовать серийно выпускаемые SBC и различные периферийные модули, ориентированные на мезонинную технологию. Стандартизация этих изделий, их широкая номенклатура и высокие технические характеристики позволяют достаточно быстро собирать на их основе системы различного назначения. Для таких SBC и модулей имеется достаточно развитое программное обеспечение, что также упрощает и ускоряет создание системы, готовой для применения в реальных условиях. Поэтому платы развития, реализующие мезонинную технологию, наиболее перспективны для построения сложнофункциональных целевых систем.
Особенно следует отметить перспективность использования при разработке АС мезонинной технологии, которая унифицирует размеры и интерфейс базовой платы-носителя и размещаемых над ней небольших плат - мезонинов (типичный размер 45x99 мм). Одна плата-носитель несет от 2 до 12 мезонинов. Каждый мезонин соединяется с носителем двумя разъемами, которые выполняют также функции механических держателей. Один из разъемов подключается к локальной шине платы-носителя, функциональное назначение контактов второго разъема определяется типом мезонина, который может содержать многоканальную систему ввода/вывода, сетевые адаптеры и другие устройстаа. Используя серийно выпускаемые рядом производителей платы-носители и набор мезонинов, разработчик может быстро реализовать сложнофункциональные целевые системы для разнообразных применений.
843
ПРОЕКТИРОВАНИЕ МПС
Лидерами в этой области являются фирмы «GreenSpring Computers» (США) и «РЕР Modular Computer» (Германия), которые выпускают большую номенклатуру плат-носителей и мезонинов. Интеллектуальные плвты-носители представляют собой одноплатные компьютеры или контроллеры, реализованные на базе высокопроизводительных микропроцессоров (MC68030, MC68040 и др.) или микроконтроллеров (МС68332, МС68360 и др.), которые имеют связь с персональным компьютером. Такие носители могут выполнять функции плат развития и использоваться в составе прототипных и целевых систем. Серийно выпускаемые мезонины (их около 300 типов) выполняют функции дополнительной памяти и различных периферийных устройств: параллельных и последовательных портов, таймеров-счетчиков, АЦП и ЦАП, сетевых и шинных контроллеров и др. При необходимости разработчик может самостоятельно спроектировать мезонин, выполняющий функции, которые необходимы для прототипной или целевой системы.
Таким образом, мезонинная технология является наиболее эффективным средством разработки АС современных электронных систем различного назначения, позволяя конфигурировать их из стандартных плат при минимальных затратах времени и средств на разработку дополнительных АС.
8.5.3. ЭМУЛЯТОРЫ ПЗУ
Данное устройство используется при отладке систем, рабочая программа которых размещается в ПЗУ. Эмулятор ПЗУ содержит ОЗУ, которое подключается к системе вместо управляющего ПЗУ, и работает под управлением подключенного к эмулятору базового компьютера. В простейшем случае эмулятор ПЗУ позволяет в процессе отладки выполнять многократное оперативное изменение рабочей программы. Окончательный вариант рабочей программы заносится в ПЗУ системы после отладки.
Более сложные «интеллектуальные» эмуляторы ПЗУ имеют более широкие функциональные возможности. Используя один из входов прерывания системы, они позволяют останавливать ее работу в заданных контрольных точках аналогично схемному эмулятору. При этом на дисплее базового компьютера может быть представлено содержимое эмулирующей памяти. В случае использования в эмуляторе памяти трассы можно обеспечить просмотр предыдущих шагов обращения к ПЗУ, т. е. проверить последовательность выбиравшихся команд. Во многих случаях такая информация является достаточной для выполнения отладки микроконтроллерных систем. В качестве примера эмуляторов ПЗУ этого класса можно привести IDS/LC, выпускаемый компанией «Cactus Logic» (США).
Таким образом, эмуляторы ПЗУ могут выполнить значительную часть функций схемных эмуляторов. При этом их реализация оказывается проще и дешевле, так как они не эмулируют функции микроконтроллера, который в процессе отладки продолжает работать в составе системы. Вследствие этого эмуляторы ПЗУ являются универсальными средствами, которые могут использоваться для отладки систем с различными моделями микроконтроллеров.
8.5.4. ВНУТРИСХЕМНЫЕ ЭМУЛЯТОРЫ
Схемный эмулятор (СЭ) представляет собой программно-аппаратный комплекс, который в процессе отладки замещает в реализуемой системе микропроцессор или микроконтроллер. В результате такой замены функционирование отлаживаемой системы становится наблюдаемым и контролируемым. Разработчик получает возможность визуального контроля за работой системы на экране дисплея и управления ее работой путем установки определенных управляющих сигналов и модификации содержимого регистров и памяти.
844
СРЕДСТВА И МЕТОДЫ ОТЛАДКИ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ
Благодаря наличию таких возможностей СЭ является наиболее универсальным и эффективным отладочным средством, используемым на этапе комплексной отладки системы.
Наиболее широкое применение получили СЭ, подключаемые к базовому управляющему компьютеру типа IBM PC или рабочей станции. Обычно такие СЭ конструктивно оформлены в виде прибора, размещенного в отдельном корпусе с автономным источником питания и соединенного с последовательным COM-портом базового компьютера. Некоторые типы эмуляторов для ускорения обмена связываются с компьютером через параллельный порт. С помощью плоского кабеля к СЭ подключается эмуляторная головка, которая имеет вилку для включения в систему вместо эмулируемого микропроцессора или микроконтроллера. В головке размещается эмулирующий микропроцессор (микроконтроллер), который выполняет те же функции, что и эмулируемый, но работает под управлением компьютера. Большинство СЭ предназначено для работы с определенным семейством микропроцессоров (микроконтроллеров), причем для эмуляции каждой модели семейства используется соответствующая головка.
В структуру СЭ входят следующие блоки:
• эмулятор микропроцессора или микроконтроллера (размещается в эмуляторной головке);
• память трассы, которая хранит значения сигналов, устанавливаемых на выводах микропроцессора (микроконтроллера) в процессе выполнения программы;
• блок контрольных прерываний, который реализует остановы в контрольных точках, заданных пользователем с клавиатуры компьютера;
• эмуляционная память ( ОЗУ), которая заменяет в процессе отладки внутреннее ПЗУ микроконтроллеров или другие разделы памяти, внешний доступ к которым в процессе отладки ограничен;
• таймер, используемый для контроля времени выполнения отлаживаемых фрагментов программы.
СЭ позволяет вводить в систему тестовую или рабочую программу и контролировать ее выполнение, обеспечивая прерывания в контрольных точках. Условиями прерывания могут быть различные комбинации значений адреса, данных и управляющих сигналов, поступающих на выводы эмулирующего микропроцессора или микроконтроллера. Эти комбинации задаются пользователем с клавиатуры управляющего компьютера. После останова пользователь может получить на экране полную информацию о текущем состоянии любых регистров и ячеек памяти системы. С помощью памяти трассы можно просмотреть состояния системной шины для определенного числа предыдущих циклов выполнения программы. Дисассемблер дает возможность анализировать выполнение программы в соответствии с ее исходным текстом на языке Ассемблера.
Память трассы работает почти аналогично памяти ЛА, поэтому СЭ может выполнять также его функции. Число устанавливаемых контрольных точек обычно составляет несколько десятков, хотя некоторые модели современных СЭ обеспечивают существенно большие возможности. Объем памяти трассы в различных СЭ позволяет контролировать от 4К до 512К программных циклов. Таймер служит для определения времени выполнения фрагментов программы с учетом реальной тактовой частоты системы.
Программное обеспечение СЭ состоит из монитора - служебной программы, обеспечивающей работу всех блоков под управлением базового компьютера, компилятора или Ассем-! блера, позволяющих программировать работу системы на языке высокого уровня или Ассемблера, и отладчика. Данные программные средства обычно функционируют в составе интегрированной среды проектирования/отладки. Большинство современных СЭ используют символьные отладчики и дисассемблеры, применение которых делает процесс отладки более простым и наглядным. Программное обеспечение СЭ реализует в процессе отладки выдачу данных на экран монитора в удобном для пользователя многооконном формате.
845
ПРОЕКТИРОВАНИЕ МПС
Многие типы СЭ содержат эмуляционное ОЗУ, которое заменяет ПЗУ отлаживаемой системы. Благодаря такой замене можно в процессе отладки производить оперативное изменение содержимого этой памяти. После отладки содержимое эмуляционного ОЗУ переносится в рабочее ПЗУ системы.
Кроме описанных сложно функциональных и дорогих моделей СЭ рядом производителей выпускаются их упрощенные варианты, реализованные на одной печатной плате. Такие СЭ обладают ограниченными возможностями: имеют существенно меньший объем памяти трассы, не реализуют функции ЛА, не обеспечивают символьной отладки и т. д. Однако они позволяют выполнять отладку систем малой и средней сложности, имеют на порядок более низкую стоимость, поэтому находят достаточно широкое практическое применение. Некоторые типы плат развития также выполняют часть функций СЭ.
Некоторые модели СЭ предоставляют возможности анализа эффективности выполняемой программы, обеспечивая информацию о частоте обращения к определенным ее фрагментам, и позаоляют производить отладку мультипроцессорных систем с помощью организации многоэмуляторных комплексов.
СЭ, реализующие набор вышеперечисленных функций, называют отладочными комплексами, или системами развития (development system). Такие комплексы выпускаются для различных семейств фирмой «Motorola» (MMDS05, MMDS11, CDS32) и рядом других производителей.
8.5.5. ИНТЕГРИРОВАННЫЕ СРЕДЫ РАЗРАБОТКИ (ОБОЛОЧКИ)
Рассмотрим состав и функции интегрированной среды разработки на примере SingleStep фирмы SDS («Software Development Systems», США), которая является наиболее распространенным средством программирования систем на базе 32-разрядных микропроцессоров и микроконтроллеров Motorola.
Широкое применение среды SingleStep определяется рядом факторов. Во-первых, среда SingleStep обеспечивает как автономную отладку программного обеспечения с помощью симуляторов, так и комплексную отладку систем с применением схемных эмуляторов, плат развития и логических анализаторов. Во-вторых, эта среда является открытой, что позволяет использовать для отладки систем большое количество программных и аппаратных средств, созданных не только SDS, но и многими другими фирмами. В-третьих, среда обеспечивает широкие возможности создания систем реального времени на базе программного обеспечения, создаваемого разработчиком, или с использованием ядра ОСРВ из имеющегося набора.
Интегрированная среда SingleStep служит для программирования и отладки систем, реализованных на базе семейств М680х0, М683хх, МРСбхх, МРСбхх, МРС8хх, МСБбххх. В качестве инструментального компьютера могут использоваться персональные компьютеры IBM-РС, работающие в среде Windows, рабочие станции фирм Sun Microsystems или Hewlett-Packard с UNIX-подобными операционными системами. Для трансляции исходных текстов используются компиляторы CrossCode фирмы CDS или компиляторы ряда других производителей: Microtec Research, Cygnus, GreenHills и др.
В состав среды SingleStep кроме символьного отладчика входят следующие программные средства (рис. 8.5):
• графические средства разработки, обеспечивающие с помощью инструментального компьютера многооконный графический интерфейс;
• симуляторы процессоров указанных выше семейств микропроцессоров и микроконтроллеров, а также модели некоторых периферийных устройств-таймеров, последовательных портов UART;
846
СРЕДСТВА И МЕТОДЫ ОТЛАДКИ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ
Ядра систем реального времени
| VxWorks"] [ Precise~| [ Nucleus"] | pSOS ~]
OSF
RTEK
RTXC
AMX
Мониторы РВ пользователя
ОС инструментального компьютера
Sun OS
SDS - Модули адаптации
Solaris
HP-UX
Windows
SDS - Графические средства разработки
SDS - Симуляторы процессоров и периферийных устройств
Интегрированная среда разработки SINGLESTEP
SDS-набор средств адаптации
SDS - Резидентные мониторы-отладчики
Схемные эмуляторы
Логические анализаторы
Платы развития
SDS CrossCode
Cygnus GNU
MetaWare
GreenHills Computers
Microtec Research
Intermetrics Microsystems
Diab Data
Компиляторы
Рис. 8.5. Состав программных средств интегрированной среды SingleStep
• резидентные мониторы-отладчики, загружаемые в память плат развития при их использовании для комплексной отладки систем;
• мониторы-драйверы, обеспечивающие в процессе комплексной отладки управление схемными эмуляторами, платами развития, логическим анализатором.
Возможны два варианта применения среды SingleStep.
В режиме автономной отладки программного обеспечения реализуется прогон программы на симуляторе со скоростью до 100 тыс. команд в секунду. При этом для большинства используемых микропроцессоров и микроконтроллеров обеспечивается точное воспроизведение числа тактов, требуемых для выполнения команд и программных модулей. Таким образом, в процессе отладки можно достаточно точно определять время выполнения программ. При отладке заполняется память трассы емкостью до 1 млн команд, которая доступна пользователю для просмотра и коррекции. Наличие моделей периферийных устройств позволяет имитировать выполнение программы в реальных условиях, когда требуется учитывать состояние других устройств системы.
В режиме комплексной отладки интегрированная среда контролирует работу отлаживаемой системы с помощью схемного эмулятора или путем подключения к плате развития, служащей в качестве прототипной системы. Для контроля состояния системы в процессе отладки может использоваться логический анализатор. При этом в память системы загружается резидентный монитор-отладчик, а инструментальный компьютер управляет схемным эмулятором, платой развития и логическим анализатором с помощью мониторов-драйверов. Среда SingleStep обеспечивает поддержку отладки с помощью режима BDM и внутренних средств эмуляции, введенных в семействах МРСбхх и MCF52xx (установка контрольных точек, точек наблюдения и др.), тестирование с применением средств JTAG. Средства SingleStep позволяют данной среде эффективно работать с рядом схемных эмулято
847
ПРОЕКТИРОВАНИЕ МПС
ров (visionICE, BDM-эмуляторы серии 300 фирмы EST) и плат развития, включая IDP, MVME162, 1603, 1604, ADS, QUADDS фирмы «Motorola», SBC фирм «Arnewsh» и «GreenSpring» и ряд других. Реализуется также совместная работа с эмуляторами ПЗУ типов PROMICE, NetROM) и логическими анализаторами фирм «Tektronix», «Hewlett-Packard».
В состав среды SingleStep входят специальные средства для разработки систем, работающих в реальном режиме времени. В этом случае пользователю предоставляется две возможности.
1. Включение в состав программного обеспечения системы ядра реального времени аналогичного тем, которые используются в современных ОСРВ. Возможно введение ядер таких распространенных ОСРВ, как pSOS, VxWorks, OSE, RTXC и ряда других. Включение ядра в программное обеспечение пользователя производится с помощью имеющихся в SingleStep модулей адаптации. Использование готовых ядер значительно сокращает время разработки программного обеспечения, дает гарантии надежного функционирования системы в реальном масштабе времени.
2. Разработка собственного монитора реального времени с помощью имеющегося в состаае среды SingleStep набора средств адаптации. Этот способ решения проблемы более трудоемкий и применяется в тех случаях, когда готовые ядра не удовлетворяют предъявляемым требованиям, чаще всего по объему необходимой памяти или времени отклика на внешние события.
Интегрированная среда Single Step может эффективно использоваться для программирования и комплексной отладки систем, реализованных на базе 32-разрядных микропроцессоров и микроконтроллеров Motorola, обеспечивая при этом широкие возможности разработки программного обеспечения для работы в режиме реального времени.
8.6. СРЕДСТВА И МЕТОДЫ КОМПЛЕКСНОЙ ОТЛАДКИ МП-СИСТЕМ
8.6.1. ПРОГРАММАТОРЫ
Эти устройства необходимы на заключительном этапе разработки систем, когда требуется записать отлаженную программу а ПЗУ, которое входит в состав микроконтроллера или реализуется в виде отдельного модуля. Выпускается два вида программаторов:
1) специализированные программаторные платы;
2) универсальные программаторы.
Программаторные платы предназначены для программирования одного типа микроконтроллеров или микросхем ПЗУ, которые включаются в имеющуюся на плате панельку. Платы подключаются к последовательному порту управляющего персонального компьютера, с помощью которого выполняется программирование. Данные вводятся с клавиатуры компьютера, отображаются на его экране и после редактирования загружаются в буферную память. Затем содержимое этой памяти переписывается в программируемое ПЗУ с помощью размещенных на плате формирователей сигналов требуемой мощности и длительности. После программирования выполняется верификация путем считывания и сравнения содержимого ПЗУ и буферной памяти. При выявлении несовпадений производится повторное программирование соответствующих ячеек.
Некоторые типы программаторных плат работают без управляющего компьютера. Они используют размещенный на плате резидентный контроллер со служебным ПЗУ, где содержится управляющая программа. Вместо буферного ОЗУ на плате располагается панелька для включения микросхемы памяти (ОЗУ или ЭСППЗУ), в которую предварительно
848
СРЕДСТВА И МЕТОДЫ КОМПЛЕКСНОЙ ОТЛАДКИ МП-СИСТЕМ
записывается требуемое содержимое ПЗУ. Под управлением контроллера производится перезапись этого содержимого в программируемое ПЗУ, верификация результата и, при необходимости, повторное программирование.
Недорогие программаторные платы (их стоимость менее 100 дол.) M68HC05PGMR, M68HC705xxPGMR выпускаются фирмой «Motorola» для семейства М68НС705, M68HC11SPGMR, М68НС71 lxxPGMR-для семейства М68НС711. Программаторные платы производятся для этих семейств также фирмой «Nash Electronics» (Model N680-4, N705-1, N705-2, N805-2, NHC11) и рядом других.
Недостатком этих плат является их специализация на программирование одной или нескольких однотипных моделей микроконтроллеров или микросхем памяти. При использовании большой номенклатуры таких изделий целесообразно применять универсальные программаторы, которые выпускаются рядом зарубежных и российских производителей.
Универсальные программаторы работают под управлением компьютера и имеют два варианта конструктивной реализации:
1) в виде платы расширения, размещаемой внутри управляющего компьютера, с которой соединяется внешний коммутационный блок, имеющий панельки для включения программируемых изделий (микроконтроллеров или микросхем ПЗУ);
2) в виде отдельного устройства, имеющего на корпусе панельки для включения программируемых изделий, которое подключается к последовательному или параллельному порту компьютера.
В качестве примера зарубежных приборов этого типа можно привести программаторы Model 3000, Model 5000 фирмы «Elan Systems», которые могут программировать всю номенклатуру семейств. Эти устройства необходимы на заключительном этапе разработки систем, когда требуется записать отлаженную программу в ПЗУ, которое входит в состав микроконтроллера или реализуется в виде отдельного модуля. Выпускается даа вида программаторов: 1) специализированные программаторные платы; 2) универсальные программаторы.
8.6.2. ЛОГИЧЕСКИЕ АНАЛИЗАТОРЫ
Логические анализаторы (ЛА) являются универсальными приборами для анализа функционирования цифровых систем. Они позволяют контролировать логическое состояние нескольких десятков точек системы в течение заданного промежутка времени и выдать информацию о состоянии в визуальном (на экране монитора) или печатном виде. Форма представления может быть символьная или графическая (временные диаграммы сигналов). Входные каналы ЛА подключаются к точкам контроля с помощью зондов-клипсов или разъемов. Число каналов в современных ЛА обычно составляет от 16 до 150. Запуск анализатора производится автоматически при поступлении на определенные каналы заданного кода (адреса, данных или комбинации управляющих сигналов) или последовательности кодов. После запуска в память ЛА записывается последовательность значений логических сигналов в точках контроля. Объем этой памяти определяет число контролируемых точек на временной оси (глубину контроля), которое для большинства ЛА составляет от 2 К до 32 К. На экран выводятся несколько десятков точек для каждого канала с возможностью просмотра всей записанной в памяти последовательности состояний. Максимальная частота дискретизации временных интервалов для различных моделей ЛА имеет значение от 20 до 200 МГц.
ЛА реализуются в виде автономных измерительных приборов или плат расширения, подключаемых к базовому (host) персональному компьютеру. Эти приборы часто включают ряд дополнительных устройств, например, программируемый генератор тестовых пос
849
ПРОЕКТИРОВАНИЕ МПС
ледовательностей. ЛА, реализованные в виде автономных приборов, выпускаются рядом ведущих производителей электронно-измерительной аппаратуры: Tektronix, Hewlett-Packard, John Fluke и др. Наиболее широко при отладке систем используются ЛА типа 16500В (Hewlett-Packard), 3001GPX и 3002GPX (Tektronix), РМ3580 (Fluke), CLAS 4000 (Embedded Performance/ Biomation). Их стоимость составляет несколько тысяч долларов.
Чтобы обеспечить разработчиков недорогими средствами контроля состояния системы, ряд производителей выпускает анализаторные платы, подключаемые к базовому персональному компьютеру, который программируется на выполнение значительной части функций ЛА. При этом для хранения последовательности состояний используется память базового компьютера. Визуализация временных диаграмм в символьной или графической форме выполняется на дисплее его монитора, можно выполнить распечатку результатов измерений на принтере. Базовый компьютер управляет процессом измерения и производит обработку результатов. Благодаря этому анализаторная плата оказывается достаточно простой и на порядок более дешевой, чем автономный ЛА.
8.6.3. ВСТРОЕННЫЕ В МП СРЕДСТВА ОТЛАДКИ
Следует отметить, что многие модели микропроцессоров и микроконтроллеров, выпускаемых фирмой «Motorola», имеют специальный режим отладки BDM, при котором реализуется ввод команд, ввод/вывод данных, управление режимом работы процессора с помощью специального последовательного порта. При его использовании микропроцессор или микроконтроллер может работать в режиме эмуляции под управлением подключаемого к этому порту персонального компьютера. Режим BDM позволяет существенно облегчить процедуру комплексной отладки и использовать при этом более простые и дешевые средства.
8.7. ОПЕРАЦИОННЫЕ СИСТЕМЫ РЕАЛЬНОГО ВРЕМЕНИ
8.7.1. ОСНОВНЫЕ СВОЙСТВА И МЕХАНИЗМЫ ОСРВ
Операционные системы реального времени (ОСРВ) используются в тех случаях, когда работоспособность обслуживаемой ими цифровой системы определяется не только результатом обработки поступившей информации, но и длительностью времени получения результата. Области практического применения ОСРВ очень широки - это системы автоматизации производства, контрольно-измерительные системы, телекоммуникационная аппаратура, авиационно-космическая и военная техника, транспорт, системы обеспечения безопасности и ряд других приложений. В этих приложениях ОСРВ должны обеспечить не только получение необходимого логического результата - отклика на внешние события, но и реализовать требуемые интервалы времени между событиями и откликом или заданную частоту приема внешних данных и выдачи результатов.
Современные ОСРВ должны удовлетворять ряду противоречивых требований: малый объем, достаточный для размещения в резидентной памяти системы, малое время отклика, реализация многозадачного режима с гибким механизмом приоритетов, наличие сервисных функций и средств поддержки для разработки прикладных программ и ряд других. В настоящее время разработчику систем предлагается ряд ОСРВ, имеющих различные характеристики и прошедших апробацию в многочисленных областях применения, что позволяет ему найти компромиссное решение для выполнения поставленной задачи. Наибо
850
ОПЕРАЦИОННЫЕ СИСТЕМЫ РЕАЛЬНОГО ВРЕМЕНИ
лее часто в системах на базе микропроцессоров и микроконтроллеров «Motorola» используются следующие ОСРВ:
OS-9 фирмы «Microware Systems»;
VxWorks фирмы «WindRiver Systems»;
LynxOS фирмы «Lynx Real-Time Systems»;
pSOS+ фирмы «Integrated Systems»;
QNX фирмы «Quantum Software Systems»;
VRTX/OS 3.0 фирмы «Ready Systems»;
Nucleus фирмы «Accelerated Technology»;
RTXC фирмы «Embedded System Products»;
OSE фирмы «Епеа Data»;
Precise/MQX фирмы «Intermetrics Microsystems Software»;
VMEexec фирмы «Motorola».
Принято подразделять ОСРВ на два класса-системы «жесткого» и «мягкого» реального времени (РВ). Системы «жесткого» РВ имеют минимальные объем и время отклика, но обладают весьма ограниченными сервисными средствами. Типичным примером ОСРВ этого класса служит VMEexec. Системы «мягкого» РВ требуют большего объема памяти, имеют более длительное время отклика, но зато удовлетворяют широкому спектру требований пользователя по режиму обслуживания задач, уровню предоставляемого сервиса. Примером такой ОСРВ может служить OS-9/9000.
Однако для современных ОСРВ данная классификация является весьма условной. Ряд ОСРВ, относящихся к классу «жестких», имеют средства интерфейса, которые позволяют в случае необходимости использовать высокоэффективные отладчики или интегрированные среды разработки, обеспечивая, таким образом, пользователя набором средств поддержки программирования/отладки систем. Например, VMEexec может использоваться совместно с интегрированной средой MULTI фирмы «GreenHills Software», VxWorks с интегрированной средой Tornado, в составе которой поставляются отладчик CrossWind и GNU-компиляторы фирмы «Cygnus Support», VRTX и pSOS с отладчиком XRAY и компиляторами фирмы «Microtec Research». С другой стороны, системы «мягкого» РВ реализуются по модульному принципу, что позволяет использовать только те средства, которые необходимы в данном приложении. В результате для конкретного применения достигается существенное сокращение объема необходимой памяти и времени отклика. Например, для ядра OS9/ 9000 время отклика не превышает 20 мкс (для VMEexec, VxWorks, pSOS - менее 10 мкс), что является вполне достаточным для многих приложений.
8.7.2. ПРИМЕРЫ ОСРВ И ИХ ФУНКЦИОНАЛЬНЫЕ ВОЗМОЖНОСТИ ДЛЯ ПРОЕКТИРОВАНИЯ/ОТЛАДКИ СИСТЕМ
В качестве примера рассмотрим ОСРВ типа OS-9 и VxWorks, которые наиболее часто используются в системах автоматизации производства и телекоммуникационных системах, реализованных на базе микропроцессоров и микроконтроллеров фирмы «Motorola».
OS-9 относится к классу систем «мягкого» РВ. Эта ОСРВ имеет две версии: OS-9 написана на языке ассемблера Motorola 68К и предназначена для работы с семействами М680х0 и М683хх, OS-9000 написана на языке С и может работать с семействами МРСбхх, МРСбхх, МРС8хх, MCF52xx, а также с микропроцессорами ряда других произаодителей: Intel 486, Pentium, SPARC, MIPS. Обе версии обеспечивают полную совместимость объектных кодов, поэтому для них обычно используется общее название - OS-9. В качестве инструментального компьютера OS-9 использует IBM-РС, работающие в среде Windows,
851
ПРОЕКТИРОВАНИЕ МПС
или рабочие станции Sun, HP, IBM RS/6000 с операционными системами типа UNIX. В резидентном варианте OS-9 функционирует на базе собственных ресурсов целевой системы.
Характерными особенностями OS-9 являются модульность и гибкость ее структуры. Модульность обеспечивает возможность конфигурации целевой ОСРВ в соответствии с классом решаемых задач. За счет исключения неиспользуемых модулей достигается сокращение объема памяти и стоимости системы. Гибкость структуры позволяет достаточно просто и быстро производить реконфигурацию системы, расширение ее функциональных возможностей.
Все функциональные компоненты OS-9: ядро реального времени (OS-9 kernel), общие средства ввода/вывода (I/O man), файловые менеджеры, средства разработки программ -реализованы в виде автономных модулей, обеспечивающих работу системы с различными аппаратными средствами. Комбинируя эти модули, разработчик может создавать целевые операционные системы различной конфигурации и функциональных возможностей -от несложных резидентных ОСРВ, хранящихся во внутреннем ПЗУ микроконтроллера, до сложнофункциональных многопользовательских систем разработки. Все модули OS-9 могут размещаться в ПЗУ. Любые модули могут удаляться или добавляться с помощью простых команд, не требующих повторной компиляции или перекомпоновки.
OS-9 предоставляет пользователю возможность выбора ядра в зависимости от функционального назначения системы.
Ядро Atomic имеет малый объем (24 Кбайт) и обеспечивает минимальное время отклика. Например, при использовании микропроцессора MC68040 с тактовой частотой 25 МГц время реакции ядра на запрос прерывания составляет всего Змкс, что соответствует быстродействию систем «жесткого» РВ. Это ядро реализует минимальное число сервисных функций (дистанционную загрузку, связь с локальной сетью, управление ведомыми микроконтроллерами) и применяется в системах, встраиваемых в различную аппаратуру.
Ядро Standard обеспечивает выполнение широкого набора функций сервиса и разработки прикладных программ. Однако для реализации этих функций требуется больший объем памяти - 67 Кбайт ПЗУ и 38 Кбайт ОЗУ для систем на базе М68х0х,М683хх (версия OS-9) до 512 Кбайт для этих же систем, использующих пакет поддержки обмена по сети Интернет, 75 Кбайт ПЗУ и 24 Кбайт ОЗУ для систем на базе PowerPC (версия OS-9000). Применение ядра Standard с различным набором других функциональных модулей позволяет реализовать системы различной сложности и назначения - от встраиваемых в аппаратуру контроллеров с резидентным программным обеспечением и простейшими средствами ввода/вывода до сложнофункциональных систем класса рабочих станций с развитой сетевой поддержкой и обеспечением разнообразных функций сервиса, включая мультимедиа.
Файловыми менеджерами называются модули, управляющие логическими потоками данных, каждый из которых имеет определенное функциональное назначение и спецификацию. В состав OS-9 входят более 20 файловых менеджеров, которые можно разделить на три группы: стандартные, сетевые и коммуникационные, графические и мультимедиа. Рассмотрим основные из них (рис. 8.6).
Стандартные менеджеры входят в основной комплект системы и предназначены для выполнения базовых функций обмена с внешними устройствами. К ним относятся следующие файловые менеджеры:
• pipeman - организующий очередь поступающих команд;
• scf — управляющий байтовым последовательным обменом (связь с терминалом и другими устройствами по последовательному каналу);
• rbf - управляющий блочным обменом с прямым доступом к памяти (связь с дисковой памятью);
• sbf- управляющий блочным последовательным обменом (связь с накопителями на магнитных лентах и другими устройствами);
• pcf- поддерживающий файловую DOS-систему (поставляется по требованию заказчика).
852
ОПЕРАЦИОННЫЕ СИСТЕМЫ РЕАЛЬНОГО БРЕМЕНИ
Стандартные менеджеры (базовые функции)
у V ТГ JT ТГ X
0S-9 Tool Kit
Ядра а___ь реального времени
ч * (Atomic или Standard)
Менеджеры графического интерфейса и мультимедиа
2=3 BSP 1
Средства поддержки проектирования/ отладки системы
X JL JLJLIJLirJLr£ nfs | | nfm | | isp | | ism | | spf | | rfnfm | | profiman |
Сетевые и коммуникационные менеджеры
Рис. 8.6. Основные модули, входящие в состав ОСРВ OS-9
Общее управление внешними устройствами обеспечивает модуль ioman.
Сетевые и коммуникационные менеджеры обеспечивают работу OS-9 с различными сетями и обмен данными по каналам связи с наиболее распространенными стандартами протоколов обмена. Чаще всего из этой группы используются следующие менеджеры:
• nfs, nfm, isp - обеспечивающие основные протоколы сетевого обмена;
• profiman - реализующий протокол обмена с шиной Profibus;
• ism - реализующий обмен по сети цифровой связи стандарта ISDN;
• spf - обеспечивающий пакетный обмен по стандартному протоколу Х.25;
• rtnfm - поддерживающий обмен по сети реального времени.
Для реализации графического интерфейса и работы с мультимедиа-приложениями используются файловые менеджеры:
• gfm - графический менеджер реального времени;
• mpfm - управляющий движущимся изображением;
• mfm - обеспечивающий пользовательский интерфейс с мультимедиа;
• g-windows - система оконного графического интерфейса, разработанная фирмой «Gespac» в виде файлового менеджера для OS-9.
Физический интерфейс OS-9 с разнообразными внешними устройствами обеспечивается большим набором драйверов, которые созданы как фирмой «Microware Systems», так и многочисленными разработчиками аппаратуры, использующей эту операционную систему для конкретных приложений. Большинство драйверов, реализующих интерфейс со стандартными внешними устройствами, входят в пакет, из которого пользователь может выбрать необходимые средства для своего проекта.
В составе OS-9 имеется также пакет программ BSP для поддержки плат развития, который обеспечивает совместную работу OS-9 с целым рядом SBC, включая SBC типа MVME162,172,1603,1604 фирмы «Motorola». Используя BSP, OS-9 и какой-либо из этих SBC, разработчик может быстро сконфигурировать мощную целевую систему для своего конкретного приложения.
853
ПРОЕКТИРОВАНИЕ МПС
OS-9 содержит средства поддержки программирования, позволяющие проектировщику создавать прикладное программное обеспечение. Эти средства включают компиляторы Ultra C/C++ , текстовый редактор EMACS, три вида отладчиков, в том числе символьные, а также разнообразные утилиты для организации контроля и сборки программных проектов. Кроме того, проектировщик может использовать большой набор совместимых с OS-9 текстовых редакторов, компиляторов C/C++, Forth, Ada, Modula-2 и других языков, которые разработаны рядом других фирм.
Для удобства пользователя совместно с OS-9 поставляются набор средств програм-мирования/отладки OS-9 Тool Kit, интегрированная среда разработки FasTrak. В состав OS-9 Tool Kit входят основные средства разработки программ, указанные выше.
Интегрированная среда разработки FasTrak предоставляет пользователю наиболее полный комплект средств программирования/отладки. FasTrak имеет две версии: для функционирования в среде Windows на инструментальных компьютерах IBM-РС; для функционирования с системой UNIX на рабочих станциях SUN, HP, IBM RS/6000. Часть программных средств FasTrak инсталлируется на инструментальном компьютере, а часть - на целевой системе пользователя. Интерфейс инструментального компьютера и целевой системы осуществляется файловым менеджером isp, который реализует протокола TCP/IP, обеспечивая связь по последовательному каналу или по сети Ethernet.
Среда FasTrak интегрирует все средства, необходимые для поддержки проектирования/отладки целевых систем. Версия FasTrak для IBM-РС содержит высокоэффективный текстовый редактор Premia’s Codewright, который имеет средства перекодировки клавиатуры, обеспечивающие пользователю возможность вести редактирование в удобном для него формате. Версия для UNIX-станций позволяет использовать любой редактор, функционирующий с ОС UNIX. В состав FasTrak входят компиляторы Ultra C/C++, возможно также использование других компиляторов, например GNU C/C++ фирмы «Cygnus Support». Отладчики FasTrak обеспечивают два режима отладки: пользовательский - для создания прикладных программ, и системный, который выполняет обслуживание прерываний, системных вызовов и обращение к ядру РВ. Реализуется также отладка мультипроцессорных систем. При выполнении контрольных прогонов рабочей программы программа-профилировщик дает информацию о количестве обращений к различным программным модулям и времени их выполнения. В составе среды FasTrak имеются средства интерфейса с логическими анализаторами фирмы «Hewlett-Packard» и схемными эмуляторами фирм «Hewlett-Packard», EST, «Applied Microsystems», «Orion». Широкий набор функциональных возможностей делает среду FasTrak эффективным средством создания программного обеспечения для разнообразных микропроцессорных и микроконтроллерных систем.
Модульная структура ОСРВ OS-9 позволяет легко конфигурировать ее в соответствии с потребностями заказчиков. В настоящее время фирма «Microware Systems» поставляет ряд системных пакетов, ориентированных на различные сферы приложения:
• Wireless OS-9 - для разработки устройств беспроводной связи: сотовых телефонов, пейджеров, портативных цифровых ассистентов (PDA);
• Internet OS-9 - для разработки устройств с доступом к сети Internet;
• Digital Audio/Video Interactive Decoder (DAVID) OS-9 - для разработки распределенных систем цифрового интерактивного телевидения.
Таким образом, ОСРВ OS-9 позволяет удовлетворить запросы широкого круга разработчиков, создающих системы реального времени и программное обеспечение для них.
VxWorks относится к классу систем «жесткого» РВ. Эта ОСРВ предназначена для работы с семействами М680х0, М683хх, МРСбхх, МРСбхх, МРС8хх, MCF52xx, а также с микропроцессорами других производителей: Intel 486, Pentium, SPARC, MIPS, DEC Alpha, HP PA-RISC. В качестве инструментального компьютера используются IBM-РС, работающие в среде Windows, или рабочие станции SUN, HP, DEC, IBM RS/6000 с операционными сис-854
ОПЕРАЦИОННЫЕ СИСТЕМЫ РЕАЛЬНОГО ВРЕМЕНИ
темами типа UNIX. При выполнении отладки VxWorks, которая инсталлируется на отлаживаемой целевой системе, работает совместно с интегрированной средой разработки Tornado, функционирующей на инструментальном компьютере.
VxWorks имеет иерархическую организацию, нижним уровнем которой служит микроядро РВ, выполняющее базовые функции планирования задач и управления их связью и синхронизацией. Все остальные функции - управление памятью, вводом/выводом, сетевым обменом и другие, реализуются дополнительными модулями. Микроядро с минимальным набором модулей занимает 20 - 40 Кбайт памяти. Для встроенных систем, имеющих жесткие ограничения на объем памяти, разработано редуцированное ядро WindStream, которое требует для работы всего 8 Кбайт ПЗУ и 2 Кбайт ОЗУ.
Для реализации графических приложений используется система графического интерфейса VX-Windows. В тех случаях, когда ограниченный объем памяти целевой системы не позволяет использовать VX-Windows, предлагается графическая библиотека RTGL, которая содержит базовые графические примитивы, наборы шрифтов и цветов, драйверы типовых устройств ввода и графических контроллеров. В состав VxWorks входят также различные средства поддержки разнообразных сетевых протоколов: Х.25, ISDN, ATM, SS7, Frame Relay и ряда других.
Специальные средства отладки в реальном масштабе времени обеспечивают трассировку заданных событий и их накопление в буферной памяти для последующего анализа. Трассировку системных событий выполняет динамический анализатор WindView, который работает аналогично логическому анализатору, отображая на экране временные диаграммы переключения задач, записи в очередь сообщений, установки светофоров и другие процессы. Монитор данных StethoScope позволяет анализировать динамическое изменение пользовательских и системных переменных, включая в себя также профилировщик процедур.
В составе VxWorks имеется пакет программ BSP для постановки данной ОСРВ на ряд плат развития, включая SBC фирмы «Motorola», что позволяет конфигурировать таким образом целевую систему для конкретного приложения. Для комплексной отладки целевых систем VxWorks обеспечивает интерфейс со схемными эмуляторами (например, типа 64700 фирмы «Hewlett-Packard», visionICE фирмы EST, TRACE-32 фирмы «Lauterbach Datentechnik») и эмуляторами ПЗУ (например, NetROM фирмы «XLNT Designs»).
Симулятор VxSim позволяет моделировать на инструментальном компьютере многозадачную среду VxWorks и интерфейс с целевой системой. Он позволяет разрабатывать и отлаживать программное обеспечение без подключения целевой системы. Среда VxWorks обеспечивает также возможности программирования мультипроцессорных систем.
Для поддержки программирования предлагается интегрированная среда разработки Tornado, в состав которой входит VxWorks 5.3 - ядро РВ и системные библиотеки, средства программирования C/C++ Тoolkit, высокоуровневый отладчик CrossWind и ряд других средств. Пакет C/C++ Toolkit содержит компиляторы GNU C/C++ фирмы «Cygnus Support». Отладчик CrossWind является расширенной версией отладчика GDB фирмы «Cygnus Support». Он имеет графический пользовательский интерфейс и поддерживает отладку как на прикладном, так и на системном уровне. Дополнительные средства среды Tornado обеспечивают управление процессом отладки, визуализацию состояния целевой системы, другие сервисные функции.
Tornado может использоваться совместно с VX-Windows, WindView, StethoScope, VxSim и рядом других средств из состава VxWorks.
Характерной особеностью среды Tornado является ее открытая архитектура, которая позволяет пользователю подключать собственные специализированные инструментальные средства и расширять возможности стандартных. Открытость реализована с помощью прикладных программных интерфейсов API, которые дают возможность различным
855
ПРОЕКТИРОВАНИЕ МПС
программным продуктам обмениваться между собой данными на инструментальном компьютере и взаимодействовать с VxWorks, установленной на целевой системе.
ОСРВ VxWorks вместе с интегрированной средой Tornado является мощным средством реализации целевых систем, работающих в условиях жестких ограничений на объем используемой памяти и время отклика на внешние события.
8.8. JTAG-ИНТЕРФЕЙС И СИСТЕМНЫЕ ФУНКЦИИ НА ЕГО ОСНОВЕ
Важной характеристикой современных приборов (не только МП и ПЛ, но и других типов БИС) является поддержка JTAG-интерфейса. Исторически JTAG-интерфейс появился как название специальной группы, созданной по инициативе фирмы «Texas Instrument», для выработки стандарта на производство тестопригодных БИС (Joint Тest Action Group - JTAG). Результатом работы этой группы явился принятый в 1990 году стандарт IEEE Std.1149.1.
Предложенный стандарт имел два различных аспекта: один состоял в разработке протокола и принципов обмена информацией между БИС, соединенными в последовательную цепочку, а другой состоял в специальной (тестово ориентированной) организации связи между содержимым БИС и её внешними контактами. Использование подобной организации выходных контактов и возможность подачи (съема) информации, находящейся в цепочке, на (с) границы БИС для задач тестирования межсоединений БИС без физического доступа к каждому её выводу получил название метода граничного сканирования (Boundary Scan Testing - BST). Термин «граничное сканирование» представляется авторам более точно соответствующим задаче сканирования состояния границы между основными элементами БИС и оборудованием, расположенным вне БИС, чем используемый иногда термин «периферийное сканирование».
Рассмотрим более детально идеи метода граничного сканирования.
На рис. 8.7 показана организация БИС, поддерживающая метод BST; рисунок позволяет понять основную концепцию граничного сканирования. Ячейки сканирования (BSC -Boundary Scan Cells) размещены между каждым внешним выводом микросхемы и схемами кристалла, образующими собственно БИС. Ячейки, с одной стороны, обеспечивают прием, сохранение или выдачу тестовой информации JTAG цепочки, а с другой стороны, обеспечивают различные режимы взаимодействия между внешними контактами БИС, запоминающими триггерами ячейки BSC и основными (внутренними) схемами кристалла.
Метод BST задумывался для выполнения следующих тестовых процедур: проверять функциональную пригодность БИС с помощью встроенных в них тестовых цепей; проверять качество соединений между различными контактами БИС, смонтированных на печатной плате; считывать или устанавливать сигналы на выходных контактах БИС в штатном режиме работы БИС. Выполнение команд тестирования базируется на соответствии длины регистров приема/передачи информации (встроенных в каждую БИС, поддерживающую методы BST) и числа тестируемых контактов БИС, а также на возможности различным образом настраивать взаимодействие разрядов этих регистров с внутренней структурой БИС и внешними контактами.
Ячейки BSC обеспечивают реализацию следующих режимов:
• за счет разрыва соединения внешних контактов и внутреннего содержимого БИС и подачи внутрь БИС информации из ячейки BSC, которая соответствует поступившим из JTAG-цепочки данным, а затем фиксации в ячейке BSC результирующей информации, которую впоследствии можно передать в JTAG-цепочку, могут быть организованы режимы самотестирования БИС, режимы программирования или чтения внутрисхемных ЗУ и т. д.;
• за счет разрыва соединения внешних контактов и внутреннего содержимого БИС и подачи на внешние выходные контакты БИС сигналов из ячейки BSC соответствующих поступив-
856
JTAG-ИНТЕРФЕЙС И СИСТЕМНЫЕ ФУНКЦИИ НА ЕГО ОСНОВЕ
Тестовые данные
Рис. 8.7. Организация граничного сканирования
шей из JTAG-цепочки информации, а затем фиксации в ячейках BSC информации, соответствующей состоянию сигналов на внешних контактах БИС, и возможности передачи этой информации в JTAG-цепочку, могут быть организованы режимы тестирования соединения БИС между собой;
• за счет фиксации в ячейках BSC сигналов от всех контактов БИС в задаваемый из JTAG-цепочки момент времени при сохранении соединения внешних контактов и внутреннего содержимого БИС, и независимости считывания этой информации в JTAG-цепочку от штатной работы БИС, может осуществляться тестирование штатного режима работы БИС.
Схема сканирующей ячейки (рис. 8.8.) содержит два мультиплексора и два D-триггера. Триггер TD1 является триггером в сдвигающем регистре данных JTAG-цепочки, в состоянии ввода/вывода данных информация сдвигается по цепочке триггеров BSC-ячеек. В этих же триггерах может фиксироваться входная информация BSC-ячеек. Триггер TD2 является триггером-защелкой, буферизирующим данные основного сдвигающего регистра. Работа ячейки зависит от режима использования. В рабочем режиме информация со входа ячейки передается на выход, соединяя выходной контакт БИС с внутренними ресурсами БИС, но при этом входная информация ячейки может фиксироваться в TD1 сдвигающего регистра. В большинстве тестовых режимов вход и выход ячейки разъединены. Входная информация ячейки может при этом фиксироваться в триггере TD1, а выходная информация будет определяться содержимым триггера TD2.
Структурная схема устройства управления граничным сканированием (ГС) приведена на рис. 8.9 . Из рисунка видно, что основными и обязательными элементами устройства управления являются три регистра - регистр команд (RI), регистр пропуска (Bypass) и регистр данных (RD), выходной мультиплексор (MUX) и контроллер управления (ТАР Controller). В цикле записи команд в БИС JTAG-цепочки регистр команд фиксирует следующую команду к исполнению (как правило, после включения питания в этот же регистр заносится идентификационный код БИС). Одноразрядный регистр пропуска обеспечивает в режимах загруз-
857
ПРОЕКТИРОВАНИЕ МПС
ячейки
Рис. 8.8. Схема ячейки BSC
ки/выгрузки команд или данных обход при сдвигах многоразрядных данных или команд, не относящихся к данной БИС. Регистр данных является источником или приемником информации при всех действиях в JTAG-цепочках.
Структура сканирующих ячеек позволяет ввести для каждой возможной тестовой процедуры выполнение определенной команды. Стандартом предусмотрена обязательность поддержания четырех команд граничного сканирования: EXTEST, SAMPLE/PRELOAD, BYPASS и INTEST; при этом допускается введение дополнительных команд, упрощающих работу с JTAG-цепочками или тестируемыми БИС.
Для решения задач самотестирования БИС предусмотрены две команды стандарта JTAG - INTEST и RUNBIST. Команда INTEST проверяет функционирование БИС путем проверки данных, зафиксированных в регистрах сканирования DR после прохождения данных (загруженных перед исполнением команды в регистр DR) через основные схемы кристалла. Команда RUNBIST производит тестирование кристалла без привлечения каких-либо внешних данных. Данные, зафиксированные в регистре DR после завершения команды, однозначно определяют исправное состояние БИС.
Для тестирования внешних соединений на печатной плате предусмотрено использование команды EXTEST. Исполнение команды предполагает отключение внутренних схем кристалла от внешних контактов - сигнал «Твотирование» на рис. 8.9. Состояния выходных контактов БИС определяются информацией, находящейся в регистрах данных DR БИС. В начале выполнения команды (при прохождении состояния автомата CAPTURE-DR) в буферных регистрах DR на фронте сигнала «Захват» фиксируется состояние сигналов на внешних контактах БИС, после этого зафиксированные данные (в состоянии автомата SHIFT-DR) при сигнале «Сдвиг» на мультиплексоре 1 могут выдвигаться из БИС и замещаться на вновь подаваемые данные, и наконец при завершении команды (при прохождении состояния UPDATE-DR) обновляется состояние регистров DR (а значит и состояния выходных контактов БИС) на фронте сигнала «Фиксация». Хотя команда EXTEST позволяет производить тестирование межсоединений без привлечения каких-либо дополнительных команд, чаще всего она используется совместно с командой SAMPLE/PRELOAD, выполняющей роль команды, загружающей информацию в регистр данных.
Для сканирования сигналов, присутствующих на внешних контактах БИС, предусмотрена команда SAMPLE/PRELOAD. Поскольку исполнение команды не предполагает отключение внутренних схем кристалла от внешних контактов - инверсное состояние сигнала «Тес-
858
JTAG-ИНТЕРФЕЙС И СИСТЕМНЫЕ ФУНКЦИИ НА ЕГО ОСНОВЕ
От выходных К основным
Рис. 8.9. Схема устройства управления командами граничного сканирования
тирование» на рис. 8.9, то в начале выполнения команды (при прохождении автоматом состояния CAPTURE-DR) в буферных регистрах DR по фронту сигнала «Захват» фиксируется состояние сигналов на внешних контактах БИС. Эти сигналы соответствуют штатному режиму работы БИС. Интерпретация содержания такого мгновенного «снимка состояния» сигналов на границе тестируемой БИС зависит от состояния других БИС, связанных с тестируемой. Если все БИС находятся в рабочем режиме, то содержание «снимка» отражает протекание штатных режимов в системе и обычно используется для целей отладки. Возможность создания произвольной конфигурации тестируемой системы - одна часть БИС формирует тестовые выходные сигналы, а другая часть БИС системы находится в рабочем режиме, позволяет организовывать совместное тестирование межсоединений и функционирования внутренних схем БИС.
Команды CLAMP и HIGHZ позволяют расширить возможности совмещенного тестирования межсоединений и рабочего состояния части БИС в проверяемой системе. Команда HIGHZ переводит все выходные контакты БИС в Z-состояние и переводит БИС в состояние BYPASS. Аппаратная реализация такой команды требует минимальных затрат, но её использование особенно эффективно при тестировании систем с шинной организацией. Для БИС микропроцессоров реализация такого состояния их выходных контактов носит название «In-Circuit emulation» и упрощает использование внешних отладочных эмуляцион-ных средств.
Команда CLAMP устанавливает на выходных контактах БИС значения, соответствующие данным регистра DR, и переводит БИС в состояние BYPASS.
859
ПРОЕКТИРОВАНИЕ МПС
Команда BYPASS позволяет установить устройство управления JTAG-интерфейсом в состояние сквозного пропуска данных через БИС. Команда соответствует отключению БИС от процедур тестирования без изъятия БИС из JTAG-цепочки.
Основу любого устройства управления JTAG-командами составляет контроллер тестирующего порта доступа (ТАР Controller). ТАР Controller - синхронный конечный автомат, изменение состояний которого происходит по состоянию управляющего сигнала JTAG-цепочки сигнала TMS, фиксируемого по переднему фронту тактового сигнала цепочки - ТСК. Контроллер формирует выходные сигналы, управляющие поведением ячеек BSC - сдвиг, захват, тестирование.
Диаграмма состояний автомата приведена на рис. 8.10. Некоторые пояснения к диаграмме. Условия переходов - значение сигнала TMS, показано на диаграмме цифрами «0» или «1». В диаграмме состояний можно выделить четыре базовых фрагмента - состояние TEST-LOG)C_RESET (сброс логики тестирования), RUN-TESTVDLE (состояние ожидания или выполнение внутренних тестов), режим управления вводом/выводом данными (семь состояний от SELECT-DR-SCAN до UPDATE-DR) режим управления вводом команд, чтением состояния от SELECT-IR-SCAN до UPDATE-IR. Основу режимов управления образуют три состояния: 1) состояния фиксации в выдвигаемых регистрах данных на момент начала фрагмента (состояние CAPTURE-DR или CAPTURE-IR); 2) состояния выдвигания зафиксированной информации из БИС и вдвигания новой информации в БИС (состояние SHIFT-DR или SHIFT-IR); 3) состояния фиксации новой информации (состояние UPDATEDR или UPDATE-IR) на момент завершения фрагмента. Состояния PAUSE-DR и PAUSE-IR позволяют приостанавливать продвижение информации в цепочке на произвольное число тактов синхронизации (например, для выполнения каких-либо действий в БИС с внешним тактированием). Состояния EXIT1-DR, EXIT2-DR, EXIT1-IR и EXIT2-IR носят вспомогательный характер (в том числе для реализации альтернативных переходов), но могут оказаться полезными при реализации устройств управления расширенных вариантов интерфейса JTAG, соответствующих новым вводимым командами.
JTAG-интерфейс проектировался для организации информационной связи между произвольным числом БИС на печатной плате, в приборе и т. д. Основное требование при этом состояло в минимизации числа контактов БИС, необходимого для организации информационного обмена. Обычно используется четыре (реже пять) выделенных для JTAG-интерфейса контакта БИС. Эти контакты образуют так называемый порт доступа (Test Access Port-TAP) контроллера управления JTAG-интерфейса (ТАР Controller).
Контакты имеют следующие названия и функциональное назначение:
ТСК (Test ClocK input) - синхронизация передачи данных и команд;
TMS (Test Mode Select) - выбор режима передачи (считывание по переднему фронту ТСК); TDI (Test Data Input) - вход данных и команд (считывание по переднему фронту ТСК); TDO (Test Data Output) - выход данных, команд или состояния (изменение по заднему фронту по спаду ТСК);
TRST (Test ReSeT)-сброс в исходное состояние контроллера (ТАР Controller).
Если на печатной плате или в устройстве установлено несколько БИС, поддерживающих JTAG-интерфейс, то эти схемы могут быть объединены в так называемую JTAG-цепочку. Устройство управления JTAG-цепочкой за счет управления контактами TMS и ТСК может установить автоматы ТАР контроллеров всех БИС в исходное состояние, загрузить различные команды в БИС, входящих в цепочку, загрузить требуемые данные и (или) прочитать данные из регистров данных.
Реализация возможностей, предоставляемых JTAG-интерфейсом, определяется правильной политикой на этапе подготовки проектной документации для печатных плат. Поскольку для некоторых типов БИС ПЛ контакты, предназначенные для организации JTAG-860
JTAG-ИНТЕРФЕЙС И СИСТЕМНЫЕ ФУНКЦИИ НА ЕГО ОСНОВЕ
TMS=1
Рис. 8.10. Диаграмма состояний автомата
л
V
3
Л
3
• t
ч
861
ПРОЕКТИРОВАНИЕ МПС
интерфейса являются опционными, желательно как минимум оставлять их резервными, а лучше выводить на контактные площадки, чтобы при необходимости можно было объединить БИС, находящиеся на печатной плате и поддерживающие методы граничного сканирования в единую JTAG-цепочку. Для некоторых ПЛ характерно отсутствие постоянно существующих ячеек граничного сканирования и необходимо на этапах контроля межсоединений загружать в подобные БИС специально подготовленную конфигурацию, которая и позволит воспользоваться методами граничного сканирования. Подобные мероприятия позволят в случае необходимости организовать тестирование межсоединений на изготовленной плате. Естественно, что все описанные выше возможности реализуются в том случае, когда управление БИС, входящими в состав JTAG-цепочки, выполняется достаточно интеллектуальным контроллером, обеспечивающим подачу предварительно разработанных тестовых последовательностей и контроль получаемых в результате тестирования последовательностей. Тестовые последовательности, как правило, создаются специальным программным обеспечением. Программное обеспечение, автоматизирующее процесс подготовки тестовых последовательностей, опирается на реализованную на плате систему межсоединений и на возможности БИС, расположенных на этой плате. Целый ряд фирм разрабатывает и поддерживает программные пакеты, автоматизирующие указанные выше тестовые процедуры.
Транспортный аспект стандарта JTAG-интерфейса (стандарт IEEE Std.1149.1) позволил стандартизировать, во-первых, прием (передачу) информации в (из) БИС, входящих в JTAG-цепочку, а во-вторых, исполнение команд JTAG-контроллерами, входящими в состав каждой БИС-цепочки. В результате он оказался прекрасным инструментом для создания расширенных версий JTAG-интерфейса (enhanced JTAG interface), позволив тем самым использовать JTAG-интерфейс не только для решения задач тестирования, нои для решения широкого круга других задач. Возможность адресного направления информации внутрь БИС, расположенной на печатной плате, и одновременное указание о запоминании этого потока информации как содержимого ПЗУ этой БИС, привел к введению специального термина для такой возможности применения JTAG-интерфейса - внутрисхемное программирование (In System Programmability - ISP). Для использования термина ISP безразлично, является ли ПЗУ памятью команд МП или памятью конфигурации БИС ПЛ. Если же в БИС находится ОЗУ с целевым назначением использования как память конфигурации схемы программируемой логики, то для такого применения JTAG-интерфейса иногда используется термин «внутрисхемное реконфигурирование» (In System Reconfigurability - ISR). Если БИС программируемой логики расположена на плате расширения с интерфейсом PCI, а поскольку по стандарту среди контактов таких плат предусмотрено наличие контактов JTAG-интерфейса, то появляется возможность репрограмми-ровать конфигурацию БИС платы расширения, не вынимая платы из компьютера. Такая возможность получила название «In Site Programmability» - ISP, с совпадением аббревиатуры для внутрисхемного программирования. И, наконец, широкое распространение в последнее время находит использование JTAG-интерфейса для обмена информацией с фрагментами БИС, предназначенными для отладки общесистемных проблем, что позволяет говорить о внутрисистемной, внутрисхемной отладке. Последнее свойство реализуется, например, в САПР Quartus фирмы «Altera» для связи со встраиваемыми логическими анализаторами как в БИС программируемой логики этой же фирмы АРЕХ20К (SignalTap embedded logical analisis), так и для защелкивания до 32 сигналов между БИС. Для БИС ПЛ класса SOPC фирмы «Triscend» таким же путем (через JTAG интерфейс) возможна установка аппаратных точек останова для встроенного в БИС (Hardware Breakpoint Unit) микроконтроллера и доступ к его основным программным элементам.
862
процедура проектирования и сведения об автоматизированных средствах проектирования для бис/сбис
8.9. ПРОЦЕДУРА ПРОЕКТИРОВАНИЯ И СВЕДЕНИЯ ОБ АВТОМАТИЗИРОВАННЫХ СРЕДСТВАХ ПРОЕКТИРОВАНИЯ ДЛЯ БИС/СБИС С ПРОГРАММИРУЕМОЙ СТРУКТУРОЙ.
СРЕДСТВА ОПИСАНИЯ ПРОЕКТА
Как уже отмечалось, разработка современных микропроцессорных систем, содержащих БИС с программируемой структурой, немыслима без широкого привлечения САПР. Правильный выбор САПР предопределяет успешность всей процедуры проектирования. Все современные методики проектирования вычислительных систем, содержащих в своем составе сложные программируемые БИС/СБИС, ориентированы на использование САПР. Правильный выбор САПР - важнейшее условие эффективного проектирования и ускорения выпуска продукции, т. е. сокращения времени до продажи (по-английски - Time-to-Market).
Методы и средства проектирования тесно связаны с выбором САПР, и, наоборот, выбор САПР определяет допустимые и целесообразные методы и средства проектирования, так что эти вопросы нельзя рассматривать в отрыве друг от друга. Такая взаимосвязь между САПР и БИС ПЛ значительно более тесная, чем между средствами проектирования МП-систем и используемым типом МП. Выбор элементной базы для проекта может также в значительной мере предопределять требуемую для реализации проекта САПР.
В общем случае при таком выборе приходится учитывать целый ряд соображений, а именно:
• распространенность САПР;
• цену САПР, ее сопровождения и модификаций;
• широту охвата задач проектирования и эффективность выполнения различных этапов и уровней проектирования;
• удобство работы с САПР и её дружественность;
• наличие широкой библиотечной поддержки стандартных решений;
• возможности корпоративной работы;
• возможность и простоту стыковки с другими САПР.
Очевидно, трудно рассчитывать на такой выбор САПР, который удовлетворял бы сразу всем, зачастую взаимно противоречивым требованиям и свойствам.
8.9.1. СВЯЗЬ ПРОЕКТНОЙ ПРОБЛЕМЫ С ВЫБОРОМ САПР
Первый этап выбора требует определения - пользоваться ли САПР фирмы-производителя выбранного класса программируемой БИС ПЛ («Xilinx», «Altera», «Atmel», AMD и др.) или воспользоваться услугами системы проектирования ведущих мировых производителей САПР: «Synopsys», «Cadence», «MentorGraphics», «Exemplar Logic», «Viewlogic», «Symplicity» и еще многих других. Фирмы - производители схем ПЛ (типа «Xilinx» или «Altera») чаще всего монополизируют возможность и право программирования БИС и поэтому при применении САПР фирм - производителей САПР как минимум на заключительных этапах их использования приходится пользоваться услугами САПР фирм - производителей схем ПЛ.
Если проектировщик решился на совместную работу с несколькими САПР (что авторам представляется в современных условиях более предпочтительным), то их выбор все равно остается достаточно многовариантной проблемой. Ни одна из САПР не является предпочтительной для всех пользоаательских приложений.
Стратегия фирм - производителей БИС ПЛ и САПР модифицировалась во времени. До начала 1990-х гг. фирмы ориентировались на узко направленную деятельность. Каждая фирма имела свою узкую специфическую направленность, в которой и концентри
863
ПРОЕКТИРОВАНИЕ МПС
ровались все усилия фирмы, чтобы обеспечить свое лидирующее положение в выбранной нише. В 1990-х годах началось более тесное взаимодействие фирм между собой. Практически все САПР стали предусматривать возможности взаимного обмена проектной информацией на любом из этапов проектирования. Технической основой этого информационного обмена явилось введение и поддержка стандартов языков. Промышленным стандартом стал язык EDIF с версиями 2.0.0 и 3.0.0. Для большинства САПР предполагается взаимодействие с помощью различных языков описания соединений (в том числе VHDL, Verilog и т. д.).
С середины 1990-х гг. начался этап совместных разработок в области САПР. В настоящее время эта тенденция сохраняется и заключается в кооперации усилий различных фирм при разработке САПР; при этом каждая фирма реализует тот фрагмент САПР, в котором она является общепризнанным лидером; важно, что при этом весь информационный поток проектирования становится единым и все этапы проектирования оказываются взаимосвязанными. Так, например, результаты моделирования работы какой-либо схемы отображаются не только в окне диалога временного моделирования, но отображаются и на электрической схеме, которая создавалась на этапе ввода информации о проекте.
Примерами кооперационных САПР являются САПР для продукции фирмы «Xilinx» -. Foundation 1.4 и 1.5, которые представляют собой результат совместной разработки фирм «Xilinx», «Aldec» и «Synopsys». Аналогичное решение принято и фирмой «Altera», теперь проектировщик может выбрать для повышения эффективности компиляции проектов, написанных на языках VHDL или Verilog HDL, либо САПР FPGA Express фирмы «Synopsys», либо САПР Leonardo Spectrum фирмы «Mentor Graphics», а для эффективного моделирования ориентироваться на пакет Model Sim фирмы «Model Technology» (подразделение фирмы «Mentor Graphics»).
Хотя подобное слияние является вполне обоснованным и ожидаемым, тенденция обращения к специализированным САПР (на определенных этапах проектирования и в определенных ситуациях) будет, по-видимому, сохраняться и в дальнейшем.
Еще более критичным оказывается вариант выбора САПР при желании обеспечить сквозное провктироввние, когда в одной САПР совмещаются средства различных уровней проектирования (например, проектирования конфигурации ПЛ и проектирования печатной платы, на которой БИС ПЛ будет находиться, или проектирование конфигурации ПЛ и моделирование её работы совместно с цифроаналоговыми элементами).
Типичным представителем САПР для смешанного или иерархического проектирования являются САПР фирм «View Logic» или OrCAD. Рассмотрим в качестве типового примера состав, назначение и особенности реализации средств, входящих в САПР Work View Office фирмы «View Logic».
Work View Office является законченной системой программного обеспечения (для РС платформ, работающих под Windows 95,98 или NT), ориентированной на автоматизацию различных уровней проектирования электронных схем. Work View Office имеет программу-оболочку навигатор проектов (в других САПР это может быть менеджер проектов), позволяющую управлять потоком проектирования как с точки зрения последовательности выполнения частей пользовательского проекта, так и с точки зрения привлекаемых стандартных библиотек. С информационной точки зрения, САПР представляет собой классическую трехступенчатую систему (ввод, обработка и верификация), предназначенную для различных видов обрабатываемой информации на каждой ступени проектирования. Так, вводимая информация может описывать схему электронного блока и предназначаться для моделирования поведения этой схемы (цифровой, аналоговой или смешанной), или для компиляции в выбранный тип ПЛ, или для разводки печатной платы.
В зависимости от целевого назначения на следующем этапе обработки информации проектировщик пользуется соответствующей компиляционной процедурой разводки печатной платы, компиляцией в выбранный тип БИС ПЛ или подготовки к моделированию.
864
ПРОЦЕДУРА ПРОЕКТИРОВАНИЯ И СВЕДЕНИЯ ОБ АВТОМАТИЗИРОВАННЫХ СРЕДСТВАХ ПРОЕКТИРОВАНИЯ ДЛЯ БИС/СБИС
И, наконец, на третьем этапе осуществляется верификация готового проекта.
При необходимости моделирования работы аналоговых или смешанных (аналого-цифровых) систем обычно используются современные версии профессиональной программы PSpice А/D, входящей в состав пакета Design Lab. Распространение имеют и другие программы (например, Micro-Cap фирмы «Spectrum Software», или APLAC 7.0, Electronics Workbench 5.0 и т. д.). Однако программный комплекс корпорации «Micro Sim» под названием Design Lab 8.0 используется для сквозного проектирования аналоговых, цифровых и смешанных аналого-цифровых устройств, синтеза устройств программируемой логики и аналоговых фильтров. Введение а комплекс интерфейса с другими САПР ПЛ позволил создать систему, позволяющую разрабатывать схемы, включающие CPLD и FPGA различных фирм, моделировать на ПК их поведение совместно с другими аналоговыми и цифровыми компонентами, разрабатывать печатные платы и на заключительном этапе повторять моделирование с учетом паразитных эффектов, соответствующих свойствам реальных образцов выходной продукции.
Таким образом, если предполагается совместное проектирование цифровых и аналоговых (в том числе и цифроаналоговых и аналого-цифровых) фрагментов или комплексный (сквозной) подход к проектированию, то проектировщик стоит перед выбором САПР ряда фирм «Micro Sim», «View logic» или OrCAD.
На выбор САПР может оказывать влияние необходимость использования результатов проектирования для различных технологических форм реализации конечной продукции. Так, если после этапа выпуска опытных образцов на базе БИС ПЛ предполагается дальнейшая реализация проекта в виде заказной БИС, то переход от ПЛ к такой форме будет наиболее простым, если при разработке и той и другой формы проектировщик будет ориентироваться на САПР одной и той же фирмы. Такие возможности (с гарантией работоспособности проекта при другой технологии изготовления) предоставляют такие фирмы как «Synopsys», «Cadence» или «Mentor Graphics» (выбор конкретной фирмы может определяться как типом полузаказ-ной или заказной БИС, так и просто симпатиями проектировщика).
Важнейшей характеристикой САПР БИС ПЛ является эффективность компиляции. Хотя рекомендуется всегда стараться при проектировании занимать под проект не более 90% ресурсов используемой БИС ПЛ (т. е. оставлять минимальные резервы для возможных модификации), стоимость БИС следующего варианта логической мощности (а иногда и отсутствие БИС с требуемым быстродействием) заставляет разработчика пытаться «уложиться» в ресурсы БИС минимально допустимой логической мощности. Одним из возможных вариантов, способствующих достижению этой цели, может оказаться использование САПР фирм «Exemplar Logic», «Symplicity» обеспечивающих для проектов, написанных на языках VHDL или Verilog HDL, как правило, самые высокие показатели по эффективности компиляции (минимальность затрачиваемых логических ресурсов и быстродействие проекта).
Существенное влияние выбор САПР оказывает и на эффективность верификации проектов. Этап отладки готового проекта традиционно (как было показано для типовых МП-систем) поддерживался средствами САПР, не является исключением и отладка проекта, загруженного в БИС ПЛ. Современная тенденция заключается во введении в перечень функций, выполняемых САПР, функций, способствующих упрощению процедуры отладки готового проекта. Например, в САПР QUARTUS фирмы «Altera» предусматривается наличие всех трех составляющих такой процедуры: отладочных средств, помещаемых в отлаживаемую БИС/СБИС, информационно-транспортировочных средств, связывающих отлаживаемую БИС и ПК с САПР, программных средств в составе САПР, управляющих и отображающих результаты отладки. Средства так называемого Signal Тар Logic Analysis позволяют регистрировать состояния не только на контактах ПЛ, но и во внутренних точках ПЛ в реальном масштабе времени, занося эту информацию в память ПЛ, передавать сохраненную информацию в компьютер с помощью интерфейса JTAG и отображать эту ин
865
ПРОЕКТИРОВАНИЕ МПС
формацию в редакторе временных диаграмм (Waveform Editor) для просмотра, анализа и отладки схемы в БИС.
Еще более сложные средства отладки требуются для БИС, совмещающих в одном кристалле устройства различной природы, например, реализованных по схеме MP+FPGA, как в приборах семейства Е5 типа SOC (системы на кристалле) фирмы «Triscend». Здесь необходимо отметить возможность обеспечения одинаково эффективной отладки не только МП-ядра (на базе MCS 52) и аппаратного ядра системной логики (типа FPFA), но и их связи между собой за счет введения в архитектуру специального устройства отладки (Hardware Breakpoint Unit). Организация такой смешанной отладки опирается на возможности, предоставляемые как архитектурой кристалла, так и собственно САПР Тriscend FastChip.
Не менее сложные средства отладки потребуются для отладки смешанных БИС, например, в анонсируемых фирмой «Atmel» приборах, реализующих в одном кристалле интерфейс PCI и логику FPGA.
Внешне значительно проще выглядит отладка систем типа SOPC, относящихся к классу generic, (например, схем фирмы «АИега»), в которых объединяются MP-ядра того или иного типа (начиная от 8-разрядных MCS 8052 и кончая 32-разрядными RISC-архитектурами) и другие части проекта, реализованные в рамках единой технологии программируемой логики. Однако, поскольку реально верификация совместной работы MP-программы и элементов периферийных устройств осуществляется в рамках типового редактора временных диаграмм САПР MAX+PLUSII, формирование даже относительно короткой последовательности команд МР может быть серьезно затруднено сложностью подготовки исходной информации.
Следующим фактором является наличие или возможность использования стандартных решений. Этот момент также может оказаться решающим при выборе САПР. Ситуация несколько улучшается и сглаживается с помощью создания переносимых проектных решений (например, записи функционирования на одном из вариантов языков описания аппаратуры VHDL, Verilog или EDIF). Однако специфика внутренней организации БИС ПЛ может приводить в таком случае к получению после компиляции не самых эффективных решений (если, конечно, в записи конструкции не учтена такая специфичность).
8.9.2. ПОСЛЕДОВАТЕЛЬНОСТЬ ПРОЕКТИРОВАНИЯ ДЛЯ БИС ПЛ
Порядок разработки системы, содержащей БИС ПЛ, был укрупненно приведен ранее. Более детально маршрут проектирования для ветви проектирования, соответствующей разработке конфигурации БИС ПЛ с использованием САПР, рассматривается ниже.
Предполагаем, что самый первый этап проектирования уже пройден и сделан выбор как определенной элементной базы, так и определенной САПР (или группы САПР). Далее разработка обычно выполняется в следующем порядке:
Этап 1. Составление содержательного описания проекта
Первая задача - переход от технического задания (ТЗ) к формализованному описанию проектируемого устройства. ТЗ, как правило, является смесью словесного и технического описания, его формализация приводит к выявлению основных блоков устройства (или алгоритма) и определению их связей и/или взаимодействия. В сущности, именно в этот момент реализуются начальные действия первого этапа. Формально же первый этап - разбиение задачи на отдельные функционально обособленные подзадачи - этап декомпозиции. Способ и средства разбиения чаще всего определяются именно функциональной завершенностью и обособленностью отдельных фрагментов, хотя в значительной степени здесь большую роль играют просто симпатии проектировщика, и лишь иногда разбиение является полностью предопределенным. Сама форма ТЗ может провоцировать проектировщика
866
ПРОЦЕДУРА ПРОЕКТИРОВАНИЯ И СВЕДЕНИЯ ОБ АВТОМАТИЗИРОВАННЫХ СРЕДСТВАХ ПРОЕКТИРОВАНИЯ ДЛЯ БИС/СБИС
на использование тех или иных средств, хотя не исключено, что более эффективным мог бы быть другой метод описания проекта или его фрагментов. Декомпозиция может сводиться к составлению граф-схем алгоритмов функционирования фрагментов или к функциональной блок-схеме устройства и его частей. Возможным вариантом для достаточно сложных систем будет разумное совмещение и поведенческого и структурного разбиения проекта. Разбиение осуществляется не только в рамках одного уровня иерархии, а для большинства проектов и разбиение на иерархически организованные уровни. Использование САПР на этом этапе проектирования - явление достаточно редкое, хотя для современных очень сложных проектов все большее распространение получают специальные блочные редакторы, позволяющие осуществлять декомпозицию проекта без детализации составных частей.
Этап 2. Разработка общей структуры проектируемой системы
Основной задачей этапа являются выбор допустимых для каждого уровня иерархии элементов, определение связей между ними и, если параметры элементов являются настраиваемыми, то и их настройка. Два момента являются определяющими для этого этапа: с одной стороны, это источник набора допустимых элементов, с другой стороны - средства описания соединений элементов между собой, а при необходимости и описание новых (специфических для этого проекта) элементов.
Совмещенное описание проекта. Как уже указывалось, возможно как только временное (поведенческое), так и только пространственное (архитектурно-структурное) описание проекта. Однако часто целесообразно совмещать обе возможности. При разработке устройств с цифровым представлением информации бывает естественным разбиение их на два блока: операционный и управления. Операционный блок (ОБ) выполняет преобразование данных и строится из стандартных частей, а блок управления (устройство управления УУ) обеспечивает необходимую последовательность операций, выполняемых в ОБ (одном или нескольких). Для этого УУ передает на входы ОБ управляющие сигналы. Последовательность действий и, следовательно, управляющих сигналов зависит от результатов операций в ОБ и внешних воздействий. Отсюда видно, что УУ удобно задавать в форме конечного автомата с памятью (АП) того или иного типа.
В сложных проектах возможно разделение УУ на несколько функционально слабо связанных пар ОБ - УУ на одном уровне иерархии или создание пары, иерархически погруженной в ОБ (реже в УУ).
Библиотеки проектировщика. Элементный состав операционного блока зависит от состава используемой библиотеки. Набор функциональных возможностей библиотечных элементов предлагаемых стандартными САПР, чрезвычайно широк, а по составу и происхождению библиотеки можно разделить на следующие:
• стандартные библиотеки фирмы разработчика САПР, содержимое которой соответствует распространенной серии схем МСИ, например, типа 74 серии;
• стандартные элементы вычислительной техники (п - входовые логические элементы, дешифраторы, мультиплексоры, счетчики и т. д.); параметры элементов при этом фиксированы;
• типовые элементы вычислительной техники (счетчики, регистры, мультиплексоры и т. д.), конкретные параметры которых (разрядность, полярность управляющих сигналов и т. д.) могут назначаться проектировщиком произвольно;
• типовые узлы вычислительных систем (периферийные устройства, аппаратные ядра микроконтроллеров и микропроцессоров), часть параметров которых варьируется проектировщиком (как правило, разработка конфигурации этих узлов выполняется либо фирмой разработчиком узла, либо в содружестве с ней);
• элементы, созданные проектировщиком и объединенные в библиотеку проектировщика.
Любой проект может быть использован в качестве подпроекта в более сложном проекте. Единую библиотеку модулей проектировщика можно и не создавать (хотя желательно
867
ПРОЕКТИРОВАНИЕ МПС
иметь некий путеводитель по собственным проектным модулям, а в лучшем случае - базу данных о выполненных проектах).
Как правило, на любом уровне иерархии помимо базовых для данного уровня элементов ОБ дополняется требуемым для функционирования набором регистров, логических схем (как правило, многофункциональных и управляемых), буферных схем и коммутируемых связей между ними. Важно, чтобы на более низких иерархических уровнях описания проекта была однозначная трактовка функционирования всех элементов ОБ.
Описание проектов. Применение САПР требует эффективных, наглядных, управляемых и контролируемых средств описания проекта. Описать проектируемое устройство можно разными способами, причем обычно применяемые способы пригодны как для описания проекта в целом, так и для описания отдельных фрагментов. Методы описания, применимые исключительно для отдельных фрагментов устройства, относятся к числу редких.
В настоящее время к наиболее распространенным универсальным способам описания проекта, применимым для любого уровня иерархии проекта, относят графический и текстовый . Реже используются непосредственная разводка схем FPGA в редакторе топологии, описания в виде требуемых временных диаграмм и др. Каждый из способов описания проекта имеет свои достоинства и недостатки. Сходство способа описания и внутренней организации и поведения разрабатываемого устройства существенно сокращает время создания проекта, упрощает его тестирование и, как правило, оказывается наиболее наглядным и понятным.
Графическое представление проекта в современных САПР может создаваться как в базисе графических символов проектировщика, так и в базисе допустимых для выбранной САПР библиотечных элементов, например, в базисе элементов стандартной серии ТТЛ(Ш). Допустимость смешивания этих двух базисов в различных комбинациях - главное достоинство графического способа - его традиционность и наглядность, связанные с привычностью разработчиков к восприятию изображений схем. Конечно, это преимущество проявляется только при правильном иерархическом и структурном разбиении проекта.
Современные языки описания аппаратуры (HDL, Hardware Description Languages) допускают описание проектируемого устройства как с точки зрения его поведения, так и с точки зрения его структуры . Эти возможности делают все более распространенным представление проекта в форме текстового описания алгоритмов функционирования его фрагментов в сочетании с текстовым же описанием межблочных соединений для сложных проектов. Достоинства текстового способа описания проекта заключаются в его компактности и относительной простоте автоматизации любых преобразований, включая начальную генерацию описания проекта. Очень важна возможность использования стандартных универсальных языков типа HDL, обеспечивающая простоту переноса проекта с одной аппаратной платформы на другую и переход от одной САПР к другой.
В отличие от текстовых графические способы представления проекта обычно узко специализированны и требуют особых средств для переноса информации о проекте в другую среду, для чего могут быть применены специальные универсальные языки передачи информации о проекте (типа языка EDIF, Electronic Design Interchange Format).
Языковое описание аппаратуры получает все большее распространение. Текстовые описания имеют две основные разновидности - языки низкого уровня (аналоги языков программирования типа Ассемблера) и языки высокого уровня.
Языки низкого уровня. Языки низкого уровня ближе к аппаратным средствам, вследствие чего представляют для компиляторов потенциальные возможности создания проектов с более выигрышными параметрами. Платой за это является обычно жесткая ориентация на определенную аппаратуру и производящую ее фирму. Примерами таких языков могут служить язык AHDL («Altera HDL») и ABEL (фирмы «Xilinx»), С помощью языков низкого уровня легче создавать проекты с наилучшими временными параметрами, так как в проектах будут учтены специфические особенности архитектуры той или иной CPLD или FPGA.
868
ПРОЦЕДУРА ПРОЕКТИРОВАНИЯ И СВЕДЕНИЯ ОБ АВТОМАТИЗИРОВАННЫХ СРЕДСТВАХ ПРОЕКТИРОВАНИЯ ДЛЯ БИС/СБИС
Языки высокого уровня. Языки высокого уровня менее связаны с аппаратными платформами и поэтому более универсальны. Среди них наиболее распространены языки VHDL и Verilog. Эти языки, как и другие алгоритмические языки высокого уровня, в принципе позволяют описать любой алгоритм в последовательной форме, т. е. через последовательность операторов присвоения и принятия решений. Основное их отличие - в способности отражать также и параллельно исполняемые в аппаратуре действия, представляемые отдельными параллельно выполняемыми процессами с общим инициализирующим воздействием.
Этап З.Описание работы управляющего автомата (УА)
На этом этапе определяется функционирование УА, обеспечивающее требуемое взаимодействие элементов ОБ. Следует подчеркнуть, что два последних этапа сильно взаимосвязаны и, если не разрабатываются параллельно, то обычно выполняются итерационно.
Формы и средства описания автомата разнообразны. Современная тенденция состоит в переходе от записи логических выражений, ограниченных правилами ТЗ, к графической форме. Описание в виде граф-схемы переходов (диаграммы состояний) становится одним из самых распространенных вариантов задания автоматов (в английской терминологии - State Machins). Графические редакторы для создания автоматов включаются в состав средств задания исходных проектов современных САПР (например, в САПР Foundation фирмы «Xilinx» разработки фирмы «Aldec»).
Редакторы разных фирм-производителей СБИС ПЛ имеют особенности, но для всех них характерны исключительная простота, естественность и дружественность интерфейса с пользователем, а также отсутствие жесткой необходимости знания выходного языка редактора. Наиболее совершенные версии программ типа StateCAD Version 3.2 пакета Workview Office фирмы «Viewlogic» обладают полным набором средств для выполнения всей проектной процедуры разработки УА, позволяющих реализовать следующие операции:
• создавать граф переходов, включая наименование состояний, направления, условия и приоритеты условий переходов, формируемые сигналы и способы их образования;
• проверять корректность составленного графа переходов (повторение имен, неоднозначность перехода, некорректность перехода и т. д.);
• компилировать проект (формировать выходной текстовый файл) в выбранном языковом базисе;
• моделировать поведение автомата в интерактивном или компиляционном режиме.
Важное достоинство программы StateCAD Version 3.2 - возможность широкого выбора форм представления результата (описания на языках высокого уровня -VHDL и Verilog и на языках низкого уровня - ABEL, AHDL).
Заметим, что специфика продукции той или иной фирмы сказывается и на языках высокого уровня, выражаясь прежде всего в отличиях в библиотеках, требуемых для работы, и в сложности и вариантности допустимых синтаксических конструкций для компиляторов. Конечные результаты компиляции одной и той же исходной граф-схемы автомата или последующей компиляции одной и той же программы с языка высокого уровня в загрузочный файл микросхемы ПЛ, полученные от компиляторов разных фирм, могут существенно различаться и иметь различную эффективность. Программа StateCAD Version 3.2 пакета Workview Office удобна тем, что перед трансляцией графа переходов нужно задать не только желательное языковое представление (VHDL, AHDL, Verilog, ABEL и т. д.), но и фирменные атрибуты, что позволяет оптимизировать запись автомата и избежать применения синтаксических конструкций, недопустимых для компиляторов соответствующих фирм.
Как уже отмечалось, при использовании графических редакторов от пользователя не требуется обязательное владение выходным языком редактора. Однако в определенных случаях такое владение исключительно полезно. Полезность ориентации в языковых конструкциях проявляется, например, в ситуациях, когда автомат должен быть минимизирован по тем или иным параметрам, прежде всего по временным интервалам между форми
869
ПРОЕКТИРОВАНИЕ МПС
руемыми выходными сигналами, что может приводить к временным состязаниям сигналов. Именно в этих случаях владение языком и искусство проектировщика облегчают получение наилучших результатов.
Этап 4. Компиляция проекта
После составления проекта и всех его частей можно приступать к самому ответственному этапу проектирования - компиляции проекта. Именно здесь проявляются все скрытые ошибки и нестыковки. Компиляция разбивается на ряд последовательных подэтапов: сборка базы данных проекта, контроль соединений, логическая минимизация проекта, монтирование проекта в заданную или выбранную схему, формирование загрузочного (конфигурационного) файла и др.
На любом подэтапе могут возникать ошибки, требующие повторной компиляции после их коррекции.
Результат компиляции - загрузочный файл, т. е. конфигурационная информация для выбранной микросхемы ПЛ. Помимо этого обычно создается и файл отчета, содержащий всю информацию как о процессе компиляции, так и о его результатах. Имеется существенное различие для компиляционных процедур схем типов CPLD и FPGA. Для схем типа FPGA помимо автоматического размещения и трассировки соединений, как правило, допустимо и ручное вмешательство проектировщика в этот процесс на любых его этапах. Этой цели служат редакторы топологии (Floorplanner), позволяющие изменять структуру проекта на кристалле и повышать производительность проектируемых устройств. А для схем типа CPLD влияние проектировщика на структуру (а следовательно, и характеристики) скомпилированной схемы чаще всего возможно только за счет косвенного воздействия, либо за счет формы описания проекта, либо за счет установленных перед компиляцией опций. Ручная трассировка выбранных цепей возможна, например, в топологическом редакторе FPGA Editor, входящем в состав САПР Foundation фирмы «Xilinx».
Этап 5. Тестирование проекта
Тестирование разработанного устройства, а в мало-мальски сложных проектах и отдельных его фрагментов - один из важнейших этапов проектирования, поскольку практически не бывает бездефектных проектов, созданных с чистого листа. Обнаружение дефектов проекта - сложнейшая задача. Скорость и тщательность тестирования во многом зависят от искусства разработчика.
В современных САПР наиболее распространено тестирование путем работы с редакторами временных диаграмм. Эти редакторы делятся на компилирующие и интерпретирующие. В многооконных САПР интерпретирующего типа легко отображаются результаты моделирования для текущего момента модельного времени во всех видах отображения проекта (сигналы в электрических схемах, в топологии), легко изменить ход эксперимента и состав отображаемых сигналов. Достоинством компилирующих систем моделирования является минимизация временных затрат.
Распространение получили два способа генерации внешних относительно проекта воздействий. Один способ состоит в задании этих воздействий в форме задания временной последовательности для редактора временных диаграмм (графический способ задания для компилирующих систем моделирования или формульный для интерпретирующих). Другой способ, особенно удобный для использования при языковом задании проекта и обычно используемый на этапе функциональной верификации проекта, состоит в написании специальной тестирующей программы. Программы для тестирования в этом случае строятся на основе архитектурно-поведенческого тела, в котором проектируемый модуль представлен как структурный компонент, а генератор воздействия - в поведенческой форме.
В большинстве реальных ЦУ после подачи на них некоторых начальных данных выполняются несколько повторяющихся циклов. Необходима проверка работы устройства на нескольких наборах однотипных данных, поэтому можно рекомендовать следующую структу
870
БАЗОВЫЕ СВЕДЕНИЯ О ЯЗЫКЕ VHDL
ру программного модуля (процесса), представляющего тестовое воздействие: генерация сигналов начальной установки, затем реализация двух вложенных циклов, причем внутренний цикл последовательно формирует тестирующие сигналы для выполнения действий на одном наборе входных данных, а во внешнем производится их изменение.
Этап 6. Определение временных характеристик разработанного устройства
Современные САПР имеют внутри себя полную информацию о структуре проектируемого устройства и временных параметрах всех его компонентов, и это позволяет автоматизировать процесс вычисления разнообразных временных характеристик проекта.
Например, в САПР МАХ + PLUS II предусмотрено автоматическое вычисление трех основных классов временных параметров:
• минимальных и максимальных задержек между источниками (входными сигналами) и приемниками (выходными сигналами), информация о которых выдается в виде матрицы задержек;
• максимально возможной производительности устройства (пропускной способности) в виде максимальной частоты тактирования элементов памяти, используемых в проекте;
• времен предустановки и выдержки сигналов, гарантирующих надежную работу схем при фиксации сигналов в синхронных элементах памяти.
Многие САПР позволяют также выделять критические пути передачи и преобразования информации для схемного или топологического представления проекта.
Хотя выполнение перечисленных вычислений не гарантирует обнаружения всех ошибок проектировщика, связанных с временными процессами в ЦУ, оно существенно уменьшает число таких ошибок или, как минимум, позволяет обнаружить в проекте места, опасные с точки зрения сбоев.
Этап 7. Организация натурных экспериментов
Последним этапом проектирования является этап экспериментальной проверки спроектированного устройства. При всей тщательности выполнения предыдущих этапов всегда существует далеко не нулевая вероятность того, что в проекте имеются дефекты, которые могут проявиться на этапе внедрения или даже штатного использования устройства и повлечь за собою тяжкие последствия.
Выполнение натурных экспериментов существенно увеличивает вероятность выпуска бездефектной продукции. Средства ускорения работ на этом этапе и возможности его переноса на ранние этапы разработки, т. е. до того момента, когда будет закончено изготовление конечного продукта, известны - это прототипные системы и средства проведения экспериментов с ними. Прототипные платы широко использовались и ранее, в частности, при создании микропроцессорных систем. Аналогична и ситуация при разработке систем и устройств на основе средств программируемой логики. Широкий спектр прототипных плат, содержащих микросхемы программируемой логики и дополнительную аппаратуру (прежде всего микросхемы быстродействующих ОЗУ), выпускается и поставляется различными отечественными и зарубежными фирмами. Здесь можно указать средства фирм «АИега» (Demo Board); «PLD Applications» (платы PCI Bus Evaluation Board); «Xilinx», «Virtual Computer Corp.», «Video Software» (платы HOT PCI Design Kit) и др.
8.10. БАЗОВЫЕ СВЕДЕНИЯ О ЯЗЫКЕ VHDL
8.10.1. ИСТОРИЧЕСКИЙ ОБЗОР И ПРОБЛЕМНАЯ ОРИЕНТАЦИЯ ЯЗЫКА
Остановимся на отдельных вопросах, относящихся к наиболее известному языку проектирования аппаратных средств VHDL (Very high speed integrated circuits Hardware Description Language). Изложенный ниже материал не претендует на роль учебника по
871
ПРОЕКТИРОВАНИЕ МПС
программированию на языке VHDL. Задача состоит скорее в ознакомлении со специфическими особенностями языка, позволяющими создавать описания проектов, отвечающих заданной структуре или поведению и синтезируемых в состав аппаратуры. Некоторые конструкции языка будут использованы далее при рассмотрении примера проектирования подсистемы МПС на основе БИС/СБИС средствами САПР.
Язык VHDL появился в начале 1980-х гг. по запросам организаций Министерства обороны США. Первая его версия, предназначенная в основном для унификации описаний проектов в различных ведомствах, была принята в 1985 г. В 1987 г. язык VHDL был принят международным институтом IEEE (Institute of Electrical and Electronic Engineers) как стандарт ANSI/IEEE Std1076-1987, обычно называемый стандартом VHDL-87. Он использовался главным образом для описания уже спроектированных систем. Работа с компиляторами (т.е. использование для задач синтеза устройств) началась с 1991 г. В 1993 г. IEEE принимает новый расширенный стандарт ANSI/IEEE Std1076-1993 VHDL-93 (синтаксис языка приведен в приложении). В книге «VHDL’92. Новые свойства языка описания аппаратуры VHDL». - М.: Радио и связь, 1995, можно найти подробное описание нового стандарта и его основных отличий от стандарта VHDL-87.
Язык может быть использован для проектирования цифровых систем разных иерархических уровней - от вентильного уровня представления схем до уровня системы в целом. В настоящее время он является, видимо, самым популярным среди проектировщиков цифровой аппаратуры. Как отмечалось выше, сравнимым по возможностям и по популярности является язык Verilog, и практически любая современная САПР средств ВТ или цифровых устройств имеет в своем составе компиляторы для этих языков.
Проблемная ориентация и основные прикладные аспекты языка VHDL связаны с его использованием в качестве рабочего инструмента для задач описания структуры и/или поведения широкого класса цифровых устройств. Описания могут использоваться для синтеза и/или моделирования таких систем. Наибольшие ограничения на набор допустимых (относительно стандарта) операторов языка имеют компиляторы для синтеза спроектированных устройств, значительно меньше ограничений существует у систем моделирования. Важнейшей особенностью языка является возможность использования при создании проектов понятий и подходов, характерных для различных типов концептуальных моделей. Проекты могут содержать описания объектов в терминах параллельных процессов, в терминах межрегистровых передач, в терминах конечных автоматов или описываться как структуры. При описании систем сточки зрения их структурной организации, для однозначной трактовки поведения систем на нижних уровнях иерархии поведение составляющих его модулей должно быть однозначно определено.
8.10.2. БАЗОВЫЕ ПОНЯТИЯ ЯЗЫКА И АРХИТЕКТУРА ПРОГРАММ
Основные понятия языка, синтаксические конструкции и типы данных содержат две составляющие - общеалгоритмическую (свойственную большинству обычных алгоритмических языков) и проблемно-ориентированную.
Общеалгоритмическая составляющая языка достаточно традиционна и содержит как традиционные операторы действия (присвоения, условия, выбора, цикла и вызова процедуры), так и традиционные типы данных: числовые, логические, символьные, перечислительные и агрегатированные (массивы, записи и файлы). Синтаксис рассмотрен несколько позже.
С точки зрения структурной организации программы, на языке VHDL используют следующие основные термины и понятия. Любой проект образуется из одного или нескольких объектов - Entity. Каждый объект проекта имеет объявление интерфейса объекта - Entity Declaration и описание архитектурного тела объекта - Architecture body. Entity Declaration 872
БАЗОВЫЕ СВЕДЕНИЯ О ЯЗЫКЕ VHDL
содержит имя объекта и его интерфейс (входы и выходы). Architecture body содержит описание структуры или поведения объекта. Верхний уровень проекта описывается через объекты верхнего уровня; если устройство иерархично, то описания объектов верхнего уровня содержат в себе обращения к компонентам более низкого уровня, которые описываются как самостоятельные объекты нижнего уровня. В свою очередь, объекты нижнего уровня могут связываться с объектами еще более низкого уровня. Для определенности функционирования системы независимо от числа уровней иерархии все объекты нижних уровней иерархии должны иметь описание, определяющее их функционирование. Один и тот же объект может иметь несколько архитектурных тел (естественно, что при моделировании поведения системы или при ее синтезе специальные средства конфигурирования (Configuration Declaration) обеспечивают выбор единственного варианта поведения). Для часто используемых описаний, констант, типов данных используется понятие объявления пакета (Package Declaration), при создании собственных (пользовательских) процедур или функций необходимо их интерфейс привести в объявлении пакета, а их содержательную часть (описание) включить в состаа тела пакета (Package Body). Механизм пакетов исключительно важен для создания типов данных, одинаково воспринимаемых и понимаемых различными объектами программы, поскольку в языке VHDL используется очень строгая типизация данных и смешение различных данных в одном выражении является ошибкой.
Проблемно-ориентированными и поэтому наиболее важными средствами и понятиями языка VHDL являются:
• средства описания иерархии проекта для описания структуры и/или поведения отдельных объектов проекта;
• средства задания и описания параллелизма для выполняемых действий и операторов; • понятие сигнала для физических объектов, имеющих временное измерение для своих значений и средства для работы с ними.
Иерархическое построение описания системы в языке VHDL является развитием традиционного иерархического подхода и отличается тем, что распространяется не только на описание поведения, но и на описание структуры системы. Архитектурное тело (Architecture Body) описывает поведение объекта или его структуру. Внутри архитектурного тела может быть и смесь структурного описания с поведенческим. Специальные синтаксические конструкции могут описывать интерфейс структурной компоненты объектов (component... port), соединение компонентов между собой (port map, generic map), создание фрагмента структуры (for...generate и if...generate) или конкретизации конфигурации (for...use). То, что описанию архитектуры предшествует описание интерфейса объекта (Entity), не является существенным отличием языка VHDL и аналогично (в определенном смысле) описанию прототипа в языке СИ.
Наиболее важным свойством языка VHDL является понятие параллелизма выполнения действий. Параллелизм начинается с введения понятий процесса (Process) и охраняемого блока (Block) и распространяется при определенных условиях на такие традиционно последовательные операторы, как вызов процедуры и оператор присвоения. Для управления параллелизмом естественно введение операторов, задающих момент запуска (абсолютных-wait ..., относительных-after), и операторов, задерживающих момент запуска (wait... until, wait... for).
Третьей важнейшей особенностью языка VHDL является введение физического типа данных. Понятие сигнала (Signal) отражает основные свойства реальных входных и выходных данных проекта. Среди различных свойств сигналов важнейшими представляются временные характеристики таких данных и, прежде всего, наличие у них прошлого, настоящего и будущего состояний. Специфические свойства сигналов потребовали введения понятия «назначение значения сигнала» (<=), основное отличие которого от понятия «присвоение значения переменной» (:=) состоит в задержке изменения состояния сигнала до тех пор,
873
ПРОЕКТИРОВАНИЕ МПС
пока не будут подготовлены результаты преобразования во всех одновременно инициированных процессах, и лишь после этого допустимо изменение значений сигналов с учетом временных требований к их формированию.
8.10.3. СИНТАКСИЧЕСКАЯ ОРГАНИЗАЦИЯ ПРОЕКТА
Описание проекта на языке VHDLстроится по следующей типовой схеме: в его начале указываются библиотеки функциональных элементов, содержимое которых будет использоваться в проекте (Library Declaration), далее при необходимости следуют описания пакетов (Package Declaration) и их тела (Package Body), далее обязательно следуют описания объектов (Entity Declaration), которые будут использованы как компоненты проектируемого устройства, и раздел архитектуры (Architecture Declaration), который может быть представлен в структурном, поведенческом или смешанном вариантах.
Использование описаний аппаратуры в САПР, т. е. для компиляции в моделирующей или синтезирующей среде, для языка VHDL, как правило, имеет некоторую специфику файловой организации (опирающуюся на то, что файлы являются одним из типов данных языка VHDL). Каждый тип описания является достаточно самостоятельной конструкцией языка VHDL, поэтому любое описание принято называть модулем проекта (Design Unit). Один или несколько модулей проекта могут быть помещены в один файл, называемый файлом проекта (Design File). Каждый проанализированный модуль проекта помещается в библиотеку проекта (Design Library) и становится библиотечным модулем (Library Unit). Такой подход позволяет создавать большое количество разнообразных проектов, построенных из одних и тех же или слегка модифицированных составляющих фрагментов. Каждая библиотека проекта имеет свое уникальное имя (идентификатор), которое может не совпадать с фактическим именем файла, содержащего проект. Такой подход не является уникальным и характерен для САПР различных фирм, где используется не только для языка VHDL.
8.10.4. ОБЩЕАЛГОРИТМИЧЕСКАЯ СОСТАВЛЯЮЩАЯ ЯЗЫКА
Как уже отмечалось, общеалгоритмическая составляющая языка VHDL семантически соответствует обычным языкам программирования, несколько нестандартным является только синтаксис некоторых операторов. Это же касается и определенных в языке типов данных. Большинство типов данных языка совпадает с типами данных, используемых обычными алгоритмическими языками. Основным проблемно-ориентированным типом данных является физический тип (Physical).
Все операторы языка VHDL делятся на две основные группы: последовательные операторы (Sequential Statement) и параллельные операторы (Concurrent Statement). Параллельные операторы связаны с проблемно-ориентированной составляющей языка и рассмотрены несколько ниже. Назначение последовательных операторов и определяемые ими действия практически полностью соответствуют операторам языков высокого уровня. Исключение составляют лишь два оператора: оператор ожидания (Wait Statement) и оператор назначения сигнала (Signal Assignment). К последовательным операторам относятся следующие операторы:
• оператор присвоения значения переменной (Variable Assignment);
• условный оператор (If);
• оператор выбора (Case);
• оператор цикла (Loop), а также связанные с ним оператор перехода к следующей итерации цикла (Next) и оператор выхода из цикла (Exit);
874
БАЗОВЫЕ СВЕДЕНИЯ О ЯЗЫКЕ VHDL
• пустой оператор (Null);
• оператор вызова процедуры (Procedure Call) и оператор возврата из процедуры (Return);
• оператор формирования сообщения (Assertion);
• оператор назначения сигнала (Signal Assignment);
• оператор ожидания (Wait).
Последовательные операторы выполняются в той последовательности, в которой они записаны (за исключением результирующего значения сигнала после исполненного оператора назначения сигнала), и тем самым порядок их перечисления соответствует установлению причинно-следственных связей между последовательными предложениями. С точки зрения изменения во времени, все события, описываемые совокупностью последовательных операторов, выполняются одновременно. Таким образом, совокупность последовательных операторов отражает алгоритм, в соответствии с которым могут быть получены из входных состояний объектов программы выходные состояния объектов. Подобное поведение последовательных операторов заставило разработчиков языка ввести ограничение на допустимое расположение последовательных операторов. Последовательные операторы могут появляться только внутри параллельного оператора - оператора процесса. Другое место, где могут встретиться последовательные операторы, это внутренность тел подпрограмм или функций, однако на вызов этого последовательного оператора процедуры или функции накладываются ограничения, характерные для любого последовательного оператора.
Синтаксические правила оформления последовательных операторов и некоторые пояснения к их использованию приводятся в приложении.
8.10.5. ПРОБЛЕМНО-ОРИЕНТИРОВАННАЯ СОСТАВЛЯЮЩАЯ ЯЗЫКА
Проблемно-ориентированная составляющая языка позволяет реализовать определенные выше свойства описываемых в языке систем. Все введенные в языке средства для этой цели оказываются серьезно связанными между собой. Как уже указывалось, к проблемно-ориентированным средствам необходимо отнести: средства для описания структурного соединения параллельно работающих компонент, средства для описания поведения во времени параллельно работающих компонент и, наконец, средства для связи параллельно-последовательно работающих компонент. Набор средств, призванных решить эти задачи, опирается на набор параллельных операторов языка, исполнение которых тесно связано с понятием сигнала и со связанными с ним атрибутами, а также с понятием времени.
Параллельные операторы определяют параллельное (во времени) поведение проекта, и порядок их выполнения не связан с порядком их появления внутри архитектурного тела данного иерархического уровня. К параллельным операторам этого типа принадлежат: • оператор процесса (Process Statement);
• оператор блока (Block Statement);
• оператор условного назначения сигнала (Conditional Signal Assignment Statement);
• оператор выборочного назначения сигнала (Selected Signal Assignment Statement);
• оператор параллельного вызова процедуры (Procedure Call Statement);
• оператор параллельного сообщения (Assert Statement).
При создании структуры соединений объектов используются два параллельных оператора - оператор конкретизации (создания экземпляра) компонента (Component Instantiation Statement) и оператор генерации (Generate Statement). Альтернативным вариантом задания компонент и их соединений между собой является понятие блока (Block Statement).
Так как именно проблемно-ориентированная составляющая языка представляет наибольший интерес и предопределяет правильную интерпретацию приводимых далее практических примеров, остановимся более подробно на элементах этой составляющей языка.
875
ПРОЕКТИРОВАНИЕ МПС
8.10.6. СТРУКТУРНОЕ ОПИСАНИЕ
Для структурной организации проекта используется ряд операторов языка. Прежде всего сама структура описания тела модуля проекта (Architecture) предполагает возможность (при структурном варианте описания) объявления в декларативной части компонентов, из которых будет собран модуль, и сигналов, при помощи которых отдельные компоненты будут соединяться друг с другом. А в исполняемой части архитектурного тела модуля проекта нужно использовать операторы, конкретизирующие объединение компонент между собой и их связь с остальными операторами архитектурного тела. Сигналы в таком случае используются в двух качествах: с одной стороны, имена сигналов отождествляются с именами цепей, соединяющих порты (контакты) отдельных компонентов между собой, а с другой стороны, те же самые имена сигналоа используются уже по прямому назначению (как воздействия, передаваемые в поведенческий модуль).
Определение тела объекта (модуля проекта)
<Architecture_Declaration>::=
АКСН1ТЕСТиКЕ<имя_архитектуры_объекта> OF <имя_объекга> IS
— объявление конфигурации
— объявление глобальных переменных и констант
— объявление функции и подпрограмм
— объявление сигналов
[ {SIGNAL<cnncoK_HMeH>: <тип>;}]
— объявление компонент
[ {COMPONENT <имя_типа_компонента> (СЕМЕР1С(<параметры_настройки>);] [PORT (<список_имен_входов>: IN <тип>);
<список_имен_выходов>: OUT <тип>;]
END COMPONENT;}]
BEGIN
— описание структурного соединения
[{<имя_компонента>:<имя_типа_компонента>
[GENERIC МАР (<список_настроек>);]
PORT МАР (<список_сигналов>);]
— описание поведения
[<параллельные_операторы>]
END [<имя_архитектуры_объекта>];
При описании структуры соединения компонентов между собой в определении архитектурного тела может быть использован параллельный оператор конкретизации компонента.
Оператор конкретизации компонента (Component Instantiation Statement)
Определение оператора.
<Component_lnstantiation_Statement>::=
<имя_компонента>:<имя_типа_компонента>
[GENERIC МАР(<параметры_настройки>)]
[РОРТМАР(<параметры_соединения>)];
Оператор позволяет использовать один и тот же тип компонента несколько раз, используя при создании очередного экземпляра компонента уникальные имена и конкретизируя связи одноименных входов. Соответствие входных и выходных портов может осуществляться как обычным позиционным соответствием формальных и фактических параметров, так и путем использования символа ключевого соответствия (=>).
Альтернативным вариантом разбиения проекта на отдельные структурные элементы (декомпозицию проекта) является использование оператора блока.
876
БАЗОВЫЕ СВЕДЕНИЯ О ЯЗЫКЕ VHDL
Оператор-блок (Block Statement)
Определение.
<Block_Statement>::=
«меткаблока >: ВЮСК[(<охранное_выражение>)]
[GENERIC (<список_парметров_настройки>);]
[GENERIC МАР (< список_настроек>);]
PORT (<список_выводов>);
PORT МАР (<список_соединений>);
«деклара ции_блока>;
BEGIN
<параллельные_операторы >
END BLOCK <метка_блока>;
Блок является подмодулем, который может использоваться внутри архитектурного тела. Блок является элементом (единицей) модульного описания структуры со своим собственным интерфейсом и функционированием. Для этого блок имеет раздел описания и раздел исполняемых операторов. Блоки могут быть иерархически вложены. Оператор блока позволяет записывать структуру и поведение модулей системы одновременно и соответственно более компактно.
В разделе деклараций блока могут размещаться: декларации подпрограмм; тела подпрограмм; типы, подтипы; декларации констант; константы; декларации атрибутов; спецификации атрибутов; альтернативные точки входа; сигналы. Использование конструкции «охранное выражение» позволяет блокировать выполнение охраняемых (сопровождаемых опцией GUARDED) параллельных операторов назначения сигналов в теле блока.
Еще одним средством, позволяющим создавать компактную запись структуры описываемой системы, является оператор генерации.
Оператор генерации (Generate Statement)
Описание оператора. э
<Generate_Statement>::= <метка >: FOR <параметр>1М <flnana3OH>GENERATE
| IF <ycnoene>GENERATE
«параллельные операторы> э
END GENERATE [<метка>]
Оператор генерации является удобным механизмом для описания объединения компонентов в регулярных структурах. Наличие вариантов FOR и IF упрощает создание структур с некоторыми вариациями начальных и конечных компонентов. Несмотря на внешнее сходство с последовательными операторами FOR и IF, следует учитывать специфику этого оператора: только параллельные операторы могут использоваться внутри параллельного оператора генерации.
8.10.7 . ОПИСАНИЕ ПОВЕДЕНИЯ ч
j
Основой описания поведения проекта или его определенной части является понятие параллельно выполняемых процессов, каждый из которых может быть выражен одним из параллельных операторов языка. Важнейшее место среди них занимает оператор процесса, содержащий внутри себя совокупность последовательных операторов.
Оператор процесса (Process Statement)
Синтаксис оператора. т
<Process_Statement>::= [<имя_процесса>] PROCESS
[<список_чувствительности>] ,
<декларативная_часть> -
877
У
ПРОЕКТИРОВАНИЕ МПС
BEGIN
<список_последовательных_операторов>
END PROCESS [<имя_процесса>]
Оператор процесса представляет собой параллельный оператор, который определяет независимое последовательное поведение некоторой части проекта. Для обеспечения последовательного поведения процесс образуется упорядоченной совокупностью последовательных операторов. С точки зрения других объектов проекта, поведение процесса выглядит либо как единое целое после изменения значения какого-либо сигнала из списка чувствительности, либо как отдельные порции, разделяемые операторами ожидания WAIT. Операторы ожидания относятся к последовательным операторам и поэтому они могут помещаться в различные места совокупности последовательных операторов процесса, разделяя процесс на отдельно и последовательно исполняемые фрагменты. Для исключения неоднозначности поведения процесс не может одновременно содержать и операторы ожидания и список сигналов запуска (список чувствительности).
Последовательный оператор ожидания (Wait Statement)
Описание оператора.
<Wait_Statement>::= WAIT [ON (<список_чувствительности>)]
[UNTIL<6yneecKoe_BbipaxeHne>] [ЕОК<выражение_времени>];
Оператор должен содержать не менее одного (допустимо наличие нескольких альтернативных вариантов) условия продолжения прерванного процесса. Это может быть как истечение заданного интервала времени, наступление заданного момента времени или наступления заданного события (условия).
Элементом, определяющим запуск процесса и взаимодействие процессов между собой, являются сигналы, и в языке необходимы операторы, управляющие изменением состояния сигналов. Одним из основных операторов этого типа является последовательный оператор назначения сигнала.
Последовательный оператор назначения сигнала (Signal Assignment Statement) Описание оператора.
<Signal_Assignment_Statement >::=<HfleHT^HKaTop_cnrnana><=[TRANSPORT]
{<выражение>[АГГЕР <время>] | NULL [АЕТЕР<время>]}
Отнесение этих операторов к последовательным позволяет включать их в совокупность последовательных операторов (прежде всего помещать внутри операторов процесса), но благодаря основному свойству сигналов - изменение значения сигнала происходит только после того, как завершены преобразования во всех процессах, инициированных общим событием, обеспечивается бесконфликтное планирование будущих значений сигнала. Использование ключевого слова «TRANSPORT» позволяет заменить предполагаемую по умолчанию инерционную задержку на транспортную задержку. При транспортной задержке все изменения <выражения> будут передаваться (назначаться) определяемому оператором сигналу независимо от их временной протяженности. В отличие от транспортной задержки инерционная задержка позволяет отразить в языке поведение реальных электронных схем, отфильтровывающих входные сигналы с длительностью менее определенного отрезка времени (величина отрезка указана после ключевого слова AFTER).
Для исключения неоднозначности окончательного значения каждый сигнал может использоваться в операторе назначения сигнала только один раз, т. е. при выполнении последовательности параллельных операторов для каждого сигнала должен быть реализован только один оператор назначения сигнала.
Для изменения значений сигналов в совокупности параллельных операторов необходимы операторы назначения значений сигналов, относящиеся к классу параллельных. Поскольку основным связующим элементом взаимодействия процессов между собой явля
878
БАЗОВЫЕ СВЕДЕНИЯ О ЯЗЫКЕ VHDL
ются сигналы, поэтому в состав языка VHDL включены более короткие по форме (чем оператор процесс) варианты параллельных операторов, определяющих условия изменений сигналов. К параллельным операторам назначения сигнала относятся две модификации-условного и селективного назначения сигнала. По принципам причинно-следственных связей каждое событие является следствием исполнения одного события (возможно, являющегося совокупностью одновременно сосуществующих событий), поэтому один и тот же физический источник не может иметь несколько инициализируемых событий. Именно поэтому в совокупности выполняемых последовательных операторов не может встречаться несколько последовательных операторов назначения значения одному и тому же сигналу, которые могли бы привести к коллизии, когда не ясно, какое же значение должен приобрести сигнал после выполнения всей совокупности операторов. Параллельные операторы назначения сигнала, по своей сути, предполагают однозначность (для каждого момента времени) состояния сигнала после исполнения оператора.
Оператор условного назначения сигнала (Conditional Signal Assignment Statement) Описание оператора.
<Conditional_Signal_Assignment_Statement>::=
<идентификатор_сигналах=[ОиАРОЕО] [TRANSPORT]
{<диаграмма> WHEN<ycnoBne>ELSE}<flnarpaMMa>
Опция «транспортный» (TRANSPORT) соответствует такой же опции для последовательного оператора назначения сигнала. Опция «охраняемый» (QUARDED) означает ссылку этого оператора на охранное выражение блока, включающего данный оператор.
Диаграмма задает порядок (или условия) изменения сигнала от текущего момента системного времени.
Определение диаграммы.
<диаграмма>::= <элемент_диаграммы>{,<элемент_диаграммы>) <элемент_диаграммы>::=<выражение_значения_сигнала> [АЕГЕР<выражение_значения_времени>].
Оператор селективного назначения сигнала (Selected Signal Assignment Statement)
Определение оператора.
<Selected_Signal_Assignment_Statement>::=
[<метка>:] WITH <выражение> SELECT
{<идентификатор_сигнала><=[ОиАРОЕО] [TRANSPORT] {<flnarpaMMa>WHEN<Bbi6op>;}<flnarpaMMe>WHEN<Bbi6op>; Оператор вызова процедуры (Call Procedure Statement) Определение оператора.
<Call_Procedure_Statement>::=
[<метки>:] <имя_процедуры>[(<список_фактических_параметров>)].
Сокращение длины программы за счет сокращения записи для однотипных действий в языке VHDL, как и в других языках, возможно ввиду наличия в языке не только последовательных операторов обращения к процедуре, но и внешне совпадающих сними параллельных операторов обращения к процедуре. Выполнение оператора параллельного вызова процедуры эквивалентно выполнению оператора процесса. Существенным моментом представляется только ограничение на типы формальных параметров процедуры, которые могут быть либо типа сигнала, либо типа константы. Соответствие формальных и фактических параметров достигается позиционным соответствием или сопоставлением имен.
Оператор параллельного сообщения (Assert Statement)
Определение оператора.
<Assert_ Statement>::=[<MeTKa>:] ASSERT <условие> [РЕРОРТ<сообщение>]
[SEVERITY <уровень_серьезности>]
<уровень_серьёзности>::=
NOTE | WARNING | ERROR | FAILURE
879
ПРОЕКТИРОВАНИЕ МПС
Вспомогательным оператором, обычно используемым в моделирующих программах, является оператор параллельного сообщения. Этот оператор полностью эквивалентен последовательному оператору сообщения, но в отличие от последовательного оператора может входить в совокупность параллельных операторов.
8.10.8 . СИНТАКСИС ОПЕРАТОРОВ ОБЩЕАЛГОРИТМИЧЕСКОЙ СОСТАВЛЯЮЩЕЙ ЯЗЫКА
Условный оператор (If Statement)
Описание оператора. ,
<lf_Statement>::=IF<ycnoBne> THEN <последовательные_операторы>
{ELSIF <условие> THEN <последовательные_операторы >}
[Е1_5Е<последовательные_операторы>]
END IF;
Оператор If языка подобен условным операторам в других языках программирования. Специфическим является требование использования при реализации любого условия совокупности последовательных операторов.
Оператор выбора (Case Statement) >
Описание оператора.
<Case_Statement>::=CASE <выражение> IS
WHEN<Bbi6op>=><nocnefloeaTenbHbie_pnepaTOpbi> {WHEN<Bbi6op>=><nocneflOBaTenbHbie операторы:»} ,
END CASE;
<выбор>::=<простое_выражение>|<дискретный_диапазон>
|<одноразмерный_массив_символов>|<другое...>
Назначение и основные правила использования оператора варианта совпадают с общеупотребительными. Оператор удобен для описания поведения цифровых автоматов. Поскольку оператор требует покрытия всех возможных вариантов выбора, допустимо использование оператора «нуль» (null_statement). Оператор «нуль» служит для точного указания об отсутствии каких-либо действий.
Оператор цикла (Loop Statement)
Описание оператора.
<Loop_Statement>::=[<MeTKa_4MKna>:][WHILE<ycnoBne>| !
ЕОК<идентификатор>^ <дискретный_диапазон>]
1_ООР<последовательные_операторы>
END 1_ООР[<метка_цикла>];
Две альтернативные формы записи оператора цикла соответствуют варианту цикла с предусловием и варианту цикла с известным числом повторений. Параметр цикла совпадает с понятием константы внутри оператора цикла (не может изменяться в теле цикла). Параметр не требует предварительного объявления, но и не может использоваться вне оператора цикла.
Внутри оператора цикла для упрощения записи могут использоваться два дополнительных оператора - NEXT и EXIT.
<Next_Statement>::=NEXT[<MeTKa_UHKna>][WHEN<ycnoBHe>];
Оператор употребляется для завершения очередной итерации цикла.
<Exit_Statement>;.-EXIT[<MeTKa_HMKna>][WHEN<ycnoBMe>];
Оператор употребляется для завершения всех итераций и выхода из цикла.
880
ОПИСАНИЕ ПРОЕКТОВ НА ЯЗЫКЕ VHDL. ПРИМЕРЫ, ИЛЛЮСТРИРУЮЩИЕ ОСНОВНЫЕ КОНСТРУКЦИИ VHDL
Оператор вызова процедуры (Call Procedure Statement) и оператор выхода из процедуры (Return Statement)
Традиционные операторы обращения к процедуре и выхода из процедуры. Оператор вызова процедуры (Call Procedure Statement).
<Са11_Ргосебиге_81а1етеп1>::=<имя_процедуры>[(<список_параметров>)];
Оператор выхода из процедуры (Return Statement).
<Retum_Statement>::=RETURN[<BbipaxeHne>];
Оператор последовательного сообщения (Assert Statement)
Определение оператора.
<Assert_ Statement>::=[<MeTKa>:] ASSERT <условие> [РЕРОРТ<сообщение>]
[SEVERITY <уровень_серьезности>]
<уровень_серьёзности>::=ГЮТЕ | WARNING | ERROR | FAILURE
Вспомогательным оператором, удобным для использования в качестве оператора, проверяющего выполнение контролирующего условия в моделирующих программах, является оператор последовательного сообщения.
Если уровень серьезности и текст сообщения опущены, то по умолчанию выполнение условия оператора приводит к выводу сообщения «Assertion violation». Этот оператор может входить в совокупность последовательных операторов.
8.11. ОПИСАНИЕ ПРОЕКТОВ НА ЯЗЫКЕ VHDL. ПРИМЕРЫ, ИЛЛЮСТРИРУЮЩИЕ ОСНОВНЫЕ КОНСТРУКЦИИ VHDL
8.11.1. СТРУКТУРНОЕ ОПИСАНИЕ
Проиллюстрируем структурные варианты описаний на простейших примерах. Пусть требуется описать на языке VHDL комбинационную схему, реализующую функцию Y = not(not(in1Ain2)Ain3) под наименованием examplel, опирающуюся на поведенческое описание функционирования двухвходового элемента типа 2И-НЕ. Схема приве- ' дена на рис. 8.11.
Листинг примера может иметь вид:
ENTITY examplel IS
PORT (in1,in2,in3: IN BIT;
y: OUT BIT;
END examplel;
ARCHITECTUREstruct OF examplel IS
COMPONENT nand2
PORT (x1, x2: IN BIT; q: OUT BIT);
END COMPONENT; '
SIGNAL z: BIT;
BEGIN
Unitl: nand2 PORT MAP (In1, In2, z);
Unit2: nand2 PORT MAP (q=> y, x1=>in3, x2=> z); END struct;
В примере описан интерфейс устройства, имеющего три входа и один выход, и структура устройства, когда оно состоит из соединения компонентов под названием nand2. Предполагается, что в проекте имеется описание интерфейса и поведения элемента типа 2 И-НЕ, по смыслу совпадающее с фрагментом:
881
ПРОЕКТИРОВАНИЕ МПС
ENTITY nand2 IS ;
PORT(in1,in2: IN BIT;
out: OUT BIT;
END nand2;
ARCHITECTURE behave OF nand2 IS »;
BEGIN
Out<= not (in 1 and In2);
END behave;
В состав устройства входят два компонента типа nand2 с именами unit 1 и unit2, подсоединяемые при помощи сигналов in 1, in2, in3 и Y к внешним контактам устройства и соединяемые между собой при помощи сигнала (цепи) под именем Z. Устройство unit 1 подключается при помощи позиционного соответствия между формальными и фактическими именами входных и выходных сигналов. Подключение устройства unit2 выполнено с применением ключевого соответствия между формальными и фактическими именами. Ключевое соответствие позволяет отобразить отсутствие соединения у выходного контакта при помощи ключевого слова OPEN.
Рассмотрим пример описания структуры 16-разрядного регистра, используя понятие Component и опираясь на конструкцию Generate. Предполагается, что в проекте поведение триггера D описано ранее и может совпадать с примером, приведенным далее в листинге.
ENTITYreg16IS
PORT (input: IN bit_VECTOR (OTO 15);
clock: IN BIT;
output: OUT BIT VECTOR (0 T015);
END reg16;
ARCHITECTURE struct OF reg16 IS
COMPONENT dff
PORT (d, elk: IN BIT; q: OUT BIT);
END COMPONENT;
BEGIN
g1: FOR i IN 1 TO 16 GENERATE
dff PORT MAP (input (i), clock, output(l));
END GENERATE g1;
Из примера очевидна компактность записи структуры устройства при применении синтаксической конструкции Generate.
882
ОПИСАНИЕ ПРОЕКТОВ НА ЯЗЫКЕ VHOL. ПРИМЕРЫ, ИЛЛЮСТРИРУЮЩИЕ ОСНОВНЫЕ КОНСТРУКЦИИ VHDL
8.11.2. ПОВЕДЕНЧЕСКОЕ ОПИСАНИЕ
Проиллюстрируем поведенческие варианты описаний на том же простейшем примере. Начиная с раздела Entity Declaration, описание может иметь следующий вид:
ENTITY input3_nand IS—entity declaration
PORT (in1,in2,in3: IN BIT; —port statement
y: OUT BIT);
END input3_orand1;
ARCHITECTURE one OF input3_nand IS
— architecture «one» of entity input3_nand1
BEGIN
nand3: PROCESS
BEGIN
IF (in3 ='1’) THEN y<=NOT (in1 AND in2);
ELSE y<=T;
END IF; ’
WAIT ON in1, in2, in3;
END PROCESS;
END;
Описание поведения 8-разрядного счетчика с тактируемым входом сброса (в архитектурном теле) можно задать следующим образом:
Synch_count; PROCESS
BEGIN
WAIT UNTIL clock=’1’;
IF (reset='1 ’) THEN count<=»00000000”;
ELSE count<=count+'1';
END IF;
END PROCESS;
Возможность различными способами описать поведение одной и той же системы или объекта, оставаясь в рамках одного архитектурного тела, приводит к понятию стиля описания (программирования). Традиционно выделяют следующие типы стилей:
• последовательный, когда преобразование потока входных данных в поток выходных данных осуществляется с использованием только последовательных операторов;
• параллельный (процессный), когда описание поведения задано в виде параллельно выполняемых процессов;
• потоковый, когда описание задано в виде последовательности параллельных операторов языка.
К специфическому стилю описания можно отнести автоматный способ описания, когда функционирование устройства задано в форме описания набора состояний устройства, правил переходов и действий, выполняемых в определенных состояниях и на определенных переходах. Распространенным вариантом автоматной формы является описание в форме конечного автомата Мура или Мили.
Введение понятия стиля и наличие различных стилей отнюдь не означает, что какой-либо стиль позволяет описать функционирование определенной системы, а другой стиль нет. Каждый стиль характеризует систему с определенной точки зрения, и события, происходящие в ней (с точки зрения проектировщика), лучше всего отражаются при помощи выбранного стиля. Вместе с тем необходимо отметить, что для САПР, синтезирующих структуру БИС ПЛ из VHDL-описания, варианты, синтезируемые различными стилями, описания, могут давать различные варианты реализации. Более того, синтезирующие компиляторы могут даже не поддерживать компиляции при определенных способах описания поведения системы.
883
ПРОЕКТИРОВАНИЕ МПС
Процессная форма описания благодаря списку инициализирующих сигналов и единовременное™ выполнения последовательных операторов в теле каждого процесса может наиболее точно описывать функционирование последовательно-параллельного взаимодействия обрабатывающих устройств. Возможность последовательного оператора назначения сигнала (находящегося в теле процесса) использовать синтаксическую конструкцию AFTER позволяет описывать (или задавать) взаимодействие процессов со сложным распределением во времени.
Потоковый стиль наиболее точно отражает процесс изменения потоков данных в системе от входа до выхода. Опираясь на свойства параллельного исполнения параллельных операторов языка и правила назначения значения сигналам, потоковый стиль позволяет описывать функционирование конвейерных структур. Наибольшее распространение, естественно, имеет смешанное описание проектов, в которых классические стили описания переплетаются в произвольных комбинациях.
8.11.3. СРАВНЕНИЕ СТРУКТУРНОГО И ПОВЕДЕНЧЕСКОГО СПОСОБОВ ОПИСАНИЯ ПРОЕКТОВ
Когда следует использовать структурный, а когда поведенческий способ описания проекта?
Структурный способ предусматривает перечисление как типов компонент и их интерфейса (их выводов), так и связей всех компонент между собой, тем самым непосредственно отражая задаваемую для реализации схему, которая и будет создана в выбранной СБИС ПЛ.
Поведенческий способ определяет функции, которые должны быть реализованы, но не говорит о том, каким именно способом это должно быть сделано. Так как схемотехнические реализации узлов и устройств практически всегда многовариантны, САПР получает для их реализации определенную свободу действий. Большое достоинство поведенческого варианта - его компактность и наглядное представление функционирования устройства, что хорошо видно хотя бы из приведенных примеров. Платой за это является ослабление контроля за способом реализации проектируемого устройства или его фрагмента, поскольку это отдается «на усмотрение» компилятора. При этом следует ожидать, что компилятор может принять реализацию схемы, которая не будет столь же эффективна по быстродействию и затратам ресурсов, как выполненная квалифицированным специалистом, хорошо знающим ресурсы и особенности структурной организации выбранной СБИС ПЛ. Поэтому чаще всего комбинируют использование структурных и поведенческих описаний в рамках одного и того же проекта. Для критичных по скорости фрагментов целесообразно использовать структурные описания. Например, задавая функции счета или суммирования, реализуют структуры с параллельными переносами, обеспечивающими наибольшее быстродействие, тогда как компилятор (при неустановленных специальных опциях), возможно, создаст более простые структуры с последовательными переносами. В то же время остальные части проекта целесообразно описать в поведенческом варианте, что существенно упрощает задачу.
8.11.4. ОПИСАНИЕ ТИПОВЫХ ФРАГМЕНТОВ ВЫЧИСЛИТЕЛЬНОЙ ТЕХНИКИ
Весьма существенным вопросом, интересующим разработчика, является наличие в языке возможностей и/или средств, ориентированных на описание типовых узлов и устройств цифровой техники. В соответствии с традиционным разбиением необходимо оценить возможности описания следующих типов узлов: комбинационных схем, регистровых схем и цифровых автоматов.
884
ОПИСАНИЕ ПРОЕКТОВ НА ЯЗЫКЕ VHDL. ПРИМЕРЫ. ИЛЛЮСТРИРУЮЩИЕ ОСНОВНЫЕ КОНСТРУКЦИИ VHDL
Функционирование комбинационных схем удобно описывать достаточно широким классом средств: арифметическими и логическими выражениями, условным или селективным (по выбору) назначением сигналу. В разделе операторов процесса допустимо использование операторов условия (IF) и выбора (CASE). Входы и выходы схемы могут быть представлены в виде сигнала или переменной. Как правило, используются следующие типы данных: bit, bit_vector, stdjogic, std_logic_vector. Использование других типов данных может требовать определения функций взаимных преобразований. Пример образования схемы под именем examplei, приведенный выше, как раз и соответствует представлению комбинационной схемы в языке VHDL.
Возможность иерархического построения проектов (плюс возможность организации пакетов для стандартных строительных кирпичиков пользовательских проектов) позволяет осуществлять проектирование в рамках привычных для разработчиков вычислительных систем элементов. Поведение триггерных элементов достаточно просто описывается средствами языка VHDL. Пользователь может создать систему элементов, наиболее точно отражающую поведение проектируемой системы. В практической деятельности используются следующие виды синхронизации триггеров: асинхронное управление, потенциальное управление или динамическое управление.
Поведение регистровых схем удобно описывать, используя либо процессное, либо блочное представление. При процессном представлении внутри оператора PROCESS обычно пользуются операторами условия (IF) и выбора (CASE). При блочном представлении возможно использование операторов условного назначения сигналу (<=... WHEN).
В качестве примера рассмотрим описание поведения триггера D типа «защелка», имеющего вход асинхронного сброса и срабатывающего по фронту тактирующего сигнала. ENTITY d_ff IS—entity declaration
PORT (d,c,r: IN BIT; — port statement
qJNOUTBIT);
ENDdJf;
ARCHITECTURE one OF d Jf IS
— architecture «one» of entity d_ff
BEGIN
beh_tr: BLOCK (c = ’1 ’ OR r = ’1 ’);
BEGIN
q<=GUARDED ‘0’ WHEN r=’1 ’
ELSE d WHEN c=T AND NOT c’STABLE
ELSE q;
END BLOCK beh_tr;
END one;
Наибольшее внимание при описании поведения регистровых схем необходимо уделять видам синхронизации входных сигналов (асинхронное, потенциальное или динамическое) и способам задания входных, выходных сигналов и внутренних состояний при описании многоразрядных схем (счетчиков, регистров сдвига и т. д.). Для определения этих переменных или сигналов в многоразрядных схемах можно использовать понятие вектора или ограниченного целого (с диапазоном изменения, связанным с разрядностью схемы). Независимо от варианта описания поведения отдельных триггеров и средств, используемых для их объединения в регистровые структуры типа регистров, счетчиков и т. д., рассмотренный подход создает предпосылки для использования языка VHDL в качестве средства, позволяющего описывать вычислительные устройства в терминах и понятиях языка, обычно называемого языком регистровых передач.
Следующим типовым фрагментом, играющим очень важную роль в проектировании, является цифровой автомат. Основные разновидности поведения автоматов сводятся
885
ПРОЕКТИРОВАНИЕ МПС
к автоматам Мили или Мура, хотя расширенные структурные возможности схем ПЛ привели к широкому практическому распространению разновидности автоматов Мили - асинхронным автоматам Мили.
Наличие в языке возможности использования перечислительного типа данных позволяет ввести перечислительные типы данных «состояния», а при желании разработчика и типы данных «входы» и «выходы». Предпочтительной представляется процессная форма описания поведения автомата. В зависимости от типа используемого автомата его архитектура может включать от одного до четырех процессов. Оператор варианта целесообразно использовать в качестве основного каркаса процессов, для чего каждому состоянию автомата назначается вариант в операторе выбора. Для описания альтернативных вариантов формирования переходов и выходных сигналов (если это необходимо) обычно применяется условный оператор. Отдельный процесс может вводиться для описания процедуры тактирования и начальной установки автомата.
В качестве примера автомата рассмотрим автомат Мили. Пусть автомат задан таблицей переходов (табл. 8.1) и таблицей выходов (табл. 8.2), где в клетках таблицы переходов записаны состояния, в которые переходит автомат из исходного состояния при соответствующем входе, а в клетках таблицы выходов - выходные сигналы при тех же условиях. Нетрудно видеть, что приведенный пример соответствует реверсивному счетчику, причем Y1 и Y2 соответствуют выдаче сигналов переноса.
Фрагмент VHDL-программы, описывающий такой автомат, имеет вид, приведенный в листинге 1. Предполагается, что перечислительный тип state задан списком имен, переменные у и х объявлены в Entity блока, в котором определен данный процесс, и их тип задан списком имен-значений.
Процесс после задания исходного состояния (s<=sO) входит в бесконечно повторяющуюся петлю, в начале которой помещен оператор WAIT. Примененная конструкция оператора соответствует синхронному автомату, состояние которого изменяется по тактирующему сигналу p_clk, причем p_clk является глобальной переменной проекта.
Важно обратить внимание на то, что изменения состояний происходят в момент появления нарастающего фронта сигнала p_cik, так как запускающее событие определено как «появление единицы и наличие переходного процесса на входе p_clk».
Синтаксическая конструкция p_clk’stable называется атрибутом сигнала. Атрибут сигнала может принимать значение «истинно» или «ложно» и характеризует некоторые свойства сигнала на момент моделирования (в данном контексте - переходный режим).
Использование в качестве условия продолжения процесса выражения «not p_clk’stable» соответствует реальной структуре устройства, реализующего автомат, в котором состояние отображается состоянием регистра. Так как этот регистр является одновременно датчиком информации о текущем состоянии и приемником нового значения, во избежание гонок необходимо использовать регистры с динамическим управлением, реагирующие на изменение сигнала, что и задается используемой конструкцией условия в операторе Wait.
Таблица 8.1 Таблица 8.2
Таблица переходов Таблица выходов
Вход Исходное состояние
so S1 S2 S3
ХО so S1 S2 S3
Х1 S1 S2 S3 SO/
Х2 S3 so/ S1 S2
Вход Исходное состояние
SO/ S1 S2 S3
ХО Y0 Y0 Y0 Y0
Х1 УО Y0 Y0 Y1
Х2 Y2 Y0 Y0 Y0
886
ОПИСАНИЕ ПРОЕКТОВ НА ЯЗЫКЕ VHDL. ПРИМЕРЫ, ИЛЛЮСТРИРУЮЩИЕ ОСНОВНЫЕ КОНСТРУКЦИИ VHDL
Листинг 1
—описано вне процесса TYPE state IS (s0,s1,s2);
TYPE input IS (x0,x1);
TYPE output IS (yO,y1 ,y2);
SIGNAL x: INPUT;
SIGNAL y_out :OUTPUT;
PROCESS
SIGNAL s: state;
BEGIN
s<=sO;
LOOP
WAIT UNTILI (p_dk=’1' AND NOT p_dk’stable);
— Реализация переходов
CASE s IS
WHEN s0=> IF x=xO THEN s<=sO;
ELSEIF (x=x1) THEN s<=s1;
ELSE s<=s2;
END IF;
WHEN s1 => IF x=xO THEN s<=s1;
ELSEIF x=x1 THEN s<=s2;
ELSE s<=sO;
END IF;
WHEN s2=> IF x=xO THEN s<=s2;
ELSEIF x=x1 THEN s<=s3;
ELSE s<=s1;
END IF; ч., >
WHEN s3=> IF x=xO THEN s<=s3;
ELSEIF x=x1 THEN s<=sO;
ELSE s<=s2;
END IF;
END CASE;
— Формирование выходов
IF (s=s3 AND x=x1) THEN y<=y1;
ELSEIF (s=sO AND x=x2) THEN y<=y2;
ELSE y<=yO;
END IF;
END LOOP;
END PROCESS;
После вычисления нового состояния и выходных сигналов (обратите внимание на то, что сигналы вычисляются на основе состояний, которые были «перед» фронтом тактирующего сигнала, а не вычисленных в текущем цикле) программа переходит в состояние ожидания нового запускающего события.
Наличие определенных стереотипов и у проектировщиков, и у САПР для описания типовых фрагментов цифровой техники позволяют упростить написание и понимание описаний на языке VHDL достаточно сложных систем.
887
ПРОЕКТИРОВАНИЕ МПС
8.12. ПРИМЕР АВТОМАТИЗИРОВАННОГО ПРОЕКТИРОВАНИЯ ЦИФРОВОГО УСТРОЙСТВА С ИСПОЛЬЗОВАНИЕМ ЯЗЫКОВ ОПИСАНИЯ АППАРАТУРЫ
Современные методы и средства проектирования рассмотрим на примере разработки микропроцессорной системы, являющейся модернизацией более ранней разработки устройства на базе микроконтроллера MCS-51 (с целью сокращения объёма примера описание будет упрощено относительно реальных условий). Переход на новую элементную базу в данном проекте прежде всего ограничивается естественным желанием проектировщика максимальным образом использовать ранее разработанные и проверенные решения, в основном это касается фрагментов программного обеспечения. В состав системы должен входить двухканальный 10-разрядный аналого-цифровой преобразователь, записывающий по запросу параллельный код в буферное ОЗУ емкостью 256 десятиразрядных слов, 8 входов и 28 выходов для дискретных сигналов. Использование схем класса СИС и МИС должно быть в модернизированном варианте минимизировано за счет использования схем программируемой логики. Для определенности, кроме специально оговоренных случаев, будем ориентироваться на микросхемы программируемой логики фирмы «Altera», а вследствие этого и на САПР этой же фирмы МАХ + PLUS II.
8.12.1. ВАРИАНТЫ РЕАЛИЗАЦИИ И ВЫБОР ЭЛЕМЕНТНОЙ БАЗЫ
Реализация проекта возможна в различных альтернативных вариантах. Сохранение задела по программному обеспечению заставляет обратиться к вариантам, имеющим в качестве МП-ядра тот или иной вариант контроллера MCS-51.
К основным вариантам можно отнести следующие:
1) с использованием БИС класса SOPC generic фирмы «АИега» и мегафункции (например, CAST) для реализации МП-ядра;
2) с использованием БИС класса SOPC фирмы «Triscend» семейства ТЕ5, содержащей в качестве МП-ядра встроенный микроконтроллер 8052 и конфигурируемую логику типа FPGA;
3) с использованием микроконтроллера, совместимого по системе команд с MCS-51 со встроенными средствами аналого-цифровой обработки (например, БИС ADuC812 фирмы «Analog Devices») и с реализацией недостающих дискретных элементов в БИС ПЛ фирмы «АИега»;
4) с использованием обычного контроллера семейства MCS-51, автономных средств аналого-цифровой обработки и размещением всей дискретной части проекта в БИС ПЛ фирмы «АИега».
Рассмотрим эти варианты более подробно.
1-й вариант реализации имеет укрупненную функциональную схему, соответствующую приведенной на рис. 8.12. Основу проекта составляет БИС класса SOPC generic, конфигурация которой включает МП-ядро (на базе стандартной мегафункции) и требуемую дополнительную логику: регистры выходные (Reg_A, Reg_B и Reg_BD), входной регистр (Reg_C), буферное ОЗУ (RAM) и автомат, управляющий работой ОЗУ (AvtRAM). Помимо БИС ПЛ схема содержит дополнительные элементы: ИС время задающего генератора (OSC), ИС ПЗУ конфигурации (EEPROM Config), ИС ПЗУ команд (EEPROM Instuction), ИС аналогового коммутатора (MUX) и ИС АЦ преобразователя (ADC). Поскольку мегафункция микроконт
888
ПРИМЕР АВТОМАТИЗИРОВАННОГО ПРОЕКТИРОВАНИЯ ЦИФРОВОГО УСТРОЙСТВА С ИСПОЛЬЗОВАНИЕМ ЯЗЫКОВ ОПИСАНИЯ АППАРАТУРЫ
роллера в этом варианте реализации требует (в зависимости от скоростных требований) от 2400 до 2860 логических ячеек, то проект потребует для своей реализации БИС ПЛ класса не ниже 10К50. Стоимость таких БИС превышает 80 дол. США, поэтому вариант вряд ли экономически оправдан даже для выпуска опытной партии устройств.
2-й вариант (рис. 8.13), опирающийся на продукцию фирмы «Triscend», потребует для своей реализации помимо БИС семейства ТЕ5 четырех схем СИС (организация БИС семейства ТЕ5 позволяет объединить в одной БИС ПЗУ память команд МК и память конфигурации БИС ПЛ - EEPROM). В силу специфики организации БИС семейства ТЕ5 буферизацию данных от АЦ-преобразователя необходимо выполнять непосредственно в памяти данных МК и ориентироваться при этом на встроенный контроллер прямого доступа к памяти. Эта специфика приводит к необходимости модернизации программного обеспечения процессорного ядра. Блоки, реализуемые конфигурируемой системной логики (CSL) кристалла ТЕ5, функционально совпадают с блоками, размещенными в БИС ПЛ предыдущего варианта. С экономической точки зрения, основные затраты, по-видимому, будут касаться не столько стоимости кристаллов (стоимость БИС семейства в зависимости от тактовой частоты и числа конфигурируемых ячеек системной логики может колебаться от 18 до 100 дол. США), сколько стоимости покупки лицензии на САПР и загрузочного оборудования, которое может достигать суммы порядка 650 дол. США (минимальные затраты около 170 дол. США).
3-й вариант реализации (рис. 8.14) является самым экономичным по числу требуемых для реализации числа микросхем. Основу схемы образуют две БИС (БИС ADuC812 фирмы «Analog Devices» и БИС ПЛ ЕРХ10К10 фирмы «Altera»). БИС ADuC812 фирмы «Analog Devices» разработчики отнесли к классу микропреобразователей (MicroConverter), поскольку БИС содержит на одном кристалле микроконтроллер, память, АЦП и ЦАП. Для реализации устройства дополнительно потребуется одна БИС конфигурационного ПЗУ (EPROM) и одна ИС времязадающего генератора (OSC). Структура устройства, конфигурируемого в БИС ПЛ, сохраняет элементы предыдущих вариантов. Как и для предыдущего варианта реализации, использование прямого доступа к памяти потребует модернизации программного обеспечения МК. Стоимость БИС ADuC812 фирмы «Analog Devices» не превышает 12 дол. США, но и стоимость БИС ЕРХ10К10 фирмы «Altera» близка к 20 дол. США. Приобретение средств, сопровождающих разработку, может потребовать затрат, не превышающих 100 дол. США. Вариант имеет предопределенные характеристики по скорости работы АЦП и экономически проигрывает следующему варианту.
4-й вариант реализации (рис. 8.15) предполагает использование в качестве МП-ядра классической микросхемы MCS-51 (в примере БИС АТ89С51 фирмы «Atmel») и применения БИС ПЛ ЕРХ10К10 для реализации недостающих дискретных компонентов. Основным достоинством варианта является возможность без каких-либо переделок использовать старое программное обеспечение. Именно это и позволяет остановиться для дальнейшей работы на этом варианте. Выбор для реализации 2-го или 3-го вариантов целесообразен только в том случае, если разработчик готов потратить время и деньги на модернизацию программного обеспечения. В связи с наличием целого ряда особенностей при проектировании устройства на базе БИС класса SOPC после подробного рассмотрения процедуры проектирования для выбранного варианта реализации приведем наиболее существенные отличия в проектной последовательности для реализации проекта на базе БИС фирмы «Triscend».
После выбора варианта реализации устройства в целом можно переходить к детализации технического задания на проектирование БИС ПЛ.
889
ПРОЕКТИРОВАНИЕ МПС
ЕРХ 10К50
Рис. 8.12. Вариант реализации проекта на БИС ПЛ класса SOPC generic
890
ПРИМЕР АВТОМАТИЗИРОВАННОГО ПРОЕКТИРОВАНИЯ ЦИФРОВОГО УСТРОЙСТВА С ИСПОЛЬЗОВАНИЕМ ЯЗЫКОВ ОПИСАНИЯ АППАРАТУРЫ
ADuC8H2
Рис. 8.14. Вариант реализации проекта на БИС ADuC812 и БИС ПЛ ЕРХ10К10
АТ89С51
Рис. 8.15. Вариант реализации проекта на БИС АТ89С51 и БИС ПЛ ЕРХ10К10
891
ПРОЕКТИРОВАНИЕ МПС
8.12.2. ПРОЕКТИРОВАНИЕ БИС ПЛ
Этап 1. Формирование требований на проектирование БИС ПЛ
К основным требованиям следует отнести:
• объем буферного ОЗУ 256 десятиразрядных слов;
• запись в ОЗУ осуществляется блоками (с чередованием данных от различных каналов) по запускающему сигналу RequstADC, формируемому внешней средой;
• после завершении записи блока оцифрованных данных во внутренний буфер ПЛ информирует МК об этом, выставляя сигнал ReadyData;
• сигнал ReadyData является источником прерывания для МК;
• чтение данных из буферного ОЗУ ПЛ осуществляется по инициативе МК путем последовательного считывания сначала восьми, а затем двух битов данных;
• помимо работы с буферным ОЗУ БИС ПЛ должно поддерживать формирование адреса для внешнего ПЗУ команд МК (Reg_BD);
• БИС ПЛ реализует функции двух выходных 8-разрядных портов (Reg_A и Reg_B) и одного входного 8-разрядного порта (Reg_C).
Перечисленные выше пункты ТЗ предопределяют основные блоки проектируемой БИС и их взаимодействие. Блочная схема устройства приведена на рис. 8.16. Функциональное назначение блоков следует из их названий. Схема укрупненно отображает следующие процессы:
запись данных от МК (Data[7..O]) по сигналу ALE в регистр адреса ПЗУ команд;
запись данных от МК по сигналу WR (при установленных в «1» 6-го и 7-го разрядов порта Р2 МК) в зависимости от адреса АО А1 в порт РА или РВ;
чтение данных в МК по сигналу RD (при установленных в «1» 6-го и 7-го разрядов порта Р2 МК) при адресе не АО и А1 из порта РС;
запись блока данных от аналого-цифрового преобразователя в буферное ОЗУ; считывание данных из буферного ОЗУ в МК;
готовность ПЛ к передаче данных индицируется сигналом ReadyData.
Этап 2. Разработка общей структуры операционного блока
Нетрудно видеть, что для реализации рассматриваемого устройства из состава библиотеки выбранной САПР можно использовать следующий набор библиотечных пара-метризируемых модулей (LPM):
• два блока ОЗУ (LPM_RAM_DQ) с организацией 256x8 и 256x2;
• 8-разрядный счетчик адреса ОЗУ (LPM_COUNTER);
• три модуля триггеров типа D (LPM_DFF), организованных в 8-разрядные регистры.
Понятие параметризированных модулей соответствует возможности настроить выбранный библиотечный элемент на определенный режим функционирования, на определенную разрядность данных, их полярность и т. д. В качестве 8-разрядных регистров можно использовать и специально разработанные блоки на базе примеров, описанных выше.
Структурная схема устройства, включающая эти операционные блоки и автомат, управляющий считыванием и записью кода из ОЗУ, может приобрести вид, приведенный на рис. 8.17. Кроме указанных выше базовых блоков в схеме присутствует ряд дополнительных элементов. Условные обозначения всех элементов схемы соответствуют стандарту, принятому в САПР МАХ + PLUS II. Необходимость введения дополнительных элементов (инверторов, D-триггеров и схем И) диктуется требованиями временной или аппаратной совместимости отдельных блоков схемы. Более подробные пояснения будут приведены в следующем разделе, поскольку этапы разработки операционной части и устройства управления операционными элементами тесно связаны и обычно выполняются итерационно.
892
ПРИМЕР АВТОМАТИЗИРОВАННОГО ПРОЕКТИРОВАНИЯ ЦИФРОВОГО УСТРОЙСТВА С ИСПОЛЬЗОВАНИЕМ ЯЗЫКОВ ОПИСАНИЯ АППАРАТУРЫ
Рис. 8.16. Блок-схема устройства, принятого в качестве примера для проектирования средствами САПР
Этап 3. Описание работы управляющего автомата
При разработке поведения управляющего автомата необходимо учесть, что функционирование устройства определяется сигналом CLOCK и происходит асинхронно относительно внешнего устройства, управляющего чтением и записью в ОЗУ и относительно другого внешнего устройства, запрашивающего и принимающего информацию в последовательной форме.
При выборе из библиотеки САПР в качестве ОЗУ-модулей типа LPM_RAM_DQ (т. е. с раздельными шинами чтения и записи данных) и при его настройке на асинхронный режим работы исчезает целый ряд проблем. Во-первых, нет необходимости введения элементов, разделяющих данные для записи и считывания. Во-вторых, существенно упрощается организация синхронизации работы управляющего автомата при записи данных в ОЗУ с асинхронно работающим АЦП.
Возможный алгоритм работы устройства управления разрабатываемого устройства, отвечающий сформулированным выше требованиям, может приобрести вид, соответствующий граф-схеме переходов автомата, приведенной на рис. 8.18. Граф-схема переходов при помощи графического редактора программы StateCAD Version 3.2 пакета Workview Office фирмы «Viewlogic» была занесена в соответствующий диаграммный файл, что, как будет показано далее, существенно упрощает не только отладку и возможные корректировки алгоритма, но и создание соответствующих программных текстов.
Перейдем к анализу автомата CntRAM, управляющего записью и считыванием данных в буферное ОЗУ и поддерживающего для этих обменов требуемое взаимодействие квитирующими сигналами.
893
894
АО
ALE
flRD
rWR
Рис. 8.17. Структурная схема устройства в САПР MAX+PLUSII
ПРОЕКТИРОВАНИЕ МПС
ПРИМЕР АВТОМАТИЗИРОВАННОГО ПРОЕКТИРОВАНИЯ ЦИФРОВОГО УСТРОЙСТВА С ИСПОЛЬЗОВАНИЕМ ЯЗЫКОВ ОПИСАНИЯ АППАРАТУРЫ
Основу алгоритма составляют два последовательно выполняемых блока.
Первый блок по сигналу запроса на преобразование ReqADC от внешнего устройства обеспечивает циклическое выполнение следующей последовательности действий. В состоянии автомата (StartWr) выставляется сигнал запуска преобразователя (StartADC), дождавшись сигнала готовности данных от АЦП (ReadyADC), считывает Юбитданныхизапи-сывает их (в состоянии WrData) в память (формируя сигнал WE). Об окончании приема данных АЦП узнает благодаря сбросу запроса на преобразование, затем автомат наращивает адрес ОЗУ (формируя в состоянии IncWrсигнал IncAdr). Признаком завершения приема блока данных является сигнал Мах, формируемый на основании анализа состояния счетчика адреса ОЗУ.
По завершении записи блока данных автомат в состоянии Pausel выставляет сигнал о заполнении ОЗУ данными ReadyData и сбрасывает счетчик адреса ОЗУ (сигнал ResAdr), подготавливая его тем самым к циклу считывания данных в МК. Этот цикл и составляет
Рис. 8.18. Граф-схема переходов автомата управления
ПРОЕКТИРОВАНИЕ МПС
основу второго блока выполняемых автоматом действий. Поскольку формирование сигналов открытия выходных буферов CsADCH и CsADCL выполняется внешними относительно автомата цепями, основной задачей блока является выполнение последовательности действий, которая, обнаружив два последовательно выставленных внешних сигнала автомата Rd, формирует сигнал IncAdr, обеспечивающий переход к следующему адресу. Число требуемых итераций цикла, как и в первом блоке, подсчитывает счетчик адреса. Следует обратить внимание на петли ожидания в состояниях WaitRd, RdBytel, Pause2 и RdByte2, наличие которых обеспечивает требуемую синхронизацию.
Для правильной работы автомата асинхронные сигналы ReqADC, ReadyADC и Rd требуют их предварительного запоминания в дополнительно введенных в схему D-триггерах. Тактирование D-триггеров сигналами nClock, т. е. задним фронтом сигнала (при условии, что автомат тактируется передним фронтом сигнала Clock), гарантирует четкую работу автомата. Для устранения паразитных врезок у выходного сигнала автомата ReadyData (которые могут вызывать ошибочные действия системы прерываний микроконтроллера) также используется D-триггер, тактируемый сигналом nClock.
Дадим некоторые пояснения к синтаксису VHDL-программы устройства упрааления.
Для автомата приведенного примера с помощью программы StateCAD Version 3.2 паке-та Workview Office фирмы «Viewlogic» была выполнена трансляция диаграммы (для разных вариантов языкового описания). Был создан вариант, ориентированный на возможности языка описания аппаратуры на языке высокого уровня VHDL (листинг 1).
При компиляции из графической формы в текстовую программа StateCAD учитывает, для компилятора какой фирмы предполагается использовать описание автомата (соответствующим образом выбирая используемые синтаксические конструкции). Аналогичные соображения должны приниматься во внимание и при ручном написании программ. Это ограничение возникает из-за того, что набор допустимых синтаксических конструкции языка для различных фирм существенно отличается от стандартного. Для примера выбрана ориентация на САПР Synopsys (как имеющую меньшие ограничения).
Листинг 1
— VHDL code created by Visual Software Solution’s StateCAD Version 3.2
— This VHDL code (for use with Synopsys) was generated using: — enumerated state assignment with structured code format.
— Minimization is enabled, implied else is enabled,
— and outputs are manually optimized.
LIBRARY ieee;
USE ieee.std_logic_1164.all;
LIBRARY synopsys;
USE synopsys.attributes.all; ;
ENTITY CntRAM IS
PORT (CLK,Max,Rd,ReadyADC,ReqADC,Reset: IN stdjogic;
IncAdr, ReadyData,ResAdr.StartADC,We: OUT stdjogic);
END;
ARCHITECTURE BEHAVIOR OF CntRAM IS
TYPE type_sreg IS (AdrNew,EndLoop,Idle,IncWr,Pausel ,Pause2,Pause3,RdBytel, RdByte2,StartWr,WaitRd,WrData);
SIGNAL sreg, next_sreg : type_sreg;
ATTRIBUTE sync_set_reset OF Reset: signal is «true»;
BEGIN
PROCESS (CLK)
BEGIN
IF CLK=' T AN D CLK’event THEN
896
ПРИМЕР АВТОМАТИЗИРОВАННОГО ПРОЕКТИРОВАНИЯ ЦИФРОВОГО УСТРОЙСТВА С ИСПОЛЬЗОВАНИЕМ ЯЗЫКОВ ОПИСАНИЯ АППАРАТУРЫ
IF(Reset=T)THEN sreg <= Idle;
ELSE
sreg <= next_sreg;
END IF;
END IF;
END PROCESS;
PROCESS (sreg, Max, Rd, ReadyADC.ReqADC, Reset) BEGIN
IncAdr <= “0”; ReadyData <= “0”; ResAdr <= “0”;
StartADC <= "0”; We <= “0”;
next_sreg<=AdrNew;
IF ( Reset='T) THEN next_sreg<=ldle; incAdr<='0'; ReadyData<='0'; StartADC<='O'; We<=’0'; ResAdr<=’1';
ELSE
CASE sreg IS
WHENAdrNew=>
ResAdr<=’0'; StartADC<=’O';
We<='0';
lncAdr<=’1'; ReadyData<=’1'; next_sreg<=Pause3;
WHEN Idle =>
lncAdr<=’0'; ReadyData<='0';
StartADC<=’O';
We<=’0'; ResAdr<=T;
IF(ReqADC=T)THEN next_sreg<=StartWr;
END IF;
IF (ReqADC=’O' )THEN next_sreg<=ldle;
END IF;
WHEN lncWr=>
ReadyData<=’0'; ResAdr<=’0';
StartADC<=’O';
We<=’0'; lncAdr<='T;
IF (Max=’O') THEN next_sreg<=StartWr;
END IF;
IF(Max=T)THEN next_sreg<=Pause1;
END IF;
WHEN Pausel =>
lncAdr<=’0'; StartADC<=’O';
We<=’0';
ResAdr<=T; ReadyData<=’1'; next_sreg<=WaitRd;
WHEN Pause2 =>
lncAdr<=’0'; ResAdr<=’0‘;
StartADC<=’O';
We<=’0‘; ReadyData<=’1';
IF (Rd-О') THEN next_sreg<=Pause2;
END IF;
897
ПРОЕКТИРОВАНИЕ МПС
IF (Rd=’T) THEN next_sreg<=RdByte2;
END IF;
WHEN Pause3 ~>
lncAdr<=’0'; ResAdr<=’0';
StartADC<=’O';
We<='0'; ReadyData<=T;
IF(Max=’1’)THEN next_sreg<=ldle;
END IF;
IF(Max=’O')THEN next_sreg<=WaitRd;
END IF;
WHEN RdBytel => lncAdr<=’0'; ResAdr<=’0'; StartADC<=’O';
We<=’0‘; ReadyData<=’1';
IF (Rd=’O') THEN next_sreg<=Pause2;
END IF;
IF ( Rd-1') THEN next_sreg<=RdByte1;
END IF;
WHEN RdByte2 => lncAdr<=’0'; ResAdr<=’0'; StartADC<=’O’;
We<=’0'; ReadyData<=T;
IF ( Rd=’O') THEN next__sreg<=AdrNew;
END IF;
IF (Rd=’T) THEN
next_sreg<=RdByte2;
END IF;
WHEN StartWr =>
lncAdr<=’0'; ReadyData<=’O';
ResAdr<=’0';
We<='0'; StartADC<='1';
IF(ReadyADC=T)THEN next_sreg<=WrData;
END IF;
IF (Ready ADC=’O') THEN n ext_s reg<=Sta rtW r;
END IF;
WHEN WaitRd =>
lncAdr<=’0'; ResAdr<=’0';
StartADC<='O';
We<=’0'; ReadyData<=’1';
IF ( Rd=’T) THEN
next_sreg<=RdByte1;
END IF;
IF ( Rd=’O') THEN n ext_sreg<=Wa it Rd;
END IF;
898
ПРИМЕР АВТОМАТИЗИРОВАННОГО ПРОЕКТИРОВАНИЯ ЦИФРОВОГО УСТРОЙСТВАС ИСПОЛЬЗОВАНИЕМ ЯЗЫКОВ ОПИСАНИЯ АППАРАТУРЫ
WHEN WrData =>
lncAdr<=’O'; ReadyData<=’O';
ResAdr<=’0';
StartADC<=’O';We<=T;
next_sreg<=lncWr;
WHEN OTHERS =>
END CASE;
END IF;
END PROCESS;
END BEHAVIOR;
Разделы проектного модуля типичны для языка VHDL. В самом начале перечисляются используемые в проекте библиотеки (IEEE и Synopsys). В заголовочном разделе ENTITY перечислены имена и типы всех сигналов: входных внешних управляющих сигналов-тактового сигнала (CLK), сигнала окончания блока данных (Мах), запросов на чтение и запись блока данных (Rd и ReqADC) соответственно, флага готовности АЦП (ReadyADC) и, наконец, начального сброса (Reset) и выходных управляющих сигналов - сигнала запуска АЦП (StartADC), сигналов управления счетчиком адреса (IncAdr, ResAdr), сигнала управления режимом записи буферного ОЗУ (We) и внешним выходным сигналом (ReadyData).
Следующий раздел - ARCHITECTURE - представляет собой описание архитектуры или поведения (в нашем случае поведения) блока, интерфейс которого был описан в ENTITY. Как и в обычных языках, в начале раздела дается описание типов и объявление переменных, используемых при описании действий, выполняемых в разделе ARCHITECTURE. В данном автомате определен перечислительный тип данных type_sreg со всем списком допустимых значений (они, естественно, совпадают с именами, введенными в граф схеме переходов). Далее в тексте объявлены два сигнала (Signal) - sreg и next_sreg введенного типа type_sreg. Введение двух сигналов связано с необходимостью определения текущего и следующего состояний автомата при переходе от одного состояния к другому.
Главная часть архитектурного тела содержит два оператора параллельного типа (процесса). Первый процесс запускается на исполнение каждый раз, когда происходит изменение сигнала CLK. Однако его основное действие - назначение автомату нового состояния -происходит только по переднему фронту сигнала CLK. Использование для тактирования автомата переднего фронта синхронизирующего сигнала (предложение IF CLK-1' AND CLK’event THEN sreg<=next_sreg; END IF;) служит для синхронизации выбранных библиотечных операционных узлов и обеспечит стабильность входных управляющих сигналов в моменты тактирования. При составлении программы автомата учитывалась необходимость его установки в исходное состояние при подаче сигнала сброса (выражение IF (Reset-Г) THEN sreg<=ldle;).
Поведение управляющего автомата в тексте программы задано вторым процессом. Второй процесс запускается каждый раз, когда изменяется состояние автомата (sreg) или изменяется какой-либо входной сигнал. Содержимое этого процесса и определяет поведение управляющего автомата. Конечные автоматы в языке VHDL удобно описывать посредством оператора выбора «CASE», используя в качестве ключа выбора варианта переменную состояния автомата в текущий момент времени. Внутри каждого варианта определяется состояние перехода и значения выходных сигналов, формируемых в соответствии с входными условиями. Состояние перехода из текущего состояния в следующее осуществляется с помощью оператора назначения переменной next_sreg нового значения. В тех случаях, когда переход из текущего состояния зависит от внешних сигналов, этот оператор назначения входит в состав условного оператора, логическое выражение которого совпадает с последовательностью условий, встречающихся на соответствующих путях переходов на схеме алгоритма. Аналогично определяются и выходные сигналы, вырабатываемые на переходах и задающие исполняемые в других блоках операции.
899
ПРОЕКТИРОВАНИЕ МПС
Этап 4. Компиляция проекта и основные параметры устройства
После создания всех фрагментов проекта и схемы проекта в целом выполняется его компиляция. Необходимость иметь буферное ОЗУ и требуемый объем ОЗУ (реализацИя ОЗУ в форме совокупности отдельных D-триггеров потребовала бы значительных логи-ческих затрат) предопределила целесообразность выбора в качестве основы реализации БИС ПЛ семейства FLEX ЮК (с организацией памяти конфигурации в форме SRAM). Ориентация памяти конфигурации на память типа SRAM заставила ввести в состав устройства специальную БИС ПЗУ, хранящую загружаемую при выключении питания память конфигурации. После успешной компиляции был получен файл отчета (*.rpt), показавший, что данный проект далеко не полностью использует возможности, предлагаемые самым младшим представителем семейства ЮК БИС EPF10K10TC144. Общие затраты БИС (по числу логических ячеек) на реализацию проекта компилятор определил всего как 17%. Правда, на реализацию модуля ОЗУ компилятор использовал 66% имеющихся у БИС ресурсов. Число задействованных контактов ввода/вывода составляет 62, что не позволило остановиться на предыдущем типоразмере корпуса БИС.
Этап 5. Тестирование проекта
Тестирование проекта также выполнялось средствами САПР МАХ + PLUS II. Созданная тестовая последовательность должна была проверять лишь ключевые моменты работы разработанного устройства. Результаты моделирования приведены на рис. 8.19. Дадим пояснения основным фрагментам моделирования.
Системное время - в интервале от 0 до 0,075 мкс. Режим начального сброса устройства. Проверка всех возможных исходных ситуаций перед сбросом весьма громоздка и в данном примере эти варианты из соображений большого объема не включены.
Системное время - в интервале от 0,075 до 0,2 мкс. Моделирование появления внешнего сигнала запроса (ReqADC) на запись в ОЗУ блока данных от АЦП. Для сокращения временной диаграммы моделирование осуществлялось для упрощенной схемы (сигнал Мах формируется после записи всего четырех адресов).
В интервале системного времени от 0,15 до 0,45 мкс в ответ на сигнал запуска цикла аналого-цифрового преобразования (StartADC) АЦП выставил сигнал готовности данных (ReadyADC), и это служит основой для записи в ОЗУ по адресу 00 данных, равных АВ и 2 (здесь, как и далее, значения всех адресов и данных будут даны в шестнадцатиричной системе счисления).
От значения системного времени 0,45 до значения 175 мкс выполняется еще три записи в ОЗУ данных: (CD 3), ( F5 1) и (7Е 2) по адресам ОЗУ 1,2 и 3.
Ввиду аппаратной независимости записи в ОЗУ и работы периферии МК одновременно с моделированием записи блока данных в ОЗУ осуществлялось моделирование:
• фиксации в момент системного времени 0,45 мкс старшей части адреса внешнего ПЗУ -по сигналу ALE фиксировалось на выходе 8-разрядного регистра АВ значение 55, выставленное на шине данных МК;
• фиксации в момент системного времени 1,3 мкс в триггерах порта РА значения С4 (следствие появления сигнала nWR при условиях Р2_6 Р = 1,2_7 = 0, АО = 0 и А1 = 0);
• фиксации в момент системного времени 1,625 мкс в триггерах порта РВ значения В9 (следствие появления сигнала nWR при условиях Р2_6 Р = 1,2_7 = 0, АО = 1 и А1 = 0).
Когда системное время достигло значения 1,75 мкс.автомат выставил сигнал о готовности данных в буфере (ReadyData) и перешел в режим ожидания блока сигналов считывания из буферного ОЗУ в МК. В ответ на сигналы nRDc соответствующими значениями сигналов Р2_6 и Р2_7 в интервалы системного времени(2,0 2,325), (2,675 3,05), (3,575 3,9), (4,325 4,75), ( 5,15 5,575), (5,85 6,25), (6,65 6,950) и (7,275 7,675) осуществляется выдача Данных, сохраненных в буферном ОЗУ, на шину данныхМК.
900
MAX+plus II 9.0 File: U:\SAPRMCUPRUAN\EXAMPL1MAXCONTU.SCF Date: 10/1 ЗЛЮ 17:25:50 Page: 1
Name: И Reset ~ [I] dock [I] ReqADC
[I] ReadyADC |l| nRD [B]m:164|sreg [I] data[7..O] [OidateO [OJdatat [O]data[7..0] [B]adr[7..O] (O)StartADC [O]ReedyData [I] atADq9.^] (I] atADC(1. 0] [Il P2_7 [П P2_6 [Olpa[7..0] (Olpb[7..01 Щ PC[7..O] [I] nWR [11 ALE [O]AB(7.-01 [Ц A1 W A0
1.825ua
125.0ns 250.0m 375.0m 500.0m 525.0m 750.0ns 875.0m
1.125US 1_25os 1.375m
1.875UB X0
J
X
^tartWf
ST
ГХ
w
ST
w
rm
rw
rx
TX
35
w
4—X.
ЖГ
WT
дат
&
—r-
re
ж
! ! ! BO- ' ' r
ire
ТГЭТ
ж
з:
со о
xw^n^ra
I i i « ~ j i
xw^x
4—Л-4-
Тед
TS
Рис. 8.19. Результаты моделирования поведения проектируемой БИС ПЛ (см. также с. 902-904)
ПРИМЕР АВТОМАТИЗИРОВАННОГО ПРОЕКТИРОВАНИЯ ЦИФРОВОГО УСТРОЙСТВА С ИСПОЛЬЗОВАНИЕМ ЯЗЫКОВ ОПИСАНИЯ АППАРАТУРЫ
Namr
0] Romt
0] dock
01 RecjADC
01 ReadyADC
01 "RD [B|m:16*|sng 01 data[7..a| [OfdataO [О0Ма1 KW<7..0f Rodf7..0l (OJSartADC (O{ ReadyData 0] utADCJO.^ 01 atADQ1..0L 01 P2-7 T
01 P2_6 Ю1Р317..0] Р1РЧ7..01 01 PCP-01 01 nWR 01 M£ [OJAB(7..01 И А1 01 АО
2.1251Я 2JSu» Z375ua 2.5ue 2.825ua 2.75u» Z875ui 3Ae 3.125us 3.25us
~ПИ1ГПГ
i
is
3.375us 3.5(M 3.825u» 3.75u* 3.875ui 4.0
WP
i ь i i a i
w
mxr
J Т 1 1 1 1 1 1 1 1 1 1 > '1 т г г г III 1 < • ।;; и и j । jf- ! N 1 1 1 1 l"l ! 'IL III 111 1 1 » 1 < 1 J « -Г-Н- rl 1 frttl i 1 1 1 1 4 1 < 1 * 1 i 1 1 I 1 l-i-t-t 1 1 1 H 1 1 1 ! 1 “ГТ—1 1 1—! 1 1 1 1 1 I 1 1 » l i I < 1 1 t till 1 1 1 1 1 ! 1 1 I I 1 1 1 1 -I-, _. 1 1 l""T 1 1— t t I » fill— 1 1 I
1 1 1 1-1 X: =1 1 1 ± шг ±±d±: 11 1
TW
Рис. 8.19. Продолжение
ПРОЕКТИРОВАНИЕ МПС
ПРИМЕР АВТОМАТИЗИРОВАННОГО ПГОЕКТИРОВАНИЯЦИ<М^»ОГОУСТРС>ИСТВАСИСПОЛЬЗОВАНИЕМЯЗЬ1КСе ОПИСАНИЯ АППАРАТУРЫ
4.125U* 4.25а» 4.375а» 4.5uc 4.625а» 4.75u» 4.875а» 5.0us 5.125us 5.25US 5.375а» 5.5u» 5 625US 5.75u* 5.875u»
Рис. 8.19. Продолжение
903
Name:______
Ш R»Mt W <*х* П) RaqADC (П ЯамДОС И nRD IB]m:ie4Hraoi Ш <»>(7.-0! KWaO КЧ«Ш>1 (<Ч<ИМ7..0| И»Л(7.Л! fOJSOrtADC (OIRMdyDrta [(] atADCfS,2j (q «1АОС(1.Л!: ДР2_7 M «_6 IQ|p47..O! 1О1РМ7.Д ш РС[7.Д iq nWR (DALE PjARTjq ; Ш A1 W AO
7.375U»
8.в25и» 6.75UB 6.675и»
7.1250» 7.25ц»
6.125Ш 6_25ив 6 375о»
7.625ц» 7.75и» 7.875и»
ЕЖЕ
ЖВЕпЖ
ПРОЕКТИРОВАНИЕ МПС
РмйЗ
Йг!
Рис. 8.19. Окончание
ПРИМЕР АВТОМАТИЗИРОВАРНОГО ПРОЕКТИРОВАНИЯ ЦИФРОВОГО УСТРОЙСТВА С ИСПОЛЬЗОВАНИЕМ ЯЗЫКОВ ОПИСАНИЯ АППАРАТУРЫ
Признаком окончания передачи блока данных служит сброс сигнала ReadyData и переход автомата в состояние Idle (в примере это происходит после 7,95 мкс).
Анализ временных диаграмм позволяет не только проверить правильность функционирования устройства, но и исследовать временное поведение отдельных элементов проекта и прежде всего определить и проконтролировать выполнение в реальной системе требуемого времени удержания некоторых сигналов.
Этап 6. Автоматическое определение временных параметров устройства
Возможности САПР вычислять временные соотношения между различными фрагментами проекта существенно облегчают проектировщику задачу проверки правильности работы проекта во временной области. Автоматизация этого этапа проектирования избавляет от необходимости ручного перебора исходных данных проекта с целью обнаружения отклонений от допустимых временных установок.
Этап 7. Практическая проверка результатов проектирования
Основным результатом работы компилятора является файл конфигурации БИС, соответствующий техническому заданию. Средства САПР позволяют на заключительных этапах работы поместить содержимое этого файла в интересующую проектировщика БИС, и на этом процесс проектирования может быть переведен в плоскость натурных экспериментов. Для рассматриваемого примера натурные эксперименты производились с использованием специального отладочного стенда, содержащего две БИС ПЛ типа 10К10. Одна БИС использовалась для загрузки конфигурации проектируемой схемы, а другая - для загрузки конфигурации автомата, создающего тестовые воздействия, совпадающие с тестовыми воздействиями модельного эксперимента. Благодаря соединению контактов БИС между собою возможно наблюдение за работой спроектированной БИС на экране осциллографа в режимах, отличающихся от реальных условий только моделированием этих условий. Эксперименты позволяют убедиться в правильности созданного файла конфигурации (или вернуться на начальные этапы проектирования БИС ПЛ) и перейти к следующему уровню проектирования - проектированию печатной платы, содержащей требуемые элементы проектируемой системы. Поскольку в проектируемой системе для загрузки конфигурации в БИС ПЛ ЕРХ10К10 предполагается использовать специальную загрузочную БИС типа ЕРС, то практическим результатом этого этапа можно считать программирование последовательного загрузочного ПЗУ (например, типа ЕРС1РС8 фирмы «Altera»).
8.12. 3. РАЗРАБОТКА МИКРОПРОЦЕССОРНОЙ СИСТЕМЫ
Завершение проектирования БИС ПЛ, включающей аппаратные ресурсы, требуемые для функционирования микропроцессорной системы, отвечающей требованиям технического задания на разработку микропроцессорной системы, позволяет приступить к выполнению последующих этапов проектирования.
Разработка конструкции платы. Исходной информацией для следующего уровня проектирования, а именно разработки конструкторско-технологической документации на печатную плату, содержащую проектируемую микропроцессорную систему, является не только информация о межсоединениях стандартных элементов системы, но и информация о размещении сигналов по контактам ввода/вывода БИС ПЛ. Однако в отличие от стандартных элементов, у которых функциональное распределение входных и выходных сигналов заранее фиксировано и не может изменяться, БИС ПЛ дают возможность проектировщику задавать собственное распределение контактов. Если по соображениям топологии межсоединений элементов на печатной плате желательно другое распределение номеров кон
905
ПРОЕКТИРОВАНИЕ МПС
тактов БИС ПЛ, то допустимо поручить компилятору САПР МАХ + PLUS II выполнить повторную компиляцию проекта с фиксированным распределением номеров контактов для всех сигналов. Процедура компиляции может при некоторых назначениях завершиться сообщением о невозможности монтирования заданной конфигурации в заданную БИС. Последовательное переназначение входных и выходных контактов, как правило, позволяет проектировщику получить конструкцию БИС, удовлетворяющую большинству его пожеланий. Подобная возможность БИС ПЛ позволяет получать очень эффективные результаты трассировки межсоединений.
Разработка программного обеспечения. В рассматриваемом варианте микропроцессорной системы этап разработки программного обеспечения не требуется, поскольку модернизация ранее существующей системы не изменила функционирования элементов, связанных с программным обеспечением МП. Программное обеспечение берется от старой разработки и может быть помещено в БИС ПЗУ команд.
Отладка микропроцессорной системы. Совместная отладка аппаратных и программных частей системы возможна только после создания опытного образца системы. Для отладки могут использоваться как традиционные средства и методы (рассмотренные в предыдущих разделах), так и методы, учитывающие возможность перепрограммирования БИС ПЛ, т. е. структуры, обрамляющей микропроцессор или микроконтроллер. Более того, могут быть разработаны специальные тестовые конфигурации (возможно, опирающиеся на тестовые варианты ПО МК), которые могут использоваться не только на этапе проверки результатов проектирования, но и на этапах изготовления, выпуска или контроля промышленной продукции.
8.12.4. ОСОБЕННОСТИ ПРОЦЕДУРЫ ПРОЕКТИРОВАНИЯ ДЛЯ БИС ПЛ КЛАССА SOPC
Хотя разработка проектов на базе схем программируемой логики типа «система на кристалле» не содержит этапов, которых не существовало бы ранее, специфика выполнения и содержание этих этапов для БИС SOPC делает целесообразным более подробное рассмотрение проектной процедуры для этих схем. Несмотря на некоторые отличия САПР, предназначенных для проектирования БИС класса SOPC (например, предлагаемых фирмами «Atmel» и «Тriscend»), наиболее характерные черты их возможностей совпадают, и далее будут рассмотрены на примере работы с САПР фирмы «Triscend» под названием FastChip. САПР FastChip ориентирована на работу с БИС фирмы «Тriscend» семейства ТЕ5.
Этап О
На начальном этапе проектирования на основе анализа ТЗ на разработку микропроцессорной системы осуществляется анализ общесистемных проблем. На этом этапе разрабатывается предполагаемая архитектура будущей системы и производится распределение ресурсов по трем возможным направлениям реализации. Отдельные фрагменты проекта при ориентации на кристаллы класса SOPC могут строиться, используя возможности, предоставляемые:
• предопределенными ресурсами МП-ядра;
• ресурсами, предоставляемыми системной логикой кристалла (SCL-логика);
• ресурсами интегральных схем, внешних относительно кристалла.
Следует отметить, что идеология реализации системы на кристалле приводит к отличиям таких систем от систем в многокристальном исполнении. Первое отличие состоит в существенном увеличении скорости реализации отдельных команд (это связано, в частности, с тем, что элементы системы находятся на одном кристалле). Второе отличие со
906
ПРИМЕР АВТОМАТИЗИРОВАННОГО ПРОЕКТИРОВАНИЯ ЦИФРОВОГО УСТРОЙСТВА С ИСПОЛЬЗОВАНИЕМ ЯЗЫКОВ ОПИСАНИЯ АППАРАТУРЫ
стоит во введении дополнительных архитектурных элементов структуры (отсутствующих при классической реализации той же структуры).
Этап 1. Этап конфигурирования аппаратных ресурсов кристалла
Поскольку в составе кристалла присутствуют элементы трех частей стандартной микроконтроллерной системы: периферийные элементы стандартного микроконтроллера (порты ввода/вывода, таймеры, система прерываний и др.), элементы конфигурируемой системной логики - CSL (ячейки FPGA и средства их межсоединений) и, наконец, элементы интерфейса между этими частями, то САПР Triscend FastChip позволяет конфигурировать элементы всех частей. Основное окно САПР, управляющее потоком проектирования для Triscend FastChip (также как и в других САПР для кристаллов класса SOC), предоставляет возможность работать с каждой частью отдельно.
Для стандартных элементов МК, которые будут использоваться программным обеспечением, САПР в интерактивном режиме позволяет определить как требуемую конфигурацию, таки данные, поддерживающие выбранную конфигурацию. Все данные будут в дальнейшем автоматически трансформироваться в требуемые управляющие слова программного обеспечения.
Для разработки конфигурации системной логики (CSL) САПР также обеспечивает удобный интерактивный механизм выбора составных фрагментов и способа их объединения. Фрагменты могут браться либо из состава системной библиотеки САПР (порты, счетчики, сумматоры и др.), либо импортироваться из других САПР. Настройка параметров фрагментов и их объединение осуществляются путем задания для блочного (интерфейсного) отображения фрагментов имен соединяющих цепей (сигналов в будущем описании конфигурационной части кристалла на языке VHDL).
Аналогично решаются и вопросы интерфейсной части проекта.
После запуска САПР Тriscend FastChip пользователь получает доступ к проектному окну. Используя это окно, он должен задать тип целевого кристалла и дать имя создаваемому проекту. Далее разработчик переходит к работе в основном окне САПР Triscend FastChip. Помимо традиционной панели инструментов у разработчика появляется доступ к трем интерактивным областям: области предопределенных ресурсов МП-ядра (таймерам, контроллеру прерываний и т. д.), области ресурсов программируемой логики (CSL) и области программирования контактов ввода/вывода. Кроме того, действия проектировщика находят отражение в области оценки затрат на реализацию проекта (число используемых ячеек, контактов и селекторов ввода/вывода).
Дальнейшие действия проектировщика связаны с необходимостью определения условий тактирования кристалла и особенностей реализации интерфейса с загрузочной памятью (памятью конфигурации и программного кода МП). Для тактирования проектировщик может выбрать один из альтернативных вариантов: использование внутреннего генератора (невысокой стабильности), внешнего генератора или внешнего кварцевого резонатора. Кроме того, возможно определение имен внутренних буферизирующих каскадов, которые впоследствии могут использоваться для тактирования тех или иных фрагментов в области ресурсов программируемой логики (CSL). Для подключения внешней памяти (external memory) необходимо определить параметры интерфейсного блока (Memory Interface Unit) - реально требуется задать объем БИС параллельной памяти (в диапазоне от 256 Кб до 16 Мб).
Следующим шагом на этом этапе является выбор ресурсов из числа предопределенных ядром МП для кристалла ТЕ. Вызвав выбранный ресурс, проектировщик получает доступ к управляющим полям ресурса, включая как требуемые режимы работы, так и необходимые загружаемые инициализирующие данные. Результатом работы является создание инициализирующих подпрограмм для программ начальной установки микроконтроллерного ядра. В любой момент времени можно контролировать воздействие установок проектировщика на инициализиционный файл (Initialization File), вызвав просмотр заголовка (View Header).
907
ПРОЕКТИРОВАНИЕ МПС
Содержание очередного шага сводится к спецификации требуемых ресурсов конфигурируемой системной логики (CSL). Построение пользовательской конфигурации этой области кристалла может строиться с привлечением элементов двух типов. Проектировщик может пользоваться библиотечными элементами САПР Triscend FastChip и элементами, импортируемыми из других САПР. Библиотечные элементы Triscend FastChip охватывают достаточно широкий диапазон обычно требуемых устройств и включают элементы и узлы стандартной микропроцессорной периферии (параллельные и последовательные порты, блоки памяти, расширители прерываний и т. д.), типовые вычислительные узлы (счетчики, регистры, сумматоры и т. д.). Наличие в составе библиотеки программируемых элементов типа LUTs (Look-Up Tables) и триггеров, совпадающих по структуре с конфигурируемыми логическими элементами FPGA, создает предпосылки для разработки проектировщиком любой конфигурации системной логики кристалла. Следует подчеркнуть, что проектирование на уровне этих элементов соответствует уровню ассемблерных программ без использования подпрограмм. Очень трудоемкий процесс, но с контролируемым и предсказуемым результатом.
Другой вариант состоит в использовании импорта из других САПР. Возможность использования компиляторов других САПР определяется «информированностью» этих САПР о структуре логических элементов FPGA Тriscend. В настоящий момент фирмой «Triscend» разработана стыковка с двумя САПР. Один вариант соответствует схемотехнической форме спецификации проектов в САПР фирмы OrCAD (подразделение корпорации «Cadence»), а другой - языковой форме проектной спецификации в пакете FPGA Express САПР фирмы «Synopsys» (язык Verilog HDL). Передача информации из этих САПР осуществляется путем формирования файлов стандарта EDIF 2.0.0. В будущем следует ожидать расширения состава таких библиотек и, как следствие, возможность привлечения САПР других фирм.
Для функционального моделирования аппаратной части кристалла (конфигурируемой системной логики - CSL) проектировщик может использовать САПР разнообразных фирм, а не только фирм «Synopsys» и «Cadence». Подобная возможность объясняется тем, что выходная информация практических всех САПР (на всех этапах) является унифицированной и допускает выбор языка (из числа стандартных языков описания аппаратуры - языки VHDL, EDIF, Verilog).
С точки зрения соединений элементов, можно выделить три типа элементов: интерфейсные элементы CSL, подключаемые к Configurable System Interconnect (CSI) Bus, для которых сразу выделяются селекторы (адресная выборка); элементы внутренней структуры CSL и элементы CSL, предполагающие наличие внешних выходных контактов, которые сразу же и резервируются. Соединение элементов между собой осуществляется путем сопоставления имен.
Последним шагом этого этапа является назначение (конкретизация) номеров внешних контактов кристалла (из зоны элементов CSL). Этим шагом завершается этап ввода информации об аппаратной части проекта, последним действием которого является сохранение проекта.
Этап 2. Создание заголовочного файла Header
После спецификации всех аппаратных ресурсов САПР Triscend FastChip выполняет программу «secondary initilization», которая формирует так называемый заголовочный файл (Tailored Header File format). Основная особенность формата этого файла состоит в том, что он содержит назначение логических адресов для символьных имен объектов, использованных в проекте. Это является одним из удобств, предлагаемых системной интеграцией. Имена всех пользовательских модулей области CSL кристалла, связанных с интерфейсной шиной (CSI Bus) микропроцессора, становятся автоматически доступными программному обеспечению микроконтроллера и могут использоваться на последующих этапах проектирования, включая компиляцию, верификацию и отладку.
Этап 3. Разработка программной части проекта
Разработка программного обеспечения для кристаллов ТЕ5 практически ничем (кроме отмеченных выше свойств расширенной версии заголовочного файла) не отличается от 908
ПРИМЕР АВТОМАТИЗИРОВАННОГО ПРОЕКТИРОВАНИЯ ЦИФРОВОГО УСТРОЙСТВА С ИСПОЛЬЗОВАНИЕМ ЯЗЫКОВ ОПИСАНИЯ АППАРАТУРЫ
стандартного процесса разработки программного обеспечения. Эта разработка должна осуществляться с помощью внешних относительно Triscend FastChip компиляторов, поскольку САПР не содержит интегрированных в ней подобных средств. В качестве средств разработки программной части проекта может использоваться большинство существующих компиляторов (таких как Franklin, IAR, Tasking и т. д.), однако более полную интеграцию с пакетом Triscend FastChip могут обеспечить инструментальные средства разработки программного обеспечения фирмы «Keil Software» или фирмы «Archimedes Software». Именно поэтому фирма рекомендует пользоваться инструментальными средствами разработки либо фирмы «Keil Software», либо фирмы «Archimedes Software».
Инструментальные средства разработки программного обеспечения современных САПР (такие как продукция фирмы «Keil Sofware») позволяют не только разрабатывать прикладные программы на языке Ассемблера или на языке Си, но и, что очень важно, поддерживают все стадии разработки этого обеспечения. Для фирмы «Keil Sofware» это интегрированная среда разработки mVision и высокоуровневый отладчик-симулятор dScope. Интегрированная среда разработки осуществляет настройку всех программ пакета и управление всеми стадиями разработки, включая вызов специализированного текстового редактора (цветовое выделение синтаксиса и диалоговое исправление ошибок), вызов менеджера проектов (простая интеграция различных файлов в проект), вызов отладчика.
Как правило, разработка программного обеспечения микроконтроллеров содержит написание трех основных частей: заголовочного файла (Header File), основной программы (Main Function) и подпрограмм обработки прерываний (Interrupt Service Routine - ISR). Разработка на этом этапе завершается компиляцией кода программ, и результатом может являться создание результирующего файла <project>.hex.
Этап 4. Кодовая симуляция и отладка
Современные инструментальные комплексы, предназначенные для проектирования программного обеспечения микропроцессоров и микроконтроллеров, включают в свой состав специальные средства для интерактивного процесса отладки. Рассматриваемый в качестве примера комплекс программ фирмы «Keil Sofware» не является исключением. Высокоуровневый отладчик-симулятор dScope, входящий в состав комплекса, позволяет производить отладку проектов на языке Ассемблера, языке Си или в смешанных форматах. С его помощью возможна также оценка производительности и эффективности кодового представления программного обеспечения и его отладка на реальной прототипной аппаратуре.
Этап 5. Компиляция и создание объектного кода
После того как объектный код программ логически отлажен, наступает время создания объектного кода программного обеспечения. Для «Keil Sofware» этому соответствует вызов директивы Link Project. Созданный в результате линкирования файл будет далее впрямую использоваться САПР Triscend FastChip.
Этап 6. Монтирование ресурсов конфигурируемой логики
Следующим этапом является компиляция аппаратной части кристалла (FPGA). Список цепей, соединяющих модули CSL, и информация, настраивающая вентили на требуемый режим функционирования, должны быть преобразованы в файл конфигурации реального кристалла. Входящие в состав САПР Triscend FastChip средства и прежде всего утилита Bind позволяют создавать память конфигурации FPGA, определяющую будущее поведение кристалла. Результаты работы на этом и предыдущем этапах позволяют однозначно определить содержание как памяти программ МК, так и памяти конфигурации FPGA.
Этап 7. Загрузка проекта
Как и в большинстве других БИС ПЛ, семейство кристаллов ТЕ5 фирмы «Triscend» позволяет загружать проект в реальный кристалл различными способами. Возможны следующие варианты загрузки проекта: в оперативную память БИС ТЕ5, в последовательную
909
ПРОЕКТИРОВАНИЕ МПС
память EPROM, во внешнюю память типа SRAM, во внешнюю память типа Flash Memory или в параллельную EPROM. Загрузка проекта в постоянную память обычно является финальным шагом в проектной процедуре. Наличие же возможности загружать проект в ОЗУ реальных микросхем непосредственно из персонального компьютера (с помощью JTAG-интерфейса) позволяет построить более эффективную процедуру верификации проекта.
Этап 8. Натурная отладка проекта
Как уже отмечалось, кристаллы ТЕ5 фирмы «Triscend» поддерживают расширенный вариант JTAG-интерфейса, обеспечивающего загрузку и программной и аппаратной частей проекта внутрь кристалла. В связи с этим возникают два варианта комплексной отладки проекта. Один состоит в использовании возможностей, заложенных в типовые инструментальные средства отладки микропроцессорных систем (например, с помощью уже упоминавшегося пакета фирмы «Keil Sofware»). Другой вариант опирается на возможности, заложенные в САПР Triscend FastChip.
САПР FastChip может работать не только в режиме редактирования и компиляции проекта, но и в режиме отладки реальной аппаратуры (Real-Time In-System Debud). Этот вариант отладки проекта непосредственно в целевой системе имеет целый ряд преимуществ по сравнению с отладкой при помощи моделирующих программ и даже по сравнению с прототипными системами. САПР позволяет загружать отлаживаемый вариант программ-' ной и конфигурационной памяти в реальную БИС целевой системы и отлаживать проект с требуемыми временными параметрами и при наличии всего целевого окружения (software и hardware). Удобство и эффективность комплексной отладки аппаратно-программных средств в САПР FastChip достигается за счет возможности устанавливать точки останова в отлаживаемых программах путем занесения информации в специальные, встроенные в кристаллы ТЕ5 аппаратные средства (Hardware Breakpoint Unit). Переход САПР FastChip в режим отладки (Debug) сопровождается открытием в основном меню дополнительного окна наблюдения за отлаживаемыми объектами (Debug Watch). Информация о состоянии отдельных модулей проекта и величинах, выбранных для наблюдения параметров, возможность модифицировать величины адресуемых элементов проекта, потактовое или пошаговое выполнение программы позволяют существенно упростить процедуру поиска обычно трудно локализуемых допущенных в проекте ошибок.
Для ускорения разработок проектов фирма «Triscend», как и большинство других фирм -производителей БИС ПЛ, выпускает специальную отладочную плату (Triscend Evaluation Board), содержащую в своей основе кристалл TE520S40. Весь комплекс средств, связанных с проектированием программируемой логики класса реконфигурируемых систем на кристалле (CSoC), начиная от архитектуры кристаллов и кончая ресурсами САПР, поддерживающих создание реальной аппаратуры на всех этапах разработки, позволяет существенно уменьшить время проектирования и ускорить выпуск конечной продукции на рынок.
ГЛABА9
АРХИТЕКТУРЫ ПАРАЛЛЕЛЬНЫХ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ
Параллельные компьютеры интересны тем, что предлагают концентрацию вычислительных ресурсов, ресурсов памяти, высокоскоростных каналов ввода/вывода для решения важных вычислительных проблем с использованием принципов параллельной обработки информации.
Именно такое неформальное определение понятия параллельного компьютера, как «совокупность процессорных элементов, которые взаимодействуют и кооперируются для быстрого решения серьезных задач» (Almasi and Gottlieb, 1989), включает в себя и суперкомпьютеры с сотнями и тысячами процессоров, и рабочие станции, объединенные в сеть, и многопроцессорные рабочие станции, и встроенные системы.
Детальный анализ современных тенденции в развитии вычислительной техники в области использования вычислительных систем, развития технологической базы, компьютерных архитектур, суперкомпьютеров показывают естественный переход от однопроцессорных систем к многопроцессорным.
Целью данной главы является определение структур вычислительных систем для изучения всего многообразия параллельных компьютерных архитектур и понимания взаимосвязи и взаимного влияния между ними. Одновременно будет кратко изложен обзор эволюции параллельных машин.
По существу, параллельные компьютеры расширяли обычные концепции компьютерных архитектур за счет добавления коммуникационной среды. Коммуникационная архитектура, как и компьютерная, имеет две важные грани. Они определяются базовыми операциями взаимодействия и синхронизации, а также организационной структурой, которая реализует данные операции.
Высшим уровнем коммуникационной архитектуры является программная модель, которая реализована в параллельной системе и используется программистом в соответствии с областью применения. Модель параллельного программирования специфицирует образ частей программы, выполняемых параллельно и обменивающихся между собой информацией, и операции синхронизации, доступные для координации взаимодействия параллельных частей программы.
Ниже рассмотрены основные классические архитектуры параллельных систем, реализованные в серийных образцах.
9.1. АРХИТЕКТУРЫ С РАЗДЕЛЯЕМОЙ ОБЩЕЙ ПАМЯТЬЮ
Один из наиболее важных классов параллельных машин - shared memory multiprocessors - многопроцессорные системы с разделяемой общей областью памяти. Ключевой характеристикой данных систем является то, что взаимодействие процессоров осуществляется как обычное выполнение инструкций доступа к памяти (т. е. loads and stores). Данный класс систем имеет большую историю развития, начало которой датируется 1960 г. (система BINAC).
Основа программной модели (Shared address) для таких архитектур, по существу, есть разделение времени доступа к общей области памяти (time - sharing). В процессах часть их адресного пространства является разделяемой с другими процессами. Каждый процесс имеет виртуальную область памяти, состоящую из адресного пространства разделяемой памяти и собственного адресного пространства. На рис. 9.1 представлена типовая модель взаимодействия процессоров через механизм разделяемой общей памяти. На рисунке показана связь виртуального адресного пространства процессов (р0 - рп), состоящего из разделяемой и собственной областей, с физической областью памяти.
911
АРХИТЕКТУРЫ ПАРАЛЛЕЛЬНЫХ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ
Рис. 9.1. Взаимодействие процессов в модели разделяемой общей памяти
Операции записи и чтения в разделяемую область памяти требуют дополнительного контроля, т. е. операционная среда выполняет специальные функции синхронизации процессов (операций записи и чтения в разделяемую область памяти). Например, должна быть блокирована операция чтения данных одного процесса до тех пор, пока в данную ячейку не будет записан результат процесса-предшественника.
Коммуникационное оборудование систем с общей памятью позволяет расширять системную память естественным образом. По существу, большинство компьютерных систем позволяют процессору и ряду контроллеров ввода/вывода обеспечивать доступ к набору модулей памяти через некоторую коммуникационную среду, как показано на рис. 9.2.
Большинство вычислительных систем содержат один или более модулей памяти (П), доступной процессору, и контроллеры ввода/вывода через аппаратную коммуникационную среду.
Наращивание мощности системы достигается простым добавлением процессоров, модулей памяти и числа контроллеров ввода/вывода (которые также являются разделяемыми) в зависимости от требований к системе. На рис. 9.2. дополнительный процессор выделен тонировкой. При этом реальный рост производительности всей системы существенно зависит от специфики системной организации конкретного компьютера, так как рост числа процессоров и процессов приводит постепенно к несбалансированности между частотой обращений к разделяемой памяти и выполнением собственно программ. Это определяется тем, что на практике не удается реализовать идеальную - Parallel Random Access Machine (PRAM), когда любой процессор может осуществить доступ к любой ячейке
912
АРХИТЕКТУРЫ С РАЗДЕЛЯЕМОЙ ОБЩЕЙ ПАМЯТЬЮ
Рис. 9.2. Расширение системы с общей памятью
памяти в любой момент времени. Для реализации данного принципа обычно используют иерархическую организацию разделяемой памяти, т. е. уменьшают количество обращений за счет, например, использования кэш-памяти (С).
Можно выделить несколько основных типов коммуникационных сетей, используемых в архитектурах разделяемой общей памяти (рис. 9.3).
Для удовлетворения требований по загрузке системы она может иметь несколько каналов ввода/вывода, которые обеспечивают прямой доступ к каждому модулю памяти. Такого типа системы имеют организацию перекрестного соединения (switch connecting) процессоров (Пр), нескольких каналов ввода/вывода (I/O) и нескольких модулей памяти (П), показанной на рис 9.3, а. Размерность рассматриваемой структуры определяется числом входов/выходов аппаратного коммутатора (swith). В ранних системах размер и стоимость рассматриваемой коммуникационной среды ограничивались малым числом процессоров. В дальнейшем рост числа процессорных элементов определялся ростом удельного веса аппаратной части с одновременным снижением ее стоимости. Цена размеров перекрестного соединения становится лимитирующим фактором, и в большинстве случаев это приводит к появлению многоуровневой иерархической структуры коммуникационной среды (multistage interconnection network), показанной на рис. 9.3, б. В этом случае цена растет медленнее, чем число портов. Понятно, что экономия приводит к увеличению времени ожидания соединения (latency) и уменьшению полосы пропускания на порт. Способность доступа ко всей памяти прямо из каждого процессора имеет несколько преимуществ: любой процессор может запустить любые процессы или обратиться к любому событию ввода/вывода, а структуры данных могут быть разделены внутри операционной системы.
Широкое применение систем с разделяемой общей памятью связано с появлением 32-битных микропроцессоров в середине 1980 г., кэш-память, плавающая запятая, и управление блоком памяти было реализовано на одной-двух платах (Bell, 1985). Большинство машин среднего уровня, включающих миникомпьютеры, серверы, рабочие станции и персональные компьютеры, имеют шинную организацию (bus interconnect) как показано на рис 9.3, в, и эта шина может быть адаптирована для поддержки многопроцессорных систем. Стандартный механизм доступа к шине позволяет любому процессору достичь любого физического адреса в системе. Как и в случае перекрестного соединения (см. рис. 9.3, а), вся память равноудалена от процессоров, поэтому все процессоры имеют одинаковое время доступа (latency) к памяти.
913
АРХИТЕКТУРЫ ПАРАЛЛЕЛЬНЫХ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ
Рис. 9.3. Типовые схемы коммуникационных сетей
Рис. 9.4. Структурная организация четырехпроцессорного компьютера Intel Pentium Pro "quad pack"
914
АРХИТЕКТУРЫ С РАЗДЕЛЯЕМОЙ ОБЩЕЙ ПАМЯТЬЮ
Такая конфигурация обычно называется symmetric multiprocessor (SMP). SMP идеально подходит как для параллельных программ, так и для мультипрограммирования. Типичным примером организации многопроцессорной системы с симметричным доступом к памяти, основанной на шинной архитектуре, является компьютер Intel Pentium Pro four-processor «quad pack», иллюстрирующий первый SMP для широкого рынка (рис. 9.4).
Материнская плата Intel quad-processor Pentium Pro использовалась во многих многопроцессорных серверах, таких как HP NetServer LX series, являясь главным элементом дизайна для систем с малым числом процессоров - small-scale design. Как показано на рис. 9.4, на ней можно было объединить до четырех процессорных модулей (Пр-модуль), содержащих Pentium Pro (166 MHz) процессор (CPU), кэш-память, контроллер прерываний, интерфейс шины. Такой модуль был реализован на одном кристалле, имеющем разъемы для прямого включения в 64-битную шину памяти. 66 MHz-шина имела пиковую пропускную способность 528 Мб/с. Двухкристальный контроллер памяти и четырехкристальный контроллер мультиплексного канала (memory interleave unit (MIU)) обеспечивали взаимодействие шины с модулями памяти (DRAM). Шина памяти через PCI-мосты сопрягалась с двумя независимыми шинами стандарта PCI, которые обеспечивали связь с монитором, сетью и устройствами ввода/вывода (I/O). Структура Pentium Pro «quad pack» была похожа на большинство ранних машин класса SMP, но ее реализация отличалась наибольшей степенью интеграции.
На рис. 9.5 показана структура сервера Sun Enterprise Server, который также поддерживает симметричный доступ к памяти (SMP), несмотря на то, что она физически распределена между процессорными платами.
В отличие от Pentium Pro «quad pack», многопроцессорный сервер Sun UltraSparc-based Enterprise является представителем систем большей размерности по числу процессоров (larger-scalle design). Широкая (256 бит), высоко поплайнизированная шина памяти имеет пропускную способность 2,5 Гб/с. Сервер имеет иерархическую структуру, где каждая плата реализует структурную единицу системы, либо вычислительный модуль (Пр-модуль) из двух процессоров и памяти, либо модуль ввода/вывода. Наличие двух типов модулей является обязательным условием работоспособности системы. Вычислительный модуль содержит два процессора UltraSparc, каждый их которых имеет двухуровневую кэш-память [первый уровень (С) - 16 Кб, второй уровень (С”) - 512 Кб], плюс два 512-bit-wide банка памяти и внутренний коммутатор. Модуль ввода/вывода поддерживает три SBUS слота для расширения функции ввода/вывода, SCSI разъем, 1ООЬТ Ethernet-порт и два конектора для подключения оптических каналов - FiberChannell interfaces. Стандартная конфигурация сервера включает в себя 24 процессорных и 6 модулей ввода/вывода. Хотя банки памяти являются физически разнесенными попарно между процессорными модулями, вся память равноудалена от процессоров и доступна им через общую шину, что соответствует требованиям SMP. Данные могут быть размещены в любом месте без влияния на производительность системы.
Факторы, ограничивающие число процессоров в системе, различны для рассмотренного случая и для архитектуры с сетью из коммутаторов (см. рис.9.3, а, б). Дополнение процессоров в коммутатор дорого, однако общая производительность системы возрастает с числом портов. Цена добавления процессоров к шине - мала, но производительность всей системы остается фиксированной. В последнем случае ограничителем является пропускная способность шины. Если цена доступа к памяти станет слишком большой, процессоры будут тратить большую часть времени на режим ожидания и преимущество большого числа процессоров будет снивелировано.
Один из естественных подходов построения масштабируемых машин с разделяемой общей памятью, поддерживающих симметричный доступ к памяти, показан на рис. 9.2. Он обеспечивает масштабируемость коммуникационной среды между процессорами и
915
АРХИТЕКТУРЫ ПАРАЛЛЕЛЬНЫХ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ
Пр-модули
Gigapllane bus (256 data, 41 address, 83 MHz)
Интерфейс шины
Модули
ввода/вывода
Рис. 9.5. Структура Sun Enterprise Server
модулями памяти. Основной недостаток заключается в том, что при каждом обращении к памяти затрачивается много времени на ожидание кругового путешествия по сети, поэтому каждый процессор должен обеспечить высокую пропускную способность.
Альтернативный подход создания масштабируемой среды взаимодействия процессоров показан на рис. 9.6.
Процессор и модули памяти интегрированы между собой таким образом, что доступ к локальной памяти осуществляется существенно быстрее, чем к удаленной. Такая организация взаимодействия процессоров носит название несимметричного доступа к памяти (nonuniform memory access - NUMA), при котором контроллер локальной памяти определяет, выполнять ли доступ к локальной памяти или осуществлять транзакцию сообщения к удаленной памяти (при этом системы ввода/вывода могут быть либо частью каждого модуля, либо консолидироваться в специальный модуль I/O). В таком случае доступ к собственным данным процессора часто может быть выполнен локально, как и доступ к разделяемым данным, если они сохранены в локальном модуле. Доступ к локальной памяти быстрый и не возрастает во времени по сравнению с удаленным доступом. Сред-
916
АРХИТЕКТУРЫ С РАЗДЕЛЯЕМОЙ ОБЩЕЙ ПАМЯТЬЮ
Рис. 9.6. Многопроцессорная система с несимметричным доступом к разделяемой памяти нее время доступа существенно уменьшается, если большую часть занимают обращения к локальной памяти. Требования к пропускной способности сети тоже уменьшаются.
Несмотря на некую привлекательность концептуальной простоты SMP-архитектуры, подход NUMA стал куда более приемлемым для больших многопроцессорных систем благодаря его неотъемлемым преимуществам, приводящим к росту производительности таких систем.
Примером такого стиля проектирования является CRAY ТЗЕ, показанный на рис. 9.7.
CRAY ТЗЕ может содержать до тысяч процессоров, работающих с глобальным общим адресным пространством. Каждый модуль (node) содержит DEC Alpha-процессор (Пр), локальную память (П), интегрированный с контроллером памяти сетевой интерфейс и сетевой коммутатор. Компьютер организован как трехмерный куб, в котором каждый модуль соединяется с его соседями через 650 Мб/с линки (стандарт point-to-point). Любой процессор может иметь доступ к любой памяти, однако идеология NUMA реализована в коммуникационной архитектуре как наилучшая для характеристик производительности системы. Контроллер памяти модуля захватывает доступ к удаленной памяти и руководит транзакцией сообщения в контроллере памяти удаленного модуля от имени локального процессора. Транзакция сообщения автоматически маршрутизируется через промежуточные модули (вершины) до места назначения, с малыми задержками на каж-
Рис. 9.7. Структура суперкомпьютера CRAY ТЗЕ
917
АРХИТЕКТУРЫ ПАРАЛЛЕЛЬНЫХ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ
дом переходе. Данные удаленной памяти не кэшируются, поскольку нет аппаратного механизма их сохранения. Система ввода/вывода CRAY ТЗЕ распределена между совокупностями вершин, располагающихся на поверхности куба, которые соединяются с внешним миром через дополнительную сеть.
В этой машине реализована структура, при которой, хотя вся память и доступна любому процессору, распределение данных между процессорами отдано программисту. Кэшпамять (С) используется только для хранения данных (инструкций) из локальной памяти. Таким образом, задача программиста - избежать частых обращений к удаленной памяти.
В заключение надо отметить, что операции взаимодействия и синхронизации в моделях программирования с разделяемой общей адресной областью, специфицируются операциями READS и WRITES разделяемых переменных. Эти операции прямо отображаются в коммуникационные абстракции, содержащие LOAD и STORE (инструкции доступа к глобальной разделяемой общей памяти), которые прямо поддержаны аппаратно через доступ к разделяемым зонам физической памяти. Программная модель и коммуникационные абстракции имеют прямую аппаратную реализацию. Для каждого процесса обращение к памяти есть адрес в его виртуальном адресном пространстве. Адрес транслируется в процесс идентификации физической области, которая может быть локальной или удаленной по отношению к процессору и которая может быть доступна другим процессорам. Трансляция адреса реализуется защищенно, в пределах разделяемого адресного пространства, как это делается в однопроцессорных системах.
Эффективность систем с разделяемой общей памятью зависит от времени ожидания доступа к памяти, связанного с пропускной способностью среды передачи данных. Для того чтобы достичь масштабируемости таких систем, все решения, включая все механизмы связи, используемые для доступа к разделяемой памяти, должны быть правильно сбалансированы.
9.2. АРХИТЕКТУРЫ С РАСПРЕДЕЛЕННОЙ ОБЛАСТЬЮ ПАМЯТИ
Ко второму важному классу параллельных машин относятся многопроцессорные системы с распределенной областью памяти (message-passing architectures - MPA). MPA используют законченные компьютеры, включающие микропроцессор, память и подсистему ввода/вывода, как узлы для построения системы, объединенные коммуникационной средой, обеспечивающую взаимодействие процессоров посредством простых операций ввода-вывода. Структура высокого уровня для МРА практически такая же, как и для NUMA-машин, т. е. машин с разделяемой памятью, показанных на рис. 9.6. Первое отличие состоит в том, что коммуникации интегрированы в уровень ввода/вывода, а не в систему доступа к памяти. Этот стиль дизайна имеет много общего с сетями из рабочих станций или кластерными системами, за исключением того, что в МРА пакетирование узлов обычно более плотное, нет монитора и клавиатуры на каждом узле, а производительность сети намного выше стандартной. Интеграция между процессором и сетью имеет склонность быть более тесной, чем традиционные структуры ввода/вывода, которые поддерживают соединения с оборудованием, которое более медленное, чем процессор. Начиная с посылки сообщения МРА, есть фундаментальное взаимодействие «Процессор - Процессор».
Системы с распределенной памятью имеют существенную дистанцию между программной моделью и действительными аппаратными примитивами. Коммуникации осуществляются через средства операционной системы, или библиотеку вызовов, которые выполняют много акций более низкого уровня, включающих операции коммуникации.
918
АРХИТЕКТУРЫ С РАСПРЕДЕЛЕННОЙ ОБЛАСТЬЮ ПАМЯТИ
Рис. 9.8. Принцип взаимодействия процессов в системах с распределенной областью памяти
Наиболее общие операции взаимодействия на пользовательском уровне (user-level) в МРА есть варианты посылки (Send) и получения (Receive) сообщения. Совместный механизм Send и Receive, вызванный передачей данных из одного процесса в другой, показан на рис 9.8.
Передача данных из одного локального адресного пространства к другому произойдет, если посылка сообщения со стороны процесса-отправителя будет востребована процессом-получателем сообщения.
С этой целью в большинстве систем с распределенной памятью сообщение специфицируется операцией Send, которая добавляет к сообщению специальный признак (tag), а операция Receive в этом случае выполняет проверку сравнения данного признака.
Сочетание посылки и согласованного приема сообщения (на основе совпадения признаков) выполняет логическую связку - синхронизацию события, т. е. копирования из памяти в память. Имеется несколько возможных вариантов синхронизации этих событий в зависимости от того, завершиться ли Send к моменту, когда Receive будет выполнен или нет (т. е. будет ли снова доступен буфер посылки для использования до момента получения подтверждения приема). Похожим образом Receive может, в принципе, подождать до момента согласованной посылки (Send) или использовать «почтовый ящик» для получения сообщения. Каждый из этих вариантов имеет несколько различную интерпретацию и различные требования к реализации.
Механизм посылки сообщений долго использовался как средство коммуникации и синхронизации совокупности арбитрирующих взаимодействующих последовательных процессов, даже на одном процессоре. В качестве примеров можно привести языки программирования типа CSP и Occam, наиболее общие функции операционных систем типа Sockets.
Первые машины с распределенной областью памяти обеспечивали аппаратную поддержку примитивов (команд), которые очень напоминали простую абстракцию взаимодействия Send/Receive на пользовательском уровне с некоторыми дополнительными ограничениями. Каждый узел системы соединялся с определенным (фиксированным) числом соседей по регулярной схеме (образцу) на основе связи «точка-точка» (poin-to-point), по
919
АРХИТЕКТУРЫ ПАРАЛЛЕЛЬНЫХ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ
ведение которой, в свою очередь, описывалось простым FIFO. Такой тип конструкции для минимального ЗО-куба показан на рис. 9.9, где каждый узел имеет связи с соседями по трем направлениям через буфер FIFO.
В ранних системах обычно использовалась структура гиперкуба (на 2П узлов), в которой каждый узел соединялся с п другими узлами, бинарные адреса которых отличались на один бит. Другие машины имели решетчатую структуру, где узлы соединялись с соседями по двум или трем измерениям. Такая технология для более ранних машин была важна, потому что только соседние процессоры могли быть использованы в качестве адресата в операциях приема/посылки. Процесс-отправитель посылал сообщение, а процесс-получатель получал сообщение через канал-link. FIFO было маленьким, так что отправитель не успевал закончить формирование сообщения до момента, когда получатель начинал его читать, поэтому посылка блокировалась до момента начала приема (на современном языке это называется синхронной передачей сообщений, так как два события совпадают по времени). Детали передачи данных были скрыты от программиста в специальной библиотеке, формирующей слой программного обеспечения между запросами на прием и передачу и реальным аппаратным обеспечением.
Такое внимание к сетевой топологии было значительно ослаблено в связи с появлением гораздо более универсальных сетей, которые поплайнизировали передачу сообщения через каждый коммутатор, формирующий внутреннюю сеть. В наиболее современных машинах с распределенной памятью нарастающая задержка, вносимая каждым этапом передачи (скачком), достаточно мала. Это существенно упрощает программную модель. Обычно процессор рассматривается как простой формирователь линейной последовательности с одинаковыми затратами на коммуникацию. Другими словами, коммуникационная абстракция отражает главным образом организационную структуру, показанную на рис. 9.6. Один из важных примеров такой машины является IBM SP-2 (рис. 9.10).
Это масштабируемый параллельный компьютер, состоящий из узлов на базе рабочих станций RS6000, масштабируемой сети и сетевым интерфейсом Nl (network interface card - NIC), содержащим специализированный процессор (i860). NIC соединен с MicroChannel I/O bus и содержит драйверы сетевого линка, память (DRAM) для буферирования сообщений. Для реализации DMA модуль содержит процессор i860, управляющий перемещением данных между памятью и сетью. Сеть представляет собой каскадное 8x8 коммутируемое перекрестное соединение (crossbar switches) (см. рис. 9.3, а). Скорость передачи сообщений по линкам составляет 40 Мб/с в каждом направлении.
Рис. 9.9. Типовая структура первых систем с распределенной областью памяти
920
АРХИТЕКТУРЫ с распределенной областью памяти
Другим примером является параллельный компьютер Intel Paragon, показанный на рис. 9.11.
Intel Paragon иллюстрирует наиболее плотное аппаратное пакетирование в узлах. Каждая плата (узел) представляет собой SMP с двумя или более процессорами (i860) и кристалл сетевого интерфейса (NI), связанный с шиной памяти (Memory bus). Один из процессоров специализируется на обслуживании сети. Узел имеет механизм DMA для передачи блоков данных через сеть высокого уровня. Сеть представляет собой ЗО-куб, аналогичный структуре сети компьютера CRAYT3E. Линки имеют пропускную способностью 175 Мб/с в каждом направлении.
МРА и разделяемое адресное пространство являются двумя очевидно различными программными моделями, каждая из которых обеспечивает ясную парадигму для разделения коммуникации и синхронизации. Тем не менее лежащие в основе данных машин базовые структуры постепенно объединяются в рамках общей организации, представляемой набором законченных компьютеров, усиленных специальным контроллером, соединяющим каждый узел с расширяемой коммуникационной сетью. Подробнее обобщенная архитектура параллельных систем будет рассмотрена в п. 9.6.
921
АРХИТЕКТУРЫ ПАРАЛЛЕЛЬНЫХ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ
Рис. 9.11. Параллельный суперкомпьютер Intel Paragon
9.3. МАТРИЧНЫЕ СИСТЕМЫ
Третий важный класс параллельных машин - матричные системы - относятся к классу single-instruction-multiple-data machines (SIMD) или data parallel architectures. Ключевой характеристикой этой модели программирования data parallel programming model является то, что операция может быть выполнена параллельно на каждом элементе большой регулярной структуры данных, таких как массивы и матрицы.
Компьютерная таксономия, известная как Flynn’s taxonomy (Flynn, 1972), появившаяся в изданиях начала 1970-х годов, определяет структуру системы в терминах числа одновременно выполняемых различных инструкций и числа обрабатываемых элементов данных. В этом случае обычные последовательные компьютеры определяются как сис-
922
МАТРИЧНЫЕ СИСТЕМЫ
темы с одиночным потоком команд и одиночным потоком данных - single-instructionsingle-date (SISD), а параллельные машины, построенные из множества обычных процессоров как системы с множественным потоком команд и множественным потоком данных - multiple-instruction-multiple-data (MIMD). Альтернативой им стали системы класса одиночного потока команд и множественного потока данных - single-instruction-multiple-data (SIMD). Исторически такой подход появился в середине 1960-х. Идея была в том, что вся последовательность инструкций могла бы быть консолидирована в управляющем процессоре. Процессор данных включал бы только ALU, память и обеспечивал простое взаимодействие с ближайшими соседями.
В SIMD-машинах модель программирования (data parallel programming model} была напрямую реализована в физическом аппаратном уровне. Обычно управляющий процессор (Пр) осуществлял рассылку каждой инструкции по массиву процессорных элементов (data processing element) (ПрЕ), которые были соединены между собой в форме регулярной решетки, как показано на рис. 9.12.
Матричные системы ориентированы на большой класс вычислительных задач, которые требуют выполнения матричных операций или обработки массивов, т.е. когда выполняются
одинаковые операции на уровне каждого элемента массива или матрицы, вовлекающие в процесс вычисления соседние элементы. Таким образом, управляющий процессор инструктирует процессоры данных по выполнению каждой операции над локальным элементом данных или все выполняют операцию коммуникации/обмена данных (все сразу).
В дальнейшем, в середине 1970-х, векторные процессоры затмили собой развитие
других многопроцессорных систем. Векторные процессоры интегрировали скалярный процессор с коллекцией функциональных единиц, которые оперировали с векторными данными на памяти с поплайновой организацией. Способность оперировать над векторами в любом месте памяти ликвидировала необходимость размещения используемых структур данных в жесткую структуру внутренних связей и значительно упростила проблему получения объединенных данных.
Набор команд первого векторного процессора CDC Star-ЮО включал в себя векторные операции, которые позволяли комбинировать два источника векторов из памяти и создавать в памяти вектор результата. Машина работала на полной скорости тогда, ког-
да векторы были соседними и, следовательно, основное время тратилось на простое транспонирование матриц. Сенсационное изменение произошло в 1976 г., когда был представлен CREY-1, в котором концепция LOAD-STORE архитектуры была расширенна на' обработку векторов и реализована в процессорах CDC 6600 и CDC 7600 (и продолжена
в современных RISC-машинах). Векторы в памяти с любым фиксированным шагом по индексу были перенесены в или из соседних (близких) регистров посредством загрузки вектора и хранения инструкций. Арифметика выполнялась на векторных регистрах. Использование очень быстрых скалярных процессоров (80 MHz), интегрированных с векторными операциями и использующих большую полупроводниковую память, привело к мировому господству суперкомпьютеров рассматриваемого класса. Более чем 20 последующих лет CRAY Research лидировал на суперкомпьютерном рынке, увеличивая пропускную способность передачи векторов в памяти, число процессоров, число векторных поплайнов и длину векторных регистров.
Рис. 9.12. Структура матричных систем
923
АРХИТЕКТУРЫ ПАРАЛЛЕЛЬНЫХ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ
Второй раз SIMD-компьютеры (data parallel machine} пережили эпоху своего возрождения в середине 1980-х, когда развитие VLSI-design привело к появлению доступного 32-разрядного микропроцессора (это были так называемые одноразрядные секционные микропроцессоры, или микропроцессоры с разрядно-модульной организацией). В уникальной петлевой архитектуре в data parallel-режиме было размещено 32 простых одноразрядных элементарных процессора на одном чипе, вместе с серией соединений с соседними процессорами. Совокупность последовательных инструкций была размещена на управляющем процессоре. Главное было в том, что такие системы с несколькими серийными процессорными элементами были созданы и имели разумную цену.
В дальнейшем технологические факторы, которые сделали это bit-serial-проекгирование привлекательным и обеспечили быстрое и недорогое проектирование на базе однокристальных процессоров с плавающей точкой, проложили путь очень быстрым микропроцессорам с интегрированными плавающими запятыми и кэш-памятью. Это устранило ценовые преимущества консолидированной последовательной логики, описанной выше, и обеспечило равенство пиковой производительности на более малом числе полных процессоров.
Таким образом, пока существует пользовательский уровень абстракции параллельных операций на больших регулярных структурах данных, продолжается и предложение интересных решений для рассматриваемого важного класса проблем. Машинная организация, поддерживая модели data parallel programming models, развивается по направлению к более общим параллельным архитектурам множественной кооперации микропроцессоров, более масштабируемой разделяемой памяти и MPA-машинам, несмотря на то, что существуют решения в области создания специализированных компьютерных сетей, поддерживающие глобальную синхронизацию процессоров. В последнем случае сетевая поддержка выступает в роли барьера, который в особых точках программы переводит каждый процесс в режим ожидания до тех пор, пока остальные процессы не достигнут заданной точки синхронизации. В действительности, SIMD-подход эволюционировал в SPMD (single-programm-multiple-data) подход, в котором все процессоры выполняют копии одних и тех же программ и имеют, таким образом, в большей мере схожесть с более структурированными формами разделяемой памяти и МР-программирования.
В середине 1980-х возрождение SIMD data parallel machine привело к появлению других архитектурных направлений, которые были исследованы в академических институтах и промышленности, но имели меньший коммерческий успех и поэтому не получили широкого распространения по сравнению с рассмотренными выше. Два подхода, которые развились до законченных программных систем, - dataflow architectures и systolic architectures.
9.4. МАШИНЫ, УПРАВЛЯЕМЫЕ ПОТОКОМ ДАННЫХ
Машины, управляемые потоком данных относятся к классу datafllow architecture. Реализация dataflow-модели вычислений может привести к наивысшей степени параллелизма, так как в ней используется альтернативный принцип управления - управление потоком данных, который не накладывает дополнительных ограничений, присущих рассмотренному выше командному принципу управления.
В вычислительных системах, управляемых потоками данных, машинах потоков данных отсутствует понятие программы как последовательности команд, а следовательно, отсутствует понятие состояния процесса. Каждая инструкция передается на исполнение, как только создаются условия для ее реализации. При наличии достаточных аппаратных средств одновременно может обрабатываться произвольное число готовых к исполнению инструкций. В dataflow-модели параллелизм не задается явно, и аппаратные сред
924
МАШИНЫ. УПРАВЛЯЕМЫЕ ПОТОКОМ ДАННЫХ
ства обработки должны его выделять на этапе исполнения. Однако следует отметить, что реализация принципа управления потоком данных вызывает ряд трудностей, часть из которых носит принципиальный характер. К их числу необходимо отнести громоздкость программы, трудность обработки итерационных циклов, трудность работы сос структурами данных.
Суть идеи datafllow-модели в том, что программа представляется графом потока данных, пример которого показан на рис. 9.13.
Инструкциям на графе соответствуют вершины, а дуги, обозначенные стрелками, указывают на отношения предшествования. Точка вершины, в которую входит дуга, называется входным портом (или входом), а точка, из которой она выходит, выходным. По дугам передаются метки, называемые токенами данных (token/ Срабатывание вершины означает выполнение инструкции. При этом срабатывание происходит в произвольный момент времени при выполнении условий, соответствующих правилу запуска. Обычно используется строгое правило запуска, согласно которому срабатывание вершины происходит при наличии хотя бы по одному токену во всех ее входных портах. Срабатывание вершины сопровождается удалением одного токена из каждого входного порта и размещением не более одного токена результата операции в выходные порты. В зависимости от конкретной архитектуры системы порты могут хранить один или несколько токенов, причем они могут использоваться по правилу FIFO или в произвольном порядке.
Рис. 9.13. Граф потока данных и стуктура потоковых машин
dH
АРХИТЕКТУРЫ ПАРАЛЛЕЛЬНЫХ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ
Граф может быть распространен на произвольную совокупность процессоров. В предельном случае процессор в машине, управляемой потоком данных, может выполнять операции как отдельный круговой поплайн, как показано на рис. 9.13.
Токен или сообщение из сети содержит данные и адрес или тэг (tag) его места назначения (вершины графа). Тэг сравнивается с хранимыми тэгами на совпадение. Если совпадение не произошло, то токен помещается в память для ожидания партнера. Если партнер найден, то токен с совпавшим тэгом удаляется из памяти и данные поступают на выполнение соответствующей инструкции. Когда результат вычислен, новое сообщение или токен, содержащий данные результата, посылаются каждому по назначению, специфицированному в инструкции. Тот же самый механизм может быть использован и для удаленного процессора.
Все архитектуры машин, управляемых потоком данных, с точки зрения механизмов организации повторной входимости, принято делить на статические и динамические. Другими словами, в них используется либо статический граф потока данных, где каждая вершина представлена примитивной операцией, либо динамический граф, в котором вершина может быть представлена вызовом произвольной функции, которая сама может быть представлена графом. В динамических (tagged-token) архитектурах эффект динамически развивающегося графа на вызываемую функцию обычно достигается появлением дополнительного информационного контекста в тэге.
Было создано несколько машин, управляемых потоком данных, как со статической, так и с динамической архитектурами. Наиболее известными являются мультипроцессор Дениса (Массачусетский технологический институт), система DDP (фирма «Texas Instruments») и LAU (исследовательский центр CERT), достаточно подробно описанные в литературе.
9.5. СИСТОЛИЧЕСКИЕ СИСТЕМЫ
Разработчики систолических архитектур ставили перед собой задачу получить систему, которая совмещала бы достоинства конвейерной и матричных обработок. Первоначально систолические архитектуры разрабатывались для узкоспециализированных вычислительных систем. Однако в дальнейшем были найдены соответствующие алгоритмы для достаточно широкого класса задач, позволяющие реализовать принципы систолической обработки.
Основной принцип систолической обработки заключается в том, чтобы выполнить все стадии обработки каждого элемента данных, извлеченного из памяти, прежде чем вновь поместить в память результат этой обработки. Этот принцип реализуется систолической матрицей процессорных элементов, в которой отдельные процессорные элементы объединены между собой прямыми и регулярными связями, образующими конвейер. Таким образом, может формироваться несколько потоков операндов, каждый из которых образован исходными операндами (элементами структуры данных, хранящейся в памяти), промежуточными результатами, полученными при выполнении элементарных операций в каждом процессорном элементе, и элементами результирующей структуры. Потоки данных синхронизированы единой для всех процессорных элементов системой тактовых сигналов. Во время тактового интервала все элементы выполняют короткую неизменную последовательность команд (или одну команду).
Рис. 9.14 иллюстрирует систолическую систему для вычисления «свертки функции», использующую простую линейную область. Во время тактового интервала входные данные продвигаются вправо, умножаются на локальный вес и аккумулируются на выходе в порядке следования.
926
СИСТОЛИЧЕСКИЕ СИСТЕМЫ
Рис. 9.14. Пример построения систолической структуры
xout = X X = xin yout = yin + W X xin
Систолические архитектуры обладают следующими достоинствами:
• минимизируются обращения к памяти, что позволяет согласовать скорость работы памяти со скоростью обработки;
• упрощается решение проблем ввода/вывода вследствие уменьшения конфликтов при обращении к памяти;
• эффективно используются технологические возможности СБИС за счет регулярности структуры систолической матрицы.
Однако для реализации этих преимуществ необходимо найти для каждой задачи соответствующие систолические алгоритмы, которые могут быть реализованы на систолической структуре системы. Такие алгоритмы существуют сегодня для широкого круга задач, среди которых задачи числовой обработки, обработки сигналов и символов; умножение и обращение матриц, решение линейных систем, дискретное преобразование Фурье, кодирование и декодирование числовых последовательностей и т. д. Большинство этих алгоритмов сводится к рекуррентным соотношениям того или иного вида. В зависимости от вида систолического алгоритма, т. е. числа операндов, участвующих в примитивных операциях, типа этих элементарных операций, М-последовательности их выполнения выбираются тип процессорного элемента и структура локальных регулярных связей между ними. К типовым конфигурациям систолических матриц относятся: линейная (рис. 9.14), для реализации алгоритмов фильтрации при обработке сигналов, сравнения цепочек литер при обработке баз данных; прямоугольная, перемножения матриц, нахождения двухмерных ДПФ; и гексагональная, для выполнения операций обращения матриц, решения линейных систем уравнений и т. д.
Однако не все алгоритмы могут быть сведены к систолическим, и во многих случаях приходится отказываться от алгоритмов с меньшей сложностью в пользу более сложных, но регулярных алгоритмов, отвечающих требованиям систолической обработки.
927
АРХИТЕКТУРЫ ПАРАЛЛЕЛЬНЫХ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ
9.6. ОБОБЩЕННАЯ АРХИТЕКТУРА ПАРАЛЛЕЛЬНЫХ СИСТЕМ
Рассматривая эволюцию основных подходов к параллельным архитектурам, можно заметить взаимопроникновение архитектур рассмотренных вычислительных систем и наличие общей типовой параллельной машинной организации, показанной на рис. 9.15. Типовая параллельная вычислительная система включает в себя множество законченных компьютеров, содержащих один или несколько процессоров (Пр) с кэш-буферами (С) и память (П), соединенных между собой через масштабируемую коммуникационную сеть. Управлять генерацией выходных сообщений или приемом входных сообщений помогает вспомогательный процессорный блок communication assist (СА) - контроллер.
С одной стороны, объединение всех подходов к построению параллельных систем в рамках одной общей структуры может показаться существенным ограничением в области дизайна. С другой стороны, все многообразие описанных выше подходов реализуется в communication assist (СА) - контроллере. Все дело в функциональности, которая должна быть им обеспечена, т. е. каков должен быть интерфейс между процессором, системой памяти и сетью.
Не удивительно, что различные программные модели определяют собственные, отличные от других требования к дизайну СА и определяют, какие системные операции являются общими и должны быть оптимизированы. В случае разделяемой памяти СА крепко интегрируется с системой памяти (П), для того чтобы управлять событиями в памяти, которые могут потребовать взаимодействия с другими узлами системы (nodes). СА должен также управлять приемом сообщений, доступом к памяти и устанавливать транзит по направлению к другому узлу системы. В случае МРА,коммуникация инициализируется четкой акцией системного или пользовательского уровня, т. е. не требуется «наблюдаемости» системных событий в памяти. Вместо этого необходимо наличие возможности быстрой посылки сообщения и формирования ответа на входящее сообщение. Можно потребовать, чтобы под ответом подразумевалось выполнение операции сравнения тэгов на совпадение, чтобы буфера были локализованы, чтобы передача данных комментировалась. Параллельные данные и систолические подходы делают акцент на
Рис. 9.15. Обобщенная масштабируемая структура параллельных систем
928
ОБОБЩЕННАЯ АРХИТЕКТУРА ПАРАЛЛЕЛЬНЫХ СИСТЕМ
быстрой глобальной синхронизации, которая может быть прямо поддержана сетевыми механизмами или СА. Datafllow-архитектура делает акцент на быстром, динамическом распределении вычислений, основанном на входных сообщениях. Систолические алгоритмы предоставляют возможность использовать общие алгоритмические модели в специальных задачах синхронизации параллельного взаимодействия. Даже при этих различиях важно заметить, что все из рассмотренных подходов имеют много общего, т. е. они требуют инициировать сетевую транзакцию как результат специфичных процессорных событий, и они требуют реализации прямых операций на удаленном узле системы для выполнения необходимых программных действий.
Мы также видим, что произошло разделение между программной моделью и машинной организацией, как только среда параллельного программирования достигла своей зрелости.
СПИСОК ЛИТЕРАТУРЫ
1. Шагурин И.И., Бердышев Е.М. Процессоры семейства Intel Р6. Архитектура, программирование, интерфейс. - М.: Горячая линия, - Т елеком, 2000 - 248с.
2. ГукМ. Процессоры Intel: от8086 до Pentium II.-СПб.: Питер, 1998г.-224с.
3. Куриянов М.С., Петров Г.А., Пузанков Д.В. Процессор Pentium: архитектура и программирование. - СПб : ТЭТУ, 1995.
4. Куприянов М.С., Матюшкин Б.Д. Цифровая обработка сигналов: процессоры, алгоритмы, средства проектирования. — СПб.: Политехника, 1999г. - 592с.
5. Куприянов М.С., Мартынов О.Е., Панфилов Д. Коммуникационные контроллеры фирмы «Motorola». -СПб, bhv, 2000г.
6. Куприянов М.С., Иванова В.Е., Матвиенко Н.И. 16- и 32-разядные микроконтроллеры и интегрированные процессоры фирмы Motorola.—М., 1998.
7. Грушин С.И.,Душутин И.Д., Мелехин В.Ф. Проектирование аппаратных средств микропроцессорных систем: Учеб, пособие,-Л.:ЛПИ им. Калинина, 1990.-78стр.
8. Армстронг Дж. Р. Моделирование цифровых систем на языке VHDL/Пер. сангл.-М.:Мир, 1992.-175 с.
9. Asheden P.J. The VHDL Cookbook. University of Adelaide, South Australia. -1990.
10. Ashenden P.J. The Designer’s Guide to VHDL. Morgan Kaufmann Publishers, Inc. San Francisco, California, 1995,688 c.
11. Бибило П.Н. Основы языка VHDL. -Минск: Ин-т техн. Кибернетики НАН Беларуси, 1999.-202 с.
12. VHDL’92. Новые свойства языка описания аппаратуры VHDL/Пер. с англ. - М.: Радио и связь, 1995,- 256 с.
13. Современные микроконтроллеры: Архитектура, средства проектирования, примеры применения, ресурсы сети Интернет. «Телесистемы». Под ред. Коршуна И.В.; Составление, пер. с англ, и литературная обработка Горбунова Б.Б.-М.: Издательство «Аким», 1998.-272 с.
14. Программируемые логические ИМС на КМОП-структурах и их применение/П.П. Мальцев, Н.И. Гарбузов, А.П. Шарапов, А.А. Кнышев.-М.: Энергоатомиздат, 1998,-158 с.
15. Угрюмов Е.П., Грушвицкий Р.И., Альшевский А.Н. БИС/СБИСс репрограммируемой структурой: Учебное пособие. - СПб.: ТЭТУ, 1997. - 96 с.
16. Угрюмов Е.П., Смирнов А.М., Альшевский А.Н. БИС с программируемой структурой: Учебное пособие.-СПб.: ТЭТУ, 1995.-64с.
17. Угрюмов Е.П. Цифровая схемотехника. -СПб.: «БХВ-Санкт-Петербург», 2000. - 528 с.
18. Антонов А.П., Мелехин В.Ф., Филиппов А.С. Обзор элементной базы фирмы Altera. -СПб.: ЭФО, 1997.-142 с.
19. Franke D., Purvis М. Hardware/software codesign. //Proc. 13th intern. Conf. Software Eng.// IEEE PS Pres. 1991. p. 344-352.
20. A framework for hardware/software codesign./ S.Kumar, B.Frank, L. Fine et al. //IEEE Computer, 1993. december, p. 39 - 45.
21. Цвиркун Ф.В. Основы синтеза структур сложных объектов. - М.: Наука , 1982.
22. P.G. Paulin, J.P.Knight: Force-directed shedulingforthe behavioral synthesis of ASIG’s.// IEEE Trans. Computer Aided Design, vol. 8, pp. 661-679,1989.
23. Kavalade K., Lee E.A. The extended partitioning problem:hardware/software mapping and implementation-bin selection.//IEEE conference on rapid system prototyping, 1995, p. 12-18.
24. Parallel Computer Architecture: A Hardware/Software Approach/David E. Culler, JaswinderPal Singh/ /Morgan Kaufmann Published, Inc. San Francisco, California, 1999.-1025c.
25. Designing and Building Parallel Programs: Concepts and Tools for Parallel Software Engineering/ Ian T. Foster//Addison-Wesley Publishing Company, Inc. 1998.-381 c.
26. Эрглис К.Э. Интерфейсы открытыыхсистем. -М.: Горячая линия,-Телеком, 2000-256с
Оглавление
Предисловие......................................................................3
Введение.........................................................................5
Глава 1. Основы микропроцессорной техники........................................8
1.1. Классификация микропроцессоров, основные варианты их архитектуры и структуры.8
1.2. Общая структура и принципы функционирования микропроцессорных систем.......19
1.3. Система команд и способы адресации операндов...............................27
1.4. Интерфейсы микропроцессорных систем........................................36
1.4.1. Основные понятия.....................................................36
1.4.2. Магистраль VME.......................................................37
1.4.3. Магистраль VXI.......................................................38
1.4.4. PCI - локальная магистраль персональных компьютеров..................39
1.5. Шина USB...................................................................41
1.5.1. Основные сведения о шине USB.........................................41
Глава 2. Процессоры общего назначения и системы на их основе....................47
2.1. Структура и функционирование процессоров Intel Р6..........................47
2.1.1. Суперскалярная архитектура и организация конвейера команд............47
2.1.2. Режимы работы процессора и организация памяти........................51
2.1.3. Регистровая модель...................................................53
2.1.4. Внутренняя кэш-память................................................62
2.1.5. Форматы команд и способы адресации...................................69
2.2. Система команд: операции над целыми числами................................75
2.2.1. Команды пересылки....................................................78
2.2.2. Команды арифметических операций......................................82
2.2.3. Команды логических операций и сдвигов................................86
2.2.4. Команды битовых и байтовых операций..................................89
2.2.5. Команды операций со строками символов................................90
2.3. Система команд: операции управления........................................92
2.3.1. Команды управления программой........................................94
2.3.2. Команды поддержки языков высокого уровня.............................98
2.3.3. Команды организации защиты памяти....................................99
2.3.4. Команды управления процессором......................................101
2.3.5. Префиксные байты....................................................104
2.4. Система команд: операции над числами с плавающей точкой...................105
2.4.1. Форматы представления чисел.........................................107
2.4.2. Выполнение операций.................................................111
2.4.3. Команды пересылки данных............................................114
2.4.4. Команды арифметических операций.....................................116
2.4.5. Команды сравнения...................................................119
2.4.6. Команды специальных операций........................................121
2.4.7. Команды управления FPU..............................................123
2.5. Система команд: операции ММХ..............................................126
2.5.1. Форматы представления данных и выполнение операций.....................127
2.5.2. Команды пересылки и преобразования данных...........................131
2.5.3. Команды арифметических операций.....................................136
2.5.4. Команды логических операций и сдвигов...............................138
2.5.5. Команды сравнения и нахождения максимума/минимума...................139
2.6. Система команд: операции SSE..............................................140
2.6.1. Форматы представления данных и выполнение операций..................142
2.6.2. Команды пересылки и преобразования данных...........................145
2.6.3. Команды арифметических операций.....................................148
2.6.4. Команды логических операций.........................................150
2.6.5. Команды сравнения и нахождения максимума/минимума...................150
2.6.6. Команды преобразованияформата чисел.................................153
931
ОГЛАВЛЕНИЕ
2.6.7. Команды управления...................................................154
2.6.8. Команды пересылки данных с управлением кэшированием..................155
2.7. Работа процессора в защищенном и реальном режимах..........................156
2.7.1. Сегментация памяти в защищенном режиме...............................157
2.7.2. Страничная организация памяти........................................163
2.7.3. Защита памяти........................................................170
2.7.4. Поддержка многозадачного режима......................................175
2.7.5. Реализация режима виртуального 8086 (V86)............................181
2.7.6. Функционирование процессора в реальном режиме........................183
2.8. Реализация прерываний и исключений. Обеспечение тестирования и отладки.....184
2.8.1. Виды прерываний и исключений, реализация их обслуживания.............185
2.8.2. Причины возникновения исключений......................................191
2.8.3. Средства обеспечения отладки..........................................195
2.8.4. Реализация тестирования и контроля функционирования..................199
2.9. RISC-микропроцессоры и RISC-микроконтроллеры семейств PowerPC (МРСбОх, МРС50х).........................................................................202
2.9.1. RISC-микропроцессоры семейств МРСбОх (PowerPC).......................203
2.9.2. RISC-микроконтроллеры семейств МРСбхх (PowerPC)......................234
Глава 3. Использование кэш-памяти и организация основной памяти.................240
3.1. Общие принципы организации кэш-памяти......................................240
3.1.1. Понятия тега, индекса и блока........................................241
3.1.2. Механизм кэш-памяти с прямым отображением данных.....................242
3.1.3. Механизм кэш-памяти с ассоциативным отображением данных..............242
3.1.4. Обновление информации в кэш-памяти...................................243
3.1.5. Согласованность кэш-памяти...........................................245
3.2. Кэш-память команд и данных.................................................246
3.2.1. Кэш-память адресной трансляции...................................... 246
3.2.2. Внутренние кэш-памяти команд и данных................................248
3.2.3. Алгоритм кэш-замещений...............................................251
3.2.4. Состояния кэш-памяти данных..........................................251
3.2.5. Согласованность внутренних кэш-памятей...............................253
3.3. Функционирование памяти....................................................256
3.3.1. Трансляция сегментов.................................................257
3.3.2. Адресация физической памяти..........................................261
3.3.3. Трансляция страниц...................................................262
3.3.4. Комбинирование сегментной и страничной трансляции....................268
3.4. Защита памяти..............................................................270
3.4.1. Зачем нужна защита?..................................................270
3.4.2. Обзор механизмов защиты..............................................270
3.4.3. Уровень защиты сегментов.............................................270
3.4.4. Уровень защиты страниц...............................................282
3.4.5. Комбинирование защиты сегментов и страниц............................283
Глава 4.8-разрядные микроконтроллеры............................................284
4.1. Структура современных 8-разрядных микроконтроллеров........................284
4.1.1. Модульный принцип построения.........................................284
4.1.2. Популярные семейства 8-разрядных МК..................................286
4.1.3. Процессорное ядро МК.................................................289
4.1.4. Резидентная память МК................................................291
4.1.5. Порты ввода/вывода...................................................296
4.1.6. Таймеры и процессоры событий.........................................300
4.1.7. Аналого-цифровые и цифроаналоговые преобразователи...................310
4.1.8. Контроллеры последовательного ввода/вывода...........................315
932
ОГЛАВЛЕНИЕ
4.2. Семейство МК MCS-51 фирмы «Intel»..........................................330
4.2.1. Архитектура МК 8051 АН...............................................330
4.2.2. Процессорное ядро МК семейства MCS-51................................333
4.2.3. Система команд МК семейства MCS-51...................................338
4.2.4. Система прерываний...................................................347
4.2.5. Порты ввода/вывода МК 8051АН.........................................351
4.2.6. Таймеры..............................................................353
4.2.7. Асинхронный порт.....................................................356
4.2.8. Организация доступа к внешней памяти.................................357
4.2.9. Развитие МК с ядром MCS-51...........................................358
4.3. Семейство МК НС08 фирмы «Motorola».........................................361
4.3.1. Архитектура МК MC68HC908GP32.........................................361
4.3.2. Процессорное ядро семейства НС08.....................................365
4.3.3. Система команд МК семейства НС08.....................................370
4.3.4. Сравнительный анализ системы команд MCS-51 и НС08....................385
4.3.5. Источники и механизм обработки прерываний............................386
4.3.6. Порты ввода/вывода...................................................391
4.3.7. Процессор событий TIM08..............................................394
4.3.8. Модуль последовательного синхронного интерфейса SPI08................405
4.3.9. Модуль последовательного асинхронного интерфейса SPI08...............410
4.3.10. Развитие семейств НС08..............................................423
4.4. RISC-микроконтроллеры семейства PIC16 фирмы «Microchip»....................426
4.4.1. Архитектура МК PIC16C54..............................................426
4.4.2. Процессорное ядро PIC16..............................................429
4.4.3. Система команд МК семейства PIC16....................................433
4.5. Принципы построения отладочных средств для 8-разрядных МК..................437
Глава 5. Коммуникационные микроконтроллеры и системы на их основе...............443
5.1. Общие понятия..............................................................443
5.1.1. Семиуровневая модель управления в сетях..............................443
5.1.2. Функции, реализуемые коммуникационным контроллером...................448
5.1.3. Семейство коммуникационных микроконтроллеров МРС860..................449
5.2. Организация коммуникационных процессорных модулей в КМК....................462
5.2.1. Структура коммуникационного процессорного модуля.....................462
5.2.2. Контроллеры коммуникационных каналов SCC.............................484
5.2.3. Контроллеры управления SMC...........................................515
5.2.4. Контроллеры дополнительных коммуникационных каналов..................528
5.3. Поддержка протоколов в коммуникационных контроллерах.......................545
5.3.1. Доступ к линиям Т1/СЕРТ. Поддержка Basic ISDN........................545
5.3.2. Виртуальные каналы и поддержка Primary ISDN..........................564
5.3.3. Работа в асинхронных каналах связи...................................584
5.3.4. Доступ к сетям с пакетной передачей (с протоколами Х.25).............603
5.3.5. Доступ к сетям Ethernet..............................................623
5.3.6. Протоколы, поддерживаемые на уровне загружаемого микрокода...........649
Глава 6. Процессоры цифровой обработки сигналов.................................665
6.1. Принципы организации процессоров обработки сигналов........................665
6.1.1. Принципы обработки сигналов в цифровых системах......................665
6.1.2. Обобщенная архитектура DSP...........................................667
6.2. Процессоры семейства DSP56000..............................................669
6.2.1. Обзор архитектуры и шинной организации DSP56000......................669
6.2.2. Порт А...............................................................694
6.2.3. Порт В...............................................................702
6.2.4. Порт С...............................................................713
933
ОГЛАВЛЕНИЕ
6.2.5. Внутрикристальный эмулятор ОпСЕ......................................736
6.2.6. Широтно-импульсный модулятор (PWM)...................................743
6.2.7. Последовательный аудиоинтерфейс (SAI)................................752
Глава 7.Программируемая логика и ее применение в микропроцессорных системах.........768
7.1. Общие сведения, классификация..............................................768
7.1.1. Уровень интеграции интегральных схем (ИС) и его влияние на качество цифровой аппаратуры и ее проектирование. БИС/СБИС программируемой логики - средство исключения интегральных схем малого и среднего уровней интеграции из состава микропроцессорных систем....768 7.1.2. Классификация ИС программируемой логики..............................769
7.1.3. Конструктивно-технологические типы современных программируемых элементов.771
7.1.4. Области применения микросхем с программируемой логикой...............773
7.2. Первые поколения микросхем с программируемой структурой....................775
7.2.1. Программируемые логические матрицы и программируемая матричная логика....775
7.2.2. Базовые матричные кристаллы..............................................778
7.3. Типичные фрагменты схемотехники ИС ПЛ. Общие свойства ИС ПЛ................779
7.3.1. Типичные схемотехнические решения........................................779
7.3.2. Свойства ИС ПЛ, важные для их применения в составе систем............782
7.4. FPGA - программируемые пользователем вентельные матрицы....................783
7.4.1. Архитектура и блоки FPGA.............................................783
7.4.2. Популярные FPGA фирмы «Xilinx».......................................787
7.5. CPLD - сложные программируемые логические устройства.......................789
7.5.1. Архитектура и блоки CPLD.............................................789
7.5.2. Популярные CPLD фирмы «Altera».......................................792
7.6. СБИС ПЛ комбинированной архитектуры........................................796
7.6.1. Общие сведения.......................................................796
7.6.2. СБИС ПЛ комбинированной архитектуры FLEX10K..........................796
7.7. СБИС программируемой логики типа «система на кристалле»....................799
7.7.1. Общие сведения.......................................................799
7.7.2. СБИС ПЛ с конфигурируемостью всех областей кристалла.................801
7.7.3. СБИс ПЛ класса «система на кристалле» с блочной архитектурой.........806
7.8. Конфигурирование БИС/СБИС программируемой логики...............................811
7.9. Методика оценки параметров ИС ПЛ...........................................813
7.9.1. Вводные замечания....................................................813
7.9.2. Об оценке сложности микросхем программируемой логики.................814
7.9.3. Об оценке быстродействия микросхем программируемой логики............815
7.9.4. Параметры популярных семейств микросхем программируемой логики...........815
7.10. Аналоговые программируемые микросхемы.....................................820
7.10.1. Общие сведения......................................................820
7.10.2. Практические разработки.............................................822
Глава 8. Проектирование МПС.....................................................825
8.1. Методика и средства проектирования.........................................825
8.1.1. Общее описание процесса проектирования...............................825
8.1.2. Классификация методик проектирования электронных схем................826
8.1.3. Области применения СпИС различных типов..............................829
8.1.4. Место БИС с программируемыми свойствами в процессе создания современной аппаратуры......................................................................830
8.1.5. Структура алгоритма проектирования...................................831
8.1.6. Сопряженное проектирование и сопряженная верификация.................834
8.2. Проектирование типовой конфигурации МП-системы.............................836
8.2.1. Типовые конфигурации МП-систем.......................................836
8.2.2. Основные этапы процедуры проектирования..............................837
934
ОГЛАВЛЕНИЕ
8.3. Средства и методы проектирования и автономной отладки аппаратных средств МП-системы...838
8.3.1. Выбор семейства МП и стандартной периферии...........................838
8.3.2. Тестовые поцедуры....................................................839
8.3.3. Аппаратные средства отладки..........................................839
8.4. Средства и методы разработки программного обеспечения......................840
8.4.1. Средства индивидуальных и интегрированных пакетов....................840
8.4.2. Программные средства поддержки проектирования/отладки систем.........841
8.5. Средства и методы отладки программного обеспечения.........................842
8.5.1. Программные системы моделирования....................................842
8.5.2. Прототипные платы....................................................842
8.5.3. Эмуляторы ПЗУ........................................................844
8.5.4. Внутрисхемные эмуляторы..............................................844
8.5.5. Интегрированные среды разработки (оболочки)..........................846
8.6. Средства и методы комплексной отладки МП-систем............................848
8.6.1. Программаторы........................................................848
8.6.2. Логические анализаторы...............................................849
8.6.3. встроенные в МП средства отладки.....................................850
8.7. Операционные системы реального времени.....................................850
8.7.1. Основные свойства и механизмы ОСРВ...................................850
8.7.2. Примеры ОСРВ и их функциональные возможности для проектирования/отладки систем..851
8.8. JTAG-интерфейс и системные функции на его основе...........................856
8.9. Процедура проектирования и сведения об автоматизированных средствах проектирования
для БИС/СБИС с программируемой структурой. Средства описания проекта............863
8.9.1. Связь проектной проблемы с выбором САПР..............................863
8.9.2. Последовательность проектирования для БИС ПЛ.........................866
8.10. Базовые сведения о языке VHDL.............................................871
8.10.1. Исторический обзор и проблемная ориентация языка....................871
8.10.2. Базовые понятия языка и архитектура программ........................872
8.10.3. Синтаксическая организация проекта..................................874
8.10.4. Общеалгоритмическая составляющая языка..............................874
8.10.5. Проблемно-ориентированная составляющая языка........................875
8.10.6. Структурное описание................................................876
8.10.7. Описание поведения..................................................877
8.10.8. Синтаксис операторов общеалгоритмической составляющей языка.........880
8.11. Описание проектов на языке VHDL. Примеры, иллюстрирующие основные конструкции VHDL...881
8.11.1. Структурное описание................................................881
8.11.2. Поведенческое описание..............................................883
8.11.3. Сравнение структурного и поведенческого способов описания проектов..884
8.11.4. Описание типовых фрагментов вычислительной техники..................884
8.12. Пример автоматизированного проектирования цифрового устройства с использованием языков описания аппаратуры......................................................888
8.12.1. Варианты реализации и выбор элементной базы.........................888
8.12.2. Проектирование БИС ПЛ...............................................892
8.12.3. Разработка микропроцессорной системы................................905
8.12.4. Особенности процедуры проектирования для БИС ПЛ класса SOPC.........906
Глава 9. Архитектуры параллельных вычислительных систем.........................911
9.1. Архитектуры с разделяемой общей памятью....................................911
9.2. Архитектуры с распределенной областью памяти...............................918
9.3. Матричные системы..........................................................922
9.4. Машины, управляемые потоком данных.........................................924
9.5. Систолические системы......................................................926
9.6. Обощенная архитектура параллельных систем..................................928
Список литературы...............................................................930
Оглавление..........................................................................